element.\n",
282 | "\n",
283 | "Technical specifications: ```{fact_sheet_chair}```\n",
284 | "\"\"\"\n",
285 | "\n",
286 | "response = get_completion(prompt)\n",
287 | "print(response)"
288 | ]
289 | },
290 | {
291 | "attachments": {},
292 | "cell_type": "markdown",
293 | "metadata": {},
294 | "source": [
295 | "## Load Python libraries to view HTML"
296 | ]
297 | },
298 | {
299 | "cell_type": "code",
300 | "execution_count": null,
301 | "metadata": {},
302 | "outputs": [],
303 | "source": [
304 | "from IPython.display import display, HTML"
305 | ]
306 | },
307 | {
308 | "cell_type": "code",
309 | "execution_count": null,
310 | "metadata": {},
311 | "outputs": [],
312 | "source": [
313 | "display(HTML(response))"
314 | ]
315 | }
316 | ],
317 | "metadata": {
318 | "kernelspec": {
319 | "display_name": "gpt_index",
320 | "language": "python",
321 | "name": "python3"
322 | },
323 | "language_info": {
324 | "codemirror_mode": {
325 | "name": "ipython",
326 | "version": 3
327 | },
328 | "file_extension": ".py",
329 | "mimetype": "text/x-python",
330 | "name": "python",
331 | "nbconvert_exporter": "python",
332 | "pygments_lexer": "ipython3",
333 | "version": "3.8.16"
334 | },
335 | "orig_nbformat": 4
336 | },
337 | "nbformat": 4,
338 | "nbformat_minor": 2
339 | }
340 |
--------------------------------------------------------------------------------
/notebooks-en/l4-summarizing.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "attachments": {},
5 | "cell_type": "markdown",
6 | "metadata": {},
7 | "source": [
8 | "[](https://colab.research.google.com/github/GitHubDaily/ChatGPT-Prompt-Engineering-for-Developers-in-Chinese/blob/master/assets/4-Summarizing/l4-summarizing.ipynb)\n",
9 | "# Summarizing\n",
10 | "In this lesson, you will summarize text with a focus on specific topics.\n",
11 | "\n",
12 | "## Setup"
13 | ]
14 | },
15 | {
16 | "cell_type": "code",
17 | "execution_count": null,
18 | "metadata": {},
19 | "outputs": [],
20 | "source": [
21 | "# Basic congfig \n",
22 | "# Install basic package and set key\n",
23 | "!pip install openai\n",
24 | "!export OPENAI_API_KEY='sk-...'"
25 | ]
26 | },
27 | {
28 | "cell_type": "code",
29 | "execution_count": null,
30 | "metadata": {},
31 | "outputs": [],
32 | "source": [
33 | "import openai\n",
34 | "import os\n",
35 | "\n",
36 | "from dotenv import load_dotenv, find_dotenv\n",
37 | "_ = load_dotenv(find_dotenv()) # read local .env file\n",
38 | "\n",
39 | "openai.api_key = os.getenv('OPENAI_API_KEY')"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {},
46 | "outputs": [],
47 | "source": [
48 | "def get_completion(prompt, model=\"gpt-3.5-turbo\"): # Andrew mentioned that the prompt/ completion paradigm is preferable for this class\n",
49 | " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
50 | " response = openai.ChatCompletion.create(\n",
51 | " model=model,\n",
52 | " messages=messages,\n",
53 | " temperature=0, # this is the degree of randomness of the model's output\n",
54 | " )\n",
55 | " return response.choices[0].message[\"content\"]"
56 | ]
57 | },
58 | {
59 | "attachments": {},
60 | "cell_type": "markdown",
61 | "metadata": {},
62 | "source": [
63 | "## Text to summarize"
64 | ]
65 | },
66 | {
67 | "cell_type": "code",
68 | "execution_count": null,
69 | "metadata": {},
70 | "outputs": [],
71 | "source": [
72 | "prod_review = \"\"\"\n",
73 | "Got this panda plush toy for my daughter's birthday, \\\n",
74 | "who loves it and takes it everywhere. It's soft and \\ \n",
75 | "super cute, and its face has a friendly look. It's \\ \n",
76 | "a bit small for what I paid though. I think there \\ \n",
77 | "might be other options that are bigger for the \\ \n",
78 | "same price. It arrived a day earlier than expected, \\ \n",
79 | "so I got to play with it myself before I gave it \\ \n",
80 | "to her.\n",
81 | "\"\"\""
82 | ]
83 | },
84 | {
85 | "attachments": {},
86 | "cell_type": "markdown",
87 | "metadata": {},
88 | "source": [
89 | "## Summarize with a word/sentence/character limit"
90 | ]
91 | },
92 | {
93 | "cell_type": "code",
94 | "execution_count": null,
95 | "metadata": {},
96 | "outputs": [],
97 | "source": [
98 | "prompt = f\"\"\"\n",
99 | "Your task is to generate a short summary of a product \\\n",
100 | "review from an ecommerce site. \n",
101 | "\n",
102 | "Summarize the review below, delimited by triple \n",
103 | "backticks, in at most 30 words. \n",
104 | "\n",
105 | "Review: ```{prod_review}```\n",
106 | "\"\"\"\n",
107 | "\n",
108 | "response = get_completion(prompt)\n",
109 | "print(response)"
110 | ]
111 | },
112 | {
113 | "attachments": {},
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "## Summarize with a focus on shipping and delivery"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": null,
123 | "metadata": {},
124 | "outputs": [],
125 | "source": [
126 | "prompt = f\"\"\"\n",
127 | "Your task is to generate a short summary of a product \\\n",
128 | "review from an ecommerce site to give feedback to the \\\n",
129 | "Shipping deparmtment. \n",
130 | "\n",
131 | "Summarize the review below, delimited by triple \n",
132 | "backticks, in at most 30 words, and focusing on any aspects \\\n",
133 | "that mention shipping and delivery of the product. \n",
134 | "\n",
135 | "Review: ```{prod_review}```\n",
136 | "\"\"\"\n",
137 | "\n",
138 | "response = get_completion(prompt)\n",
139 | "print(response)"
140 | ]
141 | },
142 | {
143 | "attachments": {},
144 | "cell_type": "markdown",
145 | "metadata": {},
146 | "source": [
147 | "## Summarize with a focus on price and value"
148 | ]
149 | },
150 | {
151 | "cell_type": "code",
152 | "execution_count": null,
153 | "metadata": {},
154 | "outputs": [],
155 | "source": [
156 | "prompt = f\"\"\"\n",
157 | "Your task is to generate a short summary of a product \\\n",
158 | "review from an ecommerce site to give feedback to the \\\n",
159 | "Shipping deparmtment. \n",
160 | "\n",
161 | "Summarize the review below, delimited by triple \n",
162 | "backticks, in at most 30 words, and focusing on any aspects \\\n",
163 | "that mention shipping and delivery of the product. \n",
164 | "\n",
165 | "Review: ```{prod_review}```\n",
166 | "\"\"\"\n",
167 | "\n",
168 | "response = get_completion(prompt)\n",
169 | "print(response)"
170 | ]
171 | },
172 | {
173 | "attachments": {},
174 | "cell_type": "markdown",
175 | "metadata": {},
176 | "source": [
177 | "## Summarize with a focus on price and value"
178 | ]
179 | },
180 | {
181 | "cell_type": "code",
182 | "execution_count": null,
183 | "metadata": {},
184 | "outputs": [],
185 | "source": [
186 | "prompt = f\"\"\"\n",
187 | "Your task is to generate a short summary of a product \\\n",
188 | "review from an ecommerce site to give feedback to the \\\n",
189 | "pricing deparmtment, responsible for determining the \\\n",
190 | "price of the product. \n",
191 | "\n",
192 | "Summarize the review below, delimited by triple \n",
193 | "backticks, in at most 30 words, and focusing on any aspects \\\n",
194 | "that are relevant to the price and perceived value. \n",
195 | "\n",
196 | "Review: ```{prod_review}```\n",
197 | "\"\"\"\n",
198 | "\n",
199 | "response = get_completion(prompt)\n",
200 | "print(response)"
201 | ]
202 | },
203 | {
204 | "attachments": {},
205 | "cell_type": "markdown",
206 | "metadata": {},
207 | "source": [
208 | "#### Comment\n",
209 | "- Summaries include topics that are not related to the topic of focus."
210 | ]
211 | },
212 | {
213 | "attachments": {},
214 | "cell_type": "markdown",
215 | "metadata": {},
216 | "source": [
217 | "## Try \"extract\" instead of \"summarize\""
218 | ]
219 | },
220 | {
221 | "cell_type": "code",
222 | "execution_count": null,
223 | "metadata": {},
224 | "outputs": [],
225 | "source": [
226 | "prompt = f\"\"\"\n",
227 | "Your task is to extract relevant information from \\ \n",
228 | "a product review from an ecommerce site to give \\\n",
229 | "feedback to the Shipping department. \n",
230 | "\n",
231 | "From the review below, delimited by triple quotes \\\n",
232 | "extract the information relevant to shipping and \\ \n",
233 | "delivery. Limit to 30 words. \n",
234 | "\n",
235 | "Review: ```{prod_review}```\n",
236 | "\"\"\"\n",
237 | "\n",
238 | "response = get_completion(prompt)\n",
239 | "print(response)"
240 | ]
241 | },
242 | {
243 | "attachments": {},
244 | "cell_type": "markdown",
245 | "metadata": {},
246 | "source": [
247 | "## Summarize multiple product reviews"
248 | ]
249 | },
250 | {
251 | "cell_type": "code",
252 | "execution_count": null,
253 | "metadata": {},
254 | "outputs": [],
255 | "source": [
256 | "review_1 = prod_review \n",
257 | "\n",
258 | "# review for a standing lamp\n",
259 | "review_2 = \"\"\"\n",
260 | "Needed a nice lamp for my bedroom, and this one \\\n",
261 | "had additional storage and not too high of a price \\\n",
262 | "point. Got it fast - arrived in 2 days. The string \\\n",
263 | "to the lamp broke during the transit and the company \\\n",
264 | "happily sent over a new one. Came within a few days \\\n",
265 | "as well. It was easy to put together. Then I had a \\\n",
266 | "missing part, so I contacted their support and they \\\n",
267 | "very quickly got me the missing piece! Seems to me \\\n",
268 | "to be a great company that cares about their customers \\\n",
269 | "and products. \n",
270 | "\"\"\"\n",
271 | "\n",
272 | "# review for an electric toothbrush\n",
273 | "review_3 = \"\"\"\n",
274 | "My dental hygienist recommended an electric toothbrush, \\\n",
275 | "which is why I got this. The battery life seems to be \\\n",
276 | "pretty impressive so far. After initial charging and \\\n",
277 | "leaving the charger plugged in for the first week to \\\n",
278 | "condition the battery, I've unplugged the charger and \\\n",
279 | "been using it for twice daily brushing for the last \\\n",
280 | "3 weeks all on the same charge. But the toothbrush head \\\n",
281 | "is too small. I’ve seen baby toothbrushes bigger than \\\n",
282 | "this one. I wish the head was bigger with different \\\n",
283 | "length bristles to get between teeth better because \\\n",
284 | "this one doesn’t. Overall if you can get this one \\\n",
285 | "around the $50 mark, it's a good deal. The manufactuer's \\\n",
286 | "replacements heads are pretty expensive, but you can \\\n",
287 | "get generic ones that're more reasonably priced. This \\\n",
288 | "toothbrush makes me feel like I've been to the dentist \\\n",
289 | "every day. My teeth feel sparkly clean! \n",
290 | "\"\"\"\n",
291 | "\n",
292 | "# review for a blender\n",
293 | "review_4 = \"\"\"\n",
294 | "So, they still had the 17 piece system on seasonal \\\n",
295 | "sale for around $49 in the month of November, about \\\n",
296 | "half off, but for some reason (call it price gouging) \\\n",
297 | "around the second week of December the prices all went \\\n",
298 | "up to about anywhere from between $70-$89 for the same \\\n",
299 | "system. And the 11 piece system went up around $10 or \\\n",
300 | "so in price also from the earlier sale price of $29. \\\n",
301 | "So it looks okay, but if you look at the base, the part \\\n",
302 | "where the blade locks into place doesn’t look as good \\\n",
303 | "as in previous editions from a few years ago, but I \\\n",
304 | "plan to be very gentle with it (example, I crush \\\n",
305 | "very hard items like beans, ice, rice, etc. in the \\ \n",
306 | "blender first then pulverize them in the serving size \\\n",
307 | "I want in the blender then switch to the whipping \\\n",
308 | "blade for a finer flour, and use the cross cutting blade \\\n",
309 | "first when making smoothies, then use the flat blade \\\n",
310 | "if I need them finer/less pulpy). Special tip when making \\\n",
311 | "smoothies, finely cut and freeze the fruits and \\\n",
312 | "vegetables (if using spinach-lightly stew soften the \\ \n",
313 | "spinach then freeze until ready for use-and if making \\\n",
314 | "sorbet, use a small to medium sized food processor) \\ \n",
315 | "that you plan to use that way you can avoid adding so \\\n",
316 | "much ice if at all-when making your smoothie. \\\n",
317 | "After about a year, the motor was making a funny noise. \\\n",
318 | "I called customer service but the warranty expired \\\n",
319 | "already, so I had to buy another one. FYI: The overall \\\n",
320 | "quality has gone done in these types of products, so \\\n",
321 | "they are kind of counting on brand recognition and \\\n",
322 | "consumer loyalty to maintain sales. Got it in about \\\n",
323 | "two days.\n",
324 | "\"\"\"\n",
325 | "\n",
326 | "reviews = [review_1, review_2, review_3, review_4]\n"
327 | ]
328 | },
329 | {
330 | "cell_type": "code",
331 | "execution_count": null,
332 | "metadata": {},
333 | "outputs": [],
334 | "source": [
335 | "for i in range(len(reviews)):\n",
336 | " prompt = f\"\"\"\n",
337 | " Your task is to generate a short summary of a product \\ \n",
338 | " review from an ecommerce site. \n",
339 | "\n",
340 | " Summarize the review below, delimited by triple \\\n",
341 | " backticks in at most 20 words. \n",
342 | "\n",
343 | " Review: ```{reviews[i]}```\n",
344 | " \"\"\"\n",
345 | "\n",
346 | " response = get_completion(prompt)\n",
347 | " print(i, response, \"\\n\")"
348 | ]
349 | },
350 | {
351 | "cell_type": "code",
352 | "execution_count": null,
353 | "metadata": {},
354 | "outputs": [],
355 | "source": []
356 | }
357 | ],
358 | "metadata": {
359 | "kernelspec": {
360 | "display_name": "gpt_index",
361 | "language": "python",
362 | "name": "python3"
363 | },
364 | "language_info": {
365 | "codemirror_mode": {
366 | "name": "ipython",
367 | "version": 3
368 | },
369 | "file_extension": ".py",
370 | "mimetype": "text/x-python",
371 | "name": "python",
372 | "nbconvert_exporter": "python",
373 | "pygments_lexer": "ipython3",
374 | "version": "3.8.16"
375 | },
376 | "orig_nbformat": 4
377 | },
378 | "nbformat": 4,
379 | "nbformat_minor": 2
380 | }
381 |
--------------------------------------------------------------------------------
/notebooks-en/l5-inferring.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "attachments": {},
5 | "cell_type": "markdown",
6 | "metadata": {},
7 | "source": [
8 | "[](https://colab.research.google.com/github/GitHubDaily/ChatGPT-Prompt-Engineering-for-Developers-in-Chinese/blob/master/assets/5-Inferring/l5-inferring.ipynb)\n",
9 | "# Inferring\n",
10 | "In this lesson, you will infer sentiment and topics from product reviews and news articles.\n",
11 | "\n",
12 | "## Setup"
13 | ]
14 | },
15 | {
16 | "cell_type": "code",
17 | "execution_count": null,
18 | "metadata": {},
19 | "outputs": [],
20 | "source": [
21 | "# Basic congfig \n",
22 | "# Install basic package and set key\n",
23 | "!pip install openai\n",
24 | "!export OPENAI_API_KEY='sk-...'"
25 | ]
26 | },
27 | {
28 | "cell_type": "code",
29 | "execution_count": null,
30 | "metadata": {},
31 | "outputs": [],
32 | "source": [
33 | "import openai\n",
34 | "import os\n",
35 | "\n",
36 | "from dotenv import load_dotenv, find_dotenv\n",
37 | "_ = load_dotenv(find_dotenv()) # read local .env file\n",
38 | "\n",
39 | "openai.api_key = os.getenv('OPENAI_API_KEY')"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {},
46 | "outputs": [],
47 | "source": [
48 | "def get_completion(prompt, model=\"gpt-3.5-turbo\"):\n",
49 | " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
50 | " response = openai.ChatCompletion.create(\n",
51 | " model=model,\n",
52 | " messages=messages,\n",
53 | " temperature=0, # this is the degree of randomness of the model's output\n",
54 | " )\n",
55 | " return response.choices[0].message[\"content\"]"
56 | ]
57 | },
58 | {
59 | "attachments": {},
60 | "cell_type": "markdown",
61 | "metadata": {},
62 | "source": [
63 | "## Product review text"
64 | ]
65 | },
66 | {
67 | "cell_type": "code",
68 | "execution_count": null,
69 | "metadata": {},
70 | "outputs": [],
71 | "source": [
72 | "lamp_review = \"\"\"\n",
73 | "Needed a nice lamp for my bedroom, and this one had \\\n",
74 | "additional storage and not too high of a price point. \\\n",
75 | "Got it fast. The string to our lamp broke during the \\\n",
76 | "transit and the company happily sent over a new one. \\\n",
77 | "Came within a few days as well. It was easy to put \\\n",
78 | "together. I had a missing part, so I contacted their \\\n",
79 | "support and they very quickly got me the missing piece! \\\n",
80 | "Lumina seems to me to be a great company that cares \\\n",
81 | "about their customers and products!!\n",
82 | "\"\"\""
83 | ]
84 | },
85 | {
86 | "attachments": {},
87 | "cell_type": "markdown",
88 | "metadata": {},
89 | "source": [
90 | "## Sentiment (positive/negative)\n"
91 | ]
92 | },
93 | {
94 | "cell_type": "code",
95 | "execution_count": null,
96 | "metadata": {},
97 | "outputs": [],
98 | "source": [
99 | "prompt = f\"\"\"\n",
100 | "What is the sentiment of the following product review, \n",
101 | "which is delimited with triple backticks?\n",
102 | "\n",
103 | "Review text: '''{lamp_review}'''\n",
104 | "\"\"\"\n",
105 | "response = get_completion(prompt)\n",
106 | "print(response)"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": null,
112 | "metadata": {},
113 | "outputs": [],
114 | "source": [
115 | "prompt = f\"\"\"\n",
116 | "What is the sentiment of the following product review, \n",
117 | "which is delimited with triple backticks?\n",
118 | "\n",
119 | "Give your answer as a single word, either \"positive\" \\\n",
120 | "or \"negative\".\n",
121 | "\n",
122 | "Review text: '''{lamp_review}'''\n",
123 | "\"\"\"\n",
124 | "response = get_completion(prompt)\n",
125 | "print(response)"
126 | ]
127 | },
128 | {
129 | "attachments": {},
130 | "cell_type": "markdown",
131 | "metadata": {},
132 | "source": [
133 | "## Identify types of emotions"
134 | ]
135 | },
136 | {
137 | "cell_type": "code",
138 | "execution_count": null,
139 | "metadata": {},
140 | "outputs": [],
141 | "source": [
142 | "prompt = f\"\"\"\n",
143 | "Identify a list of emotions that the writer of the \\\n",
144 | "following review is expressing. Include no more than \\\n",
145 | "five items in the list. Format your answer as a list of \\\n",
146 | "lower-case words separated by commas.\n",
147 | "\n",
148 | "Review text: '''{lamp_review}'''\n",
149 | "\"\"\"\n",
150 | "response = get_completion(prompt)\n",
151 | "print(response)"
152 | ]
153 | },
154 | {
155 | "attachments": {},
156 | "cell_type": "markdown",
157 | "metadata": {},
158 | "source": [
159 | "## Identify anger"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": null,
165 | "metadata": {},
166 | "outputs": [],
167 | "source": [
168 | "prompt = f\"\"\"\n",
169 | "Is the writer of the following review expressing anger?\\\n",
170 | "The review is delimited with triple backticks. \\\n",
171 | "Give your answer as either yes or no.\n",
172 | "\n",
173 | "Review text: '''{lamp_review}'''\n",
174 | "\"\"\"\n",
175 | "response = get_completion(prompt)\n",
176 | "print(response)"
177 | ]
178 | },
179 | {
180 | "attachments": {},
181 | "cell_type": "markdown",
182 | "metadata": {},
183 | "source": [
184 | "## Extract product and company name from customer reviews"
185 | ]
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": null,
190 | "metadata": {},
191 | "outputs": [],
192 | "source": [
193 | "prompt = f\"\"\"\n",
194 | "Identify the following items from the review text: \n",
195 | "- Item purchased by reviewer\n",
196 | "- Company that made the item\n",
197 | "\n",
198 | "The review is delimited with triple backticks. \\\n",
199 | "Format your response as a JSON object with \\\n",
200 | "\"Item\" and \"Brand\" as the keys. \n",
201 | "If the information isn't present, use \"unknown\" \\\n",
202 | "as the value.\n",
203 | "Make your response as short as possible.\n",
204 | " \n",
205 | "Review text: '''{lamp_review}'''\n",
206 | "\"\"\"\n",
207 | "response = get_completion(prompt)\n",
208 | "print(response)"
209 | ]
210 | },
211 | {
212 | "attachments": {},
213 | "cell_type": "markdown",
214 | "metadata": {},
215 | "source": [
216 | "## Doing multiple tasks at once"
217 | ]
218 | },
219 | {
220 | "cell_type": "code",
221 | "execution_count": null,
222 | "metadata": {},
223 | "outputs": [],
224 | "source": [
225 | "prompt = f\"\"\"\n",
226 | "Identify the following items from the review text: \n",
227 | "- Sentiment (positive or negative)\n",
228 | "- Is the reviewer expressing anger? (true or false)\n",
229 | "- Item purchased by reviewer\n",
230 | "- Company that made the item\n",
231 | "\n",
232 | "The review is delimited with triple backticks. \\\n",
233 | "Format your response as a JSON object with \\\n",
234 | "\"Sentiment\", \"Anger\", \"Item\" and \"Brand\" as the keys.\n",
235 | "If the information isn't present, use \"unknown\" \\\n",
236 | "as the value.\n",
237 | "Make your response as short as possible.\n",
238 | "Format the Anger value as a boolean.\n",
239 | "\n",
240 | "Review text: '''{lamp_review}'''\n",
241 | "\"\"\"\n",
242 | "response = get_completion(prompt)\n",
243 | "print(response)"
244 | ]
245 | },
246 | {
247 | "attachments": {},
248 | "cell_type": "markdown",
249 | "metadata": {},
250 | "source": [
251 | "## Inferring topics"
252 | ]
253 | },
254 | {
255 | "cell_type": "code",
256 | "execution_count": null,
257 | "metadata": {},
258 | "outputs": [],
259 | "source": [
260 | "story = \"\"\"\n",
261 | "In a recent survey conducted by the government, \n",
262 | "public sector employees were asked to rate their level \n",
263 | "of satisfaction with the department they work at. \n",
264 | "The results revealed that NASA was the most popular \n",
265 | "department with a satisfaction rating of 95%.\n",
266 | "\n",
267 | "One NASA employee, John Smith, commented on the findings, \n",
268 | "stating, \"I'm not surprised that NASA came out on top. \n",
269 | "It's a great place to work with amazing people and \n",
270 | "incredible opportunities. I'm proud to be a part of \n",
271 | "such an innovative organization.\"\n",
272 | "\n",
273 | "The results were also welcomed by NASA's management team, \n",
274 | "with Director Tom Johnson stating, \"We are thrilled to \n",
275 | "hear that our employees are satisfied with their work at NASA. \n",
276 | "We have a talented and dedicated team who work tirelessly \n",
277 | "to achieve our goals, and it's fantastic to see that their \n",
278 | "hard work is paying off.\"\n",
279 | "\n",
280 | "The survey also revealed that the \n",
281 | "Social Security Administration had the lowest satisfaction \n",
282 | "rating, with only 45% of employees indicating they were \n",
283 | "satisfied with their job. The government has pledged to \n",
284 | "address the concerns raised by employees in the survey and \n",
285 | "work towards improving job satisfaction across all departments.\n",
286 | "\"\"\""
287 | ]
288 | },
289 | {
290 | "attachments": {},
291 | "cell_type": "markdown",
292 | "metadata": {},
293 | "source": [
294 | "## Infer 5 topics"
295 | ]
296 | },
297 | {
298 | "cell_type": "code",
299 | "execution_count": null,
300 | "metadata": {},
301 | "outputs": [],
302 | "source": [
303 | "prompt = f\"\"\"\n",
304 | "Determine five topics that are being discussed in the \\\n",
305 | "following text, which is delimited by triple backticks.\n",
306 | "\n",
307 | "Make each item one or two words long. \n",
308 | "\n",
309 | "Format your response as a list of items separated by commas.\n",
310 | "\n",
311 | "Text sample: '''{story}'''\n",
312 | "\"\"\"\n",
313 | "response = get_completion(prompt)\n",
314 | "print(response)"
315 | ]
316 | },
317 | {
318 | "cell_type": "code",
319 | "execution_count": null,
320 | "metadata": {},
321 | "outputs": [],
322 | "source": [
323 | "response.split(sep=',')"
324 | ]
325 | },
326 | {
327 | "cell_type": "code",
328 | "execution_count": null,
329 | "metadata": {},
330 | "outputs": [],
331 | "source": [
332 | "topic_list = [\n",
333 | " \"nasa\", \"local government\", \"engineering\", \n",
334 | " \"employee satisfaction\", \"federal government\"\n",
335 | "]"
336 | ]
337 | },
338 | {
339 | "attachments": {},
340 | "cell_type": "markdown",
341 | "metadata": {},
342 | "source": [
343 | "## Make a news alert for certain topics"
344 | ]
345 | },
346 | {
347 | "cell_type": "code",
348 | "execution_count": null,
349 | "metadata": {},
350 | "outputs": [],
351 | "source": [
352 | "prompt = f\"\"\"\n",
353 | "Determine whether each item in the following list of \\\n",
354 | "topics is a topic in the text below, which\n",
355 | "is delimited with triple backticks.\n",
356 | "\n",
357 | "Give your answer as list with 0 or 1 for each topic.\\\n",
358 | "\n",
359 | "List of topics: {\", \".join(topic_list)}\n",
360 | "\n",
361 | "Text sample: '''{story}'''\n",
362 | "\"\"\"\n",
363 | "response = get_completion(prompt)\n",
364 | "print(response)"
365 | ]
366 | },
367 | {
368 | "cell_type": "code",
369 | "execution_count": null,
370 | "metadata": {},
371 | "outputs": [],
372 | "source": [
373 | "topic_dict = {i.split(': ')[0]: int(i.split(': ')[1]) for i in response.split(sep='\\n')}\n",
374 | "if topic_dict['nasa'] == 1:\n",
375 | " print(\"ALERT: New NASA story!\")"
376 | ]
377 | },
378 | {
379 | "cell_type": "markdown",
380 | "metadata": {},
381 | "source": []
382 | }
383 | ],
384 | "metadata": {
385 | "kernelspec": {
386 | "display_name": "gpt_index",
387 | "language": "python",
388 | "name": "python3"
389 | },
390 | "language_info": {
391 | "codemirror_mode": {
392 | "name": "ipython",
393 | "version": 3
394 | },
395 | "file_extension": ".py",
396 | "mimetype": "text/x-python",
397 | "name": "python",
398 | "nbconvert_exporter": "python",
399 | "pygments_lexer": "ipython3",
400 | "version": "3.8.16"
401 | },
402 | "orig_nbformat": 4
403 | },
404 | "nbformat": 4,
405 | "nbformat_minor": 2
406 | }
407 |
--------------------------------------------------------------------------------
/notebooks-en/l6-transforming.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "attachments": {},
5 | "cell_type": "markdown",
6 | "metadata": {},
7 | "source": [
8 | "[](https://colab.research.google.com/github/GitHubDaily/ChatGPT-Prompt-Engineering-for-Developers-in-Chinese/blob/master/assets/6-Transforming/l6-transforming.ipynb)\n",
9 | "# Transforming\n",
10 | "\n",
11 | "In this notebook, we will explore how to use Large Language Models for text transformation tasks such as language translation, spelling and grammar checking, tone adjustment, and format conversion.\n",
12 | "\n",
13 | "## Setup"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": null,
19 | "metadata": {},
20 | "outputs": [],
21 | "source": [
22 | "# Basic congfig \n",
23 | "# Install basic package and set key\n",
24 | "!pip install openai\n",
25 | "!export OPENAI_API_KEY='sk-...'"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": null,
31 | "metadata": {},
32 | "outputs": [],
33 | "source": [
34 | "import openai\n",
35 | "import os\n",
36 | "\n",
37 | "from dotenv import load_dotenv, find_dotenv\n",
38 | "_ = load_dotenv(find_dotenv()) # read local .env file\n",
39 | "\n",
40 | "openai.api_key = os.getenv('OPENAI_API_KEY')"
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": null,
46 | "metadata": {},
47 | "outputs": [],
48 | "source": [
49 | "def get_completion(prompt, model=\"gpt-3.5-turbo\", temperature=0): \n",
50 | " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
51 | " response = openai.ChatCompletion.create(\n",
52 | " model=model,\n",
53 | " messages=messages,\n",
54 | " temperature=temperature, \n",
55 | " )\n",
56 | " return response.choices[0].message[\"content\"]"
57 | ]
58 | },
59 | {
60 | "attachments": {},
61 | "cell_type": "markdown",
62 | "metadata": {},
63 | "source": [
64 | "## Translation\n",
65 | "\n",
66 | "ChatGPT is trained with sources in many languages. This gives the model the ability to do translation. Here are some examples of how to use this capability."
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": null,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "prompt = f\"\"\"\n",
76 | "Translate the following English text to Spanish: \\ \n",
77 | "```Hi, I would like to order a blender```\n",
78 | "\"\"\"\n",
79 | "response = get_completion(prompt)\n",
80 | "print(response)"
81 | ]
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": null,
86 | "metadata": {},
87 | "outputs": [],
88 | "source": [
89 | "prompt = f\"\"\"\n",
90 | "Tell me which language this is: \n",
91 | "```Combien coûte le lampadaire?```\n",
92 | "\"\"\"\n",
93 | "response = get_completion(prompt)\n",
94 | "print(response)"
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": null,
100 | "metadata": {},
101 | "outputs": [],
102 | "source": [
103 | "prompt = f\"\"\"\n",
104 | "Translate the following text to French and Spanish\n",
105 | "and English pirate: \\\n",
106 | "```I want to order a basketball```\n",
107 | "\"\"\"\n",
108 | "response = get_completion(prompt)\n",
109 | "print(response)"
110 | ]
111 | },
112 | {
113 | "cell_type": "code",
114 | "execution_count": null,
115 | "metadata": {},
116 | "outputs": [],
117 | "source": [
118 | "prompt = f\"\"\"\n",
119 | "Translate the following text to Spanish in both the \\\n",
120 | "formal and informal forms: \n",
121 | "'Would you like to order a pillow?'\n",
122 | "\"\"\"\n",
123 | "response = get_completion(prompt)\n",
124 | "print(response)"
125 | ]
126 | },
127 | {
128 | "attachments": {},
129 | "cell_type": "markdown",
130 | "metadata": {},
131 | "source": [
132 | "### Universal Translator\n",
133 | "Imagine you are in charge of IT at a large multinational e-commerce company. Users are messaging you with IT issues in all their native languages. Your staff is from all over the world and speaks only their native languages. You need a universal translator!"
