
{title}
9 |{date}
10 |{name}
10 |{description}
11 |7 | 12 | CC BY-NC-SA 4.0 13 | {' '} 14 | © Kelvin Qiu 15 |
16 | 17 | 京ICP备2022001803号 18 | 19 |{data.title}
15 |{data.date}
16 |Front-End Developer / Student / Beijing
36 | 15 |
16 | # 为什么要画流程图?
17 |
18 | 也没什么好解释的,画就对了。有些一下子想不出来的逻辑,就得动笔画画图才能捋清逻辑。比如计算两个日期之间差了几天,有那么多种情况要考虑,如果一边写一边考虑,大概率会翻车,但是如果现在纸面上把逻辑梳理通顺,再把纸面上的照搬到代码上,基本上不会出现问题。有一些很主观的见解,我一直觉得编程和写代码这两件事不太一样,编程更偏重于对程序结构和算法的设计,而写代码只是将已经设计好的程序写成代码,前者难度要远远高于后者,而画流程图就可以很有效地提高程序设计的效率。
19 |
20 | # 怎么画?
21 |
22 | 流程图中有一些规定好的符号来表示逻辑,见下表:
23 |
24 |
15 |
16 | # 为什么要画流程图?
17 |
18 | 也没什么好解释的,画就对了。有些一下子想不出来的逻辑,就得动笔画画图才能捋清逻辑。比如计算两个日期之间差了几天,有那么多种情况要考虑,如果一边写一边考虑,大概率会翻车,但是如果现在纸面上把逻辑梳理通顺,再把纸面上的照搬到代码上,基本上不会出现问题。有一些很主观的见解,我一直觉得编程和写代码这两件事不太一样,编程更偏重于对程序结构和算法的设计,而写代码只是将已经设计好的程序写成代码,前者难度要远远高于后者,而画流程图就可以很有效地提高程序设计的效率。
19 |
20 | # 怎么画?
21 |
22 | 流程图中有一些规定好的符号来表示逻辑,见下表:
23 |
24 |  25 |
26 | # 在哪画?
27 |
28 | ## 在线Flowchart
29 |
30 | [draw.io](https://app.diagrams.net/)是一个开源免费的流程图工具,可以在线使用,也可以下载到本地。
31 |
32 |
25 |
26 | # 在哪画?
27 |
28 | ## 在线Flowchart
29 |
30 | [draw.io](https://app.diagrams.net/)是一个开源免费的流程图工具,可以在线使用,也可以下载到本地。
31 |
32 |  33 |
34 | ## 使用VSCode
35 |
36 | Draw.io还提供了VSCode的插件,只需安装这两个插件,并且新建一个后缀名为`.drawio`的文件即可在VSCode中创作流程图。
37 |
38 |
33 |
34 | ## 使用VSCode
35 |
36 | Draw.io还提供了VSCode的插件,只需安装这两个插件,并且新建一个后缀名为`.drawio`的文件即可在VSCode中创作流程图。
37 |
38 |  39 |
40 |
39 |
40 |  41 |
42 | # 一些例子
43 |
44 | - 找出四个数字中最大的数
45 |
46 | 
47 |
48 | - 计算阶乘
49 |
50 |
41 |
42 | # 一些例子
43 |
44 | - 找出四个数字中最大的数
45 |
46 | 
47 |
48 | - 计算阶乘
49 |
50 |  51 |
52 | - 判断是否是质数
53 |
54 |
51 |
52 | - 判断是否是质数
53 |
54 |  --------------------------------------------------------------------------------
/styles/Project.module.css:
--------------------------------------------------------------------------------
1 | .title {
2 | font-size: 21px;
3 | font-weight: 400;
4 | margin-bottom: 10px;
5 | color: var(--element3);
6 | }
7 |
8 | .item {
9 | display: flex;
10 | align-items: center;
11 | gap: 20px;
12 | padding: 10px;
13 | transition: 0.3s;
14 | }
15 |
16 | .icon {
17 | color: var(--element8);
18 | scale: 1.5;
19 | transition: color 0.3s;
20 | }
21 |
22 | .name {
23 | font-size: 18px;
24 | color: var(--element2);
25 | transition: color 0.3s;
26 | }
27 |
28 | .description {
29 | font-size: 13px;
30 | width: 250px;
31 | color: var(--element1);
32 | transition: color 0.3s;
33 | }
34 |
35 | .info {
36 | display: flex;
37 | flex-direction: column;
38 | justify-content: space-between;
39 | row-gap: 5px;
40 | padding: 2px 0;
41 | cursor: pointer;
42 | }
43 |
44 | .list {
45 | display: flex;
46 | flex-wrap: wrap;
47 | justify-content: space-between;
48 | padding: 10px;
49 | row-gap: 20px;
50 | }
51 |
52 | .item:hover {
53 | background-color: var(--surface4);
54 | border-radius: 10px;
55 | }
56 |
57 | .item:hover .icon {
58 | color: var(--element9);
59 | }
60 |
61 | .item:hover .name {
62 | color: var(--element3);
63 | }
64 |
65 | .item:hover .description {
66 | color: var(--element3);
67 | }
68 |
69 | @media screen and (max-width: 600px) {
70 | .list {
71 | display: block;
72 | }
73 |
74 | .item {
75 | justify-content: center;
76 | margin-bottom: 18px;
77 | }
78 |
79 | .name {
80 | font-size: 19px;
81 | }
82 |
83 | .title {
84 | font-size: 25px;
85 | margin-bottom: 10px;
86 | margin-left: 15px;
87 | margin-top: 10px;
88 | }
89 |
90 | .icon {
91 | font-size: 30px;
92 | }
93 | }
94 |
--------------------------------------------------------------------------------
/public/posts/state-as-snapshot.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: State as a Sanpshot 状态快照
3 | date: 2022-09-17
4 | ---
5 |
6 | 正式开始前,先看看这两行代码:
7 |
8 | ```js
9 | const [num, setNum] = useState(0);
10 |
11 | setNum(num + 1);
12 | setNum(num => num + 1);
13 | ```
14 |
15 | 问题来了,**对`setNum`的两次调用是一样的吗?**为什么第一次调用传入的是一个**值**,而第二次传入的是一个**函数**呢?
16 |
17 | 先别急,再看看下面这两段代码:
18 |
19 | ```js
20 | const [num, setNum] = useState(0);
21 |
22 | setNum(num + 1);
23 | setNum(num + 1);
24 | setNum(num + 1);
25 | ```
26 |
27 | ```js
28 | const [num, setNum] = useState(0);
29 |
30 | setNum(num => num + 1);
31 | setNum(num => num + 1);
32 | setNum(num => num + 1);
33 | ```
34 |
35 | 这两段代码的运行结果一样吗?最终`num`的结果都是`3`吗?如果真的运行一下这个程序,会发现**结果**分别是:`1`和`3`。
36 |
37 | 想要了解这其中的原理,只需要理解一个词:***快照***。
38 |
39 | > State behaves more like a snapshot. Setting it does not change the state variable you already have, but instead triggers a re-render.
40 | >
41 | > 状态更像是一个快照,更新状态并不会真正改变已有的值,而是触发下一次渲染。
42 |
43 | **换句话说:在同一次渲染中,状态的值是不会改变的。**
44 |
45 | 带着这个结论去看看第一段代码:
46 |
47 | ```js
48 | const [num, setNum] = useState(0);
49 |
50 | setNum(num + 1); // 0 + 1 = 1
51 | setNum(num + 1); // 0 + 1 = 1
52 | setNum(num + 1); // 0 + 1 = 1
53 | ```
54 |
55 | 因为在*同一次渲染中,状态的值不变*,所以`num`一直是`0`,所以三个`setNum(num + 1)`中的值是相同的,都是`0 + 1= 1`,所以不论调用几遍`setNum`,结果一定都是`1`。
56 |
57 | > You can pass a *function* that calculates the next state based on the previous one in the queue.
58 | >
59 | > 你可以传入一个函数,这样就可以根据前一个状态来计算当前的状态。
60 |
61 | **官方文档中的这句话很直接的告诉我们:如果你想拿到前一个设置的状态,那你可以传入一个函数,我会把前一个的状态传给你。**
62 |
63 | 所以会看第二段代码:
64 |
65 | ```js
66 | const [num, setNum] = useState(0);
67 |
68 | setNum(num => num + 1); // 0 + 1 = 1
69 | setNum(num => num + 1); // 1 + 1 = 2
70 | setNum(num => num + 1); // 2 + 1 = 3
71 | console.log(num) // 0
72 | ```
73 |
74 | 可以看到,这里的**每一次状态更新都是基于前一个状态的值**,所以次数的`num`才会累加,结果为`3`。
75 |
76 | 可是,这不就违背了刚才说的“**在同一次渲染中,状态的值是不会改变的**”了吗?**其实也没有**。在上面例子的最后一行,我把`num`打印出来,发现结果还是`0` 没有变。
77 |
78 | 这里我故意用了相同的变量名`num`,如果你能分清这两个`num`的区别,那就真正理解了。`setNum`函数中的`num`并**不是当前状态的快照,而是React传入的上一个状态的值**。而最后打印的那个`num`才是真正的状态快照,它在一次渲染里面是不会变的。
79 |
80 | **总结来讲:**
81 |
82 | 1. 每一次渲染中的状态都是一个**快照**,它的值在本次渲染是**不会改变**的。
83 | 2. 如果想基于前一个状态来确定当前状态,可以给`setState`**传入一个函数**,来**获得前一个状态的值**。
--------------------------------------------------------------------------------
/components/NavBar.js:
--------------------------------------------------------------------------------
1 | import styles from '../styles/Nav.module.css';
2 | import Link from 'next/link';
3 | import React from 'react';
4 |
5 | const NavBar = ({ setMode, mode }) => {
6 | const handleClick = () => {
7 | setMode((prev) => (prev === 'light' ? 'dark' : 'light'));
8 | localStorage.setItem('mode', mode === 'light' ? 'dark' : 'light');
9 | };
10 |
11 | React.useEffect(() => {
12 | // toggle HTML theme
13 | if (mode === 'light') {
14 | document.documentElement.classList.remove('dark');
15 | } else {
16 | document.documentElement.classList.add('dark');
17 | }
18 | }, [mode]);
19 |
20 | return (
21 |
--------------------------------------------------------------------------------
/styles/Project.module.css:
--------------------------------------------------------------------------------
1 | .title {
2 | font-size: 21px;
3 | font-weight: 400;
4 | margin-bottom: 10px;
5 | color: var(--element3);
6 | }
7 |
8 | .item {
9 | display: flex;
10 | align-items: center;
11 | gap: 20px;
12 | padding: 10px;
13 | transition: 0.3s;
14 | }
15 |
16 | .icon {
17 | color: var(--element8);
18 | scale: 1.5;
19 | transition: color 0.3s;
20 | }
21 |
22 | .name {
23 | font-size: 18px;
24 | color: var(--element2);
25 | transition: color 0.3s;
26 | }
27 |
28 | .description {
29 | font-size: 13px;
30 | width: 250px;
31 | color: var(--element1);
32 | transition: color 0.3s;
33 | }
34 |
35 | .info {
36 | display: flex;
37 | flex-direction: column;
38 | justify-content: space-between;
39 | row-gap: 5px;
40 | padding: 2px 0;
41 | cursor: pointer;
42 | }
43 |
44 | .list {
45 | display: flex;
46 | flex-wrap: wrap;
47 | justify-content: space-between;
48 | padding: 10px;
49 | row-gap: 20px;
50 | }
51 |
52 | .item:hover {
53 | background-color: var(--surface4);
54 | border-radius: 10px;
55 | }
56 |
57 | .item:hover .icon {
58 | color: var(--element9);
59 | }
60 |
61 | .item:hover .name {
62 | color: var(--element3);
63 | }
64 |
65 | .item:hover .description {
66 | color: var(--element3);
67 | }
68 |
69 | @media screen and (max-width: 600px) {
70 | .list {
71 | display: block;
72 | }
73 |
74 | .item {
75 | justify-content: center;
76 | margin-bottom: 18px;
77 | }
78 |
79 | .name {
80 | font-size: 19px;
81 | }
82 |
83 | .title {
84 | font-size: 25px;
85 | margin-bottom: 10px;
86 | margin-left: 15px;
87 | margin-top: 10px;
88 | }
89 |
90 | .icon {
91 | font-size: 30px;
92 | }
93 | }
94 |
--------------------------------------------------------------------------------
/public/posts/state-as-snapshot.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: State as a Sanpshot 状态快照
3 | date: 2022-09-17
4 | ---
5 |
6 | 正式开始前,先看看这两行代码:
7 |
8 | ```js
9 | const [num, setNum] = useState(0);
10 |
11 | setNum(num + 1);
12 | setNum(num => num + 1);
13 | ```
14 |
15 | 问题来了,**对`setNum`的两次调用是一样的吗?**为什么第一次调用传入的是一个**值**,而第二次传入的是一个**函数**呢?
16 |
17 | 先别急,再看看下面这两段代码:
18 |
19 | ```js
20 | const [num, setNum] = useState(0);
21 |
22 | setNum(num + 1);
23 | setNum(num + 1);
24 | setNum(num + 1);
25 | ```
26 |
27 | ```js
28 | const [num, setNum] = useState(0);
29 |
30 | setNum(num => num + 1);
31 | setNum(num => num + 1);
32 | setNum(num => num + 1);
33 | ```
34 |
35 | 这两段代码的运行结果一样吗?最终`num`的结果都是`3`吗?如果真的运行一下这个程序,会发现**结果**分别是:`1`和`3`。
36 |
37 | 想要了解这其中的原理,只需要理解一个词:***快照***。
38 |
39 | > State behaves more like a snapshot. Setting it does not change the state variable you already have, but instead triggers a re-render.
40 | >
41 | > 状态更像是一个快照,更新状态并不会真正改变已有的值,而是触发下一次渲染。
42 |
43 | **换句话说:在同一次渲染中,状态的值是不会改变的。**
44 |
45 | 带着这个结论去看看第一段代码:
46 |
47 | ```js
48 | const [num, setNum] = useState(0);
49 |
50 | setNum(num + 1); // 0 + 1 = 1
51 | setNum(num + 1); // 0 + 1 = 1
52 | setNum(num + 1); // 0 + 1 = 1
53 | ```
54 |
55 | 因为在*同一次渲染中,状态的值不变*,所以`num`一直是`0`,所以三个`setNum(num + 1)`中的值是相同的,都是`0 + 1= 1`,所以不论调用几遍`setNum`,结果一定都是`1`。
56 |
57 | > You can pass a *function* that calculates the next state based on the previous one in the queue.
58 | >
59 | > 你可以传入一个函数,这样就可以根据前一个状态来计算当前的状态。
60 |
61 | **官方文档中的这句话很直接的告诉我们:如果你想拿到前一个设置的状态,那你可以传入一个函数,我会把前一个的状态传给你。**
62 |
63 | 所以会看第二段代码:
64 |
65 | ```js
66 | const [num, setNum] = useState(0);
67 |
68 | setNum(num => num + 1); // 0 + 1 = 1
69 | setNum(num => num + 1); // 1 + 1 = 2
70 | setNum(num => num + 1); // 2 + 1 = 3
71 | console.log(num) // 0
72 | ```
73 |
74 | 可以看到,这里的**每一次状态更新都是基于前一个状态的值**,所以次数的`num`才会累加,结果为`3`。
75 |
76 | 可是,这不就违背了刚才说的“**在同一次渲染中,状态的值是不会改变的**”了吗?**其实也没有**。在上面例子的最后一行,我把`num`打印出来,发现结果还是`0` 没有变。
77 |
78 | 这里我故意用了相同的变量名`num`,如果你能分清这两个`num`的区别,那就真正理解了。`setNum`函数中的`num`并**不是当前状态的快照,而是React传入的上一个状态的值**。而最后打印的那个`num`才是真正的状态快照,它在一次渲染里面是不会变的。
79 |
80 | **总结来讲:**
81 |
82 | 1. 每一次渲染中的状态都是一个**快照**,它的值在本次渲染是**不会改变**的。
83 | 2. 如果想基于前一个状态来确定当前状态,可以给`setState`**传入一个函数**,来**获得前一个状态的值**。
--------------------------------------------------------------------------------
/components/NavBar.js:
--------------------------------------------------------------------------------
1 | import styles from '../styles/Nav.module.css';
2 | import Link from 'next/link';
3 | import React from 'react';
4 |
5 | const NavBar = ({ setMode, mode }) => {
6 | const handleClick = () => {
7 | setMode((prev) => (prev === 'light' ? 'dark' : 'light'));
8 | localStorage.setItem('mode', mode === 'light' ? 'dark' : 'light');
9 | };
10 |
11 | React.useEffect(() => {
12 | // toggle HTML theme
13 | if (mode === 'light') {
14 | document.documentElement.classList.remove('dark');
15 | } else {
16 | document.documentElement.classList.add('dark');
17 | }
18 | }, [mode]);
19 |
20 | return (
21 |  25 |
26 | 想要强制禁用`Fast Forward`模式非常简单,只需要在`merge`命令后添加`--no-ff`,并且附上`commit`的名称:
27 |
28 | ```shell
29 | $ git merge --no-ff -m "merge with no-ff" dev
30 | ```
31 |
32 | 实战一下, 使用`git log --graph`看看提交后的效果:
33 |
34 |
25 |
26 | 想要强制禁用`Fast Forward`模式非常简单,只需要在`merge`命令后添加`--no-ff`,并且附上`commit`的名称:
27 |
28 | ```shell
29 | $ git merge --no-ff -m "merge with no-ff" dev
30 | ```
31 |
32 | 实战一下, 使用`git log --graph`看看提交后的效果:
33 |
34 |  35 |
36 | 
37 |
38 | 果然,无论是在终端还是在开发工具中,都可以看到强制禁用`Fast Forward`模式后,Git确实**保留了分支的信息**。
39 |
40 | ---
41 |
42 | # switch
43 |
44 | 使用`git checkout [分支]`可以切换分支,但`git checkout --[file]`又可以撤销暂存区内文件的修改。**一个命令,两个完全不同的用途**,用起来多少有些不舒服吧。
45 |
46 | 所有Git贴心的为我们添加了一个命令:`git switch`
47 |
48 | ```shell
49 | # 创建并切换到分支
50 | $ git switch -c [分支名]
51 |
52 | # 切换分支
53 | $ git switch [分支名]
54 | ```
55 |
56 | ---
57 |
58 | # 保存未提交的分支
59 |
60 | 想象一个场景,当你正在忙碌软件的开发,并且当前的开发还没有达到可以commit的标准,此时老板突然让你新建一个分支`issue-001`去修复一个bug,这时候怎么办?**怎么把当前分支没有提交的内容保存**?
61 |
62 | Git为我们提供了一个`git stash`命令来储存未提交的工作区:
63 |
64 | ```shell
65 | # 保存当前工作区的修改
66 | $ git stash
67 |
68 | # 查看当前stash中的内容
69 | $ git stash list
70 |
71 | # 将当前stash中的内容弹出,并应用到当前分支对应的工作目录上
72 | $ git stash pop
73 | ```
74 |
75 | 保存后查看`git status`应当是一个**干净的工作区**。当处理完bug后,回到没有提交的分支上,只需执行`git stash pop`即可恢复之前的修改。
76 |
77 | ---
78 |
79 | # 标签管理
80 |
81 | > **发布一个版本时,我们通常先在版本库中打一个标签(tag),这样,就唯一确定了打标签时刻的版本。将来无论什么时候,取某个标签的版本,就是把那个打标签的时刻的历史版本取出来。所以,标签也是版本库的一个快照。**
82 |
83 | ```shell
84 | # 查看已存在标签
85 | $ git tag
86 |
87 | # 打一个新标签 (默认标签是打在最新提交的commit上的)
88 | $ git tag
35 |
36 | 
37 |
38 | 果然,无论是在终端还是在开发工具中,都可以看到强制禁用`Fast Forward`模式后,Git确实**保留了分支的信息**。
39 |
40 | ---
41 |
42 | # switch
43 |
44 | 使用`git checkout [分支]`可以切换分支,但`git checkout --[file]`又可以撤销暂存区内文件的修改。**一个命令,两个完全不同的用途**,用起来多少有些不舒服吧。
45 |
46 | 所有Git贴心的为我们添加了一个命令:`git switch`
47 |
48 | ```shell
49 | # 创建并切换到分支
50 | $ git switch -c [分支名]
51 |
52 | # 切换分支
53 | $ git switch [分支名]
54 | ```
55 |
56 | ---
57 |
58 | # 保存未提交的分支
59 |
60 | 想象一个场景,当你正在忙碌软件的开发,并且当前的开发还没有达到可以commit的标准,此时老板突然让你新建一个分支`issue-001`去修复一个bug,这时候怎么办?**怎么把当前分支没有提交的内容保存**?
61 |
62 | Git为我们提供了一个`git stash`命令来储存未提交的工作区:
63 |
64 | ```shell
65 | # 保存当前工作区的修改
66 | $ git stash
67 |
68 | # 查看当前stash中的内容
69 | $ git stash list
70 |
71 | # 将当前stash中的内容弹出,并应用到当前分支对应的工作目录上
72 | $ git stash pop
73 | ```
74 |
75 | 保存后查看`git status`应当是一个**干净的工作区**。当处理完bug后,回到没有提交的分支上,只需执行`git stash pop`即可恢复之前的修改。
76 |
77 | ---
78 |
79 | # 标签管理
80 |
81 | > **发布一个版本时,我们通常先在版本库中打一个标签(tag),这样,就唯一确定了打标签时刻的版本。将来无论什么时候,取某个标签的版本,就是把那个打标签的时刻的历史版本取出来。所以,标签也是版本库的一个快照。**
82 |
83 | ```shell
84 | # 查看已存在标签
85 | $ git tag
86 |
87 | # 打一个新标签 (默认标签是打在最新提交的commit上的)
88 | $ git tag 11 | Hi, I'm Kelvin, a student at{' '} 12 | 13 | Beijing University of Technology 14 | 15 | , majoring in{' '} 16 | Software Engineering.{' '} 17 |
18 |19 | I love cats, but allergic 20 | to cats. 🐈 21 |
22 |26 | I enjoy programming. Playing around with code, discovering new tech, 27 | and building fun and useful projects are my favorite. On the{' '} 28 | 29 | projects 30 | {' '} 31 | projects page, I will show you my projects with a{' '} 32 | 38 | Github 39 | {' '} 40 | repository and an online demo.{' '} 41 |
42 |46 | In my spare time, I like creating videos about programming. Not just 47 | tutorial, but also share some opinions and experience. You can find me 48 | on 哔哩哔哩 by searching 49 | MiuMiu8802 or clicking{' '} 50 | 56 | this link 57 | 58 | . 59 |
60 |64 | Find me on{' '} 65 | 71 | Github 72 | {' '} 73 | and{' '} 74 | 80 | 哔哩哔哩 81 | 82 | . 83 |
84 |85 | Mail me at{' '} 86 | 92 | kelvinqiu802@outlook.com 93 | 94 | . 95 |
96 | 33 |
34 | 此题所求为**最大值**,并且存在一个符号为**大于等于号**的不等约束,应先根据标准公式进行变形,代码如下:
35 |
36 | ```python
37 | import numpy as np
38 | from scipy import optimize as op
39 |
40 | c = np.array([-2, -3, 5])
41 | A_eq = np.array([[1, 1, 1]])
42 | b_eq = np.array([7])
43 | A_ub = np.array([[-2, 5, -1], [1, 3, 1]])
44 | b_ub = np.array([-10, 12])
45 | x1 = (0, 7)
46 | x2 = (0, 7)
47 | x3 = (0, 7)
48 |
49 | res = op.linprog(c, A_ub, b_ub, A_eq, b_eq, bounds=(x1, x2, x3))
50 | print(res)
51 | ```
52 |
53 | 得到的结果为:
54 |
55 | >con: array([1.19830306e-08])
56 | >
57 | >**fun: -14.57142854231215**
58 | >
59 | >message: 'Optimization terminated successfully.'
60 | >
61 | >nit: 5
62 | >
63 | >slack: array([-3.70231543e-08, 3.85714287e+00])
64 | >
65 | >status: 0
66 | >
67 | >success: True
68 | >
69 | >**x: array([6.42857141e+00, 5.71428573e-01, 9.82192085e-10])**
70 |
71 | 根据官方文档,x代表最终各个x的取值,fun则代表最终结果。
72 |
73 | 
74 |
75 | ---
76 |
77 | ### 例2:
78 |
79 |
33 |
34 | 此题所求为**最大值**,并且存在一个符号为**大于等于号**的不等约束,应先根据标准公式进行变形,代码如下:
35 |
36 | ```python
37 | import numpy as np
38 | from scipy import optimize as op
39 |
40 | c = np.array([-2, -3, 5])
41 | A_eq = np.array([[1, 1, 1]])
42 | b_eq = np.array([7])
43 | A_ub = np.array([[-2, 5, -1], [1, 3, 1]])
44 | b_ub = np.array([-10, 12])
45 | x1 = (0, 7)
46 | x2 = (0, 7)
47 | x3 = (0, 7)
48 |
49 | res = op.linprog(c, A_ub, b_ub, A_eq, b_eq, bounds=(x1, x2, x3))
50 | print(res)
51 | ```
52 |
53 | 得到的结果为:
54 |
55 | >con: array([1.19830306e-08])
56 | >
57 | >**fun: -14.57142854231215**
58 | >
59 | >message: 'Optimization terminated successfully.'
60 | >
61 | >nit: 5
62 | >
63 | >slack: array([-3.70231543e-08, 3.85714287e+00])
64 | >
65 | >status: 0
66 | >
67 | >success: True
68 | >
69 | >**x: array([6.42857141e+00, 5.71428573e-01, 9.82192085e-10])**
70 |
71 | 根据官方文档,x代表最终各个x的取值,fun则代表最终结果。
72 |
73 | 
74 |
75 | ---
76 |
77 | ### 例2:
78 |
79 |  80 |
81 | 此题中有两个未知变量,x与a,当遇到两个变量时可先**将一个变量固定,单独研究一个决策变量**。
82 |
83 | 本题假设固定a,将a的初始值设为0.001,并以0.001位步长,研究分析a从0.001到0.05之间的结果变化,并画出图表。
84 |
85 | ```python
86 | import numpy as np
87 | from scipy import optimize as op
88 | import matplotlib.pyplot as plt
89 |
90 | a = 0.001
91 | c = np.array([-0.05, -0.27, -0.19, -0.185, -0.185])
92 | A_eq = np.array([[1, 1.01, 1.02, 1.045, 1.065]])
93 | b_eq = np.array([1])
94 | A_ub = np.array([[0, 0, 0, 0, 0], # 因为式中没有关于X0的不等式约束,所以第一行取0
95 | [0, 0.025, 0, 0, 0],
96 | [0, 0, 0.015, 0, 0],
97 | [0, 0, 0, 0.055, 0],
98 | [0, 0, 0, 0, 0.026]])
99 |
100 | while a < 0.05:
101 | b_ub = np.array([0, a, a, a, a])
102 | res = op.linprog(c, A_ub, b_ub, A_eq, b_eq, bounds=(0, None))
103 | plt.scatter(a, -res["fun"])
104 | a += 0.001
105 |
106 | plt.show()
107 | ```
108 |
109 | 结果如下:
110 |
111 |
80 |
81 | 此题中有两个未知变量,x与a,当遇到两个变量时可先**将一个变量固定,单独研究一个决策变量**。
82 |
83 | 本题假设固定a,将a的初始值设为0.001,并以0.001位步长,研究分析a从0.001到0.05之间的结果变化,并画出图表。
84 |
85 | ```python
86 | import numpy as np
87 | from scipy import optimize as op
88 | import matplotlib.pyplot as plt
89 |
90 | a = 0.001
91 | c = np.array([-0.05, -0.27, -0.19, -0.185, -0.185])
92 | A_eq = np.array([[1, 1.01, 1.02, 1.045, 1.065]])
93 | b_eq = np.array([1])
94 | A_ub = np.array([[0, 0, 0, 0, 0], # 因为式中没有关于X0的不等式约束,所以第一行取0
95 | [0, 0.025, 0, 0, 0],
96 | [0, 0, 0.015, 0, 0],
97 | [0, 0, 0, 0.055, 0],
98 | [0, 0, 0, 0, 0.026]])
99 |
100 | while a < 0.05:
101 | b_ub = np.array([0, a, a, a, a])
102 | res = op.linprog(c, A_ub, b_ub, A_eq, b_eq, bounds=(0, None))
103 | plt.scatter(a, -res["fun"])
104 | a += 0.001
105 |
106 | plt.show()
107 | ```
108 |
109 | 结果如下:
110 |
111 |  112 |
--------------------------------------------------------------------------------
/public/posts/check-input-is-integer.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 由Number引发的思考:如何判断用户输入的值是否为纯数字?
3 | date: 2022-06-23
4 | tags: [Web开发, JavaScript, 文章分享]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/fH8XrP.png"
6 | top_img: false
7 | categories: [文章分享, Web开发]
8 | ---
9 |
10 | ## 问题回顾
11 |
12 | 最近在阅读[现代JavaScript教程](https://javascript.info), 在Number这一章节中有这么一个**任务**:
13 |
14 |
112 |
--------------------------------------------------------------------------------
/public/posts/check-input-is-integer.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 由Number引发的思考:如何判断用户输入的值是否为纯数字?
3 | date: 2022-06-23
4 | tags: [Web开发, JavaScript, 文章分享]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/fH8XrP.png"
6 | top_img: false
7 | categories: [文章分享, Web开发]
8 | ---
9 |
10 | ## 问题回顾
11 |
12 | 最近在阅读[现代JavaScript教程](https://javascript.info), 在Number这一章节中有这么一个**任务**:
13 |
14 |  15 |
16 | 要求程序接收用户输入的一个值,并且只有当这个值为**数字**的时候才能通过,这其实就是*如何判断一个字符串是纯数字*。在Python中,只需要调用`str.isdigit()`, 或者使用`try except`就可以解决这个问题,但是在JavaScript中,好像并没有一个方便的函数来处理这个问题,并且对一个非数字的字符串强制转换为数字并不会引起错误,所以无法通过捕获异常来进行处理。
17 |
18 | ## 网上搜索
19 |
20 | 通过搜索这个问题,我意识到,网上的答案真的是鱼龙混杂,有的完全不靠谱,却还排在很前面,让你第一个看到,简直就是浪费时间。下面的这些**答案多多少少都有问题**,我会在后面一一指出:
21 |
22 | ### 答案一:
23 |
24 | ```js
25 | function checkInp() {
26 | let x = prompt('Enter a number:')
27 | if (isNaN(x))
28 | {
29 | alert("Must input numbers");
30 | return false;
31 | }
32 | }
33 | ```
34 |
35 | 答者使用`isNaN()`来判断输入的字符串是否为纯字符。乍一看好像没什么问题,如果输入一个字符串`'123aaa'`,`isNaN()`会自动使用`Number()`进行强制转换,那么`123aaa`转换完的结果就是**NaN**,那么就返回**true**,没什么问题呀~
36 |
37 | **但是!**因为`isNaN()`会自动调用`Number()`进行强制转换,也就是说,`null`、`''`和`空值`都会被转换为**0**,此时**这种方法在遇到null,空字符串的时候就失效了**。
38 |
39 |
15 |
16 | 要求程序接收用户输入的一个值,并且只有当这个值为**数字**的时候才能通过,这其实就是*如何判断一个字符串是纯数字*。在Python中,只需要调用`str.isdigit()`, 或者使用`try except`就可以解决这个问题,但是在JavaScript中,好像并没有一个方便的函数来处理这个问题,并且对一个非数字的字符串强制转换为数字并不会引起错误,所以无法通过捕获异常来进行处理。
17 |
18 | ## 网上搜索
19 |
20 | 通过搜索这个问题,我意识到,网上的答案真的是鱼龙混杂,有的完全不靠谱,却还排在很前面,让你第一个看到,简直就是浪费时间。下面的这些**答案多多少少都有问题**,我会在后面一一指出:
21 |
22 | ### 答案一:
23 |
24 | ```js
25 | function checkInp() {
26 | let x = prompt('Enter a number:')
27 | if (isNaN(x))
28 | {
29 | alert("Must input numbers");
30 | return false;
31 | }
32 | }
33 | ```
34 |
35 | 答者使用`isNaN()`来判断输入的字符串是否为纯字符。乍一看好像没什么问题,如果输入一个字符串`'123aaa'`,`isNaN()`会自动使用`Number()`进行强制转换,那么`123aaa`转换完的结果就是**NaN**,那么就返回**true**,没什么问题呀~
36 |
37 | **但是!**因为`isNaN()`会自动调用`Number()`进行强制转换,也就是说,`null`、`''`和`空值`都会被转换为**0**,此时**这种方法在遇到null,空字符串的时候就失效了**。
38 |
39 |  40 |
41 | ### 答案二:
42 |
43 | ```js
44 | function readNumber() {
45 | let userInput;
46 | do {
47 | userInput = prompt('Enter a number:');
48 | if (userInput === null || userInput === '') {
49 | return null;
50 | }
51 | } while (isNaN(userInput));
52 | return +userInput;
53 | }
54 | ```
55 |
56 | 答案二的本质跟答案一相同,还是使用`isNaN()`来进行判断,只不过它在循环体内部多进行了一次判断,把`null`和`''`的情况单独考虑,也确实能达到目的。
57 |
58 | **但是!**`''`和`' '`是不一样的,他们都会被`Number()`转换为**0**,所以如果遇到用户输入了n个空格,这个方法也就失效了。
59 |
60 | ### 答案三:
61 |
62 | ```js
63 | function checkInp()
64 | {
65 | let x = prompt('Enter a value:')
66 | let regex = /^[0-9]+$/;
67 | if (! x.match(regex))
68 | {
69 | alert("Must input numbers");
70 | return false;
71 | }
72 | }
73 | ```
74 |
75 | 这个答案我询问了一下朋友,可能是最清晰,最推荐的写法,他使用了**正则表达式**。虽然对正则表达式还一无所知,但是通过[正则可视化工具](https://jex.im/regulex/#!flags=&re=%5E(a%7Cb)*%3F%24)也可以理解`/^[0-9]+$/`的作用:
76 |
77 | 
78 |
79 | 这个正则表达式的意思就是依次检查每一个字符是否都是在0-9这个区间内,也就是纯数字。如果没有通过这个测试,则可以说明它一定不是纯数字。
80 |
81 | ### 答案四:
82 |
83 | 因为还没有学过正则,所以有没有**不用正则**的完美方法呢?
84 |
85 | 哈哈哈,我突然想到了jQuery中的`$.isNumeric()`,它做的事就是判断输入是否为纯数字。既然有了答案,就看看jQuery源码是如何实现这个功能的:
86 |
87 | ```js
88 | isNumeric: function( obj ) {
89 | return !isNaN( parseFloat( obj ) ) && isFinite( obj );
90 | }
91 | ```
92 |
93 | 这是我直接从源码中拷贝过来的,不得不说,**确实强**!
94 |
95 | 分析一下,代码的核心逻辑就是`!isNaN( parseFloat( obj ) ) && isFinite( obj );`
96 |
97 | 假设输入一个**123aaa**:
98 |
99 | 1. parseFloat('123aaa') = 123
100 | 2. ! isNaN(123) = true
101 | 3. Number('123aaa') = NaN
102 | 4. isFinite(NaN) = false
103 | 5. 结果为 true && false = false
104 |
105 | 这就是它判断的流程,再举个例子,输入`' '`;
106 |
107 | 1. parseFloat(' ') = NaN
108 | 2. ! isNaN = false
109 |
110 | 不论是什么奇奇怪怪的值,好像都能正确的返回,下面我来试着表述一下这么实现的原理:
111 |
112 | > **首先:parseFloat() 的转换只针对字符串,所以非字符串转换出来都是NaN,这样就可以规避掉那些非字符串了。**
113 | >
114 | > **其次:parseFloat() 在处理以数字开头,但含有字母的字符串,如: '123aaa'时会忽略掉后面的字母,直接返回123,这其实是我们不想要的,于是jQuery机智的加入了后面的isFinite(),它在遇到'123aaa'这类的字符串时会直接返回false,这样也就规避掉了数字与字母混合的情况。**
115 | >
116 | > **最后:这个方法最妙的其实就是parseFloat()和isFinite()配合使用,因为他们处理字符串的逻辑不同。**
--------------------------------------------------------------------------------
/public/posts/react-event-this.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: React-事件回调函数this指向问题
3 | date: 2022-05-13
4 | tags: [Web开发, React]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/CME7bN.png"
6 | top_img: false
7 | categories: [Web开发]
8 | ---
9 |
10 | 初学React时,往往会被组件中的**事件回调函数中的this指向**问题搞得头晕。本文是我的一些*自言自语*,希望自己能给自己讲清楚这个问题。
11 |
12 | # 问题分析
13 |
14 | 故事的开始要从这个错误说起:
15 |
16 | 
17 |
18 | > **无法从undefined中读取值?**
19 |
20 | 来看看**源代码**:
21 |
22 | ```jsx
23 | class Toggle extends React.Component{
24 | constructor (props) {
25 | super(props);
26 | this.state = {isOn: true};
27 | }
28 | render() {
29 | return (
30 |
40 |
41 | ### 答案二:
42 |
43 | ```js
44 | function readNumber() {
45 | let userInput;
46 | do {
47 | userInput = prompt('Enter a number:');
48 | if (userInput === null || userInput === '') {
49 | return null;
50 | }
51 | } while (isNaN(userInput));
52 | return +userInput;
53 | }
54 | ```
55 |
56 | 答案二的本质跟答案一相同,还是使用`isNaN()`来进行判断,只不过它在循环体内部多进行了一次判断,把`null`和`''`的情况单独考虑,也确实能达到目的。
57 |
58 | **但是!**`''`和`' '`是不一样的,他们都会被`Number()`转换为**0**,所以如果遇到用户输入了n个空格,这个方法也就失效了。
59 |
60 | ### 答案三:
61 |
62 | ```js
63 | function checkInp()
64 | {
65 | let x = prompt('Enter a value:')
66 | let regex = /^[0-9]+$/;
67 | if (! x.match(regex))
68 | {
69 | alert("Must input numbers");
70 | return false;
71 | }
72 | }
73 | ```
74 |
75 | 这个答案我询问了一下朋友,可能是最清晰,最推荐的写法,他使用了**正则表达式**。虽然对正则表达式还一无所知,但是通过[正则可视化工具](https://jex.im/regulex/#!flags=&re=%5E(a%7Cb)*%3F%24)也可以理解`/^[0-9]+$/`的作用:
76 |
77 | 
78 |
79 | 这个正则表达式的意思就是依次检查每一个字符是否都是在0-9这个区间内,也就是纯数字。如果没有通过这个测试,则可以说明它一定不是纯数字。
80 |
81 | ### 答案四:
82 |
83 | 因为还没有学过正则,所以有没有**不用正则**的完美方法呢?
