├── images
├── cat.jpg
└── bed_dark_room.jpg
├── .gitignore
├── environment.yml
├── run_addit_generated.ipynb
├── run_addit_real.ipynb
├── LICENSE
├── addit_scheduler.py
├── run_CLI_addit_generated.py
├── run_CLI_addit_real.py
├── addit_methods.py
├── README.md
├── visualization_utils.py
├── addit_blending_utils.py
├── addit_attention_processors.py
├── addit_attention_store.py
├── addit_flux_transformer.py
└── addit_flux_pipeline.py
/images/cat.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NVlabs/addit/HEAD/images/cat.jpg
--------------------------------------------------------------------------------
/images/bed_dark_room.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NVlabs/addit/HEAD/images/bed_dark_room.jpg
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
2 | *.parquet
3 | *.csv
4 | outputs/
5 | models_outputs/
6 | additing_set/source_imgs/
7 | additing_set/old/
8 | *.pdf
9 | *.zip
10 | affordance/source_images/
11 | affordance/extended_source_images/
12 | kaichun/
13 | out/
14 | flask_logs/
15 |
--------------------------------------------------------------------------------
/environment.yml:
--------------------------------------------------------------------------------
1 | name: addit
2 | channels:
3 | - pytorch
4 | - nvidia
5 | - defaults
6 | dependencies:
7 | - python=3.11.9
8 | - pytorch==2.3.1
9 | - pytorch-cuda=12.1
10 | - torchvision=0.18.1
11 |
12 | - pip
13 | - pip:
14 | - diffusers @ git+https://github.com/huggingface/diffusers.git@15eb77bc4cf2ccb40781cb630b9a734b43cffcb8
15 | - transformers==4.44.0
16 | - scikit-image==0.24.0
17 | - scipy==1.14.1
18 | - numpy==1.26.4
19 | - ipykernel
20 | - matplotlib
21 | - opencv-python
22 | - accelerate==0.33.0
23 | - sentencepiece==0.2.0
24 | - protobuf==5.27.3
25 | - pandas==2.2.2
26 | - pyarrow
27 | - fastparquet
28 | - python-dotenv
29 | - git+https://github.com/facebookresearch/sam2.git
--------------------------------------------------------------------------------
/run_addit_generated.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "# Copyright (C) 2025 NVIDIA Corporation. All rights reserved.\n",
10 | "#\n",
11 | "# This work is licensed under the LICENSE file\n",
12 | "# located at the root directory.\n",
13 | "import torch\n",
14 | "import random\n",
15 | "\n",
16 | "from visualization_utils import show_images\n",
17 | "from addit_flux_pipeline import AdditFluxPipeline\n",
18 | "from addit_flux_transformer import AdditFluxTransformer2DModel\n",
19 | "from addit_scheduler import AdditFlowMatchEulerDiscreteScheduler\n",
20 | "from addit_methods import add_object_generated\n",
21 | "\n",
22 | "device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
23 | "my_transformer = AdditFluxTransformer2DModel.from_pretrained(\"black-forest-labs/FLUX.1-dev\", subfolder=\"transformer\", torch_dtype=torch.bfloat16)\n",
24 | "\n",
25 | "pipe = AdditFluxPipeline.from_pretrained(\"black-forest-labs/FLUX.1-dev\", \n",
26 | " transformer=my_transformer,\n",
27 | " torch_dtype=torch.bfloat16).to(device)\n",
28 | "pipe.scheduler = AdditFlowMatchEulerDiscreteScheduler.from_config(pipe.scheduler.config)"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": null,
34 | "metadata": {},
35 | "outputs": [],
36 | "source": [
37 | "# Reset the GPU memory tracking\n",
38 | "torch.cuda.reset_max_memory_allocated(0)\n",
39 | "\n",
40 | "(prompt1, prompt2), subject_token = [\"A photo of a man sitting on a bench\", \"A photo of a man sitting on a bench with a dog\"], \"dog\"\n",
41 | "\n",
42 | "\n",
43 | "random.seed(0)\n",
44 | "seeds_src = [663]\n",
45 | "seeds_obj = [0,1,2]\n",
46 | "\n",
47 | "for seed_src in seeds_src:\n",
48 | " for seed_obj in seeds_obj:\n",
49 | " src_image, edited_image = add_object_generated(pipe, prompt1, prompt2, subject_token, seed_src, seed_obj, show_attention=True, \n",
50 | " extended_scale=1.05, structure_transfer_step=2, blend_steps=[15], \n",
51 | " localization_model=\"attention_points_sam\", display_output=True)\n",
52 | "\n",
53 | "# Report maximum GPU memory usage in GB\n",
54 | "max_memory_used = torch.cuda.max_memory_allocated(0) / (1024**3) # Convert to GB\n",
55 | "print(f\"Maximum GPU memory used: {max_memory_used:.2f} GB\")"
56 | ]
57 | }
58 | ],
59 | "metadata": {
60 | "kernelspec": {
61 | "display_name": "addit",
62 | "language": "python",
63 | "name": "python3"
64 | },
65 | "language_info": {
66 | "codemirror_mode": {
67 | "name": "ipython",
68 | "version": 3
69 | },
70 | "file_extension": ".py",
71 | "mimetype": "text/x-python",
72 | "name": "python",
73 | "nbconvert_exporter": "python",
74 | "pygments_lexer": "ipython3",
75 | "version": "3.11.9"
76 | }
77 | },
78 | "nbformat": 4,
79 | "nbformat_minor": 2
80 | }
81 |
--------------------------------------------------------------------------------
/run_addit_real.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "# Copyright (C) 2025 NVIDIA Corporation. All rights reserved.\n",
10 | "#\n",
11 | "# This work is licensed under the LICENSE file\n",
12 | "# located at the root directory.\n",
13 | "\n",
14 | "import torch\n",
15 | "import random\n",
16 | "from PIL import Image\n",
17 | "\n",
18 | "from visualization_utils import show_images\n",
19 | "from addit_flux_pipeline import AdditFluxPipeline\n",
20 | "from addit_flux_transformer import AdditFluxTransformer2DModel\n",
21 | "from addit_scheduler import AdditFlowMatchEulerDiscreteScheduler\n",
22 | "from addit_methods import add_object_real\n",
23 | "\n",
24 | "device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
25 | "my_transformer = AdditFluxTransformer2DModel.from_pretrained(\"black-forest-labs/FLUX.1-dev\", subfolder=\"transformer\", torch_dtype=torch.bfloat16)\n",
26 | "\n",
27 | "pipe = AdditFluxPipeline.from_pretrained(\"black-forest-labs/FLUX.1-dev\", \n",
28 | " transformer=my_transformer,\n",
29 | " torch_dtype=torch.bfloat16).to(device)\n",
30 | "pipe.scheduler = AdditFlowMatchEulerDiscreteScheduler.from_config(pipe.scheduler.config)"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": null,
36 | "metadata": {},
37 | "outputs": [],
38 | "source": [
39 | "# Reset the GPU memory tracking\n",
40 | "torch.cuda.reset_max_memory_allocated(0)\n",
41 | "\n",
42 | "# source_image = Image.open(\"images/cat.jpg\").resize((1024, 1024))\n",
43 | "# (prompt_src, prompt_tgt), subject_token = [\"A photo of a cat\", \"A photo of a cat wearing a scarf\"], \"scarf\"\n",
44 | "\n",
45 | "source_image = Image.open(\"images/bed_dark_room.jpg\").resize((1024, 1024))\n",
46 | "(prompt_src, prompt_tgt), subject_token = [\"A photo of a bed in a dark room\", \"A photo of a dog lying on a bed in a dark room\"], \"dog\"\n",
47 | "\n",
48 | "random.seed(0)\n",
49 | "seed_src = random.randint(0, 10000)\n",
50 | "seeds_obj = [0,1,2]\n",
51 | "\n",
52 | "for seed_obj in seeds_obj:\n",
53 | " images_list = add_object_real(pipe, source_image=source_image, prompt_source=prompt_src, prompt_object=prompt_tgt, \n",
54 | " subject_token=subject_token, seed_src=seed_src, seed_obj=seed_obj, \n",
55 | " extended_scale =1.1, structure_transfer_step=4, blend_steps = [18], #localization_model=\"attention\",\n",
56 | " use_offset=False, show_attention=True, use_inversion=True, display_output=True)\n",
57 | "\n",
58 | "# Report maximum GPU memory usage in GB\n",
59 | "max_memory_used = torch.cuda.max_memory_allocated(0) / (1024**3) # Convert to GB\n",
60 | "print(f\"Maximum GPU memory used: {max_memory_used:.2f} GB\")"
61 | ]
62 | }
63 | ],
64 | "metadata": {
65 | "kernelspec": {
66 | "display_name": "addit",
67 | "language": "python",
68 | "name": "python3"
69 | },
70 | "language_info": {
71 | "codemirror_mode": {
72 | "name": "ipython",
73 | "version": 3
74 | },
75 | "file_extension": ".py",
76 | "mimetype": "text/x-python",
77 | "name": "python",
78 | "nbconvert_exporter": "python",
79 | "pygments_lexer": "ipython3",
80 | "version": "3.11.9"
81 | }
82 | },
83 | "nbformat": 4,
84 | "nbformat_minor": 2
85 | }
86 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | NVIDIA License
2 |
3 | 1. Definitions
4 |
5 | “Licensor” means any person or entity that distributes its Work.
6 | “Work” means (a) the original work of authorship made available under this license, which may include software, documentation, or other files, and (b) any additions to or derivative works thereof that are made available under this license.
7 | The terms “reproduce,” “reproduction,” “derivative works,” and “distribution” have the meaning as provided under U.S. copyright law; provided, however, that for the purposes of this license, derivative works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work.
8 | Works are “made available” under this license by including in or with the Work either (a) a copyright notice referencing the applicability of this license to the Work, or (b) a copy of this license.
9 |
10 | 2. License Grant
11 |
12 | 2.1 Copyright Grant. Subject to the terms and conditions of this license, each Licensor grants to you a perpetual, worldwide, non-exclusive, royalty-free, copyright license to use, reproduce, prepare derivative works of, publicly display, publicly perform, sublicense and distribute its Work and any resulting derivative works in any form.
13 |
14 | 3. Limitations
15 |
16 | 3.1 Redistribution. You may reproduce or distribute the Work only if (a) you do so under this license, (b) you include a complete copy of this license with your distribution, and (c) you retain without modification any copyright, patent, trademark, or attribution notices that are present in the Work.
17 |
18 | 3.2 Derivative Works. You may specify that additional or different terms apply to the use, reproduction, and distribution of your derivative works of the Work (“Your Terms”) only if (a) Your Terms provide that the use limitation in Section 3.3 applies to your derivative works, and (b) you identify the specific derivative works that are subject to Your Terms. Notwithstanding Your Terms, this license (including the redistribution requirements in Section 3.1) will continue to apply to the Work itself.
19 |
20 | 3.3 Use Limitation. The Work and any derivative works thereof only may be used or intended for use non-commercially. Notwithstanding the foregoing, NVIDIA Corporation and its affiliates may use the Work and any derivative works commercially. As used herein, “non-commercially” means for research or evaluation purposes only.
21 |
22 | 3.4 Patent Claims. If you bring or threaten to bring a patent claim against any Licensor (including any claim, cross-claim or counterclaim in a lawsuit) to enforce any patents that you allege are infringed by any Work, then your rights under this license from such Licensor (including the grant in Section 2.1) will terminate immediately.
23 |
24 | 3.5 Trademarks. This license does not grant any rights to use any Licensor’s or its affiliates’ names, logos, or trademarks, except as necessary to reproduce the notices described in this license.
25 |
26 | 3.6 Termination. If you violate any term of this license, then your rights under this license (including the grant in Section 2.1) will terminate immediately.
27 |
28 | 4. Disclaimer of Warranty.
29 |
30 | THE WORK IS PROVIDED “AS IS” WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING WARRANTIES OR CONDITIONS OF
31 | MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE OR NON-INFRINGEMENT. YOU BEAR THE RISK OF UNDERTAKING ANY ACTIVITIES UNDER THIS LICENSE.
32 |
33 | 5. Limitation of Liability.
34 |
35 | EXCEPT AS PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER IN TORT (INCLUDING NEGLIGENCE), CONTRACT, OR OTHERWISE SHALL ANY LICENSOR BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES ARISING OUT OF OR RELATED TO THIS LICENSE, THE USE OR INABILITY TO USE THE WORK (INCLUDING BUT NOT LIMITED TO LOSS OF GOODWILL, BUSINESS INTERRUPTION, LOST PROFITS OR DATA, COMPUTER FAILURE OR MALFUNCTION, OR ANY OTHER DAMAGES OR LOSSES), EVEN IF THE LICENSOR HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
--------------------------------------------------------------------------------
/addit_scheduler.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 Stability AI, Katherine Crowson and The HuggingFace Team. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | from diffusers.schedulers.scheduling_flow_match_euler_discrete import FlowMatchEulerDiscreteScheduler, FlowMatchEulerDiscreteSchedulerOutput
16 | from typing import Union, Optional, Tuple
17 | import torch
18 |
19 | class AdditFlowMatchEulerDiscreteScheduler(FlowMatchEulerDiscreteScheduler):
20 | def step(
21 | self,
22 | model_output: torch.FloatTensor,
23 | timestep: Union[float, torch.FloatTensor],
24 | sample: torch.FloatTensor,
25 | s_churn: float = 0.0,
26 | s_tmin: float = 0.0,
27 | s_tmax: float = float("inf"),
28 | s_noise: float = 1.0,
29 | generator: Optional[torch.Generator] = None,
30 | return_dict: bool = True,
31 | step_index: Optional[int] = None,
32 | ) -> Union[FlowMatchEulerDiscreteSchedulerOutput, Tuple]:
33 | """
34 | Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
35 | process from the learned model outputs (most often the predicted noise).
36 |
37 | Args:
38 | model_output (`torch.FloatTensor`):
39 | The direct output from learned diffusion model.
40 | timestep (`float`):
41 | The current discrete timestep in the diffusion chain.
42 | sample (`torch.FloatTensor`):
43 | A current instance of a sample created by the diffusion process.
44 | s_churn (`float`):
45 | s_tmin (`float`):
46 | s_tmax (`float`):
47 | s_noise (`float`, defaults to 1.0):
48 | Scaling factor for noise added to the sample.
49 | generator (`torch.Generator`, *optional*):
50 | A random number generator.
51 | return_dict (`bool`):
52 | Whether or not to return a [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or
53 | tuple.
54 |
55 | Returns:
56 | [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or `tuple`:
57 | If return_dict is `True`, [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] is
58 | returned, otherwise a tuple is returned where the first element is the sample tensor.
59 | """
60 |
61 | if (
62 | isinstance(timestep, int)
63 | or isinstance(timestep, torch.IntTensor)
64 | or isinstance(timestep, torch.LongTensor)
65 | ):
66 | raise ValueError(
67 | (
68 | "Passing integer indices (e.g. from `enumerate(timesteps)`) as timesteps to"
69 | " `EulerDiscreteScheduler.step()` is not supported. Make sure to pass"
70 | " one of the `scheduler.timesteps` as a timestep."
71 | ),
72 | )
73 |
74 | if step_index is not None:
75 | self._step_index = step_index
76 |
77 | if self.step_index is None:
78 | self._init_step_index(timestep)
79 |
80 | # Upcast to avoid precision issues when computing prev_sample
81 | sample = sample.to(torch.float32)
82 |
83 | sigma = self.sigmas[self.step_index]
84 | sigma_next = self.sigmas[self.step_index + 1]
85 |
86 | prev_sample = sample + (sigma_next - sigma) * model_output
87 |
88 | # Calculate X_0
89 | x_0 = sample - sigma * model_output
90 |
91 | # Cast sample back to model compatible dtype
92 | prev_sample = prev_sample.to(model_output.dtype)
93 | x_0 = x_0.to(model_output.dtype)
94 |
95 | # upon completion increase step index by one
96 | self._step_index += 1
97 |
98 | if not return_dict:
99 | return (prev_sample, x_0)
100 |
101 | return FlowMatchEulerDiscreteSchedulerOutput(prev_sample=prev_sample)
--------------------------------------------------------------------------------
/run_CLI_addit_generated.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | # Copyright (C) 2025 NVIDIA Corporation. All rights reserved.
3 | #
4 | # This work is licensed under the LICENSE file
5 | # located at the root directory.
6 |
7 | import os
8 | import argparse
9 | import torch
10 | import random
11 |
12 | from visualization_utils import show_images
13 | from addit_flux_pipeline import AdditFluxPipeline
14 | from addit_flux_transformer import AdditFluxTransformer2DModel
15 | from addit_scheduler import AdditFlowMatchEulerDiscreteScheduler
16 | from addit_methods import add_object_generated
17 |
18 | def main():
19 | parser = argparse.ArgumentParser(description='Run ADDIT with generated images')
20 |
21 | # Required arguments
22 | parser.add_argument('--prompt_source', type=str, default="A photo of a cat sitting on the couch",
23 | help='Source prompt for generating the base image')
24 | parser.add_argument('--prompt_target', type=str, default="A photo of a cat wearing a red hat sitting on the couch",
25 | help='Target prompt describing the desired edited image')
26 | parser.add_argument('--subject_token', type=str, default="hat",
27 | help='Single token representing the subject to add to the image, must appear in the prompt_target')
28 |
29 | # Optional arguments
30 | parser.add_argument('--output_dir', type=str, default='outputs',
31 | help='Directory to save output images (default: outputs)')
32 | parser.add_argument('--seed_src', type=int, default=6311,
33 | help='Seed for source generation')
34 | parser.add_argument('--seed_obj', type=int, default=1,
35 | help='Seed for edited image generation')
36 | parser.add_argument('--extended_scale', type=float, default=1.05,
37 | help='Extended attention scale (default: 1.05)')
38 | parser.add_argument('--structure_transfer_step', type=int, default=2,
39 | help='Structure transfer step (default: 2)')
40 | parser.add_argument('--blend_steps', type=int, nargs='*', default=[15],
41 | help='Blend steps (default: [15])')
42 | parser.add_argument('--localization_model', type=str, default="attention_points_sam",
43 | help='Localization model (default: attention_points_sam, Options: [attention_points_sam, attention, attention_box_sam, attention_mask_sam, grounding_sam])')
44 | parser.add_argument('--show_attention', action='store_true',
45 | help='Show attention maps')
46 | parser.add_argument('--display_output', action='store_true',
47 | help='Display output images during processing')
48 |
49 | args = parser.parse_args()
50 |
51 | assert args.subject_token in args.prompt_target, "Subject token must appear in the prompt_target"
52 |
53 | # Set up device and model
54 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
55 | print(f"Using device: {device}")
56 |
57 | my_transformer = AdditFluxTransformer2DModel.from_pretrained(
58 | "black-forest-labs/FLUX.1-dev",
59 | subfolder="transformer",
60 | torch_dtype=torch.bfloat16
61 | )
62 |
63 | pipe = AdditFluxPipeline.from_pretrained(
64 | "black-forest-labs/FLUX.1-dev",
65 | transformer=my_transformer,
66 | torch_dtype=torch.bfloat16
67 | ).to(device)
68 |
69 | pipe.scheduler = AdditFlowMatchEulerDiscreteScheduler.from_config(pipe.scheduler.config)
70 |
71 | # Create output directory
72 | os.makedirs(args.output_dir, exist_ok=True)
73 |
74 | # Process the seeds
75 | print(f"\nProcessing with source seed: {args.seed_src}, object seed: {args.seed_obj}")
76 |
77 | src_image, edited_image = add_object_generated(
78 | pipe,
79 | args.prompt_source,
80 | args.prompt_target,
81 | args.subject_token,
82 | args.seed_src,
83 | args.seed_obj,
84 | show_attention=args.show_attention,
85 | extended_scale=args.extended_scale,
86 | structure_transfer_step=args.structure_transfer_step,
87 | blend_steps=args.blend_steps,
88 | localization_model=args.localization_model,
89 | display_output=args.display_output
90 | )
91 |
92 | # Save output images
93 | src_filename = f"src_{args.prompt_source}_seed-src={args.seed_src}.png"
94 | edited_filename = f"edited_{args.prompt_target}_seed-src={args.seed_src}_seed-obj={args.seed_obj}.png"
95 |
96 | src_image.save(os.path.join(args.output_dir, src_filename))
97 | edited_image.save(os.path.join(args.output_dir, edited_filename))
98 |
99 | print(f"Saved images: {src_filename}, {edited_filename}")
100 |
101 | if __name__ == "__main__":
102 | main()
--------------------------------------------------------------------------------
/run_CLI_addit_real.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | # Copyright (C) 2025 NVIDIA Corporation. All rights reserved.
