├── CONTRIBUTING.md
├── MANIFEST.in
├── README.md
├── YOLOv8_Object_Tracking_Blurring_Counting.ipynb
├── figure
├── figure1.png
└── figure2.png
├── mkdocs.yml
├── requirements.txt
├── setup.cfg
├── setup.py
└── ultralytics
├── __init__.py
├── hub
├── __init__.py
├── auth.py
├── session.py
└── utils.py
├── models
├── README.md
├── v3
│ ├── yolov3-spp.yaml
│ ├── yolov3-tiny.yaml
│ └── yolov3.yaml
├── v5
│ ├── yolov5l.yaml
│ ├── yolov5m.yaml
│ ├── yolov5n.yaml
│ ├── yolov5s.yaml
│ └── yolov5x.yaml
└── v8
│ ├── cls
│ ├── yolov8l-cls.yaml
│ ├── yolov8m-cls.yaml
│ ├── yolov8n-cls.yaml
│ ├── yolov8s-cls.yaml
│ └── yolov8x-cls.yaml
│ ├── seg
│ ├── yolov8l-seg.yaml
│ ├── yolov8m-seg.yaml
│ ├── yolov8n-seg.yaml
│ ├── yolov8s-seg.yaml
│ └── yolov8x-seg.yaml
│ ├── yolov8l.yaml
│ ├── yolov8m.yaml
│ ├── yolov8n.yaml
│ ├── yolov8s.yaml
│ ├── yolov8x.yaml
│ └── yolov8x6.yaml
├── nn
├── __init__.py
├── autobackend.py
├── modules.py
└── tasks.py
└── yolo
├── cli.py
├── configs
├── __init__.py
├── default.yaml
└── hydra_patch.py
├── data
├── __init__.py
├── augment.py
├── base.py
├── build.py
├── dataloaders
│ ├── __init__.py
│ ├── stream_loaders.py
│ ├── v5augmentations.py
│ └── v5loader.py
├── dataset.py
├── dataset_wrappers.py
├── datasets
│ ├── Argoverse.yaml
│ ├── GlobalWheat2020.yaml
│ ├── ImageNet.yaml
│ ├── Objects365.yaml
│ ├── SKU-110K.yaml
│ ├── VOC.yaml
│ ├── VisDrone.yaml
│ ├── coco.yaml
│ ├── coco128-seg.yaml
│ ├── coco128.yaml
│ └── xView.yaml
├── scripts
│ ├── download_weights.sh
│ ├── get_coco.sh
│ ├── get_coco128.sh
│ └── get_imagenet.sh
└── utils.py
├── engine
├── __init__.py
├── exporter.py
├── model.py
├── predictor.py
├── trainer.py
└── validator.py
├── utils
├── __init__.py
├── autobatch.py
├── callbacks
│ ├── __init__.py
│ ├── base.py
│ ├── clearml.py
│ ├── comet.py
│ ├── hub.py
│ └── tensorboard.py
├── checks.py
├── dist.py
├── downloads.py
├── files.py
├── instance.py
├── loss.py
├── metrics.py
├── ops.py
├── plotting.py
├── tal.py
└── torch_utils.py
└── v8
└── detect
├── __init__.py
├── predict.py
├── train.py
└── val.py
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | ## Contributing to YOLOv8 🚀
2 |
3 | We love your input! We want to make contributing to YOLOv8 as easy and transparent as possible, whether it's:
4 |
5 | - Reporting a bug
6 | - Discussing the current state of the code
7 | - Submitting a fix
8 | - Proposing a new feature
9 | - Becoming a maintainer
10 |
11 | YOLOv8 works so well due to our combined community effort, and for every small improvement you contribute you will be
12 | helping push the frontiers of what's possible in AI 😃!
13 |
14 | ## Submitting a Pull Request (PR) 🛠️
15 |
16 | Submitting a PR is easy! This example shows how to submit a PR for updating `requirements.txt` in 4 steps:
17 |
18 | ### 1. Select File to Update
19 |
20 | Select `requirements.txt` to update by clicking on it in GitHub.
21 |
22 | 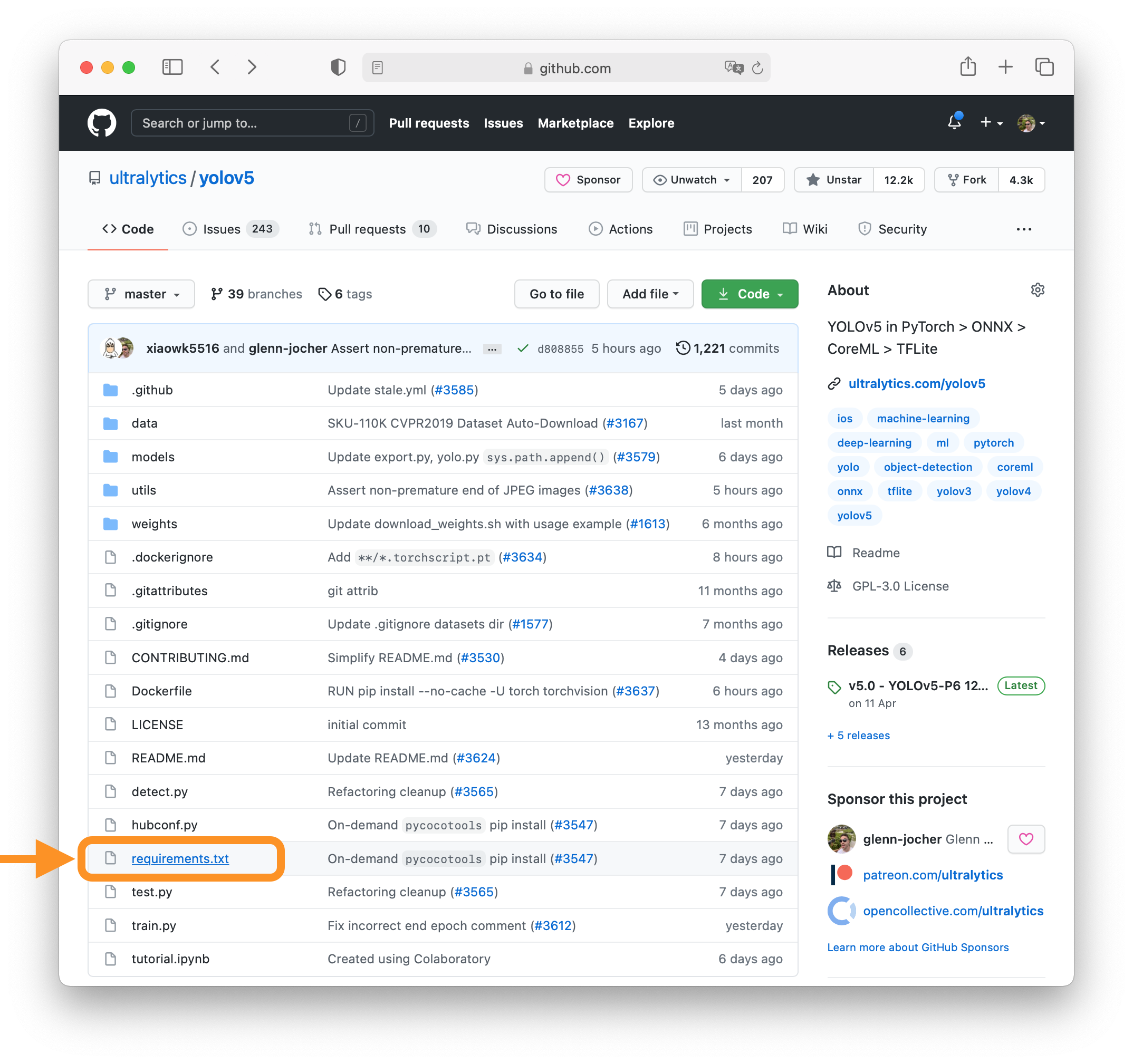
23 |
24 | ### 2. Click 'Edit this file'
25 |
26 | Button is in top-right corner.
27 |
28 | 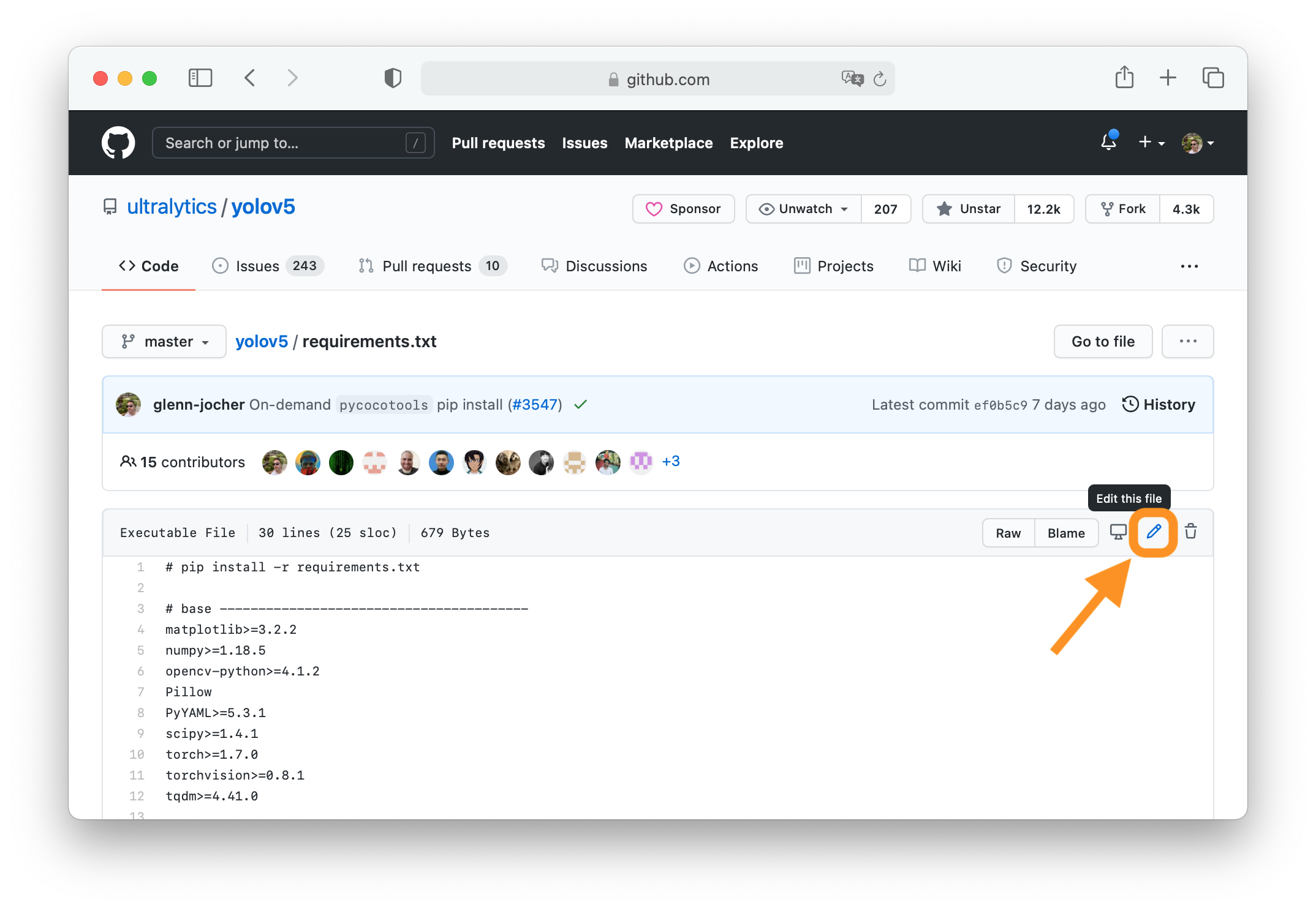
29 |
30 | ### 3. Make Changes
31 |
32 | Change `matplotlib` version from `3.2.2` to `3.3`.
33 |
34 | 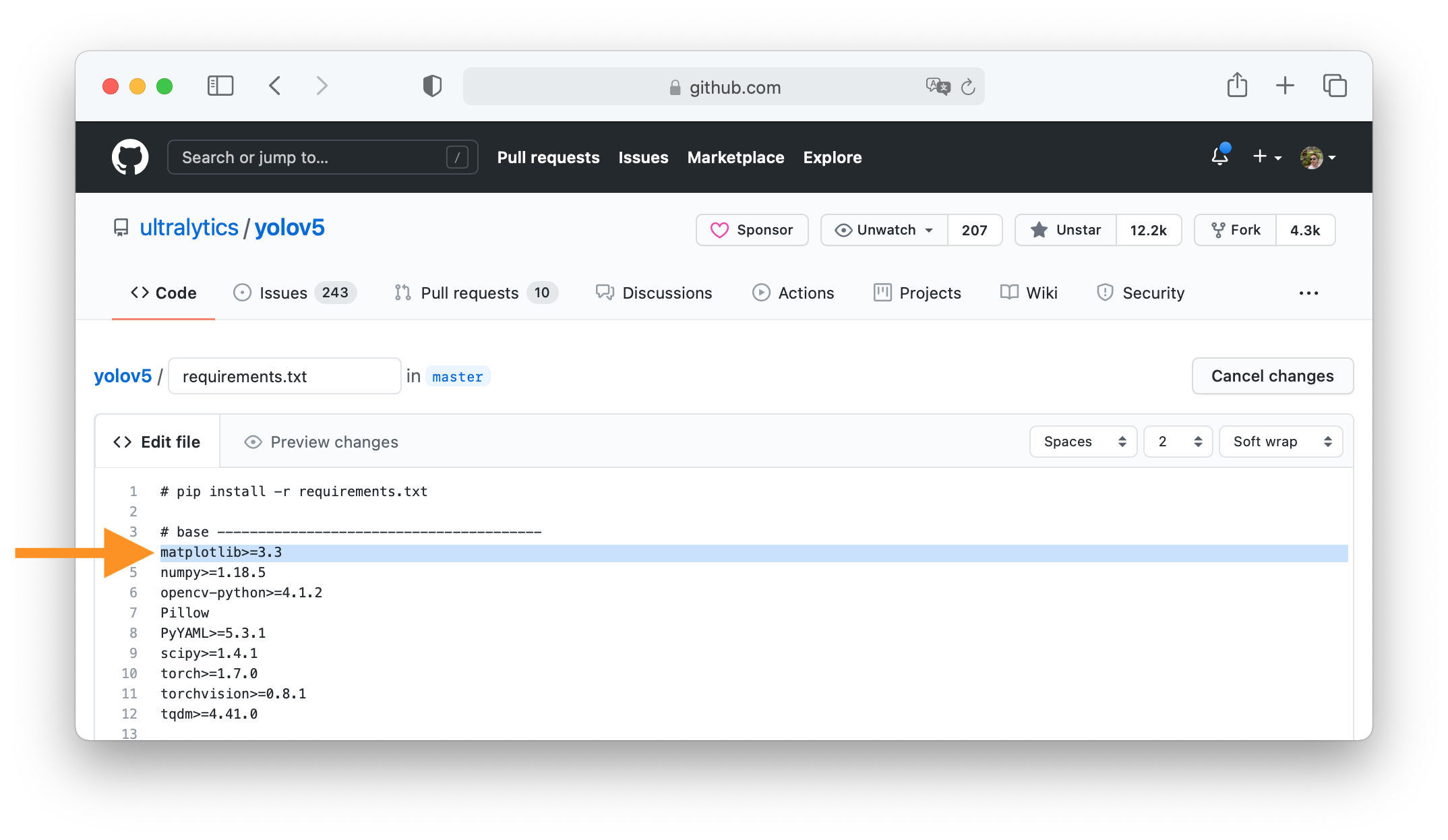
35 |
36 | ### 4. Preview Changes and Submit PR
37 |
38 | Click on the **Preview changes** tab to verify your updates. At the bottom of the screen select 'Create a **new branch**
39 | for this commit', assign your branch a descriptive name such as `fix/matplotlib_version` and click the green **Propose
40 | changes** button. All done, your PR is now submitted to YOLOv8 for review and approval 😃!
41 |
42 | 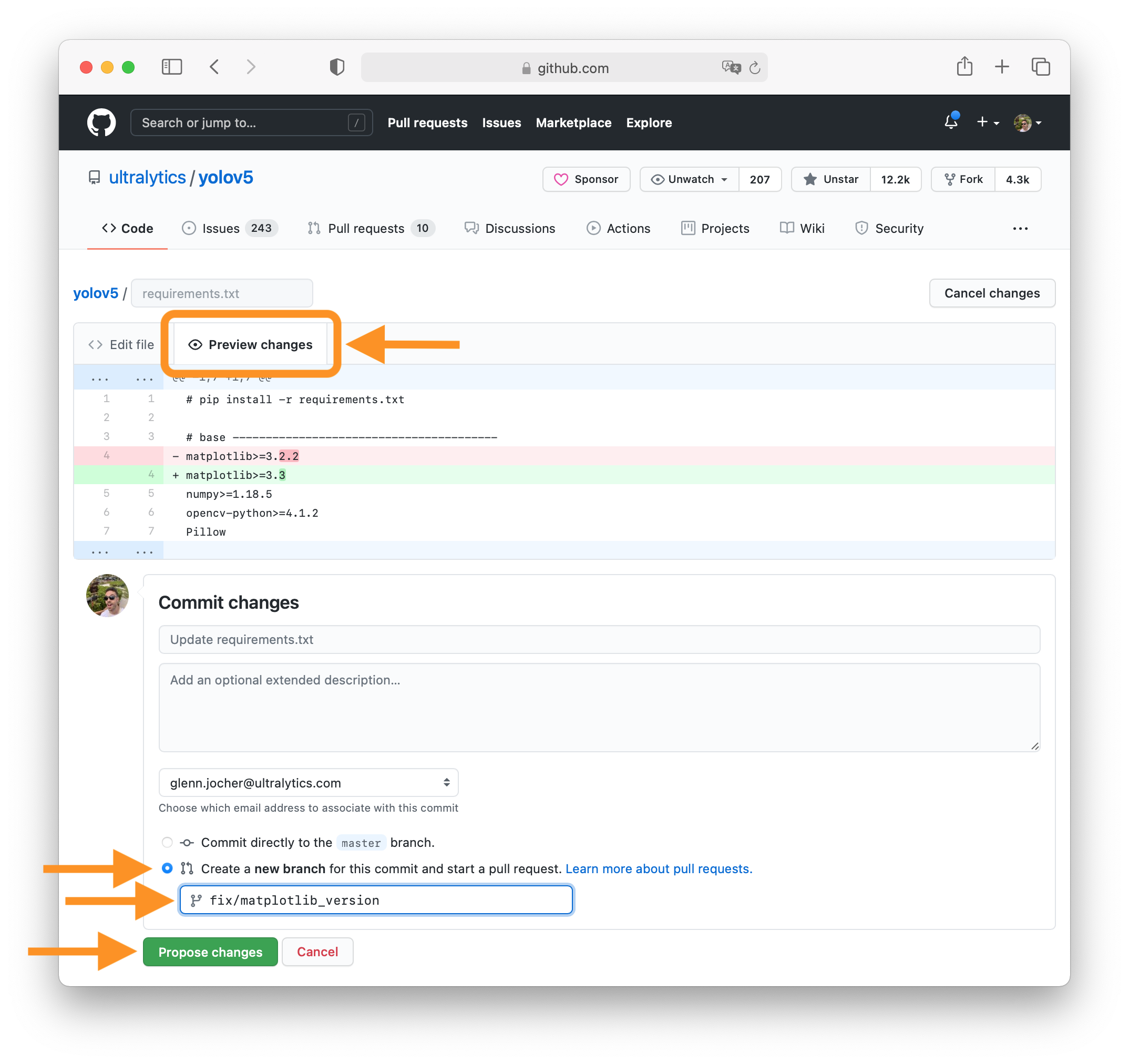
43 |
44 | ### PR recommendations
45 |
46 | To allow your work to be integrated as seamlessly as possible, we advise you to:
47 |
48 | - ✅ Verify your PR is **up-to-date** with `ultralytics/ultralytics` `master` branch. If your PR is behind you can update
49 | your code by clicking the 'Update branch' button or by running `git pull` and `git merge master` locally.
50 |
51 | 
52 |
53 | - ✅ Verify all YOLOv8 Continuous Integration (CI) **checks are passing**.
54 |
55 | 
56 |
57 | - ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase
58 | but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
59 |
60 | ### Docstrings
61 |
62 | Not all functions or classes require docstrings but when they do, we follow [google-stlye docstrings format](https://google.github.io/styleguide/pyguide.html#38-comments-and-docstrings). Here is an example:
63 |
64 | ```python
65 | """
66 | What the function does - performs nms on given detection predictions
67 |
68 | Args:
69 | arg1: The description of the 1st argument
70 | arg2: The description of the 2nd argument
71 |
72 | Returns:
73 | What the function returns. Empty if nothing is returned
74 |
75 | Raises:
76 | Exception Class: When and why this exception can be raised by the function.
77 | """
78 | ```
79 |
80 | ## Submitting a Bug Report 🐛
81 |
82 | If you spot a problem with YOLOv8 please submit a Bug Report!
83 |
84 | For us to start investigating a possible problem we need to be able to reproduce it ourselves first. We've created a few
85 | short guidelines below to help users provide what we need in order to get started.
86 |
87 | When asking a question, people will be better able to provide help if you provide **code** that they can easily
88 | understand and use to **reproduce** the problem. This is referred to by community members as creating
89 | a [minimum reproducible example](https://stackoverflow.com/help/minimal-reproducible-example). Your code that reproduces
90 | the problem should be:
91 |
92 | - ✅ **Minimal** – Use as little code as possible that still produces the same problem
93 | - ✅ **Complete** – Provide **all** parts someone else needs to reproduce your problem in the question itself
94 | - ✅ **Reproducible** – Test the code you're about to provide to make sure it reproduces the problem
95 |
96 | In addition to the above requirements, for [Ultralytics](https://ultralytics.com/) to provide assistance your code
97 | should be:
98 |
99 | - ✅ **Current** – Verify that your code is up-to-date with current
100 | GitHub [master](https://github.com/ultralytics/ultralytics/tree/main), and if necessary `git pull` or `git clone` a new
101 | copy to ensure your problem has not already been resolved by previous commits.
102 | - ✅ **Unmodified** – Your problem must be reproducible without any modifications to the codebase in this
103 | repository. [Ultralytics](https://ultralytics.com/) does not provide support for custom code ⚠️.
104 |
105 | If you believe your problem meets all of the above criteria, please close this issue and raise a new one using the 🐛
106 | **Bug Report** [template](https://github.com/ultralytics/ultralytics/issues/new/choose) and providing
107 | a [minimum reproducible example](https://stackoverflow.com/help/minimal-reproducible-example) to help us better
108 | understand and diagnose your problem.
109 |
110 | ## License
111 |
112 | By contributing, you agree that your contributions will be licensed under
113 | the [GPL-3.0 license](https://choosealicense.com/licenses/gpl-3.0/)
114 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include *.md
2 | include requirements.txt
3 | include LICENSE
4 | include setup.py
5 | recursive-include ultralytics *.yaml
6 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | YOLOv8 Object Tracking (ID + Trails) Blurring and Counting
3 |
4 | ## Google Colab File Link (A Single Click Solution)
5 | The google colab file link for yolov8 object tracking, blurring and counting is provided below, you can check the implementation in Google Colab, and its a single click implementation
6 | ,you just need to select the Run Time as GPU, and click on Run All.
7 |
8 | [`Google Colab File`](https://colab.research.google.com/drive/1haDui8z7OvITbOpGL1d0NFf6M4BxcI-y?usp=sharing)
9 |
10 | ## YOLOv8 Segmentation with DeepSORT Object Tracking
11 |
12 | [`Github Repo Link`](https://github.com/MuhammadMoinFaisal/YOLOv8_Segmentation_DeepSORT_Object_Tracking.git)
13 |
14 | ## Steps to run Code
15 |
16 | - Clone the repository
17 | ```
18 | git clone https://github.com/MuhammadMoinFaisal/YOLOv8-object-tracking-blurring-counting.git
19 | ```
20 | - Goto the cloned folder.
21 | ```
22 | cd YOLOv8-object-tracking-blurring-counting
23 | ```
24 | - Install the dependecies
25 | ```
26 | pip install -e '.[dev]'
27 |
28 | ```
29 |
30 | - Setting the Directory.
31 | ```
32 | cd ultralytics/yolo/v8/detect
33 |
34 | ```
35 | - Downloading the DeepSORT Files From The Google Drive
36 | ```
37 |
38 | https://drive.google.com/drive/folders/1kna8eWGrSfzaR6DtNJ8_GchGgPMv3VC8?usp=sharing
39 | ```
40 | - After downloading the DeepSORT Zip file from the drive, unzip it go into the subfolders and place the deep_sort_pytorch folder into the yolo/v8/detect folder
41 |
42 | - Downloading a Sample Video from the Google Drive
43 | ```
44 | gdown https://drive.google.com/uc?id=1_kt1alzcLRVxet-Drx0mt_KFSd3vrtHU
45 | ```
46 |
47 | - Run the code with mentioned command below.
