├── nets
├── __init__.py
├── inception.py
├── inception_utils.py
├── nets_factory.py
├── resnet_utils.py
├── vgg.py
├── resnet_v1.py
├── resnet_v2.py
├── inception_v1.py
├── inception_resnet_v2.py
└── inception_v4.py
├── datasets
├── __init__.py
├── dataset_factory.py
├── custom.py
├── dataset_utils.py
└── convert_tfrecord.py
├── preprocessing
├── __init__.py
├── preprocessing_factory.py
├── inception_preprocessing.py
└── vgg_preprocessing.py
├── run_train.sh
├── run_test.sh
├── run_eval.sh
├── set_eval_env.sh
├── set_test_env.sh
├── set_train_env.sh
├── convert_data.py
├── eval.py
├── README.md
├── test.py
└── train.py
/nets/__init__.py:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/datasets/__init__.py:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/preprocessing/__init__.py:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/run_train.sh:
--------------------------------------------------------------------------------
1 | source set_train_env.sh
2 | python train.py --dataset_dir=$DATASET_DIR \
3 | --train_dir=$TRAIN_DIR \
4 | --checkpoint_path=$CHECKPOINT_PATH \
5 | --labels_file=$LABELS_FILE
6 |
--------------------------------------------------------------------------------
/run_test.sh:
--------------------------------------------------------------------------------
1 | source set_test_env.sh
2 | python train.py --dataset_dir=$DATASET_DIR \
3 | --train_dir=$TRAIN_DIR \
4 | --checkpoint_path=$CHECKPOINT_PATH \
5 | --labels_file=$LABELS_FILE \
6 | --log_test=$TRAIN_DIR/test
7 |
--------------------------------------------------------------------------------
/run_eval.sh:
--------------------------------------------------------------------------------
1 | source set_eval_env.sh
2 | python -u eval.py --dataset_name=$DATASET_NAME \
3 | --dataset_dir=$DATASET_DIR \
4 | --dataset_split_name=validation \
5 | --model_name=$MODLE_NAME \
6 | --checkpoint_path=$TRAIN_DIR \
7 | --eval_dir=$TRAIN_DIR/validation
8 |
--------------------------------------------------------------------------------
/set_eval_env.sh:
--------------------------------------------------------------------------------
1 | #Validation dataset
2 | export DATASET_NAME=origin
3 |
4 | export DATASET_DIR=/../pack
5 |
6 | export CHECKPOINT_PATH=/../inception_resnet_v2.ckpt
7 | #export CHECKPOINT_PATH=/../inception_v3.ckpt
8 | #export CHECKPOINT_PATH=/../vgg_16.ckpt
9 | #export CHECKPOINT_PATH=/../vgg_19.ckpt
10 | #export CHECKPOINT_PATH=/../resnet_v1_50.ckpt
11 |
12 | export TRAIN_DIR=/../100_inception_resnet_v2_150
13 |
14 | #export MODEL_NAME=inception_v3
15 | #export MODEL_NAME=inception_v4
16 | export MODEL_NAME=inception_resnet_v2
17 | #export MODEL_NAME=vgg_16
18 | #export MODEL_NAME=vgg_19
19 | #export MODEL_NAME=resnet_v1_50
20 |
--------------------------------------------------------------------------------
/set_test_env.sh:
--------------------------------------------------------------------------------
1 | #Test dataset
2 | export DATASET_NAME=origin
3 |
4 | export DATASET_DIR=/../pack
5 |
6 | export CHECKPOINT_PATH=/../inception_resnet_v2.ckpt
7 | #export CHECKPOINT_PATH=/../inception_v3.ckpt
8 | #export CHECKPOINT_PATH=/../vgg_16.ckpt
9 | #export CHECKPOINT_PATH=/../vgg_19.ckpt
10 | #export CHECKPOINT_PATH=/../resnet_v1_50.ckpt
11 |
12 | export TRAIN_DIR=/../100_inception_resnet_v2_150
13 |
14 | export LABELS_FILE=/../labels.txt
15 |
16 | #export MODEL_NAME=inception_v3
17 | #export MODEL_NAME=inception_v4
18 | export MODEL_NAME=inception_resnet_v2
19 | #export MODEL_NAME=vgg_16
20 | #export MODEL_NAME=vgg_19
21 | #export MODEL_NAME=resnet_v1_50
22 |
--------------------------------------------------------------------------------
/set_train_env.sh:
--------------------------------------------------------------------------------
1 | #Training dataset
2 | #If Training dataset and Validation dataset in the same folder, you don't have to set "set_eval_env.sh" file
3 | export DATASET_NAME=origin
4 |
5 | export DATASET_DIR=/../pack
6 |
7 | export CHECKPOINT_PATH=/../inception_resnet_v2.ckpt
8 | #export CHECKPOINT_PATH=/../inception_v3.ckpt
9 | #export CHECKPOINT_PATH=/../vgg_16.ckpt
10 | #export CHECKPOINT_PATH=/../vgg_19.ckpt
11 | #export CHECKPOINT_PATH=/../resnet_v1_50.ckpt
12 |
13 | export TRAIN_DIR=/../100_inception_resnet_v2_150
14 |
15 | export LABELS_FILE=/../labels.txt
16 |
17 | #export MODEL_NAME=inception_v3
18 | #export MODEL_NAME=inception_v4
19 | export MODEL_NAME=inception_resnet_v2
20 | #export MODEL_NAME=vgg_16
21 | #export MODEL_NAME=vgg_19
22 | #export MODEL_NAME=resnet_v1_50
23 |
--------------------------------------------------------------------------------
/nets/inception.py:
--------------------------------------------------------------------------------
1 | """Brings all inception models under one namespace."""
2 |
3 | from __future__ import absolute_import
4 | from __future__ import division
5 | from __future__ import print_function
6 |
7 | # pylint: disable=unused-import
8 | from nets.inception_resnet_v2 import inception_resnet_v2
9 | from nets.inception_resnet_v2 import inception_resnet_v2_arg_scope
10 | from nets.inception_resnet_v2 import inception_resnet_v2_base
11 | from nets.inception_v1 import inception_v1
12 | from nets.inception_v1 import inception_v1_arg_scope
13 | from nets.inception_v1 import inception_v1_base
14 | from nets.inception_v2 import inception_v2
15 | from nets.inception_v2 import inception_v2_arg_scope
16 | from nets.inception_v2 import inception_v2_base
17 | from nets.inception_v3 import inception_v3
18 | from nets.inception_v3 import inception_v3_arg_scope
19 | from nets.inception_v3 import inception_v3_base
20 | from nets.inception_v4 import inception_v4
21 | from nets.inception_v4 import inception_v4_arg_scope
22 | from nets.inception_v4 import inception_v4_base
23 | # pylint: enable=unused-import
24 |
--------------------------------------------------------------------------------
/datasets/dataset_factory.py:
--------------------------------------------------------------------------------
1 | """A factory-pattern class which returns classification image/label pairs."""
2 |
3 | from __future__ import absolute_import
4 | from __future__ import division
5 | from __future__ import print_function
6 |
7 | from datasets import custom
8 |
9 |
10 | def get_dataset(name, split_name, dataset_dir, file_pattern=None, reader=None):
11 | """Given a dataset name and a split_name returns a Dataset.
12 |
13 | Args:
14 | name: String, the name of the dataset.
15 | split_name: A train/test split name.
16 | dataset_dir: The directory where the dataset files are stored.
17 | file_pattern: The file pattern to use for matching the dataset source files.
18 | reader: The subclass of tf.ReaderBase. If left as `None`, then the default
19 | reader defined by each dataset is used.
20 |
21 | Returns:
22 | A `Dataset` class.
23 |
24 | Raises:
25 | ValueError: If the dataset `name` is unknown.
26 | """
27 | return custom.get_split(
28 | split_name,
29 | dataset_dir,
30 | name,
31 | file_pattern,
32 | reader)
33 |
34 |
--------------------------------------------------------------------------------
/convert_data.py:
--------------------------------------------------------------------------------
1 | r"""Converts your own dataset.
2 |
3 | Usage:
4 | ```shell
5 |
6 | $ python download_and_convert_data.py \
7 | --dataset_name=mnist \
8 | --dataset_dir=/tmp/mnist
9 |
10 | $ python download_and_convert_data.py \
11 | --dataset_name=cifar10 \
12 | --dataset_dir=/tmp/cifar10
13 |
14 | $ python download_and_convert_data.py \
15 | --dataset_name=flowers \
16 | --dataset_dir=/tmp/flowers
17 | ```
18 | """
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 |
23 | import tensorflow as tf
24 |
25 | from datasets import convert_tfrecord
26 |
27 | FLAGS = tf.app.flags.FLAGS
28 |
29 | tf.app.flags.DEFINE_string(
30 | 'dataset_name',
31 | None,
32 | '')
33 |
34 | tf.app.flags.DEFINE_string(
35 | 'dataset_dir',
36 | None,
37 | 'The directory where the output TFRecords and temporary files are saved.')
38 |
39 |
40 | def main(_):
41 | if not FLAGS.dataset_name:
42 | raise ValueError('You must supply the dataset name with --dataset_name')
43 | if not FLAGS.dataset_dir:
44 | raise ValueError('You must supply the dataset directory with --dataset_dir')
45 |
46 | if FLAGS.dataset_name == 'custom':
47 | convert_tfrecord.run(FLAGS.dataset_dir, dataset_name=FLAGS.dataset_name)
48 | else:
49 | convert_tfrecord.run(FLAGS.dataset_dir, dataset_name=FLAGS.dataset_name)
50 |
51 | if __name__ == '__main__':
52 | tf.app.run()
53 |
54 |
--------------------------------------------------------------------------------
/preprocessing/preprocessing_factory.py:
--------------------------------------------------------------------------------
1 | """Contains a factory for building various models."""
2 |
3 | from __future__ import absolute_import
4 | from __future__ import division
5 | from __future__ import print_function
6 |
7 | import tensorflow as tf
8 |
9 | from preprocessing import inception_preprocessing
10 | from preprocessing import vgg_preprocessing
11 |
12 | slim = tf.contrib.slim
13 |
14 |
15 | def get_preprocessing(name, is_training=False):
16 | """Returns preprocessing_fn(image, height, width, **kwargs).
17 |
18 | Args:
19 | name: The name of the preprocessing function.
20 | is_training: `True` if the model is being used for training and `False`
21 | otherwise.
22 |
23 | Returns:
24 | preprocessing_fn: A function that preprocessing a single image (pre-batch).
25 | It has the following signature:
26 | image = preprocessing_fn(image, output_height, output_width, ...).
27 |
28 | Raises:
29 | ValueError: If Preprocessing `name` is not recognized.
30 | """
31 | preprocessing_fn_map = {
32 | 'inception': inception_preprocessing,
33 | 'inception_v1': inception_preprocessing,
34 | 'inception_v2': inception_preprocessing,
35 | 'inception_v3': inception_preprocessing,
36 | 'inception_v4': inception_preprocessing,
37 | 'inception_resnet_v2': inception_preprocessing,
38 | 'mobilenet_v1': inception_preprocessing,
39 | 'resnet_v1_50': vgg_preprocessing,
40 | 'resnet_v1_101': vgg_preprocessing,
41 | 'resnet_v1_152': vgg_preprocessing,
42 | 'vgg': vgg_preprocessing,
43 | 'vgg_a': vgg_preprocessing,
44 | 'vgg_16': vgg_preprocessing,
45 | 'vgg_19': vgg_preprocessing,
46 | }
47 |
48 | if name not in preprocessing_fn_map:
49 | raise ValueError('Preprocessing name [%s] was not recognized' % name)
50 |
51 | def preprocessing_fn(image, output_height, output_width, **kwargs):
52 | return preprocessing_fn_map[name].preprocess_image(
53 | image, output_height, output_width, is_training=is_training, **kwargs)
54 |
55 | return preprocessing_fn
56 |
--------------------------------------------------------------------------------
/nets/inception_utils.py:
--------------------------------------------------------------------------------
1 | """Contains common code shared by all inception models.
2 |
3 | Usage of arg scope:
4 | with slim.arg_scope(inception_arg_scope()):
5 | logits, end_points = inception.inception_v3(images, num_classes,
6 | is_training=is_training)
7 |
8 | """
9 | from __future__ import absolute_import
10 | from __future__ import division
11 | from __future__ import print_function
12 |
13 | import tensorflow as tf
14 |
15 | slim = tf.contrib.slim
16 |
17 |
18 | def inception_arg_scope(weight_decay=0.00004,
19 | use_batch_norm=True,
20 | batch_norm_decay=0.9997,
21 | batch_norm_epsilon=0.001,
22 | activation_fn=tf.nn.relu):
23 | """Defines the default arg scope for inception models.
24 |
25 | Args:
26 | weight_decay: The weight decay to use for regularizing the model.
27 | use_batch_norm: "If `True`, batch_norm is applied after each convolution.
28 | batch_norm_decay: Decay for batch norm moving average.
29 | batch_norm_epsilon: Small float added to variance to avoid dividing by zero
30 | in batch norm.
31 | activation_fn: Activation function for conv2d.
32 |
33 | Returns:
34 | An `arg_scope` to use for the inception models.
35 | """
36 | batch_norm_params = {
37 | # Decay for the moving averages.
38 | 'decay': batch_norm_decay,
39 | # epsilon to prevent 0s in variance.
40 | 'epsilon': batch_norm_epsilon,
41 | # collection containing update_ops.
42 | 'updates_collections': tf.GraphKeys.UPDATE_OPS,
43 | # use fused batch norm if possible.
44 | 'fused': None,
45 | }
46 | if use_batch_norm:
47 | normalizer_fn = slim.batch_norm
48 | normalizer_params = batch_norm_params
49 | else:
50 | normalizer_fn = None
51 | normalizer_params = {}
52 | # Set weight_decay for weights in Conv and FC layers.
53 | with slim.arg_scope([slim.conv2d, slim.fully_connected],
54 | weights_regularizer=slim.l2_regularizer(weight_decay)):
55 | with slim.arg_scope(
56 | [slim.conv2d],
57 | weights_initializer=slim.variance_scaling_initializer(),
58 | activation_fn=activation_fn,
59 | normalizer_fn=normalizer_fn,
60 | normalizer_params=normalizer_params) as sc:
61 | return sc
62 |
--------------------------------------------------------------------------------
/datasets/custom.py:
--------------------------------------------------------------------------------
1 | """Provides data for the flowers dataset.
2 |
3 | The dataset scripts used to create the dataset can be found at:
4 | tensorflow/models/slim/datasets/download_and_convert_flowers.py
5 | """
6 |
7 | from __future__ import absolute_import
8 | from __future__ import division
9 | from __future__ import print_function
10 |
11 | import os
12 | import tensorflow as tf
13 |
14 | from datasets import dataset_utils
15 |
16 | slim = tf.contrib.slim
17 |
18 | _FILE_PATTERN = '%s_%s_*.tfrecord'
19 |
20 | _ITEMS_TO_DESCRIPTIONS = {
21 | 'image': 'A color image of varying size.',
22 | 'label': 'A single integer between 0 and 4',
23 | }
24 |
25 |
26 | def get_split(split_name, dataset_dir, dataset_name,
27 | file_pattern=None, reader=None):
28 | """Gets a dataset tuple with instructions for reading flowers.
29 |
30 | Args:
31 | split_name: A train/validation split name.
32 | dataset_dir: The base directory of the dataset sources.
33 | file_pattern: The file pattern to use when matching the dataset sources.
34 | It is assumed that the pattern contains a '%s' string so that the split
35 | name can be inserted.
36 | reader: The TensorFlow reader type.
37 |
38 | Returns:
39 | A `Dataset` namedtuple.
40 |
41 | Raises:
42 | ValueError: if `split_name` is not a valid train/validation split.
43 | """
44 |
45 | # load dataset info from file
46 | dataset_info_file_path = os.path.join(dataset_dir, dataset_name + '.info')
47 | with open(dataset_info_file_path, 'r') as f:
48 | contents = f.read().split('\n')
49 | splits_to_sizes = {}
50 | for line in contents:
51 | info = line.split(':')
52 | splits_to_sizes[info[0]] = int(info[1])
53 |
54 | num_classes = splits_to_sizes['label']
55 |
56 | if split_name not in splits_to_sizes:
57 | raise ValueError('split name %s was not recognized.' % split_name)
58 |
59 | if not file_pattern:
60 | file_pattern = _FILE_PATTERN
61 | file_pattern = os.path.join(dataset_dir,
62 | file_pattern % (dataset_name, split_name))
63 |
64 | # Allowing None in the signature so that dataset_factory can use the default.
65 | if reader is None:
66 | reader = tf.TFRecordReader
67 |
68 | keys_to_features = {
69 | 'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''),
70 | 'image/format': tf.FixedLenFeature((), tf.string, default_value='png'),
71 | 'image/class/label': tf.FixedLenFeature(
72 | [], tf.int64, default_value=tf.zeros([], dtype=tf.int64)),
73 | }
74 |
75 | items_to_handlers = {
76 | 'image': slim.tfexample_decoder.Image(),
77 | 'label': slim.tfexample_decoder.Tensor('image/class/label'),
78 | }
79 |
80 | decoder = slim.tfexample_decoder.TFExampleDecoder(
81 | keys_to_features, items_to_handlers)
82 |
83 | labels_to_names = None
84 | if dataset_utils.has_labels(dataset_dir):
85 | labels_to_names = dataset_utils.read_label_file(dataset_dir)
86 |
87 | return slim.dataset.Dataset(
88 | data_sources=file_pattern,
89 | reader=reader,
90 | decoder=decoder,
91 | num_samples=splits_to_sizes[split_name],
92 | items_to_descriptions=_ITEMS_TO_DESCRIPTIONS,
93 | num_classes=num_classes,
94 | labels_to_names=labels_to_names)
95 |
--------------------------------------------------------------------------------
/datasets/dataset_utils.py:
--------------------------------------------------------------------------------
1 | """Contains utilities for downloading and converting datasets."""
2 | from __future__ import absolute_import
3 | from __future__ import division
4 | from __future__ import print_function
5 |
6 | import os
7 | import sys
8 | import importlib
9 | importlib.reload(sys)
10 |
11 | import tarfile
12 |
13 | from six.moves import urllib
14 | import tensorflow as tf
15 |
16 | LABELS_FILENAME = 'labels.txt'
17 |
18 |
19 | def int64_feature(values):
20 | """Returns a TF-Feature of int64s.
21 |
22 | Args:
23 | values: A scalar or list of values.
24 |
25 | Returns:
26 | a TF-Feature.
27 | """
28 | if not isinstance(values, (tuple, list)):
29 | values = [values]
30 | return tf.train.Feature(int64_list=tf.train.Int64List(value=values))
31 |
32 |
33 | def bytes_feature(values):
34 | """Returns a TF-Feature of bytes.
35 |
36 | Args:
37 | values: A string.
38 |
39 | Returns:
40 | a TF-Feature.
41 | """
42 | return tf.train.Feature(bytes_list=tf.train.BytesList(value=[values]))
43 |
44 |
45 | def image_to_tfexample(image_data, image_format, height, width, class_id):
46 | return tf.train.Example(features=tf.train.Features(feature={
47 | 'image/encoded': bytes_feature(image_data),
48 | 'image/format': bytes_feature(image_format),
49 | 'image/class/label': int64_feature(class_id),
50 | 'image/height': int64_feature(height),
51 | 'image/width': int64_feature(width),
52 | }))
53 |
54 |
55 | def download_and_uncompress_tarball(tarball_url, dataset_dir):
56 | """Downloads the `tarball_url` and uncompresses it locally.
57 |
58 | Args:
59 | tarball_url: The URL of a tarball file.
60 | dataset_dir: The directory where the temporary files are stored.
61 | """
62 | filename = tarball_url.split('/')[-1]
63 | filepath = os.path.join(dataset_dir, filename)
64 |
65 | def _progress(count, block_size, total_size):
66 | sys.stdout.write('\r>> Downloading %s %.1f%%' % (
67 | filename, float(count * block_size) / float(total_size) * 100.0))
68 | sys.stdout.flush()
69 | if not os.path.exists(file_path):
70 | filepath, _ = urllib.request.urlretrieve(tarball_url, filepath, _progress)
71 | print()
72 | statinfo = os.stat(filepath)
73 | print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
74 | tarfile.open(filepath, 'r:gz').extractall(dataset_dir)
75 |
76 |
77 | def write_label_file(labels_to_class_names, dataset_dir,
78 | filename=LABELS_FILENAME):
79 | """Writes a file with the list of class names.
80 |
81 | Args:
82 | labels_to_class_names: A map of (integer) labels to class names.
83 | dataset_dir: The directory in which the labels file should be written.
84 | filename: The filename where the class names are written.
85 | """
86 | labels_filename = os.path.join(dataset_dir, filename)
87 | with tf.gfile.Open(labels_filename, 'w') as f:
88 | for label in labels_to_class_names:
89 | class_name = labels_to_class_names[label]
90 | f.write('%d:%s\n' % (label, class_name))
91 |
92 |
93 | def has_labels(dataset_dir, filename=LABELS_FILENAME):
94 | """Specifies whether or not the dataset directory contains a label map file.
95 |
96 | Args:
97 | dataset_dir: The directory in which the labels file is found.
98 | filename: The filename where the class names are written.
99 |
100 | Returns:
101 | `True` if the labels file exists and `False` otherwise.
102 | """
103 | return tf.gfile.Exists(os.path.join(dataset_dir, filename))
104 |
105 |
106 | def read_label_file(dataset_dir, filename=LABELS_FILENAME):
107 | """Reads the labels file and returns a mapping from ID to class name.
108 |
109 | Args:
110 | dataset_dir: The directory in which the labels file is found.
111 | filename: The filename where the class names are written.
112 |
113 | Returns:
114 | A map from a label (integer) to class name.
115 | """
116 | labels_filename = os.path.join(dataset_dir, filename)
117 | with tf.gfile.Open(labels_filename, 'rb') as f:
118 | lines = f.read().decode()
119 | lines = lines.split('\n')
120 | lines = filter(None, lines)
121 |
122 | labels_to_class_names = {}
123 | for line in lines:
124 | index = line.index(':')
125 | labels_to_class_names[int(line[:index])] = line[index+1:]
126 | return labels_to_class_names
127 |
--------------------------------------------------------------------------------
/nets/nets_factory.py:
--------------------------------------------------------------------------------
1 | """Contains a factory for building various models."""
2 |
3 | from __future__ import absolute_import
4 | from __future__ import division
5 | from __future__ import print_function
6 | import functools
7 |
8 | import tensorflow as tf
9 |
10 | from nets import alexnet
11 | from nets import cifarnet
12 | from nets import inception
13 | from nets import lenet
14 | from nets import mobilenet_v1
15 | from nets import overfeat
16 | from nets import resnet_v1
17 | from nets import resnet_v2
18 | from nets import vgg
19 | from nets.nasnet import nasnet
20 |
21 | slim = tf.contrib.slim
22 |
23 | networks_map = {'alexnet_v2': alexnet.alexnet_v2,
24 | 'cifarnet': cifarnet.cifarnet,
25 | 'overfeat': overfeat.overfeat,
26 | 'vgg_a': vgg.vgg_a,
27 | 'vgg_16': vgg.vgg_16,
28 | 'vgg_19': vgg.vgg_19,
29 | 'inception_v1': inception.inception_v1,
30 | 'inception_v2': inception.inception_v2,
31 | 'inception_v3': inception.inception_v3,
32 | 'inception_v4': inception.inception_v4,
33 | 'inception_resnet_v2': inception.inception_resnet_v2,
34 | 'lenet': lenet.lenet,
35 | 'resnet_v1_50': resnet_v1.resnet_v1_50,
36 | 'resnet_v1_101': resnet_v1.resnet_v1_101,
37 | 'resnet_v1_152': resnet_v1.resnet_v1_152,
38 | 'resnet_v1_200': resnet_v1.resnet_v1_200,
39 | 'resnet_v2_50': resnet_v2.resnet_v2_50,
40 | 'resnet_v2_101': resnet_v2.resnet_v2_101,
41 | 'resnet_v2_152': resnet_v2.resnet_v2_152,
42 | 'resnet_v2_200': resnet_v2.resnet_v2_200,
43 | 'mobilenet_v1': mobilenet_v1.mobilenet_v1,
44 | 'mobilenet_v1_075': mobilenet_v1.mobilenet_v1_075,
45 | 'mobilenet_v1_050': mobilenet_v1.mobilenet_v1_050,
46 | 'mobilenet_v1_025': mobilenet_v1.mobilenet_v1_025,
47 | 'nasnet_cifar': nasnet.build_nasnet_cifar,
48 | 'nasnet_mobile': nasnet.build_nasnet_mobile,
49 | 'nasnet_large': nasnet.build_nasnet_large,
50 | }
51 |
52 | arg_scopes_map = {'alexnet_v2': alexnet.alexnet_v2_arg_scope,
53 | 'cifarnet': cifarnet.cifarnet_arg_scope,
54 | 'overfeat': overfeat.overfeat_arg_scope,
55 | 'vgg_a': vgg.vgg_arg_scope,
56 | 'vgg_16': vgg.vgg_arg_scope,
57 | 'vgg_19': vgg.vgg_arg_scope,
58 | 'inception_v1': inception.inception_v3_arg_scope,
59 | 'inception_v2': inception.inception_v3_arg_scope,
60 | 'inception_v3': inception.inception_v3_arg_scope,
61 | 'inception_v4': inception.inception_v4_arg_scope,
62 | 'inception_resnet_v2':
63 | inception.inception_resnet_v2_arg_scope,
64 | 'lenet': lenet.lenet_arg_scope,
65 | 'resnet_v1_50': resnet_v1.resnet_arg_scope,
66 | 'resnet_v1_101': resnet_v1.resnet_arg_scope,
67 | 'resnet_v1_152': resnet_v1.resnet_arg_scope,
68 | 'resnet_v1_200': resnet_v1.resnet_arg_scope,
69 | 'resnet_v2_50': resnet_v2.resnet_arg_scope,
70 | 'resnet_v2_101': resnet_v2.resnet_arg_scope,
71 | 'resnet_v2_152': resnet_v2.resnet_arg_scope,
72 | 'resnet_v2_200': resnet_v2.resnet_arg_scope,
73 | 'mobilenet_v1': mobilenet_v1.mobilenet_v1_arg_scope,
74 | 'mobilenet_v1_075': mobilenet_v1.mobilenet_v1_arg_scope,
75 | 'mobilenet_v1_050': mobilenet_v1.mobilenet_v1_arg_scope,
76 | 'mobilenet_v1_025': mobilenet_v1.mobilenet_v1_arg_scope,
77 | 'nasnet_cifar': nasnet.nasnet_cifar_arg_scope,
78 | 'nasnet_mobile': nasnet.nasnet_mobile_arg_scope,
79 | 'nasnet_large': nasnet.nasnet_large_arg_scope,
80 | }
81 |
82 |
83 | def get_network_fn(name, num_classes, weight_decay=0.0, is_training=False):
84 | """Returns a network_fn such as `logits, end_points = network_fn(images)`.
85 |
86 | Args:
87 | name: The name of the network.
88 | num_classes: The number of classes to use for classification. If 0 or None,
89 | the logits layer is omitted and its input features are returned instead.
90 | weight_decay: The l2 coefficient for the model weights.
91 | is_training: `True` if the model is being used for training and `False`
92 | otherwise.
93 |
94 | Returns:
95 | network_fn: A function that applies the model to a batch of images. It has
96 | the following signature:
97 | net, end_points = network_fn(images)
98 | The `images` input is a tensor of shape [batch_size, height, width, 3]
99 | with height = width = network_fn.default_image_size. (The permissibility
100 | and treatment of other sizes depends on the network_fn.)
