 112 |
112 |
111 |
112 |
 119 |
120 | * Image preprocessing is done in dataloader:
121 | - Image size = 64;
122 | - Center crop = 375;
123 | - Random Horizontal Flip;
124 | - Transform grey scale images to RGB image by channel replication;
125 | - Normalization (standardization) with mean=[0.5,0.5,0.5] and std=[0.5,0.5,0.5]
126 | since we use Tanh output activation function in the decoder.
127 |
128 |
129 | * Latent dimension = 128
130 | * Batch size = 64 (512 for the latent space visualization)
131 |
132 | ### Re-parametrization trick
133 |
134 | An optimization process requires a deterministic model rather than stochastic w.r.t. learnable parameters. Therefore, we have to re-parametrize the encoder outputs. Re-parametrization trick reads: , where
135 |
136 | * 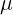 and 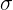 are encoder outputs,
137 | *  is the random variable.
138 |
139 | The encoder returns  for numerical stability. We do the following for the re-parametrization:
140 |
141 | ```python
142 | def reparametrize(self, mu, logvar):
143 |
144 | """ Re-parametrization trick"""
145 |
146 | logvar = logvar.mul(0.5).exp_()
147 | eps = Variable(logvar.data.new(logvar.size()).normal_())
148 |
149 | return eps.mul(logvar).add_(mu)
150 | ```
151 |
152 |
153 | ### Loss function
154 |
155 | - A VAE loss function represents the sum of a reconstruction error and KL divergence.
156 |
157 | - Generally the reconstruction error corresponds to the mean square error between a ground thruth image and a reconstructed image
158 | (here it is just a square error):
159 |
160 | ```python
161 | # reconstruction error
162 | mse = 0.5 * (x.view(len(x), -1) - x_tilde.view(len(x_tilde), -1)) ** 2
163 | ```
164 | - KL divergence is calculated for the Gaussian encoder distribution:
165 | ```
166 | # kl divergence
167 | kld = -0.5 * torch.sum(-variances.exp() - torch.pow(mus, 2) + variances + 1, 1)
168 | ```
169 |
170 | - Since we use separate optimizers for the encoder and the decoder networks we calculate the following loss function:
171 |
172 | ```python
173 | if args.mode == 'vae':
174 | loss_encoder = (1 / batch_size) * torch.sum(kld)
175 | # loss_encoder = torch.sum(kld)
176 | loss_decoder = torch.sum(recon_mse)
177 | ```
178 | - Encoder loss corresponds to the penalizer term, which pushes the approximate posterior
179 | to the prior.
180 | - Decoder loss corresponds to the reconstruction error.
181 | - We use KL-divergence weighted with batch_size or not in order to achieve a trade-off between two terms.
182 | - We minimize the sum instead of mean values.
183 |
184 |
185 | ### Metrics
186 |
187 | There is a huge issue in the existing literature regarding the evaluation of generative models. We evaluated the reconstruction ability with
188 | the common image similarity metrics:
189 |
190 | * Pearson Correlation Coefficient (PCC)
191 | * Structural Similarity (SSIM)
192 |
193 | However, they are not capable to capture human perception.
194 |
195 | ### Latent space
196 |
197 | We visualized latent space only for training with *Food-101* dataset. To do this we transform labels to numbers in the dataloader:
198 | ```python
199 | from sklearn import preprocessing
200 |
201 | # Transform labels to numbers
202 | le = preprocessing.LabelEncoder()
203 | le.fit(self.labels)
204 | self.labels = le.transform(self.labels)
205 | ```
206 | Then we use *scatter plot* during training (for training and validation sets):
207 | ```python
208 | # Visualize latent space for training set
209 | plt.figure(figsize=(10, 6))
210 | plt.scatter(mus.cpu().detach()[..., 0], mus.cpu().detach()[..., 1], c=labels, cmap='rainbow')
211 | plt.colorbar()
212 | ```
213 |
214 | ## Results
215 |
216 | ### MS COCO
217 |
218 | #### Ground truth images
219 |
220 |
119 |
120 | * Image preprocessing is done in dataloader:
121 | - Image size = 64;
122 | - Center crop = 375;
123 | - Random Horizontal Flip;
124 | - Transform grey scale images to RGB image by channel replication;
125 | - Normalization (standardization) with mean=[0.5,0.5,0.5] and std=[0.5,0.5,0.5]
126 | since we use Tanh output activation function in the decoder.
127 |
128 |
129 | * Latent dimension = 128
130 | * Batch size = 64 (512 for the latent space visualization)
131 |
132 | ### Re-parametrization trick
133 |
134 | An optimization process requires a deterministic model rather than stochastic w.r.t. learnable parameters. Therefore, we have to re-parametrize the encoder outputs. Re-parametrization trick reads: , where
135 |
136 | * 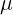 and 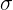 are encoder outputs,
137 | *  is the random variable.
138 |
139 | The encoder returns  for numerical stability. We do the following for the re-parametrization:
140 |
141 | ```python
142 | def reparametrize(self, mu, logvar):
143 |
144 | """ Re-parametrization trick"""
145 |
146 | logvar = logvar.mul(0.5).exp_()
147 | eps = Variable(logvar.data.new(logvar.size()).normal_())
148 |
149 | return eps.mul(logvar).add_(mu)
150 | ```
151 |
152 |
153 | ### Loss function
154 |
155 | - A VAE loss function represents the sum of a reconstruction error and KL divergence.
156 |
157 | - Generally the reconstruction error corresponds to the mean square error between a ground thruth image and a reconstructed image
158 | (here it is just a square error):
159 |
160 | ```python
161 | # reconstruction error
162 | mse = 0.5 * (x.view(len(x), -1) - x_tilde.view(len(x_tilde), -1)) ** 2
163 | ```
164 | - KL divergence is calculated for the Gaussian encoder distribution:
165 | ```
166 | # kl divergence
167 | kld = -0.5 * torch.sum(-variances.exp() - torch.pow(mus, 2) + variances + 1, 1)
168 | ```
169 |
170 | - Since we use separate optimizers for the encoder and the decoder networks we calculate the following loss function:
171 |
172 | ```python
173 | if args.mode == 'vae':
174 | loss_encoder = (1 / batch_size) * torch.sum(kld)
175 | # loss_encoder = torch.sum(kld)
176 | loss_decoder = torch.sum(recon_mse)
177 | ```
178 | - Encoder loss corresponds to the penalizer term, which pushes the approximate posterior
179 | to the prior.
180 | - Decoder loss corresponds to the reconstruction error.
181 | - We use KL-divergence weighted with batch_size or not in order to achieve a trade-off between two terms.
182 | - We minimize the sum instead of mean values.
183 |
184 |
185 | ### Metrics
186 |
187 | There is a huge issue in the existing literature regarding the evaluation of generative models. We evaluated the reconstruction ability with
188 | the common image similarity metrics:
189 |
190 | * Pearson Correlation Coefficient (PCC)
191 | * Structural Similarity (SSIM)
192 |
193 | However, they are not capable to capture human perception.
194 |
195 | ### Latent space
196 |
197 | We visualized latent space only for training with *Food-101* dataset. To do this we transform labels to numbers in the dataloader:
198 | ```python
199 | from sklearn import preprocessing
200 |
201 | # Transform labels to numbers
202 | le = preprocessing.LabelEncoder()
203 | le.fit(self.labels)
204 | self.labels = le.transform(self.labels)
205 | ```
206 | Then we use *scatter plot* during training (for training and validation sets):
207 | ```python
208 | # Visualize latent space for training set
209 | plt.figure(figsize=(10, 6))
210 | plt.scatter(mus.cpu().detach()[..., 0], mus.cpu().detach()[..., 1], c=labels, cmap='rainbow')
211 | plt.colorbar()
212 | ```
213 |
214 | ## Results
215 |
216 | ### MS COCO
217 |
218 | #### Ground truth images
219 |
220 |  221 |
222 | #### **3 training epochs:**
223 |
224 |
221 |
222 | #### **3 training epochs:**
223 |
224 |  225 |
226 |
227 | Reconstruction from sampled latent representations:
228 |
229 |
230 |
225 |
226 |
227 | Reconstruction from sampled latent representations:
228 |
229 |
230 |  231 |
232 |
233 | #### **20 training epochs:**
234 |
235 |
236 |
231 |
232 |
233 | #### **20 training epochs:**
234 |
235 |
236 |  237 |
238 | Reconstruction from sampled latent representations:
239 |
240 |
237 |
238 | Reconstruction from sampled latent representations:
239 |
240 |  241 |
242 | Since we use natural scenes, which are the most difficult for unsupervised training, the images generated
243 | from the random samples in the latent space are less meaningful in comparison to the models trained with other
244 | more structural and uniform datasets, e.g. widely used in related works CelebA dataset with faces, LSUN bedrooms etc.
245 |
246 |
247 | ### FOOD-101
248 |
249 | Let's try more uniform but smaller dataset FOOD-101. We also apply weight for KL divergence term.
250 |
251 | #### Ground truth images
252 |
253 |
241 |
242 | Since we use natural scenes, which are the most difficult for unsupervised training, the images generated
243 | from the random samples in the latent space are less meaningful in comparison to the models trained with other
244 | more structural and uniform datasets, e.g. widely used in related works CelebA dataset with faces, LSUN bedrooms etc.
245 |
246 |
247 | ### FOOD-101
248 |
249 | Let's try more uniform but smaller dataset FOOD-101. We also apply weight for KL divergence term.
250 |
251 | #### Ground truth images
252 |
253 |  254 |
255 | #### **3 training epochs:**
256 |
257 |
254 |
255 | #### **3 training epochs:**
256 |
257 |  258 |
259 | Reconstruction from sampled latent representations:
260 |
261 |
258 |
259 | Reconstruction from sampled latent representations:
260 |
261 |  262 |
263 | Latent space for the test set (alpha=1):
264 |
265 |
266 |
262 |
263 | Latent space for the test set (alpha=1):
264 |
265 |
266 |  267 |
268 |
269 | #### **10 training epochs:**
270 |
271 |
267 |
268 |
269 | #### **10 training epochs:**
270 |
271 |  272 |
273 |
274 | Reconstruction from sampled latent representations:
275 |
276 |
272 |
273 |
274 | Reconstruction from sampled latent representations:
275 |
276 |  277 |
278 |
279 | Latent space for the test set (alpha=1):
280 |
281 |
277 |
278 |
279 | Latent space for the test set (alpha=1):
280 |
281 |  282 |
283 |
284 | #### **20 training epochs:**
285 |
286 |
282 |
283 |
284 | #### **20 training epochs:**
285 |
286 |  287 |
288 | Reconstruction from sampled latent representations:
289 |
290 |
287 |
288 | Reconstruction from sampled latent representations:
289 |
290 |  291 |
292 | Latent space for the test set (alpha=1):
293 |
294 |
291 |
292 | Latent space for the test set (alpha=1):
293 |
294 |  295 |
296 | (It seems longer training is required for clusterization in the latent space.)
297 |
298 | Now the generated images (from random latent vector) are more similar to food images. The weighted KL divergence leads to better reconstructions
299 | but the generated images provide less information.
300 |
301 | ## Conclusion
302 |
303 | In order to achieve better reconstructions, the latent variables must stay away from each other. Otherwise,
304 | they may coincide, as a consequence deteriorate the reconstructions. We have to achieve a trade-off between the
305 | reconstruction error and the VAE penalizer, which pushes the encoder distribution to be similar to the prior latent distribution.
306 |
307 | The VAE reconstructions are quite noisy. The reason is the lower dimension of the latent space comparing to the input images.
308 | Another reason is the sampling in the latent space. As a result, the VAE penalizer pushes its reconstruction to the mean values of the latent representation
309 | instead of the real values.
