├── scripts
├── train_fashion.sh
├── eval_fashion.sh
├── eval_market.sh
├── test_market.sh
├── test_fashion.sh
└── train_market.sh
├── requirements.txt
├── metrics
├── README.md
├── inception.py
└── metrics.py
├── data
├── data_loader.py
├── base_data_loader.py
├── custom_dataset_data_loader.py
├── __init__.py
├── generate_fashion_datasets.py
├── image_folder.py
├── base_dataset.py
├── market_dataset.py
└── fashion_dataset.py
├── Poster.md
├── models
├── models.py
├── __init__.py
├── PTM.py
├── base_model.py
├── DPTN_model.py
├── networks.py
├── external_function.py
├── base_function.py
└── ui_model.py
├── test.py
├── util
├── image_pool.py
├── html.py
├── pose_utils.py
├── visualizer.py
└── util.py
├── options
├── test_options.py
├── train_options.py
└── base_options.py
├── train.py
├── README.md
└── LICENSE.md
/scripts/train_fashion.sh:
--------------------------------------------------------------------------------
1 | python train.py --name=DPTN_fashion --model=DPTN --dataset_mode=fashion --dataroot=./dataset/fashion --batchSize 32 --gpu_id=0
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==1.7.1
2 | torchvision==0.8.2
3 | imageio
4 | natsort
5 | scipy
6 | scikit-image
7 | pandas
8 | dominate
9 | opencv-python
10 | visdom
11 |
--------------------------------------------------------------------------------
/scripts/eval_fashion.sh:
--------------------------------------------------------------------------------
1 | python -m metrics.metrics --gt_path=./dataset/fashion/test --distorated_path=./results/DPTN_fashion --fid_real_path=./dataset/fashion/train --name=./fashion
--------------------------------------------------------------------------------
/scripts/eval_market.sh:
--------------------------------------------------------------------------------
1 | python -m metrics.metrics --gt_path=./dataset/market/test --distorated_path=./results/DPTN_market --fid_real_path=./dataset/market/train --name=./market --market
--------------------------------------------------------------------------------
/scripts/test_market.sh:
--------------------------------------------------------------------------------
1 | python test.py --name=DPTN_market --model=DPTN --dataset_mode=market --dataroot=./dataset/market --which_epoch latest --results_dir=./results/DPTN_market --batchSize 1 --gpu_id=0
--------------------------------------------------------------------------------
/scripts/test_fashion.sh:
--------------------------------------------------------------------------------
1 | python test.py --name=DPTN_fashion --model=DPTN --dataset_mode=fashion --dataroot=./dataset/fashion --which_epoch latest --results_dir ./results/DPTN_fashion --batchSize 1 --gpu_id=0
--------------------------------------------------------------------------------
/metrics/README.md:
--------------------------------------------------------------------------------
1 | Please clone the official repository **[PerceptualSimilarity](https://github.com/richzhang/PerceptualSimilarity/tree/future)** of the LPIPS score, and put the folder PerceptualSimilarity here.
2 |
--------------------------------------------------------------------------------
/scripts/train_market.sh:
--------------------------------------------------------------------------------
1 | python train.py --name=DPTN_market --model=DPTN --dataset_mode=market --dataroot=./dataset/market --dis_layer=3 --lambda_g=5 --lambda_rec 2 --t_s_ratio=0.8 --save_latest_freq=10400 --batchSize 32 --gpu_id=0
--------------------------------------------------------------------------------
/data/data_loader.py:
--------------------------------------------------------------------------------
1 |
2 | def CreateDataLoader(opt):
3 | from data.custom_dataset_data_loader import CustomDatasetDataLoader
4 | data_loader = CustomDatasetDataLoader()
5 | print(data_loader.name())
6 | data_loader.initialize(opt)
7 | return data_loader
8 |
--------------------------------------------------------------------------------
/data/base_data_loader.py:
--------------------------------------------------------------------------------
1 |
2 | class BaseDataLoader():
3 | def __init__(self):
4 | pass
5 |
6 | def initialize(self, opt):
7 | self.opt = opt
8 | pass
9 |
10 | def load_data():
11 | return None
12 |
13 |
14 |
15 |
--------------------------------------------------------------------------------
/Poster.md:
--------------------------------------------------------------------------------
1 |  2 | Our poster template can be download from [Google Drive](https://docs.google.com/presentation/d/1i02V0JZCw2mRZF99szitaOEkfVNeKR1q/edit?usp=sharing&ouid=111594135598063931892&rtpof=true&sd=true).
3 |
--------------------------------------------------------------------------------
/models/models.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import models
3 |
4 | def create_model(opt):
5 | '''
6 | if opt.model == 'pix2pixHD':
7 | from .pix2pixHD_model import Pix2PixHDModel, InferenceModel
8 | if opt.isTrain:
9 | model = Pix2PixHDModel()
10 | else:
11 | model = InferenceModel()
12 | elif opt.model == 'basic':
13 | from .basic_model import BasicModel
14 | model = BasicModel(opt)
15 | else:
16 | from .ui_model import UIModel
17 | model = UIModel()
18 | '''
19 | model = models.find_model_using_name(opt.model)(opt)
20 | if opt.verbose:
21 | print("model [%s] was created" % (model.name()))
22 | return model
23 |
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | from data.data_loader import CreateDataLoader
2 | from options.test_options import TestOptions
3 | from models.models import create_model
4 | import numpy as np
5 | import torch
6 |
7 | if __name__=='__main__':
8 | # get testing options
9 | opt = TestOptions().parse()
10 | # creat a dataset
11 | data_loader = CreateDataLoader(opt)
12 | dataset = data_loader.load_data()
13 |
14 |
15 | print(len(dataset))
16 |
17 | dataset_size = len(dataset) * opt.batchSize
18 | print('testing images = %d' % dataset_size)
19 | # create a model
20 | model = create_model(opt)
21 |
22 | with torch.no_grad():
23 | for i, data in enumerate(dataset):
24 | model.set_input(data)
25 | model.test()
26 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
1 | """This package contains modules related to function, network architectures, and models"""
2 |
3 | import importlib
4 | from .base_model import BaseModel
5 |
6 |
7 | def find_model_using_name(model_name):
8 | """Import the module "model/[model_name]_model.py"."""
9 | model_file_name = "models." + model_name + "_model"
10 | modellib = importlib.import_module(model_file_name)
11 | model = None
12 | for name, cls in modellib.__dict__.items():
13 | if name.lower() == (model_name+'model').lower() and issubclass(cls, BaseModel):
14 | model = cls
15 |
16 | if model is None:
17 | print("In %s.py, there should be a subclass of BaseModel with class name that matches %s in lowercase." % (model_file_name, model_name))
18 | exit(0)
19 |
20 | return model
21 |
22 |
23 | def get_option_setter(model_name):
24 | """Return the static method of the model class."""
25 | model = find_model_using_name(model_name)
26 | return model.modify_options
27 |
--------------------------------------------------------------------------------
/util/image_pool.py:
--------------------------------------------------------------------------------
1 | import random
2 | import torch
3 | from torch.autograd import Variable
4 | class ImagePool():
5 | def __init__(self, pool_size):
6 | self.pool_size = pool_size
7 | if self.pool_size > 0:
8 | self.num_imgs = 0
9 | self.images = []
10 |
11 | def query(self, images):
12 | if self.pool_size == 0:
13 | return images
14 | return_images = []
15 | for image in images.data:
16 | image = torch.unsqueeze(image, 0)
17 | if self.num_imgs < self.pool_size:
18 | self.num_imgs = self.num_imgs + 1
19 | self.images.append(image)
20 | return_images.append(image)
21 | else:
22 | p = random.uniform(0, 1)
23 | if p > 0.5:
24 | random_id = random.randint(0, self.pool_size-1)
25 | tmp = self.images[random_id].clone()
26 | self.images[random_id] = image
27 | return_images.append(tmp)
28 | else:
29 | return_images.append(image)
30 | return_images = Variable(torch.cat(return_images, 0))
31 | return return_images
32 |
--------------------------------------------------------------------------------
/data/custom_dataset_data_loader.py:
--------------------------------------------------------------------------------
1 | import torch.utils.data
2 | from data.base_data_loader import BaseDataLoader
3 | import data
4 |
5 | def CreateDataset(opt):
6 | '''
7 | dataset = None
8 | if opt.dataset_mode == 'fashion':
9 | from data.fashion_dataset import FashionDataset
10 | dataset = FashionDataset()
11 | else:
12 | from data.aligned_dataset import AlignedDataset
13 | dataset = AlignedDataset()
14 | '''
15 | dataset = data.find_dataset_using_name(opt.dataset_mode)()
16 | print("dataset [%s] was created" % (dataset.name()))
17 | dataset.initialize(opt)
18 | return dataset
19 |
20 | class CustomDatasetDataLoader(BaseDataLoader):
21 | def name(self):
22 | return 'CustomDatasetDataLoader'
23 |
24 | def initialize(self, opt):
25 | BaseDataLoader.initialize(self, opt)
26 | self.dataset = CreateDataset(opt)
27 | self.dataloader = torch.utils.data.DataLoader(
28 | self.dataset,
29 | batch_size=opt.batchSize,
30 | shuffle=(not opt.serial_batches) and opt.isTrain,
31 | num_workers=int(opt.nThreads))
32 |
33 | def load_data(self):
34 | return self.dataloader
35 |
36 | def __len__(self):
37 | return min(len(self.dataset), self.opt.max_dataset_size)
38 |
--------------------------------------------------------------------------------
/options/test_options.py:
--------------------------------------------------------------------------------
1 | from .base_options import BaseOptions
2 |
3 | class TestOptions(BaseOptions):
4 | def initialize(self):
5 | BaseOptions.initialize(self)
6 | self.parser.add_argument('--ntest', type=int, default=float("inf"), help='# of test examples.')
7 | self.parser.add_argument('--results_dir', type=str, default='./results/', help='saves results here.')
8 | self.parser.add_argument('--aspect_ratio', type=float, default=1.0, help='aspect ratio of result images')
9 | self.parser.add_argument('--phase', type=str, default='test', help='train, val, test, etc')
10 | self.parser.add_argument('--which_epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
11 | self.parser.add_argument('--how_many', type=int, default=50, help='how many test images to run')
12 | self.parser.add_argument('--cluster_path', type=str, default='features_clustered_010.npy', help='the path for clustered results of encoded features')
13 | self.parser.add_argument('--use_encoded_image', action='store_true', help='if specified, encode the real image to get the feature map')
14 | self.parser.add_argument("--export_onnx", type=str, help="export ONNX model to a given file")
15 | self.parser.add_argument("--engine", type=str, help="run serialized TRT engine")
16 | self.parser.add_argument("--onnx", type=str, help="run ONNX model via TRT")
17 | self.isTrain = False
18 |
--------------------------------------------------------------------------------
/data/__init__.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | import torch.utils.data
3 | from data.base_dataset import BaseDataset
4 |
5 |
6 | def find_dataset_using_name(dataset_name):
7 | # Given the option --dataset [datasetname],
8 | # the file "datasets/datasetname_dataset.py"
9 | # will be imported.
10 | dataset_filename = "data." + dataset_name + "_dataset"
11 | datasetlib = importlib.import_module(dataset_filename)
12 |
13 | # In the file, the class called DatasetNameDataset() will
14 | # be instantiated. It has to be a subclass of BaseDataset,
15 | # and it is case-insensitive.