48 |
49 | - For yolov8 object detection, Tracking, blurring and object counting
50 | ```
51 | python predict.py model=yolov8l.pt source="test1.mp4" show=True
52 | ```
53 |
54 | ### RESULTS
55 |
56 | #### YOLOv8 Object Detection, Tracking, Blurring and Counting
57 | 
58 |
59 | #### YOLOv8 Object Detection, Tracking, Blurring and Counting
60 |
61 | 
62 |
63 | ### Watch the Complete Step by Step Explanation
64 |
65 | - Video Tutorial Link [`YouTube Link`](https://www.youtube.com/watch?v=QWrP77qXEMA)
66 |
67 |
68 | []([https://www.youtube.com/watch?v=StTqXEQ2l-Y](https://www.youtube.com/watch?v=QWrP77qXEMA))
69 |
70 |
--------------------------------------------------------------------------------
/figure/figure1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MuhammadMoinFaisal/YOLOv8-object-tracking-blurring-counting/6ad9082f7d0022b22a2325e1078dc3534113f7df/figure/figure1.png
--------------------------------------------------------------------------------
/figure/figure2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MuhammadMoinFaisal/YOLOv8-object-tracking-blurring-counting/6ad9082f7d0022b22a2325e1078dc3534113f7df/figure/figure2.png
--------------------------------------------------------------------------------
/mkdocs.yml:
--------------------------------------------------------------------------------
1 | site_name: Ultralytics Docs
2 | repo_url: https://github.com/ultralytics/ultralytics
3 | repo_name: Ultralytics
4 |
5 | theme:
6 | name: "material"
7 | logo: https://github.com/ultralytics/assets/raw/main/logo/Ultralytics-logomark-white.png
8 | icon:
9 | repo: fontawesome/brands/github
10 | admonition:
11 | note: octicons/tag-16
12 | abstract: octicons/checklist-16
13 | info: octicons/info-16
14 | tip: octicons/squirrel-16
15 | success: octicons/check-16
16 | question: octicons/question-16
17 | warning: octicons/alert-16
18 | failure: octicons/x-circle-16
19 | danger: octicons/zap-16
20 | bug: octicons/bug-16
21 | example: octicons/beaker-16
22 | quote: octicons/quote-16
23 |
24 | palette:
25 | # Palette toggle for light mode
26 | - scheme: default
27 | toggle:
28 | icon: material/brightness-7
29 | name: Switch to dark mode
30 |
31 | # Palette toggle for dark mode
32 | - scheme: slate
33 | toggle:
34 | icon: material/brightness-4
35 | name: Switch to light mode
36 | features:
37 | - content.code.annotate
38 | - content.tooltips
39 | - search.highlight
40 | - search.share
41 | - search.suggest
42 | - toc.follow
43 |
44 | extra_css:
45 | - stylesheets/style.css
46 |
47 | markdown_extensions:
48 | # Div text decorators
49 | - admonition
50 | - pymdownx.details
51 | - pymdownx.superfences
52 | - tables
53 | - attr_list
54 | - def_list
55 | # Syntax highlight
56 | - pymdownx.highlight:
57 | anchor_linenums: true
58 | - pymdownx.inlinehilite
59 | - pymdownx.snippets
60 |
61 | # Button
62 | - attr_list
63 |
64 | # Content tabs
65 | - pymdownx.superfences
66 | - pymdownx.tabbed:
67 | alternate_style: true
68 |
69 | # Highlight
70 | - pymdownx.critic
71 | - pymdownx.caret
72 | - pymdownx.keys
73 | - pymdownx.mark
74 | - pymdownx.tilde
75 | plugins:
76 | - mkdocstrings
77 |
78 | # Primary navigation
79 | nav:
80 | - Quickstart: quickstart.md
81 | - CLI: cli.md
82 | - Python Interface: sdk.md
83 | - Configuration: config.md
84 | - Customization Guide: engine.md
85 | - Ultralytics HUB: hub.md
86 | - iOS and Android App: app.md
87 | - Reference:
88 | - Python Model interface: reference/model.md
89 | - Engine:
90 | - Trainer: reference/base_trainer.md
91 | - Validator: reference/base_val.md
92 | - Predictor: reference/base_pred.md
93 | - Exporter: reference/exporter.md
94 | - nn Module: reference/nn.md
95 | - operations: reference/ops.md
96 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | # Ultralytics requirements
2 | # Usage: pip install -r requirements.txt
3 |
4 | # Base ----------------------------------------
5 | hydra-core>=1.2.0
6 | matplotlib>=3.2.2
7 | numpy>=1.18.5
8 | opencv-python>=4.1.1
9 | Pillow>=7.1.2
10 | PyYAML>=5.3.1
11 | requests>=2.23.0
12 | scipy>=1.4.1
13 | torch>=1.7.0
14 | torchvision>=0.8.1
15 | tqdm>=4.64.0
16 |
17 | # Logging -------------------------------------
18 | tensorboard>=2.4.1
19 | # clearml
20 | # comet
21 |
22 | # Plotting ------------------------------------
23 | pandas>=1.1.4
24 | seaborn>=0.11.0
25 |
26 | # Export --------------------------------------
27 | # coremltools>=6.0 # CoreML export
28 | # onnx>=1.12.0 # ONNX export
29 | # onnx-simplifier>=0.4.1 # ONNX simplifier
30 | # nvidia-pyindex # TensorRT export
31 | # nvidia-tensorrt # TensorRT export
32 | # scikit-learn==0.19.2 # CoreML quantization
33 | # tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)
34 | # tensorflowjs>=3.9.0 # TF.js export
35 | # openvino-dev # OpenVINO export
36 |
37 | # Extras --------------------------------------
38 | ipython # interactive notebook
39 | psutil # system utilization
40 | thop>=0.1.1 # FLOPs computation
41 | # albumentations>=1.0.3
42 | # pycocotools>=2.0.6 # COCO mAP
43 | # roboflow
44 |
45 | # HUB -----------------------------------------
46 | GitPython>=3.1.24
47 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | # Project-wide configuration file, can be used for package metadata and other toll configurations
2 | # Example usage: global configuration for PEP8 (via flake8) setting or default pytest arguments
3 | # Local usage: pip install pre-commit, pre-commit run --all-files
4 |
5 | [metadata]
6 | license_file = LICENSE
7 | description_file = README.md
8 |
9 | [tool:pytest]
10 | norecursedirs =
11 | .git
12 | dist
13 | build
14 | addopts =
15 | --doctest-modules
16 | --durations=25
17 | --color=yes
18 |
19 | [flake8]
20 | max-line-length = 120
21 | exclude = .tox,*.egg,build,temp
22 | select = E,W,F
23 | doctests = True
24 | verbose = 2
25 | # https://pep8.readthedocs.io/en/latest/intro.html#error-codes
26 | format = pylint
27 | # see: https://www.flake8rules.com/
28 | ignore = E731,F405,E402,F401,W504,E127,E231,E501,F403
29 | # E731: Do not assign a lambda expression, use a def
30 | # F405: name may be undefined, or defined from star imports: module
31 | # E402: module level import not at top of file
32 | # F401: module imported but unused
33 | # W504: line break after binary operator
34 | # E127: continuation line over-indented for visual indent
35 | # E231: missing whitespace after ‘,’, ‘;’, or ‘:’
36 | # E501: line too long
37 | # F403: ‘from module import *’ used; unable to detect undefined names
38 |
39 | [isort]
40 | # https://pycqa.github.io/isort/docs/configuration/options.html
41 | line_length = 120
42 | # see: https://pycqa.github.io/isort/docs/configuration/multi_line_output_modes.html
43 | multi_line_output = 0
44 |
45 | [yapf]
46 | based_on_style = pep8
47 | spaces_before_comment = 2
48 | COLUMN_LIMIT = 120
49 | COALESCE_BRACKETS = True
50 | SPACES_AROUND_POWER_OPERATOR = True
51 | SPACE_BETWEEN_ENDING_COMMA_AND_CLOSING_BRACKET = False
52 | SPLIT_BEFORE_CLOSING_BRACKET = False
53 | SPLIT_BEFORE_FIRST_ARGUMENT = False
54 | # EACH_DICT_ENTRY_ON_SEPARATE_LINE = False
55 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import re
4 | from pathlib import Path
5 |
6 | import pkg_resources as pkg
7 | from setuptools import find_packages, setup
8 |
9 | # Settings
10 | FILE = Path(__file__).resolve()
11 | ROOT = FILE.parent # root directory
12 | README = (ROOT / "README.md").read_text(encoding="utf-8")
13 | REQUIREMENTS = [f'{x.name}{x.specifier}' for x in pkg.parse_requirements((ROOT / 'requirements.txt').read_text())]
14 |
15 |
16 | def get_version():
17 | file = ROOT / 'ultralytics/__init__.py'
18 | return re.search(r'^__version__ = [\'"]([^\'"]*)[\'"]', file.read_text(), re.M)[1]
19 |
20 |
21 | setup(
22 | name="ultralytics", # name of pypi package
23 | version=get_version(), # version of pypi package
24 | python_requires=">=3.7.0",
25 | license='GPL-3.0',
26 | description='Ultralytics YOLOv8 and HUB',
27 | long_description=README,
28 | long_description_content_type="text/markdown",
29 | url="https://github.com/ultralytics/ultralytics",
30 | project_urls={
31 | 'Bug Reports': 'https://github.com/ultralytics/ultralytics/issues',
32 | 'Funding': 'https://ultralytics.com',
33 | 'Source': 'https://github.com/ultralytics/ultralytics',},
34 | author="Ultralytics",
35 | author_email='hello@ultralytics.com',
36 | packages=find_packages(), # required
37 | include_package_data=True,
38 | install_requires=REQUIREMENTS,
39 | extras_require={
40 | 'dev':
41 | ['check-manifest', 'pytest', 'pytest-cov', 'coverage', 'mkdocs', 'mkdocstrings[python]', 'mkdocs-material'],},
42 | classifiers=[
43 | "Intended Audience :: Developers", "Intended Audience :: Science/Research",
44 | "License :: OSI Approved :: GNU General Public License v3 (GPLv3)", "Programming Language :: Python :: 3",
45 | "Programming Language :: Python :: 3.7", "Programming Language :: Python :: 3.8",
46 | "Programming Language :: Python :: 3.9", "Programming Language :: Python :: 3.10",
47 | "Topic :: Software Development", "Topic :: Scientific/Engineering",
48 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
49 | "Topic :: Scientific/Engineering :: Image Recognition", "Operating System :: POSIX :: Linux",
50 | "Operating System :: MacOS", "Operating System :: Microsoft :: Windows"],
51 | keywords="machine-learning, deep-learning, vision, ML, DL, AI, YOLO, YOLOv3, YOLOv5, YOLOv8, HUB, Ultralytics",
52 | entry_points={
53 | 'console_scripts': ['yolo = ultralytics.yolo.cli:cli', 'ultralytics = ultralytics.yolo.cli:cli'],})
54 |
--------------------------------------------------------------------------------
/ultralytics/__init__.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | __version__ = "8.0.3"
4 |
5 | from ultralytics.hub import checks
6 | from ultralytics.yolo.engine.model import YOLO
7 | from ultralytics.yolo.utils import ops
8 |
9 | __all__ = ["__version__", "YOLO", "hub", "checks"] # allow simpler import
10 |
--------------------------------------------------------------------------------
/ultralytics/hub/__init__.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import os
4 | import shutil
5 |
6 | import psutil
7 | import requests
8 | from IPython import display # to display images and clear console output
9 |
10 | from ultralytics.hub.auth import Auth
11 | from ultralytics.hub.session import HubTrainingSession
12 | from ultralytics.hub.utils import PREFIX, split_key
13 | from ultralytics.yolo.utils import LOGGER, emojis, is_colab
14 | from ultralytics.yolo.utils.torch_utils import select_device
15 | from ultralytics.yolo.v8.detect import DetectionTrainer
16 |
17 |
18 | def checks(verbose=True):
19 | if is_colab():
20 | shutil.rmtree('sample_data', ignore_errors=True) # remove colab /sample_data directory
21 |
22 | if verbose:
23 | # System info
24 | gib = 1 << 30 # bytes per GiB
25 | ram = psutil.virtual_memory().total
26 | total, used, free = shutil.disk_usage("/")
27 | display.clear_output()
28 | s = f'({os.cpu_count()} CPUs, {ram / gib:.1f} GB RAM, {(total - free) / gib:.1f}/{total / gib:.1f} GB disk)'
29 | else:
30 | s = ''
31 |
32 | select_device(newline=False)
33 | LOGGER.info(f'Setup complete ✅ {s}')
34 |
35 |
36 | def start(key=''):
37 | # Start training models with Ultralytics HUB. Usage: from src.ultralytics import start; start('API_KEY')
38 | def request_api_key(attempts=0):
39 | """Prompt the user to input their API key"""
40 | import getpass
41 |
42 | max_attempts = 3
43 | tries = f"Attempt {str(attempts + 1)} of {max_attempts}" if attempts > 0 else ""
44 | LOGGER.info(f"{PREFIX}Login. {tries}")
45 | input_key = getpass.getpass("Enter your Ultralytics HUB API key:\n")
46 | auth.api_key, model_id = split_key(input_key)
47 | if not auth.authenticate():
48 | attempts += 1
49 | LOGGER.warning(f"{PREFIX}Invalid API key ⚠️\n")
50 | if attempts < max_attempts:
51 | return request_api_key(attempts)
52 | raise ConnectionError(emojis(f"{PREFIX}Failed to authenticate ❌"))
53 | else:
54 | return model_id
55 |
56 | try:
57 | api_key, model_id = split_key(key)
58 | auth = Auth(api_key) # attempts cookie login if no api key is present
59 | attempts = 1 if len(key) else 0
60 | if not auth.get_state():
61 | if len(key):
62 | LOGGER.warning(f"{PREFIX}Invalid API key ⚠️\n")
63 | model_id = request_api_key(attempts)
64 | LOGGER.info(f"{PREFIX}Authenticated ✅")
65 | if not model_id:
66 | raise ConnectionError(emojis('Connecting with global API key is not currently supported. ❌'))
67 | session = HubTrainingSession(model_id=model_id, auth=auth)
68 | session.check_disk_space()
69 |
70 | # TODO: refactor, hardcoded for v8
71 | args = session.model.copy()
72 | args.pop("id")
73 | args.pop("status")
74 | args.pop("weights")
75 | args["data"] = "coco128.yaml"
76 | args["model"] = "yolov8n.yaml"
77 | args["batch_size"] = 16
78 | args["imgsz"] = 64
79 |
80 | trainer = DetectionTrainer(overrides=args)
81 | session.register_callbacks(trainer)
82 | setattr(trainer, 'hub_session', session)
83 | trainer.train()
84 | except Exception as e:
85 | LOGGER.warning(f"{PREFIX}{e}")
86 |
87 |
88 | def reset_model(key=''):
89 | # Reset a trained model to an untrained state
90 | api_key, model_id = split_key(key)
91 | r = requests.post('https://api.ultralytics.com/model-reset', json={"apiKey": api_key, "modelId": model_id})
92 |
93 | if r.status_code == 200:
94 | LOGGER.info(f"{PREFIX}model reset successfully")
95 | return
96 | LOGGER.warning(f"{PREFIX}model reset failure {r.status_code} {r.reason}")
97 |
98 |
99 | def export_model(key='', format='torchscript'):
100 | # Export a model to all formats
101 | api_key, model_id = split_key(key)
102 | formats = ('torchscript', 'onnx', 'openvino', 'engine', 'coreml', 'saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs',
103 | 'ultralytics_tflite', 'ultralytics_coreml')
104 | assert format in formats, f"ERROR: Unsupported export format '{format}' passed, valid formats are {formats}"
105 |
106 | r = requests.post('https://api.ultralytics.com/export',
107 | json={
108 | "apiKey": api_key,
109 | "modelId": model_id,
110 | "format": format})
111 | assert r.status_code == 200, f"{PREFIX}{format} export failure {r.status_code} {r.reason}"
112 | LOGGER.info(f"{PREFIX}{format} export started ✅")
113 |
114 |
115 | def get_export(key='', format='torchscript'):
116 | # Get an exported model dictionary with download URL
117 | api_key, model_id = split_key(key)
118 | formats = ('torchscript', 'onnx', 'openvino', 'engine', 'coreml', 'saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs',
119 | 'ultralytics_tflite', 'ultralytics_coreml')
120 | assert format in formats, f"ERROR: Unsupported export format '{format}' passed, valid formats are {formats}"
121 |
122 | r = requests.post('https://api.ultralytics.com/get-export',
123 | json={
124 | "apiKey": api_key,
125 | "modelId": model_id,
126 | "format": format})
127 | assert r.status_code == 200, f"{PREFIX}{format} get_export failure {r.status_code} {r.reason}"
128 | return r.json()
129 |
130 |
131 | # temp. For checking
132 | if __name__ == "__main__":
133 | start(key="b3fba421be84a20dbe68644e14436d1cce1b0a0aaa_HeMfHgvHsseMPhdq7Ylz")
134 |
--------------------------------------------------------------------------------
/ultralytics/hub/auth.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import requests
4 |
5 | from ultralytics.hub.utils import HUB_API_ROOT, request_with_credentials
6 | from ultralytics.yolo.utils import is_colab
7 |
8 | API_KEY_PATH = "https://hub.ultralytics.com/settings?tab=api+keys"
9 |
10 |
11 | class Auth:
12 | id_token = api_key = model_key = False
13 |
14 | def __init__(self, api_key=None):
15 | self.api_key = self._clean_api_key(api_key)
16 | self.authenticate() if self.api_key else self.auth_with_cookies()
17 |
18 | @staticmethod
19 | def _clean_api_key(key: str) -> str:
20 | """Strip model from key if present"""
21 | separator = "_"
22 | return key.split(separator)[0] if separator in key else key
23 |
24 | def authenticate(self) -> bool:
25 | """Attempt to authenticate with server"""
26 | try:
27 | header = self.get_auth_header()
28 | if header:
29 | r = requests.post(f"{HUB_API_ROOT}/v1/auth", headers=header)
30 | if not r.json().get('success', False):
31 | raise ConnectionError("Unable to authenticate.")
32 | return True
33 | raise ConnectionError("User has not authenticated locally.")
34 | except ConnectionError:
35 | self.id_token = self.api_key = False # reset invalid
36 | return False
37 |
38 | def auth_with_cookies(self) -> bool:
39 | """
40 | Attempt to fetch authentication via cookies and set id_token.
41 | User must be logged in to HUB and running in a supported browser.
42 | """
43 | if not is_colab():
44 | return False # Currently only works with Colab
45 | try:
46 | authn = request_with_credentials(f"{HUB_API_ROOT}/v1/auth/auto")
47 | if authn.get("success", False):
48 | self.id_token = authn.get("data", {}).get("idToken", None)
49 | self.authenticate()
50 | return True
51 | raise ConnectionError("Unable to fetch browser authentication details.")
52 | except ConnectionError:
53 | self.id_token = False # reset invalid
54 | return False
55 |
56 | def get_auth_header(self):
57 | if self.id_token:
58 | return {"authorization": f"Bearer {self.id_token}"}
59 | elif self.api_key:
60 | return {"x-api-key": self.api_key}
61 | else:
62 | return None
63 |
64 | def get_state(self) -> bool:
65 | """Get the authentication state"""
66 | return self.id_token or self.api_key
67 |
68 | def set_api_key(self, key: str):
69 | """Get the authentication state"""
70 | self.api_key = key
71 |
--------------------------------------------------------------------------------
/ultralytics/hub/session.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import signal
4 | import sys
5 | from pathlib import Path
6 | from time import sleep
7 |
8 | import requests
9 |
10 | from ultralytics import __version__
11 | from ultralytics.hub.utils import HUB_API_ROOT, check_dataset_disk_space, smart_request
12 | from ultralytics.yolo.utils import LOGGER, is_colab, threaded
13 |
14 | AGENT_NAME = f'python-{__version__}-colab' if is_colab() else f'python-{__version__}-local'
15 |
16 | session = None
17 |
18 |
19 | def signal_handler(signum, frame):
20 | """ Confirm exit """
21 | global hub_logger
22 | LOGGER.info(f'Signal received. {signum} {frame}')
23 | if isinstance(session, HubTrainingSession):
24 | hub_logger.alive = False
25 | del hub_logger
26 | sys.exit(signum)
27 |
28 |
29 | signal.signal(signal.SIGTERM, signal_handler)
30 | signal.signal(signal.SIGINT, signal_handler)
31 |
32 |
33 | class HubTrainingSession:
34 |
35 | def __init__(self, model_id, auth):
36 | self.agent_id = None # identifies which instance is communicating with server
37 | self.model_id = model_id
38 | self.api_url = f'{HUB_API_ROOT}/v1/models/{model_id}'
39 | self.auth_header = auth.get_auth_header()
40 | self.rate_limits = {'metrics': 3.0, 'ckpt': 900.0, 'heartbeat': 300.0} # rate limits (seconds)
41 | self.t = {} # rate limit timers (seconds)
42 | self.metrics_queue = {} # metrics queue
43 | self.alive = True # for heartbeats
44 | self.model = self._get_model()
45 | self._heartbeats() # start heartbeats
46 |
47 | def __del__(self):
48 | # Class destructor
49 | self.alive = False
50 |
51 | def upload_metrics(self):
52 | payload = {"metrics": self.metrics_queue.copy(), "type": "metrics"}
53 | smart_request(f'{self.api_url}', json=payload, headers=self.auth_header, code=2)
54 |
55 | def upload_model(self, epoch, weights, is_best=False, map=0.0, final=False):
56 | # Upload a model to HUB
57 | file = None
58 | if Path(weights).is_file():
59 | with open(weights, "rb") as f:
60 | file = f.read()
61 | if final:
62 | smart_request(f'{self.api_url}/upload',
63 | data={
64 | "epoch": epoch,
65 | "type": "final",
66 | "map": map},
67 | files={"best.pt": file},
68 | headers=self.auth_header,
69 | retry=10,
70 | timeout=3600,
71 | code=4)
72 | else:
73 | smart_request(f'{self.api_url}/upload',
74 | data={
75 | "epoch": epoch,
76 | "type": "epoch",
77 | "isBest": bool(is_best)},
78 | headers=self.auth_header,
79 | files={"last.pt": file},
80 | code=3)
81 |
82 | def _get_model(self):
83 | # Returns model from database by id
84 | api_url = f"{HUB_API_ROOT}/v1/models/{self.model_id}"
85 | headers = self.auth_header
86 |
87 | try:
88 | r = smart_request(api_url, method="get", headers=headers, thread=False, code=0)
89 | data = r.json().get("data", None)
90 | if not data:
91 | return
92 | assert data['data'], 'ERROR: Dataset may still be processing. Please wait a minute and try again.' # RF fix
93 | self.model_id = data["id"]
94 |
95 | return data
96 | except requests.exceptions.ConnectionError as e:
97 | raise ConnectionRefusedError('ERROR: The HUB server is not online. Please try again later.') from e
98 |
99 | def check_disk_space(self):
100 | if not check_dataset_disk_space(self.model['data']):
101 | raise MemoryError("Not enough disk space")
102 |
103 | # COMMENT: Should not be needed as HUB is now considered an integration and is in integrations_callbacks
104 | # import ultralytics.yolo.utils.callbacks.hub as hub_callbacks
105 | # @staticmethod
106 | # def register_callbacks(trainer):
107 | # for k, v in hub_callbacks.callbacks.items():
108 | # trainer.add_callback(k, v)
109 |
110 | @threaded
111 | def _heartbeats(self):
112 | while self.alive:
113 | r = smart_request(f'{HUB_API_ROOT}/v1/agent/heartbeat/models/{self.model_id}',
114 | json={
115 | "agent": AGENT_NAME,
116 | "agentId": self.agent_id},
117 | headers=self.auth_header,
118 | retry=0,
119 | code=5,
120 | thread=False)
121 | self.agent_id = r.json().get('data', {}).get('agentId', None)
122 | sleep(self.rate_limits['heartbeat'])
123 |
--------------------------------------------------------------------------------
/ultralytics/hub/utils.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import os
4 | import shutil
5 | import threading
6 | import time
7 |
8 | import requests
9 |
10 | from ultralytics.yolo.utils import DEFAULT_CONFIG_DICT, LOGGER, RANK, SETTINGS, TryExcept, colorstr, emojis
11 |
12 | PREFIX = colorstr('Ultralytics: ')
13 | HELP_MSG = 'If this issue persists please visit https://github.com/ultralytics/hub/issues for assistance.'
14 | HUB_API_ROOT = os.environ.get("ULTRALYTICS_HUB_API", "https://api.ultralytics.com")
15 |
16 |
17 | def check_dataset_disk_space(url='https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip', sf=2.0):
18 | # Check that url fits on disk with safety factor sf, i.e. require 2GB free if url size is 1GB with sf=2.0
19 | gib = 1 << 30 # bytes per GiB
20 | data = int(requests.head(url).headers['Content-Length']) / gib # dataset size (GB)
21 | total, used, free = (x / gib for x in shutil.disk_usage("/")) # bytes
22 | LOGGER.info(f'{PREFIX}{data:.3f} GB dataset, {free:.1f}/{total:.1f} GB free disk space')
23 | if data * sf < free:
24 | return True # sufficient space
25 | LOGGER.warning(f'{PREFIX}WARNING: Insufficient free disk space {free:.1f} GB < {data * sf:.3f} GB required, '
26 | f'training cancelled ❌. Please free {data * sf - free:.1f} GB additional disk space and try again.')
27 | return False # insufficient space
28 |
29 |
30 | def request_with_credentials(url: str) -> any:
31 | """ Make an ajax request with cookies attached """
32 | from google.colab import output # noqa
33 | from IPython import display # noqa
34 | display.display(
35 | display.Javascript("""
36 | window._hub_tmp = new Promise((resolve, reject) => {
37 | const timeout = setTimeout(() => reject("Failed authenticating existing browser session"), 5000)
38 | fetch("%s", {
39 | method: 'POST',
40 | credentials: 'include'
41 | })
42 | .then((response) => resolve(response.json()))
43 | .then((json) => {
44 | clearTimeout(timeout);
45 | }).catch((err) => {
46 | clearTimeout(timeout);
47 | reject(err);
48 | });
49 | });
50 | """ % url))
51 | return output.eval_js("_hub_tmp")
52 |
53 |
54 | # Deprecated TODO: eliminate this function?
55 | def split_key(key=''):
56 | """
57 | Verify and split a 'api_key[sep]model_id' string, sep is one of '.' or '_'
58 |
59 | Args:
60 | key (str): The model key to split. If not provided, the user will be prompted to enter it.
61 |
62 | Returns:
63 | Tuple[str, str]: A tuple containing the API key and model ID.
64 | """
65 |
66 | import getpass
67 |
68 | error_string = emojis(f'{PREFIX}Invalid API key ⚠️\n') # error string
69 | if not key:
70 | key = getpass.getpass('Enter model key: ')
71 | sep = '_' if '_' in key else '.' if '.' in key else None # separator
72 | assert sep, error_string
73 | api_key, model_id = key.split(sep)
74 | assert len(api_key) and len(model_id), error_string
75 | return api_key, model_id
76 |
77 |
78 | def smart_request(*args, retry=3, timeout=30, thread=True, code=-1, method="post", verbose=True, **kwargs):
79 | """
80 | Makes an HTTP request using the 'requests' library, with exponential backoff retries up to a specified timeout.
81 |
82 | Args:
83 | *args: Positional arguments to be passed to the requests function specified in method.
84 | retry (int, optional): Number of retries to attempt before giving up. Default is 3.
85 | timeout (int, optional): Timeout in seconds after which the function will give up retrying. Default is 30.
86 | thread (bool, optional): Whether to execute the request in a separate daemon thread. Default is True.
87 | code (int, optional): An identifier for the request, used for logging purposes. Default is -1.
88 | method (str, optional): The HTTP method to use for the request. Choices are 'post' and 'get'. Default is 'post'.
89 | verbose (bool, optional): A flag to determine whether to print out to console or not. Default is True.
90 | **kwargs: Keyword arguments to be passed to the requests function specified in method.
91 |
92 | Returns:
93 | requests.Response: The HTTP response object. If the request is executed in a separate thread, returns None.
94 | """
95 | retry_codes = (408, 500) # retry only these codes
96 |
97 | def func(*func_args, **func_kwargs):
98 | r = None # response
99 | t0 = time.time() # initial time for timer
100 | for i in range(retry + 1):
101 | if (time.time() - t0) > timeout:
102 | break
103 | if method == 'post':
104 | r = requests.post(*func_args, **func_kwargs) # i.e. post(url, data, json, files)
105 | elif method == 'get':
106 | r = requests.get(*func_args, **func_kwargs) # i.e. get(url, data, json, files)
107 | if r.status_code == 200:
108 | break
109 | try:
110 | m = r.json().get('message', 'No JSON message.')
111 | except AttributeError:
112 | m = 'Unable to read JSON.'
113 | if i == 0:
114 | if r.status_code in retry_codes:
115 | m += f' Retrying {retry}x for {timeout}s.' if retry else ''
116 | elif r.status_code == 429: # rate limit
117 | h = r.headers # response headers
118 | m = f"Rate limit reached ({h['X-RateLimit-Remaining']}/{h['X-RateLimit-Limit']}). " \
119 | f"Please retry after {h['Retry-After']}s."
