 11 |
11 |
11 |
11 |  26 |
26 |  26 |
26 |  27 |
27 |
5 |  6 |
6 |
 |
18 |  |
19 |  |
20 |  |
21 |
| Generic segmentation | 24 |Human segmentation | 25 |RS building segmentation | 26 |Medical segmentation | 27 |
 |
30 |  |
31 |  |
32 | |
| Industrial quality inspection | 35 |Generic video segmentation | 36 |3D medical segmentation | 37 ||
 16 |
16 |  24 |
24 | 


6 |  7 |
7 |
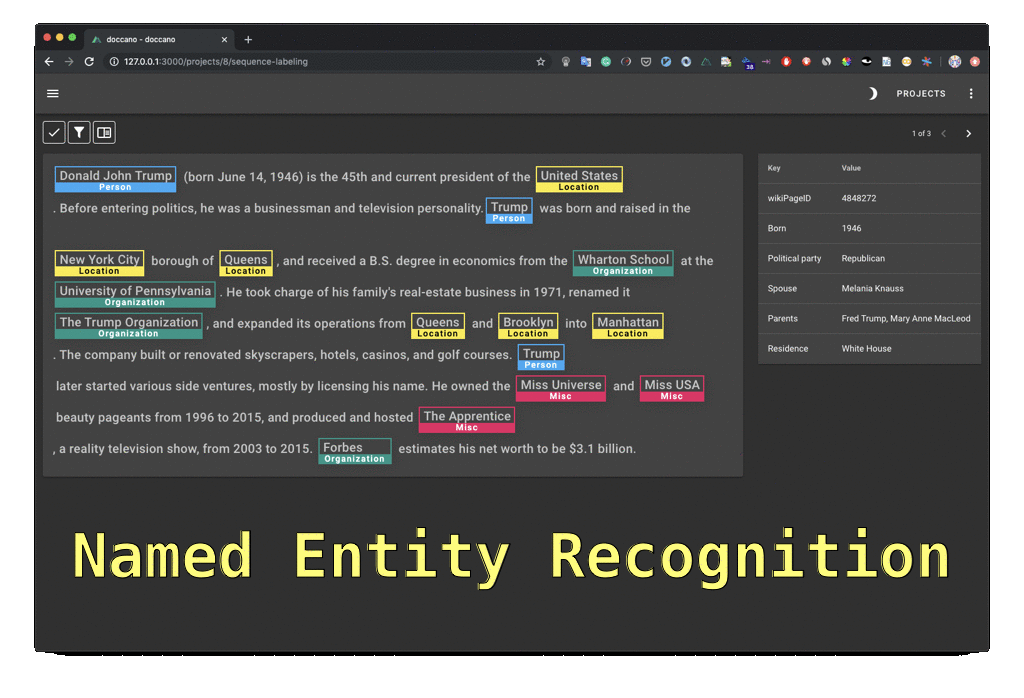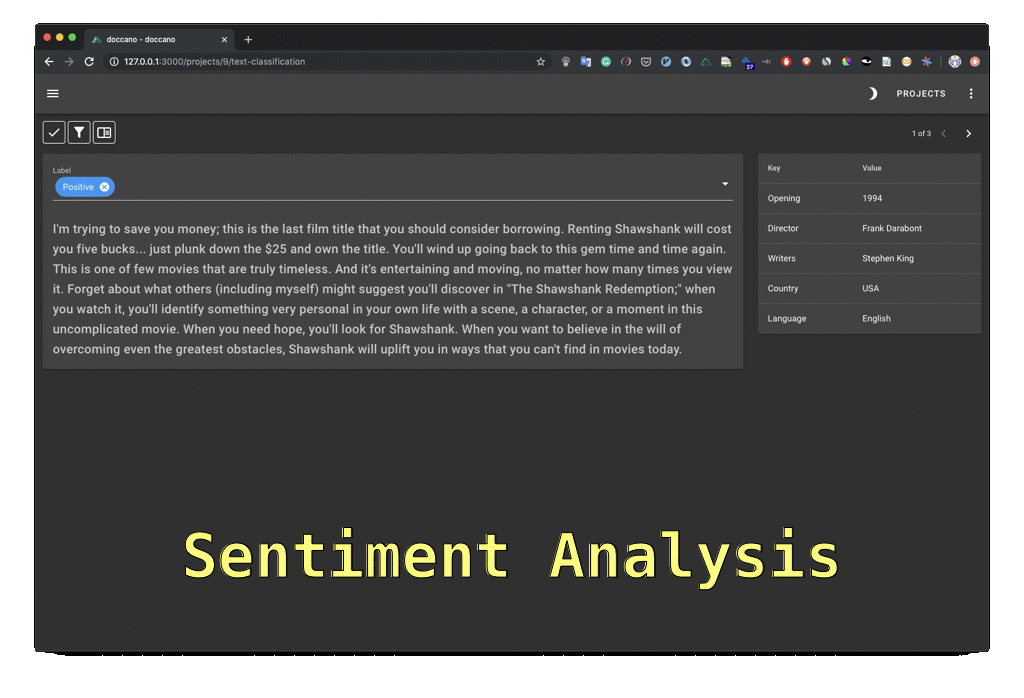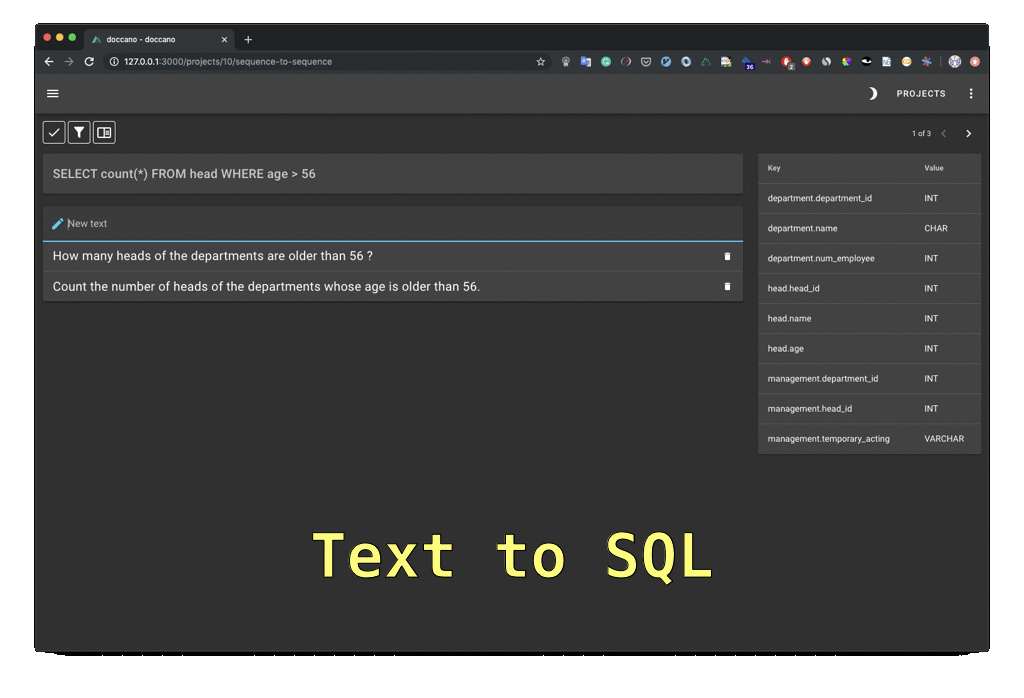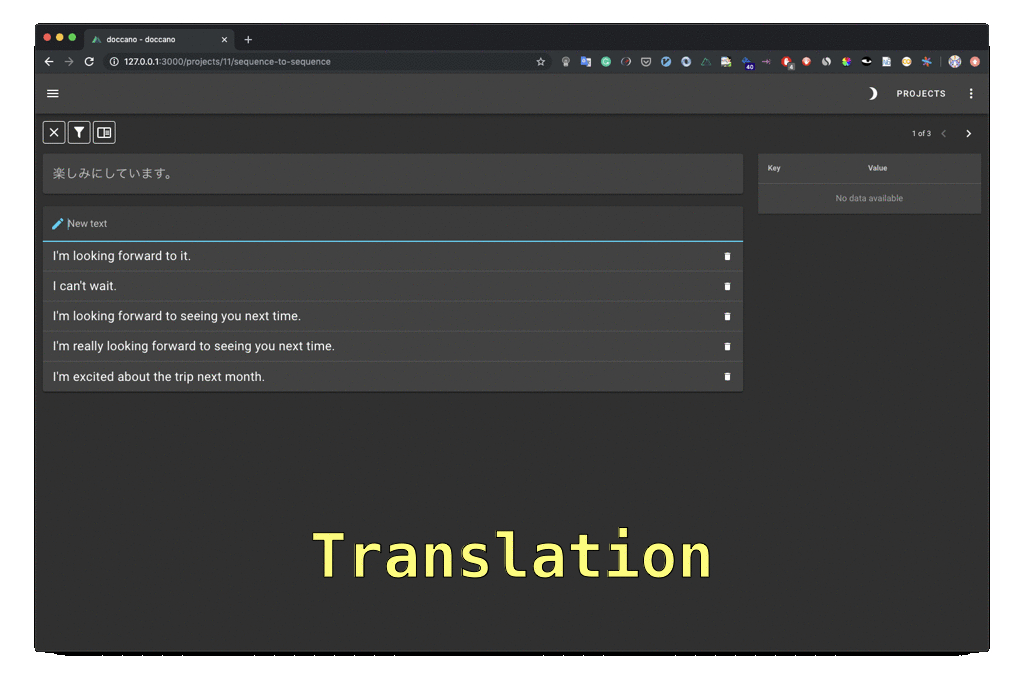

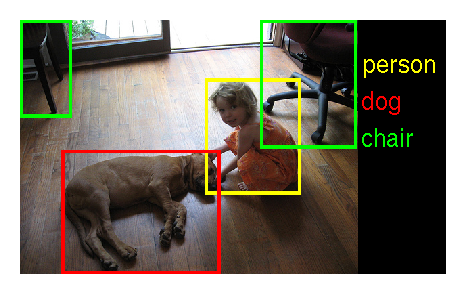 29 |
30 | 数据集 | 训练集大小 | 测试集大小 | 类别数 | 备注|
31 | :------:|:---------------:|:---------------------:|:-----------:|:-----------:
32 | [ImageNet1k](http://www.image-net.org/challenges/LSVRC/2012/)|1.2M| 50k | 1000 |
33 |
34 |
35 | ### 2 Flowers102
36 | 数据简介:一个 102 个类别的数据集,由 102 个花卉类别组成。被选为英国常见的花。每个类包含 40 到 258 张图像。可以在此类别统计页面上找到类别的详细信息和每个类别的图像数量。
37 |
38 |
29 |
30 | 数据集 | 训练集大小 | 测试集大小 | 类别数 | 备注|
31 | :------:|:---------------:|:---------------------:|:-----------:|:-----------:
32 | [ImageNet1k](http://www.image-net.org/challenges/LSVRC/2012/)|1.2M| 50k | 1000 |
33 |
34 |
35 | ### 2 Flowers102
36 | 数据简介:一个 102 个类别的数据集,由 102 个花卉类别组成。被选为英国常见的花。每个类包含 40 到 258 张图像。可以在此类别统计页面上找到类别的详细信息和每个类别的图像数量。
37 |
38 |  39 |
40 | 数据集 | 训练集大小 | 测试集大小 | 类别数 | 备注|
41 | :------:|:---------------:|:---------------------:|:-----------:|:-----------:
42 | [flowers102](https://www.robots.ox.ac.uk/~vgg/data/flowers/102/)|1k | 6k | 102 |
43 |
44 | 将下载的数据解压后,可以看到以下目录
45 |
46 | ```shell
47 | jpg/
48 | setid.mat
49 | imagelabels.mat
50 | ```
51 |
52 |
53 |
54 | ### 3 CIFAR10 / CIFAR100
55 |
56 | CIFAR-10 数据集由 10 个类的 60000 个彩色图像组成,图像分辨率为 32x32,每个类有 6000 个图像,其中训练集 5000 张,验证集 1000 张,10 个不同的类代表飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、轮船和卡车。CIFAR-100 数据集是 CIFAR-10 的扩展,由 100 个类的 60000 个彩色图像组成,图像分辨率为 32x32,每个类有 600 个图像,其中训练集 500 张,验证集 100 张。
57 |
39 |
40 | 数据集 | 训练集大小 | 测试集大小 | 类别数 | 备注|
41 | :------:|:---------------:|:---------------------:|:-----------:|:-----------:
42 | [flowers102](https://www.robots.ox.ac.uk/~vgg/data/flowers/102/)|1k | 6k | 102 |
43 |
44 | 将下载的数据解压后,可以看到以下目录
45 |
46 | ```shell
47 | jpg/
48 | setid.mat
49 | imagelabels.mat
50 | ```
51 |
52 |
53 |
54 | ### 3 CIFAR10 / CIFAR100
55 |
56 | CIFAR-10 数据集由 10 个类的 60000 个彩色图像组成,图像分辨率为 32x32,每个类有 6000 个图像,其中训练集 5000 张,验证集 1000 张,10 个不同的类代表飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、轮船和卡车。CIFAR-100 数据集是 CIFAR-10 的扩展,由 100 个类的 60000 个彩色图像组成,图像分辨率为 32x32,每个类有 600 个图像,其中训练集 500 张,验证集 100 张。
57 |  58 |
59 | 数据集地址:http://www.cs.toronto.edu/~kriz/cifar.html
60 |
61 |
62 | ### 4 MNIST
63 |
64 | 数据简介:MMNIST 是一个非常有名的手写体数字识别数据集,在很多资料中,这个数据集都会被用作深度学习的入门样例。其包含 60000 张图片数据,50000 张作为训练集,10000 张作为验证集,每张图片的大小为 28 * 28。
65 |
58 |
59 | 数据集地址:http://www.cs.toronto.edu/~kriz/cifar.html
60 |
61 |
62 | ### 4 MNIST
63 |
64 | 数据简介:MMNIST 是一个非常有名的手写体数字识别数据集,在很多资料中,这个数据集都会被用作深度学习的入门样例。其包含 60000 张图片数据,50000 张作为训练集,10000 张作为验证集,每张图片的大小为 28 * 28。
65 | 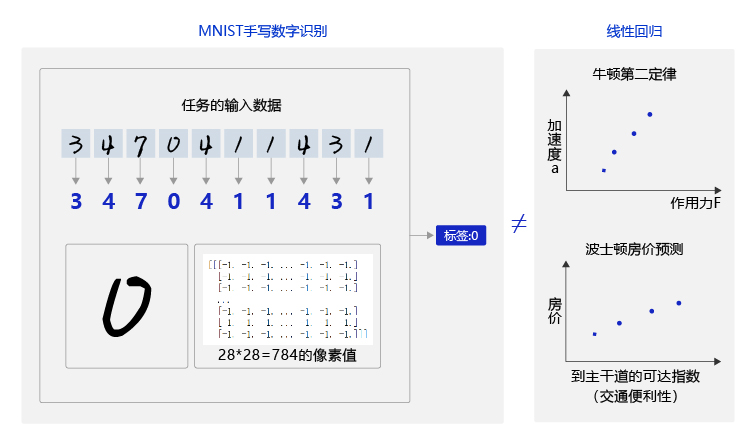 66 | 数据集地址:http://yann.lecun.com/exdb/mnist/