16 | dataset = None
17 | target_dataset_name = dataset_name.replace('_', '') + 'dataset'
18 | for name, cls in datasetlib.__dict__.items():
19 | if name.lower() == target_dataset_name.lower() \
20 | and issubclass(cls, BaseDataset):
21 | dataset = cls
22 |
23 | if dataset is None:
24 | raise ValueError("In %s.py, there should be a subclass of BaseDataset "
25 | "with class name that matches %s in lowercase." %
26 | (dataset_filename, target_dataset_name))
27 |
28 | return dataset
29 |
30 |
31 | def get_option_setter(dataset_name):
32 | dataset_class = find_dataset_using_name(dataset_name)
33 | return dataset_class.modify_commandline_options
34 |
35 | '''
36 | def create_dataloader(opt):
37 | dataset = find_dataset_using_name(opt.dataset_mode)
38 | instance = dataset()
39 | instance.initialize(opt)
40 | print("dataset [%s] of size %d was created" %
41 | (type(instance).__name__, len(instance)))
42 | dataloader = torch.utils.data.DataLoader(
43 | instance,
44 | batch_size=opt.batchSize,
45 | shuffle=not opt.serial_batches,
46 | num_workers=int(opt.nThreads),
47 | drop_last=opt.isTrain
48 | )
49 | return dataloader
50 | '''
--------------------------------------------------------------------------------
/data/generate_fashion_datasets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import shutil
3 | from PIL import Image
4 |
5 | IMG_EXTENSIONS = [
6 | '.jpg', '.JPG', '.jpeg', '.JPEG',
7 | '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP',
8 | ]
9 |
10 | def is_image_file(filename):
11 | return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
12 |
13 | def make_dataset(dir):
14 | images = []
15 | assert os.path.isdir(dir), '%s is not a valid directory' % dir
16 | new_root = './fashion'
17 | if not os.path.exists(new_root):
18 | os.mkdir(new_root)
19 |
20 | train_root = './fashion/train'
21 | if not os.path.exists(train_root):
22 | os.mkdir(train_root)
23 |
24 | test_root = './fashion/test'
25 | if not os.path.exists(test_root):
26 | os.mkdir(test_root)
27 |
28 | train_images = []
29 | train_f = open('./fashion/train.lst', 'r')
30 | for lines in train_f:
31 | lines = lines.strip()
32 | if lines.endswith('.jpg'):
33 | train_images.append(lines)
34 |
35 | test_images = []
36 | test_f = open('./fashion/test.lst', 'r')
37 | for lines in test_f:
38 | lines = lines.strip()
39 | if lines.endswith('.jpg'):
40 | test_images.append(lines)
41 |
42 | print(train_images, test_images)
43 |
44 |
45 | for root, _, fnames in sorted(os.walk(dir)):
46 | for fname in fnames:
47 | if is_image_file(fname):
48 | path = os.path.join(root, fname)
49 | path_names = path.split('/')
50 | # path_names[2] = path_names[2].replace('_', '')
51 | path_names[3] = path_names[3].replace('_', '')
52 | path_names[4] = path_names[4].split('_')[0] + "_" + "".join(path_names[4].split('_')[1:])
53 | path_names = "".join(path_names)
54 | # new_path = os.path.join(root, path_names)
55 | img = Image.open(path)
56 | imgcrop = img.crop((40, 0, 216, 256))
57 | if new_path in train_images:
58 | imgcrop.save(os.path.join(train_root, path_names))
59 | elif new_path in test_images:
60 | imgcrop.save(os.path.join(test_root, path_names))
61 |
62 | make_dataset('./fashion')
--------------------------------------------------------------------------------
/util/html.py:
--------------------------------------------------------------------------------
1 | import dominate
2 | from dominate.tags import *
3 | import os
4 |
5 |
6 | class HTML:
7 | def __init__(self, web_dir, title, refresh=0):
8 | self.title = title
9 | self.web_dir = web_dir
10 | self.img_dir = os.path.join(self.web_dir, 'images')
11 | if not os.path.exists(self.web_dir):
12 | os.makedirs(self.web_dir)
13 | if not os.path.exists(self.img_dir):
14 | os.makedirs(self.img_dir)
15 |
16 | self.doc = dominate.document(title=title)
17 | if refresh > 0:
18 | with self.doc.head:
19 | meta(http_equiv="refresh", content=str(refresh))
20 |
21 | def get_image_dir(self):
22 | return self.img_dir
23 |
24 | def add_header(self, str):
25 | with self.doc:
26 | h3(str)
27 |
28 | def add_table(self, border=1):
29 | self.t = table(border=border, style="table-layout: fixed;")
30 | self.doc.add(self.t)
31 |
32 | def add_images(self, ims, txts, links, width=512):
33 | self.add_table()
34 | with self.t:
35 | with tr():
36 | for im, txt, link in zip(ims, txts, links):
37 | with td(style="word-wrap: break-word;", halign="center", valign="top"):
38 | with p():
39 | with a(href=os.path.join('images', link)):
40 | img(style="width:%dpx" % (width), src=os.path.join('images', im))
41 | br()
42 | p(txt)
43 |
44 | def save(self):
45 | html_file = '%s/index.html' % self.web_dir
46 | f = open(html_file, 'wt')
47 | f.write(self.doc.render())
48 | f.close()
49 |
50 |
51 | if __name__ == '__main__':
52 | html = HTML('web/', 'test_html')
53 | html.add_header('hello world')
54 |
55 | ims = []
56 | txts = []
57 | links = []
58 | for n in range(4):
59 | ims.append('image_%d.jpg' % n)
60 | txts.append('text_%d' % n)
61 | links.append('image_%d.jpg' % n)
62 | html.add_images(ims, txts, links)
63 | html.save()
64 |
--------------------------------------------------------------------------------
/data/image_folder.py:
--------------------------------------------------------------------------------
1 | ###############################################################################
2 | # Code from
3 | # https://github.com/pytorch/vision/blob/master/torchvision/datasets/folder.py
4 | # Modified the original code so that it also loads images from the current
5 | # directory as well as the subdirectories
6 | ###############################################################################
7 | import torch.utils.data as data
8 | from PIL import Image
9 | import os
10 |
11 | IMG_EXTENSIONS = [
12 | '.jpg', '.JPG', '.jpeg', '.JPEG',
13 | '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP', '.tiff'
14 | ]
15 |
16 |
17 | def is_image_file(filename):
18 | return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
19 |
20 |
21 | def make_dataset(dir):
22 | images = []
23 | assert os.path.isdir(dir), '%s is not a valid directory' % dir
24 |
25 | for root, _, fnames in sorted(os.walk(dir)):
26 | for fname in fnames:
27 | if is_image_file(fname):
28 | path = os.path.join(root, fname)
29 | images.append(path)
30 |
31 | return images
32 |
33 |
34 | def default_loader(path):
35 | return Image.open(path).convert('RGB')
36 |
37 |
38 | class ImageFolder(data.Dataset):
39 |
40 | def __init__(self, root, transform=None, return_paths=False,
41 | loader=default_loader):
42 | imgs = make_dataset(root)
43 | if len(imgs) == 0:
44 | raise(RuntimeError("Found 0 images in: " + root + "\n"
45 | "Supported image extensions are: " +
46 | ",".join(IMG_EXTENSIONS)))
47 |
48 | self.root = root
49 | self.imgs = imgs
50 | self.transform = transform
51 | self.return_paths = return_paths
52 | self.loader = loader
53 |
54 | def __getitem__(self, index):
55 | path = self.imgs[index]
56 | img = self.loader(path)
57 | if self.transform is not None:
58 | img = self.transform(img)
59 | if self.return_paths:
60 | return img, path
61 | else:
62 | return img
63 |
64 | def __len__(self):
65 | return len(self.imgs)
66 |
--------------------------------------------------------------------------------
/data/base_dataset.py:
--------------------------------------------------------------------------------
1 | import torch.utils.data as data
2 | from PIL import Image
3 | import torchvision.transforms as transforms
4 | import numpy as np
5 | import random
6 |
7 |
8 | class BaseDataset(data.Dataset):
9 | def __init__(self):
10 | super(BaseDataset, self).__init__()
11 |
12 | def name(self):
13 | return 'BaseDataset'
14 |
15 | def initialize(self, opt):
16 | pass
17 |
18 | def get_params(opt, size):
19 | w, h = size
20 | new_h = h
21 | new_w = w
22 | if opt.resize_or_crop == 'resize_and_crop':
23 | new_h = new_w = opt.loadSize
24 | elif opt.resize_or_crop == 'scale_width_and_crop':
25 | new_w = opt.loadSize
26 | new_h = opt.loadSize * h // w
27 |
28 | x = random.randint(0, np.maximum(0, new_w - opt.fineSize))
29 | y = random.randint(0, np.maximum(0, new_h - opt.fineSize))
30 |
31 | flip = random.random() > 0.5
32 | return {'crop_pos': (x, y), 'flip': flip}
33 |
34 | def get_transform(opt, params, method=Image.BICUBIC, normalize=True):
35 | transform_list = []
36 | if 'resize' in opt.resize_or_crop:
37 | osize = [opt.loadSize, opt.loadSize]
38 | transform_list.append(transforms.Scale(osize, method))
39 | elif 'scale_width' in opt.resize_or_crop:
40 | transform_list.append(transforms.Lambda(lambda img: __scale_width(img, opt.loadSize, method)))
41 |
42 | if 'crop' in opt.resize_or_crop:
43 | transform_list.append(transforms.Lambda(lambda img: __crop(img, params['crop_pos'], opt.fineSize)))
44 |
45 | if opt.resize_or_crop == 'none':
46 | base = float(2 ** opt.n_downsample_global)
47 | if opt.netG == 'local':
48 | base *= (2 ** opt.n_local_enhancers)
49 | transform_list.append(transforms.Lambda(lambda img: __make_power_2(img, base, method)))
50 |
51 | if opt.isTrain and not opt.no_flip:
52 | transform_list.append(transforms.Lambda(lambda img: __flip(img, params['flip'])))
53 |
54 | transform_list += [transforms.ToTensor()]
55 |
56 | if normalize:
57 | transform_list += [transforms.Normalize((0.5, 0.5, 0.5),
58 | (0.5, 0.5, 0.5))]
59 | return transforms.Compose(transform_list)
60 |
61 |
62 | def normalize():
63 | return transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
64 |
65 |
66 | def __make_power_2(img, base, method=Image.BICUBIC):
67 | ow, oh = img.size
68 | h = int(round(oh / base) * base)
69 | w = int(round(ow / base) * base)
70 | if (h == oh) and (w == ow):
71 | return img
72 | return img.resize((w, h), method)
73 |
74 |
75 | def __scale_width(img, target_width, method=Image.BICUBIC):
76 | ow, oh = img.size
77 | if (ow == target_width):
78 | return img
79 | w = target_width
80 | h = int(target_width * oh / ow)
81 | return img.resize((w, h), method)
82 |
83 |
84 | def __crop(img, pos, size):
85 | ow, oh = img.size
86 | x1, y1 = pos
87 | tw = th = size
88 | if (ow > tw or oh > th):
89 | return img.crop((x1, y1, x1 + tw, y1 + th))
90 | return img
91 |
92 |
93 | def __flip(img, flip):
94 | if flip:
95 | return img.transpose(Image.FLIP_LEFT_RIGHT)
96 | return img
97 |
--------------------------------------------------------------------------------
/options/train_options.py:
--------------------------------------------------------------------------------
