├── .gitignore
├── results
├── imgs
│ ├── 4_result.png
│ ├── 128_result.png
│ ├── 32_result.png
│ └── 512_result.png
├── objectworld_4_trajectories
│ └── objectworld_4_trajectories_set_0
│ │ ├── iavi_1
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── runtime.npy
│ │ └── boltzmann.npy
│ │ ├── iql_16
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── runtime.npy
│ │ └── boltzmann.npy
│ │ └── iql_100
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── runtime.npy
│ │ └── boltzmann.npy
├── objectworld_8_trajectories
│ └── objectworld_8_trajectories_set_0
│ │ ├── iavi_1
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── runtime.npy
│ │ └── boltzmann.npy
│ │ └── iql_16
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── runtime.npy
│ │ └── boltzmann.npy
├── results.csv
├── objectworld_16_trajectories
│ └── objectworld_16_trajectories_set_0
│ │ ├── iavi_1
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── boltzmann.npy
│ │ └── runtime.npy
│ │ └── iql_16
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── boltzmann.npy
│ │ └── runtime.npy
├── objectworld_32_trajectories
│ └── objectworld_32_trajectories_set_0
│ │ ├── iavi_1
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── boltzmann.npy
│ │ └── runtime.npy
│ │ └── iql_100
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── runtime.npy
│ │ └── boltzmann.npy
├── objectworld_128_trajectories
│ └── objectworld_128_trajectories_set_0
│ │ ├── iavi_1
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── runtime.npy
│ │ └── boltzmann.npy
│ │ └── iql_100
│ │ ├── q.npy
│ │ ├── r.npy
│ │ ├── runtime.npy
│ │ └── boltzmann.npy
└── objectworld_512_trajectories
│ └── objectworld_512_trajectories_set_0
│ ├── iavi_1
│ ├── q.npy
│ ├── r.npy
│ ├── runtime.npy
│ └── boltzmann.npy
│ └── iql_100
│ ├── q.npy
│ ├── r.npy
│ ├── runtime.npy
│ └── boltzmann.npy
├── evaluate.sh
├── data
├── objectworld_1_trajectories
│ └── objectworld_1_trajectories_set_0
│ │ ├── ground_r.npy
│ │ ├── p_start_state.npy
│ │ ├── trajectories.npy
│ │ ├── feature_matrix.npy
│ │ ├── action_probabilities.npy
│ │ └── transition_probabilities.npy
├── objectworld_4_trajectories
│ └── objectworld_4_trajectories_set_0
│ │ ├── ground_r.npy
│ │ ├── p_start_state.npy
│ │ ├── trajectories.npy
│ │ ├── feature_matrix.npy
│ │ ├── action_probabilities.npy
│ │ └── transition_probabilities.npy
├── objectworld_32_trajectories
│ └── objectworld_32_trajectories_set_0
│ │ ├── ground_r.npy
│ │ ├── feature_matrix.npy
│ │ ├── p_start_state.npy
│ │ ├── trajectories.npy
│ │ ├── action_probabilities.npy
│ │ └── transition_probabilities.npy
├── objectworld_128_trajectories
│ └── objectworld_128_trajectories_set_0
│ │ ├── ground_r.npy
│ │ ├── trajectories.npy
│ │ ├── feature_matrix.npy
│ │ ├── p_start_state.npy
│ │ ├── action_probabilities.npy
│ │ └── transition_probabilities.npy
└── objectworld_512_trajectories
│ └── objectworld_512_trajectories_set_0
│ ├── ground_r.npy
│ ├── trajectories.npy
│ ├── feature_matrix.npy
│ ├── p_start_state.npy
│ ├── action_probabilities.npy
│ └── transition_probabilities.npy
├── train.sh
├── src
├── collect_data.py
├── algorithms
│ ├── iql.py
│ └── iavi.py
├── train.py
├── mdp
│ ├── value_iteration.py
│ ├── objectworld.py
│ └── gridworld.py
└── plot_experiments.py
└── README.md
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
--------------------------------------------------------------------------------
/results/imgs/4_result.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/imgs/4_result.png
--------------------------------------------------------------------------------
/results/imgs/128_result.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/imgs/128_result.png
--------------------------------------------------------------------------------
/results/imgs/32_result.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/imgs/32_result.png
--------------------------------------------------------------------------------
/results/imgs/512_result.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/imgs/512_result.png
--------------------------------------------------------------------------------
/evaluate.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | cd src/
4 |
5 | # evaluate iavi and iql.
6 | for i in 4 32 128 512
7 | do
8 | python plot_experiments.py $i
9 | done
10 |
11 |
12 |
--------------------------------------------------------------------------------
/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/ground_r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/ground_r.npy
--------------------------------------------------------------------------------
/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/ground_r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/ground_r.npy
--------------------------------------------------------------------------------
/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/ground_r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/ground_r.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iavi_1/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iavi_1/q.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iavi_1/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iavi_1/r.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_16/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_16/q.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_16/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_16/r.npy
--------------------------------------------------------------------------------
/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iavi_1/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iavi_1/q.npy
--------------------------------------------------------------------------------
/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iavi_1/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iavi_1/r.npy
--------------------------------------------------------------------------------
/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iql_16/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iql_16/q.npy
--------------------------------------------------------------------------------
/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iql_16/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iql_16/r.npy
--------------------------------------------------------------------------------
/results/results.csv:
--------------------------------------------------------------------------------
1 | Number of Trajectories,EVD IAVI,EVD IQL,Runtime IAVI [h],Runtime IQL [h]
2 | 4.0,15.312,15.36,0.012,0.0
3 | 32.0,8.817,15.092,0.018,0.0
4 | 128.0,2.606,11.853,0.021,0.001
5 | 512.0,2.045,3.289,0.022,0.004
6 |
--------------------------------------------------------------------------------
/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/ground_r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/ground_r.npy
--------------------------------------------------------------------------------
/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/p_start_state.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/p_start_state.npy
--------------------------------------------------------------------------------
/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/trajectories.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/trajectories.npy
--------------------------------------------------------------------------------
/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/p_start_state.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/p_start_state.npy
--------------------------------------------------------------------------------
/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/trajectories.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/trajectories.npy
--------------------------------------------------------------------------------
/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/ground_r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/ground_r.npy
--------------------------------------------------------------------------------
/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iavi_1/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iavi_1/q.npy
--------------------------------------------------------------------------------
/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iavi_1/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iavi_1/r.npy
--------------------------------------------------------------------------------
/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iql_16/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iql_16/q.npy
--------------------------------------------------------------------------------
/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iql_16/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iql_16/r.npy
--------------------------------------------------------------------------------
/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iavi_1/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iavi_1/q.npy
--------------------------------------------------------------------------------
/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iavi_1/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iavi_1/r.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_100/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_100/q.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_100/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_100/r.npy
--------------------------------------------------------------------------------
/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/trajectories.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/trajectories.npy
--------------------------------------------------------------------------------
/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/feature_matrix.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/feature_matrix.npy
--------------------------------------------------------------------------------
/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/feature_matrix.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/feature_matrix.npy
--------------------------------------------------------------------------------
/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/p_start_state.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/p_start_state.npy
--------------------------------------------------------------------------------
/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/trajectories.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/trajectories.npy
--------------------------------------------------------------------------------
/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/feature_matrix.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/feature_matrix.npy
--------------------------------------------------------------------------------
/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/trajectories.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/trajectories.npy
--------------------------------------------------------------------------------
/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iavi_1/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iavi_1/q.npy
--------------------------------------------------------------------------------
/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iavi_1/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iavi_1/r.npy
--------------------------------------------------------------------------------
/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iql_100/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iql_100/q.npy
--------------------------------------------------------------------------------
/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iql_100/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iql_100/r.npy
--------------------------------------------------------------------------------
/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iql_100/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iql_100/q.npy
