├── .github
└── workflows
│ └── automerge.yml
├── .gitignore
├── 02주차
├── 발표자료
│ ├── [2주차]_1,2장_스프링배치_김광훈.md
│ ├── [2주차]_1,2장_스프링배치_황준호.md
│ └── tmp.md
└── 요약본
│ ├── [2주차]_1,2장_스프링배치_김명수.md
│ ├── [2주차]_1,2장_스프링배치_김민석.md
│ ├── [2주차]_1,2장_스프링배치_이호빈.md
│ ├── [2주차]_1,2장_스프링배치_함호식.md
│ └── tmp.md
├── 03주차
├── 발표자료
│ ├── [3주차]_4장_스프링배치_함호식.md
│ ├── [3주차]_4장_잡과스텝이해하기-1_김성모.md
│ └── tmp.md
└── 요약본
│ ├── [3주차]_4장_잡과스텝이해하기-1_김광훈.md
│ ├── [3주차]_4장_잡과스텝이해하기-1_김명수.md
│ ├── [3주차]_4장_잡과스텝이해하기-1_김민석.md
│ ├── [3주차]_4장_잡과스텝이해하기-1_이호빈.md
│ ├── [3주차]_4장_잡과스텝이해하기-1_황준호.md
│ └── tmp.md
├── 04주차
├── 발표자료
│ ├── [4주차]_4장_잡과스텝이해하기-2_김광훈.md
│ ├── [4주차]_4장_잡과스텝이해하기-2_김명수.md
│ └── tmp.md
└── 요약본
│ ├── [4주차]_4장_스프링배치_함호식.md
│ ├── [4주차]_4장_잡과스텝이해하기-2_김민석.md
│ ├── [4주차]_4장_잡과스텝이해하기-2_김성모.md
│ ├── [4주차]_4장_잡과스텝이해하기-2_이호빈.md
│ ├── [4주차]_4장_잡과스텝이해하기-2_황준호.md
│ └── tmp.md
├── 05주차
├── 발표자료
│ ├── [5주차]_5장_JobRepository와_메타데이터_이호빈.md
│ ├── [5주차]_5장_JobRepository와메타데이터_김민석.md
│ └── tmp.md
└── 요약본
│ ├── [5주차]_5장_JobRepository와_메타데이터_김광훈.md
│ ├── [5주차]_5장_JobRepository와_메타데이터_황준호.md
│ ├── [5주차]_5장_JobRepository와메타데이터_김명수.md
│ ├── [5주차]_5장_JobRepository와메타데이터_김성모.md
│ ├── [5주차]_5장_스프링배치_함호식.md
│ └── tmp.md
├── 06주차
├── 발표자료
│ ├── [6주차]_6장_잡_실행하기_김성모.md
│ ├── [6주차]_6장_잡실행하기_이호빈.md
│ └── tmp.md
└── 요약본
│ ├── [6주차]_6장_스프링배치_함호식.md
│ ├── [6주차]_6장_잡_실행하기_김광훈.md
│ ├── [6주차]_6장_잡_실행하기_김민석.md
│ ├── [6주차]_6장_잡_실행하기_황준호.md
│ └── tmp.md
├── 07주차
├── 발표자료
│ ├── [7주차]_7장_ItemReader(1)_김성모.md
│ ├── [7주차]_7장_ItemReader_김민석.md
│ └── tmp.md
└── 요약본
│ ├── [7주차]_7장_ItemReader-1_김명수.md
│ ├── [7주차]_7장_ItemReader-1_이호빈.md
│ ├── [7주차]_7장_ItemReader-1_황준호.md
│ ├── [7주차]_7장_스프링배치_함호식.md
│ └── tmp.md
├── 08주차
├── 발표자료
│ ├── [7주차]_7장_ItemReader-2_황준호.md
│ ├── [8주차]_7장_ItemReader-2_김명수.md
│ └── tmp.md
└── 요약본
│ ├── [8주차]_7장_ItemReader(2)_김성모.md
│ ├── [8주차]_7장_ItemReader-2_김광훈.md
│ ├── [8주차]_7장_ItemReader-2_이호빈.md
│ ├── [8주차]_7장_ItemReader_김민석.md
│ ├── [8주차]_7장_스프링배치_함호식.md
│ └── tmp.md
├── 09주차
├── 발표자료
│ ├── CompositeItemProcessor.png
│ ├── [9주차]_8장_ItemProcessor_김광훈.md
│ ├── [9주차]_8장_스프링배치_함호식.md
│ └── tmp.md
└── 요약본
│ ├── [9주차]_8장_ItemProcessor_김명수.md
│ ├── [9주차]_8장_ItemProcessor_김민석.md
│ ├── [9주차]_8장_ItemProcessor_김성모.md
│ ├── [9주차]_8장_ItemProcessor_이호빈.md
│ ├── [9주차]_8장_ItemProcessor_황준호.md
│ └── tmp.md
├── 10주차
├── 발표자료
│ ├── [10주차]_9장_ItemWriter_김성모.md
│ ├── [10주차]_9장_ItemWriter_황준호.md
│ └── tmp.md
└── 요약본
│ ├── [10주차]_9장_ItemWriter_김명수.md
│ ├── [10주차]_9장_ItemWriter_김민석.md
│ ├── [10주차]_9장_ItemWriter_이호빈.md
│ ├── [10주차]_9장_스프링배치_함호식.md
│ ├── [9주차]_9장_ItemWriter-1_김광훈.md
│ └── tmp.md
├── 11주차
├── 발표자료
│ ├── [11주차]_9장_ItemWriter_김민석.md
│ ├── [11주차]_9장_ItemWriter_함호식.md
│ └── tmp.md
└── 요약본
│ ├── [11주차]_9장_ItemWriter_김광훈.md
│ ├── [11주차]_9장_ItemWriter_김명수.md
│ ├── [11주차]_9장_ItemWriter_김성모.md
│ ├── [11주차]_9장_ItemWriter_이호빈.md
│ ├── [11주차]_9장_ItemWriter_황준호.md
│ └── tmp.md
├── 12주차
├── 발표자료
│ ├── [12주차]_11장_확장과 튜닝_김성모.md
│ ├── [12주차]_11장_확장과튜닝_김광훈.md
│ └── tmp.md
└── 요약본
│ ├── [12주차]_11장_확장과튜닝_김명수.md
│ ├── [12주차]_11장_확장과튜닝_김민석.md
│ ├── [12주차]_11장_확장과튜닝_이호빈.md
│ ├── [12주차]_11장_확장과튜닝_함호식.md
│ ├── images
│ ├── visualVM_custome_test.png
│ ├── visualVM_monitor.png
│ ├── visualVM_overview.png
│ ├── visualVM_plugin.png
│ ├── visualVM_run_debug.png
│ ├── visualVM_sampler.png
│ └── visualVM_thread.png
│ └── tmp.md
├── 13주차
├── 발표자료
│ ├── [13주차]_12장_클라우드_네이티브_배치_김명수.md
│ ├── [13주차]_13장_배치_처리_테스트하기_이호빈.md
│ └── tmp.md
└── 요약본
│ ├── [13주차]_13장_배치_처리_테스트하기_김광훈.md
│ ├── [13주차]_13장_배치_처리_테스트하기_김민석.md
│ ├── [13주차]_13장_배치_처리_테스트하기_함호식.md
│ ├── [13주차]_13장_배치처리테스트하기_김성모.md
│ └── tmp.md
└── README.md
/.github/workflows/automerge.yml:
--------------------------------------------------------------------------------
1 | name: automerge
2 | on:
3 | schedule:
4 | - cron: '0 13 * * 5'
5 | jobs:
6 | automerge:
7 | runs-on: ubuntu-latest
8 | steps:
9 | - name: automerge
10 | uses: "pascalgn/automerge-action@v0.13.1"
11 | env:
12 | GITHUB_TOKEN: "${{ secrets.GITHUB_TOKEN }}"
13 | MERGE_LABELS: ""
14 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | src/main/generated/
2 | HELP.md
3 | .gradle
4 | build/
5 | !gradle/wrapper/gradle-wrapper.jar
6 | !**/src/main/**/build/
7 | !**/src/test/**/build/
8 | /log
9 |
10 | ### STS ###
11 | .apt_generated
12 | .classpath
13 | .factorypath
14 | .project
15 | .settings
16 | .springBeans
17 | .sts4-cache
18 | bin/
19 | !**/src/main/**/bin/
20 | !**/src/test/**/bin/
21 |
22 | ### IntelliJ IDEA ###
23 | .idea
24 | *.iws
25 | *.iml
26 | *.ipr
27 | out/
28 | !**/src/main/**/out/
29 | !**/src/test/**/out/
30 |
31 | ### NetBeans ###
32 | /nbproject/private/
33 | /nbbuild/
34 | /dist/
35 | /nbdist/
36 | /.nb-gradle/
37 |
38 | ### VS Code ###
39 | .vscode/
40 |
--------------------------------------------------------------------------------
/02주차/발표자료/[2주차]_1,2장_스프링배치_황준호.md:
--------------------------------------------------------------------------------
1 | ## 1장. 배치와 스프링
2 |
3 | ### 배치 처리란?
4 |
5 | - 상호작용이나 중단 없이 유한한 양의 데이터를 처리하는 것
6 | - 일단 시작되면 아무런 개입 없이 어떤 형태로든 완료된다
7 |
8 | ### 배치 처리는 왜 필요한가?
9 |
10 | 1. 필요한 정보를 실제 처리가 시작되기 전에 미리 수집할 수 있다
11 | 2. 때로는 사업적으로 도움이 된다
12 | 3. 자원을 더 효율적으로 사용할 수 있다
13 |
14 | ### 배치 처리를 개발하는 데 기술적으로 해결해야 하는 과제들
15 |
16 | 1. (코드의) 사용성
17 | - 공통 컴포넌트를 쉽게 확장해 새로운 기능을 추가할 수 있는가?
18 | - 기존 컴포넌트를 변경할 때 시스템 전체에 미치는 영향을 알 수 있도록 단위테스트가 잘 마련돼있는가?
19 | - 잡이 실패할 때 디버깅에 오랜 시간을 소비하지 않고, 언제, 어디서, 왜 실패했는지 알 수 있는가?
20 | 2. 확장성
21 | - 배치가 처리할 수 있는 규모가 웹 애플리케이션의 규모보다 몇자리 수 이상 더 클 수 있다
22 | 3. 가용성
23 | - 필요할 때 바로 배치 처리를 수행할 수 있는가?
24 | - 허용된 시간 내에 잡을 수행함으로써 다른 시스템에 영향을 미치지 않게 할 수 있는가?
25 | 4. 보안
26 | - 민감한 데이터베이스 필드는 암호화돼 있는가?
27 | - 실수로 개인 정보를 로그로 남기지는 않는가?
28 | - 자격증명이 필요한가?
29 |
30 | ### 왜 자바로 배치를 처리하는가?
31 |
32 | 1. 유지 보수성
33 | - 스프링 프레임워크는 테스트 용이성이나 추상화같은 이점을 얻을 수 있도록 설계됐다
34 | - DI를 통해 객체간 결합을 제거할 수 있다
35 | - 테스트 도구를 활용하여 유지 보수시 발행할 수 있는 위험을 줄일 수 있다
36 | - JDBC 코드나 파일I/O API를 직접 다룰 필요 없다
37 | - 트랜잭션 및 커밋 횟수같은 것들을 제공하므로 실패시 무슨 일을 해야 하는지 관리할 필요가 없다
38 | 2. 유연성
39 | - 배치 처리가 가능한 플랫폼은 메인프레임, C++/UNIX 등이 있다
40 | - 위 방식들은 JVM의 유연성과 스프링 배치의 기능들을 제공하지 않는다
41 | - 스프링 배치는 유닉스 계열 또는 윈도우 서버, 데스크탑 등등 어디에서든 돌아간다
42 | - 웹 애플리케이션에서 이미 테스트 및 디버깅 된 서비스를 배치 처리에서 동일하게 바로 사용할 수 있다
43 | 3. 확장성
44 | - 단일 서버 내의 단일 JVM에서 배치처리를 수행할수도, 나눠서 수행할수도 있다.
45 | - 클라우드 리소스를 사용하여 배치처리할 수 있다
46 | 4. 개발 리소스
47 | - 배치 처리 코드는 수명이 길기 때문에 개발 인력을 구하는 것도 중요하다.
48 | - 스프링 개발자는 많다
49 | 5. 지원
50 | - 온라인 커뮤니티가 잘 갖춰져 있다
51 | - 소스코드에 접근할 수 있고 비용을 지불하면 기술 지원을 받을 수 있다
52 | 6. 비용
53 | - 스프링 배치는 가장 저렴한 솔루션
54 |
55 | ### 스프링 배치의 사용 사례
56 |
57 | - ETL(추출, 변환, 적재) 처리
58 | - 스프링 배치의 청크기반 처리 및 확장 기능은 ETL워크로드에 자연스럽게 들어맞는다
59 | - 데이터 마이그레이션
60 | - 잡을 기동하는데 많은 코딩이 필요없다
61 | - 마이그레이션에 필요한 커밋 횟수 측정이나 롤백 기능을 제공한다
62 | - 병렬 처리
63 | - 멀티 코어 도는 멀티 서버에 처리를 분산하는 기능을 제공한다
64 |
65 | ### 스프링 배치 프레임워크
66 |
67 | - 스프링 배치의 구조
68 |
69 | - 레이어 구조로 조립된 세개의 티어로 이뤄져 있다
70 |
71 | 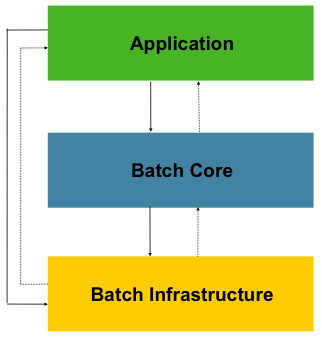
72 |
73 | - 애플리케이션 레이어
74 |
75 | - 코어 레이어와 상호작용하는데 대부분의 시간을 소비한다
76 |
77 | - 코어 레이어
78 |
79 | - 배치 도메인을 정의하는 모든 부분이 포함된다
80 | - `Job`, `Step`, `JobLauncher`, `JobParameters` 등이 있다
81 |
82 | - 인프라스트럭쳐 레이어
83 |
84 | - 파일, 데이터베이스 등으로부터 읽고 쓸 수 있게 한다
85 | - 잡 실패 후 재시도될 때 어떤 일을 수행할 지 다룰 수 있게 한다
86 |
87 | - 잡 config
88 |
89 | - 중단이나 상호작용 없이 처음부터 끝까지 실행되는 처리
90 |
91 | - 여러 개의 스텝이 모여 이뤄질 수 있다
92 |
93 | - 여러 방법으로 구성할 수 있지만, 아래는 자바 구성 클래스에 구성하는 방법을 보여준다
94 |
95 | ```java
96 | @Bean
97 | public AccountTasklet accountTasklet() {
98 | // 커스텀 컴포넌트. 스프링 배치는 AccountTasklet이 완료될때까지 execute메서드를 반복해서 호출한다. (각각은 새 트랜잭션으로 호출됨)
99 | return new AccountTasklet();
100 | }
101 |
102 | @Bean
103 | public Job accountJob() {
104 | Step accountStep = this.stepBuilderFactory.get("accountStep")
105 | .tasklet(accountTasklet())
106 | .build();
107 |
108 | return this.jobBuilderFactory.get("accountJob")
109 | .start("accountStep")
110 | .build();
111 | }
112 | ```
113 |
114 | - 잡 관리
115 |
116 | - 실패해서 재실행할 때 필요한 잡의 상태 정보를 유지해준다
117 | - 실패했을 때 데이터 무결성을 유지할 수 있도록 트랜잭션을 관리해준다
118 |
119 |
120 |
121 |
122 | ## 2장. 스프링 배치
123 |
124 | ### 스텝
125 |
126 | - 잡을 구성하는 독립된 작업의 단위
127 | - 스텝은 두가지 유형이 있음
128 | 1. tasklet기반 스텝
129 | - 비교적 더 간단함
130 | - `Tasklet`을 구현하면 됨. 스텝이 중지될 때까지 `execute`메서드가 계속 반복해서 수행된다
131 | - 초기화, 저장 프로시저 실행, 알림 전송 등과 같은 잡에서 사용
132 | 2. chunk기반 스텝
133 | - 약간 더 복잡함
134 | - 아이템 기반 처리에 사용
135 | - `ItemReader`, `ItemProcessor`(필수x), `ItemWriter`으로 구성
136 | - 스텝을 분리하는 것의 이점
137 | 1. 유연성 : 재사용할 수 있도록 여러 빌더 클래스 제공
138 | 2. 유지보수성 : 각 스텝은 독립적 -> 각 스텝의 단위테스트, 디버그, 변경 등을 할 수 있음. 또 독립적이기 때문에 여러 잡에서 재사용 가능
139 | 3. 확장성 : 스텝을 병렬로 실행할 수 있는 등의 확장 가능한 기능 제공
140 | 4. 신뢰성 : 오류 처리 방법(예외 발생시 재시도, 건너뛰기 등) 제공
141 |
142 | ### `JobRepository`
143 |
144 | - 다양한 배치 수행과 관련된 수치 데이터, 잡의 상태를 유지/관리
145 | - 실행된 스텝, 현재 상태, 읽은 아이템 수, 처리된 아이템 수 등이 저장됨
146 | - 관계형 데이터베이스 사용
147 | - 스프링 배치 내의 대부분의 주요 컴포넌트가 공유
148 |
149 | ### `JobLauncher`
150 |
151 | - `Job.execute`를 실행하는 역할
152 | - 잡이 재실행 가능한지, 잡을 어떻게 실행할건지(현재 스레드에서 할지, 스레드 풀을 통해 실행할지), 파라미터 유효성 검증 등의 처리도 함
153 |
154 | ### `Job`, `JobInstance`, `JobExecution`
155 |
156 | - `JobInstance` : 배치 잡의 논리적인 실행. "잡의 이름"과 "식별 파라미터"로 식별할 수 있다.
157 | - `JobExecution` : 배치 잡의 실제 실행. 잡을 구동할때마다 새로운 `JobExecution`을 얻는다.
158 |
159 | -> 한 잡을 같은 파라미터로 2번 실행했는데 첫번째는 실패, 두번째는 성공했다면 `JobInstance`는 1개, `JobExecution`는 2개
160 |
161 | ### `StepExecution`
162 |
163 | - `JobExecution`이 잡의 실제 실행을 나타내듯이 `StepExecution`은 스텝의 실제 실행을 나타낸다
164 | - `StepInstance`라는 개념은 존재하지 않는다
165 |
166 | ### 병렬화 방법
167 |
168 | 1. 다중 스레드 스텝을 이용해 잡 나누기
169 | - 잡은 청크라는 블록 단위로 처리되도록 구성됨
170 | - 각 청크는 독립적인 트랜잭션으로 처리됨
171 | - 일반적으로 각 청크는 연속해서 처리됨
172 | - 여러 스레드를 사용하도록 변경하면 처리량을 늘릴 수 있다
173 | 2. 스텝을 병렬로 실행
174 | - 각 스텝이 연관이 없다면 병렬로 실행하는게 효율적
175 | 3. 비동기 `ItemProcessor`/`ItemWriter` 구성
176 | - `AsynchronousItemProcessor` , `AsynchronousItemWriter` 등을 사용할 수 있다
177 | 4. 원격 청킹
178 | - 메시지 브로커등을 통해 여러 JVM에서 처리를 분산할 수 있다
179 | - 단 네트워크 사용량이 매우 많아질 수 있다
180 | 5. 파티셔닝
181 | - 원격 파티셔닝과 로컬 파티셔닝을 모두 지원한다
182 |
183 | ### Hello world!
184 |
185 | ```java
186 | @EnableBatchProcessing //배치 인프라스터럭쳐를 부트스트랩하는데 사용됨
187 | @SpringBootApplication
188 | public class BatchApplication {
189 |
190 | @Autowired
191 | private JobBuilderFactory jobBuilderFactory;
192 | @Autowired
193 | private StepBuilderFactory stepBuilderFactory;
194 |
195 | @Bean
196 | public Step step() {
197 | return stepBuilderFactory.get("step")
198 | .tasklet(new Tasklet() {
199 | @Override
200 | public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext)
201 | throws Exception {
202 | System.out.println("Hello, World!");
203 | return RepeatStatus.FINISHED; //tasklet이 완료됐음을 스프링배치에게 알리는 역할
204 | }
205 | }).build();
206 | }
207 |
208 | @Bean
209 | public Job job() {
210 | return jobBuilderFactory.get("job")
211 | .start(step())
212 | .build();
213 | }
214 |
215 | public static void main(String[] args) {
216 | SpringApplication.run(BatchApplication.class, args);
217 | }
218 | }
219 | ```
220 |
221 | - 실행하면 "Hello, World!"가 출력되고 종료된다.
222 | - 실제로 일어난 일
223 | 1. `@SpringBootApplication`이 스프링부트를 부트스트랩한다
224 | 2. `ApplicationContext` 생성됨
225 | 3. 스프링배치가 클래스 경로에 있어서` JobLauncherCommandLineRunner`가 실행됨
226 | 4. 잡이 수행되어 첫번째 스텝이 실행됨(이때 트랜잭션이 시작됨)
227 | 5. `Tasklet`이 실행됨
228 | 6. 결과가 `JobRepository`에 갱신됨
--------------------------------------------------------------------------------
/02주차/발표자료/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/02주차/요약본/[2주차]_1,2장_스프링배치_김민석.md:
--------------------------------------------------------------------------------
1 | # 1장 배치와 스프링
2 |
3 |
4 | - 배치의 장점
5 | - 실제 처리가 시작되기 전에 필요한 정보를 미리 수집할 수 있다.
6 | - 사업적인 도움. 실제 처리가 시작되기 전에 최소 할 수 있는 시간적 여유를 줄 수 있다.
7 | - 자원의 효울적 사용
8 |
9 |
10 | - 배치가 직면한 과제
11 | - 품질특성 관련한 문제
12 | - 품질특성
13 | - 
14 | - 사용성/ 유지보수성/ 확장성
15 |
16 |
17 | - 자바(스프링)를 사용하는 이유
18 | - 유지보수성
19 | - 유연성
20 | - 확장성
21 | - 개발 리소스
22 | - 지원
23 | - 비용
24 |
25 | - 스프링 배치의 기타 사용 사례
26 | - ETL
27 | - 데이터 마이그레이션
28 | - 병렬처리
29 | - 무중단/상시 데이터 처리
30 |
31 | - 스프링 배치 프레임워크
32 | - Site
33 | - https://spring.io/projects/spring-batch
34 | - Sample
35 | - https://github.com/spring-projects/spring-batch/tree/main/spring-batch-samples
36 | - 구조
37 | - 
38 | - Job 관리
39 | - 로컬/원격 병렬화
40 | - I/O 표준화하기
41 | - 에코시스템
42 | - 스프링 부트
43 | - 스프링 클라우드 태스크
44 | - 스프링 클라우드 데이터 플로우
45 | - 스프링 모든 기능
46 |
47 |
48 |
49 | # 2장 스프링 배치
50 |
51 |
52 | ## 배치 아키텍처
53 | - Job과 Step
54 | - Job
55 | - 상태를 수집하고 이전 상태에서 다음 상태로 전환.
56 | - State Machine
57 | - Step으로 구성
58 | - Step
59 | - Tasklet
60 | - 심플
61 | - 초기화/ 프로시저 실행/ 알림전송 같은 작업에서 사용
62 | - Chunk
63 | - 상대적으로 좀 더 복잡
64 | - ItemReader/ ItemProcessor/ ItemWriter 으로 구성 가능
65 | - 패키지 구성
66 | - 
67 | - 
68 | - 스텝은 각기 독립적으로 실행
69 | - 유연성/ 유지보수성/ 확장성/ 신뢰성 확보
70 |
71 | - Job 실행
72 | - JobRepository
73 | - 배치 수행과 관련된 수치 데이터 및 잡의 상태 관리
74 | - RDB 사용
75 | - 
76 | - JobLauncher
77 | - 잡 실행 담당
78 | - Job -> JobInstance -> JobExecution
79 | - 
80 |
81 |
82 | ## 병렬화
83 |
84 | - 다중 스레드 스텝
85 | - 스텝 내부의 여러 청크를 각각 스레드로 실행
86 | - 병렬 스텝
87 | - 독립적인 스텝을 병렬적으로 실행
88 | - 비동기 ItemProcessor/ItemWriter
89 | - Process와 write를 Asynch하게 실행. 결과는 Future로 반환.
