├── .gitignore
├── LICENSE
├── README.md
├── imgs
└── noe2e_learning_curve.png
└── src
├── deep_dialog
├── __init__.py
├── agents
│ ├── __init__.py
│ ├── agent.py
│ ├── agent_baselines.py
│ ├── agent_cmd.py
│ └── agent_dqn.py
├── checkpoints
│ └── rl_agent
│ │ ├── e2e
│ │ └── agt_9_performance_records.json
│ │ └── noe2e
│ │ ├── agt_9_478_500_0.98000.p
│ │ └── agt_9_performance_records.json
├── data
│ ├── dia_act_nl_pairs.v6.json
│ ├── dia_acts.txt
│ ├── dicts.v3.json
│ ├── dicts.v3.p
│ ├── movie_kb.1k.json
│ ├── movie_kb.1k.p
│ ├── movie_kb.v2.json
│ ├── movie_kb.v2.p
│ ├── slot_set.txt
│ ├── user_goals_all_turns_template.p
│ ├── user_goals_first_turn_template.part.movie.v1.p
│ └── user_goals_first_turn_template.v2.p
├── dialog_config.py
├── dialog_system
│ ├── __init__.py
│ ├── dialog_manager.py
│ ├── dict_reader.py
│ ├── kb_helper.py
│ ├── state_tracker.py
│ └── utils.py
├── models
│ ├── nlg
│ │ └── lstm_tanh_relu_[1468202263.38]_2_0.610.p
│ └── nlu
│ │ └── lstm_[1468447442.91]_39_80_0.921.p
├── nlg
│ ├── __init__.py
│ ├── decoder.py
│ ├── lstm_decoder_tanh.py
│ ├── nlg.py
│ └── utils.py
├── nlu
│ ├── __init__.py
│ ├── bi_lstm.py
│ ├── lstm.py
│ ├── nlu.py
│ ├── seq_seq.py
│ └── utils.py
├── qlearning
│ ├── __init__.py
│ ├── dqn.py
│ └── utils.py
└── usersims
│ ├── __init__.py
│ ├── usersim.py
│ └── usersim_rule.py
├── draw_learning_curve.py
└── run.py
/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2017 MiuLab and Microsoft Research
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # End-to-End Task-Completion Neural Dialogue Systems
2 | *An implementation of the
3 | [End-to-End Task-Completion Neural Dialogue Systems](http://arxiv.org/abs/1703.01008) and
4 | [A User Simulator for Task-Completion Dialogues](http://arxiv.org/abs/1612.05688).*
5 |
6 | 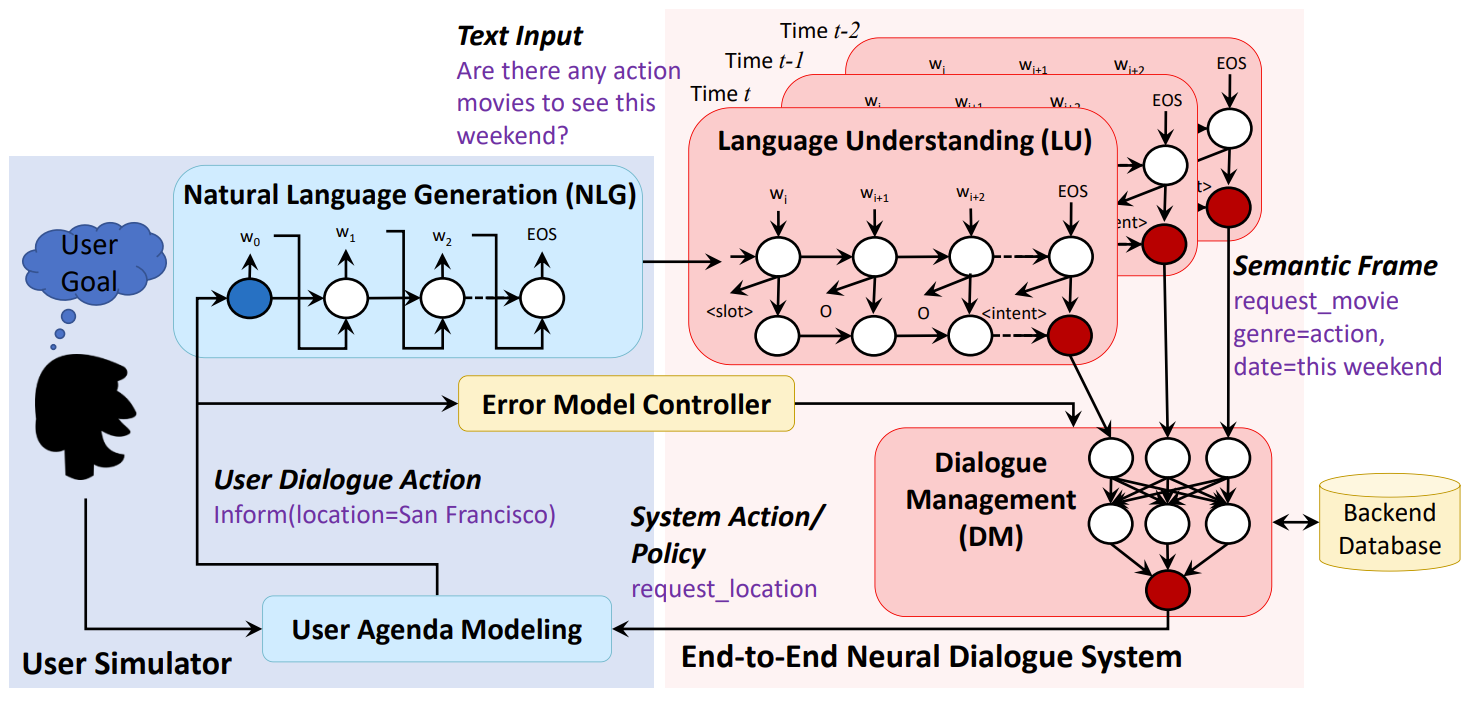
7 |
8 | This document describes how to run the simulation and different dialogue agents (rule-based, command line, reinforcement learning). More instructions to plug in your customized agents or user simulators are in the Recipe section of the paper.
9 |
10 | ## Content
11 | * [Data](#data)
12 | * [Parameter](#parameter)
13 | * [Running Dialogue Agents](#running-dialogue-agents)
14 | * [Evaluation](#evaluation)
15 | * [Reference](#reference)
16 |
17 | ## Data
18 | all the data is under this folder: ./src/deep_dialog/data
19 |
20 | * Movie Knowledge Bases
21 | `movie_kb.1k.p` --- 94% success rate (for `user_goals_first_turn_template_subsets.v1.p`)
22 | `movie_kb.v2.p` --- 36% success rate (for `user_goals_first_turn_template_subsets.v1.p`)
23 |
24 | * User Goals
25 | `user_goals_first_turn_template.v2.p` --- user goals extracted from the first user turn
26 | `user_goals_first_turn_template.part.movie.v1.p` --- a subset of user goals [Please use this one, the upper bound success rate on movie_kb.1k.json is 0.9765.]
27 |
28 | * NLG Rule Template
29 | `dia_act_nl_pairs.v6.json` --- some predefined NLG rule templates for both User simulator and Agent.
30 |
31 | * Dialog Act Intent
32 | `dia_acts.txt`
33 |
34 | * Dialog Act Slot
35 | `slot_set.txt`
36 |
37 | ## Parameter
38 |
39 | ### Basic setting
40 |
41 | `--agt`: the agent id
42 | `--usr`: the user (simulator) id
43 | `--max_turn`: maximum turns
44 | `--episodes`: how many dialogues to run
45 | `--slot_err_prob`: slot level err probability
46 | `--slot_err_mode`: which kind of slot err mode
47 | `--intent_err_prob`: intent level err probability
48 |
49 |
50 | ### Data setting
51 |
52 | `--movie_kb_path`: the movie kb path for agent side
53 | `--goal_file_path`: the user goal file path for user simulator side
54 |
55 | ### Model setting
56 |
57 | `--dqn_hidden_size`: hidden size for RL (DQN) agent
58 | `--batch_size`: batch size for DQN training
59 | `--simulation_epoch_size`: how many dialogue to be simulated in one epoch
60 | `--warm_start`: use rule policy to fill the experience replay buffer at the beginning
61 | `--warm_start_epochs`: how many dialogues to run in the warm start
62 |
63 | ### Display setting
64 |
65 | `--run_mode`: 0 for display mode (NL); 1 for debug mode (Dia_Act); 2 for debug mode (Dia_Act and NL); >3 for no display (i.e. training)
66 | `--act_level`: 0 for user simulator is Dia_Act level; 1 for user simulator is NL level
67 | `--auto_suggest`: 0 for no auto_suggest; 1 for auto_suggest
68 | `--cmd_input_mode`: 0 for NL input; 1 for Dia_Act input. (this parameter is for AgentCmd only)
69 |
70 | ### Others
71 |
72 | `--write_model_dir`: the directory to write the models
73 | `--trained_model_path`: the path of the trained RL agent model; load the trained model for prediction purpose.
74 |
75 | `--learning_phase`: train/test/all, default is all. You can split the user goal set into train and test set, or do not split (all); We introduce some randomness at the first sampled user action, even for the same user goal, the generated dialogue might be different.
76 |
77 | ## Running Dialogue Agents
78 |
79 | ### Rule Agent
80 | ```sh
81 | python run.py --agt 5 --usr 1 --max_turn 40
82 | --episodes 150
83 | --movie_kb_path ./deep_dialog/data/movie_kb.1k.p
84 | --goal_file_path ./deep_dialog/data/user_goals_first_turn_template.part.movie.v1.p
85 | --intent_err_prob 0.00
86 | --slot_err_prob 0.00
87 | --episodes 500
88 | --act_level 0
89 | ```
90 |
91 | ### Cmd Agent
92 | NL Input
93 | ```sh
94 | python run.py --agt 0 --usr 1 --max_turn 40
95 | --episodes 150
96 | --movie_kb_path ./deep_dialog/data/movie_kb.1k.p
97 | --goal_file_path ./deep_dialog/data/user_goals_first_turn_template.part.movie.v1.p
98 | --intent_err_prob 0.00
99 | --slot_err_prob 0.00
100 | --episodes 500
101 | --act_level 0
102 | --run_mode 0
103 | --cmd_input_mode 0
104 | ```
105 | Dia_Act Input
106 | ```sh
107 | python run.py --agt 0 --usr 1 --max_turn 40
108 | --episodes 150
109 | --movie_kb_path ./deep_dialog/data/movie_kb.1k.p
110 | --goal_file_path ./deep_dialog/data/user_goals_first_turn_template.part.movie.v1.p
111 | --intent_err_prob 0.00
112 | --slot_err_prob 0.00
113 | --episodes 500
114 | --act_level 0
115 | --run_mode 0
116 | --cmd_input_mode 1
117 | ```
118 |
119 | ### End2End RL Agent
120 | Train End2End RL Agent without NLU and NLG (with simulated noise in NLU)
121 | ```sh
122 | python run.py --agt 9 --usr 1 --max_turn 40
123 | --movie_kb_path ./deep_dialog/data/movie_kb.1k.p
124 | --dqn_hidden_size 80
125 | --experience_replay_pool_size 1000
126 | --episodes 500
127 | --simulation_epoch_size 100
128 | --write_model_dir ./deep_dialog/checkpoints/rl_agent/
129 | --run_mode 3
130 | --act_level 0
131 | --slot_err_prob 0.00
132 | --intent_err_prob 0.00
133 | --batch_size 16
134 | --goal_file_path ./deep_dialog/data/user_goals_first_turn_template.part.movie.v1.p
135 | --warm_start 1
136 | --warm_start_epochs 120
137 | ```
138 | Train End2End RL Agent with NLU and NLG
139 | ```sh
140 | python run.py --agt 9 --usr 1 --max_turn 40
141 | --movie_kb_path ./deep_dialog/data/movie_kb.1k.p
142 | --dqn_hidden_size 80
143 | --experience_replay_pool_size 1000
144 | --episodes 500
145 | --simulation_epoch_size 100
146 | --write_model_dir ./deep_dialog/checkpoints/rl_agent/
147 | --run_mode 3
148 | --act_level 1
149 | --slot_err_prob 0.00
150 | --intent_err_prob 0.00
151 | --batch_size 16
152 | --goal_file_path ./deep_dialog/data/user_goals_first_turn_template.part.movie.v1.p
153 | --warm_start 1
154 | --warm_start_epochs 120
155 | ```
156 | Test RL Agent with N dialogues:
157 | ```sh
158 | python run.py --agt 9 --usr 1 --max_turn 40
159 | --movie_kb_path ./deep_dialog/data/movie_kb.1k.p
160 | --dqn_hidden_size 80
161 | --experience_replay_pool_size 1000
162 | --episodes 300
163 | --simulation_epoch_size 100
164 | --write_model_dir ./deep_dialog/checkpoints/rl_agent/
165 | --slot_err_prob 0.00
166 | --intent_err_prob 0.00
167 | --batch_size 16
168 | --goal_file_path ./deep_dialog/data/user_goals_first_turn_template.part.movie.v1.p
169 | --trained_model_path ./deep_dialog/checkpoints/rl_agent/noe2e/agt_9_478_500_0.98000.p
170 | --run_mode 3
171 | ```
172 |
173 | ## Evaluation
174 | To evaluate the performance of agents, three metrics are available: success rate, average reward, average turns. Here we show the learning curve with success rate.
175 |
176 | 1. Plotting Learning Curve
177 | ``` python draw_learning_curve.py --result_file ./deep_dialog/checkpoints/rl_agent/noe2e/agt_9_performance_records.json```
178 | 2. Pull out the numbers and draw the curves in Excel
179 |
180 | ## Reference
181 |
182 | Main papers to be cited
183 | ```
184 | @inproceedings{li2017end,
185 | title={End-to-End Task-Completion Neural Dialogue Systems},
186 | author={Li, Xuijun and Chen, Yun-Nung and Li, Lihong and Gao, Jianfeng and Celikyilmaz, Asli},
187 | booktitle={Proceedings of The 8th International Joint Conference on Natural Language Processing},
188 | year={2017}
189 | }
190 |
191 | @article{li2016user,
192 | title={A User Simulator for Task-Completion Dialogues},
193 | author={Li, Xiujun and Lipton, Zachary C and Dhingra, Bhuwan and Li, Lihong and Gao, Jianfeng and Chen, Yun-Nung},
194 | journal={arXiv preprint arXiv:1612.05688},
195 | year={2016}
196 | }
197 |
--------------------------------------------------------------------------------
/imgs/noe2e_learning_curve.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MiuLab/TC-Bot/071a5a08dc85dc80adf51284d6f15f2b491098be/imgs/noe2e_learning_curve.png
--------------------------------------------------------------------------------
/src/deep_dialog/__init__.py:
--------------------------------------------------------------------------------
1 | #
--------------------------------------------------------------------------------
/src/deep_dialog/agents/__init__.py:
--------------------------------------------------------------------------------
1 | from .agent_cmd import *
2 | from .agent_baselines import *
3 | from .agent_dqn import *
--------------------------------------------------------------------------------
/src/deep_dialog/agents/agent.py:
--------------------------------------------------------------------------------
1 | """
2 | Created on May 17, 2016
3 |
4 | @author: xiul, t-zalipt
5 | """
6 |
7 | from deep_dialog import dialog_config
8 |
9 | class Agent:
10 | """ Prototype for all agent classes, defining the interface they must uphold """
11 |
12 | def __init__(self, movie_dict=None, act_set=None, slot_set=None, params=None):
13 | """ Constructor for the Agent class
14 |
15 | Arguments:
16 | movie_dict -- This is here now but doesn't belong - the agent doesn't know about movies
17 | act_set -- The set of acts. #### Shouldn't this be more abstract? Don't we want our agent to be more broadly usable?
18 | slot_set -- The set of available slots
19 | """
20 | self.movie_dict = movie_dict
21 | self.act_set = act_set
22 | self.slot_set = slot_set
23 | self.act_cardinality = len(act_set.keys())
24 | self.slot_cardinality = len(slot_set.keys())
25 |
26 | self.epsilon = params['epsilon']
27 | self.agent_run_mode = params['agent_run_mode']
28 | self.agent_act_level = params['agent_act_level']
29 |
30 |
31 | def initialize_episode(self):
32 | """ Initialize a new episode. This function is called every time a new episode is run. """
33 | self.current_action = {} # TODO Changed this variable's name to current_action
34 | self.current_action['diaact'] = None # TODO Does it make sense to call it a state if it has an act? Which act? The Most recent?
35 | self.current_action['inform_slots'] = {}
36 | self.current_action['request_slots'] = {}
37 | self.current_action['turn'] = 0
38 |
39 | def state_to_action(self, state, available_actions):
40 | """ Take the current state and return an action according to the current exploration/exploitation policy
41 |
42 | We define the agents flexibly so that they can either operate on act_slot representations or act_slot_value representations.
43 | We also define the responses flexibly, returning a dictionary with keys [act_slot_response, act_slot_value_response]. This way the command-line agent can continue to operate with values
44 |
45 | Arguments:
46 | state -- A tuple of (history, kb_results) where history is a sequence of previous actions and kb_results contains information on the number of results matching the current constraints.
47 | user_action -- A legacy representation used to run the command line agent. We should remove this ASAP but not just yet
48 | available_actions -- A list of the allowable actions in the current state
49 |
50 | Returns:
51 | act_slot_action -- An action consisting of one act and >= 0 slots as well as which slots are informed vs requested.
52 | act_slot_value_action -- An action consisting of acts slots and values in the legacy format. This can be used in the future for training agents that take value into account and interact directly with the database
53 | """
54 | act_slot_response = None
55 | act_slot_value_response = None
56 | return {"act_slot_response": act_slot_response, "act_slot_value_response": act_slot_value_response}
57 |
58 |
59 | def register_experience_replay_tuple(self, s_t, a_t, reward, s_tplus1, episode_over):
60 | """ Register feedback from the environment, to be stored as future training data
61 |
62 | Arguments:
63 | s_t -- The state in which the last action was taken
64 | a_t -- The previous agent action
65 | reward -- The reward received immediately following the action
66 | s_tplus1 -- The state transition following the latest action
67 | episode_over -- A boolean value representing whether the this is the final action.
68 |
69 | Returns:
70 | None
71 | """
72 | pass
73 |
74 |
75 | def set_nlg_model(self, nlg_model):
76 | self.nlg_model = nlg_model
77 |
78 | def set_nlu_model(self, nlu_model):
79 | self.nlu_model = nlu_model
80 |
81 |
82 | def add_nl_to_action(self, agent_action):
83 | """ Add NL to Agent Dia_Act """
84 |
85 | if agent_action['act_slot_response']:
86 | agent_action['act_slot_response']['nl'] = ""
87 | user_nlg_sentence = self.nlg_model.convert_diaact_to_nl(agent_action['act_slot_response'], 'agt') #self.nlg_model.translate_diaact(agent_action['act_slot_response']) # NLG
88 | agent_action['act_slot_response']['nl'] = user_nlg_sentence
89 | elif agent_action['act_slot_value_response']:
90 | agent_action['act_slot_value_response']['nl'] = ""
91 | user_nlg_sentence = self.nlg_model.convert_diaact_to_nl(agent_action['act_slot_value_response'], 'agt') #self.nlg_model.translate_diaact(agent_action['act_slot_value_response']) # NLG
92 | agent_action['act_slot_response']['nl'] = user_nlg_sentence
--------------------------------------------------------------------------------
/src/deep_dialog/agents/agent_baselines.py:
--------------------------------------------------------------------------------
1 | """
2 | Created on May 25, 2016
3 |
4 | @author: xiul, t-zalipt
5 | """
6 |
7 | import copy, random
8 | from deep_dialog import dialog_config
9 | from agent import Agent
10 |
11 |
12 | class InformAgent(Agent):
13 | """ A simple agent to test the system. This agent should simply inform all the slots and then issue: taskcomplete. """
14 |
15 | def initialize_episode(self):
16 | self.state = {}
17 | self.state['diaact'] = ''
18 | self.state['inform_slots'] = {}
19 | self.state['request_slots'] = {}
20 | self.state['turn'] = -1
21 | self.current_slot_id = 0
22 |
23 | def state_to_action(self, state):
24 | """ Run current policy on state and produce an action """
25 |
26 | self.state['turn'] += 2
27 | if self.current_slot_id < len(self.slot_set.keys()):
28 | slot = self.slot_set.keys()[self.current_slot_id]
29 | self.current_slot_id += 1
30 |
31 | act_slot_response = {}
32 | act_slot_response['diaact'] = "inform"
33 | act_slot_response['inform_slots'] = {slot: "PLACEHOLDER"}
34 | act_slot_response['request_slots'] = {}
35 | act_slot_response['turn'] = self.state['turn']
36 | else:
37 | act_slot_response = {'diaact': "thanks", 'inform_slots': {}, 'request_slots': {}, 'turn': self.state['turn']}
38 | return {'act_slot_response': act_slot_response, 'act_slot_value_response': None}
39 |
40 |
41 |
42 | class RequestAllAgent(Agent):
43 | """ A simple agent to test the system. This agent should simply request all the slots and then issue: thanks(). """
44 |
45 | def initialize_episode(self):
46 | self.state = {}
47 | self.state['diaact'] = ''
48 | self.state['inform_slots'] = {}
49 | self.state['request_slots'] = {}
50 | self.state['turn'] = -1
51 | self.current_slot_id = 0
52 |
53 | def state_to_action(self, state):
54 | """ Run current policy on state and produce an action """
55 |
56 | self.state['turn'] += 2
57 | if self.current_slot_id < len(dialog_config.sys_request_slots):
58 | slot = dialog_config.sys_request_slots[self.current_slot_id]
59 | self.current_slot_id += 1
60 |
61 | act_slot_response = {}
62 | act_slot_response['diaact'] = "request"
63 | act_slot_response['inform_slots'] = {}
64 | act_slot_response['request_slots'] = {slot: "PLACEHOLDER"}
65 | act_slot_response['turn'] = self.state['turn']
66 | else:
67 | act_slot_response = {'diaact': "thanks", 'inform_slots': {}, 'request_slots': {}, 'turn': self.state['turn']}
68 | return {'act_slot_response': act_slot_response, 'act_slot_value_response': None}
69 |
70 |
71 |
72 | class RandomAgent(Agent):
73 | """ A simple agent to test the interface. This agent should choose actions randomly. """
74 |
75 | def initialize_episode(self):
76 | self.state = {}
77 | self.state['diaact'] = ''
78 | self.state['inform_slots'] = {}
79 | self.state['request_slots'] = {}
80 | self.state['turn'] = -1
81 |
82 |
83 | def state_to_action(self, state):
84 | """ Run current policy on state and produce an action """
85 |
86 | self.state['turn'] += 2
87 | act_slot_response = copy.deepcopy(random.choice(dialog_config.feasible_actions))
88 | act_slot_response['turn'] = self.state['turn']
89 | return {'act_slot_response': act_slot_response, 'act_slot_value_response': None}
90 |
91 |
92 |
93 | class EchoAgent(Agent):
94 | """ A simple agent that informs all requested slots, then issues inform(taskcomplete) when the user stops making requests. """
95 |
96 | def initialize_episode(self):
97 | self.state = {}
98 | self.state['diaact'] = ''
99 | self.state['inform_slots'] = {}
100 | self.state['request_slots'] = {}
101 | self.state['turn'] = -1
102 |
103 |
104 | def state_to_action(self, state):
105 | """ Run current policy on state and produce an action """
106 | user_action = state['user_action']
107 |
108 | self.state['turn'] += 2
109 | act_slot_response = {}
110 | act_slot_response['inform_slots'] = {}
111 | act_slot_response['request_slots'] = {}
112 | ########################################################################
113 | # find out if the user is requesting anything
114 | # if so, inform it
115 | ########################################################################
116 | if user_action['diaact'] == 'request':
117 | requested_slot = user_action['request_slots'].keys()[0]
118 |
119 | act_slot_response['diaact'] = "inform"
120 | act_slot_response['inform_slots'][requested_slot] = "PLACEHOLDER"
121 | else:
122 | act_slot_response['diaact'] = "thanks"
123 |
124 | act_slot_response['turn'] = self.state['turn']
125 | return {'act_slot_response': act_slot_response, 'act_slot_value_response': None}
126 |
127 |
128 | class RequestBasicsAgent(Agent):
129 | """ A simple agent to test the system. This agent should simply request all the basic slots and then issue: thanks(). """
130 |
131 | def initialize_episode(self):
132 | self.state = {}
133 | self.state['diaact'] = 'UNK'
134 | self.state['inform_slots'] = {}
135 | self.state['request_slots'] = {}
136 | self.state['turn'] = -1
137 | self.current_slot_id = 0
138 | self.request_set = ['moviename', 'starttime', 'city', 'date', 'theater', 'numberofpeople']
139 | self.phase = 0
140 |
141 | def state_to_action(self, state):
142 | """ Run current policy on state and produce an action """
143 |
144 | self.state['turn'] += 2
145 | if self.current_slot_id < len(self.request_set):
146 | slot = self.request_set[self.current_slot_id]
147 | self.current_slot_id += 1
148 |
149 | act_slot_response = {}
150 | act_slot_response['diaact'] = "request"
151 | act_slot_response['inform_slots'] = {}
152 | act_slot_response['request_slots'] = {slot: "UNK"}
153 | act_slot_response['turn'] = self.state['turn']
154 | elif self.phase == 0:
155 | act_slot_response = {'diaact': "inform", 'inform_slots': {'taskcomplete': "PLACEHOLDER"}, 'request_slots': {}, 'turn':self.state['turn']}
156 | self.phase += 1
157 | elif self.phase == 1:
158 | act_slot_response = {'diaact': "thanks", 'inform_slots': {}, 'request_slots': {}, 'turn': self.state['turn']}
159 | else:
160 | raise Exception("THIS SHOULD NOT BE POSSIBLE (AGENT CALLED IN UNANTICIPATED WAY)")
161 | return {'act_slot_response': act_slot_response, 'act_slot_value_response': None}
162 |
163 |
--------------------------------------------------------------------------------
/src/deep_dialog/agents/agent_cmd.py:
--------------------------------------------------------------------------------
1 | """
2 | Created on May 17, 2016
3 |
4 | @author: xiul, t-zalipt
5 | """
6 |
7 |
8 | from agent import Agent
9 |
10 | class AgentCmd(Agent):
11 |
12 | def __init__(self, movie_dict=None, act_set=None, slot_set=None, params=None):
13 | """ Constructor for the Agent class """
14 |
15 | self.movie_dict = movie_dict
16 | self.act_set = act_set
17 | self.slot_set = slot_set
18 | self.act_cardinality = len(act_set.keys())
19 | self.slot_cardinality = len(slot_set.keys())
20 |
21 | self.agent_run_mode = params['agent_run_mode']
22 | self.agent_act_level = params['agent_act_level']
23 | self.agent_input_mode = params['cmd_input_mode']
24 |
25 |
26 | def state_to_action(self, state):
27 | """ Generate an action by getting input interactively from the command line """
28 |
29 | user_action = state['user_action']
30 | # get input from the command line
31 | print "Turn", user_action['turn'] + 1, "sys:",
32 | command = raw_input()
33 |
34 | if self.agent_input_mode == 0: # nl
35 | act_slot_value_response = self.generate_diaact_from_nl(command)
36 | elif self.agent_input_mode == 1: # dia_act
37 | act_slot_value_response = self.parse_str_to_diaact(command)
38 |
39 | return {"act_slot_response": act_slot_value_response, "act_slot_value_response": act_slot_value_response}
40 |
41 | def parse_str_to_diaact(self, string):
42 | """ Parse string into Dia_Act Form """
43 |
44 | annot = string.strip(' ').strip('\n').strip('\r')
45 | act = annot
46 |
47 | if annot.find('(') > 0 and annot.find(')') > 0:
48 | act = annot[0: annot.find('(')].strip(' ').lower() #Dia act
49 | annot = annot[annot.find('(')+1:-1].strip(' ') #slot-value pairs
50 | else: annot = ''
51 |
52 | act_slot_value_response = {}
53 | act_slot_value_response['diaact'] = 'UNK'
54 | act_slot_value_response['inform_slots'] = {}
55 | act_slot_value_response['request_slots'] = {}
56 |
57 | if act in self.act_set: # dialog_config.all_acts
58 | act_slot_value_response['diaact'] = act
59 | else:
60 | print ("Something wrong for your input dialog act! Please check your input ...")