84 |
85 | 哈哈哈,我突然想到了jQuery中的`$.isNumeric()`,它做的事就是判断输入是否为纯数字。既然有了答案,就看看jQuery源码是如何实现这个功能的:
86 |
87 | ```js
88 | isNumeric: function( obj ) {
89 | return !isNaN( parseFloat( obj ) ) && isFinite( obj );
90 | }
91 | ```
92 |
93 | 这是我直接从源码中拷贝过来的,不得不说,**确实强**!
94 |
95 | 分析一下,代码的核心逻辑就是`!isNaN( parseFloat( obj ) ) && isFinite( obj );`
96 |
97 | 假设输入一个**123aaa**:
98 |
99 | 1. parseFloat('123aaa') = 123
100 | 2. ! isNaN(123) = true
101 | 3. Number('123aaa') = NaN
102 | 4. isFinite(NaN) = false
103 | 5. 结果为 true && false = false
104 |
105 | 这就是它判断的流程,再举个例子,输入`' '`;
106 |
107 | 1. parseFloat(' ') = NaN
108 | 2. ! isNaN = false
109 |
110 | 不论是什么奇奇怪怪的值,好像都能正确的返回,下面我来试着表述一下这么实现的原理:
111 |
112 | > **首先:parseFloat() 的转换只针对字符串,所以非字符串转换出来都是NaN,这样就可以规避掉那些非字符串了。**
113 | >
114 | > **其次:parseFloat() 在处理以数字开头,但含有字母的字符串,如: '123aaa'时会忽略掉后面的字母,直接返回123,这其实是我们不想要的,于是jQuery机智的加入了后面的isFinite(),它在遇到'123aaa'这类的字符串时会直接返回false,这样也就规避掉了数字与字母混合的情况。**
115 | >
116 | > **最后:这个方法最妙的其实就是parseFloat()和isFinite()配合使用,因为他们处理字符串的逻辑不同。**
--------------------------------------------------------------------------------
/public/posts/react-event-this.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: React-事件回调函数this指向问题
3 | date: 2022-05-13
4 | tags: [Web开发, React]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/CME7bN.png"
6 | top_img: false
7 | categories: [Web开发]
8 | ---
9 |
10 | 初学React时,往往会被组件中的**事件回调函数中的this指向**问题搞得头晕。本文是我的一些*自言自语*,希望自己能给自己讲清楚这个问题。
11 |
12 | # 问题分析
13 |
14 | 故事的开始要从这个错误说起:
15 |
16 | 
17 |
18 | > **无法从undefined中读取值?**
19 |
20 | 来看看**源代码**:
21 |
22 | ```jsx
23 | class Toggle extends React.Component{
24 | constructor (props) {
25 | super(props);
26 | this.state = {isOn: true};
27 | }
28 | render() {
29 | return (
30 | Projects
32 |Tools
105 |Demo
122 | 30 |
31 |
30 |
31 |  32 |
33 | 从图中可以看出Pexles上的图片与视频都可免费使用,甚至无需标注原作者并且允许自由修改与创造。 **良心!**
34 |
35 | ---
36 |
37 | #### [Unsplash](httpss://unsplash.com/)
38 |
39 | 与Pexels类似,Unsplash也提供可免费使用的图片,唯一的小缺点就是没有中文站点,国内访问速度可能较慢。Unsplash也同样给出了具体的免费使用条款:
40 |
41 |
32 |
33 | 从图中可以看出Pexles上的图片与视频都可免费使用,甚至无需标注原作者并且允许自由修改与创造。 **良心!**
34 |
35 | ---
36 |
37 | #### [Unsplash](httpss://unsplash.com/)
38 |
39 | 与Pexels类似,Unsplash也提供可免费使用的图片,唯一的小缺点就是没有中文站点,国内访问速度可能较慢。Unsplash也同样给出了具体的免费使用条款:
40 |
41 |  42 |
43 |
42 |
43 |  44 |
45 | >✅ 所有图片可以免费下载使用
46 | >
47 | >✅ 商业及非商业用途都可使用
48 | >
49 | >✅ 无需任何许可
50 | >
51 | >🚫 禁止在没有对图片进行重大二次创作的前提下售卖
52 | >
53 | >🚫 禁止用Unplash的图片抢他们的生意...
54 |
55 | Unplash的使用协议多了一条**“商业及非商业用途都可使用”**,如果涉及商业用途的网站可以优先考虑Unplash。
56 |
57 | ### 2. 图片比例及内容
58 |
59 | - 如果网站主要运行在网页端,建议选择接近**16:9**大小的图片,因为标准的4K/2K/1080P的比例都是16:9,可以保证只对图片进行最小程度的变形。
60 | - 如果网站即要在网页端也在移动端运行,背景图片的压缩变形是不可避免的了,此时就要选择**图片中尽量少出现人,车,动物,家具等形状复杂的物体,因为这些物体一旦变形,对视觉的影响非常大**。大自然的风光图片很适合用来当作背景,因为它们清晰度高,景别大,复杂的物体少。
61 |
62 | ### 3. 图片体积
63 |
64 | 为了优化用户体验,一定要在保证对图片质量损失最小的情况下,尽可能压缩图片体积。压缩图片的工具非常多,这里推荐[**Doc Small**](httpss://docsmall.com/image-compress)。
65 |
66 |
44 |
45 | >✅ 所有图片可以免费下载使用
46 | >
47 | >✅ 商业及非商业用途都可使用
48 | >
49 | >✅ 无需任何许可
50 | >
51 | >🚫 禁止在没有对图片进行重大二次创作的前提下售卖
52 | >
53 | >🚫 禁止用Unplash的图片抢他们的生意...
54 |
55 | Unplash的使用协议多了一条**“商业及非商业用途都可使用”**,如果涉及商业用途的网站可以优先考虑Unplash。
56 |
57 | ### 2. 图片比例及内容
58 |
59 | - 如果网站主要运行在网页端,建议选择接近**16:9**大小的图片,因为标准的4K/2K/1080P的比例都是16:9,可以保证只对图片进行最小程度的变形。
60 | - 如果网站即要在网页端也在移动端运行,背景图片的压缩变形是不可避免的了,此时就要选择**图片中尽量少出现人,车,动物,家具等形状复杂的物体,因为这些物体一旦变形,对视觉的影响非常大**。大自然的风光图片很适合用来当作背景,因为它们清晰度高,景别大,复杂的物体少。
61 |
62 | ### 3. 图片体积
63 |
64 | 为了优化用户体验,一定要在保证对图片质量损失最小的情况下,尽可能压缩图片体积。压缩图片的工具非常多,这里推荐[**Doc Small**](httpss://docsmall.com/image-compress)。
65 |
66 |  67 |
68 | ---
69 |
70 | ## 二. 制作网站
71 |
72 | 下面将以这张图片作为例子:
73 |
74 |
67 |
68 | ---
69 |
70 | ## 二. 制作网站
71 |
72 | 下面将以这张图片作为例子:
73 |
74 |  75 |
76 | 首先创建一个div容器用来放置背景图片:
77 |
78 | ```html
79 |
86 |
87 |
88 | ```
89 |
90 | 此时,图片充满了整个屏幕,但却没有显示完整,解决方法可以使用 **background-size: cover;** 让图片自动拉伸,适应屏幕大小。 为了防止图片循环重复,加上一句 **background-repeat: no-repeat;** 会更保险。
91 |
92 | ```html
93 |
102 |
103 |
104 | ```
105 |
106 |
75 |
76 | 首先创建一个div容器用来放置背景图片:
77 |
78 | ```html
79 |
86 |
87 |
88 | ```
89 |
90 | 此时,图片充满了整个屏幕,但却没有显示完整,解决方法可以使用 **background-size: cover;** 让图片自动拉伸,适应屏幕大小。 为了防止图片循环重复,加上一句 **background-repeat: no-repeat;** 会更保险。
91 |
92 | ```html
93 |
102 |
103 |
104 | ```
105 |
106 |  107 |
108 | 现在的图片已经完全充满屏幕,并且能够根据屏幕的大小自动拉伸调整,但是图片四周却存在白色间隙,通过浏览器调试可以发现这个白色间隙是body的边缘(margin),此时的数值是8,将它修改到0即可解决问题。
109 |
110 | ```html
111 |
123 |
124 |
125 | ```
126 |
127 | 给网页加上些内容,另一个问题又出现了,当内容的长度大于图片的高度时,背景有会恢复位白色,因为此时图片已经完全显示完毕,不会再自动延伸。
128 |
129 |
107 |
108 | 现在的图片已经完全充满屏幕,并且能够根据屏幕的大小自动拉伸调整,但是图片四周却存在白色间隙,通过浏览器调试可以发现这个白色间隙是body的边缘(margin),此时的数值是8,将它修改到0即可解决问题。
109 |
110 | ```html
111 |
123 |
124 |
125 | ```
126 |
127 | 给网页加上些内容,另一个问题又出现了,当内容的长度大于图片的高度时,背景有会恢复位白色,因为此时图片已经完全显示完毕,不会再自动延伸。
128 |
129 |  130 |
131 | 这里只需要将背景图片的定位元素改为fixed,并将图片置于最下层,图片就会永远停留在屏幕上。
132 |
133 | ```html
134 |
150 |
151 |
152 | ```
153 |
154 | ---
155 |
156 | ## 三. 使用Bootstrap相册作为背景
157 |
158 | 想要获得更好的视觉效果,可以让背景中的照片滚的起来,下面是我个人网站的例子,可以看到用户甚至可以使用页面下方的bar来自由选择背景照片。
159 |
160 |
130 |
131 | 这里只需要将背景图片的定位元素改为fixed,并将图片置于最下层,图片就会永远停留在屏幕上。
132 |
133 | ```html
134 |
150 |
151 |
152 | ```
153 |
154 | ---
155 |
156 | ## 三. 使用Bootstrap相册作为背景
157 |
158 | 想要获得更好的视觉效果,可以让背景中的照片滚的起来,下面是我个人网站的例子,可以看到用户甚至可以使用页面下方的bar来自由选择背景照片。
159 |
160 |  161 |
162 | 代码直接套用Bootstrap的滚动相册,原理与上述相同:
163 |
164 | ```html
165 |
166 |
161 |
162 | 代码直接套用Bootstrap的滚动相册,原理与上述相同:
163 |
164 | ```html
165 |
166 |  193 |
194 | 可以看到有这么一大堆属性,本文将会选几个最重要最常用的进行说明。
195 |
196 | - **event.target** 返回**触发事件**的对象
197 | - `this` 返回的是**绑定事件的对象**
198 | - `event.currentTarget` 与 `this` 功能相同,返回**绑定该事件的对象**
199 | - **event.type** 返回**事件类型**
200 | - `click`, `mouseon`, `keydown` 等等
201 | - **event.preventDefault()** **阻止默认事件**
202 | - 禁用链接跳转
203 | - 禁用提交按钮提交数据
204 | - **event.stopPropagation()** **阻止事件冒泡**
205 |
206 | ```js
207 | // 阻止链接跳转
208 | Google
209 |
210 | let a = document.querySelector('a');
211 | a.addEventListener('click', e => e.preventDefault());
212 | ```
213 |
214 | ```js
215 | // 阻止事件冒泡
216 |
193 |
194 | 可以看到有这么一大堆属性,本文将会选几个最重要最常用的进行说明。
195 |
196 | - **event.target** 返回**触发事件**的对象
197 | - `this` 返回的是**绑定事件的对象**
198 | - `event.currentTarget` 与 `this` 功能相同,返回**绑定该事件的对象**
199 | - **event.type** 返回**事件类型**
200 | - `click`, `mouseon`, `keydown` 等等
201 | - **event.preventDefault()** **阻止默认事件**
202 | - 禁用链接跳转
203 | - 禁用提交按钮提交数据
204 | - **event.stopPropagation()** **阻止事件冒泡**
205 |
206 | ```js
207 | // 阻止链接跳转
208 | Google
209 |
210 | let a = document.querySelector('a');
211 | a.addEventListener('click', e => e.preventDefault());
212 | ```
213 |
214 | ```js
215 | // 阻止事件冒泡
216 |  271 |
272 | - **contextmenu 禁用右键菜单**
273 |
274 | ```js
275 | document.addEventListener('contextmenu', e => e.preventDefault());
276 | ```
277 |
278 | - **selectstart 禁止鼠标选中**
279 |
280 | ```js
281 | document.addEventListener('selectstart', e => e.preventDefault());
282 | ```
283 |
284 |
271 |
272 | - **contextmenu 禁用右键菜单**
273 |
274 | ```js
275 | document.addEventListener('contextmenu', e => e.preventDefault());
276 | ```
277 |
278 | - **selectstart 禁止鼠标选中**
279 |
280 | ```js
281 | document.addEventListener('selectstart', e => e.preventDefault());
282 | ```
283 |
284 |  285 |
286 | ## 键盘事件
287 |
288 | - **onkeyup** 松开时触发
289 | - **onkeydown** 按下时触发
290 | - **onekypress** 按下时触发 (**不能识别功能键**)
291 | - **e.key** 获得被触发的键
292 |
293 | > **执行顺序:先keydown,再keypress,最后keyup**
294 | >
295 | > **keydown 和 keypress在文本框中,先触发,然后文字才被输入**
--------------------------------------------------------------------------------
/public/posts/tkinter-cheatsheet.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Tkinter内置属性及方法速查表
3 | date: 2022-03-02
4 | tags: [Python, Tkinter, GUI]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/kXXYdu.png"
6 | top_img: false
7 | categories: [Python]
8 | ---
9 |
10 | > [*Tkinter* 8.5 reference: a GUI for Python](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/index.html)
11 |
12 | # Grid
13 |
14 | ```python
15 | a.grid(row=0, column=0)
16 | b.grid(row=1, column=1)
17 | c.grid(row=2, column=0, columnspan=2)
18 | d.grid(row=0, column=2, rowspan=2)
19 | ```
20 |
21 | [Grid Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/grid.html)
22 |
23 | # Window
24 |
25 | ```python
26 | window = tk.Tk()
27 | window.title()
28 | window.geometry()
29 | window.resizable()
30 | window.config()
31 | ```
32 |
33 | # Label
34 |
35 | ```python
36 | label = tk.Label(window,
37 | text="",
38 | width=10,
39 | height=10,
40 | font=(),
41 | bg='orange')
42 | ```
43 |
44 | [Label Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/label.html)
45 |
46 | # Button
47 |
48 | ```python
49 | button = tk.Button(window,
50 | text="",
51 | width=10,
52 | height=10,
53 | state=tk.ACTIVE,
54 | image="",
55 | command=abc)
56 | ```
57 |
58 | [Button Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/button.html)
59 |
60 | # Entry
61 |
62 | ```python
63 | entry = tk.Entry(window,
64 | width=10,
65 | fg='red',
66 | bg='blue',
67 | font=())
68 | entry.delete()
69 | entry.get()
70 | entry.insert(index, string)
71 | ```
72 |
73 | [Entry Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/entry.html)
74 |
75 | # Checkbutton
76 |
77 | ```python
78 | checkbutton = tk.Checkbutton(window,
79 | text="",
80 | textvariable=a,
81 | variable=b,
82 | offvalue=c,
83 | onvalue=d,
84 | command=abc)
85 | checkbutton.deselect()
86 | checkbutton.select()
87 | ```
88 |
89 | [Checkbutton Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/checkbutton.html)
90 |
91 | # Radiobutton
92 |
93 | ```python
94 | radiobutton = tk.Radiobutton(window,
95 | text="",
96 | value=a,
97 | variable=b,
98 | command=abc)
99 | radiobutton.select()
100 | radiobutton.deselect()
101 | ```
102 |
103 | [Radiobutton Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/radiobutton.html)
104 |
105 | # Scale
106 |
107 | ```python
108 | scale = tk.Scale(window,
109 | resolution=0.5,
110 | sliderlength=30,
111 | variable=a,
112 | command=abc)
113 | scale.get()
114 | scale.set(value)
115 | ```
116 |
117 | [Scale Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/scale.html)
118 |
119 | # Listbox
120 |
121 | ```python
122 | listbox = tk.Listbox(window,
123 | activestyle='underline')
124 | listbox.activate(index)
125 | listbox.curselection()
126 | listbox.delete(first)
127 | listbox.get(first)
128 | listbox.insert(index, text)
129 | listbox.size()
130 | ```
131 |
132 | [Listbox Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/listbox.html)
133 |
134 | # Messagebox
135 |
136 | ```python
137 | from tkinter import messagebox
138 | a = messagebox.askokcancel(title, message, options)
139 | b = messagebox.askquestion(title, message, options)
140 | c = messagebox.askretrycancel(title, message, options)
141 | d = messagebox.askyesno(title, message, options)
142 | e = messagebox.showerror(title, message, options)
143 | f = messagebox.showinfo(title, message, options)
144 | g = messagebox.showwarning(title, message, options)
145 | ```
146 |
147 | [Messagebox Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/tkMessageBox.html)
148 |
149 | # ColorChooser
150 |
151 | ```python
152 | from tkinter import colorchooser
153 | color = colorchooser.askcolor(color, title, parent)
154 | ```
155 |
156 | [ColorChooser Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/tkColorChooser.html)
157 |
158 | # Text
159 |
160 | ```python
161 | text = tk.Text(window, width, height)
162 | text.get(index1)
163 | text.insert(index, chars)
164 | ```
165 |
166 | [Text Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/text.html) / [Text Methods](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/text-methods.html)
167 |
168 | # FileDialog
169 |
170 | ```python
171 | from tkinter import filedialog
172 | open1 = filedialog.askopenfilename(option)
173 | open2 = filedialog.askdirectory(option)
174 | save1 = filedialog.asksaveasfilename(option)
175 |
176 | # /option/
177 | # defaultextension='.txt'
178 | # filetypes=[('PNG', '*.png'), (label2, pattern2), ...]
179 | # initialdir=D
180 | # initialfile=F
181 | # title=T
182 | # parent=W
183 | ```
184 |
185 | [FileDialog Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/tkFileDialog.html)
186 |
187 | # Menu
188 |
189 | ```python
190 | # Example
191 | menubar = ttk.Menu(window)
192 | window.config(menu=menubar)
193 |
194 | fileMenu = ttk.Menu(menubar)
195 | menubar.add_cascade(label='File', menu=fileMenu)
196 | fileMenu.add_command(label='Open', command=openFile)
197 | fileMenu.add_command(label='Save', command=saveFile)
198 | fileMenu.add_separator()
199 | fileMenu.add_command(label='Exit', command=quit)
200 |
201 | editMenu = ttk.Menu(menubar)
202 | menubar.add_cascade(label='Edit', menu=editMenu)
203 | editMenu.add_command(label='Cut')
204 | editMenu.add_command(label='Copy')
205 | editMenu.add_command(label='Paste')
206 | ```
207 |
208 | [Menu Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/menu.html)
209 |
210 | # Frame
211 |
212 | ```python
213 | frame = tk.Frame(window,
214 | width,
215 | height,
216 | bg)
217 | # Example
218 | frame = ttk.Frame(window, bootstyle=WARNING)
219 | frame.pack()
220 |
221 | ttk.Button(frame, text='W', width=3).pack(side=TOP)
222 | ttk.Button(frame, text='A', width=3).pack(side=LEFT)
223 | ttk.Button(frame, text='S', width=3).pack(side=LEFT)
224 | ttk.Button(frame, text='D', width=3).pack(side=LEFT)
225 | ```
226 |
227 | [Frame Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/frame.html)
228 |
229 | # TopLevel
230 |
231 | ```python
232 | newWindow = tk.Toplevel()
233 | ```
234 |
235 | [TopLevle Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/toplevel.html)
236 |
237 | # Notebook
238 |
239 | ```python
240 | # Example
241 | noteBook = ttk.Notebook(window, bootstyle=INFO)
242 |
243 | tab1 = ttk.Frame(noteBook)
244 | tab2 = ttk.Frame(noteBook)
245 |
246 | noteBook.add(tab1, text='Tab1')
247 | noteBook.add(tab2, text='Tab2')
248 | noteBook.pack()
249 |
250 | tk.Label(tab1, text='Hello Tab1', width=50, height=10).pack()
251 | tk.Label(tab2, text="Hello Tab2", width=50, height=10).pack()
252 | ```
253 |
254 | [NoteBook Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/ttk-Notebook.html)
255 |
256 |
--------------------------------------------------------------------------------
/public/posts/matplotlib-1.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Matplotlib数据可视化——2.绘制各类统计图
3 | date: 2022-01-22
4 | tags: [Python, matplotlib, 可视化]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/ZbL8Y4.png"
6 | top_img: false
7 | categories: [Python]
8 | ---
9 |
10 | > Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python. Matplotlib makes easy things easy and hard things possible. --**Matplotlib**
11 |
12 | > **注:文中的例子与数据部分来自[C语言中文网](http://c.biancheng.net/matplotlib/)**
13 |
14 | # 一. 双轴图
15 |
16 | 有时一张图上的两幅图像需要绘制两个x轴或y轴才能更加清晰的显示信息,使用Matplotlib中的 **twinx()**和**twiny()** 函数即可创建两个y轴或x轴。
17 |
18 | 
19 |
20 | >**根据官方文档可知twinx代表共享x轴并生成第二个y轴,同理twiny代表共享y轴并生成第二个x轴。**
21 |
22 | ```python
23 | import matplotlib.pyplot as plt
24 | import numpy as np
25 |
26 | x = np.arange(0, 10, 0.1)
27 | fig = plt.figure()
28 | ax1 = fig.add_axes([0.1, 0.1, 0.8, 0.8])
29 | ax1.plot(x, np.log(x))
30 | ax1.set_ylabel('Log')
31 |
32 | # 添加第二个y轴
33 | ax2 = ax1.twinx()
34 | ax2.plot(x, np.exp(x), 'r--')
35 | ax2.set_ylabel('Exp')
36 |
37 | plt.show()
38 | ```
39 |
40 |
285 |
286 | ## 键盘事件
287 |
288 | - **onkeyup** 松开时触发
289 | - **onkeydown** 按下时触发
290 | - **onekypress** 按下时触发 (**不能识别功能键**)
291 | - **e.key** 获得被触发的键
292 |
293 | > **执行顺序:先keydown,再keypress,最后keyup**
294 | >
295 | > **keydown 和 keypress在文本框中,先触发,然后文字才被输入**
--------------------------------------------------------------------------------
/public/posts/tkinter-cheatsheet.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Tkinter内置属性及方法速查表
3 | date: 2022-03-02
4 | tags: [Python, Tkinter, GUI]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/kXXYdu.png"
6 | top_img: false
7 | categories: [Python]
8 | ---
9 |
10 | > [*Tkinter* 8.5 reference: a GUI for Python](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/index.html)
11 |
12 | # Grid
13 |
14 | ```python
15 | a.grid(row=0, column=0)
16 | b.grid(row=1, column=1)
17 | c.grid(row=2, column=0, columnspan=2)
18 | d.grid(row=0, column=2, rowspan=2)
19 | ```
20 |
21 | [Grid Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/grid.html)
22 |
23 | # Window
24 |
25 | ```python
26 | window = tk.Tk()
27 | window.title()
28 | window.geometry()
29 | window.resizable()
30 | window.config()
31 | ```
32 |
33 | # Label
34 |
35 | ```python
36 | label = tk.Label(window,
37 | text="",
38 | width=10,
39 | height=10,
40 | font=(),
41 | bg='orange')
42 | ```
43 |
44 | [Label Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/label.html)
45 |
46 | # Button
47 |
48 | ```python
49 | button = tk.Button(window,
50 | text="",
51 | width=10,
52 | height=10,
53 | state=tk.ACTIVE,
54 | image="",
55 | command=abc)
56 | ```
57 |
58 | [Button Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/button.html)
59 |
60 | # Entry
61 |
62 | ```python
63 | entry = tk.Entry(window,
64 | width=10,
65 | fg='red',
66 | bg='blue',
67 | font=())
68 | entry.delete()
69 | entry.get()
70 | entry.insert(index, string)
71 | ```
72 |
73 | [Entry Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/entry.html)
74 |
75 | # Checkbutton
76 |
77 | ```python
78 | checkbutton = tk.Checkbutton(window,
79 | text="",
80 | textvariable=a,
81 | variable=b,
82 | offvalue=c,
83 | onvalue=d,
84 | command=abc)
85 | checkbutton.deselect()
86 | checkbutton.select()
87 | ```
88 |
89 | [Checkbutton Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/checkbutton.html)
90 |
91 | # Radiobutton
92 |
93 | ```python
94 | radiobutton = tk.Radiobutton(window,
95 | text="",
96 | value=a,
97 | variable=b,
98 | command=abc)
99 | radiobutton.select()
100 | radiobutton.deselect()
101 | ```
102 |
103 | [Radiobutton Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/radiobutton.html)
104 |
105 | # Scale
106 |
107 | ```python
108 | scale = tk.Scale(window,
109 | resolution=0.5,
110 | sliderlength=30,
111 | variable=a,
112 | command=abc)
113 | scale.get()
114 | scale.set(value)
115 | ```
116 |
117 | [Scale Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/scale.html)
118 |
119 | # Listbox
120 |
121 | ```python
122 | listbox = tk.Listbox(window,
123 | activestyle='underline')
124 | listbox.activate(index)
125 | listbox.curselection()
126 | listbox.delete(first)
127 | listbox.get(first)
128 | listbox.insert(index, text)
129 | listbox.size()
130 | ```
131 |
132 | [Listbox Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/listbox.html)
133 |
134 | # Messagebox
135 |
136 | ```python
137 | from tkinter import messagebox
138 | a = messagebox.askokcancel(title, message, options)
139 | b = messagebox.askquestion(title, message, options)
140 | c = messagebox.askretrycancel(title, message, options)
141 | d = messagebox.askyesno(title, message, options)
142 | e = messagebox.showerror(title, message, options)
143 | f = messagebox.showinfo(title, message, options)
144 | g = messagebox.showwarning(title, message, options)
145 | ```
146 |
147 | [Messagebox Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/tkMessageBox.html)
148 |
149 | # ColorChooser
150 |
151 | ```python
152 | from tkinter import colorchooser
153 | color = colorchooser.askcolor(color, title, parent)
154 | ```
155 |
156 | [ColorChooser Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/tkColorChooser.html)
157 |
158 | # Text
159 |
160 | ```python
161 | text = tk.Text(window, width, height)
162 | text.get(index1)
163 | text.insert(index, chars)
164 | ```
165 |
166 | [Text Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/text.html) / [Text Methods](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/text-methods.html)
167 |
168 | # FileDialog
169 |
170 | ```python
171 | from tkinter import filedialog
172 | open1 = filedialog.askopenfilename(option)
173 | open2 = filedialog.askdirectory(option)
174 | save1 = filedialog.asksaveasfilename(option)
175 |
176 | # /option/
177 | # defaultextension='.txt'
178 | # filetypes=[('PNG', '*.png'), (label2, pattern2), ...]
179 | # initialdir=D
180 | # initialfile=F
181 | # title=T
182 | # parent=W
183 | ```
184 |
185 | [FileDialog Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/tkFileDialog.html)
186 |
187 | # Menu
188 |
189 | ```python
190 | # Example
191 | menubar = ttk.Menu(window)
192 | window.config(menu=menubar)
193 |
194 | fileMenu = ttk.Menu(menubar)
195 | menubar.add_cascade(label='File', menu=fileMenu)
196 | fileMenu.add_command(label='Open', command=openFile)
197 | fileMenu.add_command(label='Save', command=saveFile)
198 | fileMenu.add_separator()
199 | fileMenu.add_command(label='Exit', command=quit)
200 |
201 | editMenu = ttk.Menu(menubar)
202 | menubar.add_cascade(label='Edit', menu=editMenu)
203 | editMenu.add_command(label='Cut')
204 | editMenu.add_command(label='Copy')
205 | editMenu.add_command(label='Paste')
206 | ```
207 |
208 | [Menu Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/menu.html)
209 |
210 | # Frame
211 |
212 | ```python
213 | frame = tk.Frame(window,
214 | width,
215 | height,
216 | bg)
217 | # Example
218 | frame = ttk.Frame(window, bootstyle=WARNING)
219 | frame.pack()
220 |
221 | ttk.Button(frame, text='W', width=3).pack(side=TOP)
222 | ttk.Button(frame, text='A', width=3).pack(side=LEFT)
223 | ttk.Button(frame, text='S', width=3).pack(side=LEFT)
224 | ttk.Button(frame, text='D', width=3).pack(side=LEFT)
225 | ```
226 |
227 | [Frame Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/frame.html)
228 |
229 | # TopLevel
230 |
231 | ```python
232 | newWindow = tk.Toplevel()
233 | ```
234 |
235 | [TopLevle Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/toplevel.html)
236 |
237 | # Notebook
238 |
239 | ```python
240 | # Example
241 | noteBook = ttk.Notebook(window, bootstyle=INFO)
242 |
243 | tab1 = ttk.Frame(noteBook)
244 | tab2 = ttk.Frame(noteBook)
245 |
246 | noteBook.add(tab1, text='Tab1')
247 | noteBook.add(tab2, text='Tab2')
248 | noteBook.pack()
249 |
250 | tk.Label(tab1, text='Hello Tab1', width=50, height=10).pack()
251 | tk.Label(tab2, text="Hello Tab2", width=50, height=10).pack()
252 | ```
253 |
254 | [NoteBook Ref](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/ttk-Notebook.html)
255 |
256 |
--------------------------------------------------------------------------------
/public/posts/matplotlib-1.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Matplotlib数据可视化——2.绘制各类统计图
3 | date: 2022-01-22
4 | tags: [Python, matplotlib, 可视化]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/ZbL8Y4.png"
6 | top_img: false
7 | categories: [Python]
8 | ---
9 |
10 | > Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python. Matplotlib makes easy things easy and hard things possible. --**Matplotlib**
11 |
12 | > **注:文中的例子与数据部分来自[C语言中文网](http://c.biancheng.net/matplotlib/)**
13 |
14 | # 一. 双轴图
15 |
16 | 有时一张图上的两幅图像需要绘制两个x轴或y轴才能更加清晰的显示信息,使用Matplotlib中的 **twinx()**和**twiny()** 函数即可创建两个y轴或x轴。
17 |
18 | 
19 |
20 | >**根据官方文档可知twinx代表共享x轴并生成第二个y轴,同理twiny代表共享y轴并生成第二个x轴。**
21 |
22 | ```python
23 | import matplotlib.pyplot as plt
24 | import numpy as np
25 |
26 | x = np.arange(0, 10, 0.1)
27 | fig = plt.figure()
28 | ax1 = fig.add_axes([0.1, 0.1, 0.8, 0.8])
29 | ax1.plot(x, np.log(x))
30 | ax1.set_ylabel('Log')
31 |
32 | # 添加第二个y轴
33 | ax2 = ax1.twinx()
34 | ax2.plot(x, np.exp(x), 'r--')
35 | ax2.set_ylabel('Exp')
36 |
37 | plt.show()
38 | ```
39 |
40 |  41 |
42 | # 二. 柱状图
43 |
44 | Matplotlib中的 **axes.bar()** 函数可以快速简单的绘制出柱状图,官方文档如下:
45 |
46 | 
47 |
48 | ```python
49 | import matplotlib.pyplot as plt
50 | import numpy as np
51 |
52 | fig = plt.figure()
53 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
54 |
55 | langs = ['Python', 'C', 'Java', 'R', 'Go']
56 | students = [20, 10, 19, 5, 8]
57 | ax.bar(langs, students) # 直接传入x和height数据即可
58 |
59 | plt.show()
60 | ```
61 |
62 |
41 |
42 | # 二. 柱状图
43 |
44 | Matplotlib中的 **axes.bar()** 函数可以快速简单的绘制出柱状图,官方文档如下:
45 |
46 | 
47 |
48 | ```python
49 | import matplotlib.pyplot as plt
50 | import numpy as np
51 |
52 | fig = plt.figure()
53 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
54 |
55 | langs = ['Python', 'C', 'Java', 'R', 'Go']
56 | students = [20, 10, 19, 5, 8]
57 | ax.bar(langs, students) # 直接传入x和height数据即可
58 |
59 | plt.show()
60 | ```
61 |
62 |  63 |
64 | ## 例1: 在同一 x 轴位置绘制多个柱状图
65 |
66 | Matplotlib本身并没有提供可以绘制多个柱状图的函数,但可以通过**设置柱状图的宽度和位置来达到这一效果**。
67 |
68 | ```
69 | import matplotlib.pyplot as plt
70 | import numpy as np
71 |
72 | fig = plt.figure()
73 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
74 |
75 | data = [[30, 25, 50, 20],
76 | [40, 23, 51, 17],
77 | [35, 22, 45, 19]]
78 | x = np.arange(4)
79 |
80 | ax.bar(x - 0.25, data[0], width=0.25) # 错开一个柱子的宽度
81 | ax.bar(x, data[1], width=0.25)
82 | ax.bar(x + 0.25, data[2], width=0.25)
83 |
84 | ax.set_xticks([0, 1, 2, 3])
85 | ax.set_xticklabels(['2015', '2016', '2017', '2018'])
86 | ax.legend(['A', 'B', 'C'])
87 |
88 | plt.show()
89 | ```
90 |
91 |
63 |
64 | ## 例1: 在同一 x 轴位置绘制多个柱状图
65 |
66 | Matplotlib本身并没有提供可以绘制多个柱状图的函数,但可以通过**设置柱状图的宽度和位置来达到这一效果**。
67 |
68 | ```
69 | import matplotlib.pyplot as plt
70 | import numpy as np
71 |
72 | fig = plt.figure()
73 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
74 |
75 | data = [[30, 25, 50, 20],
76 | [40, 23, 51, 17],
77 | [35, 22, 45, 19]]
78 | x = np.arange(4)
79 |
80 | ax.bar(x - 0.25, data[0], width=0.25) # 错开一个柱子的宽度
81 | ax.bar(x, data[1], width=0.25)
82 | ax.bar(x + 0.25, data[2], width=0.25)
83 |
84 | ax.set_xticks([0, 1, 2, 3])
85 | ax.set_xticklabels(['2015', '2016', '2017', '2018'])
86 | ax.legend(['A', 'B', 'C'])
87 |
88 | plt.show()
89 | ```
90 |
91 |  92 |
93 | ## 例2: 堆叠柱状图
94 |
95 | axes.bar()函数中有一个**bottom属性**,可以自定义柱状图的底部,因此可以使用该参数绘制堆叠柱状图。
96 |
97 | ```python
98 | import matplotlib.pyplot as plt
99 | import numpy as np
100 |
101 | # 数据
102 | countries = ['USA', 'India', 'China', 'Russia', 'Germany']
103 | bronzes = np.array([38, 17, 26, 19, 15])
104 | silvers = np.array([37, 23, 18, 18, 10])
105 | golds = np.array([46, 27, 26, 19, 17])
106 | x = np.arange(5)
107 |
108 | fig = plt.figure()
109 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
110 |
111 | ax.set_title('2019 Olympics Medal Tally') # 图表基本信息
112 | ax.set_xlabel('Countries')
113 | ax.set_ylabel('Medals')
114 |
115 | ax.bar(x, bronzes, color='#CD853F')
116 | ax.bar(x, silvers, color='silver', bottom=bronzes) # 银牌的底部是铜牌数量
117 | ax.bar(x, golds, color='gold', bottom=bronzes+silvers) # 金牌的底部是银牌+铜牌数量
118 |
119 | ax.set_xticks([0, 1, 2, 3, 4])
120 | ax.set_xticklabels(countries)
121 | ax.legend(['Bronzes', 'Silvers', 'Golds'])
122 |
123 | plt.show()
124 | ```
125 |
126 |
92 |
93 | ## 例2: 堆叠柱状图
94 |
95 | axes.bar()函数中有一个**bottom属性**,可以自定义柱状图的底部,因此可以使用该参数绘制堆叠柱状图。
96 |
97 | ```python
98 | import matplotlib.pyplot as plt
99 | import numpy as np
100 |
101 | # 数据
102 | countries = ['USA', 'India', 'China', 'Russia', 'Germany']
103 | bronzes = np.array([38, 17, 26, 19, 15])
104 | silvers = np.array([37, 23, 18, 18, 10])
105 | golds = np.array([46, 27, 26, 19, 17])
106 | x = np.arange(5)
107 |
108 | fig = plt.figure()
109 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
110 |
111 | ax.set_title('2019 Olympics Medal Tally') # 图表基本信息
112 | ax.set_xlabel('Countries')
113 | ax.set_ylabel('Medals')
114 |
115 | ax.bar(x, bronzes, color='#CD853F')
116 | ax.bar(x, silvers, color='silver', bottom=bronzes) # 银牌的底部是铜牌数量
117 | ax.bar(x, golds, color='gold', bottom=bronzes+silvers) # 金牌的底部是银牌+铜牌数量
118 |
119 | ax.set_xticks([0, 1, 2, 3, 4])
120 | ax.set_xticklabels(countries)
121 | ax.legend(['Bronzes', 'Silvers', 'Golds'])
122 |
123 | plt.show()
124 | ```
125 |
126 |  127 |
128 | # 三. 直方图
129 |
130 | 直方图可以清晰的显示不同数据的分布情况,在Matplotlib中可以使用 **axes.hist()** 函数绘制直方图,官方文档如下:
131 |
132 | 
133 |
134 | 
135 |
136 | >- **bin代表区间值,可以直接传入bins的数量,也可以用一个列表手动划分区间。**
137 |
138 | ```python
139 | import matplotlib.pyplot as plt
140 | import numpy as np
141 |
142 | fig = plt.figure()
143 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
144 |
145 | data = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27])
146 | ax.hist(data, bins=[0, 25, 50, 75, 100]) # 手动划分区间
147 |
148 | plt.show()
149 | ```
150 |
151 |
127 |
128 | # 三. 直方图
129 |
130 | 直方图可以清晰的显示不同数据的分布情况,在Matplotlib中可以使用 **axes.hist()** 函数绘制直方图,官方文档如下:
131 |
132 | 
133 |
134 | 
135 |
136 | >- **bin代表区间值,可以直接传入bins的数量,也可以用一个列表手动划分区间。**
137 |
138 | ```python
139 | import matplotlib.pyplot as plt
140 | import numpy as np
141 |
142 | fig = plt.figure()
143 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
144 |
145 | data = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27])
146 | ax.hist(data, bins=[0, 25, 50, 75, 100]) # 手动划分区间
147 |
148 | plt.show()
149 | ```
150 |
151 |  152 |
153 | 
154 |
155 | 如上,hist还有很多其他参数,比如可以设置直方图的**样式**:
156 |
157 | ```python
158 | ax.hist(data, bins=[0, 25, 50, 75, 100], histtype='step', rwidth=0.5)
159 | ```
160 |
161 |
152 |
153 | 
154 |
155 | 如上,hist还有很多其他参数,比如可以设置直方图的**样式**:
156 |
157 | ```python
158 | ax.hist(data, bins=[0, 25, 50, 75, 100], histtype='step', rwidth=0.5)
159 | ```
160 |
161 |  162 |
163 | # 四. 饼状图
164 |
165 | 使用 **axes.pie()** 即可绘制饼状图,官方文档如下:
166 |
167 | 
168 |
169 | 
170 |
171 | >**其中比较重要的属性有:x,labels,explode,autopct,radius**,**shadow**
172 | >
173 | >**autopct参数可取值:**
174 | >
175 | >- **%d%%:整数百分比;**
176 | >- **%0.1f:一位小数;**
177 | >- **%0.1f%%:一位小数百分比;**
178 | >- **%0.2f%%:两位小数百分比**
179 | >
180 | >**explode可传入一个由0和1组成的列表,列表中的1位置所对应的区域将被移出到圆外。**
181 |
182 | ```python
183 | import matplotlib.pyplot as plt
184 | import numpy as np
185 |
186 | fig = plt.figure()
187 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
188 |
189 | langs = ['C', 'C++', 'Java', 'Python', 'PHP']
190 | students = [23,17,35,29,12]
191 |
192 | ax.pie(students, labels=langs, autopct='%0.1f%%', explode=[0, 0, 0, 0, 1], shadow=True)
193 | fig.legend(langs, loc='upper left')
194 |
195 | plt.show()
196 | ```
197 |
198 |
162 |
163 | # 四. 饼状图
164 |
165 | 使用 **axes.pie()** 即可绘制饼状图,官方文档如下:
166 |
167 | 
168 |
169 | 
170 |
171 | >**其中比较重要的属性有:x,labels,explode,autopct,radius**,**shadow**
172 | >
173 | >**autopct参数可取值:**
174 | >
175 | >- **%d%%:整数百分比;**
176 | >- **%0.1f:一位小数;**
177 | >- **%0.1f%%:一位小数百分比;**
178 | >- **%0.2f%%:两位小数百分比**
179 | >
180 | >**explode可传入一个由0和1组成的列表,列表中的1位置所对应的区域将被移出到圆外。**
181 |
182 | ```python
183 | import matplotlib.pyplot as plt
184 | import numpy as np
185 |
186 | fig = plt.figure()
187 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
188 |
189 | langs = ['C', 'C++', 'Java', 'Python', 'PHP']
190 | students = [23,17,35,29,12]
191 |
192 | ax.pie(students, labels=langs, autopct='%0.1f%%', explode=[0, 0, 0, 0, 1], shadow=True)
193 | fig.legend(langs, loc='upper left')
194 |
195 | plt.show()
196 | ```
197 |
198 |  199 |
200 | # 五. 折线图
201 |
202 | 与最简单的plot原理相同,只需用 **axes.text()** 将对应数值标注即可。
203 |
204 | ```python
205 | import matplotlib.pyplot as plt
206 | import numpy as np
207 |
208 | fig = plt.figure()
209 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
210 | x = [0, 10, 15, 20]
211 | y = [10, 5, 20, 13]
212 |
213 | ax.plot(x, y, marker='D', markerfacecolor='orange')
214 | for i, j in zip(x, y): # zip函数
215 | ax.text(i, j, str(j), ha='center', va='bottom', fontsize=10) # text(x, y, str)
216 |
217 | plt.show()
218 | ```
219 |
220 |
199 |
200 | # 五. 折线图
201 |
202 | 与最简单的plot原理相同,只需用 **axes.text()** 将对应数值标注即可。
203 |
204 | ```python
205 | import matplotlib.pyplot as plt
206 | import numpy as np
207 |
208 | fig = plt.figure()
209 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
210 | x = [0, 10, 15, 20]
211 | y = [10, 5, 20, 13]
212 |
213 | ax.plot(x, y, marker='D', markerfacecolor='orange')
214 | for i, j in zip(x, y): # zip函数
215 | ax.text(i, j, str(j), ha='center', va='bottom', fontsize=10) # text(x, y, str)
216 |
217 | plt.show()
218 | ```
219 |
220 |  221 |
222 | # 六. 散点图
223 |
224 | 使用 **axes.scatter(x, y)** 可直接将(x, y)绘制在图中,配合**marker**可改变点的样式。
225 |
226 | ```python
227 | import matplotlib.pyplot as plt
228 | import numpy as np
229 |
230 | fig = plt.figure()
231 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
232 |
233 | x = [0, 10, 15, 20, 7.5, 6, 15, 15]
234 | y = [10, 5, 20, 13, 10, 14, 8, 16]
235 | ax.scatter(x, y, marker='s') # scatter
236 |
237 | plt.show()
238 | ```
239 |
240 |
221 |
222 | # 六. 散点图
223 |
224 | 使用 **axes.scatter(x, y)** 可直接将(x, y)绘制在图中,配合**marker**可改变点的样式。
225 |
226 | ```python
227 | import matplotlib.pyplot as plt
228 | import numpy as np
229 |
230 | fig = plt.figure()
231 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
232 |
233 | x = [0, 10, 15, 20, 7.5, 6, 15, 15]
234 | y = [10, 5, 20, 13, 10, 14, 8, 16]
235 | ax.scatter(x, y, marker='s') # scatter
236 |
237 | plt.show()
238 | ```
239 |
240 |  241 |
242 | # 七. 箱形图
243 |
244 | **箱型图**(也称为盒须图)于 1977 年由美国著名统计学家约翰·图基(John Tukey)发明。它能显示出一组数据的**最大值、最小值、中位数、及上下四分位数**。
245 |
246 | 
247 |
248 | 使用 **axes.boxplot(x)** ,仅需传入x值便可自动生成箱形图,官方文档如下:
249 |
250 | 
251 |
252 | > **文档中说明当x是一个二维数组时,将会自动画出其中每一组数据对应的箱形图。**
253 |
254 | ```python
255 | import matplotlib.pyplot as plt
256 | import numpy as np
257 |
258 | fig = plt.figure()
259 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
260 |
261 | np.random.seed(100)
262 | x1 = np.random.normal(100, 10, 200)
263 | x2 = np.random.normal(80, 30, 200)
264 | x3 = np.random.normal(90, 20, 200)
265 | data = [x1, x2, x3]
266 |
267 | ax.boxplot(data)
268 |
269 | plt.show()
270 | ```
271 |
272 |
241 |
242 | # 七. 箱形图
243 |
244 | **箱型图**(也称为盒须图)于 1977 年由美国著名统计学家约翰·图基(John Tukey)发明。它能显示出一组数据的**最大值、最小值、中位数、及上下四分位数**。
245 |
246 | 
247 |
248 | 使用 **axes.boxplot(x)** ,仅需传入x值便可自动生成箱形图,官方文档如下:
249 |
250 | 
251 |
252 | > **文档中说明当x是一个二维数组时,将会自动画出其中每一组数据对应的箱形图。**
253 |
254 | ```python
255 | import matplotlib.pyplot as plt
256 | import numpy as np
257 |
258 | fig = plt.figure()
259 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
260 |
261 | np.random.seed(100)
262 | x1 = np.random.normal(100, 10, 200)
263 | x2 = np.random.normal(80, 30, 200)
264 | x3 = np.random.normal(90, 20, 200)
265 | data = [x1, x2, x3]
266 |
267 | ax.boxplot(data)
268 |
269 | plt.show()
270 | ```
271 |
272 |  273 |
274 | # 附:3D绘图
275 |
276 | - 如需更详细的3D绘图教程,可参考[C语言中文网-Matplotlib教程](http://c.biancheng.net/matplotlib/3d-plot.html)。
277 |
278 |
--------------------------------------------------------------------------------
/public/posts/dsa-in-python-recursion.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: DSA in Python - Recursion【递归】
3 | date: 2022-03-10
4 | tags: [Python, 数据结构与算法]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/aqpArn.jpg"
6 | top_img: false
7 | categories: [Python, 数据结构与算法]
8 | ---
9 |
10 | > **开始前,先看几个关于递归的玩笑:**
11 | >
12 | > - In order to understand recursion, one must first understand recursion.
