├── LICENSE
├── README.md
├── README_ch.md
├── notebook_ch
├── .ipynb_checkpoints
│ └── 如何使用本书-checkpoint.ipynb
├── 1.introduction
│ ├── .ipynb_checkpoints
│ │ └── OCR技术导论-checkpoint.ipynb
│ └── OCR技术导论.ipynb
├── 2.text_detection
│ ├── .ipynb_checkpoints
│ │ ├── 文本检测FAQ-checkpoint.ipynb
│ │ ├── 文本检测实践篇-checkpoint.ipynb
│ │ └── 文本检测理论篇-checkpoint.ipynb
│ ├── 文本检测FAQ.ipynb
│ ├── 文本检测实践篇.ipynb
│ └── 文本检测理论篇.ipynb
├── 3.text_recognition
│ ├── .ipynb_checkpoints
│ │ ├── 文本识别实践部分-checkpoint.ipynb
│ │ └── 文本识别理论部分-checkpoint.ipynb
│ ├── 文本识别实践部分.ipynb
│ └── 文本识别理论部分.ipynb
├── 4.ppcor_system_strategy
│ ├── .ipynb_checkpoints
│ │ └── PP-OCR系统及优化策略-checkpoint.ipynb
│ └── PP-OCR系统及优化策略.ipynb
├── 4.ppocr_system_strategy
│ └── PP-OCR系统及优化策略.ipynb
├── 5.ppocrv2_inference_deployment
│ ├── .ipynb_checkpoints
│ │ └── PP-OCRv2预测部署实战-checkpoint.ipynb
│ └── PP-OCRv2预测部署实战.ipynb
├── 6.document_analysis
│ ├── .ipynb_checkpoints
│ │ ├── 文档分析实战-VQA-checkpoint.ipynb
│ │ ├── 文档分析实战-表格识别-checkpoint.ipynb
│ │ └── 文档分析理论-checkpoint.ipynb
│ ├── 文档分析实战-VQA.ipynb
│ ├── 文档分析实战-表格识别.ipynb
│ └── 文档分析理论.ipynb
└── 如何使用本书.ipynb
└── notebook_en
├── 1.introduction
└── introduction_to_OCR_technology.ipynb
├── 2.text_detection
├── text_detection_FAQ.ipynb
├── text_detection_practice.ipynb
└── text_detection_theory.ipynb
├── 3.text_recognition
├── text_recognition_practice.ipynb
└── text_recognition_theory.ipynb
├── 4.ppocr_system_strategy
└── ppocr_system_strategy.ipynb
├── 5.ppocrv2_inference_deployment
└── ppocrv2_inference_deployment_practice.ipynb
├── 6.document_analysis
├── document_analysis_practice-VQA.ipynb
├── document_analysis_practice-form_recognition.ipynb
└── document_analysis_theory.ipynb
└── how_to_use_these_notebooks.ipynb
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | English | [简体中文](README_ch.md)
2 |
3 | # E-book: *Dive Into OCR*
4 |
5 | "Dive Into OCR" is a textbook that combines OCR theory and practice, written by the PaddleOCR team, the main features are as follows:
6 |
7 | - OCR full-stack technology covering text detection, recognition and document analysis
8 | - Closely integrate theory and practice, cross the code implementation gap, and supporting instructional videos
9 | - Jupyter Notebook textbook, flexibly modifying code for instant results
10 |
11 | ## Structure
12 |
13 | - The first part is the preliminary knowledge of the book, including the knowledge index and resource links needed in the process of positioning and using the book content of the book
14 |
15 | - The second part is chapters 4-8 of the book, which introduce the concepts, applications, and industry practices related to the detection and identification capabilities of the OCR engine. In the "Introduction to OCR Technology", the application scenarios and challenges of OCR, the basic concepts of technology, and the pain points in industrial applications are comprehensively explained. Then, in the two chapters of "Text Detection" and "Text Recognition", the two basic tasks of OCR are introduced. In each chapter, an algorithm is accompanied by a detailed explanation of the code and practical exercises. Chapters 6 and 7 are a detailed introduction to the PP-OCR series model, PP-OCR is a set of OCR systems for industrial applications, on the basis of the basic detection and identification model, after a series of optimization strategies to achieve the general field of industrial SOTA model, while opening up a variety of predictive deployment solutions, enabling enterprises to quickly land OCR applications.
16 |
17 | - The third part is chapter 9-12 of the book, which introduces applications other than the two-stage OCR engine, including data synthesis, preprocessing algorithm, and end-to-end model, focusing on OCR's layout analysis, table recognition, visual document question and answer capabilities in the document scene, and also through the combination of algorithm and code, so that readers can deeply understand and apply.
18 |
19 |
20 | ## Address
21 | - [E-book: *Dive Into OCR* ](https://paddleocr.bj.bcebos.com/ebook/Dive_into_OCR.pdf)
22 | - Videos: [Chinese](https://aistudio.baidu.com/aistudio/education/group/info/25207), [English version coming soon]()
23 |
--------------------------------------------------------------------------------
/README_ch.md:
--------------------------------------------------------------------------------
1 | [English](README.md) | 简体中文
2 |
3 | # 《动手学OCR》电子书
4 |
5 | 《动手学OCR》是PaddleOCR团队**携手华中科技大学博导/教授,IAPR Fellow 白翔、复旦大学青年研究员陈智能、中国移动研究院视觉领域资深专家黄文辉、中国工商银行大数据人工智能实验室研究员等产学研同仁**,以及OCR开发者共同打造的结合OCR前沿理论与代码实践的教材。主要特色如下:
6 |
7 | - 覆盖从文本检测识别到文档分析的OCR全栈技术
8 | - 紧密结合理论实践,跨越代码实现鸿沟,并配套教学视频
9 | - Notebook交互式学习,灵活修改代码,即刻获得结果
10 |
11 |
12 | ## 本书结构
13 |
14 | 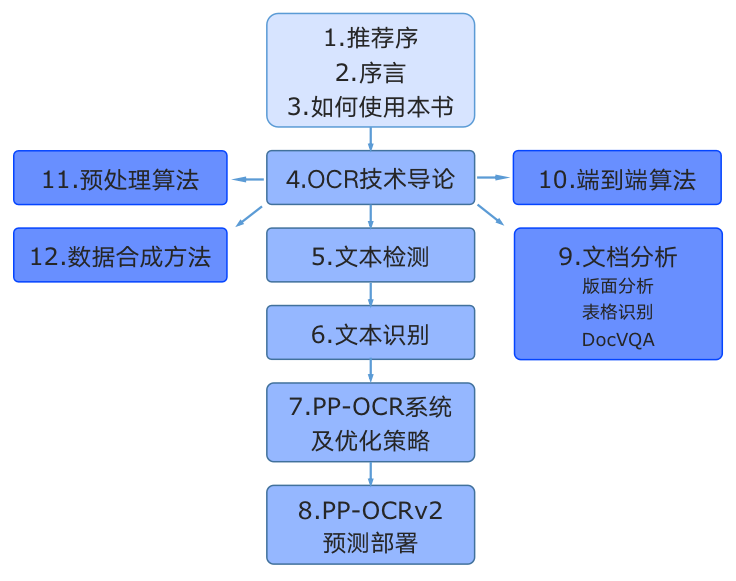
15 |
16 | - 第一部分是本书的推荐序、序言与预备知识,包含本书的定位与使用书籍内容的过程中需要用到的知识索引、资源链接等
17 | - 第二部分是本书的4-8章,介绍与OCR核心的检测、识别能力相关的概念、应用与产业实践。在“OCR技术导论”中总括性的解释OCR的应用场景和挑战、技术基本概念以及在产业应用中的痛点问题。然后在
18 | “文本检测”与“文本识别”两章中介绍OCR的两个基本任务,并在每章中配套一个算法展开代码详解与实战练习。第6、7章是关于PP-OCR系列模型的详细介绍,PP-OCR是一套面向产业应用的OCR系统,在
19 | 基础检测和识别模型的基础之上经过一系列优化策略达到通用领域的产业级SOTA模型,同时打通多种预测部署方案,赋能企业快速落地OCR应用。
20 | - 第三部分是本书的9-12章,介绍两阶段OCR引擎之外的应用,包括数据合成、预处理算法、端到端模型,重点展开了OCR在文档场景下的版面分析、表格识别、视觉文档问答的能力,同样通过算法与代码结
21 | 合的方式使得读者能够深入理解并应用。
22 |
23 |
24 | ## 资料地址
25 | - [教学视频与notebook教程](https://aistudio.baidu.com/aistudio/education/group/info/25207)
26 | - 中文版电子书下载请扫描以下二维码填写问卷后入群后领取
27 |
28 |

29 |
\n",
21 | "\n",
22 | "* **OCR有哪些应用场景?**\n",
23 | "\n",
24 | "OCR技术有着丰富的应用场景,一类典型的场景是日常生活中广泛应用的面向垂类的结构化文本识别,比如车牌识别、银行卡信息识别、身份证信息识别、火车票信息识别等等。这些小垂类的共同特点是格式固定,因此非常适合使用OCR技术进行自动化,可以极大的减轻人力成本,提升效率。\n",
25 | "\n",
26 | "这种面向垂类的结构化文本识别是目前ocr应用最广泛、并且技术相对较成熟的场景。\n",
27 | "\n",
28 | "\n",
29 | "图2 OCR技术的应用场景\n",
30 | "\n",
31 | "除了面向垂类的结构化文本识别,通用OCR技术也有广泛的应用,并且常常和其他技术结合完成多模态任务,例如在视频场景中,经常使用OCR技术进行字幕自动翻译、内容安全监控等等,或者与视觉特征相结合,完成视频理解、视频搜索等任务。\n",
32 | "\n",
33 | "\n",
34 | "图3 多模态场景中的通用OCR\n",
35 | "\n",
36 | "## 1.2 OCR技术挑战\n",
37 | "OCR的技术难点可以分为算法层和应用层两方面。\n",
38 | "\n",
39 | "* **算法层**\n",
40 | "\n",
41 | "OCR丰富的应用场景,决定了它会存在很多技术难点。这里给出了常见的8种问题:\n",
42 | "\n",
43 | "\n",
44 | "图4 OCR算法层技术难点\n",
45 | "\n",
46 | "这些问题给文本检测和文本识别都带来了巨大的技术挑战,可以看到,这些挑战主要都是面向自然场景,目前学术界的研究也主要聚焦在自然场景,OCR领域在学术上的常用数据集也都是自然场景。针对这些问题的研究很多,相对来说,识别比检测面临更大的挑战。\n",
47 | "\n",
48 | "* **应用层**\n",
49 | "\n",
50 | "在实际应用中,尤其是在广泛的通用场景下,除了上一节总结的仿射变换、尺度问题、光照不足、拍摄模糊等算法层面的技术难点,OCR技术还面临两大落地难点:\n",
51 | "1. **海量数据要求OCR能够实时处理。** OCR应用常对接海量数据,我们要求或希望数据能够得到实时处理,模型的速度做到实时是一个不小的挑战。\n",
52 | "2. **端侧应用要求OCR模型足够轻量,识别速度足够快。** OCR应用常部署在移动端或嵌入式硬件,端侧OCR应用一般有两种模式:上传到服务器 vs. 端侧直接识别,考虑到上传到服务器的方式对网络有要求,实时性较低,并且请求量过大时服务器压力大,以及数据传输的安全性问题,我们希望能够直接在端侧完成OCR识别,而端侧的存储空间和计算能力有限,因此对OCR模型的大小和预测速度有很高的要求。\n",
53 | "\n",
54 | "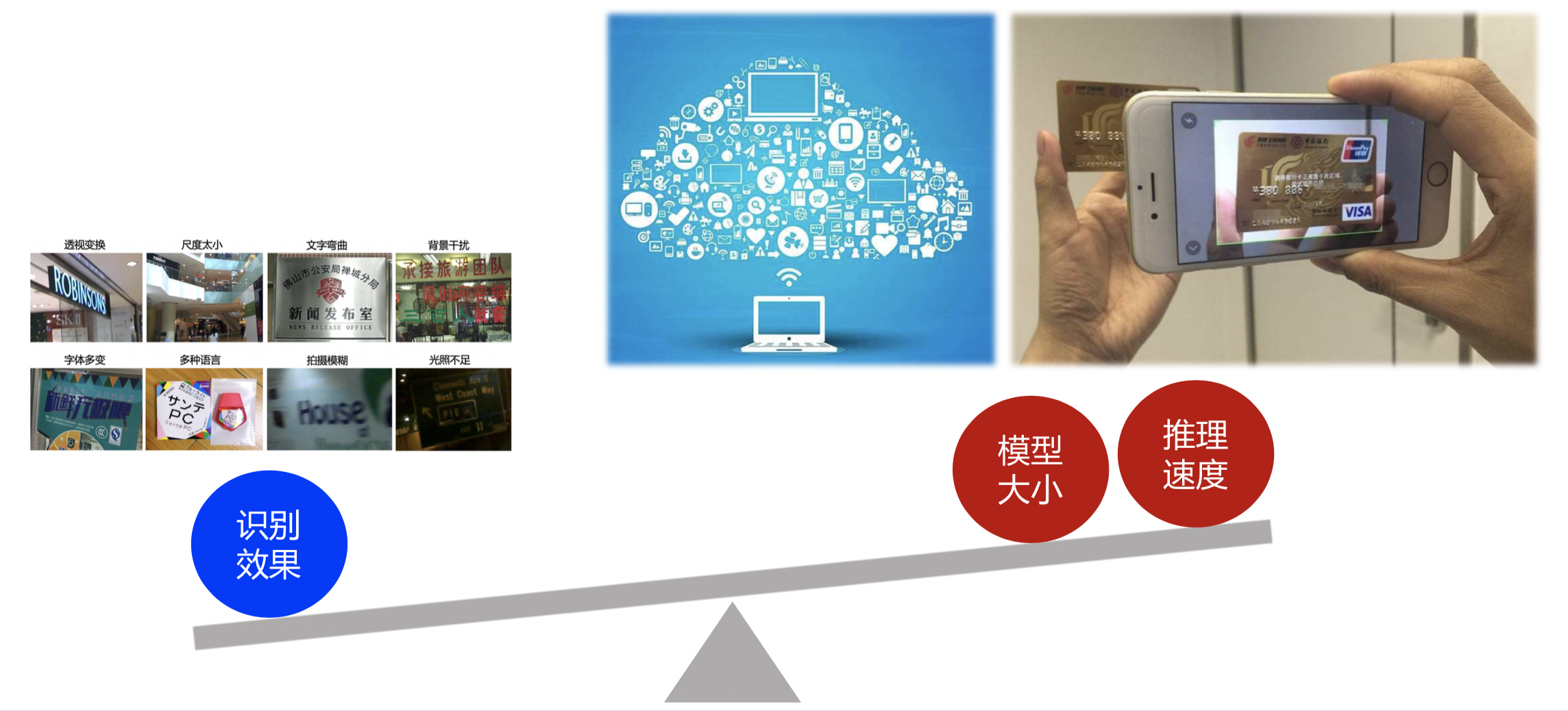\n",
55 | "图5 OCR应用层技术难点\n",
56 | "\n"
57 | ]
58 | },
59 | {
60 | "cell_type": "markdown",
61 | "metadata": {},
62 | "source": [
63 | "# 2. OCR前沿算法\n",
64 | "\n",
65 | "虽然OCR是一个相对具体的任务,但涉及了多方面的技术,包括文本检测、文本识别、端到端文本识别、文档分析等等。学术上关于OCR各项相关技术的研究层出不穷,下文将简要介绍OCR任务中的几种关键技术的相关工作。\n",
66 | "\n",
67 | "## 2.1 文本检测\n",
68 | "\n",
69 | "文本检测的任务是定位出输入图像中的文字区域。近年来学术界关于文本检测的研究非常丰富,一类方法将文本检测视为目标检测中的一个特定场景,基于通用目标检测算法进行改进适配,如TextBoxes[1]基于一阶段目标检测器SSD[2]算法,调整目标框使之适合极端长宽比的文本行,CTPN[3]则是基于Faster RCNN[4]架构改进而来。但是文本检测与目标检测在目标信息以及任务本身上仍存在一些区别,如文本一般长宽比较大,往往呈“条状”,文本行之间可能比较密集,弯曲文本等,因此又衍生了很多专用于文本检测的算法,如EAST[5]、PSENet[6]、DBNet[7]等等。\n",
70 | "\n",
71 | " \n",
72 | "图6 文本检测任务示例\n",
73 | "\n",
74 | "
\n",
72 | "图6 文本检测任务示例\n",
73 | "\n",
74 | "
\n",
75 | "\n",
76 | "目前较为流行的文本检测算法可以大致分为**基于回归**和**基于分割**的两大类文本检测算法,也有一些算法将二者相结合。基于回归的算法借鉴通用物体检测算法,通过设定anchor回归检测框,或者直接做像素回归,这类方法对规则形状文本检测效果较好,但是对不规则形状的文本检测效果会相对差一些,比如CTPN[3]对水平文本的检测效果较好,但对倾斜、弯曲文本的检测效果较差,SegLink[8]对长文本比较好,但对分布稀疏的文本效果较差;基于分割的算法引入了Mask-RCNN[9],这类算法在各种场景、对各种形状文本的检测效果都可以达到一个更高的水平,但缺点就是后处理一般会比较复杂,因此常常存在速度问题,并且无法解决重叠文本的检测问题。\n",
77 | "\n",
78 | " \n",
79 | "图7 文本检测算法概览\n",
80 | "\n",
81 | "
\n",
79 | "图7 文本检测算法概览\n",
80 | "\n",
81 | "
\n",
82 | "\n",
83 | "|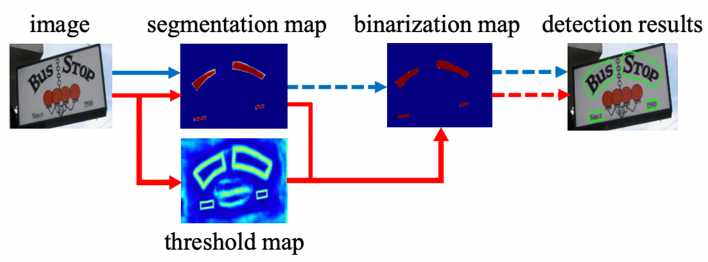|\n",
84 | "|---|---|---|\n",
85 | "图8 (左)基于回归的CTPN[3]算法优化anchor (中)基于分割的DB[7]算法优化后处理 (右)回归+分割的SAST[10]算法\n",
86 | "\n",
87 | "
\n",
88 | "\n",
89 | "文本检测相关技术将在第二章进行详细解读和实战。\n",
90 | "\n",
91 | "## 2.2 文本识别\n",
92 | "\n",
93 | "文本识别的任务是识别出图像中的文字内容,一般输入来自于文本检测得到的文本框截取出的图像文字区域。文本识别一般可以根据待识别文本形状分为**规则文本识别**和**不规则文本识别**两大类。规则文本主要指印刷字体、扫描文本等,文本大致处在水平线位置;不规则文本往往不在水平位置,存在弯曲、遮挡、模糊等问题。不规则文本场景具有很大的挑战性,也是目前文本识别领域的主要研究方向。\n",
94 | "\n",
95 | "\n",
96 | "图9 (左)规则文本 VS. (右)不规则文本\n",
97 | "\n",
98 | "
\n",
99 | "\n",
100 | "规则文本识别的算法根据解码方式的不同可以大致分为基于CTC和Sequence2Sequence两种,将网络学习到的序列特征 转化为 最终的识别结果 的处理方式不同。基于CTC的算法以经典的CRNN[11]为代表。\n",
101 | "\n",
102 | "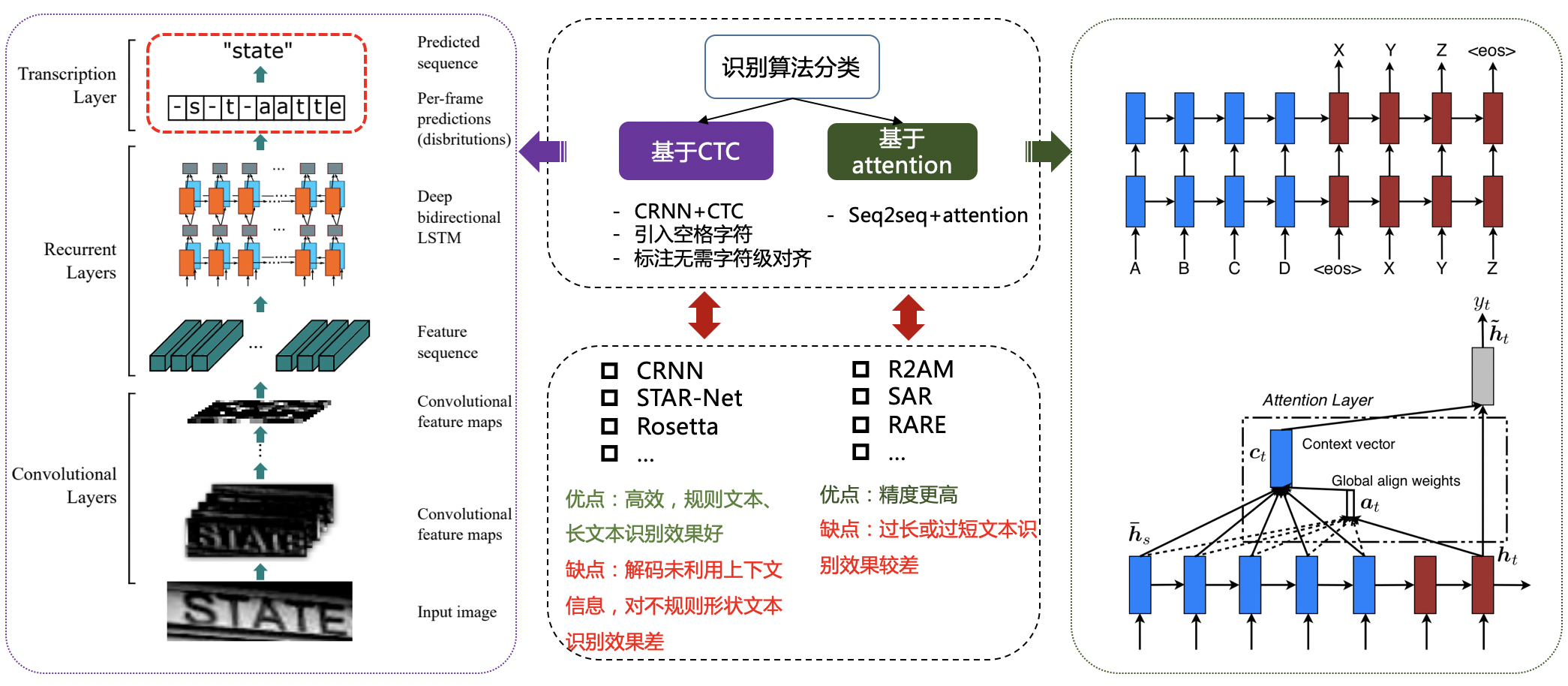\n",
103 | "图10 基于CTC的识别算法 VS. 基于Attention的识别算法\n",
104 | "\n",
105 | "不规则文本的识别算法相比更为丰富,如STAR-Net[12]等方法通过加入TPS等矫正模块,将不规则文本矫正为规则的矩形后再进行识别;RARE[13]等基于Attention的方法增强了对序列之间各部分相关性的关注;基于分割的方法将文本行的各字符作为独立个体,相比与对整个文本行做矫正后识别,识别分割出的单个字符更加容易;此外,随着近年来Transfomer[14]的快速发展和在各类任务中的有效性验证,也出现了一批基于Transformer的文本识别算法,这类方法利用transformer结构解决CNN在长依赖建模上的局限性问题,也取得了不错的效果。\n",
106 | "\n",
107 | "\n",
108 | "图11 基于字符分割的识别算法[15]\n",
109 | "\n",
110 | "
\n",
111 | "\n",
112 | "文本识别相关技术将在第三章进行详细解读和实战。\n",
113 | "\n",
114 | "## 2.3 文档结构化识别\n",
115 | "\n",
116 | "传统意义上的OCR技术可以解决文字的检测和识别需求,但在实际应用场景中,最终需要获取的往往是结构化的信息,如身份证、发票的信息格式化抽取,表格的结构化识别等等,多在快递单据抽取、合同内容比对、金融保理单信息比对、物流业单据识别等场景下应用。OCR结果+后处理是一种常用的结构化方案,但流程往往比较复杂,并且后处理需要精细设计,泛化性也比较差。在OCR技术逐渐成熟、结构化信息抽取需求日益旺盛的背景下,版面分析、表格识别、关键信息提取等关于智能文档分析的各种技术受到了越来越多的关注和研究。\n",
117 | "\n",
118 | "* **版面分析**\n",
119 | "\n",
120 | "版面分析(Layout Analysis)主要是对文档图像进行内容分类,类别一般可分为纯文本、标题、表格、图片等。现有方法一般将文档中不同的板式当做不同的目标进行检测或分割,如Soto Carlos[16]在目标检测算法Faster R-CNN的基础上,结合上下文信息并利用文档内容的固有位置信息来提高区域检测性能;Sarkar Mausoom[17]等人提出了一种基于先验的分割机制,在非常高的分辨率的图像上训练文档分割模型,解决了过度缩小原始图像导致的密集区域不同结构无法区分进而合并的问题。\n",
121 | "\n",
122 | "\n",
123 | "图12 版面分析任务示意图\n",
124 | "\n",
125 | "
\n",
126 | "\n",
127 | "* **表格识别**\n",
128 | "\n",
129 | "表格识别(Table Recognition)的任务就是将文档里的表格信息进行识别和转换到excel文件中。文本图像中表格种类和样式复杂多样,例如不同的行列合并,不同的内容文本类型等,除此之外文档的样式和拍摄时的光照环境等都为表格识别带来了极大的挑战。这些挑战使得表格识别一直是文档理解领域的研究难点。\n",
130 | "\n",
131 | "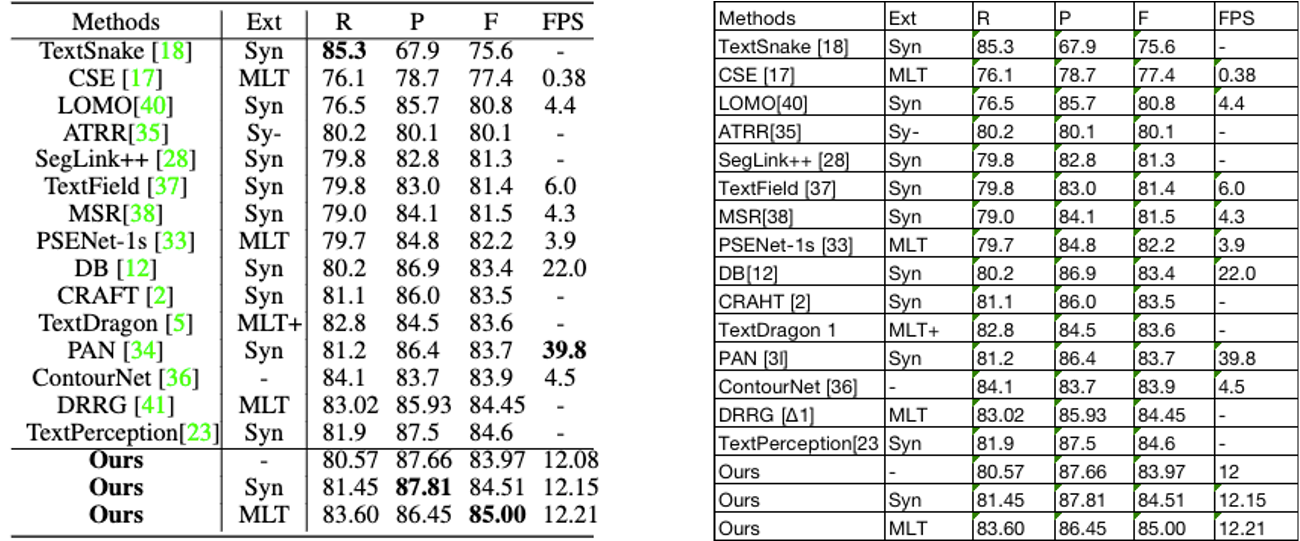\n",
132 | "\n",
133 | "图13 表格识别任务示意图\n",
134 | "\n",
135 | "
\n",
136 | "\n",
137 | "表格识别的方法种类较为丰富,早期的基于启发式规则的传统算法,如Kieninger[18]等人提出的T-Rect等算法,一般通过人工设计规则,连通域检测分析处理;近年来随着深度学习的发展,开始涌现一些基于CNN的表格结构识别算法,如Siddiqui Shoaib Ahmed[19]等人提出的DeepTabStR,Raja Sachin[20]等人提出的TabStruct-Net等;此外,随着图神经网络(Graph Neural Network)的兴起,也有一些研究者尝试将图神经网络应用到表格结构识别问题上,基于图神经网络,将表格识别看作图重建问题,如Xue Wenyuan[21]等人提出的TGRNet;基于端到端的方法直接使用网络完成表格结构的HTML表示输出,端到端的方法大多采用Seq2Seq方法来完成表格结构的预测,如一些基于Attention或Transformer的方法,如TableMaster[22]。\n",
138 | "\n",
139 | "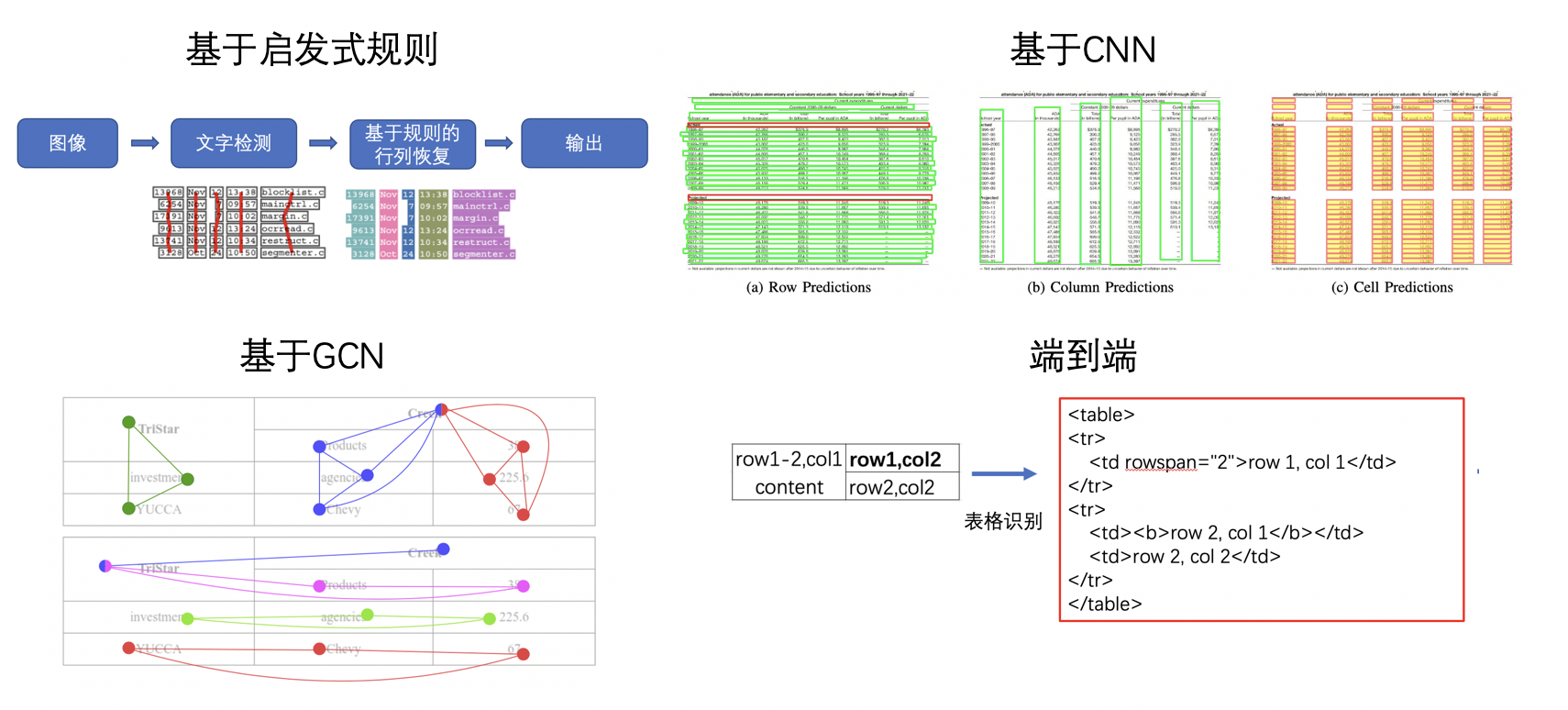\n",
140 | "图14 表格识别方法示意图\n",
141 | "\n",
142 | "
\n",
143 | "\n",
144 | "* **关键信息提取**\n",
145 | "\n",
146 | "关键信息提取(Key Information Extraction,KIE)是Document VQA中的一个重要任务,主要从图像中提取所需要的关键信息,如从身份证中提取出姓名和公民身份号码信息,这类信息的种类往往在特定任务下是固定的,但是在不同任务间是不同的。\n",
147 | "\n",
148 | "\n",
149 | "图15 DocVQA任务示意图\n",
150 | "\n",
151 | "
\n",
152 | "\n",
153 | "KIE通常分为两个子任务进行研究:\n",
154 | "\n",
155 | "- SER: 语义实体识别 (Semantic Entity Recognition),对每一个检测到的文本进行分类,如将其分为姓名,身份证。如下图中的黑色框和红色框。\n",
156 | "- RE: 关系抽取 (Relation Extraction),对每一个检测到的文本进行分类,如将其分为问题和的答案。然后对每一个问题找到对应的答案。如下图中的红色框和黑色框分别代表问题和答案,黄色线代表问题和答案之间的对应关系。\n",
157 | "\n",
158 | "\n",
159 | "图16 ser与re任务\n",
160 | "\n",
161 | "
\n",
162 | "\n",
163 | "一般的KIE方法基于命名实体识别(Named Entity Recognition,NER)[4]来研究,但是这类方法只利用了图像中的文本信息,缺少对视觉和结构信息的使用,因此精度不高。在此基础上,近几年的方法都开始将视觉和结构信息与文本信息融合到一起,按照对多模态信息进行融合时所采用的的原理可以将这些方法分为下面四种:\n",
164 | "\n",
165 | "- 基于Grid的方法\n",
166 | "- 基于Token的方法\n",
167 | "- 基于GCN的方法\n",
168 | "- 基于End to End 的方法\n",
169 | "\n",
170 | "
\n",
171 | "\n",
172 | "文档分析相关技术将在第六章进行详细解读和实战。\n",
173 | "\n",
174 | "## 2.4 其他相关技术\n",
175 | "\n",
176 | "前面主要介绍了OCR领域的三种关键技术:文本检测、文本识别、文档结构化识别,更多其他OCR相关前沿技术介绍,包括端到端文本识别、OCR中的图像预处理技术、OCR数据合成等,可参考教程第七章和第八章。\n"
177 | ]
178 | },
179 | {
180 | "cell_type": "markdown",
181 | "metadata": {},
182 | "source": [
183 | "# 3. OCR技术的产业实践\n",
184 | "\n",
185 | "\n",
186 | "\n",
187 | "> 你是小王,该怎么办? \n",
188 | "> 1. 我不会,我不行,我不干了😭\n",
189 | "> 2. 建议老板找外包公司或者商业化方案,反正花老板的钱😊\n",
190 | "> 3. 网上找找类似项目,面向Github编程😏\n",
191 | "\n",
192 | "
\n",
193 | "\n",
194 | "OCR技术最终还是要落到产业实践当中。虽然学术上关于OCR技术的研究很多,OCR技术的商业化应用相比于其他AI技术也已经相对成熟,但在实际的产业应用中,还是存在一些难点与挑战。下文将从技术和产业实践两个角度进行分析。\n",
195 | "\n",
196 | "\n",
197 | "## 3.1 产业实践难点\n",
198 | "\n",
199 | "在实际的产业实践中,开发者常常需要依托开源社区资源启动或推进项目,而开发者使用开源模型又往往面临三大难题:\n",
200 | "\n",
201 | "图17 OCR技术产业实践三大难题\n",
202 | "\n",
203 | "**1. 找不到、选不出**\n",
204 | "\n",
205 | "开源社区资源丰富,但是信息不对称导致开发者并不能高效地解决痛点问题。一方面,开源社区资源过于丰富,开发者面对一项需求,无法快速从海量的代码仓库中找到匹配业务需求的项目,即存在“找不到”的问题;另一方面,在算法选型时,英文公开数据集上的指标,无法给开发者常常面对的中文场景提供直接的参考,逐个算法验证需要耗费大量时间和人力,且不能保证选出最合适的算法,即“选不出”。\n",
206 | "\n",
207 | "**2. 不适用产业场景**\n",
208 | "\n",
209 | "开源社区中的工作往往更多地偏向效果优化,如学术论文代码开源或复现,一般更侧重算法效果,平衡考虑模型大小和速度的工作相比就少很多,而模型大小和预测耗时在产业实践中是两项不容忽视的指标,其重要程度不亚于模型效果。无论是移动端和服务器端,待识别的图像数目往往非常多,都希望模型更小,精度更高,预测速度更快。GPU太贵,最好使用CPU跑起来更经济。在满足业务需求的前提下,模型越轻量占用的资源越少。\n",
210 | "\n",
211 | "**3. 优化难、训练部署问题多**\n",
212 | "\n",
213 | "直接使用开源算法或模型一般无法直接满足业务需求,实际业务场景中,OCR面临的问题多种多样,业务场景个性化往往需要自定义数据集重新训练,现有的开源项目上,实验各种优化方法的成本较高。此外,OCR应用场景十分丰富,服务端和各种移动端设备上都有着广泛的应用需求,硬件环境多样化就需要支持丰富的部署方式,而开源社区的项目更侧重算法和模型,在预测部署这部分明显支撑不足。要把OCR技术从论文上的算法做到技术落地应用,对开发者的算法和工程能力都有很高的要求。\n",
214 | "\n",
215 | "## 3.2 产业级OCR开发套件PaddleOCR\n",
216 | "\n",
217 | "OCR产业实践需要一套完整全流程的解决方案,来加快研发进度,节约宝贵的研发时间。也就是说,超轻量模型及其全流程解决方案,尤其对于算力、存储空间有限的移动端、嵌入式设备而言,可以说是刚需。\n",
218 | "\n",
219 | "在此背景下,产业级OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)应运而生。\n",
220 | "\n",
221 | "PaddleOCR的建设思路从用户画像和需求出发,依托飞桨核心框架,精选并复现丰富的前沿算法,基于复现的算法研发更适用于产业落地的PP特色模型,并打通训推一体,提供多种预测部署方式,满足实际应用的不同需求场景。\n",
222 | "\n",
223 | "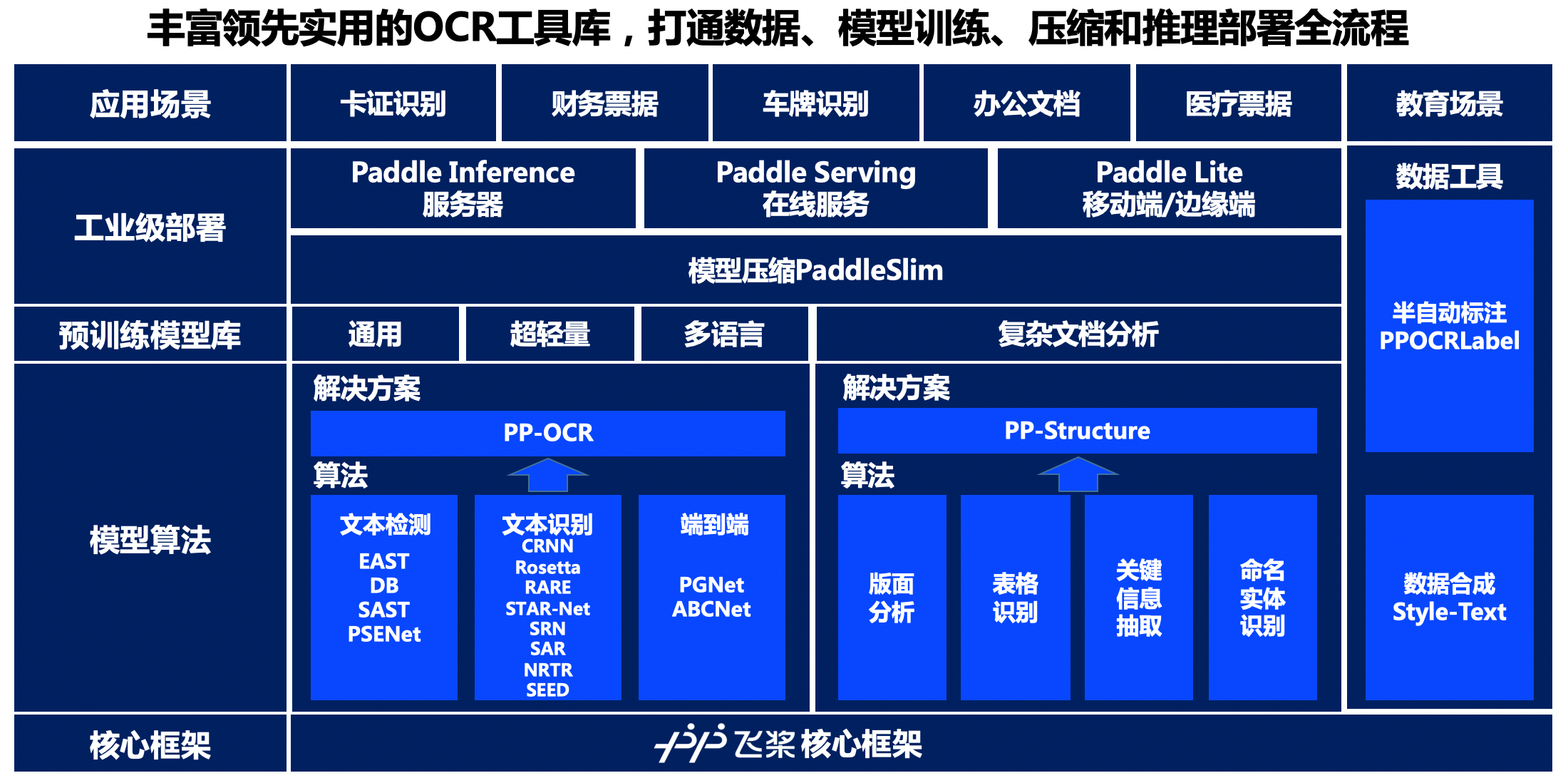\n",
224 | "图18 PaddleOCR开发套件全景图\n",
225 | "\n",
226 | "
\n",
227 | "\n",
228 | "从全景图可以看出,PaddleOCR依托于飞桨核心框架,在模型算法、预训练模型库、工业级部署等层面均提供了丰富的解决方案,并且提供了数据合成、半自动数据标注工具,满足开发者的数据生产需求。\n",
229 | "\n",
230 | "**在模型算法层面**,PaddleOCR对**文字检测识别**和**文档结构化分析**两类任务分别提供了解决方案。在文字检测识别方面,PaddleOCR复现或开源了4种文本检测算法、8种文本识别算法、1种端到端文本识别算法,并在此基础上研发了PP-OCR系列的通用文本检测识别解决方案;在文档结构化分析方面,PaddleOCR提供了版面分析、表格识别、关键信息抽取、命名实体识别等算法,并在此基础提出了PP-Structure文档分析解决方案。丰富的精选算法可以满足开发者不同业务场景的需求,代码框架的统一也方便开发者进行不同算法的优化和性能对比。\n",
231 | "\n",
232 | "**在预训练模型库层面**,基于PP-OCR和PP-Structure解决方案,PaddleOCR研发并开源了适用于产业实践的PP系列特色模型,包括通用、超轻量和多语言的文本检测识别模型,和复杂文档分析模型。PP系列特色模型均在原始算法上进行了深度优化,使其在效果和性能上均能达到产业实用级别,开发者既可以直接应用于业务场景,也可以用业务数据进行简单的finetune,便可以轻松研发出适用于自己业务需求的“实用模型”。\n",
233 | "\n",
234 | "**在工业级部署层面**,PaddleOCR提供了基于Paddle Inference的服务器端预测方案,基于Paddle Serving的服务化部署方案,以及基于Paddle-Lite的端侧部署方案,满足不同硬件环境下的部署需求,同时提供了基于PaddleSlim的模型压缩方案,可以进一步压缩模型大小。以上部署方式都完成了训推一体全流程打通,以保障开发者可以高效部署,稳定可靠。\n",
235 | "\n",
236 | "**在数据工具层面**,PaddleOCR提供了半自动数据标注工具PPOCRLabel和数据合成工具Style-Text,助力开发者更方便的生产模型训练所需的数据集和标注信息。PPOCRLabel作为业界首个开源的半自动OCR数据标注工具,针对标注过程枯燥繁琐、机械性高,大量训练数据所需人工标记,时间金钱成本昂贵的问题,内置PP-OCR模型实现预标注+人工校验的标注模式,可以极大提升标注效率,节省人力成本。数据合成工具Style-Text主要解决实际场景真实数据严重不足,传统合成算法无法合成文字风格(字体、颜色、间距、背景)的问题,只需要少许目标场景图像,就可以批量合成大量与目标场景风格相近的文本图像。\n",
237 | "\n",
238 | "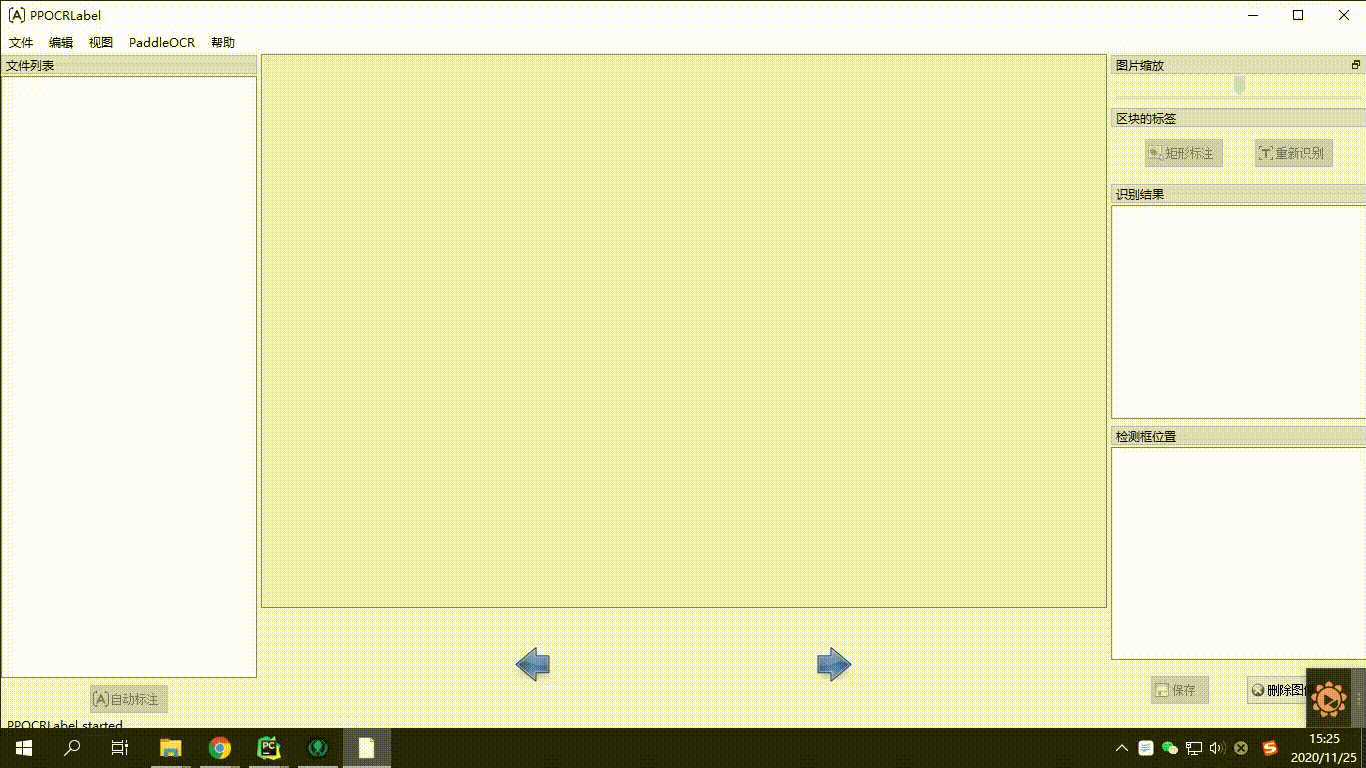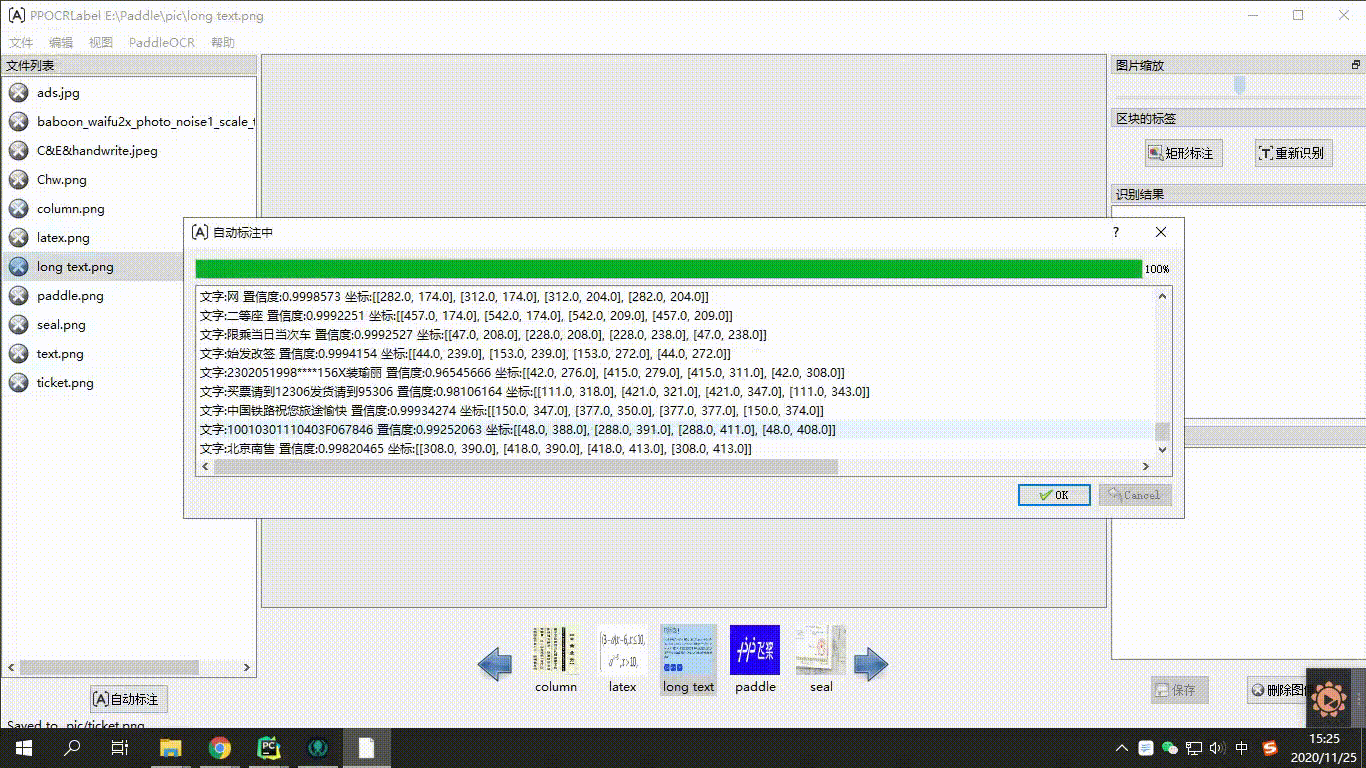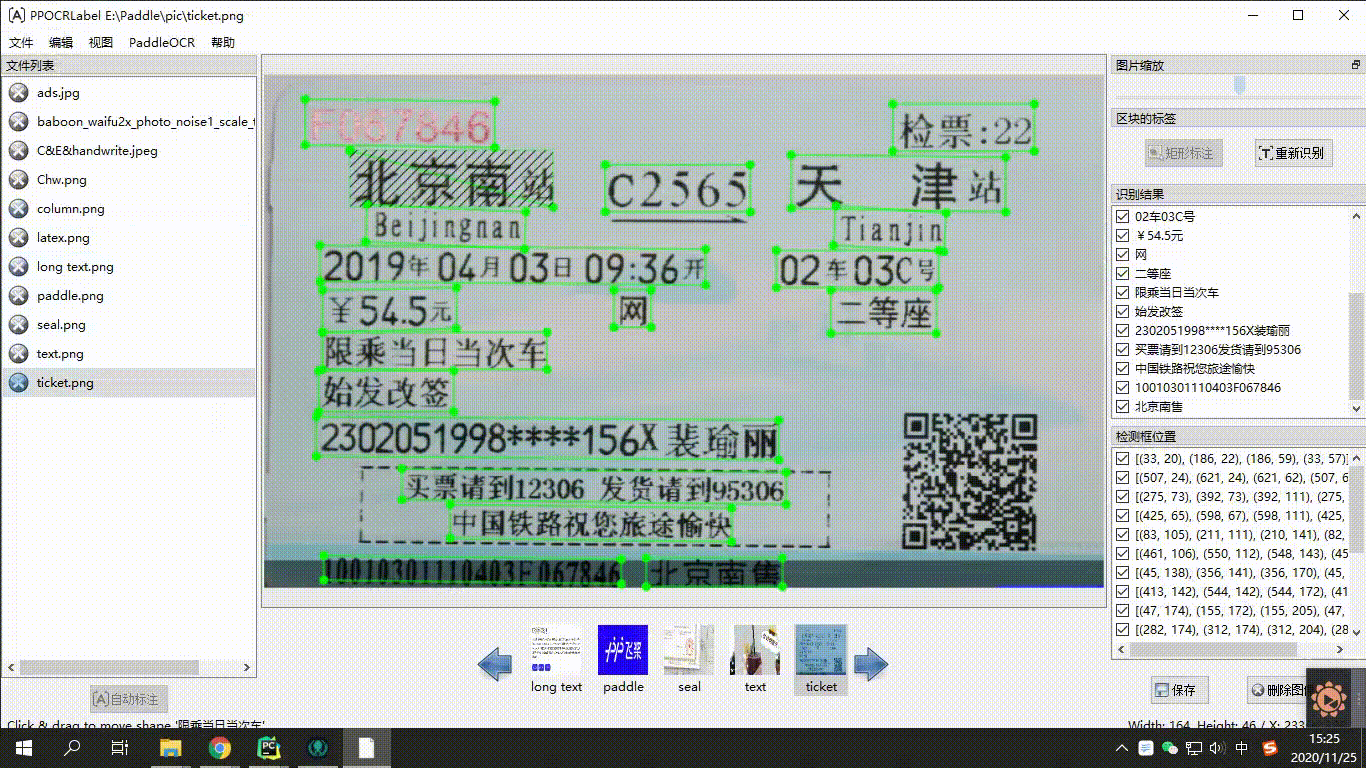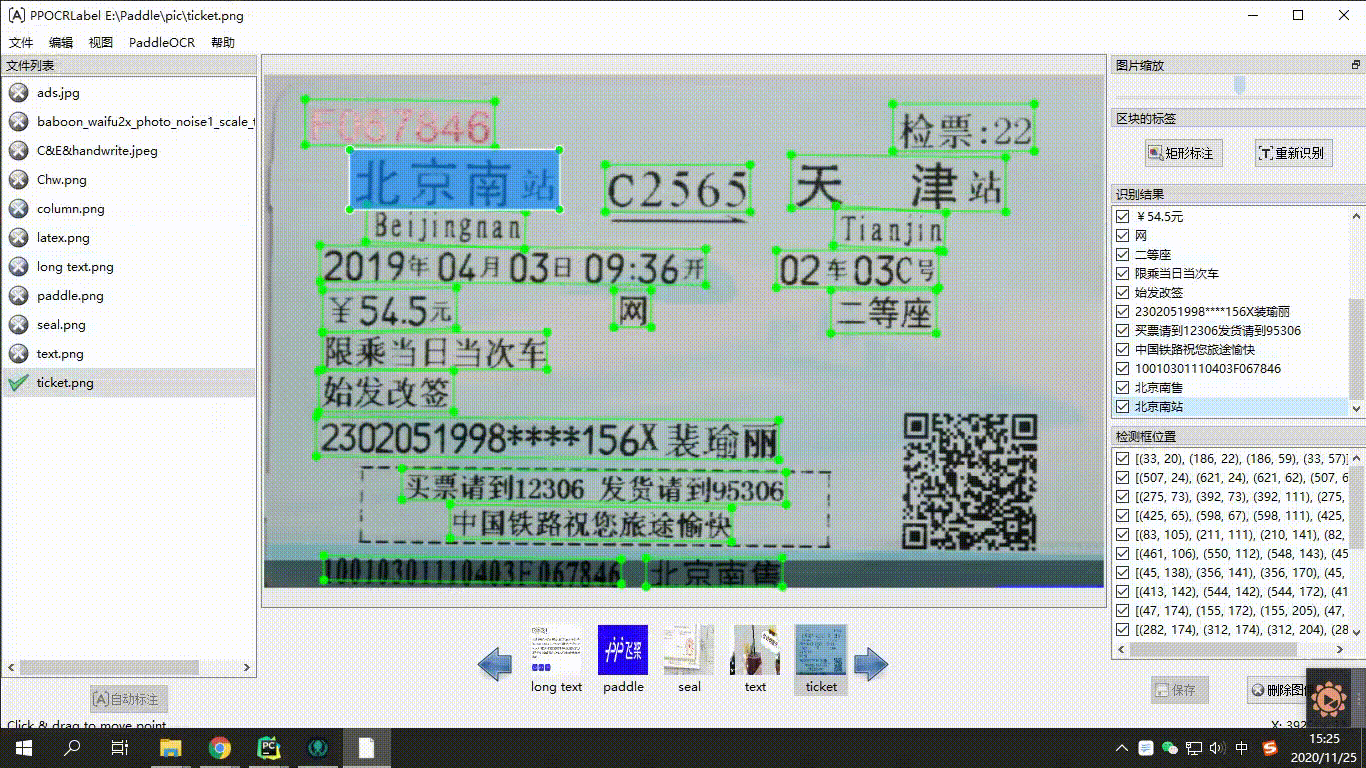\n",
239 | "图19 PPOCRLabel使用示意图\n",
240 | "\n",
241 | "
\n",
242 | "\n",
243 | "\n",
244 | "图20 Style-Text合成效果示例\n",
245 | "\n",
246 | "
\n",
247 | "\n",
248 | "### 3.2.1 PP-OCR与PP-Structrue\n",
249 | "\n",
250 | "PP系列特色模型是飞桨各视觉开发套件针对产业实践需求进行深度优化的模型,力求速度与精度平衡。PaddleOCR中的PP系列特色模型包括针对文字检测识别任务的PP-OCR系列模型和针对文档分析的PP-Structure系列模型。\n",
251 | "\n",
252 | "**(1)PP-OCR中英文模型**\n",
253 | "\n",
254 | "\n",
255 | "\n",
256 | "图21 PP-OCR中英文模型识别结果示例\n",
257 | "\n",
258 | "
\n",
259 | "\n",
260 | "PP-OCR中英文模型采用的典型的两阶段OCR算法,即检测模型+识别模型的组成方式,具体的算法框架如下:\n",
261 | "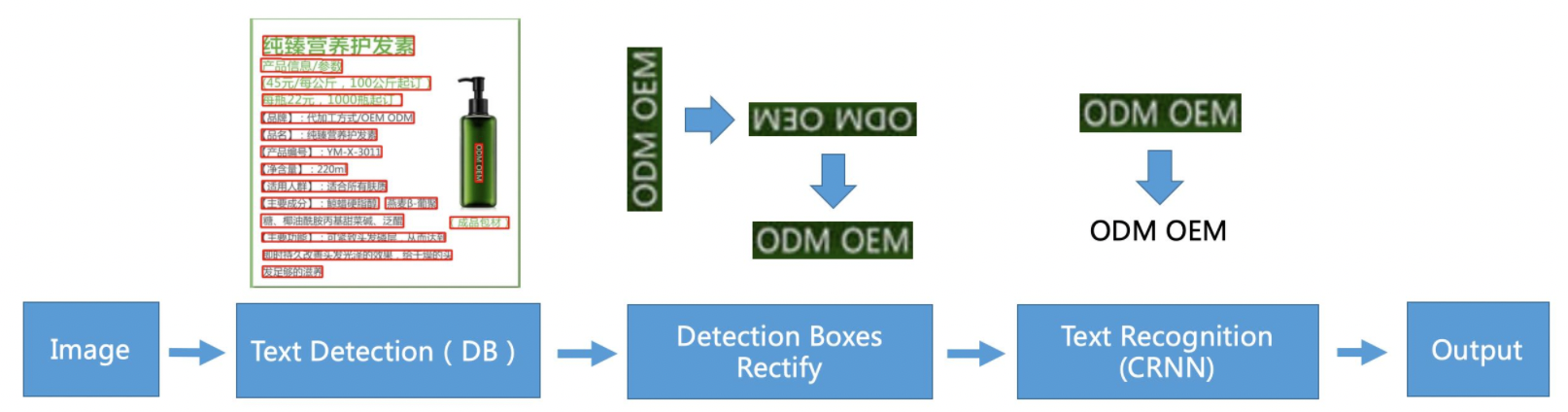\n",
262 | "图22 PP-OCR系统pipeline示意图\n",
263 | "\n",
264 | "
\n",
265 | "\n",
266 | "可以看到,除输入输出外,PP-OCR核心框架包含了3个模块,分别是:文本检测模块、检测框矫正模块、文本识别模块。\n",
267 | "- 文本检测模块:核心是一个基于[DB](https://arxiv.org/abs/1911.08947)检测算法训练的文本检测模型,检测出图像中的文字区域;\n",
268 | "- 检测框矫正模块:将检测到的文本框输入检测框矫正模块,在这一阶段,将四点表示的文本框矫正为矩形框,方便后续进行文本识别,另一方面会进行文本方向判断和校正,例如如果判断文本行是倒立的情况,则会进行转正,该功能通过训练一个文本方向分类器实现;\n",
269 | "- 文本识别模块:最后文本识别模块对矫正后的检测框进行文本识别,得到每个文本框内的文字内容,PP-OCR中使用的经典文本识别算法[CRNN](https://arxiv.org/abs/1507.05717)。\n",
270 | "\n",
271 | "PaddleOCR先后推出了PP-OCR[23]和PP-OCRv2[24]模型。\n",
272 | "\n",
273 | "PP-OCR模型分为mobile版(轻量版)和server版(通用版),其中mobile版模型主要基于轻量级骨干网络MobileNetV3进行优化,优化后模型(检测模型+文本方向分类模型+识别模型)大小仅8.1M,CPU上平均单张图像预测耗时350ms,T4 GPU上约110ms,裁剪量化后,可在精度不变的情况下进一步压缩到3.5M,便于端侧部署,在骁龙855上测试预测耗时仅260ms。更多的PP-OCR评估数据可参考[benchmark](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/benchmark.md)。\n",
274 | "\n",
275 | "PP-OCRv2保持了PP-OCR的整体框架,主要做了效果上的进一步策略优化。提升包括3个方面:\n",
276 | "- 在模型效果上,相对于PP-OCR mobile版本提升超7%;\n",
277 | "- 在速度上,相对于PP-OCR server版本提升超过220%;\n",
278 | "- 在模型大小上,11.6M的总大小,服务器端和移动端都可以轻松部署。\n",
279 | "\n",
280 | "PP-OCR和PP-OCRv2的具体优化策略将在第四章中进行详细解读。\n",
281 | "\n",
