├── LICENSE
├── README.md
├── README_CN.md
├── calflops
├── .DS_Store
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-311.pyc
│ ├── __init__.cpython-39.pyc
│ ├── big_modeling.cpython-39.pyc
│ ├── calculate_pipline.cpython-311.pyc
│ ├── calculate_pipline.cpython-39.pyc
│ ├── estimate.cpython-311.pyc
│ ├── estimate.cpython-39.pyc
│ ├── estimate.py
│ ├── flops_counter.cpython-311.pyc
│ ├── flops_counter.cpython-39.pyc
│ ├── flops_counter_hf.cpython-311.pyc
│ ├── flops_counter_hf.cpython-39.pyc
│ ├── pytorch_ops.cpython-311.pyc
│ ├── pytorch_ops.cpython-39.pyc
│ ├── utils.cpython-311.pyc
│ └── utils.cpython-39.pyc
├── calculate_pipline.py
├── estimate.py
├── flops_counter.py
├── flops_counter_hf.py
├── pytorch_ops.py
└── utils.py
├── screenshot
├── .DS_Store
├── alxnet_print_detailed.png
├── alxnet_print_result.png
├── calflops_hf1.png
├── calflops_hf2.png
├── calflops_hf3.png
├── calflops_hf4.png
├── huggingface_model_name.png
├── huggingface_model_name2.png
├── huggingface_model_name3.png
└── huggingface_model_names.png
├── test_examples
├── test_bert.py
├── test_cnn.py
└── test_llm.py
└── test_llm_huggingface.py
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) [2023] [MrYXJ]
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 | calflops: a FLOPs and Params calculate tool for neural networks
7 |
8 |
9 |
10 | 
11 | [](https://pypi.org/project/calflops/)
12 | [](https://github.com/MrYxJ/calculate-flops.pytorch/blob/main/LICENSE)
13 |
14 |
15 |
16 | English |
17 | 中文
18 |
19 |
20 |
21 |
22 | # Introduction
23 | This tool(calflops) is designed to compute the theoretical amount of FLOPs(floating-point operations)、MACs(multiply-add operations) and Parameters in all various neural networks, such as Linear、 CNN、 RNN、 GCN、**Transformer(Bert、LlaMA etc Large Language Model)**,even including **any custom models** via ```torch.nn.function.*``` as long as based on the Pytorch implementation. Meanwhile this tool supports the printing of FLOPS, Parameter calculation value and proportion of each submodule of the model, it is convient for users to understand the performance consumption of each part of the model.
24 |
25 | Latest news, calflops has launched a tool on Huggingface Space, which is more convenient for computing FLOPS in the model of 🤗Huggingface Platform. Welcome to use it:https://huggingface.co/spaces/MrYXJ/calculate-model-flops
26 |
27 |  28 |
29 |
30 |
31 | For LLM, this is probably the easiest tool to calculate FLOPs and it is very convenient for **huggingface** platform models. You can use ```calflops.calculate_flops_hf(model_name)``` by `model_name` which in [huggingface models](https://huggingface.co/models) to calculate model FLOPs without downloading entire model weights locally.Notice this method requires the model to support the empty model being created for model inference in meta device.
32 |
33 | 
34 |
35 | ``` python
36 | from calflops import calculate_flops_hf
37 |
38 | model_name = "meta-llama/Llama-2-7b"
39 | access_token = "..." # your application token for using llama2
40 | flops, macs, params = calculate_flops_hf(model_name=model_name, access_token=access_token) # default input shape: (1, 128)
41 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
42 | ```
43 |
44 |
45 | If model can't inference in meta device, you just need assign llm corresponding tokenizer to the parameter: ```transformers_tokenizer``` to pass in funcional of ```calflops.calculate_flops()```, and it will automatically help you build the model input data whose size is input_shape. Alternatively, you also can pass in the input data of models which need multi data as input that you have constructed.
46 |
47 |
48 | In addition, the implementation process of this package inspired by [ptflops](https://github.com/sovrasov/flops-counter.pytorch)、[deepspeed](https://github.com/microsoft/DeepSpeed/tree/master/deepspeed)、[hf accelerate](https://github.com/huggingface/accelerate) libraries, Thanks for their great efforts, they are both very good work. Meanwhile this package also improves some aspects to calculate FLOPs based on them.
49 |
50 | ## How to install
51 | ### Install the latest version
52 | #### From PyPI:
53 |
54 | ```python
55 | pip install --upgrade calflops
56 | ```
57 |
58 | And you also can download latest `calflops-*-py3-none-any.whl` files from https://pypi.org/project/calflops/
59 |
60 | ```python
61 | pip install calflops-*-py3-none-any.whl
62 | ```
63 |
64 | ## How to use calflops
65 |
66 | ### Example
67 | ### CNN Model
68 | If model has only one input, you just need set the model input size by parameter ```input_shape``` , it can automatically generate random model input to complete the calculation:
69 |
70 | ```python
71 | from calflops import calculate_flops
72 | from torchvision import models
73 |
74 | model = models.alexnet()
75 | batch_size = 1
76 | input_shape = (batch_size, 3, 224, 224)
77 | flops, macs, params = calculate_flops(model=model,
78 | input_shape=input_shape,
79 | output_as_string=True,
80 | output_precision=4)
81 | print("Alexnet FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
82 | #Alexnet FLOPs:4.2892 GFLOPS MACs:2.1426 GMACs Params:61.1008 M
83 | ```
84 |
85 | If the model has multiple inputs, use the parameters ```args``` or ```kargs```, as shown in the Transfomer Model below.
86 |
87 |
88 | ### Calculate Huggingface Model By Model Name(Online)
89 |
90 | No need to download the entire parameter weight of the model to the local, just by the model name can test any open source large model on the huggingface platform.
91 |
92 | 
93 |
94 |
95 | ```python
96 | from calflops import calculate_flops_hf
97 |
98 | batch_size, max_seq_length = 1, 128
99 | model_name = "baichuan-inc/Baichuan-13B-Chat"
100 |
101 | flops, macs, params = calculate_flops_hf(model_name=model_name, input_shape=(batch_size, max_seq_length))
102 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
103 | ```
104 |
105 | You can also use this model urls of huggingface platform to calculate it FLOPs.
106 |
107 | 
108 |
109 | ```python
110 | from calflops import calculate_flops_hf
111 |
112 | batch_size, max_seq_length = 1, 128
113 | model_name = "https://huggingface.co/THUDM/glm-4-9b-chat" # THUDM/glm-4-9b-chat
114 | flops, macs, params = calculate_flops_hf(model_name=model_name, input_shape=(batch_size, max_seq_length))
115 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
116 | ```
117 |
118 | ```
119 | ------------------------------------- Calculate Flops Results -------------------------------------
120 | Notations:
121 | number of parameters (Params), number of multiply-accumulate operations(MACs),
122 | number of floating-point operations (FLOPs), floating-point operations per second (FLOPS),
123 | fwd FLOPs (model forward propagation FLOPs), bwd FLOPs (model backward propagation FLOPs),
124 | default model backpropagation takes 2.00 times as much computation as forward propagation.
125 |
126 | Total Training Params: 9.4 B
127 | fwd MACs: 1.12 TMACs
128 | fwd FLOPs: 2.25 TFLOPS
129 | fwd+bwd MACs: 3.37 TMACs
130 | fwd+bwd FLOPs: 6.74 TFLOPS
131 |
132 | -------------------------------- Detailed Calculated FLOPs Results --------------------------------
133 | Each module caculated is listed after its name in the following order:
134 | params, percentage of total params, MACs, percentage of total MACs, FLOPS, percentage of total FLOPs
135 |
136 | Note: 1. A module can have torch.nn.module or torch.nn.functional to compute logits (e.g. CrossEntropyLoss).
137 | They are not counted as submodules in calflops and not to be printed out. However they make up the difference between a parent's MACs and the sum of its submodules'.
138 | 2. Number of floating-point operations is a theoretical estimation, thus FLOPS computed using that could be larger than the maximum system throughput.
139 |
140 | ChatGLMForConditionalGeneration(
141 | 9.4 B = 100% Params, 1.12 TMACs = 100% MACs, 2.25 TFLOPS = 50% FLOPs
142 | (transformer): ChatGLMModel(
143 | 9.4 B = 100% Params, 1.12 TMACs = 100% MACs, 2.25 TFLOPS = 50% FLOPs
144 | (embedding): Embedding(
145 | 620.76 M = 6.6% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs
146 | (word_embeddings): Embedding(620.76 M = 6.6% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs, 151552, 4096)
147 | )
148 | (rotary_pos_emb): RotaryEmbedding(0 = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs)
149 | (encoder): GLMTransformer(
150 | 8.16 B = 86.79% Params, 1.04 TMACs = 92.93% MACs, 2.09 TFLOPS = 46.46% FLOPs
151 | (layers): ModuleList(
152 | (0-39): 40 x GLMBlock(
153 | 203.96 M = 2.17% Params, 26.11 GMACs = 2.32% MACs, 52.21 GFLOPS = 1.16% FLOPs
154 | (input_layernorm): RMSNorm(4.1 K = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs)
155 | (self_attention): SelfAttention(
156 | 35.66 M = 0.38% Params, 4.56 GMACs = 0.41% MACs, 9.13 GFLOPS = 0.2% FLOPs
157 | (query_key_value): Linear(18.88 M = 0.2% Params, 2.42 GMACs = 0.22% MACs, 4.83 GFLOPS = 0.11% FLOPs, in_features=4096, out_features=4608, bias=True)
158 | (core_attention): CoreAttention(
159 | 0 = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs
160 | (attention_dropout): Dropout(0 = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs, p=0.0, inplace=False)
161 | )
162 | (dense): Linear(16.78 M = 0.18% Params, 2.15 GMACs = 0.19% MACs, 4.29 GFLOPS = 0.1% FLOPs, in_features=4096, out_features=4096, bias=False)
163 | )
164 | (post_attention_layernorm): RMSNorm(4.1 K = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs)
165 | (mlp): MLP(
166 | 168.3 M = 1.79% Params, 21.54 GMACs = 1.92% MACs, 43.09 GFLOPS = 0.96% FLOPs
167 | (dense_h_to_4h): Linear(112.2 M = 1.19% Params, 14.36 GMACs = 1.28% MACs, 28.72 GFLOPS = 0.64% FLOPs, in_features=4096, out_features=27392, bias=False)
168 | (dense_4h_to_h): Linear(56.1 M = 0.6% Params, 7.18 GMACs = 0.64% MACs, 14.36 GFLOPS = 0.32% FLOPs, in_features=13696, out_features=4096, bias=False)
169 | )
170 | )
171 | )
172 | (final_layernorm): RMSNorm(4.1 K = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs)
173 | )
174 | (output_layer): Linear(620.76 M = 6.6% Params, 79.46 GMACs = 7.07% MACs, 158.91 GFLOPS = 3.54% FLOPs, in_features=4096, out_features=151552, bias=False)
175 | )
176 | )
177 | ```
178 |
179 |
180 | There are some model uses that require an application first, and you only need to pass the application in through the ```access_token``` to calculate its FLOPs.
181 |
182 |
183 | 
184 |
185 | ```python
186 | from calflops import calculate_flops_hf
187 |
188 | batch_size, max_seq_length = 1, 128
189 | model_name = "meta-llama/Llama-2-7b"
190 | access_token = "" # your application for using llama2
191 |
192 | flops, macs, params = calculate_flops_hf(model_name=model_name,
193 | access_token=access_token,
194 | input_shape=(batch_size, max_seq_length))
195 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
196 | ```
197 |
198 |
199 | ### Transformer Model (Local)
200 |
201 | Compared to the CNN Model, Transformer Model if you want to use the parameter ```input_shape``` to make calflops automatically generating the input data, you should pass its corresponding tokenizer through the parameter ```transformer_tokenizer```.
202 |
203 | ``` python
204 | # Transformers Model, such as bert.
205 | from calflops import calculate_flops
206 | from transformers import AutoModel
207 | from transformers import AutoTokenizer
208 |
209 | batch_size, max_seq_length = 1, 128
210 | model_name = "hfl/chinese-roberta-wwm-ext/"
211 | model_save = "../pretrain_models/" + model_name
212 | model = AutoModel.from_pretrained(model_save)
213 | tokenizer = AutoTokenizer.from_pretrained(model_save)
214 |
215 | flops, macs, params = calculate_flops(model=model,
216 | input_shape=(batch_size,max_seq_length),
217 | transformer_tokenizer=tokenizer)
218 | print("Bert(hfl/chinese-roberta-wwm-ext) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
219 | #Bert(hfl/chinese-roberta-wwm-ext) FLOPs:67.1 GFLOPS MACs:33.52 GMACs Params:102.27 M
220 | ```
221 |
222 | If you want to use your own generated specific data to calculate FLOPs, you can use
223 | parameter ```args``` or ```kwargs```,and parameter ```input_shape``` can no longer be assigned to pass in this case. Here is an example that can be seen is inconvenient comparedt to use parameter```transformer_tokenizer```.
224 |
225 |
226 | ``` python
227 | # Transformers Model, such as bert.
228 | from calflops import calculate_flops
229 | from transformers import AutoModel
230 | from transformers import AutoTokenizer
231 |
232 |
233 | batch_size, max_seq_length = 1, 128
234 | model_name = "hfl/chinese-roberta-wwm-ext/"
235 | model_save = "/code/yexiaoju/generate_tags/models/pretrain_models/" + model_name
236 | model = AutoModel.from_pretrained(model_save)
237 | tokenizer = AutoTokenizer.from_pretrained(model_save)
238 |
239 | text = ""
240 | inputs = tokenizer(text,
241 | add_special_tokens=True,
242 | return_attention_mask=True,
243 | padding=True,
244 | truncation="longest_first",
245 | max_length=max_seq_length)
246 |
247 | if len(inputs["input_ids"]) < max_seq_length:
248 | apply_num = max_seq_length-len(inputs["input_ids"])
249 | inputs["input_ids"].extend([0]*apply_num)
250 | inputs["token_type_ids"].extend([0]*apply_num)
251 | inputs["attention_mask"].extend([0]*apply_num)
252 |
253 | inputs["input_ids"] = torch.tensor([inputs["input_ids"]])
254 | inputs["token_type_ids"] = torch.tensor([inputs["token_type_ids"]])
255 | inputs["attention_mask"] = torch.tensor([inputs["attention_mask"]])
256 |
257 | flops, macs, params = calculate_flops(model=model,
258 | kwargs = inputs,
259 | print_results=False)
260 | print("Bert(hfl/chinese-roberta-wwm-ext) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
261 | #Bert(hfl/chinese-roberta-wwm-ext) FLOPs:22.36 GFLOPS MACs:11.17 GMACs Params:102.27 M
262 | ```
263 |
264 |
265 | ### Large Language Model
266 |
267 | #### Online
268 |
269 | ```python
270 | from calflops import calculate_flops_hf
271 |
272 | batch_size, max_seq_length = 1, 128
273 | model_name = "meta-llama/Llama-2-7b"
274 | access_token = "" # your application for using llama
275 |
276 | flops, macs, params = calculate_flops_hf(model_name=model_name,
277 | access_token=access_token,
278 | input_shape=(batch_size, max_seq_length))
279 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
280 | ```
281 |
282 | #### Local
283 | Note here that the tokenizer must correspond to the llm model because llm tokenizer processes maybe are different.
284 |
285 | ``` python
286 | #Large Languase Model, such as llama2-7b.
287 | from calflops import calculate_flops
288 | from transformers import LlamaTokenizer
289 | from transformers import LlamaForCausalLM
290 |
291 | batch_size, max_seq_length = 1, 128
292 | model_name = "llama2_hf_7B"
293 | model_save = "../model/" + model_name
294 | model = LlamaForCausalLM.from_pretrained(model_save)
295 | tokenizer = LlamaTokenizer.from_pretrained(model_save)
296 | flops, macs, params = calculate_flops(model=model,
297 | input_shape=(batch_size, max_seq_length),
298 | transformer_tokenizer=tokenizer)
299 | print("Llama2(7B) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
300 | #Llama2(7B) FLOPs:1.7 TFLOPS MACs:850.00 GMACs Params:6.74 B
301 | ```
302 |
303 | ### Show each submodule result of FLOPs、MACs、Params
304 |
305 | The calflops provides a more detailed display of model FLOPs calculation information. By setting the parameter ```print_result=True```, which defaults to True, flops of the model will be printed in the terminal or jupyter interface.
306 |
307 | 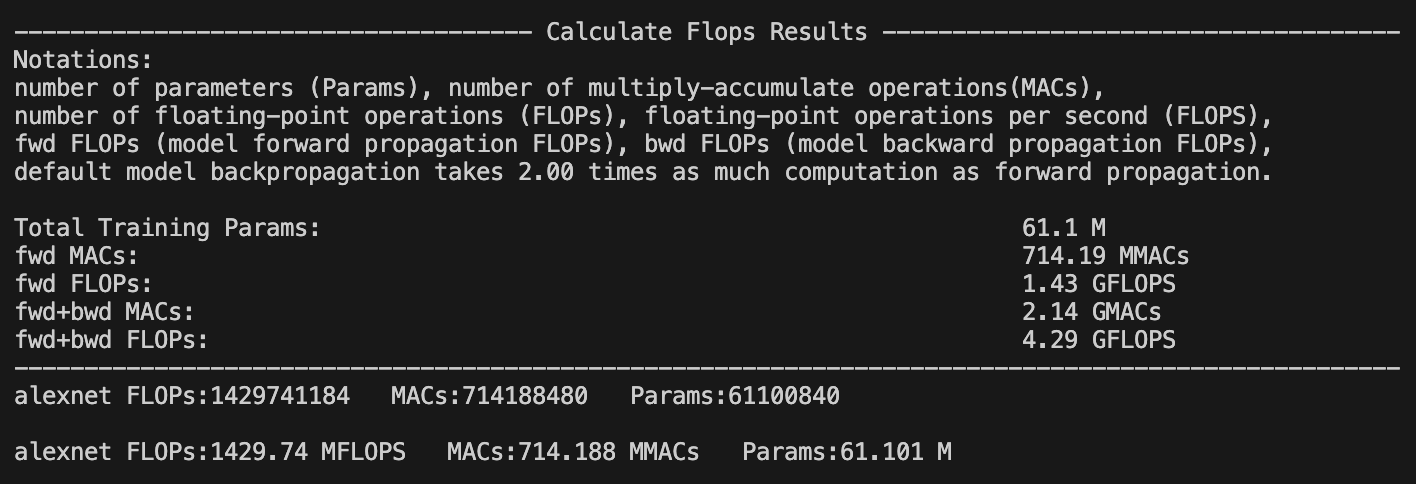
308 |
309 | Meanwhile, by setting the parameter ```print_detailed=True``` which default to True, the calflops supports the display of the calculation results and proportion of FLOPs、MACs and Parameter in each submodule of the entire model, so that it is convenient to see the largest part of the calculation consumption in the entire model.
310 |
311 | 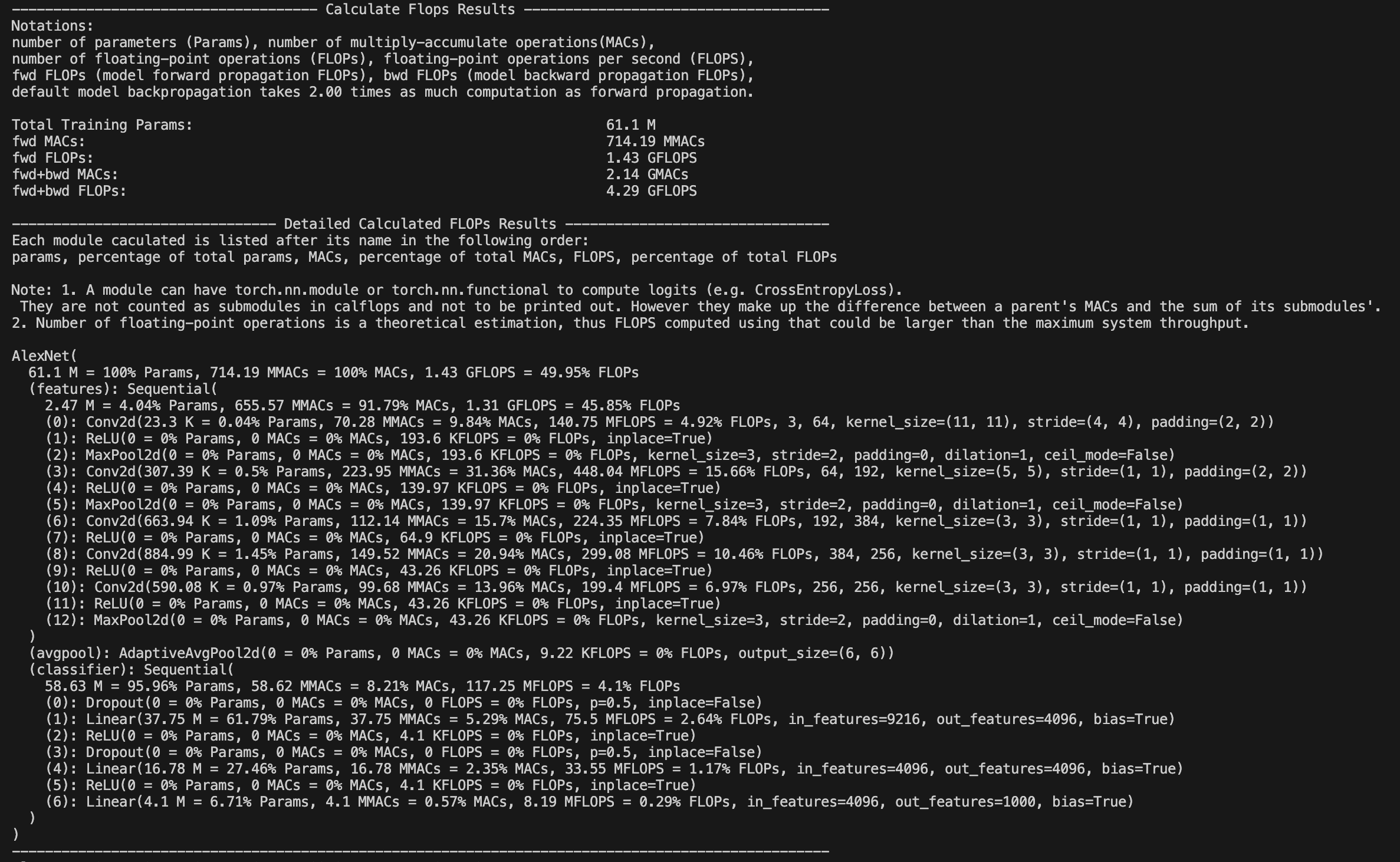
312 |
313 | ### More use introduction
314 |
315 |
28 |
29 |
30 |
31 | For LLM, this is probably the easiest tool to calculate FLOPs and it is very convenient for **huggingface** platform models. You can use ```calflops.calculate_flops_hf(model_name)``` by `model_name` which in [huggingface models](https://huggingface.co/models) to calculate model FLOPs without downloading entire model weights locally.Notice this method requires the model to support the empty model being created for model inference in meta device.