61 |
62 | if len(annot) > 0: # slot-pair values: slot[val] = id
63 | annot_segs = annot.split(';') #slot-value pairs
64 | sent_slot_vals = {} # slot-pair real value
65 | sent_rep_vals = {} # slot-pair id value
66 |
67 | for annot_seg in annot_segs:
68 | annot_seg = annot_seg.strip(' ')
69 | annot_slot = annot_seg
70 | if annot_seg.find('=') > 0:
71 | annot_slot = annot_seg[:annot_seg.find('=')]
72 | annot_val = annot_seg[annot_seg.find('=')+1:]
73 | else: #requested
74 | annot_val = 'UNK' # for request
75 | if annot_slot == 'taskcomplete': annot_val = 'FINISH'
76 |
77 | if annot_slot == 'mc_list': continue
78 |
79 | # slot may have multiple values
80 | sent_slot_vals[annot_slot] = []
81 | sent_rep_vals[annot_slot] = []
82 |
83 | if annot_val.startswith('{') and annot_val.endswith('}'):
84 | annot_val = annot_val[1:-1]
85 |
86 | if annot_slot == 'result':
87 | result_annot_seg_arr = annot_val.strip(' ').split('&')
88 | if len(annot_val.strip(' '))> 0:
89 | for result_annot_seg_item in result_annot_seg_arr:
90 | result_annot_seg_arr = result_annot_seg_item.strip(' ').split('=')
91 | result_annot_seg_slot = result_annot_seg_arr[0]
92 | result_annot_seg_slot_val = result_annot_seg_arr[1]
93 |
94 | if result_annot_seg_slot_val == 'UNK': act_slot_value_response['request_slots'][result_annot_seg_slot] = 'UNK'
95 | else: act_slot_value_response['inform_slots'][result_annot_seg_slot] = result_annot_seg_slot_val
96 | else: # result={}
97 | pass
98 | else: # multi-choice or mc_list
99 | annot_val_arr = annot_val.split('#')
100 | act_slot_value_response['inform_slots'][annot_slot] = []
101 | for annot_val_ele in annot_val_arr:
102 | act_slot_value_response['inform_slots'][annot_slot].append(annot_val_ele)
103 | else: # single choice
104 | if annot_slot in self.slot_set.keys():
105 | if annot_val == 'UNK':
106 | act_slot_value_response['request_slots'][annot_slot] = 'UNK'
107 | else:
108 | act_slot_value_response['inform_slots'][annot_slot] = annot_val
109 |
110 | return act_slot_value_response
111 |
112 | def generate_diaact_from_nl(self, string):
113 | """ Generate Dia_Act Form with NLU """
114 |
115 | agent_action = {}
116 | agent_action['diaact'] = 'UNK'
117 | agent_action['inform_slots'] = {}
118 | agent_action['request_slots'] = {}
119 |
120 | if len(string) > 0:
121 | agent_action = self.nlu_model.generate_dia_act(string)
122 |
123 | agent_action['nl'] = string
124 | return agent_action
125 |
126 | def add_nl_to_action(self, agent_action):
127 | """ Add NL to Agent Dia_Act """
128 |
129 | if self.agent_input_mode == 1:
130 | if agent_action['act_slot_response']:
131 | agent_action['act_slot_response']['nl'] = ""
132 | user_nlg_sentence = self.nlg_model.convert_diaact_to_nl(agent_action['act_slot_response'], 'agt')
133 | agent_action['act_slot_response']['nl'] = user_nlg_sentence
134 | elif agent_action['act_slot_value_response']:
135 | agent_action['act_slot_value_response']['nl'] = ""
136 | user_nlg_sentence = self.nlg_model.convert_diaact_to_nl(agent_action['act_slot_value_response'], 'agt')
137 | agent_action['act_slot_response']['nl'] = user_nlg_sentence
138 |
--------------------------------------------------------------------------------
/src/deep_dialog/agents/agent_dqn.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jun 18, 2016
3 |
4 | An DQN Agent
5 |
6 | - An DQN
7 | - Keep an experience_replay pool: training_data
8 | - Keep a copy DQN
9 |
10 | Command: python .\run.py --agt 9 --usr 1 --max_turn 40 --movie_kb_path .\deep_dialog\data\movie_kb.1k.json --dqn_hidden_size 80 --experience_replay_pool_size 1000 --replacement_steps 50 --per_train_epochs 100 --episodes 200 --err_method 2
11 |
12 |
13 | @author: xiul
14 | '''
15 |
16 |
17 | import random, copy, json
18 | import cPickle as pickle
19 | import numpy as np
20 |
21 | from deep_dialog import dialog_config
22 |
23 | from agent import Agent
24 | from deep_dialog.qlearning import DQN
25 |
26 |
27 |
28 | class AgentDQN(Agent):
29 | def __init__(self, movie_dict=None, act_set=None, slot_set=None, params=None):
30 | self.movie_dict = movie_dict
31 | self.act_set = act_set
32 | self.slot_set = slot_set
33 | self.act_cardinality = len(act_set.keys())
34 | self.slot_cardinality = len(slot_set.keys())
35 |
36 | self.feasible_actions = dialog_config.feasible_actions
37 | self.num_actions = len(self.feasible_actions)
38 |
39 | self.epsilon = params['epsilon']
40 | self.agent_run_mode = params['agent_run_mode']
41 | self.agent_act_level = params['agent_act_level']
42 | self.experience_replay_pool = [] #experience replay pool
43 |
44 | self.experience_replay_pool_size = params.get('experience_replay_pool_size', 1000)
45 | self.hidden_size = params.get('dqn_hidden_size', 60)
46 | self.gamma = params.get('gamma', 0.9)
47 | self.predict_mode = params.get('predict_mode', False)
48 | self.warm_start = params.get('warm_start', 0)
49 |
50 | self.max_turn = params['max_turn'] + 4
51 | self.state_dimension = 2 * self.act_cardinality + 7 * self.slot_cardinality + 3 + self.max_turn
52 |
53 | self.dqn = DQN(self.state_dimension, self.hidden_size, self.num_actions)
54 | self.clone_dqn = copy.deepcopy(self.dqn)
55 |
56 | self.cur_bellman_err = 0
57 |
58 | # Prediction Mode: load trained DQN model
59 | if params['trained_model_path'] != None:
60 | self.dqn.model = copy.deepcopy(self.load_trained_DQN(params['trained_model_path']))
61 | self.clone_dqn = copy.deepcopy(self.dqn)
62 | self.predict_mode = True
63 | self.warm_start = 2
64 |
65 |
66 | def initialize_episode(self):
67 | """ Initialize a new episode. This function is called every time a new episode is run. """
68 |
69 | self.current_slot_id = 0
70 | self.phase = 0
71 | self.request_set = ['moviename', 'starttime', 'city', 'date', 'theater', 'numberofpeople']
72 |
73 |
74 | def state_to_action(self, state):
75 | """ DQN: Input state, output action """
76 |
77 | self.representation = self.prepare_state_representation(state)
78 | self.action = self.run_policy(self.representation)
79 | act_slot_response = copy.deepcopy(self.feasible_actions[self.action])
80 | return {'act_slot_response': act_slot_response, 'act_slot_value_response': None}
81 |
82 |
83 | def prepare_state_representation(self, state):
84 | """ Create the representation for each state """
85 |
86 | user_action = state['user_action']
87 | current_slots = state['current_slots']
88 | kb_results_dict = state['kb_results_dict']
89 | agent_last = state['agent_action']
90 |
91 | ########################################################################
92 | # Create one-hot of acts to represent the current user action
93 | ########################################################################
94 | user_act_rep = np.zeros((1, self.act_cardinality))
95 | user_act_rep[0,self.act_set[user_action['diaact']]] = 1.0
96 |
97 | ########################################################################
98 | # Create bag of inform slots representation to represent the current user action
99 | ########################################################################
100 | user_inform_slots_rep = np.zeros((1, self.slot_cardinality))
101 | for slot in user_action['inform_slots'].keys():
102 | user_inform_slots_rep[0,self.slot_set[slot]] = 1.0
103 |
104 | ########################################################################
105 | # Create bag of request slots representation to represent the current user action
106 | ########################################################################
107 | user_request_slots_rep = np.zeros((1, self.slot_cardinality))
108 | for slot in user_action['request_slots'].keys():
109 | user_request_slots_rep[0, self.slot_set[slot]] = 1.0
110 |
111 | ########################################################################
112 | # Creat bag of filled_in slots based on the current_slots
113 | ########################################################################
114 | current_slots_rep = np.zeros((1, self.slot_cardinality))
115 | for slot in current_slots['inform_slots']:
116 | current_slots_rep[0, self.slot_set[slot]] = 1.0
117 |
118 | ########################################################################
119 | # Encode last agent act
120 | ########################################################################
121 | agent_act_rep = np.zeros((1,self.act_cardinality))
122 | if agent_last:
123 | agent_act_rep[0, self.act_set[agent_last['diaact']]] = 1.0
124 |
125 | ########################################################################
126 | # Encode last agent inform slots
127 | ########################################################################
128 | agent_inform_slots_rep = np.zeros((1, self.slot_cardinality))
129 | if agent_last:
130 | for slot in agent_last['inform_slots'].keys():
131 | agent_inform_slots_rep[0,self.slot_set[slot]] = 1.0
132 |
133 | ########################################################################
134 | # Encode last agent request slots
135 | ########################################################################
136 | agent_request_slots_rep = np.zeros((1, self.slot_cardinality))
137 | if agent_last:
138 | for slot in agent_last['request_slots'].keys():
139 | agent_request_slots_rep[0,self.slot_set[slot]] = 1.0
140 |
141 | turn_rep = np.zeros((1,1)) + state['turn'] / 10.
142 |
143 | ########################################################################
144 | # One-hot representation of the turn count?
145 | ########################################################################
146 | turn_onehot_rep = np.zeros((1, self.max_turn))
147 | turn_onehot_rep[0, state['turn']] = 1.0
148 |
149 | ########################################################################
150 | # Representation of KB results (scaled counts)
151 | ########################################################################
152 | kb_count_rep = np.zeros((1, self.slot_cardinality + 1)) + kb_results_dict['matching_all_constraints'] / 100.
153 | for slot in kb_results_dict:
154 | if slot in self.slot_set:
155 | kb_count_rep[0, self.slot_set[slot]] = kb_results_dict[slot] / 100.
156 |
157 | ########################################################################
158 | # Representation of KB results (binary)
159 | ########################################################################
160 | kb_binary_rep = np.zeros((1, self.slot_cardinality + 1)) + np.sum( kb_results_dict['matching_all_constraints'] > 0.)
161 | for slot in kb_results_dict:
162 | if slot in self.slot_set:
163 | kb_binary_rep[0, self.slot_set[slot]] = np.sum( kb_results_dict[slot] > 0.)
164 |
165 | self.final_representation = np.hstack([user_act_rep, user_inform_slots_rep, user_request_slots_rep, agent_act_rep, agent_inform_slots_rep, agent_request_slots_rep, current_slots_rep, turn_rep, turn_onehot_rep, kb_binary_rep, kb_count_rep])
166 | return self.final_representation
167 |
168 | def run_policy(self, representation):
169 | """ epsilon-greedy policy """
170 |
171 | if random.random() < self.epsilon:
172 | return random.randint(0, self.num_actions - 1)
173 | else:
174 | if self.warm_start == 1:
175 | if len(self.experience_replay_pool) > self.experience_replay_pool_size:
176 | self.warm_start = 2
177 | return self.rule_policy()
178 | else:
179 | return self.dqn.predict(representation, {}, predict_model=True)
180 |
181 | def rule_policy(self):
182 | """ Rule Policy """
183 |
184 | if self.current_slot_id < len(self.request_set):
185 | slot = self.request_set[self.current_slot_id]
186 | self.current_slot_id += 1
187 |
188 | act_slot_response = {}
189 | act_slot_response['diaact'] = "request"
190 | act_slot_response['inform_slots'] = {}
191 | act_slot_response['request_slots'] = {slot: "UNK"}
192 | elif self.phase == 0:
193 | act_slot_response = {'diaact': "inform", 'inform_slots': {'taskcomplete': "PLACEHOLDER"}, 'request_slots': {} }
194 | self.phase += 1
195 | elif self.phase == 1:
196 | act_slot_response = {'diaact': "thanks", 'inform_slots': {}, 'request_slots': {} }
197 |
198 | return self.action_index(act_slot_response)
199 |
200 | def action_index(self, act_slot_response):
201 | """ Return the index of action """
202 |
203 | for (i, action) in enumerate(self.feasible_actions):
204 | if act_slot_response == action:
205 | return i
206 | print act_slot_response
207 | raise Exception("action index not found")
208 | return None
209 |
210 |
211 | def register_experience_replay_tuple(self, s_t, a_t, reward, s_tplus1, episode_over):
212 | """ Register feedback from the environment, to be stored as future training data """
213 |
214 | state_t_rep = self.prepare_state_representation(s_t)
215 | action_t = self.action
216 | reward_t = reward
217 | state_tplus1_rep = self.prepare_state_representation(s_tplus1)
218 | training_example = (state_t_rep, action_t, reward_t, state_tplus1_rep, episode_over)
219 |
220 | if self.predict_mode == False: # Training Mode
221 | if self.warm_start == 1:
222 | self.experience_replay_pool.append(training_example)
223 | else: # Prediction Mode
224 | self.experience_replay_pool.append(training_example)
225 |
226 | def train(self, batch_size=1, num_batches=100):
227 | """ Train DQN with experience replay """
228 |
229 | for iter_batch in range(num_batches):
230 | self.cur_bellman_err = 0
231 | for iter in range(len(self.experience_replay_pool)/(batch_size)):
232 | batch = [random.choice(self.experience_replay_pool) for i in xrange(batch_size)]
233 | batch_struct = self.dqn.singleBatch(batch, {'gamma': self.gamma}, self.clone_dqn)
234 | self.cur_bellman_err += batch_struct['cost']['total_cost']
235 |
236 | print ("cur bellman err %.4f, experience replay pool %s" % (float(self.cur_bellman_err)/len(self.experience_replay_pool), len(self.experience_replay_pool)))
237 |
238 |
239 | ################################################################################
240 | # Debug Functions
241 | ################################################################################
242 | def save_experience_replay_to_file(self, path):
243 | """ Save the experience replay pool to a file """
244 |
245 | try:
246 | pickle.dump(self.experience_replay_pool, open(path, "wb"))
247 | print 'saved model in %s' % (path, )
248 | except Exception, e:
249 | print 'Error: Writing model fails: %s' % (path, )
250 | print e
251 |
252 | def load_experience_replay_from_file(self, path):
253 | """ Load the experience replay pool from a file"""
254 |
255 | self.experience_replay_pool = pickle.load(open(path, 'rb'))
256 |
257 |
258 | def load_trained_DQN(self, path):
259 | """ Load the trained DQN from a file """
260 |
261 | trained_file = pickle.load(open(path, 'rb'))
262 | model = trained_file['model']
263 |
264 | print "trained DQN Parameters:", json.dumps(trained_file['params'], indent=2)
265 | return model
--------------------------------------------------------------------------------
/src/deep_dialog/checkpoints/rl_agent/noe2e/agt_9_performance_records.json:
--------------------------------------------------------------------------------
1 | {"ave_turns": {"0": 42.0, "1": 27.34, "2": 36.84, "3": 41.36, "4": 42.0, "5": 41.52, "6": 35.46, "7": 42.0, "8": 40.16, "9": 38.76, "10": 36.82, "11": 37.94, "12": 35.76, "13": 35.52, "14": 35.84, "15": 38.14, "16": 33.12, "17": 28.24, "18": 29.04, "19": 34.1, "20": 35.12, "21": 28.56, "22": 27.78, "23": 25.58, "24": 28.78, "25": 27.02, "26": 22.84, "27": 25.28, "28": 29.58, "29": 26.78, "30": 25.64, "31": 22.22, "32": 23.96, "33": 20.1, "34": 22.64, "35": 16.12, "36": 15.96, "37": 21.06, "38": 29.94, "39": 15.32, "40": 20.36, "41": 22.36, "42": 17.12, "43": 18.18, "44": 15.2, "45": 13.92, "46": 16.42, "47": 19.98, "48": 20.1, "49": 18.42, "50": 15.84, "51": 15.4, "52": 16.84, "53": 14.74, "54": 16.72, "55": 16.88, "56": 14.58, "57": 15.98, "58": 17.06, "59": 18.18, "60": 15.0, "61": 17.34, "62": 16.7, "63": 15.14, "64": 15.4, "65": 15.96, "66": 16.46, "67": 17.14, "68": 16.04, "69": 17.0, "70": 15.78, "71": 16.62, "72": 17.74, "73": 16.94, "74": 18.16, "75": 17.04, "76": 17.1, "77": 14.12, "78": 16.42, "79": 16.3, "80": 16.08, "81": 15.86, "82": 17.52, "83": 15.48, "84": 15.56, "85": 17.16, "86": 15.24, "87": 15.42, "88": 15.16, "89": 17.56, "90": 15.78, "91": 15.04, "92": 15.28, "93": 15.98, "94": 16.48, "95": 15.52, "96": 14.82, "97": 15.72, "98": 13.94, "99": 17.32, "100": 15.98, "101": 15.0, "102": 13.54, "103": 13.78, "104": 16.0, "105": 14.52, "106": 14.88, "107": 15.94, "108": 14.78, "109": 15.9, "110": 15.6, "111": 16.62, "112": 15.06, "113": 16.9, "114": 14.36, "115": 16.24, "116": 15.04, "117": 15.3, "118": 14.24, "119": 15.36, "120": 14.74, "121": 15.42, "122": 18.52, "123": 15.82, "124": 17.86, "125": 13.16, "126": 15.42, "127": 14.42, "128": 15.12, "129": 13.9, "130": 16.68, "131": 14.42, "132": 14.56, "133": 14.7, "134": 17.06, "135": 15.92, "136": 15.16, "137": 14.08, "138": 15.94, "139": 14.38, "140": 15.6, "141": 17.02, "142": 15.24, "143": 14.48, "144": 15.06, "145": 15.4, "146": 16.16, "147": 14.56, "148": 14.18, "149": 14.46, "150": 13.72, "151": 13.84, "152": 15.04, "153": 16.02, "154": 15.54, "155": 14.94, "156": 13.86, "157": 16.02, "158": 14.42, "159": 15.1, "160": 15.76, "161": 14.3, "162": 12.88, "163": 14.86, "164": 13.0, "165": 14.02, "166": 14.44, "167": 16.58, "168": 15.14, "169": 15.26, "170": 15.28, "171": 14.26, "172": 16.56, "173": 14.3, "174": 15.26, "175": 14.06, "176": 16.8, "177": 15.12, "178": 15.22, "179": 15.98, "180": 14.6, "181": 15.36, "182": 15.44, "183": 13.1, "184": 14.6, "185": 15.1, "186": 14.54, "187": 15.92, "188": 14.96, "189": 13.56, "190": 15.7, "191": 15.22, "192": 14.46, "193": 15.28, "194": 14.28, "195": 13.28, "196": 14.68, "197": 13.76, "198": 14.04, "199": 16.78, "200": 16.02, "201": 13.84, "202": 15.22, "203": 14.76, "204": 14.54, "205": 15.76, "206": 14.98, "207": 13.58, "208": 15.14, "209": 15.48, "210": 14.44, "211": 14.3, "212": 13.66, "213": 14.64, "214": 14.08, "215": 13.32, "216": 13.68, "217": 13.22, "218": 14.8, "219": 14.34, "220": 12.76, "221": 15.5, "222": 13.38, "223": 15.26, "224": 13.26, "225": 14.36, "226": 13.58, "227": 15.04, "228": 12.44, "229": 14.58, "230": 14.04, "231": 12.76, "232": 13.36, "233": 14.52, "234": 12.1, "235": 13.7, "236": 13.78, "237": 15.1, "238": 13.74, "239": 15.9, "240": 12.92, "241": 14.38, "242": 14.98, "243": 16.86, "244": 13.1, "245": 14.62, "246": 14.54, "247": 16.12, "248": 14.52, "249": 14.62, "250": 13.72, "251": 14.84, "252": 13.46, "253": 13.1, "254": 13.4, "255": 14.34, "256": 13.92, "257": 14.4, "258": 14.92, "259": 13.14, "260": 12.92, "261": 15.1, "262": 13.38, "263": 13.68, "264": 15.58, "265": 12.8, "266": 14.28, "267": 13.1, "268": 13.9, "269": 14.26, "270": 14.6, "271": 13.3, "272": 13.26, "273": 13.04, "274": 14.36, "275": 12.42, "276": 13.86, "277": 14.98, "278": 11.78, "279": 15.42, "280": 13.06, "281": 13.56, "282": 13.96, "283": 14.04, "284": 12.72, "285": 13.9, "286": 13.98, "287": 14.26, "288": 15.42, "289": 14.96, "290": 14.4, "291": 13.08, "292": 14.28, "293": 14.84, "294": 13.92, "295": 12.5, "296": 14.7, "297": 13.82, "298": 13.12, "299": 12.68, "300": 12.7, "301": 13.32, "302": 14.48, "303": 12.6, "304": 13.52, "305": 13.68, "306": 12.42, "307": 14.26, "308": 13.9, "309": 14.98, "310": 14.04, "311": 12.64, "312": 12.54, "313": 14.8, "314": 12.8, "315": 12.94, "316": 13.72, "317": 13.52, "318": 12.26, "319": 14.72, "320": 13.74, "321": 13.4, "322": 12.72, "323": 13.28, "324": 13.54, "325": 13.68, "326": 14.2, "327": 12.78, "328": 12.64, "329": 13.14, "330": 13.6, "331": 13.22, "332": 13.5, "333": 14.0, "334": 13.3, "335": 14.38, "336": 13.76, "337": 12.2, "338": 13.44, "339": 13.42, "340": 14.36, "341": 14.58, "342": 12.8, "343": 12.54, "344": 13.24, "345": 11.76, "346": 12.98, "347": 13.06, "348": 15.0, "349": 15.18, "350": 14.3, "351": 13.74, "352": 14.56, "353": 13.54, "354": 12.04, "355": 14.28, "356": 13.18, "357": 12.28, "358": 12.8, "359": 12.96, "360": 15.24, "361": 14.18, "362": 15.76, "363": 13.76, "364": 14.58, "365": 13.36, "366": 12.34, "367": 12.02, "368": 14.06, "369": 14.7, "370": 13.92, "371": 12.86, "372": 14.3, "373": 13.56, "374": 14.28, "375": 14.92, "376": 14.86, "377": 12.54, "378": 13.4, "379": 13.28, "380": 14.68, "381": 13.68, "382": 14.66, "383": 12.04, "384": 13.86, "385": 12.22, "386": 13.3, "387": 13.56, "388": 12.36, "389": 13.02, "390": 12.5, "391": 13.0, "392": 13.8, "393": 13.94, "394": 13.12, "395": 13.46, "396": 12.62, "397": 14.04, "398": 13.1, "399": 13.44, "400": 13.38, "401": 13.14, "402": 13.02, "403": 13.3, "404": 13.54, "405": 12.74, "406": 12.62, "407": 13.98, "408": 14.32, "409": 13.08, "410": 12.14, "411": 14.02, "412": 13.42, "413": 12.78, "414": 14.08, "415": 14.8, "416": 14.62, "417": 12.88, "418": 13.84, "419": 13.26, "420": 13.68, "421": 13.08, "422": 14.94, "423": 14.22, "424": 12.88, "425": 13.2, "426": 14.2, "427": 14.1, "428": 14.92, "429": 12.8, "430": 13.78, "431": 13.24, "432": 14.36, "433": 15.2, "434": 12.64, "435": 14.12, "436": 14.04, "437": 13.6, "438": 13.8, "439": 14.26, "440": 12.76, "441": 13.48, "442": 12.8, "443": 13.8, "444": 12.94, "445": 13.8, "446": 14.52, "447": 14.3, "448": 13.28, "449": 13.7, "450": 15.18, "451": 14.32, "452": 13.36, "453": 15.7, "454": 15.18, "455": 12.2, "456": 13.0, "457": 12.84, "458": 13.84, "459": 14.88, "460": 17.34, "461": 14.76, "462": 12.06, "463": 13.64, "464": 13.1, "465": 14.16, "466": 13.54, "467": 12.82, "468": 12.36, "469": 13.78, "470": 13.9, "471": 14.6, "472": 11.9, "473": 14.18, "474": 13.84, "475": 14.32, "476": 12.92, "477": 12.84, "478": 11.18, "479": 14.7, "480": 14.34, "481": 13.32, "482": 12.52, "483": 13.48, "484": 13.2, "485": 12.0, "486": 15.96, "487": 13.8, "488": 15.06, "489": 12.38, "490": 14.9, "491": 13.52, "492": 11.68, "493": 14.74, "494": 13.5, "495": 15.46, "496": 14.28, "497": 13.54, "498": 13.84, "499": 12.74, "500": 15.26, "501": 13.62, "502": 13.28, "503": 14.34, "504": 13.28, "505": 12.38, "506": 16.44, "507": 15.34, "508": 13.32, "509": 13.24, "510": 14.34, "511": 12.68, "512": 13.16, "513": 13.98, "514": 14.26, "515": 14.44, "516": 13.96, "517": 15.44, "518": 13.08, "519": 13.18, "520": 15.2, "521": 15.94, "522": 13.54, "523": 13.7, "524": 14.44, "525": 12.52, "526": 13.44, "527": 13.32, "528": 13.54, "529": 13.42, "530": 12.84, "531": 13.28, "532": 13.84, "533": 13.3, "534": 14.46, "535": 11.36, "536": 14.74, "537": 13.26, "538": 12.26, "539": 13.62, "540": 13.86, "541": 15.36, "542": 13.94, "543": 13.2, "544": 12.16, "545": 13.92, "546": 13.76, "547": 14.2, "548": 13.58, "549": 12.28, "550": 13.36, "551": 12.9, "552": 13.76, "553": 14.18, "554": 12.72, "555": 12.98, "556": 13.68, "557": 13.8, "558": 12.62, "559": 13.24, "560": 13.66, "561": 12.46, "562": 12.5, "563": 14.66, "564": 14.0, "565": 13.7, "566": 13.28, "567": 11.68, "568": 13.2, "569": 13.82, "570": 12.38, "571": 13.82, "572": 12.5, "573": 12.68, "574": 13.26, "575": 14.72, "576": 12.26, "577": 14.4, "578": 12.6, "579": 14.88, "580": 12.74, "581": 14.54, "582": 14.94, "583": 13.16, "584": 11.7, "585": 15.2, "586": 12.06, "587": 14.04, "588": 13.04, "589": 15.66, "590": 14.36, "591": 12.56, "592": 13.18, "593": 14.22, "594": 13.48, "595": 13.14, "596": 13.88, "597": 12.28, "598": 13.08, "599": 13.8}, "ave_reward": {"0": -60.0, "1": -52.67, "2": -57.42, "3": -59.68, "4": -60.0, "5": -59.76, "6": -53.13, "7": -60.0, "8": -54.28, "9": -43.98, "10": -39.41, "11": -41.17, "12": -31.68, "13": -32.76, "14": -43.72, "15": -37.67, "16": -18.36, "17": 5.68, "18": -0.72, "19": -23.65, "20": -19.36, "21": 1.92, "22": 2.31, "23": 7.01, "24": -0.59, "25": 3.89, "26": 16.78, "27": 9.56, "28": 1.41, "29": 6.41, "30": 17.78, "31": 14.69, "32": 23.42, "33": 28.95, "34": 14.48, "35": 29.74, "36": 40.62, "37": 32.07, "38": 0.03, "39": 37.34, "40": 36.02, "41": 25.42, "42": 44.84, "43": 41.91, "44": 49.4, "45": 53.64, "46": 39.19, "47": 26.61, "48": 42.15, "49": 39.39, "50": 49.08, "51": 49.3, "52": 52.18, "53": 50.83, "54": 47.44, "55": 44.96, "56": 58.11, "57": 53.81, "58": 50.87, "59": 43.11, "60": 59.1, "61": 47.13, "62": 51.05, "63": 59.03, "64": 56.5, "65": 47.82, "66": 53.57, "67": 48.43, "68": 53.78, "69": 49.7, "70": 53.91, "71": 51.09, "72": 48.13, "73": 50.93, "74": 46.72, "75": 52.08, "76": 49.65, "77": 63.14, "78": 51.19, "79": 53.65, "80": 54.96, "81": 56.27, "82": 47.04, "83": 57.66, "84": 56.42, "85": 50.82, "86": 56.58, "87": 56.49, "88": 57.82, "89": 48.22, "90": 55.11, "91": 60.28, "92": 58.96, "93": 56.21, "94": 53.56, "95": 55.24, "96": 60.39, "97": 56.34, "98": 63.23, "99": 47.14, "100": 55.01, "101": 59.1, "102": 64.63, "103": 64.51, "104": 53.8, "105": 59.34, "106": 59.16, "107": 53.83, "108": 60.41, "109": 52.65, "110": 52.8, "111": 51.09, "112": 59.07, "113": 47.35, "114": 60.62, "115": 51.28, "116": 56.68, "117": 56.55, "118": 61.88, "119": 56.52, "120": 59.23, "121": 55.29, "122": 44.14, "123": 53.89, "124": 45.67, "125": 66.02, "126": 56.49, "127": 59.39, "128": 57.84, "129": 62.05, "130": 49.86, "131": 60.59, "132": 59.32, "133": 59.25, "134": 48.47, "135": 55.04, "136": 55.42, "137": 61.96, "138": 52.63, "139": 59.41, "140": 55.2, "141": 49.69, "142": 56.58, "143": 60.56, "144": 56.67, "145": 55.3, "146": 53.72, "147": 59.32, "148": 61.91, "149": 60.57, "150": 63.34, "151": 62.08, "152": 57.88, "153": 51.39, "154": 55.23, "155": 57.93, "156": 62.07, "157": 52.59, "158": 59.39, "159": 57.85, "160": 53.92, "161": 59.45, "162": 67.36, "163": 57.97, "164": 66.1, "165": 60.79, "166": 60.58, "167": 51.11, "168": 56.63, "169": 56.57, "170": 56.56, "171": 60.67, "172": 51.12, "173": 59.45, "174": 56.57, "175": 63.17, "176": 48.6, "177": 57.84, "178": 56.59, "179": 52.61, "180": 60.5, "181": 56.52, "182": 56.48, "183": 66.05, "184": 60.5, "185": 56.65, "186": 60.53, "187": 53.84, "188": 57.92, "189": 64.62, "190": 53.95, "191": 57.79, "192": 59.37, "193": 56.56, "194": 60.66, "195": 65.96, "196": 59.26, "197": 64.52, "198": 61.98, "199": 48.61, "200": 53.79, "201": 62.08, "202": 57.79, "203": 59.22, "204": 60.53, "205": 55.12, "206": 56.71, "207": 62.21, "208": 56.63, "209": 56.46, "210": 59.38, "211": 60.65, "212": 64.57, "213": 59.28, "214": 61.96, "215": 64.74, "216": 64.56, "217": 64.79, "218": 58.0, "219": 59.43, "220": 67.42, "221": 55.25, "222": 64.71, "223": 57.77, "224": 65.97, "225": 60.62, "226": 64.61, "227": 56.68, "228": 68.78, "229": 58.11, "230": 61.98, "231": 68.62, "232": 65.92, "233": 59.34, "234": 70.15, "235": 63.35, "236": 63.31, "237": 59.05, "238": 63.33, "239": 52.65, "240": 67.34, "241": 61.81, "242": 57.91, "243": 49.77, "244": 67.25, "245": 59.29, "246": 60.53, "247": 52.54, "248": 59.34, "249": 60.49, "250": 63.34, "251": 59.18, "252": 63.47, "253": 66.05, "254": 64.7, "255": 60.63, "256": 63.24, "257": 60.6, "258": 59.14, "259": 67.23, "260": 67.34, "261": 57.85, "262": 64.71, "263": 64.56, "264": 54.01, "265": 67.4, "266": 61.86, "267": 66.05, "268": 62.05, "269": 61.87, "270": 59.3, "271": 64.75, "272": 65.97, "273": 66.08, "274": 60.62, "275": 68.79, "276": 63.27, "277": 57.91, "278": 71.51, "279": 56.49, "280": 66.07, "281": 62.22, "282": 62.02, "283": 61.98, "284": 67.44, "285": 62.05, "286": 62.01, "287": 60.67, "288": 56.49, "289": 57.92, "290": 60.6, "291": 66.06, "292": 60.66, "293": 59.18, "294": 63.24, "295": 68.75, "296": 59.25, "297": 63.29, "298": 66.04, "299": 67.46, "300": 66.25, "301": 64.74, "302": 60.56, "303": 67.5, "304": 63.44, "305": 63.36, "306": 68.79, "307": 58.27, "308": 60.85, "309": 56.71, "310": 60.78, "311": 67.48, "312": 67.53, "313": 58.0, "314": 67.4, "315": 66.13, "316": 63.34, "317": 64.64, "318": 70.07, "319": 59.24, "320": 63.33, "321": 64.7, "322": 67.44, "323": 65.96, "324": 62.23, "325": 63.36, "326": 60.7, "327": 68.61, "328": 67.48, "329": 66.03, "330": 63.4, "331": 65.99, "332": 64.65, "333": 