13 | > - Reminds me of what happens when you google "recursion"
14 | >
15 | >
273 |
274 | # 附:3D绘图
275 |
276 | - 如需更详细的3D绘图教程,可参考[C语言中文网-Matplotlib教程](http://c.biancheng.net/matplotlib/3d-plot.html)。
277 |
278 |
--------------------------------------------------------------------------------
/public/posts/dsa-in-python-recursion.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: DSA in Python - Recursion【递归】
3 | date: 2022-03-10
4 | tags: [Python, 数据结构与算法]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/aqpArn.jpg"
6 | top_img: false
7 | categories: [Python, 数据结构与算法]
8 | ---
9 |
10 | > **开始前,先看几个关于递归的玩笑:**
11 | >
12 | > - In order to understand recursion, one must first understand recursion.
13 | > - Reminds me of what happens when you google "recursion"
14 | >
15 | >  16 | >
17 | > - I like my coffee like I like my coffee......
18 | > - The recursive centaur:
19 | >
20 | >
16 | >
17 | > - I like my coffee like I like my coffee......
18 | > - The recursive centaur:
19 | >
20 | >  21 |
22 | # 什么是递归?
23 |
24 | 一个最简单的例子,俄罗斯套娃。想要完全展开一个俄罗斯套娃,就需要**不断重复**拆开大的拿出小的,直到拆到最小的**为止**。 没错,俄罗斯套娃已经包含了递归最基本的两个特征:`重复操作` 和 `结束条件`。
25 |
26 |
21 |
22 | # 什么是递归?
23 |
24 | 一个最简单的例子,俄罗斯套娃。想要完全展开一个俄罗斯套娃,就需要**不断重复**拆开大的拿出小的,直到拆到最小的**为止**。 没错,俄罗斯套娃已经包含了递归最基本的两个特征:`重复操作` 和 `结束条件`。
25 |
26 |  27 |
28 | 下面用简单的几句话来描述一下递归的特点:
29 |
30 | > - Making problem smaller and smaller.
31 | > - Performe the same operation mutiple times.
32 | > - Ever step have smaller input to make problem smaller.
33 | > - Base condition is needed to STOP the recursion.
34 |
35 | # STACK 栈
36 |
37 | 我第一次听到stack的反应是stack overflow,一个编程答疑交流社区。没错,stack overflow的意思是栈溢出,而其中的stack就是今天要简单介绍的一种数据结构,**栈**。
38 |
39 | 栈有一个特点,`Last in, first out`,即**先进者后出**。想象一下,当把书叠起来存放时,最先被放在底下的书要最后才能拿出来,而最后放上去的书可以第一个就拿到,这就是一种栈结构。
40 |
41 | 下面通过几个简单的函数调用来理解一下栈:
42 |
43 | ```python
44 | def func1():
45 | func2()
46 | print("I'am func1")
47 |
48 | def func2():
49 | func3()
50 | print("I'am func2")
51 |
52 | def func3():
53 | func4()
54 | print("I'am func3")
55 |
56 | def func4():
57 | print("I'am func4")
58 |
59 | func1()
60 |
61 | # Result:
62 | I'am func4
63 | I'am func3
64 | I'am func2
65 | I'am func1
66 | ```
67 |
68 | 从结果可以看出,最后被调用的`func4`第一个输出,而第一个调用的`func1`最后一个输出,这符合**先进者后出**的规则。从下面这张图可以更直观的了解栈的结构。
69 |
70 |
27 |
28 | 下面用简单的几句话来描述一下递归的特点:
29 |
30 | > - Making problem smaller and smaller.
31 | > - Performe the same operation mutiple times.
32 | > - Ever step have smaller input to make problem smaller.
33 | > - Base condition is needed to STOP the recursion.
34 |
35 | # STACK 栈
36 |
37 | 我第一次听到stack的反应是stack overflow,一个编程答疑交流社区。没错,stack overflow的意思是栈溢出,而其中的stack就是今天要简单介绍的一种数据结构,**栈**。
38 |
39 | 栈有一个特点,`Last in, first out`,即**先进者后出**。想象一下,当把书叠起来存放时,最先被放在底下的书要最后才能拿出来,而最后放上去的书可以第一个就拿到,这就是一种栈结构。
40 |
41 | 下面通过几个简单的函数调用来理解一下栈:
42 |
43 | ```python
44 | def func1():
45 | func2()
46 | print("I'am func1")
47 |
48 | def func2():
49 | func3()
50 | print("I'am func2")
51 |
52 | def func3():
53 | func4()
54 | print("I'am func3")
55 |
56 | def func4():
57 | print("I'am func4")
58 |
59 | func1()
60 |
61 | # Result:
62 | I'am func4
63 | I'am func3
64 | I'am func2
65 | I'am func1
66 | ```
67 |
68 | 从结果可以看出,最后被调用的`func4`第一个输出,而第一个调用的`func1`最后一个输出,这符合**先进者后出**的规则。从下面这张图可以更直观的了解栈的结构。
69 |
70 |  71 |
72 | # 什么时候用递归?
73 |
74 | 下面的两段程序分别用`递归(recursion)`和`迭代(iteration)`的方法计算**2的n次幂**:
75 |
76 | ```python
77 | # With Recursion
78 | def powerOfTwoRecursion(n):
79 | if n == 0:
80 | return 1
81 | else:
82 | return 2 * powerOfTwoRecursion(n - 1)
83 | ```
84 |
85 | ```python
86 | # With Iteration
87 | def powerOfTwo(n):
88 | result = 1
89 | while n > 0:
90 | result = result * 2
91 | n = n - 1
92 | return result
93 | ```
94 |
95 | 直观来看,递归要比迭代的代码更**简洁**,**直观**,但因为递归每调用一个函数就要存在栈内存中,所以在完成同一件事时会占用更多的内存,耗费更长的时间。按照下面几条可以大致判断出是否要用递归来解决这个问题:
96 |
97 | > **When to use recursion?**
98 | >
99 | > - When we can easily breakdown a problem into similar subproblem.
100 | > - When we are fine with extra overhead (both time and space) that comes with it.
101 | > - When we need a quick working solution instead of efficient one.
102 | > - When traverse a tree.
103 | > - When we use memoization in recursion.
104 | >
105 | > **When to avoid it?**
106 | >
107 | > - If time and space complexity matters for us.
108 | > - Recursion uses more memory. If we use embedded memory. For example an application
109 | > that takes more memory in the phone is not efficient.
110 | > - Recursion can be slow.
111 |
112 | # 三步完成一个递归
113 |
114 | **下面以`阶乘(Factorial)`为例说明一下构造一个递归的基本三步:**
115 |
116 | >**Step1: Recursive Case - the Flow**
117 | >
118 | >**Step2: Base Case - the Stopping Criterion**
119 | >
120 | >**Step3: Unintentional Case - the Constraint**
121 |
122 | ## Step1: Recursive Case - the Flow
123 |
124 | n的阶乘写作`n!`,定义为 `n!=n×(n-1)×...×3×2×1`,也可以写为 `n!=n×(n-1)!` ,没错,从这个式子中已经可以看出递归的影子了,假设把阶乘看为一个函数,那么在第二个式子中,n的阶乘函数调用了n-1的阶乘函数,同时也把`n!`的问题转变为了`(n-1)!`。按照这个思路,`(n-1)!` 又可以转变为 `(n-2)!`的问题,此时问题正在不断的变小。
125 |
126 |
71 |
72 | # 什么时候用递归?
73 |
74 | 下面的两段程序分别用`递归(recursion)`和`迭代(iteration)`的方法计算**2的n次幂**:
75 |
76 | ```python
77 | # With Recursion
78 | def powerOfTwoRecursion(n):
79 | if n == 0:
80 | return 1
81 | else:
82 | return 2 * powerOfTwoRecursion(n - 1)
83 | ```
84 |
85 | ```python
86 | # With Iteration
87 | def powerOfTwo(n):
88 | result = 1
89 | while n > 0:
90 | result = result * 2
91 | n = n - 1
92 | return result
93 | ```
94 |
95 | 直观来看,递归要比迭代的代码更**简洁**,**直观**,但因为递归每调用一个函数就要存在栈内存中,所以在完成同一件事时会占用更多的内存,耗费更长的时间。按照下面几条可以大致判断出是否要用递归来解决这个问题:
96 |
97 | > **When to use recursion?**
98 | >
99 | > - When we can easily breakdown a problem into similar subproblem.
100 | > - When we are fine with extra overhead (both time and space) that comes with it.
101 | > - When we need a quick working solution instead of efficient one.
102 | > - When traverse a tree.
103 | > - When we use memoization in recursion.
104 | >
105 | > **When to avoid it?**
106 | >
107 | > - If time and space complexity matters for us.
108 | > - Recursion uses more memory. If we use embedded memory. For example an application
109 | > that takes more memory in the phone is not efficient.
110 | > - Recursion can be slow.
111 |
112 | # 三步完成一个递归
113 |
114 | **下面以`阶乘(Factorial)`为例说明一下构造一个递归的基本三步:**
115 |
116 | >**Step1: Recursive Case - the Flow**
117 | >
118 | >**Step2: Base Case - the Stopping Criterion**
119 | >
120 | >**Step3: Unintentional Case - the Constraint**
121 |
122 | ## Step1: Recursive Case - the Flow
123 |
124 | n的阶乘写作`n!`,定义为 `n!=n×(n-1)×...×3×2×1`,也可以写为 `n!=n×(n-1)!` ,没错,从这个式子中已经可以看出递归的影子了,假设把阶乘看为一个函数,那么在第二个式子中,n的阶乘函数调用了n-1的阶乘函数,同时也把`n!`的问题转变为了`(n-1)!`。按照这个思路,`(n-1)!` 又可以转变为 `(n-2)!`的问题,此时问题正在不断的变小。
125 |
126 |  127 |
128 | 把上面这个过程用公式表示出来是这样的:`f(n)=n×f(n-1)`, 至此就得到了递归函数的基本公式。
129 |
130 | ```python
131 | def factorial(n):
132 | return n * factorial(n - 1)
133 | # 此时只考虑了建立递归的第一步,所以这段代码会陷入无限递归
134 | ```
135 |
136 | ## Step2: Base Case - the Stopping Criterion
137 |
138 | `Base Case` 可以被称之为递归的**终止条件**,如果缺少或者终止条件不正确,则会陷入无限递归。寻找递归的终止条件往往需要参考最为特殊的那个条件。比如在阶乘这个例子中,0是所有阶乘最后一个乘数,并且`0!=1`,所以可以很自然地想到当`n=0`时,只需返回一个`1`,就可以结束这个递归,这样就找到了递归的`终止条件`。
139 |
140 | ```python
141 | def factorial(n):
142 | if n == 0: # 加入终止条件使递归可以正常停止
143 | return 1
144 | else:
145 | return n * factorial(n - 1)
146 | ```
147 |
148 | ## Step3: Unintentional Case - the Constraint
149 |
150 | 在一些递归中,还需要考虑其他可能导致程序崩溃的错误比如输入是否可以是负数,是否可以是小数等等。为了使不合法的参数在被输入时能及时被人们修正,可以使用`assert断言语句`在函数中规定好参数的取值范围,这样就可以在遇到不和法的输入时及时报错。
151 |
152 | 因为阶乘是定义在大于0的自然数上,所以`负数和小数都不应该被考虑`,这就是我们要找的`束缚条件`。
153 |
154 | ```python
155 | def factorial(n):
156 | # 当输入为非正整数时,报错。
157 | assert n >= 0 and int(n) == n, 'The number must be positive interger!'
158 | if n == 0:
159 | return 1
160 | else:
161 | return n * factorial(n - 1)
162 | ```
163 |
164 | # 一些例子
165 |
166 | ## Fibonacci Numbers
167 |
168 | >**Step1: f(n) = f(n - 1) + f(n - 2)**
169 | >
170 | >**Step2: f(0) = 0, f(1) = 1**
171 | >
172 | >**Step3: Positive Integer Only**
173 |
174 | ```python
175 | def fibonachi(n):
176 | if n in [0, 1]:
177 | return n
178 | else:
179 | return fibonachi(n - 1) + fibonachi(n - 2)
180 | ```
181 |
182 | ## The Sum of Digit (Positive Interger)
183 |
184 | >**Step1: f(n) = n%10 + f(n // 10)**
185 | >
186 | >**Step2: When n < 10, return n**
187 | >
188 | >**Step3: Positive Integer Only**
189 |
190 | ```python
191 | def sumOfDigit(n):
192 | assert n >= 0 and int(n) == n, 'The number must be a positive interger!'
193 | if n < 10:
194 | return n
195 | else:
196 | return (n % 10) + sumOfDigit(n // 10
197 | ```
198 |
199 | ## Power of Number
200 |
201 | > **Step1: x^n = x * x^(n-1)**
202 | >
203 | > **Step2: When exp=0, return 1**
204 | >
205 | > **Step3: Positive Integer Only**
206 |
207 | ```python
208 | def power(base, exp):
209 | assert exp >= 0 and int(exp) == exp, 'The exponent must be a positive integer!'
210 | if exp == 0:
211 | return 1
212 | else:
213 | return base * power(base, exp - 1)
214 | ```
215 |
216 | Also, it's not difficult to include the negative integer in the program:
217 |
218 | ```python
219 | def powerAdvanced(base, exp):
220 | assert int(exp) == exp, 'The exponent must be an interger!'
221 | if exp == 0:
222 | return 1
223 | if exp < 0:
224 | return 1 / base * powerAdvanced(base, exp + 1)
225 | else:
226 | return base * powerAdvanced(base, exp - 1)
227 | ```
228 |
229 | ## GCD (Greatest Common Divisor)
230 |
231 | Using `Euclidean Algorithm(辗转相除法)`.
232 |
233 | > **Step1: gcd(a, b) = gcd(b, a%b)**
234 | >
235 | > **Step2: When b == 0, return a**
236 | >
237 | > **Step3: Positive Integer Only**
238 |
239 |
127 |
128 | 把上面这个过程用公式表示出来是这样的:`f(n)=n×f(n-1)`, 至此就得到了递归函数的基本公式。
129 |
130 | ```python
131 | def factorial(n):
132 | return n * factorial(n - 1)
133 | # 此时只考虑了建立递归的第一步,所以这段代码会陷入无限递归
134 | ```
135 |
136 | ## Step2: Base Case - the Stopping Criterion
137 |
138 | `Base Case` 可以被称之为递归的**终止条件**,如果缺少或者终止条件不正确,则会陷入无限递归。寻找递归的终止条件往往需要参考最为特殊的那个条件。比如在阶乘这个例子中,0是所有阶乘最后一个乘数,并且`0!=1`,所以可以很自然地想到当`n=0`时,只需返回一个`1`,就可以结束这个递归,这样就找到了递归的`终止条件`。
139 |
140 | ```python
141 | def factorial(n):
142 | if n == 0: # 加入终止条件使递归可以正常停止
143 | return 1
144 | else:
145 | return n * factorial(n - 1)
146 | ```
147 |
148 | ## Step3: Unintentional Case - the Constraint
149 |
150 | 在一些递归中,还需要考虑其他可能导致程序崩溃的错误比如输入是否可以是负数,是否可以是小数等等。为了使不合法的参数在被输入时能及时被人们修正,可以使用`assert断言语句`在函数中规定好参数的取值范围,这样就可以在遇到不和法的输入时及时报错。
151 |
152 | 因为阶乘是定义在大于0的自然数上,所以`负数和小数都不应该被考虑`,这就是我们要找的`束缚条件`。
153 |
154 | ```python
155 | def factorial(n):
156 | # 当输入为非正整数时,报错。
157 | assert n >= 0 and int(n) == n, 'The number must be positive interger!'
158 | if n == 0:
159 | return 1
160 | else:
161 | return n * factorial(n - 1)
162 | ```
163 |
164 | # 一些例子
165 |
166 | ## Fibonacci Numbers
167 |
168 | >**Step1: f(n) = f(n - 1) + f(n - 2)**
169 | >
170 | >**Step2: f(0) = 0, f(1) = 1**
171 | >
172 | >**Step3: Positive Integer Only**
173 |
174 | ```python
175 | def fibonachi(n):
176 | if n in [0, 1]:
177 | return n
178 | else:
179 | return fibonachi(n - 1) + fibonachi(n - 2)
180 | ```
181 |
182 | ## The Sum of Digit (Positive Interger)
183 |
184 | >**Step1: f(n) = n%10 + f(n // 10)**
185 | >
186 | >**Step2: When n < 10, return n**
187 | >
188 | >**Step3: Positive Integer Only**
189 |
190 | ```python
191 | def sumOfDigit(n):
192 | assert n >= 0 and int(n) == n, 'The number must be a positive interger!'
193 | if n < 10:
194 | return n
195 | else:
196 | return (n % 10) + sumOfDigit(n // 10
197 | ```
198 |
199 | ## Power of Number
200 |
201 | > **Step1: x^n = x * x^(n-1)**
202 | >
203 | > **Step2: When exp=0, return 1**
204 | >
205 | > **Step3: Positive Integer Only**
206 |
207 | ```python
208 | def power(base, exp):
209 | assert exp >= 0 and int(exp) == exp, 'The exponent must be a positive integer!'
210 | if exp == 0:
211 | return 1
212 | else:
213 | return base * power(base, exp - 1)
214 | ```
215 |
216 | Also, it's not difficult to include the negative integer in the program:
217 |
218 | ```python
219 | def powerAdvanced(base, exp):
220 | assert int(exp) == exp, 'The exponent must be an interger!'
221 | if exp == 0:
222 | return 1
223 | if exp < 0:
224 | return 1 / base * powerAdvanced(base, exp + 1)
225 | else:
226 | return base * powerAdvanced(base, exp - 1)
227 | ```
228 |
229 | ## GCD (Greatest Common Divisor)
230 |
231 | Using `Euclidean Algorithm(辗转相除法)`.
232 |
233 | > **Step1: gcd(a, b) = gcd(b, a%b)**
234 | >
235 | > **Step2: When b == 0, return a**
236 | >
237 | > **Step3: Positive Integer Only**
238 |
239 |  240 |
241 | ```python
242 | # the Euclidean algorithm, or Euclid's algorithm,
243 | # is an efficient method for computing the greatest common divisor (GCD)
244 | # of two positive integers
245 |
246 | def gcd(a, b):
247 | assert int(a) == a and int(b) == b, 'The numbers must be interger only!'
248 | if a < 0:
249 | a = -1 * a
250 | if b < 0:
251 | b = -1 * b
252 |
253 | if b == 0:
254 | return a
255 | else:
256 | return gcd(b, a % b)
257 | ```
258 |
259 | ## Decimal 2 Binary
260 |
261 | > **Step1: f(n) = n%2 + 10*f(n // 2)**
262 | >
263 | > **Step2: When n=0, return 0**
264 | >
265 | > **Step3: Positive Integer Only**
266 |
267 |
240 |
241 | ```python
242 | # the Euclidean algorithm, or Euclid's algorithm,
243 | # is an efficient method for computing the greatest common divisor (GCD)
244 | # of two positive integers
245 |
246 | def gcd(a, b):
247 | assert int(a) == a and int(b) == b, 'The numbers must be interger only!'
248 | if a < 0:
249 | a = -1 * a
250 | if b < 0:
251 | b = -1 * b
252 |
253 | if b == 0:
254 | return a
255 | else:
256 | return gcd(b, a % b)
257 | ```
258 |
259 | ## Decimal 2 Binary
260 |
261 | > **Step1: f(n) = n%2 + 10*f(n // 2)**
262 | >
263 | > **Step2: When n=0, return 0**
264 | >
265 | > **Step3: Positive Integer Only**
266 |
267 |  268 |
269 | ```python
270 | def decimal2Binary(n):
271 | assert int(n) == n and n > 0, 'The number a non-negative interger only!'
272 | if n == 0:
273 | return 0
274 | else:
275 | return (n % 2) + 10 * decimal2Binary(n // 2)
276 | ```
277 |
278 |
--------------------------------------------------------------------------------
/public/posts/git-1.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Git基础教程1 -【本地版本控制】
3 | date: 2022-03-18
4 | tags: [Git, 文章分享]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/Uq3Zrg.jpg"
6 | top_img: false
7 | categories: [文章分享]
8 | ---
9 |
10 | # Git是什么?
11 |
12 | > Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
13 | >
14 | > Git是一个免费的、开源的分布式版本控制系统,旨在以快速高效的方式处理从小型到大型的所有项目。
15 |
16 | ## 什么是版本控制工具?
17 |
18 | ### 为什么需要版本控制工具?
19 |
20 | 不论是在开发过程中或是日常办公中,`版本控制`都是不可忽略的一环,每一次代码版本的迭代都应该记录在`日志`中,并且能随时在版本之间穿梭。其实在使用版本工具之前,大部分朋友也都有了版本控制的思想,比如说下面这位:
21 |
22 |
268 |
269 | ```python
270 | def decimal2Binary(n):
271 | assert int(n) == n and n > 0, 'The number a non-negative interger only!'
272 | if n == 0:
273 | return 0
274 | else:
275 | return (n % 2) + 10 * decimal2Binary(n // 2)
276 | ```
277 |
278 |
--------------------------------------------------------------------------------
/public/posts/git-1.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Git基础教程1 -【本地版本控制】
3 | date: 2022-03-18
4 | tags: [Git, 文章分享]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/Uq3Zrg.jpg"
6 | top_img: false
7 | categories: [文章分享]
8 | ---
9 |
10 | # Git是什么?
11 |
12 | > Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
13 | >
14 | > Git是一个免费的、开源的分布式版本控制系统,旨在以快速高效的方式处理从小型到大型的所有项目。
15 |
16 | ## 什么是版本控制工具?
17 |
18 | ### 为什么需要版本控制工具?
19 |
20 | 不论是在开发过程中或是日常办公中,`版本控制`都是不可忽略的一环,每一次代码版本的迭代都应该记录在`日志`中,并且能随时在版本之间穿梭。其实在使用版本工具之前,大部分朋友也都有了版本控制的思想,比如说下面这位:
21 |
22 |  23 |
24 | 虽然说这确实是一种版本控制的方法,但效率极低,也只可能用于个人。`软件工程`绝大多数需要团队合作开发,所以就更需要一个方便可靠的版本管理工具来管理整个团队的项目。
25 |
26 | ### 集中式版本控制工具
27 |
28 | `集中式版本控制工具`需要一台集中管理的服务器,这台服务器里存储了程序所有版本的完整信息,而每一个团队内的人员需要连接到这台服务器取出最新的程序版本。
29 |
30 | 比较著名的集中式版本控制工具有CVS,SVN…
31 |
32 |
33 | > - **优势:**
34 | > - 拥有一个`集中管理的服务器`
35 | > - 容易维护,容易管理
36 | > - **缺点:**
37 | > - 当发生服务器`单点故障`时,有丢失全部文件的风险
38 | > - 需要开发者全程联网开发
39 |
40 | ### 分布式版本控制工具
41 |
42 | 与集中式不同,`分布式管理工具`在每一个用户的电脑中都存放有程序完整的历史记录,也就是说每一个开发者的电脑中都有与服务器中相同的版本数据,这样不仅方便开发者进行每个 版本之间的查看和管理,还减少了服务器出现故障时的损失。
43 |
44 | 
45 |
46 | `Git`就是一个分布式版本控制工具,它的优点有:`强大的分支系统`,`支持离线工作`, `本地仓库也包含项目完整历史版本`。
47 |
48 | ------
49 |
50 | # Git基础
51 |
52 | ## 安装Git
53 |
54 | Git的安装非常简单,只需前往[Git官网](https://git-scm.com/)选择相应系统下载对应文件即可。
55 |
56 | mac用户推荐使用`homebrew`一键安装,在此不多赘述。
57 |
58 | 安装过程结束后可在`终端`输入`git --version`来检查是否安装成功:
59 |
60 | 
61 |
62 | ## 文件的状态和工作区域
63 |
64 | 在Git内,文件被分为三种状态:`已修改(modified)`,`已暂存(staged)`,`已提交(committed)`。
65 |
66 | 在Git管理项目时的三个工作区域:`工作目录`,`暂存区域`,`本地仓库`。
67 |
68 | 暂存已修改文件提交暂存区文件工作目录暂存区本地仓库
69 |
70 | > **基本的 Git 工作流程如下:**
71 | >
72 | > 1. 在工作目录中修改某些文件。
73 | > 2. 对修改后的文件进行快照,然后保存到暂存区域。
74 | > 3. 提交更新,将保存在暂存区域的文件快照永久转储到 Git 目录中。
75 |
76 | ------
77 |
78 | # 使用Git
79 |
80 | ## 初次运行Git前的配置
81 |
82 | 当你在系统上第一次安装Git后都需要进行一次简单的配置,主要的配置内容为`用户名`和`电子邮件地址`,目的是为了让团队内的其他成员知道你是谁。
83 |
84 | ```
85 | SHELL$ git config --global user.name 用户名
86 | $ git config --global user.email 你的邮箱
87 | ```
88 |
89 | `--global`选项代表此次设置好的配置将会应用于之后**所有的项目**,当然也可以对单独项目修改不同的用户名和邮箱。
90 |
91 | 
92 |
93 | ## 在工作目录中初始化新仓库
94 |
95 | 想要在目录中初始化一个新仓库时要**先将工作目录移动到项目文件夹下**,然后运行初始化命令。
96 |
97 | ```
98 | SHELL$ git init
99 | ```
100 |
101 | 初始化后,Git会在当前项目目录下生成一个隐藏文件夹`.git`,这里面存储了Git所需要的所有数据和资源,不要轻易删除或改动。
102 |
103 | 
104 |
105 | ## 跟踪新文件
106 |
107 | 初始化好一个仓库后可以创建一个`README.md`来当作项目文件,并使用`status`命令来看看现在**仓库的状态**:
108 |
109 | ```
110 | SHELL$ git status
111 | ```
112 |
113 | 
114 |
115 | Git提示有一个文件没有被跟踪,此时就要告诉Git哪些文件是需要**跟踪**的,这样Git才会帮助我们跟踪文件是否有改动。
116 |
117 | ```
118 | SHELL$ git add [文件名]
119 | $ git status
120 | ```
121 |
122 | 当想要跟踪项目文件夹下的**所有文件**时,使用`git add .`即可。
123 |
124 | 
125 |
126 | 此时Git提醒我们使用`git rm --cached [文件]`可以**取消暂存**,试试看:
127 |
128 | ```
129 | SHELL$ git rm --cached [文件] # 取消暂存,不会删除原文件
130 | $ git rm [文件] # 取消暂存的同时删除原文件
131 | ```
132 |
133 | 
134 |
135 | Git确实将已跟踪的文件移除了,让我们再把它加回来~
136 |
137 | 此时查看仓库状态时应该与下图相同,Git提示我们**有要提交的变更**。并且Git没有再提示存在没有被跟踪的文件,说明现在我们项目文件夹下的所有文件都已经被Git跟踪。也就是说,现在项目文件夹下的所有文件都已经从`工作目录`进入`暂存区`。
138 |
139 | 
140 |
141 | ## 修改已暂存文件
142 |
143 | 当要对已经暂存的文件修改时,可以直接修改,但修改之后的文件会变为`已修改`状态,需要我们再次将它添加到`已暂存`。
144 |
145 | 现在在`README.md`里随便写点东西,然后再用`git status`命令查看仓库状态:
146 |
147 | 
148 |
149 | 
150 |
151 | 此时Git提醒我们有**尚未储存的变更**,需要我们把最新的版本暂存起来。
152 |
153 | 
154 |
155 | 暂存后,再次检查状态,现在一切正常。**所以当每次修改完暂存区内的文件后都需要再次将最新版本的文件添加到暂存区。**
156 |
157 | ## 提交更新到本地库
158 |
159 | ### 提交更新
160 |
161 | 当项目中的所有文件都被添加到`暂存区`,并且是`已暂存`状态时,就可以正式的将代码提交到`本地库`。注意本地库中的代码提交记录是**无法被修改**的,所以每一次对代码的任何操作都会被记录在`日志`内。
162 |
163 | 使用`commit`命令提交代码:
164 |
165 | ```
166 | SHELL$ git commit -m "提交说明"
167 | ```
168 |
169 | 也可以使用`git commit`提交,在弹出的编辑器窗口中输入`提交说明`。
170 |
171 | 
172 |
173 | 可以看到此时已经提交成功,并且Git提示我们:**一个文件被修改,添加一行内容**。
174 |
175 | 此时再查看仓库状态,Git提示无文件要提交,干净的工作区。
176 |
177 | 
178 |
179 | 在提交完更新后可以通过`日志`查看**提交历史**。
180 |
181 | ```
182 | SHELL$ git log # 显示所有提交过的版本信息
183 | $ git reflog # 方便查看每个操作步骤所在的版本,可以根据版本号自由前进后退
184 | ```
185 |
186 | - log
187 |
188 | 
189 |
190 | - reflog
191 |
192 | 
193 |
194 | `reflog`前的7位字母和数字就是这次提交的`版本号`,比如我这次提交的版本号为`c5a2bdb`。
195 |
196 | ### 查看日志
197 |
198 | 现在让我们多进行几次修改并提交,看看`日志`会发生什么变化:
199 |
200 | 
201 |
202 | 可以看到现在项目已经有了三个历史版本,当前版本为`ThridCommit`(master分支所在处)。
203 |
204 | 如果你有IDE或者VSCode这样的文本编辑器,也可以在图形化界面中看到**日志信息**:
205 |
206 | 
207 |
208 | ### 版本穿梭
209 |
210 | 当你突然后悔对现在版本的修改,或者认为之前的版本更优秀时,就需要在版本之间穿梭,这就要用到Git的`reset`命令。
211 |
212 | ```
213 | SHELL$ git reset --hard [版本号]
214 | ```
215 |
216 | 举个例子,我现在突然发现第二个版本中的一段代码是个天才之作,但在第三个版本已经被删改了,所以我要想尽办法退回到第二个版本,可能这个操作在其他版本管理工具中实现起来很复杂,但在Git中真的非常简单。
217 |
218 | 只需先在`日志`中复制第二个版本的版本号,然后使用`reset`命令就可以回到上一个版本,此时再查看`日志`就可以发现`master`分支已经指向了第二个版本。
219 |
220 | 
221 |
222 | 
223 |
224 | ## 分支
225 |
226 | ### 什么是分支
227 |
228 | `分支(Brench)`,其实就是字面意思,从`主线`上分离出来的分支。开发自己的分支不会影响主线分支的运行,同时并行推进多个版本的开发可以做到互不影响,一个分支出现问题不会影响其他分支。并且当一个分支的任务完成时就可以将这个分支`合并`到主线并删除这个分支。
229 |
230 | 
231 |
232 | 如上图,中间的主干就是`主线(master)`,从主线上分离的两个分支`Feature-1`和`Feature-2`可以同步进行两个不同功能的开发,当分别开发完成后再`合并`到`主线`,这就是分支厉害的地方。
233 |
234 | ### 新建一个分支
235 |
236 | 在Git中新建一个分支非常简单,只需要使用`branch`命令新建分支,并使用`checkout`切换分支。
237 |
238 | ```
239 | SHELL$ git branch [分支名]
240 | $ git branch -v # 查看已存在分支
241 | $ git checkout [分支名]
242 | ```
243 |
244 | 假设现在我们要开发一个新的需求(Feature_1),就需要在一个新的分支上进行开发:
245 |
246 | 
247 |
248 | 
249 |
250 | 此时还没有进行`分支切换`,所以master的前面有一个`*`代表我们目前还在`master`这个分支上进行开发,现在使用`checkout`命令切换分支:
251 |
252 | 
253 |
254 | 
255 |
256 | 现在我们已经成功切换到了`feature_1`分支。
257 |
258 | ### 在分支上进行编辑
259 |
260 | 在分支上编辑和在主干上没什么两样,同样需要暂存文件并提交到工作目录。
261 |
262 | 假设现在我在`feature_1`这个分支上编辑`README.md`这个文件,它并不会影响到主干,所以我们可以像在主干上一样操作,迭代多个版本,最终再把分支合并到主干。
263 |
264 | 现在我们来试试看,在`feature_1`分支上对`README.md`进行两次版本更新:
265 |
266 | 
267 |
268 | 从日志中可以看出我们已经在`feature_1`分支上做了两次更新,更新后的文件内容可以使用`cat`命令查看:
269 |
270 | 
271 |
272 | 第一次更新新增了倒数第二行文本,第二次更新新增了倒数第一行文本。
273 |
274 | 现在我们已经完成了在`feature_1`分支上的编辑,下面就要将`feature_1`合并到`master`。
275 |
276 | ### 分支的合并
277 |
278 | 接下来,也到了最后一步,就是将`feature_1`和`master`分支合并。想要将A分支合并到B分支,需要先切换到B分支,然后使用`merge`命令进行合并。
279 |
280 | 回到案例,想要将`feature_1`合并到`master`分支中,就要先切换到`master`:
281 |
282 | 
283 |
284 | 切换到`master`后,使用`merge`命令合并两个分支:
285 |
286 | ```
287 | SHELL$ git merge [分支名]
288 | ```
289 |
290 | 
291 |
292 | 输入命令后,Git提示我们`README.md`文件中新增了两行内容,此时分支合并就成功了,让我们来看一下现在主干中的`README.md`文件:
293 |
294 | 
295 |
296 | 果然和想象的一样,主干中的`README.md`确实与`feature_1`中的合并成功了!
