├── .gitignore
├── LICENCE
├── README.md
├── logo.png
├── tutorial-contents-notebooks
├── .ipynb_checkpoints
│ ├── 401_CNN-checkpoint.ipynb
│ └── 406_GAN-checkpoint.ipynb
├── 201_torch_numpy.ipynb
├── 202_variable.ipynb
├── 203_activation.ipynb
├── 301_regression.ipynb
├── 302_classification.ipynb
├── 303_build_nn_quickly.ipynb
├── 304_save_reload.ipynb
├── 305_batch_train.ipynb
├── 306_optimizer.ipynb
├── 401_CNN.ipynb
├── 402_RNN.ipynb
├── 403_RNN_regressor.ipynb
├── 404_autoencoder.ipynb
├── 405_DQN_Reinforcement_learning.ipynb
├── 406_GAN.ipynb
├── 501_why_torch_dynamic_graph.ipynb
├── 502_GPU.ipynb
├── 503_dropout.ipynb
├── 504_batch_normalization.ipynb
└── mnist
│ ├── processed
│ ├── test.pt
│ └── training.pt
│ └── raw
│ ├── t10k-images-idx3-ubyte
│ ├── t10k-labels-idx1-ubyte
│ ├── train-images-idx3-ubyte
│ └── train-labels-idx1-ubyte
└── tutorial-contents
├── 201_torch_numpy.py
├── 202_variable.py
├── 203_activation.py
├── 301_regression.py
├── 302_classification.py
├── 303_build_nn_quickly.py
├── 304_save_reload.py
├── 305_batch_train.py
├── 306_optimizer.py
├── 401_CNN.py
├── 402_RNN_classifier.py
├── 403_RNN_regressor.py
├── 404_autoencoder.py
├── 405_DQN_Reinforcement_learning.py
├── 406_GAN.py
├── 406_conditional_GAN.py
├── 501_why_torch_dynamic_graph.py
├── 502_GPU.py
├── 503_dropout.py
├── 504_batch_normalization.py
└── mnist
├── processed
├── test.pt
└── training.pt
└── raw
├── t10k-images-idx3-ubyte
├── t10k-labels-idx1-ubyte
├── train-images-idx3-ubyte
└── train-labels-idx1-ubyte
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea
2 | tutorial-contents/*pkl
--------------------------------------------------------------------------------
/LICENCE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2017
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |  4 |
5 |
4 |
5 |
6 |
7 |
8 |
9 |
10 | ### If you'd like to use **Tensorflow**, no worries, I made a new **Tensorflow Tutorial** just like PyTorch. Here is the link: [https://github.com/MorvanZhou/Tensorflow-Tutorial](https://github.com/MorvanZhou/Tensorflow-Tutorial)
11 |
12 | # pyTorch Tutorials
13 |
14 | In these tutorials for pyTorch, we will build our first Neural Network and try to build some advanced Neural Network architectures developed recent years.
15 |
16 | Thanks for [liufuyang's](https://github.com/liufuyang) [**notebook files**](tutorial-contents-notebooks)
17 | which is a great contribution to this tutorial.
18 |
19 | * pyTorch basic
20 | * [torch and numpy](tutorial-contents/201_torch_numpy.py)
21 | * [Variable](tutorial-contents/202_variable.py)
22 | * [Activation](tutorial-contents/203_activation.py)
23 | * Build your first network
24 | * [Regression](tutorial-contents/301_regression.py)
25 | * [Classification](tutorial-contents/302_classification.py)
26 | * [An easy way](tutorial-contents/303_build_nn_quickly.py)
27 | * [Save and reload](tutorial-contents/304_save_reload.py)
28 | * [Train on batch](tutorial-contents/305_batch_train.py)
29 | * [Optimizers](tutorial-contents/306_optimizer.py)
30 | * Advanced neural network
31 | * [CNN](tutorial-contents/401_CNN.py)
32 | * [RNN-Classification](tutorial-contents/402_RNN_classifier.py)
33 | * [RNN-Regression](tutorial-contents/403_RNN_regressor.py)
34 | * [AutoEncoder](tutorial-contents/404_autoencoder.py)
35 | * [DQN Reinforcement Learning](tutorial-contents/405_DQN_Reinforcement_learning.py)
36 | * [A3C Reinforcement Learning](https://github.com/MorvanZhou/pytorch-A3C)
37 | * [GAN (Generative Adversarial Nets)](tutorial-contents/406_GAN.py) / [Conditional GAN](tutorial-contents/406_conditional_GAN.py)
38 | * Others (WIP)
39 | * [Why torch dynamic](tutorial-contents/501_why_torch_dynamic_graph.py)
40 | * [Train on GPU](tutorial-contents/502_GPU.py)
41 | * [Dropout](tutorial-contents/503_dropout.py)
42 | * [Batch Normalization](tutorial-contents/504_batch_normalization.py)
43 |
44 | **For Chinese speakers: All methods mentioned below have their video and text tutorial in Chinese.
45 | Visit [莫烦 Python](https://mofanpy.com/tutorials/) for more.
46 | You can watch my [Youtube channel](https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg) as well.**
47 |
48 |
49 | ### [Regression](tutorial-contents/301_regression.py)
50 |
51 |
52 |  53 |
54 |
55 | ### [Classification](tutorial-contents/302_classification.py)
56 |
57 |
58 |
53 |
54 |
55 | ### [Classification](tutorial-contents/302_classification.py)
56 |
57 |
58 | 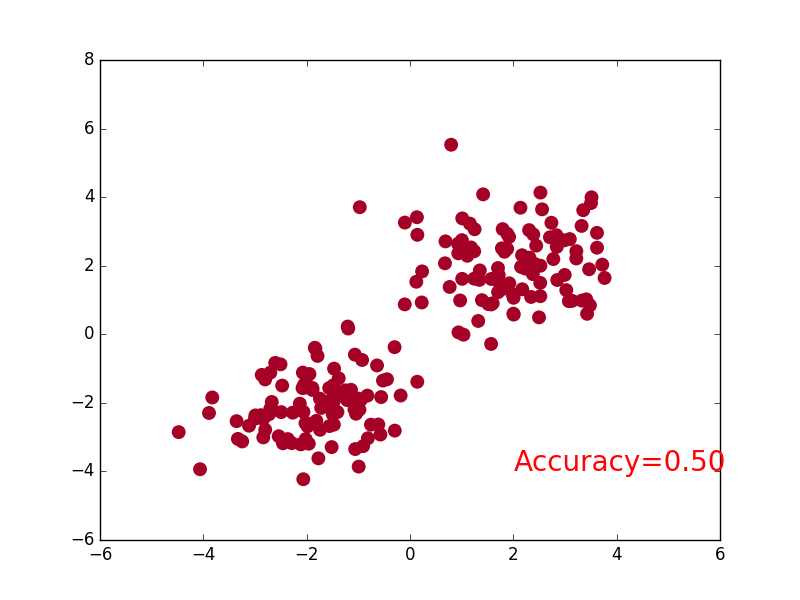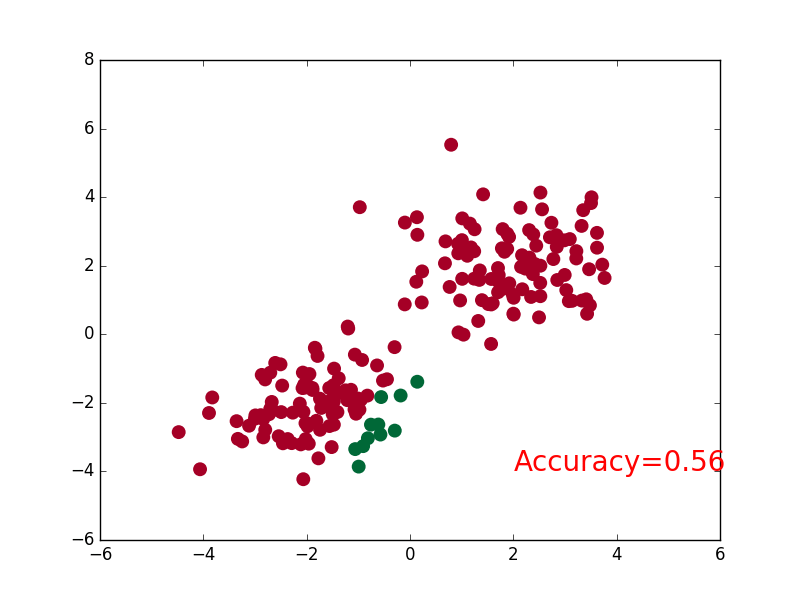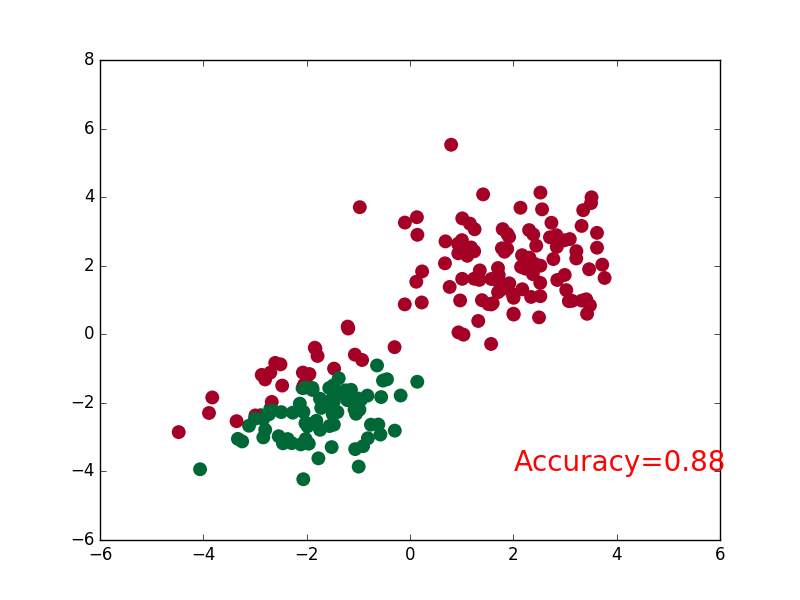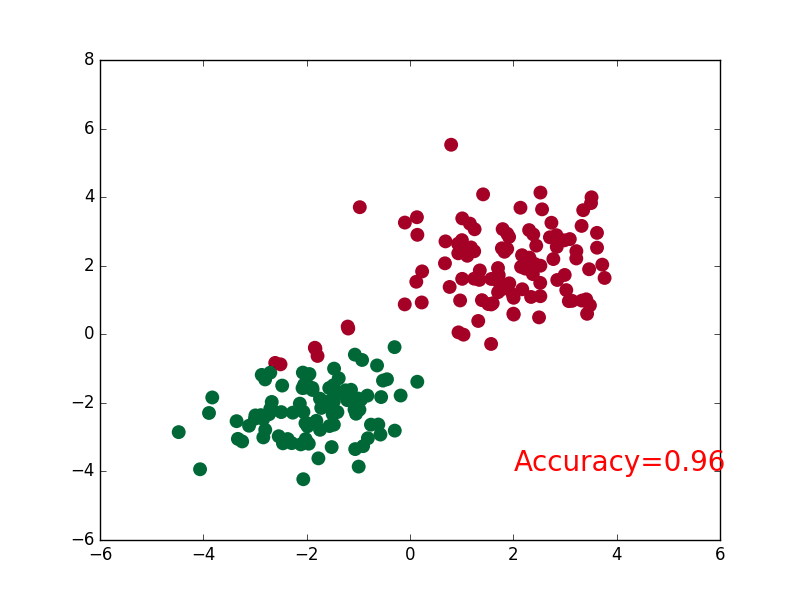 59 |
60 |
61 | ### [CNN](tutorial-contents/401_CNN.py)
62 |
63 |
59 |
60 |
61 | ### [CNN](tutorial-contents/401_CNN.py)
62 |
63 | 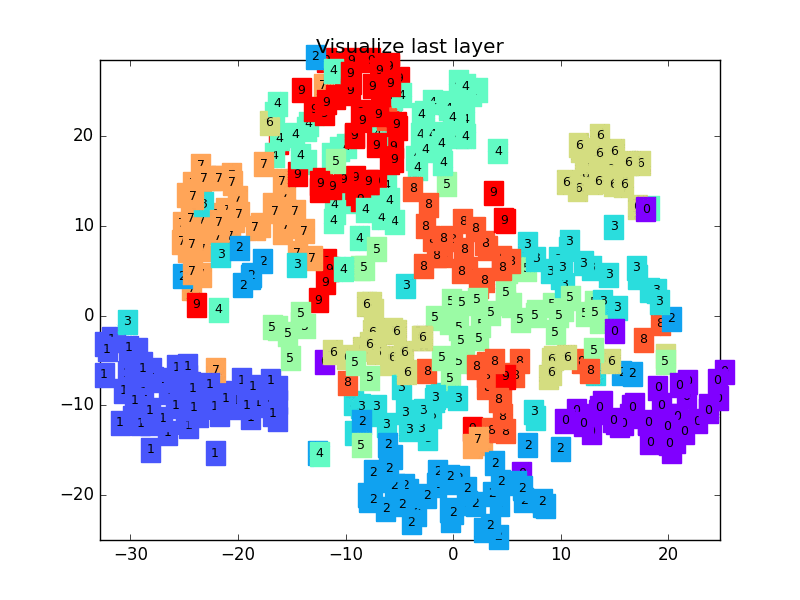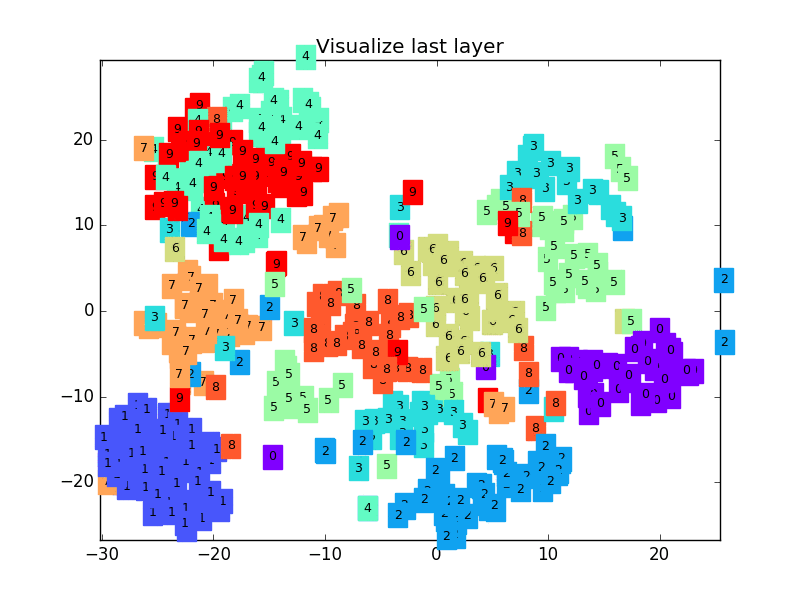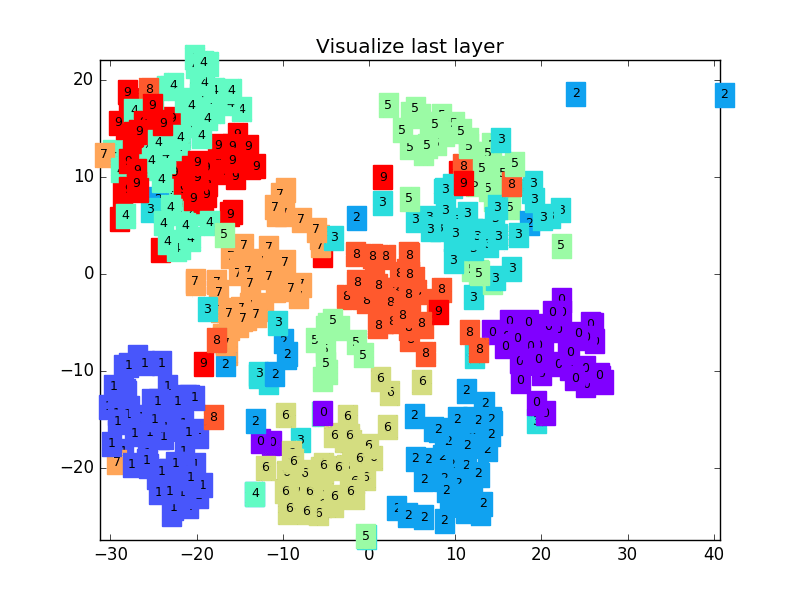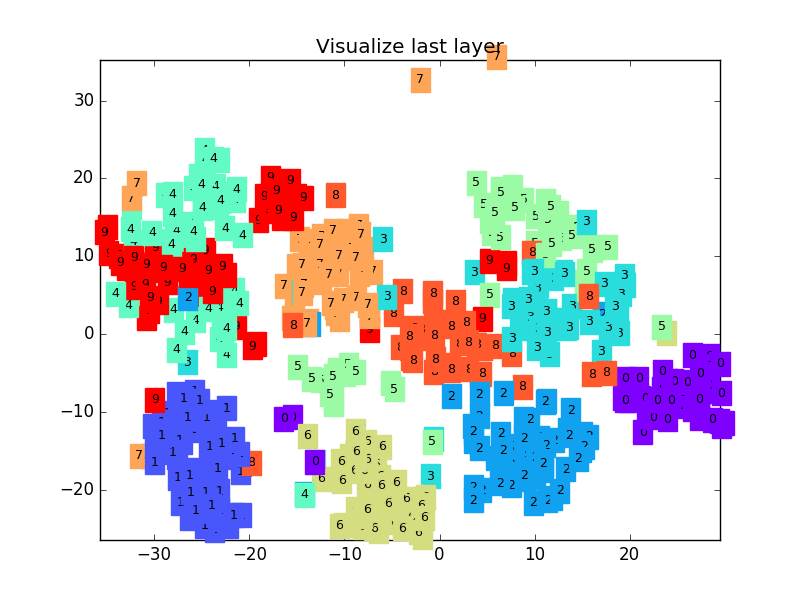 64 |
65 |
66 | ### [RNN](tutorial-contents/403_RNN_regressor.py)
67 |
68 |
69 |
64 |
65 |
66 | ### [RNN](tutorial-contents/403_RNN_regressor.py)
67 |
68 |
69 | 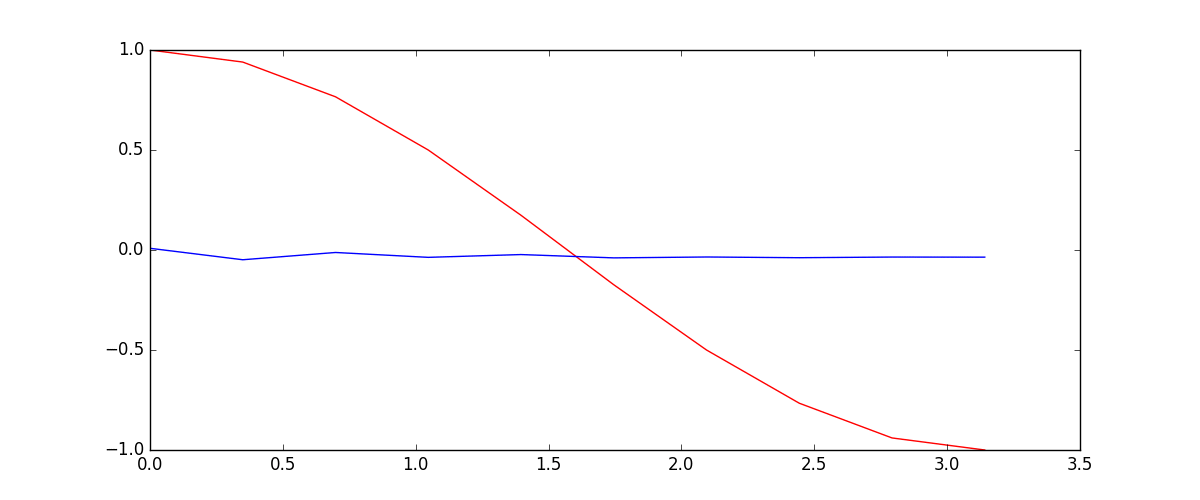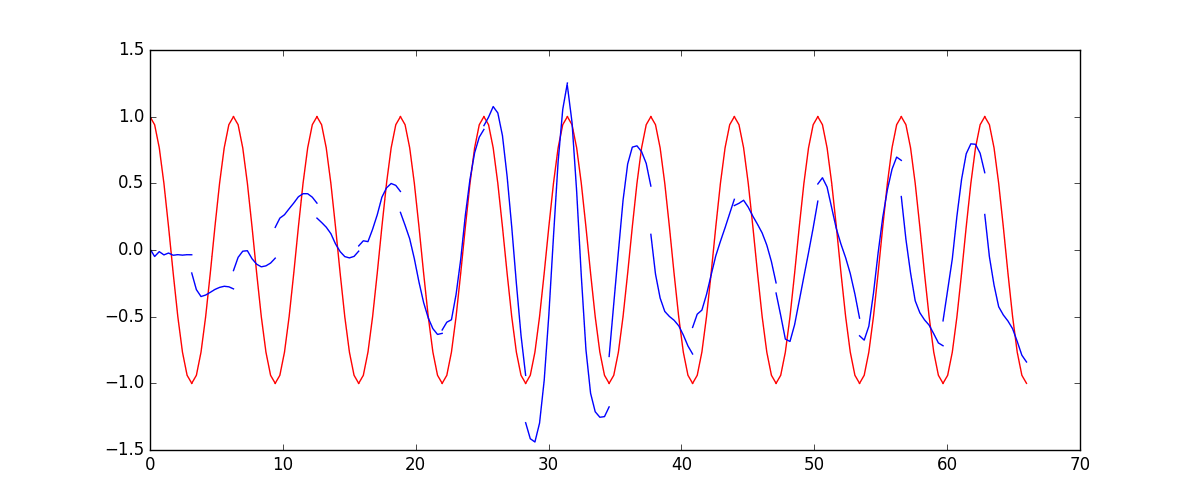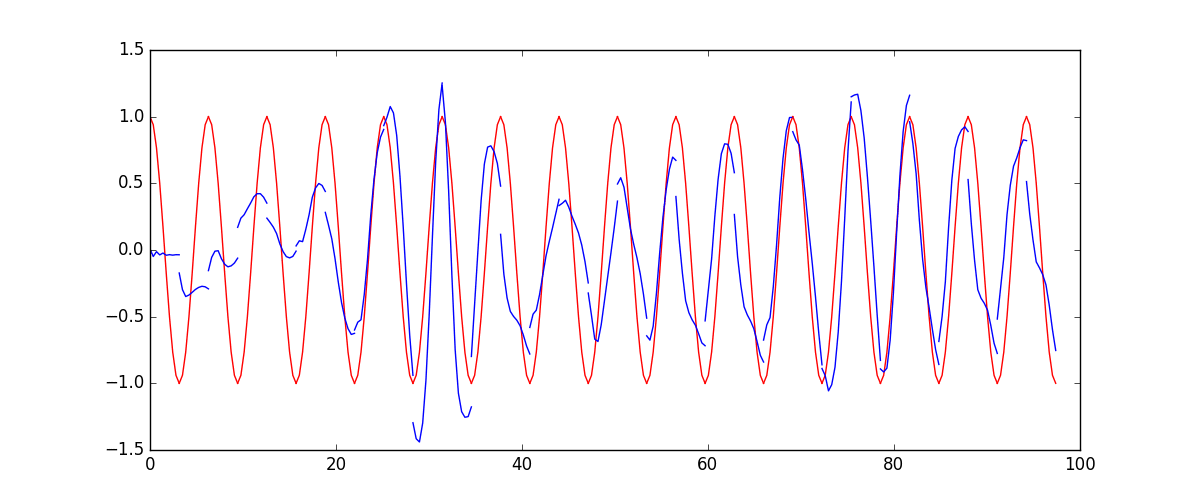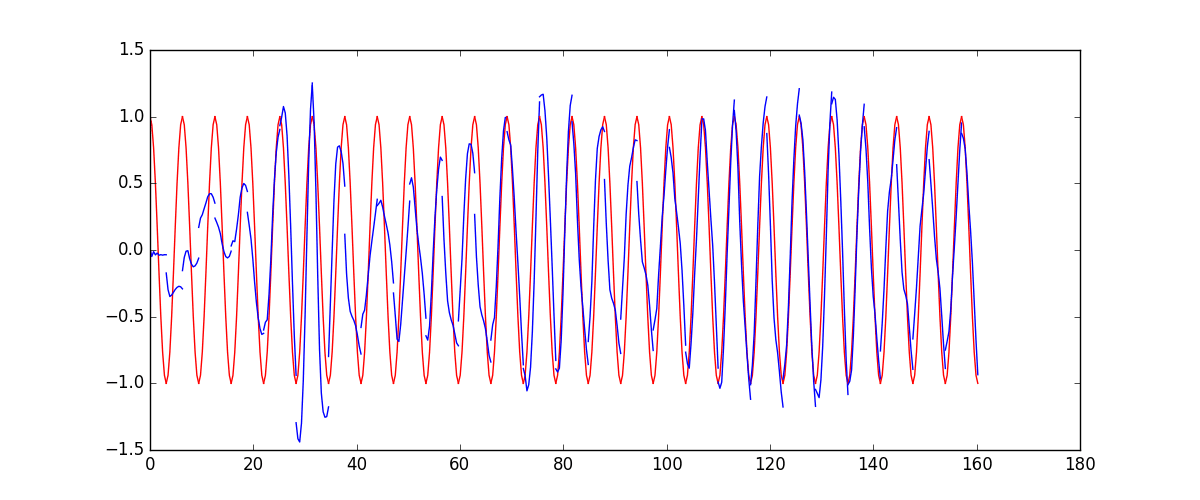 70 |
71 |
72 | ### [Autoencoder](tutorial-contents/404_autoencoder.py)
73 |
74 |
75 |
70 |
71 |
72 | ### [Autoencoder](tutorial-contents/404_autoencoder.py)
73 |
74 |
75 |  76 |
77 |
78 |
79 |
76 |
77 |
78 |
79 | 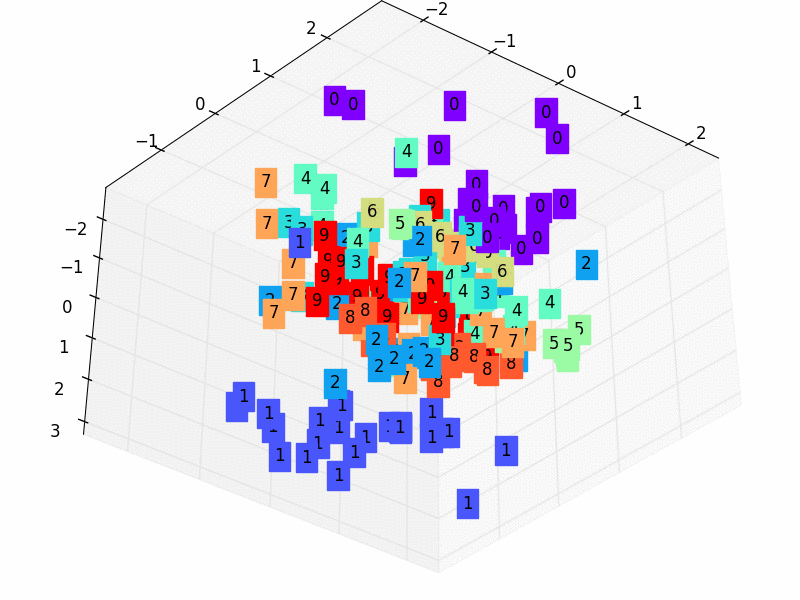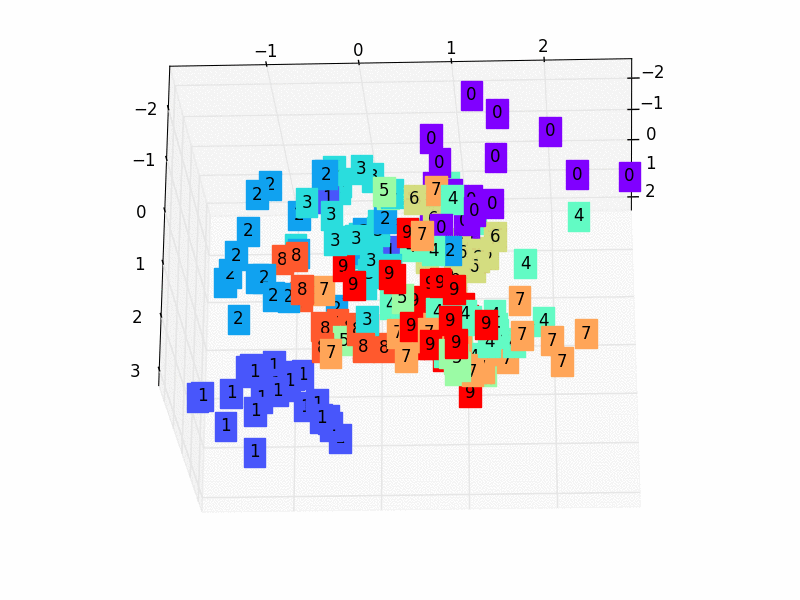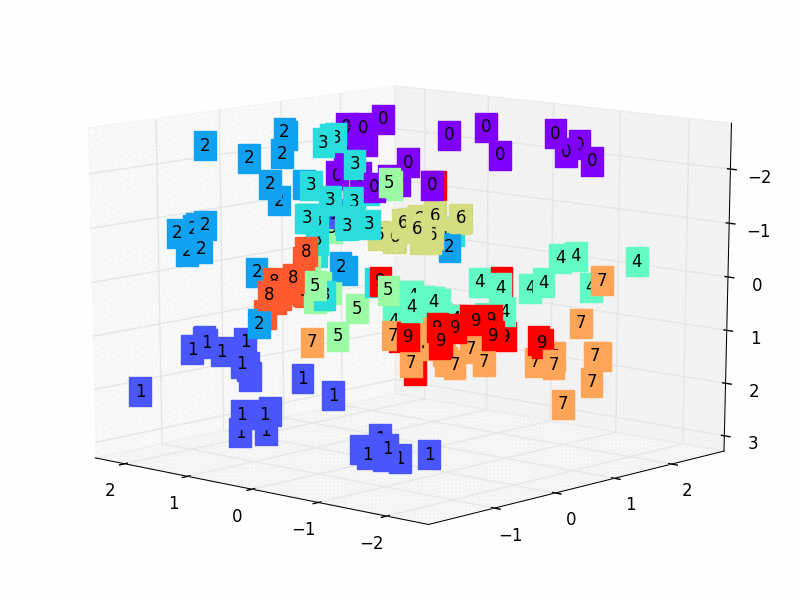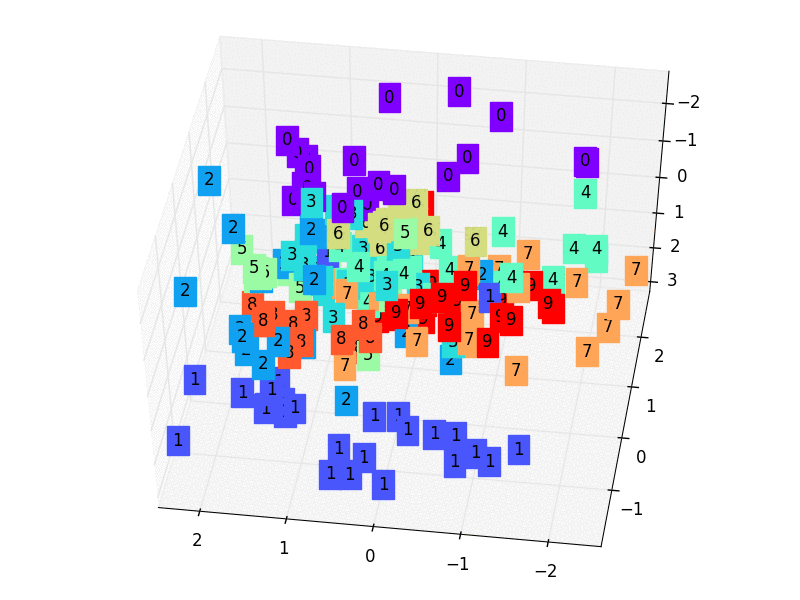 80 |
81 |
82 | ### [GAN (Generative Adversarial Nets)](tutorial-contents/406_GAN.py)
83 |
84 |
80 |
81 |
82 | ### [GAN (Generative Adversarial Nets)](tutorial-contents/406_GAN.py)
83 |
84 | 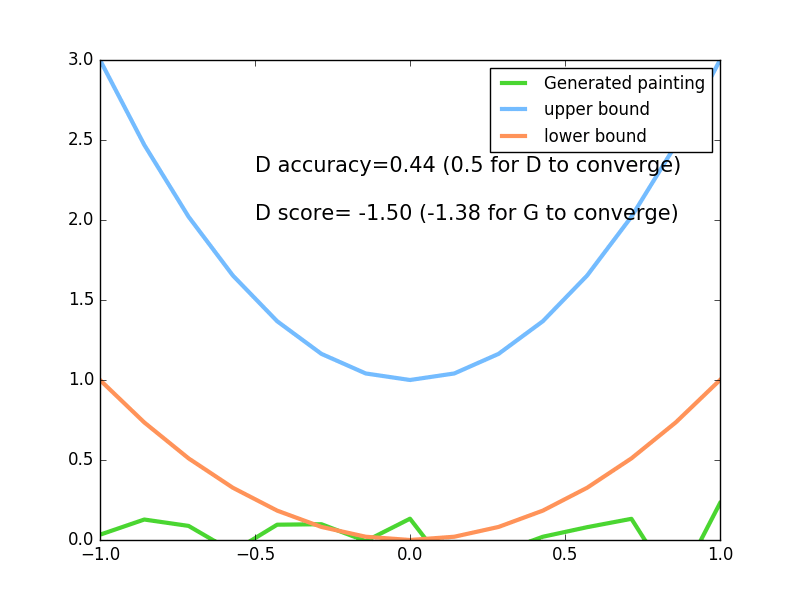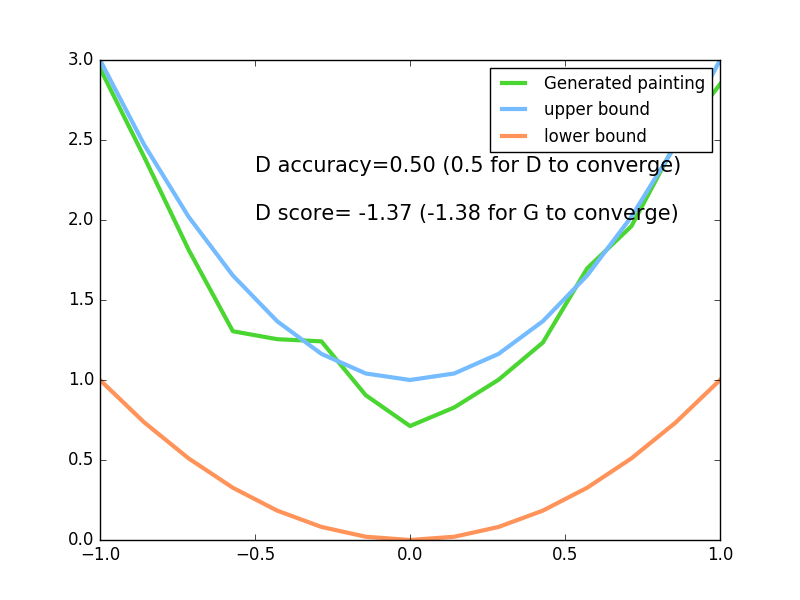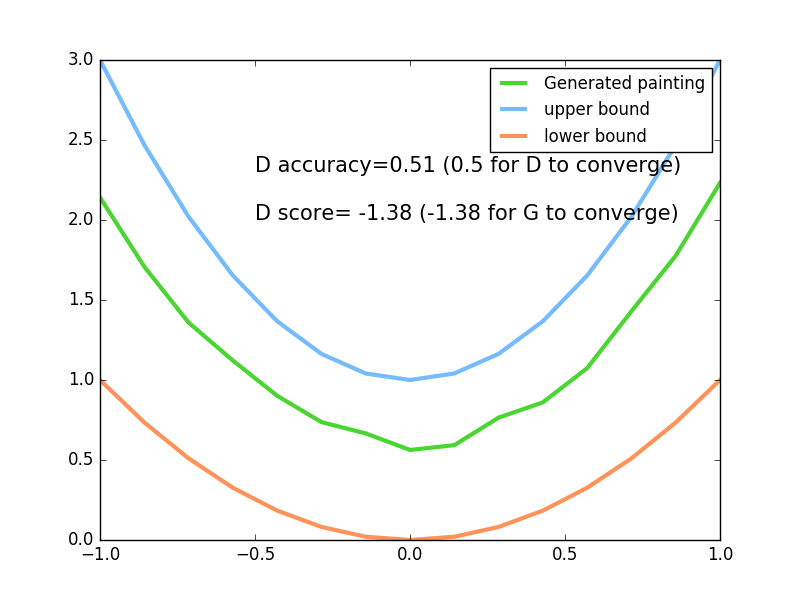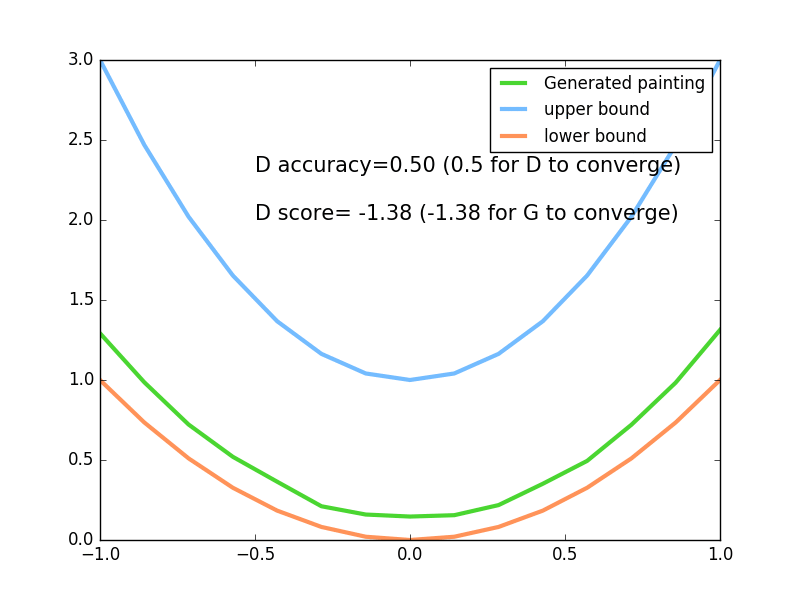 85 |
86 |
87 | ### [Dropout](tutorial-contents/503_dropout.py)
88 |
89 |
85 |
86 |
87 | ### [Dropout](tutorial-contents/503_dropout.py)
88 |
89 | 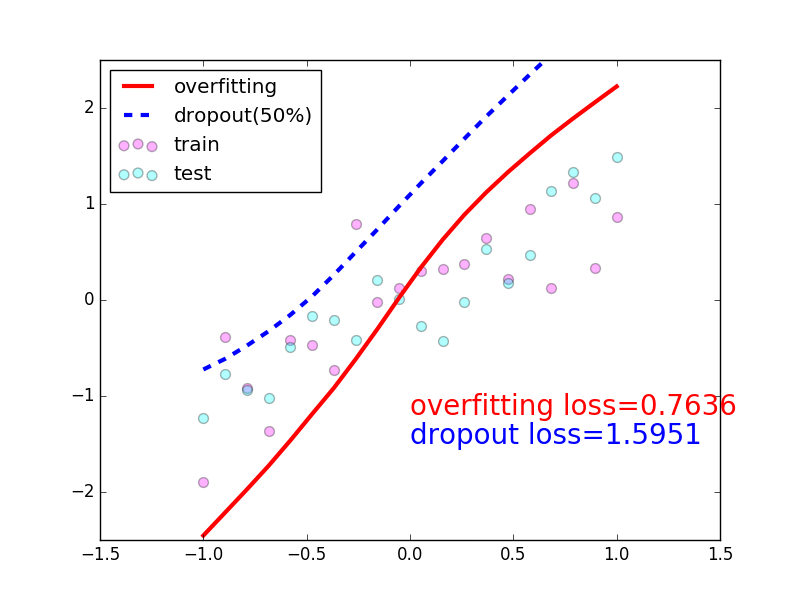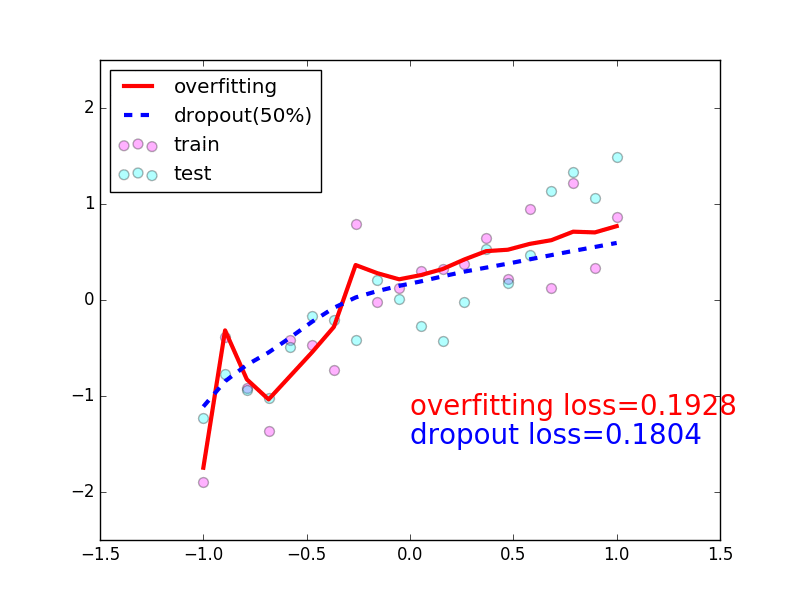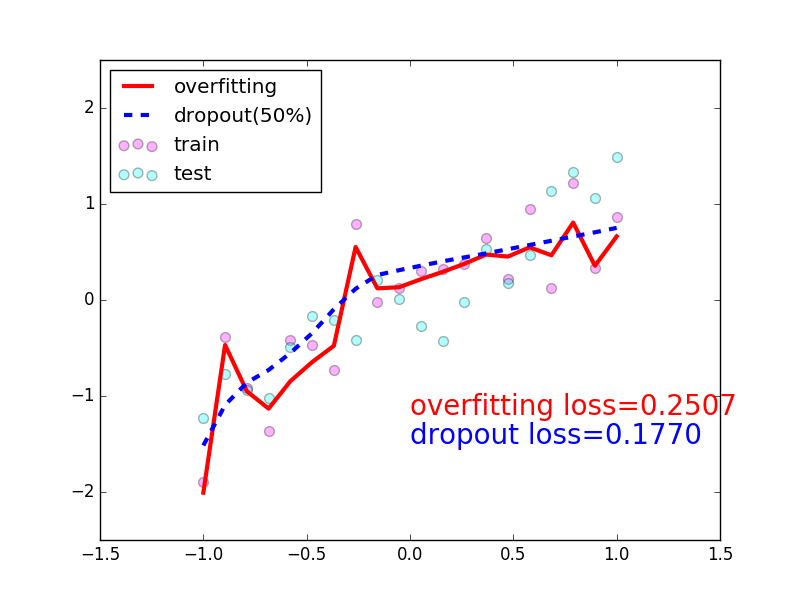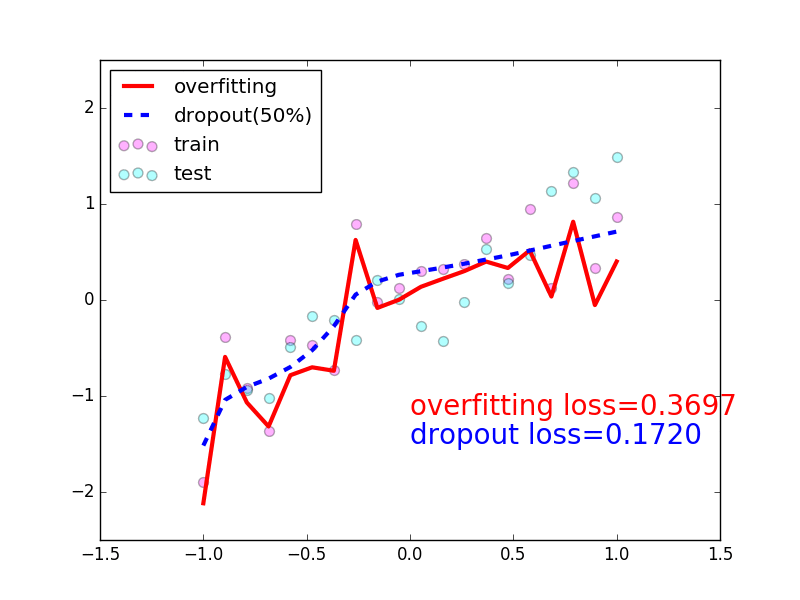 90 |
91 |
92 | ### [Batch Normalization](tutorial-contents/504_batch_normalization.py)
93 |
94 |
90 |
91 |
92 | ### [Batch Normalization](tutorial-contents/504_batch_normalization.py)
93 |
94 |  95 |
96 |
97 | # Donation
98 |
99 | *If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*
100 |
101 |
108 |
109 |
--------------------------------------------------------------------------------
/logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/logo.png
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/201_torch_numpy.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 201 Torch and Numpy\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11\n",
14 | "* numpy\n",
15 | "\n",
16 | "Details about math operation in torch can be found in: http://pytorch.org/docs/torch.html#math-operations\n"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {
23 | "collapsed": true
24 | },
25 | "outputs": [],
26 | "source": [
27 | "import torch\n",
28 | "import numpy as np"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 2,
34 | "metadata": {},
35 | "outputs": [
36 | {
37 | "name": "stdout",
38 | "output_type": "stream",
39 | "text": [
40 | "\nnumpy array: [[0 1 2]\n [3 4 5]] \ntorch tensor: tensor([[ 0, 1, 2],\n [ 3, 4, 5]], dtype=torch.int32) \ntensor to array: [[0 1 2]\n [3 4 5]]\n"
41 | ]
42 | }
43 | ],
44 | "source": [
45 | "# convert numpy to tensor or vise versa\n",
46 | "np_data = np.arange(6).reshape((2, 3))\n",
47 | "torch_data = torch.from_numpy(np_data)\n",
48 | "tensor2array = torch_data.numpy()\n",
49 | "print(\n",
50 | " '\\nnumpy array:', np_data, # [[0 1 2], [3 4 5]]\n",
51 | " '\\ntorch tensor:', torch_data, # 0 1 2 \\n 3 4 5 [torch.LongTensor of size 2x3]\n",
52 | " '\\ntensor to array:', tensor2array, # [[0 1 2], [3 4 5]]\n",
53 | ")"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": 3,
59 | "metadata": {},
60 | "outputs": [
61 | {
62 | "name": "stdout",
63 | "output_type": "stream",
64 | "text": [
65 | "\nabs \nnumpy: [1 2 1 2] \ntorch: tensor([ 1., 2., 1., 2.])\n"
66 | ]
67 | }
68 | ],
69 | "source": [
70 | "# abs\n",
71 | "data = [-1, -2, 1, 2]\n",
72 | "tensor = torch.FloatTensor(data) # 32-bit floating point\n",
73 | "print(\n",
74 | " '\\nabs',\n",
75 | " '\\nnumpy: ', np.abs(data), # [1 2 1 2]\n",
76 | " '\\ntorch: ', torch.abs(tensor) # [1 2 1 2]\n",
77 | ")"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 4,
83 | "metadata": {},
84 | "outputs": [
85 | {
86 | "data": {
87 | "text/plain": [
88 | "tensor([ 1., 2., 1., 2.])"
89 | ]
90 | },
91 | "execution_count": 4,
92 | "metadata": {},
93 | "output_type": "execute_result"
94 | }
95 | ],
96 | "source": [
97 | "tensor.abs()"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": 5,
103 | "metadata": {},
104 | "outputs": [
105 | {
106 | "name": "stdout",
107 | "output_type": "stream",
108 | "text": [
109 | "\nsin \nnumpy: [-0.84147098 -0.90929743 0.84147098 0.90929743] \ntorch: tensor([-0.8415, -0.9093, 0.8415, 0.9093])\n"
110 | ]
111 | }
112 | ],
113 | "source": [
114 | "# sin\n",
115 | "print(\n",
116 | " '\\nsin',\n",
117 | " '\\nnumpy: ', np.sin(data), # [-0.84147098 -0.90929743 0.84147098 0.90929743]\n",
118 | " '\\ntorch: ', torch.sin(tensor) # [-0.8415 -0.9093 0.8415 0.9093]\n",
119 | ")"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 6,
125 | "metadata": {},
126 | "outputs": [
127 | {
128 | "data": {
129 | "text/plain": [
130 | "tensor([ 0.2689, 0.1192, 0.7311, 0.8808])"
131 | ]
132 | },
133 | "execution_count": 6,
134 | "metadata": {},
135 | "output_type": "execute_result"
136 | }
137 | ],
138 | "source": [
139 | "tensor.sigmoid()"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 7,
145 | "metadata": {},
146 | "outputs": [
147 | {
148 | "data": {
149 | "text/plain": [
150 | "tensor([ 0.3679, 0.1353, 2.7183, 7.3891])"
151 | ]
152 | },
153 | "execution_count": 7,
154 | "metadata": {},
155 | "output_type": "execute_result"
156 | }
157 | ],
158 | "source": [
159 | "tensor.exp()"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 8,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "name": "stdout",
169 | "output_type": "stream",
170 | "text": [
171 | "\nmean \nnumpy: 0.0 \ntorch: tensor(0.)\n"
172 | ]
173 | }
174 | ],
175 | "source": [
176 | "# mean\n",
177 | "print(\n",
178 | " '\\nmean',\n",
179 | " '\\nnumpy: ', np.mean(data), # 0.0\n",
180 | " '\\ntorch: ', torch.mean(tensor) # 0.0\n",
181 | ")"
182 | ]
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": 2,
187 | "metadata": {},
188 | "outputs": [
189 | {
190 | "name": "stdout",
191 | "output_type": "stream",
192 | "text": [
193 | "\nmatrix multiplication (matmul) \nnumpy: [[ 7 10]\n [15 22]] \ntorch: tensor([[ 7., 10.],\n [15., 22.]])\n"
194 | ]
195 | }
196 | ],
197 | "source": [
198 | "# matrix multiplication\n",
199 | "data = [[1,2], [3,4]]\n",
200 | "tensor = torch.FloatTensor(data) # 32-bit floating point\n",
201 | "# correct method\n",
202 | "print(\n",
203 | " '\\nmatrix multiplication (matmul)',\n",
204 | " '\\nnumpy: ', np.matmul(data, data), # [[7, 10], [15, 22]]\n",
205 | " '\\ntorch: ', torch.mm(tensor, tensor) # [[7, 10], [15, 22]]\n",
206 | ")"
207 | ]
208 | },
209 | {
210 | "cell_type": "code",
211 | "execution_count": 3,
212 | "metadata": {},
213 | "outputs": [
214 | {
215 | "ename": "RuntimeError",
216 | "evalue": "dot: Expected 1-D argument self, but got 2-D",
217 | "traceback": [
218 | "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
219 | "\u001b[0;31mRuntimeError\u001b[0m Traceback (most recent call last)",
220 | "\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 5\u001b[0m \u001b[0;34m'\\nmatrix multiplication (dot)'\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 6\u001b[0m \u001b[0;34m'\\nnumpy: '\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mdata\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdot\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mdata\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;31m# [[7, 10], [15, 22]]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 7\u001b[0;31m \u001b[0;34m'\\ntorch: '\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mtorch\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdot\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtensor\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdot\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtensor\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;31m# 30.0. Beware that torch.dot does not broadcast, only works for 1-dimensional tensor\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 8\u001b[0m )\n",
221 | "\u001b[0;31mRuntimeError\u001b[0m: dot: Expected 1-D argument self, but got 2-D"
222 | ],
223 | "output_type": "error"
224 | }
225 | ],
226 | "source": [
227 | "# incorrect method\n",
228 | "data = np.array(data)\n",
229 | "tensor = torch.Tensor(data)\n",
230 | "print(\n",
231 | " '\\nmatrix multiplication (dot)',\n",
232 | " '\\nnumpy: ', data.dot(data), # [[7, 10], [15, 22]]\n",
233 | " '\\ntorch: ', torch.dot(tensor.dot(tensor)) # NOT WORKING! Beware that torch.dot does not broadcast, only works for 1-dimensional tensor\n",
234 | ")"
235 | ]
236 | },
237 | {
238 | "cell_type": "markdown",
239 | "metadata": {},
240 | "source": [
241 | "Note that:\n",
242 | "\n",
243 | "torch.dot(tensor1, tensor2) → float\n",
244 | "\n",
245 | "Computes the dot product (inner product) of two tensors. Both tensors are treated as 1-D vectors."
246 | ]
247 | },
248 | {
249 | "cell_type": "code",
250 | "execution_count": 10,
251 | "metadata": {},
252 | "outputs": [
253 | {
254 | "data": {
255 | "text/plain": [
256 | "tensor([[ 7., 10.],\n [ 15., 22.]])"
257 | ]
258 | },
259 | "execution_count": 10,
260 | "metadata": {},
261 | "output_type": "execute_result"
262 | }
263 | ],
264 | "source": [
265 | "tensor.mm(tensor)"
266 | ]
267 | },
268 | {
269 | "cell_type": "code",
270 | "execution_count": 11,
271 | "metadata": {},
272 | "outputs": [
273 | {
274 | "data": {
275 | "text/plain": [
276 | "tensor([[ 1., 4.],\n [ 9., 16.]])"
277 | ]
278 | },
279 | "execution_count": 11,
280 | "metadata": {},
281 | "output_type": "execute_result"
282 | }
283 | ],
284 | "source": [
285 | "tensor * tensor"
286 | ]
287 | },
288 | {
289 | "cell_type": "code",
290 | "execution_count": 13,
291 | "metadata": {},
292 | "outputs": [
293 | {
294 | "data": {
295 | "text/plain": [
296 | "tensor(7.)"
297 | ]
298 | },
299 | "execution_count": 13,
300 | "metadata": {},
301 | "output_type": "execute_result"
302 | }
303 | ],
304 | "source": [
305 | "torch.dot(torch.Tensor([2, 3]), torch.Tensor([2, 1]))"
306 | ]
307 | },
308 | {
309 | "cell_type": "code",
310 | "execution_count": null,
311 | "metadata": {
312 | "collapsed": true
313 | },
314 | "outputs": [],
315 | "source": []
316 | }
317 | ],
318 | "metadata": {
319 | "kernelspec": {
320 | "display_name": "Python 3",
321 | "language": "python",
322 | "name": "python3"
323 | },
324 | "language_info": {
325 | "codemirror_mode": {
326 | "name": "ipython",
327 | "version": 3
328 | },
329 | "file_extension": ".py",
330 | "mimetype": "text/x-python",
331 | "name": "python",
332 | "nbconvert_exporter": "python",
333 | "pygments_lexer": "ipython3",
334 | "version": "3.5.2"
335 | }
336 | },
337 | "nbformat": 4,
338 | "nbformat_minor": 2
339 | }
340 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/202_variable.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 202 Variable\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11\n",
14 | "\n",
15 | "Variable in torch is to build a computational graph,\n",
16 | "but this graph is dynamic compared with a static graph in Tensorflow or Theano.\n",
17 | "So torch does not have placeholder, torch can just pass variable to the computational graph.\n"
18 | ]
19 | },
20 | {
21 | "cell_type": "code",
22 | "execution_count": 1,
23 | "metadata": {
24 | "collapsed": true
25 | },
26 | "outputs": [],
27 | "source": [
28 | "import torch\n",
29 | "from torch.autograd import Variable"
30 | ]
31 | },
32 | {
33 | "cell_type": "code",
34 | "execution_count": 2,
35 | "metadata": {},
36 | "outputs": [
37 | {
38 | "name": "stdout",
39 | "output_type": "stream",
40 | "text": [
41 | "\n",
42 | " 1 2\n",
43 | " 3 4\n",
44 | "[torch.FloatTensor of size 2x2]\n",
45 | "\n",
46 | "Variable containing:\n",
47 | " 1 2\n",
48 | " 3 4\n",
49 | "[torch.FloatTensor of size 2x2]\n",
50 | "\n"
51 | ]
52 | }
53 | ],
54 | "source": [
55 | "tensor = torch.FloatTensor([[1,2],[3,4]]) # build a tensor\n",
56 | "variable = Variable(tensor, requires_grad=True) # build a variable, usually for compute gradients\n",
57 | "\n",
58 | "print(tensor) # [torch.FloatTensor of size 2x2]\n",
59 | "print(variable) # [torch.FloatTensor of size 2x2]"
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "metadata": {},
65 | "source": [
66 | "Till now the tensor and variable seem the same.\n",
67 | "\n",
68 | "However, the variable is a part of the graph, it's a part of the auto-gradient.\n"
69 | ]
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": 3,
74 | "metadata": {},
75 | "outputs": [
76 | {
77 | "name": "stdout",
78 | "output_type": "stream",
79 | "text": [
80 | "7.5\n",
81 | "Variable containing:\n",
82 | " 7.5000\n",
83 | "[torch.FloatTensor of size 1]\n",
84 | "\n"
85 | ]
86 | }
87 | ],
88 | "source": [
89 | "t_out = torch.mean(tensor*tensor) # x^2\n",
90 | "v_out = torch.mean(variable*variable) # x^2\n",
91 | "print(t_out)\n",
92 | "print(v_out)"
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "execution_count": 4,
98 | "metadata": {
99 | "collapsed": true
100 | },
101 | "outputs": [],
102 | "source": [
103 | "v_out.backward() # backpropagation from v_out"
104 | ]
105 | },
106 | {
107 | "cell_type": "markdown",
108 | "metadata": {},
109 | "source": [
110 | "$$ v_{out} = {{1} \\over {4}} sum(variable^2) $$\n",
111 | "\n",
112 | "the gradients w.r.t the variable, \n",
113 | "\n",
114 | "$$ {d(v_{out}) \\over d(variable)} = {{1} \\over {4}} 2 variable = {variable \\over 2}$$\n",
115 | "\n",
116 | "let's check the result pytorch calculated for us below:"
117 | ]
118 | },
119 | {
120 | "cell_type": "code",
121 | "execution_count": 5,
122 | "metadata": {},
123 | "outputs": [
124 | {
125 | "data": {
126 | "text/plain": [
127 | "Variable containing:\n",
128 | " 0.5000 1.0000\n",
129 | " 1.5000 2.0000\n",
130 | "[torch.FloatTensor of size 2x2]"
131 | ]
132 | },
133 | "execution_count": 5,
134 | "metadata": {},
135 | "output_type": "execute_result"
136 | }
137 | ],
138 | "source": [
139 | "variable.grad"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 6,
145 | "metadata": {},
146 | "outputs": [
147 | {
148 | "data": {
149 | "text/plain": [
150 | "Variable containing:\n",
151 | " 1 2\n",
152 | " 3 4\n",
153 | "[torch.FloatTensor of size 2x2]"
154 | ]
155 | },
156 | "execution_count": 6,
157 | "metadata": {},
158 | "output_type": "execute_result"
159 | }
160 | ],
161 | "source": [
162 | "variable # this is data in variable format"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 7,
168 | "metadata": {},
169 | "outputs": [
170 | {
171 | "data": {
172 | "text/plain": [
173 | "\n",
174 | " 1 2\n",
175 | " 3 4\n",
176 | "[torch.FloatTensor of size 2x2]"
177 | ]
178 | },
179 | "execution_count": 7,
180 | "metadata": {},
181 | "output_type": "execute_result"
182 | }
183 | ],
184 | "source": [
185 | "variable.data # this is data in tensor format"
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": 8,
191 | "metadata": {},
192 | "outputs": [
193 | {
194 | "data": {
195 | "text/plain": [
196 | "array([[ 1., 2.],\n",
197 | " [ 3., 4.]], dtype=float32)"
198 | ]
199 | },
200 | "execution_count": 8,
201 | "metadata": {},
202 | "output_type": "execute_result"
203 | }
204 | ],
205 | "source": [
206 | "variable.data.numpy() # numpy format"
207 | ]
208 | },
209 | {
210 | "cell_type": "markdown",
211 | "metadata": {},
212 | "source": [
213 | "Note that we did `.backward()` on `v_out` but `variable` has been assigned new values on it's `grad`.\n",
214 | "\n",
215 | "As this line \n",
216 | "```\n",
217 | "v_out = torch.mean(variable*variable)\n",
218 | "``` \n",
219 | "will make a new variable `v_out` and connect it with `variable` in computation graph."
220 | ]
221 | },
222 | {
223 | "cell_type": "code",
224 | "execution_count": 9,
225 | "metadata": {},
226 | "outputs": [
227 | {
228 | "data": {
229 | "text/plain": [
230 | "torch.autograd.variable.Variable"
231 | ]
232 | },
233 | "execution_count": 9,
234 | "metadata": {},
235 | "output_type": "execute_result"
236 | }
237 | ],
238 | "source": [
239 | "type(v_out)"
240 | ]
241 | },
242 | {
243 | "cell_type": "code",
244 | "execution_count": 10,
245 | "metadata": {},
246 | "outputs": [
247 | {
248 | "data": {
249 | "text/plain": [
250 | "torch.FloatTensor"
251 | ]
252 | },
253 | "execution_count": 10,
254 | "metadata": {},
255 | "output_type": "execute_result"
256 | }
257 | ],
258 | "source": [
259 | "type(v_out.data)"
260 | ]
261 | },
262 | {
263 | "cell_type": "code",
264 | "execution_count": null,
265 | "metadata": {
266 | "collapsed": true
267 | },
268 | "outputs": [],
269 | "source": []
270 | }
271 | ],
272 | "metadata": {
273 | "kernelspec": {
274 | "display_name": "Python 3",
275 | "language": "python",
276 | "name": "python3"
277 | },
278 | "language_info": {
279 | "codemirror_mode": {
280 | "name": "ipython",
281 | "version": 3
282 | },
283 | "file_extension": ".py",
284 | "mimetype": "text/x-python",
285 | "name": "python",
286 | "nbconvert_exporter": "python",
287 | "pygments_lexer": "ipython3",
288 | "version": "3.5.2"
289 | }
290 | },
291 | "nbformat": 4,
292 | "nbformat_minor": 2
293 | }
294 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/203_activation.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 203 Activation\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11\n",
14 | "* matplotlib\n"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {
21 | "collapsed": true
22 | },
23 | "outputs": [],
24 | "source": [
25 | "import torch\n",
26 | "import torch.nn.functional as F\n",
27 | "from torch.autograd import Variable\n",
28 | "import matplotlib.pyplot as plt"
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "### Firstly generate some fake data"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 2,
41 | "metadata": {},
42 | "outputs": [],
43 | "source": [
44 | "x = torch.linspace(-5, 5, 200) # x data (tensor), shape=(200, 1)\n",
45 | "x = Variable(x)\n",
46 | "x_np = x.data.numpy() # numpy array for plotting"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "### Following are popular activation functions"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": 3,
59 | "metadata": {
60 | "collapsed": true
61 | },
62 | "outputs": [
63 | {
64 | "name": "stderr",
65 | "output_type": "stream",
66 | "text": [
67 | "C:\\Users\\morvanzhou\\AppData\\Local\\Programs\\Python\\Python36\\lib\\site-packages\\torch\\nn\\functional.py:1006: UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.\n warnings.warn(\"nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.\")\nC:\\Users\\morvanzhou\\AppData\\Local\\Programs\\Python\\Python36\\lib\\site-packages\\torch\\nn\\functional.py:995: UserWarning: nn.functional.tanh is deprecated. Use torch.tanh instead.\n warnings.warn(\"nn.functional.tanh is deprecated. Use torch.tanh instead.\")\n"
68 | ]
69 | }
70 | ],
71 | "source": [
72 | "y_relu = F.relu(x).data.numpy()\n",
73 | "y_sigmoid = torch.sigmoid(x).data.numpy()\n",
74 | "y_tanh = F.tanh(x).data.numpy()\n",
75 | "y_softplus = F.softplus(x).data.numpy()\n",
76 | "\n",
77 | "# y_softmax = F.softmax(x)\n",
78 | "# softmax is a special kind of activation function, it is about probability\n",
79 | "# and will make the sum as 1."