32 |
33 | 
34 |
35 | ``` python
36 | from calflops import calculate_flops_hf
37 |
38 | model_name = "meta-llama/Llama-2-7b"
39 | access_token = "..." # your application token for using llama2
40 | flops, macs, params = calculate_flops_hf(model_name=model_name, access_token=access_token) # default input shape: (1, 128)
41 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
42 | ```
43 |
44 |
45 | If model can't inference in meta device, you just need assign llm corresponding tokenizer to the parameter: ```transformers_tokenizer``` to pass in funcional of ```calflops.calculate_flops()```, and it will automatically help you build the model input data whose size is input_shape. Alternatively, you also can pass in the input data of models which need multi data as input that you have constructed.
46 |
47 |
48 | In addition, the implementation process of this package inspired by [ptflops](https://github.com/sovrasov/flops-counter.pytorch)、[deepspeed](https://github.com/microsoft/DeepSpeed/tree/master/deepspeed)、[hf accelerate](https://github.com/huggingface/accelerate) libraries, Thanks for their great efforts, they are both very good work. Meanwhile this package also improves some aspects to calculate FLOPs based on them.
49 |
50 | ## How to install
51 | ### Install the latest version
52 | #### From PyPI:
53 |
54 | ```python
55 | pip install --upgrade calflops
56 | ```
57 |
58 | And you also can download latest `calflops-*-py3-none-any.whl` files from https://pypi.org/project/calflops/
59 |
60 | ```python
61 | pip install calflops-*-py3-none-any.whl
62 | ```
63 |
64 | ## How to use calflops
65 |
66 | ### Example
67 | ### CNN Model
68 | If model has only one input, you just need set the model input size by parameter ```input_shape``` , it can automatically generate random model input to complete the calculation:
69 |
70 | ```python
71 | from calflops import calculate_flops
72 | from torchvision import models
73 |
74 | model = models.alexnet()
75 | batch_size = 1
76 | input_shape = (batch_size, 3, 224, 224)
77 | flops, macs, params = calculate_flops(model=model,
78 | input_shape=input_shape,
79 | output_as_string=True,
80 | output_precision=4)
81 | print("Alexnet FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
82 | #Alexnet FLOPs:4.2892 GFLOPS MACs:2.1426 GMACs Params:61.1008 M
83 | ```
84 |
85 | If the model has multiple inputs, use the parameters ```args``` or ```kargs```, as shown in the Transfomer Model below.
86 |
87 |
88 | ### Calculate Huggingface Model By Model Name(Online)
89 |
90 | No need to download the entire parameter weight of the model to the local, just by the model name can test any open source large model on the huggingface platform.
91 |
92 | 
93 |
94 |
95 | ```python
96 | from calflops import calculate_flops_hf
97 |
98 | batch_size, max_seq_length = 1, 128
99 | model_name = "baichuan-inc/Baichuan-13B-Chat"
100 |
101 | flops, macs, params = calculate_flops_hf(model_name=model_name, input_shape=(batch_size, max_seq_length))
102 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
103 | ```
104 |
105 | You can also use this model urls of huggingface platform to calculate it FLOPs.
106 |
107 | 
108 |
109 | ```python
110 | from calflops import calculate_flops_hf
111 |
112 | batch_size, max_seq_length = 1, 128
113 | model_name = "https://huggingface.co/THUDM/glm-4-9b-chat" # THUDM/glm-4-9b-chat
114 | flops, macs, params = calculate_flops_hf(model_name=model_name, input_shape=(batch_size, max_seq_length))
115 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
116 | ```
117 |
118 | ```
119 | ------------------------------------- Calculate Flops Results -------------------------------------
120 | Notations:
121 | number of parameters (Params), number of multiply-accumulate operations(MACs),
122 | number of floating-point operations (FLOPs), floating-point operations per second (FLOPS),
123 | fwd FLOPs (model forward propagation FLOPs), bwd FLOPs (model backward propagation FLOPs),
124 | default model backpropagation takes 2.00 times as much computation as forward propagation.
125 |
126 | Total Training Params: 9.4 B
127 | fwd MACs: 1.12 TMACs
128 | fwd FLOPs: 2.25 TFLOPS
129 | fwd+bwd MACs: 3.37 TMACs
130 | fwd+bwd FLOPs: 6.74 TFLOPS
131 |
132 | -------------------------------- Detailed Calculated FLOPs Results --------------------------------
133 | Each module caculated is listed after its name in the following order:
134 | params, percentage of total params, MACs, percentage of total MACs, FLOPS, percentage of total FLOPs
135 |
136 | Note: 1. A module can have torch.nn.module or torch.nn.functional to compute logits (e.g. CrossEntropyLoss).
137 | They are not counted as submodules in calflops and not to be printed out. However they make up the difference between a parent's MACs and the sum of its submodules'.
138 | 2. Number of floating-point operations is a theoretical estimation, thus FLOPS computed using that could be larger than the maximum system throughput.
139 |
140 | ChatGLMForConditionalGeneration(
141 | 9.4 B = 100% Params, 1.12 TMACs = 100% MACs, 2.25 TFLOPS = 50% FLOPs
142 | (transformer): ChatGLMModel(
143 | 9.4 B = 100% Params, 1.12 TMACs = 100% MACs, 2.25 TFLOPS = 50% FLOPs
144 | (embedding): Embedding(
145 | 620.76 M = 6.6% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs
146 | (word_embeddings): Embedding(620.76 M = 6.6% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs, 151552, 4096)
147 | )
148 | (rotary_pos_emb): RotaryEmbedding(0 = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs)
149 | (encoder): GLMTransformer(
150 | 8.16 B = 86.79% Params, 1.04 TMACs = 92.93% MACs, 2.09 TFLOPS = 46.46% FLOPs
151 | (layers): ModuleList(
152 | (0-39): 40 x GLMBlock(
153 | 203.96 M = 2.17% Params, 26.11 GMACs = 2.32% MACs, 52.21 GFLOPS = 1.16% FLOPs
154 | (input_layernorm): RMSNorm(4.1 K = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs)
155 | (self_attention): SelfAttention(
156 | 35.66 M = 0.38% Params, 4.56 GMACs = 0.41% MACs, 9.13 GFLOPS = 0.2% FLOPs
157 | (query_key_value): Linear(18.88 M = 0.2% Params, 2.42 GMACs = 0.22% MACs, 4.83 GFLOPS = 0.11% FLOPs, in_features=4096, out_features=4608, bias=True)
158 | (core_attention): CoreAttention(
159 | 0 = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs
160 | (attention_dropout): Dropout(0 = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs, p=0.0, inplace=False)
161 | )
162 | (dense): Linear(16.78 M = 0.18% Params, 2.15 GMACs = 0.19% MACs, 4.29 GFLOPS = 0.1% FLOPs, in_features=4096, out_features=4096, bias=False)
163 | )
164 | (post_attention_layernorm): RMSNorm(4.1 K = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs)
165 | (mlp): MLP(
166 | 168.3 M = 1.79% Params, 21.54 GMACs = 1.92% MACs, 43.09 GFLOPS = 0.96% FLOPs
167 | (dense_h_to_4h): Linear(112.2 M = 1.19% Params, 14.36 GMACs = 1.28% MACs, 28.72 GFLOPS = 0.64% FLOPs, in_features=4096, out_features=27392, bias=False)
168 | (dense_4h_to_h): Linear(56.1 M = 0.6% Params, 7.18 GMACs = 0.64% MACs, 14.36 GFLOPS = 0.32% FLOPs, in_features=13696, out_features=4096, bias=False)
169 | )
170 | )
171 | )
172 | (final_layernorm): RMSNorm(4.1 K = 0% Params, 0 MACs = 0% MACs, 0 FLOPS = 0% FLOPs)
173 | )
174 | (output_layer): Linear(620.76 M = 6.6% Params, 79.46 GMACs = 7.07% MACs, 158.91 GFLOPS = 3.54% FLOPs, in_features=4096, out_features=151552, bias=False)
175 | )
176 | )
177 | ```
178 |
179 |
180 | There are some model uses that require an application first, and you only need to pass the application in through the ```access_token``` to calculate its FLOPs.
181 |
182 |
183 | 
184 |
185 | ```python
186 | from calflops import calculate_flops_hf
187 |
188 | batch_size, max_seq_length = 1, 128
189 | model_name = "meta-llama/Llama-2-7b"
190 | access_token = "" # your application for using llama2
191 |
192 | flops, macs, params = calculate_flops_hf(model_name=model_name,
193 | access_token=access_token,
194 | input_shape=(batch_size, max_seq_length))
195 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
196 | ```
197 |
198 |
199 | ### Transformer Model (Local)
200 |
201 | Compared to the CNN Model, Transformer Model if you want to use the parameter ```input_shape``` to make calflops automatically generating the input data, you should pass its corresponding tokenizer through the parameter ```transformer_tokenizer```.
202 |
203 | ``` python
204 | # Transformers Model, such as bert.
205 | from calflops import calculate_flops
206 | from transformers import AutoModel
207 | from transformers import AutoTokenizer
208 |
209 | batch_size, max_seq_length = 1, 128
210 | model_name = "hfl/chinese-roberta-wwm-ext/"
211 | model_save = "../pretrain_models/" + model_name
212 | model = AutoModel.from_pretrained(model_save)
213 | tokenizer = AutoTokenizer.from_pretrained(model_save)
214 |
215 | flops, macs, params = calculate_flops(model=model,
216 | input_shape=(batch_size,max_seq_length),
217 | transformer_tokenizer=tokenizer)
218 | print("Bert(hfl/chinese-roberta-wwm-ext) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
219 | #Bert(hfl/chinese-roberta-wwm-ext) FLOPs:67.1 GFLOPS MACs:33.52 GMACs Params:102.27 M
220 | ```
221 |
222 | If you want to use your own generated specific data to calculate FLOPs, you can use
223 | parameter ```args``` or ```kwargs```,and parameter ```input_shape``` can no longer be assigned to pass in this case. Here is an example that can be seen is inconvenient comparedt to use parameter```transformer_tokenizer```.
224 |
225 |
226 | ``` python
227 | # Transformers Model, such as bert.
228 | from calflops import calculate_flops
229 | from transformers import AutoModel
230 | from transformers import AutoTokenizer
231 |
232 |
233 | batch_size, max_seq_length = 1, 128
234 | model_name = "hfl/chinese-roberta-wwm-ext/"
235 | model_save = "/code/yexiaoju/generate_tags/models/pretrain_models/" + model_name
236 | model = AutoModel.from_pretrained(model_save)
237 | tokenizer = AutoTokenizer.from_pretrained(model_save)
238 |
239 | text = ""
240 | inputs = tokenizer(text,
241 | add_special_tokens=True,
242 | return_attention_mask=True,
243 | padding=True,
244 | truncation="longest_first",
245 | max_length=max_seq_length)
246 |
247 | if len(inputs["input_ids"]) < max_seq_length:
248 | apply_num = max_seq_length-len(inputs["input_ids"])
249 | inputs["input_ids"].extend([0]*apply_num)
250 | inputs["token_type_ids"].extend([0]*apply_num)
251 | inputs["attention_mask"].extend([0]*apply_num)
252 |
253 | inputs["input_ids"] = torch.tensor([inputs["input_ids"]])
254 | inputs["token_type_ids"] = torch.tensor([inputs["token_type_ids"]])
255 | inputs["attention_mask"] = torch.tensor([inputs["attention_mask"]])
256 |
257 | flops, macs, params = calculate_flops(model=model,
258 | kwargs = inputs,
259 | print_results=False)
260 | print("Bert(hfl/chinese-roberta-wwm-ext) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
261 | #Bert(hfl/chinese-roberta-wwm-ext) FLOPs:22.36 GFLOPS MACs:11.17 GMACs Params:102.27 M
262 | ```
263 |
264 |
265 | ### Large Language Model
266 |
267 | #### Online
268 |
269 | ```python
270 | from calflops import calculate_flops_hf
271 |
272 | batch_size, max_seq_length = 1, 128
273 | model_name = "meta-llama/Llama-2-7b"
274 | access_token = "" # your application for using llama
275 |
276 | flops, macs, params = calculate_flops_hf(model_name=model_name,
277 | access_token=access_token,
278 | input_shape=(batch_size, max_seq_length))
279 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
280 | ```
281 |
282 | #### Local
283 | Note here that the tokenizer must correspond to the llm model because llm tokenizer processes maybe are different.
284 |
285 | ``` python
286 | #Large Languase Model, such as llama2-7b.
287 | from calflops import calculate_flops
288 | from transformers import LlamaTokenizer
289 | from transformers import LlamaForCausalLM
290 |
291 | batch_size, max_seq_length = 1, 128
292 | model_name = "llama2_hf_7B"
293 | model_save = "../model/" + model_name
294 | model = LlamaForCausalLM.from_pretrained(model_save)
295 | tokenizer = LlamaTokenizer.from_pretrained(model_save)
296 | flops, macs, params = calculate_flops(model=model,
297 | input_shape=(batch_size, max_seq_length),
298 | transformer_tokenizer=tokenizer)
299 | print("Llama2(7B) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
300 | #Llama2(7B) FLOPs:1.7 TFLOPS MACs:850.00 GMACs Params:6.74 B
301 | ```
302 |
303 | ### Show each submodule result of FLOPs、MACs、Params
304 |
305 | The calflops provides a more detailed display of model FLOPs calculation information. By setting the parameter ```print_result=True```, which defaults to True, flops of the model will be printed in the terminal or jupyter interface.
306 |
307 | 
308 |
309 | Meanwhile, by setting the parameter ```print_detailed=True``` which default to True, the calflops supports the display of the calculation results and proportion of FLOPs、MACs and Parameter in each submodule of the entire model, so that it is convenient to see the largest part of the calculation consumption in the entire model.
310 |
311 | 
312 |
313 | ### More use introduction
314 |
315 |
316 | How to make output format more elegant
317 | You can use parameter output_as_string、output_precision、output_unit to determine the format of output data is value or string, if it is string, how many bits of precision to retain and the unit of value, such as FLOPs, the unit of result is "TFLOPs" or "GFLOPs", "MFLOPs".
318 |
319 |
320 |
321 |
322 | How do deal with model has multiple inputs
323 | The calflops support multiple inputs of model, just use parameter args or kwargs to construct multiple inputs can be passed in as model inference.
324 |
325 |
326 |
327 | How to calculate the results of FLOPS include forward and backward pass of the model
328 | You can use the parameter include_backPropagation to select whether the calculation of FLOPs results includes the process of model backpropagation. The default is False, that is result of FLOPs only include forward pass.
329 |
330 | In addition, the parameter compute_bp_factor to determine how many times backward as much computation as forward pass.The defaults that is 2.0, according to https://epochai.org/blog/backward-forward-FLOP-ratio
331 |
332 |
333 |
334 | How to calculate FLOPs for only part of the model module
335 | You can use the parameter ignore_modules to select which modules of model are ignored during FLOPs calculation. The default is [], that is all modules of model would be calculated in results.
336 |
337 |
338 |
339 | How to calculate FLOPs of the generate function in LLM
340 | You just need to assign "generate" to parameter forward_mode.
341 |
342 |
343 | ### **API** of the **calflops**
344 |
345 |
346 | calflops.calculate_flops()
347 |
348 | ``` python
349 | from calflops import calculate_flops
350 |
351 | def calculate_flops(model,
352 | input_shape=None,
353 | transformer_tokenizer=None,
354 | args=[],
355 | kwargs={},
356 | forward_mode="forward",
357 | include_backPropagation=False,
358 | compute_bp_factor=2.0,
359 | print_results=True,
360 | print_detailed=True,
361 | output_as_string=True,
362 | output_precision=2,
363 | output_unit=None,
364 | ignore_modules=None):
365 |
366 | """Returns the total floating-point operations, MACs, and parameters of a model.
367 |
368 | Args:
369 | model ([torch.nn.Module]): The model of input must be a PyTorch model.
370 | input_shape (tuple, optional): Input shape to the model. If args and kwargs is empty, the model takes a tensor with this shape as the only positional argument. Default to [].
371 | transformers_tokenizer (None, optional): Transforemrs Toekenizer must be special if model type is transformers and args、kwargs is empty. Default to None
372 | args (list, optinal): list of positional arguments to the model, such as bert input args is [input_ids, token_type_ids, attention_mask]. Default to []
373 | kwargs (dict, optional): dictionary of keyword arguments to the model, such as bert input kwargs is {'input_ids': ..., 'token_type_ids':..., 'attention_mask':...}. Default to {}
374 | forward_mode (str, optional): To determine the mode of model inference, Default to 'forward'. And use 'generate' if model inference uses model.generate().
375 | include_backPropagation (bool, optional): Decides whether the final return FLOPs computation includes the computation for backpropagation.
376 | compute_bp_factor (float, optional): The model backpropagation is a multiple of the forward propagation computation. Default to 2.
377 | print_results (bool, optional): Whether to print the model profile. Defaults to True.
378 | print_detailed (bool, optional): Whether to print the detailed model profile. Defaults to True.
379 | output_as_string (bool, optional): Whether to print the output as string. Defaults to True.
380 | output_precision (int, optional) : Output holds the number of decimal places if output_as_string is True. Default to 2.
381 | output_unit (str, optional): The unit used to output the result value, such as T, G, M, and K. Default is None, that is the unit of the output decide on value.
382 | ignore_modules ([type], optional): the list of modules to ignore during profiling. Defaults to None.
383 | ```
384 |
385 |
386 |
387 |
388 | calflops.calculate_flops_hf()
389 |
390 | ``` python
391 | def calculate_flops_hf(model_name,
392 | input_shape=None,
393 | library_name="transformers",
394 | trust_remote_code=True,
395 | access_token="",
396 | forward_mode="forward",
397 | include_backPropagation=False,
398 | compute_bp_factor=2.0,
399 | print_results=True,
400 | print_detailed=True,
401 | output_as_string=True,
402 | output_precision=2,
403 | output_unit=None,
404 | ignore_modules=None):
405 |
406 | """Returns the total floating-point operations, MACs, and parameters of a model.
407 |
408 | Args:
409 | model_name (str): The model name in huggingface platform https://huggingface.co/models, such as meta-llama/Llama-2-7b、baichuan-inc/Baichuan-13B-Chat etc.
410 | input_shape (tuple, optional): Input shape to the model. If args and kwargs is empty, the model takes a tensor with this shape as the only positional argument. Default to [].
411 | trust_remote_code (bool, optional): Trust the code in the remote library for the model structure.
412 | access_token (str, optional): Some models need to apply for a access token, such as meta llama2 etc.
413 | forward_mode (str, optional): To determine the mode of model inference, Default to 'forward'. And use 'generate' if model inference uses model.generate().
414 | include_backPropagation (bool, optional): Decides whether the final return FLOPs computation includes the computation for backpropagation.
415 | compute_bp_factor (float, optional): The model backpropagation is a multiple of the forward propagation computation. Default to 2.
416 | print_results (bool, optional): Whether to print the model profile. Defaults to True.
417 | print_detailed (bool, optional): Whether to print the detailed model profile. Defaults to True.
418 | output_as_string (bool, optional): Whether to print the output as string. Defaults to True.
419 | output_precision (int, optional) : Output holds the number of decimal places if output_as_string is True. Default to 2.
420 | output_unit (str, optional): The unit used to output the result value, such as T, G, M, and K. Default is None, that is the unit of the output decide on value.
421 | ignore_modules ([type], optional): the list of modules to ignore during profiling. Defaults to None.
422 |
423 | Example:
424 | .. code-block:: python
425 | from calflops import calculate_flops_hf
426 |
427 | batch_size = 1
428 | max_seq_length = 128
429 | model_name = "baichuan-inc/Baichuan-13B-Chat"
430 | flops, macs, params = calculate_flops_hf(model_name=model_name,
431 | input_shape=(batch_size, max_seq_length))
432 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
433 |
434 | Returns:
435 | The number of floating-point operations, multiply-accumulate operations (MACs), and parameters in the model.
436 | """
437 | ```
438 |
439 |
440 |
441 |
442 | calflops.generate_transformer_input()
443 |
444 | ``` python
445 | def generate_transformer_input(model_tokenizer, input_shape, device):
446 | """Automatically generates data in the form of transformes model input format.
447 |
448 | Args:
449 | input_shape (tuple):transformers model input shape: (batch_size, seq_len).
450 | tokenizer (transformer.model.tokenization): transformers model tokenization.tokenizer.
451 |
452 | Returns:
453 | dict: data format of transformers model input, it is a dict which contain 'input_ids', 'attention_mask', 'token_type_ids' etc.