134 | ]
135 | },
136 | {
137 | "cell_type": "code",
138 | "execution_count": null,
139 | "metadata": {},
140 | "outputs": [],
141 | "source": [
142 | "user_messages = [\n",
143 | " \"La performance du système est plus lente que d'habitude.\", # System performance is slower than normal \n",
144 | " \"Mi monitor tiene píxeles que no se iluminan.\", # My monitor has pixels that are not lighting\n",
145 | " \"Il mio mouse non funziona\", # My mouse is not working\n",
146 | " \"Mój klawisz Ctrl jest zepsuty\", # My keyboard has a broken control key\n",
147 | " \"我的屏幕在闪烁\" # My screen is flashing\n",
148 | "] "
149 | ]
150 | },
151 | {
152 | "cell_type": "code",
153 | "execution_count": null,
154 | "metadata": {},
155 | "outputs": [],
156 | "source": [
157 | "for issue in user_messages:\n",
158 | " prompt = f\"Tell me what language this is: ```{issue}```\"\n",
159 | " lang = get_completion(prompt)\n",
160 | " print(f\"Original message ({lang}): {issue}\")\n",
161 | "\n",
162 | " prompt = f\"\"\"\n",
163 | " Translate the following text to English \\\n",
164 | " and Korean: ```{issue}```\n",
165 | " \"\"\"\n",
166 | " response = get_completion(prompt)\n",
167 | " print(response, \"\\n\")"
168 | ]
169 | },
170 | {
171 | "attachments": {},
172 | "cell_type": "markdown",
173 | "metadata": {},
174 | "source": [
175 | "## Try it yourself!\n",
176 | "Try some translations on your own!"
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": null,
182 | "metadata": {},
183 | "outputs": [],
184 | "source": []
185 | },
186 | {
187 | "attachments": {},
188 | "cell_type": "markdown",
189 | "metadata": {},
190 | "source": [
191 | "## Tone Transformation\n",
192 | "Writing can vary based on the intended audience. ChatGPT can produce different tones.\n"
193 | ]
194 | },
195 | {
196 | "cell_type": "code",
197 | "execution_count": null,
198 | "metadata": {},
199 | "outputs": [],
200 | "source": [
201 | "prompt = f\"\"\"\n",
202 | "Translate the following from slang to a business letter: \n",
203 | "'Dude, This is Joe, check out this spec on this standing lamp.'\n",
204 | "\"\"\"\n",
205 | "response = get_completion(prompt)\n",
206 | "print(response)"
207 | ]
208 | },
209 | {
210 | "attachments": {},
211 | "cell_type": "markdown",
212 | "metadata": {},
213 | "source": [
214 | "## Format Conversion\n",
215 | "ChatGPT can translate between formats. The prompt should describe the input and output formats."
216 | ]
217 | },
218 | {
219 | "cell_type": "code",
220 | "execution_count": null,
221 | "metadata": {},
222 | "outputs": [],
223 | "source": [
224 | "data_json = { \"resturant employees\" :[ \n",
225 | " {\"name\":\"Shyam\", \"email\":\"shyamjaiswal@gmail.com\"},\n",
226 | " {\"name\":\"Bob\", \"email\":\"bob32@gmail.com\"},\n",
227 | " {\"name\":\"Jai\", \"email\":\"jai87@gmail.com\"}\n",
228 | "]}\n",
229 | "\n",
230 | "prompt = f\"\"\"\n",
231 | "Translate the following python dictionary from JSON to an HTML \\\n",
232 | "table with column headers and title: {data_json}\n",
233 | "\"\"\"\n",
234 | "response = get_completion(prompt)\n",
235 | "print(response)"
236 | ]
237 | },
238 | {
239 | "cell_type": "code",
240 | "execution_count": null,
241 | "metadata": {},
242 | "outputs": [],
243 | "source": [
244 | "from IPython.display import display, Markdown, Latex, HTML, JSON\n",
245 | "display(HTML(response))"
246 | ]
247 | },
248 | {
249 | "attachments": {},
250 | "cell_type": "markdown",
251 | "metadata": {},
252 | "source": [
253 | "## Spellcheck/Grammar check.\n",
254 | "\n",
255 | "Here are some examples of common grammar and spelling problems and the LLM's response. \n",
256 | "\n",
257 | "To signal to the LLM that you want it to proofread your text, you instruct the model to 'proofread' or 'proofread and correct'."
258 | ]
259 | },
260 | {
261 | "cell_type": "code",
262 | "execution_count": null,
263 | "metadata": {},
264 | "outputs": [],
265 | "source": [
266 | "text = [ \n",
267 | " \"The girl with the black and white puppies have a ball.\", # The girl has a ball.\n",
268 | " \"Yolanda has her notebook.\", # ok\n",
269 | " \"Its going to be a long day. Does the car need it’s oil changed?\", # Homonyms\n",
270 | " \"Their goes my freedom. There going to bring they’re suitcases.\", # Homonyms\n",
271 | " \"Your going to need you’re notebook.\", # Homonyms\n",
272 | " \"That medicine effects my ability to sleep. Have you heard of the butterfly affect?\", # Homonyms\n",
273 | " \"This phrase is to cherck chatGPT for speling abilitty\" # spelling\n",
274 | "]\n",
275 | "for t in text:\n",
276 | " prompt = f\"\"\"Proofread and correct the following text\n",
277 | " and rewrite the corrected version. If you don't find\n",
278 | " and errors, just say \"No errors found\". Don't use \n",
279 | " any punctuation around the text:\n",
280 | " ```{t}```\"\"\"\n",
281 | " response = get_completion(prompt)\n",
282 | " print(response)"
283 | ]
284 | },
285 | {
286 | "cell_type": "code",
287 | "execution_count": null,
288 | "metadata": {},
289 | "outputs": [],
290 | "source": [
291 | "text = f\"\"\"\n",
292 | "Got this for my daughter for her birthday cuz she keeps taking \\\n",
293 | "mine from my room. Yes, adults also like pandas too. She takes \\\n",
294 | "it everywhere with her, and it's super soft and cute. One of the \\\n",
295 | "ears is a bit lower than the other, and I don't think that was \\\n",
296 | "designed to be asymmetrical. It's a bit small for what I paid for it \\\n",
297 | "though. I think there might be other options that are bigger for \\\n",
298 | "the same price. It arrived a day earlier than expected, so I got \\\n",
299 | "to play with it myself before I gave it to my daughter.\n",
300 | "\"\"\"\n",
301 | "prompt = f\"proofread and correct this review: ```{text}```\"\n",
302 | "response = get_completion(prompt)\n",
303 | "print(response)"
304 | ]
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": null,
309 | "metadata": {},
310 | "outputs": [],
311 | "source": [
312 | "!pip install redlines\n",
313 | "from redlines import Redlines\n",
314 | "\n",
315 | "diff = Redlines(text,response)\n",
316 | "display(Markdown(diff.output_markdown))"
317 | ]
318 | },
319 | {
320 | "cell_type": "code",
321 | "execution_count": null,
322 | "metadata": {},
323 | "outputs": [],
324 | "source": [
325 | "prompt = f\"\"\"\n",
326 | "proofread and correct this review. Make it more compelling. \n",
327 | "Ensure it follows APA style guide and targets an advanced reader. \n",
328 | "Output in markdown format.\n",
329 | "Text: ```{text}```\n",
330 | "\"\"\"\n",
331 | "response = get_completion(prompt)\n",
332 | "display(Markdown(response))"
333 | ]
334 | },
335 | {
336 | "attachments": {},
337 | "cell_type": "markdown",
338 | "metadata": {},
339 | "source": [
340 | "## Try it yourself!\n",
341 | "Try changing the instructions to form your own review."
342 | ]
343 | },
344 | {
345 | "cell_type": "markdown",
346 | "metadata": {},
347 | "source": []
348 | },
349 | {
350 | "cell_type": "code",
351 | "execution_count": null,
352 | "metadata": {},
353 | "outputs": [],
354 | "source": []
355 | },
356 | {
357 | "attachments": {},
358 | "cell_type": "markdown",
359 | "metadata": {},
360 | "source": [
361 | "Thanks to the following sites:\n",
362 | "\n",
363 | "https://writingprompts.com/bad-grammar-examples/"
364 | ]
365 | },
366 | {
367 | "cell_type": "markdown",
368 | "metadata": {},
369 | "source": []
370 | }
371 | ],
372 | "metadata": {
373 | "kernelspec": {
374 | "display_name": "gpt_index",
375 | "language": "python",
376 | "name": "python3"
377 | },
378 | "language_info": {
379 | "codemirror_mode": {
380 | "name": "ipython",
381 | "version": 3
382 | },
383 | "file_extension": ".py",
384 | "mimetype": "text/x-python",
385 | "name": "python",
386 | "nbconvert_exporter": "python",
387 | "pygments_lexer": "ipython3",
388 | "version": "3.8.16"
389 | },
390 | "orig_nbformat": 4
391 | },
392 | "nbformat": 4,
393 | "nbformat_minor": 2
394 | }
395 |
--------------------------------------------------------------------------------
/notebooks-en/l7-expanding.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "attachments": {},
5 | "cell_type": "markdown",
6 | "metadata": {},
7 | "source": [
8 | "[](https://colab.research.google.com/github/GitHubDaily/ChatGPT-Prompt-Engineering-for-Developers-in-Chinese/blob/master/assets/7-Expanding/l7-expanding.ipynb)\n",
9 | "# Expanding\n",
10 | "In this lesson, you will generate customer service emails that are tailored to each customer's review.\n",
11 | "\n",
12 | "## Setup"
13 | ]
14 | },
15 | {
16 | "cell_type": "code",
17 | "execution_count": null,
18 | "metadata": {},
19 | "outputs": [],
20 | "source": [
21 | "# Basic congfig \n",
22 | "# Install basic package and set key\n",
23 | "!pip install openai\n",
24 | "!export OPENAI_API_KEY='sk-...'"
25 | ]
26 | },
27 | {
28 | "cell_type": "code",
29 | "execution_count": null,
30 | "metadata": {},
31 | "outputs": [],
32 | "source": [
33 | "import openai\n",
34 | "import os\n",
35 | "\n",
36 | "from dotenv import load_dotenv, find_dotenv\n",
37 | "_ = load_dotenv(find_dotenv()) # read local .env file\n",
38 | "\n",
39 | "openai.api_key = os.getenv('OPENAI_API_KEY')"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {},
46 | "outputs": [],
47 | "source": [
48 | "def get_completion(prompt, model=\"gpt-3.5-turbo\",temperature=0): # Andrew mentioned that the prompt/ completion paradigm is preferable for this class\n",
49 | " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
50 | " response = openai.ChatCompletion.create(\n",
51 | " model=model,\n",
52 | " messages=messages,\n",
53 | " temperature=temperature, # this is the degree of randomness of the model's output\n",
54 | " )\n",
55 | " return response.choices[0].message[\"content\"]"
56 | ]
57 | },
58 | {
59 | "attachments": {},
60 | "cell_type": "markdown",
61 | "metadata": {},
62 | "source": [
63 | "## Customize the automated reply to a customer email"
64 | ]
65 | },
66 | {
67 | "cell_type": "code",
68 | "execution_count": null,
69 | "metadata": {},
70 | "outputs": [],
71 | "source": [
72 | "# given the sentiment from the lesson on \"inferring\",\n",
73 | "# and the original customer message, customize the email\n",
74 | "sentiment = \"negative\"\n",
75 | "\n",
76 | "# review for a blender\n",
77 | "review = f\"\"\"\n",
78 | "So, they still had the 17 piece system on seasonal \\\n",
79 | "sale for around $49 in the month of November, about \\\n",
80 | "half off, but for some reason (call it price gouging) \\\n",
81 | "around the second week of December the prices all went \\\n",
82 | "up to about anywhere from between $70-$89 for the same \\\n",
83 | "system. And the 11 piece system went up around $10 or \\\n",
84 | "so in price also from the earlier sale price of $29. \\\n",
85 | "So it looks okay, but if you look at the base, the part \\\n",
86 | "where the blade locks into place doesn’t look as good \\\n",
87 | "as in previous editions from a few years ago, but I \\\n",
88 | "plan to be very gentle with it (example, I crush \\\n",
89 | "very hard items like beans, ice, rice, etc. in the \\ \n",
90 | "blender first then pulverize them in the serving size \\\n",
91 | "I want in the blender then switch to the whipping \\\n",
92 | "blade for a finer flour, and use the cross cutting blade \\\n",
93 | "first when making smoothies, then use the flat blade \\\n",
94 | "if I need them finer/less pulpy). Special tip when making \\\n",
95 | "smoothies, finely cut and freeze the fruits and \\\n",
96 | "vegetables (if using spinach-lightly stew soften the \\ \n",
97 | "spinach then freeze until ready for use-and if making \\\n",
98 | "sorbet, use a small to medium sized food processor) \\ \n",
99 | "that you plan to use that way you can avoid adding so \\\n",
100 | "much ice if at all-when making your smoothie. \\\n",
101 | "After about a year, the motor was making a funny noise. \\\n",
102 | "I called customer service but the warranty expired \\\n",
103 | "already, so I had to buy another one. FYI: The overall \\\n",
104 | "quality has gone done in these types of products, so \\\n",
105 | "they are kind of counting on brand recognition and \\\n",
106 | "consumer loyalty to maintain sales. Got it in about \\\n",
107 | "two days.\n",
108 | "\"\"\""
109 | ]
110 | },
111 | {
112 | "cell_type": "code",
113 | "execution_count": null,
114 | "metadata": {},
115 | "outputs": [],
116 | "source": [
117 | "prompt = f\"\"\"\n",
118 | "You are a customer service AI assistant.\n",
119 | "Your task is to send an email reply to a valued customer.\n",
120 | "Given the customer email delimited by ```, \\\n",
121 | "Generate a reply to thank the customer for their review.\n",
122 | "If the sentiment is positive or neutral, thank them for \\\n",
123 | "their review.\n",
124 | "If the sentiment is negative, apologize and suggest that \\\n",
125 | "they can reach out to customer service. \n",
126 | "Make sure to use specific details from the review.\n",
127 | "Write in a concise and professional tone.\n",
128 | "Sign the email as `AI customer agent`.\n",
129 | "Customer review: ```{review}```\n",
130 | "Review sentiment: {sentiment}\n",
131 | "\"\"\"\n",
132 | "response = get_completion(prompt)\n",
133 | "print(response)"
134 | ]
135 | },
136 | {
137 | "cell_type": "markdown",
138 | "metadata": {},
139 | "source": []
140 | }
141 | ],
142 | "metadata": {
143 | "kernelspec": {
144 | "display_name": "gpt_index",
145 | "language": "python",
146 | "name": "python3"
147 | },
148 | "language_info": {
149 | "codemirror_mode": {
150 | "name": "ipython",
151 | "version": 3
152 | },
153 | "file_extension": ".py",
154 | "mimetype": "text/x-python",
155 | "name": "python",
156 | "nbconvert_exporter": "python",
157 | "pygments_lexer": "ipython3",
158 | "version": "3.8.16"
159 | },
160 | "orig_nbformat": 4
161 | },
162 | "nbformat": 4,
163 | "nbformat_minor": 2
164 | }
165 |
--------------------------------------------------------------------------------
/notebooks-en/l8-chatbot.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "attachments": {},
5 | "cell_type": "markdown",
6 | "metadata": {},
7 | "source": [
8 | "[](https://colab.research.google.com/github/GitHubDaily/ChatGPT-Prompt-Engineering-for-Developers-in-Chinese/blob/master/assets/8-Chatbot/l8-chatbot.ipynb)\n",
9 | "# The Chat Format\n",
10 | "\n",
11 | "In this notebook, you will explore how you can utilize the chat format to have extended conversations with chatbots personalized or specialized for specific tasks or behaviors.\n",
12 | "\n",
13 | "## Setup"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": null,
19 | "metadata": {},
20 | "outputs": [],
21 | "source": [
22 | "# Basic congfig \n",
23 | "# Install basic package and set key\n",
24 | "!pip install openai\n",
25 | "!export OPENAI_API_KEY='sk-...'"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": null,
31 | "metadata": {},
32 | "outputs": [],
33 | "source": [
34 | "import os\n",
35 | "import openai\n",
36 | "from dotenv import load_dotenv, find_dotenv\n",
37 | "_ = load_dotenv(find_dotenv()) # read local .env file\n",
38 | "\n",
39 | "openai.api_key = os.getenv('OPENAI_API_KEY')"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {},
46 | "outputs": [],
47 | "source": [
48 | "def get_completion(prompt, model=\"gpt-3.5-turbo\"):\n",
49 | " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
50 | " response = openai.ChatCompletion.create(\n",
51 | " model=model,\n",
52 | " messages=messages,\n",
53 | " temperature=0, # this is the degree of randomness of the model's output\n",
54 | " )\n",
55 | " return response.choices[0].message[\"content\"]\n",
56 | "\n",
57 | "def get_completion_from_messages(messages, model=\"gpt-3.5-turbo\", temperature=0):\n",
58 | " response = openai.ChatCompletion.create(\n",
59 | " model=model,\n",
60 | " messages=messages,\n",
61 | " temperature=temperature, # this is the degree of randomness of the model's output\n",
62 | " )\n",
63 | "# print(str(response.choices[0].message))\n",
64 | " return response.choices[0].message[\"content\"]"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": null,
70 | "metadata": {},
71 | "outputs": [],
72 | "source": [
73 | "messages = [ \n",
74 | "{'role':'system', 'content':'You are an assistant that speaks like Shakespeare.'}, \n",
75 | "{'role':'user', 'content':'tell me a joke'}, \n",
76 | "{'role':'assistant', 'content':'Why did the chicken cross the road'}, \n",
77 | "{'role':'user', 'content':'I don\\'t know'} ]"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": null,
83 | "metadata": {},
84 | "outputs": [],
85 | "source": [
86 | "response = get_completion_from_messages(messages, temperature=1)\n",
87 | "print(response)"
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": null,
93 | "metadata": {},
94 | "outputs": [],
95 | "source": [
96 | "messages = [ \n",
97 | "{'role':'system', 'content':'You are friendly chatbot.'}, \n",
98 | "{'role':'user', 'content':'Hi, my name is Isa'} ]\n",
99 | "response = get_completion_from_messages(messages, temperature=1)\n",
100 | "print(response)"
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": null,
106 | "metadata": {},
107 | "outputs": [],
108 | "source": [
109 | "messages = [ \n",
110 | "{'role':'system', 'content':'You are friendly chatbot.'}, \n",
111 | "{'role':'user', 'content':'Yes, can you remind me, What is my name?'} ]\n",
112 | "response = get_completion_from_messages(messages, temperature=1)\n",
113 | "print(response)"
114 | ]
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": null,
119 | "metadata": {},
120 | "outputs": [],
121 | "source": [
122 | "messages = [ \n",
123 | "{'role':'system', 'content':'You are friendly chatbot.'},\n",
124 | "{'role':'user', 'content':'Hi, my name is Isa'},\n",
125 | "{'role':'assistant', 'content': \"Hi Isa! It's nice to meet you. \\\n",
126 | "Is there anything I can help you with today?\"},\n",
127 | "{'role':'user', 'content':'Yes, you can remind me, What is my name?'} ]\n",
128 | "response = get_completion_from_messages(messages, temperature=1)\n",
129 | "print(response)"
130 | ]
131 | },
132 | {
133 | "attachments": {},
134 | "cell_type": "markdown",
135 | "metadata": {},
136 | "source": [
137 | "# OrderBot\n",
138 | "We can automate the collection of user prompts and assistant responses to build a OrderBot. The OrderBot will take orders at a pizza restaurant. "
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": null,
144 | "metadata": {},
145 | "outputs": [],
146 | "source": [
147 | "!pip install panel jupyter_bokeh"
148 | ]
149 | },
150 | {
151 | "cell_type": "code",
152 | "execution_count": null,
153 | "metadata": {},
154 | "outputs": [],
155 | "source": [
156 | "def collect_messages(_):\n",
157 | " prompt = inp.value_input\n",
158 | " inp.value = ''\n",
159 | " context.append({'role':'user', 'content':f\"{prompt}\"})\n",
160 | " response = get_completion_from_messages(context) \n",
161 | " context.append({'role':'assistant', 'content':f\"{response}\"})\n",
162 | " panels.append(\n",
163 | " pn.Row('User:', pn.pane.Markdown(prompt, width=600)))\n",
164 | " panels.append(\n",
165 | " pn.Row('Assistant:', pn.pane.Markdown(response, width=600, style={'background-color': '#F6F6F6'})))\n",
166 | " \n",
167 | " return pn.Column(*panels)"
168 | ]
169 | },
170 | {
171 | "cell_type": "code",
172 | "execution_count": null,
173 | "metadata": {},
174 | "outputs": [],
175 | "source": [
176 | "import panel as pn # GUI\n",
177 | "pn.extension()\n",
178 | "\n",
179 | "panels = [] # collect display \n",
180 | "\n",
181 | "context = [ {'role':'system', 'content':\"\"\"\n",
182 | "You are OrderBot, an automated service to collect orders for a pizza restaurant. \\\n",
183 | "You first greet the customer, then collects the order, \\\n",
184 | "and then asks if it's a pickup or delivery. \\\n",
185 | "You wait to collect the entire order, then summarize it and check for a final \\\n",
186 | "time if the customer wants to add anything else. \\\n",
187 | "If it's a delivery, you ask for an address. \\\n",
188 | "Finally you collect the payment.\\\n",
189 | "Make sure to clarify all options, extras and sizes to uniquely \\\n",
190 | "identify the item from the menu.\\\n",
191 | "You respond in a short, very conversational friendly style. \\\n",
192 | "The menu includes \\\n",
193 | "pepperoni pizza 12.95, 10.00, 7.00 \\\n",
194 | "cheese pizza 10.95, 9.25, 6.50 \\\n",
195 | "eggplant pizza 11.95, 9.75, 6.75 \\\n",
196 | "fries 4.50, 3.50 \\\n",
197 | "greek salad 7.25 \\\n",
198 | "Toppings: \\\n",
199 | "extra cheese 2.00, \\\n",
200 | "mushrooms 1.50 \\\n",
201 | "sausage 3.00 \\\n",
202 | "canadian bacon 3.50 \\\n",
203 | "AI sauce 1.50 \\\n",
204 | "peppers 1.00 \\\n",
205 | "Drinks: \\\n",
206 | "coke 3.00, 2.00, 1.00 \\\n",
207 | "sprite 3.00, 2.00, 1.00 \\\n",
208 | "bottled water 5.00 \\\n",
209 | "\"\"\"} ] # accumulate messages\n",
210 | "\n",
211 | "\n",
212 | "inp = pn.widgets.TextInput(value=\"Hi\", placeholder='Enter text here…')\n",
213 | "button_conversation = pn.widgets.Button(name=\"Chat!\")\n",
214 | "\n",
215 | "interactive_conversation = pn.bind(collect_messages, button_conversation)\n",
216 | "\n",
217 | "dashboard = pn.Column(\n",
218 | " inp,\n",
219 | " pn.Row(button_conversation),\n",
220 | " pn.panel(interactive_conversation, loading_indicator=True, height=300),\n",
221 | ")\n",
222 | "\n",
223 | "dashboard"
224 | ]
225 | },
226 | {
227 | "cell_type": "code",
228 | "execution_count": null,
229 | "metadata": {},
230 | "outputs": [],
231 | "source": [
232 | "messages = context.copy()\n",
233 | "messages.append(\n",
234 | "{'role':'system', 'content':'create a json summary of the previous food order. Itemize the price for each item\\\n",
235 | " The fields should be 1) pizza, include size 2) list of toppings 3) list of drinks, include size 4) list of sides include size 5)total price '}, \n",
236 | ")\n",
237 | " #The fields should be 1) pizza, price 2) list of toppings 3) list of drinks, include size include price 4) list of sides include size include price, 5)total price '}, \n",
238 | "\n",
239 | "response = get_completion_from_messages(messages, temperature=0)\n",
240 | "print(response)"
241 | ]
242 | },
243 | {
244 | "cell_type": "code",
245 | "execution_count": null,
246 | "metadata": {},
247 | "outputs": [],
248 | "source": []
249 | },
250 | {
251 | "cell_type": "markdown",
252 | "metadata": {},
253 | "source": []
254 | }
255 | ],
256 | "metadata": {
257 | "kernelspec": {
258 | "display_name": "gpt_index",
259 | "language": "python",
260 | "name": "python3"
261 | },
262 | "language_info": {
263 | "codemirror_mode": {
264 | "name": "ipython",
265 | "version": 3
266 | },
267 | "file_extension": ".py",
268 | "mimetype": "text/x-python",
269 | "name": "python",
270 | "nbconvert_exporter": "python",
271 | "pygments_lexer": "ipython3",
272 | "version": "3.8.16"
273 | },
274 | "orig_nbformat": 4
275 | },
276 | "nbformat": 4,
277 | "nbformat_minor": 2
278 | }
279 |
--------------------------------------------------------------------------------
/notebooks-zh/1. 引言.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | **作者 吴恩达教授**
4 |
5 | 欢迎来到本课程,我们将为开发人员介绍 ChatGPT 提示工程。本课程由 Isa Fulford 教授和我一起授课。Isa Fulford 是 OpenAI 的技术团队成员,曾开发过受欢迎的 ChatGPT 检索插件,并且在教授人们如何在产品中使用 LLM 或 LLM 技术方面做出了很大贡献。她还参与编写了教授人们使用 Prompt 的 OpenAI cookbook。
6 |
7 | 互联网上有很多有关提示的材料,例如《30 prompts everyone has to know》之类的文章。这些文章主要集中在 ChatGPT Web 用户界面上,许多人在使用它执行特定的、通常是一次性的任务。但是,我认为 LLM 或大型语言模型作为开发人员的更强大功能是使用 API 调用到 LLM,以快速构建软件应用程序。我认为这方面还没有得到充分的重视。实际上,我们在 DeepLearning.AI 的姊妹公司 AI Fund 的团队一直在与许多初创公司合作,将这些技术应用于许多不同的应用程序上。看到 LLM API 能够让开发人员非常快速地构建应用程序,这真是令人兴奋。
8 |
9 | 在本课程中,我们将与您分享一些可能性以及如何实现它们的最佳实践。
10 |
11 | 随着大型语言模型(LLM)的发展,LLM 大致可以分为两种类型,即基础LLM和指令微调LLM。基础LLM是基于文本训练数据,训练出预测下一个单词能力的模型,其通常是在互联网和其他来源的大量数据上训练的。例如,如果你以“从前有一只独角兽”作为提示,基础LLM可能会继续预测“生活在一个与所有独角兽朋友的神奇森林中”。但是,如果你以“法国的首都是什么”为提示,则基础LLM可能会根据互联网上的文章,将答案预测为“法国最大的城市是什么?法国的人口是多少?”,因为互联网上的文章很可能是有关法国国家的问答题目列表。
12 |
13 | 许多 LLMs 的研究和实践的动力正在指令调整的 LLMs 上。指令调整的 LLMs 已经被训练来遵循指令。因此,如果你问它,“法国的首都是什么?”,它更有可能输出“法国的首都是巴黎”。指令调整的 LLMs 的训练通常是从已经训练好的基本 LLMs 开始,该模型已经在大量文本数据上进行了训练。然后,使用输入是指令、输出是其应该返回的结果的数据集来对其进行微调,要求它遵循这些指令。然后通常使用一种称为 RLHF(reinforcement learning from human feedback,人类反馈强化学习)的技术进行进一步改进,使系统更能够有帮助地遵循指令。