310 |
311 |
312 | ## References:
313 | ```
314 | 1. @misc{lin2015microsoft,
315 | title={Microsoft COCO: Common Objects in Context},
316 | author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
317 | year={2015},
318 | eprint={1405.0312},
319 | archivePrefix={arXiv},
320 | primaryClass={cs.CV}
321 | }
322 | ```
323 | ```
324 | 2. @inproceedings{lee2017cleannet,
325 | title={CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise},
326 | author={Lee, Kuang-Huei and He, Xiaodong and Zhang, Lei and Yang, Linjun},
327 | booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition ({CVPR})},
328 | year={2018}
329 | }
330 | ```
331 | ```
332 | 3. @misc{kingma2014autoencoding,
333 | title={Auto-Encoding Variational Bayes},
334 | author={Diederik P Kingma and Max Welling},
335 | year={2014},
336 | eprint={1312.6114},
337 | archivePrefix={arXiv},
338 | primaryClass={stat.ML}
339 | }
340 | ```
341 | 4. GitHub repository: https://github.com/lucabergamini/VAEGAN-PYTORCH
--------------------------------------------------------------------------------
/configs/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/configs/__init__.py
--------------------------------------------------------------------------------
/configs/data_config.py:
--------------------------------------------------------------------------------
1 | """_____________Config file used for data setup_______________"""
2 |
3 | # root where datasets are located (might be home directory)
4 | data_root = 'datasets/'
5 |
6 | # COCO dataset
7 | dataset = 'coco'
8 | coco_train_data = 'coco_train2017/train2017'
9 | coco_valid_data = 'coco_valid2017/val2017'
10 | coco_test_data = 'coco_test2017/test2017'
11 |
12 | # FOOD-101 dataset
13 | dataset = 'food-101'
14 | images_data = 'images'
15 | meta_data = 'meta'
16 |
17 | # path where save the results
18 | save_training_results = 'results/'
19 |
--------------------------------------------------------------------------------
/configs/models_config.py:
--------------------------------------------------------------------------------
1 | """______Config file used for model definition_________"""
2 |
3 | # parameters for conv layer in encoder and decoder
4 | kernel_size = 5
5 | stride = 2
6 | padding = 2
7 | dropout = 0.7
8 |
9 | # channels for conv layers
10 | encoder_channels = [64, 128, 256]
11 | decoder_channels = [256, 128, 32, 3]
12 | discrim_channels = [32, 128, 256, 256, 512]
13 |
14 | # settings for resolution 64
15 | image_size = 64
16 | fc_input = 8
17 | fc_output = 1024
18 | fc_input_gan = 8
19 | fc_output_gan = 512
20 | stride_gan = 1
21 | latent_dim = 128
22 | output_pad_dec = [True, True, True]
23 |
--------------------------------------------------------------------------------
/configs/train_config.py:
--------------------------------------------------------------------------------
1 | """____________Config file used for training____________"""
2 |
3 | pretrained_gan = None # None or pretrained model, e.g. 'vae_20210203-173210'
4 | load_epoch = 395 # number of loaded epoch
5 | evaluate = False # if you want evaluate only
6 |
7 | # Image parameters
8 | image_crop = 375
9 | image_size = 64
10 | mean = [0.5, 0.5, 0.5]
11 | std = [0.5, 0.5, 0.5]
12 |
13 | # latent space dimension
14 | latent_dim = 128
15 |
16 | # Device for training: cpu or cuda
17 | device = 'cuda:5'
18 |
19 | # Other training parameters
20 | patience = 0 # for early stopping, 0 = deactivate early stopping
21 | batch_size = 512
22 | learning_rate = 0.001
23 | weight_decay = 1e-7
24 | n_epochs = 100
25 | num_workers = 4
26 | step_size = 20 # for scheduler
27 | gamma = 0.1 # for scheduler
28 | lambda_mse = 1e-6
29 | decay_lr = 0.75
30 | decay_mse = 1
31 | beta = 1.0
32 |
33 |
34 |
35 |
--------------------------------------------------------------------------------
/data/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/data/__init__.py
--------------------------------------------------------------------------------
/data/data_loader.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | from PIL import Image
4 | from os import listdir
5 | from sklearn import preprocessing
6 |
7 |
8 | class CocoDataloader(object):
9 |
10 | def __init__(self, data_dir, transform=None):
11 | """
12 | The constructor to initialized paths to coco images
13 | :param data_dir: directory to coco images
14 | :param transform: image transformations
15 | """
16 | self.transform = transform
17 | self.image_names = [os.path.join(data_dir, img) for img in listdir(data_dir) if os.path.join(data_dir, img)]
18 |
19 | def __len__(self):
20 | return len(self.image_names)
21 |
22 | def __getitem__(self, idx):
23 |
24 | image = Image.open(self.image_names[idx])
25 |
26 | if self.transform:
27 | image = self.transform(image)
28 |
29 | return image
30 |
31 |
32 | class GreyToColor(object):
33 | """
34 | Converts grey tensor images to tensor with 3 channels
35 | """
36 |
37 | def __init__(self, size):
38 | """
39 | @param size: image size
40 | """
41 | self.image = torch.zeros([3, size, size])
42 |
43 | def __call__(self, image):
44 | """
45 | @param image: image as a torch.tensor
46 | @return: transformed image if it is grey scale, otherwise original image
47 | """
48 |
49 | out_image = self.image
50 |
51 | if image.shape[0] == 3:
52 | out_image = image
53 | else:
54 | out_image[0, :, :] = torch.unsqueeze(image, 0)
55 | out_image[1, :, :] = torch.unsqueeze(image, 0)
56 | out_image[2, :, :] = torch.unsqueeze(image, 0)
57 |
58 | return out_image
59 |
60 |
61 | class Food101Dataloader(object):
62 |
63 | def __init__(self, data_dir, img_names, transform=None):
64 | """
65 | The constructor to initialized paths to Food-101 images
66 | :param data_dir: directory to images
67 | :params: img_names from meta data
68 | :param transform: image transformations
69 | """
70 | self.transform = transform
71 | self.image_names = [os.path.join(data_dir, img) for img in img_names]
72 | self.labels = [img.split('/')[0] for img in img_names]
73 |
74 | # Transform labels to numbers
75 | le = preprocessing.LabelEncoder()
76 | le.fit(self.labels)
77 | self.labels = le.transform(self.labels)
78 |
79 | def __len__(self):
80 | return len(self.image_names)
81 |
82 | def __getitem__(self, idx):
83 |
84 | image = Image.open(self.image_names[idx].split('\n')[0] + '.jpg')
85 | label = self.labels[idx]
86 |
87 | if self.transform:
88 | image = self.transform(image)
89 |
90 | sample = {'image': image, 'label': label}
91 |
92 | return sample
93 |
--------------------------------------------------------------------------------
/docs/food1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food1.png
--------------------------------------------------------------------------------
/docs/food2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food2.png
--------------------------------------------------------------------------------
/docs/food3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food3.png
--------------------------------------------------------------------------------
/docs/food4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food4.png
--------------------------------------------------------------------------------
/docs/food5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food5.png
--------------------------------------------------------------------------------
/docs/food6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food6.png
--------------------------------------------------------------------------------
/docs/food_gt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food_gt.png
--------------------------------------------------------------------------------
/docs/img.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img.png
--------------------------------------------------------------------------------
/docs/img_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img_1.png
--------------------------------------------------------------------------------
/docs/img_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img_2.png
--------------------------------------------------------------------------------
/docs/img_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img_3.png
--------------------------------------------------------------------------------
/docs/img_4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img_4.png
--------------------------------------------------------------------------------
/docs/img_gt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img_gt.png
--------------------------------------------------------------------------------
/docs/lat1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/lat1.png
--------------------------------------------------------------------------------
/docs/lat2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/lat2.png
--------------------------------------------------------------------------------
/docs/lat3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/lat3.png
--------------------------------------------------------------------------------
/docs/vae.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/vae.png
--------------------------------------------------------------------------------
/models/vae.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | import torch.nn as nn
4 | from torch.autograd import Variable
5 | import configs.models_config as config
6 |
7 |
8 | class EncoderBlock(nn.Module):
9 |
10 | """CNN-based encoder block"""
11 |
12 | def __init__(self, channel_in, channel_out):
13 | super(EncoderBlock, self).__init__()
14 |
15 | self.conv = nn.Conv2d(in_channels=channel_in, out_channels=channel_out, kernel_size=config.kernel_size,
16 | padding=config.padding, stride=config.stride,
17 | bias=False)
18 | self.bn = nn.BatchNorm2d(num_features=channel_out, momentum=0.9)
19 |
20 | def forward(self, ten, out=False, t=False):
21 |
22 | ten = self.conv(ten)
23 | ten = self.bn(ten)
24 | ten = F.relu(ten, True)
25 |
26 | return ten
27 |
28 |
29 | class DecoderBlock(nn.Module):
30 |
31 | """CNN-based decoder block"""
32 |
33 | def __init__(self, channel_in, channel_out, out=False):
34 | super(DecoderBlock, self).__init__()
35 |
36 | # Settings for settings from different papers
37 | if out:
38 | self.conv = nn.ConvTranspose2d(channel_in, channel_out, kernel_size=config.kernel_size, padding=config.padding,
39 | stride=config.stride, output_padding=1,
40 | bias=False)
41 | else:
42 | self.conv = nn.ConvTranspose2d(channel_in, channel_out, kernel_size=config.kernel_size,
43 | padding=config.padding,
44 | stride=config.stride,
45 | bias=False)
46 | self.bn = nn.BatchNorm2d(channel_out, momentum=0.9)
47 |
48 | def forward(self, ten):
49 |
50 | ten = self.conv(ten)
51 | ten = self.bn(ten)
52 | ten = F.relu(ten, True)
53 |
54 | return ten
55 |
56 |
57 | class Encoder(nn.Module):
58 |
59 | """ VAE-based encoder"""
60 |
61 | def __init__(self, channel_in=3, z_size=128):
62 | super(Encoder, self).__init__()
63 |
64 | self.size = channel_in
65 | layers_list = []
66 | for i in range(3):
67 | layers_list.append(EncoderBlock(channel_in=self.size, channel_out=config.encoder_channels[i]))
68 | self.size = config.encoder_channels[i]
69 | self.conv = nn.Sequential(*layers_list)
70 | self.fc = nn.Sequential(nn.Linear(in_features=config.fc_input * config.fc_input * self.size,
71 | out_features=config.fc_output, bias=False),
72 | nn.BatchNorm1d(num_features=config.fc_output, momentum=0.9),
73 | nn.ReLU(True))
74 | # two linear to get the mu vector and the diagonal of the log_variance
75 | self.l_mu = nn.Linear(in_features=config.fc_output, out_features=z_size)
76 | self.l_var = nn.Linear(in_features=config.fc_output, out_features=z_size)
77 |
78 | def forward(self, ten):
79 |
80 | """
81 | :param ten: input image
82 | :return: mu: mean value
83 | :return: logvar: log of variance for numerical stability
84 | """
85 |
86 | ten = self.conv(ten)
87 | ten = ten.view(len(ten), -1)
88 | ten = self.fc(ten)
89 | mu = self.l_mu(ten)
90 | logvar = self.l_var(ten)
91 |
92 | return mu, logvar
93 |
94 | def __call__(self, *args, **kwargs):
95 | return super(Encoder, self).__call__(*args, **kwargs)
96 |
97 |
98 | class Decoder(nn.Module):
99 |
100 | """ VAE-based decoder"""
101 |
102 | def __init__(self, z_size, size):
103 | super(Decoder, self).__init__()
104 |
105 | self.fc = nn.Sequential(nn.Linear(in_features=z_size, out_features=config.fc_input * config.fc_input * size, bias=False),
106 | nn.BatchNorm1d(num_features=config.fc_input * config.fc_input * size, momentum=0.9),
107 | nn.ReLU(True))
108 | self.size = size
109 | layers_list = []
110 | layers_list.append(DecoderBlock(channel_in=self.size, channel_out=self.size, out=config.output_pad_dec[0]))
111 | layers_list.append(DecoderBlock(channel_in=self.size, channel_out=config.decoder_channels[1], out=config.output_pad_dec[1]))
112 | self.size = config.decoder_channels[1]
113 | layers_list.append(DecoderBlock(channel_in=self.size, channel_out=config.decoder_channels[2], out=config.output_pad_dec[2]))
114 | self.size = config.decoder_channels[2]
115 | # final conv to get 3 channels and tanh layer
116 | layers_list.append(nn.Sequential(
117 | nn.Conv2d(in_channels=self.size, out_channels=config.decoder_channels[3], kernel_size=5, stride=1, padding=2),
118 | nn.Tanh()
119 | ))
120 |
121 | self.conv = nn.Sequential(*layers_list)
122 |
123 | def forward(self, ten):
124 | """
125 | :param ten: re-parametrized latent variable
126 | :return: reconstructed image
127 | """
128 | ten = self.fc(ten)
129 | ten = ten.view(len(ten), -1, config.fc_input, config.fc_input)
130 | ten = self.conv(ten)
131 |
132 | return ten
133 |
134 | def __call__(self, *args, **kwargs):
135 | return super(Decoder, self).__call__(*args, **kwargs)
136 |
137 |
138 | class VAE(nn.Module):
139 |
140 | """VAE model: encoder + decoder + re-parametrization layer"""
141 |
142 | def __init__(self, device, z_size=128):
143 | super(VAE, self).__init__()
144 |
145 | self.z_size = z_size # latent space size
146 | self.encoder = Encoder(z_size=self.z_size).to(device)
147 | self.decoder = Decoder(z_size=self.z_size, size=self.encoder.size).to(device)
148 | self.init_parameters()
149 | self.device = device
150 |
151 | def init_parameters(self):
152 |
153 | """Glorot initialization"""
154 |
155 | for m in self.modules():
156 | if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.Linear)):
157 | if hasattr(m, "weight") and m.weight is not None and m.weight.requires_grad:
158 | nn.init.xavier_normal_(m.weight, 1)
159 | if hasattr(m, "bias") and m.bias is not None and m.bias.requires_grad:
160 | nn.init.constant(m.bias, 0.0)
161 |
162 | def reparametrize(self, mu, logvar):
163 |
164 | """ Re-parametrization trick"""
165 |
166 | logvar = logvar.mul(0.5).exp_()
167 | eps = Variable(logvar.data.new(logvar.size()).normal_())
168 |
169 | return eps.mul(logvar).add_(mu)
170 |
171 | def forward(self, x, gen_size=10):
172 |
173 | if x is not None:
174 | x = Variable(x).to(self.device)
175 |
176 | if self.training:
177 | mus, log_variances = self.encoder(x)
178 | z = self.reparametrize(mus, log_variances)
179 | x_tilde = self.decoder(z)
180 |
181 | # generate from random latent variable
182 | z_p = Variable(torch.randn(len(x), self.z_size).to(self.device), requires_grad=True)
183 | x_p = self.decoder(z_p)
184 | return x_tilde, x_p, mus, log_variances, z_p
185 |
186 | else:
187 | if x is None:
188 | z_p = Variable(torch.randn(gen_size, self.z_size).to(self.device), requires_grad=False)
189 | x_p = self.decoder(z_p)
190 | return x_p
191 |
192 | else:
193 | mus, log_variances = self.encoder(x)
194 | z = self.reparametrize(mus, log_variances)
195 | x_tilde = self.decoder(z)
196 | return x_tilde
197 |
198 | def __call__(self, *args, **kwargs):
199 | return super(VAE, self).__call__(*args, **kwargs)
200 |
201 | @staticmethod
202 | def loss(x, x_tilde, mus, variances):
203 |
204 | """
205 | VAE loss: reconstruction error + KL divergence
206 |
207 | :param x: ground truth image
208 | :param x_tilde: reconstruction from the decoder
209 | :param mus: mean value from the encoder
210 | :param variances: log var from the encoder
211 | :return: mse: reconstruction error
212 | :return: kld: kl divergence
213 | """
214 |
215 | # reconstruction error
216 | mse = 0.5 * (x.view(len(x), -1) - x_tilde.view(len(x_tilde), -1)) ** 2
217 |
218 | # kl divergence
219 | kld = -0.5 * torch.sum(-variances.exp() - torch.pow(mus, 2) + variances + 1, 1)
220 |
221 | return mse, kld
222 |
223 |
--------------------------------------------------------------------------------
/train_utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import math
3 | import torch
4 | import torchvision
5 | import torch.nn.functional as F
6 |
7 | from torch import nn, no_grad
8 | from torch.autograd import Variable
9 |
10 |
11 | def norm_image_prediction(pred, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
12 | """
13 | Normalizes predicted images
14 |
15 | :param pred: tensor [batch_size x channels x width x height]
16 | Predicted image
17 | :param mean: mean values for 3 channels
18 | :param std: std values for 3 channels
19 | :return: normalized predicted image
20 | """
21 | norm_img = pred.detach().clone() # deep copy of tensor
22 | for i in range(3):
23 | norm_img[:, i, :, :] = (norm_img[:, i, :, :] - mean[i]) / std[i]
24 |
25 | return norm_img
26 |
27 |
28 | def denormalize_image(pred, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
29 | """
30 | Denormalizes predicted images
31 |
32 | :param pred: tensor [batch_size x channels x width x height]
33 | Predicted image
34 | :param mean: mean values for 3 channels
35 | :param std: std values for 3 channels
36 | :return: predicted images w/o normalization
37 | """
38 |
39 | denorm_img = pred.detach().clone() # deep copy of tensor
40 | for i in range(3):
41 | denorm_img[:, i, :, :] = denorm_img[:, i, :, :] * std[i] + mean[i]
42 |
43 | return denorm_img
44 |
45 |
46 | class PearsonCorrelation(nn.Module):
47 |
48 | """
49 | Calculates Pearson Correlation Coefficient
50 | """
51 |
52 | def __init__(self):
53 | super(PearsonCorrelation, self).__init__()
54 |
55 | def forward(self, y_pred, y_true):
56 | """
57 | :param y_pred: tensor [batch_size x channels x width x height]
58 | Predicted image
59 | :param y_true: tensor [batch_size x channels x width x height]
60 | Ground truth image
61 | :return: float
62 | Pearson Correlation Coefficient
63 | """
64 |
65 | vx = y_pred - torch.mean(y_pred)
66 | vy = y_true - torch.mean(y_true)
67 |
68 | cost = torch.sum(vx * vy) / (torch.sqrt(torch.sum(vx ** 2)) * torch.sqrt(torch.sum(vy ** 2)))
69 | loss = cost.mean()
70 |
71 | return loss
72 |
73 |
74 | class StructuralSimilarity(nn.Module):
75 |
76 | """
77 | Structural Similarity Index Measure (mean of local SSIM)
78 | see Z. Wang "Image quality assessment: from error visibility to structural similarity"
79 |
80 | Calculates the SSIM between 2 images, the value is between -1 and 1:
81 | 1: images are very similar;
82 | -1: images are very different
83 |
84 | Adapted from https://github.com/pranjaldatta/SSIM-PyTorch/blob/master/SSIM_notebook.ipynb
85 | """
86 |
87 | def __init__(self, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
88 | super(StructuralSimilarity, self).__init__()
89 | self.mean = mean
90 | self.std = std
91 |
92 | def gaussian(self, window_size, sigma):
93 |
94 | """
95 | Generates a list of Tensor values drawn from a gaussian distribution with standard
96 | diviation = sigma and sum of all elements = 1.