297 |
298 | ### 删除分支
299 |
300 | 当一个分支的任务完成时,而且已经合并到了主干当中后,就可以将这个分支删除。
301 |
302 | ```
303 | SHELL$ git branch -d [分支名]
304 | ```
305 |
306 | 
307 |
308 | 此时Git提醒我们`feature_1`已被删除。
309 |
310 | ### 遇到冲突时的分支合并
311 |
312 | 当要合并的两个分支**在同一个文件的同一行有着两种完全不相同的修改时**,Git就无法自动将文件合并,此时需要人工审查代码决定谁去谁留。
313 |
314 | 举例,现在我们创建一个`feature_2`分支,并修改`README.md`文件中的第一行:
315 |
316 | 
317 |
318 | 现在回到`master`分支中同样修改`README.md`的第一行:
319 |
320 | 
321 |
322 | 还记得吗?在`master`中的`README.md`第一行是“# Hello Git! Here is Master”, 而我们在`feature_2`分支中将第一行修改为”# Hello Git! Here is Feature_2!!”,很明显,两次修改不一样,这就制造了一个代码冲突,下面试试看将`feature_2`合并到主干会发生什么。
323 |
324 | 
325 |
326 | 
327 |
328 | Git提示我们自动合并失败,需要我们**手动修正**冲突后合并。手动修正冲突的方法简单粗暴,**直接在当前分支进入要修改的文件修改即可**。
329 |
330 | 现在进入`README.md`中看看到底发生了什么~
331 |
332 | 
333 |
334 | Git自动用`<<<<<<<`,`=======`和`>>>>>>>`将两个文件冲突的地方区分了出来,现在要做的就是**手动决定谁去谁留**,并**删除Git添加的这些间隔符**。在此我决定留下`feature_2`的修改:
335 |
336 | 
337 |
338 | 当人工修改完冲突时,需要再次使用`add`命令将文件添加到暂存区,最后使用`commmit`来完成这此合并的提交。
339 |
340 | 
341 |
342 | 最后一步,删除`feature_2`分支,大功告成!
343 |
344 | > **推荐阅读:**
345 | >
346 | > - [Pro Git](https://gitee.com/progit/1-起步.html)
347 | > - [A Visual Git Reference](https://marklodato.github.io/visual-git-guide/index-en.html#diff)
348 | > - [learnGitBranching](https://github.com/pcottle/learnGitBranching)
--------------------------------------------------------------------------------
/public/posts/matplotlib-2.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Matplotlib数据可视化——1.绘图基础
3 | date: 2022-01-19
4 | tags: [Python, matplotlib, 可视化]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/ZbL8Y4.png"
6 | top_img: false
7 | categories: [Python]
8 | ---
9 |
10 | > Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python. Matplotlib makes easy things easy and hard things possible. --**Matplotlib**
11 |
12 | - [官方文档](httpss://matplotlib.org/stable/api/index)
13 |
14 | # 一. Figure对象与axes
15 |
16 | Matplotlib中的figure可以被形象的理解为一块画布,所有的图表都要画在这张画布上,所以画图的第一步就是创建一个figure对象
17 |
18 | ```python
19 | import matplotlib.pyplot as plt
20 |
21 | fig = plt.figure(figsize=[8, 6])
22 | ```
23 |
24 | 
25 |
26 | 上图为figure的所有属性,最常用的就是**figsize**,推荐单张图表以(6, 4)为大小,单位均为英尺。
27 |
28 | 创建完figure对象后,程序中已经生成了一块画布,那么现在就可以选定figure的一块区域来做图,在matplotlib中**axes**对象表示figure中的一幅图,接下来就是要在刚刚创建的figure中新建一个axes。
29 |
30 | ```python
31 | import matplotlib.pyplot as plt
32 |
33 | fig = plt.figure(figsize=(6, 4))
34 | ax1 = fig.add_axes([0.1, 0.1, 0.8, 0.8])
35 | ```
36 |
37 | 使用**add_axes**方法可以在figure中添加一个axes,其中的参数为一个列表,列表中四个值代表的意义为**【起点坐标x值,起点坐标y值,宽度,高度】**,四个数的**取值范围均为0-1**, 1代表与figure大小相同,0.5则代表figure大小的一半,下方为官方文档的表述:
38 |
39 | 
40 |
41 | 此时当添加上一句**plt.show()**将图像显示在屏幕上,因为是刚刚创建图像,所以图像上没有任何内容,如下图:
42 |
43 |
23 |
24 | 虽然说这确实是一种版本控制的方法,但效率极低,也只可能用于个人。`软件工程`绝大多数需要团队合作开发,所以就更需要一个方便可靠的版本管理工具来管理整个团队的项目。
25 |
26 | ### 集中式版本控制工具
27 |
28 | `集中式版本控制工具`需要一台集中管理的服务器,这台服务器里存储了程序所有版本的完整信息,而每一个团队内的人员需要连接到这台服务器取出最新的程序版本。
29 |
30 | 比较著名的集中式版本控制工具有CVS,SVN…
31 |
32 |
33 | > - **优势:**
34 | > - 拥有一个`集中管理的服务器`
35 | > - 容易维护,容易管理
36 | > - **缺点:**
37 | > - 当发生服务器`单点故障`时,有丢失全部文件的风险
38 | > - 需要开发者全程联网开发
39 |
40 | ### 分布式版本控制工具
41 |
42 | 与集中式不同,`分布式管理工具`在每一个用户的电脑中都存放有程序完整的历史记录,也就是说每一个开发者的电脑中都有与服务器中相同的版本数据,这样不仅方便开发者进行每个 版本之间的查看和管理,还减少了服务器出现故障时的损失。
43 |
44 | 
45 |
46 | `Git`就是一个分布式版本控制工具,它的优点有:`强大的分支系统`,`支持离线工作`, `本地仓库也包含项目完整历史版本`。
47 |
48 | ------
49 |
50 | # Git基础
51 |
52 | ## 安装Git
53 |
54 | Git的安装非常简单,只需前往[Git官网](https://git-scm.com/)选择相应系统下载对应文件即可。
55 |
56 | mac用户推荐使用`homebrew`一键安装,在此不多赘述。
57 |
58 | 安装过程结束后可在`终端`输入`git --version`来检查是否安装成功:
59 |
60 | 
61 |
62 | ## 文件的状态和工作区域
63 |
64 | 在Git内,文件被分为三种状态:`已修改(modified)`,`已暂存(staged)`,`已提交(committed)`。
65 |
66 | 在Git管理项目时的三个工作区域:`工作目录`,`暂存区域`,`本地仓库`。
67 |
68 | 暂存已修改文件提交暂存区文件工作目录暂存区本地仓库
69 |
70 | > **基本的 Git 工作流程如下:**
71 | >
72 | > 1. 在工作目录中修改某些文件。
73 | > 2. 对修改后的文件进行快照,然后保存到暂存区域。
74 | > 3. 提交更新,将保存在暂存区域的文件快照永久转储到 Git 目录中。
75 |
76 | ------
77 |
78 | # 使用Git
79 |
80 | ## 初次运行Git前的配置
81 |
82 | 当你在系统上第一次安装Git后都需要进行一次简单的配置,主要的配置内容为`用户名`和`电子邮件地址`,目的是为了让团队内的其他成员知道你是谁。
83 |
84 | ```
85 | SHELL$ git config --global user.name 用户名
86 | $ git config --global user.email 你的邮箱
87 | ```
88 |
89 | `--global`选项代表此次设置好的配置将会应用于之后**所有的项目**,当然也可以对单独项目修改不同的用户名和邮箱。
90 |
91 | 
92 |
93 | ## 在工作目录中初始化新仓库
94 |
95 | 想要在目录中初始化一个新仓库时要**先将工作目录移动到项目文件夹下**,然后运行初始化命令。
96 |
97 | ```
98 | SHELL$ git init
99 | ```
100 |
101 | 初始化后,Git会在当前项目目录下生成一个隐藏文件夹`.git`,这里面存储了Git所需要的所有数据和资源,不要轻易删除或改动。
102 |
103 | 
104 |
105 | ## 跟踪新文件
106 |
107 | 初始化好一个仓库后可以创建一个`README.md`来当作项目文件,并使用`status`命令来看看现在**仓库的状态**:
108 |
109 | ```
110 | SHELL$ git status
111 | ```
112 |
113 | 
114 |
115 | Git提示有一个文件没有被跟踪,此时就要告诉Git哪些文件是需要**跟踪**的,这样Git才会帮助我们跟踪文件是否有改动。
116 |
117 | ```
118 | SHELL$ git add [文件名]
119 | $ git status
120 | ```
121 |
122 | 当想要跟踪项目文件夹下的**所有文件**时,使用`git add .`即可。
123 |
124 | 
125 |
126 | 此时Git提醒我们使用`git rm --cached [文件]`可以**取消暂存**,试试看:
127 |
128 | ```
129 | SHELL$ git rm --cached [文件] # 取消暂存,不会删除原文件
130 | $ git rm [文件] # 取消暂存的同时删除原文件
131 | ```
132 |
133 | 
134 |
135 | Git确实将已跟踪的文件移除了,让我们再把它加回来~
136 |
137 | 此时查看仓库状态时应该与下图相同,Git提示我们**有要提交的变更**。并且Git没有再提示存在没有被跟踪的文件,说明现在我们项目文件夹下的所有文件都已经被Git跟踪。也就是说,现在项目文件夹下的所有文件都已经从`工作目录`进入`暂存区`。
138 |
139 | 
140 |
141 | ## 修改已暂存文件
142 |
143 | 当要对已经暂存的文件修改时,可以直接修改,但修改之后的文件会变为`已修改`状态,需要我们再次将它添加到`已暂存`。
144 |
145 | 现在在`README.md`里随便写点东西,然后再用`git status`命令查看仓库状态:
146 |
147 | 
148 |
149 | 
150 |
151 | 此时Git提醒我们有**尚未储存的变更**,需要我们把最新的版本暂存起来。
152 |
153 | 
154 |
155 | 暂存后,再次检查状态,现在一切正常。**所以当每次修改完暂存区内的文件后都需要再次将最新版本的文件添加到暂存区。**
156 |
157 | ## 提交更新到本地库
158 |
159 | ### 提交更新
160 |
161 | 当项目中的所有文件都被添加到`暂存区`,并且是`已暂存`状态时,就可以正式的将代码提交到`本地库`。注意本地库中的代码提交记录是**无法被修改**的,所以每一次对代码的任何操作都会被记录在`日志`内。
162 |
163 | 使用`commit`命令提交代码:
164 |
165 | ```
166 | SHELL$ git commit -m "提交说明"
167 | ```
168 |
169 | 也可以使用`git commit`提交,在弹出的编辑器窗口中输入`提交说明`。
170 |
171 | 
172 |
173 | 可以看到此时已经提交成功,并且Git提示我们:**一个文件被修改,添加一行内容**。
174 |
175 | 此时再查看仓库状态,Git提示无文件要提交,干净的工作区。
176 |
177 | 
178 |
179 | 在提交完更新后可以通过`日志`查看**提交历史**。
180 |
181 | ```
182 | SHELL$ git log # 显示所有提交过的版本信息
183 | $ git reflog # 方便查看每个操作步骤所在的版本,可以根据版本号自由前进后退
184 | ```
185 |
186 | - log
187 |
188 | 
189 |
190 | - reflog
191 |
192 | 
193 |
194 | `reflog`前的7位字母和数字就是这次提交的`版本号`,比如我这次提交的版本号为`c5a2bdb`。
195 |
196 | ### 查看日志
197 |
198 | 现在让我们多进行几次修改并提交,看看`日志`会发生什么变化:
199 |
200 | 
201 |
202 | 可以看到现在项目已经有了三个历史版本,当前版本为`ThridCommit`(master分支所在处)。
203 |
204 | 如果你有IDE或者VSCode这样的文本编辑器,也可以在图形化界面中看到**日志信息**:
205 |
206 | 
207 |
208 | ### 版本穿梭
209 |
210 | 当你突然后悔对现在版本的修改,或者认为之前的版本更优秀时,就需要在版本之间穿梭,这就要用到Git的`reset`命令。
211 |
212 | ```
213 | SHELL$ git reset --hard [版本号]
214 | ```
215 |
216 | 举个例子,我现在突然发现第二个版本中的一段代码是个天才之作,但在第三个版本已经被删改了,所以我要想尽办法退回到第二个版本,可能这个操作在其他版本管理工具中实现起来很复杂,但在Git中真的非常简单。
217 |
218 | 只需先在`日志`中复制第二个版本的版本号,然后使用`reset`命令就可以回到上一个版本,此时再查看`日志`就可以发现`master`分支已经指向了第二个版本。
219 |
220 | 
221 |
222 | 
223 |
224 | ## 分支
225 |
226 | ### 什么是分支
227 |
228 | `分支(Brench)`,其实就是字面意思,从`主线`上分离出来的分支。开发自己的分支不会影响主线分支的运行,同时并行推进多个版本的开发可以做到互不影响,一个分支出现问题不会影响其他分支。并且当一个分支的任务完成时就可以将这个分支`合并`到主线并删除这个分支。
229 |
230 | 
231 |
232 | 如上图,中间的主干就是`主线(master)`,从主线上分离的两个分支`Feature-1`和`Feature-2`可以同步进行两个不同功能的开发,当分别开发完成后再`合并`到`主线`,这就是分支厉害的地方。
233 |
234 | ### 新建一个分支
235 |
236 | 在Git中新建一个分支非常简单,只需要使用`branch`命令新建分支,并使用`checkout`切换分支。
237 |
238 | ```
239 | SHELL$ git branch [分支名]
240 | $ git branch -v # 查看已存在分支
241 | $ git checkout [分支名]
242 | ```
243 |
244 | 假设现在我们要开发一个新的需求(Feature_1),就需要在一个新的分支上进行开发:
245 |
246 | 
247 |
248 | 
249 |
250 | 此时还没有进行`分支切换`,所以master的前面有一个`*`代表我们目前还在`master`这个分支上进行开发,现在使用`checkout`命令切换分支:
251 |
252 | 
253 |
254 | 
255 |
256 | 现在我们已经成功切换到了`feature_1`分支。
257 |
258 | ### 在分支上进行编辑
259 |
260 | 在分支上编辑和在主干上没什么两样,同样需要暂存文件并提交到工作目录。
261 |
262 | 假设现在我在`feature_1`这个分支上编辑`README.md`这个文件,它并不会影响到主干,所以我们可以像在主干上一样操作,迭代多个版本,最终再把分支合并到主干。
263 |
264 | 现在我们来试试看,在`feature_1`分支上对`README.md`进行两次版本更新:
265 |
266 | 
267 |
268 | 从日志中可以看出我们已经在`feature_1`分支上做了两次更新,更新后的文件内容可以使用`cat`命令查看:
269 |
270 | 
271 |
272 | 第一次更新新增了倒数第二行文本,第二次更新新增了倒数第一行文本。
273 |
274 | 现在我们已经完成了在`feature_1`分支上的编辑,下面就要将`feature_1`合并到`master`。
275 |
276 | ### 分支的合并
277 |
278 | 接下来,也到了最后一步,就是将`feature_1`和`master`分支合并。想要将A分支合并到B分支,需要先切换到B分支,然后使用`merge`命令进行合并。
279 |
280 | 回到案例,想要将`feature_1`合并到`master`分支中,就要先切换到`master`:
281 |
282 | 
283 |
284 | 切换到`master`后,使用`merge`命令合并两个分支:
285 |
286 | ```
287 | SHELL$ git merge [分支名]
288 | ```
289 |
290 | 
291 |
292 | 输入命令后,Git提示我们`README.md`文件中新增了两行内容,此时分支合并就成功了,让我们来看一下现在主干中的`README.md`文件:
293 |
294 | 
295 |
296 | 果然和想象的一样,主干中的`README.md`确实与`feature_1`中的合并成功了!
297 |
298 | ### 删除分支
299 |
300 | 当一个分支的任务完成时,而且已经合并到了主干当中后,就可以将这个分支删除。
301 |
302 | ```
303 | SHELL$ git branch -d [分支名]
304 | ```
305 |
306 | 
307 |
308 | 此时Git提醒我们`feature_1`已被删除。
309 |
310 | ### 遇到冲突时的分支合并
311 |
312 | 当要合并的两个分支**在同一个文件的同一行有着两种完全不相同的修改时**,Git就无法自动将文件合并,此时需要人工审查代码决定谁去谁留。
313 |
314 | 举例,现在我们创建一个`feature_2`分支,并修改`README.md`文件中的第一行:
315 |
316 | 
317 |
318 | 现在回到`master`分支中同样修改`README.md`的第一行:
319 |
320 | 
321 |
322 | 还记得吗?在`master`中的`README.md`第一行是“# Hello Git! Here is Master”, 而我们在`feature_2`分支中将第一行修改为”# Hello Git! Here is Feature_2!!”,很明显,两次修改不一样,这就制造了一个代码冲突,下面试试看将`feature_2`合并到主干会发生什么。
323 |
324 | 
325 |
326 | 
327 |
328 | Git提示我们自动合并失败,需要我们**手动修正**冲突后合并。手动修正冲突的方法简单粗暴,**直接在当前分支进入要修改的文件修改即可**。
329 |
330 | 现在进入`README.md`中看看到底发生了什么~
331 |
332 | 
333 |
334 | Git自动用`<<<<<<<`,`=======`和`>>>>>>>`将两个文件冲突的地方区分了出来,现在要做的就是**手动决定谁去谁留**,并**删除Git添加的这些间隔符**。在此我决定留下`feature_2`的修改:
335 |
336 | 
337 |
338 | 当人工修改完冲突时,需要再次使用`add`命令将文件添加到暂存区,最后使用`commmit`来完成这此合并的提交。
339 |
340 | 
341 |
342 | 最后一步,删除`feature_2`分支,大功告成!
343 |
344 | > **推荐阅读:**
345 | >
346 | > - [Pro Git](https://gitee.com/progit/1-起步.html)
347 | > - [A Visual Git Reference](https://marklodato.github.io/visual-git-guide/index-en.html#diff)
348 | > - [learnGitBranching](https://github.com/pcottle/learnGitBranching)
--------------------------------------------------------------------------------
/public/posts/matplotlib-2.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Matplotlib数据可视化——1.绘图基础
3 | date: 2022-01-19
4 | tags: [Python, matplotlib, 可视化]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/ZbL8Y4.png"
6 | top_img: false
7 | categories: [Python]
8 | ---
9 |
10 | > Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python. Matplotlib makes easy things easy and hard things possible. --**Matplotlib**
11 |
12 | - [官方文档](httpss://matplotlib.org/stable/api/index)
13 |
14 | # 一. Figure对象与axes
15 |
16 | Matplotlib中的figure可以被形象的理解为一块画布,所有的图表都要画在这张画布上,所以画图的第一步就是创建一个figure对象
17 |
18 | ```python
19 | import matplotlib.pyplot as plt
20 |
21 | fig = plt.figure(figsize=[8, 6])
22 | ```
23 |
24 | 
25 |
26 | 上图为figure的所有属性,最常用的就是**figsize**,推荐单张图表以(6, 4)为大小,单位均为英尺。
27 |
28 | 创建完figure对象后,程序中已经生成了一块画布,那么现在就可以选定figure的一块区域来做图,在matplotlib中**axes**对象表示figure中的一幅图,接下来就是要在刚刚创建的figure中新建一个axes。
29 |
30 | ```python
31 | import matplotlib.pyplot as plt
32 |
33 | fig = plt.figure(figsize=(6, 4))
34 | ax1 = fig.add_axes([0.1, 0.1, 0.8, 0.8])
35 | ```
36 |
37 | 使用**add_axes**方法可以在figure中添加一个axes,其中的参数为一个列表,列表中四个值代表的意义为**【起点坐标x值,起点坐标y值,宽度,高度】**,四个数的**取值范围均为0-1**, 1代表与figure大小相同,0.5则代表figure大小的一半,下方为官方文档的表述:
38 |
39 | 
40 |
41 | 此时当添加上一句**plt.show()**将图像显示在屏幕上,因为是刚刚创建图像,所以图像上没有任何内容,如下图:
42 |
43 |  44 |
45 | ## 附1:理解Figure,Axes,Axis,Subplot之间的关系
46 |
47 |
44 |
45 | ## 附1:理解Figure,Axes,Axis,Subplot之间的关系
46 |
47 |  48 |
49 | # 二. 设置图表基本信息
50 |
51 | 一张图表可以自定义的基本信息非常多,如:**标题**,**坐标轴名称**等等,具体可以参考[官方文档](httpss://matplotlib.org/stable/api/_as_gen/mpl_toolkits.axes_grid1.mpl_axes.Axes.html#mpl_toolkits.axes_grid1.mpl_axes.Axes)。
52 |
53 | ```python
54 | ax.set_title('Hello Matplotlib')
55 | ax.set_xlabel('This is x-axis')
56 | ax.set_ylabel('This is y-axis')
57 | ```
58 |
59 |
48 |
49 | # 二. 设置图表基本信息
50 |
51 | 一张图表可以自定义的基本信息非常多,如:**标题**,**坐标轴名称**等等,具体可以参考[官方文档](httpss://matplotlib.org/stable/api/_as_gen/mpl_toolkits.axes_grid1.mpl_axes.Axes.html#mpl_toolkits.axes_grid1.mpl_axes.Axes)。
52 |
53 | ```python
54 | ax.set_title('Hello Matplotlib')
55 | ax.set_xlabel('This is x-axis')
56 | ax.set_ylabel('This is y-axis')
57 | ```
58 |
59 |  60 |
61 | ## 附2:自定义字体
62 |
63 | 在matplotlib中改变字体大小一般使用**fontdict**,具体方法可参照[官方文档](httpss://matplotlib.org/3.1.0/gallery/text_labels_and_annotations/text_fontdict.html)
64 |
65 | ```python
66 | font = {'family': 'serif',
67 | 'color': 'darkred',
68 | 'weight': 'normal',
69 | 'size': 16,
70 | }
71 | plt.xlabel('myFont', fontdict=font)
72 | ```
73 |
74 | # 三. 简单画个图
75 |
76 | 在matplotlib中,使用 **plot()** 函数就可以画出最简单的曲线。plot对数据的要求很简单,可以使用numpy来生成两个一维数组传入plot。
77 |
78 | ```python
79 | import matplotlib.pyplot as plt
80 | import numpy as np
81 |
82 | x = np.arange(-10, 10, 0.1)
83 | fig = plt.figure()
84 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
85 | ax.set_title('Hello Matplotlib')
86 | ax.plot(x, x**2)
87 | ax.plot(x, x**3)
88 | ax.legend(['x^2', 'x^3']) # 加上图例
89 | plt.show()
90 | ```
91 |
92 |
60 |
61 | ## 附2:自定义字体
62 |
63 | 在matplotlib中改变字体大小一般使用**fontdict**,具体方法可参照[官方文档](httpss://matplotlib.org/3.1.0/gallery/text_labels_and_annotations/text_fontdict.html)
64 |
65 | ```python
66 | font = {'family': 'serif',
67 | 'color': 'darkred',
68 | 'weight': 'normal',
69 | 'size': 16,
70 | }
71 | plt.xlabel('myFont', fontdict=font)
72 | ```
73 |
74 | # 三. 简单画个图
75 |
76 | 在matplotlib中,使用 **plot()** 函数就可以画出最简单的曲线。plot对数据的要求很简单,可以使用numpy来生成两个一维数组传入plot。
77 |
78 | ```python
79 | import matplotlib.pyplot as plt
80 | import numpy as np
81 |
82 | x = np.arange(-10, 10, 0.1)
83 | fig = plt.figure()
84 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
85 | ax.set_title('Hello Matplotlib')
86 | ax.plot(x, x**2)
87 | ax.plot(x, x**3)
88 | ax.legend(['x^2', 'x^3']) # 加上图例
89 | plt.show()
90 | ```
91 |
92 |  93 |
94 | 当然为了使图表观赏性更强,plot函数内还有众多参数可以更改,具体可以见[官方文档](httpss://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.plot.html?highlight=plot#matplotlib.pyplot.plot),一下只列出常用属性:
95 |
96 | | 属性 | 描述 | 属性 | 描述 |
97 | | :------------: | :------: | :-------------: | :---: |
98 | | alpha | bool | markeredgecolor | color |
99 | | color (c) | 'orange' | markeredgewidth | float |
100 | | linestyle (ls) | *见下文* | markerfacecolor | color |
101 | | linewidth (lw) | float | markersize | float |
102 | | marker | *见下文* | visible | Bool |
103 |
104 | 使用**marker**属性将数据点标记出来:
105 |
106 |
93 |
94 | 当然为了使图表观赏性更强,plot函数内还有众多参数可以更改,具体可以见[官方文档](httpss://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.plot.html?highlight=plot#matplotlib.pyplot.plot),一下只列出常用属性:
95 |
96 | | 属性 | 描述 | 属性 | 描述 |
97 | | :------------: | :------: | :-------------: | :---: |
98 | | alpha | bool | markeredgecolor | color |
99 | | color (c) | 'orange' | markeredgewidth | float |
100 | | linestyle (ls) | *见下文* | markerfacecolor | color |
101 | | linewidth (lw) | float | markersize | float |
102 | | marker | *见下文* | visible | Bool |
103 |
104 | 使用**marker**属性将数据点标记出来:
105 |
106 |  107 |
108 | ## 附3: linestyle、marker 和 legend loc
109 |
110 | ### Linestyle
111 |
112 | 
113 |
114 | ---
115 |
116 | ### Markerstyle
117 |
118 | | 符号 | 描述 | 符号 | 描述 |
119 | | :--: | :------------: | :--: | :----------: |
120 | | '.' | point | '1' | tri_down |
121 | | ',' | pixel | '2' | tri_up |
122 | | 'o' | circle | '3' | tri_left |
123 | | 'v' | triangle_down | '4' | tri_right |
124 | | '^' | triangle_up | 's' | square |
125 | | '<' | triangle_left | 'p' | pentagon |
126 | | '>' | triangle_right | '*' | star |
127 | | 'h' | hexagon1 | 'D' | diamond |
128 | | 'H' | hexagon2 | 'd' | thin_diamond |
129 | | '+' | plus | '\|' | vline |
130 | | 'x' | x | '_' | hline |
131 |
132 | ---
133 |
134 | ### Legend loc
135 |
136 | 
137 |
138 | ```python
139 | import matplotlib.pyplot as plt
140 | import numpy as np
141 |
142 | x = np.arange(-10, 10, 1)
143 | fig = plt.figure()
144 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
145 | ax.set_title('Hello Matplotlib')
146 | ax.plot(x, x**2, ls='--', marker='H', markerfacecolor='blue')
147 | ax.plot(x, x**3, ls=':', marker='D', markerfacecolor='red')
148 | ax.legend(['x^2', 'x^3'])
149 | plt.show()
150 | ```
151 |
152 |
107 |
108 | ## 附3: linestyle、marker 和 legend loc
109 |
110 | ### Linestyle
111 |
112 | 
113 |
114 | ---
115 |
116 | ### Markerstyle
117 |
118 | | 符号 | 描述 | 符号 | 描述 |
119 | | :--: | :------------: | :--: | :----------: |
120 | | '.' | point | '1' | tri_down |
121 | | ',' | pixel | '2' | tri_up |
122 | | 'o' | circle | '3' | tri_left |
123 | | 'v' | triangle_down | '4' | tri_right |
124 | | '^' | triangle_up | 's' | square |
125 | | '<' | triangle_left | 'p' | pentagon |
126 | | '>' | triangle_right | '*' | star |
127 | | 'h' | hexagon1 | 'D' | diamond |
128 | | 'H' | hexagon2 | 'd' | thin_diamond |
129 | | '+' | plus | '\|' | vline |
130 | | 'x' | x | '_' | hline |
131 |
132 | ---
133 |
134 | ### Legend loc
135 |
136 | 
137 |
138 | ```python
139 | import matplotlib.pyplot as plt
140 | import numpy as np
141 |
142 | x = np.arange(-10, 10, 1)
143 | fig = plt.figure()
144 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
145 | ax.set_title('Hello Matplotlib')
146 | ax.plot(x, x**2, ls='--', marker='H', markerfacecolor='blue')
147 | ax.plot(x, x**3, ls=':', marker='D', markerfacecolor='red')
148 | ax.legend(['x^2', 'x^3'])
149 | plt.show()
150 | ```
151 |
152 |  153 |
154 | # 四. 添加多个axes实现图中图
155 |
156 | ```python
157 | import math
158 | import matplotlib.pyplot as plt
159 | import numpy as np
160 |
161 | y = [1, 4, 9, 16, 25, 36, 49, 64]
162 | x1 = [1, 16, 30, 42, 55, 68, 77, 88]
163 | x2 = [1, 6, 12, 18, 28, 40, 52, 65]
164 |
165 | fig1 = plt.figure()
166 | ax2 = fig1.add_axes([0.1, 0.1, 0.8, 0.8])
167 | ax2.set_xlabel('Medium')
168 | ax2.set_ylabel('Size')
169 | ax2.set_title('Ads Effect on Sales')
170 | ax2.plot(x1, y, '--', marker='o')
171 | ax2.plot(x2, y, '-', marker='o')
172 | ax2.legend(labels=['TV', 'Phone'], loc='lower right')
173 |
174 | # 添加第二个axes
175 | ax3 = fig1.add_axes([0.15, 0.62, 0.3, 0.2])
176 | x = np.arange(0, 2*math.pi, 0.5)
177 | y = np.sin(x)
178 | ax3.plot(x, y, 'r--', marker='x')
179 | ax3.axhline(0, alpha=0.5)
180 | plt.show()
181 | ```
182 |
183 |
153 |
154 | # 四. 添加多个axes实现图中图
155 |
156 | ```python
157 | import math
158 | import matplotlib.pyplot as plt
159 | import numpy as np
160 |
161 | y = [1, 4, 9, 16, 25, 36, 49, 64]
162 | x1 = [1, 16, 30, 42, 55, 68, 77, 88]
163 | x2 = [1, 6, 12, 18, 28, 40, 52, 65]
164 |
165 | fig1 = plt.figure()
166 | ax2 = fig1.add_axes([0.1, 0.1, 0.8, 0.8])
167 | ax2.set_xlabel('Medium')
168 | ax2.set_ylabel('Size')
169 | ax2.set_title('Ads Effect on Sales')
170 | ax2.plot(x1, y, '--', marker='o')
171 | ax2.plot(x2, y, '-', marker='o')
172 | ax2.legend(labels=['TV', 'Phone'], loc='lower right')
173 |
174 | # 添加第二个axes
175 | ax3 = fig1.add_axes([0.15, 0.62, 0.3, 0.2])
176 | x = np.arange(0, 2*math.pi, 0.5)
177 | y = np.sin(x)
178 | ax3.plot(x, y, 'r--', marker='x')
179 | ax3.axhline(0, alpha=0.5)
180 | plt.show()
181 | ```
182 |
183 |  184 |
185 | # 五. 子图布局的两种方法
186 |
187 | ## 1. subplots() 实现方形布局
188 |
189 | 使用**subplots**进行子图布局可以实现**规则的矩形布局**,具体方法如下:
190 |
191 | ```python
192 | import matplotlib.pyplot as plt
193 | import numpy as np
194 | x = np.arange(-10, 10, 0.5)
195 | # 格式
196 | fig, axes = plt.subplots(2, 2, figsize=(10, 10)) # 注意subplots会返回figure和axes
197 |
198 | axes[0][0].plot(x, y1) # 使用[x][y]来定位子图在图中的位置
199 | axes[0][1].plot(x, y2)
200 | axes[1][0].plot(x, y3)
201 | axes[1][1].plot(x, y4)
202 | plt.show()
203 | ```
204 |
205 | 
206 |
207 |
184 |
185 | # 五. 子图布局的两种方法
186 |
187 | ## 1. subplots() 实现方形布局
188 |
189 | 使用**subplots**进行子图布局可以实现**规则的矩形布局**,具体方法如下:
190 |
191 | ```python
192 | import matplotlib.pyplot as plt
193 | import numpy as np
194 | x = np.arange(-10, 10, 0.5)
195 | # 格式
196 | fig, axes = plt.subplots(2, 2, figsize=(10, 10)) # 注意subplots会返回figure和axes
197 |
198 | axes[0][0].plot(x, y1) # 使用[x][y]来定位子图在图中的位置
199 | axes[0][1].plot(x, y2)
200 | axes[1][0].plot(x, y3)
201 | axes[1][1].plot(x, y4)
202 | plt.show()
203 | ```
204 |
205 | 
206 |
207 |  208 |
209 | ## 2. subplot2grid() 实现Grid布局
210 |
211 | grid布局与上方的subplots不同的是grid可以调整每个子图在figure中所占的行和列(**span**)。具体使用方法如下:
212 |
213 | 
214 |
215 | ```python
216 | import matplotlib.pyplot as plt
217 | import numpy as np
218 |
219 | x = np.arange(-10, 10, 0.5)
220 |
221 | fig = plt.figure(figsize=(10, 8))
222 |
223 | a1 = plt.subplot2grid((3, 3), (0, 0), colspan=2, fig=fig)
224 | a1.plot(x, x)
225 | a2 = plt.subplot2grid((3, 3), (1, 0), colspan=2, rowspan=2)
226 | a2.plot(x, x**2)
227 | a3 = plt.subplot2grid((3, 3), (0, 2), rowspan=3)
228 | a3.plot(x, x**3)
229 | plt.show()
230 | ```
231 |
232 | > **拿出一行代码仔细分析:**
233 | >
234 | > **a1 = plt.subplot2grid((3, 3), (0, 0), colspan=2, fig=fig)**
235 | >
236 | > **从官方文档中可知subplot2grid会返回一个axes,这里将axes赋值给a1。(3, 3)代表将一个方形分为3*3。(0, 0)代表图表的起点, rowspan和colspan代表跨越的行和列,fig=fig意思是将这一组子图放到fig这个画布中。**
237 |
238 |
208 |
209 | ## 2. subplot2grid() 实现Grid布局
210 |
211 | grid布局与上方的subplots不同的是grid可以调整每个子图在figure中所占的行和列(**span**)。具体使用方法如下:
212 |
213 | 
214 |
215 | ```python
216 | import matplotlib.pyplot as plt
217 | import numpy as np
218 |
219 | x = np.arange(-10, 10, 0.5)
220 |
221 | fig = plt.figure(figsize=(10, 8))
222 |
223 | a1 = plt.subplot2grid((3, 3), (0, 0), colspan=2, fig=fig)
224 | a1.plot(x, x)
225 | a2 = plt.subplot2grid((3, 3), (1, 0), colspan=2, rowspan=2)
226 | a2.plot(x, x**2)
227 | a3 = plt.subplot2grid((3, 3), (0, 2), rowspan=3)
228 | a3.plot(x, x**3)
229 | plt.show()
230 | ```
231 |
232 | > **拿出一行代码仔细分析:**
233 | >
234 | > **a1 = plt.subplot2grid((3, 3), (0, 0), colspan=2, fig=fig)**
235 | >
236 | > **从官方文档中可知subplot2grid会返回一个axes,这里将axes赋值给a1。(3, 3)代表将一个方形分为3*3。(0, 0)代表图表的起点, rowspan和colspan代表跨越的行和列,fig=fig意思是将这一组子图放到fig这个画布中。**
237 |
238 |  239 |
240 | # 六. 设置图表网格样式
241 |
242 | Matplotlib中设置网格样式的属性有很多,具体可以参考[官方文档](httpss://matplotlib.org/stable/api/_as_gen/matplotlib.axes.Axes.grid.html?highlight=matplotlib%20axes%20axes%20grid#matplotlib.axes.Axes.grid),下文将介绍最常用的几种。
243 |
244 | ```python
245 | import matplotlib.pyplot as plt
246 | import numpy as np
247 |
248 | x = np.arange(0, 10, 0.5)
249 |
250 | fig = plt.figure(figsize=(8, 6))
