:page_facing_up: 답지
52 |69 | 70 | 71 | ### 1.2 정보의 표현과 저장 `secho` 72 | 73 | # 컴퓨터 구조 74 | 75 | 76 | 77 | 1번 78 | 79 | C, C++, Python로 작성된 고급언어(소스코드)는 `1)____`를 통해 HW가 이해할 수 있는 언어로 번역된다. 80 | 81 | 이를 `2)___`라고한다. 82 | 83 | 이 `2)___`는 CPU마다 서로 다른데, 이런 언어차이를 해결하기 위해서 고급어와 `2)___` 사이의 `3)____`가 존재한다. 84 | 85 | 고-급언어 프로그램이 컴퓨터에서 처리되기 위해서 `____프로그램` -> `___ 프로그램`으로 번역되어야 한다. 86 | 87 | 88 | 89 | 어셈블리 명령어 구조는 두가지로 나뉘는데, 어떤 연산을 수행하라고 지정해주는 Opcode, 그리고 Opcode에 의해 연산될 데이터가 저장되어있는 주소를 가리키는 Operand로 구성되어있다. 90 | 91 | ex ) ADD A, 0x01 92 | 93 | - ADD(opcode) - 레지스터 A에 적재해라 94 | - 0x01에 저장된 내용을 읽어서 95 | 96 | 97 | 98 | 99 | 100 | #### 왜 어셈블리? 101 | 102 | + 기계어로 변환된 상태에서는 원래의 소스코드로 되돌리기 매우 힘들지만 어셈블리어에서는 코드로 되돌리는 것이 가능하다(번역에 가깝다) 따라서 어셈블리어를 사용하면 이미 컴파일된 실행 파일을 분석하고 기능을 추가하거나 뺼 수 있다. 103 | 104 |
:page_facing_up: 답지
106 |121 | 122 | 123 | ### 1.3 시스템의 구성 `yeha` 124 | 125 | 1. 다음 보기들을 간단히 설명해보세요. 126 | 127 | - 시스템 버스 128 | - 주소 버스 129 | - 데이터 버스 130 | - 제어 버스 131 | 132 | 2. 다음 중 시스템 버스에 속하지 않는 것은 무엇일까요? 133 | 134 | - 주소 버스 135 | - 데이터 버스 136 | - I/O버스 137 | - 제어 버스 138 | 139 | 3. Memory Read 할 때 메인 메모리가 아니라 캐시(Cache)로 먼저 전송되는 이유는 무엇일까요? 140 | 141 | 4. 메인 메모리 (Main Memory)와 SSD가 액세스(access)될 때 그 방식에 차이가 있습니다. 어떤 차이일까요? 142 | 143 | 5. I/O 디바이스 컨트롤러 (Device Controller) 에는 두 개의 레지스터가 존재합니다. 무엇일까요? 144 | 145 |
:page_facing_up: 답지
147 |195 | 196 | ### 1.4 컴퓨터 구조의 발전과정 (간단히) `kukim` 197 | 198 | 1. 다음 중에서 폰 노이만이 제안한 설계 개념의 핵심 내용에 해당하는 것은? 199 | - 가. 제어 카드와 연산 카드를 사용한다. 200 | - 나. ALU를 사용하여 연산을 처리한다. 201 | - 다. 프로그램과 데이터를 내부에 저장한다. 202 | - 라. 명령어를 선인출한다. 203 | 204 | 2. 폰 노이만 구조에 기반한 컴퓨터들은 프로그램 코드를 기억장치에 저장된 순서대로 읽어서 실행한다. 이와 관련된 CPU 내부 레지스터는 다음 중에서 어느것인가? 205 | - 가. 프로그램 카운터 206 | - 나. 누산기 207 | - 다. 명령어 레지스터 208 | - 라. MAR 209 | 210 | 3. 다음 컴퓨터 부품들 중에서 컴퓨터의 세대를 분류하는 기준이 되지 않는 것은? 211 | - 가. 트랜지스터 212 | - 나. 집적회로 (IC) 213 | - 다. LSI 214 | - 라. VLSI 215 | 216 | 4. 다음 중에서 IC의 출현에 의해 나타난 특징이라고 볼 수 없는 것은? 217 | - 가. 대량 생산이 용이해졌다. 218 | - 나. 가격이 높아졌다. 219 | - 다. 신뢰도가 높아졌다. 220 | - 라. 컴퓨터의 크기가 감소하였다. 221 | 222 |
:page_facing_up: 답지
224 |257 | -------------------------------------------------------------------------------- /08강 메인메모리.md: -------------------------------------------------------------------------------- 1 | ## 🦄 메인메모리 (8 / 13회차) 2 |
3 | 4 | ### 5.1 기억장치의 분류와 특성 `kycho` 5 | 6 | ##### [문제 1] 내부 기억장치와 외부 기억장치를 구분하는 기준이 되는 것은 무엇인가? (기본문제 5.1) 7 | 8 | ``` 9 | 가. 기억장치의 용량 10 | 나. 기억장치의 위치 11 | 다. 기억장치의 액세스 속도 12 | 라. CPU의 직접 액세스 가능 여부 13 | ``` 14 | 15 | ##### [문제 2] 다음은 기억장치의 액세스 유형에 대한 설명입니다. 보기를 참고하여 빈칸을 채우시오. 16 | 17 | ``` 18 | [보기] 직접 액세스, 임의 액세스, 연관 액세스, 순차적 액세스 19 | ``` 20 | - `__(가)__` : 기억장치에 저장된 정보들을 처음부터 순서대로 액세스하는 방식. 21 | - `__(나)__` : 읽기/쓰기 장치를 정보가 위치한 근처로 직접 이동시킨 다음에, 순차적 검색으로 최종 위치에 도달하여 액세스하는 방식. 22 | - `__(다)__` : 기억장치 내의 모든 저장장소들이 고유의 주소를 가지고 있기때문에, 어떤 임의의 주소도 직접 선택하여 액세스하는 방식. 23 | - `__(라)__` : 각 기억 장소에 포함된 키(key)값의 검색을 통하여 액세스 할 위치를 찾아내는 방식. 24 | 25 | ##### [문제 3] 다음 문장을 보고 빈칸을 채우시오. 26 | - `__(가)__`은 주소와 읽기/쓰기 신호가 기억장치에 도착한 순간부터 데이터가 저장되거나 읽혀지는 동작이 왼료되는 순간까지의 시간을 말한다. 27 | `__(나)__`은 `__(가)__`과 데이터 복원 시간을 합한 시간을 말한다. 28 | 29 | ##### [문제 4] 어떤 RAM모듈의 액세스 시간이 50ns이고, 한 번에 64비트씩 읽혀진다면, 데이터 전송률은 얼마인가? (1ns = 10-9s) 30 | 31 |
:page_facing_up: 답지
33 | 34 | ##### [문제 1] 내부 기억장치와 외부 기억장치를 구분하는 기준이 되는 것은 무엇인가? (기본문제 5.1) 35 | 36 | ``` 37 | 가. 기억장치의 용량 38 | 나. 기억장치의 위치 39 | 다. 기억장치의 액세스 속도 40 | 라. CPU의 직접 액세스 가능 여부 41 | ``` 42 | >정답 : 라.
43 | 기억장치는 CPU가 직접 액세스할 수 있는 내부 기억장치(internal memory)와 장치 제어기(device controller)를 통하여 액세스할 수 있는 외부 기억장치(external memory)로 구성된다. 44 | 45 | ##### [문제 2] 다음은 기억장치의 액세스 유형에 대한 설명입니다. 보기를 참고하여 빈칸을 채우시오. 46 | 47 | ``` 48 | [보기] 직접 액세스, 임의 액세스, 연관 액세스, 순차적 액세스 49 | ``` 50 | - `__(가)__` : 기억장치에 저장된 정보들을 처음부터 순서대로 액세스하는 방식. 51 | - `__(나)__` : 읽기/쓰기 장치를 정보가 위치한 근처로 직접 이동시킨 다음에, 순차적 검색으로 최종 위치에 도달하여 액세스하는 방식. 52 | - `__(다)__` : 기억장치 내의 모든 저장장소들이 고유의 주소를 가지고 있기때문에, 어떤 임의의 주소도 직접 선택하여 액세스하는 방식. 53 | - `__(라)__` : 각 기억 장소에 포함된 키(key)값의 검색을 통하여 액세스 할 위치를 찾아내는 방식. 54 | >정답
55 | (가) : 순차적 액세스
56 | (나) : 직접 액세스
57 | (다) : 임의 액세스
58 | (라) : 연관 액세스 59 | 60 | ##### [문제 3] 다음 문장을 보고 빈칸을 채우시오. 61 | - `__(가)__`은 주소와 읽기/쓰기 신호가 기억장치에 도착한 순간부터 데이터가 저장되거나 읽혀지는 동작이 왼료되는 순간까지의 시간을 말한다. 62 | `__(나)__`은 `__(가)__`과 데이터 복원 시간을 합한 시간을 말한다. 63 | >정답
64 | (가) : 액세스 시간(access time)
65 | (나) : 기억장치 사이클 시간(memory cycle time)
66 | ** 반도체 기억장치나 디스크와 같은 최근의 저장장치들은 읽기 동작 후에 정보가 지워지지 않기때문에 데이터 복원 시간이 없고, 액세스 시간과 기억장치 사이클 시간이 같다. 67 | 68 | ##### [문제 4] 어떤 RAM모듈의 액세스 시간이 50ns이고, 한 번에 64비트씩 읽혀진다면, 데이터 전송률[MBytes/sec]은 얼마인가? (1ns = 10-9s) 69 | >정답 : 160[MBytes/sec]
70 | 데이터 전송률은 기억장치로부터 초당 읽혀지거나 쓰여질 수 있는 비트수를 말하며 아래와 같이 구할수 있다.
71 | 데이터 전송률 = (1 / 액세스 시간) X (한 번에 읽혀지는 데이터 바이트의 수)
72 | 데이터 전송률 = {1 / (50 X 10-9)} X (64/8) = 160[MBytes/sec] 73 | 74 |
76 | 77 | ### 5.2 계층적 기억장치시스템 `jakang` 78 | 79 | 1번. 빈칸에 알맞은 답을 채워주세요 80 | 81 | `1) ________` 는 CPU와 주기억장치 간의 속도 차이를 보완해주기 위하여 데이터를 일시 저장해주는 중간 버퍼 기능을 수행한다. 82 | 83 | 계층적 기억 장치 시스템을 구성하면 하위 계층으로 내려갈수록 용량이 더 `2) ________` 비트당 가격은 `3) ________` 반면에 지역성의 원리로 인하여 액세스 빈도가 더 `4) ________` 84 | 진다. 85 | 86 | 2번. 다음 지문들의 참 거짓 여부를 표시하세요. 87 | 88 | `[ ]` 기억장치를 계층적으로 구성함으로써 속도와 용량 및 가격 면에서 더 개선된 기억장치시스템을 구성할 수 있다. 89 | 90 | `[ ]` 짧은 시간을 기준으로 보면 CPU가 기억장치의 한정된 몇몇 영역들을 주로 액세스하면서 작업을 수행하는데, 이와 같은 현상을 지역성의 원리라고 한다. 91 | 92 | `[ ]` 기억장치 계층에서 상위 계층으로 올라갈수록 용량이 감소하고, 액세스 시간은 짧아지며, CPU에 의한 액세스 빈도는 낮아진다. 93 | 94 | 3번. 계층적 기억장치시스템에서 첫 번째 계층 기억장치의 액세스 시간이 20ns 이고 두 번째 계층 기억장치의 액셰스 시간은 200ns이다. 첫 번째 계층 기억장치의 적중률이 0.8이라먼,평균 기억장치 액세스 시간은 얼마인가? 95 | 96 |
:page_facing_up: 답지
98 | 99 | 1번. 빈칸에 알맞은 답을 채워주세요 100 | 101 | `1) 캐시 메모리` 는 CPU와 주기억장치 간의 속도 차이를 보완해주기 위하여 데이터를 일시 저장해주는 중간 버퍼 기능을 수행한다. 102 | 103 | 계층적 기억 장치 시스템을 구성하면 하위 계층으로 내려갈수록 용량이 더 `2) 커지고` 비트당 가격은 `3) 떨어지는` 반면에 지역성의 원리로 인하여 액세스 빈도가 더 `4) 낮아진다` 104 | 진다. 105 | 106 | 2번. 다음 지문들의 참 거짓 여부를 표시하세요. 107 | 108 | `[ O ]` 기억장치를 계층적으로 구성함으로써 속도와 용량 및 가격 면에서 더 개선된 기억장치시스템을 구성할 수 있다. 109 | 110 | `[ O ]` 짧은 시간을 기준으로 보면 CPU가 기억장치의 한정된 몇몇 영역들을 주로 액세스하면서 작업을 수행하는데, 이와 같은 현상을 지역성의 원리라고 한다. 111 | 112 | `[ X ]` 기억장치 계층에서 상위 계층으로 올라갈수록 용량이 감소하고, 액세스 시간은 짧아지며, CPU에 의한 액세스 빈도는 낮아진다. 113 | 114 | : CPU에 의한 액세스 빈도는 높아진다. 115 | 116 | 3번. 계층적 기억장치시스템에서 첫 번째 계층 기억장치의 액세스 시간이 20ns 이고 두 번째 계층 기억장치의 액셰스 시간은 200ns이다. 첫 번째 계층 기억장치의 적중률이 0.8이라먼,평균 기억장치 액세스 시간은 얼마인가? 117 | 118 | 20 * 0.8 + 200 * 0.2 = 56ns 119 | 120 |
122 | 123 | ### 5.3 반도체 기억장치 `gaekim` 124 | 125 | 1번. 초기의 컴퓨터는 주기억장치로 임의 액세스 저장장치인 `자기 코어(magnetic core)`를 사용했으나, 최근 대부분의 컴퓨터는 주기억장치 소자로서 `반도체 기억장치 칩`들을 사용하고 있다. (O / X) 126 | 127 | 2번. 반도체 기억장치 중에서 `RAM / ROM` 은 읽기와 쓰기가 모두 가능하며, `RAM / ROM` 은 내용을 읽는 것만 가능하고 쓰는 것은 불가능하다. 128 | 129 | 3번. RAM은 제조 기술에 따라 DRAM과 SRAM으로 분류되는데, 이 중 `DRAM / SRAM` 은 캐패시터(capacitor)에 전하를 충전하는 방식으로 데이터를 저장하며, 이 때문에 주기적인 재충전(refresh)이 필요한 반도체 기억장치이다. 130 | 131 | 4번. DRAM은 비휘발성인 반면, SRAM은 휘발성이다. (O / X) 132 | 133 | 5번. DRAM은 주로 `주기억장치 / 캐시` 로 사용되며, SRAM은 `주기억장치 / 캐시` 로 사용된다. 134 | 135 | 6번. 다음 중 ROM 칩에 필요하지 않는 신호는? [기본문제 5.14] 136 | 137 | (1) 칩 선택 신호 (2) 주소 (3) 읽기 신호 (4) 쓰기 신호 138 | 139 | 7번. 다음 중에서 전원 공급이 중단되어도 내용이 지워지지 않으며, 전기적으로 지우고 다시 쓸 수도 있는 반도체 기억장치는? [기본문제 5.16] 140 | 141 | (1) ROM (2) EPROM (3) EEPROM (4) SRAM 142 | 143 |
:page_facing_up: 답지
145 | 146 | 1번. 초기의 컴퓨터는 주기억장치로 임의 액세스 저장장치인 `자기 코어(magnetic core)`를 사용했으나, 최근 대부분의 컴퓨터는 주기억장치 소자로서 `반도체 기억장치 칩` 들을 사용하고 있다. (`O`) 147 | 148 | 2번. 반도체 기억장치 중에서 `RAM` 은 읽기와 쓰기가 모두 가능하며, `ROM` 은 내용을 읽는 것만 가능하고 쓰는 것은 불가능하다. 149 | 150 | 3번. RAM은 제조 기술에 따라 DRAM과 SRAM으로 분류되는데, 이 중 `DRAM` 은 캐패시터(capacitor)에 전하를 충전하는 방식으로 데이터를 저장하며, 이 때문에 주기적인 재충전(refresh)이 필요한 반도체 기억장치이다. 151 | 152 | > SRAM은 플립-플롭(flip-flop) 기억 셀을 이용하며, 전력이 공급되는 동안에는 데이터가 계속 유지된다는 특징이 있다. 153 | 154 | 4번. DRAM은 비휘발성인 반면, SRAM은 휘발성이다. (`X`) 155 | 156 | > DRAM과 SRAM은 모두 휘발성 기억장치이다. 157 | 158 | 5번. DRAM은 주로 `주기억장치` 로 사용되며, SRAM은 `캐시` 로 사용된다. 159 | 160 | > DRAM은 SRAM보다 밀도가 높고, 같은 용량 대비 가격이 저렴하며, 주로 기억장치로 사용된다. 161 | > 162 | > SRAM은 DRAM보다 속도가 빠르며, 주로 캐시로 사용된다. 163 | 164 | 6번. 다음 중 ROM 칩에 필요하지 않는 신호는? [기본문제 5.14] 165 | 166 | (1) 칩 선택 신호 (2) 주소 (3) 읽기 신호 (4) 쓰기 신호 167 | 168 | > 정답: (4) 쓰기 신호 169 | 170 | > ROM은 데이터를 쓰는 기능이 없으므로 쓰기 신호는 필요하지 않다. 171 | 172 | 7번. 다음 중에서 전원 공급이 중단되어도 내용이 지워지지 않으며, 전기적으로 지우고 다시 쓸 수도 있는 반도체 기억장치는? [기본문제 5.16] 173 | 174 | (1) ROM (2) EPROM (3) EEPROM (4) SRAM 175 | 176 | > 정답: (3) EEPROM 177 | 178 | > ROM: 저장된 내용을 읽는 것만 가능한 반도체 기억장치 179 | > 180 | > EPROM(Erasable PROM): 자외선을 이용하여 저장된 내용을 삭제할 수 있어서 여러 번의 갱신이 가능한 PROM(Programmable ROM) 181 | > 182 | > EEPROM(Electrically Erasable PROM): 비휘발성이면서도 읽기와 쓰기가 모두 가능하며, 전기적으로도 삭제할 수 있는 PROM 183 | > 184 | > SRAM: 플립-플롭(flip-flop) 기억 셀을 이용하며, 전력이 공급되는 동안에는 데이터가 계속 유지되는 RAM 185 | 186 | 187 | 188 |
190 | 191 | ### 5.4 기억장치 모듈의 설계 `secho` 192 | 193 | **1번 다음은 n * m 크기의 메인메모리 모듈을 디자인한 그림입니다. 각 빈칸에 대해서 알맞게 채워주세요.** 194 | 195 |
196 | 197 | 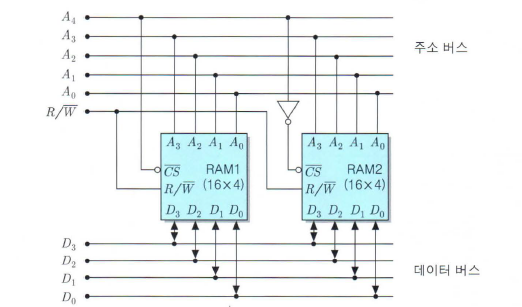 198 | 199 |
200 | 201 | - 주소버스 `_`개, 데이터 입출력 비트가 `_`개인 `_ * _bits` 크기의 RAM Chip들을 `직렬 / 병렬`접속으로 `_ * _bits` 크기의 메인메모리를 디자인했다. 202 | 203 |
204 | 205 | 206 | 207 | 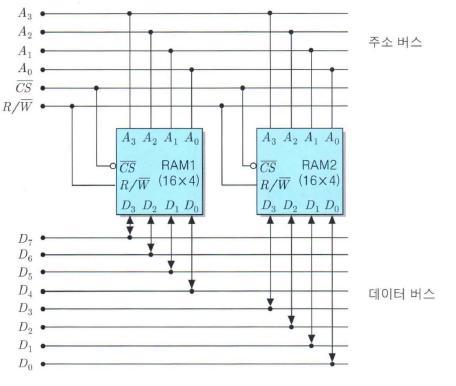 208 | 209 |
210 | 211 | - 주소버스 `_`개, 데이터 입출력 비트가 `_`개인 `_ * _bits` 크기의 RAM Chip들을 `직렬 / 병렬`접속으로 `_ * _bits` 크기의 메인메모리를 디자인했다. 212 | 213 |
214 | 215 | **2번 [연습문제 5.4]** 216 | 217 |
218 | 219 | **다음과 같은 조직을 가진 RAM들을 이용하여 1K * 32비트 기억장치 모듈을 구성하는데 필요한 칩의 수를 구하라** 220 | 221 |
222 | 223 | (1) 512 * 1비트 조직 : 224 | 225 | (2) 128 * 4비트 조직 : 226 | 227 | (3) 64 * 8비트 조직 : 228 | 229 | 230 | 231 |
:page_facing_up: 답지
233 | 234 | 1번 235 | 236 | 다음은 n * m 크기의 메인메모리 모듈을 디자인한 그림입니다. 237 | 238 | 각 빈칸에 대해서 알맞게 채워주세요. 239 | 240 |  241 | 242 | 243 | 244 | 주소버스 `4`개 데이터 입출력 비트가 `4`개인 `16 * 4bit`크기의 RAM Chip들을 `[직렬] / 병렬`접속으로 `32 * 4bit` 크기의 메인메모리를 디자인했다. 245 | 246 | - 각 RAM은 4개의 비트로 기억장소의 위치를 결정한다. 247 | - 한 램은 총 16개씩 0000 ~ 1111까지 가질 수 있지만 두 RAM을 직렬접속하면 최상단비트를 칩셀렉터로 사용해 1bit 증가된 효과를 얻을 수 있다. 248 | - 상위비트를 0,1로 set하면 00000 ~ 01111, 10000 ~ 11111까지 선택할 수 있으므로, 총 32개의 주소를 선택해 데이터 입출력을 할 수 있다. 249 | 250 | 251 | 252 | 253 | 254 | 255 | 256 |  257 | 258 | 주소버스 `4`개, 데이터 입출력 비트가 `4`개인 `16 * 4bits` 크기의 RAM Chip들을 `직렬 / [병렬]`접속으로 `16 * 8bits` 크기의 메인메모리를 디자인했다. 259 | 260 | - 컴퓨터 워드는 8bit인데 RAM크기가 4bit일때 두개의 RAM을 병렬접속하여 8비트 입출력크기를 만들 수 있다. 261 | - 칩셀렉터를 공유하고, 주소버스 4비트에 있는 데이터를 2개의 칩이 받아서 데이터버스에 총 8비트씩 입, 출력시킬 수 있다. 262 | 263 | 264 | 265 | 266 | 267 | 2번 [연습문제 5.4] 268 | 269 | 270 | 271 | **다음과 같은 조직을 가진 RAM들을 이용하여 1K * 32비트 기억장치 모듈을 구성하는데 필요한 칩의 수를 구하라** 272 | 273 | - 1K * 32는 기억장소가 2^10, 데이터 입출력이 32비트를 가짐. 274 | 275 | - 앞으로 곱 = 직렬 ,뒤로 곱 = 병렬 276 | 277 | (1) 512 * 1비트 조직 : 2개의 직렬연결 2 * (512) => 1K * 1bits => 뒤로 32개 병렬연결 (1K * 1bits) * 32 => 1K * 32bits 278 | 279 | (2) 128 * 4비트 조직 : 8개의 직렬연결 8 * (128), 8개의 병렬연결 (4) * 8 280 | 281 | (3) 64 * 8비트 조직 : 16개의 직렬연결 16 * (64), 4개의 병렬연결 (8) * 4 282 | 283 | 284 | 285 |
287 | 288 | -------------------------------------------------------------------------------- /12강 입출력 Device.md: -------------------------------------------------------------------------------- 1 | ## 🦄 I/O Device (12 / 13회차) 2 |
3 | 4 | ### 7.3 I/O 장치의 접속 - I/O제어 `gaekim` 5 |
6 | 7 | **1번.** 각종 I/O 장치들은 `(a)______`를 통해 CPU 혹은 주기억장치와 정보를 교환한다. `(a)______`와 I/O 장치를 연결해주는 인터페이스 역할을 `(b)______`가 수행한다. 8 |
9 | 10 | **2번.** CPU가 I/O 장치를 직접 접속하여 제어하지 못하는 이유가 아닌 것은? [기본문제 7.8] 11 | 12 | 13 | 가. I/O 장치마다 제어 방식이 서로 다르다. 14 | 15 | 나. I/O 장치마다 데이터 전송 속도가 시스템 버스의 속도보다 더 느리다. 16 | 17 | 다. I/O 장치의 데이터 형식이 다양하다. 18 | 19 | 라. 공급되는 전원이 다르기 때문이다. 20 | 21 |
22 | 23 | **3번.** 다음 중에서 I/O 제어기의 구성 요소가 아닌 것은? [기본문제 7.9] 24 | 25 | 가. 데이터 레지스터 26 | 27 | 나. 산술논리연산장치 28 | 29 | 다. 상태 레지스터 30 | 31 | 라. 장치 제어회로 32 |
33 | 34 |
:page_facing_up: 답지
36 |39 | 40 | **1번.** 각종 I/O 장치들은 `(a) 시스템 버스`를 통해 CPU 혹은 주기억장치와 정보를 교환한다. `(a) 시스템 버스`와 I/O 장치를 연결해주는 인터페이스 역할을 `(b) I/O 제어기 (I/O controller)`가 수행한다. 41 |
42 | 43 | **2번.** CPU가 I/O 장치를 직접 접속하여 제어하지 못하는 이유가 아닌 것은? [기본문제 7.8] 44 | 45 | 46 | 가. I/O 장치마다 제어 방식이 서로 다르다. 47 | 48 | 나. I/O 장치마다 데이터 전송 속도가 시스템 버스의 속도보다 더 느리다. 49 | 50 | 다. I/O 장치의 데이터 형식이 다양하다. 51 | 52 | **라. 공급되는 전원이 다르기 때문이다.** 53 | 54 | > 위와 같은 이유들로 I/O 장치는 시스템 버스에 직접 접속되지 못한다. 이 때 시스템 버스와 I/O 장치를 연결해주는 인터페이스 역할을 I/O 제어기(I/O contoller)가 수행한다. 55 | 56 | 57 | 58 |
59 | 60 | **3번.** 다음 중에서 I/O 제어기의 구성 요소가 아닌 것은? [기본문제 7.9] 61 | 62 | 가. 데이터 레지스터 63 | 64 | **나. 산술논리연산장치** 65 | 66 | 다. 상태 레지스터 67 | 68 | 라. 장치 제어회로 69 | 70 |
 71 |
72 |
73 |
71 |
72 |
73 | 76 | 77 | 78 | 79 | ### 7.3 I/O 장치의 접속 - I/O주소지정 `secho` 80 | 81 | #### 1번 82 | 83 | Programmed I/O방식이란 CPU가 I/O장치 상태를 반복적으로 검사하면서 동작을 처리하는 동작을 뜻합니다. 이 방식은 입출력 여부를 CPU가 반복적으로 확인하고, 전체 입출력이 완료되기 전까지 다른 작업을 할 수 없는 단점을 갖고 있습니다. 84 | 85 | 이 방식에서 사용되는 I/O장치의 주소지정방식에는 두 가지가 있는데요. 각각, 86 | 87 | 1. `M____I/O` 88 | 89 | 2. `I____-I/O` 90 | 91 | 라고 합니다. 92 | 93 | 94 | 95 | #### 2번 96 | 97 | 빈칸과 질문에 대한 답을 작성해주세요. 98 | 99 | 100 | 101 | 1번그림 102 | 103 |  104 | 105 | - I/O제어기 내의 레지스터들(`___ 레지스터` `__/__레지스터`) 에게 주소영역을 할당하는 `_________` 주소지정 방식이다. 106 | 107 | - 메인메모리에 대한 명령어, 즉 어셈블리어를 I/O장치에 대해서 `따로 / 같이` 쓰기 때문에 프로그래밍이 `용이 / 불편` 하다. 108 | 109 | - 기억장치 주소 영역을 거의 `__`비율에 가깝도록 메인메모리와 나누어 사용해 주소공간이 줄어든다는 단점이 존재한다. 110 | 111 | 112 | 113 | 2번그림 114 | 115 | **O / X 문제** 116 | 117 |  118 | 119 | - I/O장치에 별도로 주소영역을 지정하는 isolated-I/O 이다. `O / X ` 120 | 121 | - 분리된 메모리영역사용으로 기억 장치 주소공간을 효율적으로 사용가능하지만, I/O에 접근하기 위해서 별도의 명령어를 사용해야한다. ` O / X ` 122 | 123 | 124 | 125 | **쿠키 타임** 126 | 127 | 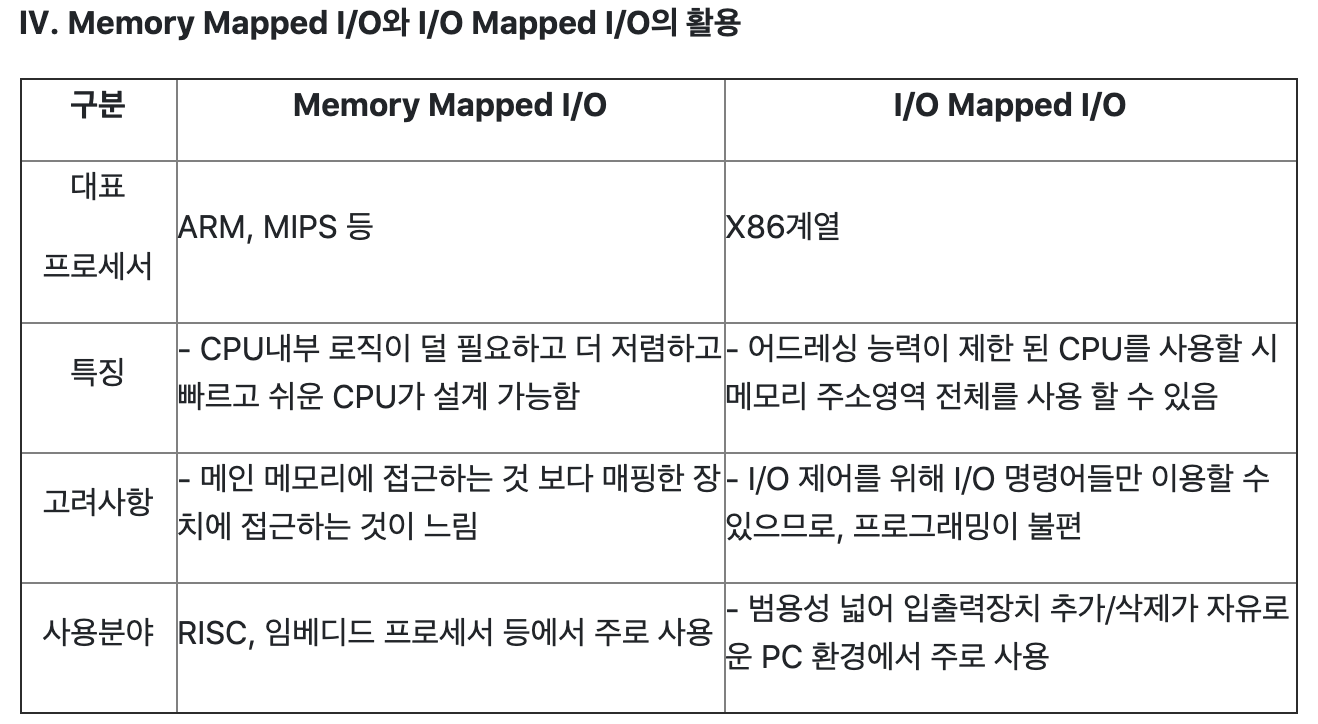 128 | 129 | 130 | 131 |
:page_facing_up: 답지
133 |184 | 185 | 186 | 187 | ### 7.4 인터럽트를 이용한 I/O `yeha` 188 | 189 | **[문제1] '인터럽트를 이용한 I/O' 방식의 장점과 단점을 간단히 적어주세요.** 190 | ``` 191 | 장점 : 192 | 단점 : 193 | ``` 194 | 195 | **[문제2] 인터럽트를 처리하기 위한 다음 방법들에 대하여 알맞은 설명을 짝지어 주세요.** 196 | ``` 197 | (a) 다중 인터럽트(multiple interrupt) 방식 198 | (b) 데이지-체인(daisy-chain) 방식 199 | (c) 소프트웨어 폴링(software polling) 방식 200 | ``` 201 | - 하드웨어가 가장 간단한 방식은 어떤 것인가요? 202 | - 우선순위를 쉽게 변경할 수 있는 방식은 어떤 것인가요? 203 | - 처리 속도가 가장 빠른 것은 어떤 방식인가요? 204 | 205 | **[문제3] 데이지-체인 방식으로 터럽트를 요구한 장치를 찾아내는 방법에 관한 설명으로 잘못된 것은 다음 중 어느 것인가요?** 206 | 가. 모든 장치들이 직렬로 연결된다. 207 | 나. 장치들의 우선순위가 고정된다. 208 | 다. 접속할 수 있는 장치의 수가 CPU의 인터럽트 입력 핀의 수에 의해 제한된다. 209 | 라. 인터럽트 벡터를 이용하여 장치의 ID를 CPU로 알려준다. 210 | 211 | **[문제4] 소프트웨어 폴링 방식으로 이용한 인터럽트-구동 I/O의 단점은 다음 중 어느 것인가요?** 212 | 가. 처리 시간이 오래 걸린다. 213 | 나. 하드웨어가 복잡하다. 214 | 다. 우선순위가 고정된다. 215 | 라. 연결될 수 있는 장치의 수가 제한된다. 216 | 217 |
:page_facing_up: 답지
219 |283 | 284 | 285 | 286 | ### 7.5 DMA를 이용한 I/O `kukim` 287 | 288 | 289 | #### [문제1] O/X 290 | - DMA를 이용한 I/O는 인터럽트-구동 I/O 방식과, 프로그램을 이용한 I/O방식 보다 더 효율적이라고 볼 수 없다. (O / X) 291 | 292 | #### [문제2] 괄호를 채워주세요. 293 | - 큰 데이터 블록을 전송하는 경우에는 CPU가 그 동작을 수행하는데 많은 시간을 소모해야 하며, 시스템 버스도 대부분의 시간 동안 그러한 I/O 동작들을 위해 사용될 수 밖에 없기 때문에 이러한 문제를 해결하기 위하여 (a)가 널리 사용되고 있다 294 | - (a)란 CPU의 개입 없이 I/O 장치와 기억장치 사이에 데이터 전송을 수행하는 메커니즘을 말한다. 295 | - (a) 방식을 사용하기 위해서는 시스템 버스에 (b)가 추가되어야 한다. (b)란 CPU 개입 없이 I/O 장치와 기억장치 간의 데이터 전송을 수행하는 (a) 동작을 지원하는 하드웨어 모듈이다. 296 | - (b)는 가능한 한 CPU의 정상적인 동작을 방해하지 않으면서 시스템 버스를 사용하는데 이를 지칭하는 용어를 (c)라고 한다 297 | 298 | #### [설명] 299 | - 주기억장치 내의 어떤 데이터블록을 디스크에 저장하기 위한 DMA 제어기 작동 방식은 아래와 같다. 300 | 301 | 1. CPU가 DMA 제어기에게 명령을 보낸다. 302 | 2. DMA 제어기는 CPU로 BUS REQ 신호를 보낸다. 303 | 3. CPU가 DMA 제어기로 BUS GRANT 신호를 보낸다. 304 | 4. DMA 제어기가 버스를 사용하여 주기억장치로부터 데이터를 읽어서 디스크 제어기로 보낸다. (디스크에 저장) 305 | 5. 저장할 데이터가 남아 있다면 2~4번 까지 반복한다. 306 | 6. 모든 데이터들의 저장이 완료되면 CPU로 INTR 신호를 보낸다. 307 | 308 |  309 | 310 | - 하나의 DMA 제어기에 직접 연결할 수 있는 I/O 제어기의 수가 제한되어있기 때문에 아래와 같이 구성되어 있다. 311 | 312 |  313 | 314 | #### [문제3] 315 | - DMA 제어기의 한계를 극복하기 위하여 사용하는 방식은 어느 것인가? 316 | 1. I/O 프로세서 317 | 2. 다중 인터럽트 318 | 3. 프로그램을 이용한 I/O 319 | 4. 멀티플렉싱 320 | 321 | 322 |
:page_facing_up: 답지
324 |368 | 369 | -------------------------------------------------------------------------------- /06강 인터럽트,서브루틴,파이프라이닝.md: -------------------------------------------------------------------------------- 1 | ## 🦄 인터럽트/서브루틴/파이프라이닝 (6 / 13회차) 2 |
3 | 4 | ### 2.3 명령어 파이프라이닝 - 2단계 `jakang` 5 | 6 | 1번. 빈칸에 알맞은 답을 채워주세요 7 | 8 | `1) ________` 이란 명령어를 실행하는데 사용되는 하드웨어를 여러 개의 독립적인 단계들로 분할하고, 그들로 하여금 동시에 서로 다른 명령어들을 처리하도록 함으로써 CPU의 성능을 높여지는 기술을 말한다. 9 | 10 | 2단계 명령어 파이프라인에서는 명령어를 실행하는 단계를 `2) ________`와 `3) ________`로 분리하여 구성할 수 있다. 11 | 12 | 2번. 다음 지문들의 참 거짓 여부를 표시하세요. 13 | 14 | `[ ]` 파이프라인이 이용되지 않았을 때와 비교해서 2단계 파이프라인 적용시 이론적으로 최대 2배까지 속도 향상을 얻을 수 있다. 15 | 16 | `[ ]` 인출 단계와 실행 단계에 할당된 시간은 다를 수 있다. 17 | 18 | `[ ]` 인출 단계의 작업이 끝나면, 실행 단계의 작업 완료 여부와 무관하게 즉시 다음 명령어를 인출할 수 있다. 19 | 20 | 3번. '6개'의 명령어가 연속적으로 실행되었다고 한다. 파이프라인이 이용되지 않은 경우가 비교했을 때, 2단계 파이프라인 적용시 속도 향상은 몇 배인가? 21 | 22 |
:page_facing_up: 답지
24 | 25 | 1번. 빈칸에 알맞은 답을 채워주세요 26 | 27 | `1) (명령어) 파이프라이닝` 이란 명령어를 실행하는데 사용되는 하드웨어를 여러 개의 독립적인 단계들로 분할하고, 그들로 하여금 동시에 서로 다른 명령어들을 처리하도록 함으로써 CPU의 성능을 높여지는 기술을 말한다. 28 | 29 | 2단계 명령어 파이프라인에서는 명령어를 실행하는 단계를 `2) 인출 단계`와 `3) 실행 단계`로 분리하여 구성할 수 있다. 30 | 31 | 2번. 다음 지문들의 참 거짓 여부를 표시하세요. 32 | 33 | `[ O ]` 파이프라인이 이용되지 않았을 때와 비교해서 2단계 파이프라인 적용시 이론적으로 최대 2배까지 속도 향상을 얻을 수 있다. 34 | 35 | `[ X ]` 인출 단계와 실행 단계에 할당된 시간은 다를 수 있다. 36 | 37 | : clock 신호로 동기화되어 있으므로 다를 수 없다. 38 | 39 | `[ X ]` 인출 단계의 작업이 끝나면, 실행 단계의 작업 완료 여부와 무관하게 즉시 다음 명령어를 인출할 수 있다. 40 | 41 | : clock 신호에 맞춰서 다음 명령어를 인출하게 된다. '일반적으로' 실행 단계의 작업이 인출 단계보다 오래 걸리므로 clock 주기는 실행 단계에 맞게 설정되는데, 다시 말하면 실행 단계의 작업이 끝날 때까지 다음 명령어를 인출하지 못하고 대기해야만 한다. 42 | 43 | 3번. '6개'의 명령어가 연속적으로 실행되었다고 한다. 파이프라인이 이용되지 않은 경우가 비교했을 때와 비교해서 2단계 파이프라인 적용시 속도 향상은 몇 배인가? (소수점 1자리까지) 44 | 45 | : 파이프라인이 적용되지 않았을 경우 -> 2 * 6 = 12주기 46 | 47 | 2단계 파이프라인이 적용되었을 경우 -> 7주기 48 | 49 | 즉, 12 / 7 = 1.7배 50 | 51 |
53 | 54 | ### 2.3 명령어 파이프라이닝 - 4단계 `gaekim` 55 | 56 | #### 4-단계 명령어 파이프라인 57 | 58 |
 59 |
60 | **1번**
61 |
62 | 다음은 4-단계 명령어 파이프라인을 순서대로 설명한 내용이다. 보기에서 알맞은 답을 찾아 빈칸을 채우시오. (영어로 답하면 안 됨)
63 | ```
64 | <보기>
65 | 오퍼랜드 인출, 명령어 해독, 실행, 명령어 인출, 메모리 검사, CPU 점검
66 | ```
67 |
68 | 1. `________` : 명령어를 기억장치로부터 인출한다.