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "### Plot to visualize these activation function"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 5,
92 | "metadata": {
93 | "collapsed": true
94 | },
95 | "outputs": [],
96 | "source": [
97 | "%matplotlib inline"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": 7,
103 | "metadata": {},
104 | "outputs": [
105 | {
106 | "data": {
107 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAe8AAAFpCAYAAAC1YKAIAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzs3XmcjvX+x/HXB1Njl61kbP2ijUhDTjqn0mmTaC+lOClt\nTqtOWrWe03bapaQiydKCSVokCifZkiyJigyVLbKbMd/fH99bBjNmu+e67uX9fDzux9zLNXN9xsN1\nfea7fb7mnENERETiR5mwAxAREZGiUfIWERGJM0reIiIicUbJW0REJM4oeYuIiMQZJW8REZE4E2jy\nNrMlZvatmc02sxlBnltECmZmr5nZSjObm8/nl5nZnMh1/D8zax50jCISTsv7ZOdcC+dcegjnFpF9\nGwicsY/PfwJOdM41Ax4C+gcRlIjsrlzYAYhI7HDOfWFmDffx+f9yvZwKpJV2TCKyt6Bb3g74xMxm\nmlmPgM8tItHVHfgw7CBEklHQLe8TnHPLzaw2MM7MvnPOfbHzw0hC7wFQsWLFYw8//PCAwxOJEb/9\nBpmZUK8e1K69z0Nnzpy52jlXK6DIADCzk/HJ+4R9HKPrWaSICns9W1i1zc3sfmCjc+7JvD5PT093\nM2ZoTpskoalT4a9/hbPPhnffBbN9Hm5mM6M5hyTSbT7GOdc0n8+PBkYCZzrnvi/Mz9T1LFI4hb2e\nA+s2N7OKZlZ553PgNCDPGa0iSev33+GSSyAtDV59tcDEHTQzqw+8B1xe2MQtItEXZLf5gcBI8zej\ncsBbzrmPAjy/SGxzDv7xD1i+HCZPhgMOCDwEMxsKnATUNLNMoA+Q4sNzLwH3ATWAFyPXcrZWjogE\nL7Dk7Zz7EdCaUJH8PPccjB4N//0vHHdcKCE45zoX8PlVwFUBhSMi+YirpWJZWVlkZmaydevWsEOJ\nutTUVNLS0khJSQk7FAnD9Olw++1+nPuWW8KOJhCJfD1Hk+4Nkpe4St6ZmZlUrlyZhg0bYjE2FlgS\nzjnWrFlDZmYmjRo1CjscCdq6dXDxxXDQQTBwYMyNc5eWRL2eo0n3BslPXNU237p1KzVq1Ei4C93M\nqFGjhlogycg5uOoq+PlnGDYMqlcPO6LAJOr1HE26N0h+4qrlDSTshZ6ov5cU4MUX/XKwxx+H448P\nO5rA6f99wfRvJHmJq5Z3PDnppJPQulbZp1mz4NZboX17uO22sKORiKuuuor58+eX6jnat2/PunXr\n9nr//vvv58kn8yx9IbKbuGt5xxLnHM45ypTR30BSRH/8ARddBLVqwaBBoP9DMWPAgAGlfo6xY8eW\n+jkksemOUURLlizhsMMO44orrqBp06YMHjyYv/zlL7Rs2ZILL7yQjRs37vU9lSpV+vP5O++8Q7du\n3QKMWGKOc3D11bBkiR/nrlkz7IiS1qZNmzjrrLNo3rw5TZs2Zfjw4bv1mr366qs0adKE1q1bc/XV\nV9OzZ08AunXrxnXXXUebNm045JBDmDhxIldeeSVHHHHEbtf30KFDadasGU2bNuWOO+748/2GDRuy\nevVqAB555BGaNGnCCSecwMKFC4P75SWuxW/L++abYfbs6P7MFi3gmWcKPGzRokUMGjSIQw89lPPO\nO49PP/2UihUr8thjj/HUU09x3333RTcuSSwvvwwjRsC//w0n5FsaPLmEdD1/9NFHHHzwwXzwwQcA\nrF+/nn79+gGwYsUKHnroIWbNmkXlypVp164dzZvvKlXx+++/8+WXX5KRkUHHjh2ZMmUKAwYMoFWr\nVsyePZvatWtzxx13MHPmTA444ABOO+00Ro0axTnnnPPnz5g5cybDhg1j9uzZZGdn07JlS4499tjo\n/jtIQlLLuxgaNGhAmzZtmDp1KvPnz6dt27a0aNGCQYMGsXTp0rDDk1g2e7ZPVKefDrlaYhKOZs2a\nMW7cOO644w4mTZpE1apV//xs2rRpnHjiiVSvXp2UlBQuvPDC3b737LPPxsxo1qwZBx54IM2aNaNM\nmTIcddRRLFmyhOnTp3PSSSdRq1YtypUrx2WXXcYXX3yx28+YNGkS5557LhUqVKBKlSp07NgxkN9b\n4l/8trwL0UIuLRUrVgT8mPepp57K0KFD93l87tmiWvKRxDZs8OPc1avDG29onDu3kK7nJk2aMGvW\nLMaOHcs999zDKaecUujv3X///QEoU6bMn893vs7OzlZRFSlVunuUQJs2bZgyZQqLFy8G/PjZ99/v\nvVfDgQceyIIFC8jJyWHkyJFBhymxwDm49lr44QcYOrTAbT4lGCtWrKBChQp06dKF22+/nVmzZv35\nWatWrfj888/5/fffyc7O5t133y3Sz27dujWff/45q1evZseOHQwdOpQTTzxxt2P+9re/MWrUKLZs\n2cKGDRt4//33o/J7SeKL35Z3DKhVqxYDBw6kc+fObNu2DYCHH36YJk2a7Hbco48+SocOHahVqxbp\n6el5TmqTBPfqq/DWW/DQQ7DHDVzC8+2333L77bdTpkwZUlJS6NevH7169QKgbt263HXXXbRu3Zrq\n1atz+OGH79atXpA6derw6KOPcvLJJ+Oc46yzzqJTp067HdOyZUsuvvhimjdvTu3atWnVqlVUfz9J\nXKHt512QvPb/XbBgAUcccURIEZW+RP/9kta330Lr1n5y2kcfQdmyUf3x0dzP28xeAzoAK/Paz9v8\nGNCzQHtgM9DNOTdrz+P2FK/X88aNG6lUqRLZ2dmce+65XHnllZx77rmBxxEP/1YSHTG3n7dIUtq4\nES68EKpVgzffjHriLgUDgTP28fmZQOPIowfQL4CYQnP//ffTokULmjZtSqNGjXabKS4SJnWbi5QW\n5+D66+H77+HTT+HAA8OOqEDOuS/MrOE+DukEvOF8l91UM6tmZnWcc78EEmDAVO1MYpWSt0hpGTgQ\nBg+GPn2gXbuwo4mWusCyXK8zI+8lZPIWKZacHNi8GTZt2vXYuBEOOSRqf8QHnrzNrCwwA1junOtQ\n1O93ziVkof5YnXsgxTRvHtxwA5x8Mtx7b9jRhMLMeuC71qlfv36exyTq9RxNujeEbONG+O03+PVX\n/3Xn4/ff/Xa+69f7r7mfr1/ve9729PrrEKUKm2G0vG8CFgBVivqNqamprFmzJuG2Edy5Z29qamrY\noUg0bNrk13NXrgxDhsTDOHdRLAfq5XqdFnlvL865/kB/8BPW9vw8Ua/naNK9IQDr1sGCBfDTT7B0\nqS9bvGSJf75smW9B56VqVT+XZefXBg12f125MlSsuPvj6KOjFnagydvM0oCzgEeAW4v6/WlpaWRm\nZrJq1aqoxxa21NRU0tLSwg5DouGf//Q3g48/hjp1wo4m2jKAnmY2DDgOWF/c8e5Evp6jSfeGKNm6\n1Vc4/OYbmD/fP+bNg1/2+O9bqxY0bOgTbfv2cNBB/nHggbsetWpBuXBHnYM++zPAv4DKeX1YUDdb\nSkoKjRo1Ks34REpm8GDfNXbPPXDqqWFHU2RmNhQ4CahpZplAHyAFwDn3EjAWv0xsMX6p2D+Key5d\nz1Kqli2DiRPhq6/845tvICvLf1axIhx5JJx2mv965JHwf/8H9ev7z+JAYMnbzHauHZ1pZifldUxB\n3WwiMe277+C66+Bvf/OT1OKQc65zAZ874IaAwhEpvD/+gAkTYNw4v7pj5w5tlSpBejrcequvt9Cy\npU/ScV6eOMiWd1ugo5m1B1KBKmb2pnOuS4AxiJSOzZv9eu7y5X0ltZC71ESSwtq1MHo0vPOOT9pZ\nWVChgq9i2KMHnHIKNG2aaPNOgACTt3PuTuBOgEjLu5cStySMm26CuXPhww+hbt2woxFJXFlZ8MEH\nMGCAn1eSne3HqG+8Ec4+G/7yF9hvv7CjLHVqHoiU1Ftv+RtJ795wxr6Kk4lIsS1ZAv36waBBfqnW\nwQfDbbf5Hq+WLSHJViyEkrydcxOBiWGcWySqvv8errkG2rb1m46ISHTNng1PPAHDh/vXHTrAVVf5\nP5STeHgqeX9zkZLautWv595vP7/NZxLfSESibuZMuPtu3zVeqZIfmrr5ZqhXr+DvTQK624gU1y23\n+OUnY8bohiISLT/95JP20KFQowb8+99w7bVwwAFhRxZTlLxFimPECHjpJejVC846K+xoROLfxo1w\n//3w3HO+F+vuu+H2233FMtmLkrdIUS1e7Mfc2rTxrQIRKZmxY32NhJ9/hu7d4cEH/YQ0yZeSt0hR\nbNsGF1/sWwbDh0NKStgRicSvlSv9Eq/hw32Vs8mT/eRPKZCSt0hR9OoFs2b5whD57JQlIoXw0UfQ\ntavfGOShh+Bf/0qK9dnRouQtUljvvAMvvOAnqnXsGHY0IvFp2zZfE+GZZ3z1s/Hj/VcpEiVvkcL4\n8Uc/Fte6NTz6aNjRiMSnFSvg/PNh6lS/+95jj/mSwlJkSt4iBdk5zm0Gw4apa0+kOKZMgQsugA0b\n4O23/XMptvjeVkUkCHfcATNm+K0+k2ALSzM7w8wWmtliM+udx+f1zWyCmX1tZnMimw2J5G/IEDj5\nZL/d5tSpStxRoOQtsi+jRsGzz/ouvnPPDTuaUmdmZYG+wJnAkUBnMztyj8PuAUY4544BLgFeDDZK\niRvOwX/+A126wPHHw/TpGt+OEiVvkfwsWQL/+Acce6yvrZwcWgOLnXM/Oue2A8OATnsc44AqkedV\ngRUBxifxIicHevaEu+6Czp19mVNVSYsaJW+RvGzfDpdc4m9AI0bA/vuHHVFQ6gLLcr3OjLyX2/1A\nFzPLBMYC/8zrB5lZDzObYWYzVq1aVRqxSqzascNP8HzxRb+88s03k+kaCoSSt0he7roLvvoKXn0V\nDjkk7GhiTWdgoHMuDWgPDDazve4lzrn+zrl051x6rVq1Ag9SQpKd7ddvDxwIffrA449DGaWaaNNs\nc5E9vf8+/Pe/cP31yTixZjmQe5eVtMh7uXUHzgBwzn1pZqlATWBlIBFK7MrKgssv9xXTHnnE/xEs\npUJ/Donk9vPPvtXQooVP4MlnOtDYzBqZ2X74CWkZexzzM3AKgJkdAaQC6hdPdjt27ErcTzyhxF3K\nAkveZpZqZtPM7Bszm2dmDwR1bpFCycry49xZWX6cOzU17IgC55zLBnoCHwML8LPK55nZg2a2s6zc\nbcDVZvYNMBTo5pxz4UQsMcE5Pzlt+HDfTd6rV9gRJbwgu823Ae2ccxvNLAWYbGYfOuemBhiDSP7u\nuQe+/NLvI9y4cdjRhMY5NxY/ES33e/flej4f0O4RskufPn6L3H/9y2/jKaUusOQd+ct8Y+RlSuSh\nv9YlNowd61sMPXr41reIFM6zz/qNRbp3V+ngAAU65m1mZc1sNn5iyzjn3Fd7fK6lJRK8zEy44go4\n+mi/WYKIFM6IEXDzzb6A0Usv+RLCEohAk7dzbodzrgV+BmtrM2u6x+daWiLBys72BSS2bvU3Im2S\nIFI406b5yZ3HHw9vveX3uJfAhDLb3Dm3DphAZLmJSGj69IHJk+Hll+Gww8KORiQ+LFsGnTrBQQfB\nyJFJObkzbEHONq9lZtUiz8sDpwLfBXV+kb188omvu9y9O1x2WdjRiMSHjRv9fvabNsGYMVC7dtgR\nJaUg+znqAIMiGx+UwS9BGRPg+UV2WbHCb5Zw1FHw3HNhRyMSH3Jy/FruOXN84j7qqLAjSlpBzjaf\nAxwT1PlE8pWdDZde6lsOI0ZAhQphRyQSH/7zH7/T3tNPw5lnhh1NUtMMA0k+Dz4In3/uay8fcUTY\n0YjEh08+gXvv9X/43nRT2NEkPZVHleTy6afw8MN+lmzXrmFHIxIfli71qzKOOgr699eSsBig5C3J\n49df/Tj34YdD375hRyMSH7Zu9Rv0ZGfDe+9BxYphRySo21ySxY4dfkb5H3/41rduQCKFc8stMGOG\nH+tO4rLBsUbJW5LDI4/AZ5/5/bmbNi34eBHxCfull3y98k6dwo5GclG3uSS+iRPhgQd8l/k//hF2\nNDHPzM4ws4VmttjMeudzzEVmNj+yQ+BbQccoAVixAq66Clq29PNEJKao5S2JbeVKPzu2cWPo108T\nbQoQqcPQF19EKROYbmYZkZ3Edh7TGLgTaOuc+93MVKUj0eTkQLdusHmzL326335hRyR7UPKWxJWT\n41vbv/8OH30ElSqFHVE8aA0sds79CGBmw4BOwPxcx1wN9HXO/Q7gnFsZeJRSup59FsaNU9ngGKZu\nc0lc//mPvwE9+6zfMUwKoy6wLNfrzMh7uTUBmpjZFDObamZ57lGgXQLj1DffQO/efoz76qvDjkby\noeQtiemLL+C++/ze3LoBRVs5oDFwEtAZeGXnvgW5aZfAOLRlix9mql4dBgzQMFMMU7e5JJ5Vq3xB\niUMO8d1+ugEVxXKgXq7XaZH3cssEvnLOZQE/mdn3+GQ+PZgQpdT8618wfz58/DHUrBl2NLIPanlL\nYsnJgSuugDVrfN3yKlXCjijeTAcam1kjM9sPuATI2OOYUfhWN2ZWE9+N/mOQQUopGDsWXnjBr+s+\n7bSwo5ECKHlLYnniCT857emn4Rjtg1NUzrlsoCfwMbAAv/vfPDN70Mw6Rg77GFhjZvOBCcDtzrk1\n4UQsUfHbb34Z5dFHw7//HXY0UgjqNpfEMWUK3H03XHghXHtt2NHELefcWGDsHu/dl+u5A26NPCTe\nOQdXXumrD372GaSmhh2RFIKStySGNWv85LQGDeCVVzTOLVJYL77ou8yff177c8eRwLrNzayemU3I\nVZVJe8pJdOTk+B3CVq7049xVq4YdkUh8mDcPevWC9u3hhhvCjkaKIMiWdzZwm3NulplVBmaa2bjc\nlZtEiuWpp+CDD+C55+DYY8OORiQ+bNvml4VVrgyvvabeqjgTWPJ2zv0C/BJ5vsHMFuCLPyh5S/FN\nnQp33gnnnQc9e4YdjUj8uPNOmDMHxoyBAw8MOxopolBmm5tZQ+AY4Kswzi8JYu1auPhiSEvzu4Wp\n5SBSOJ984ldk3HADnHVW2NFIMQQ+Yc3MKgHvAjc75/7Y47MeQA+A+vXrBx2axBPn/NKWX36ByZOh\n2l4FvkQkL6tX+zkiRxzhl1ZKXAq05W1mKfjEPcQ5996en6ucohTas89CRgY8/ji0bh12NCLxwTm/\nzefatTB0KJQvH3ZEUkyBtbzNzIBXgQXOuaeCOq8koOnTfRnHTp3gJi1aECm0V16B0aP9JM/mzcOO\nRkogyJZ3W+ByoJ2ZzY482gd4fkkE69bBRRdBnTqaIStSFN99BzffDKeeqj96E0CQs80nA7rTSvE5\nB927Q2YmTJrkdz4SkYJt3w6XXQYVKsDAgVBGlbHjnSqsSfzo2xfee89PsmnTJuxoROLHfffBrFkw\nciQcfHDY0UgU6M8viQ8zZ8Jtt/llLbeqpLZIoU2Y4Cd29ugB55wTdjQSJUreEvvWr/fj3LVrw6BB\n6vIrZWZ2hpktNLPFZtZ7H8edb2bOzNKDjE+KYPVq6NIFGjf2k9QkYajbXGKbc3D11bB0KXz+OdSo\nEXZECc3MygJ9gVOBTGC6mWXsWcY4UuL4JlRoKXbtnCOyerWvolaxYtgRSRSpCSOx7aWX4O234ZFH\noG3bsKNJBq2Bxc65H51z24FhQKc8jnsIeAzYGmRwUgQvvrirFoL2tk84St4Su2bPhltugTPPhNtv\nDzuaZFEXWJbrdWbkvT+ZWUugnnPug339IDPrYWYzzGzGqlWroh+p5G/OnF1zRG68MexopBQoeUts\n2rDBj3PXqKFx7hhiZmWAp4DbCjpWFRNDsnmz39v+gAPg9ddVCyFBacxbYo9zcM018MMPfqasbvxB\nWg7Uy/U6LfLeTpWBpsBEXzSRg4AMM+vonJsRWJSSv1tu8QVZxo3TtZPA1JyR2DNggK+7/OCD8Le/\nhR1NspkONDazRma2H3AJkLHzQ+fceudcTedcQ+dcQ2AqoMQdK956C/r39+WDTzkl7GikFCl5S2yZ\nM8eP0Z16qt9vWALlnMsGegIfAwuAEc65eWb2oJl1DDc62af58/1a7hNOgIceCjsaKWXqNpfYsXGj\nH+euVg0GD9Y4d0icc2OBsXu8d18+x54URExSgI0b4YIL/HKw4cMhJSXsiKSUKXlLbHAOrrsOFi2C\nTz+FAw8MOyKR+LCzFsLChf7aUfnTpKDkLbHh9dfhzTfhgQfg5JPDjkYkfvTtC8OG+VoIunaShvol\nJXzz5kHPntCuHdx9d9jRiMSPiRP97PIOHaB3vpVsJQEpeUu4Nm2CCy+EKlVgyBAoWzbsiETiw48/\n+nHuxo19r5XmiCQVdZtLuHr23LUm9aCDwo5GJD5s2ACdOkFOji+BWrVq2BFJwAL7U83MXjOzlWY2\nN6hzSox74w0YOBDuuUdrUkUKKyfH7xS2YAGMGAGHHhp2RBKCIPtZBgJnBHg+iWULFvjZ5SeeCH36\nhB2NSPy44w7f2n76afj738OORkISWPJ2zn0BrA3qfBLDNm/267krVvQVoTTOLVI4Tz8NTz4JN9zg\nh5wkacXUmLeZ9QB6ANSvXz/kaKTU3HgjzJ0LH32kNakihTV0KNx6K5x/Pjz7rDYcSXIxNT1RuxAl\ngSFD4NVX4a674PTTw45GJD58+il07epr/b/5pnqrJLaStyS4hQv9bmF//asvxiIiBZs2Dc49Fw47\nDEaPhtTUsCOSGKDkLcHYssWPc6em+nHucjE1YiMSm6ZN85v01K7th5mqVQs7IokRQS4VGwp8CRxm\nZplm1j2oc0sMuOUWv2PY4MGQlhZ2NLIPZnaGmS00s8VmtlfZLjO71czmm9kcMxtvZg3CiDPhTZ8O\np50GNWv6Smp164YdkcSQwJo/zrnOQZ1LYszw4fDyy36P4TPPDDsa2QczKwv0BU4FMoHpZpbhnJuf\n67CvgXTn3GYzuw54HLg4+GgT2PTpvsVdvTpMmAD16oUdkcQYdZtL6Vq82O94dPzx8PDDYUcjBWsN\nLHbO/eic2w4MAzrlPsA5N8E5tznyciqgrpRo+vxzv367enXf4tbKG8mDkreUnq1b/Th3uXJ+mYv2\nGI4HdYFluV5nRt7LT3fgw1KNKJm8955fhVG3rk/iStySD80aktLTqxd8/bWvBqWbUMIxsy5AOnBi\nPp+rbkNR9OvnC68cdxyMGeNb3iL5UMtbSsc77/h9hm+9Fc4+O+xopPCWA7kHWNMi7+3GzP4O3A10\ndM5ty+sHqW5DIWVl+Ypp118P7dv7Nd1K3FIAJW+Jvh9+gO7dfQviP/8JOxopmulAYzNrZGb7AZcA\nGbkPMLNjgJfxiXtlCDEmjjVrfDf5iy/6nqpRo6BChbCjkjigbnOJrm3b4OKL/d7Cw4bBfvuFHZEU\ngXMu28x6Ah8DZYHXnHPzzOxBYIZzLgN4AqgEvG2+ROfPzrmOoQUdr/73P7jkEvjtN7+7XteuYUck\ncUTJW6LrX/+CmTNh5Eho2DDsaKQYnHNjgbF7vHdfrufayqokcnLgiSfg7ruhQQOYMgXS08OOSuKM\nkrdEz8iR8NxzcNNNcM45YUcjEnt++AGuvBK++AIuuAAGDICqVcOOSuKQxrwlOpYs8Tel9HR4/PGw\noxGJLTt2wPPPw9FHw+zZfnOeESOUuKXY1PKWktu+3Y9z5+T4amoa5xbZZfJk+Oc/fdI+/XR45RVV\nTJMSU8tbSu7OO/0GCq+9BoccEnY0IrEhMxMuu8zvord6tZ/A+eGHStwSFWp5S8lkZMBTT/l1quef\nH3Y0IuFbsQIee8zX8we45x7o3RsqVgw3LkkoSt5SfEuXQrdu0LIlPPlk2NGIhGvZMvjvf33Szsry\nS7/uuQcaNQo7MklASt5SPFlZfo1qdrYf505NDTsikeA552uQP/+8L7Bi5pP23XdrCElKlZK3FM/d\nd8PUqT5xH3po2NGIBGv5cr/ZzsCBMG+eL2d6++1w3XV+7bZIKVPylqL74ANfZOLaa/2uYSLJ4Jdf\n/IYhw4b5Pbadg9at/bKvzp2hfPmwI5QkEmjyNrMzgGfxZRcHOOceDfL8EgWZmb5bsHlzePrpsKMR\nKT1ZWTBrFnz8Mbz/PsyY4d8/9FDo0wcuvRQaNw43RklagSVvMysL9AVOxe8RPN3MMpxz84OKQUoo\nO9u3MLZt8wUmNM4tiWTTJp+sv/jCj2P/73/+PTPfwn74Yb9DXrNm/j2REAXZ8m4NLHbO/QhgZsOA\nTkDxkvfGjX7cVYIzY4a/oQ0ZAk2ahB2NSPHk5PiZ4QsXwpw5fs/5WbP8a+f8MU2b+pUUJ57oH7Vr\nhxqyyJ6CTN51gWW5XmcCx+U+wMx6AD0A6tevv++ftm0bvPFGdCOUfatUyU/QufTSsCORUlTQ8JaZ\n7Q+8ARwLrAEuds4tCTrOfDkH69b5IZ5ly/zXpUvh++99gl60CLZu3XV8vXpwzDF+9UTLlnD88VCj\nRnjxixRCTE1Yc871B/oDpKenu30eXKMG/P57EGGJJI1CDm91B353zh1qZpcAjwEXl0pAO3b4XrYN\nG/zjjz/8Hthr1viqZTu/7ny+YoVP1ps37/5zypb1S7cOOwxOPdV/bdIEjjoKatUqldBFSlOQyXs5\nkLsuYFrkPRGJHYUZ3uoE3B95/g7wgpmZc27ff3Dvy9NPw7vv7p6oN26ELVv2/X1ly/o/5Hc+WrSA\nDh0gLW33x0EHQUpKscMTiTVBJu/pQGMza4RP2pcA6n8ViS0FDm/lPsY5l21m64EawOpin9U5v6FN\ngwZQubIfoqlcee/nlSv7JF2zpn9UqQJltEWDJJ/AknfkIu8JfIwfS3vNOTcvqPOLSLCKNIfl1lv9\nQ0QKJdAxb+fcWGBskOcUkSIpzPDWzmMyzawcUBU/cW03RZrDIiJFov4mEcntz+EtM9sPP7yVsccx\nGUDXyPMLgM9KNN4tIkUWU7PNRSRc+Q1vmdmDwAznXAbwKjDYzBYDa/EJXkQCpOQtIrvJa3jLOXdf\nrudbgQuDjktEdlG3uYiISJxR8hYREYkzSt4iIiJxRslbREQkzih5i4iIxBklbxERkTij5C0iIhJn\nlLxFRETijJK3iIhInFHyFhERiTNK3iIiInFGyVtERCTOBJK8zexCM5tnZjlmlh7EOUWkaMysupmN\nM7NFka/AM/J/AAAgAElEQVQH5HFMCzP7MnI9zzGzi8OIVSTZBdXyngucB3wR0PlEpOh6A+Odc42B\n8ZHXe9oMXOGcOwo4A3jGzKoFGKOIEFDyds4tcM4tDOJcIlJsnYBBkeeDgHP2PMA5971zblHk+Qpg\nJVArsAhFBNCYt4jscqBz7pfI81+BA/d1sJm1BvYDfijtwERkd+Wi9YPM7FPgoDw+uts5N7qQP6MH\n0CPycqOZBdlarwmsDvB8haGYCifZY2pQ2AP3dZ3mfuGcc2bm9vFz6gCDga7OuZx8jtH1vLtYiynW\n4gHFBIW8ns25fK/PqDOziUAv59yMwE5aSGY2wzkXU5PpFFPhKKboiCTXk5xzv0SS80Tn3GF5HFcF\nmAj82zn3TsBhFkos/vvHWkyxFg8opqJQt7mI7JQBdI087wrs1WNmZvsBI4E3YjVxiySDoJaKnWtm\nmcBfgA/M7OMgzisiRfIocKqZLQL+HnmNmaWb2YDIMRcBfwO6mdnsyKNFOOGKJK+ojXnvi3NuJP6v\n9VjWP+wA8qCYCkcxRYFzbg1wSh7vzwCuijx/E3gz4NCKIxb//WMtpliLBxRToQU65i0iIiIlpzFv\nERGROKPknQczu83MnJnVjIFYnjCz7yKlKEeGVc3KzM4ws4VmttjM8qq8FXQ89cxsgpnNj5TqvCns\nmHYys7Jm9rWZjQk7lmSnaznfWHQ9F0IsX8tK3nsws3rAacDPYccSMQ5o6pw7GvgeuDPoAMysLNAX\nOBM4EuhsZkcGHccesoHbnHNHAm2AG2Igpp1uAhaEHUSy07WcN13PRRKz17KS996eBv4FxMRkAOfc\nJ8657MjLqUBaCGG0BhY75350zm0HhuFLaYbGOfeLc25W5PkG/AVWN8yYAMwsDTgLGFDQsVLqdC3n\nTddzIcT6tazknYuZdQKWO+e+CTuWfFwJfBjCeesCy3K9ziQGEuVOZtYQOAb4KtxIAHgGnzDyrDom\nwdC1vE+6ngsnpq/lQJaKxZICykPehe9mC1RhSsua2d34rqUhQcYW68ysEvAucLNz7o+QY+kArHTO\nzTSzk8KMJRnoWk48sXI9x8O1nHTJ2zn397zeN7NmQCPgGzMD36U1y8xaO+d+DSOmXLF1AzoAp7hw\n1vYtB+rlep0WeS9UZpaCv9CHOOfeCzseoC3Q0czaA6lAFTN70znXJeS4EpKu5WLT9VywmL+Wtc47\nH2a2BEh3zoVaJN/MzgCeAk50zq0KKYZy+Ak2p+Av8unApc65eWHEE4nJ8NtWrnXO3RxWHPmJ/LXe\nyznXIexYkp2u5b3i0PVcBLF6LWvMO/a9AFQGxkVKUb4UdACRSTY9gY/xE0lGhHmhR7QFLgfa5SrT\n2T7kmET2JfRrGXQ9Jwq1vEVEROKMWt4iIiJxRslbREQkzih5i4iIxBklbxERkTij5C0iIhJnlLxF\nRETijJK3iIhInFHyFhERiTNK3iIiInFGyVtERCTOKHmLSJGZWTUze8fMvjOzBWb2l7BjEkkmSbcl\nqIhExbPAR865C8xsP6BC2AGJJBNtTCIiRWJmVYHZwCEh7kktktTUbS4iRdUIWAW8bmZfm9kAM6sY\ndlAiySRmW941a9Z0DRs2DDsMkZg3c+bM1c65WkGdz8zSgalAW+fcV2b2LPCHc+7ePY7rAfQAqFix\n4rGHH354UCGKxK3CXs8xO+bdsGFDZsyYEXYYIjHPzJYGfMpMINM591Xk9TtA7z0Pcs71B/oDpKen\nO13PIgUr7PWsbnMRKRLn3K/AMjM7LPLWKcD8EEMSSTox2/IWkZj2T2BIZKb5j8A/Qo5HJKkoeYtI\nkTnnZgPpYcchkqziKnlnZWWRmZnJ1q1bww6lVKWmppKWlkZKSkrYoYiIFFqy3KOjoaT3+bhK3pmZ\nmVSuXJmGDRtiZmGHUyqcc6xZs4bMzEwaNWoUdjgiIoWWDPfoaIjGfT6uJqxt3bqVGjVqJPR/CjOj\nRo0a+stVROJOMtyjoyEa9/moJG8ze83MVprZ3Hw+NzN7zswWm9kcM2tZgnMVP9A4kQy/o4gkJt2/\nCqek/07RankPBM7Yx+dnAo0jjx5AvyidN3Dr1q3jxRdfLPb3n3TSSVq/LiISAyZNmsRRRx1FixYt\nWLBgAW+99Vahvq9SpUqlHFnBopK8nXNfAGv3cUgn4A3nTQWqmVmdaJw7aCVN3iIiEhuGDBnCnXfe\nyezZs/ntt98KnbxjQVAT1uoCy3K9zoy890tA54+a3r1788MPP9CiRQtOPvlk5syZw++//05WVhYP\nP/wwnTp1YsmSJZx55pmccMIJ/O9//6Nu3bqMHj2a8uXLA/D2229z/fXXs27dOl599VX++te/hvxb\nJTjnYN06WLvWf8392LABtm7d9di2be/nO3b4R05O4b865x87z1/Urzuf16kDEyeW+j+RSKLYtGkT\nF110EZmZmezYsYN7772XmjVr0qtXL7Kzs2nVqhX9+vVj8ODBjBgxgo8//pgPP/yQH374gQULFtCi\nRQu6du3KAQccwMiRI1m/fj3Lly+nS5cu9OnTZ7dzTZw4kSeffJIxY8YA0LNnT9LT0+nWrRu9e/cm\nIyODcuXKcdppp/Hkk09G9feMqdnmuWsh169ff98H33wzzJ4d3QBatIBnntnnIY8++ihz585l9uzZ\nZGdns3nzZqpUqcLq1atp06YNHTt2BGDRokUMHTqUV155hYsuuoh3332XLl26AJCdnc20adMYO3Ys\nDzzwAJ9++ml0f49ktH07fP89zJsH8+fDDz/A8uWQmem/btlS8M/Ybz9ITYX99/dfU1P9e+XKQdmy\n/lGmzO5fU1L2fn/nA2DnuFZxvppBjRol/7cRCUNI9+iPPvqIgw8+mA8++ACA9evX07RpU8aPH0+T\nJk244oor6NevHzfffDOTJ0+mQ4cOXHDBBXsl4oEDBzJt2jTmzp1LhQoVaNWqFWeddRbp6QWXN1iz\nZg0jR47ku+++w8xYt25dyX/3PQSVvJcD9XK9Tou8t5s9ayEHE1rxOee46667+OKLLyhTpgzLly/n\nt99+A6BRo0a0aNECgGOPPZYlS5b8+X3nnXdenu9LEWzYAOPGwaRJMGUKfP01ZGf7z8qUgXr1IC0N\njj0WOnaEunWhZk2oVm33R+XKuxJ2mbhafCEieWjWrBm33XYbd9xxBx06dKBKlSo0atSIJk2aANC1\na1f69u3LzTffXODPOvXUU6kR+QP6vPPOY/LkyYVK3lWrViU1NZXu3bvToUMHOnToULJfKg9BJe8M\noKeZDQOOA9Y750rWZV7AX19BGDJkCKtWrWLmzJmkpKTQsGHDP6f+77///n8eV7ZsWbbkavnt/Kxs\n2bJk70w4UrBNm2DYMHj3XRg/3re2y5eH1q2hVy9o1gyOOgqaNPHvi0h4QrpHN2nShFmzZjF27Fju\nuece2rVrV+yfteeM8D1flytXjpycnD9f77z/lytXjmnTpjF+/HjeeecdXnjhBT777LNix5GXqCRv\nMxsKnATUNLNMoA+QAuCcewkYC7QHFgObieM6yJUrV2bDhg2A746pXbs2KSkpTJgwgaVLg97cKUks\nWgTPPw+DBsEff8Ahh8A//+lb1G3a+K5tERFgxYoVVK9enS5dulCtWjVeeOEFlixZwuLFizn00EMZ\nPHgwJ5544l7fl/vevtO4ceNYu3Yt5cuXZ9SoUbz22mu7fd6gQQPmz5/Ptm3b2LJlC+PHj+eEE05g\n48aNbN68mfbt29O2bVsOOeSQqP+eUUnezrnOBXzugBuica6w1ahRg7Zt29K0aVNatWrFd999R7Nm\nzUhPT0f7FUdZZib06eOTdtmycOGFcP318Je/7BobFhHJ5dtvv+X222+nTJkypKSk0K9fP9avX8+F\nF17454S1a6+9dq/vO/rooylbtizNmzenW7duHHDAAbRu3Zrzzz+fzMxMunTpsleXeb169bjoooto\n2rQpjRo14phjjgFgw4YNdOrUia1bt+Kc46mnnor672nOxebQcl77/y5YsIAjjjgipIiClUy/6152\n7IAXXoB77vFd49ddB717w0EHhR1ZTDKzmc65mN4kRPt5J4dEum8NHDiQGTNm8MILL5TaOfL69yrs\n9RxTs81FWLECLr0UPv8czjgD+vb13eQiIvInJW+JHVOmwLnn+olpAwfCFVeoe1xEQtGtWze6desW\ndhj5UvKW2DBqFHTu7Jd4ff45JEjXW6IysyXABmAHkB3r3fYiiSbukrdzLuEL38fqPIRS8/bbcMkl\n0KoVjBnj12NLPDjZObc67CAktiTDPToaSnqfj6uqFKmpqaxZsyahk9vOfV5TU1PDDiUYH3zgx7jb\ntvVrt5W4ReJWMtyji8U5P58nKyvysuT3+bhqeaelpZGZmcmqVavCDqVUpaamkpaWFnYYpW/WLLjg\nAl/ycMwYqFgx7Iik8BzwiZk54OVIdcTdFKncsSSEZLlHF9n69X4vherVfVVHSn6fj6vknZKSQqNG\njcIOQ6Jh5Uo45xyoVcu3vqtUCTsiKZoTnHPLzaw2MM7MvovsLvineCt3LCWne3QePvnEr5y59FIY\nPDhqk3DjqttcEkROjh/jXrUKRo6E2rXDjkiKyDm3PPJ1JTASaB1uRCIxaOlSPxH3qKPg5ZejunpG\nyVuC98wzMGGCL8Ry7LFhRyNFZGYVzazyzufAacDccKMSiTFbt/phwexseO+9qA8LxlW3uSSAefPg\nrrugUye48sqwo5HiORAYGZlRXA54yzn3UbghicSYG2+EGTP8MtjGjaP+45W8JTg5OdC9ux/f7t9f\nBVjilHPuR6B52HGIxKzXXoNXXoE77/QNlVKg5C3Bef11+OorP2lD49wikohmzfIbKJ1yCjz0UKmd\nRmPeEoy1a/3mIiecAJddFnY0IiLRt3YtnH++X0UzdKjfDbGUqOUtwXjoIf8f+4UX1F0uIoknJwe6\ndIHly2HSJJ/AS5GSt5S+ZcvgxRehWzdorqFSEUlADz0EH34I/frBcceV+unUbS6l76GHfHnA++4L\nOxIRkej78EN44AG/E+I11wRySiVvKV2LF/uZl9dcAw0ahB2NiEh0/fSTn8dz9NG+1R3QsKCSt5Su\nxx+HlBS/tltEJJFs2eInqOXkwLvvQoUKgZ1aY95Sen79FQYN8sVY6tQJOxoRkehxDm64Ab7+Gt5/\nH/7v/wI9vVreUnqef95vgXfrrWFHIiISXQMG+NoV99wDHToEfnolbykdGzf6GebnnVcqpQFFREIz\nYwb07AmnnQb33x9KCFFJ3mZ2hpktNLPFZtY7j8+7mdkqM5sdeVwVjfNKDHvjDb9/ba9eYUciIhI9\nq1f7ce6DDoK33irVQiz7UuIxbzMrC/QFTgUygelmluGcm7/HocOdcz1Lej6JA875WZctWway3lFE\nJBA7dviZ5b/+ClOmQI0aoYUSjZZ3a2Cxc+5H59x2YBhQOpXYJT5MmQJz58J116mamogkjj594JNP\nfKXI9PRQQ4lG8q4LLMv1OjPy3p7ON7M5ZvaOmdWLwnklVvXrB1Wr+k3oRUQSwahR8MgjcNVVcPXV\nYUcT2IS194GGzrmjgXHAoLwOMrMeZjbDzGasWrUqoNAkqlavhnfe8ZWGorz5vIhIKBYu9Pe0Vq38\nKpoYEI3kvRzI3ZJOi7z3J+fcGufctsjLAcCxef0g51x/51y6cy69VikXdZdSMnQobN/u/zqVhGZm\nZc3sazMbE3YsIqVmwwY491xITfWFWFJTw44IiE7yng40NrNGZrYfcAmQkfsAM8tdoaMjsCAK55VY\nNHAgHHOMLxUoie4mdC1LInPOF5lauBCGD4d6sTPiW+Lk7ZzLBnoCH+Mv5BHOuXlm9qCZdYwcdqOZ\nzTOzb4AbgW4lPa/EoLlz/Ub0XbuGHYmUMjNLA87C96SJJKYnn/TDgI89BiefHHY0u4lKeVTn3Fhg\n7B7v3Zfr+Z3AndE4l8SwQYOgXDm49NKwI5HS9wzwL6ByfgeYWQ+gB0D9+vUDCkskSsaPh9694cIL\n4bbbwo5mL6qwJtGxYwcMGQLt25f6JvQSLjPrAKx0zs3c13GawyJxa+lSuPhiOPxwvytiDC55VfKW\n6Jg0CX75xRcwkETXFuhoZkvwdR3amdmb4YYkEiVbt/oKallZMHIkVKoUdkR5UvKW6Bg+3G+Hd9ZZ\nYUcipcw5d6dzLs051xA/QfUz51yXkMMSKbmdO4XNnAmDB0OTJmFHlC8lbym57Gy/hKJDB63tFpH4\n9corvpv83nuhY8eCjw+R9vOWkps4EVat8mNEklSccxOBiSGHIVJyU6f6ncLOOMOXQY1xanlLyY0Y\n4ceFzjwz7EhERIrut9/gggsgLc1PvA1pp7CiUMtbSiYry3eZd+wI5cuHHY2ISNFkZflew7Vr4csv\noXr1sCMqFCVvKZnPPvP/6S+6KOxIRESK7o474PPP/QS15s3DjqbQ1G0uJTNiBFSpAqefHnYkIiJF\nM2wYPP003HgjdImvBRNK3lJ8O3bA6NF+lnmMFOsXESmUb7+F7t3hr3/1ZVDjjJK3FN+XX8KaNdCp\nU9iRiIgU3rp1fqewqlV972FKStgRFZnGvKX4MjL8f3p1mYtIvMjJ8V3kP//sl7kedFDYERWLkrcU\nX0YGnHSS/+tVRCQe9OkDH3wAffvC8ceHHU2xqdtcimfhQv+I8SpEIiJ/evddePhhuOoquO66sKMp\nESVvKZ733/dfzz473DhERApj7lzo2hXatIEXXojJncKKQslbiicjw6+JbNAg7EhERPZt7Vo/sbZK\nFd/63n//sCMqMSVvKbrVq2HKFHWZi0jsy86GSy6BzEx47z04+OCwI4oKTViTohs71s/YVPIWkVh3\n110wbpzfMaxNm7CjiRq1vKXoMjL8X68tW4YdiYhI/oYOhSeegOuv95PUEoiStxTN1q3w0Ud+oloZ\n/fcRkRj19de+gtrf/gbPPBN2NFGnu68UzcSJsGmTusyTmJmlmtk0M/vGzOaZ2QNhxySym1Wr4Jxz\noEYNePvtuKygVhCNeUvRZGRAhQrQrl3YkUh4tgHtnHMbzSwFmGxmHzrnpoYdmAhZWX6Xw5UrYfJk\nqF077IhKRVRa3mZ2hpktNLPFZtY7j8/3N7Phkc+/MrOG0TivBMw5n7xPP10bkSQx522MvEyJPFyI\nIYns0quX7yHs3x+OPTbsaEpNiZO3mZUF+gJnAkcCnc3syD0O6w787pw7FHgaeKyk55UQfP01LF+u\nLnPBzMqa2WxgJTDOOfdVHsf0MLMZZjZj1apVwQcpyWfgQHjuObjlFrj88rCjKVXRaHm3BhY75350\nzm0HhgF7bjPVCRgUef4OcIpZnJe3SUYZGb4q0VlnhR2JhMw5t8M51wJIA1qbWdM8junvnEt3zqXX\nqlUr+CAluUybBtde64f0Hn887GhKXTSSd11gWa7XmZH38jzGOZcNrAdqROHcEqSMDF/IXzdiiXDO\nrQMmAGeEHYsksV9+gfPOgzp1YPhwKJf407liara5utli2LJlvttcXeZJz8xqmVm1yPPywKnAd+FG\nJUlryxY/s3zdOhg1CmrWDDuiQEQjeS8H6uV6nRZ5L89jzKwcUBVYs+cPUjdbDNu5EYmSt0AdYIKZ\nzQGm48e8x4QckyQj53zxlWnT4M03/X4LSSIafQvTgcZm1gifpC8BLt3jmAygK/AlcAHwmXNOs1Pj\nSUYGNG4Mhx0WdiQSMufcHOCYsOMQ4dFH4a234JFHfOs7iZS45R0Zw+4JfAwsAEY45+aZ2YNmtrOZ\n9ipQw8wWA7cCey0nkxj2xx/w2We+1a15hiISC0aP9nXLO3eGO+8MO5rARWVU3zk3Fhi7x3v35Xq+\nFbgwGueSEHzyiS98oC5zEYkFc+bAZZdBq1bw6qtJ2aiIqQlrEqNGjfJlBo8/PuxIRCTZrVzpGxJV\nq/p7U/nyYUcUisSfTy8lk5UFH3zgN7JPguUXIhLDtm2D88+H336DSZMSZm/u4tDdWPZt0iS/BKPT\nnnV3REQC5Bxcd52vVz5sGKSnhx1RqNRtLvs2erSvY37aaWFHIiLJ7Jln4PXX4d574eKLw44mdEre\nkj/nfPL++9+hYsWwoxGRZDV2rN9w5Pzz4f77w44mJih5S/7mzIGlS9VlLiLhmT3bt7SbN4dBg6CM\n0hYoecu+jB7tl2CcfXbYkYhIMlq+HDp0gGrVYMwY9QDmoglrkr/Ro6FNGzjwwLAjEZFks3GjT9zr\n18OUKUk9szwvanlL3pYtg1mzkq7koIjEgB07fOW0OXNgxAg4+uiwI4o5anlL3jIy/FeNd4tI0G69\n1XeTv/ginHlm2NHEJLW8JW+jR/tNSLQRiYgE6bnn/OPWW/26bsmTkrfsbe1amDBBrW4RCdb778Mt\nt/jhuscfDzuamKbkLXsbNQqys+Gii8KORESSxddf+3Huli393txly4YdUUxT8pa9DR8OhxziLyKR\nPZhZPTObYGbzzWyemd0UdkwS55YsgfbtoXp1P99GS8IKpOQtu1u9GsaP90URknCbPSmUbOA259yR\nQBvgBjM7MuSYJF6tXg2nn+43HfnoI6hTJ+yI4oJmm8vuRo70yzTUZS75cM79AvwSeb7BzBYAdYH5\noQYm8WfTJr+W++efYdw4OFJ/AxaWWt6yu+HDoUkTX4pQpABm1hA4Bvgqj896mNkMM5uxatWqoEOT\nWJeV5RsJ06fD0KFwwglhRxRXlLxll5Ur/Szziy5Sl7kUyMwqAe8CNzvn/tjzc+dcf+dcunMuvVat\nWsEHKLHLObjmGr/hSN++KgZVDEressu770JOjrbbkwKZWQo+cQ9xzr0XdjwSZ+6912/ved99cO21\nYUcTl5S8ZZdhw+CII+Coo8KORGKYmRnwKrDAOfdU2PFInHnxRXjkEbjqKm3vWQJK3uL9+CN88QV0\n6aIucylIW+ByoJ2ZzY482ocdlMSB4cOhZ0+/U2G/frrXlIBmm4v3xhv+Qrr88rAjkRjnnJsM6K4r\nRTNmjG8cnHCC7+Urp/RTEiVqeZtZdTMbZ2aLIl8PyOe4Hbn+Qs8oyTmlFOTk+OR9yilQr17Y0YhI\novnsM7jgAmjRwifxChXCjijulbTbvDcw3jnXGBgfeZ2XLc65FpFHxxKeU6Jt8mT46Sfo2jXsSEQk\n0UydCh07wqGH+iIsVaqEHVFCKGny7gQMijwfBGi+fzx67TWoVAnOPTfsSEQkkcye7bf0rFPHF2Gp\nUSPsiBJGSZP3gZFqSwC/Agfmc1xqpFjDVDNTgo8la9f6SSRduqiesIhEz8KFcNppvmHw6acqexpl\nBc4YMLNPgYPy+Oju3C+cc87MXD4/poFzbrmZHQJ8ZmbfOud+yONcPYAeAPXr1y8weImCgQNh61bt\nmysi0bNoEbRr5yfBjh8PDRqEHVHCKTB5O+f+nt9nZvabmdVxzv1iZnWAlfn8jOWRrz+a2UR8OcW9\nkrdzrj/QHyA9PT2/PwQkWnJy4KWX4Pjj4eijw45GRBLBokVw0kmwfbufqNakSdgRJaSSdptnADtn\nOXUFRu95gJkdYGb7R57XxK8R1QYGseCzz/yFpla3iETD99/vStwTJkCzZmFHlLBKmrwfBU41s0XA\n3yOvMbN0MxsQOeYIYIaZfQNMAB51zil5x4KnnoLatf0SDhGRkvj+ezj5ZL/hyIQJ0LRp2BEltBKt\nknfOrQFOyeP9GcBVkef/A/TnV6z59lv48EN4+GFITQ07GhGJZwsX+jHurCzfo6fEXepUHjVZPfmk\nn12uLnMRKYmvv4a//hWys5W4A6TknYwyM+Gtt6B7d6hePexoRCReTZ7sx7hTU2HSJCXuACl5J6NH\nHvFLOG65JexIRCReffSRX8ddpw5MmaJZ5QFT8k42P/4IAwb47fgaNgw7GhGJRyNG+JKnhx3mdyPU\nngiBU/JONg884HfzueeesCMRkXj0zDNwySVw3HF+Vnnt2mFHlJSUvJPJt9/Cm2/CDTfAwQeHHY2I\nxJMdO+Cmm/xw2znnwMcfQ7VqYUeVtJS8k4Vz0LOnv9juvDPsaCTOmdlrZrbSzOaGHYsEYNMmOO88\neO45n7zfflvbeoZMyTtZDB3qx6b+8x/t7CPRMBA4I+wgJAC//upnlI8ZA88/74s7lS0bdlRJr0RF\nWiRO/P479OoF6el+eZhICTnnvjCzhmHHIaVsxgy/VfDatTBqFJx9dtgRSYRa3smgZ09YtcpvQqK/\nmCUgZtYjshXwjFWrVoUdjhTVoEFwwgn+njF5shJ3jFHyTnQjRviCLPfdB8ceG3Y0kkScc/2dc+nO\nufRatWqFHY4UVlYW3HgjdOsGbdv61vcxx4QdlexByTuRLVoE11wDrVtrkpqIFGzJEvjb3/zY9i23\n+BnlNWuGHZXkQWPeiWrDBr+co2xZGD7cr+0WEcnPu+/6OTHO+XvGRReFHZHsg1reiSgrCzp39jv9\njBihSmoSdWY2FPgSOMzMMs1MMyHj1aZNcP31fmvgww6D2bOVuOOAmmOJZscOuPxy+OADP0GtXbuw\nI5IE5JzrHHYMEgWTJ8M//gGLF/sVKY88AvvtF3ZUUghqeSeS7dvhiit8l9fjj/vxbhGRPW3ZArfd\n5se3s7N9mdMnnlDijiNqeSeK9evh/PNh/HhfiOX228OOSERi0Sef+OWjixbBtdf6pF2pUthRSRGp\n5Z0IZs6Eli3h889h4EDo3TvsiEQk1ixf7seyTz/dT0obNw769VPijlNK3vFs2zZ46CE4/njfZT5x\nInTtGnZUIhJLtmyBRx+Fww+H99+HBx/0mxT9/e9hRyYloG7zeOQcjBwJd93lZ5RffDH07aua5SKy\ny44dvkrafff5VnfHjvD003DIIWFHJlGglnc82bwZXnvNV0o7/3wwgw8/hGHDlLhFxNuxw09abd7c\nr9tOS/NDaqNHK3EnELW8Y9327f7CGzXKlzldtw6OPBJefx26dFHxFRHxsrJgyBA/YfX77303+dtv\n75GnEZIAAAchSURBVPpDXxJKie78ZnYhcD9wBNDaOTcjn+POAJ4FygIDnHOPluS8CW3jRj8eNWWK\nX4M5caKfSV6+vO/2uu46v7xDF6OIgN90aMAAP/ls2TJo0cIn7XPP1UZECaykzba5wHnAy/kdYGZl\ngb7AqUAmMN3MMpxz80t47vjjnO/6XrXKj0EtXw6Zmf7x3Xcwfz4sXbrr+EMP9X81d+rkJ5dUqBBe\n7CISO5yDL7+El1/2w2bbt8Mpp/gE3r69/rhPAiVK3s65BQC27/8orYHFzrkfI8cOAzoBJUve27bB\n2LH+P3FJHzk5RTt2+3b/2LYt/+fbtsEff/hW87p1/uv69b4gwp7Kl4cmTfys8auugqZNoU0bOOig\nEv0TiUiC+eknePNNeOMNXxWtUiW4+mpf3vTII8OOTgIUxIBpXWBZrteZwHF5HWhmPYAeAPXr19/3\nT92wAc47LzoRFpcZ7L+/r0q082vu51WqQJ06cMQRULXqrkeNGn4SSd26/mu1avpLWUT25hzMm+cn\nm40a5bfnBDj5ZLj7bt8zV7lyuDFKKApM3mb2KZBXE/Bu59zoaAbjnOsP9AdIT093+zy4WjX4+muf\n9Er6KFOmaMfuTNBlyyrpikh0rV8Pkyb5aonvvw8//ODfP+44Pxmtc2do0CDcGCV0BSZv51xJV/Iv\nB+rlep0Wea9kypXzEzNEROLZr7/C9Ol+guqECb5iYk6ObyC0a+dLHXfs6HvxRCKC6DafDjQ2s0b4\npH0JcGkA5xURiR05ObBkiZ+YOneuT9jTp/sZ4uAbJG3a+O7wdu3889TUUEOW2FXSpWLnAs8DtYAP\nzGy2c+50MzsYvySsvXMu28x6Ah/jl4q95pybV+LIRURiTXa2X0WydKlP1EuW+DXX8+f7FSVbtuw6\n9v/+D9q2hVat/KNlS6hYMazIJc6UdLb5SGBkHu+vANrnej0WGFuSc4lI7Eiq2g07dviVI2vXwm+/\nwcqVuz9++813fS9d6pd97tix+/enpcFRR8FJJ/kZ4Uce6SexHnBAKL+OJAaV5xKRIgmldkNOjk+K\n2dn+kft5Xu9t3brrsWXL7l/zer7h/9u7oxepyjiM49+HbXOFNlZw18DWtttlCwQRQcHICMu1rsuC\n6LYLBUNa/ROC7KKLCG+CvAkqkkDQoNvCMg3Kii4qiCKji8SbUH5dvDM2jDO754hz3vfsPB84zJnZ\ngXkY5re/mXPe877X0kCx7uWdvfvXrw/PNTMDc3OwZQvs2QMLC2kwWfd22zYf+raRcPM2s7ru/twN\nKytpOdtBjfnmzdS8R2FyMjXX6el0aWf3cs75+XTb+9imTalJz82lbXY2DSozy8DN28zqqjR3Q615\nG5aW4ODBNGird5uYWPuxQfenptK2cePw/Q0bvDaAtZY/uWY2ErXmbTh0KG1mVomXBDWzukYzd4OZ\nVebmbWZ13Zq7QdK9pLkbzmTOZDZWfNjczGrx3A1m+Sli9VNRuUi6Cvyy5hPvns3AXw2+XhXOVM24\nZ3ooImYbeq074noGystUWh5wJqhYz8U276ZJ+jIiduTO0cuZqnEm61fi+19aptLygDPV4XPeZmZm\nLePmbWZm1jJu3v97J3eAAZypGmeyfiW+/6VlKi0POFNlPudtZmbWMv7lbWZm1jJu3gNIOiopJG0u\nIMvrkr6X9I2kjyTNZMqxX9IPkn6S9FqODH155iV9Juk7Sd9KOpw7U5ekCUlfS/okd5Zx51oemsX1\nXEHJtezm3UfSPPAk8GvuLB3ngaWIeBT4EVhpOkDPEpBPAYvAc5IWm87R5wZwNCIWgV3AKwVk6joM\nXMkdYty5lgdzPddSbC27ed/uJHAMKGIwQESci4gbnbufk+aRbtqtJSAj4l+guwRkNhHxe0Rc7Oxf\nIxXY1pyZACQ9CBwATuXOYq7lIVzPFZRey27ePSQ9C/wWEZdzZxniZeBshtcdtARk9kbZJWkB2A58\nkTcJAG+SGsaIFqC2KlzLq3I9V1N0LY/d3OaSPgUeGPCnE8Bx0mG2Rq2WKSI+7jznBOnQ0ukms5VO\n0n3AB8CRiPgnc5Zl4M+I+ErSYzmzjAPX8vpTSj23oZbHrnlHxBODHpf0CPAwcFkSpENaFyXtjIg/\ncmTqyfYSsAzsizzX9hW5BKSkSVKhn46ID3PnAXYDz0h6GpgC7pf0XkS8kDnXuuRavmOu57UVX8u+\nznsIST8DOyIi6yT5kvYDbwB7I+Jqpgz3kAbY7CMV+QXg+ZwrSSn9V34X+DsijuTKMUzn2/qrEbGc\nO8u4cy3flsP1XEOptexz3uV7C5gGzku6JOntpgN0Btl0l4C8ArxfwBKQu4EXgcc778ulzrdks1Jl\nr2VwPa8X/uVtZmbWMv7lbWZm1jJu3mZmZi3j5m1mZtYybt5mZmYt4+ZtZmbWMm7eZmZmLePmbWZm\n1jJu3mZmZi3zH58alggIp0WVAAAAAElFTkSuQmCC\n",
108 | "text/plain": [
109 | ""
110 | ]
111 | },
112 | "metadata": {},
113 | "output_type": "display_data"
114 | }
115 | ],
116 | "source": [
117 | "plt.figure(1, figsize=(8, 6))\n",
118 | "plt.subplot(221)\n",
119 | "plt.plot(x_np, y_relu, c='red', label='relu')\n",
120 | "plt.ylim((-1, 5))\n",
121 | "plt.legend(loc='best')\n",
122 | "\n",
123 | "plt.subplot(222)\n",
124 | "plt.plot(x_np, y_sigmoid, c='red', label='sigmoid')\n",
125 | "plt.ylim((-0.2, 1.2))\n",
126 | "plt.legend(loc='best')\n",
127 | "\n",
128 | "plt.subplot(223)\n",
129 | "plt.plot(x_np, y_tanh, c='red', label='tanh')\n",
130 | "plt.ylim((-1.2, 1.2))\n",
131 | "plt.legend(loc='best')\n",
132 | "\n",
133 | "plt.subplot(224)\n",
134 | "plt.plot(x_np, y_softplus, c='red', label='softplus')\n",
135 | "plt.ylim((-0.2, 6))\n",
136 | "plt.legend(loc='best')\n",
137 | "\n",
138 | "plt.show()"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": null,
144 | "metadata": {
145 | "collapsed": true
146 | },
147 | "outputs": [],
148 | "source": []
149 | }
150 | ],
151 | "metadata": {
152 | "kernelspec": {
153 | "display_name": "Python 3",
154 | "language": "python",
155 | "name": "python3"
156 | },
157 | "language_info": {
158 | "codemirror_mode": {
159 | "name": "ipython",
160 | "version": 3
161 | },
162 | "file_extension": ".py",
163 | "mimetype": "text/x-python",
164 | "name": "python",
165 | "nbconvert_exporter": "python",
166 | "pygments_lexer": "ipython3",
167 | "version": "3.5.2"
168 | }
169 | },
170 | "nbformat": 4,
171 | "nbformat_minor": 2
172 | }
173 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/303_build_nn_quickly.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 303 Build NN Quickly\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 1,
19 | "metadata": {
20 | "collapsed": true
21 | },
22 | "outputs": [],
23 | "source": [
24 | "import torch\n",
25 | "import torch.nn.functional as F"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 2,
31 | "metadata": {
32 | "collapsed": true
33 | },
34 | "outputs": [],
35 | "source": [
36 | "# replace following class code with an easy sequential network\n",
37 | "class Net(torch.nn.Module):\n",
38 | " def __init__(self, n_feature, n_hidden, n_output):\n",
39 | " super(Net, self).__init__()\n",
40 | " self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer\n",
41 | " self.predict = torch.nn.Linear(n_hidden, n_output) # output layer\n",
42 | "\n",
43 | " def forward(self, x):\n",
44 | " x = F.relu(self.hidden(x)) # activation function for hidden layer\n",
45 | " x = self.predict(x) # linear output\n",
46 | " return x"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 3,
52 | "metadata": {
53 | "collapsed": true
54 | },
55 | "outputs": [],
56 | "source": [
57 | "net1 = Net(1, 10, 1)"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 4,
63 | "metadata": {
64 | "collapsed": true
65 | },
66 | "outputs": [],
67 | "source": [
68 | "# easy and fast way to build your network\n",
69 | "net2 = torch.nn.Sequential(\n",
70 | " torch.nn.Linear(1, 10),\n",
71 | " torch.nn.ReLU(),\n",
72 | " torch.nn.Linear(10, 1)\n",
73 | ")\n"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 5,
79 | "metadata": {},
80 | "outputs": [
81 | {
82 | "name": "stdout",
83 | "output_type": "stream",
84 | "text": [
85 | "Net (\n",
86 | " (hidden): Linear (1 -> 10)\n",
87 | " (predict): Linear (10 -> 1)\n",
88 | ")\n",
89 | "Sequential (\n",
90 | " (0): Linear (1 -> 10)\n",
91 | " (1): ReLU ()\n",
92 | " (2): Linear (10 -> 1)\n",
93 | ")\n"
94 | ]
95 | }
96 | ],
97 | "source": [
98 | "print(net1) # net1 architecture\n",
99 | "print(net2) # net2 architecture"
100 | ]
101 | },
102 | {
103 | "cell_type": "code",
104 | "execution_count": null,
105 | "metadata": {
106 | "collapsed": true
107 | },
108 | "outputs": [],
109 | "source": []
110 | }
111 | ],
112 | "metadata": {
113 | "kernelspec": {
114 | "display_name": "Python 3",
115 | "language": "python",
116 | "name": "python3"
117 | },
118 | "language_info": {
119 | "codemirror_mode": {
120 | "name": "ipython",
121 | "version": 3
122 | },
123 | "file_extension": ".py",
124 | "mimetype": "text/x-python",
125 | "name": "python",
126 | "nbconvert_exporter": "python",
127 | "pygments_lexer": "ipython3",
128 | "version": "3.5.2"
129 | }
130 | },
131 | "nbformat": 4,
132 | "nbformat_minor": 2
133 | }
134 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/305_batch_train.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 305 Batch Train\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 1,
19 | "metadata": {},
20 | "outputs": [
21 | {
22 | "data": {
23 | "text/plain": [
24 | ""
25 | ]
26 | },
27 | "execution_count": 1,
28 | "metadata": {},
29 | "output_type": "execute_result"
30 | }
31 | ],
32 | "source": [
33 | "import torch\n",
34 | "import torch.utils.data as Data\n",
35 | "\n",
36 | "torch.manual_seed(1) # reproducible"
37 | ]
38 | },
39 | {
40 | "cell_type": "code",
41 | "execution_count": 2,
42 | "metadata": {
43 | "collapsed": true
44 | },
45 | "outputs": [],
46 | "source": [
47 | "BATCH_SIZE = 5\n",
48 | "# BATCH_SIZE = 8"
49 | ]
50 | },
51 | {
52 | "cell_type": "code",
53 | "execution_count": 3,
54 | "metadata": {
55 | "collapsed": true
56 | },
57 | "outputs": [],
58 | "source": [
59 | "x = torch.linspace(1, 10, 10) # this is x data (torch tensor)\n",
60 | "y = torch.linspace(10, 1, 10) # this is y data (torch tensor)\n"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 4,
66 | "metadata": {
67 | "collapsed": true
68 | },
69 | "outputs": [],
70 | "source": [
71 | "torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)\n",
72 | "loader = Data.DataLoader(\n",
73 | " dataset=torch_dataset, # torch TensorDataset format\n",
74 | " batch_size=BATCH_SIZE, # mini batch size\n",
75 | " shuffle=True, # random shuffle for training\n",
76 | " num_workers=2, # subprocesses for loading data\n",
77 | ")"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 5,
83 | "metadata": {},
84 | "outputs": [
85 | {
86 | "name": "stdout",
87 | "output_type": "stream",
88 | "text": [
89 | "Epoch: 0 | Step: 0 | batch x: [ 6. 7. 2. 3. 1.] | batch y: [ 5. 4. 9. 8. 10.]\n",
90 | "Epoch: 0 | Step: 1 | batch x: [ 9. 10. 4. 8. 5.] | batch y: [ 2. 1. 7. 3. 6.]\n",
91 | "Epoch: 1 | Step: 0 | batch x: [ 3. 4. 2. 9. 10.] | batch y: [ 8. 7. 9. 2. 1.]\n",
92 | "Epoch: 1 | Step: 1 | batch x: [ 1. 7. 8. 5. 6.] | batch y: [ 10. 4. 3. 6. 5.]\n",
93 | "Epoch: 2 | Step: 0 | batch x: [ 3. 9. 2. 6. 7.] | batch y: [ 8. 2. 9. 5. 4.]\n",
94 | "Epoch: 2 | Step: 1 | batch x: [ 10. 4. 8. 1. 5.] | batch y: [ 1. 7. 3. 10. 6.]\n"
95 | ]
96 | }
97 | ],
98 | "source": [
99 | "for epoch in range(3): # train entire dataset 3 times\n",
100 | " for step, (batch_x, batch_y) in enumerate(loader): # for each training step\n",
101 | " # train your data...\n",
102 | " print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',\n",
103 | " batch_x.numpy(), '| batch y: ', batch_y.numpy())\n"
104 | ]
105 | },
106 | {
107 | "cell_type": "markdown",
108 | "metadata": {},
109 | "source": [
110 | "### Suppose a different batch size that cannot be fully divided by the number of data entreis:"
111 | ]
112 | },
113 | {
114 | "cell_type": "code",
115 | "execution_count": 6,
116 | "metadata": {},
117 | "outputs": [
118 | {
119 | "name": "stdout",
120 | "output_type": "stream",
121 | "text": [
122 | "Epoch: 0 | Step: 0 | batch x: [ 3. 10. 9. 4. 7. 8. 2. 1.] | batch y: [ 8. 1. 2. 7. 4. 3. 9. 10.]\n",
123 | "Epoch: 0 | Step: 1 | batch x: [ 5. 6.] | batch y: [ 6. 5.]\n",
124 | "Epoch: 1 | Step: 0 | batch x: [ 4. 8. 3. 2. 1. 10. 5. 6.] | batch y: [ 7. 3. 8. 9. 10. 1. 6. 5.]\n",
125 | "Epoch: 1 | Step: 1 | batch x: [ 7. 9.] | batch y: [ 4. 2.]\n",
126 | "Epoch: 2 | Step: 0 | batch x: [ 6. 2. 4. 10. 9. 3. 8. 5.] | batch y: [ 5. 9. 7. 1. 2. 8. 3. 6.]\n",
127 | "Epoch: 2 | Step: 1 | batch x: [ 7. 1.] | batch y: [ 4. 10.]\n"
128 | ]
129 | }
130 | ],
131 | "source": [
132 | "BATCH_SIZE = 8\n",
133 | "loader = Data.DataLoader(\n",
134 | " dataset=torch_dataset, # torch TensorDataset format\n",
135 | " batch_size=BATCH_SIZE, # mini batch size\n",
136 | " shuffle=True, # random shuffle for training\n",
137 | " num_workers=2, # subprocesses for loading data\n",
138 | ")\n",
139 | "for epoch in range(3): # train entire dataset 3 times\n",
140 | " for step, (batch_x, batch_y) in enumerate(loader): # for each training step\n",
141 | " # train your data...\n",
142 | " print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',\n",
143 | " batch_x.numpy(), '| batch y: ', batch_y.numpy())"
144 | ]
145 | },
146 | {
147 | "cell_type": "code",
148 | "execution_count": null,
149 | "metadata": {
150 | "collapsed": true
151 | },
152 | "outputs": [],
153 | "source": []
154 | }
155 | ],
156 | "metadata": {
157 | "kernelspec": {
158 | "display_name": "Python 3",
159 | "language": "python",
160 | "name": "python3"
161 | },
162 | "language_info": {
163 | "codemirror_mode": {
164 | "name": "ipython",
165 | "version": 3
166 | },
167 | "file_extension": ".py",
168 | "mimetype": "text/x-python",
169 | "name": "python",
170 | "nbconvert_exporter": "python",
171 | "pygments_lexer": "ipython3",
172 | "version": "3.5.2"
173 | }
174 | },
175 | "nbformat": 4,
176 | "nbformat_minor": 2
177 | }
178 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/402_RNN.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 402 RNN\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11\n",
14 | "* matplotlib\n"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {
21 | "collapsed": true
22 | },
23 | "outputs": [],
24 | "source": [
25 | "import torch\n",
26 | "from torch import nn\n",
27 | "from torch.autograd import Variable\n",
28 | "import torchvision.datasets as dsets\n",
29 | "import torchvision.transforms as transforms\n",
30 | "import matplotlib.pyplot as plt\n",
31 | "%matplotlib inline"
32 | ]
33 | },
34 | {
35 | "cell_type": "code",
36 | "execution_count": 2,
37 | "metadata": {},
38 | "outputs": [
39 | {
40 | "data": {
41 | "text/plain": [
42 | ""
43 | ]
44 | },
45 | "execution_count": 2,
46 | "metadata": {},
47 | "output_type": "execute_result"
48 | }
49 | ],
50 | "source": [
51 | "torch.manual_seed(1) # reproducible"
52 | ]
53 | },
54 | {
55 | "cell_type": "code",
56 | "execution_count": 3,
57 | "metadata": {
58 | "collapsed": true
59 | },
60 | "outputs": [],
61 | "source": [
62 | "# Hyper Parameters\n",
63 | "EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch\n",
64 | "BATCH_SIZE = 64\n",
65 | "TIME_STEP = 28 # rnn time step / image height\n",
66 | "INPUT_SIZE = 28 # rnn input size / image width\n",
67 | "LR = 0.01 # learning rate\n",
68 | "DOWNLOAD_MNIST = True # set to True if haven't download the data"
69 | ]
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": 4,
74 | "metadata": {
75 | "collapsed": true
76 | },
77 | "outputs": [],
78 | "source": [
79 | "# Mnist digital dataset\n",
80 | "train_data = dsets.MNIST(\n",
81 | " root='./mnist/',\n",
82 | " train=True, # this is training data\n",
83 | " transform=transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to\n",
84 | " # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]\n",
85 | " download=DOWNLOAD_MNIST, # download it if you don't have it\n",
86 | ")"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 5,
92 | "metadata": {},
93 | "outputs": [
94 | {
95 | "name": "stdout",
96 | "output_type": "stream",
97 | "text": [
98 | "torch.Size([60000, 28, 28])\n",
99 | "torch.Size([60000])\n"
100 | ]
101 | },
102 | {
103 | "data": {
104 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAP8AAAEICAYAAACQ6CLfAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAADrpJREFUeJzt3X2sVHV+x/HPp6hpxAekpkhYLYsxGDWWbRAbQ1aNYX2I\nRlFjltSERiP7hyRu0pAa+sdqWqypD81SzQY26kKzdd1EjehufKiobGtCvCIq4qKu0SzkCjWIAj5Q\nuN/+cYftXb3zm8vMmTnD/b5fyeTOnO+cOd+c8OE8zvwcEQKQz5/U3QCAehB+ICnCDyRF+IGkCD+Q\nFOEHkiL8QFKEH6Oy/aLtL23vaTy21N0TqkX4UbI4Io5pPGbW3QyqRfiBpAg/Sv7Z9se2/9v2BXU3\ng2qZe/sxGtvnStosaZ+k70u6T9KsiPhdrY2hMoQfY2L7aUm/ioh/q7sXVIPdfoxVSHLdTaA6hB/f\nYHuS7Ytt/6ntI2z/jaTvSnq67t5QnSPqbgB96UhJ/yTpdEkHJP1W0lUR8U6tXaFSHPMDSbHbDyRF\n+IGkCD+QFOEHkurp2X7bnF0EuiwixnQ/RkdbftuX2N5i+z3bt3byWQB6q+1LfbYnSHpH0jxJWyW9\nImlBRGwuzMOWH+iyXmz550h6LyLej4h9kn4h6coOPg9AD3US/mmSfj/i9dbGtD9ie5HtAdsDHSwL\nQMW6fsIvIlZKWimx2w/0k062/NsknTzi9bca0wAcBjoJ/yuSTrP9bdtHafgHH9ZU0xaAbmt7tz8i\n9tteLOkZSRMkPRgRb1XWGYCu6um3+jjmB7qvJzf5ADh8EX4gKcIPJEX4gaQIP5AU4QeSIvxAUoQf\nSIrwA0kRfiApwg8kRfiBpAg/kBThB5Ii/EBShB9IivADSRF+ICnCDyRF+IGkCD+QFOEHkiL8QFKE\nH0iK8ANJEX4gKcIPJEX4gaQIP5BU20N04/AwYcKEYv3444/v6vIXL17ctHb00UcX5505c2axfvPN\nNxfrd999d9PaggULivN++eWXxfqdd95ZrN9+++3Fej/oKPy2P5C0W9IBSfsjYnYVTQHoviq2/BdG\nxMcVfA6AHuKYH0iq0/CHpGdtv2p70WhvsL3I9oDtgQ6XBaBCne72z42Ibbb/XNJztn8bEetGviEi\nVkpaKUm2o8PlAahIR1v+iNjW+LtD0uOS5lTRFIDuazv8tifaPvbgc0nfk7SpqsYAdFcnu/1TJD1u\n++Dn/EdEPF1JV+PMKaecUqwfddRRxfp5551XrM+dO7dpbdKkScV5r7nmmmK9Tlu3bi3Wly9fXqzP\nnz+/aW337t3FeV9//fVi/aWXXirWDwdthz8i3pf0lxX2AqCHuNQHJEX4gaQIP5AU4QeSIvxAUo7o\n3U134/UOv1mzZhXra9euLda7/bXafjU0NFSs33DDDcX6nj172l724OBgsf7JJ58U61u2bGl72d0W\nER7L+9jyA0kRfiApwg8kRfiBpAg/kBThB5Ii/EBSXOevwOTJk4v19evXF+szZsyosp1Ktep9165d\nxfqFF17YtLZv377ivFnvf+gU1/kBFBF+ICnCDyRF+IGkCD+QFOEHkiL8QFIM0V2BnTt3FutLliwp\n1i+//PJi/bXXXivWW/2EdcnGjRuL9Xnz5hXre/fuLdbPPPPMprVbbrmlOC+6iy0/kBThB5Ii/EBS\nhB9IivADSRF+ICnCDyTF9/n7wHHHHVestxpOesWKFU1rN954Y3He66+/vlh/+OGHi3X0n8q+z2/7\nQds7bG8aMW2y7edsv9v4e0InzQLovbHs9v9M0iVfm3arpOcj4jRJzzdeAziMtAx/RKyT9PX7V6+U\ntKrxfJWkqyruC0CXtXtv/5SIODjY2UeSpjR7o+1Fkha1uRwAXdLxF3siIkon8iJipaSVEif8gH7S\n7qW+7banSlLj747qWgLQC+2Gf42khY3nCyU9UU07AHql5W6/7YclXSDpRNtbJf1I0p2Sfmn7Rkkf\nSrqum02Od5999llH83/66adtz3vTTTcV64888kixPjQ01PayUa+W4Y+IBU1KF1XcC4Ae4vZeICnC\nDyRF+IGkCD+QFOEHkuIrvePAxIkTm9aefPLJ4rznn39+sX7ppZcW688++2yxjt5jiG4ARYQfSIrw\nA0kRfiApwg8kRfiBpAg/kBTX+ce5U089tVjfsGFDsb5r165i/YUXXijWBwYGmtbuv//+4ry9/Lc5\nnnCdH0AR4QeSIvxAUoQfSIrwA0kRfiApwg8kxXX+5ObPn1+sP/TQQ8X6scce2/ayly5dWqyvXr26\nWB8cHCzWs+I6P4Aiwg8kRfiBpAg/kBThB5Ii/EBShB9Iiuv8KDrrrLOK9XvvvbdYv+ii9gdzXrFi\nRbG+bNmyYn3btm1tL/twVtl1ftsP2t5he9OIabfZ3mZ7Y+NxWSfNAui9sez2/0zSJaNM/9eImNV4\n/LratgB0W8vwR8Q6STt70AuAHurkhN9i2280DgtOaPYm24tsD9hu/mNuAHqu3fD/RNKpkmZJGpR0\nT7M3RsTKiJgdEbPbXBaALmgr/BGxPSIORMSQpJ9KmlNtWwC6ra3w25464uV8SZuavRdAf2p5nd/2\nw5IukHSipO2SftR4PUtSSPpA0g8iouWXq7nOP/5MmjSpWL/iiiua1lr9VoBdvly9du3aYn3evHnF\n+ng11uv8R4zhgxaMMvmBQ+4IQF/h9l4gKcIPJEX4gaQIP5AU4QeS4iu9qM1XX31VrB9xRPli1P79\n+4v1iy++uGntxRdfLM57OOOnuwEUEX4gKcIPJEX4gaQIP5AU4QeSIvxAUi2/1Yfczj777GL92muv\nLdbPOeecprVW1/Fb2bx5c7G+bt26jj5/vGPLDyRF+IGkCD+QFOEHkiL8QFKEH0iK8ANJcZ1/nJs5\nc2axvnjx4mL96quvLtZPOumkQ+5prA4cOFCsDw6Wfy1+aGioynbGHbb8QFKEH0iK8ANJEX4gKcIP\nJEX4gaQIP5BUy+v8tk+WtFrSFA0Pyb0yIn5se7KkRyRN1/Aw3ddFxCfdazWvVtfSFywYbSDlYa2u\n40+fPr2dlioxMDBQrC9btqxYX7NmTZXtpDOWLf9+SX8XEWdI+mtJN9s+Q9Ktkp6PiNMkPd94DeAw\n0TL8ETEYERsaz3dLelvSNElXSlrVeNsqSVd1q0kA1TukY37b0yV9R9J6SVMi4uD9lR9p+LAAwGFi\nzPf22z5G0qOSfhgRn9n/PxxYRESzcfhsL5K0qNNGAVRrTFt+20dqOPg/j4jHGpO3257aqE+VtGO0\neSNiZUTMjojZVTQMoBotw+/hTfwDkt6OiHtHlNZIWth4vlDSE9W3B6BbWg7RbXuupN9IelPSwe9I\nLtXwcf8vJZ0i6UMNX+rb2eKzUg7RPWVK+XTIGWecUazfd999xfrpp59+yD1VZf369cX6XXfd1bT2\nxBPl7QVfyW3PWIfobnnMHxH/JanZh110KE0B6B/c4QckRfiBpAg/kBThB5Ii/EBShB9Iip/uHqPJ\nkyc3ra1YsaI476xZs4r1GTNmtNVTFV5++eVi/Z577inWn3nmmWL9iy++OOSe0Bts+YGkCD+QFOEH\nkiL8QFKEH0iK8ANJEX4gqTTX+c8999xifcmSJcX6nDlzmtamTZvWVk9V+fzzz5vWli9fXpz3jjvu\nKNb37t3bVk/of2z5gaQIP5AU4QeSIvxAUoQfSIrwA0kRfiCpNNf558+f31G9E5s3by7Wn3rqqWJ9\n//79xXrpO/e7du0qzou82PIDSRF+ICnCDyRF+IGkCD+QFOEHkiL8QFKOiPIb7JMlrZY0RVJIWhkR\nP7Z9m6SbJP1P461LI+LXLT6rvDAAHYsIj+V9Ywn/VElTI2KD7WMlvSrpKknXSdoTEXePtSnCD3Tf\nWMPf8g6/iBiUNNh4vtv225Lq/ekaAB07pGN+29MlfUfS+sakxbbfsP2g7ROazLPI9oDtgY46BVCp\nlrv9f3ijfYyklyQti4jHbE+R9LGGzwP8o4YPDW5o8Rns9gNdVtkxvyTZPlLSU5KeiYh7R6lPl/RU\nRJzV4nMIP9BlYw1/y91+25b0gKS3Rwa/cSLwoPmSNh1qkwDqM5az/XMl/UbSm5KGGpOXSlogaZaG\nd/s/kPSDxsnB0mex5Qe6rNLd/qoQfqD7KtvtBzA+EX4gKcIPJEX4gaQIP5AU4QeSIvxAUoQfSIrw\nA0kRfiApwg8kRfiBpAg/kBThB5Lq9RDdH0v6cMTrExvT+lG/9tavfUn01q4qe/uLsb6xp9/n/8bC\n7YGImF1bAwX92lu/9iXRW7vq6o3dfiApwg8kVXf4V9a8/JJ+7a1f+5LorV219FbrMT+A+tS95QdQ\nE8IPJFVL+G1fYnuL7fds31pHD83Y/sD2m7Y31j2+YGMMxB22N42YNtn2c7bfbfwddYzEmnq7zfa2\nxrrbaPuymno72fYLtjfbfsv2LY3pta67Ql+1rLeeH/PbniDpHUnzJG2V9IqkBRGxuaeNNGH7A0mz\nI6L2G0Jsf1fSHkmrDw6FZvtfJO2MiDsb/3GeEBF/3ye93aZDHLa9S701G1b+b1XjuqtyuPsq1LHl\nnyPpvYh4PyL2SfqFpCtr6KPvRcQ6STu/NvlKSasaz1dp+B9PzzXprS9ExGBEbGg83y3p4LDyta67\nQl+1qCP80yT9fsTrrapxBYwiJD1r+1Xbi+puZhRTRgyL9pGkKXU2M4qWw7b30teGle+bddfOcPdV\n44TfN82NiL+SdKmkmxu7t30pho/Z+ula7U8knarhMRwHJd1TZzONYeUflfTDiPhsZK3OdTdKX7Ws\ntzrCv03SySNef6sxrS9ExLbG3x2SHtfwYUo/2X5whOTG3x019/MHEbE9Ig5ExJCkn6rGddcYVv5R\nST+PiMcak2tfd6P1Vdd6qyP8r0g6zfa3bR8l6fuS1tTQxzfYntg4ESPbEyV9T/039PgaSQsbzxdK\neqLGXv5Ivwzb3mxYedW87vpuuPuI6PlD0mUaPuP/O0n/UEcPTfqaIen1xuOtunuT9LCGdwP/V8Pn\nRm6U9GeSnpf0rqT/lDS5j3r7dw0P5f6GhoM2tabe5mp4l/4NSRsbj8vqXneFvmpZb9zeCyTFCT8g\nKcIPJEX4gaQIP5AU4QeSIvxAUoQfSOr/AH6evjIXWuv8AAAAAElFTkSuQmCC\n",
105 | "text/plain": [
106 | ""
107 | ]
108 | },
109 | "metadata": {},
110 | "output_type": "display_data"
111 | }
112 | ],
113 | "source": [
114 | "# plot one example\n",
115 | "print(train_data.train_data.size()) # (60000, 28, 28)\n",
116 | "print(train_data.train_labels.size()) # (60000)\n",
117 | "plt.imshow(train_data.train_data[0].numpy(), cmap='gray')\n",
118 | "plt.title('%i' % train_data.train_labels[0])\n",
119 | "plt.show()"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 6,
125 | "metadata": {
126 | "collapsed": true
127 | },
128 | "outputs": [],
129 | "source": [
130 | "# Data Loader for easy mini-batch return in training\n",
131 | "train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)"
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": 7,
137 | "metadata": {
138 | "collapsed": true
139 | },
140 | "outputs": [],
141 | "source": [
142 | "# convert test data into Variable, pick 2000 samples to speed up testing\n",
143 | "test_data = dsets.MNIST(root='./mnist/', train=False, transform=transforms.ToTensor())\n",
144 | "test_x = Variable(test_data.test_data, volatile=True).type(torch.FloatTensor)[:2000]/255. # shape (2000, 28, 28) value in range(0,1)\n",
145 | "test_y = test_data.test_labels.numpy().squeeze()[:2000] # covert to numpy array"
146 | ]
147 | },
148 | {
149 | "cell_type": "code",
150 | "execution_count": 8,
151 | "metadata": {
152 | "collapsed": true
153 | },
154 | "outputs": [],
155 | "source": [
156 | "class RNN(nn.Module):\n",
157 | " def __init__(self):\n",
158 | " super(RNN, self).__init__()\n",
159 | "\n",
160 | " self.rnn = nn.LSTM( # if use nn.RNN(), it hardly learns\n",
161 | " input_size=INPUT_SIZE,\n",
162 | " hidden_size=64, # rnn hidden unit\n",
163 | " num_layers=1, # number of rnn layer\n",
164 | " batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)\n",
165 | " )\n",
166 | "\n",
167 | " self.out = nn.Linear(64, 10)\n",
168 | "\n",
169 | " def forward(self, x):\n",
170 | " # x shape (batch, time_step, input_size)\n",
171 | " # r_out shape (batch, time_step, output_size)\n",
172 | " # h_n shape (n_layers, batch, hidden_size)\n",
173 | " # h_c shape (n_layers, batch, hidden_size)\n",
174 | " r_out, (h_n, h_c) = self.rnn(x, None) # None represents zero initial hidden state\n",
175 | "\n",
176 | " # choose r_out at the last time step\n",
177 | " out = self.out(r_out[:, -1, :])\n",
178 | " return out"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 9,
184 | "metadata": {},
185 | "outputs": [
186 | {
187 | "name": "stdout",
188 | "output_type": "stream",
189 | "text": [
190 | "RNN (\n",
191 | " (rnn): LSTM(28, 64, batch_first=True)\n",
192 | " (out): Linear (64 -> 10)\n",
193 | ")\n"
194 | ]
195 | }
196 | ],
197 | "source": [
198 | "rnn = RNN()\n",
199 | "print(rnn)"
200 | ]
201 | },
202 | {
203 | "cell_type": "code",
204 | "execution_count": 10,
205 | "metadata": {
206 | "collapsed": true
207 | },
208 | "outputs": [],
209 | "source": [
210 | "optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters\n",
211 | "loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted"
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "execution_count": 11,
217 | "metadata": {},
218 | "outputs": [
219 | {
220 | "name": "stdout",
221 | "output_type": "stream",
222 | "text": [
223 | "Epoch: 0 | train loss: 2.3127 | test accuracy: 0.14\n",
224 | "Epoch: 0 | train loss: 1.1182 | test accuracy: 0.56\n",
225 | "Epoch: 0 | train loss: 0.9374 | test accuracy: 0.68\n",
226 | "Epoch: 0 | train loss: 0.6279 | test accuracy: 0.75\n",
227 | "Epoch: 0 | train loss: 0.8004 | test accuracy: 0.75\n",
228 | "Epoch: 0 | train loss: 0.3407 | test accuracy: 0.88\n",
229 | "Epoch: 0 | train loss: 0.3342 | test accuracy: 0.89\n",
230 | "Epoch: 0 | train loss: 0.3200 | test accuracy: 0.91\n",
231 | "Epoch: 0 | train loss: 0.3430 | test accuracy: 0.92\n",
232 | "Epoch: 0 | train loss: 0.1234 | test accuracy: 0.93\n",
233 | "Epoch: 0 | train loss: 0.2714 | test accuracy: 0.92\n",
234 | "Epoch: 0 | train loss: 0.1043 | test accuracy: 0.93\n",
235 | "Epoch: 0 | train loss: 0.2893 | test accuracy: 0.93\n",
236 | "Epoch: 0 | train loss: 0.0635 | test accuracy: 0.94\n",
237 | "Epoch: 0 | train loss: 0.2412 | test accuracy: 0.94\n",
238 | "Epoch: 0 | train loss: 0.1203 | test accuracy: 0.92\n",
239 | "Epoch: 0 | train loss: 0.0807 | test accuracy: 0.94\n",
240 | "Epoch: 0 | train loss: 0.1307 | test accuracy: 0.94\n",
241 | "Epoch: 0 | train loss: 0.1166 | test accuracy: 0.95\n"
242 | ]
243 | }
244 | ],
245 | "source": [
246 | "# training and testing\n",
247 | "for epoch in range(EPOCH):\n",
248 | " for step, (x, y) in enumerate(train_loader): # gives batch data\n",
249 | " b_x = Variable(x.view(-1, 28, 28)) # reshape x to (batch, time_step, input_size)\n",
250 | " b_y = Variable(y) # batch y\n",
251 | "\n",
252 | " output = rnn(b_x) # rnn output\n",
253 | " loss = loss_func(output, b_y) # cross entropy loss\n",
254 | " optimizer.zero_grad() # clear gradients for this training step\n",
255 | " loss.backward() # backpropagation, compute gradients\n",
256 | " optimizer.step() # apply gradients\n",
257 | "\n",
258 | " if step % 50 == 0:\n",
259 | " test_output = rnn(test_x) # (samples, time_step, input_size)\n",
260 | " pred_y = torch.max(test_output, 1)[1].data.numpy().squeeze()\n",
261 | " accuracy = sum(pred_y == test_y) / float(test_y.size)\n",
262 | " print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0], '| test accuracy: %.2f' % accuracy)\n"
263 | ]
264 | },
265 | {
266 | "cell_type": "code",
267 | "execution_count": 16,
268 | "metadata": {},
269 | "outputs": [
270 | {
271 | "name": "stdout",
272 | "output_type": "stream",
273 | "text": [
274 | "[7 2 1 0 4 1 4 9 5 9] prediction number\n",
275 | "[7 2 1 0 4 1 4 9 5 9] real number\n"
276 | ]
277 | }
278 | ],
279 | "source": [
280 | "# print 10 predictions from test data\n",
281 | "test_output = rnn(test_x[:10].view(-1, 28, 28))\n",
282 | "pred_y = torch.max(test_output, 1)[1].data.numpy().squeeze()\n",
283 | "print(pred_y, 'prediction number')\n",
284 | "print(test_y[:10], 'real number')"
285 | ]
286 | },
287 | {
288 | "cell_type": "code",
289 | "execution_count": null,
290 | "metadata": {
291 | "collapsed": true
292 | },
293 | "outputs": [],
294 | "source": []
295 | }
296 | ],
297 | "metadata": {
298 | "kernelspec": {
299 | "display_name": "Python 3",
300 | "language": "python",
301 | "name": "python3"
302 | },
303 | "language_info": {
304 | "codemirror_mode": {
305 | "name": "ipython",
306 | "version": 3
307 | },
308 | "file_extension": ".py",
309 | "mimetype": "text/x-python",
310 | "name": "python",
311 | "nbconvert_exporter": "python",
312 | "pygments_lexer": "ipython3",
313 | "version": "3.5.2"
314 | }
315 | },
316 | "nbformat": 4,
317 | "nbformat_minor": 2
318 | }
319 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/405_DQN_Reinforcement_learning.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 405 DQN Reinforcement Learning\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "More about Reinforcement learning: https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/\n",
12 | "\n",
13 | "Dependencies:\n",
14 | "* torch: 0.1.11\n",
15 | "* gym: 0.8.1\n",
16 | "* numpy"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {
23 | "collapsed": true
24 | },
25 | "outputs": [],
26 | "source": [
27 | "import torch\n",
28 | "import torch.nn as nn\n",
29 | "from torch.autograd import Variable\n",
30 | "import torch.nn.functional as F\n",
31 | "import numpy as np\n",
32 | "import gym"
33 | ]
34 | },
35 | {
36 | "cell_type": "code",
37 | "execution_count": 2,
38 | "metadata": {},
39 | "outputs": [
40 | {
41 | "name": "stderr",
42 | "output_type": "stream",
43 | "text": [
44 | "[2017-06-20 22:23:40,418] Making new env: CartPole-v0\n"
45 | ]
46 | }
47 | ],
48 | "source": [
49 | "# Hyper Parameters\n",
50 | "BATCH_SIZE = 32\n",
51 | "LR = 0.01 # learning rate\n",
52 | "EPSILON = 0.9 # greedy policy\n",
53 | "GAMMA = 0.9 # reward discount\n",
54 | "TARGET_REPLACE_ITER = 100 # target update frequency\n",
55 | "MEMORY_CAPACITY = 2000\n",
56 | "env = gym.make('CartPole-v0')\n",
57 | "env = env.unwrapped\n",
58 | "N_ACTIONS = env.action_space.n\n",
59 | "N_STATES = env.observation_space.shape[0]"
60 | ]
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": 3,
65 | "metadata": {
66 | "collapsed": true
67 | },
68 | "outputs": [],
69 | "source": [
70 | "class Net(nn.Module):\n",
71 | " def __init__(self, ):\n",
72 | " super(Net, self).__init__()\n",
73 | " self.fc1 = nn.Linear(N_STATES, 10)\n",
74 | " self.fc1.weight.data.normal_(0, 0.1) # initialization\n",
75 | " self.out = nn.Linear(10, N_ACTIONS)\n",
76 | " self.out.weight.data.normal_(0, 0.1) # initialization\n",
77 | "\n",
78 | " def forward(self, x):\n",
79 | " x = self.fc1(x)\n",
80 | " x = F.relu(x)\n",
81 | " actions_value = self.out(x)\n",