282 | "除了中英文模型,PaddleOCR也基于不同的数据集训练并开源了英文数字模型、多语言识别模型,以上均为超轻量模型,适用于不同的语言场景。\n",
283 | "\n",
284 | "\n",
285 | "图23 PP-OCR的英文数字模型和多语言模型识别效果示意图\n",
286 | "\n",
287 | "
\n",
288 | "\n",
289 | "**(2)PP-Structure文档分析模型**\n",
290 | "\n",
291 | "PP-Structure支持版面分析(layout analysis)、表格识别(table recognition)、文档视觉问答(DocVQA)三种子任务。\n",
292 | "\n",
293 | "PP-Structure核心功能点如下:\n",
294 | "- 支持对图片形式的文档进行版面分析,可以划分文字、标题、表格、图片以及列表5类区域(与Layout-Parser联合使用)\n",
295 | "- 支持文字、标题、图片以及列表区域提取为文字字段(与PP-OCR联合使用)\n",
296 | "- 支持表格区域进行结构化分析,最终结果输出Excel文件\n",
297 | "- 支持Python whl包和命令行两种方式,简单易用\n",
298 | "- 支持版面分析和表格结构化两类任务自定义训练\n",
299 | "- 支持VQA任务-SER和RE\n",
300 | "\n",
301 | "\n",
302 | "图24 PP-Structure系统示意图(本图仅含版面分析+表格识别)\n",
303 | "\n",
304 | "
\n",
305 | "\n",
306 | "PP-Structure的具体方案将在第六章中进行详细解读。\n",
307 | "\n",
308 | "### 3.2.2 工业级部署方案\n",
309 | "\n",
310 | "飞桨支持全流程、全场景推理部署,模型来源主要分为三种,第一种使用PaddlePaddle API构建网络结构进行训练所得,第二种是基于飞桨套件系列,飞桨套件提供了丰富的模型库、简洁易用的API,具备开箱即用,包括视觉模型库PaddleCV、智能语音库PaddleSpeech以及自然语言处理库PaddleNLP等,第三种采用X2Paddle工具从第三方框架(PyTorh、ONNX、TensorFlow等)产出的模型。\n",
311 | "\n",
312 | "飞桨模型可以选用PaddleSlim工具进行压缩、量化以及蒸馏,支持五种部署方案,分别为服务化Paddle Serving、服务端/云端Paddle Inference、移动端/边缘端Paddle Lite、网页前端Paddle.js, 对于Paddle不支持的硬件,比如MCU、地平线、鲲云等国产芯片,可以借助Paddle2ONNX转化为支持ONNX的第三方框架。\n",
313 | "\n",
314 | "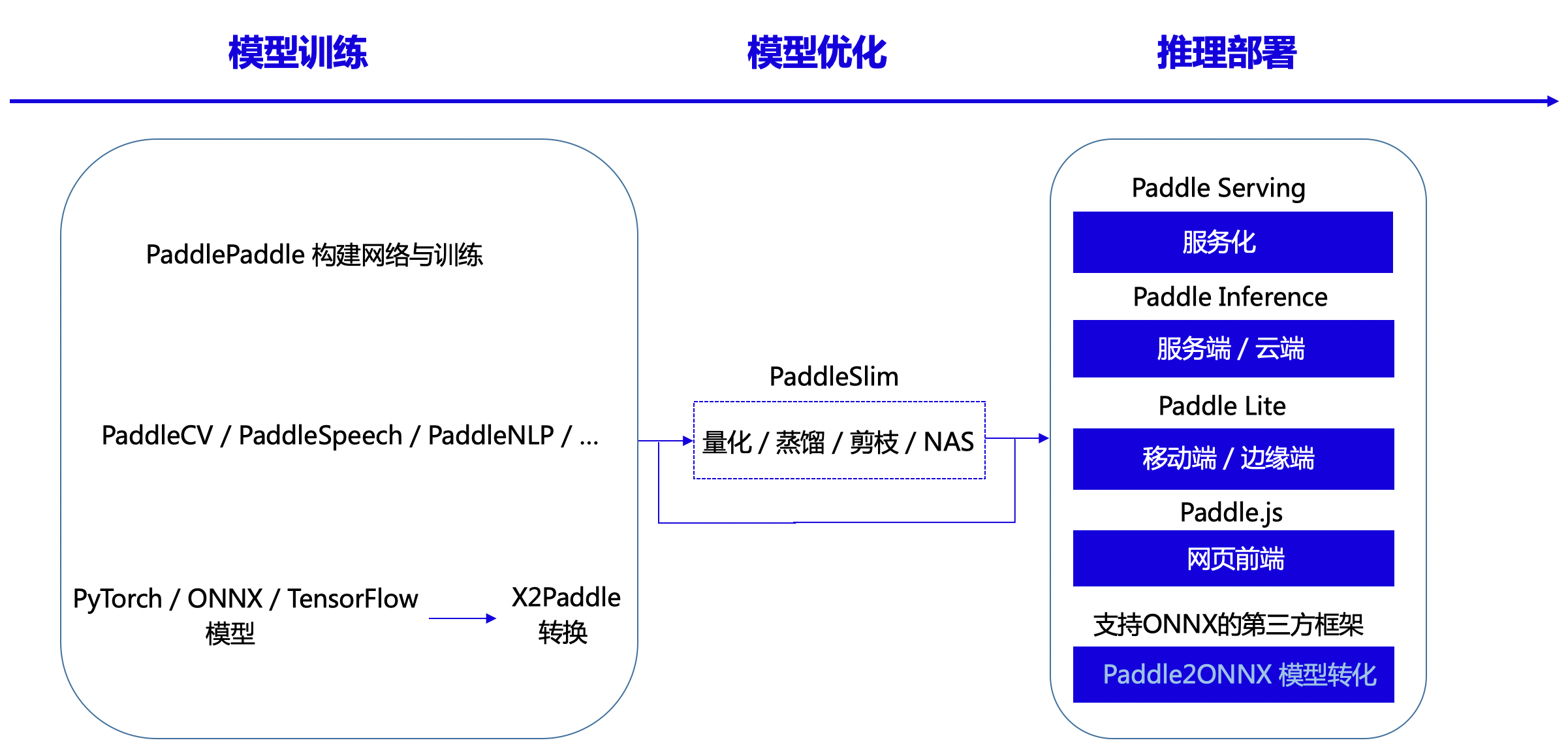\n",
315 | "图25 飞桨支持部署方式\n",
316 | "\n",
317 | "
\n",
318 | "\n",
319 | "Paddle Inference支持服务端和云端部署,具备高性能与通用性,针对不同平台和不同应用场景进行了深度的适配和优化,Paddle Inference是飞桨的原生推理库,保证模型在服务器端即训即用,快速部署,适用于高性能硬件上使用多种应用语言环境部署算法复杂的模型,硬件覆盖x86 CPU、Nvidia GPU、以及百度昆仑XPU、华为昇腾等AI加速器。\n",
320 | "\n",
321 | "Paddle Lite 是端侧推理引擎,具有轻量化和高性能特点,针对端侧设备和各应用场景进行了深度的设配和优化。当前支持Android、IOS、嵌入式Linux设备、macOS 等多个平台,硬件覆盖ARM CPU和GPU、X86 CPU和新硬件如百度昆仑、华为昇腾与麒麟、瑞芯微等。\n",
322 | "\n",
323 | "Paddle Serving是一套高性能服务框架,旨在帮助用户几个步骤快速将模型在云端服务化部署。目前Paddle Serving支持自定义前后处理、模型组合、模型热加载更新、多机多卡多模型、分布式推理、K8S部署、安全网关和模型加密部署、支持多语言多客户端访问等功能,Paddle Serving官方还提供了包括PaddleOCR在内的40多种模型的部署示例,以帮助用户更快上手。\n",
324 | "\n",
325 | "\n",
326 | "图26 飞桨支持部署方式\n",
327 | "\n",
328 | "
\n",
329 | "\n",
330 | "以上部署方案将在第五章中基于PP-OCRv2模型进行详细解读与实战。"
331 | ]
332 | },
333 | {
334 | "cell_type": "markdown",
335 | "metadata": {},
336 | "source": [
337 | "# 4. 总结\n",
338 | "\n",
339 | "本节首先介绍了OCR技术的应用场景和前沿算法,然后分析了OCR技术在产业实践中的难点与三大挑战。\n",
340 | "\n",
341 | "本教程后续章节内容安排如下:\n",
342 | "\n",
343 | "* 第二、三章分别介绍检测、识别技术并实践;\n",
344 | "* 第四章介绍PP-OCR优化策略; \n",
345 | "* 第五章进行预测部署实战; \n",
346 | "* 第六章介绍文档结构化; \n",
347 | "* 第七章介绍端到端、数据预处理、数据合成等其他OCR相关算法; \n",
348 | "* 第八章介绍OCR相关数据集和数据合成工具。\n",
349 | "\n",
350 | "# 参考文献\n",
351 | "\n",
352 | "[1] Liao, Minghui, et al. \"Textboxes: A fast text detector with a single deep neural network.\" Thirty-first AAAI conference on artificial intelligence. 2017.\n",
353 | "\n",
354 | "[2] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.\n",
355 | "\n",
356 | "[3] Tian, Zhi, et al. \"Detecting text in natural image with connectionist text proposal network.\" European conference on computer vision. Springer, Cham, 2016.\n",
357 | "\n",
358 | "[4] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28: 91-99.\n",
359 | "\n",
360 | "[5] Zhou, Xinyu, et al. \"East: an efficient and accurate scene text detector.\" Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.\n",
361 | "\n",
362 | "[6] Wang, Wenhai, et al. \"Shape robust text detection with progressive scale expansion network.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
363 | "\n",
364 | "[7] Liao, Minghui, et al. \"Real-time scene text detection with differentiable binarization.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.\n",
365 | "\n",
366 | "[8] Deng, Dan, et al. \"Pixellink: Detecting scene text via instance segmentation.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.\n",
367 | "\n",
368 | "[9] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.\n",
369 | "\n",
370 | "[10] Wang P, Zhang C, Qi F, et al. A single-shot arbitrarily-shaped text detector based on context attended multi-task \n",
371 | "learning[C]//Proceedings of the 27th ACM international conference on multimedia. 2019: 1277-1285.\n",
372 | "\n",
373 | "[11] Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\n",
374 | "\n",
375 | "[12] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\n",
376 | "\n",
377 | "[13] Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\n",
378 | "\n",
379 | "[14] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\n",
380 | "\n",
381 | "[15] Lyu P, Liao M, Yao C, et al. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 67-83.\n",
382 | "\n",
383 | "[16] Soto C, Yoo S. Visual detection with context for document layout analysis[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3464-3470.\n",
384 | "\n",
385 | "[17] Sarkar M, Aggarwal M, Jain A, et al. Document Structure Extraction using Prior based High Resolution Hierarchical Semantic Segmentation[C]//European Conference on Computer Vision. Springer, Cham, 2020: 649-666.\n",
386 | "\n",
387 | "[18] Kieninger T, Dengel A. A paper-to-HTML table converting system[C]//Proceedings of document analysis systems (DAS). 1998, 98: 356-365.\n",
388 | "\n",
389 | "[19] Siddiqui S A, Fateh I A, Rizvi S T R, et al. Deeptabstr: Deep learning based table structure recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1403-1409.\n",
390 | "\n",
391 | "[20] Raja S, Mondal A, Jawahar C V. Table structure recognition using top-down and bottom-up cues[C]//European Conference on Computer Vision. Springer, Cham, 2020: 70-86.\n",
392 | "\n",
393 | "[21] Xue W, Yu B, Wang W, et al. TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition[J]. arXiv preprint arXiv:2106.10598, 2021.\n",
394 | "\n",
395 | "[22] Ye J, Qi X, He Y, et al. PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML[J]. arXiv preprint arXiv:2105.01848, 2021.\n",
396 | "\n",
397 | "[23] Du Y, Li C, Guo R, et al. PP-OCR: A practical ultra lightweight OCR system[J]. arXiv preprint arXiv:2009.09941, 2020.\n",
398 | "\n",
399 | "[24] Du Y, Li C, Guo R, et al. PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System[J]. arXiv preprint arXiv:2109.03144, 2021.\n",
400 | "\n"
401 | ]
402 | }
403 | ],
404 | "metadata": {
405 | "kernelspec": {
406 | "display_name": "Python 3",
407 | "language": "python",
408 | "name": "python3"
409 | },
410 | "language_info": {
411 | "codemirror_mode": {
412 | "name": "ipython",
413 | "version": 3
414 | },
415 | "file_extension": ".py",
416 | "mimetype": "text/x-python",
417 | "name": "python",
418 | "nbconvert_exporter": "python",
419 | "pygments_lexer": "ipython3",
420 | "version": "3.8.8"
421 | }
422 | },
423 | "nbformat": 4,
424 | "nbformat_minor": 1
425 | }
426 |
--------------------------------------------------------------------------------
/notebook_ch/1.introduction/OCR技术导论.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "collapsed": false
7 | },
8 | "source": [
9 | "\n",
10 | "*注:以上图片来自网络*\n",
11 | "\n",
12 | "# 1. OCR技术背景\n",
13 | "## 1.1 OCR技术的应用场景\n",
14 | "\n",
15 | "* **OCR是什么**\n",
16 | "\n",
17 | "OCR(Optical Character Recognition,光学字符识别)是计算机视觉重要方向之一。传统定义的OCR一般面向扫描文档类对象,现在我们常说的OCR一般指场景文字识别(Scene Text Recognition,STR),主要面向自然场景,如下图中所示的牌匾等各种自然场景可见的文字。\n",
18 | "\n",
19 | "\n",
20 | "图1 文档场景文字识别 VS. 自然场景文字识别\n",
21 | "\n",
22 | "
\n",
23 | "\n",
24 | "* **OCR有哪些应用场景?**\n",
25 | "\n",
26 | "OCR技术有着丰富的应用场景,一类典型的场景是日常生活中广泛应用的面向垂类的结构化文本识别,比如车牌识别、银行卡信息识别、身份证信息识别、火车票信息识别等等。这些小垂类的共同特点是格式固定,因此非常适合使用OCR技术进行自动化,可以极大的减轻人力成本,提升效率。\n",
27 | "\n",
28 | "这种面向垂类的结构化文本识别是目前ocr应用最广泛、并且技术相对较成熟的场景。\n",
29 | "\n",
30 | "\n",
31 | "图2 OCR技术的应用场景\n",
32 | "\n",
33 | "除了面向垂类的结构化文本识别,通用OCR技术也有广泛的应用,并且常常和其他技术结合完成多模态任务,例如在视频场景中,经常使用OCR技术进行字幕自动翻译、内容安全监控等等,或者与视觉特征相结合,完成视频理解、视频搜索等任务。\n",
34 | "\n",
35 | "\n",
36 | "图3 多模态场景中的通用OCR\n",
37 | "\n",
38 | "## 1.2 OCR技术挑战\n",
39 | "OCR的技术难点可以分为算法层和应用层两方面。\n",
40 | "\n",
41 | "* **算法层**\n",
42 | "\n",
43 | "OCR丰富的应用场景,决定了它会存在很多技术难点。这里给出了常见的8种问题:\n",
44 | "\n",
45 | "\n",
46 | "图4 OCR算法层技术难点\n",
47 | "\n",
48 | "这些问题给文本检测和文本识别都带来了巨大的技术挑战,可以看到,这些挑战主要都是面向自然场景,目前学术界的研究也主要聚焦在自然场景,OCR领域在学术上的常用数据集也都是自然场景。针对这些问题的研究很多,相对来说,识别比检测面临更大的挑战。\n",
49 | "\n",
50 | "* **应用层**\n",
51 | "\n",
52 | "在实际应用中,尤其是在广泛的通用场景下,除了上一节总结的仿射变换、尺度问题、光照不足、拍摄模糊等算法层面的技术难点,OCR技术还面临两大落地难点:\n",
53 | "1. **海量数据要求OCR能够实时处理。** OCR应用常对接海量数据,我们要求或希望数据能够得到实时处理,模型的速度做到实时是一个不小的挑战。\n",
54 | "2. **端侧应用要求OCR模型足够轻量,识别速度足够快。** OCR应用常部署在移动端或嵌入式硬件,端侧OCR应用一般有两种模式:上传到服务器 vs. 端侧直接识别,考虑到上传到服务器的方式对网络有要求,实时性较低,并且请求量过大时服务器压力大,以及数据传输的安全性问题,我们希望能够直接在端侧完成OCR识别,而端侧的存储空间和计算能力有限,因此对OCR模型的大小和预测速度有很高的要求。\n",
55 | "\n",
56 | "\n",
57 | "图5 OCR应用层技术难点\n",
58 | "\n"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {
64 | "collapsed": false
65 | },
66 | "source": [
67 | "# 2. OCR前沿算法\n",
68 | "\n",
69 | "虽然OCR是一个相对具体的任务,但涉及了多方面的技术,包括文本检测、文本识别、端到端文本识别、文档分析等等。学术上关于OCR各项相关技术的研究层出不穷,下文将简要介绍OCR任务中的几种关键技术的相关工作。\n",
70 | "\n",
71 | "## 2.1 文本检测\n",
72 | "\n",
73 | "文本检测的任务是定位出输入图像中的文字区域。近年来学术界关于文本检测的研究非常丰富,一类方法将文本检测视为目标检测中的一个特定场景,基于通用目标检测算法进行改进适配,如TextBoxes[1]基于一阶段目标检测器SSD[2]算法,调整目标框使之适合极端长宽比的文本行,CTPN[3]则是基于Faster RCNN[4]架构改进而来。但是文本检测与目标检测在目标信息以及任务本身上仍存在一些区别,如文本一般长宽比较大,往往呈“条状”,文本行之间可能比较密集,弯曲文本等,因此又衍生了很多专用于文本检测的算法,如EAST[5]、PSENet[6]、DBNet[7]等等。\n",
74 | "\n",
75 | "\n",
76 | "图6 文本检测任务示例\n",
77 | "\n",
78 | "
\n",
79 | "\n",
80 | "目前较为流行的文本检测算法可以大致分为**基于回归**和**基于分割**的两大类文本检测算法,也有一些算法将二者相结合。基于回归的算法借鉴通用物体检测算法,通过设定anchor回归检测框,或者直接做像素回归,这类方法对规则形状文本检测效果较好,但是对不规则形状的文本检测效果会相对差一些,比如CTPN[3]对水平文本的检测效果较好,但对倾斜、弯曲文本的检测效果较差,SegLink[8]对长文本比较好,但对分布稀疏的文本效果较差;基于分割的算法引入了Mask-RCNN[9],这类算法在各种场景、对各种形状文本的检测效果都可以达到一个更高的水平,但缺点就是后处理一般会比较复杂,因此常常存在速度问题,并且无法解决重叠文本的检测问题。\n",
81 | "\n",
82 | "\n",
83 | "图7 文本检测算法概览\n",
84 | "\n",
85 | "
\n",
86 | "\n",
87 | "||\n",
88 | "|---|---|---|\n",
89 | "图8 (左)基于回归的CTPN[3]算法优化anchor (中)基于分割的DB[7]算法优化后处理 (右)回归+分割的SAST[10]算法\n",
90 | "\n",
91 | "
\n",
92 | "\n",
93 | "文本检测相关技术将在第二章进行详细解读和实战。\n",
94 | "\n",
95 | "## 2.2 文本识别\n",
96 | "\n",
97 | "文本识别的任务是识别出图像中的文字内容,一般输入来自于文本检测得到的文本框截取出的图像文字区域。文本识别一般可以根据待识别文本形状分为**规则文本识别**和**不规则文本识别**两大类。规则文本主要指印刷字体、扫描文本等,文本大致处在水平线位置;不规则文本往往不在水平位置,存在弯曲、遮挡、模糊等问题。不规则文本场景具有很大的挑战性,也是目前文本识别领域的主要研究方向。\n",
98 | "\n",
99 | "\n",
100 | "图9 (左)规则文本 VS. (右)不规则文本\n",
101 | "\n",
102 | "
\n",
103 | "\n",
104 | "规则文本识别的算法根据解码方式的不同可以大致分为基于CTC和Sequence2Sequence两种,将网络学习到的序列特征 转化为 最终的识别结果 的处理方式不同。基于CTC的算法以经典的CRNN[11]为代表。\n",
105 | "\n",
106 | "\n",
107 | "图10 基于CTC的识别算法 VS. 基于Attention的识别算法\n",
108 | "\n",
109 | "不规则文本的识别算法相比更为丰富,如STAR-Net[12]等方法通过加入TPS等矫正模块,将不规则文本矫正为规则的矩形后再进行识别;RARE[13]等基于Attention的方法增强了对序列之间各部分相关性的关注;基于分割的方法将文本行的各字符作为独立个体,相比与对整个文本行做矫正后识别,识别分割出的单个字符更加容易;此外,随着近年来Transfomer[14]的快速发展和在各类任务中的有效性验证,也出现了一批基于Transformer的文本识别算法,这类方法利用transformer结构解决CNN在长依赖建模上的局限性问题,也取得了不错的效果。\n",
110 | "\n",
111 | "\n",
112 | "图11 基于字符分割的识别算法[15]\n",
113 | "\n",
114 | "
\n",
115 | "\n",
116 | "文本识别相关技术将在第三章进行详细解读和实战。\n",
117 | "\n",
118 | "## 2.3 文档结构化识别\n",
119 | "\n",
120 | "传统意义上的OCR技术可以解决文字的检测和识别需求,但在实际应用场景中,最终需要获取的往往是结构化的信息,如身份证、发票的信息格式化抽取,表格的结构化识别等等,多在快递单据抽取、合同内容比对、金融保理单信息比对、物流业单据识别等场景下应用。OCR结果+后处理是一种常用的结构化方案,但流程往往比较复杂,并且后处理需要精细设计,泛化性也比较差。在OCR技术逐渐成熟、结构化信息抽取需求日益旺盛的背景下,版面分析、表格识别、关键信息提取等关于智能文档分析的各种技术受到了越来越多的关注和研究。\n",
121 | "\n",
122 | "* **版面分析**\n",
123 | "\n",
124 | "版面分析(Layout Analysis)主要是对文档图像进行内容分类,类别一般可分为纯文本、标题、表格、图片等。现有方法一般将文档中不同的板式当做不同的目标进行检测或分割,如Soto Carlos[16]在目标检测算法Faster R-CNN的基础上,结合上下文信息并利用文档内容的固有位置信息来提高区域检测性能;Sarkar Mausoom[17]等人提出了一种基于先验的分割机制,在非常高的分辨率的图像上训练文档分割模型,解决了过度缩小原始图像导致的密集区域不同结构无法区分进而合并的问题。\n",
125 | "\n",
126 | "\n",
127 | "图12 版面分析任务示意图\n",
128 | "\n",
129 | "
\n",
130 | "\n",
131 | "* **表格识别**\n",
132 | "\n",
133 | "表格识别(Table Recognition)的任务就是将文档里的表格信息进行识别和转换到excel文件中。文本图像中表格种类和样式复杂多样,例如不同的行列合并,不同的内容文本类型等,除此之外文档的样式和拍摄时的光照环境等都为表格识别带来了极大的挑战。这些挑战使得表格识别一直是文档理解领域的研究难点。\n",
134 | "\n",
135 | "\n",
136 | "\n",
137 | "图13 表格识别任务示意图\n",
138 | "\n",
139 | "
\n",
140 | "\n",
141 | "表格识别的方法种类较为丰富,早期的基于启发式规则的传统算法,如Kieninger[18]等人提出的T-Rect等算法,一般通过人工设计规则,连通域检测分析处理;近年来随着深度学习的发展,开始涌现一些基于CNN的表格结构识别算法,如Siddiqui Shoaib Ahmed[19]等人提出的DeepTabStR,Raja Sachin[20]等人提出的TabStruct-Net等;此外,随着图神经网络(Graph Neural Network)的兴起,也有一些研究者尝试将图神经网络应用到表格结构识别问题上,基于图神经网络,将表格识别看作图重建问题,如Xue Wenyuan[21]等人提出的TGRNet;基于端到端的方法直接使用网络完成表格结构的HTML表示输出,端到端的方法大多采用Seq2Seq方法来完成表格结构的预测,如一些基于Attention或Transformer的方法,如TableMaster[22]。\n",
142 | "\n",
143 | "\n",
144 | "图14 表格识别方法示意图\n",
145 | "\n",
146 | "
\n",
147 | "\n",
148 | "* **关键信息提取**\n",
149 | "\n",
150 | "关键信息提取(Key Information Extraction,KIE)是Document VQA中的一个重要任务,主要从图像中提取所需要的关键信息,如从身份证中提取出姓名和公民身份号码信息,这类信息的种类往往在特定任务下是固定的,但是在不同任务间是不同的。\n",
151 | "\n",
152 | "\n",
153 | "图15 DocVQA任务示意图\n",
154 | "\n",
155 | "
\n",
156 | "\n",
157 | "KIE通常分为两个子任务进行研究:\n",
158 | "\n",
159 | "- SER: 语义实体识别 (Semantic Entity Recognition),对每一个检测到的文本进行分类,如将其分为姓名,身份证。如下图中的黑色框和红色框。\n",
160 | "- RE: 关系抽取 (Relation Extraction),对每一个检测到的文本进行分类,如将其分为问题和的答案。然后对每一个问题找到对应的答案。如下图中的红色框和黑色框分别代表问题和答案,黄色线代表问题和答案之间的对应关系。\n",
161 | "\n",
162 | "\n",
163 | "图16 ser与re任务\n",
164 | "\n",
165 | "
\n",
166 | "\n",
167 | "一般的KIE方法基于命名实体识别(Named Entity Recognition,NER)[4]来研究,但是这类方法只利用了图像中的文本信息,缺少对视觉和结构信息的使用,因此精度不高。在此基础上,近几年的方法都开始将视觉和结构信息与文本信息融合到一起,按照对多模态信息进行融合时所采用的原理可以将这些方法分为下面四种:\n",
168 | "\n",
169 | "- 基于Grid的方法\n",
170 | "- 基于Token的方法\n",
171 | "- 基于GCN的方法\n",
172 | "- 基于End to End 的方法\n",
173 | "\n",
174 | "
\n",
175 | "\n",
176 | "文档分析相关技术将在第六章进行详细解读和实战。\n",
177 | "\n",
178 | "## 2.4 其他相关技术\n",
179 | "\n",
180 | "前面主要介绍了OCR领域的三种关键技术:文本检测、文本识别、文档结构化识别,更多其他OCR相关前沿技术介绍,包括端到端文本识别、OCR中的图像预处理技术、OCR数据合成等,可参考教程第七章和第八章。\n"
181 | ]
182 | },
183 | {
184 | "cell_type": "markdown",
185 | "metadata": {
186 | "collapsed": false
187 | },
188 | "source": [
189 | "# 3. OCR技术的产业实践\n",
190 | "\n",
191 | "\n",
192 | "\n",
193 | "> 你是小王,该怎么办? \n",
194 | "> 1. 我不会,我不行,我不干了😭\n",
195 | "> 2. 建议老板找外包公司或者商业化方案,反正花老板的钱😊\n",
196 | "> 3. 网上找找类似项目,面向Github编程😏\n",
197 | "\n",
198 | "
\n",
199 | "\n",
200 | "OCR技术最终还是要落到产业实践当中。虽然学术上关于OCR技术的研究很多,OCR技术的商业化应用相比于其他AI技术也已经相对成熟,但在实际的产业应用中,还是存在一些难点与挑战。下文将从技术和产业实践两个角度进行分析。\n",
201 | "\n",
202 | "\n",
203 | "## 3.1 产业实践难点\n",
204 | "\n",
205 | "在实际的产业实践中,开发者常常需要依托开源社区资源启动或推进项目,而开发者使用开源模型又往往面临三大难题:\n",
206 | "\n",
207 | "图17 OCR技术产业实践三大难题\n",
208 | "\n",
209 | "**1. 找不到、选不出**\n",
210 | "\n",
211 | "开源社区资源丰富,但是信息不对称导致开发者并不能高效地解决痛点问题。一方面,开源社区资源过于丰富,开发者面对一项需求,无法快速从海量的代码仓库中找到匹配业务需求的项目,即存在“找不到”的问题;另一方面,在算法选型时,英文公开数据集上的指标,无法给开发者常常面对的中文场景提供直接的参考,逐个算法验证需要耗费大量时间和人力,且不能保证选出最合适的算法,即“选不出”。\n",
212 | "\n",
213 | "**2. 不适用产业场景**\n",
214 | "\n",
215 | "开源社区中的工作往往更多地偏向效果优化,如学术论文代码开源或复现,一般更侧重算法效果,平衡考虑模型大小和速度的工作相比就少很多,而模型大小和预测耗时在产业实践中是两项不容忽视的指标,其重要程度不亚于模型效果。无论是移动端和服务器端,待识别的图像数目往往非常多,都希望模型更小,精度更高,预测速度更快。GPU太贵,最好使用CPU跑起来更经济。在满足业务需求的前提下,模型越轻量占用的资源越少。\n",
216 | "\n",
217 | "**3. 优化难、训练部署问题多**\n",
218 | "\n",
219 | "直接使用开源算法或模型一般无法直接满足业务需求,实际业务场景中,OCR面临的问题多种多样,业务场景个性化往往需要自定义数据集重新训练,现有的开源项目上,实验各种优化方法的成本较高。此外,OCR应用场景十分丰富,服务端和各种移动端设备上都有着广泛的应用需求,硬件环境多样化就需要支持丰富的部署方式,而开源社区的项目更侧重算法和模型,在预测部署这部分明显支撑不足。要把OCR技术从论文上的算法做到技术落地应用,对开发者的算法和工程能力都有很高的要求。\n",
220 | "\n",
221 | "## 3.2 产业级OCR开发套件PaddleOCR\n",
222 | "\n",
223 | "OCR产业实践需要一套完整全流程的解决方案,来加快研发进度,节约宝贵的研发时间。也就是说,超轻量模型及其全流程解决方案,尤其对于算力、存储空间有限的移动端、嵌入式设备而言,可以说是刚需。\n",
224 | "\n",
225 | "在此背景下,产业级OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)应运而生。\n",
226 | "\n",
227 | "PaddleOCR的建设思路从用户画像和需求出发,依托飞桨核心框架,精选并复现丰富的前沿算法,基于复现的算法研发更适用于产业落地的PP特色模型,并打通训推一体,提供多种预测部署方式,满足实际应用的不同需求场景。\n",
228 | "\n",
229 | "\n",
230 | "图18 PaddleOCR开发套件全景图\n",
231 | "\n",
232 | "
\n",
233 | "\n",
234 | "从全景图可以看出,PaddleOCR依托于飞桨核心框架,在模型算法、预训练模型库、工业级部署等层面均提供了丰富的解决方案,并且提供了数据合成、半自动数据标注工具,满足开发者的数据生产需求。\n",
235 | "\n",
236 | "**在模型算法层面**,PaddleOCR对**文字检测识别**和**文档结构化分析**两类任务分别提供了解决方案。在文字检测识别方面,PaddleOCR复现或开源了4种文本检测算法、8种文本识别算法、1种端到端文本识别算法,并在此基础上研发了PP-OCR系列的通用文本检测识别解决方案;在文档结构化分析方面,PaddleOCR提供了版面分析、表格识别、关键信息抽取、命名实体识别等算法,并在此基础提出了PP-Structure文档分析解决方案。丰富的精选算法可以满足开发者不同业务场景的需求,代码框架的统一也方便开发者进行不同算法的优化和性能对比。\n",
237 | "\n",
238 | "**在预训练模型库层面**,基于PP-OCR和PP-Structure解决方案,PaddleOCR研发并开源了适用于产业实践的PP系列特色模型,包括通用、超轻量和多语言的文本检测识别模型,和复杂文档分析模型。PP系列特色模型均在原始算法上进行了深度优化,使其在效果和性能上均能达到产业实用级别,开发者既可以直接应用于业务场景,也可以用业务数据进行简单的finetune,便可以轻松研发出适用于自己业务需求的“实用模型”。\n",
239 | "\n",
240 | "**在工业级部署层面**,PaddleOCR提供了基于Paddle Inference的服务器端预测方案,基于Paddle Serving的服务化部署方案,以及基于Paddle-Lite的端侧部署方案,满足不同硬件环境下的部署需求,同时提供了基于PaddleSlim的模型压缩方案,可以进一步压缩模型大小。以上部署方式都完成了训推一体全流程打通,以保障开发者可以高效部署,稳定可靠。\n",
241 | "\n",
242 | "**在数据工具层面**,PaddleOCR提供了半自动数据标注工具PPOCRLabel和数据合成工具Style-Text,助力开发者更方便的生产模型训练所需的数据集和标注信息。PPOCRLabel作为业界首个开源的半自动OCR数据标注工具,针对标注过程枯燥繁琐、机械性高,大量训练数据所需人工标记,时间金钱成本昂贵的问题,内置PP-OCR模型实现预标注+人工校验的标注模式,可以极大提升标注效率,节省人力成本。数据合成工具Style-Text主要解决实际场景真实数据严重不足,传统合成算法无法合成文字风格(字体、颜色、间距、背景)的问题,只需要少许目标场景图像,就可以批量合成大量与目标场景风格相近的文本图像。\n",
243 | "\n",
244 | "\n",
245 | "图19 PPOCRLabel使用示意图\n",
246 | "\n",
247 | "
\n",
248 | "\n",
249 | "\n",
250 | "图20 Style-Text合成效果示例\n",
251 | "\n",
252 | "
\n",
253 | "\n",
254 | "### 3.2.1 PP-OCR与PP-Structrue\n",
255 | "\n",
256 | "PP系列特色模型是飞桨各视觉开发套件针对产业实践需求进行深度优化的模型,力求速度与精度平衡。PaddleOCR中的PP系列特色模型包括针对文字检测识别任务的PP-OCR系列模型和针对文档分析的PP-Structure系列模型。\n",
257 | "\n",
258 | "**(1)PP-OCR中英文模型**\n",
259 | "\n",
260 | "\n",
261 | "\n",