90 | - 원격청킹
91 | - 복수 JVM 사용
92 | - 마스터 노드에서 메세지 큐를 사용하여 원격 워커 ItemProcessor로 전송
93 | - 파티셔닝
94 | - 원격청킹과 비슷하나 마스터는 워커의 스텝 수집을 위한 컨트롤러 역할만 수행
95 | - 각 워커의 스텝은 독립적으로 실행되나 마치 로컬에서 동작하는 것처럼 보임.
96 |
97 |
98 | ## Example - HelloWorld
99 |
100 | ```java
101 | @EnableBatchProcessing
102 | @SpringBootApplication
103 | public class HelloWorldApplication {
104 |
105 | @Autowired
106 | private JobBuilderFactory jobBuilderFactory;
107 |
108 | @Autowired
109 | private StepBuilderFactory stepBuilderFactory;
110 |
111 | @Bean
112 | public Step step() {
113 | return this.stepBuilderFactory.get("step1")
114 | .tasklet(new Tasklet() {
115 | @Override
116 | public RepeatStatus execute(StepContribution contribution,
117 | ChunkContext chunkContext) {
118 | System.out.println("Hello, World!");
119 | return RepeatStatus.FINISHED;
120 | }
121 | }).build();
122 | }
123 |
124 | @Bean
125 | public Job job() {
126 | return this.jobBuilderFactory.get("job")
127 | .start(step())
128 | .build();
129 | }
130 |
131 | public static void main(String[] args) {
132 | SpringApplication.run(HelloWorldApplication.class, args);
133 | }
134 | }
135 |
136 | ```
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
--------------------------------------------------------------------------------
/02주차/요약본/[2주차]_1,2장_스프링배치_이호빈.md:
--------------------------------------------------------------------------------
1 | # 1장 배치와 스프링
2 |
3 | > 배치 처리는 상호작용이나 중단 없이 유한한 양의 데이터를 처리하는 것으로 정의한다
4 |
5 | ### 배치를 작성할 때 중요하게 봐야할 점
6 |
7 | - 쉽게 확장해서 새로운 기능을 추가할 수 있는가?
8 | - 기존 코드를 변경했을 때 시스템에 미치는 영향을 알기 위해 테스트가 잘 작성되어있나?
9 | - Job이 실패할 때, 언제 어디서 왜 실패했는지 알 수 있는가?
10 | - 원하는 시간에 다른 시스템에 영향을 끼치지 않으면서 배치 처리를 할 수 있는가?
11 | - 데이터를 안전하게 저장할 수 있는가?
12 |
13 | ### 배치 개발을 자바로 하는 이유
14 |
15 | - 테스트하기 용이하고 추상화같은 이점을 얻을 수 있는 스프링 프레임워크 사용 가능
16 | - 어디서든 실행 가능한 JVM의 유연성
17 | - 커뮤니티도 빵빵함
18 |
19 | ### 스프링 배치 사용 사례
20 |
21 | - 청크 기반으로 추출, 변환, 적재 처리
22 | - 데이터 마이그레이션
23 | - 병렬 처리 → 멀티 코어, 멀티 서버에 처리를 분산하는 기능을 제공함
24 |
25 | ### 스프링 배치 구조
26 |
27 | > 애플리케이션 레이어 > 코어, 인프라스트럭처 레이어
28 |
29 | 
30 |
31 |
32 | - 애플리케이션 레이어
33 | - 코어 레이어
34 | - 인프라스트럭처 레이어
35 | - 여기에 ItemReader, ItemWriter를 비롯해 재시작과 관련된 문제를 해결할 수 있는 클래스와 인터페이스를 제공한다.
36 |
37 | # 2장 스프링 배치
38 |
39 | ### 스프링 배치
40 |
41 | - SynchonousItemProcessor를 ItemProcessor가 호출될 때마다 동일한 스레드에서 실행되게 할 수 있다
42 | - `@EnableBatchProcessing` 애너테이션은 배치 인프라를 위한 대부분의 스프링 빈 정의를 제공한다.
43 | - JobRepository, JobLauncher 등등...
44 | - 안에 @ComponentScan과 @EnableAutoConfiguration이 결합되어 있다
45 | - 즉, Job과 Step을 만들기 위해 스프링 배치가 제공하는 두 개의 빌더(JobBuilderFactory, StepBuilderFactory)만 Autowired하면 된다
46 | - 스프링 배치는 여러 빌더 클래스를 제공한다
47 |
48 | ### Step
49 |
50 | - Step은 독립된 작업의 단위
51 | - Step에는 Tasklet과 Chunk 기반 스텝이 있음
52 | - Tasklet Step은 보통 초기화, 저장 프로시저 실행, 알림 전송 등과 같은 Job에서 사용된다
53 | - Step도 Bean이라서 재사용할 수 있다
54 | - 하나의 스텝 내에서 처리할 일을 여러 스레드에 나눠서 병렬로 처리할 수 있다
55 | - retry하거나 skip을 할 수 있다
56 | - JobRepository는 RDBMS를 사용하며 JobLauncher, Job, Step과 공유한다.
57 | - JobLauncher는 Job을 실행하는 역할
58 | - Job.execute 호출
59 | - Job의 실행 방법
60 | - Job에 쓰이는 파라미터 유효성 검증 등
61 | - Step이 실행되면 JobRepository는 실행된 Step, 현재 상태, 읽은 아이템 등 모두 JobRepository에 저장한다.
62 | - Step이 각 Chunk를 처리할 때마다 JobRepository 내 StepExecution의 스텝 상태가 업데이트 된다
63 | - Step들이 서로 관련이 없다면 병렬로 Step을 실행시킬 수도 있다
64 |
65 | ### Job
66 |
67 | - Job이 다른 파라미터로 실행될 때마다 새로운 JobInstance가 생성된다.
68 | - 만약 파라미터가 같다면 새로운 JobExecution만 얻고 JobInstance는 새로 얻지 않는다
69 | - 그래서 하나의 JobInstance는 여러 개의 JobExecution을 얻을 수 있다.
70 | - Job → JobInstance → JobExecution
71 | - 각각 1:N 관계
72 | - Chunk마다 트랜잭션 단위가 되고 스레드 단위가 돼서 병렬로 처리하면 빠르게 처리할 수 있다
73 |
--------------------------------------------------------------------------------
/02주차/요약본/[2주차]_1,2장_스프링배치_함호식.md:
--------------------------------------------------------------------------------
1 | 1.배치와 스프링
2 | --
3 |
4 | ##### 배치 정의
5 | 상호작용이나 중단 없이 유한한 양의 데이터를 처리하는 것.
6 | 배치처리가 일단 시작되면, 아무런 개입 없이 어떤 형태로든 완료된다.
7 |
8 | ##### 배치 처리의 장점
9 | 1. 실제 처리가 시작되기 전에 필요한 정보를 미리 수집할 수 있다.
10 | ex) 월말 거래 내역 조회
11 | 2. 자원의 효율적 사용
12 | * 일반적인 데이터 모델 처리
13 | 1. 모델의 생성
14 | -> 배치 처리로 생성
15 | 2. 생성된 모델을 놓고 새로운 데이터 평가
16 | -> 생성된 모델로 실시간 사용
17 |
18 | ##### 배치 특징
19 | * 사용자의 개입이 없어, 일반 애플리케이션이 가지는 문제가 대체적으로 발생하지 않음
20 | * 사용량 급증과 사용자 중심의 에러 처리 문제는 배치함 처리시 예측이 가능함
21 | -> 따라서 확실한 로그와 피드백용 알림을 사용해 신속, 정확하게 에러를 발생시킨다.
22 |
23 | ---
24 |
25 | ##### 소프트웨어 아키텍처의 공통적인 속성
26 | 1. 사용성
27 | 2. 유지 보수성
28 | 3. 확장성
29 |
30 | ##### 배치 아키텍처의 속성
31 | 1. 사용성(오류 처리 및 유지 보수성과 관련)
32 | * 단위테스트가 잘 작성되었는지
33 | * 왜 실패했는지 알 수 있는지
34 | 2. 확장성
35 | * worker를 여러개 두어 동시 실행?과 같이 큰 규모의 데이터를 다룰 수 있는 것
36 | 3. 가용성
37 | * 필요할 때 배치를 실행할 수 있는지
38 | * 허용된 시간내에 잡을 수행함으로써 다른 시스템에 영향을 끼치지 않는지
39 |
40 | ###### java를 사용하는 이유
41 | * 유지보수성
42 | * 배치 특성상 코드의 수명이 길다.
43 | -> 큰 위험 없이 쉽게 수정할 수 있어야한다.
44 | * 스프링 프레임워크의 이점을 얻을 수 있다.
45 | * 유연성
46 | * 배포를 위한 JVM의 유연성(OS)
47 | * 개발 리소스
48 | * 확장성
49 | * 비용
50 |
51 | ---
52 | ##### 스프링 배치 일반적인 사용
53 | 1. ETL(추출-Extract, 변환-Transform, 적재-Load)
54 | 2. 데이터 마이그레이션
55 | * 테스트가 가능하다.
56 | * 커밋 횟수 측정, 롤백과 같은 기능 제공
57 | 3. 병렬 처리
58 | * 단일 작업을 빨리하는 것보다, 많은 작업을 병렬로 처리하는 것이 성능의 향상의 지름길이다.
59 |
60 | ---
61 | ##### 스프링 배치 프레임워크
62 | 레이어 구조(3 tier)
63 | * 애플리케이션 레이어
64 | -> 배치 처리 구축의 코드 및 구성
65 | (코어와 인프라스트럭쳐를 감싸고 있음)
66 | * 코어
67 | * 잡 - 중단이나 상호작용 없이 처음부터 끝까지 실행되는 처리
68 | * 스텝 - 잡과 관련된 입력과 출력이 있을 수 있음
69 | +) 잡(1) : 스텝(1..N)
70 | * 인프라스트럭처
71 | -> 데이터를 읽고 씀
72 | -> 잡 수행 실패 후 재시도시 어떤일을 수행할지 선택
73 |
74 | 스프링 기반으로 구축
75 | -> 의존성 주입, AOP, 트랜잭션 관리등의 필요한 기능을 사용 가능
76 |
77 |
78 | 2.스프링 배치
79 | --
80 |
81 | ##### 잡과 스텝
82 | 잡 - (스텝1 -> 스텝2 -> 스텝3)
83 | * 스텝 : 잡을 구성하는 독립된 작업 단위
84 | * tasklet 기반
85 | -> 스텝이 중지될 때까지 execute 메서드가 반복적 수행
86 | (execute마다 독립된 트랜잭션을 가짐)
87 | * chunk 기반
88 | -> 아이템 기반 처리에 사용
89 | * ItemReader
90 | * ItemProcessor (필수 아님)
91 | * ItemWriter
92 |
93 | 스텝을 분리함으로써 얻는 이점
94 | * 유연성
95 | * 유지 보수성
96 | -> 각 스텝의 코드는 독립적이므로 다른 스텝에 영향을 끼치지 않음
97 | * 확장성
98 | -> 각 스텝을 병렬로 실행 가능
99 | * 신뢰성
100 | -> 스텝의 여러 단계에 적용할 수 있는 강력한 오류 처리 방법 제공
101 | (재시도, 스킵)
102 |
103 |
104 | ##### 잡 실행
105 |
106 | * JobRepository
107 | -> 다양한 배치 수행과 관련된 수치 데이터와 잡의 상태를 유지 관리한다.
108 | (주로 RDB를 사용하여 관련 정보(배치의 시작&종료 시간, 상태, 읽기&쓰기 횟수)를 공유한다.)
109 | 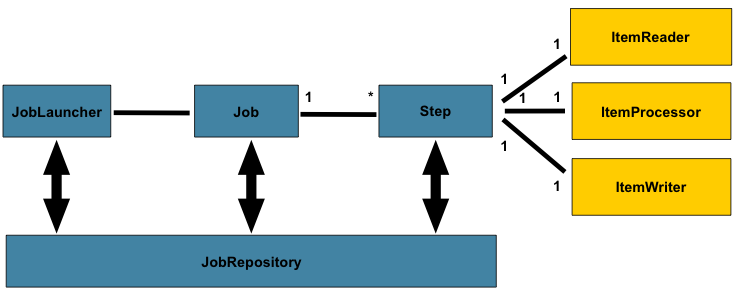
110 |
111 | * JobLauncher
112 | -> 잡을 실행하는 역할을 담당
113 | -> Job.execute를 호출, 재실행가능 여부, 잡의 실행 방법, 유효성 검증 등을 수행
114 | * JobInstance
115 | -> 잡의 이름과 잡의 논리적 실행을 위헤 제공되는 고유한 파라미터 식별 모음
116 | (잡이 다른 파라미터로 실행될 때마다 새로운 JobInstance 생성)
117 | * JobExecution
118 | -> 스프링 배치잡의 실제 실행을 의미
119 | -> 잡을 구동할 때마다 매번 새로운 JobExecution을 얻게됨
120 | -> 실패한 잡을 재실행시 새로운 JobInstance를 얻지 못하고 새로운 JobExecution이 생성됨
121 | * StepExecution스텝
122 | -> 실제 실행을 의미함
123 | -> 일반적으로 JobExecution은 여러 개의 StepExecution과 관계가 있음
124 |
125 | ##### 병렬화
126 | 1. 다중 스레드 스텝을 통한 작업분할
127 | -> 청크라는 블록단위로 처리되도록 구성(각각 독립적인 트랜잭션)
128 | -> 전체 레코드가 1,000개이고, 커밋단위를 100개로 설정했다면 2개의 스레드로 처리할 경우 이론상 2배의 처리량을 갖는다.
129 | 2. 전체 스텝의 병렬 실행
130 | -> 각 스텝이 영향을 끼치지 않는다면, 기다릴 필요 없이 병렬로 스텝을 처리할 수 있다.
131 | 3. 비동기 ItemProcessor, ItemWriter 구성
132 | -> 스텝 내의 ItemProcessor가 병목현상을 일으킬 수 있다. 현재 청크 내에서 Future를 반환하며 비동기 처리를 할 수 있다.
133 | 4. 원격 청킹
134 | -> 메시지 브로커(Rabbit MQ, Active MQ)를 통해 원격 청킹이 가능하다.
135 | (마스터에서 데이터를 읽고 원격 워커에 처리 후 다시 마스터로 전송하므로 네트워크 사용량이 많아질 수 있음)
136 | 5. 파티셔닝
137 | -> 마스터는 워커의 스텝 수집을 위한 컨트롤러 역할만 함
138 | -> 모든 워커의 스텝은 독립적으로 동작
139 |
140 | ##### annotation
141 | * EnableBatchProcessing
142 | -> 배치 인프라스트럭처를 위한 대부분의 스프링 빈 정의를 제공
143 | * JobRepository
144 | * JobLauncher
145 | * JobExplorer
146 | * PlatformTransactionManager
147 | * JobBuilderFactory
148 | * StepBuilderFactory
--------------------------------------------------------------------------------
/02주차/요약본/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/03주차/발표자료/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/03주차/요약본/[3주차]_4장_잡과스텝이해하기-1_김광훈.md:
--------------------------------------------------------------------------------
1 | # 4장. 잡과 스텝 이해하기
2 | ## 1. Job
3 | #### 잡 러너
4 | - CommandLineRunner: 스크립트 혹은 명령행에서 직접 실행
5 | - JobRegistryBackgroundJobRunner: 부트스트랩해서 기동한 자바 프로세스 내에서 쿼츠나 JMX 후크 같은 스케줄러를 실행 --> JobRegistry 생성
6 |
7 | #### 배치스키마
8 | - 데이터베이스에 배치 스키마가 존재하지 않는다면 자동 생성
9 |
10 | #### 잡 파라미터
11 | - 잡 이름 및 잡에 전달된 식별 파라미터로 식별
12 | - 동일한 식별 파라미터를 사용해 동일한 잡을 두 번 이상 실행 못 함
13 |
14 | #### 잡 파라미터 주의사항
15 | - 잡 파라미터는 스프링 부트의 명령행 기능을 사용해 프로퍼티를 구성하는 것과 다르다
16 | - 따라서 -- 접두사를 사용해 잡 파라미터를 전달하면 안 된다.
17 | - -D 인자도 사용하면 안된다.
18 | - Late binding 못쓰게 됨
19 |
20 | #### 예제 1
21 | ```java
22 | @EnableBatchProcessing // 배치 인프라스트럭처 제공
23 | @SpringBootApplication
24 | public class HelloWorldJob {
25 |
26 | @Autowired
27 | private JobBuilderFactory jobBuilderFactory; // JobBuilder 생성
28 |
29 | @Autowired
30 | private StepBuilderFactory stepBuilderFactory; // StepBuilder 생성
31 |
32 |
33 | // 잡 파라미터 validate 로직
34 | @Bean
35 | public CompositeJobParametersValidator validator() {
36 | CompositeJobParametersValidator validator =
37 | new CompositeJobParametersValidator();
38 |
39 | DefaultJobParametersValidator defaultJobParametersValidator =
40 | new DefaultJobParametersValidator(
41 | new String[] {"fileName"},
42 | new String[] {"name", "currentDate"});
43 |
44 | defaultJobParametersValidator.afterPropertiesSet();
45 |
46 | validator.setValidators(
47 | Arrays.asList(new ParameterValidator(),
48 | defaultJobParametersValidator));
49 |
50 | return validator;
51 | }
52 |
53 | // Tasklet 구현체 람다로 전달
54 | @Bean
55 | public Step step1() {
56 | return this.stepBuilderFactory.get("step1")
57 | .tasklet(helloWorldTasklet(null, null))
58 | .build();
59 | }
60 |
61 | @StepScope
62 | @Bean
63 | public Tasklet helloWorldTasklet(
64 | @Value("#{jobParameters['name']}") String name, // SPEL 을 사용해 잡 파라미터 전달
65 | @Value("#{jobParameters['fileName']}") String fileName) {
66 |
67 | return (contribution, chunkContext) -> {
68 |
69 | System.out.println(String.format("Hello, %s!", name));
70 | System.out.println(String.format("fileName = %s", fileName));
71 |
72 | return RepeatStatus.FINISHED;
73 | };
74 | }
75 |
76 | }
77 | ```
78 |
79 | #### 예제 2
80 | ```java
81 | public class JobLoggerListener {
82 |
83 | private static String START_MESSAGE = "%s is beginning execution";
84 | private static String END_MESSAGE = "%s has completed with the status %s";
85 |
86 | @BeforeJob // Job 실헹 전에 실행
87 | public void beforeJob(JobExecution jobExecution) {
88 | System.out.println(String.format(START_MESSAGE,
89 | jobExecution.getJobInstance().getJobName()));
90 | }
91 |
92 | @AfterJob // Job 실행 후에 실행
93 | public void afterJob(JobExecution jobExecution) {
94 | System.out.println(String.format(END_MESSAGE,
95 | jobExecution.getJobInstance().getJobName(),
96 | jobExecution.getStatus()));
97 | }
98 | }
99 | ```
--------------------------------------------------------------------------------
/03주차/요약본/[3주차]_4장_잡과스텝이해하기-1_이호빈.md:
--------------------------------------------------------------------------------
1 | # 4장 잡과 스텝 이해하기
2 |
3 | ## 잡
4 |
5 | - Bean 구성방식과 동일해서 재사용이 가능하며 여러 번 실행할 수 있다
6 | - 순서가 있는 여러 스텝을 가지고 있다
7 | - 외부 의존성 없이 실행할 수 있는 일련의 스텝이다
8 |
9 | ### 잡의 실행
10 |
11 | - JobRunner에서 잡의 실행이 이뤄진다
12 | - CommandLineJobRunner
13 | - 스프링 배치가 제공함
14 | - 스크립트를 이용하거나 명령행에서 직접 전달할 때
15 | - JobRegistryBackgroundJobRunner
16 | - 스프링 배치가 제공함
17 | - Quartz 같은 스케줄러를 사용해 잡을 실행할 때 (JobRegistry를 생성함)
18 | - JobLauncherCommandLineRunner
19 | - 스프링부트는 별도의 구성이 없을 때 얘를 실행시킴
20 | - 잡을 실행할 때 TaskExecutor 인터페이스를 사용한다
21 | - SyncTaskExecutor를 사용하면 JobLauncher와 동일한 스레드에서 실행된다
22 | - JobInstance는 Job이름과 실행 시에 사용되는 식별 파라미터로 사용된다.
23 | - JobInstance는 한 번 **성공적으로 완료되면** 다시 실행시킬 수 없다. 동일한 식별 파라미터를 사용하는 Job은 한 번만 실행할 수 있다
24 | - JobInstance의 상태를 알 수 있는 건 그 상태가 매번 DB에 저장되기 때문
25 | - JobExecution은 Job 실행의 실제 시도. 한 번에 시도하고 한 번에 성공했다면 JobInstance와 JobExecution 둘 다 하나만 존재한다. 또한 얘도 DB에 저장된다
26 | - 인메모리 DB로 JobRepository를 사용하지 않는다
27 | - key=value 형태로 파라미터를 전달한다
28 | - 특정 Job 파라미터가 식별에 사용되지 않게 하려면 -를 붙이자
29 |
30 | 이후, 실습으로 진행했습니다.
31 |
32 | [실습 링크](https://github.com/aegis1920/my-lab/tree/master/def-guide-spring-batch)
33 |
--------------------------------------------------------------------------------
/03주차/요약본/[3주차]_4장_잡과스텝이해하기-1_황준호.md:
--------------------------------------------------------------------------------
1 | ## 4장. 잡과 스텝 이해하기
2 |
3 | ### 잡은...
4 |
5 | - 유일하다
6 | - 잡을 여러번 실행하려고 동일한 잡을 여러번 정의할 필요가 없다
7 | - 순서를 가진 여러 스텝의 목록이다
8 | - 잡에서 스텝의 순서는 중요하다
9 | - 모든 스텝을 논리적인 순서대로 실행할 수 있다
10 | - 처음부터 끝까지 실행 가능하다
11 | - 외부 의존성 없이 실행할 수 있다
12 | - 독립적이다
13 | - 의존성을 관리할 수 있어야 한다
14 |
15 | ### 잡의 생명주기
16 |
17 | - 잡은 생명주기대로 실행된다.
18 | - 잡의 실행은 잡 러너에서 시작된다.
19 | - 잡 러너 : 잡의 이름과 여러 파라미터를 받아들여 잡을 실행시키는 역할. 스프링배치는 두가지를 제공한다
20 | 1. `CommandLineJobRunner`
21 | - 스크립트를 이용하거나 명령행에서 직접 잡을 실행할 때 사용
22 | - 스프링을 부트스트랩하고, 전달받은 파라미터를 사용해 요청된 잡을 실행한다
23 | 2. `JobRegistryBackgroundJobRunner`
24 | - `JobRegistry`를 생성하는데 사용
25 | - `JobRegistry`란? 스케줄러를 사용해 잡을 실행한다면 생성되는것. 스프링이 부트스트랩될 때 실행 가능한 잡을 가지고 있음
26 | - 이와 별개로 스프링부트가 제공하는 `JobLauncherCommandLineRunner`도 있음.
27 | - 별도의 config가 없다면 `ApplicationContext`에 정의된 모든 잡 빈을 실행함
28 | - 이 책에선 이걸 사용
29 | - `JobInstance`
30 | - 잡 이름 + 파라미터로 식별
31 | - `BATCH_JOB_INSTANCE`와 `BATCH_JOB_EXECUTION_PARAMS` 사용
32 | - 성공적으로 완료된 `JobExecution`이 있다면 완료된 것으로 간주됨.
