├── .github
└── scaling_contours.png
├── pyproject.toml
├── LICENSE
├── README.md
├── training.py
├── .gitignore
├── data_utils.py
├── main.py
├── fsdp_training.py
├── data_gen.py
└── gzip_difficulty.py
/.github/scaling_contours.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/KhoomeiK/complexity-scaling/HEAD/.github/scaling_contours.png
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.poetry]
2 | name = "complexity-scaling"
3 | version = "0.1.0"
4 | description = "data-sensitive scaling laws"
5 | authors = ["khoomeik <32777448+KhoomeiK@users.noreply.github.com>"]
6 | license = "MIT"
7 | readme = "README.md"
8 |
9 | [tool.poetry.dependencies]
10 | python = "^3.10"
11 | transformers = "^4.39.1"
12 | torch = "^2.2.1"
13 | statistics = "^1.0.3.5"
14 | pcfg = "^0.1.5"
15 | datasets = "^2.18.0"
16 |
17 |
18 | [build-system]
19 | requires = ["poetry-core"]
20 | build-backend = "poetry.core.masonry.api"
21 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2024 Rohan Pandey
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | 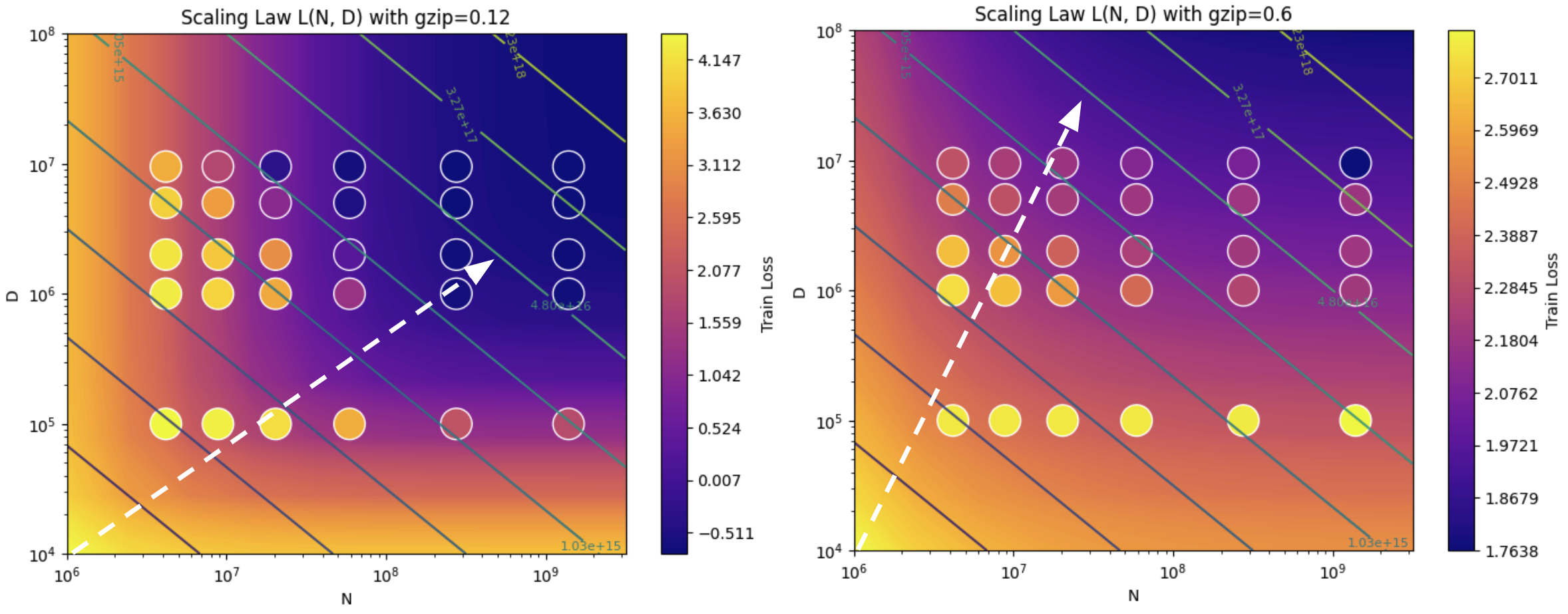 3 |
3 |
4 |
7 |
8 | 🐦 Twitter
9 | •
10 | 📄 Arxiv
11 | •
12 | 🤗 Datasets
13 |
14 |
15 | 🔗 Multimodal CodeGen for Web Data Extraction
16 |
17 |
18 | # `gzip` Predicts Data-dependent Scaling Laws
19 |
20 | This is the official code for *`gzip` Predicts Data-dependent Scaling Laws* (under review at NeurIPS 2024).
21 |
22 | We find that:
23 | 1. scaling laws are sensitive to differences in data complexity
24 | 2. `gzip`, a compression algorithm, is an effective predictor of how data complexity impacts scaling properties
25 |
26 | Our data-dependent scaling law's compute-optimal frontier increases in dataset size preference (over parameter count preference) as training data becomes more complex (harder to compress).
27 |
28 | ## Code Overview
29 | - `data_gen.py`: create PCFGs with specified syntactic properties and sample text datasets from them
30 | - `data_utils.py`: `gzip`-compressibility measurement, tokenization & HuggingFace tooling, dataloaders, etc.
31 | - `training.py`: run a single training run given model and dataset, returning loss at each train step
32 | - `main.py`: run a set of training runs across datasets & model sizes (hackily GPU-parallelized with threading)
33 | - `fsdp_training.py`: for running bigger jobs with cleaner data loading & FSDP training
34 |
35 | Upon request via email, we can also provide:
36 | - JSONL records of all training runs (this is large and can't fit on GitHub)
37 | - the Jupyter Notebook used to fit scaling laws from training runs and generate all visuals
38 |
--------------------------------------------------------------------------------
/training.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from torch.nn import CrossEntropyLoss
4 | from tqdm.auto import tqdm
5 | from torch.optim.lr_scheduler import CosineAnnealingLR
6 |
7 |
8 | def compute_perplexity(dataloader, model, device="cuda"):
9 | # adapted from: https://github.com/huggingface/evaluate/blob/main/metrics/perplexity/perplexity.py
10 | model = model.to(device)
11 |
12 | ppls = []
13 | loss_fct = CrossEntropyLoss(reduction="none")
14 |
15 | for batch in dataloader:
16 | batch.to(device)
17 | encoded_batch = batch["input_ids"]
18 | attn_mask = batch["attention_mask"]
19 |
20 | labels = encoded_batch
21 |
22 | with torch.no_grad():
23 | out_logits = model(encoded_batch, attention_mask=attn_mask).logits
24 |
25 | shift_logits = out_logits[
26 | ..., :-1, :
27 | ].contiguous() # TODO: double check that all this logic is correct
28 | shift_labels = labels[..., 1:].contiguous()
29 | shift_attention_mask_batch = attn_mask[..., 1:].contiguous()
30 |
31 | perplexity_batch = torch.exp(
32 | (
33 | loss_fct(shift_logits.transpose(1, 2), shift_labels)
34 | * shift_attention_mask_batch
35 | ).sum(1)
36 | / shift_attention_mask_batch.sum(1)
37 | )
38 |
39 | ppls += perplexity_batch.tolist()
40 |
41 | return np.mean(ppls)
42 |
43 |
44 | def run_training(
45 | model, train_dataloader, valid_dataloader, optimizer, num_epochs=10, device="cuda"
46 | ):
47 | train_loss = []
48 | valid_loss = []
49 |
50 | for epoch in range(num_epochs):
51 | lr_scheduler = CosineAnnealingLR(optimizer, T_max=len(train_dataloader))
52 | progress_bar = tqdm(
53 | range(len(train_dataloader)), desc=f"Epoch {epoch + 1}/{num_epochs}"
54 | )
55 |
56 | model.train()
57 | for batch in train_dataloader:
58 | batch = {k: v.to(device) for k, v in batch.items()}
59 | outputs = model(**batch)
60 | loss = outputs.loss
61 | loss.backward()
62 | train_loss.append(loss.item())
63 |
64 | optimizer.step()
65 | optimizer.zero_grad()
66 | progress_bar.update(1)
67 |
68 | lr_scheduler.step() # NOTE: all single-epoch scaling experiments before 4/30 mistakenly did not step the scheduler
69 |
70 | model.eval()
71 | with torch.no_grad():
72 | for batch in valid_dataloader:
73 | batch = {k: v.to(device) for k, v in batch.items()}
74 | outputs = model(**batch)
75 | loss = outputs.loss
76 | valid_loss.append(loss.item())
77 |
78 | print(
79 | f"Train Loss: {np.median(train_loss):.3f}, Valid Loss: {np.median(valid_loss):.3f}"
80 | )
81 |
82 | return train_loss, valid_loss
83 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | results/
2 | .DS_Store
3 |
4 | # Byte-compiled / optimized / DLL files
5 | __pycache__/
6 | *.py[cod]
7 | *$py.class
8 |
9 | # C extensions
10 | *.so
11 |
12 | # Distribution / packaging
13 | .Python
14 | build/
15 | develop-eggs/
16 | dist/
17 | downloads/
18 | eggs/
19 | .eggs/
20 | lib/
21 | lib64/
22 | parts/
23 | sdist/
24 | var/
25 | wheels/
26 | share/python-wheels/
27 | *.egg-info/
28 | .installed.cfg
29 | *.egg
30 | MANIFEST
31 |
32 | # PyInstaller
33 | # Usually these files are written by a python script from a template
34 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
35 | *.manifest
36 | *.spec
37 |
38 | # Installer logs
39 | pip-log.txt
40 | pip-delete-this-directory.txt
41 |
42 | # Unit test / coverage reports
43 | htmlcov/
44 | .tox/
45 | .nox/
46 | .coverage
47 | .coverage.*
48 | .cache
49 | nosetests.xml
50 | coverage.xml
51 | *.cover
52 | *.py,cover
53 | .hypothesis/