--------------------------------------------------------------------------------
/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iql_100/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iql_100/r.npy
--------------------------------------------------------------------------------
/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iavi_1/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iavi_1/q.npy
--------------------------------------------------------------------------------
/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iavi_1/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iavi_1/r.npy
--------------------------------------------------------------------------------
/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iql_100/q.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iql_100/q.npy
--------------------------------------------------------------------------------
/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iql_100/r.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iql_100/r.npy
--------------------------------------------------------------------------------
/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/feature_matrix.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/feature_matrix.npy
--------------------------------------------------------------------------------
/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/p_start_state.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/p_start_state.npy
--------------------------------------------------------------------------------
/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/feature_matrix.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/feature_matrix.npy
--------------------------------------------------------------------------------
/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/p_start_state.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/p_start_state.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iavi_1/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iavi_1/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_100/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_100/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_16/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_16/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iavi_1/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iavi_1/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iql_16/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iql_16/runtime.npy
--------------------------------------------------------------------------------
/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/action_probabilities.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/action_probabilities.npy
--------------------------------------------------------------------------------
/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/action_probabilities.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/action_probabilities.npy
--------------------------------------------------------------------------------
/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iavi_1/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iavi_1/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iavi_1/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iavi_1/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iavi_1/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iavi_1/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iql_16/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iql_16/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iql_16/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_16_trajectories/objectworld_16_trajectories_set_0/iql_16/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iavi_1/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iavi_1/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iavi_1/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iavi_1/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iql_100/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iql_100/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iavi_1/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iavi_1/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_100/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_100/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_16/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_4_trajectories/objectworld_4_trajectories_set_0/iql_16/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iavi_1/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iavi_1/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iavi_1/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iavi_1/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iql_16/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_8_trajectories/objectworld_8_trajectories_set_0/iql_16/boltzmann.npy
--------------------------------------------------------------------------------
/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/action_probabilities.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/action_probabilities.npy
--------------------------------------------------------------------------------
/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iavi_1/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iavi_1/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iql_100/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iql_100/runtime.npy
--------------------------------------------------------------------------------
/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iql_100/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_32_trajectories/objectworld_32_trajectories_set_0/iql_100/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iavi_1/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iavi_1/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iql_100/runtime.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iql_100/runtime.npy
--------------------------------------------------------------------------------
/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/action_probabilities.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/action_probabilities.npy
--------------------------------------------------------------------------------
/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/transition_probabilities.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_1_trajectories/objectworld_1_trajectories_set_0/transition_probabilities.npy
--------------------------------------------------------------------------------
/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/transition_probabilities.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_32_trajectories/objectworld_32_trajectories_set_0/transition_probabilities.npy
--------------------------------------------------------------------------------
/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/transition_probabilities.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_4_trajectories/objectworld_4_trajectories_set_0/transition_probabilities.npy
--------------------------------------------------------------------------------
/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/action_probabilities.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/action_probabilities.npy
--------------------------------------------------------------------------------
/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iql_100/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_128_trajectories/objectworld_128_trajectories_set_0/iql_100/boltzmann.npy
--------------------------------------------------------------------------------
/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iql_100/boltzmann.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/results/objectworld_512_trajectories/objectworld_512_trajectories_set_0/iql_100/boltzmann.npy
--------------------------------------------------------------------------------
/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/transition_probabilities.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_128_trajectories/objectworld_128_trajectories_set_0/transition_probabilities.npy
--------------------------------------------------------------------------------
/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/transition_probabilities.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/NrLabFreiburg/inverse-q-learning/HEAD/data/objectworld_512_trajectories/objectworld_512_trajectories_set_0/transition_probabilities.npy
--------------------------------------------------------------------------------
/train.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | cd src/
4 |
5 | # collect data.
6 | python collect_data.py 1 4 32 128 512
7 |
8 | # train iavi and iql.
9 | for i in 4 32 128 512
10 | do
11 | python train.py iavi $i
12 | python train.py iql $i 100
13 | done
14 |
15 |
16 |
--------------------------------------------------------------------------------
/src/collect_data.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Inverse Q-Learning with Constraints. NeurIPS 2020.
3 | Gabriel Kalweit, Maria Huegle, Moritz Werling and Joschka Boedecker
4 | Neurorobotics Lab, University of Freiburg
5 |
6 | This script collects data from the Objectworld environment. Run with python collect_data.py n_traj1, n_traj2 ... , where n_traj1, n_traj2 are possible numbers of trajectories. To collect 4,32 and 128 and 512 trajectories use:
7 |
8 | python collect_data.py 4 32 128 512
9 |
10 | """
11 |
12 | import sys, os
13 | import numpy as np
14 | np.set_printoptions(suppress=True)
15 | from mdp.objectworld import Objectworld
16 |
17 |
18 | if __name__ == "__main__":
19 |
20 | num_sets = 1 # number of runs for each experiment.
21 | n_traj = [int(n) for n in sys.argv[1:]]
22 |
23 | # Objectworld settings.
24 | grid_size = 32
25 | n_objects = 50
26 | n_colours = 2
27 | wind = 0.3
28 | discount = 0.99
29 | trajectory_length = 8
30 |
31 | env = Objectworld(grid_size, n_objects, n_colours, wind, discount)
32 | feature_matrix = env.feature_matrix(discrete=False)
33 |
34 |
35 | for n in n_traj:
36 | print("%s trajectories from [%s]"%(n, n_traj))
37 | for i in range(num_sets):
38 | print("\tset %s/%s"%(i+1, num_sets))
39 | store_dir = os.path.join("../data", "objectworld_%s_trajectories"%n, "objectworld_%s_trajectories_set_%s"%(n, i))
40 | os.makedirs(store_dir)
41 |
42 | n_trajectories = n
43 | trajectories, action_probabilities, transition_probabilities, ground_r= env.collect_demonstrations(n_trajectories, trajectory_length)
44 | np.save(os.path.join(store_dir, "trajectories.npy"), trajectories)
45 | np.save(os.path.join(store_dir, "action_probabilities.npy"), action_probabilities)
46 | np.save(os.path.join(store_dir, "transition_probabilities.npy"), transition_probabilities)
47 | np.save(os.path.join(store_dir, "ground_r.npy"), ground_r)
48 |
49 | p_start_state = (np.bincount(trajectories[:, 0, 0], minlength=env.n_states)/trajectories.shape[0])
50 | np.save(os.path.join(store_dir, "p_start_state.npy"), p_start_state)
51 | np.save(os.path.join(store_dir, "feature_matrix.npy"), env.feature_matrix(discrete=False))
52 |
--------------------------------------------------------------------------------
/src/algorithms/iql.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Inverse Q-Learning with Constraints. NeurIPS 2020.
3 | Gabriel Kalweit, Maria Huegle, Moritz Werling and Joschka Boedecker
4 | Neurorobotics Lab, University of Freiburg.
5 | """
6 |
7 | import numpy as np
8 | epsilon = 1e-6
9 |
10 |
11 | def inverse_q_learning(feature_matrix,nA, gamma, transitions, alpha_r, alpha_q, alpha_sh, epochs, real_distribution):
12 | """
13 | Implementation of IQL from Deep Inverse Q-learning with Constraints. Gabriel Kalweit, Maria Huegle, Moritz Wehrling and Joschka Boedecker. NeurIPS 2020.
14 | Arxiv : https://arxiv.org/abs/2008.01712
15 | """
16 | nS = feature_matrix.shape[0]
17 |
18 |
19 | # initialize tables for reward function, value functions and state-action visitation counter.