67 |
68 |
69 | ### 5 NUS-WIDE
70 |
71 | NUS-WIDE 是一个多分类数据集。该数据集包含 269648 张图片, 81 个类别,每张图片被标记为该 81 个类别中的某一类或某几类。
72 |
73 | 数据集地址:https://lms.comp.nus.edu.sg/wp-content/uploads/2019/research/nuswide/NUS-WIDE.html
74 |
--------------------------------------------------------------------------------
/docs/zh_CN/datasets/datasets/Detection.md:
--------------------------------------------------------------------------------
1 | ## 通用检测数据集
2 | 这里整理了常用检测数据集,持续更新中,欢迎各位小伙伴贡献数据集~
3 | - [COCO](#COCO)
4 | - [VOC](#VOC)
5 | - [SCUT_FIR行人检测数据集](#SCUT_FIR行人检测数据集)
6 | - [JHU-CROWD++](#JHU-CROWD++)
7 | - [CIHP人体解析数据集](#CIHP人体解析数据集)
8 | - [AHU-Crowd人群数据集](#AHU-Crowd人群数据集)
9 | - [AudioVisual人群计数](#AudioVisual人群计数)
10 | - [UCF-CC-50](#UCF-CC-50)
11 | - [北京BRT数据集](#北京BRT数据集)
12 |
13 |
14 | ## 1、COCO
15 | - **数据来源**:https://cocodataset.org/#home
16 | - **数据简介**:COCO数据是COCO 比赛使用的数据。同样的,COCO比赛数也包含多个比赛任务,其标注文件中包含多个任务的标注内容。 COCO数据集指的是COCO比赛使用的数据。用户自定义的COCO数据,json文件中的一些字段,请根据实际情况选择是否标注或是否使用默认值。
17 |
66 | 数据集地址:http://yann.lecun.com/exdb/mnist/