97 |
98 | :param window_size: 11 from the paper
99 | :param sigma: standard deviation of Gaussian distribution
100 | :return: list of values, length = window_size
101 | """
102 |
103 | gauss = torch.Tensor(
104 | [math.exp(-(x - window_size // 2) ** 2 / float(2 * sigma ** 2)) for x in range(window_size)])
105 | return gauss / gauss.sum()
106 |
107 | def create_window(self, window_size, channel=1):
108 |
109 | """
110 | :param window_size: 11 from the paper
111 | :param channel: 3 for RGB images
112 | :return: 4D window with size [channels, 1, window_size, window_size]
113 |
114 | """
115 | # Generates an 1D tensor containing values sampled from a gaussian distribution.
116 | _1d_window = self.gaussian(window_size=window_size, sigma=1.5).unsqueeze(1)
117 | # Converts it to 2D
118 | _2d_window = _1d_window.mm(_1d_window.t()).float().unsqueeze(0).unsqueeze(0)
119 | # Adds extra dimensions to convert to 4D
120 | window = torch.Tensor(_2d_window.expand(channel, 1, window_size, window_size).contiguous())
121 |
122 | return window
123 |
124 | def forward(self, img1, img2, val_range=255, window_size=11, window=None, size_average=True, full=False):
125 |
126 | """
127 | Calculating Structural Similarity Index Measure
128 |
129 | :param img1: torch.tensor
130 | :param img2: torch.tensor
131 | :param val_range: 255 for RGB images
132 | :param window_size: 11 from the paper
133 | :param window: created with create_window function
134 | :param size_average: if True calculates the mean
135 | :param full: if true, return result and contrast_metric
136 | :return: value of SSIM
137 | """
138 | try:
139 | # data validation
140 | if torch.min(img1) < 0.0 or torch.max(img1) > 1.0: # if normalized with mean and std
141 | img1 = denormalize_image(img1, mean=self.mean, std=self.std).detach().clone()
142 | if torch.min(img1) < 0.0 or torch.max(img1) > 1.0:
143 | raise ValueError
144 |
145 | if torch.min(img2) < 0.0 or torch.max(img2) > 1.0: # if normalized with mean and std
146 | img2 = denormalize_image(img2, mean=self.mean, std=self.std).detach().clone()
147 | if torch.min(img2) < 0.0 or torch.max(img2) > 1.0:
148 | raise ValueError
149 |
150 | except ValueError as error:
151 | print('Image values in SSIM must be between 0 and 1 or normalized with mean and std', error)
152 |
153 | L = val_range # L is the dynamic range of the pixel values (255 for 8-bit grayscale images),
154 |
155 | pad = window_size // 2
156 |
157 | try:
158 | _, channels, height, width = img1.size()
159 | except:
160 | channels, height, width = img1.size()
161 |
162 | # if window is not provided, init one
163 | if window is None:
164 | real_size = min(window_size, height, width) # window should be atleast 11x11
165 | window = self.create_window(real_size, channel=channels).to(img1.device)
166 |
167 | # calculating the mu parameter (locally) for both images using a gaussian filter
168 | # calculates the luminosity params
169 | mu1 = F.conv2d(img1, window, padding=pad, groups=channels)
170 | mu2 = F.conv2d(img2, window, padding=pad, groups=channels)
171 |
172 | mu1_sq = mu1 ** 2
173 | mu2_sq = mu2 ** 2
174 | mu12 = mu1 * mu2
175 |
176 | # now we calculate the sigma square parameter
177 | # Sigma deals with the contrast component
178 | sigma1_sq = F.conv2d(img1 * img1, window, padding=pad, groups=channels) - mu1_sq
179 | sigma2_sq = F.conv2d(img2 * img2, window, padding=pad, groups=channels) - mu2_sq
180 | sigma12 = F.conv2d(img1 * img2, window, padding=pad, groups=channels) - mu12
181 |
182 | # Some constants for stability
183 | C1 = (0.01) ** 2 # NOTE: Removed L from here (ref PT implementation)
184 | C2 = (0.03) ** 2
185 |
186 | contrast_metric = (2.0 * sigma12 + C2) / (sigma1_sq + sigma2_sq + C2)
187 | contrast_metric = torch.mean(contrast_metric)
188 |
189 | numerator1 = 2 * mu12 + C1
190 | numerator2 = 2 * sigma12 + C2
191 | denominator1 = mu1_sq + mu2_sq + C1
192 | denominator2 = sigma1_sq + sigma2_sq + C2
193 |
194 | ssim_score = (numerator1 * numerator2) / (denominator1 * denominator2)
195 |
196 | if size_average:
197 | result = ssim_score.mean()
198 | else:
199 | result = ssim_score.mean(1).mean(1).mean(1)
200 |
201 | if full:
202 | return result, contrast_metric
203 |
204 | return result
205 |
206 |
207 | def evaluate(model, dataloader, norm=True, mean=None, std=None, mode=None, path=None, save=False, resize=None):
208 | """
209 | Calculate metrics for the dataset specified with dataloader
210 |
211 | :param model: network for evaluation
212 | :param dataloader: DataLoader object
213 | :param norm: normalization
214 | :param mean: mean of the dataset
215 | :param std: standard deviation of the dataset
216 | :param mode: 'bold' or None
217 | :param path: path to save images
218 | :param save: True if save images, otherwise False
219 | :param resize: image size to save
220 | :return: mean PCC, mean SSIM, MSE, mean IS (inception score)
221 | """
222 |
223 | pearson_correlation = PearsonCorrelation()
224 | structural_similarity = StructuralSimilarity()
225 | mse_loss = nn.MSELoss()
226 | ssim = 0
227 | pcc = 0
228 | mse = 0
229 | is_mean = 0
230 | gt_path = path + '/ground_truth'
231 | out_path = path + '/out'
232 | if not os.path.exists(gt_path):
233 | os.makedirs(gt_path)
234 | if not os.path.exists(out_path):
235 | os.makedirs(out_path)
236 |
237 | for batch_idx, data_batch in enumerate(dataloader):
238 | model.eval()
239 |
240 | with no_grad():
241 | if mode == 'bold':
242 | data_target = Variable(data_batch['image'], requires_grad=False).cpu().detach()
243 | else:
244 | data_target = data_batch.cpu().detach()
245 | out = model(data_batch)
246 | out = out.data.cpu()
247 | if save:
248 | if resize is not None:
249 | out = F.interpolate(out, size=resize)
250 | data_target = F.interpolate(data_target, size=resize)
251 | for i, im in enumerate(out):
252 | torchvision.utils.save_image(im, fp=out_path + '/' + str(batch_idx * len(data_target) + i) + '.png', normalize=True)
253 | for i, im in enumerate(data_target):
254 | torchvision.utils.save_image(im, fp=gt_path + '/' + str(batch_idx * len(data_target) + i) + '.png', normalize=True)
255 | if norm and mean is not None and std is not None:
256 | data_target = denormalize_image(data_target, mean=mean, std=std)
257 | out = denormalize_image(out, mean=mean, std=std)
258 | pcc += pearson_correlation(out, data_target)
259 | ssim += structural_similarity(out, data_target)
260 | mse += mse_loss(out, data_target)
261 | is_mean += inception_score(out, resize=True)
262 |
263 | mean_pcc = pcc / (batch_idx+1)
264 | mean_ssim = ssim / (batch_idx+1)
265 | mse_loss = mse / (batch_idx+1)
266 | is_mean = is_mean / (batch_idx+1)
267 |
268 | return mean_pcc, mean_ssim, mse_loss, is_mean
269 |
270 |
271 | def inception_score(imgs, cuda=True, batch_size=32, resize=False, splits=1):
272 |
273 | """Computes the inception score of the generated images imgs
274 | imgs -- Torch dataset of (3xHxW) numpy images normalized in the range [-1, 1]
275 | cuda -- whether or not to run on GPU
276 | batch_size -- batch size for feeding into Inception v3
277 | splits -- number of splits
278 | https://github.com/sbarratt/inception-score-pytorch/blob/master/inception_score.py
279 | """
280 | from torchvision.models.inception import inception_v3
281 | import numpy as np
282 | from scipy.stats import entropy
283 |
284 | N = len(imgs)
285 |
286 | assert batch_size > 0
287 |
288 | # Set up dtype
289 | if cuda:
290 | dtype = torch.cuda.FloatTensor
291 | else:
292 | if torch.cuda.is_available():
293 | print("WARNING: You have a CUDA device, so you should probably set cuda=True")
294 | dtype = torch.FloatTensor
295 |
296 | # Set up dataloader
297 | dataloader = torch.utils.data.DataLoader(imgs, batch_size=batch_size)
298 |
299 | # Load inception model
300 | inception_model = inception_v3(pretrained=True, transform_input=False).type(dtype)
301 | inception_model.eval();
302 | up = nn.Upsample(size=(299, 299), mode='bilinear').type(dtype)
303 |
304 | def get_pred(x):
305 | if resize:
306 | x = up(x)
307 | x = inception_model(x)
308 | return F.softmax(x).data.cpu().numpy()
309 |
310 | # Get predictions
311 | preds = np.zeros((N, 1000))
312 |
313 | for i, batch in enumerate(dataloader, 0):
314 | batch = batch.type(dtype)
315 | batchv = Variable(batch)
316 | batch_size_i = batch.size()[0]
317 |
318 | preds[i*batch_size:i*batch_size + batch_size_i] = get_pred(batchv)
319 |
320 | # Now compute the mean kl-div
321 | split_scores = []
322 |
323 | for k in range(splits):
324 | part = preds[k * (N // splits): (k+1) * (N // splits), :]
325 | py = np.mean(part, axis=0)
326 | scores = []
327 | for i in range(part.shape[0]):
328 | pyx = part[i, :]
329 | scores.append(entropy(pyx, py))
330 | split_scores.append(np.exp(np.mean(scores)))
331 |
332 | return np.mean(split_scores)
333 |
334 |
--------------------------------------------------------------------------------
/vae_train.py:
--------------------------------------------------------------------------------
1 | import os
2 | import time
3 | import numpy
4 | import json
5 | import torch
6 | import logging
7 | import argparse
8 | import pandas as pd
9 | import matplotlib.pyplot as plt
10 |
11 | from torch import nn
12 | from torchvision.utils import make_grid
13 | from torchvision import transforms
14 | from torch.autograd import Variable
15 | from torch.utils.data import DataLoader, ConcatDataset
16 | from torch.utils.tensorboard import SummaryWriter
17 | from torch.optim.lr_scheduler import ExponentialLR
18 |
19 | import configs.train_config as gan_cfg
20 | import configs.data_config as data_cfg
21 | from models.vae import VAE
22 | from train_utils import evaluate, PearsonCorrelation, StructuralSimilarity
23 | from data.data_loader import CocoDataloader, GreyToColor, Food101Dataloader
24 |
25 | numpy.random.seed(8)
26 | torch.manual_seed(8)
27 | torch.cuda.manual_seed(8)
28 |
29 | DEBUG = False # if True results will be saved in 'debug' folder
30 |
31 | if __name__ == "__main__":
32 |
33 | parser = argparse.ArgumentParser()
34 | parser.add_argument('--output', '-o', help='user path where to save', type=str)
35 | parser.add_argument('--logs', '-l', help='path where to save logs', type=str)
36 | parser.add_argument('--batch_size', '-b', default=gan_cfg.batch_size, help='batch size for dataloader', type=int)
37 | parser.add_argument('--learning_rate', '-lr', default=gan_cfg.learning_rate, help='learning rate', type=float)
38 | parser.add_argument('--epochs', '-e', default=gan_cfg.n_epochs, help='number of epochs', type=int)
39 | parser.add_argument('--image_crop', '-im_crop', default=gan_cfg.image_crop, help='size to which image should '
40 | 'be cropped', type=int)
41 | parser.add_argument('--image_size', '-im_size', default=gan_cfg.image_size, help='size to which image should '
42 | 'be scaled', type=int)
43 | parser.add_argument('--device', '-d', default=gan_cfg.device, help='what device to use', type=str)
44 | parser.add_argument('--num_workers', '-nw', default=gan_cfg.num_workers, help='number of workers for dataloader',
45 | type=int)
46 | parser.add_argument('--step_size', '-step', default=gan_cfg.step_size, help='number of epochs after which '
47 | 'to decrease learning rate', type=int)
48 | parser.add_argument('--patience', '-p', default=gan_cfg.patience, help='number of epochs with unchanged lr '
49 | 'for early stopping', type=int)
50 | parser.add_argument('--weight_decay', '--wd', default=gan_cfg.weight_decay, help='weight decay used by optimizer',
51 | type=float)
52 | parser.add_argument('--latent_dim', '-lat_dim', default=gan_cfg.latent_dim, help='dimension of the latent space',
53 | type=int)
54 | parser.add_argument('--message', '-m', default='default message', help='experiment description', type=str)
55 | parser.add_argument('--pretrained_gan', '-pretrain', default=gan_cfg.pretrained_gan, help='pretrained gan', type=str)
56 | parser.add_argument('-load_epoch', '-pretrain_epoch', default=gan_cfg.load_epoch, help='epoch of the pretrained model',
57 | type=int)
58 | parser.add_argument('--lambda_mse', default=gan_cfg.lambda_mse, type=float, help='weight for style error')
59 | parser.add_argument('--decay_mse', default=gan_cfg.decay_mse, type=float, help='mse weight decrease')
60 | parser.add_argument('--decay_lr', default=gan_cfg.decay_lr, type=float, help='learning rate decay for lr scheduler')
61 | parser.add_argument('--beta', default=gan_cfg.beta, type=float, help='beta factor for beta-vee')
62 | parser.add_argument('--mode', default='vae', help='vae, beta-vae')
63 | parser.add_argument('--dataset', default=data_cfg.dataset, help='coco, food-101')
64 |
65 | args = parser.parse_args()
66 |
67 | # Path to pickle file with bold5000 data
68 | USER_ROOT = args.output
69 | SAVE_PATH = os.path.join(USER_ROOT, data_cfg.save_training_results)
70 |
71 | # Create directory to save weights
72 | if not os.path.exists(SAVE_PATH):
73 | os.makedirs(SAVE_PATH)
