├── images
├── diff-process.jpg
├── scope-chain.jpg
├── vnode-patch.jpg
├── old-length-and-new-one.jpg
└── old-one-and-new-length.jpg
├── docs
├── Object.create(null) 与 {} 究竟有什么不一样.md
├── 【 Vue 源码分析 】生命周期 Lifecycle.md
├── 【 Vue 源码分析 】为什么不推荐使用 $forceUpdate.md
├── 【 Vue 源码分析 】数据初始化之响应式探究(下).md
├── 【 Vue 源码分析 】编译 Compile(上).md
├── 【 Vue 源码分析 】数据初始化之依赖更新.md
├── 【 Vue 源码分析 】方法 Methods.md
├── 【 Vue 源码分析 】数据初始化之响应式探究(上).md
├── 【 Vue 源码分析 】混合 Mixin(上).md
├── 【 Vue 源码分析 】从 Template 到 DOM 过程是怎样的.md
├── 【 Vue 源码分析 】数据初始化之依赖收集(下).md
├── 【 Vue 源码分析 】数据初始化之依赖收集(上).md
├── 【 Vue 源码分析 】渲染 Render (AST -> VNode).md
├── 【 Vue 源码分析 】侦听器 Watch.md
├── 【 Vue 源码分析 】计算属性 Computed.md
├── 【 Vue 源码分析 】混合 Mixin(下).md
├── 【 Vue 源码分析 】运行机制之 Props.md
├── 【 Vue 源码分析 】异步更新队列之 NextTick.md
├── 【 Vue 源码分析 】编译 Compile(下).md
└── 【 Vue 源码分析 】如何在更新 Patch 中进行 Diff.md
└── README.md
/images/diff-process.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Leo-lin214/about-Vue/HEAD/images/diff-process.jpg
--------------------------------------------------------------------------------
/images/scope-chain.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Leo-lin214/about-Vue/HEAD/images/scope-chain.jpg
--------------------------------------------------------------------------------
/images/vnode-patch.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Leo-lin214/about-Vue/HEAD/images/vnode-patch.jpg
--------------------------------------------------------------------------------
/images/old-length-and-new-one.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Leo-lin214/about-Vue/HEAD/images/old-length-and-new-one.jpg
--------------------------------------------------------------------------------
/images/old-one-and-new-length.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Leo-lin214/about-Vue/HEAD/images/old-one-and-new-length.jpg
--------------------------------------------------------------------------------
/docs/Object.create(null) 与 {} 究竟有什么不一样.md:
--------------------------------------------------------------------------------
1 | ## 创建对象
2 |
3 | 我们都知道,创建一个 JavaScript 对象,可以有如下几种方法,分别是:
4 |
5 | - 通过`Object`实例化创建;
6 |
7 | ```javascript
8 | var obj = new Object()
9 | obj.name = 'Andraw'
10 | obj.getName = function() {
11 | return this.name
12 | }
13 | ```
14 |
15 | - 使用对象子面量方法;
16 |
17 | ```javascript
18 | var obj = {
19 | name: 'Andraw',
20 | getName: function() {
21 | return this.name
22 | }
23 | }
24 | ```
25 |
26 | 也许会有同学会提出,使用`Object.create`方法同样也可以创建对象。没错,该方法的确可以用于创建一个对象,但为啥我并没有放到上面进行提及呢?
27 |
28 | 原因很简单,就是`Object.create`方法会破坏对象的原型对象,也即相当于继承于某个指定的对象,我们来看看
29 |
30 | ```javascript
31 | function Person(name) {
32 | this.name = name
33 | }
34 | var person = new Person('Andraw')
35 | var newPerson = Object.create(person)
36 | console.log(newPerson.__proto__ === person) // true
37 | ```
38 |
39 | 好明显,变量 newPerson 的`__proto__`原型指针直接指向了变量 person。与上面两种不一样,上面两种中的变量 obj 的`__proto__`原型指针直接指向顶层的`Object.prototype`。
40 |
41 |
42 |
43 | ## 对比 Object.create(null) 与 {}
44 |
45 | 从上述的阐述,可以了解到,`Object.create`就是继承了某个指定的对象。
46 |
47 | 在`Object.create(null)`中,明显就是创建一个继承`null`的对象出来。而对于`{}`,则是顶层`Object`直接所创建的实例。
48 |
49 | 接下来就看看两者的结构有什么不一样
50 |
51 | ```javascript
52 | console.log(Object.create(null));
53 | // {}
54 | // No properties
55 |
56 | console.log({})
57 | // {}
58 | // __proto__:
59 | // constructor: ƒ Object()
60 | // hasOwnProperty: ƒ hasOwnProperty()
61 | // isPrototypeOf: ƒ isPrototypeOf()
62 | // propertyIsEnumerable: ƒ propertyIsEnumerable()
63 | // toLocaleString: ƒ toLocaleString()
64 | // toString: ƒ toString()
65 | // valueOf: ƒ valueOf()
66 | // __defineGetter__: ƒ __defineGetter__()
67 | // __defineSetter__: ƒ __defineSetter__()
68 | // __lookupGetter__: ƒ __lookupGetter__()
69 | // __lookupSetter__: ƒ __lookupSetter__()
70 | // get __proto__: ƒ __proto__()
71 | // set __proto__: ƒ __proto__()
72 | ```
73 |
74 | 从代码上可以看到,**`Object.create(null)`创建出来后就是一个没任何属性的纯对象,而`{}`则会拥有一个`__proto__`原型指针,用于指向`Object.prototype`,因此可以通过`__proto__`直接访问`Object.prototype`中的属性**。
75 |
76 | 在应用场景上,使用`Object.create(null)`可以创建一个无任何依赖的纯对象,以便对对象的维护以及处理。而`{}`由于拥有顶层`Object`,因此可以对其属性直接根据原型链来访问一些常用方法,如`toString`、`valueOf`等方法。
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】生命周期 Lifecycle.md:
--------------------------------------------------------------------------------
1 | ## 简单聊聊生命周期
2 |
3 | 对生命周期,相信各位都不陌生。在生命周期钩子函数中,可以做一些数据初始化、DOM操作等等。下面就借用一下官方给出的生命周期图示。
4 |
5 | 
6 |
7 | 官方给出的图很好理解,无非就是当程序执行到每一个阶段时,都会调用一个钩子函数,便于处理一些`javascript`业务逻辑。调用顺序如下:
8 |
9 | ```javascript
10 | // 元素挂载时
11 | beforeCreate --> created --> beforeMount --> mounted
12 |
13 | // 元素更新时
14 | beforeUpdate --> updated
15 |
16 | // 元素销毁时
17 | beforeDestroy --> destroyed
18 | ```
19 |
20 |
21 |
22 | ## 从源码的角度进行分析
23 |
24 | 在开始分析之前,不得不提一下上一章节的[【 Vue 源码分析 】混合 Mixin(上)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/[%20Vue%20源码分析%20]混合%20Mixin(上).md)中提及的生命周期合并。拥有`Mixin`的组件,会先执行`Mixin`中的生命周期钩子函数,最好再执行组件本身的生命周期钩子。
25 |
26 | 为什么要这样处理?相信很多同学都会都类似的提问,这是因为`Mixin`作为一个组件间的抽象层,一般都会处理一些配置信息、数据初始化等操作。(如果有不了解的同学,我都建议先看看上两篇的关于`Mixin`的讲解)。
27 |
28 | 其实对于生命周期的讲解,相信同学们看一下源码都会基本知道是怎么一回事,无非就是在一定的阶段直接调用相应的钩子函数即可。(哈哈,是不是很简单 😄。。)下面就进行一个简单讲解。
29 |
30 | ```javascript
31 | initLifecycle(vm);
32 |
33 | function initLifecycle (vm) {
34 | var options = vm.$options;
35 | // ...
36 | vm.$children = []; // 初始化子项
37 | vm.$refs = {}; // 初始化相关联的DOM元素
38 |
39 | vm._watcher = null; // 初始化Wacther依赖
40 | vm._inactive = null;
41 | vm._directInactive = false;
42 | vm._isMounted = false; // 是否已经执行挂载钩子函数标识
43 | vm._isDestroyed = false; // 是否执行销毁钩子函数标识
44 | vm._isBeingDestroyed = false; // 是否正处于销毁中标识
45 | }
46 | ```
47 |
48 | 在初始生命周期上,可以看到先设置一些相关配置项,如子项、依赖、挂载钩子执行标识以及销毁钩子执行标识等等。
49 |
50 | 也许你会问这些标识有什么用?其实很简单,拥有这些标识就相当于对生命周期进行一个判断,然后才允许去做一系列的逻辑处理,从而避免了生命周期逻辑处理交叉。
51 |
52 | 既然初始化了生命周期的配置,那么生命周期的钩子函数又是如何调用的呢?
53 |
54 | 在这里,我就不卖关子了,其实在所有生命周期钩子函数执行前,都会先`Mixin`混合起来,然后在每一个阶段,通过调用`callHook`函数,来执行相应阶段生命周期的钩子函数。那么我们就来看看`callHook`是咋样的 🤔
55 |
56 | ```javascript
57 | function callHook (vm, hook) {
58 | pushTarget();
59 | var handlers = vm.$options[hook]; // 先在实例上拿到对应合并好的生命周期钩子函数
60 | var info = hook + " hook"; // 标记生命周期阶段信息文案
61 | if (handlers) { // 当存在合并好的生命周期钩子函数时,就遍历执行
62 | for (var i = 0, j = handlers.length; i < j; i++) {
63 | invokeWithErrorHandling(handlers[i], vm, null, vm, info); // 执行函数并处理错误
64 | }
65 | }
66 | if (vm._hasHookEvent) { // 针对事件的处理,暂不讲解
67 | vm.$emit('hook:' + hook);
68 | }
69 | popTarget();
70 | }
71 |
72 | function invokeWithErrorHandling (
73 | handler,
74 | context,
75 | args,
76 | vm,
77 | info
78 | ) {
79 | var res;
80 | try {
81 | res = args ? handler.apply(context, args) : handler.call(context); // 绑定上下文执行生命周期钩子函数
82 | if (res && !res._isVue && isPromise(res) && !res._handled) {
83 | res.catch(function (e) { return handleError(e, vm, info + " (Promise/async)"); });
84 | // issue #9511
85 | // avoid catch triggering multiple times when nested calls
86 | res._handled = true;
87 | }
88 | } catch (e) {
89 | handleError(e, vm, info);
90 | }
91 | return res
92 | }
93 |
94 | // 不同阶段调用时,如
95 | callHook(vm, 'beforeCreate');
96 | ```
97 |
98 | 从上面可以看到,通过一个`callHook`函数来执行合并好的生命周期函数,并处理相应的错误。
99 |
100 | 总结:生命周期在理解上并不难,主要是搞清楚其怎么初始化、怎么调用即可。
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】为什么不推荐使用 $forceUpdate.md:
--------------------------------------------------------------------------------
1 | ## 从响应式对象新增属性说起
2 |
3 | 我们先看一个日常的栗子 🌰 :
4 |
5 | ```javascript
6 | // html
7 |
8 | {{ message.value }}
9 |
10 |
11 |
12 |
13 | // js
14 | const app = new Vue({
15 | el: '#app',
16 | data: {
17 | message: {
18 | value: 'Display a message...'
19 | }
20 | },
21 | methods: {
22 | showTest() {
23 | this.message.isShow = true
24 | },
25 | hideTest() {
26 | this.message.isShow = false
27 | }
28 | }
29 | })
30 | ```
31 |
32 | 我们都知道,当我们点击展示信息的按钮时,会发现信息组件是不会展示出来。官方文档也有说过,**Vue 不能检测对象属性的添加或删除**。
33 |
34 | 那么,若我想点击按钮时候,界面上信息组件能按要求展示与否时,该如何处理呢?
35 |
36 | 这里就不卖关子,其实可以有三种处理方案:
37 |
38 | - 设置响应式对象中`isShow`属性为响应式
39 | - 全局`$set`方法
40 | - `$forceUpdate`强制更新
41 |
42 | 官方中提及过,前两种方式是极其推荐的方式,而最后一种方法则是不推荐的,让我们来看看官方对`$forceUpdate`的评价:
43 |
44 | > 如果你发现你自己需要在 Vue 中做一次强制更新,99.9% 的情况,是你在某个地方做错了事。
45 |
46 | 😂,官方说的真的很直接,除非万不得已的地步,都是永远不推荐使用`$forceUpdate`方法,那到底是为什么呢?接下来让我们从源码中去看看。
47 |
48 |
49 |
50 | ## 从源码的角度分析
51 |
52 | ```javascript
53 | Vue.prototype.$forceUpdate = function () {
54 | var vm = this; // 获取当前 Vue 实例
55 | if (vm._watcher) {
56 | vm._watcher.update(); // 只对当前的 Vue 实例进行更新操作
57 | }
58 | }
59 | ```
60 |
61 | 如果看过我上一篇对于依赖更新讲解的同学,应该就很好理解这部分代码。调用`$forceUpdate`方法时,会先获取当前 Vue 实例,然后判断当前实例上是否存在 Watcher 依赖,若存在则直接调用其 update 方法来通知每一个依赖执行相应的更新回调函数。
62 |
63 | 那么问题来了,Vue 实例上的`_watcher`是在什么时候设置的?
64 |
65 | 其实在组件挂载并创建相应的 Watcher 依赖时,就已经将当前依赖挂载到当前 Vue 实例上,让我们看看源码的实现:
66 |
67 | ```javascript
68 | function mountComponent (
69 | vm,
70 | el,
71 | hydrating
72 | ) {
73 | // ...
74 | new Watcher(vm, updateComponent, noop, {
75 | before: function before () {
76 | if (vm._isMounted && !vm._isDestroyed) {
77 | callHook(vm, 'beforeUpdate');
78 | }
79 | }
80 | }, true /* isRenderWatcher */);
81 | // ...
82 | }
83 |
84 | var Watcher = function Watcher (
85 | vm,
86 | expOrFn,
87 | cb,
88 | options,
89 | isRenderWatcher
90 | ) {
91 | this.vm = vm;
92 | if (isRenderWatcher) { // 挂载组件时,默认都会为 true
93 | vm._watcher = this; // 将当前 Watcher 依赖设置到 Vue 实例上
94 | }
95 | // ...
96 | }
97 |
98 | ```
99 |
100 | 至此,一个`$forceUpdate`的实现思想你应该也有了印象。那么回到正题,你是否能看到官方还是不建议使用`$forceUpdate`方法么?
101 |
102 | 按我的理解,对比上一篇提及的全局`$set`方法,它和`$forceUpdate`有一个共同点,就是通知依赖进行更新。但是你有没有发现全局`$set`方法有一个点是`$forceUpdate`方法没有的么?
103 |
104 | 没错,那就是**设置新增的属性为响应式** 🤔 。从`$forceUpdate`方法实现上,你会发现,由此至终它只做一件事情,那就是通知 Watcher 依赖进行更新。如果对于新增属性的处理时,由于它不会将新增的属性重新设置为响应式,因此下一次若想操作新增属性时,还会需要重新调用一次`$forceUpdate`方法。另一方面,对于这类非响应式的属性的后期管理也是个大问题,当数据变得臃肿时,对于哪些是响应式属性,哪些是非响应式属性,以及是否需要调用`$forceUpdate`方法都会是一个考验开发者的难题。
105 |
106 | 直到现在,我依然觉得`$forceUpdate`方法更像我们生活里的一次性工具,用完就完事了,不需要考虑其他事情,当下次再需要做事时,再用一次新的一次性工具,用完即丢掉。但是你有没有想过,一次性工具是没有循环利用,只会导致资源的浪费~~😼。与此相反的,就是响应式,不管如何使用都会是同一样东西,刚好就符合了循环利用的目的。
107 |
108 | 好了,现在我们来总结一下不推荐使用`$forceUpdate`方法原因:
109 |
110 | - `$forceUpdate`方法无法设置新增属性为响应式;
111 | - `$forceUpdate`方法不利于后期的变量维护,对于项目中是否需要调用是不可控的;
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】数据初始化之响应式探究(下).md:
--------------------------------------------------------------------------------
1 | ## 复杂数据类型初始化时的响应式
2 |
3 | 接着上一篇的内容,由于我们定义数据时都是以一个基本数据类型来进行讲解的,如下:
4 |
5 | ```javascript
6 | data: {
7 | text: 'hello world'
8 | }
9 | ```
10 |
11 | 通过`Object.defineProperty`方法,将 text 直接挂载在 Vue 实例上,读取和修改都会通知到 data 对象同名属性值。当然这样基本数据类型是不会有问题的,但是一旦遇到复杂数据类型会不会是一样?如下:
12 |
13 | ```javascript
14 | data: {
15 | text: {
16 | value: 'hello world'
17 | }
18 | }
19 | ```
20 |
21 | 很显然,通过`this.text.value`或`app.text.value`是可以直接读取到的,但是对于设置值时,如下:
22 |
23 | ```javascript
24 | app.text.value = 'haha'
25 | ```
26 |
27 | 这样设置值后,使用`this.text.value`或`app.text.value`依然是可以能拿到最新的值,因为`this.text`或`app.text`指向的地址没变。我就不卖关子了,**接下来要讨论的依赖收集和依赖更新是分别在 get 和 set 中进行的**,同学们都可以提前知道一下。
28 |
29 | 上述的设置值是无法触发到 set 方法的,进而无法通知依赖进行相对应的更新。上一篇我也说过,**使用`Object.defineProperty`实现响应式系统,并将 data 对象中第一层数据挂载在 Vue 实例上**。其中第一层数据指的就是 text 对象挂载在 Vue 实例上,而对于第二层数据 value 则没有挂载(也就是无法响应式的)。这也就是我为什么分上下两篇进行讲解的原因,第一层数据若是基本数据类型时,则可以直接挂载在 Vue 实例上进行响应式,若是复杂数据类型时,则无法对其第二层进行响应式处理。
30 |
31 | 既然第二层数据无法响应式,那么重新让它响应式不就得了?答案是对的,那么该如何处理?Vue 中使用的方法是**递归**,通过递归来一层一层地进行响应式处理。
32 |
33 |
34 |
35 | ## 递归响应式处理
36 |
37 | 接着上一篇未完待续中的源码分析,让我们看看源码中是如何进行递归实现的。(同样地,我只会贴出相关主题的代码,其他代码同学们有空就可以进行探究 🤔 ):
38 |
39 | ```javascript
40 | function initData(vm) {
41 | var data = vm.$options.data
42 | // ...挂载 data 中元素值到 Vue 实例中
43 | observe(data, true) // 递归 data 中数据实现响应式处理
44 | }
45 |
46 | function observe(value, asRootData) { // asRootData 用于判断是否为根数据
47 | if (!isObject(value) || value instanceof VNode) { // 可用于递归到最后一层数据时,当不再是 Object 时,就直接返回
48 | return
49 | }
50 | // ...
51 | ob = new Observer(value); // 基于 Observer 构造函数实现响应式
52 | }
53 |
54 | var Observer = function Observer (value) {
55 | this.value = value;
56 | // ...
57 | if (Array.isArray(value)) { // 判断是否为数组,若是则做进一步的处理
58 | // ...
59 | } else {
60 | this.walk(value); // 将 data 中的属性转化为 getter 或 setter
61 | }
62 | }
63 |
64 | Observer.prototype.walk = function walk (obj) {
65 | var keys = Object.keys(obj);
66 | for (var i = 0; i < keys.length; i++) { // 对 data 中的值进行遍历,然后作进一步的处理
67 | defineReactive$$1(obj, keys[i]);
68 | }
69 | }
70 |
71 | function defineReactive$$1 ( // 将对象上的属性定义为响应式
72 | obj,
73 | key,
74 | val,
75 | customSetter,
76 | shallow
77 | ) {
78 | // ...
79 | var childOb = !shallow && observe(val); // 递归的关键(即判断该属性是否为对象,若是则继续递归下去,直到遍历到的属性不再是 object 为止)
80 | Object.defineProperty(obj, key, {
81 | enumerable: true,
82 | configurable: true,
83 | get: function reactiveGetter () {
84 | // 待续.................................(不卖关子,依赖收集所用)
85 | return value
86 | },
87 | set: function reactiveSetter (newVal) {
88 | // 待续.................................(依赖更新所用)
89 | }
90 | })
91 | }
92 | ```
93 |
94 | 在代码上你可以看到我的标注,在最终的将对象上属性定义为响应式 defineReactive$$1 方法上,再一次对传递进来的属性进行 observe 递归,由于在 observe 方法上会判断该属性是否为对象,若是,则继续赋予响应式,直到传递进 observe 方法中的属性不再是一个对象为止。
95 |
96 | 从源代码层面其实很好理解,无非就是遍历 data 中的对象,从第一层属性开始,若是基本数据类型,则直接通过 Object.defineProperty 方法来为其赋予响应式,若是复杂数据类型,则再次递归它,直到递归到的属性不再是复杂数据类型为止。
97 |
98 | 这篇其实内容不多,也挺好理解。讲了那么多,还是得总结一下 🌚 :
99 |
100 | - 依然使用`Object.defineProperty`方法来进行响应式处理,对于嵌套的对象,会使用递归的方式进行处理,直到递归到的数据类型为基本数据类型为止;
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】编译 Compile(上).md:
--------------------------------------------------------------------------------
1 | *在观看这篇时,还是建议童鞋们先睇睇上一篇的从 template 到 DOM 大概流程,因为对于接下来的章节都会有很大帮助的... 😂*
2 |
3 | ## Compile 主体流程
4 |
5 | 在上一个章节中,我曾留下来一个函数`compileToFunctions`,这个方法到底是用来干嘛?
6 |
7 | 相信看过上一个篇节的童鞋都会清楚,它就是用来将 template 模板内容进行语法**解析`parse`、优化`optimise`、生成渲染函数`generate`**,按三个步骤实现从模板 template 到渲染函数的。
8 |
9 | 既然是按三个步骤,我们接下来肯定会讲源码在这三个步骤中到底是如何实现的。在这之前,我还是先会给大家大概讲一下`compile`执行过程到底是如何的,因为里面会融入了多层函数嵌套,当然也少不了使用闭包形式。接下来就来看看啦 🤔
10 |
11 | ```javascript
12 | var ref$1 = createCompiler(baseOptions);
13 | var compile = ref$1.compile;
14 | var compileToFunctions = ref$1.compileToFunctions
15 | ```
16 |
17 | 千辛万苦之下,终于找到了`compileToFunctions`的来源地。由代码可以看到,通过`createCompiler`方法解释一个全局配置后得到了`compileToFuntions`,接下来就看看`createCompiler`到底干了什么东西。
18 |
19 | ```javascript
20 | var createCompiler = createCompilerCreator(function baseCompile (
21 | template,
22 | options
23 | ) {
24 | var ast = parse(template.trim(), options); // 语法解析模板 template
25 | if (options.optimize !== false) {
26 | optimize(ast, options); // 优化抽象语法树
27 | }
28 | var code = generate(ast, options); // 生成最终的渲染函数相关对象
29 | return {
30 | ast: ast,
31 | render: code.render,
32 | staticRenderFns: code.staticRenderFns
33 | }
34 | })
35 | ```
36 |
37 | `createCompiler`方法逻辑不多,就是执行方法`createCompilerCreator`,并传递方法`baseCompile`作为参数。可以预料到,方法`createCompilerCreator`实质上会返回一个函数,而**方法`baseCompile`的作用也很明显,就是实实在在的`compile`功能,包含了parse、optimise、generate三大阶段,并最终返回一个渲染函数以及抽象语法树**。接下来继续探究方法`createCompilerCreator`。
38 |
39 | ```javascript
40 | function createCompilerCreator (baseCompile) { // 将baseCompile作为了私有方法
41 | return function createCompiler (baseOptions) { // 使用闭包实现创建渲染方法
42 | function compile ( // 编译方法,返回编译后的信息如渲染方法、错误信息等
43 | template,
44 | options
45 | ) {
46 | var finalOptions = Object.create(baseOptions); // 使用继承方式,浅复制baseOptions全局基础配置
47 | var errors = []; // 用于存储错误
48 | var tips = [];
49 |
50 | var warn = function (msg, range, tip) {
51 | (tip ? tips : errors).push(msg);
52 | };
53 |
54 | if (options) {
55 | // ...
56 | // 已省略,选项信息处理
57 | }
58 |
59 | var compiled = baseCompile(template.trim(), finalOptions); // 正式开始对模板进行编译(包括parse、optimise、generate三个阶段)
60 | {
61 | detectErrors(compiled.ast, warn);
62 | }
63 | // 开始赋予处理后的错误以及提示
64 | compiled.errors = errors;
65 | compiled.tips = tips;
66 | return compiled
67 | }
68 |
69 | return {
70 | compile: compile, // 返回编译方法
71 | compileToFunctions: createCompileToFunctionFn(compile) // what?干么用的
72 | }
73 | }
74 | }
75 | ```
76 |
77 | 可以看到,`createCompilerCreator`方法使用闭包实现了编译方法`compile`,将真正的`baseCompile`作为了私有方法进行处理。
78 |
79 | `compile`方法只做两件事情,分别是
80 |
81 | - 处理`options`选项信息,如错误、提示、指令等。
82 | - 使用`baseCompile`方法直接编译模板(包含了parse、optimise、generate三个阶段),最终获得渲染方法,并返回。
83 |
84 | 到这里,也许你会觉得流程已经结束了,但是尤大大不甘心,总觉得每次编译时,不变化的地方是不是就不应该再重新编译?那么有没有一些好的方法可以处理这些场景呢?答案就是缓存。
85 |
86 | 不跟你兜圈,上述代码中留下来的`compileToFunctions`就是`comile`方法的加强版 😄。我们接着看他是如何实现的。
87 |
88 | ```javascript
89 | function createFunction (code, errors) { // 将函数字符串转化为函数
90 | try {
91 | return new Function(code) // 根据传递过来函数字符串重新转化为函数
92 | } catch (err) {
93 | errors.push({ err: err, code: code });
94 | return noop
95 | }
96 | }
97 |
98 | function createCompileToFunctionFn (compile) {
99 | var cache = Object.create(null); // 用纯对象作为映射表,私有变量,作为缓存用的
100 |
101 | return function compileToFunctions ( // 闭包实现缓存功能的compile
102 | template,
103 | options,
104 | vm
105 | ) {
106 | // ...
107 |
108 | // check cache
109 | var key = options.delimiters
110 | ? String(options.delimiters) + template
111 | : template; // 缓存中直接是根据options.delimiters
112 | if (cache[key]) { // 判断映射表中是否有对应编译结果,若有直接返回,不再进行编译
113 | return cache[key]
114 | }
115 |
116 | // compile
117 | var compiled = compile(template, options); // 若缓存中无对应的编译结果,则开始编译
118 |
119 | // check compilation errors/tips(检查对比错误以及提示是否处理完毕)
120 | // ...
121 |
122 | // turn code into functions(转化函数字符串为函数形式)
123 | var res = {};
124 | var fnGenErrors = [];
125 | res.render = createFunction(compiled.render, fnGenErrors);
126 | res.staticRenderFns = compiled.staticRenderFns.map(function (code) {
127 | return createFunction(code, fnGenErrors)
128 | });
129 |
130 | // ...