82 | " return actions_value"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 4,
88 | "metadata": {
89 | "collapsed": true
90 | },
91 | "outputs": [],
92 | "source": [
93 | "class DQN(object):\n",
94 | " def __init__(self):\n",
95 | " self.eval_net, self.target_net = Net(), Net()\n",
96 | "\n",
97 | " self.learn_step_counter = 0 # for target updating\n",
98 | " self.memory_counter = 0 # for storing memory\n",
99 | " self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # initialize memory\n",
100 | " self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR)\n",
101 | " self.loss_func = nn.MSELoss()\n",
102 | "\n",
103 | " def choose_action(self, x):\n",
104 | " x = Variable(torch.unsqueeze(torch.FloatTensor(x), 0))\n",
105 | " # input only one sample\n",
106 | " if np.random.uniform() < EPSILON: # greedy\n",
107 | " actions_value = self.eval_net.forward(x)\n",
108 | " action = torch.max(actions_value, 1)[1].data.numpy()[0, 0] # return the argmax\n",
109 | " else: # random\n",
110 | " action = np.random.randint(0, N_ACTIONS)\n",
111 | " return action\n",
112 | "\n",
113 | " def store_transition(self, s, a, r, s_):\n",
114 | " transition = np.hstack((s, [a, r], s_))\n",
115 | " # replace the old memory with new memory\n",
116 | " index = self.memory_counter % MEMORY_CAPACITY\n",
117 | " self.memory[index, :] = transition\n",
118 | " self.memory_counter += 1\n",
119 | "\n",
120 | " def learn(self):\n",
121 | " # target parameter update\n",
122 | " if self.learn_step_counter % TARGET_REPLACE_ITER == 0:\n",
123 | " self.target_net.load_state_dict(self.eval_net.state_dict())\n",
124 | " self.learn_step_counter += 1\n",
125 | "\n",
126 | " # sample batch transitions\n",
127 | " sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE)\n",
128 | " b_memory = self.memory[sample_index, :]\n",
129 | " b_s = Variable(torch.FloatTensor(b_memory[:, :N_STATES]))\n",
130 | " b_a = Variable(torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int)))\n",
131 | " b_r = Variable(torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2]))\n",
132 | " b_s_ = Variable(torch.FloatTensor(b_memory[:, -N_STATES:]))\n",
133 | "\n",
134 | " # q_eval w.r.t the action in experience\n",
135 | " q_eval = self.eval_net(b_s).gather(1, b_a) # shape (batch, 1)\n",
136 | " q_next = self.target_net(b_s_).detach() # detach from graph, don't backpropagate\n",
137 | " q_target = b_r + GAMMA * q_next.max(1)[0] # shape (batch, 1)\n",
138 | " loss = self.loss_func(q_eval, q_target)\n",
139 | "\n",
140 | " self.optimizer.zero_grad()\n",
141 | " loss.backward()\n",
142 | " self.optimizer.step()"
143 | ]
144 | },
145 | {
146 | "cell_type": "code",
147 | "execution_count": 5,
148 | "metadata": {
149 | "collapsed": true
150 | },
151 | "outputs": [],
152 | "source": [
153 | "dqn = DQN()"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": 6,
159 | "metadata": {},
160 | "outputs": [
161 | {
162 | "name": "stdout",
163 | "output_type": "stream",
164 | "text": [
165 | "\n",
166 | "Collecting experience...\n",
167 | "Ep: 201 | Ep_r: 1.59\n",
168 | "Ep: 202 | Ep_r: 4.18\n",
169 | "Ep: 203 | Ep_r: 2.73\n",
170 | "Ep: 204 | Ep_r: 1.97\n",
171 | "Ep: 205 | Ep_r: 1.18\n",
172 | "Ep: 206 | Ep_r: 0.86\n",
173 | "Ep: 207 | Ep_r: 2.88\n",
174 | "Ep: 208 | Ep_r: 1.63\n",
175 | "Ep: 209 | Ep_r: 3.91\n",
176 | "Ep: 210 | Ep_r: 3.6\n",
177 | "Ep: 211 | Ep_r: 0.98\n",
178 | "Ep: 212 | Ep_r: 3.85\n",
179 | "Ep: 213 | Ep_r: 1.81\n",
180 | "Ep: 214 | Ep_r: 2.32\n",
181 | "Ep: 215 | Ep_r: 3.75\n",
182 | "Ep: 216 | Ep_r: 3.53\n",
183 | "Ep: 217 | Ep_r: 4.75\n",
184 | "Ep: 218 | Ep_r: 2.4\n",
185 | "Ep: 219 | Ep_r: 0.64\n",
186 | "Ep: 220 | Ep_r: 1.15\n",
187 | "Ep: 221 | Ep_r: 2.3\n",
188 | "Ep: 222 | Ep_r: 7.37\n",
189 | "Ep: 223 | Ep_r: 1.25\n",
190 | "Ep: 224 | Ep_r: 5.02\n",
191 | "Ep: 225 | Ep_r: 10.29\n",
192 | "Ep: 226 | Ep_r: 17.54\n",
193 | "Ep: 227 | Ep_r: 36.2\n",
194 | "Ep: 228 | Ep_r: 6.61\n",
195 | "Ep: 229 | Ep_r: 10.04\n",
196 | "Ep: 230 | Ep_r: 55.19\n",
197 | "Ep: 231 | Ep_r: 10.03\n",
198 | "Ep: 232 | Ep_r: 13.25\n",
199 | "Ep: 233 | Ep_r: 8.75\n",
200 | "Ep: 234 | Ep_r: 3.83\n",
201 | "Ep: 235 | Ep_r: -0.92\n",
202 | "Ep: 236 | Ep_r: 5.12\n",
203 | "Ep: 237 | Ep_r: 3.56\n",
204 | "Ep: 238 | Ep_r: 5.69\n",
205 | "Ep: 239 | Ep_r: 8.43\n",
206 | "Ep: 240 | Ep_r: 29.27\n",
207 | "Ep: 241 | Ep_r: 17.95\n",
208 | "Ep: 242 | Ep_r: 44.77\n",
209 | "Ep: 243 | Ep_r: 98.0\n",
210 | "Ep: 244 | Ep_r: 38.78\n",
211 | "Ep: 245 | Ep_r: 45.02\n",
212 | "Ep: 246 | Ep_r: 27.73\n",
213 | "Ep: 247 | Ep_r: 36.96\n",
214 | "Ep: 248 | Ep_r: 48.98\n",
215 | "Ep: 249 | Ep_r: 111.36\n",
216 | "Ep: 250 | Ep_r: 95.61\n",
217 | "Ep: 251 | Ep_r: 149.77\n",
218 | "Ep: 252 | Ep_r: 29.96\n",
219 | "Ep: 253 | Ep_r: 2.79\n",
220 | "Ep: 254 | Ep_r: 20.1\n",
221 | "Ep: 255 | Ep_r: 24.25\n",
222 | "Ep: 256 | Ep_r: 3074.75\n",
223 | "Ep: 257 | Ep_r: 1258.49\n",
224 | "Ep: 258 | Ep_r: 127.39\n",
225 | "Ep: 259 | Ep_r: 283.46\n",
226 | "Ep: 260 | Ep_r: 166.96\n",
227 | "Ep: 261 | Ep_r: 101.71\n",
228 | "Ep: 262 | Ep_r: 63.45\n",
229 | "Ep: 263 | Ep_r: 288.94\n",
230 | "Ep: 264 | Ep_r: 130.49\n",
231 | "Ep: 265 | Ep_r: 207.05\n",
232 | "Ep: 266 | Ep_r: 183.71\n",
233 | "Ep: 267 | Ep_r: 142.75\n",
234 | "Ep: 268 | Ep_r: 126.53\n",
235 | "Ep: 269 | Ep_r: 310.79\n",
236 | "Ep: 270 | Ep_r: 863.2\n",
237 | "Ep: 271 | Ep_r: 365.12\n",
238 | "Ep: 272 | Ep_r: 659.52\n",
239 | "Ep: 273 | Ep_r: 103.98\n",
240 | "Ep: 274 | Ep_r: 554.83\n",
241 | "Ep: 275 | Ep_r: 246.01\n",
242 | "Ep: 276 | Ep_r: 332.23\n",
243 | "Ep: 277 | Ep_r: 323.35\n",
244 | "Ep: 278 | Ep_r: 278.71\n",
245 | "Ep: 279 | Ep_r: 613.6\n",
246 | "Ep: 280 | Ep_r: 152.21\n",
247 | "Ep: 281 | Ep_r: 402.02\n",
248 | "Ep: 282 | Ep_r: 351.4\n",
249 | "Ep: 283 | Ep_r: 115.87\n",
250 | "Ep: 284 | Ep_r: 163.26\n",
251 | "Ep: 285 | Ep_r: 631.0\n",
252 | "Ep: 286 | Ep_r: 263.47\n",
253 | "Ep: 287 | Ep_r: 511.21\n",
254 | "Ep: 288 | Ep_r: 337.18\n",
255 | "Ep: 289 | Ep_r: 819.76\n",
256 | "Ep: 290 | Ep_r: 190.83\n",
257 | "Ep: 291 | Ep_r: 442.98\n",
258 | "Ep: 292 | Ep_r: 537.24\n",
259 | "Ep: 293 | Ep_r: 1101.12\n",
260 | "Ep: 294 | Ep_r: 178.42\n",
261 | "Ep: 295 | Ep_r: 225.61\n",
262 | "Ep: 296 | Ep_r: 252.62\n",
263 | "Ep: 297 | Ep_r: 617.5\n",
264 | "Ep: 298 | Ep_r: 617.8\n",
265 | "Ep: 299 | Ep_r: 244.01\n",
266 | "Ep: 300 | Ep_r: 687.91\n",
267 | "Ep: 301 | Ep_r: 618.51\n",
268 | "Ep: 302 | Ep_r: 1405.07\n",
269 | "Ep: 303 | Ep_r: 456.95\n",
270 | "Ep: 304 | Ep_r: 340.33\n",
271 | "Ep: 305 | Ep_r: 502.91\n",
272 | "Ep: 306 | Ep_r: 441.21\n",
273 | "Ep: 307 | Ep_r: 255.81\n",
274 | "Ep: 308 | Ep_r: 403.03\n",
275 | "Ep: 309 | Ep_r: 229.1\n",
276 | "Ep: 310 | Ep_r: 308.49\n",
277 | "Ep: 311 | Ep_r: 165.37\n",
278 | "Ep: 312 | Ep_r: 153.76\n",
279 | "Ep: 313 | Ep_r: 442.05\n",
280 | "Ep: 314 | Ep_r: 229.23\n",
281 | "Ep: 315 | Ep_r: 128.52\n",
282 | "Ep: 316 | Ep_r: 358.18\n",
283 | "Ep: 317 | Ep_r: 319.03\n",
284 | "Ep: 318 | Ep_r: 381.76\n",
285 | "Ep: 319 | Ep_r: 199.19\n",
286 | "Ep: 320 | Ep_r: 418.63\n",
287 | "Ep: 321 | Ep_r: 223.95\n",
288 | "Ep: 322 | Ep_r: 222.37\n",
289 | "Ep: 323 | Ep_r: 405.4\n",
290 | "Ep: 324 | Ep_r: 311.32\n",
291 | "Ep: 325 | Ep_r: 184.85\n",
292 | "Ep: 326 | Ep_r: 1026.71\n",
293 | "Ep: 327 | Ep_r: 252.41\n",
294 | "Ep: 328 | Ep_r: 224.93\n",
295 | "Ep: 329 | Ep_r: 620.02\n",
296 | "Ep: 330 | Ep_r: 174.54\n",
297 | "Ep: 331 | Ep_r: 782.45\n",
298 | "Ep: 332 | Ep_r: 263.79\n",
299 | "Ep: 333 | Ep_r: 178.63\n",
300 | "Ep: 334 | Ep_r: 242.84\n",
301 | "Ep: 335 | Ep_r: 635.43\n",
302 | "Ep: 336 | Ep_r: 668.89\n",
303 | "Ep: 337 | Ep_r: 265.42\n",
304 | "Ep: 338 | Ep_r: 207.81\n",
305 | "Ep: 339 | Ep_r: 293.09\n",
306 | "Ep: 340 | Ep_r: 530.23\n",
307 | "Ep: 341 | Ep_r: 479.26\n",
308 | "Ep: 342 | Ep_r: 559.77\n",
309 | "Ep: 343 | Ep_r: 241.39\n",
310 | "Ep: 344 | Ep_r: 158.83\n",
311 | "Ep: 345 | Ep_r: 1510.69\n",
312 | "Ep: 346 | Ep_r: 425.17\n",
313 | "Ep: 347 | Ep_r: 266.94\n",
314 | "Ep: 348 | Ep_r: 166.08\n",
315 | "Ep: 349 | Ep_r: 630.52\n",
316 | "Ep: 350 | Ep_r: 250.95\n",
317 | "Ep: 351 | Ep_r: 625.88\n",
318 | "Ep: 352 | Ep_r: 417.7\n",
319 | "Ep: 353 | Ep_r: 867.81\n",
320 | "Ep: 354 | Ep_r: 150.62\n",
321 | "Ep: 355 | Ep_r: 230.89\n",
322 | "Ep: 356 | Ep_r: 1017.52\n",
323 | "Ep: 357 | Ep_r: 190.28\n",
324 | "Ep: 358 | Ep_r: 396.91\n",
325 | "Ep: 359 | Ep_r: 305.53\n",
326 | "Ep: 360 | Ep_r: 131.61\n",
327 | "Ep: 361 | Ep_r: 387.54\n",
328 | "Ep: 362 | Ep_r: 298.82\n",
329 | "Ep: 363 | Ep_r: 207.56\n",
330 | "Ep: 364 | Ep_r: 248.56\n",
331 | "Ep: 365 | Ep_r: 589.12\n",
332 | "Ep: 366 | Ep_r: 179.52\n",
333 | "Ep: 367 | Ep_r: 130.19\n",
334 | "Ep: 368 | Ep_r: 1220.84\n",
335 | "Ep: 369 | Ep_r: 126.35\n",
336 | "Ep: 370 | Ep_r: 133.31\n",
337 | "Ep: 371 | Ep_r: 485.81\n",
338 | "Ep: 372 | Ep_r: 823.4\n",
339 | "Ep: 373 | Ep_r: 253.26\n",
340 | "Ep: 374 | Ep_r: 466.06\n",
341 | "Ep: 375 | Ep_r: 203.27\n",
342 | "Ep: 376 | Ep_r: 386.5\n",
343 | "Ep: 377 | Ep_r: 491.02\n",
344 | "Ep: 378 | Ep_r: 239.45\n",
345 | "Ep: 379 | Ep_r: 276.93\n",
346 | "Ep: 380 | Ep_r: 331.98\n",
347 | "Ep: 381 | Ep_r: 764.79\n",
348 | "Ep: 382 | Ep_r: 198.29\n",
349 | "Ep: 383 | Ep_r: 717.18\n",
350 | "Ep: 384 | Ep_r: 562.15\n",
351 | "Ep: 385 | Ep_r: 29.44\n",
352 | "Ep: 386 | Ep_r: 344.95\n",
353 | "Ep: 387 | Ep_r: 671.87\n",
354 | "Ep: 388 | Ep_r: 299.81\n",
355 | "Ep: 389 | Ep_r: 899.76\n",
356 | "Ep: 390 | Ep_r: 319.04\n",
357 | "Ep: 391 | Ep_r: 252.11\n",
358 | "Ep: 392 | Ep_r: 865.62\n",
359 | "Ep: 393 | Ep_r: 255.64\n",
360 | "Ep: 394 | Ep_r: 81.74\n",
361 | "Ep: 395 | Ep_r: 213.13\n",
362 | "Ep: 396 | Ep_r: 422.33\n",
363 | "Ep: 397 | Ep_r: 167.47\n",
364 | "Ep: 398 | Ep_r: 507.34\n",
365 | "Ep: 399 | Ep_r: 614.0\n"
366 | ]
367 | }
368 | ],
369 | "source": [
370 | "\n",
371 | "print('\\nCollecting experience...')\n",
372 | "for i_episode in range(400):\n",
373 | " s = env.reset()\n",
374 | " ep_r = 0\n",
375 | " while True:\n",
376 | " env.render()\n",
377 | " a = dqn.choose_action(s)\n",
378 | "\n",
379 | " # take action\n",
380 | " s_, r, done, info = env.step(a)\n",
381 | "\n",
382 | " # modify the reward\n",
383 | " x, x_dot, theta, theta_dot = s_\n",
384 | " r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8\n",
385 | " r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5\n",
386 | " r = r1 + r2\n",
387 | "\n",
388 | " dqn.store_transition(s, a, r, s_)\n",
389 | "\n",
390 | " ep_r += r\n",
391 | " if dqn.memory_counter > MEMORY_CAPACITY:\n",
392 | " dqn.learn()\n",
393 | " if done:\n",
394 | " print('Ep: ', i_episode,\n",
395 | " '| Ep_r: ', round(ep_r, 2))\n",
396 | "\n",
397 | " if done:\n",
398 | " break\n",
399 | " s = s_"
400 | ]
401 | },
402 | {
403 | "cell_type": "code",
404 | "execution_count": null,
405 | "metadata": {
406 | "collapsed": true
407 | },
408 | "outputs": [],
409 | "source": []
410 | }
411 | ],
412 | "metadata": {
413 | "kernelspec": {
414 | "display_name": "Python 3",
415 | "language": "python",
416 | "name": "python3"
417 | },
418 | "language_info": {
419 | "codemirror_mode": {
420 | "name": "ipython",
421 | "version": 3
422 | },
423 | "file_extension": ".py",
424 | "mimetype": "text/x-python",
425 | "name": "python",
426 | "nbconvert_exporter": "python",
427 | "pygments_lexer": "ipython3",
428 | "version": "3.5.2"
429 | }
430 | },
431 | "nbformat": 4,
432 | "nbformat_minor": 2
433 | }
434 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/502_GPU.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 502 GPU\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11\n",
14 | "* torchvision"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "import torch\n",
24 | "import torch.nn as nn\n",
25 | "from torch.autograd import Variable\n",
26 | "import torch.utils.data as Data\n",
27 | "import torchvision\n",
28 | "\n",
29 | "torch.manual_seed(1)\n",
30 | "\n",
31 | "import matplotlib.pyplot as plt\n",
32 | "%matplotlib inline"
33 | ]
34 | },
35 | {
36 | "cell_type": "code",
37 | "execution_count": 2,
38 | "metadata": {
39 | "collapsed": true
40 | },
41 | "outputs": [],
42 | "source": [
43 | "EPOCH = 1\n",
44 | "BATCH_SIZE = 50\n",
45 | "LR = 0.001\n",
46 | "DOWNLOAD_MNIST = False"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 3,
52 | "metadata": {},
53 | "outputs": [],
54 | "source": [
55 | "train_data = torchvision.datasets.MNIST(\n",
56 | " root='./mnist/', \n",
57 | " train=True, \n",
58 | " transform=torchvision.transforms.ToTensor(), \n",
59 | " download=DOWNLOAD_MNIST,)\n",
60 | "\n",
61 | "train_loader = Data.DataLoader(\n",
62 | " dataset=train_data, \n",
63 | " batch_size=BATCH_SIZE, \n",
64 | " shuffle=True)\n",
65 | "\n",
66 | "test_data = torchvision.datasets.MNIST(\n",
67 | " root='./mnist/', train=False)\n",
68 | "\n",
69 | "# !!!!!!!! Change in here !!!!!!!!! #\n",
70 | "test_x = Variable(torch.unsqueeze(test_data.test_data, dim=1)).type(torch.FloatTensor)[:2000].cuda()/255. # Tensor on GPU\n",
71 | "test_y = test_data.test_labels[:2000].cuda()"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": 4,
77 | "metadata": {
78 | "collapsed": true
79 | },
80 | "outputs": [],
81 | "source": [
82 | "class CNN(nn.Module):\n",
83 | " def __init__(self):\n",
84 | " super(CNN, self).__init__()\n",
85 | " self.conv1 = nn.Sequential(\n",
86 | " nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2,), \n",
87 | " nn.ReLU(), \n",
88 | " nn.MaxPool2d(kernel_size=2),)\n",
89 | " self.conv2 = nn.Sequential(\n",
90 | " nn.Conv2d(16, 32, 5, 1, 2), \n",
91 | " nn.ReLU(), \n",
92 | " nn.MaxPool2d(2),)\n",
93 | " self.out = nn.Linear(32 * 7 * 7, 10)\n",
94 | "\n",
95 | " def forward(self, x):\n",
96 | " x = self.conv1(x)\n",
97 | " x = self.conv2(x)\n",
98 | " x = x.view(x.size(0), -1)\n",
99 | " output = self.out(x)\n",
100 | " return output"
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": 5,
106 | "metadata": {},
107 | "outputs": [
108 | {
109 | "data": {
110 | "text/plain": [
111 | "CNN (\n",
112 | " (conv1): Sequential (\n",
113 | " (0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))\n",
114 | " (1): ReLU ()\n",
115 | " (2): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))\n",
116 | " )\n",
117 | " (conv2): Sequential (\n",
118 | " (0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))\n",
119 | " (1): ReLU ()\n",
120 | " (2): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))\n",
121 | " )\n",
122 | " (out): Linear (1568 -> 10)\n",
123 | ")"
124 | ]
125 | },
126 | "execution_count": 5,
127 | "metadata": {},
128 | "output_type": "execute_result"
129 | }
130 | ],
131 | "source": [
132 | "cnn = CNN()\n",
133 | "\n",
134 | "# !!!!!!!! Change in here !!!!!!!!! #\n",
135 | "cnn.cuda() # Moves all model parameters and buffers to the GPU."
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": 6,
141 | "metadata": {
142 | "collapsed": true
143 | },
144 | "outputs": [],
145 | "source": [
146 | "optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)\n",
147 | "loss_func = nn.CrossEntropyLoss()\n",
148 | "\n",
149 | "losses_his = []"
150 | ]
151 | },
152 | {
153 | "cell_type": "markdown",
154 | "metadata": {},
155 | "source": [
156 | "### Training"
157 | ]
158 | },
159 | {
160 | "cell_type": "code",
161 | "execution_count": 7,
162 | "metadata": {},
163 | "outputs": [
164 | {
165 | "name": "stdout",
166 | "output_type": "stream",
167 | "text": [
168 | "Epoch: 0 | train loss: 2.3145 | test accuracy: 0.10\n",
169 | "Epoch: 0 | train loss: 0.5546 | test accuracy: 0.83\n",
170 | "Epoch: 0 | train loss: 0.5856 | test accuracy: 0.89\n",
171 | "Epoch: 0 | train loss: 0.1879 | test accuracy: 0.92\n",
172 | "Epoch: 0 | train loss: 0.0601 | test accuracy: 0.94\n",
173 | "Epoch: 0 | train loss: 0.1772 | test accuracy: 0.95\n",
174 | "Epoch: 0 | train loss: 0.0993 | test accuracy: 0.94\n",
175 | "Epoch: 0 | train loss: 0.2210 | test accuracy: 0.95\n",
176 | "Epoch: 0 | train loss: 0.0379 | test accuracy: 0.96\n",
177 | "Epoch: 0 | train loss: 0.0535 | test accuracy: 0.96\n",
178 | "Epoch: 0 | train loss: 0.0268 | test accuracy: 0.96\n",
179 | "Epoch: 0 | train loss: 0.0910 | test accuracy: 0.96\n",
180 | "Epoch: 0 | train loss: 0.0982 | test accuracy: 0.97\n",
181 | "Epoch: 0 | train loss: 0.3154 | test accuracy: 0.97\n",
182 | "Epoch: 0 | train loss: 0.0418 | test accuracy: 0.97\n",
183 | "Epoch: 0 | train loss: 0.1072 | test accuracy: 0.96\n",
184 | "Epoch: 0 | train loss: 0.0652 | test accuracy: 0.97\n",
185 | "Epoch: 0 | train loss: 0.1042 | test accuracy: 0.97\n",
186 | "Epoch: 0 | train loss: 0.1346 | test accuracy: 0.97\n",
187 | "Epoch: 0 | train loss: 0.0431 | test accuracy: 0.98\n",
188 | "Epoch: 0 | train loss: 0.0276 | test accuracy: 0.97\n",
189 | "Epoch: 0 | train loss: 0.0153 | test accuracy: 0.98\n",
190 | "Epoch: 0 | train loss: 0.0438 | test accuracy: 0.98\n",
191 | "Epoch: 0 | train loss: 0.0082 | test accuracy: 0.97\n"
192 | ]
193 | }
194 | ],
195 | "source": [
196 | "for epoch in range(EPOCH):\n",
197 | " for step, (x, y) in enumerate(train_loader):\n",
198 | "\n",
199 | " # !!!!!!!! Change in here !!!!!!!!! #\n",
200 | " b_x = Variable(x).cuda() # Tensor on GPU\n",
201 | " b_y = Variable(y).cuda() # Tensor on GPU\n",
202 | "\n",
203 | " output = cnn(b_x)\n",
204 | " loss = loss_func(output, b_y)\n",
205 | " losses_his.append(loss.data[0])\n",
206 | " optimizer.zero_grad()\n",
207 | " loss.backward()\n",
208 | " optimizer.step()\n",
209 | "\n",
210 | " if step % 50 == 0:\n",
211 | " test_output = cnn(test_x)\n",
212 | "\n",
213 | " # !!!!!!!! Change in here !!!!!!!!! #\n",
214 | " pred_y = torch.max(test_output, 1)[1].cuda().data.squeeze() # move the computation in GPU\n",
215 | "\n",
216 | " accuracy = torch.sum(pred_y == test_y).type(torch.FloatTensor) / test_y.size(0)\n",
217 | " print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0], '| test accuracy: %.2f' % accuracy)\n"
218 | ]
219 | },
220 | {
221 | "cell_type": "code",
222 | "execution_count": 8,
223 | "metadata": {},
224 | "outputs": [
225 | {
226 | "data": {
227 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYUAAAEKCAYAAAD9xUlFAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJztnXl4FFXWh38nnYQAYZNdgiwKIrITEWQRhVEWdx0VN1wZ\nnZH5HGdGUXTcGEVwdBzHDR3XGRHcERBUBBEFJOwQtrAnbAlLgIRs3ff7o6o61dVV1VXdVV2d9Hmf\nJ0+6q27dOtVVdc+955x7LgkhwDAMwzAAkOK1AAzDMEziwEqBYRiGCcJKgWEYhgnCSoFhGIYJwkqB\nYRiGCcJKgWEYhgnimlIgoneI6BARbTDYT0T0LyLKI6J1RNTHLVkYhmEYa7g5UngPwAiT/SMBdJL/\nxgF43UVZGIZhGAu4phSEEIsBHDEpciWAD4TEMgCNiai1W/IwDMMwkUn18NxtAOxVfc+Xt+3XFiSi\ncZBGE6hfv37fLl26OCpI/tFTOFpaAQDo1qYRyNHaGYZhvGflypVFQojmkcp5qRQsI4SYBmAaAGRn\nZ4ucnBxH639w5hp8vqoAALB00kikp7L/nWGY2gUR7bZSzsvWrwBAW9X3LHlb3AkEqvM/CXAuKIZh\nkhcvlcIsALfJUUj9ARQLIcJMR/HAr9IDnB+QYZhkxjXzERFNBzAUQDMiygfwBIA0ABBCvAFgLoBR\nAPIAlAK4wy1ZIhEyUmClwDBMEuOaUhBCjImwXwD4g1vnt4OfzUcMk3RUVlYiPz8fZWVlXoviKBkZ\nGcjKykJaWlpUx9cIR7Pb+AWPFBgm2cjPz0eDBg3Qvn17ENWOmEMhBA4fPoz8/Hx06NAhqjo4zAbA\nuac3DH7eUFDsoSQMw8SLsrIyNG3atNYoBAAgIjRt2jSm0Q8rBQDjL+6Eq3qdDgC4Ydoyj6VhGCZe\n1CaFoBDrNbFSAOBLIXRr08hrMRiGYTyHlYJMbewxMAyT2GRmZnotQhisFGRSWCcwDMOwUlBgncAw\njFcIIfDXv/4V3bp1Q/fu3TFjxgwAwP79+zFkyBD06tUL3bp1w08//QS/34/bb789WPall15yVBYO\nSZVRm4+EEGxOYpgk4qmvNyJ333FH6+x6ekM8cfm5lsp+/vnnWLNmDdauXYuioiKcd955GDJkCD76\n6CNceumlmDhxIvx+P0pLS7FmzRoUFBRgwwZpqZpjx445KjePFGTUOiDAcxUYhokjS5YswZgxY+Dz\n+dCyZUtceOGFWLFiBc477zy8++67ePLJJ7F+/Xo0aNAAHTt2xI4dOzB+/HjMmzcPDRs2jHwCG/BI\nQUY9MvAHBHzsZGCYpMFqjz7eDBkyBIsXL8acOXNw++2348EHH8Rtt92GtWvXYv78+XjjjTcwc+ZM\nvPPOO46dk0cKMmoV4OehAsMwcWTw4MGYMWMG/H4/CgsLsXjxYvTr1w+7d+9Gy5Ytcc899+Duu+/G\nqlWrUFRUhEAggGuvvRaTJk3CqlWrHJWFRwoyavORn3NdMAwTR66++mosXboUPXv2BBFhypQpaNWq\nFd5//31MnToVaWlpyMzMxAcffICCggLccccdCAQCAIDnnnvOUVlYKciQaqzg97NSYBjGfU6ePAlA\nMl9PnToVU6dODdk/duxYjB07Nuw4p0cHath8JJPCIwWGYRhWCgoh5iP2KTAMk6SwUpAJMR+xUmCY\npEDUQqtArNfESkGBzUcMk1RkZGTg8OHDtUoxKOspZGRkRF0HO5plUogdzQyTTGRlZSE/Px+FhYVe\ni+Ioyspr0cJKQSZknkIt6jkwDKNPWlpa1KuT1WbYfCQT6mgOeCcIwzCMh7BSkAlVCt7JwTAM4yWs\nFGRSiKOPGIZhWCnoIMBKgWGY5ISVgkzoegoeCsIwDOMhrBRk1GkuWCkwDJOssFKQ8alHCmw+Yhgm\nSWGlIKNeVIf9zAzDJCusFGTSfNU/RW2a9s4wDGMHVgoy6pECqwSGYZIVVgoyqT519BGrBYZhkhNW\nCjKpKWrzkYeCMAzDeAgrBZmQkYKHcjAMw3gJKwWZVHX0EYcfMQyTpLBSkGFHM8MwDCuFIHXTfMHP\n7FNgGCZZcVUpENEIItpCRHlENEFn/xlEtJCIVhPROiIa5aY8ZnRoVh8jzm0FgKOPGIZJXlxTCkTk\nA/AqgJEAugIYQ0RdNcUeAzBTCNEbwI0AXnNLnkgQEe4cJK3CtGDzITz06VqvRGEYhvEMN0cK/QDk\nCSF2CCEqAHwM4EpNGQGgofy5EYB9LsoTESX90X+W7MTMnHwvRWEYhvEEN5VCGwB7Vd/z5W1qngRw\nCxHlA5gLYLxeRUQ0johyiCjHzUW2KXIRhmGYWo3XjuYxAN4TQmQBGAXgQyIKk0kIMU0IkS2EyG7e\nvLlrwqjXVGAYhklG3FQKBQDaqr5nydvU3AVgJgAIIZYCyADQzEWZTGGdwDBMsuOmUlgBoBMRdSCi\ndEiO5FmaMnsADAMAIjoHklJwzz4UAdYJDMMkO64pBSFEFYD7AcwHsAlSlNFGInqaiK6Qi/0ZwD1E\ntBbAdAC3Cw/jQVN4qMAwTJKT6mblQoi5kBzI6m1/U33OBTDQTRnswDqBYZhkx2tHc0JBbEBiGCbJ\nYaWggkcKDMMkO6wUVLBSYBgm2WGloELraOYcSAzDJBusFFRoRwpfrdnHayswDJNUsFJQoXU0PzBj\nDb5co51vxzAMU3thpaAiRcencKy0Mv6CMAzDeAQrBRV6jmb12s0MwzC1HVYKIYQrAJ7lzDBMMsFK\nQYWe+ShVbyPDMEwthZWCCr3U2T5WCgzDJBGsFFToNf/sU2AYJplgpaBCz3/APgWGYZIJVgoqdKOP\nUvgnYhgmeeAWLwI+/oUYhkkiuMlTkaLjVPbxSIFhmCSCWzwVuo5mjj5iGCaJYKWgQs+n4Esh/HH6\navy41bOloxmGYeIGKwUVepFGRMCstfsw9p1fPZCIYRgmvrBSUKFnKOLM2QzDJBOsFNToaAUeITAM\nk0ywUlDBE9UYhkl2WCmoYJXAMEyyw0pBBY8UGIZJdlgpqDDTCawvGIZJBlgpqNBLnR3cF0c5GIZh\nvIKVgop0k0RHZgqDYRimtsBKQUWaydoJrBIYhkkGWCmoMFtljQcKDMMkA6wUVJj7FFgrMAxT+2Gl\nYBXWCQzDJAGsFCzCOoFhmGSAlYJF2KfAMEwywErBIuxTYBgmGXBVKRDRCCLaQkR5RDTBoMz1RJRL\nRBuJ6CM35YkFXoCNYZhkINWtionIB+BVAL8BkA9gBRHNEkLkqsp0AvAIgIFCiKNE1MIteWKF8yIx\nDJMMuDlS6AcgTwixQwhRAeBjAFdqytwD4FUhxFEAEEIcclGe2GCdwDBMEuCmUmgDYK/qe768TU1n\nAJ2J6GciWkZEI/QqIqJxRJRDRDmFhd6slcw6gWGYZMBrR3MqgE4AhgIYA+AtImqsLSSEmCaEyBZC\nZDdv3jzOIkpw7iOGYZIBN5VCAYC2qu9Z8jY1+QBmCSEqhRA7AWyFpCQSDqs6YffhElT6A+4KwzAM\n4xJuKoUVADoRUQciSgdwI4BZmjJfQholgIiaQTIn7XBRpqixohMOnyzHhVMX4YlZG12Xh2EYxg1c\nUwpCiCoA9wOYD2ATgJlCiI1E9DQRXSEXmw/gMBHlAlgI4K9CiMNuyRQLivmorNKPkvIq3TLHy6Tt\nv+QVxU0uhmEYJ3EtJBUAhBBzAczVbPub6rMA8KD8l9AoI4VBzy9E0cly7Jo82lN5GIZh3MBrR3ON\n4XBJBZbtOIyik+Vei8IwDOMarBRscOO0ZcHPB4rLoqrjqzUF6DRxLsqr/E6JxTAM4xisFKKk/3ML\nojpu8jebUekXOHyywmGJGIZhYoeVgoNILhJzFN9E5JIMwzDxh5VCnFGimKwoEIZhmHjDSsFB7Mx6\nZp3AMEwiwkqBYRiGCcJKgWEYhgliSSkQ0ZlEVEf+PJSI/qiXuI6JDOfVYxgmkbE6UvgMgJ+IzgIw\nDVKiu4RdJS0W7hzYAQBwz+AOHktij1/yipB36ITXYjAMU8OxqhQCci6jqwG8IoT4K4DW7onlHX+7\nvCt2TR6NsRe0d6V+ZaTgtKP5preXY/iLi52tlGGYpMOqUqgkojEAxgKYLW9Lc0ekxMCt9RNInqkg\neKYCwzAJiFWlcAeAAQD+LoTYSUQdAHzonljeE4tKOFpaiQmfrUNZpXEqCw5JZRgmEbGkFIQQuUKI\nPwohphNREwANhBDPuyybp8QyUCg+VYmPV+zFZ6vyHa2XYRjGbaxGHy0iooZEdBqAVZCWzXzRXdG8\nhRxYlTlgMhrggQLDMImIVfNRIyHEcQDXAPhACHE+gOHuiVVL0LER8UCBYZhExqpSSCWi1gCuR7Wj\nuVYTjZnHTj4jzn3EMEwiYlUpPA1p6cztQogVRNQRwDb3xPIeJ3r0es1+MCGeA/UzDMM4jaXlOIUQ\nnwD4RPV9B4Br3RIqIYhCK2jDWPUGA2Syj2EYxmusOpqziOgLIjok/31GRFluC+clVhzNHy7bjZPl\nVYb7dU1EwWpZKzAMk3hYNR+9C2AWgNPlv6/lbbUWKz6Fx7/cgEmzc4PftUpg7voD+HbjAd1j1UX3\nHinF0RJeiY1hGO+xqhSaCyHeFUJUyX/vAWjuolw1BrORwq+7jmDchytDtim6Rh2uOnjKQgyZutAF\n6RiGYexhVSkcJqJbiMgn/90C4LCbgnmNVZdCRpovqvq1aS5OlBkrF4ZhmHhhVSncCSkc9QCA/QCu\nA3C7SzIlBFZzH326snrWsh0vATuaGYZJRKymudgthLhCCNFcCNFCCHEVann0UTQhqZEa+lMVfpRV\nBgAAAQe1QkVVwLG6GIZJbmJZee1Bx6RIQOxMXqt2MJs39P2e/R4Fx07Jx0QpmA7Pzt3kXGUMwyQ1\nsSiFWp2xwU7uoxMmzuaQciq/gZNKYfOB485VxjBMUhOLUmCruMyxkkr84aNV2HzA+spnvJ4CwzCJ\niOmMZiI6AYNsDQDquiJRomBjHLT5wHHMWbcf36zfb/kYswyqEY8NCKSk1OqBWkJSUl4FIqBeuqVE\nAAxTIzEdKQghGgghGur8NRBC1Oo3w45PoW66FJZqp6Ffsq0Qe4+UYs4664oEkBRQx0fnYsGmg8Ft\nHMkUH859Yj66PTHfazEYxlVqdcMeC3b64dGsvfDCt1vxwrdbbR+3es8xAMB3uQcx7JyWto9nYiOW\nER7D1ARi8SnUauys0VwV4JBQhmFqB6wUDLDT9/d70H1kkxHDMG7ASsEAOz6FqjgqBafcy9e9/gvb\nxxmGCYN9Cg7gxUghVnJ2H/VaBIZhEhBXRwpENIKIthBRHhFNMCl3LREJIsp2Ux472HEeO5lm4tDx\nMhwr5TTaDMN4g2tKgYh8AF4FMBJAVwBjiKirTrkGAP4PwHK3ZIkGO+ajB2ascey8/Z5dgH7PLnCs\nPoZhGDu4OVLoByBPCLFDCFEB4GMAV+qUewbA8wDKXJSlRmE28lCUFc+IZhjGDdxUCm0A7FV9z5e3\nBSGiPgDaCiHmmFVEROOIKIeIcgoLC52XNA7k7nMmP5Fi1uLoI4Zh3MCz6CMiSgHwIoA/RyorhJgm\nhMgWQmQ3bx6fBd+cbnR/2V7kbIUqWD8wDOMUbiqFAgBtVd+z5G0KDQB0A7CIiHYB6A9gVqI4m9NT\nnf1pvOjZr9l7DO0nzMH2wpPxPznDMDUSN5XCCgCdiKgDEaUDuBHALGWnEKJYCNFMCNFeCNEewDIA\nVwghclyUyTK+FML9F53lWH1e+AC+XC3p4B+3JI7J7e73V+DGaUu9FoNhGANcm6cghKgiovsBzAfg\nA/COEGIjET0NIEcIMcu8htqF0yOFmmoy+n7TIa9FYBjGBFcnrwkh5gKYq9n2N4OyQ92UxWusNOLC\niubgjNkJwd4jpRg8ZSFmjx+Ebm0aeS0OwzgGp7mIE1ba+0p/Te3/Jx8/bJZGPDNW7I1QkmFqFqwU\nLHDXoA7BzyO7tXLtPJX+6vkJZZV+lFf5XTsXExvKIkcBjg2u8byyYBvaT5jjaGaCmgwrBRMU53Dj\numloe1pdTLqqG85u1SCmusxQK4Uuj8/DwMkLjevjtshTlIXvWCnUfKYt3gEAKONOGABWCqY0zEgD\nADTISMVPD12MW/q3i2pBHQAoLq2MWEabbbXoZHlYmXi6FIQQeHDGGqzak3zJ8/wBYXrdKfLUcl5K\nIzLFpZV4ft5mVPn5x6oJsFIw4c5BHfDk5V1xS/92wW12ciKpeVPujZiRaL3O46eq8PnqAtz53gqv\nRYk7ry7MwzWv/YKVu4/o7vcRm4+s8sycXLy+aDvmbzyou/+XvCLc9NYyz7MN862U4NTZJqT5UnD7\nwA4h29zsqf+6U78BiojOw7yzqAT7i0/FJpBSfRK+LJsPSGlJDhSHj9aA6s6BPxl/HJuUy7Z6oxUK\nx09fjcMlFThSUoHmDerEUzQJ5aXmWwmAlYJtohkpzNtwwFK5SbM32a/cgIteWBR7JUryPW74wvCl\ncA4qp/Daac9R3qGw+cgmmw6csH3Mvf9daamcnZfCzgzpaE1ewYys3PCFofgUvDZ51AbYFJdYsFKw\nScFRZ0wyelhpXyjaFj4KeFRtjNe929qEEsnFCjYxYKVgkwYZ7lncEs1Mo0iTaHIlAik8inKMFDbF\nJRSsFBKIaN8Jt5LtKS8pv6vhsPnIOVISxHzEC1dJsFKwSaWLsdbR9shjfZfW5R/D5a8swamK0Mk7\nylrRydyDM2oonGjICk+U4+u1+6I+vraQKOajZH7O1bBSsImb+YlsvRSqorH2sJ7+OhfrC4qxvqA4\nuK2kvAoXTl0UU717j5RiwSb92HQjjpZUYIcL6z8EAgLtJ8zBqwvzLJWPNEnRiRnNd763AuOnrw4q\n32Sl2j/jzfkpQUYqiQIrBZu4O1KIXEavqXLqUZ67fn/w88nyKlX90Z3h0n8uxl3v21seY/iLP+Li\nf/wY1fnMqJRj5F/+fpsj9fkcaMgKjklBC173kL3Ga/NR9brnDMBKwTZujhScqLnwRDke+XxdVMe+\n98su3dQO0b6rpRX2c8kcLqkZvWb2KTiHL0F+Sx4oSLBSsImbI4Voe0rqwybNycX0X6NP53yyTBoh\nqEck/K6Ecvf7Odi4TzK1sckhdhTzkedKIUGf9Nx9x3Hlv5egtKIqcmEHYKVgk0RRCl+sKcDri7YD\nCHVQR/NiRTwiMd8VWzjZdn+/6SBe+Har4/UmKz65FfL8t4xw/hNlkZNausGzczdhbX4xVu6OT2JK\nVgo2mXRVN5zdMrr02ZGwNnlN+i8E8Py8zdJnV6SpJlF7UImA173bmkCk6ZZBU1wMWqHSH0Agxnth\ndvQnOXvR/clvse2g/YwGThEvpclKwSaDOzXH/D8NcaVuKyGpehOanXxY9KqKtX6vJr+t2XsM7/68\nU5bBnXM4kRAv2dUKBX0K0Y/CO038Bn/+ZG1055f/m43UlZX2th50PjIuEnFMYgCAlUJC4Wanc/I3\nm9F+wpyoelOxiuVGg7z3SClKys1trFe9+jOe+jpXksGtpjfZW3QbGD0HvuA8hdjq/2J1QUzHW4r+\n8zB7XrweNVYKCYRej1q97eu1+7D7cGl4GdXjYvTgvP2TtJ6DdiEfLflHw+uPFTecsYOnLMQt/1lu\nQwbHRXCM2p6lM1JDmiiRXGZn99zfEUdYKSQQeu/E1+uq5w6Mn74a/9SJs1c/sHk6w1tC9Yup10Cr\nFc/ELzZI2wz2R4Nb7/rqPccsl410DcWllej+xHzba1o4MQJJovZGF6+jjxTzlSXzrdvCJACsFBKc\nI/KSnP/4dothGfWzvNegp6/M0LXaa1cXi/VVTYSwzUgSrNp7FCfKqyzPeHaSBPh5PMXngKPZCcxO\nn0zBFqwUEpyDJySl8MoPxo2V+nE1bIBV+WUWyk4zveMVSlQx0WYvy1Nfb8Q3qpnQeYdO4uDxspAy\nejLFGiliF7faGzv15h8tRUVVuOE8mRocPXwpsTua3Ua5z576FOKkNFkpJDjKXASrGL1XyrP81Zp9\nuCPCmstfrSnAsAipJk6UVeJoSQXe/XkX7vvfquD24S/+iPOfXRAqk86z3OOpb03rdxyP/cx5h05g\n0PML8Y4cDRVVJbWUoGnTI51gJfoovHT8iOcaKgArhVqBugdh9GArz9XjX20I2b4+vzist6sdSeiR\nPel79H7mO0vy6dmKT0aIHHKSQEB43hvfUVgCAFi243DYvkR2ggPAd7kHcTwOE7e8/hnMzUfJAyuF\nWobRw6v4FLQP/uX/XhJMzGaHch0ziKFMBm+bEALv/bzT9en7fiFcNB/Zqzg1JfyV81phmbH3SCnu\n+SAHD3y8xvVzeb2Yk6VxQhJ4mlkpRMk/ftsTfxzWyWsxAISODiKNFPQ46nISOqOe8PebDuHJr3Px\n3NzNhsfO23AAS7YVmdZ/6EQZ2k+Yg0Vb9Ec4/kD0zW6kdspqvVbCHYtLKzEzJ/q8VWp+92EOXlsU\nu9O8rFJKarj7cEnMdUXCa9VoppTc1lczVuzB9ggp43meQoJzbd8sPPibzl6LAUATKWTuZ9ZFO3fB\n6YfPSFEpI4Rjp/RNE68v2o57/7sybD6C9uVdt1dKTvfh0t3o+Mgc/HH66rDza4/ZfOA4Js3O1W0I\nFm8tRHmV1Bg69Vso50nRm5Eu///zJ2vw0KfrsPnA8ZjPN3/jQUyZZxyxZpV49oyjX2TKmbtkXou0\n162f4+HP1mPUyz/p7ov34ISVAhNGNO/YgeIyw32RIo2MXmoltxMAbD14Au0nzMH2wpOG8vmFQEAA\nszSrmemNFG55ezneXrIzLFX3toMncNs7v+L7TZH9KpLslooFR0v6aUqknYfkSLOySmPT3Ndr95n+\n1k5yqsKP4S8uDn5/9Iv1aD9hjmvni7Ztj+a4/KOlGDp1IQ4Ul4XkE4uEm07fiCZZzn3EWCXSs7Lr\ncKk9H0AUMgye8oPhPquO1CqTPAdfrZFSGHyzfn+YfMp7WiTP6dA7f3C0EqEBKDoZuykt79AJLNSY\nsswmZmlEM1SS5VV+jJ++GmPeWhazjJF4ft5mvPT91pBtHy3f4+o5ozbxRXHM/5bvwa7DpfhsVT6A\nyJPXkmkuSarXAtR0lj5yMTYfOIHFWwuxzqX0tt9uPGC6P9Lw+b1fdjkojT5miw9FCvVTel/q2dra\na1J/NapPbw4AII9UDEQIViX/r7CZgEevWqV3vWvy6GoZhGJ+CO9pCgHMzNmLjfvMzUaKrPuiCAyw\ni1kotBDC0R5z9Yzi6I6PxnwU7QqGSeBnZqUQK60b1UXrRnVx0dktcJNLPbhftoeHMapJlE7MAx+v\n1t1uNX3Bhn3Va0Qb+kaIDPcZncYvqs1HFVUBFBw7ZctWvvdIKTYfMEiZbLFBCioFXZ+CwEOfWl8t\nz+v77Q8IpPocVAry/6gXmXJIDq9CUiMptXhHPLFScBCfnhfRASIu7O7wE2v0kL790w4M7tQcnVtm\n6u7/cs0+3e1Gz7w2q6U6XNM0Wsdgr1GjEgiEhqQOnPwDmmXWCa3L5NaNfPmnmOZVZE/6PmjaspL6\nPNrbuaGgGF1bNwzmEnIS9cigKiCQ6nP8FLrX/eaP23FWi0wMO6el8XExPP/qZ90sRk2YKPVYsSp/\nvEKXXfUpENEIItpCRHlENEFn/4NElEtE64hoARG1c1Met0l1SSlsOxTfHO56j54/IDBpziZc/drP\nETOtajFqrHNlc4nywqWpep/aY5Rvq3YfDXuJIjkKpZFC6M7gyx3hUj7J2WuqEAQkX8iUeZsNQ3vV\nvg5d85H2u+FIyFjY1XuO4rJXluD1H+3NgFc4UlKB7EnfYUNBccSybq0+qO2MFJ+qxHPfbMZd7+eY\nHxdFY6n3zHiVOjuiedX5U5rimlIgIh+AVwGMBNAVwBgi6qopthpAthCiB4BPAUxxS554kOoL/zkb\n1Il9MGZmaz5eVhmX/sO2Q5L5pKIqYLtRGPrCIuwvDreDK9E2CuqRltF7smDzIduNpj9gPHkt0m/3\nU4Q5EkJIMr22aDue+npjhNqg+4aHy60vldb/oUaZgLhxX+RGXY+fthWi6GQF3ly8I2LZKhP/kRl2\nG2+ry19GM1Iw8u0YnsP+KSzjtTlQi5sjhX4A8oQQO4QQFQA+BnCluoAQYqEQQknruQxAlovyuI5b\nIwUzejz5rfMzQXWqG/FPKYa6TmoKKqsin08bujh3vbmzHADSVEpV21CqHZ9GjYveWhOAlFMnLGJJ\nqcuBn07xmWgjvB79Yj3yNKO8nF3hqbmtmw/CqagKBCeYAfqNnR2sHF1pM0mRVYm0v0M8UmkLmKeV\nD5YLWhmdf8cTLbLJTaXQBoB6ema+vM2IuwB8o7eDiMYRUQ4R5RQWFjooorN0bF7fk/PuMmgMo8Xs\n5chI81mO0FEPta0oLqtK1W5boTd5TZEt1nTNZr3fj5bvwR9UyQIB4OBxvbBZ40ir0O3hOwZP+QFd\nHp8XsWH5PvdgmG8qe9L3eGfJTvMDVSi3J9qRghFGjbJVpRBro+p1RFE06ezdJCHmKRDRLQCyAUzV\n2y+EmCaEyBZCZDdv3jy+wtnggeGJMcM5VjaYmCDqpKZYNh9ZfdkUJ2aqyUhBTVgDH+FMermPgutL\nKA1P1OGQ+p+jrcMMvTZSUTLBXTo/xYHiMtz9QQ7+T5O/qOhkOZ6enWtZTsW857RSUND+DpO/MU5/\noub7TQeDn3/deUTXVBnN+UP2KR9c1iD+gAibb1ObsqQWAGir+p4lbwuBiIYDmAjgCiGE/uyjGkKa\njk/hg7v6eSBJbOw9YvxS1UnzGc4H0GL1YVYa+VQLPgUA2F5oLw+P2YxqJ3pf1T5rqz0+fSe6ET9u\nLZSylAb1l/ERer+40shofTihMsnHm9wyRSnYNR9ZRXtV3+Ye1C2nZbwqrcn1by6NmPYdMHA0e2Td\nV3eA/j5nE7Infa+blbY2jBRWAOhERB2IKB3AjQBmqQsQUW8Ab0JSCNbyCtQwep/RJGKZewZ3iIMk\nzpDmI8sjBa016IY3l5qWV8e+m0VcXfXqz5bOryClv9A3H2lnOttFCPsRKVodZRaSuudwKca+8yse\n/Xy9pZC/39vSAAAfQ0lEQVRJPU6USdFTDTKqgx60Ce6Uuo0uhVC9Qprj5iNFhihaPT2FX1rhR5U/\nYJhgzh8QuotWmY4U5J1O++8qqgIh5/1mg7RgVUkcU8trcU0pCCGqANwPYD6ATQBmCiE2EtHTRHSF\nXGwqgEwAnxDRGiKaZVBdrWbiaG1QVuKSQmTdp6BqYgJCYHmE9Y9TVK2rrYY/QqOsF32kHOLkEpBW\nq9LaysPCb1Vfd8qN99HSihBlsu3gCUtLh364bHew16mOhLv2dXMFrUWgei1lp0NSY5nRbPQsTv12\nC4b940fd7K4hqwqqFK2V0zv1uIx8+Sec+ehcdH7sG6xQBR+YzXyPF65OXhNCzAUwV7Ptb6rPw908\nvxe0Pa2uofmFKPEiDexyoqwKhSZmCCO8XEhGN/rIxmLtkZHr0tmj17uP5FBVy3SkRPqtm2XWUfVW\ngeveWIpineyyWpPd419uwDV9pPiOjPTqGWdqu/VP2woxZ91+REIxH13z2i/Y+veREcvbxWgkpDcS\n23ukFCkphEyDkO8Vcgek6GQ52jUNDQDxq0Y66pGeFYfvXe/n4LYB7fD0ld0iljVj0/7qMPOlqowF\nyqOgHmXXmnkKycqsPwzCvAcG6+5L01lgpaZRcOwUbn/XfDlPBXUvLh7hhUboRR9V74ut7mgO/9/y\nPdhZVN2Dfe6bTcb1q6xb6nOdqvDrFddFmVSXYmDnuvU/1VlhjfxApDrebn4oqxi1yXpyD56yEAMn\n/2Do31KO0bu/RqNDc/NR9ecPlu42LhgFlRolBUBXE8TrDeI0Fw7TpH46mtRPx2Ojzwmx4QJyT8v6\nu1yrsNIjd6tHpM59pCUgBE6UVeIOi4pOD7s+hWdm5+JfC7YFe94/5xnntlLXbS2OPhwlFbeViN8v\nVhdgwJlNdfepJxdWVAVQfKoSjeqmQUCgjo28F7PW7kO6jzCiW+uQ7UZXZya2kYKqXvc5vFatT4RU\noQJe4Fc57oPviUoUzn1US7h7cMewbak+AmwsdduhWf2QHmVNZutB91J1RHpntLmP1PgDAou2RD/3\nJSR3jo02pfhUJU6rn65fp9E2C5Eys9buw7ghoc9embxgkNW2xSg5n0/VOk34bB0+X12AZpnpOFxS\ngZ3PjdY9Rg9lESR1FlnA3khBwWjWc9A8CGllvow0HxpmpAEI9YmoT2kekuqewlCnjVEUv+4zECfb\nc823Z9QAemQ1AmB/xrOXJhen0S58o4dbPSLpd9SPPhICOFUZ2/BNFUgbUz3BWuRqlm4/jLcWV08u\nM6td3Wi99F3oOgjVI4XYfmD1SGG27IMoOlnh2OQxw5GQidjKTHstiqgBIdDv7wtw8QuLgvuMcnd5\n9bapRy6KaHq/RbyaA1YKceCDO/thxrj+wZfqkZFdTMvfe+GZeOqKc2uVUnCTSL+S7uQ1VaNRFqtS\nMGlsDds5C+3zmLeWIXe/kjQwtKEIC2M1MTeUK9cXo9JVu8ScTJ2tYHQfo8keo5iElN9FvXhSyGJO\nqh8u0gqBbqE3UtAXhUcKtYbG9dJxfsemwefvmj7mKZ4euvRsjL2gPSsFi+gNq6eolvLUiz4K7hOI\nSSlEO6NZCCkzqe6+CAnxwsc9WkJb0dIKxXwUfUNOFGo+cjLPV3XGWv0GOpoRjlnm3AqN+ShY1qQ+\ns3v7Sc5e7IrBzFulngyojBRC3n1jp7kbsFKII51bNgAApKem4B+/7WlYzk6IXG0i2un8ej/Ta6oE\negG9yWvyi+YPCJyqiD6aRkA47yDXuR6tIjCzL2t/RsWnEEs7vvXgyZAcW26sHaJcUe6+4yGzpqM5\nk9k7ZDT5TilaeKJcd36DEX/9dB0ue2VJyLZ9x05ZXoND16eg9wzEqTlgR3MceePWvthYUIxGddPQ\nsG6aYTkKhtMlmVKI8rhIPSgz85EQIthoxopTd0vveoQQIb1HO+eqrHLGp6DGaqoTMw6fLEeDjDQE\ne8IBgfX5xbj830tw/0VnBctp5c47ZLAKngrlGD1/UZVBmg5lhHbdG79g9+FStGqYgUvPbYmnruxm\nnK5dvidaBXDB5B/QqUUmvnvwwoiy+nV8Clbmt7gFjxTiSKO6abjgrGaWyyeL+WjV7qMY/uKPITNN\n7fBPzQLzWvSij6qdm/Zi/rXkHTrpuIO8KhAwjToTOkrOrL2olJ8jJ+Usi0IpaGXsO+l7PDizOkmf\nALBPTma3eq9qrXON3Moa2GYoHauTZeHPVIUq9XuITPJnJQX7geNleF+ek2C4Vodm++o9R3H3+1J4\ns9XFsdRKysynwPMUajlWwsvsrnBWU9lXXAYAqJsW3RqPkRa89wfCV15TCAiB8hhGCgEBHCuVwiL1\n7mk0d3Da4h1h63ILVDdgkRoMbduvhGA6mW0zmg6L3iM/e91+DJeX2hSiWna1iSeFCOvzi5GZkWo5\nJ5BSj3oUePB4GZ6ctRFX9jo9uO3fC/NweqMM6fw2ZQfCf4fx01cj/6i9LK3KxEH1edRKSLltB6LM\n/moXVgoJjFfREF6x3sJSkFqqLMyuDQgRPmGJqk0WSshmtBwu0aSvVqFdZMcKRr+DmfnASibYeE+C\nUlDPGdCidk0IVVl1Y0sEXP7vJbCD3toP/1qwDd9sOBCWHsQsDLS6TPg+f0CErTMeK4oTfH1+MQqO\nnsKQztVLBTw7dzPGDTnT0fPpweYjj2nVUOqlfHrvgLB9ytB04qhz4ipTTSLSKAGQVkS7UpNgT2mL\nDp0oj/nFPnxSP4ooWprUC5/U9l3uQRwpNT6P2oxh1LS5qRO0o6TthSfxy/Yi2dQldMsA2iVYq/dX\nxhx9FJ68T/HjaUdh/qB8xvVplcLB42X477LdeOTz9aZyfLUm/NmyYiV4YMYa3PbOrwA491HS0a2N\nNLEtu/1pYfsUU+Owc1rEU6Qahbax1+OEjl1ZedOiGZ1oMQotjZZ66eFmtIqqAMZ9YLyA/eo91Tb4\naGYGx8qLmglzw/7xI256aznGvrsCX66RJi7qjxQoOIJZvK0o2GCqR4DR/L6KrlEvkarMaNaijErM\nmmrtQOz8Zxdg9rrIEzK1CxsBwPRf9+qUTBxYKXiEFcOQ0oNJT+XbFAtmqZ6dyFuv+H6EcMbkt/mA\nfnRNkcmIZGZOfsR6P1y223KYpF3U6xMcOl4W/Lx4qyqFiM5P40uhYPnFWwuDocSxBlkodnq1Ujit\nvr5SUJ4Pox789F/36JqPrIxS9dh6MHL0lBHxSHXBPgWPMeu8KS9GTVMKnVtmuprryC7lOpEyavNR\nrCiNyo9bC/HG4u0RSrtP/lHjNbs/ydmLlbuPGu6PhW83HsDTs3MNHa16zn5fCmFtfvVoTfHBGClG\nu6gVVKpBluKASqnr5VIyMhFpFcVFLyyyFKqbZnM2+JK8ouDnCn/AVvLBaKhZrU2SUsfn7kOg5gKD\nDJlW+fTeARjcKXwdbSXCwwv0ZiwXn5J6zD9sjn3BP7Uzc8q8LTHXFytmDepTX+cG8xY5zbgPV5pG\n3ggB/LK9KGSbdhKcE/Mf1Hy8otpUszb/mG6ZEjkk2R8QGDxloeW6tYOZnUUlljoZesv2GvFJzt7g\njHQAMQdFWIGVQgIx/uKzcMZp9cK2p6XGz9U0qnvryIVMCAj9iKB4Lz6uRm8Ck3Zx9FhYtcednndt\nQwC46a3lIduUcF4Ft9ZqABAyI1uPqoAIk8eMaE05e22ErL6/dFfI91jCp63CSsEj9J6nP19yNhY/\ndFHY9nQbPYtYUYa2HZrVj1BSn4AQIZEjCl6uL1RgM27cLk6YoJIBLyboq1dmq4wwCrHrx4jG7XG0\npAJfW8gYrLChINRvUc4jhdqPlf6z3Twzr9/cB6+M6Y0x/dralkexuwoh0NQg378e1/WVkvxl1knV\nHSm4GfkSCbfMJYw93FyTwAi1Yz3S2tJG6S+MiCbthDKnJVp4pJDkNMusA8DY9NKtTcOwbZee2xIj\nu7fG5T1Px3PX9MBtA9rZOqeSEjkggKaZ1pXCpKu64a3bstGtTSPdhGORlEJWk7q25GRCGXhWbL6g\neOB1Kq9ISsHuSMHq9SzZVu1H2bQ/Ngd6pUEyPydhpeAR2e2bAADuHNTBsMys+wfi7duyAejHrus9\nlG/emh3y/abzzwAALPzLUEtyKU4wf0CgvsGi6HpkpPnwm65SugK9Bj7SQOGqXm0sn4sJJ7NOquFK\nbomCdiZxvNGLQlPjVlqZN1URaR8ui219Z6MMr07CSsEjmmXWwa7Jo9G/o3EP7/TGdTFcbmj/eunZ\nYfvV9tKrep0ektNFoUurhtg1eXSYj6Bzy0zdc2akSY9EVSCADIuhbzueHRXyffywTmFlIo0U3EjF\nnEwEhP1Qx3gzdb63kVlOjxSsoh7pd4zSV6fgpiNegZVCDeGOgR3C1rR95abewc8392+Hl2/srT0s\nhI/H9QcATL+nP+Y/MES3jKII/AERVBCRSNE06Hohd5Ha/FiUQgMbI5raSlmlv8bNZ4k3kUwv8UhA\nGasJLZJicwJ+imowLRpkoG+7JpbL9+/YFDufG4UBZzY19FPUkTOVphChro7JSsubt/bV3f7E5V1D\nvkda9UtxCEajHG46/wz88OfIeetrM+WVAVvx78lIpDkQfpcaXPWs7kqbzmwtrBQYy1htSiPNF1BG\nB6kpFGY+Oq99k7B5FGfLq8lp6ZHVSHNe6b9RqGt5pR/f/mkIlk642FQ+PfwBERcHHAA0rme8OJKX\nZDWpizQv435rAJGjj9x/hmL1CbBPgTHk899fACC2XChtGoc7hDPkkYLPR2GO5ou6tAhzGBvpGCXR\nn4LiU7i4i35yv6qAQOeWDdCiofHM5wEG/he/EEEnq1WTFwC0bxo+UTASKyYON9x3+wXtbdfnFI9f\n1hV/v7qbZ+evCURai7s0hsWWrBKr34J9Cowhfc6QzEbKvIJoZgwvUJlclLztSi2pKSn4yyWhzu0m\n9dKDD3WnFpKj2sjEpM7PUi/dF5y8NvTs5vhFZzRgJea7R9tGutsDAYHmDepgx7OjMP2e/hHrUYg0\nw1UPMxONl87yJvXTdTPtMtWURGj0tZleneR4WSXaT5iDOetjmzPD5iMmIi/e0BN3DuyA3m0b2z42\nI82HN27pi0dHdcH7d5yHHc+OQiM55/ywLi3QSGUqefH6nrg+u20wedirN/fBR/ecjxYNjHv2Sjjt\nA8M7BUcKKUQ4XWeEYqUH1dLgXMqwPyWFbCvHkd1a4YXf9gzZNuv+gabHXHR2eG4nIDnW1G6Y4a5T\n//HLuuKju8939RxesCnKjKpa2HzERCSrST387fKuYRFAVhnRrRXGDTkTRISUFELTzDpY+sjFmDCy\nS0i5a/pkwZdCwXTeDTPScMGZ5utND+/aErsmjw7WDxibm8w6QEp0kXointpUo26Mm1iw+bdoIE0K\nzEhLweu39A3OxlbokdUYz1zVLbhMpJaXbuilu139wvbM0h/VuMGZze2HOUY7qHF7NDKiWyvTMG0t\nT1ze1dbMe6+wm7I82yCAhM1HjCe0blQXqQZmEn+wV26vzlMV0kuRYbAOs1kv++vxg/DPG3oh1ZeC\n5nKDru6xqkcZ7ZrWjziJ67YB7TD9nv66eaYUbu3fDm+Pzdbdl2kQAqs2H00fZ27GMvNNWEEZ0QHA\nZ/ddYPv47c+OQjMbM9YVnM5iqsUnd06s0rZJPcPghfM7JI45za6/QmuWVaIM2XzEhNGpRWbUC9xH\nw6jurUK+Kw2wUW56I3xy+TOb6U+aUzfs9dJ96K5yVLdvVh9X9ZZmPCvJAUf1aK06NrQupZc19boe\nBucCBpzZNMT0tfmZEfjk3gFY8rCxolBQFGZmnVRsenoElj86DJOu6oa7VLPT66Wbm1kU5RYt6olq\njXWW74wEEYX85v0sjgD2mywe/7shHW3JME6nvF2/TKqPDOdnTL5W//57wcQvjJftfGB4+GRPbecp\ns04qplzbA+d3cD+dCSuFGsa3fxqC3Kcvjdv5Xr6xN9Y9eUnwu7JwuFFv2Yhpt/bFi9f3DPopRndv\njS6tGmBMPykNh3qN4dynR+DT+6Q1q5+9untIPR/c1Q+PjOyCLq0aBm3//TqEDrWfuaobxvRriyt7\ntQmLyGndKAPX9g1PqZGR5sN57U9DVhPjiCT1XIgv/zAQSx6+CHXTfWjZMAO39G+HtqfVsxXRtPO5\nUZELqbi6t1ru6J3ayiRIdQhmRwsmqB5ZjfDUFcYRTt1lk9mo7q0izp9pmJGKW/uH5+WyrRRSUgyV\ngs/DJIxajustCSvTNDO8g6Dt+PlSCNef1xZntdDvVDkJK4UaBpF9Z2ospPlSQta2vW/omdg1ebTt\n2bNtT6uHa/pU2+5fvbkP5j0wBIPOkvwS2mUs66T6sGvy6GDuJoUzm2fidxdKiqlHVmMse2QYrs8O\nzQbbsmEGnrumB9JTU3Dz+e3wxe+rzStLHxlm2vBrmT1+EADJ/9CxefUL2attY90e+pw/DsbKx/RN\nQ2k+Qt92TdBPNmuY3cexA9rhlv6h165Ood6msTTKubxnaGqT+hYmHCo8pEqdMrJ7a/xHYy7TLrg0\n6/5BGNSpGTY+dSlyn74Ur9/cRzcpIxDeqKnJrJOK567pgbY6a4cYhVi/dENPXTNZqo9Cfhf1b+YX\nIuz5SRRaqEaKN/WrllGJ6vvDRWeFlI+H2UiBlQLjKUoOpoFnmTutjWjVKCOikux9hvVZ31qU5H6t\nG1nL4lq/Tmqw53dtn1AH9ss39sZn912Amb8bENz275v0U5PUSfPhnNahDa6SwXZYlxa4Re5ld9L0\nHH+ecHEwvFgPdWN964D22DV5NHZNHo0LOzfHsHNaopcqis0oX1X9Oqmol56Kkd1bY9qt2UhNIcwe\nPyhk1rriI9JbcW/9k5dgdA/9xZzUvhIAWPLwRVj+6DBc3TsLDXQinxpmpKGZ3MA+cXlXTLqqe/A3\nqagKhI00u7cJDwB45spzg5+n6czQby1fg9Hs/cnXdNfdbob6HvlSCDdkt8Wo7q3w3YMXYtfk0Ti7\nVeikULeX4FTDSoHxlE4tG2DlY8Nxc4L26BrXS8cTl3fFf6MIk/zH9T2x9gnJ9HbjeW11V7Uberb+\nZD4A6NA01KSTKptWBnVqhmv6ZOGZK8/FvfKoSS3vqG6hfiBAckZ/cu8A5BiMYhTUPfWhqtDbngYh\nz6c3rou8Z0ehW5tGOPd0SYmN6t4abeXR2JTreuLB33QONqyrH/9NiBL/7k/VObi++sPAsACHrCb1\n0FKe0Kg3R+S0+um4TP5d28mmuweGd5ZlC1VIi/4yFL3PCL2OnydcjFsHtA9+15t38/nvL8DEUefg\nN+e0DIZZq7mx3xn47L4BYaG02qg2hZzHhuNoSUXItuev64HXbg5VOv1UjvLnolA80eJq0DERjQDw\nMgAfgLeFEJM1++sA+ABAXwCHAdwghNjlpkxM4qFnU3Wav1/dLeoV7O4YaJzePBKN6qbhp4cuCjZs\nWhTfzJh+bTH91+r1hHu1bYz+HZvisdHnoH/HpqgKCMxaI63Y5Q8I+FIopDFTc8N5bXFFr9OR7kvB\nloMnsGn/Ccs5shSV8O4d52Fo5+YYenYLZNZJRcuGke9R+2b1sePZUUhJIQzr0hIXn9MCgzo1w6BO\nzXBr/3Y4cLwMTTSRYZ1UaVLUiufynqejX/tQmVN1/A2N66XhgrOaIeex4cH1R0b3aI3RPaqTR9ZP\n96Gkwo/2zeoHneu3X9Ae57RuEJzV/5dLOuPHrYVopblPSx6+CK0b1cU9slN8eNeWuK5vFqr8AXy5\npnoFtb7tpAZ8cKdm+GlbEd6/s580+urSAvf9bxUAqZF/YHgnNMusEwwt/e9dxp2Nmb8bgE37j6Nz\nywbxnRgphHDlD5Ii2A6gI4B0AGsBdNWU+T2AN+TPNwKYEanevn37CoapTfj9AREIBMSL324Rd723\nQuw/dkr4/YGwcvM37BftHp4tlm4vck2WNxbliXYPzxYHi0+5dg4tm/cfF+v2HotY7mhJuWj38Ozg\n38Qv1lmq/2DxKbE+X6p/V9FJcelLP4rCE2WG5TcUHBNDpvwQ8XdW5DDjWGmF6PjIHDHhs1BZl24v\nEne9t0IcK6mwdA1OACBHWGi7Sbg0C5OIBgB4Ughxqfz9EVkJPacqM18us5SIUgEcANBcmAiVnZ0t\ncnJyXJGZYRKdIyUVri6mI4RAaYXf1gJL8WTVnqPYdvAELjq7hWmerHjw2Jfrke7z4W+ajMBayir9\nqJOaEtcAET2IaKUQQn/yjQo373wbAHtV3/MBaMdKwTJCiCoiKgbQFECRuhARjQMwTv56koiiXa2j\nmbbuGgxfS2JSW66ltlwH4PK1POFWxfrEci2W1uZNzO6ABiHENADTYq2HiHKsaMqaAF9LYlJbrqW2\nXAfA12IXN6OPCgCoA8iz5G26ZWTzUSNIDmeGYRjGA9xUCisAdCKiDkSUDsmRPEtTZhaAsfLn6wD8\nYOZPYBiGYdzFNfOR7CO4H8B8SJFI7wghNhLR05C84LMA/AfAh0SUB+AIJMXhJjGboBIIvpbEpLZc\nS225DoCvxRauRR8xDMMwNQ+e0cwwDMMEYaXAMAzDBEkapUBEI4hoCxHlEdEEr+Uxg4jaEtFCIsol\noo1E9H/y9tOI6Dsi2ib/byJvJyL6l3xt64ioj7dXEA4R+YhoNRHNlr93IKLlsswz5GAEEFEd+Xue\nvL+9l3JrIaLGRPQpEW0mok1ENKCm3hci+pP8fG0goulElFFT7gsRvUNEh4hog2qb7ftARGPl8tuI\naKzeuTy4jqny87WOiL4gosaqfY/I17GFiC5VbXeufbMy7bmm/8FCyo1E+gPQGkAf+XMDAFsBdAUw\nBcAEefsEAM/Ln0cB+AZSkv3+AJZ7fQ061/QggI8AzJa/zwRwo/z5DQD3yZ9tpz6J83W8D+Bu+XM6\ngMY18b5Amji6E0Bd1f24vabcFwBDAPQBsEG1zdZ9AHAagB3y/yby5yYJcB2XAEiVPz+vuo6ucttV\nB0AHuU3zOd2+ef5wxumHHwBgvur7IwAe8VouG/J/BeA3ALYAaC1vaw1gi/z5TQBjVOWD5RLhD9Ic\nlQUALgYwW345i1QPfvD+QIpWGyB/TpXLkdfXIMvTSG5ISbO9xt0XVGcTOE3+nWcDuLQm3RcA7TWN\nqa37AGAMgDdV20PKeXUdmn1XA/if/Dmk3VLuidPtW7KYj/RSboQvv5WAyMP03gCWA2gphNgv7zoA\nQFlZPtGv758AHgKgrBTSFMAxIYSyHJVa3pDUJwCU1CeJQAcAhQDelU1hbxNRfdTA+yKEKADwAoA9\nAPZD+p1XombeFwW79yFh74+KOyGNcoA4XUeyKIUaCRFlAvgMwANCiOPqfULqEiR8PDERXQbgkBBi\npdeyOEAqpKH+60KI3gBKIJkpgtSg+9IEwJWQFN3pAOoDGOGpUA5SU+6DGUQ0EUAVgP/F87zJohSs\npNxIKIgoDZJC+J8Q4nN580Eiai3vbw3gkLw9ka9vIIAriGgXgI8hmZBeBtBYTm0ChMqbyKlP8gHk\nCyGWy98/haQkauJ9GQ5gpxCiUAhRCeBzSPeqJt4XBbv3IWHvDxHdDuAyADfLCg6I03Uki1KwknIj\nYSAigjTbe5MQ4kXVLnVakLGQfA3K9tvkKIv+AIpVw2hPEUI8IoTIEkK0h/S7/yCEuBnAQkipTYDw\na0nI1CdCiAMA9hKRsrjxMAC5qIH3BZLZqD8R1ZOfN+Vaatx9UWH3PswHcAkRNZFHTpfI2zyFpMXJ\nHgJwhRCiVLVrFoAb5UiwDgA6AfgVTrdvXjmJPHDmjIIUxbMdwESv5Ykg6yBIQ991ANbIf6Mg2XAX\nANgG4HsAp8nlCcCr8rWtB5Dt9TUYXNdQVEcfdZQf6DwAnwCoI2/PkL/nyfs7ei235hp6AciR782X\nkKJWauR9AfAUgM0ANgD4EFJUS424LwCmQ/KFVEIawd0VzX2AZLPPk//uSJDryIPkI1De/TdU5SfK\n17EFwEjVdsfaN05zwTAMwwRJFvMRwzAMYwFWCgzDMEwQVgoMwzBMEFYKDMMwTBBWCgzDMEwQVgoM\nYwARTZSziK4jojVEdD4RPUBE9byWjWHcgkNSGUYHIhoA4EUAQ4UQ5UTUDFIGyl8gxbkXeSogw7gE\njxQYRp/WAIqEEOUAICuB6yDlCVpIRAsBgIguIaKlRLSKiD6R81WBiHYR0RQiWk9EvxLRWfL238rr\nF6wlosXeXBrDGMMjBYbRQW7clwCoB2l27AwhxI9yDqdsIUSRPHr4HNLM0hIiehjSDOCn5XJvCSH+\nTkS3AbheCHEZEa0HMEIIUUBEjYUQxzy5QIYxgEcKDKODEOIkgL4AxkFKlz1DTlKmpj+khU9+JqI1\nkPLttFPtn676P0D+/DOA94joHkiLozBMQpEauQjDJCdCCD+ARQAWyT187XKNBOA7IcQYoyq0n4UQ\n9xLR+QBGA1hJRH2FEImWbZRJYnikwDA6ENHZRNRJtakXgN0ATkBaIhUAlgEYqPIX1CeizqpjblD9\nXyqXOVMIsVwI8TdIIxB1ymOG8RweKTCMPpkAXpEXTa+ClLlyHKQlHOcR0T4hxEWySWk6EdWRj3sM\nUrZKAGhCROsAlMvHAcBUWdkQpIyea+NyNQxjEXY0M4wLqB3SXsvCMHZg8xHDMAwThEcKDMMwTBAe\nKTAMwzBBWCkwDMMwQVgpMAzDMEFYKTAMwzBBWCkwDMMwQf4f32XRq5pKM7wAAAAASUVORK5CYII=\n",
228 | "text/plain": [
229 | ""
230 | ]
231 | },
232 | "metadata": {},
233 | "output_type": "display_data"
234 | }
235 | ],
236 | "source": [
237 | "plt.plot(losses_his, label='loss')\n",
238 | "plt.legend(loc='best')\n",
239 | "plt.xlabel('Steps')\n",
240 | "plt.ylabel('Loss')\n",
241 | "plt.ylim((0, 1))\n",
242 | "plt.show()"
243 | ]
244 | },
245 | {
246 | "cell_type": "markdown",
247 | "metadata": {},
248 | "source": [
249 | "### Test"
250 | ]
251 | },
252 | {
253 | "cell_type": "code",
254 | "execution_count": 11,
255 | "metadata": {},
256 | "outputs": [
257 | {
258 | "name": "stdout",
259 | "output_type": "stream",
260 | "text": [
261 | "\n",
262 | " 7\n",
263 | " 2\n",
264 | " 1\n",
265 | " 0\n",
266 | " 4\n",
267 | " 1\n",
268 | " 4\n",
269 | " 9\n",
270 | " 5\n",
271 | " 9\n",
272 | "[torch.cuda.LongTensor of size 10 (GPU 0)]\n",
273 | " prediction number\n",
274 | "\n",
275 | " 7\n",
276 | " 2\n",
277 | " 1\n",
278 | " 0\n",
279 | " 4\n",
280 | " 1\n",
281 | " 4\n",
282 | " 9\n",
283 | " 5\n",
284 | " 9\n",
285 | "[torch.cuda.LongTensor of size 10 (GPU 0)]\n",
286 | " real number\n"
287 | ]
288 | }
289 | ],
290 | "source": [
291 | "# !!!!!!!! Change in here !!!!!!!!! #\n",
292 | "test_output = cnn(test_x[:10])\n",
293 | "pred_y = torch.max(test_output, 1)[1].cuda().data.squeeze() # move the computation in GPU\n",
294 | "\n",
295 | "print(pred_y, 'prediction number')\n",
296 | "print(test_y[:10], 'real number')"
297 | ]
298 | },
299 | {
300 | "cell_type": "code",
301 | "execution_count": null,
302 | "metadata": {
303 | "collapsed": true
304 | },
305 | "outputs": [],
306 | "source": []
307 | }
308 | ],
309 | "metadata": {
310 | "kernelspec": {
311 | "display_name": "Python 3",
312 | "language": "python",
313 | "name": "python3"
314 | },
315 | "language_info": {
316 | "codemirror_mode": {
317 | "name": "ipython",
318 | "version": 3
319 | },
320 | "file_extension": ".py",
321 | "mimetype": "text/x-python",
322 | "name": "python",
323 | "nbconvert_exporter": "python",
324 | "pygments_lexer": "ipython3",
325 | "version": "3.5.2"
326 | }
327 | },
328 | "nbformat": 4,
329 | "nbformat_minor": 2
330 | }
331 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/processed/test.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents-notebooks/mnist/processed/test.pt
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/processed/training.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents-notebooks/mnist/processed/training.pt
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/raw/t10k-images-idx3-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents-notebooks/mnist/raw/t10k-images-idx3-ubyte
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/raw/t10k-labels-idx1-ubyte:
--------------------------------------------------------------------------------
1 | ������'�������� � �� ��� ��� ������������������������������������� ��� ���������� ���� ������������� ������ ���� �� ���� ���� ������ ������������������������ ��������������������������������� ������� ������������ �� �� � �������������������� ����� ���������� ����������� �������� ������ �� ������� ���������������������� ���� � ������������� ���������������������� ����������������������������� ���� ������������������� �� ���� ��� ������� ������������� ����� ���������������� ������� � ����� ������� ���� ������������������� �������� ��������������������������� � � ������������ ����������������� ���� ���������������� ���������� �� ��� ���� ���������������������� �������� � ���� �� ������������������������ �������������������������� ������������������������ ������������� �������������� ������������������������ ������������������� ���������������������������� ����������� ������� ���������� ������������ ������ �������������� ������������������������� ������� ��� ������������������������� ������ ���� ������� ������������������������������� �� ��������� ���� ����������������� ���� � � ������������ � � ���������������������� ��������������������� ������������ ����������������� �������� ������������������������ ���������� ��� �������������� ������� ��������������������� ���� ��������������������� ��� � ���������� ���� ��������������� ������������������������������������ ���� ���������� ����������������� �� ���� ���� ����� ��� ��������� �� �� ������������������������� ���� ����� �������� ������ ��� ������������������� ������������ ������� ���� ���������������������������������� � ������������������������ ���� ��� �������� ���� � ������ ���������� � �������������������������� � ����������� ���� ����������������� ���������� � ����������������������������������� ����� ���� ������� ���������� �������� ��� ������������������������� � ��������������� ��� ������� ������������ ������ �� � ��������������������������������������������� ����������� �������������� ������������ ����� ���������� ���� ���� ����������������������������� ���� ������������� ������������������� ��������������������������������������� ����������������� ������������� ������������������� ������� ������ ��������������� ��� ���������� ���� ����������� ����� ������ � ��� ���������� ����������������� ���������������� �� ������ �� ����������������� �� ��������������� ������������������ ������ ������������������ ������� ����� ����� ����������� ���� ���� ������� ��������������� ���� �������������� �� ������������������ ����������� ��������� ����� ��� ��������������������� ����������� �� ��� ������������� ����������������������������� ��� ���������� ������������������������ ����������� ������ � � ����������������������� �������������� ���� � ������������ ���� �������� ����������� ���������� ������������������� �������������������������������� �������� �� ���� ������ ���� ������� �������� ��������������� ������� ������ �� �� ���� ���� � ���������������� ����� � ������ ����� ��� ����������������� ��� � ������������������������� ������ �������������� ��� �������������� ����������������������������������������������������������������������� � ���������� ���� �� ��������������������� ��������� ��������������������������������������� �������������������������������������������� �������������������������������������������������� ������������������������������ ��������������� � ���� � ��������� ������ �������������� �������������������������������� ������ ���� ���� ���� � ����� ��������� � �� ������������������ �� �������� �������������� ��������������������������������� ���� ���� �������������������� ��������������������������������������������� � �������������������� ����� ��������������� � ���� ������ ������������������������������� ��� ���������������������� ������� ������ ��������������������� ��������� �������� � ������� ����� � � ������� �� � ���� � �� �� � �������������������������������� � ���������������������� ��������������� �� ���������� �� ������ ������ �������� ����� ������������� ��������� ������ ������������������������������ ��������� ���� � ����� ��������� ���������� ������ ���� �������� ���������� ��� ���� ���������� ������� ������������� ����������� �� ���������� ���������� � �� ���� ����������� � ������������ ������� �� �� ����� ��� � ������� ���� � �� � ��� ������� ���������� ������������� ���� ����� ������������� ��������������������� � � ������ ������ ��������� ������� ��������� ������������������������ �������� ���������� � �� ����� ���������������������� ��������������� �� � ��� ��������� ������������� ������ ����������������� ����� ���������������� ���������� ��� ���������� �� � ������� ����� � �������� ������� ���� ���������������������������� ���������������� �������� ������� ���������������� �������� ��� ����������������������� ����������� ���� �� �� ��������� ����������������� ��������� ���������������� �������� ������� ������������������������� � ��������������� ��� ������ ������������ ����������� ������ ����� � ���� ��� �� ������������ ������� ��������� ��������� �� ������ ������������������� ����� ����������������������� ���� � ������ ������������������� ����������������� ��������������������������� �������� ������������ �������� ���� �������������� ����� ��������� ��������� ��������� ����������� ��� ����������������� ���������� ������� �������������������� � � �������� � ��������������� ��������� ��������� ���� ����������������� �������� ���������������������������������� ����������� ������������������� ��� ��������� �������� ������������������ ��������� ���� � ���� �������������� ��������� ��������� ���� ����������� ����� ������������������������� ���������� �������������������� � ����������� ���������� ���������������������� �� ����������������������� �� �� �� ��������� ���� ������� ����������������������� ������������������ ����������� � ���������������������� �� ���������� ���������� ��������������������� ��������� ��������� ������ �� ����� ������������������ ��� ��������������������� ��������� ������ ������� ������� ��������������� ��������� ��������� �������������������� ����������� � ������������������������������ �������� � ��� ���������������� ��������� ��������� ��� ������ ������ � ���� ����������� � ���������������������������������������������������� �������������� ��������������������������������������������������������� ���������������� ������ ������� � ���� ��� � ������������� ������ ������� ����������������������������������� �������� �������� � ��� ������� ��� ����������������������������������� ���� �� �� �������������������� ��������������� � ���������������� ���� ��������� ������� ���� � ������������ ���������� ��������� ����������������� ������� ��������������������� ������ ������������������������ ����� ����� �� ����� ������������� ��������� ��������� ������������������������������������������ ���������������� ������ ������� � ���� ��� � �� ���������������� ��������� ��������� ���������� ������������ ��� ��� ������� � ��������� ���������������� ����������������� ���������������� ��������� ��������� ������� ����� ���������� ���������� ��������� ��� ��� ����������� ������������������������� ������� ���������������� ������������������������ �� �������� ����� �� ������� � ��������������������� ��������� ��������� ������������������� ��� ������������� ���������� ��������� �� ���������������� �� � � ����������������������������������������� �������������������������������� �� � ������ ��������������� � ����� �� ��������������� ��������� ��������� ��������������������� ���� �������� ������� ������� ��� � ��������������������� ������� ��������� ����� ��������� ��������������������������� � �������������� �� ������ ���������������������������� ��������� ��������� ������������ ���������������� �������� ��� ������� ����� ������������� �������� ���������������� �������� �� ������ ��������� ������� �� ����������������������������������� ���������� ��������� ��������� � �������������������������� ��������� ��� ���������� ���������� ��������������� �������� ������������ ��������� ������� �������� ������� ������� ���������������� ��������� ��������� ��� ������������������������������ � ���������������������� �� �� ������������� �� ������������������� �������� ������� ������ ������������� ��������� �������������������� �� ��������� � ����������������������� ������������ � �������� �������������������� ����������������� ��� ���� ���� �������������������� ��������� ��������� � ����������������������� � ���������������� ���������� �� ������������������� �������������������������������� �� �� �� ����������������������� ���������������� � �������������������� ������ ��������� ��������� ��������� ���� ����������� ����� �������������������������� ���������� ������������������ � ����������� ���������� ��������� ��������� ����������� � ���� ����������������������������������� ���������� ��� � ����� ������������� ������� ���� � ������������� ��� � ������ �������������� ���������������� ��� ������������������������ �� � ������������������������� �� ����������� ��������� ��������� ��� ����������������������������������������������� � �������� ����������� ���� ����������������� ��������� ������� ������� � � �������������������������� ���� � � ���������������� �������������� ���� ����� ������������������� ������������������������������������� ���� ������������� ��������� ���������� ������ ��� ������� ������ �������� ��������������������������������� ���� ���������� ������������� ��������� ��������� ������������ �������� ���� �������� ������� �������� �������� ������ ���������������������� ��������� ����������������� ��� ���������������� �������� ������� ��������������� �������� ����������� ��������� ��������� ������ ������������������������� � �������������� ���������������������� ���������������� ��� ������������� ������������ ��������������������������������� ��������� ���������������� ����� ������� ������������ ��������������������������� ������������������ �������
