├── requirements
├── prod.txt
├── dev.in
├── ci.in
├── dev.txt
└── ci.txt
├── tests
├── examples
│ ├── cm-2-classes.json
│ ├── perm.json
│ └── wili-labels.csv
├── test_utils.py
├── test_distribution.py
├── test_optimize.py
├── test_cli.py
├── test_clustering.py
├── test_get_cm.py
└── test_visualize.py
├── MANIFEST.in
├── docs
├── cm.png
├── cm-interface.png
├── cm-wili-2018.png
├── mnist_confusion_matrix.png
├── mnist_confusion_matrix_labels.png
├── requirements.txt
├── mnist
│ ├── labels.csv
│ └── cm.json
├── source
│ ├── io.rst
│ ├── get_cm.rst
│ ├── utils.rst
│ ├── distribution.rst
│ ├── visualize_cm.rst
│ ├── get_cm_simple.rst
│ ├── index.rst
│ ├── file_formats.rst
│ ├── mnist_example.rst
│ └── conf.py
├── Makefile
├── make.bat
├── visualizations.md
└── mnist_example.py
├── setup.py
├── clana
├── __main__.py
├── __init__.py
├── cm_metrics.py
├── config.yaml
├── distribution.py
├── get_cm.py
├── utils.py
├── templates
│ └── base.html
├── get_cm_simple.py
├── cli.py
├── io.py
├── clustering.py
├── optimize.py
└── visualize_cm.py
├── tox.ini
├── .travis.yml
├── conftest.py
├── .isort.cfg
├── .readthedocs.yml
├── Makefile
├── LICENSE
├── .github
└── workflows
│ └── python.yaml
├── requirements.txt
├── .pre-commit-config.yaml
├── .gitignore
├── setup.cfg
└── README.md
/requirements/prod.txt:
--------------------------------------------------------------------------------
1 | -r ../requirements.txt
2 |
--------------------------------------------------------------------------------
/tests/examples/cm-2-classes.json:
--------------------------------------------------------------------------------
1 | [[10, 6], [10, 42]]
2 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include README.md
2 | include clana/config.yaml
3 |
--------------------------------------------------------------------------------
/requirements/dev.in:
--------------------------------------------------------------------------------
1 | pip-tools
2 | pre-commit
3 | twine
4 | wheel
5 |
--------------------------------------------------------------------------------
/docs/cm.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MartinThoma/clana/HEAD/docs/cm.png
--------------------------------------------------------------------------------
/docs/cm-interface.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MartinThoma/clana/HEAD/docs/cm-interface.png
--------------------------------------------------------------------------------
/docs/cm-wili-2018.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MartinThoma/clana/HEAD/docs/cm-wili-2018.png
--------------------------------------------------------------------------------
/docs/mnist_confusion_matrix.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MartinThoma/clana/HEAD/docs/mnist_confusion_matrix.png
--------------------------------------------------------------------------------
/docs/mnist_confusion_matrix_labels.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MartinThoma/clana/HEAD/docs/mnist_confusion_matrix_labels.png
--------------------------------------------------------------------------------
/docs/requirements.txt:
--------------------------------------------------------------------------------
1 | numpydoc==0.9.1
2 |
3 | sphinx>=3.0.4 # not directly required, pinned by Snyk to avoid a vulnerability
4 |
--------------------------------------------------------------------------------
/docs/mnist/labels.csv:
--------------------------------------------------------------------------------
1 | Labels
2 | zero
3 | one
4 | two
5 | three
6 | four
7 | five
8 | six
9 | seven
10 | eight
11 | nine
12 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | """CLANA is a toolkit for classifier analysis."""
2 |
3 | # Third party
4 | from setuptools import setup
5 |
6 | setup()
7 |
--------------------------------------------------------------------------------
/docs/source/io.rst:
--------------------------------------------------------------------------------
1 | clana.io
2 | --------
3 |
4 | .. automodule:: clana.io
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
8 |
--------------------------------------------------------------------------------
/docs/source/get_cm.rst:
--------------------------------------------------------------------------------
1 | clana.get_cm
2 | ------------
3 |
4 | .. automodule:: clana.get_cm
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
8 |
--------------------------------------------------------------------------------
/docs/source/utils.rst:
--------------------------------------------------------------------------------
1 | clana.utils
2 | -----------
3 |
4 | .. automodule:: clana.utils
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
8 |
--------------------------------------------------------------------------------
/clana/__main__.py:
--------------------------------------------------------------------------------
1 | """Execute clana as a module."""
2 |
3 | # First party
4 | from clana.cli import entry_point
5 |
6 | if __name__ == "__main__":
7 | entry_point()
8 |
--------------------------------------------------------------------------------
/tests/test_utils.py:
--------------------------------------------------------------------------------
1 | # First party
2 | import clana.utils
3 |
4 |
5 | def test_load_labels() -> None:
6 | clana.utils.load_labels("~/.clana/data/labels.csv", 10)
7 |
--------------------------------------------------------------------------------
/docs/source/distribution.rst:
--------------------------------------------------------------------------------
1 | clana.distribution
2 | ------------------
3 |
4 | .. automodule:: clana.distribution
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
8 |
--------------------------------------------------------------------------------
/docs/source/visualize_cm.rst:
--------------------------------------------------------------------------------
1 | clana.visualize_cm
2 | ------------------
3 |
4 | .. automodule:: clana.visualize_cm
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
8 |
--------------------------------------------------------------------------------
/docs/source/get_cm_simple.rst:
--------------------------------------------------------------------------------
1 | clana.get_cm_simple
2 | -------------------
3 |
4 | .. automodule:: clana.get_cm_simple
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
8 |
--------------------------------------------------------------------------------
/tox.ini:
--------------------------------------------------------------------------------
1 | [tox]
2 | envlist = linter,py37,py38,py39
3 |
4 | [testenv]
5 | deps =
6 | -r requirements/ci.txt
7 | commands =
8 | pip install -e .
9 | pytest .
10 | flake8
11 | black --check .
12 | pydocstyle
13 | mypy .
14 |
--------------------------------------------------------------------------------
/clana/__init__.py:
--------------------------------------------------------------------------------
1 | """Get the version."""
2 |
3 | # Third party
4 | import pkg_resources
5 |
6 | try:
7 | __version__ = pkg_resources.get_distribution("clana").version
8 | except pkg_resources.DistributionNotFound:
9 | __version__ = "not installed"
10 |
--------------------------------------------------------------------------------
/.travis.yml:
--------------------------------------------------------------------------------
1 | language: python
2 | before_install:
3 | - sudo apt-get install -y libblas3 liblapack3 liblapack-dev libblas-dev
4 | python:
5 | - 3.7
6 | - 3.8
7 | - 3.9
8 | install:
9 | - pip install coveralls tox-travis
10 | script:
11 | - tox
12 | after_success:
13 | - coveralls
14 |
--------------------------------------------------------------------------------
/docs/mnist/cm.json:
--------------------------------------------------------------------------------
1 | [[5808,5,28,2,12,5,47,7,5,4],[5,6586,70,2,9,3,16,27,22,2],[35,32,5602,50,42,1,24,117,48,7],[17,14,128,5742,1,56,5,98,45,25],[12,21,25,0,5537,2,50,19,19,157],[62,13,15,93,9,4977,70,7,120,55],[29,14,13,0,9,80,5763,0,10,0],[25,24,58,6,22,2,7,6041,8,72],[64,127,150,129,45,173,47,39,4967,110],[49,9,4,52,64,49,3,326,23,5370]]
2 |
--------------------------------------------------------------------------------
/conftest.py:
--------------------------------------------------------------------------------
1 | """Configure pytest."""
2 |
3 | # Core Library
4 | import logging
5 | from typing import Any, Dict
6 |
7 |
8 | def pytest_configure(config: Dict[str, Any]) -> None:
9 | """Flake8 is to verbose. Mute it."""
10 | logging.getLogger("flake8").setLevel(logging.WARN)
11 | logging.getLogger("pydocstyle").setLevel(logging.INFO)
12 |
--------------------------------------------------------------------------------
/tests/test_distribution.py:
--------------------------------------------------------------------------------
1 | # Third party
2 | import pkg_resources
3 | from click.testing import CliRunner
4 |
5 | # First party
6 | import clana.cli
7 |
8 |
9 | def test_cli() -> None:
10 | runner = CliRunner()
11 |
12 | path = "examples/wili-y_train.txt"
13 | y_train_path = pkg_resources.resource_filename(__name__, path)
14 | _ = runner.invoke(clana.cli.distribution, ["--gt", y_train_path])
15 |
--------------------------------------------------------------------------------
/.isort.cfg:
--------------------------------------------------------------------------------
1 | [settings]
2 | line_length=79
3 | indent=' '
4 | multi_line_output=3
5 | length_sort=0
6 | import_heading_stdlib=Core Library
7 | import_heading_firstparty=First party
8 | import_heading_thirdparty=Third party
9 | import_heading_localfolder=Local
10 | known_third_party = click,jinja2,keras,matplotlib,mpl_toolkits,numpy,pkg_resources,setuptools,sklearn,yaml
11 | include_trailing_comma=True
12 | skip=docs
13 |
--------------------------------------------------------------------------------
/tests/test_optimize.py:
--------------------------------------------------------------------------------
1 | # Third party
2 | import numpy as np
3 |
4 | # First party
5 | import clana.optimize
6 |
7 |
8 | def test_move_1d() -> None:
9 | perm = np.array([8, 7, 6, 1, 2])
10 | from_start = 1
11 | from_end = 2
12 | insert_pos = 0
13 | new_perm = clana.optimize.move_1d(perm, from_start, from_end, insert_pos)
14 | new_perm = new_perm.tolist()
15 | assert new_perm == [7, 6, 8, 1, 2]
16 |
--------------------------------------------------------------------------------
/requirements/ci.in:
--------------------------------------------------------------------------------
1 | -r prod.txt
2 | black
3 | coverage
4 | flake8<4.0.0
5 | flake8_implicit_str_concat
6 | flake8-bugbear
7 | flake8-builtins
8 | flake8-comprehensions
9 | flake8-eradicate
10 | flake8-executable
11 | flake8-isort
12 | flake8-pytest-style
13 | flake8-raise
14 | flake8-simplify
15 | flake8-string-format
16 | lxml
17 | mypy
18 | pydocstyle
19 | pytest
20 | pytest-cov
21 | pytest-mccabe
22 | pytest-timeout
23 | types-pkg-resources
24 | types-PyYAML
25 | types-setuptools
26 |
--------------------------------------------------------------------------------
/.readthedocs.yml:
--------------------------------------------------------------------------------
1 | # .readthedocs.yml
2 | # Read the Docs configuration file
3 | # See https://docs.readthedocs.io/en/stable/config-file/v2.html for details
4 |
5 | # Required
6 | version: 2
7 |
8 | # Build documentation in the docs/ directory with Sphinx
9 | sphinx:
10 | configuration: docs/source/conf.py
11 |
12 | # Optionally build your docs in additional formats such as PDF and ePub
13 | formats: all
14 |
15 | # Optionally set the version of Python and requirements required to build your docs
16 | python:
17 | version: 3.6
18 | install:
19 | - requirements: docs/requirements.txt
20 |
--------------------------------------------------------------------------------
/tests/test_cli.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | """Test the CLI functions."""
4 |
5 | # Third party
6 | from click.testing import CliRunner
7 | from pkg_resources import resource_filename
8 |
9 | # First party
10 | import clana.cli
11 |
12 |
13 | def test_visualize() -> None:
14 | runner = CliRunner()
15 | cm_path = resource_filename(__name__, "examples/cm-2-classes.json")
16 | commands = ["visualize", "--cm", cm_path]
17 | result = runner.invoke(clana.cli.entry_point, commands)
18 | assert result.exit_code == 0
19 | assert "Accuracy: 76.47%" in result.output, "clana" + " ".join(commands)
20 |
--------------------------------------------------------------------------------
/tests/test_clustering.py:
--------------------------------------------------------------------------------
1 | # Third party
2 | import numpy as np
3 |
4 | # First party
5 | import clana.clustering
6 |
7 |
8 | def test_extract_clusters_local() -> None:
9 | n = 10
10 | cm = np.random.randint(low=0, high=100, size=(n, n))
11 | clana.clustering.extract_clusters(
12 | cm, labels=list(range(n)), steps=10, method="local-connectivity" # type: ignore
13 | )
14 |
15 |
16 | def test_extract_clusters_energy() -> None:
17 | n = 10
18 | cm = np.random.randint(low=0, high=100, size=(n, n))
19 | clana.clustering.extract_clusters(
20 | cm, labels=list(range(n)), steps=10, method="energy" # type: ignore
21 | )
22 |
--------------------------------------------------------------------------------
/docs/source/index.rst:
--------------------------------------------------------------------------------
1 | .. clana documentation master file, created by
2 | sphinx-quickstart on Tue Jul 2 22:30:39 2019.
3 | You can adapt this file completely to your liking, but it should at least
4 | contain the root `toctree` directive.
5 |
6 | Welcome to clana's documentation!
7 | =================================
8 |
9 | .. toctree::
10 | :maxdepth: 2
11 | :caption: Contents:
12 |
13 | mnist_example
14 | file_formats
15 | distribution
16 | io
17 | get_cm
18 | get_cm_simple
19 | utils
20 | visualize_cm
21 |
22 |
23 | Indices and tables
24 | ==================
25 |
26 | * :ref:`genindex`
27 | * :ref:`modindex`
28 | * :ref:`search`
29 |
--------------------------------------------------------------------------------
/docs/Makefile:
--------------------------------------------------------------------------------
1 | # Minimal makefile for Sphinx documentation
2 | #
3 |
4 | # You can set these variables from the command line.
5 | SPHINXOPTS =
6 | SPHINXBUILD = sphinx-build
7 | SPHINXPROJ = clana
8 | SOURCEDIR = source
9 | BUILDDIR = build
10 |
11 | # Put it first so that "make" without argument is like "make help".
12 | help:
13 | @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
14 |
15 | .PHONY: help Makefile
16 |
17 | # Catch-all target: route all unknown targets to Sphinx using the new
18 | # "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
19 | %: Makefile
20 | @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
21 |
--------------------------------------------------------------------------------
/clana/cm_metrics.py:
--------------------------------------------------------------------------------
1 | """Metrics for confusion matrices."""
2 |
3 | # Third party
4 | import numpy.typing as npt
5 |
6 |
7 | def get_accuracy(cm: npt.NDArray) -> float:
8 | """
9 | Get the accuaracy by the confusion matrix cm.
10 |
11 | Parameters
12 | ----------
13 | cm : ndarray
14 |
15 | Returns
16 | -------
17 | accuracy : float
18 |
19 | Examples
20 | --------
21 | >>> import numpy as np
22 | >>> cm = np.array([[10, 20], [30, 40]])
23 | >>> get_accuracy(cm)
24 | 0.5
25 | >>> cm = np.array([[20, 10], [30, 40]])
26 | >>> get_accuracy(cm)
27 | 0.6
28 | """
29 | return float(sum(cm[i][i] for i in range(len(cm)))) / float(cm.sum())
30 |
--------------------------------------------------------------------------------
/docs/make.bat:
--------------------------------------------------------------------------------
1 | @ECHO OFF
2 |
3 | pushd %~dp0
4 |
5 | REM Command file for Sphinx documentation
6 |
7 | if "%SPHINXBUILD%" == "" (
8 | set SPHINXBUILD=sphinx-build
9 | )
10 | set SOURCEDIR=source
11 | set BUILDDIR=build
12 | set SPHINXPROJ=clana
13 |
14 | if "%1" == "" goto help
15 |
16 | %SPHINXBUILD% >NUL 2>NUL
17 | if errorlevel 9009 (
18 | echo.
19 | echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
20 | echo.installed, then set the SPHINXBUILD environment variable to point
21 | echo.to the full path of the 'sphinx-build' executable. Alternatively you
22 | echo.may add the Sphinx directory to PATH.
23 | echo.
24 | echo.If you don't have Sphinx installed, grab it from
25 | echo.http://sphinx-doc.org/
26 | exit /b 1
27 | )
28 |
29 | %SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS%
30 | goto end
31 |
32 | :help
33 | %SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS%
34 |
35 | :end
36 | popd
37 |
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | maint:
2 | pip install -r requirements/dev.txt
3 | pre-commit autoupdate && pre-commit run --all-files
4 | pip-compile -U setup.py
5 | pip-compile -U requirements/ci.in
6 | pip-compile -U requirements/dev.in
7 |
8 | upload:
9 | make clean
10 | python setup.py sdist bdist_wheel && twine upload -s dist/*
11 |
12 | test_upload:
13 | make clean
14 | python setup.py sdist bdist_wheel && twine upload --repository pypitest -s dist/*
15 |
16 | clean:
17 | python setup.py clean --all
18 | pyclean .
19 | rm -rf clana.egg-info dist tests/reports tests/__pycache__ clana.errors.log clana.info.log clana/cm_analysis.html dist __pycache__ clana/__pycache__ build docs/build
20 |
21 | muation-test:
22 | mutmut run
23 |
24 | mutmut-results:
25 | mutmut junitxml --suspicious-policy=ignore --untested-policy=ignore > mutmut-results.xml
26 | junit2html mutmut-results.xml mutmut-results.html
27 |
28 | bandit:
29 | # Not a security application: B311 and B303 should be save
30 | # Python3 only: B322 is save
31 | bandit -r clana -s B311,B303,B322
32 |
--------------------------------------------------------------------------------
/tests/examples/perm.json:
--------------------------------------------------------------------------------
1 | [0, 161, 39, 3, 171, 5, 130, 7, 8, 35, 17, 18, 40, 159, 196, 197, 16, 19, 146, 15, 132, 113, 80, 74, 22, 24, 98, 206, 169, 155, 114, 172, 49, 175, 174, 176, 177, 140, 27, 180, 78, 145, 183, 26, 137, 138, 139, 178, 28, 210, 211, 212, 213, 62, 215, 188, 217, 41, 143, 10, 25, 37, 86, 214, 38, 101, 199, 201, 51, 43, 128, 168, 46, 162, 88, 126, 21, 136, 96, 208, 173, 129, 224, 194, 195, 89, 164, 54, 106, 218, 32, 33, 220, 121, 70, 71, 142, 68, 190, 166, 216, 202, 103, 63, 48, 95, 90, 85, 104, 109, 153, 229, 102, 97, 167, 99, 58, 61, 47, 64, 118, 158, 50, 105, 165, 231, 2, 59, 72, 73, 148, 82, 185, 6, 31, 198, 179, 141, 29, 30, 60, 193, 69, 81, 163, 83, 170, 12, 13, 203, 135, 14, 181, 204, 205, 53, 56, 100, 36, 75, 9, 117, 67, 192, 65, 66, 87, 182, 127, 44, 108, 93, 157, 225, 23, 11, 111, 184, 1, 20, 107, 186, 55, 115, 77, 207, 52, 189, 94, 134, 84, 147, 200, 79, 144, 149, 4, 223, 152, 156, 120, 150, 160, 57, 92, 76, 232, 187, 112, 116, 119, 209, 235, 191, 222, 45, 227, 228, 151, 91, 154, 221, 124, 125, 110, 131, 219, 133, 226, 230, 34, 42, 233, 234, 122, 123]
2 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2017 Martin Thoma
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/.github/workflows/python.yaml:
--------------------------------------------------------------------------------
1 | # This workflow will install Python dependencies, run tests and lint with a variety of Python versions
2 | # For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
3 |
4 | name: Python package
5 |
6 | on:
7 | push:
8 | branches: [ master ]
9 | pull_request:
10 | branches: [ master ]
11 |
12 | jobs:
13 | build:
14 |
15 | runs-on: ubuntu-latest
16 | strategy:
17 | matrix:
18 | python-version: [3.7, 3.8, 3.9]
19 |
20 | steps:
21 | - uses: actions/checkout@v2
22 | - name: Set up Python ${{ matrix.python-version }}
23 | uses: actions/setup-python@v2
24 | with:
25 | python-version: ${{ matrix.python-version }}
26 | - name: Install dependencies
27 | run: |
28 | python -m pip install --upgrade pip
29 | pip install -r requirements/ci.txt
30 | pip install .
