├── LICENSE
├── README.md
├── conv_demo.py
├── densenet.py
├── googlenet.py
├── lenet.py
├── mobilenetv1.py
├── mobilenetv2.py
├── requirements.txt
├── resnet.py
├── senet.py
├── shufflenetv1.py
├── shufflenetv2.py
├── utils.py
├── vgg.py
└── xception.py
/LICENSE:
--------------------------------------------------------------------------------
1 |
2 | Apache License
3 | Version 2.0, January 2004
4 | http://www.apache.org/licenses/
5 |
6 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
7 |
8 | 1. Definitions.
9 |
10 | "License" shall mean the terms and conditions for use, reproduction,
11 | and distribution as defined by Sections 1 through 9 of this document.
12 |
13 | "Licensor" shall mean the copyright owner or entity authorized by
14 | the copyright owner that is granting the License.
15 |
16 | "Legal Entity" shall mean the union of the acting entity and all
17 | other entities that control, are controlled by, or are under common
18 | control with that entity. For the purposes of this definition,
19 | "control" means (i) the power, direct or indirect, to cause the
20 | direction or management of such entity, whether by contract or
21 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
22 | outstanding shares, or (iii) beneficial ownership of such entity.
23 |
24 | "You" (or "Your") shall mean an individual or Legal Entity
25 | exercising permissions granted by this License.
26 |
27 | "Source" form shall mean the preferred form for making modifications,
28 | including but not limited to software source code, documentation
29 | source, and configuration files.
30 |
31 | "Object" form shall mean any form resulting from mechanical
32 | transformation or translation of a Source form, including but
33 | not limited to compiled object code, generated documentation,
34 | and conversions to other media types.
35 |
36 | "Work" shall mean the work of authorship, whether in Source or
37 | Object form, made available under the License, as indicated by a
38 | copyright notice that is included in or attached to the work
39 | (an example is provided in the Appendix below).
40 |
41 | "Derivative Works" shall mean any work, whether in Source or Object
42 | form, that is based on (or derived from) the Work and for which the
43 | editorial revisions, annotations, elaborations, or other modifications
44 | represent, as a whole, an original work of authorship. For the purposes
45 | of this License, Derivative Works shall not include works that remain
46 | separable from, or merely link (or bind by name) to the interfaces of,
47 | the Work and Derivative Works thereof.
48 |
49 | "Contribution" shall mean any work of authorship, including
50 | the original version of the Work and any modifications or additions
51 | to that Work or Derivative Works thereof, that is intentionally
52 | submitted to Licensor for inclusion in the Work by the copyright owner
53 | or by an individual or Legal Entity authorized to submit on behalf of
54 | the copyright owner. For the purposes of this definition, "submitted"
55 | means any form of electronic, verbal, or written communication sent
56 | to the Licensor or its representatives, including but not limited to
57 | communication on electronic mailing lists, source code control systems,
58 | and issue tracking systems that are managed by, or on behalf of, the
59 | Licensor for the purpose of discussing and improving the Work, but
60 | excluding communication that is conspicuously marked or otherwise
61 | designated in writing by the copyright owner as "Not a Contribution."
62 |
63 | "Contributor" shall mean Licensor and any individual or Legal Entity
64 | on behalf of whom a Contribution has been received by Licensor and
65 | subsequently incorporated within the Work.
66 |
67 | 2. Grant of Copyright License. Subject to the terms and conditions of
68 | this License, each Contributor hereby grants to You a perpetual,
69 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
70 | copyright license to reproduce, prepare Derivative Works of,
71 | publicly display, publicly perform, sublicense, and distribute the
72 | Work and such Derivative Works in Source or Object form.
73 |
74 | 3. Grant of Patent License. Subject to the terms and conditions of
75 | this License, each Contributor hereby grants to You a perpetual,
76 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
77 | (except as stated in this section) patent license to make, have made,
78 | use, offer to sell, sell, import, and otherwise transfer the Work,
79 | where such license applies only to those patent claims licensable
80 | by such Contributor that are necessarily infringed by their
81 | Contribution(s) alone or by combination of their Contribution(s)
82 | with the Work to which such Contribution(s) was submitted. If You
83 | institute patent litigation against any entity (including a
84 | cross-claim or counterclaim in a lawsuit) alleging that the Work
85 | or a Contribution incorporated within the Work constitutes direct
86 | or contributory patent infringement, then any patent licenses
87 | granted to You under this License for that Work shall terminate
88 | as of the date such litigation is filed.
89 |
90 | 4. Redistribution. You may reproduce and distribute copies of the
91 | Work or Derivative Works thereof in any medium, with or without
92 | modifications, and in Source or Object form, provided that You
93 | meet the following conditions:
94 |
95 | (a) You must give any other recipients of the Work or
96 | Derivative Works a copy of this License; and
97 |
98 | (b) You must cause any modified files to carry prominent notices
99 | stating that You changed the files; and
100 |
101 | (c) You must retain, in the Source form of any Derivative Works
102 | that You distribute, all copyright, patent, trademark, and
103 | attribution notices from the Source form of the Work,
104 | excluding those notices that do not pertain to any part of
105 | the Derivative Works; and
106 |
107 | (d) If the Work includes a "NOTICE" text file as part of its
108 | distribution, then any Derivative Works that You distribute must
109 | include a readable copy of the attribution notices contained
110 | within such NOTICE file, excluding those notices that do not
111 | pertain to any part of the Derivative Works, in at least one
112 | of the following places: within a NOTICE text file distributed
113 | as part of the Derivative Works; within the Source form or
114 | documentation, if provided along with the Derivative Works; or,
115 | within a display generated by the Derivative Works, if and
116 | wherever such third-party notices normally appear. The contents
117 | of the NOTICE file are for informational purposes only and
118 | do not modify the License. You may add Your own attribution
119 | notices within Derivative Works that You distribute, alongside
120 | or as an addendum to the NOTICE text from the Work, provided
121 | that such additional attribution notices cannot be construed
122 | as modifying the License.
123 |
124 | You may add Your own copyright statement to Your modifications and
125 | may provide additional or different license terms and conditions
126 | for use, reproduction, or distribution of Your modifications, or
127 | for any such Derivative Works as a whole, provided Your use,
128 | reproduction, and distribution of the Work otherwise complies with
129 | the conditions stated in this License.
130 |
131 | 5. Submission of Contributions. Unless You explicitly state otherwise,
132 | any Contribution intentionally submitted for inclusion in the Work
133 | by You to the Licensor shall be under the terms and conditions of
134 | this License, without any additional terms or conditions.
135 | Notwithstanding the above, nothing herein shall supersede or modify
136 | the terms of any separate license agreement you may have executed
137 | with Licensor regarding such Contributions.
138 |
139 | 6. Trademarks. This License does not grant permission to use the trade
140 | names, trademarks, service marks, or product names of the Licensor,
141 | except as required for reasonable and customary use in describing the
142 | origin of the Work and reproducing the content of the NOTICE file.
143 |
144 | 7. Disclaimer of Warranty. Unless required by applicable law or
145 | agreed to in writing, Licensor provides the Work (and each
146 | Contributor provides its Contributions) on an "AS IS" BASIS,
147 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
148 | implied, including, without limitation, any warranties or conditions
149 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
150 | PARTICULAR PURPOSE. You are solely responsible for determining the
151 | appropriateness of using or redistributing the Work and assume any
152 | risks associated with Your exercise of permissions under this License.
153 |
154 | 8. Limitation of Liability. In no event and under no legal theory,
155 | whether in tort (including negligence), contract, or otherwise,
156 | unless required by applicable law (such as deliberate and grossly
157 | negligent acts) or agreed to in writing, shall any Contributor be
158 | liable to You for damages, including any direct, indirect, special,
159 | incidental, or consequential damages of any character arising as a
160 | result of this License or out of the use or inability to use the
161 | Work (including but not limited to damages for loss of goodwill,
162 | work stoppage, computer failure or malfunction, or any and all
163 | other commercial damages or losses), even if such Contributor
164 | has been advised of the possibility of such damages.
165 |
166 | 9. Accepting Warranty or Additional Liability. While redistributing
167 | the Work or Derivative Works thereof, You may choose to offer,
168 | and charge a fee for, acceptance of support, warranty, indemnity,
169 | or other liability obligations and/or rights consistent with this
170 | License. However, in accepting such obligations, You may act only
171 | on Your own behalf and on Your sole responsibility, not on behalf
172 | of any other Contributor, and only if You agree to indemnify,
173 | defend, and hold each Contributor harmless for any liability
174 | incurred by, or claims asserted against, such Contributor by reason
175 | of your accepting any such warranty or additional liability.
176 |
177 | END OF TERMS AND CONDITIONS
178 |
179 | APPENDIX: How to apply the Apache License to your work.
180 |
181 | To apply the Apache License to your work, attach the following
182 | boilerplate notice, with the fields enclosed by brackets "[]"
183 | replaced with your own identifying information. (Don't include
184 | the brackets!) The text should be enclosed in the appropriate
185 | comment syntax for the file format. We also recommend that a
186 | file or class name and description of purpose be included on the
187 | same "printed page" as the copyright notice for easier
188 | identification within third-party archives.
189 |
190 | Copyright [2021] [Mofan Zhou]
191 |
192 | Licensed under the Apache License, Version 2.0 (the "License");
193 | you may not use this file except in compliance with the License.
194 | You may obtain a copy of the License at
195 |
196 | http://www.apache.org/licenses/LICENSE-2.0
197 |
198 | Unless required by applicable law or agreed to in writing, software
199 | distributed under the License is distributed on an "AS IS" BASIS,
200 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
201 | See the License for the specific language governing permissions and
202 | limitations under the License.
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Tutorials of Computer Vision
2 |
3 | This repo includes some implementations of Computer Vision algorithms using tf2+. Codes are easy to read and follow.
4 | If you can read Chinese, I have a teaching website for studying AI models.
5 |
6 | All toy implementations are organised as following:
7 |
8 | - CNN
9 | - [Numpy Convolution mechanism](#ConvMechanism)
10 | - [LeNet](#LeNet)
11 | - [VGG](#VGG)
12 | - [GoogLeNet](#GoogLeNet)
13 | - [ResNet](#ResNet)
14 | - [DenseNet](#DenseNet)
15 | - [SENet](#SENet)
16 | - [MobileNetV1](#MobileNetV1)
17 | - [MobileNetV2](#MobileNetV2)
18 | - [Xception](#Xception)
19 | - [ShuffleNetV1](#ShuffleNetV1)
20 | - [ShuffleNetV2](#ShuffleNetV2)
21 |
22 | # Installation
23 | ```shell script
24 | $ git clone https://github.com/MorvanZhou/Computer-Vision
25 | $ cd Computer-Vision
26 | $ pip install -r requirements.txt
27 | ```
28 | # ConvMechanism
29 | Convolution mechanism and feature map
30 |
31 | [code](/conv_demo.py) - [gif result](https://mofanpy.com/static/results/cv/conv_mechanism.gif)
32 |
33 |
34 |  35 |
36 |
37 | # LeNet
38 | [Gradient-Based Learning Applied to Document Recognition](http://www.dengfanxin.cn/wp-content/uploads/2016/03/1998Lecun.pdf)
39 |
40 | [code](/lenet.py) - [net structure](https://mofanpy.com/static/results/cv/LeNet_structure.png)
41 |
42 |
43 |
35 |
36 |
37 | # LeNet
38 | [Gradient-Based Learning Applied to Document Recognition](http://www.dengfanxin.cn/wp-content/uploads/2016/03/1998Lecun.pdf)
39 |
40 | [code](/lenet.py) - [net structure](https://mofanpy.com/static/results/cv/LeNet_structure.png)
41 |
42 |
43 | 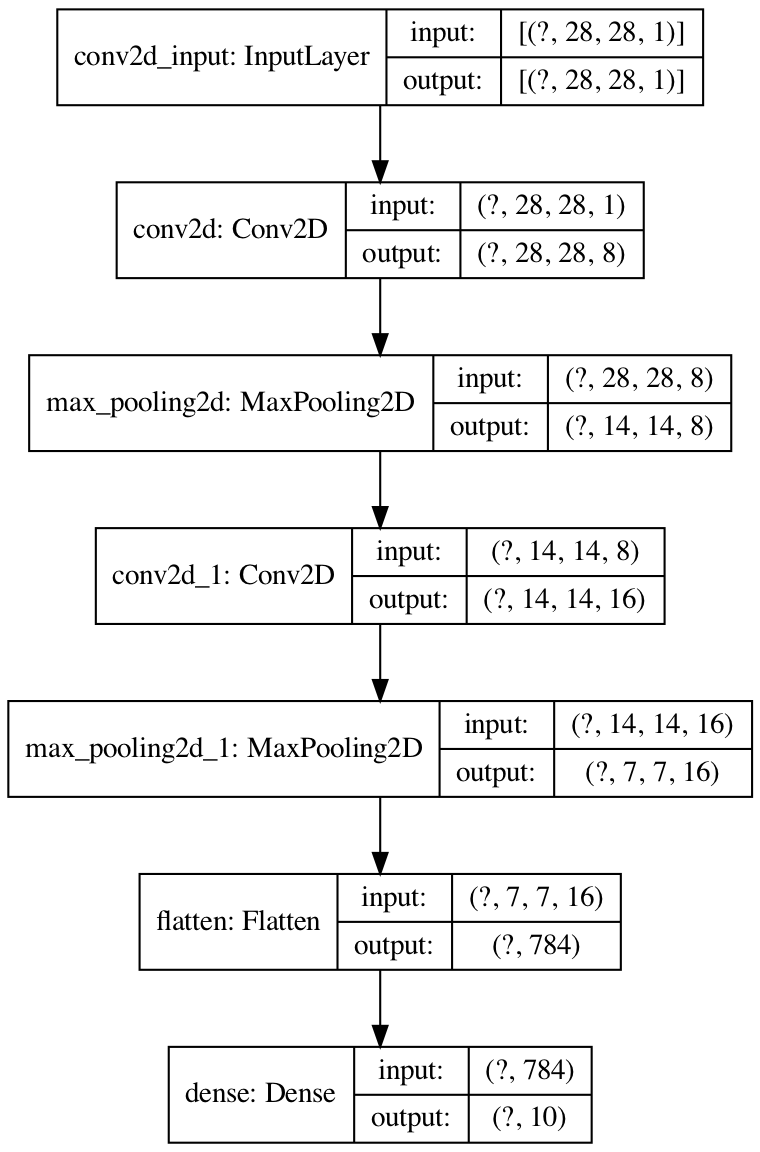 44 |
45 |
46 | # VGG
47 | [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)
48 |
49 | Deep stacked CNN.
