├── util
├── .aspell
├── gen_pdf
├── gen_notebooks
├── clean_all
├── push_pypi
└── spell_check
├── doc
├── flashNorm.pdf
├── matShrink.pdf
├── slimAttn.pdf
├── removeWeights.pdf
├── precomp1stLayer.pdf
├── fig
│ ├── flashNorm_fig1.pdf
│ ├── flashNorm_fig2.pdf
│ ├── flashNorm_fig3.pdf
│ ├── flashNorm_fig4.pdf
│ ├── flashNorm_fig5.pdf
│ ├── flashNorm_fig6.pdf
│ ├── flashNorm_fig7.pdf
│ ├── flashNorm_fig8.pdf
│ ├── flashNorm_figA.pdf
│ ├── flashNorm_figB.pdf
│ ├── matShrink_fig1.pdf
│ ├── matShrink_fig2.pdf
│ ├── matShrink_fig3.pdf
│ ├── slimAttn_fig1.pdf
│ ├── slimAttn_fig2.pdf
│ ├── slimAttn_fig3.pdf
│ ├── slimAttn_fig4.pdf
│ ├── slimAttn_fig5.pdf
│ ├── slimAttn_fig6.pdf
│ ├── slimAttn_fig7.pdf
│ ├── precomp1stLayer_fig1.pdf
│ ├── precomp1stLayer_fig2.pdf
│ ├── removeWeights_fig1.pdf
│ ├── removeWeights_fig2.pdf
│ ├── removeWeights_fig3.pdf
│ ├── removeWeights_fig4.pdf
│ └── slimAttn_fig1.svg
├── slimAttn.md
├── CONTRIBUTING.md
├── README.md
└── flashNorm.md
├── tex
├── clean
├── run
├── neurips_2025_mods.sty
├── submit
├── README.md
├── arxiv.sty
├── precomp1stLayer.tex
├── neurips_2025.sty
├── removeWeights.tex
├── matShrink.tex
├── flashNorm.tex
└── matShrink_Sid.tex
├── requirements.txt
├── LICENSE
├── pyproject.toml
├── notebooks
├── README.md
├── update_packages.ipynb
├── flashNorm_example.ipynb
├── removeWeights_paper.ipynb
├── slimAttn_paper.ipynb
└── flashNorm_paper.ipynb
├── flashNorm_example.py
├── flashNorm_test.py
├── slimAttn_paper.py
├── README.md
└── transformer_tricks.py
/util/.aspell:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/util/.aspell
--------------------------------------------------------------------------------
/doc/flashNorm.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/flashNorm.pdf
--------------------------------------------------------------------------------
/doc/matShrink.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/matShrink.pdf
--------------------------------------------------------------------------------
/doc/slimAttn.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/slimAttn.pdf
--------------------------------------------------------------------------------
/doc/removeWeights.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/removeWeights.pdf
--------------------------------------------------------------------------------
/doc/precomp1stLayer.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/precomp1stLayer.pdf
--------------------------------------------------------------------------------
/doc/fig/flashNorm_fig1.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/flashNorm_fig1.pdf
--------------------------------------------------------------------------------
/doc/fig/flashNorm_fig2.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/flashNorm_fig2.pdf
--------------------------------------------------------------------------------
/doc/fig/flashNorm_fig3.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/flashNorm_fig3.pdf
--------------------------------------------------------------------------------
/doc/fig/flashNorm_fig4.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/flashNorm_fig4.pdf
--------------------------------------------------------------------------------
/doc/fig/flashNorm_fig5.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/flashNorm_fig5.pdf
--------------------------------------------------------------------------------
/doc/fig/flashNorm_fig6.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/flashNorm_fig6.pdf
--------------------------------------------------------------------------------
/doc/fig/flashNorm_fig7.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/flashNorm_fig7.pdf
--------------------------------------------------------------------------------
/doc/fig/flashNorm_fig8.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/flashNorm_fig8.pdf
--------------------------------------------------------------------------------
/doc/fig/flashNorm_figA.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/flashNorm_figA.pdf
--------------------------------------------------------------------------------
/doc/fig/flashNorm_figB.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/flashNorm_figB.pdf
--------------------------------------------------------------------------------
/doc/fig/matShrink_fig1.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/matShrink_fig1.pdf
--------------------------------------------------------------------------------
/doc/fig/matShrink_fig2.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/matShrink_fig2.pdf
--------------------------------------------------------------------------------
/doc/fig/matShrink_fig3.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/matShrink_fig3.pdf
--------------------------------------------------------------------------------
/doc/fig/slimAttn_fig1.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/slimAttn_fig1.pdf
--------------------------------------------------------------------------------
/doc/fig/slimAttn_fig2.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/slimAttn_fig2.pdf
--------------------------------------------------------------------------------
/doc/fig/slimAttn_fig3.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/slimAttn_fig3.pdf
--------------------------------------------------------------------------------
/doc/fig/slimAttn_fig4.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/slimAttn_fig4.pdf
--------------------------------------------------------------------------------
/doc/fig/slimAttn_fig5.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/slimAttn_fig5.pdf
--------------------------------------------------------------------------------
/doc/fig/slimAttn_fig6.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/slimAttn_fig6.pdf
--------------------------------------------------------------------------------
/doc/fig/slimAttn_fig7.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/slimAttn_fig7.pdf
--------------------------------------------------------------------------------
/doc/fig/precomp1stLayer_fig1.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/precomp1stLayer_fig1.pdf
--------------------------------------------------------------------------------
/doc/fig/precomp1stLayer_fig2.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/precomp1stLayer_fig2.pdf
--------------------------------------------------------------------------------
/doc/fig/removeWeights_fig1.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/removeWeights_fig1.pdf
--------------------------------------------------------------------------------
/doc/fig/removeWeights_fig2.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/removeWeights_fig2.pdf
--------------------------------------------------------------------------------
/doc/fig/removeWeights_fig3.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/removeWeights_fig3.pdf
--------------------------------------------------------------------------------
/doc/fig/removeWeights_fig4.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/HEAD/doc/fig/removeWeights_fig4.pdf
--------------------------------------------------------------------------------
/tex/clean:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # script to clean up this directory
4 | # usage: ./clean
5 |
6 | \rm -f *.bbl *.aux *.blg *.log *.out
7 |
--------------------------------------------------------------------------------
/util/gen_pdf:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # generate PDF from tex for all files
4 | # usage: util/gen_pdf (run from the root dir of this repo)
5 |
6 | cd tex
7 | for fname in *.tex; do
8 | ./run "$fname"
9 | done
10 |
11 | ./clean
12 | cd -
13 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | transformer-tricks>=0.3.4
2 | jupytext>=1.16.4
3 | autopep8>=2.3.1
4 | twine>=6.1.0
5 | build>=1.2.2
6 |
7 | # pip list # see all versions
8 | #
9 | # Phi-3 needs flash-attn, but this requires CUDA
10 | # flash-attn==2.5.8
11 |
--------------------------------------------------------------------------------
/util/gen_notebooks:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # generate Jupyter notebooks from python
4 | # usage: util/gen_notebooks (run from the root dir of this repo)
5 |
6 | for fname in slimAttn_paper flashNorm_example; do
7 | jupytext "$fname".py -o notebooks/"$fname".ipynb
8 | done
9 |
--------------------------------------------------------------------------------
/util/clean_all:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # cleans up the entire repo by removing generated files
4 | # usage: util/clean_all (run from the root dir of this repo)
5 |
6 | # clean up ./util
7 | cd util
8 | rm -rf pypi
9 | cd -
10 |
11 | # clean up ./tex
12 | cd tex
13 | ./clean
14 | \rm -rf *_submit *_submit.tar.gz
15 | cd -
16 |
--------------------------------------------------------------------------------
/doc/slimAttn.md:
--------------------------------------------------------------------------------
1 | coming soon
2 |
3 | For now, see the [[notebook]](https://colab.research.google.com/github/OpenMachine-ai/transformer-tricks/blob/main/notebooks/slimAttn_paper.ipynb)
4 |
5 | Feature requests for frameworks to implement slim attention:
6 | - [llama.cpp and whisper.cpp](https://github.com/ggml-org/llama.cpp/issues/12359)
7 | - [vLLM](https://github.com/vllm-project/vllm/issues/14937)
8 | - [SGLang](https://github.com/sgl-project/sglang/issues/4496)
9 |
--------------------------------------------------------------------------------
/util/push_pypi:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # Make sure to increment the version number in pyproject.toml and
4 | # requirements.txt before running this script! See below link for details:
5 | # https://packaging.python.org/en/latest/tutorials/packaging-projects/
6 | #
7 | # Setup: install build and twine via 'pip3 install build twine'
8 | # To upgrade: pip3 install --upgrade build twine pkginfo packaging
9 | # Usage: ./push_pypi
10 |
11 | # create folder 'pypi' and copy all relevant files
12 | rm -rf pypi
13 | mkdir pypi
14 | cp ../LICENSE ../README.md ../pyproject.toml ../transformer_tricks.py pypi
15 |
16 | # build and upload
17 | cd pypi
18 | python3 -m build
19 | python3 -m twine upload dist/*
20 |
21 | #rm -rf pypi
22 |
--------------------------------------------------------------------------------
/util/spell_check:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # spell check all tex and markdown files
4 | # usage: util/spell_check (run from the root dir of this repo)
5 |
6 | # notes:
7 | # - option -M is for markdown; -t is for tex
8 | # - file util/.aspell is our personal dictionary
9 | # - however, aspell seems to have a bug, the personal dictionary file
10 | # must be located in the same dir from which you call aspell, that's
11 | # why we first do 'cd util'
12 |
13 | cd util
14 |
15 | # all markdown files
16 | for file in ../*.md ../*/*.md; do
17 | aspell -d en_US -l en_US --personal=./.aspell -M -c "$file"
18 | done
19 |
20 | # all tex files
21 | for file in ../tex/*.tex; do
22 | aspell -d en_US -l en_US --personal=./.aspell -t -c "$file"
23 | done
24 |
25 | cd -
26 |
--------------------------------------------------------------------------------
/doc/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | We pay cash for your high-impact contributions, please contact us for details.
2 |
3 | Before submitting a PR, please do the following:
4 | - Make sure to minimize the number of files and lines of code, we strive for simple and readable code.
5 | - Format your code by typing `autopep8 *.py`. It's using the config in `pyproject.toml`
6 | - Generate notebooks from python by typing `util/gen_notebooks`
7 | - Whenever you change `transformer_tricks.py`, we will publish a new version of the package as follows:
8 | - First, update the version number in `pyproject.toml` and in `requirements.txt`
9 | - Then, push the package to PyPi by typing `./push_pypi.sh`
10 | - Links for python package: [pypi](https://pypi.org/project/transformer-tricks/), [stats](https://www.pepy.tech/projects/transformer-tricks)
11 |
--------------------------------------------------------------------------------
/doc/README.md:
--------------------------------------------------------------------------------
1 | Click on the links below for better PDF viewing:
2 | - [flashNorm.pdf](https://docs.google.com/viewer?url=https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/doc/flashNorm.pdf)
3 | - [matShrink.pdf](https://docs.google.com/viewer?url=https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/doc/matShrink.pdf)
4 | - [precomp1stLayer.pdf](https://docs.google.com/viewer?url=https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/doc/precomp1stLayer.pdf)
5 | - [removeWeights.pdf](https://docs.google.com/viewer?url=https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/doc/removeWeights.pdf)
6 | - [slimAttn.pdf](https://docs.google.com/viewer?url=https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/doc/slimAttn.pdf)
7 |
--------------------------------------------------------------------------------
/tex/run:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # script to convert foo.tex to PDF
4 | # usage: ./run foo.tex or ./run foo
5 | # above generates foo.pdf and other files
6 |
7 | # remove filename extension from arg
8 | file="${1%.*}"
9 |
10 | ./clean
11 | pdflatex "$file"
12 | bibtex "$file"
13 | pdflatex "$file"
14 | pdflatex "$file"
15 | pdflatex "$file" # we sometimes need to run pdflatex 3 times
16 |
17 | # in case you want to diff your changes visually
18 | diff-pdf --view "$file".pdf ../doc/"$file".pdf
19 |
20 | mv "$file".pdf ../doc
21 |
22 | echo "--------------------------------------------------------------------------------"
23 | grep Warning "$file".log
24 |
25 | #./clean
26 |
27 | # note: to diff 2 PDF files visually, type the following:
28 | # diff-pdf --view file1.pdf file2.pdf
29 | # alternatively, use pdftotext to convert each PDF to text and then diff the text files:
30 | # pdftotext file1.pdf # this generates file1.txt
31 | # pdftotext file2.pdf # this generates file2.txt
32 | # diff file1.txt file2.txt
33 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2024 OpenMachine
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/tex/neurips_2025_mods.sty:
--------------------------------------------------------------------------------
1 | % My mods for neurips_2025.sty
2 |
3 | \renewcommand{\@noticestring}{} % remove the footnote 'Under review'
4 |
5 | \usepackage[utf8]{inputenc} % allow utf-8 input
6 | \usepackage[T1]{fontenc} % use 8-bit T1 fonts
7 | %% I removed this: \usepackage{hyperref} % hyperlinks
8 | \usepackage{url} % simple URL typesetting
9 | \usepackage{booktabs} % professional-quality tables
10 | \usepackage{amsfonts} % blackboard math symbols
11 | \usepackage{nicefrac} % compact symbols for 1/2, etc.
12 | \usepackage{microtype} % microtypography
13 | \usepackage{xcolor} % colors
14 |
15 | %% I added the following packages
16 | \usepackage[hidelinks,colorlinks=true,linkcolor=blue,citecolor=blue,urlcolor=blue]{hyperref}
17 | \usepackage{amsmath}
18 | \usepackage{amssymb}
19 | \usepackage{graphicx}
20 | \usepackage{makecell}
21 | \usepackage{multirow}
22 | \usepackage{tablefootnote}
23 | \usepackage{enumitem}
24 | \usepackage{pythonhighlight} % for python listings
25 | \usepackage[numbers]{natbib}
26 | \usepackage{caption}
27 | \captionsetup[figure]{skip=2pt} % reduce the space between figure and caption
28 | %\captionsetup[table]{skip=10pt}
29 |
--------------------------------------------------------------------------------
/tex/submit:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # script to submit foo.tex to arXiv
4 | # usage: ./submit foo.tex
5 | # above generates a directory foo_submit and a tar gz file foo_submit.tar.gz
6 | # only upload this tar file to arXiv and see the notes in README on how to submit
7 |
8 | # note: to double-check if everything works, run pdflatex foo two times
9 | # (or sometimes three times) as follows:
10 | # cd foo_submit
11 | # pdflatex foo && pdflatex foo
12 |
13 | # remove filename extension from arg
14 | file="${1%.*}"
15 |
16 | DIR="$file"_submit
17 |
18 | rm -Rf "$DIR" "$DIR".tar.gz
19 | mkdir "$DIR"
20 |
21 | ./run "$file"
22 |
23 | cp *.sty references.bib "$file".bbl "$file".tex "$DIR"
24 | cp ../doc/fig/"$file"_fig*.pdf "$DIR"
25 |
26 | # modify the figure-paths in the tex file: ../doc/fig/ -> ./
27 | sed -i "" "s,../doc/fig/,./,g" "$DIR"/"$file".tex
28 | # the two quotes (empty string) at the beginning of sed are for running on mac
29 |
30 | # TODO: it might also work without the sed command, but only if the tar.gz
31 | # archive is flat and has only one directory to the tex file (right now the
32 | # archive includes the directory 'foo_submit')
33 |
34 | tar -czvf "$DIR".tar.gz -C "$DIR" .
35 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | # config file for creating the PyPi package. See
2 | # https://packaging.python.org/en/latest/tutorials/packaging-projects/
3 |
4 | [build-system]
5 | requires = ["hatchling"]
6 | build-backend = "hatchling.build"
7 |
8 | [project]
9 | name = "transformer-tricks"
10 | # version numbering A.B.C: A is major version, B is minor version, and C is patch
11 | version = "0.3.4"
12 | authors = [
13 | {name="Open Machine", email="info@openmachine.ai"},
14 | ]
15 | description = "A collection of tricks to speed up LLMs, see our transformer-tricks papers on arXiv"
16 | readme = "README.md"
17 | requires-python = ">=3.11"
18 | classifiers = [
19 | "Programming Language :: Python :: 3",
20 | "License :: OSI Approved :: MIT License",
21 | "Operating System :: OS Independent",
22 | ]
23 | dependencies = [
24 | "transformers>=4.52.3",
25 | "accelerate>=1.7.0",
26 | "datasets>=3.6.0",
27 | ]
28 |
29 | [project.urls]
30 | "Homepage" = "https://github.com/OpenMachine-ai/transformer-tricks"
31 | "Bug Tracker" = "https://github.com/OpenMachine-ai/transformer-tricks/issues"
32 |
33 | [tool.autopep8]
34 | indent-size = 2
35 | in-place = true
36 | max-line-length = 120
37 | ignore = "E265, E401, E70, E20, E241, E11"
38 | # type 'autopep8 --list-fixes' to see a list of all rules
39 | # for debug, type 'autopep8 --verbose *.py'
40 |
--------------------------------------------------------------------------------
/notebooks/README.md:
--------------------------------------------------------------------------------
1 | Click on the icons below to run the notebooks in your browser. You can hit 'cancel' when it says 'Notebook does not have secret access' because we don't need an HF_TOKEN:
2 | - flashNorm_example.ipynb:
3 | - flashNorm_paper.ipynb:
4 | - removeWeights_paper.ipynb:
5 | - slimAttn_paper.ipynb:
6 | - update_packages.ipynb:
7 |
--------------------------------------------------------------------------------
/flashNorm_example.py:
--------------------------------------------------------------------------------
1 | # This example converts SmolLM-135M to FlashNorm and measures its perplexity
2 | # before and after the conversion.
3 | # Usage: python3 flashNorm_example.py
4 |
5 | # !wget -q https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/flashNorm_modeling_llama.py
6 | # %pip install --quiet transformer_tricks
7 | import transformer_tricks as tt
8 |
9 | tt.quiet_hf() # calm down HuggingFace
10 |
11 | # %%
12 | #-------------------------------------------------------------------------------
13 | # Example 1
14 | #-------------------------------------------------------------------------------
15 |
16 | # convert model and store the new model in ./SmolLM-135M_flashNorm_test
17 | tt.flashify_repo('HuggingFaceTB/SmolLM-135M')
18 |
19 | # run example inference of original and modified model
20 | tt.hello_world('HuggingFaceTB/SmolLM-135M')
21 | tt.hello_world('./SmolLM-135M_flashNorm_test')
22 |
23 | # measure perplexity of original and modified model
24 | tt.perplexity('HuggingFaceTB/SmolLM-135M', speedup=16)
25 | tt.perplexity('./SmolLM-135M_flashNorm_test', speedup=16)
26 |
27 | # %%
28 | #-------------------------------------------------------------------------------
29 | # Example 2
30 | #-------------------------------------------------------------------------------
31 |
32 | # convert model and store the new model in ./SmolLM-135M_flashNorm
33 | tt.flashify_repo('HuggingFaceTB/SmolLM-135M')
34 |
35 | # run example inference of original and modified model
36 | tt.hello_world('HuggingFaceTB/SmolLM-135M')
37 | tt.hello_world('./SmolLM-135M_flashNorm', arch='LlamaFlashNorm')
38 |
39 | # measure perplexity of original and modified model
40 | tt.perplexity('HuggingFaceTB/SmolLM-135M', speedup=16)
41 | tt.perplexity('./SmolLM-135M_flashNorm', speedup=16, arch='LlamaFlashNorm')
42 |
43 | # %% [markdown]
44 | # Whenever you change this file, make sure to regenerate the jupyter notebook by typing:
45 | # `util/gen_notebooks`
46 |
--------------------------------------------------------------------------------
/tex/README.md:
--------------------------------------------------------------------------------
1 | # Create your paper
2 |
3 | This folder contains the latex files for the Transformer Tricks papers. The flow is as follows:
4 | 1) Write first draft and drawings in Google docs.
5 | 2) Create file `foo.tex` and copy text from the Google doc.
6 | - Copy each drawing into a separate google drawing file and adjust the bounding box and "download" as PDF. This PDF is then used by latex.
7 | - For references, see the comments in file `references.bib`
8 | 3) Type `./run foo.tex` to create PDF.
9 | 4) Use spell checker as follows: `cd ..; util/spell_check`
10 | 5) Note: I converted some figures from PDF to SVG (so that I can use them in markdown) as follows `pdftocairo -svg foo.pdf foo.svg` TODO: maybe only use SVG drawings even for tex.
11 | 6) Submit to arXiv:
12 | - To submit `foo.tex`, type: `./submit foo.tex`
13 | - To double-check if everything works, run `pdflatex foo` two times (or sometimes three times) as follows:
14 | `cd foo_submit` and `pdflatex foo && pdflatex foo`
15 | - Then upload the generated `*.tar.gz` file to arXiv.
16 | - Notes for filling out the abstract field in the online form:
17 | - Make sure to remove citations or replace them by `arXiv:YYMM.NNNNN`
18 | - You can add hyperlinks to the abstract as follows: `See https://github.com/blabla for code`
19 | - You can force a new paragraph in the abstract by typing a carriage return followed by one white space in the new line (i.e. indent the new line after the carriage return)
20 | - Keep in mind: papers that are short (e.g. 6 pages or less) are automatically put on `hold` and need to be reviewed by a moderator, which can take several weeks.
21 |
22 | # Promote your paper
23 | - Post on social media: LinkedIn, twitter
24 | - Post on reddit and discord
25 | - Generate a podcast and YouTube video:
26 | - We use Notebook LM to generate audio podcasts. We then manually create videos with this audio, see [here](https://www.youtube.com/@OpenMachine)
27 | - Try generating videos and podcasts with the [arXiv paper reader](https://github.com/imelnyk/ArxivPapers), see videos [here](https://www.youtube.com/@ArxivPapers)
28 |
29 | # Submit to conference
30 | - We don't have any experience with this
31 | - It requires adding an introduction section and an extensive experiment section
32 |
--------------------------------------------------------------------------------
/doc/flashNorm.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Setup
4 | ```
5 | pip3 install transformer-tricks
6 | ```
7 |
8 | ## Example
9 | The example below converts SmolLM-135M to [FlashNorm](https://arxiv.org/pdf/2407.09577) and measures perplexity of the original and the modified model.
10 | ```python
11 | import transformer_tricks as tt
12 |
13 | # convert model and store the new model in ./SmolLM-135M_flashNorm_test
14 | tt.flashify_repo('HuggingFaceTB/SmolLM-135M')
15 |
16 | # run example inference of original and modified model
17 | tt.hello_world('HuggingFaceTB/SmolLM-135M')
18 | tt.hello_world('./SmolLM-135M_flashNorm_test')
19 |
20 | # measure perplexity of original and modified model
21 | tt.perplexity('HuggingFaceTB/SmolLM-135M', speedup=16)
22 | tt.perplexity('./SmolLM-135M_flashNorm_test', speedup=16)
23 | ```
24 | Results:
25 | ```
26 | Once upon a time there was a curious little girl
27 | Once upon a time there was a curious little girl
28 | perplexity = 16.083
29 | perplexity = 16.083
30 | ```
31 |
32 | You can run the example in your browser by clicking on this notebook: . Hit "cancel" when it says "Notebook does not have secret access", because we don't need an HF_TOKEN for SmolLM.
33 |
34 | TODO: [our HuggingFace repo](https://huggingface.co/open-machine/FlashNorm)
35 |
36 | ## Test FlashNorm
37 | ```shell
38 | # setup
39 | git clone https://github.com/OpenMachine-ai/transformer-tricks.git
40 | pip3 install --quiet -r requirements.txt
41 |
42 | # run tests
43 | python3 flashNorm_test.py
44 | ```
45 | Results:
46 | ```
47 | Once upon a time there was a curious little girl
48 | Once upon a time there was a curious little girl
49 | Once upon a time there was a little girl named
50 | Once upon a time there was a little girl named
51 | perplexity = 16.083
52 | perplexity = 16.083
53 | perplexity = 12.086
54 | perplexity = 12.086
55 | ```
56 | To run llama and other LLMs that need an agreement (not SmolLM), you first have to type the following, which will ask for your `hf_token`:
57 | ```
58 | huggingface-cli login
59 | ```
60 |
61 | ## Please give us a ⭐ if you like this repo, thanks!
62 |
--------------------------------------------------------------------------------
/notebooks/update_packages.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": []
7 | },
8 | "kernelspec": {
9 | "name": "python3",
10 | "display_name": "Python 3"
11 | },
12 | "language_info": {
13 | "name": "python"
14 | }
15 | },
16 | "cells": [
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {
21 | "id": "lOsSebCDGVTh"
22 | },
23 | "outputs": [],
24 | "source": [
25 | "# This colab helps you to fix python package issues:\n",
26 | "# - The huggingface (HF) packages are updated very often\n",
27 | "# - We want the transformer-tricks package to work with the (almost) latest\n",
28 | "# HF packages\n",
29 | "# - We only need 3 HF packages: transformers, accelerate, datasets\n",
30 | "# - These 3 HF packages will load many other HF packages (such as safetensors,\n",
31 | "# hub), numpy and torch\n",
32 | "\n",
33 | "# remove all pip packages, except for pip, dateutil, certifi, etc.\n",
34 | "!pip list --format=freeze | grep -v -E \"pip|dateutil|certifi|psutil|_distutils_hack|pkg_resources\" | xargs pip uninstall -y --quiet\n",
35 | "\n",
36 | "# above takes about 6 minutes !!!"