454 | """
455 | ```
456 |
457 |
458 |
459 |
460 |
461 | ## Citation
462 | if calflops was useful for your paper or tech report, please cite me:
463 | ```
464 | @online{calflops,
465 | author = {xiaoju ye},
466 | title = {calflops: a FLOPs and Params calculate tool for neural networks in pytorch framework},
467 | year = 2023,
468 | url = {https://github.com/MrYxJ/calculate-flops.pytorch},
469 | }
470 | ```
471 |
472 | ## Common model calculate flops
473 |
474 | ### Large Language Model
475 | Input data format: batch_size=1, seq_len=128
476 |
477 | - fwd FLOPs: The FLOPs of the model forward propagation
478 |
479 | - bwd + fwd FLOPs: The FLOPs of model forward and backward propagation
480 |
481 | In addition, note that fwd + bwd does not include calculation losses for model parameter activation recomputation, if the results wants to include activation recomputation that is only necessary to multiply the result of fwd FLOPs by 4(According to the paper: https://arxiv.org/pdf/2205.05198.pdf), and in calflops you can easily set parameter ```computer_bp_factor=3 ```to make the result of including the activate the recalculation.
482 |
483 |
484 | Model | Input Shape | Params(B)|Params(Total)| fwd FLOPs(G) | fwd MACs(G) | fwd + bwd FLOPs(G) | fwd + bwd MACs(G) |
485 | --- |--- |--- |--- |--- |--- |--- |---
486 | bloom-1b7 |(1,128) | 1.72B | 1722408960 | 310.92 | 155.42 | 932.76 | 466.27
487 | bloom-7b1 |(1,128) | 7.07B | 7069016064 | 1550.39 | 775.11 | 4651.18 | 2325.32
488 | bloomz-1b7 |(1,128) | 1.72B | 1722408960 | 310.92 | 155.42 | 932.76 | 466.27
489 | baichuan-7B |(1,128) | 7B | 7000559616 | 1733.62 | 866.78 | 5200.85 | 2600.33
490 | chatglm-6b |(1,128) | 6.17B | 6173286400 | 1587.66 | 793.75 | 4762.97 | 2381.24
491 | chatglm2-6b |(1,128) | 6.24B | 6243584000 | 1537.68 | 768.8 | 4613.03 | 2306.4
492 | Qwen-7B |(1,128) | 7.72B | 7721324544 | 1825.83 | 912.88 | 5477.48 | 2738.65
493 | llama-7b |(1,128) | 6.74B | 6738415616 | 1700.06 | 850 | 5100.19 | 2550
494 | llama2-7b |(1,128) | 6.74B | 6738415616 | 1700.06 | 850 | 5100.19 | 2550
495 | llama2-7b-chat |(1,128) | 6.74B | 6738415616 | 1700.06 | 850 | 5100.19 | 2550
496 | chinese-llama-7b | (1,128) | 6.89B | 6885486592 | 1718.89 | 859.41 |5156.67 | 2578.24
497 | chinese-llama-plus-7b| (1,128) | 6.89B | 6885486592 | 1718.89 | 859.41 |5156.67 | 2578.24
498 | EleutherAI/pythia-1.4b | (1,128) | 1.31B | 1311625216 | 312.54 | 156.23 |937.61 | 468.69
499 | EleutherAI/pythia-12b | (1,128) | 11.59B | 11586549760 | 2911.47 | 1455.59 | 8734,41 | 4366.77
500 | moss-moon-003-sft |(1,128) | 16.72B | 16717980160 | 4124.93 | 2062.39 | 12374.8 | 6187.17
501 | moss-moon-003-sft-plugin |(1,128) | 16.06B | 16060416000 | 3956.62 | 1978.24 | 11869.9 | 5934.71
502 |
503 | We can draw some simple and interesting conclusions from the table above:
504 | - The chatglm2-6b in the model of the same scale, the model parameters are smaller, and FLOPs is also smaller, which has certain advantages in speed performance.
505 | - The parameters of the llama1-7b, llama2-7b, and llama2-7b-chat models did not change at all, and FLOPs remained consistent. The structure of the model that conforms to the 7b described by [meta in its llama2 report](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) has not changed, the main difference is the increase of training data tokens.
506 | - Similarly, it can be seen from the table that the chinese-llama-7b and chinese-llama-plus-7b data are also in line with [cui's report](https://arxiv.org/pdf/2304.08177v1.pdf), just more chinese data tokens are added for training, and the model structure and parameters do not change.
507 |
508 | - ......
509 |
510 | More model FLOPs would be updated successively, see github [calculate-flops.pytorch](https://github.com/MrYxJ/calculate-flops.pytorch)
511 |
512 | ### Bert
513 |
514 | Input data format: batch_size=1, seq_len=128
515 |
516 | Model | Input Shape | Params(M)|Params(Total)| fwd FLOPs(G) | fwd MACs(G) | fwd + bwd FLOPs(G) | fwd + bwd MACs(G) |
517 | --- |--- |--- |--- |--- |--- |--- |---
518 | hfl/chinese-roberta-wwm-ext | (1,128)| 102.27M | 102267648 | 22.363 | 11.174 | 67.089 | 33.523 |
519 | ......
520 |
521 | You can use calflops to calculate the more different transformer models based bert, look forward to updating in this form.
522 |
523 |
524 | ## Benchmark
525 | ### [torchvision](https://pytorch.org/docs/1.0.0/torchvision/models.html)
526 |
527 | Input data format: batch_size = 1, actually input_shape = (1, 3, 224, 224)
528 |
529 | Note: The FLOPs in the table only takes into account the computation of forward propagation of the model, **Total** refers to the total numerical representation without unit abbreviations.
530 |
531 | Model | Input Resolution | Params(M)|Params(Total) | FLOPs(G) | FLOPs(Total) | Macs(G) | Macs(Total)
532 | --- |--- |--- |--- |--- |--- |--- |---
533 | alexnet |224x224 | 61.10 | 61100840 | 1.43 | 1429740000 | 741.19 | 7418800000
534 | vgg11 |224x224 | 132.86 | 132863000 | 15.24 | 15239200000 | 7.61 | 7609090000
535 | vgg13 |224x224 | 133.05 | 133048000 | 22.65 | 22647600000 | 11.31 | 11308500000
536 | vgg16 |224x224 | 138.36 | 138358000 | 30.97 | 30973800000 | 15.47 | 15470300000
537 | vgg19 |224x224 | 143.67 | 143667000 | 39.30 | 39300000000 | 19.63 | 19632100000
538 | vgg11_bn |224x224 | 132.87 | 132869000 | 15.25 | 15254000000 | 7.61 | 7609090000
539 | vgg13_bn |224x224 | 133.05 | 133054000 | 22.67 | 22672100000 | 11.31 | 11308500000
540 | vgg16_bn |224x224 | 138.37 | 138366000 | 31.00 | 31000900000 | 15.47 | 15470300000
541 | vgg19_bn |224x224 | 143.68 | 143678000 | 39.33 | 39329700000 | 19.63 | 19632100000
542 | resnet18 |224x224 | 11.69 | 11689500 | 3.64 | 3636250000 | 1.81 | 1814070000
543 | resnet34 |224x224 | 21.80 | 21797700 | 7.34 | 7339390000 | 3.66 | 3663760000
544 | resnet50 |224x224 | 25.56 | 25557000 | 8.21 | 8211110000 | 4.09 | 4089180000
545 | resnet101 |224x224 | 44.55 | 44549200 | 15.65 | 15690900000 | 7.80 | 7801410000
546 | resnet152 |224x224 | 60.19 | 60192800 | 23.09 | 23094300000 | 11.51 | 11513600000
547 | squeezenet1_0 |224x224 | 1.25 | 1248420 | 1.65 | 1648970000 | 0.82 | 818925000
548 | squeezenet1_1 |224x224 | 1.24 | 1235500 | 0.71 | 705014000 | 0.35 | 349152000
549 | densenet121 |224x224 | 7.98 | 7978860 | 5.72 | 5716880000 | 2.83 | 2834160000
550 | densenet169 |224x224 | 14.15 | 14195000 | 6.78 | 6778370000 | 3.36 | 3359840000
551 | densenet201 |224x224 | 20.01 | 20013900 | 8.66 | 8658520000 | 4.29 | 4291370000
552 | densenet161 |224x224 | 28.68 | 28681000 | 15.55 | 1554650000 | 7.73 | 7727900000
553 | inception_v3 |224x224 | 27.16 | 27161300 | 5.29 | 5692390000 | 2.84 | 2837920000
554 |
555 | Thanks to @[zigangzhao-ai](https://github.com/zigangzhao-ai) use ```calflops``` to static torchvision form.
556 |
557 | You also can compare torchvision results of calculate FLOPs with anthoer good tool: [ptflops readme.md](https://github.com/sovrasov/flops-counter.pytorch/).
558 |
559 |
560 |
561 | ## Concact Author
562 |
563 | Author: [MrYXJ](https://github.com/MrYxJ/)
564 |
565 | Mail: yxj2017@gmail.com
566 |
--------------------------------------------------------------------------------
/README_CN.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 | calflops: a FLOPs and Params calculate tool for neural networks
7 |
8 |
9 |
10 | 
11 | [](https://pypi.org/project/calflops/)
12 | [](https://github.com/MrYxJ/calculate-flops.pytorch/blob/main/LICENSE)
13 |
14 |
15 |
16 | English|
17 | 中文
18 |
19 |
20 |
21 | # 介绍
22 | 这个工具(calflops)的作用是通过对模型结构与实现上统计计算各种神经网络中的FLOPs(浮点运算),mac(乘加运算)和模型参数的理论量,支持模型包括:Linear, CNN, RNN, GCN, **Transformer(Bert, LlaMA等大型语言模型)** 等等, 甚至**任何自定义模型**。这是因为caflops支持基于Pytorch的```torch.nn.function.*```实现的计算操作。同时该工具支持打印模型各子模块的FLOPS、参数计算值和比例,方便用户了解模型各部分的性能消耗情况。
23 |
24 | 对于大模型,```calflops```相比其他工具可以更方便计算FLOPs,通过```calflops.calculate_flops()```您只需要通过参数```transformers_tokenizer```传递需要计算的transformer模型相应的```tokenizer```,它将自动帮助您构建```input_shape```模型输入。或者,您还可以通过``` args```, ```kwargs ```处理需要具有多个输入的模型,例如bert模型的输入需要```input_ids```, ```attention_mask```等多个字段。详细信息请参见下面```calflops.calculate_flops()```的api。
25 |
26 | 另外,这个包的实现过程受到[ptflops](https://github.com/sovrasov/flops-counter.pytorch)和[deepspeed](https://github.com/microsoft/DeepSpeed/tree/master/deepspeed)库实现的启发,他们也都是非常好的工作。同时,calflops包也在他们基础上改进了一些方面(更简单的使用,更多的模型支持),详细可以使用```pip install calflops```体验一下。
27 |
28 |
29 | ## 安装最新的版本
30 | #### From PyPI:
31 |
32 | ```python
33 | pip install calflops
34 | ```
35 |
36 | 同时你也可以从pypi calflops官方网址: https://pypi.org/project/calflops/
37 | 上下载最新版本的whl文件 `calflops-*-py3-none-any.whl` 到本地进行离线安装:
38 |
39 | ```python
40 | pip install calflops-*-py3-none-any.whl
41 | ```
42 | ## 如何使用calflops
43 | ### 举个例子
44 | ### CNN Model
45 |
46 | 如果模型的输入只有一个参数,你只需要通过对传入参数```input_shape```设置参数的大小即可,calflops会根据设定维度自动生成一个随机值作为模型的输入进行计算FLOPs。
47 |
48 | ```python
49 | from calflops import calculate_flops
50 | from torchvision import models
51 |
52 | model = models.alexnet()
53 | batch_size = 1
54 | input_shape = (batch_size, 3, 224, 224)
55 | flops, macs, params = calculate_flops(model=model,
56 | input_shape=input_shape,
57 | output_as_string=True,
58 | output_precision=4)
59 | print("Alexnet FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
60 | #Alexnet FLOPs:4.2892 GFLOPS MACs:2.1426 GMACs Params:61.1008 M
61 | ```
62 |
63 | 如果需要计算FLOPs的模型有多个输入,你也只需要通过传入参数 ```args``` 或 ```kargs```进行构造, 具体可以见下面Tranformer Model给出的例子。
64 |
65 | ### Transformer Model
66 |
67 | 相比CNN Model,Transformer Model如果想使用参数 ```input_shape``` 指定输入数据的大小自动生成输入数据时额外还需要将其对应的```tokenizer```通过参数```transformer_tokenizer```进行传入,当然这种方式相比下面通过```kwargs```传入已构造输入数据方式更方便。
68 |
69 | ``` python
70 | # Transformers Model, such as bert.
71 | from calflops import calculate_flops
72 | from transformers import AutoModel
73 | from transformers import AutoTokenizer
74 |
75 | batch_size = 1
76 | max_seq_length = 128
77 | model_name = "hfl/chinese-roberta-wwm-ext/"
78 | model_save = "../pretrain_models/" + model_name
79 | model = AutoModel.from_pretrained(model_save)
80 | tokenizer = AutoTokenizer.from_pretrained(model_save)
81 |
82 | flops, macs, params = calculate_flops(model=model,
83 | input_shape=(batch_size,max_seq_length),
84 | transformer_tokenizer=tokenizer)
85 | print("Bert(hfl/chinese-roberta-wwm-ext) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
86 | #Bert(hfl/chinese-roberta-wwm-ext) FLOPs:67.1 GFLOPS MACs:33.52 GMACs Params:102.27 M
87 | ```
88 |
89 | 如果希望使用自己生成的特定数据来计算FLOPs,可以使用参数```args```或```kwargs```,这种情况参数```input_shape```不能再传入值。下面给出一个例子,可以看出没有通过```transformer_tokenizer```方便。
90 |
91 | ``` python
92 | # Transformers Model, such as bert.
93 | from calflops import calculate_flops
94 | from transformers import AutoModel
95 | from transformers import AutoTokenizer
96 |
97 | batch_size = 1
98 | max_seq_length = 128
99 | model_name = "hfl/chinese-roberta-wwm-ext/"
100 | model_save = "/code/yexiaoju/generate_tags/models/pretrain_models/" + model_name
101 | model = AutoModel.from_pretrained(model_save)
102 | tokenizer = AutoTokenizer.from_pretrained(model_save)
103 |
104 | text = ""
105 | inputs = tokenizer(text,
106 | add_special_tokens=True,
107 | return_attention_mask=True,
108 | padding=True,
109 | truncation="longest_first",
110 | max_length=max_seq_length)
111 |
112 | if len(inputs["input_ids"]) < max_seq_length:
113 | apply_num = max_seq_length-len(inputs["input_ids"])
114 | inputs["input_ids"].extend([0]*apply_num)
115 | inputs["token_type_ids"].extend([0]*apply_num)
116 | inputs["attention_mask"].extend([0]*apply_num)
117 |
118 | inputs["input_ids"] = torch.tensor([inputs["input_ids"]])
119 | inputs["token_type_ids"] = torch.tensor([inputs["token_type_ids"]])
120 | inputs["attention_mask"] = torch.tensor([inputs["attention_mask"]])
121 |
122 | flops, macs, params = calculate_flops(model=model,
123 | kwargs = inputs,
124 | print_results=False)
125 | print("Bert(hfl/chinese-roberta-wwm-ext) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
126 | #Bert(hfl/chinese-roberta-wwm-ext) FLOPs:22.36 GFLOPS MACs:11.17 GMACs Params:102.27 M
127 | ```
128 |
129 |
130 | ### Large Language Model
131 |
132 | 请注意,传入参数```transfromer_tokenizer```与大模型的tokenzier必须是一致匹配的。
133 |
134 |
135 | ``` python
136 | #Large Languase Model, such as llama2-7b.
137 | from calflops import calculate_flops
138 | from transformers import LlamaTokenizer
139 | from transformers import LlamaForCausalLM
140 |
141 | batch_size = 1
142 | max_seq_length = 128
143 | model_name = "llama2_hf_7B"
144 | model_save = "../model/" + model_name
145 | model = LlamaForCausalLM.from_pretrained(model_save)
146 | tokenizer = LlamaTokenizer.from_pretrained(model_save)
147 | flops, macs, params = calculate_flops(model=model,
148 | input_shape=(batch_size, max_seq_length),
149 | transformer_tokenizer=tokenizer)
150 | print("Llama2(7B) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
151 | #Llama2(7B) FLOPs:1.7 TFLOPS MACs:850.00 GMACs Params:6.74 B
152 | ```
153 |
154 | ### 显示每个子模块的FLOPs, mac, Params
155 |
156 | calflops提供了更详细的显示模型FLOPs计算信息。通过设置参数```print_result=True```,默认为True。如下图所示,在终端或jupyter界面打印模型的FLOPs。
157 |
158 | 
159 |
160 | 同时,通过设置参数```print_detailed =True```,默认为True。 calflops支持显示整个模型各子模块中FLOPs、NACs和Parameter的计算结果和占比的比例,这可以直接查看整个模型哪部分的消耗计算量最大,方便后续性能的优化。
161 |
162 | 
163 |
164 | ### 更多使用介绍
165 |
166 |
167 | 如何使输出格式更优雅
168 | 您可以使用参数```output_as_string```, ```output_precision```, ```output_unit```来确定输出数据的格式是value还是string,如果是string,则保留多少位精度和值的单位,例如FLOPs的单位是“TFLOPs”或“GFLOPs”,“MFLOPs”。
169 |
170 |
171 |
172 |
173 | 如何处理有多个输入的模型
174 | calflops支持具有多个输入的模型,你只需使用参数args或kwargs进行构造,即可将多个输入作为模型推理的传入。
175 |
176 |
177 |
178 | 如何让计算FLOPS的结果包括模型的正向和反向传播
179 |
180 | 你可以使用参数include_backPropagation来选择FLOPs结果的计算是否包含模型反向传播的过程,默认缺省值为False,即FLOPs只包含模型前向传播的过程。
181 |
182 | 此外,参数compute_bp_factor用于确定向后传播的计算次数与向前传播的计算次数相同。默认值缺省值是2.0,根据技术报告:https://epochai.org/blog/backward-forward-FLOP-ratio
183 |
184 |
185 |
186 | 如何仅计算部分模型模块的FLOPs
187 | 你可以通过参数ignore_modules可以选择在计算FLOPs时忽略model中的哪些模块。默认为[],即在计算结果包括模型的所有模块。
188 |
189 |
190 |
191 | 如何计算LLM中生成函数(model.generate())的FLOPs
192 | 你只需要将“generate”赋值给参数forward_mode。
193 |
194 |
195 | ### **Api** of the **calflops**
196 |
197 |
198 | calflops.calculate_flops()
199 |
200 | ``` python
201 | from calflops import calculate_flops
202 |
203 | def calculate_flops(model,
204 | input_shape=None,
205 | transformer_tokenizer=None,
206 | args=[],
207 | kwargs={},
208 | forward_mode="forward",
209 | include_backPropagation=False,
210 | compute_bp_factor=2.0,
211 | print_results=True,
212 | print_detailed=True,
213 | output_as_string=True,
214 | output_precision=2,
215 | output_unit=None,
216 | ignore_modules=None):
217 |
218 | """Returns the total floating-point operations, MACs, and parameters of a model.
219 |
220 | Args:
221 | model ([torch.nn.Module]): The model of input must be a PyTorch model.
222 | input_shape (tuple, optional): Input shape to the model. If args and kwargs is empty, the model takes a tensor with this shape as the only positional argument. Default to [].
223 | transformers_tokenizer (None, optional): Transforemrs Toekenizer must be special if model type is transformers and args、kwargs is empty. Default to None
224 | args (list, optinal): list of positional arguments to the model, such as bert input args is [input_ids, token_type_ids, attention_mask]. Default to []
225 | kwargs (dict, optional): dictionary of keyword arguments to the model, such as bert input kwargs is {'input_ids': ..., 'token_type_ids':..., 'attention_mask':...}. Default to {}
226 | forward_mode (str, optional): To determine the mode of model inference, Default to 'forward'. And use 'generate' if model inference uses model.generate().
227 | include_backPropagation (bool, optional): Decides whether the final return FLOPs computation includes the computation for backpropagation.
228 | compute_bp_factor (float, optional): The model backpropagation is a multiple of the forward propagation computation. Default to 2.
229 | print_results (bool, optional): Whether to print the model profile. Defaults to True.
230 | print_detailed (bool, optional): Whether to print the detailed model profile. Defaults to True.
231 | output_as_string (bool, optional): Whether to print the output as string. Defaults to True.
232 | output_precision (int, optional) : Output holds the number of decimal places if output_as_string is True. Default to 2.
233 | output_unit (str, optional): The unit used to output the result value, such as T, G, M, and K. Default is None, that is the unit of the output decide on value.
234 | ignore_modules ([type], optional): the list of modules to ignore during profiling. Defaults to None.
235 | ```
236 |
237 |
238 |
239 | calflops.generate_transformer_input()
240 |
241 | ``` python
242 | def generate_transformer_input(model_tokenizer, input_shape, device):
243 | """Automatically generates data in the form of transformes model input format.
244 |
245 | Args:
246 | input_shape (tuple):transformers model input shape: (batch_size, seq_len).
247 | tokenizer (transformer.model.tokenization): transformers model tokenization.tokenizer.
248 |
249 | Returns:
250 | dict: data format of transformers model input, it is a dict which contain 'input_ids', 'attention_mask', 'token_type_ids' etc.