50 |
51 | [code](/vgg.py) - [net structure](https://mofanpy.com/static/results/cv/VGG_structure.png)
52 |
53 |
54 |
44 |
45 |
46 | # VGG
47 | [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)
48 |
49 | Deep stacked CNN.
50 |
51 | [code](/vgg.py) - [net structure](https://mofanpy.com/static/results/cv/VGG_structure.png)
52 |
53 |
54 | 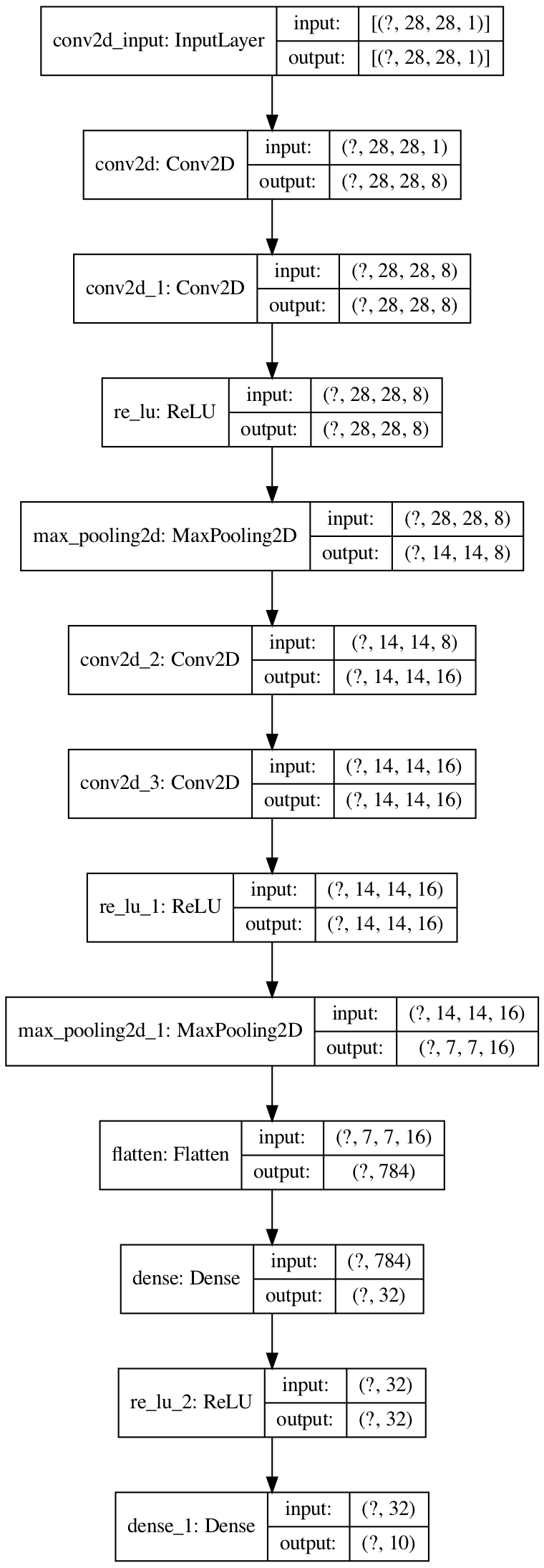 55 |
56 |
57 | # GoogLeNet
58 | [Going Deeper with Convolutions](https://arxiv.org/abs/1409.4842)
59 |
60 | Multi kernel size to capture different local information
61 |
62 | [code](/googlenet.py) - [net structure](https://mofanpy.com/static/results/cv/GoogleLeNet_structure.png)
63 |
64 |
65 |
55 |
56 |
57 | # GoogLeNet
58 | [Going Deeper with Convolutions](https://arxiv.org/abs/1409.4842)
59 |
60 | Multi kernel size to capture different local information
61 |
62 | [code](/googlenet.py) - [net structure](https://mofanpy.com/static/results/cv/GoogleLeNet_structure.png)
63 |
64 |
65 |  66 |
67 |
68 | # ResNet
69 | [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
70 |
71 | Add residual connection for better gradients.
72 |
73 | [code](/resnet.py) - [net structure](https://mofanpy.com/static/results/cv/ResNet_structure.png)
74 |
75 |
76 |
66 |
67 |
68 | # ResNet
69 | [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
70 |
71 | Add residual connection for better gradients.
72 |
73 | [code](/resnet.py) - [net structure](https://mofanpy.com/static/results/cv/ResNet_structure.png)
74 |
75 |
76 | 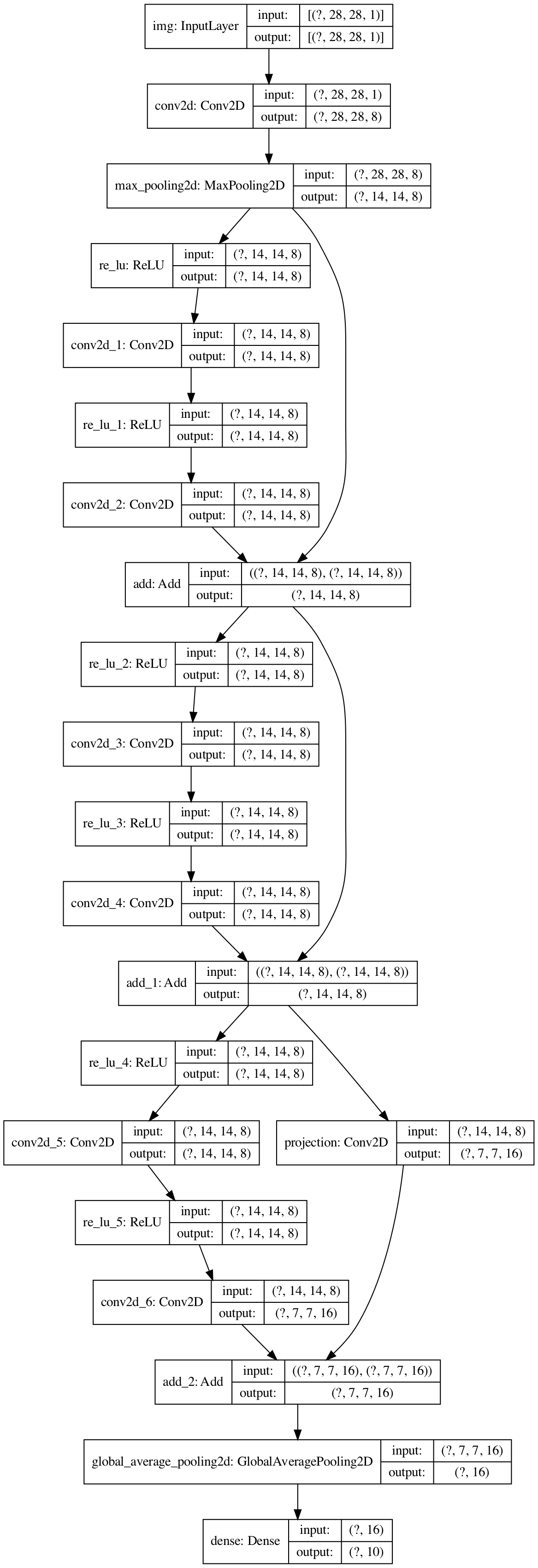 77 |
78 |
79 | # DenseNet
80 | [Densely Connected Convolutional Networks](https://arxiv.org/abs/1608.06993)
81 |
82 | Compared with resnet, it has less filter each conv, sees more previous inputs.
83 |
84 | [code](/densenet.py) - [net structure](https://mofanpy.com/static/results/cv/DenseNet_structure.png)
85 |
86 |
87 |
77 |
78 |
79 | # DenseNet
80 | [Densely Connected Convolutional Networks](https://arxiv.org/abs/1608.06993)
81 |
82 | Compared with resnet, it has less filter each conv, sees more previous inputs.
83 |
84 | [code](/densenet.py) - [net structure](https://mofanpy.com/static/results/cv/DenseNet_structure.png)
85 |
86 |
87 | 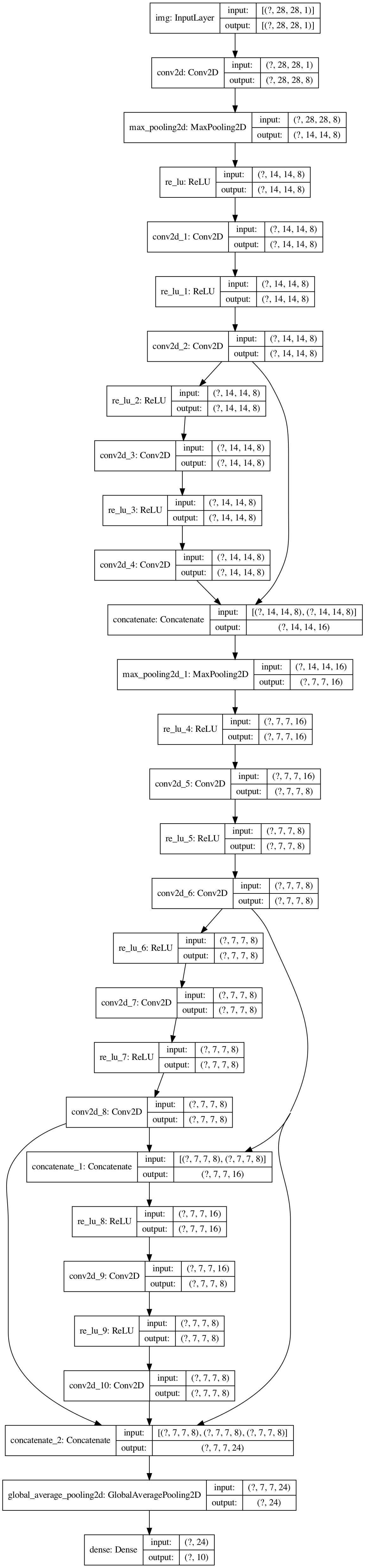 88 |
89 |
90 | # SENet
91 | [Squeeze-and-Excitation Networks](https://arxiv.org/abs/1709.01507)
92 |
93 | SE is a module that learns to scale each feature map, it can be plugged in many cnn block,
94 | larger reduction_ratio reduce parameter size in FC layers with limited accuracy drop.
95 |
96 | [code](/senet.py) - [net structure](https://mofanpy.com/static/results/cv/SENet_structure.png)
97 |
98 |
99 |
88 |
89 |
90 | # SENet
91 | [Squeeze-and-Excitation Networks](https://arxiv.org/abs/1709.01507)
92 |
93 | SE is a module that learns to scale each feature map, it can be plugged in many cnn block,
94 | larger reduction_ratio reduce parameter size in FC layers with limited accuracy drop.