54 | .pytest_cache/
55 | cover/
56 |
57 | # Translations
58 | *.mo
59 | *.pot
60 |
61 | # Django stuff:
62 | *.log
63 | local_settings.py
64 | db.sqlite3
65 | db.sqlite3-journal
66 |
67 | # Flask stuff:
68 | instance/
69 | .webassets-cache
70 |
71 | # Scrapy stuff:
72 | .scrapy
73 |
74 | # Sphinx documentation
75 | docs/_build/
76 |
77 | # PyBuilder
78 | .pybuilder/
79 | target/
80 |
81 | # Jupyter Notebook
82 | .ipynb_checkpoints
83 |
84 | # IPython
85 | profile_default/
86 | ipython_config.py
87 |
88 | # pyenv
89 | # For a library or package, you might want to ignore these files since the code is
90 | # intended to run in multiple environments; otherwise, check them in:
91 | # .python-version
92 |
93 | # pipenv
94 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
95 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
96 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
97 | # install all needed dependencies.
98 | #Pipfile.lock
99 |
100 | # poetry
101 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
102 | # This is especially recommended for binary packages to ensure reproducibility, and is more
103 | # commonly ignored for libraries.
104 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
105 | #poetry.lock
106 |
107 | # pdm
108 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
109 | #pdm.lock
110 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
111 | # in version control.
112 | # https://pdm.fming.dev/#use-with-ide
113 | .pdm.toml
114 |
115 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
116 | __pypackages__/
117 |
118 | # Celery stuff
119 | celerybeat-schedule
120 | celerybeat.pid
121 |
122 | # SageMath parsed files
123 | *.sage.py
124 |
125 | # Environments
126 | .env
127 | .venv
128 | env/
129 | venv/
130 | ENV/
131 | env.bak/
132 | venv.bak/
133 |
134 | # Spyder project settings
135 | .spyderproject
136 | .spyproject
137 |
138 | # Rope project settings
139 | .ropeproject
140 |
141 | # mkdocs documentation
142 | /site
143 |
144 | # mypy
145 | .mypy_cache/
146 | .dmypy.json
147 | dmypy.json
148 |
149 | # Pyre type checker
150 | .pyre/
151 |
152 | # pytype static type analyzer
153 | .pytype/
154 |
155 | # Cython debug symbols
156 | cython_debug/
157 |
158 | # PyCharm
159 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
160 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
161 | # and can be added to the global gitignore or merged into this file. For a more nuclear
162 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
163 | #.idea/
164 |
--------------------------------------------------------------------------------
/data_utils.py:
--------------------------------------------------------------------------------
1 | import gzip
2 | import io
3 | import random
4 | from typing import List, Union
5 | from statistics import median, stdev
6 | from torch.utils.data import DataLoader
7 | from transformers import DataCollatorWithPadding
8 | from datasets import Dataset, DatasetDict, load_dataset
9 | from huggingface_hub import HfApi, HfFolder
10 |
11 |
12 | def count_total_tokens(dataloader):
13 | total_tokens = 0
14 | for batch in dataloader:
15 | total_tokens += sum(batch["attention_mask"].flatten().tolist())
16 | return total_tokens
17 |
18 |
19 | def pad_and_mask(sequence, sequence_length):
20 | if sequence_length - len(sequence) == 0:
21 | padded_sequence = sequence
22 | elif sequence_length - len(sequence) > 0:
23 | padded_sequence = sequence + [32000] * (sequence_length - len(sequence))
24 | elif sequence_length - len(sequence) < 0:
25 | padded_sequence = sequence[:sequence_length]
26 | mask = [1 if token != 32000 else 0 for token in padded_sequence]
27 | return padded_sequence, mask
28 |
29 |
30 | def pcfg_dataset_to_dataloader(
31 | pcfg_dataset, padder_tokenizer, batch_size=8, context_length=256, dataset_name=""
32 | ):
33 | if 'code' in dataset_name:
34 | tok_seqs = pcfg_dataset
35 | else:
36 | tok_seqs = [[int(tok) for tok in doc.split(" ")] for doc in pcfg_dataset]
37 |
38 | input_ids, attention_masks = [], []
39 | for seq in tok_seqs:
40 | padded_seq, mask = pad_and_mask(seq, context_length)
41 | input_ids.append(padded_seq)
42 | attention_masks.append(mask)
43 |
44 | tokenized_dataset = Dataset.from_dict(
45 | {"input_ids": input_ids, "attention_mask": attention_masks}
46 | )
47 | tokenized_dataset = tokenized_dataset.map(
48 | lambda x: {"labels": x["input_ids"].copy()}, batched=True
49 | )
50 | tokenized_dataset.set_format("torch")
51 |
52 | data_collator = DataCollatorWithPadding(tokenizer=padder_tokenizer)
53 |
54 | dataloader = DataLoader(
55 | tokenized_dataset, shuffle=True, batch_size=batch_size, collate_fn=data_collator
56 | )
57 |
58 | return dataloader
59 |
60 |
61 | def calculate_gzipability(
62 | input_data: Union[str, List[int]], gzip_toks: bool = True
63 | ) -> int:
64 | if type(input_data) == str and not gzip_toks:
65 | input_bytes = input_data.encode("utf-8")
66 | else: # token list
67 | if type(input_data) == str:
68 | input_data = [int(tok) for tok in input_data.split(" ")]
69 | input_bytes = b"".join(
70 | int.to_bytes(i, length=4, byteorder="big", signed=True) for i in input_data
71 | )
72 |
73 | buf = io.BytesIO()
74 | with gzip.GzipFile(fileobj=buf, mode="wb") as f:
75 | f.write(input_bytes)
76 |
77 | compressed_size = buf.tell()
78 | gzipability = compressed_size / len(input_bytes)
79 |
80 | return gzipability
81 |
82 |
83 | def calculate_median_stdev_gzipability(pcfg_dataset):
84 | gzipability_scores = [
85 | calculate_gzipability(row)
86 | for row in random.sample(pcfg_dataset, min(1000, len(pcfg_dataset)))
87 | ]
88 | med = median(gzipability_scores)
89 |
90 | if len(gzipability_scores) > 1:
91 | std_dev = stdev(gzipability_scores)
92 | else:
93 | std_dev = 0 # Default to 0 if there's only one element to avoid division by zero in stdev calculation
94 |
95 | return med, std_dev
96 |
97 |
98 | def upload_to_huggingface(pcfg_dataset, gzip, dataset_stats=None):
99 | api = HfApi()
100 | token = HfFolder.get_token()
101 | if token is None:
102 | raise ValueError(
103 | "Hugging Face Hub token not found. Please login using `huggingface-cli login`."