262 | "图21 PP-OCR中英文模型识别结果示例\n",
263 | "\n",
264 | "
\n",
265 | "\n",
266 | "PP-OCR中英文模型采用的典型的两阶段OCR算法,即检测模型+识别模型的组成方式,具体的算法框架如下:\n",
267 | "\n",
268 | "图22 PP-OCR系统pipeline示意图\n",
269 | "\n",
270 | "
\n",
271 | "\n",
272 | "可以看到,除输入输出外,PP-OCR核心框架包含了3个模块,分别是:文本检测模块、检测框矫正模块、文本识别模块。\n",
273 | "- 文本检测模块:核心是一个基于[DB](https://arxiv.org/abs/1911.08947)检测算法训练的文本检测模型,检测出图像中的文字区域;\n",
274 | "- 检测框矫正模块:将检测到的文本框输入检测框矫正模块,在这一阶段,将四点表示的文本框矫正为矩形框,方便后续进行文本识别,另一方面会进行文本方向判断和校正,例如如果判断文本行是倒立的情况,则会进行转正,该功能通过训练一个文本方向分类器实现;\n",
275 | "- 文本识别模块:最后文本识别模块对矫正后的检测框进行文本识别,得到每个文本框内的文字内容,PP-OCR中使用的经典文本识别算法[CRNN](https://arxiv.org/abs/1507.05717)。\n",
276 | "\n",
277 | "PaddleOCR先后推出了PP-OCR[23]和PP-OCRv2[24]模型。\n",
278 | "\n",
279 | "PP-OCR模型分为mobile版(轻量版)和server版(通用版),其中mobile版模型主要基于轻量级骨干网络MobileNetV3进行优化,优化后模型(检测模型+文本方向分类模型+识别模型)大小仅8.1M,CPU上平均单张图像预测耗时350ms,T4 GPU上约110ms,裁剪量化后,可在精度不变的情况下进一步压缩到3.5M,便于端侧部署,在骁龙855上测试预测耗时仅260ms。更多的PP-OCR评估数据可参考[benchmark](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/benchmark.md)。\n",
280 | "\n",
281 | "PP-OCRv2保持了PP-OCR的整体框架,主要做了效果上的进一步策略优化。提升包括3个方面:\n",
282 | "- 在模型效果上,相对于PP-OCR mobile版本提升超7%;\n",
283 | "- 在速度上,相对于PP-OCR server版本提升超过220%;\n",
284 | "- 在模型大小上,11.6M的总大小,服务器端和移动端都可以轻松部署。\n",
285 | "\n",
286 | "PP-OCR和PP-OCRv2的具体优化策略将在第四章中进行详细解读。\n",
287 | "\n",
288 | "除了中英文模型,PaddleOCR也基于不同的数据集训练并开源了英文数字模型、多语言识别模型,以上均为超轻量模型,适用于不同的语言场景。\n",
289 | "\n",
290 | "\n",
291 | "图23 PP-OCR的英文数字模型和多语言模型识别效果示意图\n",
292 | "\n",
293 | "
\n",
294 | "\n",
295 | "**(2)PP-Structure文档分析模型**\n",
296 | "\n",
297 | "PP-Structure支持版面分析(layout analysis)、表格识别(table recognition)、文档视觉问答(DocVQA)三种子任务。\n",
298 | "\n",
299 | "PP-Structure核心功能点如下:\n",
300 | "- 支持对图片形式的文档进行版面分析,可以划分文字、标题、表格、图片以及列表5类区域(与Layout-Parser联合使用)\n",
301 | "- 支持文字、标题、图片以及列表区域提取为文字字段(与PP-OCR联合使用)\n",
302 | "- 支持表格区域进行结构化分析,最终结果输出Excel文件\n",
303 | "- 支持Python whl包和命令行两种方式,简单易用\n",
304 | "- 支持版面分析和表格结构化两类任务自定义训练\n",
305 | "- 支持VQA任务-SER和RE\n",
306 | "\n",
307 | "\n",
308 | "图24 PP-Structure系统示意图(本图仅含版面分析+表格识别)\n",
309 | "\n",
310 | "
\n",
311 | "\n",
312 | "PP-Structure的具体方案将在第六章中进行详细解读。\n",
313 | "\n",
314 | "### 3.2.2 工业级部署方案\n",
315 | "\n",
316 | "飞桨支持全流程、全场景推理部署,模型来源主要分为三种,第一种使用PaddlePaddle API构建网络结构进行训练所得,第二种是基于飞桨套件系列,飞桨套件提供了丰富的模型库、简洁易用的API,具备开箱即用,包括视觉模型库PaddleCV、智能语音库PaddleSpeech以及自然语言处理库PaddleNLP等,第三种采用X2Paddle工具从第三方框架(PyTorh、ONNX、TensorFlow等)产出的模型。\n",
317 | "\n",
318 | "飞桨模型可以选用PaddleSlim工具进行压缩、量化以及蒸馏,支持五种部署方案,分别为服务化Paddle Serving、服务端/云端Paddle Inference、移动端/边缘端Paddle Lite、网页前端Paddle.js, 对于Paddle不支持的硬件,比如MCU、地平线、鲲云等国产芯片,可以借助Paddle2ONNX转化为支持ONNX的第三方框架。\n",
319 | "\n",
320 | "\n",
321 | "图25 飞桨支持部署方式\n",
322 | "\n",
323 | "
\n",
324 | "\n",
325 | "Paddle Inference支持服务端和云端部署,具备高性能与通用性,针对不同平台和不同应用场景进行了深度的适配和优化,Paddle Inference是飞桨的原生推理库,保证模型在服务器端即训即用,快速部署,适用于高性能硬件上使用多种应用语言环境部署算法复杂的模型,硬件覆盖x86 CPU、Nvidia GPU、以及百度昆仑XPU、华为昇腾等AI加速器。\n",
326 | "\n",
327 | "Paddle Lite 是端侧推理引擎,具有轻量化和高性能特点,针对端侧设备和各应用场景进行了深度的设配和优化。当前支持Android、IOS、嵌入式Linux设备、macOS 等多个平台,硬件覆盖ARM CPU和GPU、X86 CPU和新硬件如百度昆仑、华为昇腾与麒麟、瑞芯微等。\n",
328 | "\n",
329 | "Paddle Serving是一套高性能服务框架,旨在帮助用户几个步骤快速将模型在云端服务化部署。目前Paddle Serving支持自定义前后处理、模型组合、模型热加载更新、多机多卡多模型、分布式推理、K8S部署、安全网关和模型加密部署、支持多语言多客户端访问等功能,Paddle Serving官方还提供了包括PaddleOCR在内的40多种模型的部署示例,以帮助用户更快上手。\n",
330 | "\n",
331 | "\n",
332 | "图26 飞桨支持部署方式\n",
333 | "\n",
334 | "
\n",
335 | "\n",
336 | "以上部署方案将在第五章中基于PP-OCRv2模型进行详细解读与实战。"
337 | ]
338 | },
339 | {
340 | "cell_type": "markdown",
341 | "metadata": {
342 | "collapsed": false
343 | },
344 | "source": [
345 | "# 4. 总结\n",
346 | "\n",
347 | "本节首先介绍了OCR技术的应用场景和前沿算法,然后分析了OCR技术在产业实践中的难点与三大挑战。\n",
348 | "\n",
349 | "本教程后续章节内容安排如下:\n",
350 | "\n",
351 | "* 第二、三章分别介绍检测、识别技术并实践;\n",
352 | "* 第四章介绍PP-OCR优化策略; \n",
353 | "* 第五章进行预测部署实战; \n",
354 | "* 第六章介绍文档结构化; \n",
355 | "* 第七章介绍端到端、数据预处理、数据合成等其他OCR相关算法; \n",
356 | "* 第八章介绍OCR相关数据集和数据合成工具。\n",
357 | "\n",
358 | "# 参考文献\n",
359 | "\n",
360 | "[1] Liao, Minghui, et al. \"Textboxes: A fast text detector with a single deep neural network.\" Thirty-first AAAI conference on artificial intelligence. 2017.\n",
361 | "\n",
362 | "[2] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.\n",
363 | "\n",
364 | "[3] Tian, Zhi, et al. \"Detecting text in natural image with connectionist text proposal network.\" European conference on computer vision. Springer, Cham, 2016.\n",
365 | "\n",
366 | "[4] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28: 91-99.\n",
367 | "\n",
368 | "[5] Zhou, Xinyu, et al. \"East: an efficient and accurate scene text detector.\" Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.\n",
369 | "\n",
370 | "[6] Wang, Wenhai, et al. \"Shape robust text detection with progressive scale expansion network.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
371 | "\n",
372 | "[7] Liao, Minghui, et al. \"Real-time scene text detection with differentiable binarization.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.\n",
373 | "\n",
374 | "[8] Deng, Dan, et al. \"Pixellink: Detecting scene text via instance segmentation.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.\n",
375 | "\n",
376 | "[9] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.\n",
377 | "\n",
378 | "[10] Wang P, Zhang C, Qi F, et al. A single-shot arbitrarily-shaped text detector based on context attended multi-task \n",
379 | "learning[C]//Proceedings of the 27th ACM international conference on multimedia. 2019: 1277-1285.\n",
380 | "\n",
381 | "[11] Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\n",
382 | "\n",
383 | "[12] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\n",
384 | "\n",
385 | "[13] Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\n",
386 | "\n",
387 | "[14] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\n",
388 | "\n",
389 | "[15] Lyu P, Liao M, Yao C, et al. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 67-83.\n",
390 | "\n",
391 | "[16] Soto C, Yoo S. Visual detection with context for document layout analysis[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3464-3470.\n",
392 | "\n",
393 | "[17] Sarkar M, Aggarwal M, Jain A, et al. Document Structure Extraction using Prior based High Resolution Hierarchical Semantic Segmentation[C]//European Conference on Computer Vision. Springer, Cham, 2020: 649-666.\n",
394 | "\n",
395 | "[18] Kieninger T, Dengel A. A paper-to-HTML table converting system[C]//Proceedings of document analysis systems (DAS). 1998, 98: 356-365.\n",
396 | "\n",
397 | "[19] Siddiqui S A, Fateh I A, Rizvi S T R, et al. Deeptabstr: Deep learning based table structure recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1403-1409.\n",
398 | "\n",
399 | "[20] Raja S, Mondal A, Jawahar C V. Table structure recognition using top-down and bottom-up cues[C]//European Conference on Computer Vision. Springer, Cham, 2020: 70-86.\n",
400 | "\n",
401 | "[21] Xue W, Yu B, Wang W, et al. TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition[J]. arXiv preprint arXiv:2106.10598, 2021.\n",
402 | "\n",
403 | "[22] Ye J, Qi X, He Y, et al. PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML[J]. arXiv preprint arXiv:2105.01848, 2021.\n",
404 | "\n",
405 | "[23] Du Y, Li C, Guo R, et al. PP-OCR: A practical ultra lightweight OCR system[J]. arXiv preprint arXiv:2009.09941, 2020.\n",
406 | "\n",
407 | "[24] Du Y, Li C, Guo R, et al. PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System[J]. arXiv preprint arXiv:2109.03144, 2021.\n",
408 | "\n"
409 | ]
410 | }
411 | ],
412 | "metadata": {
413 | "kernelspec": {
414 | "display_name": "Python 3",
415 | "language": "python",
416 | "name": "py35-paddle1.2.0"
417 | },
418 | "language_info": {
419 | "codemirror_mode": {
420 | "name": "ipython",
421 | "version": 3
422 | },
423 | "file_extension": ".py",
424 | "mimetype": "text/x-python",
425 | "name": "python",
426 | "nbconvert_exporter": "python",
427 | "pygments_lexer": "ipython3",
428 | "version": "3.7.4"
429 | }
430 | },
431 | "nbformat": 4,
432 | "nbformat_minor": 1
433 | }
434 |
--------------------------------------------------------------------------------
/notebook_ch/2.text_detection/.ipynb_checkpoints/文本检测FAQ-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 文本检测FAQ\n",
8 | "\n",
9 | "本节罗列一些开发者们使用PaddleOCR的文本检测模型常遇到的一些问题,并给出相应的问题解决方法或建议。\n",
10 | "\n",
11 | "FAQ分两个部分来介绍,分别是:\n",
12 | " - 文本检测训练相关\n",
13 | " - 文本检测预测相关"
14 | ]
15 | },
16 | {
17 | "cell_type": "markdown",
18 | "metadata": {},
19 | "source": [
20 | "## 1. 文本检测训练相关FAQ\n",
21 | "\n",
22 | "**1.1 PaddleOCR提供的文本检测算法包括哪些?**\n",
23 | "\n",
24 | "**A**:PaddleOCR中包含多种文本检测模型,包括基于回归的文本检测方法EAST、SAST,和基于分割的文本检测方法DB,PSENet。\n",
25 | "\n",
26 | "\n",
27 | "**1.2:请问PaddleOCR项目中的中文超轻量和通用模型用了哪些数据集?训练多少样本,gpu什么配置,跑了多少个epoch,大概跑了多久?**\n",
28 | "\n",
29 | "**A**:对于超轻量DB检测模型,训练数据包括开源数据集lsvt,rctw,CASIA,CCPD,MSRA,MLT,BornDigit,iflytek,SROIE和合成的数据集等,总数据量越10W,数据集分为5个部分,训练时采用随机采样策略,在4卡V100GPU上约训练500epoch,耗时3天。\n",
30 | "\n",
31 | "\n",
32 | "**1.3 文本检测训练标签是否需要具体文本标注,标签中的”###”是什么意思?**\n",
33 | "\n",
34 | "**A**:文本检测训练只需要文本区域的坐标即可,标注可以是四点或者十四点,按照左上,右上,右下,左下的顺序排列。PaddleOCR提供的标签文件中包含文本字段,对于文本区域文字不清晰会使用###代替。训练检测模型时,不会用到标签中的文本字段。\n",
35 | " \n",
36 | "**1.4 对于文本行较紧密的情况下训练的文本检测模型效果较差?**\n",
37 | "\n",
38 | "**A**:使用基于分割的方法,如DB,检测密集文本行时,最好收集一批数据进行训练,并且在训练时,并将生成二值图像的[shrink_ratio](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/ppocr/data/imaug/make_shrink_map.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L37)参数调小一些。另外,在预测的时候,可以适当减小[unclip_ratio](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L59)参数,unclip_ratio参数值越大检测框就越大。\n",
39 | "\n",
40 | "\n",
41 | "**1.5 对于一些尺寸较大的文档类图片, DB在检测时会有较多的漏检,怎么避免这种漏检的问题呢?**\n",
42 | "\n",
43 | "**A**:首先,需要确定是模型没有训练好的问题还是预测时处理的问题。如果是模型没有训练好,建议多加一些数据进行训练,或者在训练的时候多加一些数据增强。\n",
44 | "如果是预测图像过大的问题,可以增大预测时输入的最长边设置参数[det_limit_side_len](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L47),默认为960。\n",
45 | "其次,可以通过可视化后处理的分割图观察漏检的文字是否有分割结果,如果没有分割结果,说明是模型没有训练好。如果有完整的分割区域,说明是预测后处理的问题,建议调整[DB后处理参数](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L51-L53)。\n",
46 | "\n",
47 | "\n",
48 | "**1.6 DB模型弯曲文本(如略微形变的文档图像)漏检问题?**\n",
49 | "\n",
50 | "**A**: DB后处理中计算文本框平均得分时,是求rectangle区域的平均分数,容易造成弯曲文本漏检,已新增求polygon区域的平均分数,会更准确,但速度有所降低,可按需选择,在相关pr中可查看[可视化对比效果](https://github.com/PaddlePaddle/PaddleOCR/pull/2604)。该功能通过参数 [det_db_score_mode](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/tools/infer/utility.py#L51)进行选择,参数值可选[`fast`(默认)、`slow`],`fast`对应原始的rectangle方式,`slow`对应polygon方式。感谢用户[buptlihang](https://github.com/buptlihang)提[pr](https://github.com/PaddlePaddle/PaddleOCR/pull/2574)帮助解决该问题。\n",
51 | "\n",
52 | "\n",
53 | "**1.7 简单的对于精度要求不高的OCR任务,数据集需要准备多少张呢?**\n",
54 | "\n",
55 | "**A**:(1)训练数据的数量和需要解决问题的复杂度有关系。难度越大,精度要求越高,则数据集需求越大,而且一般情况实际中的训练数据越多效果越好。\n",
56 | "\n",
57 | "(2)对于精度要求不高的场景,检测任务和识别任务需要的数据量是不一样的。对于检测任务,500张图像可以保证基本的检测效果。对于识别任务,需要保证识别字典中每个字符出现在不同场景的行文本图像数目需要大于200张(举例,如果有字典中有5个字,每个字都需要出现在200张图片以上,那么最少要求的图像数量应该在200-1000张之间),这样可以保证基本的识别效果。\n",
58 | "\n",
59 | "\n",
60 | "**1.8 当训练数据量少时,如何获取更多的数据?**\n",
61 | "\n",
62 | "**A**:当训练数据量少时,可以尝试以下三种方式获取更多的数据:(1)人工采集更多的训练数据,最直接也是最有效的方式。(2)基于PIL和opencv基本图像处理或者变换。例如PIL中ImageFont, Image, ImageDraw三个模块将文字写到背景中,opencv的旋转仿射变换,高斯滤波等。(3)利用数据生成算法合成数据,例如pix2pix等算法。\n",
63 | "\n",
64 | "\n",
65 | "**1.9 如何更换文本检测/识别的backbone?**\n",
66 | "\n",
67 | "A:无论是文字检测,还是文字识别,骨干网络的选择是预测效果和预测效率的权衡。一般,选择更大规模的骨干网络,例如ResNet101_vd,则检测或识别更准确,但预测耗时相应也会增加。而选择更小规模的骨干网络,例如MobileNetV3_small_x0_35,则预测更快,但检测或识别的准确率会大打折扣。幸运的是不同骨干网络的检测或识别效果与在ImageNet数据集图像1000分类任务效果正相关。飞桨图像分类套件PaddleClas汇总了ResNet_vd、Res2Net、HRNet、MobileNetV3、GhostNet等23种系列的分类网络结构,在上述图像分类任务的top1识别准确率,GPU(V100和T4)和CPU(骁龙855)的预测耗时以及相应的117个预训练模型下载地址。\n",
68 | "\n",
69 | "(1)文字检测骨干网络的替换,主要是确定类似与ResNet的4个stages,以方便集成后续的类似FPN的检测头。此外,对于文字检测问题,使用ImageNet训练的分类预训练模型,可以加速收敛和效果提升。\n",
70 | "\n",
71 | "(2)文字识别的骨干网络的替换,需要注意网络宽高stride的下降位置。由于文本识别一般宽高比例很大,因此高度下降频率少一些,宽度下降频率多一些。可以参考[PaddleOCR中MobileNetV3骨干网络的改动](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.3/ppocr/modeling/backbones/rec_mobilenet_v3.py)。\n",
72 | "\n",
73 | "\n",
74 | "**1.10 如何对检测模型finetune,比如冻结前面的层或某些层使用小的学习率学习?**\n",
75 | "\n",
76 | "**A**:如果是冻结某些层,可以将变量的stop_gradient属性设置为True,这样计算这个变量之前的所有参数都不会更新了,参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/faq/train_cn.html#id4\n",
77 | "\n",
78 | "如果对某些层使用更小的学习率学习,静态图里还不是很方便,一个方法是在参数初始化的时候,给权重的属性设置固定的学习率,参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/api/paddle/fluid/param_attr/ParamAttr_cn.html#paramattr\n",
79 | "\n",
80 | "实际上我们实验发现,直接加载模型去fine-tune,不设置某些层不同学习率,效果也都不错。\n",
81 | "\n",
82 | "**1.11 DB的预处理部分,图片的长和宽为什么要处理成32的倍数?**\n",
83 | "\n",
84 | "**A**:和网络下采样的倍数(stride)有关。以检测中的resnet骨干网络为例,图像输入网络之后,需要经过5次2倍降采样,共32倍,因此建议输入的图像尺寸为32的倍数。\n",
85 | "\n",
86 | "\n",
87 | "**1.12 在PP-OCR系列的模型中,文本检测的骨干网络为什么没有使用SEBlock?**\n",
88 | "\n",
89 | "**A**:SE模块是MobileNetV3网络一个重要模块,目的是估计特征图每个特征通道重要性,给特征图每个特征分配权重,提高网络的表达能力。但是,对于文本检测,输入网络的分辨率比较大,一般是640\\*640,利用SE模块估计特征图每个特征通道重要性比较困难,网络提升能力有限,但是该模块又比较耗时,因此在PP-OCR系统中,文本检测的骨干网络没有使用SE模块。实验也表明,当去掉SE模块,超轻量模型大小可以减小40%,文本检测效果基本不受影响。详细可以参考PP-OCR技术文章,https://arxiv.org/abs/2009.09941.\n",
90 | "\n",
91 | "\n",
92 | "**1.13 PP-OCR检测效果不好,该如何优化?**\n",
93 | "\n",
94 | "**A**: 具体问题具体分析:\n",
95 | "- 如果在你的场景上检测效果不可用,首选是在你的数据上做finetune训练;\n",
96 | "- 如果图像过大,文字过于密集,建议不要过度压缩图像,可以尝试修改检测预处理的resize逻辑,防止图像被过度压缩;\n",
97 | "- 检测框大小过于紧贴文字或检测框过大,可以调整db_unclip_ratio这个参数,加大参数可以扩大检测框,减小参数可以减小检测框大小;\n",
98 | "- 检测框存在很多漏检问题,可以减小DB检测后处理的阈值参数det_db_box_thresh,防止一些检测框被过滤掉,也可以尝试设置det_db_score_mode为'slow';\n",
99 | "- 其他方法可以选择use_dilation为True,对检测输出的feature map做膨胀处理,一般情况下,会有效果改善;\n",
100 | "\n",
101 | "\n",
102 | "## 2. 文本检测预测相关FAQ\n",
103 | "\n",
104 | "**2.1 DB有些框太贴文本了反而去掉了一些文本的边角影响识别,这个问题有什么办法可以缓解吗?**\n",
105 | "\n",
106 | "**A**:可以把后处理的参数[unclip_ratio](https://github.com/PaddlePaddle/PaddleOCR/blob/d80afce9b51f09fd3d90e539c40eba8eb5e50dd6/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L52)适当调大一点,该参数越大文本框越大。\n",
107 | "\n",
108 | "\n",
109 | "**2.2 为什么PaddleOCR检测预测是只支持一张图片测试?即test_batch_size_per_card=1**\n",
110 | "\n",
111 | "**A**:预测的时候,对图像等比例缩放,最长边960,不同图像等比例缩放后长宽不一致,无法组成batch,所以设置为test_batch_size为1。\n",
112 | "\n",
113 | "\n",
114 | "**2.3 在CPU上加速PaddleOCR的文本检测模型预测?**\n",
115 | "\n",
116 | "**A**:x86 CPU可以使用mkldnn(OneDNN)进行加速;在支持mkldnn加速的CPU上开启[enable_mkldnn](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py#L105)参数。另外,配合增加CPU上预测使用的[线程数num_threads](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py#L106),可以有效加快CPU上的预测速度。\n",
117 | "\n",
118 | "**2.4 在GPU上加速PaddleOCR的文本检测模型预测?**\n",
119 | "\n",
120 | "**A**:GPU加速预测推荐使用TensorRT。\n",
121 | "- 1. 从[链接](https://paddleinference.paddlepaddle.org.cn/master/user_guides/download_lib.html)下载带TensorRT的Paddle安装包或者预测库。\n",
122 | "- 2. 从Nvidia官网下载[TensorRT](https://developer.nvidia.com/tensorrt),注意下载的TensorRT版本与paddle安装包中编译的TensorRT版本一致。\n",
123 | "- 3. 设置环境变量`LD_LIBRARY_PATH`,指向TensorRT的lib文件夹\n",
124 | "```\n",
125 | "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:\n",
126 | "```\n",
127 | "- 4. 开启PaddleOCR预测的[tensorrt选项](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L38)。\n",
128 | "\n",
129 | "**2.5 如何在移动端部署PaddleOCR模型?**\n",
130 | "\n",
131 | "**A**: 飞桨Paddle有专门针对移动端部署的工具[PaddleLite](https://github.com/PaddlePaddle/Paddle-Lite),并且PaddleOCR提供了DB+CRNN为demo的android arm部署代码,参考[链接](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.3/deploy/lite/readme.md)。\n",
132 | "\n",
133 | "\n",
134 | "**2.6 如何使用PaddleOCR多进程预测?**\n",
135 | "\n",
136 | "**A**: 近期PaddleOCR新增了[多进程预测控制参数](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L111),`use_mp`表示是否使用多进程,`total_process_num`表示在使用多进程时的进程数。具体使用方式请参考[文档](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.3/doc/doc_ch/inference.md#1-%E8%B6%85%E8%BD%BB%E9%87%8F%E4%B8%AD%E6%96%87ocr%E6%A8%A1%E5%9E%8B%E6%8E%A8%E7%90%86)。\n",
137 | "\n",
138 | "**2.7 预测时显存爆炸、内存泄漏问题?**\n",
139 | "\n",
140 | "**A**: 如果是训练模型的预测,由于模型太大或者输入图像太大导致显存不够用,可以参考代码在主函数运行前加上paddle.no_grad(),即可减小显存占用。如果是inference模型预测时显存占用过高,可以配置Config时,加入[config.enable_memory_optim()](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L267)用于减小内存占用。\n",
141 | "\n",
142 | "另外关于使用Paddle预测时出现内存泄漏的问题,建议安装paddle最新版本,内存泄漏已修复。"
143 | ]
144 | }
145 | ],
146 | "metadata": {
147 | "kernelspec": {
148 | "display_name": "Python 3",
149 | "language": "python",
150 | "name": "python3"
151 | },
152 | "language_info": {
153 | "codemirror_mode": {
154 | "name": "ipython",
155 | "version": 3
156 | },
157 | "file_extension": ".py",
158 | "mimetype": "text/x-python",
159 | "name": "python",
160 | "nbconvert_exporter": "python",
161 | "pygments_lexer": "ipython3",
162 | "version": "3.8.8"
163 | }
164 | },
165 | "nbformat": 4,
166 | "nbformat_minor": 1
167 | }
168 |
--------------------------------------------------------------------------------
/notebook_ch/2.text_detection/.ipynb_checkpoints/文本检测理论篇-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 文本检测算法理论\n"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## 1 文本检测\n",
15 | "\n",
16 | "文本检测任务是找出图像或视频中的文字位置。不同于目标检测任务,目标检测不仅要解决定位问题,还要解决目标分类问题。\n",
17 | "\n",
