├── .github
├── ISSUE_TEMPLATE.md
└── PULL_REQUEST_TEMPLATE.md
├── .gitignore
├── AUTHORS
├── CITATION
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── Gemfile
├── LICENSE.md
├── Makefile
├── README.md
├── _config.yml
├── _episodes
├── .gitkeep
├── 01-introduction.md
├── 02-findable.md
├── 03-accessible.md
├── 04-interoperable.md
├── 05-reusable.md
├── 07-assessment.md
└── 08-software.md
├── _episodes_rmd
├── .gitkeep
└── data
│ └── .gitkeep
├── _extras
├── .gitkeep
├── about.md
├── design.md
├── discuss.md
├── figures.md
└── guide.md
├── aio.md
├── bin
├── boilerplate
│ ├── .travis.yml
│ ├── AUTHORS
│ ├── CITATION
│ ├── CODE_OF_CONDUCT.md
│ ├── CONTRIBUTING.md
│ ├── README.md
│ ├── _config.yml
│ ├── _episodes
│ │ └── 01-introduction.md
│ ├── _extras
│ │ ├── about.md
│ │ ├── discuss.md
│ │ ├── figures.md
│ │ └── guide.md
│ ├── aio.md
│ ├── index.md
│ ├── reference.md
│ └── setup.md
├── chunk-options.R
├── generate_md_episodes.R
├── knit_lessons.sh
├── lesson_check.py
├── lesson_initialize.py
├── markdown_ast.rb
├── repo_check.py
├── test_lesson_check.py
├── util.py
└── workshop_check.py
├── code
└── .gitkeep
├── data
└── .gitkeep
├── fig
├── .gitkeep
├── anatomy-of-a-doi.jpg
├── datacite-arxiv-crossref.png
├── datacite_statistics.png
├── el-gebali-research-lifecycle.png
├── file_structures.png
├── pepe_research_lifecycle.png
└── rest-api.png
├── files
└── .gitkeep
├── index.md
├── reference.md
└── setup.md
/.github/ISSUE_TEMPLATE.md:
--------------------------------------------------------------------------------
1 | Please delete the text below before submitting your contribution.
2 |
3 | ---
4 |
5 | Thanks for contributing! If this contribution is for instructor training, please send an email to checkout@carpentries.org with a link to this contribution so we can record your progress. You’ve completed your contribution step for instructor checkout just by submitting this contribution.
6 |
7 | Please keep in mind that lesson maintainers are volunteers and it may be some time before they can respond to your contribution. Although not all contributions can be incorporated into the lesson materials, we appreciate your time and effort to improve the curriculum. If you have any questions about the lesson maintenance process or would like to volunteer your time as a contribution reviewer, please contact Kate Hertweck (k8hertweck@gmail.com).
8 |
9 | ---
10 |
--------------------------------------------------------------------------------
/.github/PULL_REQUEST_TEMPLATE.md:
--------------------------------------------------------------------------------
1 | Please delete the text below before submitting your contribution.
2 |
3 | ---
4 |
5 | Thanks for contributing! If this contribution is for instructor training, please send an email to checkout@carpentries.org with a link to this contribution so we can record your progress. You’ve completed your contribution step for instructor checkout just by submitting this contribution.
6 |
7 | Please keep in mind that lesson maintainers are volunteers and it may be some time before they can respond to your contribution. Although not all contributions can be incorporated into the lesson materials, we appreciate your time and effort to improve the curriculum. If you have any questions about the lesson maintenance process or would like to volunteer your time as a contribution reviewer, please contact Kate Hertweck (k8hertweck@gmail.com).
8 |
9 | When submitting a pull request with links, we request that you use persistent identifiers (PIDs) to articles, datasets and other research objects, when available. For more information on PIDs, see Persistent identifier. (2020-08-28). In Wikipedia. Retrieved from [https://en.wikipedia.org/wiki/Persistent_identifier](https://en.wikipedia.org/wiki/Persistent_identifier).
10 |
11 | ---
12 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
2 | *~
3 | .DS_Store
4 | .ipynb_checkpoints
5 | .sass-cache
6 | .jekyll-cache/
7 | __pycache__
8 | _site
9 | .Rproj.user
10 | .Rhistory
11 | .RData
12 | .bundle/
13 | .vendor/
14 | .docker-vendor/
15 | Gemfile.lock
16 |
--------------------------------------------------------------------------------
/AUTHORS:
--------------------------------------------------------------------------------
1 | FIXME: list authors' names and email addresses.
2 |
--------------------------------------------------------------------------------
/CITATION:
--------------------------------------------------------------------------------
1 | FIXME: describe how to cite this lesson.
2 |
--------------------------------------------------------------------------------
/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: page
3 | title: "Contributor Code of Conduct"
4 | ---
5 | As contributors and maintainers of this project,
6 | we pledge to follow the [Carpentry Code of Conduct][coc].
7 |
8 | Instances of abusive, harassing, or otherwise unacceptable behavior
9 | may be reported by following our [reporting guidelines][coc-reporting].
10 |
11 | {% include links.md %}
12 |
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing
2 |
3 | [Software Carpentry][swc-site] and [Data Carpentry][dc-site] are open source projects,
4 | and we welcome contributions of all kinds:
5 | new lessons,
6 | fixes to existing material,
7 | bug reports,
8 | and reviews of proposed changes are all welcome.
9 |
10 | ## Contributor Agreement
11 |
12 | By contributing,
13 | you agree that we may redistribute your work under [our license](LICENSE.md).
14 | In exchange,
15 | we will address your issues and/or assess your change proposal as promptly as we can,
16 | and help you become a member of our community.
17 | Everyone involved in [Software Carpentry][swc-site] and [Data Carpentry][dc-site]
18 | agrees to abide by our [code of conduct](CONDUCT.md).
19 |
20 | ## How to Contribute
21 |
22 | The easiest way to get started is to file an issue
23 | to tell us about a spelling mistake,
24 | some awkward wording,
25 | or a factual error.
26 | This is a good way to introduce yourself
27 | and to meet some of our community members.
28 |
29 | 1. If you do not have a [GitHub][github] account,
30 | you can [send us comments by email][email].
31 | However,
32 | we will be able to respond more quickly if you use one of the other methods described below.
33 |
34 | 2. If you have a [GitHub][github] account,
35 | or are willing to [create one][github-join],
36 | but do not know how to use Git,
37 | you can report problems or suggest improvements by [creating an issue][issues].
38 | This allows us to assign the item to someone
39 | and to respond to it in a threaded discussion.
40 |
41 | 3. If you are comfortable with Git,
42 | and would like to add or change material,
43 | you can submit a pull request (PR).
44 | Instructions for doing this are [included below](#using-github).
45 |
46 | ## Where to Contribute
47 |
48 | 1. If you wish to change this lesson,
49 | please work in .
51 |
52 | 2. If you wish to change the example lesson,
53 | please work in ,
54 | which documents the format of our lessons
55 | and can be viewed at .
56 |
57 | 3. If you wish to change the template used for workshop websites,
58 | please work in .
59 | The home page of that repository explains how to set up workshop websites,
60 | while the extra pages in
61 | provide more background on our design choices.
62 |
63 | 4. If you wish to change CSS style files, tools,
64 | or HTML boilerplate for lessons or workshops stored in `_includes` or `_layouts`,
65 | please work in .
66 |
67 | ## What to Contribute
68 |
69 | There are many ways to contribute,
70 | from writing new exercises and improving existing ones
71 | to updating or filling in the documentation
72 | and submitting [bug reports][issues]
73 | about things that don't work, aren't clear, or are missing.
74 | If you are looking for ideas, please see the 'Issues' tab for
75 | a list of issues associated with this repository,
76 | or you may also look at the issues for [Data Carpentry][dc-issues]
77 | and [Software Carpentry][swc-issues] projects.
78 |
79 | Comments on issues and reviews of pull requests are just as welcome:
80 | we are smarter together than we are on our own.
81 | Reviews from novices and newcomers are particularly valuable:
82 | it's easy for people who have been using these lessons for a while
83 | to forget how impenetrable some of this material can be,
84 | so fresh eyes are always welcome.
85 |
86 | ## What *Not* to Contribute
87 |
88 | Our lessons already contain more material than we can cover in a typical workshop,
89 | so we are usually *not* looking for more concepts or tools to add to them.
90 | As a rule,
91 | if you want to introduce a new idea,
92 | you must (a) estimate how long it will take to teach
93 | and (b) explain what you would take out to make room for it.
94 | The first encourages contributors to be honest about requirements;
95 | the second, to think hard about priorities.
96 |
97 | We are also not looking for exercises or other material that only run on one platform.
98 | Our workshops typically contain a mixture of Windows, Mac OS X, and Linux users;
99 | in order to be usable,
100 | our lessons must run equally well on all three.
101 |
102 | ## Using GitHub
103 |
104 | If you choose to contribute via GitHub, you may want to look at
105 | [How to Contribute to an Open Source Project on GitHub][how-contribute].
106 | To manage changes, we follow [GitHub flow][github-flow].
107 | Each lesson has two maintainers who review issues and pull requests or encourage others to do so.
108 | The maintainers are community volunteers and have final say over what gets merged into the lesson.
109 | To use the web interface for contributing to a lesson:
110 |
111 | 1. Fork the originating repository to your GitHub profile.
112 | 2. Within your version of the forked repository, move to the `gh-pages` branch and
113 | create a new branch for each significant change being made.
114 | 3. Navigate to the file(s) you wish to change within the new branches and make revisions as required.
115 | 4. Commit all changed files within the appropriate branches.
116 | 5. Create individual pull requests from each of your changed branches
117 | to the `gh-pages` branch within the originating repository.
118 | 6. If you receive feedback, make changes using your issue-specific branches of the forked
119 | repository and the pull requests will update automatically.
120 | 7. Repeat as needed until all feedback has been addressed.
121 |
122 | When starting work, please make sure your clone of the originating `gh-pages` branch is up-to-date
123 | before creating your own revision-specific branch(es) from there.
124 | Additionally, please only work from your newly-created branch(es) and *not*
125 | your clone of the originating `gh-pages` branch.
126 | Lastly, published copies of all the lessons are available in the `gh-pages` branch of the originating
127 | repository for reference while revising.
128 |
129 | ## Other Resources
130 |
131 | General discussion of [Software Carpentry][swc-site] and [Data Carpentry][dc-site]
132 | happens on the [discussion mailing list][discuss-list],
133 | which everyone is welcome to join.
134 | You can also [reach us by email][email].
135 |
136 | [email]: mailto:admin@software-carpentry.org
137 | [dc-issues]: https://github.com/issues?q=user%3Adatacarpentry
138 | [dc-lessons]: http://datacarpentry.org/lessons/
139 | [dc-site]: http://datacarpentry.org/
140 | [discuss-list]: http://lists.software-carpentry.org/listinfo/discuss
141 | [github]: https://github.com
142 | [github-flow]: https://guides.github.com/introduction/flow/
143 | [github-join]: https://github.com/join
144 | [how-contribute]: https://egghead.io/series/how-to-contribute-to-an-open-source-project-on-github
145 | [issues]: https://guides.github.com/features/issues/
146 | [swc-issues]: https://github.com/issues?q=user%3Aswcarpentry
147 | [swc-lessons]: https://software-carpentry.org/lessons/
148 | [swc-site]: https://software-carpentry.org/
149 |
--------------------------------------------------------------------------------
/Gemfile:
--------------------------------------------------------------------------------
1 | source 'https://rubygems.org'
2 | gem 'github-pages', group: :jekyll_plugins
3 |
--------------------------------------------------------------------------------
/LICENSE.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: page
3 | title: "Licenses"
4 | root: .
5 | ---
6 | ## Instructional Material
7 |
8 | All Software Carpentry and Data Carpentry instructional material is
9 | made available under the [Creative Commons Attribution
10 | license][cc-by-human]. The following is a human-readable summary of
11 | (and not a substitute for) the [full legal text of the CC BY 4.0
12 | license][cc-by-legal].
13 |
14 | You are free:
15 |
16 | * to **Share**---copy and redistribute the material in any medium or format
17 | * to **Adapt**---remix, transform, and build upon the material
18 |
19 | for any purpose, even commercially.
20 |
21 | The licensor cannot revoke these freedoms as long as you follow the
22 | license terms.
23 |
24 | Under the following terms:
25 |
26 | * **Attribution**---You must give appropriate credit (mentioning that
27 | your work is derived from work that is Copyright © Software
28 | Carpentry and, where practical, linking to
29 | http://software-carpentry.org/), provide a [link to the
30 | license][cc-by-human], and indicate if changes were made. You may do
31 | so in any reasonable manner, but not in any way that suggests the
32 | licensor endorses you or your use.
33 |
34 | **No additional restrictions**---You may not apply legal terms or
35 | technological measures that legally restrict others from doing
36 | anything the license permits. With the understanding that:
37 |
38 | Notices:
39 |
40 | * You do not have to comply with the license for elements of the
41 | material in the public domain or where your use is permitted by an
42 | applicable exception or limitation.
43 | * No warranties are given. The license may not give you all of the
44 | permissions necessary for your intended use. For example, other
45 | rights such as publicity, privacy, or moral rights may limit how you
46 | use the material.
47 |
48 | ## Software
49 |
50 | Except where otherwise noted, the example programs and other software
51 | provided by Software Carpentry and Data Carpentry are made available under the
52 | [OSI][osi]-approved
53 | [MIT license][mit-license].
54 |
55 | Permission is hereby granted, free of charge, to any person obtaining
56 | a copy of this software and associated documentation files (the
57 | "Software"), to deal in the Software without restriction, including
58 | without limitation the rights to use, copy, modify, merge, publish,
59 | distribute, sublicense, and/or sell copies of the Software, and to
60 | permit persons to whom the Software is furnished to do so, subject to
61 | the following conditions:
62 |
63 | The above copyright notice and this permission notice shall be
64 | included in all copies or substantial portions of the Software.
65 |
66 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
67 | EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
68 | MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
69 | NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
70 | LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
71 | OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
72 | WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
73 |
74 | ## Trademark
75 |
76 | "Software Carpentry" and "Data Carpentry" and their respective logos
77 | are registered trademarks of [Community Initiatives][CI].
78 |
79 | [cc-by-human]: https://creativecommons.org/licenses/by/4.0/
80 | [cc-by-legal]: https://creativecommons.org/licenses/by/4.0/legalcode
81 | [mit-license]: https://opensource.org/licenses/mit-license.html
82 | [ci]: http://communityin.org/
83 | [osi]: https://opensource.org
84 |
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | ## ========================================
2 | ## Commands for both workshop and lesson websites.
3 |
4 | # Settings
5 | MAKEFILES=Makefile $(wildcard *.mk)
6 | JEKYLL=bundle config --local set path .vendor/bundle && bundle install && bundle update && bundle exec jekyll
7 | PARSER=bin/markdown_ast.rb
8 | DST=_site
9 |
10 | # Check Python 3 is installed and determine if it's called via python3 or python
11 | # (https://stackoverflow.com/a/4933395)
12 | PYTHON3_EXE := $(shell which python3 2>/dev/null)
13 | ifneq (, $(PYTHON3_EXE))
14 | ifeq (,$(findstring Microsoft/WindowsApps/python3,$(subst \,/,$(PYTHON3_EXE))))
15 | PYTHON := python3
16 | endif
17 | endif
18 |
19 | ifeq (,$(PYTHON))
20 | PYTHON_EXE := $(shell which python 2>/dev/null)
21 | ifneq (, $(PYTHON_EXE))
22 | PYTHON_VERSION_FULL := $(wordlist 2,4,$(subst ., ,$(shell python --version 2>&1)))
23 | PYTHON_VERSION_MAJOR := $(word 1,${PYTHON_VERSION_FULL})
24 | ifneq (3, ${PYTHON_VERSION_MAJOR})
25 | $(error "Your system does not appear to have Python 3 installed.")
26 | endif
27 | PYTHON := python
28 | else
29 | $(error "Your system does not appear to have any Python installed.")
30 | endif
31 | endif
32 |
33 |
34 | # Controls
35 | .PHONY : commands clean files
36 |
37 | # Default target
38 | .DEFAULT_GOAL := commands
39 |
40 | ## I. Commands for both workshop and lesson websites
41 | ## =================================================
42 |
43 | ## * serve : render website and run a local server
44 | serve : lesson-md
45 | ${JEKYLL} serve
46 |
47 | ## * site : build website but do not run a server
48 | site : lesson-md
49 | ${JEKYLL} build
50 |
51 | ## * docker-serve : use Docker to serve the site
52 | docker-serve :
53 | docker pull carpentries/lesson-docker:latest
54 | docker run --rm -it \
55 | -v $${PWD}:/home/rstudio \
56 | -p 4000:4000 \
57 | -p 8787:8787 \
58 | -e USERID=$$(id -u) \
59 | -e GROUPID=$$(id -g) \
60 | carpentries/lesson-docker:latest
61 |
62 | ## * repo-check : check repository settings
63 | repo-check :
64 | @${PYTHON} bin/repo_check.py -s .
65 |
66 | ## * clean : clean up junk files
67 | clean :
68 | @rm -rf ${DST}
69 | @rm -rf .sass-cache
70 | @rm -rf bin/__pycache__
71 | @find . -name .DS_Store -exec rm {} \;
72 | @find . -name '*~' -exec rm {} \;
73 | @find . -name '*.pyc' -exec rm {} \;
74 |
75 | ## * clean-rmd : clean intermediate R files (that need to be committed to the repo)
76 | clean-rmd :
77 | @rm -rf ${RMD_DST}
78 | @rm -rf fig/rmd-*
79 |
80 |
81 | ##
82 | ## II. Commands specific to workshop websites
83 | ## =================================================
84 |
85 | .PHONY : workshop-check
86 |
87 | ## * workshop-check : check workshop homepage
88 | workshop-check :
89 | @${PYTHON} bin/workshop_check.py .
90 |
91 |
92 | ##
93 | ## III. Commands specific to lesson websites
94 | ## =================================================
95 |
96 | .PHONY : lesson-check lesson-md lesson-files lesson-fixme install-rmd-deps
97 |
98 | # RMarkdown files
99 | RMD_SRC = $(wildcard _episodes_rmd/??-*.Rmd)
100 | RMD_DST = $(patsubst _episodes_rmd/%.Rmd,_episodes/%.md,$(RMD_SRC))
101 |
102 | # Lesson source files in the order they appear in the navigation menu.
103 | MARKDOWN_SRC = \
104 | index.md \
105 | CODE_OF_CONDUCT.md \
106 | setup.md \
107 | $(sort $(wildcard _episodes/*.md)) \
108 | reference.md \
109 | $(sort $(wildcard _extras/*.md)) \
110 | LICENSE.md
111 |
112 | # Generated lesson files in the order they appear in the navigation menu.
113 | HTML_DST = \
114 | ${DST}/index.html \
115 | ${DST}/conduct/index.html \
116 | ${DST}/setup/index.html \
117 | $(patsubst _episodes/%.md,${DST}/%/index.html,$(sort $(wildcard _episodes/*.md))) \
118 | ${DST}/reference/index.html \
119 | $(patsubst _extras/%.md,${DST}/%/index.html,$(sort $(wildcard _extras/*.md))) \
120 | ${DST}/license/index.html
121 |
122 | ## * install-rmd-deps : Install R packages dependencies to build the RMarkdown lesson
123 | install-rmd-deps:
124 | @${SHELL} bin/install_r_deps.sh
125 |
126 | ## * lesson-md : convert Rmarkdown files to markdown
127 | lesson-md : ${RMD_DST}
128 |
129 | _episodes/%.md: _episodes_rmd/%.Rmd install-rmd-deps
130 | @mkdir -p _episodes
131 | @bin/knit_lessons.sh $< $@
132 |
133 | ## * lesson-check : validate lesson Markdown
134 | lesson-check : lesson-fixme
135 | @${PYTHON} bin/lesson_check.py -s . -p ${PARSER} -r _includes/links.md
136 |
137 | ## * lesson-check-all : validate lesson Markdown, checking line lengths and trailing whitespace
138 | lesson-check-all :
139 | @${PYTHON} bin/lesson_check.py -s . -p ${PARSER} -r _includes/links.md -l -w --permissive
140 |
141 | ## * unittest : run unit tests on checking tools
142 | unittest :
143 | @${PYTHON} bin/test_lesson_check.py
144 |
145 | ## * lesson-files : show expected names of generated files for debugging
146 | lesson-files :
147 | @echo 'RMD_SRC:' ${RMD_SRC}
148 | @echo 'RMD_DST:' ${RMD_DST}
149 | @echo 'MARKDOWN_SRC:' ${MARKDOWN_SRC}
150 | @echo 'HTML_DST:' ${HTML_DST}
151 |
152 | ## * lesson-fixme : show FIXME markers embedded in source files
153 | lesson-fixme :
154 | @grep --fixed-strings --word-regexp --line-number --no-messages FIXME ${MARKDOWN_SRC} || true
155 |
156 | ##
157 | ## IV. Auxililary (plumbing) commands
158 | ## =================================================
159 |
160 | ## * commands : show all commands.