120 | if verbose:
121 | LOGGER.warning(f"{PREFIX}{m} {HELP_MSG} ({r.status_code} #{code})")
122 | if r.status_code not in retry_codes:
123 | return r
124 | time.sleep(2 ** i) # exponential standoff
125 | return r
126 |
127 | if thread:
128 | threading.Thread(target=func, args=args, kwargs=kwargs, daemon=True).start()
129 | else:
130 | return func(*args, **kwargs)
131 |
132 |
133 | @TryExcept()
134 | def sync_analytics(cfg, all_keys=False, enabled=False):
135 | """
136 | Sync analytics data if enabled in the global settings
137 |
138 | Args:
139 | cfg (DictConfig): Configuration for the task and mode.
140 | all_keys (bool): Sync all items, not just non-default values.
141 | enabled (bool): For debugging.
142 | """
143 | if SETTINGS['sync'] and RANK in {-1, 0} and enabled:
144 | cfg = dict(cfg) # convert type from DictConfig to dict
145 | if not all_keys:
146 | cfg = {k: v for k, v in cfg.items() if v != DEFAULT_CONFIG_DICT.get(k, None)} # retain non-default values
147 | cfg['uuid'] = SETTINGS['uuid'] # add the device UUID to the configuration data
148 |
149 | # Send a request to the HUB API to sync analytics
150 | smart_request(f'{HUB_API_ROOT}/v1/usage/anonymous', json=cfg, headers=None, code=3, retry=0, verbose=False)
151 |
--------------------------------------------------------------------------------
/ultralytics/models/README.md:
--------------------------------------------------------------------------------
1 | ## Models
2 |
3 | Welcome to the Ultralytics Models directory! Here you will find a wide variety of pre-configured model configuration
4 | files (`*.yaml`s) that can be used to create custom YOLO models. The models in this directory have been expertly crafted
5 | and fine-tuned by the Ultralytics team to provide the best performance for a wide range of object detection and image
6 | segmentation tasks.
7 |
8 | These model configurations cover a wide range of scenarios, from simple object detection to more complex tasks like
9 | instance segmentation and object tracking. They are also designed to run efficiently on a variety of hardware platforms,
10 | from CPUs to GPUs. Whether you are a seasoned machine learning practitioner or just getting started with YOLO, this
11 | directory provides a great starting point for your custom model development needs.
12 |
13 | To get started, simply browse through the models in this directory and find one that best suits your needs. Once you've
14 | selected a model, you can use the provided `*.yaml` file to train and deploy your custom YOLO model with ease. See full
15 | details at the Ultralytics [Docs](https://docs.ultralytics.com), and if you need help or have any questions, feel free
16 | to reach out to the Ultralytics team for support. So, don't wait, start creating your custom YOLO model now!
17 |
18 | ### Usage
19 |
20 | Model `*.yaml` files may be used directly in the Command Line Interface (CLI) with a `yolo` command:
21 |
22 | ```bash
23 | yolo task=detect mode=train model=yolov8n.yaml data=coco128.yaml epochs=100
24 | ```
25 |
26 | They may also be used directly in a Python environment, and accepts the same
27 | [arguments](https://docs.ultralytics.com/config/) as in the CLI example above:
28 |
29 | ```python
30 | from ultralytics import YOLO
31 |
32 | model = YOLO("yolov8n.yaml") # build a YOLOv8n model from scratch
33 |
34 | model.info() # display model information
35 | model.train(data="coco128.yaml", epochs=100) # train the model
36 | ```
37 |
--------------------------------------------------------------------------------
/ultralytics/models/v3/yolov3-spp.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 1.0 # model depth multiple
6 | width_multiple: 1.0 # layer channel multiple
7 |
8 | # darknet53 backbone
9 | backbone:
10 | # [from, number, module, args]
11 | [[-1, 1, Conv, [32, 3, 1]], # 0
12 | [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
13 | [-1, 1, Bottleneck, [64]],
14 | [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
15 | [-1, 2, Bottleneck, [128]],
16 | [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
17 | [-1, 8, Bottleneck, [256]],
18 | [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
19 | [-1, 8, Bottleneck, [512]],
20 | [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
21 | [-1, 4, Bottleneck, [1024]], # 10
22 | ]
23 |
24 | # YOLOv3-SPP head
25 | head:
26 | [[-1, 1, Bottleneck, [1024, False]],
27 | [-1, 1, SPP, [512, [5, 9, 13]]],
28 | [-1, 1, Conv, [1024, 3, 1]],
29 | [-1, 1, Conv, [512, 1, 1]],
30 | [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
31 |
32 | [-2, 1, Conv, [256, 1, 1]],
33 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
34 | [[-1, 8], 1, Concat, [1]], # cat backbone P4
35 | [-1, 1, Bottleneck, [512, False]],
36 | [-1, 1, Bottleneck, [512, False]],
37 | [-1, 1, Conv, [256, 1, 1]],
38 | [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
39 |
40 | [-2, 1, Conv, [128, 1, 1]],
41 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
42 | [[-1, 6], 1, Concat, [1]], # cat backbone P3
43 | [-1, 1, Bottleneck, [256, False]],
44 | [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
45 |
46 | [[27, 22, 15], 1, Detect, [nc]], # Detect(P3, P4, P5)
47 | ]
48 |
--------------------------------------------------------------------------------
/ultralytics/models/v3/yolov3-tiny.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 1.0 # model depth multiple
6 | width_multiple: 1.0 # layer channel multiple
7 |
8 | # YOLOv3-tiny backbone
9 | backbone:
10 | # [from, number, module, args]
11 | [[-1, 1, Conv, [16, 3, 1]], # 0
12 | [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2
13 | [-1, 1, Conv, [32, 3, 1]],
14 | [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4
15 | [-1, 1, Conv, [64, 3, 1]],
16 | [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8
17 | [-1, 1, Conv, [128, 3, 1]],
18 | [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16
19 | [-1, 1, Conv, [256, 3, 1]],
20 | [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32
21 | [-1, 1, Conv, [512, 3, 1]],
22 | [-1, 1, nn.ZeroPad2d, [[0, 1, 0, 1]]], # 11
23 | [-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12
24 | ]
25 |
26 | # YOLOv3-tiny head
27 | head:
28 | [[-1, 1, Conv, [1024, 3, 1]],
29 | [-1, 1, Conv, [256, 1, 1]],
30 | [-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)
31 |
32 | [-2, 1, Conv, [128, 1, 1]],
33 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
34 | [[-1, 8], 1, Concat, [1]], # cat backbone P4
35 | [-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)
36 |
37 | [[19, 15], 1, Detect, [nc]], # Detect(P4, P5)
38 | ]
39 |
--------------------------------------------------------------------------------
/ultralytics/models/v3/yolov3.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 1.0 # model depth multiple
6 | width_multiple: 1.0 # layer channel multiple
7 |
8 | # darknet53 backbone
9 | backbone:
10 | # [from, number, module, args]
11 | [[-1, 1, Conv, [32, 3, 1]], # 0
12 | [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
13 | [-1, 1, Bottleneck, [64]],
14 | [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
15 | [-1, 2, Bottleneck, [128]],
16 | [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
17 | [-1, 8, Bottleneck, [256]],
18 | [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
19 | [-1, 8, Bottleneck, [512]],
20 | [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
21 | [-1, 4, Bottleneck, [1024]], # 10
22 | ]
23 |
24 | # YOLOv3 head
25 | head:
26 | [[-1, 1, Bottleneck, [1024, False]],
27 | [-1, 1, Conv, [512, 1, 1]],
28 | [-1, 1, Conv, [1024, 3, 1]],
29 | [-1, 1, Conv, [512, 1, 1]],
30 | [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
31 |
32 | [-2, 1, Conv, [256, 1, 1]],
33 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
34 | [[-1, 8], 1, Concat, [1]], # cat backbone P4
35 | [-1, 1, Bottleneck, [512, False]],
36 | [-1, 1, Bottleneck, [512, False]],
37 | [-1, 1, Conv, [256, 1, 1]],
38 | [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
39 |
40 | [-2, 1, Conv, [128, 1, 1]],
41 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
42 | [[-1, 6], 1, Concat, [1]], # cat backbone P3
43 | [-1, 1, Bottleneck, [256, False]],
44 | [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
45 |
46 | [[27, 22, 15], 1, Detect, [nc]], # Detect(P3, P4, P5)
47 | ]
48 |
--------------------------------------------------------------------------------
/ultralytics/models/v5/yolov5l.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 1.0 # model depth multiple
6 | width_multiple: 1.0 # layer channel multiple
7 |
8 | # YOLOv5 v6.0 backbone
9 | backbone:
10 | # [from, number, module, args]
11 | [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
12 | [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
13 | [-1, 3, C3, [128]],
14 | [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
15 | [-1, 6, C3, [256]],
16 | [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
17 | [-1, 9, C3, [512]],
18 | [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
19 | [-1, 3, C3, [1024]],
20 | [-1, 1, SPPF, [1024, 5]], # 9
21 | ]
22 |
23 | # YOLOv5 v6.0 head
24 | head:
25 | [[-1, 1, Conv, [512, 1, 1]],
26 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
27 | [[-1, 6], 1, Concat, [1]], # cat backbone P4
28 | [-1, 3, C3, [512, False]], # 13
29 |
30 | [-1, 1, Conv, [256, 1, 1]],
31 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
32 | [[-1, 4], 1, Concat, [1]], # cat backbone P3
33 | [-1, 3, C3, [256, False]], # 17 (P3/8-small)
34 |
35 | [-1, 1, Conv, [256, 3, 2]],
36 | [[-1, 14], 1, Concat, [1]], # cat head P4
37 | [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
38 |
39 | [-1, 1, Conv, [512, 3, 2]],
40 | [[-1, 10], 1, Concat, [1]], # cat head P5
41 | [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
42 |
43 | [[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)
44 | ]
--------------------------------------------------------------------------------
/ultralytics/models/v5/yolov5m.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 0.67 # model depth multiple
6 | width_multiple: 0.75 # layer channel multiple
7 |
8 | # YOLOv5 v6.0 backbone
9 | backbone:
10 | # [from, number, module, args]
11 | [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
12 | [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
13 | [-1, 3, C3, [128]],
14 | [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
15 | [-1, 6, C3, [256]],
16 | [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
17 | [-1, 9, C3, [512]],
18 | [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
19 | [-1, 3, C3, [1024]],
20 | [-1, 1, SPPF, [1024, 5]], # 9
21 | ]
22 |
23 | # YOLOv5 v6.0 head
24 | head:
25 | [[-1, 1, Conv, [512, 1, 1]],
26 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
27 | [[-1, 6], 1, Concat, [1]], # cat backbone P4
28 | [-1, 3, C3, [512, False]], # 13
29 |
30 | [-1, 1, Conv, [256, 1, 1]],
31 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
32 | [[-1, 4], 1, Concat, [1]], # cat backbone P3
33 | [-1, 3, C3, [256, False]], # 17 (P3/8-small)
34 |
35 | [-1, 1, Conv, [256, 3, 2]],
36 | [[-1, 14], 1, Concat, [1]], # cat head P4
37 | [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
38 |
39 | [-1, 1, Conv, [512, 3, 2]],
40 | [[-1, 10], 1, Concat, [1]], # cat head P5
41 | [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
42 |
43 | [[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)
44 | ]
--------------------------------------------------------------------------------
/ultralytics/models/v5/yolov5n.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 0.33 # model depth multiple
6 | width_multiple: 0.25 # layer channel multiple
7 |
8 | # YOLOv5 v6.0 backbone
9 | backbone:
10 | # [from, number, module, args]
11 | [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
12 | [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
13 | [-1, 3, C3, [128]],
14 | [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
15 | [-1, 6, C3, [256]],
16 | [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
17 | [-1, 9, C3, [512]],
18 | [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
19 | [-1, 3, C3, [1024]],
20 | [-1, 1, SPPF, [1024, 5]], # 9
21 | ]
22 |
23 | # YOLOv5 v6.0 head
24 | head:
25 | [[-1, 1, Conv, [512, 1, 1]],
26 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
27 | [[-1, 6], 1, Concat, [1]], # cat backbone P4
28 | [-1, 3, C3, [512, False]], # 13
29 |
30 | [-1, 1, Conv, [256, 1, 1]],
31 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
32 | [[-1, 4], 1, Concat, [1]], # cat backbone P3
33 | [-1, 3, C3, [256, False]], # 17 (P3/8-small)
34 |
35 | [-1, 1, Conv, [256, 3, 2]],
36 | [[-1, 14], 1, Concat, [1]], # cat head P4
37 | [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
38 |
39 | [-1, 1, Conv, [512, 3, 2]],
40 | [[-1, 10], 1, Concat, [1]], # cat head P5
41 | [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
42 |
43 | [[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)
44 | ]
--------------------------------------------------------------------------------
/ultralytics/models/v5/yolov5s.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 0.33 # model depth multiple
6 | width_multiple: 0.50 # layer channel multiple
7 |
8 |
9 | # YOLOv5 v6.0 backbone
10 | backbone:
11 | # [from, number, module, args]
12 | [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
13 | [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
14 | [-1, 3, C3, [128]],
15 | [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
16 | [-1, 6, C3, [256]],
17 | [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
18 | [-1, 9, C3, [512]],
19 | [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
20 | [-1, 3, C3, [1024]],
21 | [-1, 1, SPPF, [1024, 5]], # 9
22 | ]
23 |
24 | # YOLOv5 v6.0 head
25 | head:
26 | [[-1, 1, Conv, [512, 1, 1]],
27 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
28 | [[-1, 6], 1, Concat, [1]], # cat backbone P4
29 | [-1, 3, C3, [512, False]], # 13
30 |
31 | [-1, 1, Conv, [256, 1, 1]],
32 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
33 | [[-1, 4], 1, Concat, [1]], # cat backbone P3
34 | [-1, 3, C3, [256, False]], # 17 (P3/8-small)
35 |
36 | [-1, 1, Conv, [256, 3, 2]],
37 | [[-1, 14], 1, Concat, [1]], # cat head P4
38 | [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
39 |
40 | [-1, 1, Conv, [512, 3, 2]],
41 | [[-1, 10], 1, Concat, [1]], # cat head P5
42 | [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
43 |
44 | [[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)
45 | ]
--------------------------------------------------------------------------------
/ultralytics/models/v5/yolov5x.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 1.33 # model depth multiple
6 | width_multiple: 1.25 # layer channel multiple
7 |
8 | # YOLOv5 v6.0 backbone
9 | backbone:
10 | # [from, number, module, args]
11 | [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
12 | [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
13 | [-1, 3, C3, [128]],
14 | [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
15 | [-1, 6, C3, [256]],
16 | [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
17 | [-1, 9, C3, [512]],
18 | [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
19 | [-1, 3, C3, [1024]],
20 | [-1, 1, SPPF, [1024, 5]], # 9
21 | ]
22 |
23 | # YOLOv5 v6.0 head
24 | head:
25 | [[-1, 1, Conv, [512, 1, 1]],
26 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
27 | [[-1, 6], 1, Concat, [1]], # cat backbone P4
28 | [-1, 3, C3, [512, False]], # 13
29 |
30 | [-1, 1, Conv, [256, 1, 1]],
31 | [-1, 1, nn.Upsample, [None, 2, 'nearest']],
32 | [[-1, 4], 1, Concat, [1]], # cat backbone P3
33 | [-1, 3, C3, [256, False]], # 17 (P3/8-small)
34 |
35 | [-1, 1, Conv, [256, 3, 2]],
36 | [[-1, 14], 1, Concat, [1]], # cat head P4
37 | [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
38 |
39 | [-1, 1, Conv, [512, 3, 2]],
40 | [[-1, 10], 1, Concat, [1]], # cat head P5
41 | [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
42 |
43 | [[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)
44 | ]
--------------------------------------------------------------------------------
/ultralytics/models/v8/cls/yolov8l-cls.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 1000 # number of classes
5 | depth_multiple: 1.00 # scales module repeats
6 | width_multiple: 1.00 # scales convolution channels
7 |
8 | # YOLOv8.0n backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [1024, True]]
20 |
21 | # YOLOv8.0n head
22 | head:
23 | - [-1, 1, Classify, [nc]]
24 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/cls/yolov8m-cls.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 1000 # number of classes
5 | depth_multiple: 0.67 # scales module repeats
6 | width_multiple: 0.75 # scales convolution channels
7 |
8 | # YOLOv8.0n backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [1024, True]]
20 |
21 | # YOLOv8.0n head
22 | head:
23 | - [-1, 1, Classify, [nc]]
24 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/cls/yolov8n-cls.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 1000 # number of classes
5 | depth_multiple: 0.33 # scales module repeats
6 | width_multiple: 0.25 # scales convolution channels
7 |
8 | # YOLOv8.0n backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [1024, True]]
20 |
21 | # YOLOv8.0n head
22 | head:
23 | - [-1, 1, Classify, [nc]]
24 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/cls/yolov8s-cls.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 1000 # number of classes
5 | depth_multiple: 0.33 # scales module repeats
6 | width_multiple: 0.50 # scales convolution channels
7 |
8 | # YOLOv8.0n backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [1024, True]]
20 |
21 | # YOLOv8.0n head
22 | head:
23 | - [-1, 1, Classify, [nc]]
24 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/cls/yolov8x-cls.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 1000 # number of classes
5 | depth_multiple: 1.00 # scales module repeats
6 | width_multiple: 1.25 # scales convolution channels
7 |
8 | # YOLOv8.0n backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [1024, True]]
20 |
21 | # YOLOv8.0n head
22 | head:
23 | - [-1, 1, Classify, [nc]]
24 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/seg/yolov8l-seg.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 1.00 # scales module repeats
6 | width_multiple: 1.00 # scales convolution channels
7 |
8 | # YOLOv8.0l backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [512, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [512, True]]
20 | - [-1, 1, SPPF, [512, 5]] # 9
21 |
22 | # YOLOv8.0l head
23 | head:
24 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
25 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
26 | - [-1, 3, C2f, [512]] # 13
27 |
28 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
29 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
30 | - [-1, 3, C2f, [256]] # 17 (P3/8-small)
31 |
32 | - [-1, 1, Conv, [256, 3, 2]]
33 | - [[-1, 12], 1, Concat, [1]] # cat head P4
34 | - [-1, 3, C2f, [512]] # 20 (P4/16-medium)
35 |
36 | - [-1, 1, Conv, [512, 3, 2]]
37 | - [[-1, 9], 1, Concat, [1]] # cat head P5
38 | - [-1, 3, C2f, [512]] # 23 (P5/32-large)
39 |
40 | - [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Detect(P3, P4, P5)
41 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/seg/yolov8m-seg.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 0.67 # scales module repeats
6 | width_multiple: 0.75 # scales convolution channels
7 |
8 | # YOLOv8.0m backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [768, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [768, True]]
20 | - [-1, 1, SPPF, [768, 5]] # 9
21 |
22 | # YOLOv8.0m head
23 | head:
24 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
25 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
26 | - [-1, 3, C2f, [512]] # 13
27 |
28 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
29 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
30 | - [-1, 3, C2f, [256]] # 17 (P3/8-small)
31 |
32 | - [-1, 1, Conv, [256, 3, 2]]
33 | - [[-1, 12], 1, Concat, [1]] # cat head P4
34 | - [-1, 3, C2f, [512]] # 20 (P4/16-medium)
35 |
36 | - [-1, 1, Conv, [512, 3, 2]]
37 | - [[-1, 9], 1, Concat, [1]] # cat head P5
38 | - [-1, 3, C2f, [768]] # 23 (P5/32-large)
39 |
40 | - [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Detect(P3, P4, P5)
41 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/seg/yolov8n-seg.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 0.33 # scales module repeats
6 | width_multiple: 0.25 # scales convolution channels
7 |
8 | # YOLOv8.0n backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [1024, True]]
20 | - [-1, 1, SPPF, [1024, 5]] # 9
21 |
22 | # YOLOv8.0n head
23 | head:
24 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
25 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
26 | - [-1, 3, C2f, [512]] # 13
27 |
28 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
29 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
30 | - [-1, 3, C2f, [256]] # 17 (P3/8-small)
31 |
32 | - [-1, 1, Conv, [256, 3, 2]]
33 | - [[-1, 12], 1, Concat, [1]] # cat head P4
34 | - [-1, 3, C2f, [512]] # 20 (P4/16-medium)
35 |
36 | - [-1, 1, Conv, [512, 3, 2]]
37 | - [[-1, 9], 1, Concat, [1]] # cat head P5
38 | - [-1, 3, C2f, [1024]] # 23 (P5/32-large)
39 |
40 | - [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Detect(P3, P4, P5)
41 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/seg/yolov8s-seg.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 0.33 # scales module repeats
6 | width_multiple: 0.50 # scales convolution channels
7 |
8 | # YOLOv8.0s backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [1024, True]]
20 | - [-1, 1, SPPF, [1024, 5]] # 9
21 |
22 | # YOLOv8.0s head
23 | head:
24 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
25 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
26 | - [-1, 3, C2f, [512]] # 13
27 |
28 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
29 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
30 | - [-1, 3, C2f, [256]] # 17 (P3/8-small)
31 |
32 | - [-1, 1, Conv, [256, 3, 2]]
33 | - [[-1, 12], 1, Concat, [1]] # cat head P4
34 | - [-1, 3, C2f, [512]] # 20 (P4/16-medium)
35 |
36 | - [-1, 1, Conv, [512, 3, 2]]
37 | - [[-1, 9], 1, Concat, [1]] # cat head P5
38 | - [-1, 3, C2f, [1024]] # 23 (P5/32-large)
39 |
40 | - [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Detect(P3, P4, P5)
41 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/seg/yolov8x-seg.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 1.00 # scales module repeats
6 | width_multiple: 1.25 # scales convolution channels
7 |
8 | # YOLOv8.0x backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [512, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [512, True]]
20 | - [-1, 1, SPPF, [512, 5]] # 9
21 |
22 | # YOLOv8.0x head
23 | head:
24 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
25 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
26 | - [-1, 3, C2f, [512]] # 13
27 |
28 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
29 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
30 | - [-1, 3, C2f, [256]] # 17 (P3/8-small)
31 |
32 | - [-1, 1, Conv, [256, 3, 2]]
33 | - [[-1, 12], 1, Concat, [1]] # cat head P4
34 | - [-1, 3, C2f, [512]] # 20 (P4/16-medium)
35 |
36 | - [-1, 1, Conv, [512, 3, 2]]
37 | - [[-1, 9], 1, Concat, [1]] # cat head P5
38 | - [-1, 3, C2f, [512]] # 23 (P5/32-large)
39 |
40 | - [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Detect(P3, P4, P5)
41 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/yolov8l.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 1.00 # scales module repeats
6 | width_multiple: 1.00 # scales convolution channels
7 |
8 | # YOLOv8.0l backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [512, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [512, True]]
20 | - [-1, 1, SPPF, [512, 5]] # 9
21 |
22 | # YOLOv8.0l head
23 | head:
24 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
25 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
26 | - [-1, 3, C2f, [512]] # 13
27 |
28 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
29 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
30 | - [-1, 3, C2f, [256]] # 17 (P3/8-small)
31 |
32 | - [-1, 1, Conv, [256, 3, 2]]
33 | - [[-1, 12], 1, Concat, [1]] # cat head P4
34 | - [-1, 3, C2f, [512]] # 20 (P4/16-medium)
35 |
36 | - [-1, 1, Conv, [512, 3, 2]]
37 | - [[-1, 9], 1, Concat, [1]] # cat head P5
38 | - [-1, 3, C2f, [512]] # 23 (P5/32-large)
39 |
40 | - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
41 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/yolov8m.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 0.67 # scales module repeats
6 | width_multiple: 0.75 # scales convolution channels
7 |
8 | # YOLOv8.0m backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [768, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [768, True]]
20 | - [-1, 1, SPPF, [768, 5]] # 9
21 |
22 | # YOLOv8.0m head
23 | head:
24 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
25 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
26 | - [-1, 3, C2f, [512]] # 13
27 |
28 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
29 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
30 | - [-1, 3, C2f, [256]] # 17 (P3/8-small)
31 |
32 | - [-1, 1, Conv, [256, 3, 2]]
33 | - [[-1, 12], 1, Concat, [1]] # cat head P4
34 | - [-1, 3, C2f, [512]] # 20 (P4/16-medium)
35 |
36 | - [-1, 1, Conv, [512, 3, 2]]
37 | - [[-1, 9], 1, Concat, [1]] # cat head P5
38 | - [-1, 3, C2f, [768]] # 23 (P5/32-large)
39 |
40 | - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
41 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/yolov8n.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 0.33 # scales module repeats
6 | width_multiple: 0.25 # scales convolution channels
7 |
8 | # YOLOv8.0n backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [1024, True]]
20 | - [-1, 1, SPPF, [1024, 5]] # 9
21 |
22 | # YOLOv8.0n head
23 | head:
24 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
25 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
26 | - [-1, 3, C2f, [512]] # 13
27 |
28 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
29 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
30 | - [-1, 3, C2f, [256]] # 17 (P3/8-small)
31 |
32 | - [-1, 1, Conv, [256, 3, 2]]
33 | - [[-1, 12], 1, Concat, [1]] # cat head P4
34 | - [-1, 3, C2f, [512]] # 20 (P4/16-medium)
35 |
36 | - [-1, 1, Conv, [512, 3, 2]]
37 | - [[-1, 9], 1, Concat, [1]] # cat head P5
38 | - [-1, 3, C2f, [1024]] # 23 (P5/32-large)
39 |
40 | - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
41 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/yolov8s.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 0.33 # scales module repeats
6 | width_multiple: 0.50 # scales convolution channels
7 |
8 | # YOLOv8.0s backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [1024, True]]
20 | - [-1, 1, SPPF, [1024, 5]] # 9
21 |
22 | # YOLOv8.0s head
23 | head:
24 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
25 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
26 | - [-1, 3, C2f, [512]] # 13
27 |
28 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
29 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
30 | - [-1, 3, C2f, [256]] # 17 (P3/8-small)
31 |
32 | - [-1, 1, Conv, [256, 3, 2]]
33 | - [[-1, 12], 1, Concat, [1]] # cat head P4
34 | - [-1, 3, C2f, [512]] # 20 (P4/16-medium)
35 |
36 | - [-1, 1, Conv, [512, 3, 2]]
37 | - [[-1, 9], 1, Concat, [1]] # cat head P5
38 | - [-1, 3, C2f, [1024]] # 23 (P5/32-large)
39 |
40 | - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
41 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/yolov8x.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 1.00 # scales module repeats
6 | width_multiple: 1.25 # scales convolution channels
7 |
8 | # YOLOv8.0x backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [512, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [512, True]]
20 | - [-1, 1, SPPF, [512, 5]] # 9
21 |
22 | # YOLOv8.0x head
23 | head:
24 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
25 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
26 | - [-1, 3, C2f, [512]] # 13
27 |
28 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
29 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
30 | - [-1, 3, C2f, [256]] # 17 (P3/8-small)
31 |
32 | - [-1, 1, Conv, [256, 3, 2]]
33 | - [[-1, 12], 1, Concat, [1]] # cat head P4
34 | - [-1, 3, C2f, [512]] # 20 (P4/16-medium)
35 |
36 | - [-1, 1, Conv, [512, 3, 2]]
37 | - [[-1, 9], 1, Concat, [1]] # cat head P5
38 | - [-1, 3, C2f, [512]] # 23 (P5/32-large)
39 |
40 | - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
41 |
--------------------------------------------------------------------------------
/ultralytics/models/v8/yolov8x6.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | # Parameters
4 | nc: 80 # number of classes
5 | depth_multiple: 1.00 # scales module repeats
6 | width_multiple: 1.25 # scales convolution channels
7 |
8 | # YOLOv8.0x6 backbone
9 | backbone:
10 | # [from, repeats, module, args]
11 | - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
12 | - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
13 | - [-1, 3, C2f, [128, True]]
14 | - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
15 | - [-1, 6, C2f, [256, True]]
16 | - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
17 | - [-1, 6, C2f, [512, True]]
18 | - [-1, 1, Conv, [512, 3, 2]] # 7-P5/32
19 | - [-1, 3, C2f, [512, True]]
20 | - [-1, 1, Conv, [512, 3, 2]] # 9-P6/64
21 | - [-1, 3, C2f, [512, True]]
22 | - [-1, 1, SPPF, [512, 5]] # 11
23 |
24 | # YOLOv8.0x6 head
25 | head:
26 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
27 | - [[-1, 8], 1, Concat, [1]] # cat backbone P5
28 | - [-1, 3, C2, [512, False]] # 14
29 |
30 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
31 | - [[-1, 6], 1, Concat, [1]] # cat backbone P4
32 | - [-1, 3, C2, [512, False]] # 17
33 |
34 | - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
35 | - [[-1, 4], 1, Concat, [1]] # cat backbone P3
36 | - [-1, 3, C2, [256, False]] # 20 (P3/8-small)
37 |
38 | - [-1, 1, Conv, [256, 3, 2]]
39 | - [[-1, 17], 1, Concat, [1]] # cat head P4
40 | - [-1, 3, C2, [512, False]] # 23 (P4/16-medium)
41 |
42 | - [-1, 1, Conv, [512, 3, 2]]
43 | - [[-1, 14], 1, Concat, [1]] # cat head P5
44 | - [-1, 3, C2, [512, False]] # 26 (P5/32-large)
45 |
46 | - [-1, 1, Conv, [512, 3, 2]]
47 | - [[-1, 11], 1, Concat, [1]] # cat head P6
48 | - [-1, 3, C2, [512, False]] # 29 (P6/64-xlarge)
49 |
50 | - [[20, 23, 26, 29], 1, Detect, [nc]] # Detect(P3, P4, P5, P6)
51 |
--------------------------------------------------------------------------------
/ultralytics/nn/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MuhammadMoinFaisal/YOLOv8-object-tracking-blurring-counting/6ad9082f7d0022b22a2325e1078dc3534113f7df/ultralytics/nn/__init__.py
--------------------------------------------------------------------------------
/ultralytics/yolo/cli.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import shutil
4 | from pathlib import Path
5 |
6 | import hydra
7 |
8 | from ultralytics import hub, yolo
9 | from ultralytics.yolo.utils import DEFAULT_CONFIG, LOGGER, colorstr
10 |
11 | DIR = Path(__file__).parent
12 |
13 |
14 | @hydra.main(version_base=None, config_path=str(DEFAULT_CONFIG.parent.relative_to(DIR)), config_name=DEFAULT_CONFIG.name)
15 | def cli(cfg):
16 | """
17 | Run a specified task and mode with the given configuration.