104 | )
105 | username = api.whoami(token)["name"]
106 |
107 | dataset = [{"text": seq} for seq in pcfg_dataset]
108 | dataset_dict = {
109 | "train": Dataset.from_list(dataset), # map to list of dicts?
110 | }
111 |
112 | dataset = DatasetDict(dataset_dict)
113 | dataset.push_to_hub(f"{username}/gzipscale-{gzip:0.2f}-{('_'.join([str(x) for x in dataset_stats[:-1]])) + '-' if dataset_stats else ''}100M")
114 |
115 |
116 | def download_from_huggingface(dataset_name):
117 | dataset_dict = load_dataset(dataset_name)
118 | dataset = dataset_dict["train"]
119 |
120 | if 'code' in dataset_name:
121 | return dataset['input_ids']
122 |
123 | pcfg_dataset = dataset["text"]
124 | return pcfg_dataset
125 |
126 | def sample_code_dataset(tokenizer, context_length=256):
127 | ds = load_dataset("codeparrot/github-code", streaming=True, split="train")
128 |
129 | seqs = []
130 | try:
131 | for row in ds:
132 | if row['language'] == 'C':
133 | outputs = tokenizer(row['code'], add_special_tokens=False)
134 | if len(outputs['input_ids']) < context_length:
135 | continue
136 |
137 | input_ids = outputs['input_ids']
138 |
139 | for i, subseq in enumerate(input_ids[::context_length]):
140 | if (i+1)*context_length > len(input_ids):
141 | break
142 | seq = input_ids[i*context_length : (i+1)*context_length]
143 | seqs.append({'input_ids': seq})
144 |
145 | if len(seqs) % 10_000 < 10:
146 | print(len(seqs))
147 |
148 | if len(seqs) > 31_250_000: # 8B tokens
149 | break
150 | # except http.client.RemoteDisconnected as e:
151 | except Exception as e:
152 | print(e)
153 | print("Connection to HuggingFace Hub was lost. Saving current progress...")
154 |
155 | print(len(seqs))
156 | tokenized_code_dataset = DatasetDict({"train": Dataset.from_list(seqs)})
157 | tokenized_code_dataset.set_format("torch")
158 | tokenized_code_dataset.push_to_hub(f"khoomeik/gzipscale-code-C-{(len(seqs) * context_length / 1_000_000):0.0f}M")
159 |
160 | if __name__ == '__main__':
161 | from transformers import AutoTokenizer
162 | tokenizer = AutoTokenizer.from_pretrained(
163 | "meta-llama/Llama-2-7b-chat-hf", token="[REDACTED]"
164 | )
165 | tokenizer.add_special_tokens({"pad_token": ""})
166 |
167 | sample_code_dataset(tokenizer)
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from training import run_training
3 | from transformers import AdamW, AutoTokenizer, LlamaForCausalLM, LlamaConfig
4 | import json
5 | from data_utils import (
6 | calculate_median_stdev_gzipability,
7 | count_total_tokens,
8 | pcfg_dataset_to_dataloader,
9 | download_from_huggingface,
10 | )
11 |
12 |
13 | def run_scaling_exps(cuda_idx=None):
14 | context_length = 256
15 | llm_configuration = {
16 | "vocab_size": 32001,
17 | "hidden_size": 256,
18 | "intermediate_size": 512,
19 | "num_hidden_layers": 4,
20 | "num_attention_heads": 4,
21 | "max_position_embeddings": context_length,
22 | }
23 | tokenizer = AutoTokenizer.from_pretrained(
24 | "meta-llama/Llama-2-7b-chat-hf", token="[REDACTED]"
25 | )
26 | tokenizer.add_special_tokens({"pad_token": ""})
27 |
28 | model_sizes = {
29 | "hidden_size": [64, 128, 256, 512, 1024, 2048],
30 | "intermediate_size": [128, 256, 512, 1024, 2048, 4096],
31 | "num_hidden_layers": [2, 4, 6, 10, 20, 30],
32 | "num_attention_heads": [1, 2, 4, 8, 16, 32],
33 | }
34 |
35 | dataset_names = [
36 | # "khoomeik/gzipscale-0.32-10_500_5_10-100M",
37 | # "khoomeik/gzipscale-0.36-20_300_10_5-100M",
38 | # "khoomeik/gzipscale-0.40-30_200_15_20-100M",
39 | # "khoomeik/gzipscale-0.38-(50,100,30,15)-100M",
40 |
41 | # "khoomeik/gzipscale-code-C-256M",
42 | # "khoomeik/gzipscale-code-python-256M",
43 | # "khoomeik/gzipscale-code-html-256M",
44 |
45 | # "khoomeik/gzipscale-0.11-100M",
46 | # "khoomeik/gzipscale-0.22-100M",
47 | # "khoomeik/gzipscale-0.35-100M",
48 | # "khoomeik/gzipscale-0.42-100M",
49 | # "khoomeik/gzipscale-0.51-100M",
50 | # "khoomeik/gzipscale-0.61-100M",
51 |
52 | # "khoomeik/gzipscale-0.12-10M",
53 | # "khoomeik/gzipscale-0.23-10M",
54 | # "khoomeik/gzipscale-0.33-10M",
55 | # "khoomeik/gzipscale-0.45-10M",
56 | # "khoomeik/gzipscale-0.61-10M",
57 |
58 | "khoomeik/gzipscale-0.11-3_300_2_2-100M",
59 | "khoomeik/gzipscale-0.25-10_300_5_3-100M",
60 | "khoomeik/gzipscale-0.36-20_300_10_5-100M",
61 | "khoomeik/gzipscale-0.47-50_300_20_10-100M"
62 | ]
63 | if cuda_idx is not None:
64 | if cuda_idx == torch.cuda.device_count(): # NOTE: this is only for handling dataset #5 and will likely break on systems with >4 GPUs
65 | dataset_names = [dataset_names[cuda_idx]]
66 | cuda_idx = torch.cuda.device_count() - 1
67 | else:
68 | dataset_names = [dataset_names[cuda_idx]]
69 | # cuda_idx = 1
70 | pcfg_datasets = [download_from_huggingface(name) for name in dataset_names]
71 | med_std_gzips = [
72 | calculate_median_stdev_gzipability(pcfg_dataset)
73 | for pcfg_dataset in pcfg_datasets
74 | ]
75 | for i, pcfg_dataset in enumerate(pcfg_datasets):
76 | med, std = med_std_gzips[i]
77 | total_toks = count_total_tokens(
78 | pcfg_dataset_to_dataloader(pcfg_dataset, padder_tokenizer=tokenizer, dataset_name=dataset_names[i])
79 | )
80 | print(f"{i}: {med:.3f} +- {std:.3f} ({total_toks}) | {dataset_names[i]}")
81 |
82 | device = f"cuda:{cuda_idx}" if cuda_idx is not None else "cpu"
83 | results = []
84 |
85 | torch.cuda.empty_cache()
86 |
87 | for i, pcfg_dataset in enumerate(pcfg_datasets):
88 | for data_portion in (0.001, 0.01, 0.1, 0.2, 0.5, 0.95):
89 | med_gzip, std_gzip = med_std_gzips[i]
90 |
91 | train_data_size = int(len(pcfg_dataset) * data_portion)
92 | valid_data_size = min(100, int(train_data_size / 10))
93 | train_dataloader = pcfg_dataset_to_dataloader(
94 | pcfg_dataset[:train_data_size],
95 | padder_tokenizer=tokenizer,
96 | batch_size=32,
97 | dataset_name=dataset_names[i]
98 | )
99 | valid_dataloader = pcfg_dataset_to_dataloader(
100 | pcfg_dataset[-valid_data_size:],
101 | padder_tokenizer=tokenizer,
102 | batch_size=32,
103 | dataset_name=dataset_names[i]
104 | )
105 | train_token_ct = count_total_tokens(train_dataloader)
106 |
107 | for j in range(len(list(model_sizes.values())[0])):
108 | print("-" * 20)
109 |
110 | model_stats = {key: val[j] for key, val in model_sizes.items()}
111 | model_config_dict = {
112 | **llm_configuration,
113 | **model_stats,
114 | } # NOTE: update vocab_size and new tokenizer?