3 | #
4 | # This work is licensed under the LICENSE file
5 | # located at the root directory.
6 |
7 | import os
8 | import argparse
9 | import torch
10 | import random
11 | from PIL import Image
12 |
13 | from visualization_utils import show_images
14 | from addit_flux_pipeline import AdditFluxPipeline
15 | from addit_flux_transformer import AdditFluxTransformer2DModel
16 | from addit_scheduler import AdditFlowMatchEulerDiscreteScheduler
17 | from addit_methods import add_object_real
18 |
19 | def main():
20 | parser = argparse.ArgumentParser(description='Run ADDIT with real images')
21 |
22 | # Required arguments
23 | parser.add_argument('--source_image', type=str, default="images/bed_dark_room.jpg",
24 | help='Path to the source image')
25 | parser.add_argument('--prompt_source', type=str, default="A photo of a bed in a dark room",
26 | help='Source prompt describing the original image')
27 | parser.add_argument('--prompt_target', type=str, default="A photo of a dog lying on a bed in a dark room",
28 | help='Target prompt describing the desired edited image')
29 | parser.add_argument('--subject_token', type=str, default="dog",
30 | help='Subject token to add to the image')
31 |
32 | # Optional arguments
33 | parser.add_argument('--output_dir', type=str, default='outputs',
34 | help='Directory to save output images (default: outputs)')
35 | parser.add_argument('--seed_src', type=int, default=6311,
36 | help='Seed for source generation')
37 | parser.add_argument('--seed_obj', type=int, default=1,
38 | help='Seed for edited image generation')
39 | parser.add_argument('--extended_scale', type=float, default=1.1,
40 | help='Extended attention scale (default: 1.1)')
41 | parser.add_argument('--structure_transfer_step', type=int, default=4,
42 | help='Structure transfer step (default: 4)')
43 | parser.add_argument('--blend_steps', type=int, nargs='*', default=[18],
44 | help='Blend steps (default: [18])')
45 | parser.add_argument('--localization_model', type=str, default="attention",
46 | help='Localization model (default: attention, Options: [attention_points_sam, attention, attention_box_sam, attention_mask_sam, grounding_sam])')
47 | parser.add_argument('--use_offset', action='store_true',
48 | help='Use offset in processing')
49 | parser.add_argument('--show_attention', action='store_true',
50 | help='Show attention maps')
51 | parser.add_argument('--disable_inversion', action='store_true',
52 | help='Disable source image inversion')
53 | parser.add_argument('--display_output', action='store_true',
54 | help='Display output images during processing')
55 |
56 | args = parser.parse_args()
57 |
58 | assert args.subject_token in args.prompt_target, "Subject token must appear in the prompt_target"
59 |
60 | # Set up device and model
61 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
62 | print(f"Using device: {device}")
63 |
64 | my_transformer = AdditFluxTransformer2DModel.from_pretrained(
65 | "black-forest-labs/FLUX.1-dev",
66 | subfolder="transformer",
67 | torch_dtype=torch.bfloat16
68 | )
69 |
70 | pipe = AdditFluxPipeline.from_pretrained(
71 | "black-forest-labs/FLUX.1-dev",
72 | transformer=my_transformer,
73 | torch_dtype=torch.bfloat16
74 | ).to(device)
75 |
76 | pipe.scheduler = AdditFlowMatchEulerDiscreteScheduler.from_config(pipe.scheduler.config)
77 |
78 | # Load and resize source image
79 | source_image = Image.open(args.source_image).resize((1024, 1024))
80 | print(f"Loaded source image: {args.source_image}")
81 |
82 | # Set random seed
83 | if args.seed_src is None:
84 | random.seed(0)
85 | args.seed_src = random.randint(0, 10000)
86 |
87 | # Create output directory
88 | os.makedirs(args.output_dir, exist_ok=True)
89 |
90 | # Process the seeds
91 | print(f"\nProcessing with source seed: {args.seed_src}, object seed: {args.seed_obj}")
92 |
93 | src_image, edited_image = add_object_real(
94 | pipe,
95 | source_image=source_image,
96 | prompt_source=args.prompt_source,
97 | prompt_object=args.prompt_target,
98 | subject_token=args.subject_token,
99 | seed_src=args.seed_src,
100 | seed_obj=args.seed_obj,
101 | extended_scale=args.extended_scale,
102 | structure_transfer_step=args.structure_transfer_step,
103 | blend_steps=args.blend_steps,
104 | localization_model=args.localization_model,
105 | use_offset=args.use_offset,
106 | show_attention=args.show_attention,
107 | use_inversion=not args.disable_inversion,
108 | display_output=args.display_output
109 | )
110 |
111 | # Save output images
112 | src_filename = f"src_{args.prompt_source}_seed-src={args.seed_src}.png"
113 | edited_filename = f"edited_{args.prompt_target}_seed-src={args.seed_src}_seed-obj={args.seed_obj}.png"
114 |
115 | src_image.save(os.path.join(args.output_dir, src_filename))
116 | edited_image.save(os.path.join(args.output_dir, edited_filename))
117 |
118 | print(f"Saved images: {src_filename}, {edited_filename}")
119 |
120 | if __name__ == "__main__":
121 | main()
--------------------------------------------------------------------------------
/addit_methods.py:
--------------------------------------------------------------------------------
1 | # Copyright (C) 2025 NVIDIA Corporation. All rights reserved.
2 | #
3 | # This work is licensed under the LICENSE file
4 | # located at the root directory.
5 |
6 | import gc
7 | import torch
8 | from visualization_utils import show_images
9 |
10 | def _add_object(
11 | pipe,
12 | prompts,
13 | seed_src,
14 | seed_obj,
15 | extended_scale,
16 | source_latents,
17 | structure_transfer_step,
18 | subject_token,
19 | blend_steps,
20 | show_attention=False,
21 | localization_model="attention_points_sam",
22 | is_img_src=False,
23 | img_src_latents=None,
24 | use_offset=False,
25 | display_output=False,
26 | ):
27 | gc.collect()
28 | torch.cuda.empty_cache()
29 |
30 | out = pipe(
31 | prompt=prompts,
32 | guidance_scale=3.5 if (not is_img_src) else [1,3.5],
33 | height=1024,
34 | width=1024,
35 | max_sequence_length=512,
36 | num_inference_steps=30,
37 | seed=[seed_src, seed_obj],
38 |
39 | # Extended Attention
40 | extended_scale=extended_scale,
41 | extended_steps_multi=10,
42 | extended_steps_single=20,
43 |
44 | # Structure Transfer
45 | source_latents=source_latents,
46 | structure_transfer_step=structure_transfer_step,
47 |
48 | # Latent Blending
49 | subject_token=subject_token,
50 | localization_model=localization_model,
51 | blend_steps=blend_steps,
52 | show_attention=show_attention,
53 |
54 | # Real Image Source
55 | is_img_src=is_img_src,
56 | img_src_latents=img_src_latents,
57 | use_offset=use_offset,
58 | )
59 |
60 | if display_output:
61 | show_images(out.images)
62 |
63 | return out.images
64 |
65 | def add_object_generated(
66 | pipe,
67 | prompt_source,
68 | prompt_object,
69 | subject_token,
70 | seed_src,
71 | seed_obj,
72 | show_attention=False,
73 | extended_scale=1.05,
74 | structure_transfer_step=2,
75 | blend_steps=[15],
76 | localization_model="attention_points_sam",
77 | display_output=False
78 | ):
79 | gc.collect()
80 | torch.cuda.empty_cache()
81 |
82 | # Generate source image and latents for each seed1
83 | print('Generating source image...')
84 | source_image, source_latents = pipe(
85 | prompt=[prompt_source],
86 | guidance_scale=3.5,
87 | height=1024,
88 | width=1024,
89 | max_sequence_length=512,
90 | num_inference_steps=30,
91 | seed=[seed_src],
92 | output_type="both",
93 | )
94 | source_image = source_image[0]
95 |
96 | # Run the core combination logic
97 | print('Running Addit...')
98 | src_image, edited_image = _add_object(
99 | pipe=pipe,
100 | prompts=[prompt_source, prompt_object],
101 | subject_token=subject_token,
102 | seed_src=seed_src,
103 | seed_obj=seed_obj,
104 | source_latents=source_latents,
105 | structure_transfer_step=structure_transfer_step,
106 | extended_scale=extended_scale,
107 | blend_steps=blend_steps,
108 | show_attention=show_attention,
109 | localization_model=localization_model,
110 | display_output=display_output
111 | )
112 |
113 | return src_image, edited_image
114 |
115 | def add_object_real(
116 | pipe,
117 | source_image,
118 | prompt_source,
119 | prompt_object,
120 | subject_token,
121 | seed_src,
122 | seed_obj,
123 | localization_model="attention_points_sam",
124 | extended_scale=1.05,
125 | structure_transfer_step=4,
126 | blend_steps=[20],
127 | use_offset=False,
128 | show_attention=False,
129 | use_inversion=False,
130 | display_output=False
131 | ):
132 | print('Noising-Denoising Original Image')
133 | gc.collect()
134 | torch.cuda.empty_cache()
135 |
136 | # Get initial latents
137 | source_latents = pipe.call_img2img(
138 | prompt=prompt_source,
139 | image=source_image,
140 | num_inference_steps=30,
141 | strength=0.1,
142 | guidance_scale=3.5,
143 | output_type="latent",
144 | generator=torch.Generator(device=pipe.device).manual_seed(0)
145 | ).images
146 |
147 | # Optional inversion step
148 | img_src_latents = None
149 | if use_inversion:
150 | print('Inverting Image')
151 | gc.collect()
152 | torch.cuda.empty_cache()
153 |
154 | latents_list = pipe.call_invert(
155 | prompt=prompt_source,
156 | image=source_latents,
157 | num_inference_steps=30,
158 | guidance_scale=1,
159 | fixed_point_iterations=2,
160 | generator=torch.Generator(device=pipe.device).manual_seed(0)
161 | )
162 | img_src_latents = [x[0] for x in latents_list][::-1]
163 |
164 | print('Running Addit')
165 | gc.collect()
166 | torch.cuda.empty_cache()
167 |
168 | src_image, edited_image = _add_object(
169 | pipe,
170 | prompts=[prompt_source, prompt_object],
171 | seed_src=seed_src,
172 | seed_obj=seed_obj,
173 | extended_scale=extended_scale,
174 | source_latents=source_latents,
175 | structure_transfer_step=structure_transfer_step,
176 | subject_token=subject_token,
177 | blend_steps=blend_steps,
178 | show_attention=show_attention,
179 | localization_model=localization_model,
180 | is_img_src=True,
181 | img_src_latents=img_src_latents,
182 | use_offset=use_offset,
183 | display_output=display_output,
184 | )
185 |
186 | return src_image, edited_image
187 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 🎨 Add-it: Training-Free Object Insertion in Images With Pretrained Diffusion Models [ICLR 2025]
2 |
3 |
4 |
5 | [](https://arxiv.org/abs/2411.07232)
6 | [](https://openreview.net/forum?id=ZeaTvXw080)
7 | [](https://research.nvidia.com/labs/par/addit/)
8 | [](https://huggingface.co/spaces/nvidia/addit)
9 |
10 |
11 |
12 | ## 👥 Authors
13 |
14 | **Yoad Tewel**1,2, **Rinon Gal**1,2, **Dvir Samuel**3, **Yuval Atzmon**1, **Lior Wolf**2, **Gal Chechik**1
15 |
16 | 1NVIDIA • 2Tel Aviv University • 3Bar-Ilan University
17 |
18 |
19 |
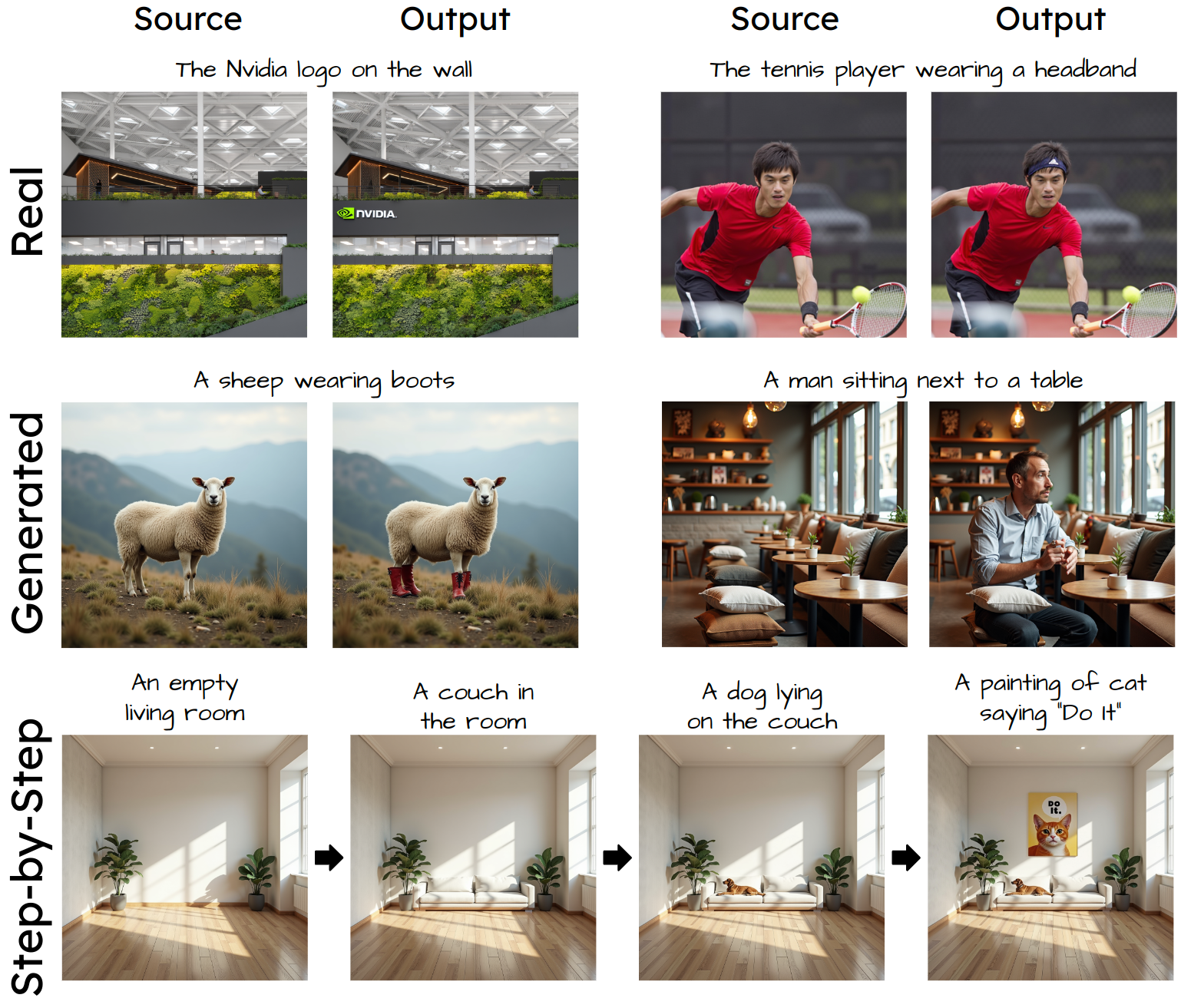
20 |
167 | 🌟 Star this repo if you find it useful! 🌟
168 |
--------------------------------------------------------------------------------
/visualization_utils.py:
--------------------------------------------------------------------------------
1 | # Copyright (C) 2025 NVIDIA Corporation. All rights reserved.
2 | #
3 | # This work is licensed under the LICENSE file
4 | # located at the root directory.