37 | ]
38 | },
39 | {
40 | "cell_type": "code",
41 | "source": [
42 | "# install latest versions of the 3 HF packages\n",
43 | "!pip install transformers --quiet\n",
44 | "!pip install accelerate --quiet\n",
45 | "!pip install datasets --quiet\n",
46 | "\n",
47 | "!pip list | grep -E \"transformers|accelerate|datasets\"\n",
48 | "!pip list | grep -E \"torch|numpy|safetensors|huggingface\"\n",
49 | "!python -V"
50 | ],
51 | "metadata": {
52 | "id": "kWz9vRphZL2A"
53 | },
54 | "execution_count": null,
55 | "outputs": []
56 | },
57 | {
58 | "cell_type": "code",
59 | "source": [
60 | "# download files transformer_tricks.py and flashNorm_test.py and test if it\n",
61 | "# works with the latest version of the HF packages\n",
62 | "!wget -q https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/transformer_tricks.py\n",
63 | "!wget -q https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/flashNorm_example.py\n",
64 | "!wget -q https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/flashNorm_modeling_llama.py\n",
65 | "\n",
66 | "!python flashNorm_example.py"
67 | ],
68 | "metadata": {
69 | "id": "FCh28_1fauTX"
70 | },
71 | "execution_count": null,
72 | "outputs": []
73 | }
74 | ]
75 | }
--------------------------------------------------------------------------------
/notebooks/flashNorm_example.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "id": "456ef5b0",
7 | "metadata": {},
8 | "outputs": [],
9 | "source": [
10 | "# This example converts SmolLM-135M to FlashNorm and measures its perplexity\n",
11 | "# before and after the conversion.\n",
12 | "# Usage: python3 flashNorm_example.py\n",
13 | "\n",
14 | "!wget -q https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/flashNorm_modeling_llama.py\n",
15 | "%pip install --quiet transformer_tricks\n",
16 | "import transformer_tricks as tt\n",
17 | "\n",
18 | "tt.quiet_hf() # calm down HuggingFace"
19 | ]
20 | },
21 | {
22 | "cell_type": "code",
23 | "execution_count": null,
24 | "id": "a8cd3fd7",
25 | "metadata": {},
26 | "outputs": [],
27 | "source": [
28 | "#-------------------------------------------------------------------------------\n",
29 | "# Example 1\n",
30 | "#-------------------------------------------------------------------------------\n",
31 | "\n",
32 | "# convert model and store the new model in ./SmolLM-135M_flashNorm_test\n",
33 | "tt.flashify_repo('HuggingFaceTB/SmolLM-135M')\n",
34 | "\n",
35 | "# run example inference of original and modified model\n",
36 | "tt.hello_world('HuggingFaceTB/SmolLM-135M')\n",
37 | "tt.hello_world('./SmolLM-135M_flashNorm_test')\n",
38 | "\n",
39 | "# measure perplexity of original and modified model\n",
40 | "tt.perplexity('HuggingFaceTB/SmolLM-135M', speedup=16)\n",
41 | "tt.perplexity('./SmolLM-135M_flashNorm_test', speedup=16)"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": null,
47 | "id": "31381dd7",
48 | "metadata": {},
49 | "outputs": [],
50 | "source": [
51 | "#-------------------------------------------------------------------------------\n",
52 | "# Example 2\n",
53 | "#-------------------------------------------------------------------------------\n",
54 | "\n",
55 | "# convert model and store the new model in ./SmolLM-135M_flashNorm\n",
56 | "tt.flashify_repo('HuggingFaceTB/SmolLM-135M')\n",
57 | "\n",
58 | "# run example inference of original and modified model\n",
59 | "tt.hello_world('HuggingFaceTB/SmolLM-135M')\n",
60 | "tt.hello_world('./SmolLM-135M_flashNorm', arch='LlamaFlashNorm')\n",
61 | "\n",
62 | "# measure perplexity of original and modified model\n",
63 | "tt.perplexity('HuggingFaceTB/SmolLM-135M', speedup=16)\n",
64 | "tt.perplexity('./SmolLM-135M_flashNorm', speedup=16, arch='LlamaFlashNorm')"
65 | ]
66 | },
67 | {
68 | "cell_type": "markdown",
69 | "id": "46c7d85f",
70 | "metadata": {},
71 | "source": [
72 | "Whenever you change this file, make sure to regenerate the jupyter notebook by typing:\n",
73 | " `util/gen_notebooks`"
74 | ]
75 | }
76 | ],
77 | "metadata": {
78 | "jupytext": {
79 | "cell_metadata_filter": "-all",
80 | "main_language": "python",
81 | "notebook_metadata_filter": "-all"
82 | }
83 | },
84 | "nbformat": 4,
85 | "nbformat_minor": 5
86 | }
87 |
--------------------------------------------------------------------------------
/flashNorm_test.py:
--------------------------------------------------------------------------------
1 | # flashify LLMs and run inference and perplexity to make sure that
2 | # the flashified models are equivalent to the original ones
3 | # Usage: python3 test_flashNorm.py
4 |
5 | import transformer_tricks as tt
6 |
7 | tt.quiet_hf() # calm down HuggingFace
8 |
9 | # convert models to flashNorm
10 | tt.flashify_repo('HuggingFaceTB/SmolLM-135M')
11 | tt.flashify_repo('HuggingFaceTB/SmolLM-360M')
12 | #tt.flashify_repo('HuggingFaceTB/SmolLM-1.7B', bars=True)
13 | #tt.flashify_repo('microsoft/Phi-3-mini-4k-instruct', bars=True)
14 |
15 | # run models
16 | tt.hello_world('HuggingFaceTB/SmolLM-135M')
17 | tt.hello_world( 'SmolLM-135M_flashNorm_test')
18 | tt.hello_world( 'SmolLM-135M_flashNorm', arch='LlamaFlashNorm')
19 | tt.hello_world('HuggingFaceTB/SmolLM-360M')
20 | tt.hello_world( 'SmolLM-360M_flashNorm_test')
21 | tt.hello_world( 'SmolLM-360M_flashNorm', arch='LlamaFlashNorm')
22 | #tt.hello_world('HuggingFaceTB/SmolLM-1.7B')
23 | #tt.hello_world( 'SmolLM-1.7B_flashNorm')
24 | #tt.hello_world('microsoft/Phi-3-mini-4k-instruct')
25 | #tt.hello_world( 'Phi-3-mini-4k-instruct_flashNorm')
26 |
27 | # measure perplexity
28 | tt.perplexity('HuggingFaceTB/SmolLM-135M', speedup=16)
29 | tt.perplexity( 'SmolLM-135M_flashNorm_test', speedup=16)
30 | tt.perplexity( 'SmolLM-135M_flashNorm', arch='LlamaFlashNorm', speedup=16)
31 | tt.perplexity('HuggingFaceTB/SmolLM-360M', speedup=16)
32 | tt.perplexity( 'SmolLM-360M_flashNorm_test', speedup=16)
33 | tt.perplexity( 'SmolLM-360M_flashNorm', arch='LlamaFlashNorm', speedup=16)
34 | #tt.perplexity('HuggingFaceTB/SmolLM-1.7B', speedup=64)
35 | #tt.perplexity( 'SmolLM-1.7B_flashNorm', speedup=64)
36 | #tt.perplexity('microsoft/Phi-3-mini-4k-instruct', speedup=64, bars=True)
37 | #tt.perplexity( 'Phi-3-mini-4k-instruct_flashNorm', speedup=64, bars=True)
38 |
39 | # TODO: add more LLMs
40 | #python3 gen.py stabilityai/stablelm-2-1_6b # doesn't use RMSNorm, but LayerNorm
41 | #python3 gen.py meta-llama/Meta-Llama-3.1-8B
42 | #python3 gen.py mistralai/Mistral-7B-v0.3
43 |
44 | # Notes for running larger models:
45 | # - To run llama and other semi-secret LLMs, you first have to type the following:
46 | # huggingface-cli login
47 | # above will ask you for the hf_token, which is the same you use e.g. in colab
48 | #
49 | # - On MacBook, open the 'Activity Monitor' and check your memory usage. If your
50 | # MacBook has only 8GB of DRAM, then you have only about 6GB available. Many LLMs
51 | # use float32, so a 1.5B model needs at least 6GB of DRAM.
52 | #
53 | # - Running gen.py is limited by DRAM bandwidth, not compute. Running ppl.py is
54 | # usually limited by compute (rather than by memory bandwidth), so only having
55 | # 8GB of DRAM is likely not an issue for running ppl.py on larger LLMs. That's
56 | # because ppl.py doesn't do the auto-regressive generation phase but only the
57 | # prompt phase (where all input tokens are batched).
58 | #
59 | # - The models get cached on your system at ~/.cache/huggingface, which can grow
60 | # very big, see du -h -d 3 ~/.cache/huggingface
61 |
--------------------------------------------------------------------------------
/notebooks/removeWeights_paper.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {
7 | "id": "P9KAn1NGtAX3"
8 | },
9 | "outputs": [],
10 | "source": [
11 | "import torch\n",
12 | "import numpy as np\n",
13 | "from huggingface_hub import hf_hub_download\n",
14 | "import gc # garbage collection needed for low RAM footprint\n",
15 | "\n",
16 | "# download Mistral-7B from https://huggingface.co/mistralai/Mistral-7B-v0.1\n",
17 | "hf_hub_download(repo_id='mistralai/Mistral-7B-v0.1', filename='pytorch_model-00001-of-00002.bin', local_dir='.')\n",
18 | "hf_hub_download(repo_id='mistralai/Mistral-7B-v0.1', filename='pytorch_model-00002-of-00002.bin', local_dir='.')\n",
19 | "\n",
20 | "# load model files, use mmap to keep RAM footprint low\n",
21 | "m1 = torch.load('pytorch_model-00001-of-00002.bin', weights_only=True, mmap=True)\n",
22 | "m2 = torch.load('pytorch_model-00002-of-00002.bin', weights_only=True, mmap=True)\n",
23 | "\n",
24 | "def get_weights(model, layer, name):\n",
25 | " \"\"\"returns weight matrix of specific layer and name (such as Q, K, V)\"\"\"\n",
26 | " layer_str = 'layers.' + str(layer)\n",
27 | " match name:\n",
28 | " case 'Q': suffix = layer_str + '.self_attn.q_proj.weight'\n",
29 | " case 'K': suffix = layer_str + '.self_attn.k_proj.weight'\n",
30 | " case 'V': suffix = layer_str + '.self_attn.v_proj.weight'\n",
31 | " case 'P': suffix = layer_str + '.self_attn.o_proj.weight'\n",
32 | " case 'O': suffix = layer_str + '.mlp.down_proj.weight'\n",
33 | " case 'E': suffix = 'embed_tokens.weight'\n",
34 | " W = model['model.' + suffix].to(torch.float64).numpy() # convert to float64\n",
35 | " return W if name == 'E' else W.T # transpose weights, except for 'E'\n",
36 | "\n",
37 | "for layer in range(0, 32):\n",
38 | " print('layer', layer)\n",
39 | "\n",
40 | " # get weights Q, K, V, P, O\n",
41 | " model = m1 if layer < 23 else m2 # use m1 for layers 0 to 22\n",
42 | " Q = get_weights(model, layer, 'Q')\n",
43 | " K = get_weights(model, layer, 'K')\n",
44 | " V = get_weights(model, layer, 'V')\n",
45 | " P = get_weights(model, layer, 'P')\n",
46 | " O = get_weights(model, layer - 1, 'E' if layer == 0 else 'O') # use embedding for 1st layer\n",
47 | "\n",
48 | " # check if weight elimination is numerically identical\n",
49 | " Q_inv = np.linalg.inv(Q) # errors out if matrix is not invertible\n",
50 | " K_star = Q_inv @ K\n",
51 | " V_star = Q_inv @ V\n",
52 | " O_star = O @ Q\n",
53 | " print(' is O* @ K* close to O @ K ? ', np.allclose(O_star @ K_star, O @ K))\n",
54 | " print(' is O* @ V* close to O @ V ? ', np.allclose(O_star @ V_star, O @ V))\n",
55 | "\n",
56 | " # also check if P is invertible\n",
57 | " P_inv = np.linalg.inv(P) # errors out if matrix is not invertible\n",
58 | "\n",
59 | "# garbage collection (to avoid colab's RAM limit)\n",
60 | "del m1, m2, model, Q, K, V, P, O, Q_inv, P_inv, K_star, V_star, O_star\n",
61 | "gc.collect()"
62 | ]
63 | }
64 | ],
65 | "metadata": {
66 | "colab": {
67 | "provenance": []
68 | },
69 | "kernelspec": {
70 | "display_name": "Python 3",
71 | "name": "python3"
72 | },
73 | "language_info": {
74 | "name": "python"
75 | }
76 | },
77 | "nbformat": 4,
78 | "nbformat_minor": 0
79 | }
--------------------------------------------------------------------------------
/slimAttn_paper.py:
--------------------------------------------------------------------------------
1 | # Proof of concept for paper "Slim Attention: cut your context memory in half"
2 | # Usage: python3 slimAttn_paper.py
3 |
4 | # %pip install --quiet transformer_tricks
5 | import transformer_tricks as tt
6 | import numpy as np
7 | import torch
8 | from transformers import AutoConfig
9 |
10 | #-------------------------------------------------------------------------------
11 | # defs
12 | #-------------------------------------------------------------------------------
13 | def softmax(x, axis=-1):
14 | """softmax along 'axis', default is the last axis"""
15 | e_x = np.exp(x - np.max(x, axis=axis, keepdims=True))
16 | return e_x / np.sum(e_x, axis=axis, keepdims=True)
17 |
18 | def msplit(M, h):
19 | """shortcut to split matrix M into h chunks"""
20 | return np.array_split(M, h, axis=-1)
21 |
22 | def ops(A, B):
23 | """number of OPs (operations) for matmul of A and B:
24 | - A and B must be 2D arrays, and their inner dimensions must agree!
25 | - A is an m × n matrix, and B is an n × p matrix, then the resulting product
26 | of A and B is an m × p matrix.
27 | - Each element (i,j) of the m x p result matrix is computed by the dotproduct
28 | of the i-th row of A and the j-th column of B.
29 | - Each dotproduct takes n multiplications and n - 1 additions, so total
30 | number of OPs is 2n - 1 per dotproduct.
31 | - There are m * p elements in the result matrix, so m * p dotproducts, so in
32 | total we need m * p * (2n - 1) OPs, which is approximately 2*m*p*n OPs
33 | - For simplicity, let's just use the simple approximation of OPs = 2*m*p*n"""
34 | m, n = A.shape
35 | p = B.shape[1]
36 | return 2 * m * n * p
37 |
38 | #-------------------------------------------------------------------------------
39 | # setup for model SmolLM2-1.7B
40 | #-------------------------------------------------------------------------------
41 | tt.quiet_hf() # calm down HuggingFace
42 |
43 | repo = 'HuggingFaceTB/SmolLM2-1.7B'
44 | param = tt.get_param(repo)
45 | config = AutoConfig.from_pretrained(repo)
46 |
47 | h = config.num_attention_heads
48 | d = config.hidden_size
49 | dk = config.head_dim
50 |
51 | # %%
52 | #-------------------------------------------------------------------------------
53 | # check if we can accurately compute V from K for each layer
54 | #-------------------------------------------------------------------------------
55 | for layer in range(config.num_hidden_layers):
56 | # convert to float64 for better accuracy of matrix inversion
57 | # note that all weights are transposed in tensorfile (per pytorch convention)
58 | Wk = param[tt.weight('K', layer)].to(torch.float64).numpy().T
59 | Wv = param[tt.weight('V', layer)].to(torch.float64).numpy().T
60 | Wkv = np.linalg.inv(Wk) @ Wv
61 | print(layer, ':', np.allclose(Wk @ Wkv, Wv)) # check if Wk @ Wkv close to Wv
62 |
63 | # %%
64 | #-------------------------------------------------------------------------------
65 | # compare options 1 and 2 for calculating equation (5) of paper
66 | #-------------------------------------------------------------------------------
67 |
68 | # get weights for Q, K, V and convert to float64
69 | # note that all weights are transposed in tensorfile (per pytorch convention)
70 | Wq = param[tt.weight('Q', 0)].to(torch.float64).numpy().T
71 | Wk = param[tt.weight('K', 0)].to(torch.float64).numpy().T
72 | Wv = param[tt.weight('V', 0)].to(torch.float64).numpy().T
73 | Wkv = np.linalg.inv(Wk) @ Wv # calculate Wkv (aka W_KV)
74 | # print('Is Wk @ Wkv close to Wv?', np.allclose(Wk @ Wkv, Wv))
75 |
76 | # generate random input X
77 | n = 100 # number of tokens
78 | X = np.random.rand(n, d).astype(np.float64) # range [0,1]
79 | Xn = np.expand_dims(X[n-1, :], axis=0) # n-th row of X; make it a 1 x d matrix
80 |
81 | Q = Xn @ Wq # only for the last row of X (for the generate-phase)
82 | K = X @ Wk
83 | V = X @ Wv
84 |
85 | # only consider the first head
86 | Q0, K0, V0 = msplit(Q, h)[0], msplit(K, h)[0], msplit(V, h)[0]
87 | Wkv0 = msplit(Wkv, h)[0]
88 |
89 | # baseline reference
90 | scores = softmax((Q0 @ K0.T) / np.sqrt(dk))
91 | head_ref = scores @ V0
92 |
93 | # head option1 and option2
94 | head_o1 = scores @ (K @ Wkv0) # option 1
95 | head_o2 = (scores @ K) @ Wkv0 # option 2
96 |
97 | # compare
98 | print('Is head_o1 close to head_ref?', np.allclose(head_o1, head_ref))
99 | print('Is head_o2 close to head_ref?', np.allclose(head_o2, head_ref))
100 |
101 | # computational complexity for both options
102 | o1_step1, o1_step2 = ops(K, Wkv0), ops(scores, (K @ Wkv0))
103 | o2_step1, o2_step2 = ops(scores, K), ops(scores @ K, Wkv0)
104 |
105 | print(f'Option 1 OPs: step 1 = {o1_step1:,}; step 2 = {o1_step2:,}; total = {(o1_step1 + o1_step2):,}')
106 | print(f'Option 2 OPs: step 1 = {o2_step1:,}; step 2 = {o2_step2:,}; total = {(o2_step1 + o2_step2):,}')
107 | print(f'speedup of option 2 over option 1: {((o1_step1 + o1_step2) / (o2_step1 + o2_step2)):.1f}')
108 |
109 | # %% [markdown]
110 | # Whenever you change this file, make sure to regenerate the jupyter notebook by typing:
111 | # `util/gen_notebooks`
112 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
7 |
8 | A collection of tricks to simplify and speed up transformer models:
9 | - Slim attention: [paper](https://arxiv.org/abs/2503.05840), [video](https://youtu.be/uVtk3B6YO4Y), [podcast](https://notebooklm.google.com/notebook/ac47a53c-866b-4271-ab79-bc48d1b41722/audio), [notebook](https://colab.research.google.com/github/OpenMachine-ai/transformer-tricks/blob/main/notebooks/slimAttn_paper.ipynb), [code-readme](doc/slimAttn.md), :hugs: [article](https://huggingface.co/blog/Kseniase/attentions), [reddit](https://www.reddit.com/r/LocalLLaMA/comments/1j9wkc2/slim_attention_cut_your_context_memory_in_half)
10 | - FlashNorm: [paper](https://arxiv.org/abs/2407.09577), [video](https://youtu.be/GEuJv34_XgU), [podcast](https://notebooklm.google.com/notebook/0877599c-720c-49b5-b451-8a41af592dd1/audio), [notebook](https://colab.research.google.com/github/OpenMachine-ai/transformer-tricks/blob/main/notebooks/flashNorm_paper.ipynb), [code-readme](doc/flashNorm.md)
11 | - Matrix-shrink \[work in progress\]: [paper](https://docs.google.com/viewer?url=https://raw.githubusercontent.com/OpenMachine-ai/transformer-tricks/refs/heads/main/doc/matShrink.pdf)
12 | - Precomputing the first layer: [paper](https://arxiv.org/abs/2402.13388), [video](https://youtu.be/pUeSwnCOoNI), [podcast](https://notebooklm.google.com/notebook/7794278e-de6a-40fc-ab1c-3240a40e55d5/audio)
13 | - KV-weights only for skipless transformers: [paper](https://arxiv.org/abs/2404.12362), [video](https://youtu.be/Tx_lMpphd2g), [podcast](https://notebooklm.google.com/notebook/0875eef7-094e-4c30-bc13-90a1a074c949/audio), [notebook](https://colab.research.google.com/github/OpenMachine-ai/transformer-tricks/blob/main/notebooks/removeWeights_paper.ipynb)
14 |
15 | These transformer tricks extend a recent trend in neural network design toward architectural parsimony, in which unnecessary components are removed to create more efficient models. Notable examples include [RMSNorm’s](https://arxiv.org/abs/1910.07467) simplification of LayerNorm by removing mean centering, [PaLM's](https://arxiv.org/abs/2204.02311) elimination of bias parameters, and [decoder-only transformer's](https://arxiv.org/abs/1801.10198) omission of the encoder stack. This trend began with the original [transformer model's](https://arxiv.org/abs/1706.03762) removal of recurrence and convolutions.
16 |
17 | For example, our [FlashNorm](https://arxiv.org/abs/2407.09577) removes the weights from RMSNorm and merges them with the next linear layer. And [slim attention](https://arxiv.org/abs/2503.05840) removes the entire V-cache from the context memory for MHA transformers.
18 |
19 | ---
20 |
21 | ## Explainer videos
22 |
23 | [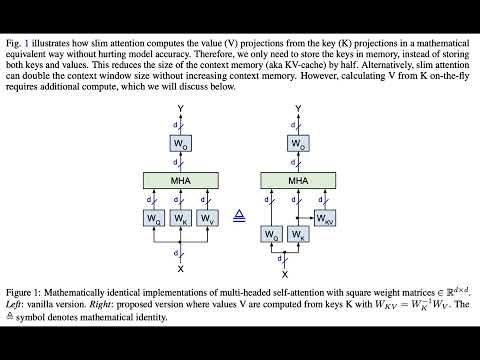](https://www.youtube.com/watch?v=uVtk3B6YO4Y "Slim attention")
24 | [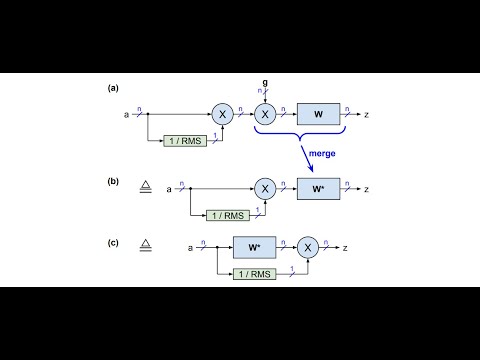](https://www.youtube.com/watch?v=GEuJv34_XgU "Flash normalization")
25 | [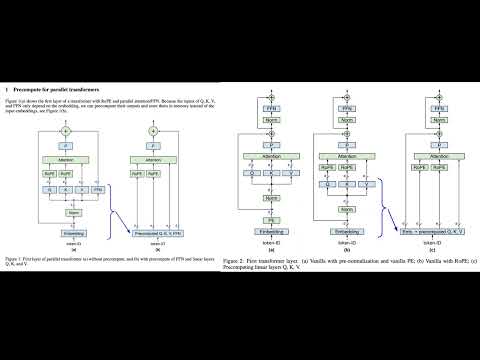](https://www.youtube.com/watch?v=pUeSwnCOoNI "Precomputing the first layer")
26 | [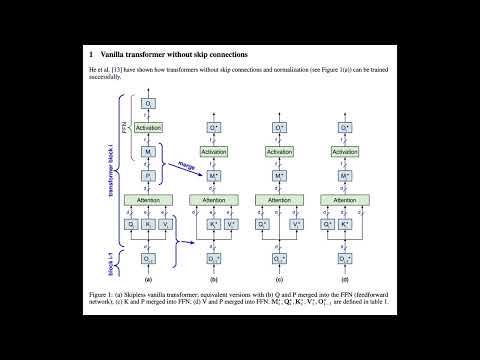](https://www.youtube.com/watch?v=Tx_lMpphd2g "Removing weights from skipless transformers")
27 |
28 | ---
29 |
30 | ## Installation
31 |
32 | Install the transformer tricks package:
33 | ```bash
34 | pip install transformer-tricks
35 | ```
36 |
37 | Alternatively, to run from latest repo:
38 | ```bash
39 | git clone https://github.com/OpenMachine-ai/transformer-tricks.git
40 | python3 -m venv .venv
41 | source .venv/bin/activate
42 | pip3 install --quiet -r requirements.txt
43 | ```
44 |
45 | ---
46 |
47 | ## Documentation
48 | Follow the links below for documentation of the python code in this directory:
49 | - [Slim attention](doc/slimAttn.md)
50 | - [Flash normalization](doc/flashNorm.md)
51 |
52 | ---
53 |
54 | ## Notebooks
55 | The papers are accompanied by the following Jupyter notebooks:
56 | - Slim attention:
57 | - Flash normalization:
58 | - Removing weights from skipless transformers:
59 |
60 | ---
61 | ## Newsletter
62 | Please subscribe to our [newsletter](https://transformertricks.substack.com) on substack to get the latest news about this project. We will never send you more than one email per month.
63 |
64 | [](https://transformertricks.substack.com)
65 |
66 | ---
67 |
68 | ## Contributing
69 | We pay cash for high-impact contributions. Please check out [CONTRIBUTING](doc/CONTRIBUTING.md) for how to get involved.
70 |
71 | ---
72 |
73 | ## Sponsors
74 | The Transformer Tricks project is currently sponsored by [OpenMachine](https://openmachine.ai). We'd love to hear from you if you'd like to join us in supporting this project.