101 | The returned `end_points` are a dictionary of intermediate activations.
102 | The returned `net` is the topmost layer, depending on `num_classes`:
103 | If `num_classes` was a non-zero integer, `net` is a logits tensor
104 | of shape [batch_size, num_classes].
105 | If `num_classes` was 0 or `None`, `net` is a tensor with the input
106 | to the logits layer of shape [batch_size, 1, 1, num_features] or
107 | [batch_size, num_features]. Dropout has not been applied to this
108 | (even if the network's original classification does); it remains for
109 | the caller to do this or not.
110 |
111 | Raises:
112 | ValueError: If network `name` is not recognized.
113 | """
114 | if name not in networks_map:
115 | raise ValueError('Name of network unknown %s' % name)
116 | func = networks_map[name]
117 | @functools.wraps(func)
118 | def network_fn(images, **kwargs):
119 | arg_scope = arg_scopes_map[name](weight_decay=weight_decay)
120 | with slim.arg_scope(arg_scope):
121 | return func(images, num_classes, is_training=is_training, **kwargs)
122 | if hasattr(func, 'default_image_size'):
123 | network_fn.default_image_size = func.default_image_size
124 |
125 | return network_fn
126 |
--------------------------------------------------------------------------------
/eval.py:
--------------------------------------------------------------------------------
1 | import math
2 | import tensorflow as tf
3 | import os
4 |
5 | from datasets import dataset_factory
6 | from nets import nets_factory
7 | from preprocessing import preprocessing_factory
8 |
9 | slim = tf.contrib.slim
10 |
11 | tf.app.flags.DEFINE_integer(
12 | 'batch_size', 20, 'The number of samples in each batch.')
13 |
14 | tf.app.flags.DEFINE_integer(
15 | 'max_num_batches', None,
16 | 'Max number of batches to evaluate by default use all.')
17 |
18 | tf.app.flags.DEFINE_string(
19 | 'master', '', 'The address of the TensorFlow master to use.')
20 |
21 | tf.app.flags.DEFINE_string(
22 | 'checkpoint_path', '/tmp/tfmodel/',
23 | 'The directory where the model was written to or an absolute path to a '
24 | 'checkpoint file.')
25 |
26 | tf.app.flags.DEFINE_string(
27 | 'eval_dir', '/tmp/tfmodel/', 'Directory where the results are saved to.')
28 |
29 | tf.app.flags.DEFINE_integer(
30 | 'num_preprocessing_threads', 4,
31 | 'The number of threads used to create the batches.')
32 |
33 | tf.app.flags.DEFINE_string(
34 | 'dataset_name', 'imagenet', 'The name of the dataset to load.')
35 |
36 | tf.app.flags.DEFINE_string(
37 | 'dataset_split_name', 'test', 'The name of the train/test split.')
38 |
39 | tf.app.flags.DEFINE_string(
40 | 'dataset_dir', None, 'The directory where the dataset files are stored.')
41 |
42 | tf.app.flags.DEFINE_integer(
43 | 'labels_offset', 0,
44 | 'An offset for the labels in the dataset. This flag is primarily used to '
45 | 'evaluate the VGG and ResNet architectures which do not use a background '
46 | 'class for the ImageNet dataset.')
47 |
48 | tf.app.flags.DEFINE_string(
49 | 'model_name', 'inception_v3', 'The name of the architecture to evaluate.')
50 |
51 | tf.app.flags.DEFINE_string(
52 | 'preprocessing_name', None, 'The name of the preprocessing to use. If left '
53 | 'as `None`, then the model_name flag is used.')
54 |
55 | tf.app.flags.DEFINE_float(
56 | 'moving_average_decay', None,
57 | 'The decay to use for the moving average.'
58 | 'If left as None, then moving averages are not used.')
59 |
60 | tf.app.flags.DEFINE_integer(
61 | 'eval_image_size', None, 'Eval image size')
62 |
63 | tf.app.flags.DEFINE_integer(
64 | 'eval_interval_secs', 600,
65 | 'The minimum number of seconds between evaluations')
66 |
67 | FLAGS = tf.app.flags.FLAGS
68 |
69 |
70 | def main(_):
71 | if not FLAGS.dataset_dir:
72 | raise ValueError('You must supply the dataset directory with --dataset_dir')
73 |
74 | tf.logging.set_verbosity(tf.logging.INFO)
75 | with tf.Graph().as_default():
76 | tf_global_step = slim.get_or_create_global_step()
77 |
78 | ######################
79 | # Select the dataset #
80 | ######################
81 | dataset = dataset_factory.get_dataset(
82 | FLAGS.dataset_name, FLAGS.dataset_split_name, FLAGS.dataset_dir)
83 |
84 | ####################
85 | # Select the model #
86 | ####################
87 | network_fn = nets_factory.get_network_fn(
88 | FLAGS.model_name,
89 | num_classes=(dataset.num_classes - FLAGS.labels_offset),
90 | is_training=False)
91 |
92 | ##############################################################
93 | # Create a dataset provider that loads data from the dataset #
94 | ##############################################################
95 | provider = slim.dataset_data_provider.DatasetDataProvider(
96 | dataset,
97 | shuffle=False,
98 | common_queue_capacity=2 * FLAGS.batch_size,
99 | common_queue_min=FLAGS.batch_size)
100 | [image, label] = provider.get(['image', 'label'])
101 | label -= FLAGS.labels_offset
102 |
103 | #####################################
104 | # Select the preprocessing function #
105 | #####################################
106 | preprocessing_name = FLAGS.preprocessing_name or FLAGS.model_name
107 | image_preprocessing_fn = preprocessing_factory.get_preprocessing(
108 | preprocessing_name,
109 | is_training=False)
110 |
111 | eval_image_size = FLAGS.eval_image_size or network_fn.default_image_size
112 |
113 | image = image_preprocessing_fn(image, eval_image_size, eval_image_size)
114 |
115 | images, labels = tf.train.batch(
116 | [image, label],
117 | batch_size=FLAGS.batch_size,
118 | num_threads=FLAGS.num_preprocessing_threads,
119 | capacity=5 * FLAGS.batch_size)
120 |
121 | ####################
122 | # Define the model #
123 | ####################
124 | logits, _ = network_fn(images)
125 |
126 | if FLAGS.moving_average_decay:
127 | variable_averages = tf.train.ExponentialMovingAverage(
128 | FLAGS.moving_average_decay, tf_global_step)
129 | variables_to_restore = variable_averages.variables_to_restore(
130 | slim.get_model_variables())
131 | variables_to_restore[tf_global_step.op.name] = tf_global_step
132 | else:
133 | variables_to_restore = slim.get_variables_to_restore()
134 |
135 | predictions = tf.argmax(logits, 1)
136 | labels = tf.squeeze(labels)
137 |
138 | # Define the metrics:
139 | names_to_values, names_to_updates = slim.metrics.aggregate_metric_map({
140 | 'Accuracy': slim.metrics.streaming_accuracy(predictions, labels),
141 | 'Recall_5': slim.metrics.streaming_recall_at_k(
142 | logits, labels, 5),
143 | #'Precision': slim.metrics.streaming_precision(predictions, labels),
144 | #'confusion_matrix': slim.metrics.confusion_matrix(
145 | # labels, predictions, num_classes=102, dtype=tf.int32, name=None, weights=None)
146 | })
147 |
148 | # Print the summaries to screen.
149 | for name, value in names_to_values.items():
150 | summary_name = 'eval/%s' % name
151 | op = tf.summary.scalar(summary_name, value, collections=[])
152 | op = tf.Print(op, [value], summary_name)
153 | tf.add_to_collection(tf.GraphKeys.SUMMARIES, op)
154 |
155 | # TODO(sguada) use num_epochs=1
156 | if FLAGS.max_num_batches:
157 | num_batches = FLAGS.max_num_batches
158 | else:
159 | # This ensures that we make a single pass over all of the data.
160 | num_batches = math.ceil(dataset.num_samples / float(FLAGS.batch_size))
161 |
162 | if tf.gfile.IsDirectory(FLAGS.checkpoint_path):
163 | if FLAGS.eval_interval_secs:
164 | checkpoint_path = FLAGS.checkpoint_path
165 | else:
166 | checkpoint_path = tf.train.latest_checkpoint(FLAGS.checkpoint_path)
167 | else:
168 | if FLAGS.eval_interval_secs:
169 | checkpoint_path, _ = os.path.split(FLAGS.checkpoint_path)
170 | else:
171 | checkpoint_path = FLAGS.checkpoint_path
172 |
173 | tf.logging.info('Evaluating %s' % checkpoint_path)
174 | # mask GPUs visible to the session so it falls back on CPU
175 | config = tf.ConfigProto(device_count={'GPU':0})
176 | if not FLAGS.eval_interval_secs:
177 | slim.evaluation.evaluate_once(
178 | master=FLAGS.master,
179 | checkpoint_path=checkpoint_path,
180 | logdir=FLAGS.eval_dir,
181 | num_evals=num_batches,
182 | eval_op=list(names_to_updates.values()),
183 | variables_to_restore=variables_to_restore,
184 | session_config=config)
185 | #)
186 | else:
187 | slim.evaluation.evaluation_loop(
188 | master=FLAGS.master,
189 | checkpoint_dir=checkpoint_path,
190 | logdir=FLAGS.eval_dir,
191 | num_evals=num_batches,
192 | eval_op=list(names_to_updates.values()),
193 | eval_interval_secs=60,
194 | variables_to_restore=variables_to_restore,
195 | session_config=config)
196 | #)
197 |
198 | if __name__ == '__main__':
199 | tf.app.run()
200 |
--------------------------------------------------------------------------------
/datasets/convert_tfrecord.py:
--------------------------------------------------------------------------------
1 | r"""Converts your own dataset to TFRecords of TF-Example protos.
2 |
3 | This module reads the files
4 | that make up the data and creates two TFRecord datasets: one for train
5 | and one for test. Each TFRecord dataset is comprised of a set of TF-Example
6 | protocol buffers, each of which contain a single image and label.
7 |
8 | The script should take about a minute to run.
9 |
10 | """
11 |
12 | from __future__ import absolute_import
13 | from __future__ import division
14 | from __future__ import print_function
15 |
16 | import math
17 | import os
18 | import random
19 | import sys
20 |
21 | import tensorflow as tf
22 |
23 | from datasets import dataset_utils
24 |
25 |
26 | # The number of images in the validation set.
27 | #_NUM_VALIDATION = 180
28 | PERCENT_VALIDATION = 2.5
29 |
30 | # Seed for repeatability.
31 | _RANDOM_SEED = 0
32 |
33 | # The number of shards per dataset split.
34 | _NUM_SHARDS = None
35 |
36 |
37 | class ImageReader(object):
38 | """Helper class that provides TensorFlow image coding utilities."""
39 |
40 | def __init__(self):
41 | # Initializes function that decodes RGB JPEG data.
42 | self._decode_jpeg_data = tf.placeholder(dtype=tf.string)
43 | self._decode_jpeg = tf.image.decode_jpeg(self._decode_jpeg_data, channels=3)
44 |
45 | def read_image_dims(self, sess, image_data):
46 | image = self.decode_jpeg(sess, image_data)
47 | return image.shape[0], image.shape[1]
48 |
49 | def decode_jpeg(self, sess, image_data):
50 | image = sess.run(self._decode_jpeg,
51 | feed_dict={self._decode_jpeg_data: image_data})
52 | assert len(image.shape) == 3
53 | assert image.shape[2] == 3
54 | return image
55 |
56 |
57 | def _get_filenames_and_classes(dataset_dir, dataset_name):
58 | """Returns a list of filenames and inferred class names.
59 |
60 | Args:
61 | dataset_dir: A directory containing a set of subdirectories representing
62 | class names. Each subdirectory should contain PNG or JPG encoded images.
63 |
64 | Returns:
65 | A list of image file paths, relative to `dataset_dir` and the list of
66 | subdirectories, representing class names.
67 | """
68 | dataset_root = os.path.join(dataset_dir, dataset_name)
69 | print('processing data in [%s] :' % dataset_root)
70 | directories = []
71 | class_names = []
72 | for filename in os.listdir(dataset_root):
73 | path = os.path.join(dataset_root, filename)
74 | if os.path.isdir(path):
75 | directories.append(path)
76 | class_names.append(filename)
77 |
78 | photo_filenames = []
79 | for directory in directories:
80 | for filename in os.listdir(directory):
81 | path = os.path.join(directory, filename)
82 | photo_filenames.append(path)
83 |
84 | return photo_filenames, sorted(class_names)
85 |
86 |
87 | def _get_dataset_filename(dataset_dir, dataset_name, split_name, shard_id):
88 | output_filename = '%s_%s_%05d-of-%05d.tfrecord' % (
89 | dataset_name, split_name, shard_id, _NUM_SHARDS)
90 | return os.path.join(dataset_dir, output_filename)
91 |
92 |
93 | def _convert_dataset(split_name,
94 | filenames,
95 | class_names_to_ids,
96 | dataset_dir,
97 | dataset_name):
98 | """Converts the given filenames to a TFRecord dataset.
99 |
100 | Args:
101 | split_name: The name of the dataset, either 'train' or 'validation'.
102 | filenames: A list of absolute paths to png or jpg images.
103 | class_names_to_ids: A dictionary from class names (strings) to ids
104 | (integers).
105 | dataset_dir: The directory where the converted datasets are stored.
106 | """
107 | assert split_name in ['train', 'validation']
108 |
109 | num_per_shard = int(math.ceil(len(filenames) / float(_NUM_SHARDS)))
110 |
111 | with tf.Graph().as_default():
112 | image_reader = ImageReader()
113 |
114 | with tf.Session('') as sess:
115 |
116 | for shard_id in range(_NUM_SHARDS):
117 | output_filename = _get_dataset_filename(
118 | dataset_dir, dataset_name, split_name, shard_id)
119 |
120 | with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer:
121 | start_ndx = shard_id * num_per_shard
122 | end_ndx = min((shard_id+1) * num_per_shard, len(filenames))
123 | for i in range(start_ndx, end_ndx):
124 | sys.stdout.write('\r>> Converting image %d/%d shard %d' % (
125 | i+1, len(filenames), shard_id))
126 | sys.stdout.flush()
127 |
128 | # Read the filename:
129 | image_data = tf.gfile.FastGFile(filenames[i], 'rb').read()
130 | height, width = image_reader.read_image_dims(sess, image_data)
131 |
132 | class_name = os.path.basename(os.path.dirname(filenames[i]))
133 | class_id = class_names_to_ids[class_name]
134 |
135 | example = dataset_utils.image_to_tfexample(
136 | image_data, b'jpg', height, width, class_id)
137 | tfrecord_writer.write(example.SerializeToString())
138 |
139 | sys.stdout.write('\n')
140 | sys.stdout.flush()
141 |
142 |
143 |
144 | def _dataset_exists(dataset_dir, dataset_name, split_name):
145 | for shard_id in range(_NUM_SHARDS):
146 | output_filename = _get_dataset_filename(
147 | dataset_dir, dataset_name, split_name, shard_id)
148 | if not tf.gfile.Exists(output_filename):
149 | return False
150 | return True
151 |
152 |
153 | def run(dataset_dir, dataset_name='dataset'):
154 | """Runs the download and conversion operation.
155 |
156 | Args:
157 | dataset_dir: The dataset directory where the dataset is stored.
158 | """
159 | if not tf.gfile.Exists(dataset_dir):
160 | tf.gfile.MakeDirs(dataset_dir)
161 |
162 |
163 | photo_filenames, class_names = _get_filenames_and_classes(dataset_dir,
164 | dataset_name)
165 | class_names_to_ids = dict(zip(class_names, range(len(class_names))))
166 |
167 | # Divide into train and test:
168 | random.seed(_RANDOM_SEED)
169 | random.shuffle(photo_filenames)
170 | #number_validation = len(photo_filenames) * PERCENT_VALIDATION //100
171 | number_validation = 1000
172 | print(' total pics number %d' % len(photo_filenames))
173 | print(' valid number: %d' % number_validation)
174 | training_filenames = photo_filenames[number_validation:]
175 | validation_filenames = photo_filenames[:number_validation]
176 |
177 | # First, convert the training and validation sets.
178 | global _NUM_SHARDS
179 | _NUM_SHARDS = len(training_filenames) // 1024
180 | _NUM_SHARDS = _NUM_SHARDS if _NUM_SHARDS else 1
181 | if _dataset_exists(dataset_dir, dataset_name, 'train'):
182 | print('Dataset files already exist. Exiting without re-creating them.')
183 | return
184 | _convert_dataset('train', training_filenames, class_names_to_ids,
185 | dataset_dir, dataset_name=dataset_name)
186 | _NUM_SHARDS = len(validation_filenames) // 1024
187 | _NUM_SHARDS = _NUM_SHARDS if _NUM_SHARDS else 1
188 | if _dataset_exists(dataset_dir, dataset_name, 'validation'):
189 | print('Dataset files already exist. Exiting without re-creating them.')
190 | return
191 | _convert_dataset('validation', validation_filenames, class_names_to_ids,
192 | dataset_dir, dataset_name=dataset_name)
193 |
194 | # write dataset info
195 | dataset_info = "label:%d\ntrain:%d\nvalidation:%d" % (
196 | len(class_names),
197 | len(training_filenames),
198 | len(validation_filenames))
199 | dataset_info_file_path = os.path.join(dataset_dir, dataset_name + '.info')
200 | with open(dataset_info_file_path, 'w') as f:
201 | f.write(dataset_info)
202 | f.flush()
203 |
204 |
205 | # Finally, write the labels file:
206 | labels_to_class_names = dict(zip(range(len(class_names)), class_names))
207 | dataset_utils.write_label_file(labels_to_class_names, dataset_dir)
208 |
209 | # _clean_up_temporary_files(dataset_dir)
210 | print('\nFinished converting the dataset!')
211 |
212 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Deep-Model-Transfer
2 | []()
3 | []()
4 |
5 | > A method for Fine-Grained image classification implemented by TensorFlow. The best accuracy we have got are 73.33%(Bird-200), 91.03%(Car-196), 72.23%(Dog-120), 96.27%(Flower-102), 86.07%(Pet-37).
6 |
7 | ------------------
8 |
9 | **Note**: For Fine-Grained image classification problem, our solution is combining deep model and transfer learning. Firstly, the deep model, e.g., [vgg-16](https://arxiv.org/abs/1409.1556), [vgg-19](https://arxiv.org/abs/1409.1556), [inception-v1](https://arxiv.org/abs/1409.4842), [inception-v2](https://arxiv.org/abs/1502.03167), [inception-v3](https://arxiv.org/abs/1512.00567), [inception-v4](https://arxiv.org/abs/1602.07261), [inception-resnet-v2](https://arxiv.org/abs/1602.07261), [resnet50](https://arxiv.org/abs/1512.03385), is pretrained in [ImageNet](http://image-net.org/challenges/LSVRC/2014/browse-synsets) dataset to gain the feature extraction abbility. Secondly, transfer the pretrained model to Fine-Grained image dataset, e.g., 🕊️[Bird-200](http://www.vision.caltech.edu/visipedia/CUB-200.html), 🚗[Car-196](https://ai.stanford.edu/~jkrause/cars/car_dataset.html), 🐶[Dog-120](http://vision.stanford.edu/aditya86/ImageNetDogs/), 🌸[Flower-102](http://www.robots.ox.ac.uk/~vgg/data/flowers/102/), 🐶🐱[Pet-37](http://www.robots.ox.ac.uk/~vgg/data/pets/).
10 |
11 | ## Installation
12 | 1. Install the requirments:
13 | - Ubuntu 16.04+
14 | - TensorFlow 1.5.0+
15 | - Python 3.5+
16 | - NumPy
17 | - Nvidia GPU(optional)
18 |
19 | 2. Clone the repository
20 | ```Shell
21 | $ git clone https://github.com/MacwinWin/Deep-Model-Transfer.git
22 | ```
23 |
24 | ## Pretrain
25 | Slim provide a log of pretrained [models](https://github.com/tensorflow/models/tree/master/research/slim). What we need is just downloading the .ckpt files and then using them. Make a new folder, download and extract the .ckpt file to the folder.
26 | ```
27 | pretrained
28 | ├── inception_v1.ckpt
29 | ├── inception_v2.ckpt
30 | ├── inception_v3.ckpt
31 | ├── inception_v4.ckpt
32 | ├── inception_resnet_v2.ckpt
33 | | └── ...
34 | ```
35 |
36 | ## Transfer
37 | 1. set environment variables
38 | - Edit the [set_train_env.sh](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/set_train_env.sh) and [set_eval_env.sh](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/set_eval_env.sh) files to specify the "DATASET_NAME", "DATASET_DIR", "CHECKPOINT_PATH", "TRAIN_DIR", "MODEL_NAME".
39 |
40 | - "DATASET_NAME" and "DATASET_DIR" define the dataset name and location. For example, the dataset structure is shown below. "DATASET_NAME" is "origin", "DATASET_DIR" is "/../Flower_102"
41 | ```
42 | Flower_102
43 | ├── _origin
44 | | ├── _class1
45 | | ├── image1.jpg
46 | | ├── image2.jpg
47 | | └── ...
48 | | └── _class2
49 | | └── ...
50 | ```
51 | - "CHECKPOINT_PATH" is the path to pretrained model. For example, '/../pretrained/inception_v1.ckpt'.
52 | - "TRAIN_DIR" stores files generated during training.
53 | - "MODEL_NAME" is the name of pretrained model, such as resnet_v1_50, vgg_19, vgg_16, inception_resnet_v2, inception_v1, inception_v2, inception_v3, inception_v4.
54 | - Source the [set_train_env.sh](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/set_train_env.sh) and [set_eval_env.sh](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/set_eval_env.sh)
55 | ```Shell
56 | $ source set_train_env.sh
57 | ```
58 | 2. prepare data
59 |
60 | We use the tfrecord format to feed the model, so we should convert the .jpg file to tfrecord file.
61 | - After downloading the dataset, arrange the iamges like the structure below.
62 | ```
63 | Flower_102
64 | ├── _origin
65 | | ├── _class1
66 | | ├── image1.jpg
67 | | ├── image2.jpg
68 | | └── ...
69 | | └── _class2
70 | | └── ...
71 |
72 | Flower_102_eval
73 | ├── _origin
74 | | ├── _class1
75 | | ├── image1.jpg
76 | | ├── image2.jpg
77 | | └── ...
78 | | └── _class2
79 | | └── ...
80 |
81 | Flower_102_test
82 | ├── _origin
83 | | ├── _class1
84 | | ├── image1.jpg
85 | | ├── image2.jpg
86 | | └── ...
87 | | └── _class2
88 | | └── ...
89 | ```
90 | If the dataset doesn't have validation set, we can extract some images from test set. The percentage or quantity is defined at [./datasets/convert_tfrecord.py](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/datasets/convert_tfrecord.py) line [170](https://github.com/MacwinWin/Deep-Model-Transfer/blob/f399fd6011bc35e42e8b6559ea3846ed0d6a57c0/datasets/convert_tfrecord.py#L170) [171](https://github.com/MacwinWin/Deep-Model-Transfer/blob/f399fd6011bc35e42e8b6559ea3846ed0d6a57c0/datasets/convert_tfrecord.py#L171).
91 |
92 | - Run [./convert_data.py](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/convert_data.py)
93 | ```Shell
94 | $ python convert_data.py \
95 | --dataset_name=$DATASET_NAME \
96 | --dataset_dir=$DATASET_DIR
97 | ```
98 | 3. train and evaluate
99 |
100 | - Edit [./train.py](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/train.py) to specify "image_size", "num_classes".
101 | - Edit [./train.py](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/train.py) line [162](https://github.com/MacwinWin/Deep-Model-Transfer/blob/f399fd6011bc35e42e8b6559ea3846ed0d6a57c0/train.py#L162) to selecet image preprocessing method.
102 | - Edit [./train.py](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/train.py) line [203](https://github.com/MacwinWin/Deep-Model-Transfer/blob/f399fd6011bc35e42e8b6559ea3846ed0d6a57c0/train.py#L203) to create the model inference.
103 | - Edit [./train.py](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/train.py) line [219](https://github.com/MacwinWin/Deep-Model-Transfer/blob/f399fd6011bc35e42e8b6559ea3846ed0d6a57c0/train.py#L219) to define the scopes that you want to exclude for restoration
104 | - Edit [./set_train_env.sh]
105 | - Run script[./run_train.sh](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/run_train.sh) to start training.
106 | - Create a new terminal window and set the [./set_eval_env.sh](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/set_eval_env.sh) to satisfy validation set.
107 | - Create a new terminal, edit [./set_eval_env.sh](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/set_eval_env.sh), and run script[./run_eval.sh](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/run_eval.sh) as the following command.
108 |
109 | **Note**: If you have 2 GPU, you can evaluate with GPU by changing [[./eval.py](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/eval.py)] line [175](https://github.com/MacwinWin/Deep-Model-Transfer/blob/f399fd6011bc35e42e8b6559ea3846ed0d6a57c0/eval.py#L175)-line[196](https://github.com/MacwinWin/Deep-Model-Transfer/blob/f399fd6011bc35e42e8b6559ea3846ed0d6a57c0/eval.py#L196) as shown below
110 | ```python
111 | #config = tf.ConfigProto(device_count={'GPU':0})
112 | if not FLAGS.eval_interval_secs:
113 | slim.evaluation.evaluate_once(
114 | master=FLAGS.master,
115 | checkpoint_path=checkpoint_path,
116 | logdir=FLAGS.eval_dir,
117 | num_evals=num_batches,
118 | eval_op=list(names_to_updates.values()),
119 | variables_to_restore=variables_to_restore
120 | #session_config=config)
121 | )
122 | else:
123 | slim.evaluation.evaluation_loop(
124 | master=FLAGS.master,
125 | checkpoint_dir=checkpoint_path,
126 | logdir=FLAGS.eval_dir,
127 | num_evals=num_batches,
128 | eval_op=list(names_to_updates.values()),
129 | eval_interval_secs=60,
130 | variables_to_restore=variables_to_restore
131 | #session_config=config)
132 | )
133 | ```
134 | 4. test
135 |
136 | The [./test.py](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/test.py) looks like [./train.py](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/train.py), so edit [./set_test_env.sh] as shown before to satisfy your environment. Then run [./run_test.py](https://github.com/MacwinWin/Deep-Model-Transfer/blob/master/run_test.sh).
137 | **Note**: After test, you can get 2 .txt file. One is ground truth lable, another is predicted lable. Edit line[303](https://github.com/MacwinWin/Deep-Model-Transfer/blob/1045afed03b0dbbe317b91b416fb9b937da40649/test.py#L303) and line[304](https://github.com/MacwinWin/Deep-Model-Transfer/blob/1045afed03b0dbbe317b91b416fb9b937da40649/test.py#L304) to change the store path.
138 |
139 | ## Visualization
140 |
141 | Through tensorboard, you can visualization the training and testing process.