1 | from .base_options import BaseOptions
2 |
3 | class TrainOptions(BaseOptions):
4 | def initialize(self):
5 | BaseOptions.initialize(self)
6 | # for displays
7 | self.parser.add_argument('--display_freq', type=int, default=200, help='frequency of showing training results on screen')
8 | self.parser.add_argument('--print_freq', type=int, default=200, help='frequency of showing training results on console')
9 | self.parser.add_argument('--save_latest_freq', type=int, default=1000, help='frequency of saving the latest results')
10 | self.parser.add_argument('--save_epoch_freq', type=int, default=1, help='frequency of saving checkpoints at the end of epochs')
11 | self.parser.add_argument('--no_html', action='store_true', help='do not save intermediate training results to [opt.checkpoints_dir]/[opt.name]/web/')
12 | self.parser.add_argument('--debug', action='store_true', help='only do one epoch and displays at each iteration')
13 |
14 | # for training
15 | self.parser.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')
16 | self.parser.add_argument('--load_pretrain', type=str, default='', help='load the pretrained model from the specified location')
17 | self.parser.add_argument('--which_epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
18 | self.parser.add_argument('--phase', type=str, default='train', help='train, val, test, etc')
19 | self.parser.add_argument('--niter', type=int, default=100, help='# of iter at starting learning rate')
20 | self.parser.add_argument('--niter_decay', type=int, default=100, help='# of iter to linearly decay learning rate to zero')
21 | self.parser.add_argument('--iter_start', type=int, default=0, help='# of iter to linearly decay learning rate to zero')
22 | self.parser.add_argument('--beta1', type=float, default=0.5, help='momentum term of adam')
23 | self.parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate for adam')
24 | self.parser.add_argument('--lr_policy', type=str, default='lambda', help='learning rate policy[lambda|step|plateau]')
25 | self.parser.add_argument('--gan_mode', type=str, default='lsgan', choices=['wgan-gp', 'hinge', 'lsgan'])
26 | # for discriminators
27 | self.parser.add_argument('--num_D', type=int, default=1, help='number of discriminators to use')
28 | self.parser.add_argument('--n_layers_D', type=int, default=3, help='only used if which_model_netD==n_layers')
29 | self.parser.add_argument('--ndf', type=int, default=64, help='# of discrim filters in first conv layer')
30 | self.parser.add_argument('--lambda_feat', type=float, default=10.0, help='weight for feature matching loss')
31 | self.parser.add_argument('--no_ganFeat_loss', action='store_true', help='if specified, do *not* use discriminator feature matching loss')
32 | self.parser.add_argument('--no_vgg_loss', action='store_true', help='if specified, do *not* use VGG feature matching loss')
33 | self.parser.add_argument('--pool_size', type=int, default=0, help='the size of image buffer that stores previously generated images')
34 |
35 | self.isTrain = True
36 |
--------------------------------------------------------------------------------
/data/market_dataset.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | from data.base_dataset import BaseDataset, get_params, get_transform, normalize
3 | from data.image_folder import make_dataset
4 | import torchvision.transforms.functional as F
5 | import torchvision.transforms as transforms
6 | from PIL import Image
7 | from util import pose_utils
8 | import pandas as pd
9 | import numpy as np
10 | import torch
11 |
12 | class MarketDataset(BaseDataset):
13 | @staticmethod
14 | def modify_commandline_options(parser, is_train):
15 | if is_train:
16 | parser.set_defaults(load_size=128)
17 | else:
18 | parser.set_defaults(load_size=128)
19 | parser.set_defaults(old_size=(128, 64))
20 | parser.set_defaults(structure_nc=18)
21 | parser.set_defaults(image_nc=3)
22 | return parser
23 |
24 | def initialize(self, opt):
25 | self.opt = opt
26 | self.root = opt.dataroot
27 | self.phase = opt.phase
28 |
29 | # prepare for image (image_dir), image_pair (name_pairs) and bone annotation (annotation_file)
30 | self.image_dir = os.path.join(self.root, self.phase)
31 | self.bone_file = os.path.join(self.root, 'market-annotation-%s.csv' % self.phase)
32 | pairLst = os.path.join(self.root, 'market-pairs-%s.csv' % self.phase)
33 | self.name_pairs = self.init_categories(pairLst)
34 | self.annotation_file = pd.read_csv(self.bone_file, sep=':')
35 | self.annotation_file = self.annotation_file.set_index('name')
36 |
37 | # load image size
38 | if isinstance(opt.loadSize, int):
39 | self.load_size = (128, 64)
40 | else:
41 | self.load_size = opt.loadSize
42 |
43 | # prepare for transformation
44 | transform_list=[]
45 | transform_list.append(transforms.ToTensor())
46 | transform_list.append(transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5)))
47 | self.trans = transforms.Compose(transform_list)
48 |
49 | def __getitem__(self, index):
50 | # prepare for source image Xs and target image Xt
51 | Xs_name, Xt_name = self.name_pairs[index]
52 | Xs_path = os.path.join(self.image_dir, Xs_name)
53 | Xt_path = os.path.join(self.image_dir, Xt_name)
54 |
55 | Xs = Image.open(Xs_path).convert('RGB')
56 | Xt = Image.open(Xt_path).convert('RGB')
57 |
58 | Xs = F.resize(Xs, self.load_size)
59 | Xt = F.resize(Xt, self.load_size)
60 |
61 | Ps = self.obtain_bone(Xs_name)
62 | Xs = self.trans(Xs)
63 | Pt = self.obtain_bone(Xt_name)
64 | Xt = self.trans(Xt)
65 |
66 | return {'Xs': Xs, 'Ps': Ps, 'Xt': Xt, 'Pt': Pt,
67 | 'Xs_path': Xs_name, 'Xt_path': Xt_name}
68 |
69 | def init_categories(self, pairLst):
70 | pairs_file_train = pd.read_csv(pairLst)
71 | size = len(pairs_file_train)
72 | pairs = []
73 | print('Loading data pairs ...')
74 | for i in range(size):
75 | pair = [pairs_file_train.iloc[i]['from'], pairs_file_train.iloc[i]['to']]
76 | pairs.append(pair)
77 |
78 | print('Loading data pairs finished ...')
79 | return pairs
80 |
81 | def getRandomAffineParam(self):
82 | if self.opt.angle is not False:
83 | angle = np.random.uniform(low=self.opt.angle[0], high=self.opt.angle[1])
84 | else:
85 | angle = 0
86 | if self.opt.scale is not False:
87 | scale = np.random.uniform(low=self.opt.scale[0], high=self.opt.scale[1])
88 | else:
89 | scale = 1
90 | if self.opt.shift is not False:
91 | shift_x = np.random.uniform(low=self.opt.shift[0], high=self.opt.shift[1])
92 | shift_y = np.random.uniform(low=self.opt.shift[0], high=self.opt.shift[1])
93 | else:
94 | shift_x = 0
95 | shift_y = 0
96 | return angle, (shift_x, shift_y), scale
97 |
98 | def obtain_bone(self, name):
99 | string = self.annotation_file.loc[name]
100 | array = pose_utils.load_pose_cords_from_strings(string['keypoints_y'], string['keypoints_x'])
101 | pose = pose_utils.cords_to_map(array, self.load_size, self.opt.old_size)
102 | pose = np.transpose(pose,(2, 0, 1))
103 | pose = torch.Tensor(pose)
104 | return pose
105 |
106 | def obtain_bone_affine(self, name, affine_matrix):
107 | string = self.annotation_file.loc[name]
108 | array = pose_utils.load_pose_cords_from_strings(string['keypoints_y'], string['keypoints_x'])
109 | pose = pose_utils.cords_to_map(array, self.load_size, self.opt.old_size, affine_matrix)
110 | pose = np.transpose(pose,(2, 0, 1))
111 | pose = torch.Tensor(pose)
112 | return pose
113 |
114 | def __len__(self):
115 | return len(self.name_pairs) // self.opt.batchSize * self.opt.batchSize
116 |
117 | def name(self):
118 | return 'MarketDataset'
--------------------------------------------------------------------------------
/data/fashion_dataset.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | from data.base_dataset import BaseDataset, get_params, get_transform, normalize
3 | from data.image_folder import make_dataset
4 | import torchvision.transforms.functional as F
5 | import torchvision.transforms as transforms
6 | from PIL import Image
7 | from util import pose_utils
8 | import pandas as pd
9 | import numpy as np
10 | import torch
11 |
12 | class FashionDataset(BaseDataset):
13 | @staticmethod
14 | def modify_commandline_options(parser, is_train):
15 | if is_train:
16 | parser.set_defaults(load_size=256)
17 | else:
18 | parser.set_defaults(load_size=256)
19 | parser.set_defaults(old_size=(256, 176))
20 | parser.set_defaults(structure_nc=18)
21 | parser.set_defaults(image_nc=3)
22 | return parser
23 |
24 | def initialize(self, opt):
25 | self.opt = opt
26 | self.root = opt.dataroot
27 | self.phase = opt.phase
28 |
29 | # prepare for image (image_dir), image_pair (name_pairs) and bone annotation (annotation_file)
30 | self.image_dir = os.path.join(self.root, self.phase)
31 | self.bone_file = os.path.join(self.root, 'fasion-resize-annotation-%s.csv' % self.phase)
32 | pairLst = os.path.join(self.root, 'fasion-resize-pairs-%s.csv' % self.phase)
33 | self.name_pairs = self.init_categories(pairLst)
34 | self.annotation_file = pd.read_csv(self.bone_file, sep=':')
35 | self.annotation_file = self.annotation_file.set_index('name')
36 |
37 | # load image size
38 | if isinstance(opt.loadSize, int):
39 | self.load_size = (opt.loadSize, opt.loadSize)
40 | else:
41 | self.load_size = opt.loadSize
42 |
43 | # prepare for transformation
44 | transform_list=[]
45 | transform_list.append(transforms.ToTensor())
46 | transform_list.append(transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5)))
47 | self.trans = transforms.Compose(transform_list)
48 |
49 | def __getitem__(self, index):
50 | # prepare for source image Xs and target image Xt
51 | Xs_name, Xt_name = self.name_pairs[index]
52 | Xs_path = os.path.join(self.image_dir, Xs_name)
53 | Xt_path = os.path.join(self.image_dir, Xt_name)
54 |
55 | Xs = Image.open(Xs_path).convert('RGB')
56 | Xt = Image.open(Xt_path).convert('RGB')
57 |
58 | Xs = F.resize(Xs, self.load_size)
59 | Xt = F.resize(Xt, self.load_size)
60 |
61 | Ps = self.obtain_bone(Xs_name)
62 | Xs = self.trans(Xs)
63 | Pt = self.obtain_bone(Xt_name)
64 | Xt = self.trans(Xt)
65 |
66 | return {'Xs': Xs, 'Ps': Ps, 'Xt': Xt, 'Pt': Pt,
67 | 'Xs_path': Xs_name, 'Xt_path': Xt_name}
68 |
69 | def init_categories(self, pairLst):
70 | pairs_file_train = pd.read_csv(pairLst)
71 | size = len(pairs_file_train)
72 | pairs = []
73 | print('Loading data pairs ...')
74 | for i in range(size):
75 | pair = [pairs_file_train.iloc[i]['from'], pairs_file_train.iloc[i]['to']]
76 | pairs.append(pair)
77 |
78 | print('Loading data pairs finished ...')