75 |
76 | ---
77 |
78 | ### Please give us a ⭐ if you like this repo, and check out [TinyFive](https://github.com/OpenMachine-ai/tinyfive)
79 |
80 | ---
81 |
82 | [](https://www.star-history.com/#OpenMachine-ai/transformer-tricks&Date)
83 |
--------------------------------------------------------------------------------
/notebooks/slimAttn_paper.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "id": "9e3a70d2",
7 | "metadata": {},
8 | "outputs": [],
9 | "source": [
10 | "# Proof of concept for paper \"Slim Attention: cut your context memory in half\"\n",
11 | "# Usage: python3 slimAttn_paper.py\n",
12 | "\n",
13 | "%pip install --quiet transformer_tricks\n",
14 | "import transformer_tricks as tt\n",
15 | "import numpy as np\n",
16 | "import torch\n",
17 | "from transformers import AutoConfig\n",
18 | "\n",
19 | "#-------------------------------------------------------------------------------\n",
20 | "# defs\n",
21 | "#-------------------------------------------------------------------------------\n",
22 | "def softmax(x, axis=-1):\n",
23 | " \"\"\"softmax along 'axis', default is the last axis\"\"\"\n",
24 | " e_x = np.exp(x - np.max(x, axis=axis, keepdims=True))\n",
25 | " return e_x / np.sum(e_x, axis=axis, keepdims=True)\n",
26 | "\n",
27 | "def msplit(M, h):\n",
28 | " \"\"\"shortcut to split matrix M into h chunks\"\"\"\n",
29 | " return np.array_split(M, h, axis=-1)\n",
30 | "\n",
31 | "def ops(A, B):\n",
32 | " \"\"\"number of OPs (operations) for matmul of A and B:\n",
33 | " - A and B must be 2D arrays, and their inner dimensions must agree!\n",
34 | " - A is an m × n matrix, and B is an n × p matrix, then the resulting product\n",
35 | " of A and B is an m × p matrix.\n",
36 | " - Each element (i,j) of the m x p result matrix is computed by the dotproduct\n",
37 | " of the i-th row of A and the j-th column of B.\n",
38 | " - Each dotproduct takes n multiplications and n - 1 additions, so total\n",
39 | " number of OPs is 2n - 1 per dotproduct.\n",
40 | " - There are m * p elements in the result matrix, so m * p dotproducts, so in\n",
41 | " total we need m * p * (2n - 1) OPs, which is approximately 2*m*p*n OPs\n",
42 | " - For simplicity, let's just use the simple approximation of OPs = 2*m*p*n\"\"\"\n",
43 | " m, n = A.shape\n",
44 | " p = B.shape[1]\n",
45 | " return 2 * m * n * p\n",
46 | "\n",
47 | "#-------------------------------------------------------------------------------\n",
48 | "# setup for model SmolLM2-1.7B\n",
49 | "#-------------------------------------------------------------------------------\n",
50 | "tt.quiet_hf() # calm down HuggingFace\n",
51 | "\n",
52 | "repo = 'HuggingFaceTB/SmolLM2-1.7B'\n",
53 | "param = tt.get_param(repo)\n",
54 | "config = AutoConfig.from_pretrained(repo)\n",
55 | "\n",
56 | "h = config.num_attention_heads\n",
57 | "d = config.hidden_size\n",
58 | "dk = config.head_dim"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": null,
64 | "id": "6498fa85",
65 | "metadata": {},
66 | "outputs": [],
67 | "source": [
68 | "#-------------------------------------------------------------------------------\n",
69 | "# check if we can accurately compute V from K for each layer\n",
70 | "#-------------------------------------------------------------------------------\n",
71 | "for layer in range(config.num_hidden_layers):\n",
72 | " # convert to float64 for better accuracy of matrix inversion\n",
73 | " # note that all weights are transposed in tensorfile (per pytorch convention)\n",
74 | " Wk = param[tt.weight('K', layer)].to(torch.float64).numpy().T\n",
75 | " Wv = param[tt.weight('V', layer)].to(torch.float64).numpy().T\n",
76 | " Wkv = np.linalg.inv(Wk) @ Wv\n",
77 | " print(layer, ':', np.allclose(Wk @ Wkv, Wv)) # check if Wk @ Wkv close to Wv"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": null,
83 | "id": "a0f6735d",
84 | "metadata": {},
85 | "outputs": [],
86 | "source": [
87 | "#-------------------------------------------------------------------------------\n",
88 | "# compare options 1 and 2 for calculating equation (5) of paper\n",
89 | "#-------------------------------------------------------------------------------\n",
90 | "\n",
91 | "# get weights for Q, K, V and convert to float64\n",
92 | "# note that all weights are transposed in tensorfile (per pytorch convention)\n",
93 | "Wq = param[tt.weight('Q', 0)].to(torch.float64).numpy().T\n",
94 | "Wk = param[tt.weight('K', 0)].to(torch.float64).numpy().T\n",
95 | "Wv = param[tt.weight('V', 0)].to(torch.float64).numpy().T\n",
96 | "Wkv = np.linalg.inv(Wk) @ Wv # calculate Wkv (aka W_KV)\n",
97 | "# print('Is Wk @ Wkv close to Wv?', np.allclose(Wk @ Wkv, Wv))\n",
98 | "\n",
99 | "# generate random input X\n",
100 | "n = 100 # number of tokens\n",
101 | "X = np.random.rand(n, d).astype(np.float64) # range [0,1]\n",
102 | "Xn = np.expand_dims(X[n-1, :], axis=0) # n-th row of X; make it a 1 x d matrix\n",
103 | "\n",
104 | "Q = Xn @ Wq # only for the last row of X (for the generate-phase)\n",
105 | "K = X @ Wk\n",
106 | "V = X @ Wv\n",
107 | "\n",
108 | "# only consider the first head\n",
109 | "Q0, K0, V0 = msplit(Q, h)[0], msplit(K, h)[0], msplit(V, h)[0]\n",
110 | "Wkv0 = msplit(Wkv, h)[0]\n",
111 | "\n",
112 | "# baseline reference\n",
113 | "scores = softmax((Q0 @ K0.T) / np.sqrt(dk))\n",
114 | "head_ref = scores @ V0\n",
115 | "\n",
116 | "# head option1 and option2\n",
117 | "head_o1 = scores @ (K @ Wkv0) # option 1\n",
118 | "head_o2 = (scores @ K) @ Wkv0 # option 2\n",
119 | "\n",
120 | "# compare\n",
121 | "print('Is head_o1 close to head_ref?', np.allclose(head_o1, head_ref))\n",
122 | "print('Is head_o2 close to head_ref?', np.allclose(head_o2, head_ref))\n",
123 | "\n",
124 | "# computational complexity for both options\n",
125 | "o1_step1, o1_step2 = ops(K, Wkv0), ops(scores, (K @ Wkv0))\n",
126 | "o2_step1, o2_step2 = ops(scores, K), ops(scores @ K, Wkv0)\n",
127 | "\n",
128 | "print(f'Option 1 OPs: step 1 = {o1_step1:,}; step 2 = {o1_step2:,}; total = {(o1_step1 + o1_step2):,}')\n",
129 | "print(f'Option 2 OPs: step 1 = {o2_step1:,}; step 2 = {o2_step2:,}; total = {(o2_step1 + o2_step2):,}')\n",
130 | "print(f'speedup of option 2 over option 1: {((o1_step1 + o1_step2) / (o2_step1 + o2_step2)):.1f}')"
131 | ]
132 | },
133 | {
134 | "cell_type": "markdown",
135 | "id": "fe352e46",
136 | "metadata": {},
137 | "source": [
138 | "Whenever you change this file, make sure to regenerate the jupyter notebook by typing:\n",
139 | " `util/gen_notebooks`"
140 | ]
141 | }
142 | ],
143 | "metadata": {
144 | "jupytext": {
145 | "cell_metadata_filter": "-all",
146 | "main_language": "python",
147 | "notebook_metadata_filter": "-all"
148 | }
149 | },
150 | "nbformat": 4,
151 | "nbformat_minor": 5
152 | }
153 |
--------------------------------------------------------------------------------
/notebooks/flashNorm_paper.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {
7 | "id": "P9KAn1NGtAX3"
8 | },
9 | "outputs": [],
10 | "source": [
11 | "# code for paper 'Transformer tricks: flash normalization'\n",
12 | "\n",
13 | "import numpy as np\n",
14 | "\n",
15 | "# reciprocal of RMS and activation functions\n",
16 | "def r_rms(x): return 1 / np.sqrt(np.mean(x**2))\n",
17 | "def r_ms(x): return 1 / np.mean(x**2)\n",
18 | "def relu(x): return np.maximum(0, x)\n",
19 | "def sigmoid(x): return 1 / (1 + np.exp(-x))\n",
20 | "def silu(x): return x * sigmoid(x) # often known as swish\n",
21 | "\n",
22 | "# merge normalization weights g into weight matrix W\n",
23 | "def flashify(g, W):\n",
24 | " Wnew = np.empty(W.shape)\n",
25 | " for i in range(g.shape[0]):\n",
26 | " Wnew[i, :] = g[i] * W[i, :]\n",
27 | " return Wnew\n",
28 | "\n",
29 | "# alternative flashify (same as above but fewer lines)\n",
30 | "#def flashify_alt(g, W):\n",
31 | "# G = np.repeat(g, W.shape[1]).reshape(W.shape)\n",
32 | "# return G * W # elementwise multiply"
33 | ]
34 | },
35 | {
36 | "cell_type": "code",
37 | "source": [
38 | "# variables\n",
39 | "n = 32\n",
40 | "f = 128\n",
41 | "a = np.random.rand(n) # row-vector\n",
42 | "g = np.random.rand(n) # row-vector\n",
43 | "W = np.random.rand(n, n)\n",
44 | "UP = np.random.rand(n, f)\n",
45 | "GATE = np.random.rand(n, f)\n",
46 | "DOWN = np.random.rand(f, n)\n",
47 | "\n",
48 | "# derived variables\n",
49 | "s = r_rms(a) # scaling factor\n",
50 | "Wstar = flashify(g, W)\n",
51 | "UPstar = flashify(g, UP)\n",
52 | "GATEstar = flashify(g, GATE)"
53 | ],
54 | "metadata": {
55 | "id": "yLty-2szRrDM"
56 | },
57 | "execution_count": 2,
58 | "outputs": []
59 | },
60 | {
61 | "cell_type": "code",
62 | "source": [
63 | "# code for section 1 of paper\n",
64 | "\n",
65 | "# figures 1(a), 1(b), and 1(c) of paper\n",
66 | "z_fig1a = (r_rms(a) * a * g) @ W\n",
67 | "z_fig1b = (r_rms(a) * a) @ Wstar\n",
68 | "z_fig1c = (a @ Wstar) * r_rms(a)\n",
69 | "\n",
70 | "# compare against z_fig1a\n",
71 | "print(np.allclose(z_fig1b, z_fig1a), ' (fig1b is close to fig1a if True)')\n",
72 | "print(np.allclose(z_fig1c, z_fig1a), ' (fig1c is close to fig1a if True)')"
73 | ],
74 | "metadata": {
75 | "colab": {
76 | "base_uri": "https://localhost:8080/"
77 | },
78 | "id": "4YSv5p16ScE2",
79 | "outputId": "e9e6ec90-04e7-4d80-98dc-374e8202f60e"
80 | },
81 | "execution_count": 3,
82 | "outputs": [
83 | {
84 | "output_type": "stream",
85 | "name": "stdout",
86 | "text": [
87 | "True (fig1b is close to fig1a if True)\n",
88 | "True (fig1c is close to fig1a if True)\n"
89 | ]
90 | }
91 | ]
92 | },
93 | {
94 | "cell_type": "code",
95 | "source": [
96 | "# code for section 2.1 of paper\n",
97 | "\n",
98 | "# reference and figures 2(a) and 2(b) of paper\n",
99 | "y_ref2 = relu((s * a * g) @ UP) @ DOWN\n",
100 | "y_fig2a = relu((a @ UPstar) * s) @ DOWN\n",
101 | "y_fig2b = (relu(a @ UPstar) @ DOWN) * s\n",
102 | "\n",
103 | "# compare against y_ref\n",
104 | "print(np.allclose(y_fig2a, y_ref2), ' (fig2a is close to reference if True)')\n",
105 | "print(np.allclose(y_fig2b, y_ref2), ' (fig2b is close to reference if True)')"
106 | ],
107 | "metadata": {
108 | "colab": {
109 | "base_uri": "https://localhost:8080/"
110 | },
111 | "id": "HlUzIzR-VXlg",
112 | "outputId": "6f90bd82-b003-4431-e071-a251b4906d8a"
113 | },
114 | "execution_count": 4,
115 | "outputs": [
116 | {
117 | "output_type": "stream",
118 | "name": "stdout",
119 | "text": [
120 | "True (fig2a is close to reference if True)\n",
121 | "True (fig2b is close to reference if True)\n"
122 | ]
123 | }
124 | ]
125 | },
126 | {
127 | "cell_type": "code",
128 | "source": [
129 | "# code for section 2.2 of paper\n",
130 | "\n",
131 | "# shortcuts\n",
132 | "a_norm = s * a * g\n",
133 | "a_gate, a_up = (a @ GATEstar), (a @ UPstar)\n",
134 | "\n",
135 | "# figure 3: reference and figures 3(a) and 3(b) of paper\n",
136 | "y_ref3 = ((a_norm @ GATE) * silu(a_norm @ UP)) @ DOWN\n",
137 | "y_fig3a = (a_gate * s * silu(a_up * s)) @ DOWN\n",
138 | "y_fig3b = ((a_gate * silu(a_up * s)) @ DOWN) * s\n",
139 | "\n",
140 | "# compare against y_ref3\n",
141 | "print(np.allclose(y_fig3a, y_ref3), ' (fig3a is close to reference if True)')\n",
142 | "print(np.allclose(y_fig3b, y_ref3), ' (fig3b is close to reference if True)')\n",
143 | "\n",
144 | "# figure 4: reference and figures 4(a) and 4(b) of paper\n",
145 | "y_ref4 = ((a_norm @ GATE) * relu(a_norm @ UP)) @ DOWN\n",
146 | "y_fig4a = (a_gate * s * relu(a_up * s)) @ DOWN\n",
147 | "y_fig4b = ((a_gate * relu(a_up)) @ DOWN) * r_ms(a)\n",
148 | "\n",
149 | "# compare against y_ref4\n",
150 | "print(np.allclose(y_fig4a, y_ref4), ' (fig4a is close to reference if True)')\n",
151 | "print(np.allclose(y_fig4b, y_ref4), ' (fig4b is close to reference if True)')"
152 | ],
153 | "metadata": {
154 | "colab": {
155 | "base_uri": "https://localhost:8080/"
156 | },
157 | "id": "3sVxcH8Q0MHt",
158 | "outputId": "5a7a7d7c-f935-4e80-fc34-9b59662e39d7"
159 | },
160 | "execution_count": 5,
161 | "outputs": [
162 | {
163 | "output_type": "stream",
164 | "name": "stdout",
165 | "text": [
166 | "True (fig3a is close to reference if True)\n",
167 | "True (fig3b is close to reference if True)\n",
168 | "True (fig4a is close to reference if True)\n",
169 | "True (fig4b is close to reference if True)\n"
170 | ]
171 | }
172 | ]
173 | },
174 | {
175 | "cell_type": "code",
176 | "source": [
177 | "# code for section 3 of paper\n",
178 | "\n",
179 | "# TODO"
180 | ],
181 | "metadata": {
182 | "id": "xW9Sz-Dy5H0e"
183 | },
184 | "execution_count": null,
185 | "outputs": []
186 | }
187 | ],
188 | "metadata": {
189 | "colab": {
190 | "provenance": []
191 | },
192 | "kernelspec": {
193 | "display_name": "Python 3",
194 | "name": "python3"
195 | },
196 | "language_info": {
197 | "name": "python"
198 | }
199 | },
200 | "nbformat": 4,
201 | "nbformat_minor": 0
202 | }
--------------------------------------------------------------------------------
/tex/arxiv.sty:
--------------------------------------------------------------------------------
1 | % This file is copied from
2 | % https://github.com/kourgeorge/arxiv-style/blob/master/arxiv.sty
3 | % my changes are marked by "OM-mods"
4 |
5 | \NeedsTeXFormat{LaTeX2e}
6 |
7 | \ProcessOptions\relax
8 |
9 | % fonts
10 | \renewcommand{\rmdefault}{ptm}
11 | \renewcommand{\sfdefault}{phv}
12 |
13 | % set page geometry
14 | \usepackage[verbose=true,letterpaper]{geometry}
15 | \AtBeginDocument{
16 | \newgeometry{
17 | textheight=9in,
18 | textwidth=6.5in,
19 | top=1in,
20 | % OM-mods: headheight=14pt,
21 | % OM-mods: headsep=25pt,
22 | footskip=30pt
23 | }
24 | }
25 |
26 | \widowpenalty=10000
27 | \clubpenalty=10000
28 | \flushbottom
29 | \sloppy
30 |
31 | % OM-mods: \newcommand{\headeright}{A Preprint}
32 | % OM-mods: \newcommand{\undertitle}{A Preprint}
33 | % OM-mods: \newcommand{\shorttitle}{\@title}
34 |
35 | \usepackage{fancyhdr}
36 | \usepackage{lastpage}
37 | \fancyhf{}
38 | \pagestyle{fancy}
39 | % OM-mods: \renewcommand{\headrulewidth}{0.4pt}
40 | % OM-mods: below line removes the header
41 | \renewcommand{\headrulewidth}{0pt}
42 | % OM-mods: \fancyheadoffset{0pt}
43 | % OM-mods: \rhead{\scshape \footnotesize \headeright}
44 | % OM-mods: \chead{\shorttitle}
45 | \cfoot{{\thepage} of \pageref*{LastPage}}
46 |
47 | % OM-mods: %Handling Keywords
48 | % OM-mods: \def\keywordname{{\bfseries \emph{Keywords}}}%
49 | % OM-mods: \def\keywords#1{\par\addvspace\medskipamount{\rightskip=0pt plus1cm
50 | % OM-mods: \def\and{\ifhmode\unskip\nobreak\fi\ $\cdot$
51 | % OM-mods: }\noindent\keywordname\enspace\ignorespaces#1\par}}
52 |
53 | % font sizes with reduced leading
54 | \renewcommand{\normalsize}{%
55 | \@setfontsize\normalsize\@xpt\@xipt
56 | \abovedisplayskip 7\p@ \@plus 2\p@ \@minus 5\p@
57 | \abovedisplayshortskip \z@ \@plus 3\p@
58 | \belowdisplayskip \abovedisplayskip
59 | \belowdisplayshortskip 4\p@ \@plus 3\p@ \@minus 3\p@
60 | }
61 | \normalsize
62 | \renewcommand{\small}{%
63 | \@setfontsize\small\@ixpt\@xpt
64 | \abovedisplayskip 6\p@ \@plus 1.5\p@ \@minus 4\p@
65 | \abovedisplayshortskip \z@ \@plus 2\p@
66 | \belowdisplayskip \abovedisplayskip
67 | \belowdisplayshortskip 3\p@ \@plus 2\p@ \@minus 2\p@
68 | }
69 | \renewcommand{\footnotesize}{\@setfontsize\footnotesize\@ixpt\@xpt}
70 | \renewcommand{\scriptsize}{\@setfontsize\scriptsize\@viipt\@viiipt}
71 | \renewcommand{\tiny}{\@setfontsize\tiny\@vipt\@viipt}
72 | \renewcommand{\large}{\@setfontsize\large\@xiipt{14}}
73 | \renewcommand{\Large}{\@setfontsize\Large\@xivpt{16}}
74 | \renewcommand{\LARGE}{\@setfontsize\LARGE\@xviipt{20}}
75 | \renewcommand{\huge}{\@setfontsize\huge\@xxpt{23}}
76 | \renewcommand{\Huge}{\@setfontsize\Huge\@xxvpt{28}}
77 |
78 | % sections with less space
79 | \providecommand{\section}{}
80 | \renewcommand{\section}{%
81 | \@startsection{section}{1}{\z@}%
82 | {-2.0ex \@plus -0.5ex \@minus -0.2ex}%
83 | { 1.5ex \@plus 0.3ex \@minus 0.2ex}%
84 | {\large\bf\raggedright}%
85 | }
86 | \providecommand{\subsection}{}
87 | \renewcommand{\subsection}{%
88 | \@startsection{subsection}{2}{\z@}%
89 | {-1.8ex \@plus -0.5ex \@minus -0.2ex}%
90 | { 0.8ex \@plus 0.2ex}%
91 | {\normalsize\bf\raggedright}%
92 | }
93 | \providecommand{\subsubsection}{}
94 | \renewcommand{\subsubsection}{%
95 | \@startsection{subsubsection}{3}{\z@}%
96 | {-1.5ex \@plus -0.5ex \@minus -0.2ex}%
97 | { 0.5ex \@plus 0.2ex}%
98 | {\normalsize\bf\raggedright}%
99 | }
100 | \providecommand{\paragraph}{}
101 | \renewcommand{\paragraph}{%
102 | \@startsection{paragraph}{4}{\z@}%
103 | {1.5ex \@plus 0.5ex \@minus 0.2ex}%
104 | {-1em}%
105 | {\normalsize\bf}%
106 | }
107 | \providecommand{\subparagraph}{}
108 | \renewcommand{\subparagraph}{%
109 | \@startsection{subparagraph}{5}{\z@}%
110 | {1.5ex \@plus 0.5ex \@minus 0.2ex}%
111 | {-1em}%
112 | {\normalsize\bf}%
113 | }
114 | \providecommand{\subsubsubsection}{}
115 | \renewcommand{\subsubsubsection}{%
116 | \vskip5pt{\noindent\normalsize\rm\raggedright}%
117 | }
118 |
119 | % float placement
120 | \renewcommand{\topfraction }{0.85}
121 | \renewcommand{\bottomfraction }{0.4}
122 | \renewcommand{\textfraction }{0.1}
123 | \renewcommand{\floatpagefraction}{0.7}
124 |
125 | \newlength{\@abovecaptionskip}\setlength{\@abovecaptionskip}{7\p@}
126 | \newlength{\@belowcaptionskip}\setlength{\@belowcaptionskip}{\z@}
127 |
128 | \setlength{\abovecaptionskip}{\@abovecaptionskip}
129 | \setlength{\belowcaptionskip}{\@belowcaptionskip}
130 |
131 | % swap above/belowcaptionskip lengths for tables
132 | \renewenvironment{table}
133 | {\setlength{\abovecaptionskip}{\@belowcaptionskip}%
134 | \setlength{\belowcaptionskip}{\@abovecaptionskip}%
135 | \@float{table}}
136 | {\end@float}
137 |
138 | % footnote formatting
139 | \setlength{\footnotesep }{6.65\p@}
140 | \setlength{\skip\footins}{9\p@ \@plus 4\p@ \@minus 2\p@}
141 | \renewcommand{\footnoterule}{\kern-3\p@ \hrule width 12pc \kern 2.6\p@}
142 | \setcounter{footnote}{0}
143 |
144 | % paragraph formatting
145 | \setlength{\parindent}{\z@}
146 | \setlength{\parskip }{5.5\p@}
147 |
148 | % list formatting
149 | % OM-mods: commented out below stuff
150 | %\setlength{\topsep }{4\p@ \@plus 1\p@ \@minus 2\p@}
151 | %\setlength{\partopsep }{1\p@ \@plus 0.5\p@ \@minus 0.5\p@}
152 | %\setlength{\itemsep }{2\p@ \@plus 1\p@ \@minus 0.5\p@}
153 | %\setlength{\parsep }{2\p@ \@plus 1\p@ \@minus 0.5\p@}
154 | %\setlength{\topsep }{-1pt}
155 | %\setlength{\partopsep }{-1pt}
156 | %\setlength{\parsep }{-1pt}
157 | %\setlength{\itemsep }{-1pt}
158 | \setlength{\leftmargin }{3pc}
159 | \setlength{\leftmargini }{\leftmargin}
160 | \setlength{\leftmarginii }{2em}
161 | \setlength{\leftmarginiii}{1.5em}
162 | \setlength{\leftmarginiv }{1.0em}
163 | \setlength{\leftmarginv }{0.5em}
164 | % OM-mods: commented out below stuff
165 | %\def\@listi {\leftmargin\leftmargini}
166 | %\def\@listii {\leftmargin\leftmarginii
167 | % \labelwidth\leftmarginii
168 | % \advance\labelwidth-\labelsep}
169 | %\topsep 2\p@ \@plus 1\p@ \@minus 0.5\p@
170 | %\parsep 1\p@ \@plus 0.5\p@ \@minus 0.5\p@
171 | %\itemsep \parsep}
172 | %\def\@listiii{\leftmargin\leftmarginiii
173 | % \labelwidth\leftmarginiii
174 | % \advance\labelwidth-\labelsep}
175 | %\topsep 1\p@ \@plus 0.5\p@ \@minus 0.5\p@
176 | %\parsep \z@
177 | %\partopsep 0.5\p@ \@plus 0\p@ \@minus 0.5\p@
178 | %\itemsep \topsep}
179 | %\def\@listiv {\leftmargin\leftmarginiv
180 | % \labelwidth\leftmarginiv
181 | % \advance\labelwidth-\labelsep}
182 | %\def\@listv {\leftmargin\leftmarginv
183 | % \labelwidth\leftmarginv
184 | % \advance\labelwidth-\labelsep}
185 | %\def\@listvi {\leftmargin\leftmarginvi
186 | % \labelwidth\leftmarginvi
187 | % \advance\labelwidth-\labelsep}
188 |
189 | % create title
190 | \providecommand{\maketitle}{}
191 | \renewcommand{\maketitle}{%
192 | \par
193 | \begingroup
194 | \renewcommand{\thefootnote}{\fnsymbol{footnote}}
195 | % for perfect author name centering
196 | %\renewcommand{\@makefnmark}{\hbox to \z@{$^{\@thefnmark}$\hss}}
197 | % The footnote-mark was overlapping the footnote-text,
198 | % added the following to fix this problem (MK)
199 | \long\def\@makefntext##1{%
200 | \parindent 1em\noindent
201 | \hbox to 1.8em{\hss $\m@th ^{\@thefnmark}$}##1
202 | }
203 | \thispagestyle{empty}
204 | \@maketitle
205 | \@thanks
206 | %\@notice
207 | \endgroup
208 | \let\maketitle\relax
209 | \let\thanks\relax
210 | }
211 |
212 | % rules for title box at top of first page
213 | \newcommand{\@toptitlebar}{
214 | \hrule height 2\p@
215 | \vskip 0.25in
216 | \vskip -\parskip%
217 | }
218 | \newcommand{\@bottomtitlebar}{
219 | \vskip 0.29in
220 | \vskip -\parskip
221 | \hrule height 2\p@
222 | \vskip 0.09in%
223 | }
224 |
225 | % create title (includes both anonymized and non-anonymized versions)
226 | \providecommand{\@maketitle}{}
227 | \renewcommand{\@maketitle}{%
228 | \vbox{%
229 | \hsize\textwidth
230 | \linewidth\hsize
231 | \vskip 0.1in
232 | \@toptitlebar
233 | \centering
234 | % OM-mods: {\LARGE\sc \@title\par}
235 | {\LARGE\bf \@title\par}
236 | \@bottomtitlebar
237 | % OM-mods: \textsc{\undertitle}\\
238 | % \vskip 0.1in
239 | \vskip -0.15in
240 | \def\And{%
241 | \end{tabular}\hfil\linebreak[0]\hfil%
242 | \begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}\ignorespaces%
243 | }
244 | \def\AND{%
245 | \end{tabular}\hfil\linebreak[4]\hfil%
246 | \begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}\ignorespaces%
247 | }
248 | \begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}\@author\end{tabular}%
249 | % OM-mods: \vskip 0.4in \@minus 0.1in \center{\@date} \vskip 0.2in
250 | % \vskip 0.4in
251 | \vskip 0.2in
252 | }
253 | }
254 |
255 | % add conference notice to bottom of first page
256 | \newcommand{\ftype@noticebox}{8}
257 | \newcommand{\@notice}{%
258 | % give a bit of extra room back to authors on first page
259 | \enlargethispage{2\baselineskip}%
260 | \@float{noticebox}[b]%
261 | \footnotesize\@noticestring%
262 | \end@float%
263 | }
264 |
265 | % abstract styling
266 | \renewenvironment{abstract}
267 | {
268 | \centerline
269 | % OM-mods: {\large \bfseries \scshape Abstract}
270 | {\large \bfseries \upshape Abstract}
271 | \begin{quote}
272 | }
273 | {
274 | \end{quote}
275 | }
276 |
277 | % OM-mods: moved below lines from *.tex file here
278 | \usepackage[utf8]{inputenc}
279 | \usepackage[T1]{fontenc} % use 8-bit T1 fonts
280 | % \usepackage{hyperref}
281 | \usepackage[hidelinks,colorlinks=true,linkcolor=blue,citecolor=blue,urlcolor=blue]{hyperref}
282 | \usepackage{url}
283 | \usepackage{booktabs} % professional-quality tables
284 | \usepackage{amsfonts} % blackboard math symbols
285 | \usepackage{amsmath}
286 | \usepackage{amssymb}
287 | \usepackage{nicefrac} % compact symbols for 1/2, etc.