142 | ```Shell
143 | $ tensorboard --logdir $TRAIN_DIR
144 | ```
145 | :point_down:Screenshot:
146 |
147 | 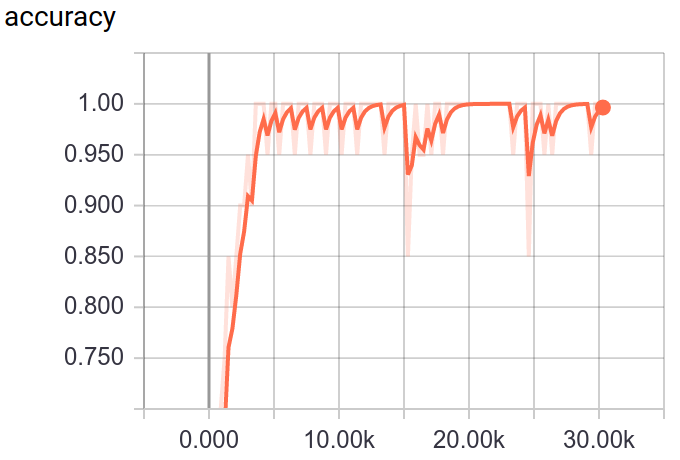
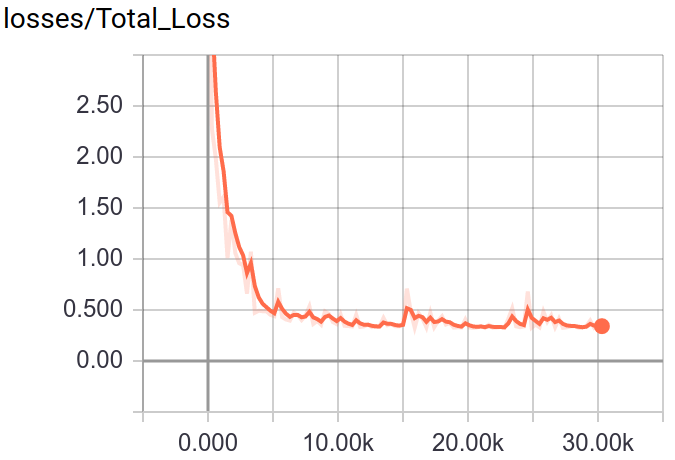 148 |
148 |
149 |
150 | 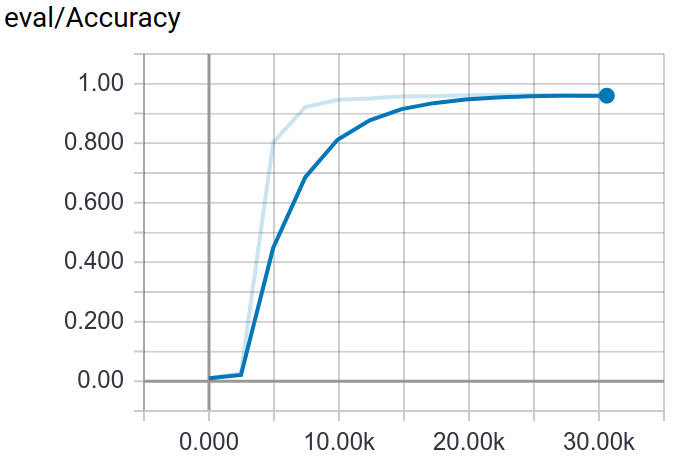
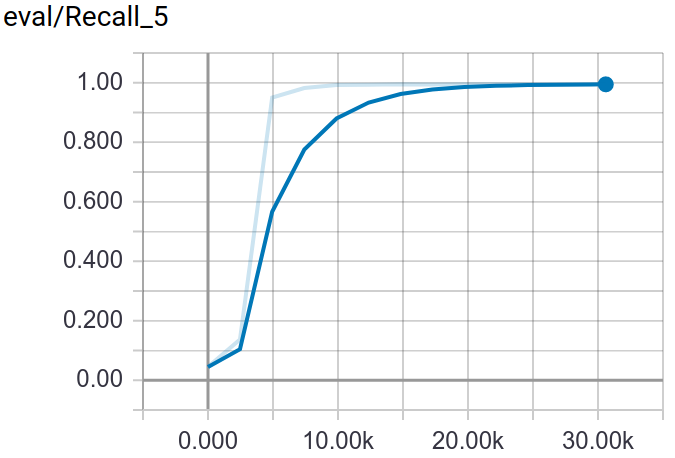 151 |
151 |
152 |
153 | ## Deploy
154 |
155 | Deploy methods support html and api. Through html method, you can upload image file and get result in web browser. If you want to get result in json format, you can use api method.
156 | Because I'm not good at front-end and back-end skill, so the code not looks professional.
157 |
158 | The deployment repository: https://github.com/MacwinWin/Deep-Model-Transfer-Deployment
159 |
160 |
161 |  162 |
162 |
163 |
164 |  165 |
165 |
166 |
--------------------------------------------------------------------------------
/nets/resnet_utils.py:
--------------------------------------------------------------------------------
1 | """Contains building blocks for various versions of Residual Networks.
2 |
3 | Residual networks (ResNets) were proposed in:
4 | Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
5 | Deep Residual Learning for Image Recognition. arXiv:1512.03385, 2015
6 |
7 | More variants were introduced in:
8 | Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
9 | Identity Mappings in Deep Residual Networks. arXiv: 1603.05027, 2016
10 |
11 | We can obtain different ResNet variants by changing the network depth, width,
12 | and form of residual unit. This module implements the infrastructure for
13 | building them. Concrete ResNet units and full ResNet networks are implemented in
14 | the accompanying resnet_v1.py and resnet_v2.py modules.
15 |
16 | Compared to https://github.com/KaimingHe/deep-residual-networks, in the current
17 | implementation we subsample the output activations in the last residual unit of
18 | each block, instead of subsampling the input activations in the first residual
19 | unit of each block. The two implementations give identical results but our
20 | implementation is more memory efficient.
21 | """
22 | from __future__ import absolute_import
23 | from __future__ import division
24 | from __future__ import print_function
25 |
26 | import collections
27 | import tensorflow as tf
28 |
29 | slim = tf.contrib.slim
30 |
31 |
32 | class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])):
33 | """A named tuple describing a ResNet block.
34 |
35 | Its parts are:
36 | scope: The scope of the `Block`.
37 | unit_fn: The ResNet unit function which takes as input a `Tensor` and
38 | returns another `Tensor` with the output of the ResNet unit.
39 | args: A list of length equal to the number of units in the `Block`. The list
40 | contains one (depth, depth_bottleneck, stride) tuple for each unit in the
41 | block to serve as argument to unit_fn.
42 | """
43 |
44 |
45 | def subsample(inputs, factor, scope=None):
46 | """Subsamples the input along the spatial dimensions.
47 |
48 | Args:
49 | inputs: A `Tensor` of size [batch, height_in, width_in, channels].
50 | factor: The subsampling factor.
51 | scope: Optional variable_scope.
52 |
53 | Returns:
54 | output: A `Tensor` of size [batch, height_out, width_out, channels] with the
55 | input, either intact (if factor == 1) or subsampled (if factor > 1).
56 | """
57 | if factor == 1:
58 | return inputs
59 | else:
60 | return slim.max_pool2d(inputs, [1, 1], stride=factor, scope=scope)
61 |
62 |
63 | def conv2d_same(inputs, num_outputs, kernel_size, stride, rate=1, scope=None):
64 | """Strided 2-D convolution with 'SAME' padding.
65 |
66 | When stride > 1, then we do explicit zero-padding, followed by conv2d with
67 | 'VALID' padding.
68 |
69 | Note that
70 |
71 | net = conv2d_same(inputs, num_outputs, 3, stride=stride)
72 |
73 | is equivalent to
74 |
75 | net = slim.conv2d(inputs, num_outputs, 3, stride=1, padding='SAME')
76 | net = subsample(net, factor=stride)
77 |
78 | whereas
79 |
80 | net = slim.conv2d(inputs, num_outputs, 3, stride=stride, padding='SAME')
81 |
82 | is different when the input's height or width is even, which is why we add the
83 | current function. For more details, see ResnetUtilsTest.testConv2DSameEven().
84 |
85 | Args:
86 | inputs: A 4-D tensor of size [batch, height_in, width_in, channels].
87 | num_outputs: An integer, the number of output filters.
88 | kernel_size: An int with the kernel_size of the filters.
89 | stride: An integer, the output stride.
90 | rate: An integer, rate for atrous convolution.
91 | scope: Scope.
92 |
93 | Returns:
94 | output: A 4-D tensor of size [batch, height_out, width_out, channels] with
95 | the convolution output.
96 | """
97 | if stride == 1:
98 | return slim.conv2d(inputs, num_outputs, kernel_size, stride=1, rate=rate,
99 | padding='SAME', scope=scope)
100 | else:
101 | kernel_size_effective = kernel_size + (kernel_size - 1) * (rate - 1)
102 | pad_total = kernel_size_effective - 1
103 | pad_beg = pad_total // 2
104 | pad_end = pad_total - pad_beg
105 | inputs = tf.pad(inputs,
106 | [[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]])
107 | return slim.conv2d(inputs, num_outputs, kernel_size, stride=stride,
108 | rate=rate, padding='VALID', scope=scope)
109 |
110 |
111 | @slim.add_arg_scope
112 | def stack_blocks_dense(net, blocks, output_stride=None,
113 | outputs_collections=None):
114 | """Stacks ResNet `Blocks` and controls output feature density.
115 |
116 | First, this function creates scopes for the ResNet in the form of
117 | 'block_name/unit_1', 'block_name/unit_2', etc.
118 |
119 | Second, this function allows the user to explicitly control the ResNet
120 | output_stride, which is the ratio of the input to output spatial resolution.
121 | This is useful for dense prediction tasks such as semantic segmentation or
122 | object detection.
123 |
124 | Most ResNets consist of 4 ResNet blocks and subsample the activations by a
125 | factor of 2 when transitioning between consecutive ResNet blocks. This results
126 | to a nominal ResNet output_stride equal to 8. If we set the output_stride to
127 | half the nominal network stride (e.g., output_stride=4), then we compute
128 | responses twice.
129 |
130 | Control of the output feature density is implemented by atrous convolution.
131 |
132 | Args:
133 | net: A `Tensor` of size [batch, height, width, channels].
134 | blocks: A list of length equal to the number of ResNet `Blocks`. Each
135 | element is a ResNet `Block` object describing the units in the `Block`.
136 | output_stride: If `None`, then the output will be computed at the nominal
137 | network stride. If output_stride is not `None`, it specifies the requested
138 | ratio of input to output spatial resolution, which needs to be equal to
139 | the product of unit strides from the start up to some level of the ResNet.
140 | For example, if the ResNet employs units with strides 1, 2, 1, 3, 4, 1,
141 | then valid values for the output_stride are 1, 2, 6, 24 or None (which
142 | is equivalent to output_stride=24).
143 | outputs_collections: Collection to add the ResNet block outputs.
144 |
145 | Returns:
146 | net: Output tensor with stride equal to the specified output_stride.
147 |
148 | Raises:
149 | ValueError: If the target output_stride is not valid.
150 | """
151 | # The current_stride variable keeps track of the effective stride of the
152 | # activations. This allows us to invoke atrous convolution whenever applying
153 | # the next residual unit would result in the activations having stride larger
154 | # than the target output_stride.
155 | current_stride = 1
156 |
157 | # The atrous convolution rate parameter.
158 | rate = 1
159 |
160 | for block in blocks:
161 | with tf.variable_scope(block.scope, 'block', [net]) as sc:
162 | for i, unit in enumerate(block.args):
163 | if output_stride is not None and current_stride > output_stride:
164 | raise ValueError('The target output_stride cannot be reached.')
165 |
166 | with tf.variable_scope('unit_%d' % (i + 1), values=[net]):
167 | # If we have reached the target output_stride, then we need to employ
168 | # atrous convolution with stride=1 and multiply the atrous rate by the
169 | # current unit's stride for use in subsequent layers.
170 | if output_stride is not None and current_stride == output_stride:
171 | net = block.unit_fn(net, rate=rate, **dict(unit, stride=1))
172 | rate *= unit.get('stride', 1)
173 |
174 | else:
175 | net = block.unit_fn(net, rate=1, **unit)
176 | current_stride *= unit.get('stride', 1)
177 | net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
178 |
179 | if output_stride is not None and current_stride != output_stride:
180 | raise ValueError('The target output_stride cannot be reached.')
181 |
182 | return net
183 |
184 |
185 | def resnet_arg_scope(weight_decay=0.0001,
186 | batch_norm_decay=0.997,
187 | batch_norm_epsilon=1e-5,
188 | batch_norm_scale=True,
189 | activation_fn=tf.nn.relu,
190 | use_batch_norm=True):
191 | """Defines the default ResNet arg scope.
192 |
193 | TODO(gpapan): The batch-normalization related default values above are
194 | appropriate for use in conjunction with the reference ResNet models
195 | released at https://github.com/KaimingHe/deep-residual-networks. When
196 | training ResNets from scratch, they might need to be tuned.
197 |
198 | Args:
199 | weight_decay: The weight decay to use for regularizing the model.
200 | batch_norm_decay: The moving average decay when estimating layer activation
201 | statistics in batch normalization.
202 | batch_norm_epsilon: Small constant to prevent division by zero when
203 | normalizing activations by their variance in batch normalization.
204 | batch_norm_scale: If True, uses an explicit `gamma` multiplier to scale the
205 | activations in the batch normalization layer.
206 | activation_fn: The activation function which is used in ResNet.
207 | use_batch_norm: Whether or not to use batch normalization.
208 |
209 | Returns:
210 | An `arg_scope` to use for the resnet models.
211 | """
212 | batch_norm_params = {
213 | 'decay': batch_norm_decay,
214 | 'epsilon': batch_norm_epsilon,
215 | 'scale': batch_norm_scale,
216 | 'updates_collections': tf.GraphKeys.UPDATE_OPS,
217 | 'fused': None, # Use fused batch norm if possible.
218 | }
219 |
220 | with slim.arg_scope(
221 | [slim.conv2d],
222 | weights_regularizer=slim.l2_regularizer(weight_decay),
223 | weights_initializer=slim.variance_scaling_initializer(),
224 | activation_fn=activation_fn,
225 | normalizer_fn=slim.batch_norm if use_batch_norm else None,
226 | normalizer_params=batch_norm_params):
227 | with slim.arg_scope([slim.batch_norm], **batch_norm_params):
228 | # The following implies padding='SAME' for pool1, which makes feature
229 | # alignment easier for dense prediction tasks. This is also used in
230 | # https://github.com/facebook/fb.resnet.torch. However the accompanying
231 | # code of 'Deep Residual Learning for Image Recognition' uses
232 | # padding='VALID' for pool1. You can switch to that choice by setting
233 | # slim.arg_scope([slim.max_pool2d], padding='VALID').
234 | with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc:
235 | return arg_sc
236 |
--------------------------------------------------------------------------------
/preprocessing/inception_preprocessing.py:
--------------------------------------------------------------------------------
1 | """Provides utilities to preprocess images for the Inception networks."""
2 |
3 | from __future__ import absolute_import
4 | from __future__ import division
5 | from __future__ import print_function
6 |
7 | import tensorflow as tf
8 |
9 | from tensorflow.python.ops import control_flow_ops
10 |
11 |
12 | def apply_with_random_selector(x, func, num_cases):
13 | """Computes func(x, sel), with sel sampled from [0...num_cases-1].
14 |
15 | Args:
16 | x: input Tensor.
17 | func: Python function to apply.
18 | num_cases: Python int32, number of cases to sample sel from.
19 |
20 | Returns:
21 | The result of func(x, sel), where func receives the value of the
22 | selector as a python integer, but sel is sampled dynamically.
23 | """
24 | sel = tf.random_uniform([], maxval=num_cases, dtype=tf.int32)
25 | # Pass the real x only to one of the func calls.
26 | return control_flow_ops.merge([
27 | func(control_flow_ops.switch(x, tf.equal(sel, case))[1], case)
28 | for case in range(num_cases)])[0]
29 |
30 |
31 | def distort_color(image, color_ordering=0, fast_mode=False, scope=None):
32 | """Distort the color of a Tensor image.
33 |
34 | Each color distortion is non-commutative and thus ordering of the color ops
35 | matters. Ideally we would randomly permute the ordering of the color ops.
36 | Rather then adding that level of complication, we select a distinct ordering
37 | of color ops for each preprocessing thread.
38 |
39 | Args:
40 | image: 3-D Tensor containing single image in [0, 1].
41 | color_ordering: Python int, a type of distortion (valid values: 0-3).
42 | fast_mode: Avoids slower ops (random_hue and random_contrast)
43 | scope: Optional scope for name_scope.
44 | Returns:
45 | 3-D Tensor color-distorted image on range [0, 1]
46 | Raises:
47 | ValueError: if color_ordering not in [0, 3]
48 | """
49 | with tf.name_scope(scope, 'distort_color', [image]):
50 | if fast_mode:
51 | if color_ordering == 0:
52 | image = tf.image.random_brightness(image, max_delta=32. / 255.)
53 | image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
54 | else:
55 | image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
56 | image = tf.image.random_brightness(image, max_delta=32. / 255.)
57 | else:
58 | if color_ordering == 0:
59 | image = tf.image.random_brightness(image, max_delta=32. / 255.)
60 | image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
61 | image = tf.image.random_hue(image, max_delta=0.2)
62 | image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
63 | elif color_ordering == 1:
64 | image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
65 | image = tf.image.random_brightness(image, max_delta=32. / 255.)
66 | image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
67 | image = tf.image.random_hue(image, max_delta=0.2)
68 | elif color_ordering == 2:
69 | image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
70 | image = tf.image.random_hue(image, max_delta=0.2)
71 | image = tf.image.random_brightness(image, max_delta=32. / 255.)
72 | image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
73 | elif color_ordering == 3:
74 | image = tf.image.random_hue(image, max_delta=0.2)
75 | image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
76 | image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
77 | image = tf.image.random_brightness(image, max_delta=32. / 255.)
78 | else:
79 | raise ValueError('color_ordering must be in [0, 3]')
80 |
81 | # The random_* ops do not necessarily clamp.
82 | return tf.clip_by_value(image, 0.0, 1.0)
83 |
84 |
85 | def distorted_bounding_box_crop(image,
86 | bbox,
87 | min_object_covered=0.1,
88 | aspect_ratio_range=(0.75, 1.33),
89 | area_range=(0.05, 1.0),
90 | max_attempts=100,
91 | scope=None):
92 | """Generates cropped_image using a one of the bboxes randomly distorted.
93 |
94 | See `tf.image.sample_distorted_bounding_box` for more documentation.
95 |
96 | Args:
97 | image: 3-D Tensor of image (it will be converted to floats in [0, 1]).
98 | bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
99 | where each coordinate is [0, 1) and the coordinates are arranged
100 | as [ymin, xmin, ymax, xmax]. If num_boxes is 0 then it would use the whole
101 | image.
102 | min_object_covered: An optional `float`. Defaults to `0.1`. The cropped
103 | area of the image must contain at least this fraction of any bounding box
104 | supplied.
105 | aspect_ratio_range: An optional list of `floats`. The cropped area of the
106 | image must have an aspect ratio = width / height within this range.
107 | area_range: An optional list of `floats`. The cropped area of the image
108 | must contain a fraction of the supplied image within in this range.
109 | max_attempts: An optional `int`. Number of attempts at generating a cropped
110 | region of the image of the specified constraints. After `max_attempts`
111 | failures, return the entire image.
112 | scope: Optional scope for name_scope.
113 | Returns:
114 | A tuple, a 3-D Tensor cropped_image and the distorted bbox
115 | """
116 | with tf.name_scope(scope, 'distorted_bounding_box_crop', [image, bbox]):
117 | # Each bounding box has shape [1, num_boxes, box coords] and
118 | # the coordinates are ordered [ymin, xmin, ymax, xmax].
119 |
120 | # A large fraction of image datasets contain a human-annotated bounding
121 | # box delineating the region of the image containing the object of interest.
122 | # We choose to create a new bounding box for the object which is a randomly
123 | # distorted version of the human-annotated bounding box that obeys an
124 | # allowed range of aspect ratios, sizes and overlap with the human-annotated
125 | # bounding box. If no box is supplied, then we assume the bounding box is
126 | # the entire image.
127 | sample_distorted_bounding_box = tf.image.sample_distorted_bounding_box(
128 | tf.shape(image),
129 | bounding_boxes=bbox,
130 | min_object_covered=min_object_covered,
131 | aspect_ratio_range=aspect_ratio_range,
132 | area_range=area_range,
133 | max_attempts=max_attempts,
134 | use_image_if_no_bounding_boxes=True)
135 | bbox_begin, bbox_size, distort_bbox = sample_distorted_bounding_box
136 |
137 | # Crop the image to the specified bounding box.
138 | cropped_image = tf.slice(image, bbox_begin, bbox_size)
139 | return cropped_image, distort_bbox
140 |
141 |
142 | def preprocess_for_train(image, height, width, bbox,
143 | fast_mode=False,
144 | scope=None):
145 | """Distort one image for training a network.
146 |
147 | Distorting images provides a useful technique for augmenting the data
148 | set during training in order to make the network invariant to aspects
149 | of the image that do not effect the label.
150 |
151 | Additionally it would create image_summaries to display the different
152 | transformations applied to the image.
153 |
154 | Args:
155 | image: 3-D Tensor of image. If dtype is tf.float32 then the range should be
156 | [0, 1], otherwise it would converted to tf.float32 assuming that the range
157 | is [0, MAX], where MAX is largest positive representable number for
158 | int(8/16/32) data type (see `tf.image.convert_image_dtype` for details).
159 | height: integer
160 | width: integer
161 | bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
162 | where each coordinate is [0, 1) and the coordinates are arranged
163 | as [ymin, xmin, ymax, xmax].
164 | fast_mode: Optional boolean, if True avoids slower transformations (i.e.
165 | bi-cubic resizing, random_hue or random_contrast).
166 | scope: Optional scope for name_scope.
167 | Returns:
168 | 3-D float Tensor of distorted image used for training with range [-1, 1].
169 | """
170 | with tf.name_scope(scope, 'distort_image', [image, height, width, bbox]):
171 | if bbox is None:
172 | bbox = tf.constant([0.0, 0.0, 1.0, 1.0],
173 | dtype=tf.float32,
174 | shape=[1, 1, 4])
175 | if image.dtype != tf.float32:
176 | image = tf.image.convert_image_dtype(image, dtype=tf.float32)
177 | # Each bounding box has shape [1, num_boxes, box coords] and
178 | # the coordinates are ordered [ymin, xmin, ymax, xmax].
179 | image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0),
180 | bbox)
181 |
182 | distorted_image, distorted_bbox = distorted_bounding_box_crop(image, bbox)
183 | # Restore the shape since the dynamic slice based upon the bbox_size loses
184 | # the third dimension.
185 | distorted_image.set_shape([None, None, 3])
186 |
187 | # This resizing operation may distort the images because the aspect
188 | # ratio is not respected. We select a resize method in a round robin
189 | # fashion based on the thread number.
190 | # Note that ResizeMethod contains 4 enumerated resizing methods.
191 |
192 | # We select only 1 case for fast_mode bilinear.
193 | num_resize_cases = 1 if fast_mode else 4
194 | distorted_image = apply_with_random_selector(
195 | distorted_image,
196 | lambda x, method: tf.image.resize_images(x, [height, width], method=method),
197 | num_cases=num_resize_cases)
198 |
199 | # Randomly flip the image horizontally.
200 | distorted_image = tf.image.random_flip_left_right(distorted_image)
201 |
202 | # Randomly distort the colors. There are 4 ways to do it.
203 | distorted_image = apply_with_random_selector(
204 | distorted_image,
205 | lambda x, ordering: distort_color(x, ordering, fast_mode),
206 | num_cases=4)
207 |
208 | distorted_image = tf.subtract(distorted_image, 0.5)
209 | distorted_image = tf.multiply(distorted_image, 2.0)
210 | return distorted_image
211 |
212 |
213 | def preprocess_for_eval(image, height, width,
214 | central_fraction=0.70, scope=None):
215 | """Prepare one image for evaluation.
216 |
217 | If height and width are specified it would output an image with that size by
218 | applying resize_bilinear.
219 |
220 | If central_fraction is specified it would cropt the central fraction of the
221 | input image.
222 |
223 | Args:
224 | image: 3-D Tensor of image. If dtype is tf.float32 then the range should be
225 | [0, 1], otherwise it would converted to tf.float32 assuming that the range
226 | is [0, MAX], where MAX is largest positive representable number for
227 | int(8/16/32) data type (see `tf.image.convert_image_dtype` for details)
228 | height: integer
229 | width: integer
230 | central_fraction: Optional Float, fraction of the image to crop.
231 | scope: Optional scope for name_scope.
232 | Returns:
233 | 3-D float Tensor of prepared image.
234 | """
235 | with tf.name_scope(scope, 'eval_image', [image, height, width]):
236 | if image.dtype != tf.float32:
237 | image = tf.image.convert_image_dtype(image, dtype=tf.float32)
238 | # Crop the central region of the image with an area containing 87.5% of
239 | # the original image.
240 | if central_fraction:
241 | image = tf.image.central_crop(image, central_fraction=central_fraction)
242 |
243 | if height and width:
244 | # Resize the image to the specified height and width.
245 | image = tf.expand_dims(image, 0)
246 | image = tf.image.resize_bilinear(image, [height, width],
247 | align_corners=False)
248 | image = tf.squeeze(image, [0])
249 | image = tf.subtract(image, 0.5)
250 | image = tf.multiply(image, 2.0)
251 | return image
252 |
253 |
254 | def preprocess_image(image, height, width,
255 | is_training=False,
256 | bbox=None,
257 | fast_mode=False):
258 | """Pre-process one image for training or evaluation.
259 |
260 | Args:
261 | image: 3-D Tensor [height, width, channels] with the image.
262 | height: integer, image expected height.
263 | width: integer, image expected width.
264 | is_training: Boolean. If true it would transform an image for train,
265 | otherwise it would transform it for evaluation.
266 | bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
267 | where each coordinate is [0, 1) and the coordinates are arranged as
268 | [ymin, xmin, ymax, xmax].
269 | fast_mode: Optional boolean, if True avoids slower transformations.
270 |
271 | Returns:
272 | 3-D float Tensor containing an appropriately scaled image
273 |
274 | Raises:
275 | ValueError: if user does not provide bounding box
276 | """
277 | if is_training:
278 | return preprocess_for_train(image, height, width, bbox, fast_mode)
279 | else:
280 | return preprocess_for_eval(image, height, width)
281 |
--------------------------------------------------------------------------------
/preprocessing/vgg_preprocessing.py:
--------------------------------------------------------------------------------
1 | """Provides utilities to preprocess images.
2 |
3 | The preprocessing steps for VGG were introduced in the following technical
4 | report:
5 |
6 | Very Deep Convolutional Networks For Large-Scale Image Recognition
7 | Karen Simonyan and Andrew Zisserman
8 | arXiv technical report, 2015
9 | PDF: http://arxiv.org/pdf/1409.1556.pdf
10 | ILSVRC 2014 Slides: http://www.robots.ox.ac.uk/~karen/pdf/ILSVRC_2014.pdf
11 | CC-BY-4.0
12 |
13 | More information can be obtained from the VGG website:
14 | www.robots.ox.ac.uk/~vgg/research/very_deep/
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import tensorflow as tf
22 |
23 | slim = tf.contrib.slim
24 |
25 | _R_MEAN = 123.68
26 | _G_MEAN = 116.78
27 | _B_MEAN = 103.94
28 |
29 | _RESIZE_SIDE_MIN = 256
30 | _RESIZE_SIDE_MAX = 512
31 |
32 |
33 | def _crop(image, offset_height, offset_width, crop_height, crop_width):
34 | """Crops the given image using the provided offsets and sizes.
35 |
36 | Note that the method doesn't assume we know the input image size but it does
37 | assume we know the input image rank.
38 |
39 | Args:
40 | image: an image of shape [height, width, channels].
41 | offset_height: a scalar tensor indicating the height offset.
42 | offset_width: a scalar tensor indicating the width offset.
43 | crop_height: the height of the cropped image.
44 | crop_width: the width of the cropped image.
45 |
46 | Returns:
47 | the cropped (and resized) image.