33 | - 한 번 성공하면 다시 실행시킬 수 없음
34 | - `JobExecution`
35 | - 잡 실행의 실제 시도
36 | - 시도할때마다 새로운 `JobExecution` 생성되고 `BATCH_JOB_EXECUTION` 테이블의 레코드로 저장됨
37 | - `JobExecution`이 실행될때의 상태는 `BATCH_JOB_EXECUTION_CONTEXT`에 저장됨 -> 오류 발생 시 그 시점부터 실행 가능
38 |
39 | ### 잡 config
40 |
41 | - `CommandLineJobRunner`에 파라미터 전달하기 : `java -jar demo.jar name=junho`
42 |
43 | - 그럼 파라미터들은 `JobParameters`와 매핑됨 (`Map`의 래퍼)
44 | - 타입 변환기능을 이용하고 싶으면 타입도 같이 넘겨준다(소문자로) : `java -jar demo.jar executionDate(date)=2020/12/27`
45 | - 전달한 파라미터는 `BATCH_JOB_EXECUTION_PARAMS` 에 저장됨
46 | - 식별에 사용하고 싶지 않는 파라미터는 `-`를 붙이면 됨 : `java -jar demo.jar executionDate(date)=2020/12/27 -name=junho`
47 |
48 | - 잡 파라미터에 접근하는 방법
49 |
50 | 1. `chunkContext`
51 |
52 | ```java
53 | @Bean
54 | public Tasklet helloWorldTasklet() {
55 | return ((contribution, chunkContext) -> {
56 | String name = (String) chunkContext.getStepContext()
57 | .getJobParameters()
58 | .get("name");
59 | System.out.println(String.format("Hello, %s!", name));
60 | return RepeatStatus.FINISHED;
61 | });
62 | }
63 | ```
64 |
65 | - `StepContribution contribution` : 아직 커밋되지 않은 현재 트랜잭션에 대한 정보(쓰기수, 읽기수 등)
66 | - `ChunkContext chunkContext` : 실행 시점의 잡 상태를 제공. 테스크릿 내에서는 처리중인 청크와 관련된 정보도 갖고있음
67 |
68 | 2. 늦은 바인딩
69 |
70 | ```java
71 | @StepScope
72 | @Bean
73 | public Tasklet helloWorldTasklet(@Value("#{jobParameters['name']}") String name) {
74 | return ((contribution, chunkContext) -> {
75 | System.out.println(String.format("Hello, %s!", name));
76 | return RepeatStatus.FINISHED;
77 | });
78 | }
79 | ```
80 |
81 | - 스코프 기능을 사용하면 늦은 바인딩을 쉽게 사용할 수 있다
82 | - 스텝 스코프, 잡 스코프 : 스텝, 잡의 실행범위에 들어갈 때까지 빈 생성을 지연시키는 기능
83 |
84 | - 스프링 배치의 파라미터 특화 기능
85 |
86 | 1. 파라미터 유효성 검증 기능
87 |
88 | - `JobParametersValidator` 인터페이스를 구현하고 잡 config에 넣어주면 됨
89 | - 필수 파라미터와 옵션 파라미터에 대한 검증만 하고 싶으면? `DefaultJobParametersValidator`
90 | - 여러 검증 구현체를 적용하고 싶으면? `CompositeJobParametersValidator`
91 |
92 | 2. 파라미터 증가 기능
93 |
94 | ```java
95 | @Bean
96 | public Job job(){
97 | return jobBuilderFactory.get("basicJob")
98 | .start(step1())
99 | .validator(validator()) //CompositeJobParametersValidator
100 | .incrementer(new RunIdIncrementer()) //JobParametersIncrementer
101 | .build();
102 | }
103 | ```
104 |
105 | - `JobParametersIncrementer` : 파라미터를 고유하게 생성할 수 있도록 해줌
106 | - `RunIdIncrementer`를 추가하면 validator에 `run.id` 를 옵션 파라미터에 추가해야 한다
107 | - 날짜를 증가시키는 것 같이 커스텀하게 만들고 싶다면 `JobParametersIncrementer` 을 구현하고 잡 config에 넣고 옵션 파라미터에 추가하면 된다
108 |
109 | - 잡 리스너
110 |
111 | - 잡 리스너로 잡의 생명주기의 여러 시점에 로직을 추가할 수 있다
112 |
113 | - 잡 리스너 작성 방법
114 |
115 | 1. `JobExecutionListener` 인터페이스 구현
116 |
117 | - `beforeJob`과 `afterJob` 메서드가 있다 : 잡 실행 전 초기화, 잡 실행 후 정리, 알림 등등에 이용한다
118 |
119 | - 구현 후 Job config에 넣음
120 |
121 | ```java
122 | @Bean
123 | public Job job() {
124 | return jobBuilderFactory.get("basicJob")
125 | .start(step1())
126 | .validator(validator())
127 | .incrementer(new RunIdIncrementer())
128 | .listener(new JobLoggerListener()) // <--
129 | .build();
130 | }
131 | ```
132 |
133 | 2. `@BeforeJob`, `@AfterJob` 사용
134 |
135 | - `JobExecutionListener` 을 implements할 필요가 없다
136 |
137 | - config가 살짝 다르다
138 |
139 | ```java
140 | @Bean
141 | public Job job() {
142 | return jobBuilderFactory.get("basicJob")
143 | .start(step1())
144 | .validator(validator())
145 | .incrementer(new RunIdIncrementer())
146 | .listener(JobListenerFactoryBean.getListener(new JobLoggerListener())) // <--
147 | .build();
148 | }
149 | ```
150 |
151 | - 리스너는 잡 리스너 외에도 스텝, 리더, 라이터 등에도 있다
152 |
153 | - `ExecutionContext`
154 |
155 | - 잡 상태는 `JobExecution`의 `ExecutionContext`에 저장된다
156 |
157 | - `ExecutionContext`은 기본적으로 잡의 세션이다
158 |
159 | - `ExecutionContext`에 담겨있는 모든 게 `JobRepository`에 저장된다
160 |
161 | - 조작하는 방법
162 |
163 | 1. `JobExecution` 또는 `StepExecution`으로부터 가져오기
164 |
165 | ```java
166 | public class HelloWorldTasklet implements Tasklet {
167 |
168 | @Override
169 | public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
170 | ExecutionContext jobContext = chunkContext.getStepContext()
171 | .getStepExecution() //getStepExecutionContext()는 변경사항이 반영되지 않음
172 | .getJobExecution()
173 | .getExecutionContext();
174 | jobContext.put(...); // <-- 조작
175 |
176 | }
177 | }
178 | ```
179 |
180 | 2. `StepExecution`의 `ExecutionContext`에 있는 키를 `JobExecution`의 `ExecutionContext`로 승격하기
181 |
182 | - ?
183 |
184 | 3. `ItemStream` 인터페이스 사용
185 |
186 | - 추후 다룸
187 |
188 | - 저장하는 법
189 |
190 | - 잡이 처리되는 동안 각 청크를 커밋하면서 잡과 스텝의 현재 `ExecutionContext`를 데이터베이스에 저장한다
191 | - `BATCH_JOB_EXECUTION_CONTEXT` 테이블
192 | - `JOB_EXECUTION_ID` 컬럼 : 관련된 `JobExecution`의 참조
193 | - `SHORT_CONTEXT` 컬럼 : `ExecutionContext`의 json 표현. 배치 처리가 진행되면서 갱신됨
194 | - `SERIALIZED_CONTEXT` 컬럼 : 직렬화된 자바 객체
--------------------------------------------------------------------------------
/03주차/요약본/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/04주차/발표자료/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/04주차/요약본/[4주차]_4장_잡과스텝이해하기-2_김민석.md:
--------------------------------------------------------------------------------
1 | # 4장 Job과 Step 이해하기 - Step
2 |
3 |
4 | ## Step 알아보기
5 |
6 | - 독립적
7 | - 순차적
8 | - 단위 작업의 조각
9 | - 자체적으로 입력/처리/출력
10 | - 트랜잭션 안에서 수행
11 | - 자유롭게 Job을 구성
12 |
13 | ### 태스크 / 청크
14 |
15 | - 청크 기반 처리
16 | 
17 |
18 | ### 스텝 구성
19 | - 상태 머신 패러다임
20 |
21 | #### 태스크릿 스텝
22 |
23 | - MethodIbvokingTaskletAdapter
24 | - POJO를 스텝으로 활용
25 | - Tasklet 인터페이스
26 | ```java
27 | public interface Tasklet {
28 |
29 | /**
30 | * Given the current context in the form of a step contribution, do whatever
31 | * is necessary to process this unit inside a transaction. Implementations
32 | * return {@link RepeatStatus#FINISHED} if finished. If not they return
33 | * {@link RepeatStatus#CONTINUABLE}. On failure throws an exception.
34 | *
35 | * @param contribution mutable state to be passed back to update the current
36 | * step execution
37 | * @param chunkContext attributes shared between invocations but not between
38 | * restarts
39 | * @return an {@link RepeatStatus} indicating whether processing is
40 | * continuable. Returning {@code null} is interpreted as {@link RepeatStatus#FINISHED}
41 | *
42 | * @throws Exception thrown if error occurs during execution.
43 | */
44 | @Nullable
45 | RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception;
46 |
47 | }
48 | ```
49 | ### 그 밖의 다른 유형 태스크릿
50 | - CallableTaskletAdapter
51 | - 다른 스레드에서 실행
52 | - 스텝을 병렬적으로 실행하는 것은 아님
53 | ```java
54 | public class CallableTaskletAdapter implements Tasklet, InitializingBean {
55 |
56 | private Callable callable;
57 |
58 | /**
59 | * Public setter for the {@link Callable}.
60 | * @param callable the {@link Callable} to set
61 | */
62 | public void setCallable(Callable callable) {
63 | this.callable = callable;
64 | }
65 |
66 | /**
67 | * Assert that the callable is set.
68 | *
69 | * @see org.springframework.beans.factory.InitializingBean#afterPropertiesSet()
70 | */
71 | @Override
72 | public void afterPropertiesSet() throws Exception {
73 | Assert.notNull(callable, "A Callable is required");
74 | }
75 |
76 | /**
77 | * Execute the provided Callable and return its {@link RepeatStatus}. Ignores
78 | * the {@link StepContribution} and the attributes.
79 | * @see Tasklet#execute(StepContribution, ChunkContext)
80 | */
81 | @Override
82 | public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
83 | return callable.call();
84 | }
85 |
86 | }
87 | ```
88 |
89 | - MethodinvokingTaskletAdaptor
90 | - 서비스의 bean과 메소드 이름을 넘겨서 기존 서비스를 실행
91 |
92 | - SystemCommandTasklet
93 | - 시스템 명령 실행
94 |
95 | #### 청크 기반 스텝
96 | - 청크 개수 지정 가능
97 | - 청크 개수에 따라 커밋
98 | - 읽기/쓰기가 청크 단위로 이루어짐
99 |
100 | #### 청크 크기 구성하기
101 | - 하드 코딩으로 소스에 정적으로 정의 가능
102 | - CompletionPolicy 인터페이스로 청크 크기 동적으로 변경 가능
103 | - 구현체
104 | - SimpleCompletionPolicy
105 | - TimeoutTerminationPolicy
106 | - CompositeCompletionPolicy
107 |
108 | #### 스텝 리스너
109 | - StepExecutionListener
110 | - ChunkListener
111 | - JobListner과 동일하게 애너테이션으로도 가능
112 |
113 | ### 스텝 플로우
114 | 스텝의 실행 순서를 구성할 수 있다
115 |
116 | #### 조건 로직
117 | - StepBuilder의 next 메서드를 통해 순서 구성
118 | - 조건별 스텝 플로우 참고
119 | - https://jojoldu.tistory.com/328
120 | ```java
121 | @EnableBatchProcessing
122 | @SpringBootApplication
123 | public class ConditionalJob {
124 |
125 | @Autowired
126 | private JobBuilderFactory jobBuilderFactory;
127 |
128 | @Autowired
129 | private StepBuilderFactory stepBuilderFactory;
130 |
131 | @Bean
132 | public Tasklet passTasklet() {
133 | return (contribution, chunkContext) -> {
134 | // return RepeatStatus.FINISHED;
135 | throw new RuntimeException("Causing a failure");
136 | };
137 | }
138 |
139 | @Bean
140 | public Tasklet successTasklet() {
141 | return (contribution, context) -> {
142 | System.out.println("Success!");
143 | return RepeatStatus.FINISHED;
144 | };
145 | }
146 |
147 | @Bean
148 | public Tasklet failTasklet() {
149 | return (contribution, context) -> {
150 | System.out.println("Failure!");
151 | return RepeatStatus.FINISHED;
152 | };
153 | }
154 |
155 | @Bean
156 | public Job job() {
157 | return this.jobBuilderFactory.get("conditionalJob")
158 | .start(firstStep())
159 | .on("FAILED").stopAndRestart(successStep())
160 | .from(firstStep())
161 | .on("*").to(successStep())
162 | .end()
163 | .build();
164 | }
165 |
166 | @Bean
167 | public Step firstStep() {
168 | return this.stepBuilderFactory.get("firstStep")
169 | .tasklet(passTasklet())
170 | .build();
171 | }
172 |
173 | @Bean
174 | public Step successStep() {
175 | return this.stepBuilderFactory.get("successStep")
176 | .tasklet(successTasklet())
177 | .build();
178 | }
179 |
180 | @Bean
181 | public Step failureStep() {
182 | return this.stepBuilderFactory.get("failureStep")
183 | .tasklet(failTasklet())
184 | .build();
185 | }
186 |
187 | public static void main(String[] args) {
188 | SpringApplication.run(ConditionalJob.class, args);
189 | }
190 | }
191 | ```
192 | - 로직으로 스텝 플로우 구성 가능
193 | - JobExecutionDecider
194 | ```java
195 | public class RandomDecider implements JobExecutionDecider {
196 |
197 | private Random random = new Random();
198 |
199 | public FlowExecutionStatus decide(JobExecution jobExecution,
200 | StepExecution stepExecution) {
201 |
202 | if (random.nextBoolean()) {
203 | return new
204 | FlowExecutionStatus(FlowExecutionStatus.COMPLETED.getName());
205 | } else {
206 | return new
207 | FlowExecutionStatus(FlowExecutionStatus.FAILED.getName());
208 | }
209 | }
210 | }
211 | ```
212 |
213 | #### 잡 종료하기
214 | - Job 종료 상태
215 | - Completed
216 | - 해당 JobInstance는 다시 실행 될 수 없다
217 | - JobBuilder에서 end()
218 | - Failed
219 | - 해당 JobInstance 재실행 가능
220 | - JobBuilder에서 fail()
221 | - Stopped
222 | - 중단점부터 다시 시작 가능
223 | - JobBuilder에서 stopAndRestart(step)
224 |
225 | #### 플로우 외부화하기
226 | - 독자적 플로우
227 |
228 | ```java
229 | @Bean
230 | public Flow preProcessingFlow() {
231 | return new FlowBuilder("preProcessingFlow").start(loadFileStep())
232 | .next(loadCustomerStep())
233 | .next(updateStartStep())
234 | .build();
235 | }
236 |
237 | @Bean
238 | public Job conditionalStepLogicJob() {
239 | return this.jobBuilderFactory.get("conditionalStepLogicJob")
240 | .start(preProcessingFlow())
241 | .next(runBatch())
242 | .build();
243 | }
244 | ```
245 |
246 | - 플로우 스텝
247 | ```java
248 | @Bean
249 | public Flow preProcessingFlow() {
250 | return new FlowBuilder("preProcessingFlow").start(loadFileStep())
251 | .next(loadCustomerStep())
252 | .next(updateStartStep())
253 | .build();
254 | }
255 |
256 | @Bean
257 | public Job conditionalStepLogicJob() {
258 | return this.jobBuilderFactory.get("conditionalStepLogicJob")
259 | .start(intializeBatch())
260 | .next(runBatch())
261 | .build();
262 | }
263 |
264 | @Bean
265 | public Step intializeBatch() {
266 | return this.stepBuilderFactory.get("initalizeBatch")
267 | .flow(preProcessingFlow())
268 | .build();
269 | }
270 | ```
271 | - 잡에서 다른 잡 호출
272 | - 가능하나 복잡도가 올라가기 때문에 사용하지 않는 것이 좋다.
273 | ```java
274 | @Bean
275 | public Job conditionalStepLogicJob() {
276 | return this.jobBuilderFactory.get("conditionalStepLogicJob")
277 | .start(intializeBatch())
278 | .next(runBatch())
279 | .build();
280 | }
281 |
282 | @Bean
283 | public Step intializeBatch() {
284 | return this.stepBuilderFactory.get("initalizeBatch")
285 | .job(preProcessingJob())
286 | .parametersExtractor(new DefaultJobParametersExtractor())
287 | .build();
288 | }
289 |
290 | @Bean
291 | public Job preProcessingJob() {
292 | return this.jobBuilderFactory.get("preProcessingJob")
293 | .start(loadFileStep())
294 | .next(loadCustomerStep())
295 | .next(updateStartStep())
296 | .build();
297 | }
298 | ```
--------------------------------------------------------------------------------
/04주차/요약본/[4주차]_4장_잡과스텝이해하기-2_김성모.md:
--------------------------------------------------------------------------------
1 | # 4장 잡과 스텝 이해하기 2편(스텝)
2 |
3 | ## 스텝 알아보기
4 |
5 | > 스텝이란? 독립적이고 순차적으로 배치 처리를 수행하는 배치 프로세서
6 |
7 | 목표 :
8 | 1. 스텝의 처리 방법
9 | 2. 스텝의 트랜잭션 처리 방법
10 | 3. 스텝 흐름 제어 방법
11 |
12 |
13 | ### 태스크릿 처리와 청크 처리 비교
14 |
15 | - 태스크릿
16 |
17 | - 청크
18 |
19 |
20 | ### 스탭 구성
21 |
22 | #### 태스크릿 스텝
23 |
24 | 1. MethodInvokingTaskletAdapter
25 | 2. CallableTaskletAdapter
26 | 3. SystemCommandTasklet
27 | 4. Tasklet 인터페이스 구현
28 |
29 |
30 |
31 | 1. MethodInvokingTaskletAdapter
32 | > 메소드를 다른 클래스에서 가져와 메서드 호출할 수 있게 해준다.
33 |
34 | ```java
35 | @Configuration
36 | public class MethodInvokingTaskletConfiguration {
37 | @Autowired
38 | private JobBuilderFactory jobBuilderFactory;
39 | @Autowired
40 | private StepBuilderFactory stepBuilderFactory;
41 |
42 | @Bean
43 | public Job methodInvokingJob() {
44 | return this.jobBuilderFactory.get("methodInvokingJob").start(methodInvokingStep()).build();
45 | }
46 |
47 | @Bean
48 | public Step methodInvokingStep() {
49 | return this.stepBuilderFactory.get("methodInvokingStep").tasklet(methodInvokingTasklet()).build();
50 | }
51 |
52 | @Bean
53 | public MethodInvokingTaskletAdapter methodInvokingTasklet() {
54 | MethodInvokingTaskletAdapter methodInvokingTaskletAdapter = new MethodInvokingTaskletAdapter();
55 |
56 | methodInvokingTaskletAdapter.setTargetObject(service());
57 | methodInvokingTaskletAdapter.setTargetMethod("serviceMethod");
58 |
59 | return methodInvokingTaskletAdapter;
60 | }
61 |
62 | @Bean
63 | public CustomService service() {
64 | return new CustomService(); // 이 클래스엔 serviceMethod라는 이름을 갖는 함수가 있다.
65 | }
66 | }
67 |
68 | ```
69 |
70 |
71 | 2. CallableTaskletAdapter
72 | > 값을 반환하고 체크 예외를 바깥으로 던질 수 있다.
73 | >
74 | > 스텝이 실행되는 스레드와 별개의 스레드에서 실행되지만 병렬 실행은 아니다.
75 |
76 | ``` java
77 |
78 | @Configuration
79 | public class CallableTaskletConfiguration {
80 | @Autowired
81 | private JobBuilderFactory jobBuilderFactory;
82 | @Autowired
83 | private StepBuilderFactory stepBuilderFactory;
84 |
85 | @Bean
86 | public Job callableJob(){
87 | return this.jobBuilderFactory.get("callableJob").start(callableStep()).build();
88 | }
89 |
90 | @Bean
91 | public Step callableStep() {
92 | return this.stepBuilderFactory.get("callableStep").tasklet(tasklet()).build();
93 | }
94 |
95 | @Bean
96 | public Callable callableObject() {
97 | return () -> {
98 | System.out.println("This was executed in another thread");
99 | return RepeatStatus.FINISHED;
100 | };
101 | }
102 |
103 | @Bean
104 | public CallableTaskletAdapter tasklet() {
105 | CallableTaskletAdapter callableTaskletAdapter = new CallableTaskletAdapter();
106 |
107 | callableTaskletAdapter.setCallable(callableObject());
108 |
109 | return callableTaskletAdapter;
110 | }
111 | }
112 |
113 |
114 | public class CustomService {
115 |
116 | public void serviceMethod() {
117 | System.out.println("Service method was called");
118 | }
119 | }
120 |
121 | ```
122 |
123 | 잡 파라미터의 값을 사용하고싶다면 다음의 추가 작업을 진행한다.
124 |
125 | ```java
126 |
127 | @Configuration
128 | public class MethodInvokingTaskletConfiguration {
129 | @Autowired
130 | private JobBuilderFactory jobBuilderFactory;
131 | @Autowired
132 | private StepBuilderFactory stepBuilderFactory;
133 |
134 | @Bean
135 | public Job methodInvokingJob() {
136 | return this.jobBuilderFactory.get("methodInvokingJob").start(methodInvokingStep()).build();
137 | }
138 |
139 | @Bean
140 | public Step methodInvokingStep() {
141 | return this.stepBuilderFactory.get("methodInvokingStep").tasklet(methodInvokingTasklet(null)).build();
142 | }
143 |
144 | @StepScope
145 | @Bean
146 | public MethodInvokingTaskletAdapter methodInvokingTasklet(
147 | @Value("#{jobParameters['message']}") String message
148 | ) {
149 | MethodInvokingTaskletAdapter methodInvokingTaskletAdapter = new MethodInvokingTaskletAdapter();
150 |
151 | methodInvokingTaskletAdapter.setTargetObject(service());
152 | methodInvokingTaskletAdapter.setTargetMethod("serviceMethod");
153 | methodInvokingTaskletAdapter.setArguments(new String[]{message});
154 |
155 | return methodInvokingTaskletAdapter;
156 | }
157 |
158 | @Bean
159 | public CustomService service() {
160 | return new CustomService();
161 | }
162 | }
163 |
164 |
165 |
166 | public class CustomService {
167 |
168 | public void serviceMethod(String message) {
169 | System.out.println("Service method was called");
170 | System.out.println(message);
171 | }
172 | }
173 | ```
174 |
175 | 3. SystemCommandTasklet
176 |
177 | > 시스템 명령을 사용할 때 사용한다.
178 |
179 | ```java
180 |
181 | @Configuration
182 | public class SystemCommandTaskletConfiguration {
183 | @Autowired
184 | private JobBuilderFactory jobBuilderFactory;
185 | @Autowired
186 | private StepBuilderFactory stepBuilderFactory;
187 |
188 | @Bean
189 | public Job systemCommandJob() {
190 | return this.jobBuilderFactory.get("systemCommandJob").start(systemCommandStep()).build();
191 | }
192 |
193 | @Bean
194 | public Step systemCommandStep() {
195 | return this.stepBuilderFactory.get("systemCommandStep").tasklet(systemCommandTasklet()).build();
196 | }
197 |
198 | @Bean
199 | public SystemCommandTasklet systemCommandTasklet() {
200 | SystemCommandTasklet systemCommandTasklet = new SystemCommandTasklet();
201 | systemCommandTasklet.setCommand("rm -rf /tmp.txt");
202 | systemCommandTasklet.setTimeout(5000);
203 | systemCommandTasklet.setInterruptOnCancel(true);
204 |
205 | return systemCommandTasklet;
206 | }
207 | }
208 |
209 | ```
210 |
211 | ```java
212 |
213 |
214 | @Configuration
215 | public class AdvancedSystemCommandTaskletConfiguration {
216 | @Autowired
217 | private JobBuilderFactory jobBuilderFactory;
218 | @Autowired
219 | private StepBuilderFactory stepBuilderFactory;
220 |
221 | @Bean
222 | public Job systemCommandJob() {
223 | return this.jobBuilderFactory.get("systemCommandJob").start(systemCommandStep()).build();
224 | }
225 |
226 | @Bean
227 | public Step systemCommandStep() {
228 | return this.stepBuilderFactory.get("systemCommandStep").tasklet(systemCommandTasklet()).build();
229 | }
230 |
231 | @Bean
232 | public SystemCommandTasklet systemCommandTasklet() {
233 | SystemCommandTasklet systemCommandTasklet = new SystemCommandTasklet();
234 | systemCommandTasklet.setCommand("touch tmp.txt");
235 | systemCommandTasklet.setTimeout(5000);
236 | systemCommandTasklet.setInterruptOnCancel(true);
237 |
238 | systemCommandTasklet.setWorkingDirectory("/Userss/mminella/spring-batch");
239 | systemCommandTasklet.setTerminationCheckInterval(5000);
240 | systemCommandTasklet.setSystemProcessExitCodeMapper(touchCodeMapper());
241 | systemCommandTasklet.setTaskExecutor(new SimpleAsyncTaskExecutor());
242 | systemCommandTasklet.setEnvironmentParams(new String[]{
243 | "JAVA_HOME=/java", "BATCH_HOME=/Users/batch"
244 | });
245 |
246 | return systemCommandTasklet;
247 | }
248 |
249 | @Bean
250 | public SimpleSystemProcessExitCodeMapper touchCodeMapper() {
251 | return new SimpleSystemProcessExitCodeMapper();
252 | }
253 | }
254 |
255 | ```
256 |
257 | 4. Tasklet 인터페이스 구현
258 |
259 |
260 | ### 청크 기반 스텝
261 |
262 | > 청크는 커밋 간격에 의해 정의된다. 한 번에 몇개의 처리를 한 뒤 기록할 떄 쓴다.