20 | r = np.zeros((nS, nA))
21 | q = np.zeros((nS, nA))
22 | q_sh = np.zeros((nS, nA))
23 | state_action_visitation = np.zeros((nS, nA))
24 |
25 | for i in range(epochs):
26 | if i%10 == 0:
27 | print("Epoch %s/%s" %(i+1, epochs))
28 |
29 | for traj in transitions:
30 | for (s, a, _, ns) in traj:
31 | state_action_visitation[s][a] += 1
32 | d = False # no terminal state
33 |
34 | # compute shifted q-function.
35 | q_sh[s, a] = (1-alpha_sh) * q_sh[s, a] + alpha_sh * (gamma * (1-d) * np.max(q[ns]))
36 |
37 | # compute log probabilities.
38 | sum_of_state_visitations = np.sum(state_action_visitation[s])
39 | log_prob = np.log((state_action_visitation[s]/sum_of_state_visitations) + epsilon)
40 |
41 | # compute eta_a and eta_b for Eq. (9).
42 | eta_a = log_prob[a] - q_sh[s][a]
43 | other_actions = [oa for oa in range(nA) if oa != a]
44 | eta_b = log_prob[other_actions] - q_sh[s][other_actions]
45 | sum_oa = (1/(nA-1)) * np.sum(r[s][other_actions] - eta_b)
46 |
47 | # update reward-function.
48 | r[s][a] = (1-alpha_r) * r[s][a] + alpha_r * (eta_a + sum_oa)
49 |
50 | # update value-function.
51 | q[s, a] = (1-alpha_q) * q[s, a] + alpha_q * (r[s, a] + gamma * (1-d) * np.max(q[ns]))
52 | s = ns
53 |
54 | # compute Boltzmann distribution.
55 | boltzman_distribution = []
56 | for s in range(nS):
57 | boltzman_distribution.append([])
58 | for a in range(nA):
59 | boltzman_distribution[-1].append(np.exp(q[s][a]))
60 | boltzman_distribution = np.array(boltzman_distribution)
61 | boltzman_distribution /= np.sum(boltzman_distribution, axis=1).reshape(-1, 1)
62 | return q, r, boltzman_distribution
63 |
--------------------------------------------------------------------------------
/src/train.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Inverse Q-Learning with Constraints. NeurIPS 2020.
3 | Gabriel Kalweit, Maria Huegle, Moritz Werling and Joschka Boedecker
4 | Neurorobotics Lab, University of Freiburg
5 |
6 | This script collects data from the Objectworld environment. Run with python collect_data.py n_traj1, n_traj2 ... , where n_traj1, n_traj2 are possible numbers of trajectories. To collect 4,32 and 128 and 512 trajectories use:
7 |
8 | python train.py alg n_traj
9 |
10 | """
11 |
12 | import numpy as np
13 | np.set_printoptions(suppress=True)
14 | import sys, os
15 | import time
16 | import random
17 | import string
18 | import time
19 | import pickle
20 |
21 | from mdp.objectworld import Objectworld
22 | from algorithms.iavi import inverse_action_value_iteration
23 | from algorithms.iql import inverse_q_learning
24 |
25 |
26 |
27 | if __name__ == "__main__":
28 | alg = sys.argv[1]
29 | supported_algorithms = [ "iavi", "iql"]
30 | assert(alg in supported_algorithms)
31 |
32 | n_traj = int(sys.argv[2])
33 |
34 | if alg == "iql":
35 | updates_or_epochs = int(sys.argv[3])
36 | else:
37 | updates_or_epochs = 1
38 |
39 | data_file = "objectworld_%s_trajectories"%n_traj
40 | data_dir = os.path.join("../data", data_file)
41 |
42 | sets = sorted(next(os.walk(data_dir))[1])
43 | for current_set in sets:
44 | print(current_set)
45 | set_dir = os.path.join(data_dir, current_set)
46 |
47 | store_dir = os.path.join("../results", data_file, current_set, "%s_%s"%(alg, updates_or_epochs))
48 | os.makedirs(store_dir, exist_ok=True)
49 |
50 | gamma = 0.9
51 | n_actions = 5
52 |
53 | feature_matrix = np.load(os.path.join(set_dir, "feature_matrix.npy"))
54 | trajectories = np.load(os.path.join(set_dir, "trajectories.npy"))
55 | action_probabilities = np.load(os.path.join(set_dir, "action_probabilities.npy"))
56 | transition_probabilities = np.load(os.path.join(set_dir, "transition_probabilities.npy"))
57 | ground_r= np.load(os.path.join(set_dir, "ground_r.npy"))
58 | p_start_state = np.load(os.path.join(set_dir, "p_start_state.npy"))
59 |
60 | is_terminal = np.zeros((feature_matrix.shape[0], n_actions))
61 |
62 | start = time.time()
63 |
64 | if alg == "iavi":
65 | q, r, boltz = inverse_action_value_iteration(feature_matrix, n_actions, gamma, transition_probabilities, action_probabilities, theta=0.01)
66 | elif alg == "iql":
67 | q, r, boltz = inverse_q_learning(feature_matrix, n_actions, gamma, trajectories, \
68 | alpha_r=0.0001, alpha_q=0.01, alpha_sh=0.01, epochs=updates_or_epochs, real_distribution=action_probabilities)
69 | else:
70 | print("Algorithm not supported.")
71 |
72 | end = time.time()
73 |
74 | np.save(os.path.join(store_dir, "runtime"), (end - start))
75 | np.save(os.path.join(store_dir, "r"), r)
76 | np.save(os.path.join(store_dir, "q"), q)
77 | np.save(os.path.join(store_dir, "boltzmann"), boltz)
78 |
--------------------------------------------------------------------------------
/src/algorithms/iavi.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Inverse Q-Learning with Constraints. NeurIPS 2020.
3 | Gabriel Kalweit, Maria Huegle, Moritz Werling and Joschka Boedecker
4 | Neurorobotics Lab, University of Freiburg.
5 | """
6 |
7 | import numpy as np
8 | epsilon = 1e-6
9 |
10 |
11 | def inverse_action_value_iteration(feature_matrix, nA, gamma, transition_probabilities, action_probabilities, theta=0.0001):
12 | """
13 | Implementation of IAVI from Deep Inverse Q-learning with Constraints. Gabriel Kalweit, Maria Huegle, Moritz Wehrling and Joschka Boedecker. NeurIPS 2020.
14 | Arxiv : https://arxiv.org/abs/2008.01712
15 | """
16 | nS = feature_matrix.shape[0]
17 |
18 | # initialize tables for reward function and value function.
19 | r = np.zeros((nS, nA))
20 | q = np.zeros((nS, nA))
21 |
22 | # compute reverse topological order.
23 | T = []
24 | for i in reversed(range(nS)):
25 | T.append([i])
26 |
27 | # do while change in r over iterations is larger than theta.
28 | diff = np.inf
29 | while diff > theta:
30 | print(diff)
31 | diff = 0
32 | for t in T[0:]:
33 | for i in t:
34 | # compute coefficient matrix X_A(s) as in Eq. (9).
35 | X = []
36 | for a in range(nA):
37 | row = np.ones(nA)
38 | for oa in range(nA):
39 | if oa == a:
40 | continue
41 | row[oa] /= -(nA-1)
42 | X.append(row)
43 | X = np.array(X)
44 |
45 | # compute target vector Y_A(s) as in Eq. (9).