131 | // 处理函数编译过程的错误
132 |
133 | return (cache[key] = res) // 缓存编译结果,并返回
134 | }
135 | }
136 | ```
137 |
138 | `compileToFunctions`方法的工作很简单,就是使用闭包形式缓存了编译结果,极大地提升编译性能。
139 |
140 | 在这里,我先不讨论`render`方法和`staticRenderFns`方法到底有何区别,因为这属于下一节的内容。🤔
141 |
142 | 看到这里,是不是会有点晕晕的哈哈,函数层层嵌套,**使用闭包实现了函数的私有性以及可缓存性**。虽然看起来复杂,但是实现的核心我们还是能好好使用的。
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】数据初始化之依赖更新.md:
--------------------------------------------------------------------------------
1 | ## 先聊聊观察者模式
2 |
3 | 观察者模式,又叫订阅-发布模式,定义了一种一对多的关系。让多个对象同时观察某一个主题对象的变化,从而执行相对应的回调函数。现在就来看一下观察者模式的实现思想:
4 |
5 | - 发布者(某一主题对象)需包含一个数组属性用于存储订阅者对象;
6 | - 订阅时:直接将订阅者`Push`到发布者数组属性中;
7 | - 退订时:通过循环遍历,将需要退订的订阅者从发布者的数组属性中删除;
8 | - 发布时:通过循环遍历,逐一执行发布者数组属性中每个元素的回调函数;
9 |
10 | 该模式思想大概了解了,那用 JavaScript 究竟如何实现呢?现在就来瞅瞅:
11 |
12 | ```javascript
13 | // 发布者
14 | function Publisher() {
15 | this.watcher = []
16 | }
17 | Publisher.prototype.addWatcher = obj => {
18 | this.watcher.push(obj)
19 | }
20 | Publisher.prototype.publish = obj => {
21 | this.watcher.forEach(item => { typeof item.update === 'function' && item.update() })
22 | }
23 |
24 | // 订阅者
25 | function Subscriber(name) {
26 | this.name = name
27 | }
28 | Subscriber.prototype.update = function() {
29 | console.log(`${this.name} is updated.........`)
30 | }
31 | ```
32 |
33 | 既然提到观察者模式,那肯定和本主题相关联。首先在 Vue 实现的依赖收集以及依赖更新中,其实就是用到了观察者模式,响应式属性就是发布者,而 Watcher 依赖就是订阅者。每当响应式属性发生更新时,都会直接通知到其 dep 中保存的所有订阅者进行响应的更新。
34 |
35 | 接下来,就让我们瞅瞅在 Vue 中是如何实现依赖更新的。
36 |
37 |
38 |
39 | ## 从源码角度分析
40 |
41 | 从前面的章节中,我有提及过,涉及到响应式属性的依赖更新,主要有两个地方,分别是 Setter 函数和全局`$set`方法。接下来我们就分别来看看 🤔 。
42 |
43 | 1. Setter 函数中依赖更新
44 |
45 | 前面提到,只有 Vue 能监测到的更新才会主动触发 Setter 函数,先看下源码中的 Setter 函数是如何处理的:
46 |
47 | ```javascript
48 | function defineReactive$$1 (
49 | obj,
50 | key,
51 | val,
52 | customSetter,
53 | shallow
54 | ) {
55 | // ...
56 | Object.defineProperty(obj, key, {
57 | enumerable: true,
58 | configurable: true,
59 | // ...
60 | set: function reactiveSetter (newVal) {
61 | // ...
62 | dep.notify();
63 | }
64 | })
65 | }
66 |
67 | Dep.prototype.notify = function notify () {
68 | var subs = this.subs.slice(); // 数组的浅复制,避免影响到元素组
69 | // ...
70 | for (var i = 0, l = subs.length; i < l; i++) {
71 | subs[i].update();
72 | }
73 | }
74 | ```
75 |
76 | 上述代码很好理解,当响应式属性更新时,会直接触发到 Setter 函数,这时候就会调用 dep 对象上的 notify 方法,该方法做的事情就是遍历其保存的 Watcher 依赖,并逐个触发其更新回调函数。
77 |
78 | 看到这里,也许你还会有一个疑问,那就是 Watcher 依赖的更新回调函数是如何产生的?
79 |
80 | 其实在元素挂载时所创建的 Watcher 依赖就已经定义了其更新回调函数,现在就来看看
81 |
82 | ```javascript
83 | function mountComponent (
84 | vm,
85 | el,
86 | hydrating
87 | ) {
88 | // ...
89 | var updateComponent;
90 | updateComponent = function () { // 更新回调函数的设置
91 | vm._update(vm._render(), hydrating);
92 | };
93 | new Watcher(vm, updateComponent, noop, {
94 | before: function before () {
95 | if (vm._isMounted && !vm._isDestroyed) {
96 | callHook(vm, 'beforeUpdate');
97 | }
98 | }
99 | }, true /* isRenderWatcher */);
100 | // ...
101 | }
102 |
103 | var Watcher = function Watcher (
104 | vm,
105 | expOrFn,
106 | cb,
107 | options,
108 | isRenderWatcher
109 | ) {
110 | // ...
111 | if (typeof expOrFn === 'function') { // expOrFn 就是更新回调函数
112 | this.getter = expOrFn;
113 | }
114 | // ...
115 | }
116 |
117 | Watcher.prototype.update = function update () {
118 | /* istanbul ignore else */
119 | // ...
120 | queueWatcher(this); // 利用队列形式进行更新每一个 Watcher 依赖,该方法中最后都会直接执行其更新回调函数
121 | };
122 |
123 | ```
124 |
125 | 可以看到的是,组件在挂载的过程中,通过 Watcher 依赖本身的 getter 属性进行收集更新回调函数。另外,当执行 Watcher 依赖的 update 方法时,即相当于执行了 queueWatcher 方法。
126 |
127 | queueWatcher 方法需要探讨一下的是,会将 Watcher 依赖推进到一个队列中,然后再按顺序滴拿出来进行更新,而所谓的更新就是直接调用了其 Watcher 依赖本身的 getter 函数,从而更新依赖中响应式属性的值。
128 |
129 |
130 |
131 | 2. 全局`$set`方法中依赖更新
132 |
133 | 在依赖收集的章节中,我有说过,官方提供的全局`$set`方法,其实就是利用`__ob__`中保存的依赖进行设置和更新的。现在我们就来看看源码究竟是如何设置和更新的:
134 |
135 | ```javascript
136 | Vue.prototype.$set = set;
137 |
138 | /**
139 | * Set a property on an object. Adds the new property and
140 | * triggers change notification if the property doesn't
141 | * already exist.
142 | */
143 | function set (target, key, val) {
144 | // ...
145 | var ob = (target).__ob__;
146 | // ...
147 | defineReactive$$1(ob.value, key, val); // 对新添加属性进行响应式处理
148 | ob.dep.notify(); // 初始化响应式处理后,同时通知更新
149 | }
150 | ```
151 |
152 | 由代码中 set 方法注释可以看到,在响应式对象上新增属性时触发更新通知。在触发更新前,会先把新增的属性进行响应式处理 defineReactive$$1 ,紧接着就是根据此前存储的`__ob__`中依赖进行逐一通知更新,其中更新过程和上述调用 Watcher 依赖的 update 方法是一样的。
153 |
154 |
155 |
156 | 现在来总结一下:
157 |
158 | - Vue 中实现依赖更新是使用了观察者模式,通过 Getter 函数和`__ob__`中收集的依赖进行逐一更新;
159 | - 对响应式属性的处理会主动触发 Setter 函数,然后使用 Getter 函数中收集的依赖进行逐一更新。对非响应式属性的处理,则需要调用全局 $set 方法,使用`__ob__`中收集的依赖进行逐一更新并且把该**新增属性进行响应式处理**;
160 | - 更新回调函数会在组件挂载时所创建的 Watcher 依赖进行设置,在通知更新时,会直接使用队列的方式进行更新,先到先处理;
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## 介绍
2 |
3 | Vuejs 源码分析在网上的分享有很多,本人也有参考和学习过,依然有一种体会就是,轮子虽多,也不及自己去探究一遍。
4 |
5 | 本项目的创建旨在个人对 Vuejs 源码的探究和学习(由于本人能力有限,各位大佬看了若有问题的话,还是多提点一下小弟 :see_no_evil: ),当然也可以是作为个人的一个小笔记,然后拿来跟大家一起分享探讨,一起成长。
6 |
7 | ~~(由于本人时间有限,更新的速度会稍微慢一丢丢,所以分享都会慢慢滴待续~)~~
8 |
9 | (现已编写完毕:muscle:)
10 |
11 | 看本项目之前,我也希望你对 Vuejs 有一定的了解,若有疑问可以看一下官方文档 https://cn.vuejs.org/v2/guide/ 。
12 |
13 |
14 |
15 | ## 目录
16 |
17 | - [【 Vue 源码分析 】数据初始化之响应式探究(上)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E6%95%B0%E6%8D%AE%E5%88%9D%E5%A7%8B%E5%8C%96%E4%B9%8B%E5%93%8D%E5%BA%94%E5%BC%8F%E6%8E%A2%E7%A9%B6%EF%BC%88%E4%B8%8A%EF%BC%89.md)
18 | - [【 Vue 源码分析 】数据初始化之响应式探究(下)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E6%95%B0%E6%8D%AE%E5%88%9D%E5%A7%8B%E5%8C%96%E4%B9%8B%E5%93%8D%E5%BA%94%E5%BC%8F%E6%8E%A2%E7%A9%B6%EF%BC%88%E4%B8%8B%EF%BC%89.md)
19 | - [【 Vue 源码分析 】数据初始化之依赖收集(上)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E6%95%B0%E6%8D%AE%E5%88%9D%E5%A7%8B%E5%8C%96%E4%B9%8B%E4%BE%9D%E8%B5%96%E6%94%B6%E9%9B%86%EF%BC%88%E4%B8%8A%EF%BC%89.md)
20 | - [【 Vue 源码分析 】数据初始化之依赖收集(下)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E6%95%B0%E6%8D%AE%E5%88%9D%E5%A7%8B%E5%8C%96%E4%B9%8B%E4%BE%9D%E8%B5%96%E6%94%B6%E9%9B%86%EF%BC%88%E4%B8%8B%EF%BC%89.md)
21 | - [【 Vue 源码分析 】数据初始化之依赖更新](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E6%95%B0%E6%8D%AE%E5%88%9D%E5%A7%8B%E5%8C%96%E4%B9%8B%E4%BE%9D%E8%B5%96%E6%9B%B4%E6%96%B0.md)
22 | - [【 Vue 源码分析 】为什么不推荐使用 $forceUpdate](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E4%B8%BA%E4%BB%80%E4%B9%88%E4%B8%8D%E6%8E%A8%E8%8D%90%E4%BD%BF%E7%94%A8%20%24forceUpdate.md)
23 |
24 | - [【 Vue 源码分析 】计算属性 Computed](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E8%AE%A1%E7%AE%97%E5%B1%9E%E6%80%A7%20Computed.md)
25 |
26 | - [【 Vue 源码分析 】侦听器 Watch](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E4%BE%A6%E5%90%AC%E5%99%A8%20Watch.md)
27 |
28 | - [【 Vue 源码分析 】方法 Methods](https://github.com/Andraw-lin/about-Vue/blob/master/docs/【%20Vue%20源码分析%20】方法%20Methods.md)
29 |
30 | - [【 Vue 源码分析 】运行机制之 Props](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E8%BF%90%E8%A1%8C%E6%9C%BA%E5%88%B6%E4%B9%8B%20Props.md)
31 |
32 | - [【 Vue 源码分析 】混合 Mixin(上)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E6%B7%B7%E5%90%88%20Mixin%EF%BC%88%E4%B8%8A%EF%BC%89.md)
33 |
34 | - [【 Vue 源码分析 】混合 Mixin(下)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E6%B7%B7%E5%90%88%20Mixin%EF%BC%88%E4%B8%8B%EF%BC%89.md)
35 |
36 | - [【 Vue 源码分析 】生命周期 Lifecycle](https://github.com/Andraw-lin/about-Vue/blob/master/docs/【%20Vue%20源码分析%20】生命周期%20Lifecycle.md)
37 |
38 | - [【 Vue 源码分析 】异步更新队列之 NextTick](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E5%BC%82%E6%AD%A5%E6%9B%B4%E6%96%B0%E9%98%9F%E5%88%97%E4%B9%8B%20NextTick.md)
39 |
40 | - [【 Vue 源码分析 】从 Template 到 DOM 过程是怎样的](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E4%BB%8E%20Template%20%E5%88%B0%20DOM%20%E8%BF%87%E7%A8%8B%E6%98%AF%E6%80%8E%E6%A0%B7%E7%9A%84.md)
41 |
42 | - [【 Vue 源码分析 】编译 Compile(上)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E7%BC%96%E8%AF%91%20Compile%EF%BC%88%E4%B8%8A%EF%BC%89.md)
43 |
44 | - [【 Vue 源码分析 】编译 Compile(下)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E7%BC%96%E8%AF%91%20Compile%EF%BC%88%E4%B8%8B%EF%BC%89.md)
45 |
46 | - [【 Vue 源码分析 】渲染 Render (AST -> VNode)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E6%B8%B2%E6%9F%93%20Render%20(AST%20-%3E%20VNode).md)
47 |
48 | - [【 Vue 源码分析 】如何在更新 Patch 中进行 Diff](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E5%A6%82%E4%BD%95%E5%9C%A8%E6%9B%B4%E6%96%B0%20Patch%20%E4%B8%AD%E8%BF%9B%E8%A1%8C%20Diff.md)
49 |
50 |
51 |
52 | ## 其他话题
53 |
54 | - [Object.create(null) 与 {} 究竟有什么不一样](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%20Lifecycle.md)
55 |
56 |
57 |
58 |
59 | ## 对本项目的疑惑
60 |
61 | 若各位大佬在看的同时,对本项目有任何想法或者意见,欢迎各位多提点 issue,因为我也想和各位大佬们一起学习和探讨。
62 |
63 | 另外,若对项目中文章提到的知识点有疑问,我是希望你可以看看 `javascript高级程序设计` 和 `设计模式` 的。因为源码里对 javascript 的基础比较看重,还有就是涉及到的设计模式会很多,所以在探讨过程中还是要慢慢领会和斟酌~
64 |
65 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】方法 Methods.md:
--------------------------------------------------------------------------------
1 | ## 先聊聊call、apply和bind
2 |
3 | 相信同学们对于 call 和 apply 的区别应该不陌生,毕竟面试时常常问到的问题。那么我们现在就再来巩固一下,我们先来看个简单的栗子🌰:
4 |
5 | ```javascript
6 | var obj = {
7 | num: 0,
8 | addNum(arg) {
9 | return this.num + arg
10 | }
11 | }
12 | var newObj = {
13 | num: 10
14 | }
15 | console.log(obj.addNum(1)) // 1
16 | console.log(obj.addNum.call(newObj, 1)) // 11
17 | console.log(obj.addNum.apply(newObj, [1])) // 11
18 | ```
19 |
20 | 代码很好理解,我们都知道,函数内部存在一个执行上下文,当我们直接执行`obj.addNum`时,this 指向的就是 obj 对象,因此输出也就是 1 。
21 |
22 | **call、apply 和 bind 一个共同点就是改变函数的执行上下文到指定的对象中**。
23 |
24 | 上述,执行`obj.call(newObj, 1)`和`obj.apply(newObj, [1])`,相当于将方法`addNum`中的 this 直接指向了 newObj 对象,因此都会输出 11。另外,你会发现,call 和 apply 方法的第二个参数会有所不同,其中 **call 是一个一个参数传递,而 apply 则是使用数组进行传递**。因此当有多个参数需要传递时,可直接使用 apply 或者 在 call 上使用扩展元算符,如下:
25 |
26 | ```javascript
27 | var arr = [1, 2, 3, 4, 5, 6]
28 | obj.addNum.call(newObj, ...arr)
29 | // 相当于
30 | obj.addNum.apply(newObj, arr)
31 | ```
32 |
33 | 因此,**call 和 apply 的区别就是,call 传递参数时是一个一个地进行传递,而 apply 则是使用数组方式进行传递。**
34 |
35 | 既然,call 和 apply 都能改变执行上下文,那么看看下面一个栗子🌰:
36 |
37 | ```javascript
38 | var num = 100
39 | var obj = {
40 | num: 0,
41 | addNum(arg) {
42 | return this.num + arg
43 | }
44 | }
45 | console.log(obj.addNum.call(null, 1))
46 | console.log(obj.addNum.apply(undefined, 1))
47 | ```
48 |
49 | 相信很多同学都见过,在使用 call 和 apply 时,第一个参数使用 null 或者 undefined,执行上下文会指向哪里?
50 |
51 | 在这里我就不卖关子了,**当使用 call 和 apply 时,第一个参数使用 null 或者 undefined,执行上下文会直接指向 window 对象。**因此,最后输出的结果都是 101。
52 |
53 | 看到这里,或许你会迷惑为什么就没提到 bind ?
54 |
55 | 虽然 bind 同样也是改变函数的执行上下文,但它却和 call 、apply 不一样,那就是绑定好执行上下文后,重新生成一个新的函数,而这个函数中执行上下文已经绑定好了并不会变。我们来看看:
56 |
57 | ```javascript
58 | var obj = {
59 | num: 0,
60 | addNum(arg) {
61 | return this.num + arg
62 | }
63 | }
64 | var newObj = {
65 | num: 10
66 | }
67 | var newObjAddNum = obj.addNum.bind(newObj)
68 | console.log(newObjAddNum(1)) // 11
69 | ```
70 |
71 | 可以看到的是,使用 bind 后,相当于帮你准备好目标对象了,即绑定好执行上下文到指定对象中去,并最终返回一个新的函数,对原来的函数并不造成任何的影响,而这也符合了纯函数思想。
72 |
73 | 现在就来总结一下:
74 |
75 | - bind 和 call 、apply 之间的区别:
76 |
77 | bind 是改变执行上下文并返回一个新的函数,而 call 和 apply 则是改变执行上下文并立即执行。另外,**bind 会有浏览器的兼容问题,它不兼容 IE6~8。**
78 |
79 | - call 和 apply 之间的区别:
80 |
81 | call 传递参数时是一个一个地进行传递,而 apply 则是使用数组方式进行传递。
82 |
83 |
84 |
85 | 既然聊到 call、apply 和 bind ,想必跟本主题是有很大的关系。没错,Vue 源码中绑定方法到实例上时,使用的就是 call、apply 以及 bind。让我们接着下去看看。
86 |
87 |
88 |
89 | ## 从源码的角度进行分析
90 |
91 | 在 Vue 源码中,实现方法挂载到 Vue 实例上,使用的是 bind 方法,但我们都知道,bind 方法会有兼容性问题,为避免这个问题,不得不使用 call 和 apply 来实现补全功能。让我们看看源码是如何实现的 🤔:
92 |
93 | ```javascript
94 | initState(vm);
95 | function initState (vm) {
96 | // ...
97 | if (opts.methods) { initMethods(vm, opts.methods); } // 初始化方法
98 | // ...
99 | }
100 |
101 | function initMethods (vm, methods) {
102 | var props = vm.$options.props;
103 | for (var key in methods) {
104 | {
105 | if (typeof methods[key] !== 'function') { // 判断方法名是否定义为函数类型
106 | warn(
107 | "Method \"" + key + "\" has type \"" + (typeof methods[key]) + "\" in the component definition. " +
108 | "Did you reference the function correctly?",
109 | vm
110 | );
111 | }
112 | if (props && hasOwn(props, key)) { // 判断方法名是否已经个props中有同名冲突
113 | warn(
114 | ("Method \"" + key + "\" has already been defined as a prop."),
115 | vm
116 | );
117 | }
118 | if ((key in vm) && isReserved(key)) { // 判断方法名是否与Vue实例中有同名冲突
119 | warn(
120 | "Method \"" + key + "\" conflicts with an existing Vue instance method. " +
121 | "Avoid defining component methods that start with _ or $."
122 | );
123 | }
124 | }
125 | vm[key] = typeof methods[key] !== 'function' ? noop : bind(methods[key], vm); // bind 函数就是关键绑定函数
126 | }
127 | }
128 | ```
129 |
130 | 上面代码中,可以看到方法`initMethods`其实就是在判断定义的方法是否为函数,以及是否和 props 、Vue 实例上会有同名冲突,一旦存在,就会抛出警告,但是你会发现程序还是得会走下去。
131 |
132 | 另外,当定义的方法是不同名并为函数时,那么就会执行 bind 方法来将方法挂载到 Vue 实例上,让我们来看看该方法是如何操作的:
133 |
134 | ```javascript
135 | function polyfillBind (fn, ctx) {
136 | function boundFn (a) {
137 | var l = arguments.length;
138 | return l
139 | ? l > 1
140 | ? fn.apply(ctx, arguments)
141 | : fn.call(ctx, a)
142 | : fn.call(ctx)
143 | }
144 |
145 | boundFn._length = fn.length;
146 | return boundFn
147 | }
148 |
149 | function nativeBind (fn, ctx) {
150 | return fn.bind(ctx)
151 | }
152 |
153 | var bind = Function.prototype.bind
154 | ? nativeBind // 对于支持 bind 方法的环境,直接使用原生的 bind 方法
155 | : polyfillBind; // 对于不支持 bind 方法的环境,则使用兼容方法来进行兼容
156 |
157 | ```
158 |
159 | 上面我们提及过,bind 方法会永久地绑定好执行上下文后,并返回一个新的方法。这样会有一个好处,那就是在方法里就不再需要管理执行上下文究竟指向哪一个对象,同时也方便后期的管理。
160 |
161 | 另外,对于不支持原生 bind 方法的环境,使用方法`polyfillBind`会根据传递进来的参数长度来决定使用 call 和 apply,这是为什么?
162 |
163 | 原因就是,call 方法需要一个参数一个参数地进行传递,而 apply 则可以直接使用数组形式进行传递。最后返回一个新的函数,这样一来就能兼容到所有不支持 bind 方法的环境。在 Vue 源码实现 Methods 中,上述的绑定代码其实很好理解,也是最简单的实现方式。
164 |
165 | 总结一下:
166 |
167 | - Vue 源码初始化方法 Methods 中,**使用 bind 方法来永久绑定执行上下文并返回一个新的函数到 Vue 实例中**,而**对于不支持 bind 原生方法的环境,则直接使用 call 或 apply 方法来进行兼容**。
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】数据初始化之响应式探究(上).md:
--------------------------------------------------------------------------------
1 | ## 数据响应式的疑惑
2 |
3 | 先看下 Vue 中编写一个 hello word 的代码:
4 |
5 | ```javascript
6 | {{ text }}
7 |
8 |
9 |
17 | ```
18 |
19 | 上述是一个很简单的栗子🌰,打开网页就可以看到一个简单的 hello word 文案,很明显,`{{ text }}`被解析到下面数据初始化时定义的 text 值。当我们作如下处理时:
20 |
21 | ```javascript
22 | app.text = 'haha'
23 | ```
24 |
25 | 会发现,模板上的`{{ text }}`值同样被更新为 haha 值,官方文档其实说的很清楚,**当一个 Vue 实例被创建时,它将 data 对象中的所有属性加入到 Vue 的响应式系统中**。这句话理解起来其实很简单,就是定义在 data 对象总的数据都会是响应式的,这也就能够说明,为什么直接操作`app.text = 'haha'`时,模板上的相对应的响应值会跟着变化。
26 |
27 | 当然,上述只是一个宏观解析,抱有好奇心的你们当然不能满足,更期待的是一个微观解析。那官方所说的响应式系统,在 Vue 实例被创建和初始化数据时是如何定义成响应式的呢??下面就会进入我们的🐷题。
28 |
29 |
30 |
31 | ## 从源码角度探究
32 |
33 | 下面先看下 Vue 源码是如何实现(下方只会编写出与该主题相关代码,当然还有很多代码没贴出,各位有空可以去探究一下 😄 ):
34 |
35 | ```javascript
36 | function initMixin(Vue) {
37 | // ...
38 | initState(vm); // 初始化状态
39 | }
40 |
41 | initMixin(Vue)
42 |
43 | function initState(vm) {
44 | // ..
45 | var opts = vm.$options
46 | if (opts.data) { // 判断 data 字段中是否有值,一旦有值初始化数据
47 | initData(vm)
48 | }
49 | }
50 |
51 | function initData(vm) {
52 | var data = vm.$options.data
53 | data = vm._data = typeof data === 'function' ? getData(data, vm) : data || {} // 旧版 data 可赋值为一个返回对象的函数,新版则直接支持了对象赋值,一旦 data 不存在时,直接初始化为一个 {} 空对象
54 | if (!isPlainObject(data)) { // 判断定义的 data 不是对象时会抛出警告⚠️,并同时初始化为一个 {} 空对象
55 | data = {};
56 | warn(
57 | 'data functions should return an object:\n' +
58 | 'https://vuejs.org/v2/guide/components.html#data-Must-Be-a-Function',
59 | vm
60 | );
61 | }
62 | var keys = Object.keys(data);
63 | var i = keys.length;
64 | while (i--) {
65 | var key = keys[i]
66 | // ...
67 | } else if (!isReserved(key)) {
68 | proxy(vm, "_data", key);
69 | }
70 | }
71 | // 待续............................(一会就待续 🤔 )
72 | }
73 |
74 | function isReserved (str) { // 判断字符串的第一个字符是否为 $ 或 _
75 | var c = (str + '').charCodeAt(0);
76 | return c === 0x24 || c === 0x5F
77 | }
78 |
79 | var sharedPropertyDefinition = {
80 | enumerable: true,
81 | configurable: true,
82 | get: noop,
83 | set: noop
84 | };
85 |
86 | function proxy (target, sourceKey, key) { // 将 data 中属性挂载在 Vue 实例上
87 | sharedPropertyDefinition.get = function proxyGetter () {
88 | return this[sourceKey][key]
89 | };
90 | sharedPropertyDefinition.set = function proxySetter (val) {
91 | this[sourceKey][key] = val;
92 | };
93 | Object.defineProperty(target, key, sharedPropertyDefinition);
94 | }
95 | ```
96 |
97 | 上述代码希望各位都可以花点时间仔细看下(因为上述代码可以很好解析在 Vue 实例上的数据是响应式的),看似很多代码,却是很好理解的,并且我也在上述贴出了相对应的注释。接下来就针对上述代码层面,分析关键点:
98 |
99 | 1. `vm.$options.data`合法性判断
100 |
101 | 初始化数据时,定义的 data 可以是函数,也可以是一个对象。一旦不是函数或对象时,都会抛出一个警告⚠️,同时初始化 data 为一个空对象。
102 |
103 | ```javascript
104 | // 合法定义
105 | data() {
106 | return {
107 | text: 'hello world'
108 | }
109 | }
110 |
111 | data: {
112 | text: 'hello world'
113 | }
114 |
115 | // 不合法定义
116 | data: 'hello world'
117 | ```
118 |
119 | 当 data 定义为函数时,会直接调用该函数并返回一个对象挂载在实例上的,这就比直接定义为对象多了一步执行函数而已。
120 |
121 |
122 |
123 | 2. isReserved
124 |
125 | 上面注释写的很清楚,该方法就是**用于判断字符串的第一个字符是否为 $ 或 _** 。也许有同学会问,这方法判断的意义在何处?
