├── .github
└── workflows
│ └── testing.yml
├── .gitignore
├── LICENSE.txt
├── README.md
├── data
├── crunchbase_companies.json.gz
├── first_names.json
├── form_frequencies.json
├── geonames.json
├── model.PNG
├── products.json
├── reuters_small.tar.gz
├── sentiment
│ ├── lexicons
│ │ ├── IBM_Debater
│ │ │ └── no_unigram.txt
│ │ ├── NRC_Sentiment_Emotion
│ │ │ ├── NRC-Emotion-Lexicon-Wordlevel-v0.92.txt
│ │ │ └── no_sent.txt
│ │ ├── NRC_VAD_Lexicon
│ │ │ └── Norwegian-no-NRC-VAD-Lexicon.txt
│ │ └── socal
│ │ │ ├── no_adj.txt
│ │ │ ├── no_adv.txt
│ │ │ ├── no_google.txt
│ │ │ ├── no_int.txt
│ │ │ ├── no_noun.txt
│ │ │ └── no_verb.txt
│ └── norec_sentence
│ │ ├── dev.txt
│ │ ├── labels.json
│ │ ├── test.txt
│ │ └── train.txt
├── skweak_logo.jpg
├── skweak_logo_thumbnail.jpg
├── skweak_procedure.png
└── wikidata_small_tokenised.json.gz
├── examples
├── ner
│ ├── Step by step NER.ipynb
│ ├── __init__.py
│ ├── conll2003_ner.py
│ ├── conll2003_prep.py
│ ├── data_utils.py
│ ├── eval_utils.py
│ └── muc6_ner.py
├── quick_start.ipynb
└── sentiment
│ ├── Step_by_step.ipynb
│ ├── __init__.py
│ ├── norec_sentiment.py
│ ├── sentiment_lexicons.py
│ ├── sentiment_models.py
│ ├── transformer_model.py
│ └── weak_supervision_sentiment.py
├── poetry.lock
├── poetry.toml
├── pyproject.toml
├── skweak
├── __init__.py
├── aggregation.py
├── analysis.py
├── base.py
├── doclevel.py
├── gazetteers.py
├── generative.py
├── heuristics.py
├── spacy.py
├── utils.py
└── voting.py
└── tests
├── __init__.py
├── conftest.py
├── test_aggregation.py
├── test_analysis.py
├── test_doclevel.py
├── test_gazetteers.py
├── test_heuristics.py
└── test_utils.py
/.github/workflows/testing.yml:
--------------------------------------------------------------------------------
1 | name: testing
2 |
3 | on: [ push ]
4 |
5 | jobs:
6 | build:
7 |
8 | runs-on: ubuntu-latest
9 | strategy:
10 | matrix:
11 | python-version: [ "3.7", "3.8", "3.9", "3.10", "3.11" ]
12 | fail-fast: false
13 |
14 | steps:
15 | - uses: actions/checkout@v3
16 | name: Checkout
17 |
18 | - name: Set up Python ${{ matrix.python-version }}
19 | uses: actions/setup-python@v4
20 | with:
21 | python-version: ${{ matrix.python-version }}
22 | cache: 'pip'
23 |
24 | - uses: Gr1N/setup-poetry@v8
25 | with:
26 | poetry-version: 1.5.1
27 |
28 | - name: Install Python dependencies
29 | run: |
30 | poetry run pip install -U pip
31 | poetry install --with dev
32 |
33 | # TODO: add mkdocs documentation, make sure examples work
34 |
35 | # - name: Lint with flake8 #TODO: use ruff
36 | # run: |
37 | # # stop the build if there are Python syntax errors or undefined names
38 | # flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
39 | # # exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
40 | # flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
41 |
42 | - name: Test with pytest
43 | run: poetry run pytest
44 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea/
2 | .venv/
3 | build/
4 | sdist/
5 | dist/
6 |
--------------------------------------------------------------------------------
/LICENSE.txt:
--------------------------------------------------------------------------------
1 | The MIT License (MIT)
2 |
3 | Copyright (C) 2021-2026 Norsk Regnesentral
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
6 |
7 | The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
8 |
9 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # skweak: Weak supervision for NLP
2 |
3 | [](https://github.com/NorskRegnesentral/skweak/blob/main/LICENSE.txt)
4 | [](https://github.com/NorskRegnesentral/skweak/stargazers)
5 | 
6 | 
7 |
8 |
9 |
10 |  11 |
11 |
12 |
13 | **Skweak is no longer actively maintained** (if you are interested to take over the project, give us a shout).
14 |
15 | Labelled data remains a scarce resource in many practical NLP scenarios. This is especially the case when working with resource-poor languages (or text domains), or when using task-specific labels without pre-existing datasets. The only available option is often to collect and annotate texts by hand, which is expensive and time-consuming.
16 |
17 | `skweak` (pronounced `/skwi:k/`) is a Python-based software toolkit that provides a concrete solution to this problem using weak supervision. `skweak` is built around a very simple idea: Instead of annotating texts by hand, we define a set of _labelling functions_ to automatically label our documents, and then _aggregate_ their results to obtain a labelled version of our corpus.
18 |
19 | The labelling functions may take various forms, such as domain-specific heuristics (like pattern-matching rules), gazetteers (based on large dictionaries), machine learning models, or even annotations from crowd-workers. The aggregation is done using a statistical model that automatically estimates the relative accuracy (and confusions) of each labelling function by comparing their predictions with one another.
20 |
21 | `skweak` can be applied to both sequence labelling and text classification, and comes with a complete API that makes it possible to create, apply and aggregate labelling functions with just a few lines of code. The toolkit is also tightly integrated with [SpaCy](http://www.spacy.io), which makes it easy to incorporate into existing NLP pipelines. Give it a try!
22 |
23 |
24 |
25 | **Full Paper**:
26 | Pierre Lison, Jeremy Barnes and Aliaksandr Hubin (2021), "[skweak: Weak Supervision Made Easy for NLP](https://aclanthology.org/2021.acl-demo.40/)", *ACL 2021 (System demonstrations)*.
27 |
28 | **Documentation & API**: See the [Wiki](https://github.com/NorskRegnesentral/skweak/wiki) for details on how to use `skweak`.
29 |
30 |
31 |
32 |
33 | https://user-images.githubusercontent.com/11574012/114999146-e0995300-9ea1-11eb-8288-2bb54dc043e7.mp4
34 |
35 |
36 |
37 |
38 |
39 | ## Dependencies
40 |
41 | - `spacy` >= 3.0.0
42 | - `hmmlearn` >= 0.3.0
43 | - `pandas` >= 0.23
44 | - `numpy` >= 1.18
45 |
46 | You also need Python >= 3.6.
47 |
48 |
49 | ## Install
50 |
51 | The easiest way to install `skweak` is through `pip`:
52 |
53 | ```shell
54 | pip install skweak
55 | ```
56 |
57 | or if you want to install from the repo:
58 |
59 | ```shell
60 | pip install --user git+https://github.com/NorskRegnesentral/skweak
61 | ```
62 |
63 | The above installation only includes the core library (not the additional examples in `examples`).
64 |
65 | Note: some examples and tests may require trained spaCy pipelines. These can be downloaded automatically using the syntax (for the pipeline `en_core_web_sm`)
66 | ```shell
67 | python -m spacy download en_core_web_sm
68 | ```
69 |
70 |
71 | ## Basic Overview
72 |
73 |
74 |
75 | 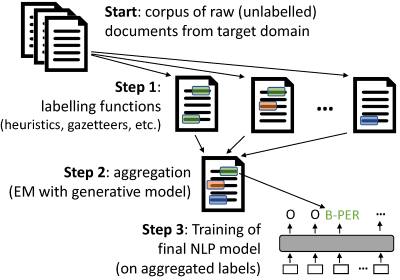 76 |
76 |
77 |
78 | Weak supervision with `skweak` goes through the following steps:
79 | - **Start**: First, you need raw (unlabelled) data from your text domain. `skweak` is build on top of [SpaCy](http://www.spacy.io), and operates with Spacy `Doc` objects, so you first need to convert your documents to `Doc` objects using SpaCy.
80 | - **Step 1**: Then, we need to define a range of labelling functions that will take those documents and annotate spans with labels. Those labelling functions can comes from heuristics, gazetteers, machine learning models, etc. See the  for more details.
81 | - **Step 2**: Once the labelling functions have been applied to your corpus, you need to _aggregate_ their results in order to obtain a single annotation layer (instead of the multiple, possibly conflicting annotations from the labelling functions). This is done in `skweak` using a generative model that automatically estimates the relative accuracy and possible confusions of each labelling function.
82 | - **Step 3**: Finally, based on those aggregated labels, we can train our final model. Step 2 gives us a labelled corpus that (probabilistically) aggregates the outputs of all labelling functions, and you can use this labelled data to estimate any kind of machine learning model. You are free to use whichever model/framework you prefer.
83 |
84 | ## Quickstart
85 |
86 | Here is a minimal example with three labelling functions (LFs) applied on a single document:
87 |
88 | ```python
89 | import spacy, re
90 | from skweak import heuristics, gazetteers, generative, utils
91 |
92 | # LF 1: heuristic to detect occurrences of MONEY entities
93 | def money_detector(doc):
94 | for tok in doc[1:]:
95 | if tok.text[0].isdigit() and tok.nbor(-1).is_currency:
96 | yield tok.i-1, tok.i+1, "MONEY"
97 | lf1 = heuristics.FunctionAnnotator("money", money_detector)
98 |
99 | # LF 2: detection of years with a regex
100 | lf2= heuristics.TokenConstraintAnnotator("years", lambda tok: re.match("(19|20)\d{2}$",
101 | tok.text), "DATE")
102 |
103 | # LF 3: a gazetteer with a few names
104 | NAMES = [("Barack", "Obama"), ("Donald", "Trump"), ("Joe", "Biden")]
105 | trie = gazetteers.Trie(NAMES)
106 | lf3 = gazetteers.GazetteerAnnotator("presidents", {"PERSON":trie})
107 |
108 | # We create a corpus (here with a single text)
109 | nlp = spacy.load("en_core_web_sm")
110 | doc = nlp("Donald Trump paid $750 in federal income taxes in 2016")
111 |
112 | # apply the labelling functions
113 | doc = lf3(lf2(lf1(doc)))
114 |
115 | # create and fit the HMM aggregation model
116 | hmm = generative.HMM("hmm", ["PERSON", "DATE", "MONEY"])
117 | hmm.fit([doc]*10)
118 |
119 | # once fitted, we simply apply the model to aggregate all functions
120 | doc = hmm(doc)
121 |
122 | # we can then visualise the final result (in Jupyter)
123 | utils.display_entities(doc, "hmm")
124 | ```
125 |
126 | Obviously, to get the most out of `skweak`, you will need more than three labelling functions. And, most importantly, you will need a larger corpus including as many documents as possible from your domain, so that the model can derive good estimates of the relative accuracy of each labelling function.
127 |
128 | ## Documentation
129 |
130 | See the [Wiki](https://github.com/NorskRegnesentral/skweak/wiki).
131 |
132 |
133 | ## License
134 |
135 | `skweak` is released under an MIT License.
136 |
137 | The MIT License is a short and simple permissive license allowing both commercial and non-commercial use of the software. The only requirement is to preserve
138 | the copyright and license notices (see file [License](https://github.com/NorskRegnesentral/skweak/blob/main/LICENSE.txt)). Licensed works, modifications, and larger works may be distributed under different terms and without source code.
139 |
140 | ## Citation
141 |
142 | See our paper describing the framework:
143 |
144 | Pierre Lison, Jeremy Barnes and Aliaksandr Hubin (2021), "[skweak: Weak Supervision Made Easy for NLP](https://aclanthology.org/2021.acl-demo.40/)", *ACL 2021 (System demonstrations)*.
145 |
146 | ```bibtex
147 | @inproceedings{lison-etal-2021-skweak,
148 | title = "skweak: Weak Supervision Made Easy for {NLP}",
149 | author = "Lison, Pierre and
150 | Barnes, Jeremy and
151 | Hubin, Aliaksandr",
152 | booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
153 | month = aug,
154 | year = "2021",
155 | address = "Online",
156 | publisher = "Association for Computational Linguistics",
157 | url = "https://aclanthology.org/2021.acl-demo.40",
158 | doi = "10.18653/v1/2021.acl-demo.40",
159 | pages = "337--346",
160 | }
161 | ```
162 |
--------------------------------------------------------------------------------
/data/crunchbase_companies.json.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NorskRegnesentral/skweak/2b6db15e8429dbda062b2cc9cc74e69f51a0a8b6/data/crunchbase_companies.json.gz
--------------------------------------------------------------------------------
/data/model.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NorskRegnesentral/skweak/2b6db15e8429dbda062b2cc9cc74e69f51a0a8b6/data/model.PNG
--------------------------------------------------------------------------------
/data/reuters_small.tar.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NorskRegnesentral/skweak/2b6db15e8429dbda062b2cc9cc74e69f51a0a8b6/data/reuters_small.tar.gz
--------------------------------------------------------------------------------
/data/sentiment/lexicons/socal/no_adv.txt:
--------------------------------------------------------------------------------
1 | vidunderlig 5
2 | herlig 5
3 | nydelig 5
4 | unntaksvis 5
5 | utmerket 5
6 | fantastisk 5
7 | fantastisk 5
8 | spektakulært 5
9 | feilfritt 5
10 | nydelig 5
11 | enestående 5
12 | perfekt 5
13 | fantastisk 5
14 | utrolig 5
15 | guddommelig 5
16 | fantastisk 5
17 | upåklagelig 5
18 | utelukkende 5
19 | fabelaktig 5
20 | bedårende 5
21 | strålende 5
22 | utrolig 5
23 | blendende 5
24 | utrolig 5
25 | strålende 5
26 | veldig bra 5
27 | orgasmisk 5
28 | hyggelig 4
29 | behagelig 4
30 | jublende 4
31 | flott 4
32 | magisk 4
33 | pent 4
34 | sprudlende 4
35 | engasjerende 4
36 | elegant 4
37 | beundringsverdig 4
38 | ypperlig 4
39 | elskelig 4
40 | mesterlig 4
41 | genialt 4
42 | fantastisk 4
43 | forfriskende 4
44 | lykkelig 4
45 | kjærlig 4
46 | høyest 4
47 | fenomenalt 4
48 | sjarmerende 4
49 | innovativt 4
50 | deilig 4
51 | mirakuløst 4
52 | fortryllende 4
53 | engrossingly 4
54 | morsomt 4
55 | vakkert 4
56 | intelligent 4
57 | gledelig 4
58 | attraktivt 4
59 | utsøkt 4
60 | kjevefall 4
61 | velvillig 4
62 | strålende 4
63 | entusiastisk 4
64 | oppladbart 4
65 | fredelig 3
66 | stilig 3
67 | eksotisk 3
68 | omfattende 3
69 | omhyggelig 3
70 | søtt 3
71 | fantasifullt 3
72 | prisverdig 3
73 | enormt 3
74 | høflig 3
75 | kjærlig 3
76 | populært 3
77 | søt 3
78 | lett 3
79 | bra 3
80 | rikt 3
81 | robust 3
82 | tilfredsstillende 3
83 | nylig 3
84 | gratis 3
85 | gripende 3
86 | muntert 3
87 | nøyaktig 3
88 | positivt 3
89 | spennende 3
90 | spennende 3
91 | gunstig 3
92 | kreativt 3
93 | festlig 3
94 | lidenskapelig 3
95 | fagmessig 3
96 | fengslende 3
97 | elegant 3
98 | kunstnerisk 3
99 | behendig 3
100 | imponerende 3
101 | intellektuelt 3
102 | levende 3
103 | ekstraordinært 3
104 | smart 3
105 | fantasifullt 3
106 | ergonomisk 3
107 | riktig 3
108 | sømløst 3
109 | fritt 3
110 | vittig 3
111 | uredd 3
112 | lyst 3
113 | fleksibelt 3
114 | adeptly 3
115 | ømt 3
116 | klokt 3
117 | triumferende 3
118 | uanstrengt 3
119 | hyggelig 3
120 | uproariously 3
121 | enormt 3
122 | morsomt 3
123 | hjertelig 3
124 | rikelig 3
125 | vellykket 3
126 | humoristisk 3
127 | tålmodig 3
128 | minneverdig 3
129 | uvurderlig 3
130 | underholdende 3
131 | ergonomisk 3
132 | dristig 3
133 | kraftig 3
134 | beleilig 3
135 | rungende 3
136 | adroitly 3
137 | romantisk 3
138 | forbløffende 3
139 | heroisk 3
140 | energisk 3
141 | sjelelig 3
142 | sjenerøst 3
143 | modig 3
144 | tappert 3
145 | rimelig 3
146 | pålitelig 3
147 | rimelig 3
148 | billig 3
149 | heldigvis 2
150 | profesjonelt 2
151 | bemerkelsesverdig 2
152 | elegant 2
153 | suspensivt 2
154 | intrikat 2
155 | treffende 2
156 | pent ferdig 2
157 | konsekvent 2
158 | pålitelig 2
159 | lyrisk 2
160 | passende 2
161 | virkelig 2
162 | riktig 2
163 | intensivt 2
164 | hjertelig 2
165 | evig 2
166 | gjerne 2
167 | modig 2
168 | forseggjort 2
169 | fersk 2
170 | godt 2
171 | overbærende 2
172 | overbevisende 2
173 | effektivt 2
174 | fargerikt 2
175 | gradvis 2
176 | rolig 2
177 | hederlig 2
178 | kjærlig 2
179 | dyktig 2
180 | liberalt 2
181 | lekent 2
182 | omtenksomt 2
183 | nøyaktig 2
184 | sannferdig 2
185 | målrettet 2
186 | heldigvis 2
187 | forsiktig 2
188 | komfortabelt 2
189 | grundig 2
190 | ivrig 2
191 | pent 2
192 | kompetent 2
193 | lovende 2
194 | pen 2
195 | nøye 2
196 | fantastisk 2
197 | delikat 2
198 | aktivt 2
199 | uskyldig 2
200 | kjærlig 2
201 | umåtelig 2
202 | trofast 2
203 | kapabel 2
204 | sammenhengende 2
205 | vanedannende 2
206 | oppfinnsomt 2
207 | reflekterende 2
208 | hjelpsomt 2
209 | nobelt 2
210 | ydmykt 2
211 | dyptgående 2
212 | ivrig 2
213 | oppriktig 2
214 | smart 2
215 | høflig 2
216 | interessant 2
217 | mystisk 2
218 | sentimentalt 2
219 | smart 2
220 | formidabelt 2
221 | fint 2
222 | lett 2
223 | eksepsjonell 2
224 | eterisk 2
225 | hovedsakelig 2
226 | ridderlig 2
227 | strategisk 2
228 | greit 2
229 | elektronisk 2
230 | kunstnerisk 2
231 | moralsk 2
232 | erotisk 2
233 | rørende 2
234 | kraftig 2
235 | optimistisk 2
236 | sterk 2
237 | spirituelt 2
238 | sympatisk 2
239 | nostalgisk 2
240 | smakfullt 2
241 | trygt 2
242 | monumentalt 2
243 | hjerteskjærende 2
244 | pent 2
245 | trygt 2
246 | avgjørende 2
247 | ansvarlig 2
248 | stolt 2
249 | forståelig nok 2
250 | mektig 2
251 | autentisk 2
252 | kompromissløst 2
253 | bedre 2
254 | digitali 2
255 | rask 2
256 | gratis 2
257 | klar 2
258 | rent 2
259 | universelt 1
260 | intuitivt 1
261 | forbausende 1
262 | ren 1
263 | stilistisk 1
264 | kjent 1
265 | rikelig 1
266 | digitalt 1
267 | lydløst 1
268 | andpusten 1
269 | naturlig 1
270 | komisk 1
271 | svimmel 1
272 | realistisk 1
273 | nøye 1
274 | skarpt 1
275 | uskyldig 1
276 | intimt 1
277 | helhet 1
278 | offisielt 1
279 | troverdig 1
280 | straks 1
281 | musikalsk 1
282 | merkbart 1
283 | unikt 1
284 | logisk 1
285 | lunefullt 1
286 | lett 1
287 | passende 1
288 | klassisk 1
289 | effektivt 1
290 | slående 1
291 | helst 1
292 | første 1
293 | hovedsakelig 1
294 | beskjedent 1
295 | rimelig 1
296 | tilstrekkelig 1
297 | elektrisk 1
298 | betydelig 1
299 | gjenkjennelig 1
300 | i det vesentlige 1
301 | tilstrekkelig 1
302 | mykt 1
303 | sikkert 1
304 | intenst 1
305 | solid 1
306 | umåtelig 1
307 | høytidelig 1
308 | varmt 1
309 | relevant 1
310 | rettferdig 1
311 | dyktig 1
312 | sikkert 1
313 | ordentlig 1
314 | normalt 1
315 | rent 1
316 | overbevisende 1
317 | billig 1
318 | sentralt 1
319 | tydelig 1
320 | bevisst 1
321 | sannsynlig 1
322 | forholdsvis 1
323 | nok 1
324 | rett frem 1
325 | sammenlignbart 1
326 | responsivt 1
327 | utpreget 1
328 | raskt 1
329 | følsomt 1
330 | spontant 1
331 | villig 1
332 | anstendig 1
333 | brønn 1
334 | dyrt 1
335 | smart 1
336 | virkelig 1
337 | legitimt 1
338 | uendelig 1
339 | raskt 1
340 | lett 1
341 | fremtredende 1
342 | verdifullt 1
343 | tilfeldig 1
344 | nyttig 1
345 | jevnt 1
346 | skyll 1
347 | gradvis 1
348 | spesielt 1
349 | sterkt 1
350 | jevnt og trutt 1
351 | automatisk 1
352 | stille 1
353 | troverdig 1
354 | tilfredsstillende 1
355 | flørtende 1
356 | uvanlig 1
357 | med rette 1
358 | globalt 1
359 | med respekt 1
360 | quirkily 1
361 | uavhengig 1
362 | enormt 1
363 | ekte 1
364 | realistisk 1
365 | myk 1
366 | stor 1
367 | rettferdig 1
368 | uheldig 1
369 | komisk 1
370 | ukonvensjonelt 1
371 | vitenskapelig 1
372 | uforutsigbart 1
373 | vanlig 1
374 | klar 1
375 | forførende 1
376 | muntert 1
377 | hypnotisk 1
378 | pålitelig 1
379 | ambisiøst 1
380 | nonchalant 1
381 | sikkert 1
382 | kompakt 1
383 | ekstra 1
384 | akseptabelt 1
385 | økonomisk 1
386 | funksjonelt 1
387 | leselig 1
388 | valgfritt 1
389 | konkurransedyktig 1
390 | merkbart 1
391 | glatt -1
392 | kjølig -1
393 | hysterisk -1
394 | stort -1
395 | blinkende -1
396 | overfladisk -1
397 | ially -1
398 | dramatisk -1
399 | rett ut -1
400 | underlig -1
401 | nedslående -1
402 | tvangsmessig -1
403 | sjelden -1
404 | tett -1
405 | kaldt -1
406 | marginalt -1
407 | skarpt -1
408 | ostelig -1
409 | snevert -1
410 | sjokkerende -1
411 | kort -1
412 | forbausende -1
413 | tydelig -1
414 | foruroligende -1
415 | svakt -1
416 | alvorlig -1
417 | løst -1
418 | opprørende -1
419 | ujevnt -1
420 | tung -1
421 | hard -1
422 | uunngåelig -1
423 | nervøst -1
424 | kommersielt -1
425 | nølende -1
426 | lite -1
427 | eksternt -1
428 | vilt -1
429 | trist -1
430 | fantastisk -1
431 | uendelig -1
432 | tomgang -1
433 | negativt -1
434 | minimalt -1
435 | ekstremt -1
436 | beskyttende -1
437 | rampete -1
438 | tett -1
439 | motvillig -1
440 | sakte -1
441 | unødvendig -1
442 | lurt -1
443 | gjennomsiktig -1
444 | gal -1
445 | følelsesmessig -1
446 | urolig -1
447 | knapt -1
448 | omtrent -1
449 | hakkete -1
450 | inkonsekvent -1
451 | tungt -1
452 | rastløs -1
453 | kompleks -1
454 | merkelig -1
455 | konvensjonelt -1
456 | spesielt -1
457 | stereotyp -1
458 | utenfor emnet -1
459 | trendig -1
460 | lang -1
461 | klinisk -1
462 | forsiktig -1
463 | politisk -1
464 | religiøst -1
465 | vanskelig -1
466 | radikalt -1
467 | feilaktig -1
468 | gjentatt -1
469 | uhyggelig -1
470 | uinteressant -1
471 | svakt -1
472 | overflødig -1
473 | mørkt -1
474 | kryptisk -1
475 | løs -1
476 | kunstig -1
477 | campily -1
478 | sporadisk -1
479 | forenklet -1
480 | sterkt -1
481 | unnskyldende -1
482 | uløselig -1
483 | flamboyant -1
484 | idealistisk -1
485 | vantro -1
486 | vanlig -1
487 | billig -1
488 | ulykkelig -1
489 | sakte -1
490 | sent -1
491 | vedvarende -1
492 | ufullstendig -1
493 | temperamentsfull -1
494 | ironisk nok -1
495 | merkelig -1
496 | blindende -1
497 | trassig -1
498 | uklart -1
499 | mørk -1
500 | innfødt -1
501 | uregelmessig -1
502 | urealistisk -1
503 | gratis -2
504 | kjølig -2
505 | heldigvis -2
506 | urimelig -2
507 | repeterende -2
508 | upassende -2
509 | uforklarlig -2
510 | unødvendig -2
511 | brashly -2
512 | dårlig -2
513 | ubarmhjertig -2
514 | ubehagelig -2
515 | lat -2
516 | støyende -2
517 | bare -2
518 | alvorlig -2
519 | voldsomt -2
520 | beryktet -2
521 | grovt -2
522 | likegyldig -2
523 | naken -2
524 | klønete -2
525 | lunken -2
526 | ulogisk -2
527 | mindnumbingly -2
528 | amatøraktig -2
529 | latterlig -2
530 | klumpete -2
531 | uberørt -2
532 | urettmessig -2
533 | umulig -2
534 | feil -2
535 | dessverre -2
536 | angivelig -2
537 | forutsigbart -2
538 | flatt -2
539 | skyldfølende -2
540 | vanvittig -2
541 | innblandet -2
542 | tregt -2
543 | uvillig -2
544 | uavbrutt -2
545 | urettferdig -2
546 | tåpelig -2
547 | dessverre -2
548 | engstelig -2
549 | sappily -2
550 | takknemlig -2
551 | urettferdig -2
552 | sårt -2
553 | icily -2
554 | hardt -2
555 | knapt -2
556 | upassende -2
557 | høyt -2
558 | lystig -2
559 | unnvikende -2
560 | kjedelig -2
561 | apprehensive -2
562 | neppe -2
563 | vagt -2
564 | overbevisende -2
565 | utålmodig -2
566 | unøyaktig -2
567 | dessverre -2
568 | voldsomt -2
569 | overdreven -2
570 | uintelligent -2
571 | feil -2
572 | skissert -2
573 | kjedelig -2
574 | sjalu -2
575 | svakt -2
576 | offensivt -2
577 | vilkårlig -2
578 | ubarmhjertig -2
579 | kjedelig -2
580 | desperat -2
581 | tankeløst -2
582 | beklager -2
583 | altfor -2
584 | mislykket -2
585 | skjelvende -2
586 | lam -2
587 | tre -2
588 | ukontrollerbart -2
589 | strengt -2
590 | desperat -2
591 | tøft -2
592 | forvirrende -2
593 | fantasiløst -2
594 | negativt -2
595 | rotete -2
596 | mistenkelig -2
597 | ulovlig -2
598 | feil -2
599 | overveldende -2
600 | sauete -2
601 | tankeløst -2
602 | ['d | ville] _rather -2
603 | generisk -2
604 | akutt -2
605 | nerdete -2
606 | urolig -2
607 | mutt -2
608 | høyt -2
609 | morsomt -2
610 | deprimerende -2
611 | uforståelig -2
612 | katatonisk -2
613 | endimensjonalt -2
614 | syk -2
615 | generelt -2
616 | ikke tiltalende -2
617 | sta -2
618 | møysommelig -2
619 | ugunstig -2
620 | tilfeldig -2
621 | frekt -2
622 | dystert -2
623 | slurvet -2
624 | sinnsykt -2
625 | latterlig -2
626 | beruset -2
627 | impulsivt -2
628 | vanskelig -2
629 | vakuum -2
630 | grådig -2
631 | naivt -2
632 | syndig -3
633 | uendelig -3
634 | uhyrlig -3
635 | lurt -3
636 | aggressivt -3
637 | kynisk -3
638 | sint -3
639 | ubehagelig -3
640 | terminalt -3
641 | dystert -3
642 | søppel -3
643 | motbydelig -3
644 | frekt -3
645 | skummelt -3
646 | frekt -3
647 | skremmende -3
648 | inhabil -3
649 | for -3
650 | blindt -3
651 | håpløst -3
652 | sinnsløs -3
653 | pretensiøst -3
654 | vilt -3
655 | skuffende -3
656 | absurd -3
657 | tunghendt -3
658 | kjedelig -3
659 | tett -3
660 | truende -3
661 | b-film -3
662 | farlig -3
663 | illevarslende -3
664 | utilgivende -3
665 | grovt -3
666 | rabiat -3
667 | hjemsøkende -3
668 | fryktelig -3
669 | uheldigvis -3
670 | urovekkende -3
671 | kjedelig -3
672 | skamløst -3
673 | krøllete -3
674 | dystert -3
675 | blatant -3
676 | egoistisk -3
677 | dårlig -3
678 | bisarrt -3
679 | grafisk -3
680 | tragisk -3
681 | problematisk -3
682 | kronisk -3
683 | død -3
684 | irriterende -3
685 | irriterende -3
686 | analt -3
687 | dødelig -3
688 | meningsløst -3
689 | arrogant -3
690 | skammelig -3
691 | dårlig -3
692 | latterlig -4
693 | uutholdelig -4
694 | unnskyldelig -4
695 | djevelsk -4
696 | ukikkelig -4
697 | avskrivning -4
698 | pervers -4
699 | dumt -4
700 | uakseptabelt -4
701 | kriminelt -4
702 | grusomt -4
703 | latterlig -4
704 | smertefullt -4
705 | notorisk -4
706 | inanely -4
707 | patetisk -4
708 | uanstendig -4
709 | meningsløst -4
710 | ynkelig -4
711 | livløst -4
712 | fornærmende -4
713 | ondsinnet -4
714 | psykotisk -4
715 | opprørende -4
716 | patologisk -4
717 | utnyttende -4
718 | idiotisk -4
719 | fryktelig -5
720 | kvalmende -5
721 | utilgivelig -5
722 | katastrofalt -5
723 | fryktelig -5
724 | sykt -5
725 | veldig -5
726 | brutalt -5
727 | forferdelig -5
728 | forferdelig -5
729 | elendig -5
730 | fryktelig -5
731 | forferdelig -5
732 | ondskapsfullt -5
733 | frastøtende -5
734 | trist -5
735 | fryktelig -5
736 | skjemmende -5
737 | ulykkelig -5
738 | grotesk -5
739 | alvorlig -5
740 | ondskapsfullt -5
741 | motbydelig -5
742 | ulidelig -5
743 | forferdelig -5
744 | fryktelig -5
745 | forferdelig -5
746 | styggt -5
747 | nøye 2
748 | kort -1
749 | ensom -1
750 | streetwise 1
751 | slu -1
752 | vital 1
753 | mind-blowingly 2
754 | melodramatisk -2
755 | ulastelig 5
756 | nasalt -1
757 | dyktig 2
758 | hjerteskjærende -2
759 | uredelig -3
760 | plettfritt 4
761 | tynt -1
762 | lystig 2
763 | vakkert 4
764 | utsmykket 2
765 | pent 2
766 | dynamisk 2
767 | kjedelig -3
768 | utilstrekkelig -1
769 | sportslig 2
770 | usammenhengende -2
771 | rettferdig -2
772 | veldedig 1
773 | flittig 2
774 | del tomt -2
775 | greit 1
776 | skjevt -1
777 | fristende 1
778 | klokt 2
779 | kostbar -1
780 | uoverkommelig -3
781 | tomt -1
782 | naturskjønt 4
783 | seremonielt 1
784 | surrealistisk -1
785 | prisbelønt 5
786 | fascinerende 5
787 | frustrerende -2
788 | moro 3
789 | periodevis -1
790 | vennlig 2
791 | kraftig 2
792 | veltalende 3
793 | freakishly -3
794 | skremmende -1
795 | bare 1
796 | omrørende 2
797 | etisk 1
798 | forsvarlig 1
799 | hensynsløs -2
800 | litt -1
801 | utrolig -2
802 | fiendishly -3
803 | skikkelig 1
804 | sørgelig -4
805 | kjapt 1
806 | rausende 3
807 | gledelig 4
808 | motbydelig -3
809 | nådeløst -3
810 | rettferdig 1
811 | nådig 2
812 | frodig 3
813 | lykksalig 4
814 | historisk 1
815 | kortfattet -1
816 | svakt -1
817 | halvhjertet -1
818 | raskt 1
819 | skremmende -2
820 | banebrytende 3
821 | på villspor -1
822 | bittert -2
823 | besatt -3
824 | hjelpeløst -3
825 | hilsen -2
826 | fortjent 1
827 | rasende -4
828 | ubønnhørlig -2
829 | uelegant -1
830 | rørende 3
831 | rolig 1
832 | spent 3
833 | godartet 1
834 | målløst -1
835 | forvirrende -2
836 | skjemmende -4
837 | raskt -2
838 | moderat 1
839 | grovt -2
840 | fantastisk 5
841 | stolt -1
842 | beroligende 1
843 | svakt -2
844 | majestetisk 4
845 | snikende -4