69 | 2. `________` : 해독기(decoder)를 이용하여 명령어를 해석한다.
70 | 3. `________` : 기억장치로부터 오퍼랜드를 인출한다.
71 | 4. `________` : 지정된 연산을 수행하고, 결과를 저장한다.
72 |
73 | **2번**
74 |
75 | 4-단계 명령어 파이프라인에서 첫 번재 명령어의 실행이 완료되는 데 걸리는 시간과 두 번째 명령어의 실행에 걸리는 시간을 올바로 짝지은 것은 어느 것인가? [기본문제 2.10]
76 |
77 | 가. 1사이클-1사이클 나. 4사이클-1사이클 다. 1사이클-4사이클 라.4사이클-4사이클
78 |
59 |
60 | **1번**
61 |
62 | 다음은 4-단계 명령어 파이프라인을 순서대로 설명한 내용이다. 보기에서 알맞은 답을 찾아 빈칸을 채우시오. (영어로 답하면 안 됨)
63 | ```
64 | <보기>
65 | 오퍼랜드 인출, 명령어 해독, 실행, 명령어 인출, 메모리 검사, CPU 점검
66 | ```
67 |
68 | 1. `________` : 명령어를 기억장치로부터 인출한다.
69 | 2. `________` : 해독기(decoder)를 이용하여 명령어를 해석한다.
70 | 3. `________` : 기억장치로부터 오퍼랜드를 인출한다.
71 | 4. `________` : 지정된 연산을 수행하고, 결과를 저장한다.
72 |
73 | **2번**
74 |
75 | 4-단계 명령어 파이프라인에서 첫 번재 명령어의 실행이 완료되는 데 걸리는 시간과 두 번째 명령어의 실행에 걸리는 시간을 올바로 짝지은 것은 어느 것인가? [기본문제 2.10]
76 |
77 | 가. 1사이클-1사이클 나. 4사이클-1사이클 다. 1사이클-4사이클 라.4사이클-4사이클
78 | 79 | 80 | **3번** 81 | 82 | 4-단계 파이프라인에서 10개의 명령어들을 실행하는 데는 모두 몇 사이클이 소요되는가? [기본문제 2.11] 83 | 84 | Hint) `T = k + (N - 1)` T: 전체 명령어 실행 시간, k: 파이프라인 단계의 수, N: 실행할 명령어들의 수 85 | 86 | 가. 10 나. 13 다. 14 라. 40 87 |
88 | 89 | **4번** 90 | 91 | 각 파이프라인 단계는 한 클록 주기씩 걸린다고 가정할 때, 4-단계 파이프라인에서 97개의 명령어를 실행하여 얻을 수 있는 속도 향상(Sp)을 구하라. (주관식) 92 | 93 | Hint) `Sp = (k * N) / (k + (N - 1))` Sp: 속도 향상, k: 파이프라인 단계의 수, N: 실행할 명령어들의 수 94 | 95 |
96 |
:page_facing_up: 답지
98 | 99 | 100 | **1번** 101 | 102 | 다음은 4-단계 명령어 파이프라인을 순서대로 설명한 내용이다. 보기에서 알맞은 답을 찾아 빈칸을 채우시오. (영어로 답하면 안 됨) 103 | ``` 104 | <보기> 105 | 오퍼랜드 인출, 명령어 해독, 실행, 명령어 인출, 메모리 검사, CPU 점검 106 | ``` 107 | 108 | 1. `명령어 인출(IF)` : 명령어를 기억장치로부터 인출한다. 109 | 2. `명령어 해독(ID)` : 해독기(decoder)를 이용하여 명령어를 해석한다. 110 | 3. `오퍼랜드 인출(OF)` : 기억장치로부터 오퍼랜드를 인출한다. 111 | 4. `실행(EX)` : 지정된 연산을 수행하고, 결과를 저장한다. 112 | 113 | **2번** 114 | 115 | 4-단계 명령어 파이프라인에서 첫 번재 명령어의 실행이 완료되는 데 걸리는 시간과 두 번째 명령어의 실행에 걸리는 시간을 올바로 짝지은 것은 어느 것인가? [기본문제 2.10] 116 | 117 | 가. 1사이클-1사이클 나. 4사이클-1사이클 다. 1사이클-4사이클 라.4사이클-4사이클 118 |
119 | 120 | > 정답: 나. 4사이클-1사이클 121 | 122 | > 첫 번째 명령어는 4단계(IF-ID-OF-EX)에 걸쳐 완료되고, 두 번째 명령어는 첫 번째 명령어의 2번째 사이클(ID)부터 인출되기 시작하므로, 첫 번째 명령어가 완료된 후 1사이클만에 두 번째 명령어가 실행된다. 123 | 124 | **3번** 125 | 126 | 4-단계 파이프라인에서 10개의 명령어들을 실행하는 데는 모두 몇 사이클이 소요되는가? [기본문제 2.11] 127 | 128 | Hint) `T = k + (N - 1)` T: 전체 명령어 실행 시간, k: 파이프라인 단계의 수, N: 실행할 명령어들의 수 129 | 130 | 가. 10 나. 13 다. 14 라. 40 131 |
132 | 133 | > 정답: 나. 13 134 | 135 | > k가 4이고 n이 10이므로 T = 4 + (10 - 1) = 13 136 | 137 | **4번** 138 | 139 | 각 파이프라인 단계는 한 클록 주기씩 걸린다고 가정할 때, 4-단계 파이프라인에서 97개의 명령어를 실행하여 얻을 수 있는 속도 향상(Sp)을 구하라. (주관식) 140 | 141 | Hint) `Sp = (k * N) / (k + (N - 1))` Sp: 속도 향상, k: 파이프라인 단계의 수, N: 실행할 명령어들의 수 142 | 143 | > 정답: 3.88 Sp 144 | 145 | > Sp = (4*97) / (4 + (97-1)) = 3.88 Sp 146 | 147 |
149 | 150 | ### 2.3 명령어 파이프라이닝 - 슈퍼스칼라 `secho` 151 | 152 | 153 | 1번 154 | 155 | `_____`는 CPU의 처리 속도를 **더욱** 높이기 위해 내부에 두개 혹은 그 이상의 `___ _____`들을 포함시킨 구조를 말한다. 156 | 157 | 158 | 159 | 2번. 160 | 161 | 슈퍼스칼라의 명령어 실행속도는 하나의 명령어 파이프라인에 비해 2배가 될 수 있는데, 한 명령어의 결과값으로 다음 명령어가 실행될 수 있는 `___ ___`이 존재하지 않아야한다는 조건이 있다. 162 | 163 | --- 164 | 165 | 교재 84p 파이프라인과 슈퍼스칼라 실행시간차이 166 | 167 | 168 | 169 | 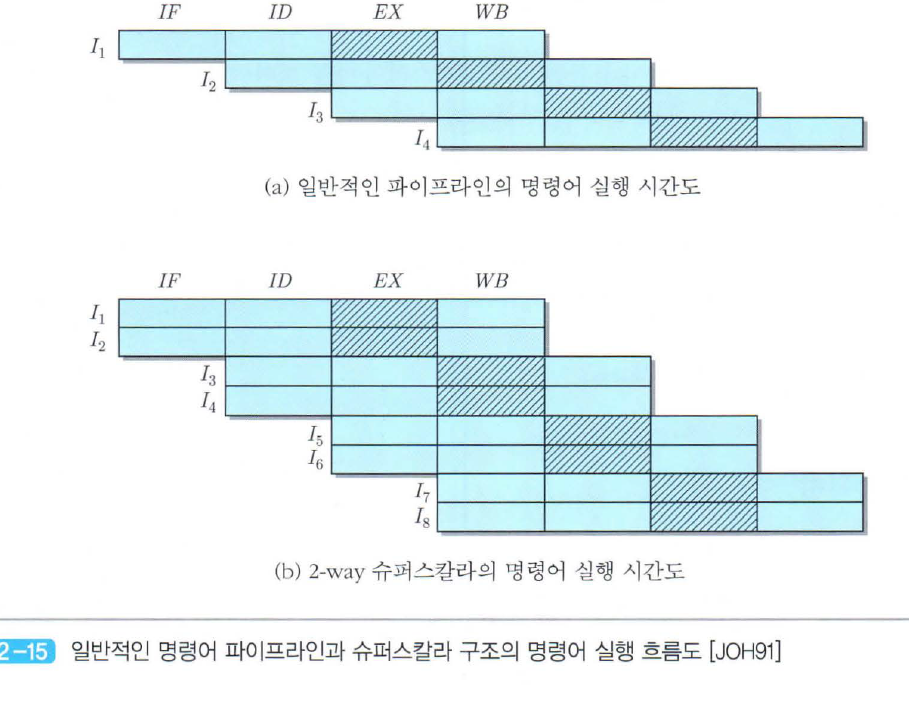 170 | 171 | - 슈퍼스칼라의 실행속도는 하나의 명령어 파이프라인을 적용한 것보다 두 배가 될 수 있으며 파이프라인을 사용하지 않은 프로세서에 비해 최대 mk배 (주기 * 명령어 갯수)까지 얻을 수 있다. (4주기 * 4개명령어) = 16대 172 | - 동시처리명령어 수를 높이면 파이프라인의 일부 단계가 유휴상태에 들어가기 때문에 속도향상은 이론보다 낮지만, 최근 고성능 프로세서들이 슈퍼스칼라 구조를 채택한다. 173 | 174 | 175 | 176 |
:page_facing_up: 답지
178 | 179 | 1번 180 | 181 | `슈퍼스칼라`는 CPU의 처리 속도를 **더욱** 높이기 위해 내부에 두개 혹은 그 이상의 `명령어 파이프라인`들을 포함시킨 구조를 말한다. 182 | 183 | - CPU 내에 명령어 파이프라인을 두어 동시에 그 수만큼 실행할 수 있도록 한 구조 = 슈퍼스칼라 184 | 185 | 2번. 186 | 187 | 슈퍼스칼라의 명령어 실행속도는 하나의 명령어 파이프라인에 비해 2배가 될 수 있는데, 한 명령어의 결과값으로 다음 명령어가 실행될 수 있는 `데이터 의존성`이 존재하지 않아야한다는 조건이 있다. 188 | 189 | - 슈퍼스칼라는 동시에 처리할 명령어들이 서로 간에 영향을 받지 않고 독립적으로 실행될 수 있어야 한다. 190 | 191 | 192 | 193 |
195 | 196 | ### 2.3 명령어 파이프라이닝 - 듀얼/멀티코어 `yeha` 197 | 198 | **1. 보기에 있는 용어와 용어에 대한 설명을 알맞게 짝지어주세요.** 199 | 200 | 201 | ``` 202 | [보기] 203 | CPU 코어 (core) 204 | 멀티 코어 프로세서 (multi-core processor) 205 | 멀티 태스킹 (multi-tasking) 206 | 스레드 (thread) 207 | ``` 208 | 209 | - `(a)` : 여러 개의 CPU 코어들을 포함하고 있는 프로세서 칩 210 | - `(b)` : 여러 CPU 코어들을 이용하여 독립적인 태스크 프로그램들을 동시에 처리하는 기술 211 | - `(c)` : 독립적으로 실행될 수 있는 최소 크기의 프로그램 단위 212 | - `(d)` : CPU 칩의 내부회로 중에서 명령어 실행에 반드시 필요한 핵심 부분들로 이루어진 하드웨어 모듈 213 | 214 | **2. 다음 설명에 대해 맞으면 O, 틀리면 X 하세요.** 215 | 216 | (1) 코어의 개수가 많을수록 성능이 향상된다. (O/X) 217 | (2) 아래는 듀얼 코어 프로세서의 내부 구성도다. 해당 모델은 각 코어가 두 개의 레지스터 세트(RS)를 가지고 있어서 스레드를 두 개씩 동시에 처리할 수 있다. (O/X) 218 |
 219 |
220 |
219 |
220 | :page_facing_up: 답지
222 | 223 | **1.** 224 | > (a) 멀티 코어 프로세서 (multi-core processor) : 여러 개의 CPU 코어들을 포함하고 있는 프로세서 칩 225 | (b) 멀티 태스킹 (multi-tasking) : 여러 CPU 코어들을 이용하여 독립적인 태스크 프로그램들을 동시에 처리하는 기술 226 | (c) 스레드 (thread) : 독립적으로 실행될 수 있는 최소 크기의 프로그램 단위 227 | (d) CPU 코어(core) : CPU 칩의 내부회로 중에서 명령어 실행에 반드시 필요한 핵심 부분들로 이루어진 하드웨어 모듈 228 | 229 | **2.** 230 | (1) 코어의 개수가 많을수록 성능이 향상된다. (X) 231 | 232 | > -> 반드시 그렇지는 않다. 233 | 단일 코어 연산만을 지원하는 소프트웨어를 사용하거나 하나의 작업을 처리할 때는 코어 개수에 의한 성능 차이를 체감하지 못하거나 단일 코어가 빠를 수 있다. 멀티 프로세서를 지원하도록 프로그래밍 해야 한다. 오래 된 게임은 코어수보다 클럭수에 영향을 더 받을 수 있다. 234 | 235 | (2) 아래는 듀얼 코어 프로세서의 내부 구성도다. 해당 모델은 각 코어가 두 개의 레지스터 세트(RS)를 가지고 있어서 스레드를 두 개씩 동시에 처리할 수 있다. (O) 236 | 237 |
238 |
239 | > -> 2코어 4스레드, 멀티 코어 멀티 스레딩 프로세서다.
240 | 2코어의 2는 '물리적'인 CPU 코어의 개수 / 4스레드의 4는 '논리적' 코어의 개수, 동시에 실행 가능한 스레드의 개수다.
241 | 위 모델에서 할당 가능한 스레드의 슬롯(동시에 실행 가능한 스레드 수)은 4개이나 생성할 수 있는 스레드 수는 메모리 등이 허용하는 한 얼마든지 많을 수 있다. 프로그램에서 얼마든지 스레드를 할당할 수 있고, 코어는 동시 실행 가능한 갯수만큼 스레드를 깨워서 실행한다.
242 | --
243 | 2코어 4스레드는 상/하권으로 분권된 책이 2세트(=4권) 있는 것으로 비유해볼 수 있다. 도서관에 두고 사서가 관리할 때, 수많은 회원이 (대출/반납 규정을 지키며) 이 책을 읽을 수 있다. 다만, 한 번에 최대 4명까지만 읽을 수 있다. 2차선, 4차선 도로로 이해할수도 있다.
244 | --
245 | 인텔의 마케팅 용어로 [하이퍼 스레딩(Hyper Threading)](https://www.intel.co.kr/content/www/kr/ko/gaming/resources/hyper-threading.html) 이 있다.
246 |
247 |
248 |
249 | 251 | 252 | 253 | ### 2.x 서브루틴 호출(Subroutine Call) `mihykim` 254 | 255 | #### [문제1]
다음 중 인터럽트와 서브루틴의 👉공통점👈에 대해 바르게 설명한 사람을 골라주세요. (복수정답) 256 | 257 | - `mihykim`: 인터럽트와 서브루틴 모두 **시스템 신호(Signal)에 의해 발생합니다.** 258 | 259 | - `sancho`: 인터럽트와 서브루틴 모두 **점프하기 전에 복귀주소를 스택에 자동으로 저장합니다.** 260 | 261 | - `jehong`: 인터럽트와 서브루틴 모두 **별도의 처리루틴으로 제어가 옮겨져서 프로그램을 수행합니다.** 262 | 263 | - `kukim`: 인터럽트와 서브루틴 모두 **복귀 명령에 의해 원래의 위치로 복귀합니다.** 264 | 265 |
266 | 267 | #### [문제2]
<보기>에서 알맞은 말을 골라 인터럽트와 서브루틴 👉차이점👈 비교 표를 완성해주세요. 268 | 269 | ``` 270 | <보기> 271 | - 코로나끝나서 마스크 벗고다녀도 될 경우 272 | - 주변 장치가 CPU에게 긴급한 처리를 요구할 경우 273 | - 유튜브에서 마음에 드는 플레이리스트를 찾았을 경우 274 | - 한 블록으로 구성된 명령어 실행 중 또 다른 블록으로 구성된 명령어를 삽입하여 실행하고 싶은 경우 275 | - 프로그램 외부(시스템) 276 | - 프로그램 편성표 277 | - 프로그램 내부(사용자) 278 | - 신호(Signal) 279 | - 핫초코(Hot Choco) 280 | - 호출(Call) 281 | - 입력 및 출력 파라미터가 없음 282 | - 대부분 입력 및 출력 파라미터가 있음 283 | ``` 284 | 285 | | 구분 | 인터럽트 | 서브루틴 | 286 | | :----------: | :----------------------------------: | :----------------------------------: | 287 | | **시점** | ` (a) ` | ` (b) ` | 288 | | **요청주체** | ` (c) ` | ` (d) ` | 289 | | **요청방법** | ` (e) ` | ` (f) ` | 290 | | **매개변수** | ` (g) ` | ` (h) ` | 291 | 292 |
293 | 294 | 295 | #### [문제3]
다음 중 서브루틴 👉명령어 종류👈에 대해 바르게 설명한 사람을 골라주세요. (복수정답) 296 | 297 | - `taelee`: **명령어 CALL** 은 현재 PC내용을 스택에 저장하고, PC에 호출될 서브루틴 시작 주소를 저장하여 원하는 서브루틴의 주소로 분기하는 명령어에요. 298 | 299 | - `yeosong`: **명령어 RET**은 스택에 저장되어 있던 주소 값을 PC로 복원하여 CALL 명령어의 바로 다음주소로 되돌아가게 하는 명령어에요. 300 | 301 | - `hylee`: **명령어 BR**은 프로그램의 실행순서를 변경하는 명령어에요. **BR** 이면 무조건 분기하는 거고, 조건코드가 0일때 분기하는 **BRZ**, 레지스터 내용이 같을 때 분기하는 **BRE**도 있어요. 302 | 303 |
:page_facing_up: 답지
305 | 306 | #### [문제1] 307 | - 정답 : `sancho`, `jehong` `kukim` 308 | 309 | ``` 310 | mihykim 311 | 인터럽트와 서브루틴 모두 시스템 신호(Signal)에 의해 발생합니다. 312 | ▶ 인터럽트는 시스템 신호(Signal)에 의해 발생하지만, 서브루틴은 호출(Call)에 의해 발생합니다. 313 | ``` 314 | 315 | #### [문제2] 316 | 317 | | 구분 | 인터럽트 | 서브루틴 | 318 | | :-----------: | :-----------------------------------------------: | :----------------------------------------------------------: | 319 | | **공통점** | | | 320 | | 복귀주소 저장 | 점프하기 전에 복귀주소를 스택에 자동으로 저장 | 〃 | 321 | | 수행방법 | 별도의 처리루틴으로 제어가 옮겨져서 프로그램 수행 | 〃 | 322 | | 복귀방법 | 복귀 명령에 의해 원래의 위치로 복귀 | 〃 | 323 | | **차이점** | | | 324 | | 시점 | 주변 장치가 CPU에게 긴급한 처리를 요구할 경우 | 한 블록으로 구성된 명령어 실행 중
또 다른 블록으로 구성된 명령어를 삽입하여 실행하고 싶은 경우 | 325 | | 요청주체 | 프로그램 외부(시스템) | 프로그램 내부(사용자) | 326 | | 요청방법 | 신호(Signal) | 호출(Call) | 327 | | 매개변수 | 입력 및 출력 파라미터가 없음 | 대부분 입력 및 출력 파라미터가 있음 | 328 | 329 | #### [문제3] 330 | - 정답 : `taelee`, `yeosong` 331 | 332 | ``` 333 | hylee 334 | 순서만 바꿔주는 분기 명령어는 서브루틴 명령어라고 하지 않는다. (별개로 간주) 335 | ``` 336 | -------------------------------------------------------------------------------- /05강 명령어실행.md: -------------------------------------------------------------------------------- 1 | ## 🦄 명령어 실행 (5 / 13회차) 2 |
3 | 4 | ### 2.2 명령어 실행 - 인출 사이클 `daelee` 5 | 6 | ##### [문제 1] 명령어 사이클에 필요한 레지스터들 입니다. 보기를 참고해 어떤 레지스터에 대한 설명인지 맞춰주세요. 7 | 8 | ``` 9 | [보기] PC, AC, IR, MAR, MBR 10 | ``` 11 | 12 | - `__(a)__` : PC에 저장된 명령어 주소가 시스템 주소 버스로 출력되기 전에 일시적으로 저장되는 레지스터 13 | - `__(b)__` : 가장 최근에 인출된 명령어가 저장되어 있는 레지스터 14 | - `__(c)__` : 기억장치에 저장될 데이터 혹은 기억장치로부터 읽혀진 데이터가 일시적으로 저장되는 레지스터 15 | - `__(d)__` : 데이터를 일시적으로 저장하는 레지스터 16 | - `__(e)__` : 다음에 인출될 명령어의 주소를 가지고 있는 레지스터 17 | 18 | 19 | 20 | 21 | ##### [문제 2] 기억장치로부터 인출된 명령어 코드를 제어 유니트에 의해 해독되기 전에 일시적으로 저장하고 있는 레지스터는 어느 것일까요? 22 | 23 | ``` 24 | 가. PC 25 | 나. MAR 26 | 다. IR 27 | 라. AC 28 | ``` 29 | 30 | 31 | 32 | ##### [문제 3] 기억장치 주소가 바이트 단위로 지정되고 명령어 길이는 32비트인 CPU에서는 인출 사이클 동안에 PC가 얼마만큼 증가될까요? 33 | 34 | ``` 35 | 가. 1 36 | 나. 2 37 | 다. 4 38 | 라. 32 39 | ``` 40 | 41 | 42 | 43 |
:page_facing_up: 답지
45 | 46 | ##### [문제 1] 명령어 사이클에 필요한 레지스터들 입니다. 보기를 참고해 어떤 레지스터에 대한 설명인지 맞춰주세요. 47 | 48 | ``` 49 | [보기] PC, AC, IR, MAR, MBR 50 | ``` 51 | 52 | - `__(a)__` : PC에 저장된 명령어 주소가 시스템 주소 버스로 출력되기 전에 일시적으로 저장되는 레지스터 53 | - `__(b)__` : 가장 최근에 인출된 명령어가 저장되어 있는 레지스터 54 | - `__(c)__` : 기억장치에 저장될 데이터 혹은 기억장치로부터 읽혀진 데이터가 일시적으로 저장되는 레지스터 55 | - `__(d)__` : 데이터를 일시적으로 저장하는 레지스터 56 | - `__(e)__` : 다음에 인출될 명령어의 주소를 가지고 있는 레지스터 57 | 58 | 59 | 60 | > **정답** (58p 참고) 61 | > 62 | > (a) : 기억장치 주소 레지스터 (Memory Address Register: `MAR`) 63 | > 64 | > (b) : 명령어 레지스터 (Instruction Register: `IR`) 65 | > 66 | > (c) : 기억장치 버퍼 레지스터 (Memory Buffer Register: `MBR`) 67 | > 68 | > (d) : 누산기(Accumulator: `AC`) 69 | > 70 | > (e) : 프로그램 카운터(Program Counter: `PC`) 71 | 72 | 73 | 74 | ##### [문제 2] 기억장치로부터 인출된 명령어 코드를 제어 유니트에 의해 해독되기 전에 일시적으로 저장하고 있는 레지스터는 어느 것일까요? 75 | 76 | ``` 77 | 가. PC 78 | 나. MAR 79 | 다. IR 80 | 라. AC 81 | ``` 82 | 83 | > **정답 : 다** 84 | > 85 | > 인출 사이클의 마지막 클록에서 수행하는 작업은 IR <- MBR. 즉 기억장치로부터 인출된 명령어는 MBR을 경유하여 IR에 저장되며, 실행 사이클 때 제어 유니트로 보내져 해독된다. 86 | 87 | 88 | 89 | ##### [문제 3] 기억장치 주소가 바이트 단위로 지정되고 명령어 길이는 32비트인 CPU에서는 인출 사이클 동안에 PC가 얼마만큼 증가될까요? 90 | 91 | ``` 92 | 가. 1 93 | 나. 2 94 | 다. 4 95 | 라. 32 96 | ``` 97 | 98 | > **정답 : 다** 99 | > 100 | > 위 환경에서는 한 명령어(32비트)가 주소(8비트) 네 개에 걸쳐 저장되기 때문에 PC는 4씩 증가한다. 101 | 102 | 103 | 104 | ##### [인출 사이클 보충 설명] 105 | 106 | 인출 사이클(fetch cycle): CPU가 기억장치의 지정된 위치(PC가 가리키는)로부터 명렁어를 읽어오는 과정. 107 | 108 | 그림 2-4는 인출 사이클 동안에 주소와 명령어 코드가 이동하는 과정을 보여주고 있다. 그림에서 원으로 표시된 기호들은 각 동작이 발생하는 클록의 주기를 나타낸다. 109 | 110 |  111 | 112 | - t0 : MAR <- PC 113 | - 현재 PC의 명령어 주소가 MAR을 통해 기억장치로 전송된다. 114 | - t1 : MBR <- M[MAR], PC <- PC+1 115 | - 기억장치의 해당 주소로부터 읽혀진 명령어 코드가 MBR에 적재된다. 116 | - 동시에 PC는 1 증가시켜 다음 명령어 주소를 가리키게 한다. 117 | - t2 : IR <- MBR 118 | - 명령어 레지스터 IR로 명령어 코드가 전송된다. 119 | 120 |
122 | 123 | ### 2.2 명령어 실행 - 실행 사이클 `sancho` 124 | 125 | 126 | 127 | ##### [문제 1] 빈칸에 실행 사이클에서 수행되는 큰 네가지 과정을 맞춰 주세요! 128 | 129 | `보기: 데이터 처리, 프로그램 제어, 데이터 이동, 데이터 저장` 130 | 131 | - `__(a)__` : CPU와 기억장치 간 혹은 CPU와 I/O 장치 간에 데이터를 불러온다. 132 | - `__(b)__` : 데이터에 대하여 산술 혹은 논리 연산을 수행한다. 133 | - `__(c)__` : 연산결과 데이터 혹은 입력장치로부터 읽어들인 데이터를 기억장치에 쓴다. 134 | - `__(d)__` : 프로그램의 실행순서를 결정한다. 135 |
136 | 137 | ##### [문제 2] 실행 사이클에서 데이터 인출을 위한 'LOAD addr' 명령어가 실행될 때 빈칸에 들어갈 용어를 적어 주세요! 138 | 139 | - t0 : `__(a)__` <- IR(addr) 140 | - t1 : `__(b)__` <- M[MAR] 141 | - t2 : `__(c)__` <- MBR
142 |
143 | 144 | ##### [문제 3] 실행 사이클에서 데이터 저장을 위한 'STA addr' 명령어가 실행될 때 빈칸에 들어갈 용어를 적어 주세요! 145 | 146 | - t0 : `__(a)__` <- IR(addr) 147 | - t1 : `__(b)__` <- AC 148 | - t2 : `__(c)__` <- MBR
149 |
150 | 151 |
:page_facing_up: 답지
153 | 154 | 155 | 156 | ##### [문제 1] 빈칸에 실행 사이클에서 수행되는 큰 네가지 과정을 맞춰 주세요! 157 | 158 | `보기: 데이터 처리, 프로그램 제어, 데이터 이동, 데이터 저장` 159 | 160 | - `__(a)__` : CPU와 기억장치 간 혹은 CPU와 I/O 장치 간에 데이터를 불러온다. 161 | - `__(b)__` : 데이터에 대하여 산술 혹은 논리 연산을 수행한다. 162 | - `__(c)__` : 연산결과 데이터 혹은 입력장치로부터 읽어들인 데이터를 기억장치에 쓴다. 163 | - `__(d)__` : 프로그램의 실행순서를 결정한다. 164 | 165 | -> a: 데이터 이동, b: 데이터 처리, c: 데이터 저장, d: 프로그램 제어 166 |
167 | 168 | ##### [문제 2] 실행 사이클에서 데이터 인출을 위한 'LOAD addr' 명령어가 실행될 때 빈칸에 들어갈 용어를 적어 주세요! 169 | 170 | - t0 : `__(a)__` <- IR(addr) 171 | - t1 : `__(b)__` <- M[MAR] 172 | - t2 : `__(c)__` <- MBR
173 | 174 | -> a: MAR, b: MBR, c: AC
175 | 설명:
176 | 첫 번째 주기인 t0에서 명령어 레지스터인 IR에 저장된 주소 addr을 메모리 주소 레지스터인 MAR에 불러오게 되구요.
177 | 두 번째 주기인 t1에서 MAR의 데이터를 인출하여 메모리 버퍼 레지스터인 MBR에 저장하게 됩니다.
178 | 세 번째 주기인 t2에서 MBR에 저장 된 데이터가 누산기인 AC에 들어가며 데이터를 불러오게 됨으로서 LOAD 명령어의 실행이 완료됩니다.
179 | 180 | ##### [문제 3] 실행 사이클에서 데이터 저장을 위한 'STA addr' 명령어가 실행될 때 빈칸에 들어갈 용어를 적어 주세요! 181 | 182 | - t0 : `__(a)__` <- IR(addr) 183 | - t1 : `__(b)__` <- AC 184 | - t2 : `__(c)__` <- MBR
185 | 186 | -> a: MAR, b: MBR, c: M[MAR]
187 | 설명:
188 | 첫 번째 주기인 t0에서 명령어 레지스터인 IR에 저장된 주소 addr을 메모리 주소 레지스터인 MAR에 불러오게 되구요.
189 | 두 번째 주기인 t1에서 누산기의 결과인 AC의 값을 메모리 버퍼 레지스터인 MBR에 저장시키구요.
190 | 세 번째 주기인 t2에서 MBR에 저장 된 데이터를 메모리 주소 레지스터인 MAR의 데이터 저장공간에 저장하게 됨으로서 STA 명령어가 끝나게 됩니다.
191 | 192 |
194 | 195 | ### 2.2 명령어 실행 - 인터럽트 사이클 `yeosong` 196 | 197 | #### 쉬어가는 문제 - 프로세서의 예외적인 제어흐름에는 크게 4가지 Interrupt, Trap, Fault, Abort 가 있다. 이들 중 비동기적으로 발생하는 예외 상황은? 198 | 199 | #### 기본 2.7 다음 중 인터럽트 사이클 동안에 수행되는 동작이 아닌 것은? 200 | 201 | ~~~ 202 | 가. 복귀할 주소를 스택에 저장한다. 203 | 나. ISR의 시작 주소를 PC에 적재한다. 204 | 다. 인터럽트 요구 신호를 검사한다. 205 | 라. 인터럽트 플래그를 세트한다. 206 | ~~~ 207 | 208 | #### 기본 2.8 CPU가 어떤 장치에 대한 인터럽트를 처리하는 도중에 우선순위가 더 낮은 인터럽트 요구가 들어왔습니다. 어떤 일이 발생할까요? 209 | 210 | 211 | #### 연습 2.2 아래와 같은 어셈블리 프로그램에 대한 기계어 코드들이 200번지부터 저장되어있다. 212 | 213 |  214 | 215 | 1) 이 프로그램이 순차적으로 실행되는 경우를 고려해 아래 표를 완성해보세요. 기억장치 300번지에는 9가, 301번지에는 5가 저장되어 있습니다. 216 | 217 |  218 | 219 | 2) 위의 프로그램에서 `SUB 301`명령을 실행중인데 개발자 `secho`가 프로세스를 백그라운드로 보내기 위해 `ctrl-z`를 눌렀고, 이 인터럽트 요구는 받아들여졌습니다. 인터럽트 사이클이 종료된 직후, CPU 레지스터들(PC, AC, IR, SP)에는 각각 어떤 값이 저장되어 있나요? 220 | (단, ISR의 시작 주소는 450번지, SP의 초기값은 999라고 가정합니다.) 221 | 222 | 인터럽트 사이클은 다음과 같습니다.
223 | **t0 : MBR ← PC** (인터럽트 처리 완료 후에 복귀할 곳을 저장하기 위해, 현재의 PC내용을 스택에 저장한다.)
224 | **t1 : MAR ← SP, PC ← ISR의 시작 주소** (스택 포인터가 MAR을 가리키게 한다. 인터럽트 처리 루틴의 시작 주소를 PC에 담는다.)
225 | **t2 : M[MAR] ← MBR, SP ← SP - 1** (메모리의 MAR번지에 MBR의 값을 저장하고, 스택 포인터가 한 칸 위로 올라간다.)
226 | 227 | - `PC` : `____` 228 | - `AC` : `____` 229 | - `IR` : `____` 230 | - `SP` : `____` 231 | 232 | #### 연습 2.3 인터럽트 사이클이 그림2-9(b)와 같이 종료된 후 처리되는 인터럽트 서비스 루틴에서 `누산기`의 내용을 스택에 저장하였다. 233 |
 234 |
235 |
236 | 1) 그 값이 저장되는 기억장치의 주소는 몇번지일까? `____`
237 | 2) SP의 내용은 어떤 값으로 변경되는가? `____`
238 |
239 | #### 연습 2.4 인터럽트 서비스 루틴을 수행하는 도중에 더 높은 우선순위를 가진 인터럽트 요구가 들어오더라도 그 루틴의 수행이 중단되지 않도록 하는 방법은?
240 |
241 |
242 |
234 |
235 |
236 | 1) 그 값이 저장되는 기억장치의 주소는 몇번지일까? `____`
237 | 2) SP의 내용은 어떤 값으로 변경되는가? `____`
238 |
239 | #### 연습 2.4 인터럽트 서비스 루틴을 수행하는 도중에 더 높은 우선순위를 가진 인터럽트 요구가 들어오더라도 그 루틴의 수행이 중단되지 않도록 하는 방법은?
240 |
241 |
242 | :page_facing_up: 답지
244 | 245 | #### 쉬어가는 문제 - 프로세서의 예외적인 제어흐름에는 크게 4가지 Interrupt, Trap, Fault, Abort 가 있다. 이들 중 비동기적으로 발생하는 예외 상황은? 246 | > 인터럽트. 특정 인스트럭션을 수행하다가 생기는 것이 아니기 때문이다.
247 | > 나머지는 지금의 인스트럭션을 실행한 결과로 동기적으로 일어난다.
248 | > Trap은 의도적인 예외 상황, Fault는 정정 가능성이 있는 오류, Abort는 복구 불가한 치명적인 오류가 있을 때 발생한다. 249 | 250 | #### 기본 2.7 다음 중 인터럽트 사이클 동안에 수행되는 동작이 아닌 것은? 251 | 252 | ~~~ 253 | 가. 복귀할 주소를 스택에 저장한다. >>> 예) MBR ← PC : 인터럽트 처리 완료 후에 복귀할 곳을 저장하기 위해, 현재의 PC내용을 스택에 저장한다. 254 | 나. ISR의 시작 주소를 PC에 적재한다. >>> 예) PC ← ISR의 시작 주소 : 인터럽트 처리 루틴의 시작 주소를 PC에 담는다. 255 | 다. 인터럽트 요구 신호를 검사한다. >>> 인터럽트 요구가 있는지 확인하고, Interrupt enabled이면 실행한다. 256 | 라. 인터럽트 플래그를 세트한다. >>> (X) 사이클 내에 항상 이루어질 필요는 없으며, 필요에 따라 삽입한다. 257 | ~~~ 258 | 259 | #### 기본 2.8 CPU가 어떤 장치에 대한 인터럽트를 처리하는 도중에 우선순위가 더 낮은 인터럽트 요구가 들어왔습니다. 어떤 일이 발생할까요? 260 | 261 | > 현재 인터럽트 서비스 루틴의 수행을 계속한다. 262 | 263 | 264 | #### 연습 2.2 아래와 같은 어셈블리 프로그램에 대한 기계어 코드들이 200번지부터 저장되어있다. 265 | 266 |  267 | 268 | 269 | 1) 이 프로그램이 순차적으로 실행되는 경우를 고려해 아래 표를 완성해보세요. 기억장치 300번지에는 9가, 301번지에는 5가 저장되어 있습니다. 270 |  271 | 272 | 273 | 274 | 275 | 2) 위의 프로그램에서 `SUB 301`명령을 실행중인데 개발자 `secho`가 프로세스를 백그라운드로 보내기 위해 `ctrl-z`를 눌렀고, 이 인터럽트 요구는 받아들여졌습니다. 인터럽트 사이클이 종료된 직후, CPU 레지스터들(PC, AC, IR, SP)에는 각각 어떤 값이 저장되어 있나요? 276 | (단, ISR의 시작 주소는 450번지, SP의 초기값은 999라고 가정합니다.) 277 | 278 | 인터럽트 사이클은 다음과 같습니다.
279 | **t0 : MBR ← PC** (인터럽트 처리 완료 후에 복귀할 곳을 저장하기 위해, 현재의 PC내용을 스택에 저장한다.)
280 | **t1 : MAR ← SP, PC ← ISR의 시작 주소** (스택 포인터가 MAR을 가리키게 한다. 인터럽트 처리 루틴의 시작 주소를 PC에 담는다.)
281 | **t2 : M[MAR] ← MBR, SP ← SP - 1** (메모리의 MAR번지에 MBR의 값을 저장하고, 스택 포인터가 한 칸 위로 올라간다.)
282 | 283 | - `PC` : `0450` t1에서 넣은 ISR의 시작 주소 284 | - `AC` : `0004` 실행중이던 명령은 마치고 ISR 하므로, SUB 301의 결과가 들어있다. 285 | - `IR` : `6301` 가장 최근에 인출된 명령어 286 | - `SP` : `0998` SP - 1의 결과 287 | 288 | 289 | #### 연습 2.3 인터럽트 사이클이 그림2-9(b)와 같이 종료된 후 처리되는 인터럽트 서비스 루틴에서 `누산기`의 내용을 스택에 저장하였다. 290 |
291 |
292 |
293 | 1) 그 값이 저장되는 기억장치의 주소는 몇번지일까? `0998` (현재 스택 포인터가 가리키는 곳이 0998이므로)
294 | 2) SP의 내용은 어떤 값으로 변경되는가? `0997` (SP ← SP - 1 수행)
295 |
296 | #### 연습 2.4 인터럽트 서비스 루틴을 수행하는 도중에 더 높은 우선순위를 가진 인터럽트 요구가 들어오더라도 그 루틴의 수행이 중단되지 않도록 하는 방법은?
297 |
298 | > 인터럽트 서비스 루틴을 시작할 때 인터럽트 disabled를 켜고, 루틴을 종료할 때 enabled로 바꾼다.