31 | - name: Test with pytest
32 | run: pytest
33 | - name: Test with mypy
34 | run: mypy . --exclude=build
35 | - name: Test with flake8
36 | run: flake8
37 | - name: Test with black
38 | run: black --check .
39 |
--------------------------------------------------------------------------------
/tests/test_get_cm.py:
--------------------------------------------------------------------------------
1 | # Third party
2 | import numpy as np
3 | import numpy.testing
4 | import pkg_resources
5 | from click.testing import CliRunner
6 |
7 | # First party
8 | import clana.cli
9 |
10 |
11 | def test_calculate_cm() -> None:
12 | labels = ["en", "de"]
13 | truths = ["de", "de", "en", "de", "en"]
14 | predictions = ["de", "en", "en", "de", "en"]
15 | res = clana.get_cm_simple.calculate_cm(labels, truths, predictions)
16 | numpy.testing.assert_array_equal(res, np.array([[2, 0], [1, 2]])) # type: ignore[no-untyped-call]
17 |
18 |
19 | def test_main() -> None:
20 | path = "examples/wili-labels.csv"
21 | labels_path = pkg_resources.resource_filename(__name__, path)
22 | path = "examples/wili-y_test.txt"
23 | gt_filepath = pkg_resources.resource_filename(__name__, path)
24 | path = "examples/cld2_results.txt"
25 | predictions_filepath = pkg_resources.resource_filename(__name__, path)
26 |
27 | runner = CliRunner()
28 | _ = runner.invoke(
29 | clana.cli.get_cm_simple,
30 | [
31 | "--labels",
32 | labels_path,
33 | "--gt",
34 | gt_filepath,
35 | "--predictions",
36 | predictions_filepath,
37 | ],
38 | )
39 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | #
2 | # This file is autogenerated by pip-compile with python 3.7
3 | # To update, run:
4 | #
5 | # pip-compile setup.py
6 | #
7 | click==8.0.3
8 | # via clana (setup.py)
9 | cycler==0.11.0
10 | # via matplotlib
11 | fonttools==4.29.0
12 | # via matplotlib
13 | importlib-metadata==4.10.1
14 | # via click
15 | jinja2==3.0.3
16 | # via clana (setup.py)
17 | joblib==1.1.0
18 | # via scikit-learn
19 | kiwisolver==1.3.2
20 | # via matplotlib
21 | markupsafe==2.0.1
22 | # via jinja2
23 | matplotlib==3.5.1
24 | # via clana (setup.py)
25 | numpy==1.22.0
26 | # via
27 | # clana (setup.py)
28 | # matplotlib
29 | # scikit-learn
30 | # scipy
31 | packaging==21.3
32 | # via matplotlib
33 | pillow==9.0.1
34 | # via matplotlib
35 | pyparsing==3.0.7
36 | # via
37 | # matplotlib
38 | # packaging
39 | python-dateutil==2.8.2
40 | # via matplotlib
41 | pyyaml==6.0
42 | # via clana (setup.py)
43 | scikit-learn==1.0.2
44 | # via clana (setup.py)
45 | scipy==1.7.3
46 | # via
47 | # clana (setup.py)
48 | # scikit-learn
49 | six==1.16.0
50 | # via python-dateutil
51 | threadpoolctl==3.0.0
52 | # via scikit-learn
53 | typing-extensions==4.0.1
54 | # via importlib-metadata
55 | zipp==3.7.0
56 | # via importlib-metadata
57 |
--------------------------------------------------------------------------------
/docs/visualizations.md:
--------------------------------------------------------------------------------
1 | # Confusion Matrices
2 |
3 | This module expects the Ground Truth labels to have exactly one value `1` and
4 | only zeros for each data element.
5 |
6 | See [File Formats](file-formats.md).
7 |
8 | ## Static Confusion Matrix
9 |
10 | ```
11 | $ clan --labels labels.csv --gt gt.csv --preds preds.csv
12 | ```
13 |
14 | Produces a static confusion matrix:
15 |
16 | 
17 |
18 | The labels are by default the short version, but a switch `--long` changes them
19 | to the long version.
20 |
21 | Optionally, the command accepts a `permutations.json` which defines another
22 | order of the elements.
23 |
24 |
25 | ## Interactive Confusion Matrix
26 |
27 | ```
28 | $ clan cm --labels labels.csv --gt gt.csv --preds preds.csv --interactive --viz data_viz.py
29 | ```
30 |
31 | Starts a webserver with an interactive version of the confusion matrix. The
32 | user can click on each of the confusions and get a list of of the identifiers.
33 | Each identifier has a link on which the user can click again. This will call
34 | the `visualize(identifier)` function within `data_viz.py`.
35 | `visualize(identifier)` has to return an HTML page. That page could simply
36 | contain a string (e.g. for NLP), an image (e.g. Computer Vision) or audio files
37 | (e.g. ASR).
38 |
39 | The interface could look like this:
40 |
41 | 
42 |
--------------------------------------------------------------------------------
/.pre-commit-config.yaml:
--------------------------------------------------------------------------------
1 | # pre-commit run --all-files
2 | repos:
3 | - repo: https://github.com/pre-commit/pre-commit-hooks
4 | rev: v4.1.0
5 | hooks:
6 | - id: check-ast
7 | - id: check-byte-order-marker
8 | - id: check-case-conflict
9 | - id: check-docstring-first
10 | - id: check-executables-have-shebangs
11 | - id: check-json
12 | - id: check-yaml
13 | - id: debug-statements
14 | - id: detect-private-key
15 | - id: end-of-file-fixer
16 | - id: trailing-whitespace
17 | - id: mixed-line-ending
18 |
19 | - repo: https://github.com/pre-commit/mirrors-mypy
20 | rev: v0.931
21 | hooks:
22 | - id: mypy
23 | args: [--ignore-missing-imports, --no-warn-unused-ignores, --install-types]
24 | additional_dependencies: [types-PyYAML, types-setuptools]
25 | - repo: https://github.com/asottile/seed-isort-config
26 | rev: v2.2.0
27 | hooks:
28 | - id: seed-isort-config
29 | - repo: https://github.com/pre-commit/mirrors-isort
30 | rev: v5.10.1
31 | hooks:
32 | - id: isort
33 | - repo: https://github.com/psf/black
34 | rev: 22.1.0
35 | hooks:
36 | - id: black
37 | - repo: https://github.com/asottile/pyupgrade
38 | rev: v2.31.0
39 | hooks:
40 | - id: pyupgrade
41 | args: [--py36-plus]
42 | - repo: https://github.com/asottile/blacken-docs
43 | rev: v1.12.0
44 | hooks:
45 | - id: blacken-docs
46 | additional_dependencies: [black==19.10b0]
47 |
--------------------------------------------------------------------------------
/tests/test_visualize.py:
--------------------------------------------------------------------------------
1 | # Third party
2 | import numpy as np
3 | import pkg_resources
4 | from click.testing import CliRunner
5 |
6 | # First party
7 | import clana.cli
8 |
9 |
10 | def test_get_cm_problems1() -> None:
11 | cm = np.array([[0, 100], [0, 10]])
12 | labels = ["0", "1"]
13 | clana.visualize_cm.get_cm_problems(cm, labels)
14 |
15 |
16 | def test_get_cm_problems2() -> None:
17 | cm = np.array([[12, 100], [0, 0]])
18 | labels = ["0", "1"]
19 | clana.visualize_cm.get_cm_problems(cm, labels)
20 |
21 |
22 | def test_simulated_annealing() -> None:
23 | n = 10
24 | cm = np.random.randint(low=0, high=100, size=(n, n))
25 | clana.visualize_cm.simulated_annealing(cm, steps=10)
26 | clana.visualize_cm.simulated_annealing(cm, steps=10, deterministic=True)
27 |
28 |
29 | def test_create_html_cm() -> None:
30 | n = 10
31 | cm = np.random.randint(low=0, high=100, size=(n, n))
32 | clana.visualize_cm.create_html_cm(cm, zero_diagonal=True)
33 |
34 |
35 | def test_plot_cm() -> None:
36 | n = 25
37 | cm = np.random.randint(low=0, high=100, size=(n, n))
38 | clana.visualize_cm.plot_cm(cm, zero_diagonal=True, labels=None)
39 |
40 |
41 | def test_plot_cm_big() -> None:
42 | n = 5
43 | cm = np.random.randint(low=0, high=100, size=(n, n))
44 | clana.visualize_cm.plot_cm(cm, zero_diagonal=True, labels=None)
45 |
46 |
47 | def test_main() -> None:
48 | path = "examples/wili-cld2-cm.json"
49 | cm_path = pkg_resources.resource_filename(__name__, path)
50 |
51 | path = "examples/perm.json"
52 | perm_path = pkg_resources.resource_filename(__name__, path)
53 |
54 | runner = CliRunner()
55 | _ = runner.invoke(
56 | clana.cli.visualize, ["--cm", cm_path, "--steps", "100", "--perm", perm_path]
57 | )
58 |
--------------------------------------------------------------------------------
/clana/config.yaml:
--------------------------------------------------------------------------------
1 | visualize:
2 | threshold: 0.1
3 | save_path: 'clana_cm.pdf' # make sure this is consistent with the format
4 | html_save_path: 'cm_analysis.html'
5 | hierarchy_path: 'hierarchy.tmp.json'
6 | xlabels_rotation: -45
7 | ylabels_rotation: 0
8 | norm: LogNorm # null or LogNorm
9 | # See https://matplotlib.org/2.0.2/examples/color/colormaps_reference.html
10 | # a sequential colormap is highly recommended
11 | # best are: viridis, plasma, inferno, magma
12 | colormap: viridis
13 | # See https://matplotlib.org/3.1.1/api/_as_gen/matplotlib.pyplot.imshow.html
14 | interpolation: "nearest"
15 | LOGGING:
16 | version: 1
17 | disable_existing_loggers: False
18 | formatters:
19 | simple:
20 | format: "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
21 |
22 | handlers:
23 | console:
24 | class: logging.StreamHandler
25 | level: DEBUG
26 | formatter: simple
27 | stream: ext://sys.stdout
28 |
29 | info_file_handler:
30 | class: logging.handlers.RotatingFileHandler
31 | level: INFO
32 | formatter: simple
33 | filename: clana.info.log
34 | maxBytes: 10485760 # 10MB
35 | backupCount: 20
36 | encoding: utf8
37 |
38 | error_file_handler:
39 | class: logging.handlers.RotatingFileHandler
40 | level: ERROR
41 | formatter: simple
42 | filename: clana.errors.log
43 | maxBytes: 10485760 # 10MB
44 | backupCount: 20
45 | encoding: utf8
46 |
47 | loggers:
48 | my_module:
49 | level: ERROR
50 | handlers: [console]
51 | propagate: no
52 |
53 | root:
54 | level: DEBUG
55 | handlers: [console, info_file_handler, error_file_handler]
56 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | env/
12 | build/
13 | develop-eggs/
14 | dist/
15 | downloads/
16 | eggs/
17 | .eggs/
18 | lib/
19 | lib64/
20 | parts/
21 | sdist/
22 | var/
23 | wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 |
28 | # PyInstaller
29 | # Usually these files are written by a python script from a template
30 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
31 | *.manifest
32 | *.spec
33 |
34 | # Installer logs
35 | pip-log.txt
36 | pip-delete-this-directory.txt
37 |
38 | # Unit test / coverage reports
39 | htmlcov/
40 | .tox/
41 | .coverage
42 | .coverage.*
43 | .cache
44 | nosetests.xml
45 | coverage.xml
46 | *.cover
47 | .hypothesis/
48 |
49 | # Translations
50 | *.mo
51 | *.pot
52 |
53 | # Django stuff:
54 | *.log
55 | local_settings.py
56 |
57 | # Flask stuff:
58 | instance/
59 | .webassets-cache
60 |
61 | # Scrapy stuff:
62 | .scrapy
63 |
64 | # Sphinx documentation
65 | docs/_build/
66 |
67 | # PyBuilder
68 | target/
69 |
70 | # Jupyter Notebook
71 | .ipynb_checkpoints
72 |
73 | # pyenv
74 | .python-version
75 |
76 | # celery beat schedule file
77 | celerybeat-schedule
78 |
79 | # SageMath parsed files
80 | *.sage.py
81 |
82 | # dotenv
83 | .env
84 |
85 | # virtualenv
86 | .venv
87 | venv/
88 | ENV/
89 |
90 | # Spyder project settings
91 | .spyderproject
92 | .spyproject
93 |
94 | # Rope project settings
95 | .ropeproject
96 |
97 | # mkdocs documentation
98 | /site
99 |
100 | # mypy
101 | .mypy_cache/
102 | tests/reports/
103 | mypy-report/
104 | .clana
105 | .mutmut-cache
106 |
107 | mutmut-results.html
108 | mutmut-results.xml
109 | clana_cm.pdf
110 | cm_analysis.html
111 | hierarchy.tmp.json
112 |
--------------------------------------------------------------------------------
/clana/distribution.py:
--------------------------------------------------------------------------------
1 | """Get the distribution of classes in a dataset."""
2 |
3 | # Core Library
4 | from typing import Dict, List
5 |
6 |
7 | def main(gt_filepath: str) -> None:
8 | """
9 | Get the distribution of classes in a file.
10 |
11 | Parameters
12 | ----------
13 | gt_filepath : str
14 | List of ground truth; one label per line
15 | """
16 | # Read text file
17 | with open(gt_filepath) as fp:
18 | read_lines = fp.readlines()
19 | labels_str = [line.rstrip("\n") for line in read_lines]
20 |
21 | distribution = get_distribution(labels_str)
22 | labels = sorted(distribution.items(), key=lambda n: (-n[1], n[0]))
23 | label_len = max(len(label[0]) for label in labels)
24 | count_len = max(len(str(label[1])) for label in labels)
25 | total_count = sum(label[1] for label in labels)
26 | for label, count in labels:
27 | print(
28 | "{percentage:5.2f}% {label:<{label_len}} "
29 | "({count:>{count_len}} elements)".format(
30 | label=label,
31 | count=count,
32 | percentage=count / float(total_count) * 100.0,
33 | label_len=label_len,
34 | count_len=count_len,
35 | )
36 | )
37 |
38 |
39 | def get_distribution(labels: List[str]) -> Dict[str, int]:
40 | """
41 | Get the distribution of the labels.
42 |
43 | Prameters
44 | ---------
45 | labels : List[str]
46 | This list is non-unique.
47 |
48 | Returns
49 | -------
50 | distribution : Dict[str, int]
51 | Maps (label => count)
52 |
53 | Examples
54 | --------
55 | >>> dist = get_distribution(['de', 'de', 'en'])
56 | >>> sorted(dist.items())
57 | [('de', 2), ('en', 1)]
58 | """
59 | distribution: Dict[str, int] = {}
60 | for label in labels:
61 | if label not in distribution:
62 | distribution[label] = 1
63 | else:
64 | distribution[label] += 1
65 | return distribution
66 |
--------------------------------------------------------------------------------
/clana/get_cm.py:
--------------------------------------------------------------------------------
1 | """Calculate the confusion matrix (CSV inputs)."""
2 |
3 | # Core Library
4 | import csv
5 | import logging
6 | from typing import List, Tuple
7 |
8 | # Third party
9 | import numpy as np
10 | import numpy.typing as npt
11 |
12 | # First party
13 | import clana.io
14 |
15 | logger = logging.getLogger(__name__)
16 |
17 |
18 | def main(predictions_filepath: str, gt_filepath: str, n: int) -> None:
19 | """
20 | Calculate a confusion matrix.
21 |
22 | Parameters
23 | ----------
24 | predictions_filepath : str
25 | CSV file with delimter ; and quoting char "
26 | The first field is an identifier, the second one is the index of the
27 | predicted label
28 | gt_filepath : str
29 | CSV file with delimter ; and quoting char "
30 | The first field is an identifier, the second one is the index of the
31 | ground truth
32 | n : int
33 | Number of classes
34 | """
35 | # Read CSV files
36 | with open(predictions_filepath) as fp:
37 | reader = csv.reader(fp, delimiter=";", quotechar='"')
38 | predictions = [tuple(row) for row in reader]
39 |
40 | with open(gt_filepath) as fp:
41 | reader = csv.reader(fp, delimiter=";", quotechar='"')
42 | truths = [tuple(row) for row in reader]
43 |
44 | cm = calculate_cm(predictions, truths, n)
45 | path = "cm.json"
46 | clana.io.write_cm(path, cm)
47 | logger.info(f"cm was written to '{path}'")
48 |
49 |
50 | def calculate_cm(
51 | truths: List[Tuple[str, ...]], predictions: List[Tuple[str, ...]], n: int
52 | ) -> npt.NDArray:
53 | """
54 | Calculate a confusion matrix.
55 |
56 | Parameters
57 | ----------
58 | truths : List[Tuple[str, str]]
59 | predictions : List[Tuple[str, str]]
60 | n : int
61 | Number of classes
62 |
63 | Returns
64 | -------
65 | confusion_matrix : numpy array (n x n)
66 | """
67 | cm = np.zeros((n, n), dtype=int)
68 |
69 | ident2truth_index = {}
70 | for identifier, truth_index in truths:
71 | ident2truth_index[identifier] = int(truth_index)
72 |
73 | if len(predictions) != len(truths):
74 | msg = f'len(predictions) = {len(predictions)} != {len(truths)} = len(truths)"'
75 | raise ValueError(msg)
76 |
77 | for ident, pred_index in predictions:
78 | cm[ident2truth_index[ident]][int(pred_index)] += 1
79 |
80 | return cm
81 |
--------------------------------------------------------------------------------
/clana/utils.py:
--------------------------------------------------------------------------------
1 | """Utility functions for clana."""
2 |
3 | # Core Library
4 | import csv
5 | import os
6 | from typing import Any, Dict, List, Optional
7 |
8 | # Third party
9 | import yaml
10 | from pkg_resources import resource_filename
11 |
12 |
13 | def load_labels(labels_file: str, n: int) -> List[str]:
14 | """
15 | Load labels from a CSV file.