846 | distraherende -1
847 | skummelt -1
848 | skrytende -1
849 | utmerket 4
850 | uklokt -2
851 | iherdig 3
852 | rasende -2
853 | ufarlig 1
854 | forgjeves -2
855 | lakonisk -1
856 | oppgitt -2
857 | lønnsomt 1
858 | forvirrende -2
859 | bekymringsfullt -3
860 | kvalmende -3
861 | lunefull -2
862 | fanatisk -3
863 | uforsiktig -1
864 | abysmalt -4
865 | bærekraftig 2
866 | foraktelig -3
867 | glumly -2
868 | uberegnelig -1
869 | sparsommelig 1
870 | torturøst -4
871 | ublu -4
872 | selvtilfreds -2
873 | feil -1
874 | skadelig -2
875 | smertefritt 1
876 | feil -1
877 | luskent -1
878 | episk 4
879 |
--------------------------------------------------------------------------------
/data/sentiment/lexicons/socal/no_int.txt:
--------------------------------------------------------------------------------
1 | minst -3
2 | mindre -1.5
3 | knapt -1.5
4 | neppe -1.5
5 | nesten -1.5
6 | ikke for -1.5
7 | ikke bare 0.5
8 | ikke bare 0.5
9 | ikke bare 0.5
10 | bare -0.5
11 | litt -0.5
12 | litt -0.5
13 | litt -0.5
14 | marginalt -0.5
15 | relativt -0.3
16 | mildt -0.3
17 | moderat -0.3
18 | noe -0.3
19 | delvis -0.3
20 | litt -0.3
21 | uten tvil -0.2
22 | stort sett -0.2
23 | hovedsakelig -0.2
24 | minst -0.9
25 | til en viss grad -0.2
26 | til en viss grad -0.2
27 | slags -0.3
28 | sorta -0.3
29 | slags -0.3
30 | ganske -0.3
31 | ganske -0.2
32 | pen -0.1
33 | heller -0.1
34 | umiddelbart 0.1
35 | ganske 0.1
36 | perfekt 0.1
37 | konsekvent 0.1
38 | virkelig 0.2
39 | klart 0.2
40 | åpenbart 0.2
41 | absolutt 0.2
42 | helt 0.2
43 | definitivt 0.2
44 | absolutt 0.2
45 | konstant 0.2
46 | høyt 0.2
47 | veldig 0.2
48 | betydelig 0.2
49 | merkbart 0.2
50 | karakteristisk 0.2
51 | ofte 0.2
52 | forferdelig 0.2
53 | totalt 0.2
54 | stort sett 0.2
55 | fullt 0.2
56 | ekstra 0.3
57 | virkelig 0.3
58 | spesielt 0.3
59 | spesielt 0.3
60 | jævla 0.3
61 | intensivt 0.3
62 | rett og slett 0.3
63 | helt 0.3
64 | sterkt 0.3
65 | bemerkelsesverdig 0.3
66 | stort sett 0.3
67 | utrolig 0.3
68 | påfallende 0.3
69 | fantastisk 0.3
70 | i det vesentlige 0.3
71 | uvanlig 0.3
72 | dramatisk 0.3
73 | intenst 0.3
74 | ekstremt 0.4
75 | så 0.4
76 | utrolig 0.4
77 | fryktelig 0.4
78 | enormt 0.4
79 | umåtelig 0.4
80 | slik 0.4
81 | utrolig 0.4
82 | sinnsykt 0.4
83 | opprørende 0.4
84 | radikalt 0.4
85 | blærende 0.4
86 | unntaksvis 0.4
87 | overstigende 0.4
88 | uten tvil 0.4
89 | vei 0.4
90 | langt 0.4
91 | dypt 0.4
92 | super 0.4
93 | dypt 0.4
94 | universelt 0.4
95 | rikelig 0.4
96 | uendelig 0.4
97 | eksponentielt 0.4
98 | enormt 0.4
99 | grundig 0.4
100 | lidenskapelig 0.4
101 | voldsomt 0.4
102 | latterlig 0.4
103 | uanstendig 0.4
104 | vilt 0.4
105 | ekstraordinært 0.5
106 | spektakulært 0.5
107 | fenomenalt 0.5
108 | monumentalt 0.5
109 | utrolig 0.5
110 | helt 0.5
111 | mer -0.5
112 | enda mer 0.5
113 | mer enn 0.5
114 | mest 1
115 | ytterste 1
116 | totalt 0.5
117 | monumental 0.5
118 | flott 0.5
119 | enorm 0.5
120 | enorme 0.5
121 | massiv 0.5
122 | fullført 0.4
123 | uendelig 0.4
124 | uendelig 0.4
125 | absolutt 0.5
126 | rungende 0.4
127 | uskadd 0.4
128 | drop dead 0.4
129 | massiv 0.5
130 | kollossal 0.5
131 | utrolig 0.5
132 | ufattelig 0.5
133 | abject 0.5
134 | en slik 0.4
135 | en slik 0.4
136 | fullstendig 0.4
137 | dobbelt 0.3
138 | klar 0.3
139 | klarere 0.2
140 | klareste 0.5
141 | stor 0.3
142 | større 0.2
143 | største 0.5
144 | åpenbart 0.03
145 | alvorlig 0.3
146 | dyp 0.3
147 | dypere 0.2
148 | dypeste 0.5
149 | betydelig 0.2
150 | viktig 0.3
151 | større 0.2
152 | avgjørende 0.3
153 | umiddelbar 0.1
154 | synlig 0.1
155 | merkbar 0.1
156 | konsistent 0.1
157 | høy 0.2
158 | høyere 0.1
159 | høyeste 0.5
160 | ekte 0.2
161 | sant 0.2
162 | ren 0.2
163 | bestemt 0.2
164 | mye 0.2
165 | liten -0.3
166 | mindre -0.2
167 | minste -0.5
168 | moll -0.3
169 | moderat -0.3
170 | mild -0.3
171 | lett -0.5
172 | minste -0.9
173 | ubetydelig -0.5
174 | ubetydelig -0.5
175 | lav -2
176 | lavere -1.5
177 | laveste -3
178 | få -2
179 | færre -1.5
180 | færrest -3
181 | mye 0.3
182 | mange 0.3
183 | flere 0.2
184 | flere 0.2
185 | forskjellige 0.2
186 | noen få -0.3
187 | et par -0.3
188 | et par -0.3
189 | mye 0.3
190 | masse 0.3
191 | i det hele tatt -0.5
192 | mye 0.5
193 | en hel masse 0.5
194 | en enorm mengde på 0.5
195 | enorme antall på 0.5
196 | en pokker på 0.5
197 | en mengde på 0.5
198 | en mutltid på 0.5
199 | tonn 0.5
200 | tonn 0.5
201 | en haug med 0.3
202 | hauger på 0.3
203 | rikelig med 0.3
204 | en viss mengde -0.2
205 | noen -0.2
206 | litt av -0.5
207 | litt av -0.5
208 | litt av -0.5
209 | vanskelig å -1.5
210 | vanskelig til -1.5
211 | tøff til -1.5
212 | ikke i nærheten av -3
213 | ikke alt det -1.2
214 | ikke det -1.5
215 | ut av -2
216 |
--------------------------------------------------------------------------------
/data/sentiment/lexicons/socal/no_verb.txt:
--------------------------------------------------------------------------------
1 | kulminerer 4
2 | opphøyelse 4
3 | glede 4
4 | ære 4
5 | stein 4
6 | elsker 4
7 | enthrall 4
8 | ærefrykt 4
9 | fascinere 4
10 | enthrall 4
11 | enthrall 4
12 | elat 4
13 | extol 3
14 | helliggjøre 3
15 | transcend 3
16 | oppnå 3
17 | beundre 3
18 | forbløffe 3
19 | verne om 3
20 | ros 3
21 | glede 3
22 | vie 3
23 | fortrylle 3
24 | elske 3
25 | energiser 3
26 | nyt 3
27 | underholde 3
28 | utmerke seg 3
29 | imponere 3
30 | innovere 3
31 | ivrig 3
32 | kjærlighet 3
33 | tryllebinde 3
34 | ros 3
35 | premie 3
36 | rave 3
37 | glede 3
38 | klang 3
39 | respekt 3
40 | gjenopprette 3
41 | revitalisere 3
42 | smak 3
43 | lykkes 3
44 | overvinne 3
45 | overgå 3
46 | trives 3
47 | triumf 3
48 | vidunder 3
49 | løft 3
50 | capitivere 3
51 | wow 3
52 | spenning 3
53 | vant 3
54 | bekrefte 3
55 | glad 3
56 | forskjønne 3
57 | skatt 3
58 | stavebind 3
59 | trollbundet 3
60 | spennende 3
61 | blende 3
62 | gush 3
63 | hjelp 2
64 | more 2
65 | applaudere 2
66 | setter pris på 2
67 | tiltrekke 2
68 | gi 2
69 | skryte av 2
70 | boost 2
71 | stell 2
72 | kjærtegn 2
73 | feire 2
74 | sjarm 2
75 | koordinere 2
76 | samarbeide 2
77 | minnes 2
78 | kompliment 2
79 | gratulerer 2
80 | erobre 2
81 | bidra 2
82 | samarbeide 2
83 | opprett 2
84 | kreditt 2
85 | dyrke 2
86 | dedikere 2
87 | fortjener 2
88 | omfavne 2
89 | oppmuntre 2
90 | godkjenne 2
91 | engasjere 2
92 | forbedre 2
93 | berike 2
94 | fremkalle 2
95 | legge til rette for 2
96 | favorisere 2
97 | passform 2
98 | oppfylle 2
99 | få 2
100 | glad 2
101 | harmoniser 2
102 | helbrede 2
103 | høydepunkt 2
104 | ære 2
105 | lys 2
106 | senk 2
107 | inspirere 2
108 | interesse 2
109 | intriger 2
110 | le 2
111 | maske 2
112 | motivere 2
113 | pleie 2
114 | overvinne 2
115 | overvant 2
116 | vær så snill 2
117 | fremgang 2
118 | blomstre 2
119 | rens 2
120 | utstråle 2
121 | rally 2
122 | høste 2
123 | forene 2
124 | innløsning 2
125 | avgrense 2
126 | kongelig 2
127 | fornyelse 2
128 | reparasjon 2
129 | løse 2
130 | gjenforene 2
131 | svale 2
132 | belønning 2
133 | rival 2
134 | gnisten 2
135 | underbygge 2
136 | søte 2
137 | svimle 2
138 | sympatisere 2
139 | tillit 2
140 | løft 2
141 | ærverdig 2
142 | vinn 2
143 | verdt 2
144 | aktelse 2
145 | styrke 2
146 | frigjør 2
147 | anbefaler 2
148 | master 2
149 | forbedre 2
150 | overgå 2
151 | skinne 2
152 | pioner 2
153 | fortjeneste 2
154 | styrke 2
155 | extol 2
156 | extoll 2
157 | takk 2
158 | oppdater 2
159 | fortjeneste 2
160 | livne opp 2
161 | frigjør 2
162 | godkjenne 2
163 | forbedre 2
164 | frita 1
165 | godta 1
166 | bekrefte 1
167 | lindre 1
168 | forbedre 1
169 | forutse 1
170 | blidgjøre 1
171 | håpe 1
172 | assistere 1
173 | passer 1
174 | bli venn 1
175 | fange 1
176 | rens 1
177 | komfort 1
178 | kommune 1
179 | kommunisere 1
180 | kompensere 1
181 | kompromiss 1
182 | kondone 1
183 | overbevise 1
184 | råd 1
185 | korstog 1
186 | verdig 1
187 | doner 1
188 | spare 1
189 | forseggjort 1
190 | pynt ut 1
191 | styrke 1
192 | aktivere 1
193 | gi 1
194 | opplyse 1
195 | overlate 1
196 | tenke 1
197 | etablere 1
198 | utvikle seg 1
199 | opphisse 1
200 | opplevelse 1
201 | bli kjent 1
202 | flatere 1
203 | tilgi 1
204 | befeste 1
205 | foster 1
206 | boltre seg 1
207 | pynt 1
208 | generere 1
209 | glans 1
210 | glitter 1
211 | glød 1
212 | tilfredsstille 1
213 | guide 1
214 | sele 1
215 | informer 1
216 | arve 1
217 | spøk 1
218 | siste 1
219 | som 1
220 | formidle 1
221 | nominere 1
222 | gi næring 1
223 | adlyde 1
224 | tilbud 1
225 | overliste 1
226 | holde ut 1
227 | seire 1
228 | utsette 1
229 | beskytt 1
230 | purr 1
231 | reaktiver 1
232 | berolige 1
233 | gjenvinne 1
234 | tilbakelent 1
235 | gjenopprette 1
236 | slapp av 1
237 | avlaste 1
238 | oppussing 1
239 | renovere 1
240 | omvende deg 1
241 | hvile 1
242 | redning 1
243 | gjenopplive 1
244 | modnes 1
245 | hilsen 1
246 | tilfredsstille 1
247 | sikker 1
248 | del 1
249 | betyr 1
250 | forenkle 1
251 | smil 1
252 | krydder 1
253 | stabiliser 1
254 | standardisere 1
255 | stimulere 1
256 | stiver 1
257 | avta 1
258 | tilstrekkelig 1
259 | dress 1
260 | støtte 1
261 | tåle 1
262 | hyllest 1
263 | oppgradere 1
264 | overliste 1
265 | promotere 1
266 | empati 1
267 | rette 1
268 | overladning 1
269 | plass til 1
270 | multitask 1
271 | oppnå 1
272 | utdannet 1
273 | strømlinjeforme 1
274 | effektivitet 1
275 | blomstre 1
276 | tjen 1
277 | innkvartering 1
278 | berolige 1
279 | oppbygg 1
280 | bli venn 1
281 | mykgjøre 1
282 | felicitate 1
283 | frikoble 1
284 | overstige 1
285 | avmystifisere 1
286 | verdi 1
287 | titillate 1
288 | reienforce 1
289 | hjelp 1
290 | garanti 1
291 | komplement 1
292 | kapitaliser 1
293 | pris 1
294 | oppnå 1
295 | argumentere -1
296 | kamp -1
297 | uskarphet -1
298 | svak -1
299 | brudd -1
300 | blåmerke -1
301 | feil -1
302 | avbryt -1
303 | utfordring -1
304 | chide -1
305 | tette -1
306 | kollidere -1
307 | kamp -1
308 | tvinge -1
309 | komplisere -1
310 | concoct -1
311 | samsvar -1
312 | konfrontere -1
313 | krever -1
314 | kvake -1
315 | dawdle -1
316 | reduksjon -1
317 | forsinkelse -1
318 | død -1
319 | avskrive -1
320 | avvik -1
321 | diktere -1
322 | motet -1
323 | avskjed -1
324 | dispensere -1
325 | misfornøyde -1
326 | kast -1
327 | tvist -1
328 | distrahere -1
329 | grøft -1
330 | skilsmisse -1
331 | dominere -1
332 | nedskift -1
333 | svindle -1
334 | fare -1
335 | håndheve -1
336 | oppsluk -1
337 | vikle -1
338 | misunnelse -1
339 | slett -1
340 | feil -1
341 | unngå -1
342 | overdrive -1
343 | ekskluder -1
344 | utføre -1
345 | eksponere -1
346 | slukk -1
347 | feign -1
348 | fidget -1
349 | flykte -1
350 | forby -1
351 | bekymre -1
352 | skremme -1
353 | rynke pannen -1
354 | fumle -1
355 | gamble -1
356 | forherlige -1
357 | grip -1
358 | grip -1
359 | stønn -1
360 | knurring -1
361 | brummen -1
362 | hamstring -1
363 | vondt -1
364 | ignorere -1
365 | implikere -1
366 | bønnfall -1
367 | fengsel -1
368 | indusere -1
369 | betennelse -1
370 | forstyrre -1
371 | avbryt -1
372 | rus -1
373 | trenge inn -1
374 | oversvømmet -1
375 | klagesang -1
376 | lekkasje -1
377 | avvikle -1
378 | blander -1
379 | oppfører seg feil -1
380 | feilkast -1
381 | villede -1
382 | villedet -1
383 | feilinformasjon -1
384 | Mishandle -1
385 | feil -1
386 | mistrust -1
387 | misforstå -1
388 | misbruk -1
389 | stønn -1
390 | mønstre -1
391 | mutter -1
392 | nøytralisere -1
393 | oppheve -1
394 | utelat -1
395 | utgang -1
396 | overoppnå -1
397 | overløp -1
398 | overse -1
399 | overmakt -1
400 | overkjørt -1
401 | overreagerer -1
402 | overforenkle -1
403 | overvelde -1
404 | skjemme bort -1
405 | omkomme -1
406 | forfølge -1
407 | plod -1
408 | forby -1
409 | lirke -1
410 | avslutt -1
411 | rasjonalisere -1
412 | tilbakevise -1
413 | trekke seg tilbake -1
414 | avstå -1
415 | rehash -1
416 | gjengjelde -1
417 | retrett -1
418 | kvitt -1
419 | rip -1
420 | risiko -1
421 | romantiser -1
422 | sag -1
423 | skåld -1
424 | skremme -1
425 | svi -1
426 | scowl -1
427 | skrape -1
428 | granske -1
429 | sjokk -1
430 | skråstrek -1
431 | slug -1
432 | smugle -1
433 | snappe -1
434 | snike -1
435 | sob -1
436 | forstuing -1
437 | stammer -1
438 | stikk -1
439 | stjal -1
440 | bortkommen -1
441 | fast -1
442 | stunt -1
443 | undertrykke -1
444 | snuble -1
445 | sverget -1
446 | rive -1
447 | erte -1
448 | dekk -1
449 | revet -1
450 | overtredelse -1
451 | felle -1
452 | overtredelse -1
453 | triks -1
454 | trudge -1
455 | angre -1
456 | underbruk -1
457 | angre -1
458 | unravel -1
459 | røtter -1
460 | avta -1
461 | varp -1
462 | sutre -1
463 | pisk -1
464 | wince -1
465 | sår -1
466 | gjesp -1
467 | kjef -1
468 | lengter -1
469 | idolize -1
470 | hemme -1
471 | pålegge -1
472 | bekymring -1
473 | emne -1
474 | tåle -1
475 | fluster -1
476 | snivel -1
477 | insinuere -1
478 | coddle -1
479 | oppscenen -1
480 | underutnytte -1
481 | squirm -1
482 | mikromanage -1
483 | hund -1
484 | hollywoodise -1
485 | sidespor -1
486 | karikatur -1
487 | uenighet -1
488 | standard -1
489 | dø -1
490 | problemer -1
491 | mistillit -1
492 | skyld -1
493 | lekter -1
494 | overoppblås -1
495 | tømme -1
496 | vondt -1
497 | krampe -1
498 | jostle -1
499 | rasle -1
500 | uklar -1
501 | rust -1
502 | feil -1
503 | lur -1
504 | knuse -1
505 | placate -1
506 | overoppheting -1
507 | døve -1
508 | prute -1
509 | cuss -1
510 | uenighet -1
511 | uoverensstemmelse -1
512 | slapp -1
513 | misfarging -1
514 | avslutte -1
515 | tretthet -1
516 | motbevise -1
517 | syltetøy -1
518 | bolt -1
519 | offer -1
520 | sverte -1
521 | belch -1
522 | feiltolke -1
523 | forlenge -1
524 | typecast -1
525 | klynge -1
526 | gjennomsyre -1
527 | koble fra -1
528 | susing -1
529 | hobble -1
530 | drivhjul -1
531 | liten -1
532 | overreach -1
533 | deform -1
534 | rangel -1
535 | prevaricate -1
536 | forhåndsdømme -1
537 | raske -1
538 | peeve -1
539 | misforstå -1
540 | misforstått -1
541 | feil fremstilling -1
542 | jabber -1
543 | irk -1
544 | impinge -1
545 | hoodwink -1
546 | gawk -1
547 | frazzle -1
548 | dupe -1
549 | desorienterende -1
550 | lure -1
551 | skremmende -1
552 | karpe -1
553 | tukt -1
554 | blab -1
555 | blabber -1
556 | beleirer -1
557 | belabor -1
558 | bjørn -1
559 | avskaffe -2
560 | anklage -2
561 | agitere -2
562 | hevder -2
563 | bakhold -2
564 | amputere -2
565 | sinne -2
566 | irritere -2
567 | motvirke -2
568 | angrep -2
569 | avverge -2
570 | babble -2
571 | grevling -2
572 | balk -2
573 | forvis -2
574 | slo -2
575 | tro -2
576 | pass opp -2
577 | bite -2
578 | blære -2
579 | blokk -2
580 | tabbe -2
581 | bry -2
582 | skryte -2
583 | bestikkelse -2
584 | bust -2
585 | feil -2
586 | gnage -2
587 | billigere -2
588 | kvele -2
589 | sammenstøt -2
590 | tvinge -2
591 | kollaps -2
592 | commiserate -2
593 | skjul -2
594 | begrense -2
595 | konflikt -2
596 | forvirre -2
597 | konspirere -2
598 | begrense -2
599 | motsier -2
600 | contrive -2
601 | begjære -2
602 | krympe -2
603 | lamme -2
604 | kritisere -2
605 | knuse -2
606 | begrense -2
607 | skade -2
608 | forfall -2
609 | lure -2
610 | nederlag -2
611 | tømme -2
612 | trykk -2
613 | frata -2
614 | latterliggjøre -2
615 | forringe -2
616 | skuffe -2
617 | ikke godkjenner -2
618 | diskreditere -2
619 | diskriminere -2
620 | motløs -2
621 | misliker -2
622 | forstyrre -2
623 | misfornøyd -2
624 | forvreng -2
625 | nød -2
626 | forstyrr -2
627 | undergang -2
628 | avløp -2
629 | drukner -2
630 | dump -2
631 | eliminere -2
632 | flau -2
633 | emote -2
634 | inngrep -2
635 | erodere -2
636 | kaste ut -2
637 | eksos -2
638 | utvise -2
639 | fabrikere -2
640 | falsk -2
641 | vakle -2
642 | flaunt -2
643 | flyndre -2
644 | kraft -2
645 | taper -2
646 | forsak -2
647 | sørge -2
648 | hemme -2
649 | sikring -2
650 | hindre -2
651 | sult -2
652 | kjas -2
653 | svekke -2
654 | hindre -2
655 | pådra -2
656 | inept -2
657 | infisere -2
658 | angrep -2
659 | påføre -2
660 | skade -2
661 | invadere -2
662 | irritere -2
663 | fare -2
664 | mangel -2
665 | lyve -2
666 | taper -2
667 | tapte -2
668 | manipulere -2
669 | rot -2
670 | spotte -2
671 | drap -2
672 | nag -2
673 | negere -2
674 | forsømmelse -2
675 | besatt -2
676 | hindre -2
677 | fornærme -2
678 | motsette -2
679 | overaktiv -2
680 | overskygge -2
681 | lamme -2
682 | nedlatende -2
683 | perplex -2
684 | overhode -2
685 | forstyrrelse -2
686 | plyndre -2
687 | pontifikat -2
688 | pout -2
689 | preen -2
690 | late som -2
691 | tiltale -2
692 | provosere -2
693 | straffe -2
694 | avvis -2
695 | rekyl -2
696 | nekte -2
697 | regress -2
698 | tilbakefall -2
699 | si fra deg -2
700 | undertrykk -2
701 | bebreid -2
702 | mislik -2
703 | begrense -2
704 | forsinke -2
705 | hevn -2
706 | gå tilbake -2
707 | tilbakekalle -2
708 | opprør -2
709 | brudd -2
710 | sap -2
711 | skjelle -2
712 | skru -2
713 | gripe -2
714 | skill -2
715 | knuse -2
716 | skjul -2
717 | makulere -2
718 | unngå -2
719 | skulk -2
720 | baktalelse -2
721 | spor -2
722 | smøre -2
723 | hån -2
724 | snorke -2
725 | spank -2
726 | gyte -2
727 | sputter -2
728 | sløse -2
729 | stilk -2
730 | skremme -2
731 | stjele -2
732 | kveler -2
733 | stagnere -2
734 | kvele -2
735 | stamme -2
736 | strekke -2
737 | sliter -2
738 | bukke under -2
739 | lider -2
740 | kvele -2
741 | tukle -2
742 | hån -2
743 | true -2
744 | thrash -2
745 | slit -2
746 | tråkke -2
747 | bagatellisere -2
748 | undergrave -2
749 | underwhelm -2
750 | vex -2
751 | bryte -2
752 | skeptisk -2
753 | avfall -2
754 | svekk -2
755 | vilje -2
756 | vri deg -2
757 | myrde -2
758 | blind -2
759 | uenig -2
760 | utstøte -2
761 | vandre -2
762 | klage -2
763 | disenchant -2
764 | revulse -2
765 | duehull -2
766 | flabbergast -2
767 | harry -2
768 | piss -2
769 | feil -2
770 | ødelegge -2
771 | skadedyr -2
772 | skjevhet -2
773 | panorere -2
774 | dra -2
775 | _ned -2
776 | mar -2
777 | klage -2
778 | skade -2
779 | forverre -2
780 | vandalisere -2
781 | avslutt -2
782 | funksjonsfeil -2
783 | tosk -2
784 | slave -2
785 | taint -2
786 | ødelagt -2
787 | flekk -2
788 | rykket ned -2
789 | sprit -2
790 | utukt -2
791 | rane -2
792 | trist -2
793 | diss -2
794 | medskyldig -2
795 | ondskap -2
796 | manglende evne -2
797 | sverte -2
798 | forurense -2
799 | smerte -2
800 | feilberegne -2
801 | mope -2
802 | plage -2
803 | accost -2
804 | unnerve -2
805 | skam -2
806 | irettesett -2
807 | overdrive -2
808 | feilbehandling -2
809 | myr -2
810 | ondartet -2
811 | trussel -2
812 | jeer -2
813 | ugyldiggjøre -2
814 | innflytelse -2
815 | heckle -2
816 | hamstrung -2
817 | gripe -2
818 | ryper -2
819 | flout -2
820 | enervate -2
821 | emasculate -2
822 | manglende respekt -2
823 | vanære -2
824 | nedsett -2
825 | debase -2
826 | kolliderer -2
827 | bungle -2
828 | besmirch -2
829 | aunguish -2
830 | fornærme -2
831 | forverre -2
832 | forfalle -2
833 | bash -2
834 | bar -3
835 | misbruk -3
836 | forverre -3
837 | alarm -3
838 | fremmedgjøre -3
839 | atrofi -3
840 | baffel -3
841 | tro -3
842 | nedgjøre -3
843 | forvirret -3
844 | eksplosjon -3
845 | bombardere -3
846 | brutalisere -3
847 | kantrer -3
848 | careen -3
849 | jukse -3
850 | fordømme -3
851 | forvirre -3
852 | korroderer -3
853 | korrupt -3
854 | stapp -3
855 | forbannelse -3
856 | utartet -3
857 | fornedre -3
858 | fordømme -3
859 | beklager -3
860 | forverres -3
861 | fortvilelse -3
862 | forkaste -3
863 | avsky -3
864 | rasende -3
865 | slaveri -3
866 | utrydde -3
867 | irritere -3
868 | utnytte -3
869 | utrydde -3
870 | mislykkes -3
871 | frustrer -3
872 | gløtt -3
873 | vevstol -3
874 | mangel -3
875 | molest -3
876 | utslette -3
877 | undertrykke -3
878 | pervertere -3
879 | plagerize -3
880 | pest -3
881 | herjing -3
882 | irettesette -3
883 | angre -3
884 | vekke opp igjen -3
885 | avvis -3
886 | avvise -3
887 | latterliggjøring -3
888 | rue -3
889 | sabotasje -3
890 | spott -3
891 | skrik -3
892 | koke -3
893 | skrumpe -3
894 | smelle -3
895 | kvele -3
896 | spyd -3
897 | sulte -3
898 | stink -3
899 | underkaste -3
900 | undergrave -3
901 | hindre -3
902 | pine -3
903 | opprørt -3
904 | usurp -3
905 | jamre -3
906 | forverres -3
907 | overfall -3
908 | halshugge -3
909 | ærekrenke -3
910 | nedbryter -3
911 | rive -3
912 | demoralisere -3
913 | fornærmelse -3
914 | råte -3
915 | suger -3
916 | bastardize -3
917 | kvalme -3
918 | plyndring -3
919 | ydmyke -3
920 | hvem_ PRP _ reek -3
921 | not_ dritt -3
922 | desillusjon -3
923 | forårsake -3
924 | stank -3
925 | stinket -3
926 | voldtekt -3
927 | kvinnelig -3
928 | ødelegge -3
929 | håpløshet -3
930 | røkelse -3
931 | fattige -3
932 | trakassere -3
933 | forurense -3
934 | ødelegge -3
935 | traumatisere -3
936 | skandalisere -3
937 | repugn -3
938 | raseri -3
939 | plagiere -3
940 | lambaste -3
941 | imperil -3
942 | glødere -3
943 | excoriate -3
944 | rådgiver -3
945 | nedsettelse -3
946 | despoil -3
947 | vanhellige -3
948 | demonisere -3
949 | bespottelse -3
950 | hjernevask -3
951 | browbeat -3
952 | appal -3
953 | forferdelig -3
954 | befoul -3
955 | plage -4
956 | utslette -4
957 | forråde -4
958 | jævla -4
959 | avskyr -4
960 | gruer -4
961 | hater -4
962 | forferdelig -4
963 | rasende -4
964 | mortify -4
965 | frastøtte -4
966 | ruin -4
967 | slakter -4
968 | ødelegge -4
969 | slakt -4
970 | forferdelig -4
971 | terrorisere -4
972 | oppkast -4
973 | kunne_ panikk -4
974 | opprør -4
975 | tortur -4
976 | spott -4
977 | avsky -4
978 | utføre -4
979 | vanære -4
980 | avsky -5
981 | forferdelig -5
982 | avsky -5
983 | kannibalisere -5
984 | uren -5
985 | forakte -5
986 |
--------------------------------------------------------------------------------
/data/sentiment/norec_sentence/labels.json:
--------------------------------------------------------------------------------
1 | {"Negative": "0", "Neutral": "1", "Positive": "2"}
--------------------------------------------------------------------------------
/data/skweak_logo.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NorskRegnesentral/skweak/2b6db15e8429dbda062b2cc9cc74e69f51a0a8b6/data/skweak_logo.jpg
--------------------------------------------------------------------------------
/data/skweak_logo_thumbnail.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NorskRegnesentral/skweak/2b6db15e8429dbda062b2cc9cc74e69f51a0a8b6/data/skweak_logo_thumbnail.jpg
--------------------------------------------------------------------------------
/data/skweak_procedure.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NorskRegnesentral/skweak/2b6db15e8429dbda062b2cc9cc74e69f51a0a8b6/data/skweak_procedure.png
--------------------------------------------------------------------------------
/data/wikidata_small_tokenised.json.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NorskRegnesentral/skweak/2b6db15e8429dbda062b2cc9cc74e69f51a0a8b6/data/wikidata_small_tokenised.json.gz
--------------------------------------------------------------------------------
/examples/ner/__init__.py:
--------------------------------------------------------------------------------
1 | from . import data_utils, conll2003_ner, eval_utils, muc6_ner, conll2003_prep
--------------------------------------------------------------------------------
/examples/ner/conll2003_ner.py:
--------------------------------------------------------------------------------
1 | from typing import Iterable, Tuple
2 | import re, json, os
3 | import snips_nlu_parsers
4 | from skweak.base import CombinedAnnotator, SpanAnnotator
5 | from skweak.spacy import ModelAnnotator, TruecaseAnnotator
6 | from skweak.heuristics import FunctionAnnotator, TokenConstraintAnnotator, SpanConstraintAnnotator, SpanEditorAnnotator
7 | from skweak.gazetteers import GazetteerAnnotator, extract_json_data
8 | from skweak.doclevel import DocumentHistoryAnnotator, DocumentMajorityAnnotator
9 | from skweak.aggregation import MajorityVoter
10 | from skweak import utils
11 | from spacy.tokens import Doc, Span # type: ignore
12 | from . import data_utils
13 |
14 | # Data files for gazetteers
15 | WIKIDATA = os.path.dirname(__file__) + "/../../data/wikidata_tokenised.json"
16 | WIKIDATA_SMALL = os.path.dirname(__file__) + "/../../data/wikidata_small_tokenised.json"
17 | COMPANY_NAMES = os.path.dirname(__file__) + "/../../data/company_names_tokenised.json"
18 | GEONAMES = os.path.dirname(__file__) + "/../../data/geonames.json"
19 | CRUNCHBASE = os.path.dirname(__file__) + "/../../data/crunchbase.json"
20 | PRODUCTS = os.path.dirname(__file__) + "/../../data/products.json"
21 | FIRST_NAMES = os.path.dirname(__file__) + "/../../data/first_names.json"
22 | FORM_FREQUENCIES = os.path.dirname(__file__) + "/../../data/form_frequencies.json"
23 |
24 |
25 | ############################################
26 | # Combination of all annotators
27 | ############################################
28 |
29 |
30 | class NERAnnotator(CombinedAnnotator):
31 | """Annotator of entities in documents, combining several sub-annotators (such as gazetteers,
32 | spacy models etc.). To add all annotators currently implemented, call add_all(). """
33 |
34 | def add_all(self):
35 | """Adds all implemented annotation functions, models and filters"""
36 |
37 | print("Loading shallow functions")
38 | self.add_shallow()
39 | print("Loading Spacy NER models")
40 | self.add_models()
41 | print("Loading gazetteer supervision modules")
42 | self.add_gazetteers()
43 | print("Loading document-level supervision sources")
44 | self.add_doc_level()
45 |
46 | return self
47 |
48 | def add_shallow(self):
49 | """Adds shallow annotation functions"""
50 |
51 | # Detection of dates, time, money, and numbers
52 | self.add_annotator(FunctionAnnotator("date_detector", date_generator))
53 | self.add_annotator(FunctionAnnotator("time_detector", time_generator))
54 | self.add_annotator(FunctionAnnotator("money_detector", money_generator))
55 |
56 | # Detection based on casing
57 | proper_detector = TokenConstraintAnnotator("proper_detector", utils.is_likely_proper, "ENT")
58 |
59 | # Detection based on casing, but allowing some lowercased tokens
60 | proper2_detector = TokenConstraintAnnotator("proper2_detector", utils.is_likely_proper, "ENT")
61 | proper2_detector.add_gap_tokens(data_utils.LOWERCASED_TOKENS | data_utils.NAME_PREFIXES)
62 |
63 | # Detection based on part-of-speech tags
64 | nnp_detector = TokenConstraintAnnotator("nnp_detector", lambda tok: tok.tag_ in {"NNP", "NNPS"}, "ENT")
65 |
66 | # Detection based on dependency relations (compound phrases)
67 | compound = lambda tok: utils.is_likely_proper(tok) and utils.in_compound(tok)
68 | compound_detector = TokenConstraintAnnotator("compound_detector", compound, "ENT")
69 |
70 | exclusives = ["date_detector", "time_detector", "money_detector"]
71 | for annotator in [proper_detector, proper2_detector, nnp_detector, compound_detector]:
72 | annotator.add_incompatible_sources(exclusives)
73 | annotator.add_gap_tokens(["'s", "-"])
74 | self.add_annotator(annotator)
75 |
76 | # We add one variants for each NE detector, looking at infrequent tokens
77 | infrequent_name = "infrequent_%s" % annotator.name
78 | self.add_annotator(SpanConstraintAnnotator(infrequent_name, annotator.name, utils.is_infrequent))
79 |
80 | # Other types (legal references etc.)