62.0, "334": 64.75, "335": 60.61, "336": 63.32, "337": 70.1, "338": 65.88, "339": 64.69, "340": 60.62, "341": 59.31, "342": 67.4, "343": 68.73, "344": 64.78, "345": 71.52, "346": 66.11, "347": 66.07, "348": 57.9, "349": 57.81, "350": 61.85, "351": 63.33, "352": 59.32, "353": 63.43, "354": 68.98, "355": 60.66, "356": 66.01, "357": 68.86, "358": 67.4, "359": 66.12, "360": 56.58, "361": 60.71, "362": 53.92, "363": 63.32, "364": 58.11, "365": 64.72, "366": 67.63, "367": 70.19, "368": 63.17, "369": 59.25, "370": 62.04, "371": 67.37, "372": 60.65, "373": 63.42, "374": 59.46, "375": 57.94, "376": 57.97, "377": 66.33, "378": 63.5, "379": 64.76, "380": 58.06, "381": 62.16, "382": 58.07, "383": 70.18, "384": 63.27, "385": 70.09, "386": 64.75, "387": 63.42, "388": 68.82, "389": 66.09, "390": 67.55, "391": 66.1, "392": 63.3, "393": 62.03, "394": 66.04, "395": 63.47, "396": 67.49, "397": 61.98, "398": 64.85, "399": 64.68, "400": 65.91, "401": 64.83, "402": 66.09, "403": 64.75, "404": 62.23, "405": 66.23, "406": 67.49, "407": 62.01, "408": 60.64, "409": 67.26, "410": 70.13, "411": 60.79, "412": 64.69, "413": 66.21, "414": 60.76, "415": 58.0, "416": 59.29, "417": 66.16, "418": 62.08, "419": 65.97, "420": 63.36, "421": 66.06, "422": 57.93, "423": 60.69, "424": 68.56, "425": 64.8, "426": 60.7, "427": 61.95, "428": 57.94, "429": 67.4, "430": 62.11, "431": 63.58, "432": 59.42, "433": 56.6, "434": 67.48, "435": 60.74, "436": 61.98, "437": 63.4, "438": 63.3, "439": 59.47, "440": 67.42, "441": 64.66, "442": 66.2, "443": 62.1, "444": 66.13, "445": 62.1, "446": 59.34, "447": 59.45, "448": 63.56, "449": 63.35, "450": 56.61, "451": 59.44, "452": 63.52, "453": 53.95, "454": 56.61, "455": 68.9, "456": 66.1, "457": 67.38, "458": 62.08, "459": 59.16, "460": 48.33, "461": 58.02, "462": 68.97, "463": 63.38, "464": 64.85, "465": 60.72, "466": 62.23, "467": 66.19, "468": 67.62, "469": 62.11, "470": 62.05, "471": 56.9, "472": 70.25, "473": 60.71, "474": 64.48, "475": 60.64, "476": 66.14, "477": 66.18, "478": 73.01, "479": 56.85, "480": 60.63, "481": 63.54, "482": 67.54, "483": 64.66, "484": 66.0, "485": 69.0, "486": 53.82, "487": 62.1, "488": 57.87, "489": 68.81, "490": 56.75, "491": 63.44, "492": 71.56, "493": 58.03, "494": 63.45, "495": 55.27, "496": 60.66, "497": 63.43, "498": 62.08, "499": 67.43, "500": 56.57, "501": 63.39, "502": 63.56, "503": 59.43, "504": 63.56, "505": 67.61, "506": 51.18, "507": 56.53, "508": 63.54, "509": 64.78, "510": 60.63, "511": 67.46, "512": 64.82, "513": 62.01, "514": 60.67, "515": 59.38, "516": 62.02, "517": 55.28, "518": 64.86, "519": 64.81, "520": 56.6, "521": 52.63, "522": 64.63, "523": 63.35, "524": 59.38, "525": 66.34, "526": 64.68, "527": 63.54, "528": 63.43, "529": 65.89, "530": 66.18, "531": 64.76, "532": 60.88, "533": 64.75, "534": 59.37, "535": 72.92, "536": 59.23, "537": 64.77, "538": 68.87, "539": 62.19, "540": 62.07, "541": 56.52, "542": 62.03, "543": 64.8, "544": 68.92, "545": 62.04, "546": 63.32, "547": 60.7, "548": 59.81, "549": 68.86, "550": 64.72, "551": 67.35, "552": 63.32, "553": 60.71, "554": 67.44, "555": 66.11, "556": 62.16, "557": 62.1, "558": 66.29, "559": 64.78, "560": 63.37, "561": 68.77, "562": 68.75, "563": 59.27, "564": 62.0, "565": 64.55, "566": 64.76, "567": 71.56, "568": 66.0, "569": 63.29, "570": 68.81, "571": 62.09, "572": 67.55, "573": 65.06, "574": 63.57, "575": 58.04, "576": 68.87, "577": 59.4, "578": 68.7, "579": 55.56, "580": 67.43, "581": 59.33, "582": 56.73, "583": 64.82, "584": 71.55, "585": 56.6, "586": 68.97, "587": 60.78, "588": 63.68, "589": 53.97, "590": 60.62, "591": 67.52, "592": 64.81, "593": 60.69, "594": 64.66, "595": 64.83, "596": 62.06, "597": 68.86, "598": 64.86, "599": 62.1}, "success_rate": {"0": 0.0, "1": 0.0, "2": 0.0, "3": 0.0, "4": 0.0, "5": 0.0, "6": 0.03, "7": 0.0, "8": 0.04, "9": 0.12, "10": 0.15, "11": 0.14, "12": 0.21, "13": 0.2, "14": 0.11, "15": 0.17, "16": 0.31, "17": 0.49, "18": 0.44, "19": 0.27, "20": 0.31, "21": 0.46, "22": 0.46, "23": 0.49, "24": 0.44, "25": 0.47, "26": 0.56, "27": 0.51, "28": 0.46, "29": 0.49, "30": 0.58, "31": 0.54, "32": 0.62, "33": 0.65, "34": 0.54, "35": 0.64, "36": 0.73, "37": 0.68, "38": 0.45, "39": 0.7, "40": 0.71, "41": 0.63, "42": 0.77, "43": 0.75, "44": 0.8, "45": 0.83, "46": 0.72, "47": 0.63, "48": 0.76, "49": 0.73, "50": 0.8, "51": 0.8, "52": 0.83, "53": 0.81, "54": 0.79, "55": 0.77, "56": 0.87, "57": 0.84, "58": 0.82, "59": 0.76, "60": 0.88, "61": 0.79, "62": 0.82, "63": 0.88, "64": 0.86, "65": 0.79, "66": 0.84, "67": 0.8, "68": 0.84, "69": 0.81, "70": 0.84, "71": 0.82, "72": 0.8, "73": 0.82, "74": 0.79, "75": 0.83, "76": 0.81, "77": 0.91, "78": 0.82, "79": 0.84, "80": 0.85, "81": 0.86, "82": 0.79, "83": 0.87, "84": 0.86, "85": 0.82, "86": 0.86, "87": 0.86, "88": 0.87, "89": 0.8, "90": 0.85, "91": 0.89, "92": 0.88, "93": 0.86, "94": 0.84, "95": 0.85, "96": 0.89, "97": 0.86, "98": 0.91, "99": 0.79, "100": 0.85, "101": 0.88, "102": 0.92, "103": 0.92, "104": 0.84, "105": 0.88, "106": 0.88, "107": 0.84, "108": 0.89, "109": 0.83, "110": 0.83, "111": 0.82, "112": 0.88, "113": 0.79, "114": 0.89, "115": 0.82, "116": 0.86, "117": 0.86, "118": 0.9, "119": 0.86, "120": 0.88, "121": 0.85, "122": 0.77, "123": 0.84, "124": 0.78, "125": 0.93, "126": 0.86, "127": 0.88, "128": 0.87, "129": 0.9, "130": 0.81, "131": 0.89, "132": 0.88, "133": 0.88, "134": 0.8, "135": 0.85, "136": 0.85, "137": 0.9, "138": 0.83, "139": 0.88, "140": 0.85, "141": 0.81, "142": 0.86, "143": 0.89, "144": 0.86, "145": 0.85, "146": 0.84, "147": 0.88, "148": 0.9, "149": 0.89, "150": 0.91, "151": 0.9, "152": 0.87, "153": 0.82, "154": 0.85, "155": 0.87, "156": 0.9, "157": 0.83, "158": 0.88, "159": 0.87, "160": 0.84, "161": 0.88, "162": 0.94, "163": 0.87, "164": 0.93, "165": 0.89, "166": 0.89, "167": 0.82, "168": 0.86, "169": 0.86, "170": 0.86, "171": 0.89, "172": 0.82, "173": 0.88, "174": 0.86, "175": 0.91, "176": 0.8, "177": 0.87, "178": 0.86, "179": 0.83, "180": 0.89, "181": 0.86, "182": 0.86, "183": 0.93, "184": 0.89, "185": 0.86, "186": 0.89, "187": 0.84, "188": 0.87, "189": 0.92, "190": 0.84, "191": 0.87, "192": 0.88, "193": 0.86, "194": 0.89, "195": 0.93, "196": 0.88, "197": 0.92, "198": 0.9, "199": 0.8, "200": 0.84, "201": 0.9, "202": 0.87, "203": 0.88, "204": 0.89, "205": 0.85, "206": 0.86, "207": 0.9, "208": 0.86, "209": 0.86, "210": 0.88, "211": 0.89, "212": 0.92, "213": 0.88, "214": 0.9, "215": 0.92, "216": 0.92, "217": 0.92, "218": 0.87, "219": 0.88, "220": 0.94, "221": 0.85, "222": 0.92, "223": 0.87, "224": 0.93, "225": 0.89, "226": 0.92, "227": 0.86, "228": 0.95, "229": 0.87, "230": 0.9, "231": 0.95, "232": 0.93, "233": 0.88, "234": 0.96, "235": 0.91, "236": 0.91, "237": 0.88, "238": 0.91, "239": 0.83, "240": 0.94, "241": 0.9, "242": 0.87, "243": 0.81, "244": 0.94, "245": 0.88, "246": 0.89, "247": 0.83, "248": 0.88, "249": 0.89, "250": 0.91, "251": 0.88, "252": 0.91, "253": 0.93, "254": 0.92, "255": 0.89, "256": 0.91, "257": 0.89, "258": 0.88, "259": 0.94, "260": 0.94, "261": 0.87, "262": 0.92, "263": 0.92, "264": 0.84, "265": 0.94, "266": 0.9, "267": 0.93, "268": 0.9, "269": 0.9, "270": 0.88, "271": 0.92, "272": 0.93, "273": 0.93, "274": 0.89, "275": 0.95, "276": 0.91, "277": 0.87, "278": 0.97, "279": 0.86, "280": 0.93, "281": 0.9, "282": 0.9, "283": 0.9, "284": 0.94, "285": 0.9, "286": 0.9, "287": 0.89, "288": 0.86, "289": 0.87, "290": 0.89, "291": 0.93, "292": 0.89, "293": 0.88, "294": 0.91, "295": 0.95, "296": 0.88, "297": 0.91, "298": 0.93, "299": 0.94, "300": 0.93, "301": 0.92, "302": 0.89, "303": 0.94, "304": 0.91, "305": 0.91, "306": 0.95, "307": 0.87, "308": 0.89, "309": 0.86, "310": 0.89, "311": 0.94, "312": 0.94, "313": 0.87, "314": 0.94, "315": 0.93, "316": 0.91, "317": 0.92, "318": 0.96, "319": 0.88, "320": 0.91, "321": 0.92, "322": 0.94, "323": 0.93, "324": 0.9, "325": 0.91, "326": 0.89, "327": 0.95, "328": 0.94, "329": 0.93, "330": 0.91, "331": 0.93, "332": 0.92, "333": 0.9, "334": 0.92, "335": 0.89, "336": 0.91, "337": 0.96, "338": 0.93, "339": 0.92, "340": 0.89, "341": 0.88, "342": 0.94, "343": 0.95, "344": 0.92, "345": 0.97, "346": 0.93, "347": 0.93, "348": 0.87, "349": 0.87, "350": 0.9, "351": 0.91, "352": 0.88, "353": 0.91, "354": 0.95, "355": 0.89, "356": 0.93, "357": 0.95, "358": 0.94, "359": 0.93, "360": 0.86, "361": 0.89, "362": 0.84, "363": 0.91, "364": 0.87, "365": 0.92, "366": 0.94, "367": 0.96, "368": 0.91, "369": 0.88, "370": 0.9, "371": 0.94, "372": 0.89, "373": 0.91, "374": 0.88, "375": 0.87, "376": 0.87, "377": 0.93, "378": 0.91, "379": 0.92, "380": 0.87, "381": 0.9, "382": 0.87, "383": 0.96, "384": 0.91, "385": 0.96, "386": 0.92, "387": 0.91, "388": 0.95, "389": 0.93, "390": 0.94, "391": 0.93, "392": 0.91, "393": 0.9, "394": 0.93, "395": 0.91, "396": 0.94, "397": 0.9, "398": 0.92, "399": 0.92, "400": 0.93, "401": 0.92, "402": 0.93, "403": 0.92, "404": 0.9, "405": 0.93, "406": 0.94, "407": 0.9, "408": 0.89, "409": 0.94, "410": 0.96, "411": 0.89, "412": 0.92, "413": 0.93, "414": 0.89, "415": 0.87, "416": 0.88, "417": 0.93, "418": 0.9, "419": 0.93, "420": 0.91, "421": 0.93, "422": 0.87, "423": 0.89, "424": 0.95, "425": 0.92, "426": 0.89, "427": 0.9, "428": 0.87, "429": 0.94, "430": 0.9, "431": 0.91, "432": 0.88, "433": 0.86, "434": 0.94, "435": 0.89, "436": 0.9, "437": 0.91, "438": 0.91, "439": 0.88, "440": 0.94, "441": 0.92, "442": 0.93, "443": 0.9, "444": 0.93, "445": 0.9, "446": 0.88, "447": 0.88, "448": 0.91, "449": 0.91, "450": 0.86, "451": 0.88, "452": 0.91, "453": 0.84, "454": 0.86, "455": 0.95, "456": 0.93, "457": 0.94, "458": 0.9, "459": 0.88, "460": 0.8, "461": 0.87, "462": 0.95, "463": 0.91, "464": 0.92, "465": 0.89, "466": 0.9, "467": 0.93, "468": 0.94, "469": 0.9, "470": 0.9, "471": 0.86, "472": 0.96, "473": 0.89, "474": 0.92, "475": 0.89, "476": 0.93, "477": 0.93, "478": 0.98, "479": 0.86, "480": 0.89, "481": 0.91, "482": 0.94, "483": 0.92, "484": 0.93, "485": 0.95, "486": 0.84, "487": 0.9, "488": 0.87, "489": 0.95, "490": 0.86, "491": 0.91, "492": 0.97, "493": 0.87, "494": 0.91, "495": 0.85, "496": 0.89, "497": 0.91, "498": 0.9, "499": 0.94, "500": 0.86, "501": 0.91, "502": 0.91, "503": 0.88, "504": 0.91, "505": 0.94, "506": 0.82, "507": 0.86, "508": 0.91, "509": 0.92, "510": 0.89, "511": 0.94, "512": 0.92, "513": 0.9, "514": 0.89, "515": 0.88, "516": 0.9, "517": 0.85, "518": 0.92, "519": 0.92, "520": 0.86, "521": 0.83, "522": 0.92, "523": 0.91, "524": 0.88, "525": 0.93, "526": 0.92, "527": 0.91, "528": 0.91, "529": 0.93, "530": 0.93, "531": 0.92, "532": 0.89, "533": 0.92, "534": 0.88, "535": 0.98, "536": 0.88, "537": 0.92, "538": 0.95, "539": 0.9, "540": 0.9, "541": 0.86, "542": 0.9, "543": 0.92, "544": 0.95, "545": 0.9, "546": 0.91, "547": 0.89, "548": 0.88, "549": 0.95, "550": 0.92, "551": 0.94, "552": 0.91, "553": 0.89, "554": 0.94, "555": 0.93, "556": 0.9, "557": 0.9, "558": 0.93, "559": 0.92, "560": 0.91, "561": 0.95, "562": 0.95, "563": 0.88, "564": 0.9, "565": 0.92, "566": 0.92, "567": 0.97, "568": 0.93, "569": 0.91, "570": 0.95, "571": 0.9, "572": 0.94, "573": 0.92, "574": 0.91, "575": 0.87, "576": 0.95, "577": 0.88, "578": 0.95, "579": 0.85, "580": 0.94, "581": 0.88, "582": 0.86, "583": 0.92, "584": 0.97, "585": 0.86, "586": 0.95, "587": 0.89, "588": 0.91, "589": 0.84, "590": 0.89, "591": 0.94, "592": 0.92, "593": 0.89, "594": 0.92, "595": 0.92, "596": 0.9, "597": 0.95, "598": 0.92, "599": 0.9}}
--------------------------------------------------------------------------------
/src/deep_dialog/data/dia_acts.txt:
--------------------------------------------------------------------------------
1 | request
2 | inform
3 | confirm_question
4 | confirm_answer
5 | greeting
6 | closing
7 | multiple_choice
8 | thanks
9 | welcome
10 | deny
11 | not_sure
--------------------------------------------------------------------------------
/src/deep_dialog/data/slot_set.txt:
--------------------------------------------------------------------------------
1 | actor
2 | actress
3 | city
4 | closing
5 | critic_rating
6 | date
7 | description
8 | distanceconstraints
9 | genre
10 | greeting
11 | implicit_value
12 | movie_series
13 | moviename
14 | mpaa_rating
15 | numberofpeople
16 | numberofkids
17 | taskcomplete
18 | other
19 | price
20 | seating
21 | starttime
22 | state
23 | theater
24 | theater_chain
25 | video_format
26 | zip
27 | result
28 | ticket
29 | mc_list
--------------------------------------------------------------------------------
/src/deep_dialog/dialog_config.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on May 17, 2016
3 |
4 | @author: xiul, t-zalipt
5 | '''
6 |
7 | sys_request_slots = ['moviename', 'theater', 'starttime', 'date', 'numberofpeople', 'genre', 'state', 'city', 'zip', 'critic_rating', 'mpaa_rating', 'distanceconstraints', 'video_format', 'theater_chain', 'price', 'actor', 'description', 'other', 'numberofkids']
8 | sys_inform_slots = ['moviename', 'theater', 'starttime', 'date', 'genre', 'state', 'city', 'zip', 'critic_rating', 'mpaa_rating', 'distanceconstraints', 'video_format', 'theater_chain', 'price', 'actor', 'description', 'other', 'numberofkids', 'taskcomplete', 'ticket']
9 |
10 | start_dia_acts = {
11 | #'greeting':[],
12 | 'request':['moviename', 'starttime', 'theater', 'city', 'state', 'date', 'genre', 'ticket', 'numberofpeople']
13 | }
14 |
15 | ################################################################################
16 | # Dialog status
17 | ################################################################################
18 | FAILED_DIALOG = -1
19 | SUCCESS_DIALOG = 1
20 | NO_OUTCOME_YET = 0
21 |
22 | # Rewards
23 | SUCCESS_REWARD = 50
24 | FAILURE_REWARD = 0
25 | PER_TURN_REWARD = 0
26 |
27 | ################################################################################
28 | # Special Slot Values
29 | ################################################################################
30 | I_DO_NOT_CARE = "I do not care"
31 | NO_VALUE_MATCH = "NO VALUE MATCHES!!!"
32 | TICKET_AVAILABLE = 'Ticket Available'
33 |
34 | ################################################################################
35 | # Constraint Check
36 | ################################################################################
37 | CONSTRAINT_CHECK_FAILURE = 0
38 | CONSTRAINT_CHECK_SUCCESS = 1
39 |
40 | ################################################################################
41 | # NLG Beam Search
42 | ################################################################################
43 | nlg_beam_size = 10
44 |
45 | ################################################################################
46 | # run_mode: 0 for dia-act; 1 for NL; 2 for no output
47 | ################################################################################
48 | run_mode = 0
49 | auto_suggest = 0
50 |
51 | ################################################################################
52 | # A Basic Set of Feasible actions to be Consdered By an RL agent
53 | ################################################################################
54 | feasible_actions = [
55 | ############################################################################
56 | # greeting actions
57 | ############################################################################
58 | #{'diaact':"greeting", 'inform_slots':{}, 'request_slots':{}},
59 | ############################################################################
60 | # confirm_question actions
61 | ############################################################################
62 | {'diaact':"confirm_question", 'inform_slots':{}, 'request_slots':{}},
63 | ############################################################################
64 | # confirm_answer actions
65 | ############################################################################
66 | {'diaact':"confirm_answer", 'inform_slots':{}, 'request_slots':{}},
67 | ############################################################################
68 | # thanks actions
69 | ############################################################################
70 | {'diaact':"thanks", 'inform_slots':{}, 'request_slots':{}},
71 | ############################################################################
72 | # deny actions
73 | ############################################################################
74 | {'diaact':"deny", 'inform_slots':{}, 'request_slots':{}},
75 | ]
76 | ############################################################################
77 | # Adding the inform actions
78 | ############################################################################
79 | for slot in sys_inform_slots:
80 | feasible_actions.append({'diaact':'inform', 'inform_slots':{slot:"PLACEHOLDER"}, 'request_slots':{}})
81 |
82 | ############################################################################
83 | # Adding the request actions
84 | ############################################################################
85 | for slot in sys_request_slots:
86 | feasible_actions.append({'diaact':'request', 'inform_slots':{}, 'request_slots': {slot: "UNK"}})
87 |
--------------------------------------------------------------------------------
/src/deep_dialog/dialog_system/__init__.py:
--------------------------------------------------------------------------------
1 | from .kb_helper import *
2 | from .state_tracker import *
3 | from .dialog_manager import *
4 | from .dict_reader import *
5 | from .utils import *
--------------------------------------------------------------------------------
/src/deep_dialog/dialog_system/dialog_manager.py:
--------------------------------------------------------------------------------
1 | """
2 | Created on May 17, 2016
3 |
4 | @author: xiul, t-zalipt
5 | """
6 |
7 | import json
8 | from . import StateTracker
9 | from deep_dialog import dialog_config
10 |
11 |
12 | class DialogManager:
13 | """ A dialog manager to mediate the interaction between an agent and a customer """
14 |
15 | def __init__(self, agent, user, act_set, slot_set, movie_dictionary):
16 | self.agent = agent
17 | self.user = user
18 | self.act_set = act_set
19 | self.slot_set = slot_set
20 | self.state_tracker = StateTracker(act_set, slot_set, movie_dictionary)
21 | self.user_action = None
22 | self.reward = 0
23 | self.episode_over = False
24 |
25 | def initialize_episode(self):
26 | """ Refresh state for new dialog """
27 |
28 | self.reward = 0
29 | self.episode_over = False
30 | self.state_tracker.initialize_episode()
31 | self.user_action = self.user.initialize_episode()
32 | self.state_tracker.update(user_action = self.user_action)
33 |
34 | if dialog_config.run_mode < 3:
35 | print ("New episode, user goal:")
36 | print json.dumps(self.user.goal, indent=2)
37 | self.print_function(user_action = self.user_action)
38 |
39 | self.agent.initialize_episode()
40 |
41 | def next_turn(self, record_training_data=True):
42 | """ This function initiates each subsequent exchange between agent and user (agent first) """
43 |
44 | ########################################################################
45 | # CALL AGENT TO TAKE HER TURN
46 | ########################################################################
47 | self.state = self.state_tracker.get_state_for_agent()
48 | self.agent_action = self.agent.state_to_action(self.state)
49 |
50 | ########################################################################
51 | # Register AGENT action with the state_tracker
52 | ########################################################################
53 | self.state_tracker.update(agent_action=self.agent_action)
54 |
55 | self.agent.add_nl_to_action(self.agent_action) # add NL to Agent Dia_Act
56 | self.print_function(agent_action = self.agent_action['act_slot_response'])
57 |
58 | ########################################################################
59 | # CALL USER TO TAKE HER TURN
60 | ########################################################################
61 | self.sys_action = self.state_tracker.dialog_history_dictionaries()[-1]
62 | self.user_action, self.episode_over, dialog_status = self.user.next(self.sys_action)
63 | self.reward = self.reward_function(dialog_status)
64 |
65 | ########################################################################
66 | # Update state tracker with latest user action
67 | ########################################################################
68 | if self.episode_over != True:
69 | self.state_tracker.update(user_action = self.user_action)
70 | self.print_function(user_action = self.user_action)
71 |
72 | ########################################################################
73 | # Inform agent of the outcome for this timestep (s_t, a_t, r, s_{t+1}, episode_over)
74 | ########################################################################
75 | if record_training_data:
76 | self.agent.register_experience_replay_tuple(self.state, self.agent_action, self.reward, self.state_tracker.get_state_for_agent(), self.episode_over)
77 |
78 | return (self.episode_over, self.reward)
79 |
80 |
81 | def reward_function(self, dialog_status):
82 | """ Reward Function 1: a reward function based on the dialog_status """
83 | if dialog_status == dialog_config.FAILED_DIALOG:
84 | reward = -self.user.max_turn #10
85 | elif dialog_status == dialog_config.SUCCESS_DIALOG:
86 | reward = 2*self.user.max_turn #20
87 | else:
88 | reward = -1
89 | return reward
90 |
91 | def reward_function_without_penalty(self, dialog_status):
92 | """ Reward Function 2: a reward function without penalty on per turn and failure dialog """
93 | if dialog_status == dialog_config.FAILED_DIALOG:
94 | reward = 0
95 | elif dialog_status == dialog_config.SUCCESS_DIALOG:
96 | reward = 2*self.user.max_turn
97 | else:
98 | reward = 0
99 | return reward
100 |
101 |
102 | def print_function(self, agent_action=None, user_action=None):
103 | """ Print Function """
104 |
105 | if agent_action:
106 | if dialog_config.run_mode == 0:
107 | if self.agent.__class__.__name__ != 'AgentCmd':
108 | print ("Turn %d sys: %s" % (agent_action['turn'], agent_action['nl']))
109 | elif dialog_config.run_mode == 1:
110 | if self.agent.__class__.__name__ != 'AgentCmd':
111 | print("Turn %d sys: %s, inform_slots: %s, request slots: %s" % (agent_action['turn'], agent_action['diaact'], agent_action['inform_slots'], agent_action['request_slots']))
112 | elif dialog_config.run_mode == 2: # debug mode
113 | print("Turn %d sys: %s, inform_slots: %s, request slots: %s" % (agent_action['turn'], agent_action['diaact'], agent_action['inform_slots'], agent_action['request_slots']))
114 | print ("Turn %d sys: %s" % (agent_action['turn'], agent_action['nl']))
115 |
116 | if dialog_config.auto_suggest == 1:
117 | print('(Suggested Values: %s)' % (self.state_tracker.get_suggest_slots_values(agent_action['request_slots'])))
118 | elif user_action:
119 | if dialog_config.run_mode == 0:
120 | print ("Turn %d usr: %s" % (user_action['turn'], user_action['nl']))
121 | elif dialog_config.run_mode == 1:
122 | print ("Turn %s usr: %s, inform_slots: %s, request_slots: %s" % (user_action['turn'], user_action['diaact'], user_action['inform_slots'], user_action['request_slots']))
123 | elif dialog_config.run_mode == 2: # debug mode, show both
124 | print ("Turn %d usr: %s, inform_slots: %s, request_slots: %s" % (user_action['turn'], user_action['diaact'], user_action['inform_slots'], user_action['request_slots']))
125 | print ("Turn %d usr: %s" % (user_action['turn'], user_action['nl']))
126 |
127 | if self.agent.__class__.__name__ == 'AgentCmd': # command line agent
128 | user_request_slots = user_action['request_slots']
129 | if 'ticket'in user_request_slots.keys(): del user_request_slots['ticket']
130 | if len(user_request_slots) > 0:
131 | possible_values = self.state_tracker.get_suggest_slots_values(user_action['request_slots'])
132 | for slot in possible_values.keys():
133 | if len(possible_values[slot]) > 0:
134 | print('(Suggested Values: %s: %s)' % (slot, possible_values[slot]))
135 | elif len(possible_values[slot]) == 0:
136 | print('(Suggested Values: there is no available %s)' % (slot))
137 | else:
138 | kb_results = self.state_tracker.get_current_kb_results()
139 | print ('(Number of movies in KB satisfying current constraints: %s)' % len(kb_results))
140 |
--------------------------------------------------------------------------------
/src/deep_dialog/dialog_system/dict_reader.py:
--------------------------------------------------------------------------------
1 | """
2 | Created on May 18, 2016
3 |
4 | @author: xiul, t-zalipt
5 | """
6 |
7 |
8 | def text_to_dict(path):
9 | """ Read in a text file as a dictionary where keys are text and values are indices (line numbers) """
10 |
11 | slot_set = {}
12 | with open(path, 'r') as f:
13 | index = 0
14 | for line in f.readlines():
15 | slot_set[line.strip('\n').strip('\r')] = index
16 | index += 1
17 | return slot_set
--------------------------------------------------------------------------------
/src/deep_dialog/dialog_system/kb_helper.py:
--------------------------------------------------------------------------------
1 | """
2 | Created on May 18, 2016
3 |
4 | @author: xiul, t-zalipt
5 | """
6 |
7 | import copy
8 | from collections import defaultdict
9 | from deep_dialog import dialog_config
10 |
11 | class KBHelper:
12 | """ An assistant to fill in values for the agent (which knows about slots of values) """
13 |
14 | def __init__(self, movie_dictionary):
15 | """ Constructor for a KBHelper """
16 |
17 | self.movie_dictionary = movie_dictionary
18 | self.cached_kb = defaultdict(list)
19 | self.cached_kb_slot = defaultdict(list)
20 |
21 |
22 | def fill_inform_slots(self, inform_slots_to_be_filled, current_slots):
23 | """ Takes unfilled inform slots and current_slots, returns dictionary of filled informed slots (with values)
24 |
25 | Arguments:
26 | inform_slots_to_be_filled -- Something that looks like {starttime:None, theater:None} where starttime and theater are slots that the agent needs filled
27 | current_slots -- Contains a record of all filled slots in the conversation so far - for now, just use current_slots['inform_slots'] which is a dictionary of the already filled-in slots
28 |
29 | Returns:
30 | filled_in_slots -- A dictionary of form {slot1:value1, slot2:value2} for each sloti in inform_slots_to_be_filled
31 | """
32 |
33 | kb_results = self.available_results_from_kb(current_slots)
34 | if dialog_config.auto_suggest == 1:
35 | print 'Number of movies in KB satisfying current constraints: ', len(kb_results)
36 |
37 | filled_in_slots = {}
38 | if 'taskcomplete' in inform_slots_to_be_filled.keys():
39 | filled_in_slots.update(current_slots['inform_slots'])
40 |
41 | for slot in inform_slots_to_be_filled.keys():
42 | if slot == 'numberofpeople':
43 | if slot in current_slots['inform_slots'].keys():
44 | filled_in_slots[slot] = current_slots['inform_slots'][slot]
45 | elif slot in inform_slots_to_be_filled.keys():
46 | filled_in_slots[slot] = inform_slots_to_be_filled[slot]
47 | continue
48 |
49 | if slot == 'ticket' or slot == 'taskcomplete':
50 | filled_in_slots[slot] = dialog_config.TICKET_AVAILABLE if len(kb_results)>0 else dialog_config.NO_VALUE_MATCH
51 | continue
52 |
53 | if slot == 'closing': continue
54 |
55 | ####################################################################
56 | # Grab the value for the slot with the highest count and fill it
57 | ####################################################################
58 | values_dict = self.available_slot_values(slot, kb_results)
59 |
60 | values_counts = [(v, values_dict[v]) for v in values_dict.keys()]
61 | if len(values_counts) > 0:
62 | filled_in_slots[slot] = sorted(values_counts, key = lambda x: -x[1])[0][0]
63 | else:
64 | filled_in_slots[slot] = dialog_config.NO_VALUE_MATCH #"NO VALUE MATCHES SNAFU!!!"