263 |
264 | #### 청크 크기 구성하기
265 | 청크 크기를 구성하는 두 가지 방식
266 | 1. 정적인 커밋 개수 설정
267 | ```java
268 |
269 | @Configuration
270 | public class ChunkJob {
271 | @Autowired
272 | private JobBuilderFactory jobBuilderFactory;
273 | @Autowired
274 | private StepBuilderFactory stepBuilderFactory;
275 |
276 | @Bean
277 | public Job chunkBasedJob() {
278 | return this.jobBuilderFactory.get("chunkBasedJob").start(chunkBasedStep()).build();
279 | }
280 |
281 | @Bean
282 | public Step chunkBasedStep() {
283 | return this.stepBuilderFactory.get("chunkBasedStep")
284 | .chunk(1000)
285 | .reader(itemReader())
286 | .writer(itemWriter())
287 | .build();
288 | }
289 |
290 | @Bean
291 | public ListItemReader itemReader() {
292 | List items = new ArrayList<>(100000);
293 |
294 | for (int i = 0; i < 100000; i++) {
295 | items.add(UUID.randomUUID().toString());
296 | }
297 |
298 | return new ListItemReader<>(items);
299 | }
300 |
301 | @Bean
302 | public ItemWriter itemWriter() {
303 | return items -> {
304 | for (String item : items) {
305 | System.out.println(">> current item = " + item);
306 | }
307 | };
308 | }
309 | }
310 | ```
311 |
312 | 2. CompletionPolicy 구현체 사용
313 |
314 | 구현체 커스터마이징 시 순서
315 | - start 메서드
316 | - update 메서드
317 | - isComplete 메서드
318 |
319 |
320 | #### 스텝 리스너
321 |
322 | > 각 스텝 시작 전 후로 이벤트 처리 가능
323 |
324 | - StepExecutionListener
325 | - ChunkListener
326 |
327 |
328 | ### 스텝 플로우
329 |
330 | #### 조건 로직
331 | > 스텝을 줄을 세워 실행하는 게 아닌 조건부로 스텝을 나눠서 진행하는 방식
332 |
333 | #### 잡 종료하기
334 |
335 | 1. Completed : 성공적으로 종료, JobInstance도 종료
336 | 2. Failed : 잡이 성공되지 않음, JobInstance 재실행 가능
337 | 3. Stopped : 잡에 오류가 발생하지 않았지만 중단된 위치에서 다시 시작 가능
338 |
339 |
340 | #### 스텝을 플로우화하기
341 | - 플로우 만들기
342 | - 플로우 스텝 만들기
343 | - 잡 스텝만들기
344 |
--------------------------------------------------------------------------------
/04주차/요약본/[4주차]_4장_잡과스텝이해하기-2_이호빈.md:
--------------------------------------------------------------------------------
1 | # 4장 잡과 스텝 이해하기 - Step
2 |
3 | - 스텝은 잡의 구성요소로 독립적이고 순차적으로 배치 처리를 수행한다
4 | - 트랜잭션은 스텝 내에서 이뤄진다
5 | - 스프링 배치는 기본적으로 각 Step이 상태로 이뤄지고, 다음 상태로 전이되는 상태 머신임
6 |
7 | ## Tasklet 모델
8 |
9 | - 단일 명령으로 실행하는 경우
10 | - 정의 방법
11 | - 여러 코드를 사용해서 사용자 코드를 Tasklet Step으로 정의할 수 있음
12 | - CallableTaskletAdapter
13 | - MethodInvokigTaskletAdapter
14 | - SystemCommandTasklet
15 | - Tasklet 인터페이스를 구현해서도 가능
16 | - 반환 값은 RepeatStatus.CONTINUABLE or RepeatStatus.FINISHED
17 | - CONTINUEABLE은 어떤 조건이 충족될 때까지 반복해서 해당 Tasklet을 실행시키고 싶을 때 사용
18 |
19 | ### SystemCommandTasklet (실습 X)
20 |
21 | - 시스템 명령을 실행할 때 사용
22 | - `rm -rf tmp.txt` 등...
23 | - 지정한 시스템 명령은 비동기로 실행된다.
24 | - 그래서 timeout 값이 중요하다
25 | - 해당 명령의 완료 여부를 terminateCheckInterval 속성을 통해 주기적으로 확인할 수 있다
26 | - interruptOnCancel 속성으로 Job이 비 정상적으로 종료될 때 시스템 프로세스와 관련된 스레드를 강제로 종료할 지 스프링 배치에게 알려준다.
27 |
28 | ## Chunk 모델
29 |
30 | - ItemReader, ItemProcessor, ItemWriter로 구성됨
31 | - ItemWriter에서 물리적 쓰기를 일괄로 처리한다
32 | - commit interval이라고 불리는 커밋 간격이 중요하다
33 | - 10개라고 설정했을 때 9개의 아이템을 처리하고 오류가 발생하면, 스프링 배치는 현재 Chunk를 롤백하고 잡이 실패했다고 표시한다.
34 | - CompletionPolicy 인터페이스는 청크의 완료 여부를 결정할 수 있는 로직을 구현할 수 있게 해준다.
35 | - 기본적으로 SimpleCompletionPolicy를 사용한다
36 | - 처리된 아이템 개수를 세다가 임계값에 도달하면 청크 완료로 표시한다.
37 | - TimeoutTerminationPolicy도 있는데 얘를 사용하면 청크 내에서 처리 시간이 해당 시간이 넘으면 해당 청크가 완료된 것으로 간주되고 모든 트랜잭션 처리가 정상으로 계속된다
38 | - CompositeCompletionPolicy를 통해 여러 Policy를 함께 구성한다
39 |
40 | ## 그 외
41 |
42 | ### StepExecutionListener, ChunkListener
43 |
44 | - StepExecutionListener, ChunkListener 인터페이스는 각각 스텝과 청크의 시작과 끝에서 특정 로직을 처리할 수 있게 해준다
45 | - afterStep 메서드는 ExitStatus를 반환하는데 Listener가 ExitStatus를 Job에 반환하기 전에 수정할 수 있기 때문
46 | - 얘들로 기본적인 무결성 검사를 할 수 있다
47 | - @BeforeStep, @AfterStep, @BeforeChunk, @AfterChunk 등을 사용할 수 있다
48 |
49 | ### JobExecutionDecider
50 |
51 | - on 메서드는 Step의 ExitStatus를 평가해 조건으로 분기할 수 있다
52 | - JobExecutionDecider 인터페이스를 구현해서 결정해줄 수 있다.
53 | - FlowExecutionStatus는 BatchStatus, ExitStatus 쌍을 래핑한 래퍼 객체다
54 |
55 | ### ExitStatus vs BatchStatus
56 |
57 | - BatchStatus
58 | - Job이나 Step의 현재 상태를 식별하는 JobExecution이나 StepExecution의 속성이다.
59 | - StepExecution이나 JobExecution 내에 보관된다
60 | - ExitStatus
61 | - Job이나 Step 종료 시 스프링 배치로 반환되는 값이다. 이는 문자열이다
62 | - Step, Chunk, Job 에서 반환될 수 있다
63 | -
64 |
65 | ### Job의 3가지 종료 상태
66 |
67 | - Completed
68 | - 성공적으로 종료. 동일한 파라미터로 다시 실행할 수 없다
69 | - builder에서 end()로 끝내버리면 Completed로 종료된다
70 | - Failed
71 | - 실패로 종료. 동일한 파라미터로 다시 실행할 수 있다
72 | - Stopped
73 | - 중단된 위치에서 Job을 다시 시작된다
74 | - 사용자가 미리 구성해둔 스텝부터 시작된다
75 | - 오류가 발생하지 않아도 중단 가능하다.
76 |
77 | ### 여러 Step을 하나로 만드는 방법 : Flow로 만들기 vs Flow Step으로 만들기 vs 외부화하지 않기
78 |
79 | - Flow로 만들기
80 | - JobRepository를 살펴보면 Job에서 Step을 구성하는 것과 차이가 없다.
81 | - 예시
82 |
83 | ```java
84 | @Bean
85 | public Flow preProcessingFlow() {
86 | return new FlowBuilder("preProcessingFlow").start(loadFileStep())
87 | .step(loadCustomStep())
88 | .step(updateStartStep())
89 | .build()
90 | }
91 | ```
92 |
93 | - Flow Step으로 만들기
94 | - Flow를 Step으로 래핑한다.
95 | - JobRepository를 살펴보면 추가적인 항목이 더해진다
96 | - 해당 플로우가 담긴 스텝을 하나의 스텝처럼 기록한다.
97 | - 플로우의 영향을 전체적으로 볼 수 있다
98 | - 예시
99 |
100 | ```java
101 | @Bean
102 | public Step intializeBatch() {
103 | return this.stepBuilderFactory.get("initalizeBatch")
104 | .flow(preProcessingFlow())
105 | .build();
106 | }
107 | ```
108 |
109 | - 플로우를 작성하지 않고 Job 내에서 다른 Job을 호출하기
110 | - 개별 Job을 만들어 함께 묶으면 실행 처리를 제어하는데 큰 제약이 있을 수 있다.
111 | - Job과 Job을 최대한 연결시키지 말자.
112 |
113 | > [실습 링크](https://github.com/aegis1920/my-lab/tree/master/def-guide-spring-batch)
114 |
--------------------------------------------------------------------------------
/04주차/요약본/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/05주차/발표자료/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/05주차/요약본/[5주차]_5장_JobRepository와_메타데이터_김광훈.md:
--------------------------------------------------------------------------------
1 | # 6장 JobRepository 와 메타데이터
2 | ## 1. JobRepository ??
3 | ### 1.1 기능
4 | #### (1) 스프링 배치는 잡이 실행될 때 잡의 상태를 JobRepository 에 저장한다.
5 | #### (2) 모니터링으로 사용할 수 있다.
6 |
7 | ### 1.2 정의
8 | #### (1) Interface
9 | #### (2) 데이터 저장소
10 |
11 | ### 1.3 RDB
12 | #### (1) BATCH_JOB_INSTANCE
13 | - 스키마의 시작점
14 | - 잡을 식별하는 고유 정보가 포함된 잡 파라미터로 잡을 처음 실행하면 생성
15 |
16 | #### (2) BATCH_JOB_EXECUTION
17 | - 배치 잡의 실제 실행 기록 저장
18 |
19 | #### (3) BATCH_JOB_EXECUTION_PARAMS
20 | - 잡이 매번 실행될 때마다 사용된 잡 파라미터 저장
21 |
22 | #### (4) BATCH_JOB_EXECUTION_CONTEXT
23 | - Execution context 관련 정보 저장
24 | - 잡의 실행 정보
25 |
26 | #### (5) BATCH_STEP_EXECUTION
27 | - 스텝의 시작, 완료, 상태에 대한 메타데이터 저장
28 |
29 | #### (6) BATCH_STEP_EXECUTION_CONTEXT
30 | = 스텝 수준에서 컴포넌틍 상태를 저장하는 데 사용
31 |
32 | ## 2. 배치 인프라스트럭처 구성
33 | ### 2.1 BatchConfigure 인터페이스
34 | #### (1) BatchConfigurer 구현체에서 빈을 생성
35 | #### (2) 그다음 SimpleBatchConfiguration 에서 스프링의 ApplicationContext 에 생성한 빈 등록
36 |
37 | ### 2.2 TransactionManager
38 | #### DefaultBatchConfigurer 가 기본적으로 setDataSource 수정자 내에서 DataSourceTransactionManager 자동 생성
39 |
40 | ### 2.3 JobExplorer
41 | #### JobExplorer 는 JobRepository 가 다루는 데이터와 동일한 데이터를 읽기 전용으로만 보는 뷰
42 | #### 기본적으로 데이터 접근 계층은 JobRepository 와 JobExplorer 간에 공유되는 동일한 공통 DAO 집합이다.
43 |
44 | ### 2.4 JobLauncher
45 | #### JobLauncher 는 스프링 배치 잡을 실행하는 진입점
46 | #### 스프링 부트는 기본적으로 스프링 배치가 제공하는 SimpleJobLauncher 를 사용한다.
47 |
--------------------------------------------------------------------------------
/05주차/요약본/[5주차]_5장_JobRepository와_메타데이터_황준호.md:
--------------------------------------------------------------------------------
1 | ## 5장. `JobRepository`와 메타데이터
2 |
3 | ### JobRepository란?
4 |
5 | - 스프링 배치 내에서 `JobRepository`를 말한 땐 둘 중 하나다
6 |
7 | 1. `JobRepository` 인터페이스
8 | 2. `JobRepository` 인터페이스를 구현해 데이터를 저장하는 데 사용되는 데이터 저장소 <- 이 절에선 주로 이걸 가리킨다
9 |
10 | - 배치 잡 내부에서 바로 사용할 수 있는 데이터 저장소 2가지
11 |
12 | 1. 관계형 데이터베이스
13 |
14 | 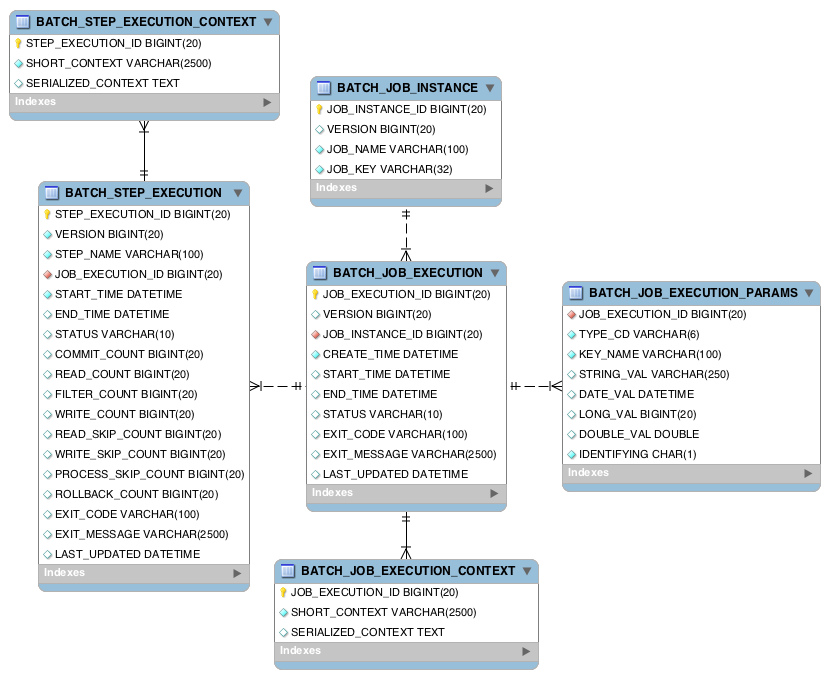
15 |
16 | - `BATCH_JOB_INSTANCE` : 잡의 논리적 실행
17 | - `BATCH_JOB_EXECUTION` : 잡의 실제 실행 기록
18 | - `BATCH_JOB_EXECUTION_PARAMS` : 잡이 매번 실행될때마다 사용된 잡 파라미터 기록
19 | - `BATCH_JOB_EXECUTION_CONTEXT` : `JobExecution`의 `ExecutionContext` 기록
20 | - `BATCH_STEP_EXECUTION` : 스텝의 시작, 완료, 상태에 대한 메타데이터 기록
21 | - `BATCH_STEP_EXECUTION_CONTEXT` : `StepExecution`의 `ExecutionContext` 기록
22 |
23 | 2. 인메모리 저장소
24 |
25 | - 개발 단계나 단위테스트를 수행할 때 사용할 수 있게 `Map`기반 인메모리 데이터베이스를 제공한다. 다음 절에서 다룬다.
26 |
27 | ### 배치 인프라스트럭쳐 config
28 |
29 | `@EnableBatchProcessing`을 사용하면 `JobRepository`를 사용할 수 있다.
30 |
31 | `JobRepository`를 비롯한 모든 스프링배치 인프라스트럭쳐를 커스터마이징을 하고 싶다면 `BatchConfigurer` 인터페이스를 사용하면 된다
32 |
33 | - `BatchConfigurer` 인터페이스
34 |
35 | - 스프링 배치 인프라스트럭쳐 컴포넌트 구성을 커스터마이징하는데 사용되는 전략 인터페이스이다. (일반적으론 `DefaultBatchConfigurer` 을 상속해서 커스터마이징한다.)
36 | - `@EnableBatchProcessing`을 사용했을때 빈이 추가되는 과정
37 | 1. `BatchConfigurer` 구현체에서 빈을 생성한다
38 | 2. `SimpleBatchConfiguration`에서 스프링의 `ApplicationContext`에 생성한 빈을 등록한다
39 |
40 | - `JobRepository`커스터마이징하기
41 |
42 | - 보통 `ApplicationContext`에 두 개 이상의 데이터소스가 존재할때 커스터마이징한다.
43 | - 예) 업무 데이터 용도의 데이터소스와 `JobRepository`용 데이터소스가 별도로 존재할때
44 |
45 | ```java
46 | public class CustomBatchConfigurer extends DefaultBatchConfigurer {
47 |
48 | @Autowired
49 | @Qualifier("repositoryDataSource") //"repositoryDataSource"가 어딘가 있다고 가정.
50 | private DataSource dataSource;
51 |
52 | @Override
53 | protected JobRepository createJobRepository() throws Exception {
54 | JobRepositoryFactoryBean factoryBean = new JobRepositoryFactoryBean();
55 | factoryBean.setDatabaseType(DatabaseType.MYSQL.getProductName());
56 | // 접두어 "BATCH_" -> "FOO_"
57 | factoryBean.setTablePrefix("FOO_");
58 | // 데이터 생성시 트랜잭션 격리레벨 "ISOLATION_SERIALIZED" -> "ISOLATION_REPEATABLE_READ"
59 | factoryBean.setIsolationLevelForCreate("ISOLATION_REPEATABLE_READ");
60 | factoryBean.setDataSource(this.dataSource);
61 | // 보통 아래의 두 메서드는 스프링 컨테이너가 호출해준다. 근데 create...메서드 모두는 스프링 컨테이너에 노출되지 않는다. 그래서 개발자가 직접 호출해줘야 한다.
62 | factoryBean.afterPropertiesSet();
63 | return factoryBean.getObject();
64 | }
65 | }
66 | ```
67 |
68 | - `TransactionManager`커스터마이징하기
69 |
70 | ```java
71 | public class CustomBatchConfigurer extends DefaultBatchConfigurer {
72 |
73 | @Autowired
74 | @Qualifier("batchTransactionManager") //"batchTransactionManager"가 어딘가 있다고 가정.
75 | private PlatformTransactionManager transactionManager;
76 |
77 | @Override
78 | public PlatformTransactionManager getTransactionManager() {
79 | return this.transactionManager;
80 | }
81 | }
82 | ```
83 |
84 | - `JobExplorer`커스터마이징하기
85 |
86 | - 배치 메타데이터를 읽기 전용으로 제공하고 싶을 때
87 |
88 | ```java
89 | public class CustomBatchConfigurer extends DefaultBatchConfigurer {
90 |
91 | @Autowired
92 | @Qualifier("repositoryDataSource")
93 | private DataSource dataSource;
94 |
95 | //JobExplorer와 JobRepository는 동일한 데이터 저장소를 사용하므로 함께 커스터마이징을 하는 게 좋다
96 | @Override
97 | protected JobRepository createJobRepository() throws Exception {
98 | JobRepositoryFactoryBean factoryBean = new JobRepositoryFactoryBean();
99 | factoryBean.setDatabaseType(DatabaseType.MYSQL.getProductName());
100 | factoryBean.setTablePrefix("FOO_");
101 | factoryBean.setIsolationLevelForCreate("ISOLATION_REPEATABLE_READ");
102 | factoryBean.setDataSource(this.dataSource);
103 | factoryBean.afterPropertiesSet();
104 | return factoryBean.getObject();
105 | }
106 |
107 | @Override
108 | protected JobExplorer createJobExplorer() throws Exception {
109 | JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
110 | factoryBean.setDataSource(this.dataSource);
111 | factoryBean.setTablePrefix("FOO_");
112 | factoryBean.afterPropertiesSet();
113 | return factoryBean.getObject();
114 | }
115 | }
116 | ```
117 |
118 | - `JobLauncher`커스터마이징하기
119 |
120 | - 스프링 배치가 기본 제공하는 `SimpleJobLauncher` 외의 방식으로 커스터마이징하고 싶을때 (예 : 컨트롤러를 통해 잡 실행하려 할때)
121 |
122 | - 데이터베이스 config
123 |
124 | ```yaml
125 | spring:
126 | datasource:
127 | driverClassName: ...
128 | url: ...
129 | username: ...
130 | password: ...
131 | batch:
132 | initialize-schema: ...
133 | ```
134 |
135 | - `initialize-schema` : 스프링부트가 스프링배치 스키마 스크립트를 실행하도록 지시
136 | - `always` : 애플리케이션을 실행할때마다 스크립트 실행. 개발 환경일때 사용하기 쉬움
137 | - `never` : 스크립트를 실행하지 않음
138 | - `embedded` : 내장 데이터베이스를 사용할때, 각 실행 시마다 데이터가 초기화된 데이터베이스 인스턴스를 사용한다는 가정으로 스크립트를 실행
139 |
140 | ### 잡 메타데이터 사용하기
141 |
142 | 어떻게 `JobRepository` 내의 정보를 얻을 수 있을까? 주로 `JobExplorer`을 사용한다.
143 |
144 | - `JobExplorer`
145 |
146 | - `JobExplorer`은 `JobRepository`의 데이터에 접근하는 시작점이다.
147 |
148 | - 대부분의 배치 프레임워크 컴포넌트가 `JobRepository`를 사용해 잡 관련 정보에 접근하지만 `JobExplorer`은 데이터베이스에 직접 접근한다.
149 |
150 | - 예시 : 잡의 `JobInstance`가 얼마나 많이 실행됐는지, 각 `JobInstance`당 얼마나 많은 실제 실행이 있었는지 확인하는 config
151 |
152 | - ```java
153 | public class ExploringTasklet implements Tasklet {
154 |
155 | private JobExplorer explorer;
156 |
157 | public ExploringTasklet(JobExplorer explorer) {
158 | this.explorer = explorer;
159 | }
160 |
161 | @Override
162 | public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception {
163 | String jobName = chunkContext.getStepContext().getJobName();
164 | List instances = explorer.getJobInstances(jobName, 0, Integer.MAX_VALUE);
165 | System.out.printf("%s 잡에는 %d개의 잡 인스턴스가 존재합니다.", jobName, instances.size());
166 |
167 | System.out.println("********************* 결과 *********************");
168 | for (JobInstance instance : instances) {
169 | List jobExecutions = explorer.getJobExecutions(instance);
170 | System.out.printf("%d 인스턴스에는 %d개의 execution이 존재합니다.",
171 | instance.getInstanceId(), jobExecutions.size());
172 | for (JobExecution jobExecution : jobExecutions) {
173 | System.out.printf("\t%d execution의 ExitStatus 결과는 %s입니다.",
174 | jobExecution.getId(), jobExecution.getExitStatus());
175 | }
176 | }
177 | return RepeatStatus.FINISHED;
178 | }
179 | }
180 | ```
181 |
182 | ```java
183 | @Autowired
184 | private JobExplorer jobExplorer;
185 |
186 | @Bean
187 | public Job explorerJob() {
188 | return jobBuilderFactory.get("explorerJob")
189 | .start(explorerStep())
190 | .build();
191 | }
192 |
193 | @Bean
194 | public Step explorerStep() {
195 | return stepBuilderFactory.get("explorerStep")
196 | .tasklet(explorerTasklet())
197 | .build();
198 | }
199 |
200 | @Bean
201 | public Tasklet explorerTasklet() {
202 | return new ExploringTasklet(jobExplorer);
203 | }
204 | ```
205 |
--------------------------------------------------------------------------------
/05주차/요약본/[5주차]_5장_JobRepository와메타데이터_김명수.md:
--------------------------------------------------------------------------------
1 | # 배치 인프라스트럭처 구성하기
2 |
3 | - [배치 인프라스트럭처 구성하기](#배치-인프라스트럭처-구성하기)
4 | - [BatchConfigurer 인터페이스](#BatchConfigurer-인터페이스)
5 | - [JobRepository 커스터마이징하기](#JobRepository-커스터마이징하기)
6 | - [TransactionManager 커스터마이징하기](#TransactionManager-커스터마이징하기)
7 | - [JobExplorer 커스터마이징하기](#JobExplorer-커스터마이징하기)
8 | - [JobLauncher 커스터마이징하기](#JobLauncher-커스터마이징하기)
9 | - [데이터베이스 구성하기](#데이터베이스-구성하기)
10 | - [잡 메타데이터 사용하기](#잡-메타데이터-사용하기)
11 |
12 | ---
13 |
14 | # 배치 인프라스트럭처 구성하기
15 |
16 | ## BatchConfigurer 인터페이스
17 |
18 | - `BatchConfigurer` 인터페이스는 스프링 배치 인프라스트럭처 컴포넌트의 구성을 커스터마이징하는 데 사용되는 전략 인터페이스(`strategy interace`)이다.