95 |
96 | [code](/senet.py) - [net structure](https://mofanpy.com/static/results/cv/SENet_structure.png)
97 |
98 |
99 | 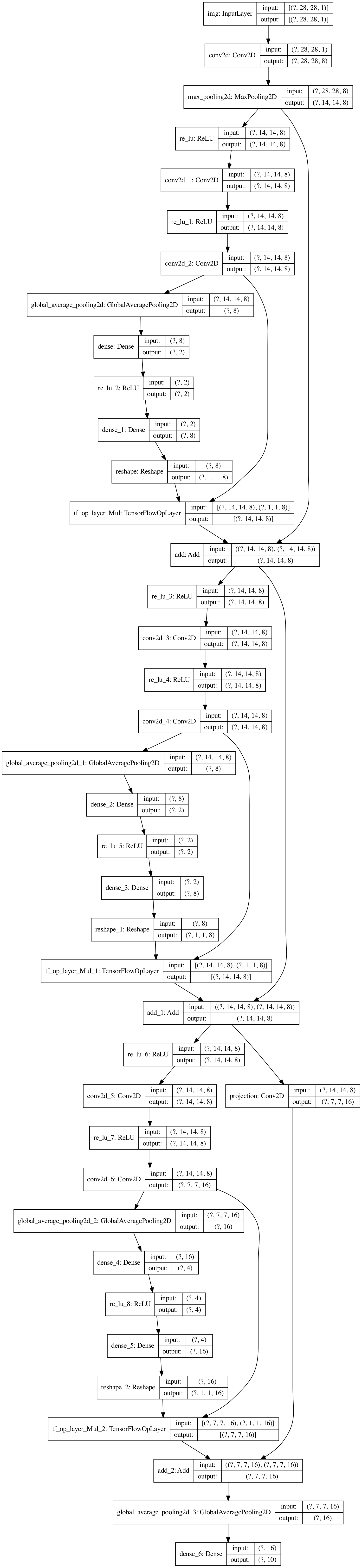 100 |
101 |
102 | # MobileNetV1
103 | [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861)
104 |
105 | Decomposed classical conv to two operations (dw+pw). Small but effective cnn optimized on mobile (cpu).
106 |
107 | [code](/mobilenetv1.py) - [net structure](https://mofanpy.com/static/results/cv/MobileNetV1_structure.png)
108 |
109 |
110 |
100 |
101 |
102 | # MobileNetV1
103 | [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861)
104 |
105 | Decomposed classical conv to two operations (dw+pw). Small but effective cnn optimized on mobile (cpu).
106 |
107 | [code](/mobilenetv1.py) - [net structure](https://mofanpy.com/static/results/cv/MobileNetV1_structure.png)
108 |
109 |
110 | 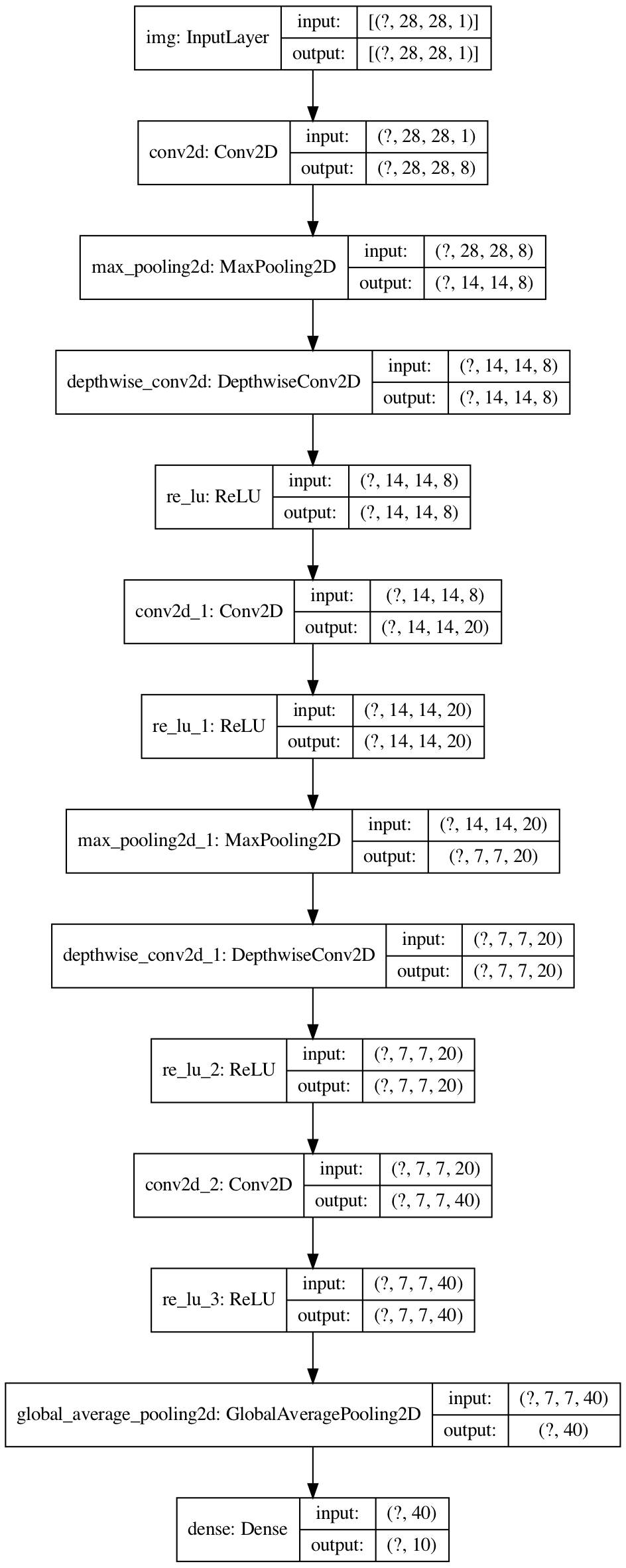 111 |
112 |
113 | # MobileNetV2
114 | [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)
115 |
116 | MobileNet v2 is v1 with residual block and layer rearrange (residual+pw+dw+pw):
117 |
118 | - mobilenet v1: dw > pw
119 | - mobilenet v2: pw > dw > pw let dw see more feature maps
120 |
121 | [code](/mobilenetv2.py) - [net structure](https://mofanpy.com/static/results/cv/MobileNetV2_structure.png)
122 |
123 |
124 |
111 |
112 |
113 | # MobileNetV2
114 | [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)
115 |
116 | MobileNet v2 is v1 with residual block and layer rearrange (residual+pw+dw+pw):
117 |
118 | - mobilenet v1: dw > pw
119 | - mobilenet v2: pw > dw > pw let dw see more feature maps
120 |
121 | [code](/mobilenetv2.py) - [net structure](https://mofanpy.com/static/results/cv/MobileNetV2_structure.png)
122 |
123 |
124 | 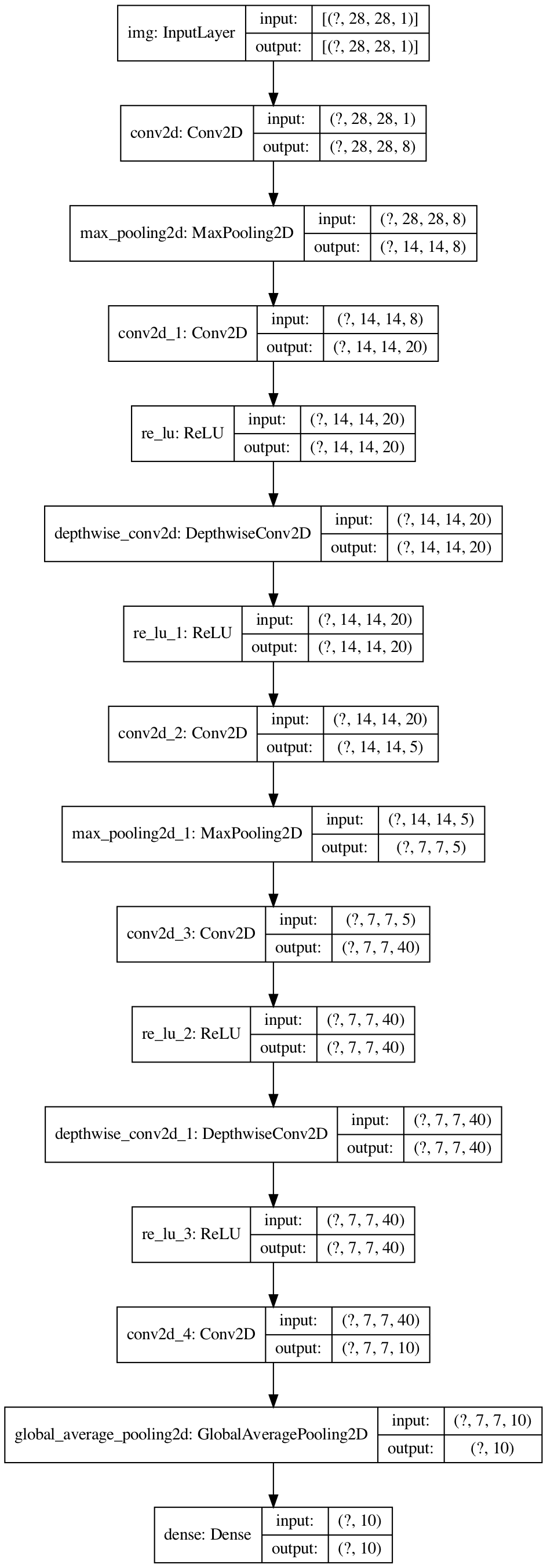 125 |
126 |
127 | # Xception
128 | [Xception: Deep Learning with Depthwise Separable Convolutions](https://arxiv.org/abs/1610.02357)
129 |
130 | Just like MobileNetV2 without last pw (residual+pw+dw).
131 |
132 | [code](/xception.py) - [net structure](https://mofanpy.com/static/results/cv/Xception_structure.png)
133 |
134 |
135 |
125 |
126 |
127 | # Xception
128 | [Xception: Deep Learning with Depthwise Separable Convolutions](https://arxiv.org/abs/1610.02357)
129 |
130 | Just like MobileNetV2 without last pw (residual+pw+dw).
131 |
132 | [code](/xception.py) - [net structure](https://mofanpy.com/static/results/cv/Xception_structure.png)
133 |
134 |
135 | 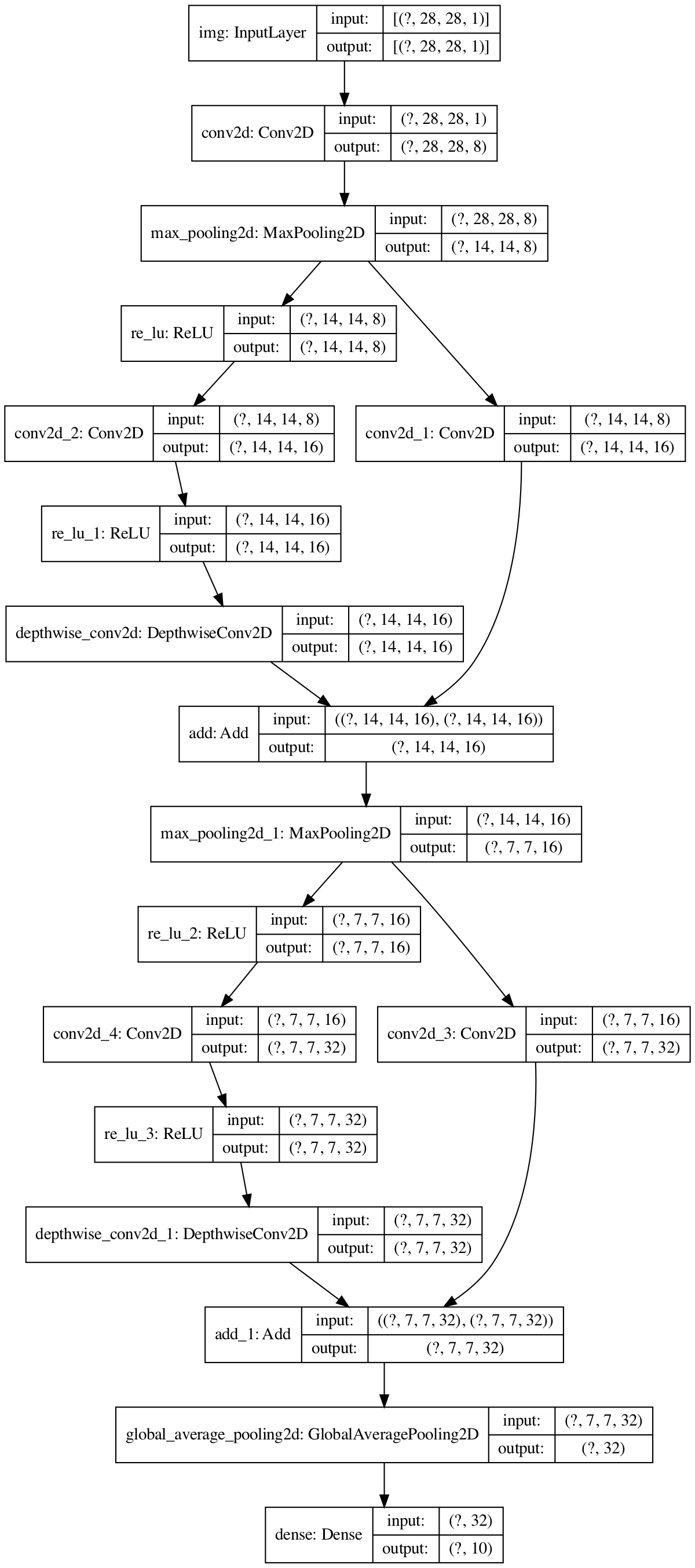 136 |
137 |
138 |
139 | # ShuffleNetV1
140 | [ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices](https://arxiv.org/abs/1707.01083)
141 |
142 | Shuffle the output from 1x1 conv, and do group conv to reduce connections and speed up computing.