14 |
15 | 因为指令调整的 LLMs 已经被训练成有益、诚实和无害的,所以与基础LLMs相比,它们更不可能输出有问题的文本,如有害输出。许多实际使用场景已经转向指令调整的LLMs。您在互联网上找到的一些最佳实践可能更适用于基础LLMs,但对于今天的大多数实际应用,我们建议将注意力集中在指令调整的LLMs上,这些LLMs更容易使用,而且由于OpenAI和其他LLM公司的工作,它们变得更加安全和更加协调。
16 |
17 | 因此,本课程将重点介绍针对指令调整 LLM 的最佳实践,这是我们建议您用于大多数应用程序的。在继续之前,我想感谢 OpenAI 和 DeepLearning.ai 团队为 Izzy 和我所提供的材料作出的贡献。我非常感激 OpenAI 的 Andrew Main、Joe Palermo、Boris Power、Ted Sanders 和 Lillian Weng,他们参与了我们的头脑风暴材料的制定和审核,为这个短期课程编制了课程大纲。我也感激 Deep Learning 方面的 Geoff Ladwig、Eddy Shyu 和 Tommy Nelson 的工作。
18 |
19 | 当您使用指令调整 LLM 时,请类似于考虑向另一个人提供指令,假设它是一个聪明但不知道您任务的具体细节的人。当 LLM 无法正常工作时,有时是因为指令不够清晰。例如,如果您说“请为我写一些关于阿兰·图灵的东西”,清楚表明您希望文本专注于他的科学工作、个人生活、历史角色或其他方面可能会更有帮助。更多的,您还可以指定文本采取像专业记者写作的语调,或者更像是您向朋友写的随笔。
20 |
21 | 当然,如果你想象一下让一位新毕业的大学生为你完成这个任务,你甚至可以提前指定他们应该阅读哪些文本片段来写关于 Alan Turing的文本,那么这能够帮助这位新毕业的大学生更好地成功完成这项任务。下一章你会看到如何让提示清晰明确,创建提示的一个重要原则,你还会从提示的第二个原则中学到给LLM时间去思考。
--------------------------------------------------------------------------------
/notebooks-zh/3. 迭代 Iterative.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 迭代式提示开发\n",
8 | "\n",
9 | "当使用 LLM 构建应用程序时,我从来没有在第一次尝试中就成功使用最终应用程序中所需的 Prompt。但这并不重要,只要您有一个好的迭代过程来不断改进您的 Prompt,那么你就能够得到一个适合任务的 Prompt。我认为在提示方面,第一次成功的几率可能会高一些,但正如上所说,第一个提示是否有效并不重要。最重要的是为您的应用程序找到有效提示的过程。\n",
10 | "\n",
11 | "因此,在本章中,我们将以从产品说明书中生成营销文案这一示例,展示一些框架,以提示你思考如何迭代地分析和完善你的 Prompt。\n",
12 | "\n",
13 | "如果您之前与我一起上过机器学习课程,您可能见过我使用的一张图表,说明了机器学习开发的流程。通常是先有一个想法,然后再实现它:编写代码,获取数据,训练模型,这会给您一个实验结果。然后您可以查看输出结果,进行错误分析,找出它在哪里起作用或不起作用,甚至可以更改您想要解决的问题的确切思路或方法,然后更改实现并运行另一个实验等等,反复迭代,以获得有效的机器学习模型。在编写 Prompt 以使用 LLM 开发应用程序时,这个过程可能非常相似,您有一个关于要完成的任务的想法,可以尝试编写第一个 Prompt,满足上一章说过的两个原则:清晰明确,并且给系统足够的时间思考。然后您可以运行它并查看结果。如果第一次效果不好,那么迭代的过程就是找出为什么指令不够清晰或为什么没有给算法足够的时间思考,以便改进想法、改进提示等等,循环多次,直到找到适合您的应用程序的 Prompt。\n"
14 | ]
15 | },
16 | {
17 | "cell_type": "markdown",
18 | "metadata": {},
19 | "source": [
20 | "## 环境配置\n",
21 | "\n",
22 | "同上一章,我们首先需要配置使用 OpenAI API 的环境"
23 | ]
24 | },
25 | {
26 | "cell_type": "code",
27 | "execution_count": 1,
28 | "metadata": {},
29 | "outputs": [],
30 | "source": [
31 | "import openai\n",
32 | "import os\n",
33 | "from dotenv import load_dotenv, find_dotenv\n",
34 | "# 导入第三方库\n",
35 | "\n",
36 | "_ = load_dotenv(find_dotenv())\n",
37 | "# 读取系统中的环境变量\n",
38 | "\n",
39 | "openai.api_key = os.getenv('OPENAI_API_KEY')\n",
40 | "# 设置 API_KEY"
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": 2,
46 | "metadata": {},
47 | "outputs": [],
48 | "source": [
49 | "# 一个封装 OpenAI 接口的函数,参数为 Prompt,返回对应结果\n",
50 | "def get_completion(prompt, model=\"gpt-3.5-turbo\"):\n",
51 | " '''\n",
52 | " prompt: 对应的提示\n",
53 | " model: 调用的模型,默认为 gpt-3.5-turbo(ChatGPT),有内测资格的用户可以选择 gpt-4\n",
54 | " '''\n",
55 | " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
56 | " response = openai.ChatCompletion.create(\n",
57 | " model=model,\n",
58 | " messages=messages,\n",
59 | " temperature=0, # 模型输出的温度系数,控制输出的随机程度\n",
60 | " )\n",
61 | " # 调用 OpenAI 的 ChatCompletion 接口\n",
62 | " return response.choices[0].message[\"content\"]\n"
63 | ]
64 | },
65 | {
66 | "cell_type": "markdown",
67 | "metadata": {},
68 | "source": [
69 | "## 任务——从产品说明书生成一份营销产品描述"
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "metadata": {},
75 | "source": [
76 | "这里有一个椅子的产品说明书,描述说它是一个中世纪灵感家族的一部分,讨论了构造、尺寸、椅子选项、材料等等,产地是意大利。假设您想要使用这份说明书帮助营销团队为在线零售网站撰写营销式描述"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 3,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "# 示例:产品说明书\n",
86 | "fact_sheet_chair = \"\"\"\n",
87 | "OVERVIEW\n",
88 | "- Part of a beautiful family of mid-century inspired office furniture, \n",
89 | "including filing cabinets, desks, bookcases, meeting tables, and more.\n",
90 | "- Several options of shell color and base finishes.\n",
91 | "- Available with plastic back and front upholstery (SWC-100) \n",
92 | "or full upholstery (SWC-110) in 10 fabric and 6 leather options.\n",
93 | "- Base finish options are: stainless steel, matte black, \n",
94 | "gloss white, or chrome.\n",
95 | "- Chair is available with or without armrests.\n",
96 | "- Suitable for home or business settings.\n",
97 | "- Qualified for contract use.\n",
98 | "\n",
99 | "CONSTRUCTION\n",
100 | "- 5-wheel plastic coated aluminum base.\n",
101 | "- Pneumatic chair adjust for easy raise/lower action.\n",
102 | "\n",
103 | "DIMENSIONS\n",
104 | "- WIDTH 53 CM | 20.87”\n",
105 | "- DEPTH 51 CM | 20.08”\n",
106 | "- HEIGHT 80 CM | 31.50”\n",
107 | "- SEAT HEIGHT 44 CM | 17.32”\n",
108 | "- SEAT DEPTH 41 CM | 16.14”\n",
109 | "\n",
110 | "OPTIONS\n",
111 | "- Soft or hard-floor caster options.\n",
112 | "- Two choices of seat foam densities: \n",
113 | "medium (1.8 lb/ft3) or high (2.8 lb/ft3)\n",
114 | "- Armless or 8 position PU armrests \n",
115 | "\n",
116 | "MATERIALS\n",
117 | "SHELL BASE GLIDER\n",
118 | "- Cast Aluminum with modified nylon PA6/PA66 coating.\n",
119 | "- Shell thickness: 10 mm.\n",
120 | "SEAT\n",
121 | "- HD36 foam\n",
122 | "\n",
123 | "COUNTRY OF ORIGIN\n",
124 | "- Italy\n",
125 | "\"\"\""
126 | ]
127 | },
128 | {
129 | "cell_type": "code",
130 | "execution_count": 4,
131 | "metadata": {},
132 | "outputs": [
133 | {
134 | "name": "stdout",
135 | "output_type": "stream",
136 | "text": [
137 | "Introducing our stunning mid-century inspired office chair, the perfect addition to any home or business setting. Part of a beautiful family of office furniture, including filing cabinets, desks, bookcases, meeting tables, and more, this chair is available in several options of shell color and base finishes to suit your style. Choose from plastic back and front upholstery (SWC-100) or full upholstery (SWC-110) in 10 fabric and 6 leather options.\n",
138 | "\n",
139 | "The chair is constructed with a 5-wheel plastic coated aluminum base and features a pneumatic chair adjust for easy raise/lower action. It is available with or without armrests and is qualified for contract use. The base finish options are stainless steel, matte black, gloss white, or chrome.\n",
140 | "\n",
141 | "Measuring at a width of 53 cm, depth of 51 cm, and height of 80 cm, with a seat height of 44 cm and seat depth of 41 cm, this chair is designed for ultimate comfort. You can also choose between soft or hard-floor caster options and two choices of seat foam densities: medium (1.8 lb/ft3) or high (2.8 lb/ft3). The armrests are available in either an armless or 8 position PU option.\n",
142 | "\n",
143 | "The materials used in the construction of this chair are of the highest quality. The shell base glider is made of cast aluminum with modified nylon PA6/PA66 coating and has a shell thickness of 10 mm. The seat is made of HD36 foam, ensuring maximum comfort and durability.\n",
144 | "\n",
145 | "This chair is made in Italy and is the perfect combination of style and functionality. Upgrade your workspace with our mid-century inspired office chair today!\n"
146 | ]
147 | }
148 | ],
149 | "source": [
150 | "# 提示:基于说明书生成营销描述\n",
151 | "prompt = f\"\"\"\n",
152 | "Your task is to help a marketing team create a \n",
153 | "description for a retail website of a product based \n",
154 | "on a technical fact sheet.\n",
155 | "\n",
156 | "Write a product description based on the information \n",
157 | "provided in the technical specifications delimited by \n",
158 | "triple backticks.\n",
159 | "\n",
160 | "Technical specifications: ```{fact_sheet_chair}```\n",
161 | "\"\"\"\n",
162 | "response = get_completion(prompt)\n",
163 | "print(response)\n"
164 | ]
165 | },
166 | {
167 | "cell_type": "code",
168 | "execution_count": 5,
169 | "metadata": {},
170 | "outputs": [],
171 | "source": [
172 | "# 示例:产品说明书\n",
173 | "fact_sheet_chair = \"\"\"\n",
174 | "概述\n",
175 | "\n",
176 | " 美丽的中世纪风格办公家具系列的一部分,包括文件柜、办公桌、书柜、会议桌等。\n",
177 | " 多种外壳颜色和底座涂层可选。\n",
178 | " 可选塑料前后靠背装饰(SWC-100)或10种面料和6种皮革的全面装饰(SWC-110)。\n",
179 | " 底座涂层选项为:不锈钢、哑光黑色、光泽白色或铬。\n",
180 | " 椅子可带或不带扶手。\n",
181 | " 适用于家庭或商业场所。\n",
182 | " 符合合同使用资格。\n",
183 | "\n",
184 | "结构\n",
185 | "\n",
186 | " 五个轮子的塑料涂层铝底座。\n",
187 | " 气动椅子调节,方便升降。\n",
188 | "\n",
189 | "尺寸\n",
190 | "\n",
191 | " 宽度53厘米|20.87英寸\n",
192 | " 深度51厘米|20.08英寸\n",
193 | " 高度80厘米|31.50英寸\n",
194 | " 座椅高度44厘米|17.32英寸\n",
195 | " 座椅深度41厘米|16.14英寸\n",
196 | "\n",
197 | "选项\n",
198 | "\n",
199 | " 软地板或硬地板滚轮选项。\n",
200 | " 两种座椅泡沫密度可选:中等(1.8磅/立方英尺)或高(2.8磅/立方英尺)。\n",
201 | " 无扶手或8个位置PU扶手。\n",
202 | "\n",
203 | "材料\n",
204 | "外壳底座滑动件\n",
205 | "\n",
206 | " 改性尼龙PA6/PA66涂层的铸铝。\n",
207 | " 外壳厚度:10毫米。\n",
208 | " 座椅\n",
209 | " HD36泡沫\n",
210 | "\n",
211 | "原产国\n",
212 | "\n",
213 | " 意大利\n",
214 | "\"\"\""
215 | ]
216 | },
217 | {
218 | "cell_type": "code",
219 | "execution_count": 6,
220 | "metadata": {},
221 | "outputs": [
222 | {
223 | "name": "stdout",
224 | "output_type": "stream",
225 | "text": [
226 | "产品描述:\n",
227 | "\n",
228 | "我们自豪地推出美丽的中世纪风格办公家具系列,其中包括文件柜、办公桌、书柜、会议桌等。我们的产品采用多种外壳颜色和底座涂层,以满足您的个性化需求。您可以选择塑料前后靠背装饰(SWC-100)或10种面料和6种皮革的全面装饰(SWC-110),以使您的办公室更加舒适和时尚。\n",
229 | "\n",
230 | "我们的底座涂层选项包括不锈钢、哑光黑色、光泽白色或铬,以满足您的不同需求。椅子可带或不带扶手,适用于家庭或商业场所。我们的产品符合合同使用资格,为您提供更加可靠的保障。\n",
231 | "\n",
232 | "我们的产品采用五个轮子的塑料涂层铝底座,气动椅子调节,方便升降。尺寸为宽度53厘米|20.87英寸,深度51厘米|20.08英寸,高度80厘米|31.50英寸,座椅高度44厘米|17.32英寸,座椅深度41厘米|16.14英寸,为您提供舒适的使用体验。\n",
233 | "\n",
234 | "我们的产品还提供软地板或硬地板滚轮选项,两种座椅泡沫密度可选:中等(1.8磅/立方英尺)或高(2.8磅/立方英尺),以及无扶手或8个位置PU扶手,以满足您的不同需求。\n",
235 | "\n",
236 | "我们的产品采用改性尼龙PA6/PA66涂层的铸铝外壳底座滑动件,外壳厚度为10毫米,座椅采用HD36泡沫,为您提供更加舒适的使用体验。我们的产品原产国为意大利,为您提供更加优质的品质保证。\n"
237 | ]
238 | }
239 | ],
240 | "source": [
241 | "# 提示:基于说明书创建营销描述\n",
242 | "prompt = f\"\"\"\n",
243 | "你的任务是帮助营销团队基于技术说明书创建一个产品的营销描述。\n",
244 | "\n",
245 | "根据```标记的技术说明书中提供的信息,编写一个产品描述。\n",
246 | "\n",
247 | "技术说明: ```{fact_sheet_chair}```\n",
248 | "\"\"\"\n",
249 | "response = get_completion(prompt)\n",
250 | "print(response)\n"
251 | ]
252 | },
253 | {
254 | "cell_type": "markdown",
255 | "metadata": {},
256 | "source": [
257 | "## 问题一:生成文本太长\n",
258 | "\n",
259 | "它似乎很好地写了一个描述,介绍了一个惊人的中世纪灵感办公椅,很好地完成了要求,即从技术说明书开始编写产品描述。但是当我看到这个时,我会觉得这个太长了。\n",
260 | "\n",
261 | "所以我有了一个想法。我写了一个提示,得到了结果。但是我对它不是很满意,因为它太长了,所以我会澄清我的提示,并说最多使用50个字。\n",
262 | "\n",
263 | "因此,我通过要求它限制生成文本长度来解决这一问题"
264 | ]
265 | },
266 | {
267 | "cell_type": "code",
268 | "execution_count": 21,
269 | "metadata": {},
270 | "outputs": [
271 | {
272 | "name": "stdout",
273 | "output_type": "stream",
274 | "text": [
275 | "Introducing our beautiful medieval-style office furniture collection, including filing cabinets, desks, bookcases, and conference tables. Choose from a variety of shell colors and base coatings, with optional plastic or fabric/leather decoration. The chair features a plastic-coated aluminum base with five wheels and pneumatic height adjustment. Perfect for home or commercial use. Made in Italy.\n"
276 | ]
277 | }
278 | ],
279 | "source": [
280 | "# 优化后的 Prompt,要求生成描述不多于 50 词\n",
281 | "prompt = f\"\"\"\n",
282 | "Your task is to help a marketing team create a \n",
283 | "description for a retail website of a product based \n",
284 | "on a technical fact sheet.\n",
285 | "\n",
286 | "Write a product description based on the information \n",
287 | "provided in the technical specifications delimited by \n",
288 | "triple backticks.\n",
289 | "\n",
290 | "Use at most 50 words.\n",
291 | "\n",
292 | "Technical specifications: ```{fact_sheet_chair}```\n",
293 | "\"\"\"\n",
294 | "response = get_completion(prompt)\n",
295 | "print(response)\n"
296 | ]
297 | },
298 | {
299 | "cell_type": "markdown",
300 | "metadata": {},
301 | "source": [
302 | "取出回答并根据空格拆分,答案为54个字,较好地完成了我的要求"
303 | ]
304 | },
305 | {
306 | "cell_type": "code",
307 | "execution_count": 22,
308 | "metadata": {},
309 | "outputs": [
310 | {
311 | "name": "stdout",
312 | "output_type": "stream",
313 | "text": [
314 | "54\n"
315 | ]
316 | }
317 | ],
318 | "source": [
319 | "lst = response.split()\n",
320 | "print(len(lst))"
321 | ]
322 | },
323 | {
324 | "cell_type": "code",
325 | "execution_count": 10,
326 | "metadata": {},
327 | "outputs": [
328 | {
329 | "name": "stdout",
330 | "output_type": "stream",
331 | "text": [
332 | "中世纪风格办公家具系列,包括文件柜、办公桌、书柜、会议桌等。多种颜色和涂层可选,可带或不带扶手。底座涂层选项为不锈钢、哑光黑色、光泽白色或铬。适用于家庭或商业场所,符合合同使用资格。意大利制造。\n"
333 | ]
334 | }
335 | ],
336 | "source": [
337 | "# 优化后的 Prompt,要求生成描述不多于 50 词\n",
338 | "prompt = f\"\"\"\n",
339 | "您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。\n",
340 | "\n",
341 | "根据```标记的技术说明书中提供的信息,编写一个产品描述。\n",
342 | "\n",
343 | "使用最多50个词。\n",
344 | "\n",
345 | "技术规格:```{fact_sheet_chair}```\n",
346 | "\"\"\"\n",
347 | "response = get_completion(prompt)\n",
348 | "print(response)\n"
349 | ]
350 | },
351 | {
352 | "cell_type": "code",
353 | "execution_count": 11,
354 | "metadata": {},
355 | "outputs": [
356 | {
357 | "data": {
358 | "text/plain": [
359 | "97"
360 | ]
361 | },
362 | "execution_count": 11,
363 | "metadata": {},
364 | "output_type": "execute_result"
365 | }
366 | ],
367 | "source": [
368 | "# 由于中文需要分词,此处直接计算整体长度\n",
369 | "len(response)"
370 | ]
371 | },
372 | {
373 | "cell_type": "markdown",
374 | "metadata": {},
375 | "source": [
376 | "LLM在遵循非常精确的字数限制方面表现得还可以,但并不那么出色。有时它会输出60或65个单词的内容,但这还算是合理的。这原因是 LLM 解释文本使用一种叫做分词器的东西,但它们往往在计算字符方面表现一般般。有很多不同的方法来尝试控制你得到的输出的长度。"
377 | ]
378 | },
379 | {
380 | "cell_type": "markdown",
381 | "metadata": {},
382 | "source": [
383 | "## 问题二:文本关注在错误的细节上\n",
384 | "\n",
385 | "我们会发现的第二个问题是,这个网站并不是直接向消费者销售,它实际上旨在向家具零售商销售家具,他们会更关心椅子的技术细节和材料。在这种情况下,你可以修改这个提示,让它更精确地描述椅子的技术细节。\n",
386 | "\n",
387 | "解决方法:要求它专注于与目标受众相关的方面。"
388 | ]
389 | },
390 | {
391 | "cell_type": "code",
392 | "execution_count": 13,
393 | "metadata": {},
394 | "outputs": [
395 | {
396 | "name": "stdout",
397 | "output_type": "stream",
398 | "text": [
399 | "Introducing our beautiful medieval-style office furniture collection, including file cabinets, desks, bookcases, and conference tables. Available in multiple shell colors and base coatings, with optional plastic or fabric/leather upholstery. Features a plastic-coated aluminum base with five wheels and pneumatic chair adjustment. Suitable for home or commercial use and made with high-quality materials, including cast aluminum with a modified nylon coating and HD36 foam. Made in Italy.\n"
400 | ]
401 | }
402 | ],
403 | "source": [
404 | "# 优化后的 Prompt,说明面向对象,应具有什么性质且侧重于什么方面\n",
405 | "prompt = f\"\"\"\n",
406 | "Your task is to help a marketing team create a \n",
407 | "description for a retail website of a product based \n",
408 | "on a technical fact sheet.\n",
409 | "\n",
410 | "Write a product description based on the information \n",
411 | "provided in the technical specifications delimited by \n",
412 | "triple backticks.\n",
413 | "\n",
414 | "The description is intended for furniture retailers, \n",
415 | "so should be technical in nature and focus on the \n",
416 | "materials the product is constructed from.\n",
417 | "\n",
418 | "Use at most 50 words.\n",
419 | "\n",
420 | "Technical specifications: ```{fact_sheet_chair}```\n",
421 | "\"\"\"\n",
422 | "response = get_completion(prompt)\n",
423 | "print(response)"
424 | ]
425 | },
426 | {
427 | "cell_type": "code",
428 | "execution_count": 14,
429 | "metadata": {},
430 | "outputs": [
431 | {
432 | "name": "stdout",
433 | "output_type": "stream",
434 | "text": [
435 | "这款中世纪风格办公家具系列包括文件柜、办公桌、书柜和会议桌等,适用于家庭或商业场所。可选多种外壳颜色和底座涂层,底座涂层选项为不锈钢、哑光黑色、光泽白色或铬。椅子可带或不带扶手,可选软地板或硬地板滚轮,两种座椅泡沫密度可选。外壳底座滑动件采用改性尼龙PA6/PA66涂层的铸铝,座椅采用HD36泡沫。原产国为意大利。\n"
436 | ]
437 | }
438 | ],
439 | "source": [
440 | "# 优化后的 Prompt,说明面向对象,应具有什么性质且侧重于什么方面\n",
441 | "prompt = f\"\"\"\n",
442 | "您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。\n",
443 | "\n",
444 | "根据```标记的技术说明书中提供的信息,编写一个产品描述。\n",
445 | "\n",
446 | "该描述面向家具零售商,因此应具有技术性质,并侧重于产品的材料构造。\n",
447 | "\n",
448 | "使用最多50个单词。\n",
449 | "\n",
450 | "技术规格: ```{fact_sheet_chair}```\n",
451 | "\"\"\"\n",
452 | "response = get_completion(prompt)\n",
453 | "print(response)"
454 | ]
455 | },
456 | {
457 | "cell_type": "markdown",
458 | "metadata": {},
459 | "source": [
460 | "我可能进一步想要在描述的结尾包括产品ID。因此,我可以进一步改进这个提示,要求在描述的结尾,包括在技术说明中的每个7个字符产品ID。"
461 | ]
462 | },
463 | {
464 | "cell_type": "code",
465 | "execution_count": 15,
466 | "metadata": {},
467 | "outputs": [
468 | {
469 | "name": "stdout",
470 | "output_type": "stream",
471 | "text": [
472 | "Introducing our beautiful medieval-style office furniture collection, featuring file cabinets, desks, bookshelves, and conference tables. Available in multiple shell colors and base coatings, with optional plastic or fabric/leather decorations. The chair comes with or without armrests and has a plastic-coated aluminum base with five wheels and pneumatic height adjustment. Suitable for home or commercial use. Made in Italy.\n",
473 | "\n",
474 | "Product IDs: SWC-100, SWC-110\n"
475 | ]
476 | }
477 | ],
478 | "source": [
479 | "# 更进一步,要求在描述末尾包含 7个字符的产品ID\n",
480 | "prompt = f\"\"\"\n",
481 | "Your task is to help a marketing team create a \n",
482 | "description for a retail website of a product based \n",
483 | "on a technical fact sheet.\n",
484 | "\n",
485 | "Write a product description based on the information \n",
486 | "provided in the technical specifications delimited by \n",
487 | "triple backticks.\n",
488 | "\n",
489 | "The description is intended for furniture retailers, \n",
490 | "so should be technical in nature and focus on the \n",
491 | "materials the product is constructed from.\n",
492 | "\n",
493 | "At the end of the description, include every 7-character \n",
494 | "Product ID in the technical specification.\n",
495 | "\n",
496 | "Use at most 50 words.\n",
497 | "\n",
498 | "Technical specifications: ```{fact_sheet_chair}```\n",
499 | "\"\"\"\n",
500 | "response = get_completion(prompt)\n",
501 | "print(response)"
502 | ]
503 | },
504 | {
505 | "cell_type": "code",
506 | "execution_count": 16,
507 | "metadata": {},
508 | "outputs": [
509 | {
510 | "name": "stdout",
511 | "output_type": "stream",
512 | "text": [
513 | "这款中世纪风格的办公家具系列包括文件柜、办公桌、书柜和会议桌等,适用于家庭或商业场所。可选多种外壳颜色和底座涂层,底座涂层选项为不锈钢、哑光黑色、光泽白色或铬。椅子可带或不带扶手,可选塑料前后靠背装饰或10种面料和6种皮革的全面装饰。座椅采用HD36泡沫,可选中等或高密度,座椅高度44厘米,深度41厘米。外壳底座滑动件采用改性尼龙PA6/PA66涂层的铸铝,外壳厚度为10毫米。原产国为意大利。产品ID:SWC-100/SWC-110。\n"
514 | ]
515 | }
516 | ],
517 | "source": [
518 | "# 更进一步\n",
519 | "prompt = f\"\"\"\n",
520 | "您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。\n",
521 | "\n",
522 | "根据```标记的技术说明书中提供的信息,编写一个产品描述。\n",
523 | "\n",
524 | "该描述面向家具零售商,因此应具有技术性质,并侧重于产品的材料构造。\n",
525 | "\n",
526 | "在描述末尾,包括技术规格中每个7个字符的产品ID。\n",
527 | "\n",
528 | "使用最多50个单词。\n",
529 | "\n",
530 | "技术规格: ```{fact_sheet_chair}```\n",
531 | "\"\"\"\n",
532 | "response = get_completion(prompt)\n",
533 | "print(response)"
534 | ]
535 | },
536 | {
537 | "cell_type": "markdown",
538 | "metadata": {},
539 | "source": [
540 | "## 问题三:需要一个表格形式的描述\n",
541 | "\n",
542 | "以上是许多开发人员通常会经历的迭代提示开发的简短示例。我的建议是,像上一章中所演示的那样,Prompt 应该保持清晰和明确,并在必要时给模型一些思考时间。在这些要求的基础上,通常值得首先尝试编写 Prompt ,看看会发生什么,然后从那里开始迭代地完善 Prompt,以逐渐接近所需的结果。因此,许多成功的Prompt都是通过这种迭代过程得出的。我将向您展示一个更复杂的提示示例,可能会让您对ChatGPT的能力有更深入的了解。\n",
543 | "\n",
544 | "这里我添加了一些额外的说明,要求它抽取信息并组织成表格,并指定表格的列、表名和格式,还要求它将所有内容格式化为可以在网页使用的 HTML。"
545 | ]
546 | },
547 | {
548 | "cell_type": "code",
549 | "execution_count": 17,
550 | "metadata": {},
551 | "outputs": [
552 | {
553 | "name": "stdout",
554 | "output_type": "stream",
555 | "text": [
556 | "
\n",
557 | "
Introducing our beautiful collection of medieval-style office furniture, including file cabinets, desks, bookcases, and conference tables. Choose from a variety of shell colors and base coatings. You can opt for plastic front and backrest decoration (SWC-100) or full decoration with 10 fabrics and 6 leathers (SWC-110). Base coating options include stainless steel, matte black, glossy white, or chrome. The chair is available with or without armrests and is suitable for both home and commercial settings. It is contract eligible.
\n",
558 | "
The structure features a plastic-coated aluminum base with five wheels. The chair is pneumatically adjustable for easy height adjustment.
\n",
559 | "
Product IDs: SWC-100, SWC-110
\n",
560 | "
\n",
561 | " Product Dimensions\n",
562 | " \n",
563 | " | Width | \n",
564 | " 20.87 inches | \n",
565 | "
\n",
566 | " \n",
567 | " | Depth | \n",
568 | " 20.08 inches | \n",
569 | "
\n",
570 | " \n",
571 | " | Height | \n",
572 | " 31.50 inches | \n",
573 | "
\n",
574 | " \n",
575 | " | Seat Height | \n",
576 | " 17.32 inches | \n",
577 | "
\n",
578 | " \n",
579 | " | Seat Depth | \n",
580 | " 16.14 inches | \n",
581 | "
\n",
582 | "
\n",
583 | "
Options include soft or hard floor casters. You can choose from two seat foam densities: medium (1.8 pounds/cubic foot) or high (2.8 pounds/cubic foot). The chair is available with or without 8-position PU armrests.
\n",
584 | "
Materials:
\n",
585 | "
\n",
586 | " - Shell, base, and sliding parts: cast aluminum coated with modified nylon PA6/PA66. Shell thickness: 10mm.
\n",
587 | " - Seat: HD36 foam
\n",
588 | "
\n",
589 | "
Made in Italy.
\n",
590 | "
\n"
591 | ]
592 | }
593 | ],
594 | "source": [
595 | "# 要求它抽取信息并组织成表格,并指定表格的列、表名和格式\n",
596 | "prompt = f\"\"\"\n",
597 | "Your task is to help a marketing team create a \n",
598 | "description for a retail website of a product based \n",
599 | "on a technical fact sheet.\n",
600 | "\n",
601 | "Write a product description based on the information \n",
602 | "provided in the technical specifications delimited by \n",
603 | "triple backticks.\n",
604 | "\n",
605 | "The description is intended for furniture retailers, \n",
606 | "so should be technical in nature and focus on the \n",
607 | "materials the product is constructed from.\n",
608 | "\n",
609 | "At the end of the description, include every 7-character \n",
610 | "Product ID in the technical specification.\n",
611 | "\n",
612 | "After the description, include a table that gives the \n",
613 | "product's dimensions. The table should have two columns.\n",
614 | "In the first column include the name of the dimension. \n",
615 | "In the second column include the measurements in inches only.\n",
616 | "\n",
617 | "Give the table the title 'Product Dimensions'.\n",
618 | "\n",
619 | "Format everything as HTML that can be used in a website. \n",
620 | "Place the description in a
element.\n",
621 | "\n",
622 | "Technical specifications: ```{fact_sheet_chair}```\n",
623 | "\"\"\"\n",
624 | "\n",
625 | "response = get_completion(prompt)\n",
626 | "print(response)"
627 | ]
628 | },
629 | {
630 | "cell_type": "code",
631 | "execution_count": 18,
632 | "metadata": {},
633 | "outputs": [
634 | {
635 | "data": {
636 | "text/html": [
637 | "
\n",
638 | "
Introducing our beautiful collection of medieval-style office furniture, including file cabinets, desks, bookcases, and conference tables. Choose from a variety of shell colors and base coatings. You can opt for plastic front and backrest decoration (SWC-100) or full decoration with 10 fabrics and 6 leathers (SWC-110). Base coating options include stainless steel, matte black, glossy white, or chrome. The chair is available with or without armrests and is suitable for both home and commercial settings. It is contract eligible.
\n",
639 | "
The structure features a plastic-coated aluminum base with five wheels. The chair is pneumatically adjustable for easy height adjustment.
\n",
640 | "
Product IDs: SWC-100, SWC-110
\n",
641 | "
\n",
642 | " Product Dimensions\n",
643 | " \n",
644 | " | Width | \n",
645 | " 20.87 inches | \n",
646 | "
\n",
647 | " \n",
648 | " | Depth | \n",
649 | " 20.08 inches | \n",
650 | "
\n",
651 | " \n",
652 | " | Height | \n",
653 | " 31.50 inches | \n",
654 | "
\n",
655 | " \n",
656 | " | Seat Height | \n",
657 | " 17.32 inches | \n",
658 | "
\n",
659 | " \n",
660 | " | Seat Depth | \n",
661 | " 16.14 inches | \n",
662 | "
\n",
663 | "
\n",
664 | "
Options include soft or hard floor casters. You can choose from two seat foam densities: medium (1.8 pounds/cubic foot) or high (2.8 pounds/cubic foot). The chair is available with or without 8-position PU armrests.
\n",
665 | "
Materials:
\n",
666 | "
\n",
667 | " - Shell, base, and sliding parts: cast aluminum coated with modified nylon PA6/PA66. Shell thickness: 10mm.
\n",
668 | " - Seat: HD36 foam
\n",
669 | "
\n",
670 | "
Made in Italy.