74 |
75 | # Info logging
76 | timestep = time.strftime("%Y%m%d-%H%M%S")
77 | logging.basicConfig(level=logging.INFO)
78 | logger = logging.getLogger()
79 | file_handler = logging.FileHandler(os.path.join(args.logs, 'train_vae_' + timestep))
80 | logger = logging.getLogger()
81 | file_handler.setLevel(logging.INFO)
82 | logger.addHandler(file_handler)
83 |
84 | # Check available gpu
85 | device = torch.device(args.device if torch.cuda.is_available() else 'cpu')
86 | logger.info("Used device: %s" % device)
87 |
88 | logging.info('set up random seeds')
89 | torch.manual_seed(12345)
90 |
91 | # Create directory for results
92 | if DEBUG:
93 | saving_dir = os.path.join(SAVE_PATH, 'debug', 'debug_vae_{}'.format(timestep))
94 | else:
95 | saving_dir = os.path.join(SAVE_PATH, 'vae', 'vae_{}'.format(timestep))
96 | if not os.path.exists(saving_dir):
97 | os.makedirs(saving_dir)
98 | if args.pretrained_gan is not None:
99 | pretrained_model_dir = os.path.join(SAVE_PATH, 'vae', args.pretrained_gan, args.pretrained_gan + '.pth')
100 | saving_name = os.path.join(saving_dir, 'vae_{}.pth'.format(timestep))
101 |
102 | # Save arguments
103 | with open(os.path.join(saving_dir, 'config.txt'), 'w') as f:
104 | json.dump(args.__dict__, f, indent=2)
105 |
106 | if args.dataset == 'food-101':
107 |
108 | FOOD_IMAGES = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.images_data)
109 | FOOD_TRAIN_META = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.meta_data, 'train.txt')
110 | FOOD_TEST_META = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.meta_data, 'test.txt')
111 |
112 | with open(FOOD_TRAIN_META) as f:
113 | train_image_names = f.readlines()
114 | with open(FOOD_TEST_META) as f:
115 | test_image_names = f.readlines()
116 |
117 | # Load data
118 | training_data = Food101Dataloader(FOOD_IMAGES, train_image_names,
119 | transform=transforms.Compose([transforms.CenterCrop((args.image_crop,
120 | args.image_crop)),
121 | transforms.Resize((args.image_size,
122 | args.image_size)),
123 | transforms.RandomHorizontalFlip(),
124 | transforms.ToTensor(),
125 | GreyToColor(args.image_size),
126 | transforms.Normalize(gan_cfg.mean,
127 | gan_cfg.std)
128 | ]))
129 |
130 | validation_data = Food101Dataloader(FOOD_IMAGES, test_image_names,
131 | transform=transforms.Compose([transforms.CenterCrop((args.image_crop,
132 | args.image_crop)),
133 | transforms.Resize((args.image_size,
134 | args.image_size)),
135 | transforms.RandomHorizontalFlip(),
136 | transforms.ToTensor(),
137 | GreyToColor(args.image_size),
138 | transforms.Normalize(gan_cfg.mean,
139 | gan_cfg.std)
140 | ]))
141 |
142 | dataloader_train = DataLoader(training_data, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers)
143 | dataloader_valid = DataLoader(validation_data, batch_size=args.batch_size, shuffle=False, num_workers=args.num_workers)
144 |
145 | elif args.dataset == 'coco':
146 |
147 | COCO_TEST_DATA = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.coco_test_data)
148 | COCO_TRAIN_DATA = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.coco_train_data)
149 | COCO_VALID_DATA = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.coco_valid_data)
150 |
151 | # Load data
152 | training_data = CocoDataloader(COCO_TRAIN_DATA,
153 | transform=transforms.Compose([transforms.CenterCrop((args.image_crop,
154 | args.image_crop)),
155 | transforms.Resize((args.image_size,
156 | args.image_size)),
157 | transforms.RandomHorizontalFlip(),
158 | transforms.ToTensor(),
159 | GreyToColor(args.image_size),
160 | transforms.Normalize(gan_cfg.mean,
161 | gan_cfg.std)
162 | ]))
163 | validation_data = CocoDataloader(COCO_VALID_DATA,
164 | transform=transforms.Compose([transforms.CenterCrop((args.image_crop,
165 | args.image_crop)),
166 | transforms.Resize((args.image_size,
167 | args.image_size)),
168 | transforms.ToTensor(),
169 | GreyToColor(args.image_size),
170 | transforms.Normalize(gan_cfg.mean,
171 | gan_cfg.std)
172 | ]))
173 | test_data = CocoDataloader(COCO_TEST_DATA,
174 | transform=transforms.Compose([transforms.CenterCrop((args.image_crop,
175 | args.image_crop)),
176 | transforms.Resize((args.image_size,
177 | args.image_size)),
178 | transforms.RandomHorizontalFlip(),
179 | transforms.ToTensor(),
180 | GreyToColor(args.image_size),
181 | transforms.Normalize(gan_cfg.mean,
182 | gan_cfg.std)
183 | ]))
184 |
185 | train_test_data = ConcatDataset([training_data, test_data])
186 |
187 | dataloader_train = DataLoader(train_test_data, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers)
188 | dataloader_valid = DataLoader(validation_data, batch_size=args.batch_size, shuffle=False, num_workers=args.num_workers)
189 |
190 | else:
191 | logging.info('Specify dataset')
192 |
193 | writer = SummaryWriter(saving_dir + '/runs_' + timestep)
194 | writer_encoder = SummaryWriter(saving_dir + '/runs_' + timestep + '/encoder')
195 | writer_decoder = SummaryWriter(saving_dir + '/runs_' + timestep + '/decoder')
196 |
197 | model = VAE(device=device, z_size=args.latent_dim).to(device)
198 |
199 | if args.pretrained_gan is not None and os.path.exists(pretrained_model_dir.replace(".pth", ".csv")):
200 |
201 | # We can continue training
202 | logging.info('Load pretrained model')
203 | model_dir = pretrained_model_dir.replace(".pth", '_{}.pth'.format(args.load_epoch))
204 | model.load_state_dict(torch.load(model_dir))
205 | model.eval()
206 | results = pd.read_csv(pretrained_model_dir.replace(".pth", ".csv"))
207 | results = {col_name: list(results[col_name].values) for col_name in results.columns}
208 | stp = 1 + len(results['epochs'])
209 | if gan_cfg.evaluate:
210 | images_dir = os.path.join(saving_dir, 'images')
211 | if not os.path.exists(images_dir):
212 | os.makedirs(images_dir)
213 | pcc, ssim, mse, is_mean = evaluate(model, dataloader_valid, norm=True, mean=gan_cfg.mean, std=gan_cfg.std,
214 | path=images_dir)
215 | print("Mean PCC:", pcc)
216 | print("Mean SSIM:", ssim)
217 | print("Mean MSE:", mse)
218 | print("IS mean", is_mean)
219 | exit(0)
220 | else:
221 | logging.info('Initialize')
222 | stp = 1
223 |
224 | results = dict(
225 | epochs=[],
226 | loss_encoder=[],
227 | loss_decoder=[]
228 | )
229 |
230 | # An optimizer for each of the sub-networks, so we can selectively backpropogate
231 | optimizer_encoder = torch.optim.RMSprop(params=model.encoder.parameters(), lr=args.learning_rate, alpha=0.9,
232 | eps=1e-8, weight_decay=0, momentum=0, centered=False)
233 | lr_encoder = ExponentialLR(optimizer_encoder, gamma=args.decay_lr)
234 | optimizer_decoder = torch.optim.RMSprop(params=model.decoder.parameters(), lr=args.learning_rate, alpha=0.9,
235 | eps=1e-8, weight_decay=0, momentum=0, centered=False)
236 | lr_decoder = ExponentialLR(optimizer_decoder, gamma=args.decay_lr)
237 |
238 | # Metrics
239 | pearson_correlation = PearsonCorrelation()
240 | structural_similarity = StructuralSimilarity(mean=gan_cfg.mean, std=gan_cfg.std)
241 | mse_loss = nn.MSELoss()
242 |
243 | result_metrics_train = {}
244 | result_metrics_valid = {}
245 | metrics_train = {'train_PCC': pearson_correlation, 'train_SSIM': structural_similarity, 'train_MSE': mse_loss}
246 | metrics_valid = {'valid_PCC': pearson_correlation, 'valid_SSIM': structural_similarity, 'valid_MSE': mse_loss}
247 |
248 | if metrics_valid is not None:
249 | for key in metrics_valid.keys():
250 | results.update({key: []})
251 | for key, value in metrics_valid.items():
252 | result_metrics_valid.update({key: 0.0})
253 |
254 | if metrics_train is not None:
255 | for key in metrics_train.keys():
256 | results.update({key: []})
257 | for key, value in metrics_train.items():
258 | result_metrics_train.update({key: 0.0})
259 |
260 | batch_number = len(dataloader_train)
261 | step_index = 0
262 |
263 | for idx_epoch in range(args.epochs):
264 |
265 | for batch_idx, data_batch in enumerate(dataloader_train):
266 |
267 | model.train()
268 |
269 | if args.dataset == 'coco':
270 | batch_size = len(data_batch)
271 |
272 | x = Variable(data_batch, requires_grad=False).float().to(device)
273 |
274 | elif args.dataset == 'food-101':
275 | batch_size = len(data_batch['image'])
276 |
277 | x = Variable(data_batch['image'], requires_grad=False).float().to(device)
278 | labels = data_batch['label']
279 |
280 | # Take model predictions/reconstruction
281 | x_tilde, x_p, mus, log_variances, z_p = model(x)
282 |
283 | # Calculate reconstruction error and KL divergence
284 | recon_mse, kld = VAE.loss(x, x_tilde, mus, log_variances)
285 |
286 | # Train encoder and decoder
287 | train_enc = True
288 | train_dec = True
289 |
290 | # Beta-VAE/GAN loss
291 | if args.mode == 'beta-vae':
292 | beta = args.beta
293 | kld_weight = 1 / batch_size
294 | loss_encoder = torch.sum(kld) * beta * kld_weight + torch.sum(recon_mse)
295 | loss_decoder = torch.sum(args.lambda_mse * recon_mse)
296 |
297 | # VAE loss
298 | if args.mode == 'vae':
299 | loss_encoder = (1 / batch_size) * torch.sum(kld)
300 | # loss_encoder = torch.sum(kld) + torch.sum(recon_mse)
301 | loss_decoder = torch.sum(recon_mse)
302 |
303 | # Register mean values
304 | loss_encoder_mean = loss_encoder.data.cpu().numpy() / batch_size
305 | loss_decoder_mean = loss_decoder.data.cpu().numpy() / batch_size
306 |
307 | # Backpropagation
308 | # clean grads
309 | model.zero_grad()
310 |
311 | if train_enc:
312 | # encoder
313 | loss_encoder.backward(retain_graph=True)
314 | # we can clamp the grad here
315 | # [p.grad.data.clamp_(-1, 1) for p in model.encoder.parameters()]
316 | # update parameters
317 | optimizer_encoder.step()
318 | # clean others, so they are not afflicted by encoder loss
319 | model.zero_grad()
320 |
321 | # Decoder
322 | if train_dec:
323 | loss_decoder.backward(retain_graph=True)
324 | # [p.grad.data.clamp_(-1, 1) for p in model.decoder.parameters()]
325 | optimizer_decoder.step()
326 |
327 | logging.info(
328 | f'Epoch {idx_epoch} {batch_idx + 1:3.0f} / {100 * (batch_idx + 1) / len(dataloader_train):2.3f}%, '
329 | f'---- encoder loss: {loss_encoder_mean:.5f} ---- | '
330 | f'---- decoder loss: {loss_decoder_mean:.5f} ---- | ')
331 |
332 | writer_encoder.add_scalar('loss_encoder_batch', loss_encoder_mean, step_index)
333 | writer_decoder.add_scalar('loss_decoder_batch', loss_decoder_mean, step_index)
334 |
335 | step_index += 1
336 |
337 | # End of epoch
338 | lr_encoder.step()
339 | lr_decoder.step()
340 |
341 | writer_encoder.add_scalar('loss_encoder', loss_encoder_mean, idx_epoch)
342 | writer_decoder.add_scalar('loss_decoder', loss_decoder_mean, idx_epoch)
343 |
344 | if not idx_epoch % 2:
345 | # Save train examples
346 | images_dir = os.path.join(saving_dir, 'images', 'train')
347 | if not os.path.exists(images_dir):
348 | os.makedirs(images_dir)
349 |
350 | # Ground truth
351 | fig, ax = plt.subplots(figsize=(10, 10))
352 | ax.set_xticks([])
353 | ax.set_yticks([])
354 | ax.imshow(make_grid(x[: 25].cpu().detach(), nrow=5, normalize=True).permute(1, 2, 0))
355 | gt_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_ground_truth_' + 'grid')
356 | plt.savefig(gt_dir)
357 |
358 | # Reconstructed images
359 | fig, ax = plt.subplots(figsize=(10, 10))
360 | ax.set_xticks([])
361 | ax.set_yticks([])
362 | ax.imshow(make_grid(x_tilde[: 25].cpu().detach(), nrow=5, normalize=True).permute(1, 2, 0))
363 | output_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_output_' + 'grid')
364 | plt.savefig(output_dir)
365 |
366 | # Visualize latent space for training set
367 | plt.figure(figsize=(10, 6))
368 | plt.scatter(mus.cpu().detach()[..., 0], mus.cpu().detach()[..., 1], c=labels, cmap='rainbow')
369 | plt.colorbar()
370 | output_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_latent')
371 | plt.savefig(output_dir)
372 | plt.show()
373 |
374 | logging.info('Evaluation')
375 |
376 | for batch_idx, data_batch in enumerate(dataloader_valid):
377 |
378 | model.eval()
379 |
380 | if args.dataset == 'coco':
381 | batch_size = len(data_batch)
382 |
383 | data_in = Variable(data_batch, requires_grad=False).float().to(device)
384 | data_target = Variable(data_batch, requires_grad=False).float().to(device)
385 |
386 | elif args.dataset == 'food-101':
387 | batch_size = len(data_batch['image'])
388 |
389 | data_in = Variable(data_batch['image'], requires_grad=False).float().to(device)
390 | data_target = Variable(data_batch['image'], requires_grad=False).float().to(device)
391 | labels = data_batch['label']
392 |
393 | out = model(data_in)
394 |
395 | # Validation metrics for the first validation batch
396 | if metrics_valid is not None:
397 | for key, metric in metrics_valid.items():
398 | if key == 'cosine_similarity':
399 | result_metrics_valid[key] = metric(out, data_target).mean()
400 | else:
401 | result_metrics_valid[key] = metric(out, data_target)
402 |
403 | # Training metrics for the last training batch
404 | if metrics_train is not None:
405 | for key, metric in metrics_train.items():