65 |
66 | return filled_in_slots
67 |
68 |
69 | def available_slot_values(self, slot, kb_results):
70 | """ Return the set of values available for the slot based on the current constraints """
71 |
72 | slot_values = {}
73 | for movie_id in kb_results.keys():
74 | if slot in kb_results[movie_id].keys():
75 | slot_val = kb_results[movie_id][slot]
76 | if slot_val in slot_values.keys():
77 | slot_values[slot_val] += 1
78 | else: slot_values[slot_val] = 1
79 | return slot_values
80 |
81 | def available_results_from_kb(self, current_slots):
82 | """ Return the available movies in the movie_kb based on the current constraints """
83 |
84 | ret_result = []
85 | current_slots = current_slots['inform_slots']
86 | constrain_keys = current_slots.keys()
87 |
88 | constrain_keys = filter(lambda k : k != 'ticket' and \
89 | k != 'numberofpeople' and \
90 | k!= 'taskcomplete' and \
91 | k != 'closing' , constrain_keys)
92 | constrain_keys = [k for k in constrain_keys if current_slots[k] != dialog_config.I_DO_NOT_CARE]
93 |
94 | query_idx_keys = frozenset(current_slots.items())
95 | cached_kb_ret = self.cached_kb[query_idx_keys]
96 |
97 | cached_kb_length = len(cached_kb_ret) if cached_kb_ret != None else -1
98 | if cached_kb_length > 0:
99 | return dict(cached_kb_ret)
100 | elif cached_kb_length == -1:
101 | return dict([])
102 |
103 | # kb_results = copy.deepcopy(self.movie_dictionary)
104 | for id in self.movie_dictionary.keys():
105 | kb_keys = self.movie_dictionary[id].keys()
106 | if len(set(constrain_keys).union(set(kb_keys)) ^ (set(constrain_keys) ^ set(kb_keys))) == len(
107 | constrain_keys):
108 | match = True
109 | for idx, k in enumerate(constrain_keys):
110 | if str(current_slots[k]).lower() == str(self.movie_dictionary[id][k]).lower():
111 | continue
112 | else:
113 | match = False
114 | if match:
115 | self.cached_kb[query_idx_keys].append((id, self.movie_dictionary[id]))
116 | ret_result.append((id, self.movie_dictionary[id]))
117 |
118 | # for slot in current_slots['inform_slots'].keys():
119 | # if slot == 'ticket' or slot == 'numberofpeople' or slot == 'taskcomplete' or slot == 'closing': continue
120 | # if current_slots['inform_slots'][slot] == dialog_config.I_DO_NOT_CARE: continue
121 | #
122 | # if slot not in self.movie_dictionary[movie_id].keys():
123 | # if movie_id in kb_results.keys():
124 | # del kb_results[movie_id]
125 | # else:
126 | # if current_slots['inform_slots'][slot].lower() != self.movie_dictionary[movie_id][slot].lower():
127 | # if movie_id in kb_results.keys():
128 | # del kb_results[movie_id]
129 |
130 | if len(ret_result) == 0:
131 | self.cached_kb[query_idx_keys] = None
132 |
133 | ret_result = dict(ret_result)
134 | return ret_result
135 |
136 | def available_results_from_kb_for_slots(self, inform_slots):
137 | """ Return the count statistics for each constraint in inform_slots """
138 |
139 | kb_results = {key:0 for key in inform_slots.keys()}
140 | kb_results['matching_all_constraints'] = 0
141 |
142 | query_idx_keys = frozenset(inform_slots.items())
143 | cached_kb_slot_ret = self.cached_kb_slot[query_idx_keys]
144 |
145 | if len(cached_kb_slot_ret) > 0:
146 | return cached_kb_slot_ret[0]
147 |
148 | for movie_id in self.movie_dictionary.keys():
149 | all_slots_match = 1
150 | for slot in inform_slots.keys():
151 | if slot == 'ticket' or inform_slots[slot] == dialog_config.I_DO_NOT_CARE:
152 | continue
153 |
154 | if slot in self.movie_dictionary[movie_id].keys():
155 | if inform_slots[slot].lower() == self.movie_dictionary[movie_id][slot].lower():
156 | kb_results[slot] += 1
157 | else:
158 | all_slots_match = 0
159 | else:
160 | all_slots_match = 0
161 | kb_results['matching_all_constraints'] += all_slots_match
162 |
163 | self.cached_kb_slot[query_idx_keys].append(kb_results)
164 | return kb_results
165 |
166 |
167 | def database_results_for_agent(self, current_slots):
168 | """ A dictionary of the number of results matching each current constraint. The agent needs this to decide what to do next. """
169 |
170 | database_results ={} # { date:100, distanceconstraints:60, theater:30, matching_all_constraints: 5}
171 | database_results = self.available_results_from_kb_for_slots(current_slots['inform_slots'])
172 | return database_results
173 |
174 | def suggest_slot_values(self, request_slots, current_slots):
175 | """ Return the suggest slot values """
176 |
177 | avail_kb_results = self.available_results_from_kb(current_slots)
178 | return_suggest_slot_vals = {}
179 | for slot in request_slots.keys():
180 | avail_values_dict = self.available_slot_values(slot, avail_kb_results)
181 | values_counts = [(v, avail_values_dict[v]) for v in avail_values_dict.keys()]
182 |
183 | if len(values_counts) > 0:
184 | return_suggest_slot_vals[slot] = []
185 | sorted_dict = sorted(values_counts, key = lambda x: -x[1])
186 | for k in sorted_dict: return_suggest_slot_vals[slot].append(k[0])
187 | else:
188 | return_suggest_slot_vals[slot] = []
189 |
190 | return return_suggest_slot_vals
--------------------------------------------------------------------------------
/src/deep_dialog/dialog_system/state_tracker.py:
--------------------------------------------------------------------------------
1 | """
2 | Created on May 20, 2016
3 |
4 | state tracker
5 |
6 | @author: xiul, t-zalipt
7 | """
8 |
9 | from . import KBHelper
10 | import numpy as np
11 | import copy
12 |
13 |
14 | class StateTracker:
15 | """ The state tracker maintains a record of which request slots are filled and which inform slots are filled """
16 |
17 | def __init__(self, act_set, slot_set, movie_dictionary):
18 | """ constructor for statetracker takes movie knowledge base and initializes a new episode
19 |
20 | Arguments:
21 | act_set -- The set of all acts availavle
22 | slot_set -- The total set of available slots
23 | movie_dictionary -- A representation of all the available movies. Generally this object is accessed via the KBHelper class
24 |
25 | Class Variables:
26 | history_vectors -- A record of the current dialog so far in vector format (act-slot, but no values)
27 | history_dictionaries -- A record of the current dialog in dictionary format
28 | current_slots -- A dictionary that keeps a running record of which slots are filled current_slots['inform_slots'] and which are requested current_slots['request_slots'] (but not filed)
29 | action_dimension -- # TODO indicates the dimensionality of the vector representaiton of the action
30 | kb_result_dimension -- A single integer denoting the dimension of the kb_results features.
31 | turn_count -- A running count of which turn we are at in the present dialog
32 | """
33 | self.movie_dictionary = movie_dictionary
34 | self.initialize_episode()
35 | self.history_vectors = None
36 | self.history_dictionaries = None
37 | self.current_slots = None
38 | self.action_dimension = 10 # TODO REPLACE WITH REAL VALUE
39 | self.kb_result_dimension = 10 # TODO REPLACE WITH REAL VALUE
40 | self.turn_count = 0
41 | self.kb_helper = KBHelper(movie_dictionary)
42 |
43 |
44 | def initialize_episode(self):
45 | """ Initialize a new episode (dialog), flush the current state and tracked slots """
46 |
47 | self.action_dimension = 10
48 | self.history_vectors = np.zeros((1, self.action_dimension))
49 | self.history_dictionaries = []
50 | self.turn_count = 0
51 | self.current_slots = {}
52 |
53 | self.current_slots['inform_slots'] = {}
54 | self.current_slots['request_slots'] = {}
55 | self.current_slots['proposed_slots'] = {}
56 | self.current_slots['agent_request_slots'] = {}
57 |
58 |
59 | def dialog_history_vectors(self):
60 | """ Return the dialog history (both user and agent actions) in vector representation """
61 | return self.history_vectors
62 |
63 |
64 | def dialog_history_dictionaries(self):
65 | """ Return the dictionary representation of the dialog history (includes values) """
66 | return self.history_dictionaries
67 |
68 |
69 | def kb_results_for_state(self):
70 | """ Return the information about the database results based on the currently informed slots """
71 | ########################################################################
72 | # TODO Calculate results based on current informed slots
73 | ########################################################################
74 | kb_results = self.kb_helper.database_results_for_agent(self.current_slots) # replace this with something less ridiculous
75 | # TODO turn results into vector (from dictionary)
76 | results = np.zeros((0, self.kb_result_dimension))
77 | return results
78 |
79 |
80 | def get_state_for_agent(self):
81 | """ Get the state representatons to send to agent """
82 | #state = {'user_action': self.history_dictionaries[-1], 'current_slots': self.current_slots, 'kb_results': self.kb_results_for_state()}
83 | state = {'user_action': self.history_dictionaries[-1], 'current_slots': self.current_slots, #'kb_results': self.kb_results_for_state(),
84 | 'kb_results_dict':self.kb_helper.database_results_for_agent(self.current_slots), 'turn': self.turn_count, 'history': self.history_dictionaries,
85 | 'agent_action': self.history_dictionaries[-2] if len(self.history_dictionaries) > 1 else None}
86 | return copy.deepcopy(state)
87 |
88 | def get_suggest_slots_values(self, request_slots):
89 | """ Get the suggested values for request slots """
90 |
91 | suggest_slot_vals = {}
92 | if len(request_slots) > 0:
93 | suggest_slot_vals = self.kb_helper.suggest_slot_values(request_slots, self.current_slots)
94 |
95 | return suggest_slot_vals
96 |
97 | def get_current_kb_results(self):
98 | """ get the kb_results for current state """
99 | kb_results = self.kb_helper.available_results_from_kb(self.current_slots)
100 | return kb_results
101 |
102 |
103 | def update(self, agent_action=None, user_action=None):
104 | """ Update the state based on the latest action """
105 |
106 | ########################################################################
107 | # Make sure that the function was called properly
108 | ########################################################################
109 | assert(not (user_action and agent_action))
110 | assert(user_action or agent_action)
111 |
112 | ########################################################################
113 | # Update state to reflect a new action by the agent.
114 | ########################################################################
115 | if agent_action:
116 |
117 | ####################################################################
118 | # Handles the act_slot response (with values needing to be filled)
119 | ####################################################################
120 | if agent_action['act_slot_response']:
121 | response = copy.deepcopy(agent_action['act_slot_response'])
122 |
123 | inform_slots = self.kb_helper.fill_inform_slots(response['inform_slots'], self.current_slots) # TODO this doesn't actually work yet, remove this warning when kb_helper is functional
124 | agent_action_values = {'turn': self.turn_count, 'speaker': "agent", 'diaact': response['diaact'], 'inform_slots': inform_slots, 'request_slots':response['request_slots']}
125 |
126 | agent_action['act_slot_response'].update({'diaact': response['diaact'], 'inform_slots': inform_slots, 'request_slots':response['request_slots'], 'turn':self.turn_count})
127 |
128 | elif agent_action['act_slot_value_response']:
129 | agent_action_values = copy.deepcopy(agent_action['act_slot_value_response'])
130 | # print("Updating state based on act_slot_value action from agent")
131 | agent_action_values['turn'] = self.turn_count
132 | agent_action_values['speaker'] = "agent"
133 |
134 | ####################################################################
135 | # This code should execute regardless of which kind of agent produced action
136 | ####################################################################
137 | for slot in agent_action_values['inform_slots'].keys():
138 | self.current_slots['proposed_slots'][slot] = agent_action_values['inform_slots'][slot]
139 | self.current_slots['inform_slots'][slot] = agent_action_values['inform_slots'][slot] # add into inform_slots
140 | if slot in self.current_slots['request_slots'].keys():
141 | del self.current_slots['request_slots'][slot]
142 |
143 | for slot in agent_action_values['request_slots'].keys():
144 | if slot not in self.current_slots['agent_request_slots']:
145 | self.current_slots['agent_request_slots'][slot] = "UNK"
146 |
147 | self.history_dictionaries.append(agent_action_values)
148 | current_agent_vector = np.ones((1, self.action_dimension))
149 | self.history_vectors = np.vstack([self.history_vectors, current_agent_vector])
150 |
151 | ########################################################################
152 | # Update the state to reflect a new action by the user
153 | ########################################################################
154 | elif user_action:
155 |
156 | ####################################################################
157 | # Update the current slots
158 | ####################################################################
159 | for slot in user_action['inform_slots'].keys():
160 | self.current_slots['inform_slots'][slot] = user_action['inform_slots'][slot]
161 | if slot in self.current_slots['request_slots'].keys():
162 | del self.current_slots['request_slots'][slot]
163 |
164 | for slot in user_action['request_slots'].keys():
165 | if slot not in self.current_slots['request_slots']:
166 | self.current_slots['request_slots'][slot] = "UNK"
167 |
168 | self.history_vectors = np.vstack([self.history_vectors, np.zeros((1,self.action_dimension))])
169 | new_move = {'turn': self.turn_count, 'speaker': "user", 'request_slots': user_action['request_slots'], 'inform_slots': user_action['inform_slots'], 'diaact': user_action['diaact']}
170 | self.history_dictionaries.append(copy.deepcopy(new_move))
171 |
172 | ########################################################################
173 | # This should never happen if the asserts passed
174 | ########################################################################
175 | else:
176 | pass
177 |
178 | ########################################################################
179 | # This code should execute after update code regardless of what kind of action (agent/user)
180 | ########################################################################
181 | self.turn_count += 1
--------------------------------------------------------------------------------
/src/deep_dialog/dialog_system/utils.py:
--------------------------------------------------------------------------------
1 | """
2 | Created on May 25, 2016
3 |
4 | @author: xiul, t-zalipt
5 | """
6 |
7 | import numpy as np
8 | ################################################################################
9 | # Some helper functions
10 | ################################################################################
11 |
12 | def unique_states(training_data):
13 | unique = []
14 | for datum in training_data:
15 | if contains(unique, datum[0]):
16 | pass
17 | else:
18 | unique.append(datum[0].copy())
19 | return unique
20 |
21 | def contains(unique, candidate_state):
22 | for state in unique:
23 | if np.array_equal(state, candidate_state):
24 | return True
25 | else:
26 | pass
27 | return False
28 |
--------------------------------------------------------------------------------
/src/deep_dialog/nlg/__init__.py:
--------------------------------------------------------------------------------
1 | from .utils import *
2 | from .nlg import *
--------------------------------------------------------------------------------
/src/deep_dialog/nlg/decoder.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jun 13, 2016
3 |
4 | @author: xiul
5 | '''
6 |
7 | from .utils import *
8 |
9 |
10 | class decoder:
11 | def __init__(self, input_size, hidden_size, output_size):
12 | pass
13 |
14 | def get_struct(self):
15 | return {'model': self.model, 'update': self.update, 'regularize': self.regularize}
16 |
17 |
18 | """ Activation Function: Sigmoid, or tanh, or ReLu"""
19 | def fwdPass(self, Xs, params, **kwargs):
20 | pass
21 |
22 | def bwdPass(self, dY, cache):
23 | pass
24 |
25 |
26 | """ Batch Forward & Backward Pass"""
27 | def batchForward(self, ds, batch, params, predict_mode = False):
28 | caches = []
29 | Ys = []
30 | for i,x in enumerate(batch):
31 | Y, out_cache = self.fwdPass(x, params, predict_mode = predict_mode)
32 | caches.append(out_cache)
33 | Ys.append(Y)
34 |
35 | # back up information for efficient backprop
36 | cache = {}
37 | if not predict_mode:
38 | cache['caches'] = caches
39 |
40 | return Ys, cache
41 |
42 | def batchBackward(self, dY, cache):
43 | caches = cache['caches']
44 | grads = {}
45 | for i in xrange(len(caches)):
46 | single_cache = caches[i]
47 | local_grads = self.bwdPass(dY[i], single_cache)
48 | mergeDicts(grads, local_grads) # add up the gradients wrt model parameters
49 |
50 | return grads
51 |
52 |
53 | """ Cost function, returns cost and gradients for model """
54 | def costFunc(self, ds, batch, params):
55 | regc = params['reg_cost'] # regularization cost
56 |
57 | # batch forward RNN
58 | Ys, caches = self.batchForward(ds, batch, params, predict_mode = False)
59 |
60 | loss_cost = 0.0
61 | smooth_cost = 1e-15
62 | dYs = []
63 |
64 | for i,x in enumerate(batch):
65 | labels = np.array(x['labels'], dtype=int)
66 |
67 | # fetch the predicted probabilities
68 | Y = Ys[i]
69 | maxes = np.amax(Y, axis=1, keepdims=True)
70 | e = np.exp(Y - maxes) # for numerical stability shift into good numerical range
71 | P = e/np.sum(e, axis=1, keepdims=True)
72 |
73 | # Cross-Entropy Cross Function
74 | loss_cost += -np.sum(np.log(smooth_cost + P[range(len(labels)), labels]))
75 |
76 | for iy,y in enumerate(labels):
77 | P[iy,y] -= 1 # softmax derivatives
78 | dYs.append(P)
79 |
80 | # backprop the RNN
81 | grads = self.batchBackward(dYs, caches)
82 |
83 | # add L2 regularization cost and gradients
84 | reg_cost = 0.0
85 | if regc > 0:
86 | for p in self.regularize:
87 | mat = self.model[p]
88 | reg_cost += 0.5*regc*np.sum(mat*mat)
89 | grads[p] += regc*mat
90 |
91 | # normalize the cost and gradient by the batch size
92 | batch_size = len(batch)
93 | reg_cost /= batch_size
94 | loss_cost /= batch_size
95 | for k in grads: grads[k] /= batch_size
96 |
97 | out = {}
98 | out['cost'] = {'reg_cost' : reg_cost, 'loss_cost' : loss_cost, 'total_cost' : loss_cost + reg_cost}
99 | out['grads'] = grads
100 | return out
101 |
102 |
103 | """ A single batch """
104 | def singleBatch(self, ds, batch, params):
105 | learning_rate = params.get('learning_rate', 0.0)
106 | decay_rate = params.get('decay_rate', 0.999)
107 | momentum = params.get('momentum', 0)
108 | grad_clip = params.get('grad_clip', 1)
109 | smooth_eps = params.get('smooth_eps', 1e-8)
110 | sdg_type = params.get('sdgtype', 'rmsprop')
111 |
112 | for u in self.update:
113 | if not u in self.step_cache:
114 | self.step_cache[u] = np.zeros(self.model[u].shape)
115 |
116 | cg = self.costFunc(ds, batch, params)
117 |
118 | cost = cg['cost']
119 | grads = cg['grads']
120 |
121 | # clip gradients if needed
122 | if params['activation_func'] == 'relu':
123 | if grad_clip > 0:
124 | for p in self.update:
125 | if p in grads:
126 | grads[p] = np.minimum(grads[p], grad_clip)
127 | grads[p] = np.maximum(grads[p], -grad_clip)
128 |
129 | # perform parameter update
130 | for p in self.update:
131 | if p in grads:
132 | if sdg_type == 'vanilla':
133 | if momentum > 0: dx = momentum*self.step_cache[p] - learning_rate*grads[p]
134 | else: dx = -learning_rate*grads[p]
135 | self.step_cache[p] = dx
136 | elif sdg_type == 'rmsprop':
137 | self.step_cache[p] = self.step_cache[p]*decay_rate + (1.0-decay_rate)*grads[p]**2
138 | dx = -(learning_rate*grads[p])/np.sqrt(self.step_cache[p] + smooth_eps)
139 | elif sdg_type == 'adgrad':
140 | self.step_cache[p] += grads[p]**2
141 | dx = -(learning_rate*grads[p])/np.sqrt(self.step_cache[p] + smooth_eps)
142 |
143 | self.model[p] += dx
144 |
145 | # create output dict and return
146 | out = {}
147 | out['cost'] = cost
148 | return out
149 |
150 |
151 | """ Evaluate on the dataset[split] """
152 | def eval(self, ds, split, params):
153 | acc = 0
154 | total = 0
155 |
156 | total_cost = 0.0
157 | smooth_cost = 1e-15
158 | perplexity = 0
159 |
160 | for i, ele in enumerate(ds.split[split]):
161 | #ele_reps = self.prepare_input_rep(ds, [ele], params)
162 | #Ys, cache = self.fwdPass(ele_reps[0], params, predict_model=True)
163 | #labels = np.array(ele_reps[0]['labels'], dtype=int)
164 |
165 | Ys, cache = self.fwdPass(ele, params, predict_model=True)
166 |
167 | maxes = np.amax(Ys, axis=1, keepdims=True)
168 | e = np.exp(Ys - maxes) # for numerical stability shift into good numerical range
169 | probs = e/np.sum(e, axis=1, keepdims=True)
170 |
171 | labels = np.array(ele['labels'], dtype=int)
172 |
173 | if np.all(np.isnan(probs)): probs = np.zeros(probs.shape)
174 |
175 | log_perplex = 0
176 | log_perplex += -np.sum(np.log2(smooth_cost + probs[range(len(labels)), labels]))
177 | log_perplex /= len(labels)
178 |
179 | loss_cost = 0
180 | loss_cost += -np.sum(np.log(smooth_cost + probs[range(len(labels)), labels]))
181 |
182 | perplexity += log_perplex #2**log_perplex
183 | total_cost += loss_cost
184 |
185 | pred_words_indices = np.nanargmax(probs, axis=1)
186 | for index, l in enumerate(labels):
187 | if pred_words_indices[index] == l:
188 | acc += 1
189 |
190 | total += len(labels)
191 |
192 | perplexity /= len(ds.split[split])
193 | total_cost /= len(ds.split[split])
194 | accuracy = 0 if total == 0 else float(acc)/total
195 |
196 | #print ("perplexity: %s, total_cost: %s, accuracy: %s" % (perplexity, total_cost, accuracy))
197 | result = {'perplexity': perplexity, 'cost': total_cost, 'accuracy': accuracy}