161 | commands :
162 | @sed -n -e '/^##/s|^##[[:space:]]*||p' $(MAKEFILE_LIST)
163 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Maintainers for Library Carpentry: FAIR Data & Software
2 |
3 | - [Chris Erdmann](https://github.com/libcce) (Lead)
4 | - [Liz Stokes](https://github.com/ragamouf)
5 | - [Kristina Hettne](https://github.com/kmhettne)
6 | - [Carmi Cronje](https://github.com/ccronje)
7 | - [Sara El-Gebali](https://github.com/selgebali)
8 |
9 | Lesson Maintainers communication is via the [team site](https://github.com/orgs/LibraryCarpentry/teams/lc-fair-maintainers).
10 |
11 | ## Library Carpentry
12 |
13 | [Library Carpentry](https://librarycarpentry.org) is a software and data skills training programme for people working in library- and information-related roles. It builds on the work of [Software Carpentry](http://software-carpentry.org/) and [Data Carpentry](http://www.datacarpentry.org/). Library Carpentry is an official Lesson Program of [The Carpentries](https://carpentries.org/).
14 |
15 | ## License
16 |
17 | All Software, Data, and Library Carpentry instructional material is made available under the [Creative Commons Attribution
18 | license](https://github.com/LibraryCarpentry/lc-fair-research/blob/gh-pages/LICENSE.md).
19 |
20 | ## Contributing
21 |
22 | There are many ways to discuss and contribute to Library Carpentry lessons. Visit the lesson [discussion page](https://librarycarpentry.org/lc-fair-research/discuss/index.html) to learn more. Also see [Contributing](https://github.com/LibraryCarpentry/lc-fair-research/blob/gh-pages/CONTRIBUTING.md).
23 |
24 | ## Code of Conduct
25 |
26 | All participants should agree to abide by The Carpentries [Code of Conduct](https://docs.carpentries.org/topic_folders/policies/code-of-conduct.html).
27 |
28 | ## Authors
29 |
30 | Library Carpentry is authored and maintained through issues, commits, and pull requests from the community.
31 |
32 | ## Citation
33 |
34 | Cite as:
35 |
36 | Library Carpentry. September 2019. https://librarycarpentry.org/lc-fair-research.
37 |
38 | ## Checking and Previewing the Lesson
39 |
40 | To check and preview a lesson locally, see [http://carpentries.github.io/lesson-example/07-checking/index.html](http://carpentries.github.io/lesson-example/07-checking/index.html).
41 |
42 |
--------------------------------------------------------------------------------
/_config.yml:
--------------------------------------------------------------------------------
1 | #------------------------------------------------------------
2 | # Values for this lesson.
3 | #------------------------------------------------------------
4 |
5 | # Which carpentry is this ("swc", "dc", "lc", or "cp")?
6 | # swc: Software Carpentry
7 | # dc: Data Carpentry
8 | # lc: Library Carpentry
9 | # cp: Carpentries (to use for instructor traning for instance)
10 | carpentry: "lc"
11 |
12 | # Overall title for pages.
13 | title: "Library Carpentry: FAIR Data and Software"
14 |
15 | # Life cycle stage of the lesson
16 | # possible values: "pre-alpha", "alpha", "beta", "stable"
17 | life_cycle: "pre-alpha"
18 |
19 | #------------------------------------------------------------
20 | # Generic settings (should not need to change).
21 | #------------------------------------------------------------
22 |
23 | # What kind of thing is this ("workshop" or "lesson")?
24 | kind: "lesson"
25 |
26 | # Magic to make URLs resolve both locally and on GitHub.
27 | # See https://help.github.com/articles/repository-metadata-on-github-pages/.
28 | # Please don't change it: / is correct.
29 | repository: /
30 |
31 | # Email address, no mailto:
32 | email: "team@carpentries.org"
33 |
34 | # Sites.
35 | amy_site: "https://amy.software-carpentry.org/workshops"
36 | carpentries_github: "https://github.com/carpentries"
37 | carpentries_pages: "https://carpentries.github.io"
38 | carpentries_site: "https://carpentries.org/"
39 | dc_site: "http://datacarpentry.org"
40 | example_repo: "https://github.com/carpentries/lesson-example"
41 | example_site: "https://carpentries.github.io/lesson-example"
42 | lc_site: "https://librarycarpentry.github.io/"
43 | swc_github: "https://github.com/swcarpentry"
44 | swc_pages: "https://swcarpentry.github.io"
45 | swc_site: "https://software-carpentry.org"
46 | template_repo: "https://github.com/carpentries/styles"
47 | training_site: "https://carpentries.github.io/instructor-training"
48 | workshop_repo: "https://github.com/carpentries/workshop-template"
49 | workshop_site: "https://carpentries.github.io/workshop-template"
50 |
51 | # Surveys.
52 | pre_survey: "https://www.surveymonkey.com/r/swc_pre_workshop_v1?workshop_id="
53 | post_survey: "https://www.surveymonkey.com/r/swc_post_workshop_v1?workshop_id="
54 | training_post_survey: "https://www.surveymonkey.com/r/post-instructor-training"
55 |
56 | # Start time in minutes (0 to be clock-independent, 540 to show a start at 09:00 am).
57 | start_time: 0
58 |
59 | # Specify that things in the episodes collection should be output.
60 | collections:
61 | episodes:
62 | output: true
63 | permalink: /:path/index.html
64 | extras:
65 | output: true
66 | permalink: /:path/index.html
67 |
68 | # Set the default layout for things in the episodes collection.
69 | defaults:
70 | - values:
71 | root: .
72 | layout: page
73 | - scope:
74 | path: ""
75 | type: episodes
76 | values:
77 | root: ..
78 | layout: episode
79 | - scope:
80 | path: ""
81 | type: extras
82 | values:
83 | root: ..
84 | layout: page
85 |
86 | # Files and directories that are not to be copied.
87 | exclude:
88 | - Makefile
89 | - bin/
90 | - .Rproj.user/
91 |
92 | # Turn on built-in syntax highlighting.
93 | highlighter: rouge
94 |
95 | remote_theme: carpentries/carpentries-theme
96 |
97 |
--------------------------------------------------------------------------------
/_episodes/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/_episodes/.gitkeep
--------------------------------------------------------------------------------
/_episodes/01-introduction.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Introduction"
3 | teaching: 0
4 | exercises: 0
5 | questions:
6 | - 'What does the acronym "FAIR" stand for, and what does it mean?'
7 | - "How can library services contribute to FAIR research?"
8 | objectives:
9 | - "Articulate the purpose and value of making research FAIR"
10 | - "Understand that library services impact various parts of the research lifecycle"
11 | keypoints:
12 | - The FAIR principles set out how to make data more usable, by humans and machines,
13 | by making it Findable, Accessible, Interoperable and Reusable.
14 | - Librarians have key expertise in information management that can help researchers
15 | navigate the process of making their research more FAIR
16 | ---
17 |
18 | ## Goals of this lesson:
19 |
20 | - To teach FAIRer research data and software management and development practices
21 | - Focus on practical approaches to being FAIRer admitting that there are no “silver bullets”
22 |
23 | ## Library services across the research lifecycle
24 |
25 | Libraries actively help researchers navigate the requirements, demands, and tools that make up the research data management landscape, particularly when it comes to the organization, preservation, and sharing of research data and software.
26 |
27 | They play a vital role in directly supporting the academic enterprise by promoting data sharing and reproducibility. Through their research training and services, particularly for early career researchers and graduate students, libraries are driving a cultural shift towards more effective data and software stewardship.
28 |
29 | As a trusted partner, and with an embedded understanding of their communities, libraries foster collaboration and facilitate coordination between community stakeholders and are a critical part of the discussion.
30 |
31 | 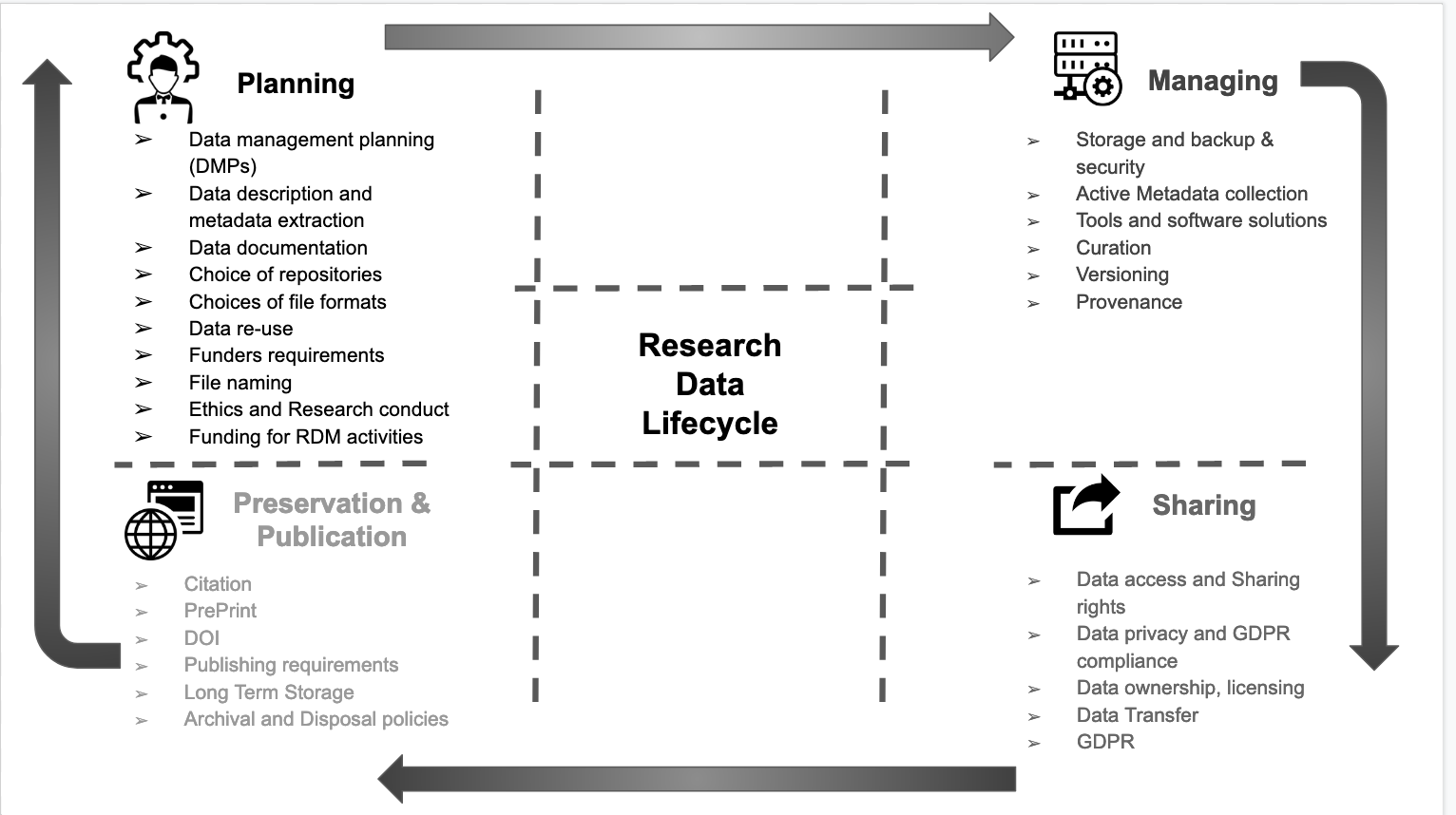
32 |
33 | El-Gebali, Sara. (2020, September 29). Research Data Life Cycle. Zenodo. [http://doi.org/10.5281/zenodo.4057867](http://doi.org/10.5281/zenodo.4057867)
34 |
35 | ## FAIR in one sentence
36 |
37 | The FAIR data principles are all about how machines and humans communicate with each other. They are not a standard, but a set of principles for developing robust, extensible infrastructure which facilitates discovery, access and reuse of research data and software.
38 |
39 | ## Where did FAIR come from?
40 |
41 | The FAIR data principles emerged from a FORCE11 workshop in 2014. This was formalised in 2016 when these were published in Scientific Data: [FAIR Guiding Principles for scientific data management and stewardship](https://doi.org/10.1038/sdata.2016.18). In this article, the authors provide general guidance on machine-actionability and improvements that can be made to streamline the findability, accessibility, interoperatbility, and reuability (FAIR) of digital assets.
42 |
43 | "as open as possible, as closed as necessary"
44 |
45 | ## FAIR brings all the stakeholders together
46 |
47 | We all win when the outputs of research are properly managed, preserved and reusable. This is applicable from big data of genomic expression all the way through to the ‘small data’ of qualitative research.
48 |
49 | Research is increasingly dependent on computational support and yet there are still many bottlenecks in the process. The overall aim of FAIR is to cut down on the inefficient processes in research by taking advantage of linked resources and the exchange of data so that all stakeholders in the research ecosystem, can automate repetitive, boring, error-prone tasks.
50 |
51 | ## Examples of Library Services implementing the FAIR principles
52 |
53 | * If your local data repository shares metadata with other aggregators, it's F for Findable.
54 | * If you advocate for researchers to use ORCIDs and seek DOIs for research data outputs, it's F for Findable
55 | * If your institution mints DOIs for research datasets... that's A for Accessible.
56 | * If your institutional data repository enables metadata for harvest by an aggregator, that's I for Interoperable.
57 | * If you provide advice and consultation services for choosing licences for research data, that's R for Reusable
58 |
59 | ## Further reading following this lesson
60 |
61 | TIB Hannover has provided the following FAIR guide with examples:
62 | [TIB Hannover FAIR Principles Guide](https://blogs.tib.eu/wp/tib/2017/09/12/the-fair-data-principles-for-research-data)
63 |
64 | The European Commission gives tips on implementing FAIR: [Six Recommendations for Implementation of FAIR Practice](https://doi.org/10.2777/986252)
65 |
66 | ## How does “FAIR” translate to your institution or workplace?
67 |
68 | Group exercise
69 | Use an etherpad / whiteboard
70 |
71 | * Does your institutional data management policy refer to FAIR principles?
72 |
73 | * If you have a data management planning tool (eg DMP online) go through the mandatory fields and identify where there are FAIR teaching moments.
74 |
75 | * Compile a list of research management tools that your institution provides access to and brainstorm examples where these tools embody the FAIR data principles.
76 |
77 | * Use the [FAIR data self assessment tool](https://www.ands.org.au/working-with-data/fairdata/fair-data-self-assessment-tool) to help frame your answers.
78 |
--------------------------------------------------------------------------------
/_episodes/02-findable.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Findable"
3 | teaching: 0
4 | exercises: 0
5 | questions:
6 | - "What is a persistent identifier or PID?"
7 | - "What types of PIDs are there?"
8 | objectives:
9 | - "Explain what globally unique, persistent, resolvable identifiers are and how they make data and metadata findable"
10 | - "Articulate what metadata is and how metadata makes data findable"
11 | - "Articulate how metadata can be explicitly linked to data and vice versa"
12 | - "Understand how and where to find data discovery platforms"
13 | - "Articulate the role of data repositories in enabling findable data"
14 | keypoints:
15 | - "First key point."
16 | ---
17 |
18 | > ## For data & software to be findable:
19 | > F1. (meta)data are assigned a globally unique and eternally persistent identifier or PID
20 | > F2. data are described with rich metadata
21 | > F3. (meta)data are registered or indexed in a searchable resource
22 | > F4. metadata specify the data identifier
23 | {: .checklist}
24 |
25 | ## Persistent identifiers (PIDs) 101
26 |
27 | A persistent identifier (PID) is a long-lasting reference to a (digital or physical) resource:
28 |
29 | - Designed to provide access to information about a resource even if the resource it describes has moved location on the web
30 | - Requires technical, governance and community to provide the persistence
31 | - There are many different PIDs available for many different types of scholarly resources e.g. articles, data, samples, authors, grants, projects, conference papers and so much more
32 |
33 | ## Different types of PIDs
34 |
35 | PIDs have community support, organizational commitment and technical infrastructure to ensure persistence of identifiers. They often are created to respond to a community need. For instance, the International Standard Book Number or ISBN was created to assign unique numbers to books, is used by book publishers, and is managed by the International ISBN Agency. Another type of PID, the Open Researcher and Contributor ID or ORCID (iD) was created to help with author disambiguation by providing unique identifiers for authors. The [ODIN Project identifies additional PIDs](https://project-thor.readme.io/docs/project-glossary) along with [Wikipedia's page on PIDs](https://en.wikipedia.org/wiki/Persistent_identifier).
36 |
37 | ## Digital Object Identifiers (DOIs)
38 |
39 | The DOI is a common identifier used for academic, professional, and governmental information such as articles, datasets, reports, and other supplemental information. The [International DOI Foundation (IDF)](https://www.doi.org/) is the agency that oversees DOIs. [CrossRef](https://www.crossref.org/) and [Datacite](https://datacite.org/) are two prominent not-for-profit registries that provide services to create or mint DOIs. Both have membership models where their clients are able to mint DOIs distinguished by their prefix. For example, DataCite features a [statistics page](https://stats.datacite.org/) where you can see registrations by members.
40 |
41 | ## Anatomy of a DOI
42 |
43 | A DOI has three main parts:
44 |
45 | - Proxy or DOI resolver service
46 | - Prefix which is unique to the registrant or member
47 | - Suffix, a unique identifier assigned locally by the registrant to an object
48 |
49 | 
50 |
51 | In the example above, the prefix is used by the Australian National Data Service (ANDS) now called the Australia Research Data Commons (ARDC) and the suffix is a unique identifier for an object at Griffith University. DataCite provides DOI [display guidance](https://support.datacite.org/docs/datacite-doi-display-guidelines
52 | ) so that they are easy to recognize and use, for both humans and machines.
53 |
54 | > ## Challenge
55 | > arXiv is a preprint repository for physics, math, computer science and related disciplines.
56 | > It allows researchers to share and access their work before it is formally published.
57 | > Visit the arXiv new papers page for [Machine Learning](https://arxiv.org/list/cs.LG/recent).
58 | > Choose any paper by clicking on the 'pdf' link next to it. Now use control + F or command + F and search for 'http'. Did the author use DOIs for their data and software?
59 | >
60 | > > ## Solution
61 | > > Authors will often link to platforms such as GitHub where they have shared their software and/or they will link to their website where they are hosting the data used in the paper. The danger here is that platforms like GitHub and personal websites are not permanent. Instead, authors can use repositories to deposit and preserve their data and software while minting a DOI. Links to software sharing platforms or personal websites might move but DOIs will always resolve to information about the software and/or data. See DataCite's [Best Practices for a Tombstone Page](https://support.datacite.org/docs/tombstone-pages).
62 | > {: .solution}
63 | {: .challenge}
64 |
65 | ## Rich Metadata
66 |
67 | More and more services are using common schemas such as [DataCite's Metadata Schema](https://schema.datacite.org) or [Dublin Core](https://www.dublincore.org) to foster greater use and discovery. A schema provides an overall structure for the metadata and describes core metadata properties. While DataCite's Metadata Schema is more general, there are discipline specific schemas such as [Data Documentation Initiative (DDI) and Darwin Core](https://en.wikipedia.org/wiki/Metadata_standard).
68 |
69 | Thanks to schemas, the process of adding metadata has been standardised to some extent but there is still room for error. For instance, DataCite [reports](https://blog.datacite.org/citation-analysis-scholix-rda/) that links between papers and data are still very low. Publishers and authors are missing this opportunity.
70 |
71 | Challenges:
72 | Automatic ORCID profile update when DOI is minted
73 | RelatedIdentifiers linking papers, data, software in Zenodo
74 |
75 | ## Connecting research outputs
76 | DOIs are everywhere. Examples.
77 |
78 | Resource IDs (articles, data, software, …)
79 | Researcher IDs
80 | Organisation IDs, Funder IDs
81 | Projects IDs
82 | Instrument IDs
83 | Ship cruises IDs
84 | Physical sample IDs,
85 | DMP IDs…
86 | videos
87 | images
88 | 3D models
89 | grey literature
90 |
91 | 
92 |
93 | https://support.datacite.org/docs/connecting-research-outputs
94 |
95 | Bullet points about the current state of linking...
96 | https://blog.datacite.org/citation-analysis-scholix-rda/
97 |
98 |
99 | ## Provenance?