115 | model_config = LlamaConfig(**model_config_dict)
116 | model = LlamaForCausalLM(model_config)
117 | model_size = sum(p.numel() for p in model.parameters())
118 |
119 | print(f"Dataset Stats: {med_gzip:.3f} +- {std_gzip:.3f}")
120 | print(f"Model Size: {model_size/1_000_000:.1f}M")
121 | print(f"Train Token Count: {train_token_ct}")
122 |
123 | model.to(device)
124 | optimizer = AdamW(model.parameters(), lr=5e-5)
125 | num_epochs = 1
126 |
127 | train_loss, valid_loss = run_training(
128 | model,
129 | train_dataloader,
130 | valid_dataloader,
131 | optimizer,
132 | num_epochs=num_epochs,
133 | device=device,
134 | )
135 |
136 | row = {
137 | "dataset_name": dataset_names[i],
138 | "dataset_gzip": (med_gzip, std_gzip),
139 | "token_ct": train_token_ct,
140 | "model_stats": model_config_dict,
141 | "model_size": model_size,
142 | "num_epochs": num_epochs,
143 | "train_loss": train_loss,
144 | "valid_loss": valid_loss,
145 | }
146 | results.append(row)
147 |
148 | with open(f"results_cuda:{cuda_idx}.jsonl", "a") as file:
149 | file.write(json.dumps(row) + "\n")
150 |
151 |
152 | if __name__ == "__main__":
153 | from concurrent.futures import ThreadPoolExecutor, wait
154 |
155 | with ThreadPoolExecutor(max_workers=torch.cuda.device_count()) as executor:
156 | futures = [executor.submit(run_scaling_exps, i) for i in range(torch.cuda.device_count())]
157 | wait(futures)
158 | # run_scaling_exps(4) # NOTE: for running dataset 5
159 |
160 | # run_scaling_exps(0)
--------------------------------------------------------------------------------
/fsdp_training.py:
--------------------------------------------------------------------------------
1 | import json
2 | import os
3 | from tqdm.auto import tqdm
4 | from datasets import Dataset, load_dataset
5 | from transformers import DataCollatorWithPadding, AdamW, AutoTokenizer, LlamaForCausalLM, LlamaConfig
6 |
7 | import torch
8 | from torch.optim.lr_scheduler import CosineAnnealingLR
9 | from torch.utils.data import DataLoader
10 | from torch.utils.data.distributed import DistributedSampler
11 | import torch.distributed as dist
12 | from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
13 | import torch.multiprocessing as mp
14 |
15 | from data_utils import pad_and_mask, download_from_huggingface
16 |
17 |
18 | def create_dataloader(
19 | dataset_name,
20 | padder_tokenizer,
21 | batch_size=32,
22 | context_length=256,
23 | rank=0,
24 | world_size=1,
25 | ):
26 | dataset = load_dataset(dataset_name)["train"]
27 | data_collator = DataCollatorWithPadding(tokenizer=padder_tokenizer)
28 | data_sampler = DistributedSampler(
29 | dataset, rank=rank, num_replicas=world_size, shuffle=True
30 | )
31 |
32 | dataloader = DataLoader(
33 | dataset,
34 | batch_size=batch_size,
35 | collate_fn=data_collator,
36 | sampler=data_sampler,
37 | # CUDA args:
38 | num_workers=2,
39 | pin_memory=True,
40 | shuffle=False,
41 | )
42 |
43 | return dataloader
44 |
45 | def pcfg_dataset_to_dataloader(
46 | pcfg_dataset,
47 | padder_tokenizer,
48 | batch_size=8,
49 | context_length=256,
50 | dataset_name="",
51 | rank=0,
52 | world_size=1,
53 | ):
54 | if "code" in dataset_name:
55 | tok_seqs = pcfg_dataset
56 | else:
57 | tok_seqs = [[int(tok) for tok in doc.split(" ")] for doc in pcfg_dataset]
58 |
59 | input_ids, attention_masks = [], []
60 | for seq in tok_seqs:
61 | padded_seq, mask = pad_and_mask(seq, context_length)
62 | input_ids.append(padded_seq)
63 | attention_masks.append(mask)
64 |
65 | tokenized_dataset = Dataset.from_dict(
66 | {"input_ids": input_ids, "attention_mask": attention_masks}
67 | )
68 | tokenized_dataset = tokenized_dataset.map(
69 | lambda x: {"labels": x["input_ids"].copy()}, batched=True
70 | )
71 | tokenized_dataset.set_format("torch")
72 |
73 | data_collator = DataCollatorWithPadding(tokenizer=padder_tokenizer)
74 | data_sampler = DistributedSampler( # TODO: refactor via `distributed` flag back into original pcfg_dataset_to_dataloader
75 | tokenized_dataset, rank=rank, num_replicas=world_size, shuffle=True
76 | )
77 |
78 | dataloader = DataLoader(
79 | tokenized_dataset,
80 | batch_size=batch_size,
81 | collate_fn=data_collator,
82 | sampler=data_sampler,
83 | # CUDA args:
84 | num_workers=2,
85 | pin_memory=True,
86 | shuffle=False,
87 | )
88 |
89 | return dataloader
90 |
91 | def setup(rank, world_size):
92 | os.environ["MASTER_ADDR"] = "localhost"
93 | os.environ["MASTER_PORT"] = "12355"
94 | dist.init_process_group("nccl", rank=rank, world_size=world_size)
95 |
96 |
97 | def cleanup():
98 | dist.destroy_process_group()
99 |
100 |
101 | def run_fsdp_training(
102 | model, train_dataloader, valid_dataloader, optimizer, num_epochs=10, rank=0
103 | ):
104 | train_loss = []
105 | valid_loss = []
106 |
107 | for epoch in range(num_epochs):
108 | lr_scheduler = CosineAnnealingLR(optimizer, T_max=len(train_dataloader))
109 | progress_bar = tqdm(
110 | range(len(train_dataloader)), desc=f"Epoch {epoch + 1}/{num_epochs}"
111 | )
112 | ddp_loss = torch.zeros(2).to(rank)
113 |
114 | model.train()
115 | for batch in train_dataloader:
116 | batch = {k: v.to(rank) for k, v in batch.items()}
117 | if 'labels' not in batch: # NOTE: hack to get around DataLoader not calling CodeDataset.__iter__
118 | batch['labels'] = batch['input_ids'].clone()
119 | optimizer.zero_grad()
120 | outputs = model(**batch)
121 | loss = outputs.loss
122 | loss.backward()
123 |
124 | optimizer.step()
125 | progress_bar.update(1)
126 |
127 | train_loss.append(loss.item())
128 | ddp_loss[0] += loss.item()
129 | ddp_loss[1] += len(batch)
130 |
131 | lr_scheduler.step()
132 |
133 | dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM)
134 |
135 | return train_loss, valid_loss
136 |
137 |
138 | def fsdp_main(rank, world_size, args):
139 | setup(rank, world_size)
140 |