16 |
17 | Parameters
18 | ----------
19 | labels_file : str
20 | n : int
21 |
22 | Returns
23 | -------
24 | labels : List[str]
25 | """
26 | if n < 0:
27 | raise ValueError(f"n={n} needs to be non-negative")
28 | if os.path.isfile(labels_file):
29 | # Read CSV file
30 | with open(labels_file) as fp:
31 | reader = csv.reader(fp, delimiter=";", quotechar='"')
32 | next(reader, None) # skip the headers
33 | parsed_csv = list(reader)
34 | labels = [el[0] for el in parsed_csv] # short by default
35 | else:
36 | labels = [str(el) for el in range(n)]
37 | return labels
38 |
39 |
40 | def load_cfg(
41 | yaml_filepath: Optional[str] = None, verbose: bool = False
42 | ) -> Dict[str, Any]:
43 | """
44 | Load a YAML configuration file.
45 |
46 | Parameters
47 | ----------
48 | yaml_filepath : str, optional (default: package config file)
49 |
50 | Returns
51 | -------
52 | cfg : Dict[str, Any]
53 | """
54 | if yaml_filepath is None:
55 | yaml_filepath = resource_filename("clana", "config.yaml")
56 | # Read YAML experiment definition file
57 | if verbose:
58 | print(f"Load config from {yaml_filepath}...")
59 | with open(yaml_filepath) as stream:
60 | cfg = yaml.safe_load(stream)
61 | cfg = make_paths_absolute(os.path.dirname(yaml_filepath), cfg)
62 | return cfg
63 |
64 |
65 | def make_paths_absolute(dir_: str, cfg: Dict[str, Any]) -> Dict[str, Any]:
66 | """
67 | Make all values for keys ending with `_path` absolute to dir_.
68 |
69 | Parameters
70 | ----------
71 | dir_ : str
72 | cfg : Dict[str, Any]
73 |
74 | Returns
75 | -------
76 | cfg : Dict[str, Any]
77 | """
78 | for key in cfg.keys():
79 | if hasattr(key, "endswith") and key.endswith("_path"):
80 | if cfg[key].startswith("~"):
81 | cfg[key] = os.path.expanduser(cfg[key])
82 | else:
83 | cfg[key] = os.path.join(dir_, cfg[key])
84 | cfg[key] = os.path.abspath(cfg[key])
85 | if type(cfg[key]) is dict:
86 | cfg[key] = make_paths_absolute(dir_, cfg[key])
87 | return cfg
88 |
--------------------------------------------------------------------------------
/requirements/dev.txt:
--------------------------------------------------------------------------------
1 | #
2 | # This file is autogenerated by pip-compile with python 3.7
3 | # To update, run:
4 | #
5 | # pip-compile requirements/dev.in
6 | #
7 | bleach==4.1.0
8 | # via readme-renderer
9 | certifi==2021.10.8
10 | # via requests
11 | cffi==1.15.0
12 | # via cryptography
13 | cfgv==3.3.1
14 | # via pre-commit
15 | charset-normalizer==2.0.10
16 | # via requests
17 | click==8.0.3
18 | # via pip-tools
19 | colorama==0.4.4
20 | # via twine
21 | cryptography==36.0.1
22 | # via secretstorage
23 | distlib==0.3.4
24 | # via virtualenv
25 | docutils==0.18.1
26 | # via readme-renderer
27 | filelock==3.4.2
28 | # via virtualenv
29 | identify==2.4.6
30 | # via pre-commit
31 | idna==3.3
32 | # via requests
33 | importlib-metadata==4.10.1
34 | # via
35 | # click
36 | # keyring
37 | # pep517
38 | # pre-commit
39 | # twine
40 | # virtualenv
41 | jeepney==0.7.1
42 | # via
43 | # keyring
44 | # secretstorage
45 | keyring==23.5.0
46 | # via twine
47 | nodeenv==1.6.0
48 | # via pre-commit
49 | packaging==21.3
50 | # via bleach
51 | pep517==0.12.0
52 | # via pip-tools
53 | pip-tools==6.4.0
54 | # via -r requirements/dev.in
55 | pkginfo==1.8.2
56 | # via twine
57 | platformdirs==2.4.1
58 | # via virtualenv
59 | pre-commit==2.17.0
60 | # via -r requirements/dev.in
61 | pycparser==2.21
62 | # via cffi
63 | pygments==2.11.2
64 | # via readme-renderer
65 | pyparsing==3.0.7
66 | # via packaging
67 | pyyaml==6.0
68 | # via pre-commit
69 | readme-renderer==32.0
70 | # via twine
71 | requests==2.27.1
72 | # via
73 | # requests-toolbelt
74 | # twine
75 | requests-toolbelt==0.9.1
76 | # via twine
77 | rfc3986==2.0.0
78 | # via twine
79 | secretstorage==3.3.1
80 | # via keyring
81 | six==1.16.0
82 | # via
83 | # bleach
84 | # virtualenv
85 | toml==0.10.2
86 | # via pre-commit
87 | tomli==2.0.0
88 | # via pep517
89 | tqdm==4.62.3
90 | # via twine
91 | twine==3.7.1
92 | # via -r requirements/dev.in
93 | typing-extensions==4.0.1
94 | # via importlib-metadata
95 | urllib3==1.26.8
96 | # via requests
97 | virtualenv==20.13.0
98 | # via pre-commit
99 | webencodings==0.5.1
100 | # via bleach
101 | wheel==0.37.1
102 | # via
103 | # -r requirements/dev.in
104 | # pip-tools
105 | zipp==3.7.0
106 | # via
107 | # importlib-metadata
108 | # pep517
109 |
110 | # The following packages are considered to be unsafe in a requirements file:
111 | # pip
112 | # setuptools
113 |
--------------------------------------------------------------------------------
/docs/source/file_formats.rst:
--------------------------------------------------------------------------------
1 | The following file formats are used within ``clana``.
2 |
3 | Label Format
4 | ============
5 |
6 | The label file format is a text format. It is used to make sense of the
7 | prediction. The order matters.
8 |
9 | Specification
10 | -------------
11 |
12 | - One label per line
13 | - It is a CSV file with ``;`` as the delimiter and ``"`` as the quoting
14 | character.
15 | - The first value is a short version of the label. It has to be unique
16 | over all short versions.
17 | - The second value is a long version of the label. It has to be unique
18 | over all long versions.
19 |
20 | Example
21 | -------
22 |
23 | Computer Vision
24 | ~~~~~~~~~~~~~~~
25 |
26 | ::
27 |
28 | car;car
29 | cat;cat
30 | dog;dog
31 | mouse;mouse
32 |
33 | mnist.csv:
34 |
35 | ::
36 |
37 | 0;0
38 | 1;1
39 | 2;2
40 | 3;3
41 | 4;4
42 | 5;5
43 | 6;6
44 | 7;7
45 | 8;8
46 | 9;9
47 |
48 | Language Identification
49 | ~~~~~~~~~~~~~~~~~~~~~~~
50 |
51 | ::
52 |
53 | German;de
54 | English;en
55 | French;fr
56 |
57 | Classification Dump Format
58 | ==========================
59 |
60 | TODO: THIS IS WAY TOO BIG!
61 |
62 | The classification dump format is a text format. It describes what the
63 | output of a classifier for some inputs.
64 |
65 | .. _specification-1:
66 |
67 | Specification
68 | -------------
69 |
70 | The Classification Dump Format is a text format.
71 |
72 | - Each line contains exactly one output of the classifier for one
73 | input.
74 | - It is a CSV file with ``;`` as the delimiter and ``"`` as the quoting
75 | character.
76 | - The first value is an identifier for the input. It is no longer than
77 | 60 characters.
78 | - The second and following values are the outputs for each label. Each
79 | of those values is a number in ``[0, 1]``.
80 | - The outputs are in the same order as in the related ``label.csv``
81 | file.
82 |
83 | .. _example-1:
84 |
85 | Example
86 | -------
87 |
88 | ::
89 |
90 | identifier 1;0.1;0.3;0.6
91 | ident 2;0.8;0.1;0.1
92 |
93 | Ground Truth Format
94 | ===================
95 |
96 | The Ground Truth Format is a text file format. It is used to describe
97 | the ground truth of data.
98 |
99 | .. _specification-2:
100 |
101 | Specification
102 | -------------
103 |
104 | - Each line contains the ground truth of exactly one element.
105 | - It is a CSV file with ``;`` as the delimiter and ``"`` as the quoting
106 | character.
107 | - The first value is an identifier for the input. It is no longer than
108 | 60 characters.
109 | - The second and following values are the outputs for each label. Each
110 | of those values is a number in ``[0, 1]``.
111 | - The outputs are in the same order as in the related ``label.csv``
112 | file.
113 |
114 | .. _example-2:
115 |
116 | Example
117 | -------
118 |
119 | ::
120 |
121 | identifier 1;1;0;1
122 | identifier 1;0.5;0;0.5
123 |
--------------------------------------------------------------------------------
/clana/templates/base.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
30 |
31 |
32 |
33 |
34 |
35 |
36 | | |
37 | {% for cell in header_cells %}
38 | {{ cell['label'] }} |
39 | {% endfor %}
40 | support |
41 |
42 |
43 |
44 | {% for row in body_rows %}
45 | {% set outer_loop = loop %}
46 |
47 | {% for cell in row['row'] %}
48 | {% if loop.index == 1 %}
49 | | {{ cell['label'] }} |
50 | {% else %}
51 | {{ cell['label'] }} |
52 | {% endif %}
53 | {% endfor %}
54 | {{ row['support']}} |
55 |
56 | {% endfor %}
57 |
58 |
59 |
88 |
89 |
90 |
91 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [metadata]
2 | # https://setuptools.readthedocs.io/en/latest/setuptools.html#configuring-setup-using-setup-cfg-files
3 | name = clana
4 |
5 | author = Martin Thoma
6 | author_email = info@martin-thoma.de
7 | maintainer = Martin Thoma
8 | maintainer_email = info@martin-thoma.de
9 |
10 | version = 0.4.0
11 |
12 | description = CLANA is a toolkit for classifier analysis.
13 | long_description = file: README.md
14 | long_description_content_type = text/markdown
15 |
16 | platforms = Linux
17 |
18 | url = https://github.com/MartinThoma/clana
19 | download_url = https://github.com/MartinThoma/clana
20 |
21 | license = MIT
22 |
23 | keywords =
24 | Machine Learning
25 | Data Science
26 | classifiers
27 | Classification
28 | Classifier Analysis
29 |
30 | classifiers =
31 | Development Status :: 4 - Beta
32 | Environment :: Console
33 | Intended Audience :: Developers
34 | Intended Audience :: Information Technology
35 | Intended Audience :: Science/Research
36 | License :: OSI Approved :: MIT License
37 | Natural Language :: English
38 | Operating System :: OS Independent
39 | Programming Language :: Python :: 3
40 | Programming Language :: Python :: 3 :: Only
41 | Programming Language :: Python :: 3.7
42 | Programming Language :: Python :: 3.8
43 | Programming Language :: Python :: 3.9
44 | Topic :: Software Development :: Libraries :: Python Modules
45 | Topic :: Scientific/Engineering :: Information Analysis
46 | Topic :: Scientific/Engineering :: Visualization
47 | Topic :: Software Development
48 | Topic :: Utilities
49 |
50 | [options]
51 | zip_safe = false
52 | include_package_data = true
53 | packages = find:
54 | python_requires = >=3.6
55 | install_requires =
56 | click>=6.7
57 | jinja2
58 | matplotlib>=2.1.1
59 | numpy>=1.20.0
60 | PyYAML>=5.1.1
61 | scikit-learn>=0.19.1
62 | scipy>=1.0.0
63 |
64 | [options.entry_points]
65 | console_scripts =
66 | clana = clana.cli:entry_point
67 |
68 | [files]
69 | package-data = clana = clana/config.yaml
70 |
71 | [tool:pytest]
72 | addopts = --doctest-modules --mccabe --cov=./clana --cov-report html:tests/reports/coverage-html --cov-report term-missing --ignore=docs/ --ignore=clana/__main__.py --durations=3 --timeout=30
73 | doctest_encoding = utf-8
74 | mccabe-complexity=10
75 |
76 | [pydocstyle]
77 | match_dir = clana
78 | ignore = D105, D413, D107, D416, D212, D203, D417
79 |
80 | [flake8]
81 | match_dir = clana
82 | max-line-length = 80
83 | exclude = tests/*,.tox/*,.nox/*,docs/*,build/*
84 | ignore = E501,SIM106
85 |
86 | [mutmut]
87 | backup = False
88 | runner = python -m pytest
89 | tests_dir = tests/
90 |
91 | [bandit]
92 | ignore = B311 # See https://github.com/PyCQA/bandit/issues/212
93 |
94 | [mypy]
95 | ignore_missing_imports=true
96 | check_untyped_defs=true
97 | disallow_untyped_defs=true
98 | disallow_any_generics=true
99 | warn_unused_ignores=true
100 | strict_optional=true
101 | python_version=3.8
102 | warn_redundant_casts=true
103 | warn_unused_configs=true
104 | disallow_untyped_calls=true
105 | disallow_incomplete_defs=true
106 | follow_imports=skip
107 |
108 | [mypy-tests.*]
109 | ignore_errors = True
110 |
--------------------------------------------------------------------------------
/docs/source/mnist_example.rst:
--------------------------------------------------------------------------------
1 | How to use clana with MNIST
2 | ===========================
3 |
4 | Prerequesites
5 | -------------
6 |
7 | Install ``clana`` and execute the example:
8 |
9 | ::
10 |
11 | $ pip install clana
12 | $ python mnist_example.py
13 |
14 | This will generate the clana files.
15 |
16 | Usage
17 | -----
18 |
19 | distribution
20 | ~~~~~~~~~~~~
21 |
22 | ::
23 |
24 | $ clana distribution --gt gt-test.csv
25 | 11.35% 1 (1135 elements)
26 | 10.32% 2 (1032 elements)
27 | 10.28% 7 (1028 elements)
28 | 10.10% 3 (1010 elements)
29 | 10.09% 9 (1009 elements)
30 | 9.82% 4 ( 982 elements)
31 | 9.80% 0 ( 980 elements)
32 | 9.74% 8 ( 974 elements)
33 | 9.58% 6 ( 958 elements)
34 | 8.92% 5 ( 892 elements)
35 |
36 | get-cm
37 | ~~~~~~
38 |
39 | This is an intermediate step required for the visualization.
40 |
41 | ::
42 |
43 | $ clana get-cm --predictions train-pred.csv --gt gt-train.csv --n 10
44 | 2019-07-02 21:53:40,547 - root - INFO - cm was written to 'cm.json'
45 |
46 | visualize
47 | ~~~~~~~~~
48 |
49 | ::
50 |
51 | $ clana visualize --cm cm.json
52 | Score: 12634
53 | 2019-07-02 22:13:54,987 - root - INFO - n=10
54 | 2019-07-02 22:13:54,987 - root - INFO - ## Starting Score: 12634.00
55 | 2019-07-02 22:13:54,988 - root - INFO - Current: 12249.00 (best: 12249.00, hot_prob_thresh=100.0000%, step=0, swap=False)
56 | 2019-07-02 22:13:54,988 - root - INFO - Current: 10457.00 (best: 10457.00, hot_prob_thresh=100.0000%, step=1, swap=False)
57 | 2019-07-02 22:13:54,988 - root - INFO - Current: 10453.00 (best: 10453.00, hot_prob_thresh=100.0000%, step=3, swap=False)
58 | 2019-07-02 22:13:54,988 - root - INFO - Current: 10340.00 (best: 10340.00, hot_prob_thresh=100.0000%, step=6, swap=True)
59 | 2019-07-02 22:13:54,989 - root - INFO - Current: 10166.00 (best: 10166.00, hot_prob_thresh=100.0000%, step=14, swap=True)
60 | 2019-07-02 22:13:54,989 - root - INFO - Current: 9644.00 (best: 9644.00, hot_prob_thresh=100.0000%, step=17, swap=True)
61 | 2019-07-02 22:13:54,989 - root - INFO - Current: 9617.00 (best: 9617.00, hot_prob_thresh=100.0000%, step=19, swap=True)
62 | 2019-07-02 22:13:54,990 - root - INFO - Current: 9528.00 (best: 9528.00, hot_prob_thresh=100.0000%, step=38, swap=False)
63 | 2019-07-02 22:13:54,992 - root - INFO - Current: 9297.00 (best: 9297.00, hot_prob_thresh=100.0000%, step=86, swap=True)
64 | 2019-07-02 22:13:54,993 - root - INFO - Current: 9092.00 (best: 9092.00, hot_prob_thresh=100.0000%, step=109, swap=True)
65 | 2019-07-02 22:13:54,994 - root - INFO - Current: 9018.00 (best: 9018.00, hot_prob_thresh=100.0000%, step=123, swap=True)
66 | Score: 9018
67 | Perm: [0, 6, 5, 3, 8, 1, 2, 7, 9, 4]
68 | 2019-07-02 22:13:55,029 - root - INFO - Classes: [0, 6, 5, 3, 8, 1, 2, 7, 9, 4]
69 | Accuracy: 94.34%
70 | 2019-07-02 22:13:55,152 - root - INFO - Save figure at '/home/moose/confusion_matrix.tmp.pdf'
71 | 2019-07-02 22:13:55,269 - root - INFO - Found threshold for local connection: 258
72 | 2019-07-02 22:13:55,269 - root - INFO - Found 9 clusters
73 | 2019-07-02 22:13:55,270 - root - INFO - silhouette_score=-0.0067092812311967
74 | 1: [0]
75 | 1: [6]
76 | 1: [5]
77 | 1: [3]
78 | 1: [8]
79 | 1: [1]
80 | 1: [2]
81 | 2: [7, 9]
82 | 1: [4]
83 |
--------------------------------------------------------------------------------
/docs/mnist_example.py:
--------------------------------------------------------------------------------
1 | """
2 | Trains a simple neural network on the MNIST dataset.
3 |
4 | Gets to 97.54% test accuracy after 10 epochs.
5 | 22 seconds per epoch on a NVIDIA Geforce 940MX.