5 |
6 | import cv2
7 | import numpy as np
8 | from PIL import Image, ImageDraw
9 | import torch
10 | import matplotlib.pyplot as plt
11 | from skimage import filters
12 | from IPython.display import display
13 |
14 | def gaussian_blur(heatmap, kernel_size=7):
15 | # Shape of heatmap: (H, W)
16 | heatmap = heatmap.cpu().numpy()
17 | heatmap = cv2.GaussianBlur(heatmap, (kernel_size, kernel_size), 0)
18 | heatmap = torch.tensor(heatmap)
19 |
20 | return heatmap
21 |
22 | def show_cam_on_image(img, mask):
23 | heatmap = cv2.applyColorMap(np.uint8(255 * mask), cv2.COLORMAP_JET)
24 | heatmap = np.float32(heatmap) / 255
25 | cam = heatmap + np.float32(img)
26 | cam = cam / np.max(cam)
27 | return cam
28 |
29 | def show_image_and_heatmap(heatmap: torch.Tensor, image: Image.Image, relevnace_res: int = 256, interpolation: str = 'bilinear', gassussian_kernel_size: int = 3):
30 | image = image.resize((relevnace_res, relevnace_res))
31 | image = np.array(image)
32 | image = (image - image.min()) / (image.max() - image.min())
33 |
34 | # Apply gaussian blur to heatmap
35 | # heatmap = gaussian_blur(heatmap, kernel_size=gassussian_kernel_size)
36 |
37 | # heatmap = (heatmap - heatmap.min()) / (heatmap.max() - heatmap.min())
38 | # otsu_thr = filters.threshold_otsu(heatmap.cpu().numpy())
39 | # heatmap = (heatmap > otsu_thr).to(heatmap.dtype)
40 |
41 | heatmap = heatmap.reshape(1, 1, heatmap.shape[-1], heatmap.shape[-1])
42 | heatmap = torch.nn.functional.interpolate(heatmap, size=relevnace_res, mode=interpolation)
43 | heatmap = (heatmap - heatmap.min()) / (heatmap.max() - heatmap.min())
44 | heatmap = heatmap.reshape(relevnace_res, relevnace_res).cpu()
45 |
46 | vis = show_cam_on_image(image, heatmap)
47 | vis = np.uint8(255 * vis)
48 | vis = cv2.cvtColor(np.array(vis), cv2.COLOR_RGB2BGR)
49 |
50 | vis = vis.astype(np.uint8)
51 | vis = Image.fromarray(vis).resize((relevnace_res, relevnace_res))
52 |
53 | return vis
54 |
55 | def show_only_heatmap(heatmap: torch.Tensor, relevnace_res: int = 256, interpolation: str = 'bilinear', gassussian_kernel_size: int = 3):
56 | # Apply gaussian blur to heatmap
57 | # heatmap = gaussian_blur(heatmap, kernel_size=gassussian_kernel_size)
58 |
59 | heatmap = heatmap.reshape(1, 1, heatmap.shape[-1], heatmap.shape[-1])
60 | heatmap = torch.nn.functional.interpolate(heatmap, size=relevnace_res, mode=interpolation)
61 | heatmap = (heatmap - heatmap.min()) / (heatmap.max() - heatmap.min())
62 | heatmap = heatmap.reshape(relevnace_res, relevnace_res).cpu()
63 |
64 | vis = heatmap
65 | vis = np.uint8(255 * vis)
66 |
67 | # Show in black and white
68 | vis = cv2.cvtColor(np.array(vis), cv2.COLOR_GRAY2BGR)
69 |
70 | vis = Image.fromarray(vis).resize((relevnace_res, relevnace_res))
71 |
72 | return vis
73 |
74 | def visualize_tokens_attentions(attention, tokens, image, heatmap_interpolation="nearest", show_on_image=True):
75 | # Tokens: list of strings
76 | # attention: tensor of shape (batch_size, num_tokens, width, height)
77 | token_vis = []
78 | for j, token in enumerate(tokens):
79 | if j >= attention.shape[0]:
80 | break
81 |
82 | if show_on_image:
83 | vis = show_image_and_heatmap(attention[j], image, relevnace_res=512, interpolation=heatmap_interpolation)
84 | else:
85 | vis = show_only_heatmap(attention[j], relevnace_res=512, interpolation=heatmap_interpolation)
86 |
87 | token_vis.append((token, vis))
88 |
89 | # Display the token and the attention map in a grid, with K tokens per row
90 | K = 4
91 | n_rows = (len(token_vis) + K - 1) // K # Ceiling division
92 | fig, axs = plt.subplots(n_rows, K, figsize=(K*5, n_rows*5))
93 |
94 | for i, (token, vis) in enumerate(token_vis):
95 | row, col = divmod(i, K)
96 | if n_rows > 1:
97 | ax = axs[row, col]
98 | elif K > 1:
99 | ax = axs[col]
100 | else:
101 | ax = axs
102 |
103 | ax.imshow(vis)
104 | ax.set_title(token)
105 | ax.axis("off")
106 |
107 | # Hide unused subplots
108 | for j in range(i + 1, n_rows * K):
109 | row, col = divmod(j, K)
110 | if n_rows > 1:
111 | axs[row, col].axis('off')
112 | elif K > 1:
113 | axs[col].axis('off')
114 |
115 | plt.tight_layout()
116 |
117 | # We want to return the figure so that we can save it to a file
118 | return fig
119 |
120 | def show_images(images, titles=None, size=1024, max_row_length=5, figsize=None, col_height=10, save_path=None):
121 | if isinstance(images, Image.Image):
122 | images = [images]
123 |
124 | if len(images) == 1:
125 | img = images[0]
126 | img = img.resize((size, size))
127 | plt.imshow(img)
128 | plt.axis('off')
129 |
130 | if titles is not None:
131 | plt.title(titles[0])
132 |
133 | if save_path:
134 | plt.savefig(save_path, bbox_inches='tight', dpi=150)
135 |
136 | plt.show()
137 | else:
138 | images = [img.resize((size, size)) for img in images]
139 |
140 | # Check if the number of titles matches the number of images
141 | if titles is not None:
142 | assert len(images) == len(titles), "Number of titles should match the number of images"
143 |
144 | n_images = len(images)
145 | n_cols = min(n_images, max_row_length)
146 | n_rows = (n_images + n_cols - 1) // n_cols # Calculate the number of rows needed
147 |
148 | if figsize is None:
149 | figsize=(n_cols * col_height, n_rows * col_height)
150 |
151 | fig, axs = plt.subplots(n_rows, n_cols, figsize=figsize)
152 | axs = axs.flatten() if isinstance(axs, np.ndarray) else [axs]
153 |
154 | # Display images in the subplots
155 | for i, img in enumerate(images):
156 | axs[i].imshow(img)
157 | if titles is not None:
158 | axs[i].set_title(titles[i])
159 | axs[i].axis("off")
160 |
161 | # Turn off any unused subplots
162 | for ax in axs[len(images):]:
163 | ax.axis("off")
164 |
165 | if save_path:
166 | plt.savefig(save_path, bbox_inches='tight', dpi=150)
167 |
168 | plt.show()
169 |
170 | def show_tensors(tensors, titles=None, size=None, max_row_length=5):
171 | # Shape of tensors: List[Tensor[H, W]]
172 | if size is not None:
173 | tensors = [torch.nn.functional.interpolate(t.unsqueeze(0).unsqueeze(0), size=(size, size), mode='bilinear').squeeze() for t in tensors]
174 |
175 | if len(tensors) == 1:
176 | plt.imshow(tensors[0].cpu().numpy())
177 | plt.axis('off')
178 |
179 | if titles is not None:
180 | plt.title(titles[0])
181 |
182 | plt.show()
183 | else:
184 | # Check if the number of titles matches the number of images
185 | if titles is not None:
186 | assert len(tensors) == len(titles), "Number of titles should match the number of images"
187 |
188 | n_tensors = len(tensors)
189 | n_cols = min(n_tensors, max_row_length)
190 | n_rows = (n_tensors + n_cols - 1) // n_cols
191 |
192 | fig, axs = plt.subplots(n_rows, n_cols, figsize=(n_cols * 10, n_rows * 10))
193 | axs = axs.flatten() if isinstance(axs, np.ndarray) else [axs]
194 |
195 | for i, tensor in enumerate(tensors):
196 | axs[i].imshow(tensor.cpu().numpy())
197 | if titles is not None:
198 | axs[i].set_title(titles[i])
199 | axs[i].axis("off")
200 |
201 | for ax in axs[len(tensors):]:
202 | ax.axis("off")
203 |
204 | plt.show()
205 |
206 | def draw_bboxes_on_image(image, bboxes, color="red", thickness=2):
207 | image = image.copy()
208 | draw = ImageDraw.Draw(image)
209 | for bbox in bboxes:
210 | draw.rectangle(bbox, outline=color, width=thickness)
211 | return image
212 |
213 | def draw_points_on_pil_image(pil_image, point_coords, point_color="red", radius=5):
214 | """
215 | Draw points (circles) on a PIL image and return the modified image.
216 |
217 | :param pil_image: PIL Image (e.g., sam_masked_image)
218 | :param point_coords: An array-like of shape (N, 2), with x,y coordinates
219 | :param point_color: Color of the point (default 'red')
220 | :param radius: Radius of the drawn circles
221 | :return: PIL Image with points drawn
222 | """
223 | # Copy so we don't modify the original
224 | out_img = pil_image.copy()
225 | draw = ImageDraw.Draw(out_img)
226 |
227 | # Draw each point
228 | for x, y in point_coords:
229 | # Calculate bounding box of the circle
230 | left_up_point = (x - radius, y - radius)
231 | right_down_point = (x + radius, y + radius)
232 | # Draw the circle
233 | draw.ellipse([left_up_point, right_down_point], fill=point_color, outline=point_color)
234 |
235 | return out_img
--------------------------------------------------------------------------------
/addit_blending_utils.py:
--------------------------------------------------------------------------------
1 | # Copyright (C) 2025 NVIDIA Corporation. All rights reserved.
2 | #
3 | # This work is licensed under the LICENSE file
4 | # located at the root directory.
5 |
6 | import torch
7 | import numpy as np
8 | import torch.nn.functional as F
9 | from skimage import filters
10 | import matplotlib.pyplot as plt
11 | from scipy.ndimage import maximum_filter, label, find_objects
12 |
13 | def dilate_mask(latents_mask, k, latents_dtype):
14 | # Reshape the mask to 2D (64x64)
15 | mask_2d = latents_mask.view(64, 64)
16 |
17 | # Create a square kernel for dilation
18 | kernel = torch.ones(2*k+1, 2*k+1, device=mask_2d.device, dtype=mask_2d.dtype)
19 |
20 | # Add two dimensions to make it compatible with conv2d
21 | mask_4d = mask_2d.unsqueeze(0).unsqueeze(0)
22 |
23 | # Perform dilation using conv2d
24 | dilated_mask = F.conv2d(mask_4d, kernel.unsqueeze(0).unsqueeze(0), padding=k)
25 |
26 | # Threshold the result to get a binary mask
27 | dilated_mask = (dilated_mask > 0).to(mask_2d.dtype)
28 |
29 | # Reshape back to the original shape and convert to the desired dtype
30 | dilated_mask = dilated_mask.view(4096, 1).to(latents_dtype)
31 |
32 | return dilated_mask
33 |
34 | def clipseg_predict(model, processor, image, text, device):
35 | inputs = processor(text=text, images=image, return_tensors="pt")
36 | inputs = {k: v.to(device) for k, v in inputs.items()}
37 |
38 | with torch.no_grad():
39 | outputs = model(**inputs)
40 | preds = outputs.logits.unsqueeze(1)
41 | preds = torch.sigmoid(preds)
42 |
43 | otsu_thr = filters.threshold_otsu(preds.cpu().numpy())
44 | subject_mask = (preds > otsu_thr).float()
45 |
46 | return subject_mask
47 |
48 | def grounding_sam_predict(model, processor, sam_predictor, image, text, device):
49 | inputs = processor(images=image, text=text, return_tensors="pt").to(device)
50 | with torch.no_grad():
51 | outputs = model(**inputs)
52 |
53 | results = processor.post_process_grounded_object_detection(
54 | outputs,
55 | inputs.input_ids,
56 | box_threshold=0.4,
57 | text_threshold=0.3,
58 | target_sizes=[image.size[::-1]]
59 | )
60 |
61 | input_boxes = results[0]["boxes"].cpu().numpy()
62 |
63 | if input_boxes.shape[0] == 0:
64 | return torch.ones((64, 64), device=device)
65 |
66 | with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
67 | sam_predictor.set_image(image)
68 | masks, scores, logits = sam_predictor.predict(
69 | point_coords=None,
70 | point_labels=None,
71 | box=input_boxes,
72 | multimask_output=False,
73 | )
74 |
75 | subject_mask = torch.tensor(masks[0], device=device)
76 |
77 | return subject_mask
78 |
79 | def mask_to_box_sam_predict(mask, sam_predictor, image, text, device):
80 | H, W = image.size
81 |
82 | # Resize clipseg mask to image size
83 | mask = F.interpolate(mask.view(1, 1, mask.shape[-2], mask.shape[-1]), size=(H, W), mode='bilinear').view(H, W)
84 | mask_indices = torch.nonzero(mask)
85 | top_left = mask_indices.min(dim=0)[0]
86 | bottom_right = mask_indices.max(dim=0)[0]
87 |
88 | # numpy shape [1,4]
89 | input_boxes = np.array([[top_left[1].item(), top_left[0].item(), bottom_right[1].item(), bottom_right[0].item()]])
90 |
91 | with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
92 | sam_predictor.set_image(image)
93 | masks, scores, logits = sam_predictor.predict(
94 | point_coords=None,
95 | point_labels=None,
96 | box=input_boxes,
97 | multimask_output=True,
98 | )
99 |
100 | # subject_mask = torch.tensor(masks[0], device=device)
101 | subject_mask = torch.tensor(np.max(masks, axis=0), device=device)
102 |
103 | return subject_mask, input_boxes[0]
104 |
105 | def mask_to_mask_sam_predict(mask, sam_predictor, image, text, device):
106 | H, W = (256, 256)
107 |
108 | # Resize clipseg mask to image size
109 | mask = F.interpolate(mask.view(1, 1, mask.shape[-2], mask.shape[-1]), size=(H, W), mode='bilinear').view(1, H, W)
110 | mask_input = mask.float().cpu().numpy()
111 |
112 | with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
113 | sam_predictor.set_image(image)
114 | masks, scores, logits = sam_predictor.predict(
115 | point_coords=None,
116 | point_labels=None,
117 | mask_input=mask_input,
118 | multimask_output=False,
119 | )
120 |
121 | subject_mask = torch.tensor(masks[0], device=device)
122 |
123 | return subject_mask
124 |
125 | def mask_to_points_sam_predict(mask, sam_predictor, image, text, device):
126 | H, W = image.size
127 |
128 | # Resize clipseg mask to image size
129 | mask = F.interpolate(mask.view(1, 1, mask.shape[-2], mask.shape[-1]), size=(H, W), mode='bilinear').view(H, W)
130 | mask_indices = torch.nonzero(mask)
131 |
132 | # Randomly sample 10 points from the mask
133 | n_points = 2
134 | point_coords = mask_indices[torch.randperm(mask_indices.shape[0])[:n_points]].float().cpu().numpy()
135 | point_labels = torch.ones((n_points,)).float().cpu().numpy()
136 |
137 | with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
138 | sam_predictor.set_image(image)
139 | masks, scores, logits = sam_predictor.predict(
140 | point_coords=point_coords,
141 | point_labels=point_labels,
142 | multimask_output=False,
143 | )
144 |
145 | subject_mask = torch.tensor(masks[0], device=device)
146 |
147 | return subject_mask
148 |
149 | def attention_to_points_sam_predict(subject_attention, subject_mask, sam_predictor, image, text, device):
150 | H, W = image.size
151 |
152 | # Resize clipseg mask to image size
153 | subject_attention = F.interpolate(subject_attention.view(1, 1, subject_attention.shape[-2], subject_attention.shape[-1]), size=(H, W), mode='bilinear').view(H, W)
154 | subject_mask = F.interpolate(subject_mask.view(1, 1, subject_mask.shape[-2], subject_mask.shape[-1]), size=(H, W), mode='bilinear').view(H, W)
155 |
156 | # Get mask_bbox
157 | subject_mask_indices = torch.nonzero(subject_mask)
158 | top_left = subject_mask_indices.min(dim=0)[0]
159 | bottom_right = subject_mask_indices.max(dim=0)[0]
160 | box_width = bottom_right[1] - top_left[1]
161 | box_height = bottom_right[0] - top_left[0]
162 |
163 | # Define the number of points and minimum distance between points
164 | n_points = 3
165 | max_thr = 0.35
166 | max_attention = torch.max(subject_attention)
167 | min_distance = max(box_width, box_height) // (n_points + 1) # Adjust this value to control spread
168 | # min_distance = max(min_distance, 75)
169 |
170 | # Initialize list to store selected points
171 | selected_points = []
172 |
173 | # Create a copy of the attention map
174 | remaining_attention = subject_attention.clone()
175 |
176 | for _ in range(n_points):
177 | if remaining_attention.max() < max_thr * max_attention:
178 | break
179 |
180 | # Find the highest attention point
181 | point = torch.argmax(remaining_attention)
182 | y, x = torch.unravel_index(point, remaining_attention.shape)
183 | y, x = y.item(), x.item()
184 |
185 | # Add the point to our list
186 | selected_points.append((x, y))
187 |
188 | # Zero out the area around the selected point
189 | y_min = max(0, y - min_distance)
190 | y_max = min(H, y + min_distance + 1)
191 | x_min = max(0, x - min_distance)
192 | x_max = min(W, x + min_distance + 1)
193 | remaining_attention[y_min:y_max, x_min:x_max] = 0
194 |
195 | # Convert selected points to numpy array
196 | point_coords = np.array(selected_points)
197 | point_labels = np.ones(point_coords.shape[0], dtype=int)
198 |
199 | with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
200 | sam_predictor.set_image(image)
201 | masks, scores, logits = sam_predictor.predict(
202 | point_coords=point_coords,
203 | point_labels=point_labels,
204 | multimask_output=False,
205 | )
206 |
207 | subject_mask = torch.tensor(masks[0], device=device)
208 |
209 | return subject_mask, point_coords
210 |
211 | def sam_refine_step(mask, sam_predictor, image, device):
212 | mask_indices = torch.nonzero(mask)
213 | top_left = mask_indices.min(dim=0)[0]
214 | bottom_right = mask_indices.max(dim=0)[0]
215 |
216 | # numpy shape [1,4]
217 | input_boxes = np.array([[top_left[1].item(), top_left[0].item(), bottom_right[1].item(), bottom_right[0].item()]])
218 |
219 | with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
220 | sam_predictor.set_image(image)
221 | masks, scores, logits = sam_predictor.predict(
222 | point_coords=None,
223 | point_labels=None,
224 | box=input_boxes,
225 | multimask_output=True,
226 | )
227 |
228 | # subject_mask = torch.tensor(masks[0], device=device)
229 | subject_mask = torch.tensor(np.max(masks, axis=0), device=device)
230 |
231 | return subject_mask, input_boxes[0]
232 |
233 |
--------------------------------------------------------------------------------
/addit_attention_processors.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 The HuggingFace Team. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | #
15 | # Copyright (C) 2025 NVIDIA Corporation. All rights reserved.
16 | #
17 | # This work is licensed under the LICENSE file
18 | # located at the root directory.
19 |
20 | from collections import defaultdict
21 | from diffusers.models.attention_processor import Attention, apply_rope
22 | from typing import Callable, List, Optional, Tuple, Union
23 |
24 | from addit_attention_store import AttentionStore
25 | from visualization_utils import show_tensors
26 |
27 | import torch
28 | import torch.nn.functional as F
29 | import numpy as np
30 | from scipy.optimize import brentq
31 |
32 | def apply_standard_attention(query, key, value, attn, attention_probs=None):
33 | batch_size, attn_heads, _, head_dim = query.shape
34 |
35 | # Do normal attention, to cache the attention scores
36 | query = query.reshape(batch_size*attn_heads, -1, head_dim)
37 | key = key.reshape(batch_size*attn_heads, -1, head_dim)
38 | value = value.reshape(batch_size*attn_heads, -1, head_dim)
39 |
40 | if attention_probs is None:
41 | attention_probs = attn.get_attention_scores(query, key)
42 |
43 | hidden_states = torch.bmm(attention_probs, value)
44 | hidden_states = hidden_states.view(batch_size, attn_heads, -1, head_dim)
45 |
46 | return hidden_states, attention_probs
47 |
48 | def apply_extended_attention(query, key, value, attention_store, attn, layer_name, step_index, extend_type="pixels",
49 | extended_scale=1., record_attention=False):
50 | batch_size = query.size(0)
51 | extend_query = query[1:]
52 |
53 | if extend_type == "full":
54 | added_key = key[0] * extended_scale
55 | added_value = value[0]
56 | elif extend_type == "text":
57 | added_key = key[0, :, :512] * extended_scale
58 | added_value = value[0, :, :512]
59 | elif extend_type == "pixels":
60 | added_key = key[0, :, 512:]
61 | added_value = value[0, :, 512:]
62 |
63 | key[1] = key[1] * extended_scale
64 |
65 | extend_key = torch.cat([added_key, key[1]], dim=1).unsqueeze(0)
66 | extend_value = torch.cat([added_value, value[1]], dim=1).unsqueeze(0)
67 |
68 | hidden_states_0 = F.scaled_dot_product_attention(query[:1], key[:1], value[:1], dropout_p=0.0, is_causal=False)
69 |
70 | if record_attention or attention_store.is_cache_attn_ratio(step_index):
71 | hidden_states_1, attention_probs_1 = apply_standard_attention(extend_query, extend_key, extend_value, attn)
72 | else:
73 | hidden_states_1 = F.scaled_dot_product_attention(extend_query, extend_key, extend_value, dropout_p=0.0, is_causal=False)
74 |
75 | if record_attention:
76 | # Store Attention
77 | seq_len = attention_probs_1.size(2) - attention_probs_1.size(1)
78 | self_attention_probs_1 = attention_probs_1[:,:,seq_len:]
79 | attention_store.store_attention(self_attention_probs_1, layer_name, 1, attn.heads)
80 |
81 | if attention_store.is_cache_attn_ratio(step_index):
82 | attention_store.store_attention_ratios(attention_probs_1, step_index, layer_name)
83 |
84 | hidden_states = torch.cat([hidden_states_0, hidden_states_1], dim=0)
85 |
86 | return hidden_states
87 |
88 | def apply_attention(query, key, value, attention_store, attn, layer_name, step_index,
89 | record_attention, extended_attention, extended_scale):
90 | if extended_attention:
91 | hidden_states = apply_extended_attention(query, key, value, attention_store, attn, layer_name, step_index,
92 | extended_scale=extended_scale,
93 | record_attention=record_attention)
94 | else:
95 | if record_attention:
96 | hidden_states_0 = F.scaled_dot_product_attention(query[:1], key[:1], value[:1], dropout_p=0.0, is_causal=False)
97 | hidden_states_1, attention_probs_1 = apply_standard_attention(query[1:], key[1:], value[1:], attn)
98 | attention_store.store_attention(attention_probs_1, layer_name, 1, attn.heads)
99 |
100 | hidden_states = torch.cat([hidden_states_0, hidden_states_1], dim=0)
101 | else:
102 | hidden_states = F.scaled_dot_product_attention(query, key, value, dropout_p=0.0, is_causal=False)
103 |
104 | return hidden_states
105 |
106 | class AdditFluxAttnProcessor2_0:
107 | """Attention processor used typically in processing the SD3-like self-attention projections."""