18 | "文本在图像中的表现形式可以视为一种‘目标’,通用的目标检测的方法也适用于文本检测,从任务本身上来看:\n",
19 | "\n",
20 | "- 目标检测:给定图像或者视频,找出目标的位置(box),并给出目标的类别;\n",
21 | "- 文本检测:给定输入图像或者视频,找出文本的区域,可以是单字符位置或者整个文本行位置;\n",
22 | "\n",
23 | "\n",
24 | "\n",
25 | " \n",
26 | "\n",
27 | "
\n",
26 | "\n",
27 | "
图1 目标检测示意图\n",
28 | "\n",
29 | " \n",
30 | "\n",
31 | "
\n",
30 | "\n",
31 | "
图2 文本检测示意图\n",
32 | "\n",
33 | "目标检测和文本检测同属于“定位”问题。但是文本检测无需对目标分类,并且文本形状复杂多样。\n",
34 | "\n",
35 | "当前所说的文本检测一般是自然场景文本检测,其难点在于:\n",
36 | "\n",
37 | "1. 自然场景中文本具有多样性:文本检测受到文字颜色、大小、字体、形状、方向、语言、以及文本长度的影响;\n",
38 | "2. 复杂的背景和干扰;文本检测受到图像失真,模糊,低分辨率,阴影,亮度等因素的影响;\n",
39 | "3. 文本密集甚至重叠会影响文字的检测;\n",
40 | "4. 文字存在局部一致性:文本行的一小部分,也可视为是独立的文本。\n",
41 | "\n",
42 | " \n",
44 | "\n",
45 | "
\n",
44 | "\n",
45 | "
图3 文本检测场景\n",
46 | "\n",
47 | "针对以上问题,衍生出了很多基于深度学习的文本检测算法,用于解决自然场景文字检测问题。这些方法可以分为基于回归和基于分割的文本检测方法。\n",
48 | "\n",
49 | "下一节将简要介绍基于深度学习技术的经典文字检测算法。"
50 | ]
51 | },
52 | {
53 | "cell_type": "markdown",
54 | "metadata": {},
55 | "source": [
56 | "## 2 文本检测方法介绍\n",
57 | "\n",
58 | "\n",
59 | "近些年来基于深度学习的文本检测算法层出不穷,这些方法大致可以分为两类:\n",
60 | "1. 基于回归的文本检测方法\n",
61 | "2. 基于分割的文本检测方法\n",
62 | "\n",
63 | "\n",
64 | "本节筛选了2017-2021年的常用文本检测方法,按照如上两类方法分类如下表格所示:\n",
65 | "\n",
66 | " \n",
68 | "
\n",
68 | "
图4 文本检测算法\n",
69 | "\n",
70 | "\n",
71 | "### 2.1 基于回归的文本检测\n",
72 | "\n",
73 | "基于回归文本检测方法和目标检测算法的方法相似,文本检测方法只有两个类别,图像中的文本视为待检测的目标,其余部分视为背景。\n",
74 | "\n",
75 | "#### 2.1.1 水平文本检测\n",
76 | "\n",
77 | "早期基于深度学习的文本检测算法是从目标检测的方法改进而来,支持水平文本检测。比如TextBoxes算法基于SSD算法改进而来,CTPN根据二阶段目标检测Fast-RCNN算法改进而来。\n",
78 | "\n",
79 | "在TextBoxes[1]算法根据一阶段目标检测器SSD调整,将默认文本框更改为适应文本方向和宽高比的规格的四边形,提供了一种端对端训练的文字检测方法,并且无需复杂的后处理。\n",
80 | "- 采用更大长宽比的预选框\n",
81 | "- 卷积核从3x3变成了1x5,更适合长文本检测\n",
82 | "- 采用多尺度输入\n",
83 | "\n",
84 | " \n",
85 | "
\n",
85 | "
图5 textbox框架图\n",
86 | "\n",
87 | "CTPN[3]基于Fast-RCNN算法,扩展RPN模块并且设计了基于CRNN的模块让整个网络从卷积特征中检测到文本序列,二阶段的方法通过ROI Pooling获得了更准确的特征定位。但是TextBoxes和CTPN只支持检测横向文本。\n",
88 | "\n",
89 | " \n",
90 | "
\n",
90 | "
图6 CTPN框架图\n",
91 | "\n",
92 | "#### 2.1.2 任意角度文本检测\n",
93 | "\n",
94 | "TextBoxes++[2]在TextBoxes基础上进行改进,支持检测任意角度的文本。从结构上来说,不同于TextBoxes,TextBoxes++针对多角度文本进行检测,首先修改预选框的宽高比,调整宽高比aspect ratio为1、2、3、5、1/2、1/3、1/5。其次是将$1*5$的卷积核改为$3*5$,更好的学习倾斜文本的特征;最后,TextBoxes++的输出旋转框的表示信息。\n",
95 | "\n",
96 | " \n",
98 | "
\n",
98 | "
图7 TextBoxes++框架图\n",
99 | "\n",
100 | "\n",
101 | "EAST[4]针对倾斜文本的定位问题,提出了two-stage的文本检测方法,包含 FCN特征提取和NMS部分。EAST提出了一种新的文本检测pipline结构,可以端对端训练并且支持检测任意朝向的文本,并且具有结构简单,性能高的特点。FCN支持输出倾斜的矩形框和水平框,可以自由选择输出格式。\n",
102 | "- 如果输出检测形状为RBox,则输出Box旋转角度以及AABB文本形状信息,AABB表示到文本框上下左右边的偏移。RBox可以旋转矩形的文本。\n",
103 | "- 如果输出检测框为四点框,则输出的最后一个维度为8个数字,表示从四边形的四个角顶点的位置偏移。该输出方式可以预测不规则四边形的文本。\n",
104 | "\n",
105 | "考虑到FCN输出的文本框是比较冗余的,比如一个文本区域的邻近的像素生成的框重合度较高,但不是同一个文本生成的检测框,重合度都很小,因此EAST提出先按行合并预测框,最后再把剩下的四边形用原始的NMS筛选。\n",
106 | "\n",
107 | " \n",
109 | "
\n",
109 | "
图8 EAST框架图 \n",
110 | "\n",
111 | "\n",
112 | "MOST[15]提出TFAM模块动态的调整粗粒度的检测结果的感受野,另外提出PA-NMS根据位置信息合并可靠的检测预测结果。此外,训练中还提出 Instance-wise IoU 损失函数,用于平衡训练,以处理不同尺度的文本实例。该方法可以和EAST方法结合,在检测极端长宽比和不同尺度的文本有更好的检测效果和性能。\n",
113 | "\n",
114 | " \n",
116 | "
\n",
116 | "
图9 MOST框架图\n",
117 | "\n",
118 | "\n",
119 | "#### 2.1.3 弯曲文本检测\n",
120 | "\n",
121 | "利用回归的方法解决弯曲文本的检测问题,一个简单的思路是用多点坐标描述弯曲文本的边界多边形,然后直接预测多边形的顶点坐标。\n",
122 | "\n",
123 | "CTD[6]提出了直接预测弯曲文本14个顶点的边界多边形,网络中利用Bi-LSTM[13]层以细化顶点的预测坐标,实现了基于回归方法的弯曲文本检测。\n",
124 | "\n",
125 | " \n",
127 | "
\n",
127 | "
图10 CTD框架图\n",
128 | "\n",
129 | "\n",
130 | "\n",
131 | "LOMO[19]针对长文本和弯曲文本问题,提出迭代的优化文本定位特征获取更精细的文本定位。该方法包括三个部分:坐标回归模块DR,迭代优化模块IRM以及任意形状表达模块SEM。它们分别用于生成文本大致区域,迭代优化文本定位特征,预测文本区域、文本中心线以及文本边界。迭代的优化文本特征可以更好的解决长文本定位问题以及获得更精确的文本区域定位。\n",
132 | " \n",
134 | "
\n",
134 | "
图11 LOMO框架图\n",
135 | "\n",
136 | "\n",
137 | "Contournet[18]基于提出对文本轮廓点建模获取弯曲文本检测框,该方法首先使用Adaptive-RPN获取文本区域的proposal特征,然后设计了局部正交纹理感知LOTM模块学习水平与竖直方向的纹理特征,并用轮廓点表示,最后,通过同时考虑两个正交方向上的特征响应,利用Point Re-Scoring算法可以有效地滤除强单向或弱正交激活的预测,最终文本轮廓可以用一组高质量的轮廓点表示出来。\n",
138 | " \n",
140 | "
\n",
140 | "
图12 Contournet框架图\n",
141 | "\n",
142 | "\n",
143 | "PCR[14]提出渐进式的坐标回归处理弯曲文本检测问题,总体分为三个阶段,首先大致检测到文本区域,获得文本框,另外通过所设计的Contour Localization Mechanism预测文本最小包围框的角点坐标,然后通过叠加多个CLM模块和RCLM模块预测得到弯曲文本。该方法利用文本轮廓信息聚合得到丰富的文本轮廓特征表示,不仅能抑制冗余的噪声点对坐标回归的影响,还能更精确的定位文本区域。\n",
144 | "\n",
145 | " \n",
147 | "
\n",
147 | "
图13 PCR框架图\n"
148 | ]
149 | },
150 | {
151 | "cell_type": "markdown",
152 | "metadata": {},
153 | "source": [
154 | "\n",
155 | "### 2.2 基于分割的文本检测\n",
156 | "\n",
157 | "基于回归的方法虽然在文本检测上取得了很好的效果,但是对解决弯曲文本往往难以得到平滑的文本包围曲线,并且模型较为复杂不具备性能优势。于是研究者们提出了基于图像分割的文本分割方法,先从像素层面做分类,判别每一个像素点是否属于一个文本目标,得到文本区域的概率图,通过后处理方式得到文本分割区域的包围曲线。\n",
158 | "\n",
159 | " \n",
161 | "
\n",
161 | "
图14 文本分割算法示意图\n",
162 | "\n",
163 | "\n",
164 | "此类方法通常是基于分割的方法实现文本检测,基于分割的方法对不规则形状的文本检测有着天然的优势。基于分割的文本检测方法主体思想为,通过分割方法得到图像中文本区域,再利用opencv,polygon等后处理得到文本区域的最小包围曲线。\n",
165 | "\n",
166 | "\n",
167 | "Pixellink[7]采用分割的方法解决文本检测问题,分割对象为文本区域,将同属于一个文本行(单词)中的像素链接在一起来分割文本,直接从分割结果中提取文本边界框,无需位置回归就能达到基于回归的文本检测的效果。但是基于分割的方法存在一个问题,对于位置相近的文本,文本分割区域容易出现“粘连“问题。Wu, Yue等人[8]提出分割文本的同时,学习文本的边界位置,用于更好的区分文本区域。另外Tian等人[9]提出将同一文本的像素映射到映射空间,在映射空间中令统一文本的映射向量距离相近,不同文本的映射向量距离变远。\n",
168 | "\n",
169 | " \n",
171 | "
\n",
171 | "
图15 PixelLink框架图\n",
172 | "\n",
173 | "MSR[20]针对文本检测的多尺度问题,提出提取相同图像的多个scale的特征,然后将这些特征融合并上采样到原图尺寸,网络最后预测文本中心区域、文本中心区域每个点到最近的边界点的x坐标偏移和y坐标偏移,最终可以得到文本区域的轮廓坐标集合。\n",
174 | "\n",
175 | " \n",
177 | "
\n",
177 | "
图16 MSR框架图\n",
178 | " \n",
179 | "针对基于分割的文本算法难以区分相邻文本的问题,PSENet[10]提出渐进式的尺度扩张网络学习文本分割区域,预测不同收缩比例的文本区域,并逐个扩大检测到的文本区域,该方法本质上是边界学习方法的变体,可以有效解决任意形状相邻文本的检测问题。\n",
180 | "\n",
181 | " \n",
183 | "
\n",
183 | "
图17 PSENet框架图\n",
184 | "\n",
185 | "假设PSENet后处理用了3个不同尺度的kernel,如上图s1,s2,s3所示。首先,从最小kernel s1开始,计算文本分割区域的连通域,得到(b),然后,对连通域沿着上下左右做尺度扩张,对于扩张区域属于s2但不属于s1的像素,进行归类,遇到冲突点时,采用“先到先得”原则,重复尺度扩张的操作,最终可以得到不同文本行的独立的分割区域。\n",
186 | "\n",
187 | "\n",
188 | "Seglink++[17]针对弯曲文本和密集文本问题,提出了一种文本块单元之间的吸引关系和排斥关系的表征,然后设计了一种最小生成树算法进行单元组合得到最终的文本检测框,并提出instance-aware 损失函数使Seglink++方法可以端对端训练。\n",
189 | "\n",
190 | " \n",
192 | "
\n",
192 | "
图18 Seglink++框架图\n",
193 | "\n",
194 | "虽然分割方法解决了弯曲文本的检测问题,但是复杂的后处理逻辑以及预测速度也是需要优化的目标。\n",
195 | "\n",
196 | "PAN[11]针对文本检测预测速度慢的问题,从网络设计和后处理方面进行改进,提升算法性能。首先,PAN使用了轻量级的ResNet18作为Backbone,另外设计了轻量级的特征增强模块FPEM和特征融合模块FFM增强Backbone提取的特征。在后处理方面,采用像素聚类方法,沿着预测的文本中心(kernel)四周合并与kernel的距离小于阈值d的像素。PAN保证高精度的同时具有更快的预测速度。\n",
197 | "\n",
198 | "\n",
199 | " \n",
201 | "
\n",
201 | "
图19 PAN框架图\n",
202 | "\n",
203 | "DBNet[12]针对基于分割的方法需要使用阈值进行二值化处理而导致后处理耗时的问题,提出了可学习阈值并巧妙地设计了一个近似于阶跃函数的二值化函数,使得分割网络在训练的时候能端对端的学习文本分割的阈值。自动调节阈值不仅带来精度的提升,同时简化了后处理,提高了文本检测的性能。\n",
204 | "\n",
205 | " \n",
207 | "
\n",
207 | "
图20 DB框架图\n",
208 | "\n",
209 | "FCENet[16]提出将文本包围曲线用傅立叶变换的参数表示,由于傅里叶系数表示在理论上可以拟合任意的封闭曲线,通过设计合适的模型预测基于傅里叶变换的任意形状文本包围框表示,从而实现了自然场景文本检测中对于高度弯曲文本实例的检测精度的提升。\n",
210 | "\n",
211 | " \n",
213 | "
\n",
213 | "
图21 FCENet框架图\n",
214 | "\n"
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {},
220 | "source": [
221 | "## 3 总结\n",
222 | "\n",
223 | "本节介绍了近几年来文本检测领域的发展,包括基于回归、分割的文本检测方法,并分别列举并介绍了一些经典论文的方法思路。下一节以PaddleOCR开源库为例,详细介绍DBNet的算法原理以及核心代码实现。"
224 | ]
225 | },
226 | {
227 | "cell_type": "markdown",
228 | "metadata": {},
229 | "source": [
230 | "## 参考文献\n",
231 | "1. Liao, Minghui, et al. \"Textboxes: A fast text detector with a single deep neural network.\" Thirty-first AAAI conference on artificial intelligence. 2017.\n",
232 | "2. Liao, Minghui, Baoguang Shi, and Xiang Bai. \"Textboxes++: A single-shot oriented scene text detector.\" IEEE transactions on image processing 27.8 (2018): 3676-3690.\n",
233 | "3. Tian, Zhi, et al. \"Detecting text in natural image with connectionist text proposal network.\" European conference on computer vision. Springer, Cham, 2016.\n",
234 | "4. Zhou, Xinyu, et al. \"East: an efficient and accurate scene text detector.\" Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.\n",
235 | "5. Wang, Fangfang, et al. \"Geometry-aware scene text detection with instance transformation network.\" Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.\n",
236 | "6. Yuliang, Liu, et al. \"Detecting curve text in the wild: New dataset and new solution.\" arXiv preprint arXiv:1712.02170 (2017).\n",
237 | "7. Deng, Dan, et al. \"Pixellink: Detecting scene text via instance segmentation.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.\n",
238 | "8. Wu, Yue, and Prem Natarajan. \"Self-organized text detection with minimal post-processing via border learning.\" Proceedings of the IEEE International Conference on Computer Vision. 2017.\n",
239 | "9. Tian, Zhuotao, et al. \"Learning shape-aware embedding for scene text detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
240 | "10. Wang, Wenhai, et al. \"Shape robust text detection with progressive scale expansion network.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
241 | "11. Wang, Wenhai, et al. \"Efficient and accurate arbitrary-shaped text detection with pixel aggregation network.\" Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.\n",
242 | "12. Liao, Minghui, et al. \"Real-time scene text detection with differentiable binarization.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.\n",
243 | "13. Hochreiter, Sepp, and Jürgen Schmidhuber. \"Long short-term memory.\" Neural computation 9.8 (1997): 1735-1780.\n",
244 | "14. Dai, Pengwen, et al. \"Progressive Contour Regression for Arbitrary-Shape Scene Text Detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.\n",
245 | "15. He, Minghang, et al. \"MOST: A Multi-Oriented Scene Text Detector with Localization Refinement.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.\n",
246 | "16. Zhu, Yiqin, et al. \"Fourier contour embedding for arbitrary-shaped text detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.\n",
247 | "17. Tang, Jun, et al. \"Seglink++: Detecting dense and arbitrary-shaped scene text by instance-aware component grouping.\" Pattern recognition 96 (2019): 106954.\n",
248 | "18. Wang, Yuxin, et al. \"Contournet: Taking a further step toward accurate arbitrary-shaped scene text detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.\n",
249 | "19. Zhang, Chengquan, et al. \"Look more than once: An accurate detector for text of arbitrary shapes.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
250 | "20. Xue C, Lu S, Zhang W. Msr: Multi-scale shape regression for scene text detection[J]. arXiv preprint arXiv:1901.02596, 2019. \n"
251 | ]
252 | }
253 | ],
254 | "metadata": {
255 | "kernelspec": {
256 | "display_name": "Python 3",
257 | "language": "python",
258 | "name": "python3"
259 | },
260 | "language_info": {
261 | "codemirror_mode": {
262 | "name": "ipython",
263 | "version": 3
264 | },
265 | "file_extension": ".py",
266 | "mimetype": "text/x-python",
267 | "name": "python",
268 | "nbconvert_exporter": "python",
269 | "pygments_lexer": "ipython3",
270 | "version": "3.8.8"
271 | }
272 | },
273 | "nbformat": 4,
274 | "nbformat_minor": 1
275 | }
276 |
--------------------------------------------------------------------------------
/notebook_ch/2.text_detection/文本检测FAQ.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "collapsed": false
7 | },
8 | "source": [
9 | "# 文本检测FAQ\n",
10 | "\n",
11 | "本节罗列一些开发者们使用PaddleOCR的文本检测模型常遇到的一些问题,并给出相应的问题解决方法或建议。\n",
12 | "\n",
13 | "FAQ分两个部分来介绍,分别是:\n",
14 | " - 文本检测训练相关\n",
15 | " - 文本检测预测相关"
16 | ]
17 | },
18 | {
19 | "cell_type": "markdown",
20 | "metadata": {
21 | "collapsed": false
22 | },
23 | "source": [
24 | "## 1. 文本检测训练相关FAQ\n",
25 | "\n",
26 | "**1.1 PaddleOCR提供的文本检测算法包括哪些?**\n",
27 | "\n",
28 | "**A**:PaddleOCR中包含多种文本检测模型,包括基于回归的文本检测方法EAST、SAST,和基于分割的文本检测方法DB,PSENet。\n",
29 | "\n",
30 | "\n",
31 | "**1.2:请问PaddleOCR项目中的中文超轻量和通用模型用了哪些数据集?训练多少样本,gpu什么配置,跑了多少个epoch,大概跑了多久?**\n",
32 | "\n",
33 | "**A**:对于超轻量DB检测模型,训练数据包括开源数据集lsvt,rctw,CASIA,CCPD,MSRA,MLT,BornDigit,iflytek,SROIE和合成的数据集等,总数据量越10W,数据集分为5个部分,训练时采用随机采样策略,在4卡V100GPU上约训练500epoch,耗时3天。\n",
34 | "\n",
35 | "\n",
36 | "**1.3 文本检测训练标签是否需要具体文本标注,标签中的”###”是什么意思?**\n",
37 | "\n",
38 | "**A**:文本检测训练只需要文本区域的坐标即可,标注可以是四点或者十四点,按照左上,右上,右下,左下的顺序排列。PaddleOCR提供的标签文件中包含文本字段,对于文本区域文字不清晰会使用###代替。训练检测模型时,不会用到标签中的文本字段。\n",
39 | " \n",
40 | "**1.4 对于文本行较紧密的情况下训练的文本检测模型效果较差?**\n",
41 | "\n",
42 | "**A**:使用基于分割的方法,如DB,检测密集文本行时,最好收集一批数据进行训练,并且在训练时,并将生成二值图像的[shrink_ratio](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/ppocr/data/imaug/make_shrink_map.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L37)参数调小一些。另外,在预测的时候,可以适当减小[unclip_ratio](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L59)参数,unclip_ratio参数值越大检测框就越大。\n",
43 | "\n",
44 | "\n",
45 | "**1.5 对于一些尺寸较大的文档类图片, DB在检测时会有较多的漏检,怎么避免这种漏检的问题呢?**\n",
46 | "\n",
47 | "**A**:首先,需要确定是模型没有训练好的问题还是预测时处理的问题。如果是模型没有训练好,建议多加一些数据进行训练,或者在训练的时候多加一些数据增强。\n",
48 | "如果是预测图像过大的问题,可以增大预测时输入的最长边设置参数[det_limit_side_len](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L47),默认为960。\n",
49 | "其次,可以通过可视化后处理的分割图观察漏检的文字是否有分割结果,如果没有分割结果,说明是模型没有训练好。如果有完整的分割区域,说明是预测后处理的问题,建议调整[DB后处理参数](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L51-L53)。\n",
50 | "\n",
51 | "\n",
52 | "**1.6 DB模型弯曲文本(如略微形变的文档图像)漏检问题?**\n",
53 | "\n",
54 | "**A**: DB后处理中计算文本框平均得分时,是求rectangle区域的平均分数,容易造成弯曲文本漏检,已新增求polygon区域的平均分数,会更准确,但速度有所降低,可按需选择,在相关pr中可查看[可视化对比效果](https://github.com/PaddlePaddle/PaddleOCR/pull/2604)。该功能通过参数 [det_db_score_mode](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/tools/infer/utility.py#L51)进行选择,参数值可选[`fast`(默认)、`slow`],`fast`对应原始的rectangle方式,`slow`对应polygon方式。感谢用户[buptlihang](https://github.com/buptlihang)提[pr](https://github.com/PaddlePaddle/PaddleOCR/pull/2574)帮助解决该问题。\n",
55 | "\n",
56 | "\n",
57 | "**1.7 简单的对于精度要求不高的OCR任务,数据集需要准备多少张呢?**\n",
58 | "\n",
59 | "**A**:(1)训练数据的数量和需要解决问题的复杂度有关系。难度越大,精度要求越高,则数据集需求越大,而且一般情况实际中的训练数据越多效果越好。\n",
60 | "\n",
61 | "(2)对于精度要求不高的场景,检测任务和识别任务需要的数据量是不一样的。对于检测任务,500张图像可以保证基本的检测效果。对于识别任务,需要保证识别字典中每个字符出现在不同场景的行文本图像数目需要大于200张(举例,如果有字典中有5个字,每个字都需要出现在200张图片以上,那么最少要求的图像数量应该在200-1000张之间),这样可以保证基本的识别效果。\n",
62 | "\n",
63 | "\n",
64 | "**1.8 当训练数据量少时,如何获取更多的数据?**\n",
65 | "\n",
66 | "**A**:当训练数据量少时,可以尝试以下三种方式获取更多的数据:(1)人工采集更多的训练数据,最直接也是最有效的方式。(2)基于PIL和opencv基本图像处理或者变换。例如PIL中ImageFont, Image, ImageDraw三个模块将文字写到背景中,opencv的旋转仿射变换,高斯滤波等。(3)利用数据生成算法合成数据,例如pix2pix等算法。\n",
67 | "\n",
68 | "\n",
69 | "**1.9 如何更换文本检测/识别的backbone?**\n",
70 | "\n",
71 | "A:无论是文字检测,还是文字识别,骨干网络的选择是预测效果和预测效率的权衡。一般,选择更大规模的骨干网络,例如ResNet101_vd,则检测或识别更准确,但预测耗时相应也会增加。而选择更小规模的骨干网络,例如MobileNetV3_small_x0_35,则预测更快,但检测或识别的准确率会大打折扣。幸运的是不同骨干网络的检测或识别效果与在ImageNet数据集图像1000分类任务效果正相关。飞桨图像分类套件PaddleClas汇总了ResNet_vd、Res2Net、HRNet、MobileNetV3、GhostNet等23种系列的分类网络结构,在上述图像分类任务的top1识别准确率,GPU(V100和T4)和CPU(骁龙855)的预测耗时以及相应的117个预训练模型下载地址。\n",
72 | "\n",
73 | "(1)文字检测骨干网络的替换,主要是确定类似与ResNet的4个stages,以方便集成后续的类似FPN的检测头。此外,对于文字检测问题,使用ImageNet训练的分类预训练模型,可以加速收敛和效果提升。\n",
74 | "\n",
75 | "(2)文字识别的骨干网络的替换,需要注意网络宽高stride的下降位置。由于文本识别一般宽高比例很大,因此高度下降频率少一些,宽度下降频率多一些。可以参考[PaddleOCR中MobileNetV3骨干网络的改动](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.3/ppocr/modeling/backbones/rec_mobilenet_v3.py)。\n",
76 | "\n",
77 | "\n",
78 | "**1.10 如何对检测模型finetune,比如冻结前面的层或某些层使用小的学习率学习?**\n",
79 | "\n",
80 | "**A**:如果是冻结某些层,可以将变量的stop_gradient属性设置为True,这样计算这个变量之前的所有参数都不会更新了,参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/faq/train_cn.html#id4\n",
81 | "\n",
82 | "如果对某些层使用更小的学习率学习,静态图里还不是很方便,一个方法是在参数初始化的时候,给权重的属性设置固定的学习率,参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/api/paddle/fluid/param_attr/ParamAttr_cn.html#paramattr\n",
83 | "\n",
84 | "实际上我们实验发现,直接加载模型去fine-tune,不设置某些层不同学习率,效果也都不错。\n",
85 | "\n",
86 | "**1.11 DB的预处理部分,图片的长和宽为什么要处理成32的倍数?**\n",
87 | "\n",
88 | "**A**:和网络下采样的倍数(stride)有关。以检测中的resnet骨干网络为例,图像输入网络之后,需要经过5次2倍降采样,共32倍,因此建议输入的图像尺寸为32的倍数。\n",
89 | "\n",
90 | "\n",
91 | "**1.12 在PP-OCR系列的模型中,文本检测的骨干网络为什么没有使用SEBlock?**\n",
92 | "\n",
93 | "**A**:SE模块是MobileNetV3网络一个重要模块,目的是估计特征图每个特征通道重要性,给特征图每个特征分配权重,提高网络的表达能力。但是,对于文本检测,输入网络的分辨率比较大,一般是640\\*640,利用SE模块估计特征图每个特征通道重要性比较困难,网络提升能力有限,但是该模块又比较耗时,因此在PP-OCR系统中,文本检测的骨干网络没有使用SE模块。实验也表明,当去掉SE模块,超轻量模型大小可以减小40%,文本检测效果基本不受影响。详细可以参考PP-OCR技术文章,https://arxiv.org/abs/2009.09941.\n",
94 | "\n",
95 | "\n",
96 | "**1.13 PP-OCR检测效果不好,该如何优化?**\n",
97 | "\n",
98 | "**A**: 具体问题具体分析:\n",
99 | "- 如果在你的场景上检测效果不可用,首选是在你的数据上做finetune训练;\n",
100 | "- 如果图像过大,文字过于密集,建议不要过度压缩图像,可以尝试修改检测预处理的resize逻辑,防止图像被过度压缩;\n",
101 | "- 检测框大小过于紧贴文字或检测框过大,可以调整db_unclip_ratio这个参数,加大参数可以扩大检测框,减小参数可以减小检测框大小;\n",
102 | "- 检测框存在很多漏检问题,可以减小DB检测后处理的阈值参数det_db_box_thresh,防止一些检测框被过滤掉,也可以尝试设置det_db_score_mode为'slow';\n",
103 | "- 其他方法可以选择use_dilation为True,对检测输出的feature map做膨胀处理,一般情况下,会有效果改善;\n",
104 | "\n",
105 | "\n",
106 | "## 2. 文本检测预测相关FAQ\n",
107 | "\n",
108 | "**2.1 DB有些框太贴文本了反而去掉了一些文本的边角影响识别,这个问题有什么办法可以缓解吗?**\n",
109 | "\n",
110 | "**A**:可以把后处理的参数[unclip_ratio](https://github.com/PaddlePaddle/PaddleOCR/blob/d80afce9b51f09fd3d90e539c40eba8eb5e50dd6/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L52)适当调大一点,该参数越大文本框越大。\n",
111 | "\n",
112 | "\n",
113 | "**2.2 为什么PaddleOCR检测预测是只支持一张图片测试?即test_batch_size_per_card=1**\n",
114 | "\n",
115 | "**A**:预测的时候,对图像等比例缩放,最长边960,不同图像等比例缩放后长宽不一致,无法组成batch,所以设置为test_batch_size为1。\n",