251 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
252 | ax.plot(x, x**2)
253 | # 设置网格
254 | ax.grid(visible=True , # 网格可见
255 | color='red', # 颜色
256 | ls=':', # linestyle
257 | alpha=0.8, # alpha值
258 | lw=0.5) # 线宽
259 | plt.show()
260 | ```
261 |
262 |
239 |
240 | # 六. 设置图表网格样式
241 |
242 | Matplotlib中设置网格样式的属性有很多,具体可以参考[官方文档](httpss://matplotlib.org/stable/api/_as_gen/matplotlib.axes.Axes.grid.html?highlight=matplotlib%20axes%20axes%20grid#matplotlib.axes.Axes.grid),下文将介绍最常用的几种。
243 |
244 | ```python
245 | import matplotlib.pyplot as plt
246 | import numpy as np
247 |
248 | x = np.arange(0, 10, 0.5)
249 |
250 | fig = plt.figure(figsize=(8, 6))
251 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
252 | ax.plot(x, x**2)
253 | # 设置网格
254 | ax.grid(visible=True , # 网格可见
255 | color='red', # 颜色
256 | ls=':', # linestyle
257 | alpha=0.8, # alpha值
258 | lw=0.5) # 线宽
259 | plt.show()
260 | ```
261 |
262 |  263 |
264 | # 七. 设置坐标轴
265 |
266 | ## 1. 坐标轴外观及边界
267 |
268 | ```python
269 | import matplotlib.pyplot as plt
270 | import numpy as np
271 |
272 | x = np.arange(0, 10, 0.1)
273 | fig = plt.figure(figsize=(8, 6))
274 | ax = fig.add_axes([0.1, 0.1, 0.7, 0.7])
275 | ax.plot(x, x**2)
276 |
277 | # 设置y轴为对数
278 | ax.set_yscale('log') # value{"linear", "log", "symlog", "logit", ...}
279 |
280 | # 设置其他轴(边界)
281 | ax.spines['top'].set_color('None')
282 | ax.spines['right'].set_color('None')
283 | ax.spines['left'].set_color('blue')
284 | ax.spines['left'].set_lw(2)
285 | ax.spines['bottom'].set_color('red')
286 | ax.spines['bottom'].set_lw(3)
287 |
288 | plt.show()
289 | ```
290 |
291 |
292 |
293 |
263 |
264 | # 七. 设置坐标轴
265 |
266 | ## 1. 坐标轴外观及边界
267 |
268 | ```python
269 | import matplotlib.pyplot as plt
270 | import numpy as np
271 |
272 | x = np.arange(0, 10, 0.1)
273 | fig = plt.figure(figsize=(8, 6))
274 | ax = fig.add_axes([0.1, 0.1, 0.7, 0.7])
275 | ax.plot(x, x**2)
276 |
277 | # 设置y轴为对数
278 | ax.set_yscale('log') # value{"linear", "log", "symlog", "logit", ...}
279 |
280 | # 设置其他轴(边界)
281 | ax.spines['top'].set_color('None')
282 | ax.spines['right'].set_color('None')
283 | ax.spines['left'].set_color('blue')
284 | ax.spines['left'].set_lw(2)
285 | ax.spines['bottom'].set_color('red')
286 | ax.spines['bottom'].set_lw(3)
287 |
288 | plt.show()
289 | ```
290 |
291 |
292 |
293 |  294 |
295 | ## 2. 设置坐标轴范围
296 |
297 | ```python
298 | import matplotlib.pyplot as plt
299 | import numpy as np
300 |
301 | x = np.arange(0, 10, 0.1)
302 | fig = plt.figure(figsize=(8, 6))
303 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
304 | ax.plot(x, x**2)
305 |
306 | # 设置坐标轴范围
307 | ax.set_xlim(2, 5)
308 | ax.set_ylim(5, 30)
309 |
310 | plt.show()
311 | ```
312 |
313 |
294 |
295 | ## 2. 设置坐标轴范围
296 |
297 | ```python
298 | import matplotlib.pyplot as plt
299 | import numpy as np
300 |
301 | x = np.arange(0, 10, 0.1)
302 | fig = plt.figure(figsize=(8, 6))
303 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
304 | ax.plot(x, x**2)
305 |
306 | # 设置坐标轴范围
307 | ax.set_xlim(2, 5)
308 | ax.set_ylim(5, 30)
309 |
310 | plt.show()
311 | ```
312 |
313 |  314 |
315 | ## 3. 设置坐标轴刻度和刻度标签
316 |
317 | ```python
318 | import matplotlib.pyplot as plt
319 | import numpy as np
320 |
321 | x = np.arange(0, 10, 0.1)
322 | fig = plt.figure(figsize=(8, 6))
323 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
324 | ax.plot(x, x**2)
325 |
326 | # 设置坐标轴刻度
327 | ax.set_xticks([1, 2, 3, 5, 7, 9, 15])
328 | ax.set_yticks([1, 10, 20, 100])
329 | ax.set_yticklabels(['A', 'B', 'C', 'D', 'E']) # 在对应位置设置刻度标签,必须在之前定义好刻度
330 |
331 | plt.show()
332 | ```
333 |
334 |
314 |
315 | ## 3. 设置坐标轴刻度和刻度标签
316 |
317 | ```python
318 | import matplotlib.pyplot as plt
319 | import numpy as np
320 |
321 | x = np.arange(0, 10, 0.1)
322 | fig = plt.figure(figsize=(8, 6))
323 | ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
324 | ax.plot(x, x**2)
325 |
326 | # 设置坐标轴刻度
327 | ax.set_xticks([1, 2, 3, 5, 7, 9, 15])
328 | ax.set_yticks([1, 10, 20, 100])
329 | ax.set_yticklabels(['A', 'B', 'C', 'D', 'E']) # 在对应位置设置刻度标签,必须在之前定义好刻度
330 |
331 | plt.show()
332 | ```
333 |
334 |  --------------------------------------------------------------------------------
/public/posts/linux-fundamental-2.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Linux 基础命令2•用户/组和权限管理
3 | date: 2022-03-29
4 | tags: [Linux]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/IJTh2M.jpg"
6 | top_img: false
7 | categories: [文章分享]
8 | ---
9 | `用户`是Linux系统工作中非常重要的一环,用户包括`用户`与`组`管理。 同时,`权限`也是Linux的一个**核心概念**,Linux可以对一个**用户**设定权限,对一个**组**设定权限,甚至还可以对一个**文件或目录**设置权限。
10 |
11 | # 了解用户权限
12 |
13 | Linux将权限分为**三部分**:`读`、`写`与`执行`,详细见下表:
14 |
15 | | 权限 | 缩写 | 代号 |
16 | | :-----------------: | :--: | :--: |
17 | | **读(read)** | r | 4 |
18 | | **写(write)** | w | 2 |
19 | | **执行(execute)** | x | 1 |
20 |
21 | 通过`ls -l`命令可以查看不同用户和组对文件和目录的权限:
22 |
23 |
--------------------------------------------------------------------------------
/public/posts/linux-fundamental-2.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Linux 基础命令2•用户/组和权限管理
3 | date: 2022-03-29
4 | tags: [Linux]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/IJTh2M.jpg"
6 | top_img: false
7 | categories: [文章分享]
8 | ---
9 | `用户`是Linux系统工作中非常重要的一环,用户包括`用户`与`组`管理。 同时,`权限`也是Linux的一个**核心概念**,Linux可以对一个**用户**设定权限,对一个**组**设定权限,甚至还可以对一个**文件或目录**设置权限。
10 |
11 | # 了解用户权限
12 |
13 | Linux将权限分为**三部分**:`读`、`写`与`执行`,详细见下表:
14 |
15 | | 权限 | 缩写 | 代号 |
16 | | :-----------------: | :--: | :--: |
17 | | **读(read)** | r | 4 |
18 | | **写(write)** | w | 2 |
19 | | **执行(execute)** | x | 1 |
20 |
21 | 通过`ls -l`命令可以查看不同用户和组对文件和目录的权限:
22 |
23 |  24 |
25 | 在之前的文章中,我们已经学会使用`ls`命令,但却没有关注前面的这些参数,其实它们**非常重要**~
26 |
27 | 现在我把上图中用红色框框起来的部分整理出来:`d` `rwx` `r-x` `r-x` `kelvin` `kelvin`
28 |
29 | 可能现在看这一串字符会毫无头绪,但请听我慢慢讲给你~
30 |
31 | > **第五个红框**中的`kelvin`代表当前文件或目录的**拥有者**,因为这是我创建的文件夹,而我的用户名为`kelvin`所以我便是这个文件夹的拥有者;
32 | >
33 | > **第六个红框**代表**所属用户组**,系统默认创建的组与用户同名,因为我的用户名是`kelvin`所以系统自动创建了一个名为`kelvin`的组,并将我加了进去。
34 | >
35 | > **第一个红框**中的`d`代表这是一个**文件夹**,如果是一个文件的话,会用`-`来占位;
36 | >
37 | > **第二个红框**代表文件或目录**拥有者**所获得的权限,`rwx`就代表拥有者同时具有**读、写、执行**的权限。
38 | >
39 | > **第三个红框**代表的是**用户组内的用户**所获得的权限,案例中,**组内的成员**权限为`r-x`代表仅**可以阅读和执行**文件但**不能修改**文件内容。
40 | >
41 | > **第四个红框**代表**其他用户**(既不是拥有者,也不在该用户组内)所获得的权限,上图中权限为`r-x`,说明其他用户的权限与组内用户**权限相同**。
42 |
43 | 上面这些基本的权限知识**非常重要**,接下来的操作都会围绕这一系列权限展开。
44 |
45 | ---
46 |
47 | # 普通用户与超级用户
48 |
49 | Linux将用户分为`普通用户`与`超级用户(root)`,**普通用户**只拥有自己和自己所在组所应有的文件权限,但超级用户的权限接近于无限,可以修改几乎Linux的任何文件。
50 |
51 | 有一些操作`普通用户`无法进行,比如在系统层面的软件安装,新建用户,修改系统文件的权限等等。这时就需要`普通用户`临时切换到`超级用户`来执行这些命令。
52 |
53 | ## 切换到超级用户
54 |
55 | 为了能够执行`超级用户(root)`才能执行的命令,有的时候我们不得不切换到`超级用户`,这里介绍一个**切换用户**的命令:
56 |
57 | ```shell
58 | $ su 用户名
59 | $ su - 用户名 # 可直接进入用户的家目录
60 | ```
61 |
62 | - 用于切换当前用户身份到其他用户身份
63 |
64 | > **-l**:改变身份时,也同时变更工作目录;
65 | >
66 | > 若不输入**用户名**,则默认切换为**root**用户,不建议使用默认用户;
67 |
68 |
24 |
25 | 在之前的文章中,我们已经学会使用`ls`命令,但却没有关注前面的这些参数,其实它们**非常重要**~
26 |
27 | 现在我把上图中用红色框框起来的部分整理出来:`d` `rwx` `r-x` `r-x` `kelvin` `kelvin`
28 |
29 | 可能现在看这一串字符会毫无头绪,但请听我慢慢讲给你~
30 |
31 | > **第五个红框**中的`kelvin`代表当前文件或目录的**拥有者**,因为这是我创建的文件夹,而我的用户名为`kelvin`所以我便是这个文件夹的拥有者;
32 | >
33 | > **第六个红框**代表**所属用户组**,系统默认创建的组与用户同名,因为我的用户名是`kelvin`所以系统自动创建了一个名为`kelvin`的组,并将我加了进去。
34 | >
35 | > **第一个红框**中的`d`代表这是一个**文件夹**,如果是一个文件的话,会用`-`来占位;
36 | >
37 | > **第二个红框**代表文件或目录**拥有者**所获得的权限,`rwx`就代表拥有者同时具有**读、写、执行**的权限。
38 | >
39 | > **第三个红框**代表的是**用户组内的用户**所获得的权限,案例中,**组内的成员**权限为`r-x`代表仅**可以阅读和执行**文件但**不能修改**文件内容。
40 | >
41 | > **第四个红框**代表**其他用户**(既不是拥有者,也不在该用户组内)所获得的权限,上图中权限为`r-x`,说明其他用户的权限与组内用户**权限相同**。
42 |
43 | 上面这些基本的权限知识**非常重要**,接下来的操作都会围绕这一系列权限展开。
44 |
45 | ---
46 |
47 | # 普通用户与超级用户
48 |
49 | Linux将用户分为`普通用户`与`超级用户(root)`,**普通用户**只拥有自己和自己所在组所应有的文件权限,但超级用户的权限接近于无限,可以修改几乎Linux的任何文件。
50 |
51 | 有一些操作`普通用户`无法进行,比如在系统层面的软件安装,新建用户,修改系统文件的权限等等。这时就需要`普通用户`临时切换到`超级用户`来执行这些命令。
52 |
53 | ## 切换到超级用户
54 |
55 | 为了能够执行`超级用户(root)`才能执行的命令,有的时候我们不得不切换到`超级用户`,这里介绍一个**切换用户**的命令:
56 |
57 | ```shell
58 | $ su 用户名
59 | $ su - 用户名 # 可直接进入用户的家目录
60 | ```
61 |
62 | - 用于切换当前用户身份到其他用户身份
63 |
64 | > **-l**:改变身份时,也同时变更工作目录;
65 | >
66 | > 若不输入**用户名**,则默认切换为**root**用户,不建议使用默认用户;
67 |
68 |  69 |
70 | ## 以超级用户身份来执行命令(推荐)
71 |
72 | 上文切换用户的方法在平时用的很少,一是因为切换用户比较麻烦,二是切换到`root`容易做出一些**危险**操作,危害系统和文件安全。
73 |
74 | 这里推荐一种更常用的方法,即**不切换到root,但却以root的身份执行命令**:
75 |
76 | ```shell
77 | $ sudo 用户名
78 | ```
79 |
80 | > 同样,如果不输入用户名,系统默认为**root**;
81 |
82 | `sudo`命令后会要求你**输入密码**,此时Linux会倒计时**五分钟**,在这五分钟之内,如果你再次使用`sudo`来执行命令,可以**免密**。
83 |
84 |
69 |
70 | ## 以超级用户身份来执行命令(推荐)
71 |
72 | 上文切换用户的方法在平时用的很少,一是因为切换用户比较麻烦,二是切换到`root`容易做出一些**危险**操作,危害系统和文件安全。
73 |
74 | 这里推荐一种更常用的方法,即**不切换到root,但却以root的身份执行命令**:
75 |
76 | ```shell
77 | $ sudo 用户名
78 | ```
79 |
80 | > 同样,如果不输入用户名,系统默认为**root**;
81 |
82 | `sudo`命令后会要求你**输入密码**,此时Linux会倒计时**五分钟**,在这五分钟之内,如果你再次使用`sudo`来执行命令,可以**免密**。
83 |
84 |  85 |
86 | ---
87 |
88 | # 用户组管理
89 |
90 | 当在一个多人项目中,为每个用户单独设置权限未免过于麻烦,但**用户组**的存在可以让你为一个用户组设定权限,并将用户添加到这个用户组中,这样这些用户就拥有了这个用户组所拥有的权限。
91 |
92 | ## 新建与删除用户组
93 |
94 | **添加与管理组**均需要使用**超级用户身份**来进行:
95 |
96 | ```shell
97 | # 新建用户组
98 | $ groupadd 组名
99 |
100 | # 删除用户组
101 | $ groupdel 组名
102 | ```
103 |
104 | 现在先试试建立一个**组**,命名为`dev`,输入完命令后没有保存,但怎么才能知道**是否创建成功**了呢?现在我来给你介绍一个文件,`/etc/group`这个文件放在`etc`文件夹下,说明它与系统配置有关,没错,`/etc/group`里就存着用户组的信息,让我们看看:
105 |
106 |
85 |
86 | ---
87 |
88 | # 用户组管理
89 |
90 | 当在一个多人项目中,为每个用户单独设置权限未免过于麻烦,但**用户组**的存在可以让你为一个用户组设定权限,并将用户添加到这个用户组中,这样这些用户就拥有了这个用户组所拥有的权限。
91 |
92 | ## 新建与删除用户组
93 |
94 | **添加与管理组**均需要使用**超级用户身份**来进行:
95 |
96 | ```shell
97 | # 新建用户组
98 | $ groupadd 组名
99 |
100 | # 删除用户组
101 | $ groupdel 组名
102 | ```
103 |
104 | 现在先试试建立一个**组**,命名为`dev`,输入完命令后没有保存,但怎么才能知道**是否创建成功**了呢?现在我来给你介绍一个文件,`/etc/group`这个文件放在`etc`文件夹下,说明它与系统配置有关,没错,`/etc/group`里就存着用户组的信息,让我们看看:
105 |
106 |  107 |
108 | 结果可能有一堆,但我们现在只关心最后两行。这里显示了两个组,`kelvin`和`dev`,`kelvin`是我在建立用户的时候系统默认创建的,而`dev`则是刚刚我手动通过命令创建的。**组名**后的数字为`GID(组标识)`,通过**GID**可知`kelvin`的组号是`1000`,`dev`的则是`1001`。
109 |
110 | 细心的你可能会发现为什么`kelvin`的组号后面还跟着一个`kelvin`,而`dev`的组号的后面只有一个冒号呢?这是因为**每个组的最后一个值代表以这个组为附加组的成员**,`kelvin`这个用户自然就在`kelvin`组内,而`dev`是刚刚新建的,自然就没有用户在内了。
111 |
112 | 在下文中我会详细介绍如何**管理组内的成员**~
113 |
114 | ---
115 |
116 | # 用户管理
117 |
118 | Linux是**多用户操作系统**,所以对于用户的管理也是Linux非常重要的一部分。
119 |
120 | 用户管理也属于管理员的责任,所以与用户管理有关的命令也需要以`超级用户(root)`的身份来运行。
121 |
122 | ## 基本用户管理命令
123 |
124 | ### 用户的创建和删除
125 |
126 | 基本的用户管理操作包括:`创建用户`、`设置密码`、`删除用户`。
127 |
128 | ```shell
129 | # 创建用户
130 | $ useradd -m -G 组名 用户名
131 |
132 | # 设置密码
133 | $ passwd 用户名
134 |
135 | # 删除用户
136 | $ userdel -r 用户名
137 | ```
138 |
139 | > ***创建用户:***
140 | >
141 | > **-g** <群组>:指定用户所属的**主组**;
142 | >
143 | > **-G** <群组>:指定用户所属的**附加群组**;
144 | >
145 | > **-m**:自动建立用户的家目录;
146 | >
147 | > ***删除用户:***
148 | >
149 | > **-f**:强制删除用户,即使用户当前已登录;
150 | >
151 | > **-r**:删除用户的同时,删除与用户相关的所有文件;
152 |
153 | 试一下吧~现在新建一个用户`lydia`, 并将`lydia`的**附加组**设定为`dev`:
154 |
155 |
107 |
108 | 结果可能有一堆,但我们现在只关心最后两行。这里显示了两个组,`kelvin`和`dev`,`kelvin`是我在建立用户的时候系统默认创建的,而`dev`则是刚刚我手动通过命令创建的。**组名**后的数字为`GID(组标识)`,通过**GID**可知`kelvin`的组号是`1000`,`dev`的则是`1001`。
109 |
110 | 细心的你可能会发现为什么`kelvin`的组号后面还跟着一个`kelvin`,而`dev`的组号的后面只有一个冒号呢?这是因为**每个组的最后一个值代表以这个组为附加组的成员**,`kelvin`这个用户自然就在`kelvin`组内,而`dev`是刚刚新建的,自然就没有用户在内了。
111 |
112 | 在下文中我会详细介绍如何**管理组内的成员**~
113 |
114 | ---
115 |
116 | # 用户管理
117 |
118 | Linux是**多用户操作系统**,所以对于用户的管理也是Linux非常重要的一部分。
119 |
120 | 用户管理也属于管理员的责任,所以与用户管理有关的命令也需要以`超级用户(root)`的身份来运行。
121 |
122 | ## 基本用户管理命令
123 |
124 | ### 用户的创建和删除
125 |
126 | 基本的用户管理操作包括:`创建用户`、`设置密码`、`删除用户`。
127 |
128 | ```shell
129 | # 创建用户
130 | $ useradd -m -G 组名 用户名
131 |
132 | # 设置密码
133 | $ passwd 用户名
134 |
135 | # 删除用户
136 | $ userdel -r 用户名
137 | ```
138 |
139 | > ***创建用户:***
140 | >
141 | > **-g** <群组>:指定用户所属的**主组**;
142 | >
143 | > **-G** <群组>:指定用户所属的**附加群组**;
144 | >
145 | > **-m**:自动建立用户的家目录;
146 | >
147 | > ***删除用户:***
148 | >
149 | > **-f**:强制删除用户,即使用户当前已登录;
150 | >
151 | > **-r**:删除用户的同时,删除与用户相关的所有文件;
152 |
153 | 试一下吧~现在新建一个用户`lydia`, 并将`lydia`的**附加组**设定为`dev`:
154 |
155 |  156 |
157 | 此时再去看看`/etc/group的情况`:
158 |
159 |
156 |
157 | 此时再去看看`/etc/group的情况`:
158 |
159 |  160 |
161 | 看看最后三行,果然`lydia`已经被添加到`dev`组中,并且系统也自动创建了名为`lydia`的组作为`lydia`的**主组**。
162 |
163 | ### 向组内添加或删除用户
164 |
165 | #### usermod
166 |
167 | ```shell
168 | # 设置用户所在组
169 | $ usermod -G 组名 用户名
170 | ```
171 |
172 | > **-g** <群组>:修改用户所属的**主组**;
173 | >
174 | > **-G** <群组>;修改用户所属的**附加群组**;
175 | >
176 | > 若想**加入多个组**,则可使用`,`来隔开每个组名;
177 |
178 | 试试看将`kelvin`加入`dev`用户组:
179 |
180 |
160 |
161 | 看看最后三行,果然`lydia`已经被添加到`dev`组中,并且系统也自动创建了名为`lydia`的组作为`lydia`的**主组**。
162 |
163 | ### 向组内添加或删除用户
164 |
165 | #### usermod
166 |
167 | ```shell
168 | # 设置用户所在组
169 | $ usermod -G 组名 用户名
170 | ```
171 |
172 | > **-g** <群组>:修改用户所属的**主组**;
173 | >
174 | > **-G** <群组>;修改用户所属的**附加群组**;
175 | >
176 | > 若想**加入多个组**,则可使用`,`来隔开每个组名;
177 |
178 | 试试看将`kelvin`加入`dev`用户组:
179 |
180 |  181 |
182 | 成功,在`/etc/group`中已经可以看到用户信息。
183 |
184 | > **注意:**`usermod`的功能是**设置**用户的组,并非**添加或删除**用户的组;
185 | >
186 | > 假设用户A已经在a组中,如果想使用`usermod`再将A添加到b组中,就必须将a、b都写上去,即`usermod -G a, b A`;
187 | >
188 | > 如果仅仅写成`usermod -G b A`,则用户A所属的a组会被删除。
189 |
190 | #### gpasswd
191 |
192 | 上文提到使用`usermod`设置用户所在组**并非真正意义上的添加或删除**用户的组,使用`gpasswd`命令可以更方便地调整用户所在组:
193 |
194 | `gpasswd [-options] [用户名] [组名]`
195 |
196 | > **-a**:添加用户到组;
197 | >
198 | > **-d**:从组删除用户;
199 |
200 | 实战一下,现在我想把`kelvin`用户移除`dev`组,然后再把它添加回来:
201 |
202 | ```shell
203 | # 将kelvin移除dev组
204 | $ gpasswd -d kelvin dev
205 |
206 | # 将kelvin加到dev组
207 | $ gpasswd -a kelvin dev
208 | ```
209 |
210 | 先执行移除命令:
211 |
212 |
181 |
182 | 成功,在`/etc/group`中已经可以看到用户信息。
183 |
184 | > **注意:**`usermod`的功能是**设置**用户的组,并非**添加或删除**用户的组;
185 | >
186 | > 假设用户A已经在a组中,如果想使用`usermod`再将A添加到b组中,就必须将a、b都写上去,即`usermod -G a, b A`;
187 | >
188 | > 如果仅仅写成`usermod -G b A`,则用户A所属的a组会被删除。
189 |
190 | #### gpasswd
191 |
192 | 上文提到使用`usermod`设置用户所在组**并非真正意义上的添加或删除**用户的组,使用`gpasswd`命令可以更方便地调整用户所在组:
193 |
194 | `gpasswd [-options] [用户名] [组名]`
195 |
196 | > **-a**:添加用户到组;
197 | >
198 | > **-d**:从组删除用户;
199 |
200 | 实战一下,现在我想把`kelvin`用户移除`dev`组,然后再把它添加回来:
201 |
202 | ```shell
203 | # 将kelvin移除dev组
204 | $ gpasswd -d kelvin dev
205 |
206 | # 将kelvin加到dev组
207 | $ gpasswd -a kelvin dev
208 | ```
209 |
210 | 先执行移除命令:
211 |
212 |  213 |
214 | 果然,现在`dev`组中只剩下`lydia`了~ 再加回来试试看:
215 |
216 |
213 |
214 | 果然,现在`dev`组中只剩下`lydia`了~ 再加回来试试看:
215 |
216 |  217 |
218 | 哈哈,又加回来了!是不是使用`gpasswd`来管理用户的**附加组**要比`usermod`更方便呢?
219 |
220 | ## 查看用户信息
221 |
222 | ### 基本命令:
223 |
224 | 下面我将介绍几个查看用户信息的基本命令:
225 |
226 | ```shell
227 | # 查看用户的UID(用户代号)和GID(组代号), 默认为当前用户
228 | $ id [用户名]
229 |
230 | # 查看用户所在的组,默认为当前用户
231 | $ groups [用户名]
232 |
233 | # 查看当前所有登陆的用户列表
234 | $ who
235 |
236 | # 查看当前登陆的用户名
237 | $ whoami
238 | ```
239 |
240 | 动手试试看:
241 |
242 |
217 |
218 | 哈哈,又加回来了!是不是使用`gpasswd`来管理用户的**附加组**要比`usermod`更方便呢?
219 |
220 | ## 查看用户信息
221 |
222 | ### 基本命令:
223 |
224 | 下面我将介绍几个查看用户信息的基本命令:
225 |
226 | ```shell
227 | # 查看用户的UID(用户代号)和GID(组代号), 默认为当前用户
228 | $ id [用户名]
229 |
230 | # 查看用户所在的组,默认为当前用户
231 | $ groups [用户名]
232 |
233 | # 查看当前所有登陆的用户列表
234 | $ who
235 |
236 | # 查看当前登陆的用户名
237 | $ whoami
238 | ```
239 |
240 | 动手试试看:
241 |
242 |  243 |
244 | 通过**id**命令可以看到用户的`UID`、`GID`和所属**组**,可以看到`kelvin`这个用户加入了两个组,一个是`kelvin`一个是`wheel`。`wheel`是一个比较特殊的组,这个组内的成员可以有一些**特殊的权限**,比如使用`su`切换到`root`用户,或者用`sudo`以超级用户身份来执行命令。
245 |
246 |
243 |
244 | 通过**id**命令可以看到用户的`UID`、`GID`和所属**组**,可以看到`kelvin`这个用户加入了两个组,一个是`kelvin`一个是`wheel`。`wheel`是一个比较特殊的组,这个组内的成员可以有一些**特殊的权限**,比如使用`su`切换到`root`用户,或者用`sudo`以超级用户身份来执行命令。
245 |
246 |  247 |
248 | 使用`group`来看看我现在的用户所在的组,这种方式要比去`/etc/group`里面查找方便的多。
249 |
250 |
247 |
248 | 使用`group`来看看我现在的用户所在的组,这种方式要比去`/etc/group`里面查找方便的多。
249 |
250 |  251 |
252 | 通过`who`命令可以查看所有登陆的用户列表,因为只有我一个人登陆,所以只有一个用户。试试再开一个终端,登陆新建立的`lydia`账户:
253 |
254 |
251 |
252 | 通过`who`命令可以查看所有登陆的用户列表,因为只有我一个人登陆,所以只有一个用户。试试再开一个终端,登陆新建立的`lydia`账户:
253 |
254 |  255 |
256 | 果然,现在已登陆的用户变成了两个~
257 |
258 | `whoami`这个命令非常好理解,就是它的英文意思“Who am I?”,我是谁?
259 |
260 |
255 |
256 | 果然,现在已登陆的用户变成了两个~
257 |
258 | `whoami`这个命令非常好理解,就是它的英文意思“Who am I?”,我是谁?
259 |
260 |  261 |
262 | 哈哈哈,果然,我就是`kelvin`。
263 |
264 | ### /etc/passwd 文件
265 |
266 | 与组的信息类似,用户的信息也存储在`etc`文件夹下:`/etc/passwd`,现在来看看这个文件里有些什么:
267 |
268 |
261 |
262 | 哈哈哈,果然,我就是`kelvin`。
263 |
264 | ### /etc/passwd 文件
265 |
266 | 与组的信息类似,用户的信息也存储在`etc`文件夹下:`/etc/passwd`,现在来看看这个文件里有些什么:
267 |
268 |  269 |
270 | 眼熟吧,又是用`:`隔开的各种参数,我来给你解释一下它们的意思:
271 |
272 | > 1. **用户名**
273 | > 2. **UID**
274 | > 3. **GID**
275 | > 4. **用户家目录**
276 | > 5. **Shell**
277 |
278 | ### 关于Shell
279 |
280 | 什么?你说你不懂`Shell`是什么? 哈哈哈
281 |
282 | **Shell**其实就是终端内运行的**软件**,比如`kelvin`这个用户使用的Shell就是`zsh`,而`lydia`使用的是`bash`。这两个Shell并不会有什么本质的区别,只是在一些功能上会有些不同的体验。
283 |
284 | ```shell
285 | # 查看当前使用的Shell
286 | $ echo $SHELL
287 |
288 | # 查看系统中的所有Shell
289 | $ cat /etc/shells
290 | ```
291 |
292 |
269 |
270 | 眼熟吧,又是用`:`隔开的各种参数,我来给你解释一下它们的意思:
271 |
272 | > 1. **用户名**
273 | > 2. **UID**
274 | > 3. **GID**
275 | > 4. **用户家目录**
276 | > 5. **Shell**
277 |
278 | ### 关于Shell
279 |
280 | 什么?你说你不懂`Shell`是什么? 哈哈哈
281 |
282 | **Shell**其实就是终端内运行的**软件**,比如`kelvin`这个用户使用的Shell就是`zsh`,而`lydia`使用的是`bash`。这两个Shell并不会有什么本质的区别,只是在一些功能上会有些不同的体验。
283 |
284 | ```shell
285 | # 查看当前使用的Shell
286 | $ echo $SHELL
287 |
288 | # 查看系统中的所有Shell
289 | $ cat /etc/shells
290 | ```
291 |
292 |  293 |
294 | 这种方式与去到`/etc/passwd`里查看相比会更简单。
295 |
296 |
293 |
294 | 这种方式与去到`/etc/passwd`里查看相比会更简单。
295 |
296 |  297 |
298 | `/etc/shells`中存储着系统中所有的Shell,如果**忘记路径或名称**可以来这里看。
299 |
300 | ```shell
301 | # 为用户切换Shell
302 | $ usermod -s /bin/bash 用户名
303 | ```
304 |
305 | 通过上面的命令可以**切换用户的Shell**,但每次切换之后需要用户**退出再重新登陆**才能生效。
306 |
307 | 关于Shell的详细内容以后会出文章介绍~
308 |
309 | ---
310 |
311 | # 修改文件权限
312 |
313 | 还记得在文章的最开始我们最先讨论了`ls -l`输出的内容的详细信息吗?
314 |
315 |
316 |
317 | 就是这张图,现在要做的是**试着修改这里面的信息**,也就是**修改文件权限**。
318 |
319 | ## 修改文件拥有者
320 |
321 | 文件的拥有者被称为`owner`,所以修改文件拥有者的命令也非常好记,即`chown(change owner)`:
322 |
323 | `chown [用户名] [文件/目录]`
324 |
325 | - 用来变更文件或目录的拥有者或所属群组
326 |
327 | > **-R**: 递归处理,将指定目录下的所有文件及子目录一并处理;
328 |
329 | 
330 |
331 | 现在有一个`01.py`文件,拥有者是`kelvin`,让我们试试将文件拥有者改为`lydia`:
332 |
333 | 
334 |
335 | 在输入密码后,命令生效,`lydia`已经成为`01.py`的拥有者。此时`kelvin`对这个文件的权限为`r-x`,来验证一下`kelvin`是不是真的不能修改`01.py`:
336 |
337 | 
338 |
339 | 果然,当用Vim打开`01.py`时显示只读。
340 |
341 | ## 修改文件所属组
342 |
343 | 当修改完文件拥有者后,还可以对其**所属组**进行修改。命令同样非常好记`chgrp (change group):`
344 |
345 | `chgrp [组名] [文件/目录]`
346 |
347 | - 用来变更文件或目录的所属群组
348 |
349 | > **-R**:递归处理,将指令目录下的所有文件及子目录一并处理;
350 |
351 | 试着把`01.py`所属的组改成`dev`:
352 |
353 | 
354 |
355 | 很简单吧,现在`01.py`的所属组已经被改为`dev`。
356 |
357 | ## 修改文件权限
358 |
359 | 修改文件权限是Linux非常重要的技能,同时也体现了Linux的灵活和强大,而且更改权限的方式非常精妙,让我来给你讲讲~
360 |
361 | 文章开头有一个关于权限的表格,我现在再给搬过来:
362 |
363 | | 权限 | 缩写 | 代号 |
364 | | :-----------------: | :--: | :--: |
365 | | **读(read)** | r | 4 |
366 | | **写(write)** | w | 2 |
367 | | **执行(execute)** | x | 1 |
368 |
369 | 三种权限非常容易理解,但它们的**代号**是什么意思呢?其实奥妙就在其中!
370 |
371 | Linux使用**代号的代数和来表示权限**。举个例子,比如一个文件的权限是`rwx`那它的权限可以被表示为`7`,即4+2+1; `rw-`可以被表示为`6`,即4+2。 有没有感觉非常神奇? 它们的代数和是**不会重复**的,所以用这种方法来表示权限真的是非常的精妙!
372 |
373 | ### chmod
374 |
375 | `chmod 755 [文件/目录]`
376 |
377 | > **-R**:递归处理,将指令目录下的所有文件及子目录一并处理;
378 |
379 | 这次我直接给你了一个例子,通过这个命令来解释`chmod`的用法。
380 |
381 | 命令中的`755`是三类权限的组合,即`拥有者` `组` `其他用户`,所以`755`的意思为`拥有者`的权限为`rwx`,`组`和`其他用户` 的权限为`r-x`。
382 |
383 | 举个例子:
384 |
385 | 将`01.py`拥有者的权限修改为`rwx`,即`7`,`组`内用户的权限设置为`--x`,即`1`,`其他用户`的权限设置为`--x`,即`1`:
386 |
387 | 
388 |
389 | 此时通过显示已经可以看出权限修改成功,我们来验证一下:
390 |
391 | `kelvin`现在在`dev`组内,试试看他能不能阅读`01,py`:
392 |
393 | 
394 |
395 | 果然,权限不够,看来我们成功啦~
396 |
397 |
--------------------------------------------------------------------------------
/public/favicon.svg:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/public/posts/tiny-compiler.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 亲手写一个超小型编译器 [tiny-compiler]
3 | date: 2022-10-18
4 | ---
5 |
6 | 前段时间一直想写一个比较完备的Markdown编译器,但因为网上相关的文章较少,已有的开源项目已经很完善,就暂时搁置了。这两天发现了[这个项目](https://github.com/jamiebuilds/the-super-tiny-compiler),它用**短短200多行代码**实现了一个超级mini的编译器,并且里面有**完整的讲解和详细的注释**,非常适合没有学习过编译原理的我学习,于是在经过一个晚上的学习和实现之后,就有了这篇文章。
7 |
8 | # 适合你阅读吗?
9 |
10 | - 虽说这个项目潇潇洒洒地只用了200多行代码实现,但对我们的JavaScript水平有一定的要求,所以如果你已经有了**不错的JS基础**,那么这个项目非常适合用来**练手和提高**。
11 | - 如果你像我一样,**之前没有接触和学习过编译原理**,那么把这个项目作为起点也非常合适。
12 | - [原项目](https://github.com/jamiebuilds/the-super-tiny-compiler)纯英文的,如果你**阅读英文些困难**的话,或许这篇文章能帮助你理解内容。
13 | - 本文只是**对重要概念和核心代码的总结和解释**,并没有原项目那样面面俱到的阐述每一句代码的含义。
14 |
15 | # 如何阅读和学习?
16 |
17 | 1. 前往[原项目](https://github.com/jamiebuilds/the-super-tiny-compiler),**先自主学习**项目的教程和代码。
18 | 2. 如果有地方不理解,回到这篇文章中看看能否找到答案。
19 | 3. 最后如果你想跟着我写一遍完整的代码,可以到[我的B站上观看视频](https://codingkelvin.fun)。 // TODO 更新视频链接
20 |
21 | # 基础知识
22 |
23 | ## 编译器/Compiler
24 |
25 | *首先,什么是编译器?*
26 |
27 | > 简单讲,编译器就是将“一种语言”翻译为“另一种语言”的程序。 -- 百度百科
28 |
29 | 上面百度百科给的解释已经简单易懂了,核心就是**把一种语言翻译为另外一种语言**。就像开头提到的,我打算写一个Markdown编译器,其实就是想**把Markdown编译成/翻译成/转换成HTML**,这就是对编译器最简单的理解。
30 |
31 | 那么在这个项目中,我们要***实现把LISP语言的函数调用语句转换为C语言的函数调用语句***。
32 |
33 | | Math | LISP | C |
34 | | :---------: | :--------------------: | :--------------------: |
35 | | 2 + 1 | (add 2 1) | add(2, 1) |
36 | | 5 - 3 | (subtract 5 3) | subtract(5, 3) |
37 | | 1 + (4 - 3) | (add 1 (subtract 4 3)) | add(1, subtract(4, 3)) |
38 |
39 | 听起来很简单对不对,接下来再简单梳理一下**具体的实现步骤**~
40 |
41 | ## 编译的三个步骤
42 |
43 | 想要完成编译,可以把它简单拆分为三大步:
44 |
45 | 1. **词法/语法分析 (Parsing)**
46 | 2. **转换 (Transformation)**
47 | 3. **代码生成 (Code Generation)**
48 |
49 | ### 词法/语法分析 (Parsing)
50 |
51 | #### 词法分析 Lexical Analysis
52 |
53 | 词法分析的目标就是**把源代码拆分成一个个词法单元(token)**,把这些拆分好的`token`放到一个`tokens`数组中。
54 |
55 | 每一个`token`都是一个简单的**对象**,里面储存了这个对象的一些**基本信息**,比如说一个数字可以被标示为`{type: 'NumberLiteral', value: 100}`。
56 |
57 | 这里放一张插图帮助大家理解~
58 |
59 |
297 |
298 | `/etc/shells`中存储着系统中所有的Shell,如果**忘记路径或名称**可以来这里看。
299 |
300 | ```shell
301 | # 为用户切换Shell
302 | $ usermod -s /bin/bash 用户名
303 | ```
304 |
305 | 通过上面的命令可以**切换用户的Shell**,但每次切换之后需要用户**退出再重新登陆**才能生效。
306 |
307 | 关于Shell的详细内容以后会出文章介绍~
308 |
309 | ---
310 |
311 | # 修改文件权限
312 |
313 | 还记得在文章的最开始我们最先讨论了`ls -l`输出的内容的详细信息吗?