141 | tokenizer = AutoTokenizer.from_pretrained(
142 | "meta-llama/Llama-2-7b-chat-hf", token="[REDACTED]"
143 | )
144 | tokenizer.add_special_tokens({"pad_token": ""})
145 |
146 | dataset_name = "khoomeik/gzipscale-code-C-8000M"
147 | pcfg_dataset = download_from_huggingface(dataset_name)
148 | train_dataloader = create_dataloader(
149 | dataset_name,
150 | padder_tokenizer=tokenizer,
151 | batch_size=32,
152 | # dataset_name=dataset_name,
153 | rank=rank,
154 | world_size=world_size,
155 | )
156 |
157 | torch.cuda.set_device(rank)
158 |
159 | model_config_dict = {
160 | "vocab_size": 32001,
161 | "hidden_size": 1024,
162 | "intermediate_size": 2048,
163 | "num_hidden_layers": 32,
164 | "num_attention_heads": 16,
165 | "max_position_embeddings": 256,
166 | }
167 | model_config = LlamaConfig(**model_config_dict)
168 | model = LlamaForCausalLM(model_config)
169 | model_size = sum(p.numel() for p in model.parameters())
170 | print(f"Model Size: {model_size/1_000_000:.1f}M")
171 |
172 | model.to(rank)
173 | model = FSDP(model)
174 |
175 | optimizer = AdamW(model.parameters(), lr=5e-5)
176 | num_epochs = 1
177 |
178 | train_loss, valid_loss = run_fsdp_training(
179 | model,
180 | train_dataloader,
181 | None,
182 | optimizer,
183 | num_epochs=num_epochs,
184 | rank=rank,
185 | )
186 |
187 | row = {
188 | "dataset_name": dataset_name,
189 | # "token_ct": train_token_ct,
190 | "model_stats": model_config_dict,
191 | "model_size": model_size,
192 | "num_epochs": num_epochs,
193 | "train_loss": train_loss,
194 | # "valid_loss": valid_loss,
195 | "cuda_rank": rank,
196 | }
197 |
198 | with open("results_fsdp.jsonl", "a") as file:
199 | file.write(json.dumps(row) + "\n")
200 |
201 | dist.barrier()
202 | states = model.state_dict()
203 | if rank == 0:
204 | torch.save(states, f"./model_{model_size}_{dataset_name.split('/')[-1]}.pt")
205 |
206 | cleanup()
207 |
208 |
209 | if __name__ == "__main__":
210 | args = {}
211 |
212 | WORLD_SIZE = torch.cuda.device_count()
213 | mp.spawn(fsdp_main, args=(WORLD_SIZE, args), nprocs=WORLD_SIZE, join=True)
214 |
--------------------------------------------------------------------------------
/data_gen.py:
--------------------------------------------------------------------------------
1 | import random
2 | from pcfg import PCFG
3 | import threading
4 |
5 | def generate_probs(num_options):
6 | if num_options <= 0:
7 | raise ValueError("Number of options must be positive")
8 |
9 | # Generate random integers for each option
10 | random_ints = [random.randint(1, 100) for _ in range(num_options)]
11 |
12 | # Calculate the total sum
13 | total = sum(random_ints)
14 |
15 | # Normalize each integer by the total sum to get probabilities
16 | probs = [i / total for i in random_ints]
17 |
18 | return probs
19 |
20 |
21 | def create_random_pcfg(
22 | num_nonterminals,
23 | num_terminals,
24 | rhs_max_options=5,
25 | rhs_max_len=5,
26 | constrain_to_pfsa=False,
27 | ):
28 | # Create non-terminal symbols
29 | nonterminals = [f"N{i}" for i in range(num_nonterminals)]
30 |
31 | # Create terminal symbols as consecutive integers
32 | terminals = [f"'{i}'" for i in range(num_terminals)]
33 |
34 | # Initialize production rules
35 | productions = []
36 |
37 | for lhs in nonterminals:
38 | rhs_options_ct = random.randint(1, rhs_max_options)
39 | rhs_option_probs = generate_probs(rhs_options_ct)
40 |
41 | rhs_options = []
42 |
43 | for rhs_option_prob in rhs_option_probs:
44 | rhs = []
45 |
46 | if constrain_to_pfsa:
47 | rhs.append(
48 | random.choice(nonterminals + terminals)
49 | ) # TODO: is this the right constraint?
50 | else:
51 | # Randomly decide the length of the right-hand side (at least 1)
52 | rhs_len = random.randint(1, rhs_max_len)
53 | for _ in range(rhs_len):
54 | rhs.append(random.choice(nonterminals + terminals))
55 |
56 | rhs_option = f"{' '.join(rhs)} [{rhs_option_prob}]"
57 | rhs_options.append(rhs_option)
58 |
59 | production = f"{lhs} -> {' | '.join(rhs_options)}"
60 | productions.append(production)
61 |
62 | start_production = f"S -> {' | '.join([f'{nonterminal} [{1/len(nonterminals)}]' for nonterminal in nonterminals])}"
63 | productions.insert(0, start_production)
64 |
65 | # Create the PCFG
66 | grammar = PCFG.fromstring("\n".join(productions))
67 |
68 | return grammar
69 |
70 |
71 | def generate_dataset(
72 | num_nonterminals,
73 | num_terminals,
74 | rhs_max_options,
75 | rhs_max_len,
76 | constrain_to_pfsa,
77 | num_toks_total,
78 | num_toks_per_seq=256,
79 | ) -> list[str]:
80 | print(num_nonterminals, num_terminals, rhs_max_options, rhs_max_len)
81 |
82 | grammar = create_random_pcfg(
83 | num_nonterminals,
84 | num_terminals,
85 | rhs_max_options=rhs_max_options,
86 | rhs_max_len=rhs_max_len,
87 | constrain_to_pfsa=constrain_to_pfsa,
88 | )
89 |
90 | dataset = []
91 | total_tokens_generated = 0
92 |
93 | while total_tokens_generated < num_toks_total:
94 | document_tokens = 0
95 | document = []
96 |
97 | while document_tokens < num_toks_per_seq:
98 | try:
99 | sentence = next(grammar.generate(1))
100 | except RecursionError:
101 | continue
102 | except StopIteration:
103 | print('No more sentences to generate')
104 | break # No more sentences can be generated
105 |
106 | sentence_token_count = sentence.count(" ") + 2
107 |
108 | available_space = num_toks_per_seq - document_tokens
109 | if sentence_token_count <= available_space:
110 | document.append(sentence)
111 | document_tokens += sentence_token_count
112 | else:
113 | # Split the sentence into words and add words until the document is full
114 | words = sentence.split()
115 | words_to_add = words[:available_space]
116 | truncated_sentence = " ".join(words_to_add)
117 |
118 | document.append(truncated_sentence)
119 | document_tokens += len(words_to_add)
120 |
121 | if document_tokens == num_toks_per_seq:
122 | break