46 | y = []
47 | for a in range(nA):
48 | other_actions = [oa for oa in range(nA) if oa != a]
49 | sum_of_oa_logs = np.sum([np.log(action_probabilities[i][oa] + epsilon) for oa in other_actions])
50 | sum_of_oa_q = np.sum([transition_probabilities[i][oa] * gamma * np.max(q[np.arange(nS)], axis=1) for oa in other_actions])
51 | y.append(np.log(action_probabilities[i][a] + epsilon)-(1/(nA-1))*sum_of_oa_logs+(1/(nA-1))*sum_of_oa_q-np.sum(transition_probabilities[i][a] * gamma * np.max(q[np.arange(nS)], axis=1)))
52 | y = np.array(y)
53 |
54 | # Find least-squares solution.
55 | x = np.linalg.lstsq(X, y, rcond=None)[0]
56 |
57 | for a in range(nA):
58 | diff = max(np.abs(r[i, a]-x[a]), diff)
59 |
60 | # compute new r and Q-values.
61 | r[i] = x
62 | for a in range(nA):
63 | q[i, a] = r[i, a] + np.sum(transition_probabilities[i][a] * gamma * np.max(q[np.arange(nS)], axis=1))
64 |
65 | # calculate Boltzmann distribution.
66 | boltzman_distribution = []
67 | for s in range(nS):
68 | boltzman_distribution.append([])
69 | for a in range(nA):
70 | boltzman_distribution[-1].append(np.exp(q[s][a]))
71 | boltzman_distribution = np.array(boltzman_distribution)
72 | boltzman_distribution /= np.sum(boltzman_distribution, axis=1).reshape(-1, 1)
73 | return q, r, boltzman_distribution
74 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Deep Inverse Q-learning with Constraints
2 |
3 | This repository is the official implementation of [Deep Inverse Q-learning with Constraints](https://arxiv.org/abs/2008.01712).
4 |
5 |
6 | 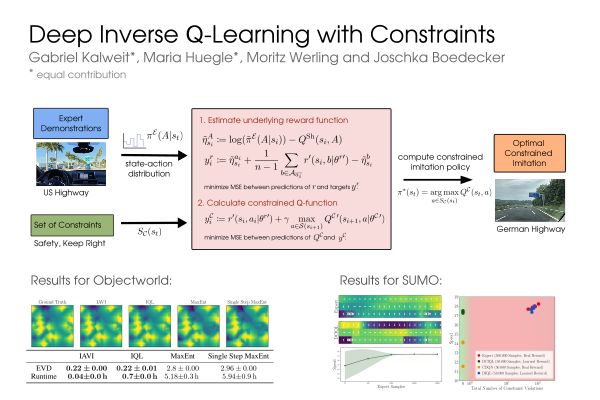
7 |
8 | Arxiv : [https://arxiv.org/abs/2008.01712](https://arxiv.org/abs/2008.01712)
9 |
10 | Blog Post: [http://nrprojects.cs.uni-freiburg.de/foundations.html#inverse](http://nrprojects.cs.uni-freiburg.de/foundations.html#inverse)
11 |
12 |
13 | Abstract: Popular Maximum Entropy Inverse Reinforcement Learning approaches require the computation of expected state visitation frequencies for the optimal policy under an estimate of the reward function. This usually requires intermediate value estimation in the inner loop of the algorithm, slowing down convergence considerably.
14 | In this work, we introduce a novel class of algorithms that only needs to solve the MDP underlying the demonstrated behavior *once* to recover the expert policy. This is possible through a formulation that exploits a probabilistic behavior assumption for the demonstrations within the structure of Q-learning. We propose Inverse Action-value Iteration which is able to fully recover an underlying reward of an external agent in *closed-form* analytically. We further provide an accompanying class of sampling-based variants which do not depend on a model of the environment. We show how to extend this class of algorithms to continuous state-spaces via function approximation and how to estimate a corresponding action-value function, leading to a policy as close as possible to the policy of the external agent, while optionally satisfying a list of predefined hard constraints. We evaluate the resulting algorithms called Inverse Action-value Iteration, Inverse Q-learning and Deep Inverse Q-learning on the Objectworld benchmark, showing a speedup of up to several orders of magnitude compared to (Deep) Max-Entropy algorithms. We further apply Deep Constrained Inverse Q-learning on the task of learning autonomous lane-changes in the open-source simulator SUMO achieving competent driving after training on data corresponding to 30 minutes of demonstrations.
15 |
16 | ## Requirements
17 |
18 | To install requirements:
19 |
20 | ```setup
21 | pip install -r requirements.txt
22 | ```
23 |
24 | >📋 Please use Python 3.7.
25 |
26 | ## Training
27 |
28 | To train IAVI and IQL, run *train.sh*:
29 |
30 | ```train
31 | #!/bin/bash
32 | # train.sh
33 |
34 | cd src/
35 |
36 | # collect data for 4, 32, 128 and 512 trajectories in the Objectworld environment.
37 | python collect_data.py 4 32 128 512
38 |
39 | # train iavi and iql for the above specified number of trajectories.
40 | for i in 4 32 128 512
41 | do
42 | python train.py iavi $i
43 | python train.py iql $i 100
44 | done
45 | ```
46 |
47 | By default, IQL is trained for 100 epochs and IAVI until a threshold of 0.01 is reached.
48 | All following steps can be executed for 4, 32, 128 and 512 transitions with the bash script. Details:
49 |
50 |
51 | #### 1. Collect trajectories in the Objectworld environment
52 |
53 | ```train
54 | python collect_data.py n_traj1 n_traj2
55 | ```
56 | The arguments n\_traj1, n\_traj2 specify the number of trajectories data should be collected for.
57 |
58 |
59 | #### 2. Train IAVI and IQL
60 |
61 | ```train
62 | python src/train.py alg n_traj [n_epochs]
63 | ```
64 |
65 | The argument alg is either "iavi" or "iql" and n\_traj the number of trajectories. For IQL, the number of epochs has to be specified with n\_epochs.
66 |
67 |
68 | ## Evaluation
69 |
70 | To evaluate the experiments, run *evaluate.sh*:
71 |
72 | ```eval
73 | #!/bin/bash
74 | # evaluate.sh
75 |
76 | cd src/
77 |
78 | # evaluate iavi and iql for the specified number of trajectories.
79 | for i in 4 32 128 512
80 | do
81 | python src/plot_experiments.py $i
82 | done
83 | ```
84 | All following steps can be executed with the bash-script. Details:
85 |
86 | #### Plot results
87 | ```console
88 | python src/plot_experiments.py n_traj
89 | ```
90 |
91 | The argument n\_traj is the number of trajectories.
92 |
93 |
94 | ## Results
95 |
96 |
97 | The results are stored in the path *results/*.
98 |
99 | 
100 | 
101 | 
102 | 
103 |
104 | Content of *result.csv*:
105 |
106 |
107 | | Trajectories | EVD IAVI | EVD IQL | Runtime IAVI [h] | Runtime IAVI [h] |
108 | | ----------- | ----------- | ----------- | ----------- | ----------- |
109 | |4.0 | 15.312 | 15.36 | 0.012 | 0.0 |
110 | |32.0 | 8.817 | 15.092 | 0.018 | 0.0 |
111 | |128.0 | 2.606 | 11.853 | 0.021 | 0.001 |
112 | |512.0 | 2.045 | 3.289 | 0.022 | 0.004 |
113 |
114 | ## Contributing
115 |
116 | >📋 Awesome that you are interested in our work! Please write an e-mail to {kalweitg, hueglem}@cs.uni-freiburg.de
117 |
--------------------------------------------------------------------------------
/src/mdp/value_iteration.py:
--------------------------------------------------------------------------------
1 | """
2 | Implementation of value iteraion. This code is used and adapted from
3 |
4 | Matthew Alger, 2015
5 | matthew.alger@anu.edu.au
6 | """
7 |
8 | import numpy as np
9 |
10 | def value(policy, n_states, transition_probabilities, reward, discount,
11 | threshold=1e-2):
12 | """
13 | Find the value function associated with a policy.
