├── .gitignore
├── .idea
├── .gitignore
├── codeStyles
│ ├── codeStyleConfig.xml
│ └── Project.xml
├── misc.xml
├── compiler.xml
├── jarRepositories.xml
└── uiDesigner.xml
├── .gitattributes
├── Kibana.JPG
├── Realtime Customer Viewership Analysis.iml
├── src
└── main
│ └── scala
│ └── com
│ └── analytics
│ └── retail
│ ├── UDFs.scala
│ └── ViewershipAnalytics.scala
├── README.md
└── pom.xml
/.gitignore:
--------------------------------------------------------------------------------
1 | projectflow.JPG
2 | Video.mp4
--------------------------------------------------------------------------------
/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # Default ignored files
2 | /shelf/
3 | /workspace.xml
4 |
--------------------------------------------------------------------------------
/.gitattributes:
--------------------------------------------------------------------------------
1 | # Auto detect text file and perform LF normalization
2 | * text=auto
3 |
--------------------------------------------------------------------------------
/Kibana.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/LoveNui/Customer-Viewership-Realtime-Analysis/HEAD/Kibana.JPG
--------------------------------------------------------------------------------
/Realtime Customer Viewership Analysis.iml:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/.idea/codeStyles/codeStyleConfig.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
10 |
11 |
12 |
13 |
14 |
--------------------------------------------------------------------------------
/.idea/compiler.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/src/main/scala/com/analytics/retail/UDFs.scala:
--------------------------------------------------------------------------------
1 | package com.analytics.retail
2 | import org.apache.spark.sql.functions._
3 |
4 | object UDFs {
5 | def emailUDF = udf {
6 | email: String => email.replaceAll("(?<=@)[^.]+(?=\\.)", "*****")
7 |
8 | }
9 | def cellUDF = udf {
10 | cell:String => cell.replaceAll("[^0-9]","")
11 | }
12 | def ageUDF = udf {
13 | age:String => val md = java.security.MessageDigest.getInstance("SHA-1")
14 | val ha = new sun.misc.BASE64Encoder().encode(md.digest(age.getBytes))
15 | ha
16 | }
17 |
18 | // 140-333-4444
19 | // 1403334444, 5
20 | // 14033XXXXX
21 | //substring will start from 0
22 |
23 | def posUDF = udf {
24 | (cell: String, pos :Int) => cell.substring(0, cell.length - pos).concat("X" * pos)
25 | }
26 | }
27 |
--------------------------------------------------------------------------------
/.idea/jarRepositories.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
--------------------------------------------------------------------------------
/.idea/codeStyles/Project.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
11 |
20 |
21 |
22 |
23 |
24 |
25 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Realtime-Customer-Viewership-Analysis
2 |
3 | In this project, i have created data pipeline using the lambda architecture (Batch and screaming flow). Project cleanup and optimization in progress.
4 |
5 | I have acquired following types of data from different sources:
6 |
7 | 1.Customer Profile Data:
8 | This a dimension data of SCD1 type stored in Oracle DB. Type of data is structured. Dynamic lookup is performed on this data every minute and cached in memory.
9 |
10 | 2.Weblog Events of Customers:
11 | This data is loaded by some other system into the linux landing pad. It is a growing, historical data of CSV type. This data is loaded once in a day.
12 |
13 |
14 | 3.HTTP Status Codes:
15 | This is a static data of XML type which is loaded only once.
16 |
17 | 4.Customer Web Events:
18 | This data represents what customers doing right now. It is a json data which is pulled from web service via NIFI and pushed to Kafka topic which is then consumed every 10 sec.
19 |
20 | Current Code Flow (will Optimize later):
21 | 1. Imported necessary libraries in POM.xml and imported in project.
22 | 2. Initialized spark Session, spark Context and logger level.
23 | 3. Loaded the static XML data and converted to Data Frame using databricks library.
24 | 4. Created StructType Schema for weblog data.
25 | 5. Loaded the weblog csv file as rdd using sc.textFile and converted to row rdd and then created dataframe using createDataFrame method to enforce null type validation.
26 | 6. Method is created to load customer profile data from DB using spark jdbc option.
27 | 7. Created a new ConstantInputDStream which always returns the same mandatory input RDD at every batch time. This is used to pull data from RDMS in a streaming fashion. In this stream we are doing the dynamic lookup by calling method to load data from DB every one minute and caching the result in memory.