406 | if key == 'cosine_similarity':
407 | result_metrics_train[key] = metric(x_tilde, x).mean()
408 | else:
409 | result_metrics_train[key] = metric(x_tilde, x)
410 |
411 | # Save validation examples
412 | images_dir = os.path.join(saving_dir, 'images', 'valid')
413 | if not os.path.exists(images_dir):
414 | os.makedirs(images_dir)
415 | os.makedirs(os.path.join(images_dir, 'random'))
416 |
417 | out = out.data.cpu()
418 |
419 | # Visualize latent space for validation set
420 | mus, var = model.encoder(data_in)
421 | plt.figure(figsize=(10, 6))
422 | plt.scatter(mus.cpu().detach()[..., 0], mus.cpu().detach()[..., 1], c=labels, cmap='rainbow')
423 | plt.colorbar()
424 | output_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_latent')
425 | plt.savefig(output_dir)
426 | plt.show()
427 |
428 | if idx_epoch == 0:
429 | fig, ax = plt.subplots(figsize=(10, 10))
430 | ax.set_xticks([])
431 | ax.set_yticks([])
432 | ax.imshow(make_grid(data_in[: 25].cpu().detach(), nrow=5, normalize=True).permute(1, 2, 0))
433 | gt_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_ground_truth_' + 'grid')
434 | plt.savefig(gt_dir)
435 |
436 | fig, ax = plt.subplots(figsize=(10, 10))
437 | ax.set_xticks([])
438 | ax.set_yticks([])
439 | ax.imshow(make_grid(out[: 25].cpu().detach(), nrow=5, normalize=True).permute(1, 2, 0))
440 | output_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_output_' + 'grid')
441 | plt.savefig(output_dir)
442 |
443 | out = (out + 1) / 2
444 | out = make_grid(out, nrow=8)
445 | writer.add_image("reconstructed", out, step_index)
446 |
447 | out = model(None, 25)
448 | out = out.data.cpu()
449 | out = (out + 1) / 2
450 | out = make_grid(out, nrow=5)
451 | writer.add_image("generated", out, step_index)
452 |
453 | fig, ax = plt.subplots(figsize=(10, 10))
454 | ax.set_xticks([])
455 | ax.set_yticks([])
456 | ax.imshow(make_grid(out[: 25].cpu().detach(), nrow=5, normalize=True).permute(1, 2, 0))
457 | output_dir = os.path.join(images_dir, 'random', 'epoch_' + str(idx_epoch) + '_output_' + 'rand')
458 | plt.savefig(output_dir)
459 |
460 | out = data_target.data.cpu()
461 | out = (out + 1) / 2
462 | out = make_grid(out, nrow=8)
463 | writer.add_image("original", out, step_index)
464 |
465 | if metrics_valid is not None:
466 | for key, values in result_metrics_valid.items():
467 | result_metrics_valid[key] = torch.mean(values)
468 | # Logging metrics
469 | if writer is not None:
470 | for key, values in result_metrics_valid.items():
471 | writer.add_scalar(key, values, stp + idx_epoch)
472 |
473 | if metrics_train is not None:
474 | for key, values in result_metrics_train.items():
475 | result_metrics_train[key] = torch.mean(values)
476 | # Logging metrics
477 | if writer is not None:
478 | for key, values in result_metrics_train.items():
479 | writer.add_scalar(key, values, stp + idx_epoch)
480 |
481 | logging.info(
482 | f'Epoch {idx_epoch} ---- train PCC: {result_metrics_train["train_PCC"].item():.5f} ---- | '
483 | f'---- train SSIM: {result_metrics_train["train_SSIM"].item():.5f} ---- '
484 | f'---- train MSE: {result_metrics_train["train_MSE"].item():.5f} ---- ')
485 |
486 | logging.info(
487 | f'Epoch {idx_epoch} ---- valid PCC: {result_metrics_valid["valid_PCC"].item():.5f} ---- | '
488 | f'---- valid SSIM: {result_metrics_valid["valid_SSIM"].item():.5f} ---- '
489 | f'---- valid MSE: {result_metrics_valid["valid_MSE"].item():.5f} ---- ')
490 |
491 | # only for one batch
492 | break
493 |
494 | if not idx_epoch % 10:
495 | torch.save(model.state_dict(), saving_name.replace('.pth', '_' + str(idx_epoch) + '.pth'))
496 | logging.info('Saving model')
497 |
498 | # Record losses & scores
499 | results['epochs'].append(idx_epoch + stp)
500 | results['loss_encoder'].append(loss_encoder_mean)
501 | results['loss_decoder'].append(loss_decoder_mean)
502 |
503 | if metrics_valid is not None:
504 | for key, value in result_metrics_valid.items():
505 | metric_value = torch.tensor(value, dtype=torch.float64).item()
506 | results[key].append(metric_value)
507 |
508 | if metrics_train is not None:
509 | for key, value in result_metrics_train.items():
510 | metric_value = torch.tensor(value, dtype=torch.float64).item()
511 | results[key].append(metric_value)
512 |
513 | results_to_save = pd.DataFrame(results)
514 | results_to_save.to_csv(saving_name.replace(".pth", ".csv"), index=False)
515 |
516 |
517 | exit(0)
518 |
--------------------------------------------------------------------------------
295 |
296 | (It seems longer training is required for clusterization in the latent space.)
297 |
298 | Now the generated images (from random latent vector) are more similar to food images. The weighted KL divergence leads to better reconstructions
299 | but the generated images provide less information.
300 |
301 | ## Conclusion
302 |
303 | In order to achieve better reconstructions, the latent variables must stay away from each other. Otherwise,
304 | they may coincide, as a consequence deteriorate the reconstructions. We have to achieve a trade-off between the
305 | reconstruction error and the VAE penalizer, which pushes the encoder distribution to be similar to the prior latent distribution.
306 |
307 | The VAE reconstructions are quite noisy. The reason is the lower dimension of the latent space comparing to the input images.
308 | Another reason is the sampling in the latent space. As a result, the VAE penalizer pushes its reconstruction to the mean values of the latent representation
309 | instead of the real values.
310 |
311 |
312 | ## References:
313 | ```
314 | 1. @misc{lin2015microsoft,
315 | title={Microsoft COCO: Common Objects in Context},
316 | author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
317 | year={2015},
318 | eprint={1405.0312},
319 | archivePrefix={arXiv},
320 | primaryClass={cs.CV}
321 | }
322 | ```
323 | ```
324 | 2. @inproceedings{lee2017cleannet,
325 | title={CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise},
326 | author={Lee, Kuang-Huei and He, Xiaodong and Zhang, Lei and Yang, Linjun},
327 | booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition ({CVPR})},
328 | year={2018}
329 | }
330 | ```
331 | ```
332 | 3. @misc{kingma2014autoencoding,
333 | title={Auto-Encoding Variational Bayes},
334 | author={Diederik P Kingma and Max Welling},
335 | year={2014},
336 | eprint={1312.6114},
337 | archivePrefix={arXiv},
338 | primaryClass={stat.ML}
339 | }
340 | ```
341 | 4. GitHub repository: https://github.com/lucabergamini/VAEGAN-PYTORCH
--------------------------------------------------------------------------------
/configs/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/configs/__init__.py
--------------------------------------------------------------------------------
/configs/data_config.py:
--------------------------------------------------------------------------------
1 | """_____________Config file used for data setup_______________"""
2 |
3 | # root where datasets are located (might be home directory)
4 | data_root = 'datasets/'
5 |
6 | # COCO dataset
7 | dataset = 'coco'
8 | coco_train_data = 'coco_train2017/train2017'
9 | coco_valid_data = 'coco_valid2017/val2017'
10 | coco_test_data = 'coco_test2017/test2017'
11 |
12 | # FOOD-101 dataset
13 | dataset = 'food-101'
14 | images_data = 'images'
15 | meta_data = 'meta'
16 |
17 | # path where save the results
18 | save_training_results = 'results/'
19 |
--------------------------------------------------------------------------------
/configs/models_config.py:
--------------------------------------------------------------------------------
1 | """______Config file used for model definition_________"""
2 |
3 | # parameters for conv layer in encoder and decoder
4 | kernel_size = 5
5 | stride = 2
6 | padding = 2
7 | dropout = 0.7
8 |
9 | # channels for conv layers
10 | encoder_channels = [64, 128, 256]
11 | decoder_channels = [256, 128, 32, 3]
12 | discrim_channels = [32, 128, 256, 256, 512]
13 |
14 | # settings for resolution 64
15 | image_size = 64
16 | fc_input = 8
17 | fc_output = 1024
18 | fc_input_gan = 8
19 | fc_output_gan = 512
20 | stride_gan = 1
21 | latent_dim = 128
22 | output_pad_dec = [True, True, True]
23 |
--------------------------------------------------------------------------------
/configs/train_config.py:
--------------------------------------------------------------------------------
1 | """____________Config file used for training____________"""
2 |
3 | pretrained_gan = None # None or pretrained model, e.g. 'vae_20210203-173210'
4 | load_epoch = 395 # number of loaded epoch
5 | evaluate = False # if you want evaluate only
6 |
7 | # Image parameters
8 | image_crop = 375
9 | image_size = 64
10 | mean = [0.5, 0.5, 0.5]
11 | std = [0.5, 0.5, 0.5]
12 |
13 | # latent space dimension
14 | latent_dim = 128
15 |
16 | # Device for training: cpu or cuda
17 | device = 'cuda:5'
18 |
19 | # Other training parameters
20 | patience = 0 # for early stopping, 0 = deactivate early stopping
21 | batch_size = 512
22 | learning_rate = 0.001
23 | weight_decay = 1e-7
24 | n_epochs = 100
25 | num_workers = 4
26 | step_size = 20 # for scheduler
27 | gamma = 0.1 # for scheduler
28 | lambda_mse = 1e-6
29 | decay_lr = 0.75
30 | decay_mse = 1
31 | beta = 1.0
32 |
33 |
34 |
35 |
--------------------------------------------------------------------------------
/data/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/data/__init__.py
--------------------------------------------------------------------------------
/data/data_loader.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | from PIL import Image
4 | from os import listdir
5 | from sklearn import preprocessing
6 |
7 |
8 | class CocoDataloader(object):
9 |
10 | def __init__(self, data_dir, transform=None):
11 | """
12 | The constructor to initialized paths to coco images
13 | :param data_dir: directory to coco images
14 | :param transform: image transformations
15 | """
16 | self.transform = transform
17 | self.image_names = [os.path.join(data_dir, img) for img in listdir(data_dir) if os.path.join(data_dir, img)]
18 |
19 | def __len__(self):
20 | return len(self.image_names)
21 |
22 | def __getitem__(self, idx):
23 |
24 | image = Image.open(self.image_names[idx])
25 |
26 | if self.transform:
27 | image = self.transform(image)
28 |
29 | return image
30 |
31 |
32 | class GreyToColor(object):
33 | """
34 | Converts grey tensor images to tensor with 3 channels
35 | """
36 |
37 | def __init__(self, size):
38 | """
39 | @param size: image size
40 | """
41 | self.image = torch.zeros([3, size, size])
42 |
43 | def __call__(self, image):
44 | """
45 | @param image: image as a torch.tensor
46 | @return: transformed image if it is grey scale, otherwise original image
47 | """
48 |
49 | out_image = self.image
50 |
51 | if image.shape[0] == 3:
52 | out_image = image
53 | else:
54 | out_image[0, :, :] = torch.unsqueeze(image, 0)
55 | out_image[1, :, :] = torch.unsqueeze(image, 0)
56 | out_image[2, :, :] = torch.unsqueeze(image, 0)
57 |
58 | return out_image
59 |
60 |
61 | class Food101Dataloader(object):
62 |
63 | def __init__(self, data_dir, img_names, transform=None):
64 | """
65 | The constructor to initialized paths to Food-101 images
66 | :param data_dir: directory to images
67 | :params: img_names from meta data
68 | :param transform: image transformations
69 | """
70 | self.transform = transform
71 | self.image_names = [os.path.join(data_dir, img) for img in img_names]
72 | self.labels = [img.split('/')[0] for img in img_names]
73 |
74 | # Transform labels to numbers
75 | le = preprocessing.LabelEncoder()
76 | le.fit(self.labels)
77 | self.labels = le.transform(self.labels)
78 |
79 | def __len__(self):
80 | return len(self.image_names)
81 |
82 | def __getitem__(self, idx):
83 |
84 | image = Image.open(self.image_names[idx].split('\n')[0] + '.jpg')
85 | label = self.labels[idx]
86 |
87 | if self.transform:
88 | image = self.transform(image)
89 |
90 | sample = {'image': image, 'label': label}
91 |
92 | return sample
93 |
--------------------------------------------------------------------------------
/docs/food1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food1.png
--------------------------------------------------------------------------------
/docs/food2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food2.png
--------------------------------------------------------------------------------
/docs/food3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food3.png
--------------------------------------------------------------------------------
/docs/food4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food4.png
--------------------------------------------------------------------------------
/docs/food5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food5.png
--------------------------------------------------------------------------------