48 |
49 | Raises:
50 | InvalidArgumentError: if the rank is not 3 or if the image dimensions are
51 | less than the crop size.
52 | """
53 | original_shape = tf.shape(image)
54 |
55 | rank_assertion = tf.Assert(
56 | tf.equal(tf.rank(image), 3),
57 | ['Rank of image must be equal to 3.'])
58 | with tf.control_dependencies([rank_assertion]):
59 | cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]])
60 |
61 | size_assertion = tf.Assert(
62 | tf.logical_and(
63 | tf.greater_equal(original_shape[0], crop_height),
64 | tf.greater_equal(original_shape[1], crop_width)),
65 | ['Crop size greater than the image size.'])
66 |
67 | offsets = tf.to_int32(tf.stack([offset_height, offset_width, 0]))
68 |
69 | # Use tf.slice instead of crop_to_bounding box as it accepts tensors to
70 | # define the crop size.
71 | with tf.control_dependencies([size_assertion]):
72 | image = tf.slice(image, offsets, cropped_shape)
73 | return tf.reshape(image, cropped_shape)
74 |
75 |
76 | def _random_crop(image_list, crop_height, crop_width):
77 | """Crops the given list of images.
78 |
79 | The function applies the same crop to each image in the list. This can be
80 | effectively applied when there are multiple image inputs of the same
81 | dimension such as:
82 |
83 | image, depths, normals = _random_crop([image, depths, normals], 120, 150)
84 |
85 | Args:
86 | image_list: a list of image tensors of the same dimension but possibly
87 | varying channel.
88 | crop_height: the new height.
89 | crop_width: the new width.
90 |
91 | Returns:
92 | the image_list with cropped images.
93 |
94 | Raises:
95 | ValueError: if there are multiple image inputs provided with different size
96 | or the images are smaller than the crop dimensions.
97 | """
98 | if not image_list:
99 | raise ValueError('Empty image_list.')
100 |
101 | # Compute the rank assertions.
102 | rank_assertions = []
103 | for i in range(len(image_list)):
104 | image_rank = tf.rank(image_list[i])
105 | rank_assert = tf.Assert(
106 | tf.equal(image_rank, 3),
107 | ['Wrong rank for tensor %s [expected] [actual]',
108 | image_list[i].name, 3, image_rank])
109 | rank_assertions.append(rank_assert)
110 |
111 | with tf.control_dependencies([rank_assertions[0]]):
112 | image_shape = tf.shape(image_list[0])
113 | image_height = image_shape[0]
114 | image_width = image_shape[1]
115 | crop_size_assert = tf.Assert(
116 | tf.logical_and(
117 | tf.greater_equal(image_height, crop_height),
118 | tf.greater_equal(image_width, crop_width)),
119 | ['Crop size greater than the image size.'])
120 |
121 | asserts = [rank_assertions[0], crop_size_assert]
122 |
123 | for i in range(1, len(image_list)):
124 | image = image_list[i]
125 | asserts.append(rank_assertions[i])
126 | with tf.control_dependencies([rank_assertions[i]]):
127 | shape = tf.shape(image)
128 | height = shape[0]
129 | width = shape[1]
130 |
131 | height_assert = tf.Assert(
132 | tf.equal(height, image_height),
133 | ['Wrong height for tensor %s [expected][actual]',
134 | image.name, height, image_height])
135 | width_assert = tf.Assert(
136 | tf.equal(width, image_width),
137 | ['Wrong width for tensor %s [expected][actual]',
138 | image.name, width, image_width])
139 | asserts.extend([height_assert, width_assert])
140 |
141 | # Create a random bounding box.
142 | #
143 | # Use tf.random_uniform and not numpy.random.rand as doing the former would
144 | # generate random numbers at graph eval time, unlike the latter which
145 | # generates random numbers at graph definition time.
146 | with tf.control_dependencies(asserts):
147 | max_offset_height = tf.reshape(image_height - crop_height + 1, [])
148 | with tf.control_dependencies(asserts):
149 | max_offset_width = tf.reshape(image_width - crop_width + 1, [])
150 | offset_height = tf.random_uniform(
151 | [], maxval=max_offset_height, dtype=tf.int32)
152 | offset_width = tf.random_uniform(
153 | [], maxval=max_offset_width, dtype=tf.int32)
154 |
155 | return [_crop(image, offset_height, offset_width,
156 | crop_height, crop_width) for image in image_list]
157 |
158 |
159 | def _central_crop(image_list, crop_height, crop_width):
160 | """Performs central crops of the given image list.
161 |
162 | Args:
163 | image_list: a list of image tensors of the same dimension but possibly
164 | varying channel.
165 | crop_height: the height of the image following the crop.
166 | crop_width: the width of the image following the crop.
167 |
168 | Returns:
169 | the list of cropped images.
170 | """
171 | outputs = []
172 | for image in image_list:
173 | image_height = tf.shape(image)[0]
174 | image_width = tf.shape(image)[1]
175 |
176 | offset_height = (image_height - crop_height) / 2
177 | offset_width = (image_width - crop_width) / 2
178 |
179 | outputs.append(_crop(image, offset_height, offset_width,
180 | crop_height, crop_width))
181 | return outputs
182 |
183 |
184 | def _mean_image_subtraction(image, means):
185 | """Subtracts the given means from each image channel.
186 |
187 | For example:
188 | means = [123.68, 116.779, 103.939]
189 | image = _mean_image_subtraction(image, means)
190 |
191 | Note that the rank of `image` must be known.
192 |
193 | Args:
194 | image: a tensor of size [height, width, C].
195 | means: a C-vector of values to subtract from each channel.
196 |
197 | Returns:
198 | the centered image.
199 |
200 | Raises:
201 | ValueError: If the rank of `image` is unknown, if `image` has a rank other
202 | than three or if the number of channels in `image` doesn't match the
203 | number of values in `means`.
204 | """
205 | if image.get_shape().ndims != 3:
206 | raise ValueError('Input must be of size [height, width, C>0]')
207 | num_channels = image.get_shape().as_list()[-1]
208 | if len(means) != num_channels:
209 | raise ValueError('len(means) must match the number of channels')
210 |
211 | channels = tf.split(axis=2, num_or_size_splits=num_channels, value=image)
212 | for i in range(num_channels):
213 | channels[i] -= means[i]
214 | return tf.concat(axis=2, values=channels)
215 |
216 |
217 | def _smallest_size_at_least(height, width, smallest_side):
218 | """Computes new shape with the smallest side equal to `smallest_side`.
219 |
220 | Computes new shape with the smallest side equal to `smallest_side` while
221 | preserving the original aspect ratio.
222 |
223 | Args:
224 | height: an int32 scalar tensor indicating the current height.
225 | width: an int32 scalar tensor indicating the current width.
226 | smallest_side: A python integer or scalar `Tensor` indicating the size of
227 | the smallest side after resize.
228 |
229 | Returns:
230 | new_height: an int32 scalar tensor indicating the new height.
231 | new_width: and int32 scalar tensor indicating the new width.
232 | """
233 | smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
234 |
235 | height = tf.to_float(height)
236 | width = tf.to_float(width)
237 | smallest_side = tf.to_float(smallest_side)
238 |
239 | scale = tf.cond(tf.greater(height, width),
240 | lambda: smallest_side / width,
241 | lambda: smallest_side / height)
242 | new_height = tf.to_int32(height * scale)
243 | new_width = tf.to_int32(width * scale)
244 | return new_height, new_width
245 |
246 |
247 | def _aspect_preserving_resize(image, smallest_side):
248 | """Resize images preserving the original aspect ratio.
249 |
250 | Args:
251 | image: A 3-D image `Tensor`.
252 | smallest_side: A python integer or scalar `Tensor` indicating the size of
253 | the smallest side after resize.
254 |
255 | Returns:
256 | resized_image: A 3-D tensor containing the resized image.
257 | """
258 | smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
259 |
260 | shape = tf.shape(image)
261 | height = shape[0]
262 | width = shape[1]
263 | new_height, new_width = _smallest_size_at_least(height, width, smallest_side)
264 | image = tf.expand_dims(image, 0)
265 | resized_image = tf.image.resize_bilinear(image, [new_height, new_width],
266 | align_corners=False)
267 | resized_image = tf.squeeze(resized_image)
268 | resized_image.set_shape([None, None, 3])
269 | return resized_image
270 |
271 |
272 | def preprocess_for_train(image,
273 | output_height,
274 | output_width,
275 | resize_side_min=_RESIZE_SIDE_MIN,
276 | resize_side_max=_RESIZE_SIDE_MAX):
277 | """Preprocesses the given image for training.
278 |
279 | Note that the actual resizing scale is sampled from
280 | [`resize_size_min`, `resize_size_max`].
281 |
282 | Args:
283 | image: A `Tensor` representing an image of arbitrary size.
284 | output_height: The height of the image after preprocessing.
285 | output_width: The width of the image after preprocessing.
286 | resize_side_min: The lower bound for the smallest side of the image for
287 | aspect-preserving resizing.
288 | resize_side_max: The upper bound for the smallest side of the image for
289 | aspect-preserving resizing.
290 |
291 | Returns:
292 | A preprocessed image.
293 | """
294 | resize_side = tf.random_uniform(
295 | [], minval=resize_side_min, maxval=resize_side_max+1, dtype=tf.int32)
296 |
297 | image = _aspect_preserving_resize(image, resize_side)
298 | image = _random_crop([image], output_height, output_width)[0]
299 | image.set_shape([output_height, output_width, 3])
300 | image = tf.to_float(image)
301 | image = tf.image.random_flip_left_right(image)
302 | return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
303 |
304 |
305 | def preprocess_for_eval(image, output_height, output_width, resize_side):
306 | """Preprocesses the given image for evaluation.
307 |
308 | Args:
309 | image: A `Tensor` representing an image of arbitrary size.
310 | output_height: The height of the image after preprocessing.
311 | output_width: The width of the image after preprocessing.
312 | resize_side: The smallest side of the image for aspect-preserving resizing.
313 |
314 | Returns:
315 | A preprocessed image.
316 | """
317 | image = _aspect_preserving_resize(image, resize_side)
318 | image = _central_crop([image], output_height, output_width)[0]
319 | image.set_shape([output_height, output_width, 3])
320 | image = tf.to_float(image)
321 | return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
322 |
323 |
324 | def preprocess_image(image, output_height, output_width, is_training=False,
325 | resize_side_min=_RESIZE_SIDE_MIN,
326 | resize_side_max=_RESIZE_SIDE_MAX):
327 | """Preprocesses the given image.
328 |
329 | Args:
330 | image: A `Tensor` representing an image of arbitrary size.
331 | output_height: The height of the image after preprocessing.
332 | output_width: The width of the image after preprocessing.
333 | is_training: `True` if we're preprocessing the image for training and
334 | `False` otherwise.
335 | resize_side_min: The lower bound for the smallest side of the image for
336 | aspect-preserving resizing. If `is_training` is `False`, then this value
337 | is used for rescaling.
338 | resize_side_max: The upper bound for the smallest side of the image for
339 | aspect-preserving resizing. If `is_training` is `False`, this value is
340 | ignored. Otherwise, the resize side is sampled from
341 | [resize_size_min, resize_size_max].
342 |
343 | Returns:
344 | A preprocessed image.
345 | """
346 | if is_training:
347 | return preprocess_for_train(image, output_height, output_width,
348 | resize_side_min, resize_side_max)
349 | else:
350 | return preprocess_for_eval(image, output_height, output_width,
351 | resize_side_min)
352 |
--------------------------------------------------------------------------------
/nets/vgg.py:
--------------------------------------------------------------------------------
1 | """Contains model definitions for versions of the Oxford VGG network.
2 |
3 | These model definitions were introduced in the following technical report:
4 |
5 | Very Deep Convolutional Networks For Large-Scale Image Recognition
6 | Karen Simonyan and Andrew Zisserman
7 | arXiv technical report, 2015
8 | PDF: http://arxiv.org/pdf/1409.1556.pdf
9 | ILSVRC 2014 Slides: http://www.robots.ox.ac.uk/~karen/pdf/ILSVRC_2014.pdf
10 | CC-BY-4.0
11 |
12 | More information can be obtained from the VGG website:
13 | www.robots.ox.ac.uk/~vgg/research/very_deep/
14 |
15 | Usage:
16 | with slim.arg_scope(vgg.vgg_arg_scope()):
17 | outputs, end_points = vgg.vgg_a(inputs)
18 |
19 | with slim.arg_scope(vgg.vgg_arg_scope()):
20 | outputs, end_points = vgg.vgg_16(inputs)
21 |
22 | @@vgg_a
23 | @@vgg_16
24 | @@vgg_19
25 | """
26 | from __future__ import absolute_import
27 | from __future__ import division
28 | from __future__ import print_function
29 |
30 | import tensorflow as tf
31 |
32 | slim = tf.contrib.slim
33 |
34 |
35 | def vgg_arg_scope(weight_decay=0.0005):
36 | """Defines the VGG arg scope.
37 |
38 | Args:
39 | weight_decay: The l2 regularization coefficient.
40 |
41 | Returns:
42 | An arg_scope.
43 | """
44 | with slim.arg_scope([slim.conv2d, slim.fully_connected],
45 | activation_fn=tf.nn.relu,
46 | weights_regularizer=slim.l2_regularizer(weight_decay),
47 | biases_initializer=tf.zeros_initializer()):
48 | with slim.arg_scope([slim.conv2d], padding='SAME') as arg_sc:
49 | return arg_sc
50 |
51 |
52 | def vgg_a(inputs,
53 | num_classes=1000,
54 | is_training=True,
55 | dropout_keep_prob=0.5,
56 | spatial_squeeze=True,
57 | scope='vgg_a',
58 | fc_conv_padding='VALID',
59 | global_pool=False):
60 | """Oxford Net VGG 11-Layers version A Example.
61 |
62 | Note: All the fully_connected layers have been transformed to conv2d layers.
63 | To use in classification mode, resize input to 224x224.
64 |
65 | Args:
66 | inputs: a tensor of size [batch_size, height, width, channels].
67 | num_classes: number of predicted classes. If 0 or None, the logits layer is
68 | omitted and the input features to the logits layer are returned instead.
69 | is_training: whether or not the model is being trained.
70 | dropout_keep_prob: the probability that activations are kept in the dropout
71 | layers during training.
72 | spatial_squeeze: whether or not should squeeze the spatial dimensions of the
73 | outputs. Useful to remove unnecessary dimensions for classification.
74 | scope: Optional scope for the variables.
75 | fc_conv_padding: the type of padding to use for the fully connected layer
76 | that is implemented as a convolutional layer. Use 'SAME' padding if you
77 | are applying the network in a fully convolutional manner and want to
78 | get a prediction map downsampled by a factor of 32 as an output.
79 | Otherwise, the output prediction map will be (input / 32) - 6 in case of
80 | 'VALID' padding.
81 | global_pool: Optional boolean flag. If True, the input to the classification
82 | layer is avgpooled to size 1x1, for any input size. (This is not part
83 | of the original VGG architecture.)
84 |
85 | Returns:
86 | net: the output of the logits layer (if num_classes is a non-zero integer),
87 | or the input to the logits layer (if num_classes is 0 or None).
88 | end_points: a dict of tensors with intermediate activations.
89 | """
90 | with tf.variable_scope(scope, 'vgg_a', [inputs]) as sc:
91 | end_points_collection = sc.original_name_scope + '_end_points'
92 | # Collect outputs for conv2d, fully_connected and max_pool2d.
93 | with slim.arg_scope([slim.conv2d, slim.max_pool2d],
94 | outputs_collections=end_points_collection):
95 | net = slim.repeat(inputs, 1, slim.conv2d, 64, [3, 3], scope='conv1')
96 | net = slim.max_pool2d(net, [2, 2], scope='pool1')
97 | net = slim.repeat(net, 1, slim.conv2d, 128, [3, 3], scope='conv2')
98 | net = slim.max_pool2d(net, [2, 2], scope='pool2')
99 | net = slim.repeat(net, 2, slim.conv2d, 256, [3, 3], scope='conv3')
100 | net = slim.max_pool2d(net, [2, 2], scope='pool3')
101 | net = slim.repeat(net, 2, slim.conv2d, 512, [3, 3], scope='conv4')
102 | net = slim.max_pool2d(net, [2, 2], scope='pool4')
103 | net = slim.repeat(net, 2, slim.conv2d, 512, [3, 3], scope='conv5')
104 | net = slim.max_pool2d(net, [2, 2], scope='pool5')
105 |
106 | # Use conv2d instead of fully_connected layers.
107 | net = slim.conv2d(net, 4096, [7, 7], padding=fc_conv_padding, scope='fc6')
108 | net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
109 | scope='dropout6')
110 | net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
111 | # Convert end_points_collection into a end_point dict.
112 | end_points = slim.utils.convert_collection_to_dict(end_points_collection)
113 | if global_pool:
114 | net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool')
115 | end_points['global_pool'] = net
116 | if num_classes:
117 | net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
118 | scope='dropout7')
119 | net = slim.conv2d(net, num_classes, [1, 1],
120 | activation_fn=None,
121 | normalizer_fn=None,
122 | scope='fc8')
123 | if spatial_squeeze:
124 | net = tf.squeeze(net, [1, 2], name='fc8/squeezed')
125 | end_points[sc.name + '/fc8'] = net
126 | return net, end_points
127 | vgg_a.default_image_size = 224
128 |
129 |
130 | def vgg_16(inputs,
131 | num_classes=1000,
132 | is_training=True,
133 | dropout_keep_prob=0.5,
134 | spatial_squeeze=True,
135 | scope='vgg_16',
136 | fc_conv_padding='VALID',
137 | global_pool=False):
138 | """Oxford Net VGG 16-Layers version D Example.
139 |
140 | Note: All the fully_connected layers have been transformed to conv2d layers.
141 | To use in classification mode, resize input to 224x224.
142 |
143 | Args:
144 | inputs: a tensor of size [batch_size, height, width, channels].
145 | num_classes: number of predicted classes. If 0 or None, the logits layer is
146 | omitted and the input features to the logits layer are returned instead.
147 | is_training: whether or not the model is being trained.
148 | dropout_keep_prob: the probability that activations are kept in the dropout
149 | layers during training.
150 | spatial_squeeze: whether or not should squeeze the spatial dimensions of the
151 | outputs. Useful to remove unnecessary dimensions for classification.
152 | scope: Optional scope for the variables.
153 | fc_conv_padding: the type of padding to use for the fully connected layer
154 | that is implemented as a convolutional layer. Use 'SAME' padding if you
155 | are applying the network in a fully convolutional manner and want to
156 | get a prediction map downsampled by a factor of 32 as an output.
157 | Otherwise, the output prediction map will be (input / 32) - 6 in case of
158 | 'VALID' padding.
159 | global_pool: Optional boolean flag. If True, the input to the classification
160 | layer is avgpooled to size 1x1, for any input size. (This is not part
161 | of the original VGG architecture.)
162 |
163 | Returns:
164 | net: the output of the logits layer (if num_classes is a non-zero integer),
165 | or the input to the logits layer (if num_classes is 0 or None).
166 | end_points: a dict of tensors with intermediate activations.
167 | """
168 | with tf.variable_scope(scope, 'vgg_16', [inputs]) as sc:
169 | end_points_collection = sc.original_name_scope + '_end_points'
170 | # Collect outputs for conv2d, fully_connected and max_pool2d.
171 | with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.max_pool2d],
172 | outputs_collections=end_points_collection):
173 | net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
174 | net = slim.max_pool2d(net, [2, 2], scope='pool1')
175 | net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
176 | net = slim.max_pool2d(net, [2, 2], scope='pool2')
177 | net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
178 | net = slim.max_pool2d(net, [2, 2], scope='pool3')
179 | net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
180 | net = slim.max_pool2d(net, [2, 2], scope='pool4')
181 | net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
182 | net = slim.max_pool2d(net, [2, 2], scope='pool5')
183 |
184 | # Use conv2d instead of fully_connected layers.
185 | net = slim.conv2d(net, 4096, [7, 7], padding=fc_conv_padding, scope='fc6')
186 | net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
187 | scope='dropout6')
188 | net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
189 | # Convert end_points_collection into a end_point dict.
190 | end_points = slim.utils.convert_collection_to_dict(end_points_collection)
191 | if global_pool:
192 | net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool')
193 | end_points['global_pool'] = net
194 | if num_classes:
195 | net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
196 | scope='dropout7')
197 | net = slim.conv2d(net, num_classes, [1, 1],
198 | activation_fn=None,
199 | normalizer_fn=None,
200 | scope='fc8')
201 | if spatial_squeeze and num_classes is not None:
202 | net = tf.squeeze(net, [1, 2], name='fc8/squeezed')
203 | end_points[sc.name + '/fc8'] = net
204 | end_points['Predictions'] = slim.softmax(net, scope='Predictions')
205 | return net, end_points
206 | vgg_16.default_image_size = 224
207 |
208 |
209 | def vgg_19(inputs,
210 | num_classes=1000,
211 | is_training=True,
212 | dropout_keep_prob=0.5,
213 | spatial_squeeze=True,
214 | scope='vgg_19',
215 | fc_conv_padding='VALID',
216 | global_pool=False):
217 | """Oxford Net VGG 19-Layers version E Example.
218 |
219 | Note: All the fully_connected layers have been transformed to conv2d layers.
220 | To use in classification mode, resize input to 224x224.
221 |
222 | Args:
223 | inputs: a tensor of size [batch_size, height, width, channels].
224 | num_classes: number of predicted classes. If 0 or None, the logits layer is
225 | omitted and the input features to the logits layer are returned instead.
226 | is_training: whether or not the model is being trained.
227 | dropout_keep_prob: the probability that activations are kept in the dropout
228 | layers during training.
229 | spatial_squeeze: whether or not should squeeze the spatial dimensions of the
230 | outputs. Useful to remove unnecessary dimensions for classification.
231 | scope: Optional scope for the variables.
232 | fc_conv_padding: the type of padding to use for the fully connected layer
233 | that is implemented as a convolutional layer. Use 'SAME' padding if you
234 | are applying the network in a fully convolutional manner and want to
235 | get a prediction map downsampled by a factor of 32 as an output.
236 | Otherwise, the output prediction map will be (input / 32) - 6 in case of
237 | 'VALID' padding.
238 | global_pool: Optional boolean flag. If True, the input to the classification
239 | layer is avgpooled to size 1x1, for any input size. (This is not part
240 | of the original VGG architecture.)
241 |
242 | Returns:
243 | net: the output of the logits layer (if num_classes is a non-zero integer),
244 | or the non-dropped-out input to the logits layer (if num_classes is 0 or
245 | None).
246 | end_points: a dict of tensors with intermediate activations.
247 | """
248 | with tf.variable_scope(scope, 'vgg_19', [inputs]) as sc:
249 | end_points_collection = sc.original_name_scope + '_end_points'
250 | # Collect outputs for conv2d, fully_connected and max_pool2d.
251 | with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.max_pool2d],
252 | outputs_collections=end_points_collection):
253 | net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
254 | net = slim.max_pool2d(net, [2, 2], scope='pool1')
255 | net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
256 | net = slim.max_pool2d(net, [2, 2], scope='pool2')
257 | net = slim.repeat(net, 4, slim.conv2d, 256, [3, 3], scope='conv3')
258 | net = slim.max_pool2d(net, [2, 2], scope='pool3')
259 | net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv4')
260 | net = slim.max_pool2d(net, [2, 2], scope='pool4')
261 | net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv5')
262 | net = slim.max_pool2d(net, [2, 2], scope='pool5')
263 |
264 | # Use conv2d instead of fully_connected layers.
265 | net = slim.conv2d(net, 4096, [7, 7], padding=fc_conv_padding, scope='fc6')
266 | net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
267 | scope='dropout6')
268 | net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
269 | # Convert end_points_collection into a end_point dict.
270 | end_points = slim.utils.convert_collection_to_dict(end_points_collection)
271 | if global_pool:
272 | net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool')
273 | end_points['global_pool'] = net
274 | if num_classes:
275 | net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
276 | scope='dropout7')
277 | net = slim.conv2d(net, num_classes, [1, 1],
278 | activation_fn=None,
279 | normalizer_fn=None,
280 | scope='fc8')
281 | if spatial_squeeze:
282 | net = tf.squeeze(net, [1, 2], name='fc8/squeezed')
283 | end_points[sc.name + '/fc8'] = net
284 | end_points['Predictions'] = slim.softmax(net, scope='Predictions')
285 | return net, end_points
286 | vgg_19.default_image_size = 224
287 |
288 | # Alias
289 | vgg_d = vgg_16
290 | vgg_e = vgg_19
291 |
--------------------------------------------------------------------------------
/nets/resnet_v1.py:
--------------------------------------------------------------------------------
1 | """Contains definitions for the original form of Residual Networks.
2 |
3 | The 'v1' residual networks (ResNets) implemented in this module were proposed
4 | by:
5 | [1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
6 | Deep Residual Learning for Image Recognition. arXiv:1512.03385
7 |
8 | Other variants were introduced in:
9 | [2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
10 | Identity Mappings in Deep Residual Networks. arXiv: 1603.05027
11 |
12 | The networks defined in this module utilize the bottleneck building block of
13 | [1] with projection shortcuts only for increasing depths. They employ batch
14 | normalization *after* every weight layer. This is the architecture used by
15 | MSRA in the Imagenet and MSCOCO 2016 competition models ResNet-101 and
16 | ResNet-152. See [2; Fig. 1a] for a comparison between the current 'v1'
17 | architecture and the alternative 'v2' architecture of [2] which uses batch
18 | normalization *before* every weight layer in the so-called full pre-activation
19 | units.
20 |
21 | Typical use:
22 |
23 | from tensorflow.contrib.slim.nets import resnet_v1
24 |
25 | ResNet-101 for image classification into 1000 classes:
26 |
27 | # inputs has shape [batch, 224, 224, 3]
28 | with slim.arg_scope(resnet_v1.resnet_arg_scope()):
29 | net, end_points = resnet_v1.resnet_v1_101(inputs, 1000, is_training=False)
30 |
31 | ResNet-101 for semantic segmentation into 21 classes:
32 |
33 | # inputs has shape [batch, 513, 513, 3]
34 | with slim.arg_scope(resnet_v1.resnet_arg_scope()):
35 | net, end_points = resnet_v1.resnet_v1_101(inputs,
36 | 21,
37 | is_training=False,
38 | global_pool=False,
39 | output_stride=16)
40 | """
41 | from __future__ import absolute_import
42 | from __future__ import division
43 | from __future__ import print_function
44 |
45 | import tensorflow as tf
46 |
47 | from nets import resnet_utils
48 |
49 |
50 | resnet_arg_scope = resnet_utils.resnet_arg_scope
51 | slim = tf.contrib.slim
52 |
53 |
54 | @slim.add_arg_scope
55 | def bottleneck(inputs,
56 | depth,
57 | depth_bottleneck,
58 | stride,
59 | rate=1,
60 | outputs_collections=None,
61 | scope=None,
62 | use_bounded_activations=False):
63 | """Bottleneck residual unit variant with BN after convolutions.
64 |
65 | This is the original residual unit proposed in [1]. See Fig. 1(a) of [2] for
66 | its definition. Note that we use here the bottleneck variant which has an
67 | extra bottleneck layer.
68 |
69 | When putting together two consecutive ResNet blocks that use this unit, one
70 | should use stride = 2 in the last unit of the first block.
71 |
72 | Args:
73 | inputs: A tensor of size [batch, height, width, channels].
74 | depth: The depth of the ResNet unit output.
75 | depth_bottleneck: The depth of the bottleneck layers.
76 | stride: The ResNet unit's stride. Determines the amount of downsampling of
77 | the units output compared to its input.