251 | """
252 | ```
253 |
254 |
255 |
256 |
257 |
258 | ## Citation
259 | if calflops was useful for your paper or tech report, please cite me:
260 | ```
261 | @online{calflops,
262 | author = {xiaoju ye},
263 | title = {calflops: a FLOPs and Params calculate tool for neural networks in pytorch framework},
264 | year = 2023,
265 | url = {https://github.com/MrYxJ/calculate-flops.pytorch},
266 | }
267 | ```
268 |
269 | ## 常见模型的FLOPs
270 |
271 | ### Large Language Model
272 | Input data format: batch_size=1, seq_len=128
273 |
274 | - fwd FLOPs: The FLOPs of the model forward propagation
275 |
276 | - bwd + fwd FLOPs: The FLOPs of model forward and backward propagation
277 |
278 | 另外注意这里fwd + bwd 没有包括模型参数激活的计算损耗,如果包括的对fwd的结果乘4即可。根据论文:https://arxiv.org/pdf/2205.05198.pdf
279 |
280 | Model | Input Shape | Params(B)|Params(Total)| fwd FLOPs(G) | fwd MACs(G) | fwd + bwd FLOPs(G) | fwd + bwd MACs(G) |
281 | --- |--- |--- |--- |--- |--- |--- |---
282 | bloom-1b7 |(1,128) | 1.72B | 1722408960 | 310.92 | 155.42 | 932.76 | 466.27
283 | bloom-7b1 |(1,128) | 7.07B | 7069016064 | 1550.39 | 775.11 | 4651.18 | 2325.32
284 | baichuan-7B |(1,128) | 7B | 7000559616 | 1733.62 | 866.78 | 5200.85 | 2600.33
285 | chatglm-6b |(1,128) | 6.17B | 6173286400 | 1587.66 | 793.75 | 4762.97 | 2381.24
286 | chatglm2-6b |(1,128) | 6.24B | 6243584000 | 1537.68 | 768.8 | 4613.03 | 2306.4
287 | Qwen-7B |(1,128) | 7.72B | 7721324544 | 1825.83 | 912.88 | 5477.48 | 2738.65
288 | llama-7b |(1,128) | 6.74B | 6738415616 | 1700.06 | 850 | 5100.19 | 2550
289 | llama2-7b |(1,128) | 6.74B | 6738415616 | 1700.06 | 850 | 5100.19 | 2550
290 | llama2-7b-chat |(1,128) | 6.74B | 6738415616 | 1700.06 | 850 | 5100.19 | 2550
291 | chinese-llama-7b | (1,128) | 6.89B | 6885486592 | 1718.89 | 859.41 |5156.67 | 2578.24
292 | chinese-llama-plus-7b| (1,128) | 6.89B | 6885486592 | 1718.89 | 859.41 |5156.67 | 2578.24
293 | moss-moon-003-sft |(1,128) | 16.72B | 16717980160 | 4124.93 | 2062.39 | 12374.8 | 6187.17
294 |
295 | 从上表中我们可以得出一些简单而有趣的发现:
296 | - chatglm2-6b在相同比例的模型中,模型参数更小,FLOPs也更小,在速度性能上具有一定的优势。
297 | - llama1-7b、llama2-7b和llama2-7b-chat模型参数一点没变、FLOPs也保持一致。符合[meta在其llama2报告](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/)中描述的llama2-7b的模型结构没有改变,主要区别是训练数据token的增加。
298 | - 类似的从表中可以看出,chinese-llama-7b和chinese-llama-plus-7b数据也符合[cui的报告](https://arxiv.org/pdf/2304.08177v1.pdf),只是增加了更多的中文数据token进行训练,模型没有改变。
299 | - ......
300 |
301 | 更多的模型FLOPs将陆续更新,参见github
302 | [calculate-flops.pytorch](https://github.com/MrYxJ/calculate-flops.pytorch)
303 |
304 | ### Bert
305 |
306 | Input data format: batch_size=1, seq_len=128
307 |
308 | Model | Input Shape | Params(M)|Params(Total)| fwd FLOPs(G) | fwd MACs(G) | fwd + bwd FLOPs() | fwd + bwd MACs(G) |
309 | --- |--- |--- |--- |--- |--- |--- |---
310 | hfl/chinese-roberta-wwm-ext | (1,128)| 102.27M | 102267648 | 67.1 | 33.52 | 201.3 | 100.57
311 | ......
312 |
313 | 你可以使用calflops来计算基于bert的更多不同模型,期待你更新在此表中。
314 |
315 |
316 | ## Benchmark
317 | ### [torchvision](https://pytorch.org/docs/1.0.0/torchvision/models.html)
318 |
319 | Input data format: batch_size = 1, actually input_shape = (1, 3, 224, 224)
320 |
321 | 注:表中FLOPs仅考虑模型正向传播的计算,**Total**为不含单位缩写的总数值表示。
322 |
323 | Model | Input Resolution | Params(M)|Params(Total) | FLOPs(G) | FLOPs(Total) | Macs(G) | Macs(Total)
324 | --- |--- |--- |--- |--- |--- |--- |---
325 | alexnet |224x224 | 61.10 | 61100840 | 1.43 | 1429740000 | 741.19 | 7418800000
326 | vgg11 |224x224 | 132.86 | 132863000 | 15.24 | 15239200000 | 7.61 | 7609090000
327 | vgg13 |224x224 | 133.05 | 133048000 | 22.65 | 22647600000 | 11.31 | 11308500000
328 | vgg16 |224x224 | 138.36 | 138358000 | 30.97 | 30973800000 | 15.47 | 15470300000
329 | vgg19 |224x224 | 143.67 | 143667000 | 39.30 | 39300000000 | 19.63 | 19632100000
330 | vgg11_bn |224x224 | 132.87 | 132869000 | 15.25 | 15254000000 | 7.61 | 7609090000
331 | vgg13_bn |224x224 | 133.05 | 133054000 | 22.67 | 22672100000 | 11.31 | 11308500000
332 | vgg16_bn |224x224 | 138.37 | 138366000 | 31.00 | 31000900000 | 15.47 | 15470300000
333 | vgg19_bn |224x224 | 143.68 | 143678000 | 39.33 | 39329700000 | 19.63 | 19632100000
334 | resnet18 |224x224 | 11.69 | 11689500 | 3.64 | 3636250000 | 1.81 | 1814070000
335 | resnet34 |224x224 | 21.80 | 21797700 | 7.34 | 7339390000 | 3.66 | 3663760000
336 | resnet50 |224x224 | 25.56 | 25557000 | 8.21 | 8211110000 | 4.09 | 4089180000
337 | resnet101 |224x224 | 44.55 | 44549200 | 15.65 | 15690900000 | 7.80 | 7801410000
338 | resnet152 |224x224 | 60.19 | 60192800 | 23.09 | 23094300000 | 11.51 | 11513600000
339 | squeezenet1_0 |224x224 | 1.25 | 1248420 | 1.65 | 1648970000 | 0.82 | 818925000
340 | squeezenet1_1 |224x224 | 1.24 | 1235500 | 0.71 | 705014000 | 0.35 | 349152000
341 | densenet121 |224x224 | 7.98 | 7978860 | 5.72 | 5716880000 | 2.83 | 2834160000
342 | densenet169 |224x224 | 14.15 | 14195000 | 6.78 | 6778370000 | 3.36 | 3359840000
343 | densenet201 |224x224 | 20.01 | 20013900 | 8.66 | 8658520000 | 4.29 | 4291370000
344 | densenet161 |224x224 | 28.68 | 28681000 | 15.55 | 1554650000 | 7.73 | 7727900000
345 | inception_v3 |224x224 | 27.16 | 27161300 | 5.29 | 5692390000 | 2.84 | 2837920000
346 |
347 | 感谢 @[zigangzhao-ai](https://github.com/zigangzhao-ai) 帮忙使用 ```calflops``` 去统计表 torchvision的结果.
348 |
349 | 你也可以将calflops计算FLOPs的结果与其他优秀的工具计算结果进行比较
350 | : [ptflops readme.md](https://github.com/sovrasov/flops-counter.pytorch/).
351 |
352 |
353 | ## Concact Author
354 |
355 | Author: [MrYXJ](https://github.com/MrYxJ/)
356 |
357 | Mail: yxj2017@gmail.com
358 |
--------------------------------------------------------------------------------
/calflops/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/.DS_Store
--------------------------------------------------------------------------------
/calflops/__init__.py:
--------------------------------------------------------------------------------
1 | # !usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 |
4 | '''
5 | Description :
6 | Version : 1.0
7 | Author : MrYXJ
8 | Mail : yxj2017@gmail.com
9 | Github : https://github.com/MrYxJ
10 | Date : 2023-08-19 10:27:55
11 | LastEditTime : 2023-09-05 15:31:43
12 | Copyright (C) 2023 mryxj. All rights reserved.
13 | '''
14 |
15 | from .flops_counter import calculate_flops
16 | from .flops_counter_hf import calculate_flops_hf
17 |
18 | from .utils import generate_transformer_input
19 | from .utils import number_to_string
20 | from .utils import flops_to_string
21 | from .utils import macs_to_string
22 | from .utils import params_to_string
23 | from .utils import bytes_to_string
24 |
25 | from .estimate import create_empty_model
--------------------------------------------------------------------------------
/calflops/__pycache__/__init__.cpython-311.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/__init__.cpython-311.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/__init__.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/__init__.cpython-39.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/big_modeling.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/big_modeling.cpython-39.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/calculate_pipline.cpython-311.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/calculate_pipline.cpython-311.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/calculate_pipline.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/calculate_pipline.cpython-39.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/estimate.cpython-311.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/estimate.cpython-311.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/estimate.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/estimate.cpython-39.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/estimate.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | # Copyright 2023 The HuggingFace Team. All rights reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | #import argparse
17 |
18 | from huggingface_hub import model_info
19 | from huggingface_hub.utils import GatedRepoError, RepositoryNotFoundError
20 |
21 | from accelerate import init_empty_weights
22 | from accelerate.utils import (
23 | # calculate_maximum_sizes,
24 | # convert_bytes,
25 | is_timm_available,
26 | is_transformers_available,
27 | )
28 |
29 |
30 | if is_transformers_available():
31 | import transformers
32 | from transformers import AutoConfig, AutoModel
33 |
34 | if is_timm_available():
35 | import timm
36 |
37 |
38 | def verify_on_hub(repo: str, token: str = None):
39 | "Verifies that the model is on the hub and returns the model info."
40 | try:
41 | return model_info(repo, token=token)
42 | except GatedRepoError:
43 | return "gated"
44 | except RepositoryNotFoundError:
45 | return "repo"
46 |
47 |
48 | def check_has_model(error):
49 | """
50 | Checks what library spawned `error` when a model is not found
51 | """
52 | if is_timm_available() and isinstance(error, RuntimeError) and "Unknown model" in error.args[0]:
53 | return "timm"
54 | elif (
55 | is_transformers_available()
56 | and isinstance(error, OSError)
57 | and "does not appear to have a file named" in error.args[0]
58 | ):
59 | return "transformers"
60 | else:
61 | return "unknown"
62 |
63 |
64 | def create_empty_model(model_name: str, library_name: str, trust_remote_code: bool = False, access_token: str = None):
65 | """
66 | Creates an empty model from its parent library on the `Hub` to calculate the overall memory consumption.
67 |
68 | Args:
69 | model_name (`str`):
70 | The model name on the Hub
71 | library_name (`str`):
72 | The library the model has an integration with, such as `transformers`. Will be used if `model_name` has no
73 | metadata on the Hub to determine the library.
74 | trust_remote_code (`bool`, `optional`, defaults to `False`):
75 | Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
76 | should only be set to `True` for repositories you trust and in which you have read the code, as it will
77 | execute code present on the Hub on your local machine.
78 | access_token (`str`, `optional`, defaults to `None`):
79 | The access token to use to access private or gated models on the Hub. (for use on the Gradio app)
80 |
81 | Returns:
82 | `torch.nn.Module`: The torch model that has been initialized on the `meta` device.
83 |
84 | """
85 | model_info = verify_on_hub(model_name, access_token)
86 | # Simplified errors
87 | if model_info == "gated":
88 | raise GatedRepoError(
89 | f"Repo for model `{model_name}` is gated. You must be authenticated to access it. Please run `huggingface-cli login`."
90 | )
91 | elif model_info == "repo":
92 | raise RepositoryNotFoundError(
93 | f"Repo for model `{model_name}` does not exist on the Hub. If you are trying to access a private repo,"
94 | " make sure you are authenticated via `huggingface-cli login` and have access."
95 | )
96 | if library_name is None:
97 | library_name = getattr(model_info, "library_name", False)
98 | if not library_name:
99 | raise ValueError(
100 | f"Model `{model_name}` does not have any library metadata on the Hub, please manually pass in a `--library_name` to use (such as `transformers`)"
101 | )
102 | if library_name == "transformers":
103 | if not is_transformers_available():
104 | raise ImportError(
105 | f"To check `{model_name}`, `transformers` must be installed. Please install it via `pip install transformers`"
106 | )
107 | print(f"Loading pretrained config for `{model_name}` from `transformers`...")
108 |
109 | #auto_map = model_info.config.get("auto_map", False)
110 | auto_map = model_info.config.get("auto_map", True)
111 | config = AutoConfig.from_pretrained(model_name, trust_remote_code=trust_remote_code)
112 |
113 | with init_empty_weights():
114 | # remote code could specify a specific `AutoModel` class in the `auto_map`
115 | constructor = AutoModel
116 | if isinstance(auto_map, dict):
117 | value = None
118 | for key in auto_map.keys():
119 | if key.startswith("AutoModelFor"):
120 | value = key
121 | break
122 | if value is not None:
123 | constructor = getattr(transformers, value)
124 | model = constructor.from_config(config, trust_remote_code=trust_remote_code)
125 | elif library_name == "timm":
126 | if not is_timm_available():
127 | raise ImportError(
128 | f"To check `{model_name}`, `timm` must be installed. Please install it via `pip install timm`"
129 | )
130 | print(f"Loading pretrained config for `{model_name}` from `timm`...")
131 | with init_empty_weights():
132 | model = timm.create_model(model_name, pretrained=False)
133 | else:
134 | raise ValueError(
135 | f"Library `{library_name}` is not supported yet, please open an issue on GitHub for us to add support."
136 | )
137 | return model
138 |
139 |
140 | def create_ascii_table(headers: list, rows: list, title: str):
141 | "Creates a pretty table from a list of rows, minimal version of `tabulate`."
142 | sep_char, in_between = "│", "─"
143 | column_widths = []
144 | for i in range(len(headers)):
145 | column_values = [row[i] for row in rows] + [headers[i]]
146 | max_column_width = max(len(value) for value in column_values)
147 | column_widths.append(max_column_width)
148 |
149 | formats = [f"%{column_widths[i]}s" for i in range(len(rows[0]))]
150 |
151 | pattern = f"{sep_char}{sep_char.join(formats)}{sep_char}"
152 | diff = 0
153 |
154 | def make_row(left_char, middle_char, right_char):
155 | return f"{left_char}{middle_char.join([in_between * n for n in column_widths])}{in_between * diff}{right_char}"
156 |
157 | separator = make_row("├", "┼", "┤")
158 | if len(title) > sum(column_widths):
159 | diff = abs(len(title) - len(separator))
160 | column_widths[-1] += diff
161 |
162 | # Update with diff
163 | separator = make_row("├", "┼", "┤")
164 | initial_rows = [
165 | make_row("┌", in_between, "┐"),
166 | f"{sep_char}{title.center(len(separator) - 2)}{sep_char}",
167 | make_row("├", "┬", "┤"),
168 | ]
169 | table = "\n".join(initial_rows) + "\n"
170 | column_widths[-1] += diff
171 | centered_line = [text.center(column_widths[i]) for i, text in enumerate(headers)]
172 | table += f"{pattern % tuple(centered_line)}\n{separator}\n"
173 | for i, line in enumerate(rows):
174 | centered_line = [t.center(column_widths[i]) for i, t in enumerate(line)]
175 | table += f"{pattern % tuple(centered_line)}\n"
176 | table += f'└{"┴".join([in_between * n for n in column_widths])}┘'
177 |
178 | return table
179 |
180 |
181 | # def estimate_command_parser(subparsers=None):
182 | # if subparsers is not None:
183 | # parser = subparsers.add_parser("estimate-memory")
184 | # else:
185 | # parser = argparse.ArgumentParser(description="Model size estimator for fitting a model onto CUDA memory.")
186 |
187 | # parser.add_argument("model_name", type=str, help="The model name on the Hugging Face Hub.")
188 | # parser.add_argument(
189 | # "--library_name",
190 | # type=str,
191 | # help="The library the model has an integration with, such as `transformers`, needed only if this information is not stored on the Hub.",
192 | # choices=["timm", "transformers"],
193 | # )
194 | # parser.add_argument(
195 | # "--dtypes",
196 | # type=str,
197 | # nargs="+",
198 | # default=["float32", "float16", "int8", "int4"],
199 | # help="The dtypes to use for the model, must be one (or many) of `float32`, `float16`, `int8`, and `int4`",
200 | # choices=["float32", "float16", "int8", "int4"],
201 | # )
202 | # parser.add_argument(
203 | # "--trust_remote_code",
204 | # action="store_true",
205 | # help="""Whether or not to allow for custom models defined on the Hub in their own modeling files. This flag
206 | # should only be used for repositories you trust and in which you have read the code, as it will execute
207 | # code present on the Hub on your local machine.""",
208 | # )
209 |
210 | # if subparsers is not None:
211 | # parser.set_defaults(func=estimate_command)
212 | # return parser
213 |
214 |
215 | # def gather_data(args):
216 | # "Creates an empty model and gathers the data for the sizes"
217 | # try:
218 | # model = create_empty_model(
219 | # args.model_name, library_name=args.library_name, trust_remote_code=args.trust_remote_code
220 | # )
221 | # except (RuntimeError, OSError) as e:
222 | # library = check_has_model(e)
223 | # if library != "unknown":
224 | # raise RuntimeError(
225 | # f"Tried to load `{args.model_name}` with `{library}` but a possible model to load was not found inside the repo."
226 | # )
227 | # raise e
228 |
229 | # total_size, largest_layer = calculate_maximum_sizes(model)
230 |
231 | # data = []
232 |
233 | # for dtype in args.dtypes:
234 | # dtype_total_size = total_size
235 | # dtype_largest_layer = largest_layer[0]
236 | # if dtype == "float16":
237 | # dtype_total_size /= 2
238 | # dtype_largest_layer /= 2
239 | # elif dtype == "int8":
240 | # dtype_total_size /= 4
241 | # dtype_largest_layer /= 4
242 | # elif dtype == "int4":
243 | # dtype_total_size /= 8
244 | # dtype_largest_layer /= 8
245 | # dtype_training_size = dtype_total_size * 4
246 | # data.append([dtype, dtype_largest_layer, dtype_total_size, dtype_training_size])
247 | # return data
248 |
249 |
250 | # def estimate_command(args):
251 | # data = gather_data(args)
252 | # for row in data:
253 | # for i, item in enumerate(row):
254 | # if isinstance(item, (int, float)):
255 | # row[i] = convert_bytes(item)
256 |
257 | # headers = ["dtype", "Largest Layer", "Total Size", "Training using Adam"]
258 |
259 | # title = f"Memory Usage for loading `{args.model_name}`"
260 | # table = create_ascii_table(headers, data, title)
261 | # print(table)
262 |
263 |
264 | # def main():
265 | # parser = estimate_command_parser()
266 | # args = parser.parse_args()
267 | # estimate_command(args)
268 |
269 |
270 | # if __name__ == "__main__":
271 | # main()
--------------------------------------------------------------------------------
/calflops/__pycache__/flops_counter.cpython-311.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/flops_counter.cpython-311.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/flops_counter.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/flops_counter.cpython-39.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/flops_counter_hf.cpython-311.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/flops_counter_hf.cpython-311.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/flops_counter_hf.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/flops_counter_hf.cpython-39.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/pytorch_ops.cpython-311.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/pytorch_ops.cpython-311.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/pytorch_ops.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/pytorch_ops.cpython-39.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/utils.cpython-311.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/utils.cpython-311.pyc
--------------------------------------------------------------------------------
/calflops/__pycache__/utils.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/calflops/__pycache__/utils.cpython-39.pyc
--------------------------------------------------------------------------------
/calflops/calculate_pipline.py:
--------------------------------------------------------------------------------
1 | # !usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 |
4 | '''
5 | Description :
6 | Version : 1.0
7 | Author : MrYXJ
8 | Mail : yxj2017@gmail.com
9 | Github : https://github.com/MrYxJ
10 | Date : 2023-08-20 11:04:11
11 | LastEditTime : 2023-09-08 23:42:00
12 | Copyright (C) 2023 mryxj. All rights reserved.
13 | '''
14 |
15 | '''
16 | The part of code is inspired by ptflops and deepspeed profiling.
17 | '''
18 |
19 | from functools import partial
20 |
21 | from .pytorch_ops import MODULE_HOOK_MAPPING
22 | from .pytorch_ops import _patch_functionals
23 | from .pytorch_ops import _patch_tensor_methods
24 | from .pytorch_ops import _reload_functionals
25 | from .pytorch_ops import _reload_tensor_methods
26 | from .utils import flops_to_string
27 | from .utils import get_module_flops
28 | from .utils import get_module_macs
29 | from .utils import macs_to_string
30 | from .utils import number_to_string
31 | from .utils import params_to_string
32 |
33 | DEFAULT_PRECISION = 2
34 | module_flop_count = []
35 | module_mac_count = []
36 | old_functions = {}
37 |
38 |
39 | class CalFlopsPipline(object):
40 | """The Pipline of calculating FLOPs(number of estimated floating-point operations) and Parameters of each module in a PyTorch model.
41 | The pipline is calculating the forward(and alson include back propagation) pass of a PyTorch model and prints the model graph with the calculated static attached to each module.
42 | It can easily get only final resulst of FLOPs about model, and also can be showed how flops and parameters are spent in the model and which modules or layers could be the bottleneck in detailed.
43 | """
44 |
45 | def __init__(self, model, include_backPropagation, compute_bp_factor, is_sparse):
46 | """Init Pipline of Calculating the FLOPs about model.