67 |
68 |
69 | ### 5 NUS-WIDE
70 |
71 | NUS-WIDE 是一个多分类数据集。该数据集包含 269648 张图片, 81 个类别,每张图片被标记为该 81 个类别中的某一类或某几类。
72 |
73 | 数据集地址:https://lms.comp.nus.edu.sg/wp-content/uploads/2019/research/nuswide/NUS-WIDE.html
74 |
--------------------------------------------------------------------------------
/docs/zh_CN/datasets/datasets/Detection.md:
--------------------------------------------------------------------------------
1 | ## 通用检测数据集
2 | 这里整理了常用检测数据集,持续更新中,欢迎各位小伙伴贡献数据集~
3 | - [COCO](#COCO)
4 | - [VOC](#VOC)
5 | - [SCUT_FIR行人检测数据集](#SCUT_FIR行人检测数据集)
6 | - [JHU-CROWD++](#JHU-CROWD++)
7 | - [CIHP人体解析数据集](#CIHP人体解析数据集)
8 | - [AHU-Crowd人群数据集](#AHU-Crowd人群数据集)
9 | - [AudioVisual人群计数](#AudioVisual人群计数)
10 | - [UCF-CC-50](#UCF-CC-50)
11 | - [北京BRT数据集](#北京BRT数据集)
12 |
13 |
14 | ## 1、COCO
15 | - **数据来源**:https://cocodataset.org/#home
16 | - **数据简介**:COCO数据是COCO 比赛使用的数据。同样的,COCO比赛数也包含多个比赛任务,其标注文件中包含多个任务的标注内容。 COCO数据集指的是COCO比赛使用的数据。用户自定义的COCO数据,json文件中的一些字段,请根据实际情况选择是否标注或是否使用默认值。
17 | 
