100 | Provenance means validation & credibility – a researcher should comply to good scientific practices and be sure about what should get a PID (and what not).
101 | Metadata is central to visibility and citability – metadata behind a PID should be provided with consideration.
102 | Policies behind a PID system ensure persistence in the WWW - point. At least metadata will be available for a long time.
103 | Machine readability will be an essential part of future discoverability – resources should be checked and formats should be adjusted (as far possible).
104 | Metrics (e.g. altmetrics) are supported by PID systems.
105 |
106 |
107 | ## Publishing behaviour of researchers
108 |
109 | According to:
110 |
111 | Technische Informationsbibliothek (TIB) (conducted by engage AG) (2017): Questionnaire and Dataset of the TIB Survey 2017 on information procurment and pubishing behaviour of researchers in the natural sciences and engineering. Technische Informationsbibliothek (TIB). DOI: [https://doi.org/10.22000/54](https://doi.org/10.22000/54)
112 |
113 | - responses from 1400 scientists in the natural sciences & engineering (across Germany)
114 | - 70% of the researchers are using DOIs for journal publications
115 | - less than 10% use DOIs for research data
116 | -- 56% answered that they don’t know about the option to use DOIs for other publications (datasets, conference papers etc.)
117 | -- 57% stated no need for DOI counselling services
118 | -- 40% of the questioned researchers need more information
119 | -- 30% cannot see a benefit from a DOI
120 |
121 | ## Choosing the right repository
122 |
123 | Ask your colleagues & collaborators
124 | Look for institutional repository at your own institution
125 |
126 | determining the right repo for your reseearch
127 | data are kept safe in a secure environment
128 | data are regularly backed up and preserved (long-term) for future use
129 | data can be easily discovered by search engines and included in online catalogues
130 | intellectual property rights and licencing of data are managed
131 | access to data can be administered and usage monitored
132 | the visibility of data can be enhanced
133 | enables more use and citation
134 | citation of data increases researchers scientific reputation
135 | Decision for or against a specific repository depends on various criteria, e.g.
136 | Data quality
137 | Discipline
138 | Institutional requirements
139 | Reputation (researcher and/or repository)
140 | Visibility of research
141 | Legal terms and conditions
142 | Data value (FAIR Principles)
143 | Exit strategy (tested?)
144 | Certificate (based only on documents?)
145 |
146 | Some recommendations:
147 | → look for the usage of PIDs
148 | → look for the usage of standards (DataCite, Dublin Core, discipline-specific metadata
149 | → look for licences offered
150 | → look for certifications (DSA / Core Trust Seal, DINI/nestor, WDS, …)
151 |
152 | Searching re3data w/ exercise
153 | https://www.re3data.org/
154 | Out of more than 2115 repository systems listed in re3data.org in July 2018, only 809 (less than 39 %!) state to provide a PID service, with 524 of them using the DOI system
155 |
156 | Search open access repos
157 | http://v2.sherpa.ac.uk/opendoar/
158 |
159 | FAIRSharing
160 | https://fairsharing.org/databases/
161 |
162 | ## Data Journals
163 |
164 | Another method available to researchers to cite and give credit to research data is to author works in data journals or supplemental approaches used by publishers, societies, disciplines, and/or journals.
165 |
166 | Articles in data journals allow authors to:
167 | - Describe their research data (including information about process, qualities, etc)
168 | - Explain how the data can be reused
169 | - Improve discoverability (through citation/linking mechanisms and indexing)
170 | - Provide information on data deposit
171 | - Allow for further (peer) review and quality assurance
172 | - Offer the opportunity for further recognition and awards
173 |
174 | Examples:
175 | - [Nature Scientific data](https://www.nature.com/sdata/) - published by Nature and established in 2013
176 | - [Geoscience Data Journal](https://rmets.onlinelibrary.wiley.com/journal/20496060) - published by Wiley and established in 2012
177 | - [Journal of Open Archaeology Data](https://openarchaeologydata.metajnl.com/) - published by Ubiquity and established in 2011
178 | - [Biodiversity Data Journal](https://bdj.pensoft.net/) - published by Pensoft and established in 2013.
179 | - [Earth System Science Data](https://www.earth-system-science-data.net/) - published by Copernicus Publications and established in 2009
180 |
181 | Also, the following study discusses data journals in depth and reviews over 100 data journals:
182 | Candela, L. , Castelli, D. , Manghi, P. and Tani, A. (2015), Data Journals: A Survey. J Assn Inf Sci Tec, 66: 1747-1762. doi:[10.1002/asi.23358](https://doi.org/10.1002/asi.23358)
183 |
184 | > ## How does your discipline share data
185 | >
186 | > Does your discipline have a data journal? Or some other mechanism to share data? For example, the American Astronomical Society (AAS) via the publisher IOP Physics offers a [supplment series](http://iopscience.iop.org/journal/0067-0049/page/article-data) as a way for astronomers to publish data.
187 | {: .discussion}
188 |
189 |
190 | List recent publications re: benefits of data sharing / software sharing
191 |
192 | Questions:
193 | Is FAIRSharing vs re3data comparison slide from TIB findability slides needed here?
194 | Should we include recent thread about handle system vs DOIs in IRs (costs)
195 | Zenodo-GitHub linking is listed in another episode, right?
196 | Include guidance for Google schema indexing...
197 |
198 | Notes:
199 | Note about authors being proactive and working with the journals/societies to improve papers referencing data, software...
200 |
201 | Tombstone
202 |
--------------------------------------------------------------------------------
/_episodes/03-accessible.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Accessible"
3 | teaching: 0
4 | exercises: 0
5 | questions:
6 | - "Key question"
7 | objectives:
8 | - "Understand what a protocol is"
9 | - "Understand authentication protocols and their role in FAIR"
10 | - "Articulate the value of landing pages"
11 | - "Explain closed, open and mediated access to data"
12 | keypoints:
13 | - "First key point."
14 | ---
15 |
16 |
17 | > ## For data & software to be accessible:
18 | > A1. (meta)data are retrievable by their identifier using a standardized communications protocol
19 | > A1.1 the protocol is open, free, and universally implementable
20 | > A1.2 the protocol allows for an authentication and authorization procedure, where necessary
21 | > A2. metadata remain accessible, even when the data are no longer available
22 | {: .checklist}
23 |
24 | ## What is a protocol?
25 | Simply put, it's an access method of exchanging data over a computer network. Each protocol has its rules for how data is formatted, compressed, checked for errors. Research repositories often use the OAI-PMH or REST API protocols to interface with data in the repository. The following image from [TutorialEdge.net: What is a RESTful API by Elliot Forbes](https://tutorialedge.net/general/what-is-a-rest-api/) provides a useful overview of how RESTful interfaces work:
26 |
27 | 
28 |
29 | Zenodo offers a visual interface for seeing how formats such as DataCite XML will look like when requested for records such as the following record from the Biodiversity Literature Repository:
30 |
31 | [Formiche di Madagascar raccolte dal Sig. A. Mocquerys nei pressi della Baia di Antongil (1897-1898).](https://sandbox.zenodo.org/record/9785/export/dcite4#.W3eDVthKjGI)
32 |
33 | Wikipedia has a list of [commonly used network protocols](https://en.wikipedia.org/wiki/Lists_of_network_protocols) but check the service you are using for documentation on the protocols it uses and whether it corresponds with the FAIR Principles. For instance, see [Zenodo's Principles](http://about.zenodo.org/principles/) page.
34 |
35 | ## Contributor information
36 | Alternatively, for sensitive/protected data, if the protocol cannot guarantee secure access, an e-mail or other contact information of a person/data manager should be provided, via the metadata, with whom access to the data can be discussed. The [DataCite metadata schema](https://schema.datacite.org/) includes contributor type and name as fields where contact information is included. Collaborative projects such as [THOR](https://project-thor.readme.io/), [FREYA](https://www.project-freya.eu/en/resources), and [ODIN](https://odin-project.eu/project-outputs/deliverables/) are working towards improving the interoperability and exchange of metadata such as contributor information.
37 |
38 | ## Author disambiguation and authentication
39 | Across the research ecosystem, publishers, repositories, funders, research information systems, have recognized the need to address the problem of author disambiguation. The illustrative example below of the many variations of the name _Jens Åge Smærup Sørensen demonstrations_ the challenge of wrangling the correct name for each individual author or contributor:
40 |
41 | 
42 |
43 | Thankfully, a number of research systems are now integrating ORCID into their authentication systems. Zenodo provides the login ORCID authentication option. Once logged in, your ORCID will be assigned to your authored and deposited works.
44 |
45 | ## Exercise to create ORCID account and authenticate via Zenodo
46 | 1. [Register](https://orcid.org/register) for an ORCID.
47 | 2. You will receive a confirmation email. Click the link in the email to establish your unique 16-digit ORCID.
48 | 3. Go to [Zenodo](https://zenodo.org/) and select Log in (if you are new to Zenodo select Sign up).
49 | 4. Go to [linked accounts](https://zenodo.org/account/settings/linkedaccounts/) and click the Connect button next to ORCID.
50 |
51 | Next time you log into Zenodo you will be able to 'Log in with ORCID':
52 |
53 | 
54 |
55 | ## Understanding whether something is open, free, and universally implementable
56 | ORCID features a [principles page](https://orcid.org/about/what-is-orcid/principles) where we can assess where it lies on the spectrum of these criteria. Can you identify statements that speak to these conditions: open, free, and universally implemetable?
57 |
58 | Answers:
59 | - ORCID is a non-profit that collects fees from its members to sustain its operations
60 | - [Creative Commons CC0 1.0 Universal (CC0)](https://tldrlegal.com/license/creative-commons-cc0-1.0-universal) license releases data into the public domain, or otherwise grants permission to use it for any purpose
61 | - It is open to any organization and transcends borders
62 |
63 | Challenge Questions:
64 | - Where can you download the freely available data?
65 | - How does ORCID solicit community input outside of its governance?
66 | - Are the tools used to create, read, update, delete ORCID data open?
67 |
68 |
69 | ## Tombstones, a very grave subject
70 |
71 | There are a variety of reasons why a placeholder with metadata or tombstone of the removed research object exists including but not limited to staff removal, spam, request from owner, data center does not exist is still, etc. A tombstone page is needed when data and software is no longer accessible. A tombstone page communicates that the record is gone, why it is gone, and in case you really must know, there is a copy of the metadata for the record. A tombstone page should include: DOI, date of deaccession, reason for deaccession, message explaining the data center's policies, and a message that a copy of the metadata is kept for record keeping purposes as well as checksums of the files. Zenodo offers us further [explanation of the reasoning behind tombstone pages](https://github.com/zenodo/zenodo/issues/160).
72 |
73 | DataCite offers [statistics](https://stats.datacite.org/) where the failure to resolve DOIs after a certain number of attempts is reported (see [DataCite statistics support page](https://support.datacite.org/docs/datacite-statistics)for more information). In the case of Zenodo and the GitHub issue above, the hidden field reveals thousands of records that are a result of spam.
74 |
75 | 
76 |
77 | If a DOI is no longer available and the data center does not have the resources to create a tombstone page, DataCite provides a generic [tombstone page](https://support.datacite.org/docs/tombstone-pages).
78 |
79 | **See the following tombstone examples:**
80 | - Zenodo tombstone: [https://zenodo.org/record/1098445](https://zenodo.org/record/1098445)
81 | - Figshare tombstone: [https://figshare.com/articles/Climate_Change/1381402](https://figshare.com/articles/Climate_Change/1381402)
82 |
83 | ## Discussion of tombstones
84 |
85 |
--------------------------------------------------------------------------------
/_episodes/04-interoperable.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Interoperable"
3 | teaching: 0
4 | exercises: 0
5 | questions:
6 | - What does interoperability mean?
7 | - What is a controlled vocabulary, a metadata schema and linked data?
8 | - How do I describe data so that humans and computers can understand?
9 | objectives:
10 | - "Explain what makes data and software (more) interoperable for machines"
11 | - "Identify widely used metadata standards for research, including generic and discipline-focussed examples"
12 | - "Explain the role of controlled vocabularies for encoding data and for annotating metadata in enabling interoperability"
13 | - "Understand how linked data standards and conventions for metadata schema documentation relate to interoperability"
14 | keypoints:
15 | - "Understand that FAIR is about both humans and machines understanding data."
16 | - "Interoperability means choosing a data format or knowledge representation language that helps machines to understand the data."
17 | ---
18 |
19 | > ## For data & software to be interoperable:
20 | > I1. (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation
21 | > I2. (meta)data use vocabularies that follow FAIR principles
22 | > I3. (meta)data include qualified references to other (meta)data
23 | {: .checklist}
24 |
25 | ## What is interoperability for data and software?
26 |
27 | Shared understanding of concepts, for humans as well as machines.
28 |
29 | ### What does it mean to be machine readable vs human readable?
30 |
31 | According to the [Open Data Handbook](http://opendatahandbook.org/glossary/en/):
32 |
33 | > *Human Readable*
34 | > "Data in a format that can be conveniently read by a human. Some human-readable formats, such as PDF, are not machine-readable as they are not structured data, i.e. the representation of the data on disk does not represent the actual relationships present in the data."
35 |
36 | > *Machine Readable*
37 | > "Data in a data format that can be automatically read and processed by a computer, such as CSV, JSON, XML, etc. Machine-readable data must be structured data. Compare human-readable.
38 | > Non-digital material (for example printed or hand-written documents) is by its non-digital nature not machine-readable. But even digital material need not be machine-readable. For example, consider a PDF document containing tables of data. These are definitely digital but are not machine-readable because a computer would struggle to access the tabular information - even though they are very human readable. The equivalent tables in a format such as a spreadsheet would be machine readable.
39 | > As another example scans (photographs) of text are not machine-readable (but are human readable!) but the equivalent text in a format such as a simple ASCII text file can machine readable and processable."
40 |
41 |
42 | > Software uses community accepted standards and platforms, making it possible for users to run the software.
43 | [Top 10 FAIR things for research software][10FTRS]
44 |
45 | [10FTRS]: https://librarycarpentry.org/Top-10-FAIR//2018/12/01/research-software/
46 |
47 | ## Describing data and software with shared, controlled vocabularies
48 |
49 | See
50 | -
51 | -
52 | -
53 |
54 | ## Representing knowledge in data and software
55 |
56 | See .
57 |
58 | ### Beyond the PDF
59 | Publishers, librarians, researchers, developers, funders, they have all been working towards a future where we can move beyond the PDF, from 'static and disparate data and knowledge representations to richly integrated content which grows and changes the more we learn." Research objects of the future will capture all aspects of scholarship: hypotheses, data, methods, results, presentations etc.) that are semantically enriched, interoperable and easily transmitted and comprehended.
60 | Attribution, Evaluation, Archiving, Impact
61 | https://sites.google.com/site/beyondthepdf/
62 |
63 | Beyond the PDF has now grown into FORCE...
64 | Towards a vision where research will move from document- to knowledge-based information flows
65 | semantic descriptions of research data & their structures
66 | aggregation, development & teaching of subject-specific vocabularies, ontologies & knowledge graphs
67 | Paper of the Future
68 | https://www.authorea.com/users/23/articles/8762-the-paper-of-the-future to Jupyter Notebooks/Stencilia
69 | https://stenci.la/
70 |
71 | ### Knowledge representation languages
72 | provide machine-readable (meta)data with a well-established formalism
73 | structured, using discipline-established vocabularies / ontologies / thesauri (RDF extensible knowledge representation model, OWL, JSON LD, schema.org)
74 | offer (meta)data ingest from relevant sources (Document Information Dictionary or Extensible Metadata Platform from PDF)
75 | provide as precise & complete metadata as possible
76 | look for metrics to evaluate the FAIRness of a controlled vocabulary / ontology / thesaurus
77 | often do not (yet) exist
78 | assist in their development
79 | clearly identify relationships between datasets in the metadata (e.g. “is new version of”, “is supplement to”, “relates to”, etc.)
80 | request support regarding these tasks from the repositories in your field of study
81 | for software: follow established code style guides (thanks to @npch!)
82 |
83 | ## Adding qualified references among data and software
84 |
85 | support referencing metadata fields between datasets via a schema (relatedIdentifer, relationType)
86 |
87 | Data Science and Digital Libraries => (research) knowledge graph(s)
88 | Scientific Data Management
89 | Visual Analytics to expose information within videos as keywords => av.tib.eu
90 | Scientific Knowledge Engineering => ontologies
91 |
92 | Example:
93 | → Automatic ORCID profile update when DOI is minted
94 | DataCite – CrossRef – ORCID
95 | collaboration
96 | → PID of choice for RDM: �Here: The Digital Object Identifier (DOI)
97 |
98 | Detour: Replication / Reproducibility Crisis
99 | doi.org/10.1073/pnas.1708272114
100 | doi.org/10.1371/journal.pbio.1002165
101 | doi.org/10.12688/f1000research.11334.1
102 | Examples of science failing due to software errors/bugs:
103 | figshare.com/authors/Neil_Chue_Hong/96503
104 |
105 |
106 | “[...] around 70% of research relies on software [...] if almost a half of that software is untested, this is a huge risk to the reliability of research results.”
107 | Results from a US survey about Research Software Engineers
108 | URSSI.us/blog/2018/06/21/results-from-a-us-survey-about-research-software-engineers (Daniel S. Katz, Sandra Gesing, Olivier Philippe, and Simon Hettrick)
109 | Olivier Philippe, Martin Hammitzsch, Stephan Janosch, Anelda van der Walt, Ben van Werkhoven, Simon Hettrick, Daniel S. Katz, Katrin Leinweber, Sandra Gesing, Stephan Druskat. 2018. doi.org/10.5281/zenodo.1194669
110 |
111 | Code style guides & formatters (thanks to Neil Chu Hong)
112 | faster than manual/menial formatting
113 | code looks the same, regardless of author
114 | can be automated enforced to keep diffs focussed
115 | PyPI.org/project/pycodestyle, /black, etc.
116 | ROpenSci packaging guide
117 | style.tidyverse.org
118 | Google.GitHub.io/styleguide
119 |
120 |
121 | If others can use your code, convey the meaning of updates with SemVer.org (CC BY 3.0)
122 | “version number[ changes] convey meaning about the underlying code” (Tom Preston-Werner)
123 |
124 |
125 | Exercise
126 | Python & R Carpentries lessons
127 |
128 | ## Linked Data
129 |
130 | [Top 10 FAIR things: Linked Open Data](https://librarycarpentry.org/Top-10-FAIR//2019/09/05/linked-open-data/)
131 |
132 | Linked data example
133 | Triples - RDF - SPARQL
134 | Wikidata exercise
135 |
136 | Standards: https://fairsharing.org/standards/
137 | schema.org: http://schema.org/
138 |
139 | ISA framework: 'Investigation' (the project context), 'Study' (a unit of research) and 'Assay' (analytical measurement) - https://isa-tools.github.io/
140 |
141 | Example of schema.org: rOpenSci/codemetar
142 |
143 | Modularity
144 | http://bioschemas.org
145 |
146 | codemeta croswalks to other standards
147 | https://codemeta.github.io/crosswalk/
148 |
149 | DCAT
150 | https://www.w3.org/TR/vocab-dcat/
151 |
152 | Using community accepted code style guidelines such as PEP 8 for Python (PEP 8 itself is FAIR)
153 |
154 | Scholix - related indentifiers - Zenodo example linking data/software to papers
155 | https://dliservice.research-infrastructures.eu/#/
156 | https://authorcarpentry.github.io/dois-citation-data/01-register-doi.html
157 |
158 | Should vocabularies from reusable episode be moved here?
159 |
--------------------------------------------------------------------------------
/_episodes/05-reusable.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Reusable"
3 | teaching: 0
4 | exercises: 0
5 | questions:
6 | - "Key question"
7 | objectives:
8 | - "Explain machine readability in terms of file naming conventions and providing provenance metadata"
9 | - "Explain how data citation works in practice"
10 | - "Understand key components of a data citation"
11 | - "Explore domain-relevant community standards including metadata standards"
12 | - "Understand how proper licensing is essential for reusability"
13 | - "Know about some of the licenses commonly used for data and software"
14 | keypoints:
15 | - "First key point."
16 | ---
17 |
18 | > ## For data & software to be reusable:
19 | > R1. (meta)data have a plurality of accurate and relevant attributes
20 | > R1.1 (meta)data are released with a clear and accessible data usage licence
21 | > R1.2 (meta)data are associated with their provenance
22 | > R1.3 (meta)data meet domain-relevant community standards
23 | {: .checklist}
24 |
25 |
26 | ## What does it mean to be machine readable vs human readable?
27 |
28 | According to the [Open Data Handbook](http://opendatahandbook.org/glossary/en/):
29 |
30 | *Human Readable*
31 | "Data in a format that can be conveniently read by a human. Some human-readable formats, such as PDF, are not machine-readable as they are not structured data, i.e. the representation of the data on disk does not represent the actual relationships present in the data."