314 |
315 |
316 |
317 | 就是这张图,现在要做的是**试着修改这里面的信息**,也就是**修改文件权限**。
318 |
319 | ## 修改文件拥有者
320 |
321 | 文件的拥有者被称为`owner`,所以修改文件拥有者的命令也非常好记,即`chown(change owner)`:
322 |
323 | `chown [用户名] [文件/目录]`
324 |
325 | - 用来变更文件或目录的拥有者或所属群组
326 |
327 | > **-R**: 递归处理,将指定目录下的所有文件及子目录一并处理;
328 |
329 | 
330 |
331 | 现在有一个`01.py`文件,拥有者是`kelvin`,让我们试试将文件拥有者改为`lydia`:
332 |
333 | 
334 |
335 | 在输入密码后,命令生效,`lydia`已经成为`01.py`的拥有者。此时`kelvin`对这个文件的权限为`r-x`,来验证一下`kelvin`是不是真的不能修改`01.py`:
336 |
337 | 
338 |
339 | 果然,当用Vim打开`01.py`时显示只读。
340 |
341 | ## 修改文件所属组
342 |
343 | 当修改完文件拥有者后,还可以对其**所属组**进行修改。命令同样非常好记`chgrp (change group):`
344 |
345 | `chgrp [组名] [文件/目录]`
346 |
347 | - 用来变更文件或目录的所属群组
348 |
349 | > **-R**:递归处理,将指令目录下的所有文件及子目录一并处理;
350 |
351 | 试着把`01.py`所属的组改成`dev`:
352 |
353 | 
354 |
355 | 很简单吧,现在`01.py`的所属组已经被改为`dev`。
356 |
357 | ## 修改文件权限
358 |
359 | 修改文件权限是Linux非常重要的技能,同时也体现了Linux的灵活和强大,而且更改权限的方式非常精妙,让我来给你讲讲~
360 |
361 | 文章开头有一个关于权限的表格,我现在再给搬过来:
362 |
363 | | 权限 | 缩写 | 代号 |
364 | | :-----------------: | :--: | :--: |
365 | | **读(read)** | r | 4 |
366 | | **写(write)** | w | 2 |
367 | | **执行(execute)** | x | 1 |
368 |
369 | 三种权限非常容易理解,但它们的**代号**是什么意思呢?其实奥妙就在其中!
370 |
371 | Linux使用**代号的代数和来表示权限**。举个例子,比如一个文件的权限是`rwx`那它的权限可以被表示为`7`,即4+2+1; `rw-`可以被表示为`6`,即4+2。 有没有感觉非常神奇? 它们的代数和是**不会重复**的,所以用这种方法来表示权限真的是非常的精妙!
372 |
373 | ### chmod
374 |
375 | `chmod 755 [文件/目录]`
376 |
377 | > **-R**:递归处理,将指令目录下的所有文件及子目录一并处理;
378 |
379 | 这次我直接给你了一个例子,通过这个命令来解释`chmod`的用法。
380 |
381 | 命令中的`755`是三类权限的组合,即`拥有者` `组` `其他用户`,所以`755`的意思为`拥有者`的权限为`rwx`,`组`和`其他用户` 的权限为`r-x`。
382 |
383 | 举个例子:
384 |
385 | 将`01.py`拥有者的权限修改为`rwx`,即`7`,`组`内用户的权限设置为`--x`,即`1`,`其他用户`的权限设置为`--x`,即`1`:
386 |
387 | 
388 |
389 | 此时通过显示已经可以看出权限修改成功,我们来验证一下:
390 |
391 | `kelvin`现在在`dev`组内,试试看他能不能阅读`01,py`:
392 |
393 | 
394 |
395 | 果然,权限不够,看来我们成功啦~
396 |
397 |
--------------------------------------------------------------------------------
/public/favicon.svg:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/public/posts/tiny-compiler.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 亲手写一个超小型编译器 [tiny-compiler]
3 | date: 2022-10-18
4 | ---
5 |
6 | 前段时间一直想写一个比较完备的Markdown编译器,但因为网上相关的文章较少,已有的开源项目已经很完善,就暂时搁置了。这两天发现了[这个项目](https://github.com/jamiebuilds/the-super-tiny-compiler),它用**短短200多行代码**实现了一个超级mini的编译器,并且里面有**完整的讲解和详细的注释**,非常适合没有学习过编译原理的我学习,于是在经过一个晚上的学习和实现之后,就有了这篇文章。
7 |
8 | # 适合你阅读吗?
9 |
10 | - 虽说这个项目潇潇洒洒地只用了200多行代码实现,但对我们的JavaScript水平有一定的要求,所以如果你已经有了**不错的JS基础**,那么这个项目非常适合用来**练手和提高**。
11 | - 如果你像我一样,**之前没有接触和学习过编译原理**,那么把这个项目作为起点也非常合适。
12 | - [原项目](https://github.com/jamiebuilds/the-super-tiny-compiler)纯英文的,如果你**阅读英文些困难**的话,或许这篇文章能帮助你理解内容。
13 | - 本文只是**对重要概念和核心代码的总结和解释**,并没有原项目那样面面俱到的阐述每一句代码的含义。
14 |
15 | # 如何阅读和学习?
16 |
17 | 1. 前往[原项目](https://github.com/jamiebuilds/the-super-tiny-compiler),**先自主学习**项目的教程和代码。
18 | 2. 如果有地方不理解,回到这篇文章中看看能否找到答案。
19 | 3. 最后如果你想跟着我写一遍完整的代码,可以到[我的B站上观看视频](https://codingkelvin.fun)。 // TODO 更新视频链接
20 |
21 | # 基础知识
22 |
23 | ## 编译器/Compiler
24 |
25 | *首先,什么是编译器?*
26 |
27 | > 简单讲,编译器就是将“一种语言”翻译为“另一种语言”的程序。 -- 百度百科
28 |
29 | 上面百度百科给的解释已经简单易懂了,核心就是**把一种语言翻译为另外一种语言**。就像开头提到的,我打算写一个Markdown编译器,其实就是想**把Markdown编译成/翻译成/转换成HTML**,这就是对编译器最简单的理解。
30 |
31 | 那么在这个项目中,我们要***实现把LISP语言的函数调用语句转换为C语言的函数调用语句***。
32 |
33 | | Math | LISP | C |
34 | | :---------: | :--------------------: | :--------------------: |
35 | | 2 + 1 | (add 2 1) | add(2, 1) |
36 | | 5 - 3 | (subtract 5 3) | subtract(5, 3) |
37 | | 1 + (4 - 3) | (add 1 (subtract 4 3)) | add(1, subtract(4, 3)) |
38 |
39 | 听起来很简单对不对,接下来再简单梳理一下**具体的实现步骤**~
40 |
41 | ## 编译的三个步骤
42 |
43 | 想要完成编译,可以把它简单拆分为三大步:
44 |
45 | 1. **词法/语法分析 (Parsing)**
46 | 2. **转换 (Transformation)**
47 | 3. **代码生成 (Code Generation)**
48 |
49 | ### 词法/语法分析 (Parsing)
50 |
51 | #### 词法分析 Lexical Analysis
52 |
53 | 词法分析的目标就是**把源代码拆分成一个个词法单元(token)**,把这些拆分好的`token`放到一个`tokens`数组中。
54 |
55 | 每一个`token`都是一个简单的**对象**,里面储存了这个对象的一些**基本信息**,比如说一个数字可以被标示为`{type: 'NumberLiteral', value: 100}`。
56 |
57 | 这里放一张插图帮助大家理解~
58 |
59 | 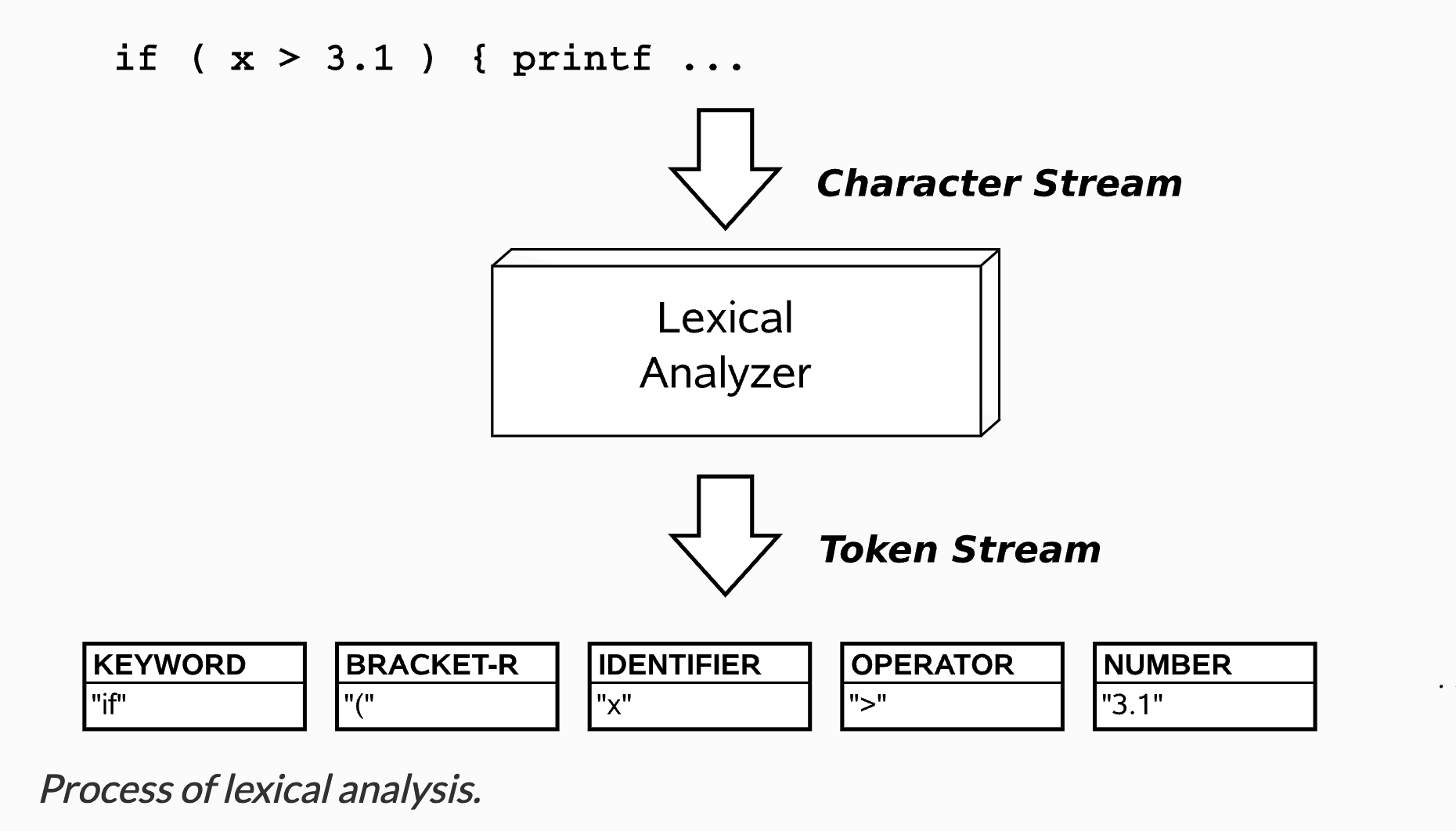 60 |
61 | 再来**举个例子,实操一下**:
62 |
63 | ```
64 | (add 3 (subtract 4 1))
65 | ```
66 |
67 | 经过词法分析,会输出结果:
68 |
69 | ```js
70 | [
71 | { type: 'paren', value: '(' },
72 | { type: 'name', value: 'add' },
73 | { type: 'number', value: '3' },
74 | { type: 'paren', value: '(' },
75 | { type: 'name', value: 'subtract' },
76 | { type: 'number', value: '4' },
77 | { type: 'number', value: '1' },
78 | { type: 'paren', value: ')' },
79 | { type: 'paren', value: ')' },
80 | ]
81 | ```
82 |
83 | #### 语法分析 Syntactic Analysis
84 |
85 | 语法分析会在词法分析后进行,它会**基于词法分析的结果**,也就是根据`tokens`数组,构建出每一个`token`之间的**关系**,最终将这些`token`全部组合成一个**大的对象**,通过这个对象就可以还原出原本语法的所有内容,一般管这个对象叫做**抽象语法树(Abstract Syntax Tree)**简称`AST`。
86 |
87 | 继续上面的例子,**经过语法分析后**,会输出结果:
88 |
89 | ```js
90 | {
91 | type: 'Program',
92 | body: [{
93 | type: 'CallExpression',
94 | name: 'add',
95 | params: [{
96 | type: 'NumberLiteral',
97 | value: '3',
98 | }, {
99 | type: 'CallExpression',
100 | name: 'subtract',
101 | params: [{
102 | type: 'NumberLiteral',
103 | value: '4',
104 | }, {
105 | type: 'NumberLiteral',
106 | value: '1',
107 | }]
108 | }]
109 | }]
110 | }
111 | ```
112 |
113 | 通过这个对象(AST),我们已经可以推导出原本程序的语法,这就是AST的作用。
114 |
115 | ### 转换 Transformation
116 |
117 | 第二部就是转换,**对上一步得到的AST进行转换**。在进行转换时,**可以对任意节点进行属性的添加/替换/删除操作**,目的是通过转换AST,能更方便地把它翻译成另一种语言.
118 |
119 | #### 遍历AST节点 Traversal
120 |
121 | 为了能对每一个节点都进行转换,就必须要进行**遍历(Traversal)**。对于AST这棵树,我们在遍历的时候采用**深度优先(depth-first)**的模式。
122 |
123 | 遍历到每一个节点后需要对每个节点进行转换,这里**会用到一种设计模式:访问者模式**,简单来说就是把操作元素的方法单独拿出来封装成一个`visitor`类,但是不用担心,如果你没有了解过这种设计模式,继续往下看,也不会有什么影响。
124 |
125 | 假设我们有两个类型的节点`NumberLiteral`和`StringLiteral`,那么想要对这两个节点进行转换,就可以定义这样一个`visitor`:
126 |
127 | ```js
128 | const vositor = {
129 | NumberLiteral: {
130 | enter(node, parent) {
131 | // do something
132 | },
133 | exit(node, parent) {
134 | // do something
135 | }
136 | },
137 | StringLiteral: {
138 | enter(node, parent) {
139 | // do something
140 | },
141 | exit(node, parent) {
142 | // do something
143 | }
144 | }
145 | }
146 | ```
147 |
148 | 这样的好处是当我进入某个节点时,只需要调用`visitor`上对应节点的`enter`方法就可以完成转换,离开时调用对应节点的`exit`即可。
149 |
150 | ### 代码生成 Code Generation
151 |
152 | 最后一步就是**根据上一步转换得到的新AST来生成出目标语言的代码**。
153 |
154 | 这个步骤非常简单,等下就会看到啦~
155 |
156 | ***下面就正式开始吧!!***
157 |
158 | # 分词器/词法解析 TOKENIZER
159 |
160 | `tokenizer`函数,它**接受一个字符串**,返回一个`tokens`数组。
161 |
162 | 词法解析的原理就是**遍历字符串中所有的字符**,如果**某个字符或多个字符符合一个词法**,就将它添加到`tokens`中。所以最外面一层一定是遍历。
163 |
164 | ```js
165 | function tokenizer(input) {
166 | let current = 0;
167 | while (current < input.length) {
168 | const char = input[current];
169 | // 在这里就要定义一些词法的规则了
170 | }
171 | }
172 | ```
173 |
174 | 在我们这个简单的项目中,**词法规则也非常少,一共只有6个**,分别是:
175 |
176 | 1. **开括号** `(`
177 | 2. **闭括号** `)`
178 | 3. **空格** -> *可以直接跳过*
179 | 4. **数字** -> *数字可能不止一位,需要向后查找完整的数字*
180 | 5. **字符串** -> *在两个双引号之间,需要去掉双引号*
181 | 6. **函数名** -> *需要向后查找,获得完整名称*
182 |
183 | 其中开括号和闭括号非常简单,遇到后直接向`tokens`中添加对应的`token`对象即可:
184 |
185 | ```js
186 | // 写在上文while循环内部
187 | if (char === '(') {
188 | tokens.push({type: 'paren', value: '('});
189 | current++;
190 | continue;
191 | }
192 | ```
193 |
194 | 这里**稍微有难度的是数字和字符串**,这里简单说明一下:
195 |
196 | ```js
197 | // 写在上文while循环内部
198 |
199 | // 对于数字,还用字符串的方式储存
200 | const NUMBERS = /[0-9]/;
201 | if (NUMBERS.test(char)) {
202 | let value = '';
203 | // 向后继续查找,看看是不是数字
204 | while (NUMBERS.test(char)) {
205 | value += char;
206 | char = input[++current]; // 先自增,再返回值
207 | }
208 | tokens.push({type: 'number', value});
209 | continue;
210 | }
211 |
212 | // 处理字符串也很类似,只是需要考虑双引号的问题
213 | if (char === '"') {
214 | let value = '';
215 | char = input[++current]; // 跳过第一个双引号
216 | while (char !== '"') {
217 | value += char;
218 | char = input[++current];
219 | }
220 | char = input[++current]; // 跳过第二个双引号
221 | tokens.push({type: 'string', value});
222 | continue;
223 | }
224 | ```
225 |
226 | 剩下的几个词法的实现也都比较简单,大家可以看代码学习,最终运行`tokenizer`函数就会得到已经经过词法分析的`tokens`数组。
227 |
228 | # 语法分析器 PARSER
229 |
230 | `parser`函数接受`tokens`数组,**返回一个AST对象**。
231 |
232 | 这里面的第一个问题就是**AST对象比较复杂**,会出现**层层嵌套**的关系,所以不可避免的就要**使用递归**了。
233 |
234 | 最终我们想达到的效果大概是这样:
235 |
236 | ```js
237 | function parser(tokens) {
238 | let current = 0;
239 |
240 | function walk() {
241 | let token = tokens[current];
242 | // walk函数会遍历每一个token,并且返回对应的AST节点
243 | }
244 |
245 | // AST的外壳
246 | let ast = {
247 | type: 'Program',
248 | body: []
249 | }
250 |
251 | // 遍历每一个语句
252 | while (current < tokens.length) {
253 | ast.body.push(walk());
254 | }
255 |
256 | return ast;
257 | }
258 | ```
259 |
260 | 现在整体框架有了,**核心任务就是去实现这个walk函数了**。
261 |
262 | 还是从简单的问题入手,处理最简单的`number` 和`string`节点:
263 |
264 | ```js
265 | // 写在walk函数内部
266 | if (token.type === 'number') {
267 | current++;
268 | return {
269 | type: 'NumberLiteral',
270 | value: token.value;
271 | }
272 | }
273 | // string同理
274 | ```
275 |
276 | 处理完简单的后,就要开始复杂一些的操作了。下面要**将表达式的调用(Call Expression)转换为AST**,因为表达式内部要接收参数,而参数也可以是另一个表达式,所以这里就要开始递归了。
277 |
278 | ```js
279 | // 写在walk内部
280 | // 表达式一定以(开始,)结束
281 | if (token.type === 'paren' && token.value === '(') {
282 | token = tokens[++current]; // 跳过(
283 |
284 | // AST节点的结构
285 | let node = {
286 | type: 'CallExpression',
287 | name: token.value,
288 | params: [],
289 | };
290 |
291 | token = tokens[++current]; // 跳过函数名token
292 |
293 | // 下面是核心,开始递归
294 | // 如果没遇到),说明后面的token就是参数,表达式还没有结束
295 | while(token.value !== ')') {
296 | node.params.push(walk()); // 递归
297 | token = tokens[current]; // 经过递归,current已经发生变化,这里更新一下token
298 | }
299 |
300 | current++; // 跳过 )
301 | }
302 | ```
303 |
304 | 好啦,到这里`parser`也完成了,**现在我们已经把一段字符串转化成了AST**。
305 |
306 | # 遍历器 TRAVERSER
307 |
308 | 现在已经得到了AST,接下来要做的就是**遍历每一个节点**。
309 |
310 | 简单想一下,对于`NumberLiteral`这样的节点,很好遍历,因为它没有子节点。但是对于`Program`和`CallExpression`来说,**他们都有一个数组用来存放子节点,所以想要完全遍历,就要去遍历这个数组。**
311 |
312 | 有了思路,我们来看一下**代码的结构**:
313 |
314 | ```js
315 | function traverser(ast, visitor) {
316 | // 遍历Array
317 | function traverseArray(array, parent) {
318 | array.forEach((child) => traverseNode(child, parent));
319 | }
320 |
321 | // 遍历Node
322 | function traverseNode(node, parent) {
323 | // 1. 进行转换 Transformation -> 调用visitor里面的函数
324 | // 2. 对于Program和CallExpression,调用traverseArray
325 | }
326 |
327 | // 开始遍历
328 | traverseNode(ast, null);
329 | }
330 | ```
331 |
332 | 现在结构应该很清晰了,在`traverseNode`函数里面要干两件事情,一是进行转换(Transformation),其实就是调用`visitor`里面对应的函数,二是继续深层遍历数组。
333 |
334 | ```js
335 | function traverseNode(node, parent) {
336 | // 从visitor中拿到对应type的方法
337 | const method = visitor[node.type];
338 | // 如果enter方法存在,就调用,完成转换
339 | if (method && method.enter) {
340 | method.enter(node, parent)
341 | }
342 |
343 | // 继续遍历数组
344 | switch (node.type) {
345 | case 'Program':
346 | traverseArray(node.body, node);
347 | break;
348 | case 'CallExpression':
349 | traverseArray(node.params, node);
350 | break;
351 | case 'NumberLiteral':
352 | case 'StringLiteral':
353 | break;
354 | default:
355 | throw new TypeError(node.type)
356 | }
357 | }
358 | ```
359 |
360 | 现在两项任务都完成了,只是`visitor`里面的**转换方法还没有定义**,所以下一步就是**定义转换的方法**。
361 |
362 | # 转换器 TRANSFORMER
363 |
364 | 在写转换器之前,一定要先**搞清楚究竟要怎么转换**。我们看一下项目例子中的转换:
365 |
366 | ```js
367 | // 转换前
368 | {
369 | "type": "Program",
370 | "body": [
371 | {
372 | "type": "CallExpression",
373 | "name": "add",
374 | "params": [
375 | {
376 | "type": "NumberLiteral",
377 | "value": "10"
378 | },
379 | {
380 | "type": "CallExpression",
381 | "name": "subtract",
382 | "params": [
383 | {
384 | "type": "NumberLiteral",
385 | "value": "20"
386 | },
387 | {
388 | "type": "NumberLiteral",
389 | "value": "100"
390 | }
391 | ]
392 | }
393 | ]
394 | }
395 | ]
396 | }
397 | ```
398 |
399 | ```js
400 | // 转换后
401 | {
402 | "type": "Program",
403 | "body": [
404 | {
405 | "type": "ExpressionStatement",
406 | "expression": {
407 | "type": "CallExpression",
408 | "callee": {
409 | "type": "Identifier",
410 | "name": "add"
411 | },
412 | "arguments": [
413 | {
414 | "type": "NumberLiteral",
415 | "value": "10"
416 | },
417 | {
418 | "type": "CallExpression",
419 | "callee": {
420 | "type": "Identifier",
421 | "name": "subtract"
422 | },
423 | "arguments": [
424 | {
425 | "type": "NumberLiteral",
426 | "value": "20"
427 | },
428 | {
429 | "type": "NumberLiteral",
430 | "value": "100"
431 | }
432 | ]
433 | }
434 | ]
435 | }
436 | }
437 | ]
438 | }
439 | ```
440 |
441 | 简单来看主要**有这么几个变化**:
442 |
443 | 1. 在最外层的CallExpression**外面包裹了一层ExpressionStatement**
444 | 2. params**属性变成了arguments**
445 | 3. CallExpression内**多了一个callee对象**
446 |
447 | 这些转换都是为了最终编译成其他语言做准备,要想完成这些转换,就需要借助`visitor`里面的方法了。
448 |
449 | 下面我们试着写一下`transformer`函数的**大体结构**:
450 |
451 | ```js
452 | function transformer(ast) {
453 | // 不在旧的AST上做转换,这里直接创建一个新的AST
454 | const newAst = {
455 | type: 'Program',
456 | body: [],
457 | }
458 |
459 | // 这里有一个小trick,因为在traversal函数中
460 | // 我们只把旧的AST传给了enter方法,所以想要修改newAst就比较困难
461 | // 这里将newAst.body的引用赋值到旧AST的一个字段上,方便获取和修改
462 | ast._context = newAst.body;
463 |
464 | // 开始遍历
465 | traverse(ast, visitor);
466 |
467 | return newAst;
468 | }
469 | ```
470 |
471 | 大体结构就是这样,但是核心的`visitor`还是没有实现,下面我们来实现一下:
472 |
473 | ```js
474 | const visitor = {
475 | // 因为CallExpression有嵌套,最复杂,我们先实现一下它
476 | CallExpression: {
477 | enter(node, parent) {
478 | // 创建一个新节点
479 | const expression = {
480 | type: 'CallExpression',
481 | callee: {
482 | type: 'Identifier',
483 | name: node.name,
484 | },
485 | arguments: [],
486 | }
487 |
488 | // 同样为了方便修改newAst,把expression.arguments的引用放到node._context上一份
489 | node._context = expression.arguments;
490 |
491 | // 判断是否为最外层的CallExpressoin,如果是,包裹ExpressionStatement
492 | if (parent.type !== 'CallExpression') {
493 | expression = {
494 | type: 'ExpressionStatement',
495 | expression: expression,
496 | }
497 | }
498 |
499 | // 把处理好的expression添加到newAst中
500 | parent._context.push(expression);
501 | }
502 | },
503 |
504 | // Number和String就很简单了,这里只实现NumberLiteral
505 | NumberLiteral: {
506 | enter(node, parent) {
507 | parent._context.push({
508 | type: 'NumberLiteral',
509 | value: node.value,
510 | })
511 | }
512 | }
513 | }
514 | ```
515 |
516 | 到此为止,**新的AST树也已经生成好了**,终于来到**最后一步**,生成代码!
517 |
518 | # 生成代码 Code Generation
519 |
520 | 根据新的AST树,不难生成出最终的代码,核心逻辑就是根据`node.type`生成不同的字符串,其中可能需要一些递归,最后把这些字符串拼接起来,就是最终的代码。
521 |
522 | 代码很简单,详细的解释在原文中有,但下面的代码也足够清晰了:
523 |
524 | ```js
525 | function codeGeneratior(node) {
526 | switch (node.type) {
527 | // 最简单的情况就是函数名,数字,字符串,这些直接返回就可以
528 | case 'Identifier':
529 | // callee中的name属性
530 | return node.name;
531 |
532 | case 'NumberLiteral':
533 | return node.value;
534 |
535 | case 'StringLiteral':
536 | // 字符串需要用双引号包裹
537 | return '"' + node.value + '"';
538 |
539 | // 复杂一些的Program, ExpressionStatement, CallExpression都需要递归
540 | // 但也没有那么复杂
541 |
542 | case 'Program':
543 | // 可能有多个语句,换行输出
544 | return node.body.map(statement => codeGenerator(statement)).join('\n');
545 |
546 | case 'ExpressionStatement':
547 | // C语言,分号结尾
548 | return codeGenerator(node.expression) + ';';
549 |
550 | case 'CallExpression':
551 | // 表达式,参数用逗号隔开
552 | return codeGenerator(node.callee) + '(' + node.arguments.map(codeGenerator).join(', ') + ')';
553 | }
554 | }
555 | ```
556 |
557 | **其实写到这我们的超级迷你编译器已经完成了,它已经能把LISP的函数调用语法转换为C语言的语法了。**
558 |
559 | # 测试
560 |
561 | **还记得我们写了多少个函数不?**下面通过一个**简单的测试用例**,回顾一下整个过程:
562 |
563 | ```js
564 | // 这里封装成compiler
565 | function compiler(input) {
566 | const tokens = tokenizer(input); // 第一步,对字符串进行词法解析,得到tokens
567 | const ast = parser(tokens); // 第二步,把tokens转换成AST
568 | const newAst = transformer(ast); // 第三步,对AST进行转换,得到新的AST
569 | const result = codeGenerator(newAst); // 第四步,根据新的AST生成转换后的字符串
570 | return result;
571 | }
572 |
573 | // TEST
574 | console.log(compiler('(add 10 (subtract 20 100)) (connect "Hello" "World")'));
575 | // add(10, subtract(20, 100));
576 | // connect("Hello", "World");
577 | ```
578 |
579 | ---
580 |
581 | **~~完结撒花啦~~**
582 |
--------------------------------------------------------------------------------
/public/posts/how-to-ask-question.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 提问的智慧[重点加粗][转自GitHub]
3 | date: 2022-02-23
4 | tags: [文章分享]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/question.jpeg"
6 | top_img: false
7 | categories: [文章分享]
8 | ---
9 |
10 | [](https://github.com/ryanhanwu/How-To-Ask-Questions-The-Smart-Way/pulls)
11 |
12 | **How To Ask Questions The Smart Way**
13 |
14 | Copyright © 2001,2006,2014 Eric S. Raymond, Rick Moen
15 |
16 | 本指南英文版版权为 Eric S. Raymond, Rick Moen 所有。
17 |
18 | 原文网址:[http://www.catb.org/~esr/faqs/smart-questions.html](http://www.catb.org/~esr/faqs/smart-questions.html)
19 |
20 | Copyleft 2001 by D.H.Grand(nOBODY/Ginux), 2010 by Gasolin, 2015 by Ryan Wu
21 |
22 | 翻译地址:https://github.com/ryanhanwu/How-To-Ask-Questions-The-Smart-Way
23 |
24 | ## 声明
25 |
26 | 许多项目在他们的使用协助/说明网页中链接了本指南,这么做很好,我们也鼓励大家都这么做。但如果你是负责管理这个项目网页的人,请在超链接附近的显著位置上注明:
27 |
28 | **本指南不提供此项目的实际支持服务!**
29 |
30 | 我们已经深刻领教到少了上述声明所带来的痛苦。因为少了这点声明,我们不停地被一些白痴纠缠。这些白痴认为既然我们发布了这本指南,那么我们就有责任解决世上所有的技术问题。
31 |
32 | 如果你因寻求某些帮助而阅读本指南,并在离开时还觉得可以从本文作者这里得到直接帮助,那你就是我们之前说的那些白痴之一。别问我们问题,我们只会忽略你。我们在这本指南中想教你如何从那些真正懂得你所遇到的软件或硬件问题的人处取得协助,而 99% 的情况下那不会是我们。除非你确定本指南的作者之一刚好是你所遇到的问题领域的专家,否则请不要打扰我们,这样大家都会开心一点。
33 |
34 | ## 简介
35 |
36 | 在[黑客](http://www.catb.org/~esr/faqs/hacker-howto.html)的世界里,当你拋出一个技术问题时,最终是否能得到有用的回答,往往取决于你所提问和追问的方式。本指南将教你如何正确的提问以获得你满意的答案。
37 |
38 | 现在开源(Open Source)软件已经相当盛行,您通常可以从其他更有经验的用户那里获得与黑客一样好的答案,这是件**好事**;和黑客相比,用户们往往对那些新手常遇到的问题更宽容一些。尽管如此,以我们在此推荐的方式对待这些有经验的用户通常也是从他们那里获得有用答案的最有效方式。
39 |
40 | 首先你应该明白,黑客们喜爱有挑战性的问题,或者能激发他们思维的好问题。如果我们并非如此,那我们也不会成为你想询问的对象。如果你给了我们一个值得反复咀嚼玩味的好问题,我们自会对你感激不尽。好问题是激励,是厚礼。好问题可以提高我们的理解力,而且通常会暴露我们以前从没意识到或者思考过的问题。对黑客而言,“好问题!”是诚挚的大力称赞。
41 |
42 | 尽管如此,黑客们有着蔑视或傲慢面对简单问题的坏名声,这有时让我们看起来对新手、无知者似乎较有敌意,但其实不是那样的。
43 |
44 | 我们不讳言我们对那些不愿思考、或者在发问前不做他们该做的事的人的蔑视。那些人是时间杀手 —— 他们只想索取,从不付出,消耗我们可用在更有趣的问题或更值得回答的人身上的时间。我们称这样的人为 `失败者(loser)` (由于历史原因,我们有时把它拼作 `lusers`)。
45 |
46 | 我们意识到许多人只是想使用我们写的软件,他们对学习技术细节没有兴趣。对大多数人而言,电脑只是种工具,是种达到目的的手段而已。他们有自己的生活并且有更要紧的事要做。我们了解这点,也从不指望每个人都对这些让我们着迷的技术问题感兴趣。尽管如此,我们回答问题的风格是指向那些真正对此有兴趣并愿意主动参与解决问题的人,这一点不会变,也不该变。如果连这都变了,我们就是在降低做自己最擅长的事情上的效率。
47 |
48 | 我们(在很大程度上)是自愿的,从繁忙的生活中抽出时间来解答疑惑,而且时常被提问淹没。所以我们无情地滤掉一些话题,特别是拋弃那些看起来像失败者的家伙,以便更高效地利用时间来回答`赢家(winner)`的问题。
49 |
50 | 如果你厌恶我们的态度,高高在上,或过于傲慢,不妨也设身处地想想。我们并没有要求你向我们屈服 —— 事实上,我们大多数人非常乐意与你平等地交流,只要你付出小小努力来满足基本要求,我们就会欢迎你加入我们的文化。但让我们帮助那些不愿意帮助自己的人是没有效率的。无知没有关系,但装白痴就是不行。
51 |
52 | 所以,你不必在技术上很在行才能吸引我们的注意,但你必须表现出能引导你变得在行的特质 —— 机敏、有想法、善于观察、乐于主动参与解决问题。如果你做不到这些使你与众不同的事情,我们建议你花点钱找家商业公司签个技术支持服务合同,而不是要求黑客个人无偿地帮助你。
53 |
54 | 如果你决定向我们求助,当然你也不希望被视为失败者,更不愿成为失败者中的一员。能立刻得到快速并有效答案的最好方法,就是像赢家那样提问 —— 聪明、自信、有解决问题的思路,只是偶尔在特定的问题上需要获得一点帮助。
55 |
56 | (欢迎对本指南提出改进意见。你可以 email 你的建议至 [esr@thyrsus.com](esr@thyrsus.com) 或 [respond-auto@linuxmafia.com](respond-auto@linuxmafia.com)。然而请注意,本文并非[网络礼节](http://www.ietf.org/rfc/rfc1855.txt)的通用指南,而我们通常会拒绝无助于在技术论坛得到有用答案的建议)。
57 |
58 | ## 在提问之前
59 |
60 | 在你准备要通过电子邮件、新闻群组或者聊天室提出技术问题前,请先做到以下事情:
61 |
62 | 1. 尝试在你准备提问的论坛的旧文章中搜索答案。
63 | 2. 尝试上网搜索以找到答案。
64 | 3. 尝试阅读手册以找到答案。
65 | 4. 尝试阅读常见问题文件(FAQ)以找到答案。
66 | 5. 尝试自己检查或试验以找到答案。
67 | 6. 向你身边的强者朋友打听以找到答案。
68 | 7. 如果你是程序开发者,请尝试阅读源代码以找到答案。
69 |
70 | 当你提出问题的时候,**请先表明你已经做了上述的努力**;这将有助于树立你并不是一个不劳而获且浪费别人的时间的提问者。如果你能**一并表达在做了上述努力的过程中所学到的东西**会更好,因为我们更乐于回答那些表现出能从答案中学习的人的问题。
71 |
72 | 运用某些策略,比如先用 Google 搜索你所遇到的各种错误信息(搜索 [Google 论坛](http://groups.google.com/)和网页),这样很可能直接就找到了能解决问题的文件或邮件列表线索。即使没有结果,在邮件列表或新闻组寻求帮助时加上一句 `我在 Google 中搜过下列句子但没有找到什么有用的东西` 也是件好事,即使它只是表明了搜索引擎不能提供哪些帮助。这么做(加上搜索过的字串)也让遇到相似问题的其他人能被搜索引擎引导到你的提问来。
73 |
74 | 别着急,不要指望几秒钟的 Google 搜索就能解决一个复杂的问题。在向专家求助之前,再阅读一下常见问题文件(FAQ)、放轻松、坐舒服一些,再花点时间思考一下这个问题。相信我们,**他们能从你的提问看出你做了多少阅读与思考,如果你是有备而来,将更有可能得到解答**。不要将所有问题一股脑拋出,只因你的第一次搜索没有找到答案(或者找到太多答案)。
75 |
76 | 准备好你的问题,再将问题仔细的思考过一遍,因为**草率的发问只能得到草率的回答**,或者根本得不到任何答案。越是能表现出在寻求帮助前你为解决问题所付出的努力,你越有可能得到实质性的帮助。
77 |
78 | 小心别问错了问题。如果你的问题基于错误的假设,某个普通黑客(J. Random Hacker)多半会一边在心里想着`蠢问题…`,一边用无意义的字面解释来答复你,希望着你会从问题的回答(而非你想得到的答案)中汲取教训。
79 |
80 | 绝不要自以为**够格**得到答案,你没有;你并没有。毕竟你没有为这种服务支付任何报酬。你将会是自己去**挣到**一个答案,靠提出有内涵的、有趣的、有思维激励作用的问题 —— 一个有潜力能贡献社区经验的问题,而不仅仅是被动的从他人处索取知识。
81 |
82 | 另一方面,表明你愿意在找答案的过程中做点什么是一个非常好的开端。`谁能给点提示?`、`我的这个例子里缺了什么?`以及`我应该检查什么地方`比`请把我需要的确切的过程贴出来`更容易得到答复。因为你表现出只要有人能指个正确方向,你就有完成它的能力和决心。
83 |
84 | ## 当你提问时
85 |
86 | ### 慎选提问的论坛
87 |
88 | 小心选择你要提问的场合。如果你做了下述的事情,你很可能被忽略掉或者被看作失败者:
89 |
90 | * 在与主题不合的论坛上贴出你的问题。
91 | * 在探讨进阶技术问题的论坛张贴非常初级的问题;反之亦然。
92 | * 在太多的不同新闻群组上重复转贴同样的问题(cross-post)。
93 | * 向既非熟人也没有义务解决你问题的人发送私人电邮。
94 |
95 | 黑客会剔除掉那些搞错场合的问题,以保护他们沟通的渠道不被无关的东西淹没。你不会想让这种事发生在自己身上的。
96 |
97 | 因此,第一步是找到对的论坛。再说一次,Google 和其它搜索引擎还是你的朋友,用它们来找到与你遭遇到困难的软硬件问题最相关的网站。通常那儿都有常见问题(FAQ)、邮件列表及相关说明文件的链接。如果你的努力(包括**阅读** FAQ)都没有结果,网站上也许还有报告 Bug(Bug-reporting)的流程或链接,如果是这样,链过去看看。
98 |
99 | 向陌生的人或论坛发送邮件最可能是风险最大的事情。举例来说,别假设一个提供丰富内容的网页的作者会想充当你的免费顾问。**不要对你的问题是否会受到欢迎做太乐观的估计 —— 如果你不确定,那就向别处发送,或者压根别发**。
100 |
101 | 在选择论坛、新闻群组或邮件列表时,别太相信名字,先看看 FAQ 或者许可书以弄清楚你的问题是否切题。发文前先翻翻已有的话题,这样可以让你感受一下那里的文化。事实上,事先在新闻组或邮件列表的历史记录中搜索与你问题相关的关键词是个极好的主意,也许这样就找到答案了。即使没有,也能帮助你归纳出更好的问题。
102 |
103 | 别像机关枪似的一次“扫射”所有的帮助渠道,这就像大喊大叫一样会使人不快。要一个一个地来。
104 |
105 | 搞清楚你的主题!最典型的错误之一是在某种致力于跨平台可移植的语言、套件或工具的论坛中提关于 Unix 或 Windows 操作系统程序界面的问题。如果你不明白为什么这是大错,最好在搞清楚这之间差异之前什么也别问。
106 |
107 | 一般来说,在仔细挑选的公共论坛中提问,会比在私有论坛中提同样的问题更容易得到有用的回答。有几个理由可以支持这点,一是看潜在的回复者有多少,二是看观众有多少。黑客较愿意回答那些能帮助到许多人的问题。
108 |
109 | 可以理解的是,老练的黑客和一些热门软件的作者正在接受过多的错发信息。就像那根最后压垮骆驼背的稻草一样,你的加入也有可能使情况走向极端 —— 已经好几次了,一些热门软件的作者由于涌入其私人邮箱的大量不堪忍受的无用邮件而不再提供支持。
110 |
111 | ### Stack Overflow
112 |
113 | 搜索,**然后**在 Stack Exchange 问。
114 |
115 | 近年来,Stack Exchange 社区已经成为回答技术及其他问题的主要渠道,尤其是那些开放源码的项目。
116 |
117 | 因为 Google 索引是即时的,在看 Stack Exchange 之前先在 Google 搜索。有很高的几率某人已经问了一个类似的问题,而且 Stack Exchange 网站们往往会是搜索结果中最前面几个。如果你在 Google 上没有找到任何答案,你再到特定相关主题的网站去找。用标签(Tag)搜索能让你更缩小你的搜索结果。
118 |
119 | Stack Exchange 已经成长到[超过一百个网站](https://stackexchange.com/sites),以下是最常用的几个站:
120 |
121 | * Super User 是问一些通用的电脑问题,如果你的问题跟代码或是写程序无关,只是一些网络连线之类的,请到这里。
122 | * Stack Overflow 是问写程序有关的问题。
123 | * Server Fault 是问服务器和网管相关的问题。
124 |
125 | ### 网站和 IRC 论坛
126 |
127 | 本地的用户群组(user group),或者你所用的 Linux 发行版本也许正在宣传他们的网页论坛或 IRC 频道,并提供新手帮助(在一些非英语国家,新手论坛很可能还是邮件列表),这些都是开始提问的好地方,特别是当你觉得遇到的也许只是相对简单或者很普通的问题时。有广告赞助的 IRC 频道是公开欢迎提问的地方,通常可以即时得到回应。
128 |
129 | 事实上,如果程序出的问题只发生在特定 Linux 发行版提供的版本(这很常见),最好先去该发行版的论坛或邮件列表中提问,再到程序本身的论坛或邮件列表提问。(否则)该项目的黑客可能仅仅回复“使用**我们的**版本”。
130 |
131 | 在任何论坛发文以前,先确认一下有没有搜索功能。如果有,就试着搜索一下问题的几个关键词,也许这会有帮助。如果在此之前你已做过通用的网页搜索(你也该这样做),还是再搜索一下论坛,搜索引擎有可能没来得及索引此论坛的全部内容。
132 |
133 | 通过论坛或 IRC 频道来提供用户支持服务有增长的趋势,电子邮件则大多为项目开发者间的交流而保留。所以最好先在论坛或 IRC 中寻求与该项目相关的协助。
134 |
135 | 在使用 IRC 的时候,首先最好不要发布很长的问题描述,有些人称之为频道洪水。最好通过一句话的问题描述来开始聊天。
136 |
137 | ### 第二步,使用项目邮件列表
138 |
139 | 当某个项目提供开发者邮件列表时,要向列表而不是其中的个别成员提问,即使你确信他能最好地回答你的问题。查一查项目的文件和首页,找到项目的邮件列表并使用它。有几个很好的理由支持我们采用这种办法:
140 |
141 | * 任何好到需要向个别开发者提出的问题,也将对整个项目群组有益。反之,如果你认为自己的问题对整个项目群组来说太愚蠢,那这也不能成为骚扰个别开发者的理由。
142 | * 向列表提问可以分散开发者的负担,个别开发者(尤其是项目领导人)也许太忙以至于没法回答你的问题。
143 | * 大多数邮件列表都会被存档,那些被存档的内容将被搜索引擎索引。如果你向列表提问并得到解答,将来其他人可以通过网页搜索找到你的问题和答案,也就不用再次发问了。
144 | * 如果某些问题经常被问到,开发者可以利用此信息来改进说明文件或软件本身,以使其更清楚。如果只是私下提问,就没有人能看到最常见问题的完整场景。
145 |
146 | 如果一个项目既有“用户”也有“开发者”(或“黑客”)邮件列表或论坛,而你又不会动到那些源代码,那么就向“用户”列表或论坛提问。不要假设自己会在开发者列表中受到欢迎,那些人多半会将你的提问视为干扰他们开发的噪音。
147 |
148 | 然而,如果你**确信**你的问题很特别,而且在“用户”列表或论坛中几天都没有回复,可以试试前往“开发者”列表或论坛发问。建议你在张贴前最好先暗地里观察几天以了解那里的行事方式(事实上这是参与任何私有或半私有列表的好主意)
149 |
150 | 如果你找不到一个项目的邮件列表,而只能查到项目维护者的电子邮件地址,尽管向他发信。即使是在这种情况下,也别假设(项目)邮件列表不存在。在你的电子邮件中,**请陈述你已经试过但没有找到合适的邮件列表,也提及你不反对将自己的邮件转发给他人**(许多人认为,即使没什么秘密,私人电子邮件也不应该被公开。通过允许将你的电子邮件转发他人,你给了相应人员处置你邮件的选择)。
151 |
152 | ### 使用有意义且描述明确的标题
153 |
154 | 在邮件列表、新闻群组或论坛中,大约 50 字以内的标题是抓住资深专家注意力的好机会。别用喋喋不休的`帮帮忙`、`跪求`、`急`(更别说`救命啊!!!!`这样让人反感的话,用这种标题会被条件反射式地忽略)来浪费这个机会。不要妄想用你的痛苦程度来打动我们,而应该是在这点空间中使用极简单扼要的描述方式来提出问题。
155 |
156 | 一个好标题范例是`目标 —— 差异`式的描述,许多技术支持组织就是这样做的。**在`目标`部分指出是哪一个或哪一组东西有问题,在`差异`部分则描述与期望的行为不一致的地方**。
157 |
158 |
159 | > 蠢问题:救命啊!我的笔记本电脑不能正常显示了!