28 | 8. Performed joining of all the 3 dataframes in a final DF to aggregate the results and store it in ElasticSearch index.
29 | 9. Visualization is created in Kibana from the ES index.
30 | 10. Final DF is streamed to output Kafka Topic.
31 |
32 | Functionality Achieved:
33 | - Unification
34 | - Federation
35 | - Lambda
36 | - SCD-1
37 |
38 | 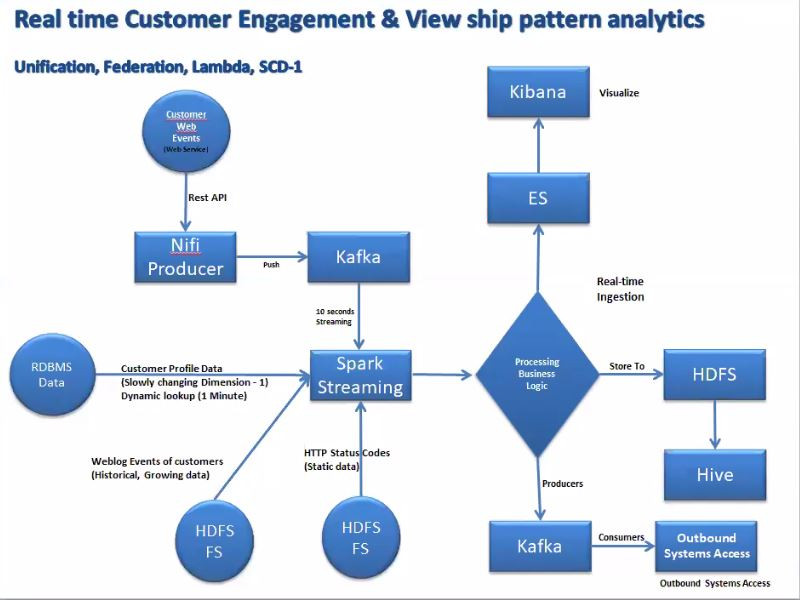
39 |
40 |
--------------------------------------------------------------------------------
/pom.xml:
--------------------------------------------------------------------------------
1 |
2 |
5 | 4.0.0
6 |
7 | org.apache.spark
8 | Realtime_Customer_Viewership_Analysis
9 | 1.0-SNAPSHOT
10 |
11 |
12 |
13 |
14 | org.apache.spark
15 | spark-core_2.11
16 | 2.4.4
17 |
18 |
19 | org.apache.spark
20 | spark-sql_2.11
21 | 2.4.4
22 |
23 |
24 | org.apache.spark
25 | spark-streaming_2.11
26 | 2.4.4
27 | provided
28 |
29 |
30 | org.apache.spark
31 | spark-hive_2.11
32 | 2.4.4
33 | provided
34 |
35 |
36 | org.apache.spark
37 | spark-sql-kafka-0-10_2.11
38 | 2.4.4
39 | provided
40 |
41 |
42 | org.apache.spark
43 | spark-streaming-kafka-0-10_2.11
44 | 2.4.4
45 |
46 |
47 | org.elasticsearch
48 | elasticsearch-spark-20_2.11
49 | 5.0.0
50 |
51 |
52 | mysql
53 | mysql-connector-java
54 | 5.1.49
55 |
56 |
57 |
58 |
--------------------------------------------------------------------------------
/.idea/uiDesigner.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | -
6 |
7 |
8 | -
9 |
10 |
11 | -
12 |
13 |
14 | -
15 |
16 |
17 | -
18 |
19 |
20 |
21 |
22 |
23 | -
24 |
25 |
26 |
27 |
28 |
29 | -
30 |
31 |
32 |
33 |
34 |
35 | -
36 |
37 |
38 |
39 |
40 |
41 | -
42 |
43 |
44 |
45 |
46 | -
47 |
48 |
49 |
50 |
51 | -
52 |
53 |
54 |
55 |
56 | -
57 |
58 |
59 |
60 |
61 | -
62 |
63 |
64 |
65 |
66 | -
67 |
68 |
69 |
70 |
71 | -
72 |
73 |
74 | -
75 |
76 |
77 |
78 |
79 | -
80 |
81 |
82 |
83 |
84 | -
85 |
86 |
87 |
88 |
89 | -
90 |
91 |
92 |
93 |
94 | -
95 |
96 |
97 |
98 |
99 | -
100 |
101 |
102 | -
103 |
104 |
105 | -
106 |
107 |
108 | -
109 |
110 |
111 | -
112 |
113 |
114 |
115 |
116 | -
117 |
118 |
119 | -
120 |
121 |
122 |
123 |
124 |
--------------------------------------------------------------------------------
/src/main/scala/com/analytics/retail/ViewershipAnalytics.scala:
--------------------------------------------------------------------------------
1 | package com.analytics.retail
2 | import org.apache.spark._
3 | import org.apache.spark.sql._
4 | import org.apache.spark.sql.functions._
5 | import org.apache.spark.sql.types.StructType
6 | import org.apache.spark.sql.types.StructField
7 | import org.apache.spark.sql.types._
8 | import org.apache.spark.streaming.StreamingContext;
9 | import org.apache.spark.streaming._;
10 | import java.io._
11 | import org.apache.kafka.clients.consumer.ConsumerRecord
12 | import org.apache.kafka.common.serialization.StringDeserializer
13 | import org.apache.spark.streaming.kafka010._
14 | import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
15 | import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
16 | import org.apache.spark.streaming._
17 | import org.apache.spark.sql.functions._
18 | import org.apache.spark.sql.types.StructType
19 | import java.lang._
20 | import org.apache.spark.SparkDriverExecutionException
21 | import org.json4s.{DefaultFormats,jackson}