/docs/food6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food6.png
--------------------------------------------------------------------------------
/docs/food_gt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/food_gt.png
--------------------------------------------------------------------------------
/docs/img.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img.png
--------------------------------------------------------------------------------
/docs/img_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img_1.png
--------------------------------------------------------------------------------
/docs/img_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img_2.png
--------------------------------------------------------------------------------
/docs/img_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img_3.png
--------------------------------------------------------------------------------
/docs/img_4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img_4.png
--------------------------------------------------------------------------------
/docs/img_gt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/img_gt.png
--------------------------------------------------------------------------------
/docs/lat1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/lat1.png
--------------------------------------------------------------------------------
/docs/lat2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/lat2.png
--------------------------------------------------------------------------------
/docs/lat3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/lat3.png
--------------------------------------------------------------------------------
/docs/vae.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MariaPdg/image-autoencoding/1ae4ccca27950a9ed2bdb7c364b073d20ae7cfa4/docs/vae.png
--------------------------------------------------------------------------------
/models/vae.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | import torch.nn as nn
4 | from torch.autograd import Variable
5 | import configs.models_config as config
6 |
7 |
8 | class EncoderBlock(nn.Module):
9 |
10 | """CNN-based encoder block"""
11 |
12 | def __init__(self, channel_in, channel_out):
13 | super(EncoderBlock, self).__init__()
14 |
15 | self.conv = nn.Conv2d(in_channels=channel_in, out_channels=channel_out, kernel_size=config.kernel_size,
16 | padding=config.padding, stride=config.stride,
17 | bias=False)
18 | self.bn = nn.BatchNorm2d(num_features=channel_out, momentum=0.9)
19 |
20 | def forward(self, ten, out=False, t=False):
21 |
22 | ten = self.conv(ten)
23 | ten = self.bn(ten)
24 | ten = F.relu(ten, True)
25 |
26 | return ten
27 |
28 |
29 | class DecoderBlock(nn.Module):
30 |
31 | """CNN-based decoder block"""
32 |
33 | def __init__(self, channel_in, channel_out, out=False):
34 | super(DecoderBlock, self).__init__()
35 |
36 | # Settings for settings from different papers
37 | if out:
38 | self.conv = nn.ConvTranspose2d(channel_in, channel_out, kernel_size=config.kernel_size, padding=config.padding,
39 | stride=config.stride, output_padding=1,
40 | bias=False)
41 | else:
42 | self.conv = nn.ConvTranspose2d(channel_in, channel_out, kernel_size=config.kernel_size,
43 | padding=config.padding,
44 | stride=config.stride,
45 | bias=False)
46 | self.bn = nn.BatchNorm2d(channel_out, momentum=0.9)
47 |
48 | def forward(self, ten):
49 |
50 | ten = self.conv(ten)
51 | ten = self.bn(ten)
52 | ten = F.relu(ten, True)
53 |
54 | return ten
55 |
56 |
57 | class Encoder(nn.Module):
58 |
59 | """ VAE-based encoder"""
60 |
61 | def __init__(self, channel_in=3, z_size=128):
62 | super(Encoder, self).__init__()
63 |
64 | self.size = channel_in
65 | layers_list = []
66 | for i in range(3):
67 | layers_list.append(EncoderBlock(channel_in=self.size, channel_out=config.encoder_channels[i]))
68 | self.size = config.encoder_channels[i]
69 | self.conv = nn.Sequential(*layers_list)
70 | self.fc = nn.Sequential(nn.Linear(in_features=config.fc_input * config.fc_input * self.size,
71 | out_features=config.fc_output, bias=False),
72 | nn.BatchNorm1d(num_features=config.fc_output, momentum=0.9),
73 | nn.ReLU(True))
74 | # two linear to get the mu vector and the diagonal of the log_variance
75 | self.l_mu = nn.Linear(in_features=config.fc_output, out_features=z_size)
76 | self.l_var = nn.Linear(in_features=config.fc_output, out_features=z_size)
77 |
78 | def forward(self, ten):
79 |
80 | """
81 | :param ten: input image
82 | :return: mu: mean value
83 | :return: logvar: log of variance for numerical stability
84 | """
85 |
86 | ten = self.conv(ten)
87 | ten = ten.view(len(ten), -1)
88 | ten = self.fc(ten)
89 | mu = self.l_mu(ten)
90 | logvar = self.l_var(ten)
91 |
92 | return mu, logvar
93 |
94 | def __call__(self, *args, **kwargs):
95 | return super(Encoder, self).__call__(*args, **kwargs)
96 |
97 |
98 | class Decoder(nn.Module):
99 |
100 | """ VAE-based decoder"""
101 |
102 | def __init__(self, z_size, size):
103 | super(Decoder, self).__init__()
104 |
105 | self.fc = nn.Sequential(nn.Linear(in_features=z_size, out_features=config.fc_input * config.fc_input * size, bias=False),
106 | nn.BatchNorm1d(num_features=config.fc_input * config.fc_input * size, momentum=0.9),
107 | nn.ReLU(True))
108 | self.size = size
109 | layers_list = []
110 | layers_list.append(DecoderBlock(channel_in=self.size, channel_out=self.size, out=config.output_pad_dec[0]))
111 | layers_list.append(DecoderBlock(channel_in=self.size, channel_out=config.decoder_channels[1], out=config.output_pad_dec[1]))
112 | self.size = config.decoder_channels[1]
113 | layers_list.append(DecoderBlock(channel_in=self.size, channel_out=config.decoder_channels[2], out=config.output_pad_dec[2]))
114 | self.size = config.decoder_channels[2]
115 | # final conv to get 3 channels and tanh layer
116 | layers_list.append(nn.Sequential(
117 | nn.Conv2d(in_channels=self.size, out_channels=config.decoder_channels[3], kernel_size=5, stride=1, padding=2),
118 | nn.Tanh()
119 | ))
120 |
121 | self.conv = nn.Sequential(*layers_list)
122 |
123 | def forward(self, ten):
124 | """
125 | :param ten: re-parametrized latent variable
126 | :return: reconstructed image
127 | """
128 | ten = self.fc(ten)
129 | ten = ten.view(len(ten), -1, config.fc_input, config.fc_input)
130 | ten = self.conv(ten)
131 |
132 | return ten
133 |
134 | def __call__(self, *args, **kwargs):
135 | return super(Decoder, self).__call__(*args, **kwargs)
136 |
137 |
138 | class VAE(nn.Module):
139 |
140 | """VAE model: encoder + decoder + re-parametrization layer"""
141 |
142 | def __init__(self, device, z_size=128):
143 | super(VAE, self).__init__()
144 |
145 | self.z_size = z_size # latent space size
146 | self.encoder = Encoder(z_size=self.z_size).to(device)
147 | self.decoder = Decoder(z_size=self.z_size, size=self.encoder.size).to(device)
148 | self.init_parameters()
149 | self.device = device
150 |
151 | def init_parameters(self):
152 |
153 | """Glorot initialization"""
154 |
155 | for m in self.modules():
156 | if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.Linear)):
157 | if hasattr(m, "weight") and m.weight is not None and m.weight.requires_grad:
158 | nn.init.xavier_normal_(m.weight, 1)
159 | if hasattr(m, "bias") and m.bias is not None and m.bias.requires_grad:
160 | nn.init.constant(m.bias, 0.0)
161 |
162 | def reparametrize(self, mu, logvar):
163 |
164 | """ Re-parametrization trick"""
165 |
166 | logvar = logvar.mul(0.5).exp_()
167 | eps = Variable(logvar.data.new(logvar.size()).normal_())
168 |
169 | return eps.mul(logvar).add_(mu)
170 |
171 | def forward(self, x, gen_size=10):
172 |
173 | if x is not None:
174 | x = Variable(x).to(self.device)
175 |
176 | if self.training:
177 | mus, log_variances = self.encoder(x)
178 | z = self.reparametrize(mus, log_variances)
179 | x_tilde = self.decoder(z)
180 |
181 | # generate from random latent variable
182 | z_p = Variable(torch.randn(len(x), self.z_size).to(self.device), requires_grad=True)
183 | x_p = self.decoder(z_p)
184 | return x_tilde, x_p, mus, log_variances, z_p
185 |
186 | else:
187 | if x is None:
188 | z_p = Variable(torch.randn(gen_size, self.z_size).to(self.device), requires_grad=False)
189 | x_p = self.decoder(z_p)
190 | return x_p
191 |
192 | else:
193 | mus, log_variances = self.encoder(x)
194 | z = self.reparametrize(mus, log_variances)
195 | x_tilde = self.decoder(z)
196 | return x_tilde
197 |
198 | def __call__(self, *args, **kwargs):
199 | return super(VAE, self).__call__(*args, **kwargs)
200 |
201 | @staticmethod
202 | def loss(x, x_tilde, mus, variances):
203 |
204 | """
205 | VAE loss: reconstruction error + KL divergence
206 |
207 | :param x: ground truth image
208 | :param x_tilde: reconstruction from the decoder
209 | :param mus: mean value from the encoder
210 | :param variances: log var from the encoder
211 | :return: mse: reconstruction error
212 | :return: kld: kl divergence
213 | """
214 |
215 | # reconstruction error
216 | mse = 0.5 * (x.view(len(x), -1) - x_tilde.view(len(x_tilde), -1)) ** 2
217 |
218 | # kl divergence
219 | kld = -0.5 * torch.sum(-variances.exp() - torch.pow(mus, 2) + variances + 1, 1)
220 |
221 | return mse, kld
222 |
223 |
--------------------------------------------------------------------------------
/train_utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import math
3 | import torch
4 | import torchvision
5 | import torch.nn.functional as F
6 |
7 | from torch import nn, no_grad
8 | from torch.autograd import Variable
9 |
10 |
11 | def norm_image_prediction(pred, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
12 | """
13 | Normalizes predicted images
14 |
15 | :param pred: tensor [batch_size x channels x width x height]
16 | Predicted image
17 | :param mean: mean values for 3 channels
18 | :param std: std values for 3 channels
19 | :return: normalized predicted image
20 | """
21 | norm_img = pred.detach().clone() # deep copy of tensor
22 | for i in range(3):
23 | norm_img[:, i, :, :] = (norm_img[:, i, :, :] - mean[i]) / std[i]
24 |
25 | return norm_img
26 |
27 |
28 | def denormalize_image(pred, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
29 | """
30 | Denormalizes predicted images
31 |
32 | :param pred: tensor [batch_size x channels x width x height]
33 | Predicted image
34 | :param mean: mean values for 3 channels
35 | :param std: std values for 3 channels
36 | :return: predicted images w/o normalization
37 | """
38 |
39 | denorm_img = pred.detach().clone() # deep copy of tensor
40 | for i in range(3):
41 | denorm_img[:, i, :, :] = denorm_img[:, i, :, :] * std[i] + mean[i]
42 |
43 | return denorm_img
44 |
45 |
46 | class PearsonCorrelation(nn.Module):
47 |
48 | """
49 | Calculates Pearson Correlation Coefficient
50 | """
51 |
52 | def __init__(self):
53 | super(PearsonCorrelation, self).__init__()
54 |
55 | def forward(self, y_pred, y_true):
56 | """
57 | :param y_pred: tensor [batch_size x channels x width x height]
58 | Predicted image
59 | :param y_true: tensor [batch_size x channels x width x height]
60 | Ground truth image
61 | :return: float
62 | Pearson Correlation Coefficient
63 | """
64 |
65 | vx = y_pred - torch.mean(y_pred)
66 | vy = y_true - torch.mean(y_true)
67 |
68 | cost = torch.sum(vx * vy) / (torch.sqrt(torch.sum(vx ** 2)) * torch.sqrt(torch.sum(vy ** 2)))
69 | loss = cost.mean()
70 |
71 | return loss
72 |
73 |
74 | class StructuralSimilarity(nn.Module):
75 |
76 | """
77 | Structural Similarity Index Measure (mean of local SSIM)
78 | see Z. Wang "Image quality assessment: from error visibility to structural similarity"
79 |
80 | Calculates the SSIM between 2 images, the value is between -1 and 1:
81 | 1: images are very similar;
82 | -1: images are very different
83 |
84 | Adapted from https://github.com/pranjaldatta/SSIM-PyTorch/blob/master/SSIM_notebook.ipynb
85 | """
86 |
87 | def __init__(self, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
88 | super(StructuralSimilarity, self).__init__()
89 | self.mean = mean
90 | self.std = std
91 |
92 | def gaussian(self, window_size, sigma):
93 |
94 | """
95 | Generates a list of Tensor values drawn from a gaussian distribution with standard
96 | diviation = sigma and sum of all elements = 1.
97 |
98 | :param window_size: 11 from the paper
99 | :param sigma: standard deviation of Gaussian distribution
100 | :return: list of values, length = window_size
101 | """
102 |
103 | gauss = torch.Tensor(
104 | [math.exp(-(x - window_size // 2) ** 2 / float(2 * sigma ** 2)) for x in range(window_size)])
105 | return gauss / gauss.sum()
106 |
107 | def create_window(self, window_size, channel=1):
108 |
109 | """
110 | :param window_size: 11 from the paper
111 | :param channel: 3 for RGB images
112 | :return: 4D window with size [channels, 1, window_size, window_size]
113 |
114 | """
115 | # Generates an 1D tensor containing values sampled from a gaussian distribution.