299 |
300 |
301 |
302 | 304 | 305 | ### 2.2 명령어 실행 - 간접 사이클 `kycho` 306 | 307 | ##### [문제 1] 다음은 간접 사이클에 대한 설명입니다. 보기를 참고하여 빈칸에 알맞은 답을 적으세요. 308 | ``` 309 | [보기] 직접 주소지정 방식, 간접 주소지정 방식, 명령어 사이클, 인출 사이클, 실행 사이클, 인터럽트 사이클 310 | ``` 311 | - **간접 사이클**은 명령어에 포함되어 있는 주소정보를 이용하여, 실제 명령어 실행에 필요한 데이터 주소를 인출하는 사이클로서, `1)____`에서 사용되며, `2)____`과 `3)____` 중간에 실행된다. 312 | 313 | 314 | ##### [문제 2] 간접 사이클 동안에 수행되는 동작을 고르세요.(기본문제 2.9) 315 | ``` 316 | 가. 기억장치로부터 데이터를 인출한다. 317 | 나. 기억장치로부터 데이터의 주소를 인출한다. 318 | 다. 기억장치로부터 명령어를 인출한다. 319 | 라. 기억장치로부터 명령어의 주소를 인출한다. 320 | ``` 321 | 322 | ##### [문제 3] 간접 사이클이 수행되는 명령어의 조건을 적으세요. 323 | 324 | ``` 325 | 326 | ``` 327 | 328 | ##### [문제 4] 간접 사이클에서는 아래와 같은 마이크로-연산들이 수행된다. 빈칸에 알맞는 답을 적으세요. 329 | 330 | - t0 : MAR <- IR(addr) 331 | - t1 : MBR <- M[MAR] 332 | - t2 : `____________` 333 | 334 |
:page_facing_up: 답지
336 | 337 | ##### [문제 1] 다음은 간접 사이클에 대한 설명입니다. 보기를 참고하여 빈칸에 알맞은 답을 적으세요. 338 | ``` 339 | [보기] 직접 주소지정 방식, 간접 주소지정 방식, 명령어 사이클, 인출 사이클, 실행 사이클, 인터럽트 사이클 340 | ``` 341 | - **간접 사이클**은 명령어에 포함되어 있는 주소정보를 이용하여, 실제 명령어 실행에 필요한 데이터 주소를 인출하는 사이클로서, `1)간접 주소지정 방식`에서 사용되며, `2)인출 사이클`과 `3)실행 사이클` 중간에 실행된다. 342 | 343 | 344 | ##### [문제 2] 간접 사이클 동안에 수행되는 동작을 고르세요.(기본문제 2.9) 345 | ``` 346 | 가. 기억장치로부터 데이터를 인출한다. 347 | 나. 기억장치로부터 데이터의 주소를 인출한다. (정답!!!) 348 | 다. 기억장치로부터 명령어를 인출한다. 349 | 라. 기억장치로부터 명령어의 주소를 인출한다. 350 | ``` 351 | > 명령어에서 포함하고 있는 주소가 '데이터의 주소'가 아닌 '데이터의 주소가 저장된 기억 장소의 주소'일때(I 비트가 1일때),
352 | 데이터의 실제 주소를 얻기 위한 목적으로 간접 사이클이 수행된다. 따라서 기억장치로부터 데이터의 실제 주소를 읽어오는 과정이 수행되어야한다. 353 | 354 | ##### [문제 3] 간접 사이클이 수행되는 명령어의 조건을 적으세요. 355 | 356 | ``` 357 | 명령어 내의 특정 비트(I비트)가 1로 세트된 경우에 간접 사이클이 수행된다. 358 | ``` 359 | 360 | ##### [문제 4] 간접 사이클에서는 아래와 같은 마이크로-연산들이 수행된다. 빈칸에 알맞는 답을 적으세요. 361 | 362 | - t0 : MAR <- IR(addr) 363 | - t1 : MBR <- M[MAR] 364 | - t2 : `IR(addr) <- MBR` 365 | > t0 : MAR <- IR(addr) : IR에 있는 주소(addr)정보를 MAR에 저장한다. ( IR(addr)에는 데이터의 주소가 담겨있는 기억 장소의 주소가 있다. )
366 | t1 : MBR <- M[MAR] : 기억장치에서 MAR위치에 있는 정보(실제 데이터의 주소)를 MBR에 저장한다.
367 | t2 : IR(addr) <- MBR : IR의 주소(addr)정보를 MBR에 저장된 실제 데이터의 주소로 변경한다. 368 |  369 |
371 | -------------------------------------------------------------------------------- /02강 ALU : Logic Operations.md: -------------------------------------------------------------------------------- 1 | ## 🦄 ALU: Logic Operations (2 / 13회차) 2 |
3 | 4 | ### 3.1 ALU의 구성 요소 `mihykim` 5 | #### [문제1]
성실한 예비개발자 'daelee'는 꿈에 그리던 기업 Nakalcoub에 면접을 보게되었습니다. 'daelee'를 도와 면접 질문의 답을 완성해주세요! 6 | - __면접관__ : "흠흠.. 머리숱이 아주 많은 지원자시군요...(부럽) 그럼 ALU가 무엇인지 간단하게 설명해주시겠어요?" 7 | - __DAELEE__ : "아 넵! ALU는... ` `" 8 |
9 | 10 | #### [문제2]
'mihykim'은 ALU 구성요소 학습을 마치고 그 내용을 블럭으로 가지런히 정리해두었습니다. 그런데 월요일 아침, 주말에 다녀간 조카가 블럭을 다 빼놓은 것을 발견했습니다. 당황한 'mihykim'을 도와 블럭순서를 바르게 맞춰주세요. 11 | ``` 12 | <블럭> 13 | [ 보수기(complementer) ] 14 | [ 시프트 레지스터 ] 15 | [ 논리연산장치(LU) ] 16 | [ 산술연산장치(AU) ] 17 | [ 상태 레지스터 ] 18 | ``` 19 | - 산술 연산(+, -, X, %)을 수행하는 장치 : `[ ]` 20 | - 논리 연산(&, |, ^, !)을 수행하는 장치 : `[ ]` 21 | - 비트들을 좌측 혹은 우측으로 이동시켜주는 레지스터 : `[ ]` 22 | - 데이터에 2의 보수를 취해주는 요소 : `[ ]` 23 | - 연산 결과의 상태를 나타내는 플래그들을 저장하는 레지스터 : `[ ]` 24 |
25 | 26 | #### [문제3]
컴퓨터구조 스터디원들은 ALU 상태레지스터 내 '상태 플래그'에 대해 서로 공유하기로 하였습니다. 다음 내용 중 사실과는 다른 내용을 이야기하는 사람은 누구일까요? (복수 정답) 27 | ``` 28 | 'gaekim' : 프로세서 설계에 따라 상태 플래그의 구성과 그 기능이 약간씩 다를 수 있대요. 29 | 30 | 'sancho' : 맞아요. 일부 아키텍처에서는 상태 레지스터가 아예 없기도 한가봐요. 그럼 주로 쓰이는 플래그들을 말해볼까요? 31 | 32 | 'hylee' : (스읍-) 음... 일단 제로 플래그(Z)가 있겠어요. 연산의 결과가 0일 경우에 참이 되지요. 33 | 34 | 'kycho' : 아, 제로플래그는 리버스 엔지니어링에서 구조를 추적하는데 매우 중요한 플래그라고 하네요. 35 | 36 | 'jakang' : 비슷하게 연산의 결과가 음수일 때 참이되는 네거티브 플래그(N)도 있어요. 37 | 38 | 'yeosong' : unsigned 숫자의 연산결과가 비트 범위를 넘어설 때 필요한 플래그도 있어요. 39 | 40 | 'jehong' : 캐리 플래그(C) 말씀하시는거죠? 처음엔 오버플로우 플래그(O)랑 헷갈렸는데 알아보니 아예 똑같은 것 같더라구요. 41 | 42 | 'taelee' : 와 다들 잘 알고 계시네요. 인터럽트 요구를 받아들일지 말지 결정하는 인터럽트 플래그(I)도 있습니다! 43 | ``` 44 |
45 | 46 | #### 먼저 푸신 분을 위한 🍪 47 | - 4비트 ALU 중 하나인 인텔 74181은 약 70개의 논리게이트를 사용했고 곱셈과 나눗셈은 할 수 없었다. 48 | - 8비트 ALU를 완전히 구축하려면 수백개의 논리게이트가 필요하다. 49 | - 수 백개의 논리게이트를 다 표현하려면 너무 복잡하니까 아래와 같은 다이어그램으로 ALU를 추상화해서 표현한다. 50 |  51 |
52 | 53 |
:page_facing_up: 답지
55 | 56 | #### [문제1]
성실한 예비개발자 'daelee'는 꿈에 그리던 기업 Nakalcoub에 면접을 보게되었습니다. 'daelee'를 도와 면접 질문의 답을 완성해주세요! 57 | - __면접관__ : "흠흠.. 머리숱이 아주 많은 지원자시군요...(부럽) 그럼 ALU가 무엇인지 간단하게 설명해주시겠어요?" 58 | - __DAELEE__ : "아 넵! ALU는 `CPU의 주요 구성요소 중 하나로, Arithmetic Logic Unit이라는 이름 그대로 산술논리연산장치를 말합니다. 59 | 덧셈뺄셈과 같은 산술연산과 AND, OR와 같은 논리연산을 수행하는 핵심적인 회로입니다.`" 60 |
61 | 62 | #### [문제2]
'mihykim'은 ALU 구성요소 학습을 마치고 그 내용을 블럭으로 가지런히 정리해두었습니다. 그런데 월요일 아침, 주말에 다녀간 조카가 블럭을 다 빼놓은 것을 발견했습니다. 당황한 'mihykim'을 도와 블럭순서를 바르게 맞춰주세요. 63 | - 산술 연산(+, -, X, %)을 수행하는 장치 : `[ 산술연산장치(AU) ]` 64 | - 논리 연산(&, |, ^, !)을 수행하는 장치 : `[ 논리연산장치(LU) ]` 65 | - 비트들을 좌측 혹은 우측으로 이동시켜주는 레지스터 : `[ 시프트 레지스터 ]` 66 | - 데이터에 2의 보수를 취해주는 요소 : `[ 보수기(complementer) ]` 67 | - 연산 결과의 상태를 나타내는 플래그들을 저장하는 레지스터 : `[ 상태 레지스터 ]` 68 |
69 | 70 | #### [문제3]
컴퓨터구조 스터디원들은 ALU 상태레지스터 내 '상태 플래그'에 대해 서로 공유하기로 하였습니다. 다음 내용 중 사실과는 다른 내용을 이야기하는 사람은 누구일까요? (복수 정답) 71 | ``` 72 | 'jehong' 73 | 캐리 플래그(C) 말씀하시는거죠? 처음엔 오버플로우 플래그(O)랑 헷갈렸는데 알아보니 확실히 다른 것이더라구요. 74 | 캐리 플래그는 최상단 비트에서 자리올림 발생 시 Set되고 75 | 오버플로우 플래그는 최대 표현 범위를 넘어섰거나, 같은 부호를 더했는데 다른 부호가 나와버릴 때 Set 된답니다. 76 | 예를 들어 1000 + 1000 => 10000 에서는 캐리 플래그가, 77 | 0111 + 0001 => 1000 에서는 오버플로우가 Set됩니다. (7 + 1 => -8) 78 | ``` 79 | ``` 80 | 'taelee' 81 | 와 다들 잘 알고 계시네요! 82 | 지금까지는 상태플래그를 이야기했는데 상태레지스터에는 CPU를 제어하기위해 사용되는 제어플래그(Control flag)도 있답니다. 83 | 그 예로 인터럽트 요구를 받아들일지 말지 결정하는 인터럽트 플래그(I)가 있습니다! 84 | ``` 85 |
86 | 87 |
89 | 90 | ### 3.2 정수의 표현 `daelee` 91 | 92 | #### 부호없는(Unsigned) 정수 표현(책 요약) 93 | 94 | - n비트 조합에서 의미있는 조합의 개수 : 2^n 95 | 96 | - 3bit 라면 000, 001, 010, 011, 100, 101, 110, 111 총 8개의 조합이 가능함. 97 | 98 | - n비트에서 표현 가능한 10진수 범위 : 0 ~ 2^n - 1 99 | 100 | - n비트로 표현된 2진수를 10진수로 변환하는 일반식 101 | 102 |  103 | 104 | 105 | - Bit Extension 방법 : 상위(좌측) 남는 비트부터 0추가 106 | 107 | - 8비트를 16비트에 저장헤야할 때 108 | - 57(10) = 00111001(8), 0000000000111001(16) 109 | 110 | #### 부호있는(Signed) 정수 표현(문제) 111 | 112 | 1. 아래와 같이 부호화-크기(signed-magnitude representation)로 표현된 수들을 10진수로 변환하세요. 113 | 114 | - 0 0110101 = 115 | - 1 0110101 = 116 | - 1 000 = 117 | 118 | 119 | 2. **부호화-크기** 표현의 가장 큰 단점 두 가지를 설명해주세요. 120 | 121 | 122 | 123 | 3. 1의 보수 표현(1’s complement representation)의 음수화(negation) 방법을 설명해주세요. 124 | 125 | 126 | 127 | 4. 2의 보수 표현(2’s complement representation)의 음수화(negation) 방법을 설명해주세요. 128 | 129 | 130 | 131 | 5. 2의 보수로 표현된 `10111010`을 10진수로 변환하세요. 132 | 133 | 134 | 135 | 136 | 137 |
:page_facing_up: 답지
139 | 140 | 1. 아래와 같이 부호화-크기(signed-magnitude representation)로 표현된 수들을 10진수로 변환하세요. 141 | 142 | - 0 0110101 = 143 | - 1 1010101 = 144 | - 1 000 = 145 | 146 | 147 | > 정답 : 148 | > 149 | > - 0 0110101 = 1 * (1x2^5 + 1x2^4 + 1x2^2 + 1x2^0) = (32 + 16 + 4 + 1) = 53 150 | > - 1 1010101 = -53 151 | > - 1 000 = 0 152 | 153 | 2. **부호화-크기** 표현의 가장 큰 단점 두 가지를 설명해주세요. 154 | 155 | > 정답 : 156 | > 157 | > 1. n비트 조합에서 의미있는 조합의 개수 : 2^n 가 아니라 2^n - 1 이다. 부호화-크기 표현에서는 1000(2)과 0000(2) 둘 다 0을 표현하므로 **하나의 조합을 낭비하게 된다.** 158 | > 2. 계산을 수행할 때 **부호비트와 크기 부분을 별도로 처리**해야한다. 크기 부분만 따로 계산한 뒤 크기 부분의 절댓값이 더 큰 수의 부호를 결과값의 부호로 세트해야함. 귀찮음. 159 | 160 | 3. 1의 보수 표현(1’s complement representation)의 음수화(negation) 방법을 설명해주세요. 161 | 162 | > 정답 : **모든 비트들을 반전한다.** (0 -> 1, 1 -> 0) 163 | > 164 | > - 1의 보수 표현에서 **Bit Extension**은 Sign Bit 다음에 Sign Bit와 같은 수를 추가하는 방식으로 이루어진다. 165 | > - 그러나 여전히 0에 대한 표현이 두 가지이므로 조합의 낭비가 발생한다. 그래서 일반적으로 컴퓨터는 2의 보수 표현법을 더 많이(아니 거의 100%) 사용한다. 166 | 167 | 4. 2의 보수 표현(2’s complement representation)의 음수화(negation) 방법을 설명해주세요. 168 | 169 | > 정답 : 모든 비트들을 반전하고, **결과값에 1을 더한다.** 170 | > 171 | > 1을 더함으로서 조합의 개수를 낭비하지 않게 되었다! 2의 보수 표현에서는 음수0이 사라진 대신, 음수0은 절대값이 가장 큰 음수와 매핑된다. 예를 들어, 100(2)은 부호화-크기 표현에서 음수 0이었지만, 2의보수 표현에서는 -4다. 172 | 173 | 5. 2의 보수로 표현된 `10111010`을 10진수로 변환하세요. 174 | 175 | > 정답 : **-70** 176 | > 177 | > 방법1. 책 145p 예제(3-4) 일반식 참고 178 | > 179 | > - -128 + (1x2^5 + 1x2^4 + 1x2^3 + 1x2^1) = -128 + (32 + 16 + 8 + 2) = -70 180 | >
181 | > 182 | > 방법2. 책 146p 예제(3-6) 참고 183 | > 184 | > 1. 10111010 - 1 한 뒤 => 10111001 185 | > 2. 0은 1로, 1은 0으로 바꿔주기 => 01000110 186 | > 3. 10진수로 변환하고 - 부호 붙이기 => -70 187 | 188 | 189 | 190 |
192 | 193 | ### 3.3 논리 연산 `sancho` 194 | 195 | #### [문제1]
선택적 세트 연산이 쓰이는 이유를 설명해주세요. 196 | 197 | #### [문제2]
선택적 세트 연산을 실행할 A레지스터가 01001100일 때 상위 4비트를 바꾸기 위한 B레지스터의 값을 적어 주세요. 198 | 199 | #### [문제3]
선택적 보수 연산이 쓰이는 이유를 설명해주세요. 200 | 201 | #### [문제4]
선택적 보수 연산을 실행할 A레지스터가 00111001일 때 모든 비트를 바꾸기 위한 B레지스터의 값을 적어 주세요. 202 | 203 | #### [문제5]
마스크 연산이 쓰이는 이유를 설명해주세요. 204 | 205 | #### [문제6]
A레지스터가 11001010, B레지스터가 10101100일 때 비교 연산 이후 A레지스터의 값을 적어 주세요. 206 | 207 |
:page_facing_up: 답지
209 | 210 | #### [문제1]
선택적 세트 연산이 쓰이는 이유를 설명해주세요. 211 | -> 선택적 세트 연산은 어떤 레지스터의 특정 비트들을 1로 세트하려고 할 때 쓰이는 연산으로 A레지스터의 바꿀 비트 위치에 1을 세트하고 OR연산을 수행합니다. 212 | 213 | #### [문제2]
선택적 세트 연산을 수행할 A레지스터가 01001100일 때 상위 4비트를 바꾸기 위한 B레지스터의 값을 적어 주세요. 214 | -> 11110000, 상위 4비트인 앞 네자리에 1로 세팅하여 A레지스터에 선택적 세트 연산을 적용하게 됩니다. 215 | 216 | #### [문제3]
선택적 보수 연산이 쓰이는 이유를 설명해주세요. 217 | -> 선택적 보수 연산은 레지스터의 특정 비트들을 보수화하기 위한 동작이며 바꿀 A레지스터에 반전시킬 비트 위치에다 1을 세트하고 XOR연산을 수행합니다. 218 | 219 | #### [문제4]
선택적 보수 연산을 실행할 A레지스터가 00111001일 때 모든 비트를 바꾸기 위한 B레지스터의 값을 적어 주세요. 220 | -> 11111111, 모든 위치에 1을 세트하여 A레지스터에 선택적 보수 연산을 적용하게 됩니다. 221 | 222 | #### [문제5]
마스크 연산이 쓰이는 이유를 설명해주세요. 223 | -> 마스크 연산은 데이터 내 특정 비트들의 값을 0으로 리셋시키기 사용하며, 바꿀 A레지스터에 대응되는 비트 위치에 0으로 세트하고 나머지 위치에 1을 세트한 후 AND 연산을 수행합니다. 224 | 225 | #### [문제6]
A레지스터가 11001010, B레지스터가 10101100일 때 비교 연산 이후 A레지스터의 값을 적어 주세요. 226 | -> 01100110, 같은 자리에 하나씩 비교하며 XOR연산을 진행하면 A레지스터의 값이 다음과 같이 바뀌게 됩니다. 227 | 228 |
230 | 231 | ### 3.4 시프트 연산 `yeosong` 232 | 233 | 234 | #### 1. 논리적 시프트 LSL, LSR은 부호비트를 복사하지 않으며, 맨 끝에 밀려나는 값은 순환시키지 않고 버린다. (O/X) 235 | 236 | #### 2. 논리적 시프트 LSL, LSR은 버리는게 없을 때, 즉 데이터 손실이 없을 때에 좌측 시프트를 한 번 하면 결과가 나누기 2한 값이 된다. (O/X) 237 | 238 | #### 3. 캐리 플래그를 포함한 시프트 연산에서 SHLC는 1번 수행시 최상위 비트를 C플래그에 저장시키게 된다. (O/X) 239 | 240 | #### 4. 캐리 플래그를 포함한 시프트 연산에서 SHRC는 1번 수행시 C플래그 값이 최상위 비트로 이동하고, 최하위 비트는 버린다. (O/X) 241 | 242 | #### 기본3.7) A 레지스터에 2의 보수로 표현된 데이터 ‘10101101’이 저장되어 있을 때, 산술적 우측 시프트를 두 번 수행한 결과는? 243 | (보기 편하도록 4비트마다 띄어서 표기하겠습니다) 244 | 245 | #### 기본3.8) A 레지스터에 ‘0101 1011’이 저장되어 있을 때, 좌측 순환 시프트를 한 번 수행한 결과는? 246 | 247 | #### 기본3.9) A 레지스터에 ‘0101 1011’이 저장되어 있고 C플래그에 1이 저장되어 있을 때, SHRC 연산을 한 번 수행한 결과는? 248 | 249 | #### 기본3.10) A 레지스터에 ‘0101 1011’이 저장되어 있고 C플래그에 ‘0’이 저장되어 있을 때, RLC 연산을 두 번 수행한 결과는? 250 | 251 | #### 연습3.8) 8비트 레지스터에 있는 2의 보수 1101 0010을 252 | 253 | 1. 논리적 우측 시프트 하면? 254 | 2. 논리적 좌측 시프트 하면? 255 | 3. 순환 우측 시프트 하면? 256 | 4. 순환 좌측 시프트 하면? 257 | 5. 산술적 우측 시프트 하면? 258 | 6. 산술적 좌측 시프트 하면? 259 | 260 | #### 연습3.9) 8비트 레지스터에 있는 2의 보수 1011 0011을 논리적 우측 시프트-> 순환 좌측 시프트-> 산술적 우측 시프트-> 산술적 좌측 시프트 한 결과는? 261 | 262 | #### 연습3.10-1) A 레지스터에 1011 0011이 저장되어있고, C플래그 값은 0일때, SHRC 연산 수행 후 값은? 263 | 264 | #### 연습3.10-2) 위의 결과값에 대해 SHLC를 두 번 수행한 값은? 265 | 266 | #### 연습3.11-1) 초기 상태에서 어떤 레지스터에 1011 0011이 저장되어 있고, C플래그 값은 1이라고 하자. RLC를 수행한 결과는? 267 | 268 | #### 연습3.11-2) 위의 값에 대해 RRC를 두 번 수행하면? 269 | 270 |
:page_facing_up: 답지
272 | 273 | #### 1. 논리적 시프트 LSL, LSR은 부호비트를 복사하지 않으며, 맨 끝에 밀려나는 값은 순환시키지 않고 버린다. (O) 274 | #### 2. 논리적 시프트 LSL, LSR은 버리는게 없을 때, 즉 데이터 손실이 없을 때에 좌측 시프트를 한 번 하면 결과가 나누기 2한 값이 된다. (X) 275 | > 앞부분 설명은 맞는데, 곱하기 2한 값이 됩니다. 예를 들면 0010 (2) -> 0100 (4) 276 | #### 3. 캐리 플래그를 포함한 시프트 연산에서 SHLC는 1번 수행시 최상위 비트를 C플래그에 저장시키게 된다. (O) 277 | #### 4. 캐리 플래그를 포함한 시프트 연산에서 SHRC는 1번 수행시 C플래그 값이 최상위 비트로 이동하고, 최하위 비트는 버린다. (O) 278 | #### 기본3.7) A 레지스터에 2의 보수로 표현된 데이터 ‘10101101’이 저장되어 있을 때, 산술적 우측 시프트를 두 번 수행한 결과는? 279 | (보기 편하도록 4비트마다 띄어서 표기하겠습니다)
280 | 산술적 우측 시프트는 부호비트를 복사해서 오른쪽으로 가죠!
281 | 1010 1101 를 ASR하면
282 | 1101 0110. 얘를 한 번 더 ASR하면
283 | 1110 1011이다. 그래서 정답은
284 | > 1110 1011 285 | 286 | #### 기본3.8) A 레지스터에 ‘0101 1011’이 저장되어 있을 때, 좌측 순환 시프트를 한 번 수행한 결과는? 287 | > 최상위의 0이 최하위로 가서 1011 0110 288 | 289 | #### 기본3.9) A 레지스터에 ‘0101 1011’이 저장되어 있고 C플래그에 1이 저장되어 있을 때, SHRC 연산을 한 번 수행한 결과는? 290 | 291 | > SHRC = Shift Right with Carry
292 | > 캐리 플래그 1, 0101 1011에서 캐리 플래그의 값이 최상위 비트에 저장되니까 답은 1010 1101. 293 | 294 | #### 기본3.10) A 레지스터에 ‘0101 1011’이 저장되어 있고 C플래그에 ‘0’이 저장되어 있을 때, RLC 연산을 두 번 수행한 결과는? 295 | 296 | RLC = Rotate Left with Carry
297 | 0 0101 1011 에서 한 번 하면
298 | 0 1011 0110 , 여기서 한 번 더 하면
299 | > 1 0110 1100 300 | 301 | #### 연습3.8) 8비트 레지스터에 있는 2의 보수 1101 0010을 302 | 303 | 1. 논리적 우측 시프트 하면? 304 | > 0110 1001 305 | 2. 논리적 좌측 시프트 하면? 306 | > 1010 0100 307 | 3. 순환 우측 시프트 하면? 308 | > 0110 1001 309 | 4. 순환 좌측 시프트 하면? 310 | > 1010 0101 311 | 5. 산술적 우측 시프트 하면? 312 | > 1110 1001 313 | 6. 산술적 좌측 시프트 하면? 314 | > 1010 0100 315 | 316 | #### 연습3.9) 8비트 레지스터에 있는 2의 보수 1011 0011을 논리적 우측 시프트-> 순환 좌측 시프트-> 산술적 우측 시프트-> 산술적 좌측 시프트 한 결과는? 317 | 318 | 1011 0011을 논리적 우측 시프트 하면 (부호비트 복사 안하고 남는 거 버리고)
319 | 0101 1001 그걸 순환 좌측 시프트 하면 (남는 거 순환 시키고)
320 | 1011 0010 그걸 산술적 우측 시프트 하면 (부호비트 복사하고, 남는 거는 버리고)
321 | 1101 1001 이걸 산술적 좌측 시프트 하면 (한 칸씩 좌측으로 밀고 남는 거는 버리고)
322 | > 1011 0010 323 | 324 | #### 연습3.10-1) A 레지스터에 1011 0011이 저장되어있고, C플래그 값은 0일때, SHRC 연산 수행 후 값은? 325 | `SHRC` : C플래그의 값이 최상위 비트로 이동하고, 남는 건 버린다.
326 | > 우측이니까 0 1011 0011에서 0 0101 1001 327 | 328 | #### 연습3.10-2) 위의 결과값에 대해 SHLC를 두 번 수행한 값은? 329 | `SHLC` : 최상위 비트가 버려지지 않고 C플래그에 저장되고, 원래의 C플래그 값은 지워진다. 남는 건 버린다.
330 | 0 0101 1001에서 1회 하면 0 1011 0010.
331 | 여기서 한 번 더 하면 1 0110 0100.
332 | > 답은 0110 0100 333 | 334 | #### 연습3.11-1) 초기 상태에서 어떤 레지스터에 1011 0011이 저장되어 있고, C플래그 값은 1이라고 하자. RLC를 수행한 결과는? 335 | `RLC` : 최상위 비트가 버려지지 않고 C플래그에 저장되고, 원래의 C플래그 값은 지워진다. 남는 건 순환
336 | 1 1011 0011 -> 1 0110 0111 337 | > 1 0110 0111 338 | 339 | 340 | #### 연습3.11-2) 위의 값에 대해 RRC를 두 번 수행하면? 341 | `RRC` : C플래그의 값이 최상위 비트로 이동, 남는 건 순환
342 | 위의 값인 1 0110 0111에서
343 | -> 1 1011 0011
344 | -> 1 1101 1001
345 | 346 | > 1 1101 1001 347 | 348 | 349 | 350 |
352 | -------------------------------------------------------------------------------- /README.md: -------------------------------------------------------------------------------- 1 | # 🖥 컴퓨터 구조 2 | 3 | - **시간:** 매주 월목 오전 10시 (11/23~) 4 | - **장소:** 디스코드😎 5 | 6 | | No. | 목 차 _(강의기준)_ | 소 단 원 _(교재기준)_ | 스케줄 | V | 7 | | :----: | :------------------------------------- | :---------------------------------------------- | :------------: | :-: | 8 | | **0** | **킥오프 미팅** | | **11/23 (월)** | 🦄 | 9 | |||||| 10 | | **1** | **[컴퓨터 시스템의 구조](./01%EA%B0%95%E3%80%80%EC%BB%B4%ED%93%A8%ED%84%B0%EC%8B%9C%EC%8A%A4%ED%85%9C%EC%9D%98%EA%B5%AC%EC%A1%B0.md)** | | **11/26 (목)** | 🦄 | 11 | | | | 1.1 컴퓨터의 기본 구조 | `①gaekim` | | 12 | | | | 1.2 정보의 표현과 저장 | `②secho` | | 13 | | | | 1.3 시스템의 구성 | `③yeha` | | 14 | | | | 1.4 컴퓨터 구조의 발전과정 *(간단히)* | `④kukim` | | 15 | | | | + OS 구술문제 [1 제출](https://github.com/Kraken-Addicts/Operating-System/issues/9) | `②secho` | | 16 | |||||| 17 | | **2** | **[ALU: Logic Operations](./02%EA%B0%95%E3%80%80ALU%20:%20Logic%20Operations.md)** | | **11/30 (월)** | 🦄 | 18 | | | | 3.1 ALU의 구성 요소 | `⑤mihykim` | | 19 | | | | 3.2 정수의 표현 | `⑥daelee` | | 20 | | | | 3.3 논리 연산 | `⑦sancho` | | 21 | | | | 3.4 시프트 연산 | `⑧yeosong` | | 22 | | | | + OS 구술문제 [1 해설](https://github.com/Kraken-Addicts/Operating-System/issues/9) | `②secho` | | 23 | |||||| 24 | | **3** | **[ALU: Arithmetic Operations](./03%EA%B0%95%E3%80%80ALU%20:%20Arithmetic%20Operations.md)** | | **12/3 (목)** | 🦄 | 25 | | | | 3.5 정수의 산술 연산 | `⑨kycho` | | 26 | | | | 3.6 부동소수점 수의 표현 | `⑩jakang` | | 27 | | | | 3.7 부동소수점 산술 연산 | `①gaekim` | | 28 | | | | + OS 구술문제 [2 제출](https://github.com/Kraken-Addicts/Operating-System/issues/10) | `①gaekim` | | 29 | |||||| 30 | | **4** | **[CPU의 기본 구성 및 명령어 세트](./04%EA%B0%95%E3%80%80CPU%EC%9D%98%EA%B8%B0%EB%B3%B8%EA%B5%AC%EC%84%B1%20%EB%B0%8F%20%EB%AA%85%EB%A0%B9%EC%96%B4%EC%84%B8%ED%8A%B8.md)** | | **12/7 (월)** | 🦄 | 31 | | | | 2.1 CPU의 기본 구조 | `②secho` | | 32 | | | | 2.4 명령어 세트 - 연산의 종류, 명령어형식 | `③yeha` | | 33 | | | | 2.4 명령어 세트 - 주소지정방식 | `④kukim` | | 34 | | | | 2.4 명령어 세트 - 상용프로세서 *(간단히)* | `⑤mihykim` | | 35 | | | | + OS 구술문제 [2 해설](https://github.com/Kraken-Addicts/Operating-System/issues/10) | `①gaekim` | | 36 | |||||| 37 | | **5** | **[명령어 실행](./05%EA%B0%95%E3%80%80%EB%AA%85%EB%A0%B9%EC%96%B4%EC%8B%A4%ED%96%89.md)** | | **12/10 (목)** | 🦄 | 38 | | | | 2.2 명령어 실행 - 인출사이클 | `⑥daelee` | | 39 | | | | 2.2 명령어 실행 - 실행사이클 | `⑦sancho` | | 40 | | | | 2.2 명령어 실행 - 인터럽트사이클 | `⑧yeosong` | | 41 | | | | 2.2 명령어 실행 - 간접사이클 | `⑨kycho` | | 42 | | | | + OS 구술문제 [3 제출](https://github.com/Kraken-Addicts/Operating-System/issues/11) | `⑥daelee` | | 43 | |||||| 44 | | **6** | **[인터럽트/서브루틴/파이프라이닝](./06%EA%B0%95%E3%80%80%EC%9D%B8%ED%84%B0%EB%9F%BD%ED%8A%B8%2C%EC%84%9C%EB%B8%8C%EB%A3%A8%ED%8B%B4%2C%ED%8C%8C%EC%9D%B4%ED%94%84%EB%9D%BC%EC%9D%B4%EB%8B%9D.md)** | | **12/14 (월)** |🦄 | 45 | | | | 2.3 명령어 파이프라이닝 - 2단계 | `⑩jakang` | | 46 | | | | 2.3 명령어 파이프라이닝 - 4단계 | `①gaekim` | | 47 | | | | 2.3 명령어 파이프라이닝 - 슈퍼스칼라 | `②secho` | | 48 | | | | 2.3 명령어 파이프라이닝 - 듀얼/멀티코어 | `③yeha` | | 49 | | | | 2.x 서브루틴 | `⑤mihykim` | | 50 | | | | + OS 구술문제 [3 해설](https://github.com/Kraken-Addicts/Operating-System/issues/11) | `⑥daelee` | | 51 | |||||| 52 | | **7** | **[제어 유니트](./07%EA%B0%95%E3%80%80%EC%A0%9C%EC%96%B4%EC%9C%A0%EB%8B%88%ED%8A%B8.md)** | | **12/17 (목)** | 🦄 | 53 | | | | 4.1 제어 유니트의 기능 | `④kukim` | | 54 | | | | 4.2 제어 유니트의 구조 | `⑤mihykim` | | 55 | | | | 4.3 마이크로명령어의 형식 | `⑥daelee` | | 56 | | | | 4.4 마이크로프로그래밍 | `⑦sancho` | | 57 | | | | 4.5 마이크로프로그램의 순서제어 | `⑧yeosong` | | 58 | | | | + OS 구술문제 [4 제출](https://github.com/Kraken-Addicts/Operating-System/issues/12) | `⑤mihykim` | | 59 | |||||| 60 | | **8** | **[Main Memory](./08강%E3%80%80메인메모리.md)** | | **12/21 (월)** | 🦄 | 61 | | | | 5.1 기억장치의 분류와 특성 | `⑨kycho` | | 62 | | | | 5.2 계층적 기억장치시스템 | `⑩jakang` | | 63 | | | | 5.3 반도체 기억장치 | `①gaekim` | | 64 | | | | 5.4 기억장치 모듈의 설계 | `②secho` | | 65 | | | | + OS 구술문제 [4 해설](https://github.com/Kraken-Addicts/Operating-System/issues/12) | `⑤mihykim` | | 66 | |||||| 67 | | **9** | **[Cache](./09강%E3%80%80캐시.md)** | | **12/24 (목)** | 🦄 | 68 | | | | 5.5 캐시 메모리 - 캐시용량, 인출방식 | `⑪taelee` | | 69 | | | | 5.5 캐시 메모리 - 사상방식 | `⑫jehong` | | 70 | | | | 5.5 캐시 메모리 - 교체알고리즘, 쓰기정책 | `⑬hylee` | | 71 | | | | 5.5 캐시 메모리 - 다중캐시 | `③yeha` | | 72 | | | | 5.6 DDR SDRAM *(간단히)* | `④kukim` | | 73 | | | | 5.7 차세대 비휘발성 기억장치 _(간단히)_ | `⑤mihykim` | | 74 | | | | + OS 구술문제 [5 제출](https://github.com/Kraken-Addicts/Operating-System/issues/13) | `⑪taelee` | | 75 | |||||| 76 | | **10** | **[Secondary Storage Device](./10강 보조저장장치.md)** | | **12/28 (월)** | 🦄 | 77 | | | | 6.1 하드 디스크 | `⑤mihykim` | | 78 | | | | 6.2 RAID | `⑦sancho` | 79 | | | | 6.3 플래시 메모리와 SSD - 플래시메모리 | `⑧yeosong` | | 80 | | | | 6.3 플래시 메모리와 SSD - SSD | `⑨kycho` | | 81 | | | | + OS 구술문제 [5 해설](https://github.com/Kraken-Addicts/Operating-System/issues/13) | `⑪taelee` | | 82 | |||||| 83 | | **11** | **[System Bus and Bus Arbitration](./11강%E3%80%80시스템버스%20및%20버스중재.md)** | | **12/31 (목)** | 🦄 | 84 | | | | 7.1 시스템 버스 | `⑩jakang` | | 85 | | | | 7.2 버스 중재 - 병렬중재방식 | `⑪taelee` | | 86 | | | | 7.2 버스 중재 - 직렬중재방식 | `⑫jehong` | | 87 | | | | 7.2 버스 중재 - 폴링방식 | `⑬hylee` | | 88 | | | | + OS 구술문제 [6 제출](https://github.com/Kraken-Addicts/Operating-System/issues/14) | `⑫jehong` | | 89 | |||||| 90 | | **12** | **[I/O Device Access](https://github.com/Kraken-Addicts/Computer-Achitecture/blob/main/12%EA%B0%95%E3%80%80%EC%9E%85%EC%B6%9C%EB%A0%A5%20Device.md)** | | **1/4 (월)** | 🦄 | 91 | | | | 7.3 I/O 장치의 접속 - I/O제어 | `①gaekim` | | 92 | | | | 7.3 I/O 장치의 접속 - I/O주소지정 | `②secho` | | 93 | | | | 7.4 인터럽트를 이용한 I/O | `③yeha` | | 94 | | | | 7.5 DMA를 이용한 I/O | `④kukim` | | 95 | | | | + OS 구술문제 [6 해설](https://github.com/Kraken-Addicts/Operating-System/issues/14) | `⑫jehong` | | 96 | |||||| 97 | | **13** | **[병렬컴퓨터](https://github.com/Kraken-Addicts/Computer-Achitecture/blob/main/13%EA%B0%95%E3%80%80%EB%B3%91%EB%A0%AC%EC%BB%B4%ED%93%A8%ED%84%B0.md)** | | **1/7 (목)** | 🦄 | 98 | | | | 8.1 병렬처리의 개념 및 필요성 | `⑥daelee` | | 99 | | | | 8.2 병렬처리의 단위 | `⑥daelee` | | 100 | | | | 8.3 병렬컴퓨터의 분류 | `⑦sancho` | | 101 | | | | 8.4 다중프로세서시스템 구조 - 공유기억장치 | `⑧yeosong` | | 102 | | | | 8.4 다중프로세서시스템 구조 - 분산기억장치 | `⑨kycho` | | 103 | | | | 8.4 다중프로세서시스템 구조 - 캐시일관성 | `⑩jakang` | | 104 | | | | 8.5 그래픽처리유니트(GPU) | `⑪taelee` | | 105 |