\n",
671 | "
"
672 | ],
673 | "text/plain": [
674 | "
"
675 | ]
676 | },
677 | "metadata": {},
678 | "output_type": "display_data"
679 | }
680 | ],
681 | "source": [
682 | "# 表格是以 HTML 格式呈现的,加载出来\n",
683 | "from IPython.display import display, HTML\n",
684 | "\n",
685 | "display(HTML(response))"
686 | ]
687 | },
688 | {
689 | "cell_type": "code",
690 | "execution_count": 19,
691 | "metadata": {},
692 | "outputs": [
693 | {
694 | "name": "stdout",
695 | "output_type": "stream",
696 | "text": [
697 | "\n",
698 | "
中世纪风格办公家具系列椅子
\n",
699 | "
这款椅子是中世纪风格办公家具系列的一部分,适用于家庭或商业场所。它有多种外壳颜色和底座涂层可选,包括不锈钢、哑光黑色、光泽白色或铬。您可以选择带或不带扶手的椅子,以及软地板或硬地板滚轮选项。此外,您可以选择两种座椅泡沫密度:中等(1.8磅/立方英尺)或高(2.8磅/立方英尺)。
\n",
700 | "
椅子的外壳底座滑动件是改性尼龙PA6/PA66涂层的铸铝,外壳厚度为10毫米。座椅采用HD36泡沫,底座是五个轮子的塑料涂层铝底座,可以进行气动椅子调节,方便升降。此外,椅子符合合同使用资格,是您理想的选择。
\n",
701 | "
产品ID:SWC-100
\n",
702 | "
\n",
705 | " 产品尺寸\n",
706 | " \n",
707 | " | 宽度 | \n",
708 | " 20.87英寸 | \n",
709 | "
\n",
710 | " \n",
711 | " | 深度 | \n",
712 | " 20.08英寸 | \n",
713 | "
\n",
714 | " \n",
715 | " | 高度 | \n",
716 | " 31.50英寸 | \n",
717 | "
\n",
718 | " \n",
719 | " | 座椅高度 | \n",
720 | " 17.32英寸 | \n",
721 | "
\n",
722 | " \n",
723 | " | 座椅深度 | \n",
724 | " 16.14英寸 | \n",
725 | "
\n",
726 | "
\n"
727 | ]
728 | }
729 | ],
730 | "source": [
731 | "# 要求它抽取信息并组织成表格,并指定表格的列、表名和格式\n",
732 | "prompt = f\"\"\"\n",
733 | "您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。\n",
734 | "\n",
735 | "根据```标记的技术说明书中提供的信息,编写一个产品描述。\n",
736 | "\n",
737 | "该描述面向家具零售商,因此应具有技术性质,并侧重于产品的材料构造。\n",
738 | "\n",
739 | "在描述末尾,包括技术规格中每个7个字符的产品ID。\n",
740 | "\n",
741 | "在描述之后,包括一个表格,提供产品的尺寸。表格应该有两列。第一列包括尺寸的名称。第二列只包括英寸的测量值。\n",
742 | "\n",
743 | "给表格命名为“产品尺寸”。\n",
744 | "\n",
745 | "将所有内容格式化为可用于网站的HTML格式。将描述放在元素中。\n",
746 | "\n",
747 | "技术规格:```{fact_sheet_chair}```\n",
748 | "\"\"\"\n",
749 | "\n",
750 | "response = get_completion(prompt)\n",
751 | "print(response)"
752 | ]
753 | },
754 | {
755 | "cell_type": "code",
756 | "execution_count": 20,
757 | "metadata": {},
758 | "outputs": [
759 | {
760 | "data": {
761 | "text/html": [
762 | "
\n",
763 | "
中世纪风格办公家具系列椅子
\n",
764 | "
这款椅子是中世纪风格办公家具系列的一部分,适用于家庭或商业场所。它有多种外壳颜色和底座涂层可选,包括不锈钢、哑光黑色、光泽白色或铬。您可以选择带或不带扶手的椅子,以及软地板或硬地板滚轮选项。此外,您可以选择两种座椅泡沫密度:中等(1.8磅/立方英尺)或高(2.8磅/立方英尺)。
\n",
765 | "
椅子的外壳底座滑动件是改性尼龙PA6/PA66涂层的铸铝,外壳厚度为10毫米。座椅采用HD36泡沫,底座是五个轮子的塑料涂层铝底座,可以进行气动椅子调节,方便升降。此外,椅子符合合同使用资格,是您理想的选择。
\n",
766 | "
产品ID:SWC-100
\n",
767 | "
\n",
768 | "\n",
769 | "
\n",
770 | " 产品尺寸\n",
771 | " \n",
772 | " | 宽度 | \n",
773 | " 20.87英寸 | \n",
774 | "
\n",
775 | " \n",
776 | " | 深度 | \n",
777 | " 20.08英寸 | \n",
778 | "
\n",
779 | " \n",
780 | " | 高度 | \n",
781 | " 31.50英寸 | \n",
782 | "
\n",
783 | " \n",
784 | " | 座椅高度 | \n",
785 | " 17.32英寸 | \n",
786 | "
\n",
787 | " \n",
788 | " | 座椅深度 | \n",
789 | " 16.14英寸 | \n",
790 | "
\n",
791 | "
"
792 | ],
793 | "text/plain": [
794 | "
"
795 | ]
796 | },
797 | "metadata": {},
798 | "output_type": "display_data"
799 | }
800 | ],
801 | "source": [
802 | "# 表格是以 HTML 格式呈现的,加载出来\n",
803 | "from IPython.display import display, HTML\n",
804 | "\n",
805 | "display(HTML(response))"
806 | ]
807 | },
808 | {
809 | "cell_type": "markdown",
810 | "metadata": {},
811 | "source": [
812 | "本章的主要内容是 LLM 在开发应用程序中的迭代式提示开发过程。开发者需要先尝试编写提示,然后通过迭代逐步完善它,直至得到需要的结果。关键在于拥有一种有效的开发Prompt的过程,而不是知道完美的Prompt。对于一些更复杂的应用程序,可以对多个样本进行迭代开发提示并进行评估。最后,可以在更成熟的应用程序中测试多个Prompt在多个样本上的平均或最差性能。在使用 Jupyter 代码笔记本示例时,请尝试不同的变化并查看结果。"
813 | ]
814 | },
815 | {
816 | "cell_type": "code",
817 | "execution_count": null,
818 | "metadata": {},
819 | "outputs": [],
820 | "source": []
821 | }
822 | ],
823 | "metadata": {
824 | "kernelspec": {
825 | "display_name": "Python 3",
826 | "language": "python",
827 | "name": "python3"
828 | },
829 | "language_info": {
830 | "codemirror_mode": {
831 | "name": "ipython",
832 | "version": 3
833 | },
834 | "file_extension": ".py",
835 | "mimetype": "text/x-python",
836 | "name": "python",
837 | "nbconvert_exporter": "python",
838 | "pygments_lexer": "ipython3",
839 | "version": "3.8.13"
840 | },
841 | "latex_envs": {
842 | "LaTeX_envs_menu_present": true,
843 | "autoclose": false,
844 | "autocomplete": true,
845 | "bibliofile": "biblio.bib",
846 | "cite_by": "apalike",
847 | "current_citInitial": 1,
848 | "eqLabelWithNumbers": true,
849 | "eqNumInitial": 1,
850 | "hotkeys": {
851 | "equation": "Ctrl-E",
852 | "itemize": "Ctrl-I"
853 | },
854 | "labels_anchors": false,
855 | "latex_user_defs": false,
856 | "report_style_numbering": false,
857 | "user_envs_cfg": false
858 | },
859 | "toc": {
860 | "base_numbering": 1,
861 | "nav_menu": {},
862 | "number_sections": true,
863 | "sideBar": true,
864 | "skip_h1_title": false,
865 | "title_cell": "Table of Contents",
866 | "title_sidebar": "Contents",
867 | "toc_cell": false,
868 | "toc_position": {},
869 | "toc_section_display": true,
870 | "toc_window_display": true
871 | }
872 | },
873 | "nbformat": 4,
874 | "nbformat_minor": 4
875 | }
876 |
--------------------------------------------------------------------------------
/notebooks-zh/4. 摘要 Summarizing.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "id": "b58204ea",
6 | "metadata": {},
7 | "source": [
8 | "# 文本概括 Summarizing"
9 | ]
10 | },
11 | {
12 | "cell_type": "markdown",
13 | "id": "b70ad003",
14 | "metadata": {},
15 | "source": [
16 | "## 1 引言"
17 | ]
18 | },
19 | {
20 | "cell_type": "markdown",
21 | "id": "12fa9ea4",
22 | "metadata": {},
23 | "source": [
24 | "当今世界上有太多的文本信息,几乎没有人能够拥有足够的时间去阅读所有我们想了解的东西。但令人感到欣喜的是,目前LLM在文本概括任务上展现了强大的水准,也已经有不少团队将这项功能插入了自己的软件应用中。\n",
25 | "\n",
26 | "本章节将介绍如何使用编程的方式,调用API接口来实现“文本概括”功能。"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "id": "1de4fd1e",
32 | "metadata": {},
33 | "source": [
34 | "首先,我们需要OpenAI包,加载API密钥,定义getCompletion函数。"
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 1,
40 | "id": "9f679f1f",
41 | "metadata": {},
42 | "outputs": [],
43 | "source": [
44 | "import openai\n",
45 | "import os\n",
46 | "OPENAI_API_KEY = os.environ.get(\"OPENAI_API_KEY\")\n",
47 | "openai.api_key = OPENAI_API_KEY\n",
48 | "\n",
49 | "def get_completion(prompt, model=\"gpt-3.5-turbo\"): \n",
50 | " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
51 | " response = openai.ChatCompletion.create(\n",
52 | " model=model,\n",
53 | " messages=messages,\n",
54 | " temperature=0, # 值越低则输出文本随机性越低\n",
55 | " )\n",
56 | " return response.choices[0].message[\"content\"]"
57 | ]
58 | },
59 | {
60 | "cell_type": "markdown",
61 | "id": "9cca835b",
62 | "metadata": {},
63 | "source": [
64 | "## 2 单一文本概括Prompt实验"
65 | ]
66 | },
67 | {
68 | "cell_type": "markdown",
69 | "id": "0c1e1b92",
70 | "metadata": {},
71 | "source": [
72 | "这里我们举了个商品评论的例子。对于电商平台来说,网站上往往存在着海量的商品评论,这些评论反映了所有客户的想法。如果我们拥有一个工具去概括这些海量、冗长的评论,便能够快速地浏览更多评论,洞悉客户的偏好,从而指导平台与商家提供更优质的服务。"
73 | ]
74 | },
75 | {
76 | "cell_type": "markdown",
77 | "id": "9dc2e2bc",
78 | "metadata": {},
79 | "source": [
80 | "**输入文本**"
81 | ]
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": 3,
86 | "id": "4d9c0eeb",
87 | "metadata": {},
88 | "outputs": [],
89 | "source": [
90 | "prod_review = \"\"\"\n",
91 | "Got this panda plush toy for my daughter's birthday, \\\n",
92 | "who loves it and takes it everywhere. It's soft and \\ \n",
93 | "super cute, and its face has a friendly look. It's \\ \n",
94 | "a bit small for what I paid though. I think there \\ \n",
95 | "might be other options that are bigger for the \\ \n",
96 | "same price. It arrived a day earlier than expected, \\ \n",
97 | "so I got to play with it myself before I gave it \\ \n",
98 | "to her.\n",
99 | "\"\"\""
100 | ]
101 | },
102 | {
103 | "cell_type": "markdown",
104 | "id": "aad5bd2a",
105 | "metadata": {},
106 | "source": [
107 | "**输入文本(中文翻译)**"
108 | ]
109 | },
110 | {
111 | "cell_type": "code",
112 | "execution_count": 4,
113 | "id": "43b5dd25",
114 | "metadata": {},
115 | "outputs": [],
116 | "source": [
117 | "prod_review_zh = \"\"\"\n",
118 | "这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。\n",
119 | "公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说,\n",
120 | "它有点小,我感觉在别的地方用同样的价钱能买到更大的。\n",
121 | "快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。\n",
122 | "\"\"\""
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "id": "662c9cd2",
128 | "metadata": {},
129 | "source": [
130 | "### 2.1 限制输出文本长度"
131 | ]
132 | },
133 | {
134 | "cell_type": "markdown",
135 | "id": "a6d10814",
136 | "metadata": {},
137 | "source": [
138 | "我们尝试限制文本长度为最多30词。"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": 4,
144 | "id": "02208fbc",
145 | "metadata": {},
146 | "outputs": [
147 | {
148 | "name": "stdout",
149 | "output_type": "stream",
150 | "text": [
151 | "Soft and cute panda plush toy loved by daughter, but a bit small for the price. Arrived early.\n"
152 | ]
153 | }
154 | ],
155 | "source": [
156 | "prompt = f\"\"\"\n",
157 | "Your task is to generate a short summary of a product \\\n",
158 | "review from an ecommerce site. \n",
159 | "\n",
160 | "Summarize the review below, delimited by triple \n",
161 | "backticks, in at most 30 words. \n",
162 | "\n",
163 | "Review: ```{prod_review}```\n",
164 | "\"\"\"\n",
165 | "\n",
166 | "response = get_completion(prompt)\n",
167 | "print(response)"
168 | ]
169 | },
170 | {
171 | "cell_type": "markdown",
172 | "id": "0df0eb90",
173 | "metadata": {},
174 | "source": [
175 | "中文翻译版本"
176 | ]
177 | },
178 | {
179 | "cell_type": "code",
180 | "execution_count": 5,
181 | "id": "bf4b39f9",
182 | "metadata": {},
183 | "outputs": [
184 | {
185 | "name": "stdout",
186 | "output_type": "stream",
187 | "text": [
188 | "可爱软熊猫公仔,女儿喜欢,面部表情和善,但价钱有点小贵,快递提前一天到货。\n"
189 | ]
190 | }
191 | ],
192 | "source": [
193 | "prompt = f\"\"\"\n",
194 | "你的任务是从电子商务网站上生成一个产品评论的简短摘要。\n",
195 | "\n",
196 | "请对三个反引号之间的评论文本进行概括,最多30个词汇。\n",
197 | "\n",
198 | "评论: ```{prod_review_zh}```\n",
199 | "\"\"\"\n",
200 | "\n",
201 | "response = get_completion(prompt)\n",
202 | "print(response)"
203 | ]
204 | },
205 | {
206 | "cell_type": "markdown",
207 | "id": "e9ab145e",
208 | "metadata": {},
209 | "source": [
210 | "### 2.2 关键角度侧重"
211 | ]
212 | },
213 | {
214 | "cell_type": "markdown",
215 | "id": "f84d0123",
216 | "metadata": {},
217 | "source": [
218 | "有时,针对不同的业务,我们对文本的侧重会有所不同。例如对于商品评论文本,物流会更关心运输时效,商家更加关心价格与商品质量,平台更关心整体服务体验。\n",
219 | "\n",
220 | "我们可以通过增加Prompt提示,来体现对于某个特定角度的侧重。"
221 | ]
222 | },
223 | {
224 | "cell_type": "markdown",
225 | "id": "d6f8509a",
226 | "metadata": {},
227 | "source": [
228 | "**侧重于运输**"
229 | ]
230 | },
231 | {
232 | "cell_type": "code",
233 | "execution_count": 6,
234 | "id": "9d8a32a6",
235 | "metadata": {},
236 | "outputs": [
237 | {
238 | "name": "stdout",
239 | "output_type": "stream",
240 | "text": [
241 | "The panda plush toy arrived a day earlier than expected, but the customer felt it was a bit small for the price paid.\n"
242 | ]
243 | }
244 | ],
245 | "source": [
246 | "prompt = f\"\"\"\n",
247 | "Your task is to generate a short summary of a product \\\n",
248 | "review from an ecommerce site to give feedback to the \\\n",
249 | "Shipping deparmtment. \n",
250 | "\n",
251 | "Summarize the review below, delimited by triple \n",
252 | "backticks, in at most 30 words, and focusing on any aspects \\\n",
253 | "that mention shipping and delivery of the product. \n",
254 | "\n",
255 | "Review: ```{prod_review}```\n",
256 | "\"\"\"\n",
257 | "\n",
258 | "response = get_completion(prompt)\n",
259 | "print(response)"
260 | ]
261 | },
262 | {
263 | "cell_type": "markdown",
264 | "id": "0bd4243a",
265 | "metadata": {},
266 | "source": [
267 | "中文翻译版本"
268 | ]
269 | },
270 | {
271 | "cell_type": "code",
272 | "execution_count": 8,
273 | "id": "80636c3e",
274 | "metadata": {},
275 | "outputs": [
276 | {
277 | "name": "stdout",
278 | "output_type": "stream",
279 | "text": [
280 | "快递提前到货,熊猫公仔软可爱,但有点小,价钱不太划算。\n"
281 | ]
282 | }
283 | ],
284 | "source": [
285 | "prompt = f\"\"\"\n",
286 | "你的任务是从电子商务网站上生成一个产品评论的简短摘要。\n",
287 | "\n",
288 | "请对三个反引号之间的评论文本进行概括,最多30个词汇,并且聚焦在产品运输上。\n",
289 | "\n",
290 | "评论: ```{prod_review_zh}```\n",
291 | "\"\"\"\n",
292 | "\n",
293 | "response = get_completion(prompt)\n",
294 | "print(response)"
295 | ]
296 | },
297 | {
298 | "cell_type": "markdown",
299 | "id": "76c97fea",
300 | "metadata": {},
301 | "source": [
302 | "可以看到,输出结果以“快递提前一天到货”开头,体现了对于快递效率的侧重。"
303 | ]
304 | },
305 | {
306 | "cell_type": "markdown",
307 | "id": "83275907",
308 | "metadata": {},
309 | "source": [
310 | "**侧重于价格与质量**"
311 | ]
312 | },
313 | {
314 | "cell_type": "code",
315 | "execution_count": 9,
316 | "id": "767f252c",
317 | "metadata": {},
318 | "outputs": [
319 | {
320 | "name": "stdout",
321 | "output_type": "stream",
322 | "text": [
323 | "The panda plush toy is soft, cute, and loved by the recipient, but the price may be too high for its size compared to other options.\n"
324 | ]
325 | }
326 | ],
327 | "source": [
328 | "prompt = f\"\"\"\n",
329 | "Your task is to generate a short summary of a product \\\n",
330 | "review from an ecommerce site to give feedback to the \\\n",
331 | "pricing deparmtment, responsible for determining the \\\n",
332 | "price of the product. \n",
333 | "\n",
334 | "Summarize the review below, delimited by triple \n",
335 | "backticks, in at most 30 words, and focusing on any aspects \\\n",
336 | "that are relevant to the price and perceived value. \n",
337 | "\n",
338 | "Review: ```{prod_review}```\n",
339 | "\"\"\"\n",
340 | "\n",
341 | "response = get_completion(prompt)\n",
342 | "print(response)"
343 | ]
344 | },
345 | {
346 | "cell_type": "markdown",
347 | "id": "cf54fac4",
348 | "metadata": {},
349 | "source": [
350 | "中文翻译版本"
351 | ]
352 | },
353 | {
354 | "cell_type": "code",
355 | "execution_count": 12,
356 | "id": "728d6c57",
357 | "metadata": {},
358 | "outputs": [
359 | {
360 | "name": "stdout",
361 | "output_type": "stream",
362 | "text": [
363 | "可爱软熊猫公仔,面部表情友好,但价钱有点高,尺寸较小。快递提前一天到货。\n"
364 | ]
365 | }
366 | ],
367 | "source": [
368 | "prompt = f\"\"\"\n",
369 | "你的任务是从电子商务网站上生成一个产品评论的简短摘要。\n",
370 | "\n",
371 | "请对三个反引号之间的评论文本进行概括,最多30个词汇,并且聚焦在产品价格和质量上。\n",
372 | "\n",
373 | "评论: ```{prod_review_zh}```\n",
374 | "\"\"\"\n",
375 | "\n",
376 | "response = get_completion(prompt)\n",
377 | "print(response)"
378 | ]
379 | },
380 | {
381 | "cell_type": "markdown",
382 | "id": "972dbb1b",
383 | "metadata": {},
384 | "source": [
385 | "可以看到,输出结果以“质量好、价格小贵、尺寸小”开头,体现了对于产品价格与质量的侧重。"
386 | ]
387 | },
388 | {
389 | "cell_type": "markdown",
390 | "id": "b3ed53d2",
391 | "metadata": {},
392 | "source": [
393 | "### 2.3 关键信息提取"
394 | ]
395 | },
396 | {
397 | "cell_type": "markdown",
398 | "id": "ba6f5c25",
399 | "metadata": {},
400 | "source": [
401 | "在2.2节中,虽然我们通过添加关键角度侧重的Prompt,使得文本摘要更侧重于某一特定方面,但是可以发现,结果中也会保留一些其他信息,如价格与质量角度的概括中仍保留了“快递提前到货”的信息。有时这些信息是有帮助的,但如果我们只想要提取某一角度的信息,并过滤掉其他所有信息,则可以要求LLM进行“文本提取(Extract)”而非“文本概括(Summarize)”。"
402 | ]
403 | },
404 | {
405 | "cell_type": "code",
406 | "execution_count": 13,
407 | "id": "2d60dc58",
408 | "metadata": {},
409 | "outputs": [
410 | {
411 | "name": "stdout",
412 | "output_type": "stream",
413 | "text": [
414 | "\"The product arrived a day earlier than expected.\"\n"
415 | ]
416 | }
417 | ],
418 | "source": [
419 | "prompt = f\"\"\"\n",
420 | "Your task is to extract relevant information from \\ \n",
421 | "a product review from an ecommerce site to give \\\n",
422 | "feedback to the Shipping department. \n",
423 | "\n",
424 | "From the review below, delimited by triple quotes \\\n",
425 | "extract the information relevant to shipping and \\ \n",
426 | "delivery. Limit to 30 words. \n",
427 | "\n",
428 | "Review: ```{prod_review}```\n",
429 | "\"\"\"\n",
430 | "\n",
431 | "response = get_completion(prompt)\n",
432 | "print(response)"
433 | ]
434 | },
435 | {
436 | "cell_type": "markdown",
437 | "id": "0339b877",
438 | "metadata": {},
439 | "source": [
440 | "中文翻译版本"
441 | ]
442 | },
443 | {
444 | "cell_type": "code",
445 | "execution_count": 19,
446 | "id": "c845ccab",
447 | "metadata": {},
448 | "outputs": [
449 | {
450 | "name": "stdout",
451 | "output_type": "stream",
452 | "text": [
453 | "快递比预期提前了一天到货。\n"
454 | ]
455 | }
456 | ],
457 | "source": [
458 | "prompt = f\"\"\"\n",
459 | "你的任务是从电子商务网站上的产品评论中提取相关信息。\n",
460 | "\n",
461 | "请从以下三个反引号之间的评论文本中提取产品运输相关的信息,最多30个词汇。\n",
462 | "\n",
463 | "评论: ```{prod_review_zh}```\n",
464 | "\"\"\"\n",
465 | "\n",
466 | "response = get_completion(prompt)\n",
467 | "print(response)"
468 | ]
469 | },
470 | {
471 | "cell_type": "markdown",
472 | "id": "50498a2b",
473 | "metadata": {},
474 | "source": [
475 | "## 3 多条文本概括Prompt实验"
476 | ]
477 | },
478 | {
479 | "cell_type": "markdown",
480 | "id": "a291541a",
481 | "metadata": {},
482 | "source": [
483 | "在实际的工作流中,我们往往有许许多多的评论文本,以下展示了一个基于for循环调用“文本概括”工具并依次打印的示例。当然,在实际生产中,对于上百万甚至上千万的评论文本,使用for循环也是不现实的,可能需要考虑整合评论、分布式等方法提升运算效率。"
484 | ]
485 | },
486 | {
487 | "cell_type": "code",
488 | "execution_count": 5,
489 | "id": "ee7caa78",
490 | "metadata": {},
491 | "outputs": [],
492 | "source": [
493 | "review_1 = prod_review \n",
494 | "\n",
495 | "# review for a standing lamp\n",
496 | "review_2 = \"\"\"\n",
497 | "Needed a nice lamp for my bedroom, and this one \\\n",
498 | "had additional storage and not too high of a price \\\n",
499 | "point. Got it fast - arrived in 2 days. The string \\\n",
500 | "to the lamp broke during the transit and the company \\\n",
501 | "happily sent over a new one. Came within a few days \\\n",
502 | "as well. It was easy to put together. Then I had a \\\n",
503 | "missing part, so I contacted their support and they \\\n",
504 | "very quickly got me the missing piece! Seems to me \\\n",
505 | "to be a great company that cares about their customers \\\n",
506 | "and products. \n",
507 | "\"\"\"\n",
508 | "\n",
509 | "# review for an electric toothbrush\n",
510 | "review_3 = \"\"\"\n",
511 | "My dental hygienist recommended an electric toothbrush, \\\n",
512 | "which is why I got this. The battery life seems to be \\\n",
513 | "pretty impressive so far. After initial charging and \\\n",
514 | "leaving the charger plugged in for the first week to \\\n",
515 | "condition the battery, I've unplugged the charger and \\\n",
516 | "been using it for twice daily brushing for the last \\\n",
517 | "3 weeks all on the same charge. But the toothbrush head \\\n",
518 | "is too small. I’ve seen baby toothbrushes bigger than \\\n",
519 | "this one. I wish the head was bigger with different \\\n",
520 | "length bristles to get between teeth better because \\\n",
521 | "this one doesn’t. Overall if you can get this one \\\n",
522 | "around the $50 mark, it's a good deal. The manufactuer's \\\n",
523 | "replacements heads are pretty expensive, but you can \\\n",
524 | "get generic ones that're more reasonably priced. This \\\n",
525 | "toothbrush makes me feel like I've been to the dentist \\\n",
526 | "every day. My teeth feel sparkly clean! \n",
527 | "\"\"\"\n",
528 | "\n",
529 | "# review for a blender\n",
530 | "review_4 = \"\"\"\n",
531 | "So, they still had the 17 piece system on seasonal \\\n",
532 | "sale for around $49 in the month of November, about \\\n",
533 | "half off, but for some reason (call it price gouging) \\\n",
534 | "around the second week of December the prices all went \\\n",
535 | "up to about anywhere from between $70-$89 for the same \\\n",
536 | "system. And the 11 piece system went up around $10 or \\\n",
537 | "so in price also from the earlier sale price of $29. \\\n",
538 | "So it looks okay, but if you look at the base, the part \\\n",
539 | "where the blade locks into place doesn’t look as good \\\n",
540 | "as in previous editions from a few years ago, but I \\\n",
541 | "plan to be very gentle with it (example, I crush \\\n",
542 | "very hard items like beans, ice, rice, etc. in the \\ \n",
543 | "blender first then pulverize them in the serving size \\\n",
544 | "I want in the blender then switch to the whipping \\\n",
545 | "blade for a finer flour, and use the cross cutting blade \\\n",
546 | "first when making smoothies, then use the flat blade \\\n",
547 | "if I need them finer/less pulpy). Special tip when making \\\n",
548 | "smoothies, finely cut and freeze the fruits and \\\n",
549 | "vegetables (if using spinach-lightly stew soften the \\ \n",
550 | "spinach then freeze until ready for use-and if making \\\n",
551 | "sorbet, use a small to medium sized food processor) \\ \n",
552 | "that you plan to use that way you can avoid adding so \\\n",
553 | "much ice if at all-when making your smoothie. \\\n",
554 | "After about a year, the motor was making a funny noise. \\\n",
555 | "I called customer service but the warranty expired \\\n",
556 | "already, so I had to buy another one. FYI: The overall \\\n",
557 | "quality has gone done in these types of products, so \\\n",
558 | "they are kind of counting on brand recognition and \\\n",
559 | "consumer loyalty to maintain sales. Got it in about \\\n",
560 | "two days.\n",
561 | "\"\"\"\n",
562 | "\n",
563 | "reviews = [review_1, review_2, review_3, review_4]"
564 | ]
565 | },
566 | {
567 | "cell_type": "code",
568 | "execution_count": 10,
569 | "id": "9d1aa5ac",
570 | "metadata": {},
571 | "outputs": [
572 | {
573 | "name": "stdout",
574 | "output_type": "stream",
575 | "text": [
576 | "0 Soft and cute panda plush toy loved by daughter, but a bit small for the price. Arrived early. \n",
577 | "\n",
578 | "1 Affordable lamp with storage, fast shipping, and excellent customer service. Easy to assemble and missing parts were quickly replaced. \n",
579 | "\n",
580 | "2 Good battery life, small toothbrush head, but effective cleaning. Good deal if bought around $50. \n",
581 | "\n",
582 | "3 The product was on sale for $49 in November, but the price increased to $70-$89 in December. The base doesn't look as good as previous editions, but the reviewer plans to be gentle with it. A special tip for making smoothies is to freeze the fruits and vegetables beforehand. The motor made a funny noise after a year, and the warranty had expired. Overall quality has decreased. \n",
583 | "\n"
584 | ]
585 | }
586 | ],
587 | "source": [
588 | "for i in range(len(reviews)):\n",
589 | " prompt = f\"\"\"\n",
590 | " Your task is to generate a short summary of a product \\ \n",
591 | " review from an ecommerce site. \n",
592 | "\n",
593 | " Summarize the review below, delimited by triple \\\n",
594 | " backticks in at most 20 words. \n",
595 | "\n",
596 | " Review: ```{reviews[i]}```\n",
597 | " \"\"\"\n",
598 | " response = get_completion(prompt)\n",
599 | " print(i, response, \"\\n\")"
600 | ]
601 | },
602 | {
603 | "cell_type": "code",
604 | "execution_count": null,
605 | "id": "eb878522",
606 | "metadata": {},
607 | "outputs": [],
608 | "source": []
609 | }
610 | ],
611 | "metadata": {
612 | "kernelspec": {
613 | "display_name": "Python 3",
614 | "language": "python",
615 | "name": "python3"
616 | },
617 | "language_info": {
618 | "codemirror_mode": {
619 | "name": "ipython",
620 | "version": 3
621 | },
622 | "file_extension": ".py",
623 | "mimetype": "text/x-python",
624 | "name": "python",
625 | "nbconvert_exporter": "python",
626 | "pygments_lexer": "ipython3",
627 | "version": "3.8.13"
628 | },
629 | "latex_envs": {
630 | "LaTeX_envs_menu_present": true,
631 | "autoclose": false,
632 | "autocomplete": true,
633 | "bibliofile": "biblio.bib",
634 | "cite_by": "apalike",
635 | "current_citInitial": 1,
636 | "eqLabelWithNumbers": true,
637 | "eqNumInitial": 1,
638 | "hotkeys": {
639 | "equation": "Ctrl-E",
640 | "itemize": "Ctrl-I"
641 | },
642 | "labels_anchors": false,
643 | "latex_user_defs": false,
644 | "report_style_numbering": false,
645 | "user_envs_cfg": false
646 | },
647 | "toc": {
648 | "base_numbering": 1,
649 | "nav_menu": {},
650 | "number_sections": true,
651 | "sideBar": true,
652 | "skip_h1_title": false,
653 | "title_cell": "Table of Contents",
654 | "title_sidebar": "Contents",
655 | "toc_cell": false,
656 | "toc_position": {},