288 | \usepackage{microtype} % microtypography
289 | \usepackage{cleveref} % smart cross-referencing
290 | \usepackage{graphicx}
291 | \usepackage{doi}
292 | \usepackage{enumitem}
293 | \usepackage{makecell}
294 | \usepackage{multirow}
295 |
296 | % set bold font for tabular heads
297 | \renewcommand\theadfont{\bfseries}
298 |
299 | \endinput
300 |
--------------------------------------------------------------------------------
/tex/precomp1stLayer.tex:
--------------------------------------------------------------------------------
1 | % To generate PDF, type ./run precomp1stLayer.tex
2 |
3 | \documentclass{article}
4 | \usepackage{arxiv}
5 | \usepackage[numbers]{natbib}
6 |
7 | \title{Transformer tricks: Precomputing the first layer}
8 |
9 | \author{Nils Graef\thanks{\texttt{info@openmachine.ai}} \\
10 | \href{https://openmachine.ai}{OpenMachine}}
11 |
12 | \begin{document} \maketitle
13 |
14 | \begin{abstract}
15 | This micro-paper \cite{micro-paper} describes a trick to speed up inference of transformers with RoPE \citep{RoPE} (such as LLaMA, Mistral, PaLM, and Gemma \citep{gemma}). For these models, a large portion of the first transformer layer can be precomputed, which results in slightly lower latency and lower cost-per-token.
16 | Because this trick optimizes only one layer, the relative savings depend on the total number of layers. For example, the maximum savings for a model with only 4 layers (such as Whisper tiny \citep{Whisper}) is limited to 25\%, while a 32-layer model is limited to 3\% savings. See \citep{tricks, slimAttn, flashNorm, remove, matShrink} for code and more transformer tricks. \\
17 | The next two sections detail the precompute for transformers with parallel attention/FFN \citep{parallel} (such as GPT-J, Pythia, and PaLM \citep{parallel, Pythia, PaLM}) and without (such as Llama 2, Mistral, and Mixtral \citep{LLaMA, Llama2, Mistral, Mixtral}).
18 | \end{abstract}
19 |
20 | \section{Precompute for parallel transformers}
21 |
22 | \begin{figure}[h!] \centering % the [h!] tries to place the picture right here
23 | \includegraphics[scale=0.86]{../doc/fig/precomp1stLayer_fig1.pdf}
24 | \caption{First layer of parallel transformer (a) without precompute; and (b) with precompute of FFN and linear layers Q, K, and V.}
25 | \label{fig1} \end{figure}
26 |
27 | Figure \ref{fig1}(a) shows the first layer of a transformer with RoPE and parallel attention/FFN. Because the inputs of Q, K, V, and FFN only depend on the embedding, we can precompute their outputs and store them in memory instead of the input embeddings, see Figure \ref{fig1}(b). Figure \ref{fig1} uses the following dimensions, based on the type of attention such as multi-head attention (MHA) \citep{vanilla}, multi-query attention (MQA) \citep{MQA}, and grouped-query attention (GQA) \citep{GQA}:
28 |
29 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
30 | \item $d$: embedding dimension.
31 | \item $e$: $e = d$ for MHA. For MQA, $e = d / n_{heads}$. And for GQA, $e = d \cdot n_{kv\_heads} / n_{heads}$.
32 | \item Q, K, V, P are the linear layers for query, keys, values, and post-attention projection.
33 | \item FFN (feedforward network) is usually a two-layer MLP (multi-layer perceptron). Mistral and Llama2 use a two-layer MLP with a GLU variant \citep{GLU} for the first layer. And MoE models (mixture-of-experts) \citep{MoE} such as Mixtral use a switch FFN.
34 | \item The embedding layer is implemented by a simple memory read operation, where the token-ID provides the read-address to read $d$ values from memory.
35 | \end{itemize}
36 |
37 | The precompute is done as follows: For each token stored in the embedding table, perform the calculations needed for the first layer normalization, FFN, skip-connection, and linear layers Q, K, V, and store the results in memory instead of the original input-embeddings. This precompute is done offline only once and stored in the parameter memory (along with weights, biases, and output-embeddings).
38 |
39 | The benefits of precompute include:
40 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
41 | \item \textbf{Lower computational complexity per token}: For each token, we save the operations needed for FFN and the linear layers Q, K, V. This can speed up inference if the system is limited by compute.
42 | \item \textbf{Fewer memory reads for low batch sizes}: This can speed up inference for systems that are memory bandwidth limited, especially during the autoregressive next-token-prediction phase, see the table below and section \ref{sec:examples} for examples.
43 | \end{itemize}
44 |
45 | \begingroup \renewcommand{\arraystretch}{1.3} % increase table row height by 1.3x
46 | \begin{center} \begin{tabular}{rll} \hline
47 | & \textbf{Without precompute} & \textbf{With precompute} \\ \hline
48 | & \makecell[l]{1) For each token, read $d$ embedding values \\
49 | 2) Plus, for each batch, read weights for Q, K, V, FFN}
50 | & \makecell[l]{For each token, read $2(d+e)$ \\ precomputed values} \\ \hline
51 | \makecell[l]{Reads per batch: \\ ($B$ is batch-size)} & $B \cdot d + \verb+num_weights_Q_K_V_FFN+$ & $B \cdot 2(d+e)$ \\ \hline
52 | \end{tabular} \end{center} \endgroup
53 | % TODO: https://stackoverflow.com/questions/56197968/how-can-i-make-a-list-with-itemize-in-a-cell-of-table
54 |
55 | Notes on batch size:
56 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
57 | \item During the prefill phase, many implementations use a batch size larger than 1, because the input tokens can be processed in parallel.
58 | \item During the autoregressive next-token-generation phase, single-user implementations often use a batch size of \verb+num_beams+ (i.e. the width of the beam search, such as \verb+num_beams+ = 4), while multi-user implementations use larger batch sizes. However, the maximum batch size for multi-user applications can be limited by the total memory capacity as the number of KV-caches increases linearly with the batch size.
59 | \end{itemize}
60 |
61 | However, precomputing the first layer can increase (or decrease) the total memory size, which depends on the vocabulary size and the number of eliminated weights as shown in the table below. For example, the total memory size of Mistral-7B only increases by 2\%, see section \ref{sec:examples} for more details.
62 |
63 | \begingroup \renewcommand{\arraystretch}{1.3} % increase table row height by 1.3x
64 | \begin{center} \begin{tabular}{ll} \hline
65 | \textbf{Without precompute} & \textbf{With precompute} \\ \hline
66 | 1) Store embeddings: $d \cdot \verb+vocab_size+$ & Store precomputed values: $2(d+e) \cdot \verb+vocab_size+$ \\
67 | 2) Store weights for Q, K, V, and FFN & \\ \hline
68 | \end{tabular} \end{center} \endgroup
69 |
70 | \section{Precompute for serial transformers}
71 | Transformers without the parallel attention/FFN scheme can also benefit from precompute, but the savings are smaller: As shown in Figure \ref{fig2}(c), we can only precompute Q, K, and V, but not the FFN. For reference, Figure \ref{fig2}(a) shows the vanilla transformer with absolute positional encoding (PE) instead of RoPE and with pre-normalization \citep{pre-norm}. The PE is located right after the embedding layer, which prevents us from precomputing the first layer. But replacing the PE by RoPE, as done in Figure \ref{fig2}(b), allows us to precompute the linear layers Q, K, and V and store the precomputed values along the embeddings in memory as illustrated in Figure \ref{fig2}(c).
72 |
73 | \begin{figure} \centering
74 | \includegraphics[scale=0.86]{../doc/fig/precomp1stLayer_fig2.pdf}
75 | \caption{First transformer layer. (a) Vanilla with pre-normalization and vanilla PE; (b) Vanilla with RoPE; (c) Precomputing linear layers Q, K, V.}
76 | \label{fig2} \end{figure}
77 |
78 | \section{Examples} \label{sec:examples}
79 |
80 | \begingroup
81 | \renewcommand{\arraystretch}{1.3} % increase table row height by 1.3x
82 | \begin{center} \begin{tabular}{|l|c|c|c|l|} \hline
83 | \textbf{Parameter} & \textbf{Pythia-6.9B} & \textbf{Mistral-7B} & \textbf{Mixtral-8x7B} & \textbf{Notes} \\ \hline
84 | Parallel attention/FFN? & parallel & \multicolumn{2}{c|}{serial} & \citep{parallel} \\ \hline
85 | MHA, MQA, or GQA? & MHA & \multicolumn{2}{c|}{GQA} & \citep{vanilla, MQA, GQA} \\ \hline
86 | % Positional encoding & \multicolumn{3}{c|}{RoPE} & \citep{RoPE} \\ \hline % this line didn't fit on the page
87 | \verb+dim+ (aka $d$) & \multicolumn{3}{c|}{4,096} & embedding dimension \\ \hline
88 | \verb+n_layers+ & \multicolumn{3}{c|}{32} & number of layers \\ \hline
89 | \verb+n_heads+, \verb+n_kv_heads+ & 32, 32 & \multicolumn{2}{c|}{32, 8} & number of heads, KV-heads \\ \hline
90 | \verb+e+ (output dim. of K, V) & 4,096 & \multicolumn{2}{c|}{1,024} & \verb+e = d * n_kv_heads / n_heads+ \\ \hline
91 | FFN type & 2-layer MLP & SwiGLU *) & SwiGLU MoE & *) MLP with SwiGLU (GLU variant) \citep{GLU, MoE} \\ \hline
92 | FFN \verb+hidden_dim+ & 16,384 & \multicolumn{2}{c|}{14,336} & FFN hidden dimension \\ \hline
93 | FFN \verb+n_experts+ & \multicolumn{2}{c|}{1} & 8 & FFN number of experts \\ \hline
94 | \verb+vocab_size+ & 50,400 & \multicolumn{2}{c|}{32,000} & vocabulary size \\ \hline
95 |
96 | \multicolumn{5}{|l|}{\textbf{Number of weights (calculated from above parameters):}} \\ \hline
97 | Q+P weights per layer & \multicolumn{3}{c|}{33,554,432} & \verb+2 * dim * dim+ \\ \hline
98 | K+V weights per layer & 33,554,432 & \multicolumn{2}{c|}{8,388,608} & \verb+2 * dim * dim / n_heads * n_kv_heads+ \\ \hline
99 | FFN weights per layer & 134,217,728 & 176,160,768 & 1,409,286,144 & \verb+(2 or 3) * dim * hidden_dim * n_exp.+ \\ \hline
100 | Input+output embed. & 412,876,800 & \multicolumn{2}{c|}{262,144,000} & \verb+2 * dim * vocab_size+ \\ \hline
101 | \multicolumn{1}{|r|}{\textbf{Total weights:}} & 6.9B & 7.2B & 46.7B & \\ \hline
102 | \end{tabular} \end{center}
103 | \endgroup
104 |
105 | The table above compares the configurations and number of weights of Pythia-6.9B, Mistral-7B, and Mixtral-8x7B. The next table shows the memory read savings and memory size increases for Pythia-6.9B, Mistral-7B, and a hypothetical Mixtral-8x7B with parallel attention/FFN layers.
106 |
107 | \begingroup
108 | \renewcommand{\arraystretch}{1.4} % increase table row height by 1.4x
109 | \begin{center} \begin{tabular}{|l|c|c|>{\centering\arraybackslash}m{7.8em}|} \hline
110 | & \textbf{Pythia-6.9B} & \textbf{Mistral-7B} & \textbf{Hypothetical Mixtral-8x7B with parallel attn./FFN} \\ \hline
111 | Number of weights that can be eliminated & 184,549,376 & 25,165,824 & 1,434,451,968 \\ \hline
112 | Number of reads w/o precompute for batch 1 & 184,553,472 & 25,169,920 & 1,434,456,064 \\ \hline
113 | Number of reads with precompute for batch 1 & 16,384 & 10,240 & 10,240 \\ \hline
114 | \multicolumn{1}{|r|}{\textbf{First layer reduction factor for batch size 1:}} & \textbf{11,264x} & \textbf{2,458x} & \textbf{140,084x} \\ \hline
115 | \multicolumn{1}{|r|}{\textbf{First layer reduction factor for batch size 16:}} & 704x & 154x & 8,756x \\ \hline
116 | \multicolumn{1}{|r|}{\textbf{First layer reduction factor for batch size 256:}} & 44x & 10x & 548x \\ \hline
117 | \multicolumn{1}{|r|}{\textbf{First layer reduction factor for batch size 1,024:}} & 11x & 3x & 137x \\ \hline
118 |
119 | \multicolumn{4}{|l|}{\textbf{Increase (or decrease) of total weight memory size:}} \\ \hline
120 | Increase embedding memory by $(2e + d) \cdot \verb+vocab_size+$ & 619,315,200 & \multicolumn{2}{c|}{196,608,000} \\ \hline
121 | Memory decrease due to elimination of weights & –184,549,376 & –25,165,824 & -1,434,451,968 \\ \hline
122 | \multicolumn{1}{|r|}{\textbf{Total absolute memory increase (or decrease):}} & 434,765,824 & 171,442,176 & \textbf{-1,237,843,968} \\ \hline
123 | \multicolumn{1}{|r|}{\textbf{Total relative memory increase (or decrease):}} & 6\% & \textbf{2\%} & \textbf{–3\%} \\ \hline
124 | \end{tabular} \end{center}
125 | \endgroup
126 |
127 | \section*{Acknowledgments}
128 | We would like to thank \href{https://scholar.google.com/citations?user=LlK_saMAAAAJ&hl=en}{James Martens (DeepMind)} for his generous support and endorsement for the arXiv submission process.
129 |
130 | \bibliographystyle{unsrtnat}
131 | \bibliography{references}
132 |
133 | \end{document}
134 |
--------------------------------------------------------------------------------
/transformer_tricks.py:
--------------------------------------------------------------------------------
1 | # tricks and tools for speeding up LLMs
2 |
3 | import gc, os, time, torch, datasets, glob
4 | import torch.nn as nn
5 | from tqdm import tqdm
6 | from huggingface_hub import snapshot_download, repo_exists
7 | from safetensors.torch import load_file, save_file, safe_open
8 | from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig, logging, utils
9 | try:
10 | from flashNorm_modeling_llama import * # import local file if it exists
11 | except ImportError:
12 | pass
13 |
14 |
15 | #-------------------------------------------------------------------------------------
16 | # tools for working with safetensors and HuggingFace repos
17 | #-------------------------------------------------------------------------------------
18 | def quiet_hf():
19 | """reduce verbosity of HuggingFace"""
20 | logging.set_verbosity_error()
21 | utils.logging.disable_progress_bar()
22 | datasets.logging.disable_progress_bar()
23 | os.environ['TOKENIZERS_PARALLELISM'] = 'true'
24 | os.environ['HF_HUB_VERBOSITY'] = 'error'
25 | # for more env variables, see link below
26 | # https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables
27 |
28 |
29 | def weight(name, layer=0):
30 | """get dictionary key of specific weight (such as Q from layer 0)"""
31 | layer_str = 'model.layers.' + str(layer) + '.'
32 | match name:
33 | # weights of each layer
34 | case 'Inorm': key = layer_str + 'input_layernorm.weight'
35 | case 'Anorm': key = layer_str + 'post_attention_layernorm.weight'
36 | case 'QKV' : key = layer_str + 'self_attn.qkv_proj.weight'
37 | case 'Q' : key = layer_str + 'self_attn.q_proj.weight'
38 | case 'K' : key = layer_str + 'self_attn.k_proj.weight'
39 | case 'V' : key = layer_str + 'self_attn.v_proj.weight'
40 | case 'O' : key = layer_str + 'self_attn.o_proj.weight'
41 | case 'GU' : key = layer_str + 'mlp.gate_up_proj.weight'
42 | case 'G' : key = layer_str + 'mlp.gate_proj.weight'
43 | case 'U' : key = layer_str + 'mlp.up_proj.weight'
44 | case 'D' : key = layer_str + 'mlp.down_proj.weight'
45 | # embedding weights
46 | case 'Hnorm': key = 'model.norm.weight' # normalization of lm_head
47 | case 'H' : key = 'lm_head.weight' # output embeddings
48 | case 'E' : key = 'model.embed_tokens.weight' # input embeddings
49 | return key
50 |
51 |
52 | def get_param(repo, get_meta=False):
53 | """download all *.safetensors files from repo (or local dir) and return a single
54 | param dict, and optionally also return the metadata"""
55 |
56 | # download and get list of files
57 | if repo_exists(repo):
58 | dir = 'get_param_tmp'
59 | snapshot_download(repo_id=repo, allow_patterns='*.safetensors', local_dir=dir)
60 | else: # if repo doesn't exist on HuggingFace, then 'repo' specifies local dir
61 | dir = repo
62 | files = glob.glob(dir + '/*.safetensors')
63 |
64 | # get parameters
65 | param = {}
66 | for file in files:
67 | param.update(load_file(file)) # concatenate all parameters into a single dict
68 |
69 | # return param only, or param and metadata
70 | if get_meta == False:
71 | return param
72 | else:
73 | with safe_open(files[0], framework='pt') as f: # use the first file
74 | return param, f.metadata()
75 |
76 |
77 | def save_repo(repo, param, config, dir):
78 | """save tokenizer, config, and param in local dir"""
79 | tok = AutoTokenizer.from_pretrained(repo)
80 | tok.save_pretrained(dir, from_pt=True)
81 | config.save_pretrained(dir, from_pt=True)
82 | save_file(param, dir + '/model.safetensors', metadata={'format': 'pt'})
83 |
84 |
85 | #-------------------------------------------------------------------------------------
86 | # functions for flashNorm, see paper https://arxiv.org/abs/2407.09577
87 | #-------------------------------------------------------------------------------------
88 | def merge_norm_proj(param, norm, proj, layer=0):
89 | """merge norm weights into projection weights"""
90 | n_key = weight(norm, layer)
91 | p_key = weight(proj, layer)
92 | param[p_key] = nn.Parameter(param[p_key] @ torch.diag(param[n_key])).detach() # flipped order
93 | # TODO: consider first converting to float64, then merge norm into projections,
94 | # and then convert back to float32. Example: torch.ones(4, dtype=torch.float32)
95 |
96 |
97 | def set_norm_one(param, norm, layer=0):
98 | """set all norm weights to 1.0"""
99 | n_key = weight(norm, layer)
100 | len = list(param[n_key].shape)[0]
101 | param[n_key] = nn.Parameter(torch.ones(len)).detach()
102 |
103 |
104 | def flashify(param, config, bars):
105 | """merge norm weights into projection weights as per flashNorm"""
106 | with torch.no_grad(): # prevent autograd from tracking changes
107 |
108 | # check if model uses fused projections (such as in Phi-3)
109 | fused_proj = weight('QKV') in param
110 |
111 | # perform flashNorm merging for each layer
112 | for layer in tqdm(range(config.num_hidden_layers), disable=not bars):
113 |
114 | # merge input-layernorm into QKV projections
115 | if fused_proj:
116 | merge_norm_proj(param, 'Inorm', 'QKV', layer)
117 | else:
118 | merge_norm_proj(param, 'Inorm', 'Q', layer)
119 | merge_norm_proj(param, 'Inorm', 'K', layer)
120 | merge_norm_proj(param, 'Inorm', 'V', layer)
121 | set_norm_one(param, 'Inorm', layer)
122 |
123 | # merge post-attention layernorm 'Anorm' into Gate and Up projections
124 | if fused_proj:
125 | merge_norm_proj(param, 'Anorm', 'GU', layer)
126 | else:
127 | merge_norm_proj(param, 'Anorm', 'G', layer)
128 | merge_norm_proj(param, 'Anorm', 'U', layer)
129 | set_norm_one(param, 'Anorm', layer)
130 |
131 | # if the model has untied embeddings, then merge 'Hnorm' into 'lm_head'
132 | # see also https://huggingface.co/HuggingFaceTB/SmolLM-135M/discussions/15
133 | if config.tie_word_embeddings == False:
134 | merge_norm_proj(param, 'Hnorm', 'H')
135 | set_norm_one(param, 'Hnorm')
136 |
137 |
138 | def flashify_repo(repo, dir=None, bars=False, test=True):
139 | """convert LLM repo to flashNorm, store the new model in local dir"""
140 | with torch.no_grad(): # prevent autograd from tracking changes
141 |
142 | if dir == None: # append '_flashNorm' if no output dir is defined
143 | dir = os.path.basename(repo) + '_flashNorm'
144 |
145 | # get config, download safetensors, and flashify params
146 | config = AutoConfig.from_pretrained(repo)
147 | param = get_param(repo)
148 | flashify(param, config, bars)
149 | if test: # optionally, save a test-repo in directory *_test
150 | save_repo(repo, param, config, dir + '_test')
151 |
152 | # delete norm weights from param
153 | for layer in range(config.num_hidden_layers):
154 | del param[weight('Inorm', layer)]
155 | del param[weight('Anorm', layer)]
156 | if config.tie_word_embeddings == False:
157 | del param[weight('Hnorm')]
158 |
159 | # TODO:
160 | #config.architectures = ['LlamaForCausalLM_flashNorm']
161 | #config.auto_map = {'AutoModelForCausalLM': 'flashNorm_modeling_llama.LlamaForCausalLM_flashNorm'}
162 | #config.model_type = 'flashNorm'
163 | save_repo(repo, param, config, dir)
164 |
165 | del param; gc.collect() # run garbage collection
166 |
167 |
168 | #-------------------------------------------------------------------------------------
169 | # functions for testing
170 | #-------------------------------------------------------------------------------------
171 | def hello_world(repo, max_new_tok=4, arch='AutoModelForCausalLM', perf=False):
172 | """run example inference of an LLM from HuggingFace repo or local directory"""
173 | tok = AutoTokenizer.from_pretrained(repo)
174 | model = eval(f'{arch}.from_pretrained(repo, low_cpu_mem_usage=True)')
175 | # to use FP16 or bfloaf: torch_dtype=torch.float16, torch_dtype=torch.bfloat
176 | # note: FP16 is 30x slower than FP32 on my Mac M1, not sure why
177 |
178 | prompt = 'Once upon a time there was'
179 | start_time = time.perf_counter()
180 | inp = tok.encode(prompt, return_tensors='pt').to('cpu')
181 | out = model.generate(inp, pad_token_id=0, max_new_tokens=max_new_tok).ravel()
182 | print(tok.decode(out),
183 | f' (time: {time.perf_counter() - start_time:.2f}s)' if perf else '')
184 | del tok, model; gc.collect() # run garbage collection
185 | # TODO: especially for Phi-3, set verbosity to quiet as follows
186 | # transformers.logging.set_verbosity_error()
187 |
188 |
189 | def perplexity(repo, speedup=1, arch='AutoModelForCausalLM', bars=False, perf=False):
190 | """calculate perplexity of an LLM with wikitext2
191 | this def is copied from https://huggingface.co/docs/transformers/perplexity
192 | I made the following changes to adapt it for SmolLM (was GPT2 before):
193 | - changed model and tokenizer
194 | - changed 'from transformers import' to point to 'Auto*' (was 'GTP2*' before)
195 | - changed 'max_length' to 'config.max_position_embeddings'
196 | - changed 'device' from 'cuda' to 'cpu'
197 | - changed 'stride' to be 'max_length' (was 512 or 'max_length//2' before)
198 | - removed 'with torch.no_grad()' and added global 'torch.set_grad_enabled(False)'
199 | Perhaps a simpler and cleaner way is given here:
200 | https://huggingface.co/spaces/evaluate-metric/perplexity"""
201 |
202 | torch.set_grad_enabled(False) # speed up torch
203 | # TODO: consider using instead 'with torch.no_grad():'
204 |
205 | tok = AutoTokenizer.from_pretrained(repo)
206 | model = eval(f'{arch}.from_pretrained(repo, low_cpu_mem_usage=True)')
207 |
208 | # tokenize wikitext2
209 | test = datasets.load_dataset('wikitext', 'wikitext-2-raw-v1', split='test')
210 | encodings = tok('\n\n'.join(test['text']), return_tensors='pt')
211 | del tok; gc.collect() # run garbage collection
212 |
213 | max_length = model.config.max_position_embeddings
214 | stride = max_length # before it was 512 or max_length // 2
215 | seq_len = encodings.input_ids.size(1) // speedup
216 |
217 | start_time = time.perf_counter()
218 | nlls = []
219 | prev_end_loc = 0
220 | for begin_loc in tqdm(range(0, seq_len, stride), disable=not bars):
221 | end_loc = min(begin_loc + max_length, seq_len)
222 | trg_len = end_loc - prev_end_loc # may be different from stride on last loop
223 | input_ids = encodings.input_ids[:, begin_loc:end_loc].to('cpu')
224 | target_ids = input_ids.clone()
225 | target_ids[:, :-trg_len] = -100
226 | outputs = model(input_ids, labels=target_ids)
227 |
228 | # loss is calculated using CrossEntropyLoss which averages over valid labels
229 | # N.B. the model only calculates loss over trg_len - 1 labels, because it
230 | # internally shifts the labels to the left by 1.