106 | 107 | - **스터디자료** 108 | - 교재: 109 | - 주교재: [컴퓨터구조론](http://www.kyobobook.co.kr/product/detailViewKor.laf?ejkGb=KOR&mallGb=KOR&barcode=9788970509693&orderClick=LAG&Kc=)(김종현 지음, 생능출판사) 110 | - 참고강의: 111 | - 강의자료: [K-MOOC 컴퓨터 구조](http://www.kmooc.kr/courses/course-v1:SMUCk+CK.SMUC03k+2017_T6/video) 112 | - 보조자료: [CrashCourse - Computer Science](https://www.youtube.com/watch?v=tpIctyqH29Q&list=PL8dPuuaLjXtNlUrzyH5r6jN9ulIgZBpdo) 113 | 114 | -------------------------------------------------------------------------------- /07강 제어유니트.md: -------------------------------------------------------------------------------- 1 | ## 🦄 제어유니트 (7 / 13회차) 2 |
3 | 4 | ### 4.1 제어 유니트의 기능 `kukim` 5 | 6 | #### 문제 1. Control Unit(제어 유닛ㅌ)의 주요 기능 두 가지는 무엇인가요? 보기에서 골라주세요 7 | 8 | ```c 9 | [보기] 10 | a) 명령어 코드 decode 11 | b) 명령어 코드 encode 12 | c) 명령어 실행에 필요한 제어 신호들의 발생 13 | d) 어셈블리어 코드 생성 14 | e) while(1) {printf("나는 제어 유니 ㅌㅌㅌㅌㅌ");} 15 | ``` 16 | 17 | #### 문제 2. Hardwired Contorl(하드와이어 제어)는 Microprogrammed Control(마이크로프로그램 제어)와는 다르게 하드웨어 변경 없이 컴퓨터 시스템 제어의 수정이 가능하다. (O / X) 18 | 19 |
:page_facing_up: 답지
21 | 22 | #### 문제 1. Control Unit(제어 유닛ㅌ)의 주요 기능 두 가지는 무엇인가요? 보기에서 골라주세요 23 | 24 | ```c 25 | [보기] 26 | a) 명령어 코드 decode 27 | b) 명령어 코드 encode 28 | c) 명령어 실행에 필요한 제어 신호들의 발생 29 | d) 어셈블리어 코드 생성 30 | e) while(1) {printf("나는 제어 유니 ㅌㅌㅌㅌㅌ");} 31 | ``` 32 | 33 | - 정답 : a, c 34 | - 제어유닛의 기능 35 | 1. 명령어 코드 해독 36 | 2. 명령어 실행에 필요한 제어 신호 발생 37 | 38 | #### 문제 2. Hardwired Contorl(하드와이어 제어)는 Microprogrammed Control(마이크로프로그램 제어)와는 다르게 하드웨어 변경 없이 컴퓨터 시스템 제어의 수정이 가능하다. (O / X) 39 | 40 | - 정답 : X (하드와이어로 동작하는 제어 유닛은 하드웨어를 변경 해야 제어 유닛을 수정할 수 있다.) 41 | 42 |
44 | 45 | ### 4.2 제어 유니트의 구조 `mihykim` 46 | 47 |

위 그림을 참조하여 다음 빈 칸에 들어갈 제어 유니트의 주요구성요소를 알맞게 넣어주세요. 50 | - `(a) `
명령어 레지스터(IR)로부터 들어오는 명령어의 연산 코드를 해독하여 해당 연산을 수행하기 위한 루틴의 시작주소를 결정함 51 | - `(b) `
다음에 실행할 마이크로명령어의 주소(제어기억장치의 특정위치)를 저장하는 레지스터 52 | - `(c) `
마이크로명령어들로 이루어진 마이크로프로그램을 저장하는 내부 기억장치 53 | - `(d) `
제어 기억장치로부터 읽혀진 마이크로 명령어를 일시적으로 저장하는 레지스터 54 | - `(e) `
마이크로프로그램에서 서브루틴이 호출되는 경우에, 현재의 CAR 내용을 일시적으로 저장하는 레지스터 55 | - `(f) `
마이크로명령어의 실행 순서를 결정하는 회로들의 집합 56 | 57 |
58 | 59 | #### [문제 2]
용량이 128단어인 제어 기억장치의 처음 절반 부분에 실행 사이클 루틴들을 저장합니다. 각 루틴을 최대 8개의 마이크로명령어로 구성될 수 있도록 하려면, 사상 함수는 다음 중 어느 것과 같아야 할까요? (기본문제4.4) 60 | - 가. 0xxx000 61 | - 나. 0xxxx00 62 | - 다. 1xxxx00 63 | - 라. 1xxx00 64 | 65 | ``` 66 | 사상(mapping)함수란? 67 | - 명령어의 연산코드를 이용하여 해당 사이클 루틴의 시작 주소를 찾는 기법 68 | - input: 연산코드 69 | - output: 루틴의 시작주소 70 | ``` 71 | 72 |
73 | 74 | #### [문제 3]
제어유니트 명령어 실행 사이클 루틴들을 제어 기억장치의 절반 하반부에 저장하려고 합니다. 각 루틴은 최대 8개의 마이크로명령어들로 구성될 수 있도록 하며, 연산코드는 5비트입니다. (연습문제4.3) 75 | - 명령어 해독을 위한 사상함수를 제시해주세요 76 | - 제어기억장치의 0번지부터 상반부에는 인출 사이클을 비롯한 공통 루틴들을 저장한다면, 제어 기억장치의 전체 용량은 몇 단어(word)가 되어야 할까요? 77 | 78 |
:page_facing_up: 답지
80 | 81 | #### [문제 1]
위 그림을 참조하여 다음 빈 칸에 들어갈 제어 유니트의 주요구성요소를 알맞게 넣어주세요. 82 | - `명령어 해독기(instruction decoder)`:
명령어 레지스터(IR)로부터 들어오는 명령어의 연산 코드를 해독하여 해당 연산을 수행하기 위한 루틴의 시작주소를 결정함 83 | - `제어 주소 레지스터(control address register, CAR)`:
다음에 실행할 마이크로명령어의 주소(제어기억장치의 특정위치)를 저장하는 레지스터 84 | - `제어 기억장치(control memory)`:
마이크로명령어들로 이루어진 마이크로프로그램을 저장하는 내부 기억장치 85 | - `제어 버퍼 레지스터(control buffer register, CBR)`:
제어 기억장치로부터 읽혀진 마이크로 명령어를 일시적으로 저장하는 레지스터 86 | - `서브루틴 레지스터(subroutine register, SBR)`:
마이크로프로그램에서 서브루틴이 호출되는 경우에, 현재의 CAR 내용을 일시적으로 저장하는 레지스터 87 | - `순서제어 모듈(sequencing module)`:
마이크로명령어의 실행 순서를 결정하는 회로들의 집합 88 | 89 | #### [문제 2]
용량이 128단어인 제어 기억장치의 처음 절반 부분에 실행 사이클 루틴들을 저장합니다. 각 루틴을 최대 8개의 마이크로명령어로 구성될 수 있도록 하려면, 사상 함수는 다음 중 어느 것과 같아야 할까요? 90 | - 답 : 가. 0xxx000 91 | ``` 92 | ??????? : 총 128(=2^7)단어 이므로 7자리 93 | 0?????? : 처음 절반이므로 최상위 비트 0 94 | 0???000 : 각 루틴에 최대 8(=2^3)가지 이므로 000 95 | 0xxx000 : 나머지는 연산코드 자리 96 | ``` 97 | 98 | #### [문제 3]
제어유니트 명령어 실행 사이클 루틴들을 제어 기억장치의 절반 하반부에 저장하려고 합니다. 각 루틴은 최대 8개의 마이크로명령어들로 구성될 수 있도록 하며, 연산코드는 5비트입니다. 99 | - 명령어 해독을 위한 사상함수를 제시해주세요 100 | - 답 : 1xxxxx000 101 | ``` 102 | 1~ : 하반부이므로 최상위 비트 1 103 | 1xxxxx~ : 연산코드 5비트 104 | 1xxxxx000 : 각 루틴에 최대 8(=2^3)가지 105 | ``` 106 | 107 | - 제어기억장치의 0번지부터 상반부에는 인출 사이클을 비롯한 공통 루틴들을 저장한다면, 제어 기억장치의 전체 용량은 몇 단어(word)가 되어야 할까요? 108 | - 답: 512 워드 109 | ``` 110 | 1xxxxx000 => 9자리, 2^9 = 512 111 | => 공통 루틴 0~255 112 | => 실행사이클 루틴 256~511 113 | ``` 114 | 115 | 참고영상 : [[유튜브]컴퓨터 구조 사상함수(microprogrammed control unit)](https://www.youtube.com/watch?v=poTz9SZtCjE) 116 | 117 |
119 | 120 | ### 4.3 마이크로명령어의 형식 `daelee` 121 | 122 |  123 | 124 | ##### [문제 1] 조건부 호출 마이크로-연산이 실행될 때 조건이 만족되었다면, 제어주소레지스터(CAR)에는 어떤 값이 적재될까요? 125 | 126 | ``` 127 | 가. CAR <- CAR+1 128 | 나. CAR <- ADF 129 | 다. CAR <- SBR 130 | 라. CAR <- SBR+1 131 | ``` 132 | 133 | 134 | 135 | ##### [문제 2] 복귀(RET) 마이크로-연산이 실행되면, 제어주소레지스터(CAR)에는 어떤 값이 적재될까요? 136 | 137 | ``` 138 | 가. CAR <- CAR+1 139 | 나. CAR <- ADF 140 | 다. CAR <- SBR 141 | 라. CAR <- SBR+1 142 | ``` 143 | 144 | 145 | 146 | 147 | ##### [문제 3] 설명이 맞으면 O, 틀리면 X 하세요. 148 | 149 | 1. 하나의 동작만 지정하고 싶을 때에는 나머지 연산필드의 값을 이진수 `000`으로 지정한다. ( O / X ) 150 | 2. 동시에 실행되는 마이크로연산들은 하나의 연산 필드에 위치시켜야 한다. ( O / X ) 151 | 3. 분기 필드의 값이 JMP/CALL라면 앞의 조건 필드가 `00` 이더라도 조건을 만족하는 지 확인한 후 분기한다. ( O / X ) 152 | 4. 호출되는 마지막 마이크로명령어의 분기 필드에는 반드시 return을 뜻하는 `10` 이 들어가야한다. ( O / X ) 153 | 154 | 155 | 156 |
:page_facing_up: 답지
158 | 159 |  160 | 161 | ##### [문제 1] 조건부 호출 마이크로-연산이 실행될 때 조건이 만족되었다면, 제어주소레지스터(CAR)에는 어떤 값이 적재될까요? 162 | 163 | ``` 164 | 가. CAR <- CAR+1 165 | 나. CAR <- ADF 166 | 다. CAR <- SBR 167 | 라. CAR <- SBR+1 168 | ``` 169 | 170 | > **정답 : 나** 171 | > 172 | > 조건을 만족한 경우 호출 연산이 실행되고, 이 경우 마지막 주소필드(ADF)의 값이 분기될 목적지 마이크로명령어 주소가 된다. 즉, ADF의 값이 CAR로 적재된다. 173 | 174 | 175 | 176 | ##### [문제 2] 복귀(RET) 마이크로-연산이 실행되면, 제어주소레지스터(CAR)에는 어떤 값이 적재될까요? 177 | 178 | ``` 179 | 가. CAR <- CAR+1 180 | 나. CAR <- ADF 181 | 다. CAR <- SBR 182 | 라. CAR <- SBR+1 183 | ``` 184 | 185 | > **정답 : 다** 186 | > 187 | > 서브루틴 레지스터(SBR)은 마이크로프로그램에서 서브 루틴이 호출되는 경우에 현재의 CAR 내용을 일시적으로 저장하는 레지스터. SBR에 저장되어 있던 주소가 CAR에 다시 적재됨으로서 호출되기 전의 프로그램 실행 순서로 되돌아가게 된다. 188 | 189 | 190 | 191 | ##### [문제 3] 설명이 맞으면 O, 틀리면 X 하세요. 192 | 193 | 1. 하나의 동작만 지정하고 싶을 때에는 나머지 연산필드의 값을 이진수 `000`으로 지정한다. ( O / X ) 194 | 2. 동시에 실행되는 마이크로연산들은 하나의 연산 필드에 위치시켜야 한다. ( O / X ) 195 | 3. 분기 필드의 값이 JMP/CALL라면 앞의 조건 필드가 `00` 이더라도 조건을 만족하는 지 확인한 후 분기한다. ( O / X ) 196 | 4. 호출되는 마지막 마이크로명령어의 분기 필드에는 반드시 return을 뜻하는 `10` 이 들어가야한다. ( O / X ) 197 | 198 | > **정답 : O, X, X, O** 199 | > 200 | > 1. O, 000은 None을 의미한다. 201 | > 2. X, 두 개의 마이크로연산을 동시에 실행시키고 싶다면 두 개의 연산필드를 사용해야 한다. 202 | > 3. X, JMP와 CALL은 앞의 조건 필드가 `00` 이라면 무조건 점프/호출이 수행된다. 203 | > 4. O 204 | 205 |
207 | 208 | ### 4.4 마이크로프로그래밍 `sancho` 209 | 210 | #### 1. 인출 사이클 루틴이 실행될 때 다음 위치에 들어갈 마이크로 명령어를 적어주세요. 211 |  212 |
213 | 214 | #### 2. 간접 사이클 루틴을 사용하려 할 때 I비트에 세트된 값은 무엇일까요? 215 | -> 216 |
217 | 218 | #### 3. 간접 사이클 루틴이 실행될 때 다음 위치에 들어갈 마이크로 명령어를 적어주세요. 219 |  220 |
221 | 222 |
:page_facing_up: 답지
224 | 225 | 226 | #### 1. 인출 사이클 루틴이 실행될 때 다음 위치에 들어갈 마이크로 명령어를 적어주세요. 227 |  228 | 1. PCTAR: 인출 사이클의 첫번째로 PC의 내용을 MAR에 보내는 과정의 마이크로 명령어는 PCTAR이며 다음 마이크로 명령어가 실행됩니다.
229 | 2. READ, INCPC: 두번째에서는 첫번째에서 읽혀진 명령어가 MBR로 적재되고 PC의 내용에 1을 증가시키는 과정이 일어납니다. 이를 마이크로 명령어로 바꾸면 READ, INCPC가 됩니다.
230 | 3. BRTIR, 세번째에서 MBR에 저장된 명령어 코드가 IR로 이동하게 되는데 마이크로 명령어로 바꾸면 BRTIR입니다. 231 |
232 | 233 | #### 2. 간접 사이클 루틴을 사용하려 할 때 I비트에 세트된 값은 무엇일까요? 234 | -> 간접 주소지정 방식을 사용하기 위해선 I비트가 1로 세트되어야 합니다. 235 |
236 | 237 | #### 3. 간접 사이클 루틴이 실행될 때 다음 위치에 들어갈 마이크로 명령어를 적어주세요. 238 |  239 | 1. IRTAR, 2. READ, 3. BRTIR
240 |
241 | -> 간접 사이클은 간접 주소지정 방식을 사용하고 있는 데이터의 실제 위치를 불러오기 위한 과정이고 이를 순서대로 마이크로 명령어로 바꾸면 IRTAR, READ, BRTIR이 됩니다.
242 | 243 | 244 |
246 | 247 | 248 | ### 4.5 마이크로프로그램의 순서제어 `yeosong` 249 | 250 | #### [문제 1]
다음 조건에 따르면 수평적 마이크로프로그래밍 방식에서 한 번에 최대 몇 개의 제어 신호들이 발생할 수 있는가? (기본문제4.8) 251 | 252 | ~~~ 253 | 두 개의 연산 필드가 각각 4비트씩으로 구성되어 있다. 254 | 255 | 가. 4개 256 | 나. 8개 257 | 다. 16개 258 | 라. 32개 259 | ~~~ 260 | 261 | #### [문제 2]
다음 조건에 따르면 수직적 마이크로프로그래밍 방식에서 한 번에 최대 몇 개의 제어 신호들이 발생할 수 있는가? (기본문제4.9) 262 | 263 | ~~~ 264 | 두 개의 연산 필드가 각각 4비트씩으로 구성되어 있다. 265 | 단, 해독기는 두 개만 사용한다고 가정한다. 266 | 267 | 가. 8개 268 | 나. 16개 269 | 다. 32개 270 | 라. 64개 271 | ~~~ 272 | 273 | #### [문제 3]
수직적 마이크로프로그래밍의 특징을 고르세요. (연습문제4.8, 기본문제4.10) 274 | 275 | ~~~ 276 | 가) 마이크로 명령어 길이가 짧다 277 | 나) 마이크로 명령어 길이가 길다 278 | 다) 제어기억장치의 용량이 적게 필요하다 279 | 라) 제어기억장치의 용량이 비교적 많이 필요하다 280 | 마) 해독기 사용으로 지연이 발생한다 281 | 바) 제어 신호의 발생을 위한 추가적 하드웨어가 필요하지 않다. 282 | 사) 제어 신호의 수를 확장시키는 것이 용이하다. 283 | ~~~ 284 | 285 | #### [문제 4]
다음 가정에 맞추어 아래 문항을 풀어보세요.(연습문제4.9) 286 | 287 | ~~~ 288 | 1. 이 제어 기억장치의 폭(=단어 길이)는 26비트다. 289 | 2. 마이크로명령어 형식에서 14비트는 마이크로-연산을 가리키는 연산 필드로 사용된다. 290 | 3. 주소 선택 필드는 분기 조건을 규정하며, 291 | 4. 그 조건을 결정하는 플래그들은 8개이다. 292 | 5. 분기의 종류는 한 가지뿐이어서 분기 필드는 필요하지 않다고 가정한다. 293 | ~~~ 294 | 295 | (1) 주소 선택 필드는 몇 비트가 필요한가?
296 | (2) 주소 필드(ADF)는 몇 비트로 구성될 수 있는가?
297 | (3) 이 제어 기억장치의 최대 용량(단어 수 × 폭)을 구하라. 298 | 299 | 300 | #### [문제 5]
다음은 제어 유닛을 간략하게 나타낸 것이다. 주어진 표를 참고하여 다음 문항에 답하시오. 301 | 302 |  303 | 304 | (1) 다음과 같은 조건일때, 실행되는 마이크로 연산으로 알맞은 것을 보기에서 고르세요. 305 | 306 | ~~~ 307 | 보기 308 | 309 | 가) CAR <- 1XXXX00
:page_facing_up: 답지
336 | 337 | #### [문제 1]
다음 조건에 따르면 수평적 마이크로프로그래밍 방식에서 한 번에 최대 몇 개의 제어 신호들이 발생할 수 있는가? (기본문제4.8) 338 | 339 | ~~~ 340 | 두 개의 연산 필드가 각각 4비트씩으로 구성되어 있다. 341 | 342 | 가. 4개 343 | 나. 8개 344 | 다. 16개 345 | 라. 32개 346 | ~~~ 347 | 348 | > **정답 : 나. 8개**
349 | > 각 비트의 값을 그대로 내려받기 때문에 4개씩 두 필드 = 8개의 신호가 발생한다. 350 | 351 | 352 | #### [문제 2]
다음 조건에 따르면 수직적 마이크로프로그래밍 방식에서 한 번에 최대 몇 개의 제어 신호들이 발생할 수 있는가? (기본문제4.9) 353 | 354 | ~~~ 355 | 두 개의 연산 필드가 각각 4비트씩으로 구성되어 있다. 356 | 단, 해독기는 두 개만 사용한다고 가정한다. 357 | 358 | 가. 8개 359 | 나. 16개 360 | 다. 32개 361 | 라. 64개 362 | ~~~ 363 | 364 | > **정답 : 다. 32개**
365 | > 비트 4개로 나타낼 수 있는 값의 경우의 수가 최대 24/sup>개이고, 이 같은 필드가 2개 있으므로
366 | > 최대 24/sup> /* 2 = 32개의 신호가 발생할 수 있다. 367 | 368 | 369 | #### [문제 3]
수직적 마이크로프로그래밍의 특징을 고르세요. (연습문제4.8, 기본문제4.10) 370 | 371 | ~~~ 372 | 가) 마이크로 명령어 길이가 짧다 373 | 나) 마이크로 명령어 길이가 길다 374 | 다) 제어기억장치의 용량이 적게 필요하다 375 | 라) 제어기억장치의 용량이 비교적 많이 필요하다 376 | 마) 해독기 사용으로 지연이 발생한다 377 | 바) 제어 신호의 발생을 위한 추가적 하드웨어가 필요하지 않다. 378 | 사) 제어 신호의 수를 확장시키는 것이 용이하다. 379 | ~~~ 380 | > **정답 : 가, 다, 마, 사**
381 | > 나, 라, 바 는 수평적 마이크로프로그래밍의 특징이다. 382 | 383 | 384 | #### [문제 4]
다음 가정에 맞추어 아래 문항을 풀어보세요.(연습문제4.9) 385 | 386 | ~~~ 387 | 1. 이 제어 기억장치의 폭(=단어 길이)는 26비트다. 388 | 2. 마이크로명령어 형식에서 14비트는 마이크로-연산을 가리키는 연산 필드로 사용된다. 389 | 3. 주소 선택 필드는 분기 조건을 규정하며, 390 | 4. 그 조건을 결정하는 플래그들은 8개이다. 391 | 5. 분기의 종류는 한 가지뿐이어서 분기 필드는 필요하지 않다고 가정한다. 392 | ~~~ 393 | 394 | ~~~ 395 | oooo oooo oooo oo bbb aaa aaa aaa 396 | ~~~~~~~~~~~~~~~~~ ~~~ ~~~~~~~~~~~ 397 | 연산 필드 플래그 8개를 주소필드 398 | 표현할 비트 3개 399 | 400 | (띄어쓰기는 시각적인 편의상 삽입하였으며 실제 구조와는 무관) 401 | ~~~ 402 | 403 | (1) 주소 선택 필드는 몇 비트가 필요한가? 404 | > **정답 : 3비트**
405 | > 8개의 플래그는 23 3비트로 모두 표현 가능하다. 406 | 407 | (2) 주소 필드(ADF)는 몇 비트로 구성될 수 있는가? 408 | > **정답 : 9**
409 | > 26 - 14 - 3 = 9
410 | > 폭 - 연산 필드 - 조건 필드 = 주소 필드 411 | 412 | (3) 이 제어 기억장치의 최대 용량(단어 수 × 폭)을 구하라. 413 | > **정답 : 29 \* 26 비트**
414 | > 주소가 9개 비트로 표현되므로, 26비트 짜리 * 워드 29개 = 13312 비트이다.
415 | > = **"26비트 폭(width)으로 512단어"** 416 | 417 | #### [문제 5] 다음은 제어 유닛을 간략하게 나타낸 것이다. 주어진 표를 참고하여 다음 문항에 답하시오. 418 | 419 |  420 | 421 | (1) 다음과 같은 조건일때, 실행되는 마이크로 연산으로 알맞은 것을 보기에서 고르세요. 422 | 423 | ~~~ 424 | 보기 425 | 426 | 가) CAR <- 1XXXX00
437 | > 표 4-5를 참고. 438 | 439 | (2) 다음과 같은 조건일때, MUX1이 받아들일 입력으로 알맞은 것을 보기에서 고르세요. 440 | 441 | ~~~ 442 | 보기 443 | 444 | 가) 0 445 | 나) 1 446 | 다) 2 447 | 라) 3 448 | ~~~ 449 | 450 | - **BR *I1* = 1** 451 | - **BR *I0* = 0** 452 | - ***C* = x (고려하지 않음)** 453 | 454 | > **정답 : 다) 2**
455 | > MUX2에서 플래그들과 조건 필드를 고려해서 조건을 출력 ->
456 | > 주소 선택 회로에서 그것들과 C를 고려해서 셀렉트 신호와 적재 신호를 출력 ->
457 | > 이에 따라 MUX1이 4개의 신호(0 ~ 3) 중 해당하는 신호의 내용을 CAR에 적재시킴
458 | > 표 4-5를 참고. 459 | 460 | 461 | 462 |
464 | -------------------------------------------------------------------------------- /03강 ALU : Arithmetic Operations.md: -------------------------------------------------------------------------------- 1 | ## 🦄 ALU: Arithmetic Operations (3 / 13회차) 2 |
3 | 4 | ### 3.5 정수의 산술 연산 `kycho` 5 | 6 | #### [문제1]
다음 문장은 덧셈을 수행하는 하드웨어에 관한 설명입니다. 빈칸에 알맞는 답을 적으세요. 7 | - `1)_____`는 여러 비트들로 이루어진 두 개의 데이터에 대한 덧셈을 수행하는 회로로서, 비트 수 만큼의 `2)_____`들로 구성이 되어있다.
8 | `2)_____`들은 `3)_____`를 전송하는 선에 의해 연결되어있다. 9 |
10 | 11 | #### [문제2]
다음 그림은 상태비트 제어회로가 포함된 4비트 병렬가산기의 구성도 입니다. 빨간박스로 표시된 상태비트 (1),(2),(3),(4)의 명칭과 간단한 설명을 작성하세요. 12 |  13 | 14 |
15 | 16 | #### [문제3]
다음은 정수의 덧셈과 뺄셈에 대한 설명입니다. 틀린것을 모두 고르세요. 17 | - 가) 2의 보수로 표현된 수들 간의 덧셈에서 올림수가 발생하면, 올림수를 버리고 결과값을 사용한다. 18 | - 나) 덧셈 과정에서 수의 표현 범위를 초과하는 경우에도 올바른 결과를 산출하게된다. 19 | - 다) 정수들의 뺄셈은 덧셈을 이용하여 수행할수 있다. 20 | - 라) 일반적으로 ALU에 뺄셈을 위한 회로를 별도로 두고 뺄셈을 수행한다. 21 | 22 |
23 | 24 | #### [문제4]
다음 그림은 부호 없는 2진수 곱셈기의 구성도 입니다. 그림을 참고하여 아래의 물음에 답하세요. 25 |  26 | 1) Q레지스터의 최하위 비트(Q0)가 1이면, 별도의 작업없이 C-A-Q레지스터의 모든 비트를 한비트씩 우측 시프트 시킨다. (O / X) 27 | 2) 최종 연산의 결과는 A레지스터에 담겨있다. (O / X) 28 | 3) 두개의 4비트 정수들을 곱하면 4번의 시프트가 발생한다 (O / X) 29 | 4) 1101 X 0101 을 수행할때, C, A, Q, M 레지스터의 초기 상태를 구하여라. 30 | 5) 1101 X 0101 을 수행할때, C, A, Q, M 레지스터의 종료 상태를 구하여라. 31 | 6) 1101 X 0101 의 결과값을 구하여라. 32 | 33 |
34 | 35 | #### [문제5]
2의 보수들 간의 곱셈을 위해 고안된 알고리즘 중 가장 널리 사용되고 있는 알고리즘은 Booth 알고리즘입니다.
Booth 알고리즘을 구현한 Booth 곱셈기와 부호 없는 2진수 곱셈기를 구성할때 차이점 2가지는 무엇인가요? 36 | 37 |
38 | 39 | #### [문제6]
다음 그림은 Booth 알고리즘의 흐름도입니다. 빈칸에 알맞는 식을 써넣으세요. 40 |  41 | 42 |
43 | 44 |
:page_facing_up: 답지
46 | 47 | #### [문제1]
다음 문장은 덧셈을 수행하는 하드웨어에 관한 설명입니다. 빈칸에 알맞는 답을 적으세요. 48 | - `1) 병렬 가산기(parallel adder)`는 여러 비트들로 이루어진 두 개의 데이터에 대한 덧셈을 수행하는 회로로서, 비트 수 만큼의 `2) 전가산기(full-adder)`들로 구성이 되어있다.
49 | `2) 전가산기(full-adder)`들은 `3) 올림수 비트(carry bit)`를 전송하는 선에 의해 연결되어있다. 50 |
51 | 52 | #### [문제2]
다음 그림은 상태비트 제어회로가 포함된 4비트 병렬가산기의 구성도 입니다. 빨간박스로 표시된 상태비트 (1),(2),(3),(4) 명칭과 간단한 설명을 작성하세요. 53 |  54 |
55 | 56 | > (1) 오버플로우(V) 플래그 : 최상위 캐리비트 2개를 XOR한 값으로 세트하며(V = C4 XOR C3), 오버플로우가 발생했는지 판단한다. 오버플로우가 발생하면 1로 세트된다.
57 | (2) 영(Z) 플래그 : 합의 모든 비트들을 NOR 게이트를 통과시켜서, 0인지 아닌지 판단한다. 합의 모든 비트들이 0이면 1로 세트된다.
58 | (3) 부호(S) 플래그 : 부호비트인 합의 최상위 비트와 직접 연결되며, 양수이면 0 음수이면 1로 세트된다.
59 | (4) 올림수(C) 플래그 : 최상위 단계의 전가산기로부터 발생하는 올림수(C4)에 의해서 세트된다.
60 | 61 |
62 | 63 | #### [문제3]
다음은 정수의 덧셈과 뺄셈에 대한 설명입니다. 틀린것을 모두 고르세요. 64 | - 가) 2의 보수로 표현된 수들 간의 덧셈에서 올림수가 발생하면, 올림수를 버리고 결과값을 사용한다. 65 | - 나) 덧셈 과정에서 수의 표현 범위를 초과하는 경우에도 올바른 결과를 산출하게된다. 66 | - 다) 정수들의 뺄셈은 덧셈을 이용하여 수행할수 있다. 67 | - 라) 일반적으로 ALU에 뺄셈을 위한 회로를 별도로 두고 뺄셈을 수행한다. 68 | ``` 69 | 나), 라) 틀렸다. 70 | ``` 71 | > 나)
덧셈 과정에서 수의 푸현 범위를 초과하는 경우에는 전혀 틀린 결과를 산출하게 된다.
예를 들어서 4비트 데이터인 0110(6)과 0011(3)을 더하게 되면 0110 + 0011 = 1001(-7)이 나오게된다.
이것을 오버플로우(overflow)라고 한다.
72 | 라)
뺄셈은 덧셈을 이용하여 수행된다. 그러므로 일반적으로 ALU에 뺄셈을 위한 회로를 별도로 두지 않고 가산기를 이용하여 뺄셈을 수행한다.
73 | 아래의 이미지처럼 보수기를 이용해서 덧셈과 뺄샘을 겸용으로 사용할수 있는 회로를 구성한다.
74 |  75 |
76 | 77 | #### [문제4]
다음 그림은 부호 없는 2진수 곱셈기의 구성도 입니다. 그림을 참고하여 아래의 물음에 답하세요. 78 |  79 | 1) Q레지스터의 최하위 비트(Q0)가 1이면, 별도의 작업없이 C-A-Q레지스터의 모든 비트를 한비트씩 우측 시프트 시킨다. (O / X) 80 | > 답 : X
81 | 제어 회로는 Q0비트를 검사하고, Q0 = 1인 경우에는 M레지스터 A레지스터의 덧셈을 수행하게 한뒤 C-A-Q레지스터의 모든 비트를 우측으로 한비트씩 시프트 시킨다. Q0 = 0 인경우에는 덧셈을 수행하지 않고 바로 시프트 시킨다. 82 | 83 | 2) 최종 연산의 결과는 A레지스터에 담겨있다. (O / X) 84 | > 답 : X
85 | 연산의 최종 결과는 A-Q레지스터에 담겨있다. 86 | 87 | 3) 두개의 4비트 정수들을 곱하면 4번의 시프트가 발생한다 (O / X) 88 | > 답 : O
89 | n비트의 경우 n번의 우측 시프트 연산이 일어난다. 90 | 91 | 4) 1101 X 0101 을 수행할때, C, A, Q, M 레지스터의 초기 상태를 구하여라. 92 | > C : 0 (0으로 초기화)
93 | A : 0000 (0으로 초기화)
94 | Q : 0101 (승수로 초기화)
95 | M : 1101 (피승수로 초기화) 96 | 97 | 5) 1101 X 0101 을 수행할때, C, A, Q, M 레지스터의 종료 상태를 구하여라. 98 | > C : 0
99 | A : 0100
100 | Q : 0001
101 | M : 1101 (피승수, 변함없음) 102 | 103 | | | C | A | Q | | 104 | | ----------- | ---- | :--- | ---- | ---------------------------------------------------- | 105 | | [초기 상태] | 0 | 0000 | 0101 | | 106 | | [사이클 1] | 0 | 1101 | 0101 | Q0 = 1 이므로, A ← A + M | 107 | | | 0 | 0110 | 1010 | 우측 시프트( C-A-Q) | 108 | | [사이클 2] | 0 | 0011 | 0101 | Q0 = 0 이므로, 우측 시프트( C-A-Q)만 수행 | 109 | | [사이클 3] | 1 | 0000 | 0101 | Q0 = 1 이므로, A ← A + M | 110 | | | 0 | 1000 | 0010 | 우측 시프트( C-A-Q) | 111 | | [사이클 4] | 0 | 0100 | 0001 | Q0 = 0 이므로, 우측 시프트( C-A-Q)만 수행 | 112 | 113 | 6) 1101 X 0101 의 결과값을 구하여라. 114 | > 답 : 65
115 | A-Q레지스터의 값이 01000001(65)이다.
116 | 1101(13) X 0101(5) = 01000001(65) 117 | 118 |
119 | 120 | #### [문제5]
2의 보수들 간의 곱셈을 위해 고안된 알고리즘 중 가장 널리 사용되고 있는 알고리즘은 Booth 알고리즘입니다.
Booth 알고리즘을 구현한 Booth 곱셈기와 부호 없는 2진수 곱셈기를 구성할때 차이점 2가지는 무엇인가요? 121 | 122 | > (1) M레지스터와 병렬 가산기 사이에 보수기(complementer)를 추가한다.
(2) Q레지스터 오른쪽에 Q-1이라고 부르는 1비트 레지스터를 추가하고, Q0와 함께 제어 회로로 입력되도록 한다.
(Q레지스터가 우측 시프트 될때, Q0 비트가 Q-1레지스터에 저장된다.) 123 | 124 |
125 | 126 | #### [문제6]
다음 그림은 Booth 알고리즘의 흐름도입니다. 빈칸에 알맞는 식을 써넣으세요. 127 |  128 | > (1) A ← A - M
129 | (2) A ← A + M 130 |
131 | 132 |
134 | 135 | ### 3.6 부동소수점 수의 표현 `jakang` 136 | 137 | #### [문제1]
138 | 다음은 kycho가 IEEE 754 표준 32비트 부동소수점에 대한 특징을 논한 것이다. 설명 중 틀린 항목의 갯수는?
139 | (가) 표준에 따르면 32비트 단일-정밀도 형식의 경우, 부호 (S) 1비트, 지수 (E) 8비트, 가수 (M) 23비트로 구성되어 있어.
140 | (나) 지수 필드는 바이어스 된 2진수로 표현되어 있는데, 이 때 바이어스 값은 127이야.
141 | (다) 그렇다면 지수 필드 패턴이 0000_0000일 때, 실제 지수 값은 바이어스 값 127을 뺀 -127이라고 할 수 있겠군!
142 | (라) 이 경우 2-127이므로, (가수) 값에 상관없이 0에 가까운 아주 작은 값을 표현하게 되는 셈이군.
143 | (마) 표준에서는 가수는 1.M X 2E-127의 형태를 가지는데, 여기서 소수점 위의 1은 숨겨진 비트라고 부르고, 가수 필드에는 나타내지 않는다고 하네. 144 |
145 | 146 | #### [문제2]
147 | 다음은 jakang이 10진수 '-253.25'를 IEEE 754 표준 32비트 부동소수점 형식으로 표현하는 과정을 나타내었다. 절차 중 틀린 항목의 갯수는?
148 | (가) 먼저 음수이므로, 부호 (S) 필드는 1이겠네.
149 | (나) 253.25는 11111101.01(2)이므로, 1.111110101 X 27으로 정리할 수 있겠군.
150 | (다) 그렇다면 지수 (E) 필드는 0000_0111에다가 바이어스 127인 0111_1111을 더한 1000_0110 이겠군.
151 | (라) 가수 (M) 필드는 1111_1101_0100_0000_0000_000이네.
152 | (마) 이를 전부 합치면 1 1000_0110 1111_1101_0100_0000_000 이겠군.
153 |
154 | 155 | #### [문제3]
156 | 부동소수점 표현으로는 ’0’을 나타낼 수 없는 이유를 설명하고, IEEE 754 표준 32-비트 부동소수점 형식에서의 ‘0’에 대한 비트 패턴을 표시하세요. 157 |
158 | 159 | #### [문제4]
160 | 10진수 '-1.625'를 IEEE 754 표준 32비트 부동소수점 형식으로 표현하세요. 161 |
162 | 163 | 164 |
:page_facing_up: 답지
166 | 167 | #### [문제1] 주어진 보기는 모두 맞다
168 | 다음은 kycho가 IEEE 754 표준 32비트 부동소수점에 대한 특징을 논한 것이다. 설명 중 틀린 항목의 갯수는?
169 | (가) (ㅇ) 표준에 따르면 32비트 단일-정밀도 형식의 경우, 부호 (S) 1비트, 지수 (E) 8비트, 가수 (M) 23비트로 구성되어 있어.
170 | (나) (ㅇ) 지수 필드는 바이어스 된 2진수로 표현되어 있는데, 이 때 바이어스 값은 127이야.
171 | (다) (ㅇ) 그렇다면 지수 필드 패턴이 0000_0000일 때, 실제 지수 값은 바이어스 값 127을 뺀 -127이라고 할 수 있겠군!
172 | (라) (ㅇ) 이 경우 2-127이므로, (가수) 값에 상관없이 0에 가까운 아주 작은 값을 표현하게 되는 셈이군.
173 | (마) (ㅇ) 표준에서는 가수는 1.M X 2E-127의 형태를 가지는데, 여기서 소수점 위의 1은 숨겨진 비트라고 부르고, 가수 필드에는 나타내지 않는다고 하네. 174 |
175 | 176 | #### [문제2] (라)와 (마)가 틀렸다
177 | 다음은 jakang이 10진수 '-253.25'를 IEEE 754 표준 32비트 부동소수점 형식으로 표현하는 과정을 나타내었다. 절차 중 틀린 항목의 갯수는?
178 | (가) (ㅇ) 먼저 음수이므로, 부호 (S) 필드는 1이겠네.
179 | (나) (ㅇ) 253.25는 11111101.01(2)이므로, 1.111110101 X 27으로 정리할 수 있겠군.
180 | (다) (ㅇ) 그렇다면 지수 (E) 필드는 0000_0111에다가 바이어스 127인 0111_1111을 더한 1000_0110 이겠군.
181 | (라) (X) 가수 (M) 필드는 1111_1101_0100_0000_0000_000이네.
182 | (마) (X) 이를 전부 합치면 1 1000_0110 1111_1101_0100_0000_000 이겠군.
183 |
가수 필드의 젤 첫 비트인 1은 숨겨진 비트이므로 생략. 즉, 111_1101_0100_0000_0000_0000이 맞다. 184 |
이를 (마)에 반영하면 1 1000_0110 111_1101_0100_0000_0000_0000이 정답이다. 185 | 186 | #### [문제3]
187 | 부동소수점 표현으로는 ’0’을 나타낼 수 없는 이유를 설명하고, IEEE 754 표준 32-비트 부동소수점 형식에서의 ‘0’에 대한 비트 패턴을 표시하세요.
188 | 189 | 부동소수점 표현식을 살펴보면 (-1)S2E-127(1.M) 이므로, 표현할 수 있는 가장 작은 절대값은 2-127(1.0)이다. 190 | 즉, 표현할 수 있는 가장 작은 수인 지수와 가수가 모두 0인 경우를 0으로 하며,
191 | 0000_0000_0000_0000_0000_0000_0000_0000 혹은 1000_0000_0000_0000_0000_0000_0000_0000을 0이라고 할 수 있다.
192 |
193 | 194 | #### [문제4]
195 | 10진수 '-1.625'를 IEEE 754 표준 32비트 부동소수점 형식으로 표현하세요.
196 | 197 | 1.625는 2진수로 표현하면 1.101이다.