81 | misc_detector = FunctionAnnotator("misc_detector", misc_generator)
82 | legal_detector = FunctionAnnotator("legal_detector", legal_generator)
83 |
84 | # Detection of companies with a legal type
85 | ends_with_legal_suffix = lambda x: x[-1].lower_.rstrip(".") in data_utils.LEGAL_SUFFIXES
86 | company_type_detector = SpanConstraintAnnotator("company_type_detector", "proper2_detector",
87 | ends_with_legal_suffix, "COMPANY")
88 |
89 | # Detection of full person names
90 | full_name_detector = SpanConstraintAnnotator("full_name_detector", "proper2_detector",
91 | FullNameDetector(), "PERSON")
92 |
93 | for annotator in [misc_detector, legal_detector, company_type_detector, full_name_detector]:
94 | annotator.add_incompatible_sources(exclusives)
95 | self.add_annotator(annotator)
96 |
97 | # General number detector
98 | number_detector = FunctionAnnotator("number_detector", number_generator)
99 | number_detector.add_incompatible_sources(exclusives + ["legal_detector", "company_type_detector"])
100 | self.add_annotator(number_detector)
101 |
102 | self.add_annotator(SnipsAnnotator("snips"))
103 | return self
104 |
105 | def add_models(self):
106 | """Adds Spacy NER models to the annotator"""
107 |
108 | self.add_annotator(ModelAnnotator("core_web_md", "en_core_web_md"))
109 | self.add_annotator(TruecaseAnnotator("core_web_md_truecase", "en_core_web_md", FORM_FREQUENCIES))
110 | self.add_annotator(ModelAnnotator("BTC", os.path.dirname(__file__) + "/../../data/btc"))
111 | self.add_annotator( TruecaseAnnotator("BTC_truecase", os.path.dirname(__file__) + "/../../data/btc", FORM_FREQUENCIES))
112 |
113 | # Avoid spans that start with an article
114 | editor = lambda span: span[1:] if span[0].lemma_ in {"the", "a", "an"} else span
115 | self.add_annotator(SpanEditorAnnotator("edited_BTC", "BTC", editor))
116 | self.add_annotator(SpanEditorAnnotator("edited_BTC_truecase", "BTC_truecase", editor))
117 | self.add_annotator(SpanEditorAnnotator("edited_core_web_md", "core_web_md", editor))
118 | self.add_annotator(SpanEditorAnnotator("edited_core_web_md_truecase", "core_web_md_truecase", editor))
119 |
120 | return self
121 |
122 | def add_gazetteers(self, full_load=True):
123 | """Adds gazetteer supervision models (company names and wikidata)."""
124 |
125 | # Annotation of company names based on a large list of companies
126 | # company_tries = extract_json_data(COMPANY_NAMES) if full_load else {}
127 |
128 | # Annotation of company, person and location names based on wikidata
129 | wiki_tries = extract_json_data(WIKIDATA) if full_load else {}
130 |
131 | # Annotation of company, person and location names based on wikidata (only entries with descriptions)
132 | wiki_small_tries = extract_json_data(WIKIDATA_SMALL)
133 |
134 | # Annotation of location names based on geonames
135 | geo_tries = extract_json_data(GEONAMES)
136 |
137 | # Annotation of organisation and person names based on crunchbase open data
138 | crunchbase_tries = extract_json_data(CRUNCHBASE)
139 |
140 | # Annotation of product names
141 | products_tries = extract_json_data(PRODUCTS)
142 |
143 | exclusives = ["date_detector", "time_detector", "money_detector", "number_detector"]
144 | for name, tries in {"wiki":wiki_tries, "wiki_small":wiki_small_tries,
145 | "geo":geo_tries, "crunchbase":crunchbase_tries, "products":products_tries}.items():
146 |
147 | # For each KB, we create two gazetters (case-sensitive or not)
148 | cased_gazetteer = GazetteerAnnotator("%s_cased"%name, tries, case_sensitive=True)
149 | uncased_gazetteer = GazetteerAnnotator("%s_uncased"%name, tries, case_sensitive=False)
150 | cased_gazetteer.add_incompatible_sources(exclusives)
151 | uncased_gazetteer.add_incompatible_sources(exclusives)
152 | self.add_annotators(cased_gazetteer, uncased_gazetteer)
153 |
154 | # We also add new sources for multitoken entities (which have higher confidence)
155 | multitoken_cased = SpanConstraintAnnotator("multitoken_%s"%(cased_gazetteer.name),
156 | cased_gazetteer.name, lambda s: len(s) > 1)
157 | multitoken_uncased = SpanConstraintAnnotator("multitoken_%s"%(uncased_gazetteer.name),
158 | uncased_gazetteer.name, lambda s: len(s) > 1)
159 | self.add_annotators(multitoken_cased, multitoken_uncased)
160 |
161 | return self
162 |
163 | def add_doc_level(self):
164 | """Adds document-level supervision sources"""
165 |
166 | self.add_annotator(ConLL2003Standardiser())
167 |
168 | maj_voter = MajorityVoter("doclevel_voter", ["LOC", "MISC", "ORG", "PER"],
169 | initial_weights={"doc_history":0, "doc_majority":0})
170 | maj_voter.add_underspecified_label("ENT", {"LOC", "MISC", "ORG", "PER"})
171 | self.add_annotator(maj_voter)
172 |
173 | self.add_annotator(DocumentHistoryAnnotator("doc_history_cased", "doclevel_voter", ["PER", "ORG"]))
174 | self.add_annotator(DocumentHistoryAnnotator("doc_history_uncased", "doclevel_voter", ["PER", "ORG"],
175 | case_sentitive=False))
176 |
177 | maj_voter = MajorityVoter("doclevel_voter", ["LOC", "MISC", "ORG", "PER"],
178 | initial_weights={"doc_majority":0})
179 | maj_voter.add_underspecified_label("ENT", {"LOC", "MISC", "ORG", "PER"})
180 | self.add_annotator(maj_voter)
181 |
182 | self.add_annotator(DocumentMajorityAnnotator("doc_majority_cased", "doclevel_voter"))
183 | self.add_annotator(DocumentMajorityAnnotator("doc_majority_uncased", "doclevel_voter",
184 | case_sensitive=False))
185 | return self
186 |
187 |
188 | ############################################
189 | # Heuristics
190 | ############################################
191 |
192 |
193 | def date_generator(doc):
194 | """Searches for occurrences of date patterns in text"""
195 |
196 | spans = []
197 |
198 | i = 0
199 | while i < len(doc):
200 | tok = doc[i]
201 | if tok.lemma_ in data_utils.DAYS | data_utils.DAYS_ABBRV:
202 | spans.append((i, i + 1, "DATE"))
203 | elif tok.is_digit and re.match("\\d+$", tok.text) and int(tok.text) > 1920 and int(tok.text) < 2040:
204 | spans.append((i, i + 1, "DATE"))
205 | elif tok.lemma_ in data_utils.MONTHS | data_utils.MONTHS_ABBRV:
206 | if tok.tag_ == "MD": # Skipping "May" used as auxiliary
207 | pass
208 | elif i > 0 and re.match("\\d+$", doc[i - 1].text) and int(doc[i - 1].text) < 32:
209 | spans.append((i - 1, i + 1, "DATE"))
210 | elif i > 1 and re.match("\\d+(?:st|nd|rd|th)$", doc[i - 2].text) and doc[i - 1].lower_ == "of":
211 | spans.append((i - 2, i + 1, "DATE"))
212 | elif i < len(doc) - 1 and re.match("\\d+$", doc[i + 1].text) and int(doc[i + 1].text) < 32:
213 | spans.append((i, i + 2, "DATE"))
214 | i += 1
215 | else:
216 | spans.append((i, i + 1, "DATE"))
217 | i += 1
218 |
219 | for start, end, content in utils.merge_contiguous_spans(spans, doc):
220 | yield start, end, content
221 |
222 |
223 | def time_generator(doc):
224 | """Searches for occurrences of time patterns in text"""
225 |
226 | i = 0
227 | while i < len(doc):
228 | tok = doc[i]
229 |
230 | if (i < len(doc) - 1 and tok.text[0].isdigit() and
231 | doc[i + 1].lower_ in {"am", "pm", "a.m.", "p.m.", "am.", "pm."}):
232 | yield i, i + 2, "TIME"
233 | i += 1
234 | elif tok.text[0].isdigit() and re.match("\\d{1,2}\\:\\d{1,2}", tok.text):
235 | yield i, i + 1, "TIME"
236 | i += 1
237 | i += 1
238 |
239 |
240 | def money_generator(doc):
241 | """Searches for occurrences of money patterns in text"""
242 |
243 | i = 0
244 | while i < len(doc):
245 | tok = doc[i]
246 | if tok.text[0].isdigit():
247 | j = i + 1
248 | while (j < len(doc) and (doc[j].text[0].isdigit() or doc[j].norm_ in data_utils.MAGNITUDES)):
249 | j += 1
250 |
251 | found_symbol = False
252 | if i > 0 and doc[i - 1].text in (data_utils.CURRENCY_CODES | data_utils.CURRENCY_SYMBOLS):
253 | i = i - 1
254 | found_symbol = True
255 | if (j < len(doc) and doc[j].text in
256 | (data_utils.CURRENCY_CODES | data_utils.CURRENCY_SYMBOLS | {"euros", "cents", "rubles"})):
257 | j += 1
258 | found_symbol = True
259 |
260 | if found_symbol:
261 | yield i, j, "MONEY"
262 | i = j
263 | else:
264 | i += 1
265 |
266 |
267 | def number_generator(doc):
268 | """Searches for occurrences of number patterns (cardinal, ordinal, quantity or percent) in text"""
269 |
270 | i = 0
271 | while i < len(doc):
272 | tok = doc[i]
273 |
274 | if tok.lower_ in data_utils.ORDINALS:
275 | yield i, i + 1, "ORDINAL"
276 |
277 | elif re.search("\\d", tok.text):
278 | j = i + 1
279 | while (j < len(doc) and (doc[j].norm_ in data_utils.MAGNITUDES)):
280 | j += 1
281 | if j < len(doc) and doc[j].lower_.rstrip(".") in data_utils.UNITS:
282 | j += 1
283 | yield i, j, "QUANTITY"
284 | elif j < len(doc) and doc[j].lower_ in ["%", "percent", "pc.", "pc", "pct", "pct.", "percents",
285 | "percentage"]:
286 | j += 1
287 | yield i, j, "PERCENT"
288 | else:
289 | yield i, j, "CARDINAL"
290 | i = j - 1
291 | i += 1
292 |
293 |
294 | class FullNameDetector():
295 | """Search for occurrences of full person names (first name followed by at least one title token)"""
296 |
297 | def __init__(self):
298 | fd = open(FIRST_NAMES)
299 | self.first_names = set(json.load(fd))
300 | fd.close()
301 |
302 | def __call__(self, span: Span) -> bool:
303 | # We assume full names are between 2 and 5 tokens
304 | if len(span) < 2 or len(span) > 5:
305 | return False
306 |
307 | return (span[0].text in self.first_names and
308 | span[-1].is_alpha and span[-1].is_title)
309 |
310 |
311 | class SnipsAnnotator(SpanAnnotator):
312 | """Annotation using the Snips NLU entity parser.
313 | You must install "snips-nlu-parsers" (pip install snips-nlu-parsers) to make it work.
314 | """
315 |
316 | def __init__(self, name: str):
317 | """Initialise the annotation tool."""
318 |
319 | super(SnipsAnnotator, self).__init__(name)
320 | self.parser = snips_nlu_parsers.BuiltinEntityParser.build(language="en")
321 |
322 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
323 | """Runs the parser on the spacy document, and convert the result to labels."""
324 |
325 | text = doc.text
326 |
327 | # The current version of Snips has a bug that makes it crash with some rare
328 | # Turkish characters, or mentions of "billion years"
329 | text = text.replace("’", "'").replace("”", "\"").replace("“", "\"").replace("—", "-")
330 | text = text.encode("iso-8859-15", "ignore").decode("iso-8859-15")
331 | text = re.sub("(\\d+) ([bm]illion(?: (?:\\d+|one|two|three|four|five|six|seven" +
332 | "|eight|nine|ten))? years?)", "\\g<1>.0 \\g<2>", text)
333 |
334 | results = self.parser.parse(text)
335 | for result in results:
336 | span = doc.char_span(result["range"]["start"], result["range"]["end"])
337 | if span is None or span.text.lower() in {"now"} or span.text in {"may"}:
338 | continue
339 | label = None
340 | if (result["entity_kind"] == "snips/number" and span.text.lower() not in
341 | {"one", "some", "few", "many", "several"}):
342 | label = "CARDINAL"
343 | elif (result["entity_kind"] == "snips/ordinal" and span.text.lower() not in
344 | {"first", "second", "the first", "the second"}):
345 | label = "ORDINAL"
346 | elif result["entity_kind"] == "snips/temperature":
347 | label = "QUANTITY"
348 | elif result["entity_kind"] == "snips/amountOfMoney":
349 | label = "MONEY"
350 | elif result["entity_kind"] == "snips/percentage":
351 | label = "PERCENT"
352 | elif result["entity_kind"] in {"snips/date", "snips/datePeriod", "snips/datetime"}:
353 | label = "DATE"
354 | elif result["entity_kind"] in {"snips/time", "snips/timePeriod"}:
355 | label = "TIME"
356 |
357 | if label:
358 | yield span.start, span.end, label
359 |
360 | def legal_generator(doc):
361 | legal_spans = []
362 | for span in utils.get_spans(doc, ["proper2_detector", "nnp_detector"]):
363 | if not utils.is_likely_proper(doc[span.end-1]):
364 | continue
365 | last_token = doc[span.end-1].text.title().rstrip("s")
366 |
367 | if last_token in data_utils.LEGAL:
368 | legal_spans.append((span.start,span.end, "LAW"))
369 |
370 |
371 | # Handling legal references such as Article 5
372 | for i in range(len(doc) - 1):
373 | if doc[i].text.rstrip("s") in {"Article", "Paragraph", "Section", "Chapter", "§"}:
374 | if doc[i + 1].text[0].isdigit() or doc[i + 1].text in data_utils.ROMAN_NUMERALS:
375 | start, end = i, i + 2
376 | if (i < len(doc) - 3 and doc[i + 2].text in {"-", "to", "and"}
377 | and (doc[i + 3].text[0].isdigit() or doc[i + 3].text in data_utils.ROMAN_NUMERALS)):
378 | end = i + 4
379 | legal_spans.append((start, end, "LAW"))
380 |
381 | # Merge contiguous spans of legal references ("Article 5, Paragraph 3")
382 | legal_spans = utils.merge_contiguous_spans(legal_spans, doc)
383 | for start, end, label in legal_spans:
384 | yield start, end, label
385 |
386 |
387 | def misc_generator(doc):
388 | """Detects occurrences of countries and various less-common entities (NORP, FAC, EVENT, LANG)"""
389 |
390 | spans = set(doc.spans["proper2_detector"])
391 | spans |= {doc[i:i+1] for i in range(len(doc))}
392 |
393 | for span in sorted(spans):
394 |
395 | span_text = span.text
396 | if span_text.isupper():
397 | span_text = span_text.title()
398 | last_token = doc[span.end-1].text
399 |
400 | if span_text in data_utils.COUNTRIES:
401 | yield span.start, span.end, "GPE"
402 |
403 | if len(span) <= 3 and (span in data_utils.NORPS or last_token in data_utils.NORPS
404 | or last_token.rstrip("s") in data_utils.NORPS):
405 | yield span.start, span.end, "NORP"
406 |
407 | if span in data_utils.LANGUAGES and doc[span.start].tag_=="NNP":
408 | yield span.start, span.end, "LANGUAGE"
409 |
410 | if last_token in data_utils.FACILITIES and len(span) > 1:
411 | yield span.start, span.end, "FAC"
412 |
413 | if last_token in data_utils.EVENTS and len(span) > 1:
414 | yield span.start, span.end, "EVENT"
415 |
416 |
417 |
418 | ############################################
419 | # Standardisation of the output labels
420 | ############################################
421 |
422 |
423 | class ConLL2003Standardiser(SpanAnnotator):
424 | """Annotator taking existing annotations and standardising them
425 | to fit the ConLL 2003 tag scheme"""
426 |
427 | def __init__(self):
428 | super(ConLL2003Standardiser, self).__init__("")
429 |
430 | def __call__(self, doc):
431 | """Annotates one single document"""
432 |
433 | for source in doc.spans:
434 |
435 | new_spans = []
436 | for span in doc.spans[source]:
437 | if "\n" in span.text:
438 | continue
439 | elif span.label_=="PERSON":
440 | new_spans.append(Span(doc, span.start, span.end, label="PER"))
441 | elif span.label_ in {"ORGANIZATION", "ORGANISATION", "COMPANY"}:
442 | new_spans.append(Span(doc, span.start, span.end, label="ORG"))
443 | elif span.label_ in {"GPE"}:
444 | new_spans.append(Span(doc, span.start, span.end, label="LOC"))
445 | elif span.label_ in {"EVENT", "FAC", "LANGUAGE", "LAW", "NORP", "PRODUCT", "WORK_OF_ART"}:
446 | new_spans.append(Span(doc, span.start, span.end, label="MISC"))
447 | else:
448 | new_spans.append(span)
449 | doc.spans[source] = new_spans
450 | return doc
451 |
452 |
--------------------------------------------------------------------------------
/examples/ner/conll2003_prep.py:
--------------------------------------------------------------------------------
1 |
2 | from .conll2003_ner import (WIKIDATA, WIKIDATA_SMALL, CRUNCHBASE, PRODUCTS,
3 | GEONAMES, COMPANY_NAMES)
4 |
5 | from . import data_utils
6 | import pickle, re, json
7 | import spacy
8 |
9 | """Contains scripts used to compile the lists of entities from Wikipedia, Geonames,
10 | Crunchbase and DBPedia. Those scripts can be ignored in most cases, as it is easier
11 | to directly rely on the already compiled json files. """
12 |
13 |
14 | ############################################
15 | # Compilation of data sources
16 | ############################################
17 |
18 |
19 | def compile_wikidata(wikidata="../data/WikidataNE_20170320_NECKAR_1_0.json_.gz", only_with_descriptions=False):
20 | """Compiles a JSON file with the wiki data"""
21 |
22 |
23 | import gzip, json
24 | fd = gzip.open(wikidata)
25 | wikidata = {"PERSON":{}, "LOC":{}, "GPE":{}, "ORG":{}}
26 | location_qs = set()
27 | for l in fd:
28 | d = json.loads(l)
29 | neClass = str(d["neClass"])
30 | name = d["norm_name"]
31 | if ("en_sitelink" not in d and neClass !="PER"):
32 | continue
33 | if "en_sitelink" in d:
34 | if "," in d["en_sitelink"] or "(" in d["en_sitelink"]:
35 | continue
36 | if name[0].isdigit() or name[-1].isdigit() or len(name) < 2:
37 | continue
38 | if neClass=="PER":
39 | neClass = "PERSON"
40 | elif neClass=="LOC":
41 | if {'Mountain Range', 'River', 'Sea', 'Continent', 'Mountain'}.intersection(d.get("location_type",set())):
42 | neClass = "LOC"
43 | else:
44 | neClass ="GPE"
45 | location_qs.add(d["id"])
46 | elif neClass=="ORG" and d["id"] in location_qs:
47 | continue
48 | if "alias" in d:
49 | d["nb_aliases"] = len(d["alias"])
50 | del d["alias"]
51 | for key_to_remove in ["de_sitelink", '$oid', "id", "coordinate", "official_website", "_id"]:
52 | if key_to_remove in d:
53 | del d[key_to_remove]
54 | if name in wikidata[neClass]:
55 | merge = wikidata[neClass][name] if len(str(wikidata[neClass][name])) > len(str(d)) else d
56 | merge["nb_entities"] = wikidata[neClass][name].get("nb_entities", 1) + 1
57 | wikidata[neClass][name] = merge
58 | else:
59 | wikidata[neClass][name] = d
60 |
61 | fd = open("data/frequencies.pkl", "rb")
62 | frequencies = pickle.load(fd)
63 | fd.close()
64 |
65 | # We only keep entities with a certain frequency
66 | for neClass in ["PERSON", "LOC", "ORG", "GPE"]:
67 | for entity in list(wikidata[neClass].keys()):
68 | if entity.lower() in frequencies and frequencies[entity.lower()]>10000:
69 | del wikidata[neClass][entity]
70 |
71 | # And prune those that cannot be encoded using latin characters
72 | for neClass in ["PERSON", "LOC", "ORG", "GPE"]:
73 | for entity in list(wikidata[neClass].keys()):
74 | try:
75 | entity.encode('iso-8859-15')
76 | except UnicodeEncodeError:
77 | del wikidata[neClass][entity]
78 |
79 |
80 | wikidata2 = {neClass:{} for neClass in wikidata}
81 | for neClass in wikidata:
82 | entities_for_class = set()
83 | for entity in wikidata[neClass]:
84 | nb_tokens = len(entity.split())
85 | if nb_tokens > 10:
86 | continue
87 | if only_with_descriptions and "description" not in wikidata[neClass][entity]:
88 | continue
89 | entities_for_class.add(entity)
90 | if "en_sitelink" in wikidata[neClass][entity]:
91 | entities_for_class.add(wikidata[neClass][entity]["en_sitelink"])
92 | wikidata2[neClass] = entities_for_class #type: ignore
93 |
94 | fd = open(WIKIDATA_SMALL if only_with_descriptions else WIKIDATA, "w")
95 | json.dump({key:sorted(names) for key,names in wikidata2.items()}, fd)
96 | fd.close()
97 |
98 |
99 | def get_alternative_company_names(name, vocab=None):
100 | """Extract a list of alternative company names (with or without legal suffix etc.)"""
101 |
102 | alternatives = {name}
103 | while True:
104 | current_nb_alternatives = len(alternatives)
105 |
106 | for alternative in list(alternatives):
107 | tokens = alternative.split()
108 | if len(tokens)==1:
109 | continue
110 |
111 | # We add an alternative name without the legal suffix
112 | if tokens[-1].lower().rstrip(".") in data_utils.LEGAL_SUFFIXES:
113 | alternatives.add(" ".join(tokens[:-1]))
114 |
115 | if tokens[-1].lower() in {"limited", "corporation"}:
116 | alternatives.add(" ".join(tokens[:-1]))
117 |
118 | if tokens[-1].lower().rstrip(".") in {"corp", "inc", "co"}:
119 | if alternative.endswith("."):
120 | alternatives.add(alternative.rstrip("."))
121 | else:
122 | alternatives.add(alternative+".")