47 |
48 | Args:
49 | model (pytorch model): The model must be a pytorh model now.
50 | compute_fwd_factor (float): Defaults to 2.0. According to https://epochai.org/blog/backward-forward-FLOP-ratio
51 | """
52 |
53 | self.model = model
54 | self.include_backPropagation = include_backPropagation # Whether the calculation results include model backpropagation
55 | self.compute_bp_factor = compute_bp_factor # Backpropagation takes twice as much computation as forward propagation
56 | self.pipline_started = False # The flag of calculating FLOPs pipline started
57 | self.func_patched = False # The flag of wheather calculating functional are patched
58 | self.is_sparse = is_sparse # Whether to exclude sparse matrix flops
59 |
60 | def start_flops_calculate(self, ignore_list=None):
61 | """Starts the pipline of calculating FLOPs.
62 |
63 | Extra attributes are added recursively to all the modules and the calculate torch.nn.functionals are monkey patched.
64 |
65 | Args:
66 | ignore_list (list, optional): the list of modules to ignore while Piplining. Defaults to None.
67 | """
68 |
69 | self.reset_flops_calculate()
70 | _patch_functionals(old_functions, module_flop_count, module_mac_count)
71 | _patch_tensor_methods(old_functions, module_flop_count, module_mac_count)
72 |
73 | def register_module_hooks(module, ignore_list):
74 | if ignore_list and type(module) in ignore_list:
75 | return
76 |
77 | # if computing the flops of a module directly
78 | if type(module) in MODULE_HOOK_MAPPING:
79 | if not hasattr(module, "__flops_handle__"):
80 | module.__flops_handle__ = module.register_forward_hook(MODULE_HOOK_MAPPING[type(module)])
81 | return
82 |
83 | # if computing the flops of the functionals in a module
84 | def pre_hook(module, input):
85 | module_flop_count.append([])
86 | module_mac_count.append([])
87 |
88 | if not hasattr(module, "__pre_hook_handle__"):
89 | module.__pre_hook_handle__ = module.register_forward_pre_hook(pre_hook)
90 |
91 | def post_hook(module, input, output):
92 | if module_flop_count:
93 | module.__flops__ += sum([elem[1] for elem in module_flop_count[-1]])
94 | module_flop_count.pop()
95 | module.__macs__ += sum([elem[1] for elem in module_mac_count[-1]])
96 | module_mac_count.pop()
97 |
98 | if not hasattr(module, "__post_hook_handle__"):
99 | module.__post_hook_handle__ = module.register_forward_hook(post_hook)
100 |
101 | self.model.apply(partial(register_module_hooks, ignore_list=ignore_list))
102 | self.pipline_started = True
103 | self.func_patched = True
104 |
105 | def stop_flops_calculate(self):
106 | """Stop the pipline of calculating FLOPs.
107 |
108 | All torch.nn.functionals are restored to their originals.
109 | """
110 | if self.pipline_started and self.func_patched:
111 | _reload_functionals(old_functions)
112 | _reload_tensor_methods(old_functions)
113 | self.func_patched = False
114 |
115 | def remove_calculate_attrs(module):
116 | if hasattr(module, "__pre_hook_handle__"):
117 | module.__pre_hook_handle__.remove()
118 | del module.__pre_hook_handle__
119 | if hasattr(module, "__post_hook_handle__"):
120 | module.__post_hook_handle__.remove()
121 | del module.__post_hook_handle__
122 | if hasattr(module, "__flops_handle__"):
123 | module.__flops_handle__.remove()
124 | del module.__flops_handle__
125 |
126 | self.model.apply(remove_calculate_attrs)
127 |
128 | def reset_flops_calculate(self):
129 | """Resets the pipline of calculating FLOPs.
130 |
131 | Adds or resets the extra attributes, include flops、macs、params.
132 | """
133 |
134 | def add_or_reset_attrs(module):
135 | module.__flops__ = 0
136 | module.__macs__ = 0
137 | module.__params__ = sum(
138 | p.count_nonzero().item() for p in module.parameters() if p.requires_grad
139 | ) if self.is_sparse else sum(
140 | p.numel() for p in module.parameters() if p.requires_grad)
141 | # just calculate parameter need training.
142 |
143 | self.model.apply(add_or_reset_attrs)
144 |
145 | def end_flops_calculate(self):
146 | """Ends the pipline of calculating FLOPs.
147 |
148 | The added attributes and handles are removed recursively on all the modules.
149 | """
150 | if not self.pipline_started:
151 | return
152 | self.stop_flops_calculate()
153 | self.pipline_started = False
154 |
155 | def remove_calculate_attrs(module):
156 | if hasattr(module, "__flops__"):
157 | del module.__flops__
158 | if hasattr(module, "__macs__"):
159 | del module.__macs__
160 | if hasattr(module, "__params__"):
161 | del module.__params__
162 |
163 | self.model.apply(remove_calculate_attrs)
164 |
165 | def get_total_flops(self, as_string=False):
166 | """Returns the total flops of the model.
167 |
168 | Args:
169 | as_string (bool, optional): whether to output the flops as string. Defaults to False.
170 |
171 | Returns:
172 | The number of multiply-accumulate operations of the model forward pass.
173 | """
174 | total_flops = get_module_flops(self.model, is_sparse=self.is_sparse)
175 | return number_to_string(total_flops) if as_string else total_flops
176 |
177 | def get_total_macs(self, as_string=False):
178 | """Returns the total MACs of the model.
179 |
180 | Args:
181 | as_string (bool, optional): whether to output the flops as string. Defaults to False.
182 |
183 | Returns:
184 | The number of multiply-accumulate operations of the model forward pass.
185 | """
186 | total_macs = get_module_macs(self.model, is_sparse=self.is_sparse)
187 | return macs_to_string(total_macs) if as_string else total_macs
188 |
189 | def get_total_params(self, as_string=False):
190 | """Returns the total number of parameters stored per rank.
191 |
192 | Args:
193 | as_string (bool, optional): whether to output the parameters as string. Defaults to False.
194 | is_sparse (bool, optional): whether to output the parameters as string. Defaults to False.
195 |
196 | Returns:
197 | The total number of parameters stored per rank.
198 | """
199 | total_params = self.model.__params__
200 | return params_to_string(total_params) if as_string else total_params
201 |
202 | def print_return_model_pipline(self, units=None, precision=DEFAULT_PRECISION, print_detailed=True,
203 | print_results=True):
204 | """Prints the model graph with the calculateing pipline attached to each module.
205 |
206 | Args:
207 | module_depth (int, optional): The depth of the model to which to print the aggregated module information. When set to -1, it prints information from the top to the innermost modules (the maximum depth).
208 | top_modules (int, optional): Limits the aggregated profile output to the number of top modules specified.
209 | print_detailed (bool, optional): Whether to print the detailed model profile.
210 | """
211 | if not self.pipline_started:
212 | return
213 |
214 | total_flops = self.get_total_flops()
215 | total_macs = self.get_total_macs()
216 | total_params = self.get_total_params()
217 |
218 | self.flops = total_flops
219 | self.macs = total_macs
220 | self.params = total_params
221 |
222 | prints = []
223 | prints.append(
224 | "\n------------------------------------- Calculate Flops Results -------------------------------------")
225 |
226 | prints.append("Notations:\n" +
227 | "number of parameters (Params), number of multiply-accumulate operations(MACs),\n" +
228 | "number of floating-point operations (FLOPs), floating-point operations per second (FLOPS),\n" +
229 | "fwd FLOPs (model forward propagation FLOPs), bwd FLOPs (model backward propagation FLOPs),\n" +
230 | "default model backpropagation takes %.2f times as much computation as forward propagation.\n" % self.compute_bp_factor)
231 |
232 | line_fmt = '{:<70} {:<8}'
233 | prints.append(line_fmt.format('Total Training Params: ', params_to_string(total_params)))
234 |
235 | prints.append(line_fmt.format('fwd MACs: ', macs_to_string(total_macs, units=units,
236 | precision=precision)))
237 | prints.append(line_fmt.format('fwd FLOPs: ', flops_to_string(total_flops, units=units,
238 | precision=precision)))
239 | prints.append(line_fmt.format('fwd+bwd MACs: ', macs_to_string(total_macs * (1 + self.compute_bp_factor),
240 | units=units, precision=precision)))
241 | prints.append(line_fmt.format('fwd+bwd FLOPs: ', flops_to_string(total_flops * (1 + self.compute_bp_factor),
242 | units=units, precision=precision)))
243 |
244 | def flops_repr(module):
245 | params = module.__params__
246 | flops = get_module_flops(module)
247 | macs = get_module_macs(module)
248 | items = [
249 | "{} = {:g}% Params".format(
250 | params_to_string(params),
251 | round(100 * params / total_params, precision) if total_params else 0),
252 | "{} = {:g}% MACs".format(macs_to_string(macs),
253 | round(100 * macs / total_macs, precision) if total_macs else 0),
254 | "{} = {:g}% FLOPs".format(flops_to_string(flops),
255 | round(100 * flops / total_flops, precision) if total_flops else 0),
256 | ]
257 | original_extra_repr = module.original_extra_repr()
258 | if original_extra_repr:
259 | items.append(original_extra_repr)
260 | return ", ".join(items)
261 |
262 | def add_extra_repr(module):
263 | flops_extra_repr = flops_repr.__get__(module)
264 | if module.extra_repr != flops_extra_repr:
265 | module.original_extra_repr = module.extra_repr
266 | module.extra_repr = flops_extra_repr
267 | assert module.extra_repr != module.original_extra_repr
268 |
269 | def del_extra_repr(module):
270 | if hasattr(module, "original_extra_repr"):
271 | module.extra_repr = module.original_extra_repr
272 | del module.original_extra_repr
273 |
274 | self.model.apply(add_extra_repr)
275 |
276 | if print_detailed:
277 | prints.append(
278 | "\n-------------------------------- Detailed Calculated FLOPs Results --------------------------------")
279 | prints.append(
280 | "Each module caculated is listed after its name in the following order: \nparams, percentage of total params, MACs, percentage of total MACs, FLOPS, percentage of total FLOPs"
281 | )
282 | prints.append(
283 | "\nNote: 1. A module can have torch.nn.module or torch.nn.functional to compute logits (e.g. CrossEntropyLoss). \n They are not counted as submodules in calflops and not to be printed out. However they make up the difference between a parent's MACs and the sum of its submodules'.\n2. Number of floating-point operations is a theoretical estimation, thus FLOPS computed using that could be larger than the maximum system throughput.\n"
284 | )
285 | prints.append(str(self.model))
286 |
287 | self.model.apply(del_extra_repr)
288 |
289 | prints.append(
290 | "---------------------------------------------------------------------------------------------------")
291 |
292 | return_print = ""
293 | for line in prints:
294 | if print_results:
295 | print(line)
296 | return_print += line + "\n"
297 | return return_print
298 |
299 | def print_model_pipline(self, units=None, precision=DEFAULT_PRECISION, print_detailed=True):
300 | """Prints the model graph with the calculateing pipline attached to each module.
301 |
302 | Args:
303 | module_depth (int, optional): The depth of the model to which to print the aggregated module information. When set to -1, it prints information from the top to the innermost modules (the maximum depth).
304 | top_modules (int, optional): Limits the aggregated profile output to the number of top modules specified.
305 | print_detailed (bool, optional): Whether to print the detailed model profile.
306 | """
307 | if not self.pipline_started:
308 | return
309 |
310 | total_flops = self.get_total_flops()
311 | total_macs = self.get_total_macs()
312 | total_params = self.get_total_params()
313 |
314 | self.flops = total_flops
315 | self.macs = total_macs
316 | self.params = total_params
317 |
318 | print("\n------------------------------------- Calculate Flops Results -------------------------------------")
319 |
320 | print("Notations:\n"
321 | "number of parameters (Params), number of multiply-accumulate operations(MACs),\n"
322 | "number of floating-point operations (FLOPs), floating-point operations per second (FLOPS),\n"
323 | "fwd FLOPs (model forward propagation FLOPs), bwd FLOPs (model backward propagation FLOPs),\n"
324 | "default model backpropagation takes %.2f times as much computation as forward propagation.\n" % self.compute_bp_factor)
325 |
326 | line_fmt = '{:<70} {:<8}'
327 |
328 | print(line_fmt.format('Total Training Params: ', params_to_string(total_params)))
329 |
330 | print(line_fmt.format('fwd MACs: ', macs_to_string(total_macs, units=units,
331 | precision=precision)))
332 | print(line_fmt.format('fwd FLOPs: ', flops_to_string(total_flops, units=units,
333 | precision=precision)))
334 | print(line_fmt.format('fwd+bwd MACs: ', macs_to_string(total_macs * (1 + self.compute_bp_factor),
335 | units=units, precision=precision)))
336 | print(line_fmt.format('fwd+bwd FLOPs: ', flops_to_string(total_flops * (1 + self.compute_bp_factor),
337 | units=units, precision=precision)))
338 |
339 | def flops_repr(module):
340 | params = module.__params__
341 | flops = get_module_flops(module)
342 | macs = get_module_macs(module)
343 | items = [
344 | "{} = {:g}% Params".format(
345 | params_to_string(params),
346 | round(100 * params / total_params, precision) if total_params else 0),
347 | "{} = {:g}% MACs".format(macs_to_string(macs),
348 | round(100 * macs / total_macs, precision) if total_macs else 0),
349 | "{} = {:g}% FLOPs".format(flops_to_string(flops),
350 | round(100 * macs / total_flops, precision) if total_flops else 0),
351 | ]
352 | original_extra_repr = module.original_extra_repr()
353 | if original_extra_repr:
354 | items.append(original_extra_repr)
355 | return ", ".join(items)
356 |
357 | def add_extra_repr(module):
358 | flops_extra_repr = flops_repr.__get__(module)
359 | if module.extra_repr != flops_extra_repr:
360 | module.original_extra_repr = module.extra_repr
361 | module.extra_repr = flops_extra_repr
362 | assert module.extra_repr != module.original_extra_repr
363 |
364 | def del_extra_repr(module):
365 | if hasattr(module, "original_extra_repr"):
366 | module.extra_repr = module.original_extra_repr
367 | del module.original_extra_repr
368 |
369 | self.model.apply(add_extra_repr)
370 |
371 | if print_detailed:
372 | print(
373 | "\n-------------------------------- Detailed Calculated FLOPs Results --------------------------------")
374 | print(
375 | "Each module caculated is listed after its name in the following order: \nparams, percentage of total params, MACs, percentage of total MACs, FLOPS, percentage of total FLOPs"
376 | )
377 | print(
378 | "\nNote: 1. A module can have torch.nn.module or torch.nn.functional to compute logits (e.g. CrossEntropyLoss). \n They are not counted as submodules in calflops and not to be printed out. However they make up the difference between a parent's MACs and the sum of its submodules'.\n2. Number of floating-point operations is a theoretical estimation, thus FLOPS computed using that could be larger than the maximum system throughput.\n"
379 | )
380 | print(self.model)
381 |
382 | self.model.apply(del_extra_repr)
383 |
384 | print("---------------------------------------------------------------------------------------------------")
385 |
--------------------------------------------------------------------------------
/calflops/estimate.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | # Copyright 2023 The HuggingFace Team. All rights reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | #import argparse
17 |
18 | from huggingface_hub import model_info
19 | from huggingface_hub.utils import GatedRepoError, RepositoryNotFoundError
20 |
21 | from accelerate import init_empty_weights
22 | from accelerate.utils import (
23 | # calculate_maximum_sizes,
24 | # convert_bytes,
25 | is_timm_available,
26 | is_transformers_available,
27 | )
28 |
29 |
30 | if is_transformers_available():
31 | import transformers
32 | from transformers import AutoConfig, AutoModel
33 |
34 | if is_timm_available():
35 | import timm
36 |
37 |
38 | def verify_on_hub(repo: str, token: str = None):
39 | "Verifies that the model is on the hub and returns the model info."
40 | try:
41 | return model_info(repo, token=token)
42 | except GatedRepoError:
43 | return "gated"
44 | except RepositoryNotFoundError:
45 | return "repo"
46 |
47 |
48 | def check_has_model(error):
49 | """
50 | Checks what library spawned `error` when a model is not found
51 | """
52 | if is_timm_available() and isinstance(error, RuntimeError) and "Unknown model" in error.args[0]:
53 | return "timm"
54 | elif (
55 | is_transformers_available()
56 | and isinstance(error, OSError)
57 | and "does not appear to have a file named" in error.args[0]
58 | ):
59 | return "transformers"
60 | else:
61 | return "unknown"
62 |
63 |
64 | def create_empty_model(model_name: str, library_name: str, trust_remote_code: bool = False, access_token: str = None):
65 | """
66 | Creates an empty model from its parent library on the `Hub` to calculate the overall memory consumption.
67 |
68 | Args:
69 | model_name (`str`):
70 | The model name on the Hub
71 | library_name (`str`):
72 | The library the model has an integration with, such as `transformers`. Will be used if `model_name` has no
73 | metadata on the Hub to determine the library.
74 | trust_remote_code (`bool`, `optional`, defaults to `False`):
75 | Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
76 | should only be set to `True` for repositories you trust and in which you have read the code, as it will
77 | execute code present on the Hub on your local machine.
78 | access_token (`str`, `optional`, defaults to `None`):
79 | The access token to use to access private or gated models on the Hub. (for use on the Gradio app)
80 |
81 | Returns:
82 | `torch.nn.Module`: The torch model that has been initialized on the `meta` device.
83 |
84 | """
85 | model_info = verify_on_hub(model_name, access_token)
86 | # Simplified errors
87 | if model_info == "gated":
88 | raise GatedRepoError(
89 | f"Repo for model `{model_name}` is gated. You must be authenticated to access it. Please run `huggingface-cli login`."
90 | )
91 | elif model_info == "repo":
92 | raise RepositoryNotFoundError(
93 | f"Repo for model `{model_name}` does not exist on the Hub. If you are trying to access a private repo,"
94 | " make sure you are authenticated via `huggingface-cli login` and have access."
95 | )
96 | if library_name is None:
97 | library_name = getattr(model_info, "library_name", False)
98 | if not library_name:
99 | raise ValueError(
100 | f"Model `{model_name}` does not have any library metadata on the Hub, please manually pass in a `--library_name` to use (such as `transformers`)"
101 | )
102 | if library_name == "transformers":
103 | if not is_transformers_available():
104 | raise ImportError(
105 | f"To check `{model_name}`, `transformers` must be installed. Please install it via `pip install transformers`"
106 | )
107 | print(f"Loading pretrained config for `{model_name}` from `transformers`...")
108 |
109 | auto_map = model_info.config.get("auto_map", False)
110 | config = AutoConfig.from_pretrained(model_name, trust_remote_code=trust_remote_code)
111 |
112 | with init_empty_weights():
113 | # remote code could specify a specific `AutoModel` class in the `auto_map`
114 | constructor = AutoModel
115 | if isinstance(auto_map, dict):
116 | value = None
117 | for key in auto_map.keys():
118 | if key.startswith("AutoModelFor"):
119 | value = key
120 | break
121 | if value is not None:
122 | constructor = getattr(transformers, value)
123 | model = constructor.from_config(config, trust_remote_code=trust_remote_code)
124 | elif library_name == "timm":
125 | if not is_timm_available():
126 | raise ImportError(
127 | f"To check `{model_name}`, `timm` must be installed. Please install it via `pip install timm`"
128 | )
129 | print(f"Loading pretrained config for `{model_name}` from `timm`...")
130 | with init_empty_weights():
131 | model = timm.create_model(model_name, pretrained=False)
132 | else:
133 | raise ValueError(
134 | f"Library `{library_name}` is not supported yet, please open an issue on GitHub for us to add support."
135 | )
136 | return model
137 |
138 |
139 | def create_ascii_table(headers: list, rows: list, title: str):
140 | "Creates a pretty table from a list of rows, minimal version of `tabulate`."
141 | sep_char, in_between = "│", "─"
142 | column_widths = []
143 | for i in range(len(headers)):
144 | column_values = [row[i] for row in rows] + [headers[i]]
145 | max_column_width = max(len(value) for value in column_values)
146 | column_widths.append(max_column_width)
147 |
148 | formats = [f"%{column_widths[i]}s" for i in range(len(rows[0]))]
149 |
150 | pattern = f"{sep_char}{sep_char.join(formats)}{sep_char}"
151 | diff = 0
152 |
153 | def make_row(left_char, middle_char, right_char):
154 | return f"{left_char}{middle_char.join([in_between * n for n in column_widths])}{in_between * diff}{right_char}"
155 |
156 | separator = make_row("├", "┼", "┤")
157 | if len(title) > sum(column_widths):
158 | diff = abs(len(title) - len(separator))
159 | column_widths[-1] += diff
160 |
161 | # Update with diff
162 | separator = make_row("├", "┼", "┤")
163 | initial_rows = [
164 | make_row("┌", in_between, "┐"),
165 | f"{sep_char}{title.center(len(separator) - 2)}{sep_char}",
166 | make_row("├", "┬", "┤"),
167 | ]
168 | table = "\n".join(initial_rows) + "\n"
169 | column_widths[-1] += diff
170 | centered_line = [text.center(column_widths[i]) for i, text in enumerate(headers)]
171 | table += f"{pattern % tuple(centered_line)}\n{separator}\n"
172 | for i, line in enumerate(rows):
173 | centered_line = [t.center(column_widths[i]) for i, t in enumerate(line)]
174 | table += f"{pattern % tuple(centered_line)}\n"
175 | table += f'└{"┴".join([in_between * n for n in column_widths])}┘'
176 |
177 | return table
178 |
179 |
180 | # def estimate_command_parser(subparsers=None):
181 | # if subparsers is not None:
182 | # parser = subparsers.add_parser("estimate-memory")
183 | # else:
184 | # parser = argparse.ArgumentParser(description="Model size estimator for fitting a model onto CUDA memory.")