198 | 부호 (S) 필드는 음수이므로 1
199 | 지수 (E) 필드는 0에서 127을 더한 0111_1111 200 | 가수 (E) 필드는 앞자리 1을 제외한 10100000... 201 | 202 | 그러므로 정답은 1_0111_1111_1010_0000_0000_0000_0000_000이다. 203 | 204 | 205 |
207 | 208 | ### 3.7 부동소수점 산술 연산 `gaekim` 209 | 210 | ``` 211 | [부동소수점 산술 연산 방법] 212 | 213 | 1. 덧셈 / 뺄셈 214 | 215 | 1단계. 두 수의 지수가 같아지도록 만든다(소수점의 위치를 이동) 216 | 217 | 2단계. 가수들끼리 덧셈 / 뺄셈한다 218 | 219 | 3단계. 결과값을 정규화한다.(가수의 숫자가 소숫점 첫째자리에서 시작하도록) 220 | 221 | 예시) 1.001001 x 2^5 → 0.1001001 x 2^6 222 | 223 | 2. 곱셈 / 나눗셈 224 | 225 | 1단계. 가수끼리 곱한다 226 | 227 | 2단계. 지수끼리 더하거나(곱셈) 뺀다(나눗셈) 228 | 229 | 3단계. 정규화한다. 230 | ``` 231 | 232 | 233 | - 다음 중 부동소수점 덧셈 과정에서 필요하지 않은 연산은 어느 것인가? [기본문제 3.15번] 234 | 235 | 236 | 가. 지수 조정 나. 정규화 다. 지수 덧셈 라. 가수 덧셈 237 | - 다음 중 부동소수점 나눗셈 과정에서 필요하지 않은 연산은 어느 것인가? [기본문제 3.16번] 238 | 239 | 240 | 가. 지수 조정 나. 정규화 다. 가수 나누기 라. 지수 뺄셈 241 | - 아래의 부동소수점 산술 연산들을 수행하고, 알맞은 답을 고르시오. [연습문제 3.24번 변형] 242 | 243 | 244 | 1번> (0.111001 x 2-5) + (0.100111 x 2-3)
245 | 246 | 247 | (가) 0.11011101 x 2-3 (나) 0.11010101 x 2-3 (다) 0.11011111 x 2-3 (라) 0.11010101 x 2-4
248 | 249 | 250 | 251 | 252 | 253 | 2번> (0.100011 x 26) - (0.111001 x 23)
254 | 255 | (가) 1.1011111 x 25 (나) 0.11111111 x 25 (다) 0.11011111 x 25 (라) 0.11011111 x 29
256 | 257 | 258 | 3번> (0.1001 x 28) x (0.1011 x 212)
259 | 260 | (가) 0.1100001 x 219 (나) 0.1010011 x 219 (다) 0.1100011 x 220 (라) 0.1100011 x 219
261 | 262 | 263 | 264 | - 부동소수점 산술연산 과정에서는 `__` 오버플로우, `__` 언더플로우, `__` 언더플로우, `__` 오버플로우 등의 문제가 발생할 가능성이 있다. 265 | 266 | 267 |
:page_facing_up: 답지
269 | 270 | 271 | - 다음 중 부동소수점 덧셈 과정에서 필요하지 않은 연산은 어느 것인가? [기본문제 3.15번] 272 | 273 | 274 | 가. 지수 조정 나. 정규화 **다. 지수 덧셈** 라. 가수 덧셈 275 | - 다음 중 부동소수점 나눗셈 과정에서 필요하지 않은 연산은 어느 것인가? [기본문제 3.16번] 276 | 277 | 278 | **가. 지수 조정** 나. 정규화 다. 가수 나누기 라. 지수 뺄셈 279 | - 아래의 부동소수점 산술 연산들을 수행하고, 알맞은 답을 고르시오. [연습문제 3.24번 변형] 280 | 281 | 282 | 1번> (0.111001 x 2-5) + (0.100111 x 2-3)
283 | 284 | 285 | (가) 0.11011101 x 2-3 **(나) 0.11010101 x 2-3** (다) 0.11011111 x 2-3 (라) 0.11010101 x 2-4
286 | 287 | 288 | 289 | 290 | 291 | 2번> (0.100011 x 26) - (0.111001 x 23)
292 | 293 | (가) 1.1011111 x 25 (나) 0.11111111 x 25 **(다) 0.11011111 x 25 ** (라) 0.11011111 x 29
294 | 295 | 296 | 3번> (0.1001 x 28) x (0.1011 x 212)
297 | 298 | (가) 0.1100001 x 219 (나) 0.1010011 x 219 (다) 0.1100011 x 220 **(라) 0.1100011 x 219
** 299 | 300 | 301 |
 302 |
303 | - 부동소수점 산술연산 과정에서는 `지수` 오버플로우, `지수` 언더플로우, `가수` 언더플로우, `가수` 오버플로우 등의 문제가 발생할 가능성이 있다.
304 | > 표현할 수 있는 범위를 넘어설 경우, 위와 같은 문제들이 발생할 수 있다.
305 |
302 |
303 | - 부동소수점 산술연산 과정에서는 `지수` 오버플로우, `지수` 언더플로우, `가수` 언더플로우, `가수` 오버플로우 등의 문제가 발생할 가능성이 있다.
304 | > 표현할 수 있는 범위를 넘어설 경우, 위와 같은 문제들이 발생할 수 있다.
305 | 307 | -------------------------------------------------------------------------------- /04강 CPU의기본구성 및 명령어세트.md: -------------------------------------------------------------------------------- 1 | ## 🦄 CPU의 기본 구성 및 명령어 세트 (4 / 13회차) 2 |
3 | 4 | ### 2.1 CPU의 기본 구조 `secho` 5 | 6 | 0번 7 | 8 | 다음은 기억장치에 저장된 명령어들을 실행함으로써 프로그램을 수행시키는 CPU의 동작과정이다. 9 | 10 | 순서에 맞게 나열해주세요. 11 | 12 | 가. 데이터 인출 13 | 14 | 나. 데이터 저장 15 | 16 | 다. 명령어 인출 17 | 18 | 라 데이터 처리 19 | 20 | 마 명령어 해독 21 | 22 | 23 | 24 | `__`와 `__`는 공통적으로 수행되지만 `___, ___, ___`는 필요한 경우에만 수행한다. 25 | 26 | 27 | 28 | 1번 29 | 30 | 빈칸에 알맞은 답을 채워주시고 간단한 설명도 작성해주세요. 31 | 32 | CPU는 `_____`,`_____`,`_____` 으로 구성된다. 33 | 34 | 35 | 36 | 2번 37 | 38 | 보기를 보고 알맞은 답을 채워주세요 39 | 40 | `가장 느리고, 가장 빠르고, 범용 레지스터, 특수기능 레지스터, 제어유닛, STORE, JUMP, IR, AR, VR, XR, MR MAR, MDR, MRI, PC, UCC, KCC, AC, SP, HP`, 41 | 42 | CPU내부의 다양한 레지스터들의 집합인 레지스터 세트는 액세스 속도가 기억장치들 중 `1) _____`, 43 | 44 | 종류로는 크게 `2) ________`와 `3) ________`가 있다. 45 | 46 | `2)____`에는 4)`__`,`__`,`__`,`__`,`___`,`___`으로 이루어져있다 47 | 48 | 49 | 50 | 51 | 52 | 3번 53 | 54 | 다음은 CPU 내부 구조에 대한 대화입니다. 55 | 56 | 대화내용을 읽고 틀리게 말한 사람을 고르세요 57 | 58 | 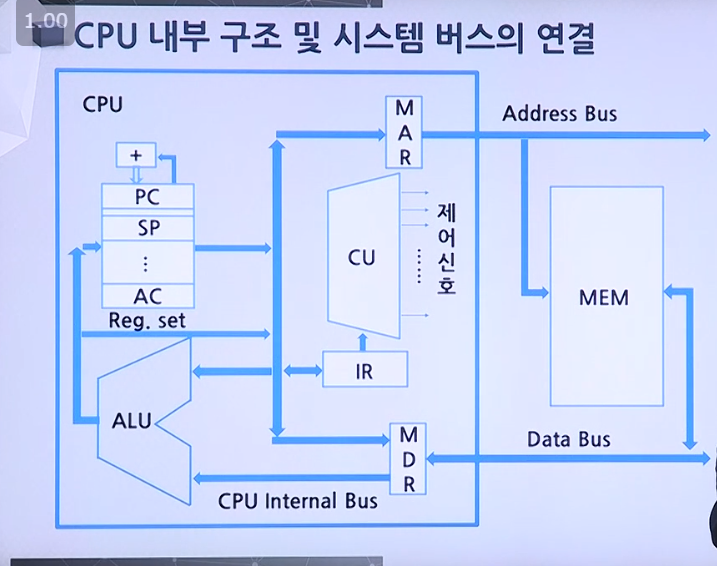 59 | 60 | 61 | 62 | Kukim : 왼쪽 네모그림 안에있는 구성요소들이 CPU의 내부 요소야 바로 ALU, 레지스터 셋, 제어유닛이 포함되어있지. 63 | 64 | Daelee : 아 그렇구나 PC위에 있는 +는 뭐야? 65 | 66 | Yeosong : 그건 내가 얘기해줄게, PC는 이전에 인출했던 명령어 주소값을 가진 레지스터인데 명령어가 인출된 이후에 자동적으로 주소값이 1씩 증가되어서 가장 최근에 수행된 명령어 주소값을 가리키게 돼 67 | 68 | Jakang : 아하 그렇구나 어 보니까 CPU Internal Bus는 CPU 내부에서만 사용하고 외부랑 직접적으로 연결이 되어있지 않네? 왜 그렇지? 그러면 어떻게 외부랑 접속될 수 있어? 69 | 70 | Taelee : 그건 CPU 내부 처리속도와 외부 처리속도랑 차이가 있기 때문이야. 그래서 직접 연결하지 않고 간접적으로 버퍼 레지스터인 MDR, MAR를 통해 시스템 버스와 접속해. 71 | 72 | Jehong : 아항 어라 근데 또 보니까 Address Bus는 Data Bus와 다르게 단방향이네? 왜지? 73 | 74 | Taelee : Address Bus가 단방향인 이유는 CPU로부터 메모리에게 주소값을 전송하지만, 반대로의 전송은 필요가 없기 때문이야 75 | 76 | 77 | 78 |
:page_facing_up: 답지
80 | 81 | 0번 82 | 83 | 다음은 기억장치에 저장된 명령어들을 실행함으로써 프로그램을 수행시키는 CPU의 동작과정이다. 84 | 85 | 순서에 맞게 나열해주세요. 86 | 87 | 가. 데이터 인출 88 | 89 | 나. 데이터 저장 90 | 91 | 다. 명령어 인출 92 | 93 | 라 데이터 처리 94 | 95 | 마 명령어 해독 96 | 97 | 98 | 99 | `다`와 `마`는 공통적으로 수행되지만 `가, 나, 라`는 필요한 경우에만 수행한다. 100 | 101 | 명령어인출과 해독은 공통적이지만 데이터 인출, 처리, 저장단계는 데이터가 필요한 경우에만 수행되기 때문(명령어 실행을 위한 데이터가 필요없는 경우도 있기 때문에.) 102 | 103 | 104 | 105 | 1번 106 | 107 | CPU는 `ALU`,`레지스터 셋`,`제어유닛` 으로 구성된다. 108 | 109 | - ALU : CPU 내부에서 산술 및 논리 연산을 수행하는 하드웨어 모듈 110 | - 레지스터 셋: CPU 내부의 다양한 레지스터들의 집합. 111 | - CPU내부에서 처리되기 때문에 액세스 속도가 컴퓨터 기억장치들 중에서 가장 빠름 112 | - CPU내의 한정된 영역에 넣어야 하기 때문에 제한적임 113 | - 제어유닛 : 명령어의 연산코드(Op-code)를 해석하고 그것을 실행하기 위한 제어 신호들을 순차적으로 발생시키는 하드웨어 모듈 114 | - 명령어 실행에 필요한 각 정보들의 전송 통로 방향을 지정 115 | - CPU 내부 요소들과 시스템 구성 요소들의 동작시간도 결정해줌 116 | 117 | 2번 118 | 119 | 보기를 보고 알맞은 답을 채워주세요 120 | 121 | `가장 느리고, 가장 빠르고, 범용 레지스터, 특수기능 레지스터, 제어유닛, STORE, JUMP, IR, AR, VR, XR, MR MAR, MDR, MRI, PC, UCC, KCC, AC, SP, HP`, 122 | 123 | CPU내부의 다양한 레지스터들의 집합인 레지스터 세트는 액세스 속도가 기억장치들 중 `1) 가장 빠르고`, 124 | 125 | 종류로는 크게 `2) 특수기능 레지스터`와 `3) 범용 레지스터`가 있다. 126 | 127 | `2)특수기능 레지스터`에는 4) `PC`,`IR`,`AC`,`SP`,`MAR`,`MDR`으로 이루어져있다 128 | 129 | 130 | 131 | 3번 132 | 133 | 다음은 CPU 내부 구조에 대한 대화입니다. 134 | 135 | 대화내용을 읽고 틀리게 말한 사람을 고르세요 136 | 137 |  138 | 139 | 140 | 141 | Kukim : 왼쪽 네모그림 안에있는 구성요소들이 CPU의 내부 요소야 바로 ALU, 레지스터 셋, 제어유닛이 포함되어있지. 142 | 143 | Daelee : 아 그렇구나 PC위에 있는 +는 뭐야? 144 | 145 | Yeosong : 그건 내가 얘기해줄게, PC는 이전에 인출했던 명령어 주소값을 가진 레지스터인데 명령어가 인출된 이후에 자동적으로 주소값이 1씩 증가되어서 가장 최근에 수행된 명령어 주소값을 가리키게 돼 146 | 147 | Jakang : 아하 그렇구나 어 보니까 CPU Internal Bus는 CPU 내부에서만 사용하고 외부랑 직접적으로 연결이 되어있지 않네? 왜 그렇지? 그러면 어떻게 외부랑 접속될 수 있어? 148 | 149 | Taelee : 그건 CPU 내부 처리속도와 외부 처리속도랑 차이가 있기 때문이야. 그래서 직접 연결하지 않고 간접적으로 버퍼 레지스터인 MDR, MAR를 통해 시스템 버스와 접속해. 150 | 151 | Jehong : 아항 어라 근데 또 보니까 Address Bus는 Data Bus와 다르게 단방향이네? 왜지? 152 | 153 | Taelee : Address Bus가 단방향인 이유는 CPU로부터 메모리에게 주소값을 전송하지만, 반대로의 전송은 필요가 없기 때문이야 154 | 155 | 156 | 157 | Yeosong: 이전이 아니라 다음에 인출할 명령어 주소값을 가진 레지스터임, 명령어 인출 후에는 1씩증가되는게 아니라 컴퓨터가 한번에 처리할 수 있는 크기, 즉 워드 크기만큼 증가한다. 158 | 159 | 160 | 161 |
163 | 164 | ### 2.4 명령어 세트 - 연산의 종류, 명령어형식 `yeha` 165 | 166 | 1. 보기에 있는 연산과 연산에 대한 설명을 알맞게 짝지어 보세요. 167 | 168 | ```c 169 | (가) 산술 연산 (나) 프로그램 제어 (다) 데이터 전송 (라) 논리 연산 (마) 입출력 (I/O) 170 | ``` 171 | 172 | - 레지스터와 레지스터 간, 레지스터와 기억장치 간, 기억장치와 기억장치 간에 데이터를 이동시키는 동작 `_________` 173 | - 덧셈, 뺄셈, 곱셈, 나눗셈과 같은 기본적인 산술 연산 `_________` 174 | - 데이터의 각 비트들 간에 대한 AND, OR, NOT, Exclusive-OR 등과 같은 연산 수행 `_________` 175 | - CPU와 외부 장치들 간에 데이터 이동을 위한 동작 `_________` 176 | - 각 명령어의 실행 순서를 변경하는 연산 `_________` 177 | 178 | 2. 다음 용어에 대해 간단히 설명해 보세요. 179 | 180 | - 연산 코드 (오퍼레이션 코드, Operation Code, Op-code) 181 | - 오퍼랜드 (Operand) 182 | 183 | 3. 다음 설명에 대해 맞으면 O, 틀리면 X 하세요. 184 | 185 | - 명령어는 CPU가 한 번에 처리할 수 있는 비트의 수로 처리된다. (O/X) 186 | 187 | - 명령어를 구성하는 비트는 용도에 따라 몇 개의 필드 (Field) 로 나눠진다. 이 때 연산 코드 (Op-code)와 오퍼랜드 (Operand) 필드는 하나씩만 사용된다. (O/X) 188 | 189 | - 명령어 형식 (instruction format) 은 명령어를 구성하는 필드의 종류&개수&배치 방식, 필드 당 비트 수를 정의한 형식이다. (O/X) 190 | 191 | - 3-주소 명령어를 사용하면 프로그램이 길이가 짧아진다. (O/X) 192 | 193 | 4. 16비트 CPU는 한 번에 16비트 단위의 데이터 처리가 가능하고, CPU의 명령어 길이도 16비트입니다. 194 | 주어진 명령어 형식을 따른다고 할 때, 빈칸을 알맞게 채워보세요. 195 | 196 | - 1-주소 명령어 (1-address instruction)에서 연산 코드는 4비트, 오퍼랜드는 12비트다. 197 | 연산 종류는 `___`가지다. 198 | 199 | 200 | - 2-주소 명령어에서 연산 코드는 4비트, 오퍼랜드1은 4비트, 오퍼랜드2는 8비트다. 오퍼랜드1만 레지스터다. 201 | 연산의 종류는 (1) `___`가지, 202 | 레지스터의 개수는 (2) `___`개, 203 | 기억장치 주소 영역의 범위는 (3) `___` ~ `___-1`, 204 | 데이터의 표현 범위는 (4) `___` ~ `___-1` 다. 205 | 206 | 207 |
:page_facing_up: 답지
209 | 210 | 1. 보기에 있는 연산과 연산에 대한 설명을 알맞게 짝지어 보세요. 211 | 212 | ```c 213 | (가) 산술 연산 (나) 프로그램 제어 (다) 데이터 전송 (라) 논리 연산 (마) 입출력 (I/O) 214 | ``` 215 | 216 | - 레지스터와 레지스터 간, 레지스터와 기억장치 간, 기억장치와 기억장치 간에 데이터를 이동시키는 동작 ((다) 데이터 전송) 217 | - 덧셈, 뺄셈, 곱셈, 나눗셈과 같은 기본적인 산술 연산 ((가) 산술 연산) 218 | - 데이터의 각 비트들 간에 대한 AND, OR, NOT, Exclusive-OR 등과 같은 연산 수행 ((라) 논리 연산) 219 | - CPU와 외부 장치들 간에 데이터 이동을 위한 동작 ((마) 입출력 (I/O)) 220 | - 각 명령어의 실행 순서를 변경하는 연산 ((나) 프로그램 제어) 221 | 222 | 2. 다음 용어에 대해 간단히 설명해 보세요. 223 | 224 | - 연산 코드 (오퍼레이션 코드, Operation Code, Op-code) 225 | - 오퍼랜드 (Operand) 226 | 227 | > 연산 코드 : CPU에서 수행될 연산을 지정해준다 (e.g. LOAD, ADD, JUMP ...) 228 | 오퍼랜드 : 연산을 수행하는 데 필요한 데이터 혹은 주소를 나타낸다. 229 | 230 | 3. 다음 설명에 대해 맞으면 O, 틀리면 X 하세요. 231 | 232 | - 명령어는 CPU가 한 번에 처리할 수 있는 비트의 수로 처리된다. (O/X) 233 | 234 | > (O) 235 | → Word 라고 하는데, 크기는 컴퓨터 종류마다 달라서 정해져 있지 않다. 236 | 237 | - 명령어를 구성하는 비트는 용도에 따라 몇 개의 필드 (Field) 로 나눠진다. 이 때 연산 코드 (Op-code)와 오퍼랜드 (Operand) 필드는 하나씩만 사용된다. (O/X) 238 | 239 | > (X) 240 | → 오퍼랜드 (Operand)는 컴퓨터의 처리 능력에 따라 여러 개로 구성된다. 각 연산은 1~2개의 입력 오퍼랜드들과 1개의 결과 오퍼랜드를 가질 수 있다. 241 | 데이터는 CPU 레지스터나 기억장치에 위치한다. 242 | 243 | - 명령어 형식 (instruction format) 은 명령어를 구성하는 필드의 종류&개수&배치 방식, 필드 당 비트 수를 정의한 형식이다. (O/X) 244 | 245 | > (O) 246 | 247 | - 3-주소 명령어를 사용하면 프로그램의 길이가 짧아진다. (O/X) 248 | 249 | > (O) 250 | → 레지스터의 수와 기억장치 용량이 고정된 상태에서 3-주소 명령어 형식을 사용하면 명령어의 비트 수가 늘어나게 된다. 결과적으로 프로그램을 저장하기 위한 기억장치 용량을 크게 줄어들지 않으며, 명령어 해독 과정이 더 복잡해지는 단점도 있다. 251 | 252 | 4. 16비트 CPU는 한 번에 16비트 단위의 데이터 처리가 가능하고, CPU의 명령어 길이도 16비트입니다. 253 | 주어진 명령어 형식을 따른다고 할 때, 빈칸을 알맞게 채워보세요. 254 | 255 | - 1-주소 명령어 (1-address instruction)에서 연산 코드는 4비트, 오퍼랜드는 12비트다. 256 | 연산 종류는 `___`가지다. 257 | 258 | > 4비트니까 24 = `16`가지다. 259 | 260 | - 2-주소 명령어에서 연산 코드는 4비트, 오퍼랜드1은 4비트, 오퍼랜드2는 8비트다. 오퍼랜드1만 레지스터다. 261 | 연산의 종류는 (1) `___`가지, 262 | 레지스터의 개수는 (2) `___`개, 263 | 기억장치 주소 영역의 범위는 (3) `___` ~ `___-1`, 264 | 데이터의 표현 범위는 (4) `___` ~ `___-1` 다. 265 | 266 | > 2-주소 명령어에서 연산 코드는 4비트, 오퍼랜드1은 4비트, 오퍼랜드2는 8비트다. 오퍼랜드1만 레지스터다. 267 | 연산의 종류는 (1) 24 = `16`가지, 268 | 레지스터의 개수는 (2) 24 = `16`개, 269 | 기억장치 주소 영역의 범위는 (3) `0` ~ ( 28 - 1), 270 | 데이터의 표현 범위는 (4) - 27 ~ ( 27 - 1) 다. 271 | 272 |
274 | 275 | ### 2.4 명령어 세트 - 주소지정방식 `kukim` 276 | 277 | #### 문제1 278 | **3-주소 명령어의 장점에 해당하는 것은?** 279 | - 가. 명령어 길이가 짧다. 280 | - 나. 프로그램 길이가 짧아진다. 281 | - 다. 임시저장장소가필요하다. 282 | - 라. 주소지정 할수 있는 기억장치 주소 영역이 증가한다 283 | 284 | #### 문제2 285 | **간접 주소지정 방식을 사용하는 명령어는 실행 사이클 동안에 기억장치를 몇 번액세스하는가?** 286 | - 가.한번 287 | - 나. 두번 288 | - 다. 세번 289 | - 라. 액세스하지 않는다. 290 | 291 | #### 문제3 292 | **아래 그림은 CPU 내부 레지스터들과 주기억장치에 그림과 같은 값들이 저장되어 있다고 가정하자.** 293 | **CPU 레지스터 및 각 기억 장소의 폭(width)은 16비트이며, 그림에서 모든 값들은 편의상 10진수로 표시하였다.** 294 | **아래의 문제에 답하시오.** 295 |  296 | 297 | ##### 3.1 298 | 1. 직접 주소지정 방식을 사용하는 명령어의 주소 필드(A)에 저장된 내용이 150일때, 유효 주소(EA) 및 그에 의해 인출되는 데이터를 구하라. 299 | 300 | 2. 명렁어 길이가 16비트이고 연산 코드가 5비트라면, 이 명령어에 의해 직접 주소지정 될 수 있는 기억장치 용량은 얼마인가? 301 | 302 | ##### 3.2 303 | 1. 간접 주소지정 방식을 사용하는 명령어의 주소 필드μ)에 저장된 내용이 ‘172’라고 가정했을 때, 유효 주소(EA) 및 그에 의해 인출되는 데이터를 구하라 304 | 305 | 306 | ##### 3.3 307 | - 조건 : 레지스터 R은 R2이다. 308 | 1. 레지스터 주소지정 방식이 사용된다면, 연산 처리 과정에서 어떤 데이터가 사용될 것인가? 309 | 2. 레지스터 간접 주소지정 방식이 사용된다면, 어떤 데이터가 사용될 것인가? 310 | 311 |
:page_facing_up: 답지
313 | 314 | #### 문제1 315 | **3-주소 명령어의 장점에 해당하는 것은?** 316 | - 가. 명령어 길이가 짧다. 317 | - **나. 프로그램 길이가 짧아진다.** 318 | - 다. 임시저장장소가필요하다. 319 | - 라. 주소지정 할수 있는 기억장치 주소 영역이 증가한다 320 | 321 | #### 문제2 322 | **간접 주소지정 방식을 사용하는 명령어는 실행 사이클 동안에 기억장치를 몇 번액세스하는가?** 323 | - 가.한번 324 | - **나. 두번** 325 | - 다. 세번 326 | - 라. 액세스하지 않는다. 327 | - 해설 : 간접 주소지정 방식은 오퍼랜드가 가르키고있는 메모리주소로 접근하고 , 접근한 메모리 주소의 값이 메모리이기에 그 주소로 다시 접근한다. 328 | 329 | #### 문제3 330 | **아래 그림은 CPU 내부 레지스터들과 주기억장치에 그림과 같은 값들이 저장되어 있다고 가정하자. 여기서, CPU 레지스터 및 각 기억 장소의 폭(width)은 16비트이며, 그림에서 모든 값들은 편의상 10진수로 표시하였다.** 331 |  332 | 333 | ##### 3.1 334 | 1. 직접 주소지정 방식을 사용하는 명령어의 주소 필드(A)에 저장된 내용이 150일때, 유효 주소(EA) 및 그에 의해 인출되는 데이터를 구하라. 335 | - 정답 : '1234' 336 | - 해설 : EA = 150이므로, 기억장치 150번지에 저장된 데이터 ‘1234'가 인출된다. 337 | 338 | 2. 명렁어 길이가 16비트이고 연산 코드가 5비트라면, 이 명령어에 의해 직접 주소지정 될 수 있는 기억장치 용량은 얼마인가? 339 | - 정답 : 4096Byte = 2^11 * 2byte 340 | - 해설 : 주소 필드가 11비트이므로, 직접 주소지정 할 수 있는 기억장치 용량은 2^11 = 2048 단어가 된다. 그런데 각 기억 장소에 저장되는 데이터의 비트 수가 16비트 (2바이트)이므로, 기억장치 용량은 4096바이트로 표현할 수도 있다. 341 | 342 |  343 | 344 | ##### 3.2 345 | 1. 간접 주소지정 방식을 사용하는 명령어의 주소 필드μ)에 저장된 내용이 ‘172’라고 가정했을 때, 유효 주소(EA) 및 그에 의해 인출되는 데이터를 구하라 346 | - 정답 : 3256 347 | - 해설 : EA는 그림 2-24의 기억장치 172번지에 저장되어 있는 ‘202’이다. 따라서 명령어 실행에 사용될 데이터로는 기억장치 202번지에 저장되어 있는‘3256’이 인출된다. 348 | 349 |  350 | 351 | ##### 3.3 352 | - 레지스터 R은 R2라고 가정한다. 353 | 1. 레지스터 주소지정 방식이 사용된다면, 연산 처리 과정에서 어떤 데이터가 사용될 것인가? 354 | - 정답 : R2에 저장되어 있는 데이터 ‘151’이 사용된다. 355 | 2. 레지스터 간접 주소지정 방식이 사용된다면, 어떤 데이터가 사용될 것인가? 356 | - 정답 : 기억장치 151번지에 저장되어 있는 데이터 ‘5678’이 사용된다. 357 | 358 |  359 | 360 |
362 | 363 | ### 2.4 명령어 세트 - 상용프로세서 (간단히) `mihykim` 364 | 365 | #### [문제1]
다음 중에서 RISC 프로세서의 특징이 아닌 것은? (기본 2.21번) 366 | - 가. 대부분 명령어들의 길이가 동일하다. 367 | - 나. 주소지정 방식이 매우 다양한다. 368 | - 다. CPU가 수행할 수 있는 연산의 종류가 적다. 369 | - 라. 명령어의 수가 최소화 되었다. 370 | 371 | #### [문제2]
다음은 맥북을 살지 고민한다는 secho의 고민을 듣고 컴퓨터구조 스터디원들이 함께 토론내용입니다. 대화 내용을 읽고 질문에 답해주세요. 372 | - __문제2-1__ 다음 중 틀린 말을 한 사람이 있을까요? 있다면 누구일까요? (정답자 1등 +100점) 373 | - 참고용어 374 | - CISC[씨스크] : Complex Instruction Set Computer 375 | - RISC[리스크] Reduced Instruction Set Computer 376 | - ARM[암] Acorn RISC Machine / Advanced RISC Machine 377 | - 로제타 : 인텔 칩에서 실행되게끔 만들어진 기존 애플리케이션이 실행하기 위해 개발된 프로그램/에뮬레이터 378 | - __문제2-2__ 결국 secho는 맥북을 사기로 결정했을까요? (정답자 전원 +100점) 379 | 380 | --- 381 | `secho`: 저 새로나온 맥북을 살까 고민 중이에요 🤔 382 | 383 | `taelee`: ARM 프로세서 탑재해서 나온거 말씀하시는거죠? '애플실리콘 M1' 이게 자체설계 ARM 프로세서래요. 384 | 385 | `gaekim`: 오! 저도 출시기사 보고 검색해봤는데 'ARM'에 'R'이 저희 컴퓨터구조 스터디에 나온 `RISC`를 의미하는 거더라고요.🙄 386 | 387 | `jakang`: 애플의 행보를 보면 `RISC`가 확실히 대세인가봐요. 회로 복잡도 증가 및 성능 한계를 극복하는 방법으로 명령어 수를 최소화하는 트렌드에 맞는거 같아요. 388 | 389 | `kycho`: 사실 이전에는 이것저것 처리할 수 있는 `CISC`가 인기였어요. 😏 390 | 391 | `daelee`: 맞아요. 1970~80년대에는 더 적은 트랜지스터로 더 복잡한 명령어도 빨리 소화할 수 있다는 점이 마케팅 포인트였대요. `RISC`에서 지루하게 명령어 4줄을 쳐야한다면 `CISC`에서는 단 1줄로 칠 수 있다! 이런식으로요. 392 | 393 | `jehong`: 인텔, AMD는 `CISC` 방식을, IBM은 `RISC` 방식을 따랐고 ARM사는 거의 아키텍처 개발만 했대요. 우리 중 아무도 태어나지 않았을 1978년 출시한 인텔 8086가 시작이었고, 대현님이 아장아장 걸어다니셨을 1999년에 경쟁사인 AMD에서 발표한 AMD64가 사실상 x86의 표준이 되었다고 해요.🧐 394 | 395 | `mihykim`: x86이라고 하시면 인텔에서 개발한 86비트 아키텍쳐를 말씀하시는거죠? 2000년대까지 승자는 `CISC`라 수 있겠지만, 보안·발열이슈로 앞으로 어떻게 될지는 지켜봐야할 것 같아요. 396 | 397 | `sancho`: 음, 제가 보기엔 맥북 특히 맥북프로를 사기에는 적합하지 않은 타이밍 같아요. 마이크로소프트의 서피스 프로, 삼성의 갤럭시북 등의 제품들도 ARM으로 플랫폼을 전환하려고 했었는데 하나 같이 애플리케이션 호환성이 좋지 못하다는 이유로 히트를 치지 못했어요. 😅 398 | 399 | `kukim`: 제 생각도 그래요. 대부분의 애플리케이션이 x86 아키텍처를 기반으로 하고 있는 상황이고, 일부 x86 기반 프로그램들은 로제타2를 거쳐서 성능 손실이 날 수 있다고도 해요. 400 | 401 | `yeha`: 앗 그렇군요. 하지만, 그래도 애플 생태계에 있는 어플리케이션만 주로 사용한다면 괜찮을 것 같기도 해요.🤗 402 | 403 | `yeosong`: 저도 공감해요. 게다가 전력소모가 상당히 적다는 강력한 장점이 있는 걸요. 맥북의 고전적인 발열 문제도 없다고 반응이 좋아요. 404 | 405 | `hylee`: (스읍-) 애플은 앞으로도 ARM을 고수할 것 같네요. 시장반응도 나쁘지 않고 자체설계 ARM 프로세서는 애플이 필요한대로 칩을 고칠 수 있는데 따로 로열티를 내지 않아도 되니 얼마나 좋겠어요.😎 406 | 407 | `secho`: 흠.. 여러모로 고민이 되는군요... 하루만 더 생각해보고 마음을 정해야겠어요! 모두 같이 고민해주셔서 감사합니다! 408 | 409 |
:page_facing_up: 답지
411 | 412 | #### [문제1]
다음 중에서 RISC 프로세서의 특징이 아닌 것은? (기본 2.21번)__ 413 | - 나. 주소지정 방식이 매우 다양한다. > 다양하지 않다! 414 | 415 | #### [문제2]
다음은 맥북을 살지 고민한다는 secho의 고민을 듣고 컴퓨터구조 스터디원들이 함께 토론을 나눈 내용입니다. 416 | - __문제2-1__ 다음 중 틀린 말을 한 사람은 누구일까요? (1등 +100점) 417 | - mihykim : x86은 32비트. 인텔에서 1978년에 개발한 인텔 8086에 적용된 아키텍쳐이자, 그 호환 프로세서 또는 후속작을 이르는 말 418 | - __문제2-2__ 결국 secho는 맥북을 사기로 결정했을까요? (정답자 전원 +100점) 419 | - 정답은 secho님께.. 420 | 421 | https://www.youtube.com/watch?v=vbkFfo7w3II 422 | 423 |
425 | -------------------------------------------------------------------------------- /11강 시스템버스 및 버스중재.md: -------------------------------------------------------------------------------- 1 | ## 🦄 시스템버스 및 버스중재 (11 / 13회차) 2 |
3 | 4 | ### 7.1 시스템 버스 `jakang` 5 | 6 | 1번. 다음 보기에서 알맞은 단어를 골라 빈칸을 채우세요. 7 | 8 | a) 버스 마스터 (bus master)
9 | b) 버스 중재 (bus arbitration)
10 | c) 버스 요구 신호 (bus request signal)
11 | d) 버스 승인 신호 (bus grant signal)
12 | e) 버스 사용중 신호 (bus busy signal)
13 | f) 동기식 버스
14 | g) 비동기식 버스
15 |
16 | `1) ________` 는 두 개 이상의 버스 마스터들이 동시에 버스 사용을 요청할 경우에 순서를 결정해주는 시스템 동작이다.
17 |
18 | `2) ________` 는 버스 사용을 요구한 마스터에게 사용을 허가한다는 것을 나타낸다.
19 |
20 | `3) ________` 는 버스 클럭을 사용하지 않으며, 각 버스 동작이 완료되는 즉시, 연관된 다음 동작이 발생되므로 동기식 버스에서와 같이 낭비되는 시간이 없다.
21 |
22 | 2번. 다음 지문들의 참 거짓 여부를 표시하세요.
23 |
24 | `[ ]` 주소 버스는 양방향 전송을 반드시 지원할 수 있어야 한다.
25 |
26 | `[ ]` 동기식 버스에서 기억장치 액세스 시간이 클록의 한 주기보다 더 긴 경우는 존재하지 않는다.
27 |
28 | `[ ]` 동기식 버스와 비교했을 때, 비동기식 버스의 인터페이스 회로는 복잡하다.
29 |
30 | 3번. 버스 대역폭은 버스를 통하여 단위 시간당 전송할 수 있는 데이터 량을 가리킨다.
31 | 그렇다면 클록 주기가 50ns이고, 데이터 버스의 폭이 32비트일 때, 버스 대역폭은 몇 MBytes/sec 얼마인가?
32 |
33 |
39 | b) 버스 중재 (bus arbitration)
40 | c) 버스 요구 신호 (bus request signal)
41 | d) 버스 승인 신호 (bus grant signal)
42 | e) 버스 사용중 신호 (bus busy signal)
43 | f) 동기식 버스
44 | g) 비동기식 버스
45 |
46 | `1) b) 버스 중재` 는 두 개 이상의 버스 마스터들이 동시에 버스 사용을 요청할 경우에 순서를 결정해주는 시스템 동작이다.
47 |
48 | `2) d) 버스 승인 신호` 는 버스 사용을 요구한 마스터에게 사용을 허가한다는 것을 나타낸다.
49 |
50 | `3) g) 비동기식 버스` 는 버스 클럭을 사용하지 않으며, 각 버스 동작이 완료되는 즉시, 연관된 다음 동작이 발생되므로 동기식 버스에서와 같이 낭비되는 시간이 없다.
51 |
52 | 2번. 다음 지문들의 참 거짓 여부를 표시하세요.
53 |
54 | `[X]` 주소 버스는 양방향 전송을 반드시 지원할 수 있어야 한다.
55 |
56 | : 주소는 CPU에 의해서만 발생되기 때문에 단방향 전송(unidirectional transfer) 기능만 있으면 된다.
57 |
58 | `[X]` 동기식 버스에서 기억장치 액세스 시간이 클록의 한 주기보다 더 긴 경우는 존재하지 않는다.
59 |
60 | : 기억장치 액세스 시간이 클록의 한 주기보다 더 길 경우에는 그만큼 더 많은 주기가 경과한 후에 기억장치가 데이터와 확인 신호를 보내게 되며. CPU 는 그동안 기다려야한다.
61 |
62 | `[O]` 동기식 버스와 비교했을 때, 비동기식 버스의 인터페이스 회로는 복잡하다.
63 |
64 | : 비동기식 버스에서는 각 버스 동작이 완료되는 즉시, 연관된 디음 동작이 발생되므로 동기식 버스에서와 같이 낭비되는 시간이 없다. 그러나 이러한 연속적 동작들을 처리하기 위한 인터페이스 회로가 복잡해지는 단점이 있다.
65 |
66 | 3번. 버스 대역폭은 버스를 통하여 단위 시간당 전송할 수 있는 데이터 량을 가리킨다.
67 | 그렇다면 클록 주기가 50ns이고, 데이터 버스의 폭이 32비트일 때, 버스 대역폭은 몇 MBytes/sec 얼마인가?
68 |
69 | 1 / (50ns) * 4Bytes = 80MBytes/sec
70 |
71 | :page_facing_up: 답지
35 |
36 | 1번. 다음 보기에서 알맞은 단어를 골라 빈칸을 채우세요.
37 |
38 | a) 버스 마스터 (bus master)
73 |
74 | ### 7.2 버스 중재 - 병렬중재방식 `taelee`
75 |
76 |
77 |
78 | #### [문제1]
다음 빈칸에 알맞은 말을 넣어주세요
79 | 한 개의 시스템 버스에 접속된 여러 개의 버스 마스터들이 동시에 버스 사용을 요구하는 경우에는 경쟁이 발생하게 된다. 이러한 현상을 (a)이라고 한다.
80 | (a)이/가 발생한 경우에 버스 마스터들 중에서 한 개씩 선택하여 순서대로 버스를 사용할 수 있게 해주는 동작을 (b)라 하며, 이러한 기능을 수행하는 하드웨어 모듈을 (c)라고 한다.