143 | But MobileNet is better in this case, this may caused by group conv cuts off some feature map communications.
144 |
145 | [code](/shufflenetv1.py) - [net structure](https://mofanpy.com/static/results/cv/ShuffleNetV1_structure.png)
146 |
147 |
148 |
136 |
137 |
138 |
139 | # ShuffleNetV1
140 | [ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices](https://arxiv.org/abs/1707.01083)
141 |
142 | Shuffle the output from 1x1 conv, and do group conv to reduce connections and speed up computing.
143 | But MobileNet is better in this case, this may caused by group conv cuts off some feature map communications.
144 |
145 | [code](/shufflenetv1.py) - [net structure](https://mofanpy.com/static/results/cv/ShuffleNetV1_structure.png)
146 |
147 |
148 | 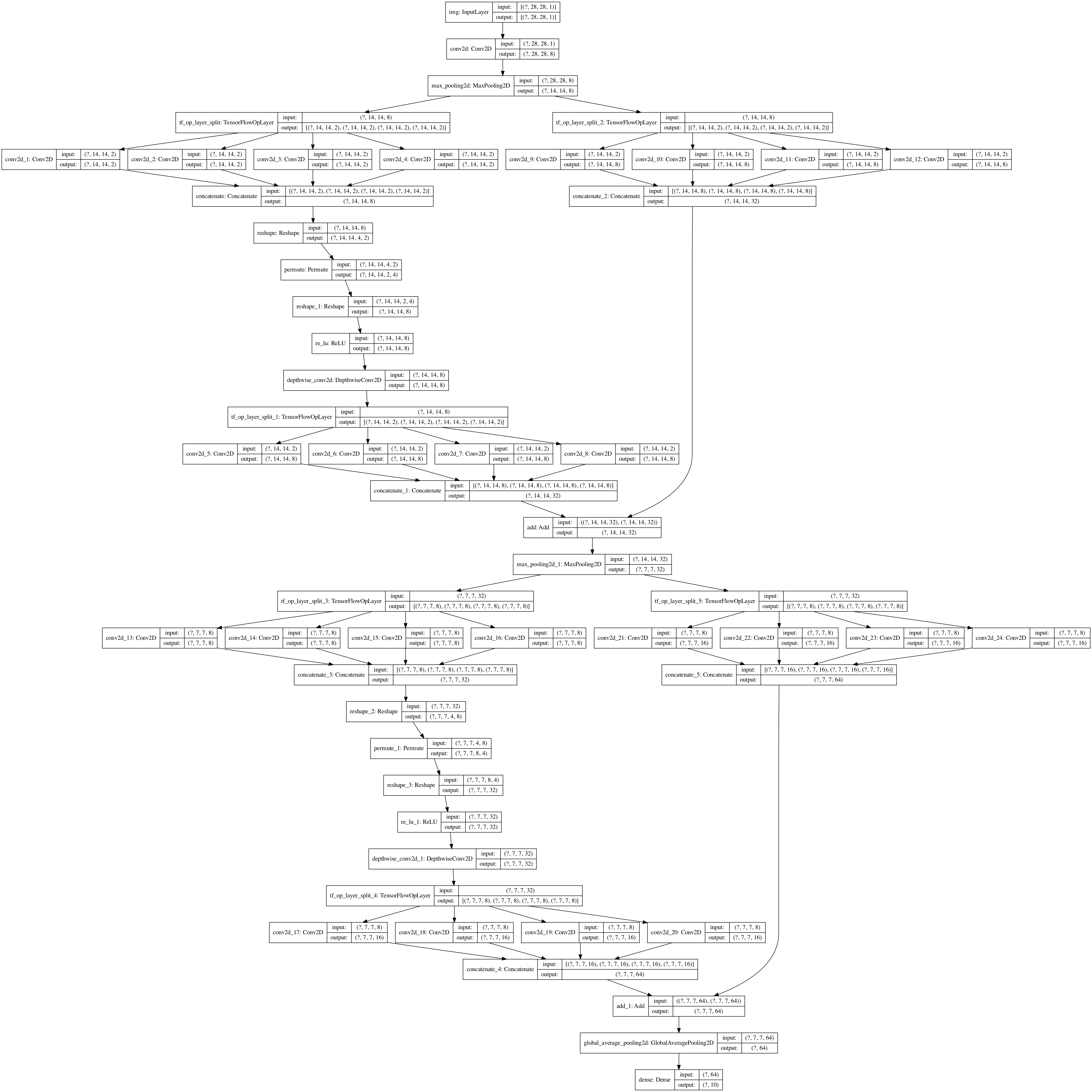 149 |
150 |
151 | # ShuffleNetV2
152 | [ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design](https://arxiv.org/abs/1807.11164)
153 |
154 | Further reduces parameters by switching group conv with split+concat, perform shuffle at end of block. Speed up calculation.
155 | But MobileNet is better in this case, this may caused by group conv cuts off some feature map communications.
156 |
157 | [code](/shufflenetv2.py) - [net structure](https://mofanpy.com/static/results/cv/ShuffleNetV2_structure.png)
158 |
159 |
160 |
149 |
150 |
151 | # ShuffleNetV2
152 | [ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design](https://arxiv.org/abs/1807.11164)
153 |
154 | Further reduces parameters by switching group conv with split+concat, perform shuffle at end of block. Speed up calculation.
155 | But MobileNet is better in this case, this may caused by group conv cuts off some feature map communications.
156 |
157 | [code](/shufflenetv2.py) - [net structure](https://mofanpy.com/static/results/cv/ShuffleNetV2_structure.png)
158 |
159 |
160 |  161 |
--------------------------------------------------------------------------------
/conv_demo.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import matplotlib.pyplot as plt
3 | import os
4 | from PIL import Image
5 | from utils import load_mnist
6 |
7 |
8 | def save_gif(imgs_dir):
9 | imgs = []
10 | imgs_path = [os.path.join(imgs_dir, p) for p in os.listdir(imgs_dir) if p.endswith(".png")]
11 | for f in sorted(imgs_path, key=os.path.getmtime):
12 | if not f.endswith(".png"):
13 | continue
14 | img = Image.open(f)
15 | img = img.resize((img.width, img.height), Image.ANTIALIAS)
16 | imgs.append(img)
17 | path = "{}/conv_mechanism.gif".format(os.path.dirname(imgs_dir))
18 | if os.path.exists(path):
19 | os.remove(path)
20 | imgs[0].save(path, append_images=imgs[1:], optimize=False, save_all=True, duration=20, loop=0)
21 | print("saved ", path)
22 |
23 |
24 | def show_conv(save_dir, image):
25 | filter = np.array([
26 | [1, 1, 1],
27 | [0, 0, 0],
28 | [-1, -1, -1]])
29 | plt.figure(0, figsize=(9, 5))
30 | ax1 = plt.subplot(121)
31 | ax1.imshow(image, cmap='gray_r')
32 | plt.xticks(())
33 | plt.yticks(())
34 | ax2 = plt.subplot(122)
35 | texts = []
36 | feature_map = np.zeros((26, 26))
37 | for i in range(26):
38 | for j in range(26):
39 |
40 | if texts:
41 | fm.remove()
42 | for n in range(3):
43 | for m in range(3):
44 | if len(texts) != 9:
45 | texts.append(ax1.text(j+m, i+n, filter[n, m], color='k', size=8, ha='center', va='center'))
46 | else:
47 | texts[n*3+m].set_position((j+m, i+n))
48 |
49 | feature_map[i, j] = np.sum(filter * image[i:i+3, j:j+3])
50 | fm = ax2.imshow(feature_map, cmap='gray', vmax=3, vmin=-3)
51 | plt.xticks(())
52 | plt.yticks(())
53 | plt.tight_layout()
54 | plt.savefig(os.path.join(save_dir, "i{}j{}.png".format(i, j)))
55 |
56 |
57 | def show_feature_map(save_dir, image):
58 | filters = [
59 | np.array([
60 | [1, 1, 1],
61 | [0, 0, 0],
62 | [-1, -1, -1]]),
63 | np.array([
64 | [-1, -1, -1],
65 | [0, 0, 0],
66 | [1, 1, 1]]),
67 | np.array([
68 | [1, 0, -1],
69 | [1, 0, -1],
70 | [1, 0, -1]]),
71 | np.array([
72 | [-1, 0, 1],
73 | [-1, 0, 1],
74 | [-1, 0, 1]])
75 | ]
76 |
77 | plt.figure(1)
78 | plt.title('Original image')
79 | plt.imshow(image, cmap='gray_r')
80 | plt.xticks(())
81 | plt.yticks(())
82 | plt.savefig(os.path.join(save_dir, "original_img.png"))
83 |
84 | plt.figure(2)
85 | for n in range(4):
86 | feature_map = np.zeros((26, 26))
87 |
88 | for i in range(26):
89 | for j in range(26):
90 | feature_map[i, j] = np.sum(image[i:i + 3, j:j + 3] * filters[n])
91 |
92 | plt.subplot(3, 4, 1 + n)
93 | plt.title('Filter%i' % n)
94 | plt.imshow(filters[n], cmap='gray', vmax=3, vmin=-3)
95 | plt.xticks(())
96 | plt.yticks(())
97 |
98 | plt.subplot(3, 4, 5 + n)
99 | plt.title('Conv%i' % n)
100 | plt.imshow(feature_map, cmap='gray', vmax=3, vmin=-3)
101 | plt.xticks(())
102 | plt.yticks(())
103 |
104 | plt.subplot(3, 4, 9 + n)
105 | plt.title('ReLU%i' % n)
106 | feature_map = np.maximum(0, feature_map)
107 | plt.imshow(feature_map, cmap='gray', vmax=3, vmin=-3)
108 | plt.xticks(())
109 | plt.yticks(())
110 |
111 | plt.tight_layout()
112 | plt.savefig(os.path.join(save_dir, "feature_map.png"))
113 |
114 |
115 | if __name__ == "__main__":
116 | result_dir = "visual/basic"
117 | conv_dir = os.path.join(result_dir, "conv")
118 | os.makedirs(conv_dir, exist_ok=True)
119 | (x_train, y_train), (x_test, y_test) = load_mnist()
120 |
121 | data = x_train[7].squeeze(axis=-1)
122 | show_feature_map(result_dir, data)
123 | show_conv(conv_dir, data)
124 | save_gif(conv_dir)
125 |
--------------------------------------------------------------------------------
/densenet.py:
--------------------------------------------------------------------------------
1 | # [Densely Connected Convolutional Networks](https://arxiv.org/abs/1608.06993)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # compared with resnet, it has less filter each conv, sees more previous inputs
13 | def bottleneck(xs, growth_rate):
14 | if len(xs) == 1:
15 | o = xs[0]
16 | else:
17 | o = layers.concatenate(xs, axis=-1) # [n, h, w, c * xs]
18 | o = layers.ReLU()(o)
19 | o = layers.Conv2D(growth_rate, kernel_size=1, strides=1)(o) # [n, h, w, c]
20 | o = layers.ReLU()(o)
21 | o = layers.Conv2D(growth_rate, kernel_size=3, strides=1, padding="same")(o) # [n, h, w, c]
22 | return o
23 |
24 |
25 | def block(x, growth_rate, n_bottleneck=2):
26 | outs = [bottleneck([x], growth_rate)] # [n, h, w, c]
27 | for i in range(1, n_bottleneck):
28 | o = bottleneck(outs, growth_rate) # [n, h, w, c]
29 | outs.append(o)
30 | return layers.concatenate(outs, axis=-1) # [n, h, w, c * n_bottleneck]
31 |
32 |
33 | def build_model():
34 | inputs = layers.Input(shape=(28, 28, 1), name="img")
35 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
36 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
37 | x = block(x, growth_rate=8, n_bottleneck=2) # [n, 14, 14, 8*2]
38 | x = layers.MaxPool2D(2)(x) # [n, 7, 7, 8*2]
39 | x = block(x, 8, 3) # [n, 7, 7, 8*3]
40 | x = layers.GlobalAveragePooling2D()(x) # [n, 24]
41 | o = layers.Dense(10)(x) # [n, 10]
42 | return keras.Model(inputs, o, name="DenseNet")
43 |
44 | # show model
45 | model = build_model()
46 | model.summary()
47 | save_model_structure(model)
48 |
49 | # define loss and optimizer
50 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
51 | opt = keras.optimizers.Adam(0.001)
52 | accuracy = keras.metrics.SparseCategoricalAccuracy()
53 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
54 |
55 | # training and validation
56 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
57 |
58 | # save model
59 | save_model_weights(model)
60 |
--------------------------------------------------------------------------------
/googlenet.py:
--------------------------------------------------------------------------------
1 | # [Going Deeper with Convolutions](https://arxiv.org/abs/1409.4842)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers, activations
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # multi kernel size to capture different local information
13 | def inception(x, f1, f2, f3, f4, name):
14 | act = activations.relu
15 | inputs = layers.Input(shape=x.shape[1:])
16 |
17 | p1 = layers.Conv2D(filters=f1, kernel_size=1, strides=1, activation=act, name="p1")(inputs)
18 |
19 | p2 = layers.Conv2D(f2[0], 1, 1, name="p21")(inputs)
20 | p2 = layers.Conv2D(f2[1], 3, 1, padding="same", activation=act, name="p22")(p2)
21 |
22 | p3 = layers.Conv2D(f3[0], 1, 1, name="p31")(inputs)
23 | p3 = layers.Conv2D(f3[1], 5, 1, padding="same", activation=act, name="p32")(p3)
24 |
25 | p4 = layers.MaxPool2D(pool_size=3, strides=1, padding="same", name="p41")(inputs)
26 | p4 = layers.Conv2D(f4, 1, activation=act, name="p42")(p4)
27 |
28 | p = layers.concatenate((p1, p2, p3, p4), axis=-1)
29 | m = keras.Model(inputs, p, name=name)
30 | return m(x)
31 |
32 |
33 | def build_model():
34 | inputs = layers.Input(shape=(28, 28, 1), name="img")
35 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
36 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
37 | x = inception(x, f1=4, f2=(2, 4), f3=(2, 4), f4=4, name="inspection1") # [n, 14, 14, 4*4]
38 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 4*4]
39 | x = inception(x, f1=8, f2=(4, 8), f3=(4, 8), f4=8, name="inspection2") # [n, 7, 7, 8*4]
40 | x = layers.GlobalAveragePooling2D()(x) # [n, 8*4]
41 | o = layers.Dense(10)(x) # [n, 10]
42 | return keras.Model(inputs, o, name="GoogLeNet")
43 |
44 |
45 | # show model
46 | model = build_model()
47 | model.summary()
48 | save_model_structure(model)
49 |
50 | # define loss and optimizer
51 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
52 | opt = keras.optimizers.Adam(0.001)
53 | accuracy = keras.metrics.SparseCategoricalAccuracy()
54 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
55 |
56 | # training and validation
57 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
58 |
59 | # save model
60 | save_model_weights(model)
61 |
62 |
63 |