126 |
127 | 其实在[官方文档](https://cn.vuejs.org/v2/api/#data)都写的很清楚,**以 `_` 或 `$` 开头的属性 不会 被 Vue 实例代理,因为它们可能和 Vue 内置的属性、API 方法冲突**。
128 |
129 | 这也就能够解析为啥要加上该方法判断了 🤔 ,就是避免和内置属性产生冲突。
130 |
131 |
132 |
133 | 3. proxy
134 |
135 | 实现 Vue 实例上访问数据的响应式系统的关键函数,**使用`Object.defineProperty` ES5 方法来实现访问器属性的响应式**。
136 |
137 | 我们都知道,对象属性分为两种,分别是数据属性和访问器属性。其中数据属性和我们平时直接操作的变量没什么区别,而访问器属性则是相当于中间加了一层代理,当访问该属性时,需经过代理 getter 获取(此时可以进行依赖的收集,后面章节会提到),当改变该属性,也需经过代理 setter 进行设置。
138 |
139 | 说了那么多,到底怎么用啊??别的不说 🙊,直接来一波 🌰 体验一下:
140 |
141 | ```javascript
142 | var book = {
143 | year: 2008
144 | }
145 | Object.defineProperty(book, '_year', {
146 | get() {
147 | return book.year
148 | },
149 | set(val) {
150 | book.year = val
151 | }
152 | })
153 | console.log(book._year) // 2008
154 | book._year = 2019
155 | console.log(book.year) // 2019
156 | ```
157 |
158 | 可以看到,每次访问`book.year`时会经过`get`方法获取真正`_year`,而每次更改`book.year`时都会经过`set`方法来操作真正的`_year`。
159 |
160 | 回到正题,proxy 方法就是将 data 中每一个定义的属性挂载在 Vue 实例上,这样每次访问`app.text`时其实就是直接读取了 data 对象中属性,同样地,每次更改`app.text`时就相当于直接更改了 data 对象中定义的属性。
161 |
162 | 因此,proxy 方法也就可以说明为什么在实例上可以直接访问到 data 对象中的数据属性以及更改其值。(当然也包括了为什么 this.text 也是可以直接访问到 data 对象中的数据属性以及更改其值)。
163 |
164 |
165 |
166 | 讲了那么多,来总结下:
167 |
168 | - Vue 中 data 的定义既可以是对象,也可以是函数。一旦不是对象或函数,就会抛出警告⚠️,并初始化 data 为一个空对象,代码还是能执行;
169 | - 在 data 对象中定义数据时,变量名绝对不能加上 $ 或 _ 作为开头;
170 | - 使用`Object.defineProperty`实现响应式系统,并将 data 对象中第一层数据挂载在 Vue 实例上,以便通过`this.text`或`app.text`来访问 data 对象中的数据;
171 |
172 |
173 |
174 | 讲到这里,对于 Vue 实现数据初始化的响应式,也许你已经有点头绪了 🤔 。既然如此,是不是已经讲完了?NoNo~
175 |
176 | 对于一开始的疑惑,当我们的直接操作`app.text = 'haha'`时,为什么模板上的相对应的响应值会跟着变化?这个问题还是没回答啊。是的,要讲解这个问题,还得继续看下去,因为其中涉及到了依赖收集以及依赖更新内容。
177 |
178 | 就好比如,iphone11 快出来了,这时候官网放出了预定功能,消费者可在上面输入手机号进行预订,当iphone11出来后,就会通知该手机号,消费者就可以直接给钱购买了。同样地,直接操作`app.text = 'haha'`时,需通知依赖们,来更新他们订阅的值。
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】混合 Mixin(上).md:
--------------------------------------------------------------------------------
1 | ## 回顾一下 Mixin
2 |
3 | 相信大家对 Mixin 并不陌生,那它究竟是有何用处呢?官方给出了解释:
4 |
5 | > 混入 (mixin) 提供了一种非常灵活的方式,来分发 Vue 组件中的可复用功能。
6 |
7 | 这段话在理解上很简单,无非就是将每个组件中共同功能抽离出来,而所有共同功能所有组成的一个对象就会被作为一个 Mixin 处理。我们看下官方给出的简单栗子🌰,这样会比较好滴理解上述的解释:
8 |
9 | ```javascript
10 | // 定义一个混入对象
11 | var myMixin = {
12 | created: function () {
13 | this.hello()
14 | },
15 | methods: {
16 | hello: function () {
17 | console.log('hello from mixin!')
18 | }
19 | }
20 | }
21 | // 定义一个使用混入对象的组件
22 | var Component = Vue.extend({
23 | mixins: [myMixin]
24 | })
25 | var component = new Component() // => "hello from mixin!"
26 | ```
27 |
28 | 当然抽离复用的功能是 Mixin 的关注的重点,但它却不是 Mixin 的处理核心。而 **Mixin 的处理核心就是选项合并。**选项合并如何理解?
29 |
30 | 简单来讲,那就是将重名冲突的属性或方法进行处理,是选择合并起来还是进行覆盖。官方文档也有提及,针对不同的情况进行不同的处理,主要有以下方面:
31 |
32 | - Data
33 |
34 | 新版 Vue 支持了 data 中直接赋于对象形式,若 data 为 Function 类型,则会先调用该函数,再进行重名合并,若 data 为 Obejct 类型,则会直接进行重名合并。如何进行重名合并?优先级如下:
35 |
36 | ```javascript
37 | 组件data > 组件mixin > 组件mixin的mixin > ... > 全局mixin
38 | ```
39 |
40 | - Props \ Methods \ Inject \ Computed
41 |
42 | 处理上跟 data 为对象的形式类似,优先级如下:
43 |
44 | ```javascript
45 | 组件 > 组件mixin > 组件mixin的mixin > ... > 全局mixin
46 | ```
47 |
48 | - Watch
49 |
50 | 监听在处理上并不是简单滴将同名属性监听进行覆盖,而是将整个 watch 对象收集起来存到一个数组中,当一个监听的属性发生变更时,调用的优先级如下:
51 |
52 | ```javascript
53 | 全局mixin > ... > 组件mixin的mixin > 组件mixin > 组件
54 | ```
55 |
56 | - Lifecycle
57 |
58 | 生命周期在处理上跟 watch 很类似,不过它是针对每个生命周期函数进行收集并存放到数组中。同名的生命周期函数调用顺序如下:
59 |
60 | ```javascript
61 | 全局mixin > ... > 组件mixin的mixin > 组件mixin > 组件
62 | ```
63 |
64 | - Component \ Directive \ Filter
65 |
66 | 该三项的处理有点特殊,利用了继承的方式来实现合并,使用原型链访问的形式,当在一个组件中找不到 component、diirective、fiter 时,会沿着原型链向上寻找,优先级如下:
67 |
68 | ```javascript
69 | 组件 > 组件mixin > 组件mixin的mixin > ... > 全局mixin
70 | ```
71 |
72 | 对于混合中要合并的选项上面都已经进行简单的阐述,可以看到的是,针对不同情况,都会使用不同的方式进行实现,特别是使用原型合并的方式用的最为精妙,利用原型链访问的原理进行查询,而这也为平时的开发中增加了一种新的认识。那么接下来我们就来看看源码对于上面不同的情况是如何实现的。🤔
73 |
74 |
75 |
76 | ## 先从源码角度进行分析 Mixin 的入口
77 |
78 | 相信我们都知道有`Vue.mixin`全局定义混合这个 API,**一般情况下,全局定义 mixin (即`Vue.mixin`)必须要在初始化 Vue 之前**。既然要用到这个 API,那也得暴露出来给我们使用对吧?好,那么就来看看是如何暴露的。
79 |
80 | ```javascript
81 | function initGlobalAPI (Vue) {
82 | // ...
83 | initMixin$1(Vue);
84 | // ...
85 | }
86 | initGlobalAPI(Vue)
87 |
88 | function initMixin$1 (Vue) { // 初始化mixin的API
89 | Vue.mixin = function (mixin) {
90 | this.options = mergeOptions(this.options, mixin); // 开始合并选项
91 | return this
92 | };
93 | }
94 | ```
95 |
96 | 到这里,代码从理解上很简单,就是直接在 Vue 上定义一个 mixin 的全局方法。至于如何进行合并选项,下面会提及。而这就是 mixin 方法的全局入口,其实它还有一个局部入口,即直接在 Vue 实例上进行初始化定义 mixin。我们接着看看局部入口是怎样的:
97 |
98 | ```javascript
99 | Vue.prototype._init = function (options) {
100 | // ...
101 | vm.$options = mergeOptions( // 开始合并选项
102 | resolveConstructorOptions(vm.constructor),
103 | options || {},
104 | vm
105 | );
106 | // ...
107 | }
108 | ```
109 |
110 | 可以看到,在初始化阶段,同样使用了方法`mergeOptions`来进行合并选项,那么这个方法究竟是怎样合并的?我们接着看下去:
111 |
112 | ```javascript
113 | /**
114 | * Merge two option objects into a new one.
115 | * Core utility used in both instantiation and inheritance.
116 | */
117 | function mergeOptions (
118 | parent, // Vue 实例本身
119 | child, // 要合并的选项
120 | vm
121 | ) {
122 | // ...
123 | // Apply extends and mixins on the child options,
124 | // but only if it is a raw options object that isn't
125 | // the result of another mergeOptions call.
126 | // Only merged options has the _base property.
127 | if (!child._base) {
128 | if (child.extends) { // 针对子组件中扩展,就开始递归其扩展直到找到最后一层的mixins出来进行合并选项
129 | parent = mergeOptions(parent, child.extends, vm);
130 | }
131 | if (child.mixins) { // 当子组件中存在mixins选项时,就开始递归寻找最后一层的mixins出来进行合并选项
132 | for (var i = 0, l = child.mixins.length; i < l; i++) {
133 | parent = mergeOptions(parent, child.mixins[i], vm);
134 | }
135 | }
136 | }
137 |
138 | var options = {};
139 | var key;
140 | for (key in parent) { // 将Vue实例上的属性与要合并的选项值中的属性进行合并
141 | mergeField(key);
142 | }
143 | for (key in child) {
144 | if (!hasOwn(parent, key)) { // 遍历要合并的选项,若遍历到的属性是Vue实例不存在的,也要进行合并处理
145 | mergeField(key);
146 | }
147 | }
148 | function mergeField (key) { // 真正的合并选项
149 | var strat = strats[key] || defaultStrat;
150 | options[key] = strat(parent[key], child[key], vm, key);
151 | }
152 | return options
153 | }
154 | ```
155 |
156 | 方法`mergeOptions`从原理的角度分析并不难,就是**递归寻找要合并选项中优先级最低的 mixin 取出来**,在遍历Vue实例上的属性进行合并处理时,其实也包含了与 Mixin 中的属性合并。然后再遍历一层一层递归回去取出来的 mixin ,若是 Vue 实例不存在的属性也进行合并处理。
157 |
158 | 那么问题来了,真正的合并选项方法中的`strats`和`defaultStrat`究竟是用来干嘛的?我们先来看看它们的结构
159 |
160 | ```javascript
161 | var strats = config.optionMergeStrategies;
162 |
163 | var config = ({
164 | // ...
165 | optionMergeStrategies: Object.create(null),
166 | // ...
167 | })
168 |
169 | var defaultStrat = function (parentVal, childVal) {
170 | return childVal === undefined
171 | ? parentVal
172 | : childVal
173 | }
174 | ```
175 |
176 | `strats`本质上就是一个空对象,那么为什么在合并选项时,还要传递对应选项 Key 值进去?好明显,在你传递 Key 值进去之前,别人就已经实现好对应选项合并的方法在里面了。
177 |
178 | 再来看看`defaultStrat`,理解上应该没什么问题,就是判断 Mixin 是否存在,一旦为 undefined 时就直接取 Vue 实例,否则直接取 Mixin 中对应的选项值。(其实这里我刚开始感觉特别绕,后面想了想也能思考出来,就是凡是上面提及的定义项外的属性,都是直接取 Mixin 中即可,因为它们已经超出了定义的范围)
179 |
180 | 看到这里,是否会感觉有点难以理解?慢慢来,总能理解到作者这样写的用意的 😄。另外你应该也知道,Mixin 中最大的 Boss 也就是`strats`了。由于篇幅缘故,对于它的源码,我们会在下一篇讲解,欢迎收看。
181 |
182 | 现在再来总结一下:
183 |
184 | - Mixin 针对不同的情景做了不同的合并处理,详细可以看上面优先级;
185 | - 合并选项使用方式是递归遍历,一直寻找到最后一项的 Mixin,再去进行合并。只有在 Vue 规定内的属性才会进行合并选项,否则直接拿 Mixin 中的选项;
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
224 |
225 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】从 Template 到 DOM 过程是怎样的.md:
--------------------------------------------------------------------------------
1 | ## Virtual DOM
2 |
3 | 虚拟 DOM 技术在前端领域中并不少见,无论是 React 还是 Vue 都已经选择拥抱了它。那么它究竟是什么东西?又有什么好处吸引着别人呢?接下来我就简单滴讲讲。🤔
4 |
5 | 首先,**虚拟 DOM 其实就是一个 Javascript 数据结构,它可以描述真实的 DOM Tree 结构**。
6 |
7 | 使用一个 Javascript 数据结构(如对象)实现虚拟 DOM,无疑实现了跨平台的能力,无需考虑兼容性等问题。当然,在更改数据时,更是将虚拟 DOM 与真实 DOM 进行比较,准确滴找出需要修改的地方,最后再一次性滴对真实 DOM 进行更改(侧面也反映了,多次更改只重渲真实 DOM 一次),有效地提高性能。
8 |
9 | 既然虚拟 DOM 好处多多,那么它的构成又是怎样的呢?在这里我会使用 Vue 中的 VNode 进行讲解。
10 |
11 |
12 |
13 | ## VNode
14 |
15 | 对于 VNode ,相信大家一点都不陌生,用于表示虚拟节点,是实现 Virtual DOM 的一种方式。那么它究竟是怎样的呢?我们就去 Vue 源码里探讨一下。
16 |
17 | ```javascript
18 | var VNode = function VNode (
19 | tag,
20 | data,
21 | children,
22 | text,
23 | elm,
24 | context,
25 | componentOptions,
26 | asyncFactory
27 | ) {
28 | this.tag = tag; // 标签名
29 | this.data = data; // 关联数据
30 | this.children = children; // 所有的子元素
31 | this.text = text; // 静态文案
32 | this.elm = elm; // DOM 节点
33 | this.ns = undefined;
34 | this.context = context; // 执行环境,即执行上下文
35 | this.fnContext = undefined;
36 | this.fnOptions = undefined;
37 | this.fnScopeId = undefined;
38 | this.key = data && data.key; // 数据相关联标识
39 | this.componentOptions = componentOptions; // 组件选项
40 | this.componentInstance = undefined;
41 | this.parent = undefined; // 父元素
42 | this.raw = false;
43 | this.isStatic = false; // 是否为静态节点(即无任何表达式)
44 | this.isRootInsert = true;
45 | this.isComment = false; // 是否为注释
46 | this.isCloned = false;
47 | this.isOnce = false;
48 | this.asyncFactory = asyncFactory;
49 | this.asyncMeta = undefined;
50 | this.isAsyncPlaceholder = false;
51 | };
52 | ```
53 |
54 | 可以看到,VNode 其实就是一个对象,包含节点中所有信息如标签名、关联数据、父元素以及子元素等等。想象一下,从根节点走一遍下来到最后一个节点,是否就可以构造一个完整的 Virtual DOM 了?😄
55 |
56 | 我们先来简单滴看一个栗子🌰。
57 |
58 | ```javascript
59 | Hello World...
60 | // 使用 VNode 表示
61 | {
62 | tag: 'span',
63 | isStatic: false,
64 | text: undefined,
65 | data: {
66 | staticClass: 'text'
67 | },
68 | children: [{
69 | tag: undefined,
70 | text: 'Hello World...'
71 | }]
72 | }
73 | ```
74 |
75 | 既然目前对 VNode 有了大概的了解,那么当我们开发的时候,编写的 template 是如何变成真实的 DOM 的呢?
76 |
77 | 不妨我们从源码的角度来探讨一下大致流程。🤔
78 |
79 |
80 |
81 | ## 源码分析 template 到 DOM 流程
82 |
83 | 我们先从在初始化 Vue 实例时来进行一步一步探讨。
84 |
85 | ```javascript
86 | function Vue (options) {
87 | // ...
88 | this._init(options)
89 | }
90 | Vue.prototype._init = function (options) {
91 | // ...
92 | if (vm.$options.el) { // 判断绑定元素选项是否存在
93 | vm.$mount(vm.$options.el); // 根据绑定元素选项开始挂载
94 | }
95 | }
96 | ```
97 |
98 | 明显滴,会先判断是否绑定有元素,再根据绑定元素选项直接挂载。那么这个挂载方法又是如何的呢?
99 |
100 | ```javascript
101 | Vue.prototype.$mount = function (
102 | el,
103 | hydrating
104 | ) {
105 | el = el && inBrowser ? query(el) : undefined;
106 | return mountComponent(this, el, hydrating) // 挂载组件
107 | }
108 |
109 | var mount = Vue.prototype.$mount;
110 | Vue.prototype.$mount = function ( // 挂载执行
111 | el,
112 | hydrating
113 | ) {
114 | el = el && query(el); // 获取元素
115 |
116 | /* istanbul ignore if */
117 | if (el === document.body || el === document.documentElement) { // 若元素是body或document,则直接跳过
118 | warn(
119 | "Do not mount Vue to or - mount to normal elements instead."
120 | );
121 | return this
122 | }
123 |
124 | var options = this.$options; // 获取Vue实例的Options选项
125 | // resolve template/el and convert to render function
126 | if (!options.render) { // 判断选项中渲染函数是否存在
127 | var template = options.template; // 获取template模版
128 | if (template) {
129 | if (typeof template === 'string') { // 判断模板是否是字符串
130 | if (template.charAt(0) === '#') { // 判断模板是否以#开头
131 | template = idToTemplate(template); // 根据对应的id获取模板内容
132 | /* istanbul ignore if */
133 | if (!template) {
134 | warn(
135 | ("Template element not found or is empty: " + (options.template)),
136 | this
137 | );
138 | }
139 | }
140 | } else if (template.nodeType) { // 判断是否为一个节点类型,若是直接获取内在HTML
141 | template = template.innerHTML;
142 | } else {
143 | {
144 | warn('invalid template option:' + template, this);
145 | }
146 | return this
147 | }
148 | } else if (el) { // 获取元素外层父元素
149 | template = getOuterHTML(el);
150 | }
151 | if (template) { // 开始compile
152 | /* istanbul ignore if */
153 | if (config.performance && mark) {
154 | mark('compile');
155 | }
156 |
157 | var ref = compileToFunctions(template, { // 根据template获得相应的渲染函数(这是重点啊!!!)
158 | outputSourceRange: "development" !== 'production',
159 | shouldDecodeNewlines: shouldDecodeNewlines,
160 | shouldDecodeNewlinesForHref: shouldDecodeNewlinesForHref,
161 | delimiters: options.delimiters,
162 | comments: options.comments
163 | }, this);
164 | var render = ref.render;
165 | var staticRenderFns = ref.staticRenderFns;
166 | options.render = render; // 把渲染相关函数赋予选项中
167 | options.staticRenderFns = staticRenderFns; // 把渲染相关函数赋予选项中
168 |
169 | /* istanbul ignore if */
170 | if (config.performance && mark) {
171 | mark('compile end');
172 | measure(("vue " + (this._name) + " compile"), 'compile', 'compile end');
173 | }
174 | }
175 | }
176 | return mount.call(this, el, hydrating) // 处理好渲染函数后,正式开始挂载
177 | }
178 | ```
179 |
180 | 由上面的代码可以看到,从 template 到 DOM 过程,需要经过两个阶段,分别是:
181 |
182 | - 通过`compileToFunctions`函数对 template 进行 compile,其中包括`parse`、`optimize`、`generate`三大阶段,进而获得渲染函数,接下去章节会分别介绍。
183 | - 通过`mountComponent`函数执行渲染函数,最终得到真实 DOM 结构。
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】数据初始化之依赖收集(下).md:
--------------------------------------------------------------------------------
1 | ## Object.defineProperty 的缺陷
2 |
3 | 相信同学们都知道原生 JS 提供的`Object.defineProperty`方法存在着缺陷,在某些场景下,对对象的操作是无法触发到其 Setter 方法的,先看个栗子 🌰 体验一下:
4 |
5 | ```javascript
6 | var book = {
7 | _config: {}
8 | }
9 | Object.defineProperty(book, 'config', {
10 | get() {
11 | return book._config
12 | },
13 | set(val) {
14 | book._config = val
15 | }
16 | })
17 |
18 | book.config = { name: 'haha' }
19 | console.log(book.config) // { name: 'haha' }
20 | book.config.year = '2019'
21 | console.log(book.config) // { name: 'haha', year: '2019' }
22 | ```
23 |
24 | 代码其实很好理解,由于属性 _config 被设置为响应式,当我们直接初始化其值时,会直接调用到 Setter 方法来进行赋值。但是对于新增属性时,会发现并没有触发到 Setter 方法,为什么呢?如果是这样的话,那为何打印出来的 book.config 中还会出现 year 属性呢?
25 |
26 | 属性 config 在一开始进行响应式时,是不会对其内部属性进行统一的响应式处理的,因此对 _config 属性内部新增一个新的属性时,很显然是不会直接触发到 Setter 函数,这样一来,当 template 模板上使用该新增的属性时,同样也无法触发到 Getter 函数。
27 |
28 | 为此,既然新增属性无法进行响应式处理,那如何去收集其依赖呢?
29 |
30 | 这里就不卖关子了,**Vue 直接在父级响应式对象里添加一个不可枚举属性`__ob__`,专门用来存储该响应式的相关的 Watcher 依赖的**。由于`__ob__`存储着相对应的 Watcher 依赖,官方文档就提供了全局`$set`方法来更新,而该方法就是利用属性`__ob__`去寻找对应的依赖的,并进行更新。
31 |
32 | 另外,除了新增属性会出现这种情况外,官方文档还提及到:
33 |
34 | 1. Vue 不能检测对象属性的添加或删除;
35 | 2. Vue 不能检测以下数组的变动:
36 | - 当你利用索引直接设置一个数组项时,例如:`vm.items[indexOfItem] = newValue`;
37 | - 当你修改数组的长度时,例如:`vm.items.length = newLength`;
38 |
39 | 接下来,我们就来看看是如何通过`__ob__`属性进行存储响应的依赖的。
40 |
41 |
42 |
43 | ## 从源码进行分析
44 |
45 | Vue 在初始化响应式 $data 时,就已经开始在每个复杂数据类型下定义一个不可枚举属性`__ob__`,再结合递归操作,就能保证所有复杂数据类型下都会有一个`__ob__`依赖项。需要注意的是,Vue 对于对象和数组的处理会有不一样的处理,我会分开来探讨一下,先看看初始化时是如何进行定义的:
46 |
47 | ```javascript
48 | function initData (vm) {
49 | var data = vm.$options.data;
50 | // ...
51 | // observe data
52 | observe(data, true /* asRootData */); // 调用响应式处理方法
53 | }
54 |
55 | function observe (value, asRootData) {
56 | // ...
57 | var ob;
58 | if (hasOwn(value, '__ob__') && value.__ob__ instanceof Observer) { // 关键点,递归过程中,一旦有复杂数据类型存在__ob__属性,就立马返回
59 | ob = value.__ob__;
60 | } else if (...) {
61 | ob = new Observer(value);
62 | }
63 | // ...
64 | return ob
65 | }
66 |
67 | var Observer = function Observer (value) {
68 | this.value = value;
69 | this.dep = new Dep(); // 用来存储依赖所用
70 | // ...
71 | def(value, '__ob__', this); // 关键点,在响应式复杂类型上定义一个__ob__属性,并且配置为不可枚举
72 | if (Array.isArray(value)) {
73 | // .......................待续(数组的处理,接下去会讲到)
74 | } else {
75 | this.walk(value);
76 | }
77 | }
78 |
79 | /**
80 | * Define a property.
81 | */
82 | function def (obj, key, val, enumerable) { // 定义属性并且配置为不可枚举
83 | Object.defineProperty(obj, key, {
84 | value: val,
85 | enumerable: !!enumerable,
86 | writable: true,
87 | configurable: true
88 | });
89 | }
90 |
91 | Observer.prototype.walk = function walk (obj) { // 逐个遍历响应式复杂数据类型中属性,并且进行响应式处理
92 | var keys = Object.keys(obj);
93 | for (var i = 0; i < keys.length; i++) {
94 | defineReactive$$1(obj, keys[i]);
95 | }
96 | };
97 |
98 | function defineReactive$$1 (
99 | obj,
100 | key,
101 | val,
102 | customSetter,
103 | shallow
104 | ) {
105 | // ...
106 | var childOb = !shallow && observe(val); // 递归处理,最终返回子组件的__ob__,用来存储父级组件的依赖用的
107 | Object.defineProperty(obj, key, {
108 | enumerable: true,
109 | configurable: true,
110 | get: function reactiveGetter () {
111 | // ...
112 | if (Dep.target) {
113 | dep.depend();
114 | if (childOb) {
115 | childOb.dep.depend(); // 子组件存储父组件的依赖
116 | // .............................待续(数组处理,接下来会讲到)
117 | }
118 | }
119 | },
120 | // ...
121 | })
122 | }
123 |
124 | ```
125 |
126 | 看完会不会觉得有点懵?现在我来简单总结一下,初始化时,从`$data`开始,由于`$data`对象本身就是一个复杂数据类型,因此会先新增一个`__ob__`属性,紧接着就开始递归遍历`$data`中属性,一旦遇到复杂数据类型就会立马添加一个`__ob__`属性,其中`__ob__`属性中的 dep 变量就是用来存储依赖 Watcher 用的。
127 |
128 | 我们都知道一开始添加的`__ob__`属性中的变量 dep 存储的依赖 Watcher 依赖肯定是空的,那么依赖会从哪里开始存储,答案就是在`Object.defineProperty`方法中的 Getter 函数,当每次递归回来的变量`childOb`有值时,即相当于返回了子组件中的`__ob__`属性,这时候除了缓存一份到自身的 dep 中外,还会把其依赖 Watcher 直接存储到子组件的`__ob__`属性的 dep 变量中去。
129 |
130 | 这样一来,就能说明为何子组件更新时,也会触发到父组件的更新。这就是因为子组件一直存储有父组件的 Watcher 依赖。
131 |
132 | 1. **Obejct**
133 |
134 | 其实上述讲述的,就是以一个 Object 对象来讲解的,先递归遍历添加`__ob__`属性,然后递归返回时在`__ob__`属性中存储父组件的相关依赖。
135 |
136 | 2. **Array**
137 |
138 | 上述代码中我已经屏蔽了数组的处理,意在避免和对象的处理混淆。接下来我们来看看数组会是如何处理的:
139 |
140 | ```javascript
141 | var Observer = function Observer (value) {
142 | def(value, '__ob__', this); // 关键点,在响应式复杂类型上定义一个__ob__属性,并且配置为不可枚举
143 | if (Array.isArray(value)) {
144 | // ...
145 | this.observeArray(value);
146 | }
147 | // ...
148 | }
149 |
150 | /**
151 | * Observe a list of Array items.
152 | */
153 | Observer.prototype.observeArray = function observeArray (items) {
154 | for (var i = 0, l = items.length; i < l; i++) {
155 | observe(items[i]);
156 | }
157 | };
158 |
159 | ```
160 |
161 | 可以看到,对于数组类型的属性,会调用方法`observeArray`来对每一项的值进行响应式处理,包括遇到复杂数据类型时就添加一个`__ob__`属性,这跟对象递归遍历其实是很类似的。再看看在 Getter 的处理:
162 |
163 | ```javascript
164 | function defineReactive$$1 (
165 | obj,
166 | key,
167 | val,
168 | customSetter,
169 | shallow
170 | ) {
171 | // ...
172 | var childOb = !shallow && observe(val); // 递归处理,最终返回子组件的__ob__,用来存储父级组件的依赖用的
173 | Object.defineProperty(obj, key, {
174 | enumerable: true,
175 | configurable: true,
176 | get: function reactiveGetter () {
177 | // ...
178 | if (Dep.target) {
179 | dep.depend();
180 | if (childOb) {
181 | childOb.dep.depend(); // 子组件存储父组件的依赖
182 | if (Array.isArray(value)) {
183 | dependArray(value);
184 | }
185 | }
186 | }
187 | },
188 | // ...
189 | })
190 | }
191 |
192 | function dependArray (value) {
193 | for (var e = (void 0), i = 0, l = value.length; i < l; i++) {
194 | e = value[i];
195 | e && e.__ob__ && e.__ob__.dep.depend();
196 | if (Array.isArray(e)) {
197 | dependArray(e);
198 | }
199 | }
200 | }
201 | ```
202 |
203 | 同样地,当遇到数组类型时,会调用方法`dependArray`来进行递归处理,向数组中每一个复杂数据类型添加父层数据的依赖 Watcher 。而遇到基础数据类型时,就会直接跳过。
204 |
205 |
206 |
207 | 好了,现在我们来总结一下:
208 |
209 | - 对于 Vue 不能监测的行为,都会利用`__ob__`来进行存储依赖;
210 | - 官方提供的全局`$set`方法,其实就是利用`__ob__`中依赖进行设置和更新的(下一篇依赖更新中会提及);
211 | - 针对对象和数组类型,默认情况都会是直接遍历对象中的属性进行响应式处理,而数组则需要提前遍历,遇到数组则继续遍历,遇到对象则直接递归处理其属性,遇到基础数据类型时就会直接跳过;
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】数据初始化之依赖收集(上).md:
--------------------------------------------------------------------------------
1 | ## 先聊聊闭包
2 |
3 | 说起闭包,可以说是大前端里老生常谈的话题了。那为啥要在这里说起它呢,自然肯定会有地方是有用到它才会拿出来进行讨论和回顾,废话不说,直奔主题。
4 |
5 | 那究竟什么是闭包?