198 | return result
199 |
200 |
201 |
202 | """ prediction on dataset[split] """
203 | def predict(self, ds, split, params):
204 | inverse_word_dict = {ds.data['word_dict'][k]:k for k in ds.data['word_dict'].keys()}
205 | for i, ele in enumerate(ds.split[split]):
206 | pred_ys, pred_words = self.forward(inverse_word_dict, ele, params, predict_model=True)
207 |
208 | sentence = ' '.join(pred_words[:-1])
209 | real_sentence = ' '.join(ele['sentence'].split(' ')[1:-1])
210 |
211 | if params['dia_slot_val'] == 2 or params['dia_slot_val'] == 3:
212 | sentence = self.post_process(sentence, ele['slotval'], ds.data['slot_dict'])
213 |
214 | print 'test case', i
215 | print 'real:', real_sentence
216 | print 'pred:', sentence
217 |
218 | """ post_process to fill the slot """
219 | def post_process(self, pred_template, slot_val_dict, slot_dict):
220 | sentence = pred_template
221 | suffix = "_PLACEHOLDER"
222 |
223 | for slot in slot_val_dict.keys():
224 | slot_vals = slot_val_dict[slot]
225 | slot_placeholder = slot + suffix
226 | if slot == 'result' or slot == 'numberofpeople': continue
227 | for slot_val in slot_vals:
228 | tmp_sentence = sentence.replace(slot_placeholder, slot_val, 1)
229 | sentence = tmp_sentence
230 |
231 | if 'numberofpeople' in slot_val_dict.keys():
232 | slot_vals = slot_val_dict['numberofpeople']
233 | slot_placeholder = 'numberofpeople' + suffix
234 | for slot_val in slot_vals:
235 | tmp_sentence = sentence.replace(slot_placeholder, slot_val, 1)
236 | sentence = tmp_sentence
237 |
238 | for slot in slot_dict.keys():
239 | slot_placeholder = slot + suffix
240 | tmp_sentence = sentence.replace(slot_placeholder, '')
241 | sentence = tmp_sentence
242 |
243 | return sentence
--------------------------------------------------------------------------------
/src/deep_dialog/nlg/lstm_decoder_tanh.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jun 13, 2016
3 |
4 | An LSTM decoder - add tanh after cell before output gate
5 |
6 | @author: xiul
7 | '''
8 |
9 | from .decoder import decoder
10 | from .utils import *
11 |
12 |
13 | class lstm_decoder_tanh(decoder):
14 | def __init__(self, diaact_input_size, input_size, hidden_size, output_size):
15 | self.model = {}
16 | # connections from diaact to hidden layer
17 | self.model['Wah'] = initWeights(diaact_input_size, 4*hidden_size)
18 | self.model['bah'] = np.zeros((1, 4*hidden_size))
19 |
20 | # Recurrent weights: take x_t, h_{t-1}, and bias unit, and produce the 3 gates and the input to cell signal
21 | self.model['WLSTM'] = initWeights(input_size + hidden_size + 1, 4*hidden_size)
22 | # Hidden-Output Connections
23 | self.model['Wd'] = initWeights(hidden_size, output_size)*0.1
24 | self.model['bd'] = np.zeros((1, output_size))
25 |
26 | self.update = ['Wah', 'bah', 'WLSTM', 'Wd', 'bd']
27 | self.regularize = ['Wah', 'WLSTM', 'Wd']
28 |
29 | self.step_cache = {}
30 |
31 | """ Activation Function: Sigmoid, or tanh, or ReLu """
32 | def fwdPass(self, Xs, params, **kwargs):
33 | predict_mode = kwargs.get('predict_mode', False)
34 | feed_recurrence = params.get('feed_recurrence', 0)
35 |
36 | Ds = Xs['diaact']
37 | Ws = Xs['words']
38 |
39 | # diaact input layer to hidden layer
40 | Wah = self.model['Wah']
41 | bah = self.model['bah']
42 | Dsh = Ds.dot(Wah) + bah
43 |
44 | WLSTM = self.model['WLSTM']
45 | n, xd = Ws.shape
46 |
47 | d = self.model['Wd'].shape[0] # size of hidden layer
48 | Hin = np.zeros((n, WLSTM.shape[0])) # xt, ht-1, bias
49 | Hout = np.zeros((n, d))
50 | IFOG = np.zeros((n, 4*d))
51 | IFOGf = np.zeros((n, 4*d)) # after nonlinearity
52 | Cellin = np.zeros((n, d))
53 | Cellout = np.zeros((n, d))
54 |
55 | for t in xrange(n):
56 | prev = np.zeros(d) if t==0 else Hout[t-1]
57 | Hin[t,0] = 1 # bias
58 | Hin[t, 1:1+xd] = Ws[t]
59 | Hin[t, 1+xd:] = prev
60 |
61 | # compute all gate activations. dots:
62 | IFOG[t] = Hin[t].dot(WLSTM)
63 |
64 | # add diaact vector here
65 | if feed_recurrence == 0:
66 | if t == 0: IFOG[t] += Dsh[0]
67 | else:
68 | IFOG[t] += Dsh[0]
69 |
70 | IFOGf[t, :3*d] = 1/(1+np.exp(-IFOG[t, :3*d])) # sigmoids; these are three gates
71 | IFOGf[t, 3*d:] = np.tanh(IFOG[t, 3*d:]) # tanh for input value
72 |
73 | Cellin[t] = IFOGf[t, :d] * IFOGf[t, 3*d:]
74 | if t>0: Cellin[t] += IFOGf[t, d:2*d]*Cellin[t-1]
75 |
76 | Cellout[t] = np.tanh(Cellin[t])
77 |
78 | Hout[t] = IFOGf[t, 2*d:3*d] * Cellout[t]
79 |
80 | Wd = self.model['Wd']
81 | bd = self.model['bd']
82 |
83 | Y = Hout.dot(Wd)+bd
84 |
85 | cache = {}
86 | if not predict_mode:
87 | cache['WLSTM'] = WLSTM
88 | cache['Hout'] = Hout
89 | cache['WLSTM'] = WLSTM
90 | cache['Wd'] = Wd
91 | cache['IFOGf'] = IFOGf
92 | cache['IFOG'] = IFOG
93 | cache['Cellin'] = Cellin
94 | cache['Cellout'] = Cellout
95 | cache['Ws'] = Ws
96 | cache['Ds'] = Ds
97 | cache['Hin'] = Hin
98 | cache['Dsh'] = Dsh
99 | cache['Wah'] = Wah
100 | cache['feed_recurrence'] = feed_recurrence
101 |
102 | return Y, cache
103 |
104 | """ Forward pass on prediction """
105 | def forward(self, dict, Xs, params, **kwargs):
106 | max_len = params.get('max_len', 30)
107 | feed_recurrence = params.get('feed_recurrence', 0)
108 | decoder_sampling = params.get('decoder_sampling', 0)
109 |
110 | Ds = Xs['diaact']
111 | Ws = Xs['words']
112 |
113 | # diaact input layer to hidden layer
114 | Wah = self.model['Wah']
115 | bah = self.model['bah']
116 | Dsh = Ds.dot(Wah) + bah
117 |
118 | WLSTM = self.model['WLSTM']
119 | xd = Ws.shape[1]
120 |
121 | d = self.model['Wd'].shape[0] # size of hidden layer
122 | Hin = np.zeros((1, WLSTM.shape[0])) # xt, ht-1, bias
123 | Hout = np.zeros((1, d))
124 | IFOG = np.zeros((1, 4*d))
125 | IFOGf = np.zeros((1, 4*d)) # after nonlinearity
126 | Cellin = np.zeros((1, d))
127 | Cellout = np.zeros((1, d))
128 |
129 | Wd = self.model['Wd']
130 | bd = self.model['bd']
131 |
132 | Hin[0,0] = 1 # bias
133 | Hin[0,1:1+xd] = Ws[0]
134 |
135 | IFOG[0] = Hin[0].dot(WLSTM)
136 | IFOG[0] += Dsh[0]
137 |
138 | IFOGf[0, :3*d] = 1/(1+np.exp(-IFOG[0, :3*d])) # sigmoids; these are three gates
139 | IFOGf[0, 3*d:] = np.tanh(IFOG[0, 3*d:]) # tanh for input value
140 |
141 | Cellin[0] = IFOGf[0, :d] * IFOGf[0, 3*d:]
142 | Cellout[0] = np.tanh(Cellin[0])
143 | Hout[0] = IFOGf[0, 2*d:3*d] * Cellout[0]
144 |
145 | pred_y = []
146 | pred_words = []
147 |
148 | Y = Hout.dot(Wd) + bd
149 | maxes = np.amax(Y, axis=1, keepdims=True)
150 | e = np.exp(Y - maxes) # for numerical stability shift into good numerical range
151 | probs = e/np.sum(e, axis=1, keepdims=True)
152 |
153 | if decoder_sampling == 0: # sampling or argmax
154 | pred_y_index = np.nanargmax(Y)
155 | else:
156 | pred_y_index = np.random.choice(Y.shape[1], 1, p=probs[0])[0]
157 | pred_y.append(pred_y_index)
158 | pred_words.append(dict[pred_y_index])
159 |
160 | time_stamp = 0
161 | while True:
162 | if dict[pred_y_index] == 'e_o_s' or time_stamp >= max_len: break
163 |
164 | X = np.zeros(xd)
165 | X[pred_y_index] = 1
166 | Hin[0,0] = 1 # bias
167 | Hin[0,1:1+xd] = X
168 | Hin[0, 1+xd:] = Hout[0]
169 |
170 | IFOG[0] = Hin[0].dot(WLSTM)
171 | if feed_recurrence == 1:
172 | IFOG[0] += Dsh[0]
173 |
174 | IFOGf[0, :3*d] = 1/(1+np.exp(-IFOG[0, :3*d])) # sigmoids; these are three gates
175 | IFOGf[0, 3*d:] = np.tanh(IFOG[0, 3*d:]) # tanh for input value
176 |
177 | C = IFOGf[0, :d]*IFOGf[0, 3*d:]
178 | Cellin[0] = C + IFOGf[0, d:2*d]*Cellin[0]
179 | Cellout[0] = np.tanh(Cellin[0])
180 | Hout[0] = IFOGf[0, 2*d:3*d]*Cellout[0]
181 |
182 | Y = Hout.dot(Wd) + bd
183 | maxes = np.amax(Y, axis=1, keepdims=True)
184 | e = np.exp(Y - maxes) # for numerical stability shift into good numerical range
185 | probs = e/np.sum(e, axis=1, keepdims=True)
186 |
187 | if decoder_sampling == 0:
188 | pred_y_index = np.nanargmax(Y)
189 | else:
190 | pred_y_index = np.random.choice(Y.shape[1], 1, p=probs[0])[0]
191 | pred_y.append(pred_y_index)
192 | pred_words.append(dict[pred_y_index])
193 |
194 | time_stamp += 1
195 |
196 | return pred_y, pred_words
197 |
198 | """ Forward pass on prediction with Beam Search """
199 | def beam_forward(self, dict, Xs, params, **kwargs):
200 | max_len = params.get('max_len', 30)
201 | feed_recurrence = params.get('feed_recurrence', 0)
202 | beam_size = params.get('beam_size', 10)
203 | decoder_sampling = params.get('decoder_sampling', 0)
204 |
205 | Ds = Xs['diaact']
206 | Ws = Xs['words']
207 |
208 | # diaact input layer to hidden layer
209 | Wah = self.model['Wah']
210 | bah = self.model['bah']
211 | Dsh = Ds.dot(Wah) + bah
212 |
213 | WLSTM = self.model['WLSTM']
214 | xd = Ws.shape[1]
215 |
216 | d = self.model['Wd'].shape[0] # size of hidden layer
217 | Hin = np.zeros((1, WLSTM.shape[0])) # xt, ht-1, bias
218 | Hout = np.zeros((1, d))
219 | IFOG = np.zeros((1, 4*d))
220 | IFOGf = np.zeros((1, 4*d)) # after nonlinearity
221 | Cellin = np.zeros((1, d))
222 | Cellout = np.zeros((1, d))
223 |
224 | Wd = self.model['Wd']
225 | bd = self.model['bd']
226 |
227 | Hin[0,0] = 1 # bias
228 | Hin[0,1:1+xd] = Ws[0]
229 |
230 | IFOG[0] = Hin[0].dot(WLSTM)
231 | IFOG[0] += Dsh[0]
232 |
233 | IFOGf[0, :3*d] = 1/(1+np.exp(-IFOG[0, :3*d])) # sigmoids; these are three gates
234 | IFOGf[0, 3*d:] = np.tanh(IFOG[0, 3*d:]) # tanh for input value
235 |
236 | Cellin[0] = IFOGf[0, :d] * IFOGf[0, 3*d:]
237 | Cellout[0] = np.tanh(Cellin[0])
238 | Hout[0] = IFOGf[0, 2*d:3*d] * Cellout[0]
239 |
240 | # keep a beam here
241 | beams = []
242 |
243 | Y = Hout.dot(Wd) + bd
244 | maxes = np.amax(Y, axis=1, keepdims=True)
245 | e = np.exp(Y - maxes) # for numerical stability shift into good numerical range
246 | probs = e/np.sum(e, axis=1, keepdims=True)
247 |
248 | # add beam search here
249 | if decoder_sampling == 0: # no sampling
250 | beam_candidate_t = (-probs[0]).argsort()[:beam_size]
251 | else:
252 | beam_candidate_t = np.random.choice(Y.shape[1], beam_size, p=probs[0])
253 | #beam_candidate_t = (-probs[0]).argsort()[:beam_size]
254 | for ele in beam_candidate_t:
255 | beams.append((np.log(probs[0][ele]), [ele], [dict[ele]], Hout[0], Cellin[0]))
256 |
257 | #beams.sort(key=lambda x:x[0], reverse=True)
258 | #beams.sort(reverse = True)
259 |
260 | time_stamp = 0
261 | while True:
262 | beam_candidates = []
263 | for b in beams:
264 | log_prob = b[0]
265 | pred_y_index = b[1][-1]
266 | cell_in = b[4]
267 | hout_prev = b[3]
268 |
269 | if b[2][-1] == "e_o_s": # this beam predicted end token. Keep in the candidates but don't expand it out any more
270 | beam_candidates.append(b)
271 | continue
272 |
273 | X = np.zeros(xd)
274 | X[pred_y_index] = 1
275 | Hin[0,0] = 1 # bias
276 | Hin[0,1:1+xd] = X
277 | Hin[0, 1+xd:] = hout_prev
278 |
279 | IFOG[0] = Hin[0].dot(WLSTM)
280 | if feed_recurrence == 1: IFOG[0] += Dsh[0]
281 |
282 | IFOGf[0, :3*d] = 1/(1+np.exp(-IFOG[0, :3*d])) # sigmoids; these are three gates
283 | IFOGf[0, 3*d:] = np.tanh(IFOG[0, 3*d:]) # tanh for input value
284 |
285 | C = IFOGf[0, :d]*IFOGf[0, 3*d:]
286 | cell_in = C + IFOGf[0, d:2*d]*cell_in
287 | cell_out = np.tanh(cell_in)
288 | hout_prev = IFOGf[0, 2*d:3*d]*cell_out
289 |
290 | Y = hout_prev.dot(Wd) + bd
291 | maxes = np.amax(Y, axis=1, keepdims=True)
292 | e = np.exp(Y - maxes) # for numerical stability shift into good numerical range
293 | probs = e/np.sum(e, axis=1, keepdims=True)
294 |
295 | if decoder_sampling == 0: # no sampling
296 | beam_candidate_t = (-probs[0]).argsort()[:beam_size]
297 | else:
298 | beam_candidate_t = np.random.choice(Y.shape[1], beam_size, p=probs[0])
299 | #beam_candidate_t = (-probs[0]).argsort()[:beam_size]
300 | for ele in beam_candidate_t:
301 | beam_candidates.append((log_prob+np.log(probs[0][ele]), np.append(b[1], ele), np.append(b[2], dict[ele]), hout_prev, cell_in))
302 |
303 | beam_candidates.sort(key=lambda x:x[0], reverse=True)
304 | #beam_candidates.sort(reverse = True) # decreasing order
305 | beams = beam_candidates[:beam_size]
306 | time_stamp += 1
307 |
308 | if time_stamp >= max_len: break
309 |
310 | return beams[0][1], beams[0][2]
311 |
312 | """ Backward Pass """
313 | def bwdPass(self, dY, cache):
314 | Wd = cache['Wd']
315 | Hout = cache['Hout']
316 | IFOG = cache['IFOG']
317 | IFOGf = cache['IFOGf']
318 | Cellin = cache['Cellin']
319 | Cellout = cache['Cellout']
320 | Hin = cache['Hin']
321 | WLSTM = cache['WLSTM']
322 | Ws = cache['Ws']
323 | Ds = cache['Ds']
324 | Dsh = cache['Dsh']
325 | Wah = cache['Wah']
326 | feed_recurrence = cache['feed_recurrence']
327 |
328 | n,d = Hout.shape
329 |
330 | # backprop the hidden-output layer
331 | dWd = Hout.transpose().dot(dY)
332 | dbd = np.sum(dY, axis=0, keepdims = True)
333 | dHout = dY.dot(Wd.transpose())
334 |
335 | # backprop the LSTM
336 | dIFOG = np.zeros(IFOG.shape)
337 | dIFOGf = np.zeros(IFOGf.shape)
338 | dWLSTM = np.zeros(WLSTM.shape)
339 | dHin = np.zeros(Hin.shape)
340 | dCellin = np.zeros(Cellin.shape)
341 | dCellout = np.zeros(Cellout.shape)
342 | dWs = np.zeros(Ws.shape)
343 |
344 | dDsh = np.zeros(Dsh.shape)
345 |
346 | for t in reversed(xrange(n)):
347 | dIFOGf[t,2*d:3*d] = Cellout[t] * dHout[t]
348 | dCellout[t] = IFOGf[t,2*d:3*d] * dHout[t]
349 |
350 | dCellin[t] += (1-Cellout[t]**2) * dCellout[t]
351 |
352 | if t>0:
353 | dIFOGf[t, d:2*d] = Cellin[t-1] * dCellin[t]
354 | dCellin[t-1] += IFOGf[t,d:2*d] * dCellin[t]
355 |
356 | dIFOGf[t, :d] = IFOGf[t,3*d:] * dCellin[t]
357 | dIFOGf[t,3*d:] = IFOGf[t, :d] * dCellin[t]
358 |
359 | # backprop activation functions
360 | dIFOG[t, 3*d:] = (1-IFOGf[t, 3*d:]**2) * dIFOGf[t, 3*d:]
361 | y = IFOGf[t, :3*d]
362 | dIFOG[t, :3*d] = (y*(1-y)) * dIFOGf[t, :3*d]
363 |
364 | # backprop matrix multiply
365 | dWLSTM += np.outer(Hin[t], dIFOG[t])
366 | dHin[t] = dIFOG[t].dot(WLSTM.transpose())
367 |
368 | if t > 0: dHout[t-1] += dHin[t,1+Ws.shape[1]:]
369 |
370 | if feed_recurrence == 0:
371 | if t == 0: dDsh[t] = dIFOG[t]
372 | else:
373 | dDsh[0] += dIFOG[t]
374 |
375 | # backprop to the diaact-hidden connections
376 | dWah = Ds.transpose().dot(dDsh)
377 | dbah = np.sum(dDsh, axis=0, keepdims = True)
378 |
379 | return {'Wah':dWah, 'bah':dbah, 'WLSTM':dWLSTM, 'Wd':dWd, 'bd':dbd}
380 |
381 |
382 | """ Batch data representation """
383 | def prepare_input_rep(self, ds, batch, params):
384 | batch_reps = []
385 | for i,x in enumerate(batch):
386 | batch_rep = {}
387 |
388 | vec = np.zeros((1, self.model['Wah'].shape[0]))
389 | vec[0][x['diaact_rep']] = 1
390 | for v in x['slotrep']:
391 | vec[0][v] = 1
392 |
393 | word_arr = x['sentence'].split(' ')
394 | word_vecs = np.zeros((len(word_arr), self.model['Wxh'].shape[0]))
395 | labels = [0] * (len(word_arr)-1)
396 | for w_index, w in enumerate(word_arr[:-1]):
397 | if w in ds.data['word_dict'].keys():
398 | w_dict_index = ds.data['word_dict'][w]
399 | word_vecs[w_index][w_dict_index] = 1
400 |
401 | if word_arr[w_index+1] in ds.data['word_dict'].keys():
402 | labels[w_index] = ds.data['word_dict'][word_arr[w_index+1]]
403 |
404 | batch_rep['diaact'] = vec
405 | batch_rep['words'] = word_vecs
406 | batch_rep['labels'] = labels
407 | batch_reps.append(batch_rep)
408 | return batch_reps
--------------------------------------------------------------------------------
/src/deep_dialog/nlg/nlg.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Oct 17, 2016
3 |
4 | --dia_act_nl_pairs.v6.json: agt and usr have their own NL.
5 |
6 |
7 | @author: xiul
8 | '''
9 |
10 | import cPickle as pickle
11 | import copy, argparse, json
12 | import numpy as np
13 |
14 | from deep_dialog import dialog_config
15 | from deep_dialog.nlg.lstm_decoder_tanh import lstm_decoder_tanh
16 |
17 |
18 | class nlg:
19 | def __init__(self):
20 | pass
21 |
22 | def post_process(self, pred_template, slot_val_dict, slot_dict):
23 | """ post_process to fill the slot in the template sentence """
24 |
25 | sentence = pred_template
26 | suffix = "_PLACEHOLDER"
27 |
28 | for slot in slot_val_dict.keys():
29 | slot_vals = slot_val_dict[slot]
30 | slot_placeholder = slot + suffix
31 | if slot == 'result' or slot == 'numberofpeople': continue
32 | if slot_vals == dialog_config.NO_VALUE_MATCH: continue
33 | tmp_sentence = sentence.replace(slot_placeholder, slot_vals, 1)
34 | sentence = tmp_sentence
35 |
36 | if 'numberofpeople' in slot_val_dict.keys():
37 | slot_vals = slot_val_dict['numberofpeople']
38 | slot_placeholder = 'numberofpeople' + suffix
39 | tmp_sentence = sentence.replace(slot_placeholder, slot_vals, 1)
40 | sentence = tmp_sentence
41 |
42 | for slot in slot_dict.keys():
43 | slot_placeholder = slot + suffix
44 | tmp_sentence = sentence.replace(slot_placeholder, '')
45 | sentence = tmp_sentence
46 |
47 | return sentence
48 |
49 |
50 | def convert_diaact_to_nl(self, dia_act, turn_msg):
51 | """ Convert Dia_Act into NL: Rule + Model """
52 |
53 | sentence = ""
54 | boolean_in = False
55 |
56 | # remove I do not care slot in task(complete)
57 | if dia_act['diaact'] == 'inform' and 'taskcomplete' in dia_act['inform_slots'].keys() and dia_act['inform_slots']['taskcomplete'] != dialog_config.NO_VALUE_MATCH:
58 | inform_slot_set = dia_act['inform_slots'].keys()
59 | for slot in inform_slot_set:
60 | if dia_act['inform_slots'][slot] == dialog_config.I_DO_NOT_CARE: del dia_act['inform_slots'][slot]
61 |
62 | if dia_act['diaact'] in self.diaact_nl_pairs['dia_acts'].keys():
63 | for ele in self.diaact_nl_pairs['dia_acts'][dia_act['diaact']]:
64 | if set(ele['inform_slots']) == set(dia_act['inform_slots'].keys()) and set(ele['request_slots']) == set(dia_act['request_slots'].keys()):
65 | sentence = self.diaact_to_nl_slot_filling(dia_act, ele['nl'][turn_msg])
66 | boolean_in = True
67 | break
68 |
69 | if dia_act['diaact'] == 'inform' and 'taskcomplete' in dia_act['inform_slots'].keys() and dia_act['inform_slots']['taskcomplete'] == dialog_config.NO_VALUE_MATCH:
70 | sentence = "Oh sorry, there is no ticket available."
71 |
72 | if boolean_in == False: sentence = self.translate_diaact(dia_act)
73 | return sentence
74 |
75 |
76 | def translate_diaact(self, dia_act):
77 | """ prepare the diaact into vector representation, and generate the sentence by Model """
78 |
79 | word_dict = self.word_dict
80 | template_word_dict = self.template_word_dict
81 | act_dict = self.act_dict
82 | slot_dict = self.slot_dict
83 | inverse_word_dict = self.inverse_word_dict
84 |
85 | act_rep = np.zeros((1, len(act_dict)))
86 | act_rep[0, act_dict[dia_act['diaact']]] = 1.0
87 |
88 | slot_rep_bit = 2
89 | slot_rep = np.zeros((1, len(slot_dict)*slot_rep_bit))
90 |
91 | suffix = "_PLACEHOLDER"
92 | if self.params['dia_slot_val'] == 2 or self.params['dia_slot_val'] == 3:
93 | word_rep = np.zeros((1, len(template_word_dict)))
94 | words = np.zeros((1, len(template_word_dict)))
95 | words[0, template_word_dict['s_o_s']] = 1.0
96 | else:
97 | word_rep = np.zeros((1, len(word_dict)))
98 | words = np.zeros((1, len(word_dict)))
99 | words[0, word_dict['s_o_s']] = 1.0
100 |
101 | for slot in dia_act['inform_slots'].keys():
102 | slot_index = slot_dict[slot]
103 | slot_rep[0, slot_index*slot_rep_bit] = 1.0
104 |
105 | for slot_val in dia_act['inform_slots'][slot]:
106 | if self.params['dia_slot_val'] == 2:
107 | slot_placeholder = slot + suffix
108 | if slot_placeholder in template_word_dict.keys():
109 | word_rep[0, template_word_dict[slot_placeholder]] = 1.0
110 | elif self.params['dia_slot_val'] == 1:
111 | if slot_val in word_dict.keys():
112 | word_rep[0, word_dict[slot_val]] = 1.0
113 |
114 | for slot in dia_act['request_slots'].keys():
115 | slot_index = slot_dict[slot]
116 | slot_rep[0, slot_index*slot_rep_bit + 1] = 1.0
117 |
118 | if self.params['dia_slot_val'] == 0 or self.params['dia_slot_val'] == 3:
119 | final_representation = np.hstack([act_rep, slot_rep])
120 | else: # dia_slot_val = 1, 2
121 | final_representation = np.hstack([act_rep, slot_rep, word_rep])
122 |
123 | dia_act_rep = {}
124 | dia_act_rep['diaact'] = final_representation
125 | dia_act_rep['words'] = words
126 |
127 | #pred_ys, pred_words = nlg_model['model'].forward(inverse_word_dict, dia_act_rep, nlg_model['params'], predict_model=True)
128 | pred_ys, pred_words = self.model.beam_forward(inverse_word_dict, dia_act_rep, self.params, predict_model=True)
129 | pred_sentence = ' '.join(pred_words[:-1])
130 | sentence = self.post_process(pred_sentence, dia_act['inform_slots'], slot_dict)
131 |
132 | return sentence
133 |
134 |
135 | def load_nlg_model(self, model_path):
136 | """ load the trained NLG model """
137 |
138 | model_params = pickle.load(open(model_path, 'rb'))
139 |
140 | hidden_size = model_params['model']['Wd'].shape[0]
141 | output_size = model_params['model']['Wd'].shape[1]
142 |
143 | if model_params['params']['model'] == 'lstm_tanh': # lstm_tanh
144 | diaact_input_size = model_params['model']['Wah'].shape[0]
145 | input_size = model_params['model']['WLSTM'].shape[0] - hidden_size - 1
146 | rnnmodel = lstm_decoder_tanh(diaact_input_size, input_size, hidden_size, output_size)
147 |
148 | rnnmodel.model = copy.deepcopy(model_params['model'])
149 | model_params['params']['beam_size'] = dialog_config.nlg_beam_size
150 |
151 | self.model = rnnmodel
152 | self.word_dict = copy.deepcopy(model_params['word_dict'])
153 | self.template_word_dict = copy.deepcopy(model_params['template_word_dict'])
154 | self.slot_dict = copy.deepcopy(model_params['slot_dict'])
155 | self.act_dict = copy.deepcopy(model_params['act_dict'])
156 | self.inverse_word_dict = {self.template_word_dict[k]:k for k in self.template_word_dict.keys()}
157 | self.params = copy.deepcopy(model_params['params'])
158 |
159 |
160 | def diaact_to_nl_slot_filling(self, dia_act, template_sentence):
161 | """ Replace the slots with its values """
162 |
163 | sentence = template_sentence
164 | counter = 0
165 | for slot in dia_act['inform_slots'].keys():
166 | slot_val = dia_act['inform_slots'][slot]
167 | if slot_val == dialog_config.NO_VALUE_MATCH:
168 | sentence = slot + " is not available!"