18 |
19 | Args:
20 | cfg (DictConfig): Configuration for the task and mode.
21 | """
22 | # LOGGER.info(f"{colorstr(f'Ultralytics YOLO v{ultralytics.__version__}')}")
23 | task, mode = cfg.task.lower(), cfg.mode.lower()
24 |
25 | # Special case for initializing the configuration
26 | if task == "init":
27 | shutil.copy2(DEFAULT_CONFIG, Path.cwd())
28 | LOGGER.info(f"""
29 | {colorstr("YOLO:")} configuration saved to {Path.cwd() / DEFAULT_CONFIG.name}.
30 | To run experiments using custom configuration:
31 | yolo task='task' mode='mode' --config-name config_file.yaml
32 | """)
33 | return
34 |
35 | # Mapping from task to module
36 | task_module_map = {"detect": yolo.v8.detect, "segment": yolo.v8.segment, "classify": yolo.v8.classify}
37 | module = task_module_map.get(task)
38 | if not module:
39 | raise SyntaxError(f"task not recognized. Choices are {', '.join(task_module_map.keys())}")
40 |
41 | # Mapping from mode to function
42 | mode_func_map = {
43 | "train": module.train,
44 | "val": module.val,
45 | "predict": module.predict,
46 | "export": yolo.engine.exporter.export,
47 | "checks": hub.checks}
48 | func = mode_func_map.get(mode)
49 | if not func:
50 | raise SyntaxError(f"mode not recognized. Choices are {', '.join(mode_func_map.keys())}")
51 |
52 | func(cfg)
53 |
--------------------------------------------------------------------------------
/ultralytics/yolo/configs/__init__.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | from pathlib import Path
4 | from typing import Dict, Union
5 |
6 | from omegaconf import DictConfig, OmegaConf
7 |
8 | from ultralytics.yolo.configs.hydra_patch import check_config_mismatch
9 |
10 |
11 | def get_config(config: Union[str, DictConfig], overrides: Union[str, Dict] = None):
12 | """
13 | Load and merge configuration data from a file or dictionary.
14 |
15 | Args:
16 | config (Union[str, DictConfig]): Configuration data in the form of a file name or a DictConfig object.
17 | overrides (Union[str, Dict], optional): Overrides in the form of a file name or a dictionary. Default is None.
18 |
19 | Returns:
20 | OmegaConf.Namespace: Training arguments namespace.
21 | """
22 | if overrides is None:
23 | overrides = {}
24 | if isinstance(config, (str, Path)):
25 | config = OmegaConf.load(config)
26 | elif isinstance(config, Dict):
27 | config = OmegaConf.create(config)
28 | # override
29 | if isinstance(overrides, str):
30 | overrides = OmegaConf.load(overrides)
31 | elif isinstance(overrides, Dict):
32 | overrides = OmegaConf.create(overrides)
33 |
34 | check_config_mismatch(dict(overrides).keys(), dict(config).keys())
35 |
36 | return OmegaConf.merge(config, overrides)
37 |
--------------------------------------------------------------------------------
/ultralytics/yolo/configs/default.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | # Default training settings and hyperparameters for medium-augmentation COCO training
3 |
4 | task: "detect" # choices=['detect', 'segment', 'classify', 'init'] # init is a special case. Specify task to run.
5 | mode: "train" # choices=['train', 'val', 'predict'] # mode to run task in.
6 |
7 | # Train settings -------------------------------------------------------------------------------------------------------
8 | model: null # i.e. yolov8n.pt, yolov8n.yaml. Path to model file
9 | data: null # i.e. coco128.yaml. Path to data file
10 | epochs: 100 # number of epochs to train for
11 | patience: 50 # TODO: epochs to wait for no observable improvement for early stopping of training
12 | batch: 16 # number of images per batch
13 | imgsz: 640 # size of input images
14 | save: True # save checkpoints
15 | cache: False # True/ram, disk or False. Use cache for data loading
16 | device: null # cuda device, i.e. 0 or 0,1,2,3 or cpu. Device to run on
17 | workers: 8 # number of worker threads for data loading
18 | project: null # project name
19 | name: null # experiment name
20 | exist_ok: False # whether to overwrite existing experiment
21 | pretrained: False # whether to use a pretrained model
22 | optimizer: 'SGD' # optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp']
23 | verbose: False # whether to print verbose output
24 | seed: 0 # random seed for reproducibility
25 | deterministic: True # whether to enable deterministic mode
26 | single_cls: False # train multi-class data as single-class
27 | image_weights: False # use weighted image selection for training
28 | rect: False # support rectangular training
29 | cos_lr: False # use cosine learning rate scheduler
30 | close_mosaic: 10 # disable mosaic augmentation for final 10 epochs
31 | resume: False # resume training from last checkpoint
32 | # Segmentation
33 | overlap_mask: True # masks should overlap during training
34 | mask_ratio: 4 # mask downsample ratio
35 | # Classification
36 | dropout: 0.0 # use dropout regularization
37 |
38 | # Val/Test settings ----------------------------------------------------------------------------------------------------
39 | val: True # validate/test during training
40 | save_json: False # save results to JSON file
41 | save_hybrid: False # save hybrid version of labels (labels + additional predictions)
42 | conf: null # object confidence threshold for detection (default 0.25 predict, 0.001 val)
43 | iou: 0.7 # intersection over union (IoU) threshold for NMS
44 | max_det: 300 # maximum number of detections per image
45 | half: False # use half precision (FP16)
46 | dnn: False # use OpenCV DNN for ONNX inference
47 | plots: True # show plots during training
48 |
49 | # Prediction settings --------------------------------------------------------------------------------------------------
50 | source: null # source directory for images or videos
51 | show: False # show results if possible
52 | save_txt: False # save results as .txt file
53 | save_conf: False # save results with confidence scores
54 | save_crop: False # save cropped images with results
55 | hide_labels: False # hide labels
56 | hide_conf: False # hide confidence scores
57 | vid_stride: 1 # video frame-rate stride
58 | line_thickness: 3 # bounding box thickness (pixels)
59 | visualize: False # visualize results
60 | augment: False # apply data augmentation to images
61 | agnostic_nms: False # class-agnostic NMS
62 | retina_masks: False # use retina masks for object detection
63 |
64 | # Export settings ------------------------------------------------------------------------------------------------------
65 | format: torchscript # format to export to
66 | keras: False # use Keras
67 | optimize: False # TorchScript: optimize for mobile
68 | int8: False # CoreML/TF INT8 quantization
69 | dynamic: False # ONNX/TF/TensorRT: dynamic axes
70 | simplify: False # ONNX: simplify model
71 | opset: 17 # ONNX: opset version
72 | workspace: 4 # TensorRT: workspace size (GB)
73 | nms: False # CoreML: add NMS
74 |
75 | # Hyperparameters ------------------------------------------------------------------------------------------------------
76 | lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
77 | lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
78 | momentum: 0.937 # SGD momentum/Adam beta1
79 | weight_decay: 0.0005 # optimizer weight decay 5e-4
80 | warmup_epochs: 3.0 # warmup epochs (fractions ok)
81 | warmup_momentum: 0.8 # warmup initial momentum
82 | warmup_bias_lr: 0.1 # warmup initial bias lr
83 | box: 7.5 # box loss gain
84 | cls: 0.5 # cls loss gain (scale with pixels)
85 | dfl: 1.5 # dfl loss gain
86 | fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
87 | label_smoothing: 0.0
88 | nbs: 64 # nominal batch size
89 | hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
90 | hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
91 | hsv_v: 0.4 # image HSV-Value augmentation (fraction)
92 | degrees: 0.0 # image rotation (+/- deg)
93 | translate: 0.1 # image translation (+/- fraction)
94 | scale: 0.5 # image scale (+/- gain)
95 | shear: 0.0 # image shear (+/- deg)
96 | perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
97 | flipud: 0.0 # image flip up-down (probability)
98 | fliplr: 0.5 # image flip left-right (probability)
99 | mosaic: 1.0 # image mosaic (probability)
100 | mixup: 0.0 # image mixup (probability)
101 | copy_paste: 0.0 # segment copy-paste (probability)
102 |
103 | # Hydra configs --------------------------------------------------------------------------------------------------------
104 | hydra:
105 | output_subdir: null # disable hydra directory creation
106 | run:
107 | dir: .
108 |
109 | # Debug, do not modify -------------------------------------------------------------------------------------------------
110 | v5loader: False # use legacy YOLOv5 dataloader
111 |
--------------------------------------------------------------------------------
/ultralytics/yolo/configs/hydra_patch.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import sys
4 | from difflib import get_close_matches
5 | from textwrap import dedent
6 |
7 | import hydra
8 | from hydra.errors import ConfigCompositionException
9 | from omegaconf import OmegaConf, open_dict # noqa
10 | from omegaconf.errors import ConfigAttributeError, ConfigKeyError, OmegaConfBaseException # noqa
11 |
12 | from ultralytics.yolo.utils import LOGGER, colorstr
13 |
14 |
15 | def override_config(overrides, cfg):
16 | override_keys = [override.key_or_group for override in overrides]
17 | check_config_mismatch(override_keys, cfg.keys())
18 | for override in overrides:
19 | if override.package is not None:
20 | raise ConfigCompositionException(f"Override {override.input_line} looks like a config group"
21 | f" override, but config group '{override.key_or_group}' does not exist.")
22 |
23 | key = override.key_or_group
24 | value = override.value()
25 | try:
26 | if override.is_delete():
27 | config_val = OmegaConf.select(cfg, key, throw_on_missing=False)
28 | if config_val is None:
29 | raise ConfigCompositionException(f"Could not delete from config. '{override.key_or_group}'"
30 | " does not exist.")
31 | elif value is not None and value != config_val:
32 | raise ConfigCompositionException("Could not delete from config. The value of"
33 | f" '{override.key_or_group}' is {config_val} and not"
34 | f" {value}.")
35 |
36 | last_dot = key.rfind(".")
37 | with open_dict(cfg):
38 | if last_dot == -1:
39 | del cfg[key]
40 | else:
41 | node = OmegaConf.select(cfg, key[:last_dot])
42 | del node[key[last_dot + 1:]]
43 |
44 | elif override.is_add():
45 | if OmegaConf.select(cfg, key, throw_on_missing=False) is None or isinstance(value, (dict, list)):
46 | OmegaConf.update(cfg, key, value, merge=True, force_add=True)
47 | else:
48 | assert override.input_line is not None
49 | raise ConfigCompositionException(
50 | dedent(f"""\
51 | Could not append to config. An item is already at '{override.key_or_group}'.
52 | Either remove + prefix: '{override.input_line[1:]}'
53 | Or add a second + to add or override '{override.key_or_group}': '+{override.input_line}'
54 | """))
55 | elif override.is_force_add():
56 | OmegaConf.update(cfg, key, value, merge=True, force_add=True)
57 | else:
58 | try:
59 | OmegaConf.update(cfg, key, value, merge=True)
60 | except (ConfigAttributeError, ConfigKeyError) as ex:
61 | raise ConfigCompositionException(f"Could not override '{override.key_or_group}'."
62 | f"\nTo append to your config use +{override.input_line}") from ex
63 | except OmegaConfBaseException as ex:
64 | raise ConfigCompositionException(f"Error merging override {override.input_line}").with_traceback(
65 | sys.exc_info()[2]) from ex
66 |
67 |
68 | def check_config_mismatch(overrides, cfg):
69 | mismatched = [option for option in overrides if option not in cfg and 'hydra.' not in option]
70 |
71 | for option in mismatched:
72 | LOGGER.info(f"{colorstr(option)} is not a valid key. Similar keys: {get_close_matches(option, cfg, 3, 0.6)}")
73 | if mismatched:
74 | exit()
75 |
76 |
77 | hydra._internal.config_loader_impl.ConfigLoaderImpl._apply_overrides_to_config = override_config
78 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/__init__.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | from .base import BaseDataset
4 | from .build import build_classification_dataloader, build_dataloader
5 | from .dataset import ClassificationDataset, SemanticDataset, YOLODataset
6 | from .dataset_wrappers import MixAndRectDataset
7 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/base.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import glob
4 | import math
5 | import os
6 | from multiprocessing.pool import ThreadPool
7 | from pathlib import Path
8 | from typing import Optional
9 |
10 | import cv2
11 | import numpy as np
12 | from torch.utils.data import Dataset
13 | from tqdm import tqdm
14 |
15 | from ..utils import NUM_THREADS, TQDM_BAR_FORMAT
16 | from .utils import HELP_URL, IMG_FORMATS, LOCAL_RANK
17 |
18 |
19 | class BaseDataset(Dataset):
20 | """Base Dataset.
21 | Args:
22 | img_path (str): image path.
23 | pipeline (dict): a dict of image transforms.
24 | label_path (str): label path, this can also be an ann_file or other custom label path.
25 | """
26 |
27 | def __init__(
28 | self,
29 | img_path,
30 | imgsz=640,
31 | label_path=None,
32 | cache=False,
33 | augment=True,
34 | hyp=None,
35 | prefix="",
36 | rect=False,
37 | batch_size=None,
38 | stride=32,
39 | pad=0.5,
40 | single_cls=False,
41 | ):
42 | super().__init__()
43 | self.img_path = img_path
44 | self.imgsz = imgsz
45 | self.label_path = label_path
46 | self.augment = augment
47 | self.single_cls = single_cls
48 | self.prefix = prefix
49 |
50 | self.im_files = self.get_img_files(self.img_path)
51 | self.labels = self.get_labels()
52 | if self.single_cls:
53 | self.update_labels(include_class=[])
54 |
55 | self.ni = len(self.labels)
56 |
57 | # rect stuff
58 | self.rect = rect
59 | self.batch_size = batch_size
60 | self.stride = stride
61 | self.pad = pad
62 | if self.rect:
63 | assert self.batch_size is not None
64 | self.set_rectangle()
65 |
66 | # cache stuff
67 | self.ims = [None] * self.ni
68 | self.npy_files = [Path(f).with_suffix(".npy") for f in self.im_files]
69 | if cache:
70 | self.cache_images(cache)
71 |
72 | # transforms
73 | self.transforms = self.build_transforms(hyp=hyp)
74 |
75 | def get_img_files(self, img_path):
76 | """Read image files."""
77 | try:
78 | f = [] # image files
79 | for p in img_path if isinstance(img_path, list) else [img_path]:
80 | p = Path(p) # os-agnostic
81 | if p.is_dir(): # dir
82 | f += glob.glob(str(p / "**" / "*.*"), recursive=True)
83 | # f = list(p.rglob('*.*')) # pathlib
84 | elif p.is_file(): # file
85 | with open(p) as t:
86 | t = t.read().strip().splitlines()
87 | parent = str(p.parent) + os.sep
88 | f += [x.replace("./", parent) if x.startswith("./") else x for x in t] # local to global path
89 | # f += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
90 | else:
91 | raise FileNotFoundError(f"{self.prefix}{p} does not exist")
92 | im_files = sorted(x.replace("/", os.sep) for x in f if x.split(".")[-1].lower() in IMG_FORMATS)
93 | # self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
94 | assert im_files, f"{self.prefix}No images found"
95 | except Exception as e:
96 | raise FileNotFoundError(f"{self.prefix}Error loading data from {img_path}: {e}\n{HELP_URL}") from e
97 | return im_files
98 |
99 | def update_labels(self, include_class: Optional[list]):
100 | """include_class, filter labels to include only these classes (optional)"""
101 | include_class_array = np.array(include_class).reshape(1, -1)
102 | for i in range(len(self.labels)):
103 | if include_class:
104 | cls = self.labels[i]["cls"]
105 | bboxes = self.labels[i]["bboxes"]
106 | segments = self.labels[i]["segments"]
107 | j = (cls == include_class_array).any(1)
108 | self.labels[i]["cls"] = cls[j]
109 | self.labels[i]["bboxes"] = bboxes[j]
110 | if segments:
111 | self.labels[i]["segments"] = segments[j]
112 | if self.single_cls:
113 | self.labels[i]["cls"] = 0
114 |
115 | def load_image(self, i):
116 | # Loads 1 image from dataset index 'i', returns (im, resized hw)
117 | im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i]
118 | if im is None: # not cached in RAM
119 | if fn.exists(): # load npy
120 | im = np.load(fn)
121 | else: # read image
122 | im = cv2.imread(f) # BGR
123 | assert im is not None, f"Image Not Found {f}"
124 | h0, w0 = im.shape[:2] # orig hw
125 | r = self.imgsz / max(h0, w0) # ratio
126 | if r != 1: # if sizes are not equal
127 | interp = cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA
128 | im = cv2.resize(im, (math.ceil(w0 * r), math.ceil(h0 * r)), interpolation=interp)
129 | return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
130 | return self.ims[i], self.im_hw0[i], self.im_hw[i] # im, hw_original, hw_resized
131 |
132 | def cache_images(self, cache):
133 | # cache images to memory or disk
134 | gb = 0 # Gigabytes of cached images
135 | self.im_hw0, self.im_hw = [None] * self.ni, [None] * self.ni
136 | fcn = self.cache_images_to_disk if cache == "disk" else self.load_image
137 | results = ThreadPool(NUM_THREADS).imap(fcn, range(self.ni))
138 | pbar = tqdm(enumerate(results), total=self.ni, bar_format=TQDM_BAR_FORMAT, disable=LOCAL_RANK > 0)
139 | for i, x in pbar:
140 | if cache == "disk":
141 | gb += self.npy_files[i].stat().st_size
142 | else: # 'ram'
143 | self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
144 | gb += self.ims[i].nbytes
145 | pbar.desc = f"{self.prefix}Caching images ({gb / 1E9:.1f}GB {cache})"
146 | pbar.close()
147 |
148 | def cache_images_to_disk(self, i):
149 | # Saves an image as an *.npy file for faster loading
150 | f = self.npy_files[i]
151 | if not f.exists():
152 | np.save(f.as_posix(), cv2.imread(self.im_files[i]))
153 |
154 | def set_rectangle(self):
155 | bi = np.floor(np.arange(self.ni) / self.batch_size).astype(int) # batch index
156 | nb = bi[-1] + 1 # number of batches
157 |
158 | s = np.array([x.pop("shape") for x in self.labels]) # hw
159 | ar = s[:, 0] / s[:, 1] # aspect ratio
160 | irect = ar.argsort()
161 | self.im_files = [self.im_files[i] for i in irect]
162 | self.labels = [self.labels[i] for i in irect]
163 | ar = ar[irect]
164 |
165 | # Set training image shapes
166 | shapes = [[1, 1]] * nb
167 | for i in range(nb):
168 | ari = ar[bi == i]
169 | mini, maxi = ari.min(), ari.max()
170 | if maxi < 1:
171 | shapes[i] = [maxi, 1]
172 | elif mini > 1:
173 | shapes[i] = [1, 1 / mini]
174 |
175 | self.batch_shapes = np.ceil(np.array(shapes) * self.imgsz / self.stride + self.pad).astype(int) * self.stride
176 | self.batch = bi # batch index of image
177 |
178 | def __getitem__(self, index):
179 | return self.transforms(self.get_label_info(index))
180 |
181 | def get_label_info(self, index):
182 | label = self.labels[index].copy()
183 | label["img"], label["ori_shape"], label["resized_shape"] = self.load_image(index)
184 | label["ratio_pad"] = (
185 | label["resized_shape"][0] / label["ori_shape"][0],
186 | label["resized_shape"][1] / label["ori_shape"][1],
187 | ) # for evaluation
188 | if self.rect:
189 | label["rect_shape"] = self.batch_shapes[self.batch[index]]
190 | label = self.update_labels_info(label)
191 | return label
192 |
193 | def __len__(self):
194 | return len(self.im_files)
195 |
196 | def update_labels_info(self, label):
197 | """custom your label format here"""
198 | return label
199 |
200 | def build_transforms(self, hyp=None):
201 | """Users can custom augmentations here
202 | like:
203 | if self.augment:
204 | # training transforms
205 | return Compose([])
206 | else:
207 | # val transforms
208 | return Compose([])
209 | """
210 | raise NotImplementedError
211 |
212 | def get_labels(self):
213 | """Users can custom their own format here.
214 | Make sure your output is a list with each element like below:
215 | dict(
216 | im_file=im_file,
217 | shape=shape, # format: (height, width)
218 | cls=cls,
219 | bboxes=bboxes, # xywh
220 | segments=segments, # xy
221 | keypoints=keypoints, # xy
222 | normalized=True, # or False
223 | bbox_format="xyxy", # or xywh, ltwh
224 | )
225 | """
226 | raise NotImplementedError
227 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/build.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import os
4 | import random
5 |
6 | import numpy as np
7 | import torch
8 | from torch.utils.data import DataLoader, dataloader, distributed
9 |
10 | from ..utils import LOGGER, colorstr
11 | from ..utils.torch_utils import torch_distributed_zero_first
12 | from .dataset import ClassificationDataset, YOLODataset
13 | from .utils import PIN_MEMORY, RANK
14 |
15 |
16 | class InfiniteDataLoader(dataloader.DataLoader):
17 | """Dataloader that reuses workers
18 |
19 | Uses same syntax as vanilla DataLoader
20 | """
21 |
22 | def __init__(self, *args, **kwargs):
23 | super().__init__(*args, **kwargs)
24 | object.__setattr__(self, "batch_sampler", _RepeatSampler(self.batch_sampler))
25 | self.iterator = super().__iter__()
26 |
27 | def __len__(self):
28 | return len(self.batch_sampler.sampler)
29 |
30 | def __iter__(self):
31 | for _ in range(len(self)):
32 | yield next(self.iterator)
33 |
34 |
35 | class _RepeatSampler:
36 | """Sampler that repeats forever
37 |
38 | Args:
39 | sampler (Sampler)
40 | """
41 |
42 | def __init__(self, sampler):
43 | self.sampler = sampler
44 |
45 | def __iter__(self):
46 | while True:
47 | yield from iter(self.sampler)
48 |
49 |
50 | def seed_worker(worker_id):
51 | # Set dataloader worker seed https://pytorch.org/docs/stable/notes/randomness.html#dataloader
52 | worker_seed = torch.initial_seed() % 2 ** 32
53 | np.random.seed(worker_seed)
54 | random.seed(worker_seed)
55 |
56 |
57 | def build_dataloader(cfg, batch_size, img_path, stride=32, label_path=None, rank=-1, mode="train"):
58 | assert mode in ["train", "val"]
59 | shuffle = mode == "train"
60 | if cfg.rect and shuffle:
61 | LOGGER.warning("WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False")
62 | shuffle = False
63 | with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
64 | dataset = YOLODataset(
65 | img_path=img_path,
66 | label_path=label_path,
67 | imgsz=cfg.imgsz,
68 | batch_size=batch_size,
69 | augment=mode == "train", # augmentation
70 | hyp=cfg, # TODO: probably add a get_hyps_from_cfg function
71 | rect=cfg.rect if mode == "train" else True, # rectangular batches
72 | cache=cfg.get("cache", None),
73 | single_cls=cfg.get("single_cls", False),
74 | stride=int(stride),
75 | pad=0.0 if mode == "train" else 0.5,
76 | prefix=colorstr(f"{mode}: "),
77 | use_segments=cfg.task == "segment",
78 | use_keypoints=cfg.task == "keypoint")
79 |
80 | batch_size = min(batch_size, len(dataset))
81 | nd = torch.cuda.device_count() # number of CUDA devices
82 | workers = cfg.workers if mode == "train" else cfg.workers * 2
83 | nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
84 | sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
85 | loader = DataLoader if cfg.image_weights or cfg.close_mosaic else InfiniteDataLoader # allow attribute updates
86 | generator = torch.Generator()
87 | generator.manual_seed(6148914691236517205 + RANK)
88 | return loader(dataset=dataset,
89 | batch_size=batch_size,
90 | shuffle=shuffle and sampler is None,
91 | num_workers=nw,
92 | sampler=sampler,
93 | pin_memory=PIN_MEMORY,
94 | collate_fn=getattr(dataset, "collate_fn", None),
95 | worker_init_fn=seed_worker,
96 | generator=generator), dataset
97 |
98 |
99 | # build classification
100 | # TODO: using cfg like `build_dataloader`
101 | def build_classification_dataloader(path,
102 | imgsz=224,
103 | batch_size=16,
104 | augment=True,
105 | cache=False,
106 | rank=-1,
107 | workers=8,
108 | shuffle=True):
109 | # Returns Dataloader object to be used with YOLOv5 Classifier
110 | with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
111 | dataset = ClassificationDataset(root=path, imgsz=imgsz, augment=augment, cache=cache)
112 | batch_size = min(batch_size, len(dataset))
113 | nd = torch.cuda.device_count()
114 | nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers])
115 | sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
116 | generator = torch.Generator()
117 | generator.manual_seed(6148914691236517205 + RANK)
118 | return InfiniteDataLoader(dataset,
119 | batch_size=batch_size,
120 | shuffle=shuffle and sampler is None,
121 | num_workers=nw,
122 | sampler=sampler,
123 | pin_memory=PIN_MEMORY,
124 | worker_init_fn=seed_worker,
125 | generator=generator) # or DataLoader(persistent_workers=True)
126 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/dataloaders/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/MuhammadMoinFaisal/YOLOv8-object-tracking-blurring-counting/6ad9082f7d0022b22a2325e1078dc3534113f7df/ultralytics/yolo/data/dataloaders/__init__.py
--------------------------------------------------------------------------------
/ultralytics/yolo/data/dataset.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | from itertools import repeat
4 | from multiprocessing.pool import Pool
5 | from pathlib import Path
6 |
7 | import torchvision
8 | from tqdm import tqdm
9 |
10 | from ..utils import NUM_THREADS, TQDM_BAR_FORMAT
11 | from .augment import *
12 | from .base import BaseDataset
13 | from .utils import HELP_URL, LOCAL_RANK, get_hash, img2label_paths, verify_image_label
14 |
15 |
16 | class YOLODataset(BaseDataset):
17 | cache_version = 1.0 # dataset labels *.cache version, >= 1.0 for YOLOv8
18 | rand_interp_methods = [cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4]
19 | """YOLO Dataset.