14 |
15 | policy: List of action ints for each state.
16 | n_states: Number of states. int.
17 | transition_probabilities: Function taking (state, action, state) to
18 | transition probabilities.
19 | reward: Vector of rewards for each state.
20 | discount: MDP discount factor. float.
21 | threshold: Convergence threshold, default 1e-2. float.
22 | -> Array of values for each state
23 | """
24 | v = np.zeros(n_states)
25 |
26 | diff = float("inf")
27 | while diff > threshold:
28 | diff = 0
29 | for s in range(n_states):
30 | vs = v[s]
31 | a = policy[s]
32 | v[s] = sum(transition_probabilities[s, a, k] *
33 | (reward[k] + discount * v[k])
34 | for k in range(n_states))
35 | diff = max(diff, abs(vs - v[s]))
36 |
37 | return v
38 |
39 | def optimal_value(n_states, n_actions, transition_probabilities, reward,
40 | discount, threshold=1e-2):
41 | """
42 | Find the optimal value function.
43 |
44 | n_states: Number of states. int.
45 | n_actions: Number of actions. int.
46 | transition_probabilities: Function taking (state, action, state) to
47 | transition probabilities.
48 | reward: Vector of rewards for each state.
49 | discount: MDP discount factor. float.
50 | threshold: Convergence threshold, default 1e-2. float.
51 | -> Array of values for each state
52 | """
53 |
54 | v = np.zeros(n_states)
55 |
56 | diff = float("inf")
57 | while diff > threshold:
58 | diff = 0
59 | for s in range(n_states):
60 | max_v = float("-inf")
61 | for a in range(n_actions):
62 | tp = transition_probabilities[s, a, :]
63 | max_v = max(max_v, np.dot(tp, reward + discount*v))
64 |
65 | new_diff = abs(v[s] - max_v)
66 | if new_diff > diff:
67 | diff = new_diff
68 | v[s] = max_v
69 |
70 | return v
71 |
72 | def find_policy(n_states, n_actions, transition_probabilities, reward, discount,
73 | threshold=1e-2, v=None, stochastic=True):
74 | """
75 | Find the optimal policy.
76 |
77 | n_states: Number of states. int.
78 | n_actions: Number of actions. int.
79 | transition_probabilities: Function taking (state, action, state) to
80 | transition probabilities.
81 | reward: Vector of rewards for each state.
82 | discount: MDP discount factor. float.
83 | threshold: Convergence threshold, default 1e-2. float.
84 | v: Value function (if known). Default None.
85 | stochastic: Whether the policy should be stochastic. Default True.
86 | -> Action probabilities for each state or action int for each state
87 | (depending on stochasticity).
88 | """
89 |
90 | if v is None:
91 | v = optimal_value(n_states, n_actions, transition_probabilities, reward,
92 | discount, threshold)
93 |
94 | if stochastic:
95 | # Get Q using equation 9.2 from Ziebart's thesis.
96 | Q = np.zeros((n_states, n_actions))
97 | for i in range(n_states):
98 | for j in range(n_actions):
99 | p = transition_probabilities[i, j, :]
100 | Q[i, j] = p.dot(reward + discount*v)
101 | Q -= Q.max(axis=1).reshape((n_states, 1)) # For numerical stability.
102 | Q = np.exp(Q)/np.exp(Q).sum(axis=1).reshape((n_states, 1))
103 | return Q
104 |
105 | def _policy(s):
106 | return max(range(n_actions),
107 | key=lambda a: sum(transition_probabilities[s, a, k] *
108 | (reward[k] + discount * v[k])
109 | for k in range(n_states)))
110 | policy = np.array([_policy(s) for s in range(n_states)])
111 | return policy
112 |
113 | if __name__ == '__main__':
114 | # Quick unit test using gridworld.
115 | import mdp.gridworld as gridworld
116 | gw = gridworld.Gridworld(3, 0.3, 0.9)
117 | v = value([gw.optimal_policy_deterministic(s) for s in range(gw.n_states)],
118 | gw.n_states,
119 | gw.transition_probability,
120 | [gw.reward(s) for s in range(gw.n_states)],
121 | gw.discount)
122 | assert np.isclose(v,
123 | [5.7194282, 6.46706692, 6.42589811,
124 | 6.46706692, 7.47058224, 7.96505174,
125 | 6.42589811, 7.96505174, 8.19268666], 1).all()
126 | opt_v = optimal_value(gw.n_states,
127 | gw.n_actions,
128 | gw.transition_probability,
129 | [gw.reward(s) for s in range(gw.n_states)],
130 | gw.discount)
131 | assert np.isclose(v, opt_v).all()
132 |
--------------------------------------------------------------------------------
/src/plot_experiments.py:
--------------------------------------------------------------------------------
1 | """
2 | Deep Inverse Q-Learning with Constraints. NeurIPS 2020.
3 | Gabriel Kalweit, Maria Huegle, Moritz Werling and Joschka Boedecker
4 | Neurorobotics Lab, University of Freiburg.
5 |
6 | This script creates figures of experiments for IAVI and IQL. Please specify the number of trajectories you want to evaluate.
7 | If you change the number of epochs for IQL, please update the output_iql parameter in the main function below.
8 |
9 | python plot_experiments.py no_traj
10 | """
11 |
12 | import os, sys
13 | import glob
14 | import numpy as np
15 | import pandas as pd
16 | import matplotlib.pyplot as plt
17 | import seaborn as sns
18 | from mdp.value_iteration import find_policy
19 |
20 | font = {'family' : 'serif',
21 | 'weight' : 'bold',
22 | 'size' : 12}
23 | plt.rc('font', **font)
24 | plt.rc('text', usetex=True)
25 |
26 |
27 |
28 | def policy_eval(policy, reward, transition_probabilities, nS, nA, discount_factor=1.0, theta=0.00001):
29 | """
30 | Policy Evaluation.
31 | """
32 | V = np.zeros(nS)
33 | while True:
34 | delta = 0
35 | for s in range(nS):
36 | v = 0
37 | for a, a_prob in enumerate(policy[s]):
38 | if a_prob == 0.0:
39 | continue
40 | ns_prob = transition_probabilities[s, a]
41 | next_v = V[np.arange(nS)]
42 | r = reward[s]
43 | v += np.sum(ns_prob * a_prob * (r + discount_factor * next_v))
44 | delta = max(delta, np.abs(v - V[s]))
45 | V[s] = v
46 | print(delta)
47 | if delta < theta:
48 | break
49 | return np.array(V)
50 |
51 |
52 | def plot_grid(trajectories, v1, v2, v3, v4, grid_size):
53 | """
54 | Plot grid.