78 | rate: An integer, rate for atrous convolution.
79 | outputs_collections: Collection to add the ResNet unit output.
80 | scope: Optional variable_scope.
81 | use_bounded_activations: Whether or not to use bounded activations. Bounded
82 | activations better lend themselves to quantized inference.
83 |
84 | Returns:
85 | The ResNet unit's output.
86 | """
87 | with tf.variable_scope(scope, 'bottleneck_v1', [inputs]) as sc:
88 | depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4)
89 | if depth == depth_in:
90 | shortcut = resnet_utils.subsample(inputs, stride, 'shortcut')
91 | else:
92 | shortcut = slim.conv2d(
93 | inputs,
94 | depth, [1, 1],
95 | stride=stride,
96 | activation_fn=tf.nn.relu6 if use_bounded_activations else None,
97 | scope='shortcut')
98 |
99 | residual = slim.conv2d(inputs, depth_bottleneck, [1, 1], stride=1,
100 | scope='conv1')
101 | residual = resnet_utils.conv2d_same(residual, depth_bottleneck, 3, stride,
102 | rate=rate, scope='conv2')
103 | residual = slim.conv2d(residual, depth, [1, 1], stride=1,
104 | activation_fn=None, scope='conv3')
105 |
106 | if use_bounded_activations:
107 | # Use clip_by_value to simulate bandpass activation.
108 | residual = tf.clip_by_value(residual, -6.0, 6.0)
109 | output = tf.nn.relu6(shortcut + residual)
110 | else:
111 | output = tf.nn.relu(shortcut + residual)
112 |
113 | return slim.utils.collect_named_outputs(outputs_collections,
114 | sc.name,
115 | output)
116 |
117 |
118 | def resnet_v1(inputs,
119 | blocks,
120 | num_classes=None,
121 | is_training=True,
122 | global_pool=True,
123 | output_stride=None,
124 | include_root_block=True,
125 | spatial_squeeze=True,
126 | reuse=None,
127 | scope=None):
128 | """Generator for v1 ResNet models.
129 |
130 | This function generates a family of ResNet v1 models. See the resnet_v1_*()
131 | methods for specific model instantiations, obtained by selecting different
132 | block instantiations that produce ResNets of various depths.
133 |
134 | Training for image classification on Imagenet is usually done with [224, 224]
135 | inputs, resulting in [7, 7] feature maps at the output of the last ResNet
136 | block for the ResNets defined in [1] that have nominal stride equal to 32.
137 | However, for dense prediction tasks we advise that one uses inputs with
138 | spatial dimensions that are multiples of 32 plus 1, e.g., [321, 321]. In
139 | this case the feature maps at the ResNet output will have spatial shape
140 | [(height - 1) / output_stride + 1, (width - 1) / output_stride + 1]
141 | and corners exactly aligned with the input image corners, which greatly
142 | facilitates alignment of the features to the image. Using as input [225, 225]
143 | images results in [8, 8] feature maps at the output of the last ResNet block.
144 |
145 | For dense prediction tasks, the ResNet needs to run in fully-convolutional
146 | (FCN) mode and global_pool needs to be set to False. The ResNets in [1, 2] all
147 | have nominal stride equal to 32 and a good choice in FCN mode is to use
148 | output_stride=16 in order to increase the density of the computed features at
149 | small computational and memory overhead, cf. http://arxiv.org/abs/1606.00915.
150 |
151 | Args:
152 | inputs: A tensor of size [batch, height_in, width_in, channels].
153 | blocks: A list of length equal to the number of ResNet blocks. Each element
154 | is a resnet_utils.Block object describing the units in the block.
155 | num_classes: Number of predicted classes for classification tasks.
156 | If 0 or None, we return the features before the logit layer.
157 | is_training: whether batch_norm layers are in training mode.
158 | global_pool: If True, we perform global average pooling before computing the
159 | logits. Set to True for image classification, False for dense prediction.
160 | output_stride: If None, then the output will be computed at the nominal
161 | network stride. If output_stride is not None, it specifies the requested
162 | ratio of input to output spatial resolution.
163 | include_root_block: If True, include the initial convolution followed by
164 | max-pooling, if False excludes it.
165 | spatial_squeeze: if True, logits is of shape [B, C], if false logits is
166 | of shape [B, 1, 1, C], where B is batch_size and C is number of classes.
167 | To use this parameter, the input images must be smaller than 300x300
168 | pixels, in which case the output logit layer does not contain spatial
169 | information and can be removed.
170 | reuse: whether or not the network and its variables should be reused. To be
171 | able to reuse 'scope' must be given.
172 | scope: Optional variable_scope.
173 |
174 | Returns:
175 | net: A rank-4 tensor of size [batch, height_out, width_out, channels_out].
176 | If global_pool is False, then height_out and width_out are reduced by a
177 | factor of output_stride compared to the respective height_in and width_in,
178 | else both height_out and width_out equal one. If num_classes is 0 or None,
179 | then net is the output of the last ResNet block, potentially after global
180 | average pooling. If num_classes a non-zero integer, net contains the
181 | pre-softmax activations.
182 | end_points: A dictionary from components of the network to the corresponding
183 | activation.
184 |
185 | Raises:
186 | ValueError: If the target output_stride is not valid.
187 | """
188 | with tf.variable_scope(scope, 'resnet_v1', [inputs], reuse=reuse) as sc:
189 | end_points_collection = sc.original_name_scope + '_end_points'
190 | with slim.arg_scope([slim.conv2d, bottleneck,
191 | resnet_utils.stack_blocks_dense],
192 | outputs_collections=end_points_collection):
193 | with slim.arg_scope([slim.batch_norm], is_training=is_training):
194 | net = inputs
195 | if include_root_block:
196 | if output_stride is not None:
197 | if output_stride % 4 != 0:
198 | raise ValueError('The output_stride needs to be a multiple of 4.')
199 | output_stride /= 4
200 | net = resnet_utils.conv2d_same(net, 64, 7, stride=2, scope='conv1')
201 | net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
202 | net = resnet_utils.stack_blocks_dense(net, blocks, output_stride)
203 | # Convert end_points_collection into a dictionary of end_points.
204 | end_points = slim.utils.convert_collection_to_dict(
205 | end_points_collection)
206 |
207 | if global_pool:
208 | # Global average pooling.
209 | net = tf.reduce_mean(net, [1, 2], name='pool5', keep_dims=True)
210 | end_points['global_pool'] = net
211 | if num_classes:
212 | net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
213 | normalizer_fn=None, scope='logits')
214 | end_points[sc.name + '/logits'] = net
215 | if spatial_squeeze:
216 | net = tf.squeeze(net, [1, 2], name='SpatialSqueeze')
217 | end_points[sc.name + '/spatial_squeeze'] = net
218 | end_points['Predictions'] = slim.softmax(net, scope='Predictions')
219 | return net, end_points
220 | resnet_v1.default_image_size = 224
221 |
222 |
223 | def resnet_v1_block(scope, base_depth, num_units, stride):
224 | """Helper function for creating a resnet_v1 bottleneck block.
225 |
226 | Args:
227 | scope: The scope of the block.
228 | base_depth: The depth of the bottleneck layer for each unit.
229 | num_units: The number of units in the block.
230 | stride: The stride of the block, implemented as a stride in the last unit.
231 | All other units have stride=1.
232 |
233 | Returns:
234 | A resnet_v1 bottleneck block.
235 | """
236 | return resnet_utils.Block(scope, bottleneck, [{
237 | 'depth': base_depth * 4,
238 | 'depth_bottleneck': base_depth,
239 | 'stride': 1
240 | }] * (num_units - 1) + [{
241 | 'depth': base_depth * 4,
242 | 'depth_bottleneck': base_depth,
243 | 'stride': stride
244 | }])
245 |
246 |
247 | def resnet_v1_50(inputs,
248 | num_classes=None,
249 | is_training=True,
250 | global_pool=True,
251 | output_stride=None,
252 | spatial_squeeze=True,
253 | reuse=None,
254 | scope='resnet_v1_50'):
255 | """ResNet-50 model of [1]. See resnet_v1() for arg and return description."""
256 | blocks = [
257 | resnet_v1_block('block1', base_depth=64, num_units=3, stride=2),
258 | resnet_v1_block('block2', base_depth=128, num_units=4, stride=2),
259 | resnet_v1_block('block3', base_depth=256, num_units=6, stride=2),
260 | resnet_v1_block('block4', base_depth=512, num_units=3, stride=1),
261 | ]
262 | return resnet_v1(inputs, blocks, num_classes, is_training,
263 | global_pool=global_pool, output_stride=output_stride,
264 | include_root_block=True, spatial_squeeze=spatial_squeeze,
265 | reuse=reuse, scope=scope)
266 | resnet_v1_50.default_image_size = resnet_v1.default_image_size
267 |
268 |
269 | def resnet_v1_101(inputs,
270 | num_classes=None,
271 | is_training=True,
272 | global_pool=True,
273 | output_stride=None,
274 | spatial_squeeze=True,
275 | reuse=None,
276 | scope='resnet_v1_101'):
277 | """ResNet-101 model of [1]. See resnet_v1() for arg and return description."""
278 | blocks = [
279 | resnet_v1_block('block1', base_depth=64, num_units=3, stride=2),
280 | resnet_v1_block('block2', base_depth=128, num_units=4, stride=2),
281 | resnet_v1_block('block3', base_depth=256, num_units=23, stride=2),
282 | resnet_v1_block('block4', base_depth=512, num_units=3, stride=1),
283 | ]
284 | return resnet_v1(inputs, blocks, num_classes, is_training,
285 | global_pool=global_pool, output_stride=output_stride,
286 | include_root_block=True, spatial_squeeze=spatial_squeeze,
287 | reuse=reuse, scope=scope)
288 | resnet_v1_101.default_image_size = resnet_v1.default_image_size
289 |
290 |
291 | def resnet_v1_152(inputs,
292 | num_classes=None,
293 | is_training=True,
294 | global_pool=True,
295 | output_stride=None,
296 | spatial_squeeze=True,
297 | reuse=None,
298 | scope='resnet_v1_152'):
299 | """ResNet-152 model of [1]. See resnet_v1() for arg and return description."""
300 | blocks = [
301 | resnet_v1_block('block1', base_depth=64, num_units=3, stride=2),
302 | resnet_v1_block('block2', base_depth=128, num_units=8, stride=2),
303 | resnet_v1_block('block3', base_depth=256, num_units=36, stride=2),
304 | resnet_v1_block('block4', base_depth=512, num_units=3, stride=1),
305 | ]
306 | return resnet_v1(inputs, blocks, num_classes, is_training,
307 | global_pool=global_pool, output_stride=output_stride,
308 | include_root_block=True, spatial_squeeze=spatial_squeeze,
309 | reuse=reuse, scope=scope)
310 | resnet_v1_152.default_image_size = resnet_v1.default_image_size
311 |
312 |
313 | def resnet_v1_200(inputs,
314 | num_classes=None,
315 | is_training=True,
316 | global_pool=True,
317 | output_stride=None,
318 | spatial_squeeze=True,
319 | reuse=None,
320 | scope='resnet_v1_200'):
321 | """ResNet-200 model of [2]. See resnet_v1() for arg and return description."""
322 | blocks = [
323 | resnet_v1_block('block1', base_depth=64, num_units=3, stride=2),
324 | resnet_v1_block('block2', base_depth=128, num_units=24, stride=2),
325 | resnet_v1_block('block3', base_depth=256, num_units=36, stride=2),
326 | resnet_v1_block('block4', base_depth=512, num_units=3, stride=1),
327 | ]
328 | return resnet_v1(inputs, blocks, num_classes, is_training,
329 | global_pool=global_pool, output_stride=output_stride,
330 | include_root_block=True, spatial_squeeze=spatial_squeeze,
331 | reuse=reuse, scope=scope)
332 | resnet_v1_200.default_image_size = resnet_v1.default_image_size
333 |
--------------------------------------------------------------------------------
/nets/resnet_v2.py:
--------------------------------------------------------------------------------
1 | """Contains definitions for the preactivation form of Residual Networks.
2 |
3 | Residual networks (ResNets) were originally proposed in:
4 | [1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
5 | Deep Residual Learning for Image Recognition. arXiv:1512.03385
6 |
7 | The full preactivation 'v2' ResNet variant implemented in this module was
8 | introduced by:
9 | [2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
10 | Identity Mappings in Deep Residual Networks. arXiv: 1603.05027
11 |
12 | The key difference of the full preactivation 'v2' variant compared to the
13 | 'v1' variant in [1] is the use of batch normalization before every weight layer.
14 |
15 | Typical use:
16 |
17 | from tensorflow.contrib.slim.nets import resnet_v2
18 |
19 | ResNet-101 for image classification into 1000 classes:
20 |
21 | # inputs has shape [batch, 224, 224, 3]
22 | with slim.arg_scope(resnet_v2.resnet_arg_scope()):
23 | net, end_points = resnet_v2.resnet_v2_101(inputs, 1000, is_training=False)
24 |
25 | ResNet-101 for semantic segmentation into 21 classes:
26 |
27 | # inputs has shape [batch, 513, 513, 3]
28 | with slim.arg_scope(resnet_v2.resnet_arg_scope()):
29 | net, end_points = resnet_v2.resnet_v2_101(inputs,
30 | 21,
31 | is_training=False,
32 | global_pool=False,
33 | output_stride=16)
34 | """
35 | from __future__ import absolute_import
36 | from __future__ import division
37 | from __future__ import print_function
38 |
39 | import tensorflow as tf
40 |
41 | from nets import resnet_utils
42 |
43 | slim = tf.contrib.slim
44 | resnet_arg_scope = resnet_utils.resnet_arg_scope
45 |
46 |
47 | @slim.add_arg_scope
48 | def bottleneck(inputs, depth, depth_bottleneck, stride, rate=1,
49 | outputs_collections=None, scope=None):
50 | """Bottleneck residual unit variant with BN before convolutions.
51 |
52 | This is the full preactivation residual unit variant proposed in [2]. See
53 | Fig. 1(b) of [2] for its definition. Note that we use here the bottleneck
54 | variant which has an extra bottleneck layer.
55 |
56 | When putting together two consecutive ResNet blocks that use this unit, one
57 | should use stride = 2 in the last unit of the first block.
58 |
59 | Args:
60 | inputs: A tensor of size [batch, height, width, channels].
61 | depth: The depth of the ResNet unit output.
62 | depth_bottleneck: The depth of the bottleneck layers.
63 | stride: The ResNet unit's stride. Determines the amount of downsampling of
64 | the units output compared to its input.
65 | rate: An integer, rate for atrous convolution.
66 | outputs_collections: Collection to add the ResNet unit output.
67 | scope: Optional variable_scope.
68 |
69 | Returns:
70 | The ResNet unit's output.
71 | """
72 | with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
73 | depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4)
74 | preact = slim.batch_norm(inputs, activation_fn=tf.nn.relu, scope='preact')
75 | if depth == depth_in:
76 | shortcut = resnet_utils.subsample(inputs, stride, 'shortcut')
77 | else:
78 | shortcut = slim.conv2d(preact, depth, [1, 1], stride=stride,
79 | normalizer_fn=None, activation_fn=None,
80 | scope='shortcut')
81 |
82 | residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride=1,
83 | scope='conv1')
84 | residual = resnet_utils.conv2d_same(residual, depth_bottleneck, 3, stride,
85 | rate=rate, scope='conv2')
86 | residual = slim.conv2d(residual, depth, [1, 1], stride=1,
87 | normalizer_fn=None, activation_fn=None,
88 | scope='conv3')
89 |
90 | output = shortcut + residual
91 |
92 | return slim.utils.collect_named_outputs(outputs_collections,
93 | sc.name,
94 | output)
95 |
96 |
97 | def resnet_v2(inputs,
98 | blocks,
99 | num_classes=None,
100 | is_training=True,
101 | global_pool=True,
102 | output_stride=None,
103 | include_root_block=True,
104 | spatial_squeeze=True,
105 | reuse=None,
106 | scope=None):
107 | """Generator for v2 (preactivation) ResNet models.
108 |
109 | This function generates a family of ResNet v2 models. See the resnet_v2_*()
110 | methods for specific model instantiations, obtained by selecting different
111 | block instantiations that produce ResNets of various depths.
112 |
113 | Training for image classification on Imagenet is usually done with [224, 224]
114 | inputs, resulting in [7, 7] feature maps at the output of the last ResNet
115 | block for the ResNets defined in [1] that have nominal stride equal to 32.
116 | However, for dense prediction tasks we advise that one uses inputs with
117 | spatial dimensions that are multiples of 32 plus 1, e.g., [321, 321]. In
118 | this case the feature maps at the ResNet output will have spatial shape
119 | [(height - 1) / output_stride + 1, (width - 1) / output_stride + 1]
120 | and corners exactly aligned with the input image corners, which greatly
121 | facilitates alignment of the features to the image. Using as input [225, 225]
122 | images results in [8, 8] feature maps at the output of the last ResNet block.
123 |
124 | For dense prediction tasks, the ResNet needs to run in fully-convolutional
125 | (FCN) mode and global_pool needs to be set to False. The ResNets in [1, 2] all
126 | have nominal stride equal to 32 and a good choice in FCN mode is to use
127 | output_stride=16 in order to increase the density of the computed features at
128 | small computational and memory overhead, cf. http://arxiv.org/abs/1606.00915.
129 |
130 | Args:
131 | inputs: A tensor of size [batch, height_in, width_in, channels].
132 | blocks: A list of length equal to the number of ResNet blocks. Each element
133 | is a resnet_utils.Block object describing the units in the block.
134 | num_classes: Number of predicted classes for classification tasks.
135 | If 0 or None, we return the features before the logit layer.
136 | is_training: whether batch_norm layers are in training mode.
137 | global_pool: If True, we perform global average pooling before computing the
138 | logits. Set to True for image classification, False for dense prediction.
139 | output_stride: If None, then the output will be computed at the nominal
140 | network stride. If output_stride is not None, it specifies the requested
141 | ratio of input to output spatial resolution.
142 | include_root_block: If True, include the initial convolution followed by
143 | max-pooling, if False excludes it. If excluded, `inputs` should be the
144 | results of an activation-less convolution.
145 | spatial_squeeze: if True, logits is of shape [B, C], if false logits is
146 | of shape [B, 1, 1, C], where B is batch_size and C is number of classes.
147 | To use this parameter, the input images must be smaller than 300x300
148 | pixels, in which case the output logit layer does not contain spatial
149 | information and can be removed.
150 | reuse: whether or not the network and its variables should be reused. To be
151 | able to reuse 'scope' must be given.
152 | scope: Optional variable_scope.
153 |
154 |
155 | Returns:
156 | net: A rank-4 tensor of size [batch, height_out, width_out, channels_out].
157 | If global_pool is False, then height_out and width_out are reduced by a
158 | factor of output_stride compared to the respective height_in and width_in,
159 | else both height_out and width_out equal one. If num_classes is 0 or None,
160 | then net is the output of the last ResNet block, potentially after global
161 | average pooling. If num_classes is a non-zero integer, net contains the
162 | pre-softmax activations.
163 | end_points: A dictionary from components of the network to the corresponding
164 | activation.
165 |
166 | Raises:
167 | ValueError: If the target output_stride is not valid.
168 | """
169 | with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse=reuse) as sc:
170 | end_points_collection = sc.original_name_scope + '_end_points'
171 | with slim.arg_scope([slim.conv2d, bottleneck,
172 | resnet_utils.stack_blocks_dense],
173 | outputs_collections=end_points_collection):
174 | with slim.arg_scope([slim.batch_norm], is_training=is_training):
175 | net = inputs
176 | if include_root_block:
177 | if output_stride is not None:
178 | if output_stride % 4 != 0:
179 | raise ValueError('The output_stride needs to be a multiple of 4.')
180 | output_stride /= 4
181 | # We do not include batch normalization or activation functions in
182 | # conv1 because the first ResNet unit will perform these. Cf.
183 | # Appendix of [2].
184 | with slim.arg_scope([slim.conv2d],
185 | activation_fn=None, normalizer_fn=None):
186 | net = resnet_utils.conv2d_same(net, 64, 7, stride=2, scope='conv1')
187 | net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
188 | net = resnet_utils.stack_blocks_dense(net, blocks, output_stride)
189 | # This is needed because the pre-activation variant does not have batch
190 | # normalization or activation functions in the residual unit output. See
191 | # Appendix of [2].
192 | net = slim.batch_norm(net, activation_fn=tf.nn.relu, scope='postnorm')
193 | # Convert end_points_collection into a dictionary of end_points.
194 | end_points = slim.utils.convert_collection_to_dict(
195 | end_points_collection)
196 |
197 | if global_pool:
198 | # Global average pooling.
199 | net = tf.reduce_mean(net, [1, 2], name='pool5', keep_dims=True)
200 | end_points['global_pool'] = net
201 | if num_classes is not None:
202 | net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
203 | normalizer_fn=None, scope='logits')
204 | end_points[sc.name + '/logits'] = net
205 | if spatial_squeeze:
206 | net = tf.squeeze(net, [1, 2], name='SpatialSqueeze')
207 | end_points[sc.name + '/spatial_squeeze'] = net
208 | end_points['predictions'] = slim.softmax(net, scope='predictions')
209 | return net, end_points
210 | resnet_v2.default_image_size = 224
211 |
212 |
213 | def resnet_v2_block(scope, base_depth, num_units, stride):
214 | """Helper function for creating a resnet_v2 bottleneck block.
215 |
216 | Args:
217 | scope: The scope of the block.
218 | base_depth: The depth of the bottleneck layer for each unit.
219 | num_units: The number of units in the block.
220 | stride: The stride of the block, implemented as a stride in the last unit.
221 | All other units have stride=1.
222 |
223 | Returns:
224 | A resnet_v2 bottleneck block.
225 | """
226 | return resnet_utils.Block(scope, bottleneck, [{
227 | 'depth': base_depth * 4,
228 | 'depth_bottleneck': base_depth,
229 | 'stride': 1
230 | }] * (num_units - 1) + [{
231 | 'depth': base_depth * 4,
232 | 'depth_bottleneck': base_depth,
233 | 'stride': stride
234 | }])
235 | resnet_v2.default_image_size = 224
236 |
237 |
238 | def resnet_v2_50(inputs,
239 | num_classes=None,
240 | is_training=True,
241 | global_pool=True,
242 | output_stride=None,
243 | spatial_squeeze=True,
244 | reuse=None,
245 | scope='resnet_v2_50'):
246 | """ResNet-50 model of [1]. See resnet_v2() for arg and return description."""
247 | blocks = [
248 | resnet_v2_block('block1', base_depth=64, num_units=3, stride=2),
249 | resnet_v2_block('block2', base_depth=128, num_units=4, stride=2),
250 | resnet_v2_block('block3', base_depth=256, num_units=6, stride=2),
251 | resnet_v2_block('block4', base_depth=512, num_units=3, stride=1),
252 | ]
253 | return resnet_v2(inputs, blocks, num_classes, is_training=is_training,
254 | global_pool=global_pool, output_stride=output_stride,
255 | include_root_block=True, spatial_squeeze=spatial_squeeze,
256 | reuse=reuse, scope=scope)
257 | resnet_v2_50.default_image_size = resnet_v2.default_image_size
258 |
259 |
260 | def resnet_v2_101(inputs,
261 | num_classes=None,
262 | is_training=True,
263 | global_pool=True,
264 | output_stride=None,
265 | spatial_squeeze=True,
266 | reuse=None,
267 | scope='resnet_v2_101'):
268 | """ResNet-101 model of [1]. See resnet_v2() for arg and return description."""
269 | blocks = [
270 | resnet_v2_block('block1', base_depth=64, num_units=3, stride=2),
271 | resnet_v2_block('block2', base_depth=128, num_units=4, stride=2),
272 | resnet_v2_block('block3', base_depth=256, num_units=23, stride=2),
273 | resnet_v2_block('block4', base_depth=512, num_units=3, stride=1),
274 | ]
275 | return resnet_v2(inputs, blocks, num_classes, is_training=is_training,
276 | global_pool=global_pool, output_stride=output_stride,
277 | include_root_block=True, spatial_squeeze=spatial_squeeze,
278 | reuse=reuse, scope=scope)
279 | resnet_v2_101.default_image_size = resnet_v2.default_image_size
280 |
281 |
282 | def resnet_v2_152(inputs,
283 | num_classes=None,
284 | is_training=True,
285 | global_pool=True,
286 | output_stride=None,
287 | spatial_squeeze=True,
288 | reuse=None,
289 | scope='resnet_v2_152'):
290 | """ResNet-152 model of [1]. See resnet_v2() for arg and return description."""
291 | blocks = [
292 | resnet_v2_block('block1', base_depth=64, num_units=3, stride=2),
293 | resnet_v2_block('block2', base_depth=128, num_units=8, stride=2),
294 | resnet_v2_block('block3', base_depth=256, num_units=36, stride=2),
295 | resnet_v2_block('block4', base_depth=512, num_units=3, stride=1),
296 | ]
297 | return resnet_v2(inputs, blocks, num_classes, is_training=is_training,
298 | global_pool=global_pool, output_stride=output_stride,
299 | include_root_block=True, spatial_squeeze=spatial_squeeze,
300 | reuse=reuse, scope=scope)
301 | resnet_v2_152.default_image_size = resnet_v2.default_image_size
302 |
303 |
304 | def resnet_v2_200(inputs,
305 | num_classes=None,
306 | is_training=True,
307 | global_pool=True,
308 | output_stride=None,
309 | spatial_squeeze=True,
310 | reuse=None,
311 | scope='resnet_v2_200'):
312 | """ResNet-200 model of [2]. See resnet_v2() for arg and return description."""
313 | blocks = [
314 | resnet_v2_block('block1', base_depth=64, num_units=3, stride=2),
315 | resnet_v2_block('block2', base_depth=128, num_units=24, stride=2),
316 | resnet_v2_block('block3', base_depth=256, num_units=36, stride=2),
317 | resnet_v2_block('block4', base_depth=512, num_units=3, stride=1),
318 | ]
319 | return resnet_v2(inputs, blocks, num_classes, is_training=is_training,
320 | global_pool=global_pool, output_stride=output_stride,
321 | include_root_block=True, spatial_squeeze=spatial_squeeze,
322 | reuse=reuse, scope=scope)
323 | resnet_v2_200.default_image_size = resnet_v2.default_image_size
324 |
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from tensorflow.python.platform import tf_logging as logging
3 | from tensorflow.contrib.framework.python.ops.variables import get_or_create_global_step
4 | import inception_preprocessing
5 | import vgg_preprocessing
6 | #from nets.nasnet.nasnet import build_nasnet_large, nasnet_large_arg_scope
7 | from nets.inception_resnet_v2 import inception_resnet_v2, inception_resnet_v2_arg_scope
8 | #from nets.inception_v4 import inception_v4, inception_v4_arg_scope
9 | from nets.inception_v3 import inception_v3, inception_v3_arg_scope
10 | from nets.resnet_v1 import resnet_v1_50, resnet_arg_scope
11 | from nets.vgg import vgg_16, vgg_arg_scope
12 | from nets.vgg import vgg_19, vgg_arg_scope
13 | import time
14 | import os
15 | from datasets import dataset_factory
16 | import numpy as np
17 | import math
18 |
19 | slim = tf.contrib.slim
20 |
21 | tf.app.flags.DEFINE_string(
22 | 'dataset_dir', '', 'The directory where the dataset files are stored.')
23 |
24 | tf.app.flags.DEFINE_string(
25 | 'train_dir', '', 'Directory where the results are saved to.')