116 | "\n",
117 | "\n",
118 | "**2.3 在CPU上加速PaddleOCR的文本检测模型预测?**\n",
119 | "\n",
120 | "**A**:x86 CPU可以使用mkldnn(OneDNN)进行加速;在支持mkldnn加速的CPU上开启[enable_mkldnn](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py#L105)参数。另外,配合增加CPU上预测使用的[线程数num_threads](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py#L106),可以有效加快CPU上的预测速度。\n",
121 | "\n",
122 | "**2.4 在GPU上加速PaddleOCR的文本检测模型预测?**\n",
123 | "\n",
124 | "**A**:GPU加速预测推荐使用TensorRT。\n",
125 | "- 1. 从[链接](https://paddleinference.paddlepaddle.org.cn/master/user_guides/download_lib.html)下载带TensorRT的Paddle安装包或者预测库。\n",
126 | "- 2. 从Nvidia官网下载[TensorRT](https://developer.nvidia.com/tensorrt),注意下载的TensorRT版本与paddle安装包中编译的TensorRT版本一致。\n",
127 | "- 3. 设置环境变量`LD_LIBRARY_PATH`,指向TensorRT的lib文件夹\n",
128 | "```\n",
129 | "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:\n",
130 | "```\n",
131 | "- 4. 开启PaddleOCR预测的[tensorrt选项](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L38)。\n",
132 | "\n",
133 | "**2.5 如何在移动端部署PaddleOCR模型?**\n",
134 | "\n",
135 | "**A**: 飞桨Paddle有专门针对移动端部署的工具[PaddleLite](https://github.com/PaddlePaddle/Paddle-Lite),并且PaddleOCR提供了DB+CRNN为demo的android arm部署代码,参考[链接](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.3/deploy/lite/readme.md)。\n",
136 | "\n",
137 | "\n",
138 | "**2.6 如何使用PaddleOCR多进程预测?**\n",
139 | "\n",
140 | "**A**: 近期PaddleOCR新增了[多进程预测控制参数](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L111),`use_mp`表示是否使用多进程,`total_process_num`表示在使用多进程时的进程数。具体使用方式请参考[文档](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.3/doc/doc_ch/inference.md#1-%E8%B6%85%E8%BD%BB%E9%87%8F%E4%B8%AD%E6%96%87ocr%E6%A8%A1%E5%9E%8B%E6%8E%A8%E7%90%86)。\n",
141 | "\n",
142 | "**2.7 预测时显存爆炸、内存泄漏问题?**\n",
143 | "\n",
144 | "**A**: 如果是训练模型的预测,由于模型太大或者输入图像太大导致显存不够用,可以参考代码在主函数运行前加上paddle.no_grad(),即可减小显存占用。如果是inference模型预测时显存占用过高,可以配置Config时,加入[config.enable_memory_optim()](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L267)用于减小内存占用。\n",
145 | "\n",
146 | "另外关于使用Paddle预测时出现内存泄漏的问题,建议安装paddle最新版本,内存泄漏已修复。"
147 | ]
148 | }
149 | ],
150 | "metadata": {
151 | "kernelspec": {
152 | "display_name": "Python 3",
153 | "language": "python",
154 | "name": "py35-paddle1.2.0"
155 | },
156 | "language_info": {
157 | "codemirror_mode": {
158 | "name": "ipython",
159 | "version": 3
160 | },
161 | "file_extension": ".py",
162 | "mimetype": "text/x-python",
163 | "name": "python",
164 | "nbconvert_exporter": "python",
165 | "pygments_lexer": "ipython3",
166 | "version": "3.7.4"
167 | }
168 | },
169 | "nbformat": 4,
170 | "nbformat_minor": 1
171 | }
172 |
--------------------------------------------------------------------------------
/notebook_ch/2.text_detection/文本检测理论篇.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "collapsed": false
7 | },
8 | "source": [
9 | "# 文本检测算法理论\n"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {
15 | "collapsed": false
16 | },
17 | "source": [
18 | "## 1 文本检测\n",
19 | "\n",
20 | "文本检测任务是找出图像或视频中的文字位置。不同于目标检测任务,目标检测不仅要解决定位问题,还要解决目标分类问题。\n",
21 | "\n",
22 | "文本在图像中的表现形式可以视为一种‘目标’,通用的目标检测的方法也适用于文本检测,从任务本身上来看:\n",
23 | "\n",
24 | "- 目标检测:给定图像或者视频,找出目标的位置(box),并给出目标的类别;\n",
25 | "- 文本检测:给定输入图像或者视频,找出文本的区域,可以是单字符位置或者整个文本行位置;\n",
26 | "\n",
27 | "\n",
28 | "\n",
29 | "\n",
30 | "\n",
31 | "
图1 目标检测示意图\n",
32 | "\n",
33 | "\n",
34 | "\n",
35 | "
图2 文本检测示意图\n",
36 | "\n",
37 | "目标检测和文本检测同属于“定位”问题。但是文本检测无需对目标分类,并且文本形状复杂多样。\n",
38 | "\n",
39 | "当前所说的文本检测一般是自然场景文本检测,其难点在于:\n",
40 | "\n",
41 | "1. 自然场景中文本具有多样性:文本检测受到文字颜色、大小、字体、形状、方向、语言、以及文本长度的影响;\n",
42 | "2. 复杂的背景和干扰;文本检测受到图像失真,模糊,低分辨率,阴影,亮度等因素的影响;\n",
43 | "3. 文本密集甚至重叠会影响文字的检测;\n",
44 | "4. 文字存在局部一致性:文本行的一小部分,也可视为是独立的文本。\n",
45 | "\n",
46 | "\n",
48 | "\n",
49 | "
图3 文本检测场景\n",
50 | "\n",
51 | "针对以上问题,衍生出了很多基于深度学习的文本检测算法,用于解决自然场景文字检测问题。这些方法可以分为基于回归和基于分割的文本检测方法。\n",
52 | "\n",
53 | "下一节将简要介绍基于深度学习技术的经典文字检测算法。"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {
59 | "collapsed": false
60 | },
61 | "source": [
62 | "## 2 文本检测方法介绍\n",
63 | "\n",
64 | "\n",
65 | "近些年来基于深度学习的文本检测算法层出不穷,这些方法大致可以分为两类:\n",
66 | "1. 基于回归的文本检测方法\n",
67 | "2. 基于分割的文本检测方法\n",
68 | "\n",
69 | "\n",
70 | "本节筛选了2017-2021年的常用文本检测方法,按照如上两类方法分类如下表格所示:\n",
71 | "\n",
72 | "\n",
74 | "
图4 文本检测算法\n",
75 | "\n",
76 | "\n",
77 | "### 2.1 基于回归的文本检测\n",
78 | "\n",
79 | "基于回归文本检测方法和目标检测算法的方法相似,文本检测方法只有两个类别,图像中的文本视为待检测的目标,其余部分视为背景。\n",
80 | "\n",
81 | "#### 2.1.1 水平文本检测\n",
82 | "\n",
83 | "早期基于深度学习的文本检测算法是从目标检测的方法改进而来,支持水平文本检测。比如TextBoxes算法基于SSD算法改进而来,CTPN根据二阶段目标检测Fast-RCNN算法改进而来。\n",
84 | "\n",
85 | "在TextBoxes[1]算法根据一阶段目标检测器SSD调整,将默认文本框更改为适应文本方向和宽高比的规格的四边形,提供了一种端对端训练的文字检测方法,并且无需复杂的后处理。\n",
86 | "- 采用更大长宽比的预选框\n",
87 | "- 卷积核从3x3变成了1x5,更适合长文本检测\n",
88 | "- 采用多尺度输入\n",
89 | "\n",
90 | "\n",
91 | "
图5 textbox框架图\n",
92 | "\n",
93 | "CTPN[3]基于Fast-RCNN算法,扩展RPN模块并且设计了基于CRNN的模块让整个网络从卷积特征中检测到文本序列,二阶段的方法通过ROI Pooling获得了更准确的特征定位。但是TextBoxes和CTPN只支持检测横向文本。\n",
94 | "\n",
95 | "\n",
96 | "
图6 CTPN框架图\n",
97 | "\n",
98 | "#### 2.1.2 任意角度文本检测\n",
99 | "\n",
100 | "TextBoxes++[2]在TextBoxes基础上进行改进,支持检测任意角度的文本。从结构上来说,不同于TextBoxes,TextBoxes++针对多角度文本进行检测,首先修改预选框的宽高比,调整宽高比aspect ratio为1、2、3、5、1/2、1/3、1/5。其次是将$1*5$的卷积核改为$3*5$,更好的学习倾斜文本的特征;最后,TextBoxes++的输出旋转框的表示信息。\n",
101 | "\n",
102 | "\n",
104 | "
图7 TextBoxes++框架图\n",
105 | "\n",
106 | "\n",
107 | "EAST[4]针对倾斜文本的定位问题,提出了two-stage的文本检测方法,包含 FCN特征提取和NMS部分。EAST提出了一种新的文本检测pipline结构,可以端对端训练并且支持检测任意朝向的文本,并且具有结构简单,性能高的特点。FCN支持输出倾斜的矩形框和水平框,可以自由选择输出格式。\n",
108 | "- 如果输出检测形状为RBox,则输出Box旋转角度以及AABB文本形状信息,AABB表示到文本框上下左右边的偏移。RBox可以旋转矩形的文本。\n",
109 | "- 如果输出检测框为四点框,则输出的最后一个维度为8个数字,表示从四边形的四个角顶点的位置偏移。该输出方式可以预测不规则四边形的文本。\n",
110 | "\n",
111 | "考虑到FCN输出的文本框是比较冗余的,比如一个文本区域的邻近的像素生成的框重合度较高,但不是同一个文本生成的检测框,重合度都很小,因此EAST提出先按行合并预测框,最后再把剩下的四边形用原始的NMS筛选。\n",
112 | "\n",
113 | "\n",
115 | "
图8 EAST框架图 \n",
116 | "\n",
117 | "\n",
118 | "MOST[15]提出TFAM模块动态的调整粗粒度的检测结果的感受野,另外提出PA-NMS根据位置信息合并可靠的检测预测结果。此外,训练中还提出 Instance-wise IoU 损失函数,用于平衡训练,以处理不同尺度的文本实例。该方法可以和EAST方法结合,在检测极端长宽比和不同尺度的文本有更好的检测效果和性能。\n",
119 | "\n",
120 | "\n",
122 | "
图9 MOST框架图\n",
123 | "\n",
124 | "\n",
125 | "#### 2.1.3 弯曲文本检测\n",
126 | "\n",
127 | "利用回归的方法解决弯曲文本的检测问题,一个简单的思路是用多点坐标描述弯曲文本的边界多边形,然后直接预测多边形的顶点坐标。\n",
128 | "\n",
129 | "CTD[6]提出了直接预测弯曲文本14个顶点的边界多边形,网络中利用Bi-LSTM[13]层以细化顶点的预测坐标,实现了基于回归方法的弯曲文本检测。\n",
130 | "\n",
131 | "\n",
133 | "
图10 CTD框架图\n",
134 | "\n",
135 | "\n",
136 | "\n",
137 | "LOMO[19]针对长文本和弯曲文本问题,提出迭代的优化文本定位特征获取更精细的文本定位。该方法包括三个部分:坐标回归模块DR,迭代优化模块IRM以及任意形状表达模块SEM。它们分别用于生成文本大致区域,迭代优化文本定位特征,预测文本区域、文本中心线以及文本边界。迭代的优化文本特征可以更好的解决长文本定位问题以及获得更精确的文本区域定位。\n",
138 | "\n",
140 | "
图11 LOMO框架图\n",
141 | "\n",
142 | "\n",
143 | "Contournet[18]基于提出对文本轮廓点建模获取弯曲文本检测框,该方法首先使用Adaptive-RPN获取文本区域的proposal特征,然后设计了局部正交纹理感知LOTM模块学习水平与竖直方向的纹理特征,并用轮廓点表示,最后,通过同时考虑两个正交方向上的特征响应,利用Point Re-Scoring算法可以有效地滤除强单向或弱正交激活的预测,最终文本轮廓可以用一组高质量的轮廓点表示出来。\n",
144 | "\n",
146 | "
图12 Contournet框架图\n",
147 | "\n",
148 | "\n",
149 | "PCR[14]提出渐进式的坐标回归处理弯曲文本检测问题,总体分为三个阶段,首先大致检测到文本区域,获得文本框,另外通过所设计的Contour Localization Mechanism预测文本最小包围框的角点坐标,然后通过叠加多个CLM模块和RCLM模块预测得到弯曲文本。该方法利用文本轮廓信息聚合得到丰富的文本轮廓特征表示,不仅能抑制冗余的噪声点对坐标回归的影响,还能更精确的定位文本区域。\n",
150 | "\n",
151 | "\n",
153 | "
图13 PCR框架图\n"
154 | ]
155 | },
156 | {
157 | "cell_type": "markdown",
158 | "metadata": {
159 | "collapsed": false
160 | },
161 | "source": [
162 | "\n",
163 | "### 2.2 基于分割的文本检测\n",
164 | "\n",
165 | "基于回归的方法虽然在文本检测上取得了很好的效果,但是对解决弯曲文本往往难以得到平滑的文本包围曲线,并且模型较为复杂不具备性能优势。于是研究者们提出了基于图像分割的文本分割方法,先从像素层面做分类,判别每一个像素点是否属于一个文本目标,得到文本区域的概率图,通过后处理方式得到文本分割区域的包围曲线。\n",
166 | "\n",
167 | "\n",
169 | "
图14 文本分割算法示意图\n",
170 | "\n",
171 | "\n",
172 | "此类方法通常是基于分割的方法实现文本检测,基于分割的方法对不规则形状的文本检测有着天然的优势。基于分割的文本检测方法主体思想为,通过分割方法得到图像中文本区域,再利用opencv,polygon等后处理得到文本区域的最小包围曲线。\n",
173 | "\n",
174 | "\n",
175 | "Pixellink[7]采用分割的方法解决文本检测问题,分割对象为文本区域,将同属于一个文本行(单词)中的像素链接在一起来分割文本,直接从分割结果中提取文本边界框,无需位置回归就能达到基于回归的文本检测的效果。但是基于分割的方法存在一个问题,对于位置相近的文本,文本分割区域容易出现“粘连“问题。Wu, Yue等人[8]提出分割文本的同时,学习文本的边界位置,用于更好的区分文本区域。另外Tian等人[9]提出将同一文本的像素映射到映射空间,在映射空间中令统一文本的映射向量距离相近,不同文本的映射向量距离变远。\n",
176 | "\n",
177 | "\n",
179 | "
图15 PixelLink框架图\n",
180 | "\n",
181 | "MSR[20]针对文本检测的多尺度问题,提出提取相同图像的多个scale的特征,然后将这些特征融合并上采样到原图尺寸,网络最后预测文本中心区域、文本中心区域每个点到最近的边界点的x坐标偏移和y坐标偏移,最终可以得到文本区域的轮廓坐标集合。\n",
182 | "\n",
183 | "\n",
185 | "
图16 MSR框架图\n",
186 | " \n",
187 | "针对基于分割的文本算法难以区分相邻文本的问题,PSENet[10]提出渐进式的尺度扩张网络学习文本分割区域,预测不同收缩比例的文本区域,并逐个扩大检测到的文本区域,该方法本质上是边界学习方法的变体,可以有效解决任意形状相邻文本的检测问题。\n",
188 | "\n",
189 | "\n",
191 | "
图17 PSENet框架图\n",
192 | "\n",
193 | "假设PSENet后处理用了3个不同尺度的kernel,如上图s1,s2,s3所示。首先,从最小kernel s1开始,计算文本分割区域的连通域,得到(b),然后,对连通域沿着上下左右做尺度扩张,对于扩张区域属于s2但不属于s1的像素,进行归类,遇到冲突点时,采用“先到先得”原则,重复尺度扩张的操作,最终可以得到不同文本行的独立的分割区域。\n",
194 | "\n",
195 | "\n",
196 | "Seglink++[17]针对弯曲文本和密集文本问题,提出了一种文本块单元之间的吸引关系和排斥关系的表征,然后设计了一种最小生成树算法进行单元组合得到最终的文本检测框,并提出instance-aware 损失函数使Seglink++方法可以端对端训练。\n",
197 | "\n",
198 | "\n",
200 | "
图18 Seglink++框架图\n",
201 | "\n",
202 | "虽然分割方法解决了弯曲文本的检测问题,但是复杂的后处理逻辑以及预测速度也是需要优化的目标。\n",
203 | "\n",
204 | "PAN[11]针对文本检测预测速度慢的问题,从网络设计和后处理方面进行改进,提升算法性能。首先,PAN使用了轻量级的ResNet18作为Backbone,另外设计了轻量级的特征增强模块FPEM和特征融合模块FFM增强Backbone提取的特征。在后处理方面,采用像素聚类方法,沿着预测的文本中心(kernel)四周合并与kernel的距离小于阈值d的像素。PAN保证高精度的同时具有更快的预测速度。\n",
205 | "\n",
206 | "\n",
207 | "\n",
209 | "
图19 PAN框架图\n",
210 | "\n",
211 | "DBNet[12]针对基于分割的方法需要使用阈值进行二值化处理而导致后处理耗时的问题,提出了可学习阈值并巧妙地设计了一个近似于阶跃函数的二值化函数,使得分割网络在训练的时候能端对端的学习文本分割的阈值。自动调节阈值不仅带来精度的提升,同时简化了后处理,提高了文本检测的性能。\n",
212 | "\n",
213 | "\n",
215 | "
图20 DB框架图\n",
216 | "\n",
217 | "FCENet[16]提出将文本包围曲线用傅立叶变换的参数表示,由于傅里叶系数表示在理论上可以拟合任意的封闭曲线,通过设计合适的模型预测基于傅里叶变换的任意形状文本包围框表示,从而实现了自然场景文本检测中对于高度弯曲文本实例的检测精度的提升。\n",
218 | "\n",
219 | "\n",
221 | "
图21 FCENet框架图\n",
222 | "\n"
223 | ]
224 | },
225 | {
226 | "cell_type": "markdown",
227 | "metadata": {
228 | "collapsed": false
229 | },
230 | "source": [
231 | "## 3 总结\n",
232 | "\n",
233 | "本节介绍了近几年来文本检测领域的发展,包括基于回归、分割的文本检测方法,并分别列举并介绍了一些经典论文的方法思路。下一节以PaddleOCR开源库为例,详细介绍DBNet的算法原理以及核心代码实现。"
234 | ]
235 | },
236 | {
237 | "cell_type": "markdown",
238 | "metadata": {
239 | "collapsed": false
240 | },
241 | "source": [
242 | "## 参考文献\n",
243 | "1. Liao, Minghui, et al. \"Textboxes: A fast text detector with a single deep neural network.\" Thirty-first AAAI conference on artificial intelligence. 2017.\n",
244 | "2. Liao, Minghui, Baoguang Shi, and Xiang Bai. \"Textboxes++: A single-shot oriented scene text detector.\" IEEE transactions on image processing 27.8 (2018): 3676-3690.\n",
245 | "3. Tian, Zhi, et al. \"Detecting text in natural image with connectionist text proposal network.\" European conference on computer vision. Springer, Cham, 2016.\n",
246 | "4. Zhou, Xinyu, et al. \"East: an efficient and accurate scene text detector.\" Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.\n",
247 | "5. Wang, Fangfang, et al. \"Geometry-aware scene text detection with instance transformation network.\" Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.\n",
248 | "6. Yuliang, Liu, et al. \"Detecting curve text in the wild: New dataset and new solution.\" arXiv preprint arXiv:1712.02170 (2017).\n",
249 | "7. Deng, Dan, et al. \"Pixellink: Detecting scene text via instance segmentation.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.\n",
250 | "8. Wu, Yue, and Prem Natarajan. \"Self-organized text detection with minimal post-processing via border learning.\" Proceedings of the IEEE International Conference on Computer Vision. 2017.\n",
251 | "9. Tian, Zhuotao, et al. \"Learning shape-aware embedding for scene text detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
252 | "10. Wang, Wenhai, et al. \"Shape robust text detection with progressive scale expansion network.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
253 | "11. Wang, Wenhai, et al. \"Efficient and accurate arbitrary-shaped text detection with pixel aggregation network.\" Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.\n",
254 | "12. Liao, Minghui, et al. \"Real-time scene text detection with differentiable binarization.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.\n",
255 | "13. Hochreiter, Sepp, and Jürgen Schmidhuber. \"Long short-term memory.\" Neural computation 9.8 (1997): 1735-1780.\n",
256 | "14. Dai, Pengwen, et al. \"Progressive Contour Regression for Arbitrary-Shape Scene Text Detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.\n",
257 | "15. He, Minghang, et al. \"MOST: A Multi-Oriented Scene Text Detector with Localization Refinement.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.\n",
258 | "16. Zhu, Yiqin, et al. \"Fourier contour embedding for arbitrary-shaped text detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.\n",
259 | "17. Tang, Jun, et al. \"Seglink++: Detecting dense and arbitrary-shaped scene text by instance-aware component grouping.\" Pattern recognition 96 (2019): 106954.\n",
260 | "18. Wang, Yuxin, et al. \"Contournet: Taking a further step toward accurate arbitrary-shaped scene text detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.\n",
261 | "19. Zhang, Chengquan, et al. \"Look more than once: An accurate detector for text of arbitrary shapes.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
262 | "20. Xue C, Lu S, Zhang W. Msr: Multi-scale shape regression for scene text detection[J]. arXiv preprint arXiv:1901.02596, 2019. \n"
263 | ]
264 | }
265 | ],
266 | "metadata": {
267 | "kernelspec": {
268 | "display_name": "Python 3",
269 | "language": "python",
270 | "name": "py35-paddle1.2.0"
271 | },
272 | "language_info": {
273 | "codemirror_mode": {
274 | "name": "ipython",
275 | "version": 3
276 | },
277 | "file_extension": ".py",
278 | "mimetype": "text/x-python",
279 | "name": "python",
280 | "nbconvert_exporter": "python",
281 | "pygments_lexer": "ipython3",
282 | "version": "3.7.4"
283 | }
284 | },
285 | "nbformat": 4,
286 | "nbformat_minor": 1
287 | }
288 |
--------------------------------------------------------------------------------
/notebook_ch/3.text_recognition/.ipynb_checkpoints/文本识别理论部分-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "\n",
8 | "# 文本识别算法理论\n",
9 | "\n",
10 | "本章主要介绍文本识别算法的理论知识,包括背景介绍、算法分类和部分经典论文思路。\n",
11 | "\n",
12 | "通过本章的学习,你可以掌握:\n",
13 | "\n",
14 | "1. 文本识别的目标\n",
15 | "\n",
16 | "2. 文本识别算法的分类\n",
17 | "\n",
18 | "3. 各类算法的典型思想\n",
19 | "\n",
20 | "\n",
21 | "## 1 背景介绍\n",
22 | "\n",
23 | "文本识别是OCR(Optical Character Recognition)的一个子任务,其任务为识别一个固定区域的的文本内容。在OCR的两阶段方法里,它接在文本检测后面,将图像信息转换为文字信息。\n",
24 | "\n",
25 | "具体地,模型输入一张定位好的文本行,由模型预测出图片中的文字内容和置信度,可视化结果如下图所示:\n",
26 | "\n",
27 | " \n",
28 | "\n",
29 | "
\n",
28 | "\n",
29 | " \n",
30 | "\n",
31 | "\n",
32 | "文本识别的应用场景很多,有文档识别、路标识别、车牌识别、工业编号识别等等,根据实际场景可以把文本识别任务分为两个大类:**规则文本识别**和**不规则文本识别**。\n",
33 | "\n",
34 | "* 规则文本识别:主要指印刷字体、扫描文本等,认为文本大致处在水平线位置\n",
35 | "\n",
36 | "* 不规则文本识别: 往往出现在自然场景中,且由于文本曲率、方向、变形等方面差异巨大,文字往往不在水平位置,存在弯曲、遮挡、模糊等问题。\n",
37 | "\n",
38 | "\n",
39 | "下图展示的是 IC15 和 IC13 的数据样式,它们分别代表了不规则文本和规则文本。可以看出不规则文本往往存在扭曲、模糊、字体差异大等问题,更贴近真实场景,也存在更大的挑战性。\n",
40 | "\n",
41 | "因此目前各大算法都试图在不规则数据集上获得更高的指标。\n",
42 | "\n",
43 | "
\n",
30 | "\n",
31 | "\n",
32 | "文本识别的应用场景很多,有文档识别、路标识别、车牌识别、工业编号识别等等,根据实际场景可以把文本识别任务分为两个大类:**规则文本识别**和**不规则文本识别**。\n",
33 | "\n",
34 | "* 规则文本识别:主要指印刷字体、扫描文本等,认为文本大致处在水平线位置\n",
35 | "\n",
36 | "* 不规则文本识别: 往往出现在自然场景中,且由于文本曲率、方向、变形等方面差异巨大,文字往往不在水平位置,存在弯曲、遮挡、模糊等问题。\n",
37 | "\n",
38 | "\n",
39 | "下图展示的是 IC15 和 IC13 的数据样式,它们分别代表了不规则文本和规则文本。可以看出不规则文本往往存在扭曲、模糊、字体差异大等问题,更贴近真实场景,也存在更大的挑战性。\n",
40 | "\n",
41 | "因此目前各大算法都试图在不规则数据集上获得更高的指标。\n",
42 | "\n",
43 | " \n",
44 | "
\n",
44 | "
IC15 图片样例(不规则文本)\n",
45 | " \n",
46 | "
\n",
46 | "
IC13 图片样例(规则文本)\n",
47 | "\n",
48 | "\n",
49 | "不同的识别算法在对比能力时,往往也在这两大类公开数据集上比较。对比多个维度上的效果,目前较为通用的英文评估集合分类如下:\n",
50 | "\n",
51 | "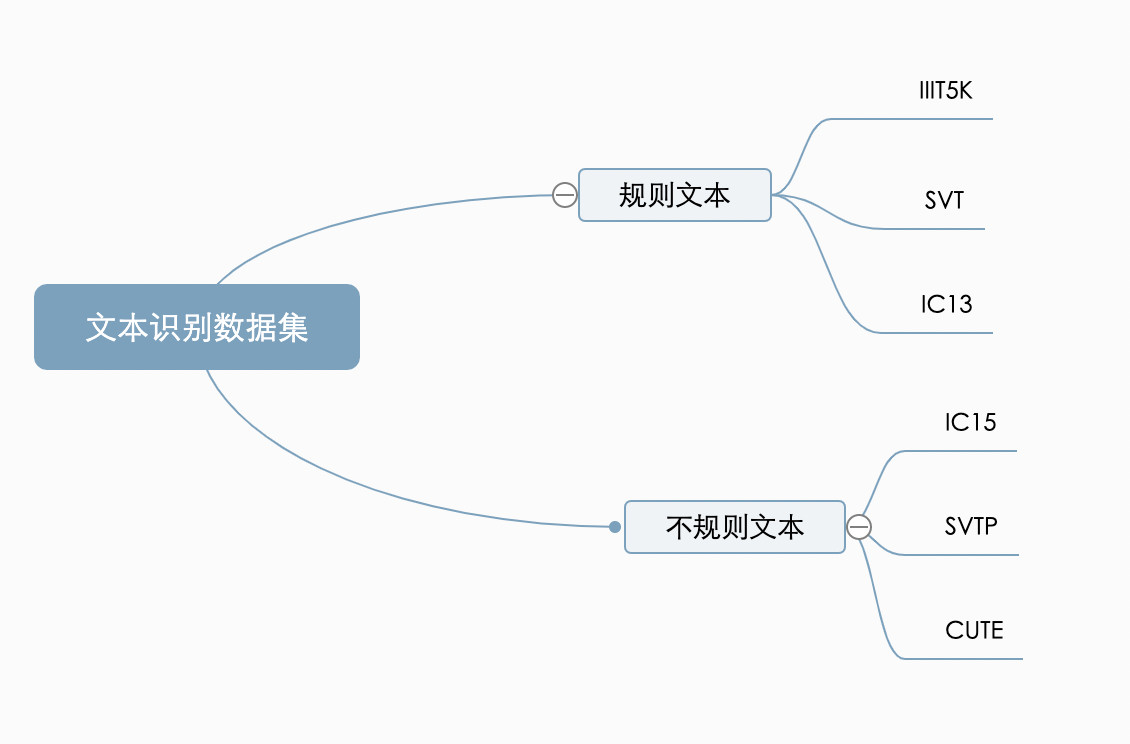 \n",
52 | "\n",
53 | "## 2 文本识别算法分类\n",
54 | "\n",
55 | "在传统的文本识别方法中,任务分为3个步骤,即图像预处理、字符分割和字符识别。需要对特定场景进行建模,一旦场景变化就会失效。面对复杂的文字背景和场景变动,基于深度学习的方法具有更优的表现。\n",
56 | "\n",
57 | "多数现有的识别算法可用如下统一框架表示,算法流程被划分为4个阶段:\n",
58 | "\n",
59 | "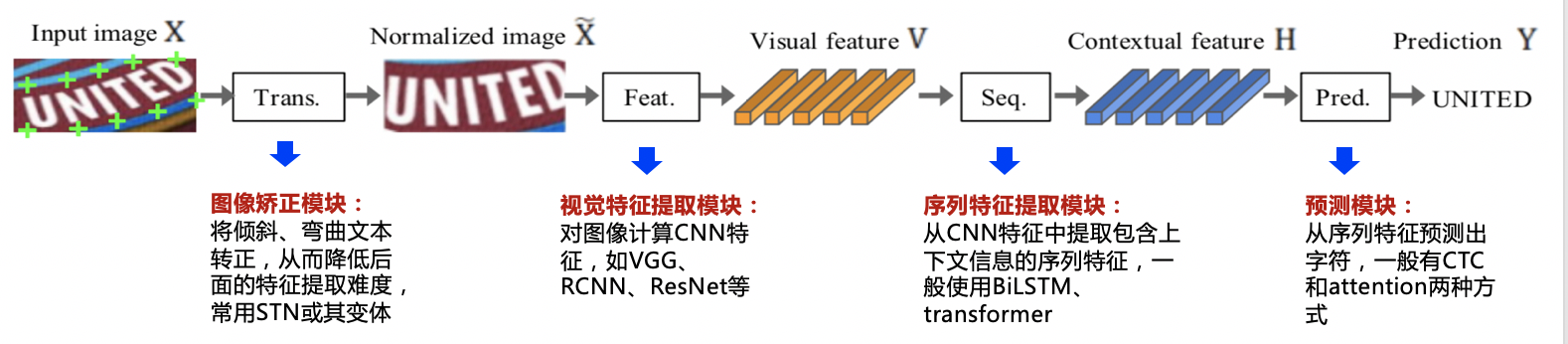\n",
60 | "\n",
61 | "\n",
62 | "我们整理了主流的算法类别和主要论文,参考下表:\n",
63 | "\n",
64 | "\n",
65 | " \n",
66 | "| 算法类别 | 主要思路 | 主要论文 |\n",
67 | "| -------- | --------------- | -------- |\n",
68 | "| 传统算法 | 滑动窗口、字符提取、动态规划 | - |\n",
69 | "| ctc | 基于ctc的方法,序列不对齐,更快速识别 | CRNN, Rosetta |\n",
70 | "| Attention | 基于attention的方法,应用于非常规文本 | RARE, DAN, PREN |\n",
71 | "| Transformer | 基于transformer的方法 | SRN, NRTR, Master, ABINet |\n",
72 | "| 校正 | 校正模块学习文本边界并校正成水平方向 | RARE, ASTER, SAR | \n",
73 | "| 分割 | 基于分割的方法,提取字符位置再做分类 | Text Scanner, Mask TextSpotter |\n",
74 | " \n",
75 | "\n",
76 | "\n",
77 | "\n",
78 | "### 2.1 规则文本识别\n",
79 | "\n",
80 | "\n",
81 | "文本识别的主流算法有两种,分别是基于 CTC (Conectionist Temporal Classification) 的算法和 Sequence2Sequence 算法,区别主要在解码阶段。\n",
82 | "\n",
83 | "基于 CTC 的算法是将编码产生的序列接入 CTC 进行解码;基于 Sequence2Sequence 的方法则是把序列接入循环神经网络(Recurrent Neural Network, RNN)模块进行循环解码,两种方式都验证有效也是主流的两大做法。\n",
84 | "\n",
85 | "
\n",
52 | "\n",
53 | "## 2 文本识别算法分类\n",
54 | "\n",
55 | "在传统的文本识别方法中,任务分为3个步骤,即图像预处理、字符分割和字符识别。需要对特定场景进行建模,一旦场景变化就会失效。面对复杂的文字背景和场景变动,基于深度学习的方法具有更优的表现。\n",