55 | """
56 | fig, axes = plt.subplots(nrows=1, ncols=4, figsize=(7,2))
57 | axes[0].imshow(v1.reshape(grid_size, grid_size), vmin=v1.min(), vmax=v1.max())
58 | axes[0].set_title("Optimal", fontsize="x-large")
59 |
60 | axes[1].imshow(v2.reshape(grid_size, grid_size), vmin=v2.min(), vmax=v2.max())
61 | axes[1].set_title("Ground Truth", fontsize="x-large")
62 |
63 | axes[2].set_title("IAVI", fontsize="x-large")
64 | im = axes[2].imshow(v2.reshape(grid_size, grid_size), vmin=v2.min(), vmax=v2.max())
65 |
66 | axes[3].set_title("IQL", fontsize="x-large")
67 | im = axes[3].imshow(v3.reshape(grid_size, grid_size), vmin=v3.min(), vmax=v3.max())
68 |
69 | axes[0].axes.get_xaxis().set_visible(False)
70 | axes[1].axes.get_xaxis().set_visible(False)
71 | axes[2].axes.get_xaxis().set_visible(False)
72 | axes[3].axes.get_xaxis().set_visible(False)
73 | axes[0].axes.get_yaxis().set_visible(False)
74 | axes[1].axes.get_yaxis().set_visible(False)
75 | axes[2].axes.get_yaxis().set_visible(False)
76 | axes[3].axes.get_yaxis().set_visible(False)
77 |
78 | axes[0].text(-5, 15, "%s Trajectories" %n_traj, rotation=90, verticalalignment='center', usetex=True)
79 |
80 | fig.tight_layout(rect=[0, 0.03, 1, 0.95])
81 | plt.savefig(os.path.join("../results/imgs/", "%d_result.png" %(trajectories)), bbox_inches='tight')
82 |
83 |
84 | def read_results(path):
85 | """
86 | Read results from path.
87 | """
88 | files = glob.glob(os.path.join(path, "*.npy"))
89 | settings = dict()
90 | for f in files:
91 | name = os.path.basename(f).split(".")[0]
92 | settings[name] = np.load(f)
93 | return settings["boltzmann"], settings["runtime"]
94 |
95 |
96 | if __name__ == '__main__':
97 |
98 | # number of trajectories to evaluate.
99 | n_traj = int(sys.argv[1])
100 |
101 | output_iavi = "../results/objectworld_%d_trajectories/objectworld_%d_trajectories_set_0/iavi_1/" %(n_traj,n_traj)
102 | output_iql = "../results/objectworld_%d_trajectories/objectworld_%d_trajectories_set_0/iql_100/" % (n_traj,n_traj)
103 |
104 |
105 | # Objectworld settings.
106 | grid_size = 32
107 | nS = grid_size**2
108 | nA = 5
109 |
110 | # load data from experiments generated by train.py.
111 | data_file = "objectworld_%s_trajectories"%n_traj
112 | data_dir = os.path.join("../data", data_file, "objectworld_%s_trajectories_set_0"%n_traj)
113 |
114 | feature_matrix = np.load(os.path.join(data_dir, "feature_matrix.npy"))
115 | trajectories = np.load(os.path.join(data_dir, "trajectories.npy"))
116 | action_probabilities = np.load(os.path.join(data_dir, "action_probabilities.npy"))
117 | transition_probabilities = np.load(os.path.join(data_dir, "transition_probabilities.npy"))
118 | ground_r= np.load(os.path.join(data_dir, "ground_r.npy"))
119 | p_start_state = np.load(os.path.join(data_dir, "p_start_state.npy"))
120 |
121 | # compute state-values.
122 | b, iavi_runtime = read_results(output_iavi)
123 | v_iavi = policy_eval(b, ground_r, transition_probabilities, nS, nA, discount_factor=0.9, theta=0.001)
124 |
125 | b, iql_runtime = read_results(output_iql)
126 | v_iql = policy_eval(b, ground_r, transition_probabilities, nS, nA, discount_factor=0.9, theta=0.001)
127 |
128 | # compute ground truth distribution.
129 | v_true = policy_eval(action_probabilities, ground_r, transition_probabilities, nS, nA, discount_factor=0.9, theta=0.001)
130 |
131 | # compute optimal distribution.
132 | b = find_policy(nS, nA, transition_probabilities, ground_r, discount=0.9, threshold=1e-2)
133 | v_real = policy_eval(b, ground_r, transition_probabilities, nS, nA, discount_factor=0.9, theta=0.001)
134 |
135 | print("IAVI Runtime: %0.2f" % (iavi_runtime/ 3600.))
136 | print("IQL Runtime: %0.2f" % (iql_runtime / 3600.))
137 | print("IAVI EVD: %0.2f" % np.square(v_real - v_iavi).mean())
138 | print("IQL EVD: %0.2f" % np.square(v_real - v_iql).mean())
139 |
140 | # create images.
141 | plot_grid(n_traj, v_real, v_true, v_iavi, v_iql, grid_size)
142 |
143 |
144 | # create result table.
145 | path = "../results/results.csv"
146 | if os.path.exists(path):
147 | df = pd.read_csv(path)
148 | else:
149 | df = pd.DataFrame(columns=["Number of Trajectories", "EVD IAVI", "EVD IQL", "Runtime IAVI [h]", "Runtime IQL [h]"])
150 |
151 | df.loc[len(df)] = [ n_traj, np.square(v_real - v_iavi).mean(), np.square(v_real - v_iql).mean(), (iavi_runtime/ 3600.), (iql_runtime/ 3600.)]
152 |
153 |
154 | df.round(3).to_csv(path, index=False)
155 | print(df.round(3))
156 |
--------------------------------------------------------------------------------
/src/mdp/objectworld.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | """
4 | Implementation of the objectworld MDP in Levine et al. 2011. This code is used and adapted from
5 |
6 | Matthew Alger, 2015
7 | matthew.alger@anu.edu.au
8 | """
9 |
10 | import math
11 | from itertools import product
12 | import numpy as np
13 | import numpy.random as rn
14 | from mdp.gridworld import Gridworld
15 | from mdp.value_iteration import find_policy
16 |
17 |
18 | class OWObject(object):
19 | """
20 | Object in objectworld.
21 | """
22 |
23 | def __init__(self, inner_colour, outer_colour):
24 | """
25 | inner_colour: Inner colour of object. int.
26 | outer_colour: Outer colour of object. int.
27 | -> OWObject
28 | """
29 |
30 | self.inner_colour = inner_colour
31 | self.outer_colour = outer_colour
32 |
33 | def __str__(self):
34 | """
35 | A string representation of this object.
36 |
37 | -> __str__
38 | """
39 |
40 | return "".format(self.inner_colour,
41 | self.outer_colour)
42 |
43 | class Objectworld(Gridworld):
44 | """
45 | Objectworld MDP.
46 | """
47 |
48 | def __init__(self, grid_size, n_objects, n_colours, wind, discount):
49 | """
50 | grid_size: Grid size. int.
51 | n_objects: Number of objects in the world. int.
52 | n_colours: Number of colours to colour objects with. int.
53 | wind: Chance of moving randomly. float.
54 | discount: MDP discount. float.
55 | -> Objectworld
56 | """
57 |
58 | super().__init__(grid_size, wind, discount)
59 |
60 | self.actions = ((1, 0), (0, 1), (-1, 0), (0, -1), (0, 0))
61 | self.n_actions = len(self.actions)
62 | self.n_objects = n_objects
63 | self.n_colours = n_colours
64 |
65 | # Generate objects.
66 | self.objects = {}
67 | for _ in range(self.n_objects):
68 | obj = OWObject(rn.randint(self.n_colours),
69 | rn.randint(self.n_colours))
70 |
71 | while True:
72 | x = rn.randint(self.grid_size)
73 | y = rn.randint(self.grid_size)
74 |
75 | if (x, y) not in self.objects:
76 | break
77 |
78 | self.objects[x, y] = obj
79 |
80 | # Preconstruct the transition probability array.
81 | self.transition_probability = np.array(
82 | [[[self._transition_probability(i, j, k)
83 | for k in range(self.n_states)]
84 | for j in range(self.n_actions)]
85 | for i in range(self.n_states)])
86 |
87 | self.transition_probability/=np.sum(self.transition_probability, axis=2, keepdims=True)
88 | #print(np.sum(self.transition_probability, axis=2).tolist())
89 | #assert(np.all(np.sum(self.transition_probability, axis=2)==1.0))
90 |
91 | def feature_vector(self, i, discrete=True):
92 | """
93 | Get the feature vector associated with a state integer.