116 | _1d_window = self.gaussian(window_size=window_size, sigma=1.5).unsqueeze(1)
117 | # Converts it to 2D
118 | _2d_window = _1d_window.mm(_1d_window.t()).float().unsqueeze(0).unsqueeze(0)
119 | # Adds extra dimensions to convert to 4D
120 | window = torch.Tensor(_2d_window.expand(channel, 1, window_size, window_size).contiguous())
121 |
122 | return window
123 |
124 | def forward(self, img1, img2, val_range=255, window_size=11, window=None, size_average=True, full=False):
125 |
126 | """
127 | Calculating Structural Similarity Index Measure
128 |
129 | :param img1: torch.tensor
130 | :param img2: torch.tensor
131 | :param val_range: 255 for RGB images
132 | :param window_size: 11 from the paper
133 | :param window: created with create_window function
134 | :param size_average: if True calculates the mean
135 | :param full: if true, return result and contrast_metric
136 | :return: value of SSIM
137 | """
138 | try:
139 | # data validation
140 | if torch.min(img1) < 0.0 or torch.max(img1) > 1.0: # if normalized with mean and std
141 | img1 = denormalize_image(img1, mean=self.mean, std=self.std).detach().clone()
142 | if torch.min(img1) < 0.0 or torch.max(img1) > 1.0:
143 | raise ValueError
144 |
145 | if torch.min(img2) < 0.0 or torch.max(img2) > 1.0: # if normalized with mean and std
146 | img2 = denormalize_image(img2, mean=self.mean, std=self.std).detach().clone()
147 | if torch.min(img2) < 0.0 or torch.max(img2) > 1.0:
148 | raise ValueError
149 |
150 | except ValueError as error:
151 | print('Image values in SSIM must be between 0 and 1 or normalized with mean and std', error)
152 |
153 | L = val_range # L is the dynamic range of the pixel values (255 for 8-bit grayscale images),
154 |
155 | pad = window_size // 2
156 |
157 | try:
158 | _, channels, height, width = img1.size()
159 | except:
160 | channels, height, width = img1.size()
161 |
162 | # if window is not provided, init one
163 | if window is None:
164 | real_size = min(window_size, height, width) # window should be atleast 11x11
165 | window = self.create_window(real_size, channel=channels).to(img1.device)
166 |
167 | # calculating the mu parameter (locally) for both images using a gaussian filter
168 | # calculates the luminosity params
169 | mu1 = F.conv2d(img1, window, padding=pad, groups=channels)
170 | mu2 = F.conv2d(img2, window, padding=pad, groups=channels)
171 |
172 | mu1_sq = mu1 ** 2
173 | mu2_sq = mu2 ** 2
174 | mu12 = mu1 * mu2
175 |
176 | # now we calculate the sigma square parameter
177 | # Sigma deals with the contrast component
178 | sigma1_sq = F.conv2d(img1 * img1, window, padding=pad, groups=channels) - mu1_sq
179 | sigma2_sq = F.conv2d(img2 * img2, window, padding=pad, groups=channels) - mu2_sq
180 | sigma12 = F.conv2d(img1 * img2, window, padding=pad, groups=channels) - mu12
181 |
182 | # Some constants for stability
183 | C1 = (0.01) ** 2 # NOTE: Removed L from here (ref PT implementation)
184 | C2 = (0.03) ** 2
185 |
186 | contrast_metric = (2.0 * sigma12 + C2) / (sigma1_sq + sigma2_sq + C2)
187 | contrast_metric = torch.mean(contrast_metric)
188 |
189 | numerator1 = 2 * mu12 + C1
190 | numerator2 = 2 * sigma12 + C2
191 | denominator1 = mu1_sq + mu2_sq + C1
192 | denominator2 = sigma1_sq + sigma2_sq + C2
193 |
194 | ssim_score = (numerator1 * numerator2) / (denominator1 * denominator2)
195 |
196 | if size_average:
197 | result = ssim_score.mean()
198 | else:
199 | result = ssim_score.mean(1).mean(1).mean(1)
200 |
201 | if full:
202 | return result, contrast_metric
203 |
204 | return result
205 |
206 |
207 | def evaluate(model, dataloader, norm=True, mean=None, std=None, mode=None, path=None, save=False, resize=None):
208 | """
209 | Calculate metrics for the dataset specified with dataloader
210 |
211 | :param model: network for evaluation
212 | :param dataloader: DataLoader object
213 | :param norm: normalization
214 | :param mean: mean of the dataset
215 | :param std: standard deviation of the dataset
216 | :param mode: 'bold' or None
217 | :param path: path to save images
218 | :param save: True if save images, otherwise False
219 | :param resize: image size to save
220 | :return: mean PCC, mean SSIM, MSE, mean IS (inception score)
221 | """
222 |
223 | pearson_correlation = PearsonCorrelation()
224 | structural_similarity = StructuralSimilarity()
225 | mse_loss = nn.MSELoss()
226 | ssim = 0
227 | pcc = 0
228 | mse = 0
229 | is_mean = 0
230 | gt_path = path + '/ground_truth'
231 | out_path = path + '/out'
232 | if not os.path.exists(gt_path):
233 | os.makedirs(gt_path)
234 | if not os.path.exists(out_path):
235 | os.makedirs(out_path)
236 |
237 | for batch_idx, data_batch in enumerate(dataloader):
238 | model.eval()
239 |
240 | with no_grad():
241 | if mode == 'bold':
242 | data_target = Variable(data_batch['image'], requires_grad=False).cpu().detach()
243 | else:
244 | data_target = data_batch.cpu().detach()
245 | out = model(data_batch)
246 | out = out.data.cpu()
247 | if save:
248 | if resize is not None:
249 | out = F.interpolate(out, size=resize)
250 | data_target = F.interpolate(data_target, size=resize)
251 | for i, im in enumerate(out):
252 | torchvision.utils.save_image(im, fp=out_path + '/' + str(batch_idx * len(data_target) + i) + '.png', normalize=True)
253 | for i, im in enumerate(data_target):
254 | torchvision.utils.save_image(im, fp=gt_path + '/' + str(batch_idx * len(data_target) + i) + '.png', normalize=True)
255 | if norm and mean is not None and std is not None:
256 | data_target = denormalize_image(data_target, mean=mean, std=std)
257 | out = denormalize_image(out, mean=mean, std=std)
258 | pcc += pearson_correlation(out, data_target)
259 | ssim += structural_similarity(out, data_target)
260 | mse += mse_loss(out, data_target)
261 | is_mean += inception_score(out, resize=True)
262 |
263 | mean_pcc = pcc / (batch_idx+1)
264 | mean_ssim = ssim / (batch_idx+1)
265 | mse_loss = mse / (batch_idx+1)
266 | is_mean = is_mean / (batch_idx+1)
267 |
268 | return mean_pcc, mean_ssim, mse_loss, is_mean
269 |
270 |
271 | def inception_score(imgs, cuda=True, batch_size=32, resize=False, splits=1):
272 |
273 | """Computes the inception score of the generated images imgs
274 | imgs -- Torch dataset of (3xHxW) numpy images normalized in the range [-1, 1]
275 | cuda -- whether or not to run on GPU
276 | batch_size -- batch size for feeding into Inception v3
277 | splits -- number of splits
278 | https://github.com/sbarratt/inception-score-pytorch/blob/master/inception_score.py
279 | """
280 | from torchvision.models.inception import inception_v3
281 | import numpy as np
282 | from scipy.stats import entropy
283 |
284 | N = len(imgs)
285 |
286 | assert batch_size > 0
287 |
288 | # Set up dtype
289 | if cuda:
290 | dtype = torch.cuda.FloatTensor
291 | else:
292 | if torch.cuda.is_available():
293 | print("WARNING: You have a CUDA device, so you should probably set cuda=True")
294 | dtype = torch.FloatTensor
295 |
296 | # Set up dataloader
297 | dataloader = torch.utils.data.DataLoader(imgs, batch_size=batch_size)
298 |
299 | # Load inception model
300 | inception_model = inception_v3(pretrained=True, transform_input=False).type(dtype)
301 | inception_model.eval();
302 | up = nn.Upsample(size=(299, 299), mode='bilinear').type(dtype)
303 |
304 | def get_pred(x):
305 | if resize:
306 | x = up(x)
307 | x = inception_model(x)
308 | return F.softmax(x).data.cpu().numpy()
309 |
310 | # Get predictions
311 | preds = np.zeros((N, 1000))
312 |
313 | for i, batch in enumerate(dataloader, 0):
314 | batch = batch.type(dtype)
315 | batchv = Variable(batch)
316 | batch_size_i = batch.size()[0]
317 |
318 | preds[i*batch_size:i*batch_size + batch_size_i] = get_pred(batchv)
319 |
320 | # Now compute the mean kl-div
321 | split_scores = []
322 |
323 | for k in range(splits):
324 | part = preds[k * (N // splits): (k+1) * (N // splits), :]
325 | py = np.mean(part, axis=0)
326 | scores = []
327 | for i in range(part.shape[0]):
328 | pyx = part[i, :]
329 | scores.append(entropy(pyx, py))
330 | split_scores.append(np.exp(np.mean(scores)))
331 |
332 | return np.mean(split_scores)
333 |
334 |
--------------------------------------------------------------------------------
/vae_train.py:
--------------------------------------------------------------------------------
1 | import os
2 | import time
3 | import numpy
4 | import json
5 | import torch
6 | import logging
7 | import argparse
8 | import pandas as pd
9 | import matplotlib.pyplot as plt
10 |
11 | from torch import nn
12 | from torchvision.utils import make_grid
13 | from torchvision import transforms
14 | from torch.autograd import Variable
15 | from torch.utils.data import DataLoader, ConcatDataset
16 | from torch.utils.tensorboard import SummaryWriter
17 | from torch.optim.lr_scheduler import ExponentialLR
18 |
19 | import configs.train_config as gan_cfg
20 | import configs.data_config as data_cfg
21 | from models.vae import VAE
22 | from train_utils import evaluate, PearsonCorrelation, StructuralSimilarity
23 | from data.data_loader import CocoDataloader, GreyToColor, Food101Dataloader
24 |
25 | numpy.random.seed(8)
26 | torch.manual_seed(8)
27 | torch.cuda.manual_seed(8)
28 |
29 | DEBUG = False # if True results will be saved in 'debug' folder
30 |
31 | if __name__ == "__main__":
32 |
33 | parser = argparse.ArgumentParser()
34 | parser.add_argument('--output', '-o', help='user path where to save', type=str)
35 | parser.add_argument('--logs', '-l', help='path where to save logs', type=str)
36 | parser.add_argument('--batch_size', '-b', default=gan_cfg.batch_size, help='batch size for dataloader', type=int)
37 | parser.add_argument('--learning_rate', '-lr', default=gan_cfg.learning_rate, help='learning rate', type=float)
38 | parser.add_argument('--epochs', '-e', default=gan_cfg.n_epochs, help='number of epochs', type=int)
39 | parser.add_argument('--image_crop', '-im_crop', default=gan_cfg.image_crop, help='size to which image should '
40 | 'be cropped', type=int)
41 | parser.add_argument('--image_size', '-im_size', default=gan_cfg.image_size, help='size to which image should '
42 | 'be scaled', type=int)
43 | parser.add_argument('--device', '-d', default=gan_cfg.device, help='what device to use', type=str)
44 | parser.add_argument('--num_workers', '-nw', default=gan_cfg.num_workers, help='number of workers for dataloader',
45 | type=int)
46 | parser.add_argument('--step_size', '-step', default=gan_cfg.step_size, help='number of epochs after which '
47 | 'to decrease learning rate', type=int)
48 | parser.add_argument('--patience', '-p', default=gan_cfg.patience, help='number of epochs with unchanged lr '
49 | 'for early stopping', type=int)
50 | parser.add_argument('--weight_decay', '--wd', default=gan_cfg.weight_decay, help='weight decay used by optimizer',
51 | type=float)
52 | parser.add_argument('--latent_dim', '-lat_dim', default=gan_cfg.latent_dim, help='dimension of the latent space',
53 | type=int)
54 | parser.add_argument('--message', '-m', default='default message', help='experiment description', type=str)
55 | parser.add_argument('--pretrained_gan', '-pretrain', default=gan_cfg.pretrained_gan, help='pretrained gan', type=str)
56 | parser.add_argument('-load_epoch', '-pretrain_epoch', default=gan_cfg.load_epoch, help='epoch of the pretrained model',
57 | type=int)
58 | parser.add_argument('--lambda_mse', default=gan_cfg.lambda_mse, type=float, help='weight for style error')
59 | parser.add_argument('--decay_mse', default=gan_cfg.decay_mse, type=float, help='mse weight decrease')
60 | parser.add_argument('--decay_lr', default=gan_cfg.decay_lr, type=float, help='learning rate decay for lr scheduler')
61 | parser.add_argument('--beta', default=gan_cfg.beta, type=float, help='beta factor for beta-vee')
62 | parser.add_argument('--mode', default='vae', help='vae, beta-vae')
63 | parser.add_argument('--dataset', default=data_cfg.dataset, help='coco, food-101')
64 |
65 | args = parser.parse_args()
66 |
67 | # Path to pickle file with bold5000 data
68 | USER_ROOT = args.output
69 | SAVE_PATH = os.path.join(USER_ROOT, data_cfg.save_training_results)
70 |
71 | # Create directory to save weights
72 | if not os.path.exists(SAVE_PATH):
73 | os.makedirs(SAVE_PATH)
74 |
75 | # Info logging
76 | timestep = time.strftime("%Y%m%d-%H%M%S")
77 | logging.basicConfig(level=logging.INFO)
78 | logger = logging.getLogger()
79 | file_handler = logging.FileHandler(os.path.join(args.logs, 'train_vae_' + timestep))
80 | logger = logging.getLogger()
81 | file_handler.setLevel(logging.INFO)
82 | logger.addHandler(file_handler)
83 |
84 | # Check available gpu
85 | device = torch.device(args.device if torch.cuda.is_available() else 'cpu')
86 | logger.info("Used device: %s" % device)
87 |
88 | logging.info('set up random seeds')
89 | torch.manual_seed(12345)
90 |
91 | # Create directory for results
92 | if DEBUG:
93 | saving_dir = os.path.join(SAVE_PATH, 'debug', 'debug_vae_{}'.format(timestep))
94 | else:
95 | saving_dir = os.path.join(SAVE_PATH, 'vae', 'vae_{}'.format(timestep))
96 | if not os.path.exists(saving_dir):
97 | os.makedirs(saving_dir)
98 | if args.pretrained_gan is not None:
99 | pretrained_model_dir = os.path.join(SAVE_PATH, 'vae', args.pretrained_gan, args.pretrained_gan + '.pth')
100 | saving_name = os.path.join(saving_dir, 'vae_{}.pth'.format(timestep))
101 |
102 | # Save arguments
103 | with open(os.path.join(saving_dir, 'config.txt'), 'w') as f:
104 | json.dump(args.__dict__, f, indent=2)
105 |
106 | if args.dataset == 'food-101':
107 |
108 | FOOD_IMAGES = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.images_data)
109 | FOOD_TRAIN_META = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.meta_data, 'train.txt')
110 | FOOD_TEST_META = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.meta_data, 'test.txt')
111 |
112 | with open(FOOD_TRAIN_META) as f:
113 | train_image_names = f.readlines()
114 | with open(FOOD_TEST_META) as f:
115 | test_image_names = f.readlines()
116 |
117 | # Load data
118 | training_data = Food101Dataloader(FOOD_IMAGES, train_image_names,
119 | transform=transforms.Compose([transforms.CenterCrop((args.image_crop,
120 | args.image_crop)),
121 | transforms.Resize((args.image_size,
122 | args.image_size)),
123 | transforms.RandomHorizontalFlip(),
124 | transforms.ToTensor(),
125 | GreyToColor(args.image_size),
126 | transforms.Normalize(gan_cfg.mean,
127 | gan_cfg.std)
128 | ]))
129 |
130 | validation_data = Food101Dataloader(FOOD_IMAGES, test_image_names,
131 | transform=transforms.Compose([transforms.CenterCrop((args.image_crop,
132 | args.image_crop)),
133 | transforms.Resize((args.image_size,
134 | args.image_size)),
135 | transforms.RandomHorizontalFlip(),
136 | transforms.ToTensor(),
137 | GreyToColor(args.image_size),
138 | transforms.Normalize(gan_cfg.mean,