79 | return pairs
80 |
81 | def getRandomAffineParam(self):
82 | if self.opt.angle is not False:
83 | angle = np.random.uniform(low=self.opt.angle[0], high=self.opt.angle[1])
84 | else:
85 | angle = 0
86 | if self.opt.scale is not False:
87 | scale = np.random.uniform(low=self.opt.scale[0], high=self.opt.scale[1])
88 | else:
89 | scale = 1
90 | if self.opt.shift is not False:
91 | shift_x = np.random.uniform(low=self.opt.shift[0], high=self.opt.shift[1])
92 | shift_y = np.random.uniform(low=self.opt.shift[0], high=self.opt.shift[1])
93 | else:
94 | shift_x = 0
95 | shift_y = 0
96 | return angle, (shift_x, shift_y), scale
97 |
98 | def obtain_bone(self, name):
99 | string = self.annotation_file.loc[name]
100 | array = pose_utils.load_pose_cords_from_strings(string['keypoints_y'], string['keypoints_x'])
101 | pose = pose_utils.cords_to_map(array, self.load_size, self.opt.old_size)
102 | pose = np.transpose(pose,(2, 0, 1))
103 | pose = torch.Tensor(pose)
104 | return pose
105 |
106 | def obtain_bone_affine(self, name, affine_matrix):
107 | string = self.annotation_file.loc[name]
108 | array = pose_utils.load_pose_cords_from_strings(string['keypoints_y'], string['keypoints_x'])
109 | pose = pose_utils.cords_to_map(array, self.load_size, self.opt.old_size, affine_matrix)
110 | pose = np.transpose(pose,(2, 0, 1))
111 | pose = torch.Tensor(pose)
112 | return pose
113 |
114 | def __len__(self):
115 | return len(self.name_pairs) // self.opt.batchSize * self.opt.batchSize
116 |
117 | def name(self):
118 | return 'FashionDataset'
--------------------------------------------------------------------------------
/metrics/inception.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 | from torchvision import models
4 |
5 |
6 | class InceptionV3(nn.Module):
7 | """Pretrained InceptionV3 network returning feature maps"""
8 |
9 | # Index of default block of inception to return,
10 | # corresponds to output of final average pooling
11 | DEFAULT_BLOCK_INDEX = 3
12 |
13 | # Maps feature dimensionality to their output blocks indices
14 | BLOCK_INDEX_BY_DIM = {
15 | 64: 0, # First max pooling features
16 | 192: 1, # Second max pooling featurs
17 | 768: 2, # Pre-aux classifier features
18 | 2048: 3 # Final average pooling features
19 | }
20 |
21 | def __init__(self,
22 | output_blocks=[DEFAULT_BLOCK_INDEX],
23 | resize_input=True,
24 | normalize_input=True,
25 | requires_grad=False):
26 | """Build pretrained InceptionV3
27 | Parameters
28 | ----------
29 | output_blocks : list of int
30 | Indices of blocks to return features of. Possible values are:
31 | - 0: corresponds to output of first max pooling
32 | - 1: corresponds to output of second max pooling
33 | - 2: corresponds to output which is fed to aux classifier
34 | - 3: corresponds to output of final average pooling
35 | resize_input : bool
36 | If true, bilinearly resizes input to width and height 299 before
37 | feeding input to model. As the network without fully connected
38 | layers is fully convolutional, it should be able to handle inputs
39 | of arbitrary size, so resizing might not be strictly needed
40 | normalize_input : bool
41 | If true, normalizes the input to the statistics the pretrained
42 | Inception network expects
43 | requires_grad : bool
44 | If true, parameters of the model require gradient. Possibly useful
45 | for finetuning the network
46 | """
47 | super(InceptionV3, self).__init__()
48 |
49 | self.resize_input = resize_input
50 | self.normalize_input = normalize_input
51 | self.output_blocks = sorted(output_blocks)
52 | self.last_needed_block = max(output_blocks)
53 |
54 | assert self.last_needed_block <= 3, \
55 | 'Last possible output block index is 3'
56 |
57 | self.blocks = nn.ModuleList()
58 |
59 | inception = models.inception_v3(pretrained=True)
60 |
61 | # Block 0: input to maxpool1
62 | block0 = [
63 | inception.Conv2d_1a_3x3,
64 | inception.Conv2d_2a_3x3,
65 | inception.Conv2d_2b_3x3,
66 | nn.MaxPool2d(kernel_size=3, stride=2)
67 | ]
68 | self.blocks.append(nn.Sequential(*block0))
69 |
70 | # Block 1: maxpool1 to maxpool2
71 | if self.last_needed_block >= 1:
72 | block1 = [
73 | inception.Conv2d_3b_1x1,
74 | inception.Conv2d_4a_3x3,
75 | nn.MaxPool2d(kernel_size=3, stride=2)
76 | ]
77 | self.blocks.append(nn.Sequential(*block1))
78 |
79 | # Block 2: maxpool2 to aux classifier
80 | if self.last_needed_block >= 2:
81 | block2 = [
82 | inception.Mixed_5b,
83 | inception.Mixed_5c,
84 | inception.Mixed_5d,
85 | inception.Mixed_6a,
86 | inception.Mixed_6b,
87 | inception.Mixed_6c,
88 | inception.Mixed_6d,
89 | inception.Mixed_6e,
90 | ]
91 | self.blocks.append(nn.Sequential(*block2))
92 |
93 | # Block 3: aux classifier to final avgpool
94 | if self.last_needed_block >= 3:
95 | block3 = [
96 | inception.Mixed_7a,
97 | inception.Mixed_7b,
98 | inception.Mixed_7c,
99 | nn.AdaptiveAvgPool2d(output_size=(1, 1))
100 | ]
101 | self.blocks.append(nn.Sequential(*block3))
102 |
103 | for param in self.parameters():
104 | param.requires_grad = requires_grad
105 |
106 | def forward(self, inp):
107 | """Get Inception feature maps
108 | Parameters
109 | ----------
110 | inp : torch.autograd.Variable
111 | Input tensor of shape Bx3xHxW. Values are expected to be in
112 | range (0, 1)
113 | Returns
114 | -------
115 | List of torch.autograd.Variable, corresponding to the selected output
116 | block, sorted ascending by index
117 | """
118 | outp = []
119 | x = inp
120 |
121 | if self.resize_input:
122 | x = F.upsample(x, size=(299, 299), mode='bilinear')
123 |
124 | if self.normalize_input:
125 | x = x.clone()
126 | x[:, 0] = x[:, 0] * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
127 | x[:, 1] = x[:, 1] * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
128 | x[:, 2] = x[:, 2] * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
129 |
130 | for idx, block in enumerate(self.blocks):
131 | x = block(x)
132 | if idx in self.output_blocks:
133 | outp.append(x)
134 |
135 | if idx == self.last_needed_block:
136 | break
137 |
138 | return outp
139 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | import time
2 | import os
3 | import numpy as np
4 | import torch
5 | from torch.autograd import Variable
6 | from collections import OrderedDict
7 | from subprocess import call
8 | import fractions
9 | def lcm(a,b): return abs(a * b)/fractions.gcd(a,b) if a and b else 0
10 |
11 | from options.train_options import TrainOptions
12 | from data.data_loader import CreateDataLoader
13 | from models.models import create_model
14 | import util.util as util
15 | from util.visualizer import Visualizer
16 | from torch.utils.tensorboard import SummaryWriter
17 |
18 | opt = TrainOptions().parse()
19 | iter_path = os.path.join(opt.checkpoints_dir, opt.name, 'iter.txt')
20 | if opt.continue_train:
21 | try:
22 | start_epoch, epoch_iter = np.loadtxt(iter_path , delimiter=',', dtype=int)
23 | except:
24 | start_epoch, epoch_iter = 1, 0
25 | print('Resuming from epoch %d at iteration %d' % (start_epoch, epoch_iter))
26 | else:
27 | start_epoch, epoch_iter = 1, 0
28 |
29 | opt.iter_start = start_epoch
30 |
31 | opt.print_freq = lcm(opt.print_freq, opt.batchSize)
32 | if opt.debug:
33 | opt.display_freq = 1
34 | opt.print_freq = 1
35 | opt.niter = 1
36 | opt.niter_decay = 0
37 | opt.max_dataset_size = 10
38 |
39 | data_loader = CreateDataLoader(opt)
40 | dataset = data_loader.load_data()
41 | dataset_size = len(data_loader)
42 | print('#training images = %d' % dataset_size)
43 | writer = SummaryWriter(comment=opt.name)
44 |
45 | model = create_model(opt)
46 | visualizer = Visualizer(opt)
47 |
48 | total_steps = (start_epoch-1) * dataset_size + epoch_iter
49 |
50 | display_delta = total_steps % opt.display_freq
51 | print_delta = total_steps % opt.print_freq
52 | save_delta = total_steps % opt.save_latest_freq
53 |
54 | for epoch in range(start_epoch, opt.niter + opt.niter_decay + 1):
55 | epoch_start_time = time.time()
56 | if epoch != start_epoch:
57 | epoch_iter = epoch_iter % dataset_size
58 | for i, data in enumerate(dataset, start=epoch_iter):
59 | print("epoch: ", epoch, "iter: ", epoch_iter, "total_iteration: ", total_steps, end=" ")
60 | if total_steps % opt.print_freq == print_delta:
61 | iter_start_time = time.time()
62 | total_steps += opt.batchSize
63 | epoch_iter += opt.batchSize
64 |
65 | save_fake = total_steps % opt.display_freq == display_delta
66 |
67 | model.set_input(data)
68 | model.optimize_parameters()
69 |
70 | losses = model.get_current_errors()
71 | for k, v in losses.items():
72 | print(k, ": ", '%.2f' % v, end=" ")
73 | lr_G, lr_D = model.get_current_learning_rate()
74 | print("learning rate G: %.7f" % lr_G, end=" ")
75 | print("learning rate D: %.7f" % lr_D, end=" ")
76 | print('\n')
77 |
78 |
79 | writer.add_scalar('Loss/app_gen_s', losses['app_gen_s'], total_steps)
80 | writer.add_scalar('Loss/content_gen_s', losses['content_gen_s'], total_steps)
81 | writer.add_scalar('Loss/style_gen_s', losses['style_gen_s'], total_steps)
82 | writer.add_scalar('Loss/app_gen_t', losses['app_gen_t'], total_steps)
83 | writer.add_scalar('Loss/ad_gen_t', losses['ad_gen_t'], total_steps)
84 | writer.add_scalar('Loss/dis_img_gen_t', losses['dis_img_gen_t'], total_steps)
85 | writer.add_scalar('Loss/content_gen_t', losses['content_gen_t'], total_steps)
86 | writer.add_scalar('Loss/style_gen_t', losses['style_gen_t'], total_steps)
87 | writer.add_scalar('LR/G', lr_G, total_steps)
88 | writer.add_scalar('LR/D', lr_D, total_steps)
89 |
90 |
91 | ############## Display results and errors ##########
92 | if total_steps % opt.print_freq == print_delta:
93 | losses = model.get_current_errors()
94 | t = (time.time() - iter_start_time) / opt.batchSize
95 | visualizer.print_current_errors(epoch, epoch_iter, total_steps, losses, lr_G, lr_D, t)
96 | if opt.display_id > 0:
97 | visualizer.plot_current_errors(total_steps, losses)
98 |
99 | if total_steps % opt.display_freq == display_delta:
100 | visualizer.display_current_results(model.get_current_visuals(), epoch)