657 | "toc_section_display": true,
658 | "toc_window_display": true
659 | }
660 | },
661 | "nbformat": 4,
662 | "nbformat_minor": 5
663 | }
664 |
--------------------------------------------------------------------------------
/notebooks-zh/5. 推断 Inferring.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "id": "3630c235-f891-4874-bd0a-5277d4d6aa82",
6 | "metadata": {},
7 | "source": [
8 | "# 推断\n",
9 | "\n",
10 | "在这节课中,你将从产品评论和新闻文章中推断情感和主题。\n",
11 | "\n",
12 | "这些任务可以看作是模型接收文本作为输入并执行某种分析的过程。这可能涉及提取标签、提取实体、理解文本情感等等。如果你想要从一段文本中提取正面或负面情感,在传统的机器学习工作流程中,需要收集标签数据集、训练模型、确定如何在云端部署模型并进行推断。这样做可能效果还不错,但是这个过程需要很多工作。而且对于每个任务,如情感分析、提取实体等等,都需要训练和部署单独的模型。\n",
13 | "\n",
14 | "大型语言模型的一个非常好的特点是,对于许多这样的任务,你只需要编写一个prompt即可开始产生结果,而不需要进行大量的工作。这极大地加快了应用程序开发的速度。你还可以只使用一个模型和一个 API 来执行许多不同的任务,而不需要弄清楚如何训练和部署许多不同的模型。\n",
15 | "\n",
16 | "\n",
17 | "## 启动"
18 | ]
19 | },
20 | {
21 | "cell_type": "code",
22 | "execution_count": 1,
23 | "id": "a821d943",
24 | "metadata": {
25 | "height": 132
26 | },
27 | "outputs": [],
28 | "source": [
29 | "import openai\n",
30 | "import os\n",
31 | "\n",
32 | "OPENAI_API_KEY = os.environ.get(\"OPENAI_API_KEY2\")\n",
33 | "openai.api_key = OPENAI_API_KEY"
34 | ]
35 | },
36 | {
37 | "cell_type": "code",
38 | "execution_count": 2,
39 | "id": "e82f5577",
40 | "metadata": {
41 | "height": 164
42 | },
43 | "outputs": [],
44 | "source": [
45 | "def get_completion(prompt, model=\"gpt-3.5-turbo\"):\n",
46 | " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
47 | " response = openai.ChatCompletion.create(\n",
48 | " model=model,\n",
49 | " messages=messages,\n",
50 | " temperature=0, # this is the degree of randomness of the model's output\n",
51 | " )\n",
52 | " return response.choices[0].message[\"content\"]"
53 | ]
54 | },
55 | {
56 | "cell_type": "markdown",
57 | "id": "51d2fdfa-c99f-4750-8574-dba7712cd7f0",
58 | "metadata": {},
59 | "source": [
60 | "## 商品评论文本\n",
61 | "\n",
62 | "这是一盏台灯的评论。"
63 | ]
64 | },
65 | {
66 | "cell_type": "code",
67 | "execution_count": 3,
68 | "id": "b0f3b49b",
69 | "metadata": {
70 | "height": 200
71 | },
72 | "outputs": [],
73 | "source": [
74 | "lamp_review = \"\"\"\n",
75 | "Needed a nice lamp for my bedroom, and this one had \\\n",
76 | "additional storage and not too high of a price point. \\\n",
77 | "Got it fast. The string to our lamp broke during the \\\n",
78 | "transit and the company happily sent over a new one. \\\n",
79 | "Came within a few days as well. It was easy to put \\\n",
80 | "together. I had a missing part, so I contacted their \\\n",
81 | "support and they very quickly got me the missing piece! \\\n",
82 | "Lumina seems to me to be a great company that cares \\\n",
83 | "about their customers and products!!\n",
84 | "\"\"\""
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": 4,
90 | "id": "bc6260f0",
91 | "metadata": {},
92 | "outputs": [],
93 | "source": [
94 | "# 中文\n",
95 | "lamp_review_zh = \"\"\"\n",
96 | "我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。\\\n",
97 | "我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。\\\n",
98 | "几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,他们很快就给我寄来了缺失的零件!\\\n",
99 | "在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!\n",
100 | "\"\"\""
101 | ]
102 | },
103 | {
104 | "cell_type": "markdown",
105 | "id": "30d6e4bd-3337-45a3-8c99-a734cdd06743",
106 | "metadata": {},
107 | "source": [
108 | "## 情感(正向/负向)\n",
109 | "\n",
110 | "现在让我们来编写一个prompt来分类这个评论的情感。如果我想让系统告诉我这个评论的情感是什么,只需要编写 “以下产品评论的情感是什么” 这个prompt,加上通常的分隔符和评论文本等等。\n",
111 | "\n",
112 | "然后让我们运行一下。结果显示这个产品评论的情感是积极的,这似乎是非常正确的。虽然这盏台灯不完美,但这个客户似乎非常满意。这似乎是一家关心客户和产品的伟大公司,可以认为积极的情感似乎是正确的答案。"
113 | ]
114 | },
115 | {
116 | "cell_type": "code",
117 | "execution_count": 5,
118 | "id": "e3157601",
119 | "metadata": {
120 | "height": 149
121 | },
122 | "outputs": [
123 | {
124 | "name": "stdout",
125 | "output_type": "stream",
126 | "text": [
127 | "The sentiment of the product review is positive.\n"
128 | ]
129 | }
130 | ],
131 | "source": [
132 | "prompt = f\"\"\"\n",
133 | "What is the sentiment of the following product review, \n",
134 | "which is delimited with triple backticks?\n",
135 | "\n",
136 | "Review text: ```{lamp_review}```\n",
137 | "\"\"\"\n",
138 | "response = get_completion(prompt)\n",
139 | "print(response)"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 6,
145 | "id": "ac5b0bb9",
146 | "metadata": {},
147 | "outputs": [
148 | {
149 | "name": "stdout",
150 | "output_type": "stream",
151 | "text": [
152 | "情感是积极的/正面的。\n"
153 | ]
154 | }
155 | ],
156 | "source": [
157 | "# 中文\n",
158 | "prompt = f\"\"\"\n",
159 | "以下用三个反引号分隔的产品评论的情感是什么?\n",
160 | "\n",
161 | "评论文本: ```{lamp_review_zh}```\n",
162 | "\"\"\"\n",
163 | "response = get_completion(prompt)\n",
164 | "print(response)"
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "id": "76be2320",
170 | "metadata": {},
171 | "source": [
172 | "如果你想要给出更简洁的答案,以便更容易进行后处理,可以使用上面的prompt并添加另一个指令,以一个单词 “正面” 或 “负面” 的形式给出答案。这样就只会打印出 “正面” 这个单词,这使得文本更容易接受这个输出并进行处理。"
173 | ]
174 | },
175 | {
176 | "cell_type": "code",
177 | "execution_count": 7,
178 | "id": "acf9ca16",
179 | "metadata": {
180 | "height": 200
181 | },
182 | "outputs": [
183 | {
184 | "name": "stdout",
185 | "output_type": "stream",
186 | "text": [
187 | "positive\n"
188 | ]
189 | }
190 | ],
191 | "source": [
192 | "prompt = f\"\"\"\n",
193 | "What is the sentiment of the following product review, \n",
194 | "which is delimited with triple backticks?\n",
195 | "\n",
196 | "Give your answer as a single word, either \"positive\" \\\n",
197 | "or \"negative\".\n",
198 | "\n",
199 | "Review text: ```{lamp_review}```\n",
200 | "\"\"\"\n",
201 | "response = get_completion(prompt)\n",
202 | "print(response)"
203 | ]
204 | },
205 | {
206 | "cell_type": "code",
207 | "execution_count": 8,
208 | "id": "84a761b3",
209 | "metadata": {},
210 | "outputs": [
211 | {
212 | "name": "stdout",
213 | "output_type": "stream",
214 | "text": [
215 | "正面\n"
216 | ]
217 | }
218 | ],
219 | "source": [
220 | "prompt = f\"\"\"\n",
221 | "以下用三个反引号分隔的产品评论的情感是什么?\n",
222 | "\n",
223 | "用一个单词回答:「正面」或「负面」。\n",
224 | "\n",
225 | "评论文本: ```{lamp_review_zh}```\n",
226 | "\"\"\"\n",
227 | "response = get_completion(prompt)\n",
228 | "print(response)"
229 | ]
230 | },
231 | {
232 | "cell_type": "markdown",
233 | "id": "81d2a973-1fa4-4a35-ae35-a2e746c0e91b",
234 | "metadata": {},
235 | "source": [
236 | "## 识别情感类型\n",
237 | "\n",
238 | "让我们看看另一个prompt,仍然使用台灯评论。这次我要让它识别出以下评论作者所表达的情感列表,不超过五个。"
239 | ]
240 | },
241 | {
242 | "cell_type": "code",
243 | "execution_count": 9,
244 | "id": "8aa7934b",
245 | "metadata": {
246 | "height": 183
247 | },
248 | "outputs": [
249 | {
250 | "name": "stdout",
251 | "output_type": "stream",
252 | "text": [
253 | "satisfied, grateful, impressed, content, pleased\n"
254 | ]
255 | }
256 | ],
257 | "source": [
258 | "prompt = f\"\"\"\n",
259 | "Identify a list of emotions that the writer of the \\\n",
260 | "following review is expressing. Include no more than \\\n",
261 | "five items in the list. Format your answer as a list of \\\n",
262 | "lower-case words separated by commas.\n",
263 | "\n",
264 | "Review text: ```{lamp_review}```\n",
265 | "\"\"\"\n",
266 | "response = get_completion(prompt)\n",
267 | "print(response)"
268 | ]
269 | },
270 | {
271 | "cell_type": "code",
272 | "execution_count": 10,
273 | "id": "e615c13a",
274 | "metadata": {},
275 | "outputs": [
276 | {
277 | "name": "stdout",
278 | "output_type": "stream",
279 | "text": [
280 | "满意,感激,信任,赞扬,愉快\n"
281 | ]
282 | }
283 | ],
284 | "source": [
285 | "# 中文\n",
286 | "prompt = f\"\"\"\n",
287 | "识别以下评论的作者表达的情感。包含不超过五个项目。将答案格式化为以逗号分隔的单词列表。\n",
288 | "\n",
289 | "评论文本: ```{lamp_review_zh}```\n",
290 | "\"\"\"\n",
291 | "response = get_completion(prompt)\n",
292 | "print(response)"
293 | ]
294 | },
295 | {
296 | "cell_type": "markdown",
297 | "id": "cc4444f7",
298 | "metadata": {},
299 | "source": [
300 | "大型语言模型非常擅长从一段文本中提取特定的东西。在上面的例子中,评论正在表达情感,这可能有助于了解客户如何看待特定的产品。"
301 | ]
302 | },
303 | {
304 | "cell_type": "markdown",
305 | "id": "a428d093-51c9-461c-b41e-114e80876409",
306 | "metadata": {},
307 | "source": [
308 | "## 识别愤怒\n",
309 | "\n",
310 | "对于很多企业来说,了解某个顾客是否非常生气很重要。所以你可能有一个类似这样的分类问题:以下评论的作者是否表达了愤怒情绪?因为如果有人真的很生气,那么可能值得额外关注,让客户支持或客户成功团队联系客户以了解情况,并为客户解决问题。"
311 | ]
312 | },
313 | {
314 | "cell_type": "code",
315 | "execution_count": 11,
316 | "id": "dba1a538",
317 | "metadata": {
318 | "height": 166
319 | },
320 | "outputs": [
321 | {
322 | "name": "stdout",
323 | "output_type": "stream",
324 | "text": [
325 | "No\n"
326 | ]
327 | }
328 | ],
329 | "source": [
330 | "prompt = f\"\"\"\n",
331 | "Is the writer of the following review expressing anger?\\\n",
332 | "The review is delimited with triple backticks. \\\n",
333 | "Give your answer as either yes or no.\n",
334 | "\n",
335 | "Review text: ```{lamp_review}```\n",
336 | "\"\"\"\n",
337 | "response = get_completion(prompt)\n",
338 | "print(response)"
339 | ]
340 | },
341 | {
342 | "cell_type": "code",
343 | "execution_count": 12,
344 | "id": "85bad324",
345 | "metadata": {},
346 | "outputs": [
347 | {
348 | "name": "stdout",
349 | "output_type": "stream",
350 | "text": [
351 | "否\n"
352 | ]
353 | }
354 | ],
355 | "source": [
356 | "# 中文\n",
357 | "prompt = f\"\"\"\n",
358 | "以下评论的作者是否表达了愤怒?评论用三个反引号分隔。给出是或否的答案。\n",
359 | "\n",
360 | "评论文本: ```{lamp_review_zh}```\n",
361 | "\"\"\"\n",
362 | "response = get_completion(prompt)\n",
363 | "print(response)"
364 | ]
365 | },
366 | {
367 | "cell_type": "markdown",
368 | "id": "11ca57a2",
369 | "metadata": {},
370 | "source": [
371 | "上面这个例子中,客户并没有生气。注意,如果使用常规的监督学习,如果想要建立所有这些分类器,不可能在几分钟内就做到这一点。我们鼓励大家尝试更改一些这样的prompt,也许询问客户是否表达了喜悦,或者询问是否有任何遗漏的部分,并看看是否可以让prompt对这个灯具评论做出不同的推论。"
372 | ]
373 | },
374 | {
375 | "cell_type": "markdown",
376 | "id": "936a771e-ca78-4e55-8088-2da6f3820ddc",
377 | "metadata": {},
378 | "source": [
379 | "## 从客户评论中提取产品和公司名称\n",
380 | "\n",
381 | "接下来,让我们从客户评论中提取更丰富的信息。信息提取是自然语言处理(NLP)的一部分,与从文本中提取你想要知道的某些事物相关。因此,在这个prompt中,我要求它识别以下内容:购买物品和制造物品的公司名称。\n",
382 | "\n",
383 | "同样,如果你试图总结在线购物电子商务网站的许多评论,对于这些评论来说,弄清楚是什么物品,谁制造了该物品,弄清楚积极和消极的情感,以跟踪特定物品或特定制造商的积极或消极情感趋势,可能会很有用。\n",
384 | "\n",
385 | "在下面这个示例中,我们要求它将响应格式化为一个 JSON 对象,其中物品和品牌是键。"
386 | ]
387 | },
388 | {
389 | "cell_type": "code",
390 | "execution_count": 13,
391 | "id": "a13bea1b",
392 | "metadata": {
393 | "height": 285
394 | },
395 | "outputs": [
396 | {
397 | "name": "stdout",
398 | "output_type": "stream",
399 | "text": [
400 | "{\n",
401 | " \"Item\": \"lamp with additional storage\",\n",
402 | " \"Brand\": \"Lumina\"\n",
403 | "}\n"
404 | ]
405 | }
406 | ],
407 | "source": [
408 | "prompt = f\"\"\"\n",
409 | "Identify the following items from the review text: \n",
410 | "- Item purchased by reviewer\n",
411 | "- Company that made the item\n",
412 | "\n",
413 | "The review is delimited with triple backticks. \\\n",
414 | "Format your response as a JSON object with \\\n",
415 | "\"Item\" and \"Brand\" as the keys. \n",
416 | "If the information isn't present, use \"unknown\" \\\n",
417 | "as the value.\n",
418 | "Make your response as short as possible.\n",
419 | " \n",
420 | "Review text: ```{lamp_review}```\n",
421 | "\"\"\"\n",
422 | "response = get_completion(prompt)\n",
423 | "print(response)"
424 | ]
425 | },
426 | {
427 | "cell_type": "code",
428 | "execution_count": 14,
429 | "id": "e9ffe056",
430 | "metadata": {},
431 | "outputs": [
432 | {
433 | "name": "stdout",
434 | "output_type": "stream",
435 | "text": [
436 | "{\n",
437 | " \"物品\": \"卧室灯\",\n",
438 | " \"品牌\": \"Lumina\"\n",
439 | "}\n"
440 | ]
441 | }
442 | ],
443 | "source": [
444 | "# 中文\n",
445 | "prompt = f\"\"\"\n",
446 | "从评论文本中识别以下项目:\n",
447 | "- 评论者购买的物品\n",
448 | "- 制造该物品的公司\n",
449 | "\n",
450 | "评论文本用三个反引号分隔。将你的响应格式化为以 “物品” 和 “品牌” 为键的 JSON 对象。\n",
451 | "如果信息不存在,请使用 “未知” 作为值。\n",
452 | "让你的回应尽可能简短。\n",
453 | " \n",
454 | "评论文本: ```{lamp_review_zh}```\n",
455 | "\"\"\"\n",
456 | "response = get_completion(prompt)\n",
457 | "print(response)"
458 | ]
459 | },
460 | {
461 | "cell_type": "markdown",
462 | "id": "954d125d",
463 | "metadata": {},
464 | "source": [
465 | "如上所示,它会说这个物品是一个卧室灯,品牌是 Luminar,你可以轻松地将其加载到 Python 字典中,然后对此输出进行其他处理。"
466 | ]
467 | },
468 | {
469 | "cell_type": "markdown",
470 | "id": "a38880a5-088f-4609-9913-f8fa41fb7ba0",
471 | "metadata": {},
472 | "source": [
473 | "## 一次完成多项任务\n",
474 | "\n",
475 | "提取上面所有这些信息使用了 3 或 4 个prompt,但实际上可以编写单个prompt来同时提取所有这些信息。"
476 | ]
477 | },
478 | {
479 | "cell_type": "code",
480 | "execution_count": 15,
481 | "id": "e7dda9e5",
482 | "metadata": {
483 | "height": 336
484 | },
485 | "outputs": [
486 | {
487 | "name": "stdout",
488 | "output_type": "stream",
489 | "text": [
490 | "{\n",
491 | " \"Sentiment\": \"positive\",\n",
492 | " \"Anger\": false,\n",
493 | " \"Item\": \"lamp with additional storage\",\n",
494 | " \"Brand\": \"Lumina\"\n",
495 | "}\n"
496 | ]
497 | }
498 | ],
499 | "source": [
500 | "prompt = f\"\"\"\n",
501 | "Identify the following items from the review text: \n",
502 | "- Sentiment (positive or negative)\n",
503 | "- Is the reviewer expressing anger? (true or false)\n",
504 | "- Item purchased by reviewer\n",
505 | "- Company that made the item\n",
506 | "\n",
507 | "The review is delimited with triple backticks. \\\n",
508 | "Format your response as a JSON object with \\\n",
509 | "\"Sentiment\", \"Anger\", \"Item\" and \"Brand\" as the keys.\n",
510 | "If the information isn't present, use \"unknown\" \\\n",
511 | "as the value.\n",
512 | "Make your response as short as possible.\n",
513 | "Format the Anger value as a boolean.\n",
514 | "\n",
515 | "Review text: ```{lamp_review}```\n",
516 | "\"\"\"\n",
517 | "response = get_completion(prompt)\n",
518 | "print(response)"
519 | ]
520 | },
521 | {
522 | "cell_type": "code",
523 | "execution_count": 16,
524 | "id": "939c2b0e",
525 | "metadata": {
526 | "scrolled": true
527 | },
528 | "outputs": [
529 | {
530 | "name": "stdout",
531 | "output_type": "stream",
532 | "text": [
533 | "{\n",
534 | " \"Sentiment\": \"正面\",\n",
535 | " \"Anger\": false,\n",
536 | " \"Item\": \"卧室灯\",\n",
537 | " \"Brand\": \"Lumina\"\n",
538 | "}\n"
539 | ]
540 | }
541 | ],
542 | "source": [
543 | "# 中文\n",
544 | "prompt = f\"\"\"\n",
545 | "从评论文本中识别以下项目:\n",
546 | "- 情绪(正面或负面)\n",
547 | "- 审稿人是否表达了愤怒?(是或否)\n",
548 | "- 评论者购买的物品\n",
549 | "- 制造该物品的公司\n",
550 | "\n",
551 | "评论用三个反引号分隔。将您的响应格式化为 JSON 对象,以 “Sentiment”、“Anger”、“Item” 和 “Brand” 作为键。\n",
552 | "如果信息不存在,请使用 “未知” 作为值。\n",
553 | "让你的回应尽可能简短。\n",
554 | "将 Anger 值格式化为布尔值。\n",
555 | "\n",
556 | "评论文本: ```{lamp_review_zh}```\n",
557 | "\"\"\"\n",
558 | "response = get_completion(prompt)\n",
559 | "print(response)"
560 | ]
561 | },
562 | {
563 | "cell_type": "markdown",
564 | "id": "5e09a673",
565 | "metadata": {},
566 | "source": [
567 | "这个例子中,我们告诉它将愤怒值格式化为布尔值,然后输出一个 JSON。大家可以自己尝试不同的变化,或者甚至尝试完全不同的评论,看看是否仍然可以准确地提取这些内容。"
568 | ]
569 | },
570 | {
571 | "cell_type": "markdown",
572 | "id": "235fc223-2c89-49ec-ac2d-78a8e74a43ac",
573 | "metadata": {},
574 | "source": [
575 | "## 推断主题\n",
576 | "\n",
577 | "大型语言模型的一个很酷的应用是推断主题。给定一段长文本,这段文本是关于什么的?有什么话题?"
578 | ]
579 | },
580 | {
581 | "cell_type": "code",
582 | "execution_count": 17,
583 | "id": "8a74cc3e",
584 | "metadata": {
585 | "height": 472
586 | },
587 | "outputs": [],
588 | "source": [
589 | "story = \"\"\"\n",
590 | "In a recent survey conducted by the government, \n",
591 | "public sector employees were asked to rate their level \n",
592 | "of satisfaction with the department they work at. \n",
593 | "The results revealed that NASA was the most popular \n",
594 | "department with a satisfaction rating of 95%.\n",
595 | "\n",
596 | "One NASA employee, John Smith, commented on the findings, \n",
597 | "stating, \"I'm not surprised that NASA came out on top. \n",
598 | "It's a great place to work with amazing people and \n",
599 | "incredible opportunities. I'm proud to be a part of \n",
600 | "such an innovative organization.\"\n",
601 | "\n",
602 | "The results were also welcomed by NASA's management team, \n",
603 | "with Director Tom Johnson stating, \"We are thrilled to \n",
604 | "hear that our employees are satisfied with their work at NASA. \n",
605 | "We have a talented and dedicated team who work tirelessly \n",
606 | "to achieve our goals, and it's fantastic to see that their \n",
607 | "hard work is paying off.\"\n",
608 | "\n",
609 | "The survey also revealed that the \n",
610 | "Social Security Administration had the lowest satisfaction \n",
611 | "rating, with only 45% of employees indicating they were \n",
612 | "satisfied with their job. The government has pledged to \n",
613 | "address the concerns raised by employees in the survey and \n",
614 | "work towards improving job satisfaction across all departments.\n",
615 | "\"\"\""
616 | ]
617 | },
618 | {
619 | "cell_type": "code",
620 | "execution_count": 18,
621 | "id": "811ff13f",
622 | "metadata": {},
623 | "outputs": [],
624 | "source": [
625 | "# 中文\n",
626 | "story_zh = \"\"\"\n",
627 | "在政府最近进行的一项调查中,要求公共部门的员工对他们所在部门的满意度进行评分。\n",
628 | "调查结果显示,NASA 是最受欢迎的部门,满意度为 95%。\n",
629 | "\n",
630 | "一位 NASA 员工 John Smith 对这一发现发表了评论,他表示:\n",
631 | "“我对 NASA 排名第一并不感到惊讶。这是一个与了不起的人们和令人难以置信的机会共事的好地方。我为成为这样一个创新组织的一员感到自豪。”\n",
632 | "\n",
633 | "NASA 的管理团队也对这一结果表示欢迎,主管 Tom Johnson 表示:\n",
634 | "“我们很高兴听到我们的员工对 NASA 的工作感到满意。\n",
635 | "我们拥有一支才华横溢、忠诚敬业的团队,他们为实现我们的目标不懈努力,看到他们的辛勤工作得到回报是太棒了。”\n",
636 | "\n",
637 | "调查还显示,社会保障管理局的满意度最低,只有 45%的员工表示他们对工作满意。\n",
638 | "政府承诺解决调查中员工提出的问题,并努力提高所有部门的工作满意度。\n",
639 | "\"\"\""
640 | ]
641 | },
642 | {
643 | "cell_type": "markdown",
644 | "id": "a8ea91d6-e841-4ee2-bed9-ca4a36df177f",
645 | "metadata": {},
646 | "source": [
647 | "## 推断5个主题\n",
648 | "\n",
649 | "上面是一篇虚构的关于政府工作人员对他们工作机构感受的报纸文章。我们可以让它确定五个正在讨论的主题,用一两个字描述每个主题,并将输出格式化为逗号分隔的列表。"
650 | ]
651 | },
652 | {
653 | "cell_type": "code",
654 | "execution_count": 19,
655 | "id": "5c267cbe",
656 | "metadata": {
657 | "height": 217
658 | },
659 | "outputs": [
660 | {
661 | "name": "stdout",
662 | "output_type": "stream",
663 | "text": [
664 | "government survey, public sector employees, job satisfaction, NASA, Social Security Administration\n"
665 | ]
666 | }
667 | ],
668 | "source": [
669 | "prompt = f\"\"\"\n",
670 | "Determine five topics that are being discussed in the \\\n",
671 | "following text, which is delimited by triple backticks.\n",
672 | "\n",
673 | "Make each item one or two words long. \n",
674 | "\n",
675 | "Format your response as a list of items separated by commas.\n",
676 | "\n",
677 | "Text sample: ```{story}```\n",
678 | "\"\"\"\n",
679 | "response = get_completion(prompt)\n",
680 | "print(response)"
681 | ]
682 | },
683 | {
684 | "cell_type": "code",
685 | "execution_count": 20,
686 | "id": "f92f90fe",
687 | "metadata": {
688 | "height": 30,
689 | "scrolled": true
690 | },
691 | "outputs": [
692 | {
693 | "data": {
694 | "text/plain": [
695 | "['government survey',\n",
696 | " ' public sector employees',\n",
697 | " ' job satisfaction',\n",
698 | " ' NASA',\n",
699 | " ' Social Security Administration']"
700 | ]
701 | },
702 | "execution_count": 20,
703 | "metadata": {},
704 | "output_type": "execute_result"
705 | }
706 | ],
707 | "source": [
708 | "response.split(sep=',')"
709 | ]
710 | },
711 | {
712 | "cell_type": "code",
713 | "execution_count": 21,
714 | "id": "cab27b65",
715 | "metadata": {},
716 | "outputs": [
717 | {
718 | "name": "stdout",
719 | "output_type": "stream",
720 | "text": [
721 | "调查结果, NASA, 社会保障管理局, 员工满意度, 政府承诺\n"
722 | ]
723 | }
724 | ],
725 | "source": [
726 | "# 中文\n",
727 | "prompt = f\"\"\"\n",
728 | "确定以下给定文本中讨论的五个主题。\n",
729 | "\n",
730 | "每个主题用1-2个单词概括。\n",
731 | "\n",
732 | "输出时用逗号分割每个主题。\n",
733 | "\n",
734 | "给定文本: ```{story_zh}```\n",
735 | "\"\"\"\n",
736 | "response = get_completion(prompt)\n",
737 | "print(response)"
738 | ]
739 | },
740 | {
741 | "cell_type": "markdown",
742 | "id": "34be1d2a-1309-4512-841a-b6f67338938b",
743 | "metadata": {},
744 | "source": [
745 | "## 为特定主题制作新闻提醒\n",
746 | "\n",
747 | "假设我们有一个新闻网站或类似的东西,这是我们感兴趣的主题:NASA、地方政府、工程、员工满意度、联邦政府等。假设我们想弄清楚,针对一篇新闻文章,其中涵盖了哪些主题。可以使用这样的prompt:确定以下主题列表中的每个项目是否是以下文本中的主题。以 0 或 1 的形式给出答案列表。"
748 | ]
749 | },
750 | {
751 | "cell_type": "code",
752 | "execution_count": 22,
753 | "id": "94b8fa65",
754 | "metadata": {
755 | "height": 81
756 | },
757 | "outputs": [],
758 | "source": [
759 | "topic_list = [\n",
760 | " \"nasa\", \"local government\", \"engineering\", \n",
761 | " \"employee satisfaction\", \"federal government\"\n",
762 | "]"
763 | ]
764 | },
765 | {
766 | "cell_type": "code",
767 | "execution_count": 23,
768 | "id": "626c5b8e",
769 | "metadata": {
770 | "height": 234
771 | },
772 | "outputs": [
773 | {
774 | "name": "stdout",
775 | "output_type": "stream",
776 | "text": [
777 | "nasa: 1\n",
778 | "local government: 0\n",
779 | "engineering: 0\n",
780 | "employee satisfaction: 1\n",
781 | "federal government: 1\n"
782 | ]
783 | }
784 | ],
785 | "source": [
786 | "prompt = f\"\"\"\n",
787 | "Determine whether each item in the following list of \\\n",
788 | "topics is a topic in the text below, which\n",
789 | "is delimited with triple backticks.\n",
790 | "\n",
791 | "Give your answer as list with 0 or 1 for each topic.\\\n",
792 | "\n",
793 | "List of topics: {\", \".join(topic_list)}\n",
794 | "\n",
795 | "Text sample: ```{story}```\n",
796 | "\"\"\"\n",
797 | "response = get_completion(prompt)\n",
798 | "print(response)"
799 | ]
800 | },
801 | {
802 | "cell_type": "code",
803 | "execution_count": 24,
804 | "id": "902a7c74",
805 | "metadata": {
806 | "height": 79
807 | },
808 | "outputs": [
809 | {
810 | "name": "stdout",
811 | "output_type": "stream",
812 | "text": [
813 | "ALERT: New NASA story!\n"
814 | ]
815 | }
816 | ],
817 | "source": [
818 | "topic_dict = {i.split(': ')[0]: int(i.split(': ')[1]) for i in response.split(sep='\\n')}\n",
819 | "if topic_dict['nasa'] == 1:\n",
820 | " print(\"ALERT: New NASA story!\")"
821 | ]
822 | },
823 | {
824 | "cell_type": "code",
825 | "execution_count": 25,
826 | "id": "9f53d337",
827 | "metadata": {},
828 | "outputs": [
829 | {
830 | "name": "stdout",
831 | "output_type": "stream",
832 | "text": [
833 | "美国航空航天局:1\n",
834 | "地方政府:1\n",
835 | "工程:0\n",
836 | "员工满意度:1\n",
837 | "联邦政府:1\n"
838 | ]
839 | }
840 | ],
841 | "source": [
842 | "# 中文\n",
843 | "prompt = f\"\"\"\n",
844 | "判断主题列表中的每一项是否是给定文本中的一个话题,\n",
845 | "\n",
846 | "以列表的形式给出答案,每个主题用 0 或 1。\n",
847 | "\n",
848 | "主题列表:美国航空航天局、地方政府、工程、员工满意度、联邦政府\n",
849 | "\n",
850 | "给定文本: ```{story_zh}```\n",
851 | "\"\"\"\n",
852 | "response = get_completion(prompt)\n",
853 | "print(response)"
854 | ]
855 | },
856 | {
857 | "cell_type": "markdown",
858 | "id": "08247dbf",
859 | "metadata": {},
860 | "source": [
861 | "所以,这个故事是关于 NASA 的。它不是关于地方政府的,不是关于工程的。它是关于员工满意度的,它是关于联邦政府的。这在机器学习中有时被称为 Zero-Shot 学习算法,因为我们没有给它任何标记的训练数据。仅凭prompt,它就能确定哪些主题在新闻文章中涵盖了。\n",
862 | "\n",
863 | "如果我们想生成一个新闻提醒,也可以使用这个处理新闻的过程。假设我非常喜欢 NASA 所做的工作,就可以构建一个这样的系统,每当 NASA 新闻出现时,输出提醒。"
864 | ]
865 | },
866 | {
867 | "cell_type": "code",
868 | "execution_count": 26,
869 | "id": "53bf1abd",
870 | "metadata": {},
871 | "outputs": [
872 | {
873 | "name": "stdout",
874 | "output_type": "stream",
875 | "text": [
876 | "提醒: 关于美国航空航天局的新消息\n"
877 | ]
878 | }
879 | ],
880 | "source": [
881 | "topic_dict = {i.split(':')[0]: int(i.split(':')[1]) for i in response.split(sep='\\n')}\n",
882 | "if topic_dict['美国航空航天局'] == 1:\n",
883 | " print(\"提醒: 关于美国航空航天局的新消息\")"
884 | ]
885 | },
886 | {
887 | "cell_type": "markdown",
888 | "id": "76ccd189",
889 | "metadata": {},
890 | "source": [
891 | "这就是关于推断的全部内容了,仅用几分钟时间,我们就可以构建多个用于对文本进行推理的系统,而以前则需要熟练的机器学习开发人员数天甚至数周的时间。这非常令人兴奋,无论是对于熟练的机器学习开发人员还是对于新手来说,都可以使用prompt来非常快速地构建和开始相当复杂的自然语言处理任务。"
892 | ]
893 | },
894 | {
895 | "cell_type": "markdown",
896 | "id": "f88408ae-469a-4b02-a043-f6b4f0b14bf9",
897 | "metadata": {},
898 | "source": [
899 | "## 尝试你的实验!"