19 | - `BatchConfigurer` -> `SimpleBatchConfiguration` 으로 빈을 등록하는데 보통 `BatchConfigurer`를 통해 커스터마이징 빈을 등록한다.
20 | - `DefaultBatchConfigurer` 를 통해 필요한 빈만 재정의한다.
21 |
22 | ```java
23 | public interface BatchConfigurer {
24 |
25 | JobRepository getJobRepository() throws Exception;
26 |
27 | PlatformTransactionManager getTransactionManager() throws Exception;
28 |
29 | JobLauncher getJobLauncher() throws Exception;
30 |
31 | JobExplorer getJobExplorer() throws Exception;
32 | }
33 | ```
34 |
35 | ---
36 |
37 | ## JobRepository 커스터마이징하기
38 |
39 | p.190의 표를 살펴보면 `JobRepositoryFactoryBean`의 여러가지 커스터마이징 옵션이 존재한다.
40 |
41 | `DefaultBatchConfigurer`를 상속해서 아래와 같이 `JobRepository`를 재정의할 수 있다.
42 |
43 | ```java
44 | @Slf4j
45 | @Profile("job-repository-custom")
46 | @Configuration
47 | public class CustomBatchConfigurer extends DefaultBatchConfigurer {
48 |
49 | @Autowired
50 | @Qualifier("repositoryDataSource")
51 | private DataSource dataSource;
52 |
53 | @Override
54 | protected JobRepository createJobRepository() throws Exception {
55 | final JobRepositoryFactoryBean factoryBean = new JobRepositoryFactoryBean();
56 |
57 | factoryBean.setDatabaseType(DatabaseType.MYSQL.getProductName());
58 | factoryBean.setTablePrefix("FOO_");
59 | factoryBean.setIsolationLevelForCreate("ISOLATION_REPEATABLE_READ");
60 | factoryBean.setDataSource(dataSource);
61 |
62 | // BatchConfigurer의 메소드는 스프링에서 직접 노출되지 않으므로
63 | // InitilizerBean.afterPropertiesSet() 및 FactoryBean.getObject() 메소드를 호출해야한다.
64 | factoryBean.afterPropertiesSet();
65 |
66 | return factoryBean.getObject();
67 | }
68 | }
69 | ```
70 |
71 | ---
72 |
73 | ## TransactionManager 커스터마이징하기
74 |
75 | `TransactionManager`의 모든 구성 옵션을 다루는 대신 이미 정의된 빈을 기반으로 어떻게 커스터마이징 하는지 살펴보자.
76 |
77 | ```java
78 | @Slf4j
79 | @Profile("customize-configurer")
80 | @Configuration
81 | public class CustomBatchConfigurer extends DefaultBatchConfigurer {
82 |
83 | @Autowired
84 | @Qualifier("batchTransactionManager")
85 | private PlatformTransactionManager transactionManager;
86 |
87 | @Override
88 | public PlatformTransactionManager getTransactionManager() {
89 | return transactionManager;
90 | }
91 | }
92 | ```
93 |
94 | ---
95 |
96 | ## JobExplorer 커스터마이징하기
97 |
98 | `JobExplorer`는 배치 메타데이터를 읽기 전용으로 제공한다.
99 |
100 | ```java
101 | @Slf4j
102 | @Profile("customize-configurer")
103 | @Configuration
104 | public class CustomBatchConfigurer extends DefaultBatchConfigurer {
105 |
106 | @Autowired
107 | @Qualifier("repositoryDataSource")
108 | private DataSource dataSource;
109 |
110 | @Override
111 | protected JobExplorer createJobExplorer() throws Exception {
112 | final JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
113 |
114 | factoryBean.setDataSource(dataSource);
115 | factoryBean.setTablePrefix("FOO_");
116 |
117 | // BatchConfigurer의 메소드는 스프링에서 직접 노출되지 않으므로
118 | // InitilizerBean.afterPropertiesSet() 및 FactoryBean.getObject() 메소드를 호출해야한다.
119 | factoryBean.afterPropertiesSet();
120 |
121 | return factoryBean.getObject();
122 | }
123 | }
124 | ```
125 |
126 | ---
127 |
128 | ## JobLauncher 커스터마이징하기
129 |
130 | - `JobLauncher`는 스프링 배치 잡을 실행하는 진입점이며 `SimpleJobLauncher`를 기본으로 사용한다.
131 | - 스프링 부트의 기본 메커니즘으로 잡을 실행할 때는 대부분 JobLauncher를 커스터마이징 할 필요가 없다.
132 | - 스프링 MVC 애플리케이션의 일부로써 특정 API 호출 시 잡을 실행하고 싶을 때 커스터마이징이 필요하다.
133 |
134 | ```java
135 | public class SimpleJobLauncher implements JobLauncher, InitializingBean {
136 |
137 | protected static final Log logger = LogFactory.getLog(SimpleJobLauncher.class);
138 |
139 | private JobRepository jobRepository;
140 | private TaskExecutor taskExecutor;
141 |
142 | ...
143 |
144 | // 사용할 JobRepository를 지정한다.
145 | public void setJobRepository(JobRepository jobRepository) {
146 | this.jobRepository = jobRepository;
147 | }
148 |
149 | // TaskExecutor를 지정한다. 기본적으로 SyncTaskExecutor가 설정된다.(아래 afterPropertiesSet())
150 | public void setTaskExecutor(TaskExecutor taskExecutor) {
151 | this.taskExecutor = taskExecutor;
152 | }
153 |
154 | @Override
155 | public void afterPropertiesSet() throws Exception {
156 | Assert.state(jobRepository != null, "A JobRepository has not been set.");
157 | if (taskExecutor == null) {
158 | logger.info("No TaskExecutor has been set, defaulting to synchronous executor.");
159 | taskExecutor = new SyncTaskExecutor();
160 | }
161 | }
162 | }
163 | ```
164 |
165 | ---
166 |
167 | ## 데이터베이스 구성하기
168 |
169 | 아래와 같은 설정으로 데이터 베이스를 구성할 수 있다.
170 |
171 | ```yaml
172 | spring:
173 | datasource:
174 | driver-class-name: com.mysql.cj.jdbc.Driver
175 | url: jdbc:mysql://localhost:53306/spring_batch
176 | username: root
177 | password: p@ssw0rd
178 | batch:
179 | jdbc:
180 | # ["always", "never", "embedded"]
181 | initialize-schema: always
182 | ```
183 |
184 | ---
185 |
186 | # 잡 메타데이터 사용하기
187 |
188 | 스프링 배치는 내부적으로 여러 DAO를 사용해 `JobRepository` 테이블에 접근하지만
189 | 프레임워크 개발자가 사용할 수 있도록 `JobExplorer`를 통해 훨씬 실용적인 API를 제공한다.
190 |
191 | (p198에 JobExplorer에서 제공하는 여러 메소드에 대한 설명이 있다.)
192 |
193 | **1. ExploringTasklet**
194 |
195 | ```java
196 | @Slf4j
197 | public class ExploringTasklet implements Tasklet {
198 |
199 | private final JobExplorer explorer;
200 |
201 | public ExploringTasklet(JobExplorer explorer) {
202 | this.explorer = explorer;
203 | }
204 |
205 | @Override
206 | public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
207 | final String jobName = chunkContext.getStepContext().getJobName();
208 | final List instances = explorer.getJobInstances(jobName, 0, Integer.MAX_VALUE);
209 |
210 | logger.info("## There are {} job instances for the job {}", instances.size(), jobName);
211 | logger.info("They have had the following results");
212 | logger.info("****************************************************");
213 | for (JobInstance instance : instances) {
214 | final List executions = explorer.getJobExecutions(instance);
215 | logger.info("> Instance {} had {} executions", instance.getInstanceId(), executions.size());
216 |
217 | for (JobExecution execution : executions) {
218 | logger.info("\tExecution {} resulted in ExitStatus {}", execution.getId(), execution.getExitStatus());
219 | }
220 | }
221 |
222 | return RepeatStatus.FINISHED;
223 | }
224 | }
225 | ```
226 |
227 | **2. Job 구성**
228 |
229 | ```java
230 | @Slf4j
231 | @EnableBatchProcessing
232 | @SpringBootApplication
233 | public class DemoApplication {
234 |
235 | @Autowired
236 | private JobBuilderFactory jobBuilderFactory;
237 |
238 | @Autowired
239 | private StepBuilderFactory stepBuilderFactory;
240 |
241 | @Autowired
242 | private JobExplorer jobExplorer;
243 |
244 | @Bean
245 | public Tasklet explorerTasklet() {
246 | return new ExploringTasklet(jobExplorer);
247 | }
248 |
249 | @Bean
250 | public Step explorerStep() {
251 | return stepBuilderFactory.get("explorerStep")
252 | .tasklet(explorerTasklet())
253 | .build();
254 | }
255 |
256 | @Bean
257 | public Job explorerJob() {
258 | return jobBuilderFactory.get("explorerJob")
259 | .start(explorerStep())
260 | .incrementer(new RunIdIncrementer())
261 | .build();
262 | }
263 | }
264 | ```
--------------------------------------------------------------------------------
/05주차/요약본/[5주차]_5장_JobRepository와메타데이터_김성모.md:
--------------------------------------------------------------------------------
1 | # 5장 JobRepository와 메타데이터
2 |
3 | ## JobRepository란?
4 |
5 | > 스프링 배치 내에서 JobRepository 인터페이스를 구현해 데이터를 저장하는 데 사용되는 데이터 저장소이다.
6 |
7 | ### 관계형 데이터베이스 사용하기
8 |
9 | 관계형 데이터베이스는 스프링 배치에서 기본적으로 제공하는 JobRepository 이다.
10 |
11 | 
12 |
13 |
14 | 1. 테이블 설명
15 |
16 | - 시작점인 `BATCH_JOB_INSTANCE`
17 |
18 | ```sql
19 | CREATE TABLE BATCH_JOB_INSTANCE (
20 | JOB_INSTANCE_ID BIGINT PRIMARY KEY ,
21 | VERSION BIGINT,
22 | JOB_NAME VARCHAR(100) NOT NULL ,
23 | JOB_KEY VARCHAR(2500)
24 | );
25 | ```
26 |
27 | - 배치 잡의 실제 실행 기록 `BAATCH_JOB_EXECUTION`
28 |
29 | > 잡이 실행될 대 마다 새 레코드 생성되고 잡이 진행되는 동안 주기적으로 업데이트 된다.
30 |
31 | ```sql
32 | CREATE TABLE BATCH_JOB_EXECUTION (
33 | JOB_EXECUTION_ID BIGINT PRIMARY KEY ,
34 | VERSION BIGINT,
35 | JOB_INSTANCE_ID BIGINT NOT NULL,
36 | CREATE_TIME TIMESTAMP NOT NULL,
37 | START_TIME TIMESTAMP DEFAULT NULL,
38 | END_TIME TIMESTAMP DEFAULT NULL,
39 | STATUS VARCHAR(10),
40 | EXIT_CODE VARCHAR(20),
41 | EXIT_MESSAGE VARCHAR(2500),
42 | LAST_UPDATED TIMESTAMP,
43 | JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
44 | constraint JOB_INSTANCE_EXECUTION_FK foreign key (JOB_INSTANCE_ID)
45 | references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
46 | ) ;
47 | ```
48 |
49 | 위 테이블과 연관된 세 개의 테이블
50 |
51 | - 연관 1. BATCH_JOB_EXECUTION_CONTEXT
52 |
53 | > 잡이 여러 번 실행되는 상황에서 관련 정보를 보관하는 장소
54 |
55 | ```sql
56 | CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
57 | JOB_EXECUTION_ID BIGINT PRIMARY KEY,
58 | SHORT_CONTEXT VARCHAR(2500) NOT NULL,
59 | SERIALIZED_CONTEXT CLOB,
60 | constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
61 | references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
62 | ) ;
63 | ```
64 |
65 |
66 | - 연관 2. BATCH_JOB_EXECUTION_PARAMS
67 |
68 | > 매번 실행될 때 마다 사용된 잡 파라미터를 보관하는 테이블
69 |
70 | ```sql
71 | CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
72 | JOB_EXECUTION_ID BIGINT NOT NULL ,
73 | TYPE_CD VARCHAR(6) NOT NULL ,
74 | KEY_NAME VARCHAR(100) NOT NULL ,
75 | STRING_VAL VARCHAR(250) ,
76 | DATE_VAL DATETIME DEFAULT NULL ,
77 | LONG_VAL BIGINT ,
78 | DOUBLE_VAL DOUBLE PRECISION ,
79 | IDENTIFYING CHAR(1) NOT NULL ,
80 | constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
81 | references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
82 | );
83 | ```
84 |
85 | - 연관 3. BATCH_STEP_EXCUTION_CONTEXT
86 |
87 | ```sql
88 | CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
89 | STEP_EXECUTION_ID BIGINT PRIMARY KEY,
90 | SHORT_CONTEXT VARCHAR(2500) NOT NULL,
91 | SERIALIZED_CONTEXT CLOB,
92 | constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
93 | references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
94 | ) ;
95 | ```
96 |
97 |
98 | - 잡에서와 마찬가지로 스텝의 상태를 저장하는 BATCH_STEP_EXECUTION
99 |
100 | ```sql
101 | CREATE TABLE BATCH_STEP_EXECUTION (
102 | STEP_EXECUTION_ID BIGINT PRIMARY KEY ,
103 | VERSION BIGINT NOT NULL,
104 | STEP_NAME VARCHAR(100) NOT NULL,
105 | JOB_EXECUTION_ID BIGINT NOT NULL,
106 | START_TIME TIMESTAMP NOT NULL ,
107 | END_TIME TIMESTAMP DEFAULT NULL,
108 | STATUS VARCHAR(10),
109 | COMMIT_COUNT BIGINT ,
110 | READ_COUNT BIGINT ,
111 | FILTER_COUNT BIGINT ,
112 | WRITE_COUNT BIGINT ,
113 | READ_SKIP_COUNT BIGINT ,
114 | WRITE_SKIP_COUNT BIGINT ,
115 | PROCESS_SKIP_COUNT BIGINT ,
116 | ROLLBACK_COUNT BIGINT ,
117 | EXIT_CODE VARCHAR(20) ,
118 | EXIT_MESSAGE VARCHAR(2500) ,
119 | LAST_UPDATED TIMESTAMP,
120 | constraint JOB_EXECUTION_STEP_FK foreign key (JOB_EXECUTION_ID)
121 | references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
122 | ) ;
123 | ```
124 |
125 | - BATCH_STEP_EXECUTION_CONTEXT
126 |
127 | ```sql
128 | CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
129 | STEP_EXECUTION_ID BIGINT PRIMARY KEY,
130 | SHORT_CONTEXT VARCHAR(2500) NOT NULL,
131 | SERIALIZED_CONTEXT CLOB,
132 | constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
133 | references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
134 | ) ;
135 | ```
136 |
137 |
138 | ## 배치 인프라스터럭쳐 구성하기
139 |
140 | > @EnableBatchProcessing 을 사용하면 기본적으로 추가 구성없이 배치가 제공하는 JobRepository를 사용할 수 있다.
141 |
142 | ### BatchConfigurer 만들기
143 | ```java
144 | public interface BatchConfigurer {
145 |
146 | JobRepository getJobRepository() throws Exception;
147 |
148 | PlatformTransactionManager getTransactionManager() throws Exception;
149 |
150 | JobLauncher getJobLauncher() throws Exception;
151 |
152 | JobExplorer getJobExplorer() throws Exception;
153 | }
154 | ```
155 |
156 | 위의 인터페이스를 구현한 구현체에서 빈을 생성하고 `SimpleBatchConfiguration`에서 스프링 `ApplicationContext`에 생성한 빈을 등록한다.
157 |
158 | 기본적으로 스프링배치가 제공하는 `DefaultBatchConfigurer`를 사용하면 모든 기본 옵션이 제공된다. 따라서 몇 개의 구성만 재정의한다면 `DefaultBatchConfigurer` 를 상속해 적절한 메소드를 재정의하는 것이 더 쉽다.
159 |
160 |
161 | ### JoRepository 커스터마이징하기
162 |
163 | `JobRepositoryFactoryBean` 이라는 `FactoryBean` 을 통해서 `JobRepository`는 생성된다.
164 |
165 | `JobRepositoryFactoryBean` 에서 제공하는 커스터마이징을 set으로 변경하여 커스터마이징할 수 있다.
166 |
167 | ### TransactionManager 커스터마이징하기
168 |
169 |
170 | 위에서 `DefaultBatchConfigurer` 를 상속해 커스터마이징을 진행하면 쉽다고 말하였는데, 이를 위하여 transaction bean 을 가져와서 getTransactionMnager()에 @Override 해주면 된다.
171 |
172 | ```java
173 | public class CustomBatchConfigurer extends DefaultBatchConfigurer {
174 |
175 | @Autowired
176 | @Qualifier("batchTransactionManager")
177 | private PlatformTransactionManager transactionManager;
178 |
179 | @Override
180 | public PlatformTransactionManager getTransactionManager() {
181 | return this.transactionManager;
182 | }
183 | }
184 | ```
185 |
186 | ### JobExplorer 커스터마이징하기
187 |
188 | ```java
189 | public class CustomBatchConfigurer extends DefaultBatchConfigurer {
190 |
191 | @Autowired
192 | @Qualifier("batchTransactionManager")
193 | private DataSource dataSource;
194 |
195 | @Override
196 | protected JobExplorer createJobExplorer() throws Exception {
197 | JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
198 | factoryBean.setDataSource(this.dataSource);
199 | factoryBean.setTablePrefix("FOO_");
200 | factoryBean.afterPropertiesSet();
201 | return factoryBean.getObject();
202 | }
203 | }
204 | ```
205 |
206 |
207 | ### JobLauncher 커스터마이징하기
208 |
209 | 스프링 배치 잡을 실행하는 진입점을 변경해야할 때 구성한다.
210 |
211 |
212 | ## 잡 메타데이터 사용하기
213 |
214 |
--------------------------------------------------------------------------------
/05주차/요약본/[5주차]_5장_스프링배치_함호식.md:
--------------------------------------------------------------------------------
1 | 4.JobRepository와 메타데이터
2 | --
3 |
4 | ##### JobRepository 활용
5 | * 배치 잡 실행 중에 오류발생시 복구
6 | * 실행중 오류 발생시 어떤 처리를 하고 있었는지 확인
7 | * 잡이 다시 실행될 수 있는지 여부
8 | * 잡이 처리되는데 걸리는 시간
9 | * 오류로 인해 재시도된 아이템 수 확인
10 |
11 |
12 | ---
13 |
14 | ##### JobRepository란?
15 |
16 | 2가지 중에 하나를 의미한다.
17 | 1. JobRepository 인터페이스
18 | 2. JobRepository를 구현해 데이터를 저장하는데 사용되는 데이터 저장소
19 |
20 | 스프링 배치는 배치 잡 내에서 바로 사용할 수 있는 두가지 데이터 저장소를 제공한다.
21 | 1. 인메모리 저장소
22 | : 외부 데이터베이스를 구성하는 것이 실제 얻는 이익보다 많은 문제를 발생시킬 수 있다.
23 | 이런 이유로 java.util.Map 객체를 데이터 저장소로 사용하는 JobRepository 구현체를 제공한다.
24 | 2. 관계형 데이터베이스
25 | 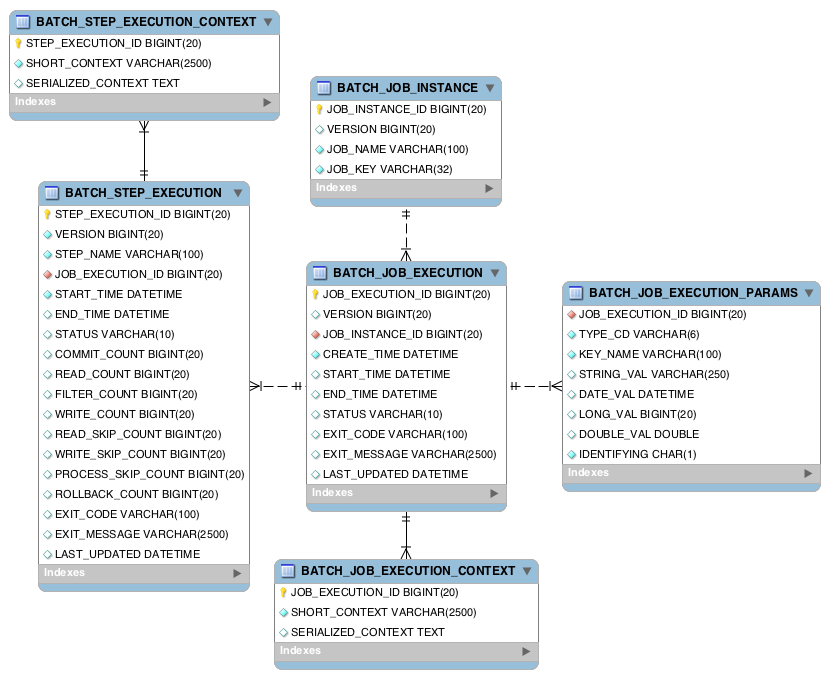
26 | * BATCH_JOB_INSTANCE
27 | -> 잡의 논리적 실행을 나타낸다.
28 | (처음 실행시 단일 레코드가 등록된다.)
29 |
30 | * BATCH_JOB_EXECUTION
31 | -> 배치잡의 실제 실행 기록을 나타낸다.
32 | (잡이 진행되는 동안 주기적으로 업데이트 된다.)
33 |
34 | * BATCH_JOB_EXECUTION_PARAMS
35 | -> 잡이 매번 실행될 때마다 사용된 잡 파라미터를 저장한다.
36 |
37 | * BATCH_JOB_EXECUTION_CONTEXT
38 | -> JoBExecution의 ExecutionContext를 저장한다.
39 |
40 | * BATCH_STEP_EXECUTION
41 | -> 스텝의 시작, 완료, 상태에 대한 메타데이터를 저장한다.
42 | -> 스텝 분석이 가능하도록 다양한 횟수 값을 저장한다.
43 | (읽기, 처리, 쓰기, 건너뛰기 횟수)
44 |
45 | * BATCH_STEP_EXECUTION_CONTEXT
46 | -> 스텝 수준에서 컴포넌트의 상태를 저장하는데 사용된다.
47 |
48 |
49 | ---
50 |
51 | ##### 배치 인프라스트럭처 구성하기
52 |
53 | @EnableBatchProcessing 애너테이션을 이용하면, 스프링 배치가 제공하는 JobRepository를 사용할 수 있다.
54 |
55 | 애너테이션 적용시 빈이 추가되는 과정
56 | 1. BatchConfigurer 구현체에서 빈을 생성한다.
57 | 2. SimpleBatchConfiguration에서 ApplicationContext에 생성한 빈을 등록한다.