20 | Args:
21 | img_path (str): image path.
22 | prefix (str): prefix.
23 | """
24 |
25 | def __init__(
26 | self,
27 | img_path,
28 | imgsz=640,
29 | label_path=None,
30 | cache=False,
31 | augment=True,
32 | hyp=None,
33 | prefix="",
34 | rect=False,
35 | batch_size=None,
36 | stride=32,
37 | pad=0.0,
38 | single_cls=False,
39 | use_segments=False,
40 | use_keypoints=False,
41 | ):
42 | self.use_segments = use_segments
43 | self.use_keypoints = use_keypoints
44 | assert not (self.use_segments and self.use_keypoints), "Can not use both segments and keypoints."
45 | super().__init__(img_path, imgsz, label_path, cache, augment, hyp, prefix, rect, batch_size, stride, pad,
46 | single_cls)
47 |
48 | def cache_labels(self, path=Path("./labels.cache")):
49 | # Cache dataset labels, check images and read shapes
50 | x = {"labels": []}
51 | nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
52 | desc = f"{self.prefix}Scanning {path.parent / path.stem}..."
53 | with Pool(NUM_THREADS) as pool:
54 | pbar = tqdm(
55 | pool.imap(verify_image_label,
56 | zip(self.im_files, self.label_files, repeat(self.prefix), repeat(self.use_keypoints))),
57 | desc=desc,
58 | total=len(self.im_files),
59 | bar_format=TQDM_BAR_FORMAT,
60 | )
61 | for im_file, lb, shape, segments, keypoint, nm_f, nf_f, ne_f, nc_f, msg in pbar:
62 | nm += nm_f
63 | nf += nf_f
64 | ne += ne_f
65 | nc += nc_f
66 | if im_file:
67 | x["labels"].append(
68 | dict(
69 | im_file=im_file,
70 | shape=shape,
71 | cls=lb[:, 0:1], # n, 1
72 | bboxes=lb[:, 1:], # n, 4
73 | segments=segments,
74 | keypoints=keypoint,
75 | normalized=True,
76 | bbox_format="xywh",
77 | ))
78 | if msg:
79 | msgs.append(msg)
80 | pbar.desc = f"{desc} {nf} images, {nm + ne} backgrounds, {nc} corrupt"
81 |
82 | pbar.close()
83 | if msgs:
84 | LOGGER.info("\n".join(msgs))
85 | if nf == 0:
86 | LOGGER.warning(f"{self.prefix}WARNING ⚠️ No labels found in {path}. {HELP_URL}")
87 | x["hash"] = get_hash(self.label_files + self.im_files)
88 | x["results"] = nf, nm, ne, nc, len(self.im_files)
89 | x["msgs"] = msgs # warnings
90 | x["version"] = self.cache_version # cache version
91 | try:
92 | np.save(path, x) # save cache for next time
93 | path.with_suffix(".cache.npy").rename(path) # remove .npy suffix
94 | LOGGER.info(f"{self.prefix}New cache created: {path}")
95 | except Exception as e:
96 | LOGGER.warning(
97 | f"{self.prefix}WARNING ⚠️ Cache directory {path.parent} is not writeable: {e}") # not writeable
98 | return x
99 |
100 | def get_labels(self):
101 | self.label_files = img2label_paths(self.im_files)
102 | cache_path = Path(self.label_files[0]).parent.with_suffix(".cache")
103 | try:
104 | cache, exists = np.load(str(cache_path), allow_pickle=True).item(), True # load dict
105 | assert cache["version"] == self.cache_version # matches current version
106 | assert cache["hash"] == get_hash(self.label_files + self.im_files) # identical hash
107 | except Exception:
108 | cache, exists = self.cache_labels(cache_path), False # run cache ops
109 |
110 | # Display cache
111 | nf, nm, ne, nc, n = cache.pop("results") # found, missing, empty, corrupt, total
112 | if exists and LOCAL_RANK in {-1, 0}:
113 | d = f"Scanning {cache_path}... {nf} images, {nm + ne} backgrounds, {nc} corrupt"
114 | tqdm(None, desc=self.prefix + d, total=n, initial=n, bar_format=TQDM_BAR_FORMAT) # display cache results
115 | if cache["msgs"]:
116 | LOGGER.info("\n".join(cache["msgs"])) # display warnings
117 | assert nf > 0, f"{self.prefix}No labels found in {cache_path}, can not start training. {HELP_URL}"
118 |
119 | # Read cache
120 | [cache.pop(k) for k in ("hash", "version", "msgs")] # remove items
121 | labels = cache["labels"]
122 | nl = len(np.concatenate([label["cls"] for label in labels], 0)) # number of labels
123 | assert nl > 0, f"{self.prefix}All labels empty in {cache_path}, can not start training. {HELP_URL}"
124 | return labels
125 |
126 | # TODO: use hyp config to set all these augmentations
127 | def build_transforms(self, hyp=None):
128 | if self.augment:
129 | mosaic = self.augment and not self.rect
130 | transforms = mosaic_transforms(self, self.imgsz, hyp) if mosaic else affine_transforms(self.imgsz, hyp)
131 | else:
132 | transforms = Compose([LetterBox(new_shape=(self.imgsz, self.imgsz), scaleup=False)])
133 | transforms.append(
134 | Format(bbox_format="xywh",
135 | normalize=True,
136 | return_mask=self.use_segments,
137 | return_keypoint=self.use_keypoints,
138 | batch_idx=True))
139 | return transforms
140 |
141 | def close_mosaic(self, hyp):
142 | self.transforms = affine_transforms(self.imgsz, hyp)
143 | self.transforms.append(
144 | Format(bbox_format="xywh",
145 | normalize=True,
146 | return_mask=self.use_segments,
147 | return_keypoint=self.use_keypoints,
148 | batch_idx=True))
149 |
150 | def update_labels_info(self, label):
151 | """custom your label format here"""
152 | # NOTE: cls is not with bboxes now, classification and semantic segmentation need an independent cls label
153 | # we can make it also support classification and semantic segmentation by add or remove some dict keys there.
154 | bboxes = label.pop("bboxes")
155 | segments = label.pop("segments")
156 | keypoints = label.pop("keypoints", None)
157 | bbox_format = label.pop("bbox_format")
158 | normalized = label.pop("normalized")
159 | label["instances"] = Instances(bboxes, segments, keypoints, bbox_format=bbox_format, normalized=normalized)
160 | return label
161 |
162 | @staticmethod
163 | def collate_fn(batch):
164 | # TODO: returning a dict can make thing easier and cleaner when using dataset in training
165 | # but I don't know if this will slow down a little bit.
166 | new_batch = {}
167 | keys = batch[0].keys()
168 | values = list(zip(*[list(b.values()) for b in batch]))
169 | for i, k in enumerate(keys):
170 | value = values[i]
171 | if k == "img":
172 | value = torch.stack(value, 0)
173 | if k in ["masks", "keypoints", "bboxes", "cls"]:
174 | value = torch.cat(value, 0)
175 | new_batch[k] = value
176 | new_batch["batch_idx"] = list(new_batch["batch_idx"])
177 | for i in range(len(new_batch["batch_idx"])):
178 | new_batch["batch_idx"][i] += i # add target image index for build_targets()
179 | new_batch["batch_idx"] = torch.cat(new_batch["batch_idx"], 0)
180 | return new_batch
181 |
182 |
183 | # Classification dataloaders -------------------------------------------------------------------------------------------
184 | class ClassificationDataset(torchvision.datasets.ImageFolder):
185 | """
186 | YOLOv5 Classification Dataset.
187 | Arguments
188 | root: Dataset path
189 | transform: torchvision transforms, used by default
190 | album_transform: Albumentations transforms, used if installed
191 | """
192 |
193 | def __init__(self, root, augment, imgsz, cache=False):
194 | super().__init__(root=root)
195 | self.torch_transforms = classify_transforms(imgsz)
196 | self.album_transforms = classify_albumentations(augment, imgsz) if augment else None
197 | self.cache_ram = cache is True or cache == "ram"
198 | self.cache_disk = cache == "disk"
199 | self.samples = [list(x) + [Path(x[0]).with_suffix(".npy"), None] for x in self.samples] # file, index, npy, im
200 |
201 | def __getitem__(self, i):
202 | f, j, fn, im = self.samples[i] # filename, index, filename.with_suffix('.npy'), image
203 | if self.cache_ram and im is None:
204 | im = self.samples[i][3] = cv2.imread(f)
205 | elif self.cache_disk:
206 | if not fn.exists(): # load npy
207 | np.save(fn.as_posix(), cv2.imread(f))
208 | im = np.load(fn)
209 | else: # read image
210 | im = cv2.imread(f) # BGR
211 | if self.album_transforms:
212 | sample = self.album_transforms(image=cv2.cvtColor(im, cv2.COLOR_BGR2RGB))["image"]
213 | else:
214 | sample = self.torch_transforms(im)
215 | return {'img': sample, 'cls': j}
216 |
217 | def __len__(self) -> int:
218 | return len(self.samples)
219 |
220 |
221 | # TODO: support semantic segmentation
222 | class SemanticDataset(BaseDataset):
223 |
224 | def __init__(self):
225 | pass
226 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/dataset_wrappers.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import collections
4 | from copy import deepcopy
5 |
6 | from .augment import LetterBox
7 |
8 |
9 | class MixAndRectDataset:
10 | """A wrapper of multiple images mixed dataset.
11 |
12 | Args:
13 | dataset (:obj:`BaseDataset`): The dataset to be mixed.
14 | transforms (Sequence[dict]): config dict to be composed.
15 | """
16 |
17 | def __init__(self, dataset):
18 | self.dataset = dataset
19 | self.imgsz = dataset.imgsz
20 |
21 | def __len__(self):
22 | return len(self.dataset)
23 |
24 | def __getitem__(self, index):
25 | labels = deepcopy(self.dataset[index])
26 | for transform in self.dataset.transforms.tolist():
27 | # mosaic and mixup
28 | if hasattr(transform, "get_indexes"):
29 | indexes = transform.get_indexes(self.dataset)
30 | if not isinstance(indexes, collections.abc.Sequence):
31 | indexes = [indexes]
32 | mix_labels = [deepcopy(self.dataset[index]) for index in indexes]
33 | labels["mix_labels"] = mix_labels
34 | if self.dataset.rect and isinstance(transform, LetterBox):
35 | transform.new_shape = self.dataset.batch_shapes[self.dataset.batch[index]]
36 | labels = transform(labels)
37 | if "mix_labels" in labels:
38 | labels.pop("mix_labels")
39 | return labels
40 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/datasets/Argoverse.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | # Argoverse-HD dataset (ring-front-center camera) http://www.cs.cmu.edu/~mengtial/proj/streaming/ by Argo AI
3 | # Example usage: python train.py --data Argoverse.yaml
4 | # parent
5 | # ├── yolov5
6 | # └── datasets
7 | # └── Argoverse ← downloads here (31.3 GB)
8 |
9 |
10 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
11 | path: ../datasets/Argoverse # dataset root dir
12 | train: Argoverse-1.1/images/train/ # train images (relative to 'path') 39384 images
13 | val: Argoverse-1.1/images/val/ # val images (relative to 'path') 15062 images
14 | test: Argoverse-1.1/images/test/ # test images (optional) https://eval.ai/web/challenges/challenge-page/800/overview
15 |
16 | # Classes
17 | names:
18 | 0: person
19 | 1: bicycle
20 | 2: car
21 | 3: motorcycle
22 | 4: bus
23 | 5: truck
24 | 6: traffic_light
25 | 7: stop_sign
26 |
27 |
28 | # Download script/URL (optional) ---------------------------------------------------------------------------------------
29 | download: |
30 | import json
31 |
32 | from tqdm import tqdm
33 | from utils.general import download, Path
34 |
35 |
36 | def argoverse2yolo(set):
37 | labels = {}
38 | a = json.load(open(set, "rb"))
39 | for annot in tqdm(a['annotations'], desc=f"Converting {set} to YOLOv5 format..."):
40 | img_id = annot['image_id']
41 | img_name = a['images'][img_id]['name']
42 | img_label_name = f'{img_name[:-3]}txt'
43 |
44 | cls = annot['category_id'] # instance class id
45 | x_center, y_center, width, height = annot['bbox']
46 | x_center = (x_center + width / 2) / 1920.0 # offset and scale
47 | y_center = (y_center + height / 2) / 1200.0 # offset and scale
48 | width /= 1920.0 # scale
49 | height /= 1200.0 # scale
50 |
51 | img_dir = set.parents[2] / 'Argoverse-1.1' / 'labels' / a['seq_dirs'][a['images'][annot['image_id']]['sid']]
52 | if not img_dir.exists():
53 | img_dir.mkdir(parents=True, exist_ok=True)
54 |
55 | k = str(img_dir / img_label_name)
56 | if k not in labels:
57 | labels[k] = []
58 | labels[k].append(f"{cls} {x_center} {y_center} {width} {height}\n")
59 |
60 | for k in labels:
61 | with open(k, "w") as f:
62 | f.writelines(labels[k])
63 |
64 |
65 | # Download
66 | dir = Path(yaml['path']) # dataset root dir
67 | urls = ['https://argoverse-hd.s3.us-east-2.amazonaws.com/Argoverse-HD-Full.zip']
68 | download(urls, dir=dir, delete=False)
69 |
70 | # Convert
71 | annotations_dir = 'Argoverse-HD/annotations/'
72 | (dir / 'Argoverse-1.1' / 'tracking').rename(dir / 'Argoverse-1.1' / 'images') # rename 'tracking' to 'images'
73 | for d in "train.json", "val.json":
74 | argoverse2yolo(dir / annotations_dir / d) # convert VisDrone annotations to YOLO labels
75 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/datasets/GlobalWheat2020.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | # Global Wheat 2020 dataset http://www.global-wheat.com/ by University of Saskatchewan
3 | # Example usage: python train.py --data GlobalWheat2020.yaml
4 | # parent
5 | # ├── yolov5
6 | # └── datasets
7 | # └── GlobalWheat2020 ← downloads here (7.0 GB)
8 |
9 |
10 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
11 | path: ../datasets/GlobalWheat2020 # dataset root dir
12 | train: # train images (relative to 'path') 3422 images
13 | - images/arvalis_1
14 | - images/arvalis_2
15 | - images/arvalis_3
16 | - images/ethz_1
17 | - images/rres_1
18 | - images/inrae_1
19 | - images/usask_1
20 | val: # val images (relative to 'path') 748 images (WARNING: train set contains ethz_1)
21 | - images/ethz_1
22 | test: # test images (optional) 1276 images
23 | - images/utokyo_1
24 | - images/utokyo_2
25 | - images/nau_1
26 | - images/uq_1
27 |
28 | # Classes
29 | names:
30 | 0: wheat_head
31 |
32 |
33 | # Download script/URL (optional) ---------------------------------------------------------------------------------------
34 | download: |
35 | from utils.general import download, Path
36 |
37 |
38 | # Download
39 | dir = Path(yaml['path']) # dataset root dir
40 | urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
41 | 'https://github.com/ultralytics/yolov5/releases/download/v1.0/GlobalWheat2020_labels.zip']
42 | download(urls, dir=dir)
43 |
44 | # Make Directories
45 | for p in 'annotations', 'images', 'labels':
46 | (dir / p).mkdir(parents=True, exist_ok=True)
47 |
48 | # Move
49 | for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
50 | 'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
51 | (dir / p).rename(dir / 'images' / p) # move to /images
52 | f = (dir / p).with_suffix('.json') # json file
53 | if f.exists():
54 | f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotations
55 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/datasets/SKU-110K.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | # SKU-110K retail items dataset https://github.com/eg4000/SKU110K_CVPR19 by Trax Retail
3 | # Example usage: python train.py --data SKU-110K.yaml
4 | # parent
5 | # ├── yolov5
6 | # └── datasets
7 | # └── SKU-110K ← downloads here (13.6 GB)
8 |
9 |
10 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
11 | path: ../datasets/SKU-110K # dataset root dir
12 | train: train.txt # train images (relative to 'path') 8219 images
13 | val: val.txt # val images (relative to 'path') 588 images
14 | test: test.txt # test images (optional) 2936 images
15 |
16 | # Classes
17 | names:
18 | 0: object
19 |
20 |
21 | # Download script/URL (optional) ---------------------------------------------------------------------------------------
22 | download: |
23 | import shutil
24 | from tqdm import tqdm
25 | from utils.general import np, pd, Path, download, xyxy2xywh
26 |
27 |
28 | # Download
29 | dir = Path(yaml['path']) # dataset root dir
30 | parent = Path(dir.parent) # download dir
31 | urls = ['http://trax-geometry.s3.amazonaws.com/cvpr_challenge/SKU110K_fixed.tar.gz']
32 | download(urls, dir=parent, delete=False)
33 |
34 | # Rename directories
35 | if dir.exists():
36 | shutil.rmtree(dir)
37 | (parent / 'SKU110K_fixed').rename(dir) # rename dir
38 | (dir / 'labels').mkdir(parents=True, exist_ok=True) # create labels dir
39 |
40 | # Convert labels
41 | names = 'image', 'x1', 'y1', 'x2', 'y2', 'class', 'image_width', 'image_height' # column names
42 | for d in 'annotations_train.csv', 'annotations_val.csv', 'annotations_test.csv':
43 | x = pd.read_csv(dir / 'annotations' / d, names=names).values # annotations
44 | images, unique_images = x[:, 0], np.unique(x[:, 0])
45 | with open((dir / d).with_suffix('.txt').__str__().replace('annotations_', ''), 'w') as f:
46 | f.writelines(f'./images/{s}\n' for s in unique_images)
47 | for im in tqdm(unique_images, desc=f'Converting {dir / d}'):
48 | cls = 0 # single-class dataset
49 | with open((dir / 'labels' / im).with_suffix('.txt'), 'a') as f:
50 | for r in x[images == im]:
51 | w, h = r[6], r[7] # image width, height
52 | xywh = xyxy2xywh(np.array([[r[1] / w, r[2] / h, r[3] / w, r[4] / h]]))[0] # instance
53 | f.write(f"{cls} {xywh[0]:.5f} {xywh[1]:.5f} {xywh[2]:.5f} {xywh[3]:.5f}\n") # write label
54 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/datasets/VOC.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | # PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
3 | # Example usage: python train.py --data VOC.yaml
4 | # parent
5 | # ├── yolov5
6 | # └── datasets
7 | # └── VOC ← downloads here (2.8 GB)
8 |
9 |
10 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
11 | path: ../datasets/VOC
12 | train: # train images (relative to 'path') 16551 images
13 | - images/train2012
14 | - images/train2007
15 | - images/val2012
16 | - images/val2007
17 | val: # val images (relative to 'path') 4952 images
18 | - images/test2007
19 | test: # test images (optional)
20 | - images/test2007
21 |
22 | # Classes
23 | names:
24 | 0: aeroplane
25 | 1: bicycle
26 | 2: bird
27 | 3: boat
28 | 4: bottle
29 | 5: bus
30 | 6: car
31 | 7: cat
32 | 8: chair
33 | 9: cow
34 | 10: diningtable
35 | 11: dog
36 | 12: horse
37 | 13: motorbike
38 | 14: person
39 | 15: pottedplant
40 | 16: sheep
41 | 17: sofa
42 | 18: train
43 | 19: tvmonitor
44 |
45 |
46 | # Download script/URL (optional) ---------------------------------------------------------------------------------------
47 | download: |
48 | import xml.etree.ElementTree as ET
49 |
50 | from tqdm import tqdm
51 | from utils.general import download, Path
52 |
53 |
54 | def convert_label(path, lb_path, year, image_id):
55 | def convert_box(size, box):
56 | dw, dh = 1. / size[0], 1. / size[1]
57 | x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
58 | return x * dw, y * dh, w * dw, h * dh
59 |
60 | in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
61 | out_file = open(lb_path, 'w')
62 | tree = ET.parse(in_file)
63 | root = tree.getroot()
64 | size = root.find('size')
65 | w = int(size.find('width').text)
66 | h = int(size.find('height').text)
67 |
68 | names = list(yaml['names'].values()) # names list
69 | for obj in root.iter('object'):
70 | cls = obj.find('name').text
71 | if cls in names and int(obj.find('difficult').text) != 1:
72 | xmlbox = obj.find('bndbox')
73 | bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
74 | cls_id = names.index(cls) # class id
75 | out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
76 |
77 |
78 | # Download
79 | dir = Path(yaml['path']) # dataset root dir
80 | url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
81 | urls = [f'{url}VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
82 | f'{url}VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
83 | f'{url}VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
84 | download(urls, dir=dir / 'images', delete=False, curl=True, threads=3)
85 |
86 | # Convert
87 | path = dir / 'images/VOCdevkit'
88 | for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
89 | imgs_path = dir / 'images' / f'{image_set}{year}'
90 | lbs_path = dir / 'labels' / f'{image_set}{year}'
91 | imgs_path.mkdir(exist_ok=True, parents=True)
92 | lbs_path.mkdir(exist_ok=True, parents=True)
93 |
94 | with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
95 | image_ids = f.read().strip().split()
96 | for id in tqdm(image_ids, desc=f'{image_set}{year}'):
97 | f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
98 | lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
99 | f.rename(imgs_path / f.name) # move image
100 | convert_label(path, lb_path, year, id) # convert labels to YOLO format
101 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/datasets/VisDrone.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | # VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
3 | # Example usage: python train.py --data VisDrone.yaml
4 | # parent
5 | # ├── yolov5
6 | # └── datasets
7 | # └── VisDrone ← downloads here (2.3 GB)
8 |
9 |
10 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
11 | path: ../datasets/VisDrone # dataset root dir
12 | train: VisDrone2019-DET-train/images # train images (relative to 'path') 6471 images
13 | val: VisDrone2019-DET-val/images # val images (relative to 'path') 548 images
14 | test: VisDrone2019-DET-test-dev/images # test images (optional) 1610 images
15 |
16 | # Classes
17 | names:
18 | 0: pedestrian
19 | 1: people
20 | 2: bicycle
21 | 3: car
22 | 4: van
23 | 5: truck
24 | 6: tricycle
25 | 7: awning-tricycle
26 | 8: bus
27 | 9: motor
28 |
29 |
30 | # Download script/URL (optional) ---------------------------------------------------------------------------------------
31 | download: |
32 | from utils.general import download, os, Path
33 |
34 | def visdrone2yolo(dir):
35 | from PIL import Image
36 | from tqdm import tqdm
37 |
38 | def convert_box(size, box):
39 | # Convert VisDrone box to YOLO xywh box
40 | dw = 1. / size[0]
41 | dh = 1. / size[1]
42 | return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
43 |
44 | (dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
45 | pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
46 | for f in pbar:
47 | img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
48 | lines = []
49 | with open(f, 'r') as file: # read annotation.txt
50 | for row in [x.split(',') for x in file.read().strip().splitlines()]:
51 | if row[4] == '0': # VisDrone 'ignored regions' class 0
52 | continue
53 | cls = int(row[5]) - 1
54 | box = convert_box(img_size, tuple(map(int, row[:4])))
55 | lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
56 | with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'labels' + os.sep), 'w') as fl:
57 | fl.writelines(lines) # write label.txt
58 |
59 |
60 | # Download
61 | dir = Path(yaml['path']) # dataset root dir
62 | urls = ['https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-train.zip',
63 | 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-val.zip',
64 | 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-dev.zip',
65 | 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-challenge.zip']
66 | download(urls, dir=dir, curl=True, threads=4)
67 |
68 | # Convert
69 | for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
70 | visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
71 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/datasets/coco.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | # COCO 2017 dataset http://cocodataset.org by Microsoft
3 | # Example usage: python train.py --data coco.yaml
4 | # parent
5 | # ├── yolov5
6 | # └── datasets
7 | # └── coco ← downloads here (20.1 GB)
8 |
9 |
10 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
11 | path: ../datasets/coco # dataset root dir
12 | train: train2017.txt # train images (relative to 'path') 118287 images
13 | val: val2017.txt # val images (relative to 'path') 5000 images
14 | test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
15 |
16 | # Classes
17 | names:
18 | 0: person
19 | 1: bicycle
20 | 2: car
21 | 3: motorcycle
22 | 4: airplane
23 | 5: bus
24 | 6: train
25 | 7: truck
26 | 8: boat
27 | 9: traffic light
28 | 10: fire hydrant
29 | 11: stop sign
30 | 12: parking meter
31 | 13: bench
32 | 14: bird
33 | 15: cat
34 | 16: dog
35 | 17: horse
36 | 18: sheep
37 | 19: cow
38 | 20: elephant
39 | 21: bear
40 | 22: zebra
41 | 23: giraffe
42 | 24: backpack
43 | 25: umbrella
44 | 26: handbag
45 | 27: tie
46 | 28: suitcase
47 | 29: frisbee
48 | 30: skis
49 | 31: snowboard
50 | 32: sports ball