900 | ]
901 | },
902 | {
903 | "cell_type": "code",
904 | "execution_count": null,
905 | "id": "1bd3553f",
906 | "metadata": {
907 | "height": 30
908 | },
909 | "outputs": [],
910 | "source": []
911 | }
912 | ],
913 | "metadata": {
914 | "kernelspec": {
915 | "display_name": "Python 3",
916 | "language": "python",
917 | "name": "python3"
918 | },
919 | "language_info": {
920 | "codemirror_mode": {
921 | "name": "ipython",
922 | "version": 3
923 | },
924 | "file_extension": ".py",
925 | "mimetype": "text/x-python",
926 | "name": "python",
927 | "nbconvert_exporter": "python",
928 | "pygments_lexer": "ipython3",
929 | "version": "3.11.3"
930 | },
931 | "latex_envs": {
932 | "LaTeX_envs_menu_present": true,
933 | "autoclose": false,
934 | "autocomplete": true,
935 | "bibliofile": "biblio.bib",
936 | "cite_by": "apalike",
937 | "current_citInitial": 1,
938 | "eqLabelWithNumbers": true,
939 | "eqNumInitial": 1,
940 | "hotkeys": {
941 | "equation": "Ctrl-E",
942 | "itemize": "Ctrl-I"
943 | },
944 | "labels_anchors": false,
945 | "latex_user_defs": false,
946 | "report_style_numbering": false,
947 | "user_envs_cfg": false
948 | },
949 | "toc": {
950 | "base_numbering": 1,
951 | "nav_menu": {},
952 | "number_sections": true,
953 | "sideBar": true,
954 | "skip_h1_title": false,
955 | "title_cell": "Table of Contents",
956 | "title_sidebar": "Contents",
957 | "toc_cell": false,
958 | "toc_position": {
959 | "height": "calc(100% - 180px)",
960 | "left": "10px",
961 | "top": "150px",
962 | "width": "256px"
963 | },
964 | "toc_section_display": true,
965 | "toc_window_display": true
966 | }
967 | },
968 | "nbformat": 4,
969 | "nbformat_minor": 5
970 | }
971 |
--------------------------------------------------------------------------------
/notebooks-zh/6. 转换 Transforming.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "id": "78624add",
6 | "metadata": {},
7 | "source": [
8 | "## 1 引言"
9 | ]
10 | },
11 | {
12 | "cell_type": "markdown",
13 | "id": "2fac57c2",
14 | "metadata": {},
15 | "source": [
16 | "LLM非常擅长将输入转换成不同的格式,例如多语种文本翻译、拼写及语法纠正、语气调整、格式转换等。\n",
17 | "\n",
18 | "本章节将介绍如何使用编程的方式,调用API接口来实现“文本转换”功能。"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "id": "f7816496",
24 | "metadata": {},
25 | "source": [
26 | "首先,我们需要OpenAI包,加载API密钥,定义getCompletion函数。"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 7,
32 | "id": "ac57ad72",
33 | "metadata": {},
34 | "outputs": [],
35 | "source": [
36 | "import openai\n",
37 | "import os\n",
38 | "OPENAI_API_KEY = os.environ.get(\"OPENAI_API_KEY2\")\n",
39 | "openai.api_key = OPENAI_API_KEY\n",
40 | "\n",
41 | "def get_completion(prompt, model=\"gpt-3.5-turbo\", temperature=0): \n",
42 | " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
43 | " response = openai.ChatCompletion.create(\n",
44 | " model=model,\n",
45 | " messages=messages,\n",
46 | " temperature=temperature, # 值越低则输出文本随机性越低\n",
47 | " )\n",
48 | " return response.choices[0].message[\"content\"]"
49 | ]
50 | },
51 | {
52 | "cell_type": "markdown",
53 | "id": "bf3733d4",
54 | "metadata": {},
55 | "source": [
56 | "## 2 文本翻译"
57 | ]
58 | },
59 | {
60 | "cell_type": "markdown",
61 | "id": "1b418e32",
62 | "metadata": {},
63 | "source": [
64 | "**中文转西班牙语**"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": 2,
70 | "id": "8a5bee0c",
71 | "metadata": {
72 | "scrolled": true
73 | },
74 | "outputs": [
75 | {
76 | "name": "stdout",
77 | "output_type": "stream",
78 | "text": [
79 | "Hola, me gustaría ordenar una batidora.\n"
80 | ]
81 | }
82 | ],
83 | "source": [
84 | "prompt = f\"\"\"\n",
85 | "将以下中文翻译成西班牙语: \\ \n",
86 | "```您好,我想订购一个搅拌机。```\n",
87 | "\"\"\"\n",
88 | "response = get_completion(prompt)\n",
89 | "print(response)"
90 | ]
91 | },
92 | {
93 | "cell_type": "markdown",
94 | "id": "e3e922b4",
95 | "metadata": {},
96 | "source": [
97 | "**识别语种**"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": 3,
103 | "id": "c2c66002",
104 | "metadata": {},
105 | "outputs": [
106 | {
107 | "name": "stdout",
108 | "output_type": "stream",
109 | "text": [
110 | "这是法语。\n"
111 | ]
112 | }
113 | ],
114 | "source": [
115 | "prompt = f\"\"\"\n",
116 | "请告诉我以下文本是什么语种: \n",
117 | "```Combien coûte le lampadaire?```\n",
118 | "\"\"\"\n",
119 | "response = get_completion(prompt)\n",
120 | "print(response)"
121 | ]
122 | },
123 | {
124 | "cell_type": "markdown",
125 | "id": "c1841354",
126 | "metadata": {},
127 | "source": [
128 | "**多语种翻译**"
129 | ]
130 | },
131 | {
132 | "cell_type": "code",
133 | "execution_count": 4,
134 | "id": "b0c4fa41",
135 | "metadata": {},
136 | "outputs": [
137 | {
138 | "name": "stdout",
139 | "output_type": "stream",
140 | "text": [
141 | "中文:我想订购一个篮球。\n",
142 | "英文:I want to order a basketball.\n",
143 | "法语:Je veux commander un ballon de basket.\n",
144 | "西班牙语:Quiero pedir una pelota de baloncesto.\n"
145 | ]
146 | }
147 | ],
148 | "source": [
149 | "prompt = f\"\"\"\n",
150 | "请将以下文本分别翻译成中文、英文、法语和西班牙语: \n",
151 | "```I want to order a basketball.```\n",
152 | "\"\"\"\n",
153 | "response = get_completion(prompt)\n",
154 | "print(response)"
155 | ]
156 | },
157 | {
158 | "cell_type": "markdown",
159 | "id": "68723ba5",
160 | "metadata": {},
161 | "source": [
162 | "**翻译+正式语气**"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 6,
168 | "id": "2c52ca54",
169 | "metadata": {},
170 | "outputs": [
171 | {
172 | "name": "stdout",
173 | "output_type": "stream",
174 | "text": [
175 | "正式语气:请问您需要订购枕头吗?\n",
176 | "非正式语气:你要不要订一个枕头?\n"
177 | ]
178 | }
179 | ],
180 | "source": [
181 | "prompt = f\"\"\"\n",
182 | "请将以下文本翻译成中文,分别展示成正式与非正式两种语气: \n",
183 | "```Would you like to order a pillow?```\n",
184 | "\"\"\"\n",
185 | "response = get_completion(prompt)\n",
186 | "print(response)"
187 | ]
188 | },
189 | {
190 | "cell_type": "markdown",
191 | "id": "b2dc4c56",
192 | "metadata": {},
193 | "source": [
194 | "**通用翻译器**"
195 | ]
196 | },
197 | {
198 | "cell_type": "markdown",
199 | "id": "54b00aa4",
200 | "metadata": {},
201 | "source": [
202 | "随着全球化与跨境商务的发展,交流的用户可能来自各个不同的国家,使用不同的语言,因此我们需要一个通用翻译器,识别各个消息的语种,并翻译成目标用户的母语,从而实现更方便的跨国交流。"
203 | ]
204 | },
205 | {
206 | "cell_type": "code",
207 | "execution_count": 2,
208 | "id": "21f3af91",
209 | "metadata": {},
210 | "outputs": [],
211 | "source": [
212 | "user_messages = [\n",
213 | " \"La performance du système est plus lente que d'habitude.\", # System performance is slower than normal \n",
214 | " \"Mi monitor tiene píxeles que no se iluminan.\", # My monitor has pixels that are not lighting\n",
215 | " \"Il mio mouse non funziona\", # My mouse is not working\n",
216 | " \"Mój klawisz Ctrl jest zepsuty\", # My keyboard has a broken control key\n",
217 | " \"我的屏幕在闪烁\" # My screen is flashing\n",
218 | "]"
219 | ]
220 | },
221 | {
222 | "cell_type": "code",
223 | "execution_count": 8,
224 | "id": "6a884190",
225 | "metadata": {},
226 | "outputs": [
227 | {
228 | "name": "stdout",
229 | "output_type": "stream",
230 | "text": [
231 | "原始消息 (法语): La performance du système est plus lente que d'habitude.\n",
232 | "\n",
233 | "中文翻译:系统性能比平时慢。\n",
234 | "英文翻译:The system performance is slower than usual. \n",
235 | "=========================================\n",
236 | "原始消息 (西班牙语): Mi monitor tiene píxeles que no se iluminan.\n",
237 | "\n",
238 | "中文翻译:我的显示器有一些像素点不亮。\n",
239 | "英文翻译:My monitor has pixels that don't light up. \n",
240 | "=========================================\n",
241 | "原始消息 (意大利语): Il mio mouse non funziona\n",
242 | "\n",
243 | "中文翻译:我的鼠标不工作了。\n",
244 | "英文翻译:My mouse is not working. \n",
245 | "=========================================\n",
246 | "原始消息 (波兰语): Mój klawisz Ctrl jest zepsuty\n",
247 | "\n",
248 | "中文翻译:我的Ctrl键坏了\n",
249 | "英文翻译:My Ctrl key is broken. \n",
250 | "=========================================\n",
251 | "原始消息 (中文): 我的屏幕在闪烁\n",
252 | "\n",
253 | "中文翻译:我的屏幕在闪烁。\n",
254 | "英文翻译:My screen is flickering. \n",
255 | "=========================================\n"
256 | ]
257 | }
258 | ],
259 | "source": [
260 | "for issue in user_messages:\n",
261 | " prompt = f\"告诉我以下文本是什么语种,直接输出语种,如法语,无需输出标点符号: ```{issue}```\"\n",
262 | " lang = get_completion(prompt)\n",
263 | " print(f\"原始消息 ({lang}): {issue}\\n\")\n",
264 | "\n",
265 | " prompt = f\"\"\"\n",
266 | " 将以下消息分别翻译成英文和中文,并写成\n",
267 | " 中文翻译:xxx\n",
268 | " 英文翻译:yyy\n",
269 | " 的格式:\n",
270 | " ```{issue}```\n",
271 | " \"\"\"\n",
272 | " response = get_completion(prompt)\n",
273 | " print(response, \"\\n=========================================\")"
274 | ]
275 | },
276 | {
277 | "cell_type": "markdown",
278 | "id": "6ab558a2",
279 | "metadata": {},
280 | "source": [
281 | "## 3 语气/风格调整"
282 | ]
283 | },
284 | {
285 | "cell_type": "markdown",
286 | "id": "b85ae847",
287 | "metadata": {},
288 | "source": [
289 | "写作的语气往往会根据受众对象而有所调整。例如,对于工作邮件,我们常常需要使用正式语气与书面用词,而对同龄朋友的微信聊天,可能更多地会使用轻松、口语化的语气。"
290 | ]
291 | },
292 | {
293 | "cell_type": "code",
294 | "execution_count": 9,
295 | "id": "84ce3099",
296 | "metadata": {},
297 | "outputs": [
298 | {
299 | "name": "stdout",
300 | "output_type": "stream",
301 | "text": [
302 | "尊敬的XXX(收件人姓名):\n",
303 | "\n",
304 | "您好!我是XXX(发件人姓名),在此向您咨询一个问题。上次我们交流时,您提到我们部门需要采购显示器,但我忘记了您所需的尺寸是多少英寸。希望您能够回复我,以便我们能够及时采购所需的设备。\n",
305 | "\n",
306 | "谢谢您的帮助!\n",
307 | "\n",
308 | "此致\n",
309 | "\n",
310 | "敬礼\n",
311 | "\n",
312 | "XXX(发件人姓名)\n"
313 | ]
314 | }
315 | ],
316 | "source": [
317 | "prompt = f\"\"\"\n",
318 | "将以下文本翻译成商务信函的格式: \n",
319 | "```小老弟,我小羊,上回你说咱部门要采购的显示器是多少寸来着?```\n",
320 | "\"\"\"\n",
321 | "response = get_completion(prompt)\n",
322 | "print(response)"
323 | ]
324 | },
325 | {
326 | "cell_type": "markdown",
327 | "id": "98df9009",
328 | "metadata": {},
329 | "source": [
330 | "## 4 格式转换"
331 | ]
332 | },
333 | {
334 | "cell_type": "markdown",
335 | "id": "0bf9c074",
336 | "metadata": {},
337 | "source": [
338 | "ChatGPT非常擅长不同格式之间的转换,例如JSON到HTML、XML、Markdown等。在下述例子中,我们有一个包含餐厅员工姓名和电子邮件的列表的JSON,我们希望将其从JSON转换为HTML。"
339 | ]
340 | },
341 | {
342 | "cell_type": "code",
343 | "execution_count": 9,
344 | "id": "fad3f358",
345 | "metadata": {},
346 | "outputs": [],
347 | "source": [
348 | "data_json = { \"resturant employees\" :[ \n",
349 | " {\"name\":\"Shyam\", \"email\":\"shyamjaiswal@gmail.com\"},\n",
350 | " {\"name\":\"Bob\", \"email\":\"bob32@gmail.com\"},\n",
351 | " {\"name\":\"Jai\", \"email\":\"jai87@gmail.com\"}\n",
352 | "]}"
353 | ]
354 | },
355 | {
356 | "cell_type": "code",
357 | "execution_count": 10,
358 | "id": "f54e7398",
359 | "metadata": {},
360 | "outputs": [
361 | {
362 | "name": "stdout",
363 | "output_type": "stream",
364 | "text": [
365 | "\n",
366 | " resturant employees\n",
367 | " \n",
368 | " \n",
369 | " | name | \n",
370 | " email | \n",
371 | "
\n",
372 | " \n",
373 | " \n",
374 | " \n",
375 | " | Shyam | \n",
376 | " shyamjaiswal@gmail.com | \n",
377 | "
\n",
378 | " \n",
379 | " | Bob | \n",
380 | " bob32@gmail.com | \n",
381 | "
\n",
382 | " \n",
383 | " | Jai | \n",
384 | " jai87@gmail.com | \n",
385 | "
\n",
386 | " \n",
387 | "
\n"
388 | ]
389 | }
390 | ],
391 | "source": [
392 | "prompt = f\"\"\"\n",
393 | "将以下Python字典从JSON转换为HTML表格,保留表格标题和列名:{data_json}\n",
394 | "\"\"\"\n",
395 | "response = get_completion(prompt)\n",
396 | "print(response)"
397 | ]
398 | },
399 | {
400 | "cell_type": "code",
401 | "execution_count": 11,
402 | "id": "a0026f3c",
403 | "metadata": {},
404 | "outputs": [
405 | {
406 | "data": {
407 | "text/html": [
408 | "\n",
409 | " resturant employees\n",
410 | " \n",
411 | " \n",
412 | " | name | \n",
413 | " email | \n",
414 | "
\n",
415 | " \n",
416 | " \n",
417 | " \n",
418 | " | Shyam | \n",
419 | " shyamjaiswal@gmail.com | \n",
420 | "
\n",
421 | " \n",
422 | " | Bob | \n",
423 | " bob32@gmail.com | \n",
424 | "
\n",
425 | " \n",
426 | " | Jai | \n",
427 | " jai87@gmail.com | \n",
428 | "
\n",
429 | " \n",
430 | "
"
431 | ],
432 | "text/plain": [
433 | ""
434 | ]
435 | },
436 | "metadata": {},
437 | "output_type": "display_data"
438 | }
439 | ],
440 | "source": [
441 | "from IPython.display import display, Markdown, Latex, HTML, JSON\n",
442 | "display(HTML(response))"
443 | ]
444 | },
445 | {
446 | "cell_type": "markdown",
447 | "id": "29b7167b",
448 | "metadata": {},
449 | "source": [
450 | "## 5 拼写及语法纠正"
451 | ]
452 | },
453 | {
454 | "cell_type": "markdown",
455 | "id": "22776140",
456 | "metadata": {},
457 | "source": [
458 | "拼写及语法的检查与纠正是一个十分常见的需求,特别是使用非母语语言,例如发表英文论文时,这是一件十分重要的事情。\n",
459 | "\n",
460 | "以下给了一个例子,有一个句子列表,其中有些句子存在拼写或语法问题,有些则没有,我们循环遍历每个句子,要求模型校对文本,如果正确则输出“未发现错误”,如果错误则输出纠正后的文本。"
461 | ]
462 | },
463 | {
464 | "cell_type": "code",
465 | "execution_count": 14,
466 | "id": "b7d04bc0",
467 | "metadata": {},
468 | "outputs": [],
469 | "source": [
470 | "text = [ \n",
471 | " \"The girl with the black and white puppies have a ball.\", # The girl has a ball.\n",
472 | " \"Yolanda has her notebook.\", # ok\n",
473 | " \"Its going to be a long day. Does the car need it’s oil changed?\", # Homonyms\n",
474 | " \"Their goes my freedom. There going to bring they’re suitcases.\", # Homonyms\n",
475 | " \"Your going to need you’re notebook.\", # Homonyms\n",
476 | " \"That medicine effects my ability to sleep. Have you heard of the butterfly affect?\", # Homonyms\n",
477 | " \"This phrase is to cherck chatGPT for speling abilitty\" # spelling\n",
478 | "]"
479 | ]
480 | },
481 | {
482 | "cell_type": "code",
483 | "execution_count": 16,
484 | "id": "1ef55b7b",
485 | "metadata": {},
486 | "outputs": [
487 | {
488 | "name": "stdout",
489 | "output_type": "stream",
490 | "text": [
491 | "0 The girl with the black and white puppies has a ball.\n",
492 | "1 未发现错误。\n",
493 | "2 It's going to be a long day. Does the car need its oil changed?\n",
494 | "3 Their goes my freedom. They're going to bring their suitcases.\n",
495 | "4 输出:You're going to need your notebook.\n",
496 | "5 That medicine affects my ability to sleep. Have you heard of the butterfly effect?\n",
497 | "6 This phrase is to check chatGPT for spelling ability.\n"
498 | ]
499 | }
500 | ],
501 | "source": [
502 | "for i in range(len(text)):\n",
503 | " prompt = f\"\"\"请校对并更正以下文本,注意纠正文本保持原始语种,无需输出原始文本。\n",
504 | " 如果您没有发现任何错误,请说“未发现错误”。\n",
505 | " \n",
506 | " 例如:\n",
507 | " 输入:I are happy.\n",
508 | " 输出:I am happy.\n",
509 | " ```{text[i]}```\"\"\"\n",
510 | " response = get_completion(prompt)\n",
511 | " print(i, response)"
512 | ]
513 | },
514 | {
515 | "cell_type": "markdown",
516 | "id": "538181e0",
517 | "metadata": {},
518 | "source": [
519 | "以下是一个简单的类Grammarly纠错示例,输入原始文本,输出纠正后的文本,并基于Redlines输出纠错过程。"
520 | ]
521 | },
522 | {
523 | "cell_type": "code",
524 | "execution_count": 18,
525 | "id": "6696b06a",
526 | "metadata": {},
527 | "outputs": [],
528 | "source": [
529 | "text = f\"\"\"\n",
530 | "Got this for my daughter for her birthday cuz she keeps taking \\\n",
531 | "mine from my room. Yes, adults also like pandas too. She takes \\\n",
532 | "it everywhere with her, and it's super soft and cute. One of the \\\n",
533 | "ears is a bit lower than the other, and I don't think that was \\\n",
534 | "designed to be asymmetrical. It's a bit small for what I paid for it \\\n",
535 | "though. I think there might be other options that are bigger for \\\n",
536 | "the same price. It arrived a day earlier than expected, so I got \\\n",
537 | "to play with it myself before I gave it to my daughter.\n",
538 | "\"\"\""
539 | ]
540 | },
541 | {
542 | "cell_type": "code",
543 | "execution_count": 14,
544 | "id": "50cca36e",
545 | "metadata": {},
546 | "outputs": [
547 | {
548 | "name": "stdout",
549 | "output_type": "stream",
550 | "text": [
551 | "I got this for my daughter's birthday because she keeps taking mine from my room. Yes, adults also like pandas too. She takes it everywhere with her, and it's super soft and cute. However, one of the ears is a bit lower than the other, and I don't think that was designed to be asymmetrical. It's also a bit smaller than I expected for the price. I think there might be other options that are bigger for the same price. On the bright side, it arrived a day earlier than expected, so I got to play with it myself before giving it to my daughter.\n"
552 | ]
553 | }
554 | ],
555 | "source": [
556 | "prompt = f\"校对并更正以下商品评论:```{text}```\"\n",
557 | "response = get_completion(prompt)\n",
558 | "print(response)"
559 | ]
560 | },
561 | {
562 | "cell_type": "code",
563 | "execution_count": 19,
564 | "id": "51de86c3",
565 | "metadata": {},
566 | "outputs": [],
567 | "source": [
568 | "response = \"\"\"\n",
569 | "I got this for my daughter's birthday because she keeps taking mine from my room. Yes, adults also like pandas too. She takes it everywhere with her, and it's super soft and cute. However, one of the ears is a bit lower than the other, and I don't think that was designed to be asymmetrical. It's also a bit smaller than I expected for the price. I think there might be other options that are bigger for the same price. On the bright side, it arrived a day earlier than expected, so I got to play with it myself before giving it to my daughter.\n",
570 | "\"\"\""
571 | ]
572 | },
573 | {
574 | "cell_type": "code",
575 | "execution_count": null,
576 | "id": "07f32f1f",
577 | "metadata": {},
578 | "outputs": [],
579 | "source": [
580 | "# 如未安装redlines,需先安装\n",
581 | "!pip3.8 install redlines"
582 | ]
583 | },
584 | {
585 | "cell_type": "code",
586 | "execution_count": 22,
587 | "id": "e8604dfb",
588 | "metadata": {},
589 | "outputs": [
590 | {
591 | "data": {
592 | "text/markdown": [
593 | "Got I got this for my daughter for her daughter's birthday cuz because she keeps taking mine from my room. room. Yes, adults also like pandas too. too. She takes it everywhere with her, and it's super soft and cute. One cute. However, one of the ears is a bit lower than the other, and I don't think that was designed to be asymmetrical. It's also a bit small smaller than I expected for what I paid for it though. the price. I think there might be other options that are bigger for the same price. It price. On the bright side, it arrived a day earlier than expected, so I got to play with it myself before I gave giving it to my daughter.\n"
594 | ],
595 | "text/plain": [
596 | ""
597 | ]
598 | },
599 | "metadata": {},
600 | "output_type": "display_data"
601 | }
602 | ],
603 | "source": [
604 | "from redlines import Redlines\n",
605 | "from IPython.display import display, Markdown\n",
606 | "\n",
607 | "diff = Redlines(text,response)\n",
608 | "display(Markdown(diff.output_markdown))"
609 | ]
610 | },
611 | {
612 | "cell_type": "markdown",
613 | "id": "3ee5d487",
614 | "metadata": {},
615 | "source": [
616 | "## 6 一个综合样例:文本翻译+拼写纠正+风格调整+格式转换"
617 | ]
618 | },
619 | {
620 | "cell_type": "code",
621 | "execution_count": 23,
622 | "id": "584dcc21",
623 | "metadata": {},
624 | "outputs": [],
625 | "source": [
626 | "text = f\"\"\"\n",
627 | "Got this for my daughter for her birthday cuz she keeps taking \\\n",
628 | "mine from my room. Yes, adults also like pandas too. She takes \\\n",
629 | "it everywhere with her, and it's super soft and cute. One of the \\\n",
630 | "ears is a bit lower than the other, and I don't think that was \\\n",
631 | "designed to be asymmetrical. It's a bit small for what I paid for it \\\n",
632 | "though. I think there might be other options that are bigger for \\\n",
633 | "the same price. It arrived a day earlier than expected, so I got \\\n",
634 | "to play with it myself before I gave it to my daughter.\n",
635 | "\"\"\""
636 | ]
637 | },
638 | {
639 | "cell_type": "code",
640 | "execution_count": 24,
641 | "id": "5061d6a3",
642 | "metadata": {
643 | "scrolled": true
644 | },
645 | "outputs": [
646 | {
647 | "data": {
648 | "text/markdown": [
649 | "【优点】\n",
650 | "- 超级柔软可爱,女儿生日礼物非常受欢迎。\n",
651 | "- 成人也喜欢熊猫,我也很喜欢它。\n",
652 | "- 提前一天到货,让我有时间玩一下。\n",
653 | "\n",
654 | "【缺点】\n",
655 | "- 一只耳朵比另一只低,不对称。\n",
656 | "- 价格有点贵,但尺寸有点小,可能有更大的同价位选择。\n",
657 | "\n",
658 | "【总结】\n",
659 | "这只熊猫玩具非常适合作为生日礼物,柔软可爱,深受孩子喜欢。虽然价格有点贵,但尺寸有点小,不对称的设计也有点让人失望。如果你想要更大的同价位选择,可能需要考虑其他选项。总的来说,这是一款不错的熊猫玩具,值得购买。"
660 | ],
661 | "text/plain": [
662 | ""
663 | ]
664 | },
665 | "metadata": {},
666 | "output_type": "display_data"
667 | }
668 | ],
669 | "source": [
670 | "prompt = f\"\"\"\n",
671 | "针对以下三个反引号之间的英文评论文本,\n",
672 | "首先进行拼写及语法纠错,\n",
673 | "然后将其转化成中文,\n",
674 | "再将其转化成优质淘宝评论的风格,从各种角度出发,分别说明产品的优点与缺点,并进行总结。\n",
675 | "润色一下描述,使评论更具有吸引力。\n",
676 | "输出结果格式为:\n",
677 | "【优点】xxx\n",
678 | "【缺点】xxx\n",
679 | "【总结】xxx\n",
680 | "注意,只需填写xxx部分,并分段输出。\n",
681 | "将结果输出成Markdown格式。\n",
682 | "```{text}```\n",
683 | "\"\"\"\n",
684 | "response = get_completion(prompt)\n",
685 | "display(Markdown(response))"
686 | ]
687 | },
688 | {
689 | "cell_type": "code",
690 | "execution_count": null,
691 | "id": "3d54f151",
692 | "metadata": {},
693 | "outputs": [],
694 | "source": []
695 | }
696 | ],
697 | "metadata": {
698 | "kernelspec": {
699 | "display_name": "Python 3",
700 | "language": "python",
701 | "name": "python3"
702 | },
703 | "language_info": {
704 | "codemirror_mode": {
705 | "name": "ipython",
706 | "version": 3
707 | },
708 | "file_extension": ".py",
709 | "mimetype": "text/x-python",
710 | "name": "python",
711 | "nbconvert_exporter": "python",
712 | "pygments_lexer": "ipython3",
713 | "version": "3.8.13"
714 | },
715 | "latex_envs": {
716 | "LaTeX_envs_menu_present": true,
717 | "autoclose": false,
718 | "autocomplete": true,
719 | "bibliofile": "biblio.bib",
720 | "cite_by": "apalike",
721 | "current_citInitial": 1,