81 |
82 |
83 | #### [문제2]
아래 그림은 어떤 중재 방식일까요?(복수정답가능)
84 | 
85 |
86 | 가. 중앙집중식 고정-우선순위 중재 방식
87 | 나. 중앙집중식 병렬 중재 방식
88 | 다. 분산식 고정-우선순위 방식
89 | 라. 분산식 직렬 중재 방식
90 |
91 | #### [문제3]
아래 그림은 위 버스 중재 방식의 신호에 따른 시간 흐름도입니다.
아래 그림을 보고 잘못된 말을 한 사람을 골라주세요(복수정답가능)
92 | 
93 |
94 | ```
95 | 🐹gaekim
96 | 그림에서 1번을 보면, 마스터 3이 BREQ3 신호를 세트해서 버스 아비터에게 사용 요청을 보내고 있어
97 | ```
98 |
99 |
100 |
101 | ```
102 | 🐯hylee
103 | 그러면 2번이 나타내는 것은 버스 중재기가 마스터 3에게
104 | BGNT3 신호를 세트하여 버스 사용을 허가한다는 신호인거야?
105 | ```
106 |
107 |
108 |
109 | ```
110 | 🐩sancho
111 | 맞아. 그리고 그림에 나타난 3번 신호를 살펴보면
112 | 마스터3이 버스 사용을 시작하여 BBUSY 신호가 발생했어.
113 |
114 | 이를 통해 다른 버스들이 버스 사용요청을 못하게 막는거지
115 | ```
116 |
117 |
118 |
119 | ```
120 | 🦨taelee
121 | 그러면 4번에서는 마스터3이 버스 사용을 마치고
122 | BBUSY신호를 내림으로써 다른 버스들에게 사용해도 된다고 알려주는 거네?
123 | ```
124 |
125 |
126 |
127 | #### [문제4]
아래 그림은 위 버스 중재 방식의 내부회로도이다. 다음중 제일 우선순위가 가장 높은 버스 마스터와 가장 낮은 버스 마스터를 알려주세요
128 | 
129 | 가장 우선순위가 높은 마스터는 몇번일까요?
130 | 가장 우선순위가 낮은 마스터는 몇번일까요?
131 |
132 | #### [문제5]
아래 그림은 분산식 고정-우선순위 방식(분산식 병렬 방식)의 구성도이다. 다음중 이에 대한 설명으로 틀린 것은?
133 | 
134 |
135 | ```
136 | 🦁daelee
137 | 위 그림에서 1번 마스터에 중재기가 없는 이유는
138 | 1번 마스터의 우선순위가 제일 높기 때문이야
139 | ```
140 |
141 |
142 |
143 | ```
144 | 🐋yeha
145 | 그러면 4번 마스터의 경우 1,2,3마스터의 요청(REQ)이 없어야지만
146 | 승인(GNT)을 받을 수 있겠네?
147 | ```
148 |
149 |
150 |
151 | ```
152 | 🐬kukim
153 | 응 하지만 승인을 받았다고 사용할 수 있는 것은 아냐 BBUSY 신호를 검사하여서,
154 | 다른 마스터가 버스를 사용하지 않는 상태인것을 확인해야 비로소 버스 사용을 시작하는 거지
155 | ```
156 |
157 |
158 |
159 | ```
160 | 🐳jehong
161 | 이런 분산식 중재 방식은 중앙집중식에 비하여
162 | 중재 회로가 복잡하기 때문에 동작 속도가 더 느린편이야
163 | ```
164 |
165 |
166 |
167 | ```
168 | 🍉secho
169 | 또한 중재기가 많다보니 하나가 고장을 일으키면 찾기 어렵다는 단점도 있지
170 | ```
171 |
172 |
173 |
174 |
175 | :page_facing_up: 답지
177 |
178 | #### [문제1]
다음 빈칸에 알맞은 말을 넣어주세요
179 | 한 개의 시스템 버스에 접속된 여러 개의 버스 마스터들이 동시에 버스 사용을 요구하는 경우에는 경쟁이 발생하게 된다. 이러한 현상을 (a)이라고 한다.
180 | (a)이/가 발생한 경우에 버스 마스터들 중에서 한 개씩 선택하여 순서대로 버스를 사용할 수 있게 해주는 동작을 (b)라 하며, 이러한 기능을 수행하는 하드웨어 모듈을 (c)라고 한다.
181 |
182 | (a) 버스 경합(bus contention)
183 | (b) 버스 중재(bus arbitration)
184 | (c) 버스 중재기(bus arbiter)
185 |
186 | #### [문제2]
아래 그림은 어떤 중재 방식일까요?(복수정답가능)
187 | 
188 |
189 | 가. 중앙집중식 고정-우선순위 중재 방식
190 | 나. 중앙집중식 병렬 중재 방식
191 | 다. 분산식 고정-우선순위 방식
192 | 라. 분산식 직렬 중재 방식
193 |
194 | 책에서는 '가', 강의에서는 '나'라고 말합니다. 고정-우선순위, 가변-우선순위 방식은 아마 병렬방식에서만 나와서 저렇게 용어가 혼재해서 쓰이는게 아닐까 싶습니다.
195 |
196 | #### [문제3]
아래 그림은 위 버스 중재 방식의 신호에 따른 시간 흐름도입니다.
아래 그림을 보고 잘못된 말을 한 사람을 골라주세요(복수정답가능)
197 | 
198 |
199 |
200 | ```
201 | 🐹gaekim
202 | 그림에서 1번을 보면, 마스터 3이 BREQ3 신호를 세트해서 버스 아비터에게 사용 요청을 보내고 있어
203 | ```
204 |
205 |
206 |
207 | ```
208 | 🐯hylee
209 | 그러면 2번이 나타내는 것은 버스 중재기가 마스터 3에게
210 | BGNT3 신호를 세트하여 버스 사용을 허가한다는 신호인거야?
211 | ```
212 |
213 |
214 |
215 | ```
216 | 🐩sancho
217 | 맞아. 그리고 그림에 나타난 3번 신호를 살펴보면
218 | 마스터3이 버스 사용을 시작하여 BBUSY 신호가 발생했어.
219 |
220 | 이를 통해 다른 버스들이 버스 사용요청을 못하게 막는거지
221 | ```
222 |
223 |
224 |
225 | ```
226 | 🦨taelee
227 | 그러면 4번에서는 마스터3이 버스 사용을 마치고
228 | BBUSY신호를 내림으로써 다른 버스들에게 사용해도 된다고 알려주는 거네?
229 | ```
230 |
231 |
232 |
233 |
234 | sancho님과 taelee의 말이 틀렸습니다.
235 | BBUSY 신호는 Active low(BBUSY위에 있는 Bar)로 Low상태가 busy상태를 나타냅니다.
236 | 따라서 3번 전까지 다른 마스터에 의해 버스가 사용중이었고 3번그림부터 4번 그림사이까지 신호가 해제되었다가 4번신호부터 비로소 마스터 3이 사용하고 있다는 신호를 알려주기 위해 BBUSY버스가 Low상태로 내려갑니다.
237 |
238 | 이때 BREQ3와 BGNT3는 모두 제거됩니다.
239 |
240 |
241 |
242 | #### [문제4]
아래 그림은 위 버스 중재 방식의 내부회로도이다. 다음중 제일 우선순위가 가장 높은 버스 마스터와 가장 낮은 버스 마스터를 알려주세요
243 | 
244 |
245 | 가장 우선순위가 높은 마스터는 몇번일까요? 1번
246 | 가장 우선순위가 낮은 마스터는 몇번일까요? 4번
247 |
248 | #### [문제5]
아래 그림은 분산식 고정-우선순위 방식(분산식 병렬 방식)의 구성도이다. 다음중 이에 대한 설명으로 틀린 것은?
249 | 
250 |
251 | ```
252 | 🦁daelee
253 | 위 그림에서 1번 마스터에 중재기가 없는 이유는
254 | 1번 마스터의 우선순위가 제일 높기 때문이야
255 | ```
256 |
257 |
258 |
259 | ```
260 | 🐋yeha
261 | 그러면 4번 마스터의 경우 1,2,3마스터의 요청(REQ)이 없어야지만
262 | 승인(GNT)을 받을 수 있겠네?
263 | ```
264 |
265 |
266 |
267 | ```
268 | 🐬kukim
269 | 응 하지만 승인을 받았다고 사용할 수 있는 것은 아냐 BBUSY 신호를 검사하여서,
270 | 다른 마스터가 버스를 사용하지 않는 상태인것을 확인해야 비로소 버스 사용을 시작하는 거지
271 | ```
272 |
273 |
274 |
275 | ```
276 | 🐳jehong
277 | 이런 분산식 중재 방식은 중앙집중식에 비하여
278 | 중재 회로가 복잡하기 때문에 동작 속도가 더 느린편이야
279 | ```
280 |
281 |
282 |
283 | ```
284 | 🍉secho
285 | 또한 중재기가 많다보니 하나가 고장을 일으키면 찾기 어렵다는 단점도 있지
286 | ```
287 |
288 |
289 | jehong님의 말이 틀렸습니다.
290 | 이런 분산식 중재 방식은 중앙집중식에 비하여 **중재 회로가 간단하여 동작 속도가 더 빠르다는 장점**이 있습니다.
291 |
292 |
293 |
295 |
296 |
297 | ### 7.2 버스 중재 - 직렬중재방식 `jehong`
298 |
299 | ##### [파트 1] 성공률 50%, 즐거운 O / X 문제
300 |
301 | 1. 중앙식 직렬 중재 방식에서 마스터는 버스 승인 신호를 받자마자 버스를 사용할 수 있다. (O / X)
302 |
303 | 2. 분산식 직렬 중재 방식에서 DBGNT 신호를 받은 중재기의 마스터는 먼저 버스를 사용하고 있던 마스터가 버스 사용을 끝내고 BBUSY 신호를 리셋시키면 바로 버스를 사용할 수 있다. (O / X)
304 |
305 | 3. 분산식 직렬 중재 방식은 어느 한 지점에 결함이 발생해도 분산식이기 때문에 다른 중재기는 영향을 받지 않는다. (O / X)
306 |
307 |
308 |
309 |
310 |
311 |
312 |
313 | ##### [파트 2] 한눈에 이해하는 머리머리 쏙쏙 그림 문제
314 |
315 | 1. <그림1>, <그림2>는 각각 어느 중재방식에 해당되는지 보기에서 골라주세요.
316 |
317 | >**보기**
318 | >
319 | >중앙집중식 병렬 중재 방식 (CPA: Centralized Parallel Arbitration Scheme)
320 | >
321 | >분산식 병렬 중재 방식 (DPA: Decentralized Parallel Arbitration Scheme)
322 | >
323 | >중앙집중식 직렬 중재 방식 (CSA: Centralized Serial Arbitration Scheme)
324 | >
325 | >분산식 직렬 중재 방식 (DSA: Decentralized Serial Arbiration Scheme)
326 |
327 | <그림1> `___________(a)____________`
328 |
329 | <그림2> `___________(b)____________`
330 |
331 |
332 |
333 | <그림1>
334 |
335 |  336 |
337 |
338 |
339 | <그림2>
340 |
341 |
336 |
337 |
338 |
339 | <그림2>
340 |
341 |  342 |
343 |
344 |
345 | 2. <그림1>을 참고해 문제에 답해 주세요. 현재 중재 동작에서 7번 마스터가 버스 사용 승인을 받아 버스를 사용하고 있고 마스터 1, 3, 6은 버스 사용 요구 신호 (BREQ)를 발생시킨 상태입니다.
346 |
347 | a) 다음 중재 동작에서 각각 **최하위**와 **최상위** 우선순위를 가진 마스터는 몇 번일까요?
348 |
349 | b) 다음 중재 동작에서 버스 사용 승인 신호를 받게 되는 마스터는 몇 번일까요?
350 |
351 |
352 |
353 | 3. <그림2>를 참고해 문제에 답해 주세요. 현재 중재 동작에서 4번 마스터가 버스 사용 승인을 받아 버스를 사용하고 있고 마스터 2, 5가 버스 사용 요구 신호 (BREQ)를 발생시킨 상태입니다.
354 |
355 | a) 다음 중재 동작에서 **최상위** 우선순위를 가진 마스터는 몇 번일까요?
356 |
357 | b) 다음 중재 동작에서 버스 사용 승인 신호를 받게 되는 마스터는 몇 번일까요?
358 |
359 |
360 |
361 |
342 |
343 |
344 |
345 | 2. <그림1>을 참고해 문제에 답해 주세요. 현재 중재 동작에서 7번 마스터가 버스 사용 승인을 받아 버스를 사용하고 있고 마스터 1, 3, 6은 버스 사용 요구 신호 (BREQ)를 발생시킨 상태입니다.
346 |
347 | a) 다음 중재 동작에서 각각 **최하위**와 **최상위** 우선순위를 가진 마스터는 몇 번일까요?
348 |
349 | b) 다음 중재 동작에서 버스 사용 승인 신호를 받게 되는 마스터는 몇 번일까요?
350 |
351 |
352 |
353 | 3. <그림2>를 참고해 문제에 답해 주세요. 현재 중재 동작에서 4번 마스터가 버스 사용 승인을 받아 버스를 사용하고 있고 마스터 2, 5가 버스 사용 요구 신호 (BREQ)를 발생시킨 상태입니다.
354 |
355 | a) 다음 중재 동작에서 **최상위** 우선순위를 가진 마스터는 몇 번일까요?
356 |
357 | b) 다음 중재 동작에서 버스 사용 승인 신호를 받게 되는 마스터는 몇 번일까요?
358 |
359 |
360 |
361 |
362 |
363 | :page_facing_up: 답지
365 |
366 | ##### [파트 1] 성공률 50%, 즐거운 O / X 문제
367 |
368 |
369 | 1. 중앙식 직렬 중재 방식에서 마스터는 버스 승인 신호를 받자마자 버스를 사용할 수 있다. (O / X)
370 |
371 | > **답: X**
372 | >
373 | > 새롭게 버스 승인 신호를 받은 마스터는 이미 버스를 사용하고 있는 마스터가 버스 사용을 끝낼 때까지 기다려야 한다. 이를 보장하기 위해 어떤 마스터도 버스를 사용하지 않을 때만 버스 중재기가 승인 신호를 발생하도록 설계되어야 한다.
374 | >
375 | > 하지만 만약 버스 중재기에 그러한 기능이 없다면 마스터는 BBUSY 신호가 해제될 때까지 요구 신호를 보내지 않거나 승인 신호를 받았더라도 버스를 사용할 수 없도록 해야 한다.
376 |
377 |
378 |
379 | 2. 분산식 직렬 중재 방식에서 DBGNT 신호를 받은 중재기의 마스터는 먼저 버스를 사용하고 있던 마스터가 버스 사용을 끝내고 BBUSY 신호를 리셋시키면 바로 버스를 사용할 수 있다. (O / X)
380 |
381 | > **답: X**
382 | >
383 | > 만약 중재기가 DBGNT 신호를 받았더라도 해당 중재기의 마스터가 버스 사용 요구를 하지 않은 상태라면, 그 신호를 우측의 중재기로 넘겨준다.
384 |
385 |
386 |
387 | 3. 분산식 직렬 중재 방식은 어느 한 지점에 결함이 발생해도 분산식이기 때문에 다른 중재기는 영향을 받지 않는다. (O / X)
388 |
389 | > **답: X**
390 | >
391 | > 분산식 직렬 중재 방식은 어느 한 지점에만 결함이 발생해도 전체 시스템이 영향을 받는다. 중재기는 DBGNT 신호를 우측 중재기로 넘겨주는 순환형 방식인데 하나의 중재기에서 결함이 발생하면 DBGNT 신호가 더이상 통과하지 못해 결국 전체 동작이 중단된다.
392 |
393 |
394 |
395 |
396 |
397 |
398 |
399 | ##### [파트 2] 한눈에 이해하는 머리머리 쏙쏙 그림 문제
400 |
401 | 1. <그림1>, <그림2>는 각각 어떤 중재방식에 해당되는지 보기에서 골라주세요.
402 |
403 | >**보기**
404 | >
405 | >중앙집중식 병렬 중재 방식 (CPA: Centralized Parallel Arbitration Scheme)
406 | >
407 | >분산식 병렬 중재 방식 (DPA: Decentralized Parallel Arbitration Scheme)
408 | >
409 | >중앙집중식 직렬 중재 방식 (CSA: Centralized Serial Arbitration Scheme)
410 | >
411 | >분산식 직렬 중재 방식 (DSA: Decentralized Serial Arbiration Scheme)
412 |
413 | <그림1> `분산식 직렬 중재 방식 (DSA: Decentralized Serial Arbiration Scheme)`
414 |
415 | <그림2> `중앙집중식 직렬 중재 방식 (CSA: Centralized Serial Arbitration Scheme)`
416 |
417 |
418 |
419 | <그림1>
420 |
421 |
422 |
423 |
424 |
425 | <그림2>
426 |
427 |
428 |
429 |
430 |
431 | 2. <그림1>을 참고해 문제에 답해 주세요. 현재 중재 동작에서 7번 마스터가 버스 사용 승인을 받아 버스를 사용하고 있고 마스터 1, 3, 6은 버스 사용 요구 신호 (BREQ)를 발생시킨 상태입니다.
432 |
433 | a) 다음 중재 동작에서 각각 **최하위**와 **최상위** 우선순위를 가진 마스터는 몇 번일까요?
434 |
435 | > **답: 최하위는 7번 마스터, 최상위는 8번 마스터**
436 | >
437 | > 현재 사용 승인을 받은 **7번 마스터**는 다음 중재 동작에서 최하위 우선권을 갖게 됩니다.
438 | >
439 | > DBGNT 신호는 시계 방향으로 우선 순위가 하나씩 낮아지므로 현재 동작의 바로 우측에 위치한 8번 마스터가 다음 동작의 최상위 우선순위를 갖게 됩니다.
440 |
441 |
442 |
443 | b) 다음 중재 동작에서 버스 사용 승인 신호를 받게 되는 마스터는 몇 번일까요?
444 |
445 | > **답: 1번 마스터**
446 | >
447 | > DBGNT 신호를 받은 중재기는 마스터가 버스 요구를 하지 않은 상태라면 신호를 우측 중재기로 넘기고, 요구를 한 상태면 마스터에 BGNT 신호를 발생시킵니다. 따라서 버스 사용을 신청한 마스터 중 현재 버스를 사용하고 있는 7번 마스터로부터 우측으로 가장 가까이 위치한 **1번 마스터**가 버스 승인 신호를 받게 됩니다.
448 |
449 |
450 |
451 | 3. <그림2>를 참고해 문제에 답해 주세요. 현재 중재 동작에서 4번 마스터가 버스 사용 승인을 받아 버스를 사용하고 있고 마스터 2, 5가 버스 사용 요구 신호 (BREQ)를 발생시킨 상태입니다.
452 |
453 | a) 다음 중재 동작에서 **최상위** 우선순위를 가진 마스터는 몇 번일까요?
454 |
455 | > **답: 1번 마스터**
456 | >
457 | > 중앙식 직렬 중재 방식에서는 버스 중재기에 가장 가까이 위치한 첫 번째 마스터인 **1번 마스터**가 가장 먼저 버스 승인 신호 (BGNT)를 받기 때문에 버스 사용에 있어 최상위 우선순위를 가지게 됩니다.
458 |
459 | b) 다음 중재 동작에서 버스 사용 승인 신호를 받게 되는 마스터는 몇 번일까요?
460 |
461 | > **답: 2번 마스터**
462 | >
463 | > 최상위 우선순위를 가진 마스터 1번 마스터는 버스 사용을 요구하지 않은 상태이므로 마스터 1번의 중재기는 DBGNT를 다음 우선순위를 가진 마스터에게 전달합니다. 버스 사용 요구를 보낸 마스터들 중 중재기에 가장 가까이 위치한, 즉 우선순위가 가장 높은 **2번 마스터**가 다음 중재 동작에서의 버스 승인 신호를 받게 됩니다.
464 |
465 |
466 |
467 |
469 |
470 | ### 7.2 버스 중재 - 폴링방식 `hylee`
471 |
472 | #### [문제1]
다음 중 폴링 방식에서 각 마스터들의 우선순위를 결정하는 것은?
473 | - 가. 먼저 신호를 보낸 순서
474 | - 나. 가장 오랫동안 사용하지 않은 정도
475 | - 다. 중재기가 검사하는 순서
476 | - 라. 마스터에 가장 가까운 위치
477 |
478 | #### [문제2]
다음은 폴링방식 구성도이다. 현재 3번 마스터가 버스를 사용중이며 1씩 증가하는 이진카운터를 사용하고 있다.(이진 카운터는 1부터 시작했다.) 이에 대해 컴퓨터 스터디원들의 토론 내용을 일부 발췌했는데 다음 중 틀린 설명은 무엇일까요? (복수정답 가능)
479 | 
480 |
481 |
482 | ---
483 | `secho`: 저 3번 마스터는 버스 사용을 하기 위해서 BBUSY 신호를 세트를 통해 중개기를 호출했어요
484 |
485 | `gaekim`: 저렇게 3번 마스터가 버스를 사용할 때 2진 카운터 동작을 멈춘다고 알고 있어요
486 |
487 | `jakang`: 이게 만약 회전 우선 방식이라면 다음에는 1번을 선택하겠죠?
488 |
489 | `kycho`: 소프트웨어 폴링 방식도 위 구성도랑 동일하게 구성돼요!
490 |
491 | `daelee`: 소프트웨어 폴링 방식은 하드웨어 방식에 비해 속도는 좀 느리지만 융통성이 높다는 장점이 있어요
492 |
493 | :page_facing_up: 답지
495 |
496 | #### [문제1]
다음 중 폴링 방식에서 각 마스터들의 우선순위를 결정하는 것은?
497 | > **답 : 다**
498 | > 폴링방식에서는 각 마스터들의 우선순위는 중재기가 마스터를 검사하는 순서에 의하여 결정된다. 이 순서는 마스터의 번호에 따라 정해질 수도 있고 가변 우선순위 알고리즘이 적용될 수도 있다.
499 |
500 | - 가. 먼저 신호를 보낸 순서
501 | - 나. 가장 오랫동안 사용하지 않은 정도
502 | - 다. 중재기가 검사하는 순서
503 | - 라. 마스터에 가장 가까운 위치
504 |
505 | #### [문제2]
다음은 폴링방식 구성도이다. 현재 3번 마스터가 버스를 사용중이며 1씩 증가하는 이진카운터를 사용하고 있다.(이진 카운터는 1부터 시작했다.) 이에 대해 컴퓨터 스터디원들의 토론 내용을 일부 발췌했는데 다음 중 틀린 설명은 무엇일까요? (복수정답 가능)
506 | 
507 |
508 |
509 | > **답 : secho - BBUSY는 버스 사용을 시작하면 세트되는 신호이다.**
510 |
511 | > **jakang - 회전 우선방식이라면 중단된 순간의 다음 값부터 출력하게됨으로 4번을 검사하게된다.**
512 |
513 |
514 | ---
515 | `secho`: 저 3번 마스터는 버스 사용을 하기 위해서 BBUSY 신호를 세트를 통해 중개기를 호출했어요
516 |
517 | `gaekim`: 저렇게 3번 마스터가 버스를 사용할 때 2진 카운터 동작을 멈춘다고 알고 있어요
518 |
519 | `jakang`: 이게 만약 회전 우선 방식이라면 다음에는 1번을 검사하겠죠?
520 |
521 | `kycho`: 소프트웨어 폴링 방식도 위 구성도랑 동일하게 구성돼요!
522 |
523 | `daelee`: 소프트웨어 폴링 방식은 하드웨어 방식에 비해 속도는 좀 느리지만 융통성이 높다는 장점이 있어요
524 |
525 |
526 |
528 |
--------------------------------------------------------------------------------
/10강 보조저장장치.md:
--------------------------------------------------------------------------------
1 | ## 🦄 보조저장장치 (10 / 13회차)
2 |
3 |
4 | ### 6.1 하드 디스크 `daelee`의 대리 `mihylee`
5 |
6 | #### [문제1~2] 디스크 구조
7 |
8 | **🔎문제1 <보기>를 참고하여 (a)~(d)를 알맞게 채워주세요**
9 | ```
10 | <보기>
11 |
12 | 디스크 팔(disk arm) - 직선 모양의 금속체
13 | 구동장치(actuator) - 디스크 팔 끝 부분에 설치된 디스크 회전 장치
14 | 헤드(head) - 전도성 코일을 통하여 표면을 자화시킴으로써 데이터를 저장하거나 데이터를 읽을때 사용하는 부분
15 | 트랙(track) - 디스크 표면에 존재하는 여러 개의 동심원
16 | 섹터(sector) - 디스크에 한 번 쓰거나 읽는 동작이 수행되는 최소의 물리적 단위
17 | ```
18 |


28 | 29 | #### [문제3] 디스크 형식화작업 30 | 31 | **🔎문제3 그림의 디스크 형식화작업(disk formatting)의 예시를 참고하여 빈칸을 채워주세요.** 32 |

38 | 39 | #### [문제4~8] 디스크 액세스 40 |

57 | 1. 헤드를 해당 트랙으로 이동시킨다. : `(a)__________________` 58 | 2. 원하는 데이터가 저장된 섹터가 헤드 아래로 회전되어 올때까지 기다린다. : `(b)__________________` 59 | 3. 원하는 데이터를 전송한다. : `(c)__________________` 60 | ``` 61 | <보기> 62 | 데이터 전송 시간(data transfer time) 63 | 회전 지연 시간(rotational latency) 64 | 탐색 시간(seek time) 65 | ``` 66 | 67 | **🔎문제7 (고도의 수학적 지식을 요하는 계산문제) 회전 속도가 7200rpm인 디스크의 최대 회전지연 시간은 얼마일까요?(기본 6.3)** 68 | - 정답: `_______`(ms) 69 | 70 | **🔎문제8 마무리 OX문제** 71 | - 디스크 드라이브는 디스크, 헤드, 디스크 팔, 구동장치, 데이터 전송선 등을 포함한다. `(O / X)` 72 | - 최근에 개발된 대용량 디스크들은 저장 밀도를 크게 높여 표면 당 트랙의 수가 2,000개 이상으로 증가했다. `(O / X)` 73 | - 평판의 양쪽 면이 모두 자화물질로 코팅된 양면 디스크(double-sided disk)이라 하고 대부분의 디스크들은 양면 디스크이다. `(O / X)` 74 | - 다중-평판 디스크 드라이브에서 동일한 반경에 위치한 트랙들의 집합을 트랙터라고한다. `(O / X)` 75 | - 직렬 ATA버스와 같은 고속의 인터페이스들이 사용되면서 데이터 전송시간은 100mbps ~200mbps 수준으로 높아졌다.`(O / X)` 76 | 77 |
:page_facing_up: 답지
79 | 80 | #### [문제1~2] 디스크 구조 81 | **🔎문제1 <보기>를 참고하여 (a)~(d)를 알맞게 채워주세요** 82 | ``` 83 | <보기> 84 | 85 | 디스크 팔(disk arm) - 직선 모양의 금속체 86 | 구동장치(actuator) - 디스크 팔 끝 부분에 설치된 디스크 회전 장치 87 | 헤드(head) - 전도성 코일을 통하여 표면을 자화시킴으로써 데이터를 저장하거나 데이터를 읽을때 사용하는 부분 88 | 트랙(track) - 디스크 표면에 존재하는 여러 개의 동심원 89 | 섹터(sector) - 디스크에 한 번 쓰거나 읽는 동작이 수행되는 최소의 물리적 단위 90 | ``` 91 |

104 | 105 | #### [문제3] 디스크 형식화작업 106 | 107 | **🔎문제3 그림의 디스크 형식화작업(disk formatting)의 예시를 참고하여 빈칸을 채워주세요.** 108 |
114 | 115 | #### [문제4~8] 디스크 액세스 116 |
133 | 1. 헤드를 해당 트랙으로 이동시킨다. : `(a)탐색 시간(seek time)` 134 | 2. 원하는 데이터가 저장된 섹터가 헤드 아래로 회전되어 올때까지 기다린다. : `(b)회전 지연 시간(rotational latency)` 135 | 3. 원하는 데이터를 전송한다. : `(c)데이터 전송 시간(data transfer time)` 136 | ``` 137 | <보기> 138 | 데이터 전송 시간(data transfer time) 139 | 회전 지연 시간(rotational latency) 140 | 탐색 시간(seek time) 141 | ``` 142 | 143 | **🔎문제7 (고도의 수학적 지식을 요하는 계산문제) 회전 속도가 7200rpm인 디스크의 최대 회전지연 시간은 얼마일까요?(기본 6.3)** 144 | - 정답: 8.33ms 145 | ``` 146 | 7200 (rot / min) * (min / 60 sec) 147 | = 120 rot / sec 148 | 149 | 1 / 120 (sec / rot) 150 | = 0.00833(s) 151 | = 8.33(ms) 152 | ``` 153 | 154 | **🔎문제8 마무리 OX문제** 155 | - 디스크 드라이브는 디스크, 헤드, 디스크 팔, 구동장치, 데이터 전송선 등을 포함한다. (O) 156 | - 최근에 개발된 대용량 디스크들은 저장 밀도를 크게 높여 표면 당 트랙의 수가 2,000개 이상으로 증가했다.(O) 157 | - 평판의 양쪽 면이 모두 자화물질로 코팅된 양면 디스크(double-sided disk)이라 하고 대부분의 디스크들은 양면 디스크이다. (O) 158 | - 다중-평판 디스크 드라이브에서 동일한 반경에 위치한 트랙들의 집합을 트랙터라고한다. (X, 실린더) 159 | - 직렬 ATA버스와 같은 고속의 인터페이스들이 사용되면서 데이터 전송시간은 100mbps ~200mbps 수준으로 높아졌다. (X, 600mbps 수준) 160 | 161 |
163 | 164 | ### 6.2 RAID `sancho` 165 | 166 | ##### [문제 1] 디스크 인터리빙이 무엇인지, 장단점과 함께 설명해주세요. 167 | -> 168 |
169 | 170 | ##### [문제 2] RAID에 대한 설명으로 올바른 것을 모두 골라주세요. 171 | ``` 172 | 가. 디스크 인터리빙을 이용할 수 있다. 173 | 나. 오류를 검증하는 부분은 해결하지 못한다. 174 | 다. 성능이 좋은 디스크 드라이브 하나를 이용해 모든 서비스를 가능하게 만든다. 175 | 라. 낮은 비용으로 높은 성능을 추구한다. 176 | ``` 177 | -> 178 |
179 | 180 | ##### [문제 3] MTTF(평균 결함 시간)이 15,000시간인 디스크 30개를 배열로 구성하였을 경우의 MTTF을 계산하세요. 181 | -> 182 |
183 | ##### [문제 4] 100GB인 디스크 6개를 RAID-1로 구성할 경우 사용가능한 디스크 용량을 구해주세요. 184 | -> 185 |
186 | 187 | ##### [문제 5] RAID-3에 대한 설명으로 다음 빈칸에 들어갈 단어를 채워주세요. 188 | RAID-3은 ```___(a)___```의 단점을 보완하기 위해 나왔으며 한개의 ```___(b)___``` 디스크를 추가하여 데이터 오류를 정정할 수 있습니다.
189 | ```___(b)___``` 디스크의 비트는 다른 디스크의 비트와 함께 ```___(c)___``` 연산을 수행하여 오류를 정정하여 원래 값을 찾을 수 있습니다.
190 | 데이터는 ```___(d)___``` 단위로 분산 저장되기 때문에 읽기 쓰기 동작에 모든 데이터가 참여가 가능하며 빠른 데이터 전송도 가능합니다. 191 |
192 | 193 | 194 |
:page_facing_up: 답지
196 | 197 | ##### [문제 1] 디스크 인터리빙이 무엇인지, 장단점과 함께 설명해주세요. 198 | ``` 199 | 디스크 인터리빙이란, 여러 개의 디스크를 분산 저장하는 기술을 말하구요. 200 | 여러 블록을 여러 디스크에 동시에 쓰고 읽을 수 있기 때문에 병목현상을 줄일 수 있다는 장점이 있으면서도, 201 | 한 디스크에 결함이 생기면 전체 데이터 파일이 손상되는 문제점을 가지고 있습니다. 202 | ``` 203 |
204 | 205 | ##### [문제 2] RAID에 대한 설명으로 올바른 것을 모두 골라주세요. 206 | 207 | ``` 208 | 가. 디스크 인터리빙을 이용할 수 있다. 209 | 나. 오류를 검증하는 부분은 해결하지 못한다. 210 | 다. 성능이 좋은 디스크 드라이브 하나를 이용해 모든 서비스를 가능하게 만든다. 211 | 라. 낮은 비용으로 높은 성능을 추구한다. 212 | ``` 213 | 214 | ``` 215 | 정답: 가, 라 216 | '가'와 '라'는 바른 설명이고, 217 | '나'의 경우 RAID-2의 검사디스크 또는 RAID-3과 4의 패리티 디스크와 같이 오류를 검증할 수 있기 때문에 틀렸고 218 | '다'의 경우 반대로 여러 디스크를 이용하여 성능을 향상시키는 것이 RAID이므로 틀렸습니다. 219 | ``` 220 |
221 | 222 | ##### [문제 3] MTTF(평균 결함 시간)이 15,000시간인 디스크 30개를 배열로 구성하였을 경우의 MTTF을 계산하세요. 223 | ``` 224 | 정답: 500시간 225 | 디스크를 배열로 구성하게 될 경우 신뢰도가 낮아지며 이 경우 MTTF는 (단일 디스크의 MTTF)/(배열 내 디스크 수)입니다. 226 | 15000/30은 500이므로 MTTF는 500시간입니다. 227 | ``` 228 |
229 | ##### [문제 4] 100GB인 디스크 6개를 RAID-1로 구성할 경우 사용가능한 디스크 용량을 구해주세요. 230 | ``` 231 | 정답: 300GB 232 | RAID-1은 디스크 미러링 방식이라고도 부르며 디스크가 짝을 이루어 읽고 쓰는 방식입니다. 233 | 100GB 6개의 디스크가 있다면 3개의 데이터 디스크와 3개의 미러 디스크로 구성되며 전체 용량의 절반인 300GB만 사용할 수 있습니다. 234 | ``` 235 |
236 | ##### [문제 5] RAID-3에 대한 설명으로 다음 빈칸에 들어갈 단어를 채워주세요. 237 | RAID-3은 ```RAID-2```의 단점을 보완하기 위해 나왔으며 한개의 ```패러티``` 디스크를 추가하여 데이터 오류를 정정할 수 있습니다.
238 | ```패러티``` 디스크의 비트는 다른 디스크의 비트와 함께 ```exclusive-OR``` 연산을 수행하여 오류를 정정하여 원래 값을 찾을 수 있습니다.
239 | 데이터는 ```비트``` 단위로 분산 저장되기 때문에 읽기 쓰기 동작에 모든 데이터가 참여가 가능하며 빠른 데이터 전송도 가능합니다. 240 |
241 | 242 |
244 | 245 | ### 6.3 플래시 메모리와 SSD - 플래시메모리 `yeosong` 246 | 247 | #### [문제 1] 데이터 “저장” 동작에서 가장 중요한 기능을 수행하는 내부요소는? (기본6.11) 248 |  249 | 250 | ~~~ 251 | 가. 제어 게이트 252 | 나. 드레인 253 | 다. 부동 게이트 254 | 라. N-채널 255 | ~~~ 256 | 257 | -> 258 |
259 | 260 | #### [문제 2] 플래시 메모리의 특성이 아닌 것은? (기본6.14) 261 | 262 | ~~~ 263 | 가. EEPROM보다 저장 밀도가 더 높다. 264 | 나. 한 비트를 저장하는 데 두 개의 트랜지스터가 사용된다. 265 | 다. 삭제는 블록 단위, 쓰기는 페이지 단위로 이루어진다. 266 | 라. SSD의 구성 요소로 사용된다. 267 | ~~~ 268 | 269 | -> 270 |
271 | 272 | 273 | 274 | #### [문제 3] NOR형 플래시와 NAND형 플래시에 관한 OX 문제이다. 275 | 276 | ~~~ 277 | a) NOR형 플래시는 트랜지스터들이 병렬이다. 278 | b) NOR형 플래시는 드레인, 소스단자(다리 사진)가 비트선과 각각 접지로 직접 연결되어있다. 279 | c) NOR형 플래시는 셀(비트) 단위의 읽기와 쓰기가 가능하다. 280 | d) NOR형 플래시는 비트선, 워드선이 트랜지스터 수만큼 필요해서 공간을 많이 차지한다. 281 | e) NOR형 플래시는 고정된 프로그램 코드를 순차적으로 인출하거나, 작은 크기의 데이터를 수시로 읽고 쓰는 에 사용될 수 있다. 282 | f) NOR형 플래시는 OS 저장장치에 적합한 플래시 메모리 유형이다. 283 | g) NOR형 플래시는 일반적으로 사용하는 대용량 저장장치를 이루는 기본 단위이다. 284 | ~~~ 285 | 286 | -> 287 |
288 | 289 | 290 | 291 | #### [문제 4] TLC(triple-level cell)에 관한 OX 문제이다. 292 | 293 | - TLC(triple-level cell)방식의 플래시 메모리는 주입되는 전자 수를 조절하여 셀 하나에 총 8비트를 저장할 수 있다. (O/X) 294 | - TLC(triple-level cell)는 읽기시간/쓰기시간/삭제시간/재기록가능횟수 4가지 모든 면에서 SLC(single-level cell)에 비해 성능이 떨어진다. (O/X) 295 | 296 | -> 297 |
298 | 299 | #### [문제 5] 3차원 V-NAND에 관한 올바른 설명을 모두 고르세요. 300 | 301 | ~~~ 302 | TLC 방식은 3비트씩 저장이 가능하지만 부동 게이트에 주입되는 전자 수의 차이를 구분하는 데 어려움을 가지고 있었다. 303 | 그러나 3차원 V-NAND에서는 그보다 더 많은 4비트씩(QLC) 저장할 수 있다. 어떤 변화가 있었을까? 304 | 305 | 가. 전자 수 측정 기술의 향상으로 읽기 시간이 2배 이상 빨라졌다. 306 | 나. 3차원셀로 바뀌면서 부동 게이트 공간이 확장되었다. 307 | 다. 셀과 셀 사이의 공간이 확보되어 데이터 간섭 현상을 감소시킬 수 있었다. 308 | ~~~ 309 | 310 | -> 311 |
312 | 313 | 314 | #### [문제 6] CTF(차지트랩플래시)와 부동게이트(floating gate) 셀의 차이는 뭘까요? (주관식) 315 | 316 | -> 317 |
318 | 319 | 320 | #### [🔎 참고] PUC 페리언더셀은 뭐지? 321 | > 주변부(peri) 회로(데이터를 저장하는 셀들을 선택하고 컨트롤하는 역할을 하는 로직회로)가
322 | > 원래는 옆에 따로 있었는데 맨 아래층에 넣어서 차지하는 면적을 줄이고 효율을 높인 것이다. 323 |
 324 |
325 |
326 | #### [🔎 읽을 거리] 플래시 메모리 업계 현황?
327 |
328 | 2019년까지 인텔은 **그래도 플로팅게이트가 CTF보다 데이터 유실률이 낮다**며
324 |
325 |
326 | #### [🔎 읽을 거리] 플래시 메모리 업계 현황?