51 | 33: kite
52 | 34: baseball bat
53 | 35: baseball glove
54 | 36: skateboard
55 | 37: surfboard
56 | 38: tennis racket
57 | 39: bottle
58 | 40: wine glass
59 | 41: cup
60 | 42: fork
61 | 43: knife
62 | 44: spoon
63 | 45: bowl
64 | 46: banana
65 | 47: apple
66 | 48: sandwich
67 | 49: orange
68 | 50: broccoli
69 | 51: carrot
70 | 52: hot dog
71 | 53: pizza
72 | 54: donut
73 | 55: cake
74 | 56: chair
75 | 57: couch
76 | 58: potted plant
77 | 59: bed
78 | 60: dining table
79 | 61: toilet
80 | 62: tv
81 | 63: laptop
82 | 64: mouse
83 | 65: remote
84 | 66: keyboard
85 | 67: cell phone
86 | 68: microwave
87 | 69: oven
88 | 70: toaster
89 | 71: sink
90 | 72: refrigerator
91 | 73: book
92 | 74: clock
93 | 75: vase
94 | 76: scissors
95 | 77: teddy bear
96 | 78: hair drier
97 | 79: toothbrush
98 |
99 |
100 | # Download script/URL (optional)
101 | download: |
102 | from utils.general import download, Path
103 | # Download labels
104 | segments = True # segment or box labels
105 | dir = Path(yaml['path']) # dataset root dir
106 | url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
107 | urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
108 | download(urls, dir=dir.parent)
109 | # Download data
110 | urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
111 | 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
112 | 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
113 | download(urls, dir=dir / 'images', threads=3)
--------------------------------------------------------------------------------
/ultralytics/yolo/data/datasets/coco128-seg.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | # COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
3 | # Example usage: python train.py --data coco128.yaml
4 | # parent
5 | # ├── yolov5
6 | # └── datasets
7 | # └── coco128-seg ← downloads here (7 MB)
8 |
9 |
10 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
11 | path: ../datasets/coco128-seg # dataset root dir
12 | train: images/train2017 # train images (relative to 'path') 128 images
13 | val: images/train2017 # val images (relative to 'path') 128 images
14 | test: # test images (optional)
15 |
16 | # Classes
17 | names:
18 | 0: person
19 | 1: bicycle
20 | 2: car
21 | 3: motorcycle
22 | 4: airplane
23 | 5: bus
24 | 6: train
25 | 7: truck
26 | 8: boat
27 | 9: traffic light
28 | 10: fire hydrant
29 | 11: stop sign
30 | 12: parking meter
31 | 13: bench
32 | 14: bird
33 | 15: cat
34 | 16: dog
35 | 17: horse
36 | 18: sheep
37 | 19: cow
38 | 20: elephant
39 | 21: bear
40 | 22: zebra
41 | 23: giraffe
42 | 24: backpack
43 | 25: umbrella
44 | 26: handbag
45 | 27: tie
46 | 28: suitcase
47 | 29: frisbee
48 | 30: skis
49 | 31: snowboard
50 | 32: sports ball
51 | 33: kite
52 | 34: baseball bat
53 | 35: baseball glove
54 | 36: skateboard
55 | 37: surfboard
56 | 38: tennis racket
57 | 39: bottle
58 | 40: wine glass
59 | 41: cup
60 | 42: fork
61 | 43: knife
62 | 44: spoon
63 | 45: bowl
64 | 46: banana
65 | 47: apple
66 | 48: sandwich
67 | 49: orange
68 | 50: broccoli
69 | 51: carrot
70 | 52: hot dog
71 | 53: pizza
72 | 54: donut
73 | 55: cake
74 | 56: chair
75 | 57: couch
76 | 58: potted plant
77 | 59: bed
78 | 60: dining table
79 | 61: toilet
80 | 62: tv
81 | 63: laptop
82 | 64: mouse
83 | 65: remote
84 | 66: keyboard
85 | 67: cell phone
86 | 68: microwave
87 | 69: oven
88 | 70: toaster
89 | 71: sink
90 | 72: refrigerator
91 | 73: book
92 | 74: clock
93 | 75: vase
94 | 76: scissors
95 | 77: teddy bear
96 | 78: hair drier
97 | 79: toothbrush
98 |
99 |
100 | # Download script/URL (optional)
101 | download: https://ultralytics.com/assets/coco128-seg.zip
--------------------------------------------------------------------------------
/ultralytics/yolo/data/datasets/coco128.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | # COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
3 | # Example usage: python train.py --data coco128.yaml
4 | # parent
5 | # ├── yolov5
6 | # └── datasets
7 | # └── coco128 ← downloads here (7 MB)
8 |
9 |
10 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
11 | path: ../datasets/coco128 # dataset root dir
12 | train: images/train2017 # train images (relative to 'path') 128 images
13 | val: images/train2017 # val images (relative to 'path') 128 images
14 | test: # test images (optional)
15 |
16 | # Classes
17 | names:
18 | 0: person
19 | 1: bicycle
20 | 2: car
21 | 3: motorcycle
22 | 4: airplane
23 | 5: bus
24 | 6: train
25 | 7: truck
26 | 8: boat
27 | 9: traffic light
28 | 10: fire hydrant
29 | 11: stop sign
30 | 12: parking meter
31 | 13: bench
32 | 14: bird
33 | 15: cat
34 | 16: dog
35 | 17: horse
36 | 18: sheep
37 | 19: cow
38 | 20: elephant
39 | 21: bear
40 | 22: zebra
41 | 23: giraffe
42 | 24: backpack
43 | 25: umbrella
44 | 26: handbag
45 | 27: tie
46 | 28: suitcase
47 | 29: frisbee
48 | 30: skis
49 | 31: snowboard
50 | 32: sports ball
51 | 33: kite
52 | 34: baseball bat
53 | 35: baseball glove
54 | 36: skateboard
55 | 37: surfboard
56 | 38: tennis racket
57 | 39: bottle
58 | 40: wine glass
59 | 41: cup
60 | 42: fork
61 | 43: knife
62 | 44: spoon
63 | 45: bowl
64 | 46: banana
65 | 47: apple
66 | 48: sandwich
67 | 49: orange
68 | 50: broccoli
69 | 51: carrot
70 | 52: hot dog
71 | 53: pizza
72 | 54: donut
73 | 55: cake
74 | 56: chair
75 | 57: couch
76 | 58: potted plant
77 | 59: bed
78 | 60: dining table
79 | 61: toilet
80 | 62: tv
81 | 63: laptop
82 | 64: mouse
83 | 65: remote
84 | 66: keyboard
85 | 67: cell phone
86 | 68: microwave
87 | 69: oven
88 | 70: toaster
89 | 71: sink
90 | 72: refrigerator
91 | 73: book
92 | 74: clock
93 | 75: vase
94 | 76: scissors
95 | 77: teddy bear
96 | 78: hair drier
97 | 79: toothbrush
98 |
99 |
100 | # Download script/URL (optional)
101 | download: https://ultralytics.com/assets/coco128.zip
--------------------------------------------------------------------------------
/ultralytics/yolo/data/datasets/xView.yaml:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | # DIUx xView 2018 Challenge https://challenge.xviewdataset.org by U.S. National Geospatial-Intelligence Agency (NGA)
3 | # -------- DOWNLOAD DATA MANUALLY and jar xf val_images.zip to 'datasets/xView' before running train command! --------
4 | # Example usage: python train.py --data xView.yaml
5 | # parent
6 | # ├── yolov5
7 | # └── datasets
8 | # └── xView ← downloads here (20.7 GB)
9 |
10 |
11 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
12 | path: ../datasets/xView # dataset root dir
13 | train: images/autosplit_train.txt # train images (relative to 'path') 90% of 847 train images
14 | val: images/autosplit_val.txt # train images (relative to 'path') 10% of 847 train images
15 |
16 | # Classes
17 | names:
18 | 0: Fixed-wing Aircraft
19 | 1: Small Aircraft
20 | 2: Cargo Plane
21 | 3: Helicopter
22 | 4: Passenger Vehicle
23 | 5: Small Car
24 | 6: Bus
25 | 7: Pickup Truck
26 | 8: Utility Truck
27 | 9: Truck
28 | 10: Cargo Truck
29 | 11: Truck w/Box
30 | 12: Truck Tractor
31 | 13: Trailer
32 | 14: Truck w/Flatbed
33 | 15: Truck w/Liquid
34 | 16: Crane Truck
35 | 17: Railway Vehicle
36 | 18: Passenger Car
37 | 19: Cargo Car
38 | 20: Flat Car
39 | 21: Tank car
40 | 22: Locomotive
41 | 23: Maritime Vessel
42 | 24: Motorboat
43 | 25: Sailboat
44 | 26: Tugboat
45 | 27: Barge
46 | 28: Fishing Vessel
47 | 29: Ferry
48 | 30: Yacht
49 | 31: Container Ship
50 | 32: Oil Tanker
51 | 33: Engineering Vehicle
52 | 34: Tower crane
53 | 35: Container Crane
54 | 36: Reach Stacker
55 | 37: Straddle Carrier
56 | 38: Mobile Crane
57 | 39: Dump Truck
58 | 40: Haul Truck
59 | 41: Scraper/Tractor
60 | 42: Front loader/Bulldozer
61 | 43: Excavator
62 | 44: Cement Mixer
63 | 45: Ground Grader
64 | 46: Hut/Tent
65 | 47: Shed
66 | 48: Building
67 | 49: Aircraft Hangar
68 | 50: Damaged Building
69 | 51: Facility
70 | 52: Construction Site
71 | 53: Vehicle Lot
72 | 54: Helipad
73 | 55: Storage Tank
74 | 56: Shipping container lot
75 | 57: Shipping Container
76 | 58: Pylon
77 | 59: Tower
78 |
79 |
80 | # Download script/URL (optional) ---------------------------------------------------------------------------------------
81 | download: |
82 | import json
83 | import os
84 | from pathlib import Path
85 |
86 | import numpy as np
87 | from PIL import Image
88 | from tqdm import tqdm
89 |
90 | from utils.dataloaders import autosplit
91 | from utils.general import download, xyxy2xywhn
92 |
93 |
94 | def convert_labels(fname=Path('xView/xView_train.geojson')):
95 | # Convert xView geoJSON labels to YOLO format
96 | path = fname.parent
97 | with open(fname) as f:
98 | print(f'Loading {fname}...')
99 | data = json.load(f)
100 |
101 | # Make dirs
102 | labels = Path(path / 'labels' / 'train')
103 | os.system(f'rm -rf {labels}')
104 | labels.mkdir(parents=True, exist_ok=True)
105 |
106 | # xView classes 11-94 to 0-59
107 | xview_class2index = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, -1, 3, -1, 4, 5, 6, 7, 8, -1, 9, 10, 11,
108 | 12, 13, 14, 15, -1, -1, 16, 17, 18, 19, 20, 21, 22, -1, 23, 24, 25, -1, 26, 27, -1, 28, -1,
109 | 29, 30, 31, 32, 33, 34, 35, 36, 37, -1, 38, 39, 40, 41, 42, 43, 44, 45, -1, -1, -1, -1, 46,
110 | 47, 48, 49, -1, 50, 51, -1, 52, -1, -1, -1, 53, 54, -1, 55, -1, -1, 56, -1, 57, -1, 58, 59]
111 |
112 | shapes = {}
113 | for feature in tqdm(data['features'], desc=f'Converting {fname}'):
114 | p = feature['properties']
115 | if p['bounds_imcoords']:
116 | id = p['image_id']
117 | file = path / 'train_images' / id
118 | if file.exists(): # 1395.tif missing
119 | try:
120 | box = np.array([int(num) for num in p['bounds_imcoords'].split(",")])
121 | assert box.shape[0] == 4, f'incorrect box shape {box.shape[0]}'
122 | cls = p['type_id']
123 | cls = xview_class2index[int(cls)] # xView class to 0-60
124 | assert 59 >= cls >= 0, f'incorrect class index {cls}'
125 |
126 | # Write YOLO label
127 | if id not in shapes:
128 | shapes[id] = Image.open(file).size
129 | box = xyxy2xywhn(box[None].astype(np.float), w=shapes[id][0], h=shapes[id][1], clip=True)
130 | with open((labels / id).with_suffix('.txt'), 'a') as f:
131 | f.write(f"{cls} {' '.join(f'{x:.6f}' for x in box[0])}\n") # write label.txt
132 | except Exception as e:
133 | print(f'WARNING: skipping one label for {file}: {e}')
134 |
135 |
136 | # Download manually from https://challenge.xviewdataset.org
137 | dir = Path(yaml['path']) # dataset root dir
138 | # urls = ['https://d307kc0mrhucc3.cloudfront.net/train_labels.zip', # train labels
139 | # 'https://d307kc0mrhucc3.cloudfront.net/train_images.zip', # 15G, 847 train images
140 | # 'https://d307kc0mrhucc3.cloudfront.net/val_images.zip'] # 5G, 282 val images (no labels)
141 | # download(urls, dir=dir, delete=False)
142 |
143 | # Convert labels
144 | convert_labels(dir / 'xView_train.geojson')
145 |
146 | # Move images
147 | images = Path(dir / 'images')
148 | images.mkdir(parents=True, exist_ok=True)
149 | Path(dir / 'train_images').rename(dir / 'images' / 'train')
150 | Path(dir / 'val_images').rename(dir / 'images' / 'val')
151 |
152 | # Split
153 | autosplit(dir / 'images' / 'train')
154 |
--------------------------------------------------------------------------------
/ultralytics/yolo/data/scripts/download_weights.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # Ultralytics YOLO 🚀, GPL-3.0 license
3 | # Download latest models from https://github.com/ultralytics/yolov5/releases
4 | # Example usage: bash data/scripts/download_weights.sh
5 | # parent
6 | # └── yolov5
7 | # ├── yolov5s.pt ← downloads here
8 | # ├── yolov5m.pt
9 | # └── ...
10 |
11 | python - < None:
34 | """
35 | > Initializes the YOLO object.
36 |
37 | Args:
38 | model (str, Path): model to load or create
39 | type (str): Type/version of models to use. Defaults to "v8".
40 | """
41 | self.type = type
42 | self.ModelClass = None # model class
43 | self.TrainerClass = None # trainer class
44 | self.ValidatorClass = None # validator class
45 | self.PredictorClass = None # predictor class
46 | self.model = None # model object
47 | self.trainer = None # trainer object
48 | self.task = None # task type
49 | self.ckpt = None # if loaded from *.pt
50 | self.cfg = None # if loaded from *.yaml
51 | self.ckpt_path = None
52 | self.overrides = {} # overrides for trainer object
53 |
54 | # Load or create new YOLO model
55 | {'.pt': self._load, '.yaml': self._new}[Path(model).suffix](model)
56 |
57 | def __call__(self, source, **kwargs):
58 | return self.predict(source, **kwargs)
59 |
60 | def _new(self, cfg: str, verbose=True):
61 | """
62 | > Initializes a new model and infers the task type from the model definitions.
63 |
64 | Args:
65 | cfg (str): model configuration file
66 | verbose (bool): display model info on load
67 | """
68 | cfg = check_yaml(cfg) # check YAML
69 | cfg_dict = yaml_load(cfg, append_filename=True) # model dict
70 | self.task = guess_task_from_head(cfg_dict["head"][-1][-2])
71 | self.ModelClass, self.TrainerClass, self.ValidatorClass, self.PredictorClass = \
72 | self._guess_ops_from_task(self.task)
73 | self.model = self.ModelClass(cfg_dict, verbose=verbose) # initialize
74 | self.cfg = cfg
75 |
76 | def _load(self, weights: str):
77 | """
78 | > Initializes a new model and infers the task type from the model head.
79 |
80 | Args:
81 | weights (str): model checkpoint to be loaded
82 | """
83 | self.model, self.ckpt = attempt_load_one_weight(weights)
84 | self.ckpt_path = weights
85 | self.task = self.model.args["task"]
86 | self.overrides = self.model.args
87 | self._reset_ckpt_args(self.overrides)
88 | self.ModelClass, self.TrainerClass, self.ValidatorClass, self.PredictorClass = \
89 | self._guess_ops_from_task(self.task)
90 |
91 | def reset(self):
92 | """
93 | > Resets the model modules.
94 | """
95 | for m in self.model.modules():
96 | if hasattr(m, 'reset_parameters'):
97 | m.reset_parameters()
98 | for p in self.model.parameters():
99 | p.requires_grad = True
100 |
101 | def info(self, verbose=False):
102 | """
103 | > Logs model info.
104 |
105 | Args:
106 | verbose (bool): Controls verbosity.
107 | """
108 | self.model.info(verbose=verbose)
109 |
110 | def fuse(self):
111 | self.model.fuse()
112 |
113 | @smart_inference_mode()
114 | def predict(self, source, **kwargs):
115 | """
116 | Visualize prediction.
117 |
118 | Args:
119 | source (str): Accepts all source types accepted by yolo
120 | **kwargs : Any other args accepted by the predictors. To see all args check 'configuration' section in docs
121 | """
122 | overrides = self.overrides.copy()
123 | overrides["conf"] = 0.25
124 | overrides.update(kwargs)
125 | overrides["mode"] = "predict"
126 | overrides["save"] = kwargs.get("save", False) # not save files by default
127 | predictor = self.PredictorClass(overrides=overrides)
128 |
129 | predictor.args.imgsz = check_imgsz(predictor.args.imgsz, min_dim=2) # check image size
130 | predictor.setup(model=self.model, source=source)
131 | return predictor()
132 |
133 | @smart_inference_mode()
134 | def val(self, data=None, **kwargs):
135 | """
136 | > Validate a model on a given dataset .
137 |
138 | Args:
139 | data (str): The dataset to validate on. Accepts all formats accepted by yolo
140 | **kwargs : Any other args accepted by the validators. To see all args check 'configuration' section in docs
141 | """
142 | overrides = self.overrides.copy()
143 | overrides.update(kwargs)
144 | overrides["mode"] = "val"
145 | args = get_config(config=DEFAULT_CONFIG, overrides=overrides)
146 | args.data = data or args.data
147 | args.task = self.task
148 |
149 | validator = self.ValidatorClass(args=args)
150 | validator(model=self.model)
151 |
152 | @smart_inference_mode()
153 | def export(self, **kwargs):
154 | """
155 | > Export model.
156 |
157 | Args:
158 | **kwargs : Any other args accepted by the predictors. To see all args check 'configuration' section in docs
159 | """
160 |
161 | overrides = self.overrides.copy()
162 | overrides.update(kwargs)
163 | args = get_config(config=DEFAULT_CONFIG, overrides=overrides)
164 | args.task = self.task
165 |
166 | exporter = Exporter(overrides=args)
167 | exporter(model=self.model)
168 |
169 | def train(self, **kwargs):
170 | """
171 | > Trains the model on a given dataset.
172 |
173 | Args:
174 | **kwargs (Any): Any number of arguments representing the training configuration. List of all args can be found in 'config' section.
175 | You can pass all arguments as a yaml file in `cfg`. Other args are ignored if `cfg` file is passed
176 | """
177 | overrides = self.overrides.copy()
178 | overrides.update(kwargs)
179 | if kwargs.get("cfg"):
180 | LOGGER.info(f"cfg file passed. Overriding default params with {kwargs['cfg']}.")
181 | overrides = yaml_load(check_yaml(kwargs["cfg"]), append_filename=True)
182 | overrides["task"] = self.task
183 | overrides["mode"] = "train"
184 | if not overrides.get("data"):
185 | raise AttributeError("dataset not provided! Please define `data` in config.yaml or pass as an argument.")
186 | if overrides.get("resume"):
187 | overrides["resume"] = self.ckpt_path
188 |
189 | self.trainer = self.TrainerClass(overrides=overrides)
190 | if not overrides.get("resume"): # manually set model only if not resuming
191 | self.trainer.model = self.trainer.get_model(weights=self.model if self.ckpt else None, cfg=self.model.yaml)
192 | self.model = self.trainer.model
193 | self.trainer.train()
194 |
195 | def to(self, device):
196 | """
197 | > Sends the model to the given device.
198 |
199 | Args:
200 | device (str): device
201 | """
202 | self.model.to(device)
203 |
204 | def _guess_ops_from_task(self, task):
205 | model_class, train_lit, val_lit, pred_lit = MODEL_MAP[task]
206 | # warning: eval is unsafe. Use with caution
207 | trainer_class = eval(train_lit.replace("TYPE", f"{self.type}"))
208 | validator_class = eval(val_lit.replace("TYPE", f"{self.type}"))
209 | predictor_class = eval(pred_lit.replace("TYPE", f"{self.type}"))
210 |
211 | return model_class, trainer_class, validator_class, predictor_class
212 |
213 | @staticmethod
214 | def _reset_ckpt_args(args):
215 | args.pop("device", None)
216 | args.pop("project", None)
217 | args.pop("name", None)
218 | args.pop("batch", None)
219 | args.pop("epochs", None)
220 | args.pop("cache", None)
221 | args.pop("save_json", None)
222 |
--------------------------------------------------------------------------------
/ultralytics/yolo/engine/validator.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import json
4 | from collections import defaultdict
5 | from pathlib import Path
6 |
7 | import torch
8 | from omegaconf import OmegaConf # noqa
9 | from tqdm import tqdm
10 |
11 | from ultralytics.nn.autobackend import AutoBackend
12 | from ultralytics.yolo.data.utils import check_dataset, check_dataset_yaml
13 | from ultralytics.yolo.utils import DEFAULT_CONFIG, LOGGER, RANK, SETTINGS, TQDM_BAR_FORMAT, callbacks
14 | from ultralytics.yolo.utils.checks import check_imgsz
15 | from ultralytics.yolo.utils.files import increment_path
16 | from ultralytics.yolo.utils.ops import Profile
17 | from ultralytics.yolo.utils.torch_utils import de_parallel, select_device, smart_inference_mode
18 |
19 |
20 | class BaseValidator:
21 | """
22 | BaseValidator
23 |
24 | A base class for creating validators.
25 |
26 | Attributes:
27 | dataloader (DataLoader): Dataloader to use for validation.
28 | pbar (tqdm): Progress bar to update during validation.
29 | logger (logging.Logger): Logger to use for validation.
30 | args (OmegaConf): Configuration for the validator.
31 | model (nn.Module): Model to validate.
32 | data (dict): Data dictionary.
33 | device (torch.device): Device to use for validation.
34 | batch_i (int): Current batch index.
35 | training (bool): Whether the model is in training mode.
36 | speed (float): Batch processing speed in seconds.
37 | jdict (dict): Dictionary to store validation results.
38 | save_dir (Path): Directory to save results.
39 | """
40 |
41 | def __init__(self, dataloader=None, save_dir=None, pbar=None, logger=None, args=None):
42 | """
43 | Initializes a BaseValidator instance.
44 |
45 | Args:
46 | dataloader (torch.utils.data.DataLoader): Dataloader to be used for validation.
47 | save_dir (Path): Directory to save results.
48 | pbar (tqdm.tqdm): Progress bar for displaying progress.
49 | logger (logging.Logger): Logger to log messages.
50 | args (OmegaConf): Configuration for the validator.
51 | """
52 | self.dataloader = dataloader
53 | self.pbar = pbar
54 | self.logger = logger or LOGGER
55 | self.args = args or OmegaConf.load(DEFAULT_CONFIG)
56 | self.model = None
57 | self.data = None
58 | self.device = None
59 | self.batch_i = None
60 | self.training = True
61 | self.speed = None
62 | self.jdict = None
63 |
64 | project = self.args.project or Path(SETTINGS['runs_dir']) / self.args.task
65 | name = self.args.name or f"{self.args.mode}"
66 | self.save_dir = save_dir or increment_path(Path(project) / name,
67 | exist_ok=self.args.exist_ok if RANK in {-1, 0} else True)
68 | (self.save_dir / 'labels' if self.args.save_txt else self.save_dir).mkdir(parents=True, exist_ok=True)
69 |
70 | if self.args.conf is None:
71 | self.args.conf = 0.001 # default conf=0.001
72 |
73 | self.callbacks = defaultdict(list, {k: [v] for k, v in callbacks.default_callbacks.items()}) # add callbacks
74 |
75 | @smart_inference_mode()
76 | def __call__(self, trainer=None, model=None):
77 | """
78 | Supports validation of a pre-trained model if passed or a model being trained
79 | if trainer is passed (trainer gets priority).
80 | """
81 | self.training = trainer is not None
82 | if self.training:
83 | self.device = trainer.device
84 | self.data = trainer.data
85 | model = trainer.ema.ema or trainer.model
86 | self.args.half = self.device.type != 'cpu' # force FP16 val during training
87 | model = model.half() if self.args.half else model.float()
88 | self.model = model
89 | self.loss = torch.zeros_like(trainer.loss_items, device=trainer.device)
90 | self.args.plots = trainer.epoch == trainer.epochs - 1 # always plot final epoch
91 | model.eval()
92 | else:
93 | callbacks.add_integration_callbacks(self)
94 | self.run_callbacks('on_val_start')
95 | assert model is not None, "Either trainer or model is needed for validation"
96 | self.device = select_device(self.args.device, self.args.batch)
97 | self.args.half &= self.device.type != 'cpu'
98 | model = AutoBackend(model, device=self.device, dnn=self.args.dnn, fp16=self.args.half)
99 | self.model = model
100 | stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
101 | imgsz = check_imgsz(self.args.imgsz, stride=stride)
102 | if engine:
103 | self.args.batch = model.batch_size
104 | else:
105 | self.device = model.device
106 | if not pt and not jit:
107 | self.args.batch = 1 # export.py models default to batch-size 1
108 | self.logger.info(
109 | f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
110 |
111 | if isinstance(self.args.data, str) and self.args.data.endswith(".yaml"):
112 | self.data = check_dataset_yaml(self.args.data)
113 | else:
114 | self.data = check_dataset(self.args.data)
115 |
116 | if self.device.type == 'cpu':
117 | self.args.workers = 0 # faster CPU val as time dominated by inference, not dataloading
118 | self.dataloader = self.dataloader or \
119 | self.get_dataloader(self.data.get("val") or self.data.set("test"), self.args.batch)
120 |
121 | model.eval()
122 | model.warmup(imgsz=(1 if pt else self.args.batch, 3, imgsz, imgsz)) # warmup
123 |
124 | dt = Profile(), Profile(), Profile(), Profile()
125 | n_batches = len(self.dataloader)
126 | desc = self.get_desc()
127 | # NOTE: keeping `not self.training` in tqdm will eliminate pbar after segmentation evaluation during training,
128 | # which may affect classification task since this arg is in yolov5/classify/val.py.