169 | break
170 | elif slot_val == dialog_config.I_DO_NOT_CARE:
171 | counter += 1
172 | sentence = sentence.replace('$'+slot+'$', '', 1)
173 | continue
174 |
175 | sentence = sentence.replace('$'+slot+'$', slot_val, 1)
176 |
177 | if counter > 0 and counter == len(dia_act['inform_slots']):
178 | sentence = dialog_config.I_DO_NOT_CARE
179 |
180 | return sentence
181 |
182 |
183 | def load_predefine_act_nl_pairs(self, path):
184 | """ Load some pre-defined Dia_Act&NL Pairs from file """
185 |
186 | self.diaact_nl_pairs = json.load(open(path, 'rb'))
187 |
188 | for key in self.diaact_nl_pairs['dia_acts'].keys():
189 | for ele in self.diaact_nl_pairs['dia_acts'][key]:
190 | ele['nl']['usr'] = ele['nl']['usr'].encode('utf-8') # encode issue
191 | ele['nl']['agt'] = ele['nl']['agt'].encode('utf-8') # encode issue
192 |
193 |
194 | def main(params):
195 | pass
196 |
197 |
198 | if __name__ == "__main__":
199 | parser = argparse.ArgumentParser()
200 |
201 | args = parser.parse_args()
202 | params = vars(args)
203 |
204 | print ("User Simulator Parameters:")
205 | print (json.dumps(params, indent=2))
206 |
207 | main(params)
208 |
--------------------------------------------------------------------------------
/src/deep_dialog/nlg/utils.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jun 13, 2016
3 |
4 | @author: xiul
5 | '''
6 |
7 | import math
8 | import numpy as np
9 |
10 |
11 | def initWeights(n,d):
12 | """ Initialization Strategy """
13 | #scale_factor = 0.1
14 | scale_factor = math.sqrt(float(6)/(n + d))
15 | return (np.random.rand(n,d)*2-1)*scale_factor
16 |
17 | def mergeDicts(d0, d1):
18 | """ for all k in d0, d0 += d1 . d's are dictionaries of key -> numpy array """
19 | for k in d1:
20 | if k in d0: d0[k] += d1[k]
21 | else: d0[k] = d1[k]
--------------------------------------------------------------------------------
/src/deep_dialog/nlu/__init__.py:
--------------------------------------------------------------------------------
1 | from .nlu import nlu
2 | from .bi_lstm import biLSTM
3 | from .lstm import lstm
--------------------------------------------------------------------------------
/src/deep_dialog/nlu/bi_lstm.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jun 13, 2016
3 |
4 | An Bidirectional LSTM Seq2Seq model
5 |
6 | @author: xiul
7 | '''
8 |
9 | from .seq_seq import SeqToSeq
10 | from .utils import *
11 |
12 |
13 | class biLSTM(SeqToSeq):
14 | def __init__(self, input_size, hidden_size, output_size):
15 | self.model = {}
16 | # Recurrent weights: take x_t, h_{t-1}, and bias unit, and produce the 3 gates and the input to cell signal
17 | self.model['WLSTM'] = initWeights(input_size + hidden_size + 1, 4*hidden_size)
18 | self.model['bWLSTM'] = initWeights(input_size + hidden_size + 1, 4*hidden_size)
19 |
20 | # Hidden-Output Connections
21 | self.model['Wd'] = initWeights(hidden_size, output_size)*0.1
22 | self.model['bd'] = np.zeros((1, output_size))
23 |
24 | # Backward Hidden-Output Connections
25 | self.model['bWd'] = initWeights(hidden_size, output_size)*0.1
26 | self.model['bbd'] = np.zeros((1, output_size))
27 |
28 | self.update = ['WLSTM', 'bWLSTM', 'Wd', 'bd', 'bWd', 'bbd']
29 | self.regularize = ['WLSTM', 'bWLSTM', 'Wd', 'bWd']
30 |
31 | self.step_cache = {}
32 |
33 | """ Activation Function: Sigmoid, or tanh, or ReLu """
34 | def fwdPass(self, Xs, params, **kwargs):
35 | predict_mode = kwargs.get('predict_mode', False)
36 |
37 | Ws = Xs['word_vectors']
38 |
39 | WLSTM = self.model['WLSTM']
40 | bWLSTM = self.model['bWLSTM']
41 |
42 | n, xd = Ws.shape
43 |
44 | d = self.model['Wd'].shape[0] # size of hidden layer
45 | Hin = np.zeros((n, WLSTM.shape[0])) # xt, ht-1, bias
46 | Hout = np.zeros((n, d))
47 | IFOG = np.zeros((n, 4*d))
48 | IFOGf = np.zeros((n, 4*d)) # after nonlinearity
49 | Cellin = np.zeros((n, d))
50 | Cellout = np.zeros((n, d))
51 |
52 | # backward
53 | bHin = np.zeros((n, WLSTM.shape[0])) # xt, ht-1, bias
54 | bHout = np.zeros((n, d))
55 | bIFOG = np.zeros((n, 4*d))
56 | bIFOGf = np.zeros((n, 4*d)) # after nonlinearity
57 | bCellin = np.zeros((n, d))
58 | bCellout = np.zeros((n, d))
59 |
60 | for t in xrange(n):
61 | prev = np.zeros(d) if t==0 else Hout[t-1]
62 | Hin[t,0] = 1 # bias
63 | Hin[t, 1:1+xd] = Ws[t]
64 | Hin[t, 1+xd:] = prev
65 |
66 | # compute all gate activations. dots:
67 | IFOG[t] = Hin[t].dot(WLSTM)
68 |
69 | IFOGf[t, :3*d] = 1/(1+np.exp(-IFOG[t, :3*d])) # sigmoids; these are three gates
70 | IFOGf[t, 3*d:] = np.tanh(IFOG[t, 3*d:]) # tanh for input value
71 |
72 | Cellin[t] = IFOGf[t, :d] * IFOGf[t, 3*d:]
73 | if t>0: Cellin[t] += IFOGf[t, d:2*d]*Cellin[t-1]
74 |
75 | Cellout[t] = np.tanh(Cellin[t])
76 | Hout[t] = IFOGf[t, 2*d:3*d] * Cellout[t]
77 |
78 | # backward hidden layer
79 | b_t = n-1-t
80 | bprev = np.zeros(d) if t == 0 else bHout[b_t+1]
81 | bHin[b_t, 0] = 1
82 | bHin[b_t, 1:1+xd] = Ws[b_t]
83 | bHin[b_t, 1+xd:] = bprev
84 |
85 | bIFOG[b_t] = bHin[b_t].dot(bWLSTM)
86 | bIFOGf[b_t, :3*d] = 1/(1+np.exp(-bIFOG[b_t, :3*d]))
87 | bIFOGf[b_t, 3*d:] = np.tanh(bIFOG[b_t, 3*d:])
88 |
89 | bCellin[b_t] = bIFOGf[b_t, :d] * bIFOGf[b_t, 3*d:]
90 | if t>0: bCellin[b_t] += bIFOGf[b_t, d:2*d] * bCellin[b_t+1]
91 |
92 | bCellout[b_t] = np.tanh(bCellin[b_t])
93 | bHout[b_t] = bIFOGf[b_t, 2*d:3*d]*bCellout[b_t]
94 |
95 | Wd = self.model['Wd']
96 | bd = self.model['bd']
97 | fY = Hout.dot(Wd)+bd
98 |
99 | bWd = self.model['bWd']
100 | bbd = self.model['bbd']
101 | bY = bHout.dot(bWd)+bbd
102 |
103 | Y = fY + bY
104 |
105 | cache = {}
106 | if not predict_mode:
107 | cache['WLSTM'] = WLSTM
108 | cache['Hout'] = Hout
109 | cache['Wd'] = Wd
110 | cache['IFOGf'] = IFOGf
111 | cache['IFOG'] = IFOG
112 | cache['Cellin'] = Cellin
113 | cache['Cellout'] = Cellout
114 | cache['Hin'] = Hin
115 |
116 | cache['bWLSTM'] = bWLSTM
117 | cache['bHout'] = bHout
118 | cache['bWd'] = bWd
119 | cache['bIFOGf'] = bIFOGf
120 | cache['bIFOG'] = bIFOG
121 | cache['bCellin'] = bCellin
122 | cache['bCellout'] = bCellout
123 | cache['bHin'] = bHin
124 |
125 | cache['Ws'] = Ws
126 |
127 | return Y, cache
128 |
129 | """ Backward Pass """
130 | def bwdPass(self, dY, cache):
131 | Wd = cache['Wd']
132 | Hout = cache['Hout']
133 | IFOG = cache['IFOG']
134 | IFOGf = cache['IFOGf']
135 | Cellin = cache['Cellin']
136 | Cellout = cache['Cellout']
137 | Hin = cache['Hin']
138 | WLSTM = cache['WLSTM']
139 |
140 | Ws = cache['Ws']
141 |
142 | bWd = cache['bWd']
143 | bHout = cache['bHout']
144 | bIFOG = cache['bIFOG']
145 | bIFOGf = cache['bIFOGf']
146 | bCellin = cache['bCellin']
147 | bCellout = cache['bCellout']
148 | bHin = cache['bHin']
149 | bWLSTM = cache['bWLSTM']
150 |
151 | n,d = Hout.shape
152 |
153 | # backprop the hidden-output layer
154 | dWd = Hout.transpose().dot(dY)
155 | dbd = np.sum(dY, axis=0, keepdims = True)
156 | dHout = dY.dot(Wd.transpose())
157 |
158 | # backprop the backward hidden-output layer
159 | dbWd = bHout.transpose().dot(dY)
160 | dbbd = np.sum(dY, axis=0, keepdims = True)
161 | dbHout = dY.dot(bWd.transpose())
162 |
163 | # backprop the LSTM (forward layer)
164 | dIFOG = np.zeros(IFOG.shape)
165 | dIFOGf = np.zeros(IFOGf.shape)
166 | dWLSTM = np.zeros(WLSTM.shape)
167 | dHin = np.zeros(Hin.shape)
168 | dCellin = np.zeros(Cellin.shape)
169 | dCellout = np.zeros(Cellout.shape)
170 |
171 | # backward-layer
172 | dbIFOG = np.zeros(bIFOG.shape)
173 | dbIFOGf = np.zeros(bIFOGf.shape)
174 | dbWLSTM = np.zeros(bWLSTM.shape)
175 | dbHin = np.zeros(bHin.shape)
176 | dbCellin = np.zeros(bCellin.shape)
177 | dbCellout = np.zeros(bCellout.shape)
178 |
179 | for t in reversed(xrange(n)):
180 | dIFOGf[t,2*d:3*d] = Cellout[t] * dHout[t]
181 | dCellout[t] = IFOGf[t,2*d:3*d] * dHout[t]
182 |
183 | dCellin[t] += (1-Cellout[t]**2) * dCellout[t]
184 |
185 | if t>0:
186 | dIFOGf[t, d:2*d] = Cellin[t-1] * dCellin[t]
187 | dCellin[t-1] += IFOGf[t,d:2*d] * dCellin[t]
188 |
189 | dIFOGf[t, :d] = IFOGf[t,3*d:] * dCellin[t]
190 | dIFOGf[t,3*d:] = IFOGf[t, :d] * dCellin[t]
191 |
192 | # backprop activation functions
193 | dIFOG[t, 3*d:] = (1-IFOGf[t, 3*d:]**2) * dIFOGf[t, 3*d:]
194 | y = IFOGf[t, :3*d]
195 | dIFOG[t, :3*d] = (y*(1-y)) * dIFOGf[t, :3*d]
196 |
197 | # backprop matrix multiply
198 | dWLSTM += np.outer(Hin[t], dIFOG[t])
199 | dHin[t] = dIFOG[t].dot(WLSTM.transpose())
200 |
201 | if t>0: dHout[t-1] += dHin[t, 1+Ws.shape[1]:]
202 |
203 | # Backward Layer
204 | b_t = n-1-t
205 | dbIFOGf[b_t, 2*d:3*d] = bCellout[b_t] * dbHout[b_t] # output gate
206 | dbCellout[b_t] = bIFOGf[b_t, 2*d:3*d] * dbHout[b_t] # dCellout
207 |
208 | dbCellin[b_t] += (1-bCellout[b_t]**2) * dbCellout[b_t]
209 |
210 | if t>0: # dcell
211 | dbIFOGf[b_t, d:2*d] = bCellin[b_t+1] * dbCellin[b_t] # forgot gate
212 | dbCellin[b_t+1] += bIFOGf[b_t, d:2*d] * dbCellin[b_t]
213 |
214 | dbIFOGf[b_t, :d] = bIFOGf[b_t, 3*d:] * dbCellin[b_t] # input gate
215 | dbIFOGf[b_t, 3*d:] = bIFOGf[b_t, :d] * dbCellin[b_t]
216 |
217 | # backprop activation functions
218 | dbIFOG[b_t, 3*d:] = (1-bIFOGf[b_t, 3*d:]**2) * dbIFOGf[b_t, 3*d:]
219 | by = bIFOGf[b_t, :3*d]
220 | dbIFOG[b_t, :3*d] = (by*(1-by)) * dbIFOGf[b_t, :3*d]
221 |
222 | dbWLSTM += np.outer(bHin[b_t], dbIFOG[b_t])
223 | dbHin[b_t] = dbIFOG[b_t].dot(bWLSTM.transpose())
224 |
225 | if t>0: dbHout[b_t+1] += dbHin[b_t, 1+Ws.shape[1]:]
226 |
227 | return {'WLSTM':dWLSTM, 'Wd':dWd, 'bd':dbd, 'bWLSTM':dbWLSTM, 'bWd':dbWd, 'bbd':dbbd}
--------------------------------------------------------------------------------
/src/deep_dialog/nlu/lstm.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jun 13, 2016
3 |
4 | An LSTM decoder - add tanh after cell before output gate
5 |
6 | @author: xiul
7 | '''
8 |
9 | from seq_seq import SeqToSeq
10 | from .utils import *
11 |
12 |
13 | class lstm(SeqToSeq):
14 | def __init__(self, input_size, hidden_size, output_size):
15 | self.model = {}
16 | # Recurrent weights: take x_t, h_{t-1}, and bias unit, and produce the 3 gates and the input to cell signal
17 | self.model['WLSTM'] = initWeights(input_size + hidden_size + 1, 4*hidden_size)
18 | # Hidden-Output Connections
19 | self.model['Wd'] = initWeights(hidden_size, output_size)*0.1
20 | self.model['bd'] = np.zeros((1, output_size))
21 |
22 | self.update = ['WLSTM', 'Wd', 'bd']
23 | self.regularize = ['WLSTM', 'Wd']
24 |
25 | self.step_cache = {}
26 |
27 | """ Activation Function: Sigmoid, or tanh, or ReLu """
28 | def fwdPass(self, Xs, params, **kwargs):
29 | predict_mode = kwargs.get('predict_mode', False)
30 |
31 | Ws = Xs['word_vectors']
32 |
33 | WLSTM = self.model['WLSTM']
34 | n, xd = Ws.shape
35 |
36 | d = self.model['Wd'].shape[0] # size of hidden layer
37 | Hin = np.zeros((n, WLSTM.shape[0])) # xt, ht-1, bias
38 | Hout = np.zeros((n, d))
39 | IFOG = np.zeros((n, 4*d))
40 | IFOGf = np.zeros((n, 4*d)) # after nonlinearity
41 | Cellin = np.zeros((n, d))
42 | Cellout = np.zeros((n, d))
43 |
44 | for t in xrange(n):
45 | prev = np.zeros(d) if t==0 else Hout[t-1]
46 | Hin[t,0] = 1 # bias
47 | Hin[t, 1:1+xd] = Ws[t]
48 | Hin[t, 1+xd:] = prev
49 |
50 | # compute all gate activations. dots:
51 | IFOG[t] = Hin[t].dot(WLSTM)
52 |
53 | IFOGf[t, :3*d] = 1/(1+np.exp(-IFOG[t, :3*d])) # sigmoids; these are three gates
54 | IFOGf[t, 3*d:] = np.tanh(IFOG[t, 3*d:]) # tanh for input value
55 |
56 | Cellin[t] = IFOGf[t, :d] * IFOGf[t, 3*d:]
57 | if t>0: Cellin[t] += IFOGf[t, d:2*d]*Cellin[t-1]
58 |
59 | Cellout[t] = np.tanh(Cellin[t])
60 |
61 | Hout[t] = IFOGf[t, 2*d:3*d] * Cellout[t]
62 |
63 | Wd = self.model['Wd']
64 | bd = self.model['bd']
65 |
66 | Y = Hout.dot(Wd)+bd
67 |
68 | cache = {}
69 | if not predict_mode:
70 | cache['WLSTM'] = WLSTM
71 | cache['Hout'] = Hout
72 | cache['Wd'] = Wd
73 | cache['IFOGf'] = IFOGf
74 | cache['IFOG'] = IFOG
75 | cache['Cellin'] = Cellin
76 | cache['Cellout'] = Cellout
77 | cache['Ws'] = Ws
78 | cache['Hin'] = Hin
79 |
80 | return Y, cache
81 |
82 | """ Backward Pass """
83 | def bwdPass(self, dY, cache):
84 | Wd = cache['Wd']
85 | Hout = cache['Hout']
86 | IFOG = cache['IFOG']
87 | IFOGf = cache['IFOGf']
88 | Cellin = cache['Cellin']
89 | Cellout = cache['Cellout']
90 | Hin = cache['Hin']
91 | WLSTM = cache['WLSTM']
92 | Ws = cache['Ws']
93 |
94 | n,d = Hout.shape
95 |
96 | # backprop the hidden-output layer
97 | dWd = Hout.transpose().dot(dY)
98 | dbd = np.sum(dY, axis=0, keepdims = True)
99 | dHout = dY.dot(Wd.transpose())
100 |
101 | # backprop the LSTM
102 | dIFOG = np.zeros(IFOG.shape)
103 | dIFOGf = np.zeros(IFOGf.shape)
104 | dWLSTM = np.zeros(WLSTM.shape)
105 | dHin = np.zeros(Hin.shape)
106 | dCellin = np.zeros(Cellin.shape)
107 | dCellout = np.zeros(Cellout.shape)
108 |
109 | for t in reversed(xrange(n)):
110 | dIFOGf[t,2*d:3*d] = Cellout[t] * dHout[t]
111 | dCellout[t] = IFOGf[t,2*d:3*d] * dHout[t]
112 |
113 | dCellin[t] += (1-Cellout[t]**2) * dCellout[t]
114 |
115 | if t>0:
116 | dIFOGf[t, d:2*d] = Cellin[t-1] * dCellin[t]
117 | dCellin[t-1] += IFOGf[t,d:2*d] * dCellin[t]
118 |
119 | dIFOGf[t, :d] = IFOGf[t,3*d:] * dCellin[t]
120 | dIFOGf[t,3*d:] = IFOGf[t, :d] * dCellin[t]
121 |
122 | # backprop activation functions
123 | dIFOG[t, 3*d:] = (1-IFOGf[t, 3*d:]**2) * dIFOGf[t, 3*d:]
124 | y = IFOGf[t, :3*d]
125 | dIFOG[t, :3*d] = (y*(1-y)) * dIFOGf[t, :3*d]
126 |
127 | # backprop matrix multiply
128 | dWLSTM += np.outer(Hin[t], dIFOG[t])
129 | dHin[t] = dIFOG[t].dot(WLSTM.transpose())
130 |
131 | if t > 0: dHout[t-1] += dHin[t, 1+Ws.shape[1]:]
132 |
133 | #dXs = dXsh.dot(Wxh.transpose())
134 | return {'WLSTM':dWLSTM, 'Wd':dWd, 'bd':dbd}
--------------------------------------------------------------------------------
/src/deep_dialog/nlu/nlu.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jul 13, 2016
3 |
4 | @author: xiul
5 | '''
6 |
7 | import cPickle as pickle
8 | import copy
9 | import numpy as np
10 |
11 | from lstm import lstm
12 | from bi_lstm import biLSTM
13 |
14 |
15 | class nlu:
16 | def __init__(self):
17 | pass
18 |
19 | def generate_dia_act(self, annot):
20 | """ generate the Dia-Act with NLU model """
21 |
22 | if len(annot) > 0:
23 | tmp_annot = annot.strip('.').strip('?').strip(',').strip('!')
24 |
25 | rep = self.parse_str_to_vector(tmp_annot)
26 | Ys, cache = self.model.fwdPass(rep, self.params, predict_model=True) # default: True
27 |
28 | maxes = np.amax(Ys, axis=1, keepdims=True)
29 | e = np.exp(Ys - maxes) # for numerical stability shift into good numerical range
30 | probs = e/np.sum(e, axis=1, keepdims=True)
31 | if np.all(np.isnan(probs)): probs = np.zeros(probs.shape)
32 |
33 | # special handling with intent label
34 | for tag_id in self.inverse_tag_dict.keys():
35 | if self.inverse_tag_dict[tag_id].startswith('B-') or self.inverse_tag_dict[tag_id].startswith('I-') or self.inverse_tag_dict[tag_id] == 'O':
36 | probs[-1][tag_id] = 0
37 |
38 | pred_words_indices = np.nanargmax(probs, axis=1)
39 | pred_tags = [self.inverse_tag_dict[index] for index in pred_words_indices]
40 |
41 | diaact = self.parse_nlu_to_diaact(pred_tags, tmp_annot)
42 | return diaact
43 | else:
44 | return None
45 |
46 |
47 | def load_nlu_model(self, model_path):
48 | """ load the trained NLU model """
49 |
50 | model_params = pickle.load(open(model_path, 'rb'))
51 |
52 | hidden_size = model_params['model']['Wd'].shape[0]
53 | output_size = model_params['model']['Wd'].shape[1]
54 |
55 | if model_params['params']['model'] == 'lstm': # lstm_
56 | input_size = model_params['model']['WLSTM'].shape[0] - hidden_size - 1
57 | rnnmodel = lstm(input_size, hidden_size, output_size)
58 | elif model_params['params']['model'] == 'bi_lstm': # bi_lstm
59 | input_size = model_params['model']['WLSTM'].shape[0] - hidden_size - 1
60 | rnnmodel = biLSTM(input_size, hidden_size, output_size)
61 |
62 | rnnmodel.model = copy.deepcopy(model_params['model'])
63 |
64 | self.model = rnnmodel
65 | self.word_dict = copy.deepcopy(model_params['word_dict'])
66 | self.slot_dict = copy.deepcopy(model_params['slot_dict'])
67 | self.act_dict = copy.deepcopy(model_params['act_dict'])
68 | self.tag_set = copy.deepcopy(model_params['tag_set'])
69 | self.params = copy.deepcopy(model_params['params'])
70 | self.inverse_tag_dict = {self.tag_set[k]:k for k in self.tag_set.keys()}
71 |
72 |
73 | def parse_str_to_vector(self, string):
74 | """ Parse string into vector representations """
75 |
76 | tmp = 'BOS ' + string + ' EOS'
77 | words = tmp.lower().split(' ')
78 |
79 | vecs = np.zeros((len(words), len(self.word_dict)))
80 | for w_index, w in enumerate(words):
81 | if w.endswith(',') or w.endswith('?'): w = w[0:-1]
82 | if w in self.word_dict.keys():
83 | vecs[w_index][self.word_dict[w]] = 1
84 | else: vecs[w_index][self.word_dict['unk']] = 1
85 |
86 | rep = {}
87 | rep['word_vectors'] = vecs
88 | rep['raw_seq'] = string
89 | return rep
90 |
91 | def parse_nlu_to_diaact(self, nlu_vector, string):
92 | """ Parse BIO and Intent into Dia-Act """
93 |
94 | tmp = 'BOS ' + string + ' EOS'
95 | words = tmp.lower().split(' ')
96 |
97 | diaact = {}
98 | diaact['diaact'] = "inform"
99 | diaact['request_slots'] = {}
100 | diaact['inform_slots'] = {}
101 |
102 | intent = nlu_vector[-1]
103 | index = 1
104 | pre_tag = nlu_vector[0]
105 | pre_tag_index = 0
106 |
107 | slot_val_dict = {}
108 |
109 | while index<(len(nlu_vector)-1): # except last Intent tag
110 | cur_tag = nlu_vector[index]
111 | if cur_tag == 'O' and pre_tag.startswith('B-'):
112 | slot = pre_tag.split('-')[1]
113 | slot_val_str = ' '.join(words[pre_tag_index:index])
114 | slot_val_dict[slot] = slot_val_str
115 | elif cur_tag.startswith('B-') and pre_tag.startswith('B-'):
116 | slot = pre_tag.split('-')[1]
117 | slot_val_str = ' '.join(words[pre_tag_index:index])
118 | slot_val_dict[slot] = slot_val_str
119 | elif cur_tag.startswith('B-') and pre_tag.startswith('I-'):
120 | if cur_tag.split('-')[1] != pre_tag.split('-')[1]:
121 | slot = pre_tag.split('-')[1]
122 | slot_val_str = ' '.join(words[pre_tag_index:index])
123 | slot_val_dict[slot] = slot_val_str
124 | elif cur_tag == 'O' and pre_tag.startswith('I-'):
125 | slot = pre_tag.split('-')[1]
126 | slot_val_str = ' '.join(words[pre_tag_index:index])
127 | slot_val_dict[slot] = slot_val_str
128 |
129 | if cur_tag.startswith('B-'): pre_tag_index = index
130 |
131 | pre_tag = cur_tag
132 | index += 1
133 |
134 | if cur_tag.startswith('B-') or cur_tag.startswith('I-'):
135 | slot = cur_tag.split('-')[1]
136 | slot_val_str = ' '.join(words[pre_tag_index:-1])
137 | slot_val_dict[slot] = slot_val_str
138 |
139 | if intent != 'null':
140 | arr = intent.split('+')
141 | diaact['diaact'] = arr[0]
142 | diaact['request_slots'] = {}
143 | for ele in arr[1:]:
144 | #request_slots.append(ele)
145 | diaact['request_slots'][ele] = 'UNK'
146 |
147 | diaact['inform_slots'] = slot_val_dict
148 |
149 | # add rule here
150 | for slot in diaact['inform_slots'].keys():
151 | slot_val = diaact['inform_slots'][slot]
152 | if slot_val.startswith('bos'):
153 | slot_val = slot_val.replace('bos', '', 1)
154 | diaact['inform_slots'][slot] = slot_val.strip(' ')
155 |
156 | self.refine_diaact_by_rules(diaact)
157 | return diaact
158 |
159 | def refine_diaact_by_rules(self, diaact):
160 | """ refine the dia_act by rules """
161 |
162 | # rule for taskcomplete
163 | if 'request_slots' in diaact.keys():
164 | if 'taskcomplete' in diaact['request_slots'].keys():
165 | del diaact['request_slots']['taskcomplete']
166 | diaact['inform_slots']['taskcomplete'] = 'PLACEHOLDER'
167 |
168 | # rule for request
169 | if len(diaact['request_slots'])>0: diaact['diaact'] = 'request'
170 |
171 |
172 |
173 |
174 | def diaact_penny_string(self, dia_act):
175 | """ Convert the Dia-Act into penny string """
176 |
177 | penny_str = ""
178 | penny_str = dia_act['diaact'] + "("
179 | for slot in dia_act['request_slots'].keys():
180 | penny_str += slot + ";"
181 |
182 | for slot in dia_act['inform_slots'].keys():
183 | slot_val_str = slot + "="
184 | if len(dia_act['inform_slots'][slot]) == 1:
185 | slot_val_str += dia_act['inform_slots'][slot][0]
186 | else:
187 | slot_val_str += "{"
188 | for slot_val in dia_act['inform_slots'][slot]:
189 | slot_val_str += slot_val + "#"
190 | slot_val_str = slot_val_str[:-1]
191 | slot_val_str += "}"
192 | penny_str += slot_val_str + ";"
193 |
194 | if penny_str[-1] == ";": penny_str = penny_str[:-1]
195 | penny_str += ")"
196 | return penny_str
--------------------------------------------------------------------------------
/src/deep_dialog/nlu/seq_seq.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jun 13, 2016
3 |
4 | @author: xiul
5 | '''
6 |
7 | from .utils import *
8 | import time, os
9 |
10 |
11 | class SeqToSeq:
12 | def __init__(self, input_size, hidden_size, output_size):
13 | pass
14 |
15 | def get_struct(self):
16 | return {'model': self.model, 'update': self.update, 'regularize': self.regularize}
17 |
18 |
19 | """ Forward Function"""
20 | def fwdPass(self, Xs, params, **kwargs):
21 | pass
22 |
23 | def bwdPass(self, dY, cache):
24 | pass
25 |
26 |
27 | """ Batch Forward & Backward Pass"""
28 | def batchForward(self, ds, batch, params, predict_mode = False):
29 | caches = []
30 | Ys = []
31 | for i,x in enumerate(batch):
32 | Y, out_cache = self.fwdPass(x, params, predict_mode = predict_mode)
33 | caches.append(out_cache)
34 | Ys.append(Y)
35 |
36 | # back up information for efficient backprop
37 | cache = {}
38 | if not predict_mode:
39 | cache['caches'] = caches
40 |
41 | return Ys, cache
42 |
43 | def batchBackward(self, dY, cache):
44 | caches = cache['caches']
45 | grads = {}
46 | for i in xrange(len(caches)):
47 | single_cache = caches[i]
48 | local_grads = self.bwdPass(dY[i], single_cache)
49 | mergeDicts(grads, local_grads) # add up the gradients wrt model parameters
50 |
51 | return grads
52 |
53 |
54 | """ Cost function, returns cost and gradients for model """
55 | def costFunc(self, ds, batch, params):
56 | regc = params['reg_cost'] # regularization cost
57 |
58 | # batch forward RNN
59 | Ys, caches = self.batchForward(ds, batch, params, predict_mode = False)
60 |
61 | loss_cost = 0.0
62 | smooth_cost = 1e-15
63 | dYs = []
64 |
65 | for i,x in enumerate(batch):
66 | labels = np.array(x['tags_rep'], dtype=int)
67 |
68 | # fetch the predicted probabilities
69 | Y = Ys[i]
70 | maxes = np.amax(Y, axis=1, keepdims=True)
71 | e = np.exp(Y - maxes) # for numerical stability shift into good numerical range
72 | P = e/np.sum(e, axis=1, keepdims=True)
73 |
74 | # Cross-Entropy Cross Function
75 | loss_cost += -np.sum(np.log(smooth_cost + P[range(len(labels)), labels]))
76 |
77 | for iy,y in enumerate(labels):
78 | P[iy,y] -= 1 # softmax derivatives
79 | dYs.append(P)
80 |
81 | # backprop the RNN
82 | grads = self.batchBackward(dYs, caches)
83 |
84 | # add L2 regularization cost and gradients
85 | reg_cost = 0.0
86 | if regc > 0:
87 | for p in self.regularize:
88 | mat = self.model[p]
89 | reg_cost += 0.5*regc*np.sum(mat*mat)
90 | grads[p] += regc*mat
91 |
92 | # normalize the cost and gradient by the batch size
93 | batch_size = len(batch)
94 | reg_cost /= batch_size
95 | loss_cost /= batch_size
96 | for k in grads: grads[k] /= batch_size
97 |
98 | out = {}
99 | out['cost'] = {'reg_cost' : reg_cost, 'loss_cost' : loss_cost, 'total_cost' : loss_cost + reg_cost}
100 | out['grads'] = grads
101 | return out
102 |
103 |
104 | """ A single batch """
105 | def singleBatch(self, ds, batch, params):
106 | learning_rate = params.get('learning_rate', 0.0)
107 | decay_rate = params.get('decay_rate', 0.999)
108 | momentum = params.get('momentum', 0)
109 | grad_clip = params.get('grad_clip', 1)
110 | smooth_eps = params.get('smooth_eps', 1e-8)
111 | sdg_type = params.get('sdgtype', 'rmsprop')
112 |
113 | for u in self.update:
114 | if not u in self.step_cache:
115 | self.step_cache[u] = np.zeros(self.model[u].shape)
116 |
117 | cg = self.costFunc(ds, batch, params)
118 |
119 | cost = cg['cost']
120 | grads = cg['grads']
121 |
122 | # clip gradients if needed
123 | if params['activation_func'] == 'relu':
124 | if grad_clip > 0:
125 | for p in self.update:
126 | if p in grads:
127 | grads[p] = np.minimum(grads[p], grad_clip)
128 | grads[p] = np.maximum(grads[p], -grad_clip)
129 |
130 | # perform parameter update
131 | for p in self.update:
132 | if p in grads:
133 | if sdg_type == 'vanilla':
134 | if momentum > 0: dx = momentum*self.step_cache[p] - learning_rate*grads[p]
135 | else: dx = -learning_rate*grads[p]
136 | self.step_cache[p] = dx
137 | elif sdg_type == 'rmsprop':
138 | self.step_cache[p] = self.step_cache[p]*decay_rate + (1.0-decay_rate)*grads[p]**2
139 | dx = -(learning_rate*grads[p])/np.sqrt(self.step_cache[p] + smooth_eps)
140 | elif sdg_type == 'adgrad':
141 | self.step_cache[p] += grads[p]**2
142 | dx = -(learning_rate*grads[p])/np.sqrt(self.step_cache[p] + smooth_eps)
143 |
144 | self.model[p] += dx
145 |
146 | # create output dict and return
147 | out = {}
148 | out['cost'] = cost
149 | return out
150 |
151 |
152 | """ Evaluate on the dataset[split] """
153 | def eval(self, ds, split, params):
154 | acc = 0
155 | total = 0
156 |
157 | total_cost = 0.0
158 | smooth_cost = 1e-15
159 |
160 | if split == 'test':
161 | res_filename = 'res_%s_[%s].txt' % (params['model'], time.time())
162 | res_filepath = os.path.join(params['test_res_dir'], res_filename)
163 | res = open(res_filepath, 'w')
164 | inverse_tag_dict = {ds.data['tag_set'][k]:k for k in ds.data['tag_set'].keys()}
165 |
166 | for i, ele in enumerate(ds.split[split]):
167 | Ys, cache = self.fwdPass(ele, params, predict_model=True)
168 |
169 | maxes = np.amax(Ys, axis=1, keepdims=True)
170 | e = np.exp(Ys - maxes) # for numerical stability shift into good numerical range
171 | probs = e/np.sum(e, axis=1, keepdims=True)
172 |
173 | labels = np.array(ele['tags_rep'], dtype=int)
174 |
175 | if np.all(np.isnan(probs)): probs = np.zeros(probs.shape)
176 |
177 | loss_cost = 0
178 | loss_cost += -np.sum(np.log(smooth_cost + probs[range(len(labels)), labels]))
179 | total_cost += loss_cost
180 |
181 | pred_words_indices = np.nanargmax(probs, axis=1)
182 |
183 | tokens = ele['raw_seq']
184 | real_tags = ele['tag_seq']
185 | for index, l in enumerate(labels):
186 | if pred_words_indices[index] == l: acc += 1
187 |
188 | if split == 'test':
189 | res.write('%s %s %s %s\n' % (tokens[index], 'NA', real_tags[index], inverse_tag_dict[pred_words_indices[index]]))
190 | if split == 'test': res.write('\n')
191 | total += len(labels)
192 |
193 | total_cost /= len(ds.split[split])
194 | accuracy = 0 if total == 0 else float(acc)/total
195 |
196 | #print ("total_cost: %s, accuracy: %s" % (total_cost, accuracy))
197 | result = {'cost': total_cost, 'accuracy': accuracy}
198 | return result
--------------------------------------------------------------------------------
/src/deep_dialog/nlu/utils.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jun 13, 2016
3 |
4 | @author: xiul
5 | '''
6 |
7 | import math
8 | import numpy as np
9 |
10 |
11 | def initWeights(n,d):
12 | """ Initialization Strategy """
13 | #scale_factor = 0.1
14 | scale_factor = math.sqrt(float(6)/(n + d))
15 | return (np.random.rand(n,d)*2-1)*scale_factor
16 |
17 | def mergeDicts(d0, d1):
18 | """ for all k in d0, d0 += d1 . d's are dictionaries of key -> numpy array """
19 | for k in d1:
20 | if k in d0: d0[k] += d1[k]
21 | else: d0[k] = d1[k]
--------------------------------------------------------------------------------
/src/deep_dialog/qlearning/__init__.py:
--------------------------------------------------------------------------------
1 | from .utils import *
2 | from .dqn import *
--------------------------------------------------------------------------------