722 | "eqLabelWithNumbers": true,
723 | "eqNumInitial": 1,
724 | "hotkeys": {
725 | "equation": "Ctrl-E",
726 | "itemize": "Ctrl-I"
727 | },
728 | "labels_anchors": false,
729 | "latex_user_defs": false,
730 | "report_style_numbering": false,
731 | "user_envs_cfg": false
732 | },
733 | "toc": {
734 | "base_numbering": 1,
735 | "nav_menu": {},
736 | "number_sections": true,
737 | "sideBar": true,
738 | "skip_h1_title": false,
739 | "title_cell": "Table of Contents",
740 | "title_sidebar": "Contents",
741 | "toc_cell": false,
742 | "toc_position": {},
743 | "toc_section_display": true,
744 | "toc_window_display": true
745 | }
746 | },
747 | "nbformat": 4,
748 | "nbformat_minor": 5
749 | }
750 |
--------------------------------------------------------------------------------
/notebooks-zh/7. 扩展 Expanding.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第七章 扩展\n",
8 | "\n",
9 | "扩展是将短文本,例如一组说明或主题列表,输入到大型语言模型中,让模型生成更长的文本,例如基于某个主题的电子邮件或论文。这样做有一些很好的用途,例如将大型语言模型用作头脑风暴的伙伴。但这种做法也存在一些问题,例如某人可能会使用它来生成大量垃圾邮件。因此,当你使用大型语言模型的这些功能时,请仅以负责任的方式和有益于人们的方式使用它们。\n",
10 | "\n",
11 | "在本章中,你将学会如何基于 OpenAI API 生成适用于每个客户评价的客户服务电子邮件。我们还将使用模型的另一个输入参数称为温度,这种参数允许您在模型响应中变化探索的程度和多样性。\n"
12 | ]
13 | },
14 | {
15 | "cell_type": "markdown",
16 | "metadata": {},
17 | "source": [
18 | "## 一、环境配置\n",
19 | "\n",
20 | "同以上几章,你需要类似的代码来配置一个可以使用 OpenAI API 的环境"
21 | ]
22 | },
23 | {
24 | "cell_type": "code",
25 | "execution_count": null,
26 | "metadata": {},
27 | "outputs": [],
28 | "source": [
29 | "# 将自己的 API-KEY 导入系统环境变量\n",
30 | "!export OPENAI_API_KEY='api-key'"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": 1,
36 | "metadata": {},
37 | "outputs": [],
38 | "source": [
39 | "import openai\n",
40 | "import os\n",
41 | "from dotenv import load_dotenv, find_dotenv\n",
42 | "# 导入第三方库\n",
43 | "\n",
44 | "_ = load_dotenv(find_dotenv())\n",
45 | "# 读取系统中的环境变量\n",
46 | "\n",
47 | "openai.api_key = os.getenv('OPENAI_API_KEY')\n",
48 | "# 设置 API_KEY"
49 | ]
50 | },
51 | {
52 | "cell_type": "code",
53 | "execution_count": 9,
54 | "metadata": {},
55 | "outputs": [],
56 | "source": [
57 | "# 一个封装 OpenAI 接口的函数,参数为 Prompt,返回对应结果\n",
58 | "def get_completion(prompt, model=\"gpt-3.5-turbo\", temperature=0):\n",
59 | " '''\n",
60 | " prompt: 对应的提示\n",
61 | " model: 调用的模型,默认为 gpt-3.5-turbo(ChatGPT),有内测资格的用户可以选择 gpt-4\n",
62 | " temperature: 温度系数\n",
63 | " '''\n",
64 | " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
65 | " response = openai.ChatCompletion.create(\n",
66 | " model=model,\n",
67 | " messages=messages,\n",
68 | " temperature=temperature, # 模型输出的温度系数,控制输出的随机程度\n",
69 | " )\n",
70 | " # 调用 OpenAI 的 ChatCompletion 接口\n",
71 | " return response.choices[0].message[\"content\"]\n"
72 | ]
73 | },
74 | {
75 | "cell_type": "markdown",
76 | "metadata": {},
77 | "source": [
78 | "## 二、定制客户邮件"
79 | ]
80 | },
81 | {
82 | "cell_type": "markdown",
83 | "metadata": {},
84 | "source": [
85 | "我们将根据客户评价和情感撰写自定义电子邮件响应。因此,我们将给定客户评价和情感,并生成自定义响应即使用 LLM 根据客户评价和评论情感生成定制电子邮件。"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "我们首先给出一个示例,包括一个评论及对应的情感"
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "execution_count": 4,
98 | "metadata": {},
99 | "outputs": [],
100 | "source": [
101 | "# given the sentiment from the lesson on \"inferring\",\n",
102 | "# and the original customer message, customize the email\n",
103 | "sentiment = \"negative\"\n",
104 | "\n",
105 | "# review for a blender\n",
106 | "review = f\"\"\"\n",
107 | "So, they still had the 17 piece system on seasonal \\\n",
108 | "sale for around $49 in the month of November, about \\\n",
109 | "half off, but for some reason (call it price gouging) \\\n",
110 | "around the second week of December the prices all went \\\n",
111 | "up to about anywhere from between $70-$89 for the same \\\n",
112 | "system. And the 11 piece system went up around $10 or \\\n",
113 | "so in price also from the earlier sale price of $29. \\\n",
114 | "So it looks okay, but if you look at the base, the part \\\n",
115 | "where the blade locks into place doesn’t look as good \\\n",
116 | "as in previous editions from a few years ago, but I \\\n",
117 | "plan to be very gentle with it (example, I crush \\\n",
118 | "very hard items like beans, ice, rice, etc. in the \\ \n",
119 | "blender first then pulverize them in the serving size \\\n",
120 | "I want in the blender then switch to the whipping \\\n",
121 | "blade for a finer flour, and use the cross cutting blade \\\n",
122 | "first when making smoothies, then use the flat blade \\\n",
123 | "if I need them finer/less pulpy). Special tip when making \\\n",
124 | "smoothies, finely cut and freeze the fruits and \\\n",
125 | "vegetables (if using spinach-lightly stew soften the \\ \n",
126 | "spinach then freeze until ready for use-and if making \\\n",
127 | "sorbet, use a small to medium sized food processor) \\ \n",
128 | "that you plan to use that way you can avoid adding so \\\n",
129 | "much ice if at all-when making your smoothie. \\\n",
130 | "After about a year, the motor was making a funny noise. \\\n",
131 | "I called customer service but the warranty expired \\\n",
132 | "already, so I had to buy another one. FYI: The overall \\\n",
133 | "quality has gone done in these types of products, so \\\n",
134 | "they are kind of counting on brand recognition and \\\n",
135 | "consumer loyalty to maintain sales. Got it in about \\\n",
136 | "two days.\n",
137 | "\"\"\""
138 | ]
139 | },
140 | {
141 | "cell_type": "code",
142 | "execution_count": 11,
143 | "metadata": {},
144 | "outputs": [],
145 | "source": [
146 | "# 我们可以在推理那章学习到如何对一个评论判断其情感倾向\n",
147 | "sentiment = \"negative\"\n",
148 | "\n",
149 | "# 一个产品的评价\n",
150 | "review = f\"\"\"\n",
151 | "他们在11月份的季节性销售期间以约49美元的价格出售17件套装,折扣约为一半。\\\n",
152 | "但由于某些原因(可能是价格欺诈),到了12月第二周,同样的套装价格全都涨到了70美元到89美元不等。\\\n",
153 | "11件套装的价格也上涨了大约10美元左右。\\\n",
154 | "虽然外观看起来还可以,但基座上锁定刀片的部分看起来不如几年前的早期版本那么好。\\\n",
155 | "不过我打算非常温柔地使用它,例如,\\\n",
156 | "我会先在搅拌机中将像豆子、冰、米饭等硬物研磨,然后再制成所需的份量,\\\n",
157 | "切换到打蛋器制作更细的面粉,或者在制作冰沙时先使用交叉切割刀片,然后使用平面刀片制作更细/不粘的效果。\\\n",
158 | "制作冰沙时,特别提示:\\\n",
159 | "将水果和蔬菜切碎并冷冻(如果使用菠菜,则轻轻煮软菠菜,然后冷冻直到使用;\\\n",
160 | "如果制作果酱,则使用小到中号的食品处理器),这样可以避免在制作冰沙时添加太多冰块。\\\n",
161 | "大约一年后,电机发出奇怪的噪音,我打电话给客服,但保修已经过期了,所以我不得不再买一个。\\\n",
162 | "总的来说,这些产品的总体质量已经下降,因此它们依靠品牌认可和消费者忠诚度来维持销售。\\\n",
163 | "货物在两天内到达。\n",
164 | "\"\"\""
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {},
170 | "source": [
171 | "我们已经使用推断课程中学到的提取了情感,这是一个关于搅拌机的客户评价,现在我们将根据情感定制回复。\n",
172 | "\n",
173 | "这里的指令是:假设你是一个客户服务AI助手,你的任务是为客户发送电子邮件回复,根据通过三个反引号分隔的客户电子邮件,生成一封回复以感谢客户的评价。"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 5,
179 | "metadata": {},
180 | "outputs": [
181 | {
182 | "name": "stdout",
183 | "output_type": "stream",
184 | "text": [
185 | "Dear Valued Customer,\n",
186 | "\n",
187 | "Thank you for taking the time to leave a review about our product. We are sorry to hear that you experienced an increase in price and that the quality of the product did not meet your expectations. We apologize for any inconvenience this may have caused you.\n",
188 | "\n",
189 | "We would like to assure you that we take all feedback seriously and we will be sure to pass your comments along to our team. If you have any further concerns, please do not hesitate to reach out to our customer service team for assistance.\n",
190 | "\n",
191 | "Thank you again for your review and for choosing our product. We hope to have the opportunity to serve you better in the future.\n",
192 | "\n",
193 | "Best regards,\n",
194 | "\n",
195 | "AI customer agent\n"
196 | ]
197 | }
198 | ],
199 | "source": [
200 | "prompt = f\"\"\"\n",
201 | "You are a customer service AI assistant.\n",
202 | "Your task is to send an email reply to a valued customer.\n",
203 | "Given the customer email delimited by ```, \\\n",
204 | "Generate a reply to thank the customer for their review.\n",
205 | "If the sentiment is positive or neutral, thank them for \\\n",
206 | "their review.\n",
207 | "If the sentiment is negative, apologize and suggest that \\\n",
208 | "they can reach out to customer service. \n",
209 | "Make sure to use specific details from the review.\n",
210 | "Write in a concise and professional tone.\n",
211 | "Sign the email as `AI customer agent`.\n",
212 | "Customer review: ```{review}```\n",
213 | "Review sentiment: {sentiment}\n",
214 | "\"\"\"\n",
215 | "response = get_completion(prompt)\n",
216 | "print(response)"
217 | ]
218 | },
219 | {
220 | "cell_type": "code",
221 | "execution_count": 6,
222 | "metadata": {},
223 | "outputs": [
224 | {
225 | "name": "stdout",
226 | "output_type": "stream",
227 | "text": [
228 | "尊敬的客户,\n",
229 | "\n",
230 | "非常感谢您对我们产品的评价。我们非常抱歉您在购买过程中遇到了价格上涨的问题。我们一直致力于为客户提供最优惠的价格,但由于市场波动,价格可能会有所变化。我们深表歉意,如果您需要任何帮助,请随时联系我们的客户服务团队。\n",
231 | "\n",
232 | "我们非常感谢您对我们产品的详细评价和使用技巧。我们将会把您的反馈传达给我们的产品团队,以便改进我们的产品质量和性能。\n",
233 | "\n",
234 | "再次感谢您对我们的支持和反馈。如果您需要任何帮助或有任何疑问,请随时联系我们的客户服务团队。\n",
235 | "\n",
236 | "祝您一切顺利!\n",
237 | "\n",
238 | "AI客户代理\n"
239 | ]
240 | }
241 | ],
242 | "source": [
243 | "prompt = f\"\"\"\n",
244 | "你是一位客户服务的AI助手。\n",
245 | "你的任务是给一位重要客户发送邮件回复。\n",
246 | "根据客户通过“```”分隔的评价,生成回复以感谢客户的评价。提醒模型使用评价中的具体细节\n",
247 | "用简明而专业的语气写信。\n",
248 | "作为“AI客户代理”签署电子邮件。\n",
249 | "客户评论:\n",
250 | "```{review}```\n",
251 | "评论情感:{sentiment}\n",
252 | "\"\"\"\n",
253 | "response = get_completion(prompt)\n",
254 | "print(response)"
255 | ]
256 | },
257 | {
258 | "cell_type": "markdown",
259 | "metadata": {},
260 | "source": [
261 | "## 三、使用温度系数\n",
262 | "\n",
263 | "接下来,我们将使用语言模型的一个称为“温度”的参数,它将允许我们改变模型响应的多样性。您可以将温度视为模型探索或随机性的程度。\n",
264 | "\n",
265 | "例如,在一个特定的短语中,“我的最爱食品”最有可能的下一个词是“比萨”,其次最有可能的是“寿司”和“塔可”。因此,在温度为零时,模型将总是选择最有可能的下一个词,而在较高的温度下,它还将选择其中一个不太可能的词,在更高的温度下,它甚至可能选择塔可,而这种可能性仅为五分之一。您可以想象,随着模型继续生成更多单词的最终响应,“我的最爱食品是比萨”将会与第一个响应“我的最爱食品是塔可”产生差异。因此,随着模型的继续,这两个响应将变得越来越不同。\n",
266 | "\n",
267 | "一般来说,在构建需要可预测响应的应用程序时,我建议使用温度为零。在所有课程中,我们一直设置温度为零,如果您正在尝试构建一个可靠和可预测的系统,我认为您应该选择这个温度。如果您尝试以更具创意的方式使用模型,可能需要更广泛地输出不同的结果,那么您可能需要使用更高的温度。"
268 | ]
269 | },
270 | {
271 | "cell_type": "code",
272 | "execution_count": 7,
273 | "metadata": {},
274 | "outputs": [],
275 | "source": [
276 | "# given the sentiment from the lesson on \"inferring\",\n",
277 | "# and the original customer message, customize the email\n",
278 | "sentiment = \"negative\"\n",
279 | "\n",
280 | "# review for a blender\n",
281 | "review = f\"\"\"\n",
282 | "So, they still had the 17 piece system on seasonal \\\n",
283 | "sale for around $49 in the month of November, about \\\n",
284 | "half off, but for some reason (call it price gouging) \\\n",
285 | "around the second week of December the prices all went \\\n",
286 | "up to about anywhere from between $70-$89 for the same \\\n",
287 | "system. And the 11 piece system went up around $10 or \\\n",
288 | "so in price also from the earlier sale price of $29. \\\n",
289 | "So it looks okay, but if you look at the base, the part \\\n",
290 | "where the blade locks into place doesn’t look as good \\\n",
291 | "as in previous editions from a few years ago, but I \\\n",
292 | "plan to be very gentle with it (example, I crush \\\n",
293 | "very hard items like beans, ice, rice, etc. in the \\ \n",
294 | "blender first then pulverize them in the serving size \\\n",
295 | "I want in the blender then switch to the whipping \\\n",
296 | "blade for a finer flour, and use the cross cutting blade \\\n",
297 | "first when making smoothies, then use the flat blade \\\n",
298 | "if I need them finer/less pulpy). Special tip when making \\\n",
299 | "smoothies, finely cut and freeze the fruits and \\\n",
300 | "vegetables (if using spinach-lightly stew soften the \\ \n",
301 | "spinach then freeze until ready for use-and if making \\\n",
302 | "sorbet, use a small to medium sized food processor) \\ \n",
303 | "that you plan to use that way you can avoid adding so \\\n",
304 | "much ice if at all-when making your smoothie. \\\n",
305 | "After about a year, the motor was making a funny noise. \\\n",
306 | "I called customer service but the warranty expired \\\n",
307 | "already, so I had to buy another one. FYI: The overall \\\n",
308 | "quality has gone done in these types of products, so \\\n",
309 | "they are kind of counting on brand recognition and \\\n",
310 | "consumer loyalty to maintain sales. Got it in about \\\n",
311 | "two days.\n",
312 | "\"\"\""
313 | ]
314 | },
315 | {
316 | "cell_type": "code",
317 | "execution_count": 10,
318 | "metadata": {},
319 | "outputs": [
320 | {
321 | "name": "stdout",
322 | "output_type": "stream",
323 | "text": [
324 | "Dear valued customer,\n",
325 | "\n",
326 | "Thank you for taking the time to share your review with us. We are sorry to hear that you were disappointed with the prices of our products and the quality of our blender. We apologize for any inconvenience this may have caused you.\n",
327 | "\n",
328 | "We value your feedback and would like to make things right for you. Please feel free to contact our customer service team so we can assist you with any concerns or issues you may have. We are committed to providing you with the best possible service and products.\n",
329 | "\n",
330 | "Thank you again for your review and for being a loyal customer. We hope to have the opportunity to serve you better in the future.\n",
331 | "\n",
332 | "Sincerely,\n",
333 | "AI customer agent\n"
334 | ]
335 | }
336 | ],
337 | "source": [
338 | "prompt = f\"\"\"\n",
339 | "You are a customer service AI assistant.\n",
340 | "Your task is to send an email reply to a valued customer.\n",
341 | "Given the customer email delimited by ```, \\\n",
342 | "Generate a reply to thank the customer for their review.\n",
343 | "If the sentiment is positive or neutral, thank them for \\\n",
344 | "their review.\n",
345 | "If the sentiment is negative, apologize and suggest that \\\n",
346 | "they can reach out to customer service. \n",
347 | "Make sure to use specific details from the review.\n",
348 | "Write in a concise and professional tone.\n",
349 | "Sign the email as `AI customer agent`.\n",
350 | "Customer review: ```{review}```\n",
351 | "Review sentiment: {sentiment}\n",
352 | "\"\"\"\n",
353 | "response = get_completion(prompt, temperature=0.7)\n",
354 | "print(response)"
355 | ]
356 | },
357 | {
358 | "cell_type": "code",
359 | "execution_count": 12,
360 | "metadata": {},
361 | "outputs": [
362 | {
363 | "name": "stdout",
364 | "output_type": "stream",
365 | "text": [
366 | "尊敬的客户,\n",
367 | "\n",
368 | "非常感谢您对我们产品的评价。我们由衷地为您在购买过程中遇到的问题表示抱歉。我们确实在12月份的第二周调整了价格,但这是由于市场因素所致,并非价格欺诈。我们深刻意识到您对产品质量的担忧,我们将尽一切努力改进产品,以提供更好的体验。\n",
369 | "\n",
370 | "我们非常感激您对我们产品的使用经验和制作技巧的分享。您的建议和反馈对我们非常重要,我们将以此为基础,进一步改进我们的产品。\n",
371 | "\n",
372 | "如果您有任何疑问或需要进一步帮助,请随时联系我们的客户服务部门。我们将尽快回复您并提供帮助。\n",
373 | "\n",
374 | "最后,请再次感谢您对我们产品的评价和选择。我们期待着未来与您的合作。\n",
375 | "\n",
376 | "此致\n",
377 | "\n",
378 | "敬礼\n",
379 | "\n",
380 | "AI客户代理\n"
381 | ]
382 | }
383 | ],
384 | "source": [
385 | "prompt = f\"\"\"\n",
386 | "你是一名客户服务的AI助手。\n",
387 | "你的任务是给一位重要的客户发送邮件回复。\n",
388 | "根据通过“```”分隔的客户电子邮件生成回复,以感谢客户的评价。\n",
389 | "如果情感是积极的或中性的,感谢他们的评价。\n",
390 | "如果情感是消极的,道歉并建议他们联系客户服务。\n",
391 | "请确保使用评论中的具体细节。\n",
392 | "以简明和专业的语气写信。\n",
393 | "以“AI客户代理”的名义签署电子邮件。\n",
394 | "客户评价:```{review}```\n",
395 | "评论情感:{sentiment}\n",
396 | "\"\"\"\n",
397 | "response = get_completion(prompt, temperature=0.7)\n",
398 | "print(response)"
399 | ]
400 | },
401 | {
402 | "cell_type": "markdown",
403 | "metadata": {},
404 | "source": [
405 | " "
406 | ]
407 | },
408 | {
409 | "cell_type": "markdown",
410 | "metadata": {},
411 | "source": [
412 | "在温度为零时,每次执行相同的提示时,您应该期望获得相同的完成。而使用温度为0.7,则每次都会获得不同的输出。\n",
413 | "\n",
414 | "所以,您可以看到它与我们之前收到的电子邮件不同。让我们再次执行它,以显示我们将再次获得不同的电子邮件。\n",
415 | "\n",
416 | "因此,我建议您自己尝试温度,以查看输出如何变化。总之,在更高的温度下,模型的输出更加随机。您几乎可以将其视为在更高的温度下,助手更易分心,但也许更有创造力。"
417 | ]
418 | }
419 | ],
420 | "metadata": {
421 | "kernelspec": {
422 | "display_name": "Python 3",
423 | "language": "python",
424 | "name": "python3"
425 | },
426 | "language_info": {
427 | "codemirror_mode": {
428 | "name": "ipython",
429 | "version": 3
430 | },
431 | "file_extension": ".py",
432 | "mimetype": "text/x-python",
433 | "name": "python",
434 | "nbconvert_exporter": "python",
435 | "pygments_lexer": "ipython3",
436 | "version": "3.8.13"
437 | },
438 | "latex_envs": {
439 | "LaTeX_envs_menu_present": true,
440 | "autoclose": false,
441 | "autocomplete": true,
442 | "bibliofile": "biblio.bib",
443 | "cite_by": "apalike",
444 | "current_citInitial": 1,
445 | "eqLabelWithNumbers": true,
446 | "eqNumInitial": 1,
447 | "hotkeys": {
448 | "equation": "Ctrl-E",
449 | "itemize": "Ctrl-I"
450 | },
451 | "labels_anchors": false,
452 | "latex_user_defs": false,
453 | "report_style_numbering": false,
454 | "user_envs_cfg": false
455 | },
456 | "toc": {
457 | "base_numbering": 1,
458 | "nav_menu": {},
459 | "number_sections": true,
460 | "sideBar": true,
461 | "skip_h1_title": false,
462 | "title_cell": "Table of Contents",
463 | "title_sidebar": "Contents",
464 | "toc_cell": false,
465 | "toc_position": {},
466 | "toc_section_display": true,
467 | "toc_window_display": false
468 | }
469 | },
470 | "nbformat": 4,
471 | "nbformat_minor": 4
472 | }
473 |
--------------------------------------------------------------------------------
/notebooks-zh/9. 总结.md:
--------------------------------------------------------------------------------
1 | 恭喜你完成了这门短期课程。
2 |
3 | 总的来说,在这门课程中,我们学习了关于prompt的两个关键原则:
4 |
5 | - 编写清晰具体的指令;
6 | - 如果适当的话,给模型一些思考时间。
7 |
8 | 你还学习了迭代式prompt开发的方法,并了解了如何找到适合你应用程序的prompt的过程是非常关键的。
9 |
10 | 我们还介绍了许多大型语言模型的功能,包括摘要、推断、转换和扩展。你还学会了如何构建自定义聊天机器人。在这门短期课程中,你学到了很多,希望你喜欢这些学习材料。
11 |
12 | 我们希望你能想出一些应用程序的想法,并尝试自己构建它们。请尝试一下并让我们知道你的想法。你可以从一个非常小的项目开始,也许它具有一定的实用价值,也可能完全没有实用价值,只是一些有趣好玩儿的东西。请利用你第一个项目的学习经验来构建更好的第二个项目,甚至更好的第三个项目等。或者,如果你已经有一个更大的项目想法,那就去做吧。
13 |
14 | 大型语言模型非常强大,作为提醒,我们希望大家负责任地使用它们,请仅构建对他人有积极影响的东西。在这个时代,构建人工智能系统的人可以对他人产生巨大的影响。因此必须负责任地使用这些工具。
15 |
16 | 现在,基于大型语言模型构建应用程序是一个非常令人兴奋和不断发展的领域。现在你已经完成了这门课程,我们认为你现在拥有了丰富的知识,可以帮助你构建其他人今天不知道如何构建的东西。因此,我希望你也能帮助我们传播并鼓励其他人也参加这门课程。
17 |
18 | 最后,希望你在完成这门课程时感到愉快,感谢你完成了这门课程。我们期待听到你构建的惊人之作。
--------------------------------------------------------------------------------
/notes/Prompt Engineering 提示工程 @Kevin的学堂.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Kevin-free/chatgpt-prompt-engineering-for-developers/a07a9368720e2c2d831bade8d8656812cfc2d268/notes/Prompt Engineering 提示工程 @Kevin的学堂.pdf
--------------------------------------------------------------------------------
/notes/Prompt Engineering 提示工程 @Kevin的学堂.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Kevin-free/chatgpt-prompt-engineering-for-developers/a07a9368720e2c2d831bade8d8656812cfc2d268/notes/Prompt Engineering 提示工程 @Kevin的学堂.png
--------------------------------------------------------------------------------
/notes/Prompt Engineering 提示工程 @Kevin的学堂.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Kevin-free/chatgpt-prompt-engineering-for-developers/a07a9368720e2c2d831bade8d8656812cfc2d268/notes/Prompt Engineering 提示工程 @Kevin的学堂.xmind
--------------------------------------------------------------------------------
/tutorial/20230723-ChatGPT最新注册教程.md:
--------------------------------------------------------------------------------
1 | # 20230723-ChatGPT 最新注册教程
2 |
3 | 
4 |
5 | ## 0 引言
6 |
7 | 大家好,我是 Kevin。
8 |
9 | 由于 ChatGPT 强大的能力和持续的热度,不仅成为我们技术圈炙手可热的话题,更是火出圈导致很多人蹭流量。我是从去年 12 月份开始使用 ChatGPT 的较早用户之一,深知它对我的帮助之大,因此想向更多人推荐学习使用。之前我曾写过一篇注册教程发在公众号,不过莫名奇怪被删了。
10 |
11 | 现在监管确实越来越严,中国的限制就不说了,国外也采取了一些措施。相信很多人都接收了 4 月 1 号开始广泛流传的“亚洲区封号”和“停止注册”的消息吧,在我看来,官方有一定程度的“频控”,但并没有一杆子打死,毕竟 OpenAI 这家公司是要盈利的,他难道会堵住自己的财路吗?传播这种言论的大多是不知情的自媒体或者无良的商家。**我们应该拥有独立思考和判断能力,获取真实的信息,避免成为韭菜!**
12 |
13 | 
14 |
15 | 估计很多人是看到上面这张图误认为“停止注册”吧,这其实只是不知道情况下操作的错误。现在注册 OpenAI 账号确实有门槛也更难,但是只要用科学的方法和正确的操作是一定能成功的。**本人在 2023 年 7 月 22 日亲自实践注册成功,下面我将用图文一步一步详细说明步骤,趁着现在还能注册,看完赶紧行动起来吧!相信你花耐心和时间一定能成功!**
16 |
17 | > 如果你觉得这篇文章不错的话,请收藏或者转发,能帮助到更多的人我也很开心。
18 | >
19 | > 防止不知道哪天这篇文章又被删除,我已将内容备份到 [GitHub](https://github.com/Kevin-free/chatgpt-prompt-engineering-for-developers) 和[个人博客](https://ifree.love/chatgpt-signup/)。
20 |
21 | [TOC]
22 |
23 | ## 1 准备工作
24 |
25 | 中国手工注册 ChatGPT 前提条件:
26 |
27 | 1. 网络代理:必需!由于众所周知的原因,中国用户需要魔 🪄 法上网,至于如何操作不便在此说明,请私聊我或者网上搜索。现在对网络的要求较高,避免使用低价人多的机场,我是使用自建机场成功的。建议全局代理到日本、美国等[支持地区](https://platform.openai.com/docs/supported-countries)。⚠️ 提示:香港是【不】行的!
28 | 2. 邮箱:必需!建议使用国外邮箱,如 Gmail,Gmail 注册不了的话可以使用 [Proton](mail.proton.me) 邮箱,另外企业邮箱也可以。⚠️ 提示:Outlook 邮箱现在是【不】行的!就会提示错误“Signup is currently unavailable, please try again later.”
29 | 3. 国外手机号:必需!用于接收验证码,有实体卡的话更好,没有的话可以使用接码平台,比如 [sms-activate](sms-activate.org/?ref=3003420),不过这个平台已经被用烂了,可能需要换很多个号码才能收到验证码,或者换其他的小众平台(至于是哪个我就不公开了,不然又得被用烂了)。⚠️ 提示:Google Voice 虚拟号是【不】行的!
30 | 4. 浏览器:建议使用 Chrome 浏览器,清除 openai 的缓存并开启无痕窗口。
31 | 5. 耐心:作者第一次是在 2022 年 12 月 14 日注册的,当时非常容易就注册好了。第二次是在 2023 年 5 月 16 日注册的,在网络和手机号上花了不少时间。估计以后会越来越难注册,如果你想学习实践建议尽快亲自注册 ChatGPT。手工注册不会像机器注册那样容易被封号,我手工注册的号至今依然稳定使用。
32 |
33 | 中国手工注册 ChatGPT 所需成本:
34 |
35 | 1. 时间:阅读教程(10min)+ OpenAI 注册操作(5min)+ 手机号注册&验证码(10min)+ buffer = 25 - 30 min。
36 | 2. 金钱:国外接码平台充值 2 美元&手续费 = 15 人民币。
37 |
38 | > 不得不说,现在手工注册 OpenAI 账号确实有一定门槛。如果你觉得麻烦可以联系我帮你手工注册,以及升级 ChatGPT Plus 也可以找我,当然需要收取一些手工费。另外你不担心被封号的风险的话,可以直接购买账号,不过需要辨别靠谱度。我认识靠谱的朋友有账号渠道(那种封号给你退款的),如果你需要的话,也可以联系我 VX:kevintao1024(💡 请备注:来意-昵称-获取渠道,如:手工注册-Kevin-个人博客,无备注不通过望理解)。
39 |
40 | ## 2 注册流程
41 |
42 | > 首先使用魔 🪄 法,开启全局代理到日本、美国等[支持地区](https://platform.openai.com/docs/supported-countries)。
43 | > 网络起着决定性的作用,很多问题可能都是网络导致的!
