├── 01 sum_tree
├── README.md
├── images
│ ├── 1_init_01.PNG
│ ├── 1_init_02.PNG
│ ├── 2_update_01.PNG
│ ├── 2_update_02.PNG
│ ├── 2_update_03.PNG
│ ├── 2_update_04.PNG
│ ├── 2_update_05.PNG
│ ├── 2_update_06.PNG
│ ├── 2_update_07.PNG
│ ├── 2_update_08.PNG
│ ├── 2_update_09.PNG
│ ├── 3_search_01.PNG
│ ├── 3_search_02.PNG
│ ├── 3_search_03.PNG
│ ├── 4_finish_01.png
│ ├── README.md
│ ├── data_100.png
│ ├── data_1000.png
│ ├── data_10000.png
│ ├── data_1000000.png
│ └── data_origin.png
└── sum_tree.py
├── 02 KNN & KD-tree
├── README.md
├── kd_tree.py
└── knn_basic.py
├── 03 min_tree
├── README.md
└── min_tree.py
├── 04 max_tree
├── README.md
└── max_tree.py
└── README.md
/01 sum_tree/README.md:
--------------------------------------------------------------------------------
1 | # Sum Tree
2 | * sum tree는 binary tree 구조로 sampling에 있어서 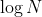 을 보장한다.
3 | * ex) 1,000,000 개의 데이터일경우 마지막 data를 단순 서치하면 1,000,000 인데, 이다.
4 | * 재밌는 특징으로 단순히 leaf node까지의 search만으로 확률적 특성이 반영된 sampling이 가능하다.
5 | - - -
6 |
7 | ### 1. Initialize
8 | * replay buffer와 sum tree를 표현할 Array를 0으로 초기화 해준다.
9 | * replay buffer의 size는 buffer_size.
10 | * sum tree의 size는 (buffer_size * 2) - 1. ex) buffer_size = 8, sum_tree size = 16 - 1 = 15 = 총 node 수.
11 | ```python
12 | self.replay_buffer = [0 for i in range(buffer_size)] # set rplay buffer size.
13 | self.array_tree = [0 for i in range((buffer_size * 2) - 1)] # set sum_tree size (double of buffer size)
14 | ```
15 |
16 |

17 |

18 |
51 |

52 |

53 |
55 |

56 |

57 |
61 |

62 |

63 |
65 |

66 |

67 |
71 |

72 |
100 |

101 |

102 |
104 |

105 |
116 |

117 |

118 |
122 |

123 |

124 |
126 |

127 |

128 |