108 |
109 | def __init__(self, layer_name: str, attention_store: AttentionStore,
110 | extended_steps: Tuple[int, int] = (0, 30), **kwargs):
111 | if not hasattr(F, "scaled_dot_product_attention"):
112 | raise ImportError("FluxAttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
113 |
114 | self.layer_name = layer_name
115 | self.layer_idx = int(layer_name.split(".")[-1])
116 | self.attention_store = attention_store
117 |
118 | self.extended_steps = (0, extended_steps) if isinstance(extended_steps, int) else extended_steps
119 |
120 | def __call__(
121 | self,
122 | attn: Attention,
123 | hidden_states: torch.FloatTensor,
124 | encoder_hidden_states: torch.FloatTensor = None,
125 | attention_mask: Optional[torch.FloatTensor] = None,
126 | image_rotary_emb: Optional[torch.Tensor] = None,
127 |
128 | step_index: Optional[int] = None,
129 | extended_scale: Optional[float] = 1.0,
130 | ) -> torch.FloatTensor:
131 | input_ndim = hidden_states.ndim
132 | if input_ndim == 4:
133 | batch_size, channel, height, width = hidden_states.shape
134 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
135 | context_input_ndim = encoder_hidden_states.ndim
136 | if context_input_ndim == 4:
137 | batch_size, channel, height, width = encoder_hidden_states.shape
138 | encoder_hidden_states = encoder_hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
139 |
140 | batch_size = encoder_hidden_states.shape[0]
141 |
142 | # `sample` projections.
143 | query = attn.to_q(hidden_states)
144 | key = attn.to_k(hidden_states)
145 | value = attn.to_v(hidden_states)
146 |
147 | inner_dim = key.shape[-1]
148 | head_dim = inner_dim // attn.heads
149 |
150 | query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
151 | key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
152 | value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
153 |
154 | if attn.norm_q is not None:
155 | query = attn.norm_q(query)
156 | if attn.norm_k is not None:
157 | key = attn.norm_k(key)
158 |
159 | # `context` projections.
160 | encoder_hidden_states_query_proj = attn.add_q_proj(encoder_hidden_states)
161 | encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
162 | encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
163 |
164 | encoder_hidden_states_query_proj = encoder_hidden_states_query_proj.view(
165 | batch_size, -1, attn.heads, head_dim
166 | ).transpose(1, 2)
167 | encoder_hidden_states_key_proj = encoder_hidden_states_key_proj.view(
168 | batch_size, -1, attn.heads, head_dim
169 | ).transpose(1, 2)
170 | encoder_hidden_states_value_proj = encoder_hidden_states_value_proj.view(
171 | batch_size, -1, attn.heads, head_dim
172 | ).transpose(1, 2)
173 |
174 | if attn.norm_added_q is not None:
175 | encoder_hidden_states_query_proj = attn.norm_added_q(encoder_hidden_states_query_proj)
176 | if attn.norm_added_k is not None:
177 | encoder_hidden_states_key_proj = attn.norm_added_k(encoder_hidden_states_key_proj)
178 |
179 | # attention
180 | query = torch.cat([encoder_hidden_states_query_proj, query], dim=2)
181 | key = torch.cat([encoder_hidden_states_key_proj, key], dim=2)
182 | value = torch.cat([encoder_hidden_states_value_proj, value], dim=2)
183 |
184 | if image_rotary_emb is not None:
185 | # YiYi to-do: update uising apply_rotary_emb
186 | # from ..embeddings import apply_rotary_emb
187 | # query = apply_rotary_emb(query, image_rotary_emb)
188 | # key = apply_rotary_emb(key, image_rotary_emb)
189 | query, key = apply_rope(query, key, image_rotary_emb)
190 |
191 | record_attention = self.attention_store.is_record_attention(self.layer_name, step_index)
192 | extend_start, extend_end = self.extended_steps
193 | extended_attention = extend_start <= step_index <= extend_end
194 |
195 | hidden_states = apply_attention(query, key, value, self.attention_store, attn, self.layer_name, step_index,
196 | record_attention, extended_attention, extended_scale)
197 |
198 | hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
199 | hidden_states = hidden_states.to(query.dtype)
200 |
201 | encoder_hidden_states, hidden_states = (
202 | hidden_states[:, : encoder_hidden_states.shape[1]],
203 | hidden_states[:, encoder_hidden_states.shape[1] :],
204 | )
205 |
206 | # linear proj
207 | hidden_states = attn.to_out[0](hidden_states)
208 | # dropout
209 | hidden_states = attn.to_out[1](hidden_states)
210 | encoder_hidden_states = attn.to_add_out(encoder_hidden_states)
211 |
212 | if input_ndim == 4:
213 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
214 | if context_input_ndim == 4:
215 | encoder_hidden_states = encoder_hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
216 |
217 | return hidden_states, encoder_hidden_states
218 |
219 | class AdditFluxSingleAttnProcessor2_0:
220 | r"""
221 | Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
222 | """
223 |
224 | def __init__(self, layer_name: str, attention_store: AttentionStore,
225 | extended_steps: Tuple[int, int] = (0, 30), **kwargs):
226 | if not hasattr(F, "scaled_dot_product_attention"):
227 | raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
228 |
229 | self.layer_name = layer_name
230 | self.layer_idx = int(layer_name.split(".")[-1])
231 | self.attention_store = attention_store
232 |
233 | self.extended_steps = (0, extended_steps) if isinstance(extended_steps, int) else extended_steps
234 |
235 | def __call__(
236 | self,
237 | attn: Attention,
238 | hidden_states: torch.Tensor,
239 | encoder_hidden_states: Optional[torch.Tensor] = None,
240 | attention_mask: Optional[torch.FloatTensor] = None,
241 | image_rotary_emb: Optional[torch.Tensor] = None,
242 | step_index: Optional[int] = None,
243 | extended_scale: Optional[float] = 1.0,
244 | ) -> torch.Tensor:
245 | input_ndim = hidden_states.ndim
246 |
247 | if input_ndim == 4:
248 | batch_size, channel, height, width = hidden_states.shape
249 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
250 |
251 | batch_size, _, _ = hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
252 |
253 | query = attn.to_q(hidden_states)
254 | if encoder_hidden_states is None:
255 | encoder_hidden_states = hidden_states
256 |
257 | key = attn.to_k(encoder_hidden_states)
258 | value = attn.to_v(encoder_hidden_states)
259 |
260 | inner_dim = key.shape[-1]
261 | head_dim = inner_dim // attn.heads
262 |
263 | query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
264 |
265 | key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
266 | value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
267 |
268 | if attn.norm_q is not None:
269 | query = attn.norm_q(query)
270 | if attn.norm_k is not None:
271 | key = attn.norm_k(key)
272 |
273 | # Apply RoPE if needed
274 | if image_rotary_emb is not None:
275 | # YiYi to-do: update uising apply_rotary_emb
276 | # from ..embeddings import apply_rotary_emb
277 | # query = apply_rotary_emb(query, image_rotary_emb)
278 | # key = apply_rotary_emb(key, image_rotary_emb)
279 | query, key = apply_rope(query, key, image_rotary_emb)
280 |
281 | # the output of sdp = (batch, num_heads, seq_len, head_dim)
282 | # TODO: add support for attn.scale when we move to Torch 2.1
283 |
284 | record_attention = self.attention_store.is_record_attention(self.layer_name, step_index)
285 | extend_start, extend_end = self.extended_steps
286 | extended_attention = extend_start <= step_index <= extend_end
287 |
288 | hidden_states = apply_attention(query, key, value, self.attention_store, attn, self.layer_name, step_index,
289 | record_attention, extended_attention, extended_scale)
290 |
291 | hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
292 | hidden_states = hidden_states.to(query.dtype)
293 |
294 | if input_ndim == 4:
295 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
296 |
297 | return hidden_states
--------------------------------------------------------------------------------
/addit_attention_store.py:
--------------------------------------------------------------------------------
1 | # Copyright (C) 2025 NVIDIA Corporation. All rights reserved.
2 | #
3 | # This work is licensed under the LICENSE file
4 | # located at the root directory.
5 |
6 | import torch
7 | from skimage import filters
8 | import cv2
9 | import torch.nn.functional as F
10 | from skimage.filters import threshold_li, threshold_yen, threshold_multiotsu
11 | import numpy as np
12 | from visualization_utils import show_tensors
13 | import matplotlib.pyplot as plt
14 |
15 | def text_to_tokens(text, tokenizer):
16 | return [tokenizer.decode(x) for x in tokenizer(text, padding="longest", return_tensors="pt").input_ids[0]]
17 |
18 | def flatten_list(l):
19 | return [item for sublist in l for item in sublist]
20 |
21 | def gaussian_blur(heatmap, kernel_size=7, sigma=0):
22 | # Shape of heatmap: (H, W)
23 | heatmap = heatmap.cpu().numpy()
24 | heatmap = cv2.GaussianBlur(heatmap, (kernel_size, kernel_size), sigma)
25 | heatmap = torch.tensor(heatmap)
26 |
27 | return heatmap
28 |
29 | def min_max_norm(x):
30 | return (x - x.min()) / (x.max() - x.min())
31 |
32 | class AttentionStore:
33 | def __init__(self, prompts, tokenizer,
34 | subject_token=None, record_attention_steps=[],
35 | is_cache_attn_ratio=False, attn_ratios_steps=[5]):
36 |
37 | self.text2image_store = {}
38 | self.image2text_store = {}
39 | self.count_per_layer = {}
40 |
41 | self.record_attention_steps = record_attention_steps
42 | self.record_attention_layers = ["transformer_blocks.13","transformer_blocks.14", "transformer_blocks.18", "single_transformer_blocks.23", "single_transformer_blocks.33"]
43 |
44 | self.attention_ratios = {}
45 | self._is_cache_attn_ratio = is_cache_attn_ratio
46 | self.attn_ratios_steps = attn_ratios_steps
47 | self.ratio_source = 'text'
48 |
49 | self.max_tokens_to_record = 10
50 |
51 | if isinstance(prompts, str):
52 | prompts = [prompts]
53 | batch_size = 1
54 | else:
55 | batch_size = len(prompts)
56 |
57 | tokens_per_prompt = []
58 |
59 | for prompt in prompts:
60 | tokens = text_to_tokens(prompt, tokenizer)
61 | tokens_per_prompt.append(tokens)
62 |
63 | self.tokens_to_record = []
64 | self.token_idxs_to_record = []
65 |
66 | if len(record_attention_steps) > 0:
67 | self.subject_tokens = flatten_list([text_to_tokens(x, tokenizer)[:-1] for x in [subject_token]])
68 | self.subject_tokens_idx = [tokens_per_prompt[1].index(x) for x in self.subject_tokens]
69 | self.add_token_idx = self.subject_tokens_idx[-1]
70 |
71 | def is_record_attention(self, layer_name, step_index):
72 | is_correct_layer = (self.record_attention_layers is None) or (layer_name in self.record_attention_layers)
73 |
74 | record_attention = (step_index in self.record_attention_steps) and (is_correct_layer)
75 |
76 | return record_attention
77 |
78 | def store_attention(self, attention_probs, layer_name, batch_size, num_heads):
79 | text_len = 512
80 | timesteps = len(self.record_attention_steps)
81 |
82 | # Split batch and heads
83 | attention_probs = attention_probs.view(batch_size, num_heads, *attention_probs.shape[1:])
84 |
85 | # Mean over the heads
86 | attention_probs = attention_probs.mean(dim=1)
87 |
88 | # Attention: text -> image
89 | attention_probs_text2image = attention_probs[:, :text_len, text_len:]
90 | attention_probs_text2image = [attention_probs_text2image[0, self.subject_tokens_idx, :]]
91 |
92 | # Attention: image -> text
93 | attention_probs_image2text = attention_probs[:, text_len:, :text_len].transpose(1,2)
94 | attention_probs_image2text = [attention_probs_image2text[0, self.subject_tokens_idx, :]]
95 |
96 | if layer_name not in self.text2image_store:
97 | self.text2image_store[layer_name] = [x for x in attention_probs_text2image]
98 | self.image2text_store[layer_name] = [x for x in attention_probs_image2text]
99 | else:
100 | self.text2image_store[layer_name] = [self.text2image_store[layer_name][i] + x for i, x in enumerate(attention_probs_text2image)]
101 | self.image2text_store[layer_name] = [self.text2image_store[layer_name][i] + x for i, x in enumerate(attention_probs_image2text)]
102 |
103 | def is_cache_attn_ratio(self, step_index):
104 | return (self._is_cache_attn_ratio) and (step_index in self.attn_ratios_steps)
105 |
106 | def store_attention_ratios(self, attention_probs, step_index, layer_name):
107 | layer_prefix = layer_name.split(".")[0]
108 |
109 | if self.ratio_source == 'pixels':
110 | extended_attention_probs = attention_probs.mean(dim=0)[512:, :]
111 | extended_attention_probs_source = extended_attention_probs[:,:4096].sum(dim=1).view(64,64).float().cpu()
112 | extended_attention_probs_text = extended_attention_probs[:,4096:4096+512].sum(dim=1).view(64,64).float().cpu()
113 | extended_attention_probs_target = extended_attention_probs[:,4096+512:].sum(dim=1).view(64,64).float().cpu()
114 | token_attention = extended_attention_probs[:,4096+self.add_token_idx].view(64,64).float().cpu()
115 |
116 | stacked_attention_ratios = torch.cat([extended_attention_probs_source, extended_attention_probs_text, extended_attention_probs_target, token_attention], dim=1)
117 | elif self.ratio_source == 'text':
118 | extended_attention_probs = attention_probs.mean(dim=0)[:512, :]
119 | extended_attention_probs_source = extended_attention_probs[:,:4096].sum(dim=0).view(64,64).float().cpu()
120 | extended_attention_probs_target = extended_attention_probs[:,4096+512:].sum(dim=0).view(64,64).float().cpu()
121 |
122 | stacked_attention_ratios = torch.cat([extended_attention_probs_source, extended_attention_probs_target], dim=1)
123 |
124 | if step_index not in self.attention_ratios:
125 | self.attention_ratios[step_index] = {}
126 |
127 | if layer_prefix not in self.attention_ratios[step_index]:
128 | self.attention_ratios[step_index][layer_prefix] = []
129 |
130 | self.attention_ratios[step_index][layer_prefix].append(stacked_attention_ratios)
131 |
132 | def get_attention_ratios(self, step_indices=None, display_imgs=False):
133 | ratios = []
134 |
135 | if step_indices is None:
136 | step_indices = list(self.attention_ratios.keys())
137 |
138 | if len(step_indices) == 1:
139 | steps = f"Step: {step_indices[0]}"
140 | else:
141 | steps = f"Steps: [{step_indices[0]}-{step_indices[-1]}]"
142 |
143 | layer_prefixes = list(self.attention_ratios[step_indices[0]].keys())
144 | scores_per_layer = {}
145 |
146 | for layer_prefix in layer_prefixes:
147 | ratios = []
148 |
149 | for step_index in step_indices:
150 | if layer_prefix in self.attention_ratios[step_index]:
151 | step_ratios = self.attention_ratios[step_index][layer_prefix]
152 | step_ratios = torch.stack(step_ratios).mean(dim=0)
153 | ratios.append(step_ratios)
154 |
155 | # Mean over the steps
156 | ratios = torch.stack(ratios).mean(dim=0)
157 |
158 | if self.ratio_source == 'pixels':
159 | source, text, target, token = torch.split(ratios, 64, dim=1)
160 | title = f"{steps}: Source={source.sum().item():.2f}, Text={text.sum().item():.2f}, Target={target.sum().item():.2f}, Token={token.sum().item():.2f}"
161 | ratios = min_max_norm(torch.cat([source, text, target], dim=1))
162 | token = min_max_norm(token)
163 | ratios = torch.cat([ratios, token], dim=1)
164 | elif self.ratio_source == 'text':
165 | source, target = torch.split(ratios, 64, dim=1)
166 | source_sum = source.sum().item()
167 | target_sum = target.sum().item()
168 | text_sum = 512 - (source_sum + target_sum)
169 |
170 | title = f"{steps}: Source={source_sum:.2f}, Target={target_sum:.2f}"
171 | ratios = min_max_norm(torch.cat([source, target], dim=1))
172 |
173 | if display_imgs:
174 | print(f"Layer: {layer_prefix}")
175 | show_tensors([ratios], [title])
176 |
177 | scores_per_layer[layer_prefix] = (source_sum, text_sum, target_sum)
178 |
179 | return scores_per_layer
180 |
181 | def plot_attention_ratios(self, step_indices=None):
182 | steps = list(self.attention_ratios.keys())
183 | score_per_layer = {
184 | 'transformer_blocks': {},
185 | 'single_transformer_blocks': {}
186 | }
187 |
188 | for i in steps:
189 | scores_per_layer = self.get_attention_ratios(step_indices=[i], display_imgs=False)
190 |
191 | for layer in self.attention_ratios[i]:
192 | source, text, target = scores_per_layer[layer]
193 | score_per_layer[layer][i] = (source, text, target)
194 |
195 | for layer_type in score_per_layer:
196 | x = list(score_per_layer[layer_type].keys())
197 | source_sums = [x[0] for x in score_per_layer[layer_type].values()]
198 | text_sums = [x[1] for x in score_per_layer[layer_type].values()]
199 | target_sums = [x[2] for x in score_per_layer[layer_type].values()]
200 |
201 | # Calculate the total sums for each stack (source + text + target)
202 | total_sums = [source_sums[j] + text_sums[j] + target_sums[j] for j in range(len(source_sums))]
203 |
204 | # Create stacked bar plots
205 | fig, ax = plt.subplots(figsize=(10, 6))
206 | indices = np.arange(len(x))
207 |
208 | # Plot source at the bottom
209 | ax.bar(indices, source_sums, label='Source', color='#6A2C70')
210 |
211 | # Plot text stacked on source
212 | ax.bar(indices, text_sums, label='Text', color='#B83B5E', bottom=source_sums)
213 |
214 | # Plot target stacked on text + source
215 | target_bottom = [source_sums[j] + text_sums[j] for j in range(len(source_sums))]
216 | ax.bar(indices, target_sums, label='Target', color='#F08A5D', bottom=target_bottom)
217 |
218 | # Annotate bars with percentage values
219 | for j, index in enumerate(indices):
220 |
221 | font_size = 12
222 |
223 | # Source percentage
224 | source_percentage = 100 * source_sums[j] / total_sums[j]
225 | ax.text(index, source_sums[j] / 2, f'{source_percentage:.1f}%',
226 | ha='center', va='center', rotation=90, color='white',
227 | fontsize=font_size, fontweight='bold')
228 |
229 | # Text percentage
230 | text_percentage = 100 * text_sums[j] / total_sums[j]
231 | ax.text(index, source_sums[j] + (text_sums[j] / 2), f'{text_percentage:.1f}%',
232 | ha='center', va='center', rotation=90, color='white',
233 | fontsize=font_size, fontweight='bold')
234 |
235 | # Target percentage
236 | target_percentage = 100 * target_sums[j] / total_sums[j]
237 | ax.text(index, source_sums[j] + text_sums[j] + (target_sums[j] / 2), f'{target_percentage:.1f}%',
238 | ha='center', va='center', rotation=90, color='white',
239 | fontsize=font_size, fontweight='bold')
240 |
241 |
242 | ax.set_xlabel('Step Index')
243 | ax.set_ylabel('Attention Ratio')
244 | ax.set_title(f'Attention Ratios for {layer_type}')
245 | ax.set_xticks(indices)
246 | ax.set_xticklabels(x)
247 |
248 | plt.legend()
249 | plt.show()
250 |
251 | def aggregate_attention(self, store, target_layers=None, resolution=None,
252 | gaussian_kernel=3, thr_type='otsu', thr_number=0.5):
253 | if target_layers is None:
254 | store_vals = list(store.values())
255 | elif isinstance(target_layers, list):
256 | store_vals = [store[x] for x in target_layers]
257 | else:
258 | raise ValueError("target_layers must be a list of layer names or None.")