22 | //import org.elasticsearch.spark.streaming._
23 | import org.elasticsearch.spark.sql._
24 | import org.elasticsearch.spark._
25 |
26 |
27 | object ViewershipAnalytics {
28 | def main(args:Array[String])
29 | {
30 | val spark = SparkSession
31 | .builder()
32 | .appName("US WEB CUSTOMER REALTIME").config("es.nodes", "localhost").config("es.port","9200")
33 | .config("es.index.auto.create","true")
34 | .config("es.mapping.id","custid")
35 | .enableHiveSupport
36 | .master("local[*]")
37 | .getOrCreate()
38 | val sc=spark.sparkContext
39 | sc.setLogLevel("error")
40 | import spark.implicits._
41 | //val objmask=new org.inceptez.framework.masking;
42 | //spark.udf.register("posmaskudf",objmask.posmask _)
43 | //val xmldata =sc.textFile("file:///home/hduser/install/usjon/USJSON_PROJECT_CONTENT/http_status.xml")
44 |
45 | println("xml data")
46 | println("xml data")
47 |
48 | val dfxml = spark.read
49 | .format("com.databricks.spark.xml")
50 | .option("rowTag", "httpstatus")
51 | .load("file:///home/hduser/install/usjon/USJSON_PROJECT_CONTENT/http_status.xml")
52 |
53 | dfxml.cache()
54 |
55 | dfxml.createOrReplaceTempView("statusxmldata")
56 | spark.sql("select * from statusxmldata").show
57 |
58 | val weblogschema = StructType(Array(
59 | StructField("username", StringType, true),
60 | StructField("ip", StringType, true),
61 | StructField("dt", StringType, true),
62 | StructField("day", StringType, true),
63 | StructField("month", StringType, true),
64 | StructField("time1", StringType, true),
65 | StructField("yr", StringType, true),
66 | StructField("hr", StringType, true),
67 | StructField("mt", StringType, true),
68 | StructField("sec", StringType, true),
69 | StructField("tz", StringType, true),
70 | StructField("verb", StringType, true),
71 | StructField("page", StringType, true),
72 | StructField("index", StringType, true),
73 | StructField("fullpage", StringType, true),
74 | StructField("referrer", StringType, true),
75 | StructField("referrer2", StringType, true),
76 | StructField("statuscd", StringType, true)));
77 |
78 | val weblogrdd= sc.textFile("file:///home/hduser/install/usjon/USJSON_PROJECT_CONTENT/WebLog")
79 |
80 | val weblogrow = weblogrdd.map(x=>x.split(",")).map(x=>Row(x(0),x(1),x(2),x(3),x(4),x(5),x(6)
81 | ,x(7),x(8),x(9),x(10),x(11),x(12),x(13),x(14),x(15),x(15),x(16)))
82 |
83 | val weblogdf=spark.createDataFrame(weblogrow,weblogschema)
84 | println("Weblog Data")
85 | println
86 | weblogdf.show()
87 | weblogdf.createOrReplaceTempView("weblog")
88 | spark.sql("select * from weblog").show
89 |
90 | // COUNTRY STATIC DB DATA
91 |
92 | def loaddb:org.apache.spark.sql.DataFrame={
93 | val sqldf = spark.read.format("jdbc")
94 | .option("url", "jdbc:mysql://localhost/custdb")
95 | .option("driver", "com.mysql.jdbc.Driver")
96 | .option("dbtable", "custprof")
97 | .option("user", "root")
98 | .option("password", "root")
99 | .load()
100 | return sqldf;
101 | }
102 |
103 | val sqldf=loaddb;
104 | sqldf.cache();
105 |
106 | println("DF created with country SQL data")
107 | sqldf.show()
108 |
109 | //sqldf.rdd.map(x=>x.mkString(",")).saveAsTextFile("file:///C://SqlData")
110 | println("sql Data extracted")
111 | sqldf.createOrReplaceTempView("custprof")
112 | //val broadcastcountry = sc.broadcast(sqldf)
113 |
114 | //println(broadcastcountry.value.count())