123 |
124 | if document:
125 | dataset.append(" 0 ".join(document))
126 | total_tokens_generated += document_tokens
127 |
128 | if total_tokens_generated >= num_toks_total or not document:
129 | break # Stop if we've met the total token count or can't generate more documents
130 |
131 | return dataset
132 |
133 | def generate_dataset_part(grammar, num_toks_per_seq, target_tokens, dataset, total_tokens_generated, lock):
134 | local_dataset = []
135 | local_tokens_generated = 0
136 | while local_tokens_generated < target_tokens:
137 | document_tokens = 0
138 | document = []
139 | while document_tokens < num_toks_per_seq:
140 | try:
141 | sentence = next(grammar.generate(1))
142 | except RecursionError:
143 | continue
144 | except StopIteration:
145 | print('No more sentences to generate')
146 | break
147 |
148 | print(sentence)
149 | sentence_token_count = sentence.count(" ") + 2
150 | available_space = num_toks_per_seq - document_tokens
151 | if sentence_token_count <= available_space:
152 | document.append(sentence)
153 | document_tokens += sentence_token_count
154 | else:
155 | words = sentence.split()
156 | words_to_add = words[:available_space]
157 | truncated_sentence = " ".join(words_to_add)
158 | document.append(truncated_sentence)
159 | document_tokens += len(words_to_add)
160 |
161 | if document_tokens == num_toks_per_seq:
162 | break
163 |
164 | if document:
165 | local_dataset.append(" 0 ".join(document))
166 | local_tokens_generated += document_tokens
167 |
168 | if local_tokens_generated >= target_tokens or not document:
169 | break
170 |
171 | with lock:
172 | dataset.extend(local_dataset)
173 | total_tokens_generated[0] += local_tokens_generated
174 |
175 | def generate_dataset_threaded(
176 | num_nonterminals,
177 | num_terminals,
178 | rhs_max_options,
179 | rhs_max_len,
180 | constrain_to_pfsa,
181 | num_toks_total,
182 | num_toks_per_seq=256,
183 | ) -> list[str]:
184 | # NOTE: threaded dataset generation isn't noticeably faster
185 | print(num_nonterminals, num_terminals, rhs_max_options, rhs_max_len)
186 |
187 | num_threads = 16
188 | threads = []
189 | lock = threading.Lock()
190 | dataset = []
191 | total_tokens_generated = 0
192 | target_tokens_per_thread = num_toks_total // num_threads
193 |
194 | grammar = create_random_pcfg(
195 | num_nonterminals,
196 | num_terminals,
197 | rhs_max_options=rhs_max_options,
198 | rhs_max_len=rhs_max_len,
199 | constrain_to_pfsa=constrain_to_pfsa,
200 | )
201 |
202 | for _ in range(num_threads):
203 | thread = threading.Thread(target=generate_dataset_part, args=(grammar, num_toks_per_seq, target_tokens_per_thread, dataset, total_tokens_generated, lock))
204 | threads.append(thread)
205 | thread.start()
206 |
207 | print(dataset)
208 |
209 | for thread in threads:
210 | thread.join()
211 |
212 | return dataset
213 |
214 | if __name__ == "__main__":
215 | from data_utils import (
216 | calculate_median_stdev_gzipability,
217 | count_total_tokens,
218 | pcfg_dataset_to_dataloader,
219 | upload_to_huggingface,
220 | )
221 | from transformers import AutoTokenizer
222 |
223 | context_length = 256
224 | tokenizer = AutoTokenizer.from_pretrained(
225 | "meta-llama/Llama-2-7b-chat-hf", token="[REDACTED]"
226 | )
227 | tokenizer.add_special_tokens({"pad_token": ""})
228 |
229 | dataset_stats = [
230 | # (3, 20, 2, 2, False),
231 | # (10, 150, 5, 3, False),
232 | # (20, 300, 10, 5, False),
233 | # (30, 400, 10, 8, False),
234 | # (100, 2000, 100, 30, False),
235 | # (50, 500, 20, 15, False),
236 |
237 | # (10, 600, 5, 10, False), # .32
238 | # (20, 300, 15, 5, False), # .36
239 | # (30, 200, 10, 15, False), # .38
240 | # (50, 100, 20, 20, False), # .34
241 |
242 | # (3, 300, 2, 2, False), # isovocab
243 | # (10, 300, 5, 3, False),
244 | # (20, 300, 10, 5, False),
245 | # (50, 300, 20, 10, False),
246 | (100, 300, 100, 30, False),
247 | (200, 300, 200, 50, False),
248 | ]
249 | for row in dataset_stats: # NOTE: runs one dataset generation + upload at a time
250 | dataset_stats = [row]
251 |
252 | pcfg_datasets = [
253 | generate_dataset(*row, 100_000_000, num_toks_per_seq=context_length)
254 | for row in dataset_stats
255 | ]
256 | med_std_gzips = [
257 | calculate_median_stdev_gzipability(pcfg_dataset)
258 | for pcfg_dataset in pcfg_datasets
259 | ]
260 | for i, pcfg_dataset in enumerate(pcfg_datasets):
261 | med, std = med_std_gzips[i]
262 | total_toks = count_total_tokens(
263 | pcfg_dataset_to_dataloader(pcfg_dataset, padder_tokenizer=tokenizer)
264 | )
265 |
266 | print(
267 | f"{i}: {med:.3f} +- {std:.3f} ({total_toks}) | [{' '.join([str(x) for x in dataset_stats[i]])}]"
268 | )
269 | upload_to_huggingface(pcfg_dataset, med, dataset_stats[i])
270 |
--------------------------------------------------------------------------------
/gzip_difficulty.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """gzip-difficulty.ipynb
3 |
4 | Automatically generated by Colaboratory.
5 |
6 | Original file is located at
7 | https://colab.research.google.com/drive/[REDACTED]
8 |
9 | # How well does compressibility predict the learnability of a dataset?
10 |
11 | - compressibility: gzipability ~= length of gzipped string / length of original string
12 | - learnability: learning difficulty ~= integral of perplexity across training steps
13 | - datasets will be synthetically generated by PCFGs and taken from standard natural language & code datasets
14 | - hopefully the real-world datasets are in the PCFG's gzipability distribution
15 |
16 |
17 |
18 | Training data preparation [reference](https://huggingface.co/learn/nlp-course/chapter3/4)
19 |
20 | ## Setup
21 | """
22 |
23 | # ! pip install nltk pcfg
24 | # ! pip install accelerate -U
25 | # ! pip install transformers[torch] datasets wandb
26 |
27 | # Commented out IPython magic to ensure Python compatibility.