6 |
7 | 按照官方的定义,**闭包是指有权访问另一个函数作用域中变量的函数**(其实我一直觉得理解官方的字面意思好别扭,而且最主要的,就是不好理解啊!!!🤮,纯属个人意见)。来个直白点的理解,就是在一个函数内部创建一个函数,而这也是创建闭包最常见的方式,看🌰:
8 |
9 | ```javascript
10 | function sum() {
11 | var a = 0
12 | return function(b) {
13 | return a += b
14 | }
15 | }
16 | var sumFun = sum()
17 | sumFun(1) // 1
18 | sumFun(1) // 2
19 | ```
20 |
21 | 从代码层面上很好理解,在 sum 函数内返回一个匿名函数,有一个点需要重点注意的是,匿名函数是可以直接访问到外层 sum 函数作用域中的 a 变量,如果你对这个有疑惑,那就要额外补补 js 的作用域链,当然有空我也可以补上来。话不多说,直接上一个该闭包中所涉及到的作用域链,如下:
22 |
23 |
24 |
25 | 
26 |
27 |
28 |
29 | 相信同学们对闭包的一个很重要的特点很熟悉,就是**闭包所涉及到的变量会一直存留在内存中,而不被垃圾回收机制回收**。这也就能说明,为什么执行两次 sumFun 函数后,输出的是 2 而不是 1 ,因为变量 a 会驻留在内存中,因此第二次执行后仍然可以读到前一次所处理的变量 a 的值。
30 |
31 | 既然闭包中的变量会长期驻留在内存,那会不会导致内存泄漏?
32 |
33 | 答案是肯定的,不当的闭包处理会让变量无法销毁释放,必要时需要进行手动释放。但是闭包也可以在一些场景下发挥着很好的作用,例如 Memoization 缓存机制。对于一些反复计算,闭包存储的值就可以立马返回,从而避免了反复的操作。
34 |
35 | 之所以提到闭包中这个缓存功能,是因为今天要探讨的依赖收集功能恰恰就是利用了这一功能进行了实现。
36 |
37 |
38 |
39 | ##理解依赖收集
40 |
41 | 提起依赖收集,也许会有同学会感到疑惑,依赖收集究竟是一个什么东西?又有什么用处?🤔
42 |
43 | 简单点来说,依赖收集就是与之相关联的事物都收集起来。在生活里,其实有很多与该概念相似的场景,比如一台即将发布的新手机,用户若想购买需提前填写手机号码进行预约,当填写完后,手机号就会被收集起来,因此该台新手机就会收集很多与之预约的手机号,等到发布当天,就会逐个通知相关手机号的用户进行购买。在这里面,预约的手机号就是一个依赖,最终会被收集起来。
44 |
45 | 说了含义,那就得提提用处。同学们应该也比较清楚,既然依赖收集起来,肯定是为了日后有需要时候就拿出来使用。好比如刚刚所说的,如果不收集预约的手机号的话,一旦手机发布后,是无法追踪到相关预约手机号进行通知的。而这就是接下去的章节要提到的依赖更新,总结一下就是,**依赖收集就是为了依赖更新而服务的**。
46 |
47 |
48 |
49 | ## 从源码角度进行探究
50 |
51 | 在上一篇递归处理响应式中有提及过,依赖收集是在 getter 中进行,而依赖更新则是在 setter 中进行。
52 |
53 | 我们现在来回顾一下`defineReactive$$1`函数,看看依赖收集是如何实现的。
54 |
55 | ```javascript
56 | function defineReactive$$1 (
57 | obj,
58 | key,
59 | val,
60 | customSetter,
61 | shallow
62 | ) {
63 | var dep = new Dep();
64 | // ...
65 | Object.defineProperty(obj, key, {
66 | enumerable: true,
67 | configurable: true,
68 | get: function reactiveGetter () {
69 | // ...
70 | if (Dep.target) { // 判断是否存在依赖目标
71 | dep.depend(); // 依赖收集
72 | // ...
73 | }
74 | }
75 | })
76 | }
77 | ```
78 |
79 | 由代码可以看到,`defineReactive$$1`函数内实现了闭包,每次属性被使用时,都会调用 getter 函数,而 getter 函数恰恰就是利用了外层函数`defineReactive$$1`中的 dep 变量(也许你会问,dep 是用来干嘛的?稍等一下哈,接下去会详细描述),而该 dep 变量就是用来缓存收集该属性相关依赖的(说白点,就是哪里用到该属性的地方就收集起来 😄 )。所以每次使用到该属性时,都会先判断与该属性依赖的目标是否存在,一旦存在就立马收集起来。
80 |
81 | 既然 dep 变量是一个 Dep 对象的实例,那么它究竟是一个什么样的结构的?我们再来看看
82 |
83 | ```javascript
84 | /**
85 | * A dep is an observable that can have multiple
86 | * directives subscribing to it.
87 | */
88 | var Dep = function Dep () {
89 | this.id = uid++;
90 | this.subs = [];
91 | };
92 |
93 | Dep.prototype.addSub = function addSub (sub) {
94 | this.subs.push(sub);
95 | };
96 |
97 | Dep.prototype.depend = function depend () {
98 | if (Dep.target) {
99 | Dep.target.addDep(this);
100 | }
101 | };
102 | ```
103 |
104 | 好明显,Dep 对象中存储有两个属性,其中一个是 id,用来标识用的,而另一个就是数组 subs,该属性就是用来收集依赖用的,其中在 Dep 对象在原型上定义两个方法,分别是 addSub 、depend,都是用来添加依赖用的(当然还定义有其他方法,有兴趣的可以自行研究一下)。
105 |
106 | 现在来总结一下:
107 |
108 | - 当存在 Dep.target 依赖目标时,就会调用 Dep.depend 方法来进行收集,其中 Dep.depend 方法实质就是数组的 push 推进;
109 | - 由于`defineReactive$$1`函数实现的是一个闭包,因此 dep 变量会一直存储在内存中,当有新的地方用到该属性时,就会继续 push 进去,而每次的 push 操作都会保留在 dep 中,直到该属性销毁为止;
110 |
111 |
112 |
113 | ## 依赖收集的疑惑
114 |
115 | 通过上述的描述,我们都大概清楚了只有存在 Dep.target 依赖目标时,才会去进行收集。既然 Dep.target 是用来存储依赖目标的,那么 Dep.target 又是从何而来的呢?接下来我们就来探究一下 Vue 是如何进行处理的。
116 |
117 | 其实 Vue 从一开始挂载元素时,就已经开始赋值 Dep.target 了,我们来看看是如何实现的:
118 |
119 | ```javascript
120 | function initMixin(Vue) {
121 | Vue.prototype._init = function (options) {
122 | var vm = this;
123 | // ...
124 | if (vm.$options.el) { // 判断是否存在挂载元素
125 | vm.$mount(vm.$options.el); // 若存在就开始进行挂载处理
126 | }
127 | };
128 | }
129 |
130 | initMixin(Vue)
131 |
132 | Vue.prototype.$mount = function (
133 | el,
134 | hydrating
135 | ) {
136 | // ...
137 | return mountComponent(this, el, hydrating) // 直接调用挂载组件方法
138 | };
139 |
140 | function mountComponent (
141 | vm,
142 | el,
143 | hydrating
144 | ) {
145 | var updateComponent;
146 | // ...
147 | updateComponent = function () {
148 | vm._update(vm._render(), hydrating); // 更新组件,并进行重新渲染(与依赖收集相关的关键处理)
149 | };
150 | // ...
151 | // we set this to vm._watcher inside the watcher's constructor
152 | // since the watcher's initial patch may call $forceUpdate (e.g. inside child
153 | // component's mounted hook), which relies on vm._watcher being already defined
154 | new Watcher(vm, updateComponent, noop, { // 创建一个 Watcher 实例(即依赖)
155 | before: function before () {
156 | if (vm._isMounted && !vm._isDestroyed) {
157 | callHook(vm, 'beforeUpdate');
158 | }
159 | }
160 | }, true /* isRenderWatcher */);
161 | }
162 | ```
163 |
164 | 从代码上可以看到,元素是在一开始挂载过程中,创建一个 Watcher 实例,也就是一个相关依赖。需注意的是,该依赖是以 template 为单位的(即多个属性都会可能收集同一个 Watcher,形成多对一的关系)。那既然挂载组件的过程中会创建相应的依赖,那么它是如何赋予到 Dep 对象上的?接着看下去:
165 |
166 | ```javascript
167 | var Watcher = function Watcher (
168 | vm,
169 | expOrFn,
170 | cb,
171 | options,
172 | isRenderWatcher
173 | ) {
174 | // options
175 | if (options) {
176 | // ...
177 | this.lazy = !!options.lazy; // lazy 用于判断组件是否延迟加载
178 | // ...
179 | }
180 | // ...
181 | this.value = this.lazy
182 | ? undefined
183 | : this.get(); // get 方法是建立和 Dep 对象的桥梁
184 | }
185 |
186 | Watcher.prototype.get = function get () {
187 | pushTarget(this); // 直接讲 Watcher 赋值到 Dep.target 上
188 | var value;
189 | var vm = this.vm;
190 | try {
191 | value = this.getter.call(vm, vm); // 赋值后,开始调用 updateComponent 方法进行渲染并进行依赖收集
192 | } catch {
193 | // ...
194 | } finally {
195 | // ...
196 | popTarget(); // 渲染结束并收集依赖后,就重置 Dep.target
197 | // ...
198 | }
199 | }
200 |
201 | var targetStack = []; // 用来记录保存创建好的 Watcher 实例的栈
202 | function pushTarget(target) {
203 | targetStack.push(target);
204 | Dep.target = target; // 赋值到当前 Dep.target 上
205 | }
206 |
207 | function popTarget () {
208 | targetStack.pop(); // 移除当前的 Watcher
209 | Dep.target = targetStack[targetStack.length - 1]; // Dep.target 永远指向 targetStack 的最后一项
210 | }
211 | ```
212 |
213 | 至此,你应该也能大概了解创建依赖 Watcher 的整个过程,在创建 Watcher 实例的同时并记录下来,然后进行渲染和依赖收集,到最后推出与此相关的 Watcher。
214 |
215 | 需要注意的是,建立好 Watcher 和 Dep 桥梁后,还需要将 Dep.target 推进相对应响应式属性的 subs 数组中,其中 updateComponent 起到了重要作用,它就是直接触发到 getter 函数进而可以推进到 subs 数组中。
216 |
217 | 现在再来总结一下:
218 |
219 | - 组件在挂载过程中,会创建相对应的 Watcher 实例,并将 Watcher 保存在 Dep.target 中,最好保存到响应式属性的闭包当中,完成依赖收集的过程;
220 | - 通过组件的渲染和依赖收集,将 Dep.target 保存在响应式属性的 subs 数组中,完成后从 targetStack 记录中推出与此相关的 Watcher ;
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
240 |
241 |
242 |
243 |
244 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】渲染 Render (AST -> VNode).md:
--------------------------------------------------------------------------------
1 | ## 渲染 Render 功能
2 |
3 | 在不了解`Render`实现情况下,很容易会认为它的功能就是直接将`AST`通过执行渲染方法从而得到真实 DOM(当初我也是这样认为的 😅)。
4 |
5 | 既然`Render`不具备上述的功能,那么它的功能又是什么呢?
6 |
7 | 看到标题,你应该也知道了答案,那就是**将`AST`转换为`VNode`节点**。那么转化为真实 DOM 又是发生在哪个步骤呢?不瞒你说,那就是**在最后一步`Diff`过程所得到两个`VNode`节点差异后,才会将差异渲染到真实环境中形成视图**。
8 |
9 | 接下来,我们就来从源码角度探究一下,`Render`是如何将`AST`转换为`VNode`的。😼
10 |
11 |
12 |
13 | ## 从源码角度进行分析
14 |
15 | 相信看过[【从 Template 到 DOM 过程是怎样的】](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E4%BB%8E%20Template%20%E5%88%B0%20DOM%20%E8%BF%87%E7%A8%8B%E6%98%AF%E6%80%8E%E6%A0%B7%E7%9A%84.md)的话,都应该比较清楚。再编译`compile`后,就会直接调用`$mount`方法,我们再来简单回顾一下。
16 |
17 | ```javascript
18 | Vue.prototype.$mount = function (
19 | el,
20 | hydrating
21 | ) {
22 | el = el && inBrowser ? query(el) : undefined;
23 | return mountComponent(this, el, hydrating) // 加载元素或组件方法
24 | }
25 |
26 | var mount = Vue.prototype.$mount
27 | Vue.prototype.$mount = function (
28 | el,
29 | hydrating
30 | ) {
31 | // ...
32 | var ref = compileToFunctions(template, { // 经过编译Compile后得到最终渲染方法相关对象
33 | outputSourceRange: "development" !== 'production',
34 | shouldDecodeNewlines: shouldDecodeNewlines,
35 | shouldDecodeNewlinesForHref: shouldDecodeNewlinesForHref,
36 | delimiters: options.delimiters,
37 | comments: options.comments
38 | }, this)
39 | var render = ref.render;
40 | var staticRenderFns = ref.staticRenderFns;
41 | options.render = render; // 将渲染方法挂载到实例选项中
42 | options.staticRenderFns = staticRenderFns; // 将收集到的静态树挂载到选项中
43 | // ...
44 | return mount.call(this, el, hydrating) // 正式开始加载元素
45 | }
46 | ```
47 |
48 | 从流程上可以看到,通过编译`Compile`后,就会将相应的渲染方法以及收集到的静态树统一挂载到选项信息中,接着正式开始加载元素。
49 |
50 | 在加载元素里,最主要就是`mountComponent`方法,我们再来看看是如何加载的 🤔。
51 |
52 | ```javascript
53 | var createEmptyVNode = function (text) { // 创建空VNode节点方法
54 | if ( text === void 0 ) text = '';
55 |
56 | var node = new VNode();
57 | node.text = text;
58 | node.isComment = true;
59 | return node
60 | }
61 |
62 | function mountComponent (
63 | vm,
64 | el,
65 | hydrating
66 | ) {
67 | vm.$el = el
68 | if (!vm.$options.render) { // 若不存在渲染方法,则作为一个创建空VNode节点来处理
69 | vm.$options.render = createEmptyVNode;
70 | // ...
71 | }
72 | callHook(vm, 'beforeMount') // 开始执行beforeMount生命周期回调
73 | var updateComponent // 转化AST为VNode节点外层方法
74 | // ...
75 | updateComponent = function () {
76 | // ...
77 | var vnode = vm._render() // 最主要的!!!直接转化AST为VNode节点
78 | // ...
79 | vm._update(vnode, hydrating) // 将转换好的VNode放到更新函数中使用patch进行比对
80 | // ...
81 | }
82 | new Watcher(vm, updateComponent, noop, { // 创建模板依赖Watcher,其中的更新函数即为updateComponent
83 | before: function before () {
84 | if (vm._isMounted && !vm._isDestroyed) {
85 | callHook(vm, 'beforeUpdate');
86 | }
87 | }
88 | }, true /* isRenderWatcher */)
89 | }
90 | ```
91 |
92 | `mountComponent`方法会先判断实例选项是否有渲染方法,若无则直接赋值为空VNode节点。接着使用变量`updateComponent`作为暴露转化`AST`为`VNode`外层方法,并在创建模板依赖时将其作为更新回调函数,这样一来,在每次更新时,都会使用`updateComponent`方法执行转化`AST`为`VNode`节点。
93 |
94 | 在上述代码中,其中`_render`方法是转化`AST`为`VNode`核心方法,而另一个`_update`方法则是最后用于`patch`比对用到的(`_update`方法暂时不讲,会在下一章`Diff`说法中提及)。现在就来继续看看`_render`方法是如何将`AST`转化为`VNode`节点的。
95 |
96 | ```javascript
97 | Vue.prototype._render = function () {
98 | var vm = this;
99 | var ref = vm.$options;
100 | var render = ref.render; // 获取实例选项中保存的渲染方法
101 | // ...
102 | var vnode; // VNode节点变量
103 | // ...
104 | vnode = render.call(vm._renderProxy, vm.$createElement) // 根据渲染方法执行相应的_c
105 | // ...
106 | return vnode
107 | }
108 | ```
109 |
110 | 可以看到,直接调用了编译`Compile`出来的渲染方法。
111 |
112 | 首先,我们来回顾一下渲染方法是咋样的?看看下面这个栗子呀。
113 |
114 | ```javascript
115 | Hello Word...
116 | // 渲染方法如下
117 | with(this) {
118 | _c('span', [_v('Hello Word...')])
119 | }
120 | ```
121 |
122 | 终究回到了上一章中留下来的问题,究竟`_c`和`_v`是干嘛用的?🤔
123 |
124 | 其实它们都是尤大大在内部封装好的各种渲染方法,不妨我们就来看看还有哪些。
125 |
126 | ```javascript
127 | function installRenderHelpers (target) { // 针对各种场景封装好的渲染方法
128 | target._o = markOnce; // 处理v-once指令的渲染方法
129 | target._n = toNumber; // 将输入值转化为数值,若转化失败则直接使用原始字符串
130 | target._s = toString; // 将输入值转化为字符串
131 | target._l = renderList; // 处理v-for指令的渲染方法
132 | target._t = renderSlot; // 处理v-slot指令的渲染方法
133 | target._q = looseEqual; // 判断两个值是否相等
134 | target._i = looseIndexOf; // 判断数组中是否存在与输入值相等的项
135 | target._m = renderStatic; // 处理静态树的渲染方法
136 | target._f = resolveFilter; // 处理选项信息中filters项
137 | target._k = checkKeyCodes; // 判断配置中是否拥有相应的eventKeyCode
138 | target._b = bindObjectProps; // 将v-bind指令绑定到相应的VNode
139 | target._v = createTextVNode; // 处理文本节点的渲染方法
140 | target._e = createEmptyVNode; // 创建空节点的渲染方法
141 | target._u = resolveScopedSlots; // 处理ScopedSlots
142 | target._g = bindObjectListeners; // 处理对象监听
143 | target._d = bindDynamicKeys; // 处理v-bind:key渲染方法
144 | target._p = prependModifier; // 判断类型是否为唯一字符串
145 | }
146 |
147 | vm._c = (a, b, c, d) => createElement(vm, a, b, c, d, false) // 创建元素VNode节点
148 | ```
149 |
150 | 上述代码,可以很仔细地展示了每一种场景的处理方案。由于时间有限,我就不会将每个场景的处理源码都提出来讲,后面有时间会回来再进行相应的讲解。
151 |
152 | 目前也大概知道每一个封装的渲染方法的含义,回到上面的主题,调用编译`Compile`出来的渲染方法,,其实就是调用`_c`创建元素`VNode`节点。
153 |
154 | 接下来我们就来看看`_c`内部是如何实现的。
155 |
156 | ```javascript
157 | function createElement (
158 | context,
159 | tag,
160 | data,
161 | children,
162 | normalizationType,
163 | alwaysNormalize
164 | ) {
165 | if (Array.isArray(data) || isPrimitive(data)) { // 判断数据是否为数组或原始数据类型
166 | normalizationType = children;
167 | children = data;
168 | data = undefined;
169 | }
170 | // ...
171 | return _createElement(context, tag, data, children, normalizationType)
172 | }
173 |
174 | function _createElement (
175 | context,
176 | tag,
177 | data,
178 | children,
179 | normalizationType
180 | ) {
181 | if (isDef(data) && isDef((data).__ob__)) { // 判断数据不为空并且无依赖时,则作为一个空VNode节点进行处理
182 | warn(
183 | "Avoid using observed data object as vnode data: " + (JSON.stringify(data)) + "\n" +
184 | 'Always create fresh vnode data objects in each render!',
185 | context
186 | ); // 避免使用非响应式数据创建VNode节点,不然导致每次渲染都包含其中
187 | return createEmptyVNode() // 返回创建的空VNode节点
188 | }
189 | // ...
190 | var vnode
191 | if (typeof tag === 'string') {
192 | // ...
193 | if (config.isReservedTag(tag)) { // 判断标签名是否为HTML标签
194 | vnode = new VNode( // 创建元素VNode节点
195 | config.parsePlatformTagName(tag), data, children,
196 | undefined, undefined, context
197 | )
198 | } else if ((!data || !data.pre) && isDef(Ctor = resolveAsset(context.$options, 'components', tag))) { // 判断是否为组件
199 | vnode = createComponent(Ctor, data, context, children, tag) // 创建组件VNode节点
200 | } else { // 其他一律当未知类型创建VNode节点
201 | vnode = new VNode(
202 | tag, data, children,
203 | undefined, undefined, context
204 | )
205 | }
206 | } else { // 若标签名不是字符串,则作为组件选项/构造函数创建组件
207 | vnode = createComponent(tag, data, context, children)
208 | }
209 | if (Array.isArray(vnode)) { // 判断生成的vnode是否为数组类型
210 | return vnode
211 | } else if (isDef(vnode)) { // 判断vnode是否为空
212 | if (isDef(ns)) { applyNS(vnode, ns); } // 定义当前节点的命名空间
213 | if (isDef(data)) { registerDeepBindings(data); } // 绑定动态的style、class
214 | return vnode
215 | } else { // 若为空,则直接返回一个空VNode节点
216 | return createEmptyVNode()
217 | }
218 | }
219 | ```
220 |
221 | 可以看到,在执行渲染方法`_c`时,最终都是返回了创建好的`VNode`节点。
222 |
223 | 代码上可能还有些方法没有细讲,如`createComponent`,其实底层都是经过一系列的处理后得到相应的`VNode`节点。另外,我个人认为创建好的`VNode`节点终究就是一个对象形式,不会存在数组形式(若有错误,希望指出哈)。
224 |
225 | 创建好的`VNode`节点最终经过绑定当前节点命名空间以及动态的`style`、`class`,最终将节点返回。
226 |
227 | 最后的最后,渲染`Render`最终实现的功能就是**将转化好的`AST`渲染方法,直接通过`VNode`构造函数构建相应的`VNode`节点**。在这个过程中,会建立一个模板依赖 Watcher,并且将转化过程作为一个更新回调方法保存,**每当响应式数据更新时,都会触发该过程,先渲染出相应的`VNode`节点,再进行`patch`比对,最后将比对的差异直接渲染成相应的真实`DOM`**。
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
240 |
241 |
242 |
243 |
244 |
245 |
246 |
247 |
248 |
249 |
250 |
251 |
252 |
253 |
254 |
255 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】侦听器 Watch.md:
--------------------------------------------------------------------------------
1 | ## 回顾侦听器 Watch
2 |
3 | 相信用过 Vue 侦听器的 Watch 的同学们,都应该比较熟悉,现在就来简单回顾一下,这对后面理解源码起来会简单好多。当然如果你觉得没必要,可以直接跳过去到下面的源码分析哈 🤔 。
4 |
5 | 侦听器 Watch 接收类型,可以是`String、Function、Object、Array`,那么这些类型你都没有用过呢,别急,下面就会挪用官方文档进行简单讲解一下。
6 |
7 | - String
8 |
9 | 对于使用字符串类型的情况不多见,但可以体现封装性
10 |
11 | ```javascript
12 | watch: {
13 | a: 'setA'
14 | },
15 | methods: {
16 | setA: function() {
17 | // ...
18 | }
19 | }
20 | ```
21 |
22 | 使用字符串时,**字符串的值就是函数名**,并且必须要在`mehods`中有定义。
23 |
24 | - Function
25 |
26 | 函数类型可以说是我们最常用的监听方式了,但需要注意其参数的表示
27 |
28 | ```javascript
29 | watch: {
30 | a: function(newValue, oldValue) {
31 | // ...
32 | }
33 | }
34 | ```
35 |
36 | **第一个参数就是更新后的值,而第二个则是更新前的值**。
37 |
38 | - Object
39 |
40 | 用于监听深层次对象中的值变化,至于其他三种方式则无法监听对象中属性变化
41 |
42 | ```javascript
43 | data: {
44 | a: {
45 | b: 1
46 | }
47 | },
48 | watch: {
49 | a: {
50 | deep: true,
51 | handle: function(newValue, oldValue) {
52 | // ...
53 | }
54 | }
55 | }
56 | ```
57 |
58 | 由于监听的是一个对象,因此当使用其他三种方式时,当改变`this.a.b`后是无法监听其变化的,为什么?后面会单独提出来讲解。使用`deep`属性即可监听深层次的变化了。
59 |
60 | - Array
61 |
62 | 用于监听多个回调函数时,按序进行
63 |
64 | ```javascript
65 | watch: {
66 | a: [
67 | 'set1',
68 | function set2(newValue, oldValue) {
69 | // ...
70 | }
71 | ]
72 | }
73 | ```
74 |
75 | 最终会按序执行其中定义的回调函数。
76 |
77 |
78 |
79 | 好了,回到刚刚讨论的问题,为什么当我更改`this.a.b`时,使用除了`Object`类型以外的方式无法监听到`a`的变化呢?
80 |
81 | 原因很简单,那就是在初始化 Watch 并建立依赖收集时,只会对第一层的属性进行收集,即定义 a 的 Watch 会被收集到响应式属性 a 的依赖中。只有当发现`Object`类型中拥有`deep: true`时,才会开始对 a 进行递归遍历,然后将 a 中所有深层响应式属性中都能收集到定义 a 的 Watch 。
82 |
83 | 当然,除了`Object`类型中`deep`属性,还有`immediate`和`handler`,现在就来讲解一下
84 |
85 | - immediate:用于通知定义的 Watch 回调函数立即调用;
86 | - handler:用于定义 Watch 的回调函数;
87 |
88 | 说了那么多,我始终都是不推荐使用 Watch 的。因为 Watch 真的不好管理,对于最终 Bug 的过程中难以找到准确的触发点。当然官方也并不是反对你使用,但是依然推崇还是计算属性来处理大部分情况,并且还拥有一个强大的缓存功能。
89 |
90 | 接下来就从源码角度进行分析,如果看过前面篇章的同学们,其实很好理解,当然没看过的同学也不要紧,我会一个一个很好滴解析哈 😄 。
91 |
92 |
93 |
94 | ##从源码角度进行分析
95 |
96 | 现在就来看看 Vue 在初始化 Vue 实例时是如何处理侦听器的。
97 |
98 | ```javascript
99 | // Firefox has a "watch" function on Object.prototype...
100 | var nativeWatch = ({}).watch;
101 |
102 | function initState (vm) {
103 | // ...
104 | if (opts.watch && opts.watch !== nativeWatch) { // 判断是否存在 watch 选项以及避免与火狐浏览器中对象原型中 watch 产生冲突
105 | initWatch(vm, opts.watch); // 初始化 watch 选项
106 | }
107 | }
108 |
109 | function initWatch (vm, watch) {
110 | for (var key in watch) { // 遍历 watch 选项中的值
111 | var handler = watch[key]; // 获取每一项定义的 watch
112 | if (Array.isArray(handler)) { // 若遍历到的属性为数组类型,则为数组中每一项值进行创建 Watch
113 | for (var i = 0; i < handler.length; i++) {
114 | createWatcher(vm, key, handler[i]);
115 | }
116 | } else {
117 | createWatcher(vm, key, handler);
118 | }
119 | }
120 | }
121 |
122 | function createWatcher (
123 | vm,
124 | expOrFn,
125 | handler,
126 | options
127 | ) {
128 | if (isPlainObject(handler)) {
129 | options = handler; // 一旦遍历到的值是一个对象时,就直接拿该项定义的 watch 作为选项配置
130 | handler = handler.handler; // 获取 watch 中定义的回调函数
131 | }
132 | if (typeof handler === 'string') { // 当遍历到的值是一个字符串时,则直接根据该字符串从实例上获取该项方法出来
133 | handler = vm[handler];
134 | }
135 | return vm.$watch(expOrFn, handler, options) // 创建 watch
136 | }
137 |
138 | Vue.prototype.$watch = function (
139 | expOrFn,
140 | cb,
141 | options
142 | ) {
143 | var vm = this;
144 | if (isPlainObject(cb)) { // 当获取到 handler 依然还是一个对象时,则继续递归调用 createWatcher 方法
145 | return createWatcher(vm, expOrFn, cb, options)
146 | }
147 | options = options || {};
148 | options.user = true;
149 | var watcher = new Watcher(vm, expOrFn, cb, options); // 建立与响应式属性间的依赖收集
150 | if (options.immediate) {
151 | try {
152 | cb.call(vm, watcher.value);
153 | } catch (error) {
154 | handleError(error, vm, ("callback for immediate watcher \"" + (watcher.expression) + "\""));
155 | }
156 | }
157 | return function unwatchFn () { // 需要注意的地方,当使用全局 $watch 时,返回的是一个可取消监听方法
158 | watcher.teardown(); // 取消监听
159 | }
160 | };
161 | ```
162 |
163 | 从上面代码可以看到,涉及的知识点并不是很多,也很好理解。现在来总结一下
164 |
165 | - 对定义的 watch 类型进行判断,若是数组类型时,则会遍历出来为每一项值创建相应的 watch;
166 | - 若 watch 定义时是一个对象类型,则直接作为依赖的 options 选项;
167 | - 当存在 immediate 属性时,会立即调用 watch 的回调函数;
168 | - 调用全局 $watch 时,都会返回一个可取消监听的方法(即监听的属性改变时,不会调用 watch 的回调函数);
169 |
170 |
171 |
172 | 接下来我们再看看,类 Watcher 是如何为 watch 选项建立与响应式属性的依赖关系的。
173 |
174 | ```javascript
175 | var bailRE = new RegExp(("[^" + (unicodeRegExp.source) + ".$_\\d]"));
176 | function parsePath (path) {
177 | if (bailRE.test(path)) {
178 | return
179 | }
180 | var segments = path.split('.');
181 | return function (obj) {
182 | for (var i = 0; i < segments.length; i++) {
183 | if (!obj) { return }
184 | obj = obj[segments[i]];
185 | }
186 | return obj
187 | }
188 | }
189 |
190 | var Watcher = function Watcher (
191 | vm,
192 | expOrFn,
193 | cb,
194 | options,
195 | isRenderWatcher
196 | ) {
197 | // ...