58 |
59 | ##### BatchConfigurer 인터페이스
60 | 스프링 배치 인프라스트럭처 컴포넌트의 구성을 커스터마이징하는데 사용되는 전략 인터페이스이다.
61 |
62 | ```java
63 | public interface BatchConfigurer {
64 |
65 | JobRepository getJobRepository() throws Exception;
66 |
67 | // 프레임워크가 제공하는 모든 트랜잭션을 관리할 때 사용
68 | PlatformTransactionManager getTransactionManager() throws Exception;
69 |
70 | JobLauncher getJobLauncher() throws Exception;
71 |
72 | JobExplorer getJobExplorer() throws Exception;
73 | }
74 | ```
75 |
76 | 스프링 배치가 제공하는 DefaultBatchConfigurer를 사용하면 기본 컴포넌트가 제공된다.
77 | 일반적인 시나리오라면 여러 컴포넌트 중에 일부만 재정의하므로,
78 | BatchConfigurer를 구현하는 것보다 DefaultBatchConfigurer를 상속해,
79 | 적절한 메서드를 재정의하는 것이 더 간편하다.
80 | ```java
81 | public class DefaultBatchConfigurer implements BatchConfigurer {
82 | ...
83 |
84 | private DataSource dataSource;
85 | private PlatformTransactionManager transactionManager;
86 | private JobRepository jobRepository;
87 | private JobLauncher jobLauncher;
88 | private JobExplorer jobExplorer;
89 |
90 | ...
91 |
92 | @PostConstruct
93 | public void initialize() {
94 | try {
95 | if(dataSource == null) {
96 | logger.warn("No datasource was provided...using a Map based JobRepository");
97 |
98 | if(getTransactionManager() == null) {
99 | logger.warn("No transaction manager was provided, using a ResourcelessTransactionManager");
100 | this.transactionManager = new ResourcelessTransactionManager();
101 | }
102 |
103 | MapJobRepositoryFactoryBean jobRepositoryFactory = new MapJobRepositoryFactoryBean(getTransactionManager());
104 | jobRepositoryFactory.afterPropertiesSet();
105 | this.jobRepository = jobRepositoryFactory.getObject();
106 |
107 | MapJobExplorerFactoryBean jobExplorerFactory = new MapJobExplorerFactoryBean(jobRepositoryFactory);
108 | jobExplorerFactory.afterPropertiesSet();
109 | this.jobExplorer = jobExplorerFactory.getObject();
110 | } else {
111 | this.jobRepository = createJobRepository();
112 | this.jobExplorer = createJobExplorer();
113 | }
114 |
115 | this.jobLauncher = createJobLauncher();
116 | } catch (Exception e) {
117 | throw new BatchConfigurationException(e);
118 | }
119 | }
120 | ...
121 | }
122 | ```
123 |
124 |
125 | JobExplorer는 JobRepository가 다루는 데이터와 `동일한 데이터`를 `읽기 전용`으로만 보는 뷰이다.
126 | -> JobExplorer와 JobRepository는 동일한 데이터 저장소를 사용하므로 동기화시키는 것이 좋다.
127 |
128 | ```java
129 | public class SimpleJobExplorer implements JobExplorer {
130 |
131 | @Override
132 | public Set findRunningJobExecutions(@Nullable String jobName) {
133 | ...
134 | }
135 |
136 | @Override
137 | public JobExecution getJobExecution(@Nullable Long executionId) {
138 | ...
139 | }
140 |
141 | @Override
142 | public List getJobNames() {
143 | return jobInstanceDao.getJobNames();
144 | }
145 | ...
146 | }
147 | ```
148 |
149 | ---
150 | ##### JobLauncher 커스터마이징
151 | JobLauncher: 스프링 배치 잡을 실행하는 진입점
152 | -> 스프링 부트는 기본적으로 스프링 배치가 제공하는 SimpleJobLauncher를 사용한다.
153 | 그러므로 대부분 JobLauncher를 커스터마이징할 필요가 없다.
154 | +) 그러나 스프링 MVC의 일부분으로 배치가 존재하며,
155 | 컨트롤러를 통해 해당 잡이 실행된다면 SimpleJobLauncher의 동작 방식을 조정할 수 있다.
156 |
157 | ```java
158 | public class SimpleJobLauncher implements JobLauncher, InitializingBean {
159 | ...
160 | // 사용할 Repository 지정
161 | public void setJobRepository(JobRepository jobRepository) {
162 | this.jobRepository = jobRepository;
163 | }
164 |
165 | // JobLauncher에 사용할 TaskExecutor를 설정한다.
166 | // default = SyncTaskExecutor
167 | public void setTaskExecutor(TaskExecutor taskExecutor) {
168 | this.taskExecutor = taskExecutor;
169 | }
170 | ...
171 | }
172 | ```
173 |
174 |
175 | ---
176 |
177 | ##### 데이터베이스 구성하기
178 |
179 | ```yaml
180 | # database
181 | spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
182 | spring.datasource.url=jdbc:mysql://localhost:3306/mysql
183 | spring.datasource.username=
184 | spring.datasource.password=
185 |
186 | # batch
187 | spring.batch.jdbc.initialize-schema=always
188 | ```
189 |
190 | spring.batch.jdbc.initialize-schema
191 | * always (개발환경에서 자주 쓰임)
192 | -> 애플케이션을 실행할 때마다 스크립트가 실행된다.
193 | -> 스프링 배치 SQL 파일에 drop문이 없고 오류 발생시 무시
194 | * never
195 | -> 스크립트를 실행하지않는다.
196 | * embedded
197 | -> 내장 데이터베이스 사용할 때, 각 실행시마다 초기화된 데이터베이스 인스턴스를 사용한다고 가정한다.
198 |
199 |
200 | ---
201 |
202 | ##### 요약
203 | 스프링 배치가 `잡과 관련된 메타데이터를 관리`하거나
204 | `실행 중인 잡의 상태를 오류 처리에 사용할 수 있도록 저장하는 기능`은
205 | 스프링 배치를 사용하는 주요 이유중에 하나다.
--------------------------------------------------------------------------------
/05주차/요약본/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/06주차/발표자료/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/06주차/요약본/[6주차]_6장_스프링배치_함호식.md:
--------------------------------------------------------------------------------
1 | 6.잡 실행하기
2 | --
3 |
4 | ##### 스프링 부트로 배치 잡 시작시키기
5 | * 스프링 부트는 CommandLineRunner와 ApplicationRunner라는 두 가지 메커니즘을 이용해 실행 시 로직을 수행한다.
6 | 두 인터페이스는 ApplicationContext가 리프레시 되고, 애플리케이션이 실행할 준비가 된 후 호출되는 하나의 메서드를 가지고 있다.
7 | 스프링 부트를 스프링 배치와 함께 사용할 때는 JobLauncherCommandLineRunner라는 특별한 CommandLineRunner가 실행된다.
8 |
9 |
10 |
11 | * 스프링 부트가 ApplicationContext 내에 구성된 CommandLineRunner를 실행할 때,
12 | 클래스패스에 spring-boot-starter-batch가 존재한다면 jobLauncherCommandLineRunner는
13 | 컨텍스트 내에서 찾아낸 모든 잡을 실행한다.
14 |
15 | 기동 시에 어떤 잡도 실행되지 않도록 설정하는 방법
16 | ```xml
17 | # application.properties
18 | spring.batch.job.enabled=false
19 | ```
20 |
21 | ```java
22 | // java code
23 | public static void main(String[] args) {
24 | SpringApplication application = new SpringApplication(NoRunJob.class);
25 |
26 | Properties properties = new Properties();
27 | properties.put("spring.batch.job.enabled", false);
28 | application.setDefaultProperties(properties);
29 |
30 | application.run(args);
31 | }
32 | ```
33 |
34 | 기동 시에 특정한 잡만 실행하는 방법
35 | ```xml
36 | # application.properties
37 | # 쉼표로 구분된 잡 목록을 가져와 순서대로 실행한다.
38 | spring.batch.job.names=JobName1, JobName2
39 | ```
40 |
41 | ---
42 |
43 | ##### REST 방식으로 잡 실행하기
44 |
45 | JobLauncher 인터페이스는 실행할 잡과 전달할 잡 파라미터를 argument로 전달 받는다.
46 | ```java
47 | // JobLauncher 인터페이스
48 | public interface JobLauncher {
49 | public JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException,
50 | JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException;
51 | }
52 | ```
53 |
54 | 배치 잡을 즉시 실행할 수 있는 REST API가 존재하는 것이 아니라,
55 | 직접 개발해야한다.
56 | ```java
57 | @PostMapping("/run")
58 | public ExitStatus runJob(@RequestBody JobLauncherRequest request) {
59 | Job job = this.context.getBean(request.getName(), Job.class);
60 |
61 | return this.jobLauncher.run(job, request.getJobParameters()).getExitStatus();
62 | }
63 | ```
64 | * 애플리케이션 기동시 배치 잡이 수행되지 않도록 `spring.batch.job.enabled=false`가 작성되어야 하고,
65 | @EnableBatchProcessing 애너테이션을 적용하면 스프링 배치가 제공하는 SimpleJobLauncher를 바로 사용할 수 있다.
66 | * 기본적으로 JobLauncher는 동기식을 실행하므로 ExitStatus를 반환할 수 있다.
67 | 대부분 배치 잡은 처리량이 많으므로 비동기 방식으로 실행하고, 비동기 방식으로 실행하면,
68 | JobExecutionID만 반환한다.
69 |
70 | ```java
71 | @PostMapping("/run")
72 | public ExitStatus runJob(@RequestBody JobLauncherRequest request) {
73 | Job job = this.context.getBean(request.getName(), Job.class);
74 |
75 | JobParameters jobParameters =
76 | new JobParametersBuilder(request.getJobParameters(), this.jobExploror)
77 | .getNextJobParameters(job)
78 | .toJobParameters();
79 |
80 | return this.jobLauncher.run(job, jobParameters).getExitStatus();
81 | }
82 | ```
83 |
84 | * `JobParametersBuilder.getNextJobParameters`를 호출하면 run.id라는 파라미터가 추가된 새로운 JobParameters 인스턴스가 생성된다.
85 | getNextJobParameters는 Job이 JobParametersIncrementer를 가지고 있는지 해당 job을 확인 후 판별한다.
86 |
87 | ---
88 | ##### 잡 중지하기
89 |
90 | 프로그래밍적으로 중지하기
91 | * 중지 트랜지션 사용하기
92 | ```java
93 | @AfterStep
94 | public ExitStatus afterStep(StepExecution stepExecution) {
95 | if (condition) {
96 | return execution.getExitStatus();
97 | } else {
98 | return ExitStatus.STOPPED;
99 | }
100 | }
101 | ```
102 | -> 조건이 유효하지 않다면, STOPPED를 반환하여 잡을 중지할 수 있다.
103 |
104 | ```java
105 | @Bean
106 | public Job transactionJob() {
107 | return this.jobBuilderFactory.get("transactionJob")
108 | .start(importTransactionFileStep())
109 | .on("STOPPED").stopAndRestart(importTransactionFileStep())
110 | .from(importTransactionFileStep()).on("*").to(appliTransactionStep())
111 | .from(appliTransactionStep()).next(generateAccountSummaryStep())
112 | .end()
113 | .build();
114 | }
115 | ```
116 | -> `importTransactionFileStep`가 가장 먼저 시작된다.
117 | 이때 ExitStatus가 STOPPED라면, 재시작시 해당 스텝부터 다시 시작한다.
118 | ExitStatus가 STOPPED가 아니라면, `appliTransactionStep`으로 넘어간다.
119 | -> 잡이 중지되면 변경중이던 청크의 내용을 롤백한다.
120 | * StepExecution을 사용해 중지하기
121 | AfterStep 대신 BeforeStep을 사용하도록 변경해 StepExecution을 사용한다.
122 | -> 이렇게 하면 StepExecution에 접근할 수 있으므로 StepExecution.setTerminateOnly() 메서드를 호출할 수 있다.
123 | ```java
124 | private void SomeProcess () {
125 | if (condition) {
126 |
127 | } else {
128 | this.stepExecution.setTerminateOnly();
129 | }
130 | }
131 |
132 | @BeforeStep
133 | public void beforeStep(StepExecution stepExecution) {
134 | this.stepExecution = execution;
135 | }
136 | ```
137 |
138 | ---
139 |
140 | ##### 오류 처리
141 |
142 | * 잡 실패
143 | -> 스프링 배치는 예외가 발생하면 기본적으로 스텝 및 잡이 실패한 것으로 간주한다.
144 |
145 | | 방식 | ExitStatus |
146 | | --- | --- |
147 | | StepExecution을 사용해 잡을 중지를 하는 방식 | STOPPED |
148 | | 예외를 발생시켜 잡을 중지하는 방식 | FAILED |
149 |
150 | `스텝이 FAILED로 식별되면 스프링 배치는 해당 스텝을 처음부터 다시 시작하지 않는다.`
151 |
152 | ---
153 |
154 | ##### 재시작 제어하기
155 |
156 | * 잡의 재시작 방지하기
157 | -> jobBuilder의 preventRestart()를 호출해 잡을 다시 시작할 수 없도록 구성할 수 있다.
158 | ```java
159 | @Bean
160 | public Job someJob() {
161 | return this.jobBuilderFactory.get("someJob")
162 | .preventRestart()
163 | .start(xxx())
164 | .build();
165 | }
166 | ```
167 | -> 잡 실패 후 다시 실행하려고 시도하면 `JobRestartException`이 발생한다.
168 | * 재시작 횟수를 제한하도록 구성하기
169 | -> 스프링 배치는 이 기능을 잡 대시 `스텝` 수준에서 제공한다.
170 | ```java
171 | @Bean
172 | public Step someStep() {
173 | return this.stepBuilderFactory.get("someStep")
174 | .startLimit(2)
175 | chunk(100)
176 | .build();
177 | }
178 | ```
179 | -> 이 잡은 두 번까지만 실행 가능하다.
180 | 재실행 횟추 제한 초과시 `StartLimitExceededException`이 발생한다.
181 |
182 | * 완료된 스텝 재실행하기
183 | -> 스프링 배치 특징 중 하나는 동일한 파라미터로 잡을 한 번만 성공적으로 실행할 수 있다.
184 | `이 문제를 해결할 방법은 없다.`
185 | 그러나 스텝에는 이 규칙이 반드시 적용되는 것은 아니다.
186 |
187 | 프레임워크의 기본 구성을 재정의함으로써 완료된 스텝을 두 번 이상 실행할 수 있다.
188 | 스텝이 잘 완료됐더라도 다시 실행할 수 있어야 한다는 것을 프레임워크에게 알리려면
189 | StepBuilder의 `allowStartIfComplete()` 메서드를 사용하면 된다.
190 | ```java
191 | @Bean
192 | public Step someStep() {
193 | return this.stepBuilderFactory.get("someStep")
194 | .allowStartIfComplete(true)
195 | chunk(100)
196 | .build();
197 | }
198 | ```
199 | -> 이 예제는 이전 실행에서 실패했거나 중지된 잡 내의 스텝이 다시 실행된다.
200 | 해당 스텝은 이전 실행 시에 완료 상태로 종료되므로 재시작할 중간 단계가 없어 처음부터 다시 시작된다.
201 |
202 | > 잡의 ExitStatus가 COMPLETED라면 모든 스텝에 `allowStartIfComplete(true);`를 적용해 구성하더라도
203 | > 이와 관계없이 잡 인스턴스를 다시 실행할 수 없다.
--------------------------------------------------------------------------------
/06주차/요약본/[6주차]_6장_잡_실행하기_김광훈.md:
--------------------------------------------------------------------------------
1 | # 잡 실행하기
2 | ## 1. 스프링 부트로 잡 실행하기
3 | #### - 스프링 부트에서는 CommandLineRunner 와 ApplicationRunner 라는 두 메커니즘을 이용해 실행 시 로직 수행
4 | #### - 스프링 부트를 스프링 배치와 함께 사용할 때는 JobLauncherCommandLineRunner 라는 CommandLineRunner 가 사용된다.
5 | #### - JobLauncherCommandLineRunner 는 스프링 배치의 JobLauncher 를 사용해 모든 잡을 실행한다.
6 | #### - 만약 특정한 잡만 실행시키고 싶다면 spring.batch.job.names 프로퍼티를 사용해 애플리케이션 기동 시에 실행할 잡을 구성할 수 있다.
7 |
8 |
9 |
10 | ## 2. REST 방식으로 잡 실행하기
11 | #### - JobLauncher 를 사용해서 API 를 실행시킬 수 있다.
12 | #### - JobLauncher 인터페이스에는 run 메서드 하나만 존재
13 | #### - 스프링 배치는 기본적으로 유일한 JobLauncher 구현체인 SimpleJobLauncher 제공
14 | #### - SimpleJobLauncher 는 전달 받은 JobParameters 조작 지원 X
15 | #### - SimpleJobLauncher 는 기본적으로 동기식이다.
16 | #### - 예시
17 | ```java
18 | @PostMappint("/run")
19 | public ExitStatus runJob(@RequestBody JobLauncherRequest request) {
20 | Job job = this.context.getBean(request.getName(), Job.class);
21 |
22 | return this.jobLauncher.run(job, request.getJobParameters())
23 | .getExitStatus();
24 | }
25 |
26 | ```
27 |
28 | #### - JobParametersIncrementer 를 사용할 떄 파라미터 변경 사항을 적용하는 JobLauncher 가 수행한다.
29 |
30 |
31 |
32 | ## 3. 쿼츠를 사용해 스케줄링하기
33 | #### - 쿼츠는 스케줄러, 잡, 트리거 세 가지 주요 컴포넌트를 가진다.
34 | - 스케줄러: 트리거 저장소 기능, 잡을 실행하는 역할
35 | - 잡: 실행할 작업의 단위
36 | - 트리거: 작업 실행 시점 정의
37 |
38 | #### - QuartzJobBean 클래스 상속해서 사용
39 |
40 |
41 | ## 4. 잡 중지
42 | #### 자연스러운 완료
43 | - 각각의 잡은 스텝이 COMPLETED 상태를 반환할 때까지 스텝을 실행했으며 모든 스텝이 완료되면 잡 자신도 COMPLETED 종료 코드를 반환
44 | - 동일한 파라미터 값으로 잡이 한 번 정상적으로 실행됐다면 또 다시 실행시킬 수 없다.
45 |
46 | #### 프로그래밍적으로 종료 (중지 트랜잭션)
47 | - 중지 트랜잭션으로 프로그래밍 방식으로 잡을 중지할 수 있다.
48 |
49 | #### StepExecution 을 사용해 중지하기
50 | - AfterStep 대신 BeforeStep 을 사용하도록 변경해 StepExecution 을 가져온다.
51 | - 이렇게 하면 StepExecution 에 접근할 수 있으므로 푸터 레코드를 읽을 때 StepExecution.setTerminateOnly() 메서드를 호출할 수 있다.
52 | - setTerminateOnly() 메서드는 스텝이 완료된 후 스프링 배치가 종료되도록 지시하는 플래그를 설정한다.
53 | - 예시
54 | ```java
55 | private Transaction process(FieldSet fieldSet) {
56 |
57 | if(this.recordCount == 25) {
58 | throw new ParseException("This isn't what I hoped to happen");
59 | }
60 |
61 | Transaction result = null;
62 |
63 | if(fieldSet != null) {
64 | if(fieldSet.getFieldCount() > 1) {
65 | result = new Transaction();
66 | result.setAccountNumber(fieldSet.readString(0));
67 | result.setTimestamp(
68 | fieldSet.readDate(1, "yyyy-MM-DD HH:mm:ss"));
69 | result.setAmount(fieldSet.readDouble(2));
70 |
71 | recordCount++;
72 | } else {
73 | expectedRecordCount = fieldSet.readInt(0);
74 |
75 | if(expectedRecordCount != this.recordCount) {
76 | this.stepExecution.setTerminateOnly();
77 | }
78 | }
79 | }
80 |
81 | return result;
82 | }
83 | ```
84 |
85 | ## 5. 재시작 제어하기
86 | #### 잡의 재시작 방지하기
87 | - preventRestart() 사용
88 |
89 | #### 재시작 횟수 제한하기
90 | - startLimit() 사용
91 |
92 | #### 완료된 스텝 재실행하기
93 | - allowStartComplete() 사용
--------------------------------------------------------------------------------
/06주차/요약본/[6주차]_6장_잡_실행하기_황준호.md:
--------------------------------------------------------------------------------
1 | ## 6장. 잡 실행하기
2 |
3 | ### 스프링 부트로 배치 잡 시작시키기
4 |
5 | - 스프링부트는 `CommandLineRunner`와 `ApplicationRunner`라는 두가지 메커니즘을 이용해 실행시 로직을 수행한다
6 |
7 | - 두 인터페이스는 한개의 메서드(`run()` : 애플리케이션이 코드를 실행할 준비가 되면 호출됨)를 가지고있다
8 | - 스프링부트를 스프링배치와 함께 사용할땐 `JobLauncherCommandLineRunner`가 사용된다
9 | - 스프링부트가 `ApplicationContext`내에 구성된 모든 `CommandLineRunner`를 실행할 때 클래스패스에 `spring-boot-starter-batch`가 존재한다면 `JobLauncherCommandLineRunner`는 컨텍스트 내에서 찾아낸 모든 잡을 실행한다.
10 | - 이전 예제는 모두 이런식으로 작동했음
11 |
12 | - 애플리케이션 기동 시에 실행할 잡 정의하는 법
13 |
14 | - 애플리케이션이 기동될때 잡이 실행되지 않도록 `spring.batch.job.enabled`를 false로 설정해야 한다 (기본값은 true)
15 |
16 | ```java
17 | public static void main(String[] args) {
18 | SpringApplication application = new SpringApplication(BatchApplication.class);
19 | Properties properties = new Properties();
20 | properties.put("spring.batch.job.enable", false);
21 | application.setDefaultProperties(properties);
22 | application.run(args);
23 | }
24 | ```
25 |
26 | - 컨텍스트의 여러 잡 중 특정 잡만 실행하는 법
27 |
28 | - `spring.batch.job.names` 프로퍼티 사용
29 |
30 | ### REST 방식으로 잡 실행하기
31 |
32 | - 컨트롤러와 `JobLauncher.run(Job, JobParameters)`을 연결시키면 된다
33 |
34 | - 스프링 배치는 기본적으로 `JobLauncher`의 구현체인 `SimpleJobLauncher`을 제공한다
35 |
36 | - `SimpleJobLauncher`은 `JobParameters`에 대한 조작을 제공하지 않으므로 전달되기 전에 조작해야 한다.
37 |
38 | - `JobLauncher`가 사용하는 `TaskExecutor`을 구성하여 동기식/비동기식을 선택할 수 있다.
39 |
40 | - `SimpleJobLauncher`은 기본적으로 동기식 (호출자와 동일한 스레드에서 잡이 수행됨)
41 | - 잡이 오래 걸리는경우 비동기가 적절할 수도 있음 (이럴땐 `JobExecution`의 id만 반환됨)
42 |
43 | - 잡 파라미터를 자동으로 증가시키고 싶다면? `JobParametersBuilder.getNextJobParameters` 이용.