123 |
124 | # If the last token is a country name (like The SAS Group Norway), add an alternative without
125 | if tokens[-1] in data_utils.COUNTRIES:
126 | alternatives.add(" ".join(tokens[:-1]))
127 |
128 | # If the name starts with a the, add an alternative without it
129 | if tokens[0].lower()=="the":
130 | alternatives.add(" ".join(tokens[1:]))
131 |
132 | # If the name ends with a generic token such as "Telenor International", add an alternative without
133 | if vocab is not None and tokens[-1] in data_utils.GENERIC_TOKENS and any([tok for tok in tokens if vocab[tok].rank==0]):
134 | alternatives.add(" ".join(tokens[:-1]))
135 |
136 | if len(alternatives)==current_nb_alternatives:
137 | break
138 |
139 | # We require the alternatives to have at least 2 characters (4 characters if the name does not look like an acronym)
140 | alternatives = {alt for alt in alternatives if len(alt) > 1 and alt.lower().rstrip(".") not in data_utils.LEGAL_SUFFIXES}
141 | alternatives = {alt for alt in alternatives if len(alt) > 3 or alt.isupper()}
142 |
143 | return alternatives
144 |
145 |
146 | def compile_company_names():
147 | """Compiles a JSON file with company names"""
148 |
149 | vocab = spacy.load("en_core_web_md").vocab
150 |
151 | fd = open("../data/graph/entity.sql.json")
152 | company_entities = set()
153 | other_org_entities = set()
154 | for l in fd:
155 | dico = json.loads(l)
156 | if ("factset_entity_type_description" not in dico or dico["factset_entity_type_description" ] not in
157 | {"Private Company", "Subsidiary", "Extinct", "Public Company", "Holding Company", "College/University",
158 | "Government", "Non-Profit Organization", "Operating Division", "Foundation/Endowment"}):
159 | continue
160 | name = dico["factset_entity_name"]
161 | name = name.split("(")[0].split(",")[0].strip(" \n\t/")
162 | if not name:
163 | continue
164 |
165 | alternatives = get_alternative_company_names(name, vocab)
166 | if dico["factset_entity_type_description" ] in {"College/University", "Government", "Non-Profit Organization", "Foundation/Endowment"}:
167 | other_org_entities.update(alternatives)
168 | else:
169 | company_entities.update(alternatives)
170 | fd.close()
171 | print("Number of extracted entities: %i companies and %i other organisations"%(len(company_entities), len(other_org_entities)))
172 | fd = open(COMPANY_NAMES, "w")
173 | json.dump({"COMPANY":sorted(company_entities), "ORG":sorted(other_org_entities)}, fd)
174 | fd.close()
175 |
176 |
177 | def compile_geographical_data(geo_source="../data/allCountries.txt", population_threshold=100000):
178 | """Compiles a JSON file with geographical locations"""
179 |
180 | names = set()
181 | fd = open(geo_source)
182 | for i, line in enumerate(fd):
183 | line_feats = line.split("\t")
184 | if len(line_feats) < 15:
185 | continue
186 | population = int(line_feats[14])
187 | if population < population_threshold:
188 | continue
189 | name = line_feats[1].strip()
190 | names.add(name)
191 | name = re.sub(".*(?:Kingdom|Republic|Province|State|Commonwealth|Region|City|Federation) of ", "", name).strip()
192 | names.add(name)
193 | name = name.replace(" City", "").replace(" Region", "").replace(" District", "").replace(" County", "").replace(" Zone", "").strip()
194 | names.add(name)
195 | name = (name.replace("Arrondissement de ", "").replace("Stadtkreis ", "").replace("Landkreis ", "").strip()
196 | .replace("Departamento de ", "").replace("Département de ", "").replace("Provincia di ", "")).strip()
197 | names.add(name)
198 | name = re.sub("^the ", "", name).strip()
199 | names.add(name)
200 | if i%10000==0:
201 | print("Number of processed lines:", i, "and number of extracted locations:", len(names))
202 | fd.close()
203 | names = {alt for alt in names if len(alt) > 2 and alt.lower().rstrip(".") not in data_utils.LEGAL_SUFFIXES}
204 | fd = open(GEONAMES, "w")
205 | json.dump({"GPE":sorted(names)}, fd)
206 | fd.close()
207 |
208 |
209 | def compile_crunchbase_data(org_data="../data/organizations.csv", people_data="../data/people.csv"):
210 | """Compiles a JSON file with company and person names from Crunchbase Open Data"""
211 |
212 | company_entities = set()
213 | other_org_entities = set()
214 |
215 | vocab = spacy.load("en_core_web_md").vocab
216 |
217 | fd = open(org_data)
218 | for line in fd:
219 | split = [s.strip() for s in line.rstrip().strip("\"").split("\",\"")]
220 | if len(split) < 5:
221 | continue
222 | name = split[1]
223 | alternatives = get_alternative_company_names(name, vocab)
224 | if split[3] in {"company", "investor"}:
225 | company_entities.update(alternatives)
226 | else:
227 | other_org_entities.update(alternatives)
228 | fd.close()
229 | print("Number of extracted entities: %i companies and %i other organisations"%(len(company_entities), len(other_org_entities)))
230 |
231 | persons = set()
232 | fd = open(people_data)
233 | for line in fd:
234 | split = [s.strip() for s in line.rstrip().strip("\"").split("\",\"")]
235 | if len(split) < 5:
236 | continue
237 | first_name = split[2]
238 | last_name = split[3]
239 | alternatives = {"%s %s"%(first_name, last_name)}
240 | # alternatives.add(last_name)
241 | alternatives.add("%s. %s"%(first_name[0], last_name))
242 | if " " in first_name:
243 | first_split = first_name.split(" ", 1)
244 | alternatives.add("%s %s"%(first_split[0], last_name))
245 | alternatives.add("%s %s. %s"%(first_split[0], first_split[1][0], last_name))
246 | alternatives.add("%s. %s. %s"%(first_split[0][0], first_split[1][0], last_name))
247 | persons.update(alternatives)
248 |
249 | # We require person names to have at least 3 characters (and not be a suffix)
250 | persons = {alt for alt in persons if len(alt) > 2 and alt.lower().rstrip(".") not in data_utils.LEGAL_SUFFIXES}
251 | fd.close()
252 | print("Number of extracted entities: %i person names"%(len(persons)))
253 |
254 | fd = open(CRUNCHBASE, "w")
255 | json.dump({"COMPANY":sorted(company_entities), "ORG":sorted(other_org_entities), "PERSON":sorted(persons)}, fd)
256 | fd.close()
257 |
258 | def compile_product_data(data="../data/dbpedia.json"):
259 | fd = open(data)
260 | all_product_names = set()
261 | for line in fd:
262 | line = line.strip().strip(",")
263 | value = json.loads(line)["label2"]["value"]
264 | if "(" in value:
265 | continue
266 |
267 | product_names = {value}
268 |
269 | # The DBpedia entries are all titled, which cause problems for products such as iPad
270 | if len(value)>2 and value[0] in {"I", "E"} and value[1].isupper() and value[2].islower():
271 | product_names.add(value[0].lower()+value[1:])
272 |
273 | # We also add plural entries
274 | for product_name in list(product_names):
275 | if len(product_name.split()) <= 2:
276 | plural = product_name + ("es" if value.endswith("s") else "s")
277 | product_names.add(plural)
278 |
279 | all_product_names.update(product_names)
280 |
281 | fd = open(PRODUCTS, "w")
282 | json.dump({"PRODUCT":sorted(all_product_names)}, fd)
283 | fd.close()
284 |
285 |
286 | def compile_wiki_product_data(data="../data/wiki_products.json"):
287 | fd = open(data)
288 | dict_list = json.load(fd)
289 | fd.close()
290 | products = set()
291 | for product_dict in dict_list:
292 | product_name = product_dict["itemLabel"]
293 | if "(" in product_name or len(product_name) <= 2:
294 | continue
295 | products.add(product_name)
296 | if len(product_name.split()) <= 2:
297 | plural = product_name + ("es" if product_name.endswith("s") else "s")
298 | products.add(plural)
299 |
300 | fd = open(WIKIDATA, "r")
301 | current_dict = json.load(fd)
302 | fd.close()
303 | current_dict["PRODUCT"] = sorted(products)
304 | fd = open(WIKIDATA, "w")
305 | json.dump(current_dict, fd)
306 | fd.close()
307 |
308 | fd = open(WIKIDATA_SMALL, "r")
309 | current_dict = json.load(fd)
310 | fd.close()
311 | current_dict["PRODUCT"] = sorted(products)
312 | fd = open(WIKIDATA_SMALL, "w")
313 | json.dump(current_dict, fd)
314 | fd.close()
315 |
--------------------------------------------------------------------------------
/examples/ner/data_utils.py:
--------------------------------------------------------------------------------
1 |
2 | """Class containing some generic entity names (in English)"""
3 |
4 | # List of currency symbols and three-letter codes
5 | CURRENCY_SYMBOLS = {"$", "¥", "£", "€", "kr", "₽", "R$", "₹", "Rp", "₪", "zł", "Rs", "₺", "RS"}
6 |
7 | CURRENCY_CODES = {"USD", "EUR", "CNY", "JPY", "GBP", "NOK", "DKK", "CAD", "RUB", "MXN", "ARS", "BGN",
8 | "BRL", "CHF", "CLP", "CZK", "INR", "IDR", "ILS", "IRR", "IQD", "KRW", "KZT", "NGN",
9 | "QAR", "SEK", "SYP", "TRY", "UAH", "AED", "AUD", "COP", "MYR", "SGD", "NZD", "THB",
10 | "HUF", "HKD", "ZAR", "PHP", "KES", "EGP", "PKR", "PLN", "XAU", "VND", "GBX"}
11 |
12 | # sets of tokens used for the shallow patterns
13 | MONTHS = {"January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November",
14 | "December"}
15 | MONTHS_ABBRV = {"Jan.", "Feb.", "Mar.", "Apr.", "May.", "Jun.", "Jul.", "Aug.", "Sep.", "Sept.", "Oct.", "Nov.", "Dec."}
16 | DAYS = {"Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"}
17 | DAYS_ABBRV = {"Mon.", "Tu.", "Tue.", "Tues.", "Wed.", "Th.", "Thu.", "Thur.", "Thurs.", "Fri.", "Sat.", "Sun."}
18 | MAGNITUDES = {"million", "billion", "mln", "bln", "bn", "thousand", "m", "k", "b", "m.", "k.", "b.", "mln.", "bln.",
19 | "bn."}
20 | UNITS = {"tons", "tonnes", "barrels", "m", "km", "miles", "kph", "mph", "kg", "°C", "dB", "ft", "gal", "gallons", "g",
21 | "kW", "s", "oz",
22 | "m2", "km2", "yards", "W", "kW", "kWh", "kWh/yr", "Gb", "MW", "kilometers", "meters", "liters", "litres", "g",
23 | "grams", "tons/yr",
24 | 'pounds', 'cubits', 'degrees', 'ton', 'kilograms', 'inches', 'inch', 'megawatts', 'metres', 'feet', 'ounces',
25 | 'watts', 'megabytes',
26 | 'gigabytes', 'terabytes', 'hectares', 'centimeters', 'millimeters', "F", "Celsius"}
27 | ORDINALS = ({"first, second, third", "fourth", "fifth", "sixth", "seventh"} |
28 | {"%i1st" % i for i in range(100)} | {"%i2nd" % i for i in range(100)} | {"%ith" % i for i in range(1000)})
29 | ROMAN_NUMERALS = {'I', 'II', 'III', 'IV', 'V', 'VI', 'VII', 'VIII', 'IX', 'X', 'XI', 'XII', 'XIII', 'XIV', 'XV', 'XVI',
30 | 'XVII',
31 | 'XVIII', 'XIX', 'XX', 'XXI', 'XXII', 'XXIII', 'XXIV', 'XXV', 'XXVI', 'XXVII', 'XXVIII', 'XXIX', 'XXX'}
32 |
33 | # Full list of country names
34 | COUNTRIES = {'Afghanistan', 'Albania', 'Algeria', 'Andorra', 'Angola', 'Antigua', 'Argentina', 'Armenia', 'Australia',
35 | 'Austria',
36 | 'Azerbaijan', 'Bahamas', 'Bahrain', 'Bangladesh', 'Barbados', 'Belarus', 'Belgium', 'Belize', 'Benin',
37 | 'Bhutan',
38 | 'Bolivia', 'Bosnia Herzegovina', 'Botswana', 'Brazil', 'Brunei', 'Bulgaria', 'Burkina', 'Burundi',
39 | 'Cambodia', 'Cameroon',
40 | 'Canada', 'Cape Verde', 'Central African Republic', 'Chad', 'Chile', 'China', 'Colombia', 'Comoros',
41 | 'Congo', 'Costa Rica',
42 | 'Croatia', 'Cuba', 'Cyprus', 'Czech Republic', 'Denmark', 'Djibouti', 'Dominica', 'Dominican Republic',
43 | 'East Timor',
44 | 'Ecuador', 'Egypt', 'El Salvador', 'Equatorial Guinea', 'Eritrea', 'Estonia', 'Ethiopia', 'Fiji',
45 | 'Finland', 'France',
46 | 'Gabon', 'Gambia', 'Georgia', 'Germany', 'Ghana', 'Greece', 'Grenada', 'Guatemala', 'Guinea',
47 | 'Guinea-Bissau', 'Guyana',
48 | 'Haiti', 'Honduras', 'Hungary', 'Iceland', 'India', 'Indonesia', 'Iran', 'Iraq', 'Ireland', 'Israel',
49 | 'Italy', 'Ivory Coast',
50 | 'Jamaica', 'Japan', 'Jordan', 'Kazakhstan', 'Kenya', 'Kiribati', 'Korea North', 'Korea South', 'Kosovo',
51 | 'Kuwait', 'Kyrgyzstan',
52 | 'Laos', 'Latvia', 'Lebanon', 'Lesotho', 'Liberia', 'Libya', 'Liechtenstein', 'Lithuania', 'Luxembourg',
53 | 'Macedonia', 'Madagascar',
54 | 'Malawi', 'Malaysia', 'Maldives', 'Mali', 'Malta', 'Marshall Islands', 'Mauritania', 'Mauritius', 'Mexico',
55 | 'Micronesia',
56 | 'Moldova', 'Monaco', 'Mongolia', 'Montenegro', 'Morocco', 'Mozambique', 'Myanmar', 'Namibia', 'Nauru',
57 | 'Nepal', 'Netherlands',
58 | 'New Zealand', 'Nicaragua', 'Niger', 'Nigeria', 'Norway', 'Oman', 'Pakistan', 'Palau', 'Panama',
59 | 'Papua New Guinea',
60 | 'Paraguay', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Qatar', 'Romania', 'Russian Federation',
61 | 'Rwanda', 'St Kitts & Nevis',
62 | 'St Lucia', 'Saint Vincent & the Grenadines', 'Samoa', 'San Marino', 'Sao Tome & Principe', 'Saudi Arabia',
63 | 'Senegal', 'Serbia',
64 | 'Seychelles', 'Sierra Leone', 'Singapore', 'Slovakia', 'Slovenia', 'Solomon Islands', 'Somalia',
65 | 'South Africa', 'South Sudan',
66 | 'Spain', 'Sri Lanka', 'Sudan', 'Suriname', 'Swaziland', 'Sweden', 'Switzerland', 'Syria', 'Taiwan',
67 | 'Tajikistan', 'Tanzania',
68 | 'Thailand', 'Togo', 'Tonga', 'Trinidad & Tobago', 'Tunisia', 'Turkey', 'Turkmenistan', 'Tuvalu', 'Uganda',
69 | 'Ukraine',
70 | 'United Arab Emirates', 'United Kingdom', 'United States', 'Uruguay', 'Uzbekistan', 'Vanuatu',
71 | 'Vatican City', 'Venezuela',
72 | 'Vietnam', 'Yemen', 'Zambia', 'Zimbabwe', "USA", "UK", "Russia", "South Korea"}
73 |
74 | # Natialities, religious and political groups
75 | NORPS = {'Afghan', 'African', 'Albanian', 'Algerian', 'American', 'Andorran', 'Anglican', 'Angolan', 'Arab', 'Aramean',
76 | 'Argentine', 'Armenian',
77 | 'Asian', 'Australian', 'Austrian', 'Azerbaijani', 'Bahamian', 'Bahraini', 'Baklan', 'Bangladeshi', 'Batswana',
78 | 'Belarusian', 'Belgian',
79 | 'Belizean', 'Beninese', 'Bermudian', 'Bhutanese', 'Bolivian', 'Bosnian', 'Brazilian', 'British', 'Bruneian',
80 | 'Buddhist',
81 | 'Bulgarian', 'Burkinabe', 'Burmese', 'Burundian', 'Californian', 'Cambodian', 'Cameroonian', 'Canadian',
82 | 'Cape Verdian', 'Catholic', 'Caymanian',
83 | 'Central African', 'Central American', 'Chadian', 'Chilean', 'Chinese', 'Christian', 'Christian-Democrat',
84 | 'Christian-Democratic',
85 | 'Colombian', 'Communist', 'Comoran', 'Congolese', 'Conservative', 'Costa Rican', 'Croat', 'Cuban', 'Cypriot',
86 | 'Czech', 'Dane', 'Danish',
87 | 'Democrat', 'Democratic', 'Djibouti', 'Dominican', 'Dutch', 'East European', 'Ecuadorean', 'Egyptian',
88 | 'Emirati', 'English', 'Equatoguinean',
89 | 'Equatorial Guinean', 'Eritrean', 'Estonian', 'Ethiopian', 'Eurasian', 'European', 'Fijian', 'Filipino',
90 | 'Finn', 'Finnish', 'French',
91 | 'Gabonese', 'Gambian', 'Georgian', 'German', 'Germanic', 'Ghanaian', 'Greek', 'Greenlander', 'Grenadan',
92 | 'Grenadian', 'Guadeloupean', 'Guatemalan',
93 | 'Guinea-Bissauan', 'Guinean', 'Guyanese', 'Haitian', 'Hawaiian', 'Hindu', 'Hinduist', 'Hispanic', 'Honduran',
94 | 'Hungarian', 'Icelander', 'Indian',
95 | 'Indonesian', 'Iranian', 'Iraqi', 'Irish', 'Islamic', 'Islamist', 'Israeli', 'Israelite', 'Italian', 'Ivorian',
96 | 'Jain', 'Jamaican', 'Japanese',
97 | 'Jew', 'Jewish', 'Jordanian', 'Kazakhstani', 'Kenyan', 'Kirghiz', 'Korean', 'Kurd', 'Kurdish', 'Kuwaiti',
98 | 'Kyrgyz', 'Labour', 'Latin',
99 | 'Latin American', 'Latvian', 'Lebanese', 'Liberal', 'Liberian', 'Libyan', 'Liechtensteiner', 'Lithuanian',
100 | 'Londoner', 'Luxembourger',
101 | 'Macedonian', 'Malagasy', 'Malawian', 'Malaysian', 'Maldivan', 'Malian', 'Maltese', 'Manxman', 'Marshallese',
102 | 'Martinican', 'Martiniquais',
103 | 'Marxist', 'Mauritanian', 'Mauritian', 'Mexican', 'Micronesian', 'Moldovan', 'Mongolian', 'Montenegrin',
104 | 'Montserratian', 'Moroccan',
105 | 'Motswana', 'Mozambican', 'Muslim', 'Myanmarese', 'Namibian', 'Nationalist', 'Nazi', 'Nauruan', 'Nepalese',
106 | 'Netherlander', 'New Yorker',
107 | 'New Zealander', 'Nicaraguan', 'Nigerian', 'Nordic', 'North American', 'North Korean', 'Norwegian', 'Orthodox',
108 | 'Pakistani', 'Palauan',
109 | 'Palestinian', 'Panamanian', 'Papua New Guinean', 'Paraguayan', 'Parisian', 'Peruvian', 'Philistine', 'Pole',
110 | 'Polish', 'Portuguese',
111 | 'Protestant', 'Puerto Rican', 'Qatari', 'Republican', 'Roman', 'Romanian', 'Russian', 'Rwandan',
112 | 'Saint Helenian', 'Saint Lucian',
113 | 'Saint Vincentian', 'Salvadoran', 'Sammarinese', 'Samoan', 'San Marinese', 'Sao Tomean', 'Saudi',
114 | 'Saudi Arabian', 'Scandinavian', 'Scottish',
115 | 'Senegalese', 'Serb', 'Serbian', 'Shia', 'Shiite', 'Sierra Leonean', 'Sikh', 'Singaporean', 'Slovak',
116 | 'Slovene', 'Social-Democrat', 'Socialist',
117 | 'Somali', 'South African', 'South American', 'South Korean', 'Soviet', 'Spaniard', 'Spanish', 'Sri Lankan',
118 | 'Sudanese', 'Sunni',
119 | 'Surinamer', 'Swazi', 'Swede', 'Swedish', 'Swiss', 'Syrian', 'Taiwanese', 'Tajik', 'Tanzanian', 'Taoist',
120 | 'Texan', 'Thai', 'Tibetan',
121 | 'Tobagonian', 'Togolese', 'Tongan', 'Tunisian', 'Turk', 'Turkish', 'Turkmen(s)', 'Tuvaluan', 'Ugandan',
122 | 'Ukrainian', 'Uruguayan', 'Uzbek',
123 | 'Uzbekistani', 'Venezuelan', 'Vietnamese', 'Vincentian', 'Virgin Islander', 'Welsh', 'West European',
124 | 'Western', 'Yemeni', 'Yemenite',
125 | 'Yugoslav', 'Zambian', 'Zimbabwean', 'Zionist'}
126 |
127 | # Facilities
128 | FACILITIES = {"Palace", "Temple", "Gate", "Museum", "Bridge", "Road", "Airport", "Hospital", "School", "Tower",
129 | "Station", "Avenue",
130 | "Prison", "Building", "Plant", "Shopping Center", "Shopping Centre", "Mall", "Church", "Synagogue",
131 | "Mosque", "Harbor", "Harbour",
132 | "Rail", "Railway", "Metro", "Tram", "Highway", "Tunnel", 'House', 'Field', 'Hall', 'Place', 'Freeway',
133 | 'Wall', 'Square', 'Park',
134 | 'Hotel'}
135 |
136 | # Legal documents
137 | LEGAL = {"Law", "Agreement", "Act", 'Bill', "Constitution", "Directive", "Treaty", "Code", "Reform", "Convention",
138 | "Resolution", "Regulation",
139 | "Amendment", "Customs", "Protocol", "Charter"}
140 |
141 | # event names
142 | EVENTS = {"War", "Festival", "Show", "Massacre", "Battle", "Revolution", "Olympics", "Games", "Cup", "Week", "Day",
143 | "Year", "Series"}
144 |
145 | # Names of languages
146 | LANGUAGES = {'Afar', 'Abkhazian', 'Avestan', 'Afrikaans', 'Akan', 'Amharic', 'Aragonese', 'Arabic', 'Aramaic',
147 | 'Assamese', 'Avaric', 'Aymara',
148 | 'Azerbaijani', 'Bashkir', 'Belarusian', 'Bulgarian', 'Bambara', 'Bislama', 'Bengali', 'Tibetan', 'Breton',
149 | 'Bosnian', 'Cantonese',
150 | 'Catalan', 'Chechen', 'Chamorro', 'Corsican', 'Cree', 'Czech', 'Chuvash', 'Welsh', 'Danish', 'German',
151 | 'Divehi', 'Dzongkha', 'Ewe',
152 | 'Greek', 'English', 'Esperanto', 'Spanish', 'Castilian', 'Estonian', 'Basque', 'Persian', 'Fulah',
153 | 'Filipino', 'Finnish', 'Fijian', 'Faroese',
154 | 'French', 'Western Frisian', 'Irish', 'Gaelic', 'Galician', 'Guarani', 'Gujarati', 'Manx', 'Hausa',
155 | 'Hebrew', 'Hindi', 'Hiri Motu',
156 | 'Croatian', 'Haitian', 'Hungarian', 'Armenian', 'Herero', 'Indonesian', 'Igbo', 'Inupiaq', 'Ido',
157 | 'Icelandic', 'Italian', 'Inuktitut',
158 | 'Japanese', 'Javanese', 'Georgian', 'Kongo', 'Kikuyu', 'Kuanyama', 'Kazakh', 'Kalaallisut', 'Greenlandic',
159 | 'Central Khmer', 'Kannada',
160 | 'Korean', 'Kanuri', 'Kashmiri', 'Kurdish', 'Komi', 'Cornish', 'Kirghiz', 'Latin', 'Luxembourgish', 'Ganda',
161 | 'Limburgish', 'Lingala', 'Lao',
162 | 'Lithuanian', 'Luba-Katanga', 'Latvian', 'Malagasy', 'Marshallese', 'Maori', 'Macedonian', 'Malayalam',
163 | 'Mongolian', 'Marathi', 'Malay',
164 | 'Maltese', 'Burmese', 'Nauru', 'Bokmål', 'Norwegian', 'Ndebele', 'Nepali', 'Ndonga', 'Dutch', 'Flemish',
165 | 'Nynorsk', 'Navajo', 'Chichewa',
166 | 'Occitan', 'Ojibwa', 'Oromo', 'Oriya', 'Ossetian', 'Punjabi', 'Pali', 'Polish', 'Pashto', 'Portuguese',
167 | 'Quechua', 'Romansh', 'Rundi',
168 | 'Romanian', 'Russian', 'Kinyarwanda', 'Sanskrit', 'Sardinian', 'Sindhi', 'Sami', 'Sango', 'Sinhalese',
169 | 'Slovak', 'Slovenian', 'Samoan',
170 | 'Shona', 'Somali', 'Albanian', 'Serbian', 'Swati', 'Sotho', 'Sundanese', 'Swedish', 'Swahili', 'Tamil',
171 | 'Telugu', 'Tajik', 'Thai',
172 | 'Tigrinya', 'Turkmen', 'Taiwanese', 'Tagalog', 'Tswana', 'Tonga', 'Turkish', 'Tsonga', 'Tatar', 'Twi',
173 | 'Tahitian', 'Uighur', 'Ukrainian',
174 | 'Urdu', 'Uzbek', 'Venda', 'Vietnamese', 'Volapük', 'Walloon', 'Wolof', 'Xhosa', 'Yiddish', 'Yoruba',
175 | 'Zhuang', 'Mandarin',
176 | 'Mandarin Chinese', 'Chinese', 'Zulu'}
177 |
178 | LEGAL_SUFFIXES = {
179 | 'ltd', # Limited ~13.000
180 | 'llc', # limited liability company (UK)
181 | 'ltda', # limitada (Brazil, Portugal)
182 | 'inc', # Incorporated ~9700
183 | 'co ltd', # Company Limited ~9200
184 | 'corp', # Corporation ~5200
185 | 'sa', # Spółka Akcyjna (Poland), Société Anonyme (France) ~3200
186 | 'plc', # Public Limited Company (Great Britain) ~2100
187 | 'ag', # Aktiengesellschaft (Germany) ~1000
188 | 'gmbh', # Gesellschaft mit beschränkter Haftung (Germany)
189 | 'bhd', # Berhad (Malaysia) ~900
190 | 'jsc', # Joint Stock Company (Russia) ~900
191 | 'co', # Corporation/Company ~900
192 | 'ab', # Aktiebolag (Sweden) ~800
193 | 'ad', # Akcionarsko Društvo (Serbia), Aktsionerno Drujestvo (Bulgaria) ~600
194 | 'tbk', # Terbuka (Indonesia) ~500
195 | 'as', # Anonim Şirket (Turkey), Aksjeselskap (Norway) ~500
196 | 'pjsc', # Public Joint Stock Company (Russia, Ukraine) ~400
197 | 'spa', # Società Per Azioni (Italy) ~300
198 | 'nv', # Naamloze vennootschap (Netherlands, Belgium) ~230
199 | 'dd', # Dioničko Društvo (Croatia) ~220
200 | 'a s', # a/s (Denmark), a.s (Slovakia) ~210
201 | 'oao', # Открытое акционерное общество (Russia) ~190
202 | 'asa', # Allmennaksjeselskap (Norway) ~160
203 | 'ojsc', # Open Joint Stock Company (Russia) ~160
204 | 'lp', # Limited Partnership (US) ~140
205 | 'llp', # limited liability partnership
206 | 'oyj', # julkinen osakeyhtiö (Finland) ~120
207 | 'de cv', # Capital Variable (Mexico) ~120
208 | 'se', # Societas Europaea (Germany) ~100
209 | 'kk', # kabushiki gaisha (Japan)
210 | 'aps', # Anpartsselskab (Denmark)
211 | 'cv', # commanditaire vennootschap (Netherlands)
212 | 'sas', # société par actions simplifiée (France)
213 | 'sro', # Spoločnosť s ručením obmedzeným (Slovakia)
214 | 'oy', # Osakeyhtiö (Finland)
215 | 'kg', # Kommanditgesellschaft (Germany)
216 | 'bv', # Besloten Vennootschap (Netherlands)
217 | 'sarl', # société à responsabilité limitée (France)
218 | 'srl', # Società a responsabilità limitata (Italy)
219 | 'sl' # Sociedad Limitada (Spain)
220 | }
221 | # Generic words that may appear in official company names but are sometimes skipped when mentioned in news articles (e.g. Nordea Bank -> Nordea)
222 | GENERIC_TOKENS = {"International", "Group", "Solutions", "Technologies", "Management", "Association", "Associates",
223 | "Partners",
224 | "Systems", "Holdings", "Services", "Bank", "Fund", "Stiftung", "Company"}
225 |
226 | # List of tokens that are typically lowercase even when they occur in capitalised segments (e.g. International Council of Shopping Centers)
227 | LOWERCASED_TOKENS = {"'s", "-", "a", "an", "the", "at", "by", "for", "in", "of", "on", "to", "up", "and"}
228 |
229 | # Prefixes to family names that are often in lowercase
230 | NAME_PREFIXES = {"-", "von", "van", "de", "di", "le", "la", "het", "'t'", "dem", "der", "den", "d'", "ter"}
231 |
--------------------------------------------------------------------------------
/examples/ner/eval_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pandas
3 | import sklearn.metrics
4 | from skweak import utils
5 | from spacy.tokens import Span # type: ignore
6 |
7 | def evaluate(docs, all_labels, target_sources):
8 | """Extracts the evaluation results for one or more sources, and add them to a pandas DataFrame."""