259 |
260 | # store vals = List[layers] of Tensor[batch_size, text_tokens, image_tokens]
261 | batch_size = len(store_vals[0])
262 |
263 | attention_maps = []
264 | attention_masks = []
265 |
266 | for i in range(batch_size):
267 | # Average over the layers
268 | agg_vals = torch.stack([x[i] for x in store_vals]).mean(dim=0)
269 |
270 | if resolution is None:
271 | size = int(agg_vals.shape[-1] ** 0.5)
272 | resolution = (size, size)
273 |
274 | agg_vals = agg_vals.view(agg_vals.shape[0], *resolution)
275 |
276 | if gaussian_kernel > 0:
277 | agg_vals = torch.stack([gaussian_blur(x.float(), kernel_size=gaussian_kernel) for x in agg_vals]).to(agg_vals.dtype)
278 |
279 | mask_vals = agg_vals.clone()
280 |
281 | for j in range(mask_vals.shape[0]):
282 | mask_vals[j] = (mask_vals[j] - mask_vals[j].min()) / (mask_vals[j].max() - mask_vals[j].min())
283 | np_vals = mask_vals[j].float().cpu().numpy()
284 |
285 | otsu_thr = filters.threshold_otsu(np_vals)
286 | li_thr = threshold_li(np_vals, initial_guess=otsu_thr)
287 | yen_thr = threshold_yen(np_vals)
288 |
289 | if thr_type == 'otsu':
290 | thr = otsu_thr
291 | elif thr_type == 'yen':
292 | thr = yen_thr
293 | elif thr_type == 'li':
294 | thr = li_thr
295 | elif thr_type == 'number':
296 | thr = thr_number
297 | elif thr_type == 'multiotsu':
298 | thrs = threshold_multiotsu(np_vals, classes=3)
299 |
300 | if thrs[1] > thrs[0] * 3.5:
301 | thr = thrs[1]
302 | else:
303 | thr = thrs[0]
304 |
305 | # Take the closest threshold to otsu_thr
306 | # thr = thrs[np.argmin(np.abs(thrs - otsu_thr))]
307 |
308 | # alpha = 0.8
309 | # thr = (alpha * thr + (1-alpha) * mask_vals[j].max())
310 |
311 | mask_vals[j] = (mask_vals[j] > thr).to(mask_vals[j].dtype)
312 |
313 | attention_maps.append(agg_vals)
314 | attention_masks.append(mask_vals)
315 |
316 | return attention_maps, attention_masks, self.tokens_to_record
317 |
--------------------------------------------------------------------------------
/addit_flux_transformer.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 Black Forest Labs, The HuggingFace Team. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | from typing import Any, Dict, List, Optional, Union
16 |
17 | import torch
18 | import torch.nn as nn
19 | import torch.nn.functional as F
20 |
21 | from diffusers.configuration_utils import ConfigMixin, register_to_config
22 | from diffusers.loaders import FromOriginalModelMixin, PeftAdapterMixin
23 | from diffusers.models.attention import FeedForward
24 | from diffusers.models.attention_processor import Attention, FluxAttnProcessor2_0, FluxSingleAttnProcessor2_0
25 | from diffusers.models.modeling_utils import ModelMixin
26 | from diffusers.models.normalization import AdaLayerNormContinuous, AdaLayerNormZero, AdaLayerNormZeroSingle
27 | from diffusers.utils import USE_PEFT_BACKEND, is_torch_version, logging, scale_lora_layers, unscale_lora_layers
28 | from diffusers.utils.torch_utils import maybe_allow_in_graph
29 | from diffusers.models.embeddings import CombinedTimestepGuidanceTextProjEmbeddings, CombinedTimestepTextProjEmbeddings
30 | from diffusers.models.modeling_outputs import Transformer2DModelOutput
31 |
32 | from addit_attention_processors import AdditFluxAttnProcessor2_0, AdditFluxSingleAttnProcessor2_0
33 |
34 | logger = logging.get_logger(__name__) # pylint: disable=invalid-name
35 |
36 |
37 | # YiYi to-do: refactor rope related functions/classes
38 | def rope(pos: torch.Tensor, dim: int, theta: int) -> torch.Tensor:
39 | assert dim % 2 == 0, "The dimension must be even."
40 |
41 | scale = torch.arange(0, dim, 2, dtype=torch.float64, device=pos.device) / dim
42 | omega = 1.0 / (theta**scale)
43 |
44 | batch_size, seq_length = pos.shape
45 | out = torch.einsum("...n,d->...nd", pos, omega)
46 | cos_out = torch.cos(out)
47 | sin_out = torch.sin(out)
48 |
49 | stacked_out = torch.stack([cos_out, -sin_out, sin_out, cos_out], dim=-1)
50 | out = stacked_out.view(batch_size, -1, dim // 2, 2, 2)
51 | return out.float()
52 |
53 |
54 | # YiYi to-do: refactor rope related functions/classes
55 | class EmbedND(nn.Module):
56 | def __init__(self, dim: int, theta: int, axes_dim: List[int]):
57 | super().__init__()
58 | self.dim = dim
59 | self.theta = theta
60 | self.axes_dim = axes_dim
61 |
62 | def forward(self, ids: torch.Tensor) -> torch.Tensor:
63 | n_axes = ids.shape[-1]
64 | emb = torch.cat(
65 | [rope(ids[..., i], self.axes_dim[i], self.theta) for i in range(n_axes)],
66 | dim=-3,
67 | )
68 | return emb.unsqueeze(1)
69 |
70 |
71 | @maybe_allow_in_graph
72 | class AdditFluxSingleTransformerBlock(nn.Module):
73 | r"""
74 | A Transformer block following the MMDiT architecture, introduced in Stable Diffusion 3.
75 |
76 | Reference: https://arxiv.org/abs/2403.03206
77 |
78 | Parameters:
79 | dim (`int`): The number of channels in the input and output.
80 | num_attention_heads (`int`): The number of heads to use for multi-head attention.
81 | attention_head_dim (`int`): The number of channels in each head.
82 | context_pre_only (`bool`): Boolean to determine if we should add some blocks associated with the
83 | processing of `context` conditions.
84 | """
85 |
86 | def __init__(self, dim, num_attention_heads, attention_head_dim, mlp_ratio=4.0):
87 | super().__init__()
88 | self.mlp_hidden_dim = int(dim * mlp_ratio)
89 |
90 | self.norm = AdaLayerNormZeroSingle(dim)
91 | self.proj_mlp = nn.Linear(dim, self.mlp_hidden_dim)
92 | self.act_mlp = nn.GELU(approximate="tanh")
93 | self.proj_out = nn.Linear(dim + self.mlp_hidden_dim, dim)
94 |
95 | processor = FluxSingleAttnProcessor2_0()
96 | self.attn = Attention(
97 | query_dim=dim,
98 | cross_attention_dim=None,
99 | dim_head=attention_head_dim,
100 | heads=num_attention_heads,
101 | out_dim=dim,
102 | bias=True,
103 | processor=processor,
104 | qk_norm="rms_norm",
105 | eps=1e-6,
106 | pre_only=True,
107 | )
108 |
109 | def forward(
110 | self,
111 | hidden_states: torch.FloatTensor,
112 | temb: torch.FloatTensor,
113 | image_rotary_emb=None,
114 | proccesor_kwargs=None,
115 | ):
116 | residual = hidden_states
117 | norm_hidden_states, gate = self.norm(hidden_states, emb=temb)
118 | mlp_hidden_states = self.act_mlp(self.proj_mlp(norm_hidden_states))
119 |
120 | attn_output = self.attn(
121 | hidden_states=norm_hidden_states,
122 | image_rotary_emb=image_rotary_emb,
123 | **(proccesor_kwargs or {}),
124 | )
125 |
126 | hidden_states = torch.cat([attn_output, mlp_hidden_states], dim=2)
127 | gate = gate.unsqueeze(1)
128 | hidden_states = gate * self.proj_out(hidden_states)
129 | hidden_states = residual + hidden_states
130 | if hidden_states.dtype == torch.float16:
131 | hidden_states = hidden_states.clip(-65504, 65504)
132 |
133 | return hidden_states
134 |
135 |
136 | @maybe_allow_in_graph
137 | class AdditFluxTransformerBlock(nn.Module):
138 | r"""
139 | A Transformer block following the MMDiT architecture, introduced in Stable Diffusion 3.
140 |
141 | Reference: https://arxiv.org/abs/2403.03206
142 |
143 | Parameters:
144 | dim (`int`): The number of channels in the input and output.
145 | num_attention_heads (`int`): The number of heads to use for multi-head attention.
146 | attention_head_dim (`int`): The number of channels in each head.
147 | context_pre_only (`bool`): Boolean to determine if we should add some blocks associated with the
148 | processing of `context` conditions.
149 | """
150 |
151 | def __init__(self, dim, num_attention_heads, attention_head_dim, qk_norm="rms_norm", eps=1e-6):
152 | super().__init__()
153 |
154 | self.norm1 = AdaLayerNormZero(dim)
155 |
156 | self.norm1_context = AdaLayerNormZero(dim)
157 |
158 | if hasattr(F, "scaled_dot_product_attention"):
159 | processor = FluxAttnProcessor2_0()
160 | else:
161 | raise ValueError(
162 | "The current PyTorch version does not support the `scaled_dot_product_attention` function."
163 | )
164 | self.attn = Attention(
165 | query_dim=dim,
166 | cross_attention_dim=None,
167 | added_kv_proj_dim=dim,
168 | dim_head=attention_head_dim,
169 | heads=num_attention_heads,
170 | out_dim=dim,
171 | context_pre_only=False,
172 | bias=True,
173 | processor=processor,
174 | qk_norm=qk_norm,
175 | eps=eps,
176 | )
177 |
178 | self.norm2 = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
179 | self.ff = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
180 |
181 | self.norm2_context = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
182 | self.ff_context = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
183 |
184 | # let chunk size default to None
185 | self._chunk_size = None
186 | self._chunk_dim = 0
187 |
188 | def forward(
189 | self,
190 | hidden_states: torch.FloatTensor,
191 | encoder_hidden_states: torch.FloatTensor,
192 | temb: torch.FloatTensor,
193 | image_rotary_emb=None,
194 | proccesor_kwargs=None,
195 | ):
196 | norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(hidden_states, emb=temb)
197 |
198 | norm_encoder_hidden_states, c_gate_msa, c_shift_mlp, c_scale_mlp, c_gate_mlp = self.norm1_context(
199 | encoder_hidden_states, emb=temb
200 | )
201 |
202 | # Attention.
203 | attn_output, context_attn_output = self.attn(
204 | hidden_states=norm_hidden_states,
205 | encoder_hidden_states=norm_encoder_hidden_states,
206 | image_rotary_emb=image_rotary_emb,
207 | **(proccesor_kwargs or {}),
208 | )
209 |
210 | # Process attention outputs for the `hidden_states`.
211 | attn_output = gate_msa.unsqueeze(1) * attn_output
212 | hidden_states = hidden_states + attn_output
213 |
214 | norm_hidden_states = self.norm2(hidden_states)
215 | norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
216 |
217 | ff_output = self.ff(norm_hidden_states)
218 | ff_output = gate_mlp.unsqueeze(1) * ff_output
219 |
220 | hidden_states = hidden_states + ff_output
221 |
222 | # Process attention outputs for the `encoder_hidden_states`.
223 |
224 | context_attn_output = c_gate_msa.unsqueeze(1) * context_attn_output
225 | encoder_hidden_states = encoder_hidden_states + context_attn_output
226 |
227 | norm_encoder_hidden_states = self.norm2_context(encoder_hidden_states)
228 | norm_encoder_hidden_states = norm_encoder_hidden_states * (1 + c_scale_mlp[:, None]) + c_shift_mlp[:, None]
229 |
230 | context_ff_output = self.ff_context(norm_encoder_hidden_states)
231 | encoder_hidden_states = encoder_hidden_states + c_gate_mlp.unsqueeze(1) * context_ff_output
232 | if encoder_hidden_states.dtype == torch.float16:
233 | encoder_hidden_states = encoder_hidden_states.clip(-65504, 65504)
234 |
235 | return encoder_hidden_states, hidden_states
236 |
237 |
238 | class AdditFluxTransformer2DModel(ModelMixin, ConfigMixin, PeftAdapterMixin, FromOriginalModelMixin):
239 | """
240 | The Transformer model introduced in Flux.
241 |
242 | Reference: https://blackforestlabs.ai/announcing-black-forest-labs/
243 |
244 | Parameters:
245 | patch_size (`int`): Patch size to turn the input data into small patches.
246 | in_channels (`int`, *optional*, defaults to 16): The number of channels in the input.
247 | num_layers (`int`, *optional*, defaults to 18): The number of layers of MMDiT blocks to use.
248 | num_single_layers (`int`, *optional*, defaults to 18): The number of layers of single DiT blocks to use.
249 | attention_head_dim (`int`, *optional*, defaults to 64): The number of channels in each head.
250 | num_attention_heads (`int`, *optional*, defaults to 18): The number of heads to use for multi-head attention.
251 | joint_attention_dim (`int`, *optional*): The number of `encoder_hidden_states` dimensions to use.
252 | pooled_projection_dim (`int`): Number of dimensions to use when projecting the `pooled_projections`.
253 | guidance_embeds (`bool`, defaults to False): Whether to use guidance embeddings.
254 | """
255 |
256 | _supports_gradient_checkpointing = True
257 |
258 | @register_to_config
259 | def __init__(
260 | self,
261 | patch_size: int = 1,
262 | in_channels: int = 64,
263 | num_layers: int = 19,
264 | num_single_layers: int = 38,
265 | attention_head_dim: int = 128,
266 | num_attention_heads: int = 24,
267 | joint_attention_dim: int = 4096,
268 | pooled_projection_dim: int = 768,
269 | guidance_embeds: bool = False,
270 | axes_dims_rope: List[int] = [16, 56, 56],
271 | ):
272 | super().__init__()
273 | self.out_channels = in_channels
274 | self.inner_dim = self.config.num_attention_heads * self.config.attention_head_dim
275 |
276 | self.pos_embed = EmbedND(dim=self.inner_dim, theta=10000, axes_dim=axes_dims_rope)
277 | text_time_guidance_cls = (
278 | CombinedTimestepGuidanceTextProjEmbeddings if guidance_embeds else CombinedTimestepTextProjEmbeddings
279 | )
280 | self.time_text_embed = text_time_guidance_cls(
281 | embedding_dim=self.inner_dim, pooled_projection_dim=self.config.pooled_projection_dim
282 | )
283 |
284 | self.context_embedder = nn.Linear(self.config.joint_attention_dim, self.inner_dim)
285 | self.x_embedder = torch.nn.Linear(self.config.in_channels, self.inner_dim)
286 |
287 | self.transformer_blocks = nn.ModuleList(
288 | [
289 | AdditFluxTransformerBlock(
290 | dim=self.inner_dim,
291 | num_attention_heads=self.config.num_attention_heads,
292 | attention_head_dim=self.config.attention_head_dim,
293 | )
294 | for i in range(self.config.num_layers)
295 | ]
296 | )
297 |
298 | self.single_transformer_blocks = nn.ModuleList(
299 | [
300 | AdditFluxSingleTransformerBlock(
301 | dim=self.inner_dim,
302 | num_attention_heads=self.config.num_attention_heads,
303 | attention_head_dim=self.config.attention_head_dim,
304 | )
305 | for i in range(self.config.num_single_layers)
306 | ]
307 | )
308 |
309 | self.norm_out = AdaLayerNormContinuous(self.inner_dim, self.inner_dim, elementwise_affine=False, eps=1e-6)
310 | self.proj_out = nn.Linear(self.inner_dim, patch_size * patch_size * self.out_channels, bias=True)
311 |
312 | self.gradient_checkpointing = False
313 |
314 | def _set_gradient_checkpointing(self, module, value=False):
315 | if hasattr(module, "gradient_checkpointing"):
316 | module.gradient_checkpointing = value
317 |
318 | @property
319 | def attn_processors(self):
320 | r"""
321 | Returns:
322 | `dict` of attention processors: A dictionary containing all attention processors used in the model with
323 | indexed by its weight name.
324 | """
325 | # set recursively
326 | processors = {}
327 |
328 | def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors):
329 | if hasattr(module, "get_processor"):
330 | processors[f"{name}.processor"] = module.get_processor()
331 |
332 | for sub_name, child in module.named_children():
333 | fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
334 |
335 | return processors
336 |
337 | for name, module in self.named_children():
338 | fn_recursive_add_processors(name, module, processors)
339 |
340 | return processors
341 |
342 | def set_attn_processor(
343 | self, processor
344 | ):
345 | r"""
346 | Sets the attention processor to use to compute attention.
347 |
348 | Parameters:
349 | processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
350 | The instantiated processor class or a dictionary of processor classes that will be set as the processor
351 | for **all** `Attention` layers.
352 |
353 | If `processor` is a dict, the key needs to define the path to the corresponding cross attention
354 | processor. This is strongly recommended when setting trainable attention processors.
355 | """
356 | count = len(self.attn_processors.keys())
357 |
358 | if isinstance(processor, dict) and len(processor) != count:
359 | raise ValueError(
360 | f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
361 | f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
362 | )
363 |
364 | def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
365 | if hasattr(module, "set_processor"):
366 | if not isinstance(processor, dict):
367 | module.set_processor(processor)
368 | else:
369 | module.set_processor(processor.pop(f"{name}.processor"))
370 |
371 | for sub_name, child in module.named_children():
372 | fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
373 |
374 | for name, module in self.named_children():
375 | fn_recursive_attn_processor(name, module, processor)
376 |
377 | def forward(
378 | self,
379 | hidden_states: torch.Tensor,
380 | encoder_hidden_states: torch.Tensor = None,
381 | pooled_projections: torch.Tensor = None,
382 | timestep: torch.LongTensor = None,
383 | img_ids: torch.Tensor = None,
384 | txt_ids: torch.Tensor = None,
385 | guidance: torch.Tensor = None,
386 | joint_attention_kwargs: Optional[Dict[str, Any]] = None,
387 | return_dict: bool = True,
388 | proccesor_kwargs: Optional[Dict[str, Any]] = None,
389 | ) -> Union[torch.FloatTensor, Transformer2DModelOutput]:
390 | """
391 | The [`FluxTransformer2DModel`] forward method.
392 |
393 | Args:
394 | hidden_states (`torch.FloatTensor` of shape `(batch size, channel, height, width)`):
395 | Input `hidden_states`.
396 | encoder_hidden_states (`torch.FloatTensor` of shape `(batch size, sequence_len, embed_dims)`):
397 | Conditional embeddings (embeddings computed from the input conditions such as prompts) to use.
398 | pooled_projections (`torch.FloatTensor` of shape `(batch_size, projection_dim)`): Embeddings projected
399 | from the embeddings of input conditions.
400 | timestep ( `torch.LongTensor`):
401 | Used to indicate denoising step.
402 | block_controlnet_hidden_states: (`list` of `torch.Tensor`):
403 | A list of tensors that if specified are added to the residuals of transformer blocks.
404 | joint_attention_kwargs (`dict`, *optional*):
405 | A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
406 | `self.processor` in
407 | [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
408 | return_dict (`bool`, *optional*, defaults to `True`):
409 | Whether or not to return a [`~models.transformer_2d.Transformer2DModelOutput`] instead of a plain
410 | tuple.
411 |
412 | Returns:
413 | If `return_dict` is True, an [`~models.transformer_2d.Transformer2DModelOutput`] is returned, otherwise a
414 | `tuple` where the first element is the sample tensor.
415 | """
416 | if joint_attention_kwargs is not None:
417 | joint_attention_kwargs = joint_attention_kwargs.copy()
418 | lora_scale = joint_attention_kwargs.pop("scale", 1.0)
419 | else:
420 | lora_scale = 1.0
421 |
422 | if USE_PEFT_BACKEND:
423 | # weight the lora layers by setting `lora_scale` for each PEFT layer
424 | scale_lora_layers(self, lora_scale)
425 | else:
426 | if joint_attention_kwargs is not None and joint_attention_kwargs.get("scale", None) is not None:
427 | logger.warning(
428 | "Passing `scale` via `joint_attention_kwargs` when not using the PEFT backend is ineffective."