101 | if hasattr(model, 'distribution'):
102 | visualizer.plot_current_distribution(model.get_current_dis())
103 |
104 | if total_steps % opt.save_latest_freq == save_delta:
105 | print('saving the latest model (epoch %d, total_steps %d)' % (epoch, total_steps))
106 | model.save_networks('latest')
107 | if opt.dataset_mode == 'market':
108 | model.save_networks(total_steps)
109 | np.savetxt(iter_path, (epoch, epoch_iter), delimiter=',', fmt='%d')
110 |
111 | if epoch_iter >= dataset_size:
112 | break
113 |
114 | # end of epoch
115 | iter_end_time = time.time()
116 | print('End of epoch %d / %d \t Time Taken: %d sec' %
117 | (epoch, opt.niter + opt.niter_decay, time.time() - epoch_start_time))
118 |
119 | ### save model for this epoch
120 | if epoch % opt.save_epoch_freq == 0 or (epoch > opt.niter and epoch % (opt.save_epoch_freq//2) == 0):
121 | print('saving the model at the end of epoch %d, iters %d' % (epoch, total_steps))
122 | model.save_networks('latest')
123 | model.save_networks(epoch)
124 | np.savetxt(iter_path, (epoch+1, 0), delimiter=',', fmt='%d')
125 |
126 | ### linearly decay learning rate after certain iterations
127 | model.update_learning_rate()
128 |
--------------------------------------------------------------------------------
/util/pose_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from scipy.ndimage.filters import gaussian_filter
3 | from skimage.draw import circle, line_aa, polygon
4 | import json
5 |
6 | import matplotlib
7 | matplotlib.use('Agg')
8 | import matplotlib.pyplot as plt
9 | import matplotlib.patches as mpatches
10 | from collections import defaultdict
11 | import skimage.measure, skimage.transform
12 | import sys
13 |
14 | LIMB_SEQ = [[1,2], [1,5], [2,3], [3,4], [5,6], [6,7], [1,8], [8,9],
15 | [9,10], [1,11], [11,12], [12,13], [1,0], [0,14], [14,16],
16 | [0,15], [15,17], [2,16], [5,17]]
17 |
18 | COLORS = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0],
19 | [0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255],
20 | [170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
21 |
22 |
23 | LABELS = ['nose', 'neck', 'Rsho', 'Relb', 'Rwri', 'Lsho', 'Lelb', 'Lwri',
24 | 'Rhip', 'Rkne', 'Rank', 'Lhip', 'Lkne', 'Lank', 'Leye', 'Reye', 'Lear', 'Rear']
25 |
26 | MISSING_VALUE = -1
27 |
28 |
29 | def map_to_cord(pose_map, threshold=0.1):
30 | all_peaks = [[] for i in range(18)]
31 | pose_map = pose_map[..., :18]
32 |
33 | y, x, z = np.where(np.logical_and(pose_map == pose_map.max(axis = (0, 1)),
34 | pose_map > threshold))
35 | for x_i, y_i, z_i in zip(x, y, z):
36 | all_peaks[z_i].append([x_i, y_i])
37 |
38 | x_values = []
39 | y_values = []
40 |
41 | for i in range(18):
42 | if len(all_peaks[i]) != 0:
43 | x_values.append(all_peaks[i][0][0])
44 | y_values.append(all_peaks[i][0][1])
45 | else:
46 | x_values.append(MISSING_VALUE)
47 | y_values.append(MISSING_VALUE)
48 |
49 | return np.concatenate([np.expand_dims(y_values, -1), np.expand_dims(x_values, -1)], axis=1)
50 |
51 |
52 | def cords_to_map(cords, img_size, old_size=None, affine_matrix=None, sigma=6):
53 | old_size = img_size if old_size is None else old_size
54 | cords = cords.astype(float)
55 | result = np.zeros(img_size + cords.shape[0:1], dtype='float32')
56 | for i, point in enumerate(cords):
57 | if point[0] == MISSING_VALUE or point[1] == MISSING_VALUE:
58 | continue
59 | point[0] = point[0]/old_size[0] * img_size[0]
60 | point[1] = point[1]/old_size[1] * img_size[1]
61 | if affine_matrix is not None:
62 | point_ =np.dot(affine_matrix, np.matrix([point[1], point[0], 1]).reshape(3,1))
63 | point_0 = int(point_[1])
64 | point_1 = int(point_[0])
65 | else:
66 | point_0 = int(point[0])
67 | point_1 = int(point[1])
68 | xx, yy = np.meshgrid(np.arange(img_size[1]), np.arange(img_size[0]))
69 | result[..., i] = np.exp(-((yy - point_0) ** 2 + (xx - point_1) ** 2) / (2 * sigma ** 2))
70 | return result
71 |
72 |
73 | def draw_pose_from_cords(pose_joints, img_size, radius=2, draw_joints=True):
74 | colors = np.zeros(shape=img_size + (3, ), dtype=np.uint8)
75 | mask = np.zeros(shape=img_size, dtype=bool)
76 |
77 | if draw_joints:
78 | for f, t in LIMB_SEQ:
79 | from_missing = pose_joints[f][0] == MISSING_VALUE or pose_joints[f][1] == MISSING_VALUE
80 | to_missing = pose_joints[t][0] == MISSING_VALUE or pose_joints[t][1] == MISSING_VALUE
81 | if from_missing or to_missing:
82 | continue
83 | yy, xx, val = line_aa(pose_joints[f][0], pose_joints[f][1], pose_joints[t][0], pose_joints[t][1])
84 | colors[yy, xx] = np.expand_dims(val, 1) * 255
85 | mask[yy, xx] = True
86 |
87 | for i, joint in enumerate(pose_joints):
88 | if pose_joints[i][0] == MISSING_VALUE or pose_joints[i][1] == MISSING_VALUE:
89 | continue
90 | yy, xx = circle(joint[0], joint[1], radius=radius, shape=img_size)
91 | colors[yy, xx] = COLORS[i]
92 | mask[yy, xx] = True
93 |
94 | return colors, mask
95 |
96 |
97 | def draw_pose_from_map(pose_map, threshold=0.1, **kwargs):
98 | cords = map_to_cord(pose_map, threshold=threshold)
99 | return draw_pose_from_cords(cords, pose_map.shape[:2], **kwargs)
100 |
101 |
102 | def load_pose_cords_from_strings(y_str, x_str):
103 | y_cords = json.loads(y_str)
104 | x_cords = json.loads(x_str)
105 | return np.concatenate([np.expand_dims(y_cords, -1), np.expand_dims(x_cords, -1)], axis=1)
106 |
107 | def mean_inputation(X):
108 | X = X.copy()
109 | for i in range(X.shape[1]):
110 | for j in range(X.shape[2]):
111 | val = np.mean(X[:, i, j][X[:, i, j] != -1])
112 | X[:, i, j][X[:, i, j] == -1] = val
113 | return X
114 |
115 | def draw_legend():
116 | handles = [mpatches.Patch(color=np.array(color) / 255.0, label=name) for color, name in zip(COLORS, LABELS)]
117 | plt.legend(handles=handles, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
118 |
119 | def produce_ma_mask(kp_array, img_size, point_radius=4):
120 | from skimage.morphology import dilation, erosion, square
121 | mask = np.zeros(shape=img_size, dtype=bool)
122 | limbs = [[2,3], [2,6], [3,4], [4,5], [6,7], [7,8], [2,9], [9,10],
123 | [10,11], [2,12], [12,13], [13,14], [2,1], [1,15], [15,17],
124 | [1,16], [16,18], [2,17], [2,18], [9,12], [12,6], [9,3], [17,18]]
125 | limbs = np.array(limbs) - 1
126 | for f, t in limbs:
127 | from_missing = kp_array[f][0] == MISSING_VALUE or kp_array[f][1] == MISSING_VALUE
128 | to_missing = kp_array[t][0] == MISSING_VALUE or kp_array[t][1] == MISSING_VALUE
129 | if from_missing or to_missing:
130 | continue
131 |
132 | norm_vec = kp_array[f] - kp_array[t]
133 | norm_vec = np.array([-norm_vec[1], norm_vec[0]])
134 | norm_vec = point_radius * norm_vec / np.linalg.norm(norm_vec)
135 |
136 |
137 | vetexes = np.array([
138 | kp_array[f] + norm_vec,
139 | kp_array[f] - norm_vec,
140 | kp_array[t] - norm_vec,
141 | kp_array[t] + norm_vec
142 | ])
143 | yy, xx = polygon(vetexes[:, 0], vetexes[:, 1], shape=img_size)
144 | mask[yy, xx] = True
145 |
146 | for i, joint in enumerate(kp_array):
147 | if kp_array[i][0] == MISSING_VALUE or kp_array[i][1] == MISSING_VALUE:
148 | continue
149 | yy, xx = circle(joint[0], joint[1], radius=point_radius, shape=img_size)
150 | mask[yy, xx] = True
151 |
152 | mask = dilation(mask, square(5))
153 | mask = erosion(mask, square(5))
154 | return mask
155 |
156 | if __name__ == "__main__":
157 | import pandas as pd
158 | from skimage.io import imread
159 | import pylab as plt
160 | import os
161 | i = 5
162 | df = pd.read_csv('data/market-annotation-train.csv', sep=':')
163 |
164 | for index, row in df.iterrows():
165 | pose_cords = load_pose_cords_from_strings(row['keypoints_y'], row['keypoints_x'])
166 |
167 | colors, mask = draw_pose_from_cords(pose_cords, (128, 64))
168 |
169 | mmm = produce_ma_mask(pose_cords, (128, 64)).astype(float)[..., np.newaxis].repeat(3, axis=-1)
170 | print(mmm.shape)
171 | img = imread('data/market-dataset/train/' + row['name'])
172 |
173 | mmm[mask] = colors[mask]
174 |
175 | print (mmm)
176 | plt.subplot(1, 1, 1)
177 | plt.imshow(mmm)
178 | plt.show()
179 |
--------------------------------------------------------------------------------
/options/base_options.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | from util import util
4 | import torch
5 | import data
6 | import models
7 |
8 | class BaseOptions():
9 | def __init__(self):
10 | self.parser = argparse.ArgumentParser()
11 | self.initialized = False
12 |
13 | def initialize(self):
14 | # experiment specifics
15 | self.parser.add_argument('--name', type=str, default='label2city', help='name of the experiment. It decides where to store samples and models')
16 | self.parser.add_argument('--gpu_ids', type=str, default='0', help='gpu ids: e.g. 0 0,1,2, 0,2. use -1 for CPU')
17 | self.parser.add_argument('--checkpoints_dir', type=str, default='./checkpoints', help='models are saved here')
18 | self.parser.add_argument('--model', type=str, default='pix2pixHD', help='which model to use')
19 | self.parser.add_argument('--norm', type=str, default='instance', help='instance normalization or batch normalization')
20 | self.parser.add_argument('--use_dropout', action='store_true', help='use dropout for the generator')
21 | self.parser.add_argument('--data_type', default=32, type=int, choices=[8, 16, 32], help="Supported data type i.e. 8, 16, 32 bit")
22 | self.parser.add_argument('--verbose', action='store_true', default=False, help='toggles verbose')
23 | self.parser.add_argument('--fp16', action='store_true', default=False, help='train with AMP')
24 | self.parser.add_argument('--local_rank', type=int, default=0, help='local rank for distributed training')
25 |
26 | # input/output sizes
27 | self.parser.add_argument('--image_nc', type=int, default=3)
28 | self.parser.add_argument('--pose_nc', type=int, default=18)
29 | self.parser.add_argument('--batchSize', type=int, default=1, help='input batch size')
30 | self.parser.add_argument('--old_size', type=int, default=(256, 176), help='Scale images to this size. The final image will be cropped to --crop_size.')