9 |
10 | if isinstance(target_sources, str):
11 | target_sources = [target_sources]
12 |
13 | records = []
14 | for source in target_sources:
15 | results = get_results(docs, all_labels, source)
16 | labels = set(results["label_weights"].keys())
17 | for name in sorted(labels) + ["micro", "weighted", "macro"]:
18 | if name in results:
19 | record = results[name]
20 | record["label"] = name
21 | record["model"] = source
22 | if name in labels:
23 | record["proportion"] = results["label_weights"][name]
24 | records.append(record)
25 |
26 | df = pandas.DataFrame.from_records(records)
27 | df["proportion"] = df.proportion.apply(lambda x: "%.1f %%"%(x*100) if not np.isnan(x) else "")
28 | df["tok_cee"] = df.tok_cee.apply(lambda x: str(x) if not np.isnan(x) else "")
29 | df["tok_acc"] = df.tok_acc.apply(lambda x: str(x) if not np.isnan(x) else "")
30 | df["coverage"] = df.coverage.apply(lambda x: str(x) if not np.isnan(x) else "")
31 | df = df.set_index(["label", "proportion", "model"]).sort_index()
32 | df = df[["tok_precision", "tok_recall", "tok_f1", "tok_cee", "tok_acc", "coverage",
33 | "ent_precision", "ent_recall", "ent_f1"]]
34 | return df
35 |
36 |
37 |
38 | def get_results(docs, all_labels, target_source, conf_threshold=0.5):
39 | """Computes the usual metrics (precision, recall, F1, cross-entropy) on the dataset, using the spacy entities
40 | in each document as gold standard, and the annotations of a given source as the predicted values"""
41 |
42 |
43 | all_numbers = compute_raw_numbers(docs, all_labels, target_source, conf_threshold)
44 | tok_tp, tok_fp, tok_fn, tok_logloss, tok_nb, tok_tp_tn, ent_tp, ent_fp, ent_fn, ent_support, tok_support = all_numbers
45 |
46 | # We then compute the metrics themselves
47 | results = {}
48 | for label in ent_support:
49 | ent_pred = ent_tp[label]+ent_fp[label] + 1E-10
50 | ent_true = ent_tp[label]+ent_fn[label] + 1E-10
51 | tok_pred = tok_tp[label]+tok_fp[label] + 1E-10
52 | tok_true = tok_tp[label]+tok_fn[label] + 1E-10
53 | results[label] = {}
54 | results[label]["ent_precision"] = round(ent_tp[label]/ent_pred, 3)
55 | results[label]["ent_recall"] = round(ent_tp[label]/ent_true, 3)
56 | results[label]["tok_precision"] = round(tok_tp[label]/tok_pred, 3)
57 | results[label]["tok_recall"] = round(tok_tp[label]/tok_true, 3)
58 |
59 | ent_f1_numerator = (results[label]["ent_precision"] * results[label]["ent_recall"])
60 | ent_f1_denominator = (results[label]["ent_precision"] +results[label]["ent_recall"]) + 1E-10
61 | results[label]["ent_f1"] = 2*round(ent_f1_numerator / ent_f1_denominator, 3)
62 |
63 | tok_f1_numerator = (results[label]["tok_precision"] * results[label]["tok_recall"])
64 | tok_f1_denominator = (results[label]["tok_precision"] +results[label]["tok_recall"]) + 1E-10
65 | results[label]["tok_f1"] = 2*round(tok_f1_numerator / tok_f1_denominator, 3)
66 |
67 | results["macro"] = {"ent_precision":round(np.mean([results[l]["ent_precision"] for l in ent_support]), 3),
68 | "ent_recall":round(np.mean([results[l]["ent_recall"] for l in ent_support]), 3),
69 | "tok_precision":round(np.mean([results[l]["tok_precision"] for l in ent_support]), 3),
70 | "tok_recall":round(np.mean([results[l]["tok_recall"] for l in ent_support]), 3)}
71 |
72 |
73 | label_weights = {l:ent_support[l]/sum(ent_support.values()) for l in ent_support}
74 | results["label_weights"] = label_weights
75 | results["weighted"] = {"ent_precision":round(np.sum([results[l]["ent_precision"]*label_weights[l]
76 | for l in ent_support]), 3),
77 | "ent_recall":round(np.sum([results[l]["ent_recall"]*label_weights[l]
78 | for l in ent_support]), 3),
79 | "tok_precision":round(np.sum([results[l]["tok_precision"]*label_weights[l]
80 | for l in ent_support]), 3),
81 | "tok_recall":round(np.sum([results[l]["tok_recall"]*label_weights[l]
82 | for l in ent_support]), 3)}
83 |
84 | ent_pred = sum([ent_tp[l] for l in ent_support]) + sum([ent_fp[l] for l in ent_support]) + 1E-10
85 | ent_true = sum([ent_tp[l] for l in ent_support]) + sum([ent_fn[l] for l in ent_support]) + 1E-10
86 | tok_pred = sum([tok_tp[l] for l in ent_support]) + sum([tok_fp[l] for l in ent_support]) + 1E-10
87 | tok_true = sum([tok_tp[l] for l in ent_support]) + sum([tok_fn[l] for l in ent_support]) + 1E-10
88 | results["micro"] = {"ent_precision":round(sum([ent_tp[l] for l in ent_support]) / ent_pred, 3),
89 | "ent_recall":round(sum([ent_tp[l] for l in ent_support]) / ent_true, 3),
90 | "tok_precision":round(sum([tok_tp[l] for l in ent_support]) /tok_pred, 3),
91 | "tok_recall":round(sum([tok_tp[l] for l in ent_support]) / tok_true, 3),
92 | "tok_cee":round(tok_logloss/tok_nb, 3),
93 | "tok_acc": round(tok_tp_tn/tok_nb, 3),
94 | "coverage":round((sum(tok_tp.values()) +sum(tok_fp.values())) / sum(tok_support.values()), 3)}
95 |
96 | for metric in ["macro", "weighted", "micro"]:
97 | ent_f1_numerator = (results[metric]["ent_precision"] * results[metric]["ent_recall"])
98 | ent_f1_denominator = (results[metric]["ent_precision"] +results[metric]["ent_recall"]) + 1E-10
99 | results[metric]["ent_f1"] = 2*round(ent_f1_numerator / ent_f1_denominator, 3)
100 |
101 | tok_f1_numerator = (results[metric]["tok_precision"] * results[metric]["tok_recall"])
102 | tok_f1_denominator = (results[metric]["tok_precision"] +results[metric]["tok_recall"]) + 1E-10
103 | results[metric]["tok_f1"] = 2*round(tok_f1_numerator / tok_f1_denominator, 3)
104 |
105 | return results
106 |
107 |
108 | def compute_raw_numbers(docs, all_labels, target_source, conf_threshold=0.5):
109 | """Computes the raw metrics (true positives, true negatives, ...) on the dataset, using the spacy entities
110 | in each document as gold standard, and the annotations of a given source as the predicted values"""
111 |
112 | # We start by computing the TP, FP and FN values
113 | tok_tp = {}
114 | tok_fp = {}
115 | tok_fn ={}
116 |
117 | tok_logloss = 0
118 | tok_nb = 0
119 | tok_tp_tn = 0
120 |
121 | ent_tp ={}
122 | ent_fp = {}
123 | ent_fn = {}
124 | ent_support = {}
125 | tok_support = {}
126 |
127 | for doc in docs:
128 | if target_source in doc.spans:
129 | spans = utils.get_spans_with_probs(doc, target_source)
130 | else:
131 | spans = []
132 | spans = [span for (span, prob) in spans if prob >= conf_threshold]
133 |
134 | for label in all_labels:
135 | true_spans = {(ent.start, ent.end) for ent in doc.ents if ent.label_==label}
136 | pred_spans = {(span.start,span.end) for span in spans if span.label_==label}
137 |
138 | ent_tp[label] = ent_tp.get(label,0) + len(true_spans.intersection(pred_spans))
139 | ent_fp[label] = ent_fp.get(label,0) + len(pred_spans - true_spans)
140 | ent_fn[label] = ent_fn.get(label,0) + len(true_spans - pred_spans)
141 | ent_support[label] = ent_support.get(label, 0) + len(true_spans)
142 |
143 | true_tok_labels = {i for start,end in true_spans for i in range(start, end)}
144 | pred_tok_labels = {i for start,end in pred_spans for i in range(start, end)}
145 | tok_tp[label] = tok_tp.get(label, 0) + len(true_tok_labels.intersection(pred_tok_labels))
146 | tok_fp[label] = tok_fp.get(label, 0) + len(pred_tok_labels - true_tok_labels)
147 | tok_fn[label] = tok_fn.get(label,0) + len(true_tok_labels - pred_tok_labels)
148 | tok_support[label] = tok_support.get(label, 0) + len(true_tok_labels)
149 |
150 | gold_probs, pred_probs = _get_probs(doc, all_labels, target_source)
151 | tok_logloss += sklearn.metrics.log_loss(gold_probs, pred_probs, normalize=False)
152 | tok_tp_tn += sum(gold_probs.argmax(axis=1) == pred_probs.argmax(axis=1))
153 | tok_nb += len(doc)
154 |
155 | return (tok_tp, tok_fp, tok_fn, tok_logloss, tok_nb, tok_tp_tn, ent_tp,
156 | ent_fp, ent_fn, ent_support, tok_support)
157 |
158 |
159 | def _get_probs(doc, all_labels, target_source):
160 | """Retrieves the gold and predicted probabilities (as matrices)"""
161 |
162 | out_label_indices = {"O":0}
163 | for label in all_labels:
164 | for prefix in "BI":
165 | out_label_indices["%s-%s" % (prefix, label)] = len(out_label_indices)
166 |
167 | gold_probs = np.zeros((len(doc), len(out_label_indices)), dtype=np.int16)
168 | for ent in doc.ents:
169 | gold_probs[ent.start, out_label_indices.get("B-%s" % ent.label_, 0)] = 1
170 | for i in range(ent.start+1, ent.end):
171 | gold_probs[i, out_label_indices.get("I-%s" % ent.label_, 0)] = 1
172 |
173 | pred_probs = np.zeros(gold_probs.shape)
174 | if target_source in doc.spans and "probs" in doc.spans[target_source].attrs:
175 | for tok_pos, labels in doc.spans[target_source].attrs["probs"].items():
176 | for label, label_prob in labels.items():
177 | pred_probs[tok_pos, out_label_indices[label]] = label_prob
178 | pred_probs[:,0] = np.clip(1-pred_probs[:,1:].sum(axis=1), 0.0, 1.0)
179 | else:
180 | vector = utils.spans_to_array(doc, all_labels, [target_source])[:,0]
181 | pred_probs[np.arange(vector.size), vector] = True
182 |
183 | return gold_probs, pred_probs
184 |
185 |
186 | def show_errors(docs, all_labels, target_source, conf_threshold=0.5):
187 | """Utilities to display the errors/omissions of a given source"""
188 |
189 | for i, doc in enumerate(docs):
190 |
191 | spans = utils.get_spans_with_probs(doc, target_source)
192 |
193 | print("Doc %i:"%i, doc)
194 | true_spans = {(ent.start, ent.end):ent.label_ for ent in doc.ents}
195 | pred_spans = {(span.start,span.end):span.label_ for span, prob in spans if prob >=conf_threshold}
196 |
197 | for start,end in true_spans:
198 | if (start,end) not in pred_spans:
199 | print("Not found: %s [%i:%i] -> %s"%(doc[start:end], start, end, true_spans[(start,end)]))
200 | elif true_spans[(start,end)]!=pred_spans[(start,end)]:
201 | print("Wrong label: %s [%i:%i] -> %s but predicted as %s"%(doc[start:end], start, end,
202 | true_spans[(start,end)], pred_spans[(start,end)]))
203 |
204 | for start,end in pred_spans:
205 | if (start,end) not in true_spans:
206 | print("Spurious: %s [%i:%i] -> %s"%(doc[start:end], start, end, pred_spans[(start,end)]))
207 |
--------------------------------------------------------------------------------
/examples/sentiment/__init__.py:
--------------------------------------------------------------------------------
1 | from . import norec_sentiment, sentiment_lexicons, sentiment_models, transformer_model, weak_supervision_sentiment
--------------------------------------------------------------------------------
/examples/sentiment/norec_sentiment.py:
--------------------------------------------------------------------------------
1 | from skweak.base import CombinedAnnotator
2 | from .sentiment_lexicons import LexiconAnnotator, NRC_SentAnnotator, VADAnnotator, SocalAnnotator, BUTAnnotator
3 | from .sentiment_models import DocBOWAnnotator, MultilingualAnnotator, MBertAnnotator
4 | import os
5 | from spacy.tokens import Doc #type: ignore
6 | from typing import Sequence, Tuple, Optional, Iterable
7 | from collections import defaultdict
8 |
9 |
10 | class FullSentimentAnnotator(CombinedAnnotator):
11 | """Annotation based on the heuristic"""
12 |
13 | def add_all(self):
14 | """Adds all implemented annotation functions, models and filters"""
15 |
16 | print("Loading lexicon functions")
17 | self.add_lexicons()
18 | print("Loading learned sentiment model functions")
19 | self.add_ml_models()
20 |
21 | return self
22 |
23 | def add_lexicons(self):
24 | """Adds Spacy NER models to the annotator"""
25 |
26 | self.add_annotator(LexiconAnnotator("norsent_forms", "../data/sentiment/lexicons/norsentlex/Fullform"))
27 | self.add_annotator(LexiconAnnotator("norsent_lemma", "../data/sentiment/lexicons/norsentlex/Lemma"))
28 |
29 | self.add_annotator(VADAnnotator("NRC_VAD", "../data/sentiment/lexicons/NRC_VAD_Lexicon/Norwegian-no-NRC-VAD-Lexicon.txt"))
30 |
31 | self.add_annotator(SocalAnnotator("Socal-adj", "../data/sentiment/lexicons/socal/no_adj.txt"))
32 |
33 | self.add_annotator(SocalAnnotator("Socal-adv", "../data/sentiment/lexicons/socal/no_adv.txt"))
34 |
35 | self.add_annotator(SocalAnnotator("Socal-google", "../data/sentiment/lexicons/socal/no_google.txt"))
36 |
37 | self.add_annotator(SocalAnnotator("Socal-int", "../data/sentiment/lexicons/socal/no_int.txt"))
38 |
39 | self.add_annotator(SocalAnnotator("Socal-noun", "../data/sentiment/lexicons/socal/no_noun.txt"))
40 | self.add_annotator(SocalAnnotator("Socal-verb", "../data/sentiment/lexicons/socal/no_verb.txt"))
41 |
42 | self.add_annotator(SocalAnnotator("IBM", "../data/sentiment/lexicons/IBM_Debater/no_unigram.txt"))
43 |
44 | self.add_annotator(NRC_SentAnnotator("NRC-Sent-Emo", "../data/sentiment/lexicons/NRC_Sentiment_Emotion/no_sent.txt"))
45 |
46 | self.add_annotator(BUTAnnotator("norsent_forms-BUT", "../data/sentiment/lexicons/norsentlex/Fullform"))
47 |
48 | self.add_annotator(BUTAnnotator("norsent_lemma-BUT", "../data/sentiment/lexicons/norsentlex/Lemma"))
49 |
50 | return self
51 |
52 | def add_ml_models(self):
53 | self.add_annotator(DocBOWAnnotator("doc-level-norec", "../data/sentiment/models/bow"))
54 | self.add_annotator(MultilingualAnnotator("nlptown-bert-multilingual-sentiment"))
55 | self.add_annotator(MBertAnnotator("mbert-sst"))
56 | return self
57 |
58 |
--------------------------------------------------------------------------------
/examples/sentiment/sentiment_lexicons.py:
--------------------------------------------------------------------------------
1 | from skweak.base import SpanAnnotator
2 | import os
3 | from spacy.tokens import Doc #type: ignore
4 | from typing import Sequence, Tuple, Optional, Iterable
5 | from collections import defaultdict
6 |
7 | ####################################################################
8 | # Labelling sources based on lexicons
9 | ####################################################################
10 |
11 | class LexiconAnnotator(SpanAnnotator):
12 | """Annotation based on a sentiment lexicon"""
13 |
14 | def __init__(self, name, lexicon_dir, margin=0):
15 | """Creates a new annotator based on a Spacy model. """
16 | super(LexiconAnnotator, self).__init__(name)
17 |
18 | self.margin = margin
19 |
20 | pos_file = None
21 | for file in os.listdir(lexicon_dir):
22 | if "positive" in file.lower() and "txt" in file:
23 | pos_file = os.path.join(lexicon_dir, file)
24 | self.pos = set([l.strip() for l in open(pos_file)])
25 | if pos_file is None:
26 | print("No positive lexicon file found in {}".format(lexicon_dir))
27 |
28 | neg_file = None
29 | for file in os.listdir(lexicon_dir):
30 | if "negative" in file.lower() and "txt" in file:
31 | neg_file = os.path.join(lexicon_dir, file)
32 | self.neg = set([l.strip() for l in open(neg_file)])
33 | if neg_file is None:
34 | print("No negative lexicon file found in {}".format(lexicon_dir))
35 |
36 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
37 | pos = 0
38 | neg = 0
39 |
40 | # Iterate through tokens and add up positive and negative tokens
41 | for token in doc:
42 | if token.text in self.pos:
43 | pos += 1
44 | if token.text in self.neg:
45 | neg += 1
46 |
47 | # check if there are more pos or neg tokens, plus a margin
48 | # Regarding labels: positive: 2, neutral: 1, negative: 0
49 | if pos > (neg + self.margin):
50 | label = 2
51 | elif neg > (pos + self.margin):
52 | label = 0
53 | else:
54 | label = 1
55 | yield 0, len(doc), label #type: ignore
56 |
57 |
58 | class VADAnnotator(SpanAnnotator):
59 | """Annotation based on a sentiment lexicon"""
60 |
61 | def __init__(self, name, lexicon_path, margin=0.2):
62 | """Creates a new annotator based on a Spacy model. """
63 | super(VADAnnotator, self).__init__(name)
64 |
65 | self.margin = margin
66 |
67 | self.lexicon = defaultdict(lambda: 0.5)
68 | for i, line in enumerate(open(lexicon_path)):
69 | if i > 0: # skip the header
70 | en_term, no_term, v, a, d = line.strip().split("\t")
71 | self.lexicon[no_term] = float(v)
72 |
73 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
74 | scores = [0.5]
75 |
76 | # Iterate through tokens and add up positive and negative tokens
77 | for token in doc:
78 | scores.append(self.lexicon[token.text])
79 |
80 | mean_score = sum(scores) / len(scores)
81 | # check if there are more pos or neg tokens, plus a margin
82 | # Regarding labels: positive: 2, neutral: 1, negative: 0
83 | if mean_score > (0.5 + self.margin):
84 | label = 2
85 | elif mean_score < (0.5 + self.margin):
86 | label = 0
87 | else:
88 | label = 1
89 | yield 0, len(doc), label #type: ignore
90 |
91 |
92 |
93 | class SocalAnnotator(SpanAnnotator):
94 | """Annotation based on a sentiment lexicon"""
95 |
96 | def __init__(self, name, lexicon_path, margin=0):
97 | """Creates a new annotator based on a Spacy model. """
98 | super(SocalAnnotator, self).__init__(name)
99 |
100 | self.margin = margin
101 |
102 | self.lexicon = defaultdict(lambda: 0)
103 | for i, line in enumerate(open(lexicon_path)):
104 | if i > 0: # skip the header
105 | try:
106 | no_term, score = line.strip().split("\t")
107 | self.lexicon[no_term] = float(score) #type: ignore
108 | except ValueError:
109 | print(str(i) + ": " + line)
110 |
111 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
112 | scores = [0]
113 |
114 | # Iterate through tokens and add up positive and negative tokens
115 | for token in doc:
116 | scores.append(self.lexicon[token.text])
117 |
118 | mean_score = sum(scores) / len(scores)
119 | # check if there are more pos or neg tokens, plus a margin
120 | # Regarding labels: positive: 2, neutral: 1, negative: 0
121 | if mean_score > (0 + self.margin):
122 | label = 2
123 | elif mean_score < (0 + self.margin):
124 | label = 0
125 | else:
126 | label = 1
127 | yield 0, len(doc), label #type: ignore
128 |
129 |
130 | class NRC_SentAnnotator(SpanAnnotator):
131 | """Annotation based on a sentiment lexicon"""
132 |
133 | def __init__(self, name, lexicon_path, margin=0):
134 | """Creates a new annotator based on a Spacy model. """
135 | super(NRC_SentAnnotator, self).__init__(name)
136 |
137 | self.margin = margin
138 | self.pos = set()
139 | self.neg = set()
140 |
141 | for i, line in enumerate(open(lexicon_path)):
142 | try:
143 | no_term, sent, score = line.strip().split("\t")
144 | if int(score) == 1:
145 | if sent == "positive":
146 | self.pos.add(no_term)
147 | if sent == "negative":
148 | self.neg.add(no_term)
149 | except:
150 | pass
151 |
152 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
153 | pos = 0
154 | neg = 0
155 |
156 | # Iterate through tokens and add up positive and negative tokens
157 | for token in doc:
158 | if token.text in self.pos:
159 | pos += 1
160 | if token.text in self.neg:
161 | neg += 1
162 |
163 | # check if there are more pos or neg tokens, plus a margin
164 | # Regarding labels: positive: 2, neutral: 1, negative: 0
165 | if pos > (neg + self.margin):
166 | label = 2
167 | elif neg > (pos + self.margin):
168 | label = 0
169 | else:
170 | label = 1
171 | yield 0, len(doc), label #type: ignore
172 |
173 |
174 | class BUTAnnotator(SpanAnnotator):
175 | """Annotation based on the heuristic"""
176 |
177 | def __init__(self, name, lexicon_dir, margin=0):
178 | """Creates a new annotator based on a Spacy model. """
179 | super(BUTAnnotator, self).__init__(name)
180 |
181 | self.margin = margin
182 |
183 | pos_file = None
184 | for file in os.listdir(lexicon_dir):
185 | if "positive" in file.lower() and "txt" in file:
186 | pos_file = os.path.join(lexicon_dir, file)
187 | self.pos = set([l.strip() for l in open(pos_file)])
188 | if pos_file is None:
189 | print("No positive lexicon file found in {}".format(lexicon_dir))
190 |
191 | neg_file = None
192 | for file in os.listdir(lexicon_dir):
193 | if "negative" in file.lower() and "txt" in file:
194 | neg_file = os.path.join(lexicon_dir, file)
195 | self.neg = set([l.strip() for l in open(neg_file)])
196 | if neg_file is None:
197 | print("No negative lexicon file found in {}".format(lexicon_dir))
198 |
199 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
200 | pos = 0
201 | neg = 0
202 |
203 | # Iterate through tokens and add up positive and negative tokens
204 | tokens = [t.text for t in doc]
205 | if "men" in tokens:
206 | idx = tokens.index("men") + 1
207 | for token in tokens[idx:]:
208 | if token in self.pos:
209 | pos += 1
210 | if token in self.neg:
211 | neg += 1
212 |
213 | # check if there are more pos or neg tokens, plus a margin
214 | # Regarding labels: positive: 2, neutral: 1, negative: 0
215 | if pos > (neg + self.margin):
216 | label = 2
217 | elif neg > (pos + self.margin):
218 | label = 0
219 | else:
220 | label = 1
221 | yield 0, len(doc), label #type: ignore
222 |
--------------------------------------------------------------------------------
/examples/sentiment/sentiment_models.py:
--------------------------------------------------------------------------------
1 | from skweak.base import SpanAnnotator
2 | import os
3 | from spacy.tokens import Doc # type: ignore
4 | from typing import Sequence, Tuple, Optional, Iterable
5 | from collections import defaultdict
6 |
7 | from sklearn.svm import LinearSVC
8 | from sklearn.feature_extraction.text import TfidfVectorizer
9 | from sklearn.metrics import f1_score
10 |
11 | from transformers import pipeline, BertForSequenceClassification, BertTokenizer
12 |
13 | import tarfile
14 | import pickle
15 | import os
16 |
17 |
18 | class MBertAnnotator(SpanAnnotator):
19 | """Annotation based on multi-lingual BERT trained on Stanford Sentiment Treebank"""
20 | def __init__(self, name):
21 | super(MBertAnnotator, self).__init__(name)
22 | self.classifier = BertForSequenceClassification.from_pretrained("../data/sentiment/models/sst", num_labels=3)
23 | self.classifier.eval() # type: ignore
24 | self.tokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-uncased")
25 | print("Loaded mBERT from {}".format("../data/sentiment/models/sst"))
26 |
27 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
28 |
29 | text = [" ".join([t.text for t in doc])]
30 | encoding = self.tokenizer(text, return_tensors='pt', padding=True, truncation=True)
31 | output = self.classifier(**encoding)
32 | # classifier outputs a dict, eg {'label': '5 stars', 'score': 0.99}
33 | # so we need to get the label and transform it to an int
34 | _, p = output.logits.max(1)
35 | label = int(p[0])
36 | yield 0, len(doc), label # type: ignore
37 |
38 |
39 | class MultilingualAnnotator(SpanAnnotator):
40 | """Annotation based on multi-lingual BERT trained on review data in 6 languages"""
41 |
42 | def __init__(self, name):
43 | """Creates a new annotator based on a Spacy model. """
44 | super(MultilingualAnnotator, self).__init__(name)
45 |
46 | self.classifier = pipeline('sentiment-analysis', model="nlptown/bert-base-multilingual-uncased-sentiment")
47 | print("Loaded nlptown/bert-base-multilingual-uncased-sentiment")
48 |
49 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
50 |
51 | text = [" ".join([t.text for t in doc])]
52 | labels = self.classifier(text)[0]
53 | # classifier outputs a dict, eg {'label': '5 stars', 'score': 0.99}
54 | # so we need to get the label and transform it to an int
55 | pred = int(labels["label"][0])
56 |
57 | # check if there are more pos or neg tokens, plus a margin
58 | # Regarding labels: positive: 2, neutral: 1, negative: 0
59 | if pred > 3:
60 | label = 2
61 | elif pred < 3:
62 | label = 0
63 | else:
64 | label = 1
65 | yield 0, len(doc), label # type: ignore
66 |
67 |
68 | class DocBOWAnnotator(SpanAnnotator):
69 | """Annotation based on a TF-IDF Bag-of-words document-level classifier"""
70 |
71 | def __init__(self, name, model_path, doclevel_data=None):
72 | """Creates a new annotator based on a Spacy model. """
73 | super(DocBOWAnnotator, self).__init__(name)
74 |
75 | self.model_path = model_path
76 | self.doclevel_data = doclevel_data
77 |
78 | if self.doclevel_data is not None:
79 | print("Fitting model on {}".format(self.doclevel_data))
80 | self.fit(doclevel_data)
81 | print("Saving vectorizer and model to {}".format(model_path))
82 | self.save_model(self.model_path)
83 | else:
84 | try:
85 | self.load_model(self.model_path)
86 | print("Loaded model from {}".format(self.model_path))
87 | except FileNotFoundError:
88 | print("Trained model not found. Train a model first by providing the doclevel_data when instantiating the annotator.")
89 |
90 | def save_model(self, model_path):
91 | os.makedirs(model_path, exist_ok=True)
92 | with open(os.path.join(model_path, "vectorizer.pkl"), "wb") as o:
93 | pickle.dump(self.vectorizer, o)
94 |
95 | with open(os.path.join(model_path, "bow_model.pkl"), "wb") as o:
96 | pickle.dump(self.model, o)
97 |
98 | def load_model(self, model_path):
99 | with open(os.path.join(model_path, "vectorizer.pkl"), "rb") as o:
100 | self.vectorizer = pickle.load(o)
101 | with open(os.path.join(model_path, "bow_model.pkl"), "rb") as o:
102 | self.model = pickle.load(o)
103 |
104 | def open_norec_doc(self, file_path, split="train"):
105 | tar = tarfile.open(file_path, "r:gz")
106 |
107 | train_names = [tarinfo for tarinfo in tar.getmembers() if split in tarinfo.name and ".conllu" in tarinfo.name]
108 |
109 | docs, ratings = [], []
110 |
111 | for fname in train_names:
112 | content = tar.extractfile(fname)
113 | language = content.readline().decode("utf8").rstrip("\n")[-2:]
114 | rating = content.readline().decode("utf8").rstrip("\n")[-1]
115 | doc_id = content.readline().decode("utf8").rstrip("\n").split()[-1]
116 |
117 | words = []
118 | for line in content:
119 | line = line.decode("utf8")
120 | if line[0] == '#':
121 | continue
122 | if not line.rstrip("\n"):
123 | continue
124 | else:
125 | words.append(line.split("\t")[1])
126 |
127 | docs.append(" ".join(words))
128 | ratings.append(int(rating))
129 | return docs, ratings
130 |
131 | def fit(self, file_path):
132 | train_docs, train_ratings = self.open_norec_doc(file_path, split="train")
133 | test_docs, test_ratings = self.open_norec_doc(file_path, split="test")
134 |
135 | self.vectorizer = TfidfVectorizer()
136 | trainX = self.vectorizer.fit_transform(train_docs)
137 | self.model = LinearSVC()
138 | self.model.fit(trainX, train_ratings)
139 |
140 | testX = self.vectorizer.transform(test_docs)
141 |
142 | pred = self.model.predict(testX)
143 | print("Doc-level F1: {0:.3f}".format(f1_score(test_ratings, pred, average="macro")))
144 |
145 |
146 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
147 |
148 | text = [" ".join([t.text for t in doc])]
149 | X = self.vectorizer.transform(text)
150 | pred = self.model.predict(X)[0]
151 |
152 | # check if there are more pos or neg tokens, plus a margin
153 | # Regarding labels: positive: 2, neutral: 1, negative: 0
154 | if pred > 4:
155 | label = 2
156 | elif pred < 3:
157 | label = 0
158 | else:
159 | label = 1
160 | yield 0, len(doc), label
161 |
162 |
--------------------------------------------------------------------------------
/examples/sentiment/transformer_model.py:
--------------------------------------------------------------------------------
1 | from transformers import BertTokenizer, BertForSequenceClassification
2 | from transformers import AdamW
3 | from transformers import get_linear_schedule_with_warmup
4 |
5 | from torch.nn import functional as F
6 | import torch
7 | import numpy as np
8 |
9 | import argparse
10 | from tqdm import tqdm
11 |
12 | from sklearn.metrics import f1_score
13 |
14 | import sys
15 | sys.path.insert(0, "..")