429 | )
430 | hidden_states = self.x_embedder(hidden_states)
431 |
432 | timestep = timestep.to(hidden_states.dtype) * 1000
433 | if guidance is not None:
434 | guidance = guidance.to(hidden_states.dtype) * 1000
435 | else:
436 | guidance = None
437 | temb = (
438 | self.time_text_embed(timestep, pooled_projections)
439 | if guidance is None
440 | else self.time_text_embed(timestep, guidance, pooled_projections)
441 | )
442 | encoder_hidden_states = self.context_embedder(encoder_hidden_states)
443 |
444 | ids = torch.cat((txt_ids, img_ids), dim=1)
445 | image_rotary_emb = self.pos_embed(ids)
446 |
447 | for index_block, block in enumerate(self.transformer_blocks):
448 | if self.training and self.gradient_checkpointing:
449 |
450 | def create_custom_forward(module, return_dict=None):
451 | def custom_forward(*inputs):
452 | if return_dict is not None:
453 | return module(*inputs, return_dict=return_dict)
454 | else:
455 | return module(*inputs)
456 |
457 | return custom_forward
458 |
459 | ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
460 | encoder_hidden_states, hidden_states = torch.utils.checkpoint.checkpoint(
461 | create_custom_forward(block),
462 | hidden_states,
463 | encoder_hidden_states,
464 | temb,
465 | image_rotary_emb,
466 | **ckpt_kwargs,
467 | )
468 |
469 | else:
470 | encoder_hidden_states, hidden_states = block(
471 | hidden_states=hidden_states,
472 | encoder_hidden_states=encoder_hidden_states,
473 | temb=temb,
474 | image_rotary_emb=image_rotary_emb,
475 | proccesor_kwargs=proccesor_kwargs,
476 | )
477 |
478 | hidden_states = torch.cat([encoder_hidden_states, hidden_states], dim=1)
479 |
480 | for index_block, block in enumerate(self.single_transformer_blocks):
481 | if self.training and self.gradient_checkpointing:
482 |
483 | def create_custom_forward(module, return_dict=None):
484 | def custom_forward(*inputs):
485 | if return_dict is not None:
486 | return module(*inputs, return_dict=return_dict)
487 | else:
488 | return module(*inputs)
489 |
490 | return custom_forward
491 |
492 | ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
493 | hidden_states = torch.utils.checkpoint.checkpoint(
494 | create_custom_forward(block),
495 | hidden_states,
496 | temb,
497 | image_rotary_emb,
498 | **ckpt_kwargs,
499 | )
500 |
501 | else:
502 | hidden_states = block(
503 | hidden_states=hidden_states,
504 | temb=temb,
505 | image_rotary_emb=image_rotary_emb,
506 | proccesor_kwargs=proccesor_kwargs,
507 | )
508 |
509 | hidden_states = hidden_states[:, encoder_hidden_states.shape[1] :, ...]
510 |
511 | hidden_states = self.norm_out(hidden_states, temb)
512 | output = self.proj_out(hidden_states)
513 |
514 | if USE_PEFT_BACKEND:
515 | # remove `lora_scale` from each PEFT layer
516 | unscale_lora_layers(self, lora_scale)
517 |
518 | if not return_dict:
519 | return (output,)
520 |
521 | return Transformer2DModelOutput(sample=output)
522 |
--------------------------------------------------------------------------------
/addit_flux_pipeline.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 Black Forest Labs and The HuggingFace Team. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | #
15 | # Copyright (C) 2025 NVIDIA Corporation. All rights reserved.
16 | #
17 | # This work is licensed under the LICENSE file
18 | # located at the root directory.
19 |
20 | from typing import Any, Callable, Dict, List, Optional, Union
21 | import torch
22 | import numpy as np
23 | from PIL import Image
24 | from diffusers.pipelines.flux.pipeline_flux import FluxPipeline, calculate_shift, retrieve_timesteps
25 | from diffusers.pipelines.flux.pipeline_output import FluxPipelineOutput
26 | from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
27 | from diffusers.utils.torch_utils import randn_tensor
28 | import matplotlib.pyplot as plt
29 |
30 | import torch.fft
31 | import torch.nn.functional as F
32 |
33 | from diffusers.models.attention_processor import FluxAttnProcessor2_0, FluxSingleAttnProcessor2_0
34 | from addit_attention_processors import AdditFluxAttnProcessor2_0, AdditFluxSingleAttnProcessor2_0
35 | from addit_attention_store import AttentionStore
36 |
37 | from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
38 | from skimage import filters
39 | from visualization_utils import show_image_and_heatmap, show_images, draw_points_on_pil_image, draw_bboxes_on_image
40 | from addit_blending_utils import clipseg_predict, grounding_sam_predict, mask_to_box_sam_predict, \
41 | mask_to_mask_sam_predict, attention_to_points_sam_predict
42 |
43 | from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
44 | from sam2.sam2_image_predictor import SAM2ImagePredictor
45 |
46 | from scipy.optimize import brentq
47 | from scipy.optimize import root_scalar
48 |
49 | def register_my_attention_processors(transformer, attention_store, extended_steps_multi, extended_steps_single):
50 | attn_procs = {}
51 |
52 | for i, (name, processor) in enumerate(transformer.attn_processors.items()):
53 | layer_name = ".".join(name.split(".")[:2])
54 |
55 | if layer_name.startswith("transformer_blocks"):
56 | attn_procs[name] = AdditFluxAttnProcessor2_0(layer_name=layer_name,
57 | attention_store=attention_store,
58 | extended_steps=extended_steps_multi)
59 | elif layer_name.startswith("single_transformer_blocks"):
60 | attn_procs[name] = AdditFluxSingleAttnProcessor2_0(layer_name=layer_name,
61 | attention_store=attention_store,
62 | extended_steps=extended_steps_single)
63 |
64 | transformer.set_attn_processor(attn_procs)
65 |
66 | def register_regular_attention_processors(transformer):
67 | attn_procs = {}
68 |
69 | for i, (name, processor) in enumerate(transformer.attn_processors.items()):
70 | layer_name = ".".join(name.split(".")[:2])
71 |
72 | if layer_name.startswith("transformer_blocks"):
73 | attn_procs[name] = FluxAttnProcessor2_0()
74 | elif layer_name.startswith("single_transformer_blocks"):
75 | attn_procs[name] = FluxSingleAttnProcessor2_0()
76 |
77 | transformer.set_attn_processor(attn_procs)
78 |
79 | def img2img_retrieve_latents(
80 | encoder_output: torch.Tensor, generator: Optional[torch.Generator] = None, sample_mode: str = "sample"
81 | ):
82 | if hasattr(encoder_output, "latent_dist") and sample_mode == "sample":
83 | return encoder_output.latent_dist.sample(generator)
84 | elif hasattr(encoder_output, "latent_dist") and sample_mode == "argmax":
85 | return encoder_output.latent_dist.mode()
86 | elif hasattr(encoder_output, "latents"):
87 | return encoder_output.latents
88 | else:
89 | raise AttributeError("Could not access latents of provided encoder_output")
90 |
91 | class AdditFluxPipeline(FluxPipeline):
92 | def prepare_latents(
93 | self,
94 | batch_size,
95 | num_channels_latents,
96 | height,
97 | width,
98 | dtype,
99 | device,
100 | generator,
101 | latents=None,
102 | ):
103 | height = 2 * (int(height) // self.vae_scale_factor)
104 | width = 2 * (int(width) // self.vae_scale_factor)
105 |
106 | shape = (batch_size, num_channels_latents, height, width)
107 |
108 | if latents is not None:
109 | latent_image_ids = self._prepare_latent_image_ids(batch_size, height, width, device, dtype)
110 | return latents.to(device=device, dtype=dtype), latent_image_ids
111 |
112 | if isinstance(generator, list) and len(generator) != batch_size:
113 | raise ValueError(
114 | f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
115 | f" size of {batch_size}. Make sure the batch size matches the length of the generators."
116 | )
117 |
118 | if isinstance(generator, list):
119 | latents = torch.empty(shape, device=device, dtype=dtype)
120 |
121 | latents_list = [randn_tensor(shape, generator=g, device=device, dtype=dtype) for g in generator]
122 |
123 | for i, l_i in enumerate(latents_list):
124 | latents[i] = l_i[i]
125 | else:
126 | latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
127 |
128 | latents = self._pack_latents(latents, batch_size, num_channels_latents, height, width)
129 |
130 | latent_image_ids = self._prepare_latent_image_ids(batch_size, height, width, device, dtype)
131 |
132 | return latents, latent_image_ids
133 |
134 | @torch.no_grad()
135 | def __call__(
136 | self,
137 | prompt: Union[str, List[str]] = None,
138 | prompt_2: Optional[Union[str, List[str]]] = None,
139 | height: Optional[int] = None,
140 | width: Optional[int] = None,
141 | num_inference_steps: int = 28,
142 | timesteps: List[int] = None,
143 | guidance_scale: Union[float, List[float]] = 7.0,
144 | num_images_per_prompt: Optional[int] = 1,
145 | generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
146 | latents: Optional[torch.FloatTensor] = None,
147 | prompt_embeds: Optional[torch.FloatTensor] = None,
148 | pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
149 | output_type: Optional[str] = "pil",
150 | return_dict: bool = True,
151 | joint_attention_kwargs: Optional[Dict[str, Any]] = None,
152 | callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
153 | callback_on_step_end_tensor_inputs: List[str] = ["latents"],
154 | max_sequence_length: int = 512,
155 |
156 | seed: Optional[Union[int, List[int]]] = None,
157 | same_latent_for_all_prompts: bool = False,
158 |
159 | # Extended Attention
160 | extended_steps_multi: Optional[int] = -1,
161 | extended_steps_single: Optional[int] = -1,
162 | extended_scale: Optional[Union[float, str]] = 1.0,
163 |
164 | # Structure Transfer
165 | source_latents: Optional[torch.FloatTensor] = None,
166 | structure_transfer_step: int = 5,
167 |
168 | # Latent Blending
169 | subject_token: Optional[str] = None,
170 | localization_model: Optional[str] = "attention_points_sam",
171 | blend_steps: List[int] = [],
172 | show_attention: bool = False,
173 |
174 | # Real Image Source
175 | is_img_src: bool = False,
176 | use_offset: bool = False,
177 | img_src_latents: Optional[List[torch.FloatTensor]] = None,
178 | ):
179 | r"""
180 | Function invoked when calling the pipeline for generation.
181 |
182 | Args:
183 | prompt (`str` or `List[str]`, *optional*):
184 | The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
185 | instead.
186 | prompt_2 (`str` or `List[str]`, *optional*):
187 | The prompt or prompts to be sent to `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
188 | will be used instead
189 | height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
190 | The height in pixels of the generated image. This is set to 1024 by default for the best results.
191 | width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
192 | The width in pixels of the generated image. This is set to 1024 by default for the best results.
193 | num_inference_steps (`int`, *optional*, defaults to 50):
194 | The number of denoising steps. More denoising steps usually lead to a higher quality image at the
195 | expense of slower inference.
196 | timesteps (`List[int]`, *optional*):
197 | Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
198 | in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
199 | passed will be used. Must be in descending order.
200 | guidance_scale (`float`, *optional*, defaults to 7.0):
201 | Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
202 | `guidance_scale` is defined as `w` of equation 2. of [Imagen
203 | Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
204 | 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
205 | usually at the expense of lower image quality.
206 | num_images_per_prompt (`int`, *optional*, defaults to 1):
207 | The number of images to generate per prompt.
208 | generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
209 | One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
210 | to make generation deterministic.
211 | latents (`torch.FloatTensor`, *optional*):
212 | Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
213 | generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
214 | tensor will ge generated by sampling using the supplied random `generator`.
215 | prompt_embeds (`torch.FloatTensor`, *optional*):
216 | Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
217 | provided, text embeddings will be generated from `prompt` input argument.
218 | pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
219 | Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
220 | If not provided, pooled text embeddings will be generated from `prompt` input argument.
221 | output_type (`str`, *optional*, defaults to `"pil"`):
222 | The output format of the generate image. Choose between
223 | [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
224 | return_dict (`bool`, *optional*, defaults to `True`):
225 | Whether or not to return a [`~pipelines.flux.FluxPipelineOutput`] instead of a plain tuple.
226 | joint_attention_kwargs (`dict`, *optional*):
227 | A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
228 | `self.processor` in
229 | [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
230 | callback_on_step_end (`Callable`, *optional*):
231 | A function that calls at the end of each denoising steps during the inference. The function is called
232 | with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
233 | callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
234 | `callback_on_step_end_tensor_inputs`.
235 | callback_on_step_end_tensor_inputs (`List`, *optional*):
236 | The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
237 | will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
238 | `._callback_tensor_inputs` attribute of your pipeline class.
239 | max_sequence_length (`int` defaults to 512): Maximum sequence length to use with the `prompt`.
240 |
241 | Examples:
242 |
243 | Returns:
244 | [`~pipelines.flux.FluxPipelineOutput`] or `tuple`: [`~pipelines.flux.FluxPipelineOutput`] if `return_dict`
245 | is True, otherwise a `tuple`. When returning a tuple, the first element is a list with the generated
246 | images.
247 | """
248 |
249 | device = self._execution_device
250 |
251 | # Blend Steps
252 | blend_models = {}
253 | if len(blend_steps) > 0:
254 | if localization_model == "clipseg":
255 | blend_models["clipseg_processor"] = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
256 | blend_models["clipseg_model"] = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined").to(device)
257 | elif localization_model == "grounding_sam":
258 | grounding_dino_model_id = "IDEA-Research/grounding-dino-base"
259 | blend_models["grounding_processor"] = AutoProcessor.from_pretrained(grounding_dino_model_id)
260 | blend_models["grounding_model"] = AutoModelForZeroShotObjectDetection.from_pretrained(grounding_dino_model_id).to(device)
261 | blend_models["sam_predictor"] = SAM2ImagePredictor.from_pretrained("facebook/sam2-hiera-large")
262 | elif localization_model == "clipseg_sam":
263 | blend_models["clipseg_processor"] = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
264 | blend_models["clipseg_model"] = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined").to(device)
265 | blend_models["sam_predictor"] = SAM2ImagePredictor.from_pretrained("facebook/sam2-hiera-large")
266 | elif localization_model == "attention":
267 | pass
268 | elif localization_model in ["attention_box_sam", "attention_mask_sam", "attention_points_sam"]:
269 | blend_models["sam_predictor"] = SAM2ImagePredictor.from_pretrained("facebook/sam2-hiera-large")
270 |
271 | height = height or self.default_sample_size * self.vae_scale_factor
272 | width = width or self.default_sample_size * self.vae_scale_factor
273 |
274 | # 1. Check inputs. Raise error if not correct
275 | self.check_inputs(
276 | prompt,
277 | prompt_2,
278 | height,
279 | width,
280 | prompt_embeds=prompt_embeds,
281 | pooled_prompt_embeds=pooled_prompt_embeds,
282 | callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
283 | max_sequence_length=max_sequence_length,
284 | )
285 |
286 | self._guidance_scale = guidance_scale
287 | self._joint_attention_kwargs = joint_attention_kwargs
288 | self._interrupt = False
289 |
290 | # 2. Define call parameters
291 | if prompt is not None and isinstance(prompt, str):
292 | batch_size = 1
293 | elif prompt is not None and isinstance(prompt, list):
294 | batch_size = len(prompt)
295 | else:
296 | batch_size = prompt_embeds.shape[0]
297 |
298 | device = self._execution_device
299 |
300 | lora_scale = (
301 | self.joint_attention_kwargs.get("scale", None) if self.joint_attention_kwargs is not None else None
302 | )
303 | (
304 | prompt_embeds,
305 | pooled_prompt_embeds,
306 | text_ids,
307 | ) = self.encode_prompt(
308 | prompt=prompt,
309 | prompt_2=prompt_2,
310 | prompt_embeds=prompt_embeds,
311 | pooled_prompt_embeds=pooled_prompt_embeds,
312 | device=device,
313 | num_images_per_prompt=num_images_per_prompt,
314 | max_sequence_length=max_sequence_length,
315 | lora_scale=lora_scale,
316 | )
317 |
318 | # 4. Prepare latent variables
319 | if (generator is None) and seed is not None:
320 | if isinstance(seed, int):
321 | generator = torch.Generator(device=device).manual_seed(seed)
322 | else:
323 | assert len(seed) == batch_size, "The number of seeds must match the batch size"
324 | generator = [torch.Generator(device=device).manual_seed(s) for s in seed]
325 |
326 | num_channels_latents = self.transformer.config.in_channels // 4
327 | latents, latent_image_ids = self.prepare_latents(
328 | batch_size * num_images_per_prompt,
329 | num_channels_latents,
330 | height,
331 | width,
332 | prompt_embeds.dtype,
333 | device,
334 | generator,
335 | latents,
336 | )
337 |
338 | if same_latent_for_all_prompts:
339 | latents = latents[:1].repeat(batch_size * num_images_per_prompt, 1, 1)
340 |
341 | noise = latents.clone()
342 |
343 | attention_store_kwargs = {}
344 |
345 | if extended_scale == "auto":
346 | is_auto_extend_scale = True
347 | extended_scale = 1.05
348 | attention_store_kwargs["is_cache_attn_ratio"] = True
349 | auto_extended_step = 5
350 | target_auto_ratio = 1.05
351 | else:
352 | is_auto_extend_scale = False
353 |
354 | if len(blend_steps) > 0:
355 | attn_steps = range(blend_steps[0] - 2, blend_steps[0] + 1)
356 | attention_store_kwargs["record_attention_steps"] = attn_steps
357 |
358 | self.attention_store = AttentionStore(prompts=prompt, tokenizer=self.tokenizer_2, subject_token=subject_token, **attention_store_kwargs)
359 | register_my_attention_processors(self.transformer, self.attention_store, extended_steps_multi, extended_steps_single)
360 |
361 | # 5. Prepare timesteps
362 | sigmas = np.linspace(1.0, 1 / num_inference_steps, num_inference_steps)
363 | image_seq_len = latents.shape[1]
364 | mu = calculate_shift(
365 | image_seq_len,
366 | self.scheduler.config.base_image_seq_len,
367 | self.scheduler.config.max_image_seq_len,
368 | self.scheduler.config.base_shift,
369 | self.scheduler.config.max_shift,
370 | )
371 | timesteps, num_inference_steps = retrieve_timesteps(
372 | self.scheduler,
373 | num_inference_steps,
374 | device,
375 | timesteps,
376 | sigmas,
377 | mu=mu,
378 | )
379 | num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
380 | self._num_timesteps = len(timesteps)
381 |
382 | # handle guidance
383 | if self.transformer.config.guidance_embeds:
384 | if isinstance(guidance_scale, float):
385 | guidance = torch.full([1], guidance_scale, device=device, dtype=torch.float32)
386 | guidance = guidance.expand(latents.shape[0])
387 | elif isinstance(guidance_scale, list):
388 | assert len(guidance_scale) == latents.shape[0], "The number of guidance scales must match the batch size"
389 | guidance = torch.tensor(guidance_scale, device=device, dtype=torch.float32)
390 | else:
391 | guidance = None
392 |
393 | if is_img_src and img_src_latents is None:
394 | assert source_latents is not None, "source_latents must be provided when is_img_src is True"
395 |
396 | rand_noise = noise[0].clone()
397 | img_src_latents = []
398 |
399 | for i in range(timesteps.shape[0]):
400 | sigma = self.scheduler.sigmas[i]
401 | img_src_latents.append((1.0 - sigma) * source_latents[0] + sigma * rand_noise)
402 |
403 | # 6. Denoising loop
404 | with self.progress_bar(total=num_inference_steps) as progress_bar:
405 | for i, t in enumerate(timesteps):
406 | if self.interrupt:
407 | continue
408 |
409 | # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
410 | timestep = t.expand(latents.shape[0]).to(latents.dtype)
411 |
412 | # For denoising from source image
413 | if is_img_src:
414 | latents[0] = img_src_latents[i]
415 |
416 | # For Structure Transfer
417 | if (source_latents is not None) and i == structure_transfer_step:
418 | sigma = self.scheduler.sigmas[i]
419 | latents[1] = (1.0 - sigma) * source_latents[0] + sigma * noise[1]
420 |
421 | if is_auto_extend_scale and i == auto_extended_step:
422 | def f(gamma):
423 | self.attention_store.attention_ratios[i] = {}
424 | noise_pred = self.transformer(
425 | hidden_states=latents,
426 | timestep=timestep / 1000,
427 | guidance=guidance,
428 | pooled_projections=pooled_prompt_embeds,
429 | encoder_hidden_states=prompt_embeds,
430 | txt_ids=text_ids,
431 | img_ids=latent_image_ids,
432 | joint_attention_kwargs=self.joint_attention_kwargs,
433 | return_dict=False,
434 | proccesor_kwargs={"step_index": i, "extended_scale": gamma},
435 | )[0]
436 |