32 |
33 | *Machine Readable*
34 | "Data in a data format that can be automatically read and processed by a computer, such as CSV, JSON, XML, etc. Machine-readable data must be structured data. Compare human-readable.
35 |
36 | Non-digital material (for example printed or hand-written documents) is by its non-digital nature not machine-readable. But even digital material need not be machine-readable. For example, consider a PDF document containing tables of data. These are definitely digital but are not machine-readable because a computer would struggle to access the tabular information - even though they are very human readable. The equivalent tables in a format such as a spreadsheet would be machine readable.
37 |
38 | As another example scans (photographs) of text are not machine-readable (but are human readable!) but the equivalent text in a format such as a simple ASCII text file can machine readable and processable."
39 |
40 |
41 | ## File naming best practices
42 | A file name should be unique, consistent and descriptive. This allows for increased visibility and discoverability and can be used to easily classify and sort files. Remember, a file name is the primary identifier to the file and its contents.
43 | ### Do’s and Don’ts of file naming:
44 | #### Do’s:
45 | - Make use of file naming tools for bulk naming such as Ant Renamer, RenameIT or Rename4Mac.
46 | - Create descriptive, meaningful, easily understood names no less than 12-14 characters.
47 | - Use identifiers to make it easier to classify types of files i.e. Int1 (interview 1)
48 | - Make sure the 3-letter file format extension is present at the end of the name (e.g. .doc, .xls, .mov, .tif)
49 | - If applicable, include versioning within file names
50 | - For dates use the ISO 8601 standard: YYYY-MM-DD and place at the end of the file number UNLESS you need to organise your files chronologically.
51 | - For experimental data files, consider using the project/experiment name and conditions in abbreviations
52 | - Add a README file in your top directory which details your naming convention, directory structure and abbreviations
53 | - - When combining elements in file name, use common [special letter case](https://en.wikipedia.org/wiki/Letter_case#Special_case_styles) patterns such as Kebab-case, CamelCase, or Snake_case, preferably use hyphens (-) or underscores (_)
54 | #### Don’ts:
55 | - Avoid naming files/folders with individual persons names as it impedes handover and data sharing.
56 | - Avoid long names
57 | - Avoid using spaces, dots, commas and special characters (e.g. ~ ! @ # $ % ^ & * ( ) ` ; < > ? , [ ] { } ‘ “)
58 | - Avoid repetition for ex. Directory name Electron_Microscopy_Images, then you don’t need to name the files ELN_MI_Img_20200101.img
59 |
60 | #### Examples:
61 | - Stanford Libraries [guidance on file naming](https://guides.library.stanford.edu/data-best-practices) is a great place to start.
62 | - [Dryad example](http://datadryad.com/pages/reusabilityBestPractices):
63 | - 1900-2000_sasquatch_migration_coordinates.csv
64 | - Smith-fMRI-neural-response-to-cupcakes-vs-vegetables.nii.gz
65 | - 2015-SimulationOfTropicalFrogEvolution.R
66 |
67 | ## Directory structures and README files
68 | A clear directory structure will make it easier to locate files and versions and this is particularly important when collaborating with others. Consider a hierarchical file structure starting from broad topics to more specific ones nested inside, restricting the level of folders to 3 or 4 with a limited number of items inside each of them.
69 |
70 | The UK data services offers an example of directory structure and naming: https://ukdataservice.ac.uk/manage-data/format/organising.aspx
71 |
72 | For others to reuse your research, it is important to include a README file and to organize your files in a logical way. Consider the following file structure examples from Dryad:
73 |
74 | 
75 |
76 | It is also good practice to include README files to describe how the data was collected, processed, and analyzed. In other words, README files help others correctly interpret and reanalyze your data. A README file can include file names/directory structure, glossary/definitions of acronyms/terms, description of the parameters/variables and units of measurement, report precision/accuracy/uncertainty in measurements, standards/calibrations used, environment/experimental conditions, quality assurance/quality control applied, known problems, research date information, description of relationships/dependencies, additional resources/references, methods/software/data used, example records, and other supplemental information.
77 |
78 | - Dryad README file example:
79 | https://doi.org/10.5061/dryad.j512f21p
80 |
81 | - Awesome README list (for software):
82 | https://github.com/matiassingers/awesome-readme
83 |
84 | - Different Format Types
85 | https://data.library.virginia.edu/data-management/plan/format-types/
86 |
87 |
88 | ## Disciplinary Data Formats
89 |
90 | Many disciplines have developed formal metadata standards that enable re-use of data; however, these standards are not universal and often it requires background knowledge to indentify, contextualize, and interpret the underlying data. Interoperability between disciplines is still a challenge based on the continued use of custom metadata schmes, and the development of new, incompatiable standards. Thankfully, DataCite is providing a common, overarching metadata standard across disciplinary datasets, albeit at a generic vs granular level.
91 |
92 | In the meantime, the Research Data Alliance (RDA) Metadata Standards Directory - Working Group developed a collaborative, open directory of metadata standards, applicable to scientific data, to help the research community learn about metadata standards, controlled vocabularies, and the underlying elements across the different disciplines, to potentially help with mapping data elements from different sources.
93 |
94 | Exercise/Quiz?
95 |
96 | [Metadata Standards Directory](http://rd-alliance.github.io/metadata-directory/standards/)
97 | Features: Standards, Extensions, Tools, and Use Cases
98 |
99 | ## Quality Control
100 | Quality control is a fundamental step in research, which ensures the integrity of the data and could affect its use and reuse and is required in order to identify potential problems.
101 |
102 | It is therefore essential to outline how data collection will be controlled at various stages (data collection,digitisation or data entry, checking and analysis).
103 |
104 | ## Versioning
105 | In order to keep track of changes made to a file/dataset, versioning can be an efficient way to see who did what and when, in collaborative work this can be very useful.
106 |
107 | A version control strategy will allow you to easily detect the most current/final version, organize, manage and record any edits made while working on the document/data, drafting, editing and analysis.
108 |
109 | Consider the following practices:
110 | - Outline the master file and identify major files for instance; original, pre-review, 1st revision, 2nd revision, final revision, submitted.
111 | - Outline strategy for archiving and storing: Where to store the minor and major versions, how long will you retain them accordingly.
112 | - Maintain a record of file locations, a good place is in the README files
113 |
114 | Example:
115 | UK Data service version control guide:
116 | https://www.ukdataservice.ac.uk/manage-data/format/versioning.aspx
117 |
118 | ## Research vocabularies
119 | Research Vocabularies Australia https://vocabs.ands.org.au/
120 | AGROVOC & VocBench http://aims.fao.org/vest-registry/vocabularies/agrovoc
121 | Dimensions Fields of Research https://dimensions.freshdesk.com/support/solutions/articles/23000012844-what-are-fields-of-research-
122 |
123 |
124 | Versioning/SHA
125 | https://swcarpentry.github.io/git-novice/reference
126 |
127 | Binder - executable environment, making your code immediately reproducible by anyone, anywhere.
128 | https://blog.jupyter.org/binder-2-0-a-tech-guide-2017-fd40515a3a84
129 |
130 | Narrative & Documentation
131 | Jupyter Notebooks
132 | https://www.contentful.com/blog/2018/06/01/create-interactive-tutorials-jupyter-notebooks/
133 |
134 |
135 | Licenses
136 | Licenses rarely used
137 | From GitHub https://blog.github.com/2015-03-09-open-source-license-usage-on-github-com/
138 |
139 | Lack of licenses provide friction, understanding of whether can reuse
140 | Peter Murray Project - ContentMine - The Right to Read is the Right to Mine - OpenMinTed
141 | Creative Commons Wizard and GitHub software licensing wizards (highlight attribution, non commercial)
142 |
143 |
144 | Lessons to teach with this episode
145 | Data Carpentry - tidy data/data organization with spreadsheets
146 | https://datacarpentry.org/lessons/
147 | Library Carpentry - intro to data/tidy data
148 |
149 |
150 | Exercise?
151 | Reference Management w/ Zotero or other
152 |
153 | demo: import Zenodo.org/record/1308061 into Zotero
154 | demo: RStudio > Packages > Update, run PANGAEA example, then install updates
155 | https://tibhannover.github.io/2018-07-09-FAIR-Data-and-Software/FAIR-remix-PANGAEA/index.html
156 |
157 | Useful content for Licenses
158 | Note: TIB Hannover Slides https://docs.google.com/presentation/d/1mSeanQqO0Y2khA8KK48wtQQ_JGYncGexjnspzs7cWLU/edit#slide=id.g3a64c782ff_1_138
159 |
160 | Additional licensing resources:
161 | Choose an open source license: https://choosealicense.com/
162 | 4 Simple recommendations for Open Source Software https://softdev4research.github.io/4OSS-lesson/
163 | Use a license: https://softdev4research.github.io/4OSS-lesson/03-use-license/index.html
164 | Top 10 FAIR Imaging https://librarycarpentry.org/Top-10-FAIR//2019/06/27/imaging/
165 | Licensing your work: https://librarycarpentry.org/Top-10-FAIR//2019/06/27/imaging/#9-licensing-your-work
166 | The Turing Way a Guide for reproducible Research: https://the-turing-way.netlify.app/welcome
167 | Licensing https://the-turing-way.netlify.app/reproducible-research/licensing.html
168 | The Open Science Training Handbook: https://open-science-training-handbook.gitbook.io/book/
169 | Open Licensing and file formats https://open-science-training-handbook.gitbook.io/book/open-science-basics/open-licensing-and-file-formats#6-open-licensing-and-file-formats
170 | DCC How to license research data https://www.dcc.ac.uk/guidance/how-guides/license-research-data
171 |
172 |
173 | ## Exercise- Thanks, but no Thanks!
174 | In groups of 2-3 discuss and note down;
175 | - Have you ever received data you couldn’t use? & why not?
176 | - Have you tried replicating an experiment, yours or someone else? What challenges did you face?
177 |
178 |
--------------------------------------------------------------------------------
/_episodes/07-assessment.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Assessment"
3 | teaching: 10
4 | exercises: 50
5 | questions:
6 | - "How can I assess the FAIRness of myself, an organisation, a service, a community… ?"
7 | - "Which FAIR assessment tools exist to understand how FAIR you are?"
8 | objectives:
9 | - "Assess the current FAIRness level of myself, organisation, service, community..."
10 | - "Know about available tools for assessing FAIRness."
11 | - "Understand the next steps you can take to being FAIRer."
12 |
13 | keypoints:
14 | - "Assessments and plans are helpful tools for understanding next steps/action plans for becoming more FAIR."
15 | ---
16 |
17 | ## Reasons for assessment
18 |
19 | FAIR is a journey. Technology and the way people work is shifting often and what might be FAIR today might not be months, years from now. A FAIR assessment now is a snapshot in time. Nevertheless, individuals, organizations, disciplines, services, countries, and communities will look to how FAIR they are. The reasons are various, including gaining a better understanding, comparing with others, making improvements, and participating further in the scholarly ecosystem, to name a handful. Ultimately, an assessment can be a helpful guide on the path to becoming more FAIR.
20 |
21 | > ## Mirror, mirror on the wall, who is the FAIRest one of all?
22 | > [Mirror, mirror on the wall, who is the FAIRest one of all?](https://forschungsdaten-thueringen.de/entry/mirror-mirror-on-the-wall-tkfdm-announces-fairest-dataset-award.html) - In March 2020, Theuringen FDM-TAGE offered awards to the FAIRest datasets based on the FAIR principles. The [FAIRest Dataset winners were announced](https://forschungsdaten-thueringen.de/entry/and-the-winner-is.html) in June 2020. What is FAIR about the winning datasets? Is there anything else that can be done to make them FAIRer?
23 | >
24 | {: .callout}
25 |
26 | ## FAIR is a vision, NOT a standard
27 |
28 | The FAIR principles are a way of reaching for best data and software practices, coming to a convergence on what those are, and how to get there. They are NOT rules. They are NOT a standard. They are NOT a requirement. The principles were not meant to be prescriptive but instead offer a vision to optimise data/software sharing and reuse by humans and machines.
29 |
30 | > ## Inconsistent interpretations
31 | > The lack of information on how to implement the FAIR principles have led to inconsistent interpretations. Jacobsen, A., de Miranda Azevedo, R., Juty, N., Batista, D., Coles, S., Cornet, R., ... & Goble, C. (2020). [FAIR principles: interpretations and implementation considerations](https://www.mitpressjournals.org/doi/full/10.1162/dint_r_00024) describes implementation considerations.
32 | >
33 | {: .callout}
34 |
35 | ## Types of assessment
36 |
37 | Depending on your needs, whether you want to assess yourself, a service, your organization or community, or even your country or region, FAIR assessment or evaluation tools are available to help guide you in your path towards FAIR betterment. The following are some resources and exercises to help you get started.
38 |
39 |
40 | ## Individual assessment
41 |
42 | How FAIR are you? The FAIRsFAIR project has developed an assessment tool called [FAIR-Aware](https://fairaware.dans.knaw.nl) that both helps you understand the principles and also how you can improve the FAIRness of your research. Before taking the assessment, have a target dataset/software in mind to prepare you for the questions which include questions about yourself and 10 questions about FAIR. Each question provides additional information and guidance and helps you assess your current FAIRness level along with potential actions to take. The assessment takes 10 to 30 minutes to complete depending on your familiarity with the subject and issues covered.
43 |
44 | > ## Challenge
45 | > Encourage your workshop participants to review the episodes in this FAIR lesson and take the [FAIR-Aware](https://fairaware.dans.knaw.nl) assessment ahead of time. In person (or virtual), ask the participants to split up into groups and to highlight some of their key questions/findings from the FAIR-Aware assessment. Ask them to note their questions/findings/anything else in the session’s collaborative notes. After a duration, ask the groups to return to the main group and call on each group (leader) to summarise their discussion. Synthesise some of the key points and discuss next steps on how participants can address their FAIRness moving forward.
46 | {: .challenge}
47 |
48 | Alternatively, the [Australian Research Data Commons (ARDC) FAIR data assessment tool](https://ardc.edu.au/resources/working-with-data/fair-data/fair-self-assessment-tool/) and/or the *[How FAIR are your data?](http://doi.org/10.5281/zenodo.3405141)* checklist by Jones and Grootveld are also available and can be substituted for the FAIR-Aware assessment tool.
49 |
50 | ## Evaluate the FAIRness of digital resources
51 | How FAIR is your service and the digital resources you share? How can your service enable greater machine discoverability and (re)use of its digital resoruces? Evaluation of your service's FAIRness lies on a continuum based on the behaviors and norms of your community. Frameworks and tools to assess services are currently under development and what options are available should be paired with the evaulation of what makes sense to your community.
52 |
53 | > ## FAIR Evaluation Services
54 | > The [FAIR Evaluation Service](https://fairsharing.github.io/FAIR-Evaluator-FrontEnd/#!/) is available to assess the FAIRness of your digital resources. Developed by the Maturity Indicator Authoring Group, FAIR Maturity Indicators are available to test your service via a submission process. The rationale for the Service are explained in *[Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud](http://doi.org/10.3233/ISU-170824)*. To get started, the Group can also be reached via their Service.
55 | >
56 | {: .callout}
57 |
58 | As a service provider, for example a data repository, you might want to assess the FAIRness of datasets in your systems. You can do this by using one of the resources at [FAIRassist](https://fairassist.org/#!/) or you can start your assessment manually (as a group exercise). Some infrastructure providers have provided overviews of how their services enable FAIR.
59 |
60 | - [Zenodo offers an overview](https://about.zenodo.org/principles/) of how the service responds to the FAIR principles.
61 | - Figshare also [published a statement paper](https://doi.org/10.6084/m9.figshare.7476428.v1 ) on how it supports the FAIR principles.
62 |
63 | > ## Challenge
64 | > Encourage your workshop participants to review the episodes in this FAIR lesson and then review the FAIR principles responses/statements from Zenodo and Figshare above before the workshop. Again, ahead of the workshop, ask the participants to develop similar responses/statements for a service at their organisation, in their community. An outline with brief bullet points is best. Pre-assign workshop participants to groups and ask them to share their responses/statements with each other. Then in person (or virtual), ask the participants to split up into their pre-assigned groups and to discuss each other's responses/statements. Ask them to note their questions/findings/anything else in the session’s collaborative notes. After a duration, ask the groups to return to the main group and call on each group (leader) to summarise their discussion. Synthesise some of the key points and discuss next steps on how participants can address their FAIRness moving forward.
65 | {: .challenge}
66 |
67 | > ## Quantifying FAIR
68 | > In a recent DataONE webinar titled *[Quatifying FAIR](https://www.dataone.org/uploads/dataonewebinar_jonesslaughter_fairmetadata_190514.pdf)*, Jones and Slaughter describe tests that have been conducted to assess the FAIRness of digital resources across their services. The [MetaDIG](https://github.com/NCEAS/metadig-checks) tool is referenced, used to check the quality of metadata in these services. Based on this work, DataONE also lists a [Make your data FAIR](https://www.dataone.org/fair/) tool as coming soon
69 | >
70 | {: .callout}
71 |
72 | ## Community assessment
73 |
74 | Communities can also assess how FAIR they are and develop goals and/or action plans for advancing FAIR. Communities can range from topical to regional and even organisational. A recently published report from the Directorate-General for Research and Innovation (European Commission) titled "Turning FAIR into reality" is an invaluable resource for creating action plans and turning FAIR into reality for communities. The report includes a survey and analysis of what is needed to implement FAIR, concrete recommendations and actions for stakeholders, and example case studies to learn from. Ultimately, the report serves as a useful framework for mapping a community's next steps towards a FAIRer future.
75 |
76 | > ## Challenge
77 | > Encourage your workshop participants to first read:
78 | >
79 | > Collins, Sandra, et al. "Turning FAIR into reality: Final report and action plan from the European Commission expert group on FAIR data." (2018). [https://op.europa.eu/en/publication-detail/-/publication/7769a148-f1f6-11e8-9982-01aa75ed71a1](https://op.europa.eu/en/publication-detail/-/publication/7769a148-f1f6-11e8-9982-01aa75ed71a1)
80 | >
81 | > Leverage the recommendations (pictured below) and organise group discussions on these themes. Ask the participants to brainstorm initial responses to these themes ahead of the workshop and collect their initial responses in a collaborative document, structured by the themes. During the workshop, ask the participants to join their groups based on the themes they initially responded to and discuss each other's responses. Ask them to note their questions/findings/anything else in the session’s collaborative notes. After a duration, ask the groups to return to the main group and call on each group (leader) to summarise their discussion. Synthesise some of the key points and discuss next steps on how participants can address their FAIRness moving forward.
82 | >
83 | > 
84 | {: .challenge}
85 |
86 | > ## Challenge
87 | > Alternatively, start your community off on the path to FAIR by setting up an initial study group. The group's goal, to scan, and possibly survey, work that has been done by community members (or like communities) on example/case studies, policies, recommendation, guidance, etc to collect resources to help inform future FAIR discussions/initiatives. Consider structuring your group work to produce guidance, e.g. [Top 10 FAIR Data and Software Things](https://librarycarpentry.org/Top-10-FAIR/):
88 | >
89 | > Paula Andrea Martinez, Christopher Erdmann, Natasha Simons, Reid Otsuji, Stephanie Labou, Ryan Johnson, … Eliane Fankhauser. (2019, February). Top 10 FAIR Data & Software Things. Zenodo. [http://doi.org/10.5281/zenodo.3409968](http://doi.org/10.5281/zenodo.3409968)
90 | >
91 | {: .challenge}
92 |
93 | ## Other assessment tools
94 |
95 | To see a list of additional resources for the assessment and/or evaluation of digital objects against the FAIR principles, see [FAIRassist](https://fairassist.org/).
96 |
97 | ## Planning
98 |
99 | Data and software management plans are also a helpful tool for planning out how you/your group will manage data and software throughout your project but they also provide a mechanism for assessment at different checkpoints. Revisiting your plan at different checkpoints allows you to review how well you are doing, incorporate findings, and make improvements. This allows your plan to evolve, be more actionable, and less static.