198 | // options
199 | if (options) {
200 | this.deep = !!options.deep; // 针对有定义 deep 属性,会赋予 watcher 中内在的 deep
201 | // ...
202 | } else {
203 | this.deep = this.user = this.lazy = this.sync = false;
204 | }
205 | this.cb = cb; // 获取 watch 的回调函数
206 | // ...
207 | if (typeof expOrFn === 'function') {
208 | this.getter = expOrFn;
209 | } else { // 定义的 expOrFn 并不是一个函数类型,因此最后会使用 parsePath 去解析
210 | this.getter = parsePath(expOrFn);
211 | if (!this.getter) {
212 | this.getter = noop;
213 | warn(
214 | "Failed watching path: \"" + expOrFn + "\" " +
215 | 'Watcher only accepts simple dot-delimited paths. ' +
216 | 'For full control, use a function instead.',
217 | vm
218 | );
219 | }
220 | }
221 | this.value = this.lazy // 开始执行计算 watch
222 | ? undefined
223 | : this.get();
224 | }
225 |
226 | Watcher.prototype.get = function get () {
227 | pushTarget(this);
228 | var value;
229 | var vm = this.vm;
230 | try {
231 | value = this.getter.call(vm, vm); // 关键点,由于引用到响应式属性,因此最终会在响应式 Getter 中收集该定义的 watch 依赖
232 | } catch (e) {
233 | if (this.user) {
234 | handleError(e, vm, ("getter for watcher \"" + (this.expression) + "\""));
235 | } else {
236 | throw e
237 | }
238 | } finally {
239 | // "touch" every property so they are all tracked as
240 | // dependencies for deep watching
241 | if (this.deep) { // deep 属性的关键,就是递归遍历,为每一个响应式属性收集当前创建的 Watcher
242 | traverse(value);
243 | }
244 | popTarget();
245 | this.cleanupDeps();
246 | }
247 | return value
248 | };
249 | ```
250 |
251 | 代码中可以很好理解,前面我已经说了,在创建 Watcher 依赖时,需要传更新回调函数`expOrFn`进来以便进行计算。但是 watch 会稍微一点点不一样,`expOrFn`传递的却是一个属性名,而`cb`才是更新回调函数。
252 |
253 | 既然`expOrFn`不是一个函数类型,因此就会调用`parsePath`方法进行解析,返回一个解析回调。在最后`this.get()`方法中,会调用到`this.getter`中的解析回调,并传入当前 vue 实例。最终从 vue 实例上解析出来一个同名响应式属性,以至于触发了响应式属性的 Getter 函数,这样一来,响应式属性就收集了当前创建 Watcher。
254 |
255 | 另一方面,也可以看到,在`this.get`方法中,当发现`this.deep`存在时,会调用`traverse`方法来为每一个深层响应式属性收集当前创建的 Watcher 依赖,让我们再来看看是如何处理的。
256 |
257 | ```javascript
258 | var seenObjects = new _Set(); // 创建一个集合
259 |
260 | function traverse (val) {
261 | _traverse(val, seenObjects); // 开始遍历操作
262 | seenObjects.clear();
263 | }
264 |
265 | function _traverse (val, seen) {
266 | var i, keys;
267 | var isA = Array.isArray(val);
268 | if ((!isA && !isObject(val)) || Object.isFrozen(val) || val instanceof VNode) {
269 | return
270 | }
271 | if (val.__ob__) {
272 | var depId = val.__ob__.dep.id;
273 | if (seen.has(depId)) {
274 | return
275 | }
276 | seen.add(depId); // 当 __ob__ 中不存在当前 Watcher 时,就开始收集
277 | }
278 | if (isA) {
279 | i = val.length;
280 | while (i--) { _traverse(val[i], seen); } // 如果遍历到的是数组,那么就会递归遍历其中每一项值,并建立依赖关系
281 | } else {
282 | keys = Object.keys(val);
283 | i = keys.length;
284 | while (i--) { _traverse(val[keys[i]], seen); } // 当遍历到的是对象时,同样也会递归遍历其中每一项值,并建立依赖关系
285 | }
286 | }
287 | ```
288 |
289 | 我们可以看到,当存在 deep 属性时,就证明该监听的对象为一个复杂数据类型。前面我也提到过,对于监听复杂数据类型时,使用原有的`Object.defineProprtty`方法是无法实现完整的监听,而是使用一个变量`__ob__`进行存储。
290 |
291 | 因此,上面的方法`_traverse`就是遍历复杂数据类型,然后为每一个复杂数据类型的`__ob__`收集当前创建的依赖 Watcher。
292 |
293 | 那么,如果是更新呢?过程又是如何的?
294 |
295 | 其实 watch 的更新过程和前面所说的更新过程都是一样,都是调用`queueWatcher`方法,按照队列的形式进行。虽然 Watch 涉及的东西不多,但是要重点注意其中`deep `和`immediate`两个属性,由于这两个属性的存在,可以很好处理一些日常开发难题,但最后,我还是建议大家多使用计算属性来处理问题,毕竟滥用 watch 的话,到最后是一个难以维护的事实。
296 |
297 |
298 |
299 |
300 |
301 |
302 |
303 |
304 |
305 |
306 |
307 |
308 |
309 |
310 |
311 |
312 |
313 |
314 |
315 |
316 |
317 |
318 |
319 |
320 |
321 |
322 |
323 |
324 |
325 |
326 |
327 |
328 |
329 |
330 |
331 |
332 |
333 |
334 |
335 |
336 |
337 |
338 |
339 |
340 |
341 |
342 |
343 |
344 |
345 |
346 |
347 |
348 |
349 |
350 |
351 |
352 |
353 |
354 |
355 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】计算属性 Computed.md:
--------------------------------------------------------------------------------
1 | ## 先理解计算属性
2 |
3 | 一提及到 Vue 的计算属性,想必大家都会想到其最大的优点——**缓存**。官方文档也有提到
4 |
5 | > 对于任何复杂逻辑,你都应当使用**计算属性**。
6 |
7 | 如何理解?不是可以直接使用方法处理吗?话不多说,直接看一个栗子 🌰 :
8 |
9 | ```javascript
10 | // html
11 |
12 | {{ allName }}
13 | {{ setAllName() }}
14 | {{ tag }}
15 |
16 |
17 | // js
18 | const app = new Vue({
19 | data: {
20 | firstName: 'haha',
21 | lastName: 'hehe',
22 | tag: false
23 | },
24 | computed: {
25 | allName() {
26 | return firstName + ' ' + lastName
27 | }
28 | },
29 | methods: {
30 | setAllName() {
31 | return firstName + ' ' + lastName
32 | }
33 | }
34 | })
35 | ```
36 |
37 | 相信很多同学对于上述的代码并不陌生,在界面上展示时,`allName`和`setAllName()`显示的效果是一样的,并没有什么区别。那真的就是没有任何区别了吗?
38 |
39 | 其实不是的,当我把变量`tag`的值设为 true 时,虽然展示的效果一样,但是两者背后渲染原理完全不同。其中就是上面提到的缓存功能。
40 |
41 | 为何这么说?你只要记住一点,**计算属性是基于它们的响应式依赖进行缓存的**。因此,当把变量`tag`的值设为 true 时,界面会重新渲染,由于计算属性`allName`是基于变量 firstName 和 lastName 的,而这两者并没有变化,所以会直接返回此前保存的计算值回来。相反,方法则不大一样了,因为重新渲染时,模板解析`setAllName`方法时,是无法辨别其有没有使用过该方法的,所以又会重新计算一遍并返回值回来。最终**在处理效率上,计算属性是完胜方法处理的**。
42 |
43 | 另一方面,既然计算属性是基于响应式依赖进行计算与否的,那么它也可以很好滴取代掉 Watch 侦听。什么意思?
44 |
45 | 如果你以前用过 Angular 的话,相信你会有一个很大的体会,那就是最喜欢滥用 watch 来监听某个属性是否变化,然后来进行相应的处理,那么使用计算属性的出现就很好滴避免了滥用 watch 行为,让代码在后期的维护和理解上都会有一个质的提升。官方文档中也有提到
46 |
47 | > 通常更好的做法是使用计算属性而不是命令式的 `watch` 回调。
48 |
49 | 在这里,真的由不得感叹一下,尤大大可以发明出计算属性出来。👏🏽
50 |
51 | 既然上面都说到计算属性有那么牛,那究竟它是如何实现的呢?在这里,我们可以从两方面进行入手,分别是:
52 |
53 | - 计算属性是如何进行计算的?
54 | - 计算属性是如何进行缓存的?
55 |
56 |
57 |
58 | ## 从源码角度进行分析
59 |
60 | 让我们先从初始化阶段是如何处理计算属性的,上源码
61 |
62 | ```javascript
63 | var computedWatcherOptions = { lazy: true }; // 关键中的关键,用于缓存作用的
64 |
65 | function initState (vm) {
66 | // ...
67 | if (opts.computed) { initComputed(vm, opts.computed); } // 先判断是否已定义计算属性,若有则直接初始化计算属性
68 | }
69 |
70 | function initComputed (vm, computed) {
71 | var watchers = vm._computedWatchers = Object.create(null); // 创建一个纯对象,新建依赖所用
72 | // ...
73 | for (var key in computed) {
74 | var userDef = computed[key]; // 获取当前用户定义的计算属性
75 | var getter = typeof userDef === 'function' ? userDef : userDef.get; // 判断当前定义的计算属性是否为函数,若不是则直接获取其 Getter
76 | if (getter == null) { // 一旦 getter 不是函数时,就给出警告(蕴含着知识点,undefined == null)
77 | warn(
78 | ("Getter is missing for computed property \"" + key + "\"."),
79 | vm
80 | );
81 | }
82 | if (!isSSR) { // 不是服务端渲染时,就直接为每个计算属性创建一个相关依赖
83 | // create internal watcher for the computed property.
84 | watchers[key] = new Watcher(
85 | vm,
86 | getter || noop,
87 | noop,
88 | computedWatcherOptions // 关键中的关键,用于缓存作用的
89 | );
90 | }
91 | if (!(key in vm)) { // 判断是否为新创建的计算属性
92 | defineComputed(vm, key, userDef); // 关键函数,主要负责计算属性响应式处理
93 | }
94 | }
95 | }
96 | ```
97 |
98 | 理解这段代码并不难,主要有以下几个知识点:
99 |
100 | - 使用`Object.create(null)`创建一个纯对象(相关链接,可看其他话题中[Object.create(null) 与 {} 究竟有什么不一样](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E8%AE%A1%E7%AE%97%E5%B1%9E%E6%80%A7%20Computed.md))
101 | - 判断计算属性定义时的类型
102 | - 为每个计算属性创建各自的依赖
103 | - 新定义的计算属性,使用`defineComputed`方法进行响应式处理
104 |
105 | 可以看到,每个计算属性本身就会被作为一个 Watcher 依赖,现在就来看看`defineComputed`方法是如何进行响应式处理的
106 |
107 | ```javascript
108 | var sharedPropertyDefinition = {
109 | enumerable: true,
110 | configurable: true,
111 | get: noop,
112 | set: noop
113 | };
114 |
115 | function defineComputed (
116 | target,
117 | key,
118 | userDef
119 | ) {
120 | var shouldCache = !isServerRendering(); // 是否为服务端渲染
121 | if (typeof userDef === 'function') { // 针对计算属性直接定义为函数的形式
122 | sharedPropertyDefinition.get = shouldCache
123 | ? createComputedGetter(key) // 关键函数,主要负责计算属性的缓存以及与 $data 建立依赖收集
124 | : createGetterInvoker(userDef);
125 | sharedPropertyDefinition.set = noop;
126 | } else { // 一旦定义的不是函数类型,则直接从 Getter 里面去拿
127 | sharedPropertyDefinition.get = userDef.get
128 | ? shouldCache && userDef.cache !== false
129 | ? createComputedGetter(key) // 关键函数,主要负责计算属性的缓存以及与 $data 建立依赖收集
130 | : createGetterInvoker(userDef.get)
131 | : noop;
132 | sharedPropertyDefinition.set = userDef.set || noop;
133 | }
134 | if (sharedPropertyDefinition.set === noop) { // 同时针对 Setter 未设置,默认配置一个警告函数
135 | sharedPropertyDefinition.set = function () {
136 | warn(
137 | ("Computed property \"" + key + "\" was assigned to but it has no setter."),
138 | this
139 | );
140 | };
141 | }
142 | Object.defineProperty(target, key, sharedPropertyDefinition); // 进行响应式的处理
143 | }
144 | ```
145 |
146 | 由此可以看到,每个计算属性除了被定义为 Watcher 外,还会作一个响应式处理。便于建立与页面调用时的依赖,一旦页面更新后,同时判断是否需要重新计算,由于计算属性拥有着强大的缓存功能,因此若依赖的响应式属性 data 没有变化时,则会直接返回原来计算的值,避免重新计算。
147 |
148 | 接下来我们来看看方法`createComputedGetter`是如何处理缓存以及与 $data 建立依赖收集的
149 |
150 | ```javascript
151 | function createComputedGetter (key) {
152 | return function computedGetter () {
153 | var watcher = this._computedWatchers && this._computedWatchers[key]; // 拿到每一个计算属性已经定义好的 Watcher
154 | if (watcher) {
155 | if (watcher.dirty) { // 缓存的关键,只有 dirty 为 true 时才会进行重新计算,否则直接获取已经计算好的值
156 | watcher.evaluate();
157 | }
158 | if (Dep.target) { // 建立依赖的关键,建立与页面之间的依赖
159 | watcher.depend();
160 | }
161 | return watcher.value
162 | }
163 | }
164 | }
165 | ```
166 |
167 | 也许有同学会有疑惑,究竟 dirty 是什么?以及 Dep.target 又是啥?
168 |
169 | 我们先来重新回顾一下计算属性在创建 Watcher 时是如何传递值的,以及 Wacther 类中是如何处理的。
170 |
171 | ```javascript
172 | // ...
173 | // create internal watcher for the computed property.
174 | watchers[key] = new Watcher(
175 | vm,
176 | getter || noop,
177 | noop,
178 | computedWatcherOptions // 关键中的关键,用于缓存作用的
179 | );
180 | // ...
181 | var Watcher = function Watcher (
182 | vm,
183 | expOrFn, // 更新回调函数
184 | cb,
185 | options, // 选项配置
186 | isRenderWatcher
187 | ) {
188 | // ...
189 | if (options) {
190 | // ...
191 | this.lazy = !!options.lazy;
192 | // ...
193 | }
194 | // ...
195 | this.dirty = this.lazy;
196 | }
197 | ```
198 |
199 | 计算属性在创建 Watcher 依赖时,会传递一个 lazy 为 true 的属性,该属性不是懒惰的意思,可以理解成缓慢变化的意思即不变。将 lazy 直接赋予到 Watcher 的 dirty 属性中(至于 dirty ,可以理解为是否为脏数据)。因此一开始,计算属性在页面中都会被计算一遍。另一方面,由于会把计算属性的 Getter 函数传入到 Wacther 作为更新回调函数使用,一旦依赖的响应式属性变化时,就会调用更新回调函数进行重新计算计算属性的值。
200 |
201 | 当页面第一次引用了计算属性时,dirty 的值肯定会为 true ,就会调用 Watcher 的 evaluate 方法。接下来,我们来看看 evaluate 方法
202 |
203 | ```javascript
204 | /**
205 | * Evaluate the value of the watcher.
206 | * This only gets called for lazy watchers.
207 | */
208 | Watcher.prototype.evaluate = function evaluate () {
209 | this.value = this.get();
210 | this.dirty = false;
211 | };
212 |
213 | /**
214 | * Evaluate the getter, and re-collect dependencies.
215 | */
216 | Watcher.prototype.get = function get () {
217 | pushTarget(this);
218 | var value;
219 | var vm = this.vm;
220 | try {
221 | value = this.getter.call(vm, vm); // 引用响应式属性,建立与响应式属性之间的依赖
222 | // ...
223 | } finally {
224 | // ...
225 | popTarget();
226 | // ...
227 | }
228 | return value
229 | };
230 | ```
231 |
232 | 好明显,evaluate 方法就是开始计算计算属性的值,然后再设置其 dirty 属性为 false,这时候就会被认为是已经更新的值了,下一次在调用时就不会进行重新计算。另一方面,由于在调用 this.getter 函数(即更新回调函数)时,会引用响应式属性并在响应式属性中收集到计算属性的依赖。
233 |
234 | 那么问题来了,什么时候 dirty 才会被设回 true ?还有就是为什么引用响应式属性就会在响应式属性中收集到计算属性的依赖?现在我来简单解析一下:
235 |
236 | - 什么时候 dirty 才会被设回 true ?
237 |
238 | 计算属性的 Watcher 只会被收集到相对应的响应式属性中,因此在响应式属性更改后,通知到相对应的 Watcher 进行更新,其实就会在 update 函数中进行设置 dirty 为 false,我们来看看
239 |
240 | ```javascript
241 | /**
242 | * Subscriber interface.
243 | * Will be called when a dependency changes.
244 | */
245 | Watcher.prototype.update = function update () {
246 | /* istanbul ignore else */
247 | if (this.lazy) {
248 | this.dirty = true;
249 | }
250 | // ...
251 | };
252 | ```
253 |
254 | 可以看到,由于计算属性的 lazy 会 true,因此在响应式属性更新时,你有没有发现仅仅只是把 dirty 设回为 true ,并没有调用更新回调函数?
255 |
256 | 这也是一个**优化点**,就是**要等到页面调用的地方更新时,才会通知计算属性重新计算值**(类似于我们的按需引入一样)。
257 |
258 | - 为什么引用响应式属性就会在响应式属性中收集到计算属性的依赖?
259 |
260 | 相信看到我之前的文章,应该都知道,响应式属性都会设置 Getter 和 Setter ,因此当计算属性计算值时,会引用到响应式属性,这样机会将计算属性的 Watcher 收集到了响应式属性中。
261 |
262 |
263 |
264 | 好了,接下来我们再看看如下代码,究竟是什么用呢?
265 |
266 | ```javascript
267 | // ...
268 | if (Dep.target) { // 建立依赖的关键,建立响应式属性与页面之间的依赖
269 | watcher.depend();
270 | }
271 | // ...
272 | ```
273 |
274 | 前面可以看到,当将计算属性被收集到响应式属性中后,会调用`popTarget`方法将`Dep.target`重新指回到页面的 Watcher,这时候调用
275 |
276 | `watcher.depend()`后就会将页面的 Watcher 收集到了响应式属性中。这也就说明,当页面调用计算属性时,响应式更改后,设置计算属性的 dirty 为 true 后,并不是由计算属性去通知页面更新的,而是以让有响应式属性通知页面更新后,再去重新计算计算属性的值。
277 |
278 | 看到这里,是否会迷惑了?😄 其实尤大大是真的很厉害,利用一个标记位来实现计算属性的缓存功能,而且只有在调用到其计算属性时才去开始计算其值,实现了一个按需调用的思想。
279 |
280 | 我们现在来总结一下:
281 |
282 | - 定义计算属性时,会依次为每一个计算属性创建相应的 Watcher,并设置成响应式;
283 | - 当模板中引用到计算属性时,会先将计算属性的 Watcher 收集到相应的响应式属性中,并且计算到值后会把`dirty`缓存标记位设置为 false,这样一来,下次模板更新后,发现`dirty`标记位为 false,就不会重新计算。同时响应式属性会收集到模板的 Wather;
284 | - 当响应式属性更改时,会先设置计算属性的`dirty`缓存标记位为 true,然后通知模板进行更新。模板在更新的过程中发现计算属性的`dirty`缓存标记位为 true,这时候就会重新计算其值并返回;
285 |
286 |
287 |
288 |
289 |
290 |
291 |
292 |
293 |
294 |
295 |
296 |
297 |
298 |
299 |
300 |
301 |
302 |
303 |
304 |
305 |
306 |
307 |
308 |
309 |
310 |
311 |
312 |
313 |
314 |
315 |
316 |
317 |
318 |
319 |
320 |
321 |
322 |
323 |
324 |
325 |
326 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】混合 Mixin(下).md:
--------------------------------------------------------------------------------
1 | 本篇主要接着上一篇中提及的关键点,对`strats`中原先定义好的合并规则的探究。我们知道,Mixin 会对不同的场景做不同的合并处理,因此我们接下来也会分情况来进行分析。
2 |
3 |
4 |
5 | ## 源码角度分析 Data 合并
6 |
7 | 先回顾一下对于 Data 合并的优先级处理,如下:
8 |
9 | ```javascript
10 | 组件data > 组件mixin > 组件mixin的mixin > ... > 全局mixin
11 | ```
12 |
13 | 我们现在就来看看源码是如何实现`strats`对象对 Data 合并的定义。
14 |
15 | ```javascript
16 | strats.data = function (
17 | parentVal,
18 | childVal,
19 | vm
20 | ) {
21 | // ...
22 | return mergeDataOrFn(parentVal, childVal, vm) // 开始合并Vue实例上data与Mixin上的data
23 | }
24 |
25 | /**
26 | * Data
27 | */
28 | function mergeDataOrFn (
29 | parentVal,
30 | childVal,
31 | vm
32 | ) {
33 | // ...
34 | return function mergedInstanceDataFn () {
35 | // instance merge
36 | var instanceData = typeof childVal === 'function' // 判断Mixin中定义的data是否为函数
37 | ? childVal.call(vm, vm) // 若为函数,则直接调用并返回
38 | : childVal; // 否则直接返回data对象或为空
39 | var defaultData = typeof parentVal === 'function' // 判断Vue实例上中定义的data是否为函数
40 | ? parentVal.call(vm, vm) // 若为函数,则直接调用并返回
41 | : parentVal; // 否则直接返回data对象或为空
42 | if (instanceData) {
43 | return mergeData(instanceData, defaultData) // 正式合并处理
44 | } else {
45 | return defaultData
46 | }
47 | }
48 | }
49 |
50 | /**
51 | * Helper that recursively merges two data objects together.
52 | */
53 | function mergeData (to, from) {
54 | if (!from) { return to } // 一旦不存在Mixin时,直接返回Vue实例即可
55 | var key, toVal, fromVal;
56 |
57 | var keys = hasSymbol // 先获取Mixin中data的每一项属性Key值所组成的数组
58 | ? Reflect.ownKeys(from)
59 | : Object.keys(from);
60 |
61 | for (var i = 0; i < keys.length; i++) {
62 | key = keys[i];
63 | // in case the object is already observed...
64 | if (key === '__ob__') { continue } // 跳过key值为__ob__的选项(该选项存储的是依赖)
65 | toVal = to[key];
66 | fromVal = from[key];
67 | if (!hasOwn(to, key)) { // 当遍历data属性的key值在Vue实例data上是不存在时,则直接赋值到Vue实例data上
68 | set(to, key, fromVal);
69 | } else if (
70 | toVal !== fromVal &&
71 | isPlainObject(toVal) &&
72 | isPlainObject(fromVal) // 当遍历data属性值是一个对象时,则继续递归遍历下去与Vue实例data对象中同名属性值进行合并处理
73 | ) {
74 | mergeData(toVal, fromVal); // 递归遍历复杂数据类型进行合并
75 | }
76 | }
77 | return to // 最后处理合并好的data对象并返回
78 | }
79 |
80 | /**
81 | * Set a property on an object. Adds the new property and
82 | * triggers change notification if the property doesn't
83 | * already exist.
84 | */
85 | function set (target, key, val) {
86 | // ...
87 | var ob = (target).__ob__;
88 | // ...
89 | defineReactive$$1(ob.value, key, val); // 在对应Vue实例data中设置相应的值,并赋予响应式处理
90 | ob.dep.notify(); // 并更新对应回调
91 | return val
92 | }
93 | ```
94 |
95 | 代码看上去复杂了许多,但当你细心斟酌,总能体会到其中意思。
96 |
97 | 总结一下:**Data 对于重名的合并处理,不属于该 Vue 实例 Data 上定义的才会去赋值或响应式处理,属于该 Vue 实例 Data 上定义的,若是基本数据类型则会直接取该值,若是复杂数据类型则会继续递归遍历其里面的属性值,而对于不重名的合并处理,则是优先级高会覆盖优先级低的**。
98 |
99 |
100 |
101 | ## 源码角度分析 Props \ Methods \ Inject \ Computed 合并
102 |
103 | Props \ Methods \ Inject \ Computed 这四者的合并会很好理解,遇到同名的属性,优先级高的就会直接取替到优先级低的。我们先来回顾一下该类的优先级:
104 |
105 | ```javascript
106 | 组件 > 组件mixin > 组件mixin的mixin > ... > 全局mixin
107 | ```
108 |
109 | 其实可以看到的是,处理上感觉跟 Data 上一致,但事实并不是如此。Props \ Methods \ Inject \ Computed 对于同名属性会直接覆盖处理,相当于 Data 上对于不重名属性的合并处理。我们看看源码咋实现的
110 |
111 | ```javascript
112 | /**
113 | * Other object hashes.
114 | */
115 | strats.props =
116 | strats.methods =
117 | strats.inject =
118 | strats.computed = function (
119 | parentVal,
120 | childVal,
121 | vm,
122 | key
123 | ) {
124 | // ...
125 | if (!parentVal) { return childVal } // 当Vue实例上没有该选项(即Props\Methods\Inject\Computed)时,直接取Mixin中的
126 | var ret = Object.create(null); // 创建一个空对象
127 | extend(ret, parentVal); // 将对应选项中属性值赋值到新创建的对象中
128 | if (childVal) { extend(ret, childVal); } // 当存在子实例时,会进行覆盖处理
129 | return ret
130 | }
131 |
132 | /**
133 | * Mix properties into target object.
134 | */
135 | function extend (to, _from) { // 覆盖处理
136 | for (var key in _from) {
137 | to[key] = _from[key];
138 | }
139 | return to
140 | }
141 | ```
142 |
143 | 看完上述的代码,我感觉完全懵了,为什么?你会发现使用`extend`方法进行覆盖处理时候,它会拿最后一层的 Mixin 中 Props \ Methods \ Inject \ Computed 的直接覆盖了 Vue 实例上已有的,然后逐层递归回来覆盖,那么问题来了,虽然说优先级高的会覆盖优先级低的,那么这样逐层递归回去时,到了第一层时是不是就是组件的 Mixin?