--------------------------------------------------------------------------------
/lenet.py:
--------------------------------------------------------------------------------
1 | # [Gradient-Based Learning Applied to Document Recognition](http://www.dengfanxin.cn/wp-content/uploads/2016/03/1998Lecun.pdf)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 | # define model
12 | model = keras.Sequential([
13 | layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same", input_shape=(28, 28, 1)), # [n, 28, 28, 8]
14 | layers.MaxPool2D(pool_size=2, strides=2), # [n, 14, 14, 8]
15 | layers.Conv2D(16, 3, 1, "same"), # [n, 14, 14, 16]
16 | layers.MaxPool2D(2, 2), # [n, 7, 7, 16]
17 | layers.Flatten(), # [n, 7*7*16]
18 | layers.Dense(10) # [n, 10]
19 | ], name="LeNet")
20 |
21 | # show model
22 | model.summary()
23 | save_model_structure(model)
24 |
25 | # define loss and optimizer
26 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
27 | opt = keras.optimizers.Adam(0.001)
28 | accuracy = keras.metrics.SparseCategoricalAccuracy()
29 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
30 |
31 | # training and validation
32 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
33 |
34 | # save model
35 | save_model_weights(model)
36 |
37 |
38 |
--------------------------------------------------------------------------------
/mobilenetv1.py:
--------------------------------------------------------------------------------
1 | # [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # (dw+pw). small but effective cnn optimized on mobile (cpu)
13 | def block(x, filters):
14 | # Depthwise Separable convolutions
15 | o = layers.DepthwiseConv2D(kernel_size=3, strides=1, padding="same")(x) # [n, h, w, c] dw
16 | o = layers.ReLU()(o)
17 | o = layers.Conv2D(filters, 1, 1)(o) # [n, h, w, f] pw
18 | o = layers.ReLU()(o)
19 | return o
20 |
21 |
22 | def build_model():
23 | inputs = layers.Input(shape=(28, 28, 1), name="img")
24 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
25 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
26 | x = block(x, filters=20) # [n, 14, 14, 20]
27 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 20]
28 | x = block(x, 40) # [n, 7, 7, 40]
29 | x = layers.GlobalAveragePooling2D()(x) # [n, 40]
30 | o = layers.Dense(10)(x) # [n, 10]
31 | return keras.Model(inputs, o, name="MobileNetV1")
32 |
33 |
34 | # show model
35 | model = build_model()
36 | model.summary()
37 | save_model_structure(model)
38 |
39 | # define loss and optimizer
40 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
41 | opt = keras.optimizers.Adam(0.001)
42 | accuracy = keras.metrics.SparseCategoricalAccuracy()
43 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
44 |
45 | # training and validation
46 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
47 |
48 | # save model
49 | save_model_weights(model)
50 |
--------------------------------------------------------------------------------
/mobilenetv2.py:
--------------------------------------------------------------------------------
1 | # [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # (residual+pw+dw+pw). mobilenet v1 with residual block and layer rearrange
13 | def block(x, filters, expand_ratio=4):
14 | # mobilenet v1: dw > pw
15 | # mobilenet v2: pw > dw > pw let dw see more feature maps
16 | o = layers.Conv2D(int(filters*expand_ratio), 1, 1)(x) # [n, h, w, c*e] pw expansion
17 | o = layers.ReLU()(o)
18 | o = layers.DepthwiseConv2D(kernel_size=3, strides=1, padding="same")(o) # [n, h/s, w/s, c*e] dw
19 | o = layers.ReLU()(o)
20 | o = layers.Conv2D(filters, 1, 1)(o) # [n, h, w, c] pw
21 | if x.shape[-1] == filters:
22 | o = layers.add((o, x)) # residual connection
23 | return o
24 |
25 |
26 | def build_model():
27 | inputs = layers.Input(shape=(28, 28, 1), name="img")
28 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
29 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
30 | x = block(x, filters=5) # [n, 14, 14, 5]
31 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 5]
32 | x = block(x, 10) # [n, 7, 7, 10]
33 | x = layers.GlobalAveragePooling2D()(x) # [n, 10]
34 | o = layers.Dense(10)(x) # [n, 10]
35 | return keras.Model(inputs, o, name="MobileNetV2")
36 |
37 |
38 | # show model
39 | model = build_model()
40 | model.summary()
41 | save_model_structure(model)
42 |
43 | # define loss and optimizer
44 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
45 | opt = keras.optimizers.Adam(0.001)
46 | accuracy = keras.metrics.SparseCategoricalAccuracy()
47 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
48 |
49 | # training and validation
50 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
51 |
52 | # save model
53 | save_model_weights(model)
54 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | matplotlib==3.3.3
2 | numpy==1.18.5
3 | Pillow==8.0.1
4 | tensorflow==2.3.0
5 | pydot==1.4.1
6 |
--------------------------------------------------------------------------------
/resnet.py:
--------------------------------------------------------------------------------
1 | # [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # add residual connection for better gradients
13 | def bottleneck(x, filters, strides=1):
14 | c = x.shape[-1]
15 | if c != filters:
16 | shortcut = layers.Conv2D(filters, 1, strides, "same")(x)
17 | else:
18 | shortcut = x
19 | o = layers.ReLU()(x)
20 | o = layers.Conv2D(c, kernel_size=3, strides=1, padding="same")(o) # [n, h, w, c]
21 | o = layers.ReLU()(o)
22 | o = layers.Conv2D(filters, 3, strides, "same")(o) # [n, h/s, w/s, f]
23 | o = layers.add((o, shortcut))
24 | return o
25 |
26 |
27 | def block(x, filters, strides=1, n_bottleneck=2):
28 | o = bottleneck(x, filters, strides) # [n, h/s, w/s, f]
29 | for i in range(1, n_bottleneck):
30 | o = bottleneck(o, filters, 1) # [n, h/s, w/s, f]
31 | return o
32 |
33 |
34 | def build_model():
35 | inputs = layers.Input(shape=(28, 28, 1), name="img")
36 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
37 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
38 | x = block(x, filters=8, strides=1, n_bottleneck=2) # [n, 14, 14, 8]
39 | x = block(x, 16, 2, 1) # [n, 7, 7, 16]
40 | x = layers.GlobalAveragePooling2D()(x) # [n, 16]
41 | o = layers.Dense(10)(x) # [n, 10]
42 | return keras.Model(inputs, o, name="ResNet")
43 |
44 | # show model
45 | model = build_model()
46 | model.summary()
47 | save_model_structure(model)
48 |
49 | # define loss and optimizer
50 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
51 | opt = keras.optimizers.Adam(0.001)
52 | accuracy = keras.metrics.SparseCategoricalAccuracy()
53 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
54 |
55 | # training and validation
56 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
57 |
58 | # save model
59 | save_model_weights(model)
60 |
--------------------------------------------------------------------------------
/senet.py:
--------------------------------------------------------------------------------
1 | # [Squeeze-and-Excitation Networks](https://arxiv.org/abs/1709.01507)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # SE is a module that learns to scale each feature map, we can plug in a resnet block
13 | # larger reduction_ratio reduce parameter size in FC layers with limited accuracy drop
14 | def se(x, reduction_ratio=4):
15 | c = x.shape[-1]
16 | s = layers.GlobalAveragePooling2D()(x)
17 | s = layers.Dense(c // reduction_ratio)(s)
18 | s = layers.ReLU()(s)
19 | s = layers.Dense(c, activation=keras.activations.sigmoid)(s)
20 | return x * layers.Reshape((1, 1, c))(s)
21 |
22 |
23 | def bottleneck(x, filters, strides=1, reduction_ratio=4):
24 | in_channels = x.shape[-1]
25 | if in_channels != filters:
26 | shortcut = layers.Conv2D(filters, 1, strides, "same", name="projection")(x)
27 | else:
28 | shortcut = x
29 | o = layers.ReLU()(x)
30 | o = layers.Conv2D(in_channels, kernel_size=3, strides=1, padding="same")(o) # [n, h, w, c]
31 | o = layers.ReLU()(o)
32 | o = layers.Conv2D(filters, 3, strides, "same")(o) # [n, h/s, w/s, f]
33 | o = se(o, reduction_ratio)
34 | o = layers.add((o, shortcut))
35 | return o
36 |
37 |
38 | def block(x, filters, strides=1, n_bottleneck=2):
39 | o = bottleneck(x, filters, strides) # [n, h/s, w/s, f]
40 | for i in range(1, n_bottleneck):
41 | o = bottleneck(o, filters, 1) # [n, h/s, w/s, f]
42 | return o
43 |
44 |
45 | def build_model():
46 | inputs = layers.Input(shape=(28, 28, 1), name="img")
47 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
48 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
49 | x = block(x, filters=8, strides=1, n_bottleneck=2) # [n, 14, 14, 8]
50 | x = block(x, 16, 2, 1) # [n, 7, 7, 16]
51 | x = layers.GlobalAveragePooling2D()(x) # [n, 16]
52 | o = layers.Dense(10)(x) # [n, 10]
53 | return keras.Model(inputs, o, name="SENet")
54 |
55 | # show model
56 | model = build_model()
57 | model.summary()
58 | save_model_structure(model)
59 |
60 | # define loss and optimizer
61 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
62 | opt = keras.optimizers.Adam(0.001)
63 | accuracy = keras.metrics.SparseCategoricalAccuracy()
64 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
65 |
66 | # training and validation
67 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
68 |
69 | # save model
70 | save_model_weights(model)
71 |
--------------------------------------------------------------------------------
/shufflenetv1.py:
--------------------------------------------------------------------------------
1 | # [ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices](https://arxiv.org/abs/1707.01083)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | import tensorflow as tf
7 | from utils import load_mnist, save_model_structure, save_model_weights
8 |
9 | # get data
10 | (x_train, y_train), (x_test, y_test) = load_mnist()
11 |
12 |
13 | # Grouped 1x1 conv to reduce parameters, but shuffle grouped feature maps to mix isolated feature map.