160 |
161 | > 聪明问题:X.org 6.8.1 的鼠标光标会变形,某牌显卡 MV1005 芯片组。
162 |
163 | > 更聪明问题:X.org 6.8.1 的鼠标光标,在某牌显卡 MV1005 芯片组环境下 - 会变形。
164 |
165 | 编写`目标 —— 差异` 式描述的过程有助于你组织对问题的细致思考。是什么被影响了? 仅仅是鼠标光标或者还有其它图形?只在 X.org 的 X 版中出现?或只是出现在 6.8.1 版中? 是针对某牌显卡芯片组?或者只是其中的 MV1005 型号? 一个黑客只需瞄一眼就能够立即明白你的环境**和**你遇到的问题。
166 |
167 | 总而言之,请想像一下你正在一个只显示标题的存档讨论串(Thread)索引中查寻。让你的标题更好地反映问题,可使下一个搜索类似问题的人能够关注这个讨论串,而不用再次提问相同的问题。
168 |
169 | 如果你想在回复中提出问题,记得要修改内容标题,以表明你是在问一个问题, 一个看起来像 `Re: 测试` 或者 `Re: 新 bug` 的标题很难引起足够重视。另外,在不影响连贯性之下,适当引用并删减前文的内容,能给新来的读者留下线索。
170 |
171 | 对于讨论串,不要直接点击回复来开始一个全新的讨论串,这将限制你的观众。因为有些邮件阅读程序,比如 mutt ,允许用户按讨论串排序并通过折叠讨论串来隐藏消息,这样做的人永远看不到你发的消息。
172 |
173 | 仅仅改变标题还不够。mutt 和其它一些邮件阅读程序还会检查邮件标题以外的其它信息,以便为其指定讨论串。所以宁可发一个全新的邮件。
174 |
175 | 在网页论坛上,好的提问方式稍有不同,因为讨论串与特定的信息紧密结合,并且通常在讨论串外就看不到里面的内容,故通过回复提问,而非改变标题是可接受的。不是所有论坛都允许在回复中出现分离的标题,而且这样做了基本上没有人会去看。不过,通过回复提问,这本身就是暧昧的做法,因为它们只会被正在查看该标题的人读到。所以,除非你**只想**在该讨论串当前活跃的人群中提问,不然还是另起炉灶比较好。
176 |
177 | ### 使问题容易回复
178 |
179 | 以`请将你的回复发送到……`来结束你的问题多半会使你得不到回答。如果你觉得花几秒钟在邮件客户端设置一下回复地址都麻烦,我们也觉得花几秒钟思考你的问题更麻烦。如果你的邮件程序不支持这样做,[换个好点的](http://linuxmafia.com/faq/Mail/muas.html);如果是操作系统不支持这种邮件程序,也换个好点的。
180 |
181 | 在论坛,要求通过电子邮件回复是非常无礼的,除非你认为回复的信息可能比较敏感(有人会为了某些未知的原因,只让你而不是整个论坛知道答案)。如果你只是想在有人回复讨论串时得到电子邮件提醒,可以要求网页论坛发送给你。几乎所有论坛都支持诸如`追踪此讨论串`、`有回复时发送邮件提醒`等功能。
182 |
183 | ### 使用清晰、正确、精准且合乎语法的语句
184 |
185 | 我们从经验中发现,**粗心的提问者通常也会粗心地写程序与思考**(我敢打包票)。回答粗心大意者的问题很不值得,我们宁愿把时间耗在别处。
186 |
187 | **使用清晰、正确、精准且合乎语法的语句**。一般来说,如果你觉得这样做很麻烦,不想在乎这些,那我们也觉得麻烦,不想在乎你的提问。花点额外的精力斟酌一下字句,用不着太僵硬与正式 —— 事实上,黑客文化很看重能准确地使用非正式、俚语和幽默的语句。但它**必须很**准确,而且有迹象表明你是在思考和关注问题。
188 |
189 | 正确地拼写、使用标点和大小写,不要将`its`混淆为`it's`,`loose`搞成`lose`或者将`discrete`弄成`discreet`。不要**全部用大写**,这会被视为无礼的大声嚷嚷(全部小写也好不到哪去,因为不易阅读。[Alan Cox](http://en.wikipedia.org/wiki/Alan_Cox) 也许可以这样做,但你不行)。
190 |
191 | 更白话的说,如果你写得像是个半文盲[译注:[小白](http://zh.wikipedia.org/wiki/小白)],那多半得不到理睬。也不要使用即时通信中的简写或[火星文](http://zh.wikipedia.org/wiki/火星文),如将`的`简化为`d`会使你看起来像一个为了少打几个键而省字的小白。更糟的是,如果像个小孩似地鬼画符那绝对是在找死,可以肯定没人会理你(或者最多是给你一大堆指责与挖苦)。
192 |
193 | **如果在使用非母语的论坛提问,你可以犯点拼写和语法上的小错,但决不能在思考上马虎**(没错,我们通常能弄清两者的分别)。同时,除非你知道回复者使用的语言,否则请使用英语书写。繁忙的黑客一般会直接删除用他们看不懂的语言写的消息。在网络上英语是通用语言,用英语书写可以将你的问题在尚未被阅读就被直接删除的可能性降到最低。
194 |
195 | 如果英文是你的外语(Second language),**提示潜在回复者你有潜在的语言困难是很好的**:
196 | [译注:以下附上原文以供使用]
197 |
198 | > English is not my native language; please excuse typing errors.
199 |
200 | * 英文不是我的母语,请原谅我的错字或语法。
201 |
202 |
203 | > If you speak $LANGUAGE, please email/PM me;
204 | > I may need assistance translating my question.
205 |
206 | * 如果你说**某语言**,请向我发电邮/私信;
207 | * 我需要有人协助我翻译我的问题。
208 |
209 |
210 | > I am familiar with the technical terms,
211 | > but some slang expressions and idioms are difficult for me.
212 |
213 | * 我对技术名词很熟悉,但对于俗语或是特别用法不甚了解。
214 |
215 |
216 | > I've posted my question in $LANGUAGE and English.
217 | > I'll be glad to translate responses, if you only use one or the other.
218 |
219 | * 我把我的问题用**某语言**和英文写出来。
220 | * 如果你只用其中的一种语言回答,我会乐意将回复翻译成为你使用的语言。
221 |
222 | ### 使用易于读取且标准的文件格式发送问题
223 |
224 | 如果你人为地将问题搞得难以阅读,它多半会被忽略,人们更愿读易懂的问题,所以:
225 |
226 | * 使用纯文字而不是 HTML ([关闭 HTML](http://archive.birdhouse.org/etc/evilmail.html) 并不难)。
227 | * 使用 MIME 附件通常是可以的,前提是真正有内容(譬如附带的源代码或 patch),而不仅仅是邮件程序生成的模板(譬如只是信件内容的拷贝)。
228 | * 不要发送一段文字只是一行句子但自动换行后会变成多行的邮件(这使得回复部分内容非常困难)。设想你的读者是在 80 个字符宽的终端机上阅读邮件,最好设置你的换行分割点小于 80 字。
229 | * 但是,对一些特殊的文件**不要**设置固定宽度(譬如日志文件拷贝或会话记录)。数据应该原样包含,让回复者有信心他们看到的是和你看到的一样的东西。
230 | * 在英语论坛中,不要使用`Quoted-Printable` MIME 编码发送消息。这种编码对于张贴非 ASCII 语言可能是必须的,但很多邮件程序并不支持这种编码。当它们处理换行时,那些文本中四处散布的`=20`符号既难看也分散注意力,甚至有可能破坏内容的语意。
231 | * 绝对,**永远**不要指望黑客们阅读使用封闭格式编写的文档,像微软公司的 Word 或 Excel 文件等。大多数黑客对此的反应就像有人将还在冒热气的猪粪倒在你家门口时你的反应一样。即便他们能够处理,他们也很厌恶这么做。
232 | * 如果你从使用 Windows 的电脑发送电子邮件,关闭微软愚蠢的`智能引号`功能 (从[选项] > [校订] > [自动校正选项],勾选掉`智能引号`单选框),以免在你的邮件中到处散布垃圾字符。
233 | * 在论坛,勿滥用`表情符号`和`HTML`功能(当它们提供时)。一两个表情符号通常没有问题,但花哨的彩色文本倾向于使人认为你是个无能之辈。过滥地使用表情符号、色彩和字体会使你看来像个傻笑的小姑娘。这通常不是个好主意,除非你只是对性而不是对答案感兴趣。
234 |
235 | 如果你使用图形用户界面的邮件程序(如微软公司的 Outlook 或者其它类似的),注意它们的默认设置不一定满足这些要求。大多数这类程序有基于选单的`查看源代码`命令,用它来检查发送文件夹中的邮件,以确保发送的是纯文本文件同时没有一些奇怪的字符。
236 |
237 | ### 精确地描述问题并言之有物
238 |
239 | * **仔细、清楚地描述你的问题或 Bug 的症状。**
240 | * **描述问题发生的环境**(机器配置、操作系统、应用程序、以及相关的信息),提供经销商的发行版和版本号(如:`Fedora Core 4`、`Slackware 9.1`等)。
241 | * **描述在提问前你是怎样去研究和理解这个问题的。**
242 | * **描述在提问前为确定问题而采取的诊断步骤。**
243 | * **描述最近做过什么可能相关的硬件或软件变更。**
244 | * **尽可能地提供一个可以`重现这个问题的可控环境`的方法**。
245 |
246 | 尽量去揣测一个黑客会怎样反问你,在你提问之前预先将黑客们可能提出的问题回答一遍。
247 |
248 | 以上几点中,当你报告的是你认为可能在代码中的问题时,给黑客一个可以重现你的问题的环境尤其重要。当你这么做时,你得到有效的回答的机会和速度都会大大的提升。
249 |
250 | [Simon Tatham](http://www.chiark.greenend.org.uk/~sgtatham/) 写过一篇名为《[如何有效的报告 Bug](http://www.chiark.greenend.org.uk/~sgtatham/bugs-cn.html)》的出色文章。强力推荐你也读一读。
251 |
252 | ### 话不在多而在精
253 |
254 | **你需要提供精确有内容的信息。**这并不是要求你简单的把成堆的出错代码或者资料完全转录到你的提问中。如果你有庞大而复杂的测试样例能重现程序挂掉的情境,尽量将它剪裁得越小越好。
255 |
256 | 这样做的用处至少有三点。
257 | 第一,表现出你为简化问题付出了努力,这可以使你得到回答的机会增加;
258 | 第二,简化问题使你更有可能得到**有用**的答案;
259 | 第三,在精炼你的 bug 报告的过程中,你很可能就自己找到了解决方法或权宜之计。
260 |
261 | ### 别动辄声称找到 Bug
262 |
263 | **当你在使用软件中遇到问题,除非你非常、非常的有根据,不要动辄声称找到了 Bug。**提示:除非你能提供解决问题的源代码补丁,或者提供回归测试来表明前一版本中行为不正确,否则你都多半不够完全确信。这同样适用在网页和文件,如果你(声称)发现了文件的`Bug`,你应该能提供相应位置的修正或替代文件。
264 |
265 | 请记得,还有其他许多用户没遇到你发现的问题,否则你在阅读文件或搜索网页时就应该发现了(你在抱怨前[已经做了这些,是吧](#在提问之前)?)。这也意味着很有可能是你弄错了而不是软件本身有问题。
266 |
267 | 编写软件的人总是非常辛苦地使它尽可能完美。**如果你声称找到了 Bug,也就是在质疑他们的能力,即使你是对的,也有可能会冒犯到其中某部分人。**当你在标题中嚷嚷着有`Bug`时,这尤其严重。
268 |
269 | 提问时,即使你私下非常确信已经发现一个真正的 Bug,最好写得像是**你**做错了什么。如果真的有 Bug,你会在回复中看到这点。这样做的话,如果真有 Bug,维护者就会向你道歉,这总比你惹恼别人然后欠别人一个道歉要好一点。
270 |
271 | ### 低声下气不能代替你的功课
272 |
273 | 有些人明白他们不该粗鲁或傲慢的提问并要求得到答复,但他们选择另一个极端 —— 低声下气:`我知道我只是个可悲的新手,一个撸瑟,但...`。这既使人困扰,也没有用,尤其是伴随着与实际问题含糊不清的描述时更令人反感。
274 |
275 | **别用原始灵长类动物的把戏来浪费你我的时间。取而代之的是,尽可能清楚地描述背景条件和你的问题情况。这比低声下气更好地定位了你的位置。**
276 |
277 | 有时网页论坛会设有专为新手提问的版面,如果你真的认为遇到了初学者的问题,到那去就是了,但一样别那么低声下气。
278 |
279 | ### 描述问题症状而非你的猜测
280 |
281 | **告诉黑客们你认为问题是怎样造成的并没什么帮助。**(如果你的推断如此有效,还用向别人求助吗?),因此要确信你原原本本告诉了他们问题的症状,而不是你的解释和理论;让黑客们来推测和诊断。如果你认为陈述自己的猜测很重要,清楚地说明这只是你的猜测,并描述为什么它们不起作用。
282 |
283 | **蠢问题**
284 |
285 | > 我在编译内核时接连遇到 SIG11 错误,
286 | > 我怀疑某条飞线搭在主板的走线上了,这种情况应该怎样检查最好?
287 |
288 | **聪明问题**
289 | > 我的组装电脑是 FIC-PA2007 主机板搭载 AMD K6/233 CPU(威盛 Apollo VP2 芯片组),
290 | > 256MB Corsair PC133 SDRAM 内存,在编译内核时,从开机 20 分钟以后就频频产生 SIG11 错误,
291 | > 但是在头 20 分钟内从没发生过相同的问题。重新启动也没有用,但是关机一晚上就又能工作 20 分钟。
292 | > 所有内存都换过了,没有效果。相关部分的标准编译记录如下…。
293 |
294 | 由于以上这点似乎让许多人觉得难以配合,这里有句话可以提醒你:`所有的诊断专家都来自密苏里州。` 美国国务院的官方座右铭则是:`让我看看`(出自国会议员 Willard D. Vandiver 在 1899 年时的讲话:`我来自一个出产玉米,棉花,牛蒡和民主党人的国家,滔滔雄辩既不能说服我,也不会让我满意。我来自密苏里州,你必须让我看看。`) 针对诊断者而言,这并不是一种怀疑,而只是一种真实而有用的需求,以便让他们看到的是与你看到的原始证据尽可能一致的东西,而不是你的猜测与归纳的结论。所以,大方的展示给我们看吧!
295 |
296 | ### 按发生时间先后列出问题症状
297 |
298 | 问题发生前的一系列操作,往往就是对找出问题最有帮助的线索。因此,你的说明里应该包含你的操作步骤,以及机器和软件的反应,直到问题发生。在命令行处理的情况下,提供一段操作记录(例如运行脚本工具所生成的),并引用相关的若干行(如 20 行)记录会非常有帮助。
299 |
300 | 如果挂掉的程序有诊断选项(如 -v 的详述开关),试着选择这些能在记录中增加调试信息的选项。记住,**`多`不等于`好`**。试着选取适当的调试级别以便提供有用的信息而不是让读者淹没在垃圾中。
301 |
302 | 如果你的说明很长(如超过四个段落),在开头简述问题,接下来再按时间顺序详述会有所帮助。这样黑客们在读你的记录时就知道该注意哪些内容了。
303 |
304 | ### 描述目标而不是过程
305 |
306 | 如果你想弄清楚如何做某事(而不是报告一个 Bug),**在开头就描述你的目标,然后才陈述重现你所卡住的特定步骤**。
307 |
308 | 经常寻求技术帮助的人在心中有个更高层次的目标,而他们在自以为能达到目标的特定道路上被卡住了,然后跑来问该怎么走,但没有意识到这条路本身就有问题。结果要费很大的劲才能搞定。
309 |
310 | **蠢问题**
311 | > 我怎样才能从某绘图程序的颜色选择器中取得十六进制的 RGB 值?
312 |
313 | **聪明问题**
314 |
315 | > 我正试着用替换一幅图片的色码(color table)成自己选定的色码,**我现在知道的唯一方法是**编辑每个色码区块(table slot),
316 | > 但却无法从某绘图程序的颜色选择器取得十六进制的 RGB 值。
317 |
318 | 第二种提问法比较聪明,你可能得到像是```建议采用另一个更合适的工具```的回复。
319 |
320 | ### 别要求使用私人电邮回复
321 |
322 | 黑客们认为问题的解决过程应该公开、透明,此过程中如果更有经验的人注意到不完整或者不当之处,最初的回复才能够、也应该被纠正。同时,作为提供帮助者可以得到一些奖励,奖励就是他的能力和学识被其他同行看到。
323 |
324 | 当你要求私下回复时,这个过程和奖励都被中止。别这样做,让**回复者**来决定是否私下回答 —— 如果他真这么做了,通常是因为他认为问题编写太差或者太肤浅,以至于不可能使其他人产生兴趣。
325 |
326 | 这条规则存在一条有限的例外,如果你确信提问可能会引来大量雷同的回复时,那么这个神奇的提问句会是`向我发电邮,我将为论坛归纳这些回复`。试着将邮件列表或新闻群组从洪水般的雷同回复中解救出来是非常有礼貌的 —— 但你必须信守诺言。
327 |
328 | ### 清楚明确的表达你的问题以及需求
329 |
330 | 漫无边际的提问是近乎无休无止的时间黑洞。最有可能给你有用答案的人通常也正是最忙的人(他们忙是因为要亲自完成大部分工作)。这样的人对无节制的时间黑洞相当厌恶,所以他们也倾向于厌恶那些漫无边际的提问。
331 |
332 | 如果你明确表述需要回答者做什么(如提供指点、发送一段代码、检查你的补丁、或是其他等等),就最有可能得到有用的答案。因为这会定出一个时间和精力的上限,便于回答者能集中精力来帮你。这么做很棒。
333 |
334 | 要理解专家们所处的世界,请把专业技能想像为充裕的资源,而回复的时间则是稀缺的资源。你要求他们奉献的时间越少,你越有可能从真正专业而且很忙的专家那里得到解答。
335 |
336 | 所以,界定一下你的问题,使专家花在辨识你的问题和回答所需要付出的时间减到最少,这技巧对你有用答案相当有帮助 —— 但这技巧通常和简化问题有所区别。因此,问`我想更好地理解 X,可否指点一下哪有好一点说明?`通常比问`你能解释一下 X 吗?`更好。如果你的代码不能运作,通常请别人看看哪里有问题,比要求别人替你改正要明智得多。
337 |
338 | ### 询问有关代码的问题时
339 |
340 | **别要求他人帮你调试有问题的代码**,不提示一下应该从何入手。张贴几百行的代码,然后说一声:`它不能工作`会让你完全被忽略。只贴几十行代码,然后说一句:`在第七行以后,我期待它显示
60 |
61 | 再来**举个例子,实操一下**:
62 |
63 | ```
64 | (add 3 (subtract 4 1))
65 | ```
66 |
67 | 经过词法分析,会输出结果:
68 |
69 | ```js
70 | [
71 | { type: 'paren', value: '(' },
72 | { type: 'name', value: 'add' },
73 | { type: 'number', value: '3' },
74 | { type: 'paren', value: '(' },
75 | { type: 'name', value: 'subtract' },
76 | { type: 'number', value: '4' },
77 | { type: 'number', value: '1' },
78 | { type: 'paren', value: ')' },
79 | { type: 'paren', value: ')' },
80 | ]
81 | ```
82 |
83 | #### 语法分析 Syntactic Analysis
84 |
85 | 语法分析会在词法分析后进行,它会**基于词法分析的结果**,也就是根据`tokens`数组,构建出每一个`token`之间的**关系**,最终将这些`token`全部组合成一个**大的对象**,通过这个对象就可以还原出原本语法的所有内容,一般管这个对象叫做**抽象语法树(Abstract Syntax Tree)**简称`AST`。
86 |
87 | 继续上面的例子,**经过语法分析后**,会输出结果:
88 |
89 | ```js
90 | {
91 | type: 'Program',
92 | body: [{
93 | type: 'CallExpression',
94 | name: 'add',
95 | params: [{
96 | type: 'NumberLiteral',
97 | value: '3',
98 | }, {
99 | type: 'CallExpression',
100 | name: 'subtract',
101 | params: [{
102 | type: 'NumberLiteral',
103 | value: '4',
104 | }, {
105 | type: 'NumberLiteral',
106 | value: '1',
107 | }]
108 | }]
109 | }]
110 | }
111 | ```
112 |
113 | 通过这个对象(AST),我们已经可以推导出原本程序的语法,这就是AST的作用。
114 |
115 | ### 转换 Transformation
116 |
117 | 第二部就是转换,**对上一步得到的AST进行转换**。在进行转换时,**可以对任意节点进行属性的添加/替换/删除操作**,目的是通过转换AST,能更方便地把它翻译成另一种语言.
118 |
119 | #### 遍历AST节点 Traversal
120 |
121 | 为了能对每一个节点都进行转换,就必须要进行**遍历(Traversal)**。对于AST这棵树,我们在遍历的时候采用**深度优先(depth-first)**的模式。
122 |
123 | 遍历到每一个节点后需要对每个节点进行转换,这里**会用到一种设计模式:访问者模式**,简单来说就是把操作元素的方法单独拿出来封装成一个`visitor`类,但是不用担心,如果你没有了解过这种设计模式,继续往下看,也不会有什么影响。
124 |
125 | 假设我们有两个类型的节点`NumberLiteral`和`StringLiteral`,那么想要对这两个节点进行转换,就可以定义这样一个`visitor`:
126 |
127 | ```js
128 | const vositor = {
129 | NumberLiteral: {
130 | enter(node, parent) {
131 | // do something
132 | },
133 | exit(node, parent) {
134 | // do something
135 | }
136 | },
137 | StringLiteral: {
138 | enter(node, parent) {
139 | // do something
140 | },
141 | exit(node, parent) {
142 | // do something
143 | }
144 | }
145 | }
146 | ```
147 |
148 | 这样的好处是当我进入某个节点时,只需要调用`visitor`上对应节点的`enter`方法就可以完成转换,离开时调用对应节点的`exit`即可。
149 |
150 | ### 代码生成 Code Generation
151 |
152 | 最后一步就是**根据上一步转换得到的新AST来生成出目标语言的代码**。
153 |
154 | 这个步骤非常简单,等下就会看到啦~
155 |
156 | ***下面就正式开始吧!!***
157 |
158 | # 分词器/词法解析 TOKENIZER
159 |
160 | `tokenizer`函数,它**接受一个字符串**,返回一个`tokens`数组。
161 |
162 | 词法解析的原理就是**遍历字符串中所有的字符**,如果**某个字符或多个字符符合一个词法**,就将它添加到`tokens`中。所以最外面一层一定是遍历。
163 |
164 | ```js
165 | function tokenizer(input) {
166 | let current = 0;
167 | while (current < input.length) {
168 | const char = input[current];
169 | // 在这里就要定义一些词法的规则了
170 | }
171 | }
172 | ```
173 |
174 | 在我们这个简单的项目中,**词法规则也非常少,一共只有6个**,分别是:
175 |
176 | 1. **开括号** `(`
177 | 2. **闭括号** `)`
178 | 3. **空格** -> *可以直接跳过*
179 | 4. **数字** -> *数字可能不止一位,需要向后查找完整的数字*
180 | 5. **字符串** -> *在两个双引号之间,需要去掉双引号*
181 | 6. **函数名** -> *需要向后查找,获得完整名称*
182 |
183 | 其中开括号和闭括号非常简单,遇到后直接向`tokens`中添加对应的`token`对象即可:
184 |
185 | ```js
186 | // 写在上文while循环内部
187 | if (char === '(') {
188 | tokens.push({type: 'paren', value: '('});
189 | current++;
190 | continue;
191 | }
192 | ```
193 |
194 | 这里**稍微有难度的是数字和字符串**,这里简单说明一下:
195 |
196 | ```js
197 | // 写在上文while循环内部
198 |
199 | // 对于数字,还用字符串的方式储存
200 | const NUMBERS = /[0-9]/;
201 | if (NUMBERS.test(char)) {
202 | let value = '';
203 | // 向后继续查找,看看是不是数字
204 | while (NUMBERS.test(char)) {
205 | value += char;
206 | char = input[++current]; // 先自增,再返回值
207 | }
208 | tokens.push({type: 'number', value});
209 | continue;
210 | }
211 |
212 | // 处理字符串也很类似,只是需要考虑双引号的问题
213 | if (char === '"') {
214 | let value = '';
215 | char = input[++current]; // 跳过第一个双引号
216 | while (char !== '"') {
217 | value += char;
218 | char = input[++current];
219 | }
220 | char = input[++current]; // 跳过第二个双引号
221 | tokens.push({type: 'string', value});
222 | continue;
223 | }
224 | ```
225 |
226 | 剩下的几个词法的实现也都比较简单,大家可以看代码学习,最终运行`tokenizer`函数就会得到已经经过词法分析的`tokens`数组。
227 |
228 | # 语法分析器 PARSER
229 |
230 | `parser`函数接受`tokens`数组,**返回一个AST对象**。
231 |
232 | 这里面的第一个问题就是**AST对象比较复杂**,会出现**层层嵌套**的关系,所以不可避免的就要**使用递归**了。
233 |
234 | 最终我们想达到的效果大概是这样:
235 |
236 | ```js
237 | function parser(tokens) {
238 | let current = 0;
239 |
240 | function walk() {
241 | let token = tokens[current];
242 | // walk函数会遍历每一个token,并且返回对应的AST节点
243 | }
244 |
245 | // AST的外壳
246 | let ast = {
247 | type: 'Program',
248 | body: []
249 | }
250 |
251 | // 遍历每一个语句
252 | while (current < tokens.length) {
253 | ast.body.push(walk());
254 | }
255 |
256 | return ast;
257 | }
258 | ```
259 |
260 | 现在整体框架有了,**核心任务就是去实现这个walk函数了**。
261 |
262 | 还是从简单的问题入手,处理最简单的`number` 和`string`节点:
263 |
264 | ```js
265 | // 写在walk函数内部
266 | if (token.type === 'number') {
267 | current++;
268 | return {
269 | type: 'NumberLiteral',
270 | value: token.value;
271 | }
272 | }
273 | // string同理
274 | ```
275 |
276 | 处理完简单的后,就要开始复杂一些的操作了。下面要**将表达式的调用(Call Expression)转换为AST**,因为表达式内部要接收参数,而参数也可以是另一个表达式,所以这里就要开始递归了。
277 |
278 | ```js
279 | // 写在walk内部
280 | // 表达式一定以(开始,)结束
281 | if (token.type === 'paren' && token.value === '(') {
282 | token = tokens[++current]; // 跳过(
283 |
284 | // AST节点的结构
285 | let node = {
286 | type: 'CallExpression',
287 | name: token.value,
288 | params: [],
289 | };
290 |
291 | token = tokens[++current]; // 跳过函数名token
292 |
293 | // 下面是核心,开始递归
294 | // 如果没遇到),说明后面的token就是参数,表达式还没有结束
295 | while(token.value !== ')') {
296 | node.params.push(walk()); // 递归
297 | token = tokens[current]; // 经过递归,current已经发生变化,这里更新一下token
298 | }
299 |
300 | current++; // 跳过 )
301 | }
302 | ```
303 |
304 | 好啦,到这里`parser`也完成了,**现在我们已经把一段字符串转化成了AST**。
305 |
306 | # 遍历器 TRAVERSER
307 |
308 | 现在已经得到了AST,接下来要做的就是**遍历每一个节点**。
309 |
310 | 简单想一下,对于`NumberLiteral`这样的节点,很好遍历,因为它没有子节点。但是对于`Program`和`CallExpression`来说,**他们都有一个数组用来存放子节点,所以想要完全遍历,就要去遍历这个数组。**
311 |
312 | 有了思路,我们来看一下**代码的结构**:
313 |
314 | ```js
315 | function traverser(ast, visitor) {
316 | // 遍历Array
317 | function traverseArray(array, parent) {
318 | array.forEach((child) => traverseNode(child, parent));
319 | }
320 |
321 | // 遍历Node
322 | function traverseNode(node, parent) {
323 | // 1. 进行转换 Transformation -> 调用visitor里面的函数
324 | // 2. 对于Program和CallExpression,调用traverseArray
325 | }
326 |
327 | // 开始遍历
328 | traverseNode(ast, null);
329 | }
330 | ```
331 |
332 | 现在结构应该很清晰了,在`traverseNode`函数里面要干两件事情,一是进行转换(Transformation),其实就是调用`visitor`里面对应的函数,二是继续深层遍历数组。
333 |
334 | ```js
335 | function traverseNode(node, parent) {
336 | // 从visitor中拿到对应type的方法
337 | const method = visitor[node.type];
338 | // 如果enter方法存在,就调用,完成转换
339 | if (method && method.enter) {
340 | method.enter(node, parent)
341 | }
342 |
343 | // 继续遍历数组
344 | switch (node.type) {
345 | case 'Program':
346 | traverseArray(node.body, node);
347 | break;
348 | case 'CallExpression':
349 | traverseArray(node.params, node);
350 | break;
351 | case 'NumberLiteral':
352 | case 'StringLiteral':
353 | break;
354 | default:
355 | throw new TypeError(node.type)
356 | }
357 | }
358 | ```
359 |
360 | 现在两项任务都完成了,只是`visitor`里面的**转换方法还没有定义**,所以下一步就是**定义转换的方法**。
361 |
362 | # 转换器 TRANSFORMER
363 |
364 | 在写转换器之前,一定要先**搞清楚究竟要怎么转换**。我们看一下项目例子中的转换:
365 |
366 | ```js
367 | // 转换前
368 | {
369 | "type": "Program",
370 | "body": [
371 | {
372 | "type": "CallExpression",
373 | "name": "add",
374 | "params": [
375 | {
376 | "type": "NumberLiteral",
377 | "value": "10"
378 | },
379 | {
380 | "type": "CallExpression",
381 | "name": "subtract",
382 | "params": [
383 | {
384 | "type": "NumberLiteral",
385 | "value": "20"
386 | },
387 | {
388 | "type": "NumberLiteral",
389 | "value": "100"
390 | }
391 | ]
392 | }
393 | ]
394 | }
395 | ]
396 | }
397 | ```
398 |
399 | ```js
400 | // 转换后
401 | {
402 | "type": "Program",
403 | "body": [
404 | {
405 | "type": "ExpressionStatement",
406 | "expression": {
407 | "type": "CallExpression",
408 | "callee": {
409 | "type": "Identifier",
410 | "name": "add"
411 | },
412 | "arguments": [
413 | {
414 | "type": "NumberLiteral",
415 | "value": "10"
416 | },
417 | {
418 | "type": "CallExpression",
419 | "callee": {
420 | "type": "Identifier",
421 | "name": "subtract"
422 | },
423 | "arguments": [
424 | {
425 | "type": "NumberLiteral",
426 | "value": "20"
427 | },
428 | {
429 | "type": "NumberLiteral",
430 | "value": "100"
431 | }
432 | ]
433 | }
434 | ]
435 | }
436 | }
437 | ]
438 | }
439 | ```
440 |
441 | 简单来看主要**有这么几个变化**:
442 |
443 | 1. 在最外层的CallExpression**外面包裹了一层ExpressionStatement**
444 | 2. params**属性变成了arguments**
445 | 3. CallExpression内**多了一个callee对象**
446 |
447 | 这些转换都是为了最终编译成其他语言做准备,要想完成这些转换,就需要借助`visitor`里面的方法了。
448 |
449 | 下面我们试着写一下`transformer`函数的**大体结构**:
450 |
451 | ```js
452 | function transformer(ast) {
453 | // 不在旧的AST上做转换,这里直接创建一个新的AST
454 | const newAst = {
455 | type: 'Program',
456 | body: [],
457 | }
458 |
459 | // 这里有一个小trick,因为在traversal函数中
460 | // 我们只把旧的AST传给了enter方法,所以想要修改newAst就比较困难
461 | // 这里将newAst.body的引用赋值到旧AST的一个字段上,方便获取和修改
462 | ast._context = newAst.body;
463 |
464 | // 开始遍历
465 | traverse(ast, visitor);
466 |
467 | return newAst;
468 | }
469 | ```
470 |
471 | 大体结构就是这样,但是核心的`visitor`还是没有实现,下面我们来实现一下:
472 |
473 | ```js
474 | const visitor = {
475 | // 因为CallExpression有嵌套,最复杂,我们先实现一下它
476 | CallExpression: {
477 | enter(node, parent) {
478 | // 创建一个新节点
479 | const expression = {
480 | type: 'CallExpression',
481 | callee: {
482 | type: 'Identifier',
483 | name: node.name,
484 | },
485 | arguments: [],
486 | }
487 |
488 | // 同样为了方便修改newAst,把expression.arguments的引用放到node._context上一份
489 | node._context = expression.arguments;
490 |
491 | // 判断是否为最外层的CallExpressoin,如果是,包裹ExpressionStatement
492 | if (parent.type !== 'CallExpression') {
493 | expression = {
494 | type: 'ExpressionStatement',
495 | expression: expression,
496 | }
497 | }
498 |
499 | // 把处理好的expression添加到newAst中
500 | parent._context.push(expression);
501 | }
502 | },
503 |
504 | // Number和String就很简单了,这里只实现NumberLiteral
505 | NumberLiteral: {
506 | enter(node, parent) {
507 | parent._context.push({
508 | type: 'NumberLiteral',
509 | value: node.value,
510 | })
511 | }
512 | }
513 | }
514 | ```
515 |
516 | 到此为止,**新的AST树也已经生成好了**,终于来到**最后一步**,生成代码!