6 | """
7 |
8 | # Core Library
9 | from typing import Any, Tuple
10 |
11 | # Third party
12 | import keras
13 | import numpy as np
14 | import numpy.typing as npt
15 | from keras import backend as K
16 | from keras.datasets import mnist
17 | from keras.layers import Conv2D, Dense, Dropout, Flatten, MaxPooling2D
18 | from keras.models import Sequential
19 |
20 | # First party
21 | from clana.io import write_gt, write_predictions
22 |
23 |
24 | def main() -> None:
25 | batch_size = 128
26 | num_classes = 10
27 | epochs = 1
28 |
29 | # input image dimensions
30 | img_rows, img_cols = 28, 28
31 |
32 | # the data, split between train and test sets
33 | (x_train, y_train), (x_test, y_test) = mnist.load_data()
34 |
35 | # Write gt for CLANA
36 | write_gt(dict(enumerate(y_train)), "gt-train.csv") # type: ignore
37 | write_gt(dict(enumerate(y_test)), "gt-test.csv") # type: ignore
38 |
39 | x_train, y_train = preprocess(x_train, y_train, img_rows, img_cols, num_classes)
40 | x_test, y_test = preprocess(x_test, y_test, img_rows, img_cols, num_classes)
41 | input_shape = get_shape(img_rows, img_cols)
42 | model = create_model(input_shape, num_classes)
43 |
44 | model.fit(
45 | x_train,
46 | y_train,
47 | batch_size=batch_size,
48 | epochs=epochs,
49 | verbose=1,
50 | validation_data=(x_test, y_test),
51 | )
52 |
53 | y_train_pred = model.predict(x_train)
54 | y_test_pred = model.predict(x_train)
55 |
56 | # Write gt for CLANA
57 | y_train_pred_a = np.argmax(y_train_pred, axis=1)
58 | y_test_pred_a = np.argmax(y_test_pred, axis=1)
59 | write_predictions(dict(enumerate(y_train_pred_a)), "train-pred.csv") # type: ignore
60 | write_predictions(dict(enumerate(y_test_pred_a)), "test-pred.csv") # type: ignore
61 |
62 | score = model.evaluate(x_test, y_test, verbose=0)
63 | print("Test loss:", score[0])
64 | print("Test accuracy:", score[1])
65 |
66 |
67 | def get_shape(img_rows: int, img_cols: int) -> Tuple[int, int, int]:
68 | if K.image_data_format() == "channels_first":
69 | input_shape = (1, img_rows, img_cols)
70 | else:
71 | input_shape = (img_rows, img_cols, 1)
72 | return input_shape
73 |
74 |
75 | def preprocess(
76 | features: npt.NDArray,
77 | targets: npt.NDArray,
78 | img_rows: int,
79 | img_cols: int,
80 | num_classes: int,
81 | ) -> Tuple[Any, Any]:
82 | if K.image_data_format() == "channels_first":
83 | features = features.reshape(features.shape[0], 1, img_rows, img_cols)
84 | else:
85 | features = features.reshape(features.shape[0], img_rows, img_cols, 1)
86 | features = features.astype("float32")
87 | features /= 255
88 | print("x shape:", features.shape)
89 | print(f"{features.shape[0]} samples")
90 |
91 | # convert class vectors to binary class matrices
92 | targets = keras.utils.to_categorical(targets, num_classes)
93 | return features, targets
94 |
95 |
96 | def create_model(input_shape: Tuple[int, int, int], num_classes: int) -> Any:
97 | model = Sequential()
98 | model.add(
99 | Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape)
100 | )
101 | model.add(MaxPooling2D(pool_size=(2, 2)))
102 | model.add(Dropout(0.25))
103 | model.add(Flatten())
104 | model.add(Dense(16, activation="relu"))
105 | model.add(Dropout(0.5))
106 | model.add(Dense(num_classes, activation="softmax"))
107 |
108 | model.compile(
109 | loss=keras.losses.categorical_crossentropy,
110 | optimizer=keras.optimizers.Adadelta(),
111 | metrics=["accuracy"],
112 | )
113 | return model
114 |
115 |
116 | if __name__ == "__main__":
117 | main()
118 |
--------------------------------------------------------------------------------
/requirements/ci.txt:
--------------------------------------------------------------------------------
1 | #
2 | # This file is autogenerated by pip-compile with python 3.7
3 | # To update, run:
4 | #
5 | # pip-compile requirements/ci.in
6 | #
7 | astor==0.8.1
8 | # via flake8-simplify
9 | attrs==20.3.0
10 | # via
11 | # flake8-bugbear
12 | # flake8-eradicate
13 | # flake8-implicit-str-concat
14 | # pytest
15 | black==22.1.0
16 | # via -r ci.in
17 | click==8.0.3
18 | # via
19 | # -r ../requirements.txt
20 | # black
21 | coverage[toml]==6.3
22 | # via
23 | # -r ci.in
24 | # pytest-cov
25 | cycler==0.11.0
26 | # via
27 | # -r ../requirements.txt
28 | # matplotlib
29 | eradicate==2.0.0
30 | # via flake8-eradicate
31 | flake8==3.9.2
32 | # via
33 | # -r ci.in
34 | # flake8-bugbear
35 | # flake8-builtins
36 | # flake8-comprehensions
37 | # flake8-eradicate
38 | # flake8-executable
39 | # flake8-isort
40 | # flake8-raise
41 | # flake8-simplify
42 | # flake8-string-format
43 | flake8-bugbear==22.1.11
44 | # via -r ci.in
45 | flake8-builtins==1.5.3
46 | # via -r ci.in
47 | flake8-comprehensions==3.8.0
48 | # via -r ci.in
49 | flake8-eradicate==1.2.0
50 | # via -r ci.in
51 | flake8-executable==2.1.1
52 | # via -r ci.in
53 | flake8-implicit-str-concat==0.2.0
54 | # via -r ci.in
55 | flake8-isort==4.1.1
56 | # via -r ci.in
57 | flake8-plugin-utils==1.3.2
58 | # via flake8-pytest-style
59 | flake8-pytest-style==1.6.0
60 | # via -r ci.in
61 | flake8-raise==0.0.5
62 | # via -r ci.in
63 | flake8-simplify==0.15.1
64 | # via -r ci.in
65 | flake8-string-format==0.3.0
66 | # via -r ci.in
67 | fonttools==4.29.0
68 | # via
69 | # -r ../requirements.txt
70 | # matplotlib
71 | importlib-metadata==4.10.1
72 | # via -r ../requirements.txt
73 | iniconfig==1.1.1
74 | # via pytest
75 | isort==5.10.1
76 | # via flake8-isort
77 | jinja2==3.0.3
78 | # via -r ../requirements.txt
79 | joblib==1.1.0
80 | # via
81 | # -r ../requirements.txt
82 | # scikit-learn
83 | kiwisolver==1.3.2
84 | # via
85 | # -r ../requirements.txt
86 | # matplotlib
87 | lxml==4.7.1
88 | # via -r ci.in
89 | markupsafe==2.0.1
90 | # via
91 | # -r ../requirements.txt
92 | # jinja2
93 | matplotlib==3.5.1
94 | # via -r ../requirements.txt
95 | mccabe==0.6.1
96 | # via
97 | # flake8
98 | # pytest-mccabe
99 | more-itertools==8.12.0
100 | # via flake8-implicit-str-concat
101 | mypy==0.931
102 | # via -r ci.in
103 | mypy-extensions==0.4.3
104 | # via
105 | # black
106 | # mypy
107 | numpy==1.21.5
108 | # via
109 | # -r ../requirements.txt
110 | # matplotlib
111 | # scikit-learn
112 | # scipy
113 | packaging==21.3
114 | # via
115 | # -r ../requirements.txt
116 | # matplotlib
117 | # pytest
118 | pathspec==0.9.0
119 | # via black
120 | pillow==9.0.1
121 | # via
122 | # -r ../requirements.txt
123 | # matplotlib
124 | platformdirs==2.4.1
125 | # via black
126 | pluggy==1.0.0
127 | # via pytest
128 | py==1.11.0
129 | # via pytest
130 | pycodestyle==2.7.0
131 | # via flake8
132 | pydocstyle==6.1.1
133 | # via -r ci.in
134 | pyflakes==2.3.1
135 | # via flake8
136 | pyparsing==3.0.7
137 | # via
138 | # -r ../requirements.txt
139 | # matplotlib
140 | # packaging
141 | pytest==6.2.5
142 | # via
143 | # -r ci.in
144 | # pytest-cov
145 | # pytest-mccabe
146 | # pytest-timeout
147 | pytest-cov==3.0.0
148 | # via -r ci.in
149 | pytest-mccabe==2.0
150 | # via -r ci.in
151 | pytest-timeout==2.1.0
152 | # via -r ci.in
153 | python-dateutil==2.8.2
154 | # via
155 | # -r ../requirements.txt
156 | # matplotlib
157 | pyyaml==6.0
158 | # via -r ../requirements.txt
159 | scikit-learn==1.0.2
160 | # via -r ../requirements.txt
161 | scipy==1.7.3
162 | # via
163 | # -r ../requirements.txt
164 | # scikit-learn
165 | six==1.16.0
166 | # via
167 | # -r ../requirements.txt
168 | # python-dateutil
169 | snowballstemmer==2.2.0
170 | # via pydocstyle
171 | testfixtures==6.18.3
172 | # via flake8-isort
173 | threadpoolctl==3.0.0
174 | # via
175 | # -r ../requirements.txt
176 | # scikit-learn
177 | toml==0.10.2
178 | # via pytest
179 | tomli==2.0.0
180 | # via
181 | # black
182 | # mypy
183 | types-pkg-resources==0.1.3
184 | # via -r ci.in
185 | types-pyyaml==6.0.3
186 | # via -r ci.in
187 | types-setuptools==57.4.8
188 | # via -r ci.in
189 | typing-extensions==4.0.1
190 | # via
191 | # -r ../requirements.txt
192 | # mypy
193 | zipp==3.7.0
194 | # via
195 | # -r ../requirements.txt
196 | # importlib-metadata
197 |
--------------------------------------------------------------------------------
/clana/get_cm_simple.py:
--------------------------------------------------------------------------------
1 | """Calculate the confusion matrix (one label per line)."""
2 |
3 | # Core Library
4 | import csv
5 | import json
6 | import logging
7 | import os
8 | import sys
9 | from typing import Dict, List, Tuple
10 |
11 | # Third party
12 | import numpy as np
13 | import numpy.typing as npt
14 | import sklearn.metrics
15 |
16 | # First party
17 | import clana.utils
18 |
19 | logger = logging.getLogger(__name__)
20 |
21 |
22 | def main(
23 | label_filepath: str, gt_filepath: str, predictions_filepath: str, clean: bool
24 | ) -> None:
25 | """
26 | Get a simple confunsion matrix.
27 |
28 | Parameters
29 | ----------
30 | label_filepath : str
31 | Path to a CSV file with delimiter ;
32 | gt_filepath : str
33 | Path to a CSV file with delimiter ;
34 | predictions : str
35 | Path to a CSV file with delimiter ;
36 | clean : bool, optional (default: False)
37 | Remove classes that the classifier doesn't know
38 | """
39 | label_filepath = os.path.abspath(label_filepath)
40 | labels = clana.utils.load_labels(label_filepath, 0)
41 |
42 | # Read CSV files
43 | with open(gt_filepath) as fp:
44 | reader = csv.reader(fp, delimiter=";", quotechar='"')
45 | truths = [row[0] for row in reader]
46 |
47 | with open(predictions_filepath) as fp:
48 | reader = csv.reader(fp, delimiter=";", quotechar='"')
49 | predictions = [row[0] for row in reader]
50 |
51 | cm = calculate_cm(labels, truths, predictions, clean=False)
52 | # Write JSON file
53 | cm_filepath = os.path.abspath("cm.json")
54 | logger.info(f"Write results to '{cm_filepath}'.")
55 | with open(cm_filepath, "w") as outfile:
56 | str_ = json.dumps(
57 | cm.tolist(), indent=2, separators=(",", ": "), ensure_ascii=False
58 | )
59 | outfile.write(str_)
60 | print(cm)
61 |
62 |
63 | def calculate_cm(
64 | labels: List[str],
65 | truths: List[str],
66 | predictions: List[str],
67 | replace_unk_preds: bool = False,
68 | clean: bool = False,
69 | ) -> npt.NDArray:
70 | """
71 | Calculate a confusion matrix.
72 |
73 | Parameters
74 | ----------
75 | labels : List[int]
76 | truths : List[int]
77 | predictions : List[int]
78 | replace_unk_preds : bool, optional (default: True)
79 | If a prediction is not in the labels in label_filepath, replace it
80 | with UNK
81 | clean : bool, optional (default: False)
82 | Remove classes that the classifier doesn't know
83 |
84 | Returns
85 | -------
86 | confusion_matrix : numpy array (n x n)
87 | """
88 | # Check data
89 | if len(predictions) != len(truths):
90 | msg = f"len(predictions) = {len(predictions)} != {len(truths)} = len(truths)"
91 | raise ValueError(msg)
92 |
93 | label2i = {} # map a label to 0, ..., n
94 | for i, label in enumerate(labels):
95 | label2i[label] = i
96 |
97 | if clean:
98 | truths, predictions = clean_truths(truths, predictions)
99 |
100 | if replace_unk_preds:
101 | predictions = clean_preds(predictions, label2i)
102 |
103 | n = _sanity_check(truths, labels, label2i, predictions)
104 |
105 | # TODO: do no always filter
106 | filter_data_unk = True
107 | if filter_data_unk:
108 | truths2, predictions2 = [], []
109 | for tru, pred in zip(truths, predictions):
110 | if pred != "unk": # TODO: tru != 'UNK'!!!
111 | truths2.append(tru)
112 | predictions2.append(pred)
113 | truths = truths2
114 | predictions = predictions2
115 |
116 | report = sklearn.metrics.classification_report(truths, predictions, labels=labels)
117 | print(report)
118 | print(f"Accuracy: {sklearn.metrics.accuracy_score(truths, predictions) * 100:.2f}%")
119 |
120 | cm = np.zeros((n, n), dtype=int)
121 |
122 | for truth_label, pred_label in zip(truths, predictions):
123 | cm[label2i[truth_label]][label2i[pred_label]] += 1
124 |
125 | return cm
126 |
127 |
128 | def clean_truths(
129 | truths: List[str], predictions: List[str]
130 | ) -> Tuple[List[str], List[str]]:
131 | """
132 | Remove classes that the classifier doesn't know.
133 |
134 | Parameters
135 | ----------
136 | truths : List[int]
137 | predictions : List[int]
138 |
139 | Returns
140 | -------
141 | truths, predictions : List[int], List[int]
142 | """
143 | preds = []
144 | truths_tmp = []
145 | for tru, pred in zip(truths, predictions):
146 | if tru in predictions:
147 | truths_tmp.append(tru)
148 | preds.append(pred)
149 | predictions = preds
150 | truths = truths_tmp
151 | return truths, predictions
152 |
153 |
154 | def clean_preds(predictions: List[str], label2i: Dict[str, int]) -> List[str]:
155 | """
156 | If a prediction is not in the labels in label_filepath, replace it with UNK.
157 |
158 | Parameters
159 | ----------
160 | predictions : List[str]
161 | label2i : Dict[str, int]
162 | Maps a label to an index
163 |
164 | Returns
165 | -------
166 | predictions : List[str]
167 | """
168 | preds = []
169 | for pred in predictions:
170 | if pred in label2i:
171 | preds.append(pred)
172 | else:
173 | preds.append("UNK")
174 | predictions = preds
175 | return predictions
176 |
177 |
178 | def _sanity_check(
179 | truths: List[str],
180 | labels: List[str],
181 | label2i: Dict[str, int],
182 | predictions: List[str],
183 | ) -> int:
184 | for label in truths:
185 | if label not in label2i:
186 | logger.error(f"Could not find label '{label}'")
187 | sys.exit(-1)
188 |
189 | n = len(labels)
190 | for label in predictions:
191 | if label not in label2i:
192 | label2i[label] = len(labels)
193 | n = len(labels) + 1
194 | logger.error(
195 | f"Could not find label '{label}' in labels file => Add class UNK"
196 | )
197 | return n
198 |
--------------------------------------------------------------------------------
/clana/cli.py:
--------------------------------------------------------------------------------
1 | """
2 | clana is a toolkit for classifier analysis.
3 |
4 | It specifies some file formats and comes with some tools for typical tasks of
5 | classifier analysis.
6 | """
7 | # Core Library
8 | import logging.config
9 | import os
10 | import random
11 | from typing import Optional
12 |
13 | # Third party
14 | import click
15 | import matplotlib
16 |
17 | # First party
18 | import clana
19 | import clana.distribution
20 | import clana.get_cm
21 | import clana.get_cm_simple
22 | import clana.visualize_cm
23 |
24 | matplotlib.use("Agg")
25 |
26 |
27 | config = clana.utils.load_cfg(verbose=True)
28 | logging.config.dictConfig(config["LOGGING"])
29 | logging.getLogger("matplotlib").setLevel("WARN")
30 | random.seed(0)
31 |
32 |
33 | @click.group()
34 | @click.version_option(version=clana.__version__)
35 | def entry_point() -> None:
36 | """
37 | Clana is a toolkit for classifier analysis.
38 |
39 | See https://arxiv.org/abs/1707.09725, Chapter 4.
40 | """
41 |
42 |
43 | gt_option = click.option(
44 | "--gt",
45 | "gt_filepath",
46 | required=True,
47 | type=click.Path(exists=True),
48 | help="CSV file with delimiter ;",
49 | )
50 | predictions_option = click.option(
51 | "--predictions",
52 | "predictions_filepath",
53 | required=True,
54 | type=click.Path(exists=True),
55 | help="CSV file with delimiter ;",
56 | )
57 |
58 |
59 | @entry_point.group()
60 | def get_cm() -> None:
61 | """Generate a confusion matrix file."""
62 |
63 |
64 | @get_cm.command(name="simple")
65 | @click.option(
66 | "--labels",
67 | "label_filepath",
68 | required=True,
69 | type=click.Path(exists=True),
70 | help="CSV file with delimiter ;",
71 | )
72 | @predictions_option
73 | @gt_option
74 | @click.option(
75 | "--clean",
76 | default=False,
77 | is_flag=True,
78 | help="Remove classes that the classifier doesn't know",
79 | )
80 | def get_cm_simple(
81 | label_filepath: str, predictions_filepath: str, gt_filepath: str, clean: bool
82 | ) -> None:
83 | """
84 | Generate a confusion matrix.
85 |
86 | The input can be a flat list of predictions and a flat list of ground truth
87 | elements. Each prediction is on its own line. Additional information can be
88 | after a semicolon.
89 | """
90 | clana.get_cm_simple.main(label_filepath, gt_filepath, predictions_filepath, clean)
91 |
92 |
93 | @get_cm.command(name="standard")
94 | @predictions_option
95 | @gt_option
96 | @click.option("--n", "n", required=True, type=int, help="Number of classes")
97 | def get_cm_standard(predictions_filepath: str, gt_filepath: str, n: int) -> None:
98 | """
99 | Generate a confusion matrix from predictions and ground truth.
100 |
101 | The predictions need to be a list of `identifier;prediction` and the
102 | ground truth needs to be a list of `identifier;truth` of same length.
103 | """
104 | clana.get_cm.main(predictions_filepath, gt_filepath, n)
105 |
106 |
107 | @entry_point.command(name="distribution")
108 | @gt_option
109 | def distribution(gt_filepath: str) -> None:
110 | """Get the distribution of classes in a dataset."""
111 | clana.distribution.main(gt_filepath)
112 |
113 |
114 | @entry_point.command(name="visualize")
115 | @click.option("--cm", "cm_file", type=click.Path(exists=True), required=True)
116 | @click.option(
117 | "--perm",
118 | "perm_file",
119 | help="json file which defines a permutation to start with.",
120 | type=click.Path(),
121 | default=None,
122 | )
123 | @click.option(
124 | "--steps",
125 | default=1000,
126 | show_default=True,
127 | help="Number of steps to find a good permutation.",
128 | )
129 | @click.option("--labels", "labels_file", default="")
130 | @click.option(
131 | "--zero_diagonal",
132 | is_flag=True,
133 | help=(
134 | "Good classifiers have the highest elements on the diagonal. "
135 | "This option sets the diagonal to zero so that errors "
136 | "can be seen more easily."
137 | ),
138 | )
139 | @click.option(
140 | "--output",
141 | "output_image_path",
142 | type=click.Path(exists=False),
143 | help="Where to store the image (either .png or .pdf)",
144 | default=os.path.abspath(config["visualize"]["save_path"]),
145 | show_default=True,
146 | )
147 | @click.option(
148 | "--limit_classes", type=int, help="Limit the number of classes in the output"
149 | )
150 | def visualize(
151 | cm_file: str,
152 | perm_file: str,
153 | steps: int,
154 | labels_file: str,
155 | zero_diagonal: bool,
156 | output_image_path: str,
157 | limit_classes: Optional[int] = None,
158 | ) -> None:
159 | """Optimize and visualize a confusion matrix."""