56 | "\n",
57 | "多数现有的识别算法可用如下统一框架表示,算法流程被划分为4个阶段:\n",
58 | "\n",
59 | "\n",
60 | "\n",
61 | "\n",
62 | "我们整理了主流的算法类别和主要论文,参考下表:\n",
63 | "\n",
64 | "\n",
65 | " \n",
66 | "| 算法类别 | 主要思路 | 主要论文 |\n",
67 | "| -------- | --------------- | -------- |\n",
68 | "| 传统算法 | 滑动窗口、字符提取、动态规划 | - |\n",
69 | "| ctc | 基于ctc的方法,序列不对齐,更快速识别 | CRNN, Rosetta |\n",
70 | "| Attention | 基于attention的方法,应用于非常规文本 | RARE, DAN, PREN |\n",
71 | "| Transformer | 基于transformer的方法 | SRN, NRTR, Master, ABINet |\n",
72 | "| 校正 | 校正模块学习文本边界并校正成水平方向 | RARE, ASTER, SAR | \n",
73 | "| 分割 | 基于分割的方法,提取字符位置再做分类 | Text Scanner, Mask TextSpotter |\n",
74 | " \n",
75 | "\n",
76 | "\n",
77 | "\n",
78 | "### 2.1 规则文本识别\n",
79 | "\n",
80 | "\n",
81 | "文本识别的主流算法有两种,分别是基于 CTC (Conectionist Temporal Classification) 的算法和 Sequence2Sequence 算法,区别主要在解码阶段。\n",
82 | "\n",
83 | "基于 CTC 的算法是将编码产生的序列接入 CTC 进行解码;基于 Sequence2Sequence 的方法则是把序列接入循环神经网络(Recurrent Neural Network, RNN)模块进行循环解码,两种方式都验证有效也是主流的两大做法。\n",
84 | "\n",
85 | "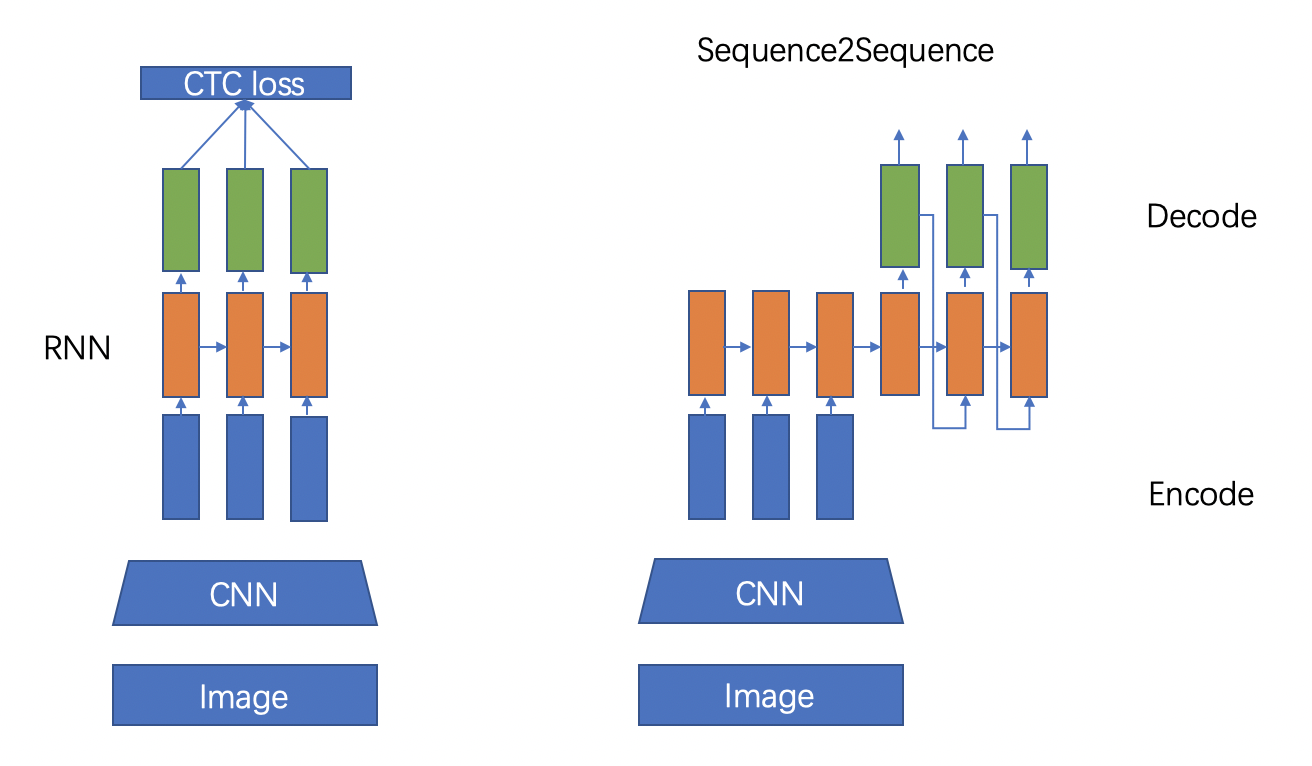 \n",
86 | "
\n",
86 | "
左:基于CTC的方法,右:基于Sequece2Sequence的方法 \n",
87 | "\n",
88 | "\n",
89 | "#### 2.1.1 基于CTC的算法\n",
90 | "\n",
91 | "基于 CTC 最典型的算法是CRNN (Convolutional Recurrent Neural Network)[1],它的特征提取部分使用主流的卷积结构,常用的有ResNet、MobileNet、VGG等。由于文本识别任务的特殊性,输入数据中存在大量的上下文信息,卷积神经网络的卷积核特性使其更关注于局部信息,缺乏长依赖的建模能力,因此仅使用卷积网络很难挖掘到文本之间的上下文联系。为了解决这一问题,CRNN文本识别算法引入了双向 LSTM(Long Short-Term Memory) 用来增强上下文建模,通过实验证明双向LSTM模块可以有效的提取出图片中的上下文信息。最终将输出的特征序列输入到CTC模块,直接解码序列结果。该结构被验证有效,并广泛应用在文本识别任务中。Rosetta[2]是FaceBook提出的识别网络,由全卷积模型和CTC组成。Gao Y[3]等人使用CNN卷积替代LSTM,参数更少,性能提升精度持平。\n",
92 | "\n",
93 | "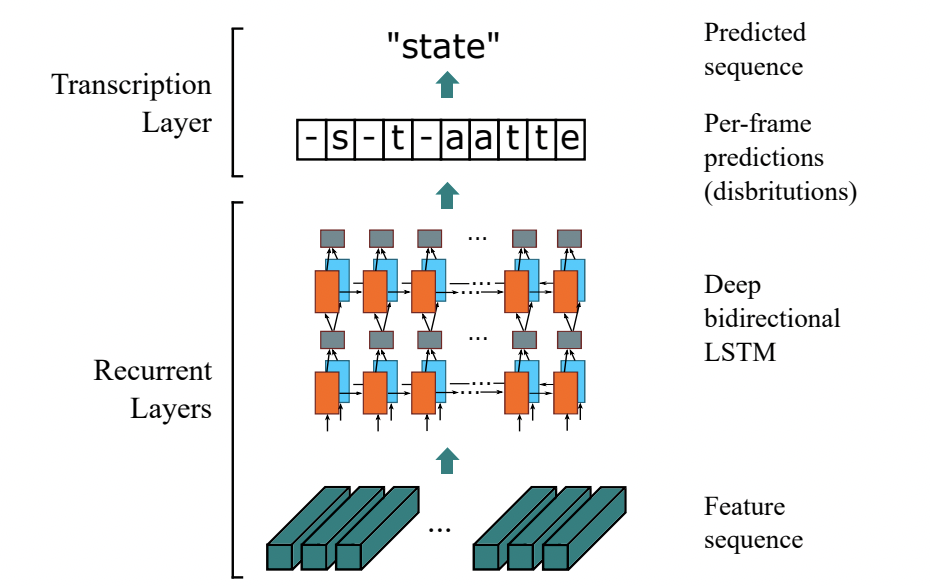 \n",
94 | " CRNN 结构图 \n",
95 | "\n",
96 | "\n",
97 | "#### 2.1.2 Sequence2Sequence 算法\n",
98 | "\n",
99 | "Sequence2Sequence 算法是由编码器 Encoder 把所有的输入序列都编码成一个统一的语义向量,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻的输出作为后一个时刻的输入,循环解码,直到输出停止符为止。一般编码器是一个RNN,对于每个输入的词,编码器输出向量和隐藏状态,并将隐藏状态用于下一个输入的单词,循环得到语义向量;解码器是另一个RNN,它接收编码器输出向量并输出一系列字以创建转换。受到 Sequence2Sequence 在翻译领域的启发, Shi[4]提出了一种基于注意的编解码框架来识别文本,通过这种方式,rnn能够从训练数据中学习隐藏在字符串中的字符级语言模型。\n",
100 | "\n",
101 | "
\n",
94 | " CRNN 结构图 \n",
95 | "\n",
96 | "\n",
97 | "#### 2.1.2 Sequence2Sequence 算法\n",
98 | "\n",
99 | "Sequence2Sequence 算法是由编码器 Encoder 把所有的输入序列都编码成一个统一的语义向量,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻的输出作为后一个时刻的输入,循环解码,直到输出停止符为止。一般编码器是一个RNN,对于每个输入的词,编码器输出向量和隐藏状态,并将隐藏状态用于下一个输入的单词,循环得到语义向量;解码器是另一个RNN,它接收编码器输出向量并输出一系列字以创建转换。受到 Sequence2Sequence 在翻译领域的启发, Shi[4]提出了一种基于注意的编解码框架来识别文本,通过这种方式,rnn能够从训练数据中学习隐藏在字符串中的字符级语言模型。\n",
100 | "\n",
101 | "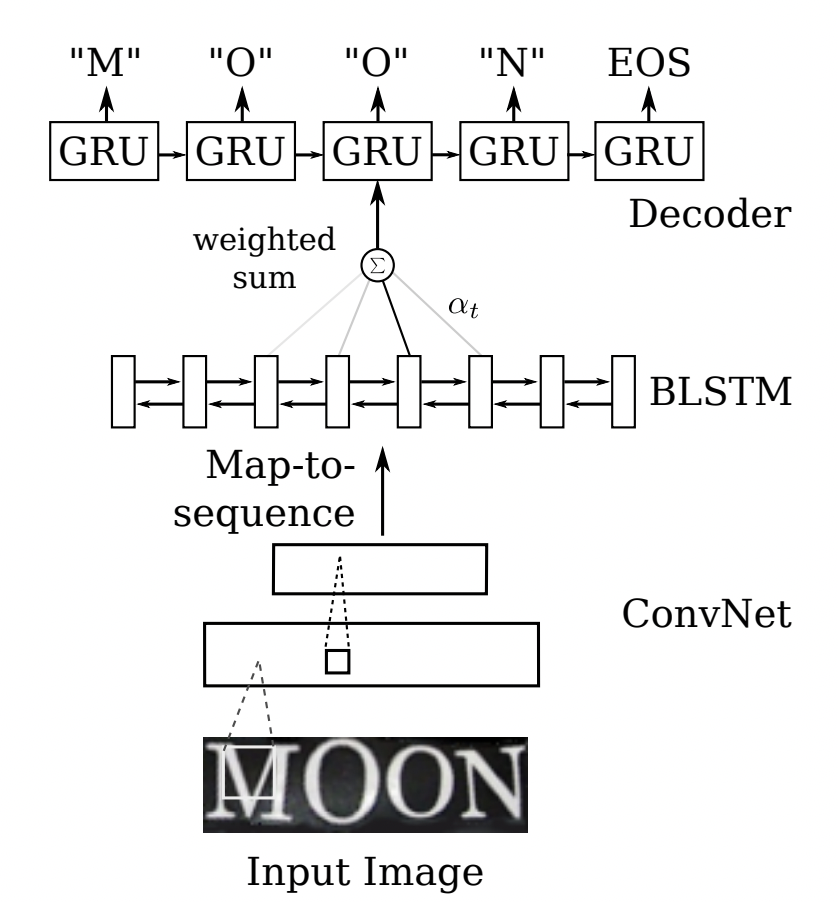 \n",
102 | " Sequence2Sequence 结构图 \n",
103 | "\n",
104 | "以上两个算法在规则文本上都有很不错的效果,但由于网络设计的局限性,这类方法很难解决弯曲和旋转的不规则文本识别任务。为了解决这类问题,部分算法研究人员在以上两类算法的基础上提出了一系列改进算法。\n",
105 | "\n",
106 | "### 2.2 不规则文本识别\n",
107 | "\n",
108 | "* 不规则文本识别算法可以被分为4大类:基于校正的方法;基于 Attention 的方法;基于分割的方法;基于 Transformer 的方法。\n",
109 | "\n",
110 | "#### 2.2.1 基于校正的方法\n",
111 | "\n",
112 | "基于校正的方法利用一些视觉变换模块,将非规则的文本尽量转换为规则文本,然后使用常规方法进行识别。\n",
113 | "\n",
114 | "RARE[4]模型首先提出了对不规则文本的校正方案,整个网络分为两个主要部分:一个空间变换网络STN(Spatial Transformer Network) 和一个基于Sequence2Squence的识别网络。其中STN就是校正模块,不规则文本图像进入STN,通过TPS(Thin-Plate-Spline)变换成一个水平方向的图像,该变换可以一定程度上校正弯曲、透射变换的文本,校正后送入序列识别网络进行解码。\n",
115 | "\n",
116 | "
\n",
102 | " Sequence2Sequence 结构图 \n",
103 | "\n",
104 | "以上两个算法在规则文本上都有很不错的效果,但由于网络设计的局限性,这类方法很难解决弯曲和旋转的不规则文本识别任务。为了解决这类问题,部分算法研究人员在以上两类算法的基础上提出了一系列改进算法。\n",
105 | "\n",
106 | "### 2.2 不规则文本识别\n",
107 | "\n",
108 | "* 不规则文本识别算法可以被分为4大类:基于校正的方法;基于 Attention 的方法;基于分割的方法;基于 Transformer 的方法。\n",
109 | "\n",
110 | "#### 2.2.1 基于校正的方法\n",
111 | "\n",
112 | "基于校正的方法利用一些视觉变换模块,将非规则的文本尽量转换为规则文本,然后使用常规方法进行识别。\n",
113 | "\n",
114 | "RARE[4]模型首先提出了对不规则文本的校正方案,整个网络分为两个主要部分:一个空间变换网络STN(Spatial Transformer Network) 和一个基于Sequence2Squence的识别网络。其中STN就是校正模块,不规则文本图像进入STN,通过TPS(Thin-Plate-Spline)变换成一个水平方向的图像,该变换可以一定程度上校正弯曲、透射变换的文本,校正后送入序列识别网络进行解码。\n",
115 | "\n",
116 | "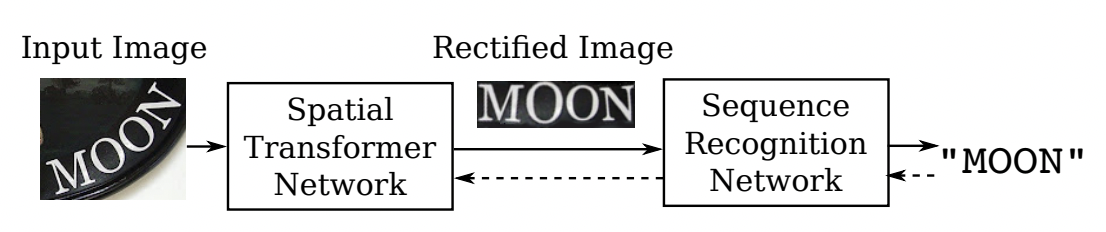 \n",
117 | " RARE 结构图 \n",
118 | "\n",
119 | "RARE论文指出,该方法在不规则文本数据集上有较大的优势,特别比较了CUTE80和SVTP这两个数据集,相较CRNN高出5个百分点以上,证明了校正模块的有效性。基于此[6]同样结合了空间变换网络(STN)和基于注意的序列识别网络的文本识别系统。\n",
120 | "\n",
121 | "基于校正的方法有较好的迁移性,除了RARE这类基于Attention的方法外,STAR-Net[5]将校正模块应用到基于CTC的算法上,相比传统CRNN也有很好的提升。\n",
122 | "\n",
123 | "#### 2.2.2 基于Attention的方法\n",
124 | "\n",
125 | "基于 Attention 的方法主要关注的是序列之间各部分的相关性,该方法最早在机器翻译领域提出,认为在文本翻译的过程中当前词的结果主要由某几个单词影响的,因此需要给有决定性的单词更大的权重。在文本识别领域也是如此,将编码后的序列解码时,每一步都选择恰当的context来生成下一个状态,这样有利于得到更准确的结果。\n",
126 | "\n",
127 | "R^2AM [7] 首次将 Attention 引入文本识别领域,该模型首先将输入图像通过递归卷积层提取编码后的图像特征,然后利用隐式学习到的字符级语言统计信息通过递归神经网络解码输出字符。在解码过程中引入了Attention 机制实现了软特征选择,以更好地利用图像特征,这一有选择性的处理方式更符合人类的直觉。\n",
128 | "\n",
129 | "
\n",
117 | " RARE 结构图 \n",
118 | "\n",
119 | "RARE论文指出,该方法在不规则文本数据集上有较大的优势,特别比较了CUTE80和SVTP这两个数据集,相较CRNN高出5个百分点以上,证明了校正模块的有效性。基于此[6]同样结合了空间变换网络(STN)和基于注意的序列识别网络的文本识别系统。\n",
120 | "\n",
121 | "基于校正的方法有较好的迁移性,除了RARE这类基于Attention的方法外,STAR-Net[5]将校正模块应用到基于CTC的算法上,相比传统CRNN也有很好的提升。\n",
122 | "\n",
123 | "#### 2.2.2 基于Attention的方法\n",
124 | "\n",
125 | "基于 Attention 的方法主要关注的是序列之间各部分的相关性,该方法最早在机器翻译领域提出,认为在文本翻译的过程中当前词的结果主要由某几个单词影响的,因此需要给有决定性的单词更大的权重。在文本识别领域也是如此,将编码后的序列解码时,每一步都选择恰当的context来生成下一个状态,这样有利于得到更准确的结果。\n",
126 | "\n",
127 | "R^2AM [7] 首次将 Attention 引入文本识别领域,该模型首先将输入图像通过递归卷积层提取编码后的图像特征,然后利用隐式学习到的字符级语言统计信息通过递归神经网络解码输出字符。在解码过程中引入了Attention 机制实现了软特征选择,以更好地利用图像特征,这一有选择性的处理方式更符合人类的直觉。\n",
128 | "\n",
129 | "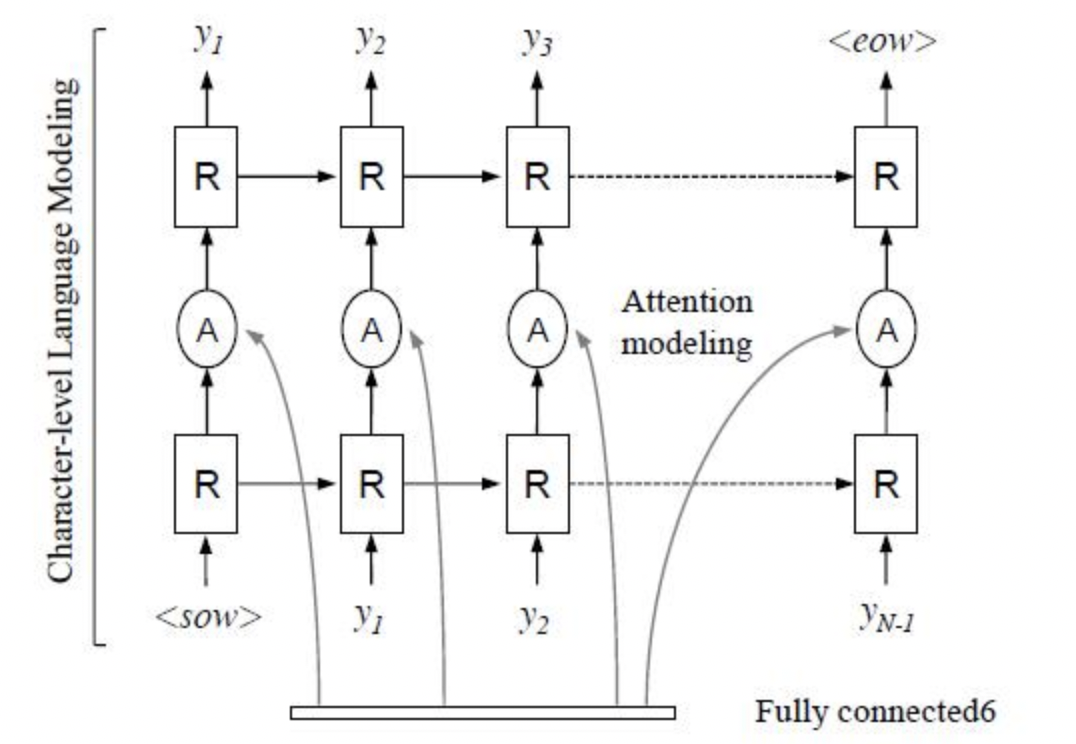 \n",
130 | " R^2AM 结构图 \n",
131 | "\n",
132 | "后续有大量算法在Attention领域进行探索和更新,例如SAR[8]将1D attention拓展到2D attention上,校正模块提到的RARE也是基于Attention的方法。实验证明基于Attention的方法相比CTC的方法有很好的精度提升。\n",
133 | "\n",
134 | "
\n",
130 | " R^2AM 结构图 \n",
131 | "\n",
132 | "后续有大量算法在Attention领域进行探索和更新,例如SAR[8]将1D attention拓展到2D attention上,校正模块提到的RARE也是基于Attention的方法。实验证明基于Attention的方法相比CTC的方法有很好的精度提升。\n",
133 | "\n",
134 | " \n",
135 | "\n",
136 | "\n",
137 | "#### 2.2.3 基于分割的方法\n",
138 | "\n",
139 | "基于分割的方法是将文本行的各字符作为独立个体,相比与对整个文本行做矫正后识别,识别分割出的单个字符更加容易。它试图从输入的文本图像中定位每个字符的位置,并应用字符分类器来获得这些识别结果,将复杂的全局问题简化成了局部问题解决,在不规则文本场景下有比较不错的效果。然而这种方法需要字符级别的标注,数据获取上存在一定的难度。Lyu[9]等人提出了一种用于单词识别的实例分词模型,该模型在其识别部分使用了基于 FCN(Fully Convolutional Network) 的方法。[10]从二维角度考虑文本识别问题,设计了一个字符注意FCN来解决文本识别问题,当文本弯曲或严重扭曲时,该方法对规则文本和非规则文本都具有较优的定位结果。\n",
140 | "\n",
141 | "
\n",
135 | "\n",
136 | "\n",
137 | "#### 2.2.3 基于分割的方法\n",
138 | "\n",
139 | "基于分割的方法是将文本行的各字符作为独立个体,相比与对整个文本行做矫正后识别,识别分割出的单个字符更加容易。它试图从输入的文本图像中定位每个字符的位置,并应用字符分类器来获得这些识别结果,将复杂的全局问题简化成了局部问题解决,在不规则文本场景下有比较不错的效果。然而这种方法需要字符级别的标注,数据获取上存在一定的难度。Lyu[9]等人提出了一种用于单词识别的实例分词模型,该模型在其识别部分使用了基于 FCN(Fully Convolutional Network) 的方法。[10]从二维角度考虑文本识别问题,设计了一个字符注意FCN来解决文本识别问题,当文本弯曲或严重扭曲时,该方法对规则文本和非规则文本都具有较优的定位结果。\n",
140 | "\n",
141 | " \n",
142 | " Mask TextSpotter 结构图 \n",
143 | "\n",
144 | "\n",
145 | "\n",
146 | "#### 2.2.4 基于Transformer的方法\n",
147 | "\n",
148 | "随着 Transformer 的快速发展,分类和检测领域都验证了 Transformer 在视觉任务中的有效性。如规则文本识别部分所说,CNN在长依赖建模上存在局限性,Transformer 结构恰好解决了这一问题,它可以在特征提取器中关注全局信息,并且可以替换额外的上下文建模模块(LSTM)。\n",
149 | "\n",
150 | "一部分文本识别算法使用 Transformer 的 Encoder 结构和卷积共同提取序列特征,Encoder 由多个 MultiHeadAttentionLayer 和 Positionwise Feedforward Layer 堆叠而成的block组成。MulitHeadAttention 中的 self-attention 利用矩阵乘法模拟了RNN的时序计算,打破了RNN中时序长时依赖的障碍。也有一部分算法使用 Transformer 的 Decoder 模块解码,相比传统RNN可获得更强的语义信息,同时并行计算具有更高的效率。\n",
151 | "\n",
152 | "SRN[11] 算法将Transformer的Encoder模块接在ResNet50后,增强了2D视觉特征。并提出了一个并行注意力模块,将读取顺序用作查询,使得计算与时间无关,最终并行输出所有时间步长的对齐视觉特征。此外SRN还利用Transformer的Eecoder作为语义模块,将图片的视觉信息和语义信息做融合,在遮挡、模糊等不规则文本上有较大的收益。\n",
153 | "\n",
154 | "NRTR[12] 使用了完整的Transformer结构对输入图片进行编码和解码,只使用了简单的几个卷积层做高层特征提取,在文本识别上验证了Transformer结构的有效性。\n",
155 | "\n",
156 | "
\n",
142 | " Mask TextSpotter 结构图 \n",
143 | "\n",
144 | "\n",
145 | "\n",
146 | "#### 2.2.4 基于Transformer的方法\n",
147 | "\n",
148 | "随着 Transformer 的快速发展,分类和检测领域都验证了 Transformer 在视觉任务中的有效性。如规则文本识别部分所说,CNN在长依赖建模上存在局限性,Transformer 结构恰好解决了这一问题,它可以在特征提取器中关注全局信息,并且可以替换额外的上下文建模模块(LSTM)。\n",
149 | "\n",
150 | "一部分文本识别算法使用 Transformer 的 Encoder 结构和卷积共同提取序列特征,Encoder 由多个 MultiHeadAttentionLayer 和 Positionwise Feedforward Layer 堆叠而成的block组成。MulitHeadAttention 中的 self-attention 利用矩阵乘法模拟了RNN的时序计算,打破了RNN中时序长时依赖的障碍。也有一部分算法使用 Transformer 的 Decoder 模块解码,相比传统RNN可获得更强的语义信息,同时并行计算具有更高的效率。\n",
151 | "\n",
152 | "SRN[11] 算法将Transformer的Encoder模块接在ResNet50后,增强了2D视觉特征。并提出了一个并行注意力模块,将读取顺序用作查询,使得计算与时间无关,最终并行输出所有时间步长的对齐视觉特征。此外SRN还利用Transformer的Eecoder作为语义模块,将图片的视觉信息和语义信息做融合,在遮挡、模糊等不规则文本上有较大的收益。\n",
153 | "\n",
154 | "NRTR[12] 使用了完整的Transformer结构对输入图片进行编码和解码,只使用了简单的几个卷积层做高层特征提取,在文本识别上验证了Transformer结构的有效性。\n",
155 | "\n",
156 | "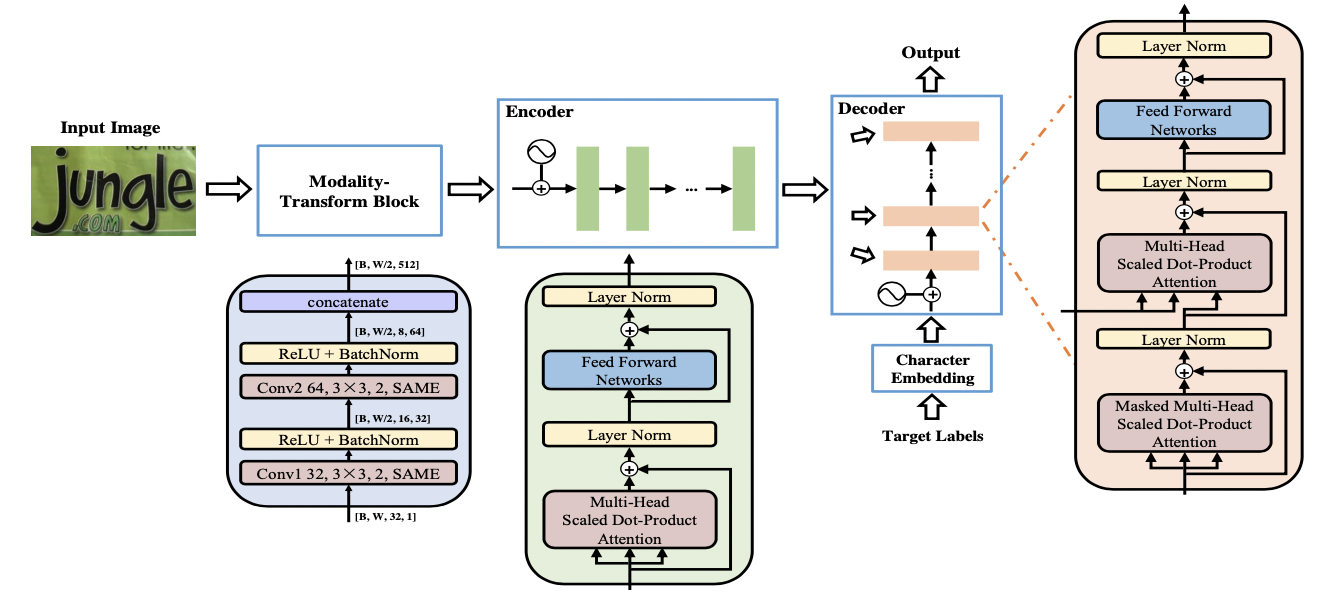 \n",
157 | " NRTR 结构图 \n",
158 | "\n",
159 | "SRACN[13]使用Transformer的解码器替换LSTM,再一次验证了并行训练的高效性和精度优势。\n",
160 | "\n",
161 | "## 3 总结\n",
162 | "\n",
163 | "本节主要介绍了文本识别相关的理论知识和主流算法,包括基于CTC的方法、基于Sequence2Sequence的方法以及基于分割的方法,并分别列举了经典论文的思路和贡献。下一节将基于CRNN算法进行实践课程讲解,从组网到优化完成整个训练过程,\n",
164 | "\n",
165 | "## 4 参考文献\n",
166 | "\n",
167 | "\n",
168 | "[1]Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\n",
169 | "\n",
170 | "[2]Fedor Borisyuk, Albert Gordo, and Viswanath Sivakumar. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 71–79. ACM, 2018.\n",
171 | "\n",
172 | "[3]Gao, Y., Chen, Y., Wang, J., & Lu, H. (2017). Reading scene text with attention convolutional sequence modeling. arXiv preprint arXiv:1709.04303.\n",
173 | "\n",
174 | "[4]Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\n",
175 | "\n",
176 | "[5] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\n",
177 | "\n",
178 | "[6]Baoguang Shi, Mingkun Yang, XingGang Wang, Pengyuan Lyu, Xiang Bai, and Cong Yao. Aster: An attentional scene text recognizer with flexible rectification. IEEE transactions on pattern analysis and machine intelligence, 31(11):855–868, 2018.\n",
179 | "\n",
180 | "[7] Lee C Y , Osindero S . Recursive Recurrent Nets with Attention Modeling for OCR in the Wild[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.\n",
181 | "\n",
182 | "[8]Li, H., Wang, P., Shen, C., & Zhang, G. (2019, July). Show, attend and read: A simple and strong baseline for irregular text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8610-8617).\n",
183 | "\n",
184 | "[9]P. Lyu, C. Yao, W. Wu, S. Yan, and X. Bai. Multi-oriented scene text detection via corner localization and region segmentation. In Proc. CVPR, pages 7553–7563, 2018.\n",
185 | "\n",
186 | "[10] Liao, M., Zhang, J., Wan, Z., Xie, F., Liang, J., Lyu, P., ... & Bai, X. (2019, July). Scene text recognition from two-dimensional perspective. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8714-8721).\n",
187 | "\n",
188 | "[11] Yu, D., Li, X., Zhang, C., Liu, T., Han, J., Liu, J., & Ding, E. (2020). Towards accurate scene text recognition with semantic reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12113-12122).\n",
189 | "\n",
190 | "[12] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\n",
191 | "\n",
192 | "[13]Yang, L., Wang, P., Li, H., Li, Z., & Zhang, Y. (2020). A holistic representation guided attention network for scene text recognition. Neurocomputing, 414, 67-75.\n",
193 | "\n",
194 | "[14]Wang, T., Zhu, Y., Jin, L., Luo, C., Chen, X., Wu, Y., ... & Cai, M. (2020, April). Decoupled attention network for text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 07, pp. 12216-12224).\n",
195 | "\n",
196 | "[15] Wang, Y., Xie, H., Fang, S., Wang, J., Zhu, S., & Zhang, Y. (2021). From two to one: A new scene text recognizer with visual language modeling network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 14194-14203).\n",
197 | "\n",
198 | "[16] Fang, S., Xie, H., Wang, Y., Mao, Z., & Zhang, Y. (2021). Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7098-7107).\n",
199 | "\n",
200 | "[17] Yan, R., Peng, L., Xiao, S., & Yao, G. (2021). Primitive Representation Learning for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 284-293)."
201 | ]
202 | },
203 | {
204 | "cell_type": "markdown",
205 | "metadata": {},
206 | "source": []
207 | }
208 | ],
209 | "metadata": {
210 | "kernelspec": {
211 | "display_name": "Python 3",
212 | "language": "python",
213 | "name": "python3"
214 | },
215 | "language_info": {
216 | "codemirror_mode": {
217 | "name": "ipython",
218 | "version": 3
219 | },
220 | "file_extension": ".py",
221 | "mimetype": "text/x-python",
222 | "name": "python",
223 | "nbconvert_exporter": "python",
224 | "pygments_lexer": "ipython3",
225 | "version": "3.8.8"
226 | }
227 | },
228 | "nbformat": 4,
229 | "nbformat_minor": 1
230 | }
231 |
--------------------------------------------------------------------------------
/notebook_ch/3.text_recognition/文本识别理论部分.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "collapsed": false
7 | },
8 | "source": [
9 | "\n",
10 | "# 文本识别算法理论\n",
11 | "\n",
12 | "本章主要介绍文本识别算法的理论知识,包括背景介绍、算法分类和部分经典论文思路。\n",
13 | "\n",
14 | "通过本章的学习,你可以掌握:\n",
15 | "\n",
16 | "1. 文本识别的目标\n",
17 | "\n",
18 | "2. 文本识别算法的分类\n",
19 | "\n",
20 | "3. 各类算法的典型思想\n",
21 | "\n",
22 | "\n",
23 | "## 1 背景介绍\n",
24 | "\n",
25 | "文本识别是OCR(Optical Character Recognition)的一个子任务,其任务为识别一个固定区域的文本内容。在OCR的两阶段方法里,它接在文本检测后面,将图像信息转换为文字信息。\n",
26 | "\n",
27 | "具体地,模型输入一张定位好的文本行,由模型预测出图片中的文字内容和置信度,可视化结果如下图所示:\n",
28 | "\n",
29 | "\n",
30 | "\n",
31 | "\n",
32 | "\n",
33 | "\n",
34 | "文本识别的应用场景很多,有文档识别、路标识别、车牌识别、工业编号识别等等,根据实际场景可以把文本识别任务分为两个大类:**规则文本识别**和**不规则文本识别**。\n",
35 | "\n",
36 | "* 规则文本识别:主要指印刷字体、扫描文本等,认为文本大致处在水平线位置\n",
37 | "\n",
38 | "* 不规则文本识别: 往往出现在自然场景中,且由于文本曲率、方向、变形等方面差异巨大,文字往往不在水平位置,存在弯曲、遮挡、模糊等问题。\n",
39 | "\n",
40 | "\n",
41 | "下图展示的是 IC15 和 IC13 的数据样式,它们分别代表了不规则文本和规则文本。可以看出不规则文本往往存在扭曲、模糊、字体差异大等问题,更贴近真实场景,也存在更大的挑战性。\n",
42 | "\n",
43 | "因此目前各大算法都试图在不规则数据集上获得更高的指标。\n",
44 | "\n",
45 | "\n",
46 | "
\n",
157 | " NRTR 结构图 \n",
158 | "\n",
159 | "SRACN[13]使用Transformer的解码器替换LSTM,再一次验证了并行训练的高效性和精度优势。\n",
160 | "\n",
161 | "## 3 总结\n",
162 | "\n",
163 | "本节主要介绍了文本识别相关的理论知识和主流算法,包括基于CTC的方法、基于Sequence2Sequence的方法以及基于分割的方法,并分别列举了经典论文的思路和贡献。下一节将基于CRNN算法进行实践课程讲解,从组网到优化完成整个训练过程,\n",
164 | "\n",
165 | "## 4 参考文献\n",
166 | "\n",
167 | "\n",
168 | "[1]Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\n",
169 | "\n",
170 | "[2]Fedor Borisyuk, Albert Gordo, and Viswanath Sivakumar. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 71–79. ACM, 2018.\n",
171 | "\n",
172 | "[3]Gao, Y., Chen, Y., Wang, J., & Lu, H. (2017). Reading scene text with attention convolutional sequence modeling. arXiv preprint arXiv:1709.04303.\n",
173 | "\n",
174 | "[4]Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\n",
175 | "\n",
176 | "[5] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\n",
177 | "\n",
178 | "[6]Baoguang Shi, Mingkun Yang, XingGang Wang, Pengyuan Lyu, Xiang Bai, and Cong Yao. Aster: An attentional scene text recognizer with flexible rectification. IEEE transactions on pattern analysis and machine intelligence, 31(11):855–868, 2018.\n",
179 | "\n",
180 | "[7] Lee C Y , Osindero S . Recursive Recurrent Nets with Attention Modeling for OCR in the Wild[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.\n",
181 | "\n",
182 | "[8]Li, H., Wang, P., Shen, C., & Zhang, G. (2019, July). Show, attend and read: A simple and strong baseline for irregular text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8610-8617).\n",
183 | "\n",
184 | "[9]P. Lyu, C. Yao, W. Wu, S. Yan, and X. Bai. Multi-oriented scene text detection via corner localization and region segmentation. In Proc. CVPR, pages 7553–7563, 2018.\n",
185 | "\n",
186 | "[10] Liao, M., Zhang, J., Wan, Z., Xie, F., Liang, J., Lyu, P., ... & Bai, X. (2019, July). Scene text recognition from two-dimensional perspective. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8714-8721).\n",
187 | "\n",
188 | "[11] Yu, D., Li, X., Zhang, C., Liu, T., Han, J., Liu, J., & Ding, E. (2020). Towards accurate scene text recognition with semantic reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12113-12122).\n",
189 | "\n",
190 | "[12] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\n",
191 | "\n",
192 | "[13]Yang, L., Wang, P., Li, H., Li, Z., & Zhang, Y. (2020). A holistic representation guided attention network for scene text recognition. Neurocomputing, 414, 67-75.\n",
193 | "\n",
194 | "[14]Wang, T., Zhu, Y., Jin, L., Luo, C., Chen, X., Wu, Y., ... & Cai, M. (2020, April). Decoupled attention network for text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 07, pp. 12216-12224).\n",
195 | "\n",
196 | "[15] Wang, Y., Xie, H., Fang, S., Wang, J., Zhu, S., & Zhang, Y. (2021). From two to one: A new scene text recognizer with visual language modeling network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 14194-14203).\n",
197 | "\n",
198 | "[16] Fang, S., Xie, H., Wang, Y., Mao, Z., & Zhang, Y. (2021). Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7098-7107).\n",
199 | "\n",
200 | "[17] Yan, R., Peng, L., Xiao, S., & Yao, G. (2021). Primitive Representation Learning for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 284-293)."