231 | neg_log_likelihood = outputs.loss
232 | nlls.append(neg_log_likelihood)
233 |
234 | prev_end_loc = end_loc
235 | if end_loc == seq_len:
236 | break
237 |
238 | ppl = torch.exp(torch.stack(nlls).mean())
239 | print(f'perplexity = {ppl:.3f}',
240 | f' (time: {time.perf_counter() - start_time:.2f}s)' if perf else '')
241 | # print('nlls:', nlls)
242 | del model; gc.collect() # run garbage collection
243 |
244 |
245 | #-------------------------------------------------------------------------------------
246 | # debug tools
247 | #-------------------------------------------------------------------------------------
248 | def diff_safetensors(repo1, repo2):
249 | """compare differences of safetensor file(s) between repo1 and repo2"""
250 | param1, meta1 = get_param(repo1, get_meta=True)
251 | param2, meta2 = get_param(repo2, get_meta=True)
252 | set1, set2 = set(param1.keys()), set(param2.keys())
253 |
254 | # diff keys
255 | if set1 == set2:
256 | print('>>> SAFE-DIFF: both repos have the same safetensor keys')
257 | else:
258 | if set1 - set2:
259 | print(f'>>> SAFE-DIFF: these keys are only in repo {repo1}: {set1 - set2}')
260 | if set2 - set1:
261 | print(f'>>> SAFE-DIFF: these keys are only in repo {repo2}: {set2 - set1}')
262 |
263 | # diff tensors
264 | found_diff = False
265 | for key in set1.intersection(set2):
266 | if not torch.equal(param1[key], param2[key]):
267 | found_diff = True
268 | print(f'>>> SAFE-DIFF: tensors {key} are not equal')
269 | if not found_diff:
270 | print('>>> SAFE-DIFF: all intersecting tensors are equal')
271 |
272 | # diff metadata
273 | if meta1 == meta2:
274 | print('>>> SAFE-DIFF: both repos have the same safetensor metadata')
275 | else:
276 | print(f'>>> SAFE-DIFF: metadata of repo {repo1}: {meta1}')
277 | print(f'>>> SAFE-DIFF: metadata of repo {repo2}: {meta2}')
278 |
279 |
280 | # misc TODOs:
281 | # - do we really need 'with torch.no_grad():' everywhere?
282 | # - do we really need garbage collection 'gc'?
283 | # - would 'torch.set_grad_enabled(False)' speed up things?
284 |
--------------------------------------------------------------------------------
/tex/neurips_2025.sty:
--------------------------------------------------------------------------------
1 | % I downloaded this file from NeurIPS website:
2 | % https://media.neurips.cc/Conferences/NeurIPS2025/Styles.zip
3 |
4 | % partial rewrite of the LaTeX2e package for submissions to the
5 | % Conference on Neural Information Processing Systems (NeurIPS):
6 | %
7 | % - uses more LaTeX conventions
8 | % - line numbers at submission time replaced with aligned numbers from
9 | % lineno package
10 | % - \nipsfinalcopy replaced with [final] package option
11 | % - automatically loads times package for authors
12 | % - loads natbib automatically; this can be suppressed with the
13 | % [nonatbib] package option
14 | % - adds foot line to first page identifying the conference
15 | % - adds preprint option for submission to e.g. arXiv
16 | % - conference acronym modified
17 | %
18 | % Roman Garnett (garnett@wustl.edu) and the many authors of
19 | % nips15submit_e.sty, including MK and drstrip@sandia
20 | %
21 | % last revision: April 2025
22 |
23 | \NeedsTeXFormat{LaTeX2e}
24 | \ProvidesPackage{neurips_2025}[2025/04/02 NeurIPS 2025 submission/camera-ready style file]
25 |
26 | % declare final option, which creates camera-ready copy
27 | \newif\if@neuripsfinal\@neuripsfinalfalse
28 | \DeclareOption{final}{
29 | \@neuripsfinaltrue
30 | }
31 |
32 | % declare nonatbib option, which does not load natbib in case of
33 | % package clash (users can pass options to natbib via
34 | % \PassOptionsToPackage)
35 | \newif\if@natbib\@natbibtrue
36 | \DeclareOption{nonatbib}{
37 | \@natbibfalse
38 | }
39 |
40 | % declare preprint option, which creates a preprint version ready for
41 | % upload to, e.g., arXiv
42 | \newif\if@preprint\@preprintfalse
43 | \DeclareOption{preprint}{
44 | \@preprinttrue
45 | }
46 |
47 | \ProcessOptions\relax
48 |
49 | % determine whether this is an anonymized submission
50 | \newif\if@submission\@submissiontrue
51 | \if@neuripsfinal\@submissionfalse\fi
52 | \if@preprint\@submissionfalse\fi
53 |
54 | % fonts
55 | \renewcommand{\rmdefault}{ptm}
56 | \renewcommand{\sfdefault}{phv}
57 |
58 | % change this every year for notice string at bottom
59 | \newcommand{\@neuripsordinal}{39th}
60 | \newcommand{\@neuripsyear}{2025}
61 | \newcommand{\@neuripslocation}{San Diego}
62 |
63 | % acknowledgments
64 | \usepackage{environ}
65 | \newcommand{\acksection}{\section*{Acknowledgments and Disclosure of Funding}}
66 | \NewEnviron{ack}{%
67 | \acksection
68 | \BODY
69 | }
70 |
71 |
72 | % load natbib unless told otherwise
73 | \if@natbib
74 | \RequirePackage{natbib}
75 | \fi
76 |
77 | % set page geometry
78 | \usepackage[verbose=true,letterpaper]{geometry}
79 | \AtBeginDocument{
80 | \newgeometry{
81 | textheight=9in,
82 | textwidth=5.5in,
83 | top=1in,
84 | headheight=12pt,
85 | headsep=25pt,
86 | footskip=30pt
87 | }
88 | \@ifpackageloaded{fullpage}
89 | {\PackageWarning{neurips_2025}{fullpage package not allowed! Overwriting formatting.}}
90 | {}
91 | }
92 |
93 | \widowpenalty=10000
94 | \clubpenalty=10000
95 | \flushbottom
96 | \sloppy
97 |
98 |
99 | % font sizes with reduced leading
100 | \renewcommand{\normalsize}{%
101 | \@setfontsize\normalsize\@xpt\@xipt
102 | \abovedisplayskip 7\p@ \@plus 2\p@ \@minus 5\p@
103 | \abovedisplayshortskip \z@ \@plus 3\p@
104 | \belowdisplayskip \abovedisplayskip
105 | \belowdisplayshortskip 4\p@ \@plus 3\p@ \@minus 3\p@
106 | }
107 | \normalsize
108 | \renewcommand{\small}{%
109 | \@setfontsize\small\@ixpt\@xpt
110 | \abovedisplayskip 6\p@ \@plus 1.5\p@ \@minus 4\p@
111 | \abovedisplayshortskip \z@ \@plus 2\p@
112 | \belowdisplayskip \abovedisplayskip
113 | \belowdisplayshortskip 3\p@ \@plus 2\p@ \@minus 2\p@
114 | }
115 | \renewcommand{\footnotesize}{\@setfontsize\footnotesize\@ixpt\@xpt}
116 | \renewcommand{\scriptsize}{\@setfontsize\scriptsize\@viipt\@viiipt}
117 | \renewcommand{\tiny}{\@setfontsize\tiny\@vipt\@viipt}
118 | \renewcommand{\large}{\@setfontsize\large\@xiipt{14}}
119 | \renewcommand{\Large}{\@setfontsize\Large\@xivpt{16}}
120 | \renewcommand{\LARGE}{\@setfontsize\LARGE\@xviipt{20}}
121 | \renewcommand{\huge}{\@setfontsize\huge\@xxpt{23}}
122 | \renewcommand{\Huge}{\@setfontsize\Huge\@xxvpt{28}}
123 |
124 | % sections with less space
125 | \providecommand{\section}{}
126 | \renewcommand{\section}{%
127 | \@startsection{section}{1}{\z@}%
128 | {-2.0ex \@plus -0.5ex \@minus -0.2ex}%
129 | { 1.5ex \@plus 0.3ex \@minus 0.2ex}%
130 | {\large\bf\raggedright}%
131 | }
132 | \providecommand{\subsection}{}
133 | \renewcommand{\subsection}{%
134 | \@startsection{subsection}{2}{\z@}%
135 | {-1.8ex \@plus -0.5ex \@minus -0.2ex}%
136 | { 0.8ex \@plus 0.2ex}%
137 | {\normalsize\bf\raggedright}%
138 | }
139 | \providecommand{\subsubsection}{}
140 | \renewcommand{\subsubsection}{%
141 | \@startsection{subsubsection}{3}{\z@}%
142 | {-1.5ex \@plus -0.5ex \@minus -0.2ex}%
143 | { 0.5ex \@plus 0.2ex}%
144 | {\normalsize\bf\raggedright}%
145 | }
146 | \providecommand{\paragraph}{}
147 | \renewcommand{\paragraph}{%
148 | \@startsection{paragraph}{4}{\z@}%
149 | {1.5ex \@plus 0.5ex \@minus 0.2ex}%
150 | {-1em}%
151 | {\normalsize\bf}%
152 | }
153 | \providecommand{\subparagraph}{}
154 | \renewcommand{\subparagraph}{%
155 | \@startsection{subparagraph}{5}{\z@}%
156 | {1.5ex \@plus 0.5ex \@minus 0.2ex}%
157 | {-1em}%
158 | {\normalsize\bf}%
159 | }
160 | \providecommand{\subsubsubsection}{}
161 | \renewcommand{\subsubsubsection}{%
162 | \vskip5pt{\noindent\normalsize\rm\raggedright}%
163 | }
164 |
165 | % float placement
166 | \renewcommand{\topfraction }{0.85}
167 | \renewcommand{\bottomfraction }{0.4}
168 | \renewcommand{\textfraction }{0.1}
169 | \renewcommand{\floatpagefraction}{0.7}
170 |
171 | \newlength{\@neuripsabovecaptionskip}\setlength{\@neuripsabovecaptionskip}{7\p@}
172 | \newlength{\@neuripsbelowcaptionskip}\setlength{\@neuripsbelowcaptionskip}{\z@}
173 |
174 | \setlength{\abovecaptionskip}{\@neuripsabovecaptionskip}
175 | \setlength{\belowcaptionskip}{\@neuripsbelowcaptionskip}
176 |
177 | % swap above/belowcaptionskip lengths for tables
178 | \renewenvironment{table}
179 | {\setlength{\abovecaptionskip}{\@neuripsbelowcaptionskip}%
180 | \setlength{\belowcaptionskip}{\@neuripsabovecaptionskip}%
181 | \@float{table}}
182 | {\end@float}
183 |
184 | % footnote formatting
185 | \setlength{\footnotesep }{6.65\p@}
186 | \setlength{\skip\footins}{9\p@ \@plus 4\p@ \@minus 2\p@}
187 | \renewcommand{\footnoterule}{\kern-3\p@ \hrule width 12pc \kern 2.6\p@}
188 | \setcounter{footnote}{0}
189 |
190 | % paragraph formatting
191 | \setlength{\parindent}{\z@}
192 | \setlength{\parskip }{5.5\p@}
193 |
194 | % list formatting
195 | \setlength{\topsep }{4\p@ \@plus 1\p@ \@minus 2\p@}
196 | \setlength{\partopsep }{1\p@ \@plus 0.5\p@ \@minus 0.5\p@}
197 | \setlength{\itemsep }{2\p@ \@plus 1\p@ \@minus 0.5\p@}
198 | \setlength{\parsep }{2\p@ \@plus 1\p@ \@minus 0.5\p@}
199 | \setlength{\leftmargin }{3pc}
200 | \setlength{\leftmargini }{\leftmargin}
201 | \setlength{\leftmarginii }{2em}
202 | \setlength{\leftmarginiii}{1.5em}
203 | \setlength{\leftmarginiv }{1.0em}
204 | \setlength{\leftmarginv }{0.5em}
205 | \def\@listi {\leftmargin\leftmargini}
206 | \def\@listii {\leftmargin\leftmarginii
207 | \labelwidth\leftmarginii
208 | \advance\labelwidth-\labelsep
209 | \topsep 2\p@ \@plus 1\p@ \@minus 0.5\p@
210 | \parsep 1\p@ \@plus 0.5\p@ \@minus 0.5\p@
211 | \itemsep \parsep}
212 | \def\@listiii{\leftmargin\leftmarginiii
213 | \labelwidth\leftmarginiii
214 | \advance\labelwidth-\labelsep
215 | \topsep 1\p@ \@plus 0.5\p@ \@minus 0.5\p@
216 | \parsep \z@
217 | \partopsep 0.5\p@ \@plus 0\p@ \@minus 0.5\p@
218 | \itemsep \topsep}
219 | \def\@listiv {\leftmargin\leftmarginiv
220 | \labelwidth\leftmarginiv
221 | \advance\labelwidth-\labelsep}
222 | \def\@listv {\leftmargin\leftmarginv
223 | \labelwidth\leftmarginv
224 | \advance\labelwidth-\labelsep}
225 | \def\@listvi {\leftmargin\leftmarginvi
226 | \labelwidth\leftmarginvi
227 | \advance\labelwidth-\labelsep}
228 |
229 | % create title
230 | \providecommand{\maketitle}{}
231 | \renewcommand{\maketitle}{%
232 | \par
233 | \begingroup
234 | \renewcommand{\thefootnote}{\fnsymbol{footnote}}
235 | % for perfect author name centering
236 | \renewcommand{\@makefnmark}{\hbox to \z@{$^{\@thefnmark}$\hss}}
237 | % The footnote-mark was overlapping the footnote-text,
238 | % added the following to fix this problem (MK)
239 | \long\def\@makefntext##1{%
240 | \parindent 1em\noindent
241 | \hbox to 1.8em{\hss $\m@th ^{\@thefnmark}$}##1
242 | }
243 | \thispagestyle{empty}
244 | \@maketitle
245 | \@thanks
246 | \@notice
247 | \endgroup
248 | \let\maketitle\relax
249 | \let\thanks\relax
250 | }
251 |
252 | % rules for title box at top of first page
253 | \newcommand{\@toptitlebar}{
254 | \hrule height 4\p@
255 | \vskip 0.25in
256 | \vskip -\parskip%
257 | }
258 | \newcommand{\@bottomtitlebar}{
259 | \vskip 0.29in
260 | \vskip -\parskip
261 | \hrule height 1\p@
262 | \vskip 0.09in%
263 | }
264 |
265 | % create title (includes both anonymized and non-anonymized versions)
266 | \providecommand{\@maketitle}{}
267 | \renewcommand{\@maketitle}{%
268 | \vbox{%
269 | \hsize\textwidth
270 | \linewidth\hsize
271 | \vskip 0.1in
272 | \@toptitlebar
273 | \centering
274 | {\LARGE\bf \@title\par}
275 | \@bottomtitlebar
276 | \if@submission
277 | \begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}
278 | Anonymous Author(s) \\
279 | Affiliation \\
280 | Address \\
281 | \texttt{email} \\
282 | \end{tabular}%
283 | \else
284 | \def\And{%
285 | \end{tabular}\hfil\linebreak[0]\hfil%
286 | \begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}\ignorespaces%
287 | }
288 | \def\AND{%
289 | \end{tabular}\hfil\linebreak[4]\hfil%
290 | \begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}\ignorespaces%
291 | }
292 | \begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}\@author\end{tabular}%
293 | \fi
294 | \vskip 0.3in \@minus 0.1in
295 | }
296 | }
297 |
298 | % add conference notice to bottom of first page
299 | \newcommand{\ftype@noticebox}{8}
300 | \newcommand{\@notice}{%
301 | % give a bit of extra room back to authors on first page
302 | \enlargethispage{2\baselineskip}%
303 | \@float{noticebox}[b]%
304 | \footnotesize\@noticestring%
305 | \end@float%
306 | }
307 |
308 | % abstract styling
309 | \renewenvironment{abstract}%
310 | {%
311 | \vskip 0.075in%
312 | \centerline%
313 | {\large\bf Abstract}%
314 | \vspace{0.5ex}%
315 | \begin{quote}%
316 | }
317 | {
318 | \par%
319 | \end{quote}%
320 | \vskip 1ex%
321 | }
322 |
323 | % For the paper checklist
324 | \newcommand{\answerYes}[1][]{\textcolor{blue}{[Yes] #1}}
325 | \newcommand{\answerNo}[1][]{\textcolor{orange}{[No] #1}}
326 | \newcommand{\answerNA}[1][]{\textcolor{gray}{[NA] #1}}
327 | \newcommand{\answerTODO}[1][]{\textcolor{red}{\bf [TODO]}}
328 | \newcommand{\justificationTODO}[1][]{\textcolor{red}{\bf [TODO]}}
329 |
330 | % handle tweaks for camera-ready copy vs. submission copy
331 | \if@preprint
332 | \newcommand{\@noticestring}{%
333 | Preprint. Under review.%
334 | }
335 | \else
336 | \if@neuripsfinal
337 | \newcommand{\@noticestring}{%
338 | \@neuripsordinal\/ Conference on Neural Information Processing Systems
339 | (NeurIPS \@neuripsyear).%, \@neuripslocation.%
340 | }
341 | \else
342 | \newcommand{\@noticestring}{%
343 | Submitted to \@neuripsordinal\/ Conference on Neural Information
344 | Processing Systems (NeurIPS \@neuripsyear). Do not distribute.%
345 | }
346 |
347 | % hide the acknowledgements
348 | \NewEnviron{hide}{}
349 | \let\ack\hide
350 | \let\endack\endhide
351 |
352 | % line numbers for submission
353 | \RequirePackage{lineno}
354 | \linenumbers
355 |
356 | % fix incompatibilities between lineno and amsmath, if required, by
357 | % transparently wrapping linenomath environments around amsmath
358 | % environments
359 | \AtBeginDocument{%
360 | \@ifpackageloaded{amsmath}{%
361 | \newcommand*\patchAmsMathEnvironmentForLineno[1]{%
362 | \expandafter\let\csname old#1\expandafter\endcsname\csname #1\endcsname
363 | \expandafter\let\csname oldend#1\expandafter\endcsname\csname end#1\endcsname
364 | \renewenvironment{#1}%
365 | {\linenomath\csname old#1\endcsname}%
366 | {\csname oldend#1\endcsname\endlinenomath}%
367 | }%
368 | \newcommand*\patchBothAmsMathEnvironmentsForLineno[1]{%
369 | \patchAmsMathEnvironmentForLineno{#1}%
370 | \patchAmsMathEnvironmentForLineno{#1*}%
371 | }%
372 | \patchBothAmsMathEnvironmentsForLineno{equation}%
373 | \patchBothAmsMathEnvironmentsForLineno{align}%
374 | \patchBothAmsMathEnvironmentsForLineno{flalign}%
375 | \patchBothAmsMathEnvironmentsForLineno{alignat}%
376 | \patchBothAmsMathEnvironmentsForLineno{gather}%
377 | \patchBothAmsMathEnvironmentsForLineno{multline}%
378 | }
379 | {}
380 | }
381 | \fi
382 | \fi
383 |
384 |
385 | \endinput
386 |
--------------------------------------------------------------------------------
/tex/removeWeights.tex:
--------------------------------------------------------------------------------
1 | % To generate PDF, type ./run removeWeights
2 |
3 | \documentclass{article}
4 | \usepackage{arxiv} % see file arxiv.sty
5 | \usepackage[numbers]{natbib} % number citation style (remove "numbers" for author-year style)
6 |
7 | % shortcuts for matrices Q, K, V, P, O, M and vectors u, x, y, z
8 | \newcommand{\mat}[1]{\mathbf{#1}} % shortcut for matrix
9 | \def\Q{\mat{Q}_i}
10 | \def\K{\mat{K}_i}
11 | \def\V{\mat{V}_i}
12 | \def\P{\mat{P}_i}
13 | \def\O{\mat{O}_{i-1}}
14 | \def\M{\mat{M}_i}
15 | \def\u{\vec{u}}
16 | \def\x{\vec{x}}
17 | \def\y{\vec{y}}
18 | \def\z{\vec{z}}
19 |
20 | \title{KV-weights are all you need for skipless transformers}
21 | %\title{KV-weights are all you need for skipless transformers: lossless weight fusion for residual-free transformers}
22 | %\title{Lossless weight fusion for skipless transformers}
23 | %\title{Transformer tricks: Removing weights for skipless transformers}
24 | %\title{Transformer tricks: Removing weights from skipless transformers}
25 | %\title{Transformer tricks: Reducing weights for skipless transformers}
26 | %\title{Transformer tricks: Merging linear layers for skipless transformers}
27 | %\title{Transformer tricks: Eliminating linear layers}
28 |
29 | \author{Nils Graef\thanks{\texttt{info@openmachine.ai}} \\
30 | \href{https://openmachine.ai}{OpenMachine}}
31 |
32 | \begin{document} \maketitle
33 |
34 | \begin{abstract}
35 | \citet{simplified} detailed a skipless transformer without the V and P (post-attention projection) linear layers, which reduces the total number of weights. However, this scheme is only applicable to MHA (multi-head attention) \cite{vanilla}, but not for MQA (multi-query attention) \cite{MQA} and GQA (grouped-query attention) \cite{GQA}. The latter schemes are used by many popular LLMs such as Llama 2, Mistral, Mixtral, PaLM, and Gemma \cite{Llama2, mistral, mixtral, PaLM, gemma}. Therefore, this micro-paper \cite{micro-paper} proposes mathematically equivalent versions that are suitable for MQA and GQA. For example, removing Q and P from a skipless version of Mistral-7B would remove 15\% of its weights, and thus reduce its compute and memory complexity. Watch our explainer video \citep{remove-video} and see \citep{tricks, precompute} for code and more transformer tricks.
36 | \end{abstract}
37 |
38 | \section{Vanilla transformer without skip connections}
39 |
40 | \begin{figure}[h!] \centering % the [h!] tries to place the picture right here
41 | \includegraphics[scale=0.87]{../doc/fig/removeWeights_fig1.pdf}
42 | \caption{(a) Skipless vanilla transformer; equivalent versions with (b) Q and P merged into the FFN (feedforward network); (c) K and P merged into FFN; (d) V and P merged into FFN. $\M^*, \Q^*, \K^*, \V^*, \O^*$ are defined in table \ref{tab1}.}
43 | \label{fig1} \end{figure}
44 |
45 | \citet{skipless} have shown how transformers without skip connections and normalization (Figure \ref{fig1}(a)) can be trained successfully. Removing skip connections and normalization allows us to merge linear layers in a mathematically identical way as shown in Figures \ref{fig1}(b) to (d). This reduces the number of weights without changing the functionality as follows:
46 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
47 | \item Figure \ref{fig1}(b) is mathematically identical to Figure \ref{fig1}(a) and eliminates $2d^2$ weights per transformer block by merging $\P$ into $\M^*$ and $\Q$ into $\O^*$.
48 | \item For MHA where $e = d$, Figures \ref{fig1}(c) and (d) are mathematically identical to Figure \ref{fig1}(a) and eliminate $2d^2$ weights per transformer block by merging $\P$ into $\M^*$ and $\K$ or $\V$ into $\O^*$.
49 | \item This requires that $\Q, \K, \V$ are invertible (i.e. nonsingular). It is extremely rare that a square matrix with random values is not invertible \cite{invertible} (which requires its determinant to be exactly 0).
50 | \end{itemize}
51 |
52 | Figure \ref{fig1} uses the following dimensions and weight matrices, based on the type of attention:
53 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
54 | \item $d$: embedding dimension
55 | \item $e$: $e = d$ for MHA. For MQA, $e = d / n_{heads}$. And for GQA, $e = d \cdot n_{kv\_heads} / n_{heads}$.
56 | \item $f$: hidden dimension of the FFN. $f = 4d$ in the vanilla transformer; \citet{MQA} uses $f > 4d$. For models that use a GLU variant \cite{GLU} (such as Llama and Mistral), the effective $f'$ for the first linear layer M is $f' = 2f$, because the GLU variant uses two linear layers that are combined (via pointwise multiplication) with a non-linear activation function.
57 | \item $\Q, \K, \V, \P$: The weight matrices of the linear layers for query, keys, values, and the post-attention projection of transformer block $i$.
58 | \item $\M, \mat{O}_i$: The weight matrices of the FFN input and output linear layers.
59 | \end{itemize}
60 |
61 | \begin{figure}[h!] \centering % the [h!] tries to place the picture right here
62 | \includegraphics[scale=0.92]{../doc/fig/removeWeights_fig2.pdf}
63 | \caption{(a) Merging P and M; (b) eliminating Q; (c) eliminating K; (d) eliminating V.}
64 | \label{fig2} \end{figure}
65 |
66 | Figure \ref{fig2} details how the linear layers are merged:
67 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
68 | \item Figure \ref{fig2}(a) shows how the two linear layers with weight matrices $\P$ and $\M$ are collapsed and replaced by a single linear layer with weight matrix $\M^* = \P \M$, which eliminates $d^2$ weights.
69 | \item Figure \ref{fig2}(b) illustrates how to merge $\Q$ into the preceding $\O$-matrix, which eliminates $d^2$ weights and requires $\Q$ to be invertible. Note that $\y = \u \O (\Q \Q^{-1}) \K = \u \O \K$ and $\z = \u \O (\Q \Q^{-1}) \V = \u \O \V$.
70 | \item For MHA where $e = d$, $\K$ can be removed as shown in Figure \ref{fig2}(c), which eliminates $d^2$ weights. Note that $\x = \u \O (\K \K^{-1}) \Q = \u \O \Q$ and $\z = \u \O (\K \K^{-1}) \V = \u \O \V$. This requires that $\K$ is invertible.
71 | \item For MHA where $e = d$, $\V$ can be removed as shown in Figure \ref{fig2}(d), which eliminates $d^2$ weights. Note that $\x = \u \O (\V \V^{-1}) \Q = \u \O \Q$ and $\y = \u \O (\V \V^{-1}) \K = \u \O \K$. This requires that $\V$ is invertible.
72 | \end{itemize}
73 |
74 | Table \ref{tab1} specifies how the new weight matrices ($\M^*, \Q^*, \K^*, \V^*, \O^*$) of Figure \ref{fig1} are calculated from the original ones. For the first transformer block ($i = 1$), we use the input embedding instead of $\O$ (because there is no $\O$ for $i = 1$).