26 |
27 | tf.app.flags.DEFINE_string(
28 | 'checkpoint_path', '',
29 | 'The directory where the model was written to or an absolute path to a '
30 | 'checkpoint file.')
31 |
32 | tf.app.flags.DEFINE_string(
33 | 'labels_file', '', 'The label of the dataset to load.')
34 |
35 | tf.app.flags.DEFINE_string(
36 | 'log_test', '', 'The directory where the test result are stored.')
37 |
38 | FLAGS = tf.app.flags.FLAGS
39 |
40 | #State the batch_size to evaluate each time, which can be a lot more than the training batch
41 | batch_size = 1
42 |
43 | #State the number of epochs to evaluate
44 | num_epochs = 1
45 |
46 | #State the image size you're resizing your images to. We will use the default inception size of 299.
47 | image_size = 299
48 |
49 | #State the number of classes to predict:
50 | num_classes = 102
51 |
52 | #Get the latest checkpoint file
53 | checkpoint_file = tf.train.latest_checkpoint(FLAGS.train_dir)
54 |
55 | #State the labels file and read it
56 |
57 | labels = open(FLAGS.labels_file, 'r')
58 |
59 | #Create a dictionary to refer each label to their string name
60 | labels_to_name = {}
61 | for line in labels:
62 | label, string_name = line.split(':')
63 | string_name = string_name[:-1] #Remove newline
64 | labels_to_name[int(label)] = string_name
65 |
66 | #Create the file pattern of your TFRecord files so that it could be recognized later on
67 | file_pattern = 'origin_%s_*.tfrecord'
68 |
69 | #Create a dictionary that will help people understand your dataset better. This is required by the Dataset class later.
70 | items_to_descriptions = {
71 | 'image': 'A 3-channel RGB coloured flower image that is either tulips, sunflowers, roses, dandelion, or daisy.',
72 | 'label': 'A label that is as such -- 0:daisy, 1:dandelion, 2:roses, 3:sunflowers, 4:tulips'
73 | }
74 |
75 | #============== DATASET LOADING ======================
76 | #We now create a function that creates a Dataset class which will give us many TFRecord files to feed in the examples into a queue in parallel.
77 | def get_split(split_name, dataset_dir, file_pattern=file_pattern, file_pattern_for_counting='flowers'):
78 | '''
79 | Obtains the split - training or validation - to create a Dataset class for feeding the examples into a queue later on. This function will
80 | set up the decoder and dataset information all into one Dataset class so that you can avoid the brute work later on.
81 | Your file_pattern is very important in locating the files later.
82 |
83 | INPUTS:
84 | - split_name(str): 'train' or 'validation'. Used to get the correct data split of tfrecord files
85 | - dataset_dir(str): the dataset directory where the tfrecord files are located
86 | - file_pattern(str): the file name structure of the tfrecord files in order to get the correct data
87 | - file_pattern_for_counting(str): the string name to identify your tfrecord files for counting
88 |
89 | OUTPUTS:
90 | - dataset (Dataset): A Dataset class object where we can read its various components for easier batch creation later.
91 | '''
92 |
93 | #First check whether the split_name is train or validation
94 | if split_name not in ['train', 'validation']:
95 | raise ValueError('The split_name %s is not recognized. Please input either train or validation as the split_name' % (split_name))
96 |
97 | #Create the full path for a general file_pattern to locate the tfrecord_files
98 | file_pattern_path = os.path.join(dataset_dir, file_pattern % (split_name))
99 |
100 | #Count the total number of examples in all of these shard
101 | num_samples = 0
102 | file_pattern_for_counting = file_pattern_for_counting + '_' + split_name
103 | tfrecords_to_count = [os.path.join(dataset_dir, file) for file in os.listdir(dataset_dir) if file.startswith(file_pattern_for_counting)]
104 | for tfrecord_file in tfrecords_to_count:
105 | for record in tf.python_io.tf_record_iterator(tfrecord_file):
106 | num_samples += 1
107 |
108 | #Create a reader, which must be a TFRecord reader in this case
109 | reader = tf.TFRecordReader
110 |
111 | #Create the keys_to_features dictionary for the decoder
112 | keys_to_features = {
113 | 'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''),
114 | 'image/format': tf.FixedLenFeature((), tf.string, default_value='jpg'),
115 | 'image/class/label': tf.FixedLenFeature(
116 | [], tf.int64, default_value=tf.zeros([], dtype=tf.int64)),
117 | }
118 |
119 | #Create the items_to_handlers dictionary for the decoder.
120 | items_to_handlers = {
121 | 'image': slim.tfexample_decoder.Image(),
122 | 'label': slim.tfexample_decoder.Tensor('image/class/label'),
123 | }
124 |
125 | #Start to create the decoder
126 | decoder = slim.tfexample_decoder.TFExampleDecoder(keys_to_features, items_to_handlers)
127 |
128 | #Create the labels_to_name file
129 | labels_to_name_dict = labels_to_name
130 |
131 | #Actually create the dataset
132 | dataset = dataset_factory.get_dataset(
133 | 'origin', 'validation', dataset_dir)
134 |
135 | return dataset
136 |
137 |
138 | def load_batch(dataset, batch_size, height=image_size, width=image_size, is_training=False):
139 | '''
140 | Loads a batch for training.
141 |
142 | INPUTS:
143 | - dataset(Dataset): a Dataset class object that is created from the get_split function
144 | - batch_size(int): determines how big of a batch to train
145 | - height(int): the height of the image to resize to during preprocessing
146 | - width(int): the width of the image to resize to during preprocessing
147 | - is_training(bool): to determine whether to perform a training or evaluation preprocessing
148 |
149 | OUTPUTS:
150 | - images(Tensor): a Tensor of the shape (batch_size, height, width, channels) that contain one batch of images
151 | - labels(Tensor): the batch's labels with the shape (batch_size,) (requires one_hot_encoding).
152 |
153 | '''
154 | #First create the data_provider object
155 | data_provider = slim.dataset_data_provider.DatasetDataProvider(
156 | dataset,
157 | common_queue_capacity = 24 + 3 * batch_size,
158 | common_queue_min = 24)
159 |
160 | #Obtain the raw image using the get method
161 | raw_image, label = data_provider.get(['image', 'label'])
162 |
163 | #Perform the correct preprocessing for this image depending if it is training or evaluating
164 | image = inception_preprocessing.preprocess_image(raw_image, height, width, is_training)
165 | #image = vgg_preprocessing.preprocess_image(raw_image, height, width)
166 |
167 | #As for the raw images, we just do a simple reshape to batch it up
168 | raw_image = tf.expand_dims(raw_image, 0)
169 | raw_image = tf.image.resize_nearest_neighbor(raw_image, [height, width])
170 | raw_image = tf.squeeze(raw_image)
171 |
172 | #Batch up the image by enqueing the tensors internally in a FIFO queue and dequeueing many elements with tf.train.batch.
173 | images, raw_images, labels = tf.train.batch(
174 | [image, raw_image, label],
175 | batch_size = batch_size,
176 | num_threads = 4,
177 | capacity = 4 * batch_size,
178 | allow_smaller_final_batch = True)
179 |
180 | return images, raw_images, labels
181 |
182 | def run():
183 | #Create log_dir for evaluation information
184 | if not os.path.exists(FLAGS.log_test):
185 | os.makedirs(FLAGS.log_test)
186 |
187 | #Just construct the graph from scratch again
188 | with tf.Graph().as_default() as graph:
189 | tf.logging.set_verbosity(tf.logging.INFO)
190 | #Get the dataset first and load one batch of validation images and labels tensors. Set is_training as False so as to use the evaluation preprocessing
191 | dataset = get_split('validation', FLAGS.dataset_dir)
192 | images, raw_images, labels = load_batch(dataset, batch_size = batch_size, is_training = False)
193 |
194 | #Create some information about the training steps
195 | #num_batches_per_epoch = int(dataset.num_samples / batch_size)
196 | # This ensures that we make a single pass over all of the data.
197 | num_batches_per_epoch = math.ceil(dataset.num_samples / float(batch_size))
198 | num_steps_per_epoch = num_batches_per_epoch
199 |
200 | #Now create the inference model but set is_training=False
201 | #with slim.arg_scope(nasnet_large_arg_scope()):
202 | # logits, end_points = build_nasnet_large(images, num_classes = dataset.num_classes, is_training = False)
203 | #with slim.arg_scope(resnet_arg_scope()):
204 | # logits, end_points = resnet_v1_50(images, num_classes = dataset.num_classes, is_training = False)
205 | #with slim.arg_scope(inception_v3_arg_scope()):
206 | # logits, end_points = inception_v3(images, num_classes = dataset.num_classes, is_training = False)
207 | with slim.arg_scope(inception_resnet_v2_arg_scope()):
208 | logits, end_points = inception_resnet_v2(images, num_classes = dataset.num_classes, is_training = False)
209 | #with slim.arg_scope(inception_v4_arg_scope()):
210 | # logits, end_points = inception_v4(images, num_classes = dataset.num_classes, is_training = False)
211 | #with slim.arg_scope(vgg_arg_scope()):
212 | # logits, end_points = vgg_16(images, num_classes = dataset.num_classes, is_training = False)
213 | #with slim.arg_scope(vgg_arg_scope()):
214 | # logits, end_points = vgg_19(images, num_classes = dataset.num_classes, is_training = False)
215 |
216 | # #get all the variables to restore from the checkpoint file and create the saver function to restore
217 | variables_to_restore = slim.get_variables_to_restore()
218 | saver = tf.train.Saver(variables_to_restore)
219 | def restore_fn(sess):
220 | return saver.restore(sess, checkpoint_file)
221 |
222 | #Perform one-hot-encoding of the labels (Try one-hot-encoding within the load_batch function!)
223 | one_hot_labels = slim.one_hot_encoding(labels, dataset.num_classes)
224 |
225 | #Performs the equivalent to tf.nn.sparse_softmax_cross_entropy_with_logits but enhanced with checks
226 | loss = tf.losses.softmax_cross_entropy(onehot_labels = one_hot_labels, logits = logits)
227 | total_loss = tf.losses.get_total_loss() #obtain the regularization losses as well
228 |
229 | #Just define the metrics to track without the loss or whatsoever
230 | predictions = tf.argmax(logits, 1)
231 | #predictions = tf.argmax(end_points['Predictions'], 1)
232 | labels = tf.squeeze(labels)
233 | accuracy, accuracy_update = tf.contrib.metrics.streaming_accuracy(predictions, labels)
234 | metrics_op = tf.group(accuracy_update)
235 |
236 | #Create the global step and an increment op for monitoring
237 | global_step = get_or_create_global_step()
238 | global_step_op = tf.assign(global_step, global_step + 1) #no apply_gradient method so manually increasing the global_step
239 |
240 | labels_all = []
241 | predictions_all = []
242 | #Create a evaluation step function
243 | def eval_step(sess, metrics_op, global_step):
244 | '''
245 | Simply takes in a session, runs the metrics op and some logging information.
246 | '''
247 | start_time = time.time()
248 | _, global_step_count, labels_, predictions_, accuracy_value, = sess.run([metrics_op, global_step_op, labels, predictions, accuracy])
249 | time_elapsed = time.time() - start_time
250 | #Log some information
251 | logging.info('Global Step %s: Streaming Accuracy: %.4f (%.2f sec/step)', global_step_count, accuracy_value, time_elapsed)
252 | #labels_all = np.append(labels_all, labels_)
253 | #predictions_all = np.append(predictions_all, labels_)
254 | #labels_all = labels_all.astype(int)
255 | #predictions_all = predictions_all.astype(int)
256 | #print(labels_)
257 | #print(predictions_)
258 | return accuracy_value, labels_, predictions_
259 |
260 |
261 | #Define some scalar quantities to monitor
262 | tf.summary.scalar('Validation_Accuracy', accuracy)
263 | tf.summary.scalar('Loss_validation', total_loss)
264 | my_summary_op = tf.summary.merge_all()
265 |
266 | #Get your supervisor
267 | sv = tf.train.Supervisor(logdir = log_eval, summary_op = None, saver = None, init_fn = restore_fn)
268 |
269 | all_predictions = np.zeros(
270 | (dataset.num_samples, num_classes), dtype=np.float32)
271 | all_labels = np.zeros(
272 | (dataset.num_samples, num_classes), dtype=np.float32)
273 |
274 | #Now we are ready to run in one session
275 | #config = tf.ConfigProto(device_count={'GPU':0}) # mask GPUs visible to the session so it falls back on CPU
276 | with sv.managed_session() as sess:
277 | for step in range(num_steps_per_epoch * num_epochs):
278 | sess.run(sv.global_step)
279 | #print vital information every start of the epoch as always
280 | if step % num_batches_per_epoch == 0:
281 | logging.info('Epoch: %s/%s', step / num_batches_per_epoch + 1, num_epochs)
282 | logging.info('Current Streaming Accuracy: %.4f', sess.run(accuracy))
283 | logging.info('Current Loss: %.4f', sess.run(total_loss))
284 | #Compute summaries every 10 steps and continue evaluating
285 | #if step % 10 == 0:
286 | # eval_step(sess, metrics_op = metrics_op, global_step = sv.global_step)
287 | # summaries = sess.run(my_summary_op)
288 | # sv.summary_computed(sess, summaries)
289 |
290 |
291 | #Otherwise just run as per normal
292 | else:
293 | _, labels_, predictions_ = eval_step(sess, metrics_op = metrics_op, global_step = sv.global_step)
294 | labels_all = np.append(labels_all, labels_)
295 | predictions_all = np.append(predictions_all, predictions_)
296 | labels_all = labels_all.astype(int)
297 | predictions_all = predictions_all.astype(int)
298 | print(labels_)
299 | print(predictions_)
300 | #At the end of all the evaluation, show the final accuracy
301 | logging.info('Final Streaming Accuracy: %.4f', sess.run(accuracy))
302 | logging.info('Final Loss: %.4f', sess.run(total_loss))
303 | np.savetxt("/../labels.txt", labels_all)
304 | np.savetxt("/../predictions.txt", predictions_all)
305 | #print(labels_all)
306 | #print(predictions_all)
307 | #Now we want to visualize the last batch's images just to see what our model has predicted
308 | #raw_images, labels, predictions = sess.run([raw_images, labels, predictions])
309 |
310 | logging.info('Model evaluation has completed! Visit TensorBoard for more information regarding your evaluation.')
311 |
312 | if __name__ == '__main__':
313 | run()
314 |
--------------------------------------------------------------------------------
/nets/inception_v1.py:
--------------------------------------------------------------------------------
1 | """Contains the definition for inception v1 classification network."""
2 |
3 | from __future__ import absolute_import
4 | from __future__ import division
5 | from __future__ import print_function
6 |
7 | import tensorflow as tf
8 |
9 | from nets import inception_utils
10 |
11 | slim = tf.contrib.slim
12 | trunc_normal = lambda stddev: tf.truncated_normal_initializer(0.0, stddev)
13 |
14 |
15 | def inception_v1_base(inputs,
16 | final_endpoint='Mixed_5c',
17 | scope='InceptionV1'):
18 | """Defines the Inception V1 base architecture.
19 |
20 | This architecture is defined in:
21 | Going deeper with convolutions
22 | Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed,
23 | Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich.
24 | http://arxiv.org/pdf/1409.4842v1.pdf.
25 |
26 | Args:
27 | inputs: a tensor of size [batch_size, height, width, channels].
28 | final_endpoint: specifies the endpoint to construct the network up to. It
29 | can be one of ['Conv2d_1a_7x7', 'MaxPool_2a_3x3', 'Conv2d_2b_1x1',
30 | 'Conv2d_2c_3x3', 'MaxPool_3a_3x3', 'Mixed_3b', 'Mixed_3c',
31 | 'MaxPool_4a_3x3', 'Mixed_4b', 'Mixed_4c', 'Mixed_4d', 'Mixed_4e',
32 | 'Mixed_4f', 'MaxPool_5a_2x2', 'Mixed_5b', 'Mixed_5c']
33 | scope: Optional variable_scope.
34 |
35 | Returns:
36 | A dictionary from components of the network to the corresponding activation.
37 |
38 | Raises:
39 | ValueError: if final_endpoint is not set to one of the predefined values.
40 | """
41 | end_points = {}
42 | with tf.variable_scope(scope, 'InceptionV1', [inputs]):
43 | with slim.arg_scope(
44 | [slim.conv2d, slim.fully_connected],
45 | weights_initializer=trunc_normal(0.01)):
46 | with slim.arg_scope([slim.conv2d, slim.max_pool2d],
47 | stride=1, padding='SAME'):
48 | end_point = 'Conv2d_1a_7x7'
49 | net = slim.conv2d(inputs, 64, [7, 7], stride=2, scope=end_point)
50 | end_points[end_point] = net
51 | if final_endpoint == end_point: return net, end_points
52 | end_point = 'MaxPool_2a_3x3'
53 | net = slim.max_pool2d(net, [3, 3], stride=2, scope=end_point)
54 | end_points[end_point] = net
55 | if final_endpoint == end_point: return net, end_points
56 | end_point = 'Conv2d_2b_1x1'
57 | net = slim.conv2d(net, 64, [1, 1], scope=end_point)
58 | end_points[end_point] = net
59 | if final_endpoint == end_point: return net, end_points
60 | end_point = 'Conv2d_2c_3x3'
61 | net = slim.conv2d(net, 192, [3, 3], scope=end_point)
62 | end_points[end_point] = net
63 | if final_endpoint == end_point: return net, end_points
64 | end_point = 'MaxPool_3a_3x3'
65 | net = slim.max_pool2d(net, [3, 3], stride=2, scope=end_point)
66 | end_points[end_point] = net
67 | if final_endpoint == end_point: return net, end_points
68 |
69 | end_point = 'Mixed_3b'
70 | with tf.variable_scope(end_point):
71 | with tf.variable_scope('Branch_0'):
72 | branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
73 | with tf.variable_scope('Branch_1'):
74 | branch_1 = slim.conv2d(net, 96, [1, 1], scope='Conv2d_0a_1x1')
75 | branch_1 = slim.conv2d(branch_1, 128, [3, 3], scope='Conv2d_0b_3x3')
76 | with tf.variable_scope('Branch_2'):
77 | branch_2 = slim.conv2d(net, 16, [1, 1], scope='Conv2d_0a_1x1')
78 | branch_2 = slim.conv2d(branch_2, 32, [3, 3], scope='Conv2d_0b_3x3')
79 | with tf.variable_scope('Branch_3'):
80 | branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3')
81 | branch_3 = slim.conv2d(branch_3, 32, [1, 1], scope='Conv2d_0b_1x1')
82 | net = tf.concat(
83 | axis=3, values=[branch_0, branch_1, branch_2, branch_3])
84 | end_points[end_point] = net
85 | if final_endpoint == end_point: return net, end_points
86 |
87 | end_point = 'Mixed_3c'
88 | with tf.variable_scope(end_point):
89 | with tf.variable_scope('Branch_0'):
90 | branch_0 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
91 | with tf.variable_scope('Branch_1'):
92 | branch_1 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
93 | branch_1 = slim.conv2d(branch_1, 192, [3, 3], scope='Conv2d_0b_3x3')
94 | with tf.variable_scope('Branch_2'):
95 | branch_2 = slim.conv2d(net, 32, [1, 1], scope='Conv2d_0a_1x1')
96 | branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
97 | with tf.variable_scope('Branch_3'):
98 | branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3')
99 | branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
100 | net = tf.concat(
101 | axis=3, values=[branch_0, branch_1, branch_2, branch_3])
102 | end_points[end_point] = net
103 | if final_endpoint == end_point: return net, end_points
104 |
105 | end_point = 'MaxPool_4a_3x3'
106 | net = slim.max_pool2d(net, [3, 3], stride=2, scope=end_point)
107 | end_points[end_point] = net
108 | if final_endpoint == end_point: return net, end_points
109 |
110 | end_point = 'Mixed_4b'
111 | with tf.variable_scope(end_point):
112 | with tf.variable_scope('Branch_0'):
113 | branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
114 | with tf.variable_scope('Branch_1'):
115 | branch_1 = slim.conv2d(net, 96, [1, 1], scope='Conv2d_0a_1x1')
116 | branch_1 = slim.conv2d(branch_1, 208, [3, 3], scope='Conv2d_0b_3x3')
117 | with tf.variable_scope('Branch_2'):
118 | branch_2 = slim.conv2d(net, 16, [1, 1], scope='Conv2d_0a_1x1')
119 | branch_2 = slim.conv2d(branch_2, 48, [3, 3], scope='Conv2d_0b_3x3')
120 | with tf.variable_scope('Branch_3'):
121 | branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3')
122 | branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
123 | net = tf.concat(
124 | axis=3, values=[branch_0, branch_1, branch_2, branch_3])
125 | end_points[end_point] = net
126 | if final_endpoint == end_point: return net, end_points
127 |
128 | end_point = 'Mixed_4c'
129 | with tf.variable_scope(end_point):
130 | with tf.variable_scope('Branch_0'):
131 | branch_0 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
132 | with tf.variable_scope('Branch_1'):
133 | branch_1 = slim.conv2d(net, 112, [1, 1], scope='Conv2d_0a_1x1')
134 | branch_1 = slim.conv2d(branch_1, 224, [3, 3], scope='Conv2d_0b_3x3')
135 | with tf.variable_scope('Branch_2'):
136 | branch_2 = slim.conv2d(net, 24, [1, 1], scope='Conv2d_0a_1x1')
137 | branch_2 = slim.conv2d(branch_2, 64, [3, 3], scope='Conv2d_0b_3x3')
138 | with tf.variable_scope('Branch_3'):
139 | branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3')
140 | branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
141 | net = tf.concat(
142 | axis=3, values=[branch_0, branch_1, branch_2, branch_3])
143 | end_points[end_point] = net
144 | if final_endpoint == end_point: return net, end_points
145 |
146 | end_point = 'Mixed_4d'
147 | with tf.variable_scope(end_point):
148 | with tf.variable_scope('Branch_0'):
149 | branch_0 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
150 | with tf.variable_scope('Branch_1'):
151 | branch_1 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
152 | branch_1 = slim.conv2d(branch_1, 256, [3, 3], scope='Conv2d_0b_3x3')
153 | with tf.variable_scope('Branch_2'):
154 | branch_2 = slim.conv2d(net, 24, [1, 1], scope='Conv2d_0a_1x1')
155 | branch_2 = slim.conv2d(branch_2, 64, [3, 3], scope='Conv2d_0b_3x3')
156 | with tf.variable_scope('Branch_3'):
157 | branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3')
158 | branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
159 | net = tf.concat(
160 | axis=3, values=[branch_0, branch_1, branch_2, branch_3])
161 | end_points[end_point] = net
162 | if final_endpoint == end_point: return net, end_points
163 |
164 | end_point = 'Mixed_4e'
165 | with tf.variable_scope(end_point):
166 | with tf.variable_scope('Branch_0'):
167 | branch_0 = slim.conv2d(net, 112, [1, 1], scope='Conv2d_0a_1x1')
168 | with tf.variable_scope('Branch_1'):
169 | branch_1 = slim.conv2d(net, 144, [1, 1], scope='Conv2d_0a_1x1')
170 | branch_1 = slim.conv2d(branch_1, 288, [3, 3], scope='Conv2d_0b_3x3')
171 | with tf.variable_scope('Branch_2'):
172 | branch_2 = slim.conv2d(net, 32, [1, 1], scope='Conv2d_0a_1x1')
173 | branch_2 = slim.conv2d(branch_2, 64, [3, 3], scope='Conv2d_0b_3x3')
174 | with tf.variable_scope('Branch_3'):
175 | branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3')
176 | branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
177 | net = tf.concat(
178 | axis=3, values=[branch_0, branch_1, branch_2, branch_3])
179 | end_points[end_point] = net
180 | if final_endpoint == end_point: return net, end_points
181 |
182 | end_point = 'Mixed_4f'
183 | with tf.variable_scope(end_point):
184 | with tf.variable_scope('Branch_0'):
185 | branch_0 = slim.conv2d(net, 256, [1, 1], scope='Conv2d_0a_1x1')
186 | with tf.variable_scope('Branch_1'):
187 | branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
188 | branch_1 = slim.conv2d(branch_1, 320, [3, 3], scope='Conv2d_0b_3x3')
189 | with tf.variable_scope('Branch_2'):
190 | branch_2 = slim.conv2d(net, 32, [1, 1], scope='Conv2d_0a_1x1')
191 | branch_2 = slim.conv2d(branch_2, 128, [3, 3], scope='Conv2d_0b_3x3')
192 | with tf.variable_scope('Branch_3'):
193 | branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3')
194 | branch_3 = slim.conv2d(branch_3, 128, [1, 1], scope='Conv2d_0b_1x1')
195 | net = tf.concat(
196 | axis=3, values=[branch_0, branch_1, branch_2, branch_3])
197 | end_points[end_point] = net
198 | if final_endpoint == end_point: return net, end_points
199 |
200 | end_point = 'MaxPool_5a_2x2'
201 | net = slim.max_pool2d(net, [2, 2], stride=2, scope=end_point)
202 | end_points[end_point] = net
203 | if final_endpoint == end_point: return net, end_points
204 |
205 | end_point = 'Mixed_5b'
206 | with tf.variable_scope(end_point):
207 | with tf.variable_scope('Branch_0'):
208 | branch_0 = slim.conv2d(net, 256, [1, 1], scope='Conv2d_0a_1x1')
209 | with tf.variable_scope('Branch_1'):
210 | branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
211 | branch_1 = slim.conv2d(branch_1, 320, [3, 3], scope='Conv2d_0b_3x3')
212 | with tf.variable_scope('Branch_2'):
213 | branch_2 = slim.conv2d(net, 32, [1, 1], scope='Conv2d_0a_1x1')
214 | branch_2 = slim.conv2d(branch_2, 128, [3, 3], scope='Conv2d_0a_3x3')
215 | with tf.variable_scope('Branch_3'):
216 | branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3')
217 | branch_3 = slim.conv2d(branch_3, 128, [1, 1], scope='Conv2d_0b_1x1')
218 | net = tf.concat(
219 | axis=3, values=[branch_0, branch_1, branch_2, branch_3])
220 | end_points[end_point] = net
221 | if final_endpoint == end_point: return net, end_points
222 |
223 | end_point = 'Mixed_5c'
224 | with tf.variable_scope(end_point):
225 | with tf.variable_scope('Branch_0'):
226 | branch_0 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
227 | with tf.variable_scope('Branch_1'):
228 | branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
229 | branch_1 = slim.conv2d(branch_1, 384, [3, 3], scope='Conv2d_0b_3x3')
230 | with tf.variable_scope('Branch_2'):
231 | branch_2 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
232 | branch_2 = slim.conv2d(branch_2, 128, [3, 3], scope='Conv2d_0b_3x3')
233 | with tf.variable_scope('Branch_3'):
234 | branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3')
235 | branch_3 = slim.conv2d(branch_3, 128, [1, 1], scope='Conv2d_0b_1x1')
236 | net = tf.concat(
237 | axis=3, values=[branch_0, branch_1, branch_2, branch_3])
238 | end_points[end_point] = net
239 | if final_endpoint == end_point: return net, end_points
240 | raise ValueError('Unknown final endpoint %s' % final_endpoint)
241 |
242 |
243 | def inception_v1(inputs,
244 | num_classes=1000,
245 | is_training=True,
246 | dropout_keep_prob=0.8,
247 | prediction_fn=slim.softmax,
248 | spatial_squeeze=True,
249 | reuse=None,
250 | scope='InceptionV1',
251 | global_pool=False):
252 | """Defines the Inception V1 architecture.
253 |
254 | This architecture is defined in:
255 |
256 | Going deeper with convolutions
257 | Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed,
258 | Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich.