160 | print_file_format_issues(cm_file, labels_file, perm_file)
161 | clana.visualize_cm.main(
162 | cm_file,
163 | perm_file,
164 | steps,
165 | labels_file,
166 | zero_diagonal,
167 | limit_classes,
168 | output_image_path,
169 | )
170 |
171 |
172 | def print_file_format_issues(cm_file: str, labels_file: str, perm_file: str) -> None:
173 | """
174 | Get all potential issues of the file formats.
175 |
176 | Parameters
177 | ----------
178 | cm_file : str
179 | labels_file : str
180 | perm_file : str
181 | """
182 | if not (cm_file.lower().endswith("json") or cm_file.lower().endswith("csv")):
183 | print(f"[WARNING] A json file is expected for the cm_file, but was {cm_file}")
184 | if not (perm_file is None or perm_file.lower().endswith("json")):
185 | print(
186 | f"[WARNING] A json file is expected fo the perm_file, but was {perm_file}"
187 | )
188 | cm = clana.io.read_confusion_matrix(cm_file)
189 | labels = clana.io.read_labels(labels_file, len(cm))
190 | special_labels = ["UNK"]
191 | if len(labels) - len(special_labels) < len(cm):
192 | print(
193 | "[WARNING] The shape of the confusion matrix is {cm_shape}, but "
194 | "only {nb_labels} labels were found: {labels}".format(
195 | cm_shape=cm.shape, nb_labels=len(labels), labels=labels
196 | )
197 | )
198 | print(
199 | "Please keep in mind that the first row of the labels file is "
200 | "the header of the CSV (delimiter: ;)"
201 | )
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [](https://zenodo.org/badge/latestdoi/102892750)
2 | [](https://badge.fury.io/py/clana)
3 | [](https://pypi.org/project/clana/)
4 | [](http://clana.readthedocs.io/en/latest/?badge=latest)
5 | [](https://travis-ci.org/MartinThoma/clana)
6 | [](https://coveralls.io/github/MartinThoma/clana?branch=master)
7 | [](https://github.com/psf/black)
8 | 
9 | 
10 | [](https://www.codefactor.io/repository/github/martinthoma/clana/overview/master)
11 |
12 | # clana
13 |
14 | `clana` is a library and command line application to visualize confusion matrices of
15 | classifiers with lots of classes. The two key contribution of clana are
16 | Confusion Matrix Ordering (CMO) as explained in chapter 5 of [Analysis and Optimization of Convolutional Neural Network Architectures](https://arxiv.org/abs/1707.09725) and an optimization
17 | algorithm to to achieve it. The CMO technique can be applied to any multi-class
18 | classifier and helps to understand which groups of classes are most similar.
19 |
20 |
21 | ## Installation
22 |
23 | The recommended way to install clana is:
24 |
25 | ```
26 | $ pip install clana --user --upgrade
27 | ```
28 |
29 | If you want the latest version:
30 |
31 | ```
32 | $ git clone https://github.com/MartinThoma/clana.git; cd clana
33 | $ pip install -e . --user
34 | ```
35 |
36 | ## Usage
37 |
38 | ```
39 | $ clana --help
40 | Usage: clana [OPTIONS] COMMAND [ARGS]...
41 |
42 | Clana is a toolkit for classifier analysis.
43 |
44 | See https://arxiv.org/abs/1707.09725, Chapter 4.
45 |
46 | Options:
47 | --version Show the version and exit.
48 | --help Show this message and exit.
49 |
50 | Commands:
51 | distribution Get the distribution of classes in a dataset.
52 | get-cm Generate a confusion matrix from predictions and ground...
53 | get-cm-simple Generate a confusion matrix.
54 | visualize Optimize and visualize a confusion matrix.
55 |
56 | ```
57 |
58 | The visualize command gives you images like this:
59 |
60 | 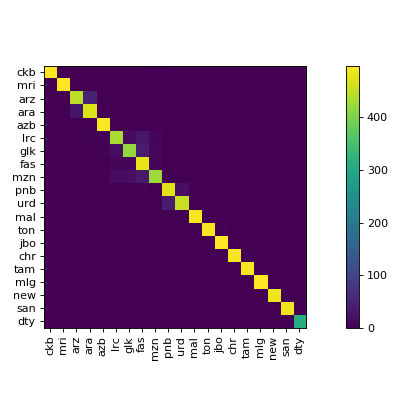
61 |
62 | ### MNIST example
63 |
64 | ```
65 | $ cd docs/
66 | $ python mnist_example.py # creates `train-pred.csv` and `test-pred.csv`
67 | $ clana get-cm --gt gt-train.csv --predictions train-pred.csv --n 10
68 | 2019-09-14 09:47:30,655 - root - INFO - cm was written to 'cm.json'
69 | $ clana visualize --cm cm.json --zero_diagonal
70 | Score: 13475
71 | 2019-09-14 09:49:41,593 - root - INFO - n=10
72 | 2019-09-14 09:49:41,593 - root - INFO - ## Starting Score: 13475.00
73 | 2019-09-14 09:49:41,594 - root - INFO - Current: 13060.00 (best: 13060.00, hot_prob_thresh=100.0000%, step=0, swap=False)
74 | [...]
75 | 2019-09-14 09:49:41,606 - root - INFO - Current: 9339.00 (best: 9339.00, hot_prob_thresh=100.0000%, step=238, swap=False)
76 | Score: 9339
77 | Perm: [0, 6, 5, 8, 3, 2, 1, 7, 9, 4]
78 | 2019-09-14 09:49:41,639 - root - INFO - Classes: [0, 6, 5, 8, 3, 2, 1, 7, 9, 4]
79 | Accuracy: 93.99%
80 | 2019-09-14 09:49:41,725 - root - INFO - Save figure at '/home/moose/confusion_matrix.tmp.pdf'
81 | 2019-09-14 09:49:41,876 - root - INFO - Found threshold for local connection: 398
82 | 2019-09-14 09:49:41,876 - root - INFO - Found 9 clusters
83 | 2019-09-14 09:49:41,877 - root - INFO - silhouette_score=-0.012313948323292875
84 | 1: [0]
85 | 1: [6]
86 | 1: [5]
87 | 1: [8]
88 | 1: [3]
89 | 1: [2]
90 | 1: [1]
91 | 2: [7, 9]
92 | 1: [4]
93 | ```
94 |
95 | This gives
96 |
97 | 
98 |
99 | #### Label Manipulation
100 |
101 | Prepare a `labels.csv` which **has to have a header row**:
102 |
103 | ```
104 | $ clana visualize --cm cm.json --zero_diagonal --labels mnist/labels.csv
105 | ```
106 |
107 | 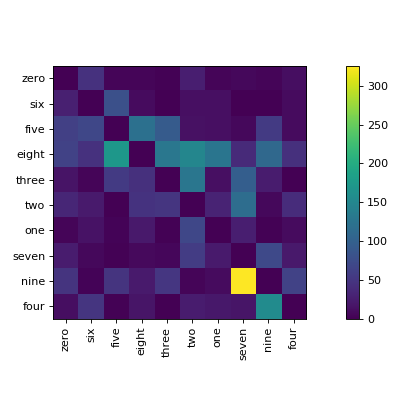
108 |
109 |
110 | ### Data distribution
111 |
112 | ```
113 | $ clana distribution --gt gt.csv --labels labels.csv [--out out/] [--long]
114 | ```
115 |
116 | prints one line per label, e.g.
117 |
118 | ```
119 | 60% cat (56789 elements)
120 | 20% dog (12345 elements)
121 | 5% mouse (1337 elements)
122 | 1% tux (314 elements)
123 | ```
124 |
125 | If `--out` is specified, it creates a horizontal bar chart. The first bar is
126 | the most common class, the second bar is the second most common class, ...
127 |
128 | It uses the short labels, except `--long` is added to the command.
129 |
130 |
131 | ### Visualizations
132 |
133 | See [visualizations](docs/visualizations.md)
134 |
135 | ## Usage as a library
136 |
137 | ```
138 | >>> import numpy as np
139 | >>> arr = np.array([[9, 4, 7, 3, 8, 5, 2, 8, 7, 6],
140 | [4, 9, 2, 8, 5, 8, 7, 3, 6, 7],
141 | [7, 2, 9, 1, 6, 3, 0, 8, 5, 4],
142 | [3, 8, 1, 9, 4, 7, 8, 2, 5, 6],
143 | [8, 5, 6, 4, 9, 6, 3, 7, 8, 7],
144 | [5, 8, 3, 7, 6, 9, 6, 4, 7, 8],
145 | [2, 7, 0, 8, 3, 6, 9, 1, 4, 5],
146 | [8, 3, 8, 2, 7, 4, 1, 9, 6, 5],
147 | [7, 6, 5, 5, 8, 7, 4, 6, 9, 8],
148 | [6, 7, 4, 6, 7, 8, 5, 5, 8, 9]])
149 | >>> from clana.optimize import simulated_annealing
150 | >>> result = simulated_annealing(arr)
151 | >>> result.cm
152 | array([[9, 8, 7, 6, 5, 4, 3, 2, 1, 0],
153 | [8, 9, 8, 7, 6, 5, 4, 3, 2, 1],
154 | [7, 8, 9, 8, 7, 6, 5, 4, 3, 2],
155 | [6, 7, 8, 9, 8, 7, 6, 5, 4, 3],
156 | [5, 6, 7, 8, 9, 8, 7, 6, 5, 4],
157 | [4, 5, 6, 7, 8, 9, 8, 7, 6, 5],
158 | [3, 4, 5, 6, 7, 8, 9, 8, 7, 6],
159 | [2, 3, 4, 5, 6, 7, 8, 9, 8, 7],
160 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 8],
161 | [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
162 | >>> result.perm
163 | array([2, 7, 0, 4, 8, 9, 5, 1, 3, 6])
164 | ```
165 |
166 | You can visualize the `result.cm` and use the `result.perm` to get your labels
167 | in the same order:
168 |
169 | ```
170 | # Just some example labels
171 | # ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10']
172 | >>> labels = [str(el) for el in range(11)]
173 | >>> np.array(labels)[result.perm]
174 | array(['2', '7', '0', '4', '8', '9', '5', '1', '3', '6'], dtype=' v documentation" by default.
124 | # html_title = u'mpu v0.1.0'
125 |
126 | # A shorter title for the navigation bar. Default is the same as html_title.
127 | # html_short_title = None
128 |
129 | # The name of an image file (relative to this directory) to place at the top
130 | # of the sidebar.
131 | # html_logo = None
132 |
133 | # The name of an image file (relative to this directory) to use as a favicon of
134 | # the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
135 | # pixels large.
136 | # html_favicon = None
137 |
138 | # Add any paths that contain custom static files (such as style sheets) here,
139 | # relative to this directory. They are copied after the builtin static files,
140 | # so a file named "default.css" will overwrite the builtin "default.css".
141 | html_static_path = ["_static"]
142 |
143 | # Custom sidebar templates, must be a dictionary that maps document names
144 | # to template names.
145 | #
146 | # This is required for the alabaster theme
147 | # refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars
148 | html_sidebars = {
149 | "**": [
150 | "relations.html", # needs 'show_related': True theme option to display
151 | "searchbox.html",
152 | ]
153 | }
154 |
155 |
156 | # -- Options for HTMLHelp output ------------------------------------------
157 |
158 | # Output file base name for HTML help builder.
159 | htmlhelp_basename = "clanadoc"
160 |
161 |
162 | # -- Options for LaTeX output ---------------------------------------------
163 |
164 | latex_elements: Dict[str, Any] = {
165 | # The paper size ('letterpaper' or 'a4paper').
166 | #
167 | # 'papersize': 'letterpaper',
168 | # The font size ('10pt', '11pt' or '12pt').
169 | #
170 | # 'pointsize': '10pt',
171 | # Additional stuff for the LaTeX preamble.
172 | #
173 | # 'preamble': '',
174 | # Latex figure (float) alignment
175 | #
176 | # 'figure_align': 'htbp',
177 | }
178 |
179 | # Grouping the document tree into LaTeX files. List of tuples
180 | # (source start file, target name, title,
181 | # author, documentclass [howto, manual, or own class]).
182 | latex_documents = [
183 | (master_doc, "clana.tex", "clana Documentation", "Martin Thoma", "manual")
184 | ]
185 |
186 |
187 | # -- Options for manual page output ---------------------------------------
188 |
189 | # One entry per manual page. List of tuples
190 | # (source start file, name, description, authors, manual section).
191 | man_pages = [(master_doc, "clana", "clana Documentation", [author], 1)]
192 |
193 |
194 | # -- Options for Texinfo output -------------------------------------------
195 |
196 | # Grouping the document tree into Texinfo files. List of tuples
197 | # (source start file, target name, title, author,
198 | # dir menu entry, description, category)
199 | texinfo_documents = [
200 | (
201 | master_doc,
202 | "clana",
203 | "clana Documentation",
204 | author,
205 | "clana",
206 | "One line description of project.",
207 | "Miscellaneous",
208 | )
209 | ]
210 |
--------------------------------------------------------------------------------
/clana/io.py:
--------------------------------------------------------------------------------
1 | """
2 | Everything related to IO.
3 |
4 | Reading / writing configuration, matrices and permutations.
5 | """
6 |
7 | # Core Library
8 | import csv
9 | import hashlib
10 | import json
11 | import os
12 | from typing import Any, Dict, List, Optional, cast
13 |
14 | # Third party
15 | import numpy as np
16 | import numpy.typing as npt
17 | import yaml
18 |
19 | # First party
20 | import clana.utils
21 |
22 | INFINITY = float("inf")
23 |
24 |
25 | class ClanaCfg:
26 | """Methods related to clanas configuration and permutations."""
27 |
28 | @classmethod
29 | def read_clana_cfg(cls, cfg_file: str) -> Dict[str, Any]:
30 | """
31 | Read a .clana config file which contains permutations.
32 |
33 | Parameters
34 | ----------
35 | cfg_file : str
36 |
37 | Returns
38 | -------
39 | cfg : Dict[str, Any]
40 | """
41 | if os.path.isfile(cfg_file):
42 | with open(cfg_file) as stream:
43 | cfg = yaml.safe_load(stream)
44 | else:
45 | cfg = {"version": clana.__version__, "data": {}}
46 | return cfg
47 |
48 | @classmethod
49 | def get_cfg_path_from_cm_path(cls, cm_file: str) -> str:
50 | """
51 | Get the configuration path from the path of the confusion matrix.
52 |
53 | Parameters
54 | ----------
55 | cm_file : str
56 |
57 | Returns
58 | -------
59 | cfg_path : str
60 | """
61 | return os.path.join(os.path.dirname(os.path.abspath(cm_file)), ".clana")
62 |
63 | @classmethod
64 | def get_perm(cls, cm_file: str) -> List[int]:
65 | """
66 | Get the best permutation found so far for a given cm_file.
67 |
68 | Fallback: list(range(n))
69 |
70 | Parameters
71 | ----------
72 | cm_file : str
73 |
74 | Returns
75 | -------
76 | perm : List[int]
77 | """
78 | cfg_file = cls.get_cfg_path_from_cm_path(cm_file)
79 | cfg = cls.read_clana_cfg(cfg_file)
80 | cm_file_base = os.path.basename(cm_file)
81 | cm = read_confusion_matrix(cm_file)
82 | n = len(cm)
83 | perm = list(range(n))
84 | if cm_file_base in cfg["data"]:
85 | cm_file_md5 = md5(cm_file)
86 | if cm_file_md5 in cfg["data"][cm_file_base]:
87 | print(
88 | "Loaded permutation found in {it} iterations".format(
89 | it=cfg["data"][cm_file_base][cm_file_md5]["iterations"]
90 | )
91 | )
92 | perm = cfg["data"][cm_file_base][cm_file_md5]["permutation"]
93 | return perm
94 |
95 | @classmethod
96 | def store_permutation(
97 | cls, cm_file: str, permutation: npt.NDArray, iterations: int
98 | ) -> None:
99 | """
100 | Store a permutation.
101 |
102 | Parameters
103 | ----------
104 | cm_file : str
105 | permutation : npt.NDArray
106 | iterations : int
107 | """
108 | cm_file = os.path.abspath(cm_file)
109 | cfg_file = cls.get_cfg_path_from_cm_path(cm_file)
110 | if os.path.isfile(cfg_file):
111 | cfg = ClanaCfg.read_clana_cfg(cfg_file)
112 | else:
113 | cfg = {"version": clana.__version__, "data": {}}
114 |
115 | cm_file_base = os.path.basename(cm_file)
116 | if cm_file_base not in cfg["data"]:
117 | cfg["data"][cm_file_base] = {}
118 | cm_file_md5 = md5(cm_file)
119 | if cm_file_md5 not in cfg["data"][cm_file_base]:
120 | cfg["data"][cm_file_base][cm_file_md5] = {
121 | "permutation": permutation.tolist(),
122 | "iterations": 0,
123 | }
124 | cfg["data"][cm_file_base][cm_file_md5]["permutation"] = permutation.tolist()
125 | cfg["data"][cm_file_base][cm_file_md5]["iterations"] += iterations
126 |
127 | # Write file
128 | print(cfg_file)
129 | with open(cfg_file, "w") as outfile:
130 | yaml.dump(cfg, outfile, default_flow_style=False, allow_unicode=True)
131 |
132 |
133 | def read_confusion_matrix(cm_file: str, make_max: float = INFINITY) -> npt.NDArray:
134 | """
135 | Load confusion matrix.
136 |
137 | Parameters
138 | ----------
139 | cm_file : str
140 | Path to a JSON file which contains a confusion matrix (List[List[int]])
141 | make_max : float, optional (default: +Infinity)
142 | Crop values at this value.
143 |
144 | Returns
145 | -------
146 | cm : npt.NDArray
147 | """
148 | with open(cm_file) as f:
149 | if cm_file.lower().endswith("csv"):
150 | cm_list = []
151 | with open(cm_file, newline="") as csvfile:
152 | spamreader = csv.reader(csvfile, delimiter=",", quotechar='"')
153 | for row in spamreader:
154 | cm_list.append([int(el) for el in row])
155 | else:
156 | cm_list = json.load(f)
157 | cm = np.array(cm_list)
158 |
159 | # Crop values
160 | n = len(cm)
161 | for i in range(n):
162 | for j in range(n):
163 | if i == j:
164 | continue
165 | cm[i][j] = cast(int, min(cm[i][j], make_max))
166 |
167 | return cm
168 |
169 |
170 | def read_permutation(cm_file: str, perm_file: Optional[str]) -> List[int]:
171 | """
172 | Load permutation.
173 |
174 | Parameters
175 | ----------
176 | cm_file : str
177 | perm_file : Optional[str]
178 | Path to a JSON file which contains a permutation of n numbers.