437 | scores_per_layer = self.attention_store.get_attention_ratios(step_indices=[i], display_imgs=False)
438 | source_sum, text_sum, target_sum = scores_per_layer['transformer_blocks']
439 |
440 | # We want to find the gamma that makes the ratio equal to K
441 | ratio = (target_sum / source_sum)
442 | return (ratio - target_auto_ratio)
443 |
444 | gamma_sol = brentq(f, 1.0, 1.2, xtol=0.01)
445 |
446 | print('Chosen gamma:', gamma_sol)
447 | extended_scale = gamma_sol
448 | else:
449 | noise_pred = self.transformer(
450 | hidden_states=latents,
451 | timestep=timestep / 1000,
452 | guidance=guidance,
453 | pooled_projections=pooled_prompt_embeds,
454 | encoder_hidden_states=prompt_embeds,
455 | txt_ids=text_ids,
456 | img_ids=latent_image_ids,
457 | joint_attention_kwargs=self.joint_attention_kwargs,
458 | return_dict=False,
459 | proccesor_kwargs={"step_index": i, "extended_scale": extended_scale},
460 | )[0]
461 |
462 | # compute the previous noisy sample x_t -> x_t-1
463 | latents_dtype = latents.dtype
464 | latents, x0 = self.scheduler.step(noise_pred, t, latents, return_dict=False, step_index=i)
465 |
466 | if use_offset and is_img_src and (i+1 < len(img_src_latents)):
467 | next_latent = img_src_latents[i+1]
468 | offset = (next_latent - latents[0])
469 | latents[1] = latents[1] + offset
470 |
471 | # blend latents
472 | if i in blend_steps and (subject_token is not None) and (localization_model is not None):
473 | x0 = self._unpack_latents(x0, height, width, self.vae_scale_factor)
474 | x0 = (x0 / self.vae.config.scaling_factor) + self.vae.config.shift_factor
475 | images = self.vae.decode(x0, return_dict=False)[0]
476 | images = self.image_processor.postprocess(images, output_type="pil")
477 |
478 | self.do_step_blend(images, latents, subject_token, localization_model, show_attention, i, blend_models)
479 |
480 | if latents.dtype != latents_dtype:
481 | if torch.backends.mps.is_available():
482 | # some platforms (eg. apple mps) misbehave due to a pytorch bug: https://github.com/pytorch/pytorch/pull/99272
483 | latents = latents.to(latents_dtype)
484 |
485 | if callback_on_step_end is not None:
486 | callback_kwargs = {}
487 | for k in callback_on_step_end_tensor_inputs:
488 | callback_kwargs[k] = locals()[k]
489 | callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
490 |
491 | latents = callback_outputs.pop("latents", latents)
492 | prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
493 |
494 | # call the callback, if provided
495 | if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
496 | progress_bar.update()
497 |
498 | # if XLA_AVAILABLE:
499 | # xm.mark_step()
500 |
501 | if output_type == "latent":
502 | image = latents
503 | elif output_type == "both":
504 | return_latents = latents
505 | latents = self._unpack_latents(latents, height, width, self.vae_scale_factor)
506 |
507 | latents = (latents / self.vae.config.scaling_factor) + self.vae.config.shift_factor
508 | image = self.vae.decode(latents, return_dict=False)[0]
509 | image = self.image_processor.postprocess(image, output_type="pil")
510 |
511 | return (image, return_latents)
512 | else:
513 | latents = self._unpack_latents(latents, height, width, self.vae_scale_factor)
514 |
515 | latents = (latents / self.vae.config.scaling_factor) + self.vae.config.shift_factor
516 | image = self.vae.decode(latents, return_dict=False)[0]
517 | image = self.image_processor.postprocess(image, output_type=output_type)
518 |
519 | # Offload all models
520 | self.maybe_free_model_hooks()
521 |
522 | if not return_dict:
523 | return (image,)
524 |
525 | return FluxPipelineOutput(images=image)
526 |
527 | def do_step_blend(self, images, latents, subject_token, localization_model,
528 | show_attention, i, blend_models):
529 |
530 | device = latents.device
531 | latents_dtype = latents.dtype
532 |
533 | clipseg_processor = blend_models.get("clipseg_processor", None)
534 | clipseg_model = blend_models.get("clipseg_model", None)
535 | grounding_processor = blend_models.get("grounding_processor", None)
536 | grounding_model = blend_models.get("grounding_model", None)
537 | sam_predictor = blend_models.get("sam_predictor", None)
538 |
539 | image_to_display = []
540 | titles_to_display = []
541 |
542 | if show_attention:
543 | image_to_display += [images[0], images[1]]
544 | titles_to_display += ["Source X0", "Target X0"]
545 |
546 | if localization_model == "clipseg":
547 | subject_mask = clipseg_predict(clipseg_model, clipseg_processor, [images[-1]], f"A photo of {subject_token}", device)
548 | elif localization_model == "grounding_sam":
549 | subject_mask = grounding_sam_predict(grounding_model, grounding_processor, sam_predictor, images[-1], f"A {subject_token}.", device)
550 | elif localization_model == "clipseg_sam":
551 | subject_mask = clipseg_predict(clipseg_model, clipseg_processor, [images[-1]], f"A photo of {subject_token}", device)
552 | subject_mask = mask_to_box_sam_predict(subject_mask, sam_predictor, images[-1], None, device)
553 | elif localization_model == "attention":
554 | store = self.attention_store.image2text_store
555 | attention_maps, attention_masks, tokens = self.attention_store.aggregate_attention(store, target_layers=None, gaussian_kernel=3)
556 |
557 | subject_mask = attention_masks[0][-1].to(device)
558 | subject_attention = attention_maps[0][-1].to(device)
559 |
560 | if show_attention:
561 | attentioned_image = show_image_and_heatmap(subject_attention.float(), images[1], relevnace_res=512)
562 | attention_masked_image = show_image_and_heatmap(subject_mask.float(), images[1], relevnace_res=512)
563 |
564 | image_to_display += [attentioned_image, attention_masked_image]
565 | titles_to_display += ["Attention", "Attention Mask"]
566 |
567 | elif localization_model == "attention_box_sam":
568 | store = self.attention_store.image2text_store
569 | attention_maps, attention_masks, tokens = self.attention_store.aggregate_attention(store, target_layers=None, gaussian_kernel=3)
570 |
571 | attention_mask = attention_masks[0][-1].to(device)
572 | subject_attention = attention_maps[0][-1].to(device)
573 |
574 | subject_mask, bbox = mask_to_box_sam_predict(attention_mask, sam_predictor, images[-1], None, device)
575 |
576 | if show_attention:
577 | attentioned_image = show_image_and_heatmap(subject_attention.float(), images[1], relevnace_res=512)
578 | attention_masked_image = show_image_and_heatmap(attention_mask.float(), images[1], relevnace_res=512)
579 |
580 | sam_masked_image = show_image_and_heatmap(subject_mask.float(), images[1], relevnace_res=1024)
581 | sam_masked_image = draw_bboxes_on_image(sam_masked_image, [bbox.tolist()], color="green", thickness=5)
582 |
583 | image_to_display += [attentioned_image, attention_masked_image, sam_masked_image]
584 | titles_to_display += ["Attention", "Attention Mask", "SAM Mask"]
585 |
586 | elif localization_model == "attention_mask_sam":
587 | store = self.attention_store.image2text_store
588 | attention_maps, attention_masks, tokens = self.attention_store.aggregate_attention(store, target_layers=None, gaussian_kernel=3)
589 |
590 | attention_mask = attention_masks[0][-1].to(device)
591 | subject_attention = attention_maps[0][-1].to(device)
592 |
593 | subject_mask = mask_to_mask_sam_predict(attention_mask, sam_predictor, images[-1], None, device)
594 |
595 | if show_attention:
596 | print('Attention:')
597 | attentioned_image = show_image_and_heatmap(subject_attention.float(), images[1], relevnace_res=512)
598 | attention_masked_image = show_image_and_heatmap(attention_mask.float(), images[1], relevnace_res=512)
599 | sam_masked_image = show_image_and_heatmap(subject_mask.float(), images[1], relevnace_res=1024)
600 |
601 | image_to_display += [attentioned_image, attention_masked_image, sam_masked_image]
602 | titles_to_display += ["Attention", "Attention Mask", "SAM Mask"]
603 |
604 | elif localization_model == "attention_points_sam":
605 | store = self.attention_store.image2text_store
606 | attention_maps, attention_masks, tokens = self.attention_store.aggregate_attention(store, target_layers=None, gaussian_kernel=3)
607 |
608 | attention_mask = attention_masks[0][-1].to(device)
609 | subject_attention = attention_maps[0][-1].to(device)
610 |
611 | subject_mask, point_coords = attention_to_points_sam_predict(subject_attention, attention_mask, sam_predictor, images[1], None, device)
612 |
613 | if show_attention:
614 | print('Attention:')
615 | attentioned_image = show_image_and_heatmap(subject_attention.float(), images[1], relevnace_res=512)
616 | attention_masked_image = show_image_and_heatmap(attention_mask.float(), images[1], relevnace_res=512)
617 |
618 | sam_masked_image = show_image_and_heatmap(subject_mask.float(), images[1], relevnace_res=1024)
619 | sam_masked_image = draw_points_on_pil_image(sam_masked_image, point_coords, point_color="green", radius=10)
620 |
621 | image_to_display += [attentioned_image, attention_masked_image, sam_masked_image]
622 | titles_to_display += ["Attention", "Attention Mask", "SAM Mask"]
623 |
624 | if show_attention:
625 | show_images(image_to_display, titles_to_display, size=512, save_path="attn_vis.png")
626 |
627 | # Resize the mask to latents size
628 | latents_mask = torch.nn.functional.interpolate(subject_mask.view(1,1,subject_mask.shape[-2],subject_mask.shape[-1]), size=64, mode='bilinear').view(4096, 1).to(latents_dtype)
629 | latents_mask[latents_mask > 0.01] = 1
630 |
631 | latents[1] = latents[1] * latents_mask + latents[0] * (1 - latents_mask)
632 |
633 | ############# Image to Image Methods #############
634 | def img2img_encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
635 | if isinstance(generator, list):
636 | image_latents = [
637 | img2img_retrieve_latents(self.vae.encode(image[i : i + 1]), generator=generator[i])
638 | for i in range(image.shape[0])
639 | ]
640 | image_latents = torch.cat(image_latents, dim=0)
641 | else:
642 | image_latents = img2img_retrieve_latents(self.vae.encode(image), generator=generator)
643 |
644 | image_latents = (image_latents - self.vae.config.shift_factor) * self.vae.config.scaling_factor
645 |
646 | return image_latents
647 |
648 | def img2img_prepare_latents(
649 | self,
650 | image,
651 | timestep,
652 | batch_size,
653 | num_channels_latents,
654 | height,
655 | width,
656 | dtype,
657 | device,
658 | generator,
659 | latents=None,
660 | ):
661 | if isinstance(generator, list) and len(generator) != batch_size:
662 | raise ValueError(
663 | f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
664 | f" size of {batch_size}. Make sure the batch size matches the length of the generators."
665 | )
666 |
667 | height = 2 * (int(height) // self.vae_scale_factor)
668 | width = 2 * (int(width) // self.vae_scale_factor)
669 |
670 | shape = (batch_size, num_channels_latents, height, width)
671 | latent_image_ids = self.img2img_prepare_latent_image_ids(batch_size, height, width, device, dtype)
672 |
673 | if latents is not None:
674 | return latents.to(device=device, dtype=dtype), latent_image_ids
675 |
676 | image = image.to(device=device, dtype=dtype)
677 | image_latents = self.img2img_encode_vae_image(image=image, generator=generator)
678 | if batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] == 0:
679 | # expand init_latents for batch_size
680 | additional_image_per_prompt = batch_size // image_latents.shape[0]
681 | image_latents = torch.cat([image_latents] * additional_image_per_prompt, dim=0)
682 | elif batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] != 0:
683 | raise ValueError(
684 | f"Cannot duplicate `image` of batch size {image_latents.shape[0]} to {batch_size} text prompts."
685 | )
686 | else:
687 | image_latents = torch.cat([image_latents], dim=0)
688 |
689 | noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
690 | latents = self.scheduler.scale_noise(image_latents, timestep, noise)
691 | latents = self._pack_latents(latents, batch_size, num_channels_latents, height, width)
692 | return latents, latent_image_ids
693 |
694 | def img2img_check_inputs(
695 | self,
696 | prompt,
697 | prompt_2,
698 | strength,
699 | height,
700 | width,
701 | prompt_embeds=None,
702 | pooled_prompt_embeds=None,
703 | callback_on_step_end_tensor_inputs=None,
704 | max_sequence_length=None,
705 | ):
706 | if strength < 0 or strength > 1:
707 | raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
708 |
709 | if height % 8 != 0 or width % 8 != 0:
710 | raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
711 |
712 | if callback_on_step_end_tensor_inputs is not None and not all(
713 | k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
714 | ):
715 | raise ValueError(
716 | f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
717 | )
718 |
719 | if prompt is not None and prompt_embeds is not None:
720 | raise ValueError(
721 | f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
722 | " only forward one of the two."
723 | )
724 | elif prompt_2 is not None and prompt_embeds is not None:
725 | raise ValueError(
726 | f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
727 | " only forward one of the two."
728 | )
729 | elif prompt is None and prompt_embeds is None:
730 | raise ValueError(
731 | "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
732 | )
733 | elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
734 | raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
735 | elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
736 | raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
737 |
738 | if prompt_embeds is not None and pooled_prompt_embeds is None:
739 | raise ValueError(
740 | "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
741 | )
742 |
743 | if max_sequence_length is not None and max_sequence_length > 512:
744 | raise ValueError(f"`max_sequence_length` cannot be greater than 512 but is {max_sequence_length}")
745 |
746 | # Copied from diffusers.pipelines.stable_diffusion_3.pipeline_stable_diffusion_3_img2img.StableDiffusion3Img2ImgPipeline.get_timesteps
747 | def img2img_get_timesteps(self, num_inference_steps, strength, device):
748 | # get the original timestep using init_timestep
749 | init_timestep = min(num_inference_steps * strength, num_inference_steps)
750 |
751 | t_start = int(max(num_inference_steps - init_timestep, 0))
752 | timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
753 | if hasattr(self.scheduler, "set_begin_index"):
754 | self.scheduler.set_begin_index(t_start * self.scheduler.order)
755 |
756 | return timesteps, num_inference_steps - t_start
757 |
758 | @staticmethod
759 | # Copied from diffusers.pipelines.flux.pipeline_flux.FluxPipeline._prepare_latent_image_ids
760 | def img2img_prepare_latent_image_ids(batch_size, height, width, device, dtype):
761 | latent_image_ids = torch.zeros(height // 2, width // 2, 3)
762 | latent_image_ids[..., 1] = latent_image_ids[..., 1] + torch.arange(height // 2)[:, None]
763 | latent_image_ids[..., 2] = latent_image_ids[..., 2] + torch.arange(width // 2)[None, :]
764 |
765 | latent_image_id_height, latent_image_id_width, latent_image_id_channels = latent_image_ids.shape
766 |
767 | latent_image_ids = latent_image_ids.reshape(
768 | latent_image_id_height * latent_image_id_width, latent_image_id_channels
769 | )
770 |
771 | return latent_image_ids.to(device=device, dtype=dtype)
772 |
773 | @torch.no_grad()
774 | def call_img2img(
775 | self,
776 | prompt: Union[str, List[str]] = None,
777 | prompt_2: Optional[Union[str, List[str]]] = None,
778 | image: PipelineImageInput = None,
779 | height: Optional[int] = None,
780 | width: Optional[int] = None,
781 | strength: float = 0.6,
782 | num_inference_steps: int = 28,
783 | timesteps: List[int] = None,
784 | guidance_scale: float = 7.0,
785 | num_images_per_prompt: Optional[int] = 1,
786 | generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
787 | latents: Optional[torch.FloatTensor] = None,
788 | prompt_embeds: Optional[torch.FloatTensor] = None,
789 | pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
790 | output_type: Optional[str] = "pil",
791 | return_dict: bool = True,
792 | joint_attention_kwargs: Optional[Dict[str, Any]] = None,
793 | callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
794 | callback_on_step_end_tensor_inputs: List[str] = ["latents"],
795 | max_sequence_length: int = 512,
796 | ):
797 | r"""
798 | Function invoked when calling the pipeline for generation.
799 |
800 | Args:
801 | prompt (`str` or `List[str]`, *optional*):
802 | The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
803 | instead.
804 | prompt_2 (`str` or `List[str]`, *optional*):
805 | The prompt or prompts to be sent to `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
806 | will be used instead
807 | image (`torch.Tensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.Tensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
808 | `Image`, numpy array or tensor representing an image batch to be used as the starting point. For both
809 | numpy array and pytorch tensor, the expected value range is between `[0, 1]` If it's a tensor or a list
810 | or tensors, the expected shape should be `(B, C, H, W)` or `(C, H, W)`. If it is a numpy array or a
811 | list of arrays, the expected shape should be `(B, H, W, C)` or `(H, W, C)` It can also accept image
812 | latents as `image`, but if passing latents directly it is not encoded again.
813 | height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
814 | The height in pixels of the generated image. This is set to 1024 by default for the best results.
815 | width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
816 | The width in pixels of the generated image. This is set to 1024 by default for the best results.
817 | strength (`float`, *optional*, defaults to 1.0):
818 | Indicates extent to transform the reference `image`. Must be between 0 and 1. `image` is used as a
819 | starting point and more noise is added the higher the `strength`. The number of denoising steps depends
820 | on the amount of noise initially added. When `strength` is 1, added noise is maximum and the denoising
821 | process runs for the full number of iterations specified in `num_inference_steps`. A value of 1
822 | essentially ignores `image`.
823 | num_inference_steps (`int`, *optional*, defaults to 50):
824 | The number of denoising steps. More denoising steps usually lead to a higher quality image at the
825 | expense of slower inference.
826 | timesteps (`List[int]`, *optional*):
827 | Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
828 | in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
829 | passed will be used. Must be in descending order.
830 | guidance_scale (`float`, *optional*, defaults to 7.0):
831 | Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
832 | `guidance_scale` is defined as `w` of equation 2. of [Imagen
833 | Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
834 | 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
835 | usually at the expense of lower image quality.
836 | num_images_per_prompt (`int`, *optional*, defaults to 1):
837 | The number of images to generate per prompt.
838 | generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
839 | One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
840 | to make generation deterministic.
841 | latents (`torch.FloatTensor`, *optional*):
842 | Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
843 | generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
844 | tensor will ge generated by sampling using the supplied random `generator`.
845 | prompt_embeds (`torch.FloatTensor`, *optional*):
846 | Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
847 | provided, text embeddings will be generated from `prompt` input argument.
848 | pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
849 | Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
850 | If not provided, pooled text embeddings will be generated from `prompt` input argument.
851 | output_type (`str`, *optional*, defaults to `"pil"`):
852 | The output format of the generate image. Choose between
853 | [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
854 | return_dict (`bool`, *optional*, defaults to `True`):
855 | Whether or not to return a [`~pipelines.flux.FluxPipelineOutput`] instead of a plain tuple.
856 | joint_attention_kwargs (`dict`, *optional*):
857 | A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
858 | `self.processor` in
859 | [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
860 | callback_on_step_end (`Callable`, *optional*):
861 | A function that calls at the end of each denoising steps during the inference. The function is called
862 | with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
863 | callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
864 | `callback_on_step_end_tensor_inputs`.
865 | callback_on_step_end_tensor_inputs (`List`, *optional*):
866 | The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
867 | will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
868 | `._callback_tensor_inputs` attribute of your pipeline class.
869 | max_sequence_length (`int` defaults to 512): Maximum sequence length to use with the `prompt`.