201 | ]
202 | },
203 | {
204 | "cell_type": "markdown",
205 | "metadata": {},
206 | "source": []
207 | }
208 | ],
209 | "metadata": {
210 | "kernelspec": {
211 | "display_name": "Python 3",
212 | "language": "python",
213 | "name": "python3"
214 | },
215 | "language_info": {
216 | "codemirror_mode": {
217 | "name": "ipython",
218 | "version": 3
219 | },
220 | "file_extension": ".py",
221 | "mimetype": "text/x-python",
222 | "name": "python",
223 | "nbconvert_exporter": "python",
224 | "pygments_lexer": "ipython3",
225 | "version": "3.8.8"
226 | }
227 | },
228 | "nbformat": 4,
229 | "nbformat_minor": 1
230 | }
231 |
--------------------------------------------------------------------------------
/notebook_ch/3.text_recognition/文本识别理论部分.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "collapsed": false
7 | },
8 | "source": [
9 | "\n",
10 | "# 文本识别算法理论\n",
11 | "\n",
12 | "本章主要介绍文本识别算法的理论知识,包括背景介绍、算法分类和部分经典论文思路。\n",
13 | "\n",
14 | "通过本章的学习,你可以掌握:\n",
15 | "\n",
16 | "1. 文本识别的目标\n",
17 | "\n",
18 | "2. 文本识别算法的分类\n",
19 | "\n",
20 | "3. 各类算法的典型思想\n",
21 | "\n",
22 | "\n",
23 | "## 1 背景介绍\n",
24 | "\n",
25 | "文本识别是OCR(Optical Character Recognition)的一个子任务,其任务为识别一个固定区域的文本内容。在OCR的两阶段方法里,它接在文本检测后面,将图像信息转换为文字信息。\n",
26 | "\n",
27 | "具体地,模型输入一张定位好的文本行,由模型预测出图片中的文字内容和置信度,可视化结果如下图所示:\n",
28 | "\n",
29 | "\n",
30 | "\n",
31 | "\n",
32 | "\n",
33 | "\n",
34 | "文本识别的应用场景很多,有文档识别、路标识别、车牌识别、工业编号识别等等,根据实际场景可以把文本识别任务分为两个大类:**规则文本识别**和**不规则文本识别**。\n",
35 | "\n",
36 | "* 规则文本识别:主要指印刷字体、扫描文本等,认为文本大致处在水平线位置\n",
37 | "\n",
38 | "* 不规则文本识别: 往往出现在自然场景中,且由于文本曲率、方向、变形等方面差异巨大,文字往往不在水平位置,存在弯曲、遮挡、模糊等问题。\n",
39 | "\n",
40 | "\n",
41 | "下图展示的是 IC15 和 IC13 的数据样式,它们分别代表了不规则文本和规则文本。可以看出不规则文本往往存在扭曲、模糊、字体差异大等问题,更贴近真实场景,也存在更大的挑战性。\n",
42 | "\n",
43 | "因此目前各大算法都试图在不规则数据集上获得更高的指标。\n",
44 | "\n",
45 | "\n",
46 | "
IC15 图片样例(不规则文本)\n",
47 | "\n",
48 | "
IC13 图片样例(规则文本)\n",
49 | "\n",
50 | "\n",
51 | "不同的识别算法在对比能力时,往往也在这两大类公开数据集上比较。对比多个维度上的效果,目前较为通用的英文评估集合分类如下:\n",
52 | "\n",
53 | "\n",
54 | "\n",
55 | "## 2 文本识别算法分类\n",
56 | "\n",
57 | "在传统的文本识别方法中,任务分为3个步骤,即图像预处理、字符分割和字符识别。需要对特定场景进行建模,一旦场景变化就会失效。面对复杂的文字背景和场景变动,基于深度学习的方法具有更优的表现。\n",
58 | "\n",
59 | "多数现有的识别算法可用如下统一框架表示,算法流程被划分为4个阶段:\n",
60 | "\n",
61 | "\n",
62 | "\n",
63 | "\n",
64 | "我们整理了主流的算法类别和主要论文,参考下表:\n",
65 | "\n",
66 | "\n",
67 | " \n",
68 | "| 算法类别 | 主要思路 | 主要论文 |\n",
69 | "| -------- | --------------- | -------- |\n",
70 | "| 传统算法 | 滑动窗口、字符提取、动态规划 | - |\n",
71 | "| ctc | 基于ctc的方法,序列不对齐,更快速识别 | CRNN, Rosetta |\n",
72 | "| Attention | 基于attention的方法,应用于非常规文本 | RARE, DAN, PREN |\n",
73 | "| Transformer | 基于transformer的方法 | SRN, NRTR, Master, ABINet |\n",
74 | "| 校正 | 校正模块学习文本边界并校正成水平方向 | RARE, ASTER, SAR | \n",
75 | "| 分割 | 基于分割的方法,提取字符位置再做分类 | Text Scanner, Mask TextSpotter |\n",
76 | " \n",
77 | "\n",
78 | "\n",
79 | "\n",
80 | "### 2.1 规则文本识别\n",
81 | "\n",
82 | "\n",
83 | "文本识别的主流算法有两种,分别是基于 CTC (Conectionist Temporal Classification) 的算法和 Sequence2Sequence 算法,区别主要在解码阶段。\n",
84 | "\n",
85 | "基于 CTC 的算法是将编码产生的序列接入 CTC 进行解码;基于 Sequence2Sequence 的方法则是把序列接入循环神经网络(Recurrent Neural Network, RNN)模块进行循环解码,两种方式都验证有效也是主流的两大做法。\n",
86 | "\n",
87 | "\n",
88 | "
左:基于CTC的方法,右:基于Sequece2Sequence的方法 \n",
89 | "\n",
90 | "\n",
91 | "#### 2.1.1 基于CTC的算法\n",
92 | "\n",
93 | "基于 CTC 最典型的算法是CRNN (Convolutional Recurrent Neural Network)[1],它的特征提取部分使用主流的卷积结构,常用的有ResNet、MobileNet、VGG等。由于文本识别任务的特殊性,输入数据中存在大量的上下文信息,卷积神经网络的卷积核特性使其更关注于局部信息,缺乏长依赖的建模能力,因此仅使用卷积网络很难挖掘到文本之间的上下文联系。为了解决这一问题,CRNN文本识别算法引入了双向 LSTM(Long Short-Term Memory) 用来增强上下文建模,通过实验证明双向LSTM模块可以有效的提取出图片中的上下文信息。最终将输出的特征序列输入到CTC模块,直接解码序列结果。该结构被验证有效,并广泛应用在文本识别任务中。Rosetta[2]是FaceBook提出的识别网络,由全卷积模型和CTC组成。Gao Y[3]等人使用CNN卷积替代LSTM,参数更少,性能提升精度持平。\n",
94 | "\n",
95 | "\n",
96 | " CRNN 结构图 \n",
97 | "\n",
98 | "\n",
99 | "#### 2.1.2 Sequence2Sequence 算法\n",
100 | "\n",
101 | "Sequence2Sequence 算法是由编码器 Encoder 把所有的输入序列都编码成一个统一的语义向量,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻的输出作为后一个时刻的输入,循环解码,直到输出停止符为止。一般编码器是一个RNN,对于每个输入的词,编码器输出向量和隐藏状态,并将隐藏状态用于下一个输入的单词,循环得到语义向量;解码器是另一个RNN,它接收编码器输出向量并输出一系列字以创建转换。受到 Sequence2Sequence 在翻译领域的启发, Shi[4]提出了一种基于注意的编解码框架来识别文本,通过这种方式,rnn能够从训练数据中学习隐藏在字符串中的字符级语言模型。\n",
102 | "\n",
103 | "\n",
104 | " Sequence2Sequence 结构图 \n",
105 | "\n",
106 | "以上两个算法在规则文本上都有很不错的效果,但由于网络设计的局限性,这类方法很难解决弯曲和旋转的不规则文本识别任务。为了解决这类问题,部分算法研究人员在以上两类算法的基础上提出了一系列改进算法。\n",
107 | "\n",
108 | "### 2.2 不规则文本识别\n",
109 | "\n",
110 | "* 不规则文本识别算法可以被分为4大类:基于校正的方法;基于 Attention 的方法;基于分割的方法;基于 Transformer 的方法。\n",
111 | "\n",
112 | "#### 2.2.1 基于校正的方法\n",
113 | "\n",
114 | "基于校正的方法利用一些视觉变换模块,将非规则的文本尽量转换为规则文本,然后使用常规方法进行识别。\n",
115 | "\n",
116 | "RARE[4]模型首先提出了对不规则文本的校正方案,整个网络分为两个主要部分:一个空间变换网络STN(Spatial Transformer Network) 和一个基于Sequence2Squence的识别网络。其中STN就是校正模块,不规则文本图像进入STN,通过TPS(Thin-Plate-Spline)变换成一个水平方向的图像,该变换可以一定程度上校正弯曲、透射变换的文本,校正后送入序列识别网络进行解码。\n",
117 | "\n",
118 | "\n",
119 | " RARE 结构图 \n",
120 | "\n",
121 | "RARE论文指出,该方法在不规则文本数据集上有较大的优势,特别比较了CUTE80和SVTP这两个数据集,相较CRNN高出5个百分点以上,证明了校正模块的有效性。基于此[6]同样结合了空间变换网络(STN)和基于注意的序列识别网络的文本识别系统。\n",
122 | "\n",
123 | "基于校正的方法有较好的迁移性,除了RARE这类基于Attention的方法外,STAR-Net[5]将校正模块应用到基于CTC的算法上,相比传统CRNN也有很好的提升。\n",
124 | "\n",
125 | "#### 2.2.2 基于Attention的方法\n",
126 | "\n",
127 | "基于 Attention 的方法主要关注的是序列之间各部分的相关性,该方法最早在机器翻译领域提出,认为在文本翻译的过程中当前词的结果主要由某几个单词影响的,因此需要给有决定性的单词更大的权重。在文本识别领域也是如此,将编码后的序列解码时,每一步都选择恰当的context来生成下一个状态,这样有利于得到更准确的结果。\n",
128 | "\n",
129 | "R^2AM [7] 首次将 Attention 引入文本识别领域,该模型首先将输入图像通过递归卷积层提取编码后的图像特征,然后利用隐式学习到的字符级语言统计信息通过递归神经网络解码输出字符。在解码过程中引入了Attention 机制实现了软特征选择,以更好地利用图像特征,这一有选择性的处理方式更符合人类的直觉。\n",
130 | "\n",
131 | "\n",
132 | " R^2AM 结构图 \n",
133 | "\n",
134 | "后续有大量算法在Attention领域进行探索和更新,例如SAR[8]将1D attention拓展到2D attention上,校正模块提到的RARE也是基于Attention的方法。实验证明基于Attention的方法相比CTC的方法有很好的精度提升。\n",
135 | "\n",
136 | "\n",
137 | "\n",
138 | "\n",
139 | "#### 2.2.3 基于分割的方法\n",
140 | "\n",
141 | "基于分割的方法是将文本行的各字符作为独立个体,相比与对整个文本行做矫正后识别,识别分割出的单个字符更加容易。它试图从输入的文本图像中定位每个字符的位置,并应用字符分类器来获得这些识别结果,将复杂的全局问题简化成了局部问题解决,在不规则文本场景下有比较不错的效果。然而这种方法需要字符级别的标注,数据获取上存在一定的难度。Lyu[9]等人提出了一种用于单词识别的实例分词模型,该模型在其识别部分使用了基于 FCN(Fully Convolutional Network) 的方法。[10]从二维角度考虑文本识别问题,设计了一个字符注意FCN来解决文本识别问题,当文本弯曲或严重扭曲时,该方法对规则文本和非规则文本都具有较优的定位结果。\n",
142 | "\n",
143 | "\n",
144 | " Mask TextSpotter 结构图 \n",
145 | "\n",
146 | "\n",
147 | "\n",
148 | "#### 2.2.4 基于Transformer的方法\n",
149 | "\n",
150 | "随着 Transformer 的快速发展,分类和检测领域都验证了 Transformer 在视觉任务中的有效性。如规则文本识别部分所说,CNN在长依赖建模上存在局限性,Transformer 结构恰好解决了这一问题,它可以在特征提取器中关注全局信息,并且可以替换额外的上下文建模模块(LSTM)。\n",
151 | "\n",
152 | "一部分文本识别算法使用 Transformer 的 Encoder 结构和卷积共同提取序列特征,Encoder 由多个 MultiHeadAttentionLayer 和 Positionwise Feedforward Layer 堆叠而成的block组成。MulitHeadAttention 中的 self-attention 利用矩阵乘法模拟了RNN的时序计算,打破了RNN中时序长时依赖的障碍。也有一部分算法使用 Transformer 的 Decoder 模块解码,相比传统RNN可获得更强的语义信息,同时并行计算具有更高的效率。\n",
153 | "\n",
154 | "SRN[11] 算法将Transformer的Encoder模块接在ResNet50后,增强了2D视觉特征。并提出了一个并行注意力模块,将读取顺序用作查询,使得计算与时间无关,最终并行输出所有时间步长的对齐视觉特征。此外SRN还利用Transformer的Eecoder作为语义模块,将图片的视觉信息和语义信息做融合,在遮挡、模糊等不规则文本上有较大的收益。\n",
155 | "\n",
156 | "NRTR[12] 使用了完整的Transformer结构对输入图片进行编码和解码,只使用了简单的几个卷积层做高层特征提取,在文本识别上验证了Transformer结构的有效性。\n",
157 | "\n",
158 | "\n",
159 | " NRTR 结构图 \n",
160 | "\n",
161 | "SRACN[13]使用Transformer的解码器替换LSTM,再一次验证了并行训练的高效性和精度优势。\n",
162 | "\n",
163 | "## 3 总结\n",
164 | "\n",
165 | "本节主要介绍了文本识别相关的理论知识和主流算法,包括基于CTC的方法、基于Sequence2Sequence的方法以及基于分割的方法,并分别列举了经典论文的思路和贡献。下一节将基于CRNN算法进行实践课程讲解,从组网到优化完成整个训练过程,\n",
166 | "\n",
167 | "## 4 参考文献\n",
168 | "\n",
169 | "\n",
170 | "[1]Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\n",
171 | "\n",
172 | "[2]Fedor Borisyuk, Albert Gordo, and Viswanath Sivakumar. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 71–79. ACM, 2018.\n",
173 | "\n",
174 | "[3]Gao, Y., Chen, Y., Wang, J., & Lu, H. (2017). Reading scene text with attention convolutional sequence modeling. arXiv preprint arXiv:1709.04303.\n",
175 | "\n",
176 | "[4]Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\n",
177 | "\n",
178 | "[5] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\n",
179 | "\n",
180 | "[6]Baoguang Shi, Mingkun Yang, XingGang Wang, Pengyuan Lyu, Xiang Bai, and Cong Yao. Aster: An attentional scene text recognizer with flexible rectification. IEEE transactions on pattern analysis and machine intelligence, 31(11):855–868, 2018.\n",
181 | "\n",
182 | "[7] Lee C Y , Osindero S . Recursive Recurrent Nets with Attention Modeling for OCR in the Wild[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.\n",
183 | "\n",
184 | "[8]Li, H., Wang, P., Shen, C., & Zhang, G. (2019, July). Show, attend and read: A simple and strong baseline for irregular text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8610-8617).\n",
185 | "\n",
186 | "[9]P. Lyu, C. Yao, W. Wu, S. Yan, and X. Bai. Multi-oriented scene text detection via corner localization and region segmentation. In Proc. CVPR, pages 7553–7563, 2018.\n",
187 | "\n",
188 | "[10] Liao, M., Zhang, J., Wan, Z., Xie, F., Liang, J., Lyu, P., ... & Bai, X. (2019, July). Scene text recognition from two-dimensional perspective. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8714-8721).\n",
189 | "\n",
190 | "[11] Yu, D., Li, X., Zhang, C., Liu, T., Han, J., Liu, J., & Ding, E. (2020). Towards accurate scene text recognition with semantic reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12113-12122).\n",
191 | "\n",
192 | "[12] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\n",
193 | "\n",
194 | "[13]Yang, L., Wang, P., Li, H., Li, Z., & Zhang, Y. (2020). A holistic representation guided attention network for scene text recognition. Neurocomputing, 414, 67-75.\n",
195 | "\n",
196 | "[14]Wang, T., Zhu, Y., Jin, L., Luo, C., Chen, X., Wu, Y., ... & Cai, M. (2020, April). Decoupled attention network for text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 07, pp. 12216-12224).\n",
197 | "\n",
198 | "[15] Wang, Y., Xie, H., Fang, S., Wang, J., Zhu, S., & Zhang, Y. (2021). From two to one: A new scene text recognizer with visual language modeling network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 14194-14203).\n",
199 | "\n",
200 | "[16] Fang, S., Xie, H., Wang, Y., Mao, Z., & Zhang, Y. (2021). Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7098-7107).\n",
201 | "\n",
202 | "[17] Yan, R., Peng, L., Xiao, S., & Yao, G. (2021). Primitive Representation Learning for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 284-293)."
203 | ]
204 | },
205 | {
206 | "cell_type": "markdown",
207 | "metadata": {
208 | "collapsed": false
209 | },
210 | "source": []
211 | }
212 | ],
213 | "metadata": {
214 | "kernelspec": {
215 | "display_name": "Python 3",
216 | "language": "python",
217 | "name": "py35-paddle1.2.0"
218 | },
219 | "language_info": {
220 | "codemirror_mode": {
221 | "name": "ipython",
222 | "version": 3
223 | },
224 | "file_extension": ".py",
225 | "mimetype": "text/x-python",
226 | "name": "python",
227 | "nbconvert_exporter": "python",
228 | "pygments_lexer": "ipython3",
229 | "version": "3.7.4"
230 | }
231 | },
232 | "nbformat": 4,
233 | "nbformat_minor": 1
234 | }
235 |
--------------------------------------------------------------------------------
/notebook_ch/如何使用本书.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "collapsed": false
7 | },
8 | "source": [
9 | "# 1. 课程预备知识\n",
10 | "\n",
11 | "本课所涉及的OCR模型建立在深度学习的基础之上,因此与其相关的基础知识、环境配置、项目工程与其他资料将在本节介绍,尤其对深度学习不熟悉的读者可以查看和学习相应内容。\n",
12 | "\n",
13 | "### 1.1 预备知识\n",
14 | "\n",
15 | "深度学习的“学习”由机器学习中的神经元、感知机、多层神经网络等内容一路发展而来,因此了解基础的机器学习算法对于深度学习的理解和应用有很大帮助。而深度学习的“深”则体现在对大量信息处理过程中使用的卷积、池化等一系列以向量为基础的数学运算。如果缺乏这两者的理论基础,可以学习李宏毅老师的[线性代数](https://aistudio.baidu.com/aistudio/course/introduce/2063)和[机器学习](https://aistudio.baidu.com/aistudio/course/introduce/1978)课程。\n",
16 | "\n",
17 | "对于深度学习本身的理解,可以参考百度杰出架构师毕然老师的零基础课程:[百度架构师手把手带你零基础实践深度学习](https://aistudio.baidu.com/aistudio/course/introduce/1297),其中覆盖了深度学习的发展历史,通过一个经典案例介绍深度学习的完整组成部分,是一套以实践为导向的深度学习课程。\n",
18 | "\n",
19 | "对于理论知识的实践,[Python基础知识](https://aistudio.baidu.com/aistudio/course/introduce/1224)必不可少,同时为了快速复现深度学习模型,本课程使用的深度学习框架为:飞桨PaddlePaddle。如果你已经使用过其他框架,通过[快速上手文档](https://www.paddlepaddle.org.cn/documentation/docs/zh/practices/quick_start/hello_paddle.html)可以迅速了解飞桨的使用方法。\n",
20 | "\n",
21 | "### 1.2 基础环境准备\n",
22 | "\n",
23 | "如果你想在本地环境运行本课程的代码且之前未搭建过Python环境,可以根据[零基础运行环境准备](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.3/doc/doc_ch/environment.md),根据自己的操作系统安装Anaconda或docker环境。\n",
24 | "\n",
25 | "如果你没有本地资源,可以通过AI Studio实训平台完成代码运行,其中的每个项目都通过Notebook的方式呈现,方便开发者学习。若对Notebook的相关操作不熟悉,可以参考[AI Studio项目说明](https://ai.baidu.com/ai-doc/AISTUDIO/0k3e2tfzm)。\n",
26 | "\n",
27 | "### 1.3 获取和运行代码\n",
28 | "\n",
29 | "本课程依托PaddleOCR的代码库形成,首先,克隆PaddleOCR的完整项目:\n",
30 | "\n",
31 | "```bash\n",
32 | "#【推荐】\n",
33 | "git clone https://github.com/PaddlePaddle/PaddleOCR\n",
34 | "\n",
35 | "# 如果因为网络问题无法pull成功,也可选择使用码云上的托管:\n",
36 | "git clone https://gitee.com/paddlepaddle/PaddleOCR\n",
37 | "```\n",
38 | "\n",
39 | "> 注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。\n",
40 | ">\n",
41 | "> \t\t如果你不熟悉git操作,可以直接在PaddleOCR的首页的 `Code` 中下载压缩包\n",
42 | "\n",
43 | "然后安装第三方库:\n",
44 | "\n",
45 | "```bash\n",
46 | "cd PaddleOCR\n",
47 | "pip3 install -r requirements.txt\n",
48 | "```\n",
49 | "\n",
50 | "\n",
51 | "\n",
52 | "### 1.4 查阅资料\n",
53 | "\n",
54 | "[PaddleOCR使用文档](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.3/README_ch.md#%E6%96%87%E6%A1%A3%E6%95%99%E7%A8%8B) (中文) 中详细介绍了如何使用PaddleOCR完成模型应用、训练和部署。文档内容丰富,大多数用户的问题都在文档或FAQ中有所描述,尤其在[FAQ(中文)](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.3/doc/doc_ch/FAQ.md)中,按照深度学习的应用过程沉淀了用户的常见问题,建议大家仔细阅读。\n",
55 | "\n",
56 | "### 1.5 寻求帮助\n",
57 | "\n",
58 | "如果你在使用PaddleOCR的过程中遇到BUG、易用性或者文档相关的问题,可通过[Github issue](https://github.com/PaddlePaddle/PaddleOCR/issues)与官方联系,请按照issue模板尽可能多的提供信息,以便官方人员迅速定位问题。同时,微信群是广大PaddleOCR用户的日常交流阵地,更适合提问一些咨询类问题,除了有PaddleOCR团队成员以外,还会有热心开发者回答大家的问题。"
59 | ]
60 | }
61 | ],
62 | "metadata": {
63 | "kernelspec": {
64 | "display_name": "Python 3",
65 | "language": "python",
66 | "name": "py35-paddle1.2.0"
67 | },
68 | "language_info": {
69 | "codemirror_mode": {
70 | "name": "ipython",
71 | "version": 3
72 | },
73 | "file_extension": ".py",
74 | "mimetype": "text/x-python",
75 | "name": "python",
76 | "nbconvert_exporter": "python",
77 | "pygments_lexer": "ipython3",
78 | "version": "3.7.4"
79 | }
80 | },
81 | "nbformat": 4,
82 | "nbformat_minor": 1
83 | }
84 |
--------------------------------------------------------------------------------
/notebook_en/2.text_detection/text_detection_FAQ.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Text detection FAQ\n",
8 | "\n",
9 | "This section lists some of the problems that developers often encounter when using PaddleOCR's text detection model, and gives corresponding solutions or suggestions.\n",
10 | "\n",
11 | "The FAQ is introduced in two parts, namely:\n",
12 | " -Text detection training related\n",
13 | " -Text detection and prediction related"
14 | ]
15 | },
16 | {
17 | "cell_type": "markdown",
18 | "metadata": {},
19 | "source": [
20 | "## 1. FAQ about Text Detection Training\n",
21 | "\n",
22 | "**1.1 What are the text detection algorithms provided by PaddleOCR?**\n",
23 | "\n",
24 | "**A**: PaddleOCR contains a variety of text detection models, including regression-based text detection methods EAST and SAST, and segmentation-based text detection methods DB, PSENet.\n",
25 | "\n",
26 | "\n",
27 | "**1.2: What data sets are used in the Chinese ultra-lightweight and general models in the PaddleOCR project? How many samples were trained, what configuration of GPUs, how many epochs were run, and how long did they run?**\n",
28 | "\n",
29 | "**A**: For the ultra-lightweight DB detection model, the training data includes open source data sets lsvt, rctw, CASIA, CCPD, MSRA, MLT, BornDigit, iflytek, SROIE and synthetic data sets, etc. The total data volume is 10W, The data set is divided into 5 parts. A random sampling strategy is used during training. The training takes about 500 epochs on a 4-card V100GPU, which takes 3 days.\n",
30 | "\n",
31 | "\n",
32 | "**1.3 Does the text detection training label require specific text labeling? What does the \"###\" in the label mean?**\n",
33 | "\n",
34 | "**A**: Text detection training only needs the coordinates of the text area. The label can be four or fourteen points, arranged in the order of upper left, upper right, lower right, and lower left. The label file provided by PaddleOCR contains text fields. For unclear text in the text area, ### will be used instead. When training the detection model, the text field in the label will not be used.\n",
35 | " \n",
36 | "**1.4 Is the effect of the text detection model trained when the text lines are tight?**\n",
37 | "\n",
38 | "**A**: When using segmentation-based methods, such as DB, to detect dense text lines, it is best to collect a batch of data for training, and during training, a binary image will be generated [shrink_ratio](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/ppocr/data/imaug/make_shrink_map.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L37)Turn down the parameter. In addition, when forecasting, you can appropriately reduce [unclip_ratio](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L59) parameter, the larger the unclip_ratio parameter value, the larger the detection frame.\n",
39 | "\n",
40 | "\n",
41 | "**1.5 For some large-sized document images, DB will have more missed inspections during inspection. How to avoid this kind of missed inspections?**\n",
42 | "\n",
43 | "**A**: First of all, you need to determine whether the model is not well-trained or is the problem handled during prediction. If the model is not well trained, it is recommended to add more data for training, or add more data to enhance it during training.\n",
44 | "If the problem is that the predicted image is too large, you can increase the longest side setting parameter [det_limit_side_len] entered during prediction [det_limit_side_len](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L47), which is 960 by default.\n",
45 | "Secondly, you can observe whether the missed text has segmentation results by visualizing the post-processed segmentation map. If there is no segmentation result, the model is not well trained. If there is a complete segmentation area, it means that it is a problem of post-prediction processing. In this case, it is recommended to adjust [DB post-processing parameters](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L51-L53)。\n",
46 | "\n",
47 | "\n",
48 | "**1.6 The problem of missed detection of DB model bending text (such as a slightly deformed document image)?**\n",
49 | "\n",
50 | "**A**: When calculating the average score of the text box in the DB post-processing, it is the average score of the rectangle area, which is easy to cause the missed detection of the curved text. The average score of the polygon area has been added, which will be more accurate, but the speed is somewhat different. Decrease, can be selected as needed, and you can view the [Visual Contrast Effect] (https://github.com/PaddlePaddle/PaddleOCR/pull/2604) in the relevant pr. This function is selected by the parameter [det_db_score_mode](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/tools/infer/utility.py#L51), the parameter value is optional [`fast` (default) , `slow`], `fast` corresponds to the original rectangle mode, and `slow` corresponds to the polygon mode. Thanks to the user [buptlihang](https://github.com/buptlihang) for mentioning [pr](https://github.com/PaddlePaddle/PaddleOCR/pull/2574) to help solve this problem.\n",
51 | "\n",
52 | "\n",
53 | "**1.7 For simple OCR tasks with low accuracy requirements, how many data sets do I need to prepare?**\n",
54 | "\n",
55 | "**A**: (1) The amount of training data is related to the complexity of the problem to be solved. The greater the difficulty and the higher the accuracy requirements, the greater the data set requirements, and in general, the more training data in practice, the better the effect.\n",
56 | "\n",
57 | "(2) For scenes with low accuracy requirements, the amount of data required for detection tasks and recognition tasks is different. For inspection tasks, 500 images can guarantee the basic inspection results. For recognition tasks, it is necessary to ensure that the number of line text images in which each character in the recognition dictionary appears in different scenes needs to be greater than 200 (for example, if there are 5 words in the dictionary, each word needs to appear in more than 200 pictures, then The minimum required number of images should be between 200-1000), so that the basic recognition effect can be guaranteed.\n",
58 | "\n",
59 | "\n",
60 | "**1.8 How to get more data when the amount of training data is small?**\n",
61 | "\n",
62 | "**A**: When the amount of training data is small, you can try the following three ways to get more data: (1) Collect more training data manually, the most direct and effective way. (2) Basic image processing or transformation based on PIL and opencv. For example, the three modules of ImageFont, Image, ImageDraw in PIL write text into the background, opencv's rotating affine transformation, Gaussian filtering and so on. (3) Synthesize data using data generation algorithms, such as algorithms such as pix2pix.\n",
63 | "\n",
64 | "\n",
65 | "**1.9 How to replace the backbone of text detection/recognition?**\n",
66 | "\n",
67 | "A: Whether it is text detection or text recognition, the choice of backbone network is a trade-off between prediction effect and prediction efficiency. Generally, if you choose a larger-scale backbone network, such as ResNet101_vd, the detection or recognition will be more accurate, but the prediction time will increase accordingly. However, choosing a smaller-scale backbone network, such as MobileNetV3_small_x0_35, will predict faster, but the accuracy of detection or recognition will be greatly reduced. Fortunately, the detection or recognition effects of different backbone networks are positively correlated with the image 1000 classification task in the ImageNet dataset. PaddleClas, a flying paddle image classification suite, summarizes 23 series of classification network structures such as ResNet_vd, Res2Net, HRNet, MobileNetV3, GhostNet, etc. The top1 recognition accuracy rate of the above image classification task, GPU (V100 and T4) and CPU (Snapdragon 855) The prediction time-consuming and the corresponding 117 pre-training model download addresses.\n",
68 | "\n",
69 | "(1) The replacement of the text detection backbone network is mainly to determine 4 stages similar to ResNet to facilitate the integration of subsequent detection heads similar to FPN. In addition, for the text detection problem, the classification pre-training model trained by ImageNet can accelerate the convergence and improve the effect.\n",
70 | "\n",
71 | "(2) The replacement of the backbone network for text recognition requires attention to the drop position of the network width and height stride. Since text recognition generally has a large ratio of width to height, the frequency of height reduction is less, and the frequency of width reduction is more. You can refer to [Changes to the MobileNetV3 backbone network in PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.3/ppocr/modeling/backbones/rec_mobilenet_v3.py)。\n",
72 | "\n",
73 | "\n",
74 | "**1.10 How to finetune the detection model, such as freezing the previous layer or learning with a small learning rate for some layers?**\n",
75 | "\n",
76 | "**A**: If you freeze certain layers, you can set the stop_gradient property of the variable to True, so that all the parameters before calculating this variable will not be updated, refer to: https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/faq/train_cn.html#id4\n",
77 | "\n",
78 | "If learning with a smaller learning rate for some layers is not very convenient in the static graph, one method is to set a fixed learning rate for the weight attribute when the parameters are initialized, refer to: https://www.paddlepaddle.org.cn/documentation/docs/en/develop/api/paddle/fluid/param_attr/ParamAttr_cn.html#paramattr\n",
79 | "\n",
80 | "In fact, our experiment found that directly loading the model to fine-tune without setting different learning rates of certain layers, the effect is also good.\n",
81 | "\n",
82 | "**1.11 In the preprocessing part of DB, why should the length and width of the picture be processed into multiples of 32?**\n",
83 | "\n",
84 | "**A**: It is related to the stride of the network downsampling. Take the resnet backbone network under inspection as an example. After the image is input to the network, it needs to be downsampled by 2 times for 5 times, a total of 32 times. Therefore, it is recommended that the input image size be a multiple of 32.\n",
85 | "\n",
86 | "\n",
87 | "**1.12 In the PP-OCR series models, why does the backbone network for text detection not use SEBlock?**\n",
88 | "\n",
89 | "**A**: The SE module is an important module of the MobileNetV3 network. Its purpose is to estimate the importance of each feature channel of the feature map, assign weights to each feature of the feature map, and improve the expressive ability of the network. However, for text detection, the resolution of the input network is relatively large, generally 640\\*640. It is difficult to use the SE module to estimate the importance of each feature channel of the feature map. The network improvement ability is limited, but the module is relatively time-consuming. In the PP-OCR system, the backbone network for text detection does not use the SE module. Experiments also show that when the SE module is removed, the size of the ultra-lightweight model can be reduced by 40%, and the text detection effect is basically not affected. For details, please refer to the PP-OCR technical article, https://arxiv.org/abs/2009.09941.\n",
90 | "\n",
91 | "\n",
92 | "**1.13 The PP-OCR detection effect is not good, how to optimize it?**\n",
93 | "\n",
94 | "**A**: Specific analysis of specific issues:\n",
95 | "- If the detection effect is not available on your scene, the first choice is to do finetune training on your data;\n",
96 | "- If the image is too large and the text is too dense, it is recommended not to over-compress the image. You can try to modify the resize logic of the detection preprocessing to prevent the image from being over-compressed;\n",
97 | "- The size of the detection frame is too close to the text or the detection frame is too large, you can adjust the db_unclip_ratio parameter, increasing the parameter can enlarge the detection frame, and reducing the parameter can reduce the size of the detection frame;\n",
98 | "- There are many missed detection problems in the detection frame, which can reduce the threshold parameter det_db_box_thresh for DB detection to prevent some detection frames from being filtered out. You can also try to set det_db_score_mode to'slow';\n",
99 | "- Other methods can choose use_dilation as True to expand the feature map of the detection output. In general, the effect will be improved.\n",
100 | "\n",
101 | "\n",
102 | "## 2. FAQ about Text Detection and Prediction\n",
103 | "\n",
104 | "**2.1 In DB, some boxes are too pasted with text, but some corners of the text are removed to affect the recognition. Is there any way to alleviate this problem?**\n",
105 | "\n",
106 | "**A**: The post-processing parameter [unclip_ratio](https://github.com/PaddlePaddle/PaddleOCR/blob/d80afce9b51f09fd3d90e539c40eba8eb5e50dd6/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L52) can be appropriately increased. the larger the parameter, the larger the text box.\n",
107 | "\n",
108 | "\n",
109 | "**2.2 Why does the PaddleOCR detection prediction only support one image test? That is, test_batch_size_per_card=1**\n",
110 | "\n",
111 | "**A**: When predicting, the image is scaled in equal proportions, the longest side is 960, and the length and width of different images after scaling in equal proportions are inconsistent, and they cannot form a batch, so set test_batch_size to 1.\n",
112 | "\n",
113 | "\n",
114 | "**2.3 Accelerate PaddleOCR's text detection model prediction on the CPU?**\n",
115 | "\n",
116 | "**A**: x86 CPU can use mkldnn (OneDNN) for acceleration; enable [enable_mkldnn](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py#L105) Parameters. In addition, in conjunction with increasing the number of threads used for prediction on the CPU, [num_threads](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py#L106) can effectively speed up the prediction speed on the CPU.\n",
117 | "\n",
118 | "**2.4 Accelerate PaddleOCR's text detection model prediction on GPU?**\n",
119 | "\n",
120 | "**A**: TensorRT is recommended for GPU accelerated prediction.\n",
121 | "- 1. Download the Paddle installation package or prediction library with TensorRT from [link](https://paddleinference.paddlepaddle.org.cn/master/user_guides/download_lib.html).\n",
122 | "- 2. Download the [TensorRT](https://developer.nvidia.com/tensorrt) from the Nvidia official website. Note that the downloaded TensorRT version is consistent with the TensorRT version compiled in the paddle installation package.\n",
123 | "- 3. Set the environment variable `LD_LIBRARY_PATH` to point to the lib folder of TensorRT\n",
124 | "```\n",
125 | "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:\n",
126 | "```\n",
127 | "- 4. Enable [tensorrt option](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L38).\n",
128 | "\n",
129 | "**2.5 How to deploy PaddleOCR model on the mobile terminal?**\n",
130 | "\n",
131 | "**A**: Flying Oar Paddle has a special tool for mobile deployment [PaddleLite](https://github.com/PaddlePaddle/Paddle-Lite), and PaddleOCR provides DB+CRNN as the demo android arm deployment code , Refer to [link](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.3/deploy/lite/readme.md).\n",
132 | "\n",
133 | "\n",
134 | "**2.6 How to use PaddleOCR multi-process prediction?**\n",
135 | "\n",
136 | "**A**: PaddleOCR recently added [Multi-Process Predictive Control Parameters](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L111), `use_mp` indicates whether When using multiple processes, `total_process_num` indicates the number of processes when using multiple processes. For specific usage, please refer to [document](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.3/doc/doc_ch/inference.md#1-%E8%B6%85%E8%BD%BB%E9%87%8F%E4%B8%AD%E6%96%87ocr%E6%A8%A1%E5%9E%8B%E6%8E%A8%E7%90%86).\n",
137 | "\n",
138 | "**2.7 Video memory explosion and memory leak during prediction?**\n",
139 | "\n",
140 | "**A**: If it is the prediction of the training model, the video memory is not enough because the model is too large or the input image is too large, you can refer to the code and add paddle.no_grad() before the main function runs to reduce the video memory usage. If the memory usage of the inference model is too high, you can add [config.enable_memory_optim()](https://github.com/PaddlePaddle/PaddleOCR/blob/8b656a3e13631dfb1ac21d2095d4d4a4993ef710/tools/infer/utility.py?_pjax=%23js-repo-pjax-container%2C%20div%5Bitemtype%3D%22http%3A%2F%2Fschema.org%2FSoftwareSourceCode%22%5D%20main%2C%20%5Bdata-pjax-container%5D#L267) to reduce the memory usage when configuring Config.\n",
141 | "\n",
142 | "In addition, regarding the memory leak when using Paddle to predict, it is recommended to install the latest version of paddle. The memory leak has been fixed."
143 | ]
144 | }
145 | ],
146 | "metadata": {
147 | "kernelspec": {
148 | "display_name": "Python 3 (ipykernel)",
149 | "language": "python",
150 | "name": "python3"
151 | },
152 | "language_info": {
153 | "codemirror_mode": {
154 | "name": "ipython",
155 | "version": 3
156 | },
157 | "file_extension": ".py",
158 | "mimetype": "text/x-python",
159 | "name": "python",
160 | "nbconvert_exporter": "python",
161 | "pygments_lexer": "ipython3",
162 | "version": "3.8.5"
163 | }
164 | },
165 | "nbformat": 4,
166 | "nbformat_minor": 4
167 | }
168 |
--------------------------------------------------------------------------------
/notebook_en/2.text_detection/text_detection_theory.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Text Detection Algorithm Theory\n"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## 1 Text Detection\n",
15 | "\n",
16 | "The task of text detection is to find out the position of text in an image or video. Different from the task of target detection, target detection must not only solve the positioning problem, but also solve the problem of target classification.\n",
17 | "\n",
18 | "The manifestation of text in images can be regarded as a kind of 'target', and general target detection methods are also suitable for text detection. From the perspective of the task itself:\n",
19 | "\n",
20 | "- Target detection: Given an image or video, find out the location (box) of the target, and give the target category;\n",
21 | "- Text detection: Given an input image or video, find out the area of the text, which can be a single character position or a whole text line position;\n",
22 | "\n",
23 | "\n",
24 | "\n",
25 | "\n",
26 | "\n",
27 | "
Figure 1: Schematic diagram of target detection\n",
28 | "\n",
29 | "\n",
30 | "\n",
31 | "
Figure 2: Schematic diagram of text detection\n",
32 | "\n",
33 | "Object detection and text detection are both \"location\" problems. But text detection does not need to classify the target, and the shape of the text is complex and diverse.\n",
34 | "\n",
35 | "The current text detection is generally natural scene text detection. The difficulty lies in:\n",
36 | "\n",
37 | "1. Text in natural scenes is diverse: text detection is affected by text color, size, font, shape, direction, language, and text length;\n",
38 | "2. Complex background and interference; text detection is affected by image distortion, blur, low resolution, shadow, brightness and other factors;\n",
39 | "3. Dense or overlapping text will affect text detection;\n",
40 | "4. Local consistency of text: a small part of a text line can also be considered as independent text.\n",
41 | "\n",
42 | "\n",
44 | "\n",
45 | "
Figure 3: Text detection scene\n",
46 | "\n",
47 | "In response to the above problems, many text detection algorithms based on deep learning have been derived to solve the problem of text detection in natural scenes. These methods can be divided into regression-based and segmentation-based text detection methods.\n",
48 | "\n",
49 | "The next section will briefly introduce the classic text detection algorithm based on deep learning technology."