/src/deep_dialog/qlearning/dqn.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jun 18, 2016
3 |
4 | @author: xiul
5 | '''
6 |
7 | from .utils import *
8 |
9 |
10 | class DQN:
11 |
12 | def __init__(self, input_size, hidden_size, output_size):
13 | self.model = {}
14 | # input-hidden
15 | self.model['Wxh'] = initWeight(input_size, hidden_size)
16 | self.model['bxh'] = np.zeros((1, hidden_size))
17 |
18 | # hidden-output
19 | self.model['Wd'] = initWeight(hidden_size, output_size)*0.1
20 | self.model['bd'] = np.zeros((1, output_size))
21 |
22 | self.update = ['Wxh', 'bxh', 'Wd', 'bd']
23 | self.regularize = ['Wxh', 'Wd']
24 |
25 | self.step_cache = {}
26 |
27 |
28 | def getStruct(self):
29 | return {'model': self.model, 'update': self.update, 'regularize': self.regularize}
30 |
31 |
32 | """Activation Function: Sigmoid, or tanh, or ReLu"""
33 | def fwdPass(self, Xs, params, **kwargs):
34 | predict_mode = kwargs.get('predict_mode', False)
35 | active_func = params.get('activation_func', 'relu')
36 |
37 | # input layer to hidden layer
38 | Wxh = self.model['Wxh']
39 | bxh = self.model['bxh']
40 | Xsh = Xs.dot(Wxh) + bxh
41 |
42 | hidden_size = self.model['Wd'].shape[0] # size of hidden layer
43 | H = np.zeros((1, hidden_size)) # hidden layer representation
44 |
45 | if active_func == 'sigmoid':
46 | H = 1/(1+np.exp(-Xsh))
47 | elif active_func == 'tanh':
48 | H = np.tanh(Xsh)
49 | elif active_func == 'relu': # ReLU
50 | H = np.maximum(Xsh, 0)
51 | else: # no activation function
52 | H = Xsh
53 |
54 | # decoder at the end; hidden layer to output layer
55 | Wd = self.model['Wd']
56 | bd = self.model['bd']
57 | Y = H.dot(Wd) + bd
58 |
59 | # cache the values in forward pass, we expect to do a backward pass
60 | cache = {}
61 | if not predict_mode:
62 | cache['Wxh'] = Wxh
63 | cache['Wd'] = Wd
64 | cache['Xs'] = Xs
65 | cache['Xsh'] = Xsh
66 | cache['H'] = H
67 |
68 | cache['bxh'] = bxh
69 | cache['bd'] = bd
70 | cache['activation_func'] = active_func
71 |
72 | cache['Y'] = Y
73 |
74 | return Y, cache
75 |
76 | def bwdPass(self, dY, cache):
77 | Wd = cache['Wd']
78 | H = cache['H']
79 | Xs = cache['Xs']
80 | Xsh = cache['Xsh']
81 | Wxh = cache['Wxh']
82 |
83 | active_func = cache['activation_func']
84 | n,d = H.shape
85 |
86 | dH = dY.dot(Wd.transpose())
87 | # backprop the decoder
88 | dWd = H.transpose().dot(dY)
89 | dbd = np.sum(dY, axis=0, keepdims=True)
90 |
91 | dXsh = np.zeros(Xsh.shape)
92 | dXs = np.zeros(Xs.shape)
93 |
94 | if active_func == 'sigmoid':
95 | dH = (H-H**2)*dH
96 | elif active_func == 'tanh':
97 | dH = (1-H**2)*dH
98 | elif active_func == 'relu':
99 | dH = (H>0)*dH # backprop ReLU
100 | else:
101 | dH = dH
102 |
103 | # backprop to the input-hidden connection
104 | dWxh = Xs.transpose().dot(dH)
105 | dbxh = np.sum(dH, axis=0, keepdims = True)
106 |
107 | # backprop to the input
108 | dXsh = dH
109 | dXs = dXsh.dot(Wxh.transpose())
110 |
111 | return {'Wd': dWd, 'bd': dbd, 'Wxh':dWxh, 'bxh':dbxh}
112 |
113 |
114 | """batch Forward & Backward Pass"""
115 | def batchForward(self, batch, params, predict_mode = False):
116 | caches = []
117 | Ys = []
118 | for i,x in enumerate(batch):
119 | Xs = np.array([x['cur_states']], dtype=float)
120 |
121 | Y, out_cache = self.fwdPass(Xs, params, predict_mode = predict_mode)
122 | caches.append(out_cache)
123 | Ys.append(Y)
124 |
125 | # back up information for efficient backprop
126 | cache = {}
127 | if not predict_mode:
128 | cache['caches'] = caches
129 |
130 | return Ys, cache
131 |
132 | def batchDoubleForward(self, batch, params, clone_dqn, predict_mode = False):
133 | caches = []
134 | Ys = []
135 | tYs = []
136 |
137 | for i,x in enumerate(batch):
138 | Xs = x[0]
139 | Y, out_cache = self.fwdPass(Xs, params, predict_mode = predict_mode)
140 | caches.append(out_cache)
141 | Ys.append(Y)
142 |
143 | tXs = x[3]
144 | tY, t_cache = clone_dqn.fwdPass(tXs, params, predict_mode = False)
145 |
146 | tYs.append(tY)
147 |
148 | # back up information for efficient backprop
149 | cache = {}
150 | if not predict_mode:
151 | cache['caches'] = caches
152 |
153 | return Ys, cache, tYs
154 |
155 | def batchBackward(self, dY, cache):
156 | caches = cache['caches']
157 |
158 | grads = {}
159 | for i in xrange(len(caches)):
160 | single_cache = caches[i]
161 | local_grads = self.bwdPass(dY[i], single_cache)
162 | mergeDicts(grads, local_grads) # add up the gradients wrt model parameters
163 |
164 | return grads
165 |
166 |
167 | """ cost function, returns cost and gradients for model """
168 | def costFunc(self, batch, params, clone_dqn):
169 | regc = params.get('reg_cost', 1e-3)
170 | gamma = params.get('gamma', 0.9)
171 |
172 | # batch forward
173 | Ys, caches, tYs = self.batchDoubleForward(batch, params, clone_dqn, predict_mode = False)
174 |
175 | loss_cost = 0.0
176 | dYs = []
177 | for i,x in enumerate(batch):
178 | Y = Ys[i]
179 | nY = tYs[i]
180 |
181 | action = np.array(x[1], dtype=int)
182 | reward = np.array(x[2], dtype=float)
183 |
184 | n_action = np.nanargmax(nY[0])
185 | max_next_y = nY[0][n_action]
186 |
187 | eposide_terminate = x[4]
188 |
189 | target_y = reward
190 | if eposide_terminate != True: target_y += gamma*max_next_y
191 |
192 | pred_y = Y[0][action]
193 |
194 | nY = np.zeros(nY.shape)
195 | nY[0][action] = target_y
196 | Y = np.zeros(Y.shape)
197 | Y[0][action] = pred_y
198 |
199 | # Cost Function
200 | loss_cost += (target_y - pred_y)**2
201 |
202 | dY = -(nY - Y)
203 | #dY = np.minimum(dY, 1)
204 | #dY = np.maximum(dY, -1)
205 | dYs.append(dY)
206 |
207 | # backprop the RNN
208 | grads = self.batchBackward(dYs, caches)
209 |
210 | # add L2 regularization cost and gradients
211 | reg_cost = 0.0
212 | if regc > 0:
213 | for p in self.regularize:
214 | mat = self.model[p]
215 | reg_cost += 0.5*regc*np.sum(mat*mat)
216 | grads[p] += regc*mat
217 |
218 | # normalize the cost and gradient by the batch size
219 | batch_size = len(batch)
220 | reg_cost /= batch_size
221 | loss_cost /= batch_size
222 | for k in grads: grads[k] /= batch_size
223 |
224 | out = {}
225 | out['cost'] = {'reg_cost' : reg_cost, 'loss_cost' : loss_cost, 'total_cost' : loss_cost + reg_cost}
226 | out['grads'] = grads
227 | return out
228 |
229 |
230 | """ A single batch """
231 | def singleBatch(self, batch, params, clone_dqn):
232 | learning_rate = params.get('learning_rate', 0.001)
233 | decay_rate = params.get('decay_rate', 0.999)
234 | momentum = params.get('momentum', 0.1)
235 | grad_clip = params.get('grad_clip', -1e-3)
236 | smooth_eps = params.get('smooth_eps', 1e-8)
237 | sdg_type = params.get('sdgtype', 'rmsprop')
238 | activation_func = params.get('activation_func', 'relu')
239 |
240 | for u in self.update:
241 | if not u in self.step_cache:
242 | self.step_cache[u] = np.zeros(self.model[u].shape)
243 |
244 | cg = self.costFunc(batch, params, clone_dqn)
245 |
246 | cost = cg['cost']
247 | grads = cg['grads']
248 |
249 | # clip gradients if needed
250 | if activation_func.lower() == 'relu':
251 | if grad_clip > 0:
252 | for p in self.update:
253 | if p in grads:
254 | grads[p] = np.minimum(grads[p], grad_clip)
255 | grads[p] = np.maximum(grads[p], -grad_clip)
256 |
257 | # perform parameter update
258 | for p in self.update:
259 | if p in grads:
260 | if sdg_type == 'vanilla':
261 | if momentum > 0:
262 | dx = momentum*self.step_cache[p] - learning_rate*grads[p]
263 | else:
264 | dx = -learning_rate*grads[p]
265 | self.step_cache[p] = dx
266 | elif sdg_type == 'rmsprop':
267 | self.step_cache[p] = self.step_cache[p]*decay_rate + (1.0-decay_rate)*grads[p]**2
268 | dx = -(learning_rate*grads[p])/np.sqrt(self.step_cache[p] + smooth_eps)
269 | elif sdg_type == 'adgrad':
270 | self.step_cache[p] += grads[p]**2
271 | dx = -(learning_rate*grads[p])/np.sqrt(self.step_cache[p] + smooth_eps)
272 |
273 | self.model[p] += dx
274 |
275 | out = {}
276 | out['cost'] = cost
277 | return out
278 |
279 | """ prediction """
280 | def predict(self, Xs, params, **kwargs):
281 | Ys, caches = self.fwdPass(Xs, params, predict_model=True)
282 | pred_action = np.argmax(Ys)
283 |
284 | return pred_action
285 |
--------------------------------------------------------------------------------
/src/deep_dialog/qlearning/utils.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Jun 18, 2016
3 |
4 | @author: xiul
5 | '''
6 |
7 | import numpy as np
8 | import math
9 |
10 |
11 | def initWeight(n,d):
12 | scale_factor = math.sqrt(float(6)/(n + d))
13 | #scale_factor = 0.1
14 | return (np.random.rand(n,d)*2-1)*scale_factor
15 |
16 | """ for all k in d0, d0 += d1 . d's are dictionaries of key -> numpy array """
17 | def mergeDicts(d0, d1):
18 | for k in d1:
19 | if k in d0:
20 | d0[k] += d1[k]
21 | else:
22 | d0[k] = d1[k]
--------------------------------------------------------------------------------
/src/deep_dialog/usersims/__init__.py:
--------------------------------------------------------------------------------
1 | from .usersim_rule import *
--------------------------------------------------------------------------------
/src/deep_dialog/usersims/usersim.py:
--------------------------------------------------------------------------------
1 |
2 | """
3 | Created on June 7, 2016
4 |
5 | a rule-based user simulator
6 |
7 | @author: xiul, t-zalipt
8 | """
9 |
10 | import random
11 |
12 |
13 | class UserSimulator:
14 | """ Parent class for all user sims to inherit from """
15 |
16 | def __init__(self, movie_dict=None, act_set=None, slot_set=None, start_set=None, params=None):
17 | """ Constructor shared by all user simulators """
18 |
19 | self.movie_dict = movie_dict
20 | self.act_set = act_set
21 | self.slot_set = slot_set
22 | self.start_set = start_set
23 |
24 | self.max_turn = params['max_turn']
25 | self.slot_err_probability = params['slot_err_probability']
26 | self.slot_err_mode = params['slot_err_mode']
27 | self.intent_err_probability = params['intent_err_probability']
28 |
29 |
30 | def initialize_episode(self):
31 | """ Initialize a new episode (dialog)"""
32 |
33 | print "initialize episode called, generating goal"
34 | self.goal = random.choice(self.start_set)
35 | self.goal['request_slots']['ticket'] = 'UNK'
36 | episode_over, user_action = self._sample_action()
37 | assert (episode_over != 1),' but we just started'
38 | return user_action
39 |
40 |
41 | def next(self, system_action):
42 | pass
43 |
44 |
45 |
46 | def set_nlg_model(self, nlg_model):
47 | self.nlg_model = nlg_model
48 |
49 | def set_nlu_model(self, nlu_model):
50 | self.nlu_model = nlu_model
51 |
52 |
53 |
54 | def add_nl_to_action(self, user_action):
55 | """ Add NL to User Dia_Act """
56 |
57 | user_nlg_sentence = self.nlg_model.convert_diaact_to_nl(user_action, 'usr')
58 | user_action['nl'] = user_nlg_sentence
59 |
60 | if self.simulator_act_level == 1:
61 | user_nlu_res = self.nlu_model.generate_dia_act(user_action['nl']) # NLU
62 | if user_nlu_res != None:
63 | #user_nlu_res['diaact'] = user_action['diaact'] # or not?
64 | user_action.update(user_nlu_res)
--------------------------------------------------------------------------------
/src/deep_dialog/usersims/usersim_rule.py:
--------------------------------------------------------------------------------
1 | """
2 | Created on May 14, 2016
3 |
4 | a rule-based user simulator
5 |
6 | -- user_goals_first_turn_template.revised.v1.p: all goals
7 | -- user_goals_first_turn_template.part.movie.v1.p: moviename in goal.inform_slots
8 | -- user_goals_first_turn_template.part.nomovie.v1.p: no moviename in goal.inform_slots
9 |
10 | @author: xiul, t-zalipt
11 | """
12 |
13 | from .usersim import UserSimulator
14 | import argparse, json, random, copy
15 |
16 | from deep_dialog import dialog_config
17 |
18 |
19 |
20 | class RuleSimulator(UserSimulator):
21 | """ A rule-based user simulator for testing dialog policy """
22 |
23 | def __init__(self, movie_dict=None, act_set=None, slot_set=None, start_set=None, params=None):
24 | """ Constructor shared by all user simulators """
25 |
26 | self.movie_dict = movie_dict
27 | self.act_set = act_set
28 | self.slot_set = slot_set
29 | self.start_set = start_set
30 |
31 | self.max_turn = params['max_turn']
32 | self.slot_err_probability = params['slot_err_probability']
33 | self.slot_err_mode = params['slot_err_mode']
34 | self.intent_err_probability = params['intent_err_probability']
35 |
36 | self.simulator_run_mode = params['simulator_run_mode']
37 | self.simulator_act_level = params['simulator_act_level']
38 |
39 | self.learning_phase = params['learning_phase']
40 |
41 | def initialize_episode(self):
42 | """ Initialize a new episode (dialog)
43 | state['history_slots']: keeps all the informed_slots
44 | state['rest_slots']: keep all the slots (which is still in the stack yet)
45 | """
46 |
47 | self.state = {}
48 | self.state['history_slots'] = {}
49 | self.state['inform_slots'] = {}
50 | self.state['request_slots'] = {}
51 | self.state['rest_slots'] = []
52 | self.state['turn'] = 0
53 |
54 | self.episode_over = False
55 | self.dialog_status = dialog_config.NO_OUTCOME_YET
56 |
57 | #self.goal = random.choice(self.start_set)
58 | self.goal = self._sample_goal(self.start_set)
59 | self.goal['request_slots']['ticket'] = 'UNK'
60 | self.constraint_check = dialog_config.CONSTRAINT_CHECK_FAILURE
61 |
62 | """ Debug: build a fake goal mannually """
63 | #self.debug_falk_goal()
64 |
65 | # sample first action
66 | user_action = self._sample_action()
67 | assert (self.episode_over != 1),' but we just started'
68 | return user_action
69 |
70 | def _sample_action(self):
71 | """ randomly sample a start action based on user goal """
72 |
73 | self.state['diaact'] = random.choice(dialog_config.start_dia_acts.keys())
74 |
75 | # "sample" informed slots
76 | if len(self.goal['inform_slots']) > 0:
77 | known_slot = random.choice(self.goal['inform_slots'].keys())
78 | self.state['inform_slots'][known_slot] = self.goal['inform_slots'][known_slot]
79 |
80 | if 'moviename' in self.goal['inform_slots'].keys(): # 'moviename' must appear in the first user turn
81 | self.state['inform_slots']['moviename'] = self.goal['inform_slots']['moviename']
82 |
83 | for slot in self.goal['inform_slots'].keys():
84 | if known_slot == slot or slot == 'moviename': continue
85 | self.state['rest_slots'].append(slot)
86 |
87 | self.state['rest_slots'].extend(self.goal['request_slots'].keys())
88 |
89 | # "sample" a requested slot
90 | request_slot_set = list(self.goal['request_slots'].keys())
91 | request_slot_set.remove('ticket')
92 | if len(request_slot_set) > 0:
93 | request_slot = random.choice(request_slot_set)
94 | else:
95 | request_slot = 'ticket'
96 | self.state['request_slots'][request_slot] = 'UNK'
97 |
98 | if len(self.state['request_slots']) == 0:
99 | self.state['diaact'] = 'inform'
100 |
101 | if (self.state['diaact'] in ['thanks','closing']): self.episode_over = True #episode_over = True
102 | else: self.episode_over = False #episode_over = False
103 |
104 | sample_action = {}
105 | sample_action['diaact'] = self.state['diaact']
106 | sample_action['inform_slots'] = self.state['inform_slots']
107 | sample_action['request_slots'] = self.state['request_slots']
108 | sample_action['turn'] = self.state['turn']
109 |
110 | self.add_nl_to_action(sample_action)
111 | return sample_action
112 |
113 | def _sample_goal(self, goal_set):
114 | """ sample a user goal """
115 |
116 | sample_goal = random.choice(self.start_set[self.learning_phase])
117 | return sample_goal
118 |
119 |
120 | def corrupt(self, user_action):
121 | """ Randomly corrupt an action with error probs (slot_err_probability and slot_err_mode) on Slot and Intent (intent_err_probability). """
122 |
123 | for slot in user_action['inform_slots'].keys():
124 | slot_err_prob_sample = random.random()
125 | if slot_err_prob_sample < self.slot_err_probability: # add noise for slot level
126 | if self.slot_err_mode == 0: # replace the slot_value only
127 | if slot in self.movie_dict.keys(): user_action['inform_slots'][slot] = random.choice(self.movie_dict[slot])
128 | elif self.slot_err_mode == 1: # combined
129 | slot_err_random = random.random()
130 | if slot_err_random <= 0.33:
131 | if slot in self.movie_dict.keys(): user_action['inform_slots'][slot] = random.choice(self.movie_dict[slot])
132 | elif slot_err_random > 0.33 and slot_err_random <= 0.66:
133 | del user_action['inform_slots'][slot]
134 | random_slot = random.choice(self.movie_dict.keys())
135 | user_action[random_slot] = random.choice(self.movie_dict[random_slot])
136 | else:
137 | del user_action['inform_slots'][slot]
138 | elif self.slot_err_mode == 2: #replace slot and its values
139 | del user_action['inform_slots'][slot]
140 | random_slot = random.choice(self.movie_dict.keys())
141 | user_action[random_slot] = random.choice(self.movie_dict[random_slot])
142 | elif self.slot_err_mode == 3: # delete the slot
143 | del user_action['inform_slots'][slot]
144 |
145 | intent_err_sample = random.random()
146 | if intent_err_sample < self.intent_err_probability: # add noise for intent level
147 | user_action['diaact'] = random.choice(self.act_set.keys())
148 |
149 | def debug_falk_goal(self):
150 | """ Debug function: build a fake goal mannually (Can be moved in future) """
151 |
152 | self.goal['inform_slots'].clear()
153 | #self.goal['inform_slots']['city'] = 'seattle'
154 | self.goal['inform_slots']['numberofpeople'] = '2'
155 | #self.goal['inform_slots']['theater'] = 'amc pacific place 11 theater'
156 | #self.goal['inform_slots']['starttime'] = '10:00 pm'
157 | #self.goal['inform_slots']['date'] = 'tomorrow'
158 | self.goal['inform_slots']['moviename'] = 'zoology'
159 | self.goal['inform_slots']['distanceconstraints'] = 'close to 95833'
160 | self.goal['request_slots'].clear()
161 | self.goal['request_slots']['ticket'] = 'UNK'
162 | self.goal['request_slots']['theater'] = 'UNK'
163 | self.goal['request_slots']['starttime'] = 'UNK'
164 | self.goal['request_slots']['date'] = 'UNK'
165 |
166 | def next(self, system_action):
167 | """ Generate next User Action based on last System Action """
168 |
169 | self.state['turn'] += 2
170 | self.episode_over = False
171 | self.dialog_status = dialog_config.NO_OUTCOME_YET
172 |
173 | sys_act = system_action['diaact']
174 |
175 | if (self.max_turn > 0 and self.state['turn'] > self.max_turn):
176 | self.dialog_status = dialog_config.FAILED_DIALOG
177 | self.episode_over = True
178 | self.state['diaact'] = "closing"
179 | else:
180 | self.state['history_slots'].update(self.state['inform_slots'])
181 | self.state['inform_slots'].clear()
182 |
183 | if sys_act == "inform":
184 | self.response_inform(system_action)
185 | elif sys_act == "multiple_choice":
186 | self.response_multiple_choice(system_action)
187 | elif sys_act == "request":
188 | self.response_request(system_action)
189 | elif sys_act == "thanks":
190 | self.response_thanks(system_action)
191 | elif sys_act == "confirm_answer":
192 | self.response_confirm_answer(system_action)
193 | elif sys_act == "closing":
194 | self.episode_over = True
195 | self.state['diaact'] = "thanks"
196 |
197 | self.corrupt(self.state)
198 |
199 | response_action = {}
200 | response_action['diaact'] = self.state['diaact']
201 | response_action['inform_slots'] = self.state['inform_slots']
202 | response_action['request_slots'] = self.state['request_slots']
203 | response_action['turn'] = self.state['turn']
204 | response_action['nl'] = ""
205 |
206 | # add NL to dia_act
207 | self.add_nl_to_action(response_action)
208 | return response_action, self.episode_over, self.dialog_status
209 |
210 |
211 | def response_confirm_answer(self, system_action):
212 | """ Response for Confirm_Answer (System Action) """
213 |
214 | if len(self.state['rest_slots']) > 0:
215 | request_slot = random.choice(self.state['rest_slots'])
216 |
217 | if request_slot in self.goal['request_slots'].keys():
218 | self.state['diaact'] = "request"
219 | self.state['request_slots'][request_slot] = "UNK"
220 | elif request_slot in self.goal['inform_slots'].keys():
221 | self.state['diaact'] = "inform"
222 | self.state['inform_slots'][request_slot] = self.goal['inform_slots'][request_slot]
223 | if request_slot in self.state['rest_slots']:
224 | self.state['rest_slots'].remove(request_slot)
225 | else:
226 | self.state['diaact'] = "thanks"
227 |
228 | def response_thanks(self, system_action):
229 | """ Response for Thanks (System Action) """
230 |
231 | self.episode_over = True
232 | self.dialog_status = dialog_config.SUCCESS_DIALOG
233 |
234 | request_slot_set = copy.deepcopy(self.state['request_slots'].keys())
235 | if 'ticket' in request_slot_set:
236 | request_slot_set.remove('ticket')
237 | rest_slot_set = copy.deepcopy(self.state['rest_slots'])
238 | if 'ticket' in rest_slot_set:
239 | rest_slot_set.remove('ticket')
240 |
241 | if len(request_slot_set) > 0 or len(rest_slot_set) > 0:
242 | self.dialog_status = dialog_config.FAILED_DIALOG
243 |
244 | for info_slot in self.state['history_slots'].keys():
245 | if self.state['history_slots'][info_slot] == dialog_config.NO_VALUE_MATCH:
246 | self.dialog_status = dialog_config.FAILED_DIALOG
247 | if info_slot in self.goal['inform_slots'].keys():
248 | if self.state['history_slots'][info_slot] != self.goal['inform_slots'][info_slot]:
249 | self.dialog_status = dialog_config.FAILED_DIALOG
250 |
251 | if 'ticket' in system_action['inform_slots'].keys():
252 | if system_action['inform_slots']['ticket'] == dialog_config.NO_VALUE_MATCH:
253 | self.dialog_status = dialog_config.FAILED_DIALOG
254 |
255 | if self.constraint_check == dialog_config.CONSTRAINT_CHECK_FAILURE:
256 | self.dialog_status = dialog_config.FAILED_DIALOG
257 |
258 | def response_request(self, system_action):
259 | """ Response for Request (System Action) """
260 |
261 | if len(system_action['request_slots'].keys()) > 0:
262 | slot = system_action['request_slots'].keys()[0] # only one slot
263 | if slot in self.goal['inform_slots'].keys(): # request slot in user's constraints #and slot not in self.state['request_slots'].keys():
264 | self.state['inform_slots'][slot] = self.goal['inform_slots'][slot]
265 | self.state['diaact'] = "inform"
266 | if slot in self.state['rest_slots']: self.state['rest_slots'].remove(slot)
267 | if slot in self.state['request_slots'].keys(): del self.state['request_slots'][slot]
268 | self.state['request_slots'].clear()
269 | elif slot in self.goal['request_slots'].keys() and slot not in self.state['rest_slots'] and slot in self.state['history_slots'].keys(): # the requested slot has been answered
270 | self.state['inform_slots'][slot] = self.state['history_slots'][slot]
271 | self.state['request_slots'].clear()
272 | self.state['diaact'] = "inform"
273 | elif slot in self.goal['request_slots'].keys() and slot in self.state['rest_slots']: # request slot in user's goal's request slots, and not answered yet
274 | self.state['diaact'] = "request" # "confirm_question"
275 | self.state['request_slots'][slot] = "UNK"
276 |
277 | ########################################################################
278 | # Inform the rest of informable slots
279 | ########################################################################
280 | for info_slot in self.state['rest_slots']:
281 | if info_slot in self.goal['inform_slots'].keys():
282 | self.state['inform_slots'][info_slot] = self.goal['inform_slots'][info_slot]
283 |
284 | for info_slot in self.state['inform_slots'].keys():
285 | if info_slot in self.state['rest_slots']:
286 | self.state['rest_slots'].remove(info_slot)
287 | else:
288 | if len(self.state['request_slots']) == 0 and len(self.state['rest_slots']) == 0:
289 | self.state['diaact'] = "thanks"
290 | else:
291 | self.state['diaact'] = "inform"
292 | self.state['inform_slots'][slot] = dialog_config.I_DO_NOT_CARE
293 | else: # this case should not appear
294 | if len(self.state['rest_slots']) > 0:
295 | random_slot = random.choice(self.state['rest_slots'])
296 | if random_slot in self.goal['inform_slots'].keys():
297 | self.state['inform_slots'][random_slot] = self.goal['inform_slots'][random_slot]
298 | self.state['rest_slots'].remove(random_slot)
299 | self.state['diaact'] = "inform"
300 | elif random_slot in self.goal['request_slots'].keys():
301 | self.state['request_slots'][random_slot] = self.goal['request_slots'][random_slot]
302 | self.state['diaact'] = "request"
303 |
304 | def response_multiple_choice(self, system_action):
305 | """ Response for Multiple_Choice (System Action) """
306 |
307 | slot = system_action['inform_slots'].keys()[0]
308 | if slot in self.goal['inform_slots'].keys():
309 | self.state['inform_slots'][slot] = self.goal['inform_slots'][slot]
310 | elif slot in self.goal['request_slots'].keys():
311 | self.state['inform_slots'][slot] = random.choice(system_action['inform_slots'][slot])
312 |
313 | self.state['diaact'] = "inform"
314 | if slot in self.state['rest_slots']: self.state['rest_slots'].remove(slot)
315 | if slot in self.state['request_slots'].keys(): del self.state['request_slots'][slot]
316 |
317 | def response_inform(self, system_action):
318 | """ Response for Inform (System Action) """
319 |
320 | if 'taskcomplete' in system_action['inform_slots'].keys(): # check all the constraints from agents with user goal
321 | self.state['diaact'] = "thanks"
322 | #if 'ticket' in self.state['rest_slots']: self.state['request_slots']['ticket'] = 'UNK'
323 | self.constraint_check = dialog_config.CONSTRAINT_CHECK_SUCCESS
324 |
325 | if system_action['inform_slots']['taskcomplete'] == dialog_config.NO_VALUE_MATCH:
326 | self.state['history_slots']['ticket'] = dialog_config.NO_VALUE_MATCH
327 | if 'ticket' in self.state['rest_slots']: self.state['rest_slots'].remove('ticket')
328 | if 'ticket' in self.state['request_slots'].keys(): del self.state['request_slots']['ticket']
329 |
330 | for slot in self.goal['inform_slots'].keys():
331 | # Deny, if the answers from agent can not meet the constraints of user
332 | if slot not in system_action['inform_slots'].keys() or (self.goal['inform_slots'][slot].lower() != system_action['inform_slots'][slot].lower()):
333 | self.state['diaact'] = "deny"
334 | self.state['request_slots'].clear()
335 | self.state['inform_slots'].clear()
336 | self.constraint_check = dialog_config.CONSTRAINT_CHECK_FAILURE
337 | break
338 | else:
339 | for slot in system_action['inform_slots'].keys():
340 | self.state['history_slots'][slot] = system_action['inform_slots'][slot]
341 |
342 | if slot in self.goal['inform_slots'].keys():
343 | if system_action['inform_slots'][slot] == self.goal['inform_slots'][slot]:
344 | if slot in self.state['rest_slots']: self.state['rest_slots'].remove(slot)
345 |
346 | if len(self.state['request_slots']) > 0:
347 | self.state['diaact'] = "request"
348 | elif len(self.state['rest_slots']) > 0:
349 | rest_slot_set = copy.deepcopy(self.state['rest_slots'])
350 | if 'ticket' in rest_slot_set:
351 | rest_slot_set.remove('ticket')
352 |
353 | if len(rest_slot_set) > 0:
354 | inform_slot = random.choice(rest_slot_set) # self.state['rest_slots']
355 | if inform_slot in self.goal['inform_slots'].keys():
356 | self.state['inform_slots'][inform_slot] = self.goal['inform_slots'][inform_slot]
357 | self.state['diaact'] = "inform"
358 | self.state['rest_slots'].remove(inform_slot)
359 | elif inform_slot in self.goal['request_slots'].keys():
360 | self.state['request_slots'][inform_slot] = 'UNK'
361 | self.state['diaact'] = "request"
362 | else:
363 | self.state['request_slots']['ticket'] = 'UNK'
364 | self.state['diaact'] = "request"
365 | else: # how to reply here?