31 | self.parser.add_argument('--loadSize', type=int, default=256, help='scale images to this size')
32 | self.parser.add_argument('--fineSize', type=int, default=512, help='then crop to this size')
33 | self.parser.add_argument('--label_nc', type=int, default=35, help='# of input label channels')
34 | self.parser.add_argument('--input_nc', type=int, default=3, help='# of input image channels')
35 | self.parser.add_argument('--output_nc', type=int, default=3, help='# of output image channels')
36 |
37 | # for setting inputs
38 | self.parser.add_argument('--dataset_mode', type=str, default='fashion')
39 | self.parser.add_argument('--dataroot', type=str, default='/media/data2/zhangpz/DataSet/Fashion')
40 | self.parser.add_argument('--resize_or_crop', type=str, default='scale_width', help='scaling and cropping of images at load time [resize_and_crop|crop|scale_width|scale_width_and_crop]')
41 | self.parser.add_argument('--serial_batches', action='store_true', help='if true, takes images in order to make batches, otherwise takes them randomly')
42 | self.parser.add_argument('--no_flip', action='store_true', help='if specified, do not flip the images for data argumentation')
43 | self.parser.add_argument('--nThreads', default=2, type=int, help='# threads for loading data')
44 | self.parser.add_argument('--max_dataset_size', type=int, default=float("inf"), help='Maximum number of samples allowed per dataset. If the dataset directory contains more than max_dataset_size, only a subset is loaded.')
45 |
46 | # for displays
47 | self.parser.add_argument('--display_winsize', type=int, default=512, help='display window size')
48 | self.parser.add_argument('--tf_log', action='store_true', help='if specified, use tensorboard logging. Requires tensorflow installed')
49 | self.parser.add_argument('--display_id', type=int, default=0, help='display id of the web') # 1
50 | self.parser.add_argument('--display_port', type=int, default=8096, help='visidom port of the web display')
51 | self.parser.add_argument('--display_single_pane_ncols', type=int, default=0,
52 | help='if positive, display all images in a single visidom web panel')
53 | self.parser.add_argument('--display_env', type=str, default=self.parser.parse_known_args()[0].name.replace('_', ''),
54 | help='the environment of visidom display')
55 | # for instance-wise features
56 | self.parser.add_argument('--no_instance', action='store_true', help='if specified, do *not* add instance map as input')
57 | self.parser.add_argument('--instance_feat', action='store_true', help='if specified, add encoded instance features as input')
58 | self.parser.add_argument('--label_feat', action='store_true', help='if specified, add encoded label features as input')
59 | self.parser.add_argument('--feat_num', type=int, default=3, help='vector length for encoded features')
60 | self.parser.add_argument('--load_features', action='store_true', help='if specified, load precomputed feature maps')
61 | self.parser.add_argument('--n_downsample_E', type=int, default=4, help='# of downsampling layers in encoder')
62 | self.parser.add_argument('--nef', type=int, default=16, help='# of encoder filters in the first conv layer')
63 | self.parser.add_argument('--n_clusters', type=int, default=10, help='number of clusters for features')
64 |
65 | self.initialized = True
66 |
67 | def parse(self, save=True):
68 | if not self.initialized:
69 | self.initialize()
70 | opt, _ = self.parser.parse_known_args()
71 | # modify the options for different models
72 | model_option_set = models.get_option_setter(opt.model)
73 | self.parser = model_option_set(self.parser, self.isTrain)
74 |
75 | data_option_set = data.get_option_setter(opt.dataset_mode)
76 | self.parser = data_option_set(self.parser, self.isTrain)
77 |
78 | self.opt = self.parser.parse_args()
79 | self.opt.isTrain = self.isTrain # train or test
80 |
81 | if torch.cuda.is_available():
82 | self.opt.device = torch.device("cuda")
83 | torch.backends.cudnn.benchmark = True # cudnn auto-tuner
84 | else:
85 | self.opt.device = torch.device("cpu")
86 |
87 | str_ids = self.opt.gpu_ids.split(',')
88 | self.opt.gpu_ids = []
89 | for str_id in str_ids:
90 | id = int(str_id)
91 | if id >= 0:
92 | self.opt.gpu_ids.append(id)
93 |
94 | # set gpu ids
95 | if len(self.opt.gpu_ids) > 0:
96 | torch.cuda.set_device(self.opt.gpu_ids[0])
97 |
98 | args = vars(self.opt)
99 |
100 | print('------------ Options -------------')
101 | for k, v in sorted(args.items()):
102 | print('%s: %s' % (str(k), str(v)))
103 | print('-------------- End ----------------')
104 |
105 | # save to the disk
106 | expr_dir = os.path.join(self.opt.checkpoints_dir, self.opt.name)
107 | util.mkdirs(expr_dir)
108 | if save and not (self.isTrain and self.opt.continue_train):
109 | name = 'train' if self.isTrain else 'test'
110 | file_name = os.path.join(expr_dir, name+'_opt.txt')
111 | with open(file_name, 'wt') as opt_file:
112 | opt_file.write('------------ Options -------------\n')
113 | for k, v in sorted(args.items()):
114 | opt_file.write('%s: %s\n' % (str(k), str(v)))
115 | opt_file.write('-------------- End ----------------\n')
116 | return self.opt
117 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Dual-task Pose Transformer Network
2 | The source code for our paper "[Exploring Dual-task Correlation for Pose Guided Person Image Generation](https://openaccess.thecvf.com/content/CVPR2022/papers/Zhang_Exploring_Dual-Task_Correlation_for_Pose_Guided_Person_Image_Generation_CVPR_2022_paper.pdf)“, Pengze Zhang, Lingxiao Yang, Jianhuang Lai, and Xiaohua Xie, CVPR 2022. Video: [[Chinese](https://www.koushare.com/video/videodetail/35887)] [[English](https://www.youtube.com/watch?v=p9o3lOlZBSE)]
3 |
2 | Our poster template can be download from [Google Drive](https://docs.google.com/presentation/d/1i02V0JZCw2mRZF99szitaOEkfVNeKR1q/edit?usp=sharing&ouid=111594135598063931892&rtpof=true&sd=true).
3 |
--------------------------------------------------------------------------------
/models/models.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import models
3 |
4 | def create_model(opt):
5 | '''
6 | if opt.model == 'pix2pixHD':
7 | from .pix2pixHD_model import Pix2PixHDModel, InferenceModel
8 | if opt.isTrain:
9 | model = Pix2PixHDModel()
10 | else:
11 | model = InferenceModel()
12 | elif opt.model == 'basic':
13 | from .basic_model import BasicModel
14 | model = BasicModel(opt)
15 | else:
16 | from .ui_model import UIModel
17 | model = UIModel()
18 | '''
19 | model = models.find_model_using_name(opt.model)(opt)
20 | if opt.verbose:
21 | print("model [%s] was created" % (model.name()))
22 | return model
23 |
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | from data.data_loader import CreateDataLoader
2 | from options.test_options import TestOptions
3 | from models.models import create_model
4 | import numpy as np
5 | import torch
6 |
7 | if __name__=='__main__':
8 | # get testing options
9 | opt = TestOptions().parse()
10 | # creat a dataset
11 | data_loader = CreateDataLoader(opt)
12 | dataset = data_loader.load_data()
13 |
14 |
15 | print(len(dataset))
16 |
17 | dataset_size = len(dataset) * opt.batchSize
18 | print('testing images = %d' % dataset_size)
19 | # create a model
20 | model = create_model(opt)
21 |
22 | with torch.no_grad():
23 | for i, data in enumerate(dataset):
24 | model.set_input(data)
25 | model.test()
26 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
1 | """This package contains modules related to function, network architectures, and models"""
2 |
3 | import importlib
4 | from .base_model import BaseModel
5 |
6 |
7 | def find_model_using_name(model_name):
8 | """Import the module "model/[model_name]_model.py"."""
9 | model_file_name = "models." + model_name + "_model"
10 | modellib = importlib.import_module(model_file_name)
11 | model = None
12 | for name, cls in modellib.__dict__.items():
13 | if name.lower() == (model_name+'model').lower() and issubclass(cls, BaseModel):
14 | model = cls
15 |
16 | if model is None:
17 | print("In %s.py, there should be a subclass of BaseModel with class name that matches %s in lowercase." % (model_file_name, model_name))
18 | exit(0)
19 |
20 | return model
21 |
22 |
23 | def get_option_setter(model_name):
24 | """Return the static method of the model class."""
25 | model = find_model_using_name(model_name)
26 | return model.modify_options
27 |
--------------------------------------------------------------------------------
/util/image_pool.py:
--------------------------------------------------------------------------------
1 | import random
2 | import torch
3 | from torch.autograd import Variable
4 | class ImagePool():
5 | def __init__(self, pool_size):
6 | self.pool_size = pool_size
7 | if self.pool_size > 0:
8 | self.num_imgs = 0
9 | self.images = []
10 |
11 | def query(self, images):
12 | if self.pool_size == 0:
13 | return images
14 | return_images = []
15 | for image in images.data:
16 | image = torch.unsqueeze(image, 0)
17 | if self.num_imgs < self.pool_size:
18 | self.num_imgs = self.num_imgs + 1
19 | self.images.append(image)
20 | return_images.append(image)
21 | else:
22 | p = random.uniform(0, 1)
23 | if p > 0.5:
24 | random_id = random.randint(0, self.pool_size-1)
25 | tmp = self.images[random_id].clone()
26 | self.images[random_id] = image
27 | return_images.append(tmp)
28 | else:
29 | return_images.append(image)
30 | return_images = Variable(torch.cat(return_images, 0))
31 | return return_images
32 |
--------------------------------------------------------------------------------
/data/custom_dataset_data_loader.py:
--------------------------------------------------------------------------------
1 | import torch.utils.data
2 | from data.base_data_loader import BaseDataLoader
3 | import data
4 |
5 | def CreateDataset(opt):
6 | '''
7 | dataset = None
8 | if opt.dataset_mode == 'fashion':
9 | from data.fashion_dataset import FashionDataset
10 | dataset = FashionDataset()
11 | else:
12 | from data.aligned_dataset import AlignedDataset
13 | dataset = AlignedDataset()
14 | '''
15 | dataset = data.find_dataset_using_name(opt.dataset_mode)()
16 | print("dataset [%s] was created" % (dataset.name()))
17 | dataset.initialize(opt)
18 | return dataset
19 |
20 | class CustomDatasetDataLoader(BaseDataLoader):
21 | def name(self):
22 | return 'CustomDatasetDataLoader'
23 |
24 | def initialize(self, opt):
25 | BaseDataLoader.initialize(self, opt)
26 | self.dataset = CreateDataset(opt)
27 | self.dataloader = torch.utils.data.DataLoader(
28 | self.dataset,
29 | batch_size=opt.batchSize,
30 | shuffle=(not opt.serial_batches) and opt.isTrain,
31 | num_workers=int(opt.nThreads))
32 |
33 | def load_data(self):
34 | return self.dataloader
35 |
36 | def __len__(self):
37 | return min(len(self.dataset), self.opt.max_dataset_size)
38 |
--------------------------------------------------------------------------------
/options/test_options.py:
--------------------------------------------------------------------------------
1 | from .base_options import BaseOptions
2 |
3 | class TestOptions(BaseOptions):
4 | def initialize(self):
5 | BaseOptions.initialize(self)
6 | self.parser.add_argument('--ntest', type=int, default=float("inf"), help='# of test examples.')
7 | self.parser.add_argument('--results_dir', type=str, default='./results/', help='saves results here.')
8 | self.parser.add_argument('--aspect_ratio', type=float, default=1.0, help='aspect ratio of result images')
9 | self.parser.add_argument('--phase', type=str, default='test', help='train, val, test, etc')
10 | self.parser.add_argument('--which_epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
11 | self.parser.add_argument('--how_many', type=int, default=50, help='how many test images to run')
12 | self.parser.add_argument('--cluster_path', type=str, default='features_clustered_010.npy', help='the path for clustered results of encoded features')
13 | self.parser.add_argument('--use_encoded_image', action='store_true', help='if specified, encode the real image to get the feature map')
14 | self.parser.add_argument("--export_onnx", type=str, help="export ONNX model to a given file")
15 | self.parser.add_argument("--engine", type=str, help="run serialized TRT engine")
16 | self.parser.add_argument("--onnx", type=str, help="run ONNX model via TRT")
17 | self.isTrain = False
18 |
--------------------------------------------------------------------------------
/data/__init__.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | import torch.utils.data
3 | from data.base_dataset import BaseDataset
4 |
5 |
6 | def find_dataset_using_name(dataset_name):
7 | # Given the option --dataset [datasetname],
8 | # the file "datasets/datasetname_dataset.py"
9 | # will be imported.