94 |
95 | i: State int.
96 | discrete: Whether the feature vectors should be discrete (default True).
97 | bool.
98 | -> Feature vector.
99 | """
100 |
101 | sx, sy = self.int_to_point(i)
102 |
103 | nearest_inner = {} # colour: distance
104 | nearest_outer = {} # colour: distance
105 |
106 | for y in range(self.grid_size):
107 | for x in range(self.grid_size):
108 | if (x, y) in self.objects:
109 | dist = math.hypot((x - sx), (y - sy))
110 | obj = self.objects[x, y]
111 | if obj.inner_colour in nearest_inner:
112 | if dist < nearest_inner[obj.inner_colour]:
113 | nearest_inner[obj.inner_colour] = dist
114 | else:
115 | nearest_inner[obj.inner_colour] = dist
116 | if obj.outer_colour in nearest_outer:
117 | if dist < nearest_outer[obj.outer_colour]:
118 | nearest_outer[obj.outer_colour] = dist
119 | else:
120 | nearest_outer[obj.outer_colour] = dist
121 |
122 | # Need to ensure that all colours are represented.
123 | for c in range(self.n_colours):
124 | if c not in nearest_inner:
125 | nearest_inner[c] = 0
126 | if c not in nearest_outer:
127 | nearest_outer[c] = 0
128 |
129 | if discrete:
130 | state = np.zeros((2*self.n_colours*self.grid_size,))
131 | i = 0
132 | for c in range(self.n_colours):
133 | for d in range(1, self.grid_size+1):
134 | if nearest_inner[c] < d:
135 | state[i] = 1
136 | i += 1
137 | if nearest_outer[c] < d:
138 | state[i] = 1
139 | i += 1
140 | assert i == 2*self.n_colours*self.grid_size
141 | assert (state >= 0).all()
142 | else:
143 | # Continuous features.
144 | state = np.zeros((2*self.n_colours))
145 | i = 0
146 | for c in range(self.n_colours):
147 | state[i] = nearest_inner[c]
148 | i += 1
149 | state[i] = nearest_outer[c]
150 | i += 1
151 |
152 | return state
153 |
154 | def feature_matrix(self, discrete=True):
155 | """
156 | Get the feature matrix for this objectworld.
157 |
158 | discrete: Whether the feature vectors should be discrete (default True).
159 | bool.
160 | -> NumPy array with shape (n_states, n_states).
161 | """
162 |
163 | return np.array([self.feature_vector(i, discrete)
164 | for i in range(self.n_states)])
165 |
166 | def reward(self, state_int):
167 | """
168 | Get the reward for a state int.
169 |
170 | state_int: State int.
171 | -> reward float
172 | """
173 |
174 | x, y = self.int_to_point(state_int)
175 |
176 | near_c0 = False
177 | near_c1 = False
178 | for (dx, dy) in product(range(-3, 4), range(-3, 4)):
179 | if 0 <= x + dx < self.grid_size and 0 <= y + dy < self.grid_size:
180 | if (abs(dx) + abs(dy) <= 3 and
181 | (x+dx, y+dy) in self.objects and
182 | self.objects[x+dx, y+dy].outer_colour == 0):
183 | near_c0 = True
184 | if (abs(dx) + abs(dy) <= 2 and
185 | (x+dx, y+dy) in self.objects and
186 | self.objects[x+dx, y+dy].outer_colour == 1):
187 | near_c1 = True
188 |
189 | if near_c0 and near_c1:
190 | return 1
191 | if near_c0:
192 | return -1
193 | return 0
194 |
195 | def generate_trajectories(self, n_trajectories, trajectory_length, policy):
196 | """
197 | Generate n_trajectories trajectories with length trajectory_length.
198 |
199 | n_trajectories: Number of trajectories. int.
200 | trajectory_length: Length of an episode. int.
201 | policy: Map from state integers to action integers.
202 | -> [[(state int, action int, reward float)]]
203 | """
204 |
205 | return super().generate_trajectories(n_trajectories, trajectory_length,
206 | policy,
207 | True)
208 |
209 | def collect_demonstrations(self, n_trajectories, trajectory_length):
210 |
211 | ground_r = np.array([self.reward(s) for s in range(self.n_states)])
212 |
213 | policy = find_policy(self.n_states, self.n_actions, self.transition_probability,
214 | ground_r, self.discount, stochastic=False)
215 |
216 | trajectories = self.generate_trajectories(n_trajectories,
217 | trajectory_length,
218 | lambda s: policy[s])
219 |
220 |
221 | action_probabilities = np.zeros((self.n_states, self.n_actions))
222 | for traj in trajectories:
223 | for (s, a, r, ns) in traj:
224 | action_probabilities[s][a] += 1
225 | action_probabilities[action_probabilities.sum(axis=1) == 0] = 1e-5
226 | action_probabilities /= action_probabilities.sum(axis=1).reshape(self.n_states, 1)
227 |
228 | return trajectories, action_probabilities, self.transition_probability, ground_r
229 |
230 | def optimal_policy(self, state_int):
231 | raise NotImplementedError(
232 | "Optimal policy is not implemented for Objectworld.")
233 | def optimal_policy_deterministic(self, state_int):
234 | raise NotImplementedError(
235 | "Optimal policy is not implemented for Objectworld.")
236 |
237 |
238 |
239 |
240 |
--------------------------------------------------------------------------------
/src/mdp/gridworld.py:
--------------------------------------------------------------------------------
1 | """
2 | Implementation of a gridworld MDP. This code is copied and adapted from
3 |
4 | Matthew Alger, 2015
5 | matthew.alger@anu.edu.au
6 | """
7 |
8 | import numpy as np
9 | import numpy.random as rn
10 |
11 | class Gridworld(object):
12 | """
13 | Gridworld MDP.
14 | """
15 |
16 | def __init__(self, grid_size, wind, discount):
17 | """
18 | grid_size: Grid size. int.
19 | wind: Chance of moving randomly. float.
20 | discount: MDP discount. float.
21 | -> Gridworld
22 | """
23 |
24 | self.actions = ((1, 0), (0, 1), (-1, 0), (0, -1))
25 | self.n_actions = len(self.actions)
26 | self.n_states = grid_size**2
27 | self.grid_size = grid_size
28 | self.wind = wind
29 | self.discount = discount
30 |
31 | # Preconstruct the transition probability array.
32 | self.transition_probability = np.array(
33 | [[[self._transition_probability(i, j, k)
34 | for k in range(self.n_states)]
35 | for j in range(self.n_actions)]
36 | for i in range(self.n_states)])
37 |
38 | def __str__(self):
39 | return "Gridworld({}, {}, {})".format(self.grid_size, self.wind,
40 | self.discount)
41 |
42 | def feature_vector(self, i, feature_map="ident"):
43 | """
44 | Get the feature vector associated with a state integer.
45 |
46 | i: State int.
47 | feature_map: Which feature map to use (default ident). String in {ident,
48 | coord, proxi}.
49 | -> Feature vector.
50 | """
51 |
52 | if feature_map == "coord":
53 | f = np.zeros(self.grid_size)
54 | x, y = i % self.grid_size, i // self.grid_size
55 | f[x] += 1
56 | f[y] += 1
57 | return f
58 | if feature_map == "proxi":
59 | f = np.zeros(self.n_states)
60 | x, y = i % self.grid_size, i // self.grid_size
61 | for b in range(self.grid_size):
62 | for a in range(self.grid_size):
63 | dist = abs(x - a) + abs(y - b)
64 | f[self.point_to_int((a, b))] = dist
65 | return f
66 | # Assume identity map.