366 | self.state['diaact'] = "thanks" # replies "closing"? or replies "confirm_answer"
367 | else: # != value Should we deny here or ?
368 | ########################################################################
369 | # TODO When agent informs(slot=value), where the value is different with the constraint in user goal, Should we deny or just inform the correct value?
370 | ########################################################################
371 | self.state['diaact'] = "inform"
372 | self.state['inform_slots'][slot] = self.goal['inform_slots'][slot]
373 | if slot in self.state['rest_slots']: self.state['rest_slots'].remove(slot)
374 | else:
375 | if slot in self.state['rest_slots']:
376 | self.state['rest_slots'].remove(slot)
377 | if slot in self.state['request_slots'].keys():
378 | del self.state['request_slots'][slot]
379 |
380 | if len(self.state['request_slots']) > 0:
381 | request_set = list(self.state['request_slots'].keys())
382 | if 'ticket' in request_set:
383 | request_set.remove('ticket')
384 |
385 | if len(request_set) > 0:
386 | request_slot = random.choice(request_set)
387 | else:
388 | request_slot = 'ticket'
389 |
390 | self.state['request_slots'][request_slot] = "UNK"
391 | self.state['diaact'] = "request"
392 | elif len(self.state['rest_slots']) > 0:
393 | rest_slot_set = copy.deepcopy(self.state['rest_slots'])
394 | if 'ticket' in rest_slot_set:
395 | rest_slot_set.remove('ticket')
396 |
397 | if len(rest_slot_set) > 0:
398 | inform_slot = random.choice(rest_slot_set) #self.state['rest_slots']
399 | if inform_slot in self.goal['inform_slots'].keys():
400 | self.state['inform_slots'][inform_slot] = self.goal['inform_slots'][inform_slot]
401 | self.state['diaact'] = "inform"
402 | self.state['rest_slots'].remove(inform_slot)
403 |
404 | if 'ticket' in self.state['rest_slots']:
405 | self.state['request_slots']['ticket'] = 'UNK'
406 | self.state['diaact'] = "request"
407 | elif inform_slot in self.goal['request_slots'].keys():
408 | self.state['request_slots'][inform_slot] = self.goal['request_slots'][inform_slot]
409 | self.state['diaact'] = "request"
410 | else:
411 | self.state['request_slots']['ticket'] = 'UNK'
412 | self.state['diaact'] = "request"
413 | else:
414 | self.state['diaact'] = "thanks" # or replies "confirm_answer"
415 |
416 |
417 |
418 |
419 | def main(params):
420 | user_sim = RuleSimulator()
421 | user_sim.initialize_episode()
422 |
423 |
424 |
425 | if __name__ == "__main__":
426 | parser = argparse.ArgumentParser()
427 |
428 | args = parser.parse_args()
429 | params = vars(args)
430 |
431 | print ("User Simulator Parameters:")
432 | print (json.dumps(params, indent=2))
433 |
434 | main(params)
435 |
--------------------------------------------------------------------------------
/src/draw_learning_curve.py:
--------------------------------------------------------------------------------
1 | '''
2 | Created on Nov 3, 2016
3 |
4 | draw a learning curve
5 |
6 | @author: xiul
7 | '''
8 |
9 | import argparse, json
10 | import matplotlib.pyplot as plt
11 |
12 |
13 | def read_performance_records(path):
14 | """ load the performance score (.json) file """
15 |
16 | data = json.load(open(path, 'rb'))
17 | for key in data['success_rate'].keys():
18 | if int(key) > -1:
19 | print("%s\t%s\t%s\t%s" % (key, data['success_rate'][key], data['ave_turns'][key], data['ave_reward'][key]))
20 |
21 |
22 | def load_performance_file(path):
23 | """ load the performance score (.json) file """
24 |
25 | data = json.load(open(path, 'rb'))
26 | numbers = {'x': [], 'success_rate':[], 'ave_turns':[], 'ave_rewards':[]}
27 | keylist = [int(key) for key in data['success_rate'].keys()]
28 | keylist.sort()
29 |
30 | for key in keylist:
31 | if int(key) > -1:
32 | numbers['x'].append(int(key))
33 | numbers['success_rate'].append(data['success_rate'][str(key)])
34 | numbers['ave_turns'].append(data['ave_turns'][str(key)])
35 | numbers['ave_rewards'].append(data['ave_reward'][str(key)])
36 | return numbers
37 |
38 | def draw_learning_curve(numbers):
39 | """ draw the learning curve """
40 |
41 | plt.xlabel('Simulation Epoch')
42 | plt.ylabel('Success Rate')
43 | plt.title('Learning Curve')
44 | plt.grid(True)
45 |
46 | plt.plot(numbers['x'], numbers['success_rate'], 'r', lw=1)
47 | plt.show()
48 |
49 |
50 |
51 | def main(params):
52 | cmd = params['cmd']
53 |
54 | if cmd == 0:
55 | numbers = load_performance_file(params['result_file'])
56 | draw_learning_curve(numbers)
57 | elif cmd == 1:
58 | read_performance_records(params['result_file'])
59 |
60 |
61 | if __name__ == "__main__":
62 | parser = argparse.ArgumentParser()
63 |
64 | parser.add_argument('--cmd', dest='cmd', type=int, default=1, help='cmd')
65 |
66 | parser.add_argument('--result_file', dest='result_file', type=str, default='./deep_dialog/checkpoints/rl_agent/11142016/noe2e/agt_9_performance_records.json', help='path to the result file')
67 |
68 | args = parser.parse_args()
69 | params = vars(args)
70 | print json.dumps(params, indent=2)
71 |
72 | main(params)
--------------------------------------------------------------------------------
/src/run.py:
--------------------------------------------------------------------------------
1 | """
2 | Created on May 22, 2016
3 |
4 | This should be a simple minimalist run file. It's only responsibility should be to parse the arguments (which agent, user simulator to use) and launch a dialog simulation.
5 |
6 | Rule-agent: python run.py --agt 6 --usr 1 --max_turn 40 --episodes 150 --movie_kb_path .\deep_dialog\data\movie_kb.1k.p --run_mode 2
7 |
8 | movie_kb:
9 | movie_kb.1k.p: 94% success rate
10 | movie_kb.v2.p: 36% success rate
11 |
12 | user goal files:
13 | first turn: user_goals_first_turn_template.v2.p
14 | all turns: user_goals_all_turns_template.p
15 | user_goals_first_turn_template.part.movie.v1.p: a subset of user goal. [Please use this one, the upper bound success rate on movie_kb.1k.json is 0.9765.]
16 |
17 | Commands:
18 | Rule: python run.py --agt 5 --usr 1 --max_turn 40 --episodes 150 --movie_kb_path .\deep_dialog\data\movie_kb.1k.p --goal_file_path .\deep_dialog\data\user_goals_first_turn_template.part.movie.v1.p --intent_err_prob 0.00 --slot_err_prob 0.00 --episodes 500 --act_level 1 --run_mode 1
19 |
20 | Training:
21 | RL: python run.py --agt 9 --usr 1 --max_turn 40 --movie_kb_path .\deep_dialog\data\movie_kb.1k.p --dqn_hidden_size 80 --experience_replay_pool_size 1000 --episodes 500 --simulation_epoch_size 100 --write_model_dir .\deep_dialog\checkpoints\rl_agent\ --run_mode 3 --act_level 0 --slot_err_prob 0.05 --intent_err_prob 0.00 --batch_size 16 --goal_file_path .\deep_dialog\data\user_goals_first_turn_template.part.movie.v1.p --warm_start 1 --warm_start_epochs 120
22 |
23 | Predict:
24 | RL: python run.py --agt 9 --usr 1 --max_turn 40 --movie_kb_path .\deep_dialog\data\movie_kb.1k.p --dqn_hidden_size 80 --experience_replay_pool_size 1000 --episodes 300 --simulation_epoch_size 100 --write_model_dir .\deep_dialog\checkpoints\rl_agent\ --slot_err_prob 0.00 --intent_err_prob 0.00 --batch_size 16 --goal_file_path .\deep_dialog\data\user_goals_first_turn_template.part.movie.v1.p --episodes 200 --trained_model_path .\deep_dialog\checkpoints\rl_agent\agt_9_22_30_0.37000.p --run_mode 3
25 |
26 | @author: xiul, t-zalipt
27 | """
28 |
29 |
30 | import argparse, json, copy, os
31 | import cPickle as pickle
32 |
33 | from deep_dialog.dialog_system import DialogManager, text_to_dict
34 | from deep_dialog.agents import AgentCmd, InformAgent, RequestAllAgent, RandomAgent, EchoAgent, RequestBasicsAgent, AgentDQN
35 | from deep_dialog.usersims import RuleSimulator
36 |
37 | from deep_dialog import dialog_config
38 | from deep_dialog.dialog_config import *
39 |
40 | from deep_dialog.nlu import nlu
41 | from deep_dialog.nlg import nlg
42 |
43 |
44 | """
45 | Launch a dialog simulation per the command line arguments
46 | This function instantiates a user_simulator, an agent, and a dialog system.
47 | Next, it triggers the simulator to run for the specified number of episodes.
48 | """
49 |
50 |
51 |
52 | if __name__ == "__main__":
53 | parser = argparse.ArgumentParser()
54 |
55 | parser.add_argument('--dict_path', dest='dict_path', type=str, default='./deep_dialog/data/dicts.v3.p', help='path to the .json dictionary file')
56 | parser.add_argument('--movie_kb_path', dest='movie_kb_path', type=str, default='./deep_dialog/data/movie_kb.1k.p', help='path to the movie kb .json file')
57 | parser.add_argument('--act_set', dest='act_set', type=str, default='./deep_dialog/data/dia_acts.txt', help='path to dia act set; none for loading from labeled file')
58 | parser.add_argument('--slot_set', dest='slot_set', type=str, default='./deep_dialog/data/slot_set.txt', help='path to slot set; none for loading from labeled file')
59 | parser.add_argument('--goal_file_path', dest='goal_file_path', type=str, default='./deep_dialog/data/user_goals_first_turn_template.part.movie.v1.p', help='a list of user goals')
60 | parser.add_argument('--diaact_nl_pairs', dest='diaact_nl_pairs', type=str, default='./deep_dialog/data/dia_act_nl_pairs.v6.json', help='path to the pre-defined dia_act&NL pairs')
61 |
62 | parser.add_argument('--max_turn', dest='max_turn', default=20, type=int, help='maximum length of each dialog (default=20, 0=no maximum length)')
63 | parser.add_argument('--episodes', dest='episodes', default=1, type=int, help='Total number of episodes to run (default=1)')
64 | parser.add_argument('--slot_err_prob', dest='slot_err_prob', default=0.05, type=float, help='the slot err probability')
65 | parser.add_argument('--slot_err_mode', dest='slot_err_mode', default=0, type=int, help='slot_err_mode: 0 for slot_val only; 1 for three errs')
66 | parser.add_argument('--intent_err_prob', dest='intent_err_prob', default=0.05, type=float, help='the intent err probability')
67 |
68 | parser.add_argument('--agt', dest='agt', default=0, type=int, help='Select an agent: 0 for a command line input, 1-6 for rule based agents')
69 | parser.add_argument('--usr', dest='usr', default=0, type=int, help='Select a user simulator. 0 is a Frozen user simulator.')
70 |
71 | parser.add_argument('--epsilon', dest='epsilon', type=float, default=0, help='Epsilon to determine stochasticity of epsilon-greedy agent policies')
72 |
73 | # load NLG & NLU model
74 | parser.add_argument('--nlg_model_path', dest='nlg_model_path', type=str, default='./deep_dialog/models/nlg/lstm_tanh_relu_[1468202263.38]_2_0.610.p', help='path to model file')
75 | parser.add_argument('--nlu_model_path', dest='nlu_model_path', type=str, default='./deep_dialog/models/nlu/lstm_[1468447442.91]_39_80_0.921.p', help='path to the NLU model file')
76 |
77 | parser.add_argument('--act_level', dest='act_level', type=int, default=0, help='0 for dia_act level; 1 for NL level')
78 | parser.add_argument('--run_mode', dest='run_mode', type=int, default=0, help='run_mode: 0 for default NL; 1 for dia_act; 2 for both')
79 | parser.add_argument('--auto_suggest', dest='auto_suggest', type=int, default=0, help='0 for no auto_suggest; 1 for auto_suggest')
80 | parser.add_argument('--cmd_input_mode', dest='cmd_input_mode', type=int, default=0, help='run_mode: 0 for NL; 1 for dia_act')
81 |
82 | # RL agent parameters
83 | parser.add_argument('--experience_replay_pool_size', dest='experience_replay_pool_size', type=int, default=1000, help='the size for experience replay')
84 | parser.add_argument('--dqn_hidden_size', dest='dqn_hidden_size', type=int, default=60, help='the hidden size for DQN')
85 | parser.add_argument('--batch_size', dest='batch_size', type=int, default=16, help='batch size')
86 | parser.add_argument('--gamma', dest='gamma', type=float, default=0.9, help='gamma for DQN')
87 | parser.add_argument('--predict_mode', dest='predict_mode', type=bool, default=False, help='predict model for DQN')
88 | parser.add_argument('--simulation_epoch_size', dest='simulation_epoch_size', type=int, default=50, help='the size of validation set')
89 | parser.add_argument('--warm_start', dest='warm_start', type=int, default=1, help='0: no warm start; 1: warm start for training')
90 | parser.add_argument('--warm_start_epochs', dest='warm_start_epochs', type=int, default=100, help='the number of epochs for warm start')
91 |
92 | parser.add_argument('--trained_model_path', dest='trained_model_path', type=str, default=None, help='the path for trained model')
93 | parser.add_argument('-o', '--write_model_dir', dest='write_model_dir', type=str, default='./deep_dialog/checkpoints/', help='write model to disk')
94 | parser.add_argument('--save_check_point', dest='save_check_point', type=int, default=10, help='number of epochs for saving model')
95 |
96 | parser.add_argument('--success_rate_threshold', dest='success_rate_threshold', type=float, default=0.3, help='the threshold for success rate')
97 |
98 | parser.add_argument('--split_fold', dest='split_fold', default=5, type=int, help='the number of folders to split the user goal')
99 | parser.add_argument('--learning_phase', dest='learning_phase', default='all', type=str, help='train/test/all; default is all')
100 |
101 | args = parser.parse_args()
102 | params = vars(args)
103 |
104 | print 'Dialog Parameters: '
105 | print json.dumps(params, indent=2)
106 |
107 |
108 | max_turn = params['max_turn']
109 | num_episodes = params['episodes']
110 |
111 | agt = params['agt']
112 | usr = params['usr']
113 |
114 | dict_path = params['dict_path']
115 | goal_file_path = params['goal_file_path']
116 |
117 | # load the user goals from .p file
118 | all_goal_set = pickle.load(open(goal_file_path, 'rb'))
119 |
120 | # split goal set
121 | split_fold = params.get('split_fold', 5)
122 | goal_set = {'train':[], 'valid':[], 'test':[], 'all':[]}
123 | for u_goal_id, u_goal in enumerate(all_goal_set):
124 | if u_goal_id % split_fold == 1: goal_set['test'].append(u_goal)
125 | else: goal_set['train'].append(u_goal)
126 | goal_set['all'].append(u_goal)
127 | # end split goal set
128 |
129 | movie_kb_path = params['movie_kb_path']
130 | movie_kb = pickle.load(open(movie_kb_path, 'rb'))
131 |
132 | act_set = text_to_dict(params['act_set'])
133 | slot_set = text_to_dict(params['slot_set'])
134 |
135 | ################################################################################
136 | # a movie dictionary for user simulator - slot:possible values
137 | ################################################################################
138 | movie_dictionary = pickle.load(open(dict_path, 'rb'))
139 |
140 | dialog_config.run_mode = params['run_mode']
141 | dialog_config.auto_suggest = params['auto_suggest']
142 |
143 | ################################################################################
144 | # Parameters for Agents
145 | ################################################################################
146 | agent_params = {}
147 | agent_params['max_turn'] = max_turn
148 | agent_params['epsilon'] = params['epsilon']
149 | agent_params['agent_run_mode'] = params['run_mode']
150 | agent_params['agent_act_level'] = params['act_level']
151 |
152 | agent_params['experience_replay_pool_size'] = params['experience_replay_pool_size']
153 | agent_params['dqn_hidden_size'] = params['dqn_hidden_size']
154 | agent_params['batch_size'] = params['batch_size']
155 | agent_params['gamma'] = params['gamma']
156 | agent_params['predict_mode'] = params['predict_mode']
157 | agent_params['trained_model_path'] = params['trained_model_path']
158 | agent_params['warm_start'] = params['warm_start']
159 | agent_params['cmd_input_mode'] = params['cmd_input_mode']
160 |
161 |
162 | if agt == 0:
163 | agent = AgentCmd(movie_kb, act_set, slot_set, agent_params)
164 | elif agt == 1:
165 | agent = InformAgent(movie_kb, act_set, slot_set, agent_params)
166 | elif agt == 2:
167 | agent = RequestAllAgent(movie_kb, act_set, slot_set, agent_params)
168 | elif agt == 3:
169 | agent = RandomAgent(movie_kb, act_set, slot_set, agent_params)
170 | elif agt == 4:
171 | agent = EchoAgent(movie_kb, act_set, slot_set, agent_params)
172 | elif agt == 5:
173 | agent = RequestBasicsAgent(movie_kb, act_set, slot_set, agent_params)
174 | elif agt == 9:
175 | agent = AgentDQN(movie_kb, act_set, slot_set, agent_params)
176 |
177 | ################################################################################
178 | # Add your agent here
179 | ################################################################################
180 | else:
181 | pass
182 |
183 | ################################################################################
184 | # Parameters for User Simulators
185 | ################################################################################
186 | usersim_params = {}
187 | usersim_params['max_turn'] = max_turn
188 | usersim_params['slot_err_probability'] = params['slot_err_prob']
189 | usersim_params['slot_err_mode'] = params['slot_err_mode']
190 | usersim_params['intent_err_probability'] = params['intent_err_prob']
191 | usersim_params['simulator_run_mode'] = params['run_mode']
192 | usersim_params['simulator_act_level'] = params['act_level']
193 | usersim_params['learning_phase'] = params['learning_phase']
194 |
195 | if usr == 0:# real user
196 | user_sim = RealUser(movie_dictionary, act_set, slot_set, goal_set, usersim_params)
197 | elif usr == 1:
198 | user_sim = RuleSimulator(movie_dictionary, act_set, slot_set, goal_set, usersim_params)
199 |
200 | ################################################################################
201 | # Add your user simulator here
202 | ################################################################################
203 | else:
204 | pass
205 |
206 |
207 | ################################################################################
208 | # load trained NLG model
209 | ################################################################################
210 | nlg_model_path = params['nlg_model_path']
211 | diaact_nl_pairs = params['diaact_nl_pairs']
212 | nlg_model = nlg()
213 | nlg_model.load_nlg_model(nlg_model_path)
214 | nlg_model.load_predefine_act_nl_pairs(diaact_nl_pairs)
215 |
216 | agent.set_nlg_model(nlg_model)
217 | user_sim.set_nlg_model(nlg_model)
218 |
219 |
220 | ################################################################################
221 | # load trained NLU model
222 | ################################################################################
223 | nlu_model_path = params['nlu_model_path']
224 | nlu_model = nlu()
225 | nlu_model.load_nlu_model(nlu_model_path)
226 |
227 | agent.set_nlu_model(nlu_model)
228 | user_sim.set_nlu_model(nlu_model)
229 |
230 |
231 | ################################################################################
232 | # Dialog Manager
233 | ################################################################################
234 | dialog_manager = DialogManager(agent, user_sim, act_set, slot_set, movie_kb)
235 |
236 |
237 | ################################################################################
238 | # Run num_episodes Conversation Simulations
239 | ################################################################################
240 | status = {'successes': 0, 'count': 0, 'cumulative_reward': 0}
241 |
242 | simulation_epoch_size = params['simulation_epoch_size']
243 | batch_size = params['batch_size'] # default = 16
244 | warm_start = params['warm_start']
245 | warm_start_epochs = params['warm_start_epochs']
246 |
247 | success_rate_threshold = params['success_rate_threshold']
248 | save_check_point = params['save_check_point']
249 |
250 |
251 | """ Best Model and Performance Records """
252 | best_model = {}
253 | best_res = {'success_rate': 0, 'ave_reward':float('-inf'), 'ave_turns': float('inf'), 'epoch':0}
254 | best_model['model'] = copy.deepcopy(agent)
255 | best_res['success_rate'] = 0
256 |
257 | performance_records = {}
258 | performance_records['success_rate'] = {}
259 | performance_records['ave_turns'] = {}
260 | performance_records['ave_reward'] = {}
261 |
262 |
263 | """ Save model """
264 | def save_model(path, agt, success_rate, agent, best_epoch, cur_epoch):
265 | filename = 'agt_%s_%s_%s_%.5f.p' % (agt, best_epoch, cur_epoch, success_rate)
266 | filepath = os.path.join(path, filename)
267 | checkpoint = {}
268 | if agt == 9: checkpoint['model'] = copy.deepcopy(agent.dqn.model)
269 | checkpoint['params'] = params
270 | try:
271 | pickle.dump(checkpoint, open(filepath, "wb"))
272 | print 'saved model in %s' % (filepath, )
273 | except Exception, e:
274 | print 'Error: Writing model fails: %s' % (filepath, )
275 | print e
276 |
277 | """ save performance numbers """
278 | def save_performance_records(path, agt, records):
279 | filename = 'agt_%s_performance_records.json' % (agt)
280 | filepath = os.path.join(path, filename)
281 | try:
282 | json.dump(records, open(filepath, "wb"))
283 | print 'saved model in %s' % (filepath, )
284 | except Exception, e:
285 | print 'Error: Writing model fails: %s' % (filepath, )
286 | print e
287 |
288 | """ Run N simulation Dialogues """
289 | def simulation_epoch(simulation_epoch_size):
290 | successes = 0
291 | cumulative_reward = 0
292 | cumulative_turns = 0
293 |
294 | res = {}
295 | for episode in xrange(simulation_epoch_size):
296 | dialog_manager.initialize_episode()
297 | episode_over = False
298 | while(not episode_over):
299 | episode_over, reward = dialog_manager.next_turn()
300 | cumulative_reward += reward
301 | if episode_over:
302 | if reward > 0:
303 | successes += 1
304 | print ("simulation episode %s: Success" % (episode))
305 | else: print ("simulation episode %s: Fail" % (episode))
306 | cumulative_turns += dialog_manager.state_tracker.turn_count
307 |
308 | res['success_rate'] = float(successes)/simulation_epoch_size
309 | res['ave_reward'] = float(cumulative_reward)/simulation_epoch_size
310 | res['ave_turns'] = float(cumulative_turns)/simulation_epoch_size
311 | print ("simulation success rate %s, ave reward %s, ave turns %s" % (res['success_rate'], res['ave_reward'], res['ave_turns']))
312 | return res
313 |
314 | """ Warm_Start Simulation (by Rule Policy) """
315 | def warm_start_simulation():
316 | successes = 0
317 | cumulative_reward = 0
318 | cumulative_turns = 0
319 |
320 | res = {}
321 | warm_start_run_epochs = 0
322 | for episode in xrange(warm_start_epochs):
323 | dialog_manager.initialize_episode()
324 | episode_over = False
325 | while(not episode_over):
326 | episode_over, reward = dialog_manager.next_turn()
327 | cumulative_reward += reward
328 | if episode_over:
329 | if reward > 0:
330 | successes += 1
331 | print ("warm_start simulation episode %s: Success" % (episode))
332 | else: print ("warm_start simulation episode %s: Fail" % (episode))
333 | cumulative_turns += dialog_manager.state_tracker.turn_count
334 |
335 | warm_start_run_epochs += 1
336 |
337 | if len(agent.experience_replay_pool) >= agent.experience_replay_pool_size:
338 | break
339 |
340 | agent.warm_start = 2
341 | res['success_rate'] = float(successes)/warm_start_run_epochs
342 | res['ave_reward'] = float(cumulative_reward)/warm_start_run_epochs
343 | res['ave_turns'] = float(cumulative_turns)/warm_start_run_epochs
344 | print ("Warm_Start %s epochs, success rate %s, ave reward %s, ave turns %s" % (episode+1, res['success_rate'], res['ave_reward'], res['ave_turns']))
345 | print ("Current experience replay buffer size %s" % (len(agent.experience_replay_pool)))
346 |
347 |
348 |
349 | def run_episodes(count, status):
350 | successes = 0
351 | cumulative_reward = 0
352 | cumulative_turns = 0
353 |
354 | if agt == 9 and params['trained_model_path'] == None and warm_start == 1:
355 | print ('warm_start starting ...')
356 | warm_start_simulation()
357 | print ('warm_start finished, start RL training ...')
358 |
359 | for episode in xrange(count):
360 | print ("Episode: %s" % (episode))
361 | dialog_manager.initialize_episode()
362 | episode_over = False
363 |
364 | while(not episode_over):
365 | episode_over, reward = dialog_manager.next_turn()
366 | cumulative_reward += reward
367 |
368 | if episode_over:
369 | if reward > 0:
370 | print ("Successful Dialog!")
371 | successes += 1
372 | else: print ("Failed Dialog!")
373 |
374 | cumulative_turns += dialog_manager.state_tracker.turn_count
375 |
376 | # simulation
377 | if agt == 9 and params['trained_model_path'] == None:
378 | agent.predict_mode = True
379 | simulation_res = simulation_epoch(simulation_epoch_size)
380 |
381 | performance_records['success_rate'][episode] = simulation_res['success_rate']
382 | performance_records['ave_turns'][episode] = simulation_res['ave_turns']
383 | performance_records['ave_reward'][episode] = simulation_res['ave_reward']
384 |
385 | if simulation_res['success_rate'] >= best_res['success_rate']:
386 | if simulation_res['success_rate'] >= success_rate_threshold: # threshold = 0.30
387 | agent.experience_replay_pool = []
388 | simulation_epoch(simulation_epoch_size)
389 |
390 | if simulation_res['success_rate'] > best_res['success_rate']:
391 | best_model['model'] = copy.deepcopy(agent)
392 | best_res['success_rate'] = simulation_res['success_rate']
393 | best_res['ave_reward'] = simulation_res['ave_reward']
394 | best_res['ave_turns'] = simulation_res['ave_turns']
395 | best_res['epoch'] = episode
396 |
397 | agent.clone_dqn = copy.deepcopy(agent.dqn)
398 | agent.train(batch_size, 1)
399 | agent.predict_mode = False
400 |
401 | print ("Simulation success rate %s, Ave reward %s, Ave turns %s, Best success rate %s" % (performance_records['success_rate'][episode], performance_records['ave_reward'][episode], performance_records['ave_turns'][episode], best_res['success_rate']))
402 | if episode % save_check_point == 0 and params['trained_model_path'] == None: # save the model every 10 episodes
403 | save_model(params['write_model_dir'], agt, best_res['success_rate'], best_model['model'], best_res['epoch'], episode)
404 | save_performance_records(params['write_model_dir'], agt, performance_records)
405 |
406 | print("Progress: %s / %s, Success rate: %s / %s Avg reward: %.2f Avg turns: %.2f" % (episode+1, count, successes, episode+1, float(cumulative_reward)/(episode+1), float(cumulative_turns)/(episode+1)))
407 | print("Success rate: %s / %s Avg reward: %.2f Avg turns: %.2f" % (successes, count, float(cumulative_reward)/count, float(cumulative_turns)/count))
408 | status['successes'] += successes
409 | status['count'] += count
410 |
411 | if agt == 9 and params['trained_model_path'] == None:
412 | save_model(params['write_model_dir'], agt, float(successes)/count, best_model['model'], best_res['epoch'], count)
413 | save_performance_records(params['write_model_dir'], agt, performance_records)
414 |
415 | run_episodes(num_episodes, status)
416 |
--------------------------------------------------------------------------------