10 | dataset_filename = "data." + dataset_name + "_dataset"
11 | datasetlib = importlib.import_module(dataset_filename)
12 |
13 | # In the file, the class called DatasetNameDataset() will
14 | # be instantiated. It has to be a subclass of BaseDataset,
15 | # and it is case-insensitive.
16 | dataset = None
17 | target_dataset_name = dataset_name.replace('_', '') + 'dataset'
18 | for name, cls in datasetlib.__dict__.items():
19 | if name.lower() == target_dataset_name.lower() \
20 | and issubclass(cls, BaseDataset):
21 | dataset = cls
22 |
23 | if dataset is None:
24 | raise ValueError("In %s.py, there should be a subclass of BaseDataset "
25 | "with class name that matches %s in lowercase." %
26 | (dataset_filename, target_dataset_name))
27 |
28 | return dataset
29 |
30 |
31 | def get_option_setter(dataset_name):
32 | dataset_class = find_dataset_using_name(dataset_name)
33 | return dataset_class.modify_commandline_options
34 |
35 | '''
36 | def create_dataloader(opt):
37 | dataset = find_dataset_using_name(opt.dataset_mode)
38 | instance = dataset()
39 | instance.initialize(opt)
40 | print("dataset [%s] of size %d was created" %
41 | (type(instance).__name__, len(instance)))
42 | dataloader = torch.utils.data.DataLoader(
43 | instance,
44 | batch_size=opt.batchSize,
45 | shuffle=not opt.serial_batches,
46 | num_workers=int(opt.nThreads),
47 | drop_last=opt.isTrain
48 | )
49 | return dataloader
50 | '''
--------------------------------------------------------------------------------
/data/generate_fashion_datasets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import shutil
3 | from PIL import Image
4 |
5 | IMG_EXTENSIONS = [
6 | '.jpg', '.JPG', '.jpeg', '.JPEG',
7 | '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP',
8 | ]
9 |
10 | def is_image_file(filename):
11 | return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
12 |
13 | def make_dataset(dir):
14 | images = []
15 | assert os.path.isdir(dir), '%s is not a valid directory' % dir
16 | new_root = './fashion'
17 | if not os.path.exists(new_root):
18 | os.mkdir(new_root)
19 |
20 | train_root = './fashion/train'
21 | if not os.path.exists(train_root):
22 | os.mkdir(train_root)
23 |
24 | test_root = './fashion/test'
25 | if not os.path.exists(test_root):
26 | os.mkdir(test_root)
27 |
28 | train_images = []
29 | train_f = open('./fashion/train.lst', 'r')
30 | for lines in train_f:
31 | lines = lines.strip()
32 | if lines.endswith('.jpg'):
33 | train_images.append(lines)
34 |
35 | test_images = []
36 | test_f = open('./fashion/test.lst', 'r')
37 | for lines in test_f:
38 | lines = lines.strip()
39 | if lines.endswith('.jpg'):
40 | test_images.append(lines)
41 |
42 | print(train_images, test_images)
43 |
44 |
45 | for root, _, fnames in sorted(os.walk(dir)):
46 | for fname in fnames:
47 | if is_image_file(fname):
48 | path = os.path.join(root, fname)
49 | path_names = path.split('/')
50 | # path_names[2] = path_names[2].replace('_', '')
51 | path_names[3] = path_names[3].replace('_', '')
52 | path_names[4] = path_names[4].split('_')[0] + "_" + "".join(path_names[4].split('_')[1:])
53 | path_names = "".join(path_names)
54 | # new_path = os.path.join(root, path_names)
55 | img = Image.open(path)
56 | imgcrop = img.crop((40, 0, 216, 256))
57 | if new_path in train_images:
58 | imgcrop.save(os.path.join(train_root, path_names))
59 | elif new_path in test_images:
60 | imgcrop.save(os.path.join(test_root, path_names))
61 |
62 | make_dataset('./fashion')
--------------------------------------------------------------------------------
/util/html.py:
--------------------------------------------------------------------------------
1 | import dominate
2 | from dominate.tags import *
3 | import os
4 |
5 |
6 | class HTML:
7 | def __init__(self, web_dir, title, refresh=0):
8 | self.title = title
9 | self.web_dir = web_dir
10 | self.img_dir = os.path.join(self.web_dir, 'images')
11 | if not os.path.exists(self.web_dir):
12 | os.makedirs(self.web_dir)
13 | if not os.path.exists(self.img_dir):
14 | os.makedirs(self.img_dir)
15 |
16 | self.doc = dominate.document(title=title)
17 | if refresh > 0:
18 | with self.doc.head:
19 | meta(http_equiv="refresh", content=str(refresh))
20 |
21 | def get_image_dir(self):
22 | return self.img_dir
23 |
24 | def add_header(self, str):
25 | with self.doc:
26 | h3(str)
27 |
28 | def add_table(self, border=1):
29 | self.t = table(border=border, style="table-layout: fixed;")
30 | self.doc.add(self.t)
31 |
32 | def add_images(self, ims, txts, links, width=512):
33 | self.add_table()
34 | with self.t:
35 | with tr():
36 | for im, txt, link in zip(ims, txts, links):
37 | with td(style="word-wrap: break-word;", halign="center", valign="top"):
38 | with p():
39 | with a(href=os.path.join('images', link)):
40 | img(style="width:%dpx" % (width), src=os.path.join('images', im))
41 | br()
42 | p(txt)
43 |
44 | def save(self):
45 | html_file = '%s/index.html' % self.web_dir
46 | f = open(html_file, 'wt')
47 | f.write(self.doc.render())
48 | f.close()
49 |
50 |
51 | if __name__ == '__main__':
52 | html = HTML('web/', 'test_html')
53 | html.add_header('hello world')
54 |
55 | ims = []
56 | txts = []
57 | links = []
58 | for n in range(4):
59 | ims.append('image_%d.jpg' % n)
60 | txts.append('text_%d' % n)
61 | links.append('image_%d.jpg' % n)
62 | html.add_images(ims, txts, links)
63 | html.save()
64 |
--------------------------------------------------------------------------------
/data/image_folder.py:
--------------------------------------------------------------------------------
1 | ###############################################################################
2 | # Code from
3 | # https://github.com/pytorch/vision/blob/master/torchvision/datasets/folder.py
4 | # Modified the original code so that it also loads images from the current
5 | # directory as well as the subdirectories
6 | ###############################################################################
7 | import torch.utils.data as data
8 | from PIL import Image
9 | import os
10 |
11 | IMG_EXTENSIONS = [
12 | '.jpg', '.JPG', '.jpeg', '.JPEG',
13 | '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP', '.tiff'
14 | ]
15 |
16 |
17 | def is_image_file(filename):
18 | return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
19 |
20 |
21 | def make_dataset(dir):
22 | images = []
23 | assert os.path.isdir(dir), '%s is not a valid directory' % dir
24 |
25 | for root, _, fnames in sorted(os.walk(dir)):
26 | for fname in fnames:
27 | if is_image_file(fname):
28 | path = os.path.join(root, fname)
29 | images.append(path)
30 |
31 | return images
32 |
33 |
34 | def default_loader(path):
35 | return Image.open(path).convert('RGB')
36 |
37 |
38 | class ImageFolder(data.Dataset):
39 |
40 | def __init__(self, root, transform=None, return_paths=False,
41 | loader=default_loader):
42 | imgs = make_dataset(root)
43 | if len(imgs) == 0:
44 | raise(RuntimeError("Found 0 images in: " + root + "\n"
45 | "Supported image extensions are: " +
46 | ",".join(IMG_EXTENSIONS)))
47 |
48 | self.root = root
49 | self.imgs = imgs
50 | self.transform = transform
51 | self.return_paths = return_paths
52 | self.loader = loader
53 |
54 | def __getitem__(self, index):
55 | path = self.imgs[index]
56 | img = self.loader(path)
57 | if self.transform is not None:
58 | img = self.transform(img)
59 | if self.return_paths:
60 | return img, path
61 | else:
62 | return img
63 |
64 | def __len__(self):
65 | return len(self.imgs)
66 |
--------------------------------------------------------------------------------
/data/base_dataset.py:
--------------------------------------------------------------------------------
1 | import torch.utils.data as data
2 | from PIL import Image
3 | import torchvision.transforms as transforms
4 | import numpy as np
5 | import random
6 |
7 |
8 | class BaseDataset(data.Dataset):
9 | def __init__(self):
10 | super(BaseDataset, self).__init__()
11 |
12 | def name(self):
13 | return 'BaseDataset'
14 |
15 | def initialize(self, opt):
16 | pass
17 |
18 | def get_params(opt, size):
19 | w, h = size
20 | new_h = h
21 | new_w = w
22 | if opt.resize_or_crop == 'resize_and_crop':
23 | new_h = new_w = opt.loadSize
24 | elif opt.resize_or_crop == 'scale_width_and_crop':
25 | new_w = opt.loadSize
26 | new_h = opt.loadSize * h // w
27 |
28 | x = random.randint(0, np.maximum(0, new_w - opt.fineSize))
29 | y = random.randint(0, np.maximum(0, new_h - opt.fineSize))
30 |
31 | flip = random.random() > 0.5
32 | return {'crop_pos': (x, y), 'flip': flip}
33 |
34 | def get_transform(opt, params, method=Image.BICUBIC, normalize=True):
35 | transform_list = []
36 | if 'resize' in opt.resize_or_crop:
37 | osize = [opt.loadSize, opt.loadSize]
38 | transform_list.append(transforms.Scale(osize, method))
39 | elif 'scale_width' in opt.resize_or_crop:
40 | transform_list.append(transforms.Lambda(lambda img: __scale_width(img, opt.loadSize, method)))
41 |
42 | if 'crop' in opt.resize_or_crop:
43 | transform_list.append(transforms.Lambda(lambda img: __crop(img, params['crop_pos'], opt.fineSize)))
44 |
45 | if opt.resize_or_crop == 'none':
46 | base = float(2 ** opt.n_downsample_global)
47 | if opt.netG == 'local':
48 | base *= (2 ** opt.n_local_enhancers)
49 | transform_list.append(transforms.Lambda(lambda img: __make_power_2(img, base, method)))
50 |
51 | if opt.isTrain and not opt.no_flip:
52 | transform_list.append(transforms.Lambda(lambda img: __flip(img, params['flip'])))
53 |
54 | transform_list += [transforms.ToTensor()]
55 |
56 | if normalize:
57 | transform_list += [transforms.Normalize((0.5, 0.5, 0.5),
58 | (0.5, 0.5, 0.5))]
59 | return transforms.Compose(transform_list)
60 |
61 |
62 | def normalize():
63 | return transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
64 |
65 |
66 | def __make_power_2(img, base, method=Image.BICUBIC):
67 | ow, oh = img.size
68 | h = int(round(oh / base) * base)
69 | w = int(round(ow / base) * base)
70 | if (h == oh) and (w == ow):
71 | return img
72 | return img.resize((w, h), method)
73 |
74 |
75 | def __scale_width(img, target_width, method=Image.BICUBIC):
76 | ow, oh = img.size
77 | if (ow == target_width):
78 | return img
79 | w = target_width
80 | h = int(target_width * oh / ow)
81 | return img.resize((w, h), method)
82 |
83 |
84 | def __crop(img, pos, size):
85 | ow, oh = img.size
86 | x1, y1 = pos
87 | tw = th = size
88 | if (ow > tw or oh > th):
89 | return img.crop((x1, y1, x1 + tw, y1 + th))
90 | return img
91 |