28 | # ! wandb login --relogin # [REDACTED]
29 |
30 | # # %env WANDB_ENTITY=rspandey
31 | # # %env WANDB_PROJECT=LM-Training
32 |
33 | """## Load Model"""
34 |
35 | from transformers import LlamaForCausalLM, LlamaConfig
36 |
37 | configuration = {
38 | "vocab_size": 32001,
39 | "hidden_size": 256,
40 | "intermediate_size": 512,
41 | "num_hidden_layers": 4,
42 | "num_attention_heads": 4,
43 | "max_position_embeddings": 256,
44 | }
45 | context_length = configuration["max_position_embeddings"]
46 |
47 | config = LlamaConfig(**configuration)
48 | model = LlamaForCausalLM(config)
49 |
50 | print(f"Param Count: {sum(p.numel() for p in model.parameters()) / 1_000_000:.1f}M")
51 |
52 | from transformers import AutoTokenizer
53 |
54 | tokenizer = AutoTokenizer.from_pretrained(
55 | "meta-llama/Llama-2-7b-chat-hf", token="[REDACTED]"
56 | ) # TODO: replace with actual model name
57 |
58 | tokenizer.add_special_tokens({"pad_token": ""})
59 | model.resize_token_embeddings(len(tokenizer))
60 |
61 | """## Real Data"""
62 |
63 | from torch.utils.data import DataLoader
64 | from transformers import DataCollatorWithPadding
65 | from datasets import load_dataset, DatasetDict
66 |
67 |
68 | def count_total_tokens(dataloader):
69 | total_tokens = 0
70 | for batch in dataloader:
71 | total_tokens += sum(batch["attention_mask"].flatten().tolist())
72 | return total_tokens
73 |
74 |
75 | """## CFG Data
76 |
77 | https://www.nltk.org/api/nltk.grammar.PCFG.html
78 |
79 | https://www.nltk.org/_modules/nltk/parse/generate.html
80 | """
81 |
82 |
83 | def generate_probs(num_options):
84 | if num_options <= 0:
85 | raise ValueError("Number of options must be positive")
86 |
87 | # Generate random integers for each option
88 | random_ints = [random.randint(1, 100) for _ in range(num_options)]
89 |
90 | # Calculate the total sum
91 | total = sum(random_ints)
92 |
93 | # Normalize each integer by the total sum to get probabilities
94 | probs = [i / total for i in random_ints]
95 |
96 | return probs
97 |
98 |
99 | import random
100 | import math
101 | from nltk import Nonterminal
102 | from pcfg import PCFG
103 |
104 |
105 | def create_random_pcfg(
106 | num_nonterminals,
107 | num_terminals,
108 | rhs_max_options=5,
109 | rhs_max_len=5,
110 | constrain_to_pfsa=False,
111 | ):
112 | # Create non-terminal symbols
113 | nonterminals = [f"N{i}" for i in range(num_nonterminals)]
114 |
115 | # Create terminal symbols as consecutive integers
116 | terminals = [f"'{i}'" for i in range(num_terminals)]
117 |
118 | # Initialize production rules
119 | productions = []
120 |
121 | for lhs in nonterminals:
122 | rhs_options_ct = random.randint(1, rhs_max_options)
123 | rhs_option_probs = generate_probs(rhs_options_ct)
124 |
125 | rhs_options = []
126 |
127 | for rhs_option_prob in rhs_option_probs:
128 | rhs = []
129 |
130 | if constrain_to_pfsa:
131 | rhs.append(
132 | random.choice(nonterminals + terminals)
133 | ) # TODO: is this the right constraint?
134 | else:
135 | # Randomly decide the length of the right-hand side (at least 1)
136 | rhs_len = random.randint(1, rhs_max_len)
137 | for _ in range(rhs_len):
138 | rhs.append(random.choice(nonterminals + terminals))
139 |
140 | rhs_option = f"{' '.join(rhs)} [{rhs_option_prob}]"
141 | rhs_options.append(rhs_option)
142 |
143 | production = f"{lhs} -> {' | '.join(rhs_options)}"
144 | productions.append(production)
145 |
146 | start_production = f"S -> {' | '.join([f'{nonterminal} [{1/len(nonterminals)}]' for nonterminal in nonterminals])}"
147 | productions.insert(0, start_production)
148 |
149 | # Create the PCFG
150 | grammar = PCFG.fromstring("\n".join(productions))
151 |
152 | return grammar
153 |
154 |
155 | def generate_dataset(
156 | num_nonterminals,
157 | num_terminals,
158 | rhs_max_options,
159 | rhs_max_len,
160 | constrain_to_pfsa,
161 | num_toks_total,
162 | num_toks_per_seq=context_length,
163 | ):
164 | grammar = create_random_pcfg(
165 | num_nonterminals,
166 | num_terminals,
167 | rhs_max_options=rhs_max_options,
168 | rhs_max_len=rhs_max_len,
169 | constrain_to_pfsa=constrain_to_pfsa,
170 | )
171 |
172 | dataset = []
173 | total_tokens_generated = 0
174 |
175 | while total_tokens_generated < num_toks_total:
176 | document_tokens = 0
177 | document = []
178 |
179 | while document_tokens < num_toks_per_seq:
180 | try:
181 | sentence = next(grammar.generate(1))
182 | except RecursionError:
183 | continue
184 | except StopIteration:
185 | break # No more sentences can be generated
186 |
187 | sentence_token_count = sentence.count(" ") + 2
188 |
189 | available_space = num_toks_per_seq - document_tokens
190 | if sentence_token_count <= available_space:
191 | document.append(sentence)
192 | document_tokens += sentence_token_count
193 | else:
194 | # Split the sentence into words and add words until the document is full
195 | words = sentence.split()
196 | words_to_add = words[:available_space]
197 | truncated_sentence = " ".join(words_to_add)
198 |
199 | document.append(truncated_sentence)
200 | document_tokens += len(words_to_add)
201 |
202 | if document_tokens == num_toks_per_seq:
203 | break
204 |
205 | if document:
206 | dataset.append(" 0 ".join(document))
207 | total_tokens_generated += document_tokens
208 |
209 | if total_tokens_generated >= num_toks_total or not document:
210 | break # Stop if we've met the total token count or can't generate more documents
211 |
212 | return dataset
213 |
214 |
215 | dataset_stats = [
216 | (5, 50, 3, 2, False),
217 | (10, 150, 5, 3, False),
218 | (20, 300, 10, 5, False),
219 | (50, 600, 30, 15, False),
220 | (100, 2000, 100, 30, False),
221 | ]
222 | pcfg_datasets = [generate_dataset(*row, 1_000_000) for row in dataset_stats]
223 |
224 | from datasets import Dataset
225 |
226 |
227 | def pad_and_mask(sequence, sequence_length):
228 | if sequence_length - len(sequence) == 0:
229 | padded_sequence = sequence
230 | elif sequence_length - len(sequence) > 0:
231 | padded_sequence = sequence + [32000] * (sequence_length - len(sequence))
232 | elif sequence_length - len(sequence) < 0:
233 | padded_sequence = sequence[:sequence_length]
234 | mask = [1 if token != 32000 else 0 for token in padded_sequence]
235 | return padded_sequence, mask
236 |
237 |
238 | def pcfg_dataset_to_dataloader(pcfg_dataset, batch_size=8, padder_tokenizer=tokenizer):
239 | tok_seqs = [[int(tok) for tok in doc.split(" ")] for doc in pcfg_dataset]
240 |
241 | input_ids, attention_masks = [], []
242 | for seq in tok_seqs:
243 | padded_seq, mask = pad_and_mask(seq, context_length)
244 | input_ids.append(padded_seq)
245 | attention_masks.append(mask)
246 |
247 | tokenized_dataset = Dataset.from_dict(
248 | {"input_ids": input_ids, "attention_mask": attention_masks}
249 | )
250 | tokenized_dataset = tokenized_dataset.map(
251 | lambda x: {"labels": x["input_ids"].copy()}, batched=True
252 | )
253 | tokenized_dataset.set_format("torch")
254 |
255 | data_collator = DataCollatorWithPadding(tokenizer=padder_tokenizer)
256 |
257 | dataloader = DataLoader(
258 | tokenized_dataset, shuffle=True, batch_size=batch_size, collate_fn=data_collator
259 | )
260 |
261 | return dataloader
262 |
263 |
264 | """## gzip"""
265 |
266 | import gzip
267 | import io
268 | from typing import List, Union
269 |
270 |
271 | def calculate_gzipability(
272 | input_data: Union[str, List[int]], gzip_toks: bool = True
273 | ) -> int:
274 | if type(input_data) == str and not gzip_toks:
275 | input_bytes = input_data.encode("utf-8")
276 | else: # token list
277 | if type(input_data) == str:
278 | input_data = [int(tok) for tok in input_data.split(" ")]
279 | input_bytes = b"".join(
280 | int.to_bytes(i, length=4, byteorder="big", signed=True) for i in input_data
281 | )
282 |
283 | buf = io.BytesIO()
284 | with gzip.GzipFile(fileobj=buf, mode="wb") as f:
285 | f.write(input_bytes)
286 |
287 | compressed_size = buf.tell()
288 | gzipability = compressed_size / len(input_bytes)
289 |
290 | return gzipability
291 |
292 |
293 | from statistics import median, stdev
294 |
295 |
296 | def calculate_median_stdev_gzipability(pcfg_dataset):
297 | gzipability_scores = [
298 | calculate_gzipability([int(tok) for tok in row.split(" ")])
299 | for row in pcfg_dataset
300 | ]
301 | med = median(gzipability_scores)
302 |
303 | if len(gzipability_scores) > 1:
304 | std_dev = stdev(gzipability_scores)
305 | else:
306 | std_dev = 0 # Default to 0 if there's only one element to avoid division by zero in stdev calculation
307 |
308 | return med, std_dev
309 |
310 |
311 | for i, pcfg_dataset in enumerate(pcfg_datasets):
312 | med, std = calculate_median_stdev_gzipability(pcfg_dataset)
313 | total_toks = count_total_tokens(pcfg_dataset_to_dataloader(pcfg_dataset))
314 |
315 | print(
316 | f"{i}: {med:.3f} +- {std:.3f} ({total_toks}) | [{' '.join([str(x) for x in dataset_stats[i]])}]"
317 | )
318 |
319 | """## Training
320 |
321 | Train on 2 synthetic datasets of similar token count but diff gzipability medians; compare perplexity sum over N epochs.