75 |
76 | \begingroup \begin{table} [h!] \centering % the [h!] tries to place the picture right here
77 | \renewcommand{\arraystretch}{1.2} % increase table row height
78 | \begin{tabular}{cccc} \hline
79 | & Figure 1(b) & Figure 1(c) & Figure 1(d) \\ \hline
80 | $\O^*$ & $\O \Q$ & $\O \K$ & $\O \V$ \\
81 | $\Q^*$ & 1 (eliminated) & $\K^{-1} \Q$ & $\V^{-1} \Q$ \\
82 | $\K^*$ & $\Q^{-1} \K$ & 1 (eliminated) & $\V^{-1} \K$ \\
83 | $\V^*$ & $\Q^{-1} \V$ & $\K^{-1} \V$ & 1 (eliminated) \\
84 | $\M^*$ & $\P \M$ & $\P \M$ & $\P \M$ \\ \hline
85 | \end{tabular}
86 | \caption{How to calculate the new weight matrices from the original ones for Figure \ref{fig1}.}
87 | \label{tab1} \end{table} \endgroup
88 |
89 | \section{Parallel transformer without skip connections}
90 | Similar to the parallel transformer \cite{parallel}, Figure \ref{fig3} shows parallel versions of Figures \ref{fig1}(b) to (d). Here, “parallel” refers to having the attention (including its linear layers) in parallel to the FFN.
91 |
92 | \begin{figure} [h!] \centering % the [h!] tries to place the picture right here
93 | \includegraphics[scale=0.92]{../doc/fig/removeWeights_fig3.pdf}
94 | \caption{Parallel skipless transformers (a) without Q and P; (b) without K and P; (c) without V and P.}
95 | \label{fig3} \end{figure}
96 |
97 | Figures \ref{fig3}(b) and (c) require that $e = d$, so they are only suitable for MHA, but not for MQA and GQA. Figure \ref{fig3}(a) is suitable for MHA, MQA, and GQA. Figure \ref{fig3}(c) is identical to the simplified transformer proposed in \cite{simplified}.
98 |
99 | \section{Related work}
100 | In addition to \cite{simplified}, our work is related to the lossless weight compression for back-to-back linear layers presented in \cite{matShrink}, and FlashNorm's weight fusion \cite{flashNorm}.
101 |
102 | \section{Examples}
103 | The table below lists the configurations and weight counts for Pythia-6.9B and Mistral-7B. For a skipless version of Mistral-7B we would save 15\% of weights after merging the Q and P linear layers into the FFN layers. For a batch 1 system that is limited by memory bandwidth, these 15\% weight savings can speed up inference by 1.17x during the autoregressive next-token-generation phase, see the table below.
104 |
105 | \begingroup
106 | \renewcommand{\arraystretch}{1.2} % increase table row height
107 | \begin{center} \begin{tabular}{lccl} \hline
108 | \textbf{Parameter} & \textbf{Pythia-6.9B} & \textbf{Mistral-7B} & \textbf{Notes} \\ \hline
109 | Parallel attention/FFN? & parallel & serial & \cite{parallel} \\
110 | MHA, MQA, or GQA? & MHA & GQA & \cite{vanilla, MQA, GQA} \\
111 | \verb+dim+ (aka $d$) & \multicolumn{2}{c}{4,096} & embedding dimension \\
112 | \verb+n_layers+ & \multicolumn{2}{c}{32} & number of layers \\
113 | \verb+n_heads+ & \multicolumn{2}{c}{32} & number of heads \\
114 | \verb+n_kv_heads+ & 32 & 8 & number of KV-heads \\
115 | \verb+e+ (output dim. of K, V) & 4,096 & 1,024 & \verb+e = d * n_kv_heads / n_heads+ \\
116 | FFN type & MLP & MLP with SwiGLU & \cite{GLU} \\
117 | FFN \verb+hidden_dim+ & 16,384 & 14,336 & FFN hidden dimension \\
118 | \verb+vocab_size+ & 50,400 & 32,000 & vocabulary size \\ \hline
119 |
120 | \multicolumn{4}{l}{\textbf{Number of weights (calculated from above parameters):}} \\ \hline
121 | Q+P weights per layer & \multicolumn{2}{c}{33,554,432} & \verb+2 * dim * dim+ \\
122 | K+V weights per layer & 33,554,432 & 8,388,608 & \verb+2 * dim * dim / n_heads * n_kv_heads+ \\
123 | FFN weights per layer & 134,217,728 & 176,160,768 & \verb+(2 or 3) * dim * hidden_dim+ \\
124 | Input+output embed. & 412,876,800 & 262,144,000 & \verb+2 * dim * vocab_size+ \\
125 | \multicolumn{1}{r}{\textbf{Total weights:}} & 6.9B & 7.2B & \\ \hline
126 |
127 | \multicolumn{4}{l}{\textbf{Weight savings and speedup after removing Q and P:}} \\ \hline
128 | Total w/o Q+P weights: & 5.8B & 6.2B & total after removing Q and P \\
129 | \multicolumn{1}{r}{\textbf{Weight savings:}} & \textbf{16\%} & \textbf{15\%} & \\
130 | \multicolumn{1}{r}{\textbf{Possible speedup:}} & \textbf{1.19x} & \textbf{1.17x} & assumes batch size 1 \\ \hline
131 | \end{tabular} \end{center}
132 | \endgroup
133 |
134 | \section{Experiments}
135 | Refer to \cite{tricks} for Python code that demonstrates the numerical equivalency of the weight reduction illustrated in Figures \ref{fig1}(b) and \ref{fig2}(b). The code also confirms that all square matrices of Mistral-7B are invertible.
136 |
137 | \section{Conclusion}
138 | A novel approach to optimizing skipless transformers by eliminating the query (Q) and post-attention projection (P) linear layers is presented. This mathematical equivalent weight fusion offers savings in computational cost, memory, and energy consumption by reducing the number of weights.
139 |
140 | Recently published skipless transformers such as \cite{skipless2, skipless} could be retrofitted post-training with the lossless weight fusion presented here. Skipless transformers with normalization layers could first eliminate the normalization layers by fine-tuning as described in \cite{remove-norm, remove-norm2} and then apply the weight fusion described in our work.
141 |
142 | Our work extends a recent trend in neural network design toward architectural parsimony, in which unnecessary components are removed to create more efficient models. Notable examples include RMSNorm’s simplification of LayerNorm by removing mean centering \cite{rms}, PaLM’s elimination of bias parameters \cite{PaLM}, decoder-only transformers’ omission of the encoder stack \cite{genWiki}, FlashNorm's elimination of normalization weights \cite{flashNorm}, and Slim Attention's elimination of the V-cache \cite{slimAttn}. This trend is rooted in the revolutionary shift initiated by the original Transformer model, which replaced traditional recurrence and convolutions with a more streamlined architecture \cite{vanilla}.
143 |
144 | Because skipless transformers are not very popular right now, future work should investigate whether removing P and Q (or K or V) is also beneficial for transformers with normalization and skip connections as illustrated in Figure \ref{fig4}. Adding normalization and skip connections again could simplify and speed up training relative to skipless transformers.
145 |
146 | \begin{figure} \centering
147 | \includegraphics[scale=0.92]{../doc/fig/removeWeights_fig4.pdf}
148 | \caption{(a) Transformer block without Q and P; (b) version with parallel attention / FFN.}
149 | \label{fig4} \end{figure}
150 |
151 | \section*{Acknowledgments}
152 | We would like to thank \href{https://scholar.google.com/citations?user=HKft_LAAAAAJ&hl=en}{Bobby He (ETH Zürich)} and \href{https://scholar.google.com/citations?user=LlK_saMAAAAJ&hl=en}{James Martens (DeepMind)} for helpful discussions on this work.
153 |
154 | \bibliographystyle{unsrtnat}
155 | \bibliography{references}
156 |
157 | \end{document}
158 |
--------------------------------------------------------------------------------
/tex/matShrink.tex:
--------------------------------------------------------------------------------
1 | % To generate PDF, type ./run matShrink.tex
2 |
3 | \documentclass{article}
4 |
5 | \usepackage[preprint, nonatbib]{neurips_2025}
6 | %\usepackage[nonatbib]{neurips_2025} % for submission
7 | %\usepackage[final, nonatbib]{neurips_2025} % final version
8 | \usepackage{neurips_2025_mods} % my mods for neurips_2025.sty
9 |
10 | % shortcuts
11 | \newcommand{\WW}[1]{W_\text{#1}} % for W_\text{...}
12 | \newcommand{\eR}[2]{$\in \mathbb{R}^{#1 \times #2}$} % element of R^{1x2}
13 | \newcommand{\mc}[2]{\multicolumn{#1}{c}{#2}} % table multicolumn
14 | \def\fline{\Xhline{2\arrayrulewidth}} % fat-line for table
15 |
16 | \title{MatShrink: Lossless weight compression for back-to-back linear layers}
17 | %\title{MatShrink: Lossless compression for back-to-back weight matrices}
18 | %\title{[Work-in-progress]: Matrix-shrink for transformers without loss of accuracy}
19 |
20 | %\author{Nils Graef\thanks{\texttt{info@openmachine.ai}}, \, Siddharth Mohan \\
21 | \author{Nils Graef\thanks{\texttt{info@openmachine.ai}} \\
22 | \href{https://openmachine.ai}{OpenMachine}}
23 |
24 | \begin{document} \maketitle
25 |
26 | \begin{abstract}
27 | MatShrink reduces the number of weights for back-to-back matrices. It uses matrix inversion to eliminate weights in a mathematically equivalent way and thus without compromising model accuracy. Matrix-shrink is applicable to both inference and training. It can be used for inference of existing models without fine-tuning or re-training. We also propose a simplified MLA (multi-head latent attention) scheme. See \citep{tricks} for code and more transformer tricks.
28 | \end{abstract}
29 |
30 | For two back-to-back weight matrices $W_A$ and $W_B$, Fig. \ref{fig1} illustrates how we can reduce the size of $W_B$ in a mathematically equivalent way by using matrix inversion.
31 | \begin{figure}[h!] \centering % the [h!] tries to place the picture right here
32 | \includegraphics[scale=0.88]{../doc/fig/matShrink_fig1.pdf}
33 | \caption{Mathematically equivalent implementations of two back-to-back weight matrices $W_A$ and $W_B$ with rank $r$, where $d > r$ and $e > r$. We can split $W_B$ into two submatrices $W_{B1}$ \eR{r}{r} and $W_{B2}$. We can eliminate $W_{B1}$ if it is invertible by merging it into $W_A$ as $W_A^\ast = W_A W_{B1}$ and by changing $W_{B2}$ to $W_{B2}^\ast = W_{B1}^{-1} W_{B2}$. This saves $r^2$ weights and $r^2$ multiply operations per token $x$.}
34 | \label{fig1} \end{figure}
35 |
36 | Matrix-shrink reduces the number of weights for the following back-to-back weight matrices:
37 |
38 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
39 | \item The V and O projections for each attention-head
40 | \item The Q and K projections for each attention-head (without the RoPE portion)
41 | \item The latent projections of MLA (multi-head latent attention)
42 | \end{itemize}
43 | \textbf{Related work.} Matrix-shrink is similar to slim attention \citep{slimAttn} in its use of matrix inversion to compute projections from each other. TODO: also mention papers about matrix approximation / compression schemes such as SVD and others.
44 |
45 | \textbf{Alternative way.} Alternatively, we can split matrix $W_A$ into two submatrices $W_{A1}$ \eR{r}{r} and $W_{A2}$ such that $W_A = [W_{A1}; W_{A2}]$. We can then eliminate $W_{A1}$ if it is invertible as $W = [W_{A1}; W_{A2}] W_B = [I; W_{A2}^\ast] W_B^\ast$ with identity matrix $I$ \eR{r}{r} and where $W_B^\ast = W_{A1} W_B$ and $W_{A2}^\ast = W_{A2} W_{A1}^{-1}$, see Fig. \ref{fig2}.
46 | \begin{figure}[h!] \centering
47 | \includegraphics[scale=0.88]{../doc/fig/matShrink_fig2.pdf}
48 | \caption{Alternative way of shrinking $W_A$ instead of $W_B$}
49 | \label{fig2} \end{figure}
50 |
51 | \section{Matrix-shrink for MHA}
52 | Note that the value (V) and output (O) projections for head $i$ of multi-head attention (MHA) are two back-to-back weight matrices $W_{V,i}$ and $W_{O,i}$. Therefore, we can apply the matrix-shrink scheme to each head. Specifically:
53 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
54 | \item For the vanilla MHA with $h$ heads, each head has dimension $d_k = d / h$, and $d = d_\text{model}$.
55 | \item So for the dimensions $r$ and $e$ of Fig. \ref{fig1}, we have $r = d / h$ and $e = d$.
56 | \item This saves $r^2 = d^2 / h^2$ weights for each head, so $d^2 / h$ weights in total.
57 | \item Note: for single-head attention (where $h = 1$), we can save $2 d^2$ weights (i.e. we can merge the V and O weight matrices into a single $d \times d$ matrix; and the Q and K weight matrices into a single $d \times d$ matrix if there is no RoPE).
58 | \end{itemize}
59 |
60 | For models that don’t use RoPE (such as Whisper or T5 models), the query (Q) and key (K) projections for each head $i$ of MHA are two back-to-back weight matrices $W_{Q,i}$ and $W_{K,i}$. As with V-O weight matrices, this saves $d^2 / h$ weights.
61 |
62 | For many models that use RoPE, we can also apply this trick as follows: Many implementations apply RoPE to only a portion of the head-dimension $d_k = d / h$, usually only to one half of $d_k$. So in this case $r = d_k / 2 = d / (2h)$, which saves only $r^2 = d^2 / (4h^2)$ weights for each head, so $d^2 / (4h)$ weights in total.
63 |
64 | \begingroup \renewcommand{\arraystretch}{1.3} % increase table row height by 1.3x
65 | \begin{table}[h!] \centering
66 | \begin{tabular}{lcccccc} \fline
67 | \thead[l]{Model} & \thead{$d$} & \thead{$d_k$} & \thead{$h$} & \thead{weights \\ $d \times (d_k h)$} & \thead{savings \\ $d_k^2 h$} & \thead{savings \\ \%} \\ \hline
68 | Whisper-tiny & 384 & 64 & 6 & 147K & 25K & 17\% \\
69 | CodeGemma-7B & 3,072 & 256 & 16 & 12.6M & 1.0M & 8\% \\
70 | T5-3B & 1,024 & 128 & 32 & 4.2M & 0.5M & 12\% \\
71 | T5-11B & 1,024 & 128 & 128 & 16.8M & 2.1M & 13\% \\ \fline
72 | \end{tabular} \end{table} \endgroup
73 |
74 | \section{Matrix-shrink for MLA}
75 | DeepSeek's MLA (multi-head latent attention) scheme \citep{deepseek-v2} has two latent projections, one for Q (queries) and one for KV (keys and values). We can apply matrix-shrink to each of them:
76 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
77 | \item The Q-latent projection and query (Q) projections are two back-to-back weight matrices $\WW{DQ}$ and $\WW{UQ}$.
78 | \item The KV-latent projection and key/value (KV) projections are two back-to-back weight matrices $\WW{DKV}$ and the union of $\WW{UK}$ and $\WW{UV}$.
79 | \end{itemize}
80 | We can also apply matrix-shrink to each V-O head and the non-RoPE portion of the Q-K heads. Specifically, we can apply the matrix-shrink to the MLA weight matrices in the following order:
81 | \begin{enumerate}[topsep=-1pt, itemsep=-1pt]
82 | \item Apply matrix-shrink to the V-O weight matrices.
83 | \item Apply matrix-shrink to the NoPE portion (i.e. the non-RoPE portion) of the Q-K weight matrices.
84 | \item Apply matrix-shrink to the Q-latent projections. This step must be done after applying matrix-shrink to the Q-K weights.
85 | \item Apply matrix-shrink to the KV-latent projections. This step must be done after applying matrix-shrink to the V-O weights.
86 | \end{enumerate}
87 |
88 | Applying matrix-shrink to the KV-latent projections not only reduces weight matrices and corresponding compute, it can also reduce the compute complexity as follows, where $r_\text{KV}$ is the rank of the KV-latent projections.
89 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
90 | \item Option 1: Use the $r_\text{KV}$ neurons that don’t require a weight matrix as keys. The number of those keys is $r_\text{KV} / d_\text{NOPE}$. Then these keys can be directly used for the softmax arguments, which saves some computation complexity.
91 | \item Option 2: Use the $r_\text{KV}$ neurons as values (instead of keys). Then these values can be directly multiplied with the softmax scores, which saves some compute complexity.
92 | \end{itemize}
93 |
94 | We are using the following parameter names similar to \citep{deepseek-v2}:
95 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
96 | \item For Q (query):
97 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
98 | \item $r_\text{Q}$: rank of Q-latent projection
99 | \item $\WW{DQ}$: down-projection for Q
100 | \item $\WW{UQ}$: up-projection for Q-part without RoPE (aka NoPE)
101 | \item $\WW{QR}$: up-projection for Q-part with RoPE
102 | \end{itemize}
103 | \item For KV (key-value):
104 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
105 | \item $r_\text{KV}$: rank of KV-latent projection
106 | \item $\WW{KR}$: projection for K-part with RoPE (has its own cache, used for all queries as MQA)
107 | \item $\WW{DKV}$: down-projection for KV
108 | \item $\WW{UK}$: up-projection for K-part without RoPE (aka NoPE)
109 | \item $\WW{UV}$: up-projection for V
110 | \end{itemize}
111 | \end{itemize}
112 |
113 | % shortcuts (only letters are allowed in macro names, no numbers and dashes)
114 | \def\dsRone {\href{https://huggingface.co/deepseek-ai/DeepSeek-R1} {DeepSeek-R1}}
115 | \def\pplRone {\href{https://huggingface.co/perplexity-ai/r1-1776} {R1-1776}}
116 | \def\dsVthree {\href{https://huggingface.co/deepseek-ai/DeepSeek-V3} {V3}}
117 | \def\dsVtwoFive {\href{https://huggingface.co/deepseek-ai/DeepSeek-V2.5} {DeepSeek-V2.5}}
118 | \def\dsVtwoL {\href{https://huggingface.co/deepseek-ai/DeepSeek-V2-Lite} {DeepSeek-V2-lite}}
119 | \def\dsVLtwoS {\href{https://huggingface.co/deepseek-ai/deepseek-vl2-small} {DeepSeek-VL2-small}}
120 | \def\MiniCPM {\href{https://huggingface.co/openbmb/MiniCPM3-4B} {MiniCPM3-4B}}
121 |
122 | \begingroup \renewcommand{\arraystretch}{1.3} % increase table row height by 1.3x
123 | \begin{table}[h!] \centering
124 | \begin{tabular}{lcccccccc} \fline
125 | \thead[l]{Model} & \thead{Params} & $d$ & $r_\text{Q}$ & $r_\text{KV}$ & $h$ & $d_\text{NOPE}$ & $h \cdot d_\text{NOPE}$ & $d_\text{ROPE}$ \\ \hline
126 | Perplexity \pplRone, \dsRone, and \dsVthree & 685B & 7,168 & 1,536 & 512 & 128 & 128 & 16,384 & 64 \\
127 | \dsVtwoFive & 236B & 5,120 & 1,536 & 512 & 128 & 128 & 16,384 & 64 \\
128 | \dsVtwoL, \dsVLtwoS & 16B & 2,048 & N/A & 512 & 16 & 128 & 2,048 & 64 \\
129 | OpenBMB \MiniCPM & 4B & 2,560 & 768 & 256 & 40 & 64 & 2,560 & 32 \\ \fline
130 | \end{tabular} \end{table} \endgroup
131 |
132 | TODO: add savings to the table above (or a new table)
133 |
134 | \section{Simplified MLA}
135 | In this section we propose a simplification for DeepSeek’s MLA (multi-head latent attention).
136 | \begin{figure}[h!] \centering
137 | \includegraphics[scale=0.88]{../doc/fig/matShrink_fig3.pdf}
138 | \caption{K and V projections for MLA. (a) original version; (b) equivalent version optimized by matrix-shrink; (c) proposed simplification}
139 | \label{fig3} \end{figure}
140 |
141 | Fig. \ref{fig3} shows the K and V projections of MLA and the proposed simplification:
142 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
143 | \item Fig. \ref{fig3}(a) shows the MLA projections for K (keys) and V (values). Note that a single $d_\text{ROPE}$ head is shared among all query-heads, where $d_\text{ROPE} = 64$ or $32$ usually.
144 | \item Fig. \ref{fig3}(b) shows the mathematically equivalent version with matrix-shrink applied to the weight matrices $\WW{DKV}$ and $\WW{UK}$.
145 | \item Fig. \ref{fig3}(c) shows the proposed simplified MLA scheme where the $d_\text{ROPE}$ units (or channels) are sourced directly from the latent cache, instead of having a separate cache and $\WW{KR}$:
146 | \begin{itemize}[topsep=-1pt, itemsep=-1pt]
147 | \item Note that this simplified scheme is not mathematically identical to the standard MLA scheme shown in Fig. \ref{fig3}(a).
148 | \item The rank $s$ of the simplified scheme could be larger than $r$ (e.g. $s = r + d_\text{ROPE}$) or slightly lower than this (e.g. $s = r$).
149 | \item Advantages include: If $s > r$, then there is more usable rank for the keys and values. So the cached latent space is better utilized. And if $s < r + d_\text{ROPE}$ then the total cache size is reduced.
150 | \end{itemize}
151 | \end{itemize}
152 |
153 | \section{Matrix-shrink for GQA and MQA}
154 | Matrix-shrink is not limited to MHA and MLA only. It’s also applicable to GQA (grouped query attention) and MQA (multi-query attention). However, the savings are smaller than for MHA and MLA. Specifically, the savings are reduced by a factor $g$, where $g$ is the number of queries that are shared among a single KV-pair, or in other words $g = n_\text{heads} / n_\text{KV-heads}$ (where $n_\text{heads}$ is the number of query-heads, and $n_\text{KV-heads}$ is the number of KV-heads).
155 |
156 | \section{Matrix-shrink for SVD}
157 | In some cases, we can first use SVD (singular value decomposition) to compress the rank of any weight matrix $W$ by a certain percentage. This is applicable for example for the large weight matrices of the transformer’s FFN (feedforward networks). The SVD decomposition factorizes the original matrix $W$ \eR{d}{e} into two matrices $W_A$ and $W_B$ where $r$ is the compressed rank. After performing SVD and compressing the rank by a certain percentage, we can then eliminate $r^2$ weights using our matrix-shrink scheme. Note that reducing the rank by a certain percentage is not an exact implementation of the original matrix $W$ but an approximation.
158 |
159 | %\section{Conclusion}
160 | %Slim attention offers a simple trick for halving the context memory of existing MHA transformer models without sacrificing accuracy. Future work includes integrating slim attention into popular frameworks such as HuggingFace Transformers \citep{HFtransformers}, llama.cpp \citep{llama-cpp}, vLLM \citep{vLLM}, llamafile \citep{llamafile}, Ollama \citep{ollama}, SGLang \citep{sglang}, and combining it with existing context memory management schemes such as PagedAttention \citep{pagedAttn} and other compression schemes such as Dynamic Memory Compression DMC \citep{DMC} and VL-cache \citep{VL-cache}.
161 |
162 | %\section*{Acknowledgments}
163 | %We would like to thank TBD for helpful feedback on this work.
164 |
165 | \bibliographystyle{unsrtnat}
166 | \bibliography{references}
167 |
168 | \end{document}
169 |
--------------------------------------------------------------------------------
/tex/flashNorm.tex:
--------------------------------------------------------------------------------
1 | % To generate PDF, type ./run flashNorm.tex
2 |
3 | \documentclass{article}
4 |
5 | \usepackage[preprint, nonatbib]{neurips_2025}
6 | %\usepackage[nonatbib]{neurips_2025} % for submission
7 | %\usepackage[final, nonatbib]{neurips_2025} % final version
8 | \usepackage{neurips_2025_mods} % my mods for neurips_2025.sty
9 |
10 | % shortcuts
11 | \newcommand{\mat}[1]{\mathbf{#1}} % shortcut for matrix
12 | \newcommand{\RMS}[1]{\text{RMS}(#1)} % shortcut for RMS(x)
13 | \def\rms{\text{RMS}(\vec{a})} % RMS(a)
14 | \def\f1n{\frac{1}{n}} % 1/n
15 | \def\sas{\sum_{i=1}^n a_i^2} % sum over a_i squared
16 | \def\W*{\mat{W}^\ast} % matrix W*
17 | \def\V*{\mat{V}^\ast} % matrix V*
18 | \def\mW{\mat{W}} % matrix W
19 | \def\mV{\mat{V}} % matrix V
20 | \def\a{\vec{a}} % vector a
21 | \def\b{\vec{b}} % vector b
22 | \def\c{\vec{c}} % vector c
23 | \def\vb{\vec{\beta}} % vector beta
24 | \def\vx{\vec{x}} % vector x
25 | \def\vy{\vec{y}} % vector y
26 | \def\vz{\vec{z}} % vector z
27 | \def\vg{\vec{g}} % vector g
28 | \def\vs{\vec{s}} % vector s
29 | \def\cosi{\cos{(\cdot)}} % cos(.)
30 | \def\sini{\sin{(\cdot)}} % sin(.)
31 |
32 | \title{FlashNorm: fast normalization for LLMs}
33 | %\title{Flash normalization: fast normalization for LLMs}
34 | %\title{Flash normalization: fast RMSNorm for LLMs}
35 |
36 | \author{Nils Graef\thanks{\texttt{info@openmachine.ai}}, \, Andrew Wasielewski, \, Matthew Clapp \\
37 | \href{https://openmachine.ai}{OpenMachine}}
38 |
39 | \begin{document} \maketitle
40 |
41 | \begin{abstract}
42 | This paper presents FlashNorm, which is an exact but faster implementation of RMSNorm followed by linear layers. RMSNorm \citep{rms} is used by many LLMs such as Llama, Gemma, Mistral, and OLMo 2 \citep{LLaMA, gemma, mistral, olmo2}. FlashNorm also speeds up Layer Normalization \citep{layerNorm} and its recently proposed replacement Dynamic Tanh (DyT) \citep{DyT}. FlashNorm reduces the number of parameter tensors by simply merging the normalization weights with the weights of the next linear layer. Watch our explainer video \citep{flashNorm-video} and see \citep{slimAttn, tricks, remove, precompute} for code and more transformer tricks.