100 |
101 | Resources and examples include:
102 |
103 | Data:
104 | - [Data Stewardship Wizard](https://ds-wizard.org/)
105 | - [DMPonline](https://dmponline.dcc.ac.uk/)
106 | - [DMPTool](https://dmptool.org/)
107 | - [ICPSR example pans](https://www.icpsr.umich.edu/web/pages/datamanagement/dmp/plan.html)
108 | - [LIBER Research Data Management Plan (DMP) Catalogue](https://libereurope.eu/working-group/research-data-management/plans/)
109 |
110 | Software:
111 | - [ELIXIR Software Management Plan](https://tinyurl.com/ELIXIR-SMP-draft-version-2 )
112 | - [SSI Software Management Plans](https://www.software.ac.uk/software-management-plans)
113 | - [CLARIAH Guidelines for Software Quality](https://github.com/CLARIAH/software-quality-guidelines/blob/v1.0/softwareguidelines.pdf)
114 | - [EURISE Network Software Quality Checklist](https://github.com/eurise-network/technical-reference/blob/v0.1/quality/software-checklist.rst)
115 |
116 | > ## Challenge
117 | > Use one of the resources above to draft a plan for your research project (as an individual and/or group). As an individual, ask a colleague to review your draft, provide feedback, and discuss. As a group, outline the plan questions in a collaborative document and work together to draft responses, then discuss together as a group. Consider publishing your plan to share with others.
118 | >
119 | {: .challenge}
120 |
121 | ## Resources
122 | This is a developing area, so if you have any resources that you would like to share, please add them to this lesson via a pull request or GitHub issue.
123 |
124 |
--------------------------------------------------------------------------------
/_episodes/08-software.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Software"
3 | teaching: 0
4 | exercises: 0
5 | questions:
6 | - "Key question"
7 | objectives:
8 | - "The objective of this lesson is to get learners up to speed on how the FAIR principles apply to software, and to make learners aware of accepted best practices."
9 | keypoints:
10 | - "First key point."
11 | ---
12 |
13 | # Applying FAIR to software
14 |
15 | The FAIR principles have been developed with research data in mind, however they are relevant to all digital objects resulting from the research process - which includes software. The discussion around FAIRification of software - particularly with respect to how the principles can be adapted, reinterpreted, or expanded - is ongoing. This position paper (https://doi.org/10.3233/DS-190026) elaborates on this discussion and provides an overview on how the 15 FAIR Guiding Principles can be applied to software.
16 |
17 | **BTW what do we mean by software here?**
18 | Software can refer to programming scripts and packages such as those for R & Python, as well as programs and webtools/webservices such as ......
19 | For the most part, this lesson focuses on the former.
20 |
21 | **Note/Acknowledgements**
22 |
23 | This lesson draft, complied during the FAIR lesson sprint @CarpentryCon2020, draws heavily from the Top 10 FAIR Data & Software Things + FAIR Software Guide (see reference list).
24 |
25 | ## Findable
26 |
27 | For software to be findable,
28 | - **it should be accompanied with sufficiently rich metadata and persistent identifiers.**
29 |
30 | 1. Software should be well documented to to increase findability and eventually, reusability. This metadata can start with a minimum set of information that includes a short description and meaningful keywords. This documentation be further improved by applying metadata standards such as those from CodeMeta (https://codemeta.github.io/terms/) or DataCite.
31 |
32 | 2. Software should be registered in a dedicated registry such as Research Software Directory, rOpenSci project, Zenodo. These registries will usually request the previously mentioned metadata descriptors, and they are optimized to show up in search engine results. _question to be resolved: how is a registry different from a repository?_
33 |
34 | 3. When attaching identifiers to software, they should be unqiue and persistent. They should point only the one version and location of your software. A software registry usually provides a PID, otherwise you can obtain one from another organization and include it in your metadata yourself. See: Software Hertigage archive.
35 |
36 | 4. Your software can also be hosted/deposited in an open and publicly accessible repository, preferably with version control and citation guidelines. Examples: Zenodo or GitHub (see GitHub doc on citing code, but note the issue about attaching identifiers and the 'permanence' of GitHub). _Still have to check the difference between registries and repositories._
37 |
38 | ## Accessible
39 |
40 | For software to be accessible,
41 | - **software metadata should be in machine and human readable formats.**
42 | - **software and metadata should be deposited in a trusted community-approved repository.**
43 |
44 | 1. _What does it mean to make metadata machine and human readable? This should be covered in a previous lesson and referred back here..._
45 |
46 | 2. The (executable) software and metadata should be publicly accessible and downloadable. These downloadable and executable files can be hosted or deposited in a repository / registry, as well as project websites.
47 |
48 | ## Interoperable
49 |
50 | For softare to be interoperable,
51 | - **community accepted standards and platforms should be used, making it possible for other users to run the software.**
52 |
53 | 1. Interoperability is increased when there is documentation that outlines functions of the software. This means providing clear and concise descriptions of all the operations available with the software, including input and output functions and the data types associated with them.
54 |
55 | 2. If community standards are available, input and output formats should adhere to them. This makes it easy to exchange data between software (the data itself will be better linked too).
56 |
57 | ## Reusable
58 |
59 | For software to be reusable,
60 | - **it should have a clear licence and documentation.**
61 |
62 | 1. Software should be sufficiently documented beyond metadata. This could include instructions, troubleshooting, statements on dependencies, examples or tutorials.
63 |
64 | 2. Include a license. This informs potential users on how they may/may not (re)use the software.
65 |
66 | 3. Include a citation guideline, if you'd like to receive credit or acknowledgement for your work.
67 |
68 | 4. Combine best practices for software development with FAIR. This would include working out of a repository with version control (which allows for tracking changes and transparency), following code standards, building modual code etc.
69 |
70 | 5. In addition to 4, you can use a software quality checklist. There are several available and you can select which is most suitable for your software. A good checklist will include items which allow for a granular evaluation of the software, explains the rationale behind the check, and explains how to implement the check. It can cover documentation, testing, standardization of code etc. You quality checklist could be maintained in your README file.
71 |
72 | ## References
73 |
74 | - position paper: https://doi.org/10.3233/DS-190026
75 | - Top 10 Fair Data & Software Things: https://librarycarpentry.org/Top-10-FAIR//2018/12/01/research-software/
76 | - FAIR Software guide: https://fair-software.eu/
77 | - Netherlands eScience Center FAIR Software lesson outline: https://escience-academy.github.io/2020-09-08-4tu-fair-software/
78 | - CarpentryCon2020 FAIR Software course: https://www.youtube.com/watch?time_continue=321&v=-x81mpkQAWo&feature=emb_logo / Etherpad: https://pad.carpentries.org/cchome-FAIR-software
79 | - FSCI2020 FAIR Data course (session 3 slides): https://osf.io/jx2tp/
80 |
81 | ---------------------
82 |
83 | ## Lessons to teach in connection with this section and exercises
84 | [Software Carpentry: Version Control with Git](https://swcarpentry.github.io/git-novice/) or [Library Carpentry: Intro to Git](https://librarycarpentry.github.io/lc-git/)
85 | [Making your Code Citeable](https://guides.github.com/activities/citable-code/)
86 | Does an exercise or lesson exist that we can point to involving Software Heritage?
87 |
--------------------------------------------------------------------------------
/_episodes_rmd/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/_episodes_rmd/.gitkeep
--------------------------------------------------------------------------------
/_episodes_rmd/data/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/_episodes_rmd/data/.gitkeep
--------------------------------------------------------------------------------
/_extras/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/_extras/.gitkeep
--------------------------------------------------------------------------------
/_extras/about.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: page
3 | title: About
4 | ---
5 | {% include carpentries.html %}
6 |
--------------------------------------------------------------------------------
/_extras/design.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: page
3 | title: "Lesson Design"
4 | permalink: /design/
5 | ---
6 |
7 | This lesson is being developed using elements from *A Lesson Design Process* Chapter in Greg Wilson's [Teaching Tech Together](http://teachtogether.tech/en/). Please see the organizing wiki for this lesson:
8 |
--------------------------------------------------------------------------------
/_extras/discuss.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: page
3 | title: Discussion
4 | ---
5 | FIXME
6 |
--------------------------------------------------------------------------------
/_extras/figures.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: page
3 | title: Figures
4 | ---
5 |
34 | {% comment %}
35 | Create anchor for each one of the episodes.
36 | {% endcomment %}
37 | {% for episode in site.episodes %}
38 |
39 | {% endfor %}
40 |
--------------------------------------------------------------------------------
/_extras/guide.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: page
3 | title: "Instructor Notes"
4 | ---
5 | FIXME
6 |
--------------------------------------------------------------------------------
/aio.md:
--------------------------------------------------------------------------------
1 | ---
2 | permalink: /aio/index.html
3 | ---
4 |
5 | {% comment %}
6 | As a maintainer, you don't need to edit this file.
7 | If you notice that something doesn't work, please
8 | open an issue: https://github.com/carpentries/styles/issues/new
9 | {% endcomment %}
10 |
11 | {% include base_path.html %}
12 |
13 | {% include aio-script.md %}
14 |
--------------------------------------------------------------------------------
/bin/boilerplate/.travis.yml:
--------------------------------------------------------------------------------
1 | # dist: trusty # Ubuntu 14.04
2 | language: python
3 | python: 3.6
4 | branches:
5 | only:
6 | - gh-pages
7 | - /.*/
8 | before_install:
9 | - sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E084DAB9
10 | - echo "deb https://cran.rstudio.com/bin/linux/ubuntu trusty/" | sudo tee -a /etc/apt/sources.list
11 | - sudo apt-get update -y
12 | - sudo apt-get install -y r-base
13 | - sudo Rscript -e "install.packages('knitr', repos = 'https://', dependencies = TRUE)"
14 | - sudo Rscript -e "install.packages('stringr', repos = 'https://cran.rstudio.com', dependencies = TRUE)"
15 | - sudo Rscript -e "install.packages('checkpoint', repos = 'https://cran.rstudio.com', dependencies = TRUE)"
16 | - sudo Rscript -e "install.packages('ggplot2', repos = 'https://cran.rstudio.com', dependencies = TRUE)"
17 | - rvm default
18 | - gem install json kramdown jekyll
19 | install:
20 | - pip install pyyaml
21 | script:
22 | - make lesson-check-all
23 | - make --always-make site
24 |
--------------------------------------------------------------------------------
/bin/boilerplate/AUTHORS:
--------------------------------------------------------------------------------
1 | FIXME: list authors' names and email addresses.
--------------------------------------------------------------------------------
/bin/boilerplate/CITATION:
--------------------------------------------------------------------------------
1 | FIXME: describe how to cite this lesson.
--------------------------------------------------------------------------------
/bin/boilerplate/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: page
3 | title: "Contributor Code of Conduct"
4 | ---
5 | As contributors and maintainers of this project,
6 | we pledge to follow the [Carpentry Code of Conduct][coc].
7 |
8 | Instances of abusive, harassing, or otherwise unacceptable behavior
9 | may be reported by following our [reporting guidelines][coc-reporting].
10 |
11 | {% include links.md %}
12 |
--------------------------------------------------------------------------------
/bin/boilerplate/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing
2 |
3 | [Software Carpentry][swc-site] and [Data Carpentry][dc-site] are open source projects,
4 | and we welcome contributions of all kinds:
5 | new lessons,
6 | fixes to existing material,
7 | bug reports,
8 | and reviews of proposed changes are all welcome.
9 |
10 | ## Contributor Agreement
11 |
12 | By contributing,
13 | you agree that we may redistribute your work under [our license](LICENSE.md).
14 | In exchange,
15 | we will address your issues and/or assess your change proposal as promptly as we can,
16 | and help you become a member of our community.
17 | Everyone involved in [Software Carpentry][swc-site] and [Data Carpentry][dc-site]
18 | agrees to abide by our [code of conduct](CODE_OF_CONDUCT.md).
19 |
20 | ## How to Contribute
21 |
22 | The easiest way to get started is to file an issue
23 | to tell us about a spelling mistake,
24 | some awkward wording,
25 | or a factual error.
26 | This is a good way to introduce yourself
27 | and to meet some of our community members.
28 |
29 | 1. If you do not have a [GitHub][github] account,
30 | you can [send us comments by email][email].
31 | However,
32 | we will be able to respond more quickly if you use one of the other methods described below.
33 |
34 | 2. If you have a [GitHub][github] account,
35 | or are willing to [create one][github-join],
36 | but do not know how to use Git,
37 | you can report problems or suggest improvements by [creating an issue][issues].
38 | This allows us to assign the item to someone
39 | and to respond to it in a threaded discussion.
40 |
41 | 3. If you are comfortable with Git,
42 | and would like to add or change material,
43 | you can submit a pull request (PR).
44 | Instructions for doing this are [included below](#using-github).
45 |
46 | ## Where to Contribute
47 |
48 | 1. If you wish to change this lesson,
49 | please work in ,
50 | which can be viewed at .
51 |
52 | 2. If you wish to change the example lesson,
53 | please work in ,
54 | which documents the format of our lessons
55 | and can be viewed at .
56 |
57 | 3. If you wish to change the template used for workshop websites,
58 | please work in .
59 | The home page of that repository explains how to set up workshop websites,
60 | while the extra pages in
61 | provide more background on our design choices.
62 |
63 | 4. If you wish to change CSS style files, tools,
64 | or HTML boilerplate for lessons or workshops stored in `_includes` or `_layouts`,
65 | please work in .
66 |
67 | ## What to Contribute
68 |
69 | There are many ways to contribute,
70 | from writing new exercises and improving existing ones
71 | to updating or filling in the documentation
72 | and submitting [bug reports][issues]
73 | about things that don't work, aren't clear, or are missing.
74 | If you are looking for ideas, please see the 'Issues' tab for
75 | a list of issues associated with this repository,
76 | or you may also look at the issues for [Data Carpentry][dc-issues]
77 | and [Software Carpentry][swc-issues] projects.
78 |
79 | Comments on issues and reviews of pull requests are just as welcome:
80 | we are smarter together than we are on our own.
81 | Reviews from novices and newcomers are particularly valuable:
82 | it's easy for people who have been using these lessons for a while
83 | to forget how impenetrable some of this material can be,
84 | so fresh eyes are always welcome.
85 |
86 | ## What *Not* to Contribute
87 |
88 | Our lessons already contain more material than we can cover in a typical workshop,
89 | so we are usually *not* looking for more concepts or tools to add to them.
90 | As a rule,
91 | if you want to introduce a new idea,
92 | you must (a) estimate how long it will take to teach
93 | and (b) explain what you would take out to make room for it.
94 | The first encourages contributors to be honest about requirements;
95 | the second, to think hard about priorities.
96 |
97 | We are also not looking for exercises or other material that only run on one platform.
98 | Our workshops typically contain a mixture of Windows, Mac OS X, and Linux users;
99 | in order to be usable,
100 | our lessons must run equally well on all three.
101 |
102 | ## Using GitHub
103 |
104 | If you choose to contribute via GitHub, you may want to look at
105 | [How to Contribute to an Open Source Project on GitHub][how-contribute].
106 | To manage changes, we follow [GitHub flow][github-flow].
107 | Each lesson has two maintainers who review issues and pull requests or encourage others to do so.
108 | The maintainers are community volunteers and have final say over what gets merged into the lesson.
109 | To use the web interface for contributing to a lesson:
110 |
111 | 1. Fork the originating repository to your GitHub profile.
112 | 2. Within your version of the forked repository, move to the `gh-pages` branch and
113 | create a new branch for each significant change being made.
114 | 3. Navigate to the file(s) you wish to change within the new branches and make revisions as required.
115 | 4. Commit all changed files within the appropriate branches.
116 | 5. Create individual pull requests from each of your changed branches
117 | to the `gh-pages` branch within the originating repository.
118 | 6. If you receive feedback, make changes using your issue-specific branches of the forked
119 | repository and the pull requests will update automatically.
120 | 7. Repeat as needed until all feedback has been addressed.
121 |
122 | When starting work, please make sure your clone of the originating `gh-pages` branch is up-to-date
123 | before creating your own revision-specific branch(es) from there.
124 | Additionally, please only work from your newly-created branch(es) and *not*
125 | your clone of the originating `gh-pages` branch.
126 | Lastly, published copies of all the lessons are available in the `gh-pages` branch of the originating
127 | repository for reference while revising.
128 |
129 | ## Other Resources
130 |
131 | General discussion of [Software Carpentry][swc-site] and [Data Carpentry][dc-site]
132 | happens on the [discussion mailing list][discuss-list],
133 | which everyone is welcome to join.
134 | You can also [reach us by email][email].
135 |
136 | [email]: mailto:admin@software-carpentry.org
137 | [dc-issues]: https://github.com/issues?q=user%3Adatacarpentry
138 | [dc-lessons]: http://datacarpentry.org/lessons/
139 | [dc-site]: http://datacarpentry.org/
140 | [discuss-list]: http://lists.software-carpentry.org/listinfo/discuss
141 | [github]: https://github.com
142 | [github-flow]: https://guides.github.com/introduction/flow/
143 | [github-join]: https://github.com/join
144 | [how-contribute]: https://egghead.io/series/how-to-contribute-to-an-open-source-project-on-github
145 | [issues]: https://guides.github.com/features/issues/
146 | [swc-issues]: https://github.com/issues?q=user%3Aswcarpentry
147 | [swc-lessons]: https://software-carpentry.org/lessons/
148 | [swc-site]: https://software-carpentry.org/
149 |
--------------------------------------------------------------------------------
/bin/boilerplate/README.md:
--------------------------------------------------------------------------------
1 | # FIXME Lesson title
2 |
3 | [](https://swc-slack-invite.herokuapp.com/)
4 |
5 | FIXME
6 |
7 | ## Contributing
8 |
9 | We welcome all contributions to improve the lesson! Maintainers will do their best to help you if you have any
10 | questions, concerns, or experience any difficulties along the way.
11 |
12 | We'd like to ask you to familiarize yourself with our [Contribution Guide](CONTRIBUTING.md) and have a look at
13 | the [more detailed guidelines][lesson-example] on proper formatting, ways to render the lesson locally, and even
14 | how to write new episodes.
15 |
16 | ## Maintainer(s)
17 |
18 | * FIXME
19 |
20 | ## Authors
21 |
22 | A list of contributors to the lesson can be found in [AUTHORS](AUTHORS)
23 |
24 | ## Citation
25 |
26 | To cite this lesson, please consult with [CITATION](CITATION)
27 |
28 | [lesson-example]: https://carpentries.github.io/lesson-example
29 |
--------------------------------------------------------------------------------
/bin/boilerplate/_config.yml:
--------------------------------------------------------------------------------
1 | #------------------------------------------------------------
2 | # Values for this lesson.
3 | #------------------------------------------------------------
4 |
5 | # Which carpentry is this ("swc", "dc", "lc", or "cp")?
6 | # swc: Software Carpentry
7 | # dc: Data Carpentry
8 | # lc: Library Carpentry
9 | # cp: Carpentries (to use for instructor traning for instance)
10 | carpentry: "swc"
11 |
12 | # Overall title for pages.
13 | title: "Lesson Title"
14 |
15 | #------------------------------------------------------------
16 | # Generic settings (should not need to change).
17 | #------------------------------------------------------------
18 |
19 | # What kind of thing is this ("workshop" or "lesson")?
20 | kind: "lesson"
21 |
22 | # Magic to make URLs resolve both locally and on GitHub.
23 | # See https://help.github.com/articles/repository-metadata-on-github-pages/.
24 | # Please don't change it: / is correct.
25 | repository: /
26 |
27 | # Email address, no mailto:
28 | email: "team@carpentries.org"
29 |
30 | # Sites.
31 | amy_site: "https://amy.software-carpentry.org/workshops"
32 | carpentries_github: "https://github.com/carpentries"
33 | carpentries_pages: "https://carpentries.github.io"
34 | carpentries_site: "https://carpentries.org/"
35 | dc_site: "http://datacarpentry.org"
36 | example_repo: "https://github.com/carpentries/lesson-example"
37 | example_site: "https://carpentries.github.io/lesson-example"
38 | lc_site: "https://librarycarpentry.github.io/"
39 | swc_github: "https://github.com/swcarpentry"
40 | swc_pages: "https://swcarpentry.github.io"
41 | swc_site: "https://software-carpentry.org"
42 | template_repo: "https://github.com/carpentries/styles"
43 | training_site: "https://carpentries.github.io/instructor-training"
44 | workshop_repo: "https://github.com/carpentries/workshop-template"
45 | workshop_site: "https://carpentries.github.io/workshop-template"
46 |
47 | # Surveys.
48 | pre_survey: "https://www.surveymonkey.com/r/swc_pre_workshop_v1?workshop_id="
49 | post_survey: "https://www.surveymonkey.com/r/swc_post_workshop_v1?workshop_id="
50 | training_post_survey: "https://www.surveymonkey.com/r/post-instructor-training"
51 |
52 | # Start time in minutes (0 to be clock-independent, 540 to show a start at 09:00 am).
53 | start_time: 0
54 |
55 | # Specify that things in the episodes collection should be output.
56 | collections:
57 | episodes:
58 | output: true
59 | permalink: /:path/index.html
60 | extras:
61 | output: true
62 | permalink: /:path/index.html
63 |
64 | # Set the default layout for things in the episodes collection.