322 |
323 | TODO:
324 | - ensure I don't have train data in the validation set (how many unique sentences is the grammar generating)
325 | - model is unnecessarily large since vocab size is 32001
326 | - set padder_tokenizer for pcfg dataloader during each training run based on terminal_ct of pcfg_dataset
327 | - pass name and run hyperparams to wandb
328 |
329 | """
330 |
331 | import numpy as np
332 | from torch.nn import CrossEntropyLoss
333 |
334 |
335 | def compute_perplexity(dataloader, model, device="cuda"):
336 | # adapted from: https://github.com/huggingface/evaluate/blob/main/metrics/perplexity/perplexity.py
337 | model = model.to(device)
338 |
339 | ppls = []
340 | loss_fct = CrossEntropyLoss(reduction="none")
341 |
342 | for batch in dataloader:
343 | batch.to(device)
344 | encoded_batch = batch["input_ids"]
345 | attn_mask = batch["attention_mask"]
346 |
347 | labels = encoded_batch
348 |
349 | with torch.no_grad():
350 | out_logits = model(encoded_batch, attention_mask=attn_mask).logits
351 |
352 | shift_logits = out_logits[
353 | ..., :-1, :
354 | ].contiguous() # TODO: double check that all this logic is correct
355 | shift_labels = labels[..., 1:].contiguous()
356 | shift_attention_mask_batch = attn_mask[..., 1:].contiguous()
357 |
358 | perplexity_batch = torch.exp(
359 | (
360 | loss_fct(shift_logits.transpose(1, 2), shift_labels)
361 | * shift_attention_mask_batch
362 | ).sum(1)
363 | / shift_attention_mask_batch.sum(1)
364 | )
365 |
366 | ppls += perplexity_batch.tolist()
367 |
368 | return np.mean(ppls)
369 |
370 |
371 | from tqdm.auto import tqdm
372 |
373 |
374 | def run_training(model, train_dataloader, valid_dataloader, num_epochs=10):
375 | train_perplexities = []
376 | valid_perplexities = []
377 |
378 | for epoch in range(num_epochs):
379 | progress_bar = tqdm(
380 | range(len(train_dataloader)), desc=f"Epoch {epoch + 1}/{num_epochs}"
381 | )
382 |
383 | model.train()
384 | for batch in train_dataloader:
385 | batch = {k: v.to(device) for k, v in batch.items()}
386 | outputs = model(**batch)
387 | loss = outputs.loss
388 | loss.backward()
389 |
390 | optimizer.step()
391 | optimizer.zero_grad()
392 | progress_bar.update(1)
393 |
394 | train_perplexity = compute_perplexity(train_dataloader, model)
395 | train_perplexities.append(train_perplexity)
396 |
397 | model.eval()
398 | with torch.no_grad():
399 | valid_perplexity = compute_perplexity(valid_dataloader, model)
400 | valid_perplexities.append(valid_perplexity)
401 |
402 | print(
403 | f"Epoch {epoch}: Training Perplexity: {train_perplexity}, Validation Perplexity: {valid_perplexity}"
404 | )
405 |
406 | return train_perplexities, valid_perplexities
407 |
408 |
409 | import torch
410 |
411 | med_std_gzips = [
412 | calculate_median_stdev_gzipability(pcfg_dataset) for pcfg_dataset in pcfg_datasets
413 | ]
414 |
415 | model_sizes = {
416 | "hidden_size": [64, 128, 256, 512, 1024],
417 | "intermediate_size": [128, 256, 512, 1024, 2048],
418 | "num_hidden_layers": [2, 4, 6, 10, 20],
419 | "num_attention_heads": [1, 2, 4, 8, 16],
420 | }
421 |
422 | device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
423 |
424 | from transformers import AdamW
425 | import json
426 |
427 | results = []
428 |
429 | for data_portion in (0.01, 0.1, 0.2, 0.5, 0.95):
430 | for i, pcfg_dataset in enumerate(pcfg_datasets):
431 | med_gzip, std_gzip = med_std_gzips[i]
432 |
433 | train_data_size = int(len(pcfg_dataset) * data_portion)
434 | valid_data_size = min(100, int(train_data_size / 10))
435 | train_dataloader = pcfg_dataset_to_dataloader(pcfg_dataset[:train_data_size])
436 | valid_dataloader = pcfg_dataset_to_dataloader(pcfg_dataset[-valid_data_size:])
437 | train_token_ct = count_total_tokens(train_dataloader)
438 |
439 | for j in range(len(list(model_sizes.values())[0])):
440 | print("-" * 20)
441 |
442 | model_stats = {key: val[j] for key, val in model_sizes.items()}
443 | model_config_dict = {
444 | **configuration,
445 | **model_stats,
446 | } # NOTE: update vocab_size and new tokenizer?
447 | model_config = LlamaConfig(**model_config_dict)
448 | model = LlamaForCausalLM(model_config)
449 | model_size = sum(p.numel() for p in model.parameters())
450 |
451 | print(
452 | f"Dataset Stats: {med_gzip:.3f} +- {std_gzip:.3f} | {dataset_stats[i]}"
453 | )
454 | print(f"Model Size: {model_size/1_000_000:.1f}M")
455 | print(f"Train Token Count: {train_token_ct}")
456 |
457 | model.to(device)
458 | optimizer = AdamW(model.parameters(), lr=5e-5)
459 | num_epochs = 10
460 |
461 | train_perplexities, valid_perplexities = run_training(
462 | model, train_dataloader, valid_dataloader, num_epochs=num_epochs
463 | )
464 |
465 | row = {
466 | "dataset_stats": dataset_stats[i],
467 | "dataset_gzip": (med_gzip, std_gzip),
468 | "token_ct": train_token_ct,
469 | "model_stats": model_config_dict,
470 | "model_size": model_size,
471 | "num_epochs": num_epochs,
472 | "train_pplx": train_perplexities,
473 | "valid_pplx": valid_perplexities,
474 | }
475 | results.append(row)
476 |
477 | with open("results.jsonl", "a") as file:
478 | file.write(json.dumps(row) + "\n")
479 |
--------------------------------------------------------------------------------