185 |
186 | # parser.add_argument("model_name", type=str, help="The model name on the Hugging Face Hub.")
187 | # parser.add_argument(
188 | # "--library_name",
189 | # type=str,
190 | # help="The library the model has an integration with, such as `transformers`, needed only if this information is not stored on the Hub.",
191 | # choices=["timm", "transformers"],
192 | # )
193 | # parser.add_argument(
194 | # "--dtypes",
195 | # type=str,
196 | # nargs="+",
197 | # default=["float32", "float16", "int8", "int4"],
198 | # help="The dtypes to use for the model, must be one (or many) of `float32`, `float16`, `int8`, and `int4`",
199 | # choices=["float32", "float16", "int8", "int4"],
200 | # )
201 | # parser.add_argument(
202 | # "--trust_remote_code",
203 | # action="store_true",
204 | # help="""Whether or not to allow for custom models defined on the Hub in their own modeling files. This flag
205 | # should only be used for repositories you trust and in which you have read the code, as it will execute
206 | # code present on the Hub on your local machine.""",
207 | # )
208 |
209 | # if subparsers is not None:
210 | # parser.set_defaults(func=estimate_command)
211 | # return parser
212 |
213 |
214 | # def gather_data(args):
215 | # "Creates an empty model and gathers the data for the sizes"
216 | # try:
217 | # model = create_empty_model(
218 | # args.model_name, library_name=args.library_name, trust_remote_code=args.trust_remote_code
219 | # )
220 | # except (RuntimeError, OSError) as e:
221 | # library = check_has_model(e)
222 | # if library != "unknown":
223 | # raise RuntimeError(
224 | # f"Tried to load `{args.model_name}` with `{library}` but a possible model to load was not found inside the repo."
225 | # )
226 | # raise e
227 |
228 | # total_size, largest_layer = calculate_maximum_sizes(model)
229 |
230 | # data = []
231 |
232 | # for dtype in args.dtypes:
233 | # dtype_total_size = total_size
234 | # dtype_largest_layer = largest_layer[0]
235 | # if dtype == "float16":
236 | # dtype_total_size /= 2
237 | # dtype_largest_layer /= 2
238 | # elif dtype == "int8":
239 | # dtype_total_size /= 4
240 | # dtype_largest_layer /= 4
241 | # elif dtype == "int4":
242 | # dtype_total_size /= 8
243 | # dtype_largest_layer /= 8
244 | # dtype_training_size = dtype_total_size * 4
245 | # data.append([dtype, dtype_largest_layer, dtype_total_size, dtype_training_size])
246 | # return data
247 |
248 |
249 | # def estimate_command(args):
250 | # data = gather_data(args)
251 | # for row in data:
252 | # for i, item in enumerate(row):
253 | # if isinstance(item, (int, float)):
254 | # row[i] = convert_bytes(item)
255 |
256 | # headers = ["dtype", "Largest Layer", "Total Size", "Training using Adam"]
257 |
258 | # title = f"Memory Usage for loading `{args.model_name}`"
259 | # table = create_ascii_table(headers, data, title)
260 | # print(table)
261 |
262 |
263 | # def main():
264 | # parser = estimate_command_parser()
265 | # args = parser.parse_args()
266 | # estimate_command(args)
267 |
268 |
269 | # if __name__ == "__main__":
270 | # main()
--------------------------------------------------------------------------------
/calflops/flops_counter.py:
--------------------------------------------------------------------------------
1 | # !usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 |
4 | '''
5 | Description :
6 | Version : 1.0
7 | Author : MrYXJ
8 | Mail : yxj2017@gmail.com
9 | Github : https://github.com/MrYxJ
10 | Date : 2023-08-19 10:28:55
11 | LastEditTime : 2023-09-07 23:39:17
12 | Copyright (C) 2023 mryxj. All rights reserved.
13 | '''
14 |
15 | import torch
16 | import torch.nn as nn
17 |
18 | from .calculate_pipline import CalFlopsPipline
19 | from .utils import flops_to_string
20 | from .utils import generate_transformer_input
21 | from .utils import macs_to_string
22 | from .utils import params_to_string
23 |
24 |
25 | def calculate_flops(model,
26 | input_shape=None,
27 | transformer_tokenizer=None,
28 | args=[],
29 | kwargs={},
30 | forward_mode="forward",
31 | include_backPropagation=False,
32 | compute_bp_factor=2.0,
33 | print_results=True,
34 | print_detailed=True,
35 | output_as_string=True,
36 | output_precision=2,
37 | output_unit=None,
38 | ignore_modules=None,
39 | is_sparse=False):
40 | """Returns the total floating-point operations, MACs, and parameters of a model.
41 |
42 | Args:
43 | model ([torch.nn.Module]): The model of input must be a PyTorch model.
44 | input_shape (tuple, optional): Input shape to the model. If args and kwargs is empty, the model takes a tensor with this shape as the only positional argument. Default to [].
45 | transformers_tokenizer (None, optional): Transforemrs Toekenizer must be special if model type is transformers and args、kwargs is empty. Default to None
46 | args (list, optional): list of positional arguments to the model, such as bert input args is [input_ids, token_type_ids, attention_mask]. Default to []
47 | kwargs (dict, optional): dictionary of keyword arguments to the model, such as bert input kwargs is {'input_ids': ..., 'token_type_ids':..., 'attention_mask':...}. Default to {}
48 | forward_mode (str, optional): To determine the mode of model inference, Default to 'forward'. And use 'generate' if model inference uses model.generate().
49 | include_backPropagation (bool, optional): Decides whether the final return FLOPs computation includes the computation for backpropagation.
50 | compute_bp_factor (float, optional): The model backpropagation is a multiple of the forward propagation computation. Default to 2.
51 | print_results (bool, optional): Whether to print the model profile. Defaults to True.
52 | print_detailed (bool, optional): Whether to print the detailed model profile. Defaults to True.
53 | output_as_string (bool, optional): Whether to print the output as string. Defaults to True.
54 | output_precision (int, optional) : Output holds the number of decimal places if output_as_string is True. Default to 2.
55 | output_unit (str, optional): The unit used to output the result value, such as T, G, M, and K. Default is None, that is the unit of the output decide on value.
56 | ignore_modules ([type], optional): the list of modules to ignore during profiling. Defaults to None.
57 | is_sparse (bool, optional): Whether to exclude sparse matrix flops. Defaults to False.
58 |
59 | Example:
60 | .. code-block:: python
61 | from calflops import calculate_flops
62 |
63 | # Deep Learning Model, such as alexnet.
64 | from torchvision import models
65 |
66 | model = models.alexnet()
67 | batch_size = 1
68 | flops, macs, params = calculate_flops(model=model,
69 | input_shape=(batch_size, 3, 224, 224),
70 | output_as_string=True,
71 | output_precision=4)
72 | print("Alexnet FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
73 | #Alexnet FLOPs:1.4297 GFLOPS MACs:714.188 MMACs Params:61.1008 M
74 |
75 | # Transformers Model, such as bert.
76 | from transformers import AutoModel
77 | from transformers import AutoTokenizer
78 | batch_size = 1
79 | max_seq_length = 128
80 | model_name = "hfl/chinese-roberta-wwm-ext/"
81 | model_save = "../pretrain_models/" + model_name
82 | model = AutoModel.from_pretrained(model_save)
83 | tokenizer = AutoTokenizer.from_pretrained(model_save)
84 | flops, macs, params = calculate_flops(model=model,
85 | input_shape=(batch_size, max_seq_length),
86 | transformer_tokenizer=tokenizer)
87 | print("Bert(hfl/chinese-roberta-wwm-ext) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
88 | #Bert(hfl/chinese-roberta-wwm-ext) FLOPs:22.36 GFLOPS MACs:11.17 GMACs Params:102.27 M
89 |
90 | # Large Languase Model, such as llama2-7b.
91 | from transformers import LlamaTokenizer
92 | from transformers import LlamaForCausalLM
93 | batch_size = 1
94 | max_seq_length = 128
95 | model_name = "llama2_hf_7B"
96 | model_save = "../model/" + model_name
97 | model = LlamaForCausalLM.from_pretrained(model_save)
98 | tokenizer = LlamaTokenizer.from_pretrained(model_save)
99 | flops, macs, params = calculate_flops(model=model,
100 | input_shape=(batch_size, max_seq_length),
101 | transformer_tokenizer=tokenizer)
102 | print("Llama2(7B) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
103 | #Llama2(7B) FLOPs:1.7 TFLOPS MACs:850.00 GMACs Params:6.74 B
104 |
105 | Returns:
106 | The number of floating-point operations, multiply-accumulate operations (MACs), and parameters in the model.
107 | """
108 |
109 | assert isinstance(model, nn.Module), "model must be a PyTorch module"
110 | # assert transformers_tokenizer and auto_generate_transformers_input and "transformers" in str(type(model)), "The model must be a transformers model if args of auto_generate_transformers_input is True and transformers_tokenizer is not None"
111 | model.eval()
112 |
113 | is_transformer = True if "transformers" in str(type(model)) else False
114 |
115 | calculate_flops_pipline = CalFlopsPipline(model=model,
116 | include_backPropagation=include_backPropagation,
117 | compute_bp_factor=compute_bp_factor,
118 | is_sparse=is_sparse)
119 | calculate_flops_pipline.start_flops_calculate(ignore_list=ignore_modules)
120 |
121 | device = next(model.parameters()).device
122 | model = model.to(device)
123 |
124 | if input_shape is not None:
125 | assert len(args) == 0 and len(
126 | kwargs) == 0, "args and kwargs must be empty value if input_shape is not None, then will be generate random input by inpust_shape"
127 | assert type(input_shape) is tuple, "input_shape must be a tuple"
128 | assert len(input_shape) >= 1, "input_shape must have at least one element"
129 |
130 | if transformer_tokenizer is None: # model is not transformers model
131 | assert is_transformer is False, "the model is must not transformer model if input_shape is not None and transformer_tokenizer is None"
132 | try:
133 | input = torch.ones(()).new_empty(
134 | (*input_shape,),
135 | dtype=next(model.parameters()).dtype,
136 | device=device,
137 | )
138 | except StopIteration:
139 | input = torch.ones(()).new_empty((*input_shape,))
140 | args = [input]
141 | else:
142 | assert len(
143 | input_shape) == 2, "the format of input_shape must be (batch_size, seq_len) if model is transformers model and auto_generate_transformers_input if True"
144 | kwargs = generate_transformer_input(input_shape=input_shape,
145 | model_tokenizer=transformer_tokenizer,
146 | device=device)
147 | else:
148 | assert transformer_tokenizer or (len(args) > 0 or len(
149 | kwargs) > 0), "input_shape or args or kwargs one of there parameters must specified if auto_generate_input is False"
150 | if transformer_tokenizer:
151 | kwargs = generate_transformer_input(input_shape=None,
152 | model_tokenizer=transformer_tokenizer,
153 | device=device)
154 |
155 | if kwargs:
156 | for key, value in kwargs.items():
157 | if torch.is_tensor(value):
158 | kwargs[key] = value.to(device)
159 | else:
160 | kwargs = {}
161 | for index in range(len(args)):
162 | args[index] = args[index].to(device)
163 |
164 | if forward_mode == 'forward':
165 | _ = model(*args, **kwargs)
166 | elif forward_mode == 'generate':
167 | _ = model.generate(*args, **kwargs)
168 | else:
169 | raise NotImplementedError("forward_mode should be either forward or generate")
170 |
171 | flops = calculate_flops_pipline.get_total_flops()
172 | macs = calculate_flops_pipline.get_total_macs()
173 | params = calculate_flops_pipline.get_total_params()
174 |
175 | if print_results:
176 | return_print = calculate_flops_pipline.print_model_pipline(units=output_unit,
177 | precision=output_precision,
178 | print_detailed=print_detailed)
179 |
180 | calculate_flops_pipline.end_flops_calculate()
181 |
182 | if include_backPropagation:
183 | flops = flops * (1 + compute_bp_factor)
184 | macs = macs * (1 + compute_bp_factor)
185 |
186 | if output_as_string:
187 | return flops_to_string(flops, units=output_unit, precision=output_precision), \
188 | macs_to_string(macs, units=output_unit, precision=output_precision), \
189 | params_to_string(params, units=output_unit, precision=output_precision)
190 |
191 | return flops, macs, params
192 |
--------------------------------------------------------------------------------
/calflops/flops_counter_hf.py:
--------------------------------------------------------------------------------
1 | # !usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 |
4 | '''
5 | Description :
6 | Version : 1.0
7 | Author : MrYXJ
8 | Mail : yxj2017@gmail.com
9 | Github : https://github.com/MrYxJ
10 | Date : 2023-09-03 11:03:58
11 | LastEditTime : 2023-09-09 15:17:53
12 | Copyright (C) 2023 mryxj. All rights reserved.
13 | '''
14 |
15 |
16 | import torch
17 | import torch.nn as nn
18 | from transformers import AutoTokenizer
19 |
20 | from .utils import generate_transformer_input
21 | from .utils import flops_to_string
22 | from .utils import macs_to_string
23 | from .utils import params_to_string
24 | from .estimate import create_empty_model
25 | from .calculate_pipline import CalFlopsPipline
26 |
27 |
28 | def calculate_flops_hf(model_name,
29 | empty_model=None,
30 | input_shape=None,
31 | trust_remote_code=True,
32 | access_token="",
33 | forward_mode="forward",
34 | include_backPropagation=False,
35 | compute_bp_factor=2.0,
36 | print_results=True,
37 | print_detailed=True,
38 | output_as_string=True,
39 | output_precision=2,
40 | output_unit=None,
41 | ignore_modules=None,
42 | return_results=False):
43 |
44 | """Returns the total floating-point operations, MACs, and parameters of a model.
45 |
46 | Args:
47 | model_name (str): The model name in huggingface platform https://huggingface.co/models, such as meta-llama/Llama-2-7b、baichuan-inc/Baichuan-13B-Chat etc.
48 | input_shape (tuple, optional): Input shape to the model. If args and kwargs is empty, the model takes a tensor with this shape as the only positional argument. Default to [].
49 | trust_remote_code (bool, optional): Trust the code in the remote library for the model structure.
50 | access_token (str, optional): Some models need to apply for a access token, such as meta llama2 etc.
51 | forward_mode (str, optional): To determine the mode of model inference, Default to 'forward'. And use 'generate' if model inference uses model.generate().
52 | include_backPropagation (bool, optional): Decides whether the final return FLOPs computation includes the computation for backpropagation.
53 | compute_bp_factor (float, optional): The model backpropagation is a multiple of the forward propagation computation. Default to 2.
54 | print_results (bool, optional): Whether to print the model profile. Defaults to True.
55 | print_detailed (bool, optional): Whether to print the detailed model profile. Defaults to True.
56 | output_as_string (bool, optional): Whether to print the output as string. Defaults to True.
57 | output_precision (int, optional) : Output holds the number of decimal places if output_as_string is True. Default to 2.
58 | output_unit (str, optional): The unit used to output the result value, such as T, G, M, and K. Default is None, that is the unit of the output decide on value.
59 | ignore_modules ([type], optional): the list of modules to ignore during profiling. Defaults to None.
60 |
61 | Example:
62 | .. code-block:: python
63 | from calflops import calculate_flops_hf
64 |
65 | batch_size = 1
66 | max_seq_length = 128
67 | model_name = "baichuan-inc/Baichuan-13B-Chat"
68 | flops, macs, params = calculate_flops_hf(model_name=model_name,
69 | input_shape=(batch_size, max_seq_length))
70 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
71 |
72 | Returns:
73 | The number of floating-point operations, multiply-accumulate operations (MACs), and parameters in the model.
74 | """
75 |
76 | if empty_model == None:
77 | empty_model = create_empty_model(model_name=model_name,
78 | library_name=None,
79 | trust_remote_code=trust_remote_code,
80 | access_token=access_token)
81 |
82 | tokenizer = AutoTokenizer.from_pretrained(model_name,
83 | trust_remote_code=trust_remote_code,
84 | access_token=access_token)
85 |
86 | assert isinstance(empty_model, nn.Module), "model must be a PyTorch module"
87 | device = next(empty_model.parameters()).device
88 | empty_model = empty_model.to(device)
89 | empty_model.eval()
90 |
91 | calculate_flops_pipline = CalFlopsPipline(model=empty_model,
92 | include_backPropagation=include_backPropagation,
93 | compute_bp_factor=compute_bp_factor)
94 | calculate_flops_pipline.start_flops_calculate(ignore_list=ignore_modules)
95 |
96 | if input_shape is not None:
97 | assert type(input_shape) is tuple, "input_shape must be a tuple"
98 | assert len(input_shape) >= 1, "input_shape must have at least one element"
99 | assert len(input_shape) == 2, "the format of input_shape must be (batch_size, seq_len) if model is transformers model and auto_generate_transformers_input if True"
100 | kwargs = generate_transformer_input(input_shape=input_shape,
101 | model_tokenizer=tokenizer,
102 | device=device)
103 | else:
104 | kwargs = generate_transformer_input(input_shape=None,
105 | model_tokenizer=tokenizer,
106 | device=device)
107 |
108 | for key, value in kwargs.items():
109 | kwargs[key] = value.to(device)
110 |
111 | try:
112 | if forward_mode == 'forward':
113 | _ = empty_model(**kwargs)
114 | if forward_mode == 'generate':
115 | _ = empty_model.generate(**kwargs)
116 | except Exception as e:
117 | ErrorInformation = """The model:%s meet a problem in forwarding, perhaps because the model:%s cannot be deduced on meta device.
118 | You can downloaded complete model parameters in locally from huggingface platform, and then using another function:calflops.calculate_flops(model, tokenizer) to calculate FLOPs on the gpu device.\n
119 | Error Information: %s\n.
120 | """ % (model_name, model_name, e)
121 | print(ErrorInformation)
122 | return None, None, None
123 | else:
124 | flops = calculate_flops_pipline.get_total_flops()
125 | macs = calculate_flops_pipline.get_total_macs()
126 | params = calculate_flops_pipline.get_total_params()
127 |
128 |
129 | print_return = calculate_flops_pipline.print_return_model_pipline(units=output_unit,
130 | precision=output_precision,
131 | print_detailed=print_detailed,
132 | print_results=print_results)
133 |
134 | calculate_flops_pipline.end_flops_calculate()
135 |
136 | if include_backPropagation:
137 | flops = flops * (1 + compute_bp_factor)
138 | macs = macs * (1 + compute_bp_factor)
139 |
140 | if output_as_string:
141 | flops = flops_to_string(flops, units=output_unit, precision=output_precision)
142 | macs = macs_to_string(macs, units=output_unit, precision=output_precision)
143 | params = params_to_string(params, units=output_unit, precision=output_precision)
144 |
145 | if return_results:
146 | return flops, macs, params, print_return
147 | else:
148 | return flops, macs, params
149 |
150 |
151 |
--------------------------------------------------------------------------------
/calflops/pytorch_ops.py:
--------------------------------------------------------------------------------
1 | # !usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 |
4 | '''
5 | Description :
6 | Version : 1.0
7 | Author : MrYXJ
8 | Mail : yxj2017@gmail.com
9 | Github : https://github.com/MrYxJ
10 | Date : 2023-08-19 22:34:47
11 | LastEditTime : 2023-08-23 11:17:33
12 | Copyright (C) 2023 mryxj. All rights reserved.
13 | '''
14 |
15 | '''
16 | The part of code is inspired by ptflops and deepspeed profiling.