50 | ]
51 | },
52 | {
53 | "cell_type": "markdown",
54 | "metadata": {
55 | "tags": []
56 | },
57 | "source": [
58 | "## 2 Introduction to Text Detection Methods\n",
59 | "\n",
60 | "\n",
61 | "In recent years, deep learning-based text detection algorithms have emerged one after another. These methods can be roughly divided into two categories:\n",
62 | "1. Regression-based text detection method\n",
63 | "2. Text detection method based on segmentation\n",
64 | "\n",
65 | "\n",
66 | "This section screens the commonly used text detection methods from 2017 to 2021, and is classified according to the above two types of methods as shown in the following table:\n",
67 | "\n",
68 | "\n",
70 | "
Figure 4: Text detection algorithm\n",
71 | "\n",
72 | "\n",
73 | "### 2.1 Regression-based Text Detection\n",
74 | "\n",
75 | "The method based on the regression text detection method is similar to the method of the target detection algorithm. The text detection method has only two categories. The text in the image is regarded as the target to be detected, and the rest is regarded as the background.\n",
76 | "\n",
77 | "#### 2.1.1 Horizontal Text Detection\n",
78 | "\n",
79 | "Early text detection algorithms based on deep learning are improved from the target detection method and support horizontal text detection. For example, the TextBoxes algorithm is improved based on the SSD algorithm, and the CTPN is improved based on the two-stage target detection Fast-RCNN algorithm.\n",
80 | "\n",
81 | "In TextBoxes[1], the algorithm is adjusted according to the one-stage target detector SSD, and the default text box is changed to a quadrilateral that adapts to the specifications of the text direction and aspect ratio, providing an end-to-end training text detection method without complicated Post-processing.\n",
82 | "-Use a pre-selection box with a larger aspect ratio\n",
83 | "-The convolution kernel has been changed from 3x3 to 1x5, which is more suitable for long text detection\n",
84 | "-Adopt multi-scale input\n",
85 | "\n",
86 | "\n",
87 | "
Figure 5: Textbox frame diagram\n",
88 | "\n",
89 | "CTPN[3] is based on the Fast-RCNN algorithm, expands the RPN module and designs a CRNN-based module to allow the entire network to detect text sequences from convolutional features. The two-stage method obtains more accurate feature positioning through ROI Pooling. But TextBoxes and CTPN only support the detection of horizontal text.\n",
90 | "\n",
91 | "\n",
92 | "
Figure 6: CTPN frame diagram\n",
93 | "\n",
94 | "#### 2.1.2 Any Angle Text Detection\n",
95 | "\n",
96 | "TextBoxes++[2] is improved on the basis of TextBoxes, and supports the detection of text at any angle. Structurally, unlike TextBoxes, TextBoxes++ detects multi-angle text. First, modify the aspect ratio of the preselection box and adjust the aspect ratio to 1, 2, 3, 5, 1/2, 1/3, 1/5. The second is to change the $1*5$ convolution kernel to $3*5$ to better learn the characteristics of the slanted text; finally, the representation information of the output rotating box of TextBoxes++.\n",
97 | "\n",
98 | "\n",
100 | "
Figure 7: TextBoxes++ frame diagram\n",
101 | "\n",
102 | "\n",
103 | "EAST [4] proposed a two-stage text detection method for the location of slanted text, including FCN feature extraction and NMS part. EAST proposes a new text detection pipline structure, which can be trained end-to-end and supports the detection of text in any orientation, and has the characteristics of simple structure and high performance. FCN supports the output of inclined rectangular frame and horizontal frame, and the output format can be freely selected.\n",
104 | "-If the output detection shape is RBox, output Box rotation angle and AABB text shape information, AABB represents the offset to the top, bottom, left, and right sides of the text box. RBox can rotate rectangular text.\n",
105 | "-If the output detection box is a four-point box, the last dimension of the output is 8 numbers, which represents the position offset from the four corner vertices of the quadrilateral. This output method can predict irregular quadrilateral text.\n",
106 | "\n",
107 | "Considering that the text box output by FCN is relatively redundant, for example, the box generated by the adjacent pixels of a text area has a high degree of coincidence. But it is not the detection frame generated by the same text, and the degree of coincidence is very small. Therefore, EAST proposes to merge the prediction boxes by row first. Finally, filter the remaining quads with the original NMS.\n",
108 | "\n",
109 | "\n",
111 | "
Figure 8: EAST frame diagram\n",
112 | "\n",
113 | "\n",
114 | "MOST [15] proposed that the TFAM module dynamically adjusts the receptive field of coarse-grained detection results, and also proposed that PA-NMS combines reliable detection and prediction results based on location information. In addition, the Instance-wise IoU loss function is also proposed during training, which is used to balance training to handle text instances of different scales. This method can be combined with the EAST method, and has better detection effect and performance in detecting texts with extreme aspect ratios and different scales.\n",
115 | "\n",
116 | "\n",
118 | "
Figure 9: MOST frame diagram\n",
119 | "\n",
120 | "\n",
121 | "#### 2.1.3 Curved Text Detection\n",
122 | "\n",
123 | "Using regression to solve the problem of curved text detection, a simple idea is to describe the boundary polygon of the curved text with multi-point coordinates, and then directly predict the vertex coordinates of the polygon.\n",
124 | "\n",
125 | "CTD [6] proposed to directly predict the boundary polygons of 14 vertices of curved text. The network uses the Bi-LSTM [13] layer to refine the prediction coordinates of the vertices, and realizes the detection of curved text based on the regression method.\n",
126 | "\n",
127 | "\n",
129 | "
Figure 10: CTD frame diagram\n",
130 | "\n",
131 | "\n",
132 | "\n",
133 | "LOMO [19] proposes iterative optimization of text localization features to obtain finer text localization for long text and curved text problems. The method consists of three parts: the coordinate regression module DR, the iterative optimization module IRM and the arbitrary shape expression module SEM. They are used to generate approximate text regions, iteratively optimize text localization features, and predict text regions, text centerlines, and text boundaries. Iteratively optimized text features can better solve the problem of long text localization and obtain more accurate text area localization.\n",
134 | "\n",
136 | "
Figure 11: LOMO frame diagram\n",
137 | "\n",
138 | "\n",
139 | "Contournet [18] is based on the proposed modeling of text contour points to obtain a curved text detection frame. This method first uses Adaptive-RPN to obtain the proposal features of the text area, and then designs a local orthogonal texture perception LOTM module to learn horizontal and vertical textures. The feature is represented by contour points. Finally, by considering the feature responses in two orthogonal directions at the same time, the Point Re-Scoring algorithm can effectively filter out the prediction of strong unidirectional or weak orthogonal activation, and the final text contour can be used as a group of high-quality contour points are shown.\n",
140 | "\n",
142 | "
Figure 12: Contournet frame diagram\n",
143 | "\n",
144 | "\n",
145 | "PCR [14] proposed progressive coordinate regression to deal with curved text detection. The problem is divided into three stages. Firstly, the text area is roughly detected, and the text box is obtained. In addition, the corners of the smallest bounding box of the text are predicted by the designed Contour Localization Mechanism. Coordinates, and then the curved text is predicted by superimposing multiple CLM modules and RCLM modules. This method uses the text contour information aggregation to obtain a rich text contour feature representation, which can not only suppress the influence of redundant noise points on the coordinate regression, but also locate the text area more accurately.\n",
146 | "\n",
147 | "\n",
149 | "
Figure 13: PCR frame diagram"
150 | ]
151 | },
152 | {
153 | "cell_type": "markdown",
154 | "metadata": {},
155 | "source": [
156 | "\n",
157 | "### 2.2 Text Detection Based on Segmentation\n",
158 | "\n",
159 | "Although the regression-based method has achieved good results in text detection, it is often difficult to obtain a smooth text surrounding curve for solving curved text, and the model is more complex and does not have performance advantages. Therefore, researchers proposed a text segmentation method based on image segmentation. First, classify at the pixel level, determine whether each pixel belongs to a text target, obtain the probability map of the text area, and obtain the enclosing curve of the text segmentation area through post-processing. .\n",
160 | "\n",
161 | "\n",
163 | "
Figure 14: Schematic diagram of text segmentation algorithm\n",
164 | "\n",
165 | "\n",
166 | "Such methods are usually based on segmentation to achieve text detection, and segmentation-based methods have natural advantages for text detection with irregular shapes. The main idea of the segmentation-based text detection method is to obtain the text area in the image through the segmentation method, and then use opencv, polygon and other post-processing to obtain the minimum enclosing curve of the text area.\n",
167 | "\n",
168 | "\n",
169 | "Pixellink [7] uses a segmentation method to solve the text detection problem. The segmentation object is a text area. The pixels in the same text line (word) are linked together to segment the text, and the text bounding box is directly extracted from the segmentation result without a position. Regression can achieve the effect of text detection based on regression. However, there is a problem with the segmentation-based method. For texts with similar positions, the text segmentation area is prone to \"sticky\" problems. Wu, Yue et al. [8] proposed to separate the text while learning the boundary position of the text to better distinguish the text area. In addition, Tian et al. [9] proposed to map the pixels of the same text to the mapping space. In the mapping space, the distance of the mapping vector of the unified text is close, and the distance of the mapping vector of different texts becomes longer.\n",
170 | "\n",
171 | "\n",
173 | "
Figure 15: PixelLink frame diagram\n",
174 | "\n",
175 | "For the multi-scale problem of text detection, MSR [20] proposes to extract multiple scale features of the same image, then merge these features and up-sample to the original image size. The network finally predicts the text center area and each point of the text center area. The x-coordinate offset and y-coordinate offset of the nearest boundary point can finally get the contour coordinate set of the text area.\n",
176 | "\n",
177 | "\n",
179 | "
Figure 16: MSR frame diagram\n",
180 | " \n",
181 | "Aiming at the problem of segmentation-based text algorithms that are difficult to distinguish between adjacent texts, PSENet [10] proposed a progressive scale expansion network to learn text segmentation regions, predict text regions with different shrinkage ratios, and expand the detected text regions one by one. The essence of this method is The above is a variant of the boundary learning method, which can effectively solve the problem of detecting adjacent text of any shape.\n",
182 | "\n",
183 | "\n",
185 | "
Figure 17: PSENet frame diagram\n",
186 | "\n",
187 | "Assume that PSENet post-processing uses 3 kernels of different scales, as shown in the above figure s1, s2, and s3. First, start from the minimum kernel s1, calculate the connected domain of the text segmentation area, and get (b), and then expand the connected domain along the up, down, left, and right, and classify the pixels that belong to s2 but not to s1 in the expanded area. When encountering conflicts, the principle of \"first come first served\" is adopted, and the scale expansion operation is repeated, and finally independent segmented regions of different text lines can be obtained.\n",
188 | "\n",
189 | "\n",
190 | "Seglink++ [17] proposed a characterization of the attraction and repulsion relationship between text block units for curved text and dense text, and then designed a minimum spanning tree algorithm to combine the units to obtain the final text detection box, and An instance-aware loss function is proposed so that the Seglink++ method can be trained end-to-end.\n",
191 | "\n",
192 | "\n",
194 | "
Figure 18: Seglink++ frame diagram\n",
195 | "\n",
196 | "Although the segmentation method solves the problem of curved text detection, complex post-processing logic and prediction speed are also goals that need to be optimized.\n",
197 | "\n",
198 | "PAN [11] aims at the problem of slow text detection and prediction speed, and improves the performance of the algorithm from the aspects of network design and post-processing. First, PAN uses the lightweight ResNet18 as the Backbone, and also designs the lightweight feature enhancement module FPEM and feature fusion module FFM to enhance the features extracted by the Backbone. In terms of post-processing, a pixel clustering method is used to merge pixels whose distance from the kernel is less than the threshold d along the predicted text center (kernel). PAN guarantees high accuracy while having faster prediction speed.\n",
199 | "\n",
200 | "\n",
201 | "\n",
203 | "
Figure 19: PAN frame diagram\n",
204 | "\n",
205 | "DBNet [12] aimed at the problem of time-consuming post-processing that requires the use of thresholds for binarization based on segmentation methods. It proposed a learnable threshold and cleverly designed a binarization function that approximates the step function to make the segmentation The network can learn the threshold of text segmentation end-to-end during training. The automatic adjustment of the threshold not only improves accuracy, but also simplifies post-processing and improves the performance of text detection.\n",
206 | "\n",
207 | "\n",
209 | "
Figure 20: DB frame diagram\n",
210 | "\n",
211 | "FCENet [16] proposed to express the text enclosing curve with Fourier transform parameters. Since the Fourier coefficient representation can theoretically fit any closed curve, by designing a suitable model to predict an arbitrary shape text enclosing box based on Fourier transform In this way, the detection accuracy of highly curved text instances in natural scene text detection is improved.\n",
212 | "\n",
213 | "\n",
215 | "
Figure 21: FCENet frame diagram\n",
216 | "\n"
217 | ]
218 | },
219 | {
220 | "cell_type": "markdown",
221 | "metadata": {},
222 | "source": [
223 | "## 3 Summary\n",
224 | "\n",
225 | "This section introduces the development of the field of text detection in recent years, including text detection methods based on regression and segmentation, and respectively enumerates and introduces the method ideas of some classic papers. The next section takes the PaddleOCR open source library as an example to introduce in detail the algorithm principles and core code implementation of DBNet."
226 | ]
227 | },
228 | {
229 | "cell_type": "markdown",
230 | "metadata": {},
231 | "source": [
232 | "## Reference\n",
233 | "1. Liao, Minghui, et al. \"Textboxes: A fast text detector with a single deep neural network.\" Thirty-first AAAI conference on artificial intelligence. 2017.\n",
234 | "2. Liao, Minghui, Baoguang Shi, and Xiang Bai. \"Textboxes++: A single-shot oriented scene text detector.\" IEEE transactions on image processing 27.8 (2018): 3676-3690.\n",
235 | "3. Tian, Zhi, et al. \"Detecting text in natural image with connectionist text proposal network.\" European conference on computer vision. Springer, Cham, 2016.\n",
236 | "4. Zhou, Xinyu, et al. \"East: an efficient and accurate scene text detector.\" Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.\n",
237 | "5. Wang, Fangfang, et al. \"Geometry-aware scene text detection with instance transformation network.\" Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.\n",
238 | "6. Yuliang, Liu, et al. \"Detecting curve text in the wild: New dataset and new solution.\" arXiv preprint arXiv:1712.02170 (2017).\n",
239 | "7. Deng, Dan, et al. \"Pixellink: Detecting scene text via instance segmentation.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.\n",
240 | "8. Wu, Yue, and Prem Natarajan. \"Self-organized text detection with minimal post-processing via border learning.\" Proceedings of the IEEE International Conference on Computer Vision. 2017.\n",
241 | "9. Tian, Zhuotao, et al. \"Learning shape-aware embedding for scene text detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
242 | "10. Wang, Wenhai, et al. \"Shape robust text detection with progressive scale expansion network.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
243 | "11. Wang, Wenhai, et al. \"Efficient and accurate arbitrary-shaped text detection with pixel aggregation network.\" Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.\n",
244 | "12. Liao, Minghui, et al. \"Real-time scene text detection with differentiable binarization.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.\n",
245 | "13. Hochreiter, Sepp, and Jürgen Schmidhuber. \"Long short-term memory.\" Neural computation 9.8 (1997): 1735-1780.\n",
246 | "14. Dai, Pengwen, et al. \"Progressive Contour Regression for Arbitrary-Shape Scene Text Detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.\n",
247 | "15. He, Minghang, et al. \"MOST: A Multi-Oriented Scene Text Detector with Localization Refinement.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.\n",
248 | "16. Zhu, Yiqin, et al. \"Fourier contour embedding for arbitrary-shaped text detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.\n",
249 | "17. Tang, Jun, et al. \"Seglink++: Detecting dense and arbitrary-shaped scene text by instance-aware component grouping.\" Pattern recognition 96 (2019): 106954.\n",
250 | "18. Wang, Yuxin, et al. \"Contournet: Taking a further step toward accurate arbitrary-shaped scene text detection.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.\n",
251 | "19. Zhang, Chengquan, et al. \"Look more than once: An accurate detector for text of arbitrary shapes.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\n",
252 | "20. Xue C, Lu S, Zhang W. Msr: Multi-scale shape regression for scene text detection[J]. arXiv preprint arXiv:1901.02596, 2019. \n"
253 | ]
254 | }
255 | ],
256 | "metadata": {
257 | "kernelspec": {
258 | "display_name": "Python 3",
259 | "language": "python",
260 | "name": "py35-paddle1.2.0"
261 | },
262 | "language_info": {
263 | "codemirror_mode": {
264 | "name": "ipython",
265 | "version": 3
266 | },
267 | "file_extension": ".py",
268 | "mimetype": "text/x-python",
269 | "name": "python",
270 | "nbconvert_exporter": "python",
271 | "pygments_lexer": "ipython3",
272 | "version": "3.7.4"
273 | }
274 | },
275 | "nbformat": 4,
276 | "nbformat_minor": 4
277 | }
278 |
--------------------------------------------------------------------------------
/notebook_en/3.text_recognition/text_recognition_theory.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "\n",
8 | "# Text Recognition Algorithm Theory\n",
9 | "\n",
10 | "This chapter mainly introduces the theoretical knowledge of text recognition algorithms, including background introduction, algorithm classification and some classic paper ideas.\n",
11 | "\n",
12 | "Through the study of this chapter, you can master:\n",
13 | "\n",
14 | "1. The goal of text recognition\n",
15 | "\n",
16 | "2. Classification of text recognition algorithms\n",
17 | "\n",
18 | "3. Typical ideas of various algorithms\n",
19 | "\n",
20 | "\n",
21 | "## 1 Background Introduction\n",
22 | "\n",
23 | "Text recognition is a subtask of OCR (Optical Character Recognition), and its task is to recognize the text content of a fixed area. In the two-stage method of OCR, it is followed by text detection and converts image information into text information.\n",
24 | "\n",
25 | "Specifically, the model inputs a positioned text line, and the model predicts the text content and confidence level in the picture. The visualization results are shown in the following figure:\n",
26 | "\n",
27 | "\n",
28 | "\n",
29 | "\n",
30 | "
Figure 1: Visualization results of model predicttion\n",
31 | "\n",
32 | "There are many application scenarios for text recognition, including document recognition, road sign recognition, license plate recognition, industrial number recognition, etc. According to actual scenarios, text recognition tasks can be divided into two categories: **Regular text recognition** and **Irregular Text recognition**.\n",
33 | "\n",
34 | "* Regular text recognition: mainly refers to printed fonts, scanned text, etc., and the text is considered to be roughly in the horizontal position\n",
35 | "\n",
36 | "* Irregular text recognition: It often appears in natural scenes, and due to the huge differences in text curvature, direction, deformation, etc., the text is often not in the horizontal position, and there are problems such as bending, occlusion, and blurring.\n",
37 | "\n",
38 | "\n",
39 | "The figure below shows the data patterns of IC15 and IC13, which represent irregular text and regular text respectively. It can be seen that irregular text often has problems such as distortion, blurring, and large font differences. It is closer to the real scene and is also more challenging.\n",
40 | "\n",
41 | "Therefore, the current major algorithms are trying to obtain higher indicators on irregular data sets.\n",
42 | "\n",
43 | "\n",
44 | "
Figure 2: IC15 picture sample (irregular text)\n",
45 | "\n",
46 | "
Figure 3: IC13 picture sample (rule text)\n",
47 | "\n",
48 | "\n",
49 | "When comparing the capabilities of different recognition algorithms, they are often compared on these two types of public data sets. Comparing the effects on multiple dimensions, currently the more common English benchmark data sets are classified as follows:\n",
50 | "\n",
51 | "\n",
52 | "
Figure 4: Common English benchmark data sets\n",
53 | "\n",
54 | "## 2 Text Recognition Algorithm Classification\n",
55 | "\n",
56 | "In the traditional text recognition method, the task is divided into 3 steps, namely image preprocessing, character segmentation and character recognition. It is necessary to model a specific scene, and it will become invalid once the scene changes. In the face of complex text backgrounds and scene changes, methods based on deep learning have better performance.\n",
57 | "\n",
58 | "Most existing recognition algorithms can be represented by the following unified framework, and the algorithm flow is divided into 4 stages:\n",
59 | "\n",
60 | "\n",
61 | "\n",
62 | "\n",
63 | "We have sorted out the mainstream algorithm categories and main papers, refer to the following table:\n",
64 | "\n",
65 | " \n",
66 | "| Algorithm category | Main ideas | Main papers |\n",
67 | "| -------- | --------------- | -------- |\n",
68 | "| Traditional algorithm | Sliding window, character extraction, dynamic programming |-|\n",
69 | "| ctc | Based on ctc method, sequence is not aligned, faster recognition | CRNN, Rosetta |\n",
70 | "| Attention | Attention-based method, applied to unconventional text | RARE, DAN, PREN |\n",
71 | "| Transformer | Transformer-based method | SRN, NRTR, Master, ABINet |\n",
72 | "| Correction | The correction module learns the text boundary and corrects it to the horizontal direction | RARE, ASTER, SAR |\n",
73 | "| Segmentation | Based on the method of segmentation, extract the character position and then do classification | Text Scanner, Mask TextSpotter |\n",
74 | " \n",
75 | "\n",
76 | "\n",
77 | "\n",
78 | "### 2.1 Regular Text Recognition\n",
79 | "\n",
80 | "\n",
81 | "There are two mainstream algorithms for text recognition, namely the CTC (Conectionist Temporal Classification)-based algorithm and the Sequence2Sequence algorithm. The difference is mainly in the decoding stage.\n",
82 | "\n",
83 | "The CTC-based algorithm connects the encoded sequence to the CTC for decoding; the Sequence2Sequence-based method connects the sequence to the Recurrent Neural Network (RNN) module for cyclic decoding. Both methods have been verified to be effective and mainstream. Two major practices.\n",
84 | "\n",
85 | "\n",
86 | "
Figure 5: Left: CTC-based method, right: Sequece2Sequence-based method \n",
87 | "\n",
88 | "\n",
89 | "#### 2.1.1 Algorithm Based on CTC\n",
90 | "\n",
91 | "The most typical algorithm based on CTC is CRNN (Convolutional Recurrent Neural Network) [1], and its feature extraction part uses mainstream convolutional structures, commonly used ResNet, MobileNet, VGG, etc. Due to the particularity of text recognition tasks, there is a large amount of contextual information in the input data. The convolution kernel characteristics of convolutional neural networks make it more focused on local information and lack long-dependent modeling capabilities, so it is difficult to use only convolutional networks. Dig into the contextual connections between texts. In order to solve this problem, the CRNN text recognition algorithm introduces the bidirectional LSTM (Long Short-Term Memory) to enhance the context modeling. Experiments prove that the bidirectional LSTM module can effectively extract the context information in the picture. Finally, the output feature sequence is input to the CTC module, and the sequence result is directly decoded. This structure has been verified to be effective and widely used in text recognition tasks. Rosetta [2] is a recognition network proposed by FaceBook, which consists of a fully convolutional model and CTC. Gao Y [3] et al. used CNN convolution instead of LSTM, with fewer parameters, and the performance improvement accuracy was the same.\n",
92 | "\n",
93 | "\n",
94 | "Figure 6: CRNN structure diagram \n",
95 | "\n",
96 | "\n",
97 | "#### 2.1.2 Sequence2Sequence algorithm\n",
98 | "\n",
99 | "In the Sequence2Sequence algorithm, the Encoder encodes all input sequences into a unified semantic vector, which is then decoded by the Decoder. In the decoding process of the decoder, the output of the previous moment is continuously used as the input of the next moment, and the decoding is performed in a loop until the stop character is output. The general encoder is an RNN. For each input word, the encoder outputs a vector and hidden state, and uses the hidden state for the next input word to get the semantic vector in a loop; the decoder is another RNN, which receives the encoder Output a vector and output a series of words to create a transformation. Inspired by Sequence2Sequence in the field of translation, Shi [4] proposed an attention-based codec framework to recognize text. In this way, rnn can learn character-level language models hidden in strings from training data.\n",
100 | "\n",
101 | "\n",
102 | "Figure 7: Sequence2Sequence structure diagram \n",
103 | "\n",
104 | "The above two algorithms have very good effects on regular text, but due to the limitations of network design, this type of method is difficult to solve the task of irregular text recognition of bending and rotation. In order to solve such problems, some algorithm researchers have proposed a series of improved algorithms on the basis of the above two types of algorithms.\n",
105 | "\n",
106 | "### 2.2 Irregular Text Recognition\n",
107 | "\n",
108 | "* Irregular text recognition algorithms can be divided into 4 categories: correction-based methods; Attention-based methods; segmentation-based methods; and Transformer-based methods.\n",
109 | "\n",
110 | "#### 2.2.1 Correction-based Method\n",
111 | "\n",
112 | "The correction-based method uses some visual transformation modules to convert irregular text into regular text as much as possible, and then uses conventional methods for recognition.\n",
113 | "\n",
114 | "The RARE [4] model first proposed a correction scheme for irregular text. The entire network is divided into two main parts: a spatial transformation network STN (Spatial Transformer Network) and a recognition network based on Sequence2Squence. Among them, STN is the correction module. Irregular text images enter STN and are transformed into a horizontal image through TPS (Thin-Plate-Spline). This transformation can correct curved and transmissive text to a certain extent, and send it to sequence recognition after correction. Network for decoding.\n",
115 | "\n",
116 | "\n",
117 | "Figure 8: RARE structure diagram \n",
118 | "\n",
119 | "The RARE paper pointed out that this method has greater advantages in irregular text data sets, especially comparing the two data sets CUTE80 and SVTP, which are more than 5 percentage points higher than CRNN, which proves the effectiveness of the correction module. Based on this [6] also combines a text recognition system with a spatial transformation network (STN) and an attention-based sequence recognition network.\n",
120 | "\n",
121 | "Correction-based methods have better migration. In addition to Attention-based methods such as RARE, STAR-Net [5] applies correction modules to CTC-based algorithms, which is also a good improvement compared to traditional CRNN.\n",
122 | "\n",
123 | "#### 2.2.2 Attention-based Method\n",
124 | "\n",
125 | "The Attention-based method mainly focuses on the correlation between the parts of the sequence. This method was first proposed in the field of machine translation. It is believed that the result of the current word in the process of text translation is mainly affected by certain words, so it needs to be The decisive word has greater weight. The same is true in the field of text recognition. When decoding the encoded sequence, each step selects the appropriate context to generate the next state, which is conducive to obtaining more accurate results.\n",
126 | "\n",
127 | "R^2AM [7] first introduced Attention into the field of text recognition. The model first extracts the encoded image features from the input image through a recursive convolutional layer, and then uses the implicitly learned character-level language statistics to decode the output through a recurrent neural network character. In the decoding process, the Attention mechanism is introduced to realize soft feature selection to make better use of image features. This selective processing method is more in line with human intuition.\n",
128 | "\n",
129 | "\n",
130 | "Figure 9: R^2AM structure drawing \n",
131 | "\n",
132 | "A large number of algorithms will be explored and updated in the field of Attention in the future. For example, SAR[8] extends 1D attention to 2D attention. The RARE mentioned in the correction module is also a method based on Attention. Experiments prove that the Attention-based method has a good accuracy improvement compared with the CTC method.\n",
133 | "\n",
134 | "\n",
135 | "Figure 10: Attention diagram\n",
136 | "\n",
137 | "\n",
138 | "#### 2.2.3 Method Based on Segmentation\n",
139 | "\n",
140 | "The method based on segmentation is to treat each character of the text line as an independent individual, and it is easier to recognize the segmented individual characters than to recognize the entire text line after correction. It attempts to locate the position of each character in the input text image, and applies a character classifier to obtain these recognition results, simplifying the complex global problem into a local problem solving, and it has a relatively good effect in the irregular text scene. However, this method requires character-level labeling, and there is a certain degree of difficulty in data acquisition. Lyu [9] et al. proposed an instance word segmentation model for word recognition, which uses a method based on FCN (Fully Convolutional Network) in its recognition part. [10] Considering the problem of text recognition from a two-dimensional perspective, a character attention FCN is designed to solve the problem of text recognition. When the text is bent or severely distorted, this method has better positioning results for both regular and irregular text.\n",
141 | "\n",
142 | "\n",
143 | "Figure 11: Mask TextSpotter structure diagram \n",
144 | "\n",
145 | "\n",
146 | "\n",
147 | "#### 2.2.4 Transformer-based Method\n",
148 | "\n",
149 | "With the rapid development of Transformer, both classification and detection fields have verified the effectiveness of Transformer in visual tasks. As mentioned in the regular text recognition part, CNN has limitations in long-dependency modeling. The Transformer structure just solves this problem. It can focus on global information in the feature extractor and can replace additional context modeling modules (LSTM ).\n",
150 | "\n",
151 | "Part of the text recognition algorithm uses Transformer's Encoder structure and convolution to extract sequence features. The Encoder is composed of multiple blocks stacked by MultiHeadAttentionLayer and Positionwise Feedforward Layer. The self-attention in MulitHeadAttention uses matrix multiplication to simulate the timing calculation of RNN, breaking the barrier of long-term dependence on timing in RNN. There are also some algorithms that use Transformer's Decoder module to decode, which can obtain stronger semantic information than traditional RNNs, and parallel computing has higher efficiency.\n",
152 | "\n",
153 | "The SRN[11] algorithm connects the Encoder module of Transformer to ResNet50 to enhance the 2D visual features. A parallel attention module is proposed, which uses the reading order as a query, making the calculation independent of time, and finally outputs the aligned visual features of all time steps in parallel. In addition, SRN also uses Transformer's Eecoder as a semantic module to integrate the visual information and semantic information of the picture, which has greater benefits in irregular text such as occlusion and blur.\n",
154 | "\n",
155 | "NRTR [12] uses a complete Transformer structure to encode and decode the input picture, and only uses a few simple convolutional layers for high-level feature extraction, and verifies the effectiveness of the Transformer structure in text recognition.\n",
156 | "\n",
157 | "\n",
158 | "Figure 12: NRTR structure drawing \n",
159 | "\n",
160 | "SRACN [13] uses Transformer's decoder to replace LSTM, once again verifying the efficiency and accuracy advantages of parallel training.\n",
161 | "\n",
162 | "## 3 Summary\n",
163 | "\n",
164 | "This section mainly introduces the theoretical knowledge and mainstream algorithms related to text recognition, including CTC-based methods, Sequence2Sequence-based methods, and segmentation-based methods. The ideas and contributions of classic papers are listed respectively. The next section will explain the practical course based on the CRNN algorithm, from networking to optimization to complete the entire training process,\n",
165 | "\n",
166 | "## 4 Reference\n",
167 | "\n",
168 | "\n",
169 | "[1]Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\n",
170 | "\n",
171 | "[2]Fedor Borisyuk, Albert Gordo, and Viswanath Sivakumar. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 71–79. ACM, 2018.\n",
172 | "\n",
173 | "[3]Gao, Y., Chen, Y., Wang, J., & Lu, H. (2017). Reading scene text with attention convolutional sequence modeling. arXiv preprint arXiv:1709.04303.\n",
174 | "\n",
175 | "[4]Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\n",
176 | "\n",
177 | "[5] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\n",
178 | "\n",
179 | "[6]Baoguang Shi, Mingkun Yang, XingGang Wang, Pengyuan Lyu, Xiang Bai, and Cong Yao. Aster: An attentional scene text recognizer with flexible rectification. IEEE transactions on pattern analysis and machine intelligence, 31(11):855–868, 2018.\n",
180 | "\n",
181 | "[7] Lee C Y , Osindero S . Recursive Recurrent Nets with Attention Modeling for OCR in the Wild[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.\n",
182 | "\n",
183 | "[8]Li, H., Wang, P., Shen, C., & Zhang, G. (2019, July). Show, attend and read: A simple and strong baseline for irregular text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8610-8617).\n",
184 | "\n",
185 | "[9]P. Lyu, C. Yao, W. Wu, S. Yan, and X. Bai. Multi-oriented scene text detection via corner localization and region segmentation. In Proc. CVPR, pages 7553–7563, 2018.\n",
186 | "\n",
187 | "[10] Liao, M., Zhang, J., Wan, Z., Xie, F., Liang, J., Lyu, P., ... & Bai, X. (2019, July). Scene text recognition from two-dimensional perspective. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 8714-8721).\n",
188 | "\n",
189 | "[11] Yu, D., Li, X., Zhang, C., Liu, T., Han, J., Liu, J., & Ding, E. (2020). Towards accurate scene text recognition with semantic reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12113-12122).\n",
190 | "\n",
191 | "[12] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\n",
192 | "\n",
193 | "[13]Yang, L., Wang, P., Li, H., Li, Z., & Zhang, Y. (2020). A holistic representation guided attention network for scene text recognition. Neurocomputing, 414, 67-75.\n",
194 | "\n",
195 | "[14]Wang, T., Zhu, Y., Jin, L., Luo, C., Chen, X., Wu, Y., ... & Cai, M. (2020, April). Decoupled attention network for text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 07, pp. 12216-12224).\n",
196 | "\n",
197 | "[15] Wang, Y., Xie, H., Fang, S., Wang, J., Zhu, S., & Zhang, Y. (2021). From two to one: A new scene text recognizer with visual language modeling network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 14194-14203).\n",
198 | "\n",
199 | "[16] Fang, S., Xie, H., Wang, Y., Mao, Z., & Zhang, Y. (2021). Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7098-7107).\n",
200 | "\n",
201 | "[17] Yan, R., Peng, L., Xiao, S., & Yao, G. (2021). Primitive Representation Learning for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 284-293)."
202 | ]
203 | }
204 | ],
205 | "metadata": {
206 | "kernelspec": {
207 | "display_name": "Python 3",
208 | "language": "python",
209 | "name": "py35-paddle1.2.0"
210 | },
211 | "language_info": {
212 | "codemirror_mode": {
213 | "name": "ipython",
214 | "version": 3
215 | },
216 | "file_extension": ".py",
217 | "mimetype": "text/x-python",
218 | "name": "python",
219 | "nbconvert_exporter": "python",
220 | "pygments_lexer": "ipython3",
221 | "version": "3.7.4"
222 | }
223 | },
224 | "nbformat": 4,
225 | "nbformat_minor": 4
226 | }
227 |
--------------------------------------------------------------------------------
/notebook_en/how_to_use_these_notebooks.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "tags": []
7 | },
8 | "source": [
9 | "# 1. Course Prerequisites\n",
10 | "\n",
11 | "The OCR model involved in this course is based on deep learning, so its related basic knowledge, environment configuration, project engineering and other materials will be introduced in this section, especially for readers who are not familiar with deep learning. content.\n",
12 | "\n",
13 | "### 1.1 Preliminary Knowledge\n",
14 | "\n",
15 | "The \"learning\" of deep learning has been developed from the content of neurons, perceptrons, and multilayer neural networks in machine learning. Therefore, understanding the basic machine learning algorithms is of great help to the understanding and application of deep learning. The \"deepness\" of deep learning is embodied in a series of vector-based mathematical operations such as convolution and pooling used in the process of processing a large amount of information. If you lack the theoretical foundation of the two, you can learn from teacher Li Hongyi's [Linear Algebra](https://aistudio.baidu.com/aistudio/course/introduce/2063) and [Machine Learning](https://aistudio.baidu.com/aistudio/course/introduce/1978) courses.\n",
16 | "\n",
17 | "For the understanding of deep learning itself, you can refer to the zero-based course of Bai Ran, an outstanding architect of Baidu: [Baidu architects take you hands-on with zero-based practice deep learning](https://aistudio.baidu.com/aistudio/course/introduce/1297), which covers the development history of deep learning and introduces the complete components of deep learning through a classic case. It is a set of practice-oriented deep learning courses.\n",
18 | "\n",
19 | "For the practice of theoretical knowledge, [Python basic knowledge](https://aistudio.baidu.com/aistudio/course/introduce/1224) is essential. At the same time, in order to quickly reproduce the deep learning model, the deep learning framework used in this course For: Flying PaddlePaddle. If you have used other frameworks, you can quickly learn how to use flying paddles through [Quick Start Document](https://www.paddlepaddle.org.cn/documentation/docs/zh/practices/quick_start/hello_paddle.html).\n",
20 | "\n",
21 | "### 1.2 Basic Environment Preparation\n",
22 | "\n",
23 | "If you want to run the code of this course in a local environment and have not built a Python environment before, you can follow the [zero-base operating environment preparation](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.3/doc/doc_ch/environment.md), install Anaconda or docker environment according to your operating system.\n",
24 | "\n",
25 | "If you don't have local resources, you can run the code through the AI Studio training platform. Each item in it is presented in a notebook, which is convenient for developers to learn. If you are not familiar with the related operations of Notebook, you can refer to [AI Studio Project Description](https://ai.baidu.com/ai-doc/AISTUDIO/0k3e2tfzm).\n",
26 | "\n",
27 | "### 1.3 Get and Run the Code\n",
28 | "\n",
29 | "This course relies on the formation of PaddleOCR's code repository. First, clone the complete project of PaddleOCR:\n",
30 | "\n",
31 | "```bash\n",
32 | "# [recommend]\n",
33 | "git clone https://github.com/PaddlePaddle/PaddleOCR\n",
34 | "\n",
35 | "# If you cannot pull successfully due to network problems, you can also choose to use the hosting on Code Cloud:\n",
36 | "git clone https://gitee.com/paddlepaddle/PaddleOCR\n",
37 | "```\n",
38 | "\n",
39 | "> Note: The code cloud hosted code may not be able to synchronize the update of this github project in real time, there is a delay of 3~5 days, please use the recommended method first.\n",
40 | ">\n",
41 | "> If you are not familiar with git operations, you can download the compressed package directly from the `Code` on the homepage of PaddleOCR\n",
42 | "\n",
43 | "Then install third-party libraries:\n",
44 | "\n",
45 | "```bash\n",
46 | "cd PaddleOCR\n",
47 | "pip3 install -r requirements.txt\n",
48 | "```\n",
49 | "\n",
50 | "\n",
51 | "\n",
52 | "### 1.4 Access to Information\n",
53 | "\n",
54 | "[PaddleOCR Usage Document](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.3/README.md) describes in detail how to use PaddleOCR to complete model application, training and deployment. The document is rich in content, most of the user’s questions are described in the document or FAQ, especially in [FAQ](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.3/doc/doc_en/FAQ_en.md), in accordance with the application process of deep learning, has precipitated the user's common questions, it is recommended that you read it carefully.\n",
55 | "\n",
56 | "### 1.5 Ask for Help\n",
57 | "\n",
58 | "If you encounter BUG, ease of use or documentation related issues while using PaddleOCR, you can contact the official via [Github issue](https://github.com/PaddlePaddle/PaddleOCR/issues), please follow the issue template Provide as much information as possible so that official personnel can quickly locate the problem. At the same time, the WeChat group is the daily communication position for the majority of PaddleOCR users, and it is more suitable for asking some consulting questions. In addition to the PaddleOCR team members, there will also be enthusiastic developers answering your questions."
59 | ]
60 | }
61 | ],
62 | "metadata": {
63 | "kernelspec": {
64 | "display_name": "Python 3",
65 | "language": "python",
66 | "name": "py35-paddle1.2.0"
67 | },
68 | "language_info": {
69 | "codemirror_mode": {
70 | "name": "ipython",
71 | "version": 3
72 | },
73 | "file_extension": ".py",
74 | "mimetype": "text/x-python",
75 | "name": "python",
76 | "nbconvert_exporter": "python",
77 | "pygments_lexer": "ipython3",
78 | "version": "3.7.4"
79 | }
80 | },
81 | "nbformat": 4,
82 | "nbformat_minor": 4
83 | }
84 |
--------------------------------------------------------------------------------