14 | def shuffle(x, groups):
15 | _, h, w, c = x.shape
16 | gc = c // groups
17 | o = layers.Reshape((h, w, groups, gc))(x) # [n, h, w, g, gc]
18 | o = layers.Permute((1, 2, 4, 3))(o) # shuffle in groups
19 | o = layers.Reshape((h, w, c))(o)
20 | return o
21 |
22 |
23 | def group_conv(x, filters, groups):
24 | assert x.shape[-1] % groups == 0
25 | assert filters % groups == 0
26 | if tf.test.is_built_with_gpu_support():
27 | o = layers.Conv2D(filters, 1, 1, groups=groups)(x) # [n, h, w, f] pw, groups=groups not works on cpu (tf=2.3.0)
28 | else:
29 | o = layers.concatenate([
30 | layers.Conv2D(filters // groups, 1, 1)(g) for g in tf.split(x, groups, axis=-1)
31 | ], axis=-1) # this works on cpu [n, h, w, f]
32 | return o
33 |
34 |
35 | def block(x, filters, groups=4):
36 | o = group_conv(x, x.shape[-1], groups) # [n, h, w, c] gpw
37 | o = shuffle(o, groups)
38 | o = layers.ReLU()(o)
39 | o = layers.DepthwiseConv2D(kernel_size=3, strides=1, padding="same")(o) # [n, h, w, c] dw
40 | o = group_conv(o, filters, groups) # [n, h, w, f] gpw
41 | if x.shape[-1] != filters:
42 | x = group_conv(x, filters, groups) # [n, h, w, f]
43 | o = layers.add((o, x)) # residual connection
44 | return o
45 |
46 |
47 | def build_model():
48 | inputs = layers.Input(shape=(28, 28, 1), name="img")
49 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
50 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
51 | x = block(x, filters=32, groups=4) # [n, 14, 14, 32]
52 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 32]
53 | x = block(x, 64, 4) # [n, 7, 7, 64]
54 | x = layers.GlobalAveragePooling2D()(x) # [n, 64]
55 | o = layers.Dense(10)(x) # [n, 10]
56 | return keras.Model(inputs, o, name="ShuffleNetV1")
57 |
58 |
59 | # show model
60 | model = build_model()
61 | model.summary()
62 | save_model_structure(model)
63 |
64 | # define loss and optimizer
65 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
66 | opt = keras.optimizers.Adam(0.001)
67 | accuracy = keras.metrics.SparseCategoricalAccuracy()
68 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
69 |
70 | # training and validation
71 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
72 |
73 | # save model
74 | save_model_weights(model)
75 |
--------------------------------------------------------------------------------
/shufflenetv2.py:
--------------------------------------------------------------------------------
1 | # [ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design](https://arxiv.org/abs/1807.11164)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | import tensorflow as tf
7 | from utils import load_mnist, save_model_structure, save_model_weights
8 |
9 | # get data
10 | (x_train, y_train), (x_test, y_test) = load_mnist()
11 |
12 |
13 | # Further reduces parameters by switching group conv with split+concat, perform shuffle at end of block.
14 | # Speed up calculation.
15 | def shuffle(x, groups):
16 | _, h, w, c = x.shape
17 | gc = c // groups
18 | o = layers.Reshape((h, w, groups, gc))(x) # [n, h, w, g, gc]
19 | o = layers.Permute((1, 2, 4, 3))(o) # shuffle in groups
20 | o = layers.Reshape((h, w, c))(o)
21 | return o
22 |
23 |
24 | def block(x, filters):
25 | x1, x2 = tf.split(x, 2, axis=-1) # x1 [n, h, w, c/2], x2 [n, h, w, c/2]
26 | c = x.shape[-1]
27 | o = layers.Conv2D(x2.shape[-1], 1, 1)(x2) # [n, h, w, c/2]
28 | o = layers.ReLU()(o)
29 | o = layers.DepthwiseConv2D(kernel_size=3, strides=1, padding="same")(o) # [n, h, w, c/2]
30 | o = layers.ReLU()(o)
31 | o = layers.Conv2D(filters//2, 1, 1)(o) # [n, h, w, f/2]
32 | if filters != c:
33 | x1 = layers.Conv2D(filters//2, 1, 1)(x1) # [n, h, w, f/2]
34 | o = layers.concatenate([x1, o], axis=-1) # [n, h, w, f]
35 | o = shuffle(o, 2) #
36 | return o
37 |
38 |
39 | def build_model():
40 | inputs = layers.Input(shape=(28, 28, 1), name="img")
41 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
42 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
43 | x = block(x, filters=32) # [n, 14, 14, 32]
44 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 32]
45 | x = block(x, 64) # [n, 7, 7, 64]
46 | x = layers.GlobalAveragePooling2D()(x) # [n, 64]
47 | o = layers.Dense(10)(x) # [n, 10]
48 | return keras.Model(inputs, o, name="ShuffleNetV2")
49 |
50 |
51 | # show model
52 | model = build_model()
53 | model.summary()
54 | save_model_structure(model)
55 |
56 | # define loss and optimizer
57 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
58 | opt = keras.optimizers.Adam(0.001)
59 | accuracy = keras.metrics.SparseCategoricalAccuracy()
60 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
61 |
62 | # training and validation
63 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
64 |
65 | # save model
66 | save_model_weights(model)
67 |
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import os
3 | from urllib.request import urlretrieve
4 | from tensorflow import keras
5 |
6 | MNIST_PATH = "./mnist.npz"
7 |
8 |
9 | def load_mnist(path="./mnist.npz", norm=True):
10 | if not os.path.isfile(path):
11 | print("not mnist data is found, try downloading...")
12 | urlretrieve("https://s3.amazonaws.com/img-datasets/mnist.npz", path)
13 | with np.load(path, allow_pickle=True) as f:
14 | x_train = f['x_train'].astype(np.float32)[:, :, :, None]
15 | y_train = f['y_train'].astype(np.float32)[:, None]
16 | x_test = f['x_test'].astype(np.float32)[:, :, :, None]
17 | y_test = f['y_test'].astype(np.float32)[:, None]
18 | if norm:
19 | x_train /= 255
20 | x_test /= 255
21 | return (x_train, y_train), (x_test, y_test)
22 |
23 |
24 | def save_model_structure(model: keras.Model, path=None):
25 | if path is None:
26 | path = "visual/{}/{}_structure.png".format(model.name, model.name)
27 | os.makedirs(os.path.dirname(path), exist_ok=True)
28 | try:
29 | keras.utils.plot_model(model, show_shapes=True, expand_nested=True, dpi=150, to_file=path)
30 | except Exception as e:
31 | print(e)
32 |
33 |
34 | def save_model_weights(model: keras.Model, path=None):
35 | if path is None:
36 | path = "visual/{}/model/net".format(model.name)
37 | os.makedirs(os.path.dirname(path), exist_ok=True)
38 | model.save_weights(path)
39 |
40 |
41 | def load_model_weights(model: keras.Model, path=None):
42 | if path is None:
43 | path = "visual/{}/model/net".format(model.name)
44 | model.load_weights(path)
--------------------------------------------------------------------------------
/vgg.py:
--------------------------------------------------------------------------------
1 | # [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 | # define model
12 | # like LeNet with more layers and activations
13 | model = keras.Sequential([
14 | layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same", input_shape=(28, 28, 1)), # [n, 28, 28, 8]
15 | layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same", input_shape=(28, 28, 1)), # [n, 28, 28, 8]
16 | layers.ReLU(),
17 | layers.MaxPool2D(pool_size=2, strides=2), # [n, 14, 14, 8]
18 | layers.Conv2D(16, 3, 1, "same"), # [n, 14, 14, 16]
19 | layers.Conv2D(16, 3, 1, "same"), # [n, 14, 14, 16]
20 | layers.ReLU(),
21 | layers.MaxPool2D(2, 2), # [n, 7, 7, 16]
22 | layers.Flatten(), # [n, 7*7*16]
23 | layers.Dense(32), # [n, 32]
24 | layers.ReLU(),
25 | layers.Dense(10) # [n, 32]
26 | ], name="VGG")
27 |
28 | # show model
29 | model.summary()
30 | save_model_structure(model)
31 |
32 | # define loss and optimizer
33 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
34 | opt = keras.optimizers.Adam(0.001)
35 | accuracy = keras.metrics.SparseCategoricalAccuracy()
36 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
37 |
38 | # training and validation
39 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
40 |
41 | # save model
42 | save_model_weights(model)
43 |
--------------------------------------------------------------------------------
/xception.py:
--------------------------------------------------------------------------------
1 | # [Xception: Deep Learning with Depthwise Separable Convolutions](https://arxiv.org/abs/1610.02357)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # (residual+pw+dw) just like mobilenetv2 without last pw
13 | def block(x, filters):
14 | if x.shape[-1] != filters:
15 | shortcut = layers.Conv2D(filters, 1, 1)(x)
16 | else:
17 | shortcut = x
18 | o = layers.ReLU()(x)
19 | o = layers.Conv2D(filters, 1, 1)(o) # [n, h, w, f] pw
20 | o = layers.ReLU()(o)
21 | o = layers.DepthwiseConv2D(3, 1, "same")(o) # [n, h, w, f] dw
22 | o = layers.add((o, shortcut)) # residual connection
23 | return o
24 |
25 |
26 | def build_model():
27 | inputs = layers.Input(shape=(28, 28, 1), name="img")
28 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
29 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
30 | x = block(x, filters=16) # [n, 14, 14, 16]
31 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 16]
32 | x = block(x, 32) # [n, 7, 7, 32]
33 | x = layers.GlobalAveragePooling2D()(x) # [n, 32]
34 | o = layers.Dense(10)(x) # [n, 10]
35 | return keras.Model(inputs, o, name="Xception")
36 |
37 |
38 | # show model
39 | model = build_model()
40 | model.summary()
41 | save_model_structure(model)
42 |
43 | # define loss and optimizer
44 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
45 | opt = keras.optimizers.Adam(0.001)
46 | accuracy = keras.metrics.SparseCategoricalAccuracy()
47 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
48 |
49 | # training and validation
50 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
51 |
52 | # save model
53 | save_model_weights(model)
54 |
--------------------------------------------------------------------------------
161 |
--------------------------------------------------------------------------------
/conv_demo.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import matplotlib.pyplot as plt
3 | import os
4 | from PIL import Image
5 | from utils import load_mnist
6 |
7 |
8 | def save_gif(imgs_dir):
9 | imgs = []
10 | imgs_path = [os.path.join(imgs_dir, p) for p in os.listdir(imgs_dir) if p.endswith(".png")]
11 | for f in sorted(imgs_path, key=os.path.getmtime):
12 | if not f.endswith(".png"):
13 | continue
14 | img = Image.open(f)
15 | img = img.resize((img.width, img.height), Image.ANTIALIAS)
16 | imgs.append(img)
17 | path = "{}/conv_mechanism.gif".format(os.path.dirname(imgs_dir))
18 | if os.path.exists(path):
19 | os.remove(path)
20 | imgs[0].save(path, append_images=imgs[1:], optimize=False, save_all=True, duration=20, loop=0)
21 | print("saved ", path)
22 |
23 |
24 | def show_conv(save_dir, image):
25 | filter = np.array([
26 | [1, 1, 1],
27 | [0, 0, 0],
28 | [-1, -1, -1]])
29 | plt.figure(0, figsize=(9, 5))
30 | ax1 = plt.subplot(121)
31 | ax1.imshow(image, cmap='gray_r')
32 | plt.xticks(())
33 | plt.yticks(())
34 | ax2 = plt.subplot(122)
35 | texts = []
36 | feature_map = np.zeros((26, 26))
37 | for i in range(26):
38 | for j in range(26):
39 |
40 | if texts:
41 | fm.remove()
42 | for n in range(3):
43 | for m in range(3):
44 | if len(texts) != 9:
45 | texts.append(ax1.text(j+m, i+n, filter[n, m], color='k', size=8, ha='center', va='center'))
46 | else:
47 | texts[n*3+m].set_position((j+m, i+n))
48 |
49 | feature_map[i, j] = np.sum(filter * image[i:i+3, j:j+3])
50 | fm = ax2.imshow(feature_map, cmap='gray', vmax=3, vmin=-3)
51 | plt.xticks(())
52 | plt.yticks(())
53 | plt.tight_layout()
54 | plt.savefig(os.path.join(save_dir, "i{}j{}.png".format(i, j)))
55 |
56 |
57 | def show_feature_map(save_dir, image):
58 | filters = [
59 | np.array([
60 | [1, 1, 1],
61 | [0, 0, 0],
62 | [-1, -1, -1]]),
63 | np.array([
64 | [-1, -1, -1],
65 | [0, 0, 0],
66 | [1, 1, 1]]),
67 | np.array([
68 | [1, 0, -1],
69 | [1, 0, -1],
70 | [1, 0, -1]]),
71 | np.array([
72 | [-1, 0, 1],
73 | [-1, 0, 1],
74 | [-1, 0, 1]])
75 | ]
76 |
77 | plt.figure(1)
78 | plt.title('Original image')
79 | plt.imshow(image, cmap='gray_r')
80 | plt.xticks(())
81 | plt.yticks(())
82 | plt.savefig(os.path.join(save_dir, "original_img.png"))
83 |
84 | plt.figure(2)
85 | for n in range(4):
86 | feature_map = np.zeros((26, 26))
87 |
88 | for i in range(26):
89 | for j in range(26):
90 | feature_map[i, j] = np.sum(image[i:i + 3, j:j + 3] * filters[n])
91 |
92 | plt.subplot(3, 4, 1 + n)
93 | plt.title('Filter%i' % n)
94 | plt.imshow(filters[n], cmap='gray', vmax=3, vmin=-3)
95 | plt.xticks(())
96 | plt.yticks(())
97 |
98 | plt.subplot(3, 4, 5 + n)
99 | plt.title('Conv%i' % n)
100 | plt.imshow(feature_map, cmap='gray', vmax=3, vmin=-3)
101 | plt.xticks(())
102 | plt.yticks(())
103 |
104 | plt.subplot(3, 4, 9 + n)
105 | plt.title('ReLU%i' % n)
106 | feature_map = np.maximum(0, feature_map)
107 | plt.imshow(feature_map, cmap='gray', vmax=3, vmin=-3)
108 | plt.xticks(())
109 | plt.yticks(())
110 |
111 | plt.tight_layout()
112 | plt.savefig(os.path.join(save_dir, "feature_map.png"))
113 |
114 |
115 | if __name__ == "__main__":
116 | result_dir = "visual/basic"
117 | conv_dir = os.path.join(result_dir, "conv")
118 | os.makedirs(conv_dir, exist_ok=True)
119 | (x_train, y_train), (x_test, y_test) = load_mnist()
120 |
121 | data = x_train[7].squeeze(axis=-1)
122 | show_feature_map(result_dir, data)
123 | show_conv(conv_dir, data)
124 | save_gif(conv_dir)
125 |
--------------------------------------------------------------------------------
/densenet.py:
--------------------------------------------------------------------------------
1 | # [Densely Connected Convolutional Networks](https://arxiv.org/abs/1608.06993)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # compared with resnet, it has less filter each conv, sees more previous inputs
13 | def bottleneck(xs, growth_rate):
14 | if len(xs) == 1:
15 | o = xs[0]
16 | else:
17 | o = layers.concatenate(xs, axis=-1) # [n, h, w, c * xs]
18 | o = layers.ReLU()(o)