44 |
45 | ```java
46 | // inputJobParameters은 입력받은 잡 파라미터, JobExplorer은 autowired
47 | JobParameters jobParameters = new JobParametersBuilder(inputJobParameters, jobExplorer)
48 | .getNextJobParameters(job) //입력받은 job 정보로 찾은 job(incrementer config가 되어 있어야 함)
49 | .toJobParameters();
50 | return jobLauncher.run(job, jobParameters).getExitStatus();
51 | ```
52 |
53 | - 쿼츠로 스케줄링하기
54 |
55 | - 쿼츠의 컴포넌트
56 |
57 | - 스케줄러 : 연관된 트리거가 작동할 때 잡을 실행하는 역할
58 | - `SchedulerFactory`를 통해 가져올 수 있음
59 | - `JobDetails` 및 트리거의 저장소 기능
60 | - 트리거 : 작업 실행 시점
61 | - 트리거가 작동돼 쿼츠에게 잡을 실행하도록 지시하면 잡의 개별 실행을 정의하는 `JobDetails` 객체가 생성됨
62 | - 잡 : 실행할 작업의 단위
63 |
64 | - config
65 |
66 | ```java
67 | //배치 잡을 기동하는 쿼츠 잡
68 | //일정 이벤트가 발생할 때 잡을 실행
69 | public class BatchScheduledJob extends QuartzJobBean {
70 |
71 | @Autowired
72 | private Job job;
73 |
74 | @Autowired
75 | private JobExplorer jobExplorer;
76 |
77 | @Autowired
78 | private JobLauncher jobLauncher;
79 |
80 | @Override
81 | protected void executeInternal(JobExecutionContext context) {
82 | JobParameters jobParameters = new JobParametersBuilder(this.jobExplorer)
83 | .getNextJobParameters(this.job)
84 | .toJobParameters();
85 |
86 | try {
87 | this.jobLauncher.run(this.job, jobParameters);
88 | } catch (Exception e) {
89 | e.printStackTrace();
90 | }
91 | }
92 | }
93 | ```
94 |
95 | ```java
96 | @Configuration
97 | public class QuartzConfig {
98 |
99 | // Trigger: 스케줄과 JobDetail을 연결함
100 | @Bean
101 | public Trigger jobTrigger() {
102 | SimpleScheduleBuilder scheduleBuilder = SimpleScheduleBuilder.simpleSchedule()
103 | .withIntervalInSeconds(5).withRepeatCount(4); // 5초마다 실행, 4번 반복 (총 5번 실행됨)
104 |
105 | return TriggerBuilder.newTrigger()
106 | .forJob(quartzJobDetail())
107 | .withSchedule(scheduleBuilder)
108 | .build();
109 | }
110 |
111 | // JobDetail: 실행할 쿼츠 잡 수행 시에 사용되는 메타데이터
112 | @Bean
113 | public JobDetail quartzJobDetail() {
114 | return JobBuilder.newJob(BatchScheduledJob.class)
115 | .storeDurably()
116 | .build();
117 | }
118 | }
119 | ```
120 |
121 | ### 잡 중지하기
122 |
123 | 잡을 종료하는 방법엔 여러가지가 있다
124 |
125 | 1. 자연스럽게 완료되어 종료
126 |
127 | - 모든 스텝이 `COMPLETED` 상태가 되어 잡도 `COMPLETED` 상태가 됨
128 |
129 | 2. 프로그래밍적으로 종료
130 |
131 | - 중지 트랜지션으로 종료
132 |
133 | ```java
134 | @Bean
135 | public Job job() {
136 | return this.jobBuilderFactory.get("job")
137 | .start(step1())
138 | .on("STOPPED").stopAndRestart(step1()) //재시작시 step1부터 다시시작
139 | .from(step1())
140 | .on("*").to(step2())
141 | .from(step2())
142 | .next(step3()).end()
143 | .build();
144 | }
145 |
146 | private Step step1() {
147 | return this.stepBuilderFactory.get("step1")
148 | .chunk(100)
149 | .reader(customReader())
150 | .writer(customWriter())
151 | .allowStartIfComplete(true) // 잡이 재시작되면 이 스텝이 다시 실행되도록
152 | .listener(customReader()) //customReader의 @AfterStep를 붙인 메서드에서 특정 조건일때 STOPPED를 반환
153 | .build();
154 | }
155 |
156 | private Step step2() {
157 | ...
158 | }
159 |
160 | private Step step3() {
161 | ...
162 | }
163 | ```
164 |
165 | - `StepExecution.setTermimateOnly()`를 이용해 종료 (위 예보다 더 효율적, config가 더 깔끔해짐)
166 |
167 | ```java
168 | @Bean
169 | public Job job() {
170 | return this.jobBuilderFactory.get("job") //깔끔해짐
171 | .start(step1())
172 | .next(step2())
173 | .next(step3())
174 | .build();
175 | }
176 |
177 | private Step step1() {
178 | return this.stepBuilderFactory.get("step1")
179 | .chunk(100)
180 | .reader(customReader())
181 | .writer(customWriter())
182 | .allowStartIfComplete(true)
183 | //customReader의 @BeforeStep붙인 메서드에서 StepExecution을 가져와서 필드에 저장하고,
184 | //특정 조건일때 this.stepExecution.setTerminateOnly(); 하면 됨.
185 | .listener(customReader())
186 | .build();
187 | }
188 |
189 | private Step step2() {
190 | ...
191 | }
192 |
193 | private Step step3() {
194 | ...
195 | }
196 | ```
197 |
198 | 3. 오류를 던저 종료
199 |
200 | - 스프링 배치는 예외가 발생하면 기본적으로 스텝 및 잡이 실패한 것으로 간주한다
201 | - `StepExecution`을 사용해 잡을 중지하는 것과 예외를 발생시켜 잡을 중지하는것의 차이 : 잡의 상태
202 | - 전자는 `ExitStatus.STOPPED` 상태로 스텝이 완료된 후 잡 중지
203 | - 후자는 스텝이 완료되지 않음. 스텝과 잡에 `ExitStatus.FAILED` 레이블이 지정됨
204 | - 스텝이 `FAILED`로 식별되면 스텝을 처음부터 다시 실행하는 게 아니라 실패한 지점부터 실행한다
205 | - `[청크1: 아이템1,2,3], [청크2: 아이템4,5,6], [청크3: 아이템7,8,9]`일때, 아이템5에서 예외가 발생한 경우, 아이템4,5는 롤백된다. 재시작하면 청크1은 건너뛰고 청크2부터 다시 시작된다.
206 |
207 | ### 재시작 제어하기
208 |
209 | 스텝1에서 성공적이었다면 스텝2에서 실패하더라도 스텝1을 재시작하고 싶지 않을수도 있다.
210 |
211 | - 잡의 재시작 방지하기
212 |
213 | ```java
214 | @Bean
215 | public Job job() {
216 | return this.jobBuilderFactory.get("job")
217 | .preventRestart() // 잡이 실패하거나 어떤 이유로든 중지된 경우에 다시 실행할 수 없도록 함
218 | .start(step1())
219 | .next(step2())
220 | .next(step3())
221 | .build();
222 | }
223 | ```
224 |
225 | 다시 실행하려고 시도하면 `JobRestartException`이 발생함
226 |
227 | - 재시작 횟수를 제한하도록 구성하기
228 |
229 | - step1을 두번만 시도하도록 구성
230 |
231 | ```java
232 | private Step step1() {
233 | return this.stepBuilderFactory.get("step1")
234 | .startLimit(2) // 두번까지만 실행 가능
235 | .chunk(100)
236 | .reader(customReader())
237 | .writer(customWriter())
238 | .allowStartIfComplete(true) // 배치 잡 재실행시 수행할 일 결정
239 | .listener(customReader())
240 | .build();
241 | }
242 | ```
243 |
244 | 2번 넘게 실행되면 `StartLimitExceededException` 발생함
245 |
246 | - 완료된 스텝 재실행하기
247 |
248 | - 잡은 동일 파라미터로 성공하면 다시 실행 못한다
249 | - 스텝은 재정의로 이 규칙을 피할 수 있다
250 | - `StepBuilder.allowStartIfComplete()`를 사용하면 된다
--------------------------------------------------------------------------------
/06주차/요약본/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/07주차/발표자료/[7주차]_7장_ItemReader(1)_김성모.md:
--------------------------------------------------------------------------------
1 | # 7장 ItemReader
2 |
3 | ## ItemReader 인터페이스
4 |
5 | ```java
6 | public interface ItemReader {
7 |
8 | @Nullable
9 | T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
10 |
11 | }
12 | ```
13 |
14 | 스텝에 입력을 제공할 때, `ItemReader` 인터페이스의 `read()` 메소드를 정의한다.
15 |
16 | 스프링 배치는 여러 입력 유형에 맞는 여러 구현체를 제공한다.
17 |
18 | 제공하는 입력 유형은 플랫 파일, 여러 데이터베이스, JMS 리소스, 기타 입력 소스 등 다양하다.
19 |
20 | ## 파일 입력
21 |
22 | 다양한 입력 유형을 처리할 때 어떤 파일 입력을 처리하는 지 방법에 대해 알아보자.
23 |
24 | ### 플랫 파일
25 |
26 | `XML` 과 `JSON` 과는 다르게 데이터 포맷이나 의미를 정의하는 메타데이터가 없는 파일을 `플랫 파일`이라고 한다.
27 |
28 | 스프링 배치에서는 `FlatFileItemReader` 클래스를 사용한다.
29 |
30 | `FlatFileItemReader` 는 메인 컴포넌트 두 개로 이뤄진다.
31 |
32 | - Resource(읽을 대상 파일)
33 | - LineMapper(ResultSet을 객체로 맵핑)
34 |
35 | `LineMapper` 는 인터페이스로 구성되어 여러 구현체가 있는데, 그 중 가장 많이 사용하는 구현체는 `DefaultLineMapper` 이다.
36 |
37 | `DefaultLineMapper` 는 파일에서 읽은 Raw String 을 두 단계 처리를 거쳐 도메인 객체로 변환한다.
38 |
39 | 1. LineTokenizer : 파일의 레코드 한 줄씩 파싱해 `FieldSet` 으로 만든다.
40 | 2. FieldSetMapper : `FieldSet` 을 도메인 객체로 매핑한다.
41 |
42 | #### 고정 너비 파일
43 |
44 | 위에서 말했듯, 파일을 읽어서 레코드를 한 줄씩 파싱 후 도메인 객체에 매핑할 예정이다 예시를 위하여 고객 정보를 담은 resource 파일과 Customer 도메인 객체를 생성하자
45 |
46 | ```text
47 | Aimee CHoover 7341Vel Avenue Mobile AL35928
48 | Jonas UGilbert 8852In St. Saint Paul MN57321
49 | Regan MBaxter 4851Nec Av. Gulfport MS33193
50 | Octavius TJohnson 7418Cum Road Houston TX51507
51 | Sydnee NRobinson 894 Ornare. Ave Olathe KS25606
52 | Stuart KMckenzie 5529Orci Av. Nampa ID18562
53 | Petra ZLara 8401Et St. Georgia GA70323
54 | Cherokee TLara 8516Mauris St. Seattle WA28720
55 | Athena YBurt 4951Mollis Rd. Newark DE41034
56 | Kaitlin MMacias 5715Velit St. Chandler AZ86176
57 | Leroy XCherry 7810Vulputate St. Seattle WA37703
58 | Connor WMontoya 4122Mauris Av. College AK99743
59 | Byron XMedina 7875At Road Rock Springs WY37733
60 | Penelope YSandoval 2643Fringilla Av. College AK99557
61 | Rashad VOchoa 6587Lacus Street Flint MI96640
62 | Jordan UOneil 170 Mattis Ave Bellevue WA44941
63 | Caesar ODaugherty 7483Libero Ave Frankfort KY56493
64 | Wynne DRoth 8086Erat Street Owensboro KY50476
65 | Robin IRoberson 8014Pellentesque Street Casper WY84633
66 | Adrienne CCarpenter 8141Aliquam Avenue Tucson AZ85057
67 | ```
68 |
69 | ```java
70 |
71 | @Getter
72 | @Setter
73 | public class Customer {
74 | private String firstName;
75 | private String middleInitial;
76 | private String lastName;
77 | private String addressNumber;
78 | private String street;
79 | private String address;
80 | private String city;
81 | private String state;
82 | private String zipCode;
83 |
84 | public Customer() {
85 | }
86 |
87 | public Customer(String firstName, String middleName, String lastName, String addressNumber, String street, String city, String state, String zipCode) {
88 | this.firstName = firstName;
89 | this.middleInitial = middleName;
90 | this.lastName = lastName;
91 | this.addressNumber = addressNumber;
92 | this.street = street;
93 | this.city = city;
94 | this.state = state;
95 | this.zipCode = zipCode;
96 | }
97 |
98 | @Override
99 | public String toString() {
100 | return "Customer{" +
101 | "firstName='" + firstName + '\'' +
102 | ", middleInitial='" + middleInitial + '\'' +
103 | ", lastName='" + lastName + '\'' +
104 | ", address='" + address + '\'' +
105 | ", addressNumber='" + addressNumber + '\'' +
106 | ", street='" + street + '\'' +
107 | ", city='" + city + '\'' +
108 | ", state='" + state + '\'' +
109 | ", zipCode='" + zipCode + '\'' +
110 | '}';
111 | }
112 | }
113 | ```
114 |
115 | 읽어들일 파일과 레코드를 읽어 매핑할 객체가 준비가 되었다면 간단한 ItemReader, ItemWriter, Step, Job 을 구성해보자
116 |
117 | ```java
118 |
119 | @Configuration
120 | public class FixedWidthJobConfiguration {
121 | @Autowired
122 | private JobBuilderFactory jobBuilderFactory;
123 |
124 | @Autowired
125 | private StepBuilderFactory stepBuilderFactory;
126 |
127 | @Bean
128 | @StepScope
129 | public FlatFileItemReader fixedWidthItemReader(
130 | @Value("#{jobParameters['customerFile']}") Resource inputFile) {
131 |
132 | return new FlatFileItemReaderBuilder()
133 | .name("fixedWidthItemReader")
134 | .resource(inputFile)
135 | .fixedLength()
136 | .columns(new Range[]{new Range(1, 11), new Range(12, 12), new Range(13, 22),
137 | new Range(23, 26), new Range(27, 46), new Range(47, 62), new Range(63, 64),
138 | new Range(65, 69)})
139 | .names(new String[]{"firstName", "middleInitial", "lastName",
140 | "addressNumber", "street", "city", "state", "zipCode"})
141 | .targetType(Customer.class)
142 | .build();
143 | }
144 |
145 | @Bean
146 | public ItemWriter fixedWidthItemWriter() {
147 | return (items) -> items.forEach(System.out::println);
148 | }
149 |
150 | @Bean
151 | public Step fixedWidthStep() {
152 | return this.stepBuilderFactory.get("fixedWidthStep")
153 | .chunk(10)
154 | .reader(fixedWidthItemReader(null))
155 | .writer(fixedWidthItemWriter())
156 | .build();
157 | }
158 |
159 | @Bean
160 | public Job fixedWidthJob() {
161 | return this.jobBuilderFactory.get("fixedWidthJob")
162 | .start(fixedWidthStep())
163 | .build();
164 | }
165 | }
166 | ```
167 |
168 | #### 구분자로 구분된 파일
169 |
170 | #### 커스텀 레코드 파싱
171 |
172 | #### 여러 가지 레코드 포맷
173 |
174 | #### 여러 줄에 걸친 레코드
175 |
176 | #### 여러 개의 소스
177 |
178 | ### XML
179 |
180 | ### JSON
--------------------------------------------------------------------------------
/07주차/발표자료/[7주차]_7장_ItemReader_김민석.md:
--------------------------------------------------------------------------------
1 | # 7장 ItemReader - 1부 (~json)
2 |
3 | 청크 기반 스텝은 ItemReader - ItemProcessor - ItemWriter 로 구성.
4 |
5 | 스프링 배치는 거의 모든 유형의 입력 데이터를 읽을 수 있는 기반 코드를 제공함과 동시에 커스터마이징 할 수 있는 기능도 지원함.
6 |
7 | 7장에서는 ItemReader가 제공하는 다양한 기능을 알아본다.
8 |
9 | ## ItemReader 인터페이스
10 |
11 | ```java
12 | public interface ItemReader {
13 |
14 | @Nullable
15 | T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
16 |
17 | }
18 | ```
19 |
20 | - 스프링 배치는 처리할 입력 유형에 맞는 ItemReader의 여러 구현체 제공
21 | 
22 | 
23 |
24 | - 스텝 내에서 동작 방식
25 | - 스프링 배치가 read 메서드 호출
26 | - 아이템 한개 반환
27 | - 청크의 개수 만큼 반복
28 | - 청크 개수 만큼 확보되면 ItemProcessor -> ItemWriter로 청크 전달
29 |
30 |
31 | ## 파일 입력
32 |
33 | 스프링 배치는 파일을 고성능 IO 로 읽어 올 수 있는 선언적 방식의 리더를 제공
34 |
35 | ### 플랫 파일
36 |
37 | 플랫 파일 : 구분자가 없는 한개 이상의 레코드로 구성된 텍스트 파일
38 |
39 | FlatFileItemReader 사용.
40 |
41 | 
42 |
43 | FlatFileItemReader은 내부적으로 Resource(파일)와 LineMapper(DefaultLineMapper) 구현체로 구성.
44 |
45 | LineMapper는 LineTokenizer와 FieldSetMapper로 구성.
46 |
47 | FlatFileItemReader는 빌더를 사용하여 여러 옵션을 줄 수 있다.
48 |
49 | - 동작방식
50 | - 레코드 한 개에 해당하는 문자열이 LineMapper로 전달
51 | - LineTokenizer가 원시 문자열을 파싱해서 FieldSet으로 만든다
52 | - FieldSetMapper가 FieldSet을 토대로 도메인 객체로 매핑
53 |
54 |
55 | #### 고정 너비 파일
56 |
57 | 고정 너비 파일 : 레코드의 각 항목이 고정된 길이로 표현
58 |
59 | ```text
60 | Aimee CHoover 7341Vel Avenue Mobile AL35928
61 | Jonas UGilbert 8852In St. Saint Paul MN57321
62 | Regan MBaxter 4851Nec Av. Gulfport MS33193
63 | Octavius TJohnson 7418Cum Road Houston TX51507
64 | Sydnee NRobinson 894 Ornare. Ave Olathe KS25606
65 | Stuart KMckenzie 5529Orci Av. Nampa ID18562
66 | ```
67 |
68 | - LineMapper : DefaultLineMapper
69 | - LineTokenizer : FixedLengthTokenizer
70 | - FieldSetMapper : BeanWrapperFieldSetMapper
71 |
72 | ``
73 |
74 | #### 필드가 구분자로 구분된 파일
75 |
76 | delimited file : 레코드의 각 항목이 특정한 딜리미터로 구분되어 있는 텍스트 파일
77 |
78 | ```text
79 | Aimee,C,Hoover,7341,Vel Avenue,Mobile,AL,35928
80 | Jonas,U,Gilbert,8852,In St.,Saint Paul,MN,57321
81 | Regan,M,Baxter,4851,Nec Av.,Gulfport,MS,33193
82 | Octavius,T,Johnson,7418,Cum Road,Houston,TX,51507
83 | Sydnee,N,Robinson,894,Ornare. Ave,Olathe,KS,25606
84 | Stuart,K,Mckenzie,5529,Orci Av.,Nampa,ID,18562
85 | ```
86 |
87 | - LineMapper : DefaultLineMapper
88 | - LineTokenizer : DelimitedLineTokenizer
89 | - FieldSetMapper : BeanWrapperFieldSetMapper
90 |
91 | ``
92 |
93 | 건물번호와 거리명을 붙여서 단일 필드로 매핑
94 |
95 | FieldSetMapper의 커스텀 구현체 사용.
96 |
97 | FieldSet에서는 여러 타입의 값을 읽어올 수 있는 다양한 메서드 제공.
98 | (예제에서는 DefaultFieldSet class)
99 |
100 | - LineMapper : DefaultLineMapper
101 | - LineTokenizer : DelimitedLineTokenizer
102 | - FieldSetMapper : Custom
103 |
104 | ``
105 |
106 | #### 커스텀 레코드 파싱
107 |
108 | 건물번호와 거리명을 합칠 때 커스텀 LineTokenizer 구현체 사용.
109 |
110 | ```java
111 | public interface LineTokenizer {
112 |
113 | FieldSet tokenize(String line);
114 | }
115 | ```
116 |
117 | 커스텀 LineTokenizer는 아래와 같은 경우에도 사용
118 | - 특이한 파일 포맷 파싱
119 | - 서드파티 파일 포맷 파싱
120 | - 특수한 타입 변환 요구 조건 처리
121 |
122 | - LineMapper : DefaultLineMapper
123 | - LineTokenizer : Custom
124 | - FieldSetMapper : BeanWrapperFieldSetMapper
125 |
126 |
127 | ``
128 |
129 | #### 여러 가지 레코드 포맷
130 |
131 | 한 파일 안에 여러 레코드가 섞여 있을 경우 PatternMatchingCompositeLineMapper 사용.
132 |
133 | 기존 DefaultLineMapper는 단일 필드매퍼와 토크나이저를 사용했지만 PatternMatchingCompositeLineMapper는 Map을 통해서 패턴 매칭을 사용하여 다양한 매퍼와 토크나이저 사용 가능.
134 |
135 | ```text
136 | CUST,Warren,Q,Darrow,8272 4th Street,New York,IL,76091
137 | TRANS,1165965,2011-01-22 00:13:29,51.43
138 | CUST,Ann,V,Gates,9247 Infinite Loop Drive,Hollywood,NE,37612
139 | CUST,Erica,I,Jobs,8875 Farnam Street,Aurora,IL,36314
140 | TRANS,8116369,2011-01-21 20:40:52,-14.83
141 | TRANS,8116369,2011-01-21 15:50:17,-45.45
142 | TRANS,8116369,2011-01-21 16:52:46,-74.6
143 | TRANS,8116369,2011-01-22 13:51:05,48.55
144 | TRANS,8116369,2011-01-21 16:51:59,98.53
145 | ```
146 |
147 | - LineMapper : PatternMatchingCompositeLineMapper
148 | - LineTokenizer(CUST) : DelimitedLineTokenizer
149 | - FieldSetMapper(CUST) : BeanWrapperFieldSetMapper
150 | - LineTokenizer(TRANS) : DelimitedLineTokenizer
151 | - FieldSetMapper(TRANS) : Custom
152 |
153 | ``
154 |
155 |
156 | #### 여러 줄에 걸친 레코드
157 |
158 | 하나의 커스터머에 여러개의 트랜잭션을 가진 도메인 객체로 변환하고 싶을때는?
159 |
160 | - LineMapper : PatternMatchingCompositeLineMapper
161 | - LineTokenizer(CUST) : DelimitedLineTokenizer
162 | - FieldSetMapper(CUST) : BeanWrapperFieldSetMapper
163 | - LineTokenizer(TRANS) : DelimitedLineTokenizer
164 | - FieldSetMapper(TRANS) : Custom
165 |
166 |
167 | ``
168 |
169 | #### 여러 개의 소스
170 |
171 | 여러 개의 파일에서 읽어야 하는 경우라면?
172 |
173 | 
174 |
175 | ``
176 |
177 |
178 | ### XML
179 |
180 | 파일 포맷의 차이는 메타데이터의 차이.
181 |
182 | XML은 태그라는 메타데이터를 사용하여 데이터를 완전히 설명 함.
183 |
184 | XML 파서는 대표적으로 DOM과 SAX가 있다. DOM은 한번에 읽어 들이는 방식으로 효율적이지 않기 때문에 이벤트 기반의 SAX 사용.
185 |
186 | 스프링 배치에서는 문서 내 각 섹션을 독립적으로 파싱하는 StAX 파서 사용.
187 |
188 | ```text
189 | StAX(Streaming API for XML)는 XML 문서를 처리하는 자바 API로서, 기존 DOM 및 SAX에 추가된 API이다.
190 |
191 | 기존 XML API는 2가지 방식이었다.
192 |
193 | 트리 기반 : 문서 전체를 트리(Tree) 구조로 메모리로 읽어서 랜덤하게 접근이 가능하다.
194 | 이벤트 기반 : 문서의 한 항목식 이벤트가 발생하여 응용 프로그램에서 처리한다.
195 | 2가지 방식은 각각 보완작용을 한다. 트리 기반(DOM)은 문서의 구조 해석이 가능하고, 이벤트 기반(SAX)은 메모리를 적게 사용하면서 신속한 작동이 가능하다.
196 |
197 | StAX는 이러한 방식의 중간 방식으로 설계되었다. StAX 방식은 프로그램의 동작점, 즉 문서의 한지점을 가리키는 커서가 있는 방식이다. 이러한 이유로 응용 프로그램은 필요에 따라 정보를 추출할 수 있게 된다. (pull 형) 이것이 기존 SAX와 같은 이벤트 기반 API와 다른 점이다. SAX는 파서에서 응용 프로그램으로 데이터를 보내는 방식이다. (push형)
198 |
199 | https://ko.wikipedia.org/wiki/StAX
200 | ```
201 |
202 | ItemReader 구현체는 StaxEventItemReader 사용
203 |
204 | XML 바인딩은 JAXB 사용.
205 |
206 | ``
207 |
208 | ### JSON
209 |
210 | XML과 방식은 거의 유사.
211 |
212 | 매퍼는 Jackson이나 Gson 사용.