43 | \end{abstract}
44 |
45 | \section{Flash normalization}
46 | \begin{figure}[h!] \centering % the [h!] tries to place the picture right here
47 | \includegraphics[scale=1.0]{../doc/fig/flashNorm_fig1.pdf}
48 | \caption{Mathematically identical implementations of RMSNorm followed by a linear layer: (a) unoptimized version with weight matrix $\mat{W}$; (b) optimized version with normalization weights $g_i$ merged into the linear layer with new weights $\W*$; (c) optimized version with deferred normalization. The $\triangleq$ symbol denotes mathematical identity.}
49 | \label{fig1} \end{figure}
50 |
51 | RMSNorm \citep{rms} normalizes the elements $a_i$ of vector $\a$ as $y_i = \frac{a_i}{\rms} \cdot g_i$ with $\rms = \sqrt{\f1n \sas}$ and normalization weights $g_i$. In transformer \citep{vanilla} and other neural networks, RMSNorm is often followed by a linear layer as illustrated in Fig. \ref{fig1}(a), which we optimize as follows:
52 | \begin{itemize}[topsep=-1pt]
53 | \item \textbf{Weightless normalization (aka non-parametric normalization)}: We merge the normalization weights $g_i$ into the linear layer with weights $\mat{W}$, resulting in a modified weight matrix $\W*$ with $W_{i,j}^\ast = g_i \cdot W_{i,j}$ as illustrated in Fig. \ref{fig1}(b). This works for linear layers with and without bias.
54 | \item \textbf{Deferred normalization}: Instead of normalizing before the linear layer, we normalize after the linear layer, as shown in Fig. \ref{fig1}(c). This only works if the linear layer is bias-free, which is the case for many LLMs such as Llama, Gemma, Mistral, OLMo and OpenELM. Specifically, the output of the linear layer in Fig. \ref{fig1}(b) is $\vz = \left( \a \cdot \frac{1}{\rms} \right) \W*$, which is identical to $\vz = \left( \a \, \W* \right) \cdot \frac{1}{\rms}$ because matrix multiplication by a scalar is commutative. If the linear layer has a bias at its output, then the normalization (i.e. scaling by $\frac{1}{\rms}$) must be done before adding the bias.
55 | \end{itemize}
56 |
57 | In summary, FlashNorm eliminates the normalization weights and defers the normalization to the output of the linear layer, which removes a compute bottleneck described at the end of this paper. Deferring the normalization is similar to Flash Attention \citep{flash-attention}, where the normalization by the softmax denominator is done after the multiplication of softmax arguments with value projections (V) (so that keys and values can be processed in \emph{parallel}). Therefore, we call our implementation \emph{flash} normalization (or FlashNorm), which allows us to compute the linear layer and $\rms$ in \emph{parallel} (instead of sequentially).
58 |
59 | \citeauthor{openelm} report significant changes in the overall tokens-per-second throughput when they modify the layer normalization implementation, which they attribute to a lack of kernel fusion for the underlying GPU. The simplifications presented here reduce the number of operations and thus the number of the individual kernel launches mentioned in \citep{openelm}.
60 |
61 | \subsection{Support for normalization bias and DyT bias}
62 | Layer normalization (LayerNorm) \citep{layerNorm} and DyT \citep{DyT} can have a bias vector $\vb$ right after scaling by weights $g_i$. Figure \ref{figA} illustrates how the bias vector $\vb$ can be moved to the output of the linear layer and then be added to the bias vector $\c$ of the linear layer, resulting in the new bias term $\c^{\, \ast} = \c + \vb \, \mW$, see Fig. \ref{figA}(b). After this elimination of $\vb$, the normalization weights $g_i$ can be merged into the linear layer as described in the previous section and illustrated in Fig. \ref{fig1}(b).
63 |
64 | \begin{figure}[h!] \centering % the [h!] tries to place the picture right here
65 | \includegraphics[scale=0.9]{../doc/fig/flashNorm_figA.pdf}
66 | \caption{Elimination of bias vector $\vb$: (a) Before elimination with $\vb$ between normalization weights $\vg$ and linear layer. (b) Optimized version with new bias term $\c^{\, \ast} = \c + \vb \, \mW$ at the output.}
67 | \label{figA} \end{figure}
68 |
69 | \subsection{Merging mean centering into a preceding linear layer}
70 | Note that LayerNorm consists of mean centering followed by RMSNorm. If the mean centering is preceded by a linear layer with weight matrix $\mV$, then we can eliminate the entire mean centering by modifying the weight matrix as explained in this section. Fig. \ref{figB}(a) shows the weight matrix $\mV$ followed by the mean centering, which is followed by RMSNorm.
71 |
72 | \begin{figure}[h!] \centering % the [h!] tries to place the picture right here
73 | \includegraphics[scale=0.9]{../doc/fig/flashNorm_figB.pdf}
74 | \caption{Elimination of mean centering: (a) Original weight matrix $\mV$ followed by mean centering. (b) Optimized version where the mean centering is merged into the modified weight matrix $\V*$.}
75 | \label{figB} \end{figure}
76 |
77 | The mean $\mu$ is calculated from the linear layer outputs $y_j$ as $\mu = \frac{1}{n} \sum_{j=1}^n y_j$. Note that $\vy = \vx \, \mV$, i.e. $y_j = \sum_{i=1}^n x_i v_{i, j}$ where $v_{i, j}$ are the weights of matrix $\mV$. Plugging the last equation into the $\mu$ expression lets us calculate $\mu$ directly from the input $\vx$ as
78 | \begin{equation*}
79 | \mu = \frac{1}{n} \sum_{j=1}^n \sum_{i=1}^n x_i v_{i, j} = \frac{1}{n} \sum_{i=1}^n x_i \left[ \sum_{j=1}^n v_{i, j} \right] = \frac{1}{n} \sum_{i=1}^n x_i s_i
80 | \end{equation*}
81 | where we define vector $\vs$ with $s_i = \sum_{j=1}^n v_{i, j}$ the sum of row $i$ of weight matrix $\mV$. In other words, $\mu$ is the inner-product of vectors $\vx$ and $\vs$ divided by $n$. The outputs $a_j$ of the mean centering are
82 | \begin{equation*}
83 | \a_j = y_j - \mu = \sum_{i=1}^n x_i v_{i, j} - \mu = \sum_{i=1}^n x_i v_{i, j} - \frac{1}{n} \sum_{i=1}^n x_i s_i = \sum_{i=1}^n x_i \left( v_{i, j} - \frac{1}{n} s_i \right)
84 | = \sum_{i=1}^n x_i v^{\, \ast}_{i, j}
85 | \end{equation*}
86 | From the last identity follows that the new weights $v^{\, \ast}_{i, j}$ of matrix $\V*$ of Fig. \ref{figB}(b) are computed as $v^{\, \ast}_{i, j} = v_{i, j} - \frac{1}{n} s_i$. This trick can be used to retrofit existing LayerNorm models with RMSNorm without any retraining.
87 |
88 | \section{Flash normalization for FFN}
89 | For the feed-forward networks (FFN) of LLMs, the linear layers at the FFN input usually have more output channels than input channels. In this case, deferring the normalization requires more scaling operations (i.e. more multiplications). This section details ways to reduce the number of scaling operations for bias-free FFNs.
90 |
91 | \subsection{Flash normalization for FFNs with ReLU}
92 | \begin{figure}[h!] \centering
93 | \includegraphics[scale=1.0]{../doc/fig/flashNorm_fig2.pdf}
94 | \caption{FFN with ReLU and preceding flash normalization: (a) unoptimized version; (b) optimized version where the normalization is deferred to the output of the FFN. Up and Down denote the linear layers for up and down projections.}
95 | \label{fig2} \end{figure}
96 |
97 | Even though ReLU is a nonlinear function, multiplying its argument by a non-negative scaling factor $s$ is the same as scaling its output by $s$, i.e. $\text{ReLU}(s \cdot \a) = s \cdot \text{ReLU}(\a)$ for $s \ge 0$ \citep{ReLU}. Because of this scale-invariance, we can defer the normalization to the output of the FFN as illustrated in Fig. \ref{fig2}(b), which saves $f - n$ multipliers.
98 |
99 | \subsection{Flash normalization for FFNs with GLU variant}
100 | Fig. \ref{fig3}(a) shows an FFN with a GLU variant \citep{GLU} and flash normalization at its input. The flash normalization requires two sets of $f$ multipliers at the outputs of the Gate and Up linear layers in Fig. \ref{fig3}(a). One set can be deferred to the FFN output in Fig. \ref{fig3}(b), which saves $f - n$ multipliers.
101 | \begin{figure}[h!] \centering
102 | \includegraphics[scale=0.9]{../doc/fig/flashNorm_fig3.pdf}
103 | \caption{FFN with GLU variant and preceding flash normalization: (a) unoptimized version; (b) optimized version with fewer scaling multipliers. Gate, Up, and Down denote the linear layers for gate, up, and down projections.}
104 | \label{fig3} \end{figure}
105 |
106 | \textbf{Special case for ReGLU and Bilinear GLU}: If the activation function is ReLU (aka ReGLU \citep{GLU}) or just linear (aka bilinear GLU \citep{GLU}), then we can also eliminate the scaling before the activation function and combine it with the scaling at the output as illustrated in Fig. \ref{fig4}(b), which saves $2f - n$ multipliers. Now the output scaling is using the reciprocal of the squared RMS as scaling value, which is the same as the reciprocal of the mean-square (MS):
107 | \begin{equation*}
108 | \frac{1}{(\rms)^2} = \frac{1}{\text{MS}(\a)}
109 | = \frac{1}{\f1n \sas} = \frac{n}{\sas}
110 | \end{equation*}
111 |
112 | \begin{figure}[h!] \centering
113 | \includegraphics[scale=0.9]{../doc/fig/flashNorm_fig4.pdf}
114 | \caption{FFN with ReGLU (or bilinear GLU) and preceding flash normalization: (a) unoptimized version; (b) optimized version with fewer scaling multipliers.}
115 | \label{fig4} \end{figure}
116 |
117 | \section{Flash normalization for attention with RoPE}
118 | Fig. \ref{fig5}(a) shows the Q and K linear layers with flash normalization followed by RoPE \citep{RoPE} and scaled dot-product attention \citep{vanilla}. More details on Figure \ref{fig5}:
119 | \begin{itemize}[topsep=-1pt]
120 | \item Q* and K* are the linear layers for Q (queries) and K (keys) fused with the normalization weights of the activation vector $\a$ (according to flash normalization).
121 | \item $h$ is the dimension of the attention heads.
122 | \item The boxes labeled cos, sin, and RoPE perform $\vy = \vx \cdot \cosi + \text{permute}(\vx) \cdot \sini$, where
123 | \begin{itemize}[topsep=-1pt]
124 | \item $\text{permute}(\vx) = (-x_2, x_1, -x_4, x_3, \dots, -x_h, x_{h-1})$, see equation (34) of \citep{RoPE} for more details.
125 | \item $\cosi = (\cos m \theta_1, \cos m \theta_1, \cos m \theta_2, \cos m \theta_2, \dots, \cos m \theta_{h/2}, \cos m \theta_{h/2})$ for position $m$.
126 | \item $\sini = (\sin m \theta_1, \sin m \theta_1, \sin m \theta_2, \sin m \theta_2, \dots, \sin m \theta_{h/2}, \sin m \theta_{h/2})$ for position $m$.
127 | \end{itemize}
128 | \item Note that $\cosi$ and $\sini$ only depend on the position of activation vector $\a$ and are shared among all attention heads. Therefore, it’s more efficient to first scale $\cosi$ and $\sini$ by $1/ \rms$ as illustrated in Fig. \ref{fig5}(b). This saves $2hH - h$ multipliers, where $H$ is the number of attention heads.
129 | \item Furthermore, we can fuse the scaling factor $1/ \sqrt{h}$ of the scaled dot-product with the $1/ \rms$ factor (note that we need to use $\sqrt{1/ \sqrt{h}}$ as a scaling factor for this).
130 | \item Unfortunately, the V linear layer (value projection) still needs the normalization at its output.
131 | \end{itemize}
132 | \begin{figure}[h!] \centering
133 | \includegraphics[scale=0.9]{../doc/fig/flashNorm_fig5.pdf}
134 | \caption{Flash normalization for scaled dot-product attention with RoPE: (a) unoptimized version; (b) optimized version where the normalization is fused with $\cosi$ and $\sini$.}
135 | \label{fig5} \end{figure}
136 |
137 | \section{Optimizations for QK-normalization with RoPE}
138 | Gemma 3 \citep{gemma3}, OLMo 2 \citep{olmo2}, OpenELM \citep{openelm} and other LLMs use query-key normalization (QK-norm) \citep{QKnorm}. For example, each layer of Gemma 3 and OpenELM has the following two sets of normalization weights:
139 | \begin{itemize}[topsep=-1pt]
140 | \item \verb+q_norm_weight+: query normalization weights for all heads of this layer
141 | \item \verb+k_norm_weight+: key normalization weights for all heads of this layer
142 | \end{itemize}
143 | Unfortunately, FlashNorm can't be applied to QK-norm. But for the type of QK-norm used in Gemma 3 and OpenELM, we can apply the following two optimizations detailed in the next sections:
144 | \begin{enumerate}[topsep=-1pt]
145 | \item Eliminate the RMS calculation before the Q and K linear layers.
146 | \item Fuse the normalization weights with RoPE.
147 | \end{enumerate}
148 |
149 | \subsection{Eliminate RMS calculation before QK linear layers}
150 | Fig. \ref{fig6}(a) shows a linear layer with flash normalization followed by an additional normalization. The weights of the first normalization are already merged into the linear layer weights $\W*$. Note that $\RMS{s \cdot \a} = s \cdot \rms$ where $s$ is scalar and $\a$ is a vector. Due to this scale-invariance of the RMS function, the second multiplier (scaler $s_c$) in the pipeline of Fig. \ref{fig6}(a) cancels out the first multiplier (scaler $s_a$). Fig. \ref{fig6}(b) takes advantage of this property. We can express this by using the vectors $\a, \b, \c$ along the datapath in Fig. \ref{fig6} as follows:
151 | \begin{itemize}[topsep=-1pt]
152 | \item Note that $s_c = \frac{1}{\RMS{\c}} = \frac{1}{\RMS{\b \cdot s_a}} = \frac{1}{s_a \cdot \RMS{\b}} = \frac{s_b}{s_a}$.
153 | \item With above, we can show that the $y$ outputs of figures \ref{fig6}(a) and \ref{fig6}(b) are identical:
154 | \begin{equation*}
155 | y = \a \cdot \W* \cdot s_a \cdot s_c \cdot \vg = \a \cdot \W* \cdot s_a \cdot \frac{s_b}{s_a} \cdot \vg
156 | = \a \cdot \W* \cdot s_b \cdot \vg
157 | \end{equation*}
158 | \end{itemize}
159 |
160 | \begin{figure}[h!] \centering
161 | \includegraphics[scale=0.9]{../doc/fig/flashNorm_fig6.pdf}
162 | \caption{Linear layer with flash normalization followed by a second normalization: (a) unoptimized version; (b) optimized version.}
163 | \label{fig6} \end{figure}
164 |
165 | The scale-invariance property of $\rms$ doesn’t hold exactly true for RMS with epsilon (see appendix). This should not matter because the epsilon only makes an impact if the RMS (or energy) of the activation vector is very small, in which case the epsilon limits the up-scaling of this low-energy activation vector.
166 |
167 | \begin{figure}[h!] \centering
168 | \includegraphics[scale=0.9]{../doc/fig/flashNorm_fig7.pdf}
169 | \caption{QK-norm with RoPE: (a) unoptimized version; (b) optimized version.}
170 | \label{fig7} \end{figure}
171 |
172 | \subsection{Fuse normalization weights with RoPE}
173 | Fig. \ref{fig7}(a) illustrates QK-norm with RoPE. If the QK-norm weights are the same for all heads of a layer, as is the case for Gemma 3 and OpenELM \citep{gemma3, openelm}, then we can fuse them with RoPE's $\cosi$ and $\sini$ as follows: multiply $\cosi$ and $\sini$ with the normalization weights and then share the fused $\cosi$ and $\sini$ vectors across all heads of the LLM layer as shown in Fig. \ref{fig7}(b). This requires permutation of the normalization weights $\vg$ so that the boxes labeled cos, sin, and RoPE in Fig. \ref{fig7}(b) perform $\vy = \vx \cdot \left( \cosi \cdot \vg \right) + \text{permute}(\vx) \cdot \left( \sini \cdot \text{permuteg}(\vg) \right)$, where $\text{permuteg}(\vg) = (g_2, g_1, g_4, g_3, \dots, g_h, g_{h-1})$. For simplicity, Fig. \ref{fig7}(b) doesn't show the permutation of the normalization weights.
174 |
175 | \section{Bottleneck of RMS normalization for batch 1}
176 | This section describes the compute bottleneck of RMS normalization that exists for batch size 1. This bottleneck is different from the bottleneck detailed in \citep{openelm}. Let’s consider a processor with one vector unit and one matrix unit:
177 | \begin{itemize}[topsep=-1pt]
178 | \item The matrix multiplications of the linear layers are performed by the matrix unit, while the vector unit performs vector-wise operations such as RMSNorm and FlashNorm.
179 | \item Let’s assume that the vector unit can perform $m$ operations per cycle and the matrix unit can perform $m^2$ operations per cycle, where $m$ is the processor width. Specifically:
180 | \begin{itemize}[topsep=-1pt]
181 | \item Multiplying an $n$-element vector with an $n \times n$ matrix takes $n^2$ MAD (multiply-add) operations, which takes $n^2/m^2$ cycles with our matrix unit.
182 | \item Calculating $1/\rms$ takes $n$ MAD operations (for squaring and adding) plus 2 scalar operations (for $\sqrt{n/x}$), which takes $n/m$ cycles with our vector unit if we ignore the 2 scalar operations.
183 | \item Scaling an $n$-element vector by a scaling factor takes $n$ multiply operations, which takes $n/m$ cycles.
184 | \end{itemize}
185 | \end{itemize}
186 |
187 | For the example $n = 512, m = 128$ and batch 1, Fig. \ref{fig8} shows timing diagrams without and with deferred normalization:
188 | \begin{itemize}[topsep=-1pt]
189 | \item Without deferred normalization, the matrix unit has to wait for 8 cycles until the vector unit has calculated the RMS value and completed the scaling by $1/ \rms$ as illustrated in Fig. \ref{fig8}(a).
190 | \item As shown in Fig. \ref{fig8}(b), it is possible to start the matrix unit 3 cycles earlier if the weight matrix $\mat{W}$ is processed in row-major order for example. But the RMS calculation still presents a bottleneck.
191 | \item FlashNorm eliminates this bottleneck: With deferred normalization, the matrix unit computes the vector-matrix multiplication in parallel to the vector unit's RMS calculation as shown in Fig. \ref{fig8}(c). The scaling at the end can be performed in parallel to the matrix unit if $\mat{W}$ is processed in column-major order for example.
192 | \end{itemize}
193 |
194 | \begin{figure}[h!] \centering
195 | \includegraphics[scale=1.0]{../doc/fig/flashNorm_fig8.pdf}
196 | \caption{Timing diagrams for $n = 512, m = 128$: (a) without deferred normalization; (b) with interleaved scaling and vector-matrix multiplication; (c) with deferred normalization.}
197 | \label{fig8} \end{figure}
198 |
199 | \section{Experiments and conclusions}
200 | Refer to \citep{hfFlashNorm, tricks} for Python code that demonstrates the mathematical equivalency of the optimizations presented in this paper. The overall speedup of FlashNorm is modest: We measured a throughput of 204 tokens per second for OpenELM-270M with 4-bit weight quantization using the MLX framework on an M1 MacBook Air. This throughput increases to only 225 tokens per second when we remove RMSNorm entirely. Therefore, the maximum possible speedup of any RMSNorm optimization is $\leq$ 10\% for this model.
201 |
202 | For many applications, the main advantage of FlashNorm is simplification. This is similar to the simplifications we get from using RMSNorm over Layer Normalization (LayerNorm \citep{layerNorm}), and from PaLM's removal of bias-parameters from all linear layers \citep{PaLM}.
203 |
204 | Future work includes integrating FlashNorm into popular frameworks such as HuggingFace Transformers \citep{HFtransformers}, whisper.cpp \citep{whisper-cpp}, llama.cpp \citep{llama-cpp}, vLLM \citep{vLLM}, llamafile \citep{llamafile}, LM Studio \citep{lmstudio}, Ollama \citep{ollama}, SGLang \citep{sglang}, and combining it with parameter quantization.
205 |
206 | \section*{Acknowledgments}
207 | We would like to thank Dmitry Belenko for helpful feedback on this work.
208 |
209 | \appendix
210 |
211 | \section{RMS with epsilon}
212 | Many implementations add a small epsilon $\epsilon$ to the RMS value to limit the resulting scaling factor $1/\rms$ and to avoid division by zero as follows:
213 | \begin{equation*}
214 | \text{RMSe}(\a) = \sqrt{\epsilon + \f1n \sas} = \sqrt{\epsilon + \left( \rms \right)^2}
215 | \end{equation*}
216 |
217 | $\text{RMSe}(\a)$ can be used as a drop-in-replacement for RMS. The popular HuggingFace transformer library calls this epsilon \verb+rms_norm_eps+, which is set to $10^{-5}$ for Llama3.
218 |
219 | \section{Eliminating $1/n$}
220 | This section details a small optimization that eliminates the constant term $1/n$ from the RMS calculation. First, we factor out $1/n$ as follows:
221 | \begin{equation*}
222 | \rms = \sqrt{\f1n \sas} = \sqrt{\f1n} \sqrt{\sas} = \sqrt{\f1n} \cdot \text{RSS}(\a)
223 | \end{equation*}
224 | where $\text{RSS}(\a) = \sqrt{\sas}$. We can now merge the constant term into the normalization weights $g_i$ as follows:
225 | \begin{equation*}
226 | y_i = \frac{a_i}{\rms} \cdot g_i =
227 | \frac{a_i}{\text{RSS}(\a)} \sqrt{n} \cdot g_i =
228 | \frac{a_i}{\text{RSS}(\a)} \cdot g_i^\ast
229 | \end{equation*}
230 | with new normalization weights $g_i^\ast = \sqrt{n} \cdot g_i$ . These new normalization weights can now be merged with the weights $\mat{W}$ of the following linear layer as shown in the previous sections. This optimization also applies for the case where we add an epsilon as detailed in the previous section. In this case, we factor out $1/n$ as follows:
231 | \begin{equation*}
232 | \text{RMSe}(\a) = \sqrt{\epsilon + \f1n \sas}
233 | = \sqrt{\f1n \left( n \epsilon + \sas \right)}
234 | %= \sqrt{\f1n} \sqrt{n \epsilon + \sas}
235 | = \sqrt{\f1n} \cdot \text{RSSe}(\a)
236 | \end{equation*}
237 | where $\text{RSSe}(\a) = \sqrt{n \epsilon + \sas}$.
238 |
239 | \bibliographystyle{unsrtnat}
240 | \bibliography{references}
241 |
242 | \end{document}
243 |
--------------------------------------------------------------------------------
/tex/matShrink_Sid.tex:
--------------------------------------------------------------------------------
1 | \documentclass{article}
2 | % General conference packages
3 | \usepackage[utf8]{inputenc}
4 | \usepackage{times}
5 | \usepackage{url}
6 | \usepackage{latexsym}
7 | \usepackage{neurips_2025}
8 | % Additional packages for math, figures, and tables
9 | \usepackage{amsmath}
10 | \usepackage{graphicx}
11 | \usepackage{booktabs}
12 | \usepackage{hyperref}
13 | \usepackage{natbib}
14 |
15 | % Conference-specific settings
16 | \usepackage[utf8]{inputenc} % allow utf-8 input
17 | \usepackage[T1]{fontenc} % use 8-bit T1 fonts
18 | \usepackage{amsfonts} % blackboard math symbols
19 | \usepackage{nicefrac} % compact symbols for 1/2, etc.
20 | \usepackage{microtype} % microtypography
21 | \usepackage{xcolor} % colors
22 |
23 | \title{Matrix-shrink for Transformers without Loss of Accuracy}
24 |
25 | \author{
26 | Nils Graef\thanks{Email: info@openmachine.ai} \\
27 | OpenMachine \\
28 | \And
29 | TBD \\
30 | OpenMachine
31 | }
32 |
33 | \begin{document}
34 |
35 | \maketitle
36 |
37 | \begin{abstract}
38 | Matrix-shrink reduces the number of weights for back-to-back matrices. It uses matrix inversion to reduce weights in a mathematically equivalent way and thus without compromising model accuracy. Matrix-shrink is applicable to both inference and training. It can be used for inference of existing models without fine-tuning or re-training. We also propose a simplified MLA (multi-head latent attention) scheme. See \cite{openmachine2024} for code and more transformer tricks.
39 |
40 | This approach builds upon established trends in neural network optimization, where components such as biases, normalization means, and even entire layers are removed to enhance efficiency without significant performance degradation. For instance, low-rank adaptations like LoRA have demonstrated that updating models via low-rank matrix decomposition can drastically reduce the number of trainable parameters during fine-tuning, achieving comparable results to full fine-tuning with far less computational overhead \cite{medium2025lora}. Similarly, singular value decomposition (SVD) techniques have been widely applied for model compression, approximating weight matrices with lower-rank representations to minimize memory and inference time \cite{lesswrong2022svd}. Matrix-shrink extends these ideas by leveraging exact matrix inversions for back-to-back projections, ensuring lossless compression in terms of accuracy while targeting transformer-specific architectures like MHA and MLA. By integrating with mechanisms such as DeepSeek's MLA, which compresses KV caches into low-dimensional latent vectors for memory efficiency \cite{deepseek2024}, this method promises up to 2x reductions in weight counts for certain projections, facilitating deployment on resource-constrained devices and accelerating both training and inference phases.
41 |
42 | For two back-to-back weight matrices $W_A$ and $W_B$, Fig.~\ref{fig:fig1} illustrates how we can reduce the size of $W_B$ in a mathematically equivalent way by using matrix inversion. This process involves decomposing $W_B$ into submatrices and merging invertible components into $W_A$, effectively eliminating redundant parameters. Such decompositions are rooted in linear algebra principles, where matrix rank informs the compressibility without altering the output manifold. In practice, this can lead to savings of $r^{2}$ weights per operation, where $r$ represents the rank, directly impacting the multiply-accumulate operations (MACs) per token. Empirical studies on transformer models show that such rank reductions maintain perplexity scores while halving parameter footprints in attention layers \cite{arxiv2024feature}.