870 |
871 | Examples:
872 |
873 | Returns:
874 | [`~pipelines.flux.FluxPipelineOutput`] or `tuple`: [`~pipelines.flux.FluxPipelineOutput`] if `return_dict`
875 | is True, otherwise a `tuple`. When returning a tuple, the first element is a list with the generated
876 | images.
877 | """
878 |
879 | height = height or self.default_sample_size * self.vae_scale_factor
880 | width = width or self.default_sample_size * self.vae_scale_factor
881 |
882 | # 1. Check inputs. Raise error if not correct
883 | self.img2img_check_inputs(
884 | prompt,
885 | prompt_2,
886 | strength,
887 | height,
888 | width,
889 | prompt_embeds=prompt_embeds,
890 | pooled_prompt_embeds=pooled_prompt_embeds,
891 | callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
892 | max_sequence_length=max_sequence_length,
893 | )
894 |
895 | self._guidance_scale = guidance_scale
896 | self._joint_attention_kwargs = joint_attention_kwargs
897 | self._interrupt = False
898 |
899 | # 2. Preprocess image
900 | init_image = self.image_processor.preprocess(image, height=height, width=width)
901 | init_image = init_image.to(dtype=torch.float32)
902 |
903 | # 3. Define call parameters
904 | if prompt is not None and isinstance(prompt, str):
905 | batch_size = 1
906 | elif prompt is not None and isinstance(prompt, list):
907 | batch_size = len(prompt)
908 | else:
909 | batch_size = prompt_embeds.shape[0]
910 |
911 | device = self._execution_device
912 |
913 | lora_scale = (
914 | self.joint_attention_kwargs.get("scale", None) if self.joint_attention_kwargs is not None else None
915 | )
916 | (
917 | prompt_embeds,
918 | pooled_prompt_embeds,
919 | text_ids,
920 | ) = self.encode_prompt(
921 | prompt=prompt,
922 | prompt_2=prompt_2,
923 | prompt_embeds=prompt_embeds,
924 | pooled_prompt_embeds=pooled_prompt_embeds,
925 | device=device,
926 | num_images_per_prompt=num_images_per_prompt,
927 | max_sequence_length=max_sequence_length,
928 | lora_scale=lora_scale,
929 | )
930 |
931 | register_regular_attention_processors(self.transformer)
932 |
933 | # 4.Prepare timesteps
934 | sigmas = np.linspace(1.0, 1 / num_inference_steps, num_inference_steps)
935 | image_seq_len = (int(height) // self.vae_scale_factor) * (int(width) // self.vae_scale_factor)
936 | mu = calculate_shift(
937 | image_seq_len,
938 | self.scheduler.config.base_image_seq_len,
939 | self.scheduler.config.max_image_seq_len,
940 | self.scheduler.config.base_shift,
941 | self.scheduler.config.max_shift,
942 | )
943 | timesteps, num_inference_steps = retrieve_timesteps(
944 | self.scheduler,
945 | num_inference_steps,
946 | device,
947 | timesteps,
948 | sigmas,
949 | mu=mu,
950 | )
951 | timesteps, num_inference_steps = self.img2img_get_timesteps(num_inference_steps, strength, device)
952 |
953 | if num_inference_steps < 1:
954 | raise ValueError(
955 | f"After adjusting the num_inference_steps by strength parameter: {strength}, the number of pipeline"
956 | f"steps is {num_inference_steps} which is < 1 and not appropriate for this pipeline."
957 | )
958 | latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
959 |
960 | # 5. Prepare latent variables
961 | num_channels_latents = self.transformer.config.in_channels // 4
962 |
963 | latents, latent_image_ids = self.img2img_prepare_latents(
964 | init_image,
965 | latent_timestep,
966 | batch_size * num_images_per_prompt,
967 | num_channels_latents,
968 | height,
969 | width,
970 | prompt_embeds.dtype,
971 | device,
972 | generator,
973 | latents,
974 | )
975 |
976 | num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
977 | self._num_timesteps = len(timesteps)
978 |
979 | # handle guidance
980 | if self.transformer.config.guidance_embeds:
981 | guidance = torch.full([1], guidance_scale, device=device, dtype=torch.float32)
982 | guidance = guidance.expand(latents.shape[0])
983 | else:
984 | guidance = None
985 |
986 | text_ids = text_ids.expand(latents.shape[0], -1, -1)
987 | latent_image_ids = latent_image_ids.expand(latents.shape[0], -1, -1)
988 |
989 | # 6. Denoising loop
990 | with self.progress_bar(total=num_inference_steps) as progress_bar:
991 | for i, t in enumerate(timesteps):
992 | if self.interrupt:
993 | continue
994 |
995 | # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
996 | timestep = t.expand(latents.shape[0]).to(latents.dtype)
997 | noise_pred = self.transformer(
998 | hidden_states=latents,
999 | timestep=timestep / 1000,
1000 | guidance=guidance,
1001 | pooled_projections=pooled_prompt_embeds,
1002 | encoder_hidden_states=prompt_embeds,
1003 | txt_ids=text_ids,
1004 | img_ids=latent_image_ids,
1005 | joint_attention_kwargs=self.joint_attention_kwargs,
1006 | return_dict=False,
1007 | )[0]
1008 |
1009 | # compute the previous noisy sample x_t -> x_t-1
1010 | latents_dtype = latents.dtype
1011 | latents = self.scheduler.step(noise_pred, t, latents, return_dict=False)[0]
1012 |
1013 | if latents.dtype != latents_dtype:
1014 | if torch.backends.mps.is_available():
1015 | # some platforms (eg. apple mps) misbehave due to a pytorch bug: https://github.com/pytorch/pytorch/pull/99272
1016 | latents = latents.to(latents_dtype)
1017 |
1018 | if callback_on_step_end is not None:
1019 | callback_kwargs = {}
1020 | for k in callback_on_step_end_tensor_inputs:
1021 | callback_kwargs[k] = locals()[k]
1022 | callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
1023 |
1024 | latents = callback_outputs.pop("latents", latents)
1025 | prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
1026 |
1027 | # call the callback, if provided
1028 | if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
1029 | progress_bar.update()
1030 |
1031 | # if XLA_AVAILABLE:
1032 | # xm.mark_step()
1033 |
1034 | if output_type == "latent":
1035 | image = latents
1036 |
1037 | else:
1038 | latents = self._unpack_latents(latents, height, width, self.vae_scale_factor)
1039 | latents = (latents / self.vae.config.scaling_factor) + self.vae.config.shift_factor
1040 | image = self.vae.decode(latents, return_dict=False)[0]
1041 | image = self.image_processor.postprocess(image, output_type=output_type)
1042 |
1043 | # Offload all models
1044 | self.maybe_free_model_hooks()
1045 |
1046 | if not return_dict:
1047 | return (image,)
1048 |
1049 | return FluxPipelineOutput(images=image)
1050 |
1051 | ############# Invert Methods #############
1052 | def invert_prepare_latents(
1053 | self,
1054 | image,
1055 | timestep,
1056 | batch_size,
1057 | num_channels_latents,
1058 | height,
1059 | width,
1060 | dtype,
1061 | device,
1062 | generator,
1063 | latents=None,
1064 | add_noise=False,
1065 | ):
1066 | if isinstance(generator, list) and len(generator) != batch_size:
1067 | raise ValueError(
1068 | f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
1069 | f" size of {batch_size}. Make sure the batch size matches the length of the generators."
1070 | )
1071 |
1072 | height = 2 * (int(height) // self.vae_scale_factor)
1073 | width = 2 * (int(width) // self.vae_scale_factor)
1074 |
1075 | shape = (batch_size, num_channels_latents, height, width)
1076 | latent_image_ids = self._prepare_latent_image_ids(batch_size, height, width, device, dtype)
1077 |
1078 | if latents is not None:
1079 | return latents.to(device=device, dtype=dtype), latent_image_ids
1080 |
1081 | image = image.to(device=device, dtype=dtype)
1082 | image_latents = self.img2img_encode_vae_image(image=image, generator=generator)
1083 |
1084 | if batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] == 0:
1085 | # expand init_latents for batch_size
1086 | additional_image_per_prompt = batch_size // image_latents.shape[0]
1087 | image_latents = torch.cat([image_latents] * additional_image_per_prompt, dim=0)
1088 | elif batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] != 0:
1089 | raise ValueError(
1090 | f"Cannot duplicate `image` of batch size {image_latents.shape[0]} to {batch_size} text prompts."
1091 | )
1092 | else:
1093 | image_latents = torch.cat([image_latents], dim=0)
1094 |
1095 | if add_noise:
1096 | noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
1097 | latents = self.scheduler.scale_noise(image_latents, timestep, noise)
1098 | else:
1099 | latents = image_latents
1100 |
1101 | latents = self._pack_latents(latents, batch_size, num_channels_latents, height, width)
1102 |
1103 | return latents, latent_image_ids
1104 |
1105 | @torch.no_grad()
1106 | def call_invert(
1107 | self,
1108 | prompt: Union[str, List[str]] = None,
1109 | prompt_2: Optional[Union[str, List[str]]] = None,
1110 | image: PipelineImageInput = None,
1111 | height: Optional[int] = None,
1112 | width: Optional[int] = None,
1113 | num_inference_steps: int = 28,
1114 | timesteps: List[int] = None,
1115 | guidance_scale: float = 7.0,
1116 | num_images_per_prompt: Optional[int] = 1,
1117 | generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
1118 | latents: Optional[torch.FloatTensor] = None,
1119 | prompt_embeds: Optional[torch.FloatTensor] = None,
1120 | pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
1121 | output_type: Optional[str] = "pil",
1122 | return_dict: bool = True,
1123 | joint_attention_kwargs: Optional[Dict[str, Any]] = None,
1124 | callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
1125 | callback_on_step_end_tensor_inputs: List[str] = ["latents"],
1126 | max_sequence_length: int = 512,
1127 |
1128 | fixed_point_iterations: int = 1,
1129 | ):
1130 | r"""
1131 | Function invoked when calling the pipeline for generation.
1132 |
1133 | Args:
1134 | prompt (`str` or `List[str]`, *optional*):
1135 | The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
1136 | instead.
1137 | prompt_2 (`str` or `List[str]`, *optional*):
1138 | The prompt or prompts to be sent to `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
1139 | will be used instead
1140 | height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
1141 | The height in pixels of the generated image. This is set to 1024 by default for the best results.
1142 | width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
1143 | The width in pixels of the generated image. This is set to 1024 by default for the best results.
1144 | num_inference_steps (`int`, *optional*, defaults to 50):
1145 | The number of denoising steps. More denoising steps usually lead to a higher quality image at the
1146 | expense of slower inference.
1147 | timesteps (`List[int]`, *optional*):
1148 | Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
1149 | in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
1150 | passed will be used. Must be in descending order.
1151 | guidance_scale (`float`, *optional*, defaults to 7.0):
1152 | Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
1153 | `guidance_scale` is defined as `w` of equation 2. of [Imagen
1154 | Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1155 | 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
1156 | usually at the expense of lower image quality.
1157 | num_images_per_prompt (`int`, *optional*, defaults to 1):
1158 | The number of images to generate per prompt.
1159 | generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
1160 | One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
1161 | to make generation deterministic.
1162 | latents (`torch.FloatTensor`, *optional*):
1163 | Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
1164 | generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
1165 | tensor will ge generated by sampling using the supplied random `generator`.
1166 | prompt_embeds (`torch.FloatTensor`, *optional*):
1167 | Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
1168 | provided, text embeddings will be generated from `prompt` input argument.
1169 | pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
1170 | Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
1171 | If not provided, pooled text embeddings will be generated from `prompt` input argument.
1172 | output_type (`str`, *optional*, defaults to `"pil"`):
1173 | The output format of the generate image. Choose between
1174 | [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
1175 | return_dict (`bool`, *optional*, defaults to `True`):
1176 | Whether or not to return a [`~pipelines.flux.FluxPipelineOutput`] instead of a plain tuple.
1177 | joint_attention_kwargs (`dict`, *optional*):
1178 | A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
1179 | `self.processor` in
1180 | [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
1181 | callback_on_step_end (`Callable`, *optional*):
1182 | A function that calls at the end of each denoising steps during the inference. The function is called
1183 | with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
1184 | callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
1185 | `callback_on_step_end_tensor_inputs`.
1186 | callback_on_step_end_tensor_inputs (`List`, *optional*):
1187 | The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
1188 | will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
1189 | `._callback_tensor_inputs` attribute of your pipeline class.
1190 | max_sequence_length (`int` defaults to 512): Maximum sequence length to use with the `prompt`.
1191 |
1192 | Examples:
1193 |
1194 | Returns:
1195 | [`~pipelines.flux.FluxPipelineOutput`] or `tuple`: [`~pipelines.flux.FluxPipelineOutput`] if `return_dict`
1196 | is True, otherwise a `tuple`. When returning a tuple, the first element is a list with the generated
1197 | images.
1198 | """
1199 | height = height or self.default_sample_size * self.vae_scale_factor
1200 | width = width or self.default_sample_size * self.vae_scale_factor
1201 |
1202 | # 1. Check inputs. Raise error if not correct
1203 | self.check_inputs(
1204 | prompt,
1205 | prompt_2,
1206 | height,
1207 | width,
1208 | prompt_embeds=prompt_embeds,
1209 | pooled_prompt_embeds=pooled_prompt_embeds,
1210 | callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
1211 | max_sequence_length=max_sequence_length,
1212 | )
1213 |
1214 | self._guidance_scale = guidance_scale
1215 | self._joint_attention_kwargs = joint_attention_kwargs
1216 | self._interrupt = False
1217 |
1218 | # 1.5. Preprocess image
1219 | if isinstance(image, Image.Image):
1220 | init_image = self.image_processor.preprocess(image, height=height, width=width)
1221 | elif isinstance(image, torch.Tensor):
1222 | init_image = image
1223 | latents = image
1224 | else:
1225 | raise ValueError("Image must be of type `PIL.Image.Image` or `torch.Tensor`")
1226 |
1227 | init_image = init_image.to(dtype=torch.float32)
1228 |
1229 | # 2. Define call parameters
1230 | if prompt is not None and isinstance(prompt, str):
1231 | batch_size = 1
1232 | elif prompt is not None and isinstance(prompt, list):
1233 | batch_size = len(prompt)
1234 | else:
1235 | batch_size = prompt_embeds.shape[0]
1236 |
1237 | device = self._execution_device
1238 |
1239 | lora_scale = (
1240 | self.joint_attention_kwargs.get("scale", None) if self.joint_attention_kwargs is not None else None
1241 | )
1242 | (
1243 | prompt_embeds,
1244 | pooled_prompt_embeds,
1245 | text_ids,
1246 | ) = self.encode_prompt(
1247 | prompt=prompt,
1248 | prompt_2=prompt_2,
1249 | prompt_embeds=prompt_embeds,
1250 | pooled_prompt_embeds=pooled_prompt_embeds,
1251 | device=device,
1252 | num_images_per_prompt=num_images_per_prompt,
1253 | max_sequence_length=max_sequence_length,
1254 | lora_scale=lora_scale,
1255 | )
1256 |
1257 | # 4. Prepare latent variables
1258 | num_channels_latents = self.transformer.config.in_channels // 4
1259 | # latents, latent_image_ids = self.prepare_latents(
1260 | # batch_size * num_images_per_prompt,
1261 | # num_channels_latents,
1262 | # height,
1263 | # width,
1264 | # prompt_embeds.dtype,
1265 | # device,
1266 | # generator,
1267 | # latents,
1268 | # )
1269 | latents, latent_image_ids = self.invert_prepare_latents(
1270 | init_image,
1271 | None,
1272 | batch_size * num_images_per_prompt,
1273 | num_channels_latents,
1274 | height,
1275 | width,
1276 | prompt_embeds.dtype,
1277 | device,
1278 | generator,
1279 | latents,
1280 | False
1281 | )
1282 |
1283 | register_regular_attention_processors(self.transformer)
1284 |
1285 | # 5. Prepare timesteps
1286 | sigmas = np.linspace(1.0, 1 / num_inference_steps, num_inference_steps)
1287 | image_seq_len = latents.shape[1]
1288 | mu = calculate_shift(
1289 | image_seq_len,
1290 | self.scheduler.config.base_image_seq_len,
1291 | self.scheduler.config.max_image_seq_len,
1292 | self.scheduler.config.base_shift,
1293 | self.scheduler.config.max_shift,
1294 | )
1295 |
1296 | # For Inversion, reverse the sigmas
1297 | # sigmas = sigmas[::-1]
1298 |
1299 | timesteps, num_inference_steps = retrieve_timesteps(
1300 | self.scheduler,
1301 | num_inference_steps,
1302 | device,
1303 | timesteps,
1304 | sigmas,
1305 | mu=mu,
1306 | )
1307 | num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
1308 | self._num_timesteps = len(timesteps)
1309 |
1310 | # handle guidance
1311 | if self.transformer.config.guidance_embeds:
1312 | guidance = torch.tensor([guidance_scale], device=device)
1313 | guidance = guidance.expand(latents.shape[0])
1314 | else:
1315 | guidance = None
1316 |
1317 | self.scheduler.sigmas = reversed(self.scheduler.sigmas)
1318 |
1319 | timesteps_zero_start = reversed(torch.cat([self.scheduler.timesteps[1:], torch.tensor([0], device=device)]))
1320 | timesteps_one_start = reversed(self.scheduler.timesteps)
1321 |
1322 | self.scheduler.timesteps = timesteps_zero_start
1323 | # self.scheduler.timesteps = timesteps_one_start
1324 |
1325 | timesteps = self.scheduler.timesteps
1326 |
1327 | latents_list = []
1328 | latents_list.append(latents)
1329 |
1330 | # 6. Denoising loop
1331 | with self.progress_bar(total=num_inference_steps * fixed_point_iterations) as progress_bar:
1332 | for i, t in enumerate(timesteps):
1333 | original_latents = latents.clone()
1334 | for j in range(fixed_point_iterations):
1335 | if self.interrupt:
1336 | continue
1337 |
1338 | if j == 0:
1339 | # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
1340 | timestep = timesteps[i].expand(latents.shape[0]).to(latents.dtype)
1341 | else:
1342 | timestep = timesteps_one_start[i].expand(latents.shape[0]).to(latents.dtype)
1343 |
1344 | noise_pred = self.transformer(
1345 | hidden_states=latents,
1346 | # YiYi notes: divide it by 1000 for now because we scale it by 1000 in the transforme rmodel (we should not keep it but I want to keep the inputs same for the model for testing)
1347 | timestep=timestep / 1000,
1348 | guidance=guidance,
1349 | pooled_projections=pooled_prompt_embeds,
1350 | encoder_hidden_states=prompt_embeds,
1351 | txt_ids=text_ids,
1352 | img_ids=latent_image_ids,
1353 | joint_attention_kwargs=self.joint_attention_kwargs,
1354 | return_dict=False,
1355 | )[0]
1356 |
1357 | # compute the previous noisy sample x_t -> x_t-1
1358 | latents_dtype = latents.dtype
1359 |
1360 | # noise_pred = -noise_pred
1361 | latents = self.scheduler.step(noise_pred, t, original_latents, return_dict=False, step_index=i)[0]
1362 |
1363 | if latents.dtype != latents_dtype:
1364 | if torch.backends.mps.is_available():
1365 | # some platforms (eg. apple mps) misbehave due to a pytorch bug: https://github.com/pytorch/pytorch/pull/99272
1366 | latents = latents.to(latents_dtype)
1367 |
1368 | if callback_on_step_end is not None:
1369 | callback_kwargs = {}
1370 | for k in callback_on_step_end_tensor_inputs:
1371 | callback_kwargs[k] = locals()[k]
1372 | callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
1373 |
1374 | latents = callback_outputs.pop("latents", latents)
1375 | prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
1376 |
1377 | # call the callback, if provided
1378 | if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
1379 | progress_bar.update()
1380 |
1381 | # if XLA_AVAILABLE:
1382 | # xm.mark_step()
1383 |
1384 | latents_list.append(latents)
1385 |
1386 | # Offload all models
1387 | self.maybe_free_model_hooks()
1388 |
1389 | return latents_list
--------------------------------------------------------------------------------