213 |
214 | ``
--------------------------------------------------------------------------------
/07주차/발표자료/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/07주차/요약본/[7주차]_7장_ItemReader-1_이호빈.md:
--------------------------------------------------------------------------------
1 | # 7-1장 ItemReader
2 |
3 | - 스프링 배치는 거의 모든 유형의 입력 데이터를 처리할 수 있는 표준 방법을 제공한다
4 |
5 | ### ItemReader 인터페이스
6 |
7 | - 스프링 배치의 ItemReader와 javax(JSR)의 ItemReader는 다르다.
8 | - JSR의 ItemReader는 ItemSteam과 ItemReader를 조합한 것
9 | - ItemReader의 read()를 호출하면 Step 내에서 처리할 Item 한 개를 반환한다.
10 |
11 | ### 파일 입력
12 |
13 | - 플랫파일
14 | - 한 개 이상의 레코드가 포함된 파일. 메타데이터가 없다
15 | - 파일 형태에 여러 경우가 있을 수 있다.
16 | - 고정 너비로 있는 경우, 구분자로 구분된 경우(csv), 여러 줄로 구성된 레코드를 읽는 경우, 다중 파일을 읽는 경우
17 | - FlatFileItemReader
18 | - 읽어들일 대상 파일을 나타내는 Resource, 필드의 묶음을 나타내는 LineMapper 인터페이스가 있다
19 | - LineMapper 구현체인 DefaultLineMapper를 통해서 읽을 수 있다.
20 | - String을 대상으로 도메인 객체로 변환해줄 수 있다
21 | - LineTokenizer로 해당 줄을 파싱하고, FieldSetMapper로 도메인 객체를 매핑한다
22 | - 커스텀 LineTokenizer, 커스텀 FieldSetMapper로 만들어줄 수 있다
23 | - 파싱 후, 원하는 대로 도메인 필드에 넣어줄 수 있다. (e.g. street + address = address 혹은 조건을 추가한다든지 등...)
24 |
25 | > 각각 입력 파일에 대한 구현체들을 제공한다.
26 | >
27 |
28 | ### ItemReader 인터페이스 vs ItemStreamReader 인터페이스
29 |
30 | - ItemReader
31 | - 데이터를 제공하고 다음으로 가게 해주는 인터페이스
32 | - read() 밖에 없다.
33 | - ItemStreamReader
34 | - ItemReader와 ItemStream을 합친 것
35 | - ItemStream
36 | - 에러가 발생했을 때 상태를 ExecutionContext에 저장하거나 ExecutionContext에 있는 상태를 꺼내서 복원하기 위함
37 | - 그래서 open, update, close 등이 있음
38 |
39 | ### XML
40 |
41 | - XML 파일을 입력 받기 위해서 JAXB 라는 구현체를 이용한다. (여러 구현체가 있음)
42 |
43 | [실습 링크](https://github.com/aegis1920/my-lab/tree/master/def-guide-spring-batch)
44 |
--------------------------------------------------------------------------------
/07주차/요약본/[7주차]_7장_ItemReader-1_황준호.md:
--------------------------------------------------------------------------------
1 | ## 7장. ItemReader
2 |
3 | ### ItemReader 인터페이스
4 |
5 | ```java
6 | public interface ItemReader {
7 | T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
8 | }
9 | ```
10 |
11 | - `ItemReader` 인터페이스는 전략 인터페이스다
12 | - 스프링 배치는 플랫 파일, 여러 데이터베이스, JMS 리소스 등등 유형의 구현체를 제공한다
13 | - `ItemReader`나 `ItemReader` 하위 인터페이스를 구현해서 커스텀하게 사용할수도 있다
14 |
15 | ### 파일 입력
16 |
17 | #### 플랫 파일
18 |
19 | - 가장 많이 사용하는 구현체인 `DefaultLineMapper`는 다음 두 개가 처리를 담당한다
20 |
21 | 1. `LineTokenizer` : 파일의 한 줄 -> `FieldSet`
22 | 2. `FieldSetMapper` : `FieldSet` -> 객체
23 |
24 | - 고정 너비 파일
25 |
26 | ```java
27 | @Bean
28 | @StepScope
29 | public FlatFileItemReader customerItemReader(@Value("#{jobParameters['customerFile']})") Resource inputFile) {
30 | return new FlatFileItemReaderBuilder()
31 | .name("customerItemReader")
32 | .resource(inputFile)
33 | .fixedLength()
34 | .columns(
35 | new Range[]{new Range(1, 11), new Range(12, 12), new Range(13, 22), new Range(23, 26),
36 | new Range(27, 46), new Range(47, 62), new Range(63, 64), new Range(65, 69)}
37 | )
38 | .names(
39 | new String[]{"firstName", "middleInitial", "lastName", "addressNumber", "street",
40 | "city", "state", "zipCode"}
41 | )
42 | .targetType(Customer.class)
43 | .build();
44 | }
45 | ```
46 |
47 | - 필드가 구분자로 구분된 파일
48 |
49 | ```java
50 | @Bean
51 | @StepScope
52 | public FlatFileItemReader customerItemReader(
53 | @Value("#{jobParameters['customerFile']})") Resource inputFile) {
54 | return new FlatFileItemReaderBuilder()
55 | .name("customerItemReader")
56 | .delimited()
57 | .names(new String[]{"firstName", "middleInitial", "lastName", "addressNumber", "street",
58 | "city", "state", "zipCode"})
59 | .targetType(Customer.class)
60 | .resource(inputFile)
61 | .build();
62 | }
63 | ```
64 |
65 | 매핑을 커스텀하게 하고 싶으면?
66 |
67 | ```java
68 | @Bean
69 | @StepScope
70 | public FlatFileItemReader customerItemReader(
71 | @Value("#{jobParameters['customerFile']})") Resource inputFile) {
72 | return new FlatFileItemReaderBuilder()
73 | .name("customerItemReader")
74 | .delimited()
75 | .names(new String[]{"firstName", "middleInitial", "lastName", "addressNumber", "street",
76 | "city", "state", "zipCode"})
77 | .fieldSetMapper(new CustomFieldSetMapper())
78 | .resource(inputFile)
79 | .build();
80 | }
81 | ```
82 |
83 | - `LineTokenizer`직접 구현
84 |
85 | - `LineTokenizer`을 implements하여 `FlatFileItemReader` config에서 설정한다
86 |
87 | ```java
88 | public interface LineTokenizer {
89 | FieldSet tokenizer(String line);
90 | }
91 | ```
92 |
93 | - 예
94 |
95 | ```java
96 | @Bean
97 | @StepScope
98 | public FlatFileItemReader customerItemReader(
99 | @Value("#{jobParameters['customerFile']})") Resource inputFile) {
100 | return new FlatFileItemReaderBuilder()
101 | .name("customerItemReader")
102 | .lineTokenizer(new CustomerFileLineTokenizer()) // <--
103 | .resource(inputFile)
104 | .build();
105 | }
106 | ```
107 |
108 | - 여러 형식이 섞여 있는 경우
109 |
110 | - 예 : 접두사로 고객데이터, 거래데이터가 섞여 있는 경우
111 |
112 | ```
113 | CUST,Warren,Q,Darrow,8272 4th Street,New York,IL,76091
114 | TRANS,1165965,2011-01-22 00:13:29,51.43
115 | CUST,Ann,V,Gates,9247 Infinite Loop Drive,Hollywood,NE,37612
116 | CUST,Erica,I,Jobs,8875 Farnam Street,Aurora,IL,36314
117 | TRANS,8116369,2011-01-21 20:40:52,-14.83
118 | TRANS,8116369,2011-01-21 15:50:17,-45.45
119 | TRANS,8116369,2011-01-21 16:52:46,-74.6
120 | TRANS,8116369,2011-01-22 13:51:05,48.55
121 | TRANS,8116369,2011-01-21 16:51:59,98.53
122 | ```
123 |
124 | - ```java
125 | @Bean
126 | public PatternMatchingCompositeLineMapper lineTokenizer() {
127 | Map lineTokenizers = new HashMap<>(2);
128 | lineTokenizers.put("CUST*", customerLineTokenizer());
129 | lineTokenizers.put("TRANS*", transactionLineTokenizer());
130 |
131 | Map fieldSetMappers = new HashMap<>(2);
132 | BeanWrapperFieldSetMapper customerFieldSetMapper = new BeanWrapperFieldSetMapper<>();
133 | customerFieldSetMapper.setTargetType(Customer.class);
134 | fieldSetMappers.put("CUST*", customerFieldSetMapper);
135 | fieldSetMappers.put("TRANS*", new TransactionFieldSetMapper());
136 |
137 | PatternMatchingCompositeLineMapper lineMappers = new PatternMatchingCompositeLineMapper();
138 | lineMappers.setTokenizers(lineTokenizers);
139 | lineMappers.setFieldSetMappers(fieldSetMappers);
140 | return lineMappers;
141 | }
142 |
143 | @Bean
144 | public DelimitedLineTokenizer transactionLineTokenizer() {
145 | DelimitedLineTokenizer lineTokenizer = new DelimitedLineTokenizer();
146 | lineTokenizer.setNames("prefix", "accountNumber", "transactionDate", "amount");
147 | return lineTokenizer;
148 | }
149 |
150 | @Bean
151 | public DelimitedLineTokenizer customerLineTokenizer() {
152 | DelimitedLineTokenizer lineTokenizer = new DelimitedLineTokenizer();
153 | lineTokenizer.setNames(
154 | "firstName", "middleInitial", "lastName", "address", "city", "state", "zipCode"
155 | );
156 | lineTokenizer.setIncludedFields(1, 2, 3, 4, 5, 6, 7);
157 | return lineTokenizer;
158 | }
159 | ```
160 |
161 | ```java
162 | public class TransactionFieldSetMapper implements FieldSetMapper {
163 | public Transaction mapFieldSet(FieldSet fieldSet) {
164 | Transaction trans = new Transaction();
165 | trans.setAccountNumber(fieldSet.readString("accountNumber"));
166 | trans.setAmount(fieldSet.readDouble("amount"));
167 | trans.setTransactionDate(fieldSet.readDate("transactionDate", "yyyy-MM-dd HH:mm:ss"));
168 | return trans;
169 | }
170 | }
171 | ```
172 |
173 | - 이후 예제 생략
174 |
175 | #### XML
176 |
177 | - XML파서로는 DOM파서와 SAX파서를 많이 이용한다
178 | - DOM파서는 부하가 커서 배치 처리엔 적합하지 않아 SAX파서를 자주 사용한다
179 | - SAX파서 : 특정 엘리먼트를 만나면 이벤트를 발생시키는 이벤트 기반 파서
180 | - 스프링 배치에서는 StAX파서를 사용한다
181 | - 해야하는 것들
182 | - oxm관련 의존성 추가
183 | - 도메인 객체에 JAXB 애너테이션 추가
184 | - @XmlRootElement, @XmlElementWrapper, @XmlElement ...
185 | - 마샬러 설정
186 | - 아이템리더 설정
187 |
188 | ### JSON
189 |
190 | - JsonItemReader는 3가지 의존성이 필요하다
191 |
192 | 1. 배치를 재시작할때 사용하는 배치의 이름
193 | 2. 파싱에 사용할 `JsonObjectReader`
194 | 3. 읽어들일 리소스
195 |
196 | ```java
197 | @Bean
198 | @StepScope
199 | public JsonItemReader customerFileReader(
200 | @Value("#{jobParameters['customerFile']}") Resource inputFile) {
201 |
202 | ObjectMapper objectMapper = new ObjectMapper();
203 | ObjectMapper.setDateFormat(new SimpleDateFormat("yyyy-MM-dd hh:mm:ss"));
204 |
205 | JacksonJsonObjectReader jsonObjectReader = new JacksonJsonObjectReader<>(Customer.class);
206 | jsonObjectReader.setMapper(objectMapper);
207 |
208 | return new JsonItemReaderBuilder()
209 | .name("customerFileReader") // <-- 1
210 | .jsonObjectReader(jsonObjectReader) // <-- 2
211 | .resource(inputFile) // <-- 3
212 | .build();
213 | }
214 | ```
215 |
--------------------------------------------------------------------------------
/07주차/요약본/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/08주차/발표자료/tmp.md:
--------------------------------------------------------------------------------
1 | # test
2 |
--------------------------------------------------------------------------------
/08주차/요약본/[8주차]_7장_ItemReader(2)_김성모.md:
--------------------------------------------------------------------------------
1 | # 7장 ItemReader(2)
2 |
3 | ## 데이터베이스 입력
4 |
5 | ### JDBC
6 |
7 | `Cursor` 와 `Paging` 기법을 통해 JDBC에서 수백 만건의 데이터를 모두 적재하지 않고 가져올 수 있다.
8 |
9 | - Cursor
10 |
11 | `RowMapper` 인터페이스를 구현하여 도메인 객체에 매핑시킨 후 `Cursor` 를 열어 스트리밍하게 데이터를 가져올 수 있다.
12 |
13 | ```java
14 | public JdbcCursorItemReader customerItemReader(Datasource datasource){
15 | return new JdbcCursorItemReaderBuilder()
16 | .name("blah")
17 | .dataSource(dataSource)
18 | .sql("select * from customer")
19 | .rowMapper(new CustomerRowMapper())
20 | .build();
21 | }
22 | ```
23 |
24 | 이제 `JdbcCursorItemReader`의 read 메소드를 호출하게 되면 데이터베이스는 로우 하나를 반환한다.
25 |
26 | - Paging 처리
27 |
28 | `JdbcPagingItemReader` 를 itemReader에서 구현해주면 된다.
29 | 또한 `SqlPaingQueryProviderFactoryBean` 으로 sql 을 작성한 뒤 위의 객체의 세팅값으로
30 | queuryProvider에 주입해주면 된다.
31 |
32 |
33 | ### 하이버네이트
34 |
35 | 자에의 ORM 기술인 하이버네이트를 활용해 모델 객체를 데이터베이스 테이블로 매핑할 수 있다.
36 |
37 | 배치 처리에서 하이버네이트를 사용하기 위해서는 스테이트풀 세션을 주의해야만 한다. (OOM 발생할 수 있음)
38 |
39 | 스프링배치가 제공하는 ItemReader는 이런 점을 해결하도록 개발되었다.
40 |
41 | #### 하이버네이트 커서로 처리하기
42 |
43 | 사전 작업으로는 HibernateBatchConfigurer를 DefaultBatchConfigurer를 상속받아
44 | getTransactionManager()를 오버라이딩 시켜줄 수 있도록 해야한다.
45 |
46 | transactionManager에 쓰일 객체 = new HibernateTransactionManager();
47 |
48 | 그 후 `HibernateCursorItemReader`를 구현하면 된다.
49 |
50 |
51 | #### 하이버네이트 페이징 기법
52 |
53 | `HibernatePagingItemReader` 를 구현하면 된다.
54 |
55 | ### JPA
56 |
57 | 위의 하이버네이트는 JPA 를 구현한 구현체이다.
58 |
59 | 페이징 처리는 `JpaPagingItemReader` 를 구현하게 되며 위 하이버네이트와 동일한 방식이다.
60 |
61 | ### 저장 프로시저
62 |
63 | 데이터베이스는 목적에 맞춘 저장 프로시저가 포함되어 있을 수 있다. 스프링 배치에서는 `StoredProcudereItemReader` 컴포넌트를 사용하여 구성할 수 있다.
64 |
65 | 프로시저는 데이터베이스에서 만들어놓고 이를 배치에서 사용하게끔 호출한다고 보면 된다.
66 |
67 | `StoredProcedureItemReader` 를 사용하며 프로시저명을 지정해주면 된다.
68 |
69 | ### 스프링 데이터
70 |
71 | #### 몽고 DB
72 |
73 | 몽고 DB는 `MongoItemReader`로 페이지 기반이다.
74 |
75 | #### 스프링데이터 레포지토리
76 |
77 | `RepositoryItemReader`를 활용해 일관된 방식으로 레포지토리를 운용할 수 있다.
78 |
79 | ## 기존 서비스
80 |
81 | 기존 어플리케이션의 코드를 사용하기 위해서는 `ItemReaderAdapter` 를 활용하여 처리할 수 있다
82 |
83 | ## 커스텀 입력
84 |
85 | 위와 같이 여러 제공에도 불구하고 커스텀으로 처리해야하는 상황이 발생할 수 있다.
86 | 이땐 `ItemReader ` 인터페이스를 구현한 Custom ItemReader 를 만들 수 있다.
87 |
88 | 중요 포인트는 `ItemReader` 의 read 메소드를 구현해주기만 하면 된다.
89 |
90 | 만약 리더의 상태를 저장해서 이 전에 종료된 지점부터 리더를 다시 시작하려면 `ItemStream`
91 | 인터페이스를 구현해야한다. `ItemStreamSuport` 라는 추상클래스도 함께 구현할 때 넣고
92 | read 메소드를 구현하게되면 Custom ItemReader 를 만들 수 있다.
93 |
94 | ## 에러 처리
95 |
96 | - 레코드 건너뛰기 : 에러가 발생했을 때 레코드를 건너뛰도록 step에서 설정할 수 있다.
97 |
98 | - 잘못된 레코드 로그 남기기 : ItemListener를 만들어서 `@OnReadError` 를 처리하도록 작업한다.
99 |
100 | - 입력이 없을 때 처리 : `@AfterStep` 을 구현하여 처리한다.
--------------------------------------------------------------------------------
/08주차/요약본/[8주차]_7장_ItemReader-2_김광훈.md:
--------------------------------------------------------------------------------
1 | # 7-2장 ItemReader
2 | ## 하이버네이트
3 | #### 배치에서 사용하면 스테이프풀 세션 구현체를 사용
4 | #### 하이버네이트는 캐싱을 하기 때문에 OOM 발생할 수 있음
5 | #### 그래서 스트링 배치의 ItemReader 사용하면 Commit 할 때 세션을 플러시하여 이 문제를 해결해줌
6 | #### 스프링 배치는 DataSourceTransactionManager 를 사용함
7 | #### 그렇기 때문에 만약 하이버네이트를 사용한다면 HibernateTransactionManager 로 Config 수정을 해야함
8 |
9 | ## JPA
10 | #### JpaTransactionManager 를 사용한다.
11 | #### ItemReader 는 커서는 지원하지 않지만 페이징은 지원
12 | #### 쿼리는 JPQL 을 사용하는 것 같음
13 |
14 | ## 스프링 데이터 리포지터리
15 | #### 스프링 데이터 리포지터리는 Repository 추상화를 사용하여 스프링 데이터가 제공하는 인터페이스 중 하나를 상속하는 인터페이스를 정의하면 기본적인 CRUD 작업을 지원해준다.
16 | #### 스프링 배치와 스프링 데이터는 호환성이 좋은데, 그 이유는 스프링 배치가 스프링 데이터의 PagingAndSortingRepository 를 활용하기 때문이다.
17 | #### 예제를 살펴보면 ItemReader 에서 methodName 으로 익숙한 "findByCity" 와 같은 쿼리를 사용할 수 있다.
18 |
19 | ## 예외 처리
20 | #### 레코드 건너뛰기
21 | - skipLimit( ) 으로 레코드 건너뛰기 가능 -> 10회까지 건너뛰기 가능
22 | - noSkip( ) 으로 특정 예외 건너뛸 수 있음
23 | #### 로그 남기기
24 | - ItemListener 를 사용해서 잘못된 레코드를 기록할 수 있음
25 | - ItemListenerSupport 를 사용하고 onReadError 메서드를 오버라이드해서 발생한 에러 기록
26 | - @OnReadError 애노테이션 사용 가능
27 |
28 |
--------------------------------------------------------------------------------
/08주차/요약본/[8주차]_7장_ItemReader-2_이호빈.md:
--------------------------------------------------------------------------------
1 | # 7-2장 ItemReader (데이터베이스 입력)
2 |
3 | 대부분의 내용은 [실습 코드](https://github.com/aegis1920/my-lab/tree/master/def-guide-spring-batch)에 있습니다.
4 |
5 | - DB는 배치 처리에서 훌륭한 입력소스다
6 | - DB에 내장된 트랜잭션
7 | - 파일보다 확장성이 좋으며 복구 기능이 좋다
8 |
9 | ## JDBC
10 |
11 | - 스프링이 제공하는 JdbcTemplate을 사용하면
12 | - 전체 ResultSet을 한 row씩 순서대로 가져오면서 필요한 도메인 객체로 변환해 메모리에 저장한다
13 | - 전체 데이터를 한 번에 메모리에 저장하지 않기 위해 스프링 배치는 Cursor와 Paging을 제공한다.
14 |
15 | ### Cursor
16 |
17 | - DB에서 하나의 레코드를 한 번에 가져옴(항상 1 row)
18 | - next()를 호출할 때마다 실행됨. 그리고 다음 레코드로 커서를 옮김
19 |
20 | ### Paging
21 |
22 | - DB에서 Chunk 크기(e.g. 10 row)만큼의 레코드를 한 번에 가져옴
23 | - 고유한 SQL 쿼리를 통해 생성됨
24 |
25 | ### JDBC Cursor 처리
26 |
27 | - JdbcTemplate이 ResultSet을 Domain 객체로 매핑하는데 RowMapper 구현체가 필요하다
28 | - RowMapper 구현체는 Spring Framework Core가 제공하는 JDBC 지원 표준 컴포넌트다
29 | - JdbcCursorItemReader는 ResultSet을 생성하면서 Cursor를 연 다음, 스프링 배치가 read()를 호출할 때마다 Domain 객체로 매핑할 row를 가져온다.
30 | - ResultSet은 ThreadSafe 하지 않으므로 다중 스레드 환경에서는 사용할 수 없다.
31 |
32 | ### JDBC Paging 처리
33 |
34 | - 스프링 배치가 Page라는 청크로 결과 목록을 반환한다
35 | - 한 번에 SQL 쿼리 하나를 실행해 레코드를 하나씩 가져오는 대신, 각 페이지마다 새로운 쿼리를 실행한 뒤 쿼리 결과를 한 번에 메모리에 적재한다??
36 | - 페이지 크기(반환될 레코드 개수)와 페이지 번호(현재 처리중인 페이지 번호)를 가지고 쿼리를 할 수 있어야 한다.
37 | - PagingQueryProvider 인터페이스의 구현체를 제공해야 한다. DB마다 그 구현체가 다른데 SqlPagingQueryProviderFactoryBean을 사용하면 사용하는 DB가 어떤 건지 감지할 수 있다
38 | - Paging 기법은 각 페이지의 쿼리를 실행할 때마다 동일한 레코드 정렬 순서를 보장하려면 순서가 중요하다. 그래서 sortKey가 있다.
39 | - SqlPagingQueryProviderFactoryBean에서 DataSource를 받는 이유는 이 DataSource를 사용해 DB 타입을 결정하기 때문
40 |
41 | ### Hibernate
42 |
43 | - XML 파일 또는 애너테이션을 사용해서 객체를 데이터베이스 테이블로 매핑하는 구성을 한다
44 | - 그래서 DB 구조를 알지 못해도 객체 구조 기반으로 쿼리를 작성할 수 있다
45 | - 하이버네이트의 기본 세션은 stateful이다. 즉, 아이템 백만 건을 조회하고 사용한다면 해당 아이템들을 모두 캐시에 쌓으면서 OOME가 발생한다.
46 | - 스프링 배치가 제공하는 하이버네이트 기반 ItemReader는 Commit할 때 세션을 Flush해서 배치처리를 잘할 수 있도록 한다.
47 |
48 | ### Hibernate Cursor 처리
49 |
50 | - sessionFactory, Customer 엔티티, HibernateCursorItemReader가 필요하다
51 | - pageSize()만 추가하면 끝
52 |
53 | ### JPA
54 |
55 | - Cursor 기반 방법을 제공하지 않는다.
56 | - 커스텀 BatchConfigurer 구현체를 생성할 필요도 없다. JpaTransactionManger 구성을 알아서 처리하기 때문
57 |
58 | ### 저장 프로시저
59 |
60 | - DB에 저장되는 해당 DB 전용 함수
61 | - StoredProcedureItemReader로 프로시저를 만들어 SQL로 정의된 함수를 실행시켜줄 수 있다
62 |
63 | ### 몽고 DB
64 |
65 | - 기본으로 레플리케이션, 샤딩을 제공한다
66 | - MongoItemReader는 page 기반 ItemReader다
67 | - `spring-boot-starter-data-mongodb` 의존성을 추가한다
68 | - application.yml에 DB 설정 : `spring.data.mongodb.database: tweets`
69 |
70 | ```sql
71 | @Bean
72 | @StepScope
73 | public MongoItemReader