19 | o = layers.Conv2D(growth_rate, kernel_size=1, strides=1)(o) # [n, h, w, c]
20 | o = layers.ReLU()(o)
21 | o = layers.Conv2D(growth_rate, kernel_size=3, strides=1, padding="same")(o) # [n, h, w, c]
22 | return o
23 |
24 |
25 | def block(x, growth_rate, n_bottleneck=2):
26 | outs = [bottleneck([x], growth_rate)] # [n, h, w, c]
27 | for i in range(1, n_bottleneck):
28 | o = bottleneck(outs, growth_rate) # [n, h, w, c]
29 | outs.append(o)
30 | return layers.concatenate(outs, axis=-1) # [n, h, w, c * n_bottleneck]
31 |
32 |
33 | def build_model():
34 | inputs = layers.Input(shape=(28, 28, 1), name="img")
35 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
36 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
37 | x = block(x, growth_rate=8, n_bottleneck=2) # [n, 14, 14, 8*2]
38 | x = layers.MaxPool2D(2)(x) # [n, 7, 7, 8*2]
39 | x = block(x, 8, 3) # [n, 7, 7, 8*3]
40 | x = layers.GlobalAveragePooling2D()(x) # [n, 24]
41 | o = layers.Dense(10)(x) # [n, 10]
42 | return keras.Model(inputs, o, name="DenseNet")
43 |
44 | # show model
45 | model = build_model()
46 | model.summary()
47 | save_model_structure(model)
48 |
49 | # define loss and optimizer
50 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
51 | opt = keras.optimizers.Adam(0.001)
52 | accuracy = keras.metrics.SparseCategoricalAccuracy()
53 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
54 |
55 | # training and validation
56 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
57 |
58 | # save model
59 | save_model_weights(model)
60 |
--------------------------------------------------------------------------------
/googlenet.py:
--------------------------------------------------------------------------------
1 | # [Going Deeper with Convolutions](https://arxiv.org/abs/1409.4842)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers, activations
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # multi kernel size to capture different local information
13 | def inception(x, f1, f2, f3, f4, name):
14 | act = activations.relu
15 | inputs = layers.Input(shape=x.shape[1:])
16 |
17 | p1 = layers.Conv2D(filters=f1, kernel_size=1, strides=1, activation=act, name="p1")(inputs)
18 |
19 | p2 = layers.Conv2D(f2[0], 1, 1, name="p21")(inputs)
20 | p2 = layers.Conv2D(f2[1], 3, 1, padding="same", activation=act, name="p22")(p2)
21 |
22 | p3 = layers.Conv2D(f3[0], 1, 1, name="p31")(inputs)
23 | p3 = layers.Conv2D(f3[1], 5, 1, padding="same", activation=act, name="p32")(p3)
24 |
25 | p4 = layers.MaxPool2D(pool_size=3, strides=1, padding="same", name="p41")(inputs)
26 | p4 = layers.Conv2D(f4, 1, activation=act, name="p42")(p4)
27 |
28 | p = layers.concatenate((p1, p2, p3, p4), axis=-1)
29 | m = keras.Model(inputs, p, name=name)
30 | return m(x)
31 |
32 |
33 | def build_model():
34 | inputs = layers.Input(shape=(28, 28, 1), name="img")
35 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
36 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
37 | x = inception(x, f1=4, f2=(2, 4), f3=(2, 4), f4=4, name="inspection1") # [n, 14, 14, 4*4]
38 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 4*4]
39 | x = inception(x, f1=8, f2=(4, 8), f3=(4, 8), f4=8, name="inspection2") # [n, 7, 7, 8*4]
40 | x = layers.GlobalAveragePooling2D()(x) # [n, 8*4]
41 | o = layers.Dense(10)(x) # [n, 10]
42 | return keras.Model(inputs, o, name="GoogLeNet")
43 |
44 |
45 | # show model
46 | model = build_model()
47 | model.summary()
48 | save_model_structure(model)
49 |
50 | # define loss and optimizer
51 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
52 | opt = keras.optimizers.Adam(0.001)
53 | accuracy = keras.metrics.SparseCategoricalAccuracy()
54 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
55 |
56 | # training and validation
57 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
58 |
59 | # save model
60 | save_model_weights(model)
61 |
62 |
63 |
--------------------------------------------------------------------------------
/lenet.py:
--------------------------------------------------------------------------------
1 | # [Gradient-Based Learning Applied to Document Recognition](http://www.dengfanxin.cn/wp-content/uploads/2016/03/1998Lecun.pdf)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 | # define model
12 | model = keras.Sequential([
13 | layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same", input_shape=(28, 28, 1)), # [n, 28, 28, 8]
14 | layers.MaxPool2D(pool_size=2, strides=2), # [n, 14, 14, 8]
15 | layers.Conv2D(16, 3, 1, "same"), # [n, 14, 14, 16]
16 | layers.MaxPool2D(2, 2), # [n, 7, 7, 16]
17 | layers.Flatten(), # [n, 7*7*16]
18 | layers.Dense(10) # [n, 10]
19 | ], name="LeNet")
20 |
21 | # show model
22 | model.summary()
23 | save_model_structure(model)
24 |
25 | # define loss and optimizer
26 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
27 | opt = keras.optimizers.Adam(0.001)
28 | accuracy = keras.metrics.SparseCategoricalAccuracy()
29 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
30 |
31 | # training and validation
32 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
33 |
34 | # save model
35 | save_model_weights(model)
36 |
37 |
38 |
--------------------------------------------------------------------------------
/mobilenetv1.py:
--------------------------------------------------------------------------------
1 | # [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # (dw+pw). small but effective cnn optimized on mobile (cpu)
13 | def block(x, filters):
14 | # Depthwise Separable convolutions
15 | o = layers.DepthwiseConv2D(kernel_size=3, strides=1, padding="same")(x) # [n, h, w, c] dw
16 | o = layers.ReLU()(o)
17 | o = layers.Conv2D(filters, 1, 1)(o) # [n, h, w, f] pw
18 | o = layers.ReLU()(o)
19 | return o
20 |
21 |
22 | def build_model():
23 | inputs = layers.Input(shape=(28, 28, 1), name="img")
24 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
25 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
26 | x = block(x, filters=20) # [n, 14, 14, 20]
27 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 20]
28 | x = block(x, 40) # [n, 7, 7, 40]
29 | x = layers.GlobalAveragePooling2D()(x) # [n, 40]
30 | o = layers.Dense(10)(x) # [n, 10]
31 | return keras.Model(inputs, o, name="MobileNetV1")
32 |
33 |
34 | # show model
35 | model = build_model()
36 | model.summary()
37 | save_model_structure(model)
38 |
39 | # define loss and optimizer
40 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
41 | opt = keras.optimizers.Adam(0.001)
42 | accuracy = keras.metrics.SparseCategoricalAccuracy()
43 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
44 |
45 | # training and validation
46 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
47 |
48 | # save model
49 | save_model_weights(model)
50 |
--------------------------------------------------------------------------------
/mobilenetv2.py:
--------------------------------------------------------------------------------
1 | # [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # (residual+pw+dw+pw). mobilenet v1 with residual block and layer rearrange
13 | def block(x, filters, expand_ratio=4):
14 | # mobilenet v1: dw > pw
15 | # mobilenet v2: pw > dw > pw let dw see more feature maps
16 | o = layers.Conv2D(int(filters*expand_ratio), 1, 1)(x) # [n, h, w, c*e] pw expansion
17 | o = layers.ReLU()(o)
18 | o = layers.DepthwiseConv2D(kernel_size=3, strides=1, padding="same")(o) # [n, h/s, w/s, c*e] dw
19 | o = layers.ReLU()(o)
20 | o = layers.Conv2D(filters, 1, 1)(o) # [n, h, w, c] pw
21 | if x.shape[-1] == filters:
22 | o = layers.add((o, x)) # residual connection
23 | return o
24 |
25 |
26 | def build_model():
27 | inputs = layers.Input(shape=(28, 28, 1), name="img")
28 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
29 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
30 | x = block(x, filters=5) # [n, 14, 14, 5]
31 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 5]
32 | x = block(x, 10) # [n, 7, 7, 10]
33 | x = layers.GlobalAveragePooling2D()(x) # [n, 10]
34 | o = layers.Dense(10)(x) # [n, 10]
35 | return keras.Model(inputs, o, name="MobileNetV2")
36 |
37 |
38 | # show model
39 | model = build_model()
40 | model.summary()
41 | save_model_structure(model)
42 |
43 | # define loss and optimizer
44 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
45 | opt = keras.optimizers.Adam(0.001)
46 | accuracy = keras.metrics.SparseCategoricalAccuracy()
47 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
48 |
49 | # training and validation
50 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
51 |
52 | # save model
53 | save_model_weights(model)
54 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | matplotlib==3.3.3
2 | numpy==1.18.5
3 | Pillow==8.0.1
4 | tensorflow==2.3.0
5 | pydot==1.4.1
6 |
--------------------------------------------------------------------------------
/resnet.py:
--------------------------------------------------------------------------------
1 | # [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # add residual connection for better gradients
13 | def bottleneck(x, filters, strides=1):
14 | c = x.shape[-1]
15 | if c != filters:
16 | shortcut = layers.Conv2D(filters, 1, strides, "same")(x)
17 | else:
18 | shortcut = x
19 | o = layers.ReLU()(x)
20 | o = layers.Conv2D(c, kernel_size=3, strides=1, padding="same")(o) # [n, h, w, c]
21 | o = layers.ReLU()(o)
22 | o = layers.Conv2D(filters, 3, strides, "same")(o) # [n, h/s, w/s, f]
23 | o = layers.add((o, shortcut))
24 | return o
25 |
26 |
27 | def block(x, filters, strides=1, n_bottleneck=2):
28 | o = bottleneck(x, filters, strides) # [n, h/s, w/s, f]
29 | for i in range(1, n_bottleneck):
30 | o = bottleneck(o, filters, 1) # [n, h/s, w/s, f]
31 | return o
32 |
33 |
34 | def build_model():
35 | inputs = layers.Input(shape=(28, 28, 1), name="img")
36 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
37 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
38 | x = block(x, filters=8, strides=1, n_bottleneck=2) # [n, 14, 14, 8]
39 | x = block(x, 16, 2, 1) # [n, 7, 7, 16]
40 | x = layers.GlobalAveragePooling2D()(x) # [n, 16]
41 | o = layers.Dense(10)(x) # [n, 10]
42 | return keras.Model(inputs, o, name="ResNet")
43 |
44 | # show model
45 | model = build_model()
46 | model.summary()
47 | save_model_structure(model)
48 |
49 | # define loss and optimizer
50 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
51 | opt = keras.optimizers.Adam(0.001)
52 | accuracy = keras.metrics.SparseCategoricalAccuracy()
53 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
54 |
55 | # training and validation
56 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
57 |
58 | # save model
59 | save_model_weights(model)
60 |
--------------------------------------------------------------------------------
/senet.py:
--------------------------------------------------------------------------------
1 | # [Squeeze-and-Excitation Networks](https://arxiv.org/abs/1709.01507)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # SE is a module that learns to scale each feature map, we can plug in a resnet block
13 | # larger reduction_ratio reduce parameter size in FC layers with limited accuracy drop
14 | def se(x, reduction_ratio=4):
15 | c = x.shape[-1]
16 | s = layers.GlobalAveragePooling2D()(x)
17 | s = layers.Dense(c // reduction_ratio)(s)
18 | s = layers.ReLU()(s)
19 | s = layers.Dense(c, activation=keras.activations.sigmoid)(s)
20 | return x * layers.Reshape((1, 1, c))(s)
21 |
22 |
23 | def bottleneck(x, filters, strides=1, reduction_ratio=4):
24 | in_channels = x.shape[-1]
25 | if in_channels != filters:
26 | shortcut = layers.Conv2D(filters, 1, strides, "same", name="projection")(x)
27 | else:
28 | shortcut = x
29 | o = layers.ReLU()(x)
30 | o = layers.Conv2D(in_channels, kernel_size=3, strides=1, padding="same")(o) # [n, h, w, c]
31 | o = layers.ReLU()(o)
32 | o = layers.Conv2D(filters, 3, strides, "same")(o) # [n, h/s, w/s, f]
33 | o = se(o, reduction_ratio)
34 | o = layers.add((o, shortcut))
35 | return o
36 |
37 |
38 | def block(x, filters, strides=1, n_bottleneck=2):
39 | o = bottleneck(x, filters, strides) # [n, h/s, w/s, f]
40 | for i in range(1, n_bottleneck):
41 | o = bottleneck(o, filters, 1) # [n, h/s, w/s, f]
42 | return o
43 |
44 |
45 | def build_model():
46 | inputs = layers.Input(shape=(28, 28, 1), name="img")
47 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
48 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
49 | x = block(x, filters=8, strides=1, n_bottleneck=2) # [n, 14, 14, 8]
50 | x = block(x, 16, 2, 1) # [n, 7, 7, 16]
51 | x = layers.GlobalAveragePooling2D()(x) # [n, 16]
52 | o = layers.Dense(10)(x) # [n, 10]
53 | return keras.Model(inputs, o, name="SENet")
54 |
55 | # show model
56 | model = build_model()
57 | model.summary()
58 | save_model_structure(model)
59 |
60 | # define loss and optimizer
61 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
62 | opt = keras.optimizers.Adam(0.001)
63 | accuracy = keras.metrics.SparseCategoricalAccuracy()
64 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
65 |
66 | # training and validation
67 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
68 |
69 | # save model
70 | save_model_weights(model)
71 |
--------------------------------------------------------------------------------
/shufflenetv1.py:
--------------------------------------------------------------------------------
1 | # [ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices](https://arxiv.org/abs/1707.01083)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | import tensorflow as tf
7 | from utils import load_mnist, save_model_structure, save_model_weights
8 |
9 | # get data
10 | (x_train, y_train), (x_test, y_test) = load_mnist()
11 |
12 |
13 | # Grouped 1x1 conv to reduce parameters, but shuffle grouped feature maps to mix isolated feature map.