179 |
180 | Returns
181 | -------
182 | perm : List[int]
183 | Permutation of the numbers 0, ..., n-1
184 | """
185 | if not os.path.isfile(cm_file):
186 | raise ValueError(f"cm_file={cm_file} is not a file")
187 | if perm_file is not None and os.path.isfile(perm_file):
188 | with open(perm_file) as data_file:
189 | if perm_file.lower().endswith("csv"):
190 | with open(perm_file) as file:
191 | content = file.read()
192 | perm = [int(el) for el in content.split(",")]
193 | else:
194 | perm = json.load(data_file)
195 | else:
196 | perm = ClanaCfg.get_perm(cm_file)
197 | return perm
198 |
199 |
200 | def read_labels(labels_file: str, n: int) -> List[str]:
201 | """
202 | Load labels.
203 |
204 | Please note that this contains one additional "UNK" label for
205 | unknown classes.
206 |
207 | Parameters
208 | ----------
209 | labels_file : str
210 | n : int
211 |
212 | Returns
213 | -------
214 | labels : List[str]
215 | """
216 | labels = clana.utils.load_labels(labels_file, n)
217 | labels.append("UNK")
218 | return labels
219 |
220 |
221 | def write_labels(labels_file: str, labels: List[str]) -> None:
222 | """
223 | Write labels to labels_file.
224 |
225 | Parameters
226 | ----------
227 | labels_file : str
228 | labels: List[str]
229 | """
230 | with open(labels_file, "w") as outfile:
231 | str_ = json.dumps(labels, indent=2, separators=(",", ": "), ensure_ascii=False)
232 | outfile.write(str_)
233 |
234 |
235 | def write_predictions(identifier2prediction: Dict[str, str], filepath: str) -> None:
236 | """
237 | Create a predictions file.
238 |
239 | Parameters
240 | ----------
241 | identifier2prediction : Dict[str, str]
242 | Map an identifier (as used in write_gt) to a prediction.
243 | The prediction is a single class, not a distribution.
244 | filepath : str
245 | Write to this CSV file.
246 | """
247 | with open(filepath, "w") as f:
248 | for identifier, prediction in identifier2prediction.items():
249 | f.write(f"{identifier};{prediction}\n")
250 |
251 |
252 | def write_gt(identifier2label: Dict[str, str], filepath: str) -> None:
253 | """
254 | Write ground truth to a file.
255 |
256 | Parameters
257 | ----------
258 | identifier2label : Dict[str, str]
259 | filepath : str
260 | Write to this CSV file.
261 | """
262 | with open(filepath, "w") as f:
263 | for identifier, label in identifier2label.items():
264 | f.write(f"{identifier};{label}\n")
265 |
266 |
267 | def write_cm(path: str, cm: npt.NDArray) -> None:
268 | """
269 | Write confusion matrix to path.
270 |
271 | Parameters
272 | ----------
273 | path : str
274 | cm : npt.NDArray
275 | """
276 | with open(path, "w") as outfile:
277 | str_ = json.dumps(cm.tolist(), separators=(",", ": "), ensure_ascii=False)
278 | outfile.write(str_)
279 |
280 |
281 | def md5(fname: str) -> str:
282 | """Compute MD5 hash of a file."""
283 | hash_md5 = hashlib.md5()
284 | with open(fname, "rb") as f:
285 | for chunk in iter(lambda: f.read(4096), b""):
286 | hash_md5.update(chunk)
287 | return hash_md5.hexdigest()
288 |
--------------------------------------------------------------------------------
/clana/clustering.py:
--------------------------------------------------------------------------------
1 | """Everything about clustering classes of a confusion matrix."""
2 |
3 | # Core Library
4 | import logging
5 | import random
6 | from typing import List, TypeVar, Union, cast
7 |
8 | # Third party
9 | import numpy as np
10 | import numpy.typing as npt
11 |
12 | # First party
13 | import clana.utils
14 |
15 | cfg = clana.utils.load_cfg()
16 | logger = logging.getLogger(__name__)
17 |
18 |
19 | T = TypeVar("T")
20 |
21 |
22 | def apply_grouping(labels: List[T], grouping: List[int]) -> List[List[T]]:
23 | """
24 | Return list of grouped labels.
25 |
26 | Parameters
27 | ----------
28 | labels : List[T]
29 | grouping : List[int]
30 |
31 | Returns
32 | -------
33 | grouped_labels : List[List[T]]
34 |
35 | Examples
36 | --------
37 | >>> labels = ['de', 'en', 'fr']
38 | >>> grouping = [False, True]
39 | >>> apply_grouping(labels, grouping)
40 | [['de', 'en'], ['fr']]
41 | """
42 | groups = []
43 | current_group = [labels[0]]
44 | for label, cut in zip(labels[1:], grouping):
45 | if cut:
46 | groups.append(current_group)
47 | current_group = [label]
48 | else:
49 | current_group.append(label)
50 | groups.append(current_group)
51 | return groups
52 |
53 |
54 | def _remove_single_element_groups(hierarchy: List[List[T]]) -> List[Union[T, List[T]]]:
55 | """
56 | Flatten sub-lists of length 1.
57 |
58 | Parameters
59 | ----------
60 | hierarchy : List[List]
61 |
62 | Returns
63 | -------
64 | hierarchy : list of el / lists
65 |
66 | Examples
67 | --------
68 | >>> hierarchy = [[0], [1, 2]]
69 | >>> _remove_single_element_groups(hierarchy)
70 | [0, [1, 2]]
71 | """
72 | h_new: List[Union[T, List[T]]] = []
73 | for el in hierarchy:
74 | if len(el) > 1:
75 | h_new.append(el)
76 | else:
77 | h_new.append(el[0])
78 | return h_new
79 |
80 |
81 | def extract_clusters(
82 | cm: npt.NDArray,
83 | labels: List[str],
84 | steps: int = 10**4,
85 | lambda_: float = 0.013,
86 | method: str = "local-connectivity",
87 | interactive: bool = False,
88 | ) -> List[int]:
89 | """
90 | Find clusters in cm.
91 |
92 | Idea:
93 | mininmize lambda (error between clusters) - (count of clusters)
94 | s.t.: Each inter-cluster accuracy has to be lower than the overall
95 | accuracy
96 |
97 | Parameters
98 | ----------
99 | cm : npt.NDArray
100 | labels : List[str]
101 | steps : int
102 | lambda_ : float
103 | The closer to 0, the more groups
104 | The bigger, the bigger groups
105 | method : {'local-connectivity', 'energy'}
106 | interactive : bool
107 |
108 | Returns
109 | -------
110 | clustes : List[int]
111 | """
112 | if method == "energy":
113 | n = len(cm)
114 | grouping = [0 for _ in range(n - 1)]
115 | minimal_score = get_score(cm, grouping, lambda_)
116 | best_grouping = grouping[:]
117 | for _ in range(steps):
118 | pos = random.randint(0, n - 2)
119 | grouping = best_grouping[:]
120 | grouping[pos] = bool((grouping[pos] + 1) % 2)
121 | current_score = get_score(cm, grouping, lambda_)
122 | if current_score < minimal_score:
123 | best_grouping = grouping
124 | minimal_score = current_score
125 | logger.info(f"Best grouping: {grouping} (score: {minimal_score})")
126 | elif method == "local-connectivity":
127 | if interactive:
128 | thres: Union[float, int] = find_thres_interactive(cm, labels)
129 | else:
130 | thres = find_thres(cm, cfg["visualize"]["threshold"])
131 | logger.info(f"Found threshold for local connection: {thres}")
132 | best_grouping = split_at_con_thres(cm, thres, labels, interactive=interactive)
133 | else:
134 | raise NotImplementedError(f"method='{method}'")
135 | logger.info(f"Found {sum(best_grouping) + 1} clusters")
136 | return best_grouping
137 |
138 |
139 | def create_weight_matrix(grouping: List[int]) -> npt.NDArray:
140 | """
141 | Create a matrix which contains the distance to the diagonal.
142 |
143 | Parameters
144 | ----------
145 | grouping : List[int]
146 |
147 | Returns
148 | -------
149 | weight_matrix : npt.NDArray
150 | A symmetric matrix
151 | """
152 | n = len(grouping) + 1
153 | weight_matrix = np.zeros((n, n))
154 | for i in range(n):
155 | seen_1 = False
156 | for j in range(i + 1, n):
157 | if seen_1:
158 | weight_matrix[i][j] = 1
159 | elif grouping[j - 1] == 1:
160 | seen_1 = True
161 | weight_matrix[i][j] = 1
162 | return weight_matrix + weight_matrix.transpose()
163 |
164 |
165 | def get_score(cm: npt.NDArray, grouping: List[int], lambda_: float) -> float:
166 | """
167 | Get the score of a confusion matrix.
168 |
169 | Parameters
170 | ----------
171 | cm : npt.NDArray
172 | grouping : List[int]
173 | lambda_ : float
174 |
175 | Returns
176 | -------
177 | score : float
178 | """
179 | # First party
180 | from clana.visualize_cm import calculate_score
181 |
182 | inter_cluster_err = 0.0
183 | weights = create_weight_matrix(grouping)
184 | inter_cluster_err = calculate_score(cm, weights)
185 | return lambda_ * inter_cluster_err - sum(grouping)
186 |
187 |
188 | def find_thres(cm: npt.NDArray, percentage: float) -> float:
189 | """
190 | Find a threshold for grouping.
191 |
192 | Parameters
193 | ----------
194 | cm : npt.NDArray
195 | percentage : float
196 | Probability that two neighboring classes belong togehter
197 |
198 | Returns
199 | -------
200 | connectivity : float
201 | """
202 | n = int(len(cm) * (1.0 - percentage)) - 1
203 | con = sorted(get_neighboring_connectivity(cm))
204 | return con[n]
205 |
206 |
207 | def find_thres_interactive(cm: npt.NDArray, labels: List[str]) -> float:
208 | """
209 | Find a threshold for grouping.
210 |
211 | The threshold is the minimum connection strength for two classes to be
212 | within the same cluster.
213 |
214 | Parameters
215 | ----------
216 | cm : npt.NDArray
217 | labels : List[str]
218 |
219 | Returns
220 | -------
221 | pos_str : float
222 | """
223 | n = len(cm)
224 | con = sorted(zip(get_neighboring_connectivity(cm), zip(range(n - 1), range(1, n))))
225 | pos_str = None
226 |
227 | # Lowest position from which we know that they are connected
228 | pos_up = n - 1
229 |
230 | # Highest position from which we know that they are not connected
231 | neg_low = 0
232 | while pos_up - 1 > neg_low:
233 | print(f"pos_up={pos_up}, neg_low={neg_low}, pos_str={pos_str}")
234 | pos = int((pos_up + neg_low) / 2)
235 | con_str, (i1, i2) = con[pos]
236 | should_be_conn = input(
237 | f"Should {labels[i1]} and {labels[i2]} be in one cluster? (y/n): "
238 | )
239 | if should_be_conn == "n":
240 | neg_low = pos
241 | elif should_be_conn == "y":
242 | pos_up = pos
243 | pos_str = con_str
244 | else:
245 | print(f"Please type only 'y' or 'n'. You typed {should_be_conn}.")
246 | pos_str = cast(float, pos_str)
247 | return pos_str
248 |
249 |
250 | def get_neighboring_connectivity(cm: npt.NDArray) -> List[float]:
251 | """
252 | Get how strong neighboring classes are connected.
253 |
254 | Parameters
255 | ----------
256 | cm : npt.NDArray
257 |
258 | Returns
259 | -------
260 | con : List[float]
261 | """
262 | con = []
263 | n = len(cm)
264 | for i in range(n - 1):
265 | con.append(cm[i][i + 1] + cm[i + 1][i])
266 | return con
267 |
268 |
269 | def split_at_con_thres(
270 | cm: npt.NDArray, thres: float, labels: List[str], interactive: bool
271 | ) -> List[int]:
272 | """
273 | Two classes are not in the same group if they are not connected strong.
274 |
275 | Minimum connection strength is thres. The bigger this value, the more
276 | clusters / the smaller clusters you will get.
277 | """
278 | con = get_neighboring_connectivity(cm)
279 | grouping = []
280 | for i, el in enumerate(con):
281 | if el == thres and interactive:
282 | should_conn = "-"
283 | while should_conn not in ["y", "n"]:
284 | should_conn = input(
285 | f"Should {labels[i]} and {labels[i + 1]} be in one "
286 | "cluster? (y/n): "
287 | )
288 | if should_conn == "y":
289 | grouping.append(0)
290 | elif should_conn == "n":
291 | grouping.append(1)
292 | else:
293 | print("please type either 'y' or 'n'")
294 | else:
295 | grouping.append(el < thres)
296 | return grouping
297 |
--------------------------------------------------------------------------------
/clana/optimize.py:
--------------------------------------------------------------------------------
1 | """Optimize the column order of a confusion matrix."""
2 |
3 | # Core Library
4 | import logging
5 | import random
6 | from typing import Callable, List, NamedTuple, Tuple, Union
7 |
8 | # Third party
9 | import numpy as np
10 | import numpy.typing as npt
11 |
12 | logger = logging.getLogger(__name__)
13 |
14 |
15 | class OptimizationResult(NamedTuple):
16 | """The result of a matrix column/row order optimiataion (CMO)."""
17 |
18 | cm: npt.NDArray
19 | perm: npt.NDArray
20 |
21 |
22 | def calculate_score(cm: npt.NDArray, weights: npt.NDArray) -> int:
23 | """
24 | Calculate a score how close big elements of cm are to the diagonal.
25 |
26 | Parameters
27 | ----------
28 | cm : npt.NDArray
29 | The confusion matrix
30 | weights : npt.NDArray
31 | The weights matrix.
32 | It has to have the same shape as the confusion matrix
33 |
34 | Examples
35 | --------
36 | >>> cm = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
37 | >>> weights = calculate_weight_matrix(3)
38 | >>> weights.shape
39 | (3, 3)
40 | >>> calculate_score(cm, weights)
41 | 32
42 | """
43 | assert cm.shape == weights.shape
44 | return int(np.tensordot(cm, weights, axes=((0, 1), (0, 1))))
45 |
46 |
47 | def simulated_annealing(
48 | current_cm: npt.NDArray,
49 | current_perm: Union[None, List[int], npt.NDArray] = None,
50 | score: Callable[[npt.NDArray, npt.NDArray], float] = calculate_score,
51 | steps: int = 2 * 10**5,
52 | temp: float = 100.0,
53 | cooling_factor: float = 0.99,
54 | deterministic: bool = False,
55 | ) -> OptimizationResult:
56 | """
57 | Optimize current_cm by randomly swapping elements.
58 |
59 | Parameters
60 | ----------
61 | current_cm : npt.NDArray
62 | current_perm : None or iterable, optional (default: None)
63 | score: Callable[[npt.NDArray, npt.NDArray], float], optional
64 | (default: )
65 | steps : int, optional (default: 2 * 10**4)
66 | temp : float > 0.0, optional (default: 100.0)
67 | Temperature
68 | cooling_factor: float in (0, 1), optional (default: 0.99)
69 |
70 | Returns
71 | -------
72 | best_result : OptimizationResult
73 | """
74 | if temp <= 0.0:
75 | raise ValueError(f"temp={temp} needs to be positive")
76 | if cooling_factor <= 0.0 or cooling_factor >= 1.0:
77 | raise ValueError(
78 | f"cooling_factor={cooling_factor} needs to be in the interval (0, 1)"
79 | )
80 | n = len(current_cm)
81 | logger.info(f"n={n}")
82 |
83 | # Load the initial permutation
84 | if current_perm is None:
85 | current_perm = np.array(list(range(n)))
86 | current_perm = np.array(current_perm)
87 |
88 | # Pre-calculate weights
89 | weights = calculate_weight_matrix(n)
90 |
91 | # Apply the permutation
92 | current_cm = apply_permutation(current_cm, current_perm)
93 | current_score = score(current_cm, weights)
94 |
95 | best_cm = current_cm
96 | best_score = current_score
97 | best_perm = current_perm
98 |
99 | logger.info(f"## Starting Score: {current_score:0.2f}")
100 | for step in range(steps):
101 | tmp_cm = np.array(current_cm, copy=True)
102 | perm, make_swap = generate_permutation(n, current_perm, tmp_cm)
103 | tmp_score = score(tmp_cm, weights)
104 |
105 | # Should be swapped?
106 | if deterministic:
107 | chance = 1.0
108 | else:
109 | chance = random.random()
110 | temp *= 0.99
111 | hot_prob_thresh = min(1, np.exp(-(tmp_score - current_score) / temp))
112 | if chance <= hot_prob_thresh:
113 | changed = False
114 | if best_score > tmp_score: # minimize
115 | best_perm = perm
116 | best_cm = tmp_cm
117 | best_score = tmp_score
118 | changed = True
119 | current_score = tmp_score
120 | current_cm = tmp_cm
121 | current_perm = perm
122 | if changed:
123 | logger.info(
124 | (
125 | "Current: %0.2f (best: %0.2f, "
126 | "hot_prob_thresh=%0.4f%%, step=%i, swap=%s)"
127 | ),
128 | current_score,
129 | best_score,
130 | (hot_prob_thresh * 100),
131 | step,
132 | str(make_swap),
133 | )
134 | return OptimizationResult(cm=best_cm, perm=best_perm)
135 |
136 |
137 | def calculate_weight_matrix(n: int) -> npt.NDArray:
138 | """
139 | Calculate the weights for each position.
140 |
141 | The weight is the distance to the diagonal.
142 |
143 | Parameters
144 | ----------
145 | n : int
146 |
147 | Examples
148 | --------
149 | >>> calculate_weight_matrix(3)
150 | array([[0. , 1.01, 2.02],
151 | [1.01, 0. , 1.03],
152 | [2.02, 1.03, 0. ]])
153 | """
154 | weights = np.abs(np.arange(n) - np.arange(n)[:, None])
155 | weights = np.array(weights, dtype=float)
156 | for i in range(n):
157 | for j in range(n):
158 | if i == j:
159 | continue
160 | weights[i][j] += (i + j) * 0.01
161 | return weights
162 |
163 |
164 | def generate_permutation(
165 | n: int, current_perm: npt.NDArray, tmp_cm: npt.NDArray
166 | ) -> Tuple[npt.NDArray, bool]:
167 | """
168 | Generate a new permutation.
169 |
170 | Parameters
171 | ----------
172 | n : int
173 | current_perm : List[int]
174 | tmp_cm : npt.NDArray
175 |
176 | Return
177 | ------
178 | perm, make_swap : List[int], bool
179 | """
180 | swap_prob = 0.5
181 | make_swap = random.random() < swap_prob
182 | if n < 3:
183 | # In this case block-swaps don't make any sense
184 | make_swap = True
185 | if make_swap:
186 | # Choose what to swap
187 | i = random.randint(0, n - 1)
188 | j = i
189 | while j == i:
190 | j = random.randint(0, n - 1)
191 | # Define permutation
192 | perm = swap_1d(current_perm.copy(), i, j)
193 | # Define values after swap
194 | tmp_cm = swap(tmp_cm, i, j)
195 | else:
196 | # block-swap
197 | block_len = n
198 | while block_len >= n - 1:
199 | from_start = random.randint(0, n - 3)
200 | from_end = random.randint(from_start + 1, n - 2)
201 | block_len = from_start - from_end
202 | insert_pos = from_start
203 | while not (insert_pos < from_start or insert_pos > from_end):
204 | insert_pos = random.randint(0, n - 1)
205 | perm = move_1d(current_perm.copy(), from_start, from_end, insert_pos)
206 |
207 | # Define values after swap
208 | tmp_cm = move(tmp_cm, from_start, from_end, insert_pos)
209 | return perm, make_swap
210 |
211 |
212 | def apply_permutation(
213 | cm: npt.NDArray, perm: Union[List[int], npt.NDArray]
214 | ) -> npt.NDArray:
215 | """
216 | Apply permutation to a matrix.