327 |
328 | 2019년까지 인텔은 **그래도 플로팅게이트가 CTF보다 데이터 유실률이 낮다**며 329 | 셀당 5비트를 저장하는 플로팅게이트 플래시 메모리를 연구하다가.. [기사1](https://zdnet.co.kr/view/?no=20190927033637&from=Mobile) 330 |
2020년에 **낸드 플래시 사업부를 SK하이닉스에 매각**했다고 하네요. [기사2](https://news.einfomax.co.kr/news/articleView.html?idxno=4113467) 331 | 332 | 333 |
:page_facing_up: 답지
335 | 336 | #### [문제 1] 데이터 “저장” 동작에서 가장 중요한 기능을 수행하는 내부요소는? (기본6.11) 337 |  338 | 339 | ~~~ 340 | 가. 제어 게이트 341 | 나. 드레인 342 | 다. 부동 게이트 343 | 라. N-채널 344 | ~~~ 345 | 346 | > 다. 부동 게이트 (floating gate) 347 |
348 | 349 | #### [문제 2] 플래시 메모리의 특성이 아닌 것은? (기본6.14) 350 | 351 | ~~~ 352 | 가. EEPROM보다 저장 밀도가 더 높다. 353 | 나. 한 비트를 저장하는 데 두 개의 트랜지스터가 사용된다. 354 | 다. 삭제는 블록 단위, 쓰기는 페이지 단위로 이루어진다. 355 | 라. SSD의 구성 요소로 사용된다. 356 | ~~~ 357 | 358 | > 나. 한 비트를 저장하는 데 **1개의 트랜지스터**가 사용된다. 359 |
360 | 361 | #### [문제 3] NOR형 플래시와 NAND형 플래시에 관한 OX 문제이다. 362 | 363 | ~~~ 364 | a) NOR형 플래시는 트랜지스터들이 병렬이다. 365 | b) NOR형 플래시는 드레인, 소스단자(다리 사진)가 비트선과 각각 접지로 직접 연결되어있다. 366 | c) NOR형 플래시는 셀(비트) 단위의 읽기와 쓰기가 가능하다. 367 | d) NOR형 플래시는 비트선, 워드선이 트랜지스터 수만큼 필요해서 공간을 많이 차지한다. 368 | e) NOR형 플래시는 고정된 프로그램 코드를 순차적으로 인출하거나, 작은 크기의 데이터를 수시로 읽고 쓰는 어플리케이션에 사용될 수 있다. 369 | f) NOR형 플래시는 OS 저장장치에 적합한 플래시 메모리 유형이다. 370 | g) NOR형 플래시는 일반적으로 사용하는 대용량 저장장치를 이루는 기본 단위이다. 371 | ~~~ 372 | 373 | > g만 X다. 이는 NAND형 플래시에 대한 설명이다. 나머지는 모두 맞는 설명이다. 374 | 375 |
376 | 377 | #### [문제 4] TLC(triple-level cell)에 관한 OX 문제이다. 378 | 379 | - TLC(triple-level cell)방식의 플래시 메모리는 주입되는 전자 수를 조절하여 셀 하나에 총 8비트를 저장할 수 있다. (O/X) 380 | > (X) 전자 수를 8단계로 구분하여 총 2^3가지 저장이 가능 = 3비트가 저장된다. 381 | 382 | - TLC(triple-level cell)는 읽기시간/쓰기시간/삭제시간/재기록가능횟수 4가지 모든 면에서 SLC(single-level cell)에 비해 성능이 떨어진다. 383 | > (O) 표 6-3에서 정확한 수치를 비교해볼 수 있다.
384 | > 더 많은 전자를 주입하고 세는 데에 더 세밀한 조작이 필요하기 때문에 이런 시간차가 발생한다. 385 | 386 |
 387 |
388 |
387 |
388 | 389 | 390 | #### [문제 5] 3차원 V-NAND에 관한 올바른 설명을 모두 고르세요. 391 | 392 | ~~~ 393 | TLC 방식은 3비트씩 저장이 가능하지만 부동 게이트에 주입되는 전자 수의 차이를 구분하는 데 어려움을 가지고 있었다. 394 | 그러나 3차원 V-NAND에서는 그보다 더 많은 4비트씩(QLC) 저장할 수 있다. 어떤 변화가 있었을까? 395 | 396 | 가. 전자 수 측정 기술의 향상으로 읽기 시간이 2배 이상 빨라졌다. 397 | 나. 3차원셀로 바뀌면서 부동 게이트 공간이 확장되었다. 398 | 다. 셀과 셀 사이의 공간이 확보되어 데이터 간섭 현상을 감소시킬 수 있었다. 399 | ~~~ 400 | 401 | > 나, 다. 402 | 403 |
404 | 405 | #### [문제 6] CTF(차지트랩플래시)와 부동게이트(floating gate) 셀의 차이는 뭘까요? (주관식) 406 | 407 | > 부동게이트는 도체에 전자를 저장하고, 408 | > CTF는 부도체에 전자를 담는다. 409 | 410 | 전자를 도체에 담으면 411 | 1) 셀이 가까이 있어도 셀간 간섭이 잘 차단되고 412 | 2) 셀의 높이가 낮아져서(부도체가 도체보다 두께가 얇으므로)
413 | 부동 게이트보다 집적도를 높여 용량을 키울 수 있었다. 414 | 415 |
 416 |
417 | > CTF와 플로팅게이트 차이(출처:sk하이닉스)
418 |
419 |
416 |
417 | > CTF와 플로팅게이트 차이(출처:sk하이닉스)
418 |
419 | 421 | 422 | 423 | ### 6.3 플래시 메모리와 SSD - SSD `kycho` 424 | 425 | ##### [문제 1] 다음은 SSD에 대한 설명입니다. 빈칸에 알맞는 답을 작성하시오. 426 | 427 | SSD(Solid-State Drive)는 저장 밀도가 높은 ```___(가)___```로 구성된 대용량 비휘발성 반도체 저장장치입니다.
428 | 하드 디스크와는 달리 ```___(나)___```가 없기 때문에 안정정과 신뢰도가 높다는 장점이 있습니다.
429 | 430 | ##### [문제 2] SSD에서 데이터 저장과 인출, 칩 관리 등과 같은 핵심적인 기능을 수행하는 전자회로 모듈을 무엇이라고 하는가? 431 |
432 | 433 | ##### [문제 3] 다음은 SSD구성에 대한 그림이다. 그림을 참고하여 빈칸에 들어갈 소프트웨어의 명칭과 주요 역할을 작성하시오. 434 | 435 |  436 |
437 | 438 | ##### [문제 4] 플래시 변환 계층(FTL)은 페이지 주소와 섹터 주소간의 매핑 외에도, SSD의 성능향상을 위하여 수행하는 중요한 기능이 몇가지 더 있다. 어떠한 기능들이 있는지 작성하시오. 439 |
440 | 441 | ##### [문제 5] SSD의 구성요소인 플래시 메모리는 블록 단위의 삭제만 가능하기 때문에 쓰레기 수집(garbage collection)과정이 필요하다. 이 과정의 효율을 높이기 위한 운영체제(OS) 차원의 지원에 해당하는 것은?(기본문제 6.18) 442 | ``` 443 | 가. 주소 매핑 444 | 나. 오버-프로비저닝 445 | 다. TRIM 446 | 라. 미러링 447 | ``` 448 | 449 |
:page_facing_up: 답지
451 | 452 | ##### [문제 1] 다음은 SSD에 대한 설명입니다. 빈칸에 알맞는 답을 작성하시오. 453 | 454 | SSD(Solid-State Drive)는 저장 밀도가 높은 ```___(가)___```로 구성된 대용량 비휘발성 반도체 저장장치입니다.
455 | 하드 디스크와는 달리 ```___(나)___```가 없기 때문에 안정정과 신뢰도가 높다는 장점이 있습니다.
456 | >정답
457 | (가) : NAND형 플래시 메모리
458 | (나) : 기계장치 459 | 460 | ##### [문제 2] SSD에서 데이터 저장과 인출, 칩 관리 등과 같은 핵심적인 기능을 수행하는 전자회로 모듈을 무엇이라고 하는가? 461 | >정답 : SSD 제어기
462 | ** 데이터 저장과 인출, 칩 관리 등과 같은 핵심적인 기능을 수행하는 SSD 제어기는 펌웨어 수준의 프로그램 코드를 수행하는 임베디드 프로세서로 구현되며, SSD의 성능을 결정해주는 중요한 장치이다. 463 | 464 | ##### [문제 3] 다음은 SSD구성에 대한 그림이다. 그림을 참고하여 빈칸에 들어갈 소프트웨어의 명칭과 주요 역할을 작성하시오. 465 | 466 |  467 | >정답
468 | 명칭 : 플래시 변환 계층(Flash Translation Layer, FTL)
469 | 역할 : 기존의 파일시스템이나 운영체제가 HDD와 같은 방법으로 SSD를 엑세스 할수 있도록 해준다.
470 |
** SSD 제어기가 수행하는 FTL은 플래시 메모리의 블록과 페이지를 논리적으로 HDD의 트랙 및 섹터와 같은 구조로 변환해줌으로써 기존의 파일 시스템이나 운영체제와 같은 소프트웨어들이 SSD를 HDD와 같은 방법으로 접근할수 있도록 도와준다. 471 | 472 | ##### [문제 4] 플래시 변환 계층(FTL)은 페이지 주소와 섹터 주소간의 매핑 외에도, SSD의 성능향상을 위하여 수행하는 중요한 기능이 몇가지 더 있다. 어떠한 기능들이 있는지 작성하시오. 473 | >정답 : 마모 평준화(wear leveling), 쓰레기 수집(garbage collection), 초과 대비공간(over-provisioning)
474 | **
475 | 마모 평준화 : 플래시 메모리의 모든 페이지들이 균등하게 사용되도록 관리함으써 수명을 연장시키는 기술
476 | 쓰레기 수집 : 수정되었으나 삭제되지 않은 무효 페이지들을 모아두었다가 한꺼번에 삭제하는 작업
477 | 초과 대비공간 : 마모평준화의 효과를 높이기 위하여 SSD 내부에 추가해주는 여유 저장 공간 478 | 479 | 480 | ##### [문제 5] SSD의 구성요소인 플래시 메모리는 블록 단위의 삭제만 가능하기 때문에 쓰레기 수집(garbage collection)과정이 필요하다. 이 과정의 효율을 높이기 위한 운영체제(OS) 차원의 지원에 해당하는 것은?(기본문제 6.18) 481 | ``` 482 | 가. 주소 매핑 483 | 나. 오버-프로비저닝 484 | 다. TRIM 485 | 라. 미러링 486 | ``` 487 | >정답 : 다.
488 | ** TRIM 명령은 OS로 하여금 SSD 제어기에게 무효가 된 페이지들을 통보해줌으로써 쓰레기 수집의 효율을 높여 SSD의 성능을 향상시켜주는 보조 기능이다. 쓰레기 수집과 TRIM 명령은 삭제 횟수를 최소화시키는 데도 도움이 된다. 489 | 490 |
492 | -------------------------------------------------------------------------------- /13강 병렬컴퓨터.md: -------------------------------------------------------------------------------- 1 | # 🥳 HAPPY MIHYKIM DAY 🎉 2 | 3 |
 4 |
5 |
4 |
5 | 6 | 7 | ## 🦄 병렬컴퓨터 (13 / 13회차) 8 | 9 | ### 8.1 병렬처리의 개념 및 필요성 `daelee` 10 |
11 | 12 | #### [문제 1] 주로 슈퍼컴퓨터의 성능을 나타내는데 사용 되는 단위인 `플롭스(FLOPS)`는 어떤 단어의 약자(약어)일까요? 13 | 14 | 15 | #### [문제 2] `문제 분할`이란, 병렬처리를 위하여 하나의 문제를 여러 개로 나누는 작업을 말합니다. 하지만 문제 분할이 불가능한 경우도 있는데요, 어떤 경우일까요? 16 | 17 | 18 |
19 | 20 |
:page_facing_up: 답지
22 |25 | 26 | #### [문제 1] 주로 슈퍼컴퓨터의 성능을 나타내는데 사용 되는 단위인 `플롭스(FLOPS)`는 어떤 단어의 약자(약어)일까요? 27 | 28 | > 정답 : FLOPS == **FLoating point Operations Per Second** 29 | > 30 | > 초당 처리할 수 있는 부동소수점 연산의 횟수 31 | 32 | #### [문제 2] `문제 분할`이란, 병렬처리를 위하여 하나의 문제를 여러 개로 나누는 작업을 말합니다. 하지만 문제 분할이 불가능한 경우도 있는데요, 어떤 경우일까요? 33 | 34 | > 정답 : 35 | > 36 | > 1. 순차적으로 처리되어야만 하는 프로그램의 경우 37 | > 2. 균등한 크기로 나누지 못했을 때 프로세서 이용율이 낮아져 오히려 성능이 낮아지는 프로그램의 경우 38 |
39 | 40 |
43 | 44 | ### 8.2 병렬처리의 단위 `daelee` 45 |
46 | 47 | > 한 프로그램이 분할되어 각 프로세서에 분담되는 `단위 프로그램의 크기`에 따라 다양한 수준의 `병렬성`(parallelism)이 존재할 수 있다. 48 | 49 | #### [문제 1] 다음은 다양한 수준의 병렬성에 대한 예시들 입니다. 보기를 참고해 어떤 병렬성에 대한 예시인지 빈 칸에 적어주세요. 50 | 51 | ``` 52 | 작업-단위 병렬성, 태스크-단위 병렬성, 스레드-단위 병렬성, 명령어-단위 병렬성 53 | ``` 54 | 55 | 1. **<미혜👩🦰생일파티🎂준비위원장> 현준🙋♂️** 56 | 57 | 현준은 미혜 생일파티의 효율적인 준비를 위해 산초에게는 파티룸을 예약을, 쿠킴에게는 스터디원 초대를, 개킴에게는 생일 선물을 구매 해오라는 명령을 동시에 내렸다. 58 | 59 | : `__(a)__` 60 | 61 | 2. 현준은 미혜의 생일 케이크를 사러 둘썸플레이스에 방문한 김에, 집에 가는 길에 마실 아메리카노를 함께 구매했다. 62 | 63 | : `__(b)__` 64 | 65 | 3. 현준은 미혜에게 보낼 생일카드 롤링페이퍼를 제작하기 위해 파티 참여원들에게 각각 17글자 이내의 축하 메세지를 적어 자정까지 메시지로 보내달라고 부탁했다. 66 | 67 | : `__(c)__` 68 | 69 | 4. 현준은 총 13명의 파티 참여원들을 위해 미혜의 생일 케이크를 똑같은 크기의 13조각으로 잘라 나눠주었다. 70 | 71 | : `__(d)__` 72 | 73 |
74 | 75 |
:page_facing_up: 답지
77 |80 | 81 | > 한 프로그램이 분할되어 각 프로세서에 분담되는 `단위 프로그램의 크기`에 따라 다양한 수준의 `병렬성`(parallelism)이 존재할 수 있다. 82 | 83 | #### [문제 1] 다음은 다양한 수준의 병렬성에 대한 예시들 입니다. 보기를 참고해 어떤 병렬성에 대한 예시인지 빈 칸에 적어주세요. 84 | 85 | ``` 86 | 작업-단위 병렬성, 태스크-단위 병렬성, 스레드-단위 병렬성, 명령어-단위 병렬성 87 | ``` 88 | 89 | 1. **<미혜👩🦰생일파티🎂준비위원장> 현준🙋♂️** 90 | 91 | 현준은 미혜 생일파티의 효율적인 준비를 위해 산초에게는 파티룸을 예약을, 쿠킴에게는 스터디원 초대를, 개킴에게는 생일 선물을 구매 해오라는 명령을 동시에 내렸다. 92 | 93 | : `__(a)__` 94 | 95 | 2. 현준은 미혜의 생일 케이크를 사러 둘썸플레이스에 방문한 김에, 집에 가는 길에 마실 아메리카노를 함께 구매했다. 96 | 97 | : `__(b)__` 98 | 99 | 3. 현준은 미혜에게 보낼 생일카드 롤링페이퍼를 제작하기 위해 파티 참여원들에게 각각 17글자 이내의 축하 메세지를 적어 자정까지 메시지로 보내달라고 부탁했다. 100 | 101 | : `__(c)__` 102 | 103 | 4. 현준은 총 13명의 파티 참여원들을 위해 미혜의 생일 케이크를 똑같은 크기의 13조각으로 잘라 나눠주었다. 104 | 105 | : `__(d)__` 106 | 107 | > 정답 : 108 | > 109 | > - **(a) 태스크-단위 병렬성** 110 | > - 하나의 큰 작업을 내부적으로 기능에 따라 작은 프로그램으로 분리한 후 각 프로세스로 병렬 처리. 111 | > - **(b) 작업-단위 병렬성** 112 | > - 서로 다른 사용자 또는 한 사용자에 의해 여러 개의 프로그램이 독립적인 작업 단위으로서 병렬로 처리. 113 | > - **(c) 명령어-단위 병렬성** 114 | > - 명령어들이 사용할 데이터들 간에 의존 관계가 존재하지 않는다면 여러 명령어를 동시에 병렬로 수행할 수 있다. 슈퍼스칼라 구조를 가진 프로세서들은 이 병렬성을 이용하여 처리 속도를 높일 수 있다. 115 | > - **(d) 스레드-단위 병렬성** 116 | > - 동시에 처리될 수 있는 가작 작은 크기의 독립적인 단위로 나눠 병렬 처리. 멀티 스레딩. 117 | 118 | ##### 119 | 120 |
121 | 122 |
125 | 126 | ### 8.3 병렬컴퓨터의 분류 `sancho` 127 |
128 | 129 | 130 | #### [문제 1] Flynn의 분류에 따라 빈칸에 들어갈 이름을 적어 주세요. 131 | `__(a)__` : 한번에 한 개씩의 명령어와 데이터를 순서대로 처리하는 시스템
132 | `__(b)__` : 하나의 명령어 스트림을 실행하고 여러개 명령어 스트림을 동시 처리하는 시스템
133 | `__(c)__` : 여러 프로세서가 서로 다른 명령어를 실행하지만 데이터들을 하나의 스트림으로 처리하는 시스템
134 | `__(d)__` : N개의 프로세서들이 서로 다른 명령어와 데이터들을 처리하는 시스템
135 |
136 | 137 | #### [문제 2] MIMD에서 액세스 유형에 따른 분류로 설명에 대한 정답을 맞춰 주세요. 138 | 1. 상호연결망에 의해 접속된 기억장치들을 공유하고 어느 영역이든 액세스에 걸리는 시간이 같은 모델은? 139 | 2. UMA모듈이 상호연결망에 접속되며 전역 공유-기억장치를 가질 수 있고 모든 기억 장치들이 하나의 주소 공간을 형성하는 분산 공유 기억장치 형태로 구성되는 것은? 140 | 3. 프로세스가 원격 기억장치에 직접 액세스할 수 없고 노드에 액세스 요구 메세지를 보내어 전달받는 방식은? 141 |
142 | 143 | #### [문제 3] 분산시스템에 대해 설명해주세요. 144 | -> 145 |
146 | 147 | #### [문제 4] 클러스터 컴퓨터에 대해 설명해주세요. 148 | -> 149 |
150 | 151 | 152 |
153 | 154 |
:page_facing_up: 답지
156 |159 | 160 | #### [문제 1] Flynn의 분류에 따라 빈칸에 들어갈 이름을 적어 주세요. 161 | `SISD(단일 명령어 스트림-단일 데이터 스트림)조직` : 한번에 한 개씩의 명령어와 데이터를 순서대로 처리하는 시스템
162 | `SIMD(단일 명령어 스트림-복수 데이터 스트림)조직` : 하나의 명령어 스트림을 실행하고 여러개 명령어 스트림을 동시 처리하는 시스템
163 | `MISD(복수 명령어 스트림-단일 데이터 스트림)조직` : 여러 프로세서가 서로 다른 명령어를 실행하지만 데이터들을 하나의 스트림으로 처리하는 시스템
164 | `MIMD(복수 명령어 스트림-복수 데이터 스트림)조직` : N개의 프로세서들이 서로 다른 명령어와 데이터들을 처리하는 시스템
165 |
166 | #### [문제 2] MIMD에서 액세스 유형에 따른 분류로 설명에 대한 정답을 맞춰 주세요. 167 | 1. 상호연결망에 의해 접속된 기억장치들을 공유하고 어느 영역이든 액세스에 걸리는 시간이 같은 모델은? `UMA` 168 | 2. UMA모듈이 상호연결망에 접속되며 전역 공유-기억장치를 가질 수 있고 모든 기억 장치들이 하나의 주소 공간을 형성하는 분산 공유 기억장치 형태로 구성되는 것은? `NUMA` 169 | 3. 프로세스가 원격 기억장치에 직접 액세스할 수 없고 노드에 액세스 요구 메세지를 보내어 전달받는 방식은? `NORMA` 170 |
171 | #### [문제 3] 분산시스템에 대해 설명해주세요. 172 | -> 노드는 독립적인 컴퓨터이며 정보를 교환하거나 병렬처리가 필요할 때 네트워크를 통하여 통신합니다. 173 |
174 | #### [문제 4] 클러스터 컴퓨터에 대해 설명해주세요. 175 | -> 고속 LAN이나 네트워크 스위치에 의해 연결된 PC나 워크스테이션의 집합체로 모든 노드에 포함된 자원들이 단일 시스템 이미지로 사용될 수 있습니다. 사용자도 하나의 큰 시스템으로 간주하고 사용할 수 있습니다. 176 |
177 | 178 |
181 | 182 | ### 8.4 다중프로세서시스템 구조 - 공유기억장치 `yeosong` 183 |
184 | 185 | #### [문제 1] `공유 기억장치` 컴퓨터시스템에서 사용되는 상호연결 구조가 아닌 것은? (기본 8.10) 186 | 187 | ~~~ 188 | 가. 버스 189 | 나. 다단계상호연결망(MIN) 190 | 다. 매시 191 | 라. 크로스바스위치 192 | ~~~ 193 | 194 | -> 195 |
196 | 197 | #### [문제 2] 다음 중에서 `하드웨어 복잡도`가 가장 높은 연결 구조는 어느 것인가? 198 | 199 | ~~~ 200 | 가. 크로스바스위치 201 | 나. 다단계상호연결망 202 | 다. 버스 203 | 라. 계층버스 204 | ~~~ 205 | 206 | -> 207 |
208 | 209 | #### [문제 3] `공유-버스 시스템`에서 버스에 대한 `경합`을 줄이기 위한 방법을 한 가지만 답해보세요. (단답식) 210 | 211 | -> 212 |
213 | 214 | 215 | #### [문제 4] `버스 병목`을 줄이기 위해 높은 연결성을 제공하는 `크로스바 스위치`에 관한 문제입니다. 216 | 217 |
 218 |
219 | 1) 이와 같은 `크로스바 스위치` 모델에서 `프로세서`와 `메모리 모듈`이 **8개**씩 있는 경우,
220 | 이를 모두 연결하기 위한 `크로스바 스위치` 개수는?
221 |
222 | ->
223 |
218 |
219 | 1) 이와 같은 `크로스바 스위치` 모델에서 `프로세서`와 `메모리 모듈`이 **8개**씩 있는 경우,
220 | 이를 모두 연결하기 위한 `크로스바 스위치` 개수는?
221 |
222 | ->
223 | 224 | 225 | 226 | #### [문제 5] 크로스바 스위치의 개념을 이용하면서도 하드웨어 복잡성을 줄여주는 `오메가 네트워크`에 관한 문제입니다. 227 | 228 |
 229 |
230 | - 이와 같은 `오메가 네트워크` 모델에서 `프로세서`와 `메모리 모듈`이 **8개**씩 있는 경우, 이를 `오메가 네트워크`로 연결하기 위한 `스위칭 소자` 개수는?
231 |
232 | ->
233 |
229 |
230 | - 이와 같은 `오메가 네트워크` 모델에서 `프로세서`와 `메모리 모듈`이 **8개**씩 있는 경우, 이를 `오메가 네트워크`로 연결하기 위한 `스위칭 소자` 개수는?
231 |
232 | ->
233 | 234 | 235 | - 이 경우 필요한 `단계(스테이지)`의 수는? (참고: **s = log2N**) 236 | 237 | -> 238 |
239 | 240 |
:page_facing_up: 답지
242 |245 | 246 | #### [문제 1] `공유 기억장치` 컴퓨터시스템에서 사용되는 상호연결 구조가 아닌 것은? (기본 8.10) 247 | 248 | ~~~ 249 | 가. 버스 250 | 나. 다단계상호연결망(MIN) 251 | 다. 매시 252 | 라. 크로스바스위치 253 | ~~~ 254 | 255 | **->** 다. 매시
256 | **->** 439쪽. 가,나,라는 하나의 `공유 기억장치`에 접근하기 위한 방법이고,
257 | **->** `매시 네트워크`는 `분산 기억장치` 시스템 구조중 하나다. 258 |
259 | 260 | #### [문제 2] 다음 중에서 `하드웨어 복잡도`가 가장 높은 연결 구조는 어느 것인가? 261 | 262 | ~~~ 263 | 가. 크로스바스위치 264 | 나. 다단계상호연결망 265 | 다. 버스 266 | 라. 계층버스 267 | ~~~ 268 | 269 | **->** 가. 크로스바스위치
270 | **->** 프로세서 N개당 스위칭 소자가 N2개 필요하며 연결선도 그만큼 많이 필요하다. 271 |
272 | 273 | #### [문제 3] `공유-버스 시스템`에서 버스에 대한 `경합`을 줄이기 위한 방법을 한 가지만 답해보세요. (단답식) 274 | 275 | **->** 1. 캐시의 사용 2. 버스 수의 증가 3. 버스의 고속화가 있겠습니다. 276 |
277 | 278 | 279 | #### [문제 4] `버스 병목`을 줄이기 위해 높은 연결성을 제공하는 `크로스바 스위치`에 관한 문제입니다. 280 | 281 |
282 |
283 | - 이와 같은 `크로스바 스위치` 모델에서 `프로세서`와 `메모리 모듈`이 **8개**씩 있는 경우, 이를 모두 연결하기 위한 `크로스바 스위치` 개수는?
284 |
285 | **->** N2개로, 82 = 64개
286 | 287 | 288 | 289 | #### [문제 5] 크로스바 스위치의 개념을 이용하면서도 하드웨어 복잡성을 줄여주는 `오메가 네트워크`에 관한 문제입니다. 290 | 291 |
292 |
293 | - 이와 같은 `오메가 네트워크` 모델에서 `프로세서`와 `메모리 모듈`이 **8개**씩 있는 경우,
294 | 이를 `오메가 네트워크`로 연결하기 위한 `스위칭 소자` 개수는?
295 |
296 | **->** N/2로, 8/2 = 4개
297 | 298 | 299 | - 이 경우 필요한 `단계(스테이지)`의 수는? (참고: **필요한 스테이지 수 s = log2N**) 300 | 301 | **->** 3 302 |
303 | 304 |
307 | 308 | ### 8.4 다중프로세서시스템 구조 - 분산기억장치 `kycho` 309 |
310 | 311 | #### [문제 1] 다음은 분산-기억장치 시스템에 대한 설명입니다. OX를 체크하시오. 312 | - 분산-기억장치 시스템에서는 프로세서들이 기억장치를 공유한다. (O / X) 313 | - 분산-기억장치 시스템에서는 각 프로세서가 실행할 프로그램이 컴파일 단계에서부터 별도로 작성되어 각 프로세서의 기억장치에 적재되며, 프로세스들에 의해 공유되는 데이터들만 서로 교환된다. (O / X) 314 | - 분산-기억장치 시스템에서는 프로세서간의 통신량이 공유-기억장치 시스템에 비해 증가한다. ( O / X ) 315 | - 분산-기억장치 시스템에서는 프로세서간 통신 시간은 증가한다. ( O / X ) 316 |
317 | 318 | #### [문제 2] 다음 그림들을 보고 네트워크 구조 명칭을 작성해 주시오. 319 |  320 |
321 | 322 | #### [문제 3] 네트워크 내에서 가장 멀리 떨어진 노드들 간의 거리를 나타내는 용어는 무엇인가? 323 |
324 | 325 | #### [문제 4] 다섯 층으로 이루어진 트리 구조의 네트워크 지름은 얼마인가? (연습문제 8.10) 326 |
327 | 328 | #### [문제 5] E-큐브 라우팅을 이용하는 4차원 하이퍼큐브에서 패킷이 0번(0000) 노드에서 14번(1110) 노드로 전송될때 알맞는 경로는 무엇인가? 329 |  330 | ``` 331 | (가) 0000 -> 1000 -> 1100 -> 1110 332 | (나) 0000 -> 0010 -> 0110 -> 1110 333 | (다) 0000 -> 0100 -> 0110 -> 1110 334 | (라) 0000 -> 1000 -> 1010 -> 1110 335 | ``` 336 |
337 | 338 |
:page_facing_up: 답지
340 |343 | 344 | #### [문제 1] 다음은 분산-기억장치 시스템에 대한 설명입니다. OX를 체크하시오. 345 | - 분산-기억장치 시스템에서는 프로세서들이 기억장치를 공유한다. ( X ) 346 | >분산-기억장치 시스템에서는 프로세스들이 기억장치를 공유하지 않고, 각 프로세서가 자신의 기억장치를 별도로 가지고 있다. 347 | - 분산-기억장치 시스템에서는 각 프로세서가 실행할 프로그램이 컴파일 단계에서부터 별도로 작성되어 각 프로세서의 기억장치에 적재되며, 프로세스들에 의해 공유되는 데이터들만 서로 교환된다. ( O ) 348 | - 분산-기억장치 시스템에서는 프로세서간의 통신량이 공유-기억장치 시스템에 비해 증가한다. ( X ) 349 | >프로세스들은 공유되는 데이터들만 서로 교환하기 때문에 통신량은 크게 줄어든다. 350 | - 분산-기억장치 시스템에서는 프로세서간 통신 시간은 증가한다. ( O ) 351 | >프로세서간 통신은 일반적으로 메시지-패싱 방식으로 이루어지기 때문에 통신 시간이 증가한다. 352 |
353 | 354 | #### [문제 2] 다음 그림들을 보고 네트워크 구조 명칭을 작성해 주시오. 355 |  356 |
357 | 358 | #### [문제 3] 네트워크 내에서 가장 멀리 떨어진 노드들 간의 거리를 나타내는 용어는 무엇인가? 359 | >정답 : 네트워크 지름 360 | 361 | #### [문제 4] 다섯 층으로 이루어진 트리 구조의 네트워크 지름은 얼마인가? (연습문제 8.10) 362 | >정답 : 8
363 | 트리 구조에서 층의 수를 K라고 할때 네트워크 지름은 2(K - 1)이다.
364 | K = 5이므로, 네트워크 지름은 8이 된다.
365 | 간단하게 아래의 그림을 통해서도 네트워크 지름이 8임을 확인할 수 있다. 366 |  367 | 368 | #### [문제 5] E-큐브 라우팅을 이용하는 4차원 하이퍼큐브에서 패킷이 0번(0000) 노드에서 14번(1110) 노드로 전송될때 알맞는 경로는 무엇인가? 369 |  370 | ``` 371 | (가) 0000 -> 1000 -> 1100 -> 1110 372 | (나) 0000 -> 0010 -> 0110 -> 1110 373 | (다) 0000 -> 0100 -> 0110 -> 1110 374 | (라) 0000 -> 1000 -> 1010 -> 1110 375 | ``` 376 | >정답 : (나)
377 | 0000 XOR 1110 => 1110 (b3b2b1b0)
378 | b0 = 0 => x방향으로 이동 없음.
379 | b1 = 1 => y방향으로 이동
380 | b2 = 1 => z방향으로 이동
381 | b3 = 1 => 4차원 방향으로 이동
382 | 따라서, 아래 그림과 같이 0000 -> 0010 -> 0110 -> 1110 으로 이동한다. 383 |  384 | 385 |
386 | 387 |
390 | 391 | ### 8.4 다중프로세서시스템 구조 - 캐시일관성 `jakang` 392 |
393 | 1번. 다음 보기의 지문들을 읽고, 각각 'write-through' 정책과 'write-back' 정책 중 어떤 것과 관련되었는지를 구분하시오. 394 | 395 | `* Write-through ____________` 396 | 397 | `* Write-back ____________` 398 | 399 | a) 이 정책을 사용하는 경우, 캐시의 값을 바꿀 때 주기억장치를 같이 갱신한다.
400 | b) 이 정책의 복잡도는 다른 정책에 비해 크다.
401 | c) 이 정책을 사용하는 경우 스누프 제어기가 시스템 버스상의 쓰기 동작들만 감시하면 된다.
402 | d) 데이터가 수정된 캐시의 스누프 제어기는 그 사실을 다른 모든 스누프 제어기들에게 별도로 통보해야한다.
403 | 404 | 2번. 다음은 Write-back 쓰기 정책을 사용하는 시스템을 위한 캐시 일관성 유지 프로토콜 중 하나인 MESI 프로토콜과 관련한 것이다. 각 지문들의 참 거짓 여부를 표시하세요. 405 | 406 | `[ ]` 무효 상태는 다른 프로세서에 의해 데이터의 내용이 수정되었고, 그에 따라 현재 캐시에 적재되어 있는 그 데이터는 무효가 되었다는 것을 나타낸다. 407 | 408 | `[ ]` 배타 상태는 현재 캐시에 적재되어 있는 데이터가 다른 캐시에도 있는 복사본이고, 주기억장치의 내용과 동일한 상태라는 것을 나타낸다. 409 | 410 | `[ ]` 배타 상태에서 수정 상태로 바뀐 경우, 다른 캐시들에게 이 사실을 알릴 필요가 없다. 411 | 412 | `[ ]` 여러 캐시에 같은 데이터가 적재되어 있을 때 이들 캐시 중 한 곳에서 데이터가 새로운 값으로 수정되었다면, 프로세스는 무효화 신호를 다른 모든 캐시들로 보내고, 바뀐 데이터의 상태를 배타 상태로 바꾼다. 413 | 414 | 3번. 다음은 MESI 프로토콜을 사용하는 시스템에서 P1과 P2의 캐시에 X가 있고, P2가 X의 값을 Y로 변경하고 이어서 P1이 X의 값을 Z로 변경하려고 할 때 일어난 일들이다. 순서에 맞게 배열하시오. 415 | 416 | `___ -> ___ -> ___ -> ___` 417 | 418 | a) P1 캐시에 유효한 데이터가 캐시에 없기 때문에 '수정을 위한 읽기' 과정이 일어난다.
419 | b) P2는 자신의 데이ㅓ를 무효 상태로 변경한다.
420 | c) P2는 P1으로 캐시간 전송을 통해 자신의 데이터 Y를 보내준다.
421 | d) P1은 새로운 데이터 Z를 쓰고, 상태를 수정 상태로 세트한다.
422 |
423 |
437 | b) 이 정책의 복잡도는 다른 정책에 비해 크다.
438 | c) 이 정책을 사용하는 경우 스누프 제어기가 시스템 버스상의 쓰기 동작들만 감시하면 된다.
439 | d) 데이터가 수정된 캐시의 스누프 제어기는 그 사실을 다른 모든 스누프 제어기들에게 별도로 통보해야한다.
440 |
441 | 2번. 다음은 Write-back 쓰기 정책을 사용하는 시스템을 위한 캐시 일관성 유지 프로토콜 중 하나인 MESI 프로토콜과 관련한 것이다. 각 지문들의 참 거짓 여부를 표시하세요.
442 |
443 | `[ O ]` 무효 상태는 다른 프로세서에 의해 데이터의 내용이 수정되었고, 그에 따라 현재 캐시에 적재되어 있는 그 데이터는 무효가 되었다는 것을 나타낸다.
444 |
445 | `[ X ]` 배타 상태는 현재 캐시에 적재되어 있는 데이터가 다른 캐시에도 있는 복사본이고, 주기억장치의 내용과 동일한 상태라는 것을 나타낸다.
446 |
447 | : 다른 캐시에는 없는 복사본일 때에 배타 상태라고 한다.
448 |
449 | `[ O ]` 배타 상태에서 수정 상태로 바뀐 경우, 다른 캐시들에게 이 사실을 알릴 필요가 없다.
450 |
451 | `[ X ]` 여러 캐시에 같은 데이터가 적재되어 있을 때 이들 캐시 중 한 곳에서 데이터가 새로운 값으로 수정되었다면, 프로세스는 무효화 신호를 다른 모든 캐시들로 보내고, 바뀐 데이터의 상태를 배타 상태로 바꾼다.
452 |
453 | : 수정 상태로 바꾼다. 배타 상태는 주기억장치와 캐시의 데이터가 같을 때 해당함.
454 |
455 | 3번. 다음은 MESI 프로토콜을 사용하는 시스템에서 P1과 P2의 캐시에 X가 있고, P2가 X의 값을 Y로 변경하고 이어서 P1이 X의 값을 Z로 변경하려고 할 때 일어난 일들이다. 순서에 맞게 배열하시오.
456 |
457 | `a) -> c) -> b) -> d)`
458 |
459 | a) P1 캐시에 유효한 데이터가 캐시에 없기 때문에 '수정을 위한 읽기' 과정이 일어난다.
460 | b) P2는 자신의 데이ㅓ를 무효 상태로 변경한다.
461 | c) P2는 P1으로 캐시간 전송을 통해 자신의 데이터 Y를 보내준다.
462 | d) P1은 새로운 데이터 Z를 쓰고, 상태를 수정 상태로 세트한다.
463 |
424 |
425 | :page_facing_up: 답지
427 |
430 | 1번. 다음 보기의 지문들을 읽고, 각각 'write-through' 정책과 'write-back' 정책 중 어떤 것과 관련되었는지를 구분하시오.
431 |
432 | `* Write-through a) c)`
433 |
434 | `* Write-back b) d)`
435 |
436 | a) 이 정책을 사용하는 경우, 캐시의 값을 바꿀 때 주기억장치를 같이 갱신한다.
464 |
465 |
468 |
469 |
470 |
471 | ### 8.5 그래픽처리유니트(GPU) `taelee`
472 |
473 |
474 |
475 | #### [문제1]
그래픽처리 전용 프로세서이던 GPU가 일반목적용이라는 의미를 가진 GPGPU로 불리며 널리 보급되는 계기가 된 두 가지 주요 기술들은 무엇인가?(연습문제 8.17)
476 |
477 |
478 |
479 | #### [문제2]
CUDA 프로그래밍 모델에서 다음 설명에 맞는 용어들을 짝지어주세요
480 | ```보기) 디바이스, SM, 호스트, SP```
481 | 1) 일반적인 CPU를 지칭
482 | 2) GPU와 같은 병렬프로세서를 지칭
483 | 3) 실제 프로그램 코드를 수행하는 다수의 프로세서
484 | 4) 3번에서 지칭한 프로세서들 여러개들의 집합 + 프로세서들이 정보를 공유할 수 있게 도와주는 '공유기 억장치'
485 |
486 |
487 | #### [문제3]
다음은 CUDA 프로그램이 실행되는 과정이다. 빈칸은 채워주세요
488 |
489 | ```보기) SM, SP, 블록, 스레드```
490 | 1) 호스트가 순차적 코드를 실행한다.
491 | 2) 커널 함수가 호출되면, 병렬 커널 코드가 디바이스로 보내진다.
492 | 3) 디바이스에서 커널이 그리드(다수의 블록 및 스레드들 포함)를 생성한다.
493 | 4) 그리드 내에 '(a)'은 GPU내의 '(b)'에 1대1로 할당된다.
494 | 5) 그러면 (b)은 블록내의 '(c)'를 GPU내의 '(d)'에게 1대1로 할당한다.
495 | 4) 모든 스레드들의 실행이 완료되면 그리드가 종료되고, 결과값들이 호스트로 전송된다.
496 | 5) 호스트는 다음 순차적 코드를 실행하며, 또다른 커널을 만난다면 2~4번 과정을 반복한다.