65 | defaults:
66 | - values:
67 | root: .
68 | layout: page
69 | - scope:
70 | path: ""
71 | type: episodes
72 | values:
73 | root: ..
74 | layout: episode
75 | - scope:
76 | path: ""
77 | type: extras
78 | values:
79 | root: ..
80 | layout: page
81 |
82 | # Files and directories that are not to be copied.
83 | exclude:
84 | - Makefile
85 | - bin/
86 | - .Rproj.user/
87 |
88 | # Turn on built-in syntax highlighting.
89 | highlighter: rouge
90 |
--------------------------------------------------------------------------------
/bin/boilerplate/_episodes/01-introduction.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Introduction"
3 | teaching: 0
4 | exercises: 0
5 | questions:
6 | - "Key question (FIXME)"
7 | objectives:
8 | - "First objective. (FIXME)"
9 | keypoints:
10 | - "First key point. (FIXME)"
11 | ---
12 | FIXME
13 |
14 | {% include links.md %}
15 |
--------------------------------------------------------------------------------
/bin/boilerplate/_extras/about.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: About
3 | ---
4 | {% include carpentries.html %}
5 | {% include links.md %}
6 |
--------------------------------------------------------------------------------
/bin/boilerplate/_extras/discuss.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Discussion
3 | ---
4 | FIXME
5 |
6 | {% include links.md %}
7 |
--------------------------------------------------------------------------------
/bin/boilerplate/_extras/figures.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Figures
3 | ---
4 |
33 | {% comment %}
34 | Create anchor for each one of the episodes.
35 | {% endcomment %}
36 | {% for episode in site.episodes %}
37 |
38 | {% endfor %}
39 |
40 | {% include links.md %}
41 |
--------------------------------------------------------------------------------
/bin/boilerplate/_extras/guide.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Instructor Notes"
3 | ---
4 | FIXME
5 |
6 | {% include links.md %}
7 |
--------------------------------------------------------------------------------
/bin/boilerplate/aio.md:
--------------------------------------------------------------------------------
1 | ---
2 | ---
3 |
29 | {% comment %}
30 | Create anchor for each one of the episodes.
31 | {% endcomment %}
32 | {% for episode in site.episodes %}
33 |
34 | {% endfor %}
35 |
--------------------------------------------------------------------------------
/bin/boilerplate/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: lesson
3 | root: . # Is the only page that don't follow the partner /:path/index.html
4 | permalink: index.html # Is the only page that don't follow the partner /:path/index.html
5 | ---
6 | FIXME: home page introduction
7 |
8 | > ## Prerequisites
9 | >
10 | > FIXME
11 | {: .prereq}
12 |
13 | {% include links.md %}
14 |
--------------------------------------------------------------------------------
/bin/boilerplate/reference.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: reference
3 | ---
4 |
5 | ## Glossary
6 |
7 | FIXME
8 |
9 | {% include links.md %}
10 |
--------------------------------------------------------------------------------
/bin/boilerplate/setup.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Setup
3 | ---
4 | FIXME
5 |
6 |
7 | {% include links.md %}
8 |
--------------------------------------------------------------------------------
/bin/chunk-options.R:
--------------------------------------------------------------------------------
1 | # These settings control the behavior of all chunks in the novice R materials.
2 | # For example, to generate the lessons with all the output hidden, simply change
3 | # `results` from "markup" to "hide".
4 | # For more information on available chunk options, see
5 | # http://yihui.name/knitr/options#chunk_options
6 |
7 | library("knitr")
8 |
9 | fix_fig_path <- function(pth) file.path("..", pth)
10 |
11 |
12 | ## We set the path for the figures globally below, so if we want to
13 | ## customize it for individual episodes, we can append a prefix to the
14 | ## global path. For instance, if we call knitr_fig_path("01-") in the
15 | ## first episode of the lesson, it will generate the figures in
16 | ## `fig/rmd-01-`
17 | knitr_fig_path <- function(prefix) {
18 | new_path <- paste0(opts_chunk$get("fig.path"),
19 | prefix)
20 | opts_chunk$set(fig.path = new_path)
21 | }
22 |
23 | ## We use the rmd- prefix for the figures generated by the lssons so
24 | ## they can be easily identified and deleted by `make clean-rmd`. The
25 | ## working directory when the lessons are generated is the root so the
26 | ## figures need to be saved in fig/, but when the site is generated,
27 | ## the episodes will be one level down. We fix the path using the
28 | ## `fig.process` option.
29 |
30 | opts_chunk$set(tidy = FALSE, results = "markup", comment = NA,
31 | fig.align = "center", fig.path = "fig/rmd-",
32 | fig.process = fix_fig_path)
33 |
34 | # The hooks below add html tags to the code chunks and their output so that they
35 | # are properly formatted when the site is built.
36 |
37 | hook_in <- function(x, options) {
38 | stringr::str_c("\n\n~~~\n",
39 | paste0(x, collapse="\n"),
40 | "\n~~~\n{: .language-r}\n\n")
41 | }
42 |
43 | hook_out <- function(x, options) {
44 | x <- gsub("\n$", "", x)
45 | stringr::str_c("\n\n~~~\n",
46 | paste0(x, collapse="\n"),
47 | "\n~~~\n{: .output}\n\n")
48 | }
49 |
50 | hook_error <- function(x, options) {
51 | x <- gsub("\n$", "", x)
52 | stringr::str_c("\n\n~~~\n",
53 | paste0(x, collapse="\n"),
54 | "\n~~~\n{: .error}\n\n")
55 | }
56 |
57 | knit_hooks$set(source = hook_in, output = hook_out, warning = hook_error,
58 | error = hook_error, message = hook_out)
59 |
--------------------------------------------------------------------------------
/bin/generate_md_episodes.R:
--------------------------------------------------------------------------------
1 | generate_md_episodes <- function() {
2 |
3 | library("methods")
4 |
5 | if (require("knitr") && packageVersion("knitr") < '1.9.19')
6 | stop("knitr must be version 1.9.20 or higher")
7 |
8 | if (!require("stringr"))
9 | stop("The package stringr is required for generating the lessons.")
10 |
11 | if (require("checkpoint") && packageVersion("checkpoint") >= '0.4.0') {
12 | required_pkgs <-
13 | checkpoint:::scanForPackages(project = "_episodes_rmd",
14 | verbose=FALSE, use.knitr = TRUE)$pkgs
15 | } else {
16 | stop("The checkpoint package (>= 0.4.0) is required to build the lessons.")
17 | }
18 |
19 | missing_pkgs <- required_pkgs[!(required_pkgs %in% rownames(installed.packages()))]
20 |
21 | if (length(missing_pkgs)) {
22 | message("Installing missing required packages: ",
23 | paste(missing_pkgs, collapse=", "))
24 | install.packages(missing_pkgs)
25 | }
26 |
27 | ## find all the Rmd files, and generate the paths for their respective outputs
28 | src_rmd <- list.files(pattern = "??-*.Rmd$", path = "_episodes_rmd", full.names = TRUE)
29 | dest_md <- file.path("_episodes", gsub("Rmd$", "md", basename(src_rmd)))
30 |
31 | ## knit the Rmd into markdown
32 | mapply(function(x, y) {
33 | knitr::knit(x, output = y)
34 | }, src_rmd, dest_md)
35 |
36 | # Read the generated md files and add comments advising not to edit them
37 | vapply(dest_md, function(y) {
38 | con <- file(y)
39 | mdfile <- readLines(con)
40 | if (mdfile[1] != "---")
41 | stop("Input file does not have a valid header")
42 | mdfile <- append(mdfile, "# Please do not edit this file directly; it is auto generated.", after = 1)
43 | mdfile <- append(mdfile, paste("# Instead, please edit",
44 | basename(y), "in _episodes_rmd/"), after = 2)
45 | writeLines(mdfile, con)
46 | close(con)
47 | return(paste("Warning added to YAML header of", y))
48 | },
49 | character(1))
50 | }
51 |
52 | generate_md_episodes()
53 |
--------------------------------------------------------------------------------
/bin/knit_lessons.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | # Only try running R to translate files if there are some files present.
4 | # The Makefile passes in the names of files.
5 |
6 | if [ $# -ne 0 ] ; then
7 | Rscript -e "source('bin/generate_md_episodes.R')"
8 | fi
9 |
--------------------------------------------------------------------------------
/bin/lesson_check.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 |
3 | """
4 | Check lesson files and their contents.
5 | """
6 |
7 |
8 | import os
9 | import glob
10 | import re
11 | from argparse import ArgumentParser
12 |
13 | from util import (Reporter, read_markdown, load_yaml, check_unwanted_files,
14 | require)
15 |
16 | __version__ = '0.3'
17 |
18 | # Where to look for source Markdown files.
19 | SOURCE_DIRS = ['', '_episodes', '_extras']
20 |
21 | # Required files: each entry is ('path': YAML_required).
22 | # FIXME: We do not yet validate whether any files have the required
23 | # YAML headers, but should in the future.
24 | # The '%' is replaced with the source directory path for checking.
25 | # Episodes are handled specially, and extra files in '_extras' are also handled
26 | # specially. This list must include all the Markdown files listed in the
27 | # 'bin/initialize' script.
28 | REQUIRED_FILES = {
29 | '%/CODE_OF_CONDUCT.md': True,
30 | '%/CONTRIBUTING.md': False,
31 | '%/LICENSE.md': True,
32 | '%/README.md': False,
33 | '%/_extras/discuss.md': True,
34 | '%/_extras/guide.md': True,
35 | '%/index.md': True,
36 | '%/reference.md': True,
37 | '%/setup.md': True,
38 | }
39 |
40 | # Episode filename pattern.
41 | P_EPISODE_FILENAME = re.compile(r'/_episodes/(\d\d)-[-\w]+.md$')
42 |
43 | # Pattern to match lines ending with whitespace.
44 | P_TRAILING_WHITESPACE = re.compile(r'\s+$')
45 |
46 | # Pattern to match figure references in HTML.
47 | P_FIGURE_REFS = re.compile(r']+src="([^"]+)"[^>]*>')
48 |
49 | # Pattern to match internally-defined Markdown links.
50 | P_INTERNAL_LINK_REF = re.compile(r'\[([^\]]+)\]\[([^\]]+)\]')
51 |
52 | # Pattern to match reference links (to resolve internally-defined references).
53 | P_INTERNAL_LINK_DEF = re.compile(r'^\[([^\]]+)\]:\s*(.+)')
54 |
55 | # What kinds of blockquotes are allowed?
56 | KNOWN_BLOCKQUOTES = {
57 | 'callout',
58 | 'challenge',
59 | 'checklist',
60 | 'discussion',
61 | 'keypoints',
62 | 'objectives',
63 | 'prereq',
64 | 'quotation',
65 | 'solution',
66 | 'testimonial'
67 | }
68 |
69 | # What kinds of code fragments are allowed?
70 | KNOWN_CODEBLOCKS = {
71 | 'error',
72 | 'output',
73 | 'source',
74 | 'language-bash',
75 | 'html',
76 | 'language-make',
77 | 'language-matlab',
78 | 'language-python',
79 | 'language-r',
80 | 'language-shell',
81 | 'language-sql'
82 | }
83 |
84 | # What fields are required in teaching episode metadata?
85 | TEACHING_METADATA_FIELDS = {
86 | ('title', str),
87 | ('teaching', int),
88 | ('exercises', int),
89 | ('questions', list),
90 | ('objectives', list),
91 | ('keypoints', list)
92 | }
93 |
94 | # What fields are required in break episode metadata?
95 | BREAK_METADATA_FIELDS = {
96 | ('layout', str),
97 | ('title', str),
98 | ('break', int)
99 | }
100 |
101 | # How long are lines allowed to be?
102 | MAX_LINE_LEN = 100
103 |
104 |
105 | def main():
106 | """Main driver."""
107 |
108 | args = parse_args()
109 | args.reporter = Reporter()
110 | check_config(args.reporter, args.source_dir)
111 | args.references = read_references(args.reporter, args.reference_path)
112 |
113 | docs = read_all_markdown(args.source_dir, args.parser)
114 | check_fileset(args.source_dir, args.reporter, list(docs.keys()))
115 | check_unwanted_files(args.source_dir, args.reporter)
116 | for filename in list(docs.keys()):
117 | checker = create_checker(args, filename, docs[filename])
118 | checker.check()
119 |
120 | args.reporter.report()
121 | if args.reporter.messages and not args.permissive:
122 | exit(1)
123 |
124 |
125 | def parse_args():
126 | """Parse command-line arguments."""
127 |
128 | parser = ArgumentParser(description="""Check episode files in a lesson.""")
129 | parser.add_argument('-l', '--linelen',
130 | default=False,
131 | action="store_true",
132 | dest='line_lengths',
133 | help='Check line lengths')
134 | parser.add_argument('-p', '--parser',
135 | default=None,
136 | dest='parser',
137 | help='path to Markdown parser')
138 | parser.add_argument('-r', '--references',
139 | default=None,
140 | dest='reference_path',
141 | help='path to Markdown file of external references')
142 | parser.add_argument('-s', '--source',
143 | default=os.curdir,
144 | dest='source_dir',
145 | help='source directory')
146 | parser.add_argument('-w', '--whitespace',
147 | default=False,
148 | action="store_true",
149 | dest='trailing_whitespace',
150 | help='Check for trailing whitespace')
151 | parser.add_argument('--permissive',
152 | default=False,
153 | action="store_true",
154 | dest='permissive',
155 | help='Do not raise an error even if issues are detected')
156 |
157 | args, extras = parser.parse_known_args()
158 | require(args.parser is not None,
159 | 'Path to Markdown parser not provided')
160 | require(not extras,
161 | 'Unexpected trailing command-line arguments "{0}"'.format(extras))
162 |
163 | return args
164 |
165 |
166 | def check_config(reporter, source_dir):
167 | """Check configuration file."""
168 |
169 | config_file = os.path.join(source_dir, '_config.yml')
170 | config = load_yaml(config_file)
171 | reporter.check_field(config_file, 'configuration',
172 | config, 'kind', 'lesson')
173 | reporter.check_field(config_file, 'configuration',
174 | config, 'carpentry', ('swc', 'dc', 'lc', 'cp'))
175 | reporter.check_field(config_file, 'configuration', config, 'title')
176 | reporter.check_field(config_file, 'configuration', config, 'email')
177 |
178 | for defaults in [
179 | {'values': {'root': '.', 'layout': 'page'}},
180 | {'values': {'root': '..', 'layout': 'episode'}, 'scope': {'type': 'episodes', 'path': ''}},
181 | {'values': {'root': '..', 'layout': 'page'}, 'scope': {'type': 'extras', 'path': ''}}
182 | ]:
183 | reporter.check(defaults in config.get('defaults', []),
184 | 'configuration',
185 | '"root" not set to "." in configuration')
186 |
187 |
188 | def read_references(reporter, ref_path):
189 | """Read shared file of reference links, returning dictionary of valid references
190 | {symbolic_name : URL}
191 | """
192 |
193 | result = {}
194 | urls_seen = set()
195 | if ref_path:
196 | with open(ref_path, 'r') as reader:
197 | for (num, line) in enumerate(reader):
198 | line_num = num + 1
199 | m = P_INTERNAL_LINK_DEF.search(line)
200 | require(m,
201 | '{0}:{1} not valid reference:\n{2}'.format(ref_path, line_num, line.rstrip()))
202 | name = m.group(1)
203 | url = m.group(2)
204 | require(name,
205 | 'Empty reference at {0}:{1}'.format(ref_path, line_num))
206 | reporter.check(name not in result,
207 | ref_path,
208 | 'Duplicate reference {0} at line {1}',
209 | name, line_num)
210 | reporter.check(url not in urls_seen,
211 | ref_path,
212 | 'Duplicate definition of URL {0} at line {1}',
213 | url, line_num)
214 | result[name] = url
215 | urls_seen.add(url)
216 | return result
217 |
218 |
219 | def read_all_markdown(source_dir, parser):
220 | """Read source files, returning
221 | {path : {'metadata':yaml, 'metadata_len':N, 'text':text, 'lines':[(i, line, len)], 'doc':doc}}
222 | """
223 |
224 | all_dirs = [os.path.join(source_dir, d) for d in SOURCE_DIRS]
225 | all_patterns = [os.path.join(d, '*.md') for d in all_dirs]
226 | result = {}
227 | for pat in all_patterns:
228 | for filename in glob.glob(pat):
229 | data = read_markdown(parser, filename)
230 | if data:
231 | result[filename] = data
232 | return result
233 |
234 |
235 | def check_fileset(source_dir, reporter, filenames_present):
236 | """Are all required files present? Are extraneous files present?"""
237 |
238 | # Check files with predictable names.
239 | required = [p.replace('%', source_dir) for p in REQUIRED_FILES]
240 | missing = set(required) - set(filenames_present)
241 | for m in missing:
242 | reporter.add(None, 'Missing required file {0}', m)
243 |
244 | # Check episode files' names.
245 | seen = []
246 | for filename in filenames_present:
247 | if '_episodes' not in filename:
248 | continue
249 | m = P_EPISODE_FILENAME.search(filename)
250 | if m and m.group(1):
251 | seen.append(m.group(1))
252 | else:
253 | reporter.add(
254 | None, 'Episode {0} has badly-formatted filename', filename)
255 |
256 | # Check for duplicate episode numbers.
257 | reporter.check(len(seen) == len(set(seen)),
258 | None,
259 | 'Duplicate episode numbers {0} vs {1}',
260 | sorted(seen), sorted(set(seen)))
261 |
262 | # Check that numbers are consecutive.
263 | seen = sorted([int(s) for s in seen])
264 | clean = True
265 | for i in range(len(seen) - 1):
266 | clean = clean and ((seen[i+1] - seen[i]) == 1)
267 | reporter.check(clean,
268 | None,
269 | 'Missing or non-consecutive episode numbers {0}',
270 | seen)
271 |
272 |
273 | def create_checker(args, filename, info):
274 | """Create appropriate checker for file."""
275 |
276 | for (pat, cls) in CHECKERS:
277 | if pat.search(filename):
278 | return cls(args, filename, **info)
279 | return NotImplemented
280 |
281 | class CheckBase:
282 | """Base class for checking Markdown files."""
283 |
284 | def __init__(self, args, filename, metadata, metadata_len, text, lines, doc):
285 | """Cache arguments for checking."""
286 |
287 | self.args = args
288 | self.reporter = self.args.reporter # for convenience
289 | self.filename = filename
290 | self.metadata = metadata
291 | self.metadata_len = metadata_len
292 | self.text = text
293 | self.lines = lines
294 | self.doc = doc
295 |
296 | self.layout = None
297 |
298 | def check(self):
299 | """Run tests."""
300 |
301 | self.check_metadata()
302 | self.check_line_lengths()
303 | self.check_trailing_whitespace()
304 | self.check_blockquote_classes()
305 | self.check_codeblock_classes()
306 | self.check_defined_link_references()
307 |
308 | def check_metadata(self):
309 | """Check the YAML metadata."""
310 |
311 | self.reporter.check(self.metadata is not None,
312 | self.filename,
313 | 'Missing metadata entirely')
314 |
315 | if self.metadata and (self.layout is not None):
316 | self.reporter.check_field(
317 | self.filename, 'metadata', self.metadata, 'layout', self.layout)
318 |
319 | def check_line_lengths(self):
320 | """Check the raw text of the lesson body."""
321 |
322 | if self.args.line_lengths:
323 | over = [i for (i, l, n) in self.lines if (
324 | n > MAX_LINE_LEN) and (not l.startswith('!'))]
325 | self.reporter.check(not over,
326 | self.filename,
327 | 'Line(s) are too long: {0}',
328 | ', '.join([str(i) for i in over]))
329 |
330 | def check_trailing_whitespace(self):
331 | """Check for whitespace at the ends of lines."""
332 |
333 | if self.args.trailing_whitespace:
334 | trailing = [
335 | i for (i, l, n) in self.lines if P_TRAILING_WHITESPACE.match(l)]
336 | self.reporter.check(not trailing,
337 | self.filename,
338 | 'Line(s) end with whitespace: {0}',
339 | ', '.join([str(i) for i in trailing]))
340 |
341 | def check_blockquote_classes(self):
342 | """Check that all blockquotes have known classes."""
343 |
344 | for node in self.find_all(self.doc, {'type': 'blockquote'}):
345 | cls = self.get_val(node, 'attr', 'class')
346 | self.reporter.check(cls in KNOWN_BLOCKQUOTES,
347 | (self.filename, self.get_loc(node)),
348 | 'Unknown or missing blockquote type {0}',
349 | cls)
350 |
351 | def check_codeblock_classes(self):
352 | """Check that all code blocks have known classes."""