17 | '''
18 |
19 | import numpy as np
20 | import torch
21 | import torch.nn as nn
22 | import torch.nn.functional as F
23 |
24 | from typing import List
25 | from typing import Optional
26 | from collections import OrderedDict
27 |
28 | Tensor = torch.Tensor
29 |
30 |
31 | def _prod(dims):
32 | p = 1
33 | for v in dims:
34 | p *= v
35 | return p
36 |
37 | def _linear_flops_compute(input, weight, bias=None):
38 | out_features = weight.shape[0]
39 | macs = input.numel() * out_features
40 | return 2 * macs, macs
41 |
42 | # Activation just calculate FLOPs, MACs is 0
43 | def _relu_flops_compute(input, inplace=False):
44 | return input.numel(), 0
45 |
46 |
47 | def _prelu_flops_compute(input: Tensor, weight: Tensor):
48 | return input.numel(), 0
49 |
50 |
51 | def _elu_flops_compute(input: Tensor, alpha: float = 1.0, inplace: bool = False):
52 | return input.numel(), 0
53 |
54 |
55 | def _leaky_relu_flops_compute(input: Tensor, negative_slope: float = 0.01, inplace: bool = False):
56 | return input.numel(), 0
57 |
58 |
59 | def _relu6_flops_compute(input: Tensor, inplace: bool = False):
60 | return input.numel(), 0
61 |
62 |
63 | def _silu_flops_compute(input: Tensor, inplace: bool = False):
64 | return input.numel(), 0
65 |
66 |
67 | def _gelu_flops_compute(input, **kwargs):
68 | return input.numel(), 0
69 |
70 |
71 | def _pool_flops_compute(input,
72 | kernel_size,
73 | stride=None,
74 | padding=0,
75 | dilation=None,
76 | ceil_mode=False,
77 | count_include_pad=True,
78 | divisor_override=None,
79 | return_indices=None):
80 | return input.numel(), 0
81 |
82 |
83 | def _conv_flops_compute(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1):
84 | assert weight.shape[1] * groups == input.shape[1]
85 |
86 | batch_size = input.shape[0]
87 | in_channels = input.shape[1]
88 | out_channels = weight.shape[0]
89 | kernel_dims = list(weight.shape[2:])
90 | input_dims = list(input.shape[2:])
91 |
92 | length = len(input_dims)
93 |
94 | strides = stride if type(stride) is tuple else (stride, ) * length
95 | dilations = dilation if type(dilation) is tuple else (dilation, ) * length
96 | if isinstance(padding, str):
97 | if padding == 'valid':
98 | paddings = (0, ) * length
99 | elif padding == 'same':
100 | paddings = ()
101 | for d, k in zip(dilations, kernel_dims):
102 | total_padding = d * (k - 1)
103 | paddings += (total_padding // 2, )
104 | elif isinstance(padding, tuple):
105 | paddings = padding
106 | else:
107 | paddings = (padding, ) * length
108 |
109 | output_dims = []
110 | for idx, input_dim in enumerate(input_dims):
111 | output_dim = (input_dim + 2 * paddings[idx] - (dilations[idx] *
112 | (kernel_dims[idx] - 1) + 1)) // strides[idx] + 1
113 | output_dims.append(output_dim)
114 |
115 | filters_per_channel = out_channels // groups
116 | conv_per_position_macs = int(_prod(kernel_dims)) * in_channels * filters_per_channel
117 | active_elements_count = batch_size * int(_prod(output_dims))
118 | overall_conv_macs = conv_per_position_macs * active_elements_count
119 | overall_conv_flops = 2 * overall_conv_macs
120 |
121 | bias_flops = 0
122 | if bias is not None:
123 | bias_flops = out_channels * active_elements_count
124 |
125 | return int(overall_conv_flops + bias_flops), int(overall_conv_macs)
126 |
127 |
128 | def _conv_trans_flops_compute(
129 | input,
130 | weight,
131 | bias=None,
132 | stride=1,
133 | padding=0,
134 | output_padding=0,
135 | groups=1,
136 | dilation=1,
137 | ):
138 | batch_size = input.shape[0]
139 | in_channels = input.shape[1]
140 | out_channels = weight.shape[1]
141 | kernel_dims = list(weight.shape[2:])
142 | input_dims = list(input.shape[2:])
143 |
144 | length = len(input_dims)
145 |
146 | paddings = padding if type(padding) is tuple else (padding, ) * length
147 | strides = stride if type(stride) is tuple else (stride, ) * length
148 | dilations = dilation if type(dilation) is tuple else (dilation, ) * length
149 |
150 | output_dims = []
151 | for idx, input_dim in enumerate(input_dims):
152 |
153 | output_dim = (input_dim + 2 * paddings[idx] - (dilations[idx] *
154 | (kernel_dims[idx] - 1) + 1)) // strides[idx] + 1
155 | output_dims.append(output_dim)
156 |
157 | paddings = padding if type(padding) is tuple else (padding, padding)
158 | strides = stride if type(stride) is tuple else (stride, stride)
159 | dilations = dilation if type(dilation) is tuple else (dilation, dilation)
160 |
161 | filters_per_channel = out_channels // groups
162 | conv_per_position_macs = int(_prod(kernel_dims)) * in_channels * filters_per_channel
163 | active_elements_count = batch_size * int(_prod(input_dims))
164 | overall_conv_macs = conv_per_position_macs * active_elements_count
165 | overall_conv_flops = 2 * overall_conv_macs
166 |
167 | bias_flops = 0
168 | if bias is not None:
169 | bias_flops = out_channels * batch_size * int(_prod(output_dims))
170 |
171 | return int(overall_conv_flops + bias_flops), int(overall_conv_macs)
172 |
173 |
174 | def _batch_norm_flops_compute(
175 | input,
176 | running_mean,
177 | running_var,
178 | weight=None,
179 | bias=None,
180 | training=False,
181 | momentum=0.1,
182 | eps=1e-05,
183 | ):
184 | has_affine = weight is not None
185 | if training:
186 | # estimation
187 | return input.numel() * (5 if has_affine else 4), 0
188 | flops = input.numel() * (2 if has_affine else 1)
189 | return flops, 0
190 |
191 |
192 | def _layer_norm_flops_compute(
193 | input: Tensor,
194 | normalized_shape: List[int],
195 | weight: Optional[Tensor] = None,
196 | bias: Optional[Tensor] = None,
197 | eps: float = 1e-5,
198 | ):
199 | has_affine = weight is not None
200 | # estimation
201 | return input.numel() * (5 if has_affine else 4), 0
202 |
203 |
204 | def _group_norm_flops_compute(input: Tensor,
205 | num_groups: int,
206 | weight: Optional[Tensor] = None,
207 | bias: Optional[Tensor] = None,
208 | eps: float = 1e-5):
209 | has_affine = weight is not None
210 | # estimation
211 | return input.numel() * (5 if has_affine else 4), 0
212 |
213 |
214 | def _instance_norm_flops_compute(
215 | input: Tensor,
216 | running_mean: Optional[Tensor] = None,
217 | running_var: Optional[Tensor] = None,
218 | weight: Optional[Tensor] = None,
219 | bias: Optional[Tensor] = None,
220 | use_input_stats: bool = True,
221 | momentum: float = 0.1,
222 | eps: float = 1e-5,
223 | ):
224 | has_affine = weight is not None
225 | # estimation
226 | return input.numel() * (5 if has_affine else 4), 0
227 |
228 |
229 | def _upsample_flops_compute(*args, **kwargs):
230 | input = args[0]
231 | size = kwargs.get('size', None)
232 | if size is None and len(args) > 1:
233 | size = args[1]
234 |
235 | if size is not None:
236 | if isinstance(size, tuple) or isinstance(size, list):
237 | return int(_prod(size)), 0
238 | else:
239 | return int(size), 0
240 |
241 | scale_factor = kwargs.get('scale_factor', None)
242 | if scale_factor is None and len(args) > 2:
243 | scale_factor = args[2]
244 | assert scale_factor is not None, "either size or scale_factor should be defined"
245 |
246 | flops = input.numel()
247 | if isinstance(scale_factor, tuple) and len(scale_factor) == len(input):
248 | flops * int(_prod(scale_factor))
249 | else:
250 | flops * scale_factor**len(input)
251 | return flops, 0
252 |
253 |
254 | def _softmax_flops_compute(input, dim=None, _stacklevel=3, dtype=None):
255 | return input.numel(), 0
256 |
257 |
258 | def _embedding_flops_compute(
259 | input,
260 | weight,
261 | padding_idx=None,
262 | max_norm=None,
263 | norm_type=2.0,
264 | scale_grad_by_freq=False,
265 | sparse=False,
266 | ):
267 | return 0, 0
268 |
269 |
270 | def _dropout_flops_compute(input, p=0.5, training=True, inplace=False):
271 | return 0, 0
272 |
273 |
274 | def _matmul_flops_compute(input, other, *, out=None):
275 | """
276 | Count flops for the matmul operation.
277 | """
278 | macs = _prod(input.shape) * other.shape[-1]
279 | return 2 * macs, macs
280 |
281 |
282 | def _addmm_flops_compute(input, mat1, mat2, *, beta=1, alpha=1, out=None):
283 | """
284 | Count flops for the addmm operation.
285 | """
286 | macs = _prod(mat1.shape) * mat2.shape[-1]
287 | return 2 * macs + _prod(input.shape), macs
288 |
289 |
290 | def _einsum_flops_compute(equation, *operands):
291 | """
292 | Count flops for the einsum operation.
293 | """
294 | equation = equation.replace(" ", "")
295 | input_shapes = [o.shape for o in operands]
296 |
297 | # Re-map equation so that same equation with different alphabet
298 | # representations will look the same.
299 | letter_order = OrderedDict((k, 0) for k in equation if k.isalpha()).keys()
300 | mapping = {ord(x): 97 + i for i, x in enumerate(letter_order)}
301 | equation = equation.translate(mapping)
302 |
303 | np_arrs = [np.zeros(s) for s in input_shapes]
304 | optim = np.einsum_path(equation, *np_arrs, optimize="optimal")[1]
305 | for line in optim.split("\n"):
306 | if "optimized flop" in line.lower():
307 | flop = int(float(line.split(":")[-1]))
308 | return flop, 0
309 | raise NotImplementedError("Unsupported einsum operation.")
310 |
311 |
312 | def _tensor_addmm_flops_compute(self, mat1, mat2, *, beta=1, alpha=1, out=None):
313 | """
314 | Count flops for the tensor addmm operation.
315 | """
316 | macs = _prod(mat1.shape) * mat2.shape[-1]
317 | return 2 * macs + _prod(self.shape), macs
318 |
319 |
320 | def _mul_flops_compute(input, other, *, out=None):
321 | return _elementwise_flops_compute(input, other)
322 |
323 |
324 | def _add_flops_compute(input, other, *, alpha=1, out=None):
325 | return _elementwise_flops_compute(input, other)
326 |
327 |
328 | def _elementwise_flops_compute(input, other):
329 | if not torch.is_tensor(input):
330 | if torch.is_tensor(other):
331 | return _prod(other.shape), 0
332 | else:
333 | return 1, 0
334 | elif not torch.is_tensor(other):
335 | return _prod(input.shape), 0
336 | else:
337 | dim_input = len(input.shape)
338 | dim_other = len(other.shape)
339 | max_dim = max(dim_input, dim_other)
340 |
341 | final_shape = []
342 | for i in range(max_dim):
343 | in_i = input.shape[i] if i < dim_input else 1
344 | ot_i = other.shape[i] if i < dim_other else 1
345 | if in_i > ot_i:
346 | final_shape.append(in_i)
347 | else:
348 | final_shape.append(ot_i)
349 | flops = _prod(final_shape)
350 | return flops, 0
351 |
352 |
353 | def wrapFunc(func, funcFlopCompute, old_functions, module_flop_count, module_mac_count):
354 | oldFunc = func
355 | name = func.__str__
356 | old_functions[name] = oldFunc
357 |
358 | def newFunc(*args, **kwds):
359 | flops, macs = funcFlopCompute(*args, **kwds)
360 | if module_flop_count:
361 | module_flop_count[-1].append((name, flops))
362 | if module_mac_count and macs:
363 | module_mac_count[-1].append((name, macs))
364 | return oldFunc(*args, **kwds)
365 |
366 | newFunc.__str__ = func.__str__
367 |
368 | return newFunc
369 |
370 |
371 | def _rnn_flops(flops, rnn_module, w_ih, w_hh, input_size):
372 | gates_size = w_ih.shape[0]
373 | # matrix matrix mult ih state and internal state
374 | flops += 2 * w_ih.shape[0] * w_ih.shape[1] - gates_size
375 | # matrix matrix mult hh state and internal state
376 | flops += 2 * w_hh.shape[0] * w_hh.shape[1] - gates_size
377 | if isinstance(rnn_module, (nn.RNN, nn.RNNCell)):
378 | # add both operations
379 | flops += rnn_module.hidden_size
380 | elif isinstance(rnn_module, (nn.GRU, nn.GRUCell)):
381 | # hadamard of r
382 | flops += rnn_module.hidden_size
383 | # adding operations from both states
384 | flops += rnn_module.hidden_size * 3
385 | # last two hadamard _product and add
386 | flops += rnn_module.hidden_size * 3
387 | elif isinstance(rnn_module, (nn.LSTM, nn.LSTMCell)):
388 | # adding operations from both states
389 | flops += rnn_module.hidden_size * 4
390 | # two hadamard _product and add for C state
391 | flops += rnn_module.hidden_size + rnn_module.hidden_size + rnn_module.hidden_size
392 | # final hadamard
393 | flops += rnn_module.hidden_size + rnn_module.hidden_size + rnn_module.hidden_size
394 | return flops
395 |
396 |
397 | def _rnn_forward_hook(rnn_module, input, output):
398 | flops = 0
399 | # input is a tuple containing a sequence to process and (optionally) hidden state
400 | inp = input[0]
401 | batch_size = inp.shape[0]
402 | seq_length = inp.shape[1]
403 | num_layers = rnn_module.num_layers
404 |
405 | for i in range(num_layers):
406 | w_ih = rnn_module.__getattr__("weight_ih_l" + str(i))
407 | w_hh = rnn_module.__getattr__("weight_hh_l" + str(i))
408 | if i == 0:
409 | input_size = rnn_module.input_size
410 | else:
411 | input_size = rnn_module.hidden_size
412 | flops = _rnn_flops(flops, rnn_module, w_ih, w_hh, input_size)
413 | if rnn_module.bias:
414 | b_ih = rnn_module.__getattr__("bias_ih_l" + str(i))
415 | b_hh = rnn_module.__getattr__("bias_hh_l" + str(i))
416 | flops += b_ih.shape[0] + b_hh.shape[0]
417 |
418 | flops *= batch_size
419 | flops *= seq_length
420 | if rnn_module.bidirectional:
421 | flops *= 2
422 | rnn_module.__flops__ += int(flops)
423 |
424 |
425 | def _rnn_cell_forward_hook(rnn_cell_module, input, output):
426 | flops = 0
427 | inp = input[0]
428 | batch_size = inp.shape[0]
429 | w_ih = rnn_cell_module.__getattr__("weight_ih")
430 | w_hh = rnn_cell_module.__getattr__("weight_hh")
431 | input_size = inp.shape[1]
432 | flops = _rnn_flops(flops, rnn_cell_module, w_ih, w_hh, input_size)
433 | if rnn_cell_module.bias:
434 | b_ih = rnn_cell_module.__getattr__("bias_ih")
435 | b_hh = rnn_cell_module.__getattr__("bias_hh")
436 | flops += b_ih.shape[0] + b_hh.shape[0]
437 |
438 | flops *= batch_size
439 | rnn_cell_module.__flops__ += int(flops)
440 |
441 |
442 | MODULE_HOOK_MAPPING = {
443 | # RNN
444 | nn.RNN: _rnn_forward_hook,
445 | nn.GRU: _rnn_forward_hook,
446 | nn.LSTM: _rnn_forward_hook,
447 | nn.RNNCell: _rnn_cell_forward_hook,
448 | nn.LSTMCell: _rnn_cell_forward_hook,
449 | nn.GRUCell: _rnn_cell_forward_hook,
450 | }
451 |
452 | def _patch_functionals(old_functions, module_flop_count, module_mac_count):
453 | # FC
454 | F.linear = wrapFunc(F.linear, _linear_flops_compute, old_functions, module_flop_count, module_mac_count)
455 | # convolutions
456 | F.conv1d = wrapFunc(F.conv1d, _conv_flops_compute, old_functions, module_flop_count, module_mac_count)
457 | F.conv2d = wrapFunc(F.conv2d, _conv_flops_compute, old_functions, module_flop_count, module_mac_count)
458 | F.conv3d = wrapFunc(F.conv3d, _conv_flops_compute, old_functions, module_flop_count, module_mac_count)
459 |
460 | # conv transposed
461 | F.conv_transpose1d = wrapFunc(F.conv_transpose1d, _conv_trans_flops_compute, old_functions, module_flop_count, module_mac_count)
462 | F.conv_transpose2d = wrapFunc(F.conv_transpose2d, _conv_trans_flops_compute, old_functions, module_flop_count, module_mac_count)
463 | F.conv_transpose3d = wrapFunc(F.conv_transpose3d, _conv_trans_flops_compute, old_functions, module_flop_count, module_mac_count)
464 |
465 | # activations
466 | F.relu = wrapFunc(F.relu, _relu_flops_compute, old_functions, module_flop_count, module_mac_count)
467 | F.prelu = wrapFunc(F.prelu, _prelu_flops_compute, old_functions, module_flop_count, module_mac_count)
468 | F.elu = wrapFunc(F.elu, _elu_flops_compute, old_functions, module_flop_count, module_mac_count)
469 | F.leaky_relu = wrapFunc(F.leaky_relu, _leaky_relu_flops_compute, old_functions, module_flop_count, module_mac_count)
470 | F.relu6 = wrapFunc(F.relu6, _relu6_flops_compute, old_functions, module_flop_count, module_mac_count)
471 | if hasattr(F, "silu"):
472 | F.silu = wrapFunc(F.silu, _silu_flops_compute, old_functions, module_flop_count, module_mac_count)
473 | F.gelu = wrapFunc(F.gelu, _gelu_flops_compute, old_functions, module_flop_count, module_mac_count)
474 |
475 | # Normalizations
476 | F.batch_norm = wrapFunc(F.batch_norm, _batch_norm_flops_compute, old_functions, module_flop_count, module_mac_count)
477 | F.layer_norm = wrapFunc(F.layer_norm, _layer_norm_flops_compute, old_functions, module_flop_count, module_mac_count)
478 | F.instance_norm = wrapFunc(F.instance_norm, _instance_norm_flops_compute, old_functions, module_flop_count, module_mac_count)
479 | F.group_norm = wrapFunc(F.group_norm, _group_norm_flops_compute, old_functions, module_flop_count, module_mac_count)
480 |
481 | # poolings
482 | F.avg_pool1d = wrapFunc(F.avg_pool1d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
483 | F.avg_pool2d = wrapFunc(F.avg_pool2d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
484 | F.avg_pool3d = wrapFunc(F.avg_pool3d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
485 | F.max_pool1d = wrapFunc(F.max_pool1d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
486 | F.max_pool2d = wrapFunc(F.max_pool2d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
487 | F.max_pool3d = wrapFunc(F.max_pool3d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
488 | F.adaptive_avg_pool1d = wrapFunc(F.adaptive_avg_pool1d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
489 | F.adaptive_avg_pool2d = wrapFunc(F.adaptive_avg_pool2d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
490 | F.adaptive_avg_pool3d = wrapFunc(F.adaptive_avg_pool3d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
491 | F.adaptive_max_pool1d = wrapFunc(F.adaptive_max_pool1d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
492 | F.adaptive_max_pool2d = wrapFunc(F.adaptive_max_pool2d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
493 | F.adaptive_max_pool3d = wrapFunc(F.adaptive_max_pool3d, _pool_flops_compute, old_functions, module_flop_count, module_mac_count)
494 |
495 | # upsample
496 | F.upsample = wrapFunc(F.upsample, _upsample_flops_compute, old_functions, module_flop_count, module_mac_count)
497 | F.interpolate = wrapFunc(F.interpolate, _upsample_flops_compute, old_functions, module_flop_count, module_mac_count)
498 |
499 | # softmax
500 | F.softmax = wrapFunc(F.softmax, _softmax_flops_compute, old_functions, module_flop_count, module_mac_count)
501 |
502 | # embedding
503 | F.embedding = wrapFunc(F.embedding, _embedding_flops_compute, old_functions, module_flop_count, module_mac_count)
504 |
505 |
506 | def _patch_tensor_methods(old_functions, module_flop_count, module_mac_count):
507 | torch.matmul = wrapFunc(torch.matmul, _matmul_flops_compute, old_functions, module_flop_count, module_mac_count)
508 | torch.Tensor.matmul = wrapFunc(torch.Tensor.matmul, _matmul_flops_compute, old_functions, module_flop_count, module_mac_count)
509 | # torch.mm = wrapFunc(torch.mm, _matmul_flops_compute, old_functions, module_flop_count, module_mac_count)
510 | # torch.Tensor.mm = wrapFunc(torch.Tensor.mm, _matmul_flops_compute, old_functions, module_flop_count, module_mac_count)
511 | # torch.bmm = wrapFunc(torch.bmm, _matmul_flops_compute, old_functions, module_flop_count, module_mac_count)
512 | # torch.Tensor.bmm = wrapFunc(torch.Tensor.bmm, _matmul_flops_compute, old_functions, module_flop_count, module_mac_count)
513 |
514 | torch.addmm = wrapFunc(torch.addmm, _addmm_flops_compute, old_functions, module_flop_count, module_mac_count)
515 | torch.Tensor.addmm = wrapFunc(torch.Tensor.addmm, _tensor_addmm_flops_compute, old_functions, module_flop_count, module_mac_count)
516 |
517 | torch.mul = wrapFunc(torch.mul, _mul_flops_compute, old_functions, module_flop_count, module_mac_count)
518 | torch.Tensor.mul = wrapFunc(torch.Tensor.mul, _mul_flops_compute, old_functions, module_flop_count, module_mac_count)
519 |
520 | torch.add = wrapFunc(torch.add, _add_flops_compute, old_functions, module_flop_count, module_mac_count)
521 | torch.Tensor.add = wrapFunc(torch.Tensor.add, _add_flops_compute, old_functions, module_flop_count, module_mac_count)
522 |
523 | torch.einsum = wrapFunc(torch.einsum, _einsum_flops_compute, old_functions, module_flop_count, module_mac_count)
524 |
525 | torch.baddbmm = wrapFunc(torch.baddbmm, _tensor_addmm_flops_compute, old_functions, module_flop_count, module_mac_count)
526 |
527 |
528 | def _reload_functionals(old_functions):
529 | # torch.nn.functional does not support importlib.reload()
530 | F.linear = old_functions[F.linear.__str__]
531 | F.conv1d = old_functions[F.conv1d.__str__]
532 | F.conv2d = old_functions[F.conv2d.__str__]
533 | F.conv3d = old_functions[F.conv3d.__str__]
534 | F.conv_transpose1d = old_functions[F.conv_transpose1d.__str__]
535 | F.conv_transpose2d = old_functions[F.conv_transpose2d.__str__]
536 | F.conv_transpose3d = old_functions[F.conv_transpose3d.__str__]
537 | F.relu = old_functions[F.relu.__str__]
538 | F.prelu = old_functions[F.prelu.__str__]
539 | F.elu = old_functions[F.elu.__str__]
540 | F.leaky_relu = old_functions[F.leaky_relu.__str__]
541 | F.relu6 = old_functions[F.relu6.__str__]
542 | if hasattr(F, "silu"):
543 | F.silu = old_functions[F.silu.__str__]
544 | F.gelu = old_functions[F.gelu.__str__]
545 | F.batch_norm = old_functions[F.batch_norm.__str__]
546 | F.layer_norm = old_functions[F.layer_norm.__str__]
547 | F.instance_norm = old_functions[F.instance_norm.__str__]
548 | F.group_norm = old_functions[F.group_norm.__str__]
549 | F.avg_pool1d = old_functions[F.avg_pool1d.__str__]
550 | F.avg_pool2d = old_functions[F.avg_pool2d.__str__]
551 | F.avg_pool3d = old_functions[F.avg_pool3d.__str__]
552 | F.max_pool1d = old_functions[F.max_pool1d.__str__]
553 | F.max_pool2d = old_functions[F.max_pool2d.__str__]
554 | F.max_pool3d = old_functions[F.max_pool3d.__str__]
555 | F.adaptive_avg_pool1d = old_functions[F.adaptive_avg_pool1d.__str__]
556 | F.adaptive_avg_pool2d = old_functions[F.adaptive_avg_pool2d.__str__]
557 | F.adaptive_avg_pool3d = old_functions[F.adaptive_avg_pool3d.__str__]
558 | F.adaptive_max_pool1d = old_functions[F.adaptive_max_pool1d.__str__]
559 | F.adaptive_max_pool2d = old_functions[F.adaptive_max_pool2d.__str__]
560 | F.adaptive_max_pool3d = old_functions[F.adaptive_max_pool3d.__str__]
561 | F.upsample = old_functions[F.upsample.__str__]
562 | F.interpolate = old_functions[F.interpolate.__str__]
563 | F.softmax = old_functions[F.softmax.__str__]
564 | F.embedding = old_functions[F.embedding.__str__]
565 |
566 |
567 | def _reload_tensor_methods(old_functions):
568 | torch.matmul = old_functions[torch.matmul.__str__]
569 | torch.Tensor.matmul = old_functions[torch.Tensor.matmul.__str__]
570 | # torch.mm = old_functions[torch.mm.__str__]
571 | # torch.Tensor.mm = old_functions[torch.Tensor.mm.__str__]
572 | # torch.bmm = old_functions[torch.matmul.__str__]
573 | # torch.Tensor.bmm = old_functions[torch.Tensor.bmm.__str__]
574 | torch.addmm = old_functions[torch.addmm.__str__]
575 | torch.Tensor.addmm = old_functions[torch.Tensor.addmm.__str__]
576 | torch.mul = old_functions[torch.mul.__str__]
577 | torch.Tensor.mul = old_functions[torch.Tensor.mul.__str__]
578 | torch.add = old_functions[torch.add.__str__]
579 | torch.Tensor.add = old_functions[torch.Tensor.add.__str__]
580 | torch.einsum = old_functions[torch.einsum.__str__]
581 | torch.baddbmm = old_functions[torch.baddbmm.__str__]
582 |
--------------------------------------------------------------------------------
/calflops/utils.py:
--------------------------------------------------------------------------------
1 | # !usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 |
4 | '''
5 | Description :
6 | Version : 1.0
7 | Author : MrYXJ
8 | Mail : yxj2017@gmail.com
9 | Github : https://github.com/MrYxJ
10 | Date : 2023-08-19 11:01:23
11 | LastEditTime : 2023-09-05 15:51:50
12 | Copyright (C) 2023 mryxj. All rights reserved.