115 |
116 | val ssc1 = new StreamingContext(sc, Seconds(30))
117 |
118 | import org.apache.spark.streaming.dstream.ConstantInputDStream;
119 | val dynamiclkp=new ConstantInputDStream(ssc1,sc.parallelize(Seq())).window(Seconds(60),Seconds(60))
120 |
121 | dynamiclkp.foreachRDD{
122 | x=>{
123 | val x=sqldf;
124 | x.unpersist;
125 | val sqldf1=loaddb;
126 |
127 | sqldf1.cache();
128 | println(sqldf1.count())
129 | sqldf1.createOrReplaceTempView("custprof")
130 | }
131 | }
132 |
133 | import org.apache.spark.sql.functions._
134 |
135 | val kafkaParams = Map[String, Object](
136 | "bootstrap.servers" -> "localhost:9092",
137 | "key.deserializer" -> classOf[StringDeserializer],
138 | "value.deserializer" -> classOf[StringDeserializer],
139 | "group.id" -> "usdatagroup",
140 | "auto.offset.reset" -> "latest",
141 | "enable.auto.commit" -> (false: java.lang.Boolean)
142 | )
143 |
144 | val topics = Array("user_info")
145 | val stream = KafkaUtils.createDirectStream[String, String](
146 | ssc1,
147 | PreferConsistent,
148 | Subscribe[String, String](topics, kafkaParams)
149 | )
150 | //ssc1.checkpoint("hdfs://localhost:54310/user/hduser/usjsonckpt")
151 | println("Reading data from kafka")
152 | val streamdata= stream.map(record => (record.value))
153 |
154 | //streamdata.print()
155 | streamdata.foreachRDD(rdd=>
156 |
157 | if(!rdd.isEmpty()){
158 | //val offsetranges=rdd.asInstanceOf[HasOffsetRanges].offsetRanges
159 | val jsondf =spark.read.option("multiline", "true").option("mode", "DROPMALFORMED").json(rdd)
160 | try {
161 | //val userwithid= jsondf.withColumn("results",explode($"results")).select("results[0].username")
162 | jsondf.printSchema();
163 | jsondf.createOrReplaceTempView("usdataview")
164 | //
165 |
166 | /*val maskeddf=spark.sql("""select
167 | explode(results) as res,
168 | info.page as page,
169 | posmaskudf(res.cell,0,4) as cell,
170 | res.name.first as first,
171 | res.dob.age as age,
172 | posmaskudf(res.email,0,5) as email,res.location.city as uscity,res.location.coordinates.latitude as latitude,
173 | res.location.coordinates.longitude as longitude,res.location.country as country,
174 | res.location.state as state,
175 | res.location.timezone as timezone,res.login.username as username
176 | from usdataview """)
177 | maskeddf.show(false)
178 | */
179 | val finaldf= spark.sql(""" select concat(usd.username,day,month,yr,hr,mt,sec) as custid,
180 | row_number() over(partition by usd.username order by yr,month,day,hr,mt,sec) as version,
181 | usd.page,usd.cell,usd.first,usd.age,usd.email,
182 | concat(usd.latitude,usd.longitude) as coordinates,usd.uscity,usd.country,usd.state,usd.username
183 | ,cp.age as age,cp.profession as profession,wl.ip,wl.dt,concat(wl.yr,'-',wl.time1,'-',wl.day) as fulldt,
184 | wl.verb,wl.page,wl.statuscd,ws.category,ws.desc,case when wl.dt is null then 'new customer' else
185 | 'existing customer' end as custtype
186 | from
187 | (select
188 | explode(results) as res,
189 | info.page as page,res.cell as cell,
190 | res.name.first as first,
191 | res.dob.age as age,
192 | res.email as email,res.location.city as uscity,res.location.coordinates.latitude as latitude,
193 | res.location.coordinates.longitude as longitude,res.location.country as country,
194 | res.location.state as state,