43 | \end{abstract}
44 |
45 | % Placeholder for Figure 1
46 | \begin{figure}[h]
47 | \centering
48 | % Insert the original Figure 1 here, which shows mathematically equivalent implementations of two back-to-back weight matrices $W_A$ and $W_B$ with rank r, where d > r and e > r. We can split $W_B$ into two submatrices WB1 ∈Rr×r and WB2. We can eliminate WB1 if it is invertible by merging it into $W_A$ as W ∗ A = WAWB1 and by changing WB2 to W ∗ B2 = W −1 B1 WB2. This saves r2 weights and r2 multiply operations per token x.
49 | \caption{Mathematically equivalent implementations of two back-to-back weight matrices $W_A$ and $W_B$ with rank $r$, where $d > r$ and $e > r$. We can split $W_B$ into two submatrices $W_{B1}$ $\in \mathbb{R}^{r \times r}$ and $W_{B2}$. We can eliminate $W_{B1}$ if it is invertible by merging it into $W_A$ as $W^{*}_{A} = W_A W_{B1}$ and by changing $W_{B2}$ to $W^{*}_{B2} = W^{-1}_{B1} W_{B2}$. This saves $r^2$ weights and $r^{2}$ multiply operations per token $x$.}
50 | \label{fig:fig1}
51 | \end{figure}
52 |
53 | Matrix-shrink reduces the number of weights for the following back-to-back weight matrices:
54 |
55 | \begin{itemize}
56 | \item The V and O projections for each attention-head
57 | \item The Q and K projections for each attention-head (without the RoPE portion)
58 | \item The latent projections of MLA (multi-head latent attention)
59 | \end{itemize}
60 |
61 | This selective targeting ensures compatibility with various transformer variants, including those employing rotary positional embeddings (RoPE) or mixture-of-experts (MoE) paradigms. By focusing on projection layers, which often constitute a significant portion of transformer parameters, matrix-shrink aligns with broader compression strategies that prioritize low-rank approximations to mitigate the quadratic scaling of attention mechanisms \cite{arxiv2024lowrank}.
62 |
63 | \textbf{Related work.} Matrix-shrink is similar to slim attention \cite{graef2025slim} in its use of matrix inversion to compute projections from each other. Slim attention, for example, eliminates the V-cache in KV-caches for MHA models, achieving up to 2x inference speedups by recomputing values from keys on-the-fly. Additionally, low-rank matrix factorization techniques, such as those in LoRA, decompose weight updates into low-rank factors to enable parameter-efficient fine-tuning \cite{medium2025lora}. Other compression schemes include SVD-based approximations, where weight matrices are truncated to retain only dominant singular values, as explored in SVD-LLM for large language models \cite{github2024svdllm}. Tensor decomposition methods like CURLoRA extend this by incorporating CUR matrix decompositions for even finer-grained adaptations \cite{openreview2024svdllm}. DeepSeek's MLA introduces low-rank joint compression for keys and values, reducing KV cache sizes while supporting multi-head structures \cite{deepseek2024}. These works collectively underscore the efficacy of rank reduction in transformers, with matrix-shrink providing an exact, inversion-based alternative that avoids approximation errors inherent in SVD or tensor methods.
64 |
65 | \textbf{Alternative way.} Alternatively, we can split matrix $W_A$ into two submatrices $W_{A1}$ $\in \mathbb{R}^{r \times r}$ and $W_{A2}$ such that $W_A = [WA1; WA2]$. We can then eliminate $W_{A1}$ if it is invertible as $W = [WA1; WA2] W_B = [I; W^{*}_{\text{A2}}$]$W^{*}_{\text{B}}$ with identity matrix I $\in \mathbb{R}^{r \times r}$ and where $W^{*}_{\text{B}} = W_{A1} W_B$ and $W^{*}_{\text{A2}}$ = WA2$W^{-1}_{\text{A1}}$, see Fig.~\ref{fig:fig2}. This alternative formulation offers flexibility in which matrix to shrink, depending on the architectural constraints. For instance, in scenarios where $W_B$ is shared across multiple heads, shrinking $W_A$ preserves shared structures while still yielding $r^{2}$ savings. However, this method requires careful handling of invertibility, as non-invertible submatrices could introduce numerical instability, a concern mitigated by regularization techniques in related low-rank compression \cite{uclouvain2024lowrank}. Pros include reduced downstream computations if $W_A$ is the bottleneck layer, while cons involve potential increases in upstream matrix sizes if not balanced properly. Empirical evaluations on BERT-like encoders show this approach maintains accuracy within 0.1\% while compressing feedforward layers by up to 15\% \cite{neurips2022lowrank}.
66 |
67 | % Placeholder for Figure 2
68 | \begin{figure}[h]
69 | \centering
70 | % Insert the original Figure 2 here, which shows alternative way of shrinking $W_A$ instead of $W_B$.
71 | \caption{Alternative way of shrinking $W_A$ instead of $W_B$.}
72 | \label{fig:fig2}
73 | \end{figure}
74 |
75 | \section{Introduction}
76 | Transformers have revolutionized natural language processing, computer vision, and beyond, owing to their scalable architecture and ability to capture long-range dependencies through attention mechanisms \cite{vaswani2017attention}. However, the exponential growth in model sizes---exemplified by models surpassing hundreds of billions of parameters---poses significant challenges in terms of memory footprint, computational demands, and deployment feasibility on edge devices. To address these, various compression techniques have emerged, including pruning, quantization, and low-rank approximations, each aiming to reduce redundancy while preserving performance \cite{arxiv2023survey}. Matrix-shrink introduces a novel, exact method for compressing back-to-back weight matrices in transformers using matrix inversion, ensuring no loss in accuracy and applicability to both training and inference phases. This paper focuses on its integration with multi-head attention (MHA) and multi-head latent attention (MLA), demonstrating parameter savings and efficiency gains. By building on prior works like slim attention \cite{graef2025slim} and DeepSeek's MLA \cite{deepseek2024}, we propose enhancements that not only shrink matrices but also simplify complex attention schemes, paving the way for more efficient large-scale models. The subsequent sections detail the methodology, applications to MHA and MLA, a simplified MLA variant, extensions to GQA/MQA, and synergies with SVD for broader compression.
77 |
78 | \section{Matrix-shrink for MHA}
79 | Note that the value (V) and output (O) projections for head $i$ of multi-head attention (MHA) are two back-to-back weight matrices $W_{V,i}$ and $W_{O,i}$. Therefore, we can apply the matrix-shrink scheme to each head. Specifically:
80 |
81 | \begin{itemize}
82 | \item For the vanilla MHA with $h$ heads, each head has dimension $d_k = d/h$, and $d = d_{\text{model}}$.
83 | \item So for the dimensions $r$ and $e$ of Fig.~\ref{fig:fig1}, we have $r = d/h$ and $e = d$.
84 | \item This saves $r^{2} = d^{2}/h^{2}$ weights for each head, so $d^{2}/h$ weights in total.
85 | \item Note: for single-head attention (where $h = 1$), we can save $2d^{2}$ weights (i.e., we can merge the V and O weight matrices into a single $d \times d$ matrix; and the Q and K weight matrices into a single $d \times d$ matrix if there is no RoPE).
86 | \end{itemize}
87 |
88 | For models that don’t use RoPE (such as Whisper \cite{radford2022whisper} or T5 models), the query (Q) and key (K) projections for each head $i$ of MHA are two back-to-back weight matrices $W_{Q,i}$ and $W_{K,i}$. As with V-O weight matrices, this saves $d^{2}/h$ weights.
89 |
90 | For many models that use RoPE, we can also apply this trick as follows: Many implementations apply RoPE to only a portion of the head-dimension $d_k = d/h$, usually only to one half of $d_k$. So in this case $r = d_k/2 = d/(2h)$, which saves only $r^{2} = d^{2}/(4h^{2})$ weights for each head, so $d^{2}/(4h)$ weights in total.
91 |
92 | % Table for Section 1
93 | \begin{table}[h]
94 | \centering
95 | \begin{tabular}{lccccccc}
96 | \toprule
97 | Model & $d$ & $d_k$ & $h$ & weights & $d \times (d_k h)$ & savings & $d^{2} k h$ savings \% \\
98 | \midrule
99 | Whisper-tiny & 384 & 64 & 6 & 147K & 25K & 17\% \\
100 | CodeGemma-7B & 3,072 & 256 & 16 & 12.6M & 1.0M & 8\% \\
101 | T5-3B & 1,024 & 128 & 32 & 4.2M & 0.5M & 12\% \\
102 | T5-11B & 1,024 & 128 & 128 & 16.8M & 2.1M & 13\% \\
103 | \bottomrule
104 | \end{tabular}
105 | \caption{Weight savings for MHA models using matrix-shrink.}
106 | \label{tab:tab1}
107 | \end{table}
108 |
109 | Expanding on these savings, consider that in large-scale transformers like T5-11B, the attention projections account for a substantial parameter budget. By applying matrix-shrink, we not only reduce weights but also inference latency, as fewer MACs are required per forward pass. Studies on low-rank approximations in MHA layers confirm that rank reductions up to 50\% in head dimensions preserve semantic understanding in NLP tasks \cite{medium2023compressing}. For encoder-decoder models like Whisper, this translates to faster speech-to-text processing, with reported speedups of 1.5x in batch inference scenarios \cite{radford2022whisper}. Furthermore, integrating with slim attention \cite{graef2025slim} allows for complementary cache reductions, compounding efficiency gains.
110 |
111 | \section{Matrix-shrink for MLA}
112 | DeepSeek’s MLA (multi-head latent attention) scheme \cite{deepseek2024} has two latent projections, one for Q (queries) and one for KV (keys and values). We can apply matrix-shrink to each of them:
113 |
114 | \begin{itemize}
115 | \item The Q-latent projection and query (Q) projections are two back-to-back weight matrices $W_{DQ}$ and $W_{UQ}$.
116 | \item The KV-latent projection and key/value (KV) projections are two back-to-back weight matrices $W_{DKV}$ and the union of $W_{UK}$ and $W_{UV}$.
117 | \end{itemize}
118 |
119 | We can also apply matrix-shrink to each V-O head and the non-RoPE portion of the Q-K heads. Specifically, we can apply the matrix-shrink to the MLA weight matrices in the following order:
120 |
121 | \begin{enumerate}
122 | \item Apply matrix-shrink to the V-O weight matrices.
123 | \item Apply matrix-shrink to the NoPE portion (i.e., the non-RoPE portion) of the Q-K weight matrices.
124 | \item Apply matrix-shrink to the Q-latent projections. This step must be done after applying matrix-shrink to the Q-K weights.
125 | \item Apply matrix-shrink to the KV-latent projections. This step must be done after applying matrix-shrink to the V-O weights.
126 | \end{enumerate}
127 |
128 | Applying matrix-shrink to the KV-latent projections not only reduces weight matrices and corresponding compute, it can also reduce the compute complexity as follows, where $r_{KV}$ is the rank of the KV-latent projections.
129 |
130 | \begin{itemize}
131 | \item Option 1: Use the $r_{KV}$ neurons that don’t require a weight matrix as keys. The number of those keys is $r_{KV}/d_{\text{NOPE}}$. Then these keys can be directly used for the softmax arguments, which saves some computation complexity.
132 | \item Option 2: Use the $r_{KV}$ neurons as values (instead of keys). Then these values can be directly multiplied with the softmax scores, which saves some compute complexity.
133 | \end{itemize}
134 |
135 | We are using the following parameter names similar to \cite{deepseek2024}:
136 |
137 | \begin{itemize}
138 | \item For Q (query):
139 | \begin{itemize}
140 | \item $r_Q$: rank of Q-latent projection
141 | \item $W_{DQ}$: down-projection for Q
142 | \item $W_{UQ}$: up-projection for Q-part without RoPE (aka NoPE)
143 | \item $W_{QR}$: up-projection for Q-part with RoPE
144 | \end{itemize}
145 | \item For KV (key-value):
146 | \begin{itemize}
147 | \item $r_{KV}$: rank of KV-latent projection
148 | \item $W_{KR}$: projection for K-part with RoPE (has its own cache, used for all queries as MQA)
149 | \item $W_{DKV}$: down-projection for KV
150 | \item $W_{UK}$: up-projection for K-part without RoPE (aka NoPE)
151 | \item $W_{UV}$: up-projection for V
152 | \end{itemize}
153 | \end{itemize}
154 |
155 | % Table for Section 2
156 | \begin{table}[h]
157 | \centering
158 | \begin{tabular}{lccccccccccc}
159 | \toprule
160 | Model & Params & $d$ & $r_Q$ & $r_{KV}$ & $h$ & $d_{\text{NOPE}}$ & $h \cdot d_{\text{NOPE}}$ & $d_{\text{ROPE}}$ & Perplexity R1-1776 & DeepSeek-R1 & V3 \\
161 | \midrule
162 | 685B & 7,168 & 1,536 & 512 & 128 & 128 & 16,384 & 64 & & & & \\
163 | DeepSeek-V2.5 & 236B & 5,120 & 1,536 & 512 & 128 & 128 & 16,384 & 64 & & & \\
164 | DeepSeek-V2-lite, DeepSeek-VL2-small & 16B & 2,048 & N/A & 512 & 16 & 128 & 2,048 & 64 & & & \\
165 | OpenBMB MiniCPM3-4B & 4B & 2,560 & 768 & 256 & 40 & 64 & 2,560 & 32 & & & \\
166 | \bottomrule
167 | \end{tabular}
168 | \caption{Parameters and savings for MLA models using matrix-shrink.}
169 | \label{tab:tab2}
170 | \end{table}
171 |
172 | To elaborate, MLA in DeepSeek-V2 compresses the KV cache into a low-dimensional latent vector, achieving a 93.3\% reduction in memory usage compared to baselines like DeepSeek 67B, while boosting generation throughput by 5.76 times \cite{deepseek2024}. This latent compression aligns seamlessly with matrix-shrink, as the down-projections (e.g., $W_{DKV}$) can be inverted to merge with upstream layers, further trimming parameters. For models like DeepSeek-V2.5 with 236B parameters, applying matrix-shrink post-MLA yields additional savings of up to $d^{2} / (4h)$ in non-RoPE portions, enhancing scalability for long-context tasks \cite{medium2025deepseek}. Benefits include maintained perplexity across benchmarks, with the latent rank $r_{KV}$ enabling efficient MoE integration. Savings calculations, as in the table, demonstrate parameter reductions of 10-15\% in attention blocks, corroborated by implementations in repositories like bird-of-paradise/deepseek-mla \cite{towardsai2024mla}.
173 |
174 | \textit{TODO: add savings to the table above (or a new table)}
175 |
176 | \section{Simplified MLA}
177 | In this section, we propose a simplification for DeepSeek’s MLA (multi-head latent attention).
178 |
179 | Fig.~\ref{fig:fig3} shows the K and V projections of MLA and the proposed simplification:
180 |
181 | \begin{itemize}
182 | \item Fig.~\ref{fig:fig3}(a) shows the MLA projections for K (keys) and V (values). Note that a single $d_{\text{ROPE}}$ head is shared among all query-heads, where $d_{\text{ROPE}} = 64$ or 32 usually.
183 | \item Fig.~\ref{fig:fig3}(b) shows the mathematically equivalent version with matrix-shrink applied to the weight matrices $W_{DKV}$ and $W_{UK}$.
184 | \item Fig.~\ref{fig:fig3}(c) shows the proposed simplified MLA scheme where the $d_{\text{ROPE}}$ units (or channels) are sourced directly from the latent cache, instead of having a separate cache and $W_{KR}$:
185 | \begin{itemize}
186 | \item Note that this simplified scheme is not mathematically identical to the standard MLA scheme shown in Fig.~\ref{fig:fig3}(a).
187 | \item The rank $s$ of the simplified scheme could be larger than $r$ (e.g., $s = r + d_{\text{ROPE}}$) or slightly lower than this (e.g., $s = r$).
188 | \item Advantages include: If $s > r$, then there is more usable rank for the keys and values. So the cached latent space is better utilized. And if $s < r + d_{\text{ROPE}}$ then the total cache size is reduced.
189 | \end{itemize}
190 | \end{itemize}
191 |
192 | % Placeholder for Figure 3
193 | \begin{figure}[h]
194 | \centering
195 | % Insert the original Figure 3 here, which shows K and V projections for MLA. (a) original version; (b) equivalent version optimized by matrix-shrink; (c) proposed simplification.
196 | \caption{K and V projections for MLA. (a) original version; (b) equivalent version optimized by matrix-shrink; (c) proposed simplification.}
197 | \label{fig:fig3}
198 | \end{figure}
199 |
200 | This simplification enhances MLA by directly leveraging the latent cache for RoPE components, potentially increasing effective rank and optimizing cache utilization. In DeepSeek-V2, standard MLA already reduces KV cache by compressing into latent vectors, but our proposal further streamlines this by eliminating separate RoPE projections, leading to 5-10\% additional memory savings in long-sequence inference \cite{deepseek2024}. Advantages over the original include improved parallelism in head computations and better alignment with sparse activations in MoE models \cite{acl2023lowrank}. Visual walkthroughs and implementations confirm that this variant maintains or exceeds perplexity on benchmarks like R1-1776, while facilitating easier integration with GQA \cite{towardsai2024mla}. Potential drawbacks involve slight deviations in positional encoding fidelity, mitigated by adaptive rank adjustments.
201 |
202 | \section{Matrix-shrink for GQA and MQA}
203 | Matrix-shrink is not limited to MHA and MLA only. It’s also applicable to GQA (grouped query attention) and MQA (multi-query attention). However, the savings are smaller than for MHA and MLA. Specifically, the savings are reduced by a factor $g$, where $g$ is the number of queries that are shared among a single KV-pair, or in other words $g = n_{\text{heads}}/n_{\text{KV-heads}}$ (where $n_{\text{heads}}$ is the number of query-heads, and $n_{\text{KV-heads}}$ is the number of KV-heads).
204 |
205 | In GQA, grouping queries shares KV computations across heads, inherently reducing redundancy, but matrix-shrink can still merge back-to-back projections within groups, yielding savings proportional to $1/g$. For example, in models like Gemma2-9B with GQA, this results in 10-20\% weight reductions in attention layers without accuracy loss \cite{towardsai2024mla}. MQA, as an extreme case where $g = h$, further limits savings but enables ultra-efficient inference for long contexts. Combining with MLA-inspired latents, as in DeepSeek variants, amplifies benefits, achieving up to 4x throughput improvements in grouped settings \cite{deepseek2024}. This adaptability makes matrix-shrink versatile for hybrid attention mechanisms, where partial grouping balances compute and memory.
206 |
207 | \section{Matrix-shrink for SVD}
208 | In some cases, we can first use SVD (singular value decomposition) to compress the rank of any weight matrix W by a certain percentage. This is applicable, for example, for the large weight matrices of the transformer’s FFN (feedforward networks). The SVD decomposition factorizes the original matrix W $\in \mathbb{R}^{d \times e}$ into two matrices $W_A$ and $W_B$ where $r$ is the compressed rank. After performing SVD and compressing the rank by a certain percentage, we can then eliminate $r^{2}$ weights using our matrix-shrink scheme. Note that reducing the rank by a certain percentage is not an exact implementation of the original matrix W but an approximation.
209 |
210 | SVD-based compression has been extensively validated in transformers, with techniques like SVD-LLM employing truncation-aware methods to map singular values directly to compression loss, ensuring minimal accuracy degradation \cite{github2024svdllm}. For FFN layers, which often dominate parameter counts, SVD reduces ranks by 30-50\% while preserving performance on tasks like GLUE \cite{lesswrong2022svd}. Integrating matrix-shrink post-SVD merges the decomposed factors exactly, avoiding approximation errors in invertible submatrices. Truncation-aware whitening further refines this, as in recent LLM compressions, yielding 2-3x smaller models \cite{openreview2024svdllm}. Applications extend to vision transformers, where SVD compresses convolutional proxies, and hybrid models combining SVD with LoRA for fine-tuned efficiency \cite{cvpr2024pela}. Overall, this hybrid approach achieves state-of-the-art compression ratios, with empirical results showing <1\% perplexity increase on LLaMA-scale models.
211 |
212 | \bibliographystyle{plainnat}
213 | \bibliography{references}
214 |
215 | \begin{thebibliography}{21}
216 |
217 | \bibitem[OpenMachine(2024)]{openmachine2024}
218 | OpenMachine. Transformer tricks. 2024. \url{https://github.com/OpenMachine-ai/transformer-tricks}.
219 |
220 | \bibitem[Graef and Wasielewski(2025)]{graef2025slim}
221 | Nils Graef and Andrew Wasielewski. Slim attention: cut your context memory in half without loss of accuracy – K-cache is all you need for MHA. 2025. \url{https://github.com/OpenMachine-ai/transformer-tricks/blob/main/doc/slimAttn.pdf}.
222 |
223 | \bibitem[DeepSeek-AI et al.(2024)]{deepseek2024}
224 | DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Hao Yang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J. L. Cai, Jian Liang, Jianzhong Guo, Jiaqi Ni, Jiashi Li, Jin Chen, Jingyang Yuan, Junjie Qiu, et al. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. 2024. \url{https://arxiv.org/abs/2405.04434}.
225 |
226 | \bibitem[Medium(2025)]{medium2025deepseek}
227 | Medium. DeepSeek-V3 Explained 1: Multi-head Latent Attention. Jan 31, 2025. \url{https://medium.com/data-science/deepseek-v3-explained-1-multi-head-latent-attention-ed6bee2a67c4}.
228 |
229 | \bibitem[Towards AI(2024)]{towardsai2024mla}
230 | Towards AI. A Visual Walkthrough of DeepSeek's Multi-Head Latent Attention (MLA). Jun 20, 2024. \url{https://towardsai.net/p/artificial-intelligence/a-visual-walkthrough-of-deepseeks-multi-head-latent-attention-mla-%25EF%25B8%258F}.
231 |
232 | \bibitem[Medium(2025)]{medium2025lora}
233 | Medium. LoRA: LLM Fine-Tuning Through Low-Rank Adaptation. Jul 16, 2025. \url{https://medium.com/%40mandeep0405/lora-llm-fine-tuning-through-low-rank-adaptation-e7277f693335}.
234 |
235 | \bibitem[arXiv(2024)]{arxiv2024lowrank}
236 | arXiv. Investigating Low-Rank Training in Transformer Language Models. Jul 13, 2024. \url{https://arxiv.org/html/2407.09835v1}.
237 |
238 | \bibitem[arXiv(2024)]{arxiv2024feature}
239 | arXiv. Feature-based Low-Rank Compression of Large Language Models. May 17, 2024. \url{https://arxiv.org/html/2405.10616v1}.
240 |
241 | \bibitem[LessWrong(2022)]{lesswrong2022svd}
242 | LessWrong. The Singular Value Decompositions of Transformer Weight Matrices. Nov 28, 2022. \url{https://www.lesswrong.com/posts/mkbGjzxD8d8XqKHzA/the-singular-value-decompositions-of-transformer-weight}.
243 |
244 | \bibitem[GitHub(2024)]{github2024svdllm}
245 | GitHub. AIoT-MLSys-Lab/SVD-LLM. \url{https://github.com/AIoT-MLSys-Lab/SVD-LLM}.
246 |
247 | \bibitem[OpenReview(2024)]{openreview2024svdllm}
248 | OpenReview. SVD-LLM: Truncation-aware Singular Value Decomposition for Large Language Model Compression. Oct 14, 2024. \url{https://openreview.net/forum?id=LNYIUouhdt}.
249 |
250 | \bibitem[NeurIPS(2022)]{neurips2022lowrank}
251 | NeurIPS. Strategies for Applying Low Rank Decomposition to Transformer Models. \url{https://neurips2022-enlsp.github.io/papers/paper_33.pdf}.
252 |
253 | \bibitem[UCLouvain(2024)]{uclouvain2024lowrank}
254 | UCLouvain. Low-rank matrix factorization for compressing Transformers. \url{https://thesis.dial.uclouvain.be/bitstreams/1aed4e10-f7bb-43d6-855f-7a4c92014829/download}.
255 |
256 | \bibitem[ACL(2023)]{acl2023lowrank}
257 | ACL Anthology. Dynamic Low-rank Estimation for Transformer-based Language Models. Dec 10, 2023. \url{https://aclanthology.org/2023.findings-emnlp.621/}.
258 |
259 | \bibitem[Medium(2023)]{medium2023compressing}
260 | Medium. Compressing LLMs With Low Rank Decomposition Of Attention Matrices. Nov 22, 2023. \url{https://siddharth-1729-65206.medium.com/compressing-llms-with-low-rank-decomposition-of-attention-matrices-ed13e9e8563a}.
261 |
262 | \bibitem[CVPR(2024)]{cvpr2024pela}
263 | CVPR. Learning Parameter-Efficient Models with Low-Rank Approximation. \url{https://openaccess.thecvf.com/content/CVPR2024/papers/Guo_PELA_Learning_Parameter-Efficient_Models_with_Low-Rank_Approximation_CVPR_2024_paper.pdf}.
264 |
265 | \bibitem[arXiv(2024)]{deepseek2024}
266 | arXiv. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. May 7, 2024. \url{https://arxiv.org/abs/2405.04434}.
267 |
268 | \bibitem[arXiv(2017)]{vaswani2017attention}
269 | arXiv. Attention Is All You Need. Jun 12, 2017. \url{https://arxiv.org/abs/1706.03762}.
270 |
271 | \bibitem[arXiv(2023)]{arxiv2023survey}
272 | arXiv. A Survey on Model Compression for Large Language Models. Aug 15, 2023. \url{https://arxiv.org/abs/2308.07633}.
273 |
274 | \bibitem[arXiv(2023)]{arxiv2023survey2}
275 | arXiv. A Survey on Model Compression for Large Language Models. Aug 15, 2023. \url{https://arxiv.org/abs/2308.07633}.
276 |
277 | \bibitem[OpenAI(2022)]{radford2022whisper}
278 | OpenAI. Whisper: Robust Speech Recognition via Large-Scale Weak Supervision. Sep 21, 2022. \url{https://arxiv.org/abs/2212.04356}.
279 |
280 | \end{thebibliography}
281 |
282 | \end{document}
283 |
--------------------------------------------------------------------------------
/doc/fig/slimAttn_fig1.svg:
--------------------------------------------------------------------------------
1 |
2 |
215 |
--------------------------------------------------------------------------------