14 | def shuffle(x, groups):
15 | _, h, w, c = x.shape
16 | gc = c // groups
17 | o = layers.Reshape((h, w, groups, gc))(x) # [n, h, w, g, gc]
18 | o = layers.Permute((1, 2, 4, 3))(o) # shuffle in groups
19 | o = layers.Reshape((h, w, c))(o)
20 | return o
21 |
22 |
23 | def group_conv(x, filters, groups):
24 | assert x.shape[-1] % groups == 0
25 | assert filters % groups == 0
26 | if tf.test.is_built_with_gpu_support():
27 | o = layers.Conv2D(filters, 1, 1, groups=groups)(x) # [n, h, w, f] pw, groups=groups not works on cpu (tf=2.3.0)
28 | else:
29 | o = layers.concatenate([
30 | layers.Conv2D(filters // groups, 1, 1)(g) for g in tf.split(x, groups, axis=-1)
31 | ], axis=-1) # this works on cpu [n, h, w, f]
32 | return o
33 |
34 |
35 | def block(x, filters, groups=4):
36 | o = group_conv(x, x.shape[-1], groups) # [n, h, w, c] gpw
37 | o = shuffle(o, groups)
38 | o = layers.ReLU()(o)
39 | o = layers.DepthwiseConv2D(kernel_size=3, strides=1, padding="same")(o) # [n, h, w, c] dw
40 | o = group_conv(o, filters, groups) # [n, h, w, f] gpw
41 | if x.shape[-1] != filters:
42 | x = group_conv(x, filters, groups) # [n, h, w, f]
43 | o = layers.add((o, x)) # residual connection
44 | return o
45 |
46 |
47 | def build_model():
48 | inputs = layers.Input(shape=(28, 28, 1), name="img")
49 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
50 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
51 | x = block(x, filters=32, groups=4) # [n, 14, 14, 32]
52 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 32]
53 | x = block(x, 64, 4) # [n, 7, 7, 64]
54 | x = layers.GlobalAveragePooling2D()(x) # [n, 64]
55 | o = layers.Dense(10)(x) # [n, 10]
56 | return keras.Model(inputs, o, name="ShuffleNetV1")
57 |
58 |
59 | # show model
60 | model = build_model()
61 | model.summary()
62 | save_model_structure(model)
63 |
64 | # define loss and optimizer
65 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
66 | opt = keras.optimizers.Adam(0.001)
67 | accuracy = keras.metrics.SparseCategoricalAccuracy()
68 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
69 |
70 | # training and validation
71 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
72 |
73 | # save model
74 | save_model_weights(model)
75 |
--------------------------------------------------------------------------------
/shufflenetv2.py:
--------------------------------------------------------------------------------
1 | # [ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design](https://arxiv.org/abs/1807.11164)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | import tensorflow as tf
7 | from utils import load_mnist, save_model_structure, save_model_weights
8 |
9 | # get data
10 | (x_train, y_train), (x_test, y_test) = load_mnist()
11 |
12 |
13 | # Further reduces parameters by switching group conv with split+concat, perform shuffle at end of block.
14 | # Speed up calculation.
15 | def shuffle(x, groups):
16 | _, h, w, c = x.shape
17 | gc = c // groups
18 | o = layers.Reshape((h, w, groups, gc))(x) # [n, h, w, g, gc]
19 | o = layers.Permute((1, 2, 4, 3))(o) # shuffle in groups
20 | o = layers.Reshape((h, w, c))(o)
21 | return o
22 |
23 |
24 | def block(x, filters):
25 | x1, x2 = tf.split(x, 2, axis=-1) # x1 [n, h, w, c/2], x2 [n, h, w, c/2]
26 | c = x.shape[-1]
27 | o = layers.Conv2D(x2.shape[-1], 1, 1)(x2) # [n, h, w, c/2]
28 | o = layers.ReLU()(o)
29 | o = layers.DepthwiseConv2D(kernel_size=3, strides=1, padding="same")(o) # [n, h, w, c/2]
30 | o = layers.ReLU()(o)
31 | o = layers.Conv2D(filters//2, 1, 1)(o) # [n, h, w, f/2]
32 | if filters != c:
33 | x1 = layers.Conv2D(filters//2, 1, 1)(x1) # [n, h, w, f/2]
34 | o = layers.concatenate([x1, o], axis=-1) # [n, h, w, f]
35 | o = shuffle(o, 2) #
36 | return o
37 |
38 |
39 | def build_model():
40 | inputs = layers.Input(shape=(28, 28, 1), name="img")
41 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
42 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
43 | x = block(x, filters=32) # [n, 14, 14, 32]
44 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 32]
45 | x = block(x, 64) # [n, 7, 7, 64]
46 | x = layers.GlobalAveragePooling2D()(x) # [n, 64]
47 | o = layers.Dense(10)(x) # [n, 10]
48 | return keras.Model(inputs, o, name="ShuffleNetV2")
49 |
50 |
51 | # show model
52 | model = build_model()
53 | model.summary()
54 | save_model_structure(model)
55 |
56 | # define loss and optimizer
57 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
58 | opt = keras.optimizers.Adam(0.001)
59 | accuracy = keras.metrics.SparseCategoricalAccuracy()
60 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
61 |
62 | # training and validation
63 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
64 |
65 | # save model
66 | save_model_weights(model)
67 |
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import os
3 | from urllib.request import urlretrieve
4 | from tensorflow import keras
5 |
6 | MNIST_PATH = "./mnist.npz"
7 |
8 |
9 | def load_mnist(path="./mnist.npz", norm=True):
10 | if not os.path.isfile(path):
11 | print("not mnist data is found, try downloading...")
12 | urlretrieve("https://s3.amazonaws.com/img-datasets/mnist.npz", path)
13 | with np.load(path, allow_pickle=True) as f:
14 | x_train = f['x_train'].astype(np.float32)[:, :, :, None]
15 | y_train = f['y_train'].astype(np.float32)[:, None]
16 | x_test = f['x_test'].astype(np.float32)[:, :, :, None]
17 | y_test = f['y_test'].astype(np.float32)[:, None]
18 | if norm:
19 | x_train /= 255
20 | x_test /= 255
21 | return (x_train, y_train), (x_test, y_test)
22 |
23 |
24 | def save_model_structure(model: keras.Model, path=None):
25 | if path is None:
26 | path = "visual/{}/{}_structure.png".format(model.name, model.name)
27 | os.makedirs(os.path.dirname(path), exist_ok=True)
28 | try:
29 | keras.utils.plot_model(model, show_shapes=True, expand_nested=True, dpi=150, to_file=path)
30 | except Exception as e:
31 | print(e)
32 |
33 |
34 | def save_model_weights(model: keras.Model, path=None):
35 | if path is None:
36 | path = "visual/{}/model/net".format(model.name)
37 | os.makedirs(os.path.dirname(path), exist_ok=True)
38 | model.save_weights(path)
39 |
40 |
41 | def load_model_weights(model: keras.Model, path=None):
42 | if path is None:
43 | path = "visual/{}/model/net".format(model.name)
44 | model.load_weights(path)
--------------------------------------------------------------------------------
/vgg.py:
--------------------------------------------------------------------------------
1 | # [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 | # define model
12 | # like LeNet with more layers and activations
13 | model = keras.Sequential([
14 | layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same", input_shape=(28, 28, 1)), # [n, 28, 28, 8]
15 | layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same", input_shape=(28, 28, 1)), # [n, 28, 28, 8]
16 | layers.ReLU(),
17 | layers.MaxPool2D(pool_size=2, strides=2), # [n, 14, 14, 8]
18 | layers.Conv2D(16, 3, 1, "same"), # [n, 14, 14, 16]
19 | layers.Conv2D(16, 3, 1, "same"), # [n, 14, 14, 16]
20 | layers.ReLU(),
21 | layers.MaxPool2D(2, 2), # [n, 7, 7, 16]
22 | layers.Flatten(), # [n, 7*7*16]
23 | layers.Dense(32), # [n, 32]
24 | layers.ReLU(),
25 | layers.Dense(10) # [n, 32]
26 | ], name="VGG")
27 |
28 | # show model
29 | model.summary()
30 | save_model_structure(model)
31 |
32 | # define loss and optimizer
33 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
34 | opt = keras.optimizers.Adam(0.001)
35 | accuracy = keras.metrics.SparseCategoricalAccuracy()
36 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
37 |
38 | # training and validation
39 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
40 |
41 | # save model
42 | save_model_weights(model)
43 |
--------------------------------------------------------------------------------
/xception.py:
--------------------------------------------------------------------------------
1 | # [Xception: Deep Learning with Depthwise Separable Convolutions](https://arxiv.org/abs/1610.02357)
2 | # dependency file: https://github.com/MorvanZhou/Computer-Vision/requirements.txt
3 |
4 | from tensorflow import keras
5 | from tensorflow.keras import layers
6 | from utils import load_mnist, save_model_structure, save_model_weights
7 |
8 | # get data
9 | (x_train, y_train), (x_test, y_test) = load_mnist()
10 |
11 |
12 | # (residual+pw+dw) just like mobilenetv2 without last pw
13 | def block(x, filters):
14 | if x.shape[-1] != filters:
15 | shortcut = layers.Conv2D(filters, 1, 1)(x)
16 | else:
17 | shortcut = x
18 | o = layers.ReLU()(x)
19 | o = layers.Conv2D(filters, 1, 1)(o) # [n, h, w, f] pw
20 | o = layers.ReLU()(o)
21 | o = layers.DepthwiseConv2D(3, 1, "same")(o) # [n, h, w, f] dw
22 | o = layers.add((o, shortcut)) # residual connection
23 | return o
24 |
25 |
26 | def build_model():
27 | inputs = layers.Input(shape=(28, 28, 1), name="img")
28 | x = layers.Conv2D(filters=8, kernel_size=3, strides=1, padding="same")(inputs) # [n, 28, 28, 8]
29 | x = layers.MaxPool2D(pool_size=2, strides=2)(x) # [n, 14, 14, 8]
30 | x = block(x, filters=16) # [n, 14, 14, 16]
31 | x = layers.MaxPool2D(2, 2)(x) # [n, 7, 7, 16]
32 | x = block(x, 32) # [n, 7, 7, 32]
33 | x = layers.GlobalAveragePooling2D()(x) # [n, 32]
34 | o = layers.Dense(10)(x) # [n, 10]
35 | return keras.Model(inputs, o, name="Xception")
36 |
37 |
38 | # show model
39 | model = build_model()
40 | model.summary()
41 | save_model_structure(model)
42 |
43 | # define loss and optimizer
44 | loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
45 | opt = keras.optimizers.Adam(0.001)
46 | accuracy = keras.metrics.SparseCategoricalAccuracy()
47 | model.compile(optimizer=opt, loss=loss, metrics=[accuracy])
48 |
49 | # training and validation
50 | model.fit(x=x_train, y=y_train, batch_size=32, epochs=3, validation_data=(x_test, y_test))
51 |
52 | # save model
53 | save_model_weights(model)
54 |
--------------------------------------------------------------------------------