129 | # bar = tqdm(self.dataloader, desc, n_batches, not self.training, bar_format=TQDM_BAR_FORMAT)
130 | bar = tqdm(self.dataloader, desc, n_batches, bar_format=TQDM_BAR_FORMAT)
131 | self.init_metrics(de_parallel(model))
132 | self.jdict = [] # empty before each val
133 | for batch_i, batch in enumerate(bar):
134 | self.run_callbacks('on_val_batch_start')
135 | self.batch_i = batch_i
136 | # pre-process
137 | with dt[0]:
138 | batch = self.preprocess(batch)
139 |
140 | # inference
141 | with dt[1]:
142 | preds = model(batch["img"])
143 |
144 | # loss
145 | with dt[2]:
146 | if self.training:
147 | self.loss += trainer.criterion(preds, batch)[1]
148 |
149 | # pre-process predictions
150 | with dt[3]:
151 | preds = self.postprocess(preds)
152 |
153 | self.update_metrics(preds, batch)
154 | if self.args.plots and batch_i < 3:
155 | self.plot_val_samples(batch, batch_i)
156 | self.plot_predictions(batch, preds, batch_i)
157 |
158 | self.run_callbacks('on_val_batch_end')
159 | stats = self.get_stats()
160 | self.check_stats(stats)
161 | self.print_results()
162 | self.speed = tuple(x.t / len(self.dataloader.dataset) * 1E3 for x in dt) # speeds per image
163 | self.run_callbacks('on_val_end')
164 | if self.training:
165 | model.float()
166 | results = {**stats, **trainer.label_loss_items(self.loss.cpu() / len(self.dataloader), prefix="val")}
167 | return {k: round(float(v), 5) for k, v in results.items()} # return results as 5 decimal place floats
168 | else:
169 | self.logger.info('Speed: %.1fms pre-process, %.1fms inference, %.1fms loss, %.1fms post-process per image' %
170 | self.speed)
171 | if self.args.save_json and self.jdict:
172 | with open(str(self.save_dir / "predictions.json"), 'w') as f:
173 | self.logger.info(f"Saving {f.name}...")
174 | json.dump(self.jdict, f) # flatten and save
175 | stats = self.eval_json(stats) # update stats
176 | return stats
177 |
178 | def run_callbacks(self, event: str):
179 | for callback in self.callbacks.get(event, []):
180 | callback(self)
181 |
182 | def get_dataloader(self, dataset_path, batch_size):
183 | raise NotImplementedError("get_dataloader function not implemented for this validator")
184 |
185 | def preprocess(self, batch):
186 | return batch
187 |
188 | def postprocess(self, preds):
189 | return preds
190 |
191 | def init_metrics(self, model):
192 | pass
193 |
194 | def update_metrics(self, preds, batch):
195 | pass
196 |
197 | def get_stats(self):
198 | return {}
199 |
200 | def check_stats(self, stats):
201 | pass
202 |
203 | def print_results(self):
204 | pass
205 |
206 | def get_desc(self):
207 | pass
208 |
209 | @property
210 | def metric_keys(self):
211 | return []
212 |
213 | # TODO: may need to put these following functions into callback
214 | def plot_val_samples(self, batch, ni):
215 | pass
216 |
217 | def plot_predictions(self, batch, preds, ni):
218 | pass
219 |
220 | def pred_to_json(self, preds, batch):
221 | pass
222 |
223 | def eval_json(self, stats):
224 | pass
225 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/autobatch.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | """
3 | Auto-batch utils
4 | """
5 |
6 | from copy import deepcopy
7 |
8 | import numpy as np
9 | import torch
10 |
11 | from ultralytics.yolo.utils import LOGGER, colorstr
12 | from ultralytics.yolo.utils.torch_utils import profile
13 |
14 |
15 | def check_train_batch_size(model, imgsz=640, amp=True):
16 | # Check YOLOv5 training batch size
17 | with torch.cuda.amp.autocast(amp):
18 | return autobatch(deepcopy(model).train(), imgsz) # compute optimal batch size
19 |
20 |
21 | def autobatch(model, imgsz=640, fraction=0.7, batch_size=16):
22 | # Automatically estimate best YOLOv5 batch size to use `fraction` of available CUDA memory
23 | # Usage:
24 | # import torch
25 | # from utils.autobatch import autobatch
26 | # model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False)
27 | # print(autobatch(model))
28 |
29 | # Check device
30 | prefix = colorstr('AutoBatch: ')
31 | LOGGER.info(f'{prefix}Computing optimal batch size for --imgsz {imgsz}')
32 | device = next(model.parameters()).device # get model device
33 | if device.type == 'cpu':
34 | LOGGER.info(f'{prefix}CUDA not detected, using default CPU batch-size {batch_size}')
35 | return batch_size
36 | if torch.backends.cudnn.benchmark:
37 | LOGGER.info(f'{prefix} ⚠️ Requires torch.backends.cudnn.benchmark=False, using default batch-size {batch_size}')
38 | return batch_size
39 |
40 | # Inspect CUDA memory
41 | gb = 1 << 30 # bytes to GiB (1024 ** 3)
42 | d = str(device).upper() # 'CUDA:0'
43 | properties = torch.cuda.get_device_properties(device) # device properties
44 | t = properties.total_memory / gb # GiB total
45 | r = torch.cuda.memory_reserved(device) / gb # GiB reserved
46 | a = torch.cuda.memory_allocated(device) / gb # GiB allocated
47 | f = t - (r + a) # GiB free
48 | LOGGER.info(f'{prefix}{d} ({properties.name}) {t:.2f}G total, {r:.2f}G reserved, {a:.2f}G allocated, {f:.2f}G free')
49 |
50 | # Profile batch sizes
51 | batch_sizes = [1, 2, 4, 8, 16]
52 | try:
53 | img = [torch.empty(b, 3, imgsz, imgsz) for b in batch_sizes]
54 | results = profile(img, model, n=3, device=device)
55 | except Exception as e:
56 | LOGGER.warning(f'{prefix}{e}')
57 |
58 | # Fit a solution
59 | y = [x[2] for x in results if x] # memory [2]
60 | p = np.polyfit(batch_sizes[:len(y)], y, deg=1) # first degree polynomial fit
61 | b = int((f * fraction - p[1]) / p[0]) # y intercept (optimal batch size)
62 | if None in results: # some sizes failed
63 | i = results.index(None) # first fail index
64 | if b >= batch_sizes[i]: # y intercept above failure point
65 | b = batch_sizes[max(i - 1, 0)] # select prior safe point
66 | if b < 1 or b > 1024: # b outside of safe range
67 | b = batch_size
68 | LOGGER.warning(f'{prefix}WARNING ⚠️ CUDA anomaly detected, recommend restart environment and retry command.')
69 |
70 | fraction = (np.polyval(p, b) + r + a) / t # actual fraction predicted
71 | LOGGER.info(f'{prefix}Using batch-size {b} for {d} {t * fraction:.2f}G/{t:.2f}G ({fraction * 100:.0f}%) ✅')
72 | return b
73 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/callbacks/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import add_integration_callbacks, default_callbacks
2 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/callbacks/base.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 | """
3 | Base callbacks
4 | """
5 |
6 |
7 | # Trainer callbacks ----------------------------------------------------------------------------------------------------
8 | def on_pretrain_routine_start(trainer):
9 | pass
10 |
11 |
12 | def on_pretrain_routine_end(trainer):
13 | pass
14 |
15 |
16 | def on_train_start(trainer):
17 | pass
18 |
19 |
20 | def on_train_epoch_start(trainer):
21 | pass
22 |
23 |
24 | def on_train_batch_start(trainer):
25 | pass
26 |
27 |
28 | def optimizer_step(trainer):
29 | pass
30 |
31 |
32 | def on_before_zero_grad(trainer):
33 | pass
34 |
35 |
36 | def on_train_batch_end(trainer):
37 | pass
38 |
39 |
40 | def on_train_epoch_end(trainer):
41 | pass
42 |
43 |
44 | def on_fit_epoch_end(trainer):
45 | pass
46 |
47 |
48 | def on_model_save(trainer):
49 | pass
50 |
51 |
52 | def on_train_end(trainer):
53 | pass
54 |
55 |
56 | def on_params_update(trainer):
57 | pass
58 |
59 |
60 | def teardown(trainer):
61 | pass
62 |
63 |
64 | # Validator callbacks --------------------------------------------------------------------------------------------------
65 | def on_val_start(validator):
66 | pass
67 |
68 |
69 | def on_val_batch_start(validator):
70 | pass
71 |
72 |
73 | def on_val_batch_end(validator):
74 | pass
75 |
76 |
77 | def on_val_end(validator):
78 | pass
79 |
80 |
81 | # Predictor callbacks --------------------------------------------------------------------------------------------------
82 | def on_predict_start(predictor):
83 | pass
84 |
85 |
86 | def on_predict_batch_start(predictor):
87 | pass
88 |
89 |
90 | def on_predict_batch_end(predictor):
91 | pass
92 |
93 |
94 | def on_predict_end(predictor):
95 | pass
96 |
97 |
98 | # Exporter callbacks ---------------------------------------------------------------------------------------------------
99 | def on_export_start(exporter):
100 | pass
101 |
102 |
103 | def on_export_end(exporter):
104 | pass
105 |
106 |
107 | default_callbacks = {
108 | # Run in trainer
109 | 'on_pretrain_routine_start': on_pretrain_routine_start,
110 | 'on_pretrain_routine_end': on_pretrain_routine_end,
111 | 'on_train_start': on_train_start,
112 | 'on_train_epoch_start': on_train_epoch_start,
113 | 'on_train_batch_start': on_train_batch_start,
114 | 'optimizer_step': optimizer_step,
115 | 'on_before_zero_grad': on_before_zero_grad,
116 | 'on_train_batch_end': on_train_batch_end,
117 | 'on_train_epoch_end': on_train_epoch_end,
118 | 'on_fit_epoch_end': on_fit_epoch_end, # fit = train + val
119 | 'on_model_save': on_model_save,
120 | 'on_train_end': on_train_end,
121 | 'on_params_update': on_params_update,
122 | 'teardown': teardown,
123 |
124 | # Run in validator
125 | 'on_val_start': on_val_start,
126 | 'on_val_batch_start': on_val_batch_start,
127 | 'on_val_batch_end': on_val_batch_end,
128 | 'on_val_end': on_val_end,
129 |
130 | # Run in predictor
131 | 'on_predict_start': on_predict_start,
132 | 'on_predict_batch_start': on_predict_batch_start,
133 | 'on_predict_batch_end': on_predict_batch_end,
134 | 'on_predict_end': on_predict_end,
135 |
136 | # Run in exporter
137 | 'on_export_start': on_export_start,
138 | 'on_export_end': on_export_end}
139 |
140 |
141 | def add_integration_callbacks(instance):
142 | from .clearml import callbacks as clearml_callbacks
143 | from .comet import callbacks as comet_callbacks
144 | from .hub import callbacks as hub_callbacks
145 | from .tensorboard import callbacks as tb_callbacks
146 |
147 | for x in clearml_callbacks, comet_callbacks, hub_callbacks, tb_callbacks:
148 | for k, v in x.items():
149 | instance.callbacks[k].append(v) # callback[name].append(func)
150 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/callbacks/clearml.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | from ultralytics.yolo.utils.torch_utils import get_flops, get_num_params
4 |
5 | try:
6 | import clearml
7 | from clearml import Task
8 |
9 | assert hasattr(clearml, '__version__')
10 | except (ImportError, AssertionError):
11 | clearml = None
12 |
13 |
14 | def _log_images(imgs_dict, group="", step=0):
15 | task = Task.current_task()
16 | if task:
17 | for k, v in imgs_dict.items():
18 | task.get_logger().report_image(group, k, step, v)
19 |
20 |
21 | def on_pretrain_routine_start(trainer):
22 | # TODO: reuse existing task
23 | task = Task.init(project_name=trainer.args.project or "YOLOv8",
24 | task_name=trainer.args.name,
25 | tags=['YOLOv8'],
26 | output_uri=True,
27 | reuse_last_task_id=False,
28 | auto_connect_frameworks={'pytorch': False})
29 | task.connect(dict(trainer.args), name='General')
30 |
31 |
32 | def on_train_epoch_end(trainer):
33 | if trainer.epoch == 1:
34 | _log_images({f.stem: str(f) for f in trainer.save_dir.glob('train_batch*.jpg')}, "Mosaic", trainer.epoch)
35 |
36 |
37 | def on_fit_epoch_end(trainer):
38 | if trainer.epoch == 0:
39 | model_info = {
40 | "Parameters": get_num_params(trainer.model),
41 | "GFLOPs": round(get_flops(trainer.model), 3),
42 | "Inference speed (ms/img)": round(trainer.validator.speed[1], 3)}
43 | Task.current_task().connect(model_info, name='Model')
44 |
45 |
46 | def on_train_end(trainer):
47 | Task.current_task().update_output_model(model_path=str(trainer.best),
48 | model_name=trainer.args.name,
49 | auto_delete_file=False)
50 |
51 |
52 | callbacks = {
53 | "on_pretrain_routine_start": on_pretrain_routine_start,
54 | "on_train_epoch_end": on_train_epoch_end,
55 | "on_fit_epoch_end": on_fit_epoch_end,
56 | "on_train_end": on_train_end} if clearml else {}
57 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/callbacks/comet.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | from ultralytics.yolo.utils.torch_utils import get_flops, get_num_params
4 |
5 | try:
6 | import comet_ml
7 |
8 | except (ModuleNotFoundError, ImportError):
9 | comet_ml = None
10 |
11 |
12 | def on_pretrain_routine_start(trainer):
13 | experiment = comet_ml.Experiment(project_name=trainer.args.project or "YOLOv8",)
14 | experiment.log_parameters(dict(trainer.args))
15 |
16 |
17 | def on_train_epoch_end(trainer):
18 | experiment = comet_ml.get_global_experiment()
19 | experiment.log_metrics(trainer.label_loss_items(trainer.tloss, prefix="train"), step=trainer.epoch + 1)
20 | if trainer.epoch == 1:
21 | for f in trainer.save_dir.glob('train_batch*.jpg'):
22 | experiment.log_image(f, name=f.stem, step=trainer.epoch + 1)
23 |
24 |
25 | def on_fit_epoch_end(trainer):
26 | experiment = comet_ml.get_global_experiment()
27 | experiment.log_metrics(trainer.metrics, step=trainer.epoch + 1)
28 | if trainer.epoch == 0:
29 | model_info = {
30 | "model/parameters": get_num_params(trainer.model),
31 | "model/GFLOPs": round(get_flops(trainer.model), 3),
32 | "model/speed(ms)": round(trainer.validator.speed[1], 3)}
33 | experiment.log_metrics(model_info, step=trainer.epoch + 1)
34 |
35 |
36 | def on_train_end(trainer):
37 | experiment = comet_ml.get_global_experiment()
38 | experiment.log_model("YOLOv8", file_or_folder=trainer.best, file_name="best.pt", overwrite=True)
39 |
40 |
41 | callbacks = {
42 | "on_pretrain_routine_start": on_pretrain_routine_start,
43 | "on_train_epoch_end": on_train_epoch_end,
44 | "on_fit_epoch_end": on_fit_epoch_end,
45 | "on_train_end": on_train_end} if comet_ml else {}
46 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/callbacks/hub.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import json
4 | from time import time
5 |
6 | import torch
7 |
8 | from ultralytics.hub.utils import PREFIX, sync_analytics
9 | from ultralytics.yolo.utils import LOGGER
10 |
11 |
12 | def on_pretrain_routine_end(trainer):
13 | session = getattr(trainer, 'hub_session', None)
14 | if session:
15 | # Start timer for upload rate limit
16 | LOGGER.info(f"{PREFIX}View model at https://hub.ultralytics.com/models/{session.model_id} 🚀")
17 | session.t = {'metrics': time(), 'ckpt': time()} # start timer on self.rate_limit
18 |
19 |
20 | def on_fit_epoch_end(trainer):
21 | session = getattr(trainer, 'hub_session', None)
22 | if session:
23 | session.metrics_queue[trainer.epoch] = json.dumps(trainer.metrics) # json string
24 | if time() - session.t['metrics'] > session.rate_limits['metrics']:
25 | session.upload_metrics()
26 | session.t['metrics'] = time() # reset timer
27 | session.metrics_queue = {} # reset queue
28 |
29 |
30 | def on_model_save(trainer):
31 | session = getattr(trainer, 'hub_session', None)
32 | if session:
33 | # Upload checkpoints with rate limiting
34 | is_best = trainer.best_fitness == trainer.fitness
35 | if time() - session.t['ckpt'] > session.rate_limits['ckpt']:
36 | LOGGER.info(f"{PREFIX}Uploading checkpoint {session.model_id}")
37 | session.upload_model(trainer.epoch, trainer.last, is_best)
38 | session.t['ckpt'] = time() # reset timer
39 |
40 |
41 | def on_train_end(trainer):
42 | session = getattr(trainer, 'hub_session', None)
43 | if session:
44 | # Upload final model and metrics with exponential standoff
45 | LOGGER.info(f"{PREFIX}Training completed successfully ✅\n"
46 | f"{PREFIX}Uploading final {session.model_id}")
47 | session.upload_model(trainer.epoch, trainer.best, map=trainer.metrics['metrics/mAP50-95(B)'], final=True)
48 | session.alive = False # stop heartbeats
49 | LOGGER.info(f"{PREFIX}View model at https://hub.ultralytics.com/models/{session.model_id} 🚀")
50 |
51 |
52 | def on_train_start(trainer):
53 | sync_analytics(trainer.args)
54 |
55 |
56 | def on_val_start(validator):
57 | sync_analytics(validator.args)
58 |
59 |
60 | def on_predict_start(predictor):
61 | sync_analytics(predictor.args)
62 |
63 |
64 | def on_export_start(exporter):
65 | sync_analytics(exporter.args)
66 |
67 |
68 | callbacks = {
69 | "on_pretrain_routine_end": on_pretrain_routine_end,
70 | "on_fit_epoch_end": on_fit_epoch_end,
71 | "on_model_save": on_model_save,
72 | "on_train_end": on_train_end,
73 | "on_train_start": on_train_start,
74 | "on_val_start": on_val_start,
75 | "on_predict_start": on_predict_start,
76 | "on_export_start": on_export_start}
77 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/callbacks/tensorboard.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | from torch.utils.tensorboard import SummaryWriter
4 |
5 | writer = None # TensorBoard SummaryWriter instance
6 |
7 |
8 | def _log_scalars(scalars, step=0):
9 | for k, v in scalars.items():
10 | writer.add_scalar(k, v, step)
11 |
12 |
13 | def on_pretrain_routine_start(trainer):
14 | global writer
15 | writer = SummaryWriter(str(trainer.save_dir))
16 |
17 |
18 | def on_batch_end(trainer):
19 | _log_scalars(trainer.label_loss_items(trainer.tloss, prefix="train"), trainer.epoch + 1)
20 |
21 |
22 | def on_fit_epoch_end(trainer):
23 | _log_scalars(trainer.metrics, trainer.epoch + 1)
24 |
25 |
26 | callbacks = {
27 | "on_pretrain_routine_start": on_pretrain_routine_start,
28 | "on_fit_epoch_end": on_fit_epoch_end,
29 | "on_batch_end": on_batch_end}
30 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/dist.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import os
4 | import shutil
5 | import socket
6 | import sys
7 | import tempfile
8 |
9 | from . import USER_CONFIG_DIR
10 |
11 |
12 | def find_free_network_port() -> int:
13 | # https://github.com/Lightning-AI/lightning/blob/master/src/lightning_lite/plugins/environments/lightning.py
14 | """Finds a free port on localhost.
15 |
16 | It is useful in single-node training when we don't want to connect to a real main node but have to set the
17 | `MASTER_PORT` environment variable.
18 | """
19 | s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
20 | s.bind(("", 0))
21 | port = s.getsockname()[1]
22 | s.close()
23 | return port
24 |
25 |
26 | def generate_ddp_file(trainer):
27 | import_path = '.'.join(str(trainer.__class__).split(".")[1:-1])
28 |
29 | if not trainer.resume:
30 | shutil.rmtree(trainer.save_dir) # remove the save_dir
31 | content = f'''config = {dict(trainer.args)} \nif __name__ == "__main__":
32 | from ultralytics.{import_path} import {trainer.__class__.__name__}
33 |
34 | trainer = {trainer.__class__.__name__}(config=config)
35 | trainer.train()'''
36 | (USER_CONFIG_DIR / 'DDP').mkdir(exist_ok=True)
37 | with tempfile.NamedTemporaryFile(prefix="_temp_",
38 | suffix=f"{id(trainer)}.py",
39 | mode="w+",
40 | encoding='utf-8',
41 | dir=USER_CONFIG_DIR / 'DDP',
42 | delete=False) as file:
43 | file.write(content)
44 | return file.name
45 |
46 |
47 | def generate_ddp_command(world_size, trainer):
48 | import __main__ # noqa local import to avoid https://github.com/Lightning-AI/lightning/issues/15218
49 | file_name = os.path.abspath(sys.argv[0])
50 | using_cli = not file_name.endswith(".py")
51 | if using_cli:
52 | file_name = generate_ddp_file(trainer)
53 | return [
54 | sys.executable, "-m", "torch.distributed.run", "--nproc_per_node", f"{world_size}", "--master_port",
55 | f"{find_free_network_port()}", file_name] + sys.argv[1:]
56 |
57 |
58 | def ddp_cleanup(command, trainer):
59 | # delete temp file if created
60 | tempfile_suffix = f"{id(trainer)}.py"
61 | if tempfile_suffix in "".join(command):
62 | for chunk in command:
63 | if tempfile_suffix in chunk:
64 | os.remove(chunk)
65 | break
66 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/downloads.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import logging
4 | import os
5 | import subprocess
6 | import urllib
7 | from itertools import repeat
8 | from multiprocessing.pool import ThreadPool
9 | from pathlib import Path
10 | from zipfile import ZipFile
11 |
12 | import requests
13 | import torch
14 |
15 | from ultralytics.yolo.utils import LOGGER
16 |
17 |
18 | def safe_download(file, url, url2=None, min_bytes=1E0, error_msg=''):
19 | # Attempts to download file from url or url2, checks and removes incomplete downloads < min_bytes
20 | file = Path(file)
21 | assert_msg = f"Downloaded file '{file}' does not exist or size is < min_bytes={min_bytes}"
22 | try: # url1
23 | LOGGER.info(f'Downloading {url} to {file}...')
24 | torch.hub.download_url_to_file(url, str(file), progress=LOGGER.level <= logging.INFO)
25 | assert file.exists() and file.stat().st_size > min_bytes, assert_msg # check
26 | except Exception as e: # url2
27 | if file.exists():
28 | file.unlink() # remove partial downloads
29 | LOGGER.info(f'ERROR: {e}\nRe-attempting {url2 or url} to {file}...')
30 | os.system(f"curl -# -L '{url2 or url}' -o '{file}' --retry 3 -C -") # curl download, retry and resume on fail
31 | finally:
32 | if not file.exists() or file.stat().st_size < min_bytes: # check
33 | if file.exists():
34 | file.unlink() # remove partial downloads
35 | LOGGER.info(f"ERROR: {assert_msg}\n{error_msg}")
36 | LOGGER.info('')
37 |
38 |
39 | def is_url(url, check=True):
40 | # Check if string is URL and check if URL exists
41 | try:
42 | url = str(url)
43 | result = urllib.parse.urlparse(url)
44 | assert all([result.scheme, result.netloc]) # check if is url
45 | return (urllib.request.urlopen(url).getcode() == 200) if check else True # check if exists online
46 | except (AssertionError, urllib.request.HTTPError):
47 | return False
48 |
49 |
50 | def attempt_download(file, repo='ultralytics/assets', release='v0.0.0'):
51 | # Attempt file download from GitHub release assets if not found locally. release = 'latest', 'v6.2', etc.
52 |
53 | def github_assets(repository, version='latest'):
54 | # Return GitHub repo tag and assets (i.e. ['yolov8n.pt', 'yolov5m.pt', ...])
55 | # Return GitHub repo tag and assets (i.e. ['yolov8n.pt', 'yolov8s.pt', ...])
56 | if version != 'latest':
57 | version = f'tags/{version}' # i.e. tags/v6.2
58 | response = requests.get(f'https://api.github.com/repos/{repository}/releases/{version}').json() # github api
59 | return response['tag_name'], [x['name'] for x in response['assets']] # tag, assets
60 |
61 | file = Path(str(file).strip().replace("'", ''))
62 | if not file.exists():
63 | # URL specified
64 | name = Path(urllib.parse.unquote(str(file))).name # decode '%2F' to '/' etc.
65 | if str(file).startswith(('http:/', 'https:/')): # download
66 | url = str(file).replace(':/', '://') # Pathlib turns :// -> :/
67 | file = name.split('?')[0] # parse authentication https://url.com/file.txt?auth...
68 | if Path(file).is_file():
69 | LOGGER.info(f'Found {url} locally at {file}') # file already exists
70 | else:
71 | safe_download(file=file, url=url, min_bytes=1E5)
72 | return file
73 |
74 | # GitHub assets
75 | assets = [f'yolov5{size}{suffix}.pt' for size in 'nsmlx' for suffix in ('', '6', '-cls', '-seg')] # default
76 | assets = [f'yolov8{size}{suffix}.pt' for size in 'nsmlx' for suffix in ('', '6', '-cls', '-seg')] # default
77 | try:
78 | tag, assets = github_assets(repo, release)
79 | except Exception:
80 | try:
81 | tag, assets = github_assets(repo) # latest release
82 | except Exception:
83 | try:
84 | tag = subprocess.check_output('git tag', shell=True, stderr=subprocess.STDOUT).decode().split()[-1]
85 | except Exception:
86 | tag = release
87 |
88 | file.parent.mkdir(parents=True, exist_ok=True) # make parent dir (if required)
89 | if name in assets:
90 | url3 = 'https://drive.google.com/drive/folders/1EFQTEUeXWSFww0luse2jB9M1QNZQGwNl' # backup gdrive mirror
91 | safe_download(
92 | file,
93 | url=f'https://github.com/{repo}/releases/download/{tag}/{name}',
94 | min_bytes=1E5,
95 | error_msg=f'{file} missing, try downloading from https://github.com/{repo}/releases/{tag} or {url3}')
96 |
97 | return str(file)
98 |
99 |
100 | def download(url, dir=Path.cwd(), unzip=True, delete=True, curl=False, threads=1, retry=3):
101 | # Multithreaded file download and unzip function, used in data.yaml for autodownload
102 | def download_one(url, dir):
103 | # Download 1 file
104 | success = True
105 | if Path(url).is_file():
106 | f = Path(url) # filename
107 | else: # does not exist
108 | f = dir / Path(url).name
109 | LOGGER.info(f'Downloading {url} to {f}...')
110 | for i in range(retry + 1):
111 | if curl:
112 | s = 'sS' if threads > 1 else '' # silent
113 | r = os.system(
114 | f'curl -# -{s}L "{url}" -o "{f}" --retry 9 -C -') # curl download with retry, continue
115 | success = r == 0
116 | else:
117 | torch.hub.download_url_to_file(url, f, progress=threads == 1) # torch download
118 | success = f.is_file()
119 | if success:
120 | break
121 | elif i < retry:
122 | LOGGER.warning(f'⚠️ Download failure, retrying {i + 1}/{retry} {url}...')
123 | else:
124 | LOGGER.warning(f'❌ Failed to download {url}...')
125 |
126 | if unzip and success and f.suffix in ('.zip', '.tar', '.gz'):
127 | LOGGER.info(f'Unzipping {f}...')