259 | http://arxiv.org/pdf/1409.4842v1.pdf.
260 |
261 | The default image size used to train this network is 224x224.
262 |
263 | Args:
264 | inputs: a tensor of size [batch_size, height, width, channels].
265 | num_classes: number of predicted classes. If 0 or None, the logits layer
266 | is omitted and the input features to the logits layer (before dropout)
267 | are returned instead.
268 | is_training: whether is training or not.
269 | dropout_keep_prob: the percentage of activation values that are retained.
270 | prediction_fn: a function to get predictions out of logits.
271 | spatial_squeeze: if True, logits is of shape [B, C], if false logits is of
272 | shape [B, 1, 1, C], where B is batch_size and C is number of classes.
273 | reuse: whether or not the network and its variables should be reused. To be
274 | able to reuse 'scope' must be given.
275 | scope: Optional variable_scope.
276 | global_pool: Optional boolean flag to control the avgpooling before the
277 | logits layer. If false or unset, pooling is done with a fixed window
278 | that reduces default-sized inputs to 1x1, while larger inputs lead to
279 | larger outputs. If true, any input size is pooled down to 1x1.
280 |
281 | Returns:
282 | net: a Tensor with the logits (pre-softmax activations) if num_classes
283 | is a non-zero integer, or the non-dropped-out input to the logits layer
284 | if num_classes is 0 or None.
285 | end_points: a dictionary from components of the network to the corresponding
286 | activation.
287 | """
288 | # Final pooling and prediction
289 | with tf.variable_scope(scope, 'InceptionV1', [inputs], reuse=reuse) as scope:
290 | with slim.arg_scope([slim.batch_norm, slim.dropout],
291 | is_training=is_training):
292 | net, end_points = inception_v1_base(inputs, scope=scope)
293 | with tf.variable_scope('Logits'):
294 | if global_pool:
295 | # Global average pooling.
296 | net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool')
297 | end_points['global_pool'] = net
298 | else:
299 | # Pooling with a fixed kernel size.
300 | net = slim.avg_pool2d(net, [7, 7], stride=1, scope='AvgPool_0a_7x7')
301 | end_points['AvgPool_0a_7x7'] = net
302 | if not num_classes:
303 | return net, end_points
304 | net = slim.dropout(net, dropout_keep_prob, scope='Dropout_0b')
305 | logits = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
306 | normalizer_fn=None, scope='Conv2d_0c_1x1')
307 | if spatial_squeeze:
308 | logits = tf.squeeze(logits, [1, 2], name='SpatialSqueeze')
309 |
310 | end_points['Logits'] = logits
311 | end_points['Predictions'] = prediction_fn(logits, scope='Predictions')
312 | return logits, end_points
313 | inception_v1.default_image_size = 224
314 |
315 | inception_v1_arg_scope = inception_utils.inception_arg_scope
316 |
--------------------------------------------------------------------------------
/nets/inception_resnet_v2.py:
--------------------------------------------------------------------------------
1 | """Contains the definition of the Inception Resnet V2 architecture.
2 |
3 | As described in http://arxiv.org/abs/1602.07261.
4 |
5 | Inception-v4, Inception-ResNet and the Impact of Residual Connections
6 | on Learning
7 | Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi
8 | """
9 | from __future__ import absolute_import
10 | from __future__ import division
11 | from __future__ import print_function
12 |
13 |
14 | import tensorflow as tf
15 |
16 | slim = tf.contrib.slim
17 |
18 |
19 | def block35(net, scale=1.0, activation_fn=tf.nn.relu, scope=None, reuse=None):
20 | """Builds the 35x35 resnet block."""
21 | with tf.variable_scope(scope, 'Block35', [net], reuse=reuse):
22 | with tf.variable_scope('Branch_0'):
23 | tower_conv = slim.conv2d(net, 32, 1, scope='Conv2d_1x1')
24 | with tf.variable_scope('Branch_1'):
25 | tower_conv1_0 = slim.conv2d(net, 32, 1, scope='Conv2d_0a_1x1')
26 | tower_conv1_1 = slim.conv2d(tower_conv1_0, 32, 3, scope='Conv2d_0b_3x3')
27 | with tf.variable_scope('Branch_2'):
28 | tower_conv2_0 = slim.conv2d(net, 32, 1, scope='Conv2d_0a_1x1')
29 | tower_conv2_1 = slim.conv2d(tower_conv2_0, 48, 3, scope='Conv2d_0b_3x3')
30 | tower_conv2_2 = slim.conv2d(tower_conv2_1, 64, 3, scope='Conv2d_0c_3x3')
31 | mixed = tf.concat(axis=3, values=[tower_conv, tower_conv1_1, tower_conv2_2])
32 | up = slim.conv2d(mixed, net.get_shape()[3], 1, normalizer_fn=None,
33 | activation_fn=None, scope='Conv2d_1x1')
34 | net += scale * up
35 | if activation_fn:
36 | net = activation_fn(net)
37 | return net
38 |
39 |
40 | def block17(net, scale=1.0, activation_fn=tf.nn.relu, scope=None, reuse=None):
41 | """Builds the 17x17 resnet block."""
42 | with tf.variable_scope(scope, 'Block17', [net], reuse=reuse):
43 | with tf.variable_scope('Branch_0'):
44 | tower_conv = slim.conv2d(net, 192, 1, scope='Conv2d_1x1')
45 | with tf.variable_scope('Branch_1'):
46 | tower_conv1_0 = slim.conv2d(net, 128, 1, scope='Conv2d_0a_1x1')
47 | tower_conv1_1 = slim.conv2d(tower_conv1_0, 160, [1, 7],
48 | scope='Conv2d_0b_1x7')
49 | tower_conv1_2 = slim.conv2d(tower_conv1_1, 192, [7, 1],
50 | scope='Conv2d_0c_7x1')
51 | mixed = tf.concat(axis=3, values=[tower_conv, tower_conv1_2])
52 | up = slim.conv2d(mixed, net.get_shape()[3], 1, normalizer_fn=None,
53 | activation_fn=None, scope='Conv2d_1x1')
54 | net += scale * up
55 | if activation_fn:
56 | net = activation_fn(net)
57 | return net
58 |
59 |
60 | def block8(net, scale=1.0, activation_fn=tf.nn.relu, scope=None, reuse=None):
61 | """Builds the 8x8 resnet block."""
62 | with tf.variable_scope(scope, 'Block8', [net], reuse=reuse):
63 | with tf.variable_scope('Branch_0'):
64 | tower_conv = slim.conv2d(net, 192, 1, scope='Conv2d_1x1')
65 | with tf.variable_scope('Branch_1'):
66 | tower_conv1_0 = slim.conv2d(net, 192, 1, scope='Conv2d_0a_1x1')
67 | tower_conv1_1 = slim.conv2d(tower_conv1_0, 224, [1, 3],
68 | scope='Conv2d_0b_1x3')
69 | tower_conv1_2 = slim.conv2d(tower_conv1_1, 256, [3, 1],
70 | scope='Conv2d_0c_3x1')
71 | mixed = tf.concat(axis=3, values=[tower_conv, tower_conv1_2])
72 | up = slim.conv2d(mixed, net.get_shape()[3], 1, normalizer_fn=None,
73 | activation_fn=None, scope='Conv2d_1x1')
74 | net += scale * up
75 | if activation_fn:
76 | net = activation_fn(net)
77 | return net
78 |
79 |
80 | def inception_resnet_v2_base(inputs,
81 | final_endpoint='Conv2d_7b_1x1',
82 | output_stride=16,
83 | align_feature_maps=False,
84 | scope=None):
85 | """Inception model from http://arxiv.org/abs/1602.07261.
86 |
87 | Constructs an Inception Resnet v2 network from inputs to the given final
88 | endpoint. This method can construct the network up to the final inception
89 | block Conv2d_7b_1x1.
90 |
91 | Args:
92 | inputs: a tensor of size [batch_size, height, width, channels].
93 | final_endpoint: specifies the endpoint to construct the network up to. It
94 | can be one of ['Conv2d_1a_3x3', 'Conv2d_2a_3x3', 'Conv2d_2b_3x3',
95 | 'MaxPool_3a_3x3', 'Conv2d_3b_1x1', 'Conv2d_4a_3x3', 'MaxPool_5a_3x3',
96 | 'Mixed_5b', 'Mixed_6a', 'PreAuxLogits', 'Mixed_7a', 'Conv2d_7b_1x1']
97 | output_stride: A scalar that specifies the requested ratio of input to
98 | output spatial resolution. Only supports 8 and 16.
99 | align_feature_maps: When true, changes all the VALID paddings in the network
100 | to SAME padding so that the feature maps are aligned.
101 | scope: Optional variable_scope.
102 |
103 | Returns:
104 | tensor_out: output tensor corresponding to the final_endpoint.
105 | end_points: a set of activations for external use, for example summaries or
106 | losses.
107 |
108 | Raises:
109 | ValueError: if final_endpoint is not set to one of the predefined values,
110 | or if the output_stride is not 8 or 16, or if the output_stride is 8 and
111 | we request an end point after 'PreAuxLogits'.
112 | """
113 | if output_stride != 8 and output_stride != 16:
114 | raise ValueError('output_stride must be 8 or 16.')
115 |
116 | padding = 'SAME' if align_feature_maps else 'VALID'
117 |
118 | end_points = {}
119 |
120 | def add_and_check_final(name, net):
121 | end_points[name] = net
122 | return name == final_endpoint
123 |
124 | with tf.variable_scope(scope, 'InceptionResnetV2', [inputs]):
125 | with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
126 | stride=1, padding='SAME'):
127 | # 149 x 149 x 32
128 | net = slim.conv2d(inputs, 32, 3, stride=2, padding=padding,
129 | scope='Conv2d_1a_3x3')
130 | if add_and_check_final('Conv2d_1a_3x3', net): return net, end_points
131 |
132 | # 147 x 147 x 32
133 | net = slim.conv2d(net, 32, 3, padding=padding,
134 | scope='Conv2d_2a_3x3')
135 | if add_and_check_final('Conv2d_2a_3x3', net): return net, end_points
136 | # 147 x 147 x 64
137 | net = slim.conv2d(net, 64, 3, scope='Conv2d_2b_3x3')
138 | if add_and_check_final('Conv2d_2b_3x3', net): return net, end_points
139 | # 73 x 73 x 64
140 | net = slim.max_pool2d(net, 3, stride=2, padding=padding,
141 | scope='MaxPool_3a_3x3')
142 | if add_and_check_final('MaxPool_3a_3x3', net): return net, end_points
143 | # 73 x 73 x 80
144 | net = slim.conv2d(net, 80, 1, padding=padding,
145 | scope='Conv2d_3b_1x1')
146 | if add_and_check_final('Conv2d_3b_1x1', net): return net, end_points
147 | # 71 x 71 x 192
148 | net = slim.conv2d(net, 192, 3, padding=padding,
149 | scope='Conv2d_4a_3x3')
150 | if add_and_check_final('Conv2d_4a_3x3', net): return net, end_points
151 | # 35 x 35 x 192
152 | net = slim.max_pool2d(net, 3, stride=2, padding=padding,
153 | scope='MaxPool_5a_3x3')
154 | if add_and_check_final('MaxPool_5a_3x3', net): return net, end_points
155 |
156 | # 35 x 35 x 320
157 | with tf.variable_scope('Mixed_5b'):
158 | with tf.variable_scope('Branch_0'):
159 | tower_conv = slim.conv2d(net, 96, 1, scope='Conv2d_1x1')
160 | with tf.variable_scope('Branch_1'):
161 | tower_conv1_0 = slim.conv2d(net, 48, 1, scope='Conv2d_0a_1x1')
162 | tower_conv1_1 = slim.conv2d(tower_conv1_0, 64, 5,
163 | scope='Conv2d_0b_5x5')
164 | with tf.variable_scope('Branch_2'):
165 | tower_conv2_0 = slim.conv2d(net, 64, 1, scope='Conv2d_0a_1x1')
166 | tower_conv2_1 = slim.conv2d(tower_conv2_0, 96, 3,
167 | scope='Conv2d_0b_3x3')
168 | tower_conv2_2 = slim.conv2d(tower_conv2_1, 96, 3,
169 | scope='Conv2d_0c_3x3')
170 | with tf.variable_scope('Branch_3'):
171 | tower_pool = slim.avg_pool2d(net, 3, stride=1, padding='SAME',
172 | scope='AvgPool_0a_3x3')
173 | tower_pool_1 = slim.conv2d(tower_pool, 64, 1,
174 | scope='Conv2d_0b_1x1')
175 | net = tf.concat(
176 | [tower_conv, tower_conv1_1, tower_conv2_2, tower_pool_1], 3)
177 |
178 | if add_and_check_final('Mixed_5b', net): return net, end_points
179 | # TODO(alemi): Register intermediate endpoints
180 | net = slim.repeat(net, 10, block35, scale=0.17)
181 |
182 | # 17 x 17 x 1088 if output_stride == 8,
183 | # 33 x 33 x 1088 if output_stride == 16
184 | use_atrous = output_stride == 8
185 |
186 | with tf.variable_scope('Mixed_6a'):
187 | with tf.variable_scope('Branch_0'):
188 | tower_conv = slim.conv2d(net, 384, 3, stride=1 if use_atrous else 2,
189 | padding=padding,
190 | scope='Conv2d_1a_3x3')
191 | with tf.variable_scope('Branch_1'):
192 | tower_conv1_0 = slim.conv2d(net, 256, 1, scope='Conv2d_0a_1x1')
193 | tower_conv1_1 = slim.conv2d(tower_conv1_0, 256, 3,
194 | scope='Conv2d_0b_3x3')
195 | tower_conv1_2 = slim.conv2d(tower_conv1_1, 384, 3,
196 | stride=1 if use_atrous else 2,
197 | padding=padding,
198 | scope='Conv2d_1a_3x3')
199 | with tf.variable_scope('Branch_2'):
200 | tower_pool = slim.max_pool2d(net, 3, stride=1 if use_atrous else 2,
201 | padding=padding,
202 | scope='MaxPool_1a_3x3')
203 | net = tf.concat([tower_conv, tower_conv1_2, tower_pool], 3)
204 |
205 | if add_and_check_final('Mixed_6a', net): return net, end_points
206 |
207 | # TODO(alemi): register intermediate endpoints
208 | with slim.arg_scope([slim.conv2d], rate=2 if use_atrous else 1):
209 | net = slim.repeat(net, 20, block17, scale=0.10)
210 | if add_and_check_final('PreAuxLogits', net): return net, end_points
211 |
212 | if output_stride == 8:
213 | # TODO(gpapan): Properly support output_stride for the rest of the net.
214 | raise ValueError('output_stride==8 is only supported up to the '
215 | 'PreAuxlogits end_point for now.')
216 |
217 | # 8 x 8 x 2080
218 | with tf.variable_scope('Mixed_7a'):
219 | with tf.variable_scope('Branch_0'):
220 | tower_conv = slim.conv2d(net, 256, 1, scope='Conv2d_0a_1x1')
221 | tower_conv_1 = slim.conv2d(tower_conv, 384, 3, stride=2,
222 | padding=padding,
223 | scope='Conv2d_1a_3x3')
224 | with tf.variable_scope('Branch_1'):
225 | tower_conv1 = slim.conv2d(net, 256, 1, scope='Conv2d_0a_1x1')
226 | tower_conv1_1 = slim.conv2d(tower_conv1, 288, 3, stride=2,
227 | padding=padding,
228 | scope='Conv2d_1a_3x3')
229 | with tf.variable_scope('Branch_2'):
230 | tower_conv2 = slim.conv2d(net, 256, 1, scope='Conv2d_0a_1x1')
231 | tower_conv2_1 = slim.conv2d(tower_conv2, 288, 3,
232 | scope='Conv2d_0b_3x3')
233 | tower_conv2_2 = slim.conv2d(tower_conv2_1, 320, 3, stride=2,
234 | padding=padding,
235 | scope='Conv2d_1a_3x3')
236 | with tf.variable_scope('Branch_3'):
237 | tower_pool = slim.max_pool2d(net, 3, stride=2,
238 | padding=padding,
239 | scope='MaxPool_1a_3x3')
240 | net = tf.concat(
241 | [tower_conv_1, tower_conv1_1, tower_conv2_2, tower_pool], 3)
242 |
243 | if add_and_check_final('Mixed_7a', net): return net, end_points
244 |
245 | # TODO(alemi): register intermediate endpoints
246 | net = slim.repeat(net, 9, block8, scale=0.20)
247 | net = block8(net, activation_fn=None)
248 |
249 | # 8 x 8 x 1536
250 | net = slim.conv2d(net, 1536, 1, scope='Conv2d_7b_1x1')
251 | if add_and_check_final('Conv2d_7b_1x1', net): return net, end_points
252 |
253 | raise ValueError('final_endpoint (%s) not recognized', final_endpoint)
254 |
255 |
256 | def inception_resnet_v2(inputs, num_classes=1001, is_training=True,
257 | dropout_keep_prob=0.8,
258 | reuse=None,
259 | scope='InceptionResnetV2',
260 | create_aux_logits=True):
261 | """Creates the Inception Resnet V2 model.
262 |
263 | Args:
264 | inputs: a 4-D tensor of size [batch_size, height, width, 3].
265 | num_classes: number of predicted classes.
266 | is_training: whether is training or not.
267 | dropout_keep_prob: float, the fraction to keep before final layer.
268 | reuse: whether or not the network and its variables should be reused. To be
269 | able to reuse 'scope' must be given.
270 | scope: Optional variable_scope.
271 | create_aux_logits: Whether to include the auxilliary logits.
272 |
273 | Returns:
274 | logits: the logits outputs of the model.
275 | end_points: the set of end_points from the inception model.
276 | """
277 | end_points = {}
278 |
279 | with tf.variable_scope(scope, 'InceptionResnetV2', [inputs, num_classes],
280 | reuse=reuse) as scope:
281 | with slim.arg_scope([slim.batch_norm, slim.dropout],
282 | is_training=is_training):
283 |
284 | net, end_points = inception_resnet_v2_base(inputs, scope=scope)
285 |
286 | if create_aux_logits:
287 | with tf.variable_scope('AuxLogits'):
288 | aux = end_points['PreAuxLogits']
289 | aux = slim.avg_pool2d(aux, 5, stride=3, padding='VALID',
290 | scope='Conv2d_1a_3x3')
291 | aux = slim.conv2d(aux, 128, 1, scope='Conv2d_1b_1x1')
292 | aux = slim.conv2d(aux, 768, aux.get_shape()[1:3],
293 | padding='VALID', scope='Conv2d_2a_5x5')
294 | aux = slim.flatten(aux)
295 | aux = slim.fully_connected(aux, num_classes, activation_fn=None,
296 | scope='Logits')
297 | end_points['AuxLogits'] = aux
298 |
299 | with tf.variable_scope('Logits'):
300 | net = slim.avg_pool2d(net, net.get_shape()[1:3], padding='VALID',
301 | scope='AvgPool_1a_8x8')
302 | net = slim.flatten(net)
303 |
304 | net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
305 | scope='Dropout')
306 |
307 | end_points['PreLogitsFlatten'] = net
308 | logits = slim.fully_connected(net, num_classes, activation_fn=None,
309 | scope='Logits')
310 | end_points['Logits'] = logits
311 | end_points['Predictions'] = tf.nn.softmax(logits, name='Predictions')
312 |
313 | return logits, end_points
314 | inception_resnet_v2.default_image_size = 299
315 |
316 |
317 | def inception_resnet_v2_arg_scope(weight_decay=0.00004,
318 | batch_norm_decay=0.9997,
319 | batch_norm_epsilon=0.001):
320 | """Yields the scope with the default parameters for inception_resnet_v2.
321 |
322 | Args:
323 | weight_decay: the weight decay for weights variables.
324 | batch_norm_decay: decay for the moving average of batch_norm momentums.
325 | batch_norm_epsilon: small float added to variance to avoid dividing by zero.
326 |
327 | Returns:
328 | a arg_scope with the parameters needed for inception_resnet_v2.
329 | """
330 | # Set weight_decay for weights in conv2d and fully_connected layers.
331 | with slim.arg_scope([slim.conv2d, slim.fully_connected],
332 | weights_regularizer=slim.l2_regularizer(weight_decay),
333 | biases_regularizer=slim.l2_regularizer(weight_decay)):
334 |
335 | batch_norm_params = {
336 | 'decay': batch_norm_decay,
337 | 'epsilon': batch_norm_epsilon,
338 | }
339 | # Set activation_fn and parameters for batch_norm.
340 | with slim.arg_scope([slim.conv2d], activation_fn=tf.nn.relu,
341 | normalizer_fn=slim.batch_norm,
342 | normalizer_params=batch_norm_params) as scope:
343 | return scope
344 |
--------------------------------------------------------------------------------
/nets/inception_v4.py:
--------------------------------------------------------------------------------
1 | """Contains the definition of the Inception V4 architecture.
2 |
3 | As described in http://arxiv.org/abs/1602.07261.
4 |
5 | Inception-v4, Inception-ResNet and the Impact of Residual Connections
6 | on Learning
7 | Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi
8 | """
9 | from __future__ import absolute_import
10 | from __future__ import division
11 | from __future__ import print_function
12 |
13 | import tensorflow as tf
14 |
15 | from nets import inception_utils
16 |
17 | slim = tf.contrib.slim
18 |
19 |
20 | def block_inception_a(inputs, scope=None, reuse=None):
21 | """Builds Inception-A block for Inception v4 network."""
22 | # By default use stride=1 and SAME padding
23 | with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
24 | stride=1, padding='SAME'):
25 | with tf.variable_scope(scope, 'BlockInceptionA', [inputs], reuse=reuse):
26 | with tf.variable_scope('Branch_0'):
27 | branch_0 = slim.conv2d(inputs, 96, [1, 1], scope='Conv2d_0a_1x1')
28 | with tf.variable_scope('Branch_1'):
29 | branch_1 = slim.conv2d(inputs, 64, [1, 1], scope='Conv2d_0a_1x1')
30 | branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope='Conv2d_0b_3x3')
31 | with tf.variable_scope('Branch_2'):
32 | branch_2 = slim.conv2d(inputs, 64, [1, 1], scope='Conv2d_0a_1x1')
33 | branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
34 | branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
35 | with tf.variable_scope('Branch_3'):
36 | branch_3 = slim.avg_pool2d(inputs, [3, 3], scope='AvgPool_0a_3x3')
37 | branch_3 = slim.conv2d(branch_3, 96, [1, 1], scope='Conv2d_0b_1x1')
38 | return tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])
39 |
40 |
41 | def block_reduction_a(inputs, scope=None, reuse=None):
42 | """Builds Reduction-A block for Inception v4 network."""
43 | # By default use stride=1 and SAME padding
44 | with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
45 | stride=1, padding='SAME'):
46 | with tf.variable_scope(scope, 'BlockReductionA', [inputs], reuse=reuse):
47 | with tf.variable_scope('Branch_0'):
48 | branch_0 = slim.conv2d(inputs, 384, [3, 3], stride=2, padding='VALID',
49 | scope='Conv2d_1a_3x3')
50 | with tf.variable_scope('Branch_1'):
51 | branch_1 = slim.conv2d(inputs, 192, [1, 1], scope='Conv2d_0a_1x1')
52 | branch_1 = slim.conv2d(branch_1, 224, [3, 3], scope='Conv2d_0b_3x3')
53 | branch_1 = slim.conv2d(branch_1, 256, [3, 3], stride=2,
54 | padding='VALID', scope='Conv2d_1a_3x3')
55 | with tf.variable_scope('Branch_2'):
56 | branch_2 = slim.max_pool2d(inputs, [3, 3], stride=2, padding='VALID',
57 | scope='MaxPool_1a_3x3')
58 | return tf.concat(axis=3, values=[branch_0, branch_1, branch_2])
59 |
60 |
61 | def block_inception_b(inputs, scope=None, reuse=None):
62 | """Builds Inception-B block for Inception v4 network."""
63 | # By default use stride=1 and SAME padding
64 | with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
65 | stride=1, padding='SAME'):
66 | with tf.variable_scope(scope, 'BlockInceptionB', [inputs], reuse=reuse):
67 | with tf.variable_scope('Branch_0'):
68 | branch_0 = slim.conv2d(inputs, 384, [1, 1], scope='Conv2d_0a_1x1')
69 | with tf.variable_scope('Branch_1'):
70 | branch_1 = slim.conv2d(inputs, 192, [1, 1], scope='Conv2d_0a_1x1')
71 | branch_1 = slim.conv2d(branch_1, 224, [1, 7], scope='Conv2d_0b_1x7')
72 | branch_1 = slim.conv2d(branch_1, 256, [7, 1], scope='Conv2d_0c_7x1')
73 | with tf.variable_scope('Branch_2'):
74 | branch_2 = slim.conv2d(inputs, 192, [1, 1], scope='Conv2d_0a_1x1')
75 | branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0b_7x1')
76 | branch_2 = slim.conv2d(branch_2, 224, [1, 7], scope='Conv2d_0c_1x7')
77 | branch_2 = slim.conv2d(branch_2, 224, [7, 1], scope='Conv2d_0d_7x1')
78 | branch_2 = slim.conv2d(branch_2, 256, [1, 7], scope='Conv2d_0e_1x7')
79 | with tf.variable_scope('Branch_3'):
80 | branch_3 = slim.avg_pool2d(inputs, [3, 3], scope='AvgPool_0a_3x3')
81 | branch_3 = slim.conv2d(branch_3, 128, [1, 1], scope='Conv2d_0b_1x1')
82 | return tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])
83 |
84 |
85 | def block_reduction_b(inputs, scope=None, reuse=None):
86 | """Builds Reduction-B block for Inception v4 network."""
87 | # By default use stride=1 and SAME padding
88 | with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
89 | stride=1, padding='SAME'):
90 | with tf.variable_scope(scope, 'BlockReductionB', [inputs], reuse=reuse):
91 | with tf.variable_scope('Branch_0'):
92 | branch_0 = slim.conv2d(inputs, 192, [1, 1], scope='Conv2d_0a_1x1')
93 | branch_0 = slim.conv2d(branch_0, 192, [3, 3], stride=2,
94 | padding='VALID', scope='Conv2d_1a_3x3')
95 | with tf.variable_scope('Branch_1'):
96 | branch_1 = slim.conv2d(inputs, 256, [1, 1], scope='Conv2d_0a_1x1')
97 | branch_1 = slim.conv2d(branch_1, 256, [1, 7], scope='Conv2d_0b_1x7')
98 | branch_1 = slim.conv2d(branch_1, 320, [7, 1], scope='Conv2d_0c_7x1')
99 | branch_1 = slim.conv2d(branch_1, 320, [3, 3], stride=2,
100 | padding='VALID', scope='Conv2d_1a_3x3')
101 | with tf.variable_scope('Branch_2'):
102 | branch_2 = slim.max_pool2d(inputs, [3, 3], stride=2, padding='VALID',
103 | scope='MaxPool_1a_3x3')
104 | return tf.concat(axis=3, values=[branch_0, branch_1, branch_2])
105 |
106 |
107 | def block_inception_c(inputs, scope=None, reuse=None):
108 | """Builds Inception-C block for Inception v4 network."""