195 | res.location.timezone as timezone,res.login.username as username
196 | from usdataview where info.page is not null) as usd left outer join custprof cp on (substr(regexp_replace(cell,'[()-]',''),0,5)=cp.id)
197 | left outer join weblog wl on (wl.username=substr(regexp_replace(cell,'[()-]',''),0,5))
198 | left outer join statusxmldata ws on (wl.statuscd=ws.cd)""")
199 |
200 | finaldf.show(false)
201 |
202 | finaldf.saveToEs("usdataidx/usdatatype")
203 |
204 | println("data written to ES")
205 | /* StructField("username", StringType, true),
206 | StructField("ip", StringType, true),
207 | StructField("dt", StringType, true),
208 | StructField("day", StringType, true),
209 | StructField("month", StringType, true),
210 | StructField("time1", StringType, true),
211 | StructField("yr", StringType, true),
212 | StructField("hr", StringType, true),
213 | StructField("mt", StringType, true),
214 | StructField("sec", StringType, true),
215 | StructField("tz", StringType, true),
216 | StructField("verb", StringType, true),
217 | StructField("page", StringType, true),
218 | StructField("index", StringType, true),
219 | StructField("fullpage", StringType, true),
220 | StructField("referrer", StringType, true),
221 | StructField("referrer2", StringType, true),
222 | StructField("statuscd", StringType, true))); */
223 | //userwithid.show(false)
224 |
225 | /* val userwithoutid= jsondf.withColumn("results",explode($"results")).select("results.user.username")
226 | .withColumn("username",regexp_replace(col("username"), "([0-9])", "")).show()
227 | */
228 |
229 | /* val newjsondf= jsondf.withColumn("results",explode($"results")).select("nationality",
230 |
231 | "seed","version","results.user.username","results.user.location.city",
232 |
233 | "results.user.location.state","results.user.location.street","results.user.location.zip",
234 |
235 | "results.user.md5","results.user.gender","results.user.name.first","results.user.name.last","results.user.name.title","results.user.password",
236 |
237 | "results.user.phone","results.user.picture.large","results.user.picture.medium","results.user.picture.thumbnail",
238 |
239 | "results.user.registered","results.user.salt","results.user.sha1","results.user.sha256")
240 | .withColumn("username",regexp_replace(col("username"), "([0-9])", "")).withColumn("phone",regexp_replace(col("phone"), "([(,),-])", "")).withColumn("time_stamp", lit(current_timestamp()))
241 |
242 | newjsondf.show(false)
243 | */
244 | //newjsondf.rdd.coalesce(1).map(x=>x.mkString(",")).saveAsTextFile("file:///home/hduser/usdatastreamdata")
245 |
246 | //s streamdata.asInstanceOf[CanCommitOffsets].commitAsync(offsetranges)
247 | }
248 |
249 | catch {
250 | case ex1: java.lang.IllegalArgumentException => {
251 | println("Illegal arg exception")
252 | }
253 |
254 | case ex2: java.lang.ArrayIndexOutOfBoundsException => {
255 | println("Array index out of bound")
256 | }
257 |
258 | case ex3: org.apache.spark.SparkException => {
259 | println("Spark common exception")
260 |
261 | }
262 |
263 | case ex6: java.lang.NullPointerException => {
264 | println("Values Ignored")
265 |
266 | }
267 | }
268 | }
269 |
270 | )
271 |
272 | ssc1.start()
273 | ssc1.awaitTermination()
274 |
275 | }
276 | }
277 |
278 |
--------------------------------------------------------------------------------