16 | from skweak.utils import docbin_reader
17 |
18 | class SSTDataLoader():
19 | def __init__(self, datafile, num_examples=None):
20 | labels, examples = [], []
21 | for line in open(datafile):
22 | label, sent = line.strip().split("\t", 1)
23 | labels.append(int(label))
24 | examples.append(sent)
25 | if num_examples is not None:
26 | labels = labels[:num_examples]
27 | examples = examples[:num_examples]
28 | self.labels = np.array(labels)
29 | self.examples = np.array(examples)
30 |
31 | def get_batches(self, batch_size=32, shuffle=True):
32 | if shuffle:
33 | idxs = np.arange(len(self.labels))
34 | np.random.shuffle(idxs)
35 | labels = list(self.labels[idxs])
36 | examples = list(self.examples[idxs])
37 | else:
38 | labels = list(self.labels)
39 | examples = list(self.examples)
40 | num_batches = self.get_num_batches(batch_size)
41 | i = 0
42 | for batch in range(num_batches):
43 | blabels = torch.tensor(labels[i:i+batch_size])
44 | bexamples = examples[i:i+batch_size]
45 | i += batch_size
46 | yield (blabels, bexamples)
47 |
48 | def get_num_batches(self, batch_size=32):
49 | num_batches = len(self.labels) // batch_size
50 | if (len(self.labels) % batch_size) > 0:
51 | num_batches += 1
52 | return num_batches
53 |
54 | class DocbinDataLoader():
55 | def __init__(self, datafile, num_examples=None, gold=False):
56 | labels, examples = [], []
57 | for doc in docbin_reader(datafile):
58 | examples.append(doc.text)
59 | if gold:
60 | labels.append(doc.user_data["gold"])
61 | else:
62 | labels.append(list(doc.user_data["agg_spans"]["hmm"].values())[0])
63 | if num_examples is not None:
64 | labels = labels[:num_examples]
65 | examples = examples[:num_examples]
66 | self.labels = np.array(labels)
67 | self.examples = np.array(examples)
68 |
69 | def get_batches(self, batch_size=32, shuffle=True):
70 | if shuffle:
71 | idxs = np.arange(len(self.labels))
72 | np.random.shuffle(idxs)
73 | labels = list(self.labels[idxs])
74 | examples = list(self.examples[idxs])
75 | else:
76 | labels = list(self.labels)
77 | examples = list(self.examples)
78 | num_batches = self.get_num_batches(batch_size)
79 | i = 0
80 | for batch in range(num_batches):
81 | blabels = torch.tensor(labels[i:i+batch_size])
82 | bexamples = examples[i:i+batch_size]
83 | i += batch_size
84 | yield (blabels, bexamples)
85 |
86 | def get_num_batches(self, batch_size=32):
87 | num_batches = len(self.labels) // batch_size
88 | if (len(self.labels) % batch_size) > 0:
89 | num_batches += 1
90 | return num_batches
91 |
92 | def train(model, save_dir="../data/sentiment/models/norbert"):
93 | model.train()
94 |
95 |
96 | optimizer = AdamW(model.parameters(), lr=1e-5)
97 |
98 | num_train_steps = int(len(train_loader.examples) / args.train_batch_size) * args.num_train_epochs
99 |
100 | scheduler = get_linear_schedule_with_warmup(optimizer, args.warmup_steps, num_train_steps)
101 |
102 | best_dev_f1 = 0.0
103 |
104 | print("training for {} epochs...".format(args.num_train_epochs))
105 |
106 | for epoch_num, epoch in enumerate(range(args.num_train_epochs)):
107 | model.train()
108 | train_loss = 0
109 | num_batches = 0
110 | train_preds = []
111 | train_gold = []
112 | for b in tqdm(train_loader.get_batches(batch_size=args.train_batch_size), total=train_loader.get_num_batches(batch_size=args.train_batch_size)):
113 | labels, sents = b
114 | encoding = tokenizer(sents, return_tensors='pt', padding=True, truncation=True, max_length=150)
115 |
116 | outputs = model(**encoding)
117 | _, p = outputs.logits.max(1)
118 | train_preds.extend(p.tolist())
119 | train_gold.extend(labels.tolist())
120 | loss = F.cross_entropy(outputs.logits, labels)
121 | train_loss += loss.data
122 | num_batches += 1
123 | loss.backward()
124 | optimizer.step() #type: ignore
125 | scheduler.step() #type: ignore
126 | optimizer.zero_grad() #type: ignore
127 | print("Epoch {0}: Loss {1:.3f}".format(epoch_num + 1, train_loss / num_batches))
128 | print("Train F1: {0:.3f}".format(f1_score(train_gold, train_preds, average="macro")))
129 |
130 |
131 | model.eval()
132 | dev_loss = 0
133 | num_batches = 0
134 | dev_preds = []
135 | dev_gold = []
136 | for b in tqdm(dev_loader.get_batches(batch_size=args.eval_batch_size), total=dev_loader.get_num_batches(batch_size=args.eval_batch_size)):
137 | labels, sents = b
138 | encoding = tokenizer(sents, return_tensors='pt', padding=True, truncation=True, max_length=150)
139 |
140 | outputs = model(**encoding)
141 | _, p = outputs.logits.max(1)
142 | dev_preds.extend(p.tolist())
143 | dev_gold.extend(labels.tolist())
144 | loss = F.cross_entropy(outputs.logits, labels)
145 | dev_loss += loss.data
146 | num_batches += 1
147 | dev_f1 = f1_score(dev_gold, dev_preds, average="macro")
148 | print("Dev F1: {0:.3f}".format(dev_f1))
149 |
150 | if dev_f1 > best_dev_f1: #type: ignore
151 | best_dev_f1 = dev_f1
152 | print("Current best dev: {0:.3f}".format(best_dev_f1))
153 | print("Saving model")
154 | model.save_pretrained(save_dir)
155 |
156 |
157 | def test(model):
158 | print("loading best model on dev data")
159 | model.eval()
160 | test_loss = 0
161 | num_batches = 0
162 | test_preds = []
163 | test_gold = []
164 | for b in tqdm(test_loader.get_batches(batch_size=args.eval_batch_size), total=test_loader.get_num_batches(batch_size=args.eval_batch_size)):
165 | labels, sents = b
166 | encoding = tokenizer(sents, return_tensors='pt', padding=True, truncation=True, max_length=150)
167 |
168 | outputs = model(**encoding)
169 | _, p = outputs.logits.max(1)
170 | test_preds.extend(p.tolist())
171 | test_gold.extend(labels.tolist())
172 | loss = F.cross_entropy(outputs.logits, labels)
173 | test_loss += loss.data
174 | num_batches += 1
175 | test_f1 = f1_score(test_gold, test_preds, average="macro")
176 | print("Test F1: {0:.3f}".format(test_f1))
177 |
178 | if __name__ == "__main__":
179 | parser = argparse.ArgumentParser()
180 | parser.add_argument("--train_batch_size", default=16, type=int)
181 | parser.add_argument("--eval_batch_size", default=16, type=int)
182 | parser.add_argument("--num_train_epochs", default=20, type=int)
183 | parser.add_argument("--warmup_steps", default=50, type=int)
184 | parser.add_argument("--model",
185 | default="../data/sentiment/models/norbert")
186 | parser.add_argument("--save_dir",
187 | default="../data/sentiment/models/nobert")
188 | parser.add_argument("--train", action="store_true")
189 | parser.add_argument("--test", action="store_true")
190 | parser.add_argument("--train_on_gold", action="store_true")
191 |
192 |
193 | args = parser.parse_args()
194 |
195 | print("loading data...")
196 | # train_loader = SSTDataLoader("../data/sentiment/sst/train.txt")
197 | # dev_loader = SSTDataLoader("../data/sentiment/sst/dev.txt")
198 | # test_loader = SSTDataLoader("../data/sentiment/sst/test.txt")
199 | train_loader = DocbinDataLoader("../data/sentiment/norec_sentence/train_pred.docbin", num_examples=500, gold=args.train_on_gold)
200 | dev_loader = DocbinDataLoader("../data/sentiment/norec_sentence/dev_pred.docbin", num_examples=500, gold=args.train_on_gold)
201 | test_loader = DocbinDataLoader("../data/sentiment/norec_sentence/test_pred.docbin", gold=True)
202 |
203 | print("loading model...")
204 | tokenizer = BertTokenizer.from_pretrained("ltgoslo/norbert")
205 | model = BertForSequenceClassification.from_pretrained(args.model, num_labels=3)
206 |
207 | if args.train:
208 | train(model, args.save_dir)
209 |
210 | # Test model
211 | if args.test:
212 | test(model)
213 |
214 |
--------------------------------------------------------------------------------
/examples/sentiment/weak_supervision_sentiment.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import spacy
3 | from spacy.tokens import DocBin
4 | import pandas as pd
5 |
6 | from .norec_sentiment import FullSentimentAnnotator
7 | from skweak import utils
8 | from sklearn.metrics import f1_score
9 | from .sentiment_models import MBertAnnotator
10 |
11 | from sklearn.svm import LinearSVC
12 | from sklearn.feature_extraction.text import TfidfVectorizer
13 |
14 | import skweak
15 |
16 |
17 | ##################################################################
18 | # Preprocessing
19 | ##################################################################
20 |
21 | nlp = spacy.load("nb_core_news_md")
22 |
23 | train_doc_bin = DocBin(store_user_data=True)
24 | dev_doc_bin = DocBin(store_user_data=True)
25 | test_doc_bin = DocBin(store_user_data=True)
26 |
27 | train = pd.read_csv("./data/sentiment/norec_sentence/train.txt", delimiter="\t", header=None) #type: ignore
28 | dev = pd.read_csv("./data/sentiment/norec_sentence/dev.txt", delimiter="\t", header=None) #type: ignore
29 | test = pd.read_csv("./data/sentiment/norec_sentence/test.txt", delimiter="\t", header=None) #type: ignore
30 |
31 | for sid, (label, sent) in train.iterrows():
32 | doc = nlp(sent)
33 | doc.user_data["gold"] = label
34 | train_doc_bin.add(doc)
35 | train_doc_bin.to_disk("./data/sentiment/norec_sentence/train.docbin")
36 |
37 | for sid, (label, sent) in dev.iterrows():
38 | doc = nlp(sent)
39 | doc.user_data["gold"] = label
40 | dev_doc_bin.add(doc)
41 | dev_doc_bin.to_disk("./data/sentiment/norec_sentence/dev.docbin")
42 |
43 | for sid, (label, sent) in test.iterrows():
44 | doc = nlp(sent)
45 | doc.user_data["gold"] = label
46 | test_doc_bin.add(doc)
47 | test_doc_bin.to_disk("./data/sentiment/norec_sentence/test.docbin")
48 |
49 |
50 | ##################################################################
51 | # Weak supervision
52 | ##################################################################
53 |
54 | ann = FullSentimentAnnotator()
55 | ann.add_all()
56 |
57 | ann.annotate_docbin("./data/sentiment/norec_sentence/train.docbin", "./data/sentiment/norec_sentence/train_pred.docbin")
58 |
59 | ann.annotate_docbin("./data/sentiment/norec_sentence/dev.docbin", "./data/sentiment/norec_sentence/dev_pred.docbin")
60 |
61 | ann.annotate_docbin("./data/sentiment/norec_sentence/test_pred.docbin", "./data/sentiment/norec_sentence/test_pred.docbin")
62 |
63 | unified_model = skweak.aggregation.HMM("hmm", [0, 1, 2], sequence_labelling=False) #type: ignore
64 | unified_model.fit("./data/sentiment/norec_sentence/train_pred.docbin")
65 | unified_model.annotate_docbin("./data/sentiment/norec_sentence/train_pred.docbin", "./data/sentiment/norec_sentence/train_pred.docbin")
66 |
67 | #unified_model = skweak.aggregation.HMM("hmm", [0, 1, 2], sequence_labelling=False)
68 | #unified_model.fit("./data/sentiment/norec_sentence/dev_pred.docbin")
69 | unified_model.annotate_docbin("./data/sentiment/norec_sentence/dev_pred.docbin", "./data/sentiment/norec_sentence/dev_pred.docbin")
70 |
71 | #unified_model = skweak.aggregation.HMM("hmm", [0, 1, 2], sequence_labelling=False)
72 | #unified_model.fit("./data/sentiment/norec_sentence/test_pred.docbin")
73 | unified_model.annotate_docbin("./data/sentiment/norec_sentence/test_pred.docbin", "./data/sentiment/norec_sentence/test_pred.docbin")
74 |
75 | mv = skweak.aggregation.MajorityVoter("mv", [0, 1, 2], sequence_labelling=False) #type: ignore
76 | mv.annotate_docbin("./data/sentiment/norec_sentence/test_pred.docbin", "./data/sentiment/norec_sentence/test_pred.docbin")
77 |
78 | pred_docs = list(utils.docbin_reader("./data/sentiment/norec_sentence/test_pred.docbin"))
79 |
80 |
81 | ##################################################################
82 | # Evaluation of upper bound
83 | ##################################################################
84 |
85 |
86 | train_docs = list(utils.docbin_reader("./data/sentiment/norec_sentence/train.docbin"))
87 |
88 | pred_docs = list(utils.docbin_reader("./data/sentiment/norec_sentence/test_pred.docbin"))
89 |
90 | vectorizer = TfidfVectorizer(ngram_range=(1, 3))
91 | model = LinearSVC()
92 |
93 | train = [" ".join([t.text for t in doc]) for doc in train_docs]
94 | trainX = vectorizer.fit_transform(train)
95 | train_y = [doc.user_data["gold"] for doc in train_docs]
96 | model.fit(trainX, train_y)
97 |
98 | test = [" ".join([t.text for t in doc]) for doc in pred_docs]
99 | testX = vectorizer.transform(test)
100 | pred = model.predict(testX)
101 |
102 | gold = [d.user_data["gold"] for d in pred_docs]
103 |
104 | f1 = f1_score(gold, pred, average="macro")
105 | print("Upper Bound F1: {0:.3f}".format(f1))
106 |
107 | ##################################################################
108 | # Evaluation of majority baseline
109 | ##################################################################
110 |
111 | maj_class = [1] * len(gold)
112 | maj_f1 = f1_score(gold, maj_class, average="macro")
113 | print("Majority class: {0:.3f}".format(maj_f1))
114 |
115 | print("-" * 25)
116 |
117 | ##################################################################
118 | # Evaluation of labelling functions
119 | ##################################################################
120 |
121 |
122 | for lexicon in pred_docs[0].user_data["spans"].keys():
123 | pred = []
124 | for d in pred_docs:
125 | for span in d.spans[lexicon]:
126 | pred.append(span.label_)
127 |
128 | lex_f1 = f1_score(gold, pred, average="macro")
129 | print("{0}:\t{1:.3f}".format(lexicon, lex_f1))
130 |
131 | ##################################################################
132 | # Evaluation of aggregating functions
133 | ##################################################################
134 |
135 |
136 |
137 | for aggregator in ["mv", "hmm"]:
138 | pred = []
139 | for d in pred_docs:
140 | for span in d.spans[aggregator]:
141 | pred.append(span.label_)
142 | hmm_f1 = f1_score(gold, pred, average="macro")
143 | print("{0}:\t{1:.3f}".format(aggregator, hmm_f1))
144 |
145 |
--------------------------------------------------------------------------------
/poetry.toml:
--------------------------------------------------------------------------------
1 | [virtualenvs]
2 | in-project = true
3 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.poetry]
2 | name = "skweak"
3 | version = "0.3.3"
4 | description = "Software toolkit for weak supervision in NLP"
5 | authors = ["Perre Lison "]
6 | maintainers = ["Perre Lison "]
7 | keywords = ["weak supervision", "sklearn", "scikit-learn", "nlp", "text processing", "language processing",
8 | "text mining", "text classification", "token classification", "ner", "named entity recognition", "hmm", "spacy"]
9 | repository = "https://github.com/NorskRegnesentral/skweak"
10 | license = "MIT"
11 | readme = "README.md"
12 | classifiers = [
13 | "Programming Language :: Python :: 3",
14 | "Programming Language :: Python :: 3.7",
15 | "Programming Language :: Python :: 3.8",
16 | "Programming Language :: Python :: 3.9",
17 | "Programming Language :: Python :: 3.10",
18 | "Programming Language :: Python :: 3.11",
19 | "License :: OSI Approved :: MIT License",
20 | "Operating System :: OS Independent",
21 | "Intended Audience :: Developers",
22 | "Intended Audience :: Science/Research",
23 | "Topic :: Text Processing",
24 | "Topic :: Text Processing :: Linguistic",
25 | "Topic :: Scientific/Engineering",
26 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
27 | "Topic :: Scientific/Engineering :: Human Machine Interfaces",
28 | "Topic :: Scientific/Engineering :: Information Analysis",
29 | ]
30 | packages = [{ include = "skweak" }]
31 |
32 | [tool.poetry.dependencies]
33 | python = ">=3.7.4,<3.12"
34 | spacy = "^3.0"
35 | hmmlearn = "~0.3.0"
36 | scipy = "^1.5.4"
37 | pandas = ">=0.23,<3.0"
38 |
39 | [tool.poetry.group.dev]
40 | optional = true
41 |
42 | [tool.poetry.group.dev.dependencies]
43 | pytest = "^7.4.2"
44 | spacy = "~3.6.1"
45 |
46 | # Fixed spaCy model dependencies
47 | en_core_web_sm = { url = "https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.6.0/en_core_web_sm-3.6.0-py3-none-any.whl" }
48 | en_core_web_md = { url = "https://github.com/explosion/spacy-models/releases/download/en_core_web_md-3.6.0/en_core_web_md-3.6.0-py3-none-any.whl" }
49 |
50 | # Workaround for using up-to-date binary wheels for all Python versions
51 | numpy = [
52 | { version = "~1.21.1", python = ">=3.7,<3.9" },
53 | { version = "~1.26", python = ">=3.9,<3.12" }
54 | ]
55 | scipy = [
56 | { version = "~1.7.3", python = ">=3.7,<3.9" },
57 | { version = "~1.11.2", python = ">=3.9,<3.12" }
58 | ]
59 | scikit-learn = [
60 | { version = "~1.0.2", python = ">=3.7,<3.8" },
61 | { version = "~1.3.1", python = ">=3.8,<3.12" }
62 | ]
63 | pandas = [
64 | { version = "~1.3.5", python = ">=3.7,<3.9" },
65 | { version = "~2.1.1", python = ">=3.9,<3.12" }
66 | ]
67 |
68 | # TODO: Shall we use black?
69 |
70 | [tool.pytest.ini_options]
71 | testpaths = ["tests"]
72 | addopts = "-s -v --durations=0"
73 | cache_dir = ".cache/pytest"
74 |
75 | [build-system]
76 | requires = ["poetry-core"]
77 | build-backend = "poetry.core.masonry.api"
78 |
--------------------------------------------------------------------------------
/skweak/__init__.py:
--------------------------------------------------------------------------------
1 | from . import base, doclevel, gazetteers, heuristics, aggregation, utils, spacy, voting, generative
2 | __version__ = "0.3.3"
3 |
--------------------------------------------------------------------------------
/skweak/base.py:
--------------------------------------------------------------------------------
1 | import itertools
2 | from abc import abstractmethod
3 | from typing import Iterable, Optional, Sequence, Tuple
4 |
5 | from spacy.tokens import Doc, Span # type: ignore
6 |
7 | from . import utils
8 |
9 | ############################################
10 | # Abstract class for all annotators
11 | ############################################
12 |
13 | class AbstractAnnotator:
14 | """Base class for all annotation or aggregation sources
15 | employed in skweak"""
16 |
17 | def __init__(self, name: str):
18 | """Initialises the annotator with a name"""
19 | self.name = name
20 |
21 | @abstractmethod
22 | def __call__(self, doc: Doc) -> Doc:
23 | """Annotates a single Spacy Doc object"""
24 |
25 | raise NotImplementedError()
26 |
27 | def pipe(self, docs: Iterable[Doc]) -> Iterable[Doc]:
28 | """Annotates a stream of Spacy Doc objects"""
29 |
30 | # This is the default implementation, which should be replaced if
31 | # we have better ways of annotating large numbers of documents
32 | for doc in docs:
33 | yield self(doc)
34 |
35 | def annotate_docbin(self, docbin_input_path: str,
36 | docbin_output_path: Optional[str] = None,
37 | spacy_model_name: str = "en_core_web_md",
38 | cutoff: Optional[int] = None, nb_to_skip: int = 0):
39 | """Runs the annotator on the documents of a DocBin file, and write the output
40 | to docbin_output_path (or to the same file if it is set to None). The spacy
41 | model name must be the same as the one used to create the DocBin file in the
42 | first place.
43 |
44 | If cutoff is set, the annotation stops after the given number of documents. If
45 | nb_to_skip is set, the method skips a number of documents at the start.
46 | """
47 |
48 | docs = utils.docbin_reader(docbin_input_path, spacy_model_name,
49 | cutoff=cutoff, nb_to_skip=nb_to_skip)
50 | new_docs = []
51 | for doc in self.pipe(docs):
52 | new_docs.append(doc)
53 | if len(new_docs) % 1000 == 0:
54 | print("Number of processed documents:", len(new_docs))
55 |
56 | docbin_output_path = docbin_output_path or docbin_input_path
57 | utils.docbin_writer(new_docs, docbin_output_path)
58 |
59 |
60 | ####################################################################
61 | # Type of annotators
62 | ####################################################################
63 |
64 | class SpanAnnotator(AbstractAnnotator):
65 | """Generic class for the annotation of token spans"""
66 |
67 | def __init__(self, name: str):
68 | """Initialises the annotator with a source name"""
69 |
70 | super(SpanAnnotator, self).__init__(name)
71 |
72 | # Set of other labelling sources that have priority
73 | self.incompatible_sources = []
74 |
75 | # type:ignore
76 | def add_incompatible_sources(self, other_sources: Sequence[str]):
77 | """Specifies a list of sources that are not compatible with the current
78 | source and should take precedence over it in case of overlap"""
79 |
80 | self.incompatible_sources.extend(other_sources)
81 |
82 | def __call__(self, doc: Doc) -> Doc:
83 |
84 | # We start by clearing all existing annotations
85 | doc.spans[self.name] = []
86 |
87 | # And we look at all suggested spans
88 | for start, end, label in self.find_spans(doc):
89 |
90 | # We only add the span if it is compatible with other sources
91 | if self._is_allowed_span(doc, start, end):
92 | span = Span(doc, start, end, label)
93 | doc.spans[self.name].append(span)
94 |
95 | return doc
96 |
97 | @abstractmethod
98 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
99 | """Generates (start, end, label) triplets corresponding to token-level
100 | spans associated with a given label. """
101 |
102 | raise NotImplementedError("Must implement find_spans method")
103 |
104 | def _is_allowed_span(self, doc, start, end):
105 | """Checks whether the span is allowed (given incompatibilities with other sources)"""
106 |
107 | for other_source in self.incompatible_sources:
108 |
109 | intervals = sorted((span.start, span.end) for span in
110 | doc.spans.get(other_source, []))
111 |
112 | # Performs a binary search to efficiently detect overlapping spans
113 | start_search, end_search = utils._binary_search(
114 | start, end, intervals)
115 | for interval_start, interval_end in intervals[start_search:end_search]:
116 | if start < interval_end and end > interval_start:
117 | return False
118 | return True
119 |
120 |
121 | class TextAnnotator(AbstractAnnotator):
122 | """Abstract class for labelling functions used for text classification
123 | (the goal being to predict the label of a full document)"""
124 |
125 | def __call__(self, doc: Doc) -> Doc:
126 |
127 | # We start by clearing all existing annotations
128 |
129 | doc.spans[self.name] = []
130 |
131 | result = self.get_label(doc)
132 |
133 | # We only add the annotation is the function returns a label
134 | if result is not None:
135 | span = Span(doc, 0, len(doc), result)
136 | doc.spans[self.name].append(span)
137 |
138 | return doc
139 |
140 | @abstractmethod
141 | def get_label(self, doc: Doc) -> Optional[str]:
142 | """Returns the label of the document as predicted by the function,
143 | or None if the labelling function "abstains" from giving a prediction"""
144 | raise NotImplementedError("Must implement get_label method")
145 |
146 |
147 | ####################################################################
148 | # Combination of annotators
149 | ####################################################################
150 |
151 |
152 | class CombinedAnnotator(AbstractAnnotator):
153 | """Annotator of entities in documents, combining several sub-annotators """
154 |
155 | def __init__(self):
156 | super(CombinedAnnotator, self).__init__("")
157 | self.annotators = []
158 |
159 | def __call__(self, doc: Doc) -> Doc:
160 | """Annotates a single document with the sub-annotators
161 | NB: avoid using this method for large collections of documents (as it is quite
162 | inefficient), and prefer the method pipe that runs on batches of documents.
163 | """
164 |
165 | for annotator in self.annotators:
166 | doc = annotator(doc)
167 | return doc
168 |
169 | def pipe(self, docs: Iterable[Doc]) -> Iterable[Doc]:
170 | """Annotates the stream of documents using the sub-annotators."""
171 |
172 | # We duplicate the streams of documents
173 | streams = itertools.tee(docs, len(self.annotators)+1)
174 |
175 | # We create one pipe per annotator
176 | pipes = [annotator.pipe(stream) for annotator, stream in
177 | zip(self.annotators, streams[1:])]
178 |
179 | for doc in streams[0]:
180 | for pipe in pipes:
181 | try:
182 | next(pipe)
183 | except BaseException as e:
184 | print("ignoring document:", doc)
185 | raise e
186 |
187 | yield doc
188 |
189 | def add_annotator(self, annotator: AbstractAnnotator):
190 | """Adds an annotator to the list"""
191 |
192 | self.annotators.append(annotator)
193 | return self
194 |
195 | def add_annotators(self, *annotators: AbstractAnnotator):
196 | """Adds several annotators to the list"""
197 |
198 | for annotator in annotators:
199 | self.add_annotator(annotator)
200 | return self
201 |
202 | def get_annotator(self, annotator_name: str):
203 | """Returns the annotator identified by its name (and throws an
204 | exception if no annotator can be found)"""
205 |
206 | for annotator in self.annotators:
207 | if annotator.name == annotator_name:
208 | return annotator
209 |
210 | raise RuntimeError("Could not find annotator %s" % annotator_name)
211 |
--------------------------------------------------------------------------------
/skweak/doclevel.py:
--------------------------------------------------------------------------------
1 | from collections import defaultdict
2 | from typing import Dict, Iterable, List, Tuple
3 |
4 | from . import base, utils
5 | from .gazetteers import GazetteerAnnotator, Trie
6 | from spacy.tokens import Doc, Span # type: ignore
7 |
8 | class DocumentHistoryAnnotator(base.SpanAnnotator):
9 | """Annotation based on the document history:
10 | 1) if a person name has been mentioned in full (at least two consecutive tokens,
11 | most often first name followed by last name), then mark future occurrences of the
12 | last token (last name) as a PER as well.
13 | 2) if an organisation has been mentioned together with a legal type, mark all other
14 | occurrences (possibly without the legal type at the end) also as a COMPANY.
15 | """
16 |
17 | def __init__(self, basename: str, other_name: str, labels: List[str],
18 | case_sensitive=True):
19 | """Creates a new annotator looking at the global document context, based on another
20 | annotation layer (typically a layer aggregating existing annotations). Only the
21 | labels specified in the argument will be taken into account."""
22 |
23 | super(DocumentHistoryAnnotator, self).__init__(basename)
24 | self.other_name = other_name
25 | self.labels = labels
26 | self.case_sensitive = case_sensitive
27 |
28 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
29 | """Search for spans on one single document"""
30 |
31 | # Extract the first mentions of each entity
32 | first_observed = self.get_first_mentions(doc)
33 |
34 | # We construct tries based on the first mentions
35 | tries = {label: Trie() for label in self.labels}
36 | first_observed_bounds = set()
37 | for tokens, span in first_observed.items():
38 | tries[span.label_].add(tokens)
39 | first_observed_bounds.add((span.start, span.end))
40 |
41 | gazetteer = GazetteerAnnotator(self.name, tries, case_sensitive=self.case_sensitive,
42 | additional_checks=not self.case_sensitive)
43 |
44 | for start, end, label in gazetteer.find_spans(doc):
45 | if (start, end) not in first_observed_bounds:
46 | yield start, end, label
47 |
48 | return doc
49 |
50 | def get_first_mentions(self, doc) -> Dict[List[str], Span]:
51 | """Returns a set containing the first mentions of each entity as triples
52 | (start, end, label) according to the "other_name' layer.
53 |
54 | The first mentions also contains subsequences: for instance, a named entity
55 | "Pierre Lison" will also contain the first mentions of ['Pierre'] and ['Lison'].
56 | """
57 | if self.other_name not in doc.spans:
58 | return {}
59 |
60 | first_observed = {}
61 | for span in doc.spans[self.other_name]:
62 |
63 | # NB: We only consider entities with at least two tokens
64 | if span.label_ not in self.labels or len(span) < 2:
65 | continue
66 |
67 | # We also extract subsequences
68 | for length in range(1, len(span)+1):
69 | for i in range(length, len(span)+1):
70 |
71 | start2 = span.start + i-length
72 | end2 = span.start + i
73 | subseq = tuple(tok.text for tok in doc[start2:end2])
74 |
75 | # We ony consider first mentions
76 | if subseq in first_observed:
77 | continue
78 |
79 | # To avoid too many FPs, the mention must have at least 4 charactes
80 | if sum(len(tok) for tok in subseq) <4:
81 | continue
82 |
83 | # And if the span looks like a proper name, then at least one
84 | # token in the subsequence must look like a proper name too
85 | if (any(utils.is_likely_proper(tok) for tok in span) and not
86 | any(utils.is_likely_proper(tok) for tok in doc[start2:end2])):
87 | continue
88 |
89 | first_observed[subseq] = Span(doc, start2, end2, span.label_)
90 |
91 | return first_observed
92 |
93 |
94 | class DocumentMajorityAnnotator(base.SpanAnnotator):
95 | """Annotation based on majority label for the same entity string elsewhere in the
96 | document. The annotation creates two layers for each label, one for case-sensitive
97 | occurrences of the entity string in the document, and one for case-insensitive
98 | occurrences.