353 |
354 | for node in self.find_all(self.doc, {'type': 'codeblock'}):
355 | cls = self.get_val(node, 'attr', 'class')
356 | self.reporter.check(cls in KNOWN_CODEBLOCKS,
357 | (self.filename, self.get_loc(node)),
358 | 'Unknown or missing code block type {0}',
359 | cls)
360 |
361 | def check_defined_link_references(self):
362 | """Check that defined links resolve in the file.
363 |
364 | Internally-defined links match the pattern [text][label].
365 | """
366 |
367 | result = set()
368 | for node in self.find_all(self.doc, {'type': 'text'}):
369 | for match in P_INTERNAL_LINK_REF.findall(node['value']):
370 | text = match[0]
371 | link = match[1]
372 | if link not in self.args.references:
373 | result.add('"{0}"=>"{1}"'.format(text, link))
374 | self.reporter.check(not result,
375 | self.filename,
376 | 'Internally-defined links may be missing definitions: {0}',
377 | ', '.join(sorted(result)))
378 |
379 | def find_all(self, node, pattern, accum=None):
380 | """Find all matches for a pattern."""
381 |
382 | assert isinstance(pattern, dict), 'Patterns must be dictionaries'
383 | if accum is None:
384 | accum = []
385 | if self.match(node, pattern):
386 | accum.append(node)
387 | for child in node.get('children', []):
388 | self.find_all(child, pattern, accum)
389 | return accum
390 |
391 | def match(self, node, pattern):
392 | """Does this node match the given pattern?"""
393 |
394 | for key in pattern:
395 | if key not in node:
396 | return False
397 | val = pattern[key]
398 | if isinstance(val, str):
399 | if node[key] != val:
400 | return False
401 | elif isinstance(val, dict):
402 | if not self.match(node[key], val):
403 | return False
404 | return True
405 |
406 | @staticmethod
407 | def get_val(node, *chain):
408 | """Get value one or more levels down."""
409 |
410 | curr = node
411 | for selector in chain:
412 | curr = curr.get(selector, None)
413 | if curr is None:
414 | break
415 | return curr
416 |
417 | def get_loc(self, node):
418 | """Convenience method to get node's line number."""
419 |
420 | result = self.get_val(node, 'options', 'location')
421 | if self.metadata_len is not None:
422 | result += self.metadata_len
423 | return result
424 |
425 |
426 | class CheckNonJekyll(CheckBase):
427 | """Check a file that isn't translated by Jekyll."""
428 |
429 | def check_metadata(self):
430 | self.reporter.check(self.metadata is None,
431 | self.filename,
432 | 'Unexpected metadata')
433 |
434 |
435 | class CheckIndex(CheckBase):
436 | """Check the main index page."""
437 |
438 | def __init__(self, args, filename, metadata, metadata_len, text, lines, doc):
439 | super().__init__(args, filename, metadata, metadata_len, text, lines, doc)
440 | self.layout = 'lesson'
441 |
442 | def check_metadata(self):
443 | super().check_metadata()
444 | self.reporter.check(self.metadata.get('root', '') == '.',
445 | self.filename,
446 | 'Root not set to "."')
447 |
448 |
449 | class CheckEpisode(CheckBase):
450 | """Check an episode page."""
451 |
452 | def check(self):
453 | """Run extra tests."""
454 |
455 | super().check()
456 | self.check_reference_inclusion()
457 |
458 | def check_metadata(self):
459 | super().check_metadata()
460 | if self.metadata:
461 | if 'layout' in self.metadata:
462 | if self.metadata['layout'] == 'break':
463 | self.check_metadata_fields(BREAK_METADATA_FIELDS)
464 | else:
465 | self.reporter.add(self.filename,
466 | 'Unknown episode layout "{0}"',
467 | self.metadata['layout'])
468 | else:
469 | self.check_metadata_fields(TEACHING_METADATA_FIELDS)
470 |
471 | def check_metadata_fields(self, expected):
472 | """Check metadata fields."""
473 | for (name, type_) in expected:
474 | if name not in self.metadata:
475 | self.reporter.add(self.filename,
476 | 'Missing metadata field {0}',
477 | name)
478 | elif not isinstance(self.metadata[name], type_):
479 | self.reporter.add(self.filename,
480 | '"{0}" has wrong type in metadata ({1} instead of {2})',
481 | name, type(self.metadata[name]), type_)
482 |
483 | def check_reference_inclusion(self):
484 | """Check that links file has been included."""
485 |
486 | if not self.args.reference_path:
487 | return
488 |
489 | for (i, last_line, line_len) in reversed(self.lines):
490 | if last_line:
491 | break
492 |
493 | require(last_line,
494 | 'No non-empty lines in {0}'.format(self.filename))
495 |
496 | include_filename = os.path.split(self.args.reference_path)[-1]
497 | if include_filename not in last_line:
498 | self.reporter.add(self.filename,
499 | 'episode does not include "{0}"',
500 | include_filename)
501 |
502 |
503 | class CheckReference(CheckBase):
504 | """Check the reference page."""
505 |
506 | def __init__(self, args, filename, metadata, metadata_len, text, lines, doc):
507 | super().__init__(args, filename, metadata, metadata_len, text, lines, doc)
508 | self.layout = 'reference'
509 |
510 |
511 | class CheckGeneric(CheckBase):
512 | """Check a generic page."""
513 |
514 | def __init__(self, args, filename, metadata, metadata_len, text, lines, doc):
515 | super().__init__(args, filename, metadata, metadata_len, text, lines, doc)
516 |
517 |
518 | CHECKERS = [
519 | (re.compile(r'CONTRIBUTING\.md'), CheckNonJekyll),
520 | (re.compile(r'README\.md'), CheckNonJekyll),
521 | (re.compile(r'index\.md'), CheckIndex),
522 | (re.compile(r'reference\.md'), CheckReference),
523 | (re.compile(r'_episodes/.*\.md'), CheckEpisode),
524 | (re.compile(r'aio\.md'), CheckNonJekyll),
525 | (re.compile(r'.*\.md'), CheckGeneric)
526 | ]
527 |
528 |
529 | if __name__ == '__main__':
530 | main()
531 |
--------------------------------------------------------------------------------
/bin/lesson_initialize.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 |
3 | """Initialize a newly-created repository."""
4 |
5 |
6 | import sys
7 | import os
8 | import shutil
9 |
10 | BOILERPLATE = (
11 | '.travis.yml',
12 | 'AUTHORS',
13 | 'CITATION',
14 | 'CODE_OF_CONDUCT.md',
15 | 'CONTRIBUTING.md',
16 | 'README.md',
17 | '_config.yml',
18 | '_episodes/01-introduction.md',
19 | '_extras/about.md',
20 | '_extras/discuss.md',
21 | '_extras/figures.md',
22 | '_extras/guide.md',
23 | 'aio.md',
24 | 'index.md',
25 | 'reference.md',
26 | 'setup.md',
27 | )
28 |
29 |
30 | def main():
31 | """Check for collisions, then create."""
32 |
33 | # Check.
34 | errors = False
35 | for path in BOILERPLATE:
36 | if os.path.exists(path):
37 | print('Warning: {0} already exists.'.format(path), file=sys.stderr)
38 | errors = True
39 | if errors:
40 | print('**Exiting without creating files.**', file=sys.stderr)
41 | sys.exit(1)
42 |
43 | # Create.
44 | for path in BOILERPLATE:
45 | shutil.copyfile(
46 | "bin/boilerplate/{}".format(path),
47 | path
48 | )
49 |
50 |
51 | if __name__ == '__main__':
52 | main()
53 |
--------------------------------------------------------------------------------
/bin/markdown_ast.rb:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env ruby
2 |
3 | # Use Kramdown parser to produce AST for Markdown document.
4 |
5 | require "kramdown"
6 | require "json"
7 |
8 | markdown = STDIN.read()
9 | doc = Kramdown::Document.new(markdown)
10 | tree = doc.to_hash_a_s_t
11 | puts JSON.pretty_generate(tree)
12 |
--------------------------------------------------------------------------------
/bin/repo_check.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 |
3 | """
4 | Check repository settings.
5 | """
6 |
7 |
8 | import sys
9 | import os
10 | from subprocess import Popen, PIPE
11 | import re
12 | from argparse import ArgumentParser
13 |
14 | from util import Reporter, require
15 |
16 | # Import this way to produce a more useful error message.
17 | try:
18 | import requests
19 | except ImportError:
20 | print('Unable to import requests module: please install requests', file=sys.stderr)
21 | sys.exit(1)
22 |
23 |
24 | # Pattern to match Git command-line output for remotes => (user name, project name).
25 | P_GIT_REMOTE = re.compile(r'upstream\s+[^:]+:([^/]+)/([^.]+)\.git\s+\(fetch\)')
26 |
27 | # Repository URL format string.
28 | F_REPO_URL = 'https://github.com/{0}/{1}/'
29 |
30 | # Pattern to match repository URLs => (user name, project name)
31 | P_REPO_URL = re.compile(r'https?://github\.com/([^.]+)/([^/]+)/?')
32 |
33 | # API URL format string.
34 | F_API_URL = 'https://api.github.com/repos/{0}/{1}/labels'
35 |
36 | # Expected labels and colors.
37 | EXPECTED = {
38 | 'help wanted': 'dcecc7',
39 | 'status:in progress': '9bcc65',
40 | 'status:changes requested': '679f38',
41 | 'status:wait': 'fff2df',
42 | 'status:refer to cac': 'ffdfb2',
43 | 'status:need more info': 'ee6c00',
44 | 'status:blocked': 'e55100',
45 | 'status:out of scope': 'eeeeee',
46 | 'status:duplicate': 'bdbdbd',
47 | 'type:typo text': 'f8bad0',
48 | 'type:bug': 'eb3f79',
49 | 'type:formatting': 'ac1357',
50 | 'type:template and tools': '7985cb',
51 | 'type:instructor guide': '00887a',
52 | 'type:discussion': 'b2e5fc',
53 | 'type:enhancement': '7fdeea',
54 | 'type:clarification': '00acc0',
55 | 'type:teaching example': 'ced8dc',
56 | 'good first issue': 'ffeb3a',
57 | 'high priority': 'd22e2e'
58 | }
59 |
60 |
61 | def main():
62 | """
63 | Main driver.
64 | """
65 |
66 | args = parse_args()
67 | reporter = Reporter()
68 | repo_url = get_repo_url(args.repo_url)
69 | check_labels(reporter, repo_url)
70 | reporter.report()
71 |
72 |
73 | def parse_args():
74 | """
75 | Parse command-line arguments.
76 | """
77 |
78 | parser = ArgumentParser(description="""Check repository settings.""")
79 | parser.add_argument('-r', '--repo',
80 | default=None,
81 | dest='repo_url',
82 | help='repository URL')
83 | parser.add_argument('-s', '--source',
84 | default=os.curdir,
85 | dest='source_dir',
86 | help='source directory')
87 |
88 | args, extras = parser.parse_known_args()
89 | require(not extras,
90 | 'Unexpected trailing command-line arguments "{0}"'.format(extras))
91 |
92 | return args
93 |
94 |
95 | def get_repo_url(repo_url):
96 | """
97 | Figure out which repository to query.
98 | """
99 |
100 | # Explicitly specified.
101 | if repo_url is not None:
102 | return repo_url
103 |
104 | # Guess.
105 | cmd = 'git remote -v'
106 | p = Popen(cmd, shell=True, stdin=PIPE, stdout=PIPE,
107 | close_fds=True, universal_newlines=True)
108 | stdout_data, stderr_data = p.communicate()
109 | stdout_data = stdout_data.split('\n')
110 | matches = [P_GIT_REMOTE.match(line) for line in stdout_data]
111 | matches = [m for m in matches if m is not None]
112 | require(len(matches) == 1,
113 | 'Unexpected output from git remote command: "{0}"'.format(matches))
114 |
115 | username = matches[0].group(1)
116 | require(
117 | username, 'empty username in git remote output {0}'.format(matches[0]))
118 |
119 | project_name = matches[0].group(2)
120 | require(
121 | username, 'empty project name in git remote output {0}'.format(matches[0]))
122 |
123 | url = F_REPO_URL.format(username, project_name)
124 | return url
125 |
126 |
127 | def check_labels(reporter, repo_url):
128 | """
129 | Check labels in repository.
130 | """
131 |
132 | actual = get_labels(repo_url)
133 | extra = set(actual.keys()) - set(EXPECTED.keys())
134 |
135 | reporter.check(not extra,
136 | None,
137 | 'Extra label(s) in repository {0}: {1}',
138 | repo_url, ', '.join(sorted(extra)))
139 |
140 | missing = set(EXPECTED.keys()) - set(actual.keys())
141 | reporter.check(not missing,
142 | None,
143 | 'Missing label(s) in repository {0}: {1}',
144 | repo_url, ', '.join(sorted(missing)))
145 |
146 | overlap = set(EXPECTED.keys()).intersection(set(actual.keys()))
147 | for name in sorted(overlap):
148 | reporter.check(EXPECTED[name].lower() == actual[name].lower(),
149 | None,
150 | 'Color mis-match for label {0} in {1}: expected {2}, found {3}',
151 | name, repo_url, EXPECTED[name], actual[name])
152 |
153 |
154 | def get_labels(repo_url):
155 | """
156 | Get actual labels from repository.
157 | """
158 |
159 | m = P_REPO_URL.match(repo_url)
160 | require(
161 | m, 'repository URL {0} does not match expected pattern'.format(repo_url))
162 |
163 | username = m.group(1)
164 | require(username, 'empty username in repository URL {0}'.format(repo_url))
165 |
166 | project_name = m.group(2)
167 | require(
168 | username, 'empty project name in repository URL {0}'.format(repo_url))
169 |
170 | url = F_API_URL.format(username, project_name)
171 | r = requests.get(url)
172 | require(r.status_code == 200,
173 | 'Request for {0} failed with {1}'.format(url, r.status_code))
174 |
175 | result = {}
176 | for entry in r.json():
177 | result[entry['name']] = entry['color']
178 | return result
179 |
180 |
181 | if __name__ == '__main__':
182 | main()
183 |
--------------------------------------------------------------------------------
/bin/test_lesson_check.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 |
3 | import unittest
4 |
5 | import lesson_check
6 | import util
7 |
8 |
9 | class TestFileList(unittest.TestCase):
10 | def setUp(self):
11 | self.reporter = util.Reporter() # TODO: refactor reporter class.
12 |
13 | def test_file_list_has_expected_entries(self):
14 | # For first pass, simply assume that all required files are present
15 | all_filenames = [filename.replace('%', '')
16 | for filename in lesson_check.REQUIRED_FILES]
17 |
18 | lesson_check.check_fileset('', self.reporter, all_filenames)
19 | self.assertEqual(len(self.reporter.messages), 0)
20 |
21 |
22 | if __name__ == "__main__":
23 | unittest.main()
24 |
--------------------------------------------------------------------------------
/bin/util.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | import json
4 | from subprocess import Popen, PIPE
5 |
6 | # Import this way to produce a more useful error message.
7 | try:
8 | import yaml
9 | except ImportError:
10 | print('Unable to import YAML module: please install PyYAML', file=sys.stderr)
11 | sys.exit(1)
12 |
13 |
14 | # Things an image file's name can end with.
15 | IMAGE_FILE_SUFFIX = {
16 | '.gif',
17 | '.jpg',
18 | '.png',
19 | '.svg'
20 | }
21 |
22 | # Files that shouldn't be present.
23 | UNWANTED_FILES = [
24 | '.nojekyll'
25 | ]
26 |
27 | # Marker to show that an expected value hasn't been provided.
28 | # (Can't use 'None' because that might be a legitimate value.)
29 | REPORTER_NOT_SET = []
30 |
31 |
32 | class Reporter:
33 | """Collect and report errors."""
34 |
35 | def __init__(self):
36 | """Constructor."""
37 | self.messages = []
38 |
39 | def check_field(self, filename, name, values, key, expected=REPORTER_NOT_SET):
40 | """Check that a dictionary has an expected value."""
41 |
42 | if key not in values:
43 | self.add(filename, '{0} does not contain {1}', name, key)
44 | elif expected is REPORTER_NOT_SET:
45 | pass
46 | elif type(expected) in (tuple, set, list):
47 | if values[key] not in expected:
48 | self.add(
49 | filename, '{0} {1} value {2} is not in {3}', name, key, values[key], expected)
50 | elif values[key] != expected:
51 | self.add(filename, '{0} {1} is {2} not {3}',
52 | name, key, values[key], expected)
53 |
54 | def check(self, condition, location, fmt, *args):
55 | """Append error if condition not met."""
56 |
57 | if not condition:
58 | self.add(location, fmt, *args)
59 |
60 | def add(self, location, fmt, *args):
61 | """Append error unilaterally."""
62 |
63 | self.messages.append((location, fmt.format(*args)))
64 |
65 | @staticmethod
66 | def pretty(item):
67 | location, message = item
68 | if isinstance(location, type(None)):
69 | return message
70 | elif isinstance(location, str):
71 | return location + ': ' + message
72 | elif isinstance(location, tuple):
73 | return '{0}:{1}: '.format(*location) + message
74 |
75 | print('Unknown item "{0}"'.format(item), file=sys.stderr)
76 | return NotImplemented
77 |
78 | @staticmethod
79 | def key(item):
80 | location, message = item
81 | if isinstance(location, type(None)):
82 | return ('', -1, message)
83 | elif isinstance(location, str):
84 | return (location, -1, message)
85 | elif isinstance(location, tuple):
86 | return (location[0], location[1], message)
87 |
88 | print('Unknown item "{0}"'.format(item), file=sys.stderr)
89 | return NotImplemented
90 |
91 | def report(self, stream=sys.stdout):
92 | """Report all messages in order."""
93 |
94 | if not self.messages:
95 | return
96 |
97 | for m in sorted(self.messages, key=self.key):
98 | print(self.pretty(m), file=stream)
99 |
100 |
101 | def read_markdown(parser, path):
102 | """
103 | Get YAML and AST for Markdown file, returning
104 | {'metadata':yaml, 'metadata_len':N, 'text':text, 'lines':[(i, line, len)], 'doc':doc}.
105 | """
106 |
107 | # Split and extract YAML (if present).
108 | with open(path, 'r') as reader:
109 | body = reader.read()
110 | metadata_raw, metadata_yaml, body = split_metadata(path, body)
111 |
112 | # Split into lines.
113 | metadata_len = 0 if metadata_raw is None else metadata_raw.count('\n')
114 | lines = [(metadata_len+i+1, line, len(line))
115 | for (i, line) in enumerate(body.split('\n'))]
116 |
117 | # Parse Markdown.
118 | cmd = 'ruby {0}'.format(parser)
119 | p = Popen(cmd, shell=True, stdin=PIPE, stdout=PIPE,
120 | close_fds=True, universal_newlines=True)
121 | stdout_data, stderr_data = p.communicate(body)
122 | doc = json.loads(stdout_data)
123 |
124 | return {
125 | 'metadata': metadata_yaml,
126 | 'metadata_len': metadata_len,
127 | 'text': body,
128 | 'lines': lines,
129 | 'doc': doc
130 | }
131 |
132 |
133 | def split_metadata(path, text):
134 | """
135 | Get raw (text) metadata, metadata as YAML, and rest of body.
136 | If no metadata, return (None, None, body).
137 | """
138 |
139 | metadata_raw = None
140 | metadata_yaml = None
141 |
142 | pieces = text.split('---', 2)
143 | if len(pieces) == 3:
144 | metadata_raw = pieces[1]
145 | text = pieces[2]
146 | try:
147 | metadata_yaml = yaml.load(metadata_raw)
148 | except yaml.YAMLError as e:
149 | print('Unable to parse YAML header in {0}:\n{1}'.format(
150 | path, e), file=sys.stderr)
151 | sys.exit(1)
152 |
153 | return metadata_raw, metadata_yaml, text
154 |
155 |
156 | def load_yaml(filename):
157 | """
158 | Wrapper around YAML loading so that 'import yaml' is only needed
159 | in one file.
160 | """
161 |
162 | try:
163 | with open(filename, 'r') as reader:
164 | return yaml.load(reader)
165 | except (yaml.YAMLError, IOError) as e:
166 | print('Unable to load YAML file {0}:\n{1}'.format(
167 | filename, e), file=sys.stderr)
168 | sys.exit(1)
169 |
170 |
171 | def check_unwanted_files(dir_path, reporter):
172 | """
173 | Check that unwanted files are not present.
174 | """
175 |
176 | for filename in UNWANTED_FILES:
177 | path = os.path.join(dir_path, filename)
178 | reporter.check(not os.path.exists(path),
179 | path,
180 | "Unwanted file found")
181 |
182 |
183 | def require(condition, message):
184 | """Fail if condition not met."""