109 | # By default use stride=1 and SAME padding
110 | with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
111 | stride=1, padding='SAME'):
112 | with tf.variable_scope(scope, 'BlockInceptionC', [inputs], reuse=reuse):
113 | with tf.variable_scope('Branch_0'):
114 | branch_0 = slim.conv2d(inputs, 256, [1, 1], scope='Conv2d_0a_1x1')
115 | with tf.variable_scope('Branch_1'):
116 | branch_1 = slim.conv2d(inputs, 384, [1, 1], scope='Conv2d_0a_1x1')
117 | branch_1 = tf.concat(axis=3, values=[
118 | slim.conv2d(branch_1, 256, [1, 3], scope='Conv2d_0b_1x3'),
119 | slim.conv2d(branch_1, 256, [3, 1], scope='Conv2d_0c_3x1')])
120 | with tf.variable_scope('Branch_2'):
121 | branch_2 = slim.conv2d(inputs, 384, [1, 1], scope='Conv2d_0a_1x1')
122 | branch_2 = slim.conv2d(branch_2, 448, [3, 1], scope='Conv2d_0b_3x1')
123 | branch_2 = slim.conv2d(branch_2, 512, [1, 3], scope='Conv2d_0c_1x3')
124 | branch_2 = tf.concat(axis=3, values=[
125 | slim.conv2d(branch_2, 256, [1, 3], scope='Conv2d_0d_1x3'),
126 | slim.conv2d(branch_2, 256, [3, 1], scope='Conv2d_0e_3x1')])
127 | with tf.variable_scope('Branch_3'):
128 | branch_3 = slim.avg_pool2d(inputs, [3, 3], scope='AvgPool_0a_3x3')
129 | branch_3 = slim.conv2d(branch_3, 256, [1, 1], scope='Conv2d_0b_1x1')
130 | return tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])
131 |
132 |
133 | def inception_v4_base(inputs, final_endpoint='Mixed_7d', scope=None):
134 | """Creates the Inception V4 network up to the given final endpoint.
135 |
136 | Args:
137 | inputs: a 4-D tensor of size [batch_size, height, width, 3].
138 | final_endpoint: specifies the endpoint to construct the network up to.
139 | It can be one of [ 'Conv2d_1a_3x3', 'Conv2d_2a_3x3', 'Conv2d_2b_3x3',
140 | 'Mixed_3a', 'Mixed_4a', 'Mixed_5a', 'Mixed_5b', 'Mixed_5c', 'Mixed_5d',
141 | 'Mixed_5e', 'Mixed_6a', 'Mixed_6b', 'Mixed_6c', 'Mixed_6d', 'Mixed_6e',
142 | 'Mixed_6f', 'Mixed_6g', 'Mixed_6h', 'Mixed_7a', 'Mixed_7b', 'Mixed_7c',
143 | 'Mixed_7d']
144 | scope: Optional variable_scope.
145 |
146 | Returns:
147 | logits: the logits outputs of the model.
148 | end_points: the set of end_points from the inception model.
149 |
150 | Raises:
151 | ValueError: if final_endpoint is not set to one of the predefined values,
152 | """
153 | end_points = {}
154 |
155 | def add_and_check_final(name, net):
156 | end_points[name] = net
157 | return name == final_endpoint
158 |
159 | with tf.variable_scope(scope, 'InceptionV4', [inputs]):
160 | with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
161 | stride=1, padding='SAME'):
162 | # 299 x 299 x 3
163 | net = slim.conv2d(inputs, 32, [3, 3], stride=2,
164 | padding='VALID', scope='Conv2d_1a_3x3')
165 | if add_and_check_final('Conv2d_1a_3x3', net): return net, end_points
166 | # 149 x 149 x 32
167 | net = slim.conv2d(net, 32, [3, 3], padding='VALID',
168 | scope='Conv2d_2a_3x3')
169 | if add_and_check_final('Conv2d_2a_3x3', net): return net, end_points
170 | # 147 x 147 x 32
171 | net = slim.conv2d(net, 64, [3, 3], scope='Conv2d_2b_3x3')
172 | if add_and_check_final('Conv2d_2b_3x3', net): return net, end_points
173 | # 147 x 147 x 64
174 | with tf.variable_scope('Mixed_3a'):
175 | with tf.variable_scope('Branch_0'):
176 | branch_0 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID',
177 | scope='MaxPool_0a_3x3')
178 | with tf.variable_scope('Branch_1'):
179 | branch_1 = slim.conv2d(net, 96, [3, 3], stride=2, padding='VALID',
180 | scope='Conv2d_0a_3x3')
181 | net = tf.concat(axis=3, values=[branch_0, branch_1])
182 | if add_and_check_final('Mixed_3a', net): return net, end_points
183 |
184 | # 73 x 73 x 160
185 | with tf.variable_scope('Mixed_4a'):
186 | with tf.variable_scope('Branch_0'):
187 | branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
188 | branch_0 = slim.conv2d(branch_0, 96, [3, 3], padding='VALID',
189 | scope='Conv2d_1a_3x3')
190 | with tf.variable_scope('Branch_1'):
191 | branch_1 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
192 | branch_1 = slim.conv2d(branch_1, 64, [1, 7], scope='Conv2d_0b_1x7')
193 | branch_1 = slim.conv2d(branch_1, 64, [7, 1], scope='Conv2d_0c_7x1')
194 | branch_1 = slim.conv2d(branch_1, 96, [3, 3], padding='VALID',
195 | scope='Conv2d_1a_3x3')
196 | net = tf.concat(axis=3, values=[branch_0, branch_1])
197 | if add_and_check_final('Mixed_4a', net): return net, end_points
198 |
199 | # 71 x 71 x 192
200 | with tf.variable_scope('Mixed_5a'):
201 | with tf.variable_scope('Branch_0'):
202 | branch_0 = slim.conv2d(net, 192, [3, 3], stride=2, padding='VALID',
203 | scope='Conv2d_1a_3x3')
204 | with tf.variable_scope('Branch_1'):
205 | branch_1 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID',
206 | scope='MaxPool_1a_3x3')
207 | net = tf.concat(axis=3, values=[branch_0, branch_1])
208 | if add_and_check_final('Mixed_5a', net): return net, end_points
209 |
210 | # 35 x 35 x 384
211 | # 4 x Inception-A blocks
212 | for idx in range(4):
213 | block_scope = 'Mixed_5' + chr(ord('b') + idx)
214 | net = block_inception_a(net, block_scope)
215 | if add_and_check_final(block_scope, net): return net, end_points
216 |
217 | # 35 x 35 x 384
218 | # Reduction-A block
219 | net = block_reduction_a(net, 'Mixed_6a')
220 | if add_and_check_final('Mixed_6a', net): return net, end_points
221 |
222 | # 17 x 17 x 1024
223 | # 7 x Inception-B blocks
224 | for idx in range(7):
225 | block_scope = 'Mixed_6' + chr(ord('b') + idx)
226 | net = block_inception_b(net, block_scope)
227 | if add_and_check_final(block_scope, net): return net, end_points
228 |
229 | # 17 x 17 x 1024
230 | # Reduction-B block
231 | net = block_reduction_b(net, 'Mixed_7a')
232 | if add_and_check_final('Mixed_7a', net): return net, end_points
233 |
234 | # 8 x 8 x 1536
235 | # 3 x Inception-C blocks
236 | for idx in range(3):
237 | block_scope = 'Mixed_7' + chr(ord('b') + idx)
238 | net = block_inception_c(net, block_scope)
239 | if add_and_check_final(block_scope, net): return net, end_points
240 | raise ValueError('Unknown final endpoint %s' % final_endpoint)
241 |
242 |
243 | def inception_v4(inputs, num_classes=1001, is_training=True,
244 | dropout_keep_prob=0.8,
245 | reuse=None,
246 | scope='InceptionV4',
247 | create_aux_logits=True):
248 | """Creates the Inception V4 model.
249 |
250 | Args:
251 | inputs: a 4-D tensor of size [batch_size, height, width, 3].
252 | num_classes: number of predicted classes. If 0 or None, the logits layer
253 | is omitted and the input features to the logits layer (before dropout)
254 | are returned instead.
255 | is_training: whether is training or not.
256 | dropout_keep_prob: float, the fraction to keep before final layer.
257 | reuse: whether or not the network and its variables should be reused. To be
258 | able to reuse 'scope' must be given.
259 | scope: Optional variable_scope.
260 | create_aux_logits: Whether to include the auxiliary logits.
261 |
262 | Returns:
263 | net: a Tensor with the logits (pre-softmax activations) if num_classes
264 | is a non-zero integer, or the non-dropped input to the logits layer
265 | if num_classes is 0 or None.
266 | end_points: the set of end_points from the inception model.
267 | """
268 | end_points = {}
269 | with tf.variable_scope(scope, 'InceptionV4', [inputs], reuse=reuse) as scope:
270 | with slim.arg_scope([slim.batch_norm, slim.dropout],
271 | is_training=is_training):
272 | net, end_points = inception_v4_base(inputs, scope=scope)
273 |
274 | with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
275 | stride=1, padding='SAME'):
276 | # Auxiliary Head logits
277 | if create_aux_logits and num_classes:
278 | with tf.variable_scope('AuxLogits'):
279 | # 17 x 17 x 1024
280 | aux_logits = end_points['Mixed_6h']
281 | aux_logits = slim.avg_pool2d(aux_logits, [5, 5], stride=3,
282 | padding='VALID',
283 | scope='AvgPool_1a_5x5')
284 | aux_logits = slim.conv2d(aux_logits, 128, [1, 1],
285 | scope='Conv2d_1b_1x1')
286 | aux_logits = slim.conv2d(aux_logits, 768,
287 | aux_logits.get_shape()[1:3],
288 | padding='VALID', scope='Conv2d_2a')
289 | aux_logits = slim.flatten(aux_logits)
290 | aux_logits = slim.fully_connected(aux_logits, num_classes,
291 | activation_fn=None,
292 | scope='Aux_logits')
293 | end_points['AuxLogits'] = aux_logits
294 |
295 | # Final pooling and prediction
296 | # TODO(sguada,arnoegw): Consider adding a parameter global_pool which
297 | # can be set to False to disable pooling here (as in resnet_*()).
298 | with tf.variable_scope('Logits'):
299 | # 8 x 8 x 1536
300 | kernel_size = net.get_shape()[1:3]
301 | if kernel_size.is_fully_defined():
302 | net = slim.avg_pool2d(net, kernel_size, padding='VALID',
303 | scope='AvgPool_1a')
304 | else:
305 | net = tf.reduce_mean(net, [1, 2], keep_dims=True,
306 | name='global_pool')
307 | end_points['global_pool'] = net
308 | if not num_classes:
309 | return net, end_points
310 | # 1 x 1 x 1536
311 | net = slim.dropout(net, dropout_keep_prob, scope='Dropout_1b')
312 | net = slim.flatten(net, scope='PreLogitsFlatten')
313 | end_points['PreLogitsFlatten'] = net
314 | # 1536
315 | logits = slim.fully_connected(net, num_classes, activation_fn=None,
316 | scope='Logits')
317 | end_points['Logits'] = logits
318 | end_points['Predictions'] = tf.nn.softmax(logits, name='Predictions')
319 | return logits, end_points
320 | inception_v4.default_image_size = 299
321 |
322 |
323 | inception_v4_arg_scope = inception_utils.inception_arg_scope
324 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | #from tensorflow.contrib.framework.python.ops.variables import get_or_create_global_step
3 | from tensorflow.python.platform import tf_logging as logging
4 | import preprocessing.inception_preprocessing
5 | import preprocessing.vgg_preprocessing
6 | #from nets.inception_resnet_v2 import inception_resnet_v2, inception_resnet_v2_arg_scope
7 | from nets.inception_resnet_v2 import inception_resnet_v2, inception_resnet_v2_arg_scope
8 | from nets.inception_v1 import inception_v1, inception_v1_arg_scope
9 | #from nets.inception_v4 import inception_v4, inception_v4_arg_scope
10 | from nets.inception_v3 import inception_v3, inception_v3_arg_scope
11 | from nets.vgg import vgg_16, vgg_arg_scope
12 | from nets.vgg import vgg_19, vgg_arg_scope
13 | from nets.resnet_v1 import resnet_v1_50, resnet_arg_scope
14 | import os
15 | import time
16 | from datasets import dataset_factory
17 |
18 | slim = tf.contrib.slim
19 |
20 | tf.app.flags.DEFINE_string(
21 | 'dataset_dir', '', 'The directory where the dataset files are stored.')
22 |
23 | tf.app.flags.DEFINE_string(
24 | 'train_dir', '', 'Directory where the results are saved to.')
25 |
26 | tf.app.flags.DEFINE_string(
27 | 'checkpoint_path', '',
28 | 'The directory where the model was written to or an absolute path to a '
29 | 'checkpoint file.')
30 |
31 | tf.app.flags.DEFINE_string(
32 | 'labels_file', '', 'The label of the dataset to load.')
33 |
34 | FLAGS = tf.app.flags.FLAGS
35 |
36 | #State the image size you're resizing your images to. We will use the default inception size of 299.
37 | image_size = 299
38 |
39 | #State the number of classes to predict:
40 | num_classes = 100
41 |
42 | labels = open(FLAGS.labels_file, 'r')
43 |
44 | #Create a dictionary to refer each label to their string name
45 | labels_to_name = {}
46 | for line in labels:
47 | label, string_name = line.split(':')
48 | string_name = string_name[:-1] #Remove newline
49 | labels_to_name[int(label)] = string_name
50 |
51 | #Create the file pattern of your TFRecord files so that it could be recognized later on
52 | file_pattern = 'origin_%s_*.tfrecord'
53 |
54 | #Create a dictionary that will help people understand your dataset better. This is required by the Dataset class later.
55 | items_to_descriptions = {
56 | 'image': 'A 3-channel RGB coloured flower image that is either tulips, sunflowers, roses, dandelion, or daisy.',
57 | 'label': 'A label that is as such -- 0:daisy, 1:dandelion, 2:roses, 3:sunflowers, 4:tulips'
58 | }
59 |
60 |
61 | #================= TRAINING INFORMATION ==================
62 | #State the number of epochs to train
63 | num_epochs = 150
64 |
65 | #State your batch size
66 | batch_size = 20
67 |
68 | #Learning rate information and configuration (Up to you to experiment)
69 | initial_learning_rate = 0.001
70 | learning_rate_decay_factor = 0.7
71 | num_epochs_before_decay = 10
72 |
73 | #============== DATASET LOADING ======================
74 | #We now create a function that creates a Dataset class which will give us many TFRecord files to feed in the examples into a queue in parallel.
75 | def get_split(split_name, dataset_dir, file_pattern=file_pattern, file_pattern_for_counting='flowers'):
76 | '''
77 | Obtains the split - training or validation - to create a Dataset class for feeding the examples into a queue later on. This function will
78 | set up the decoder and dataset information all into one Dataset class so that you can avoid the brute work later on.
79 | Your file_pattern is very important in locating the files later.
80 |
81 | INPUTS:
82 | - split_name(str): 'train' or 'validation'. Used to get the correct data split of tfrecord files
83 | - dataset_dir(str): the dataset directory where the tfrecord files are located
84 | - file_pattern(str): the file name structure of the tfrecord files in order to get the correct data
85 | - file_pattern_for_counting(str): the string name to identify your tfrecord files for counting
86 |
87 | OUTPUTS:
88 | - dataset (Dataset): A Dataset class object where we can read its various components for easier batch creation later.
89 | '''
90 |
91 | #First check whether the split_name is train or validation
92 | if split_name not in ['train', 'validation']:
93 | raise ValueError('The split_name %s is not recognized. Please input either train or validation as the split_name' % (split_name))
94 |
95 | #Create the full path for a general file_pattern to locate the tfrecord_files
96 | file_pattern_path = os.path.join(dataset_dir, file_pattern % (split_name))
97 |
98 | #Count the total number of examples in all of these shard
99 | num_samples = 0
100 | file_pattern_for_counting = file_pattern_for_counting + '_' + split_name
101 | tfrecords_to_count = [os.path.join(dataset_dir, file) for file in os.listdir(dataset_dir) if file.startswith(file_pattern_for_counting)]
102 | for tfrecord_file in tfrecords_to_count:
103 | for record in tf.python_io.tf_record_iterator(tfrecord_file):
104 | num_samples += 1
105 |
106 | #Create a reader, which must be a TFRecord reader in this case
107 | reader = tf.TFRecordReader
108 |
109 | #Create the keys_to_features dictionary for the decoder
110 | keys_to_features = {
111 | 'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''),
112 | 'image/format': tf.FixedLenFeature((), tf.string, default_value='jpg'),
113 | 'image/class/label': tf.FixedLenFeature(
114 | [], tf.int64, default_value=tf.zeros([], dtype=tf.int64)),
115 | }
116 |
117 | #Create the items_to_handlers dictionary for the decoder.
118 | items_to_handlers = {
119 | 'image': slim.tfexample_decoder.Image(),
120 | 'label': slim.tfexample_decoder.Tensor('image/class/label'),
121 | }
122 |
123 | #Start to create the decoder
124 | decoder = slim.tfexample_decoder.TFExampleDecoder(keys_to_features, items_to_handlers)
125 |
126 | #Create the labels_to_name file
127 | labels_to_name_dict = labels_to_name
128 |
129 | #Actually create the dataset
130 | dataset = dataset_factory.get_dataset(
131 | 'origin', 'train', dataset_dir)
132 |
133 | return dataset
134 |
135 |
136 | def load_batch(dataset, batch_size, height=image_size, width=image_size, is_training=True):
137 | '''
138 | Loads a batch for training.
139 |
140 | INPUTS:
141 | - dataset(Dataset): a Dataset class object that is created from the get_split function
142 | - batch_size(int): determines how big of a batch to train
143 | - height(int): the height of the image to resize to during preprocessing
144 | - width(int): the width of the image to resize to during preprocessing
145 | - is_training(bool): to determine whether to perform a training or evaluation preprocessing
146 |
147 | OUTPUTS:
148 | - images(Tensor): a Tensor of the shape (batch_size, height, width, channels) that contain one batch of images
149 | - labels(Tensor): the batch's labels with the shape (batch_size,) (requires one_hot_encoding).
150 |
151 | '''
152 | #First create the data_provider object
153 | data_provider = slim.dataset_data_provider.DatasetDataProvider(
154 | dataset,
155 | common_queue_capacity = 24 + 3 * batch_size,
156 | common_queue_min = 24)
157 |
158 | #Obtain the raw image using the get method
159 | raw_image, label = data_provider.get(['image', 'label'])
160 |
161 | #Perform the correct preprocessing for this image depending if it is training or evaluating
162 | image = preprocessing.inception_preprocessing.preprocess_image(raw_image, height, width, is_training)
163 | #image = preprocessing.inception_preprocessing_nogeo.preprocess_image(raw_image, height, width, is_training)
164 | #image = preprocessing.inception_preprocessing_noaug.preprocess_image(raw_image, height, width, is_training)
165 | #image = preprocessing.inception_preprocessing_nocolor.preprocess_image(raw_image, height, width, is_training)
166 | #image = preprocessing.vgg_preprocessing.preprocess_image(raw_image, height, width, is_training)
167 |
168 | #As for the raw images, we just do a simple reshape to batch it up
169 | raw_image = tf.expand_dims(raw_image, 0)
170 | raw_image = tf.image.resize_nearest_neighbor(raw_image, [height, width])
171 | raw_image = tf.squeeze(raw_image)
172 |
173 | #Batch up the image by enqueing the tensors internally in a FIFO queue and dequeueing many elements with tf.train.batch.
174 | images, raw_images, labels = tf.train.batch(
175 | [image, raw_image, label],
176 | batch_size = batch_size,
177 | num_threads = 4,
178 | capacity = 4 * batch_size,
179 | allow_smaller_final_batch = True)
180 |
181 | return images, raw_images, labels
182 |
183 | def run():
184 | #Create the log directory here. Must be done here otherwise import will activate this unneededly.
185 | if not os.path.exists(FLAGS.train_dir):
186 | os.mkdir(FLAGS.train_dir)
187 |
188 | #======================= TRAINING PROCESS =========================
189 | #Now we start to construct the graph and build our model
190 | with tf.Graph().as_default() as graph:
191 | tf.logging.set_verbosity(tf.logging.INFO) #Set the verbosity to INFO level
192 |
193 | #First create the dataset and load one batch
194 | dataset = get_split('train', FLAGS.dataset_dir, file_pattern=file_pattern)
195 | images, _, labels = load_batch(dataset, batch_size=batch_size)
196 |
197 | #Know the number steps to take before decaying the learning rate and batches per epoch
198 | num_batches_per_epoch = int(dataset.num_samples / batch_size)
199 | num_steps_per_epoch = num_batches_per_epoch #Because one step is one batch processed
200 | decay_steps = int(num_epochs_before_decay * num_steps_per_epoch)
201 |
202 | #Create the model inference
203 | with slim.arg_scope(inception_resnet_v2_arg_scope()):
204 | logits, end_points = inception_resnet_v2(images, num_classes = dataset.num_classes, is_training = True)
205 | #with slim.arg_scope(inception_v3_arg_scope()):
206 | # logits, end_points = inception_v3(images, num_classes = dataset.num_classes, is_training = True)
207 | #with slim.arg_scope(vgg_arg_scope()):
208 | # logits, end_points = vgg_16(images, num_classes = dataset.num_classes, is_training = True)
209 | #with slim.arg_scope(vgg_arg_scope()):
210 | # logits, end_points = vgg_19(images, num_classes = dataset.num_classes, is_training = True)
211 | #with slim.arg_scope(resnet_arg_scope()):
212 | # logits, end_points = resnet_v1_50(images, num_classes = dataset.num_classes, is_training = True)
213 | #with slim.arg_scope(inception_v1_arg_scope()):
214 | # logits, end_points = inception_v1(images, num_classes = dataset.num_classes, is_training = True)
215 | #with slim.arg_scope(nasnet_large_arg_scope()):
216 | # logits, end_points = build_nasnet_large(images, num_classes = dataset.num_classes, is_training = True)
217 |
218 | #Define the scopes that you want to exclude for restoration
219 | #exclude = ['InceptionV4/Logits/', 'InceptionV4/AuxLogits/Aux_logits']
220 | exclude = ['InceptionResnetV2/Logits', 'InceptionResnetV2/AuxLogits']
221 | #exclude = ['InceptionV3/Logits', 'InceptionV3/AuxLogits']
222 | #exclude = ['vgg_16/fc8']
223 | #exclude = ['vgg_19/fc8']
224 | #exclude = ['resnet_v1_50/logits']
225 | #exclude = ['InceptionV1/Logits']
226 | #exclude = ['aux_11', 'final_layer']
227 | variables_to_restore = slim.get_variables_to_restore(exclude = exclude)
228 |
229 | #Perform one-hot-encoding of the labels (Try one-hot-encoding within the load_batch function!)
230 | one_hot_labels = slim.one_hot_encoding(labels, dataset.num_classes)
231 |
232 | #Performs the equivalent to tf.nn.sparse_softmax_cross_entropy_with_logits but enhanced with checks
233 | loss = tf.losses.softmax_cross_entropy(onehot_labels = one_hot_labels, logits = logits)
234 | total_loss = tf.losses.get_total_loss() #obtain the regularization losses as well
235 |
236 | #Create the global step for monitoring the learning_rate and training.
237 | global_step = tf.train.get_or_create_global_step()
238 |
239 | #Define your exponentially decaying learning rate
240 | lr = tf.train.exponential_decay(
241 | learning_rate = initial_learning_rate,
242 | global_step = global_step,
243 | decay_steps = decay_steps,
244 | decay_rate = learning_rate_decay_factor,
245 | staircase = True)
246 |
247 | #Now we can define the optimizer that takes on the learning rate
248 | optimizer = tf.train.AdamOptimizer(learning_rate = lr)
249 |
250 | #Create the train_op.
251 | train_op = slim.learning.create_train_op(total_loss, optimizer)
252 |
253 | #State the metrics that you want to predict. We get a predictions that is not one_hot_encoded.
254 | predictions = tf.argmax(end_points['Predictions'], 1)
255 | probabilities = end_points['Predictions']
256 | correct_prediction = tf.equal(predictions, labels)
257 | accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
258 | #accuracy, accuracy_update = tf.contrib.metrics.accuracy(predictions, labels)
259 | #metrics_op = tf.group(accuracy_update, probabilities)
260 |
261 |
262 | #Now finally create all the summaries you need to monitor and group them into one summary op.
263 | tf.summary.scalar('losses/Total_Loss', total_loss)
264 | tf.summary.scalar('accuracy', accuracy)
265 | tf.summary.scalar('learning_rate', lr)
266 |
267 | my_summary_op = tf.summary.merge_all()
268 |
269 | #Now we need to create a training step function that runs both the train_op, metrics_op and updates the global_step concurrently.
270 | def train_step(sess, train_op, global_step):
271 | '''
272 | Simply runs a session for the three arguments provided and gives a logging on the time elapsed for each global step
273 | '''
274 | #Check the time for each sess run
275 | start_time = time.time()
276 | total_loss, global_step_count = sess.run([train_op, global_step])
277 | #total_loss, global_step_count, _ = sess.run([train_op, global_step, metrics_op])
278 | time_elapsed = time.time() - start_time
279 |
280 | #Run the logging to print some results
281 | if global_step_count % 500 == 0:
282 | logging.info('global step %s: loss: %.4f (%.2f sec/step)', global_step_count, total_loss, time_elapsed)
283 |
284 | return total_loss, global_step_count
285 |
286 | #Now we create a saver function that actually restores the variables from a checkpoint file in a sess
287 | saver = tf.train.Saver(variables_to_restore)
288 | def restore_fn(sess):
289 | return saver.restore(sess, FLAGS.checkpoint_path)
290 |
291 | #Define your supervisor for running a managed session. Do not run the summary_op automatically or else it will consume too much memory
292 | sv = tf.train.Supervisor(logdir = FLAGS.train_dir, summary_op = None, init_fn = restore_fn, save_model_secs = 1200)
293 | config = tf.ConfigProto()
294 | config.gpu_options.allow_growth = False
295 | #Run the managed session
296 | with sv.managed_session(config = config) as sess:
297 | for step in range(num_steps_per_epoch * num_epochs):
298 | #At the start of every epoch, show the vital information:
299 | if step % num_batches_per_epoch == 0:
300 | logging.info('Epoch %s/%s', step/num_batches_per_epoch + 1, num_epochs)
301 | learning_rate_value, accuracy_value, loss_train = sess.run([lr, accuracy, total_loss])
302 | logging.info('Current Learning Rate: %s', learning_rate_value)
303 | logging.info('Current Streaming Accuracy: %s', accuracy_value)
304 | logging.info('Current Loss: %s', loss_train)
305 |
306 | # optionally, print your logits and predictions for a sanity check that things are going fine.
307 | logits_value, probabilities_value, predictions_value, labels_value = sess.run([logits, probabilities, predictions, labels])
308 | #print ('logits: \n', logits_value)
309 | #print ('Probabilities: \n', probabilities_value)
310 | #print ('predictions: \n', predictions_value)
311 | #print ('Labels:\n:', labels_value)
312 |
313 | #Log the summaries every 10 step.
314 | if step % 1200 == 0:
315 | loss, _ = train_step(sess, train_op, sv.global_step)
316 | summaries = sess.run(my_summary_op)
317 | sv.summary_computed(sess, summaries)
318 |
319 | #If not, simply run the training step
320 | else:
321 | loss, _ = train_step(sess, train_op, sv.global_step)
322 |
323 | #We log the final training loss and accuracy
324 | logging.info('Final Loss: %s', loss)
325 | logging.info('Final Accuracy: %s', sess.run(accuracy))
326 |
327 | #Once all the training has been done, save the log files and checkpoint model
328 | logging.info('Finished training! Saving model to disk now.')
329 | # saver.save(sess, "./flowers_model.ckpt")
330 | sv.saver.save(sess, sv.save_path, global_step = sv.global_step)
331 |
332 |
333 | if __name__ == '__main__':
334 | run()
335 |
--------------------------------------------------------------------------------