99 | """
100 |
101 | def __init__(self, basename: str, other_name: str, case_sensitive=True):
102 | """Creates a new annotator that looks at (often aggregated) annotations from
103 | another layer, and annotates entities based on their majority label elsewhere
104 | in the document. """
105 |
106 | super(DocumentMajorityAnnotator, self).__init__(basename)
107 | self.other_name = other_name
108 | self.case_sensitive = case_sensitive
109 |
110 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
111 | """Generates span annotations for one single document based on
112 | majority labels"""
113 |
114 | # We search for the majority label for each entity string
115 | majority_labels = self.get_majority_labels(doc)
116 |
117 | # we build trie to easily search for these entities in the text
118 | tries = {label: Trie()
119 | for label in set(majority_labels.values())}
120 | for ent_tokens, label in majority_labels.items():
121 | tries[label].add(list(ent_tokens))
122 |
123 | gazetteer = GazetteerAnnotator(self.name, tries, self.case_sensitive,
124 | additional_checks=not self.case_sensitive)
125 | for start, end, label in gazetteer.find_spans(doc):
126 | yield start, end, label
127 |
128 | def get_majority_labels(self, doc: Doc) -> Dict[Tuple[str], str]:
129 | """Given a document, searches for the majority label for each entity string
130 | with at least self.min_counts number of occurrences. """
131 |
132 | # Get the counts for each label per entity string
133 | # (and also for each form, to take various casings into account)
134 | label_counts = defaultdict(dict)
135 | form_counts = defaultdict(dict)
136 | spans = utils.get_spans_with_probs(doc, self.other_name)
137 | all_tokens_low = [tok.lower_ for tok in doc]
138 | checked = {}
139 | for span, prob in spans:
140 |
141 | # We only apply document majority for strings occurring more than once
142 | tokens_low = tuple(all_tokens_low[span.start:span.end])
143 | if tokens_low not in checked:
144 | occurs_several_times = utils.at_least_nb_occurrences(
145 | tokens_low, all_tokens_low, 2)
146 | checked[tokens_low] = occurs_several_times
147 | else:
148 | occurs_several_times = checked[tokens_low]
149 |
150 | # If the string occurs more than once, update the counts
151 | if occurs_several_times:
152 | label_counts[tokens_low][span.label_] = \
153 | label_counts[tokens_low].get(span.label_, 0) + prob
154 | tokens = tuple(tok.text for tok in span)
155 | form_counts[tokens_low][tokens] = form_counts[tokens_low].get(
156 | tokens, 0) + prob
157 |
158 | # Search for the most common label for each entity string
159 | majority_labels = {}
160 | for lower_tokens, labels_for_ent in label_counts.items():
161 | majority_label = max(
162 | labels_for_ent, key=lambda x: labels_for_ent[x])
163 | forms_for_ent = form_counts[lower_tokens]
164 | majority_form = max(forms_for_ent, key=lambda x: forms_for_ent[x])
165 |
166 | majority_labels[majority_form] = majority_label
167 |
168 | return majority_labels
169 |
--------------------------------------------------------------------------------
/skweak/gazetteers.py:
--------------------------------------------------------------------------------
1 | import gzip
2 | import json
3 | import re
4 | from typing import Dict, Iterable, List, Optional, Tuple
5 |
6 | from spacy.tokens import Doc, Span, Token # type: ignore
7 |
8 | from . import base, utils
9 |
10 | ############################################
11 | # Gazetteer annotator
12 | ############################################
13 |
14 | class GazetteerAnnotator(base.SpanAnnotator):
15 | """Annotation using a gazetteer, i.e. a large list of entity terms. The annotation can
16 | look at either case-sensitive and case-insensitive occurrences. The annotator relies
17 | on a token-level trie for efficient search. """
18 |
19 | def __init__(self, name: str, tries: Dict[str, 'Trie'], case_sensitive: bool = True,
20 | lookahead: int = 10, additional_checks: bool=True):
21 | """Creates a new gazeteer, based on:
22 | - a trie
23 | - an output label associated with the trie
24 | - a flag indicating whether the gazetteer should be case-sensitive or not
25 | - the maximum size of the lookahead window
26 | - a flag indicating whether to do additional checks to reduce the
27 | number of false positives when searching for named entities"""
28 |
29 | super(GazetteerAnnotator, self).__init__(name)
30 |
31 | self.tries = tries
32 | self.case_sensitive = case_sensitive
33 | self.lookahead = lookahead
34 | self.additional_checks = additional_checks
35 |
36 |
37 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
38 | """Search for occurrences of entity terms in the spacy document"""
39 |
40 | # We extract the tokens (as list of strings)
41 | tokens = utils.get_tokens(doc)
42 |
43 | # We extract the (token-level) indices for next sentence boundaries
44 | next_sentence_boundaries = utils.get_next_sentence_boundaries(doc)
45 |
46 | i = 0
47 | while i < len(doc):
48 |
49 | tok = doc[i]
50 |
51 | # We create a lookahead window starting at the token
52 | lookahead_length = self._get_lookahead(tok, next_sentence_boundaries[i])
53 |
54 | if lookahead_length:
55 |
56 | window = tokens[i:i+lookahead_length]
57 | matches = []
58 | # We loop on all tries (one per label)
59 | for label, trie in self.tries.items():
60 |
61 | # We search for the longest match
62 | match = trie.find_longest_match(window, self.case_sensitive)
63 | if match:
64 | # We check whether the match is valid
65 | if (not self.additional_checks or
66 | self._is_valid_match(doc[i:i+len(match)], match)):
67 | matches.append((match, label))
68 |
69 | # We choose the longest match(es)
70 | if matches:
71 | max_length = max(len(match) for match, _ in matches)
72 | for match, label in matches:
73 | if len(match)==max_length:
74 | yield i, i+max_length, label
75 |
76 | # We skip the text until the end of the match
77 | i += max_length-1
78 |
79 | i += 1
80 |
81 | def _get_lookahead(self, token: Token, next_sentence_boundary: int) -> int:
82 | """Returns the longest possible span starting with the current token, and
83 | satisfying the three following criteria:
84 | - the maximum length of the span is self.lookahead
85 | - the span cannot start with a punctuation symbol or within a compound phrase
86 | - the span cannot cross sentence boundaries
87 | """
88 |
89 | if token.is_punct:
90 | return 0
91 | elif (self.additional_checks and token.i > 0 and token.nbor(-1).dep_ == "compound"
92 | and token.nbor(-1).head == token):
93 | return 0
94 |
95 | return min(next_sentence_boundary-token.i, self.lookahead)
96 |
97 | def _is_valid_match(self, match_span: Span, ent_tokens: List[str]) -> bool:
98 | """Checks whether the match satisfies the following criteria:
99 | - the match does not end with a punctuation symbol or within a compound phrase
100 | (with a head that looks like a proper name)
101 | - if the actual tokens of the entity contains tokens in "title" case, the match
102 | must contain at least one token that looks like a proper name
103 | (to avoid too many false positives).
104 | """
105 |
106 | last_token = match_span[-1]
107 | if last_token.is_punct:
108 | return False
109 | elif match_span.end < len(match_span.doc):
110 | if (last_token.dep_ == "compound" and last_token.head.i > last_token.i
111 | and utils.is_likely_proper(last_token.head)):
112 | return False
113 |
114 | if (any(tok.istitle() for tok in ent_tokens) and
115 | not any(utils.is_likely_proper(tok) for tok in match_span)):
116 | return False
117 | return True
118 |
119 |
120 | ############################################
121 | # Trie data structure (used for gazetteers)
122 | ############################################
123 |
124 | class Trie:
125 | """Implementation of a trie for searching for occurrences of terms in a text.
126 |
127 | Internally, the trie is made of nodes expressed as (dict, bool) pairs, where the
128 | dictionary expressed possible edges (tokens) going out from the node, and the boolean
129 | indicates whether the node is terminal or not.
130 | """
131 |
132 | def __init__(self, entries: List[List[str]] = None):
133 | """Creates a new trie. If provided, entries must be a list of tokenised entries"""
134 |
135 | self.start = {}
136 | self.len = 0
137 |
138 | if entries is not None:
139 | for entry in entries:
140 | self.add(entry)
141 |
142 | def find_longest_match(self, tokens: List[str], case_sensitive=True) -> List[str]:
143 | """Search for the longest match (that is, the longest element in the trie that matches
144 | a prefix of the provided tokens). The tokens must be expressed as a list of strings.
145 | The method returns the match as a list of tokens, which is empty is no match could
146 | be found.
147 |
148 | If case_sensitive is set to False, the method also checks for matches of alternative
149 | casing of the words (lowercase, uppercase and titled)
150 | """
151 |
152 | edges = self.start
153 | prefix_length = 0
154 | matches = []
155 |
156 | for i, token in enumerate(tokens):
157 |
158 | match = self._find_match(token, edges, case_sensitive)
159 | if match:
160 | edges, is_terminal = edges[match]
161 | matches.append(match)
162 | if is_terminal:
163 | prefix_length = i+1
164 | else:
165 | break
166 |
167 | return matches[:prefix_length]
168 |
169 | def _find_match(self, token: str, branch: Dict, case_sensitive: bool) -> Optional[str]:
170 | """Checks whether the token matches any edge in the branch. If yes,
171 | returns the match (which can be slightly different from the token if
172 | case_sensitive is set to False). Otherwise returns None."""
173 |
174 | if not branch:
175 | return None
176 | elif case_sensitive:
177 | return token if token in branch else None
178 | elif token in branch:
179 | return token
180 |
181 | if not token.istitle():
182 | titled = token.title()
183 | if titled in branch:
184 | return titled
185 | if not token.islower():
186 | lowered = token.lower()
187 | if lowered in branch:
188 | return lowered
189 | if not token.isupper():
190 | uppered = token.upper()
191 | if uppered in branch:
192 | return uppered
193 |
194 | return None
195 |
196 | def __contains__(self, tokens: List[str]) -> bool:
197 | """Returns whether the list of tokens are contained in the trie
198 | (in case-sensitive mode)"""
199 |
200 | return self.contains(tokens)
201 |
202 | def contains(self, tokens: List[str], case_sensitive=True) -> bool:
203 | """Returns whether the list of tokens are contained in the trie"""
204 |
205 | edges = self.start
206 | is_terminal = False
207 | for token in tokens:
208 | match = self._find_match(token, edges, case_sensitive)
209 | if not match:
210 | return False
211 | edges, is_terminal = edges[match]
212 | return is_terminal
213 |
214 | def add(self, tokens: List[str]):
215 | """Adds a new (tokens, value) pair to the trie"""
216 |
217 | # We add new edges to the trie
218 | edges = self.start
219 | for token in tokens[:-1]:
220 |
221 | # We create a sub-dictionary if it does not exist
222 | if token not in edges:
223 | newdict = {}
224 | edges[token] = (newdict, False)
225 | edges = newdict
226 |
227 | else:
228 | next_edges, is_terminal = edges[token]
229 |
230 | # If the current set of edges is None, map to a dictionary
231 | if next_edges is None:
232 | newdict = {}
233 | edges[token] = (newdict, is_terminal)
234 | edges = newdict
235 | else:
236 | edges = next_edges
237 |
238 | last_token = tokens[-1]
239 | if last_token not in edges:
240 | edges[last_token] = (None, True)
241 | else:
242 | edges[last_token] = (edges[last_token][0], True)
243 |
244 | self.len += 1
245 |
246 | def __len__(self) -> int:
247 | """Returns the total number of (tokens, value) pairs in the trie"""
248 | return self.len
249 |
250 | def __iter__(self):
251 | """Generates all elements from the trie"""
252 |
253 | for tokens in self._iter_from_edges(self.start):
254 | yield tokens
255 |
256 | def _iter_from_edges(self, edges):
257 | """Generates all elements from a branch in the trie"""
258 |
259 | for token, (sub_branch, is_terminal) in edges.items():
260 | if is_terminal:
261 | yield [token]
262 | if sub_branch is not None:
263 | for tokens2 in self._iter_from_edges(sub_branch):
264 | yield [token, *tokens2]
265 |
266 | def __repr__(self) -> str:
267 | """Returns a representation of the trie as a flattened list"""
268 |
269 | return list(self).__repr__()
270 |
271 |
272 | ############################################
273 | # Utility functions
274 | ############################################
275 |
276 |
277 | def extract_json_data(json_file: str, cutoff: Optional[int] = None,
278 | spacy_model="en_core_web_md") -> Dict[str, Trie]:
279 | """Extract entities from a Json file and build trie from it (one per class).
280 |
281 | If cutoff is set to a number, stops the extraction after a number of values
282 | for each class (useful for debugging purposes)."""
283 |
284 | print("Extracting data from", json_file)
285 | tries = {}
286 | tokeniser = None
287 | if json_file.endswith(".json.gz"):
288 | fd = gzip.open(json_file, "r")
289 | data = json.loads(fd.read().decode("utf-8"))
290 | fd.close()
291 | elif json_file.endswith(".json"):
292 | fd = open(json_file)
293 | data = json.load(fd)
294 | fd.close()
295 | else:
296 | raise RuntimeError(str(json_file) + " does not look like a JSON file")
297 |
298 | for neClass, names in data.items():
299 |
300 | remaining = []
301 | if cutoff is not None:
302 | names = names[:cutoff]
303 | print("Populating trie for class %s (number: %i)" %
304 | (neClass, len(names)))
305 |
306 | trie = Trie()
307 | for name in names:
308 | if type(name) == str:
309 | tokens = name.split(" ")
310 |
311 | # If the tokens contain special characters, we need to run spacy to
312 | # ensure we get the same tokenisation as in spacy-tokenised texts
313 | if any(tok for tok in tokens if not tok.isalpha()
314 | and not tok.isnumeric() and not re.match("[A-Z]\\.$", tok)):
315 | import spacy
316 | tokeniser = tokeniser or spacy.load(
317 | spacy_model).tokenizer
318 | tokens = [t.text for t in tokeniser(name)]
319 |
320 | if len(tokens) > 0:
321 | trie.add(tokens)
322 |
323 | # If the items are already tokenised, we can load the trie faster
324 | elif type(name) == list:
325 | if len(name) > 0:
326 | trie.add(name)
327 |
328 | tries[neClass] = trie
329 | return tries
330 |
--------------------------------------------------------------------------------
/skweak/heuristics.py:
--------------------------------------------------------------------------------
1 | import re
2 | from typing import (Callable, Collection, Dict, Iterable, Optional, Sequence,
3 | Set, Tuple)
4 |
5 | from spacy.tokens import Doc, Span, Token # type: ignore
6 |
7 | from .base import SpanAnnotator
8 |
9 | ####################################################################
10 | # Labelling sources based on heuristics / handcrafted rules
11 | ####################################################################
12 |
13 |
14 | class FunctionAnnotator(SpanAnnotator):
15 | """Annotation based on a heuristic function that generates (start,end,label)
16 | given a spacy document"""
17 |
18 | def __init__(self, name: str,
19 | function: Callable[[Doc], Iterable[Tuple[int, int, str]]],
20 | to_exclude: Sequence[str] = ()):
21 | """Create an annotator based on a function generating labelled spans given
22 | a Spacy Doc object. Spans that overlap with existing spans from sources
23 | listed in 'to_exclude' are ignored. """
24 |
25 | super(FunctionAnnotator, self).__init__(name)
26 | self.find_spans = function
27 | self.add_incompatible_sources(to_exclude)
28 |
29 |
30 | class RegexAnnotator(SpanAnnotator):
31 | """Annotation based on a heuristic regular expression that generates
32 | (start,end,label) given a spacy document"""
33 |
34 | def __init__(
35 | self,
36 | name: str,
37 | pattern: str,
38 | tag: str,
39 | to_exclude: Sequence[str] = (),
40 | alignment_mode : str = "expand",
41 | ):
42 | """Create an annotator based on a regular expression generating labelled
43 | spans given a Spacy Doc object. The regex matches are tagged with the
44 | value of the 'tag' param. Spans that overlap with existing spans
45 | from sources listed in 'to_exclude' are ignored."""
46 |
47 | super().__init__(name)
48 | self.pattern = pattern
49 | self.tag = tag
50 | self.alignment_mode = alignment_mode
51 | self.add_incompatible_sources(to_exclude)
52 |
53 |
54 | @staticmethod
55 | def regex_search(pattern, string):
56 |
57 | prev_end = 0
58 | while True:
59 | match = re.search(pattern, string)
60 | if not match:
61 | break
62 |
63 | start, end = match.span()
64 | yield start + prev_end, end + prev_end
65 | prev_end += end
66 | string = string[end:]
67 |
68 |
69 | def find_spans(self, doc):
70 |
71 | for start, end in self.regex_search(self.pattern, doc.text):
72 | span = doc.char_span(start, end, self.tag, alignment_mode=self.alignment_mode)
73 | yield span.start, span.end, self.tag
74 |
75 |
76 | class TokenConstraintAnnotator(SpanAnnotator):
77 | """Annotator relying on a token-level constraint. Continuous spans that
78 | satisfy this constraint will be marked by the provided label."""
79 |
80 | def __init__(self, name: str, constraint: Callable[[Token], bool],
81 | label: str, min_characters=3,
82 | gap_tokens:Optional[Set]=None):
83 | """Given a token-level constraint, a label name, and a minimum
84 | number of characters, annotates with the label all (maximal)
85 | contiguous spans whose tokens satisfy the constraint."""
86 |
87 | super(TokenConstraintAnnotator, self).__init__(name)
88 | self.constraint = constraint
89 | self.label = label
90 | self.min_characters = min_characters
91 |
92 | # Hyphens should'nt stop a span
93 | self.gap_tokens = gap_tokens if gap_tokens is not None else {"-"}
94 |
95 | def add_gap_tokens(self, gap_tokens: Collection[str]):
96 | """Adds tokens (typically function words) that are allowed in the span
97 | even if they do not satisfy the constraint, provided they are surrounded
98 | by words that do satisfy the constraint. """
99 |
100 | self.gap_tokens.update(gap_tokens)
101 |
102 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
103 | """
104 | Searches for all spans whose tokens satisfy the constraint (and meet
105 | the minimum character length), and marks those with the provided label.
106 | """
107 |
108 | i = 0
109 | while i < len(doc):
110 | tok = doc[i]
111 | # We search for the longest span that satisfy the constraint
112 | if self.constraint(tok):
113 | j = i+1
114 | while j < len(doc):
115 | # We check the constraint
116 | if self.constraint(doc[j]) and self._is_allowed_span(doc, i, j+1):
117 | j += 1
118 |
119 | # We also check whether the token is a gap word
120 | elif (doc[j].text in self.gap_tokens and j < len(doc)-1
121 | and self.constraint(doc[j+1])
122 | and self._is_allowed_span(doc, i, j+2)):
123 | j += 2
124 | else:
125 | break
126 |
127 | # We check whether the span has a minimal length
128 | if len(doc[i:j].text) >= self.min_characters:
129 | yield i, j, self.label
130 |
131 | i = j
132 | else:
133 | i += 1
134 |
135 |
136 | class SpanConstraintAnnotator(SpanAnnotator):
137 | """Annotation by looking at text spans (from another source)
138 | that satisfy a span-level constraint"""
139 |
140 | def __init__(self, name: str, other_name: str, constraint: Callable[[Span], bool],
141 | label: Optional[str] = None):
142 | """Creates a new annotator that looks at the annotations from the
143 | other_name source, and adds them to this source if it satisfied a
144 | given constraint on spans. If label is other than None, the method
145 | simply reuses the same label as the one specified by other_name."""
146 |
147 | super(SpanConstraintAnnotator, self).__init__(name)
148 | self.other_name = other_name
149 | self.constraint = constraint
150 | self.label = label
151 |
152 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
153 | """Loops through the spans annotated by the other source, and, for each, checks
154 | whether they satisfy the provided constraint. If yes, adds the labelled span
155 | to the annotations for this source. """
156 |
157 | if self.other_name not in doc.spans:
158 | return
159 |
160 | for span in doc.spans[self.other_name]:
161 | if self.constraint(span):
162 | yield span.start, span.end, (self.label or span.label_)
163 |
164 |
165 | class SpanEditorAnnotator(SpanAnnotator):
166 | """Annotation by editing/correcting text spans from another source
167 | based on a simple editing function"""
168 |
169 | def __init__(self, name: str, other_name: str, editor: Callable[[Span], Span],
170 | label: Optional[str] = None):
171 | """Creates a new annotator that looks at the annotations from the
172 | other_name source, and edits the span according to a given function.
173 | If label is other than None, the method simply reuses the same label
174 | as the one specified by other_name."""
175 |
176 | super(SpanEditorAnnotator, self).__init__(name)
177 | self.other_name = other_name
178 | self.editor = editor
179 | self.label = label
180 |
181 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
182 | """Loops through the spans annotated by the other source and runs the
183 | editor function on it. """
184 |
185 | if self.other_name not in doc.spans:
186 | return
187 |
188 | for span in doc.spans[self.other_name]:
189 | edited = self.editor(span)
190 | if edited is not None and edited.end > edited.start:
191 | yield edited.start, edited.end, (self.label or span.label_)
192 |
193 |
194 | ####################################################################
195 | # Other labelling sources
196 | ####################################################################
197 |
198 | class VicinityAnnotator(SpanAnnotator):
199 | """Annotator based on cue words located in the vicinity (window of
200 | surrounding words) of a given span. """
201 |
202 | def __init__(self, name: str, cue_words: Dict[str, str], other_name: str,
203 | max_window: int = 8):
204 | """Creates a new annotator based on a set of cue words (each mapped
205 | to a given output label) along with the name of another labelling
206 | source from which span candidates will be extracted."""
207 |
208 | super(VicinityAnnotator, self).__init__(name)
209 |
210 | self.cue_words = cue_words
211 | self.other_name = other_name
212 | self.max_window = max_window
213 |
214 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
215 | """Searches for spans that have a cue word in their vicinity - and if
216 | yes, tag the span with the label associated with the cue word."""
217 |
218 | if self.other_name not in doc.spans:
219 | return
220 |
221 | # We loop on the span candidates from the other labelling source
222 | for span in doc.spans[self.other_name]:
223 |
224 | # Determine the boundaries of the context (based on the window)
225 | # NB: we do not wish to cross sentence boundaries
226 | left_bound = max(span.sent.start, span.start - self.max_window//2+1)
227 | right_bound = min(span.sent.end, span.end+self.max_window//2+1)
228 |
229 | for tok in doc[left_bound:right_bound]:
230 | for tok_form in {tok.text, tok.lower_, tok.lemma_}:
231 | if tok_form in self.cue_words:
232 | yield span.start, span.end, self.cue_words[tok_form]
233 |
--------------------------------------------------------------------------------
/skweak/spacy.py:
--------------------------------------------------------------------------------
1 | import itertools
2 | import json
3 | from typing import Dict, Iterable, List, Tuple
4 |
5 | import spacy
6 | from spacy.tokens import Doc, Span # type: ignore
7 |
8 | from .base import SpanAnnotator
9 |
10 | ####################################################################
11 | # Labelling source based on neural models
12 | ####################################################################
13 |
14 |
15 | class ModelAnnotator(SpanAnnotator):
16 | """Annotation based on a spacy NER model"""
17 |
18 | def __init__(self, name:str, model_path:str,
19 | disabled:List[str]=["parser", "tagger", "lemmatizer", "attribute_ruler"]):
20 | """Creates a new annotator based on a Spacy model. """
21 |
22 | super(ModelAnnotator, self).__init__(name)
23 | self.model = spacy.load(model_path, disable=disabled)
24 |
25 |
26 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
27 | """Annotates one single document using the Spacy NER model"""
28 |
29 | # Create a new document (to avoid conflicting annotations)
30 | doc2 = self.create_new_doc(doc)
31 | # And run the model
32 | for _, proc in self.model.pipeline:
33 | doc2 = proc(doc2)
34 | # Add the annotation
35 | for ent in doc2.ents:
36 | yield ent.start, ent.end, ent.label_
37 |
38 | def pipe(self, docs: Iterable[Doc]) -> Iterable[Doc]:
39 | """Annotates the stream of documents based on the Spacy model"""
40 |
41 | stream1, stream2 = itertools.tee(docs, 2)
42 |
43 | # Remove existing entities from the document
44 | stream2 = (self.create_new_doc(d) for d in stream2)
45 |
46 | # And run the model
47 | for _, proc in self.model.pipeline:
48 | stream2 = proc.pipe(stream2)
49 |
50 | for doc, doc_copy in zip(stream1, stream2):
51 |
52 | doc.spans[self.name] = []
53 |
54 | # Add the annotation
55 | for ent in doc_copy.ents:
56 | doc.spans[self.name].append(Span(doc, ent.start, ent.end, ent.label_))
57 |
58 | yield doc
59 |
60 | def create_new_doc(self, doc: Doc) -> Doc:
61 | """Create a new, empty Doc (but with the same tokenisation as before)"""
62 |
63 | return spacy.tokens.Doc(self.model.vocab, [tok.text for tok in doc], #type: ignore
64 | [tok.whitespace_ for tok in doc])
65 |
66 |
67 | class TruecaseAnnotator(ModelAnnotator):
68 | """Spacy model annotator that preprocess all texts to convert them to a
69 | "truecased" representation (see below)"""
70 |
71 | def __init__(self, name:str, model_path:str, form_frequencies:str,
72 | disabled:List[str]=["parser", "tagger", "lemmatizer", "attribute_ruler"]):
73 | """Creates a new annotator based on a Spacy model, and a dictionary containing
74 | the most common case forms for a given word (to be able to truecase the document)."""
75 |
76 | super(TruecaseAnnotator, self).__init__(name, model_path, disabled)
77 | with open(form_frequencies) as fd:
78 | self.form_frequencies = json.load(fd)
79 |
80 | def create_new_doc(self, doc: Doc, min_prob: float = 0.25) -> Doc:
81 | """Performs truecasing of the tokens in the spacy document. Based on relative
82 | frequencies of word forms, tokens that
83 | (1) are made of letters, with a first letter in uppercase
84 | (2) and are not sentence start
85 | (3) and have a relative frequency below min_prob
86 | ... will be replaced by its most likely case (such as lowercase). """
87 |
88 | if not self.form_frequencies:
89 | raise RuntimeError(
90 | "Cannot truecase without a dictionary of form frequencies")
91 |
92 | tokens = []
93 | spaces = []
94 | doctext = doc.text
95 | for tok in doc:
96 | toktext = tok.text
97 |
98 | # We only change casing for words in Title or UPPER
99 | if tok.is_alpha and toktext[0].isupper():
100 | cond1 = tok.is_upper and len(toktext) > 2 # word in uppercase
101 | cond2 = toktext[0].isupper(
102 | ) and not tok.is_sent_start # titled word
103 | if cond1 or cond2:
104 | token_lc = toktext.lower()
105 | if token_lc in self.form_frequencies:
106 | frequencies = self.form_frequencies[token_lc]
107 | if frequencies.get(toktext, 0) < min_prob:
108 | alternative = sorted(
109 | frequencies.keys(), key=lambda x: frequencies[x])[-1]
110 |
111 | # We do not change from Title to to UPPER
112 | if not tok.is_title or not alternative.isupper():
113 | toktext = alternative
114 |
115 | tokens.append(toktext)
116 |
117 | # Spacy needs to know whether the token is followed by a space
118 | if tok.i < len(doc)-1:
119 | spaces.append(doctext[tok.idx+len(tok)].isspace())
120 | else:
121 | spaces.append(False)
122 |
123 | # Creates a new document with the tokenised words and space information
124 | doc2 = Doc(self.model.vocab, words=tokens, spaces=spaces) #type: ignore
125 | return doc2
126 |
127 |
128 | class LabelMapper(SpanAnnotator):
129 | """When using ModelAnnotators, e.g. spacy_lg models, often the
130 | labels introduced is not what one is looking for. This function takes in
131 | a dict of labels to replace and desired label to replace with, e.g.
132 | {
133 | ('FAC','GPE'):"LOC",
134 | ('NORP'):"ORG",
135 | ('DATE','EVENT', ..., 'WORK_OF_ART'): "MISC"
136 | }
137 | """
138 |
139 | def __init__(
140 | self,
141 | name: str,
142 | mapping: Dict[Iterable[str], str],
143 | sources: Iterable[str],
144 | inplace: bool = True,
145 | ):
146 | """Creates a new annotator that looks at the labels of certain
147 | span groups (specified by 'sources') for each doc. If the label
148 | is found in the mapping dictionary, it is replaced accordingly.
149 | If the inplace flag is active, the labels are modified in their
150 | respective span groups. If inactive, creates a new span group
151 | for all relabelled spans."""
152 |
153 | super().__init__(name)
154 | self.sources = sources
155 | self.inplace = inplace
156 |
157 | # populate mapping dict
158 | self.mapping = {}
159 | for k, v in mapping.items():
160 | if isinstance(k, str):
161 | self.mapping[k] = v
162 | else:
163 | for key in k:
164 | self.mapping[key] = v
165 |
166 |
167 | def find_spans(self, doc: Doc) -> Iterable[Tuple[int, int, str]]:
168 | """Loops through the spans annotated by the other source and runs the
169 | editor function on it. Unique because it doesn't return spans but instead
170 | edits the span groups in place!"""
171 |
172 | for source in set(self.sources).intersection(doc.spans):
173 |
174 | new_group = []
175 | for span in doc.spans[source]:
176 |
177 | if span.label_ in self.mapping:
178 |
179 | span = Span(
180 | doc,
181 | span.start,
182 | span.end,
183 | self.mapping.get(span.label_)
184 | )
185 |
186 | if self.inplace:
187 | new_group.append(span)
188 | else:
189 | yield span.start, span.end, span.label_
190 |
191 | if self.inplace:
192 | doc.spans[source] = new_group
193 |
--------------------------------------------------------------------------------
/skweak/voting.py:
--------------------------------------------------------------------------------
1 | import warnings
2 | from typing import Dict, List, Optional
3 |
4 | import numpy as np
5 | import pandas
6 |
7 | from .aggregation import (AbstractAggregator, MultilabelAggregatorMixin,
8 | SequenceAggregatorMixin, TextAggregatorMixin)
9 |
10 | warnings.simplefilter(action='ignore', category=FutureWarning)
11 |
12 |
13 | ############################################
14 | # Majority voting
15 | ############################################
16 |
17 |
18 | class MajorityVoterMixin(AbstractAggregator):
19 | """Implementation of a subset of methods from AbstractAggregator when
20 | the aggregation is performed for text/span classification.
21 | This class should not be instantiated directly."""
22 |
23 | def __init__(self, initial_weights=None):
24 | """Do not call this initializer directly, and use the fully
25 | implemented classes (MajorityVoter, NaiveBayes, HMM, etc.) instead"""
26 |
27 | # initial_weights is a dictionary associating source names to numerical weights
28 | # in the range [0, +inf]. The default assumes weights = 1 for all functions. You
29 | # can disable a labelling function by giving it a weight of 0. """
30 |
31 | self.weights = initial_weights if initial_weights else {}
32 |
33 | def aggregate(self, obs: pandas.DataFrame) -> pandas.DataFrame:
34 | """Takes as input a 2D dataframe of shape (nb_entries, nb_sources)
35 | associating each token/span to a set of observations from labelling
36 | sources, and returns a 2D dataframe of shape (nb_entries, nb_labels)
37 | assocating each entry to the probability of each output label.
38 |
39 | This probability is here computed based on making each source "vote"
40 | on its output label. The most likely label will thus be the one that
41 | is indicated by most sources. If underspecified labels are included, they
42 | are also part of the vote count. """
43 |
44 | weights = np.array([self.weights.get(source, 1) for source in obs.columns])
45 |
46 | # We count the votes for each label on all sources
47 | # (taking weights into account)
48 | def count_fun(x):
49 | return np.bincount(x[x>=0], weights=weights[x>=0],
50 | minlength=len(self.observed_labels))
51 | label_votes = np.apply_along_axis(count_fun, 1, obs.values).astype(np.float32)
52 |
53 | # For token-level sequence labelling, we need to normalise the number
54 | # of "O" occurrences, since they both indicate the absence of
55 | # prediction, but are also a possible output
56 | if self.observed_labels[0]=="O":
57 | label_votes = self.normalise_o_labels(label_votes)
58 |
59 | # We transform the votes from observations into output labels,
60 | out_label_votes = label_votes.dot(self._get_vote_matrix())
61 |
62 | # Normalisation
63 | total = np.expand_dims(out_label_votes.sum(axis=1), axis=1)
64 | probs = out_label_votes / (total + 1E-30)
65 | df = pandas.DataFrame(probs, index=obs.index, columns=self.out_labels)
66 | return df
67 |
68 |
69 | def normalise_o_labels(self, label_votes, power_base=3.0):
70 | """The normalised counts for the O labels are defined as B^(c-t),
71 | where c are the raw counts for the O labels, t are the total number of
72 | counts per data point, and B is a constant."""
73 |
74 | # If an observation is not voting for anything, we consider it as "O"
75 | not_voting_obs = (self._get_vote_matrix().sum(axis=1) == 0)
76 | label_votes[:,0] += label_votes[:,not_voting_obs].sum(axis=1)
77 | label_votes[:,not_voting_obs] = 0
78 |
79 | # Do the normalisation
80 | diff = label_votes[:,0] - label_votes.sum(axis=1)
81 | label_votes[:,0] = power_base ** diff
82 | return label_votes
83 |
84 |
85 |
86 | ############################################
87 | # Concrete majority voter aggregators
88 | ############################################
89 |
90 | class MajorityVoter(MajorityVoterMixin,TextAggregatorMixin):
91 | """Aggregator for text classification based on majority voting"""
92 |
93 | def __init__(self, name:str, labels:List[str],
94 | initial_weights:Optional[Dict[str,float]]=None):
95 | """Creates a new aggregator for text classification using majority
96 | voting. For each unique span annotated by at least one labelling source,
97 | the class constructs a probability distribution over possible labels
98 | based on the number of labelling sources "voting" for that label.