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/raw/train-images-idx3-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents-notebooks/mnist/raw/train-images-idx3-ubyte
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/raw/train-labels-idx1-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents-notebooks/mnist/raw/train-labels-idx1-ubyte
--------------------------------------------------------------------------------
/tutorial-contents/201_torch_numpy.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.1.11
7 | numpy
8 | """
9 | import torch
10 | import numpy as np
11 |
12 | # details about math operation in torch can be found in: http://pytorch.org/docs/torch.html#math-operations
13 |
14 | # convert numpy to tensor or vise versa
15 | np_data = np.arange(6).reshape((2, 3))
16 | torch_data = torch.from_numpy(np_data)
17 | tensor2array = torch_data.numpy()
18 | print(
19 | '\nnumpy array:', np_data, # [[0 1 2], [3 4 5]]
20 | '\ntorch tensor:', torch_data, # 0 1 2 \n 3 4 5 [torch.LongTensor of size 2x3]
21 | '\ntensor to array:', tensor2array, # [[0 1 2], [3 4 5]]
22 | )
23 |
24 |
25 | # abs
26 | data = [-1, -2, 1, 2]
27 | tensor = torch.FloatTensor(data) # 32-bit floating point
28 | print(
29 | '\nabs',
30 | '\nnumpy: ', np.abs(data), # [1 2 1 2]
31 | '\ntorch: ', torch.abs(tensor) # [1 2 1 2]
32 | )
33 |
34 | # sin
35 | print(
36 | '\nsin',
37 | '\nnumpy: ', np.sin(data), # [-0.84147098 -0.90929743 0.84147098 0.90929743]
38 | '\ntorch: ', torch.sin(tensor) # [-0.8415 -0.9093 0.8415 0.9093]
39 | )
40 |
41 | # mean
42 | print(
43 | '\nmean',
44 | '\nnumpy: ', np.mean(data), # 0.0
45 | '\ntorch: ', torch.mean(tensor) # 0.0
46 | )
47 |
48 | # matrix multiplication
49 | data = [[1,2], [3,4]]
50 | tensor = torch.FloatTensor(data) # 32-bit floating point
51 | # correct method
52 | print(
53 | '\nmatrix multiplication (matmul)',
54 | '\nnumpy: ', np.matmul(data, data), # [[7, 10], [15, 22]]
55 | '\ntorch: ', torch.mm(tensor, tensor) # [[7, 10], [15, 22]]
56 | )
57 | # incorrect method
58 | data = np.array(data)
59 | print(
60 | '\nmatrix multiplication (dot)',
61 | '\nnumpy: ', data.dot(data), # [[7, 10], [15, 22]]
62 | '\ntorch: ', tensor.dot(tensor) # this will convert tensor to [1,2,3,4], you'll get 30.0
63 | )
--------------------------------------------------------------------------------
/tutorial-contents/202_variable.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.1.11
7 | """
8 | import torch
9 | from torch.autograd import Variable
10 |
11 | # Variable in torch is to build a computational graph,
12 | # but this graph is dynamic compared with a static graph in Tensorflow or Theano.
13 | # So torch does not have placeholder, torch can just pass variable to the computational graph.
14 |
15 | tensor = torch.FloatTensor([[1,2],[3,4]]) # build a tensor
16 | variable = Variable(tensor, requires_grad=True) # build a variable, usually for compute gradients
17 |
18 | print(tensor) # [torch.FloatTensor of size 2x2]
19 | print(variable) # [torch.FloatTensor of size 2x2]
20 |
21 | # till now the tensor and variable seem the same.
22 | # However, the variable is a part of the graph, it's a part of the auto-gradient.
23 |
24 | t_out = torch.mean(tensor*tensor) # x^2
25 | v_out = torch.mean(variable*variable) # x^2
26 | print(t_out)
27 | print(v_out) # 7.5
28 |
29 | v_out.backward() # backpropagation from v_out
30 | # v_out = 1/4 * sum(variable*variable)
31 | # the gradients w.r.t the variable, d(v_out)/d(variable) = 1/4*2*variable = variable/2
32 | print(variable.grad)
33 | '''
34 | 0.5000 1.0000
35 | 1.5000 2.0000
36 | '''
37 |
38 | print(variable) # this is data in variable format
39 | """
40 | Variable containing:
41 | 1 2
42 | 3 4
43 | [torch.FloatTensor of size 2x2]
44 | """
45 |
46 | print(variable.data) # this is data in tensor format
47 | """
48 | 1 2
49 | 3 4
50 | [torch.FloatTensor of size 2x2]
51 | """
52 |
53 | print(variable.data.numpy()) # numpy format
54 | """
55 | [[ 1. 2.]
56 | [ 3. 4.]]
57 | """
--------------------------------------------------------------------------------
/tutorial-contents/203_activation.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import torch.nn.functional as F
11 | from torch.autograd import Variable
12 | import matplotlib.pyplot as plt
13 |
14 | # fake data
15 | x = torch.linspace(-5, 5, 200) # x data (tensor), shape=(100, 1)
16 | x = Variable(x)
17 | x_np = x.data.numpy() # numpy array for plotting
18 |
19 | # following are popular activation functions
20 | y_relu = torch.relu(x).data.numpy()
21 | y_sigmoid = torch.sigmoid(x).data.numpy()
22 | y_tanh = torch.tanh(x).data.numpy()
23 | y_softplus = F.softplus(x).data.numpy() # there's no softplus in torch
24 | # y_softmax = torch.softmax(x, dim=0).data.numpy() softmax is a special kind of activation function, it is about probability
25 |
26 | # plt to visualize these activation function
27 | plt.figure(1, figsize=(8, 6))
28 | plt.subplot(221)
29 | plt.plot(x_np, y_relu, c='red', label='relu')
30 | plt.ylim((-1, 5))
31 | plt.legend(loc='best')
32 |
33 | plt.subplot(222)
34 | plt.plot(x_np, y_sigmoid, c='red', label='sigmoid')
35 | plt.ylim((-0.2, 1.2))
36 | plt.legend(loc='best')
37 |
38 | plt.subplot(223)
39 | plt.plot(x_np, y_tanh, c='red', label='tanh')
40 | plt.ylim((-1.2, 1.2))
41 | plt.legend(loc='best')
42 |
43 | plt.subplot(224)
44 | plt.plot(x_np, y_softplus, c='red', label='softplus')
45 | plt.ylim((-0.2, 6))
46 | plt.legend(loc='best')
47 |
48 | plt.show()
49 |
--------------------------------------------------------------------------------
/tutorial-contents/301_regression.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import torch.nn.functional as F
11 | import matplotlib.pyplot as plt
12 |
13 | # torch.manual_seed(1) # reproducible
14 |
15 | x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
16 | y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
17 |
18 | # torch can only train on Variable, so convert them to Variable
19 | # The code below is deprecated in Pytorch 0.4. Now, autograd directly supports tensors
20 | # x, y = Variable(x), Variable(y)
21 |
22 | # plt.scatter(x.data.numpy(), y.data.numpy())
23 | # plt.show()
24 |
25 |
26 | class Net(torch.nn.Module):
27 | def __init__(self, n_feature, n_hidden, n_output):
28 | super(Net, self).__init__()
29 | self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
30 | self.predict = torch.nn.Linear(n_hidden, n_output) # output layer
31 |
32 | def forward(self, x):
33 | x = F.relu(self.hidden(x)) # activation function for hidden layer
34 | x = self.predict(x) # linear output
35 | return x
36 |
37 | net = Net(n_feature=1, n_hidden=10, n_output=1) # define the network
38 | print(net) # net architecture
39 |
40 | optimizer = torch.optim.SGD(net.parameters(), lr=0.2)
41 | loss_func = torch.nn.MSELoss() # this is for regression mean squared loss
42 |
43 | plt.ion() # something about plotting
44 |
45 | for t in range(200):
46 | prediction = net(x) # input x and predict based on x
47 |
48 | loss = loss_func(prediction, y) # must be (1. nn output, 2. target)
49 |
50 | optimizer.zero_grad() # clear gradients for next train
51 | loss.backward() # backpropagation, compute gradients
52 | optimizer.step() # apply gradients
53 |
54 | if t % 5 == 0:
55 | # plot and show learning process
56 | plt.cla()
57 | plt.scatter(x.data.numpy(), y.data.numpy())
58 | plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
59 | plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
60 | plt.pause(0.1)
61 |
62 | plt.ioff()
63 | plt.show()
64 |
--------------------------------------------------------------------------------
/tutorial-contents/302_classification.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import torch.nn.functional as F
11 | import matplotlib.pyplot as plt
12 |
13 | # torch.manual_seed(1) # reproducible
14 |
15 | # make fake data
16 | n_data = torch.ones(100, 2)
17 | x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)
18 | y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)
19 | x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)
20 | y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)
21 | x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating
22 | y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer
23 |
24 | # The code below is deprecated in Pytorch 0.4. Now, autograd directly supports tensors
25 | # x, y = Variable(x), Variable(y)
26 |
27 | # plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
28 | # plt.show()
29 |
30 |
31 | class Net(torch.nn.Module):
32 | def __init__(self, n_feature, n_hidden, n_output):
33 | super(Net, self).__init__()
34 | self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
35 | self.out = torch.nn.Linear(n_hidden, n_output) # output layer
36 |
37 | def forward(self, x):
38 | x = F.relu(self.hidden(x)) # activation function for hidden layer
39 | x = self.out(x)
40 | return x
41 |
42 | net = Net(n_feature=2, n_hidden=10, n_output=2) # define the network
43 | print(net) # net architecture
44 |
45 | optimizer = torch.optim.SGD(net.parameters(), lr=0.02)
46 | loss_func = torch.nn.CrossEntropyLoss() # the target label is NOT an one-hotted
47 |
48 | plt.ion() # something about plotting
49 |
50 | for t in range(100):
51 | out = net(x) # input x and predict based on x
52 | loss = loss_func(out, y) # must be (1. nn output, 2. target), the target label is NOT one-hotted
53 |
54 | optimizer.zero_grad() # clear gradients for next train
55 | loss.backward() # backpropagation, compute gradients
56 | optimizer.step() # apply gradients
57 |
58 | if t % 2 == 0:
59 | # plot and show learning process
60 | plt.cla()
61 | prediction = torch.max(out, 1)[1]
62 | pred_y = prediction.data.numpy()
63 | target_y = y.data.numpy()
64 | plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
65 | accuracy = float((pred_y == target_y).astype(int).sum()) / float(target_y.size)
66 | plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
67 | plt.pause(0.1)
68 |
69 | plt.ioff()
70 | plt.show()
71 |
--------------------------------------------------------------------------------
/tutorial-contents/303_build_nn_quickly.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.1.11
7 | """
8 | import torch
9 | import torch.nn.functional as F
10 |
11 |
12 | # replace following class code with an easy sequential network
13 | class Net(torch.nn.Module):
14 | def __init__(self, n_feature, n_hidden, n_output):
15 | super(Net, self).__init__()
16 | self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
17 | self.predict = torch.nn.Linear(n_hidden, n_output) # output layer
18 |
19 | def forward(self, x):
20 | x = F.relu(self.hidden(x)) # activation function for hidden layer
21 | x = self.predict(x) # linear output
22 | return x
23 |
24 | net1 = Net(1, 10, 1)
25 |
26 | # easy and fast way to build your network
27 | net2 = torch.nn.Sequential(
28 | torch.nn.Linear(1, 10),
29 | torch.nn.ReLU(),
30 | torch.nn.Linear(10, 1)
31 | )
32 |
33 |
34 | print(net1) # net1 architecture
35 | """
36 | Net (
37 | (hidden): Linear (1 -> 10)
38 | (predict): Linear (10 -> 1)
39 | )
40 | """
41 |
42 | print(net2) # net2 architecture
43 | """
44 | Sequential (
45 | (0): Linear (1 -> 10)
46 | (1): ReLU ()
47 | (2): Linear (10 -> 1)
48 | )
49 | """
--------------------------------------------------------------------------------
/tutorial-contents/304_save_reload.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import matplotlib.pyplot as plt
11 |
12 | # torch.manual_seed(1) # reproducible
13 |
14 | # fake data
15 | x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
16 | y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
17 |
18 | # The code below is deprecated in Pytorch 0.4. Now, autograd directly supports tensors
19 | # x, y = Variable(x, requires_grad=False), Variable(y, requires_grad=False)
20 |
21 |
22 | def save():
23 | # save net1
24 | net1 = torch.nn.Sequential(
25 | torch.nn.Linear(1, 10),
26 | torch.nn.ReLU(),
27 | torch.nn.Linear(10, 1)
28 | )
29 | optimizer = torch.optim.SGD(net1.parameters(), lr=0.5)
30 | loss_func = torch.nn.MSELoss()
31 |
32 | for t in range(100):
33 | prediction = net1(x)
34 | loss = loss_func(prediction, y)
35 | optimizer.zero_grad()
36 | loss.backward()
37 | optimizer.step()
38 |
39 | # plot result
40 | plt.figure(1, figsize=(10, 3))
41 | plt.subplot(131)
42 | plt.title('Net1')
43 | plt.scatter(x.data.numpy(), y.data.numpy())
44 | plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
45 |
46 | # 2 ways to save the net
47 | torch.save(net1, 'net.pkl') # save entire net
48 | torch.save(net1.state_dict(), 'net_params.pkl') # save only the parameters
49 |
50 |
51 | def restore_net():
52 | # restore entire net1 to net2
53 | net2 = torch.load('net.pkl')
54 | prediction = net2(x)
55 |
56 | # plot result
57 | plt.subplot(132)
58 | plt.title('Net2')
59 | plt.scatter(x.data.numpy(), y.data.numpy())
60 | plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
61 |
62 |
63 | def restore_params():
64 | # restore only the parameters in net1 to net3
65 | net3 = torch.nn.Sequential(
66 | torch.nn.Linear(1, 10),
67 | torch.nn.ReLU(),
68 | torch.nn.Linear(10, 1)
69 | )
70 |
71 | # copy net1's parameters into net3
72 | net3.load_state_dict(torch.load('net_params.pkl'))
73 | prediction = net3(x)
74 |
75 | # plot result
76 | plt.subplot(133)
77 | plt.title('Net3')
78 | plt.scatter(x.data.numpy(), y.data.numpy())
79 | plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
80 | plt.show()
81 |
82 | # save net1
83 | save()
84 |
85 | # restore entire net (may slow)
86 | restore_net()
87 |
88 | # restore only the net parameters
89 | restore_params()
90 |
--------------------------------------------------------------------------------
/tutorial-contents/305_batch_train.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.1.11
7 | """
8 | import torch
9 | import torch.utils.data as Data
10 |
11 | torch.manual_seed(1) # reproducible
12 |
13 | BATCH_SIZE = 5
14 | # BATCH_SIZE = 8
15 |
16 | x = torch.linspace(1, 10, 10) # this is x data (torch tensor)
17 | y = torch.linspace(10, 1, 10) # this is y data (torch tensor)
18 |
19 | torch_dataset = Data.TensorDataset(x, y)
20 | loader = Data.DataLoader(
21 | dataset=torch_dataset, # torch TensorDataset format
22 | batch_size=BATCH_SIZE, # mini batch size
23 | shuffle=True, # random shuffle for training
24 | num_workers=2, # subprocesses for loading data
25 | )
26 |
27 |
28 | def show_batch():
29 | for epoch in range(3): # train entire dataset 3 times
30 | for step, (batch_x, batch_y) in enumerate(loader): # for each training step
31 | # train your data...
32 | print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
33 | batch_x.numpy(), '| batch y: ', batch_y.numpy())
34 |
35 |
36 | if __name__ == '__main__':
37 | show_batch()
38 |
39 |
--------------------------------------------------------------------------------
/tutorial-contents/306_optimizer.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import torch.utils.data as Data
11 | import torch.nn.functional as F
12 | import matplotlib.pyplot as plt
13 |
14 | # torch.manual_seed(1) # reproducible
15 |
16 | LR = 0.01
17 | BATCH_SIZE = 32
18 | EPOCH = 12
19 |
20 | # fake dataset
21 | x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
22 | y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
23 |
24 | # plot dataset
25 | plt.scatter(x.numpy(), y.numpy())
26 | plt.show()
27 |
28 | # put dateset into torch dataset
29 | torch_dataset = Data.TensorDataset(x, y)
30 | loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
31 |
32 |
33 | # default network
34 | class Net(torch.nn.Module):
35 | def __init__(self):
36 | super(Net, self).__init__()
37 | self.hidden = torch.nn.Linear(1, 20) # hidden layer
38 | self.predict = torch.nn.Linear(20, 1) # output layer
39 |
40 | def forward(self, x):
41 | x = F.relu(self.hidden(x)) # activation function for hidden layer
42 | x = self.predict(x) # linear output
43 | return x
44 |
45 | if __name__ == '__main__':
46 | # different nets
47 | net_SGD = Net()
48 | net_Momentum = Net()
49 | net_RMSprop = Net()
50 | net_Adam = Net()
51 | nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
52 |
53 | # different optimizers
54 | opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
55 | opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
56 | opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
57 | opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
58 | optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
59 |
60 | loss_func = torch.nn.MSELoss()
61 | losses_his = [[], [], [], []] # record loss
62 |
63 | # training
64 | for epoch in range(EPOCH):
65 | print('Epoch: ', epoch)
66 | for step, (b_x, b_y) in enumerate(loader): # for each training step
67 | for net, opt, l_his in zip(nets, optimizers, losses_his):
68 | output = net(b_x) # get output for every net
69 | loss = loss_func(output, b_y) # compute loss for every net
70 | opt.zero_grad() # clear gradients for next train
71 | loss.backward() # backpropagation, compute gradients
72 | opt.step() # apply gradients
73 | l_his.append(loss.data.numpy()) # loss recoder
74 |
75 | labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
76 | for i, l_his in enumerate(losses_his):
77 | plt.plot(l_his, label=labels[i])
78 | plt.legend(loc='best')
79 | plt.xlabel('Steps')
80 | plt.ylabel('Loss')
81 | plt.ylim((0, 0.2))
82 | plt.show()
83 |
--------------------------------------------------------------------------------
/tutorial-contents/401_CNN.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | torchvision
8 | matplotlib
9 | """
10 | # library
11 | # standard library
12 | import os
13 |
14 | # third-party library
15 | import torch
16 | import torch.nn as nn
17 | import torch.utils.data as Data
18 | import torchvision
19 | import matplotlib.pyplot as plt
20 |
21 | # torch.manual_seed(1) # reproducible
22 |
23 | # Hyper Parameters
24 | EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
25 | BATCH_SIZE = 50
26 | LR = 0.001 # learning rate
27 | DOWNLOAD_MNIST = False
28 |
29 |
30 | # Mnist digits dataset
31 | if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
32 | # not mnist dir or mnist is empyt dir
33 | DOWNLOAD_MNIST = True
34 |
35 | train_data = torchvision.datasets.MNIST(
36 | root='./mnist/',
37 | train=True, # this is training data
38 | transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
39 | # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
40 | download=DOWNLOAD_MNIST,
41 | )
42 |
43 | # plot one example
44 | print(train_data.train_data.size()) # (60000, 28, 28)
45 | print(train_data.train_labels.size()) # (60000)
46 | plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
47 | plt.title('%i' % train_data.train_labels[0])
48 | plt.show()
49 |
50 | # Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
51 | train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
52 |
53 | # pick 2000 samples to speed up testing
54 | test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
55 | test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
56 | test_y = test_data.test_labels[:2000]
57 |
58 |
59 | class CNN(nn.Module):
60 | def __init__(self):
61 | super(CNN, self).__init__()
62 | self.conv1 = nn.Sequential( # input shape (1, 28, 28)
63 | nn.Conv2d(
64 | in_channels=1, # input height
65 | out_channels=16, # n_filters
66 | kernel_size=5, # filter size
67 | stride=1, # filter movement/step
68 | padding=2, # if want same width and length of this image after Conv2d, padding=(kernel_size-1)/2 if stride=1
69 | ), # output shape (16, 28, 28)
70 | nn.ReLU(), # activation
71 | nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
72 | )
73 | self.conv2 = nn.Sequential( # input shape (16, 14, 14)
74 | nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
75 | nn.ReLU(), # activation
76 | nn.MaxPool2d(2), # output shape (32, 7, 7)
77 | )
78 | self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
79 |
80 | def forward(self, x):
81 | x = self.conv1(x)
82 | x = self.conv2(x)
83 | x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
84 | output = self.out(x)
85 | return output, x # return x for visualization
86 |
87 |
88 | cnn = CNN()
89 | print(cnn) # net architecture
90 |
91 | optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
92 | loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
93 |
94 | # following function (plot_with_labels) is for visualization, can be ignored if not interested
95 | from matplotlib import cm
96 | try: from sklearn.manifold import TSNE; HAS_SK = True
97 | except: HAS_SK = False; print('Please install sklearn for layer visualization')
98 | def plot_with_labels(lowDWeights, labels):
99 | plt.cla()
100 | X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
101 | for x, y, s in zip(X, Y, labels):
102 | c = cm.rainbow(int(255 * s / 9)); plt.text(x, y, s, backgroundcolor=c, fontsize=9)
103 | plt.xlim(X.min(), X.max()); plt.ylim(Y.min(), Y.max()); plt.title('Visualize last layer'); plt.show(); plt.pause(0.01)
104 |
105 | plt.ion()
106 | # training and testing
107 | for epoch in range(EPOCH):
108 | for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
109 |
110 | output = cnn(b_x)[0] # cnn output
111 | loss = loss_func(output, b_y) # cross entropy loss
112 | optimizer.zero_grad() # clear gradients for this training step
113 | loss.backward() # backpropagation, compute gradients
114 | optimizer.step() # apply gradients
115 |
116 | if step % 50 == 0:
117 | test_output, last_layer = cnn(test_x)
118 | pred_y = torch.max(test_output, 1)[1].data.numpy()
119 | accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
120 | print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
121 | if HAS_SK:
122 | # Visualization of trained flatten layer (T-SNE)
123 | tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
124 | plot_only = 500
125 | low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
126 | labels = test_y.numpy()[:plot_only]
127 | plot_with_labels(low_dim_embs, labels)
128 | plt.ioff()
129 |
130 | # print 10 predictions from test data
131 | test_output, _ = cnn(test_x[:10])
132 | pred_y = torch.max(test_output, 1)[1].data.numpy()
133 | print(pred_y, 'prediction number')
134 | print(test_y[:10].numpy(), 'real number')
135 |
--------------------------------------------------------------------------------
/tutorial-contents/402_RNN_classifier.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | torchvision
9 | """
10 | import torch
11 | from torch import nn
12 | import torchvision.datasets as dsets
13 | import torchvision.transforms as transforms
14 | import matplotlib.pyplot as plt
15 |
16 |
17 | # torch.manual_seed(1) # reproducible
18 |
19 | # Hyper Parameters
20 | EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
21 | BATCH_SIZE = 64
22 | TIME_STEP = 28 # rnn time step / image height
23 | INPUT_SIZE = 28 # rnn input size / image width
24 | LR = 0.01 # learning rate
25 | DOWNLOAD_MNIST = True # set to True if haven't download the data
26 |
27 |
28 | # Mnist digital dataset
29 | train_data = dsets.MNIST(
30 | root='./mnist/',
31 | train=True, # this is training data
32 | transform=transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
33 | # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
34 | download=DOWNLOAD_MNIST, # download it if you don't have it
35 | )
36 |
37 | # plot one example
38 | print(train_data.train_data.size()) # (60000, 28, 28)
39 | print(train_data.train_labels.size()) # (60000)
40 | plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
41 | plt.title('%i' % train_data.train_labels[0])
42 | plt.show()
43 |
44 | # Data Loader for easy mini-batch return in training
45 | train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
46 |
47 | # convert test data into Variable, pick 2000 samples to speed up testing
48 | test_data = dsets.MNIST(root='./mnist/', train=False, transform=transforms.ToTensor())
49 | test_x = test_data.test_data.type(torch.FloatTensor)[:2000]/255. # shape (2000, 28, 28) value in range(0,1)
50 | test_y = test_data.test_labels.numpy()[:2000] # covert to numpy array
51 |
52 |
53 | class RNN(nn.Module):
54 | def __init__(self):
55 | super(RNN, self).__init__()
56 |
57 | self.rnn = nn.LSTM( # if use nn.RNN(), it hardly learns
58 | input_size=INPUT_SIZE,
59 | hidden_size=64, # rnn hidden unit
60 | num_layers=1, # number of rnn layer
61 | batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
62 | )
63 |
64 | self.out = nn.Linear(64, 10)
65 |
66 | def forward(self, x):
67 | # x shape (batch, time_step, input_size)
68 | # r_out shape (batch, time_step, output_size)
69 | # h_n shape (n_layers, batch, hidden_size)
70 | # h_c shape (n_layers, batch, hidden_size)
71 | r_out, (h_n, h_c) = self.rnn(x, None) # None represents zero initial hidden state
72 |
73 | # choose r_out at the last time step
74 | out = self.out(r_out[:, -1, :])
75 | return out
76 |
77 |
78 | rnn = RNN()
79 | print(rnn)
80 |
81 | optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
82 | loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
83 |
84 | # training and testing
85 | for epoch in range(EPOCH):
86 | for step, (b_x, b_y) in enumerate(train_loader): # gives batch data
87 | b_x = b_x.view(-1, 28, 28) # reshape x to (batch, time_step, input_size)
88 |
89 | output = rnn(b_x) # rnn output
90 | loss = loss_func(output, b_y) # cross entropy loss
91 | optimizer.zero_grad() # clear gradients for this training step
92 | loss.backward() # backpropagation, compute gradients
93 | optimizer.step() # apply gradients
94 |
95 | if step % 50 == 0:
96 | test_output = rnn(test_x) # (samples, time_step, input_size)
97 | pred_y = torch.max(test_output, 1)[1].data.numpy()
98 | accuracy = float((pred_y == test_y).astype(int).sum()) / float(test_y.size)
99 | print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
100 |
101 | # print 10 predictions from test data
102 | test_output = rnn(test_x[:10].view(-1, 28, 28))
103 | pred_y = torch.max(test_output, 1)[1].data.numpy()
104 | print(pred_y, 'prediction number')
105 | print(test_y[:10], 'real number')
106 |
107 |
--------------------------------------------------------------------------------
/tutorial-contents/403_RNN_regressor.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | numpy
9 | """
10 | import torch
11 | from torch import nn
12 | import numpy as np
13 | import matplotlib.pyplot as plt
14 |
15 | # torch.manual_seed(1) # reproducible
16 |
17 | # Hyper Parameters
18 | TIME_STEP = 10 # rnn time step
19 | INPUT_SIZE = 1 # rnn input size
20 | LR = 0.02 # learning rate
21 |
22 | # show data
23 | steps = np.linspace(0, np.pi*2, 100, dtype=np.float32) # float32 for converting torch FloatTensor
24 | x_np = np.sin(steps)
25 | y_np = np.cos(steps)
26 | plt.plot(steps, y_np, 'r-', label='target (cos)')
27 | plt.plot(steps, x_np, 'b-', label='input (sin)')
28 | plt.legend(loc='best')
29 | plt.show()
30 |
31 |
32 | class RNN(nn.Module):
33 | def __init__(self):
34 | super(RNN, self).__init__()
35 |
36 | self.rnn = nn.RNN(
37 | input_size=INPUT_SIZE,
38 | hidden_size=32, # rnn hidden unit
39 | num_layers=1, # number of rnn layer
40 | batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
41 | )
42 | self.out = nn.Linear(32, 1)
43 |
44 | def forward(self, x, h_state):
45 | # x (batch, time_step, input_size)
46 | # h_state (n_layers, batch, hidden_size)
47 | # r_out (batch, time_step, hidden_size)
48 | r_out, h_state = self.rnn(x, h_state)
49 |
50 | outs = [] # save all predictions
51 | for time_step in range(r_out.size(1)): # calculate output for each time step
52 | outs.append(self.out(r_out[:, time_step, :]))
53 | return torch.stack(outs, dim=1), h_state
54 |
55 | # instead, for simplicity, you can replace above codes by follows
56 | # r_out = r_out.view(-1, 32)
57 | # outs = self.out(r_out)
58 | # outs = outs.view(-1, TIME_STEP, 1)
59 | # return outs, h_state
60 |
61 | # or even simpler, since nn.Linear can accept inputs of any dimension
62 | # and returns outputs with same dimension except for the last
63 | # outs = self.out(r_out)
64 | # return outs
65 |
66 | rnn = RNN()
67 | print(rnn)
68 |
69 | optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
70 | loss_func = nn.MSELoss()
71 |
72 | h_state = None # for initial hidden state
73 |
74 | plt.figure(1, figsize=(12, 5))
75 | plt.ion() # continuously plot
76 |
77 | for step in range(100):
78 | start, end = step * np.pi, (step+1)*np.pi # time range
79 | # use sin predicts cos
80 | steps = np.linspace(start, end, TIME_STEP, dtype=np.float32, endpoint=False) # float32 for converting torch FloatTensor
81 | x_np = np.sin(steps)
82 | y_np = np.cos(steps)
83 |
84 | x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis]) # shape (batch, time_step, input_size)
85 | y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
86 |
87 | prediction, h_state = rnn(x, h_state) # rnn output
88 | # !! next step is important !!
89 | h_state = h_state.data # repack the hidden state, break the connection from last iteration
90 |
91 | loss = loss_func(prediction, y) # calculate loss
92 | optimizer.zero_grad() # clear gradients for this training step
93 | loss.backward() # backpropagation, compute gradients
94 | optimizer.step() # apply gradients
95 |
96 | # plotting
97 | plt.plot(steps, y_np.flatten(), 'r-')
98 | plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
99 | plt.draw(); plt.pause(0.05)
100 |
101 | plt.ioff()
102 | plt.show()
103 |
--------------------------------------------------------------------------------
/tutorial-contents/404_autoencoder.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | numpy
9 | """
10 | import torch
11 | import torch.nn as nn
12 | import torch.utils.data as Data
13 | import torchvision
14 | import matplotlib.pyplot as plt
15 | from mpl_toolkits.mplot3d import Axes3D
16 | from matplotlib import cm
17 | import numpy as np
18 |
19 |
20 | # torch.manual_seed(1) # reproducible
21 |
22 | # Hyper Parameters
23 | EPOCH = 10
24 | BATCH_SIZE = 64
25 | LR = 0.005 # learning rate
26 | DOWNLOAD_MNIST = False
27 | N_TEST_IMG = 5
28 |
29 | # Mnist digits dataset
30 | train_data = torchvision.datasets.MNIST(
31 | root='./mnist/',
32 | train=True, # this is training data
33 | transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
34 | # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
35 | download=DOWNLOAD_MNIST, # download it if you don't have it
36 | )
37 |
38 | # plot one example
39 | print(train_data.train_data.size()) # (60000, 28, 28)
40 | print(train_data.train_labels.size()) # (60000)
41 | plt.imshow(train_data.train_data[2].numpy(), cmap='gray')
42 | plt.title('%i' % train_data.train_labels[2])
43 | plt.show()
44 |
45 | # Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
46 | train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
47 |
48 |
49 | class AutoEncoder(nn.Module):
50 | def __init__(self):
51 | super(AutoEncoder, self).__init__()
52 |
53 | self.encoder = nn.Sequential(
54 | nn.Linear(28*28, 128),
55 | nn.Tanh(),
56 | nn.Linear(128, 64),
57 | nn.Tanh(),
58 | nn.Linear(64, 12),
59 | nn.Tanh(),
60 | nn.Linear(12, 3), # compress to 3 features which can be visualized in plt
61 | )
62 | self.decoder = nn.Sequential(
63 | nn.Linear(3, 12),
64 | nn.Tanh(),
65 | nn.Linear(12, 64),
66 | nn.Tanh(),
67 | nn.Linear(64, 128),
68 | nn.Tanh(),
69 | nn.Linear(128, 28*28),
70 | nn.Sigmoid(), # compress to a range (0, 1)
71 | )
72 |
73 | def forward(self, x):
74 | encoded = self.encoder(x)
75 | decoded = self.decoder(encoded)
76 | return encoded, decoded
77 |
78 |
79 | autoencoder = AutoEncoder()
80 |
81 | optimizer = torch.optim.Adam(autoencoder.parameters(), lr=LR)
82 | loss_func = nn.MSELoss()
83 |
84 | # initialize figure
85 | f, a = plt.subplots(2, N_TEST_IMG, figsize=(5, 2))
86 | plt.ion() # continuously plot
87 |
88 | # original data (first row) for viewing
89 | view_data = train_data.train_data[:N_TEST_IMG].view(-1, 28*28).type(torch.FloatTensor)/255.
90 | for i in range(N_TEST_IMG):
91 | a[0][i].imshow(np.reshape(view_data.data.numpy()[i], (28, 28)), cmap='gray'); a[0][i].set_xticks(()); a[0][i].set_yticks(())
92 |
93 | for epoch in range(EPOCH):
94 | for step, (x, b_label) in enumerate(train_loader):
95 | b_x = x.view(-1, 28*28) # batch x, shape (batch, 28*28)
96 | b_y = x.view(-1, 28*28) # batch y, shape (batch, 28*28)
97 |
98 | encoded, decoded = autoencoder(b_x)
99 |
100 | loss = loss_func(decoded, b_y) # mean square error
101 | optimizer.zero_grad() # clear gradients for this training step
102 | loss.backward() # backpropagation, compute gradients
103 | optimizer.step() # apply gradients
104 |
105 | if step % 100 == 0:
106 | print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy())
107 |
108 | # plotting decoded image (second row)
109 | _, decoded_data = autoencoder(view_data)
110 | for i in range(N_TEST_IMG):
111 | a[1][i].clear()
112 | a[1][i].imshow(np.reshape(decoded_data.data.numpy()[i], (28, 28)), cmap='gray')
113 | a[1][i].set_xticks(()); a[1][i].set_yticks(())
114 | plt.draw(); plt.pause(0.05)
115 |
116 | plt.ioff()
117 | plt.show()
118 |
119 | # visualize in 3D plot
120 | view_data = train_data.train_data[:200].view(-1, 28*28).type(torch.FloatTensor)/255.
121 | encoded_data, _ = autoencoder(view_data)
122 | fig = plt.figure(2); ax = Axes3D(fig)
123 | X, Y, Z = encoded_data.data[:, 0].numpy(), encoded_data.data[:, 1].numpy(), encoded_data.data[:, 2].numpy()
124 | values = train_data.train_labels[:200].numpy()
125 | for x, y, z, s in zip(X, Y, Z, values):
126 | c = cm.rainbow(int(255*s/9)); ax.text(x, y, z, s, backgroundcolor=c)
127 | ax.set_xlim(X.min(), X.max()); ax.set_ylim(Y.min(), Y.max()); ax.set_zlim(Z.min(), Z.max())
128 | plt.show()
129 |
--------------------------------------------------------------------------------
/tutorial-contents/405_DQN_Reinforcement_learning.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 | More about Reinforcement learning: https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/
5 |
6 | Dependencies:
7 | torch: 0.4
8 | gym: 0.8.1
9 | numpy
10 | """
11 | import torch
12 | import torch.nn as nn
13 | import torch.nn.functional as F
14 | import numpy as np
15 | import gym
16 |
17 | # Hyper Parameters
18 | BATCH_SIZE = 32
19 | LR = 0.01 # learning rate
20 | EPSILON = 0.9 # greedy policy
21 | GAMMA = 0.9 # reward discount
22 | TARGET_REPLACE_ITER = 100 # target update frequency
23 | MEMORY_CAPACITY = 2000
24 | env = gym.make('CartPole-v0')
25 | env = env.unwrapped
26 | N_ACTIONS = env.action_space.n
27 | N_STATES = env.observation_space.shape[0]
28 | ENV_A_SHAPE = 0 if isinstance(env.action_space.sample(), int) else env.action_space.sample().shape # to confirm the shape
29 |
30 |
31 | class Net(nn.Module):
32 | def __init__(self, ):
33 | super(Net, self).__init__()
34 | self.fc1 = nn.Linear(N_STATES, 50)
35 | self.fc1.weight.data.normal_(0, 0.1) # initialization
36 | self.out = nn.Linear(50, N_ACTIONS)
37 | self.out.weight.data.normal_(0, 0.1) # initialization
38 |
39 | def forward(self, x):
40 | x = self.fc1(x)
41 | x = F.relu(x)
42 | actions_value = self.out(x)
43 | return actions_value
44 |
45 |
46 | class DQN(object):
47 | def __init__(self):
48 | self.eval_net, self.target_net = Net(), Net()
49 |
50 | self.learn_step_counter = 0 # for target updating
51 | self.memory_counter = 0 # for storing memory
52 | self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # initialize memory
53 | self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR)
54 | self.loss_func = nn.MSELoss()
55 |
56 | def choose_action(self, x):
57 | x = torch.unsqueeze(torch.FloatTensor(x), 0)
58 | # input only one sample
59 | if np.random.uniform() < EPSILON: # greedy
60 | actions_value = self.eval_net.forward(x)
61 | action = torch.max(actions_value, 1)[1].data.numpy()
62 | action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE) # return the argmax index
63 | else: # random
64 | action = np.random.randint(0, N_ACTIONS)
65 | action = action if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE)
66 | return action
67 |
68 | def store_transition(self, s, a, r, s_):
69 | transition = np.hstack((s, [a, r], s_))
70 | # replace the old memory with new memory
71 | index = self.memory_counter % MEMORY_CAPACITY
72 | self.memory[index, :] = transition
73 | self.memory_counter += 1
74 |
75 | def learn(self):
76 | # target parameter update
77 | if self.learn_step_counter % TARGET_REPLACE_ITER == 0:
78 | self.target_net.load_state_dict(self.eval_net.state_dict())
79 | self.learn_step_counter += 1
80 |
81 | # sample batch transitions
82 | sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE)
83 | b_memory = self.memory[sample_index, :]
84 | b_s = torch.FloatTensor(b_memory[:, :N_STATES])
85 | b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int))
86 | b_r = torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2])
87 | b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:])
88 |
89 | # q_eval w.r.t the action in experience
90 | q_eval = self.eval_net(b_s).gather(1, b_a) # shape (batch, 1)
91 | q_next = self.target_net(b_s_).detach() # detach from graph, don't backpropagate
92 | q_target = b_r + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1) # shape (batch, 1)
93 | loss = self.loss_func(q_eval, q_target)
94 |
95 | self.optimizer.zero_grad()
96 | loss.backward()
97 | self.optimizer.step()
98 |
99 | dqn = DQN()
100 |
101 | print('\nCollecting experience...')
102 | for i_episode in range(400):
103 | s = env.reset()
104 | ep_r = 0
105 | while True:
106 | env.render()
107 | a = dqn.choose_action(s)
108 |
109 | # take action
110 | s_, r, done, info = env.step(a)
111 |
112 | # modify the reward
113 | x, x_dot, theta, theta_dot = s_
114 | r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
115 | r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
116 | r = r1 + r2
117 |
118 | dqn.store_transition(s, a, r, s_)
119 |
120 | ep_r += r
121 | if dqn.memory_counter > MEMORY_CAPACITY:
122 | dqn.learn()
123 | if done:
124 | print('Ep: ', i_episode,
125 | '| Ep_r: ', round(ep_r, 2))
126 |
127 | if done:
128 | break
129 | s = s_
--------------------------------------------------------------------------------
/tutorial-contents/406_GAN.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | numpy
8 | matplotlib
9 | """
10 | import torch
11 | import torch.nn as nn
12 | import numpy as np
13 | import matplotlib.pyplot as plt
14 |
15 | # torch.manual_seed(1) # reproducible
16 | # np.random.seed(1)
17 |
18 | # Hyper Parameters
19 | BATCH_SIZE = 64
20 | LR_G = 0.0001 # learning rate for generator
21 | LR_D = 0.0001 # learning rate for discriminator
22 | N_IDEAS = 5 # think of this as number of ideas for generating an art work (Generator)
23 | ART_COMPONENTS = 15 # it could be total point G can draw in the canvas
24 | PAINT_POINTS = np.vstack([np.linspace(-1, 1, ART_COMPONENTS) for _ in range(BATCH_SIZE)])
25 |
26 | # show our beautiful painting range
27 | # plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + 1, c='#74BCFF', lw=3, label='upper bound')
28 | # plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + 0, c='#FF9359', lw=3, label='lower bound')
29 | # plt.legend(loc='upper right')
30 | # plt.show()
31 |
32 |
33 | def artist_works(): # painting from the famous artist (real target)
34 | a = np.random.uniform(1, 2, size=BATCH_SIZE)[:, np.newaxis]
35 | paintings = a * np.power(PAINT_POINTS, 2) + (a-1)
36 | paintings = torch.from_numpy(paintings).float()
37 | return paintings
38 |
39 | G = nn.Sequential( # Generator
40 | nn.Linear(N_IDEAS, 128), # random ideas (could from normal distribution)
41 | nn.ReLU(),
42 | nn.Linear(128, ART_COMPONENTS), # making a painting from these random ideas
43 | )
44 |
45 | D = nn.Sequential( # Discriminator
46 | nn.Linear(ART_COMPONENTS, 128), # receive art work either from the famous artist or a newbie like G
47 | nn.ReLU(),
48 | nn.Linear(128, 1),
49 | nn.Sigmoid(), # tell the probability that the art work is made by artist
50 | )
51 |
52 | opt_D = torch.optim.Adam(D.parameters(), lr=LR_D)
53 | opt_G = torch.optim.Adam(G.parameters(), lr=LR_G)
54 |
55 | plt.ion() # something about continuous plotting
56 |
57 | for step in range(10000):
58 | artist_paintings = artist_works() # real painting from artist
59 | G_ideas = torch.randn(BATCH_SIZE, N_IDEAS, requires_grad=True) # random ideas\n
60 | G_paintings = G(G_ideas) # fake painting from G (random ideas)
61 | prob_artist1 = D(G_paintings) # D try to reduce this prob
62 | G_loss = torch.mean(torch.log(1. - prob_artist1))
63 | opt_G.zero_grad()
64 | G_loss.backward()
65 | opt_G.step()
66 |
67 | prob_artist0 = D(artist_paintings) # D try to increase this prob
68 | prob_artist1 = D(G_paintings.detach()) # D try to reduce this prob
69 | D_loss = - torch.mean(torch.log(prob_artist0) + torch.log(1. - prob_artist1))
70 | opt_D.zero_grad()
71 | D_loss.backward(retain_graph=True) # reusing computational graph
72 | opt_D.step()
73 |
74 | if step % 50 == 0: # plotting
75 | plt.cla()
76 | plt.plot(PAINT_POINTS[0], G_paintings.data.numpy()[0], c='#4AD631', lw=3, label='Generated painting',)
77 | plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + 1, c='#74BCFF', lw=3, label='upper bound')
78 | plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + 0, c='#FF9359', lw=3, label='lower bound')
79 | plt.text(-.5, 2.3, 'D accuracy=%.2f (0.5 for D to converge)' % prob_artist0.data.numpy().mean(), fontdict={'size': 13})
80 | plt.text(-.5, 2, 'D score= %.2f (-1.38 for G to converge)' % -D_loss.data.numpy(), fontdict={'size': 13})
81 | plt.ylim((0, 3));plt.legend(loc='upper right', fontsize=10);plt.draw();plt.pause(0.01)
82 |
83 | plt.ioff()
84 | plt.show()
--------------------------------------------------------------------------------
/tutorial-contents/406_conditional_GAN.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | numpy
8 | matplotlib
9 | """
10 | import torch
11 | import torch.nn as nn
12 | import numpy as np
13 | import matplotlib.pyplot as plt
14 |
15 | # torch.manual_seed(1) # reproducible
16 | # np.random.seed(1)
17 |
18 | # Hyper Parameters
19 | BATCH_SIZE = 64
20 | LR_G = 0.0001 # learning rate for generator
21 | LR_D = 0.0001 # learning rate for discriminator
22 | N_IDEAS = 5 # think of this as number of ideas for generating an art work (Generator)
23 | ART_COMPONENTS = 15 # it could be total point G can draw in the canvas
24 | PAINT_POINTS = np.vstack([np.linspace(-1, 1, ART_COMPONENTS) for _ in range(BATCH_SIZE)])
25 |
26 | # show our beautiful painting range
27 | # plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + 1, c='#74BCFF', lw=3, label='upper bound')
28 | # plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + 0, c='#FF9359', lw=3, label='lower bound')
29 | # plt.legend(loc='upper right')
30 | # plt.show()
31 |
32 |
33 | def artist_works_with_labels(): # painting from the famous artist (real target)
34 | a = np.random.uniform(1, 2, size=BATCH_SIZE)[:, np.newaxis]
35 | paintings = a * np.power(PAINT_POINTS, 2) + (a-1)
36 | labels = (a-1) > 0.5 # upper paintings (1), lower paintings (0), two classes
37 | paintings = torch.from_numpy(paintings).float()
38 | labels = torch.from_numpy(labels.astype(np.float32))
39 | return paintings, labels
40 |
41 |
42 | G = nn.Sequential( # Generator
43 | nn.Linear(N_IDEAS+1, 128), # random ideas (could from normal distribution) + class label
44 | nn.ReLU(),
45 | nn.Linear(128, ART_COMPONENTS), # making a painting from these random ideas
46 | )
47 |
48 | D = nn.Sequential( # Discriminator
49 | nn.Linear(ART_COMPONENTS+1, 128), # receive art work either from the famous artist or a newbie like G with label
50 | nn.ReLU(),
51 | nn.Linear(128, 1),
52 | nn.Sigmoid(), # tell the probability that the art work is made by artist
53 | )
54 |
55 | opt_D = torch.optim.Adam(D.parameters(), lr=LR_D)
56 | opt_G = torch.optim.Adam(G.parameters(), lr=LR_G)
57 |
58 | plt.ion() # something about continuous plotting
59 |
60 | for step in range(10000):
61 | artist_paintings, labels = artist_works_with_labels() # real painting, label from artist
62 | G_ideas = torch.randn(BATCH_SIZE, N_IDEAS) # random ideas
63 | G_inputs = torch.cat((G_ideas, labels), 1) # ideas with labels
64 | G_paintings = G(G_inputs) # fake painting w.r.t label from G
65 |
66 | D_inputs0 = torch.cat((artist_paintings, labels), 1) # all have their labels
67 | D_inputs1 = torch.cat((G_paintings, labels), 1)
68 | prob_artist0 = D(D_inputs0) # D try to increase this prob
69 | prob_artist1 = D(D_inputs1) # D try to reduce this prob
70 |
71 | D_score0 = torch.log(prob_artist0) # maximise this for D
72 | D_score1 = torch.log(1. - prob_artist1) # maximise this for D
73 | D_loss = - torch.mean(D_score0 + D_score1) # minimise the negative of both two above for D
74 | G_loss = torch.mean(D_score1) # minimise D score w.r.t G
75 |
76 | opt_D.zero_grad()
77 | D_loss.backward(retain_graph=True) # reusing computational graph
78 | opt_D.step()
79 |
80 | opt_G.zero_grad()
81 | G_loss.backward()
82 | opt_G.step()
83 |
84 | if step % 200 == 0: # plotting
85 | plt.cla()
86 | plt.plot(PAINT_POINTS[0], G_paintings.data.numpy()[0], c='#4AD631', lw=3, label='Generated painting',)
87 | bound = [0, 0.5] if labels.data[0, 0] == 0 else [0.5, 1]
88 | plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + bound[1], c='#74BCFF', lw=3, label='upper bound')
89 | plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + bound[0], c='#FF9359', lw=3, label='lower bound')
90 | plt.text(-.5, 2.3, 'D accuracy=%.2f (0.5 for D to converge)' % prob_artist0.data.numpy().mean(), fontdict={'size': 13})
91 | plt.text(-.5, 2, 'D score= %.2f (-1.38 for G to converge)' % -D_loss.data.numpy(), fontdict={'size': 13})
92 | plt.text(-.5, 1.7, 'Class = %i' % int(labels.data[0, 0]), fontdict={'size': 13})
93 | plt.ylim((0, 3));plt.legend(loc='upper right', fontsize=10);plt.draw();plt.pause(0.1)
94 |
95 | plt.ioff()
96 | plt.show()
97 |
98 | # plot a generated painting for upper class
99 | z = torch.randn(1, N_IDEAS)
100 | label = torch.FloatTensor([[1.]]) # for upper class
101 | G_inputs = torch.cat((z, label), 1)
102 | G_paintings = G(G_inputs)
103 | plt.plot(PAINT_POINTS[0], G_paintings.data.numpy()[0], c='#4AD631', lw=3, label='G painting for upper class',)
104 | plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + bound[1], c='#74BCFF', lw=3, label='upper bound (class 1)')
105 | plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + bound[0], c='#FF9359', lw=3, label='lower bound (class 1)')
106 | plt.ylim((0, 3));plt.legend(loc='upper right', fontsize=10);plt.show()
--------------------------------------------------------------------------------
/tutorial-contents/501_why_torch_dynamic_graph.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | numpy
9 | """
10 | import torch
11 | from torch import nn
12 | import numpy as np
13 | import matplotlib.pyplot as plt
14 |
15 | # torch.manual_seed(1) # reproducible
16 |
17 | # Hyper Parameters
18 | INPUT_SIZE = 1 # rnn input size / image width
19 | LR = 0.02 # learning rate
20 |
21 |
22 | class RNN(nn.Module):
23 | def __init__(self):
24 | super(RNN, self).__init__()
25 |
26 | self.rnn = nn.RNN(
27 | input_size=1,
28 | hidden_size=32, # rnn hidden unit
29 | num_layers=1, # number of rnn layer
30 | batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
31 | )
32 | self.out = nn.Linear(32, 1)
33 |
34 | def forward(self, x, h_state):
35 | # x (batch, time_step, input_size)
36 | # h_state (n_layers, batch, hidden_size)
37 | # r_out (batch, time_step, output_size)
38 | r_out, h_state = self.rnn(x, h_state)
39 |
40 | outs = [] # this is where you can find torch is dynamic
41 | for time_step in range(r_out.size(1)): # calculate output for each time step
42 | outs.append(self.out(r_out[:, time_step, :]))
43 | return torch.stack(outs, dim=1), h_state
44 |
45 |
46 | rnn = RNN()
47 | print(rnn)
48 |
49 | optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
50 | loss_func = nn.MSELoss() # the target label is not one-hotted
51 |
52 | h_state = None # for initial hidden state
53 |
54 | plt.figure(1, figsize=(12, 5))
55 | plt.ion() # continuously plot
56 |
57 | ######################## Below is different #########################
58 |
59 | ################ static time steps ##########
60 | # for step in range(60):
61 | # start, end = step * np.pi, (step+1)*np.pi # time steps
62 | # # use sin predicts cos
63 | # steps = np.linspace(start, end, 10, dtype=np.float32)
64 |
65 | ################ dynamic time steps #########
66 | step = 0
67 | for i in range(60):
68 | dynamic_steps = np.random.randint(1, 4) # has random time steps
69 | start, end = step * np.pi, (step + dynamic_steps) * np.pi # different time steps length
70 | step += dynamic_steps
71 |
72 | # use sin predicts cos
73 | steps = np.linspace(start, end, 10 * dynamic_steps, dtype=np.float32)
74 |
75 | ####################### Above is different ###########################
76 |
77 | print(len(steps)) # print how many time step feed to RNN
78 |
79 | x_np = np.sin(steps) # float32 for converting torch FloatTensor
80 | y_np = np.cos(steps)
81 |
82 | x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis]) # shape (batch, time_step, input_size)
83 | y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
84 |
85 | prediction, h_state = rnn(x, h_state) # rnn output
86 | # !! next step is important !!