144 |
145 | 一开始我也是错误滴认为递归回到第一层时刚好就是组件的 Mixin 😂,但后面细心看了看代码,就发现了其实第一层应该就是 Child,而这个 Child 刚好就是`this.$options`,为此`this.$options`指向的就是 Vue 实例上的选项了。因此最后还是能够遵循优先级高的覆盖优先级低的。
146 |
147 | 总结一下: **Props \ Methods \ Inject \ Computed 对于重名的属性会取优先级高的,即直接按优先级高的覆盖优先级低的。对于只有优先级低的拥有,而优先级高的没有的属性,则会直接赋值处理**。
148 |
149 |
150 |
151 | ## 源码角度分析 Watch 合并
152 |
153 | 监听的合并处理的不是 Watch 选项中同名的属性,而是整个 Watch 选项,将组件的 Watch 选项和 Mixin 中的 Watch 选项组合成一个数组,优先级高的放在第一位,以此类推。在上一篇提及过,Watch 调用的优先级如下:
154 |
155 | ```javascript
156 | 全局mixin > ... > 组件mixin的mixin > 组件mixin > 组件
157 | ```
158 |
159 | 现在我们就来从源码的角度进行分析一下。
160 |
161 | ```javascript
162 | /**
163 | * Watchers.
164 | *
165 | * Watchers hashes should not overwrite one
166 | * another, so we merge them as arrays.
167 | */
168 | strats.watch = function (
169 | parentVal,
170 | childVal,
171 | vm,
172 | key
173 | ) {
174 | // work around Firefox's Object.prototype.watch...
175 | if (parentVal === nativeWatch) { parentVal = undefined; } // 判断是否为原生对象的Watch
176 | if (childVal === nativeWatch) { childVal = undefined; } // 判断是否为原生对象的Watch
177 | /* istanbul ignore if */
178 | if (!childVal) { return Object.create(parentVal || null) } // 当Mixin不存在时,重新创一个新的对象
179 | // ...
180 | if (!parentVal) { return childVal } // 当Mixin存在而Vue实例中不存在时,则直接取Mixin中的
181 | var ret = {};
182 | extend(ret, parentVal); // 先将Vue实例中的选项添加到新对象中
183 | for (var key$1 in childVal) { // 从最后一层Mixin递归遍历开始,直到this.$options
184 | var parent = ret[key$1];
185 | var child = childVal[key$1];
186 | if (parent && !Array.isArray(parent)) { // 一旦Vue实例中存在Watch选项不是数组时,则赋予一个数组形式
187 | parent = [parent];
188 | }
189 | ret[key$1] = parent
190 | ? parent.concat(child) // 合并数组处理
191 | : Array.isArray(child) ? child : [child]; // 最后一层Mixin时,由于parent不会存在Watch选项,因此会赋予一个数组形式
192 | }
193 | return ret
194 | }
195 | ```
196 |
197 | 经过上一次清晰滴知道 Child 最终会递归到`this.$options`时,就会相对好理解上面代码。原理上就是从最后一层的 Mixin 逐层递归回来时,进行数组合并,明显滴全局的 Mixin 会被放到数组的第一位,需要知道的是,**一开始 Vue 实例上是不会有 Watch 选项的**。
198 |
199 | 总结一下:**Watch 选项会使用数组合并来处理,从最后一层的 Mixin 递归回来,逐层数组合并,因此全局 Mixin 会被放到数组的第一位,以此类推,到了`this.$options`后,会将其中的 Watch 选项添加到数组的末尾。而执行时,全局 Mixin 会先执行,以此类推,直到组件中的 Watch 选项最后才执行**。
200 |
201 |
202 |
203 | ## 源码角度分析 Lifecycle 合并
204 |
205 | 生命周期的合并其实在处理上跟监听的合并基本一致,也是通过数组来进行合并的。我们先来看看生命周期合并后调用的优先级,如下:
206 |
207 | ```
208 | 全局mixin > ... > 组件mixin的mixin > 组件mixin > 组件
209 | ```
210 |
211 | 既然也是全局 Mixin 的先执行,那么合并的方式也是一样的,我们就来看看源码里是如何实现的:
212 |
213 | ```javascript
214 | var LIFECYCLE_HOOKS = [
215 | 'beforeCreate',
216 | 'created',
217 | 'beforeMount',
218 | 'mounted',
219 | 'beforeUpdate',
220 | 'updated',
221 | 'beforeDestroy',
222 | 'destroyed',
223 | 'activated',
224 | 'deactivated',
225 | 'errorCaptured',
226 | 'serverPrefetch'
227 | ]
228 |
229 | LIFECYCLE_HOOKS.forEach(function (hook) {
230 | strats[hook] = mergeHook; // 每一种生命周期函数都会拥有一个单独的合并处理函数mergeHook
231 | })
232 |
233 | /**
234 | * Hooks and props are merged as arrays.
235 | */
236 | function mergeHook (
237 | parentVal,
238 | childVal
239 | ) {
240 | var res = childVal
241 | ? parentVal
242 | ? parentVal.concat(childVal) // 合并数组处理
243 | : Array.isArray(childVal)
244 | ? childVal
245 | : [childVal]
246 | : parentVal;
247 | return res
248 | ? dedupeHooks(res) // 删除重复的生命周期函数
249 | : res
250 | }
251 | ```
252 |
253 | 可以看到,代码在合并的处理上基本跟 Watch 的处理是一致的,都是从最后一层 Mixin 递归遍历回来,直到组件本身的生命周期函数为止。因此在调用顺序方面,都是先执行全局 Mixin 中定义的生命周期函数,以此类推回到组件本身生命周期函数的。
254 |
255 | 总结一下:**Lifecycle 在合并处理上跟 Watch 是一致的,都是使用数组合并方式,从最后一层的 Mixin (即全局 Mixin )开始递归回来,直到组件本身,因此调用顺序也会先执行全局 Mixin,最后才执行组件本身的生命周期函数**。
256 |
257 |
258 |
259 | ## 源码角度分析 Component \ Directive \ Filter 合并
260 |
261 | 在上一篇中,我有提及过,这三项的合并处理与其他项的合并处理会很不一样,使用的是**原型链方式**来合并处理。
262 |
263 | 相信同学们都清楚原型链的访问方式,在访问一个对象中的变量时,会沿着原型链进行查找,直到`Object.prototype`为止。而尤大大恰恰就巧妙滴利用了这一点,使用最简单方式进行了合并处理,不得不服 🤔。
264 |
265 | 我们先来回顾一下该三项访问的优先级关系:
266 |
267 | ```javascript
268 | 组件 > 组件mixin > 组件mixin的mixin > ... > 全局mixin
269 | ```
270 |
271 | 可以看到的是,先访问组件本身的这三项内容,一旦找不到了才会去找组件 Mixin 的,以此类推,直到全局 Mixin 为止。我们就先来看看源码是如何实现原型链合并的。
272 |
273 | ```javascript
274 | var ASSET_TYPES = [
275 | 'component',
276 | 'directive',
277 | 'filter'
278 | ]
279 |
280 | ASSET_TYPES.forEach(function (type) {
281 | strats[type + 's'] = mergeAssets;
282 | })
283 |
284 | /**
285 | * Assets
286 | *
287 | * When a vm is present (instance creation), we need to do
288 | * a three-way merge between constructor options, instance
289 | * options and parent options.
290 | */
291 | function mergeAssets (
292 | parentVal,
293 | childVal,
294 | vm,
295 | key
296 | ) {
297 | var res = Object.create(parentVal || null); // 继承上一次递归处理好的对象
298 | if (childVal) {
299 | // ...
300 | return extend(res, childVal) // 将递归到的对象直接进行赋值处理
301 | } else {
302 | return res // 否则直接返回该对象
303 | }
304 | }
305 | ```
306 |
307 | 代码从理解上应该不会有太大的问题,在最后一层的 Mixin (即全局 Mixin)时,会先继承了一个 Vue 实例上的项,其实这时 Vue 实例上的项并没有任何东西。逐层递归回来,每一次都会继承上一次处理好的结果,这样一来,到组件本身时,就会直接将组件本身赋予到原型链的最底层,因此在访问时就会先访问组件本身再去沿着原型链进行向上查找。
308 |
309 | 总结一下: **Component \ Directive \ Filter 使用原型链的方式来进行合并处理,从最后一层 Mixin (即全局 Mixin)递归回来,每一次合并时都会先继承上一次处理好的对象,以此类推,到组件本身时,就会将组件直接放到了原型链的最底层。因此在访问时,就会先访问组件本身的,再沿着原型链向上询问**。
310 |
311 |
312 |
313 |
314 |
315 |
316 |
317 |
318 |
319 |
320 |
321 |
322 |
323 |
324 |
325 |
326 |
327 |
328 |
329 |
330 |
331 |
332 |
333 |
334 |
335 |
336 |
337 |
338 |
339 |
340 |
341 |
342 |
343 |
344 |
345 |
346 |
347 |
348 |
349 |
350 |
351 |
352 |
353 |
354 |
355 |
356 |
357 |
358 |
359 |
360 |
361 |
362 |
363 |
364 |
365 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】运行机制之 Props.md:
--------------------------------------------------------------------------------
1 | ## 先聊聊 with
2 |
3 | 相信很多同学面对 with 语句时,都会相对陌生(因为平时实际开发中很少会用到)。那它究竟是用来干嘛的?官方文档给出的解释如下:
4 |
5 | > **with语句** 扩展一个语句的作用域链
6 |
7 | 这句话如何理解?简单滴说,改变作用域链中优先读取的变量值。说白点,相当于在一个作用域中访问一个变量时,会先判断改变量是否存在于`with`指定的对象中,若存在则直接读取,否则会沿着作用域链一直向上找。
8 |
9 | 我们先来看一个栗子🌰简单了解一下:
10 |
11 | ```javascript
12 | function add() {
13 | var a = 1
14 | with(this) {
15 | return a + 1
16 | }
17 | }
18 |
19 | console.log(add())
20 | console.log(add.call({}))
21 | console.log(add.call({ a: 2 }))
22 | ```
23 |
24 | 上面的代码很好理解,那究竟三个输出会得到什么呢?现在就来讲解一下
25 |
26 | 1. 第一个输出为 2。道理很简单,当执行单纯`add`方法时,执行上下文 this 指向的是 window 对象。因此在 with 语句中,访问 a 变量时,会先从 this (即 window 对象)中进行寻找,一旦不存在,就会沿着作用域链向上找,即会到函数作用域 add 中寻找,从而得到了结果 2;
27 | 2. 第二个输出为 2。同样地,因为一个空对象中 {} 并木有 a 属性的值,因此也是直接去到函数作用域中进行寻找,从而得到 2;
28 | 3. 第三个输出为 3。好明显,在对象 { a: 2 } 中有一个属性 a 为 2,因此直接得到结果为 3;
29 |
30 | 通过上面的解析,可以看到,其实原理上跟我们上一节中的使用`call和apply`是一个道理,都是改变执行上下文,但是`with`语句却有着与众不同的地方,那就是找不到值了,不会报错而是会继续往作用域链向上进行寻找,直到找到为止。
31 |
32 | 对于应用场景来说,针对访问多层属性的值特别有用,举个例子:
33 |
34 | ```javascript
35 | var obj = {
36 | item1: {
37 | item2: {
38 | a: 1,
39 | b: 2,
40 | c: 3
41 | }
42 | }
43 | }
44 |
45 | console.log(obj.item1.item2.a) // 1
46 | console.log(obj.item1.item2.b) // 2
47 | console.log(obj.item1.item2.b) // 3
48 |
49 | // 相当于
50 | with(obj.item1.item2) {
51 | console.log(a) // 1
52 | console.log(b) // 2
53 | console.log(c) // 3
54 | }
55 | ```
56 |
57 | 可以看到,使用`with`语句可以很好滴简化了我们平时频繁访问多层对象中属性的问题。那么,`with语句`就这么好使,没弊端吗?
58 |
59 | 事实上并不是的,在官方文档中并不推荐我们使用`with语句`。原因有几个:
60 |
61 | - 由于`with`语句都会使得作用域先从指定的对象中进行寻找,对于那些本来就不是这个对象的属性,查找起来将会特别慢;
62 |
63 | - `with`语句并不利于阅读;
64 |
65 | - `with`语句无法向前兼容,举个例子:
66 |
67 | ```javascript
68 | function f(foo, values) {
69 | with (foo) {
70 | console.log(values)
71 | }
72 | }
73 | ```
74 |
75 | 我们都知道,foo 为数组时,在 ES5 中都会返回正确的结果,而由于在 ES6 中,数组中已经拓展了一个`Array.prototype.values`方法,因此在 ES6 环境中就无法得到正确的结果了;
76 |
77 | 以上的弊端均来自[官方文档](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Statements/with),有兴趣的同学都可以去了解一下。
78 |
79 | 而在 Vue 中同样使用了`with`语句进行传递作用域,既然它有那么多的弊端,为何还要用它呢?其实[尤大大也在github上解析了一番](https://github.com/vuejs/vue/issues/4115),简单来说,就是为了方便管理,才会统一使用`with`语句。
80 |
81 |
82 |
83 | ## 父组件是如何通过 Props 传递到子组件?
84 |
85 | 由于篇幅原因,其实该小节的内容涉及到一个很重要的知识点,那就是`compile编译分析`(会在后面的章节进行讲解)。所以小弟我会先绕过它,去寻找与该节相关的东西。望同学们体谅一下,也是为了方便大家好理解。
86 |
87 | 在开始之前,建议同学们还是看看[官方文档中渲染函数一章节](https://cn.vuejs.org/v2/guide/components-registration.html),也是为了方便理解
88 |
89 | 在组件进行挂载编译时,都会被解析成一个渲染函数,而这个渲染函数中就会使用到上一节所提到`with`语句来进行作用域的传递。我们先从一个栗子🌰开始入手:
90 |
91 | ```javascript
92 | // html
93 |
96 |
97 | // js
98 | new Vue({
99 | el: '#app',
100 | components: {
101 | Person: {
102 | name: 'person',
103 | props: {
104 | 'name'
105 | },
106 | template: '{{ this.name }}'
107 | }
108 | },
109 | data: {
110 | name: 'andraw'
111 | }
112 | })
113 | ```
114 |
115 | 上面的代码在经过 Vue 源码挂载时,会得到如何渲染函数:
116 |
117 | ```javascript
118 | (function anonymous(
119 | ) {
120 | with(this){
121 | return _c(
122 | 'div',
123 | {attrs:{"id":"app"}},
124 | [
125 | _c(
126 | 'person',
127 | {attrs:{"name":name}}
128 | )
129 | ], 1)}
130 | })
131 | ```
132 |
133 | 看到这个渲染函数,是否会被懵逼?现在就来讲解一下
134 |
135 | - with:可观看上一节的内容,目的就是为了把当前 vue 实例作用域绑定到 this 中,从而使父组件中传递给子组件的属性,都会先从当前 vue 实例(即父组件)中进行寻找。好明显,此时`person`组件中 attrs 的 name 属性会先从当前 vue 实例(即父组件)中寻找,值也为`andraw`;
136 |
137 | - _c:在初始化 Render 的过程中,就已经将其作为`createElement`的通道,源码如下:
138 |
139 | ```javascript
140 | initRender(vm);
141 |
142 | function initRender (vm) {
143 | // ...
144 | vm._c = function (a, b, c, d) { return createElement(vm, a, b, c, d, false); };
145 | // ...
146 | }
147 | ```
148 |
149 | 因此,可以说**`_c`其实就是指向`createELement`方法**。而对于`_c`方法中的参数,其实可以看下官方文档中的渲染函数章节,里面会有比较详细的讲解。
150 |
151 |
152 |
153 | 现在来总结一下:父组件使用`with`语句以及渲染函数`createELement`来实现了将 Props 传递到子组件中。
154 |
155 | 当然,你也会有疑惑,究竟`createElement`是何方神圣?如果你用过`React`的话,其实会很好理解,当然我也会在后面的`compile编译`章节中提及。我们先跳过,然后接着看下去先哈 😂.....
156 |
157 |
158 |
159 | ## 从源码角度进行分析
160 |
161 | 这一次,通过源码阅读,主要探索的方面包括如何初始化 Props、以及如何进行更新。
162 |
163 | ```javascript
164 | initState(vm);
165 |
166 | function initState(vm) {
167 | vm._watchers = [];
168 | var opts = vm.$options;
169 | if (opts.props) { initProps(vm, opts.props); }
170 | // ...
171 | }
172 |
173 | function initProps (vm, propsOptions) {
174 | var propsData = vm.$options.propsData || {}; // 获取Vue实例选项上的Props
175 | var props = vm._props = {}; // 获取挂载Vue实例上的_props
176 | var keys = vm.$options._propKeys = []; // Props的Key值组成的数组
177 | // ...
178 | for (var key in propsOptions) loop( key ); // 循环遍历 vue 实例选项中Props,并且执行响应式处理以及挂载在对应实例上
179 | // ...
180 | }
181 | ```
182 |
183 | 初始化 Props 的关键点就在于`loop`函数,让我们接着该函数做了什么事情。
184 |
185 | ```javascript
186 | var sharedPropertyDefinition = {
187 | enumerable: true,
188 | configurable: true,
189 | get: noop,
190 | set: noop
191 | };
192 | function proxy (target, sourceKey, key) {
193 | sharedPropertyDefinition.get = function proxyGetter () {
194 | return this[sourceKey][key]
195 | };
196 | sharedPropertyDefinition.set = function proxySetter (val) {
197 | this[sourceKey][key] = val;
198 | };
199 | Object.defineProperty(target, key, sharedPropertyDefinition);
200 | }
201 |
202 | var loop = function ( key ) {
203 | keys.push(key); // 每遍历一次Props中的值,都会收集其Key
204 | // ...
205 | defineReactive$$1(props, key, value, function () { // 将Vue实例上对象的_props中每一项属性都设置响应式
206 | if (!isRoot && !isUpdatingChildComponent) { // 配置的Setter函数,避免子组件直接操作Props的警告
207 | warn(
208 | "Avoid mutating a prop directly since the value will be " +
209 | "overwritten whenever the parent component re-renders. " +
210 | "Instead, use a data or computed property based on the prop's " +
211 | "value. Prop being mutated: \"" + key + "\"",
212 | vm
213 | );
214 | }
215 | });
216 | // static props are already proxied on the component's prototype
217 | // during Vue.extend(). We only need to proxy props defined at
218 | // instantiation here.
219 | if (!(key in vm)) { // 遍历时若发现新属性时,就将新属性重新挂载到Vue实例的_props中
220 | proxy(vm, "_props", key);
221 | }
222 | };
223 | ```
224 |
225 | 理解上应该不会有太大的问题,`loop`函数中主要做了以下几件事:
226 |
227 | - defineReactive$$1
228 |
229 | 相信看过前面章节的童鞋们对这个函数应该都不会陌生,其实就是对Vue实例上的 _props 对象中每一个属性都配置成响应式的,这样一来,当父组件中传递进来的 Props 变化时,则会通知相应的子组件中更新函数进行更新;
230 |
231 | - 对相应的子组件配置Props属性的Setter警告函数
232 |
233 | 用过Vue的童鞋们应该都会遇到直接更改一个 Props 中的属性时,会抛出一个警告。而这个警告就是在 Vue 遍历 _props 对象中的值时,都会默认配置一个警告 Setter 函数;
234 |
235 | - proxy
236 |
237 | 在遍历的过程中,一旦发现有新的属性时,都会将新属性重新挂载到 Vue 实例的 _props 中。这里有一个很重要的知识点,**当我们直接访问一个 Props 中的属性时,即上面栗子中`this.name`,其实是直接访问了 Vue 实例的 _props 对象中值而已**。
238 |
239 | 至此,我们也知道 Vue 源码是如何实现初始化 Props 的了,那么,究竟是父组件是如何通知更新 Props 的呢?我们接着看下去。
240 |
241 | 由于父组件在更新的过程中,会通知子组件也进行更新,这时候就会调取一个方法`updateChildComponent`,而这个方法里就会对 Props 进行更新。我们就来看看是如何处理的:
242 |
243 | ```javascript
244 | updateChildComponent(
245 | child,
246 | options.propsData, // updated props
247 | options.listeners, // updated listeners
248 | vnode, // new parent vnode
249 | options.children // new children
250 | );
251 |
252 | function updateChildComponent (
253 | vm,
254 | propsData,
255 | listeners,
256 | parentVnode,
257 | renderChildren
258 | ) {
259 | // ...
260 | // update props
261 | if (propsData && vm.$options.props) {
262 | toggleObserving(false); // 关闭依赖监听
263 | var props = vm._props; // 获取Vue实例上_props对象
264 | var propKeys = vm.$options._propKeys || []; // 获取保留在Vue实例上的props key值
265 | for (var i = 0; i < propKeys.length; i++) { // 循环遍历props key
266 | var key = propKeys[i];
267 | var propOptions = vm.$options.props; // wtf flow?
268 | props[key] = validateProp(key, propOptions, propsData, vm); // 先校验Props中定义的数据类型是否符合,符合的话就直接返回,并且直接赋值给Vue实例上_props对象中相应的属性中
269 | }
270 | toggleObserving(true); // 打开依赖监听
271 | // keep a copy of raw propsData
272 | vm.$options.propsData = propsData; // 新的PropsData直接取替掉选项中旧的PropsData
273 | }
274 | // ...
275 | }
276 | ```
277 |
278 | 一开始看到这里代码时,我是懵逼状态的,因为很容易绕不出来 😂。。在这里面会有几个问题,分别是:
279 |
280 | - validateProp 作用究竟是什么?
281 |
282 | 相信用过 Props 的同学都清楚,在传递给子组件时,子组件中是有权限决定传递的值类型的,大大提高传递的规范,举个例子:
283 |
284 | ```javascript
285 | props: {
286 | name: {
287 | type: String,
288 | required: true
289 | }
290 | }
291 | ```
292 |
293 | 代码很好理解,就是规定 name 属性的类型以及是否必传。而**方法`validateProp`作用就是校验父组件传递给子组件的值是否按要求传递,若正确传递则直接赋值给 _props 对象上相应的属性**。
294 |
295 | - 校验通过后,直接赋值给 _props 对象上相应的属性的用意何在?
296 |
297 | 上面提到过,_props 对象上的每一个属性都会使用 proxy 方法进行响应式挂载。那么当我直接赋值到 _props 对象上相应的属性时,就会触发到其 Setter 函数进行相应的依赖更新。因此,当父组件更新一个传递到子组件的属性时,首先会触发其 Setter 函数通知父组件进行更新,然后通过渲染函数传递到子组件后,更新子组件中的 Props。这时候,由于此时的 Props 对象中的属性收集到了子组件的依赖,更改后会通知相应的依赖进行更新。
298 |
299 | - toggleObserving 究竟是干嘛用的?
300 |
301 | 要理解该方法的用处,必须先从前面响应式探究章节有了解过方法`observe`,为什么要提到它?
302 |
303 | 首先它是一个递归遍历方法,**Props 在通知子组件依赖更新时,必须搞清楚的一点,就是是整个值的变化来进行通知**。如何理解?简单滴说,对于属性值为基本数据类型的,当值改变时,是可以直接通知子组件进行更新的,而对于复杂数据类型来说,前面章节我们说到过,在更新时,会递归遍历其对象内部的属性来通知相应的依赖进行更新。
304 |
305 | 那么**当调用方法`toggleObserving`为 false 时,对于基础数据类型来说,当其值变化时则直接通知子组件更新,而对于其复杂数据类型来说,则不会递归下去,而只会监听整个复杂数据类型替换时,才会去通知子组件进行更新。因此在 Props 中所有属性通知完后,又会重新调用方法`toggleObserving`为 true 来打开递归开关**。(真的不得不服尤大大啊,这么好的优化思路都能想出来,牛人 👍)
306 |
307 |
308 |
309 | 至此,你大概也知道整个更新流程了,但是我当时还是存在疑惑的,既然基础数据类型值更改或复杂数据类型整个值更改,可以直接通知到子组件进行更新,那么是否会有一种情况就是,复杂数据类型中属性更改时,又是如何通知子组件更新的呢??🤔
310 |
311 | 对于这个问题,当时的我也是想到想发烂咋。。。最后还是看代码后才能一步一步滴理解其深奥之处。
312 |
313 | 首先,我们一开始已经忽略一个方法,那就是`defineReactive$$1`,这个方法真的用的秒,可以看看上面的代码,在初始化 Props 时候,会对 Props 每一项的属性进行使用该方法进行响应式的处理,包括了复杂数据类型的中属性,此时该属性不但收集了父组件依赖,还收集了子组件的依赖,这样一来,当复杂数据类型中属性变化时,会先通知父组件更新,再通知子组件进行更新。(这时候我真的不得不服到五体投地。。。)
314 |
315 | 总结一下:
316 |
317 | - 当 Props 中属性为基础数据类型值更改或复杂数据类型替换时,会通过 Setter 函数通知父组件进行更新,然后通过渲染函数,传递到子组件中更新其 Props 中对象相应的值,这时候就会触发到相应值的 Setter 来通知子组件进行更新;
318 | - 当 Props 中属性为复杂数据类型的属性更改时,由于使用`defineReactive$$1`方法收集到了父组件依赖以及子组件的依赖,这时候会先通知父组件进行更新,再通知子组件进行更新;
319 |
320 |
321 |
322 |
323 |
324 |
325 |
326 |
327 |
328 |
329 |
330 |
331 |
332 |
333 |
334 |
335 |
336 |
337 |
338 |
339 |
340 |
341 |
342 |
343 |
344 |
345 |
346 |
347 |
348 |
349 |
350 |
351 |
352 |
353 |
354 |
355 |
356 |
357 |
358 |
359 |
360 |
361 |
362 |
363 |
364 |
365 |
366 |
367 |
368 |
369 |
370 |
371 |
372 |
373 |
374 |
375 |
376 |
377 |
378 |
379 |
380 |
381 |
382 |
383 |
384 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】异步更新队列之 NextTick.md:
--------------------------------------------------------------------------------
1 | ## 所谓的宏任务和微任务
2 |
3 | *提到宏任务和微任务,相信对于部分同学来说并不陌生,但还是得简单讲讲(当然关心源码的童鞋们可以直接拉到下面哈 😅)。*
4 |
5 | JavaScript 是一个单线程、单进程语言,那么它在运行中的执行过程又是如何的呢?
6 |
7 | 1. 首先,JavaScript 主进程会作为一个宏任务开始执行,此时,主进程代码就会从上到下开始解释执行。
8 | 2. 在解释执行的过程中,当遇到宏任务时,就会将其放入到宏任务队列中,当遇到微任务时,则将其放入到微任务队列中。宏任务队列和微任务队列都是采用队列的数据结构形式进行存储和读取。
9 | 3. 当主进程中的代码执行完毕后,会优先检查微任务队列中是否有任务,若有则会按队列的先进先出的原则执行相应代码。
10 | 4. 微任务队列执行完毕后,又会开始下一轮的循环,检查宏任务队列,执行下一个宏任务,执行完毕后接着又会检查微任务队列。如此循环,直到宏任务队列以及微任务队列都为空为止。
11 | 5. 微任务和宏任务的执行过程就组成了所谓的`Event Loop`。
12 |
13 | 看完上面,是否会有点懵逼?😅 所以究竟什么是宏任务?什么又是微任务啊?
14 |
15 | 甭急。接下来就给你看看。
16 |
17 | > 宏任务
18 |
19 | | 类型 | 浏览器 | Node |
20 | | :-------------------: | :----: | :--: |
21 | | js 主进程代码 | ✅ | ✅ |
22 | | I/O | ✅ | ✅ |
23 | | setTimout | ✅ | ✅ |
24 | | setInterval | ✅ | ✅ |
25 | | setImmediate | ❌ | ✅ |
26 | | requestAnimationFrame | ✅ | ❌ |
27 |
28 | 注:`requestAnimationFrame` 是要求浏览器在下次重绘之前调用指定的回调函数更新动画,该方法要传入一个回调函数作为参数。[详见MDN关于requestAnimationFrame讲解](https://developer.mozilla.org/zh-CN/docs/Web/API/window/requestAnimationFrame)
29 |
30 | > 微任务
31 |
32 | | 类型 | 浏览器 | Node |
33 | | :-----------------------------: | :----: | :--: |
34 | | Promise中的then、catch、finally | ✅ | ✅ |
35 | | process.nextTick | ❌ | ✅ |
36 | | async / await | ✅ | ✅ |
37 | | MutationObserver | ✅ | ❌ |
38 |
39 | 注:`MutationObserver` 接口提供了监视DOM树所做更改的能力,属于DOM3 Events规范的一部分。[详见 MDN 关于MutationObserver讲解](https://developer.mozilla.org/zh-CN/docs/Web/API/MutationObserver)
40 |
41 | 为啥要提及宏任务和微任务呢?很简单,因为今天的主角`nextTick`就是基于上述提及的知识点进行实现的。
42 |
43 |
44 |
45 | ## NextTick 究竟是啥?又有啥用?