217 |
218 | Parameters
219 | ----------
220 | cm : ndarray
221 | perm : List[int]
222 |
223 | Examples
224 | --------
225 | >>> cm = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
226 | >>> perm = np.array([2, 0, 1])
227 | >>> apply_permutation(cm, perm)
228 | array([[8, 6, 7],
229 | [2, 0, 1],
230 | [5, 3, 4]])
231 | """
232 | return cm[perm].transpose()[perm].transpose()
233 |
234 |
235 | def move_1d(
236 | perm: npt.NDArray, from_start: int, from_end: int, insert_pos: int
237 | ) -> npt.NDArray:
238 | """
239 | Move a block in a list.
240 |
241 | Parameters
242 | ----------
243 | perm : npt.NDArray
244 | Permutation
245 | from_start : int
246 | from_end : int
247 | insert_pos : int
248 |
249 | Returns
250 | -------
251 | perm : npt.NDArray
252 | The new permutation
253 | """
254 | if not (insert_pos < from_start or insert_pos > from_end):
255 | raise ValueError(
256 | f"insert_pos={insert_pos} needs to be smaller than "
257 | f"from_start={from_start} or greater than from_end={from_end}"
258 | )
259 | if insert_pos > from_end:
260 | p_new = list(range(from_end + 1, insert_pos + 1)) + list(
261 | range(from_start, from_end + 1)
262 | )
263 | else:
264 | p_new = list(range(from_start, from_end + 1)) + list(
265 | range(insert_pos, from_start)
266 | )
267 | p_old = sorted(p_new)
268 | perm[p_old] = perm[p_new]
269 | return perm
270 |
271 |
272 | def move(
273 | cm: npt.NDArray, from_start: int, from_end: int, insert_pos: int
274 | ) -> npt.NDArray:
275 | """
276 | Move rows from_start - from_end to insert_pos in-place.
277 |
278 | Parameters
279 | ----------
280 | cm : npt.NDArray
281 | from_start : int
282 | from_end : int
283 | insert_pos : int
284 |
285 | Returns
286 | -------
287 | cm : npt.NDArray
288 |
289 | Examples
290 | --------
291 | >>> cm = np.array([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 0, 1], [2, 3, 4, 5]])
292 | >>> move(cm, 1, 2, 0)
293 | array([[5, 6, 4, 7],
294 | [9, 0, 8, 1],
295 | [1, 2, 0, 3],
296 | [3, 4, 2, 5]])
297 | """
298 | if not (insert_pos < from_start or insert_pos > from_end):
299 | raise ValueError(
300 | f"insert_pos={insert_pos} needs to be smaller than "
301 | f"from_start={from_start} or greater than from_end={from_end}"
302 | )
303 | if insert_pos > from_end:
304 | p_new = list(range(from_end + 1, insert_pos + 1)) + list(
305 | range(from_start, from_end + 1)
306 | )
307 | else:
308 | p_new = list(range(from_start, from_end + 1)) + list(
309 | range(insert_pos, from_start)
310 | )
311 | p_old = sorted(p_new)
312 | # swap columns
313 | cm[:, p_old] = cm[:, p_new]
314 | # swap rows
315 | cm[p_old, :] = cm[p_new, :]
316 | return cm
317 |
318 |
319 | def swap_1d(perm: npt.NDArray, i: int, j: int) -> npt.NDArray:
320 | """
321 | Swap two elements of a 1-D numpy array in-place.
322 |
323 | Parameters
324 | ----------
325 | parm : npt.NDArray
326 | i : int
327 | j : int
328 |
329 | Examples
330 | --------
331 | >>> perm = np.array([2, 1, 2, 3, 4, 5, 6])
332 | >>> swap_1d(perm, 2, 6)
333 | array([2, 1, 6, 3, 4, 5, 2])
334 | """
335 | perm[i], perm[j] = perm[j], perm[i]
336 | return perm
337 |
338 |
339 | def swap(cm: npt.NDArray, i: int, j: int) -> npt.NDArray:
340 | """
341 | Swap row and column i and j in-place.
342 |
343 | Parameters
344 | ----------
345 | cm : npt.NDArray
346 | i : int
347 | j : int
348 |
349 | Returns
350 | -------
351 | cm : npt.NDArray
352 |
353 | Examples
354 | --------
355 | >>> cm = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
356 | >>> swap(cm, 2, 0)
357 | array([[8, 7, 6],
358 | [5, 4, 3],
359 | [2, 1, 0]])
360 | """
361 | # swap columns
362 | copy = cm[:, i].copy()
363 | cm[:, i] = cm[:, j]
364 | cm[:, j] = copy
365 | # swap rows
366 | copy = cm[i, :].copy()
367 | cm[i, :] = cm[j, :]
368 | cm[j, :] = copy
369 | return cm
370 |
--------------------------------------------------------------------------------
/clana/visualize_cm.py:
--------------------------------------------------------------------------------
1 | """
2 | Optimize confusion matrix.
3 |
4 | For more information, see
5 |
6 | * http://cs.stackexchange.com/q/70627/2914
7 | * http://datascience.stackexchange.com/q/17079/8820
8 | """
9 |
10 | # Core Library
11 | import json
12 | import logging
13 | from typing import List, Optional, Tuple
14 |
15 | # Third party
16 | import numpy as np
17 | import numpy.typing as npt
18 | from jinja2 import Template
19 | from mpl_toolkits.axes_grid1 import make_axes_locatable
20 | from pkg_resources import resource_filename
21 | from sklearn.metrics import silhouette_score
22 |
23 | # First party
24 | import clana.clustering
25 | import clana.cm_metrics
26 | import clana.io
27 | import clana.utils
28 | from clana.optimize import (
29 | calculate_score,
30 | calculate_weight_matrix,
31 | simulated_annealing,
32 | )
33 |
34 | cfg = clana.utils.load_cfg()
35 | logger = logging.getLogger(__name__)
36 |
37 |
38 | def main(
39 | cm_file: str,
40 | perm_file: str,
41 | steps: int,
42 | labels_file: str,
43 | zero_diagonal: bool,
44 | limit_classes: Optional[int] = None,
45 | output: Optional[str] = None,
46 | ) -> None:
47 | """
48 | Run optimization and generate output.
49 |
50 | Parameters
51 | ----------
52 | cm_file : str
53 | perm_file : str
54 | steps : int
55 | labels_file : str
56 | zero_diagonal : bool
57 | limit_classes : int, optional (default: no limit)
58 | output : str
59 | """
60 | cm = clana.io.read_confusion_matrix(cm_file)
61 | perm = clana.io.read_permutation(cm_file, perm_file)
62 | labels = clana.io.read_labels(labels_file, len(cm))
63 | n, m = cm.shape
64 | if n != m:
65 | raise ValueError(
66 | f"Confusion matrix is expected to be square, but was {n} x {m}"
67 | )
68 | if len(labels) - 1 != n:
69 | print(
70 | "Confusion matrix is {n} x {n}, but len(labels)={nb_labels}".format(
71 | n=n, nb_labels=len(labels)
72 | )
73 | )
74 |
75 | cm_orig = cm.copy()
76 |
77 | get_cm_problems(cm, labels)
78 |
79 | weights = calculate_weight_matrix(len(cm))
80 | print(f"Score: {calculate_score(cm, weights)}")
81 | result = simulated_annealing(
82 | cm, perm, score=calculate_score, deterministic=True, steps=steps
83 | )
84 | print(f"Score: {calculate_score(result.cm, weights)}")
85 | print(f"Perm: {list(result.perm)}")
86 | clana.io.ClanaCfg.store_permutation(cm_file, result.perm, steps)
87 | labels = [labels[i] for i in result.perm]
88 | class_indices = list(range(len(labels)))
89 | class_indices = [class_indices[i] for i in result.perm]
90 | logger.info(f"Classes: {labels}")
91 | acc = clana.cm_metrics.get_accuracy(cm_orig)
92 | print(f"Accuracy: {acc * 100:0.2f}%")
93 | start = 0
94 | if limit_classes is None:
95 | limit_classes = len(cm)
96 | if output is None:
97 | output = cfg["visualize"]["save_path"]
98 | plot_cm(
99 | result.cm[start:limit_classes, start:limit_classes],
100 | zero_diagonal=zero_diagonal,
101 | labels=labels[start:limit_classes],
102 | output=output,
103 | )
104 | create_html_cm(
105 | result.cm[start:limit_classes, start:limit_classes],
106 | zero_diagonal=zero_diagonal,
107 | labels=labels[start:limit_classes],
108 | )
109 | if len(cm) < 5:
110 | print(
111 | f"You only have {len(cm)} classes. Clustering for less than "
112 | "5 classes should be done manually."
113 | )
114 | return
115 | grouping = clana.clustering.extract_clusters(result.cm, labels)
116 | y_pred = [0]
117 | cluster_i = 0
118 | for el in grouping:
119 | if el:
120 | cluster_i += 1
121 | y_pred.append(cluster_i)
122 | logger.info(f"silhouette_score={silhouette_score(cm, y_pred)}")
123 | # Store grouping as hierarchy
124 | with open(cfg["visualize"]["hierarchy_path"], "w") as outfile:
125 | hierarchy = clana.clustering.apply_grouping(class_indices, grouping)
126 | hierarchy_mixed = clana.clustering._remove_single_element_groups(hierarchy)
127 | str_ = json.dumps(
128 | hierarchy_mixed,
129 | indent=4,
130 | sort_keys=True,
131 | separators=(",", ":"),
132 | ensure_ascii=False,
133 | )
134 | outfile.write(str_)
135 |
136 | # Print nice
137 | for group in clana.clustering.apply_grouping(labels, grouping):
138 | print(f"\t{len(group)}: {list(group)}")
139 |
140 |
141 | def get_cm_problems(cm: npt.NDArray, labels: List[str]) -> None:
142 | """
143 | Find problems of a classifier by analzing its confusion matrix.
144 |
145 | Parameters
146 | ----------
147 | cm : ndarray
148 | labels : List[str]
149 | """
150 | n = len(cm)
151 |
152 | # Find classes which are not present in the dataset
153 | for i in range(n):
154 | if sum(cm[i]) == 0:
155 | logger.warning(f"The class '{labels[i]}' was not in the dataset.")
156 |
157 | # Find classes which are never predicted
158 | cm = cm.transpose()
159 | never_predicted = []
160 | for i in range(n):
161 | if sum(cm[i]) == 0:
162 | never_predicted.append(labels[i])
163 | if len(never_predicted) > 0:
164 | logger.warning(f"The following classes were never predicted: {never_predicted}")
165 |
166 |
167 | def plot_cm(
168 | cm: npt.NDArray,
169 | zero_diagonal: bool = False,
170 | labels: Optional[List[str]] = None,
171 | output: str = cfg["visualize"]["save_path"],
172 | ) -> None:
173 | """
174 | Plot a confusion matrix.
175 |
176 | Parameters
177 | ----------
178 | cm : npt.NDArray
179 | zero_diagonal : bool, optional (default: False)
180 | labels : Optional[List[str]]
181 | If this is not given, then numbers are assigned to the classes
182 | """
183 | # Third party
184 | from matplotlib import pyplot as plt
185 | from matplotlib.colors import LogNorm
186 |
187 | n = len(cm)
188 | if zero_diagonal:
189 | for i in range(n):
190 | cm[i][i] = 0
191 | if n > 20:
192 | size = int(n / 4.0)
193 | else:
194 | size = 5
195 | fig = plt.figure(figsize=(size, size), dpi=80)
196 | plt.clf()
197 | ax = fig.add_subplot(111)
198 | ax.set_aspect(1)
199 | if labels is None:
200 | labels = [str(i) for i in range(len(cm))]
201 | x = list(range(len(cm)))
202 | plt.xticks(x, labels, rotation=cfg["visualize"]["xlabels_rotation"])
203 | y = list(range(len(cm)))
204 | plt.yticks(y, labels, rotation=cfg["visualize"]["ylabels_rotation"])
205 | if cfg["visualize"]["norm"] == "LogNorm":
206 | norm = LogNorm(vmin=max(1, np.min(cm)), vmax=np.max(cm)) # type: ignore
207 | elif cfg["visualize"]["norm"] is None:
208 | norm = None
209 | else:
210 | raise NotImplementedError(
211 | f"visualize->norm={cfg['visualize']['norm']} is not implemented. "
212 | "Try None or LogNorm"
213 | )
214 | res = ax.imshow(
215 | np.array(cm),
216 | cmap=cfg["visualize"]["colormap"],
217 | interpolation=cfg["visualize"]["interpolation"],
218 | norm=norm,
219 | )
220 | width, height = cm.shape
221 |
222 | divider = make_axes_locatable(ax)
223 | cax = divider.append_axes("right", size="5%", pad=0.5)
224 | plt.colorbar(res, cax=cax)
225 | plt.tight_layout()
226 |
227 | logger.info(f"Save figure at '{output}'")
228 | plt.savefig(output)
229 |
230 |
231 | def create_html_cm(
232 | cm: npt.NDArray, zero_diagonal: bool = False, labels: Optional[List[str]] = None
233 | ) -> None:
234 | """
235 | Plot a confusion matrix.
236 |
237 | Parameters
238 | ----------
239 | cm : npt.NDArray
240 | zero_diagonal : bool, optional (default: False)
241 | If this is set to True, then the diagonal is overwritten with zeroes.
242 | labels : Optional[List[str]]
243 | If this is not given, then numbers are assigned to the classes
244 | """
245 | if labels is None:
246 | labels = [str(i) for i in range(len(cm))]
247 |
248 | el_max = 200
249 |
250 | template_path = resource_filename("clana", "templates/base.html")
251 | with open(template_path) as f:
252 | base = f.read()
253 |
254 | cm_t = cm.transpose()
255 | header_cells = []
256 | for i, label in enumerate(labels):
257 | precision = cm[i][i] / float(sum(cm_t[i]))
258 | background_color = "transparent"
259 | if precision < 0.2:
260 | background_color = "red"
261 | elif precision > 0.98:
262 | background_color = "green"
263 | header_cells.append(
264 | {
265 | "precision": f"{precision:0.2f}",
266 | "background-color": background_color,
267 | "label": label,
268 | }
269 | )
270 |
271 | body_rows = []
272 | for i, label, row in zip(range(len(labels)), labels, cm):
273 | body_row = []
274 | row_str = [str(el) for el in row]
275 | support = sum(row)
276 | recall = cm[i][i] / float(support)
277 | background_color = "transparent"
278 | if recall < 0.2:
279 | background_color = "red"
280 | elif recall >= 0.98:
281 | background_color = "green"
282 | body_row.append(
283 | {
284 | "label": label,
285 | "recall": f"{recall:.2f}",
286 | "background-color": background_color,
287 | }
288 | )
289 | for _j, pred_label, el in zip(range(len(labels)), labels, row_str):
290 | background_color = "transparent"
291 | if el == "0":
292 | el = ""
293 | else:
294 | background_color = get_color_code(float(el), el_max)
295 |
296 | body_row.append(
297 | {
298 | "label": el,
299 | "true": label,
300 | "pred": pred_label,
301 | "background-color": background_color,
302 | }
303 | )
304 |
305 | body_rows.append({"row": body_row, "support": support})
306 |
307 | html_template = Template(base)
308 | html = html_template.render(header_cells=header_cells, body_rows=body_rows)
309 |
310 | with open(cfg["visualize"]["html_save_path"], "w") as f:
311 | f.write(html)
312 |
313 |
314 | def get_color(white_to_black: float) -> Tuple[int, int, int]:
315 | """
316 | Get grayscale color.
317 |
318 | Parameters
319 | ----------
320 | white_to_black : float
321 |
322 | Returns
323 | -------
324 | color : Tuple
325 |
326 | Examples
327 | --------
328 | >>> get_color(0)
329 | (255, 255, 255)
330 | >>> get_color(0.5)
331 | (128, 128, 128)
332 | >>> get_color(1)
333 | (0, 0, 0)
334 | """
335 | if not (0 <= white_to_black <= 1):
336 | raise ValueError(
337 | f"white_to_black={white_to_black} is not in the interval [0, 1]"
338 | )
339 |
340 | index = 255 - int(255 * white_to_black)
341 | r, g, b = index, index, index
342 | return int(r), int(g), int(b)
343 |
344 |
345 | def get_color_code(val: float, max_val: float) -> str:
346 | """
347 | Get a HTML color code which is between 0 and max_val.