87 | h_state = h_state.data # repack the hidden state, break the connection from last iteration
88 |
89 | loss = loss_func(prediction, y) # cross entropy loss
90 | optimizer.zero_grad() # clear gradients for this training step
91 | loss.backward() # backpropagation, compute gradients
92 | optimizer.step() # apply gradients
93 |
94 | # plotting
95 | plt.plot(steps, y_np.flatten(), 'r-')
96 | plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
97 | plt.draw()
98 | plt.pause(0.05)
99 |
100 | plt.ioff()
101 | plt.show()
102 |
--------------------------------------------------------------------------------
/tutorial-contents/502_GPU.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | torchvision
8 | """
9 | import torch
10 | import torch.nn as nn
11 | import torch.utils.data as Data
12 | import torchvision
13 |
14 | # torch.manual_seed(1)
15 |
16 | EPOCH = 1
17 | BATCH_SIZE = 50
18 | LR = 0.001
19 | DOWNLOAD_MNIST = False
20 |
21 | train_data = torchvision.datasets.MNIST(root='./mnist/', train=True, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST,)
22 | train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
23 |
24 | test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
25 |
26 | # !!!!!!!! Change in here !!!!!!!!! #
27 | test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000].cuda()/255. # Tensor on GPU
28 | test_y = test_data.test_labels[:2000].cuda()
29 |
30 |
31 | class CNN(nn.Module):
32 | def __init__(self):
33 | super(CNN, self).__init__()
34 | self.conv1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2,),
35 | nn.ReLU(), nn.MaxPool2d(kernel_size=2),)
36 | self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(2),)
37 | self.out = nn.Linear(32 * 7 * 7, 10)
38 |
39 | def forward(self, x):
40 | x = self.conv1(x)
41 | x = self.conv2(x)
42 | x = x.view(x.size(0), -1)
43 | output = self.out(x)
44 | return output
45 |
46 | cnn = CNN()
47 |
48 | # !!!!!!!! Change in here !!!!!!!!! #
49 | cnn.cuda() # Moves all model parameters and buffers to the GPU.
50 |
51 | optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
52 | loss_func = nn.CrossEntropyLoss()
53 |
54 | for epoch in range(EPOCH):
55 | for step, (x, y) in enumerate(train_loader):
56 |
57 | # !!!!!!!! Change in here !!!!!!!!! #
58 | b_x = x.cuda() # Tensor on GPU
59 | b_y = y.cuda() # Tensor on GPU
60 |
61 | output = cnn(b_x)
62 | loss = loss_func(output, b_y)
63 | optimizer.zero_grad()
64 | loss.backward()
65 | optimizer.step()
66 |
67 | if step % 50 == 0:
68 | test_output = cnn(test_x)
69 |
70 | # !!!!!!!! Change in here !!!!!!!!! #
71 | pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
72 |
73 | accuracy = torch.sum(pred_y == test_y).type(torch.FloatTensor) / test_y.size(0)
74 | print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.cpu().numpy(), '| test accuracy: %.2f' % accuracy)
75 |
76 |
77 | test_output = cnn(test_x[:10])
78 |
79 | # !!!!!!!! Change in here !!!!!!!!! #
80 | pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
81 |
82 | print(pred_y, 'prediction number')
83 | print(test_y[:10], 'real number')
84 |
--------------------------------------------------------------------------------
/tutorial-contents/503_dropout.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import matplotlib.pyplot as plt
11 |
12 | # torch.manual_seed(1) # reproducible
13 |
14 | N_SAMPLES = 20
15 | N_HIDDEN = 300
16 |
17 | # training data
18 | x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
19 | y = x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
20 |
21 | # test data
22 | test_x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
23 | test_y = test_x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
24 |
25 | # show data
26 | plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
27 | plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
28 | plt.legend(loc='upper left')
29 | plt.ylim((-2.5, 2.5))
30 | plt.show()
31 |
32 | net_overfitting = torch.nn.Sequential(
33 | torch.nn.Linear(1, N_HIDDEN),
34 | torch.nn.ReLU(),
35 | torch.nn.Linear(N_HIDDEN, N_HIDDEN),
36 | torch.nn.ReLU(),
37 | torch.nn.Linear(N_HIDDEN, 1),
38 | )
39 |
40 | net_dropped = torch.nn.Sequential(
41 | torch.nn.Linear(1, N_HIDDEN),
42 | torch.nn.Dropout(0.5), # drop 50% of the neuron
43 | torch.nn.ReLU(),
44 | torch.nn.Linear(N_HIDDEN, N_HIDDEN),
45 | torch.nn.Dropout(0.5), # drop 50% of the neuron
46 | torch.nn.ReLU(),
47 | torch.nn.Linear(N_HIDDEN, 1),
48 | )
49 |
50 | print(net_overfitting) # net architecture
51 | print(net_dropped)
52 |
53 | optimizer_ofit = torch.optim.Adam(net_overfitting.parameters(), lr=0.01)
54 | optimizer_drop = torch.optim.Adam(net_dropped.parameters(), lr=0.01)
55 | loss_func = torch.nn.MSELoss()
56 |
57 | plt.ion() # something about plotting
58 |
59 | for t in range(500):
60 | pred_ofit = net_overfitting(x)
61 | pred_drop = net_dropped(x)
62 | loss_ofit = loss_func(pred_ofit, y)
63 | loss_drop = loss_func(pred_drop, y)
64 |
65 | optimizer_ofit.zero_grad()
66 | optimizer_drop.zero_grad()
67 | loss_ofit.backward()
68 | loss_drop.backward()
69 | optimizer_ofit.step()
70 | optimizer_drop.step()
71 |
72 | if t % 10 == 0:
73 | # change to eval mode in order to fix drop out effect
74 | net_overfitting.eval()
75 | net_dropped.eval() # parameters for dropout differ from train mode
76 |
77 | # plotting
78 | plt.cla()
79 | test_pred_ofit = net_overfitting(test_x)
80 | test_pred_drop = net_dropped(test_x)
81 | plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.3, label='train')
82 | plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.3, label='test')
83 | plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(), 'r-', lw=3, label='overfitting')
84 | plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(), 'b--', lw=3, label='dropout(50%)')
85 | plt.text(0, -1.2, 'overfitting loss=%.4f' % loss_func(test_pred_ofit, test_y).data.numpy(), fontdict={'size': 20, 'color': 'red'})
86 | plt.text(0, -1.5, 'dropout loss=%.4f' % loss_func(test_pred_drop, test_y).data.numpy(), fontdict={'size': 20, 'color': 'blue'})
87 | plt.legend(loc='upper left'); plt.ylim((-2.5, 2.5));plt.pause(0.1)
88 |
89 | # change back to train mode
90 | net_overfitting.train()
91 | net_dropped.train()
92 |
93 | plt.ioff()
94 | plt.show()
--------------------------------------------------------------------------------
/tutorial-contents/504_batch_normalization.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | numpy
9 | """
10 | import torch
11 | from torch import nn
12 | from torch.nn import init
13 | import torch.utils.data as Data
14 | import matplotlib.pyplot as plt
15 | import numpy as np
16 |
17 | # torch.manual_seed(1) # reproducible
18 | # np.random.seed(1)
19 |
20 | # Hyper parameters
21 | N_SAMPLES = 2000
22 | BATCH_SIZE = 64
23 | EPOCH = 12
24 | LR = 0.03
25 | N_HIDDEN = 8
26 | ACTIVATION = torch.tanh
27 | B_INIT = -0.2 # use a bad bias constant initializer
28 |
29 | # training data
30 | x = np.linspace(-7, 10, N_SAMPLES)[:, np.newaxis]
31 | noise = np.random.normal(0, 2, x.shape)
32 | y = np.square(x) - 5 + noise
33 |
34 | # test data
35 | test_x = np.linspace(-7, 10, 200)[:, np.newaxis]
36 | noise = np.random.normal(0, 2, test_x.shape)
37 | test_y = np.square(test_x) - 5 + noise
38 |
39 | train_x, train_y = torch.from_numpy(x).float(), torch.from_numpy(y).float()
40 | test_x = torch.from_numpy(test_x).float()
41 | test_y = torch.from_numpy(test_y).float()
42 |
43 | train_dataset = Data.TensorDataset(train_x, train_y)
44 | train_loader = Data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
45 |
46 | # show data
47 | plt.scatter(train_x.numpy(), train_y.numpy(), c='#FF9359', s=50, alpha=0.2, label='train')
48 | plt.legend(loc='upper left')
49 |
50 |
51 | class Net(nn.Module):
52 | def __init__(self, batch_normalization=False):
53 | super(Net, self).__init__()
54 | self.do_bn = batch_normalization
55 | self.fcs = []
56 | self.bns = []
57 | self.bn_input = nn.BatchNorm1d(1, momentum=0.5) # for input data
58 |
59 | for i in range(N_HIDDEN): # build hidden layers and BN layers
60 | input_size = 1 if i == 0 else 10
61 | fc = nn.Linear(input_size, 10)
62 | setattr(self, 'fc%i' % i, fc) # IMPORTANT set layer to the Module
63 | self._set_init(fc) # parameters initialization
64 | self.fcs.append(fc)
65 | if self.do_bn:
66 | bn = nn.BatchNorm1d(10, momentum=0.5)
67 | setattr(self, 'bn%i' % i, bn) # IMPORTANT set layer to the Module
68 | self.bns.append(bn)
69 |
70 | self.predict = nn.Linear(10, 1) # output layer
71 | self._set_init(self.predict) # parameters initialization
72 |
73 | def _set_init(self, layer):
74 | init.normal_(layer.weight, mean=0., std=.1)
75 | init.constant_(layer.bias, B_INIT)
76 |
77 | def forward(self, x):
78 | pre_activation = [x]
79 | if self.do_bn: x = self.bn_input(x) # input batch normalization
80 | layer_input = [x]
81 | for i in range(N_HIDDEN):
82 | x = self.fcs[i](x)
83 | pre_activation.append(x)
84 | if self.do_bn: x = self.bns[i](x) # batch normalization
85 | x = ACTIVATION(x)
86 | layer_input.append(x)
87 | out = self.predict(x)
88 | return out, layer_input, pre_activation
89 |
90 | nets = [Net(batch_normalization=False), Net(batch_normalization=True)]
91 |
92 | # print(*nets) # print net architecture
93 |
94 | opts = [torch.optim.Adam(net.parameters(), lr=LR) for net in nets]
95 |
96 | loss_func = torch.nn.MSELoss()
97 |
98 |
99 | def plot_histogram(l_in, l_in_bn, pre_ac, pre_ac_bn):
100 | for i, (ax_pa, ax_pa_bn, ax, ax_bn) in enumerate(zip(axs[0, :], axs[1, :], axs[2, :], axs[3, :])):
101 | [a.clear() for a in [ax_pa, ax_pa_bn, ax, ax_bn]]
102 | if i == 0:
103 | p_range = (-7, 10);the_range = (-7, 10)
104 | else:
105 | p_range = (-4, 4);the_range = (-1, 1)
106 | ax_pa.set_title('L' + str(i))
107 | ax_pa.hist(pre_ac[i].data.numpy().ravel(), bins=10, range=p_range, color='#FF9359', alpha=0.5);ax_pa_bn.hist(pre_ac_bn[i].data.numpy().ravel(), bins=10, range=p_range, color='#74BCFF', alpha=0.5)
108 | ax.hist(l_in[i].data.numpy().ravel(), bins=10, range=the_range, color='#FF9359');ax_bn.hist(l_in_bn[i].data.numpy().ravel(), bins=10, range=the_range, color='#74BCFF')
109 | for a in [ax_pa, ax, ax_pa_bn, ax_bn]: a.set_yticks(());a.set_xticks(())
110 | ax_pa_bn.set_xticks(p_range);ax_bn.set_xticks(the_range)
111 | axs[0, 0].set_ylabel('PreAct');axs[1, 0].set_ylabel('BN PreAct');axs[2, 0].set_ylabel('Act');axs[3, 0].set_ylabel('BN Act')
112 | plt.pause(0.01)
113 |
114 |
115 | if __name__ == "__main__":
116 | f, axs = plt.subplots(4, N_HIDDEN + 1, figsize=(10, 5))
117 | plt.ion() # something about plotting
118 | plt.show()
119 |
120 | # training
121 | losses = [[], []] # recode loss for two networks
122 |
123 | for epoch in range(EPOCH):
124 | print('Epoch: ', epoch)
125 | layer_inputs, pre_acts = [], []
126 | for net, l in zip(nets, losses):
127 | net.eval() # set eval mode to fix moving_mean and moving_var
128 | pred, layer_input, pre_act = net(test_x)
129 | l.append(loss_func(pred, test_y).data.item())
130 | layer_inputs.append(layer_input)
131 | pre_acts.append(pre_act)
132 | net.train() # free moving_mean and moving_var
133 | plot_histogram(*layer_inputs, *pre_acts) # plot histogram
134 |
135 | for step, (b_x, b_y) in enumerate(train_loader):
136 | for net, opt in zip(nets, opts): # train for each network
137 | pred, _, _ = net(b_x)
138 | loss = loss_func(pred, b_y)
139 | opt.zero_grad()
140 | loss.backward()
141 | opt.step() # it will also learns the parameters in Batch Normalization
142 |
143 | plt.ioff()
144 |
145 | # plot training loss
146 | plt.figure(2)
147 | plt.plot(losses[0], c='#FF9359', lw=3, label='Original')
148 | plt.plot(losses[1], c='#74BCFF', lw=3, label='Batch Normalization')
149 | plt.xlabel('step');plt.ylabel('test loss');plt.ylim((0, 2000));plt.legend(loc='best')
150 |
151 | # evaluation
152 | # set net to eval mode to freeze the parameters in batch normalization layers
153 | [net.eval() for net in nets] # set eval mode to fix moving_mean and moving_var
154 | preds = [net(test_x)[0] for net in nets]
155 | plt.figure(3)
156 | plt.plot(test_x.data.numpy(), preds[0].data.numpy(), c='#FF9359', lw=4, label='Original')
157 | plt.plot(test_x.data.numpy(), preds[1].data.numpy(), c='#74BCFF', lw=4, label='Batch Normalization')
158 | plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='r', s=50, alpha=0.2, label='train')
159 | plt.legend(loc='best')
160 | plt.show()
161 |
--------------------------------------------------------------------------------
/tutorial-contents/mnist/processed/test.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents/mnist/processed/test.pt
--------------------------------------------------------------------------------
/tutorial-contents/mnist/processed/training.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents/mnist/processed/training.pt
--------------------------------------------------------------------------------
/tutorial-contents/mnist/raw/t10k-images-idx3-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents/mnist/raw/t10k-images-idx3-ubyte
--------------------------------------------------------------------------------
/tutorial-contents/mnist/raw/t10k-labels-idx1-ubyte:
--------------------------------------------------------------------------------
1 | ������'�������� � �� ��� ��� ������������������������������������� ��� ���������� ���� ������������� ������ ���� �� ���� ���� ������ ������������������������ ��������������������������������� ������� ������������ �� �� � �������������������� ����� ���������� ����������� �������� ������ �� ������� ���������������������� ���� � ������������� ���������������������� ����������������������������� ���� ������������������� �� ���� ��� ������� ������������� ����� ���������������� ������� � ����� ������� ���� ������������������� �������� ��������������������������� � � ������������ ����������������� ���� ���������������� ���������� �� ��� ���� ���������������������� �������� � ���� �� ������������������������ �������������������������� ������������������������ ������������� �������������� ������������������������ ������������������� ���������������������������� ����������� ������� ���������� ������������ ������ �������������� ������������������������� ������� ��� ������������������������� ������ ���� ������� ������������������������������� �� ��������� ���� ����������������� ���� � � ������������ � � ���������������������� ��������������������� ������������ ����������������� �������� ������������������������ ���������� ��� �������������� ������� ��������������������� ���� ��������������������� ��� � ���������� ���� ��������������� ������������������������������������ ���� ���������� ����������������� �� ���� ���� ����� ��� ��������� �� �� ������������������������� ���� ����� �������� ������ ��� ������������������� ������������ ������� ���� ���������������������������������� � ������������������������ ���� ��� �������� ���� � ������ ���������� � �������������������������� � ����������� ���� ����������������� ���������� � ����������������������������������� ����� ���� ������� ���������� �������� ��� ������������������������� � ��������������� ��� ������� ������������ ������ �� � ��������������������������������������������� ����������� �������������� ������������ ����� ���������� ���� ���� ����������������������������� ���� ������������� ������������������� ��������������������������������������� ����������������� ������������� ������������������� ������� ������ ��������������� ��� ���������� ���� ����������� ����� ������ � ��� ���������� ����������������� ���������������� �� ������ �� ����������������� �� ��������������� ������������������ ������ ������������������ ������� ����� ����� ����������� ���� ���� ������� ��������������� ���� �������������� �� ������������������ ����������� ��������� ����� ��� ��������������������� ����������� �� ��� ������������� ����������������������������� ��� ���������� ������������������������ ����������� ������ � � ����������������������� �������������� ���� � ������������ ���� �������� ����������� ���������� ������������������� �������������������������������� �������� �� ���� ������ ���� ������� �������� ��������������� ������� ������ �� �� ���� ���� � ���������������� ����� � ������ ����� ��� ����������������� ��� � ������������������������� ������ �������������� ��� �������������� ����������������������������������������������������������������������� � ���������� ���� �� ��������������������� ��������� ��������������������������������������� �������������������������������������������� �������������������������������������������������� ������������������������������ ��������������� � ���� � ��������� ������ �������������� �������������������������������� ������ ���� ���� ���� � ����� ��������� � �� ������������������ �� �������� �������������� ��������������������������������� ���� ���� �������������������� ��������������������������������������������� � �������������������� ����� ��������������� � ���� ������ ������������������������������� ��� ���������������������� ������� ������ ��������������������� ��������� �������� � ������� ����� � � ������� �� � ���� � �� �� � �������������������������������� � ���������������������� ��������������� �� ���������� �� ������ ������ �������� ����� ������������� ��������� ������ ������������������������������ ��������� ���� � ����� ��������� ���������� ������ ���� �������� ���������� ��� ���� ���������� ������� ������������� ����������� �� ���������� ���������� � �� ���� ����������� � ������������ ������� �� �� ����� ��� � ������� ���� � �� � ��� ������� ���������� ������������� ���� ����� ������������� ��������������������� � � ������ ������ ��������� ������� ��������� ������������������������ �������� ���������� � �� ����� ���������������������� ��������������� �� � ��� ��������� ������������� ������ ����������������� ����� ���������������� ���������� ��� ���������� �� � ������� ����� � �������� ������� ���� ���������������������������� ���������������� �������� ������� ���������������� �������� ��� ����������������������� ����������� ���� �� �� ��������� ����������������� ��������� ���������������� �������� ������� ������������������������� � ��������������� ��� ������ ������������ ����������� ������ ����� � ���� ��� �� ������������ ������� ��������� ��������� �� ������ ������������������� ����� ����������������������� ���� � ������ ������������������� ����������������� ��������������������������� �������� ������������ �������� ���� �������������� ����� ��������� ��������� ��������� ����������� ��� ����������������� ���������� ������� �������������������� � � �������� � ��������������� ��������� ��������� ���� ����������������� �������� ���������������������������������� ����������� ������������������� ��� ��������� �������� ������������������ ��������� ���� � ���� �������������� ��������� ��������� ���� ����������� ����� ������������������������� ���������� �������������������� � ����������� ���������� ���������������������� �� ����������������������� �� �� �� ��������� ���� ������� ����������������������� ������������������ ����������� � ���������������������� �� ���������� ���������� ��������������������� ��������� ��������� ������ �� ����� ������������������ ��� ��������������������� ��������� ������ ������� ������� ��������������� ��������� ��������� �������������������� ����������� � ������������������������������ �������� � ��� ���������������� ��������� ��������� ��� ������ ������ � ���� ����������� � ���������������������������������������������������� �������������� ��������������������������������������������������������� ���������������� ������ ������� � ���� ��� � ������������� ������ ������� ����������������������������������� �������� �������� � ��� ������� ��� ����������������������������������� ���� �� �� �������������������� ��������������� � ���������������� ���� ��������� ������� ���� � ������������ ���������� ��������� ����������������� ������� ��������������������� ������ ������������������������ ����� ����� �� ����� ������������� ��������� ��������� ������������������������������������������ ���������������� ������ ������� � ���� ��� � �� ���������������� ��������� ��������� ���������� ������������ ��� ��� ������� � ��������� ���������������� ����������������� ���������������� ��������� ��������� ������� ����� ���������� ���������� ��������� ��� ��� ����������� ������������������������� ������� ���������������� ������������������������ �� �������� ����� �� ������� � ��������������������� ��������� ��������� ������������������� ��� ������������� ���������� ��������� �� ���������������� �� � � ����������������������������������������� �������������������������������� �� � ������ ��������������� � ����� �� ��������������� ��������� ��������� ��������������������� ���� �������� ������� ������� ��� � ��������������������� ������� ��������� ����� ��������� ��������������������������� � �������������� �� ������ ���������������������������� ��������� ��������� ������������ ���������������� �������� ��� ������� ����� ������������� �������� ���������������� �������� �� ������ ��������� ������� �� ����������������������������������� ���������� ��������� ��������� � �������������������������� ��������� ��� ���������� ���������� ��������������� �������� ������������ ��������� ������� �������� ������� ������� ���������������� ��������� ��������� ��� ������������������������������ � ���������������������� �� �� ������������� �� ������������������� �������� ������� ������ ������������� ��������� �������������������� �� ��������� � ����������������������� ������������ � �������� �������������������� ����������������� ��� ���� ���� �������������������� ��������� ��������� � ����������������������� � ���������������� ���������� �� ������������������� �������������������������������� �� �� �� ����������������������� ���������������� � �������������������� ������ ��������� ��������� ��������� ���� ����������� ����� �������������������������� ���������� ������������������ � ����������� ���������� ��������� ��������� ����������� � ���� ����������������������������������� ���������� ��� � ����� ������������� ������� ���� � ������������� ��� � ������ �������������� ���������������� ��� ������������������������ �� � ������������������������� �� ����������� ��������� ��������� ��� ����������������������������������������������� � �������� ����������� ���� ����������������� ��������� ������� ������� � � �������������������������� ���� � � ���������������� �������������� ���� ����� ������������������� ������������������������������������� ���� ������������� ��������� ���������� ������ ��� ������� ������ �������� ��������������������������������� ���� ���������� ������������� ��������� ��������� ������������ �������� ���� �������� ������� �������� �������� ������ ���������������������� ��������� ����������������� ��� ���������������� �������� ������� ��������������� �������� ����������� ��������� ��������� ������ ������������������������� � �������������� ���������������������� ���������������� ��� ������������� ������������ ��������������������������������� ��������� ���������������� ����� ������� ������������ ��������������������������� ������������������ �������
--------------------------------------------------------------------------------
/tutorial-contents/mnist/raw/train-images-idx3-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents/mnist/raw/train-images-idx3-ubyte
--------------------------------------------------------------------------------
/tutorial-contents/mnist/raw/train-labels-idx1-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents/mnist/raw/train-labels-idx1-ubyte
--------------------------------------------------------------------------------
95 |
96 |
97 | # Donation
98 |
99 | *If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*
100 |
101 |
108 |
109 |
--------------------------------------------------------------------------------
/logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/logo.png
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/201_torch_numpy.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 201 Torch and Numpy\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11\n",
14 | "* numpy\n",
15 | "\n",
16 | "Details about math operation in torch can be found in: http://pytorch.org/docs/torch.html#math-operations\n"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {
23 | "collapsed": true
24 | },
25 | "outputs": [],
26 | "source": [
27 | "import torch\n",
28 | "import numpy as np"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 2,
34 | "metadata": {},
35 | "outputs": [
36 | {
37 | "name": "stdout",
38 | "output_type": "stream",
39 | "text": [
40 | "\nnumpy array: [[0 1 2]\n [3 4 5]] \ntorch tensor: tensor([[ 0, 1, 2],\n [ 3, 4, 5]], dtype=torch.int32) \ntensor to array: [[0 1 2]\n [3 4 5]]\n"
41 | ]
42 | }
43 | ],
44 | "source": [
45 | "# convert numpy to tensor or vise versa\n",
46 | "np_data = np.arange(6).reshape((2, 3))\n",
47 | "torch_data = torch.from_numpy(np_data)\n",
48 | "tensor2array = torch_data.numpy()\n",
49 | "print(\n",
50 | " '\\nnumpy array:', np_data, # [[0 1 2], [3 4 5]]\n",
51 | " '\\ntorch tensor:', torch_data, # 0 1 2 \\n 3 4 5 [torch.LongTensor of size 2x3]\n",
52 | " '\\ntensor to array:', tensor2array, # [[0 1 2], [3 4 5]]\n",
53 | ")"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": 3,
59 | "metadata": {},
60 | "outputs": [
61 | {
62 | "name": "stdout",
63 | "output_type": "stream",
64 | "text": [
65 | "\nabs \nnumpy: [1 2 1 2] \ntorch: tensor([ 1., 2., 1., 2.])\n"
66 | ]
67 | }
68 | ],
69 | "source": [
70 | "# abs\n",
71 | "data = [-1, -2, 1, 2]\n",
72 | "tensor = torch.FloatTensor(data) # 32-bit floating point\n",
73 | "print(\n",
74 | " '\\nabs',\n",
75 | " '\\nnumpy: ', np.abs(data), # [1 2 1 2]\n",
76 | " '\\ntorch: ', torch.abs(tensor) # [1 2 1 2]\n",
77 | ")"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 4,
83 | "metadata": {},
84 | "outputs": [
85 | {
86 | "data": {
87 | "text/plain": [
88 | "tensor([ 1., 2., 1., 2.])"
89 | ]
90 | },
91 | "execution_count": 4,
92 | "metadata": {},
93 | "output_type": "execute_result"
94 | }
95 | ],
96 | "source": [
97 | "tensor.abs()"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": 5,
103 | "metadata": {},
104 | "outputs": [
105 | {
106 | "name": "stdout",
107 | "output_type": "stream",
108 | "text": [
109 | "\nsin \nnumpy: [-0.84147098 -0.90929743 0.84147098 0.90929743] \ntorch: tensor([-0.8415, -0.9093, 0.8415, 0.9093])\n"
110 | ]
111 | }
112 | ],
113 | "source": [
114 | "# sin\n",
115 | "print(\n",
116 | " '\\nsin',\n",
117 | " '\\nnumpy: ', np.sin(data), # [-0.84147098 -0.90929743 0.84147098 0.90929743]\n",
118 | " '\\ntorch: ', torch.sin(tensor) # [-0.8415 -0.9093 0.8415 0.9093]\n",
119 | ")"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 6,
125 | "metadata": {},
126 | "outputs": [
127 | {
128 | "data": {
129 | "text/plain": [
130 | "tensor([ 0.2689, 0.1192, 0.7311, 0.8808])"
131 | ]
132 | },
133 | "execution_count": 6,
134 | "metadata": {},
135 | "output_type": "execute_result"
136 | }
137 | ],
138 | "source": [
139 | "tensor.sigmoid()"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 7,
145 | "metadata": {},
146 | "outputs": [
147 | {
148 | "data": {
149 | "text/plain": [
150 | "tensor([ 0.3679, 0.1353, 2.7183, 7.3891])"
151 | ]
152 | },
153 | "execution_count": 7,
154 | "metadata": {},
155 | "output_type": "execute_result"
156 | }
157 | ],
158 | "source": [
159 | "tensor.exp()"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 8,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "name": "stdout",
169 | "output_type": "stream",
170 | "text": [
171 | "\nmean \nnumpy: 0.0 \ntorch: tensor(0.)\n"
172 | ]
173 | }
174 | ],
175 | "source": [
176 | "# mean\n",
177 | "print(\n",
178 | " '\\nmean',\n",
179 | " '\\nnumpy: ', np.mean(data), # 0.0\n",
180 | " '\\ntorch: ', torch.mean(tensor) # 0.0\n",
181 | ")"
182 | ]
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": 2,
187 | "metadata": {},
188 | "outputs": [
189 | {
190 | "name": "stdout",
191 | "output_type": "stream",
192 | "text": [
193 | "\nmatrix multiplication (matmul) \nnumpy: [[ 7 10]\n [15 22]] \ntorch: tensor([[ 7., 10.],\n [15., 22.]])\n"
194 | ]
195 | }
196 | ],
197 | "source": [
198 | "# matrix multiplication\n",
199 | "data = [[1,2], [3,4]]\n",
200 | "tensor = torch.FloatTensor(data) # 32-bit floating point\n",
201 | "# correct method\n",
202 | "print(\n",
203 | " '\\nmatrix multiplication (matmul)',\n",
204 | " '\\nnumpy: ', np.matmul(data, data), # [[7, 10], [15, 22]]\n",
205 | " '\\ntorch: ', torch.mm(tensor, tensor) # [[7, 10], [15, 22]]\n",
206 | ")"
207 | ]
208 | },
209 | {
210 | "cell_type": "code",
211 | "execution_count": 3,
212 | "metadata": {},
213 | "outputs": [
214 | {
215 | "ename": "RuntimeError",
216 | "evalue": "dot: Expected 1-D argument self, but got 2-D",
217 | "traceback": [
218 | "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
219 | "\u001b[0;31mRuntimeError\u001b[0m Traceback (most recent call last)",
220 | "\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 5\u001b[0m \u001b[0;34m'\\nmatrix multiplication (dot)'\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 6\u001b[0m \u001b[0;34m'\\nnumpy: '\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mdata\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdot\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mdata\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;31m# [[7, 10], [15, 22]]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 7\u001b[0;31m \u001b[0;34m'\\ntorch: '\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mtorch\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdot\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtensor\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdot\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtensor\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;31m# 30.0. Beware that torch.dot does not broadcast, only works for 1-dimensional tensor\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 8\u001b[0m )\n",
221 | "\u001b[0;31mRuntimeError\u001b[0m: dot: Expected 1-D argument self, but got 2-D"
222 | ],
223 | "output_type": "error"
224 | }
225 | ],
226 | "source": [
227 | "# incorrect method\n",
228 | "data = np.array(data)\n",
229 | "tensor = torch.Tensor(data)\n",
230 | "print(\n",
231 | " '\\nmatrix multiplication (dot)',\n",
232 | " '\\nnumpy: ', data.dot(data), # [[7, 10], [15, 22]]\n",
233 | " '\\ntorch: ', torch.dot(tensor.dot(tensor)) # NOT WORKING! Beware that torch.dot does not broadcast, only works for 1-dimensional tensor\n",
234 | ")"
235 | ]
236 | },
237 | {
238 | "cell_type": "markdown",
239 | "metadata": {},
240 | "source": [
241 | "Note that:\n",
242 | "\n",
243 | "torch.dot(tensor1, tensor2) → float\n",
244 | "\n",
245 | "Computes the dot product (inner product) of two tensors. Both tensors are treated as 1-D vectors."
246 | ]
247 | },
248 | {
249 | "cell_type": "code",
250 | "execution_count": 10,
251 | "metadata": {},
252 | "outputs": [
253 | {
254 | "data": {
255 | "text/plain": [
256 | "tensor([[ 7., 10.],\n [ 15., 22.]])"
257 | ]
258 | },
259 | "execution_count": 10,
260 | "metadata": {},
261 | "output_type": "execute_result"
262 | }
263 | ],
264 | "source": [
265 | "tensor.mm(tensor)"
266 | ]
267 | },
268 | {
269 | "cell_type": "code",
270 | "execution_count": 11,
271 | "metadata": {},
272 | "outputs": [
273 | {
274 | "data": {
275 | "text/plain": [
276 | "tensor([[ 1., 4.],\n [ 9., 16.]])"
277 | ]
278 | },
279 | "execution_count": 11,
280 | "metadata": {},
281 | "output_type": "execute_result"
282 | }
283 | ],
284 | "source": [
285 | "tensor * tensor"
286 | ]
287 | },
288 | {
289 | "cell_type": "code",
290 | "execution_count": 13,
291 | "metadata": {},
292 | "outputs": [
293 | {
294 | "data": {
295 | "text/plain": [
296 | "tensor(7.)"
297 | ]
298 | },
299 | "execution_count": 13,
300 | "metadata": {},
301 | "output_type": "execute_result"
302 | }
303 | ],
304 | "source": [
305 | "torch.dot(torch.Tensor([2, 3]), torch.Tensor([2, 1]))"
306 | ]
307 | },
308 | {
309 | "cell_type": "code",
310 | "execution_count": null,
311 | "metadata": {
312 | "collapsed": true
313 | },
314 | "outputs": [],
315 | "source": []
316 | }
317 | ],
318 | "metadata": {
319 | "kernelspec": {
320 | "display_name": "Python 3",
321 | "language": "python",
322 | "name": "python3"
323 | },
324 | "language_info": {
325 | "codemirror_mode": {
326 | "name": "ipython",
327 | "version": 3
328 | },
329 | "file_extension": ".py",
330 | "mimetype": "text/x-python",
331 | "name": "python",
332 | "nbconvert_exporter": "python",
333 | "pygments_lexer": "ipython3",
334 | "version": "3.5.2"
335 | }
336 | },
337 | "nbformat": 4,
338 | "nbformat_minor": 2
339 | }
340 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/202_variable.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 202 Variable\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11\n",
14 | "\n",
15 | "Variable in torch is to build a computational graph,\n",
16 | "but this graph is dynamic compared with a static graph in Tensorflow or Theano.\n",
17 | "So torch does not have placeholder, torch can just pass variable to the computational graph.\n"
18 | ]
19 | },
20 | {
21 | "cell_type": "code",
22 | "execution_count": 1,
23 | "metadata": {
24 | "collapsed": true
25 | },
26 | "outputs": [],
27 | "source": [
28 | "import torch\n",
29 | "from torch.autograd import Variable"
30 | ]
31 | },
32 | {
33 | "cell_type": "code",
34 | "execution_count": 2,
35 | "metadata": {},
36 | "outputs": [
37 | {
38 | "name": "stdout",
39 | "output_type": "stream",
40 | "text": [
41 | "\n",
42 | " 1 2\n",
43 | " 3 4\n",
44 | "[torch.FloatTensor of size 2x2]\n",
45 | "\n",
46 | "Variable containing:\n",
47 | " 1 2\n",
48 | " 3 4\n",
49 | "[torch.FloatTensor of size 2x2]\n",
50 | "\n"
51 | ]
52 | }
53 | ],
54 | "source": [
55 | "tensor = torch.FloatTensor([[1,2],[3,4]]) # build a tensor\n",
56 | "variable = Variable(tensor, requires_grad=True) # build a variable, usually for compute gradients\n",
57 | "\n",
58 | "print(tensor) # [torch.FloatTensor of size 2x2]\n",
59 | "print(variable) # [torch.FloatTensor of size 2x2]"
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "metadata": {},
65 | "source": [
66 | "Till now the tensor and variable seem the same.\n",
67 | "\n",
68 | "However, the variable is a part of the graph, it's a part of the auto-gradient.\n"
69 | ]
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": 3,
74 | "metadata": {},
75 | "outputs": [
76 | {
77 | "name": "stdout",
78 | "output_type": "stream",
79 | "text": [
80 | "7.5\n",
81 | "Variable containing:\n",
82 | " 7.5000\n",
83 | "[torch.FloatTensor of size 1]\n",
84 | "\n"
85 | ]
86 | }
87 | ],
88 | "source": [
89 | "t_out = torch.mean(tensor*tensor) # x^2\n",
90 | "v_out = torch.mean(variable*variable) # x^2\n",
91 | "print(t_out)\n",
92 | "print(v_out)"
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "execution_count": 4,
98 | "metadata": {
99 | "collapsed": true
100 | },
101 | "outputs": [],
102 | "source": [
103 | "v_out.backward() # backpropagation from v_out"
104 | ]
105 | },
106 | {
107 | "cell_type": "markdown",
108 | "metadata": {},
109 | "source": [
110 | "$$ v_{out} = {{1} \\over {4}} sum(variable^2) $$\n",
111 | "\n",
112 | "the gradients w.r.t the variable, \n",
113 | "\n",
114 | "$$ {d(v_{out}) \\over d(variable)} = {{1} \\over {4}} 2 variable = {variable \\over 2}$$\n",
115 | "\n",
116 | "let's check the result pytorch calculated for us below:"
117 | ]
118 | },
119 | {
120 | "cell_type": "code",
121 | "execution_count": 5,
122 | "metadata": {},
123 | "outputs": [
124 | {
125 | "data": {
126 | "text/plain": [
127 | "Variable containing:\n",
128 | " 0.5000 1.0000\n",
129 | " 1.5000 2.0000\n",
130 | "[torch.FloatTensor of size 2x2]"
131 | ]
132 | },
133 | "execution_count": 5,
134 | "metadata": {},
135 | "output_type": "execute_result"
136 | }
137 | ],
138 | "source": [
139 | "variable.grad"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 6,
145 | "metadata": {},
146 | "outputs": [
147 | {
148 | "data": {
149 | "text/plain": [
150 | "Variable containing:\n",
151 | " 1 2\n",
152 | " 3 4\n",
153 | "[torch.FloatTensor of size 2x2]"
154 | ]
155 | },
156 | "execution_count": 6,
157 | "metadata": {},
158 | "output_type": "execute_result"
159 | }
160 | ],
161 | "source": [
162 | "variable # this is data in variable format"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 7,
168 | "metadata": {},
169 | "outputs": [
170 | {
171 | "data": {
172 | "text/plain": [
173 | "\n",
174 | " 1 2\n",
175 | " 3 4\n",
176 | "[torch.FloatTensor of size 2x2]"
177 | ]
178 | },
179 | "execution_count": 7,
180 | "metadata": {},
181 | "output_type": "execute_result"
182 | }
183 | ],
184 | "source": [
185 | "variable.data # this is data in tensor format"
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": 8,
191 | "metadata": {},
192 | "outputs": [
193 | {
194 | "data": {
195 | "text/plain": [
196 | "array([[ 1., 2.],\n",
197 | " [ 3., 4.]], dtype=float32)"
198 | ]
199 | },
200 | "execution_count": 8,
201 | "metadata": {},
202 | "output_type": "execute_result"
203 | }
204 | ],
205 | "source": [
206 | "variable.data.numpy() # numpy format"
207 | ]
208 | },
209 | {
210 | "cell_type": "markdown",
211 | "metadata": {},
212 | "source": [
213 | "Note that we did `.backward()` on `v_out` but `variable` has been assigned new values on it's `grad`.\n",
214 | "\n",
215 | "As this line \n",
216 | "```\n",
217 | "v_out = torch.mean(variable*variable)\n",
218 | "``` \n",
219 | "will make a new variable `v_out` and connect it with `variable` in computation graph."
220 | ]
221 | },
222 | {
223 | "cell_type": "code",
224 | "execution_count": 9,
225 | "metadata": {},
226 | "outputs": [
227 | {
228 | "data": {
229 | "text/plain": [
230 | "torch.autograd.variable.Variable"
231 | ]
232 | },
233 | "execution_count": 9,
234 | "metadata": {},
235 | "output_type": "execute_result"
236 | }
237 | ],
238 | "source": [
239 | "type(v_out)"
240 | ]
241 | },
242 | {
243 | "cell_type": "code",
244 | "execution_count": 10,
245 | "metadata": {},
246 | "outputs": [
247 | {
248 | "data": {
249 | "text/plain": [
250 | "torch.FloatTensor"
251 | ]
252 | },
253 | "execution_count": 10,
254 | "metadata": {},
255 | "output_type": "execute_result"
256 | }
257 | ],
258 | "source": [
259 | "type(v_out.data)"
260 | ]
261 | },
262 | {
263 | "cell_type": "code",
264 | "execution_count": null,
265 | "metadata": {
266 | "collapsed": true
267 | },
268 | "outputs": [],
269 | "source": []
270 | }
271 | ],
272 | "metadata": {
273 | "kernelspec": {
274 | "display_name": "Python 3",
275 | "language": "python",
276 | "name": "python3"
277 | },
278 | "language_info": {
279 | "codemirror_mode": {
280 | "name": "ipython",
281 | "version": 3
282 | },
283 | "file_extension": ".py",
284 | "mimetype": "text/x-python",
285 | "name": "python",
286 | "nbconvert_exporter": "python",
287 | "pygments_lexer": "ipython3",
288 | "version": "3.5.2"
289 | }
290 | },
291 | "nbformat": 4,
292 | "nbformat_minor": 2
293 | }
294 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/203_activation.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 203 Activation\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11\n",
14 | "* matplotlib\n"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {
21 | "collapsed": true
22 | },
23 | "outputs": [],
24 | "source": [
25 | "import torch\n",
26 | "import torch.nn.functional as F\n",
27 | "from torch.autograd import Variable\n",
28 | "import matplotlib.pyplot as plt"
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "### Firstly generate some fake data"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 2,
41 | "metadata": {},
42 | "outputs": [],
43 | "source": [
44 | "x = torch.linspace(-5, 5, 200) # x data (tensor), shape=(200, 1)\n",
45 | "x = Variable(x)\n",
46 | "x_np = x.data.numpy() # numpy array for plotting"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "### Following are popular activation functions"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": 3,
59 | "metadata": {
60 | "collapsed": true
61 | },
62 | "outputs": [
63 | {
64 | "name": "stderr",
65 | "output_type": "stream",
66 | "text": [
67 | "C:\\Users\\morvanzhou\\AppData\\Local\\Programs\\Python\\Python36\\lib\\site-packages\\torch\\nn\\functional.py:1006: UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.\n warnings.warn(\"nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.\")\nC:\\Users\\morvanzhou\\AppData\\Local\\Programs\\Python\\Python36\\lib\\site-packages\\torch\\nn\\functional.py:995: UserWarning: nn.functional.tanh is deprecated. Use torch.tanh instead.\n warnings.warn(\"nn.functional.tanh is deprecated. Use torch.tanh instead.\")\n"
68 | ]
69 | }
70 | ],
71 | "source": [
72 | "y_relu = F.relu(x).data.numpy()\n",
73 | "y_sigmoid = torch.sigmoid(x).data.numpy()\n",
74 | "y_tanh = F.tanh(x).data.numpy()\n",
75 | "y_softplus = F.softplus(x).data.numpy()\n",
76 | "\n",
77 | "# y_softmax = F.softmax(x)\n",
78 | "# softmax is a special kind of activation function, it is about probability\n",
79 | "# and will make the sum as 1."
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "### Plot to visualize these activation function"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 5,
92 | "metadata": {
93 | "collapsed": true
94 | },
95 | "outputs": [],
96 | "source": [
97 | "%matplotlib inline"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": 7,
103 | "metadata": {},
104 | "outputs": [
105 | {
106 | "data": {
107 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAe8AAAFpCAYAAAC1YKAIAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzs3XmcjvX+x/HXB1Njl61kbP2ijUhDTjqn0mmTaC+lOClt\nTqtOWrWe03bapaQiydKCSVokCifZkiyJigyVLbKbMd/fH99bBjNmu+e67uX9fDzux9zLNXN9xsN1\nfea7fb7mnENERETiR5mwAxAREZGiUfIWERGJM0reIiIicUbJW0REJM4oeYuIiMQZJW8REZE4E2jy\nNrMlZvatmc02sxlBnltECmZmr5nZSjObm8/nl5nZnMh1/D8zax50jCISTsv7ZOdcC+dcegjnFpF9\nGwicsY/PfwJOdM41Ax4C+gcRlIjsrlzYAYhI7HDOfWFmDffx+f9yvZwKpJV2TCKyt6Bb3g74xMxm\nmlmPgM8tItHVHfgw7CBEklHQLe8TnHPLzaw2MM7MvnPOfbHzw0hC7wFQsWLFYw8//PCAwxOJEb/9\nBpmZUK8e1K69z0Nnzpy52jlXK6DIADCzk/HJ+4R9HKPrWaSICns9W1i1zc3sfmCjc+7JvD5PT093\nM2ZoTpskoalT4a9/hbPPhnffBbN9Hm5mM6M5hyTSbT7GOdc0n8+PBkYCZzrnvi/Mz9T1LFI4hb2e\nA+s2N7OKZlZ553PgNCDPGa0iSev33+GSSyAtDV59tcDEHTQzqw+8B1xe2MQtItEXZLf5gcBI8zej\ncsBbzrmPAjy/SGxzDv7xD1i+HCZPhgMOCDwEMxsKnATUNLNMoA+Q4sNzLwH3ATWAFyPXcrZWjogE\nL7Dk7Zz7EdCaUJH8PPccjB4N//0vHHdcKCE45zoX8PlVwFUBhSMi+YirpWJZWVlkZmaydevWsEOJ\nutTUVNLS0khJSQk7FAnD9Olw++1+nPuWW8KOJhCJfD1Hk+4Nkpe4St6ZmZlUrlyZhg0bYjE2FlgS\nzjnWrFlDZmYmjRo1CjscCdq6dXDxxXDQQTBwYMyNc5eWRL2eo0n3BslPXNU237p1KzVq1Ei4C93M\nqFGjhlogycg5uOoq+PlnGDYMqlcPO6LAJOr1HE26N0h+4qrlDSTshZ6ov5cU4MUX/XKwxx+H448P\nO5rA6f99wfRvJHmJq5Z3PDnppJPQulbZp1mz4NZboX17uO22sKORiKuuuor58+eX6jnat2/PunXr\n9nr//vvv58kn8yx9IbKbuGt5xxLnHM45ypTR30BSRH/8ARddBLVqwaBBoP9DMWPAgAGlfo6xY8eW\n+jkksemOUURLlizhsMMO44orrqBp06YMHjyYv/zlL7Rs2ZILL7yQjRs37vU9lSpV+vP5O++8Q7du\n3QKMWGKOc3D11bBkiR/nrlkz7IiS1qZNmzjrrLNo3rw5TZs2Zfjw4bv1mr366qs0adKE1q1bc/XV\nV9OzZ08AunXrxnXXXUebNm045JBDmDhxIldeeSVHHHHEbtf30KFDadasGU2bNuWOO+748/2GDRuy\nevVqAB555BGaNGnCCSecwMKFC4P75SWuxW/L++abYfbs6P7MFi3gmWcKPGzRokUMGjSIQw89lPPO\nO49PP/2UihUr8thjj/HUU09x3333RTcuSSwvvwwjRsC//w0n5FsaPLmEdD1/9NFHHHzwwXzwwQcA\nrF+/nn79+gGwYsUKHnroIWbNmkXlypVp164dzZvvKlXx+++/8+WXX5KRkUHHjh2ZMmUKAwYMoFWr\nVsyePZvatWtzxx13MHPmTA444ABOO+00Ro0axTnnnPPnz5g5cybDhg1j9uzZZGdn07JlS4499tjo\n/jtIQlLLuxgaNGhAmzZtmDp1KvPnz6dt27a0aNGCQYMGsXTp0rDDk1g2e7ZPVKefDrlaYhKOZs2a\nMW7cOO644w4mTZpE1apV//xs2rRpnHjiiVSvXp2UlBQuvPDC3b737LPPxsxo1qwZBx54IM2aNaNM\nmTIcddRRLFmyhOnTp3PSSSdRq1YtypUrx2WXXcYXX3yx28+YNGkS5557LhUqVKBKlSp07NgxkN9b\n4l/8trwL0UIuLRUrVgT8mPepp57K0KFD93l87tmiWvKRxDZs8OPc1avDG29onDu3kK7nJk2aMGvW\nLMaOHcs999zDKaecUujv3X///QEoU6bMn893vs7OzlZRFSlVunuUQJs2bZgyZQqLFy8G/PjZ99/v\nvVfDgQceyIIFC8jJyWHkyJFBhymxwDm49lr44QcYOrTAbT4lGCtWrKBChQp06dKF22+/nVmzZv35\nWatWrfj888/5/fffyc7O5t133y3Sz27dujWff/45q1evZseOHQwdOpQTTzxxt2P+9re/MWrUKLZs\n2cKGDRt4//33o/J7SeKL35Z3DKhVqxYDBw6kc+fObNu2DYCHH36YJk2a7Hbco48+SocOHahVqxbp\n6el5TmqTBPfqq/DWW/DQQ7DHDVzC8+2333L77bdTpkwZUlJS6NevH7169QKgbt263HXXXbRu3Zrq\n1atz+OGH79atXpA6derw6KOPcvLJJ+Oc46yzzqJTp067HdOyZUsuvvhimjdvTu3atWnVqlVUfz9J\nXKHt512QvPb/XbBgAUcccURIEZW+RP/9kta330Lr1n5y2kcfQdmyUf3x0dzP28xeAzoAK/Paz9v8\nGNCzQHtgM9DNOTdrz+P2FK/X88aNG6lUqRLZ2dmce+65XHnllZx77rmBxxEP/1YSHTG3n7dIUtq4\nES68EKpVgzffjHriLgUDgTP28fmZQOPIowfQL4CYQnP//ffTokULmjZtSqNGjXabKS4SJnWbi5QW\n5+D66+H77+HTT+HAA8OOqEDOuS/MrOE+DukEvOF8l91UM6tmZnWcc78EEmDAVO1MYpWSt0hpGTgQ\nBg+GPn2gXbuwo4mWusCyXK8zI+8lZPIWKZacHNi8GTZt2vXYuBEOOSRqf8QHnrzNrCwwA1junOtQ\n1O93ziVkof5YnXsgxTRvHtxwA5x8Mtx7b9jRhMLMeuC71qlfv36exyTq9RxNujeEbONG+O03+PVX\n/3Xn4/ff/Xa+69f7r7mfr1/ve9729PrrEKUKm2G0vG8CFgBVivqNqamprFmzJuG2Edy5Z29qamrY\noUg0bNrk13NXrgxDhsTDOHdRLAfq5XqdFnlvL865/kB/8BPW9vw8Ua/naNK9IQDr1sGCBfDTT7B0\nqS9bvGSJf75smW9B56VqVT+XZefXBg12f125MlSsuPvj6KOjFnagydvM0oCzgEeAW4v6/WlpaWRm\nZrJq1aqoxxa21NRU0tLSwg5DouGf//Q3g48/hjp1wo4m2jKAnmY2DDgOWF/c8e5Evp6jSfeGKNm6\n1Vc4/OYbmD/fP+bNg1/2+O9bqxY0bOgTbfv2cNBB/nHggbsetWpBuXBHnYM++zPAv4DKeX1YUDdb\nSkoKjRo1Ks34REpm8GDfNXbPPXDqqWFHU2RmNhQ4CahpZplAHyAFwDn3EjAWv0xsMX6p2D+Key5d\nz1Kqli2DiRPhq6/845tvICvLf1axIhx5JJx2mv965JHwf/8H9ev7z+JAYMnbzHauHZ1pZifldUxB\n3WwiMe277+C66+Bvf/OT1OKQc65zAZ874IaAwhEpvD/+gAkTYNw4v7pj5w5tlSpBejrcequvt9Cy\npU/ScV6eOMiWd1ugo5m1B1KBKmb2pnOuS4AxiJSOzZv9eu7y5X0ltZC71ESSwtq1MHo0vPOOT9pZ\nWVChgq9i2KMHnHIKNG2aaPNOgACTt3PuTuBOgEjLu5cStySMm26CuXPhww+hbt2woxFJXFlZ8MEH\nMGCAn1eSne3HqG+8Ec4+G/7yF9hvv7CjLHVqHoiU1Ftv+RtJ795wxr6Kk4lIsS1ZAv36waBBfqnW\nwQfDbbf5Hq+WLSHJViyEkrydcxOBiWGcWySqvv8errkG2rb1m46ISHTNng1PPAHDh/vXHTrAVVf5\nP5STeHgqeX9zkZLautWv595vP7/NZxLfSESibuZMuPtu3zVeqZIfmrr5ZqhXr+DvTQK624gU1y23\n+OUnY8bohiISLT/95JP20KFQowb8+99w7bVwwAFhRxZTlLxFimPECHjpJejVC846K+xoROLfxo1w\n//3w3HO+F+vuu+H2233FMtmLkrdIUS1e7Mfc2rTxrQIRKZmxY32NhJ9/hu7d4cEH/YQ0yZeSt0hR\nbNsGF1/sWwbDh0NKStgRicSvlSv9Eq/hw32Vs8mT/eRPKZCSt0hR9OoFs2b5whD57JQlIoXw0UfQ\ntavfGOShh+Bf/0qK9dnRouQtUljvvAMvvOAnqnXsGHY0IvFp2zZfE+GZZ3z1s/Hj/VcpEiVvkcL4\n8Uc/Fte6NTz6aNjRiMSnFSvg/PNh6lS/+95jj/mSwlJkSt4iBdk5zm0Gw4apa0+kOKZMgQsugA0b\n4O23/XMptvjeVkUkCHfcATNm+K0+k2ALSzM7w8wWmtliM+udx+f1zWyCmX1tZnMimw2J5G/IEDj5\nZL/d5tSpStxRoOQtsi+jRsGzz/ouvnPPDTuaUmdmZYG+wJnAkUBnMztyj8PuAUY4544BLgFeDDZK\niRvOwX/+A126wPHHw/TpGt+OEiVvkfwsWQL/+Acce6yvrZwcWgOLnXM/Oue2A8OATnsc44AqkedV\ngRUBxifxIicHevaEu+6Czp19mVNVSYsaJW+RvGzfDpdc4m9AI0bA/vuHHVFQ6gLLcr3OjLyX2/1A\nFzPLBMYC/8zrB5lZDzObYWYzVq1aVRqxSqzascNP8HzxRb+88s03k+kaCoSSt0he7roLvvoKXn0V\nDjkk7GhiTWdgoHMuDWgPDDazve4lzrn+zrl051x6rVq1Ag9SQpKd7ddvDxwIffrA449DGaWaaNNs\nc5E9vf8+/Pe/cP31yTixZjmQe5eVtMh7uXUHzgBwzn1pZqlATWBlIBFK7MrKgssv9xXTHnnE/xEs\npUJ/Donk9vPPvtXQooVP4MlnOtDYzBqZ2X74CWkZexzzM3AKgJkdAaQC6hdPdjt27ErcTzyhxF3K\nAkveZpZqZtPM7Bszm2dmDwR1bpFCycry49xZWX6cOzU17IgC55zLBnoCHwML8LPK55nZg2a2s6zc\nbcDVZvYNMBTo5pxz4UQsMcE5Pzlt+HDfTd6rV9gRJbwgu823Ae2ccxvNLAWYbGYfOuemBhiDSP7u\nuQe+/NLvI9y4cdjRhMY5NxY/ES33e/flej4f0O4RskufPn6L3H/9y2/jKaUusOQd+ct8Y+RlSuSh\nv9YlNowd61sMPXr41reIFM6zz/qNRbp3V+ngAAU65m1mZc1sNn5iyzjn3Fd7fK6lJRK8zEy44go4\n+mi/WYKIFM6IEXDzzb6A0Usv+RLCEohAk7dzbodzrgV+BmtrM2u6x+daWiLBys72BSS2bvU3Im2S\nIFI406b5yZ3HHw9vveX3uJfAhDLb3Dm3DphAZLmJSGj69IHJk+Hll+Gww8KORiQ+LFsGnTrBQQfB\nyJFJObkzbEHONq9lZtUiz8sDpwLfBXV+kb188omvu9y9O1x2WdjRiMSHjRv9fvabNsGYMVC7dtgR\nJaUg+znqAIMiGx+UwS9BGRPg+UV2WbHCb5Zw1FHw3HNhRyMSH3Jy/FruOXN84j7qqLAjSlpBzjaf\nAxwT1PlE8pWdDZde6lsOI0ZAhQphRyQSH/7zH7/T3tNPw5lnhh1NUtMMA0k+Dz4In3/uay8fcUTY\n0YjEh08+gXvv9X/43nRT2NEkPZVHleTy6afw8MN+lmzXrmFHIxIfli71qzKOOgr699eSsBig5C3J\n49df/Tj34YdD375hRyMSH7Zu9Rv0ZGfDe+9BxYphRySo21ySxY4dfkb5H3/41rduQCKFc8stMGOG\nH+tO4rLBsUbJW5LDI4/AZ5/5/bmbNi34eBHxCfull3y98k6dwo5GclG3uSS+iRPhgQd8l/k//hF2\nNDHPzM4ws4VmttjMeudzzEVmNj+yQ+BbQccoAVixAq66Clq29PNEJKao5S2JbeVKPzu2cWPo108T\nbQoQqcPQF19EKROYbmYZkZ3Edh7TGLgTaOuc+93MVKUj0eTkQLdusHmzL326335hRyR7UPKWxJWT\n41vbv/8OH30ElSqFHVE8aA0sds79CGBmw4BOwPxcx1wN9HXO/Q7gnFsZeJRSup59FsaNU9ngGKZu\nc0lc//mPvwE9+6zfMUwKoy6wLNfrzMh7uTUBmpjZFDObamZ57lGgXQLj1DffQO/efoz76qvDjkby\noeQtiemLL+C++/ze3LoBRVs5oDFwEtAZeGXnvgW5aZfAOLRlix9mql4dBgzQMFMMU7e5JJ5Vq3xB\niUMO8d1+ugEVxXKgXq7XaZH3cssEvnLOZQE/mdn3+GQ+PZgQpdT8618wfz58/DHUrBl2NLIPanlL\nYsnJgSuugDVrfN3yKlXCjijeTAcam1kjM9sPuATI2OOYUfhWN2ZWE9+N/mOQQUopGDsWXnjBr+s+\n7bSwo5ECKHlLYnniCT857emn4Rjtg1NUzrlsoCfwMbAAv/vfPDN70Mw6Rg77GFhjZvOBCcDtzrk1\n4UQsUfHbb34Z5dFHw7//HXY0UgjqNpfEMWUK3H03XHghXHtt2NHELefcWGDsHu/dl+u5A26NPCTe\nOQdXXumrD372GaSmhh2RFIKStySGNWv85LQGDeCVVzTOLVJYL77ou8yff177c8eRwLrNzayemU3I\nVZVJe8pJdOTk+B3CVq7049xVq4YdkUh8mDcPevWC9u3hhhvCjkaKIMiWdzZwm3NulplVBmaa2bjc\nlZtEiuWpp+CDD+C55+DYY8OORiQ+bNvml4VVrgyvvabeqjgTWPJ2zv0C/BJ5vsHMFuCLPyh5S/FN\nnQp33gnnnQc9e4YdjUj8uPNOmDMHxoyBAw8MOxopolBmm5tZQ+AY4Kswzi8JYu1auPhiSEvzu4Wp\n5SBSOJ984ldk3HADnHVW2NFIMQQ+Yc3MKgHvAjc75/7Y47MeQA+A+vXrBx2axBPn/NKWX36ByZOh\n2l4FvkQkL6tX+zkiRxzhl1ZKXAq05W1mKfjEPcQ5996en6ucohTas89CRgY8/ji0bh12NCLxwTm/\nzefatTB0KJQvH3ZEUkyBtbzNzIBXgQXOuaeCOq8koOnTfRnHTp3gJi1aECm0V16B0aP9JM/mzcOO\nRkogyJZ3W+ByoJ2ZzY482gd4fkkE69bBRRdBnTqaIStSFN99BzffDKeeqj96E0CQs80nA7rTSvE5\nB927Q2YmTJrkdz4SkYJt3w6XXQYVKsDAgVBGlbHjnSqsSfzo2xfee89PsmnTJuxoROLHfffBrFkw\nciQcfHDY0UgU6M8viQ8zZ8Jtt/llLbeqpLZIoU2Y4Cd29ugB55wTdjQSJUreEvvWr/fj3LVrw6BB\n6vIrZWZ2hpktNLPFZtZ7H8edb2bOzNKDjE+KYPVq6NIFGjf2k9QkYajbXGKbc3D11bB0KXz+OdSo\nEXZECc3MygJ9gVOBTGC6mWXsWcY4UuL4JlRoKXbtnCOyerWvolaxYtgRSRSpCSOx7aWX4O234ZFH\noG3bsKNJBq2Bxc65H51z24FhQKc8jnsIeAzYGmRwUgQvvrirFoL2tk84St4Su2bPhltugTPPhNtv\nDzuaZFEXWJbrdWbkvT+ZWUugnnPug339IDPrYWYzzGzGqlWroh+p5G/OnF1zRG68MexopBQoeUts\n2rDBj3PXqKFx7hhiZmWAp4DbCjpWFRNDsnmz39v+gAPg9ddVCyFBacxbYo9zcM018MMPfqasbvxB\nWg7Uy/U6LfLeTpWBpsBEXzSRg4AMM+vonJsRWJSSv1tu8QVZxo3TtZPA1JyR2DNggK+7/OCD8Le/\nhR1NspkONDazRma2H3AJkLHzQ+fceudcTedcQ+dcQ2AqoMQdK956C/r39+WDTzkl7GikFCl5S2yZ\nM8eP0Z16qt9vWALlnMsGegIfAwuAEc65eWb2oJl1DDc62af58/1a7hNOgIceCjsaKWXqNpfYsXGj\nH+euVg0GD9Y4d0icc2OBsXu8d18+x54URExSgI0b4YIL/HKw4cMhJSXsiKSUKXlLbHAOrrsOFi2C\nTz+FAw8MOyKR+LCzFsLChf7aUfnTpKDkLbHh9dfhzTfhgQfg5JPDjkYkfvTtC8OG+VoIunaShvol\nJXzz5kHPntCuHdx9d9jRiMSPiRP97PIOHaB3vpVsJQEpeUu4Nm2CCy+EKlVgyBAoWzbsiETiw48/\n+nHuxo19r5XmiCQVdZtLuHr23LUm9aCDwo5GJD5s2ACdOkFOji+BWrVq2BFJwAL7U83MXjOzlWY2\nN6hzSox74w0YOBDuuUdrUkUKKyfH7xS2YAGMGAGHHhp2RBKCIPtZBgJnBHg+iWULFvjZ5SeeCH36\nhB2NSPy44w7f2n76afj738OORkISWPJ2zn0BrA3qfBLDNm/267krVvQVoTTOLVI4Tz8NTz4JN9zg\nh5wkacXUmLeZ9QB6ANSvXz/kaKTU3HgjzJ0LH32kNakihTV0KNx6K5x/Pjz7rDYcSXIxNT1RuxAl\ngSFD4NVX4a674PTTw45GJD58+il07epr/b/5pnqrJLaStyS4hQv9bmF//asvxiIiBZs2Dc49Fw47\nDEaPhtTUsCOSGKDkLcHYssWPc6em+nHucjE1YiMSm6ZN85v01K7th5mqVQs7IokRQS4VGwp8CRxm\nZplm1j2oc0sMuOUWv2PY4MGQlhZ2NLIPZnaGmS00s8VmtlfZLjO71czmm9kcMxtvZg3CiDPhTZ8O\np50GNWv6Smp164YdkcSQwJo/zrnOQZ1LYszw4fDyy36P4TPPDDsa2QczKwv0BU4FMoHpZpbhnJuf\n67CvgXTn3GYzuw54HLg4+GgT2PTpvsVdvTpMmAD16oUdkcQYdZtL6Vq82O94dPzx8PDDYUcjBWsN\nLHbO/eic2w4MAzrlPsA5N8E5tznyciqgrpRo+vxzv367enXf4tbKG8mDkreUnq1b/Th3uXJ+mYv2\nGI4HdYFluV5nRt7LT3fgw1KNKJm8955fhVG3rk/iStySD80aktLTqxd8/bWvBqWbUMIxsy5AOnBi\nPp+rbkNR9OvnC68cdxyMGeNb3iL5UMtbSsc77/h9hm+9Fc4+O+xopPCWA7kHWNMi7+3GzP4O3A10\ndM5ty+sHqW5DIWVl+Ypp118P7dv7Nd1K3FIAJW+Jvh9+gO7dfQviP/8JOxopmulAYzNrZGb7AZcA\nGbkPMLNjgJfxiXtlCDEmjjVrfDf5iy/6nqpRo6BChbCjkjigbnOJrm3b4OKL/d7Cw4bBfvuFHZEU\ngXMu28x6Ah8DZYHXnHPzzOxBYIZzLgN4AqgEvG2+ROfPzrmOoQUdr/73P7jkEvjtN7+7XteuYUck\ncUTJW6LrX/+CmTNh5Eho2DDsaKQYnHNjgbF7vHdfrufayqokcnLgiSfg7ruhQQOYMgXS08OOSuKM\nkrdEz8iR8NxzcNNNcM45YUcjEnt++AGuvBK++AIuuAAGDICqVcOOSuKQxrwlOpYs8Tel9HR4/PGw\noxGJLTt2wPPPw9FHw+zZfnOeESOUuKXY1PKWktu+3Y9z5+T4amoa5xbZZfJk+Oc/fdI+/XR45RVV\nTJMSU8tbSu7OO/0GCq+9BoccEnY0IrEhMxMuu8zvord6tZ/A+eGHStwSFWp5S8lkZMBTT/l1quef\nH3Y0IuFbsQIee8zX8we45x7o3RsqVgw3LkkoSt5SfEuXQrdu0LIlPPlk2NGIhGvZMvjvf33Szsry\nS7/uuQcaNQo7MklASt5SPFlZfo1qdrYf505NDTsikeA552uQP/+8L7Bi5pP23XdrCElKlZK3FM/d\nd8PUqT5xH3po2NGIBGv5cr/ZzsCBMG+eL2d6++1w3XV+7bZIKVPylqL74ANfZOLaa/2uYSLJ4Jdf\n/IYhw4b5Pbadg9at/bKvzp2hfPmwI5QkEmjyNrMzgGfxZRcHOOceDfL8EgWZmb5bsHlzePrpsKMR\nKT1ZWTBrFnz8Mbz/PsyY4d8/9FDo0wcuvRQaNw43RklagSVvMysL9AVOxe8RPN3MMpxz84OKQUoo\nO9u3MLZt8wUmNM4tiWTTJp+sv/jCj2P/73/+PTPfwn74Yb9DXrNm/j2REAXZ8m4NLHbO/QhgZsOA\nTkDxkvfGjX7cVYIzY4a/oQ0ZAk2ahB2NSPHk5PiZ4QsXwpw5fs/5WbP8a+f8MU2b+pUUJ57oH7Vr\nhxqyyJ6CTN51gWW5XmcCx+U+wMx6AD0A6tevv++ftm0bvPFGdCOUfatUyU/QufTSsCORUlTQ8JaZ\n7Q+8ARwLrAEuds4tCTrOfDkH69b5IZ5ly/zXpUvh++99gl60CLZu3XV8vXpwzDF+9UTLlnD88VCj\nRnjxixRCTE1Yc871B/oDpKenu30eXKMG/P57EGGJJI1CDm91B353zh1qZpcAjwEXl0pAO3b4XrYN\nG/zjjz/8Hthr1viqZTu/7ny+YoVP1ps37/5zypb1S7cOOwxOPdV/bdIEjjoKatUqldBFSlOQyXs5\nkLsuYFrkPRGJHYUZ3uoE3B95/g7wgpmZc27ff3Dvy9NPw7vv7p6oN26ELVv2/X1ly/o/5Hc+WrSA\nDh0gLW33x0EHQUpKscMTiTVBJu/pQGMza4RP2pcA6n8ViS0FDm/lPsY5l21m64EawOpin9U5v6FN\ngwZQubIfoqlcee/nlSv7JF2zpn9UqQJltEWDJJ/AknfkIu8JfIwfS3vNOTcvqPOLSLCKNIfl1lv9\nQ0QKJdAxb+fcWGBskOcUkSIpzPDWzmMyzawcUBU/cW03RZrDIiJFov4mEcntz+EtM9sPP7yVsccx\nGUDXyPMLgM9KNN4tIkUWU7PNRSRc+Q1vmdmDwAznXAbwKjDYzBYDa/EJXkQCpOQtIrvJa3jLOXdf\nrudbgQuDjktEdlG3uYiISJxR8hYREYkzSt4iIiJxRslbREQkzih5i4iIxBklbxERkTij5C0iIhJn\nlLxFRETijJK3iIhInFHyFhERiTNK3iIiInFGyVtERCTOBJK8zexCM5tnZjlmlh7EOUWkaMysupmN\nM7NFka/AM/J/AAAgAElEQVQH5HFMCzP7MnI9zzGzi8OIVSTZBdXyngucB3wR0PlEpOh6A+Odc42B\n8ZHXe9oMXOGcOwo4A3jGzKoFGKOIEFDyds4tcM4tDOJcIlJsnYBBkeeDgHP2PMA5971zblHk+Qpg\nJVArsAhFBNCYt4jscqBz7pfI81+BA/d1sJm1BvYDfijtwERkd+Wi9YPM7FPgoDw+uts5N7qQP6MH\n0CPycqOZBdlarwmsDvB8haGYCifZY2pQ2AP3dZ3mfuGcc2bm9vFz6gCDga7OuZx8jtH1vLtYiynW\n4gHFBIW8ns25fK/PqDOziUAv59yMwE5aSGY2wzkXU5PpFFPhKKboiCTXk5xzv0SS80Tn3GF5HFcF\nmAj82zn3TsBhFkos/vvHWkyxFg8opqJQt7mI7JQBdI087wrs1WNmZvsBI4E3YjVxiySDoJaKnWtm\nmcBfgA/M7OMgzisiRfIocKqZLQL+HnmNmaWb2YDIMRcBfwO6mdnsyKNFOOGKJK+ojXnvi3NuJP6v\n9VjWP+wA8qCYCkcxRYFzbg1wSh7vzwCuijx/E3gz4NCKIxb//WMtpliLBxRToQU65i0iIiIlpzFv\nERGROKPknQczu83MnJnVjIFYnjCz7yKlKEeGVc3KzM4ws4VmttjM8qq8FXQ89cxsgpnNj5TqvCns\nmHYys7Jm9rWZjQk7lmSnaznfWHQ9F0IsX8tK3nsws3rAacDPYccSMQ5o6pw7GvgeuDPoAMysLNAX\nOBM4EuhsZkcGHccesoHbnHNHAm2AG2Igpp1uAhaEHUSy07WcN13PRRKz17KS996eBv4FxMRkAOfc\nJ8657MjLqUBaCGG0BhY75350zm0HhuFLaYbGOfeLc25W5PkG/AVWN8yYAMwsDTgLGFDQsVLqdC3n\nTddzIcT6tazknYuZdQKWO+e+CTuWfFwJfBjCeesCy3K9ziQGEuVOZtYQOAb4KtxIAHgGnzDyrDom\nwdC1vE+6ngsnpq/lQJaKxZICykPehe9mC1RhSsua2d34rqUhQcYW68ysEvAucLNz7o+QY+kArHTO\nzTSzk8KMJRnoWk48sXI9x8O1nHTJ2zn397zeN7NmQCPgGzMD36U1y8xaO+d+DSOmXLF1AzoAp7hw\n1vYtB+rlep0WeS9UZpaCv9CHOOfeCzseoC3Q0czaA6lAFTN70znXJeS4EpKu5WLT9VywmL+Wtc47\nH2a2BEh3zoVaJN/MzgCeAk50zq0KKYZy+Ak2p+Av8unApc65eWHEE4nJ8NtWrnXO3RxWHPmJ/LXe\nyznXIexYkp2u5b3i0PVcBLF6LWvMO/a9AFQGxkVKUb4UdACRSTY9gY/xE0lGhHmhR7QFLgfa5SrT\n2T7kmET2JfRrGXQ9Jwq1vEVEROKMWt4iIiJxRslbREQkzih5i4iIxBklbxERkTij5C0iIhJnlLxF\nRETijJK3iIhInFHyFhERiTNK3iIiInFGyVtERCTOKHmLSJGZWTUze8fMvjOzBWb2l7BjEkkmSbcl\nqIhExbPAR865C8xsP6BC2AGJJBNtTCIiRWJmVYHZwCEh7kktktTUbS4iRdUIWAW8bmZfm9kAM6sY\ndlAiySRmW941a9Z0DRs2DDsMkZg3c+bM1c65WkGdz8zSgalAW+fcV2b2LPCHc+7ePY7rAfQAqFix\n4rGHH354UCGKxK3CXs8xO+bdsGFDZsyYEXYYIjHPzJYGfMpMINM591Xk9TtA7z0Pcs71B/oDpKen\nO13PIgUr7PWsbnMRKRLn3K/AMjM7LPLWKcD8EEMSSTox2/IWkZj2T2BIZKb5j8A/Qo5HJKkoeYtI\nkTnnZgPpYcchkqziKnlnZWWRmZnJ1q1bww6lVKWmppKWlkZKSkrYoYiIFFqy3KOjoaT3+bhK3pmZ\nmVSuXJmGDRtiZmGHUyqcc6xZs4bMzEwaNWoUdjgiIoWWDPfoaIjGfT6uJqxt3bqVGjVqJPR/CjOj\nRo0a+stVROJOMtyjoyEa9/moJG8ze83MVprZ3Hw+NzN7zswWm9kcM2tZgnMVP9A4kQy/o4gkJt2/\nCqek/07RankPBM7Yx+dnAo0jjx5AvyidN3Dr1q3jxRdfLPb3n3TSSVq/LiISAyZNmsRRRx1FixYt\nWLBgAW+99Vahvq9SpUqlHFnBopK8nXNfAGv3cUgn4A3nTQWqmVmdaJw7aCVN3iIiEhuGDBnCnXfe\nyezZs/ntt98KnbxjQVAT1uoCy3K9zoy890tA54+a3r1788MPP9CiRQtOPvlk5syZw++//05WVhYP\nP/wwnTp1YsmSJZx55pmccMIJ/O9//6Nu3bqMHj2a8uXLA/D2229z/fXXs27dOl599VX++te/hvxb\nJTjnYN06WLvWf8392LABtm7d9di2be/nO3b4R05O4b865x87z1/Urzuf16kDEyeW+j+RSKLYtGkT\nF110EZmZmezYsYN7772XmjVr0qtXL7Kzs2nVqhX9+vVj8ODBjBgxgo8//pgPP/yQH374gQULFtCi\nRQu6du3KAQccwMiRI1m/fj3Lly+nS5cu9OnTZ7dzTZw4kSeffJIxY8YA0LNnT9LT0+nWrRu9e/cm\nIyODcuXKcdppp/Hkk09G9feMqdnmuWsh169ff98H33wzzJ4d3QBatIBnntnnIY8++ihz585l9uzZ\nZGdns3nzZqpUqcLq1atp06YNHTt2BGDRokUMHTqUV155hYsuuoh3332XLl26AJCdnc20adMYO3Ys\nDzzwAJ9++ml0f49ktH07fP89zJsH8+fDDz/A8uWQmem/btlS8M/Ybz9ITYX99/dfU1P9e+XKQdmy\n/lGmzO5fU1L2fn/nA2DnuFZxvppBjRol/7cRCUNI9+iPPvqIgw8+mA8++ACA9evX07RpU8aPH0+T\nJk244oor6NevHzfffDOTJ0+mQ4cOXHDBBXsl4oEDBzJt2jTmzp1LhQoVaNWqFWeddRbp6QWXN1iz\nZg0jR47ku+++w8xYt25dyX/3PQSVvJcD9XK9Tou8t5s9ayEHE1rxOee46667+OKLLyhTpgzLly/n\nt99+A6BRo0a0aNECgGOPPZYlS5b8+X3nnXdenu9LEWzYAOPGwaRJMGUKfP01ZGf7z8qUgXr1IC0N\njj0WOnaEunWhZk2oVm33R+XKuxJ2mbhafCEieWjWrBm33XYbd9xxBx06dKBKlSo0atSIJk2aANC1\na1f69u3LzTffXODPOvXUU6kR+QP6vPPOY/LkyYVK3lWrViU1NZXu3bvToUMHOnToULJfKg9BJe8M\noKeZDQOOA9Y750rWZV7AX19BGDJkCKtWrWLmzJmkpKTQsGHDP6f+77///n8eV7ZsWbbkavnt/Kxs\n2bJk70w4UrBNm2DYMHj3XRg/3re2y5eH1q2hVy9o1gyOOgqaNPHvi0h4QrpHN2nShFmzZjF27Fju\nuece2rVrV+yfteeM8D1flytXjpycnD9f77z/lytXjmnTpjF+/HjeeecdXnjhBT777LNix5GXqCRv\nMxsKnATUNLNMoA+QAuCcewkYC7QHFgObieM6yJUrV2bDhg2A746pXbs2KSkpTJgwgaVLg97cKUks\nWgTPPw+DBsEff8Ahh8A//+lb1G3a+K5tERFgxYoVVK9enS5dulCtWjVeeOEFlixZwuLFizn00EMZ\nPHgwJ5544l7fl/vevtO4ceNYu3Yt5cuXZ9SoUbz22mu7fd6gQQPmz5/Ptm3b2LJlC+PHj+eEE05g\n48aNbN68mfbt29O2bVsOOeSQqP+eUUnezrnOBXzugBuica6w1ahRg7Zt29K0aVNatWrFd999R7Nm\nzUhPT0f7FUdZZib06eOTdtmycOGFcP318Je/7BobFhHJ5dtvv+X222+nTJkypKSk0K9fP9avX8+F\nF17454S1a6+9dq/vO/rooylbtizNmzenW7duHHDAAbRu3Zrzzz+fzMxMunTpsleXeb169bjoooto\n2rQpjRo14phjjgFgw4YNdOrUia1bt+Kc46mnnor672nOxebQcl77/y5YsIAjjjgipIiClUy/6152\n7IAXXoB77vFd49ddB717w0EHhR1ZTDKzmc65mN4kRPt5J4dEum8NHDiQGTNm8MILL5TaOfL69yrs\n9RxTs81FWLECLr0UPv8czjgD+vb13eQiIvInJW+JHVOmwLnn+olpAwfCFVeoe1xEQtGtWze6desW\ndhj5UvKW2DBqFHTu7Jd4ff45JEjXW6IysyXABmAHkB3r3fYiiSbukrdzLuEL38fqPIRS8/bbcMkl\n0KoVjBnj12NLPDjZObc67CAktiTDPToaSnqfj6uqFKmpqaxZsyahk9vOfV5TU1PDDiUYH3zgx7jb\ntvVrt5W4ReJWMtyji8U5P58nKyvysuT3+bhqeaelpZGZmcmqVavCDqVUpaamkpaWFnYYpW/WLLjg\nAl/ycMwYqFgx7Iik8BzwiZk54OVIdcTdFKncsSSEZLlHF9n69X4vherVfVVHSn6fj6vknZKSQqNG\njcIOQ6Jh5Uo45xyoVcu3vqtUCTsiKZoTnHPLzaw2MM7MvovsLvineCt3LCWne3QePvnEr5y59FIY\nPDhqk3DjqttcEkROjh/jXrUKRo6E2rXDjkiKyDm3PPJ1JTASaB1uRCIxaOlSPxH3qKPg5ZejunpG\nyVuC98wzMGGCL8Ry7LFhRyNFZGYVzazyzufAacDccKMSiTFbt/phwexseO+9qA8LxlW3uSSAefPg\nrrugUye48sqwo5HiORAYGZlRXA54yzn3UbghicSYG2+EGTP8MtjGjaP+45W8JTg5OdC9ux/f7t9f\nBVjilHPuR6B52HGIxKzXXoNXXoE77/QNlVKg5C3Bef11+OorP2lD49wikohmzfIbKJ1yCjz0UKmd\nRmPeEoy1a/3mIiecAJddFnY0IiLRt3YtnH++X0UzdKjfDbGUqOUtwXjoIf8f+4UX1F0uIoknJwe6\ndIHly2HSJJ/AS5GSt5S+ZcvgxRehWzdorqFSEUlADz0EH34I/frBcceV+unUbS6l76GHfHnA++4L\nOxIRkej78EN44AG/E+I11wRySiVvKV2LF/uZl9dcAw0ahB2NiEh0/fSTn8dz9NG+1R3QsKCSt5Su\nxx+HlBS/tltEJJFs2eInqOXkwLvvQoUKgZ1aY95Sen79FQYN8sVY6tQJOxoRkehxDm64Ab7+Gt5/\nH/7v/wI9vVreUnqef95vgXfrrWFHIiISXQMG+NoV99wDHToEfnolbykdGzf6GebnnVcqpQFFREIz\nYwb07AmnnQb33x9KCFFJ3mZ2hpktNLPFZtY7j8+7mdkqM5sdeVwVjfNKDHvjDb9/ba9eYUciIhI9\nq1f7ce6DDoK33irVQiz7UuIxbzMrC/QFTgUygelmluGcm7/HocOdcz1Lej6JA875WZctWway3lFE\nJBA7dviZ5b/+ClOmQI0aoYUSjZZ3a2Cxc+5H59x2YBhQOpXYJT5MmQJz58J116mamogkjj594JNP\nfKXI9PRQQ4lG8q4LLMv1OjPy3p7ON7M5ZvaOmdWLwnklVvXrB1Wr+k3oRUQSwahR8MgjcNVVcPXV\nYUcT2IS194GGzrmjgXHAoLwOMrMeZjbDzGasWrUqoNAkqlavhnfe8ZWGorz5vIhIKBYu9Pe0Vq38\nKpoYEI3kvRzI3ZJOi7z3J+fcGufctsjLAcCxef0g51x/51y6cy69VikXdZdSMnQobN/u/zqVhGZm\nZc3sazMbE3YsIqVmwwY491xITfWFWFJTw44IiE7yng40NrNGZrYfcAmQkfsAM8tdoaMjsCAK55VY\nNHAgHHOMLxUoie4mdC1LInPOF5lauBCGD4d6sTPiW+Lk7ZzLBnoCH+Mv5BHOuXlm9qCZdYwcdqOZ\nzTOzb4AbgW4lPa/EoLlz/Ub0XbuGHYmUMjNLA87C96SJJKYnn/TDgI89BiefHHY0u4lKeVTn3Fhg\n7B7v3Zfr+Z3AndE4l8SwQYOgXDm49NKwI5HS9wzwL6ByfgeYWQ+gB0D9+vUDCkskSsaPh9694cIL\n4bbbwo5mL6qwJtGxYwcMGQLt25f6JvQSLjPrAKx0zs3c13GawyJxa+lSuPhiOPxwvytiDC55VfKW\n6Jg0CX75xRcwkETXFuhoZkvwdR3amdmb4YYkEiVbt/oKallZMHIkVKoUdkR5UvKW6Bg+3G+Hd9ZZ\nYUcipcw5d6dzLs051xA/QfUz51yXkMMSKbmdO4XNnAmDB0OTJmFHlC8lbym57Gy/hKJDB63tFpH4\n9corvpv83nuhY8eCjw+R9vOWkps4EVat8mNEklSccxOBiSGHIVJyU6f6ncLOOMOXQY1xanlLyY0Y\n4ceFzjwz7EhERIrut9/gggsgLc1PvA1pp7CiUMtbSiYry3eZd+wI5cuHHY2ISNFkZflew7Vr4csv\noXr1sCMqFCVvKZnPPvP/6S+6KOxIRESK7o474PPP/QS15s3DjqbQ1G0uJTNiBFSpAqefHnYkIiJF\nM2wYPP003HgjdImvBRNK3lJ8O3bA6NF+lnmMFOsXESmUb7+F7t3hr3/1ZVDjjJK3FN+XX8KaNdCp\nU9iRiIgU3rp1fqewqlV972FKStgRFZnGvKX4MjL8f3p1mYtIvMjJ8V3kP//sl7kedFDYERWLkrcU\nX0YGnHSS/+tVRCQe9OkDH3wAffvC8ceHHU2xqdtcimfhQv+I8SpEIiJ/evddePhhuOoquO66sKMp\nESVvKZ733/dfzz473DhERApj7lzo2hXatIEXXojJncKKQslbiicjw6+JbNAg7EhERPZt7Vo/sbZK\nFd/63n//sCMqMSVvKbrVq2HKFHWZi0jsy86GSy6BzEx47z04+OCwI4oKTViTohs71s/YVPIWkVh3\n110wbpzfMaxNm7CjiRq1vKXoMjL8X68tW4YdiYhI/oYOhSeegOuv95PUEoiStxTN1q3w0Ud+oloZ\n/fcRkRj19de+gtrf/gbPPBN2NFGnu68UzcSJsGmTusyTmJmlmtk0M/vGzOaZ2QNhxySym1Wr4Jxz\noEYNePvtuKygVhCNeUvRZGRAhQrQrl3YkUh4tgHtnHMbzSwFmGxmHzrnpoYdmAhZWX6Xw5UrYfJk\nqF077IhKRVRa3mZ2hpktNLPFZtY7j8/3N7Phkc+/MrOG0TivBMw5n7xPP10bkSQx522MvEyJPFyI\nIYns0quX7yHs3x+OPTbsaEpNiZO3mZUF+gJnAkcCnc3syD0O6w787pw7FHgaeKyk55UQfP01LF+u\nLnPBzMqa2WxgJTDOOfdVHsf0MLMZZjZj1apVwQcpyWfgQHjuObjlFrj88rCjKVXRaHm3BhY75350\nzm0HhgF7bjPVCRgUef4OcIpZnJe3SUYZGb4q0VlnhR2JhMw5t8M51wJIA1qbWdM8junvnEt3zqXX\nqlUr+CAluUybBtde64f0Hn887GhKXTSSd11gWa7XmZH38jzGOZcNrAdqROHcEqSMDF/IXzdiiXDO\nrQMmAGeEHYsksV9+gfPOgzp1YPhwKJf407liara5utli2LJlvttcXeZJz8xqmVm1yPPywKnAd+FG\nJUlryxY/s3zdOhg1CmrWDDuiQEQjeS8H6uV6nRZ5L89jzKwcUBVYs+cPUjdbDNu5EYmSt0AdYIKZ\nzQGm48e8x4QckyQj53zxlWnT4M03/X4LSSIafQvTgcZm1gifpC8BLt3jmAygK/AlcAHwmXNOs1Pj\nSUYGNG4Mhx0WdiQSMufcHOCYsOMQ4dFH4a234JFHfOs7iZS45R0Zw+4JfAwsAEY45+aZ2YNmtrOZ\n9ipQw8wWA7cCey0nkxj2xx/w2We+1a15hiISC0aP9nXLO3eGO+8MO5rARWVU3zk3Fhi7x3v35Xq+\nFbgwGueSEHzyiS98oC5zEYkFc+bAZZdBq1bw6qtJ2aiIqQlrEqNGjfJlBo8/PuxIRCTZrVzpGxJV\nq/p7U/nyYUcUisSfTy8lk5UFH3zgN7JPguUXIhLDtm2D88+H336DSZMSZm/u4tDdWPZt0iS/BKPT\nnnV3REQC5Bxcd52vVz5sGKSnhx1RqNRtLvs2erSvY37aaWFHIiLJ7Jln4PXX4d574eKLw44mdEre\nkj/nfPL++9+hYsWwoxGRZDV2rN9w5Pzz4f77w44mJih5S/7mzIGlS9VlLiLhmT3bt7SbN4dBg6CM\n0hYoecu+jB7tl2CcfXbYkYhIMlq+HDp0gGrVYMwY9QDmoglrkr/Ro6FNGzjwwLAjEZFks3GjT9zr\n18OUKUk9szwvanlL3pYtg1mzkq7koIjEgB07fOW0OXNgxAg4+uiwI4o5anlL3jIy/FeNd4tI0G69\n1XeTv/ginHlm2NHEJLW8JW+jR/tNSLQRiYgE6bnn/OPWW/26bsmTkrfsbe1amDBBrW4RCdb778Mt\nt/jhuscfDzuamKbkLXsbNQqys+Gii8KORESSxddf+3Huli393txly4YdUUxT8pa9DR8OhxziLyKR\nPZhZPTObYGbzzWyemd0UdkwS55YsgfbtoXp1P99GS8IKpOQtu1u9GsaP90URknCbPSmUbOA259yR\nQBvgBjM7MuSYJF6tXg2nn+43HfnoI6hTJ+yI4oJmm8vuRo70yzTUZS75cM79AvwSeb7BzBYAdYH5\noQYm8WfTJr+W++efYdw4OFJ/AxaWWt6yu+HDoUkTX4pQpABm1hA4Bvgqj896mNkMM5uxatWqoEOT\nWJeV5RsJ06fD0KFwwglhRxRXlLxll5Ur/Szziy5Sl7kUyMwqAe8CNzvn/tjzc+dcf+dcunMuvVat\nWsEHKLHLObjmGr/hSN++KgZVDEressu770JOjrbbkwKZWQo+cQ9xzr0XdjwSZ+6912/ved99cO21\nYUcTl5S8ZZdhw+CII+Coo8KORGKYmRnwKrDAOfdU2PFInHnxRXjkEbjqKm3vWQJK3uL9+CN88QV0\n6aIucylIW+ByoJ2ZzY482ocdlMSB4cOhZ0+/U2G/frrXlIBmm4v3xhv+Qrr88rAjkRjnnJsM6K4r\nRTNmjG8cnHCC7+Urp/RTEiVqeZtZdTMbZ2aLIl8PyOe4Hbn+Qs8oyTmlFOTk+OR9yilQr17Y0YhI\novnsM7jgAmjRwifxChXCjijulbTbvDcw3jnXGBgfeZ2XLc65FpFHxxKeU6Jt8mT46Sfo2jXsSEQk\n0UydCh07wqGH+iIsVaqEHVFCKGny7gQMijwfBGi+fzx67TWoVAnOPTfsSEQkkcye7bf0rFPHF2Gp\nUSPsiBJGSZP3gZFqSwC/Agfmc1xqpFjDVDNTgo8la9f6SSRduqiesIhEz8KFcNppvmHw6acqexpl\nBc4YMLNPgYPy+Oju3C+cc87MXD4/poFzbrmZHQJ8ZmbfOud+yONcPYAeAPXr1y8weImCgQNh61bt\nmysi0bNoEbRr5yfBjh8PDRqEHVHCKTB5O+f+nt9nZvabmdVxzv1iZnWAlfn8jOWRrz+a2UR8OcW9\nkrdzrj/QHyA9PT2/PwQkWnJy4KWX4Pjj4eijw45GRBLBokVw0kmwfbufqNakSdgRJaSSdptnADtn\nOXUFRu95gJkdYGb7R57XxK8R1QYGseCzz/yFpla3iETD99/vStwTJkCzZmFHlLBKmrwfBU41s0XA\n3yOvMbN0MxsQOeYIYIaZfQNMAB51zil5x4KnnoLatf0SDhGRkvj+ezj5ZL/hyIQJ0LRp2BEltBKt\nknfOrQFOyeP9GcBVkef/A/TnV6z59lv48EN4+GFITQ07GhGJZwsX+jHurCzfo6fEXepUHjVZPfmk\nn12uLnMRKYmvv4a//hWys5W4A6TknYwyM+Gtt6B7d6hePexoRCReTZ7sx7hTU2HSJCXuACl5J6NH\nHvFLOG65JexIRCReffSRX8ddpw5MmaJZ5QFT8k42P/4IAwb47fgaNgw7GhGJRyNG+JKnhx3mdyPU\nngiBU/JONg884HfzueeesCMRkXj0zDNwySVw3HF+Vnnt2mFHlJSUvJPJt9/Cm2/CDTfAwQeHHY2I\nxJMdO+Cmm/xw2znnwMcfQ7VqYUeVtJS8k4Vz0LOnv9juvDPsaCTOmdlrZrbSzOaGHYsEYNMmOO88\neO45n7zfflvbeoZMyTtZDB3qx6b+8x/t7CPRMBA4I+wgJAC//upnlI8ZA88/74s7lS0bdlRJr0RF\nWiRO/P479OoF6el+eZhICTnnvjCzhmHHIaVsxgy/VfDatTBqFJx9dtgRSYRa3smgZ09YtcpvQqK/\nmCUgZtYjshXwjFWrVoUdjhTVoEFwwgn+njF5shJ3jFHyTnQjRviCLPfdB8ceG3Y0kkScc/2dc+nO\nufRatWqFHY4UVlYW3HgjdOsGbdv61vcxx4QdlexByTuRLVoE11wDrVtrkpqIFGzJEvjb3/zY9i23\n+BnlNWuGHZXkQWPeiWrDBr+co2xZGD7cr+0WEcnPu+/6OTHO+XvGRReFHZHsg1reiSgrCzp39jv9\njBihSmoSdWY2FPgSOMzMMs1MMyHj1aZNcP31fmvgww6D2bOVuOOAmmOJZscOuPxy+OADP0GtXbuw\nI5IE5JzrHHYMEgWTJ8M//gGLF/sVKY88AvvtF3ZUUghqeSeS7dvhiit8l9fjj/vxbhGRPW3ZArfd\n5se3s7N9mdMnnlDijiNqeSeK9evh/PNh/HhfiOX228OOSERi0Sef+OWjixbBtdf6pF2pUthRSRGp\n5Z0IZs6Eli3h889h4EDo3TvsiEQk1ixf7seyTz/dT0obNw769VPijlNK3vFs2zZ46CE4/njfZT5x\nInTtGnZUIhJLtmyBRx+Fww+H99+HBx/0mxT9/e9hRyYloG7zeOQcjBwJd93lZ5RffDH07aua5SKy\ny44dvkrafff5VnfHjvD003DIIWFHJlGglnc82bwZXnvNV0o7/3wwgw8/hGHDlLhFxNuxw09abd7c\nr9tOS/NDaqNHK3EnELW8Y9327f7CGzXKlzldtw6OPBJefx26dFHxFRHxsrJgyBA/YfX77303+dtv\n75GnEZIAAAchSURBVPpDXxJKie78ZnYhcD9wBNDaOTcjn+POAJ4FygIDnHOPluS8CW3jRj8eNWWK\nX4M5caKfSV6+vO/2uu46v7xDF6OIgN90aMAAP/ls2TJo0cIn7XPP1UZECaykzba5wHnAy/kdYGZl\ngb7AqUAmMN3MMpxz80t47vjjnO/6XrXKj0EtXw6Zmf7x3Xcwfz4sXbrr+EMP9X81d+rkJ5dUqBBe\n7CISO5yDL7+El1/2w2bbt8Mpp/gE3r69/rhPAiVK3s65BQC27/8orYHFzrkfI8cOAzoBJUve27bB\n2LH+P3FJHzk5RTt2+3b/2LYt/+fbtsEff/hW87p1/uv69b4gwp7Kl4cmTfys8auugqZNoU0bOOig\nEv0TiUiC+eknePNNeOMNXxWtUiW4+mpf3vTII8OOTgIUxIBpXWBZrteZwHF5HWhmPYAeAPXr19/3\nT92wAc47LzoRFpcZ7L+/r0q082vu51WqQJ06cMQRULXqrkeNGn4SSd26/mu1avpLWUT25hzMm+cn\nm40a5bfnBDj5ZLj7bt8zV7lyuDFKKApM3mb2KZBXE/Bu59zoaAbjnOsP9AdIT093+zy4WjX4+muf\n9Er6KFOmaMfuTNBlyyrpikh0rV8Pkyb5aonvvw8//ODfP+44Pxmtc2do0CDcGCV0BSZv51xJV/Iv\nB+rlep0Wea9kypXzEzNEROLZr7/C9Ol+guqECb5iYk6ObyC0a+dLHXfs6HvxRCKC6DafDjQ2s0b4\npH0JcGkA5xURiR05ObBkiZ+YOneuT9jTp/sZ4uAbJG3a+O7wdu3889TUUEOW2FXSpWLnAs8DtYAP\nzGy2c+50MzsYvySsvXMu28x6Ah/jl4q95pybV+LIRURiTXa2X0WydKlP1EuW+DXX8+f7FSVbtuw6\n9v/+D9q2hVat/KNlS6hYMazIJc6UdLb5SGBkHu+vANrnej0WGFuSc4lI7Eiq2g07dviVI2vXwm+/\nwcqVuz9++813fS9d6pd97tix+/enpcFRR8FJJ/kZ4Uce6SexHnBAKL+OJAaV5xKRIgmldkNOjk+K\n2dn+kft5Xu9t3brrsWXL7l/zer7h/9u7oxepyjiM49+HbXOFNlZw18DWtttlCwQRQcHICMu1rsuC\n6LYLBUNa/ROC7KKLCG+CvAkqkkDQoNvCMg3Kii4qiCKji8SbUH5dvDM2jDO754hz3vfsPB84zJnZ\ngXkY5re/mXPe877X0kCx7uWdvfvXrw/PNTMDc3OwZQvs2QMLC2kwWfd22zYf+raRcPM2s7ru/twN\nKytpOdtBjfnmzdS8R2FyMjXX6el0aWf3cs75+XTb+9imTalJz82lbXY2DSozy8DN28zqqjR3Q615\nG5aW4ODBNGird5uYWPuxQfenptK2cePw/Q0bvDaAtZY/uWY2ErXmbTh0KG1mVomXBDWzukYzd4OZ\nVebmbWZ13Zq7QdK9pLkbzmTOZDZWfNjczGrx3A1m+Sli9VNRuUi6Cvyy5hPvns3AXw2+XhXOVM24\nZ3ooImYbeq074noGystUWh5wJqhYz8U276ZJ+jIiduTO0cuZqnEm61fi+19aptLygDPV4XPeZmZm\nLePmbWZm1jJu3v97J3eAAZypGmeyfiW+/6VlKi0POFNlPudtZmbWMv7lbWZm1jJu3gNIOiopJG0u\nIMvrkr6X9I2kjyTNZMqxX9IPkn6S9FqODH155iV9Juk7Sd9KOpw7U5ekCUlfS/okd5Zx51oemsX1\nXEHJtezm3UfSPPAk8GvuLB3ngaWIeBT4EVhpOkDPEpBPAYvAc5IWm87R5wZwNCIWgV3AKwVk6joM\nXMkdYty5lgdzPddSbC27ed/uJHAMKGIwQESci4gbnbufk+aRbtqtJSAj4l+guwRkNhHxe0Rc7Oxf\nIxXY1pyZACQ9CBwATuXOYq7lIVzPFZRey27ePSQ9C/wWEZdzZxniZeBshtcdtARk9kbZJWkB2A58\nkTcJAG+SGsaIFqC2KlzLq3I9V1N0LY/d3OaSPgUeGPCnE8Bx0mG2Rq2WKSI+7jznBOnQ0ukms5VO\n0n3AB8CRiPgnc5Zl4M+I+ErSYzmzjAPX8vpTSj23oZbHrnlHxBODHpf0CPAwcFkSpENaFyXtjIg/\ncmTqyfYSsAzsizzX9hW5BKSkSVKhn46ID3PnAXYDz0h6GpgC7pf0XkS8kDnXuuRavmOu57UVX8u+\nznsIST8DOyIi6yT5kvYDbwB7I+Jqpgz3kAbY7CMV+QXg+ZwrSSn9V34X+DsijuTKMUzn2/qrEbGc\nO8u4cy3flsP1XEOptexz3uV7C5gGzku6JOntpgN0Btl0l4C8ArxfwBKQu4EXgcc778ulzrdks1Jl\nr2VwPa8X/uVtZmbWMv7lbWZm1jJu3mZmZi3j5m1mZtYybt5mZmYt4+ZtZmbWMm7eZmZmLePmbWZm\n1jJu3mZmZi3zH58alggIp0WVAAAAAElFTkSuQmCC\n",
108 | "text/plain": [
109 | ""
110 | ]
111 | },
112 | "metadata": {},
113 | "output_type": "display_data"
114 | }
115 | ],
116 | "source": [
117 | "plt.figure(1, figsize=(8, 6))\n",
118 | "plt.subplot(221)\n",
119 | "plt.plot(x_np, y_relu, c='red', label='relu')\n",
120 | "plt.ylim((-1, 5))\n",
121 | "plt.legend(loc='best')\n",
122 | "\n",
123 | "plt.subplot(222)\n",
124 | "plt.plot(x_np, y_sigmoid, c='red', label='sigmoid')\n",
125 | "plt.ylim((-0.2, 1.2))\n",
126 | "plt.legend(loc='best')\n",
127 | "\n",
128 | "plt.subplot(223)\n",
129 | "plt.plot(x_np, y_tanh, c='red', label='tanh')\n",
130 | "plt.ylim((-1.2, 1.2))\n",
131 | "plt.legend(loc='best')\n",
132 | "\n",
133 | "plt.subplot(224)\n",
134 | "plt.plot(x_np, y_softplus, c='red', label='softplus')\n",
135 | "plt.ylim((-0.2, 6))\n",
136 | "plt.legend(loc='best')\n",
137 | "\n",
138 | "plt.show()"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": null,
144 | "metadata": {
145 | "collapsed": true
146 | },
147 | "outputs": [],
148 | "source": []
149 | }
150 | ],
151 | "metadata": {
152 | "kernelspec": {
153 | "display_name": "Python 3",
154 | "language": "python",
155 | "name": "python3"
156 | },
157 | "language_info": {
158 | "codemirror_mode": {
159 | "name": "ipython",
160 | "version": 3
161 | },
162 | "file_extension": ".py",
163 | "mimetype": "text/x-python",
164 | "name": "python",
165 | "nbconvert_exporter": "python",
166 | "pygments_lexer": "ipython3",
167 | "version": "3.5.2"
168 | }
169 | },
170 | "nbformat": 4,
171 | "nbformat_minor": 2
172 | }
173 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/303_build_nn_quickly.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 303 Build NN Quickly\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 1,
19 | "metadata": {
20 | "collapsed": true
21 | },
22 | "outputs": [],
23 | "source": [
24 | "import torch\n",
25 | "import torch.nn.functional as F"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 2,
31 | "metadata": {
32 | "collapsed": true
33 | },
34 | "outputs": [],
35 | "source": [
36 | "# replace following class code with an easy sequential network\n",
37 | "class Net(torch.nn.Module):\n",
38 | " def __init__(self, n_feature, n_hidden, n_output):\n",
39 | " super(Net, self).__init__()\n",
40 | " self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer\n",
41 | " self.predict = torch.nn.Linear(n_hidden, n_output) # output layer\n",
42 | "\n",
43 | " def forward(self, x):\n",
44 | " x = F.relu(self.hidden(x)) # activation function for hidden layer\n",
45 | " x = self.predict(x) # linear output\n",
46 | " return x"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 3,
52 | "metadata": {
53 | "collapsed": true
54 | },
55 | "outputs": [],
56 | "source": [
57 | "net1 = Net(1, 10, 1)"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 4,
63 | "metadata": {
64 | "collapsed": true
65 | },
66 | "outputs": [],
67 | "source": [
68 | "# easy and fast way to build your network\n",
69 | "net2 = torch.nn.Sequential(\n",
70 | " torch.nn.Linear(1, 10),\n",
71 | " torch.nn.ReLU(),\n",
72 | " torch.nn.Linear(10, 1)\n",
73 | ")\n"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 5,
79 | "metadata": {},
80 | "outputs": [
81 | {
82 | "name": "stdout",
83 | "output_type": "stream",
84 | "text": [
85 | "Net (\n",
86 | " (hidden): Linear (1 -> 10)\n",
87 | " (predict): Linear (10 -> 1)\n",
88 | ")\n",
89 | "Sequential (\n",
90 | " (0): Linear (1 -> 10)\n",
91 | " (1): ReLU ()\n",
92 | " (2): Linear (10 -> 1)\n",
93 | ")\n"
94 | ]
95 | }
96 | ],
97 | "source": [
98 | "print(net1) # net1 architecture\n",
99 | "print(net2) # net2 architecture"
100 | ]
101 | },
102 | {
103 | "cell_type": "code",
104 | "execution_count": null,
105 | "metadata": {
106 | "collapsed": true
107 | },
108 | "outputs": [],
109 | "source": []
110 | }
111 | ],
112 | "metadata": {
113 | "kernelspec": {
114 | "display_name": "Python 3",
115 | "language": "python",
116 | "name": "python3"
117 | },
118 | "language_info": {
119 | "codemirror_mode": {
120 | "name": "ipython",
121 | "version": 3
122 | },
123 | "file_extension": ".py",
124 | "mimetype": "text/x-python",
125 | "name": "python",
126 | "nbconvert_exporter": "python",
127 | "pygments_lexer": "ipython3",
128 | "version": "3.5.2"
129 | }
130 | },
131 | "nbformat": 4,
132 | "nbformat_minor": 2
133 | }
134 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/305_batch_train.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 305 Batch Train\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 1,
19 | "metadata": {},
20 | "outputs": [
21 | {
22 | "data": {
23 | "text/plain": [
24 | ""
25 | ]
26 | },
27 | "execution_count": 1,
28 | "metadata": {},
29 | "output_type": "execute_result"
30 | }
31 | ],
32 | "source": [
33 | "import torch\n",
34 | "import torch.utils.data as Data\n",
35 | "\n",
36 | "torch.manual_seed(1) # reproducible"
37 | ]
38 | },
39 | {
40 | "cell_type": "code",
41 | "execution_count": 2,
42 | "metadata": {
43 | "collapsed": true
44 | },
45 | "outputs": [],
46 | "source": [
47 | "BATCH_SIZE = 5\n",
48 | "# BATCH_SIZE = 8"
49 | ]
50 | },
51 | {
52 | "cell_type": "code",
53 | "execution_count": 3,
54 | "metadata": {
55 | "collapsed": true
56 | },
57 | "outputs": [],
58 | "source": [
59 | "x = torch.linspace(1, 10, 10) # this is x data (torch tensor)\n",
60 | "y = torch.linspace(10, 1, 10) # this is y data (torch tensor)\n"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 4,
66 | "metadata": {
67 | "collapsed": true
68 | },
69 | "outputs": [],
70 | "source": [
71 | "torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)\n",
72 | "loader = Data.DataLoader(\n",
73 | " dataset=torch_dataset, # torch TensorDataset format\n",
74 | " batch_size=BATCH_SIZE, # mini batch size\n",
75 | " shuffle=True, # random shuffle for training\n",
76 | " num_workers=2, # subprocesses for loading data\n",
77 | ")"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 5,
83 | "metadata": {},
84 | "outputs": [
85 | {
86 | "name": "stdout",
87 | "output_type": "stream",
88 | "text": [
89 | "Epoch: 0 | Step: 0 | batch x: [ 6. 7. 2. 3. 1.] | batch y: [ 5. 4. 9. 8. 10.]\n",
90 | "Epoch: 0 | Step: 1 | batch x: [ 9. 10. 4. 8. 5.] | batch y: [ 2. 1. 7. 3. 6.]\n",
91 | "Epoch: 1 | Step: 0 | batch x: [ 3. 4. 2. 9. 10.] | batch y: [ 8. 7. 9. 2. 1.]\n",
92 | "Epoch: 1 | Step: 1 | batch x: [ 1. 7. 8. 5. 6.] | batch y: [ 10. 4. 3. 6. 5.]\n",
93 | "Epoch: 2 | Step: 0 | batch x: [ 3. 9. 2. 6. 7.] | batch y: [ 8. 2. 9. 5. 4.]\n",
94 | "Epoch: 2 | Step: 1 | batch x: [ 10. 4. 8. 1. 5.] | batch y: [ 1. 7. 3. 10. 6.]\n"
95 | ]
96 | }
97 | ],
98 | "source": [
99 | "for epoch in range(3): # train entire dataset 3 times\n",
100 | " for step, (batch_x, batch_y) in enumerate(loader): # for each training step\n",
101 | " # train your data...\n",
102 | " print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',\n",
103 | " batch_x.numpy(), '| batch y: ', batch_y.numpy())\n"
104 | ]
105 | },
106 | {
107 | "cell_type": "markdown",
108 | "metadata": {},
109 | "source": [
110 | "### Suppose a different batch size that cannot be fully divided by the number of data entreis:"
111 | ]
112 | },
113 | {
114 | "cell_type": "code",
115 | "execution_count": 6,
116 | "metadata": {},
117 | "outputs": [
118 | {
119 | "name": "stdout",
120 | "output_type": "stream",
121 | "text": [
122 | "Epoch: 0 | Step: 0 | batch x: [ 3. 10. 9. 4. 7. 8. 2. 1.] | batch y: [ 8. 1. 2. 7. 4. 3. 9. 10.]\n",
123 | "Epoch: 0 | Step: 1 | batch x: [ 5. 6.] | batch y: [ 6. 5.]\n",
124 | "Epoch: 1 | Step: 0 | batch x: [ 4. 8. 3. 2. 1. 10. 5. 6.] | batch y: [ 7. 3. 8. 9. 10. 1. 6. 5.]\n",
125 | "Epoch: 1 | Step: 1 | batch x: [ 7. 9.] | batch y: [ 4. 2.]\n",
126 | "Epoch: 2 | Step: 0 | batch x: [ 6. 2. 4. 10. 9. 3. 8. 5.] | batch y: [ 5. 9. 7. 1. 2. 8. 3. 6.]\n",
127 | "Epoch: 2 | Step: 1 | batch x: [ 7. 1.] | batch y: [ 4. 10.]\n"
128 | ]
129 | }
130 | ],
131 | "source": [
132 | "BATCH_SIZE = 8\n",
133 | "loader = Data.DataLoader(\n",
134 | " dataset=torch_dataset, # torch TensorDataset format\n",
135 | " batch_size=BATCH_SIZE, # mini batch size\n",
136 | " shuffle=True, # random shuffle for training\n",
137 | " num_workers=2, # subprocesses for loading data\n",
138 | ")\n",
139 | "for epoch in range(3): # train entire dataset 3 times\n",
140 | " for step, (batch_x, batch_y) in enumerate(loader): # for each training step\n",
141 | " # train your data...\n",
142 | " print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',\n",
143 | " batch_x.numpy(), '| batch y: ', batch_y.numpy())"
144 | ]
145 | },
146 | {
147 | "cell_type": "code",
148 | "execution_count": null,
149 | "metadata": {
150 | "collapsed": true
151 | },
152 | "outputs": [],
153 | "source": []
154 | }
155 | ],
156 | "metadata": {
157 | "kernelspec": {
158 | "display_name": "Python 3",
159 | "language": "python",
160 | "name": "python3"
161 | },
162 | "language_info": {
163 | "codemirror_mode": {
164 | "name": "ipython",
165 | "version": 3
166 | },
167 | "file_extension": ".py",
168 | "mimetype": "text/x-python",
169 | "name": "python",
170 | "nbconvert_exporter": "python",
171 | "pygments_lexer": "ipython3",
172 | "version": "3.5.2"
173 | }
174 | },
175 | "nbformat": 4,
176 | "nbformat_minor": 2
177 | }
178 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/402_RNN.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 402 RNN\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11\n",
14 | "* matplotlib\n"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {
21 | "collapsed": true
22 | },
23 | "outputs": [],
24 | "source": [
25 | "import torch\n",
26 | "from torch import nn\n",
27 | "from torch.autograd import Variable\n",
28 | "import torchvision.datasets as dsets\n",
29 | "import torchvision.transforms as transforms\n",
30 | "import matplotlib.pyplot as plt\n",
31 | "%matplotlib inline"
32 | ]
33 | },
34 | {
35 | "cell_type": "code",
36 | "execution_count": 2,
37 | "metadata": {},
38 | "outputs": [
39 | {
40 | "data": {
41 | "text/plain": [
42 | ""
43 | ]
44 | },
45 | "execution_count": 2,
46 | "metadata": {},
47 | "output_type": "execute_result"
48 | }
49 | ],
50 | "source": [
51 | "torch.manual_seed(1) # reproducible"
52 | ]
53 | },
54 | {
55 | "cell_type": "code",
56 | "execution_count": 3,
57 | "metadata": {
58 | "collapsed": true
59 | },
60 | "outputs": [],
61 | "source": [
62 | "# Hyper Parameters\n",
63 | "EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch\n",
64 | "BATCH_SIZE = 64\n",
65 | "TIME_STEP = 28 # rnn time step / image height\n",
66 | "INPUT_SIZE = 28 # rnn input size / image width\n",
67 | "LR = 0.01 # learning rate\n",
68 | "DOWNLOAD_MNIST = True # set to True if haven't download the data"
69 | ]
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": 4,
74 | "metadata": {
75 | "collapsed": true
76 | },
77 | "outputs": [],
78 | "source": [
79 | "# Mnist digital dataset\n",
80 | "train_data = dsets.MNIST(\n",
81 | " root='./mnist/',\n",
82 | " train=True, # this is training data\n",
83 | " transform=transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to\n",
84 | " # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]\n",
85 | " download=DOWNLOAD_MNIST, # download it if you don't have it\n",
86 | ")"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 5,
92 | "metadata": {},
93 | "outputs": [
94 | {
95 | "name": "stdout",
96 | "output_type": "stream",
97 | "text": [
98 | "torch.Size([60000, 28, 28])\n",
99 | "torch.Size([60000])\n"
100 | ]
101 | },
102 | {
103 | "data": {
104 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAP8AAAEICAYAAACQ6CLfAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAADrpJREFUeJzt3X2sVHV+x/HPp6hpxAekpkhYLYsxGDWWbRAbQ1aNYX2I\nRlFjltSERiP7hyRu0pAa+sdqWqypD81SzQY26kKzdd1EjehufKiobGtCvCIq4qKu0SzkCjWIAj5Q\nuN/+cYftXb3zm8vMmTnD/b5fyeTOnO+cOd+c8OE8zvwcEQKQz5/U3QCAehB+ICnCDyRF+IGkCD+Q\nFOEHkiL8QFKEH6Oy/aLtL23vaTy21N0TqkX4UbI4Io5pPGbW3QyqRfiBpAg/Sv7Z9se2/9v2BXU3\ng2qZe/sxGtvnStosaZ+k70u6T9KsiPhdrY2hMoQfY2L7aUm/ioh/q7sXVIPdfoxVSHLdTaA6hB/f\nYHuS7Ytt/6ntI2z/jaTvSnq67t5QnSPqbgB96UhJ/yTpdEkHJP1W0lUR8U6tXaFSHPMDSbHbDyRF\n+IGkCD+QFOEHkurp2X7bnF0EuiwixnQ/RkdbftuX2N5i+z3bt3byWQB6q+1LfbYnSHpH0jxJWyW9\nImlBRGwuzMOWH+iyXmz550h6LyLej4h9kn4h6coOPg9AD3US/mmSfj/i9dbGtD9ie5HtAdsDHSwL\nQMW6fsIvIlZKWimx2w/0k062/NsknTzi9bca0wAcBjoJ/yuSTrP9bdtHafgHH9ZU0xaAbmt7tz8i\n9tteLOkZSRMkPRgRb1XWGYCu6um3+jjmB7qvJzf5ADh8EX4gKcIPJEX4gaQIP5AU4QeSIvxAUoQf\nSIrwA0kRfiApwg8kRfiBpAg/kBThB5Ii/EBShB9IivADSRF+ICnCDyRF+IGkCD+QFOEHkiL8QFKE\nH0iK8ANJEX4gKcIPJEX4gaQIP5BU20N04/AwYcKEYv3444/v6vIXL17ctHb00UcX5505c2axfvPN\nNxfrd999d9PaggULivN++eWXxfqdd95ZrN9+++3Fej/oKPy2P5C0W9IBSfsjYnYVTQHoviq2/BdG\nxMcVfA6AHuKYH0iq0/CHpGdtv2p70WhvsL3I9oDtgQ6XBaBCne72z42Ibbb/XNJztn8bEetGviEi\nVkpaKUm2o8PlAahIR1v+iNjW+LtD0uOS5lTRFIDuazv8tifaPvbgc0nfk7SpqsYAdFcnu/1TJD1u\n++Dn/EdEPF1JV+PMKaecUqwfddRRxfp5551XrM+dO7dpbdKkScV5r7nmmmK9Tlu3bi3Wly9fXqzP\nnz+/aW337t3FeV9//fVi/aWXXirWDwdthz8i3pf0lxX2AqCHuNQHJEX4gaQIP5AU4QeSIvxAUo7o\n3U134/UOv1mzZhXra9euLda7/bXafjU0NFSs33DDDcX6nj172l724OBgsf7JJ58U61u2bGl72d0W\nER7L+9jyA0kRfiApwg8kRfiBpAg/kBThB5Ii/EBSXOevwOTJk4v19evXF+szZsyosp1Ktep9165d\nxfqFF17YtLZv377ivFnvf+gU1/kBFBF+ICnCDyRF+IGkCD+QFOEHkiL8QFIM0V2BnTt3FutLliwp\n1i+//PJi/bXXXivWW/2EdcnGjRuL9Xnz5hXre/fuLdbPPPPMprVbbrmlOC+6iy0/kBThB5Ii/EBS\nhB9IivADSRF+ICnCDyTF9/n7wHHHHVestxpOesWKFU1rN954Y3He66+/vlh/+OGHi3X0n8q+z2/7\nQds7bG8aMW2y7edsv9v4e0InzQLovbHs9v9M0iVfm3arpOcj4jRJzzdeAziMtAx/RKyT9PX7V6+U\ntKrxfJWkqyruC0CXtXtv/5SIODjY2UeSpjR7o+1Fkha1uRwAXdLxF3siIkon8iJipaSVEif8gH7S\n7qW+7banSlLj747qWgLQC+2Gf42khY3nCyU9UU07AHql5W6/7YclXSDpRNtbJf1I0p2Sfmn7Rkkf\nSrqum02Od5999llH83/66adtz3vTTTcV64888kixPjQ01PayUa+W4Y+IBU1KF1XcC4Ae4vZeICnC\nDyRF+IGkCD+QFOEHkuIrvePAxIkTm9aefPLJ4rznn39+sX7ppZcW688++2yxjt5jiG4ARYQfSIrw\nA0kRfiApwg8kRfiBpAg/kBTX+ce5U089tVjfsGFDsb5r165i/YUXXijWBwYGmtbuv//+4ry9/Lc5\nnnCdH0AR4QeSIvxAUoQfSIrwA0kRfiApwg8kxXX+5ObPn1+sP/TQQ8X6scce2/ayly5dWqyvXr26\nWB8cHCzWs+I6P4Aiwg8kRfiBpAg/kBThB5Ii/EBShB9Iiuv8KDrrrLOK9XvvvbdYv+ii9gdzXrFi\nRbG+bNmyYn3btm1tL/twVtl1ftsP2t5he9OIabfZ3mZ7Y+NxWSfNAui9sez2/0zSJaNM/9eImNV4\n/LratgB0W8vwR8Q6STt70AuAHurkhN9i2280DgtOaPYm24tsD9hu/mNuAHqu3fD/RNKpkmZJGpR0\nT7M3RsTKiJgdEbPbXBaALmgr/BGxPSIORMSQpJ9KmlNtWwC6ra3w25464uV8SZuavRdAf2p5nd/2\nw5IukHSipO2SftR4PUtSSPpA0g8iouWXq7nOP/5MmjSpWL/iiiua1lr9VoBdvly9du3aYn3evHnF\n+ng11uv8R4zhgxaMMvmBQ+4IQF/h9l4gKcIPJEX4gaQIP5AU4QeS4iu9qM1XX31VrB9xRPli1P79\n+4v1iy++uGntxRdfLM57OOOnuwEUEX4gKcIPJEX4gaQIP5AU4QeSIvxAUi2/1Yfczj777GL92muv\nLdbPOeecprVW1/Fb2bx5c7G+bt26jj5/vGPLDyRF+IGkCD+QFOEHkiL8QFKEH0iK8ANJcZ1/nJs5\nc2axvnjx4mL96quvLtZPOumkQ+5prA4cOFCsDw6Wfy1+aGioynbGHbb8QFKEH0iK8ANJEX4gKcIP\nJEX4gaQIP5BUy+v8tk+WtFrSFA0Pyb0yIn5se7KkRyRN1/Aw3ddFxCfdazWvVtfSFywYbSDlYa2u\n40+fPr2dlioxMDBQrC9btqxYX7NmTZXtpDOWLf9+SX8XEWdI+mtJN9s+Q9Ktkp6PiNMkPd94DeAw\n0TL8ETEYERsaz3dLelvSNElXSlrVeNsqSVd1q0kA1TukY37b0yV9R9J6SVMi4uD9lR9p+LAAwGFi\nzPf22z5G0qOSfhgRn9n/PxxYRESzcfhsL5K0qNNGAVRrTFt+20dqOPg/j4jHGpO3257aqE+VtGO0\neSNiZUTMjojZVTQMoBotw+/hTfwDkt6OiHtHlNZIWth4vlDSE9W3B6BbWg7RbXuupN9IelPSwe9I\nLtXwcf8vJZ0i6UMNX+rb2eKzUg7RPWVK+XTIGWecUazfd999xfrpp59+yD1VZf369cX6XXfd1bT2\nxBPl7QVfyW3PWIfobnnMHxH/JanZh110KE0B6B/c4QckRfiBpAg/kBThB5Ii/EBShB9Iip/uHqPJ\nkyc3ra1YsaI476xZs4r1GTNmtNVTFV5++eVi/Z577inWn3nmmWL9iy++OOSe0Bts+YGkCD+QFOEH\nkiL8QFKEH0iK8ANJEX4gqTTX+c8999xifcmSJcX6nDlzmtamTZvWVk9V+fzzz5vWli9fXpz3jjvu\nKNb37t3bVk/of2z5gaQIP5AU4QeSIvxAUoQfSIrwA0kRfiCpNNf558+f31G9E5s3by7Wn3rqqWJ9\n//79xXrpO/e7du0qzou82PIDSRF+ICnCDyRF+IGkCD+QFOEHkiL8QFKOiPIb7JMlrZY0RVJIWhkR\nP7Z9m6SbJP1P461LI+LXLT6rvDAAHYsIj+V9Ywn/VElTI2KD7WMlvSrpKknXSdoTEXePtSnCD3Tf\nWMPf8g6/iBiUNNh4vtv225Lq/ekaAB07pGN+29MlfUfS+sakxbbfsP2g7ROazLPI9oDtgY46BVCp\nlrv9f3ijfYyklyQti4jHbE+R9LGGzwP8o4YPDW5o8Rns9gNdVtkxvyTZPlLSU5KeiYh7R6lPl/RU\nRJzV4nMIP9BlYw1/y91+25b0gKS3Rwa/cSLwoPmSNh1qkwDqM5az/XMl/UbSm5KGGpOXSlogaZaG\nd/s/kPSDxsnB0mex5Qe6rNLd/qoQfqD7KtvtBzA+EX4gKcIPJEX4gaQIP5AU4QeSIvxAUoQfSIrw\nA0kRfiApwg8kRfiBpAg/kBThB5Lq9RDdH0v6cMTrExvT+lG/9tavfUn01q4qe/uLsb6xp9/n/8bC\n7YGImF1bAwX92lu/9iXRW7vq6o3dfiApwg8kVXf4V9a8/JJ+7a1f+5LorV219FbrMT+A+tS95QdQ\nE8IPJFVL+G1fYnuL7fds31pHD83Y/sD2m7Y31j2+YGMMxB22N42YNtn2c7bfbfwddYzEmnq7zfa2\nxrrbaPuymno72fYLtjfbfsv2LY3pta67Ql+1rLeeH/PbniDpHUnzJG2V9IqkBRGxuaeNNGH7A0mz\nI6L2G0Jsf1fSHkmrDw6FZvtfJO2MiDsb/3GeEBF/3ye93aZDHLa9S701G1b+b1XjuqtyuPsq1LHl\nnyPpvYh4PyL2SfqFpCtr6KPvRcQ6STu/NvlKSasaz1dp+B9PzzXprS9ExGBEbGg83y3p4LDyta67\nQl+1qCP80yT9fsTrrapxBYwiJD1r+1Xbi+puZhRTRgyL9pGkKXU2M4qWw7b30teGle+bddfOcPdV\n44TfN82NiL+SdKmkmxu7t30pho/Z+ula7U8knarhMRwHJd1TZzONYeUflfTDiPhsZK3OdTdKX7Ws\ntzrCv03SySNef6sxrS9ExLbG3x2SHtfwYUo/2X5whOTG3x019/MHEbE9Ig5ExJCkn6rGddcYVv5R\nST+PiMcak2tfd6P1Vdd6qyP8r0g6zfa3bR8l6fuS1tTQxzfYntg4ESPbEyV9T/039PgaSQsbzxdK\neqLGXv5Ivwzb3mxYedW87vpuuPuI6PlD0mUaPuP/O0n/UEcPTfqaIen1xuOtunuT9LCGdwP/V8Pn\nRm6U9GeSnpf0rqT/lDS5j3r7dw0P5f6GhoM2tabe5mp4l/4NSRsbj8vqXneFvmpZb9zeCyTFCT8g\nKcIPJEX4gaQIP5AU4QeSIvxAUoQfSOr/AH6evjIXWuv8AAAAAElFTkSuQmCC\n",
105 | "text/plain": [
106 | ""
107 | ]
108 | },
109 | "metadata": {},
110 | "output_type": "display_data"
111 | }
112 | ],
113 | "source": [
114 | "# plot one example\n",
115 | "print(train_data.train_data.size()) # (60000, 28, 28)\n",
116 | "print(train_data.train_labels.size()) # (60000)\n",
117 | "plt.imshow(train_data.train_data[0].numpy(), cmap='gray')\n",
118 | "plt.title('%i' % train_data.train_labels[0])\n",
119 | "plt.show()"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 6,
125 | "metadata": {
126 | "collapsed": true
127 | },
128 | "outputs": [],
129 | "source": [
130 | "# Data Loader for easy mini-batch return in training\n",
131 | "train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)"
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": 7,
137 | "metadata": {
138 | "collapsed": true
139 | },
140 | "outputs": [],
141 | "source": [
142 | "# convert test data into Variable, pick 2000 samples to speed up testing\n",
143 | "test_data = dsets.MNIST(root='./mnist/', train=False, transform=transforms.ToTensor())\n",
144 | "test_x = Variable(test_data.test_data, volatile=True).type(torch.FloatTensor)[:2000]/255. # shape (2000, 28, 28) value in range(0,1)\n",
145 | "test_y = test_data.test_labels.numpy().squeeze()[:2000] # covert to numpy array"
146 | ]
147 | },
148 | {
149 | "cell_type": "code",
150 | "execution_count": 8,
151 | "metadata": {
152 | "collapsed": true
153 | },
154 | "outputs": [],
155 | "source": [
156 | "class RNN(nn.Module):\n",
157 | " def __init__(self):\n",
158 | " super(RNN, self).__init__()\n",
159 | "\n",
160 | " self.rnn = nn.LSTM( # if use nn.RNN(), it hardly learns\n",
161 | " input_size=INPUT_SIZE,\n",
162 | " hidden_size=64, # rnn hidden unit\n",
163 | " num_layers=1, # number of rnn layer\n",
164 | " batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)\n",
165 | " )\n",
166 | "\n",
167 | " self.out = nn.Linear(64, 10)\n",
168 | "\n",
169 | " def forward(self, x):\n",
170 | " # x shape (batch, time_step, input_size)\n",
171 | " # r_out shape (batch, time_step, output_size)\n",
172 | " # h_n shape (n_layers, batch, hidden_size)\n",
173 | " # h_c shape (n_layers, batch, hidden_size)\n",
174 | " r_out, (h_n, h_c) = self.rnn(x, None) # None represents zero initial hidden state\n",
175 | "\n",
176 | " # choose r_out at the last time step\n",
177 | " out = self.out(r_out[:, -1, :])\n",
178 | " return out"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 9,
184 | "metadata": {},
185 | "outputs": [
186 | {
187 | "name": "stdout",
188 | "output_type": "stream",
189 | "text": [
190 | "RNN (\n",
191 | " (rnn): LSTM(28, 64, batch_first=True)\n",
192 | " (out): Linear (64 -> 10)\n",
193 | ")\n"
194 | ]
195 | }
196 | ],
197 | "source": [
198 | "rnn = RNN()\n",
199 | "print(rnn)"
200 | ]
201 | },
202 | {
203 | "cell_type": "code",
204 | "execution_count": 10,
205 | "metadata": {
206 | "collapsed": true
207 | },
208 | "outputs": [],
209 | "source": [
210 | "optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters\n",
211 | "loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted"
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "execution_count": 11,
217 | "metadata": {},
218 | "outputs": [
219 | {
220 | "name": "stdout",
221 | "output_type": "stream",
222 | "text": [
223 | "Epoch: 0 | train loss: 2.3127 | test accuracy: 0.14\n",
224 | "Epoch: 0 | train loss: 1.1182 | test accuracy: 0.56\n",
225 | "Epoch: 0 | train loss: 0.9374 | test accuracy: 0.68\n",
226 | "Epoch: 0 | train loss: 0.6279 | test accuracy: 0.75\n",
227 | "Epoch: 0 | train loss: 0.8004 | test accuracy: 0.75\n",
228 | "Epoch: 0 | train loss: 0.3407 | test accuracy: 0.88\n",
229 | "Epoch: 0 | train loss: 0.3342 | test accuracy: 0.89\n",
230 | "Epoch: 0 | train loss: 0.3200 | test accuracy: 0.91\n",
231 | "Epoch: 0 | train loss: 0.3430 | test accuracy: 0.92\n",
232 | "Epoch: 0 | train loss: 0.1234 | test accuracy: 0.93\n",
233 | "Epoch: 0 | train loss: 0.2714 | test accuracy: 0.92\n",
234 | "Epoch: 0 | train loss: 0.1043 | test accuracy: 0.93\n",
235 | "Epoch: 0 | train loss: 0.2893 | test accuracy: 0.93\n",
236 | "Epoch: 0 | train loss: 0.0635 | test accuracy: 0.94\n",
237 | "Epoch: 0 | train loss: 0.2412 | test accuracy: 0.94\n",
238 | "Epoch: 0 | train loss: 0.1203 | test accuracy: 0.92\n",
239 | "Epoch: 0 | train loss: 0.0807 | test accuracy: 0.94\n",
240 | "Epoch: 0 | train loss: 0.1307 | test accuracy: 0.94\n",
241 | "Epoch: 0 | train loss: 0.1166 | test accuracy: 0.95\n"
242 | ]
243 | }
244 | ],
245 | "source": [
246 | "# training and testing\n",
247 | "for epoch in range(EPOCH):\n",
248 | " for step, (x, y) in enumerate(train_loader): # gives batch data\n",
249 | " b_x = Variable(x.view(-1, 28, 28)) # reshape x to (batch, time_step, input_size)\n",
250 | " b_y = Variable(y) # batch y\n",
251 | "\n",
252 | " output = rnn(b_x) # rnn output\n",
253 | " loss = loss_func(output, b_y) # cross entropy loss\n",
254 | " optimizer.zero_grad() # clear gradients for this training step\n",
255 | " loss.backward() # backpropagation, compute gradients\n",
256 | " optimizer.step() # apply gradients\n",
257 | "\n",
258 | " if step % 50 == 0:\n",
259 | " test_output = rnn(test_x) # (samples, time_step, input_size)\n",
260 | " pred_y = torch.max(test_output, 1)[1].data.numpy().squeeze()\n",
261 | " accuracy = sum(pred_y == test_y) / float(test_y.size)\n",
262 | " print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0], '| test accuracy: %.2f' % accuracy)\n"
263 | ]
264 | },
265 | {
266 | "cell_type": "code",
267 | "execution_count": 16,
268 | "metadata": {},
269 | "outputs": [
270 | {
271 | "name": "stdout",
272 | "output_type": "stream",
273 | "text": [
274 | "[7 2 1 0 4 1 4 9 5 9] prediction number\n",
275 | "[7 2 1 0 4 1 4 9 5 9] real number\n"
276 | ]
277 | }
278 | ],
279 | "source": [
280 | "# print 10 predictions from test data\n",
281 | "test_output = rnn(test_x[:10].view(-1, 28, 28))\n",
282 | "pred_y = torch.max(test_output, 1)[1].data.numpy().squeeze()\n",
283 | "print(pred_y, 'prediction number')\n",
284 | "print(test_y[:10], 'real number')"
285 | ]
286 | },
287 | {
288 | "cell_type": "code",
289 | "execution_count": null,
290 | "metadata": {
291 | "collapsed": true
292 | },
293 | "outputs": [],
294 | "source": []
295 | }
296 | ],
297 | "metadata": {
298 | "kernelspec": {
299 | "display_name": "Python 3",
300 | "language": "python",
301 | "name": "python3"
302 | },
303 | "language_info": {
304 | "codemirror_mode": {
305 | "name": "ipython",
306 | "version": 3
307 | },
308 | "file_extension": ".py",
309 | "mimetype": "text/x-python",
310 | "name": "python",
311 | "nbconvert_exporter": "python",
312 | "pygments_lexer": "ipython3",
313 | "version": "3.5.2"
314 | }
315 | },
316 | "nbformat": 4,
317 | "nbformat_minor": 2
318 | }
319 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/405_DQN_Reinforcement_learning.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 405 DQN Reinforcement Learning\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "More about Reinforcement learning: https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/\n",
12 | "\n",
13 | "Dependencies:\n",
14 | "* torch: 0.1.11\n",
15 | "* gym: 0.8.1\n",
16 | "* numpy"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": 1,
22 | "metadata": {
23 | "collapsed": true
24 | },
25 | "outputs": [],
26 | "source": [
27 | "import torch\n",
28 | "import torch.nn as nn\n",
29 | "from torch.autograd import Variable\n",
30 | "import torch.nn.functional as F\n",
31 | "import numpy as np\n",
32 | "import gym"
33 | ]
34 | },
35 | {
36 | "cell_type": "code",
37 | "execution_count": 2,
38 | "metadata": {},
39 | "outputs": [
40 | {
41 | "name": "stderr",
42 | "output_type": "stream",
43 | "text": [
44 | "[2017-06-20 22:23:40,418] Making new env: CartPole-v0\n"
45 | ]
46 | }
47 | ],
48 | "source": [
49 | "# Hyper Parameters\n",
50 | "BATCH_SIZE = 32\n",
51 | "LR = 0.01 # learning rate\n",
52 | "EPSILON = 0.9 # greedy policy\n",
53 | "GAMMA = 0.9 # reward discount\n",
54 | "TARGET_REPLACE_ITER = 100 # target update frequency\n",
55 | "MEMORY_CAPACITY = 2000\n",
56 | "env = gym.make('CartPole-v0')\n",
57 | "env = env.unwrapped\n",
58 | "N_ACTIONS = env.action_space.n\n",
59 | "N_STATES = env.observation_space.shape[0]"
60 | ]
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": 3,
65 | "metadata": {
66 | "collapsed": true
67 | },
68 | "outputs": [],
69 | "source": [
70 | "class Net(nn.Module):\n",
71 | " def __init__(self, ):\n",
72 | " super(Net, self).__init__()\n",
73 | " self.fc1 = nn.Linear(N_STATES, 10)\n",
74 | " self.fc1.weight.data.normal_(0, 0.1) # initialization\n",
75 | " self.out = nn.Linear(10, N_ACTIONS)\n",
76 | " self.out.weight.data.normal_(0, 0.1) # initialization\n",
77 | "\n",
78 | " def forward(self, x):\n",
79 | " x = self.fc1(x)\n",
80 | " x = F.relu(x)\n",
81 | " actions_value = self.out(x)\n",
82 | " return actions_value"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 4,
88 | "metadata": {
89 | "collapsed": true
90 | },
91 | "outputs": [],
92 | "source": [
93 | "class DQN(object):\n",
94 | " def __init__(self):\n",
95 | " self.eval_net, self.target_net = Net(), Net()\n",
96 | "\n",
97 | " self.learn_step_counter = 0 # for target updating\n",
98 | " self.memory_counter = 0 # for storing memory\n",
99 | " self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # initialize memory\n",
100 | " self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR)\n",
101 | " self.loss_func = nn.MSELoss()\n",
102 | "\n",
103 | " def choose_action(self, x):\n",
104 | " x = Variable(torch.unsqueeze(torch.FloatTensor(x), 0))\n",
105 | " # input only one sample\n",
106 | " if np.random.uniform() < EPSILON: # greedy\n",
107 | " actions_value = self.eval_net.forward(x)\n",
108 | " action = torch.max(actions_value, 1)[1].data.numpy()[0, 0] # return the argmax\n",
109 | " else: # random\n",
110 | " action = np.random.randint(0, N_ACTIONS)\n",
111 | " return action\n",
112 | "\n",
113 | " def store_transition(self, s, a, r, s_):\n",
114 | " transition = np.hstack((s, [a, r], s_))\n",
115 | " # replace the old memory with new memory\n",
116 | " index = self.memory_counter % MEMORY_CAPACITY\n",
117 | " self.memory[index, :] = transition\n",
118 | " self.memory_counter += 1\n",
119 | "\n",
120 | " def learn(self):\n",
121 | " # target parameter update\n",
122 | " if self.learn_step_counter % TARGET_REPLACE_ITER == 0:\n",
123 | " self.target_net.load_state_dict(self.eval_net.state_dict())\n",
124 | " self.learn_step_counter += 1\n",
125 | "\n",
126 | " # sample batch transitions\n",
127 | " sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE)\n",
128 | " b_memory = self.memory[sample_index, :]\n",
129 | " b_s = Variable(torch.FloatTensor(b_memory[:, :N_STATES]))\n",
130 | " b_a = Variable(torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int)))\n",
131 | " b_r = Variable(torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2]))\n",
132 | " b_s_ = Variable(torch.FloatTensor(b_memory[:, -N_STATES:]))\n",
133 | "\n",
134 | " # q_eval w.r.t the action in experience\n",
135 | " q_eval = self.eval_net(b_s).gather(1, b_a) # shape (batch, 1)\n",
136 | " q_next = self.target_net(b_s_).detach() # detach from graph, don't backpropagate\n",
137 | " q_target = b_r + GAMMA * q_next.max(1)[0] # shape (batch, 1)\n",
138 | " loss = self.loss_func(q_eval, q_target)\n",
139 | "\n",
140 | " self.optimizer.zero_grad()\n",
141 | " loss.backward()\n",
142 | " self.optimizer.step()"
143 | ]
144 | },
145 | {
146 | "cell_type": "code",
147 | "execution_count": 5,
148 | "metadata": {
149 | "collapsed": true
150 | },
151 | "outputs": [],
152 | "source": [
153 | "dqn = DQN()"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": 6,
159 | "metadata": {},
160 | "outputs": [
161 | {
162 | "name": "stdout",
163 | "output_type": "stream",
164 | "text": [
165 | "\n",
166 | "Collecting experience...\n",
167 | "Ep: 201 | Ep_r: 1.59\n",
168 | "Ep: 202 | Ep_r: 4.18\n",
169 | "Ep: 203 | Ep_r: 2.73\n",
170 | "Ep: 204 | Ep_r: 1.97\n",
171 | "Ep: 205 | Ep_r: 1.18\n",
172 | "Ep: 206 | Ep_r: 0.86\n",
173 | "Ep: 207 | Ep_r: 2.88\n",
174 | "Ep: 208 | Ep_r: 1.63\n",
175 | "Ep: 209 | Ep_r: 3.91\n",
176 | "Ep: 210 | Ep_r: 3.6\n",
177 | "Ep: 211 | Ep_r: 0.98\n",
178 | "Ep: 212 | Ep_r: 3.85\n",
179 | "Ep: 213 | Ep_r: 1.81\n",
180 | "Ep: 214 | Ep_r: 2.32\n",
181 | "Ep: 215 | Ep_r: 3.75\n",
182 | "Ep: 216 | Ep_r: 3.53\n",
183 | "Ep: 217 | Ep_r: 4.75\n",
184 | "Ep: 218 | Ep_r: 2.4\n",
185 | "Ep: 219 | Ep_r: 0.64\n",
186 | "Ep: 220 | Ep_r: 1.15\n",
187 | "Ep: 221 | Ep_r: 2.3\n",
188 | "Ep: 222 | Ep_r: 7.37\n",
189 | "Ep: 223 | Ep_r: 1.25\n",
190 | "Ep: 224 | Ep_r: 5.02\n",
191 | "Ep: 225 | Ep_r: 10.29\n",
192 | "Ep: 226 | Ep_r: 17.54\n",
193 | "Ep: 227 | Ep_r: 36.2\n",
194 | "Ep: 228 | Ep_r: 6.61\n",
195 | "Ep: 229 | Ep_r: 10.04\n",
196 | "Ep: 230 | Ep_r: 55.19\n",
197 | "Ep: 231 | Ep_r: 10.03\n",
198 | "Ep: 232 | Ep_r: 13.25\n",
199 | "Ep: 233 | Ep_r: 8.75\n",
200 | "Ep: 234 | Ep_r: 3.83\n",
201 | "Ep: 235 | Ep_r: -0.92\n",
202 | "Ep: 236 | Ep_r: 5.12\n",
203 | "Ep: 237 | Ep_r: 3.56\n",
204 | "Ep: 238 | Ep_r: 5.69\n",
205 | "Ep: 239 | Ep_r: 8.43\n",
206 | "Ep: 240 | Ep_r: 29.27\n",
207 | "Ep: 241 | Ep_r: 17.95\n",
208 | "Ep: 242 | Ep_r: 44.77\n",
209 | "Ep: 243 | Ep_r: 98.0\n",
210 | "Ep: 244 | Ep_r: 38.78\n",
211 | "Ep: 245 | Ep_r: 45.02\n",
212 | "Ep: 246 | Ep_r: 27.73\n",
213 | "Ep: 247 | Ep_r: 36.96\n",
214 | "Ep: 248 | Ep_r: 48.98\n",
215 | "Ep: 249 | Ep_r: 111.36\n",
216 | "Ep: 250 | Ep_r: 95.61\n",
217 | "Ep: 251 | Ep_r: 149.77\n",
218 | "Ep: 252 | Ep_r: 29.96\n",
219 | "Ep: 253 | Ep_r: 2.79\n",
220 | "Ep: 254 | Ep_r: 20.1\n",
221 | "Ep: 255 | Ep_r: 24.25\n",
222 | "Ep: 256 | Ep_r: 3074.75\n",
223 | "Ep: 257 | Ep_r: 1258.49\n",
224 | "Ep: 258 | Ep_r: 127.39\n",
225 | "Ep: 259 | Ep_r: 283.46\n",
226 | "Ep: 260 | Ep_r: 166.96\n",
227 | "Ep: 261 | Ep_r: 101.71\n",
228 | "Ep: 262 | Ep_r: 63.45\n",
229 | "Ep: 263 | Ep_r: 288.94\n",
230 | "Ep: 264 | Ep_r: 130.49\n",
231 | "Ep: 265 | Ep_r: 207.05\n",
232 | "Ep: 266 | Ep_r: 183.71\n",
233 | "Ep: 267 | Ep_r: 142.75\n",
234 | "Ep: 268 | Ep_r: 126.53\n",
235 | "Ep: 269 | Ep_r: 310.79\n",
236 | "Ep: 270 | Ep_r: 863.2\n",
237 | "Ep: 271 | Ep_r: 365.12\n",
238 | "Ep: 272 | Ep_r: 659.52\n",
239 | "Ep: 273 | Ep_r: 103.98\n",
240 | "Ep: 274 | Ep_r: 554.83\n",
241 | "Ep: 275 | Ep_r: 246.01\n",
242 | "Ep: 276 | Ep_r: 332.23\n",
243 | "Ep: 277 | Ep_r: 323.35\n",
244 | "Ep: 278 | Ep_r: 278.71\n",
245 | "Ep: 279 | Ep_r: 613.6\n",
246 | "Ep: 280 | Ep_r: 152.21\n",
247 | "Ep: 281 | Ep_r: 402.02\n",
248 | "Ep: 282 | Ep_r: 351.4\n",
249 | "Ep: 283 | Ep_r: 115.87\n",
250 | "Ep: 284 | Ep_r: 163.26\n",
251 | "Ep: 285 | Ep_r: 631.0\n",
252 | "Ep: 286 | Ep_r: 263.47\n",
253 | "Ep: 287 | Ep_r: 511.21\n",
254 | "Ep: 288 | Ep_r: 337.18\n",
255 | "Ep: 289 | Ep_r: 819.76\n",
256 | "Ep: 290 | Ep_r: 190.83\n",
257 | "Ep: 291 | Ep_r: 442.98\n",
258 | "Ep: 292 | Ep_r: 537.24\n",
259 | "Ep: 293 | Ep_r: 1101.12\n",
260 | "Ep: 294 | Ep_r: 178.42\n",
261 | "Ep: 295 | Ep_r: 225.61\n",
262 | "Ep: 296 | Ep_r: 252.62\n",
263 | "Ep: 297 | Ep_r: 617.5\n",
264 | "Ep: 298 | Ep_r: 617.8\n",
265 | "Ep: 299 | Ep_r: 244.01\n",
266 | "Ep: 300 | Ep_r: 687.91\n",
267 | "Ep: 301 | Ep_r: 618.51\n",
268 | "Ep: 302 | Ep_r: 1405.07\n",
269 | "Ep: 303 | Ep_r: 456.95\n",
270 | "Ep: 304 | Ep_r: 340.33\n",
271 | "Ep: 305 | Ep_r: 502.91\n",
272 | "Ep: 306 | Ep_r: 441.21\n",
273 | "Ep: 307 | Ep_r: 255.81\n",
274 | "Ep: 308 | Ep_r: 403.03\n",
275 | "Ep: 309 | Ep_r: 229.1\n",
276 | "Ep: 310 | Ep_r: 308.49\n",
277 | "Ep: 311 | Ep_r: 165.37\n",
278 | "Ep: 312 | Ep_r: 153.76\n",
279 | "Ep: 313 | Ep_r: 442.05\n",
280 | "Ep: 314 | Ep_r: 229.23\n",
281 | "Ep: 315 | Ep_r: 128.52\n",
282 | "Ep: 316 | Ep_r: 358.18\n",
283 | "Ep: 317 | Ep_r: 319.03\n",
284 | "Ep: 318 | Ep_r: 381.76\n",
285 | "Ep: 319 | Ep_r: 199.19\n",
286 | "Ep: 320 | Ep_r: 418.63\n",
287 | "Ep: 321 | Ep_r: 223.95\n",
288 | "Ep: 322 | Ep_r: 222.37\n",
289 | "Ep: 323 | Ep_r: 405.4\n",
290 | "Ep: 324 | Ep_r: 311.32\n",
291 | "Ep: 325 | Ep_r: 184.85\n",
292 | "Ep: 326 | Ep_r: 1026.71\n",
293 | "Ep: 327 | Ep_r: 252.41\n",
294 | "Ep: 328 | Ep_r: 224.93\n",
295 | "Ep: 329 | Ep_r: 620.02\n",
296 | "Ep: 330 | Ep_r: 174.54\n",
297 | "Ep: 331 | Ep_r: 782.45\n",
298 | "Ep: 332 | Ep_r: 263.79\n",
299 | "Ep: 333 | Ep_r: 178.63\n",
300 | "Ep: 334 | Ep_r: 242.84\n",
301 | "Ep: 335 | Ep_r: 635.43\n",
302 | "Ep: 336 | Ep_r: 668.89\n",
303 | "Ep: 337 | Ep_r: 265.42\n",
304 | "Ep: 338 | Ep_r: 207.81\n",
305 | "Ep: 339 | Ep_r: 293.09\n",
306 | "Ep: 340 | Ep_r: 530.23\n",
307 | "Ep: 341 | Ep_r: 479.26\n",
308 | "Ep: 342 | Ep_r: 559.77\n",
309 | "Ep: 343 | Ep_r: 241.39\n",
310 | "Ep: 344 | Ep_r: 158.83\n",
311 | "Ep: 345 | Ep_r: 1510.69\n",
312 | "Ep: 346 | Ep_r: 425.17\n",
313 | "Ep: 347 | Ep_r: 266.94\n",
314 | "Ep: 348 | Ep_r: 166.08\n",
315 | "Ep: 349 | Ep_r: 630.52\n",
316 | "Ep: 350 | Ep_r: 250.95\n",
317 | "Ep: 351 | Ep_r: 625.88\n",
318 | "Ep: 352 | Ep_r: 417.7\n",
319 | "Ep: 353 | Ep_r: 867.81\n",
320 | "Ep: 354 | Ep_r: 150.62\n",
321 | "Ep: 355 | Ep_r: 230.89\n",
322 | "Ep: 356 | Ep_r: 1017.52\n",
323 | "Ep: 357 | Ep_r: 190.28\n",
324 | "Ep: 358 | Ep_r: 396.91\n",
325 | "Ep: 359 | Ep_r: 305.53\n",
326 | "Ep: 360 | Ep_r: 131.61\n",
327 | "Ep: 361 | Ep_r: 387.54\n",
328 | "Ep: 362 | Ep_r: 298.82\n",
329 | "Ep: 363 | Ep_r: 207.56\n",
330 | "Ep: 364 | Ep_r: 248.56\n",
331 | "Ep: 365 | Ep_r: 589.12\n",
332 | "Ep: 366 | Ep_r: 179.52\n",
333 | "Ep: 367 | Ep_r: 130.19\n",
334 | "Ep: 368 | Ep_r: 1220.84\n",
335 | "Ep: 369 | Ep_r: 126.35\n",
336 | "Ep: 370 | Ep_r: 133.31\n",
337 | "Ep: 371 | Ep_r: 485.81\n",
338 | "Ep: 372 | Ep_r: 823.4\n",
339 | "Ep: 373 | Ep_r: 253.26\n",
340 | "Ep: 374 | Ep_r: 466.06\n",
341 | "Ep: 375 | Ep_r: 203.27\n",
342 | "Ep: 376 | Ep_r: 386.5\n",
343 | "Ep: 377 | Ep_r: 491.02\n",
344 | "Ep: 378 | Ep_r: 239.45\n",
345 | "Ep: 379 | Ep_r: 276.93\n",
346 | "Ep: 380 | Ep_r: 331.98\n",
347 | "Ep: 381 | Ep_r: 764.79\n",
348 | "Ep: 382 | Ep_r: 198.29\n",
349 | "Ep: 383 | Ep_r: 717.18\n",
350 | "Ep: 384 | Ep_r: 562.15\n",
351 | "Ep: 385 | Ep_r: 29.44\n",
352 | "Ep: 386 | Ep_r: 344.95\n",
353 | "Ep: 387 | Ep_r: 671.87\n",
354 | "Ep: 388 | Ep_r: 299.81\n",
355 | "Ep: 389 | Ep_r: 899.76\n",
356 | "Ep: 390 | Ep_r: 319.04\n",
357 | "Ep: 391 | Ep_r: 252.11\n",
358 | "Ep: 392 | Ep_r: 865.62\n",
359 | "Ep: 393 | Ep_r: 255.64\n",
360 | "Ep: 394 | Ep_r: 81.74\n",
361 | "Ep: 395 | Ep_r: 213.13\n",
362 | "Ep: 396 | Ep_r: 422.33\n",
363 | "Ep: 397 | Ep_r: 167.47\n",
364 | "Ep: 398 | Ep_r: 507.34\n",
365 | "Ep: 399 | Ep_r: 614.0\n"
366 | ]
367 | }
368 | ],
369 | "source": [
370 | "\n",
371 | "print('\\nCollecting experience...')\n",
372 | "for i_episode in range(400):\n",
373 | " s = env.reset()\n",
374 | " ep_r = 0\n",
375 | " while True:\n",
376 | " env.render()\n",
377 | " a = dqn.choose_action(s)\n",
378 | "\n",
379 | " # take action\n",
380 | " s_, r, done, info = env.step(a)\n",
381 | "\n",
382 | " # modify the reward\n",
383 | " x, x_dot, theta, theta_dot = s_\n",
384 | " r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8\n",
385 | " r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5\n",
386 | " r = r1 + r2\n",
387 | "\n",
388 | " dqn.store_transition(s, a, r, s_)\n",
389 | "\n",
390 | " ep_r += r\n",
391 | " if dqn.memory_counter > MEMORY_CAPACITY:\n",
392 | " dqn.learn()\n",
393 | " if done:\n",
394 | " print('Ep: ', i_episode,\n",
395 | " '| Ep_r: ', round(ep_r, 2))\n",
396 | "\n",
397 | " if done:\n",
398 | " break\n",
399 | " s = s_"
400 | ]
401 | },
402 | {
403 | "cell_type": "code",
404 | "execution_count": null,
405 | "metadata": {
406 | "collapsed": true
407 | },
408 | "outputs": [],
409 | "source": []
410 | }
411 | ],
412 | "metadata": {
413 | "kernelspec": {
414 | "display_name": "Python 3",
415 | "language": "python",
416 | "name": "python3"
417 | },
418 | "language_info": {
419 | "codemirror_mode": {
420 | "name": "ipython",
421 | "version": 3
422 | },
423 | "file_extension": ".py",
424 | "mimetype": "text/x-python",
425 | "name": "python",
426 | "nbconvert_exporter": "python",
427 | "pygments_lexer": "ipython3",
428 | "version": "3.5.2"
429 | }
430 | },
431 | "nbformat": 4,
432 | "nbformat_minor": 2
433 | }
434 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/502_GPU.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 502 GPU\n",
8 | "\n",
9 | "View more, visit my tutorial page: https://mofanpy.com/tutorials/\n",
10 | "My Youtube Channel: https://www.youtube.com/user/MorvanZhou\n",
11 | "\n",
12 | "Dependencies:\n",
13 | "* torch: 0.1.11\n",
14 | "* torchvision"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "import torch\n",
24 | "import torch.nn as nn\n",
25 | "from torch.autograd import Variable\n",
26 | "import torch.utils.data as Data\n",
27 | "import torchvision\n",
28 | "\n",
29 | "torch.manual_seed(1)\n",
30 | "\n",
31 | "import matplotlib.pyplot as plt\n",
32 | "%matplotlib inline"
33 | ]
34 | },
35 | {
36 | "cell_type": "code",
37 | "execution_count": 2,
38 | "metadata": {
39 | "collapsed": true
40 | },
41 | "outputs": [],
42 | "source": [
43 | "EPOCH = 1\n",
44 | "BATCH_SIZE = 50\n",
45 | "LR = 0.001\n",
46 | "DOWNLOAD_MNIST = False"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 3,
52 | "metadata": {},
53 | "outputs": [],
54 | "source": [
55 | "train_data = torchvision.datasets.MNIST(\n",
56 | " root='./mnist/', \n",
57 | " train=True, \n",
58 | " transform=torchvision.transforms.ToTensor(), \n",
59 | " download=DOWNLOAD_MNIST,)\n",
60 | "\n",
61 | "train_loader = Data.DataLoader(\n",
62 | " dataset=train_data, \n",
63 | " batch_size=BATCH_SIZE, \n",
64 | " shuffle=True)\n",
65 | "\n",
66 | "test_data = torchvision.datasets.MNIST(\n",
67 | " root='./mnist/', train=False)\n",
68 | "\n",
69 | "# !!!!!!!! Change in here !!!!!!!!! #\n",
70 | "test_x = Variable(torch.unsqueeze(test_data.test_data, dim=1)).type(torch.FloatTensor)[:2000].cuda()/255. # Tensor on GPU\n",
71 | "test_y = test_data.test_labels[:2000].cuda()"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": 4,
77 | "metadata": {
78 | "collapsed": true
79 | },
80 | "outputs": [],
81 | "source": [
82 | "class CNN(nn.Module):\n",
83 | " def __init__(self):\n",
84 | " super(CNN, self).__init__()\n",
85 | " self.conv1 = nn.Sequential(\n",
86 | " nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2,), \n",
87 | " nn.ReLU(), \n",
88 | " nn.MaxPool2d(kernel_size=2),)\n",
89 | " self.conv2 = nn.Sequential(\n",
90 | " nn.Conv2d(16, 32, 5, 1, 2), \n",
91 | " nn.ReLU(), \n",
92 | " nn.MaxPool2d(2),)\n",
93 | " self.out = nn.Linear(32 * 7 * 7, 10)\n",
94 | "\n",
95 | " def forward(self, x):\n",
96 | " x = self.conv1(x)\n",
97 | " x = self.conv2(x)\n",
98 | " x = x.view(x.size(0), -1)\n",
99 | " output = self.out(x)\n",
100 | " return output"
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": 5,
106 | "metadata": {},
107 | "outputs": [
108 | {
109 | "data": {
110 | "text/plain": [
111 | "CNN (\n",
112 | " (conv1): Sequential (\n",
113 | " (0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))\n",
114 | " (1): ReLU ()\n",
115 | " (2): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))\n",
116 | " )\n",
117 | " (conv2): Sequential (\n",
118 | " (0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))\n",
119 | " (1): ReLU ()\n",
120 | " (2): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))\n",
121 | " )\n",
122 | " (out): Linear (1568 -> 10)\n",
123 | ")"
124 | ]
125 | },
126 | "execution_count": 5,
127 | "metadata": {},
128 | "output_type": "execute_result"
129 | }
130 | ],
131 | "source": [
132 | "cnn = CNN()\n",
133 | "\n",
134 | "# !!!!!!!! Change in here !!!!!!!!! #\n",
135 | "cnn.cuda() # Moves all model parameters and buffers to the GPU."