185 |
186 | if not condition:
187 | print(message, file=sys.stderr)
188 | sys.exit(1)
189 |
--------------------------------------------------------------------------------
/bin/workshop_check.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 |
3 | '''Check that a workshop's index.html metadata is valid. See the
4 | docstrings on the checking functions for a summary of the checks.
5 | '''
6 |
7 |
8 | import sys
9 | import os
10 | import re
11 | from datetime import date
12 | from util import Reporter, split_metadata, load_yaml, check_unwanted_files
13 |
14 | # Metadata field patterns.
15 | EMAIL_PATTERN = r'[^@]+@[^@]+\.[^@]+'
16 | HUMANTIME_PATTERN = r'((0?[1-9]|1[0-2]):[0-5]\d(am|pm)(-|to)(0?[1-9]|1[0-2]):[0-5]\d(am|pm))|((0?\d|1\d|2[0-3]):[0-5]\d(-|to)(0?\d|1\d|2[0-3]):[0-5]\d)'
17 | EVENTBRITE_PATTERN = r'\d{9,10}'
18 | URL_PATTERN = r'https?://.+'
19 |
20 | # Defaults.
21 | CARPENTRIES = ("dc", "swc")
22 | DEFAULT_CONTACT_EMAIL = 'admin@software-carpentry.org'
23 |
24 | USAGE = 'Usage: "workshop_check.py path/to/root/directory"'
25 |
26 | # Country and language codes. Note that codes mean different things: 'ar'
27 | # is 'Arabic' as a language but 'Argentina' as a country.
28 |
29 | ISO_COUNTRY = [
30 | 'ad', 'ae', 'af', 'ag', 'ai', 'al', 'am', 'an', 'ao', 'aq', 'ar', 'as',
31 | 'at', 'au', 'aw', 'ax', 'az', 'ba', 'bb', 'bd', 'be', 'bf', 'bg', 'bh',
32 | 'bi', 'bj', 'bm', 'bn', 'bo', 'br', 'bs', 'bt', 'bv', 'bw', 'by', 'bz',
33 | 'ca', 'cc', 'cd', 'cf', 'cg', 'ch', 'ci', 'ck', 'cl', 'cm', 'cn', 'co',
34 | 'cr', 'cu', 'cv', 'cx', 'cy', 'cz', 'de', 'dj', 'dk', 'dm', 'do', 'dz',
35 | 'ec', 'ee', 'eg', 'eh', 'er', 'es', 'et', 'eu', 'fi', 'fj', 'fk', 'fm',
36 | 'fo', 'fr', 'ga', 'gb', 'gd', 'ge', 'gf', 'gg', 'gh', 'gi', 'gl', 'gm',
37 | 'gn', 'gp', 'gq', 'gr', 'gs', 'gt', 'gu', 'gw', 'gy', 'hk', 'hm', 'hn',
38 | 'hr', 'ht', 'hu', 'id', 'ie', 'il', 'im', 'in', 'io', 'iq', 'ir', 'is',
39 | 'it', 'je', 'jm', 'jo', 'jp', 'ke', 'kg', 'kh', 'ki', 'km', 'kn', 'kp',
40 | 'kr', 'kw', 'ky', 'kz', 'la', 'lb', 'lc', 'li', 'lk', 'lr', 'ls', 'lt',
41 | 'lu', 'lv', 'ly', 'ma', 'mc', 'md', 'me', 'mg', 'mh', 'mk', 'ml', 'mm',
42 | 'mn', 'mo', 'mp', 'mq', 'mr', 'ms', 'mt', 'mu', 'mv', 'mw', 'mx', 'my',
43 | 'mz', 'na', 'nc', 'ne', 'nf', 'ng', 'ni', 'nl', 'no', 'np', 'nr', 'nu',
44 | 'nz', 'om', 'pa', 'pe', 'pf', 'pg', 'ph', 'pk', 'pl', 'pm', 'pn', 'pr',
45 | 'ps', 'pt', 'pw', 'py', 'qa', 're', 'ro', 'rs', 'ru', 'rw', 'sa', 'sb',
46 | 'sc', 'sd', 'se', 'sg', 'sh', 'si', 'sj', 'sk', 'sl', 'sm', 'sn', 'so',
47 | 'sr', 'st', 'sv', 'sy', 'sz', 'tc', 'td', 'tf', 'tg', 'th', 'tj', 'tk',
48 | 'tl', 'tm', 'tn', 'to', 'tr', 'tt', 'tv', 'tw', 'tz', 'ua', 'ug', 'um',
49 | 'us', 'uy', 'uz', 'va', 'vc', 've', 'vg', 'vi', 'vn', 'vu', 'wf', 'ws',
50 | 'ye', 'yt', 'za', 'zm', 'zw'
51 | ]
52 |
53 | ISO_LANGUAGE = [
54 | 'aa', 'ab', 'ae', 'af', 'ak', 'am', 'an', 'ar', 'as', 'av', 'ay', 'az',
55 | 'ba', 'be', 'bg', 'bh', 'bi', 'bm', 'bn', 'bo', 'br', 'bs', 'ca', 'ce',
56 | 'ch', 'co', 'cr', 'cs', 'cu', 'cv', 'cy', 'da', 'de', 'dv', 'dz', 'ee',
57 | 'el', 'en', 'eo', 'es', 'et', 'eu', 'fa', 'ff', 'fi', 'fj', 'fo', 'fr',
58 | 'fy', 'ga', 'gd', 'gl', 'gn', 'gu', 'gv', 'ha', 'he', 'hi', 'ho', 'hr',
59 | 'ht', 'hu', 'hy', 'hz', 'ia', 'id', 'ie', 'ig', 'ii', 'ik', 'io', 'is',
60 | 'it', 'iu', 'ja', 'jv', 'ka', 'kg', 'ki', 'kj', 'kk', 'kl', 'km', 'kn',
61 | 'ko', 'kr', 'ks', 'ku', 'kv', 'kw', 'ky', 'la', 'lb', 'lg', 'li', 'ln',
62 | 'lo', 'lt', 'lu', 'lv', 'mg', 'mh', 'mi', 'mk', 'ml', 'mn', 'mr', 'ms',
63 | 'mt', 'my', 'na', 'nb', 'nd', 'ne', 'ng', 'nl', 'nn', 'no', 'nr', 'nv',
64 | 'ny', 'oc', 'oj', 'om', 'or', 'os', 'pa', 'pi', 'pl', 'ps', 'pt', 'qu',
65 | 'rm', 'rn', 'ro', 'ru', 'rw', 'sa', 'sc', 'sd', 'se', 'sg', 'si', 'sk',
66 | 'sl', 'sm', 'sn', 'so', 'sq', 'sr', 'ss', 'st', 'su', 'sv', 'sw', 'ta',
67 | 'te', 'tg', 'th', 'ti', 'tk', 'tl', 'tn', 'to', 'tr', 'ts', 'tt', 'tw',
68 | 'ty', 'ug', 'uk', 'ur', 'uz', 've', 'vi', 'vo', 'wa', 'wo', 'xh', 'yi',
69 | 'yo', 'za', 'zh', 'zu'
70 | ]
71 |
72 |
73 | def look_for_fixme(func):
74 | """Decorator to fail test if text argument starts with "FIXME"."""
75 |
76 | def inner(arg):
77 | if (arg is not None) and \
78 | isinstance(arg, str) and \
79 | arg.lstrip().startswith('FIXME'):
80 | return False
81 | return func(arg)
82 | return inner
83 |
84 |
85 | @look_for_fixme
86 | def check_layout(layout):
87 | '''"layout" in YAML header must be "workshop".'''
88 |
89 | return layout == 'workshop'
90 |
91 |
92 | @look_for_fixme
93 | def check_carpentry(layout):
94 | '''"carpentry" in YAML header must be "dc" or "swc".'''
95 |
96 | return layout in CARPENTRIES
97 |
98 |
99 | @look_for_fixme
100 | def check_country(country):
101 | '''"country" must be a lowercase ISO-3166 two-letter code.'''
102 |
103 | return country in ISO_COUNTRY
104 |
105 |
106 | @look_for_fixme
107 | def check_language(language):
108 | '''"language" must be a lowercase ISO-639 two-letter code.'''
109 |
110 | return language in ISO_LANGUAGE
111 |
112 |
113 | @look_for_fixme
114 | def check_humandate(date):
115 | """
116 | 'humandate' must be a human-readable date with a 3-letter month
117 | and 4-digit year. Examples include 'Feb 18-20, 2025' and 'Feb 18
118 | and 20, 2025'. It may be in languages other than English, but the
119 | month name should be kept short to aid formatting of the main
120 | Software Carpentry web site.
121 | """
122 |
123 | if ',' not in date:
124 | return False
125 |
126 | month_dates, year = date.split(',')
127 |
128 | # The first three characters of month_dates are not empty
129 | month = month_dates[:3]
130 | if any(char == ' ' for char in month):
131 | return False
132 |
133 | # But the fourth character is empty ("February" is illegal)
134 | if month_dates[3] != ' ':
135 | return False
136 |
137 | # year contains *only* numbers
138 | try:
139 | int(year)
140 | except:
141 | return False
142 |
143 | return True
144 |
145 |
146 | @look_for_fixme
147 | def check_humantime(time):
148 | """
149 | 'humantime' is a human-readable start and end time for the
150 | workshop, such as '09:00 - 16:00'.
151 | """
152 |
153 | return bool(re.match(HUMANTIME_PATTERN, time.replace(' ', '')))
154 |
155 |
156 | def check_date(this_date):
157 | """
158 | 'startdate' and 'enddate' are machine-readable start and end dates
159 | for the workshop, and must be in YYYY-MM-DD format, e.g.,
160 | '2015-07-01'.
161 | """
162 |
163 | # YAML automatically loads valid dates as datetime.date.
164 | return isinstance(this_date, date)
165 |
166 |
167 | @look_for_fixme
168 | def check_latitude_longitude(latlng):
169 | """
170 | 'latlng' must be a valid latitude and longitude represented as two
171 | floating-point numbers separated by a comma.
172 | """
173 |
174 | try:
175 | lat, lng = latlng.split(',')
176 | lat = float(lat)
177 | lng = float(lng)
178 | return (-90.0 <= lat <= 90.0) and (-180.0 <= lng <= 180.0)
179 | except ValueError:
180 | return False
181 |
182 |
183 | def check_instructors(instructors):
184 | """
185 | 'instructor' must be a non-empty comma-separated list of quoted
186 | names, e.g. ['First name', 'Second name', ...']. Do not use 'TBD'
187 | or other placeholders.
188 | """
189 |
190 | # YAML automatically loads list-like strings as lists.
191 | return isinstance(instructors, list) and len(instructors) > 0
192 |
193 |
194 | def check_helpers(helpers):
195 | """
196 | 'helper' must be a comma-separated list of quoted names,
197 | e.g. ['First name', 'Second name', ...']. The list may be empty.
198 | Do not use 'TBD' or other placeholders.
199 | """
200 |
201 | # YAML automatically loads list-like strings as lists.
202 | return isinstance(helpers, list) and len(helpers) >= 0
203 |
204 |
205 | @look_for_fixme
206 | def check_emails(emails):
207 | """
208 | 'emails' must be a comma-separated list of valid email addresses.
209 | The list may be empty. A valid email address consists of characters,
210 | an '@', and more characters. It should not contain the default contact
211 | """
212 |
213 | # YAML automatically loads list-like strings as lists.
214 | if (isinstance(emails, list) and len(emails) >= 0):
215 | for email in emails:
216 | if ((not bool(re.match(EMAIL_PATTERN, email))) or (email == DEFAULT_CONTACT_EMAIL)):
217 | return False
218 | else:
219 | return False
220 |
221 | return True
222 |
223 |
224 | def check_eventbrite(eventbrite):
225 | """
226 | 'eventbrite' (the Eventbrite registration key) must be 9 or more
227 | digits. It may appear as an integer or as a string.
228 | """
229 |
230 | if isinstance(eventbrite, int):
231 | return True
232 | else:
233 | return bool(re.match(EVENTBRITE_PATTERN, eventbrite))
234 |
235 |
236 | @look_for_fixme
237 | def check_collaborative_notes(collaborative_notes):
238 | """
239 | 'collaborative_notes' must be a valid URL.
240 | """
241 |
242 | return bool(re.match(URL_PATTERN, collaborative_notes))
243 |
244 |
245 | @look_for_fixme
246 | def check_pass(value):
247 | """
248 | This test always passes (it is used for 'checking' things like the
249 | workshop address, for which no sensible validation is feasible).
250 | """
251 |
252 | return True
253 |
254 |
255 | HANDLERS = {
256 | 'layout': (True, check_layout, 'layout isn\'t "workshop"'),
257 |
258 | 'carpentry': (True, check_carpentry, 'carpentry isn\'t in ' +
259 | ', '.join(CARPENTRIES)),
260 |
261 | 'country': (True, check_country,
262 | 'country invalid: must use lowercase two-letter ISO code ' +
263 | 'from ' + ', '.join(ISO_COUNTRY)),
264 |
265 | 'language': (False, check_language,
266 | 'language invalid: must use lowercase two-letter ISO code' +
267 | ' from ' + ', '.join(ISO_LANGUAGE)),
268 |
269 | 'humandate': (True, check_humandate,
270 | 'humandate invalid. Please use three-letter months like ' +
271 | '"Jan" and four-letter years like "2025"'),
272 |
273 | 'humantime': (True, check_humantime,
274 | 'humantime doesn\'t include numbers'),
275 |
276 | 'startdate': (True, check_date,
277 | 'startdate invalid. Must be of format year-month-day, ' +
278 | 'i.e., 2014-01-31'),
279 |
280 | 'enddate': (False, check_date,
281 | 'enddate invalid. Must be of format year-month-day, i.e.,' +
282 | ' 2014-01-31'),
283 |
284 | 'latlng': (True, check_latitude_longitude,
285 | 'latlng invalid. Check that it is two floating point ' +
286 | 'numbers, separated by a comma'),
287 |
288 | 'instructor': (True, check_instructors,
289 | 'instructor list isn\'t a valid list of format ' +
290 | '["First instructor", "Second instructor",..]'),
291 |
292 | 'helper': (True, check_helpers,
293 | 'helper list isn\'t a valid list of format ' +
294 | '["First helper", "Second helper",..]'),
295 |
296 | 'email': (True, check_emails,
297 | 'contact email list isn\'t a valid list of format ' +
298 | '["me@example.org", "you@example.org",..] or contains incorrectly formatted email addresses or ' +
299 | '"{0}".'.format(DEFAULT_CONTACT_EMAIL)),
300 |
301 | 'eventbrite': (False, check_eventbrite, 'Eventbrite key appears invalid'),
302 |
303 | 'collaborative_notes': (False, check_collaborative_notes, 'Collaborative Notes URL appears invalid'),
304 |
305 | 'venue': (False, check_pass, 'venue name not specified'),
306 |
307 | 'address': (False, check_pass, 'address not specified')
308 | }
309 |
310 | # REQUIRED is all required categories.
311 | REQUIRED = {k for k in HANDLERS if HANDLERS[k][0]}
312 |
313 | # OPTIONAL is all optional categories.
314 | OPTIONAL = {k for k in HANDLERS if not HANDLERS[k][0]}
315 |
316 |
317 | def check_blank_lines(reporter, raw):
318 | """
319 | Blank lines are not allowed in category headers.
320 | """
321 |
322 | lines = [(i, x) for (i, x) in enumerate(
323 | raw.strip().split('\n')) if not x.strip()]
324 | reporter.check(not lines,
325 | None,
326 | 'Blank line(s) in header: {0}',
327 | ', '.join(["{0}: {1}".format(i, x.rstrip()) for (i, x) in lines]))
328 |
329 |
330 | def check_categories(reporter, left, right, msg):
331 | """
332 | Report differences (if any) between two sets of categories.
333 | """
334 |
335 | diff = left - right
336 | reporter.check(len(diff) == 0,
337 | None,
338 | '{0}: offending entries {1}',
339 | msg, sorted(list(diff)))
340 |
341 |
342 | def check_file(reporter, path, data):
343 | """
344 | Get header from file, call all other functions, and check file for
345 | validity.
346 | """
347 |
348 | # Get metadata as text and as YAML.
349 | raw, header, body = split_metadata(path, data)
350 |
351 | # Do we have any blank lines in the header?
352 | check_blank_lines(reporter, raw)
353 |
354 | # Look through all header entries. If the category is in the input
355 | # file and is either required or we have actual data (as opposed to
356 | # a commented-out entry), we check it. If it *isn't* in the header
357 | # but is required, report an error.
358 | for category in HANDLERS:
359 | required, handler, message = HANDLERS[category]
360 | if category in header:
361 | if required or header[category]:
362 | reporter.check(handler(header[category]),
363 | None,
364 | '{0}\n actual value "{1}"',
365 | message, header[category])
366 | elif required:
367 | reporter.add(None,
368 | 'Missing mandatory key "{0}"',
369 | category)
370 |
371 | # Check whether we have missing or too many categories
372 | seen_categories = set(header.keys())
373 | check_categories(reporter, REQUIRED, seen_categories,
374 | 'Missing categories')
375 | check_categories(reporter, seen_categories, REQUIRED.union(OPTIONAL),
376 | 'Superfluous categories')
377 |
378 |
379 | def check_config(reporter, filename):
380 | """
381 | Check YAML configuration file.
382 | """
383 |
384 | config = load_yaml(filename)
385 |
386 | kind = config.get('kind', None)
387 | reporter.check(kind == 'workshop',
388 | filename,
389 | 'Missing or unknown kind of event: {0}',
390 | kind)
391 |
392 | carpentry = config.get('carpentry', None)
393 | reporter.check(carpentry in ('swc', 'dc'),
394 | filename,
395 | 'Missing or unknown carpentry: {0}',
396 | carpentry)
397 |
398 |
399 | def main():
400 | '''Run as the main program.'''
401 |
402 | if len(sys.argv) != 2:
403 | print(USAGE, file=sys.stderr)
404 | sys.exit(1)
405 |
406 | root_dir = sys.argv[1]
407 | index_file = os.path.join(root_dir, 'index.html')
408 | config_file = os.path.join(root_dir, '_config.yml')
409 |
410 | reporter = Reporter()
411 | check_config(reporter, config_file)
412 | check_unwanted_files(root_dir, reporter)
413 | with open(index_file) as reader:
414 | data = reader.read()
415 | check_file(reporter, index_file, data)
416 | reporter.report()
417 |
418 |
419 | if __name__ == '__main__':
420 | main()
421 |
--------------------------------------------------------------------------------
/code/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/code/.gitkeep
--------------------------------------------------------------------------------
/data/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/data/.gitkeep
--------------------------------------------------------------------------------
/fig/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/fig/.gitkeep
--------------------------------------------------------------------------------
/fig/anatomy-of-a-doi.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/fig/anatomy-of-a-doi.jpg
--------------------------------------------------------------------------------
/fig/datacite-arxiv-crossref.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/fig/datacite-arxiv-crossref.png
--------------------------------------------------------------------------------
/fig/datacite_statistics.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/fig/datacite_statistics.png
--------------------------------------------------------------------------------
/fig/el-gebali-research-lifecycle.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/fig/el-gebali-research-lifecycle.png
--------------------------------------------------------------------------------
/fig/file_structures.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/fig/file_structures.png
--------------------------------------------------------------------------------
/fig/pepe_research_lifecycle.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/fig/pepe_research_lifecycle.png
--------------------------------------------------------------------------------
/fig/rest-api.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/fig/rest-api.png
--------------------------------------------------------------------------------
/files/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LibraryCarpentry/lc-fair-research/6dc5a89613cfcd137d835372821f4e532c1ca9bc/files/.gitkeep
--------------------------------------------------------------------------------
/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: lesson
3 | root: .
4 | permalink: index.html # Is the only page that don't follow the partner /:path/index.html
5 | ---
6 | FIXME: home page introduction
7 |
8 | > ## Under Design
9 | >
10 | > **This lesson is currently in its early design stage;
11 | > please check [the design notes]({{ page.root }}/design/)
12 | > to see what we have so far.
13 | > Contributions are very welcome:
14 | > we would be particularly grateful for exercises
15 | > and for commentary on the ones already there.**
16 | {: .callout}
17 |
18 | > ## Prerequisites
19 | >
20 | > FIXME
21 | {: .prereq}
22 |
--------------------------------------------------------------------------------
/reference.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: reference
3 | root: .
4 | ---
5 |
6 | ## Glossary
7 |
8 | FIXME
9 |
--------------------------------------------------------------------------------
/setup.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: page
3 | title: Setup
4 | root: .
5 | ---
6 | FIXME
7 |
--------------------------------------------------------------------------------