348 |
349 | Parameters
350 | ----------
351 | val : number
352 | max_val : number
353 |
354 | Returns
355 | -------
356 | color_code : str
357 |
358 | Examples
359 | --------
360 | >>> get_color_code(0, 100)
361 | '#ffffff'
362 | >>> get_color_code(100, 100)
363 | '#000000'
364 | >>> get_color_code(50, 100)
365 | '#808080'
366 | """
367 | value = min(1.0, float(val) / max_val)
368 | r, g, b = get_color(value)
369 | return f"#{r:02x}{g:02x}{b:02x}"
370 |
--------------------------------------------------------------------------------
/tests/examples/wili-labels.csv:
--------------------------------------------------------------------------------
1 | Label;English;Wiki Code;ISO 369-3;German;Language family;Writing system;Remarks;Synonyms
2 | ace;Achinese;ace;ace;Achinesisch;Austronesian;;;
3 | afr;Afrikaans;af;afr;Afrikaans;Indo-European;;;
4 | als;Alemannic German;als;gsw;Alemannisch;Indo-European;;(ursprünglich nur Elsässisch);
5 | amh;Amharic;am;amh;Amharisch;Afro-Asiatic;;;
6 | ang;Old English ;ang;ang;Altenglisch;Indo-European;;(ca. 450-1100);Angelsächsisch
7 | ara;Arabic;ar;ara;Arabisch;Afro-Asiatic;;;
8 | arg;Aragonese;an;arg;Aragonesisch;Indo-European;;;
9 | arz;Egyptian Arabic;arz;arz;Ägyptisch-Arabisch;Afro-Asiatic;;;
10 | asm;Assamese;as;asm;Assamesisch;Indo-European;;;
11 | ast;Asturian;ast;ast;Asturisch;Indo-European;;;
12 | ava;Avar;av;ava;Awarisch;Northeast Caucasian;;;
13 | aym;Aymara;ay;aym;Aymara;Aymaran;;;
14 | azb;South Azerbaijani;azb;azb;Südaserbaidschanisch;Turkic;Arabic;;
15 | aze;Azerbaijani;az;aze;Aserbaidschanisch;Turkic;Latin;;
16 | bak;Bashkir;ba;bak;Baschkirisch;Turkic;;;
17 | bar;Bavarian;bar;bar;Bairisch;Indo-European;;;
18 | bcl;Central Bikol;bcl;bcl;Bikolano;Austronesian;;;
19 | be-tarask;Belarusian (Taraschkewiza);be-tarask;;Weißrussisch (Taraschkewiza);Indo-European;;;
20 | bel;Belarusian;be;bel;Weißrussisch;Indo-European;;(normativ);
21 | ben;Bengali;bn;ben;Bengalisch;Indo-European;;;
22 | bho;Bhojpuri;bh;bho;Bhojpuri;Indo-European;;;
23 | bjn;Banjar;bjn;bjn;Banjaresisch;Austronesian;;;
24 | bod;Tibetan;bo;bod;Tibetisch;Sino-Tibetan;;;
25 | bos;Bosnian;bs;bos;Bosnisch;Indo-European;;;
26 | bpy;Bishnupriya;bpy;bpy;Bishnupriya Manipuri;Indo-European;;;
27 | bre;Breton;br;bre;Bretonisch;Indo-European;;;
28 | bul;Bulgarian;bg;bul;Bulgarisch;Indo-European;;;
29 | bxr;Buryat;bxr;bxr;Burjatisch;Mongolic;Cyrillic:::Mongolian script:::Vagindra script:::Latin;;Buriat
30 | cat;Catalan;ca;cat;Katalanisch;Indo-European;Latin;;
31 | cbk;Chavacano;cbk-zam;cbk;Chabacano;Indo-European;;;
32 | cdo;Min Dong;cdo;cdo;Min Dong;Sino-Tibetan;;;
33 | ceb;Cebuano;ceb;ceb;Cebuano;Austronesian;Latin;;
34 | ces;Czech;cs;ces;Tschechisch;Indo-European;Latin;;
35 | che;Chechen;ce;che;Tschetschenisch;Northeast Caucasian;;;
36 | chr;Cherokee;chr;chr;Cherokee;Iroquoian;;;
37 | chv;Chuvash;cv;chv;Tschuwaschisch;Turkic;;;
38 | ckb;Central Kurdish;ckb;ckb;Sorani;Indo-European;;;
39 | cor;Cornish;kw;cor;Kornisch;Indo-European;;;
40 | cos;Corsican;co;cos;Korsisch;Indo-European;;;
41 | crh;Crimean Tatar;crh;crh;Krimtatarisch;Turkic;;;
42 | csb;Kashubian;csb;csb;Kaschubisch;Indo-European;;;
43 | cym;Welsh;cy;cym;Walisisch;Indo-European;;;
44 | dan;Danish;da;dan;Dänisch;Indo-European;;;
45 | deu;German;de;deu;Deutsch;Indo-European;Latin;;
46 | diq;Dimli;diq;diq;Süd-Zazaisch;Indo-European;;;
47 | div;Dhivehi;dv;div;Dhivehi;Indo-European;;;
48 | dsb;Lower Sorbian;dsb;dsb;Niedersorbisch;Indo-European;;;
49 | dty;Doteli;dty;dty;Doteli;Indo-European;;;
50 | egl;Emilian;eml;egl;Emilianisch;Indo-European;;;
51 | ell;Modern Greek;el;ell;Griechisch;Indo-European;;(1453-);
52 | eng;English;en;eng;Englisch;Indo-European;Latin;;
53 | epo;Esperanto;eo;epo;Esperanto;Constructed;;;
54 | est;Estonian;et;est;Estnisch;Uralic;;;
55 | eus;Basque;eu;eus;Baskisch;Language isolate;;;
56 | ext;Extremaduran;ext;ext;Extremadurisch;Indo-European;;;
57 | fao;Faroese;fo;fao;Färöisch;Indo-European;;;
58 | fas;Persian;fa;fas;Persisch;Indo-European;;;
59 | fin;Finnish;fi;fin;Finnisch;Uralic;Latin;;
60 | fra;French;fr;fra;Französisch;Indo-European;Latin;;
61 | frp;Arpitan;frp;frp;Frankoprovenzalisch;Indo-European;;;
62 | fry;Western Frisian;fy;fry;Westfriesisch;Indo-European;;;
63 | fur;Friulian;fur;fur;Furlanisch;Indo-European;;;
64 | gag;Gagauz;gag;gag;Gagausisch;Turkic;;;
65 | gla;Scottish Gaelic;gd;gla;Schottisch-Gälisch;Indo-European;;;
66 | gle;Irish;ga;gle;Irisch;Indo-European;;;
67 | glg;Galician;gl;glg;Galicisch;Indo-European;;;
68 | glk;Gilaki;glk;glk;Gilaki;Indo-European;;;
69 | glv;Manx;gv;glv;Manx;Indo-European;;;
70 | grn;Guarani;gn;grn;Guaraní;Tupi-Guarani;;;
71 | guj;Gujarati;gu;guj;Gujarati;Indo-European;;;
72 | hak;Hakka Chinese;hak;hak;Hakka;Sino-Tibetan;;;
73 | hat;Haitian Creole;ht;hat;Haitianisch;Indo-European;;;
74 | hau;Hausa;ha;hau;Hausa;Afro-Asiatic;Latin;;Chadic
75 | hbs;Serbo-Croatian;sh;hbs;Serbokroatisch;Indo-European;;;
76 | heb;Hebrew;he;heb;Hebräisch;Afro-Asiatic;;;
77 | hif;Fiji Hindi;hif;hif;Fidschi-Hindi;Indo-European;;;
78 | hin;Hindi;hi;hin;Hindi;Indo-European;;;
79 | hrv;Croatian;hr;hrv;Kroatisch;Indo-European;;;
80 | hsb;Upper Sorbian;hsb;hsb;Obersorbisch;Indo-European;;;
81 | hun;Hungarian;hu;hun;Ungarisch;Uralic;;;
82 | hye;Armenian;hy;hye;Armenisch;Indo-European;;;
83 | ibo;Igbo;ig;ibo;Igbo;Niger-Congo;Latin;;
84 | ido;Ido;io;ido;Ido;Constructed;;;
85 | ile;Interlingue;ie;ile;Interlingue;Constructed;;;
86 | ilo;Iloko;ilo;ilo;Ilokano;Austronesian;;;
87 | ina;Interlingua;ia;ina;Interlingua;Constructed;;;
88 | ind;Indonesian;id;ind;Indonesisch;Austronesian;Latin;;
89 | isl;Icelandic;is;isl;Isländisch;Indo-European;;;
90 | ita;Italian;it;ita;Italienisch;Indo-European;Latin;;
91 | jam;Jamaican Patois;jam;jam;Jamaikanisch-kreolisch;Indo-European;;;
92 | jav;Javanese;jv;jav;Javanisch;Austronesian;;;
93 | jbo;Lojban;jbo;jbo;Lojban;Constructed;Latin;;
94 | jpn;Japanese;ja;jpn;Japanisch;Japonic;;;
95 | kaa;Karakalpak;kaa;kaa;Karakalpakisch;Turkic;;;
96 | kab;Kabyle;kab;kab;Kabylisch;Afro-Asiatic;;;
97 | kan;Kannada;kn;kan;Kannada;Dravidian;;;
98 | kat;Georgian;ka;kat;Georgisch;South Caucasian;;;
99 | kaz;Kazakh;kk;kaz;Kasachisch;Turkic;;;
100 | kbd;Kabardian;kbd;kbd;Kabardinisch;Northeast Caucasian;Cyrillic:::Latin:::Arabic;;Kabardino-Cherkess:::East Circassian
101 | khm;Central Khmer;km;khm;Khmer;Austronesian;;;
102 | kin;Kinyarwanda;rw;kin;Kinyarwanda;Niger-Congo;Latin;;Fumbira
103 | kir;Kirghiz;ky;kir;Kirgisisch;Turkic;;;
104 | koi;Komi-Permyak;koi;koi;Komi-Permjakisch;Uralic;;;
105 | kok;Konkani;gom;kok;Konkani;Indo-European;;;
106 | kom;Komi;kv;kom;Komi;Uralic;;;
107 | kor;Korean;ko;kor;Koreanisch;Koreanic;;;
108 | krc;Karachay-Balkar;krc;krc;Karatschai-balkarisch;Turkic;;;
109 | ksh;Ripuarisch;ksh;ksh;Kölsch;Indo-European;;;
110 | kur;Kurdish;ku;kur;Kurdisch;Indo-European;Latin;;
111 | lad;Ladino;lad;lad;Judenspanisch;Indo-European;;;
112 | lao;Lao;lo;lao;Laotisch;Tai-Kadai;;;
113 | lat;Latin;la;lat;Latein;Indo-European;;;
114 | lav;Latvian;lv;lav;Lettisch;Indo-European;;;
115 | lez;Lezghian;lez;lez;Lesgisch;Northeast Caucasian;;;
116 | lij;Ligurian;lij;lij;Ligurisch;Indo-European;;(Romanisch);
117 | lim;Limburgan;li;lim;Limburgisch;Indo-European;;;
118 | lin;Lingala;ln;lin;Lingála;Niger-Congo;;;
119 | lit;Lithuanian;lt;lit;Litauisch;Indo-European;;;
120 | lmo;Lombard;lmo;lmo;Lombardisch;Indo-European;;;
121 | lrc;Northern Luri;lrc;lrc;nördliches Luri;Indo-European;;;
122 | ltg;Latgalian;ltg;ltg;Lettgallisch;Indo-European;;;
123 | ltz;Luxembourgish;lb;ltz;Luxemburgisch;Indo-European;;;
124 | lug;Luganda;lg;lug;Luganda;Niger-Congo;Latin;;Ganda
125 | lzh;Literary Chinese;zh-classical;lzh;klassisches Chinesisch;Sino-Tibetan;;;
126 | mai;Maithili;mai;mai;Maithili;Indo-European;;;
127 | mal;Malayalam;ml;mal;Malayalam;Dravidian;;;
128 | map-bms;Banyumasan;map-bms;map-bms;Banyumasan;Austronesian;;Javanese;
129 | mar;Marathi;mr;mar;Marathi;Indo-European;;;
130 | mdf;Moksha;mdf;mdf;Mokschanisch;Uralic;Cyrillic;;
131 | mhr;Eastern Mari;mhr;mhr;Ostmari;Uralic;;;
132 | min;Minangkabau;min;min;Minangkabauisch;Austronesian;;;
133 | mkd;Macedonian;mk;mkd;Mazedonisch;Indo-European;;;
134 | mlg;Malagasy;mg;mlg;Malagasy;Austronesian;;;
135 | mlt;Maltese;mt;mlt;Maltesisch;Afro-Asiatic;;;
136 | mon;Mongolian;mn;mon;Mongolisch;Mongolic;;;
137 | mri;Maori;mi;mri;Maori;Austronesian;;;
138 | mrj;Western Mari;mrj;mrj;Westmari;Uralic;;;
139 | msa;Malay;ms;msa;Malaiisch;Austronesian;;;
140 | mwl;Mirandese;mwl;mwl;Mirandés;Indo-European;;;
141 | mya;Burmese;my;mya;Birmanisch;Sino-Tibetan;;;
142 | myv;Erzya;myv;myv;Ersja-Mordwinisch;Uralic;;;
143 | mzn;Mazanderani;mzn;mzn;Masanderanisch;Indo-European;;;
144 | nan;Min Nan Chinese;zh-min-nan;nan;Min Nan;Sino-Tibetan;;;
145 | nap;Neapolitan;nap;nap;Neapolitanisch;Indo-European;;;
146 | nav;Navajo;nv;nav;Navajo;Dené-Yeniseian;;;
147 | nci;Classical Nahuatl;nah;nci;Nahuatl;Uto-Aztecan;;;
148 | nds;Low German;nds;nds;Niedersächsisch/Ostniederdeutsch;Indo-European;;;
149 | nds-nl;West Low German;nds-nl;nds;Nedersaksisch;Indo-European;;;
150 | nep;Nepali (macrolanguage);ne;nep;Nepali;Indo-European;;;
151 | new;Newari;new;new;Newari;Sino-Tibetan;;;
152 | nld;Dutch;nl;nld;Niederländisch;Indo-European;Latin;;
153 | nno;Norwegian Nynorsk;nn;nno;Nynorsk;Indo-European;;;
154 | nob;Bokmål;nb;nob;Bokmål;Indo-European;Latin;Norwegian;
155 | nrm;Narom;nrm;nrm;Normannisch;Austronesian;;;
156 | nso;Northern Sotho;nso;nso;Nord-Sotho;Niger-Congo;;;
157 | oci;Occitan;oc;oci;Okzitanisch;Indo-European;;(post 1500);
158 | olo;Livvi-Karelian;olo;olo;Olonetzisch;Uralic;;;
159 | ori;Oriya;or;ori;Oriya;Indo-European;;;
160 | orm;Oromo;om;orm;Oromo;Afro-Asiatic;Latin:::Ge'ez ;;
161 | oss;Ossetian;os;oss;Ossetisch;Indo-European;;;
162 | pag;Pangasinan;pag;pag;Pangasinensisch;Austronesian;;;
163 | pam;Pampanga;pam;pam;Kapampangan;Austronesian;;;
164 | pan;Panjabi;pa;pan;Panjabi in Gurmukhi-Schrift;Indo-European;;;
165 | pap;Papiamento;pap;pap;Papiamentu;Indo-European;;;
166 | pcd;Picard;pcd;pcd;Picardisch;Indo-European;;;
167 | pdc;Pennsylvania German;pdc;pdc;Pennsylvaniadeutsch;Indo-European;;;Deitsch:::Pennsylvania Deitsch:::Pennsilfaanisch Deitsch:::Pennsylvania Dutch
168 | pfl;Palatine German;pfl;pfl;Pfälzisch;Indo-European;;;
169 | pnb;Western Panjabi;pnb;pnb;Panjabi;Indo-European;Arabic;;
170 | pol;Polish;pl;pol;Polnisch;Indo-European;Latin;;
171 | por;Portuguese;pt;por;Portugiesisch;Indo-European;Latin;;
172 | pus;Pushto;ps;pus;Paschtunisch;Indo-European;;;
173 | que;Quechua;qu;que;Quechua;Quechuan;;;
174 | roa-tara;Tarantino dialect;roa-tara;;Tarandíne;Indo-European;;;
175 | roh;Romansh;rm;roh;Bündnerromanisch;Indo-European;;;
176 | ron;Romanian;ro;ron;Rumänisch;Indo-European;;;
177 | rue;Rusyn;rue;rue;Karpato-Russinisch;Indo-European;;;
178 | rup;Aromanian;roa-rup;rup;Aromunisch;Indo-European;Latin;Macedo-Romanian::Vlach;
179 | rus;Russian;ru;rus;Russisch;Indo-European;Cyrillic;;
180 | sah;Yakut;sah;sah;Jakutisch;Turkic;;;
181 | san;Sanskrit;sa;san;Sanskrit;Indo-European;;;
182 | scn;Sicilian;scn;scn;Sizilianisch;Indo-European;;;
183 | sco;Scots;sco;sco;Scots;Indo-European;;;
184 | sgs;Samogitian;bat-smg;sgs;Schemaitisch;Indo-European;;;
185 | sin;Sinhala;si;sin;Singhalesisch;Indo-European;;;
186 | slk;Slovak;sk;slk;Slowakisch;Indo-European;;;
187 | slv;Slovene;sl;slv;Slowenisch;Indo-European;;;
188 | sme;Northern Sami;se;sme;Nordsamisch;Uralic;;;
189 | sna;Shona;sn;sna;Shona;Niger-Congo;;;
190 | snd;Sindhi;sd;snd;Sindhi;Indo-European;;;
191 | som;Somali;so;som;Somali;Afro-Asiatic;;;
192 | spa;Spanish;es;spa;Spanisch;Indo-European;Latin;;
193 | sqi;Albanian;sq;sqi;Albanisch;Indo-European;;;
194 | srd;Sardinian;sc;srd;Sardisch;Indo-European;;;
195 | srn;Sranan;srn;srn;Sranantongo;Indo-European;;;Sranan Tongo:::Sranantongo:::Surinaams:::Surinamese:::Surinamese Creole:::Taki Taki
196 | srp;Serbian;sr;srp;Serbisch;Indo-European;;;
197 | stq;Saterfriesisch;stq;stq;Saterfriesisch;Indo-European;;;
198 | sun;Sundanese;su;sun;Sundanesisch;Austronesian;;;
199 | swa;Swahili (macrolanguage);sw;swa;Swahili;Niger-Congo;;;
200 | swe;Swedish;sv;swe;Schwedisch;Indo-European;Latin;;
201 | szl;Silesian;szl;szl;Schlesisch;Indo-European;;(polnischer Dialekt);
202 | tam;Tamil;ta;tam;Tamil;Dravidian;;;
203 | tat;Tatar;tt;tat;Tatarisch;Turkic;;;
204 | tcy;Tulu;tcy;tcy;Tulu;Dravidian;Kannada:::Tigalari;;
205 | tel;Telugu;te;tel;Telugu;Dravidian;;;
206 | tet;Tetum;tet;tet;Tetum;Austronesian;;;
207 | tgk;Tajik;tg;tgk;Tadschikisch;Indo-European;;;
208 | tgl;Tagalog;tl;tgl;Tagalog;Austronesian;;;
209 | tha;Thai;th;tha;Thailändisch;Tai-Kadai;;;
210 | ton;Tongan;to;ton;Tongaisch;Austronesian;Latin;;
211 | tsn;Tswana;tn;tsn;Setswana;Niger-Congo;Latin;;Setswana
212 | tuk;Turkmen;tk;tuk;Turkmenisch;Turkic;;;
213 | tur;Turkish;tr;tur;Türkisch;Turkic;;;
214 | tyv;Tuvan;tyv;tyv;Tuwinisch;Turkic;Cyrillic;;
215 | udm;Udmurt;udm;udm;Udmurtisch;Uralic;;;
216 | uig;Uighur;ug;uig;Uigurisch;Turkic;;;
217 | ukr;Ukrainian;uk;ukr;Ukrainisch;Indo-European;Cyrillic;;
218 | urd;Urdu;ur;urd;Urdu;Indo-European;;;
219 | uzb;Uzbek;uz;uzb;Usbekisch;Turkic;;;
220 | vec;Venetian;vec;vec;Venetisch;Indo-European;;;
221 | vep;Veps;vep;vep;Wepsisch;Uralic;;;
222 | vie;Vietnamese;vi;vie;Vietnamesisch;Austronesian;Latin;;
223 | vls;Vlaams;vls;vls;Westflämisch;Indo-European;;;
224 | vol;Volapük;vo;vol;Volapük;Constructed;;;
225 | vro;Võro;fiu-vro;vro;Võro;Uralic;;;
226 | war;Waray;war;war;Wáray-Wáray;Austronesian;Latin;;
227 | wln;Walloon;wa;wln;Wallonisch;Indo-European;;;
228 | wol;Wolof;wo;wol;Wolof;Niger-Congo;Latin:::Arabic;;
229 | wuu;Wu Chinese;wuu;wuu;Wu;Sino-Tibetan;;;
230 | xho;Xhosa;xh;xho;isiXhosa;Niger-Congo;Latin;;isiXhosa
231 | xmf;Mingrelian;xmf;xmf;Mingrelisch;Kartvelian;;;
232 | yid;Yiddish;yi;yid;Jiddisch;Indo-European;;;
233 | yor;Yoruba;yo;yor;Yoruba;Niger-Congo;;;
234 | zea;Zeeuws;zea;zea;Seeländisch;Indo-European;;;
235 | zh-yue;Cantonese;zh-yue;;Kantonesisch;Sino-Tibetan;;;
236 | zho;Standard Chinese;zh;zho;Chinesisch;Sino-Tibetan;;;
237 |
--------------------------------------------------------------------------------