44 | > 可以访问 [ipaddress](https://www.ipaddress.my/?lang=zh_CN) 查看你当前使用的网络 IP。
45 |
46 | 
47 |
48 | ### 2.1 注册国外邮箱
49 |
50 | OpenAI 风控又升级了,现在注册使用国内邮箱和 Outlook 邮箱,就会出现误以为“停止注册”的信息:
51 |
52 | 
53 |
54 | 现在可以使用 Gmail 注册,如果你没有的话可以使用以下方案。
55 |
56 | > 如果你有企业邮箱也是可以的,或者你有域名注册企业邮箱也很简单。可以在[网易企业邮箱](https://qy.163.com/)注册。亲测是能够注册 OpenAI 账号的,⚠️ 温馨提示:网易企业邮箱将 OpenAI 的邮件放到垃圾邮件中了,当时我还以为不可以呢。
57 |
58 | 
59 |
60 | 企业邮箱有一定要求,那我用人人都可行的方案来介绍。分享一个可以免费使用的平台 [proton](https://proton.me/),按照下图操作注册一个新邮箱。
61 |
62 | 
63 |
64 | 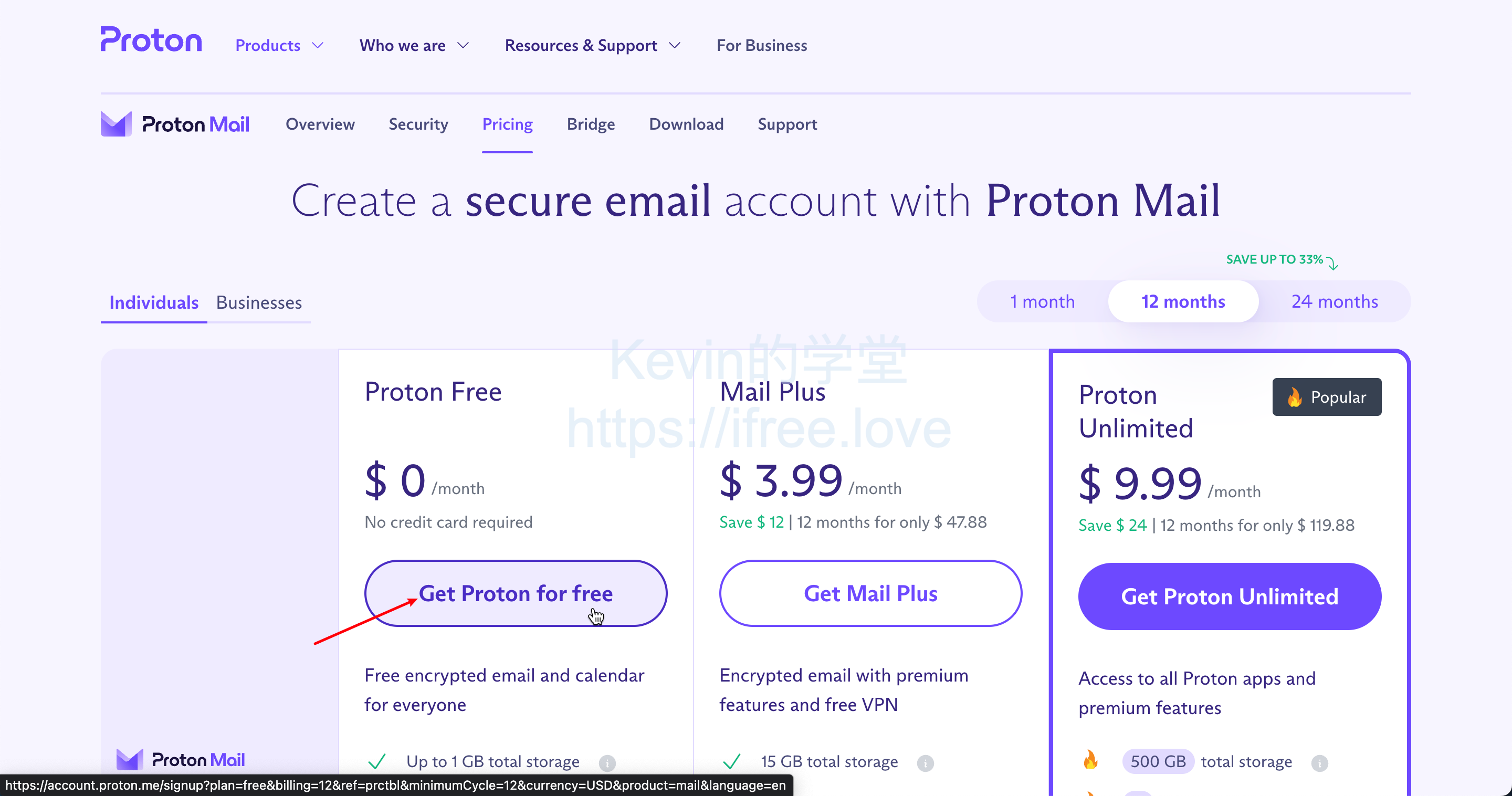
65 |
66 | 
67 |
68 | 
69 |
70 | 
71 |
72 | 
73 |
74 | 
75 |
76 | ### 2.2 注册接码平台
77 |
78 | 如果你有实体卡可以跳过这步。
79 |
80 | 在第三方接码平台注册并购买号码用于接收验证码,这里还是以 [sms-activate](https://sms-activate.org/?ref=3003420) 为例说明,虽然太多人用导致号码被用烂了,可能需要换很多个号码才能收到验证码,不过性价比和可靠性还是可以的。当然也可以使用其他小众接码平台,这里不公开介绍了,避免又被用烂了。可以关注个人公众号「Kevin 的学堂」回复“接码平台”获取,或者添加个人 VX:kevintao1024(💡 请备注:来意-昵称-获取渠道,如:手工注册-Kevin-个人博客,无备注不通过望理解)。
81 |
82 | 1. 注册接码平台账号
83 |
84 | 打开 [sms-activate](https://sms-activate.org/?ref=3003420),点击右上角的注册,输入邮箱和密码。
85 |
86 | 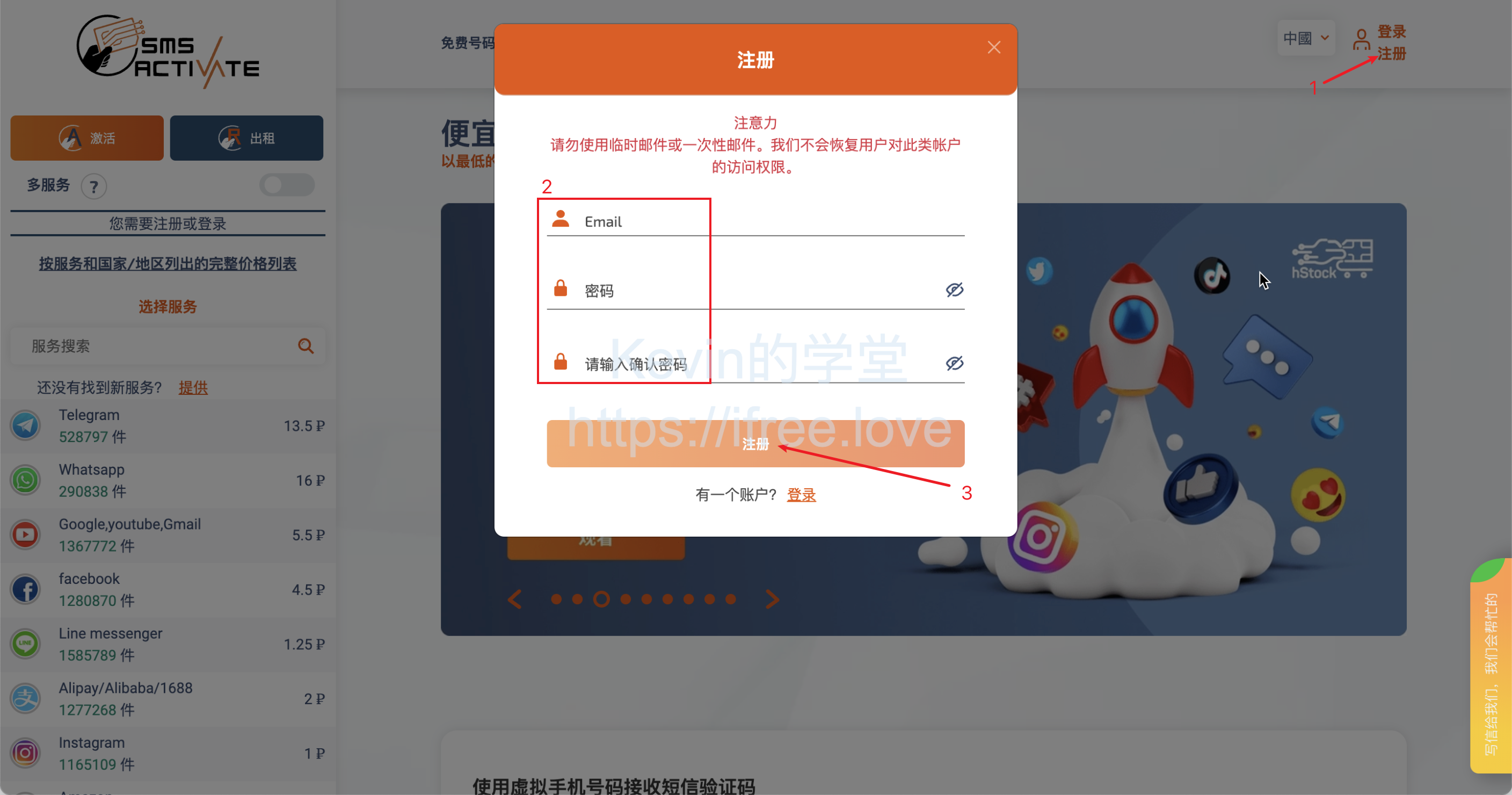
87 |
88 | 然后平台会发一封验证用电子邮件到你的邮箱,“电子邮件已发送到您的电子邮件。请点击信中的链接。也许在垃圾邮件文件夹中”
89 |
90 | 
91 |
92 | 点击邮件中的确认地址,或复制该地址到浏览器打开即可,验证通过后就可以在平台购买付费号码了,但在购买前需要先充值,购买号码时再进行扣除。
93 |
94 | 1. 账号充值
95 |
96 | 点击右上角的余额下面充值
97 |
98 | 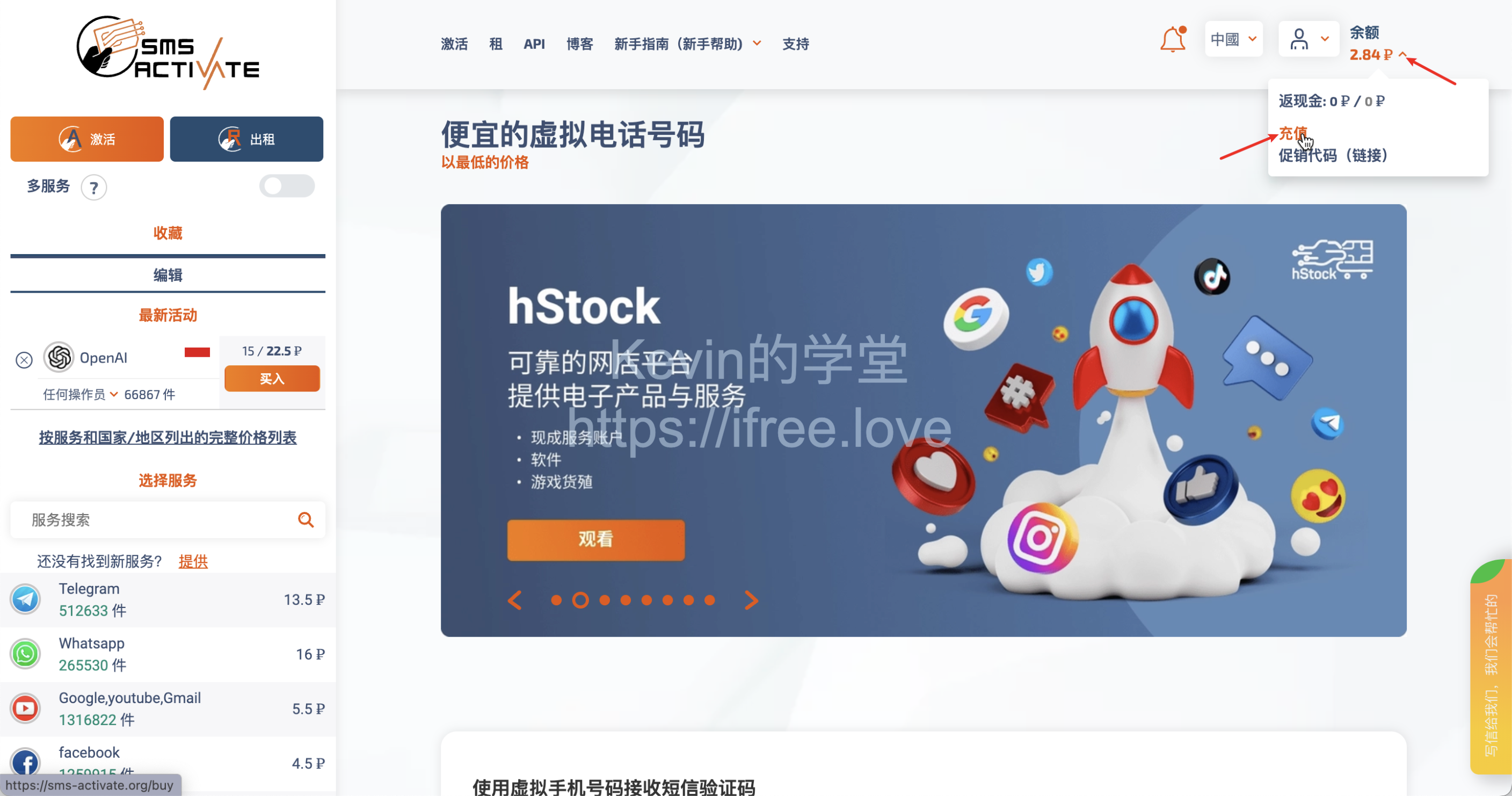
99 |
100 | 将页面拉到下面,找到支付宝,点击支付宝进行充值。很方便。
101 |
102 | 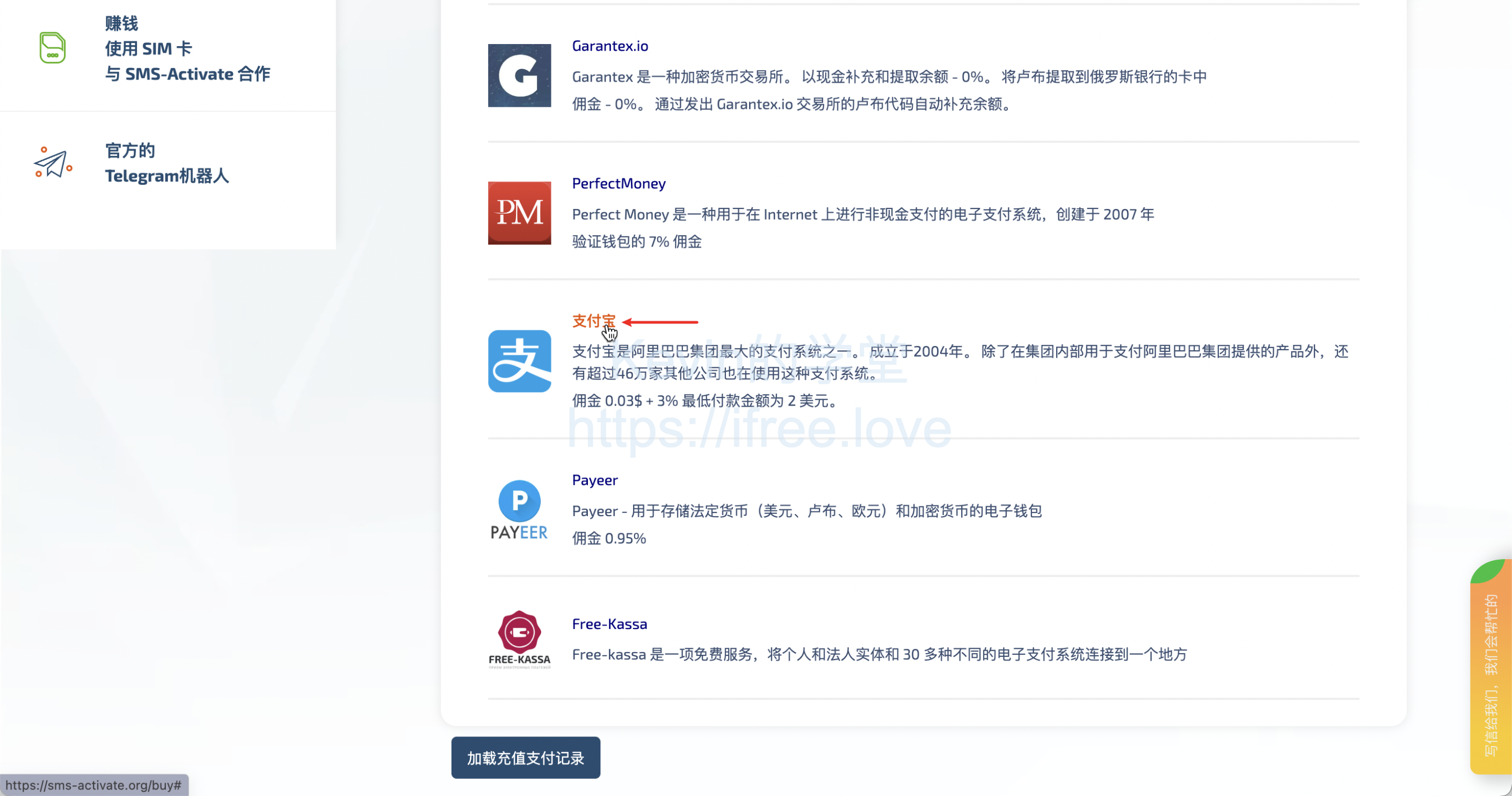
103 |
104 | > 注意 ⚠️ 由于 OpenAI 注册需求太多了,接码平台对充值费用也做了调整,目前的充值使用支付宝最低金额 2 美元,官方原文是:“Commission 0.03$ + 3% The minimum payment amount is 2 USD”,即最低充值 2 美元,充值 10 美元以下,服务费是每笔$0.03 再加上充值金额的 3%。例如充值 9 美元,服务费是 0.03+0.27,一共付款 9.3 美元才对(但后台显示 9.31 美元)。充值超过 10 美元,免服务费。
105 |
106 | 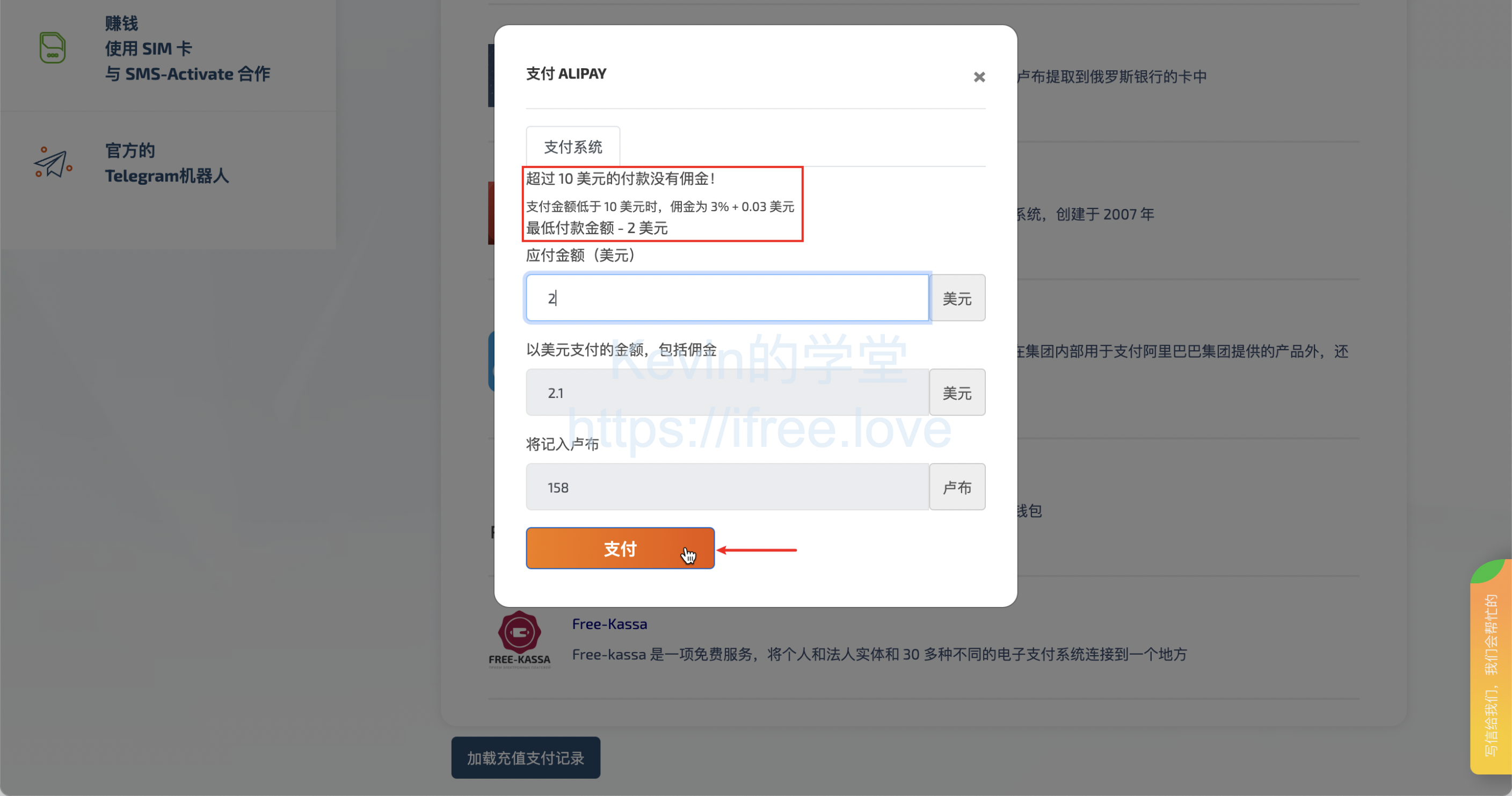
107 |
108 | > 我在 2022 年 12 月 14 号充值时最低 0.2 美元即可,手续费也低,真是早就是优势啊。平台规则经常变动,看你操作时如何。
109 |
110 | 
111 |
112 | 点击支付会弹出支付宝付款码,扫码支付即可。
113 |
114 | 
115 |
116 | 3. 购买手机号
117 |
118 | 在 sms-activate 网站左侧搜索栏输入 openai,在 OpenAI 服务列表中选择一个国家,点击右边的购物车即可购买。可以选便宜有货的,比如印度尼西亚性价比和数量都行,一个不行多试几个,实在不行买个贵的 😂
119 |
120 | 
121 |
122 | 点击购买后就可以看到这个界面,这个界面包含了接码手机号,还有未来接到短信之后会出现的区域,以及一个可以取消购买的按钮。
123 |
124 | 
125 |
126 | **注意 ⚠️ 号码有效期是 20 分钟,验证码有效期是 5 分钟。如果在 OpenAI 填了号码,却提示号码不可用或等了 3 分钟都没有收到验证码,可以返回 sms-activate 页面,取消刚刚购买的号码,重新再换个号接码就好。在没有收到验证码之前,都是不收费的,可以重复取消再购买。**
127 |
128 | ### 2.3 注册 OpenAI 账号
129 |
130 | 1. 填写邮箱密码
131 |
132 | 前面的铺垫工作做好了,接下来开始注册 OpenAI 账号,首先打开 https://platform.openai.com/signup ,点击注册。填写邮箱、密码。注意 ⚠️ 邮箱建议使用国外邮箱,国内邮箱和 Outlook 邮箱无法注册。
133 |
134 | 
135 |
136 | 
137 |
138 | 2. 验证邮箱
139 |
140 | 进入邮箱收取注册邮件,点击链接,这里强调一定要全程开启代理服务器,否则你使用国内 IP 可能就会遇到所在国家/地区不可用的错误信息:“Not available OpenAI’s services are not available in your country.”。
141 |
142 | 
143 |
144 | 然后在打开的页面中输入名、姓、出生日期(超过 18 岁即可)。
145 |
146 | 
147 |
148 | 3. 验证手机号码
149 |
150 | 然后下一个页面就要验证手机号码了,输入你在接码平台买的号码,注意 ⚠️ 复制号码的话记得把前面的国家代码删掉。然后点击发送验证码。
151 |
152 | 
153 |
154 | 在接码平台等待验证码并复制到确认区。
155 |
156 | 
157 |
158 | **注意 ⚠️ 号码有效期是 20 分钟,验证码有效期是 5 分钟。如果在 OpenAI 填了号码,却提示号码不可用或等了 3 分钟都没有收到验证码,可以返回 sms-activate 页面,取消刚刚购买的号码,重新再换个号接码就好。在没有收到验证码之前,都是不收费的,可以重复取消再购买。**
159 |
160 | 🎉 恭喜你,验证成功就成功注册了 ChatGPT 账号,并自动跳转到 OpenAI 后台。
161 |
162 | 
163 |
164 | 可以看到账号有 5 美元的免费额度,如果是开发人员可以使用 API 进行开发。当然也可以直接访问 ChatGPT 官网界面是不消耗 API 的。
165 |
166 | 
167 |
168 | > 这里提醒下免费额度是有有效期的,我去年 12 月注册的号,送的 18 美金没用上就过期了,血亏 🤣
169 |
170 | 
171 |
172 | 可以点击右边的菜单栏或者直接访问 chat.openai.com/chat 使用 ChatGPT。
173 |
174 | 
175 |
176 | 简单测试一下 ChatGPT。
177 |
178 | 
179 |
180 | > 这篇文章主要介绍 ChatGPT 的注册,就不多介绍 ChatGPT 的使用了,大家感兴趣的话可以关注个人公众号「Kevin 的学堂」,相关内容首发在公众号。防止被删我把内容备份到个人 [GitHub](https://github.com/Kevin-free/chatgpt-prompt-engineering-for-developers) 仓库了,欢迎 Follow & Star~
181 | > 💡 对了,我正在学习使用 ChatGPT 开发 AI 应用,如果你也感兴趣欢迎加我 VX:kevintao1024,也可以加入我免费创建的 ChatGPT&AI 交流群,一起交流学习。
182 |
183 | 另外,想给你推荐下我和大佬创建的 「**ChatGPT & AI 破局俱乐部**」,你可以点击[AI 破局俱乐部社群资料](https://d16rg8unadx.feishu.cn/docx/QQN8dPfruo2zlbxuxn6c2H8JnJg)查看详情。**三天内无理由全额退款**!可能有人抱有质疑态度,认为这是割韭菜,也可能有人一看到知识星球四个字就很反感,**但真实情况怎么样只有你亲自体验了才知道!如果你也对 AI 感兴趣想抓住机会,必须躬身入局行动起来!如何在瞬息万变的 AI 风口中行动呢?一个人可能走得更快,一群人才能走得更远!**
184 |
185 | 起初我也质疑过,但是看到越来越多的大佬加入和高质量内容,就不在顾虑了。你可以点击[火出圈的 ChatGPT!AI 时代如何破局?](https://ifree.love/ad-findyi/)了解详情,或者先进来看看,**把知识学到也是血赚!三天内无理由全额退款!**
186 |
187 | 
188 |
189 | ## 3 常用网站
190 |
191 | OpenAI 登录:https://platform.openai.com/signup
192 |
193 | ChatGPT 对话:https://chat.openai.com/chat
194 |
195 | 查看 API 剩余额度:https://platform.openai.com/account/usage
196 |
197 | 新建 API KEY:https://platform.openai.com/account/api-keys
198 |
199 | ## 4 常见问题
200 |
201 | ### 4.1 ChatGPT 是什么?有中文版和 APP 吗?
202 |
203 | ChatGPT 是由 OpenAI 开发的一个人工智能聊天机器人程序,于 2022 年 11 月推出。它能用中、英文回答你的各种问题,还能帮你翻译、算数学、甚至写代码检查日志。
204 |
205 | ChatGPT 注册阶段和后台使用上都是没有中文的,但是你跟 ChatGPT 沟通时是可以使用中文的,它可以理解中文,也能用中文回答你,如果它没有用中文回答你,你可以对它说,请用中文回答我即可。
206 |
207 | 请注意,~~OpenAI 官方并没有提供 ChatGPT APP~~,OpenAI 官方在 2023 年 5 月 19 日上线了 iOS ChatGPT 应用程序,OpenAI 官方在 2023 年 7 月 22 日宣布上线 Android ChatGPT 应用程序。你在任意平台看到的其他的所谓的 ChatGPT 官方版都是假的,都是第三方封装的(但是打着官方名义就很低俗啦),注意辨别。如果你实在要用手机使用 ChatGPT,可以使用浏览器前往 ChatGPT 网页版撩拨,或者自己部署一些好玩的应用。
208 |
209 | ### 4.2 正版 ChatGPT 与 国内盗版 ChatGPT(API)的区别?
210 |
211 | 现在所有使用 OpenAI API KEY 的项目,都不是基于 ChatGPT 开发的项目,官方并未发布 ChatGPT 的 API 接口。如果你自己有分别使用过 ChatGPT 的官方 chat 和 OpenAI 的 API 接口 chat,**你会发现 API 接口 chat 比 ChatGPT 的官方 chat“笨”得多**。
212 |
213 | 
214 |
215 | ### 4.3 ChatGPT 要钱吗?
216 |
217 | 目前不用,注册完成之后,有 5 美元的赠金,这部分赠金是用来支付 GPT-3 API 的调用,你使用网页版 ChatGPT 是不用支付费用的。
218 |
219 | ### 4.4 ChatGPT 和 ChatGPT Plus 区别?Plus 值得开吗?
220 |
221 | ChatGPT 和 ChatGPT Plus 是 OpenAI 提供的两种服务计划。它们之间的区别主要在于以下几个方面:
222 |
223 | 1. 价格:ChatGPT 是免费的,而 ChatGPT Plus 是一个付费计划,每月订阅费用为 20 美元。
224 |
225 | 2. 访问优先权:订阅 ChatGPT Plus 的用户可以享有访问优先权。这意味着当访问量较大时,他们可以在免费用户之前进入系统,从而减少等待时间。
226 |
227 | 3. 增强功能:ChatGPT Plus 用户还可以获得一些额外的增强功能和优先支持。比如 Plus 用户已经可以使用联网、插件功能。
228 |
229 | 至于是否值得订阅 ChatGPT Plus,这取决于您对服务的需求和预算。如果您对系统响应时间较为敏感,或者希望享受额外的增强功能和优先支持,那么 ChatGPT Plus 可能对您有吸引力。如果您对等待时间没有太大的关注,并且不需要额外的功能或支持,那么免费版的 ChatGPT 也可以满足您的需求。
230 |
231 | 至于如何升级 ChatGPT Plus 可以查看这篇[教程](https://chatgpt-plus.github.io/chatgpt-plus/),说实话门槛有点高,时间和金钱成本都不小,有需要的话可以私聊 VX:kevintao1024。
232 |
233 | ## 5 常见报错
234 |
235 | ### 5.1 访问时报错:Not available in your country
236 |
237 | 
238 |
239 | 报错原因:
240 |
241 | 国家不支持。网络 IP 不能在中国,香港也是不行的。
242 |
243 | 解决方案:
244 |
245 | 将网络 IP 代理到[支持国家](https://platform.openai.com/docs/supported-countries),建议代理到新加坡、日本、美国等地。
246 |
247 | ### 5.2 访问时报错:Sorry, you have been blocked
248 |
249 | 
250 |
251 | 报错原因:
252 |
253 | 1. 网络原因。
254 | 2. 浏览器原因。
255 |
256 | 解决方案:
257 |
258 | 1. 更换代理网络。低价人多的机场容易触发此报错。
259 | 2. 清除 OpenAI 的 cookies 和缓存。
260 | 3. 使用无痕模式或者换一个浏览器。
261 |
262 | ### 5.3 注册时报错:Signup is currently unavailable, please try again later
263 |
264 | 
265 |
266 | 报错原因:
267 |
268 | 邮箱原因。OpenAI 风控设升级了,现在使用国内邮箱、Outlook 邮箱注册就会报这个错误。
269 |
270 | 解决方案:
271 |
272 | 更换邮箱。建议使用国外邮箱,如 Gmail,Gmail 注册不了的话可以使用 [Proton](mail.proton.me) 邮箱,另外企业邮箱也可以。
273 |
274 | ### 5.4 发送验证码时报错:Your account was flagged for potential abuse
275 |
276 | 
277 |
278 | 报错原因:
279 |
280 | 1. 网络原因。
281 | 2. 号码原因。
282 |
283 | 解决方案:
284 |
285 | 1. 更换代理网络。
286 | 2. 更换手机号或者接码平台。
287 |
288 | ### 5.5 登录时报错:We ran into an issue while authenticating you
289 |
290 | 
291 |
292 | 报错原因:
293 |
294 | 1. 网络原因。
295 |
296 | 解决方案:
297 |
298 | 1. 更换代理网络。
299 |
300 | 另外以上问题都可以在 help.openai.com 官网帮助中心查找,实在不行可以发邮件给 support@openai.com 。虽然不一定有帮助。
301 |
302 | > 有不少朋友曾问我 ChatGPT 如何注册的问题,于是写了这篇更为详细的文章。策略可能还会变,这篇文章我也会保持更新。如果你有何问题欢迎留言或者联系我~
303 | > 这就是这篇文章的全部内容了,感谢你的耐心查看,希望对你有所帮助。也欢迎你分享这篇文章帮助到更多人!
304 |
305 | ## 6 链接
306 |
307 | 1. GitHub:https://github.com/Kevin-free/chatgpt-prompt-engineering-for-developers
308 | 2. 个人博客:https://ifree.love/chatgpt-signup/
309 | 3. OpenAI 支持地区:https://platform.openai.com/docs/supported-countries
310 | 4. proton 邮箱:https://proton.me/
311 | 5. sms-activate 接码平台:https://sms-activate.org/?ref=3003420
312 | 6. ipaddress:https://www.ipaddress.my/?lang=zh_CN
313 | 7. 网易企业邮箱:https://qy.163.com/
314 | 8. AI 破局俱乐部社群资料:https://d16rg8unadx.feishu.cn/docx/QQN8dPfruo2zlbxuxn6c2H8JnJg
315 | 9. 火出圈的 ChatGPT!AI 时代如何破局?:https://ifree.love/ad-findyi/
316 | 10. ChatGPT Plus 升级教程:https://chatgpt-plus.github.io/chatgpt-plus/
317 |
318 | ## 7 参考
319 |
320 | 1. Why can't I log in to OpenAI API? https://help.openai.com/en/articles/6613629-why-can-t-i-log-in-to-openai-api
321 | 2. 注册 Chatgpt 手机号无法验证出现“Your account was flagged for potential abuse”提示账号被标记滥用的最新解决办法 https://cloud.tencent.com/developer/beta/article/2266372
322 | 3. https://www.evlit.com/477.html
323 | 4. https://juejin.cn/post/7214512376669175845#heading-8
324 |
--------------------------------------------------------------------------------