99 |
100 | Arguments:
101 | - name is the aggregator name
102 | - labels is a list of output labels to aggregate. Labels that are not
103 | mentioned here are ignored.
104 | - initial_weights provides a numeric weight to labelling sources.
105 | If left unspecified, the class assumes uniform weights.
106 | """
107 | AbstractAggregator.__init__(self, name, labels)
108 | MajorityVoterMixin.__init__(self,initial_weights)
109 |
110 |
111 | class SequentialMajorityVoter(MajorityVoterMixin,SequenceAggregatorMixin):
112 | """Aggregator for sequence labelling based on majority voting"""
113 |
114 | def __init__(self, name:str, labels:List[str], prefixes:str="BIO",
115 | initial_weights:Optional[Dict[str,float]]=None):
116 | """Creates a new aggregator for sequence labelling using majority
117 | voting. For each token annotated by at least one labelling source,
118 | the class constructs a probability distribution over possible labels
119 | based on the number of labelling sources "voting" for that label.
120 |
121 | Arguments:
122 | - name is the aggregator name
123 | - labels is a list of output labels to aggregate. Labels that are not
124 | mentioned here are ignored.
125 | - prefixes is the tagging scheme to use, such as IO, BIO or BILUO
126 | - initial_weights provides a numeric weight to labelling sources.
127 | If left unspecified, the class assumes uniform weights.
128 | """
129 | AbstractAggregator.__init__(self, name, labels)
130 | SequenceAggregatorMixin.__init__(self, prefixes)
131 | MajorityVoterMixin.__init__(self,initial_weights)
132 |
133 |
134 |
135 | class MultilabelMajorityVoter(MultilabelAggregatorMixin, MajorityVoterMixin,
136 | TextAggregatorMixin,AbstractAggregator):
137 |
138 | def __init__(self, name:str, labels:List[str],
139 | initial_weights:Optional[Dict[str,float]]=None):
140 | """Creates a new, multilabel aggregator for text classification using majority
141 | voting. For each unique span annotated by at least one labelling source,
142 | the class constructs a probability distribution over possible labels
143 | based on the number of labelling sources "voting" for that label.
144 |
145 | Arguments:
146 | - name is the aggregator name
147 | - labels is a list of output labels to aggregate. Labels that are not
148 | mentioned here are ignored.
149 | - initial_weights provides a numeric weight to labelling sources.
150 | If left unspecified, the class assumes uniform weights.
151 |
152 | The class allows for multiple labelling to be valid for each text.
153 | Labels are incompatible with one another should be provided through the
154 | set_exclusive_labels method.
155 | """
156 | AbstractAggregator.__init__(self, name, labels)
157 | MajorityVoterMixin.__init__(self, initial_weights=initial_weights)
158 | MultilabelAggregatorMixin.__init__(self, MajorityVoter, initial_weights=initial_weights)
159 |
160 |
161 |
162 | class MultilabelSequentialMajorityVoter(MultilabelAggregatorMixin, SequenceAggregatorMixin,
163 | AbstractAggregator):
164 |
165 | def __init__(self, name:str, labels:List[str], prefixes:str="BIO",
166 | initial_weights:Optional[Dict[str,float]]=None):
167 | """Creates a new, multilabel aggregator for sequence labelling
168 | using majority voting. For each token annotated by at least one
169 | labelling source, the class constructs a probability distribution
170 | over possible labels based on the number of labelling sources
171 | "voting" for that label.
172 |
173 | Arguments:
174 | - name is the aggregator name
175 | - labels is a list of output labels to aggregate. Labels that are not
176 | mentioned here are ignored.
177 | - prefixes is the tagging scheme to use, such as IO, BIO or BILUO
178 | - initial_weights provides a numeric weight to labelling sources.
179 | If left unspecified, the class assumes uniform weights.
180 |
181 | The class allows for multiple labelling to be valid for each token.
182 | Labels are incompatible with one another should be provided through the
183 | set_exclusive_labels method.
184 | """
185 | AbstractAggregator.__init__(self, name, labels)
186 | SequenceAggregatorMixin.__init__(self, prefixes)
187 | MultilabelAggregatorMixin.__init__(self, SequentialMajorityVoter, initial_weights=initial_weights)
188 |
--------------------------------------------------------------------------------
/tests/__init__.py:
--------------------------------------------------------------------------------
1 | from . import test_doclevel, test_gazetteers, test_heuristics, test_aggregation, test_utils
--------------------------------------------------------------------------------
/tests/conftest.py:
--------------------------------------------------------------------------------
1 |
2 | import pytest
3 | import spacy
4 |
5 | @pytest.fixture(scope="session")
6 | def nlp():
7 | import spacy
8 | return spacy.load("en_core_web_md")
9 |
10 | @pytest.fixture(scope="session")
11 | def nlp_small():
12 | import spacy
13 | return spacy.load("en_core_web_sm")
--------------------------------------------------------------------------------
/tests/test_doclevel.py:
--------------------------------------------------------------------------------
1 |
2 | import skweak
3 | import re
4 | from spacy.tokens import Span # type: ignore
5 |
6 | def test_subsequences():
7 | text = ["This", "is", "a", "test", "."]
8 | subsequences = [["This"], ["is"], ["a"], ["test"], ["."], ["This", "is"], ["is", "a"],
9 | ["a", "test"], ["test", "."], ["This", "is", "a"], ["is", "a", "test"],
10 | ["a", "test", "."], ["This", "is", "a", "test"], ["is", "a", "test", "."]]
11 | assert sorted(skweak.utils.get_subsequences(text)) == sorted(subsequences + [text])
12 |
13 |
14 | def test_history(nlp):
15 | text = re.sub("\\s+", " ", """This is a story about Pierre Lison and his work at
16 | Yetanothername Inc., which is just a name we invented. But of course,
17 | Lison did not really work for Yetanothername, because it is a fictious
18 | name, even when spelled like YETANOTHERNAME.""")
19 | doc = nlp(text)
20 | annotator1 = skweak.spacy.ModelAnnotator("spacy", "en_core_web_sm")
21 | annotator2 = skweak.doclevel.DocumentHistoryAnnotator("hist_cased", "spacy", ["PERSON", "ORG"])
22 | annotator3 = skweak.doclevel.DocumentHistoryAnnotator("hist_uncased", "spacy", ["PERSON", "ORG"],
23 | case_sensitive=False)
24 | doc = annotator3(annotator2(annotator1(doc)))
25 | assert Span(doc, 5, 7, "PERSON") in doc.spans["spacy"]
26 | assert Span(doc, 11, 13, "ORG") in doc.spans["spacy"]
27 | assert Span(doc, 26, 27, "PERSON") in doc.spans["hist_cased"]
28 | assert Span(doc, 32, 33, "ORG") in doc.spans["hist_cased"]
29 | assert Span(doc, 32, 33, "ORG") in doc.spans["hist_uncased"]
30 | print("DEBUG", doc[45], doc[45].lemma_, doc[45].tag_)
31 | assert Span(doc, 45, 46, "ORG") in doc.spans["hist_uncased"]
32 |
33 |
34 | def test_majority(nlp):
35 | text = re.sub("\\s+", " ", """This is a story about Pierre Lison from Belgium. He
36 | is working as a researcher at the Norwegian Computing Center. The work
37 | of Pierre Lison includes among other weak supervision. He was born and
38 | studied in belgium but does not live in Belgium anymore. """)
39 | doc = nlp(text)
40 | annotator1 = skweak.spacy.ModelAnnotator("spacy", "en_core_web_md")
41 | annotator2 = skweak.doclevel.DocumentMajorityAnnotator("maj_cased", "spacy")
42 | annotator3 = skweak.doclevel.DocumentMajorityAnnotator("maj_uncased", "spacy",
43 | case_sensitive=False)
44 | doc = annotator3(annotator2(annotator1(doc)))
45 | assert Span(doc, 5, 7, "PERSON") in doc.spans["spacy"]
46 | assert Span(doc, 8, 9, "GPE") in doc.spans["spacy"]
47 | assert Span(doc, 17, 21, "ORG") in doc.spans["spacy"]
48 | assert Span(doc, 25, 27, "PERSON") in doc.spans["spacy"]
49 | assert Span(doc, 45, 46, "GPE") in doc.spans["spacy"]
50 | assert Span(doc, 5, 7, "PERSON") in doc.spans["maj_cased"]
51 | assert Span(doc, 25, 27, "PERSON") in doc.spans["maj_cased"]
52 | assert Span(doc, 8, 9, "GPE") in doc.spans["maj_cased"]
53 | assert Span(doc, 45, 46, "GPE") in doc.spans["maj_cased"]
54 | assert Span(doc, 8, 9, "GPE") in doc.spans["maj_uncased"]
55 | # assert Span(doc, 39, 40, "GPE") in doc.spans["maj_uncased"]
56 | assert Span(doc, 45, 46, "GPE") in doc.spans["maj_uncased"]
57 |
58 |
59 | def test_truecase(nlp):
60 | text = re.sub("\\s+", " ", """This is A STORY about Pierre LISON from BELGIUM. He IS
61 | WORKING as a RESEARCHER at the Norwegian COMPUTING Center. The WORK of
62 | Pierre LISON includes AMONG OTHER weak SUPERVISION. He WAS BORN AND
63 | studied in belgium BUT does NOT LIVE IN BELGIUM anymore.""")
64 | doc = nlp(text)
65 | annotator1 = skweak.spacy.TruecaseAnnotator("truecase", "en_core_web_sm", "data/form_frequencies.json")
66 | doc = annotator1(doc)
67 | assert Span(doc, 5, 7, "PERSON") in doc.spans["truecase"]
68 | assert Span(doc, 8, 9, "GPE") in doc.spans["truecase"]
69 | assert Span(doc, 18, 19, "NORP") in doc.spans["truecase"]
70 | assert Span(doc, 25, 27, "PERSON") in doc.spans["truecase"]
71 | assert Span(doc, 45, 46, "GPE") in doc.spans["truecase"]
72 |
--------------------------------------------------------------------------------
/tests/test_gazetteers.py:
--------------------------------------------------------------------------------
1 | from skweak import gazetteers, utils
2 | import json, gzip
3 | from spacy.tokens import Span #type: ignore
4 |
5 | def test_trie1():
6 | trie = gazetteers.Trie()
7 | trie.add(["Donald", "Trump"])
8 | trie.add(["Donald", "Duck"])
9 | trie.add(["Donald", "Duck", "Magazine"])
10 |
11 | assert ["Donald", "Trump"] in trie
12 | assert ["Donald", "Duck"] in trie
13 | assert ["Donald", "Duck", "Magazine"] in trie
14 | assert ["Donald"] not in trie
15 | assert ["Trump"] not in trie
16 | assert ["Pierre"] not in trie
17 | assert trie.find_longest_match(["Donald", "Trump", "was", "the"]) == ["Donald", "Trump"]
18 | assert trie.find_longest_match(["Donald", "Duck", "was", "the"]) == ["Donald", "Duck"]
19 | assert trie.find_longest_match(["Donald", "Duck", "Magazine", "the"]) == ["Donald", "Duck", "Magazine"]
20 |
21 | assert trie.find_longest_match(["Donald"]) == []
22 | assert trie.find_longest_match(["Pierre"]) == []
23 |
24 | assert sorted(trie) == [["Donald", "Duck"], ["Donald", "Duck", "Magazine"],
25 | ["Donald", "Trump"]]
26 |
27 |
28 | def test_trie2(nlp, json_file="data/wikidata_small_tokenised.json.gz", cutoff=100):
29 | tries = gazetteers.extract_json_data(json_file, cutoff=cutoff)
30 | fd = gzip.open(json_file, "r")
31 | data = json.loads(fd.read().decode("utf-8"))
32 | fd.close()
33 |
34 | for neClass, names_for_class in data.items():
35 | nb_names = 0
36 | trie = tries[neClass]
37 | for name in names_for_class:
38 | tokens = list(name)
39 | if len(tokens)==0:
40 | continue
41 | assert tokens in trie
42 | assert trie.find_longest_match(tokens) == tokens
43 | nb_names += 1
44 | if nb_names >= cutoff:
45 | break
46 |
47 | def test_trie_case_insensitive():
48 | trie = gazetteers.Trie()
49 | trie.add(["Donald", "Trump"])
50 | trie.add(["Donald", "Duck"])
51 | trie.add(["Donald", "Duck", "Magazine"])
52 |
53 | assert trie.find_longest_match(["Donald", "Trump", "was", "the"],
54 | case_sensitive=False) == ["Donald", "Trump"]
55 | assert trie.find_longest_match(["Donald", "trump", "was", "the"],
56 | case_sensitive=False) == ["Donald", "Trump"]
57 | assert trie.find_longest_match(["DONALD", "trump", "was", "the"],
58 | case_sensitive=False) == ["Donald", "Trump"]
59 | assert trie.find_longest_match(["Donald", "Duck", "Magazine", "the"],
60 | case_sensitive=False) == ["Donald", "Duck", "Magazine"]
61 | assert trie.find_longest_match(["Donald", "Duck", "magazine", "the"],
62 | case_sensitive=False) == ["Donald", "Duck", "Magazine"]
63 |
64 | assert trie.find_longest_match(["Donald"], case_sensitive=False) == []
65 |
66 | def test_gazetteer(nlp):
67 | trie = gazetteers.Trie()
68 | trie.add(["Donald", "Trump"])
69 | trie.add(["Donald", "Duck"])
70 | trie.add(["Donald", "Duck", "Magazine"])
71 | trie.add(["Apple"])
72 |
73 | gazetteer = gazetteers.GazetteerAnnotator("test_gazetteer", {"ENT":trie})
74 | doc1 = nlp("Donald Trump is now reading Donald Duck Magazine.")
75 | doc2 = nlp("Donald Trump (unrelated with Donald Duck) is now reading Donald Duck Magazine.")
76 | doc1, doc2 = gazetteer.pipe([doc1, doc2])
77 | assert Span(doc1, 0, 2, "ENT") in doc1.spans["test_gazetteer"]
78 | assert Span(doc1, 5, 8, "ENT") in doc1.spans["test_gazetteer"]
79 | assert Span(doc2, 0, 2, "ENT") in doc2.spans["test_gazetteer"]
80 | assert Span(doc2, 5, 7, "ENT") in doc2.spans["test_gazetteer"]
81 | assert Span(doc2, 11, 14, "ENT") in doc2.spans["test_gazetteer"]
82 |
83 | gazetteer = gazetteers.GazetteerAnnotator("test_gazetteer", {"ENT":trie}, case_sensitive=False)
84 | doc1 = nlp("Donald Trump is now reading Donald Duck Magazine.")
85 | doc2 = nlp("Donald trump (unrelated with donald Duck) is now reading Donald Duck magazine.")
86 |
87 | doc3 = nlp("At Apple, we do not like to simply eat an apple.")
88 | doc1, doc2, doc3 = gazetteer.pipe([doc1, doc2, doc3])
89 | assert Span(doc1, 0, 2, "ENT") in doc1.spans["test_gazetteer"]
90 | assert Span(doc1, 5, 8, "ENT") in doc1.spans["test_gazetteer"]
91 | assert Span(doc2, 0, 2, "ENT") in doc2.spans["test_gazetteer"]
92 | assert Span(doc2, 5, 7, "ENT") in doc2.spans["test_gazetteer"]
93 | assert Span(doc2, 11, 14, "ENT") in doc2.spans["test_gazetteer"]
94 | assert Span(doc3, 1, 2, "ENT") in doc3.spans["test_gazetteer"]
95 |
96 |
97 | def test_gazetteer2(nlp):
98 |
99 | class Trie2(gazetteers.Trie):
100 | def __init__(self):
101 | super(Trie2, self).__init__()
102 | self.nb_queries = 0
103 |
104 | def find_longest_match(self, tokens, case_sensitive=True):
105 | self.nb_queries += 1
106 | return super(Trie2, self).find_longest_match(tokens, case_sensitive)
107 |
108 | trie = Trie2()
109 | trie.add(["Donald", "Trump"])
110 | trie.add(["Donald", "Duck"])
111 | trie.add(["Donald", "Duck", "Magazine"])
112 |
113 | gazetteer = gazetteers.GazetteerAnnotator("test_gazetteer", {"ENT":trie})
114 | doc1 = nlp("Donald Trump is now reading Donald Duck Magazine.")
115 | gazetteer(doc1)
116 | assert trie.nb_queries == 5
117 |
--------------------------------------------------------------------------------
/tests/test_heuristics.py:
--------------------------------------------------------------------------------
1 |
2 | import skweak
3 | import re
4 | from spacy.tokens import Span #type: ignore
5 |
6 | def time_generator(doc):
7 | i = 0
8 | while i < len(doc):
9 | tok = doc[i]
10 |
11 | if (i < len(doc)-1 and tok.text[0].isdigit() and
12 | doc[i+1].lower_ in {"am", "pm", "a.m.", "p.m.", "am.", "pm."}):
13 | yield i, i+2, "TIME"
14 | i += 1
15 | elif tok.text[0].isdigit() and re.match("\\d{1,2}\\:\\d{1,2}", tok.text):
16 | yield i, i+1, "TIME"
17 | i += 1
18 | i += 1
19 |
20 | def number_generator(doc):
21 | i = 0
22 | while i < len(doc):
23 | tok = doc[i]
24 |
25 | if re.search("\\d", tok.text):
26 | j = i+1
27 | if j < len(doc) and doc[j].lower_ in ["%", "percent", "pc.", "pc", "pct",
28 | "pct.", "percents", "percentage"]:
29 | j += 1
30 | yield i, j, "PERCENT"
31 | elif not re.search("[a-zA-Z]", tok.text):
32 | yield i, j, "CARDINAL"
33 | i = j-1
34 | i += 1
35 |
36 | def test_function(nlp):
37 | doc = nlp("I woke up at 07:30 this morning, being 95% reloaded, with 8 hours of sleep.")
38 | annotator1 = skweak.heuristics.FunctionAnnotator("time", time_generator)
39 | annotator2 = skweak.heuristics.FunctionAnnotator("number", number_generator)
40 | annotator2.add_incompatible_sources(["time"])
41 | annotator = skweak.base.CombinedAnnotator()
42 | annotator.add_annotator(annotator1)
43 | annotator.add_annotator(annotator2)
44 | doc = annotator(doc)
45 | assert Span(doc, 4,5, "TIME") in doc.spans["time"]
46 | assert Span(doc, 9, 11, "PERCENT") in doc.spans["number"]
47 | assert Span(doc, 14, 15, "CARDINAL") in doc.spans["number"]
48 |
49 |
50 | def test_gap_tokens(nlp):
51 | doc = nlp("The Norwegian Computing Center's Employee Union is a long entity, much longer than Jean-Pierre.")
52 | annotator1 = skweak.heuristics.TokenConstraintAnnotator("test1", skweak.utils.is_likely_proper, "ENT")
53 | doc = annotator1(doc)
54 | assert Span(doc, 1, 4, "ENT") in doc.spans["test1"]
55 | assert Span(doc, 5, 7, "ENT") in doc.spans["test1"]
56 | assert Span(doc, 15, 18, "ENT") in doc.spans["test1"]
57 | annotator2 = skweak.heuristics.TokenConstraintAnnotator("test2", skweak.utils.is_likely_proper, "ENT")
58 | annotator2.add_gap_tokens(["'s", "-"])
59 | doc = annotator2(doc)
60 | assert Span(doc, 1, 7, "ENT") in doc.spans["test2"]
61 | assert Span(doc, 15, 18, "ENT") in doc.spans["test2"]
62 |
63 | def test_span_annotator(nlp):
64 | doc = nlp("My name is Pierre Lison and I work at the Norwegian Computing Center.")
65 | annotator = skweak.heuristics.TokenConstraintAnnotator("proper", skweak.utils.is_likely_proper, "ENT")
66 | doc = annotator(doc)
67 | assert Span(doc, 3, 5, "ENT") in doc.spans["proper"]
68 | assert Span(doc, 10, 13, "ENT") in doc.spans["proper"]
69 | annotator2 = skweak.heuristics.SpanConstraintAnnotator("rare_proper", "proper", skweak.utils.is_infrequent)
70 | doc = annotator2(doc)
71 | # assert Span(doc, 3, 5, "ENT") in doc.spans["rare_proper"]
72 |
73 |
74 | def test_vicinity(nlp):
75 | doc = nlp("My name is Pierre Lison.")
76 | annotator1 = skweak.heuristics.TokenConstraintAnnotator("proper", skweak.utils.is_likely_proper, "ENT")
77 | annotator2 = skweak.heuristics.VicinityAnnotator("neighbours", {"name":"PERSON"}, "proper")
78 | annotator = skweak.base.CombinedAnnotator().add_annotators(annotator1, annotator2)
79 | doc = annotator(doc)
80 | assert Span(doc, 3, 5, "ENT") in doc.spans["proper"]
81 | assert Span(doc, 3, 5, "PERSON") in doc.spans["neighbours"]
82 |
83 |
84 |
85 |
86 | def test_model(nlp):
87 | doc = nlp("My name is Pierre Lison, I come from Belgium and I work at the Norwegian Computing Center.")
88 |
89 | annotator = skweak.spacy.ModelAnnotator("core_web_md", "en_core_web_md")
90 | doc = annotator(doc)
91 | assert Span(doc, 3, 5, "PERSON") in doc.spans["core_web_md"]
92 | assert Span(doc, 9, 10, "GPE") in doc.spans["core_web_md"]
93 | assert (Span(doc, 14, 18, "FAC") in doc.spans["core_web_md"]
94 | or Span(doc, 14, 18, "ORG") in doc.spans["core_web_md"])
95 |
96 | doc.ents = ()
97 | doc, *_ = annotator.pipe([doc])
98 | assert Span(doc, 3, 5, "PERSON") in doc.spans["core_web_md"]
99 | assert Span(doc, 9, 10, "GPE") in doc.spans["core_web_md"]
100 | assert (Span(doc, 14, 18, "FAC") in doc.spans["core_web_md"]
101 | or Span(doc, 14, 18, "ORG") in doc.spans["core_web_md"])
102 |
103 | doc.ents = ()
104 | annotator1 = skweak.heuristics.TokenConstraintAnnotator("proper", skweak.utils.is_likely_proper, "ENT")
105 | annotator2 = skweak.heuristics.VicinityAnnotator("neighbours", {"name":"PERSON"}, "proper")
106 | annotator = skweak.base.CombinedAnnotator().add_annotators(annotator, annotator1, annotator2)
107 | doc, *_ = annotator.pipe([doc])
108 | assert Span(doc, 3, 5, "PERSON") in doc.spans["core_web_md"]
109 | assert Span(doc, 9, 10, "GPE") in doc.spans["core_web_md"]
110 | assert (Span(doc, 14, 18, "FAC") in doc.spans["core_web_md"]
111 | or Span(doc, 14, 18, "ORG") in doc.spans["core_web_md"])
112 | assert Span(doc, 3, 5, "ENT") in doc.spans["proper"]
113 | assert Span(doc, 9, 10, "ENT") in doc.spans["proper"]
114 | assert Span(doc, 15, 18, "ENT") in doc.spans["proper"]
115 |
--------------------------------------------------------------------------------
/tests/test_utils.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from skweak import utils
3 | import os
4 | from spacy.tokens import Span #type: ignore
5 |
6 | def test_likely_proper(nlp_small, nlp):
7 | for nlpx in [nlp_small, nlp]:
8 | doc = nlpx("This is a test. Please tell me that is works.")
9 | for tok in doc:
10 | assert not utils.is_likely_proper(tok)
11 | doc = nlpx("Pierre Lison is living in Oslo.")
12 | for i, tok in enumerate(doc):
13 | assert utils.is_likely_proper(tok) == (i in {0,1,5})
14 | doc = nlpx("Short sentence. But here, Beyond can be an organisation.")
15 | for i, tok in enumerate(doc):
16 | assert utils.is_likely_proper(tok) == (i in {6})
17 |
18 | doc = nlp_small("Buying an iPad makes you ekrjøewlkrj in the USA.")
19 | for i, tok in enumerate(doc):
20 | assert utils.is_likely_proper(tok) == (i in {2,8})
21 | doc = nlp("Buying an iPad makes you ekrjøewlkrj in the USA.")
22 | for i, tok in enumerate(doc):
23 | assert utils.is_likely_proper(tok) == (i in {2,8,5})
24 |
25 |
26 | def test_infrequent(nlp_small, nlp):
27 | doc = nlp_small("The Moscow Art Museum awaits you")
28 | assert not utils.is_infrequent(doc[:5])
29 | doc = nlp("The Moscow Art Museum awaits you")
30 | assert utils.is_infrequent(doc[:5])
31 | doc = nlp_small("completelyUnknownToken")
32 | assert not utils.is_infrequent(doc[:1])
33 | doc = nlp("completelyUnknownToken")
34 | assert utils.is_infrequent(doc[:1])
35 |
36 | def test_compound(nlp):
37 | doc = nlp("The White House focuses on risk assessment.")
38 | assert not utils.in_compound(doc[0])
39 | assert utils.in_compound(doc[1])
40 | assert utils.in_compound(doc[2])
41 | assert not utils.in_compound(doc[3])
42 | assert not utils.in_compound(doc[4])
43 | assert utils.in_compound(doc[5])
44 | assert utils.in_compound(doc[6])
45 | assert not utils.in_compound(doc[7])
46 |
47 |
48 |
49 | def test_get_spans(nlp_small):
50 |
51 | doc = nlp_small("This is just a small test for checking that the method works correctly")
52 | doc.spans["source1"] = [Span(doc, 0, 2, label="LABEL1"),
53 | Span(doc, 4, 5, label="LABEL2")]
54 | doc.spans["source2"] = [Span(doc, 0, 1, label="LABEL3"),
55 | Span(doc, 2, 6, label="LABEL2")]
56 | doc.spans["source4"] = [Span(doc, 0, 2, label="LABEL2")]
57 | doc.spans["source3"] = [Span(doc, 7, 9, label="LABEL2"),
58 | Span(doc, 1, 4, label="LABEL1")]
59 |
60 | assert set((span.start, span.end) for span in
61 | utils.get_spans(doc, ["source1", "source2"])) == {(0,2), (2,6)}
62 | assert set((span.start, span.end) for span in
63 | utils.get_spans(doc, ["source1", "source3"])) == {(1,4), (4,5), (7,9)}
64 | assert {(span.start, span.end):span.label_ for span in
65 | utils.get_spans(doc, ["source1", "source4"])} == {(0,2):"LABEL2", (4,5):"LABEL2"}
66 | assert set((span.start, span.end) for span in
67 | utils.get_spans(doc, ["source2", "source3"])) == {(0,1), (2,6), (7,9)}
68 |
69 |
70 |
71 |
72 | def test_replace_ner(nlp_small):
73 | doc = nlp_small("Pierre Lison is working at the Norwegian Computing Center.")
74 | assert doc.ents[0].text=="Pierre Lison"
75 | assert doc.ents[0].label_=="PERSON"
76 | doc.spans["test"] = [Span(doc, 6, 9, label="RESEARCH_ORG")]
77 | doc = utils.replace_ner_spans(doc, "test")
78 | assert doc.ents[0].text=="Norwegian Computing Center"
79 | assert doc.ents[0].label_=="RESEARCH_ORG"
80 |
81 |
82 | def test_docbins(nlp_small, temp_file="data/temporary_test.docbin"):
83 | doc = nlp_small("Pierre Lison is working at the Norwegian Computing Center.")
84 | doc2 = nlp_small("He is working on various NLP topics.")
85 | doc.spans["test"] = [Span(doc, 0, 2, label="PERSON")]
86 | utils.docbin_writer([doc, doc2], temp_file)
87 | doc3, doc4 = list(utils.docbin_reader(temp_file, "en_core_web_sm"))
88 | assert doc.text == doc3.text
89 | assert doc2.text == doc4.text
90 | assert [(e.text, e.label_) for e in doc.ents] == [(e.text, e.label_) for e in doc3.ents]
91 | assert doc.user_data == doc3.user_data
92 | os.remove(temp_file)
93 |
94 |
95 |
96 | def test_json(nlp_small, temp_file="data/temporary_test.json"):
97 | import spacy
98 | if int(spacy.__version__[0]) > 2:
99 | return
100 |
101 | doc = nlp_small("Pierre Lison is working at the Norwegian Computing Center.")
102 | doc2 = nlp_small("He is working on various NLP topics.")
103 | doc.spans["test"] = [Span(doc, 6, 9, label="RESEARCH_ORG")]
104 | doc2.spans["test"] = []
105 |
106 | utils.json_writer([doc, doc2], temp_file, source="test")
107 | fd = open(temp_file, "r")
108 | assert "I-RESEARCH_ORG" in fd.read()
109 | fd.close()
110 | os.remove(temp_file)
111 |
112 |
113 | def test_valid_transitions():
114 | assert utils.is_valid_start("O")
115 | assert utils.is_valid_start("B-ORG")
116 | assert not utils.is_valid_start("I-ORG")
117 | assert utils.is_valid_start("I-ORG", "IO")
118 | assert utils.is_valid_start("U-ORG", "BILUO")
119 | assert not utils.is_valid_start("L-ORG")
120 |
121 | assert utils.is_valid_transition("O","O")
122 | assert utils.is_valid_transition("O","B-ORG")
123 | assert utils.is_valid_transition("O","U-ORG")
124 | assert not utils.is_valid_transition("O","I-ORG")
125 | assert utils.is_valid_transition("O","I-ORG", "IO")
126 | assert not utils.is_valid_transition("O","L-ORG")
127 |
128 | assert utils.is_valid_transition("B-ORG","I-ORG")
129 | assert utils.is_valid_transition("B-ORG","L-ORG", "BILUO")
130 | assert not utils.is_valid_transition("B-ORG","I-GPE")
131 | assert not utils.is_valid_transition("B-ORG","B-ORG", "BILUO")
132 | assert utils.is_valid_transition("I-ORG", "B-ORG")
133 | assert not utils.is_valid_transition("I-ORG", "B-ORG", "BILUO")
134 | assert not utils.is_valid_transition("I-ORG", "O", "BILUO")
135 | assert utils.is_valid_transition("I-ORG", "O")
136 | assert utils.is_valid_transition("I-ORG", "O", "IO")
137 | assert utils.is_valid_transition("I-ORG", "U-GPE")
138 | assert not utils.is_valid_transition("I-ORG", "I-GPE")
139 | assert utils.is_valid_transition("I-ORG", "U-GPE")
140 | assert utils.is_valid_transition("I-ORG", "L-ORG", "BILUO")
141 | assert not utils.is_valid_transition("L-ORG", "L-ORG", "BILUO")
142 | assert not utils.is_valid_transition("L-ORG", "I-ORG", "BILUO")
143 | assert utils.is_valid_transition("U-ORG", "U-ORG")
144 | assert utils.is_valid_transition("U-ORG", "U-GPE")
145 | assert utils.is_valid_transition("U-ORG", "O")
146 | assert utils.is_valid_transition("L-ORG", "O", "BILUO")
147 | assert not utils.is_valid_transition("I-ORG", "O", "BILUO")
148 |
--------------------------------------------------------------------------------