139 | gan_cfg.std)
140 | ]))
141 |
142 | dataloader_train = DataLoader(training_data, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers)
143 | dataloader_valid = DataLoader(validation_data, batch_size=args.batch_size, shuffle=False, num_workers=args.num_workers)
144 |
145 | elif args.dataset == 'coco':
146 |
147 | COCO_TEST_DATA = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.coco_test_data)
148 | COCO_TRAIN_DATA = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.coco_train_data)
149 | COCO_VALID_DATA = os.path.join(USER_ROOT, data_cfg.data_root, data_cfg.dataset, data_cfg.coco_valid_data)
150 |
151 | # Load data
152 | training_data = CocoDataloader(COCO_TRAIN_DATA,
153 | transform=transforms.Compose([transforms.CenterCrop((args.image_crop,
154 | args.image_crop)),
155 | transforms.Resize((args.image_size,
156 | args.image_size)),
157 | transforms.RandomHorizontalFlip(),
158 | transforms.ToTensor(),
159 | GreyToColor(args.image_size),
160 | transforms.Normalize(gan_cfg.mean,
161 | gan_cfg.std)
162 | ]))
163 | validation_data = CocoDataloader(COCO_VALID_DATA,
164 | transform=transforms.Compose([transforms.CenterCrop((args.image_crop,
165 | args.image_crop)),
166 | transforms.Resize((args.image_size,
167 | args.image_size)),
168 | transforms.ToTensor(),
169 | GreyToColor(args.image_size),
170 | transforms.Normalize(gan_cfg.mean,
171 | gan_cfg.std)
172 | ]))
173 | test_data = CocoDataloader(COCO_TEST_DATA,
174 | transform=transforms.Compose([transforms.CenterCrop((args.image_crop,
175 | args.image_crop)),
176 | transforms.Resize((args.image_size,
177 | args.image_size)),
178 | transforms.RandomHorizontalFlip(),
179 | transforms.ToTensor(),
180 | GreyToColor(args.image_size),
181 | transforms.Normalize(gan_cfg.mean,
182 | gan_cfg.std)
183 | ]))
184 |
185 | train_test_data = ConcatDataset([training_data, test_data])
186 |
187 | dataloader_train = DataLoader(train_test_data, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers)
188 | dataloader_valid = DataLoader(validation_data, batch_size=args.batch_size, shuffle=False, num_workers=args.num_workers)
189 |
190 | else:
191 | logging.info('Specify dataset')
192 |
193 | writer = SummaryWriter(saving_dir + '/runs_' + timestep)
194 | writer_encoder = SummaryWriter(saving_dir + '/runs_' + timestep + '/encoder')
195 | writer_decoder = SummaryWriter(saving_dir + '/runs_' + timestep + '/decoder')
196 |
197 | model = VAE(device=device, z_size=args.latent_dim).to(device)
198 |
199 | if args.pretrained_gan is not None and os.path.exists(pretrained_model_dir.replace(".pth", ".csv")):
200 |
201 | # We can continue training
202 | logging.info('Load pretrained model')
203 | model_dir = pretrained_model_dir.replace(".pth", '_{}.pth'.format(args.load_epoch))
204 | model.load_state_dict(torch.load(model_dir))
205 | model.eval()
206 | results = pd.read_csv(pretrained_model_dir.replace(".pth", ".csv"))
207 | results = {col_name: list(results[col_name].values) for col_name in results.columns}
208 | stp = 1 + len(results['epochs'])
209 | if gan_cfg.evaluate:
210 | images_dir = os.path.join(saving_dir, 'images')
211 | if not os.path.exists(images_dir):
212 | os.makedirs(images_dir)
213 | pcc, ssim, mse, is_mean = evaluate(model, dataloader_valid, norm=True, mean=gan_cfg.mean, std=gan_cfg.std,
214 | path=images_dir)
215 | print("Mean PCC:", pcc)
216 | print("Mean SSIM:", ssim)
217 | print("Mean MSE:", mse)
218 | print("IS mean", is_mean)
219 | exit(0)
220 | else:
221 | logging.info('Initialize')
222 | stp = 1
223 |
224 | results = dict(
225 | epochs=[],
226 | loss_encoder=[],
227 | loss_decoder=[]
228 | )
229 |
230 | # An optimizer for each of the sub-networks, so we can selectively backpropogate
231 | optimizer_encoder = torch.optim.RMSprop(params=model.encoder.parameters(), lr=args.learning_rate, alpha=0.9,
232 | eps=1e-8, weight_decay=0, momentum=0, centered=False)
233 | lr_encoder = ExponentialLR(optimizer_encoder, gamma=args.decay_lr)
234 | optimizer_decoder = torch.optim.RMSprop(params=model.decoder.parameters(), lr=args.learning_rate, alpha=0.9,
235 | eps=1e-8, weight_decay=0, momentum=0, centered=False)
236 | lr_decoder = ExponentialLR(optimizer_decoder, gamma=args.decay_lr)
237 |
238 | # Metrics
239 | pearson_correlation = PearsonCorrelation()
240 | structural_similarity = StructuralSimilarity(mean=gan_cfg.mean, std=gan_cfg.std)
241 | mse_loss = nn.MSELoss()
242 |
243 | result_metrics_train = {}
244 | result_metrics_valid = {}
245 | metrics_train = {'train_PCC': pearson_correlation, 'train_SSIM': structural_similarity, 'train_MSE': mse_loss}
246 | metrics_valid = {'valid_PCC': pearson_correlation, 'valid_SSIM': structural_similarity, 'valid_MSE': mse_loss}
247 |
248 | if metrics_valid is not None:
249 | for key in metrics_valid.keys():
250 | results.update({key: []})
251 | for key, value in metrics_valid.items():
252 | result_metrics_valid.update({key: 0.0})
253 |
254 | if metrics_train is not None:
255 | for key in metrics_train.keys():
256 | results.update({key: []})
257 | for key, value in metrics_train.items():
258 | result_metrics_train.update({key: 0.0})
259 |
260 | batch_number = len(dataloader_train)
261 | step_index = 0
262 |
263 | for idx_epoch in range(args.epochs):
264 |
265 | for batch_idx, data_batch in enumerate(dataloader_train):
266 |
267 | model.train()
268 |
269 | if args.dataset == 'coco':
270 | batch_size = len(data_batch)
271 |
272 | x = Variable(data_batch, requires_grad=False).float().to(device)
273 |
274 | elif args.dataset == 'food-101':
275 | batch_size = len(data_batch['image'])
276 |
277 | x = Variable(data_batch['image'], requires_grad=False).float().to(device)
278 | labels = data_batch['label']
279 |
280 | # Take model predictions/reconstruction
281 | x_tilde, x_p, mus, log_variances, z_p = model(x)
282 |
283 | # Calculate reconstruction error and KL divergence
284 | recon_mse, kld = VAE.loss(x, x_tilde, mus, log_variances)
285 |
286 | # Train encoder and decoder
287 | train_enc = True
288 | train_dec = True
289 |
290 | # Beta-VAE/GAN loss
291 | if args.mode == 'beta-vae':
292 | beta = args.beta
293 | kld_weight = 1 / batch_size
294 | loss_encoder = torch.sum(kld) * beta * kld_weight + torch.sum(recon_mse)
295 | loss_decoder = torch.sum(args.lambda_mse * recon_mse)
296 |
297 | # VAE loss
298 | if args.mode == 'vae':
299 | loss_encoder = (1 / batch_size) * torch.sum(kld)
300 | # loss_encoder = torch.sum(kld) + torch.sum(recon_mse)
301 | loss_decoder = torch.sum(recon_mse)
302 |
303 | # Register mean values
304 | loss_encoder_mean = loss_encoder.data.cpu().numpy() / batch_size
305 | loss_decoder_mean = loss_decoder.data.cpu().numpy() / batch_size
306 |
307 | # Backpropagation
308 | # clean grads
309 | model.zero_grad()
310 |
311 | if train_enc:
312 | # encoder
313 | loss_encoder.backward(retain_graph=True)
314 | # we can clamp the grad here
315 | # [p.grad.data.clamp_(-1, 1) for p in model.encoder.parameters()]
316 | # update parameters
317 | optimizer_encoder.step()
318 | # clean others, so they are not afflicted by encoder loss
319 | model.zero_grad()
320 |
321 | # Decoder
322 | if train_dec:
323 | loss_decoder.backward(retain_graph=True)
324 | # [p.grad.data.clamp_(-1, 1) for p in model.decoder.parameters()]
325 | optimizer_decoder.step()
326 |
327 | logging.info(
328 | f'Epoch {idx_epoch} {batch_idx + 1:3.0f} / {100 * (batch_idx + 1) / len(dataloader_train):2.3f}%, '
329 | f'---- encoder loss: {loss_encoder_mean:.5f} ---- | '
330 | f'---- decoder loss: {loss_decoder_mean:.5f} ---- | ')
331 |
332 | writer_encoder.add_scalar('loss_encoder_batch', loss_encoder_mean, step_index)
333 | writer_decoder.add_scalar('loss_decoder_batch', loss_decoder_mean, step_index)
334 |
335 | step_index += 1
336 |
337 | # End of epoch
338 | lr_encoder.step()
339 | lr_decoder.step()
340 |
341 | writer_encoder.add_scalar('loss_encoder', loss_encoder_mean, idx_epoch)
342 | writer_decoder.add_scalar('loss_decoder', loss_decoder_mean, idx_epoch)
343 |
344 | if not idx_epoch % 2:
345 | # Save train examples
346 | images_dir = os.path.join(saving_dir, 'images', 'train')
347 | if not os.path.exists(images_dir):
348 | os.makedirs(images_dir)
349 |
350 | # Ground truth
351 | fig, ax = plt.subplots(figsize=(10, 10))
352 | ax.set_xticks([])
353 | ax.set_yticks([])
354 | ax.imshow(make_grid(x[: 25].cpu().detach(), nrow=5, normalize=True).permute(1, 2, 0))
355 | gt_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_ground_truth_' + 'grid')
356 | plt.savefig(gt_dir)
357 |
358 | # Reconstructed images
359 | fig, ax = plt.subplots(figsize=(10, 10))
360 | ax.set_xticks([])
361 | ax.set_yticks([])
362 | ax.imshow(make_grid(x_tilde[: 25].cpu().detach(), nrow=5, normalize=True).permute(1, 2, 0))
363 | output_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_output_' + 'grid')
364 | plt.savefig(output_dir)
365 |
366 | # Visualize latent space for training set
367 | plt.figure(figsize=(10, 6))
368 | plt.scatter(mus.cpu().detach()[..., 0], mus.cpu().detach()[..., 1], c=labels, cmap='rainbow')
369 | plt.colorbar()
370 | output_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_latent')
371 | plt.savefig(output_dir)
372 | plt.show()
373 |
374 | logging.info('Evaluation')
375 |
376 | for batch_idx, data_batch in enumerate(dataloader_valid):
377 |
378 | model.eval()
379 |
380 | if args.dataset == 'coco':
381 | batch_size = len(data_batch)
382 |
383 | data_in = Variable(data_batch, requires_grad=False).float().to(device)
384 | data_target = Variable(data_batch, requires_grad=False).float().to(device)
385 |
386 | elif args.dataset == 'food-101':
387 | batch_size = len(data_batch['image'])
388 |
389 | data_in = Variable(data_batch['image'], requires_grad=False).float().to(device)
390 | data_target = Variable(data_batch['image'], requires_grad=False).float().to(device)
391 | labels = data_batch['label']
392 |
393 | out = model(data_in)
394 |
395 | # Validation metrics for the first validation batch
396 | if metrics_valid is not None:
397 | for key, metric in metrics_valid.items():
398 | if key == 'cosine_similarity':
399 | result_metrics_valid[key] = metric(out, data_target).mean()
400 | else:
401 | result_metrics_valid[key] = metric(out, data_target)
402 |
403 | # Training metrics for the last training batch
404 | if metrics_train is not None:
405 | for key, metric in metrics_train.items():
406 | if key == 'cosine_similarity':
407 | result_metrics_train[key] = metric(x_tilde, x).mean()
408 | else:
409 | result_metrics_train[key] = metric(x_tilde, x)
410 |
411 | # Save validation examples
412 | images_dir = os.path.join(saving_dir, 'images', 'valid')
413 | if not os.path.exists(images_dir):
414 | os.makedirs(images_dir)
415 | os.makedirs(os.path.join(images_dir, 'random'))
416 |
417 | out = out.data.cpu()
418 |
419 | # Visualize latent space for validation set
420 | mus, var = model.encoder(data_in)
421 | plt.figure(figsize=(10, 6))
422 | plt.scatter(mus.cpu().detach()[..., 0], mus.cpu().detach()[..., 1], c=labels, cmap='rainbow')
423 | plt.colorbar()
424 | output_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_latent')
425 | plt.savefig(output_dir)
426 | plt.show()
427 |
428 | if idx_epoch == 0:
429 | fig, ax = plt.subplots(figsize=(10, 10))
430 | ax.set_xticks([])
431 | ax.set_yticks([])
432 | ax.imshow(make_grid(data_in[: 25].cpu().detach(), nrow=5, normalize=True).permute(1, 2, 0))
433 | gt_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_ground_truth_' + 'grid')
434 | plt.savefig(gt_dir)
435 |
436 | fig, ax = plt.subplots(figsize=(10, 10))
437 | ax.set_xticks([])
438 | ax.set_yticks([])
439 | ax.imshow(make_grid(out[: 25].cpu().detach(), nrow=5, normalize=True).permute(1, 2, 0))
440 | output_dir = os.path.join(images_dir, 'epoch_' + str(idx_epoch) + '_output_' + 'grid')
441 | plt.savefig(output_dir)
442 |
443 | out = (out + 1) / 2
444 | out = make_grid(out, nrow=8)
445 | writer.add_image("reconstructed", out, step_index)
446 |
447 | out = model(None, 25)
448 | out = out.data.cpu()
449 | out = (out + 1) / 2
450 | out = make_grid(out, nrow=5)
451 | writer.add_image("generated", out, step_index)
452 |
453 | fig, ax = plt.subplots(figsize=(10, 10))
454 | ax.set_xticks([])
455 | ax.set_yticks([])
456 | ax.imshow(make_grid(out[: 25].cpu().detach(), nrow=5, normalize=True).permute(1, 2, 0))
457 | output_dir = os.path.join(images_dir, 'random', 'epoch_' + str(idx_epoch) + '_output_' + 'rand')
458 | plt.savefig(output_dir)
459 |
460 | out = data_target.data.cpu()
461 | out = (out + 1) / 2
462 | out = make_grid(out, nrow=8)
463 | writer.add_image("original", out, step_index)
464 |
465 | if metrics_valid is not None:
466 | for key, values in result_metrics_valid.items():
467 | result_metrics_valid[key] = torch.mean(values)
468 | # Logging metrics
469 | if writer is not None:
470 | for key, values in result_metrics_valid.items():
471 | writer.add_scalar(key, values, stp + idx_epoch)
472 |
473 | if metrics_train is not None:
474 | for key, values in result_metrics_train.items():
475 | result_metrics_train[key] = torch.mean(values)
476 | # Logging metrics
477 | if writer is not None:
478 | for key, values in result_metrics_train.items():
479 | writer.add_scalar(key, values, stp + idx_epoch)
480 |
481 | logging.info(
482 | f'Epoch {idx_epoch} ---- train PCC: {result_metrics_train["train_PCC"].item():.5f} ---- | '
483 | f'---- train SSIM: {result_metrics_train["train_SSIM"].item():.5f} ---- '
484 | f'---- train MSE: {result_metrics_train["train_MSE"].item():.5f} ---- ')
485 |
486 | logging.info(
487 | f'Epoch {idx_epoch} ---- valid PCC: {result_metrics_valid["valid_PCC"].item():.5f} ---- | '
488 | f'---- valid SSIM: {result_metrics_valid["valid_SSIM"].item():.5f} ---- '
489 | f'---- valid MSE: {result_metrics_valid["valid_MSE"].item():.5f} ---- ')
490 |
491 | # only for one batch
492 | break
493 |
494 | if not idx_epoch % 10:
495 | torch.save(model.state_dict(), saving_name.replace('.pth', '_' + str(idx_epoch) + '.pth'))
496 | logging.info('Saving model')
497 |
498 | # Record losses & scores
499 | results['epochs'].append(idx_epoch + stp)
500 | results['loss_encoder'].append(loss_encoder_mean)
501 | results['loss_decoder'].append(loss_decoder_mean)
502 |
503 | if metrics_valid is not None:
504 | for key, value in result_metrics_valid.items():
505 | metric_value = torch.tensor(value, dtype=torch.float64).item()
506 | results[key].append(metric_value)
507 |
508 | if metrics_train is not None:
509 | for key, value in result_metrics_train.items():
510 | metric_value = torch.tensor(value, dtype=torch.float64).item()
511 | results[key].append(metric_value)
512 |
513 | results_to_save = pd.DataFrame(results)
514 | results_to_save.to_csv(saving_name.replace(".pth", ".csv"), index=False)
515 |
516 |
517 | exit(0)
518 |
--------------------------------------------------------------------------------