67 | f = np.zeros(self.n_states)
68 | f[i] = 1
69 | return f
70 |
71 | def feature_matrix(self, feature_map="ident"):
72 | """
73 | Get the feature matrix for this gridworld.
74 |
75 | feature_map: Which feature map to use (default ident). String in {ident,
76 | coord, proxi}.
77 | -> NumPy array with shape (n_states, d_states).
78 | """
79 |
80 | features = []
81 | for n in range(self.n_states):
82 | f = self.feature_vector(n, feature_map)
83 | features.append(f)
84 | return np.array(features)
85 |
86 | def int_to_point(self, i):
87 | """
88 | Convert a state int into the corresponding coordinate.
89 |
90 | i: State int.
91 | -> (x, y) int tuple.
92 | """
93 |
94 | return (i % self.grid_size, i // self.grid_size)
95 |
96 | def point_to_int(self, p):
97 | """
98 | Convert a coordinate into the corresponding state int.
99 |
100 | p: (x, y) tuple.
101 | -> State int.
102 | """
103 |
104 | return p[0] + p[1]*self.grid_size
105 |
106 | def neighbouring(self, i, k):
107 | """
108 | Get whether two points neighbour each other. Also returns true if they
109 | are the same point.
110 |
111 | i: (x, y) int tuple.
112 | k: (x, y) int tuple.
113 | -> bool.
114 | """
115 |
116 | return abs(i[0] - k[0]) + abs(i[1] - k[1]) <= 1
117 |
118 | def _transition_probability(self, i, j, k):
119 | """
120 | Get the probability of transitioning from state i to state k given
121 | action j.
122 |
123 | i: State int.
124 | j: Action int.
125 | k: State int.
126 | -> p(s_k | s_i, a_j)
127 | """
128 |
129 | xi, yi = self.int_to_point(i)
130 | xj, yj = self.actions[j]
131 | xk, yk = self.int_to_point(k)
132 |
133 | if not self.neighbouring((xi, yi), (xk, yk)):
134 | return 0.0
135 |
136 | # Is k the intended state to move to?
137 | if (xi + xj, yi + yj) == (xk, yk):
138 | return 1 - self.wind + self.wind/self.n_actions
139 |
140 | # If these are not the same point, then we can move there by wind.
141 | if (xi, yi) != (xk, yk):
142 | return self.wind/self.n_actions
143 |
144 | # If these are the same point, we can only move here by either moving
145 | # off the grid or being blown off the grid. Are we on a corner or not?
146 | if (xi, yi) in {(0, 0), (self.grid_size-1, self.grid_size-1),
147 | (0, self.grid_size-1), (self.grid_size-1, 0)}:
148 | # Corner.
149 | # Can move off the edge in two directions.
150 | # Did we intend to move off the grid?
151 | if not (0 <= xi + xj < self.grid_size and
152 | 0 <= yi + yj < self.grid_size):
153 | # We intended to move off the grid, so we have the regular
154 | # success chance of staying here plus an extra chance of blowing
155 | # onto the *other* off-grid square.
156 | return 1 - self.wind + 2*self.wind/self.n_actions
157 | else:
158 | # We can blow off the grid in either direction only by wind.
159 | return 2*self.wind/self.n_actions
160 | else:
161 | # Not a corner. Is it an edge?
162 | if (xi not in {0, self.grid_size-1} and
163 | yi not in {0, self.grid_size-1}):
164 | # Not an edge.
165 | return 0.0
166 |
167 | # Edge.
168 | # Can only move off the edge in one direction.
169 | # Did we intend to move off the grid?
170 | if not (0 <= xi + xj < self.grid_size and
171 | 0 <= yi + yj < self.grid_size):
172 | # We intended to move off the grid, so we have the regular
173 | # success chance of staying here.
174 | return 1 - self.wind + self.wind/self.n_actions
175 | else:
176 | # We can blow off the grid only by wind.
177 | return self.wind/self.n_actions
178 |
179 | def reward(self, state_int):
180 | """
181 | Reward for being in state state_int.
182 |
183 | state_int: State integer. int.
184 | -> Reward.
185 | """
186 |
187 | if state_int == self.n_states - 1:
188 | return 1
189 | return 0
190 |
191 | def average_reward(self, n_trajectories, trajectory_length, policy):
192 | """
193 | Calculate the average total reward obtained by following a given policy
194 | over n_paths paths.
195 |
196 | policy: Map from state integers to action integers.
197 | n_trajectories: Number of trajectories. int.
198 | trajectory_length: Length of an episode. int.
199 | -> Average reward, standard deviation.
200 | """
201 |
202 | trajectories = self.generate_trajectories(n_trajectories,
203 | trajectory_length, policy)
204 | rewards = [[r for _, _, r in trajectory] for trajectory in trajectories]
205 | rewards = np.array(rewards)
206 |
207 | # Add up all the rewards to find the total reward.
208 | total_reward = rewards.sum(axis=1)
209 |
210 | # Return the average reward and standard deviation.
211 | return total_reward.mean(), total_reward.std()
212 |
213 | def optimal_policy(self, state_int):
214 | """
215 | The optimal policy for this gridworld.
216 |
217 | state_int: What state we are in. int.
218 | -> Action int.
219 | """
220 |
221 | sx, sy = self.int_to_point(state_int)
222 |
223 | if sx < self.grid_size and sy < self.grid_size:
224 | return rn.randint(0, 2)
225 | if sx < self.grid_size-1:
226 | return 0
227 | if sy < self.grid_size-1:
228 | return 1
229 | raise ValueError("Unexpected state.")
230 |
231 | def optimal_policy_deterministic(self, state_int):
232 | """
233 | Deterministic version of the optimal policy for this gridworld.
234 |
235 | state_int: What state we are in. int.
236 | -> Action int.
237 | """
238 |
239 | sx, sy = self.int_to_point(state_int)
240 | if sx < sy:
241 | return 0
242 | return 1
243 |
244 | def generate_trajectories(self, n_trajectories, trajectory_length, policy,
245 | random_start=False):
246 | """
247 | Generate n_trajectories trajectories with length trajectory_length,
248 | following the given policy.
249 |
250 | n_trajectories: Number of trajectories. int.
251 | trajectory_length: Length of an episode. int.
252 | policy: Map from state integers to action integers.
253 | random_start: Whether to start randomly (default False). bool.
254 | -> [[(state int, action int, reward float)]]
255 | """
256 |
257 | trajectories = []
258 | for _ in range(n_trajectories):
259 | if random_start:
260 | sx, sy = rn.randint(self.grid_size), rn.randint(self.grid_size)
261 | else:
262 | sx, sy = 0, 0
263 |
264 | trajectory = []
265 | for _ in range(trajectory_length):
266 | if rn.random() < self.wind:
267 | action = self.actions[rn.randint(0, 4)]
268 | else:
269 | # Follow the given policy.
270 | action = self.actions[policy(self.point_to_int((sx, sy)))]
271 |
272 | if (0 <= sx + action[0] < self.grid_size and
273 | 0 <= sy + action[1] < self.grid_size):
274 | next_sx = sx + action[0]
275 | next_sy = sy + action[1]
276 | else:
277 | next_sx = sx
278 | next_sy = sy
279 |
280 | state_int = self.point_to_int((sx, sy))
281 | action_int = self.actions.index(action)
282 | next_state_int = self.point_to_int((next_sx, next_sy))
283 | reward = self.reward(next_state_int)
284 | trajectory.append((state_int, action_int, reward,next_state_int))
285 |
286 | sx = next_sx
287 | sy = next_sy
288 |
289 | trajectories.append(trajectory)
290 |
291 | return np.array(trajectories)
292 |
--------------------------------------------------------------------------------