128 | if f.suffix == '.zip':
129 | ZipFile(f).extractall(path=dir) # unzip
130 | elif f.suffix == '.tar':
131 | os.system(f'tar xf {f} --directory {f.parent}') # unzip
132 | elif f.suffix == '.gz':
133 | os.system(f'tar xfz {f} --directory {f.parent}') # unzip
134 | if delete:
135 | f.unlink() # remove zip
136 |
137 | dir = Path(dir)
138 | dir.mkdir(parents=True, exist_ok=True) # make directory
139 | if threads > 1:
140 | pool = ThreadPool(threads)
141 | pool.imap(lambda x: download_one(*x), zip(url, repeat(dir))) # multithreaded
142 | pool.close()
143 | pool.join()
144 | else:
145 | for u in [url] if isinstance(url, (str, Path)) else url:
146 | download_one(u, dir)
147 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/files.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import contextlib
4 | import glob
5 | import os
6 | import urllib
7 | from datetime import datetime
8 | from pathlib import Path
9 | from zipfile import ZipFile
10 |
11 |
12 | class WorkingDirectory(contextlib.ContextDecorator):
13 | # Usage: @WorkingDirectory(dir) decorator or 'with WorkingDirectory(dir):' context manager
14 | def __init__(self, new_dir):
15 | self.dir = new_dir # new dir
16 | self.cwd = Path.cwd().resolve() # current dir
17 |
18 | def __enter__(self):
19 | os.chdir(self.dir)
20 |
21 | def __exit__(self, exc_type, exc_val, exc_tb):
22 | os.chdir(self.cwd)
23 |
24 |
25 | def increment_path(path, exist_ok=False, sep='', mkdir=False):
26 | """
27 | Increments a file or directory path, i.e. runs/exp --> runs/exp{sep}2, runs/exp{sep}3, ... etc.
28 |
29 | If the path exists and exist_ok is not set to True, the path will be incremented by appending a number and sep to
30 | the end of the path. If the path is a file, the file extension will be preserved. If the path is a directory, the
31 | number will be appended directly to the end of the path. If mkdir is set to True, the path will be created as a
32 | directory if it does not already exist.
33 |
34 | Args:
35 | path (str or pathlib.Path): Path to increment.
36 | exist_ok (bool, optional): If True, the path will not be incremented and will be returned as-is. Defaults to False.
37 | sep (str, optional): Separator to use between the path and the incrementation number. Defaults to an empty string.
38 | mkdir (bool, optional): If True, the path will be created as a directory if it does not exist. Defaults to False.
39 |
40 | Returns:
41 | pathlib.Path: Incremented path.
42 | """
43 | path = Path(path) # os-agnostic
44 | if path.exists() and not exist_ok:
45 | path, suffix = (path.with_suffix(''), path.suffix) if path.is_file() else (path, '')
46 |
47 | # Method 1
48 | for n in range(2, 9999):
49 | p = f'{path}{sep}{n}{suffix}' # increment path
50 | if not os.path.exists(p): #
51 | break
52 | path = Path(p)
53 |
54 | if mkdir:
55 | path.mkdir(parents=True, exist_ok=True) # make directory
56 |
57 | return path
58 |
59 |
60 | def unzip_file(file, path=None, exclude=('.DS_Store', '__MACOSX')):
61 | # Unzip a *.zip file to path/, excluding files containing strings in exclude list
62 | if path is None:
63 | path = Path(file).parent # default path
64 | with ZipFile(file) as zipObj:
65 | for f in zipObj.namelist(): # list all archived filenames in the zip
66 | if all(x not in f for x in exclude):
67 | zipObj.extract(f, path=path)
68 |
69 |
70 | def file_age(path=__file__):
71 | # Return days since last file update
72 | dt = (datetime.now() - datetime.fromtimestamp(Path(path).stat().st_mtime)) # delta
73 | return dt.days # + dt.seconds / 86400 # fractional days
74 |
75 |
76 | def file_date(path=__file__):
77 | # Return human-readable file modification date, i.e. '2021-3-26'
78 | t = datetime.fromtimestamp(Path(path).stat().st_mtime)
79 | return f'{t.year}-{t.month}-{t.day}'
80 |
81 |
82 | def file_size(path):
83 | # Return file/dir size (MB)
84 | mb = 1 << 20 # bytes to MiB (1024 ** 2)
85 | path = Path(path)
86 | if path.is_file():
87 | return path.stat().st_size / mb
88 | elif path.is_dir():
89 | return sum(f.stat().st_size for f in path.glob('**/*') if f.is_file()) / mb
90 | else:
91 | return 0.0
92 |
93 |
94 | def url2file(url):
95 | # Convert URL to filename, i.e. https://url.com/file.txt?auth -> file.txt
96 | url = str(Path(url)).replace(':/', '://') # Pathlib turns :// -> :/
97 | return Path(urllib.parse.unquote(url)).name.split('?')[0] # '%2F' to '/', split https://url.com/file.txt?auth
98 |
99 |
100 | def get_latest_run(search_dir='.'):
101 | # Return path to most recent 'last.pt' in /runs (i.e. to --resume from)
102 | last_list = glob.glob(f'{search_dir}/**/last*.pt', recursive=True)
103 | return max(last_list, key=os.path.getctime) if last_list else ''
104 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/loss.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 |
7 | from .metrics import bbox_iou
8 | from .tal import bbox2dist
9 |
10 |
11 | class VarifocalLoss(nn.Module):
12 | # Varifocal loss by Zhang et al. https://arxiv.org/abs/2008.13367
13 | def __init__(self):
14 | super().__init__()
15 |
16 | def forward(self, pred_score, gt_score, label, alpha=0.75, gamma=2.0):
17 | weight = alpha * pred_score.sigmoid().pow(gamma) * (1 - label) + gt_score * label
18 | with torch.cuda.amp.autocast(enabled=False):
19 | loss = (F.binary_cross_entropy_with_logits(pred_score.float(), gt_score.float(), reduction="none") *
20 | weight).sum()
21 | return loss
22 |
23 |
24 | class BboxLoss(nn.Module):
25 |
26 | def __init__(self, reg_max, use_dfl=False):
27 | super().__init__()
28 | self.reg_max = reg_max
29 | self.use_dfl = use_dfl
30 |
31 | def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
32 | # IoU loss
33 | weight = torch.masked_select(target_scores.sum(-1), fg_mask).unsqueeze(-1)
34 | iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
35 | loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
36 |
37 | # DFL loss
38 | if self.use_dfl:
39 | target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
40 | loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
41 | loss_dfl = loss_dfl.sum() / target_scores_sum
42 | else:
43 | loss_dfl = torch.tensor(0.0).to(pred_dist.device)
44 |
45 | return loss_iou, loss_dfl
46 |
47 | @staticmethod
48 | def _df_loss(pred_dist, target):
49 | # Return sum of left and right DFL losses
50 | tl = target.long() # target left
51 | tr = tl + 1 # target right
52 | wl = tr - target # weight left
53 | wr = 1 - wl # weight right
54 | return (F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl +
55 | F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr).mean(-1, keepdim=True)
56 |
--------------------------------------------------------------------------------
/ultralytics/yolo/utils/tal.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 |
7 | from .checks import check_version
8 | from .metrics import bbox_iou
9 |
10 | TORCH_1_10 = check_version(torch.__version__, '1.10.0')
11 |
12 |
13 | def select_candidates_in_gts(xy_centers, gt_bboxes, eps=1e-9):
14 | """select the positive anchor center in gt
15 |
16 | Args:
17 | xy_centers (Tensor): shape(h*w, 4)
18 | gt_bboxes (Tensor): shape(b, n_boxes, 4)
19 | Return:
20 | (Tensor): shape(b, n_boxes, h*w)
21 | """
22 | n_anchors = xy_centers.shape[0]
23 | bs, n_boxes, _ = gt_bboxes.shape
24 | lt, rb = gt_bboxes.view(-1, 1, 4).chunk(2, 2) # left-top, right-bottom
25 | bbox_deltas = torch.cat((xy_centers[None] - lt, rb - xy_centers[None]), dim=2).view(bs, n_boxes, n_anchors, -1)
26 | # return (bbox_deltas.min(3)[0] > eps).to(gt_bboxes.dtype)
27 | return bbox_deltas.amin(3).gt_(eps)
28 |
29 |
30 | def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):
31 | """if an anchor box is assigned to multiple gts,
32 | the one with the highest iou will be selected.
33 |
34 | Args:
35 | mask_pos (Tensor): shape(b, n_max_boxes, h*w)
36 | overlaps (Tensor): shape(b, n_max_boxes, h*w)
37 | Return:
38 | target_gt_idx (Tensor): shape(b, h*w)
39 | fg_mask (Tensor): shape(b, h*w)
40 | mask_pos (Tensor): shape(b, n_max_boxes, h*w)
41 | """
42 | # (b, n_max_boxes, h*w) -> (b, h*w)
43 | fg_mask = mask_pos.sum(-2)
44 | if fg_mask.max() > 1: # one anchor is assigned to multiple gt_bboxes
45 | mask_multi_gts = (fg_mask.unsqueeze(1) > 1).repeat([1, n_max_boxes, 1]) # (b, n_max_boxes, h*w)
46 | max_overlaps_idx = overlaps.argmax(1) # (b, h*w)
47 | is_max_overlaps = F.one_hot(max_overlaps_idx, n_max_boxes) # (b, h*w, n_max_boxes)
48 | is_max_overlaps = is_max_overlaps.permute(0, 2, 1).to(overlaps.dtype) # (b, n_max_boxes, h*w)
49 | mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos) # (b, n_max_boxes, h*w)
50 | fg_mask = mask_pos.sum(-2)
51 | # find each grid serve which gt(index)
52 | target_gt_idx = mask_pos.argmax(-2) # (b, h*w)
53 | return target_gt_idx, fg_mask, mask_pos
54 |
55 |
56 | class TaskAlignedAssigner(nn.Module):
57 |
58 | def __init__(self, topk=13, num_classes=80, alpha=1.0, beta=6.0, eps=1e-9):
59 | super().__init__()
60 | self.topk = topk
61 | self.num_classes = num_classes
62 | self.bg_idx = num_classes
63 | self.alpha = alpha
64 | self.beta = beta
65 | self.eps = eps
66 |
67 | @torch.no_grad()
68 | def forward(self, pd_scores, pd_bboxes, anc_points, gt_labels, gt_bboxes, mask_gt):
69 | """This code referenced to
70 | https://github.com/Nioolek/PPYOLOE_pytorch/blob/master/ppyoloe/assigner/tal_assigner.py
71 |
72 | Args:
73 | pd_scores (Tensor): shape(bs, num_total_anchors, num_classes)
74 | pd_bboxes (Tensor): shape(bs, num_total_anchors, 4)
75 | anc_points (Tensor): shape(num_total_anchors, 2)
76 | gt_labels (Tensor): shape(bs, n_max_boxes, 1)
77 | gt_bboxes (Tensor): shape(bs, n_max_boxes, 4)
78 | mask_gt (Tensor): shape(bs, n_max_boxes, 1)
79 | Returns:
80 | target_labels (Tensor): shape(bs, num_total_anchors)
81 | target_bboxes (Tensor): shape(bs, num_total_anchors, 4)
82 | target_scores (Tensor): shape(bs, num_total_anchors, num_classes)
83 | fg_mask (Tensor): shape(bs, num_total_anchors)
84 | """
85 | self.bs = pd_scores.size(0)
86 | self.n_max_boxes = gt_bboxes.size(1)
87 |
88 | if self.n_max_boxes == 0:
89 | device = gt_bboxes.device
90 | return (torch.full_like(pd_scores[..., 0], self.bg_idx).to(device), torch.zeros_like(pd_bboxes).to(device),
91 | torch.zeros_like(pd_scores).to(device), torch.zeros_like(pd_scores[..., 0]).to(device),
92 | torch.zeros_like(pd_scores[..., 0]).to(device))
93 |
94 | mask_pos, align_metric, overlaps = self.get_pos_mask(pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points,
95 | mask_gt)
96 |
97 | target_gt_idx, fg_mask, mask_pos = select_highest_overlaps(mask_pos, overlaps, self.n_max_boxes)
98 |
99 | # assigned target
100 | target_labels, target_bboxes, target_scores = self.get_targets(gt_labels, gt_bboxes, target_gt_idx, fg_mask)
101 |
102 | # normalize
103 | align_metric *= mask_pos
104 | pos_align_metrics = align_metric.amax(axis=-1, keepdim=True) # b, max_num_obj
105 | pos_overlaps = (overlaps * mask_pos).amax(axis=-1, keepdim=True) # b, max_num_obj
106 | norm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)
107 | target_scores = target_scores * norm_align_metric
108 |
109 | return target_labels, target_bboxes, target_scores, fg_mask.bool(), target_gt_idx
110 |
111 | def get_pos_mask(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt):
112 | # get anchor_align metric, (b, max_num_obj, h*w)
113 | align_metric, overlaps = self.get_box_metrics(pd_scores, pd_bboxes, gt_labels, gt_bboxes)
114 | # get in_gts mask, (b, max_num_obj, h*w)
115 | mask_in_gts = select_candidates_in_gts(anc_points, gt_bboxes)
116 | # get topk_metric mask, (b, max_num_obj, h*w)
117 | mask_topk = self.select_topk_candidates(align_metric * mask_in_gts,
118 | topk_mask=mask_gt.repeat([1, 1, self.topk]).bool())
119 | # merge all mask to a final mask, (b, max_num_obj, h*w)
120 | mask_pos = mask_topk * mask_in_gts * mask_gt
121 |
122 | return mask_pos, align_metric, overlaps
123 |
124 | def get_box_metrics(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes):
125 | ind = torch.zeros([2, self.bs, self.n_max_boxes], dtype=torch.long) # 2, b, max_num_obj
126 | ind[0] = torch.arange(end=self.bs).view(-1, 1).repeat(1, self.n_max_boxes) # b, max_num_obj
127 | ind[1] = gt_labels.long().squeeze(-1) # b, max_num_obj
128 | # get the scores of each grid for each gt cls
129 | bbox_scores = pd_scores[ind[0], :, ind[1]] # b, max_num_obj, h*w
130 |
131 | overlaps = bbox_iou(gt_bboxes.unsqueeze(2), pd_bboxes.unsqueeze(1), xywh=False, CIoU=True).squeeze(3).clamp(0)
132 | align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
133 | return align_metric, overlaps
134 |
135 | def select_topk_candidates(self, metrics, largest=True, topk_mask=None):
136 | """
137 | Args:
138 | metrics: (b, max_num_obj, h*w).
139 | topk_mask: (b, max_num_obj, topk) or None
140 | """
141 |
142 | num_anchors = metrics.shape[-1] # h*w
143 | # (b, max_num_obj, topk)
144 | topk_metrics, topk_idxs = torch.topk(metrics, self.topk, dim=-1, largest=largest)
145 | if topk_mask is None:
146 | topk_mask = (topk_metrics.max(-1, keepdim=True) > self.eps).tile([1, 1, self.topk])
147 | # (b, max_num_obj, topk)
148 | topk_idxs = torch.where(topk_mask, topk_idxs, 0)
149 | # (b, max_num_obj, topk, h*w) -> (b, max_num_obj, h*w)
150 | is_in_topk = F.one_hot(topk_idxs, num_anchors).sum(-2)
151 | # filter invalid bboxes
152 | is_in_topk = torch.where(is_in_topk > 1, 0, is_in_topk)
153 | return is_in_topk.to(metrics.dtype)
154 |
155 | def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
156 | """
157 | Args:
158 | gt_labels: (b, max_num_obj, 1)
159 | gt_bboxes: (b, max_num_obj, 4)
160 | target_gt_idx: (b, h*w)
161 | fg_mask: (b, h*w)
162 | """
163 |
164 | # assigned target labels, (b, 1)
165 | batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
166 | target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # (b, h*w)
167 | target_labels = gt_labels.long().flatten()[target_gt_idx] # (b, h*w)
168 |
169 | # assigned target boxes, (b, max_num_obj, 4) -> (b, h*w)
170 | target_bboxes = gt_bboxes.view(-1, 4)[target_gt_idx]
171 |
172 | # assigned target scores
173 | target_labels.clamp(0)
174 | target_scores = F.one_hot(target_labels, self.num_classes) # (b, h*w, 80)
175 | fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # (b, h*w, 80)
176 | target_scores = torch.where(fg_scores_mask > 0, target_scores, 0)
177 |
178 | return target_labels, target_bboxes, target_scores
179 |
180 |
181 | def make_anchors(feats, strides, grid_cell_offset=0.5):
182 | """Generate anchors from features."""
183 | anchor_points, stride_tensor = [], []
184 | assert feats is not None
185 | dtype, device = feats[0].dtype, feats[0].device
186 | for i, stride in enumerate(strides):
187 | _, _, h, w = feats[i].shape
188 | sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset # shift x
189 | sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset # shift y
190 | sy, sx = torch.meshgrid(sy, sx, indexing='ij') if TORCH_1_10 else torch.meshgrid(sy, sx)
191 | anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2))
192 | stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device))
193 | return torch.cat(anchor_points), torch.cat(stride_tensor)
194 |
195 |
196 | def dist2bbox(distance, anchor_points, xywh=True, dim=-1):
197 | """Transform distance(ltrb) to box(xywh or xyxy)."""
198 | lt, rb = torch.split(distance, 2, dim)
199 | x1y1 = anchor_points - lt
200 | x2y2 = anchor_points + rb
201 | if xywh:
202 | c_xy = (x1y1 + x2y2) / 2
203 | wh = x2y2 - x1y1
204 | return torch.cat((c_xy, wh), dim) # xywh bbox
205 | return torch.cat((x1y1, x2y2), dim) # xyxy bbox
206 |
207 |
208 | def bbox2dist(anchor_points, bbox, reg_max):
209 | """Transform bbox(xyxy) to dist(ltrb)."""
210 | x1y1, x2y2 = torch.split(bbox, 2, -1)
211 | return torch.cat((anchor_points - x1y1, x2y2 - anchor_points), -1).clamp(0, reg_max - 0.01) # dist (lt, rb)
212 |
--------------------------------------------------------------------------------
/ultralytics/yolo/v8/detect/__init__.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | from .predict import DetectionPredictor, predict
4 | from .train import DetectionTrainer, train
5 | from .val import DetectionValidator, val
6 |
--------------------------------------------------------------------------------
/ultralytics/yolo/v8/detect/train.py:
--------------------------------------------------------------------------------
1 | # Ultralytics YOLO 🚀, GPL-3.0 license
2 |
3 | from copy import copy
4 |
5 | import hydra
6 | import torch
7 | import torch.nn as nn
8 |
9 | from ultralytics.nn.tasks import DetectionModel
10 | from ultralytics.yolo import v8
11 | from ultralytics.yolo.data import build_dataloader
12 | from ultralytics.yolo.data.dataloaders.v5loader import create_dataloader
13 | from ultralytics.yolo.engine.trainer import BaseTrainer
14 | from ultralytics.yolo.utils import DEFAULT_CONFIG, colorstr
15 | from ultralytics.yolo.utils.loss import BboxLoss
16 | from ultralytics.yolo.utils.ops import xywh2xyxy
17 | from ultralytics.yolo.utils.plotting import plot_images, plot_results
18 | from ultralytics.yolo.utils.tal import TaskAlignedAssigner, dist2bbox, make_anchors
19 | from ultralytics.yolo.utils.torch_utils import de_parallel
20 |
21 |
22 | # BaseTrainer python usage
23 | class DetectionTrainer(BaseTrainer):
24 |
25 | def get_dataloader(self, dataset_path, batch_size, mode="train", rank=0):
26 | # TODO: manage splits differently
27 | # calculate stride - check if model is initialized
28 | gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
29 | return create_dataloader(path=dataset_path,
30 | imgsz=self.args.imgsz,
31 | batch_size=batch_size,
32 | stride=gs,
33 | hyp=dict(self.args),
34 | augment=mode == "train",
35 | cache=self.args.cache,
36 | pad=0 if mode == "train" else 0.5,
37 | rect=self.args.rect,
38 | rank=rank,
39 | workers=self.args.workers,
40 | close_mosaic=self.args.close_mosaic != 0,
41 | prefix=colorstr(f'{mode}: '),
42 | shuffle=mode == "train",
43 | seed=self.args.seed)[0] if self.args.v5loader else \
44 | build_dataloader(self.args, batch_size, img_path=dataset_path, stride=gs, rank=rank, mode=mode)[0]
45 |
46 | def preprocess_batch(self, batch):
47 | batch["img"] = batch["img"].to(self.device, non_blocking=True).float() / 255
48 | return batch
49 |
50 | def set_model_attributes(self):
51 | nl = de_parallel(self.model).model[-1].nl # number of detection layers (to scale hyps)
52 | self.args.box *= 3 / nl # scale to layers
53 | # self.args.cls *= self.data["nc"] / 80 * 3 / nl # scale to classes and layers
54 | self.args.cls *= (self.args.imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
55 | self.model.nc = self.data["nc"] # attach number of classes to model
56 | self.model.args = self.args # attach hyperparameters to model
57 | # TODO: self.model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc
58 | self.model.names = self.data["names"]
59 |
60 | def get_model(self, cfg=None, weights=None, verbose=True):
61 | model = DetectionModel(cfg, ch=3, nc=self.data["nc"], verbose=verbose)
62 | if weights:
63 | model.load(weights)
64 |
65 | return model
66 |
67 | def get_validator(self):
68 | self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
69 | return v8.detect.DetectionValidator(self.test_loader,
70 | save_dir=self.save_dir,
71 | logger=self.console,
72 | args=copy(self.args))
73 |
74 | def criterion(self, preds, batch):
75 | if not hasattr(self, 'compute_loss'):
76 | self.compute_loss = Loss(de_parallel(self.model))
77 | return self.compute_loss(preds, batch)
78 |
79 | def label_loss_items(self, loss_items=None, prefix="train"):
80 | """
81 | Returns a loss dict with labelled training loss items tensor
82 | """
83 | # Not needed for classification but necessary for segmentation & detection
84 | keys = [f"{prefix}/{x}" for x in self.loss_names]
85 | if loss_items is not None:
86 | loss_items = [round(float(x), 5) for x in loss_items] # convert tensors to 5 decimal place floats
87 | return dict(zip(keys, loss_items))
88 | else:
89 | return keys
90 |
91 | def progress_string(self):
92 | return ('\n' + '%11s' *
93 | (4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
94 |
95 | def plot_training_samples(self, batch, ni):
96 | plot_images(images=batch["img"],
97 | batch_idx=batch["batch_idx"],
98 | cls=batch["cls"].squeeze(-1),
99 | bboxes=batch["bboxes"],
100 | paths=batch["im_file"],
101 | fname=self.save_dir / f"train_batch{ni}.jpg")
102 |
103 | def plot_metrics(self):
104 | plot_results(file=self.csv) # save results.png
105 |
106 |
107 | # Criterion class for computing training losses
108 | class Loss:
109 |
110 | def __init__(self, model): # model must be de-paralleled
111 |
112 | device = next(model.parameters()).device # get model device
113 | h = model.args # hyperparameters
114 |
115 | m = model.model[-1] # Detect() module
116 | self.bce = nn.BCEWithLogitsLoss(reduction='none')
117 | self.hyp = h
118 | self.stride = m.stride # model strides
119 | self.nc = m.nc # number of classes
120 | self.no = m.no
121 | self.reg_max = m.reg_max
122 | self.device = device
123 |
124 | self.use_dfl = m.reg_max > 1
125 | self.assigner = TaskAlignedAssigner(topk=10, num_classes=self.nc, alpha=0.5, beta=6.0)
126 | self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=self.use_dfl).to(device)
127 | self.proj = torch.arange(m.reg_max, dtype=torch.float, device=device)
128 |
129 | def preprocess(self, targets, batch_size, scale_tensor):
130 | if targets.shape[0] == 0:
131 | out = torch.zeros(batch_size, 0, 5, device=self.device)
132 | else:
133 | i = targets[:, 0] # image index
134 | _, counts = i.unique(return_counts=True)
135 | out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
136 | for j in range(batch_size):
137 | matches = i == j
138 | n = matches.sum()
139 | if n:
140 | out[j, :n] = targets[matches, 1:]
141 | out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
142 | return out
143 |
144 | def bbox_decode(self, anchor_points, pred_dist):
145 | if self.use_dfl:
146 | b, a, c = pred_dist.shape # batch, anchors, channels
147 | pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
148 | # pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
149 | # pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
150 | return dist2bbox(pred_dist, anchor_points, xywh=False)
151 |
152 | def __call__(self, preds, batch):
153 | loss = torch.zeros(3, device=self.device) # box, cls, dfl
154 | feats = preds[1] if isinstance(preds, tuple) else preds
155 | pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
156 | (self.reg_max * 4, self.nc), 1)
157 |
158 | pred_scores = pred_scores.permute(0, 2, 1).contiguous()
159 | pred_distri = pred_distri.permute(0, 2, 1).contiguous()
160 |
161 | dtype = pred_scores.dtype
162 | batch_size = pred_scores.shape[0]
163 | imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
164 | anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
165 |
166 | # targets
167 | targets = torch.cat((batch["batch_idx"].view(-1, 1), batch["cls"].view(-1, 1), batch["bboxes"]), 1)
168 | targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
169 | gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
170 | mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
171 |
172 | # pboxes
173 | pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
174 |
175 | _, target_bboxes, target_scores, fg_mask, _ = self.assigner(
176 | pred_scores.detach().sigmoid(), (pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
177 | anchor_points * stride_tensor, gt_labels, gt_bboxes, mask_gt)
178 |
179 | target_bboxes /= stride_tensor
180 | target_scores_sum = target_scores.sum()
181 |
182 | # cls loss
183 | # loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
184 | loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
185 |
186 | # bbox loss
187 | if fg_mask.sum():
188 | loss[0], loss[2] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores,
189 | target_scores_sum, fg_mask)
190 |
191 | loss[0] *= self.hyp.box # box gain
192 | loss[1] *= self.hyp.cls # cls gain
193 | loss[2] *= self.hyp.dfl # dfl gain
194 |
195 | return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
196 |
197 |
198 | @hydra.main(version_base=None, config_path=str(DEFAULT_CONFIG.parent), config_name=DEFAULT_CONFIG.name)
199 | def train(cfg):
200 | cfg.model = cfg.model or "yolov8n.yaml"
201 | cfg.data = cfg.data or "coco128.yaml" # or yolo.ClassificationDataset("mnist")
202 | # trainer = DetectionTrainer(cfg)
203 | # trainer.train()
204 | from ultralytics import YOLO
205 | model = YOLO(cfg.model)
206 | model.train(**cfg)
207 |
208 |
209 | if __name__ == "__main__":
210 | """
211 | CLI usage:
212 | python ultralytics/yolo/v8/detect/train.py model=yolov8n.yaml data=coco128 epochs=100 imgsz=640
213 |
214 | TODO:
215 | yolo task=detect mode=train model=yolov8n.yaml data=coco128.yaml epochs=100
216 | """
217 | train()
218 |
--------------------------------------------------------------------------------