497 |
498 | (a):
499 | (b):
500 | (c):
501 | (d):
502 |
503 |
504 |
505 | :page_facing_up: 답지
507 |
510 |
511 | #### [문제1]
그래픽처리 전용 프로세서이던 GPU가 일반목적용이라는 의미를 가진 GPGPU로 불리며 널리 보급되는 계기가 된 두 가지 주요 기술들은 무엇인가?(연습문제 8.17)
512 |
513 | - **통합된 그래픽 및 계산 구조**: 그래픽 응용뿐 아니라 일반적인 계산에도 적합한 통합적인 하드웨어 구조
514 | - **CUDA 프로그래밍 모델**: 일반적인 프로그래밍 언어들을 이용하여 GPU를 위한 프로그램을 쉽게 작성할 수 있게 해주는 프로그래머-친화적 병렬컴퓨팅 플랫폼으로서, NVIDIA사에 의해 개발된 프로그래밍 모델
515 | CUDA 프로그래밍의 예)
516 |
517 | ### 프리미어 New File 첫페이지
518 |  519 |
520 | ### Vrew 설정 페이지
521 |
519 |
520 | ### Vrew 설정 페이지
521 |  522 |
523 |
522 |
523 |
524 |
525 | #### [문제2]
CUDA 프로그래밍 모델에서 다음 설명에 맞는 용어들을 짝지어주세요
526 | ```보기) 디바이스, SM, 호스트, SP```
527 | 1) 일반적인 CPU를 지칭
528 | 2) GPU와 같은 병렬프로세서를 지칭
529 | 3) 실제 프로그램 코드를 수행하는 다수의 프로세서
530 | 4) 3번에서 지칭한 프로세서들 여러개들의 집합 + 프로세서들이 정보를 공유할 수 있게 도와주는 '공유기 억장치'
531 |
532 | **1) 호스트**
533 | **2) 디바이스**
534 | **3) SP(Streaming Processor)**
535 | **4) SM(Streaming Multiprocessor)**
536 |
537 |
538 |
539 | #### [문제3]
다음은 CUDA 프로그램이 실행되는 과정이다. 빈칸은 채워주세요
540 |
541 | ```보기) SM, SP, 블록, 스레드```
542 | 1) 호스트가 순차적 코드를 실행한다.
543 | 2) 커널 함수가 호출되면, 병렬 커널 코드가 디바이스로 보내진다.
544 | 3) 디바이스에서 커널이 그리드(다수의 블록 및 스레드들 포함)를 생성한다.
545 | 4) 그리드 내에 '(a)'은 GPU내의 '(b)'에 1대1로 할당된다.
546 | 5) 그러면 (b)은 블록내의 '(c)'를 GPU내의 '(d)'에게 1대1로 할당한다.
547 | 4) 모든 스레드들의 실행이 완료되면 그리드가 종료되고, 결과값들이 호스트로 전송된다.
548 | 5) 호스트는 다음 순차적 코드를 실행하며, 또다른 커널을 만난다면 2~4번 과정을 반복한다.
549 |
550 | **(a): 블록**
551 | **(b): SM(Streaming Multiprocessor)**
552 | **(c): 쓰레드**
553 | **(d): SP(Streaming Processor)**
554 |
555 |
556 |
559 |
560 | ```
561 |
562 | ```
563 |
--------------------------------------------------------------------------------
/09강 캐시.md:
--------------------------------------------------------------------------------
1 | ## 🦄 캐시 (9 / 13회차)
2 |
3 |
4 | ### 5.5 캐시 메모리 - 캐시용량, 인출방식 `taelee`
5 |
6 |
7 |
8 | #### [문제1]
CPU가 기억장치를 500번 액세스하는 동안에 원하는 데이터가 캐시에 있었던 횟수가 450번이었다면, 캐시 적중률은 얼마인가? (기본 5.19)
9 | 가. 0.45
10 | 나. 0.5
11 | 다. 0.9
12 | 라. 0.95
13 |
14 |
15 |
16 |
17 | #### [문제2]
캐시 액세스 시간이 10ns이고 주기억장치 액세스 시간이 200ns인 시스템에서 캐시 적중률이 0.8이라면, 평균 기억장치 액세스 시간은 얼마나 되는가? (기본 5.20)
18 | 가. 20ns
19 | 나. 48ns
20 | 다. 162ns
21 | 라. 210ns
22 |
23 |
24 |
25 |
26 | #### [문제3]
다음은 캐시를 만드는 일을 하는 캐시 설계가들의 대화이다. 각 주장에 맞는 지역성의 원리를 써주세요
27 |
28 | `taelee`: 자네들 프로그래밍에서 제일 중요한게 뭔줄 아나? 바로 반복문이야 반복문!!! 프로그래머는 중복을 피해야돼!
29 | 따라서 캐시 적중률을 높이려면 반복문처럼 가까운 미래에 쓰일 명령어를 캐시에 우선적으로 올려야돼!
30 | 그렇게 되면 반복문을 만났을 때 적중률이 아주 팡팡 터진다구!!
31 |
32 | `jakang`: 이보게 등장하자마자 왜이리 급발진을 하는겐가? 그리고 하나는 알고 둘은 모르는구만! 물론 반복문 같은 상황에서는 자네처럼 설계하는게 적중률이 좋겠지만 배열을 한번 생각해보게나
33 | 배열은 한번 만들어놓으면 배열에 담긴 값들을 아주 쉽게 그리고 '자주' 꺼내다 쓰게 된다고!
34 | 따라서 캐시 적중률을 올리려면 메인 메모리에서 인출했던 값 근처의 값들도 같이 적재해야돼! 그러면 적중률이 팡팡팡 터진다구
35 |
36 | `daelee`: 이보게들 복잡하게 그러지 말고 그냥 명령어가 저장된 순서대로 차곡차곡 순서대로 캐시에 올리면 어떻겠나?
37 |
38 |
39 |
40 |
41 | #### [문제4]
다음은 캐시 인출 방식에 대한 설명입니다. 빈칸을 채워주세요.
42 |
43 | 캐시 인출 방식에는 (a) 방식과 (b) 방식이 있다.
44 | (b) 방식은 CPU가 원하는 정보를 인출할 때 그 정보와 근접한 위치에 있는 정보들을 함께 인출하여 캐시에 적재하는데 그 이유는 (c) 때문이다.
45 | 이때 함께 인출되는 정보들의 그룹을 (d)라고 한다.
46 | 캐시는 (e)들로 구성되는데 이곳에 위에서 인출된 (d)를 적재된다.
47 |
48 |
49 |
50 |
51 | :page_facing_up: 답지
53 |
54 | #### [문제1]
CPU가 기억장치를 500번 액세스하는 동안에 원하는 데이터가 캐시에 있었던 횟수가 450번이었다면, 캐시 적중률은 얼마인가? (기본 5.19)
55 | 가. 0.45
56 | 나. 0.5
57 | **다. 0.9**
58 | 라. 0.95
59 |
60 | 풀이) 450/500 = 0.9
61 |
62 |
63 | #### [문제2]
캐시 액세스 시간이 10ns이고 주기억장치 액세스 시간이 200ns인 시스템에서 캐시 적중률이 0.8이라면, 평균 기억장치 액세스 시간은 얼마나 되는가? (기본 5.20)
64 | 가. 20ns
65 | **나. 48ns**
66 | 다. 162ns
67 | 라. 210ns
68 |
69 |
70 | 풀이) 10ns *0.8 + 200ns * 0.2 = 48ns
71 |
72 |
73 |
74 | #### [문제3]
다음은 캐시를 만드는 일을 하는 캐시 설계가들의 대화이다. 각 주장에 맞는 지역성의 원리를 써주세요
75 |
76 | `taelee`: 자네들 프로그래밍에서 제일 중요한게 뭔줄 아나? 바로 반복문이야 반복문!!! 프로그래머는 중복을 피해야돼!
77 | 따라서 캐시 적중률을 높이려면 반복문처럼 가까운 미래에 쓰일 명령어를 캐시에 우선적으로 올려야돼!
78 | 그렇게 되면 반복문을 만났을 때 적중률이 아주 팡팡 터진다구!!
79 |
80 | `jakang`: 이보게 등장하자마자 왜이리 급발진을 하는겐가? 그리고 하나는 알고 둘은 모르는구만! 물론 반복문 같은 상황에서는 자네처럼 설계하는게 적중률이 좋겠지만 배열을 한번 생각해보게나
81 | 배열은 한번 만들어놓으면 배열에 담긴 값들을 아주 쉽게 그리고 '자주' 꺼내다 쓰게 된다고!
82 | 따라서 캐시 적중률을 올리려면 메인 메모리에서 인출했던 값 근처의 값들도 같이 적재해야돼! 그러면 적중률이 팡팡팡 터진다구
83 |
84 | `daelee`: 이보게들 복잡하게 그러지 말고 그냥 명령어가 저장된 순서대로 차곡차곡 순서대로 캐시에 올리면 어떻겠나?
85 |
86 |
87 |
88 |
89 | `taelee`: 시간적 지역성(temporal locality)
90 |
91 | `jakang`: 공간적 지역성(spatial locality)
92 |
93 | `daelee`: 순차적 지역성(sequential locality)
94 |
95 |
96 |
97 | #### [문제4]
다음은 캐시 인출 방식에 대한 설명입니다. 빈칸을 채워주세요.
98 |
99 | 캐시 인출 방식에는 (a) 방식과 (b) 방식이 있다.
100 | (b) 방식은 CPU가 원하는 정보를 인출할 때 그 정보와 근접한 위치에 있는 정보들을 함께 인출하여 캐시에 적재하는데 그 이유는 (c) 때문이다.
101 | 이때 함께 인출되는 정보들의 그룹을 (d)라고 한다.
102 | 캐시는 (e)들로 구성되는데 이곳에 위에서 인출된 (d)를 적재된다.
103 |
104 |
105 | (a): 요구 인출(demand fetch)
106 | (b): 선인출(prefetch)
107 | (c): 지역성(locality)
108 | (d): 블록(block)
109 | (e): 라인(line) 혹은 슬롯(slot)
110 |
111 |
112 |
113 |
114 |
116 |
117 | ### 5.5 캐시 메모리 - 사상방식 jehong
118 |
119 | #### [문제 1] 장단점
120 |
121 | 보기를 참고해 두 사상방식의 장단점을 골라주세요
122 |
123 | ```
124 | <보기>
125 | a. Locality가 높다면 Hit Ratio가 매우 높아진다.
126 | b. 각 메인메모리 block이 적재될 수 있는 cache line이 한 개뿐이기 때문에 그 line을 공유하는 다른 블록이 적재되는 경우 교체된다. 만약 같은 라인에 사상된 두 개의 블록들로부터 데이터들을 번갈아 읽어와야 한다면 적중률이 낮아진다.
127 | c. Cache line들의 Tag들을 병렬로 검사하기 위해 매우 복잡하고 비용이 높은 회로가 필요해 하드웨어적으로 부담이 된다.
128 | d. 하드웨어가 간단하고 구현 비용이 적게 든다.
129 | e. 새로운 block이 cache로 적재될 때 line의 선택이 매우 자유롭다.
130 | ```
131 |
132 | | 사상방식 | 장점 | 단점 |
133 | | ------------------------------------------ | ---- | ---- |
134 | | 완전-연관 사상 (Fully-Associative Mapping) | | |
135 | | 직접 사상 (Direct Mapping) | | |
136 |
137 |
138 |
139 |
140 |
141 | #### [문제 2] 교재 연습문제
142 |
143 | **[연습 5.20]** 주기억장치 용량이 1MByte이고 캐시의 용량은 16KByte인 시스템에서 캐시 라인의 크기는 4바이트이다. 직접-사상 방식이 사용되는 경우에 아래 물음에 답하라.
144 |
145 | 1) 캐시에는 몇 개의 라인들이 존재하는가?
146 |
147 | 2) 주기억장치 블록의 수는 몇 개가 되는가?
148 |
149 | 3) 한 라인을 공유하는 주기억장치 블록들의 수는 몇 개인가?
150 |
151 | 4) 주소 형식과 각 필드의 비트 수를 결정하라.
152 |
153 |
154 |
155 | **[연습 5.21]** 세트-연관 캐시가 64개의 라인들을 가지고 있으며, 각 세트는 4개의 라인들로 구성된다. 주기억장치는 4096개의 블록들을 가지고 있으며, 각 블록은 16바이트로 구성된다. 주기억장치 주소의 형식을 결정하라.
156 |
157 |
158 |
159 |
160 |
161 | #### [문제 3] 캐시적중/캐시미스
162 |
163 | 다음은 [구글 독스](https://docs.google.com/spreadsheets/d/1loOrURClC-CGRWanTPE5sI6Gw77OU9OBAlVA1bD1Wxw/edit?usp=sharing) 로 이동해서 문제를 풀어주세요. CPU로부터 주어진 기억장치 주소들을 바탕으로 **캐시 적중 여부를 확인**하고 캐시 미스인 경우에는 **캐시 라인의 적재상황**을 채워주세요. 각 사상방식별로 총 **3개의 스프레드시트**가 있습니다.
164 |
165 |
166 |
167 |
168 |
169 | :page_facing_up: 답지
171 |
172 |
173 |
174 | #### [문제 1] 장단점
175 |
176 | 보기를 참고해 두 사상방식의 장단점을 골라주세요
177 |
178 | ```
179 | <보기>
180 | a. Locality가 높다면 Hit Ratio가 매우 높아진다.
181 | b. 각 메인메모리 block이 적재될 수 있는 cache line이 한 개뿐이기 때문에 그 line을 공유하는 다른 블록이 적재되는 경우 교체된다. 만약 같은 라인에 사상된 두 개의 블록들로부터 데이터들을 번갈아 읽어와야 한다면 적중률이 낮아진다.
182 | c. Cache line들의 Tag들을 병렬로 검사하기 위해 매우 복잡하고 비용이 높은 회로가 필요해 하드웨어적으로 부담이 된다.
183 | d. 하드웨어가 간단하고 구현 비용이 적게 든다.
184 | e. 새로운 block이 cache로 적재될 때 line의 선택이 매우 자유롭다.
185 | ```
186 |
187 | | 사상방식 | 장점 | 단점 |
188 | | ------------------------------------------ | ---- | ---- |
189 | | 완전-연관 사상 (Fully-Associative Mapping) | a, e | c |
190 | | 직접 사상 (Direct Mapping) | d | b |
191 |
192 |
193 |
194 |
195 |
196 | #### [문제 2] 교재 연습문제
197 |
198 | **[연습 5.20]** 주기억장치 용량이 1MByte이고 캐시의 용량은 16KByte인 시스템에서 캐시 라인의 크기는 4바이트이다. 직접-사상 방식이 사용되는 경우에 아래 물음에 답하라.
199 |
200 | 1) 캐시에는 몇 개의 라인들이 존재하는가?
201 |
202 | >**답: 212개**
203 | >
204 | >`캐시 용량` = 16KByte = 24 x 210 Byte = 214 Byte
205 | >
206 | >`캐시 라인 크기` = 4 Byte = 22 Byte
207 | >
208 | >`캐시 라인 수` = `캐시 용량` / `캐시 라인 크기` = 214 / 22 = 212
209 |
210 |
211 |
212 | 2) 주기억장치 블록의 수는 몇 개가 되는가?
213 |
214 | > **답: 218개**
215 | >
216 | > `주기억장치 용량` = 1MByte = 220 Byte
217 | >
218 | > `블록 크기` = 캐시 라인의 크기 = 22 Byte
219 | >
220 | > `블록의 수` = `주기억장치 용량` / `블록의 크기` = 220 / 22 = 218
221 |
222 |
223 |
224 | 3) 한 라인을 공유하는 주기억장치 블록들의 수는 몇 개인가?
225 |
226 | > **답: 26개**
227 | >
228 | > `블록의 수` = 218개
229 | >
230 | > `캐시 라인 수` = 212개
231 | >
232 | > `블록의 수` / `캐시 라인 수` = 218 / 212 = 26
233 |
234 |
235 |
236 | 4) 주소 형식과 각 필드의 비트 수를 결정하라.
237 |
238 | > **답: 태그 6비트, 라인 12비트, 단어 2비트**
239 | >
240 | > `주기억장치 용량` = 220 Byte 이므로 기억장치 주소는 총 20비트
241 | >
242 | > `블록 크기` = 22 이므로 단어는 2비트
243 | >
244 | > `캐시 라인 수` = 212 이므로 라인은 12비트
245 | >
246 | > 태그 필드는 20 - 2 - 12 = 6비트
247 |
248 |
249 |
250 | **[연습 5.21]** 세트-연관 캐시가 64개의 라인들을 가지고 있으며, 각 세트는 4개의 라인들로 구성된다. 주기억장치는 4096개의 블록들을 가지고 있으며, 각 블록은 16바이트로 구성된다. 주기억장치 주소의 형식을 결정하라.
251 |
252 | > **답: 태그 8비트, 세트 4비트, 단어 2비트**
253 | >
254 | > `주기억장치 용량` = `블록의 수` x `블록 크기`
255 | >
256 | > = 4096 x 16 Byte = 212 x 24 = 216 이므로 기억장치 주소는 총 16비트
257 | >
258 | > `블록 크기` = 24 이므로 단어는 4비트
259 | >
260 | > `세트 수` = `캐시 라인 수` / `세트당 라인 수` = 64 / 4 = 26 / 22 = 24 이므로 세트는 4비트
261 | >
262 | > 태그 필드는 16 - 4 - 4 = 8비트
263 |
264 |
265 |
266 |
267 |
268 | #### [문제 3] 캐시적중/캐시미스
269 |
270 | 다음은 [구글 독스](https://docs.google.com/spreadsheets/d/1loOrURClC-CGRWanTPE5sI6Gw77OU9OBAlVA1bD1Wxw/edit?usp=sharing) 로 이동해서 문제를 풀어주세요. CPU로부터 주어진 기억장치 주소들을 바탕으로 **캐시 적중 여부를 확인**하고 캐시 미스인 경우에는 **캐시 라인의 적재상황**을 채워주세요. 각 사상방식별로 총 **3개의 스프레드시트**가 있습니다.
271 |
272 | > 답지는 구글 독스 `ANSWER` 를 확인해주세요
273 |
274 |
276 |
277 | ### 5.5 캐시 메모리 - 교체알고리즘, 쓰기정책 `hylee`
278 |
279 |
280 | #### [문제 1]
281 | 세트-연관 사상 캐시로 아래와 같은 블록들이 연속적으로 액서스 됩니다. (연습문제 5.26)
282 |
283 |
284 | `1 2 2 1 3 1 4 5 4 7 4 1`
285 |
286 |
287 |
288 | 교체 알고리즘과 세트 당 라인 수가 다음과 같을 때의 캐시 적중률을 각각 구해주세요
289 |
290 | (1) FIFO 알고리즘, 라인 수 = 4개
291 |
292 | (2) LRU 알고리즘, 라인 수 = 4개
293 |
294 |
295 |
296 |
297 | #### [문제 2]
298 | 보기 중에 아래의 설명들과 알맞는 교체알고리즘을 골라서 짝지어주세요.
299 |
300 | ```(a) LFU (b) FIFO (c) LIU (d) LRU (e) LCU ```
301 |
302 | 1. 캐시에 가장 오랫동안 적재되어 있었던 블록을 교체하는 방식은?
303 |
304 | 2. 캐시에 적재된 이후 참조되었던 횟수가 가장 적은 블록을 교체하는 방식은?
305 |
306 | 3. 사용되지 않은 채로 가장 오랫동안 적재되어 있던 블록을 교체하는 방식은?
307 |
308 |
309 |
310 | #### [문제 3] 익명의 누군가 캐시의 쓰기 정책인 write-back 과 write-through에 대한 설명을 서로 섞어버렸습니다. 다시 각 쓰기정책에 알맞게 나누어주세요.
311 |
312 | ```
313 | write-back에 대한 설명들 : _______
314 | write-through에 대한 설명들 : _______
315 | ```
316 |
317 |
318 | (a) 모든 쓰기 동작들이 캐시로 뿐만 아니라 주기억장치로도 동시에 행해진다.
319 | (b) 읽기 및 쓰기 동작에서 미스가 발생한 경우에 새로 적재하려는 라인의 데이터가 수정된 상태이면 추가적인 시간이 소요된다.
320 | (c) 쓰기 동작 횟수가 최소화 된다.
321 | (d) 쓰기 시간이 짧아진다.
322 | (e) 쓰기 동작에 걸리는 시간이 길어진다.
323 | (f) 주기억장치의 블록을 무효상태에 있게 한다.
324 |
325 |
326 |
327 | :page_facing_up: 답지
329 |
330 | #### [문제 1]
331 | 세트-연관 사상 캐시로 아래와 같은 블록들이 연속적으로 액서스 됩니다. (연습문제 5.26)
332 |
333 |
334 | `1 2 2 1 3 1 4 5 4 7 4 1`
335 |
336 |
337 |
338 | 교체 알고리즘과 세트 당 라인 수가 다음과 같을 때의 캐시 적중률을 각각 구해주세요
339 | (주황색 바탕이면 캐시 적중)
340 |
341 | (1) FIFO 알고리즘, 라인 수 = 4개
342 |
H = 5 / 12
343 |
344 | 
345 |
346 |
347 | (2) LRU 알고리즘, 라인 수 = 4개
348 |
H = 6 / 12
349 |
350 | 
351 |
352 |
353 |
354 | #### [문제 2]
355 | 보기 중에 아래의 설명들과 알맞는 교체알고리즘을 골라서 짝지어주세요.
356 |
357 | ```(a) LFU (b) FIFO (c) LIU (d) LRU (e) LCU ```
358 |
359 | 1. 캐시에 가장 오랫동안 적재되어 있었던 블록을 교체하는 방식은?
360 |
**(b) FIFO (First-IN-First-Out)**
361 | 2. 캐시에 적재된 이후 참조되었던 횟수가 가장 적은 블록을 교체하는 방식은?
362 |
**(a) LFU (Least Frequently Used)**
363 | 3. 사용되지 않은 채로 가장 오랫동안 적재되어 있던 블록을 교체하는 방식은?
364 |
**(d) LRU (Least Recently Used)**
365 |
366 |
367 | #### [문제 3] 익명의 누군가 캐시의 쓰기 정책인 write-back 과 write-through에 대한 설명을 서로 섞어버렸습니다. 다시 각 쓰기정책에 알맞게 나누어주세요.
368 |
369 | ```
370 | write-back에 대한 설명들 : b, c, d, f
371 | write-through에 대한 설명들 : a, e,
372 | ```
373 |
374 |
375 | (a) 모든 쓰기 동작들이 캐시로 뿐만 아니라 주기억장치로도 동시에 행해진다.
376 | (b) 읽기 및 쓰기 동작에서 미스가 발생한 경우에 새로 적재하려는 라인의 데이터가 수정된 상태이면 추가적인 시간이 소요된다.
377 | (c) 쓰기 동작 횟수가 최소화 된다.
378 | (d) 쓰기 시간이 짧아진다.
379 | (e) 쓰기 동작에 걸리는 시간이 길어진다.
380 | (f) 주기억장치의 블록을 무효상태에 있게 한다.
381 |
382 |
383 |
384 |
385 |
387 |
388 | ### 5.5 캐시 메모리 - 다중캐시 `yeha`
389 |
390 | [문제 1] 각 보기에 대해 알맞은 설명을 모두 짝지어주세요.
391 | ```
392 | (1) 계층적 캐시(hierarchical cache)
393 | (2) 온-칩 캐시 (on-chip cache)
394 | (3) 분리 캐시 (split cache)
395 | ```
396 |
397 | a. 외부 버스를 통해 엑세스할 수 있는 캐시보다 액세스 시간이 더 짧아 전체 시스템 성능 향상에 도움이 된다.
398 | b. 명령어와 데이터를 분리하여 별도로 저장하는 캐시 구조
399 | c. CPU 칩 내부에 포함되어 있는 캐시
400 | d. 여러 레벨의 캐시들을 계층적으로 설치한 구조
401 | e. 칩에 집적할 수 있는 회로의 밀도가 높아짐에 따라 이 캐시가 가능하게 되었다.
402 |
403 | [문제 2] 2-단계 캐시 (L1 및 L2)와 주기억장치(M)로 구성된 기억장치시스템에서 용량의 크기 관계를 바르게 표시한 것은?
404 | a. L1 > L2 > M
405 | b. M > L1 > L2
406 | c. L1 < L2 < M
407 | d. M < L1 < L2
408 |
409 | [문제 3] 다음 설명을 읽고 맞으면 O, 틀리면 X하세요.
410 |
411 | 2-단계 캐시 (L1 및 L2)를 가진 시스템이 있습니다. CPU가 기억장치를 엑세스하려고 할 때,
412 | (1) 캐시 제어기는 L1와 L2를 검사한다. (O/X)
413 | (2) 데이터가 L1, L2에 없는 경우에만 주기억 장치를 액세스하게 된다. (O/X)
414 | (3) L1은 L2에 비해 속도는 더 빠르고, 적중률은 더 낮다. (O/X)
415 |
416 | [문제 4] 분리 캐시(split cache)를 사용하는 주요 이유는 무엇인가요?
417 | a. 캐시 엑세스 충돌 제거
418 | b. 캐시 크기 확장
419 | c. 캐시 적중률 향상
420 | d. 데이터 일관성 유지
421 |
422 | :page_facing_up: 답지
424 |
425 | [문제 1] 각 보기에 대해 알맞은 설명을 모두 짝지어주세요.
426 | ```
427 | (1) 계층적 캐시 (hierarchical cache)
428 | d. 여러 레벨의 캐시들을 계층적으로 설치한 구조
429 | (2) 온-칩 캐시 (on-chip cache)
430 | a. 시스템 버스를 통해 엑세스할 수 있는 캐시보다 액세스 시간이 더 짧아 전체 시스템 성능 향상에 도움이 된다.
431 | => 인출할 명령어나 데이터가 온-칩 캐시에 있다면 CPU 내부 버스를 통해 더 신속하게 엑세스할 수 있다.
432 | c. CPU 칩 내부에 포함되어 있는 캐시
433 | e. 칩에 집적할 수 있는 회로의 밀도가 높아짐에 따라 이 캐시가 가능하게 되었다.
434 | (3) 분리 캐시 (split cache)
435 | b. 명령어와 데이터를 분리하여 별도로 저장하는 캐시 구조
436 | ```
437 |
438 | [문제 2] 2-단계 캐시 (L1 및 L2)와 주기억장치(M)로 구성된 기억장치시스템에서 용량의 크기 관계를 바르게 표시한 것은?
439 |
440 | > c. L1 < L2 < M
441 | : L1은 온-칩 캐시며, 첫 번째 레벨 (1차) 캐시다. L2는 외부 캐시고, 두 번째 레벨 (2차) 캐시다. (최근 CPU 칩의 집적도가 높아짐에 따라 L2도 칩 내부에 포함되고 있다고 한다.) 온-칩 캐시인 L1의 크기는 제한되고, 외부에 있는 L2는 상대적으로 더 큰 용량을 가진다.
442 | L1, L2, 주기억장치는 계층적 구조를 이룬다. L1은 L2 내용의 일부분을 저장하고 있다. L1의 모든 내용이 L2에도 존재한다. 이러한 관계를 L2가 L1의 슈퍼-세트(super-set)라고 한다.
443 |
444 | [문제 3] 다음 설명을 읽고 맞으면 O, 틀리면 X하세요.
445 |
446 | 2-단계 캐시 (L1 및 L2)를 가진 시스템이 있습니다. CPU가 기억장치를 엑세스하려고 할 때,
447 | (1) 캐시 제어기는 L1와 L2를 검사한다. (X)
448 | > L1를 먼저 검사한 후 없을 때 L2를 검사한다.
449 |
450 | (2) 데이터가 L1, L2에 없는 경우에만 주기억 장치를 액세스하게 된다. (O)
451 | (3) L1은 L2에 비해 속도는 더 빠르고, 적중률은 더 낮다. (O)
452 |
453 | [문제 4] 분리 캐시(split cache)를 사용하는 주요 이유는 무엇인가요?
454 | > a. 캐시 엑세스 충돌 제거
455 | : 최근 명령어만 저장하는 명령어 캐시(instruction cache)와 데이터 캐시(data cache)로 분리시켜 용도를 구분하고 있다. 명령어 실행 파이프라인에서 명령어 인출 단계와 오퍼랜드 인출 단계 간에 캐시에 대한 충돌 현상을 제거할 수 있다. 대부분의 고속 프로세서에서 사용한다.
456 |
457 |
458 |
460 |
461 |
462 | ### 5.6 DDR SDRAM `kukim`
463 |
464 | #### 문제 : 다음은 쿠키 학생의 라이브 발표 입니다. 떨지 않도록 괄호의 a,b,c,d를 채워주세요.
465 | - a :
466 | - b :
467 | - c :
468 | - d :
469 |
470 | 안녕하세요. 메인 메모리 엑세스 기술의 발전에 대한 주제로 발표를 맡게된 쿠키입니다.
471 |
472 | 과거 Main Memory(RAM)은 DRAM의 집적도 기술의 발전으로 용량이 증가했어요 하지만 엑세스 속도는 증가하지 못하여 CPU와 RAM 사이의 엑세스 속도 문제로 병목 현상이 발생하였습니다. 이 문제를 해결하기 앞서 DRAM의 데이터 전송방식(엑세스)를 알아볼까요?
473 |
474 | DRAM이 CPU에 데이터 전송하는 방식은 비동기식이라고 해요. 이는 CPU가 RAM에 필요한 정보가 있거나 제어 신호가 들어오는 즉시 RAM이 엑세스 동작을 수행하는데 이때 엑세스가 시작하는 순간 CPU는 다른일을 하지 못하고 기다려야 했습니다.
475 |
476 | 이를 해결하기 위해서 DRAM 칩 내부를 조작하여 데이터 전송 방식을 동기식으로 변경하였는데 이것이 바로 (`a`) 입니다.
477 |
478 | (`a`)의 동작 방식은 다음의 예와 같아요.
479 |
480 | 1. CPU는 한 클록 주기 동안 시스템 버스를 통하여 주소와 읽기 신호를 기억장치로 보낸 다음 결과를 기다리지 않고 내부적으로 다른 연산을 수행한다.
481 | 2. (`a`)은 신호를 받은 즉시 엑세스 동작을 시작하고, 시스템 버스 사용권을 얻은 후 다음 한 클록 주기 동안 CPU에게 데이터를 전송한다.
482 | 3. CPU는 데이터를 받아 연산 수행한다.
483 |
484 | (`a`)은 DRAM에 비해 엑세스 속도가 빨라졌지만 한 클록 주기 당 기억장치 대역폭(memory bandwidth)만큼 데이터를 보낼 수 밖에 없었어요. 더 많은 데이터를 전송하기 위해선 어떻게 해야할까요?
485 |
486 | 이때 나온 기술이 바로 (`b`) 이에요. 한 클록 주기 당 기억장치 대역폭 만큼 데이터를 보내는데 이때 한 클록 주기 당 두 번 데이터를 전송하는 것이죠!
487 |
488 | 예를 들어 CPU와 MM(Main Memory)사이 버스 폭이 64bit이고 버스 클록 주파수가 100MHz라면 기억장치 대역폭은 (`c`)[MBytes/sec] 입니다. 이는 CPU와 기억장치 간에 초당 1억 번의 데이터 전송이 이루어지며, 매 전송 때마다 8바이트씩 이동되는 것이죠.
489 |
490 | 오우 참 멋지죠? 그렇다면 (`b`) 방식이라면 기억장치 대역폭은 무엇일까요? 네 바로 (`d`)[MByte/sec] 입니다. 다음 시간은 개킴님을 따라하는 미혜님같은 개킴같은 김미님이 발표하시겠습니다. 감사합니다.
491 |
492 | :page_facing_up: 답지
494 |
495 | #### 문제 : 다음은 쿠키 학생의 라이브 발표 입니다. 떨지 않도록 괄호의 a,b,c,d를 채워주세요.
496 | - a : SDRAM(동기식 DRAM)
497 | - b : DDR SDRAM(Double Data Rate SDRAM)
498 | - c : 800
499 | - d : 1600
500 |
501 | 안녕하세요. 메인 메모리 엑세스 기술의 발전에 대한 주제로 발표를 맡게된 쿠키입니다.
502 |
503 | 과거 Main Memory(RAM)은 DRAM의 집적도 기술의 발전으로 용량이 증가했어요 하지만 엑세스 속도는 증가하지 못하여 CPU와 RAM 사이의 엑세스 속도 문제로 병목 현상이 발생하였습니다. 이 문제를 해결하기 앞서 DRAM의 데이터 전송방식(엑세스)를 알아볼까요?
504 |
505 | DRAM이 CPU에 데이터 전송하는 방식은 비동기식이라고 해요. 이는 CPU가 RAM에 필요한 정보가 있거나 제어 신호가 들어오는 즉시 RAM이 엑세스 동작을 수행하는데 이때 엑세스가 시작하는 순간 CPU는 다른일을 하지 못하고 기다려야 했습니다.
506 |
507 | 이를 해결하기 위해서 DRAM 칩 내부를 조작하여 데이터 전송 방식을 동기식으로 변경하였는데 이것이 바로 (**SDRAM**) 입니다.
508 |
509 | (**SDRAM(동기식 DRAM)**)의 동작 방식은 다음의 예와 같아요.
510 |
511 | 1. CPU는 한 클록 주기 동안 시스템 버스를 통하여 주소와 읽기 신호를 기억장치로 보낸 다음 결과를 기다리지 않고 내부적으로 다른 연산을 수행한다.
512 | 2. (**SDRAM**)은 신호를 받은 즉시 엑세스 동작을 시작하고, 시스템 버스 사용권을 얻은 후 다음 한 클록 주기 동안 CPU에게 데이터를 전송한다.
513 | 3. CPU는 데이터를 받아 연산 수행한다.
514 |
515 | (**SDRAM**)은 DRAM에 비해 엑세스 속도가 빨라졌지만 한 클록 주기 당 기억장치 대역폭(memory bandwidth)만큼 데이터를 보낼 수 밖에 없었어요. 더 많은 데이터를 전송하기 위해선 어떻게 해야할까요?
516 |
517 | 이때 나온 기술이 바로 (**DDR(Double data rate) SDRAM**) 이에요. 한 클록 주기 당 기억장치 대역폭 만큼 데이터를 보내는데 이때 한 클록 주기 당 두 번 데이터를 전송하는 것이죠!
518 |
519 | 예를 들어 CPU와 MM(Main Memory)사이 버스 폭이 64bit이고 버스 클록 주파수가 100MHz라면 기억장치 대역폭은 (100MHz * 64) / 8 = (**800**)[MBytes/sec] 입니다. 이는 CPU와 기억장치 간에 초당 1억 번의 데이터 전송이 이루어지며, 매 전송 때마다 8바이트씩 이동되는 것이죠.
520 |
521 | 오우 참 멋지죠? 그렇다면 (**DDR**) 방식이라면 기억장치 대역폭은 무엇일까요? 네 바로 (**1600**)[MByte/sec] 입니다. 다음 시간은 개킴님을 따라하는 미혜님같은 개킴같은 김미님이 발표하시겠습니다.
522 |
523 |
525 |
526 |
527 | ### 5.7 차세대 비휘발성 기억장치 `mihykim`
528 |
529 | #### 다음 대화를 읽고, (a)와 (b)에 들어갈 단어를 맞춰주세요.
530 | - [힌트] 문제에 답이 모두 언급되어 있으니 꼼꼼히 읽어주세요.
531 |
532 | ```
533 | 😫kukim
534 | 교수님이 이번에는 차세대 '비휘발성 기억장치'를 주제로 라이브 발표를 준비해보라고 하셔서 걱정이에요.
535 | ```
536 | ```
537 | 🤔mihykim
538 | 헐 또요?
539 | 근데 지금 시점에 차세대 기억장치를 왜 찾으시는걸까연? 지금도 충분히 EEPROM도 있고, SDRAM도 있는뎅..
540 | ```
541 | ```
542 | 😳secho
543 | 흐음 (농담곰 고민모드)
544 | 제가 알기론 EEPROM은 비휘발성이지만 액세스 시간이 긴 편이어서 한계가 있다네요.
545 | ```
546 | ```
547 | 🙄jehong
548 | 아항~ 그렇겠네요.
549 | DRAM은 계속 발전하고 있다지만 휘발성이라 또 한계가 있는 듯 해용.
550 | ```
551 | ```
552 | 🧐jakang
553 | 맞아요~
554 | 게다가 DRAM은 지금 이미 작아질대로 작아져서 더 작게 만들면 양자현상 때문에 메모리 역할을 못한대요.
555 | ```
556 | ```
557 | 😲yeha
558 | 비휘발성이면서도 속도가 빠른 기억장치가 없다니...
559 | 건희야, 그럼 두 마리 토끼를 잡을 수 있는 기억장치가 차세대 기억장치라고 발표하면 어때?
560 | ```
561 | ```
562 | 😝daelee
563 | 앗ㅠ 지금 쿠킴님 차례인가요ㅠ
564 | 늦어서 죄송합니다ㅠ 대신 끝나고 캐롤 불러드릴게요ㅠ
565 | ```
566 | ```
567 | 😎taelee
568 | 여러분, 놀라지 마세요.
569 | 제가 방금 연희님께서 말씀하신 키워드로 검색해봤는데 'PRAM', 'FRAM', 'MRAM'이 나왔어요.
570 | 수십년동안 기억장치 개발이 추진되었는데 실질적으로 사업화된건 이 셋 뿐이래요.
571 | 쿠킴님 발표준비 이거면 끝이시겠는데요.
572 | 어때요, 쩔었어요?
573 | ```
574 | ```
575 | 😄gaekim
576 | 오오오오... 대,,박,,,
577 | 쿠킴님 추카드려요오,,,
578 | 그럼 RAM 앞에 붙은 'P', 'F', 그리고 'M'은 무슨 뜻이에요오,,,?
579 | ```
580 | ```
581 | 😌hylee
582 | (스-읍)아 이거 제가 공대 짬밥으로 맞출 수 있을 것 같아요
583 | P는 Phase Change를 의미해서 상변화를 이용하는 거고
584 | F는 Ferro-electric(강유전체)를 의미해서 분극을 이용하는 거에요.
585 | ```
586 | ```
587 | 🤯mihykim
588 | 네...?
589 | 한국어로 다시 설명해주세연...
590 | ```
591 | ```
592 | 😌hylee
593 | (스-읍)아, 강유전체는 외부의 전기장이 없이도 스스로 분극을 가지는 재료에요.
594 | ```
595 | ```
596 | 😁yeosong
597 | 헉 어렵네요....ㅋㅋㅋ
598 | 저만 모르겠는거 아니죠...ㅋㅋㅋ
599 | 아 M은 Magneto-resistive(자기저항)인가봐요!
600 | ```
601 | ```
602 | 😃kycho
603 | 그렇군요!
604 | 차세대 기억장치와 함께라면, 반도체 집적도가 2년마다 2배로 증가한다는 '무어의 법칙'이 부활하는 것도 기대해 볼 수 있겠어요.
605 | 반도체 메모리 용량이 매년 2배로 늘어난 다는 '황의 법칙'의 부활도요.
606 | ```
607 | ```
608 | 😋sancho
609 | 오호~
610 | 조금 신기한 점은 기존의 기억장치들은 다 '___(a)___' 기반이었는데, 지금 언급된 차세대 기억장치들은 다 '___(b)___' 기반이네요.
611 | ```
612 | ```
613 | 🥰kukim
614 | 전하~~~ 성은이 망극
615 | 앗 죄송합니다.
616 | 모두들 같이 고민해주셔서 감사해요!
617 | 그럼 다같이 머리님 캐롤을 들어볼까요~?
618 | ```
619 |

:page_facing_up: 답지
623 | 624 | ``` 625 | 😋sancho 626 | 오호~ 627 | 조금 신기한 점은 기존의 기억장치들은 다 '전하' 기반이었는데, 지금 언급된 차세대 기억장치들은 다 '저항' 기반이네요. 628 | ``` 629 | 630 |
632 | --------------------------------------------------------------------------------