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": 6,
141 | "metadata": {
142 | "collapsed": true
143 | },
144 | "outputs": [],
145 | "source": [
146 | "optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)\n",
147 | "loss_func = nn.CrossEntropyLoss()\n",
148 | "\n",
149 | "losses_his = []"
150 | ]
151 | },
152 | {
153 | "cell_type": "markdown",
154 | "metadata": {},
155 | "source": [
156 | "### Training"
157 | ]
158 | },
159 | {
160 | "cell_type": "code",
161 | "execution_count": 7,
162 | "metadata": {},
163 | "outputs": [
164 | {
165 | "name": "stdout",
166 | "output_type": "stream",
167 | "text": [
168 | "Epoch: 0 | train loss: 2.3145 | test accuracy: 0.10\n",
169 | "Epoch: 0 | train loss: 0.5546 | test accuracy: 0.83\n",
170 | "Epoch: 0 | train loss: 0.5856 | test accuracy: 0.89\n",
171 | "Epoch: 0 | train loss: 0.1879 | test accuracy: 0.92\n",
172 | "Epoch: 0 | train loss: 0.0601 | test accuracy: 0.94\n",
173 | "Epoch: 0 | train loss: 0.1772 | test accuracy: 0.95\n",
174 | "Epoch: 0 | train loss: 0.0993 | test accuracy: 0.94\n",
175 | "Epoch: 0 | train loss: 0.2210 | test accuracy: 0.95\n",
176 | "Epoch: 0 | train loss: 0.0379 | test accuracy: 0.96\n",
177 | "Epoch: 0 | train loss: 0.0535 | test accuracy: 0.96\n",
178 | "Epoch: 0 | train loss: 0.0268 | test accuracy: 0.96\n",
179 | "Epoch: 0 | train loss: 0.0910 | test accuracy: 0.96\n",
180 | "Epoch: 0 | train loss: 0.0982 | test accuracy: 0.97\n",
181 | "Epoch: 0 | train loss: 0.3154 | test accuracy: 0.97\n",
182 | "Epoch: 0 | train loss: 0.0418 | test accuracy: 0.97\n",
183 | "Epoch: 0 | train loss: 0.1072 | test accuracy: 0.96\n",
184 | "Epoch: 0 | train loss: 0.0652 | test accuracy: 0.97\n",
185 | "Epoch: 0 | train loss: 0.1042 | test accuracy: 0.97\n",
186 | "Epoch: 0 | train loss: 0.1346 | test accuracy: 0.97\n",
187 | "Epoch: 0 | train loss: 0.0431 | test accuracy: 0.98\n",
188 | "Epoch: 0 | train loss: 0.0276 | test accuracy: 0.97\n",
189 | "Epoch: 0 | train loss: 0.0153 | test accuracy: 0.98\n",
190 | "Epoch: 0 | train loss: 0.0438 | test accuracy: 0.98\n",
191 | "Epoch: 0 | train loss: 0.0082 | test accuracy: 0.97\n"
192 | ]
193 | }
194 | ],
195 | "source": [
196 | "for epoch in range(EPOCH):\n",
197 | " for step, (x, y) in enumerate(train_loader):\n",
198 | "\n",
199 | " # !!!!!!!! Change in here !!!!!!!!! #\n",
200 | " b_x = Variable(x).cuda() # Tensor on GPU\n",
201 | " b_y = Variable(y).cuda() # Tensor on GPU\n",
202 | "\n",
203 | " output = cnn(b_x)\n",
204 | " loss = loss_func(output, b_y)\n",
205 | " losses_his.append(loss.data[0])\n",
206 | " optimizer.zero_grad()\n",
207 | " loss.backward()\n",
208 | " optimizer.step()\n",
209 | "\n",
210 | " if step % 50 == 0:\n",
211 | " test_output = cnn(test_x)\n",
212 | "\n",
213 | " # !!!!!!!! Change in here !!!!!!!!! #\n",
214 | " pred_y = torch.max(test_output, 1)[1].cuda().data.squeeze() # move the computation in GPU\n",
215 | "\n",
216 | " accuracy = torch.sum(pred_y == test_y).type(torch.FloatTensor) / test_y.size(0)\n",
217 | " print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0], '| test accuracy: %.2f' % accuracy)\n"
218 | ]
219 | },
220 | {
221 | "cell_type": "code",
222 | "execution_count": 8,
223 | "metadata": {},
224 | "outputs": [
225 | {
226 | "data": {
227 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYUAAAEKCAYAAAD9xUlFAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJztnXl4FFXWh38nnYQAYZNdgiwKIrITEWQRhVEWdx0VN1wZ\nnZH5HGdGUXTcGEVwdBzHDR3XGRHcERBUBBEFJOwQtrAnbAlLgIRs3ff7o6o61dVV1VXdVV2d9Hmf\nJ0+6q27dOtVVdc+955x7LgkhwDAMwzAAkOK1AAzDMEziwEqBYRiGCcJKgWEYhgnCSoFhGIYJwkqB\nYRiGCcJKgWEYhgnimlIgoneI6BARbTDYT0T0LyLKI6J1RNTHLVkYhmEYa7g5UngPwAiT/SMBdJL/\nxgF43UVZGIZhGAu4phSEEIsBHDEpciWAD4TEMgCNiai1W/IwDMMwkUn18NxtAOxVfc+Xt+3XFiSi\ncZBGE6hfv37fLl26OCpI/tFTOFpaAQDo1qYRyNHaGYZhvGflypVFQojmkcp5qRQsI4SYBmAaAGRn\nZ4ucnBxH639w5hp8vqoAALB00kikp7L/nWGY2gUR7bZSzsvWrwBAW9X3LHlb3AkEqvM/CXAuKIZh\nkhcvlcIsALfJUUj9ARQLIcJMR/HAr9IDnB+QYZhkxjXzERFNBzAUQDMiygfwBIA0ABBCvAFgLoBR\nAPIAlAK4wy1ZIhEyUmClwDBMEuOaUhBCjImwXwD4g1vnt4OfzUcMk3RUVlYiPz8fZWVlXoviKBkZ\nGcjKykJaWlpUx9cIR7Pb+AWPFBgm2cjPz0eDBg3Qvn17ENWOmEMhBA4fPoz8/Hx06NAhqjo4zAbA\nuac3DH7eUFDsoSQMw8SLsrIyNG3atNYoBAAgIjRt2jSm0Q8rBQDjL+6Eq3qdDgC4Ydoyj6VhGCZe\n1CaFoBDrNbFSAOBLIXRr08hrMRiGYTyHlYJMbewxMAyT2GRmZnotQhisFGRSWCcwDMOwUlBgncAw\njFcIIfDXv/4V3bp1Q/fu3TFjxgwAwP79+zFkyBD06tUL3bp1w08//QS/34/bb789WPall15yVBYO\nSZVRm4+EEGxOYpgk4qmvNyJ333FH6+x6ekM8cfm5lsp+/vnnWLNmDdauXYuioiKcd955GDJkCD76\n6CNceumlmDhxIvx+P0pLS7FmzRoUFBRgwwZpqZpjx445KjePFGTUOiDAcxUYhokjS5YswZgxY+Dz\n+dCyZUtceOGFWLFiBc477zy8++67ePLJJ7F+/Xo0aNAAHTt2xI4dOzB+/HjMmzcPDRs2jHwCG/BI\nQUY9MvAHBHzsZGCYpMFqjz7eDBkyBIsXL8acOXNw++2348EHH8Rtt92GtWvXYv78+XjjjTcwc+ZM\nvPPOO46dk0cKMmoV4OehAsMwcWTw4MGYMWMG/H4/CgsLsXjxYvTr1w+7d+9Gy5Ytcc899+Duu+/G\nqlWrUFRUhEAggGuvvRaTJk3CqlWrHJWFRwoyavORn3NdMAwTR66++mosXboUPXv2BBFhypQpaNWq\nFd5//31MnToVaWlpyMzMxAcffICCggLccccdCAQCAIDnnnvOUVlYKciQaqzg97NSYBjGfU6ePAlA\nMl9PnToVU6dODdk/duxYjB07Nuw4p0cHath8JJPCIwWGYRhWCgoh5iP2KTAMk6SwUpAJMR+xUmCY\npEDUQqtArNfESkGBzUcMk1RkZGTg8OHDtUoxKOspZGRkRF0HO5plUogdzQyTTGRlZSE/Px+FhYVe\ni+Ioyspr0cJKQSZknkIt6jkwDKNPWlpa1KuT1WbYfCQT6mgOeCcIwzCMh7BSkAlVCt7JwTAM4yWs\nFGRSiKOPGIZhWCnoIMBKgWGY5ISVgkzoegoeCsIwDOMhrBRk1GkuWCkwDJOssFKQ8alHCmw+Yhgm\nSWGlIKNeVIf9zAzDJCusFGTSfNU/RW2a9s4wDGMHVgoy6pECqwSGYZIVVgoyqT519BGrBYZhkhNW\nCjKpKWrzkYeCMAzDeAgrBZmQkYKHcjAMw3gJKwWZVHX0EYcfMQyTpLBSkGFHM8MwDCuFIHXTfMHP\n7FNgGCZZcVUpENEIItpCRHlENEFn/xlEtJCIVhPROiIa5aY8ZnRoVh8jzm0FgKOPGIZJXlxTCkTk\nA/AqgJEAugIYQ0RdNcUeAzBTCNEbwI0AXnNLnkgQEe4cJK3CtGDzITz06VqvRGEYhvEMN0cK/QDk\nCSF2CCEqAHwM4EpNGQGgofy5EYB9LsoTESX90X+W7MTMnHwvRWEYhvEEN5VCGwB7Vd/z5W1qngRw\nCxHlA5gLYLxeRUQ0johyiCjHzUW2KXIRhmGYWo3XjuYxAN4TQmQBGAXgQyIKk0kIMU0IkS2EyG7e\nvLlrwqjXVGAYhklG3FQKBQDaqr5nydvU3AVgJgAIIZYCyADQzEWZTGGdwDBMsuOmUlgBoBMRdSCi\ndEiO5FmaMnsADAMAIjoHklJwzz4UAdYJDMMkO64pBSFEFYD7AcwHsAlSlNFGInqaiK6Qi/0ZwD1E\ntBbAdAC3Cw/jQVN4qMAwTJKT6mblQoi5kBzI6m1/U33OBTDQTRnswDqBYZhkx2tHc0JBbEBiGCbJ\nYaWggkcKDMMkO6wUVLBSYBgm2WGloELraOYcSAzDJBusFFRoRwpfrdnHayswDJNUsFJQoXU0PzBj\nDb5co51vxzAMU3thpaAiRcencKy0Mv6CMAzDeAQrBRV6jmb12s0MwzC1HVYKIYQrAJ7lzDBMMsFK\nQYWe+ShVbyPDMEwthZWCCr3U2T5WCgzDJBGsFFToNf/sU2AYJplgpaBCz3/APgWGYZIJVgoqdKOP\nUvgnYhgmeeAWLwI+/oUYhkkiuMlTkaLjVPbxSIFhmCSCWzwVuo5mjj5iGCaJYKWgQs+n4Esh/HH6\navy41bOloxmGYeIGKwUVepFGRMCstfsw9p1fPZCIYRgmvrBSUKFnKOLM2QzDJBOsFNToaAUeITAM\nk0ywUlDBE9UYhkl2WCmoYJXAMEyyw0pBBY8UGIZJdlgpqDDTCawvGIZJBlgpqNBLnR3cF0c5GIZh\nvIKVgop0k0RHZgqDYRimtsBKQUWaydoJrBIYhkkGWCmoMFtljQcKDMMkA6wUVJj7FFgrMAxT+2Gl\nYBXWCQzDJAGsFCzCOoFhmGSAlYJF2KfAMEwywErBIuxTYBgmGXBVKRDRCCLaQkR5RDTBoMz1RJRL\nRBuJ6CM35YkFXoCNYZhkINWtionIB+BVAL8BkA9gBRHNEkLkqsp0AvAIgIFCiKNE1MIteWKF8yIx\nDJMMuDlS6AcgTwixQwhRAeBjAFdqytwD4FUhxFEAEEIcclGe2GCdwDBMEuCmUmgDYK/qe768TU1n\nAJ2J6GciWkZEI/QqIqJxRJRDRDmFhd6slcw6gWGYZMBrR3MqgE4AhgIYA+AtImqsLSSEmCaEyBZC\nZDdv3jzOIkpw7iOGYZIBN5VCAYC2qu9Z8jY1+QBmCSEqhRA7AWyFpCQSDqs6YffhElT6A+4KwzAM\n4xJuKoUVADoRUQciSgdwI4BZmjJfQholgIiaQTIn7XBRpqixohMOnyzHhVMX4YlZG12Xh2EYxg1c\nUwpCiCoA9wOYD2ATgJlCiI1E9DQRXSEXmw/gMBHlAlgI4K9CiMNuyRQLivmorNKPkvIq3TLHy6Tt\nv+QVxU0uhmEYJ3EtJBUAhBBzAczVbPub6rMA8KD8l9AoI4VBzy9E0cly7Jo82lN5GIZh3MBrR3ON\n4XBJBZbtOIyik+Vei8IwDOMarBRscOO0ZcHPB4rLoqrjqzUF6DRxLsqr/E6JxTAM4xisFKKk/3ML\nojpu8jebUekXOHyywmGJGIZhYoeVgoNILhJzFN9E5JIMwzDxh5VCnFGimKwoEIZhmHjDSsFB7Mx6\nZp3AMEwiwkqBYRiGCcJKgWEYhgliSSkQ0ZlEVEf+PJSI/qiXuI6JDOfVYxgmkbE6UvgMgJ+IzgIw\nDVKiu4RdJS0W7hzYAQBwz+AOHktij1/yipB36ITXYjAMU8OxqhQCci6jqwG8IoT4K4DW7onlHX+7\nvCt2TR6NsRe0d6V+ZaTgtKP5preXY/iLi52tlGGYpMOqUqgkojEAxgKYLW9Lc0ekxMCt9RNInqkg\neKYCwzAJiFWlcAeAAQD+LoTYSUQdAHzonljeE4tKOFpaiQmfrUNZpXEqCw5JZRgmEbGkFIQQuUKI\nPwohphNREwANhBDPuyybp8QyUCg+VYmPV+zFZ6vyHa2XYRjGbaxGHy0iooZEdBqAVZCWzXzRXdG8\nhRxYlTlgMhrggQLDMImIVfNRIyHEcQDXAPhACHE+gOHuiVVL0LER8UCBYZhExqpSSCWi1gCuR7Wj\nuVYTjZnHTj4jzn3EMEwiYlUpPA1p6cztQogVRNQRwDb3xPIeJ3r0es1+MCGeA/UzDMM4jaXlOIUQ\nnwD4RPV9B4Br3RIqIYhCK2jDWPUGA2Syj2EYxmusOpqziOgLIjok/31GRFluC+clVhzNHy7bjZPl\nVYb7dU1EwWpZKzAMk3hYNR+9C2AWgNPlv6/lbbUWKz6Fx7/cgEmzc4PftUpg7voD+HbjAd1j1UX3\nHinF0RJeiY1hGO+xqhSaCyHeFUJUyX/vAWjuolw1BrORwq+7jmDchytDtim6Rh2uOnjKQgyZutAF\n6RiGYexhVSkcJqJbiMgn/90C4LCbgnmNVZdCRpovqvq1aS5OlBkrF4ZhmHhhVSncCSkc9QCA/QCu\nA3C7SzIlBFZzH326snrWsh0vATuaGYZJRKymudgthLhCCNFcCNFCCHEVann0UTQhqZEa+lMVfpRV\nBgAAAQe1QkVVwLG6GIZJbmJZee1Bx6RIQOxMXqt2MJs39P2e/R4Fx07Jx0QpmA7Pzt3kXGUMwyQ1\nsSiFWp2xwU7uoxMmzuaQciq/gZNKYfOB485VxjBMUhOLUmCruMyxkkr84aNV2HzA+spnvJ4CwzCJ\niOmMZiI6AYNsDQDquiJRomBjHLT5wHHMWbcf36zfb/kYswyqEY8NCKSk1OqBWkJSUl4FIqBeuqVE\nAAxTIzEdKQghGgghGur8NRBC1Oo3w45PoW66FJZqp6Ffsq0Qe4+UYs4664oEkBRQx0fnYsGmg8Ft\nHMkUH859Yj66PTHfazEYxlVqdcMeC3b64dGsvfDCt1vxwrdbbR+3es8xAMB3uQcx7JyWto9nYiOW\nER7D1ARi8SnUauys0VwV4JBQhmFqB6wUDLDT9/d70H1kkxHDMG7ASsEAOz6FqjgqBafcy9e9/gvb\nxxmGCYN9Cg7gxUghVnJ2H/VaBIZhEhBXRwpENIKIthBRHhFNMCl3LREJIsp2Ux472HEeO5lm4tDx\nMhwr5TTaDMN4g2tKgYh8AF4FMBJAVwBjiKirTrkGAP4PwHK3ZIkGO+ajB2ascey8/Z5dgH7PLnCs\nPoZhGDu4OVLoByBPCLFDCFEB4GMAV+qUewbA8wDKXJSlRmE28lCUFc+IZhjGDdxUCm0A7FV9z5e3\nBSGiPgDaCiHmmFVEROOIKIeIcgoLC52XNA7k7nMmP5Fi1uLoI4Zh3MCz6CMiSgHwIoA/RyorhJgm\nhMgWQmQ3bx6fBd+cbnR/2V7kbIUqWD8wDOMUbiqFAgBtVd+z5G0KDQB0A7CIiHYB6A9gVqI4m9NT\nnf1pvOjZr9l7DO0nzMH2wpPxPznDMDUSN5XCCgCdiKgDEaUDuBHALGWnEKJYCNFMCNFeCNEewDIA\nVwghclyUyTK+FML9F53lWH1e+AC+XC3p4B+3JI7J7e73V+DGaUu9FoNhGANcm6cghKgiovsBzAfg\nA/COEGIjET0NIEcIMcu8htqF0yOFmmoy+n7TIa9FYBjGBFcnrwkh5gKYq9n2N4OyQ92UxWusNOLC\niubgjNkJwd4jpRg8ZSFmjx+Ebm0aeS0OwzgGp7mIE1ba+0p/Te3/Jx8/bJZGPDNW7I1QkmFqFqwU\nLHDXoA7BzyO7tXLtPJX+6vkJZZV+lFf5XTsXExvKIkcBjg2u8byyYBvaT5jjaGaCmgwrBRMU53Dj\numloe1pdTLqqG85u1SCmusxQK4Uuj8/DwMkLjevjtshTlIXvWCnUfKYt3gEAKONOGABWCqY0zEgD\nADTISMVPD12MW/q3i2pBHQAoLq2MWEabbbXoZHlYmXi6FIQQeHDGGqzak3zJ8/wBYXrdKfLUcl5K\nIzLFpZV4ft5mVPn5x6oJsFIw4c5BHfDk5V1xS/92wW12ciKpeVPujZiRaL3O46eq8PnqAtz53gqv\nRYk7ry7MwzWv/YKVu4/o7vcRm4+s8sycXLy+aDvmbzyou/+XvCLc9NYyz7MN862U4NTZJqT5UnD7\nwA4h29zsqf+6U78BiojOw7yzqAT7i0/FJpBSfRK+LJsPSGlJDhSHj9aA6s6BPxl/HJuUy7Z6oxUK\nx09fjcMlFThSUoHmDerEUzQJ5aXmWwmAlYJtohkpzNtwwFK5SbM32a/cgIteWBR7JUryPW74wvCl\ncA4qp/Daac9R3qGw+cgmmw6csH3Mvf9daamcnZfCzgzpaE1ewYys3PCFofgUvDZ51AbYFJdYsFKw\nScFRZ0wyelhpXyjaFj4KeFRtjNe929qEEsnFCjYxYKVgkwYZ7lncEs1Mo0iTaHIlAik8inKMFDbF\nJRSsFBKIaN8Jt5LtKS8pv6vhsPnIOVISxHzEC1dJsFKwSaWLsdbR9shjfZfW5R/D5a8swamK0Mk7\nylrRydyDM2oonGjICk+U4+u1+6I+vraQKOajZH7O1bBSsImb+YlsvRSqorH2sJ7+OhfrC4qxvqA4\nuK2kvAoXTl0UU717j5RiwSb92HQjjpZUYIcL6z8EAgLtJ8zBqwvzLJWPNEnRiRnNd763AuOnrw4q\n32Sl2j/jzfkpQUYqiQIrBZu4O1KIXEavqXLqUZ67fn/w88nyKlX90Z3h0n8uxl3v21seY/iLP+Li\nf/wY1fnMqJRj5F/+fpsj9fkcaMgKjklBC173kL3Ga/NR9brnDMBKwTZujhScqLnwRDke+XxdVMe+\n98su3dQO0b6rpRX2c8kcLqkZvWb2KTiHL0F+Sx4oSLBSsImbI4Voe0rqwybNycX0X6NP53yyTBoh\nqEck/K6Ecvf7Odi4TzK1sckhdhTzkedKIUGf9Nx9x3Hlv5egtKIqcmEHYKVgk0RRCl+sKcDri7YD\nCHVQR/NiRTwiMd8VWzjZdn+/6SBe+Har4/UmKz65FfL8t4xw/hNlkZNausGzczdhbX4xVu6OT2JK\nVgo2mXRVN5zdMrr02ZGwNnlN+i8E8Py8zdJnV6SpJlF7UImA173bmkCk6ZZBU1wMWqHSH0Agxnth\ndvQnOXvR/clvse2g/YwGThEvpclKwSaDOzXH/D8NcaVuKyGpehOanXxY9KqKtX6vJr+t2XsM7/68\nU5bBnXM4kRAv2dUKBX0K0Y/CO038Bn/+ZG1055f/m43UlZX2th50PjIuEnFMYgCAlUJC4Wanc/I3\nm9F+wpyoelOxiuVGg7z3SClKys1trFe9+jOe+jpXksGtpjfZW3QbGD0HvuA8hdjq/2J1QUzHW4r+\n8zB7XrweNVYKCYRej1q97eu1+7D7cGl4GdXjYvTgvP2TtJ6DdiEfLflHw+uPFTecsYOnLMQt/1lu\nQwbHRXCM2p6lM1JDmiiRXGZn99zfEUdYKSQQeu/E1+uq5w6Mn74a/9SJs1c/sHk6w1tC9Yup10Cr\nFc/ELzZI2wz2R4Nb7/rqPccsl410DcWllej+xHzba1o4MQJJovZGF6+jjxTzlSXzrdvCJACsFBKc\nI/KSnP/4dothGfWzvNegp6/M0LXaa1cXi/VVTYSwzUgSrNp7FCfKqyzPeHaSBPh5PMXngKPZCcxO\nn0zBFqwUEpyDJySl8MoPxo2V+nE1bIBV+WUWyk4zveMVSlQx0WYvy1Nfb8Q3qpnQeYdO4uDxspAy\nejLFGiliF7faGzv15h8tRUVVuOE8mRocPXwpsTua3Ua5z576FOKkNFkpJDjKXASrGL1XyrP81Zp9\nuCPCmstfrSnAsAipJk6UVeJoSQXe/XkX7vvfquD24S/+iPOfXRAqk86z3OOpb03rdxyP/cx5h05g\n0PML8Y4cDRVVJbWUoGnTI51gJfoovHT8iOcaKgArhVqBugdh9GArz9XjX20I2b4+vzist6sdSeiR\nPel79H7mO0vy6dmKT0aIHHKSQEB43hvfUVgCAFi243DYvkR2ggPAd7kHcTwOE7e8/hnMzUfJAyuF\nWobRw6v4FLQP/uX/XhJMzGaHch0ziKFMBm+bEALv/bzT9en7fiFcNB/Zqzg1JfyV81phmbH3SCnu\n+SAHD3y8xvVzeb2Yk6VxQhJ4mlkpRMk/ftsTfxzWyWsxAISODiKNFPQ46nISOqOe8PebDuHJr3Px\n3NzNhsfO23AAS7YVmdZ/6EQZ2k+Yg0Vb9Ec4/kD0zW6kdspqvVbCHYtLKzEzJ/q8VWp+92EOXlsU\nu9O8rFJKarj7cEnMdUXCa9VoppTc1lczVuzB9ggp43meQoJzbd8sPPibzl6LAUATKWTuZ9ZFO3fB\n6YfPSFEpI4Rjp/RNE68v2o57/7sybD6C9uVdt1dKTvfh0t3o+Mgc/HH66rDza4/ZfOA4Js3O1W0I\nFm8tRHmV1Bg69Vso50nRm5Eu///zJ2vw0KfrsPnA8ZjPN3/jQUyZZxyxZpV49oyjX2TKmbtkXou0\n162f4+HP1mPUyz/p7ov34ISVAhNGNO/YgeIyw32RIo2MXmoltxMAbD14Au0nzMH2wpOG8vmFQEAA\nszSrmemNFG55ezneXrIzLFX3toMncNs7v+L7TZH9KpLslooFR0v6aUqknYfkSLOySmPT3Ndr95n+\n1k5yqsKP4S8uDn5/9Iv1aD9hjmvni7Ztj+a4/KOlGDp1IQ4Ul4XkE4uEm07fiCZZzn3EWCXSs7Lr\ncKk9H0AUMgye8oPhPquO1CqTPAdfrZFSGHyzfn+YfMp7WiTP6dA7f3C0EqEBKDoZuykt79AJLNSY\nsswmZmlEM1SS5VV+jJ++GmPeWhazjJF4ft5mvPT91pBtHy3f4+o5ozbxRXHM/5bvwa7DpfhsVT6A\nyJPXkmkuSarXAtR0lj5yMTYfOIHFWwuxzqX0tt9uPGC6P9Lw+b1fdjkojT5miw9FCvVTel/q2dra\na1J/NapPbw4AII9UDEQIViX/r7CZgEevWqV3vWvy6GoZhGJ+CO9pCgHMzNmLjfvMzUaKrPuiCAyw\ni1kotBDC0R5z9Yzi6I6PxnwU7QqGSeBnZqUQK60b1UXrRnVx0dktcJNLPbhftoeHMapJlE7MAx+v\n1t1uNX3Bhn3Va0Qb+kaIDPcZncYvqs1HFVUBFBw7ZctWvvdIKTYfMEiZbLFBCioFXZ+CwEOfWl8t\nz+v77Q8IpPocVAry/6gXmXJIDq9CUiMptXhHPLFScBCfnhfRASIu7O7wE2v0kL790w4M7tQcnVtm\n6u7/cs0+3e1Gz7w2q6U6XNM0Wsdgr1GjEgiEhqQOnPwDmmXWCa3L5NaNfPmnmOZVZE/6PmjaspL6\nPNrbuaGgGF1bNwzmEnIS9cigKiCQ6nP8FLrX/eaP23FWi0wMO6el8XExPP/qZ90sRk2YKPVYsSp/\nvEKXXfUpENEIItpCRHlENEFn/4NElEtE64hoARG1c1Met0l1SSlsOxTfHO56j54/IDBpziZc/drP\nETOtajFqrHNlc4nywqWpep/aY5Rvq3YfDXuJIjkKpZFC6M7gyx3hUj7J2WuqEAQkX8iUeZsNQ3vV\nvg5d85H2u+FIyFjY1XuO4rJXluD1H+3NgFc4UlKB7EnfYUNBccSybq0+qO2MFJ+qxHPfbMZd7+eY\nHxdFY6n3zHiVOjuiedX5U5rimlIgIh+AVwGMBNAVwBgi6qopthpAthCiB4BPAUxxS554kOoL/zkb\n1Il9MGZmaz5eVhmX/sO2Q5L5pKIqYLtRGPrCIuwvDreDK9E2CuqRltF7smDzIduNpj9gPHkt0m/3\nU4Q5EkJIMr22aDue+npjhNqg+4aHy60vldb/oUaZgLhxX+RGXY+fthWi6GQF3ly8I2LZKhP/kRl2\nG2+ry19GM1Iw8u0YnsP+KSzjtTlQi5sjhX4A8oQQO4QQFQA+BnCluoAQYqEQQknruQxAlovyuI5b\nIwUzejz5rfMzQXWqG/FPKYa6TmoKKqsin08bujh3vbmzHADSVEpV21CqHZ9GjYveWhOAlFMnLGJJ\nqcuBn07xmWgjvB79Yj3yNKO8nF3hqbmtmw/CqagKBCeYAfqNnR2sHF1pM0mRVYm0v0M8UmkLmKeV\nD5YLWhmdf8cTLbLJTaXQBoB6ema+vM2IuwB8o7eDiMYRUQ4R5RQWFjooorN0bF7fk/PuMmgMo8Xs\n5chI81mO0FEPta0oLqtK1W5boTd5TZEt1nTNZr3fj5bvwR9UyQIB4OBxvbBZ40ir0O3hOwZP+QFd\nHp8XsWH5PvdgmG8qe9L3eGfJTvMDVSi3J9qRghFGjbJVpRBro+p1RFE06ezdJCHmKRDRLQCyAUzV\n2y+EmCaEyBZCZDdv3jy+wtnggeGJMcM5VjaYmCDqpKZYNh9ZfdkUJ2aqyUhBTVgDH+FMermPgutL\nKA1P1OGQ+p+jrcMMvTZSUTLBXTo/xYHiMtz9QQ7+T5O/qOhkOZ6enWtZTsW857RSUND+DpO/MU5/\noub7TQeDn3/deUTXVBnN+UP2KR9c1iD+gAibb1ObsqQWAGir+p4lbwuBiIYDmAjgCiGE/uyjGkKa\njk/hg7v6eSBJbOw9YvxS1UnzGc4H0GL1YVYa+VQLPgUA2F5oLw+P2YxqJ3pf1T5rqz0+fSe6ET9u\nLZSylAb1l/ERer+40shofTihMsnHm9wyRSnYNR9ZRXtV3+Ye1C2nZbwqrcn1by6NmPYdMHA0e2Td\nV3eA/j5nE7Infa+blbY2jBRWAOhERB2IKB3AjQBmqQsQUW8Ab0JSCNbyCtQwep/RJGKZewZ3iIMk\nzpDmI8sjBa016IY3l5qWV8e+m0VcXfXqz5bOryClv9A3H2lnOttFCPsRKVodZRaSuudwKca+8yse\n/Xy9pZC/39vSAAAfQ0lEQVRJPU6USdFTDTKqgx60Ce6Uuo0uhVC9Qprj5iNFhihaPT2FX1rhR5U/\nYJhgzh8QuotWmY4U5J1O++8qqgIh5/1mg7RgVUkcU8trcU0pCCGqANwPYD6ATQBmCiE2EtHTRHSF\nXGwqgEwAnxDRGiKaZVBdrWbiaG1QVuKSQmTdp6BqYgJCYHmE9Y9TVK2rrYY/QqOsF32kHOLkEpBW\nq9LaysPCb1Vfd8qN99HSihBlsu3gCUtLh364bHew16mOhLv2dXMFrUWgei1lp0NSY5nRbPQsTv12\nC4b940fd7K4hqwqqFK2V0zv1uIx8+Sec+ehcdH7sG6xQBR+YzXyPF65OXhNCzAUwV7Ptb6rPw908\nvxe0Pa2uofmFKPEiDexyoqwKhSZmCCO8XEhGN/rIxmLtkZHr0tmj17uP5FBVy3SkRPqtm2XWUfVW\ngeveWIpineyyWpPd419uwDV9pPiOjPTqGWdqu/VP2woxZ91+REIxH13z2i/Y+veREcvbxWgkpDcS\n23ukFCkphEyDkO8Vcgek6GQ52jUNDQDxq0Y66pGeFYfvXe/n4LYB7fD0ld0iljVj0/7qMPOlqowF\nyqOgHmXXmnkKycqsPwzCvAcG6+5L01lgpaZRcOwUbn/XfDlPBXUvLh7hhUboRR9V74ut7mgO/9/y\nPdhZVN2Dfe6bTcb1q6xb6nOdqvDrFddFmVSXYmDnuvU/1VlhjfxApDrebn4oqxi1yXpyD56yEAMn\n/2Do31KO0bu/RqNDc/NR9ecPlu42LhgFlRolBUBXE8TrDeI0Fw7TpH46mtRPx2Ojzwmx4QJyT8v6\nu1yrsNIjd6tHpM59pCUgBE6UVeIOi4pOD7s+hWdm5+JfC7YFe94/5xnntlLXbS2OPhwlFbeViN8v\nVhdgwJlNdfepJxdWVAVQfKoSjeqmQUCgjo28F7PW7kO6jzCiW+uQ7UZXZya2kYKqXvc5vFatT4RU\noQJe4Fc57oPviUoUzn1US7h7cMewbak+AmwsdduhWf2QHmVNZutB91J1RHpntLmP1PgDAou2RD/3\nJSR3jo02pfhUJU6rn65fp9E2C5Eys9buw7ghoc9embxgkNW2xSg5n0/VOk34bB0+X12AZpnpOFxS\ngZ3PjdY9Rg9lESR1FlnA3khBwWjWc9A8CGllvow0HxpmpAEI9YmoT2kekuqewlCnjVEUv+4zECfb\nc823Z9QAemQ1AmB/xrOXJhen0S58o4dbPSLpd9SPPhICOFUZ2/BNFUgbUz3BWuRqlm4/jLcWV08u\nM6td3Wi99F3oOgjVI4XYfmD1SGG27IMoOlnh2OQxw5GQidjKTHstiqgBIdDv7wtw8QuLgvuMcnd5\n9bapRy6KaHq/RbyaA1YKceCDO/thxrj+wZfqkZFdTMvfe+GZeOqKc2uVUnCTSL+S7uQ1VaNRFqtS\nMGlsDds5C+3zmLeWIXe/kjQwtKEIC2M1MTeUK9cXo9JVu8ScTJ2tYHQfo8keo5iElN9FvXhSyGJO\nqh8u0gqBbqE3UtAXhUcKtYbG9dJxfsemwefvmj7mKZ4euvRsjL2gPSsFi+gNq6eolvLUiz4K7hOI\nSSlEO6NZCCkzqe6+CAnxwsc9WkJb0dIKxXwUfUNOFGo+cjLPV3XGWv0GOpoRjlnm3AqN+ShY1qQ+\ns3v7Sc5e7IrBzFulngyojBRC3n1jp7kbsFKII51bNgAApKem4B+/7WlYzk6IXG0i2un8ej/Ta6oE\negG9yWvyi+YPCJyqiD6aRkA47yDXuR6tIjCzL2t/RsWnEEs7vvXgyZAcW26sHaJcUe6+4yGzpqM5\nk9k7ZDT5TilaeKJcd36DEX/9dB0ue2VJyLZ9x05ZXoND16eg9wzEqTlgR3MceePWvthYUIxGddPQ\nsG6aYTkKhtMlmVKI8rhIPSgz85EQIthoxopTd0vveoQQIb1HO+eqrHLGp6DGaqoTMw6fLEeDjDQE\ne8IBgfX5xbj830tw/0VnBctp5c47ZLAKngrlGD1/UZVBmg5lhHbdG79g9+FStGqYgUvPbYmnruxm\nnK5dvidaBXDB5B/QqUUmvnvwwoiy+nV8Clbmt7gFjxTiSKO6abjgrGaWyyeL+WjV7qMY/uKPITNN\n7fBPzQLzWvSij6qdm/Zi/rXkHTrpuIO8KhAwjToTOkrOrL2olJ8jJ+Usi0IpaGXsO+l7PDizOkmf\nALBPTma3eq9qrXON3Moa2GYoHauTZeHPVIUq9XuITPJnJQX7geNleF+ek2C4Vodm++o9R3H3+1J4\ns9XFsdRKysynwPMUajlWwsvsrnBWU9lXXAYAqJsW3RqPkRa89wfCV15TCAiB8hhGCgEBHCuVwiL1\n7mk0d3Da4h1h63ILVDdgkRoMbduvhGA6mW0zmg6L3iM/e91+DJeX2hSiWna1iSeFCOvzi5GZkWo5\nJ5BSj3oUePB4GZ6ctRFX9jo9uO3fC/NweqMM6fw2ZQfCf4fx01cj/6i9LK3KxEH1edRKSLltB6LM\n/moXVgoJjFfREF6x3sJSkFqqLMyuDQgRPmGJqk0WSshmtBwu0aSvVqFdZMcKRr+DmfnASibYeE+C\nUlDPGdCidk0IVVl1Y0sEXP7vJbCD3toP/1qwDd9sOBCWHsQsDLS6TPg+f0CErTMeK4oTfH1+MQqO\nnsKQztVLBTw7dzPGDTnT0fPpweYjj2nVUOqlfHrvgLB9ytB04qhz4ipTTSLSKAGQVkS7UpNgT2mL\nDp0oj/nFPnxSP4ooWprUC5/U9l3uQRwpNT6P2oxh1LS5qRO0o6TthSfxy/Yi2dQldMsA2iVYq/dX\nxhx9FJ68T/HjaUdh/qB8xvVplcLB42X477LdeOTz9aZyfLUm/NmyYiV4YMYa3PbOrwA491HS0a2N\nNLEtu/1pYfsUU+Owc1rEU6Qahbax1+OEjl1ZedOiGZ1oMQotjZZ66eFmtIqqAMZ9YLyA/eo91Tb4\naGYGx8qLmglzw/7xI256aznGvrsCX66RJi7qjxQoOIJZvK0o2GCqR4DR/L6KrlEvkarMaNaijErM\nmmrtQOz8Zxdg9rrIEzK1CxsBwPRf9+qUTBxYKXiEFcOQ0oNJT+XbFAtmqZ6dyFuv+H6EcMbkt/mA\nfnRNkcmIZGZOfsR6P1y223KYpF3U6xMcOl4W/Lx4qyqFiM5P40uhYPnFWwuDocSxBlkodnq1Ujit\nvr5SUJ4Pox789F/36JqPrIxS9dh6MHL0lBHxSHXBPgWPMeu8KS9GTVMKnVtmuprryC7lOpEyavNR\nrCiNyo9bC/HG4u0RSrtP/lHjNbs/ydmLlbuPGu6PhW83HsDTs3MNHa16zn5fCmFtfvVoTfHBGClG\nu6gVVKpBluKASqnr5VIyMhFpFcVFLyyyFKqbZnM2+JK8ouDnCn/AVvLBaKhZrU2SUsfn7kOg5gKD\nDJlW+fTeARjcKXwdbSXCwwv0ZiwXn5J6zD9sjn3BP7Uzc8q8LTHXFytmDepTX+cG8xY5zbgPV5pG\n3ggB/LK9KGSbdhKcE/Mf1Hy8otpUszb/mG6ZEjkk2R8QGDxloeW6tYOZnUUlljoZesv2GvFJzt7g\njHQAMQdFWIGVQgIx/uKzcMZp9cK2p6XGz9U0qnvryIVMCAj9iKB4Lz6uRm8Ck3Zx9FhYtcednndt\nQwC46a3lIduUcF4Ft9ZqABAyI1uPqoAIk8eMaE05e22ErL6/dFfI91jCp63CSsEj9J6nP19yNhY/\ndFHY9nQbPYtYUYa2HZrVj1BSn4AQIZEjCl6uL1RgM27cLk6YoJIBLyboq1dmq4wwCrHrx4jG7XG0\npAJfW8gYrLChINRvUc4jhdqPlf6z3Twzr9/cB6+M6Y0x/dralkexuwoh0NQg378e1/WVkvxl1knV\nHSm4GfkSCbfMJYw93FyTwAi1Yz3S2tJG6S+MiCbthDKnJVp4pJDkNMusA8DY9NKtTcOwbZee2xIj\nu7fG5T1Px3PX9MBtA9rZOqeSEjkggKaZ1pXCpKu64a3bstGtTSPdhGORlEJWk7q25GRCGXhWbL6g\neOB1Kq9ISsHuSMHq9SzZVu1H2bQ/Ngd6pUEyPydhpeAR2e2bAADuHNTBsMys+wfi7duyAejHrus9\nlG/emh3y/abzzwAALPzLUEtyKU4wf0CgvsGi6HpkpPnwm65SugK9Bj7SQOGqXm0sn4sJJ7NOquFK\nbomCdiZxvNGLQlPjVlqZN1URaR8ui219Z6MMr07CSsEjmmXWwa7Jo9G/o3EP7/TGdTFcbmj/eunZ\nYfvV9tKrep0ektNFoUurhtg1eXSYj6Bzy0zdc2akSY9EVSCADIuhbzueHRXyffywTmFlIo0U3EjF\nnEwEhP1Qx3gzdb63kVlOjxSsoh7pd4zSV6fgpiNegZVCDeGOgR3C1rR95abewc8392+Hl2/srT0s\nhI/H9QcATL+nP+Y/MES3jKII/AERVBCRSNE06Hohd5Ha/FiUQgMbI5raSlmlv8bNZ4k3kUwv8UhA\nGasJLZJicwJ+imowLRpkoG+7JpbL9+/YFDufG4UBZzY19FPUkTOVphChro7JSsubt/bV3f7E5V1D\nvkda9UtxCEajHG46/wz88OfIeetrM+WVAVvx78lIpDkQfpcaXPWs7kqbzmwtrBQYy1htSiPNF1BG\nB6kpFGY+Oq99k7B5FGfLq8lp6ZHVSHNe6b9RqGt5pR/f/mkIlk642FQ+PfwBERcHHAA0rme8OJKX\nZDWpizQv435rAJGjj9x/hmL1CbBPgTHk899fACC2XChtGoc7hDPkkYLPR2GO5ou6tAhzGBvpGCXR\nn4LiU7i4i35yv6qAQOeWDdCiofHM5wEG/he/EEEnq1WTFwC0bxo+UTASKyYON9x3+wXtbdfnFI9f\n1hV/v7qbZ+evCURai7s0hsWWrBKr34J9Cowhfc6QzEbKvIJoZgwvUJlclLztSi2pKSn4yyWhzu0m\n9dKDD3WnFpKj2sjEpM7PUi/dF5y8NvTs5vhFZzRgJea7R9tGutsDAYHmDepgx7OjMP2e/hHrUYg0\nw1UPMxONl87yJvXTdTPtMtWURGj0tZleneR4WSXaT5iDOetjmzPD5iMmIi/e0BN3DuyA3m0b2z42\nI82HN27pi0dHdcH7d5yHHc+OQiM55/ywLi3QSGUqefH6nrg+u20wedirN/fBR/ecjxYNjHv2Sjjt\nA8M7BUcKKUQ4XWeEYqUH1dLgXMqwPyWFbCvHkd1a4YXf9gzZNuv+gabHXHR2eG4nIDnW1G6Y4a5T\n//HLuuKju8939RxesCnKjKpa2HzERCSrST387fKuYRFAVhnRrRXGDTkTRISUFELTzDpY+sjFmDCy\nS0i5a/pkwZdCwXTeDTPScMGZ5utND+/aErsmjw7WDxibm8w6QEp0kXointpUo26Mm1iw+bdoIE0K\nzEhLweu39A3OxlbokdUYz1zVLbhMpJaXbuilu139wvbM0h/VuMGZze2HOUY7qHF7NDKiWyvTMG0t\nT1ze1dbMe6+wm7I82yCAhM1HjCe0blQXqQZmEn+wV26vzlMV0kuRYbAOs1kv++vxg/DPG3oh1ZeC\n5nKDru6xqkcZ7ZrWjziJ67YB7TD9nv66eaYUbu3fDm+Pzdbdl2kQAqs2H00fZ27GMvNNWEEZ0QHA\nZ/ddYPv47c+OQjMbM9YVnM5iqsUnd06s0rZJPcPghfM7JI45za6/QmuWVaIM2XzEhNGpRWbUC9xH\nw6jurUK+Kw2wUW56I3xy+TOb6U+aUzfs9dJ96K5yVLdvVh9X9ZZmPCvJAUf1aK06NrQupZc19boe\nBucCBpzZNMT0tfmZEfjk3gFY8rCxolBQFGZmnVRsenoElj86DJOu6oa7VLPT66Wbm1kU5RYt6olq\njXWW74wEEYX85v0sjgD2mywe/7shHW3JME6nvF2/TKqPDOdnTL5W//57wcQvjJftfGB4+GRPbecp\ns04qplzbA+d3cD+dCSuFGsa3fxqC3Kcvjdv5Xr6xN9Y9eUnwu7JwuFFv2Yhpt/bFi9f3DPopRndv\njS6tGmBMPykNh3qN4dynR+DT+6Q1q5+9untIPR/c1Q+PjOyCLq0aBm3//TqEDrWfuaobxvRriyt7\ntQmLyGndKAPX9g1PqZGR5sN57U9DVhPjiCT1XIgv/zAQSx6+CHXTfWjZMAO39G+HtqfVsxXRtPO5\nUZELqbi6t1ru6J3ayiRIdQhmRwsmqB5ZjfDUFcYRTt1lk9mo7q0izp9pmJGKW/uH5+WyrRRSUgyV\ngs/DJIxajustCSvTNDO8g6Dt+PlSCNef1xZntdDvVDkJK4UaBpF9Z2ospPlSQta2vW/omdg1ebTt\n2bNtT6uHa/pU2+5fvbkP5j0wBIPOkvwS2mUs66T6sGvy6GDuJoUzm2fidxdKiqlHVmMse2QYrs8O\nzQbbsmEGnrumB9JTU3Dz+e3wxe+rzStLHxlm2vBrmT1+EADJ/9CxefUL2attY90e+pw/DsbKx/RN\nQ2k+Qt92TdBPNmuY3cexA9rhlv6h165Ood6msTTKubxnaGqT+hYmHCo8pEqdMrJ7a/xHYy7TLrg0\n6/5BGNSpGTY+dSlyn74Ur9/cRzcpIxDeqKnJrJOK567pgbY6a4cYhVi/dENPXTNZqo9Cfhf1b+YX\nIuz5SRRaqEaKN/WrllGJ6vvDRWeFlI+H2UiBlQLjKUoOpoFnmTutjWjVKCOikux9hvVZ31qU5H6t\nG1nL4lq/Tmqw53dtn1AH9ss39sZn912Amb8bENz275v0U5PUSfPhnNahDa6SwXZYlxa4Re5ld9L0\nHH+ecHEwvFgPdWN964D22DV5NHZNHo0LOzfHsHNaopcqis0oX1X9Oqmol56Kkd1bY9qt2UhNIcwe\nPyhk1rriI9JbcW/9k5dgdA/9xZzUvhIAWPLwRVj+6DBc3TsLDXQinxpmpKGZ3MA+cXlXTLqqe/A3\nqagKhI00u7cJDwB45spzg5+n6czQby1fg9Hs/cnXdNfdbob6HvlSCDdkt8Wo7q3w3YMXYtfk0Ti7\nVeikULeX4FTDSoHxlE4tG2DlY8Nxc4L26BrXS8cTl3fFf6MIk/zH9T2x9gnJ9HbjeW11V7Uberb+\nZD4A6NA01KSTKptWBnVqhmv6ZOGZK8/FvfKoSS3vqG6hfiBAckZ/cu8A5BiMYhTUPfWhqtDbngYh\nz6c3rou8Z0ehW5tGOPd0SYmN6t4abeXR2JTreuLB33QONqyrH/9NiBL/7k/VObi++sPAsACHrCb1\n0FKe0Kg3R+S0+um4TP5d28mmuweGd5ZlC1VIi/4yFL3PCL2OnydcjFsHtA9+15t38/nvL8DEUefg\nN+e0DIZZq7mx3xn47L4BYaG02qg2hZzHhuNoSUXItuev64HXbg5VOv1UjvLnolA80eJq0DERjQDw\nMgAfgLeFEJM1++sA+ABAXwCHAdwghNjlpkxM4qFnU3Wav1/dLeoV7O4YaJzePBKN6qbhp4cuCjZs\nWhTfzJh+bTH91+r1hHu1bYz+HZvisdHnoH/HpqgKCMxaI63Y5Q8I+FIopDFTc8N5bXFFr9OR7kvB\nloMnsGn/Ccs5shSV8O4d52Fo5+YYenYLZNZJRcuGke9R+2b1sePZUUhJIQzr0hIXn9MCgzo1w6BO\nzXBr/3Y4cLwMTTSRYZ1UaVLUiufynqejX/tQmVN1/A2N66XhgrOaIeex4cH1R0b3aI3RPaqTR9ZP\n96Gkwo/2zeoHneu3X9Ae57RuEJzV/5dLOuPHrYVopblPSx6+CK0b1cU9slN8eNeWuK5vFqr8AXy5\npnoFtb7tpAZ8cKdm+GlbEd6/s580+urSAvf9bxUAqZF/YHgnNMusEwwt/e9dxp2Nmb8bgE37j6Nz\nywbxnRgphHDlD5Ii2A6gI4B0AGsBdNWU+T2AN+TPNwKYEanevn37CoapTfj9AREIBMSL324Rd723\nQuw/dkr4/YGwcvM37BftHp4tlm4vck2WNxbliXYPzxYHi0+5dg4tm/cfF+v2HotY7mhJuWj38Ozg\n38Qv1lmq/2DxKbE+X6p/V9FJcelLP4rCE2WG5TcUHBNDpvwQ8XdW5DDjWGmF6PjIHDHhs1BZl24v\nEne9t0IcK6mwdA1OACBHWGi7Sbg0C5OIBgB4Ughxqfz9EVkJPacqM18us5SIUgEcANBcmAiVnZ0t\ncnJyXJGZYRKdIyUVri6mI4RAaYXf1gJL8WTVnqPYdvAELjq7hWmerHjw2Jfrke7z4W+ajMBayir9\nqJOaEtcAET2IaKUQQn/yjQo373wbAHtV3/MBaMdKwTJCiCoiKgbQFECRuhARjQMwTv56koiiXa2j\nmbbuGgxfS2JSW66ltlwH4PK1POFWxfrEci2W1uZNzO6ABiHENADTYq2HiHKsaMqaAF9LYlJbrqW2\nXAfA12IXN6OPCgCoA8iz5G26ZWTzUSNIDmeGYRjGA9xUCisAdCKiDkSUDsmRPEtTZhaAsfLn6wD8\nYOZPYBiGYdzFNfOR7CO4H8B8SJFI7wghNhLR05C84LMA/AfAh0SUB+AIJMXhJjGboBIIvpbEpLZc\nS225DoCvxRauRR8xDMMwNQ+e0cwwDMMEYaXAMAzDBEkapUBEI4hoCxHlEdEEr+Uxg4jaEtFCIsol\noo1E9H/y9tOI6Dsi2ib/byJvJyL6l3xt64ioj7dXEA4R+YhoNRHNlr93IKLlsswz5GAEEFEd+Xue\nvL+9l3JrIaLGRPQpEW0mok1ENKCm3hci+pP8fG0goulElFFT7gsRvUNEh4hog2qb7ftARGPl8tuI\naKzeuTy4jqny87WOiL4gosaqfY/I17GFiC5VbXeufbMy7bmm/8FCyo1E+gPQGkAf+XMDAFsBdAUw\nBcAEefsEAM/Ln0cB+AZSkv3+AJZ7fQ061/QggI8AzJa/zwRwo/z5DQD3yZ9tpz6J83W8D+Bu+XM6\ngMY18b5Amji6E0Bd1f24vabcFwBDAPQBsEG1zdZ9AHAagB3y/yby5yYJcB2XAEiVPz+vuo6ucttV\nB0AHuU3zOd2+ef5wxumHHwBgvur7IwAe8VouG/J/BeA3ALYAaC1vaw1gi/z5TQBjVOWD5RLhD9Ic\nlQUALgYwW345i1QPfvD+QIpWGyB/TpXLkdfXIMvTSG5ISbO9xt0XVGcTOE3+nWcDuLQm3RcA7TWN\nqa37AGAMgDdV20PKeXUdmn1XA/if/Dmk3VLuidPtW7KYj/RSboQvv5WAyMP03gCWA2gphNgv7zoA\nQFlZPtGv758AHgKgrBTSFMAxIYSyHJVa3pDUJwCU1CeJQAcAhQDelU1hbxNRfdTA+yKEKADwAoA9\nAPZD+p1XombeFwW79yFh74+KOyGNcoA4XUeyKIUaCRFlAvgMwANCiOPqfULqEiR8PDERXQbgkBBi\npdeyOEAqpKH+60KI3gBKIJkpgtSg+9IEwJWQFN3pAOoDGOGpUA5SU+6DGUQ0EUAVgP/F87zJohSs\npNxIKIgoDZJC+J8Q4nN580Eiai3vbw3gkLw9ka9vIIAriGgXgI8hmZBeBtBYTm0ChMqbyKlP8gHk\nCyGWy98/haQkauJ9GQ5gpxCiUAhRCeBzSPeqJt4XBbv3IWHvDxHdDuAyADfLCg6I03Uki1KwknIj\nYSAigjTbe5MQ4kXVLnVakLGQfA3K9tvkKIv+AIpVw2hPEUI8IoTIEkK0h/S7/yCEuBnAQkipTYDw\na0nI1CdCiAMA9hKRsrjxMAC5qIH3BZLZqD8R1ZOfN+Vaatx9UWH3PswHcAkRNZFHTpfI2zyFpMXJ\nHgJwhRCiVLVrFoAb5UiwDgA6AfgVTrdvXjmJPHDmjIIUxbMdwESv5Ykg6yBIQ991ANbIf6Mg2XAX\nANgG4HsAp8nlCcCr8rWtB5Dt9TUYXNdQVEcfdZQf6DwAnwCoI2/PkL/nyfs7ei235hp6AciR782X\nkKJWauR9AfAUgM0ANgD4EFJUS424LwCmQ/KFVEIawd0VzX2AZLPPk//uSJDryIPkI1De/TdU5SfK\n17EFwEjVdsfaN05zwTAMwwRJFvMRwzAMYwFWCgzDMEwQVgoMwzBMEFYKDMMwTBBWCgzDMEwQVgoM\nYwARTZSziK4jojVEdD4RPUBE9byWjWHcgkNSGUYHIhoA4EUAQ4UQ5UTUDFIGyl8gxbkXeSogw7gE\njxQYRp/WAIqEEOUAICuB6yDlCVpIRAsBgIguIaKlRLSKiD6R81WBiHYR0RQiWk9EvxLRWfL238rr\nF6wlosXeXBrDGMMjBYbRQW7clwCoB2l27AwhxI9yDqdsIUSRPHr4HNLM0hIiehjSDOCn5XJvCSH+\nTkS3AbheCHEZEa0HMEIIUUBEjYUQxzy5QIYxgEcKDKODEOIkgL4AxkFKlz1DTlKmpj+khU9+JqI1\nkPLttFPtn676P0D+/DOA94joHkiLozBMQpEauQjDJCdCCD+ARQAWyT187XKNBOA7IcQYoyq0n4UQ\n9xLR+QBGA1hJRH2FEImWbZRJYnikwDA6ENHZRNRJtakXgN0ATkBaIhUAlgEYqPIX1CeizqpjblD9\nXyqXOVMIsVwI8TdIIxB1ymOG8RweKTCMPpkAXpEXTa+ClLlyHKQlHOcR0T4hxEWySWk6EdWRj3sM\nUrZKAGhCROsAlMvHAcBUWdkQpIyea+NyNQxjEXY0M4wLqB3SXsvCMHZg8xHDMAwThEcKDMMwTBAe\nKTAMwzBBWCkwDMMwQVgpMAzDMEFYKTAMwzBBWCkwDMMwQf4f32XRq5pKM7wAAAAASUVORK5CYII=\n",
228 | "text/plain": [
229 | ""
230 | ]
231 | },
232 | "metadata": {},
233 | "output_type": "display_data"
234 | }
235 | ],
236 | "source": [
237 | "plt.plot(losses_his, label='loss')\n",
238 | "plt.legend(loc='best')\n",
239 | "plt.xlabel('Steps')\n",
240 | "plt.ylabel('Loss')\n",
241 | "plt.ylim((0, 1))\n",
242 | "plt.show()"
243 | ]
244 | },
245 | {
246 | "cell_type": "markdown",
247 | "metadata": {},
248 | "source": [
249 | "### Test"
250 | ]
251 | },
252 | {
253 | "cell_type": "code",
254 | "execution_count": 11,
255 | "metadata": {},
256 | "outputs": [
257 | {
258 | "name": "stdout",
259 | "output_type": "stream",
260 | "text": [
261 | "\n",
262 | " 7\n",
263 | " 2\n",
264 | " 1\n",
265 | " 0\n",
266 | " 4\n",
267 | " 1\n",
268 | " 4\n",
269 | " 9\n",
270 | " 5\n",
271 | " 9\n",
272 | "[torch.cuda.LongTensor of size 10 (GPU 0)]\n",
273 | " prediction number\n",
274 | "\n",
275 | " 7\n",
276 | " 2\n",
277 | " 1\n",
278 | " 0\n",
279 | " 4\n",
280 | " 1\n",
281 | " 4\n",
282 | " 9\n",
283 | " 5\n",
284 | " 9\n",
285 | "[torch.cuda.LongTensor of size 10 (GPU 0)]\n",
286 | " real number\n"
287 | ]
288 | }
289 | ],
290 | "source": [
291 | "# !!!!!!!! Change in here !!!!!!!!! #\n",
292 | "test_output = cnn(test_x[:10])\n",
293 | "pred_y = torch.max(test_output, 1)[1].cuda().data.squeeze() # move the computation in GPU\n",
294 | "\n",
295 | "print(pred_y, 'prediction number')\n",
296 | "print(test_y[:10], 'real number')"
297 | ]
298 | },
299 | {
300 | "cell_type": "code",
301 | "execution_count": null,
302 | "metadata": {
303 | "collapsed": true
304 | },
305 | "outputs": [],
306 | "source": []
307 | }
308 | ],
309 | "metadata": {
310 | "kernelspec": {
311 | "display_name": "Python 3",
312 | "language": "python",
313 | "name": "python3"
314 | },
315 | "language_info": {
316 | "codemirror_mode": {
317 | "name": "ipython",
318 | "version": 3
319 | },
320 | "file_extension": ".py",
321 | "mimetype": "text/x-python",
322 | "name": "python",
323 | "nbconvert_exporter": "python",
324 | "pygments_lexer": "ipython3",
325 | "version": "3.5.2"
326 | }
327 | },
328 | "nbformat": 4,
329 | "nbformat_minor": 2
330 | }
331 |
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/processed/test.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents-notebooks/mnist/processed/test.pt
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/processed/training.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents-notebooks/mnist/processed/training.pt
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/raw/t10k-images-idx3-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents-notebooks/mnist/raw/t10k-images-idx3-ubyte
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/raw/t10k-labels-idx1-ubyte:
--------------------------------------------------------------------------------
1 | ������'�������� � �� ��� ��� ������������������������������������� ��� ���������� ���� ������������� ������ ���� �� ���� ���� ������ ������������������������ ��������������������������������� ������� ������������ �� �� � �������������������� ����� ���������� ����������� �������� ������ �� ������� ���������������������� ���� � ������������� ���������������������� ����������������������������� ���� ������������������� �� ���� ��� ������� ������������� ����� ���������������� ������� � ����� ������� ���� ������������������� �������� ��������������������������� � � ������������ ����������������� ���� ���������������� ���������� �� ��� ���� ���������������������� �������� � ���� �� ������������������������ �������������������������� ������������������������ ������������� �������������� ������������������������ ������������������� ���������������������������� ����������� ������� ���������� ������������ ������ �������������� ������������������������� ������� ��� ������������������������� ������ ���� ������� ������������������������������� �� ��������� ���� ����������������� ���� � � ������������ � � ���������������������� ��������������������� ������������ ����������������� �������� ������������������������ ���������� ��� �������������� ������� ��������������������� ���� ��������������������� ��� � ���������� ���� ��������������� ������������������������������������ ���� ���������� ����������������� �� ���� ���� ����� ��� ��������� �� �� ������������������������� ���� ����� �������� ������ ��� ������������������� ������������ ������� ���� ���������������������������������� � ������������������������ ���� ��� �������� ���� � ������ ���������� � �������������������������� � ����������� ���� ����������������� ���������� � ����������������������������������� ����� ���� ������� ���������� �������� ��� ������������������������� � ��������������� ��� ������� ������������ ������ �� � ��������������������������������������������� ����������� �������������� ������������ ����� ���������� ���� ���� ����������������������������� ���� ������������� ������������������� ��������������������������������������� ����������������� ������������� ������������������� ������� ������ ��������������� ��� ���������� ���� ����������� ����� ������ � ��� ���������� ����������������� ���������������� �� ������ �� ����������������� �� ��������������� ������������������ ������ ������������������ ������� ����� ����� ����������� ���� ���� ������� ��������������� ���� �������������� �� ������������������ ����������� ��������� ����� ��� ��������������������� ����������� �� ��� ������������� ����������������������������� ��� ���������� ������������������������ ����������� ������ � � ����������������������� �������������� ���� � ������������ ���� �������� ����������� ���������� ������������������� �������������������������������� �������� �� ���� ������ ���� ������� �������� ��������������� ������� ������ �� �� ���� ���� � ���������������� ����� � ������ ����� ��� ����������������� ��� � ������������������������� ������ �������������� ��� �������������� ����������������������������������������������������������������������� � ���������� ���� �� ��������������������� ��������� ��������������������������������������� �������������������������������������������� �������������������������������������������������� ������������������������������ ��������������� � ���� � ��������� ������ �������������� �������������������������������� ������ ���� ���� ���� � ����� ��������� � �� ������������������ �� �������� �������������� ��������������������������������� ���� ���� �������������������� ��������������������������������������������� � �������������������� ����� ��������������� � ���� ������ ������������������������������� ��� ���������������������� ������� ������ ��������������������� ��������� �������� � ������� ����� � � ������� �� � ���� � �� �� � �������������������������������� � ���������������������� ��������������� �� ���������� �� ������ ������ �������� ����� ������������� ��������� ������ ������������������������������ ��������� ���� � ����� ��������� ���������� ������ ���� �������� ���������� ��� ���� ���������� ������� ������������� ����������� �� ���������� ���������� � �� ���� ����������� � ������������ ������� �� �� ����� ��� � ������� ���� � �� � ��� ������� ���������� ������������� ���� ����� ������������� ��������������������� � � ������ ������ ��������� ������� ��������� ������������������������ �������� ���������� � �� ����� ���������������������� ��������������� �� � ��� ��������� ������������� ������ ����������������� ����� ���������������� ���������� ��� ���������� �� � ������� ����� � �������� ������� ���� ���������������������������� ���������������� �������� ������� ���������������� �������� ��� ����������������������� ����������� ���� �� �� ��������� ����������������� ��������� ���������������� �������� ������� ������������������������� � ��������������� ��� ������ ������������ ����������� ������ ����� � ���� ��� �� ������������ ������� ��������� ��������� �� ������ ������������������� ����� ����������������������� ���� � ������ ������������������� ����������������� ��������������������������� �������� ������������ �������� ���� �������������� ����� ��������� ��������� ��������� ����������� ��� ����������������� ���������� ������� �������������������� � � �������� � ��������������� ��������� ��������� ���� ����������������� �������� ���������������������������������� ����������� ������������������� ��� ��������� �������� ������������������ ��������� ���� � ���� �������������� ��������� ��������� ���� ����������� ����� ������������������������� ���������� �������������������� � ����������� ���������� ���������������������� �� ����������������������� �� �� �� ��������� ���� ������� ����������������������� ������������������ ����������� � ���������������������� �� ���������� ���������� ��������������������� ��������� ��������� ������ �� ����� ������������������ ��� ��������������������� ��������� ������ ������� ������� ��������������� ��������� ��������� �������������������� ����������� � ������������������������������ �������� � ��� ���������������� ��������� ��������� ��� ������ ������ � ���� ����������� � ���������������������������������������������������� �������������� ��������������������������������������������������������� ���������������� ������ ������� � ���� ��� � ������������� ������ ������� ����������������������������������� �������� �������� � ��� ������� ��� ����������������������������������� ���� �� �� �������������������� ��������������� � ���������������� ���� ��������� ������� ���� � ������������ ���������� ��������� ����������������� ������� ��������������������� ������ ������������������������ ����� ����� �� ����� ������������� ��������� ��������� ������������������������������������������ ���������������� ������ ������� � ���� ��� � �� ���������������� ��������� ��������� ���������� ������������ ��� ��� ������� � ��������� ���������������� ����������������� ���������������� ��������� ��������� ������� ����� ���������� ���������� ��������� ��� ��� ����������� ������������������������� ������� ���������������� ������������������������ �� �������� ����� �� ������� � ��������������������� ��������� ��������� ������������������� ��� ������������� ���������� ��������� �� ���������������� �� � � ����������������������������������������� �������������������������������� �� � ������ ��������������� � ����� �� ��������������� ��������� ��������� ��������������������� ���� �������� ������� ������� ��� � ��������������������� ������� ��������� ����� ��������� ��������������������������� � �������������� �� ������ ���������������������������� ��������� ��������� ������������ ���������������� �������� ��� ������� ����� ������������� �������� ���������������� �������� �� ������ ��������� ������� �� ����������������������������������� ���������� ��������� ��������� � �������������������������� ��������� ��� ���������� ���������� ��������������� �������� ������������ ��������� ������� �������� ������� ������� ���������������� ��������� ��������� ��� ������������������������������ � ���������������������� �� �� ������������� �� ������������������� �������� ������� ������ ������������� ��������� �������������������� �� ��������� � ����������������������� ������������ � �������� �������������������� ����������������� ��� ���� ���� �������������������� ��������� ��������� � ����������������������� � ���������������� ���������� �� ������������������� �������������������������������� �� �� �� ����������������������� ���������������� � �������������������� ������ ��������� ��������� ��������� ���� ����������� ����� �������������������������� ���������� ������������������ � ����������� ���������� ��������� ��������� ����������� � ���� ����������������������������������� ���������� ��� � ����� ������������� ������� ���� � ������������� ��� � ������ �������������� ���������������� ��� ������������������������ �� � ������������������������� �� ����������� ��������� ��������� ��� ����������������������������������������������� � �������� ����������� ���� ����������������� ��������� ������� ������� � � �������������������������� ���� � � ���������������� �������������� ���� ����� ������������������� ������������������������������������� ���� ������������� ��������� ���������� ������ ��� ������� ������ �������� ��������������������������������� ���� ���������� ������������� ��������� ��������� ������������ �������� ���� �������� ������� �������� �������� ������ ���������������������� ��������� ����������������� ��� ���������������� �������� ������� ��������������� �������� ����������� ��������� ��������� ������ ������������������������� � �������������� ���������������������� ���������������� ��� ������������� ������������ ��������������������������������� ��������� ���������������� ����� ������� ������������ ��������������������������� ������������������ �������
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/raw/train-images-idx3-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents-notebooks/mnist/raw/train-images-idx3-ubyte
--------------------------------------------------------------------------------
/tutorial-contents-notebooks/mnist/raw/train-labels-idx1-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents-notebooks/mnist/raw/train-labels-idx1-ubyte
--------------------------------------------------------------------------------
/tutorial-contents/201_torch_numpy.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.1.11
7 | numpy
8 | """
9 | import torch
10 | import numpy as np
11 |
12 | # details about math operation in torch can be found in: http://pytorch.org/docs/torch.html#math-operations
13 |
14 | # convert numpy to tensor or vise versa
15 | np_data = np.arange(6).reshape((2, 3))
16 | torch_data = torch.from_numpy(np_data)
17 | tensor2array = torch_data.numpy()
18 | print(
19 | '\nnumpy array:', np_data, # [[0 1 2], [3 4 5]]
20 | '\ntorch tensor:', torch_data, # 0 1 2 \n 3 4 5 [torch.LongTensor of size 2x3]
21 | '\ntensor to array:', tensor2array, # [[0 1 2], [3 4 5]]
22 | )
23 |
24 |
25 | # abs
26 | data = [-1, -2, 1, 2]
27 | tensor = torch.FloatTensor(data) # 32-bit floating point
28 | print(
29 | '\nabs',
30 | '\nnumpy: ', np.abs(data), # [1 2 1 2]
31 | '\ntorch: ', torch.abs(tensor) # [1 2 1 2]
32 | )
33 |
34 | # sin
35 | print(
36 | '\nsin',
37 | '\nnumpy: ', np.sin(data), # [-0.84147098 -0.90929743 0.84147098 0.90929743]
38 | '\ntorch: ', torch.sin(tensor) # [-0.8415 -0.9093 0.8415 0.9093]
39 | )
40 |
41 | # mean
42 | print(
43 | '\nmean',
44 | '\nnumpy: ', np.mean(data), # 0.0
45 | '\ntorch: ', torch.mean(tensor) # 0.0
46 | )
47 |
48 | # matrix multiplication
49 | data = [[1,2], [3,4]]
50 | tensor = torch.FloatTensor(data) # 32-bit floating point
51 | # correct method
52 | print(
53 | '\nmatrix multiplication (matmul)',
54 | '\nnumpy: ', np.matmul(data, data), # [[7, 10], [15, 22]]
55 | '\ntorch: ', torch.mm(tensor, tensor) # [[7, 10], [15, 22]]
56 | )
57 | # incorrect method
58 | data = np.array(data)
59 | print(
60 | '\nmatrix multiplication (dot)',
61 | '\nnumpy: ', data.dot(data), # [[7, 10], [15, 22]]
62 | '\ntorch: ', tensor.dot(tensor) # this will convert tensor to [1,2,3,4], you'll get 30.0
63 | )
--------------------------------------------------------------------------------
/tutorial-contents/202_variable.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.1.11
7 | """
8 | import torch
9 | from torch.autograd import Variable
10 |
11 | # Variable in torch is to build a computational graph,
12 | # but this graph is dynamic compared with a static graph in Tensorflow or Theano.