46 |
47 | `nextTick`从字面上可理解为下一个钩子,再结合参数为一个回调函数,那么就可以理解**在某个时间段内,触发当前的钩子函数**。
48 |
49 | 问题来了,某个时间段是在什么时候?
50 |
51 | 在这里就不卖关子,这个时间段就是使用上述提及的微任务进行实现的,简单地说就是等到主进程的 js 代码执行完毕后,才会去执行该回调函数。
52 |
53 | 这样子设计有什么好处呢?甭急,先看看官方文档的一个解释。
54 |
55 | > Vue 在更新DOM时时异步执行的,只要侦听到数据变化,Vue将开启一个队列,并缓冲在同一事件循环中的所有数据变更,若同一个watcher被多次触发时,只会被推入到队列中一次。
56 |
57 | 接下来我们就来简单滴解释一下这句话中到底蕴含了多少个知识点哈...🤔
58 |
59 | - Vue 在更新DOM时时异步执行的。
60 |
61 | 既然 Vue 在更新DOM时是异步的,若此时想获取DOM的某些数据,按同步方式获取肯定是无法获取的。而`nextTick`却是弥补了这一缺陷,开启一个队列,等待宏任务执行完毕后,就会执行该队列中函数(即传进`nextTick`中回调函数)。
62 |
63 | ```javascript
64 | {{ message }}
65 |
66 | const app = new Vue({
67 | el: '#app',
68 | data: {
69 | message: ''
70 | }
71 | })
72 | app.message = 'haha'
73 | console.log(app.$el.textContent) // ''
74 | app.nextTick(() => {
75 | console.log(app.$el.textContent) // 'haha'
76 | })
77 | ```
78 |
79 | - 多次操作一个数据,DOM 渲染只会执行一次。
80 |
81 | 由于 Vue 使用`Object.defineProperty`实现数据响应式的,那么当多次操作一个响应式数据时,就不可避免滴多次执行其`setter`方法。
82 |
83 | 尤大大也想到这一点,使用`nextTick`另起一个队列,当多次操作同一个数据时,就根据其`Watcher id`是否已经存在于该队列中,若存在则直接丢掉。这样一来,就可以保证一个数据的多次更改回调只会出现在队列中一次。这样就会有效地提升整个数据响应性能。
84 |
85 | **结合`nextTick`和`Watcher id`就实现了一个多次操作一个数据只会渲染一次的性能提升。🐂**
86 |
87 | 好啦,既然对`nextTick`有了一个大概的了解,那么我们就来向源码进发。
88 |
89 |
90 |
91 | ## 从源码的角度进行探讨
92 |
93 | 在官方文档,已经提及过`nextTick`的实现,我们来看看。
94 |
95 | > Vue 在内部对异步队列尝试使用原生的`Promise.then`、`MutationObserver`、`setImmediate`,如果执行环境不支持,则会采用`setTimeout(fn, 0)`代替。
96 |
97 | 接下来我们就从源码层面进行探究~🤔
98 |
99 | ```javascript
100 | renderMixin(Vue)
101 | function renderMixin (Vue) {
102 | // ...
103 | Vue.prototype.$nextTick = function (fn) {
104 | return nextTick(fn, this)
105 | }
106 | // ...
107 | }
108 | ```
109 |
110 | 在页面渲染初始化之际,会暴露出`$nextTick API`出来,以方便开发者能够在`nextTick`中获得异步更新的DOM。
111 |
112 | 上面也提到过,当响应式数据多次更新时,会直接调用`nextTick`来作为一个队列。
113 |
114 | ```javascript
115 | Watcher.prototype.update = function update () { // 依赖更新操作
116 | /* istanbul ignore else */
117 | if (this.lazy) { // 用于计算属性,前面篇节有提及
118 | this.dirty = true;
119 | } else if (this.sync) { // 用于判断是否为 watcher,前面篇节也有提及
120 | this.run();
121 | } else { // 除了上述情况外,最后只剩下DOM更新操作了
122 | queueWatcher(this); // 将依赖推进队列处理函数
123 | }
124 | }
125 | var queue = [] // 全局DOM依赖Watcher队列
126 | var has = {} // 全局DOM依赖Watcher映射表
127 | var waiting = false // 是否需要等待上一个异步任务执行完毕的标志
128 | function queueWatcher (watcher) {
129 | var id = watcher.id; // 获取对应依赖的唯一标识id
130 | if (has[id] == null) { // 判断映射表has中是否存在该id,若有就直接跳走,避免了频繁操作导致不停滴调用回调函数
131 | has[id] = true;
132 | if (!flushing) { // 判断全局的队列DOM依赖队列是否为空
133 | queue.push(watcher);
134 | } else {
135 | // if already flushing, splice the watcher based on its id
136 | // if already past its id, it will be run next immediately.
137 | var i = queue.length - 1;
138 | while (i > index && queue[i].id > watcher.id) {
139 | i--;
140 | }
141 | queue.splice(i + 1, 0, watcher);
142 | }
143 | // queue the flush
144 | if (!waiting) {
145 | waiting = true;
146 |
147 | if (!config.async) { // 由于config.async配置默认都是为true,因此可以忽略
148 | flushSchedulerQueue();
149 | return
150 | }
151 | nextTick(flushSchedulerQueue); // 把DOM依赖回调函数都放进异步队列中
152 | }
153 | }
154 | }
155 | ```
156 |
157 | 上述代码可以看到,使用`queue`存储了所有DOM依赖Watcher,同时**使用`has`对象模拟了所有DOM依赖的Watcher映射表,进而避免了多次操作一个响应式属性而导致页面不停渲染**。
158 |
159 | 上面的代码重点就在于一个`nextTick`函数。接下来我们就来看看它是做点什么的
160 |
161 | ```javascript
162 | var callbacks = [] // 用于存储DOM依赖Watcher回调函数任务队列
163 | var pending = false // 用于确定是否已经注册微任务
164 | function nextTick (cb, ctx) {
165 | var _resolve;
166 | callbacks.push(function () { // 存储DOM依赖Watcher回调函数
167 | if (cb) {
168 | try {
169 | cb.call(ctx); // 每个回调函数都是执行传进来的callback,这里就是flushSchedulerQueue函数(下面会提到)
170 | } catch (e) {
171 | handleError(e, ctx, 'nextTick');
172 | }
173 | } else if (_resolve) {
174 | _resolve(ctx);
175 | }
176 | });
177 | if (!pending) { // 还没注册微任务,因此开始创建微任务
178 | pending = true; // 每一次都只允许创建一个微任务的任务队列,避免注册过程中误入注册
179 | timerFunc(); // 创建一个微任务,便于独立于主进程代码
180 | }
181 | // $flow-disable-line
182 | if (!cb && typeof Promise !== 'undefined') {
183 | return new Promise(function (resolve) {
184 | _resolve = resolve;
185 | })
186 | }
187 | }
188 | ```
189 |
190 | 可以看到,**nextTick 的工作就是创建存储DOM依赖Watcher回调函数任务队列,接着就会判断是否已经注册了微任务,若无注册,则开始注册微任务,并且每次都只允许创建一个微任务**。
191 |
192 | 接下来我们就继续看看是如何创建微任务的
193 |
194 | ```javascript
195 | var timerFunc
196 | if (typeof Promise !== 'undefined' && isNative(Promise)) { // 优先判断是否支持Promise
197 | var p = Promise.resolve();
198 | timerFunc = function () { // 使用Promise创建一个微任务
199 | p.then(flushCallbacks);
200 | // In problematic UIWebViews, Promise.then doesn't completely break, but
201 | // it can get stuck in a weird state where callbacks are pushed into the
202 | // microtask queue but the queue isn't being flushed, until the browser
203 | // needs to do some other work, e.g. handle a timer. Therefore we can
204 | // "force" the microtask queue to be flushed by adding an empty timer.
205 | if (isIOS) { setTimeout(noop); }
206 | };
207 | isUsingMicroTask = true;
208 | } else if (!isIE && typeof MutationObserver !== 'undefined' && (
209 | isNative(MutationObserver) ||
210 | // PhantomJS and iOS 7.x
211 | MutationObserver.toString() === '[object MutationObserverConstructor]'
212 | )) { // 接着判断是否支持MutationObserver
213 | // Use MutationObserver where native Promise is not available,
214 | // e.g. PhantomJS, iOS7, Android 4.4
215 | // (#6466 MutationObserver is unreliable in IE11)
216 | var counter = 1;
217 | var observer = new MutationObserver(flushCallbacks);
218 | var textNode = document.createTextNode(String(counter));
219 | observer.observe(textNode, { // 使用MutationObserver来监听DOM节点变化
220 | characterData: true
221 | });
222 | timerFunc = function () { // 执行微任务则会动态创建一个节点来触发MutationObserver变化来调取回调函数
223 | counter = (counter + 1) % 2;
224 | textNode.data = String(counter);
225 | };
226 | isUsingMicroTask = true;
227 | } else if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) { // 接着判断是否支持setImmediate
228 | // Fallback to setImmediate.
229 | // Techinically it leverages the (macro) task queue,
230 | // but it is still a better choice than setTimeout.
231 | timerFunc = function () { // 使用setImmediate来创建微任务
232 | setImmediate(flushCallbacks);
233 | };
234 | } else { // 若上述都不支持,最后使用setTimeout创建微任务
235 | // Fallback to setTimeout.
236 | timerFunc = function () {
237 | setTimeout(flushCallbacks, 0);
238 | };
239 | }
240 | ```
241 |
242 | 创建微任务是很简单理解的,符合官方文档的说法,**先是判断是否支持Promise创建、接着判断是否支持MutationObserver创建、再判断是否支持setImmediate创建、到最后才会使用setTimeout来创建微任务**。
243 |
244 | 到这里是否有点恍然大悟了?🤣
245 |
246 | 还没结束呢。`flushCallbacks`函数是干嘛?相信你都知道的,那就是**遍历DOM依赖Watcher任务队列,按顺序来执行其回调函数**。
247 |
248 | ```javascript
249 | function flushCallbacks () {
250 | pending = false; // 遍历回调函数任务队列,意味着可以创建微任务
251 | var copies = callbacks.slice(0); // 浅复制任务队列
252 | callbacks.length = 0; // 重置全局任务队列为空
253 | for (var i = 0; i < copies.length; i++) { // 正式遍历全局任务队列
254 | copies[i](); // 按顺序滴执行每个任务队列的回调函数
255 | }
256 | }
257 | ```
258 |
259 | 到这里,也许你会有疑问,究竟每一个回调函数里面又是啥?
260 |
261 | 首先,这个`copies[i]`回调函数会有两种情况
262 |
263 | - **内部更改响应式属性,DOM元素重新渲染**(即`flushSchedulerQueue`函数)。
264 | - **外部调用全局`$nextTick`传递进来的回调函数**。
265 |
266 | 外部调用全局的`$nextTick`没啥好讲的,就是直接调用自定函数即可。现在就来讲讲`flushSchedulerQueue`函数,我们来看看它是做点什么的。
267 |
268 | ```javascript
269 | /**
270 | * Flush both queues and run the watchers.
271 | * 无非就是将queues中的watcher进行遍历以及执行每个watcher的回调函数
272 | */
273 | function flushSchedulerQueue () {
274 | currentFlushTimestamp = getNow(); // 获取当前时间戳
275 | flushing = true; // 已经在遍历DOM依赖的Watcher队列,不能再添加Watcher进入队列
276 | var watcher, id;
277 |
278 | // Sort queue before flush.
279 | // This ensures that:
280 | // 1. Components are updated from parent to child. (because parent is always
281 | // created before the child)
282 | // 2. A component's user watchers are run before its render watcher (because
283 | // user watchers are created before the render watcher)
284 | // 3. If a component is destroyed during a parent component's watcher run,
285 | // its watchers can be skipped.
286 | queue.sort(function (a, b) { return a.id - b.id; }); // 使用快排的方式进行排序Watcher队列
287 |
288 | // do not cache length because more watchers might be pushed
289 | // as we run existing watchers
290 | for (index = 0; index < queue.length; index++) { // 开始遍历
291 | watcher = queue[index];
292 | if (watcher.before) {
293 | watcher.before();
294 | }
295 | id = watcher.id; // 获取每个Watcher的id
296 | has[id] = null; // 并设置响应的映射表为空值,允许下一轮的更新
297 | watcher.run(); // 获取最新的响应式属性值并更新DOM
298 | }
299 |
300 | // keep copies of post queues before resetting state
301 | var activatedQueue = activatedChildren.slice();
302 | var updatedQueue = queue.slice(); // 浅复制Watcher队列,新建一个更新队列
303 |
304 | resetSchedulerState(); // 重置异步队列状态
305 |
306 | // call component updated and activated hooks
307 | callActivatedHooks(activatedQueue);
308 | callUpdatedHooks(updatedQueue); // 调用更新钩子函数
309 | // ...
310 | }
311 |
312 | /**
313 | * Reset the scheduler's state.
314 | */
315 | function resetSchedulerState () { // 重置包括异步队列、Watcher映射表、异步队列函数都执行完毕标志、异步队列都遍历完毕标志
316 | index = queue.length = activatedChildren.length = 0;
317 | has = {};
318 | {
319 | circular = {};
320 | }
321 | waiting = flushing = false;
322 | }
323 | ```
324 |
325 | 很简单,由于响应式属性的更改,其实是需要重新渲染的,因此使用了一个异步队列遍历后并巧妙结合一个全局映射表来让页面只会渲染一次,避免了多次频繁操作数据而导致的页面不断渲染,有效地将性能得到提升。
326 |
327 | 现在就来总结一下:
328 |
329 | - `nextTick`中回调函数会使用微任务来包裹,独立于主进程运行。
330 | - 使用映射表`has`来结合到异步队列上,有效避免多次频繁操作数据而导致的页面不断渲染,只会执行一次效果。
331 |
332 |
333 |
334 |
335 |
336 |
337 |
338 |
339 |
340 |
341 |
342 |
343 |
344 |
345 |
346 |
347 |
348 |
349 |
350 |
351 |
352 |
353 |
354 |
355 |
356 |
357 |
358 |
359 |
360 |
361 |
362 |
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】编译 Compile(下).md:
--------------------------------------------------------------------------------
1 | *今天接着上一篇内容,主要来对编译的三大阶段 parse、optimise、generate 进行一个简单讲解,由于每一个阶段都涉及到很长的代码,所以我都会简单引入一些代码来说说,至少是知道每一个阶段是如何实现的,至于细微的细节方面,后面有时间的话我也会进行讲解。 🙈*
2 |
3 |
4 |
5 | ## 语法解析 Parse
6 |
7 | 想到语法解析,就不得不提起 AST。那到底什么是 AST 呢?
8 |
9 | AST ( abstract syntax tree )是抽象语法树,用来描述树形结构的。 其实在前面讲解从 template 到 DOM 时也提到过,现在再次拿来举个例子,这样才会比较直白点。
10 |
11 | ```javascript
12 | Hello World...
13 | // 使用 VNode 表示
14 | {
15 | tag: 'span',
16 | isStatic: false,
17 | text: undefined,
18 | data: {
19 | staticClass: 'text'
20 | },
21 | children: [{
22 | tag: undefined,
23 | text: 'Hello World...'
24 | }]
25 | }
26 | ```
27 |
28 | 上述使用 VNode 表示了 AST,每一个子项都会塞进 children 属性中,一层嵌套一层,最终将以一棵树形式表示了真实的 DOM 结构。
29 |
30 | 说了那么多,是时候回到源码层面了,看看源码中是如何实现。
31 |
32 | ```javascript
33 | /**
34 | * Convert HTML string to AST.
35 | */
36 | function parse (
37 | template,
38 | options
39 | ) {
40 | // ...
41 | var stack = [] // 使用栈数据结构保存每个DOM节点的AST
42 | // ...
43 | var root // template中根元素
44 | var currentParent // 当前节点的父元素节点
45 | // ...
46 | parseHTML(template, { // 正式开始对模板进行解析执行
47 | // ...
48 |
49 | })
50 | }
51 | ```
52 |
53 | 对于`parseHTML`方法,内部其实就是使用了**正则表达式对模板进行了解析匹配**。现在我们就来看看`parseHTML`方法是如何实现的额(当然我也会稍微缩略了...)
54 |
55 | ```javascript
56 | var isPlainTextElement = makeMap('script,style,textarea', true)
57 |
58 | function parseHTML (html, options) {
59 | var stack = [] // 用来暂时性地保存父子节点间关系
60 | // ...
61 | var last, lastTag // 分别用来表示当前模板,是否是最后一个标签
62 | while(html) {
63 | last = html // 获取当前剩余模板
64 | if (!lastTag || !isPlainTextElement(lastTag)) { // 判断是最后一个标签,或最后一个标签是为特殊标签名
65 | var textEnd = html.indexof('<') // 获取<标志符在模板的索引号
66 | if (textEnd === 0) { // 当索引号为0时,肯定是一个首标签符
67 | if (comment.test(html)) { // 首标签符是否是注释
68 | // ...
69 | continue
70 | }
71 | var doctypeMatch = html.match(doctype) // 首标签符是否为doctype
72 | if (doctypeMatch) {
73 | // ...
74 | continue
75 | }
76 | var endTagMatch = html.match(endTag) // 首标签符是否为最后一个尾标签
77 | if (endTagMatch) {
78 | // ...
79 | parseEndTag(endTagMatch[1], curIndex, index) // 处理尾标签符
80 | continue
81 | }
82 | var startTagMatch = parseStartTag() // 前面都不通过后,直接作为一个首标签符进行处理
83 | if (startTagMatch) {
84 | handleStartTag(startTagMatch) // 正式处理首标签符
85 | continue
86 | }
87 | }
88 | var text // 模板中的文本
89 | if (textEnd >= 0) { // 当索引号大于或等于0时,在索引为0到符号为<为止,都是作为一个文本进行处理
90 | // ...
91 | text = html.substring(0, textEnd) // 截取获得文本
92 | }
93 | if (textEnd < 0) { // 当索引号为小于0时,那么肯定不再存在标签,直接作为文本进行处理
94 | text = html
95 | }
96 | if (options.chars && text) { // 获取相对应的文本后,就进行文本处理,如文本中有表达式或静态文案等
97 | options.chars(text, index - text.length, index)
98 | }
99 | } else { // 最后一个标签或者是特殊标签名的处理
100 | // ...
101 | parseEndTag(stackedTag, index - endTagLength, index)
102 | }
103 | }
104 | }
105 | ```
106 |
107 | 看完上述的代码,其实可以很简单滴来总结一下`parseHTML`的流程主要是做了哪些工作。
108 |
109 | - 遍历模板内容,先匹配标志符`<`索引号。若匹配成功,则作为首标签处理,判断是否是注释、doctype等特殊处理,然后**再判断若为尾标签则直接作为尾标签处理,若不为尾标签则直接作为首标签处理**。
110 | - 若匹配到标志符`<`索引号是大于0,那么在索引号为0到标志符`<`索引号为止,都是作为一个文本进行处理,因此会对模板进行截取。若匹配到标志符`<`索引号是小于0,那么整个模板都是一个文本,直接作为文本处理。
111 | - 当前面两个步骤处理好的`lastTag`是尾标签后,直接作为一个尾标签使用`parseEndTag`进行处理。
112 |
113 | 那么问题来了,看了半天上述代码,我都找不出任何有关 AST 方面的东西啊?
114 |
115 | 其实在处理首标签符方法`handleStartTag`中,就是会创建一个 AST,我们来看看 😄。
116 |
117 | ```javascript
118 | function handleStartTag (match) {
119 | // ...
120 | // 首标签中属性、指令等处理
121 | if (options.start) { // 该选项上面我并没有指出,其实就是真正生成ast方法
122 | options.start(tagName, attrs, unary, match.start, match.end);
123 | }
124 | }
125 |
126 | parseHTML(template, {
127 | // ...
128 | start: function start (tag, attrs, unary, start$1, end) {
129 | // ...
130 | var element = createASTElement(tag, attrs, currentParent) // 根据匹配到的首标签生成相应的ast
131 | // ...
132 | }
133 | })
134 |
135 | function createASTElement ( // 生成ast
136 | tag,
137 | attrs,
138 | parent
139 | ) {
140 | return {
141 | type: 1,
142 | tag: tag,
143 | attrsList: attrs,
144 | attrsMap: makeAttrsMap(attrs),
145 | rawAttrsMap: {},
146 | parent: parent,
147 | children: []
148 | }
149 | }
150 | ```
151 |
152 | 是吧(虽然我省略了很多,但还是知道有那么回事好点),在匹配到首标签时,就会生成一个ast,并对后续的尾标签以及子元素做相应的处理。
153 |
154 |
155 |
156 | ## 优化编译 Optimise
157 |
158 | 上述简单介绍了`parse`阶段,那么到了`optimise`阶段,又是做点什么工作的?当然你看英文意思都很清楚,肯定是优化鸭 🤔。那么问题来了,既然是优化,那么是怎么优化呢?
159 |
160 | 我们就先来看看源码是如何实现优化编译的。
161 |
162 | ```javascript
163 | function optimize (root, options) { // 优化编译开始
164 | if (!root) { return } // 必须是直接拿编译好的ast进行优化功能
165 | // ...
166 | // first pass: mark all non-static nodes.
167 | markStatic$1(root); // 标记所有非静态节点
168 | // second pass: mark static roots.
169 | markStaticRoots(root, false); // 标记所有静态树
170 | }
171 | ```
172 |
173 | 代码很简单,无非就是标记非静态节点或静态节点,那么这样做有啥用呢?其实这个函数我没有标出官方注释,在注释中说明的很清楚,现在就来展示一下官方注释是如何解释的。
174 |
175 | > Goal of the optimizer: walk the generated template AST tree and detect sub-trees that are purely static, i.e. parts of the DOM that never needs to change.
176 | >
177 | > 优化器的目标:遍历生成的模板AST树,并检测纯静态的子树,即永远不需要更改的DOM。
178 | >
179 | > 1. Hoist them into constants, so that we no longer need to create fresh nodes for them on each re-render;
180 | >
181 | > 将它们提升为常量,这样我们就不再需要在每次重新渲染时为他们创建新的节点;
182 | >
183 | > 2. Completely skip them in the patching process.
184 | >
185 | > 在更改过程中完全跳过它们进行编译。
186 |
187 | 看了官方解释,是否眼前一亮,无非就是对静态节点范围的标记,然后在下次编译时就会跳过并且在渲染过程中也不会再次渲染该节点,因为**静态节点都是不可变得**。
188 |
189 | 接下来我们就来看看它们是如何分别标记静态节点以及非静态节点的。
190 |
191 | ```javascript
192 | function isStatic (node) { // 判断是否为非静态节点
193 | if (node.type === 2) { // expression(表达式)
194 | return false
195 | }
196 | if (node.type === 3) { // text(文本)
197 | return true
198 | }
199 | return !!(node.pre || (
200 | !node.hasBindings && // no dynamic bindings(非动态绑定)
201 | !node.if && !node.for && // not v-if or v-for or v-else(无指令)
202 | !isBuiltInTag(node.tag) && // not a built-in(节点不在建立过程中)
203 | isPlatformReservedTag(node.tag) && // not a component(不是一个组件)
204 | !isDirectChildOfTemplateFor(node) &&
205 | Object.keys(node).every(isStaticKey)
206 | ))
207 | }
208 | function markStatic$1 (node) { // 标记非静态节点处理
209 | node.static = isStatic(node) // 判断当前节点是否为非静态节点
210 | if (node.type === 1) { // 作为元素节点处理
211 | // ...
212 | for (var i = 0, l = node.children.length; i < l; i++) { // 遍历字节点
213 | var child = node.children[i];
214 | markStatic$1(child); // 递归遍历标记下去
215 | if (!child.static) {
216 | node.static = false;
217 | }
218 | }
219 | }
220 | }
221 | function markStaticRoots (node, isInFor) { // 标记静态树处理
222 | if (node.type === 1) {
223 | // ...
224 | if (node.static && node.children.length && !(
225 | node.children.length === 1 &&
226 | node.children[0].type === 3
227 | )) { // 要使节点具有静态根功能,那么必须拥有字节点,并且字节点只能是文本
228 | node.staticRoot = true; // 直接标记为静态树
229 | return
230 | } else { // 否则则不是静态树
231 | node.staticRoot = false
232 | }
233 | if (node.children) {
234 | for (var i = 0, l = node.children.length; i < l; i++) {
235 | markStaticRoots(node.children[i], isInFor || !!node.for); // 继续递归处理
236 | }
237 | }
238 | // ...
239 | }
240 | }
241 | ```
242 |
243 | 看完上述代码,我最直观的感受是,**使用递归形式实现了静态树和非静态节点标记功能**。一旦是静态树,那么就直接标记为静态树,并且在下次编译时就会直接跳过以及在渲染时不会再次重新创建。
244 |
245 | 另外需要说明的一点是,`node.type`是代表了不同类型。
246 |
247 | - 1:表示元素节点。
248 | - 2:表示表达式。
249 | - 3:表示文本。
250 |
251 | 总结一下:**优化编译`Optimise`功能在于标记非静态节点以及静态树**。
252 |
253 |
254 |
255 | ##生成渲染方法 Generate
256 |
257 | 终于到了生成渲染方法`generate`,相信你们对他功能也有所了解,就是经过优化编译后的 AST,直接转换成渲染方法。那么它究竟又是如何实现的,我们接着看下去。
258 |
259 | ```javascript
260 | function generate ( // 生成渲染方法
261 | ast,
262 | options
263 | ) {
264 | var state = new CodegenState(options); // 初始化配置信息
265 | var code = ast ? genElement(ast, state) : '_c("div")'; // 根据ast以及配置信息生成渲染方法
266 | return {
267 | render: ("with(this){return " + code + "}"), // 渲染方法字符串
268 | staticRenderFns: state.staticRenderFns // 静态树
269 | }
270 | }
271 | ```
272 |
273 | 我们就来看看每一个过程大概是怎样的。
274 |
275 | ```javascript
276 | var CodegenState = function CodegenState (options) {
277 | this.options = options; // 缓存一份选项信息
278 | this.warn = options.warn || baseWarn; // 获取选项中警告信息
279 | this.transforms = pluckModuleFunction(options.modules, 'transformCode');
280 | this.dataGenFns = pluckModuleFunction(options.modules, 'genData');
281 | this.directives = extend(extend({}, baseDirectives), options.directives); // 获取选项中指令信息
282 | var isReservedTag = options.isReservedTag || no;
283 | this.maybeComponent = function (el) { return !!el.component || !isReservedTag(el.tag); }; // 是否为组件
284 | this.onceId = 0;
285 | this.staticRenderFns = []; // 用于保存静态树
286 | this.pre = false;
287 | }
288 | ```
289 |
290 | 可以看到,`CodegenState`方法主要是针对选项进行配置一些简单信息,其中最为重要的就是使用`staticRenderFns`数组来保存静态树。
291 |
292 | 接下来,就是`genELement`方法,这个方法很重要,主要是通过 AST 转换成相应的渲染方法。
293 |
294 | ```javascript
295 | function genElement (el, state) {
296 | if (el.parent) {
297 | el.pre = el.pre || el.parent.pre;
298 | }
299 |
300 | if (el.staticRoot && !el.staticProcessed) { // 判断是否静态树
301 | return genStatic(el, state)
302 | } else if (el.once && !el.onceProcessed) { // 判断是否为v-once指令节点
303 | return genOnce(el, state)
304 | } else if (el.for && !el.forProcessed) { // 判断是否为v-for指令节点
305 | return genFor(el, state)
306 | } else if (el.if && !el.ifProcessed) { // 判断是否为v-if指令节点
307 | return genIf(el, state)
308 | } else if (el.tag === 'template' && !el.slotTarget && !state.pre) { // 判断是否为模板元素,若是则继续获取子节点
309 | return genChildren(el, state) || 'void 0'
310 | } else if (el.tag === 'slot') { // 判断是否为v-slot指令节点
311 | return genSlot(el, state)
312 | } else { // 若以上都不通过,则都作为元素或组件节点来处理
313 | // component or element
314 | var code;
315 | if (el.component) { // 组件节点处理
316 | code = genComponent(el.component, el, state);
317 | } else { // 元素节点处理
318 | var data;
319 | if (!el.plain || (el.pre && state.maybeComponent(el))) {
320 | data = genData$2(el, state); // 获取元素中相应的数据
321 | }
322 |
323 | var children = el.inlineTemplate ? null : genChildren(el, state, true); // 继续获取子节点
324 | code = "_c('" + (el.tag) + "'" + (data ? ("," + data) : '') + (children ? ("," + children) : '') + ")"; // 最终得到渲染方法字符串
325 | }
326 | // module transforms
327 | // ...