13 | '''
14 |
15 | import importlib
16 |
17 | import torch
18 |
19 | DEFAULT_PRECISION = 2
20 |
21 |
22 | # def generate_transformer_input(model_tokenizer, input_shape, device):
23 | # """Automatically generates data in the form of transformes model input format.
24 |
25 | # Args:
26 | # input_shape (tuple):transformers model input shape: (batch_size, seq_len).
27 | # tokenizer (transformer.model.tokenization): transformers model tokenization.tokenizer.
28 |
29 | # Returns:
30 | # dict: data format of transformers model input, it is a dict contain 'input_ids', 'attention_mask', sometime contain 'token_type_ids'.
31 | # """
32 |
33 | # if input_shape is None:
34 | # input_shape = [1, 128] # defautl (batch_size=1, seq_len=128)
35 |
36 | # max_length = input_shape[1]
37 | # model_input_ids = []
38 | # model_attention_mask = []
39 | # model_token_type_ids = []
40 | # model_position_ids = []
41 |
42 | # import numpy as np
43 | # inp_seq = ""
44 | # for _ in range(input_shape[0]):
45 | # inputs = model_tokenizer.encode_plus(
46 | # inp_seq,
47 | # add_special_tokens=True,
48 | # truncation_strategy='longest_first',
49 | # )
50 | # origin_length = len(inputs["input_ids"])
51 | # padding_length = max_length - origin_length
52 |
53 | # for key in inputs.keys():
54 | # if key == "input_ids":
55 | # input_ids = inputs["input_ids"]
56 | # pad_token = model_tokenizer.pad_token_id if model_tokenizer.pad_token_id else 0
57 | # input_ids = input_ids + ([pad_token] * padding_length)
58 | # assert len(input_ids) == max_length, "len(input_ids) must equal max_length"
59 | # model_input_ids.append(input_ids)
60 | # elif key == "attention_mask":
61 | # attention_mask = [1] * origin_length
62 | # attention_mask = attention_mask + ([0] * padding_length)
63 | # assert len(attention_mask) == max_length, "len(attention_mask) must equal max_length"
64 | # model_attention_mask.append(attention_mask)
65 | # elif key == "token_type_ids":
66 | # token_type_ids = inputs['token_type_ids']
67 | # pad_token_segment_id = 0
68 | # token_type_ids = token_type_ids + ([pad_token_segment_id] * padding_length)
69 | # assert len(token_type_ids) == max_length, "len(token_type_ids) must equal max_length"
70 | # model_token_type_ids.append(token_type_ids)
71 | # elif key == "position_ids":
72 | # position_ids = inputs['position_ids']
73 | # if isinstance(position_ids, list):
74 | # for i in range(origin_length, max_length):
75 | # position_ids.append(i)
76 | # assert len(position_ids) == max_length, "len(position_ids) must equal max_length"
77 | # elif isinstance(position_ids, np.ndarray):
78 | # pass
79 | # model_position_ids.append(position_ids)
80 |
81 | # # Batch size input_shape[0], sequence length input_shape[128]
82 | # inputs = {}
83 | # if len(model_input_ids) > 0:
84 | # inputs.update({"input_ids": torch.tensor(model_input_ids).to(device)})
85 | # if len(model_attention_mask) > 0 and not isinstance(model_attention_mask[0], list):
86 | # inputs.update({"attention_mask": torch.tensor(model_attention_mask).to(device)})
87 | # if len(model_token_type_ids) > 0:
88 | # inputs.update({'token_type_ids': torch.tensor(model_token_type_ids).to(device)})
89 | # if len(model_position_ids) > 0 and not isinstance(model_position_ids[0], np.ndarray):
90 | # inputs.update({'position_ids': torch.tensor(model_position_ids).to(device)})
91 |
92 | # return inputs
93 |
94 | def generate_transformer_input(model_tokenizer, input_shape, device):
95 | """Automatically generates data in the form of transformes model input format.
96 |
97 | Args:
98 | input_shape (tuple):transformers model input shape: (batch_size, seq_len).
99 | tokenizer (transformer.model.tokenization): transformers model tokenization.tokenizer.
100 |
101 | Returns:
102 | dict: data format of transformers model input, it is a dict contain 'input_ids', 'attention_mask', sometime contain 'token_type_ids'.
103 | """
104 |
105 | if input_shape is None:
106 | input_shape = [1, 128] # defautl (batch_size=1, seq_len=128)
107 |
108 | max_length = input_shape[1]
109 | model_input_ids = []
110 | model_attention_mask = []
111 | model_token_type_ids = []
112 | model_position_ids = []
113 |
114 | inp_seq = ""
115 | for _ in range(input_shape[0]):
116 | inputs = model_tokenizer.encode_plus(
117 | inp_seq,
118 | add_special_tokens=True,
119 | truncation_strategy='longest_first',
120 | )
121 | origin_length = len(inputs["input_ids"])
122 | padding_length = max_length - origin_length
123 |
124 | for key in inputs.keys():
125 | if key == "input_ids":
126 | input_ids = inputs["input_ids"]
127 | pad_token = model_tokenizer.pad_token_id if model_tokenizer.pad_token_id else 0
128 | input_ids = input_ids + ([pad_token] * padding_length)
129 | assert len(input_ids) == max_length, "len(input_ids) must equal max_length"
130 | model_input_ids.append(input_ids)
131 | elif key == "attention_mask":
132 | attention_mask = [1] * origin_length
133 | attention_mask = attention_mask + ([0] * padding_length)
134 | assert len(attention_mask) == max_length, "len(attention_mask) must equal max_length"
135 | model_attention_mask.append(attention_mask)
136 | elif key == "token_type_ids":
137 | token_type_ids = inputs['token_type_ids']
138 | pad_token_segment_id = 0
139 | token_type_ids = token_type_ids + ([pad_token_segment_id] * padding_length)
140 | assert len(token_type_ids) == max_length, "len(token_type_ids) must equal max_length"
141 | model_token_type_ids.append(token_type_ids)
142 | elif key == "position_ids": # chatglm2 use position id
143 | position_ids = inputs['position_ids']
144 | for i in range(origin_length, max_length):
145 | position_ids.append(i)
146 | assert len(position_ids) == max_length, "len(position_ids) must equal max_length"
147 | model_position_ids.append(position_ids)
148 |
149 | # Batch size input_shape[0], sequence length input_shape[128]
150 | inputs = {}
151 | if len(model_input_ids) > 0:
152 | inputs.update({"input_ids": torch.tensor(model_input_ids).to(device)})
153 | if len(model_attention_mask) > 0:
154 | inputs.update({"attention_mask": torch.tensor(model_attention_mask).to(device)})
155 | if len(model_token_type_ids) > 0:
156 | inputs.update({'token_type_ids': torch.tensor(model_token_type_ids).to(device)})
157 | if len(model_position_ids) > 0:
158 | inputs.update({'position_ids': torch.tensor(model_position_ids).to(device)})
159 |
160 | return inputs
161 |
162 |
163 | def number_to_string(num, units=None, precision=DEFAULT_PRECISION):
164 | if units is None:
165 | if num >= 1e12:
166 | magnitude, units = 1e12, "T"
167 | elif num >= 1e9:
168 | magnitude, units = 1e9, "G"
169 | elif num >= 1e6:
170 | magnitude, units = 1e6, "M"
171 | elif num >= 1e3:
172 | magnitude, units = 1e3, "K"
173 | elif num >= 1 or num == 0:
174 | magnitude, units = 1, ""
175 | elif num >= 1e-3:
176 | magnitude, units = 1e-3, "m"
177 | else:
178 | magnitude, units = 1e-6, "u"
179 | else:
180 | if units == "T":
181 | magnitude = 1e12
182 | elif units == "G":
183 | magnitude = 1e9
184 | elif units == "M":
185 | magnitude = 1e6
186 | elif units == "K":
187 | magnitude = 1e3
188 | elif units == "m":
189 | magnitude = 1e-3
190 | elif units == "u":
191 | magnitude = 1e-6
192 | else:
193 | magnitude = 1
194 | return f"{round(num / magnitude, precision):g} {units}"
195 |
196 |
197 | def macs_to_string(macs, units=None, precision=DEFAULT_PRECISION):
198 | """Converts macs in numeric form to string form.
199 |
200 | Args:
201 | macs (int): Calculate the results of the model macs in numerical form.
202 | units (str, optional): The unit of macs after conversion to string representation, such as TMACs、GMACs、MMACs、KMACs
203 | precision (int, optional): The number of digits of the result is preserved. Defaults to DEFAULT_PRECISION.
204 |
205 | Returns:
206 | string: The string representation of macs.
207 | """
208 | return f"{number_to_string(macs, units=units, precision=precision)}MACs"
209 |
210 |
211 | def flops_to_string(flops, units=None, precision=DEFAULT_PRECISION):
212 | """Converts flops in numeric form to string form.
213 |
214 | Args:
215 | flops (int): Calculate the results of the model flops in numerical form.
216 | units (str, optional): The unit of flops after conversion to string representation, such as TFLOPs,GFLOPs,MFLOPs,KFLOPs.
217 | precision (int, optional): The number of digits of the result is preserved. Defaults to DEFAULT_PRECISION.
218 |
219 | Returns:
220 | string: The string representation of flops.
221 | """
222 | return f"{number_to_string(flops, units=units, precision=precision)}FLOPS"
223 |
224 |
225 | def bytes_to_string(b, units=None, precision=DEFAULT_PRECISION):
226 | """Converts bytes in numeric form to string form.
227 |
228 | Args:
229 | b (int): Calculate the results of the bytes in numerical form.
230 | units (str, optional): The unit of bytes after conversion to string representation, such as TB,GB,MB,KB.
231 | precision (int, optional): The number of digits of the result is preserved. Defaults to DEFAULT_PRECISION.
232 |
233 | Returns:
234 | string: The string representation of bytes.
235 | """
236 | return f"{number_to_string(b, units=units, precision=precision)}B"
237 |
238 |
239 | def params_to_string(params_num, units=None, precision=DEFAULT_PRECISION):
240 | """Converts params in numeric form to string form.
241 |
242 | Args:
243 | params_num (int): Calculate the results of the model param in numerical form.
244 | units (str, optional): The unit of params after conversion to string representation.
245 | precision (int, optional): The number of digits of the result is preserved. Defaults to DEFAULT_PRECISION.
246 |
247 | Returns:
248 | string: The string representation of params.
249 | """
250 | units = units.replace("B", "G") if units else units
251 | return number_to_string(params_num, units=units, precision=precision).replace("G", "B").strip()
252 |
253 |
254 | def get_module_flops(module, is_sparse=False):
255 | """Recursively compute the FLOP s of the model
256 |
257 | Args:
258 | module (pytorch module): model format must be pytorch
259 | is_sparse (bool, Optional): Whether to exclude sparse weight. Defaults to False.
260 |
261 | Returns:
262 | int: The sum of the entire model flops
263 | """
264 | sum_flops = module.__flops__ * sum(
265 | p.count_nonzero().item() for p in module.parameters() if p.requires_grad
266 | ) / sum(p.numel() for p in module.parameters() if p.requires_grad) if is_sparse else module.__flops__
267 | # iterate over immediate children modules
268 | for child in module.children():
269 | sum_flops += get_module_flops(child, is_sparse=is_sparse)
270 | return sum_flops
271 |
272 |
273 | def get_module_macs(module, is_sparse=False):
274 | """Recursively compute the macs s of the model
275 |
276 | Args:
277 | module (pytorch module): model format must be pytorch
278 | is_sparse (bool, Optional): Whether to exclude sparse weight. Defaults to False.
279 |
280 | Returns:
281 | int: The sum of the entire model macs
282 | """
283 | sum_macs = module.__macs__ * sum(
284 | p.count_nonzero().item() for p in module.parameters() if p.requires_grad
285 | ) / sum(p.numel() for p in module.parameters() if p.requires_grad) if is_sparse else module.__macs__
286 | # iterate over immediate children modules
287 | for child in module.children():
288 | sum_macs += get_module_macs(child, is_sparse=is_sparse)
289 | return sum_macs
290 |
291 |
292 | def convert_bytes(size):
293 | "Converts `size` from bytes to the largest possible unit"
294 | for x in ["bytes", "KB", "MB", "GB", "TB"]:
295 | if size < 1024.0:
296 | return f"{round(size, 2)} {x}"
297 | size /= 1024.0
298 |
299 | return f"{round(size, 2)} PB"
300 |
301 |
302 | def _is_package_available(pkg_name):
303 | # Check we're not importing a "pkg_name" directory somewhere but the actual library by trying to grab the version
304 | package_exists = importlib.util.find_spec(pkg_name) is not None
305 | if package_exists:
306 | try:
307 | _ = importlib.metadata.metadata(pkg_name)
308 | return True
309 | except importlib.metadata.PackageNotFoundError:
310 | return False
311 |
--------------------------------------------------------------------------------
/screenshot/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/.DS_Store
--------------------------------------------------------------------------------
/screenshot/alxnet_print_detailed.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/alxnet_print_detailed.png
--------------------------------------------------------------------------------
/screenshot/alxnet_print_result.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/alxnet_print_result.png
--------------------------------------------------------------------------------
/screenshot/calflops_hf1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/calflops_hf1.png
--------------------------------------------------------------------------------
/screenshot/calflops_hf2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/calflops_hf2.png
--------------------------------------------------------------------------------
/screenshot/calflops_hf3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/calflops_hf3.png
--------------------------------------------------------------------------------
/screenshot/calflops_hf4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/calflops_hf4.png
--------------------------------------------------------------------------------
/screenshot/huggingface_model_name.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/huggingface_model_name.png
--------------------------------------------------------------------------------
/screenshot/huggingface_model_name2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/huggingface_model_name2.png
--------------------------------------------------------------------------------
/screenshot/huggingface_model_name3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/huggingface_model_name3.png
--------------------------------------------------------------------------------
/screenshot/huggingface_model_names.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MrYxJ/calculate-flops.pytorch/027e89a24daf23ee7ed79ca4abee3fb59b5b23cd/screenshot/huggingface_model_names.png
--------------------------------------------------------------------------------
/test_examples/test_bert.py:
--------------------------------------------------------------------------------
1 | # !usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 |
4 | '''
5 | Description :
6 | Version : 1.0
7 | Author : MrYXJ
8 | Mail : yxj2017@gmail.com
9 | Github : https://github.com/MrYxJ
10 | Date : 2023-08-24 11:48:59
11 | LastEditTime : 2023-08-24 19:42:16
12 | Copyright (C) 2023 mryxj. All rights reserved.
13 | '''
14 |
15 | from calflops import calculate_flops
16 | from transformers import AutoModel
17 | from transformers import AutoTokenizer
18 |
19 | batch_size = 1
20 | max_seq_length = 128
21 | model_name = "hfl/chinese-roberta-wwm-ext/"
22 | model_save = "../pretrain_models/" + model_name
23 | model = AutoModel.from_pretrained(model_save)
24 | tokenizer = AutoTokenizer.from_pretrained(model_save)
25 |
26 | flops, macs, params = calculate_flops(model=model,
27 | input_shape=(batch_size,max_seq_length),
28 | transformer_tokenizer=tokenizer)
29 | print("Bert(hfl/chinese-roberta-wwm-ext) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
30 |
--------------------------------------------------------------------------------
/test_examples/test_cnn.py:
--------------------------------------------------------------------------------
1 | # !usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 |
4 | '''
5 | Description :
6 | Version : 1.0
7 | Author : MrYXJ
8 | Mail : yxj2017@gmail.com
9 | Github : https://github.com/MrYxJ
10 | Date : 2023-08-19 13:05:48
11 | LastEditTime : 2023-09-09 00:26:18
12 | Copyright (C) 2023 mryxj. All rights reserved.
13 | '''
14 | # import os
15 | # os.system("pip install calflops")
16 |
17 | from calflops import calculate_flops
18 | from torchvision import models
19 |
20 | model = models.alexnet()
21 | batch_size = 1
22 |
23 | # output
24 | flops, macs, params = calculate_flops(model=model,
25 | input_shape=(batch_size, 3, 224, 224),
26 | output_as_string=False,
27 | print_results=True,
28 | print_detailed=True)
29 | print("alexnet FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
30 |
31 | #
32 | flops, macs, params = calculate_flops(model=model,
33 | input_shape=(batch_size, 3, 224, 224),
34 | print_results=False,
35 | print_detailed=False,
36 | output_as_string=True,
37 | output_precision=3,
38 | output_unit='M')
39 | print("alexnet FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
--------------------------------------------------------------------------------
/test_examples/test_llm.py:
--------------------------------------------------------------------------------
1 | # !usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 |
4 | '''
5 | Description :
6 | Version : 1.0
7 | Author : MrYXJ
8 | Mail : yxj2017@gmail.com
9 | Github : https://github.com/MrYxJ
10 | Date : 2023-08-24 11:49:08
11 | LastEditTime : 2023-09-03 11:38:11
12 | Copyright (C) 2023 mryxj. All rights reserved.
13 | '''
14 |
15 | from calflops import calculate_flops
16 | from transformers import LlamaTokenizer
17 | from transformers import LlamaForCausalLM
18 |
19 | batch_size = 1
20 | max_seq_length = 128
21 | model_name = "llama2_hf_7B"
22 | model_save = "../model/" + model_name
23 | model = LlamaForCausalLM.from_pretrained(model_save)
24 | tokenizer = LlamaTokenizer.from_pretrained(model_save)
25 | flops, macs, params = calculate_flops(model=model,
26 | input_shape=(batch_size, max_seq_length),
27 | transformer_tokenizer=tokenizer)
28 | print("Llama2(7B) FLOPs:%s MACs:%s Params:%s \n" %(flops, macs, params))
29 |
30 |
--------------------------------------------------------------------------------
/test_llm_huggingface.py:
--------------------------------------------------------------------------------
1 | # !usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 |
4 | '''
5 | Description :
6 | Version : 1.0
7 | Author : MrYXJ
8 | Mail : yxj2017@gmail.com
9 | Github : https://github.com/MrYxJ
10 | Date : 2023-09-03 11:21:30
11 | LastEditTime : 2023-09-09 00:56:46
12 | Copyright (C) 2023 mryxj. All rights reserved.
13 | '''
14 |
15 | from calflops import calculate_flops_hf
16 |
17 | batch_size = 1
18 | max_seq_length = 128
19 | # model_name = "baichuan-inc/Baichuan-13B-Chat"
20 | # flops, macs, params = calculate_flops_hf(model_name=model_name,
21 | # input_shape=(batch_size, max_seq_length))
22 | # print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
23 |
24 |
25 | model_name = "baichuan-inc/Baichuan2-13B-Chat"
26 | flops, macs, params, print_results = calculate_flops_hf(model_name=model_name,
27 | input_shape=(batch_size, max_seq_length),
28 | forward_mode="forward",
29 | print_results=False,
30 | return_results=True)
31 |
32 | print(print_results)
33 | print("%s FLOPs:%s MACs:%s Params:%s \n" %(model_name, flops, macs, params))
34 |
--------------------------------------------------------------------------------