517 |
518 | # 生成代码 Code Generation
519 |
520 | 根据新的AST树,不难生成出最终的代码,核心逻辑就是根据`node.type`生成不同的字符串,其中可能需要一些递归,最后把这些字符串拼接起来,就是最终的代码。
521 |
522 | 代码很简单,详细的解释在原文中有,但下面的代码也足够清晰了:
523 |
524 | ```js
525 | function codeGeneratior(node) {
526 | switch (node.type) {
527 | // 最简单的情况就是函数名,数字,字符串,这些直接返回就可以
528 | case 'Identifier':
529 | // callee中的name属性
530 | return node.name;
531 |
532 | case 'NumberLiteral':
533 | return node.value;
534 |
535 | case 'StringLiteral':
536 | // 字符串需要用双引号包裹
537 | return '"' + node.value + '"';
538 |
539 | // 复杂一些的Program, ExpressionStatement, CallExpression都需要递归
540 | // 但也没有那么复杂
541 |
542 | case 'Program':
543 | // 可能有多个语句,换行输出
544 | return node.body.map(statement => codeGenerator(statement)).join('\n');
545 |
546 | case 'ExpressionStatement':
547 | // C语言,分号结尾
548 | return codeGenerator(node.expression) + ';';
549 |
550 | case 'CallExpression':
551 | // 表达式,参数用逗号隔开
552 | return codeGenerator(node.callee) + '(' + node.arguments.map(codeGenerator).join(', ') + ')';
553 | }
554 | }
555 | ```
556 |
557 | **其实写到这我们的超级迷你编译器已经完成了,它已经能把LISP的函数调用语法转换为C语言的语法了。**
558 |
559 | # 测试
560 |
561 | **还记得我们写了多少个函数不?**下面通过一个**简单的测试用例**,回顾一下整个过程:
562 |
563 | ```js
564 | // 这里封装成compiler
565 | function compiler(input) {
566 | const tokens = tokenizer(input); // 第一步,对字符串进行词法解析,得到tokens
567 | const ast = parser(tokens); // 第二步,把tokens转换成AST
568 | const newAst = transformer(ast); // 第三步,对AST进行转换,得到新的AST
569 | const result = codeGenerator(newAst); // 第四步,根据新的AST生成转换后的字符串
570 | return result;
571 | }
572 |
573 | // TEST
574 | console.log(compiler('(add 10 (subtract 20 100)) (connect "Hello" "World")'));
575 | // add(10, subtract(20, 100));
576 | // connect("Hello", "World");
577 | ```
578 |
579 | ---
580 |
581 | **~~完结撒花啦~~**
582 |
--------------------------------------------------------------------------------
/public/posts/how-to-ask-question.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 提问的智慧[重点加粗][转自GitHub]
3 | date: 2022-02-23
4 | tags: [文章分享]
5 | cover: "https://imgbed.codingkelvin.fun/uPic/question.jpeg"
6 | top_img: false
7 | categories: [文章分享]
8 | ---
9 |
10 | [](https://github.com/ryanhanwu/How-To-Ask-Questions-The-Smart-Way/pulls)
11 |
12 | **How To Ask Questions The Smart Way**
13 |
14 | Copyright © 2001,2006,2014 Eric S. Raymond, Rick Moen
15 |
16 | 本指南英文版版权为 Eric S. Raymond, Rick Moen 所有。
17 |
18 | 原文网址:[http://www.catb.org/~esr/faqs/smart-questions.html](http://www.catb.org/~esr/faqs/smart-questions.html)
19 |
20 | Copyleft 2001 by D.H.Grand(nOBODY/Ginux), 2010 by Gasolin, 2015 by Ryan Wu
21 |
22 | 翻译地址:https://github.com/ryanhanwu/How-To-Ask-Questions-The-Smart-Way
23 |
24 | ## 声明
25 |
26 | 许多项目在他们的使用协助/说明网页中链接了本指南,这么做很好,我们也鼓励大家都这么做。但如果你是负责管理这个项目网页的人,请在超链接附近的显著位置上注明:
27 |
28 | **本指南不提供此项目的实际支持服务!**
29 |
30 | 我们已经深刻领教到少了上述声明所带来的痛苦。因为少了这点声明,我们不停地被一些白痴纠缠。这些白痴认为既然我们发布了这本指南,那么我们就有责任解决世上所有的技术问题。
31 |
32 | 如果你因寻求某些帮助而阅读本指南,并在离开时还觉得可以从本文作者这里得到直接帮助,那你就是我们之前说的那些白痴之一。别问我们问题,我们只会忽略你。我们在这本指南中想教你如何从那些真正懂得你所遇到的软件或硬件问题的人处取得协助,而 99% 的情况下那不会是我们。除非你确定本指南的作者之一刚好是你所遇到的问题领域的专家,否则请不要打扰我们,这样大家都会开心一点。
33 |
34 | ## 简介
35 |
36 | 在[黑客](http://www.catb.org/~esr/faqs/hacker-howto.html)的世界里,当你拋出一个技术问题时,最终是否能得到有用的回答,往往取决于你所提问和追问的方式。本指南将教你如何正确的提问以获得你满意的答案。
37 |
38 | 现在开源(Open Source)软件已经相当盛行,您通常可以从其他更有经验的用户那里获得与黑客一样好的答案,这是件**好事**;和黑客相比,用户们往往对那些新手常遇到的问题更宽容一些。尽管如此,以我们在此推荐的方式对待这些有经验的用户通常也是从他们那里获得有用答案的最有效方式。
39 |
40 | 首先你应该明白,黑客们喜爱有挑战性的问题,或者能激发他们思维的好问题。如果我们并非如此,那我们也不会成为你想询问的对象。如果你给了我们一个值得反复咀嚼玩味的好问题,我们自会对你感激不尽。好问题是激励,是厚礼。好问题可以提高我们的理解力,而且通常会暴露我们以前从没意识到或者思考过的问题。对黑客而言,“好问题!”是诚挚的大力称赞。
41 |
42 | 尽管如此,黑客们有着蔑视或傲慢面对简单问题的坏名声,这有时让我们看起来对新手、无知者似乎较有敌意,但其实不是那样的。
43 |
44 | 我们不讳言我们对那些不愿思考、或者在发问前不做他们该做的事的人的蔑视。那些人是时间杀手 —— 他们只想索取,从不付出,消耗我们可用在更有趣的问题或更值得回答的人身上的时间。我们称这样的人为 `失败者(loser)` (由于历史原因,我们有时把它拼作 `lusers`)。
45 |
46 | 我们意识到许多人只是想使用我们写的软件,他们对学习技术细节没有兴趣。对大多数人而言,电脑只是种工具,是种达到目的的手段而已。他们有自己的生活并且有更要紧的事要做。我们了解这点,也从不指望每个人都对这些让我们着迷的技术问题感兴趣。尽管如此,我们回答问题的风格是指向那些真正对此有兴趣并愿意主动参与解决问题的人,这一点不会变,也不该变。如果连这都变了,我们就是在降低做自己最擅长的事情上的效率。
47 |
48 | 我们(在很大程度上)是自愿的,从繁忙的生活中抽出时间来解答疑惑,而且时常被提问淹没。所以我们无情地滤掉一些话题,特别是拋弃那些看起来像失败者的家伙,以便更高效地利用时间来回答`赢家(winner)`的问题。
49 |
50 | 如果你厌恶我们的态度,高高在上,或过于傲慢,不妨也设身处地想想。我们并没有要求你向我们屈服 —— 事实上,我们大多数人非常乐意与你平等地交流,只要你付出小小努力来满足基本要求,我们就会欢迎你加入我们的文化。但让我们帮助那些不愿意帮助自己的人是没有效率的。无知没有关系,但装白痴就是不行。
51 |
52 | 所以,你不必在技术上很在行才能吸引我们的注意,但你必须表现出能引导你变得在行的特质 —— 机敏、有想法、善于观察、乐于主动参与解决问题。如果你做不到这些使你与众不同的事情,我们建议你花点钱找家商业公司签个技术支持服务合同,而不是要求黑客个人无偿地帮助你。
53 |
54 | 如果你决定向我们求助,当然你也不希望被视为失败者,更不愿成为失败者中的一员。能立刻得到快速并有效答案的最好方法,就是像赢家那样提问 —— 聪明、自信、有解决问题的思路,只是偶尔在特定的问题上需要获得一点帮助。
55 |
56 | (欢迎对本指南提出改进意见。你可以 email 你的建议至 [esr@thyrsus.com](esr@thyrsus.com) 或 [respond-auto@linuxmafia.com](respond-auto@linuxmafia.com)。然而请注意,本文并非[网络礼节](http://www.ietf.org/rfc/rfc1855.txt)的通用指南,而我们通常会拒绝无助于在技术论坛得到有用答案的建议)。
57 |
58 | ## 在提问之前
59 |
60 | 在你准备要通过电子邮件、新闻群组或者聊天室提出技术问题前,请先做到以下事情:
61 |
62 | 1. 尝试在你准备提问的论坛的旧文章中搜索答案。
63 | 2. 尝试上网搜索以找到答案。
64 | 3. 尝试阅读手册以找到答案。
65 | 4. 尝试阅读常见问题文件(FAQ)以找到答案。
66 | 5. 尝试自己检查或试验以找到答案。
67 | 6. 向你身边的强者朋友打听以找到答案。
68 | 7. 如果你是程序开发者,请尝试阅读源代码以找到答案。
69 |
70 | 当你提出问题的时候,**请先表明你已经做了上述的努力**;这将有助于树立你并不是一个不劳而获且浪费别人的时间的提问者。如果你能**一并表达在做了上述努力的过程中所学到的东西**会更好,因为我们更乐于回答那些表现出能从答案中学习的人的问题。
71 |
72 | 运用某些策略,比如先用 Google 搜索你所遇到的各种错误信息(搜索 [Google 论坛](http://groups.google.com/)和网页),这样很可能直接就找到了能解决问题的文件或邮件列表线索。即使没有结果,在邮件列表或新闻组寻求帮助时加上一句 `我在 Google 中搜过下列句子但没有找到什么有用的东西` 也是件好事,即使它只是表明了搜索引擎不能提供哪些帮助。这么做(加上搜索过的字串)也让遇到相似问题的其他人能被搜索引擎引导到你的提问来。
73 |
74 | 别着急,不要指望几秒钟的 Google 搜索就能解决一个复杂的问题。在向专家求助之前,再阅读一下常见问题文件(FAQ)、放轻松、坐舒服一些,再花点时间思考一下这个问题。相信我们,**他们能从你的提问看出你做了多少阅读与思考,如果你是有备而来,将更有可能得到解答**。不要将所有问题一股脑拋出,只因你的第一次搜索没有找到答案(或者找到太多答案)。
75 |
76 | 准备好你的问题,再将问题仔细的思考过一遍,因为**草率的发问只能得到草率的回答**,或者根本得不到任何答案。越是能表现出在寻求帮助前你为解决问题所付出的努力,你越有可能得到实质性的帮助。
77 |
78 | 小心别问错了问题。如果你的问题基于错误的假设,某个普通黑客(J. Random Hacker)多半会一边在心里想着`蠢问题…`,一边用无意义的字面解释来答复你,希望着你会从问题的回答(而非你想得到的答案)中汲取教训。
79 |
80 | 绝不要自以为**够格**得到答案,你没有;你并没有。毕竟你没有为这种服务支付任何报酬。你将会是自己去**挣到**一个答案,靠提出有内涵的、有趣的、有思维激励作用的问题 —— 一个有潜力能贡献社区经验的问题,而不仅仅是被动的从他人处索取知识。
81 |
82 | 另一方面,表明你愿意在找答案的过程中做点什么是一个非常好的开端。`谁能给点提示?`、`我的这个例子里缺了什么?`以及`我应该检查什么地方`比`请把我需要的确切的过程贴出来`更容易得到答复。因为你表现出只要有人能指个正确方向,你就有完成它的能力和决心。
83 |
84 | ## 当你提问时
85 |
86 | ### 慎选提问的论坛
87 |
88 | 小心选择你要提问的场合。如果你做了下述的事情,你很可能被忽略掉或者被看作失败者:
89 |
90 | * 在与主题不合的论坛上贴出你的问题。
91 | * 在探讨进阶技术问题的论坛张贴非常初级的问题;反之亦然。
92 | * 在太多的不同新闻群组上重复转贴同样的问题(cross-post)。
93 | * 向既非熟人也没有义务解决你问题的人发送私人电邮。
94 |
95 | 黑客会剔除掉那些搞错场合的问题,以保护他们沟通的渠道不被无关的东西淹没。你不会想让这种事发生在自己身上的。
96 |
97 | 因此,第一步是找到对的论坛。再说一次,Google 和其它搜索引擎还是你的朋友,用它们来找到与你遭遇到困难的软硬件问题最相关的网站。通常那儿都有常见问题(FAQ)、邮件列表及相关说明文件的链接。如果你的努力(包括**阅读** FAQ)都没有结果,网站上也许还有报告 Bug(Bug-reporting)的流程或链接,如果是这样,链过去看看。
98 |
99 | 向陌生的人或论坛发送邮件最可能是风险最大的事情。举例来说,别假设一个提供丰富内容的网页的作者会想充当你的免费顾问。**不要对你的问题是否会受到欢迎做太乐观的估计 —— 如果你不确定,那就向别处发送,或者压根别发**。
100 |
101 | 在选择论坛、新闻群组或邮件列表时,别太相信名字,先看看 FAQ 或者许可书以弄清楚你的问题是否切题。发文前先翻翻已有的话题,这样可以让你感受一下那里的文化。事实上,事先在新闻组或邮件列表的历史记录中搜索与你问题相关的关键词是个极好的主意,也许这样就找到答案了。即使没有,也能帮助你归纳出更好的问题。
102 |
103 | 别像机关枪似的一次“扫射”所有的帮助渠道,这就像大喊大叫一样会使人不快。要一个一个地来。
104 |
105 | 搞清楚你的主题!最典型的错误之一是在某种致力于跨平台可移植的语言、套件或工具的论坛中提关于 Unix 或 Windows 操作系统程序界面的问题。如果你不明白为什么这是大错,最好在搞清楚这之间差异之前什么也别问。
106 |
107 | 一般来说,在仔细挑选的公共论坛中提问,会比在私有论坛中提同样的问题更容易得到有用的回答。有几个理由可以支持这点,一是看潜在的回复者有多少,二是看观众有多少。黑客较愿意回答那些能帮助到许多人的问题。
108 |
109 | 可以理解的是,老练的黑客和一些热门软件的作者正在接受过多的错发信息。就像那根最后压垮骆驼背的稻草一样,你的加入也有可能使情况走向极端 —— 已经好几次了,一些热门软件的作者由于涌入其私人邮箱的大量不堪忍受的无用邮件而不再提供支持。
110 |
111 | ### Stack Overflow
112 |
113 | 搜索,**然后**在 Stack Exchange 问。
114 |
115 | 近年来,Stack Exchange 社区已经成为回答技术及其他问题的主要渠道,尤其是那些开放源码的项目。
116 |
117 | 因为 Google 索引是即时的,在看 Stack Exchange 之前先在 Google 搜索。有很高的几率某人已经问了一个类似的问题,而且 Stack Exchange 网站们往往会是搜索结果中最前面几个。如果你在 Google 上没有找到任何答案,你再到特定相关主题的网站去找。用标签(Tag)搜索能让你更缩小你的搜索结果。
118 |
119 | Stack Exchange 已经成长到[超过一百个网站](https://stackexchange.com/sites),以下是最常用的几个站:
120 |
121 | * Super User 是问一些通用的电脑问题,如果你的问题跟代码或是写程序无关,只是一些网络连线之类的,请到这里。
122 | * Stack Overflow 是问写程序有关的问题。
123 | * Server Fault 是问服务器和网管相关的问题。
124 |
125 | ### 网站和 IRC 论坛
126 |
127 | 本地的用户群组(user group),或者你所用的 Linux 发行版本也许正在宣传他们的网页论坛或 IRC 频道,并提供新手帮助(在一些非英语国家,新手论坛很可能还是邮件列表),这些都是开始提问的好地方,特别是当你觉得遇到的也许只是相对简单或者很普通的问题时。有广告赞助的 IRC 频道是公开欢迎提问的地方,通常可以即时得到回应。
128 |
129 | 事实上,如果程序出的问题只发生在特定 Linux 发行版提供的版本(这很常见),最好先去该发行版的论坛或邮件列表中提问,再到程序本身的论坛或邮件列表提问。(否则)该项目的黑客可能仅仅回复“使用**我们的**版本”。
130 |
131 | 在任何论坛发文以前,先确认一下有没有搜索功能。如果有,就试着搜索一下问题的几个关键词,也许这会有帮助。如果在此之前你已做过通用的网页搜索(你也该这样做),还是再搜索一下论坛,搜索引擎有可能没来得及索引此论坛的全部内容。
132 |
133 | 通过论坛或 IRC 频道来提供用户支持服务有增长的趋势,电子邮件则大多为项目开发者间的交流而保留。所以最好先在论坛或 IRC 中寻求与该项目相关的协助。
134 |
135 | 在使用 IRC 的时候,首先最好不要发布很长的问题描述,有些人称之为频道洪水。最好通过一句话的问题描述来开始聊天。
136 |
137 | ### 第二步,使用项目邮件列表
138 |
139 | 当某个项目提供开发者邮件列表时,要向列表而不是其中的个别成员提问,即使你确信他能最好地回答你的问题。查一查项目的文件和首页,找到项目的邮件列表并使用它。有几个很好的理由支持我们采用这种办法:
140 |
141 | * 任何好到需要向个别开发者提出的问题,也将对整个项目群组有益。反之,如果你认为自己的问题对整个项目群组来说太愚蠢,那这也不能成为骚扰个别开发者的理由。
142 | * 向列表提问可以分散开发者的负担,个别开发者(尤其是项目领导人)也许太忙以至于没法回答你的问题。
143 | * 大多数邮件列表都会被存档,那些被存档的内容将被搜索引擎索引。如果你向列表提问并得到解答,将来其他人可以通过网页搜索找到你的问题和答案,也就不用再次发问了。
144 | * 如果某些问题经常被问到,开发者可以利用此信息来改进说明文件或软件本身,以使其更清楚。如果只是私下提问,就没有人能看到最常见问题的完整场景。
145 |
146 | 如果一个项目既有“用户”也有“开发者”(或“黑客”)邮件列表或论坛,而你又不会动到那些源代码,那么就向“用户”列表或论坛提问。不要假设自己会在开发者列表中受到欢迎,那些人多半会将你的提问视为干扰他们开发的噪音。
147 |
148 | 然而,如果你**确信**你的问题很特别,而且在“用户”列表或论坛中几天都没有回复,可以试试前往“开发者”列表或论坛发问。建议你在张贴前最好先暗地里观察几天以了解那里的行事方式(事实上这是参与任何私有或半私有列表的好主意)
149 |
150 | 如果你找不到一个项目的邮件列表,而只能查到项目维护者的电子邮件地址,尽管向他发信。即使是在这种情况下,也别假设(项目)邮件列表不存在。在你的电子邮件中,**请陈述你已经试过但没有找到合适的邮件列表,也提及你不反对将自己的邮件转发给他人**(许多人认为,即使没什么秘密,私人电子邮件也不应该被公开。通过允许将你的电子邮件转发他人,你给了相应人员处置你邮件的选择)。
151 |
152 | ### 使用有意义且描述明确的标题
153 |
154 | 在邮件列表、新闻群组或论坛中,大约 50 字以内的标题是抓住资深专家注意力的好机会。别用喋喋不休的`帮帮忙`、`跪求`、`急`(更别说`救命啊!!!!`这样让人反感的话,用这种标题会被条件反射式地忽略)来浪费这个机会。不要妄想用你的痛苦程度来打动我们,而应该是在这点空间中使用极简单扼要的描述方式来提出问题。
155 |
156 | 一个好标题范例是`目标 —— 差异`式的描述,许多技术支持组织就是这样做的。**在`目标`部分指出是哪一个或哪一组东西有问题,在`差异`部分则描述与期望的行为不一致的地方**。
157 |
158 |
159 | > 蠢问题:救命啊!我的笔记本电脑不能正常显示了!
160 |
161 | > 聪明问题:X.org 6.8.1 的鼠标光标会变形,某牌显卡 MV1005 芯片组。
162 |
163 | > 更聪明问题:X.org 6.8.1 的鼠标光标,在某牌显卡 MV1005 芯片组环境下 - 会变形。
164 |
165 | 编写`目标 —— 差异` 式描述的过程有助于你组织对问题的细致思考。是什么被影响了? 仅仅是鼠标光标或者还有其它图形?只在 X.org 的 X 版中出现?或只是出现在 6.8.1 版中? 是针对某牌显卡芯片组?或者只是其中的 MV1005 型号? 一个黑客只需瞄一眼就能够立即明白你的环境**和**你遇到的问题。
166 |
167 | 总而言之,请想像一下你正在一个只显示标题的存档讨论串(Thread)索引中查寻。让你的标题更好地反映问题,可使下一个搜索类似问题的人能够关注这个讨论串,而不用再次提问相同的问题。
168 |
169 | 如果你想在回复中提出问题,记得要修改内容标题,以表明你是在问一个问题, 一个看起来像 `Re: 测试` 或者 `Re: 新 bug` 的标题很难引起足够重视。另外,在不影响连贯性之下,适当引用并删减前文的内容,能给新来的读者留下线索。
170 |
171 | 对于讨论串,不要直接点击回复来开始一个全新的讨论串,这将限制你的观众。因为有些邮件阅读程序,比如 mutt ,允许用户按讨论串排序并通过折叠讨论串来隐藏消息,这样做的人永远看不到你发的消息。
172 |
173 | 仅仅改变标题还不够。mutt 和其它一些邮件阅读程序还会检查邮件标题以外的其它信息,以便为其指定讨论串。所以宁可发一个全新的邮件。
174 |
175 | 在网页论坛上,好的提问方式稍有不同,因为讨论串与特定的信息紧密结合,并且通常在讨论串外就看不到里面的内容,故通过回复提问,而非改变标题是可接受的。不是所有论坛都允许在回复中出现分离的标题,而且这样做了基本上没有人会去看。不过,通过回复提问,这本身就是暧昧的做法,因为它们只会被正在查看该标题的人读到。所以,除非你**只想**在该讨论串当前活跃的人群中提问,不然还是另起炉灶比较好。
176 |
177 | ### 使问题容易回复
178 |
179 | 以`请将你的回复发送到……`来结束你的问题多半会使你得不到回答。如果你觉得花几秒钟在邮件客户端设置一下回复地址都麻烦,我们也觉得花几秒钟思考你的问题更麻烦。如果你的邮件程序不支持这样做,[换个好点的](http://linuxmafia.com/faq/Mail/muas.html);如果是操作系统不支持这种邮件程序,也换个好点的。
180 |
181 | 在论坛,要求通过电子邮件回复是非常无礼的,除非你认为回复的信息可能比较敏感(有人会为了某些未知的原因,只让你而不是整个论坛知道答案)。如果你只是想在有人回复讨论串时得到电子邮件提醒,可以要求网页论坛发送给你。几乎所有论坛都支持诸如`追踪此讨论串`、`有回复时发送邮件提醒`等功能。
182 |
183 | ### 使用清晰、正确、精准且合乎语法的语句
184 |
185 | 我们从经验中发现,**粗心的提问者通常也会粗心地写程序与思考**(我敢打包票)。回答粗心大意者的问题很不值得,我们宁愿把时间耗在别处。
186 |
187 | **使用清晰、正确、精准且合乎语法的语句**。一般来说,如果你觉得这样做很麻烦,不想在乎这些,那我们也觉得麻烦,不想在乎你的提问。花点额外的精力斟酌一下字句,用不着太僵硬与正式 —— 事实上,黑客文化很看重能准确地使用非正式、俚语和幽默的语句。但它**必须很**准确,而且有迹象表明你是在思考和关注问题。
188 |
189 | 正确地拼写、使用标点和大小写,不要将`its`混淆为`it's`,`loose`搞成`lose`或者将`discrete`弄成`discreet`。不要**全部用大写**,这会被视为无礼的大声嚷嚷(全部小写也好不到哪去,因为不易阅读。[Alan Cox](http://en.wikipedia.org/wiki/Alan_Cox) 也许可以这样做,但你不行)。
190 |
191 | 更白话的说,如果你写得像是个半文盲[译注:[小白](http://zh.wikipedia.org/wiki/小白)],那多半得不到理睬。也不要使用即时通信中的简写或[火星文](http://zh.wikipedia.org/wiki/火星文),如将`的`简化为`d`会使你看起来像一个为了少打几个键而省字的小白。更糟的是,如果像个小孩似地鬼画符那绝对是在找死,可以肯定没人会理你(或者最多是给你一大堆指责与挖苦)。
192 |
193 | **如果在使用非母语的论坛提问,你可以犯点拼写和语法上的小错,但决不能在思考上马虎**(没错,我们通常能弄清两者的分别)。同时,除非你知道回复者使用的语言,否则请使用英语书写。繁忙的黑客一般会直接删除用他们看不懂的语言写的消息。在网络上英语是通用语言,用英语书写可以将你的问题在尚未被阅读就被直接删除的可能性降到最低。
194 |
195 | 如果英文是你的外语(Second language),**提示潜在回复者你有潜在的语言困难是很好的**:
196 | [译注:以下附上原文以供使用]
197 |
198 | > English is not my native language; please excuse typing errors.
199 |
200 | * 英文不是我的母语,请原谅我的错字或语法。
201 |
202 |
203 | > If you speak $LANGUAGE, please email/PM me;
204 | > I may need assistance translating my question.
205 |
206 | * 如果你说**某语言**,请向我发电邮/私信;
207 | * 我需要有人协助我翻译我的问题。
208 |
209 |
210 | > I am familiar with the technical terms,
211 | > but some slang expressions and idioms are difficult for me.
212 |
213 | * 我对技术名词很熟悉,但对于俗语或是特别用法不甚了解。
214 |
215 |
216 | > I've posted my question in $LANGUAGE and English.
217 | > I'll be glad to translate responses, if you only use one or the other.
218 |
219 | * 我把我的问题用**某语言**和英文写出来。
220 | * 如果你只用其中的一种语言回答,我会乐意将回复翻译成为你使用的语言。
221 |
222 | ### 使用易于读取且标准的文件格式发送问题
223 |
224 | 如果你人为地将问题搞得难以阅读,它多半会被忽略,人们更愿读易懂的问题,所以:
225 |
226 | * 使用纯文字而不是 HTML ([关闭 HTML](http://archive.birdhouse.org/etc/evilmail.html) 并不难)。
227 | * 使用 MIME 附件通常是可以的,前提是真正有内容(譬如附带的源代码或 patch),而不仅仅是邮件程序生成的模板(譬如只是信件内容的拷贝)。
228 | * 不要发送一段文字只是一行句子但自动换行后会变成多行的邮件(这使得回复部分内容非常困难)。设想你的读者是在 80 个字符宽的终端机上阅读邮件,最好设置你的换行分割点小于 80 字。
229 | * 但是,对一些特殊的文件**不要**设置固定宽度(譬如日志文件拷贝或会话记录)。数据应该原样包含,让回复者有信心他们看到的是和你看到的一样的东西。
230 | * 在英语论坛中,不要使用`Quoted-Printable` MIME 编码发送消息。这种编码对于张贴非 ASCII 语言可能是必须的,但很多邮件程序并不支持这种编码。当它们处理换行时,那些文本中四处散布的`=20`符号既难看也分散注意力,甚至有可能破坏内容的语意。
231 | * 绝对,**永远**不要指望黑客们阅读使用封闭格式编写的文档,像微软公司的 Word 或 Excel 文件等。大多数黑客对此的反应就像有人将还在冒热气的猪粪倒在你家门口时你的反应一样。即便他们能够处理,他们也很厌恶这么做。
232 | * 如果你从使用 Windows 的电脑发送电子邮件,关闭微软愚蠢的`智能引号`功能 (从[选项] > [校订] > [自动校正选项],勾选掉`智能引号`单选框),以免在你的邮件中到处散布垃圾字符。
233 | * 在论坛,勿滥用`表情符号`和`HTML`功能(当它们提供时)。一两个表情符号通常没有问题,但花哨的彩色文本倾向于使人认为你是个无能之辈。过滥地使用表情符号、色彩和字体会使你看来像个傻笑的小姑娘。这通常不是个好主意,除非你只是对性而不是对答案感兴趣。
234 |
235 | 如果你使用图形用户界面的邮件程序(如微软公司的 Outlook 或者其它类似的),注意它们的默认设置不一定满足这些要求。大多数这类程序有基于选单的`查看源代码`命令,用它来检查发送文件夹中的邮件,以确保发送的是纯文本文件同时没有一些奇怪的字符。
236 |
237 | ### 精确地描述问题并言之有物
238 |
239 | * **仔细、清楚地描述你的问题或 Bug 的症状。**
240 | * **描述问题发生的环境**(机器配置、操作系统、应用程序、以及相关的信息),提供经销商的发行版和版本号(如:`Fedora Core 4`、`Slackware 9.1`等)。
241 | * **描述在提问前你是怎样去研究和理解这个问题的。**
242 | * **描述在提问前为确定问题而采取的诊断步骤。**
243 | * **描述最近做过什么可能相关的硬件或软件变更。**
244 | * **尽可能地提供一个可以`重现这个问题的可控环境`的方法**。
245 |
246 | 尽量去揣测一个黑客会怎样反问你,在你提问之前预先将黑客们可能提出的问题回答一遍。
247 |
248 | 以上几点中,当你报告的是你认为可能在代码中的问题时,给黑客一个可以重现你的问题的环境尤其重要。当你这么做时,你得到有效的回答的机会和速度都会大大的提升。
249 |
250 | [Simon Tatham](http://www.chiark.greenend.org.uk/~sgtatham/) 写过一篇名为《[如何有效的报告 Bug](http://www.chiark.greenend.org.uk/~sgtatham/bugs-cn.html)》的出色文章。强力推荐你也读一读。
251 |
252 | ### 话不在多而在精
253 |
254 | **你需要提供精确有内容的信息。**这并不是要求你简单的把成堆的出错代码或者资料完全转录到你的提问中。如果你有庞大而复杂的测试样例能重现程序挂掉的情境,尽量将它剪裁得越小越好。
255 |
256 | 这样做的用处至少有三点。
257 | 第一,表现出你为简化问题付出了努力,这可以使你得到回答的机会增加;
258 | 第二,简化问题使你更有可能得到**有用**的答案;
259 | 第三,在精炼你的 bug 报告的过程中,你很可能就自己找到了解决方法或权宜之计。
260 |
261 | ### 别动辄声称找到 Bug
262 |
263 | **当你在使用软件中遇到问题,除非你非常、非常的有根据,不要动辄声称找到了 Bug。**提示:除非你能提供解决问题的源代码补丁,或者提供回归测试来表明前一版本中行为不正确,否则你都多半不够完全确信。这同样适用在网页和文件,如果你(声称)发现了文件的`Bug`,你应该能提供相应位置的修正或替代文件。
264 |
265 | 请记得,还有其他许多用户没遇到你发现的问题,否则你在阅读文件或搜索网页时就应该发现了(你在抱怨前[已经做了这些,是吧](#在提问之前)?)。这也意味着很有可能是你弄错了而不是软件本身有问题。
266 |
267 | 编写软件的人总是非常辛苦地使它尽可能完美。**如果你声称找到了 Bug,也就是在质疑他们的能力,即使你是对的,也有可能会冒犯到其中某部分人。**当你在标题中嚷嚷着有`Bug`时,这尤其严重。
268 |
269 | 提问时,即使你私下非常确信已经发现一个真正的 Bug,最好写得像是**你**做错了什么。如果真的有 Bug,你会在回复中看到这点。这样做的话,如果真有 Bug,维护者就会向你道歉,这总比你惹恼别人然后欠别人一个道歉要好一点。
270 |
271 | ### 低声下气不能代替你的功课
272 |
273 | 有些人明白他们不该粗鲁或傲慢的提问并要求得到答复,但他们选择另一个极端 —— 低声下气:`我知道我只是个可悲的新手,一个撸瑟,但...`。这既使人困扰,也没有用,尤其是伴随着与实际问题含糊不清的描述时更令人反感。
274 |
275 | **别用原始灵长类动物的把戏来浪费你我的时间。取而代之的是,尽可能清楚地描述背景条件和你的问题情况。这比低声下气更好地定位了你的位置。**
276 |
277 | 有时网页论坛会设有专为新手提问的版面,如果你真的认为遇到了初学者的问题,到那去就是了,但一样别那么低声下气。
278 |
279 | ### 描述问题症状而非你的猜测
280 |
281 | **告诉黑客们你认为问题是怎样造成的并没什么帮助。**(如果你的推断如此有效,还用向别人求助吗?),因此要确信你原原本本告诉了他们问题的症状,而不是你的解释和理论;让黑客们来推测和诊断。如果你认为陈述自己的猜测很重要,清楚地说明这只是你的猜测,并描述为什么它们不起作用。
282 |
283 | **蠢问题**
284 |
285 | > 我在编译内核时接连遇到 SIG11 错误,
286 | > 我怀疑某条飞线搭在主板的走线上了,这种情况应该怎样检查最好?
287 |
288 | **聪明问题**
289 | > 我的组装电脑是 FIC-PA2007 主机板搭载 AMD K6/233 CPU(威盛 Apollo VP2 芯片组),
290 | > 256MB Corsair PC133 SDRAM 内存,在编译内核时,从开机 20 分钟以后就频频产生 SIG11 错误,
291 | > 但是在头 20 分钟内从没发生过相同的问题。重新启动也没有用,但是关机一晚上就又能工作 20 分钟。
292 | > 所有内存都换过了,没有效果。相关部分的标准编译记录如下…。
293 |
294 | 由于以上这点似乎让许多人觉得难以配合,这里有句话可以提醒你:`所有的诊断专家都来自密苏里州。` 美国国务院的官方座右铭则是:`让我看看`(出自国会议员 Willard D. Vandiver 在 1899 年时的讲话:`我来自一个出产玉米,棉花,牛蒡和民主党人的国家,滔滔雄辩既不能说服我,也不会让我满意。我来自密苏里州,你必须让我看看。`) 针对诊断者而言,这并不是一种怀疑,而只是一种真实而有用的需求,以便让他们看到的是与你看到的原始证据尽可能一致的东西,而不是你的猜测与归纳的结论。所以,大方的展示给我们看吧!
295 |
296 | ### 按发生时间先后列出问题症状
297 |
298 | 问题发生前的一系列操作,往往就是对找出问题最有帮助的线索。因此,你的说明里应该包含你的操作步骤,以及机器和软件的反应,直到问题发生。在命令行处理的情况下,提供一段操作记录(例如运行脚本工具所生成的),并引用相关的若干行(如 20 行)记录会非常有帮助。
299 |
300 | 如果挂掉的程序有诊断选项(如 -v 的详述开关),试着选择这些能在记录中增加调试信息的选项。记住,**`多`不等于`好`**。试着选取适当的调试级别以便提供有用的信息而不是让读者淹没在垃圾中。
301 |
302 | 如果你的说明很长(如超过四个段落),在开头简述问题,接下来再按时间顺序详述会有所帮助。这样黑客们在读你的记录时就知道该注意哪些内容了。
303 |
304 | ### 描述目标而不是过程
305 |
306 | 如果你想弄清楚如何做某事(而不是报告一个 Bug),**在开头就描述你的目标,然后才陈述重现你所卡住的特定步骤**。
307 |
308 | 经常寻求技术帮助的人在心中有个更高层次的目标,而他们在自以为能达到目标的特定道路上被卡住了,然后跑来问该怎么走,但没有意识到这条路本身就有问题。结果要费很大的劲才能搞定。
309 |
310 | **蠢问题**
311 | > 我怎样才能从某绘图程序的颜色选择器中取得十六进制的 RGB 值?
312 |
313 | **聪明问题**
314 |
315 | > 我正试着用替换一幅图片的色码(color table)成自己选定的色码,**我现在知道的唯一方法是**编辑每个色码区块(table slot),
316 | > 但却无法从某绘图程序的颜色选择器取得十六进制的 RGB 值。
317 |
318 | 第二种提问法比较聪明,你可能得到像是```建议采用另一个更合适的工具```的回复。
319 |
320 | ### 别要求使用私人电邮回复
321 |
322 | 黑客们认为问题的解决过程应该公开、透明,此过程中如果更有经验的人注意到不完整或者不当之处,最初的回复才能够、也应该被纠正。同时,作为提供帮助者可以得到一些奖励,奖励就是他的能力和学识被其他同行看到。
323 |
324 | 当你要求私下回复时,这个过程和奖励都被中止。别这样做,让**回复者**来决定是否私下回答 —— 如果他真这么做了,通常是因为他认为问题编写太差或者太肤浅,以至于不可能使其他人产生兴趣。
325 |
326 | 这条规则存在一条有限的例外,如果你确信提问可能会引来大量雷同的回复时,那么这个神奇的提问句会是`向我发电邮,我将为论坛归纳这些回复`。试着将邮件列表或新闻群组从洪水般的雷同回复中解救出来是非常有礼貌的 —— 但你必须信守诺言。
327 |
328 | ### 清楚明确的表达你的问题以及需求
329 |
330 | 漫无边际的提问是近乎无休无止的时间黑洞。最有可能给你有用答案的人通常也正是最忙的人(他们忙是因为要亲自完成大部分工作)。这样的人对无节制的时间黑洞相当厌恶,所以他们也倾向于厌恶那些漫无边际的提问。
331 |
332 | 如果你明确表述需要回答者做什么(如提供指点、发送一段代码、检查你的补丁、或是其他等等),就最有可能得到有用的答案。因为这会定出一个时间和精力的上限,便于回答者能集中精力来帮你。这么做很棒。
333 |
334 | 要理解专家们所处的世界,请把专业技能想像为充裕的资源,而回复的时间则是稀缺的资源。你要求他们奉献的时间越少,你越有可能从真正专业而且很忙的专家那里得到解答。
335 |
336 | 所以,界定一下你的问题,使专家花在辨识你的问题和回答所需要付出的时间减到最少,这技巧对你有用答案相当有帮助 —— 但这技巧通常和简化问题有所区别。因此,问`我想更好地理解 X,可否指点一下哪有好一点说明?`通常比问`你能解释一下 X 吗?`更好。如果你的代码不能运作,通常请别人看看哪里有问题,比要求别人替你改正要明智得多。
337 |
338 | ### 询问有关代码的问题时
339 |
340 | **别要求他人帮你调试有问题的代码**,不提示一下应该从何入手。张贴几百行的代码,然后说一声:`它不能工作`会让你完全被忽略。只贴几十行代码,然后说一句:`在第七行以后,我期待它显示