328 | return code
329 | }
330 | }
331 | ```
332 |
333 | 可以看到**`genElement`方法就是针对 AST,处理一些静态树、特殊指令节点、组件节点以及元素节点并生成相应的渲染方法字符串**。
334 |
335 | 由于每一项代码都很长,我就暂时不放出来进行讨论,后面有机会的话我会再回来跟你们一起探讨哈 😂。
336 |
337 | 现在就拿`genStatic`方法作为栗子举个栗子看看其源码实现。
338 |
339 | ```javascript
340 | function genStatic (el, state) { // 生成静态树的渲染方法
341 | // ...
342 | state.staticRenderFns.push(("with(this){return " + (genElement(el, state)) + "}")); // 将静态树渲染方法指定作用域直接Push进staticRenderFns中进行保存
343 | state.pre = originalPreState;
344 | return ("_m(" + (state.staticRenderFns.length - 1) + (el.staticInFor ? ',true' : '') + ")") // 返回使用渲染方法包裹的静态树
345 | }
346 | ```
347 |
348 | `genStatic`方法工作只有两个,分别是
349 |
350 | - 使用`_m`渲染方法包裹该作用域,组装成节点最终的渲染方法。
351 |
352 | - 将静态树使用`with`操作符将渲染方法绑定相应作用域,并保存到`staticRenderFns`属性中。
353 |
354 | 注:`with`作用域在[【 Vue 源码分析 】运行机制之 Props](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E8%BF%90%E8%A1%8C%E6%9C%BA%E5%88%B6%E4%B9%8B%20Props.md) 中提及过,忘记的童鞋们有兴趣还是可以返回去看看哈。
355 |
356 | 对于上述过程,也许你会有疑惑了,究竟`_m`、`_c`是什么东西,又是能干嘛的?别急,在下一章 Render 中我会慢慢提到的。
357 |
358 | 看到这里,其实就可以明白,**在`generate`方法中最终处理的其实就是生成渲染方法以及将绑定好作用的静态树渲染方法保存起来**。
359 |
360 |
361 |
362 | 🙈 至此,编译阶段基本讲解完啦,可能有些地方讲的还是比较简单,望见谅哈。现在回头来总结一下,`Compile`编译阶段到底做了哪些事情。
363 |
364 | - 一个完整编译阶段,必须经过语法解析`parse`、优化编译`optimise`、生成渲染方法`generate`三大阶段。
365 | - 语法解析`parse`主要负责**将`template`模板内容转换成相应的`AST`抽象语法树**。
366 | - 优化编译`optimise`主要负责**遍历转换好的`AST`抽象语法树,分别标记非静态节点和静态树**。
367 | - 生成渲染方法`generate`主要负责**对优化好的`AST`抽象语法树生成相应的渲染方法,并将绑定好作用域的静态树渲染方法保存起来**。
--------------------------------------------------------------------------------
/docs/【 Vue 源码分析 】如何在更新 Patch 中进行 Diff.md:
--------------------------------------------------------------------------------
1 | ## 何为 Patch?
2 |
3 | 相信看过[【 Vue 源码分析 】渲染 Render (AST -> VNode)](https://github.com/Andraw-lin/about-Vue/blob/master/docs/%E3%80%90%20Vue%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%20%E3%80%91%E6%B8%B2%E6%9F%93%20Render%20(AST%20-%3E%20VNode).md) 的童鞋们都还有点印象,就是我在最后执行渲染方法后,留下一个方法没有讲到,就是`_update`方法。忘记的童鞋也没关系,我简单滴截取一下代码过来,如下:
4 |
5 | ```javascript
6 | updateComponent = function () { // 模板依赖Watcher更新回调方法
7 | // ...
8 | var vnode = vm._render() // 最主要的!!!直接转化AST为VNode节点
9 | // ...
10 | vm._update(vnode, hydrating) // 将转换好的VNode放到更新函数中使用patch进行比对
11 | // ...
12 | }
13 | ```
14 |
15 | 通过执行`_c`渲染方法将相应的`AST`转化为`VNode`节点后,再将生成的`VNode`树作为参数传进`_update`方法中进行相应的`patch`。
16 |
17 | 好了,问题来了,那么究竟什么是`patch`呢?
18 |
19 | 所谓`patch`,按字面就是补丁,而在`Vue`中则是比较的意思。怎么理解呢?
20 |
21 | **当响应式数据更改时,都会触发模板的`updateComponent`方法,生成新的`VNode`树,由于旧的`VNode`树会直接映射到真实`DOM`中的每一个节点,因此通过对新旧`VNode`树进行`patch`比较后,得出两个`VNode`树最小的差异,再将这些差异渲染到视图上**。
22 |
23 | 文字看的不是很清楚?🤔 甭急,下面就列出图来就会好理解了。
24 |
25 | 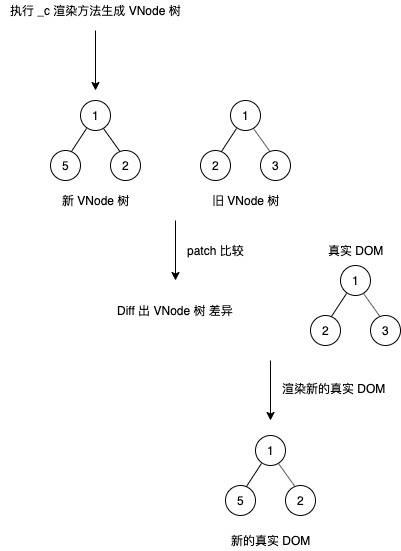
26 |
27 |
28 |
29 | 有上图在,是否会豁然开朗点哈哈。但是从图中,我们又发现了另外一个知识点,`Diff`出`VNode`树间的差异,那么`Diff`又是啥?
30 |
31 | 其实`Diff`就是一种实现`patch`的比较算法,可以很高效地处理两个新旧`VNode`树间的差异。接下来我们就来介绍一下这个算法。🤔
32 |
33 |
34 |
35 | ## Diff 算法
36 |
37 | 话不多说,直奔主题。
38 |
39 | `Diff`算法的核心就是**针对具有相同父节点的同层新旧子节点进行比较,而不是使用逐层搜索递归遍历的方式**。**时间复杂度为`O(n)`**。
40 |
41 | 如何理解?
42 |
43 | 说白点,就是**当新旧`VNode`树在同一层具有相同的`VNode`节点时,才会继续对其子节点进行比较**。一旦旧`VNode`树同层中的节点在新`VNode`树中不存在或者是多余的,都会在新的真实`DOM`中进行添加或者删除。下面就拿一副图进行解释。
44 |
45 | 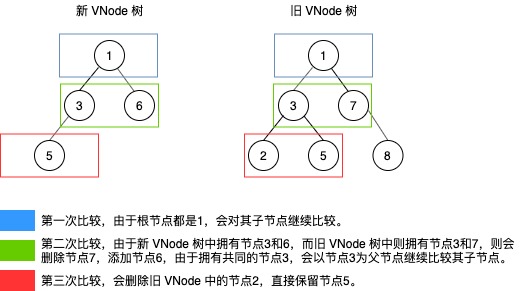
46 |
47 | 从上面的示例图可以看到,`Diff`算法中只会对同一层的元素进行比较,并且必须拥有相同节点元素,才会对其子节点进行比较,其他多余的同层节点都会一律做删除或添加操作。
48 |
49 | 接下来,我们就从源码角度来看看这过程到底是如何发生的。🤔
50 |
51 |
52 |
53 | ## 从源码角度进行探究
54 |
55 | 我们依然是从`_update`方法入手,看看到底是如何操作的。
56 |
57 | ```javascript
58 | Vue.prototype._update = function (vnode, hydrating) {
59 | var vm = this; // 缓存vue实例
60 | var prevEl = vm.$el; // 获取实例中真实DOM元素
61 | var prevVnode = vm._vnode; // 获取旧VNode树
62 | vm._vnode = vnode; // 将新VNode树保存到实例的_vnode上,便于下次更新获取旧VNode树
63 |
64 | if (!prevVnode) { // 判断是否有旧VNode树,并进行相应的处理
65 | // initial render
66 | vm.$el = vm.__patch__(vm.$el, vnode, hydrating, false /* removeOnly */); // 最开始的一次,即第一次渲染时是没有旧VNode树,直接执行__patch__
67 | } else {
68 | // updates
69 | vm.$el = vm.__patch__(prevVnode, vnode); // 新VNode树与旧VNode树进行__patch__
70 | }
71 | // ...
72 | }
73 | ```
74 |
75 | 每一次更新模板时,都会先将渲染好的新`VNode`树保存到实例的`_vnode`属性上,这样做的目的是为了下一次更新时,能获取到旧`VNode`树进行比较。
76 |
77 | 针对是否拥有旧的`VNode`树,使用`__patch__`方法执行相应逻辑,也即执行了`patch`过程。
78 |
79 | ```javascript
80 | var inBrowser = typeof window !== 'undefined'; // 浏览器环境
81 | Vue.prototype.__patch__ = inBrowser ? patch : noop; // 只有在浏览器环境才能进行patch
82 |
83 | var patch = createPatchFunction({ nodeOps: nodeOps, modules: modules })
84 | ```
85 |
86 | 可以看到,**只有在浏览器的环境下才能进行`patch`过程**,而实现`patch`的,就是`createPatchFunction`方法,我们接着看下去。
87 |
88 | ```javascript
89 | function createPatchFunction (backend) {
90 | // ...
91 | // 省略了很多私有工具方法,下面会拿出一些进行说明
92 | return function patch (oldVnode, vnode, hydrating, removeOnly) {
93 | if (isUndef(oldVnode)) { // 当旧VNode树不存在时,则直接创建一个根元素
94 | // empty mount (likely as component), create new root element
95 | isInitialPatch = true;
96 | createElm(vnode, insertedVnodeQueue); // 直接根据新VNode树并生成真实DOM
97 | } else { // 当存在旧VNode树时,则进行相应的比较
98 | // ...
99 | if (sameVnode(oldVnode, vnode)) { // 当新旧节点间是否相同时
100 | // patch existing root node
101 | patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly); // 当新旧节点相同时则进行patch比较
102 | } else { // 当新旧节点间不相同时
103 | var oldElm = oldVnode.elm; // 获取旧节点元素
104 | var parentElm = nodeOps.parentNode(oldElm); // 获取旧节点的父节点
105 |
106 | // create new node
107 | createElm( // 由于新旧节点是不同的,因此会根据新节点创建一个新的节点
108 | vnode,
109 | insertedVnodeQueue,
110 | // extremely rare edge case: do not insert if old element is in a
111 | // leaving transition. Only happens when combining transition +
112 | // keep-alive + HOCs. (#4590)
113 | oldElm._leaveCb ? null : parentElm,
114 | nodeOps.nextSibling(oldElm)
115 | );
116 |
117 | // destroy old node
118 | if (isDef(parentElm)) { // 当创建好新节点后,也会把旧节点进行删除
119 | removeVnodes(parentElm, [oldVnode], 0, 0);
120 | } else if (isDef(oldVnode.tag)) { // 删除响应节点后,也会调用相应的回调
121 | invokeDestroyHook(oldVnode);
122 | }
123 | }
124 | }
125 | }
126 | }
127 | ```
128 |
129 | 好啦,对于`patch`比较过程,你也应该有了一个大概了解。现在就来简单总结一下上述代码。
130 |
131 | - 当旧`VNode`树不存在时,直接根据新`VNode`树创建相应的真实`DOM`。
132 | - 当旧`VNode`树存在时,则会调用`sameVnode`方法比较当前新旧节点是否相同。
133 | - 当新旧节点是相同时,会调用`patchVnode`方法比较新旧节点(过程就是继续比较其子节点,递归下去~)。
134 | - 当新旧节点是不同时,则会先按照新`VNode`节点创建新的真实`DOM`节点,再根据旧`VNode`节点将相应的真实`DOM`节点进行删除。
135 |
136 | 是不是很简单 🤔...那么问题来了,不是说`patch`过程是使用`Diff`算法进行比较的吗?怎么还看不到,甭急,下面我会讲到哈。
137 |
138 | 在上面的总结中,我们是可以看到两个方法,分别是`sameVnode`方法和`patchVnode`方法。接下来我们就来探讨一下这两个方法。
139 |
140 | ```javascript
141 | function sameVnode (a, b) { // 判断两个节点间是否相同
142 | return (
143 | a.key === b.key && ( // 两个节点间相同,首先是唯一标识key必须相同
144 | (
145 | a.tag === b.tag &&
146 | a.isComment === b.isComment &&
147 | isDef(a.data) === isDef(b.data) &&
148 | sameInputType(a, b) // 接着就是节点标签名、是否为注释、数据是否为空、input类型都必须相同
149 | ) || (
150 | isTrue(a.isAsyncPlaceholder) &&
151 | a.asyncFactory === b.asyncFactory &&
152 | isUndef(b.asyncFactory.error)
153 | )
154 | )
155 | )
156 | }
157 |
158 | function sameInputType (a, b) { // 比较两个节点的input类型是否相同
159 | if (a.tag !== 'input') { return true }
160 | var i;
161 | var typeA = isDef(i = a.data) && isDef(i = i.attrs) && i.type;
162 | var typeB = isDef(i = b.data) && isDef(i = i.attrs) && i.type;
163 | return typeA === typeB || isTextInputType(typeA) && isTextInputType(typeB)
164 | }
165 | ```
166 |
167 | 比较两个新旧节点间是很简单的,主要是按照下面几个属性进行判断。
168 |
169 | - `VNode`节点唯一标识`key`。
170 | - 是否同为注释`isComment`。
171 | - 数据属性是否为空`isDef`。
172 | - 是否为相同的`input`类型`sameInputType`。
173 |
174 | 此时,不禁又有问题了,判断两个节点相同,只是仅仅判断其数据属性是否为空就可以了吗??
175 |
176 | 其实,这样做不是没有目的的,**首先两个相同的节点,若仅仅只是`data`值不一样时,这样就没必要新创建一个新的节点,并把新的`data`赋值到节点。而是在原有节点上,仅仅将其`data`进行更改,这样一来就可以对性能得到有效的提升**。
177 |
178 | 好啦,接着就到我们的主角`patchVnode`方法了,这个才是`Diff`相关方法,我们先来看看源码是如何实现的。🤔
179 |
180 | ```javascript
181 | function patchVnode (
182 | oldVnode,
183 | vnode,
184 | insertedVnodeQueue,
185 | ownerArray,
186 | index,
187 | removeOnly
188 | ) {
189 | if (oldVnode === vnode) { // 当发现两个节点是完全一模一样时,则直接返回
190 | return
191 | }
192 | // ...
193 | var elm = vnode.elm = oldVnode.elm;
194 | // ...
195 | var i;
196 | var data = vnode.data;
197 | if (isDef(data) && isDef(i = data.hook) && isDef(i = i.prepatch)) {
198 | i(oldVnode, vnode); // 根据新VNode更新旧VNode的选项配置、数据属性、propsData等
199 | }
200 |
201 | var oldCh = oldVnode.children; // 获取旧节点的子节点集合
202 | var ch = vnode.children; // 获取新节点的子节点集合
203 | // ...
204 | if (isUndef(vnode.text)) { // 当新VNode节点不是文本节点时
205 | if (isDef(oldCh) && isDef(ch)) { // 当旧VNode子节点和新VNode子节点都不为空时
206 | if (oldCh !== ch) { updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly); } // 当旧VNode节点子节点和新VNode节点子节点不等时,再递归执行updateChildren比较子节点
207 | } else if (isDef(ch)) { // 当只有新VNode子节点存在而旧VNode子节点不存在时
208 | // ...
209 | if (isDef(oldVnode.text)) { nodeOps.setTextContent(elm, ''); } // 当旧VNode节点是文本节点时,先置空文本
210 | addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue); // 根据位置对真实DOM添加新的节点
211 | } else if (isDef(oldCh)) { // 当只有旧VNode子节点存在而新VNode子节点不存在时
212 | removeVnodes(elm, oldCh, 0, oldCh.length - 1); // 直接移除所有多余节点
213 | } else if (isDef(oldVnode.text)) { // 当只有旧VNode子节点存在并且是文本节点时
214 | nodeOps.setTextContent(elm, ''); // 直接置空文本处理
215 | }
216 | } else if (oldVnode.text !== vnode.text) { // 当旧VNode文本节点不等于新VNode文本节点时
217 | nodeOps.setTextContent(elm, vnode.text); // 直接将旧VNode节点设置为新VNode节点文本内容
218 | }
219 | // ...
220 | }
221 | ```
222 |
223 | `patchVnode`方法做的事情不多,最主要就是按照一下场景做了处理。
224 |
225 | - 当新`VNode`节点不是文本节点时。
226 | - 当新`VNode`节点和旧`VNode`节点都存在时,若两个节点不等,直接执行`updateChildren`递归执行其子节点进行比较。
227 | - 当只有新`VNode`节点存在时,若旧`VNode`节点是文本节点,先置空文本内容,再直接在真实`DOM`中相应位置新增新`VNode`节点。
228 | - 当只有旧`VNode`节点存在时,直接移除真实`DOM`中相应位置的多余旧`VNode`节点。
229 | - 当只有旧`VNode`节点存在并且它是文本节点时,直接置空文本内容即可。
230 | - 当新`VNode`节点是文本节点时。若两个文本节点内容不一致,直接在真实`DOM`中对应旧`VNode`节点位置文本内容设置为新`VNode`节点文本内容即可。
231 |
232 | 接下来才是最重点呀。。😅 在上面中留下了`updateChildren`方法,那么这个方法又是干啥?
233 |
234 | 不瞒你说,**`updateChildren`方法在根据场景`Diff`后,将旧`VNode`树作出相应的改动**。在没有看源码之前,我会先阐述一下。
235 |
236 | **`Diff`算法过程中,在将旧`VNode`树改动时,优先考虑相同位置的相同节点,再考虑需要移动的相同节点,最后才考虑创建或删除节点**。
237 |
238 | 有了上面的简单理解,我们就来继续探究啦 😄。
239 |
240 | ```javascript
241 | function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
242 | var oldStartIdx = 0; // 旧节点开始位置
243 | var newStartIdx = 0; // 新节点开始位置
244 | var oldEndIdx = oldCh.length - 1; // 旧节点结束位置
245 | var oldStartVnode = oldCh[0]; // 旧节点第一个元素
246 | var oldEndVnode = oldCh[oldEndIdx]; // 旧节点最后一个元素
247 | var newEndIdx = newCh.length - 1; // 新节点结束位置
248 | var newStartVnode = newCh[0]; // 新节点第一个元素
249 | var newEndVnode = newCh[newEndIdx]; // 新节点最后一个元素
250 | var oldKeyToIdx, idxInOld, vnodeToMove, refElm;
251 | // ...
252 | while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) { // 同时从新旧子节点集合开始遍历
253 | if (isUndef(oldStartVnode)) { // 从第一项开始,一直遍历旧节点初始元素直到不为空为止
254 | oldStartVnode = oldCh[++oldStartIdx]; // Vnode has been moved left
255 | } else if (isUndef(oldEndVnode)) { // 从最后一项开始,一直遍历旧节点直到不为空为止
256 | oldEndVnode = oldCh[--oldEndIdx];
257 | } else if (sameVnode(oldStartVnode, newStartVnode)) { // (相同位置场景)当第一项旧节点和第一项新节点相同时,则继续执行patchVnode递归执行下去
258 | patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx);
259 | oldStartVnode = oldCh[++oldStartIdx];
260 | newStartVnode = newCh[++newStartIdx];
261 | } else if (sameVnode(oldEndVnode, newEndVnode)) { // (相同位置场景)当最后一项旧节点和最后一项新节点相同时,则继续执行patchVnode递归执行下去
262 | patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx);
263 | oldEndVnode = oldCh[--oldEndIdx];
264 | newEndVnode = newCh[--newEndIdx];
265 | } else if (sameVnode(oldStartVnode, newEndVnode)) { // (需要移动场景)当第一项旧节点和最后一项新节点相同时,先执行patchVnode递归执行下去,再执行insertBefore将真实DOM节点插入到相应位置
266 | patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx);
267 | canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm));
268 | oldStartVnode = oldCh[++oldStartIdx];
269 | newEndVnode = newCh[--newEndIdx];
270 | } else if (sameVnode(oldEndVnode, newStartVnode)) { // (需要移动场景)当最后一项旧节点和第一项新节点相同时,先执行patchVnode递归执行下去,再执行insertBefore将真实DOM节点插入到相应位置
271 | patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx);
272 | canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm);
273 | oldEndVnode = oldCh[--oldEndIdx];
274 | newStartVnode = newCh[++newStartIdx];
275 | } else { // 比较头尾都无相同元素时,直接判断新节点是否在旧节点结合中,若有则直接移动相应的位置,若无则直接新建一个节点
276 | if (isUndef(oldKeyToIdx)) { oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx); } // 将旧节点结合创建一个哈希表
277 | idxInOld = isDef(newStartVnode.key)
278 | ? oldKeyToIdx[newStartVnode.key]
279 | : findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx); // 根据哈希表,判断新节点是否在哈希表中,并获得对应旧节点的索引位置
280 | if (isUndef(idxInOld)) { // 当新节点不在旧节点集合中时,新建一个真实DOM节点
281 | createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx);
282 | } else { // 当新节点在旧节点集合中时,则会先判断两个节点是否相同
283 | vnodeToMove = oldCh[idxInOld]; // 根据索引位置获得旧节点
284 | if (sameVnode(vnodeToMove, newStartVnode)) { // 当两个节点是相同时,继续执行patchVnode递归执行下去,再执行insertBefore将真实DOM节点插入到相应位置
285 | patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx);
286 | oldCh[idxInOld] = undefined;
287 | canMove && nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm);
288 | } else { // 当两个节点不同时,直接新建一个新的DOM节点
289 | // same key but different element. treat as new element
290 | createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx);
291 | }
292 | }
293 | newStartVnode = newCh[++newStartIdx]
294 | }
295 | }
296 | if (oldStartIdx > oldEndIdx) { // 跳出循环后,若新节点依旧存在,那么就要遍历剩余的新节点并逐个新增到真实DOM中
297 | refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm;
298 | addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue);
299 | } else if (newStartIdx > newEndIdx) { // 跳出循环后,若旧节点依旧存在,那么就要将真实DOM中对应旧VNode节点进行删除操作
300 | removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx);
301 | }
302 | }
303 | ```
304 |
305 | 看完上面一坨代码,是否会觉得晕晕的?既然晕,那我们就一步一步地来总结下,总会找到突破点的。🤔
306 |
307 | 1. 执行方法时,首先会先获取新旧`VNode`子节点集合的初始位置、结束位置、第一项元素以及最后一项元素。
308 |
309 | 2. 接着使用`sameVnode`方法判断新旧子节点集合头头、尾尾节点是否相同。分两种情况:
310 |
311 | - 当旧子节点集合第一项元素和新子节点集合第一项元素相同时,执行`patchVnode`方法递归遍历它们子节点集合下去。
312 | - 当旧子节点集合最后一项元素和新子节点集合最后一项元素相同时,执行`patchVnode`方法递归遍历它们子节点集合下去。
313 |
314 | 这两种情况均属于**原地将元素更改即可,无需移动元素**,消耗性能最小。
315 |
316 | 3. 再使用`sameVnode`方法判断新旧子节点集合头尾、尾头节点是否相同。分为两种情况:
317 |
318 | - 当旧子节点集合第一项元素和新子节点集合最后一项元素相同时,执行`patchVnode`方法递归遍历它们子节点集合下去,然后执行`insertBefore`方法将真实`DOM`对应旧`VNode`节点的位置移到最后一位。(看图好理解 😂)
319 |
320 | 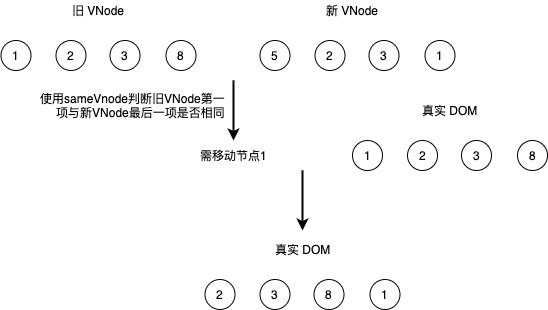
321 |
322 |
323 |
324 | - 当旧子节点集合最后一项元素和新子节点集合第一项元素相同时,执行`patchVnode`方法递归遍历它们子节点集合下去,然后执行`insertBefore`方法将真实`DOM`对应旧`VNode`节点的位置移到第一位。(看图好理解 😂)
325 |
326 | 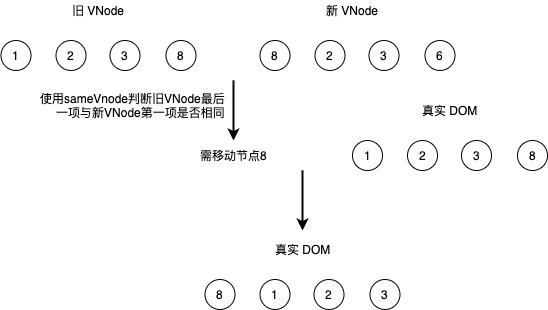
327 |
328 | 这两种可均属于**移动元素更改,需移动元素**,消耗性能一般。
329 |
330 | 4. 当头尾节点都比较完毕后,使用`createKeyToOldIdx`方法将旧子节点集合转化一个哈希表形式,然后获取新节点在旧子节点哈希表中位置 t。也分为两种情况:
331 |
332 | - 当位置 t 不存在时,那么直接使用`createElm`方法在真实`DOM`中创建节点。
333 | - 当位置 t 存在时。分为两种情况:
334 | + 若同一个位置的新旧两个节点是相同节点,执行`patchVnode`方法递归遍历它们子节点集合下去,然后执行`insertBefore`方法将真实`DOM`对应旧`VNode`节点移到位置 t 。
335 | + 若同一个位置的新旧两个节点是不相同节点,执行`createElm`方法在真实`DOM`中位置 t 创建节点。
336 |
337 | 5. 跳出循环后,剩余两种情况处理:
338 |
339 | - 当新子节点集合中还有剩余节点时,那么遍历其剩余节点,使用`createElm`方法逐个创建真实`DOM`节点。
340 | - 当旧子节点集合中还有剩余节点时,那么遍历其剩余节点,使用`removeNode`方法逐个在真实`DOM`中进行删除。
341 |
342 | 看完上面的总结后,有木有一种豁然开朗的感觉 😄。
343 |
344 | 或许你会对上面又会产生另外的疑惑,为什么最后使用哈希表来查询?不瞒你说,使用哈希表目的,在于能更快地根据传递值找出相应的位置是否拥有值。相关知识童鞋们可以自行查找。在这里我就不在陈述了~
345 |
346 | 终于要写完啦,😂 哈哈。敲的我手都快软了。可能你会觉得还有些知识点并没有提到,的确,由于我的时间有一定限制,所以也么有把所有知识点都一一讲述,但我还是希望大家能够一起学习一起进步的。
347 |
348 | 最后的最后,还是很感谢童鞋们的观看 💪。也祝大家在即将踏入的2020年里身体健康、万事如意,最重要的还是升官发财哈 😆
349 |
350 |
351 |
352 |
353 |
354 |
355 |
356 |
357 |
358 |
359 |
360 |
361 |
362 |
363 |
364 |
365 |
366 |
367 |
368 |
369 |
370 |
371 |
372 |
373 |
374 |
375 |
376 |
377 |
378 |
379 |
380 |
381 |
382 |
383 |
384 |
385 |
386 |
387 |
388 |
389 |
390 |
391 |
392 |
393 |
394 |
395 |
396 |
--------------------------------------------------------------------------------