13 | # So torch does not have placeholder, torch can just pass variable to the computational graph.
14 |
15 | tensor = torch.FloatTensor([[1,2],[3,4]]) # build a tensor
16 | variable = Variable(tensor, requires_grad=True) # build a variable, usually for compute gradients
17 |
18 | print(tensor) # [torch.FloatTensor of size 2x2]
19 | print(variable) # [torch.FloatTensor of size 2x2]
20 |
21 | # till now the tensor and variable seem the same.
22 | # However, the variable is a part of the graph, it's a part of the auto-gradient.
23 |
24 | t_out = torch.mean(tensor*tensor) # x^2
25 | v_out = torch.mean(variable*variable) # x^2
26 | print(t_out)
27 | print(v_out) # 7.5
28 |
29 | v_out.backward() # backpropagation from v_out
30 | # v_out = 1/4 * sum(variable*variable)
31 | # the gradients w.r.t the variable, d(v_out)/d(variable) = 1/4*2*variable = variable/2
32 | print(variable.grad)
33 | '''
34 | 0.5000 1.0000
35 | 1.5000 2.0000
36 | '''
37 |
38 | print(variable) # this is data in variable format
39 | """
40 | Variable containing:
41 | 1 2
42 | 3 4
43 | [torch.FloatTensor of size 2x2]
44 | """
45 |
46 | print(variable.data) # this is data in tensor format
47 | """
48 | 1 2
49 | 3 4
50 | [torch.FloatTensor of size 2x2]
51 | """
52 |
53 | print(variable.data.numpy()) # numpy format
54 | """
55 | [[ 1. 2.]
56 | [ 3. 4.]]
57 | """
--------------------------------------------------------------------------------
/tutorial-contents/203_activation.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import torch.nn.functional as F
11 | from torch.autograd import Variable
12 | import matplotlib.pyplot as plt
13 |
14 | # fake data
15 | x = torch.linspace(-5, 5, 200) # x data (tensor), shape=(100, 1)
16 | x = Variable(x)
17 | x_np = x.data.numpy() # numpy array for plotting
18 |
19 | # following are popular activation functions
20 | y_relu = torch.relu(x).data.numpy()
21 | y_sigmoid = torch.sigmoid(x).data.numpy()
22 | y_tanh = torch.tanh(x).data.numpy()
23 | y_softplus = F.softplus(x).data.numpy() # there's no softplus in torch
24 | # y_softmax = torch.softmax(x, dim=0).data.numpy() softmax is a special kind of activation function, it is about probability
25 |
26 | # plt to visualize these activation function
27 | plt.figure(1, figsize=(8, 6))
28 | plt.subplot(221)
29 | plt.plot(x_np, y_relu, c='red', label='relu')
30 | plt.ylim((-1, 5))
31 | plt.legend(loc='best')
32 |
33 | plt.subplot(222)
34 | plt.plot(x_np, y_sigmoid, c='red', label='sigmoid')
35 | plt.ylim((-0.2, 1.2))
36 | plt.legend(loc='best')
37 |
38 | plt.subplot(223)
39 | plt.plot(x_np, y_tanh, c='red', label='tanh')
40 | plt.ylim((-1.2, 1.2))
41 | plt.legend(loc='best')
42 |
43 | plt.subplot(224)
44 | plt.plot(x_np, y_softplus, c='red', label='softplus')
45 | plt.ylim((-0.2, 6))
46 | plt.legend(loc='best')
47 |
48 | plt.show()
49 |
--------------------------------------------------------------------------------
/tutorial-contents/301_regression.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import torch.nn.functional as F
11 | import matplotlib.pyplot as plt
12 |
13 | # torch.manual_seed(1) # reproducible
14 |
15 | x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
16 | y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
17 |
18 | # torch can only train on Variable, so convert them to Variable
19 | # The code below is deprecated in Pytorch 0.4. Now, autograd directly supports tensors
20 | # x, y = Variable(x), Variable(y)
21 |
22 | # plt.scatter(x.data.numpy(), y.data.numpy())
23 | # plt.show()
24 |
25 |
26 | class Net(torch.nn.Module):
27 | def __init__(self, n_feature, n_hidden, n_output):
28 | super(Net, self).__init__()
29 | self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
30 | self.predict = torch.nn.Linear(n_hidden, n_output) # output layer
31 |
32 | def forward(self, x):
33 | x = F.relu(self.hidden(x)) # activation function for hidden layer
34 | x = self.predict(x) # linear output
35 | return x
36 |
37 | net = Net(n_feature=1, n_hidden=10, n_output=1) # define the network
38 | print(net) # net architecture
39 |
40 | optimizer = torch.optim.SGD(net.parameters(), lr=0.2)
41 | loss_func = torch.nn.MSELoss() # this is for regression mean squared loss
42 |
43 | plt.ion() # something about plotting
44 |
45 | for t in range(200):
46 | prediction = net(x) # input x and predict based on x
47 |
48 | loss = loss_func(prediction, y) # must be (1. nn output, 2. target)
49 |
50 | optimizer.zero_grad() # clear gradients for next train
51 | loss.backward() # backpropagation, compute gradients
52 | optimizer.step() # apply gradients
53 |
54 | if t % 5 == 0:
55 | # plot and show learning process
56 | plt.cla()
57 | plt.scatter(x.data.numpy(), y.data.numpy())
58 | plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
59 | plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
60 | plt.pause(0.1)
61 |
62 | plt.ioff()
63 | plt.show()
64 |
--------------------------------------------------------------------------------
/tutorial-contents/302_classification.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import torch.nn.functional as F
11 | import matplotlib.pyplot as plt
12 |
13 | # torch.manual_seed(1) # reproducible
14 |
15 | # make fake data
16 | n_data = torch.ones(100, 2)
17 | x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)
18 | y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)
19 | x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)
20 | y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)
21 | x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating
22 | y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer
23 |
24 | # The code below is deprecated in Pytorch 0.4. Now, autograd directly supports tensors
25 | # x, y = Variable(x), Variable(y)
26 |
27 | # plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
28 | # plt.show()
29 |
30 |
31 | class Net(torch.nn.Module):
32 | def __init__(self, n_feature, n_hidden, n_output):
33 | super(Net, self).__init__()
34 | self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
35 | self.out = torch.nn.Linear(n_hidden, n_output) # output layer
36 |
37 | def forward(self, x):
38 | x = F.relu(self.hidden(x)) # activation function for hidden layer
39 | x = self.out(x)
40 | return x
41 |
42 | net = Net(n_feature=2, n_hidden=10, n_output=2) # define the network
43 | print(net) # net architecture
44 |
45 | optimizer = torch.optim.SGD(net.parameters(), lr=0.02)
46 | loss_func = torch.nn.CrossEntropyLoss() # the target label is NOT an one-hotted
47 |
48 | plt.ion() # something about plotting
49 |
50 | for t in range(100):
51 | out = net(x) # input x and predict based on x
52 | loss = loss_func(out, y) # must be (1. nn output, 2. target), the target label is NOT one-hotted
53 |
54 | optimizer.zero_grad() # clear gradients for next train
55 | loss.backward() # backpropagation, compute gradients
56 | optimizer.step() # apply gradients
57 |
58 | if t % 2 == 0:
59 | # plot and show learning process
60 | plt.cla()
61 | prediction = torch.max(out, 1)[1]
62 | pred_y = prediction.data.numpy()
63 | target_y = y.data.numpy()
64 | plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
65 | accuracy = float((pred_y == target_y).astype(int).sum()) / float(target_y.size)
66 | plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
67 | plt.pause(0.1)
68 |
69 | plt.ioff()
70 | plt.show()
71 |
--------------------------------------------------------------------------------
/tutorial-contents/303_build_nn_quickly.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.1.11
7 | """
8 | import torch
9 | import torch.nn.functional as F
10 |
11 |
12 | # replace following class code with an easy sequential network
13 | class Net(torch.nn.Module):
14 | def __init__(self, n_feature, n_hidden, n_output):
15 | super(Net, self).__init__()
16 | self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
17 | self.predict = torch.nn.Linear(n_hidden, n_output) # output layer
18 |
19 | def forward(self, x):
20 | x = F.relu(self.hidden(x)) # activation function for hidden layer
21 | x = self.predict(x) # linear output
22 | return x
23 |
24 | net1 = Net(1, 10, 1)
25 |
26 | # easy and fast way to build your network
27 | net2 = torch.nn.Sequential(
28 | torch.nn.Linear(1, 10),
29 | torch.nn.ReLU(),
30 | torch.nn.Linear(10, 1)
31 | )
32 |
33 |
34 | print(net1) # net1 architecture
35 | """
36 | Net (
37 | (hidden): Linear (1 -> 10)
38 | (predict): Linear (10 -> 1)
39 | )
40 | """
41 |
42 | print(net2) # net2 architecture
43 | """
44 | Sequential (
45 | (0): Linear (1 -> 10)
46 | (1): ReLU ()
47 | (2): Linear (10 -> 1)
48 | )
49 | """
--------------------------------------------------------------------------------
/tutorial-contents/304_save_reload.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import matplotlib.pyplot as plt
11 |
12 | # torch.manual_seed(1) # reproducible
13 |
14 | # fake data
15 | x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
16 | y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
17 |
18 | # The code below is deprecated in Pytorch 0.4. Now, autograd directly supports tensors
19 | # x, y = Variable(x, requires_grad=False), Variable(y, requires_grad=False)
20 |
21 |
22 | def save():
23 | # save net1
24 | net1 = torch.nn.Sequential(
25 | torch.nn.Linear(1, 10),
26 | torch.nn.ReLU(),
27 | torch.nn.Linear(10, 1)
28 | )
29 | optimizer = torch.optim.SGD(net1.parameters(), lr=0.5)
30 | loss_func = torch.nn.MSELoss()
31 |
32 | for t in range(100):
33 | prediction = net1(x)
34 | loss = loss_func(prediction, y)
35 | optimizer.zero_grad()
36 | loss.backward()
37 | optimizer.step()
38 |
39 | # plot result
40 | plt.figure(1, figsize=(10, 3))
41 | plt.subplot(131)
42 | plt.title('Net1')
43 | plt.scatter(x.data.numpy(), y.data.numpy())
44 | plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
45 |
46 | # 2 ways to save the net
47 | torch.save(net1, 'net.pkl') # save entire net
48 | torch.save(net1.state_dict(), 'net_params.pkl') # save only the parameters
49 |
50 |
51 | def restore_net():
52 | # restore entire net1 to net2
53 | net2 = torch.load('net.pkl')
54 | prediction = net2(x)
55 |
56 | # plot result
57 | plt.subplot(132)
58 | plt.title('Net2')
59 | plt.scatter(x.data.numpy(), y.data.numpy())
60 | plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
61 |
62 |
63 | def restore_params():
64 | # restore only the parameters in net1 to net3
65 | net3 = torch.nn.Sequential(
66 | torch.nn.Linear(1, 10),
67 | torch.nn.ReLU(),
68 | torch.nn.Linear(10, 1)
69 | )
70 |
71 | # copy net1's parameters into net3
72 | net3.load_state_dict(torch.load('net_params.pkl'))
73 | prediction = net3(x)
74 |
75 | # plot result
76 | plt.subplot(133)
77 | plt.title('Net3')
78 | plt.scatter(x.data.numpy(), y.data.numpy())
79 | plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
80 | plt.show()
81 |
82 | # save net1
83 | save()
84 |
85 | # restore entire net (may slow)
86 | restore_net()
87 |
88 | # restore only the net parameters
89 | restore_params()
90 |
--------------------------------------------------------------------------------
/tutorial-contents/305_batch_train.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.1.11
7 | """
8 | import torch
9 | import torch.utils.data as Data
10 |
11 | torch.manual_seed(1) # reproducible
12 |
13 | BATCH_SIZE = 5
14 | # BATCH_SIZE = 8
15 |
16 | x = torch.linspace(1, 10, 10) # this is x data (torch tensor)
17 | y = torch.linspace(10, 1, 10) # this is y data (torch tensor)
18 |
19 | torch_dataset = Data.TensorDataset(x, y)
20 | loader = Data.DataLoader(
21 | dataset=torch_dataset, # torch TensorDataset format
22 | batch_size=BATCH_SIZE, # mini batch size
23 | shuffle=True, # random shuffle for training
24 | num_workers=2, # subprocesses for loading data
25 | )
26 |
27 |
28 | def show_batch():
29 | for epoch in range(3): # train entire dataset 3 times
30 | for step, (batch_x, batch_y) in enumerate(loader): # for each training step
31 | # train your data...
32 | print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
33 | batch_x.numpy(), '| batch y: ', batch_y.numpy())
34 |
35 |
36 | if __name__ == '__main__':
37 | show_batch()
38 |
39 |
--------------------------------------------------------------------------------
/tutorial-contents/306_optimizer.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import torch.utils.data as Data
11 | import torch.nn.functional as F
12 | import matplotlib.pyplot as plt
13 |
14 | # torch.manual_seed(1) # reproducible
15 |
16 | LR = 0.01
17 | BATCH_SIZE = 32
18 | EPOCH = 12
19 |
20 | # fake dataset
21 | x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
22 | y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
23 |
24 | # plot dataset
25 | plt.scatter(x.numpy(), y.numpy())
26 | plt.show()
27 |
28 | # put dateset into torch dataset
29 | torch_dataset = Data.TensorDataset(x, y)
30 | loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
31 |
32 |
33 | # default network
34 | class Net(torch.nn.Module):
35 | def __init__(self):
36 | super(Net, self).__init__()
37 | self.hidden = torch.nn.Linear(1, 20) # hidden layer
38 | self.predict = torch.nn.Linear(20, 1) # output layer
39 |
40 | def forward(self, x):
41 | x = F.relu(self.hidden(x)) # activation function for hidden layer
42 | x = self.predict(x) # linear output
43 | return x
44 |
45 | if __name__ == '__main__':
46 | # different nets
47 | net_SGD = Net()
48 | net_Momentum = Net()
49 | net_RMSprop = Net()
50 | net_Adam = Net()
51 | nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
52 |
53 | # different optimizers
54 | opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
55 | opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
56 | opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
57 | opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
58 | optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
59 |
60 | loss_func = torch.nn.MSELoss()
61 | losses_his = [[], [], [], []] # record loss
62 |
63 | # training
64 | for epoch in range(EPOCH):
65 | print('Epoch: ', epoch)
66 | for step, (b_x, b_y) in enumerate(loader): # for each training step
67 | for net, opt, l_his in zip(nets, optimizers, losses_his):
68 | output = net(b_x) # get output for every net
69 | loss = loss_func(output, b_y) # compute loss for every net
70 | opt.zero_grad() # clear gradients for next train
71 | loss.backward() # backpropagation, compute gradients
72 | opt.step() # apply gradients
73 | l_his.append(loss.data.numpy()) # loss recoder
74 |
75 | labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
76 | for i, l_his in enumerate(losses_his):
77 | plt.plot(l_his, label=labels[i])
78 | plt.legend(loc='best')
79 | plt.xlabel('Steps')
80 | plt.ylabel('Loss')
81 | plt.ylim((0, 0.2))
82 | plt.show()
83 |
--------------------------------------------------------------------------------
/tutorial-contents/401_CNN.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | torchvision
8 | matplotlib
9 | """
10 | # library
11 | # standard library
12 | import os
13 |
14 | # third-party library
15 | import torch
16 | import torch.nn as nn
17 | import torch.utils.data as Data
18 | import torchvision
19 | import matplotlib.pyplot as plt
20 |
21 | # torch.manual_seed(1) # reproducible
22 |
23 | # Hyper Parameters
24 | EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
25 | BATCH_SIZE = 50
26 | LR = 0.001 # learning rate
27 | DOWNLOAD_MNIST = False
28 |
29 |
30 | # Mnist digits dataset
31 | if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
32 | # not mnist dir or mnist is empyt dir
33 | DOWNLOAD_MNIST = True
34 |
35 | train_data = torchvision.datasets.MNIST(
36 | root='./mnist/',
37 | train=True, # this is training data
38 | transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
39 | # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
40 | download=DOWNLOAD_MNIST,
41 | )
42 |
43 | # plot one example
44 | print(train_data.train_data.size()) # (60000, 28, 28)
45 | print(train_data.train_labels.size()) # (60000)
46 | plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
47 | plt.title('%i' % train_data.train_labels[0])
48 | plt.show()
49 |
50 | # Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
51 | train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
52 |
53 | # pick 2000 samples to speed up testing
54 | test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
55 | test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
56 | test_y = test_data.test_labels[:2000]
57 |
58 |
59 | class CNN(nn.Module):
60 | def __init__(self):
61 | super(CNN, self).__init__()
62 | self.conv1 = nn.Sequential( # input shape (1, 28, 28)
63 | nn.Conv2d(
64 | in_channels=1, # input height
65 | out_channels=16, # n_filters
66 | kernel_size=5, # filter size
67 | stride=1, # filter movement/step
68 | padding=2, # if want same width and length of this image after Conv2d, padding=(kernel_size-1)/2 if stride=1
69 | ), # output shape (16, 28, 28)
70 | nn.ReLU(), # activation
71 | nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
72 | )
73 | self.conv2 = nn.Sequential( # input shape (16, 14, 14)
74 | nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
75 | nn.ReLU(), # activation
76 | nn.MaxPool2d(2), # output shape (32, 7, 7)
77 | )
78 | self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
79 |
80 | def forward(self, x):
81 | x = self.conv1(x)
82 | x = self.conv2(x)
83 | x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
84 | output = self.out(x)
85 | return output, x # return x for visualization
86 |
87 |
88 | cnn = CNN()
89 | print(cnn) # net architecture
90 |
91 | optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
92 | loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
93 |
94 | # following function (plot_with_labels) is for visualization, can be ignored if not interested
95 | from matplotlib import cm
96 | try: from sklearn.manifold import TSNE; HAS_SK = True
97 | except: HAS_SK = False; print('Please install sklearn for layer visualization')
98 | def plot_with_labels(lowDWeights, labels):
99 | plt.cla()
100 | X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
101 | for x, y, s in zip(X, Y, labels):
102 | c = cm.rainbow(int(255 * s / 9)); plt.text(x, y, s, backgroundcolor=c, fontsize=9)
103 | plt.xlim(X.min(), X.max()); plt.ylim(Y.min(), Y.max()); plt.title('Visualize last layer'); plt.show(); plt.pause(0.01)
104 |
105 | plt.ion()
106 | # training and testing
107 | for epoch in range(EPOCH):
108 | for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
109 |
110 | output = cnn(b_x)[0] # cnn output
111 | loss = loss_func(output, b_y) # cross entropy loss
112 | optimizer.zero_grad() # clear gradients for this training step
113 | loss.backward() # backpropagation, compute gradients
114 | optimizer.step() # apply gradients
115 |
116 | if step % 50 == 0:
117 | test_output, last_layer = cnn(test_x)
118 | pred_y = torch.max(test_output, 1)[1].data.numpy()
119 | accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
120 | print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
121 | if HAS_SK:
122 | # Visualization of trained flatten layer (T-SNE)
123 | tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
124 | plot_only = 500
125 | low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
126 | labels = test_y.numpy()[:plot_only]
127 | plot_with_labels(low_dim_embs, labels)
128 | plt.ioff()
129 |
130 | # print 10 predictions from test data
131 | test_output, _ = cnn(test_x[:10])
132 | pred_y = torch.max(test_output, 1)[1].data.numpy()
133 | print(pred_y, 'prediction number')
134 | print(test_y[:10].numpy(), 'real number')
135 |
--------------------------------------------------------------------------------
/tutorial-contents/402_RNN_classifier.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | torchvision
9 | """
10 | import torch
11 | from torch import nn
12 | import torchvision.datasets as dsets
13 | import torchvision.transforms as transforms
14 | import matplotlib.pyplot as plt
15 |
16 |
17 | # torch.manual_seed(1) # reproducible
18 |
19 | # Hyper Parameters
20 | EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
21 | BATCH_SIZE = 64
22 | TIME_STEP = 28 # rnn time step / image height
23 | INPUT_SIZE = 28 # rnn input size / image width
24 | LR = 0.01 # learning rate
25 | DOWNLOAD_MNIST = True # set to True if haven't download the data
26 |
27 |
28 | # Mnist digital dataset
29 | train_data = dsets.MNIST(
30 | root='./mnist/',
31 | train=True, # this is training data
32 | transform=transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
33 | # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
34 | download=DOWNLOAD_MNIST, # download it if you don't have it
35 | )
36 |
37 | # plot one example
38 | print(train_data.train_data.size()) # (60000, 28, 28)
39 | print(train_data.train_labels.size()) # (60000)
40 | plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
41 | plt.title('%i' % train_data.train_labels[0])
42 | plt.show()
43 |
44 | # Data Loader for easy mini-batch return in training
45 | train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
46 |
47 | # convert test data into Variable, pick 2000 samples to speed up testing
48 | test_data = dsets.MNIST(root='./mnist/', train=False, transform=transforms.ToTensor())
49 | test_x = test_data.test_data.type(torch.FloatTensor)[:2000]/255. # shape (2000, 28, 28) value in range(0,1)
50 | test_y = test_data.test_labels.numpy()[:2000] # covert to numpy array
51 |
52 |
53 | class RNN(nn.Module):
54 | def __init__(self):
55 | super(RNN, self).__init__()
56 |
57 | self.rnn = nn.LSTM( # if use nn.RNN(), it hardly learns
58 | input_size=INPUT_SIZE,
59 | hidden_size=64, # rnn hidden unit
60 | num_layers=1, # number of rnn layer
61 | batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
62 | )
63 |
64 | self.out = nn.Linear(64, 10)
65 |
66 | def forward(self, x):
67 | # x shape (batch, time_step, input_size)
68 | # r_out shape (batch, time_step, output_size)
69 | # h_n shape (n_layers, batch, hidden_size)
70 | # h_c shape (n_layers, batch, hidden_size)
71 | r_out, (h_n, h_c) = self.rnn(x, None) # None represents zero initial hidden state
72 |
73 | # choose r_out at the last time step
74 | out = self.out(r_out[:, -1, :])
75 | return out
76 |
77 |
78 | rnn = RNN()
79 | print(rnn)
80 |
81 | optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
82 | loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
83 |
84 | # training and testing
85 | for epoch in range(EPOCH):
86 | for step, (b_x, b_y) in enumerate(train_loader): # gives batch data
87 | b_x = b_x.view(-1, 28, 28) # reshape x to (batch, time_step, input_size)
88 |
89 | output = rnn(b_x) # rnn output
90 | loss = loss_func(output, b_y) # cross entropy loss
91 | optimizer.zero_grad() # clear gradients for this training step
92 | loss.backward() # backpropagation, compute gradients
93 | optimizer.step() # apply gradients
94 |
95 | if step % 50 == 0:
96 | test_output = rnn(test_x) # (samples, time_step, input_size)
97 | pred_y = torch.max(test_output, 1)[1].data.numpy()
98 | accuracy = float((pred_y == test_y).astype(int).sum()) / float(test_y.size)
99 | print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
100 |
101 | # print 10 predictions from test data
102 | test_output = rnn(test_x[:10].view(-1, 28, 28))
103 | pred_y = torch.max(test_output, 1)[1].data.numpy()
104 | print(pred_y, 'prediction number')
105 | print(test_y[:10], 'real number')
106 |
107 |
--------------------------------------------------------------------------------
/tutorial-contents/403_RNN_regressor.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | numpy
9 | """
10 | import torch
11 | from torch import nn
12 | import numpy as np
13 | import matplotlib.pyplot as plt
14 |
15 | # torch.manual_seed(1) # reproducible
16 |
17 | # Hyper Parameters
18 | TIME_STEP = 10 # rnn time step
19 | INPUT_SIZE = 1 # rnn input size
20 | LR = 0.02 # learning rate
21 |
22 | # show data
23 | steps = np.linspace(0, np.pi*2, 100, dtype=np.float32) # float32 for converting torch FloatTensor
24 | x_np = np.sin(steps)
25 | y_np = np.cos(steps)
26 | plt.plot(steps, y_np, 'r-', label='target (cos)')
27 | plt.plot(steps, x_np, 'b-', label='input (sin)')
28 | plt.legend(loc='best')
29 | plt.show()
30 |
31 |
32 | class RNN(nn.Module):
33 | def __init__(self):
34 | super(RNN, self).__init__()
35 |
36 | self.rnn = nn.RNN(
37 | input_size=INPUT_SIZE,
38 | hidden_size=32, # rnn hidden unit
39 | num_layers=1, # number of rnn layer
40 | batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
41 | )
42 | self.out = nn.Linear(32, 1)
43 |
44 | def forward(self, x, h_state):
45 | # x (batch, time_step, input_size)
46 | # h_state (n_layers, batch, hidden_size)
47 | # r_out (batch, time_step, hidden_size)
48 | r_out, h_state = self.rnn(x, h_state)
49 |
50 | outs = [] # save all predictions
51 | for time_step in range(r_out.size(1)): # calculate output for each time step
52 | outs.append(self.out(r_out[:, time_step, :]))
53 | return torch.stack(outs, dim=1), h_state
54 |
55 | # instead, for simplicity, you can replace above codes by follows
56 | # r_out = r_out.view(-1, 32)
57 | # outs = self.out(r_out)
58 | # outs = outs.view(-1, TIME_STEP, 1)
59 | # return outs, h_state
60 |
61 | # or even simpler, since nn.Linear can accept inputs of any dimension
62 | # and returns outputs with same dimension except for the last
63 | # outs = self.out(r_out)
64 | # return outs
65 |
66 | rnn = RNN()
67 | print(rnn)
68 |
69 | optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
70 | loss_func = nn.MSELoss()
71 |
72 | h_state = None # for initial hidden state
73 |
74 | plt.figure(1, figsize=(12, 5))
75 | plt.ion() # continuously plot
76 |
77 | for step in range(100):
78 | start, end = step * np.pi, (step+1)*np.pi # time range
79 | # use sin predicts cos
80 | steps = np.linspace(start, end, TIME_STEP, dtype=np.float32, endpoint=False) # float32 for converting torch FloatTensor
81 | x_np = np.sin(steps)
82 | y_np = np.cos(steps)
83 |
84 | x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis]) # shape (batch, time_step, input_size)
85 | y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
86 |
87 | prediction, h_state = rnn(x, h_state) # rnn output
88 | # !! next step is important !!
89 | h_state = h_state.data # repack the hidden state, break the connection from last iteration
90 |
91 | loss = loss_func(prediction, y) # calculate loss
92 | optimizer.zero_grad() # clear gradients for this training step
93 | loss.backward() # backpropagation, compute gradients
94 | optimizer.step() # apply gradients
95 |
96 | # plotting
97 | plt.plot(steps, y_np.flatten(), 'r-')
98 | plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
99 | plt.draw(); plt.pause(0.05)
100 |
101 | plt.ioff()
102 | plt.show()
103 |
--------------------------------------------------------------------------------
/tutorial-contents/404_autoencoder.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | numpy
9 | """
10 | import torch
11 | import torch.nn as nn
12 | import torch.utils.data as Data
13 | import torchvision
14 | import matplotlib.pyplot as plt
15 | from mpl_toolkits.mplot3d import Axes3D
16 | from matplotlib import cm
17 | import numpy as np
18 |
19 |
20 | # torch.manual_seed(1) # reproducible
21 |
22 | # Hyper Parameters
23 | EPOCH = 10
24 | BATCH_SIZE = 64
25 | LR = 0.005 # learning rate
26 | DOWNLOAD_MNIST = False
27 | N_TEST_IMG = 5
28 |
29 | # Mnist digits dataset
30 | train_data = torchvision.datasets.MNIST(
31 | root='./mnist/',
32 | train=True, # this is training data
33 | transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
34 | # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
35 | download=DOWNLOAD_MNIST, # download it if you don't have it
36 | )
37 |
38 | # plot one example
39 | print(train_data.train_data.size()) # (60000, 28, 28)
40 | print(train_data.train_labels.size()) # (60000)
41 | plt.imshow(train_data.train_data[2].numpy(), cmap='gray')
42 | plt.title('%i' % train_data.train_labels[2])
43 | plt.show()
44 |
45 | # Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
46 | train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
47 |
48 |
49 | class AutoEncoder(nn.Module):
50 | def __init__(self):
51 | super(AutoEncoder, self).__init__()
52 |
53 | self.encoder = nn.Sequential(
54 | nn.Linear(28*28, 128),
55 | nn.Tanh(),
56 | nn.Linear(128, 64),
57 | nn.Tanh(),
58 | nn.Linear(64, 12),
59 | nn.Tanh(),
60 | nn.Linear(12, 3), # compress to 3 features which can be visualized in plt
61 | )
62 | self.decoder = nn.Sequential(
63 | nn.Linear(3, 12),
64 | nn.Tanh(),
65 | nn.Linear(12, 64),
66 | nn.Tanh(),
67 | nn.Linear(64, 128),
68 | nn.Tanh(),
69 | nn.Linear(128, 28*28),
70 | nn.Sigmoid(), # compress to a range (0, 1)
71 | )
72 |
73 | def forward(self, x):
74 | encoded = self.encoder(x)
75 | decoded = self.decoder(encoded)
76 | return encoded, decoded
77 |
78 |
79 | autoencoder = AutoEncoder()
80 |
81 | optimizer = torch.optim.Adam(autoencoder.parameters(), lr=LR)
82 | loss_func = nn.MSELoss()
83 |
84 | # initialize figure
85 | f, a = plt.subplots(2, N_TEST_IMG, figsize=(5, 2))
86 | plt.ion() # continuously plot
87 |
88 | # original data (first row) for viewing
89 | view_data = train_data.train_data[:N_TEST_IMG].view(-1, 28*28).type(torch.FloatTensor)/255.
90 | for i in range(N_TEST_IMG):
91 | a[0][i].imshow(np.reshape(view_data.data.numpy()[i], (28, 28)), cmap='gray'); a[0][i].set_xticks(()); a[0][i].set_yticks(())
92 |
93 | for epoch in range(EPOCH):
94 | for step, (x, b_label) in enumerate(train_loader):
95 | b_x = x.view(-1, 28*28) # batch x, shape (batch, 28*28)
96 | b_y = x.view(-1, 28*28) # batch y, shape (batch, 28*28)
97 |
98 | encoded, decoded = autoencoder(b_x)
99 |
100 | loss = loss_func(decoded, b_y) # mean square error
101 | optimizer.zero_grad() # clear gradients for this training step
102 | loss.backward() # backpropagation, compute gradients
103 | optimizer.step() # apply gradients
104 |
105 | if step % 100 == 0:
106 | print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy())
107 |
108 | # plotting decoded image (second row)
109 | _, decoded_data = autoencoder(view_data)
110 | for i in range(N_TEST_IMG):
111 | a[1][i].clear()
112 | a[1][i].imshow(np.reshape(decoded_data.data.numpy()[i], (28, 28)), cmap='gray')
113 | a[1][i].set_xticks(()); a[1][i].set_yticks(())
114 | plt.draw(); plt.pause(0.05)
115 |
116 | plt.ioff()
117 | plt.show()
118 |
119 | # visualize in 3D plot
120 | view_data = train_data.train_data[:200].view(-1, 28*28).type(torch.FloatTensor)/255.
121 | encoded_data, _ = autoencoder(view_data)
122 | fig = plt.figure(2); ax = Axes3D(fig)
123 | X, Y, Z = encoded_data.data[:, 0].numpy(), encoded_data.data[:, 1].numpy(), encoded_data.data[:, 2].numpy()
124 | values = train_data.train_labels[:200].numpy()
125 | for x, y, z, s in zip(X, Y, Z, values):
126 | c = cm.rainbow(int(255*s/9)); ax.text(x, y, z, s, backgroundcolor=c)
127 | ax.set_xlim(X.min(), X.max()); ax.set_ylim(Y.min(), Y.max()); ax.set_zlim(Z.min(), Z.max())
128 | plt.show()
129 |
--------------------------------------------------------------------------------
/tutorial-contents/405_DQN_Reinforcement_learning.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 | More about Reinforcement learning: https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/
5 |
6 | Dependencies:
7 | torch: 0.4
8 | gym: 0.8.1
9 | numpy
10 | """
11 | import torch
12 | import torch.nn as nn
13 | import torch.nn.functional as F
14 | import numpy as np
15 | import gym
16 |
17 | # Hyper Parameters
18 | BATCH_SIZE = 32
19 | LR = 0.01 # learning rate
20 | EPSILON = 0.9 # greedy policy
21 | GAMMA = 0.9 # reward discount
22 | TARGET_REPLACE_ITER = 100 # target update frequency
23 | MEMORY_CAPACITY = 2000
24 | env = gym.make('CartPole-v0')
25 | env = env.unwrapped
26 | N_ACTIONS = env.action_space.n
27 | N_STATES = env.observation_space.shape[0]
28 | ENV_A_SHAPE = 0 if isinstance(env.action_space.sample(), int) else env.action_space.sample().shape # to confirm the shape
29 |
30 |
31 | class Net(nn.Module):
32 | def __init__(self, ):
33 | super(Net, self).__init__()
34 | self.fc1 = nn.Linear(N_STATES, 50)
35 | self.fc1.weight.data.normal_(0, 0.1) # initialization
36 | self.out = nn.Linear(50, N_ACTIONS)
37 | self.out.weight.data.normal_(0, 0.1) # initialization
38 |
39 | def forward(self, x):
40 | x = self.fc1(x)
41 | x = F.relu(x)
42 | actions_value = self.out(x)
43 | return actions_value
44 |
45 |
46 | class DQN(object):
47 | def __init__(self):
48 | self.eval_net, self.target_net = Net(), Net()
49 |
50 | self.learn_step_counter = 0 # for target updating
51 | self.memory_counter = 0 # for storing memory
52 | self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # initialize memory
53 | self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR)
54 | self.loss_func = nn.MSELoss()
55 |
56 | def choose_action(self, x):
57 | x = torch.unsqueeze(torch.FloatTensor(x), 0)
58 | # input only one sample
59 | if np.random.uniform() < EPSILON: # greedy
60 | actions_value = self.eval_net.forward(x)
61 | action = torch.max(actions_value, 1)[1].data.numpy()
62 | action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE) # return the argmax index
63 | else: # random
64 | action = np.random.randint(0, N_ACTIONS)
65 | action = action if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE)
66 | return action
67 |
68 | def store_transition(self, s, a, r, s_):
69 | transition = np.hstack((s, [a, r], s_))
70 | # replace the old memory with new memory
71 | index = self.memory_counter % MEMORY_CAPACITY
72 | self.memory[index, :] = transition
73 | self.memory_counter += 1
74 |
75 | def learn(self):
76 | # target parameter update
77 | if self.learn_step_counter % TARGET_REPLACE_ITER == 0:
78 | self.target_net.load_state_dict(self.eval_net.state_dict())
79 | self.learn_step_counter += 1
80 |
81 | # sample batch transitions
82 | sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE)
83 | b_memory = self.memory[sample_index, :]
84 | b_s = torch.FloatTensor(b_memory[:, :N_STATES])
85 | b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int))
86 | b_r = torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2])
87 | b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:])
88 |
89 | # q_eval w.r.t the action in experience
90 | q_eval = self.eval_net(b_s).gather(1, b_a) # shape (batch, 1)
91 | q_next = self.target_net(b_s_).detach() # detach from graph, don't backpropagate
92 | q_target = b_r + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1) # shape (batch, 1)
93 | loss = self.loss_func(q_eval, q_target)
94 |
95 | self.optimizer.zero_grad()
96 | loss.backward()
97 | self.optimizer.step()
98 |
99 | dqn = DQN()
100 |
101 | print('\nCollecting experience...')
102 | for i_episode in range(400):
103 | s = env.reset()
104 | ep_r = 0
105 | while True:
106 | env.render()
107 | a = dqn.choose_action(s)
108 |
109 | # take action
110 | s_, r, done, info = env.step(a)
111 |
112 | # modify the reward
113 | x, x_dot, theta, theta_dot = s_
114 | r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
115 | r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
116 | r = r1 + r2
117 |
118 | dqn.store_transition(s, a, r, s_)
119 |
120 | ep_r += r
121 | if dqn.memory_counter > MEMORY_CAPACITY:
122 | dqn.learn()
123 | if done:
124 | print('Ep: ', i_episode,
125 | '| Ep_r: ', round(ep_r, 2))
126 |
127 | if done:
128 | break
129 | s = s_
--------------------------------------------------------------------------------
/tutorial-contents/406_GAN.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | numpy
8 | matplotlib
9 | """
10 | import torch
11 | import torch.nn as nn
12 | import numpy as np
13 | import matplotlib.pyplot as plt
14 |
15 | # torch.manual_seed(1) # reproducible
16 | # np.random.seed(1)
17 |
18 | # Hyper Parameters
19 | BATCH_SIZE = 64
20 | LR_G = 0.0001 # learning rate for generator
21 | LR_D = 0.0001 # learning rate for discriminator
22 | N_IDEAS = 5 # think of this as number of ideas for generating an art work (Generator)
23 | ART_COMPONENTS = 15 # it could be total point G can draw in the canvas
24 | PAINT_POINTS = np.vstack([np.linspace(-1, 1, ART_COMPONENTS) for _ in range(BATCH_SIZE)])
25 |
26 | # show our beautiful painting range
27 | # plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + 1, c='#74BCFF', lw=3, label='upper bound')
28 | # plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + 0, c='#FF9359', lw=3, label='lower bound')
29 | # plt.legend(loc='upper right')
30 | # plt.show()
31 |
32 |
33 | def artist_works(): # painting from the famous artist (real target)
34 | a = np.random.uniform(1, 2, size=BATCH_SIZE)[:, np.newaxis]
35 | paintings = a * np.power(PAINT_POINTS, 2) + (a-1)
36 | paintings = torch.from_numpy(paintings).float()
37 | return paintings
38 |
39 | G = nn.Sequential( # Generator
40 | nn.Linear(N_IDEAS, 128), # random ideas (could from normal distribution)
41 | nn.ReLU(),
42 | nn.Linear(128, ART_COMPONENTS), # making a painting from these random ideas
43 | )
44 |
45 | D = nn.Sequential( # Discriminator
46 | nn.Linear(ART_COMPONENTS, 128), # receive art work either from the famous artist or a newbie like G
47 | nn.ReLU(),
48 | nn.Linear(128, 1),
49 | nn.Sigmoid(), # tell the probability that the art work is made by artist
50 | )
51 |
52 | opt_D = torch.optim.Adam(D.parameters(), lr=LR_D)
53 | opt_G = torch.optim.Adam(G.parameters(), lr=LR_G)
54 |
55 | plt.ion() # something about continuous plotting
56 |
57 | for step in range(10000):
58 | artist_paintings = artist_works() # real painting from artist
59 | G_ideas = torch.randn(BATCH_SIZE, N_IDEAS, requires_grad=True) # random ideas\n
60 | G_paintings = G(G_ideas) # fake painting from G (random ideas)
61 | prob_artist1 = D(G_paintings) # D try to reduce this prob
62 | G_loss = torch.mean(torch.log(1. - prob_artist1))
63 | opt_G.zero_grad()
64 | G_loss.backward()
65 | opt_G.step()
66 |
67 | prob_artist0 = D(artist_paintings) # D try to increase this prob
68 | prob_artist1 = D(G_paintings.detach()) # D try to reduce this prob
69 | D_loss = - torch.mean(torch.log(prob_artist0) + torch.log(1. - prob_artist1))
70 | opt_D.zero_grad()
71 | D_loss.backward(retain_graph=True) # reusing computational graph
72 | opt_D.step()
73 |
74 | if step % 50 == 0: # plotting
75 | plt.cla()
76 | plt.plot(PAINT_POINTS[0], G_paintings.data.numpy()[0], c='#4AD631', lw=3, label='Generated painting',)
77 | plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + 1, c='#74BCFF', lw=3, label='upper bound')
78 | plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + 0, c='#FF9359', lw=3, label='lower bound')
79 | plt.text(-.5, 2.3, 'D accuracy=%.2f (0.5 for D to converge)' % prob_artist0.data.numpy().mean(), fontdict={'size': 13})
80 | plt.text(-.5, 2, 'D score= %.2f (-1.38 for G to converge)' % -D_loss.data.numpy(), fontdict={'size': 13})
81 | plt.ylim((0, 3));plt.legend(loc='upper right', fontsize=10);plt.draw();plt.pause(0.01)
82 |
83 | plt.ioff()
84 | plt.show()
--------------------------------------------------------------------------------
/tutorial-contents/406_conditional_GAN.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | numpy
8 | matplotlib
9 | """
10 | import torch
11 | import torch.nn as nn
12 | import numpy as np
13 | import matplotlib.pyplot as plt
14 |
15 | # torch.manual_seed(1) # reproducible
16 | # np.random.seed(1)
17 |
18 | # Hyper Parameters
19 | BATCH_SIZE = 64
20 | LR_G = 0.0001 # learning rate for generator
21 | LR_D = 0.0001 # learning rate for discriminator
22 | N_IDEAS = 5 # think of this as number of ideas for generating an art work (Generator)
23 | ART_COMPONENTS = 15 # it could be total point G can draw in the canvas
24 | PAINT_POINTS = np.vstack([np.linspace(-1, 1, ART_COMPONENTS) for _ in range(BATCH_SIZE)])
25 |
26 | # show our beautiful painting range
27 | # plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + 1, c='#74BCFF', lw=3, label='upper bound')
28 | # plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + 0, c='#FF9359', lw=3, label='lower bound')
29 | # plt.legend(loc='upper right')
30 | # plt.show()
31 |
32 |
33 | def artist_works_with_labels(): # painting from the famous artist (real target)
34 | a = np.random.uniform(1, 2, size=BATCH_SIZE)[:, np.newaxis]
35 | paintings = a * np.power(PAINT_POINTS, 2) + (a-1)
36 | labels = (a-1) > 0.5 # upper paintings (1), lower paintings (0), two classes
37 | paintings = torch.from_numpy(paintings).float()
38 | labels = torch.from_numpy(labels.astype(np.float32))
39 | return paintings, labels
40 |
41 |
42 | G = nn.Sequential( # Generator
43 | nn.Linear(N_IDEAS+1, 128), # random ideas (could from normal distribution) + class label
44 | nn.ReLU(),
45 | nn.Linear(128, ART_COMPONENTS), # making a painting from these random ideas
46 | )
47 |
48 | D = nn.Sequential( # Discriminator
49 | nn.Linear(ART_COMPONENTS+1, 128), # receive art work either from the famous artist or a newbie like G with label
50 | nn.ReLU(),
51 | nn.Linear(128, 1),
52 | nn.Sigmoid(), # tell the probability that the art work is made by artist
53 | )
54 |
55 | opt_D = torch.optim.Adam(D.parameters(), lr=LR_D)
56 | opt_G = torch.optim.Adam(G.parameters(), lr=LR_G)
57 |
58 | plt.ion() # something about continuous plotting
59 |
60 | for step in range(10000):
61 | artist_paintings, labels = artist_works_with_labels() # real painting, label from artist
62 | G_ideas = torch.randn(BATCH_SIZE, N_IDEAS) # random ideas
63 | G_inputs = torch.cat((G_ideas, labels), 1) # ideas with labels
64 | G_paintings = G(G_inputs) # fake painting w.r.t label from G
65 |
66 | D_inputs0 = torch.cat((artist_paintings, labels), 1) # all have their labels
67 | D_inputs1 = torch.cat((G_paintings, labels), 1)
68 | prob_artist0 = D(D_inputs0) # D try to increase this prob
69 | prob_artist1 = D(D_inputs1) # D try to reduce this prob
70 |
71 | D_score0 = torch.log(prob_artist0) # maximise this for D
72 | D_score1 = torch.log(1. - prob_artist1) # maximise this for D
73 | D_loss = - torch.mean(D_score0 + D_score1) # minimise the negative of both two above for D
74 | G_loss = torch.mean(D_score1) # minimise D score w.r.t G
75 |
76 | opt_D.zero_grad()
77 | D_loss.backward(retain_graph=True) # reusing computational graph
78 | opt_D.step()
79 |
80 | opt_G.zero_grad()
81 | G_loss.backward()
82 | opt_G.step()
83 |
84 | if step % 200 == 0: # plotting
85 | plt.cla()
86 | plt.plot(PAINT_POINTS[0], G_paintings.data.numpy()[0], c='#4AD631', lw=3, label='Generated painting',)
87 | bound = [0, 0.5] if labels.data[0, 0] == 0 else [0.5, 1]
88 | plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + bound[1], c='#74BCFF', lw=3, label='upper bound')
89 | plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + bound[0], c='#FF9359', lw=3, label='lower bound')
90 | plt.text(-.5, 2.3, 'D accuracy=%.2f (0.5 for D to converge)' % prob_artist0.data.numpy().mean(), fontdict={'size': 13})
91 | plt.text(-.5, 2, 'D score= %.2f (-1.38 for G to converge)' % -D_loss.data.numpy(), fontdict={'size': 13})
92 | plt.text(-.5, 1.7, 'Class = %i' % int(labels.data[0, 0]), fontdict={'size': 13})
93 | plt.ylim((0, 3));plt.legend(loc='upper right', fontsize=10);plt.draw();plt.pause(0.1)
94 |
95 | plt.ioff()
96 | plt.show()
97 |
98 | # plot a generated painting for upper class
99 | z = torch.randn(1, N_IDEAS)
100 | label = torch.FloatTensor([[1.]]) # for upper class
101 | G_inputs = torch.cat((z, label), 1)
102 | G_paintings = G(G_inputs)
103 | plt.plot(PAINT_POINTS[0], G_paintings.data.numpy()[0], c='#4AD631', lw=3, label='G painting for upper class',)
104 | plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + bound[1], c='#74BCFF', lw=3, label='upper bound (class 1)')
105 | plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + bound[0], c='#FF9359', lw=3, label='lower bound (class 1)')
106 | plt.ylim((0, 3));plt.legend(loc='upper right', fontsize=10);plt.show()
--------------------------------------------------------------------------------
/tutorial-contents/501_why_torch_dynamic_graph.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | numpy
9 | """
10 | import torch
11 | from torch import nn
12 | import numpy as np
13 | import matplotlib.pyplot as plt
14 |
15 | # torch.manual_seed(1) # reproducible
16 |
17 | # Hyper Parameters
18 | INPUT_SIZE = 1 # rnn input size / image width
19 | LR = 0.02 # learning rate
20 |
21 |
22 | class RNN(nn.Module):
23 | def __init__(self):
24 | super(RNN, self).__init__()
25 |
26 | self.rnn = nn.RNN(
27 | input_size=1,
28 | hidden_size=32, # rnn hidden unit
29 | num_layers=1, # number of rnn layer
30 | batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
31 | )
32 | self.out = nn.Linear(32, 1)
33 |
34 | def forward(self, x, h_state):
35 | # x (batch, time_step, input_size)
36 | # h_state (n_layers, batch, hidden_size)
37 | # r_out (batch, time_step, output_size)
38 | r_out, h_state = self.rnn(x, h_state)
39 |
40 | outs = [] # this is where you can find torch is dynamic
41 | for time_step in range(r_out.size(1)): # calculate output for each time step
42 | outs.append(self.out(r_out[:, time_step, :]))
43 | return torch.stack(outs, dim=1), h_state
44 |
45 |
46 | rnn = RNN()
47 | print(rnn)
48 |
49 | optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
50 | loss_func = nn.MSELoss() # the target label is not one-hotted
51 |
52 | h_state = None # for initial hidden state
53 |
54 | plt.figure(1, figsize=(12, 5))
55 | plt.ion() # continuously plot
56 |
57 | ######################## Below is different #########################
58 |
59 | ################ static time steps ##########
60 | # for step in range(60):
61 | # start, end = step * np.pi, (step+1)*np.pi # time steps
62 | # # use sin predicts cos
63 | # steps = np.linspace(start, end, 10, dtype=np.float32)
64 |
65 | ################ dynamic time steps #########
66 | step = 0
67 | for i in range(60):
68 | dynamic_steps = np.random.randint(1, 4) # has random time steps
69 | start, end = step * np.pi, (step + dynamic_steps) * np.pi # different time steps length
70 | step += dynamic_steps
71 |
72 | # use sin predicts cos
73 | steps = np.linspace(start, end, 10 * dynamic_steps, dtype=np.float32)
74 |
75 | ####################### Above is different ###########################
76 |
77 | print(len(steps)) # print how many time step feed to RNN
78 |
79 | x_np = np.sin(steps) # float32 for converting torch FloatTensor
80 | y_np = np.cos(steps)
81 |
82 | x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis]) # shape (batch, time_step, input_size)
83 | y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
84 |
85 | prediction, h_state = rnn(x, h_state) # rnn output
86 | # !! next step is important !!
87 | h_state = h_state.data # repack the hidden state, break the connection from last iteration
88 |
89 | loss = loss_func(prediction, y) # cross entropy loss
90 | optimizer.zero_grad() # clear gradients for this training step
91 | loss.backward() # backpropagation, compute gradients
92 | optimizer.step() # apply gradients
93 |
94 | # plotting
95 | plt.plot(steps, y_np.flatten(), 'r-')
96 | plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
97 | plt.draw()
98 | plt.pause(0.05)
99 |
100 | plt.ioff()
101 | plt.show()
102 |
--------------------------------------------------------------------------------
/tutorial-contents/502_GPU.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | torchvision
8 | """
9 | import torch
10 | import torch.nn as nn
11 | import torch.utils.data as Data
12 | import torchvision
13 |
14 | # torch.manual_seed(1)
15 |
16 | EPOCH = 1
17 | BATCH_SIZE = 50
18 | LR = 0.001
19 | DOWNLOAD_MNIST = False
20 |
21 | train_data = torchvision.datasets.MNIST(root='./mnist/', train=True, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST,)
22 | train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
23 |
24 | test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
25 |
26 | # !!!!!!!! Change in here !!!!!!!!! #
27 | test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000].cuda()/255. # Tensor on GPU
28 | test_y = test_data.test_labels[:2000].cuda()
29 |
30 |
31 | class CNN(nn.Module):
32 | def __init__(self):
33 | super(CNN, self).__init__()
34 | self.conv1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2,),
35 | nn.ReLU(), nn.MaxPool2d(kernel_size=2),)
36 | self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(2),)
37 | self.out = nn.Linear(32 * 7 * 7, 10)
38 |
39 | def forward(self, x):
40 | x = self.conv1(x)
41 | x = self.conv2(x)
42 | x = x.view(x.size(0), -1)
43 | output = self.out(x)
44 | return output
45 |
46 | cnn = CNN()
47 |
48 | # !!!!!!!! Change in here !!!!!!!!! #
49 | cnn.cuda() # Moves all model parameters and buffers to the GPU.
50 |
51 | optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
52 | loss_func = nn.CrossEntropyLoss()
53 |
54 | for epoch in range(EPOCH):
55 | for step, (x, y) in enumerate(train_loader):
56 |
57 | # !!!!!!!! Change in here !!!!!!!!! #
58 | b_x = x.cuda() # Tensor on GPU
59 | b_y = y.cuda() # Tensor on GPU
60 |
61 | output = cnn(b_x)
62 | loss = loss_func(output, b_y)
63 | optimizer.zero_grad()
64 | loss.backward()
65 | optimizer.step()
66 |
67 | if step % 50 == 0:
68 | test_output = cnn(test_x)
69 |
70 | # !!!!!!!! Change in here !!!!!!!!! #
71 | pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
72 |
73 | accuracy = torch.sum(pred_y == test_y).type(torch.FloatTensor) / test_y.size(0)
74 | print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.cpu().numpy(), '| test accuracy: %.2f' % accuracy)
75 |
76 |
77 | test_output = cnn(test_x[:10])
78 |
79 | # !!!!!!!! Change in here !!!!!!!!! #
80 | pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
81 |
82 | print(pred_y, 'prediction number')
83 | print(test_y[:10], 'real number')
84 |
--------------------------------------------------------------------------------
/tutorial-contents/503_dropout.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | """
9 | import torch
10 | import matplotlib.pyplot as plt
11 |
12 | # torch.manual_seed(1) # reproducible
13 |
14 | N_SAMPLES = 20
15 | N_HIDDEN = 300
16 |
17 | # training data
18 | x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
19 | y = x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
20 |
21 | # test data
22 | test_x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
23 | test_y = test_x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
24 |
25 | # show data
26 | plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
27 | plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
28 | plt.legend(loc='upper left')
29 | plt.ylim((-2.5, 2.5))
30 | plt.show()
31 |
32 | net_overfitting = torch.nn.Sequential(
33 | torch.nn.Linear(1, N_HIDDEN),
34 | torch.nn.ReLU(),
35 | torch.nn.Linear(N_HIDDEN, N_HIDDEN),
36 | torch.nn.ReLU(),
37 | torch.nn.Linear(N_HIDDEN, 1),
38 | )
39 |
40 | net_dropped = torch.nn.Sequential(
41 | torch.nn.Linear(1, N_HIDDEN),
42 | torch.nn.Dropout(0.5), # drop 50% of the neuron
43 | torch.nn.ReLU(),
44 | torch.nn.Linear(N_HIDDEN, N_HIDDEN),
45 | torch.nn.Dropout(0.5), # drop 50% of the neuron
46 | torch.nn.ReLU(),
47 | torch.nn.Linear(N_HIDDEN, 1),
48 | )
49 |
50 | print(net_overfitting) # net architecture
51 | print(net_dropped)
52 |
53 | optimizer_ofit = torch.optim.Adam(net_overfitting.parameters(), lr=0.01)
54 | optimizer_drop = torch.optim.Adam(net_dropped.parameters(), lr=0.01)
55 | loss_func = torch.nn.MSELoss()
56 |
57 | plt.ion() # something about plotting
58 |
59 | for t in range(500):
60 | pred_ofit = net_overfitting(x)
61 | pred_drop = net_dropped(x)
62 | loss_ofit = loss_func(pred_ofit, y)
63 | loss_drop = loss_func(pred_drop, y)
64 |
65 | optimizer_ofit.zero_grad()
66 | optimizer_drop.zero_grad()
67 | loss_ofit.backward()
68 | loss_drop.backward()
69 | optimizer_ofit.step()
70 | optimizer_drop.step()
71 |
72 | if t % 10 == 0:
73 | # change to eval mode in order to fix drop out effect
74 | net_overfitting.eval()
75 | net_dropped.eval() # parameters for dropout differ from train mode
76 |
77 | # plotting
78 | plt.cla()
79 | test_pred_ofit = net_overfitting(test_x)
80 | test_pred_drop = net_dropped(test_x)
81 | plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.3, label='train')
82 | plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.3, label='test')
83 | plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(), 'r-', lw=3, label='overfitting')
84 | plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(), 'b--', lw=3, label='dropout(50%)')
85 | plt.text(0, -1.2, 'overfitting loss=%.4f' % loss_func(test_pred_ofit, test_y).data.numpy(), fontdict={'size': 20, 'color': 'red'})
86 | plt.text(0, -1.5, 'dropout loss=%.4f' % loss_func(test_pred_drop, test_y).data.numpy(), fontdict={'size': 20, 'color': 'blue'})
87 | plt.legend(loc='upper left'); plt.ylim((-2.5, 2.5));plt.pause(0.1)
88 |
89 | # change back to train mode
90 | net_overfitting.train()
91 | net_dropped.train()
92 |
93 | plt.ioff()
94 | plt.show()
--------------------------------------------------------------------------------
/tutorial-contents/504_batch_normalization.py:
--------------------------------------------------------------------------------
1 | """
2 | View more, visit my tutorial page: https://mofanpy.com/tutorials/
3 | My Youtube Channel: https://www.youtube.com/user/MorvanZhou
4 |
5 | Dependencies:
6 | torch: 0.4
7 | matplotlib
8 | numpy
9 | """
10 | import torch
11 | from torch import nn
12 | from torch.nn import init
13 | import torch.utils.data as Data
14 | import matplotlib.pyplot as plt
15 | import numpy as np
16 |
17 | # torch.manual_seed(1) # reproducible
18 | # np.random.seed(1)
19 |
20 | # Hyper parameters
21 | N_SAMPLES = 2000
22 | BATCH_SIZE = 64
23 | EPOCH = 12
24 | LR = 0.03
25 | N_HIDDEN = 8
26 | ACTIVATION = torch.tanh
27 | B_INIT = -0.2 # use a bad bias constant initializer
28 |
29 | # training data
30 | x = np.linspace(-7, 10, N_SAMPLES)[:, np.newaxis]
31 | noise = np.random.normal(0, 2, x.shape)
32 | y = np.square(x) - 5 + noise
33 |
34 | # test data
35 | test_x = np.linspace(-7, 10, 200)[:, np.newaxis]
36 | noise = np.random.normal(0, 2, test_x.shape)
37 | test_y = np.square(test_x) - 5 + noise
38 |
39 | train_x, train_y = torch.from_numpy(x).float(), torch.from_numpy(y).float()
40 | test_x = torch.from_numpy(test_x).float()
41 | test_y = torch.from_numpy(test_y).float()
42 |
43 | train_dataset = Data.TensorDataset(train_x, train_y)
44 | train_loader = Data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
45 |
46 | # show data
47 | plt.scatter(train_x.numpy(), train_y.numpy(), c='#FF9359', s=50, alpha=0.2, label='train')
48 | plt.legend(loc='upper left')
49 |
50 |
51 | class Net(nn.Module):
52 | def __init__(self, batch_normalization=False):
53 | super(Net, self).__init__()
54 | self.do_bn = batch_normalization
55 | self.fcs = []
56 | self.bns = []
57 | self.bn_input = nn.BatchNorm1d(1, momentum=0.5) # for input data
58 |
59 | for i in range(N_HIDDEN): # build hidden layers and BN layers
60 | input_size = 1 if i == 0 else 10
61 | fc = nn.Linear(input_size, 10)
62 | setattr(self, 'fc%i' % i, fc) # IMPORTANT set layer to the Module
63 | self._set_init(fc) # parameters initialization
64 | self.fcs.append(fc)
65 | if self.do_bn:
66 | bn = nn.BatchNorm1d(10, momentum=0.5)
67 | setattr(self, 'bn%i' % i, bn) # IMPORTANT set layer to the Module
68 | self.bns.append(bn)
69 |
70 | self.predict = nn.Linear(10, 1) # output layer
71 | self._set_init(self.predict) # parameters initialization
72 |
73 | def _set_init(self, layer):
74 | init.normal_(layer.weight, mean=0., std=.1)
75 | init.constant_(layer.bias, B_INIT)
76 |
77 | def forward(self, x):
78 | pre_activation = [x]
79 | if self.do_bn: x = self.bn_input(x) # input batch normalization
80 | layer_input = [x]
81 | for i in range(N_HIDDEN):
82 | x = self.fcs[i](x)
83 | pre_activation.append(x)
84 | if self.do_bn: x = self.bns[i](x) # batch normalization
85 | x = ACTIVATION(x)
86 | layer_input.append(x)
87 | out = self.predict(x)
88 | return out, layer_input, pre_activation
89 |
90 | nets = [Net(batch_normalization=False), Net(batch_normalization=True)]
91 |
92 | # print(*nets) # print net architecture
93 |
94 | opts = [torch.optim.Adam(net.parameters(), lr=LR) for net in nets]
95 |
96 | loss_func = torch.nn.MSELoss()
97 |
98 |
99 | def plot_histogram(l_in, l_in_bn, pre_ac, pre_ac_bn):
100 | for i, (ax_pa, ax_pa_bn, ax, ax_bn) in enumerate(zip(axs[0, :], axs[1, :], axs[2, :], axs[3, :])):
101 | [a.clear() for a in [ax_pa, ax_pa_bn, ax, ax_bn]]
102 | if i == 0:
103 | p_range = (-7, 10);the_range = (-7, 10)
104 | else:
105 | p_range = (-4, 4);the_range = (-1, 1)
106 | ax_pa.set_title('L' + str(i))
107 | ax_pa.hist(pre_ac[i].data.numpy().ravel(), bins=10, range=p_range, color='#FF9359', alpha=0.5);ax_pa_bn.hist(pre_ac_bn[i].data.numpy().ravel(), bins=10, range=p_range, color='#74BCFF', alpha=0.5)
108 | ax.hist(l_in[i].data.numpy().ravel(), bins=10, range=the_range, color='#FF9359');ax_bn.hist(l_in_bn[i].data.numpy().ravel(), bins=10, range=the_range, color='#74BCFF')
109 | for a in [ax_pa, ax, ax_pa_bn, ax_bn]: a.set_yticks(());a.set_xticks(())
110 | ax_pa_bn.set_xticks(p_range);ax_bn.set_xticks(the_range)
111 | axs[0, 0].set_ylabel('PreAct');axs[1, 0].set_ylabel('BN PreAct');axs[2, 0].set_ylabel('Act');axs[3, 0].set_ylabel('BN Act')
112 | plt.pause(0.01)
113 |
114 |
115 | if __name__ == "__main__":
116 | f, axs = plt.subplots(4, N_HIDDEN + 1, figsize=(10, 5))
117 | plt.ion() # something about plotting
118 | plt.show()
119 |
120 | # training
121 | losses = [[], []] # recode loss for two networks
122 |
123 | for epoch in range(EPOCH):
124 | print('Epoch: ', epoch)
125 | layer_inputs, pre_acts = [], []
126 | for net, l in zip(nets, losses):
127 | net.eval() # set eval mode to fix moving_mean and moving_var
128 | pred, layer_input, pre_act = net(test_x)
129 | l.append(loss_func(pred, test_y).data.item())
130 | layer_inputs.append(layer_input)
131 | pre_acts.append(pre_act)
132 | net.train() # free moving_mean and moving_var
133 | plot_histogram(*layer_inputs, *pre_acts) # plot histogram
134 |
135 | for step, (b_x, b_y) in enumerate(train_loader):
136 | for net, opt in zip(nets, opts): # train for each network
137 | pred, _, _ = net(b_x)
138 | loss = loss_func(pred, b_y)
139 | opt.zero_grad()
140 | loss.backward()
141 | opt.step() # it will also learns the parameters in Batch Normalization
142 |
143 | plt.ioff()
144 |
145 | # plot training loss
146 | plt.figure(2)
147 | plt.plot(losses[0], c='#FF9359', lw=3, label='Original')
148 | plt.plot(losses[1], c='#74BCFF', lw=3, label='Batch Normalization')
149 | plt.xlabel('step');plt.ylabel('test loss');plt.ylim((0, 2000));plt.legend(loc='best')
150 |
151 | # evaluation
152 | # set net to eval mode to freeze the parameters in batch normalization layers
153 | [net.eval() for net in nets] # set eval mode to fix moving_mean and moving_var
154 | preds = [net(test_x)[0] for net in nets]
155 | plt.figure(3)
156 | plt.plot(test_x.data.numpy(), preds[0].data.numpy(), c='#FF9359', lw=4, label='Original')
157 | plt.plot(test_x.data.numpy(), preds[1].data.numpy(), c='#74BCFF', lw=4, label='Batch Normalization')
158 | plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='r', s=50, alpha=0.2, label='train')
159 | plt.legend(loc='best')
160 | plt.show()
161 |
--------------------------------------------------------------------------------
/tutorial-contents/mnist/processed/test.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents/mnist/processed/test.pt
--------------------------------------------------------------------------------
/tutorial-contents/mnist/processed/training.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents/mnist/processed/training.pt
--------------------------------------------------------------------------------
/tutorial-contents/mnist/raw/t10k-images-idx3-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents/mnist/raw/t10k-images-idx3-ubyte
--------------------------------------------------------------------------------
/tutorial-contents/mnist/raw/t10k-labels-idx1-ubyte:
--------------------------------------------------------------------------------
1 | ������'�������� � �� ��� ��� ������������������������������������� ��� ���������� ���� ������������� ������ ���� �� ���� ���� ������ ������������������������ ��������������������������������� ������� ������������ �� �� � �������������������� ����� ���������� ����������� �������� ������ �� ������� ���������������������� ���� � ������������� ���������������������� ����������������������������� ���� ������������������� �� ���� ��� ������� ������������� ����� ���������������� ������� � ����� ������� ���� ������������������� �������� ��������������������������� � � ������������ ����������������� ���� ���������������� ���������� �� ��� ���� ���������������������� �������� � ���� �� ������������������������ �������������������������� ������������������������ ������������� �������������� ������������������������ ������������������� ���������������������������� ����������� ������� ���������� ������������ ������ �������������� ������������������������� ������� ��� ������������������������� ������ ���� ������� ������������������������������� �� ��������� ���� ����������������� ���� � � ������������ � � ���������������������� ��������������������� ������������ ����������������� �������� ������������������������ ���������� ��� �������������� ������� ��������������������� ���� ��������������������� ��� � ���������� ���� ��������������� ������������������������������������ ���� ���������� ����������������� �� ���� ���� ����� ��� ��������� �� �� ������������������������� ���� ����� �������� ������ ��� ������������������� ������������ ������� ���� ���������������������������������� � ������������������������ ���� ��� �������� ���� � ������ ���������� � �������������������������� � ����������� ���� ����������������� ���������� � ����������������������������������� ����� ���� ������� ���������� �������� ��� ������������������������� � ��������������� ��� ������� ������������ ������ �� � ��������������������������������������������� ����������� �������������� ������������ ����� ���������� ���� ���� ����������������������������� ���� ������������� ������������������� ��������������������������������������� ����������������� ������������� ������������������� ������� ������ ��������������� ��� ���������� ���� ����������� ����� ������ � ��� ���������� ����������������� ���������������� �� ������ �� ����������������� �� ��������������� ������������������ ������ ������������������ ������� ����� ����� ����������� ���� ���� ������� ��������������� ���� �������������� �� ������������������ ����������� ��������� ����� ��� ��������������������� ����������� �� ��� ������������� ����������������������������� ��� ���������� ������������������������ ����������� ������ � � ����������������������� �������������� ���� � ������������ ���� �������� ����������� ���������� ������������������� �������������������������������� �������� �� ���� ������ ���� ������� �������� ��������������� ������� ������ �� �� ���� ���� � ���������������� ����� � ������ ����� ��� ����������������� ��� � ������������������������� ������ �������������� ��� �������������� ����������������������������������������������������������������������� � ���������� ���� �� ��������������������� ��������� ��������������������������������������� �������������������������������������������� �������������������������������������������������� ������������������������������ ��������������� � ���� � ��������� ������ �������������� �������������������������������� ������ ���� ���� ���� � ����� ��������� � �� ������������������ �� �������� �������������� ��������������������������������� ���� ���� �������������������� ��������������������������������������������� � �������������������� ����� ��������������� � ���� ������ ������������������������������� ��� ���������������������� ������� ������ ��������������������� ��������� �������� � ������� ����� � � ������� �� � ���� � �� �� � �������������������������������� � ���������������������� ��������������� �� ���������� �� ������ ������ �������� ����� ������������� ��������� ������ ������������������������������ ��������� ���� � ����� ��������� ���������� ������ ���� �������� ���������� ��� ���� ���������� ������� ������������� ����������� �� ���������� ���������� � �� ���� ����������� � ������������ ������� �� �� ����� ��� � ������� ���� � �� � ��� ������� ���������� ������������� ���� ����� ������������� ��������������������� � � ������ ������ ��������� ������� ��������� ������������������������ �������� ���������� � �� ����� ���������������������� ��������������� �� � ��� ��������� ������������� ������ ����������������� ����� ���������������� ���������� ��� ���������� �� � ������� ����� � �������� ������� ���� ���������������������������� ���������������� �������� ������� ���������������� �������� ��� ����������������������� ����������� ���� �� �� ��������� ����������������� ��������� ���������������� �������� ������� ������������������������� � ��������������� ��� ������ ������������ ����������� ������ ����� � ���� ��� �� ������������ ������� ��������� ��������� �� ������ ������������������� ����� ����������������������� ���� � ������ ������������������� ����������������� ��������������������������� �������� ������������ �������� ���� �������������� ����� ��������� ��������� ��������� ����������� ��� ����������������� ���������� ������� �������������������� � � �������� � ��������������� ��������� ��������� ���� ����������������� �������� ���������������������������������� ����������� ������������������� ��� ��������� �������� ������������������ ��������� ���� � ���� �������������� ��������� ��������� ���� ����������� ����� ������������������������� ���������� �������������������� � ����������� ���������� ���������������������� �� ����������������������� �� �� �� ��������� ���� ������� ����������������������� ������������������ ����������� � ���������������������� �� ���������� ���������� ��������������������� ��������� ��������� ������ �� ����� ������������������ ��� ��������������������� ��������� ������ ������� ������� ��������������� ��������� ��������� �������������������� ����������� � ������������������������������ �������� � ��� ���������������� ��������� ��������� ��� ������ ������ � ���� ����������� � ���������������������������������������������������� �������������� ��������������������������������������������������������� ���������������� ������ ������� � ���� ��� � ������������� ������ ������� ����������������������������������� �������� �������� � ��� ������� ��� ����������������������������������� ���� �� �� �������������������� ��������������� � ���������������� ���� ��������� ������� ���� � ������������ ���������� ��������� ����������������� ������� ��������������������� ������ ������������������������ ����� ����� �� ����� ������������� ��������� ��������� ������������������������������������������ ���������������� ������ ������� � ���� ��� � �� ���������������� ��������� ��������� ���������� ������������ ��� ��� ������� � ��������� ���������������� ����������������� ���������������� ��������� ��������� ������� ����� ���������� ���������� ��������� ��� ��� ����������� ������������������������� ������� ���������������� ������������������������ �� �������� ����� �� ������� � ��������������������� ��������� ��������� ������������������� ��� ������������� ���������� ��������� �� ���������������� �� � � ����������������������������������������� �������������������������������� �� � ������ ��������������� � ����� �� ��������������� ��������� ��������� ��������������������� ���� �������� ������� ������� ��� � ��������������������� ������� ��������� ����� ��������� ��������������������������� � �������������� �� ������ ���������������������������� ��������� ��������� ������������ ���������������� �������� ��� ������� ����� ������������� �������� ���������������� �������� �� ������ ��������� ������� �� ����������������������������������� ���������� ��������� ��������� � �������������������������� ��������� ��� ���������� ���������� ��������������� �������� ������������ ��������� ������� �������� ������� ������� ���������������� ��������� ��������� ��� ������������������������������ � ���������������������� �� �� ������������� �� ������������������� �������� ������� ������ ������������� ��������� �������������������� �� ��������� � ����������������������� ������������ � �������� �������������������� ����������������� ��� ���� ���� �������������������� ��������� ��������� � ����������������������� � ���������������� ���������� �� ������������������� �������������������������������� �� �� �� ����������������������� ���������������� � �������������������� ������ ��������� ��������� ��������� ���� ����������� ����� �������������������������� ���������� ������������������ � ����������� ���������� ��������� ��������� ����������� � ���� ����������������������������������� ���������� ��� � ����� ������������� ������� ���� � ������������� ��� � ������ �������������� ���������������� ��� ������������������������ �� � ������������������������� �� ����������� ��������� ��������� ��� ����������������������������������������������� � �������� ����������� ���� ����������������� ��������� ������� ������� � � �������������������������� ���� � � ���������������� �������������� ���� ����� ������������������� ������������������������������������� ���� ������������� ��������� ���������� ������ ��� ������� ������ �������� ��������������������������������� ���� ���������� ������������� ��������� ��������� ������������ �������� ���� �������� ������� �������� �������� ������ ���������������������� ��������� ����������������� ��� ���������������� �������� ������� ��������������� �������� ����������� ��������� ��������� ������ ������������������������� � �������������� ���������������������� ���������������� ��� ������������� ������������ ��������������������������������� ��������� ���������������� ����� ������� ������������ ��������������������������� ������������������ �������
--------------------------------------------------------------------------------
/tutorial-contents/mnist/raw/train-images-idx3-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents/mnist/raw/train-images-idx3-ubyte
--------------------------------------------------------------------------------
/tutorial-contents/mnist/raw/train-labels-idx1-ubyte:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MorvanZhou/PyTorch-Tutorial/dbe154a9e56635e51c6b0c2ccea8ae36cfb585a7/tutorial-contents/mnist/raw/train-labels-idx1-ubyte
--------------------------------------------------------------------------------
 107 |
107 |  114 |
114 |