92 |
93 | def __flip(img, flip):
94 | if flip:
95 | return img.transpose(Image.FLIP_LEFT_RIGHT)
96 | return img
97 |
--------------------------------------------------------------------------------
/options/train_options.py:
--------------------------------------------------------------------------------
1 | from .base_options import BaseOptions
2 |
3 | class TrainOptions(BaseOptions):
4 | def initialize(self):
5 | BaseOptions.initialize(self)
6 | # for displays
7 | self.parser.add_argument('--display_freq', type=int, default=200, help='frequency of showing training results on screen')
8 | self.parser.add_argument('--print_freq', type=int, default=200, help='frequency of showing training results on console')
9 | self.parser.add_argument('--save_latest_freq', type=int, default=1000, help='frequency of saving the latest results')
10 | self.parser.add_argument('--save_epoch_freq', type=int, default=1, help='frequency of saving checkpoints at the end of epochs')
11 | self.parser.add_argument('--no_html', action='store_true', help='do not save intermediate training results to [opt.checkpoints_dir]/[opt.name]/web/')
12 | self.parser.add_argument('--debug', action='store_true', help='only do one epoch and displays at each iteration')
13 |
14 | # for training
15 | self.parser.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')
16 | self.parser.add_argument('--load_pretrain', type=str, default='', help='load the pretrained model from the specified location')
17 | self.parser.add_argument('--which_epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
18 | self.parser.add_argument('--phase', type=str, default='train', help='train, val, test, etc')
19 | self.parser.add_argument('--niter', type=int, default=100, help='# of iter at starting learning rate')
20 | self.parser.add_argument('--niter_decay', type=int, default=100, help='# of iter to linearly decay learning rate to zero')
21 | self.parser.add_argument('--iter_start', type=int, default=0, help='# of iter to linearly decay learning rate to zero')
22 | self.parser.add_argument('--beta1', type=float, default=0.5, help='momentum term of adam')
23 | self.parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate for adam')
24 | self.parser.add_argument('--lr_policy', type=str, default='lambda', help='learning rate policy[lambda|step|plateau]')
25 | self.parser.add_argument('--gan_mode', type=str, default='lsgan', choices=['wgan-gp', 'hinge', 'lsgan'])
26 | # for discriminators
27 | self.parser.add_argument('--num_D', type=int, default=1, help='number of discriminators to use')
28 | self.parser.add_argument('--n_layers_D', type=int, default=3, help='only used if which_model_netD==n_layers')
29 | self.parser.add_argument('--ndf', type=int, default=64, help='# of discrim filters in first conv layer')
30 | self.parser.add_argument('--lambda_feat', type=float, default=10.0, help='weight for feature matching loss')
31 | self.parser.add_argument('--no_ganFeat_loss', action='store_true', help='if specified, do *not* use discriminator feature matching loss')
32 | self.parser.add_argument('--no_vgg_loss', action='store_true', help='if specified, do *not* use VGG feature matching loss')
33 | self.parser.add_argument('--pool_size', type=int, default=0, help='the size of image buffer that stores previously generated images')
34 |
35 | self.isTrain = True
36 |
--------------------------------------------------------------------------------
/data/market_dataset.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | from data.base_dataset import BaseDataset, get_params, get_transform, normalize
3 | from data.image_folder import make_dataset
4 | import torchvision.transforms.functional as F
5 | import torchvision.transforms as transforms
6 | from PIL import Image
7 | from util import pose_utils
8 | import pandas as pd
9 | import numpy as np
10 | import torch
11 |
12 | class MarketDataset(BaseDataset):
13 | @staticmethod
14 | def modify_commandline_options(parser, is_train):
15 | if is_train:
16 | parser.set_defaults(load_size=128)
17 | else:
18 | parser.set_defaults(load_size=128)
19 | parser.set_defaults(old_size=(128, 64))
20 | parser.set_defaults(structure_nc=18)
21 | parser.set_defaults(image_nc=3)
22 | return parser
23 |
24 | def initialize(self, opt):
25 | self.opt = opt
26 | self.root = opt.dataroot
27 | self.phase = opt.phase
28 |
29 | # prepare for image (image_dir), image_pair (name_pairs) and bone annotation (annotation_file)
30 | self.image_dir = os.path.join(self.root, self.phase)
31 | self.bone_file = os.path.join(self.root, 'market-annotation-%s.csv' % self.phase)
32 | pairLst = os.path.join(self.root, 'market-pairs-%s.csv' % self.phase)
33 | self.name_pairs = self.init_categories(pairLst)
34 | self.annotation_file = pd.read_csv(self.bone_file, sep=':')
35 | self.annotation_file = self.annotation_file.set_index('name')
36 |
37 | # load image size
38 | if isinstance(opt.loadSize, int):
39 | self.load_size = (128, 64)
40 | else:
41 | self.load_size = opt.loadSize
42 |
43 | # prepare for transformation
44 | transform_list=[]
45 | transform_list.append(transforms.ToTensor())
46 | transform_list.append(transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5)))
47 | self.trans = transforms.Compose(transform_list)
48 |
49 | def __getitem__(self, index):
50 | # prepare for source image Xs and target image Xt
51 | Xs_name, Xt_name = self.name_pairs[index]
52 | Xs_path = os.path.join(self.image_dir, Xs_name)
53 | Xt_path = os.path.join(self.image_dir, Xt_name)
54 |
55 | Xs = Image.open(Xs_path).convert('RGB')
56 | Xt = Image.open(Xt_path).convert('RGB')
57 |
58 | Xs = F.resize(Xs, self.load_size)
59 | Xt = F.resize(Xt, self.load_size)
60 |
61 | Ps = self.obtain_bone(Xs_name)
62 | Xs = self.trans(Xs)
63 | Pt = self.obtain_bone(Xt_name)
64 | Xt = self.trans(Xt)
65 |
66 | return {'Xs': Xs, 'Ps': Ps, 'Xt': Xt, 'Pt': Pt,
67 | 'Xs_path': Xs_name, 'Xt_path': Xt_name}
68 |
69 | def init_categories(self, pairLst):
70 | pairs_file_train = pd.read_csv(pairLst)
71 | size = len(pairs_file_train)
72 | pairs = []
73 | print('Loading data pairs ...')
74 | for i in range(size):
75 | pair = [pairs_file_train.iloc[i]['from'], pairs_file_train.iloc[i]['to']]
76 | pairs.append(pair)
77 |
78 | print('Loading data pairs finished ...')
79 | return pairs
80 |
81 | def getRandomAffineParam(self):
82 | if self.opt.angle is not False:
83 | angle = np.random.uniform(low=self.opt.angle[0], high=self.opt.angle[1])
84 | else:
85 | angle = 0
86 | if self.opt.scale is not False:
87 | scale = np.random.uniform(low=self.opt.scale[0], high=self.opt.scale[1])
88 | else:
89 | scale = 1
90 | if self.opt.shift is not False:
91 | shift_x = np.random.uniform(low=self.opt.shift[0], high=self.opt.shift[1])
92 | shift_y = np.random.uniform(low=self.opt.shift[0], high=self.opt.shift[1])
93 | else:
94 | shift_x = 0
95 | shift_y = 0
96 | return angle, (shift_x, shift_y), scale
97 |
98 | def obtain_bone(self, name):
99 | string = self.annotation_file.loc[name]
100 | array = pose_utils.load_pose_cords_from_strings(string['keypoints_y'], string['keypoints_x'])
101 | pose = pose_utils.cords_to_map(array, self.load_size, self.opt.old_size)
102 | pose = np.transpose(pose,(2, 0, 1))
103 | pose = torch.Tensor(pose)
104 | return pose
105 |
106 | def obtain_bone_affine(self, name, affine_matrix):
107 | string = self.annotation_file.loc[name]
108 | array = pose_utils.load_pose_cords_from_strings(string['keypoints_y'], string['keypoints_x'])
109 | pose = pose_utils.cords_to_map(array, self.load_size, self.opt.old_size, affine_matrix)
110 | pose = np.transpose(pose,(2, 0, 1))
111 | pose = torch.Tensor(pose)
112 | return pose
113 |
114 | def __len__(self):
115 | return len(self.name_pairs) // self.opt.batchSize * self.opt.batchSize
116 |
117 | def name(self):
118 | return 'MarketDataset'
--------------------------------------------------------------------------------
/data/fashion_dataset.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | from data.base_dataset import BaseDataset, get_params, get_transform, normalize
3 | from data.image_folder import make_dataset
4 | import torchvision.transforms.functional as F
5 | import torchvision.transforms as transforms
6 | from PIL import Image
7 | from util import pose_utils
8 | import pandas as pd
9 | import numpy as np
10 | import torch
11 |
12 | class FashionDataset(BaseDataset):
13 | @staticmethod
14 | def modify_commandline_options(parser, is_train):
15 | if is_train:
16 | parser.set_defaults(load_size=256)
17 | else:
18 | parser.set_defaults(load_size=256)
19 | parser.set_defaults(old_size=(256, 176))
20 | parser.set_defaults(structure_nc=18)
21 | parser.set_defaults(image_nc=3)
22 | return parser
23 |
24 | def initialize(self, opt):
25 | self.opt = opt
26 | self.root = opt.dataroot
27 | self.phase = opt.phase
28 |
29 | # prepare for image (image_dir), image_pair (name_pairs) and bone annotation (annotation_file)
30 | self.image_dir = os.path.join(self.root, self.phase)
31 | self.bone_file = os.path.join(self.root, 'fasion-resize-annotation-%s.csv' % self.phase)
32 | pairLst = os.path.join(self.root, 'fasion-resize-pairs-%s.csv' % self.phase)
33 | self.name_pairs = self.init_categories(pairLst)
34 | self.annotation_file = pd.read_csv(self.bone_file, sep=':')
35 | self.annotation_file = self.annotation_file.set_index('name')
36 |
37 | # load image size
38 | if isinstance(opt.loadSize, int):
39 | self.load_size = (opt.loadSize, opt.loadSize)
40 | else:
41 | self.load_size = opt.loadSize
42 |
43 | # prepare for transformation
44 | transform_list=[]
45 | transform_list.append(transforms.ToTensor())
46 | transform_list.append(transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5)))
47 | self.trans = transforms.Compose(transform_list)
48 |
49 | def __getitem__(self, index):
50 | # prepare for source image Xs and target image Xt
51 | Xs_name, Xt_name = self.name_pairs[index]
52 | Xs_path = os.path.join(self.image_dir, Xs_name)
53 | Xt_path = os.path.join(self.image_dir, Xt_name)
54 |
55 | Xs = Image.open(Xs_path).convert('RGB')
56 | Xt = Image.open(Xt_path).convert('RGB')
57 |
58 | Xs = F.resize(Xs, self.load_size)
59 | Xt = F.resize(Xt, self.load_size)
60 |
61 | Ps = self.obtain_bone(Xs_name)
62 | Xs = self.trans(Xs)
63 | Pt = self.obtain_bone(Xt_name)
64 | Xt = self.trans(Xt)
65 |
66 | return {'Xs': Xs, 'Ps': Ps, 'Xt': Xt, 'Pt': Pt,
67 | 'Xs_path': Xs_name, 'Xt_path': Xt_name}
68 |
69 | def init_categories(self, pairLst):
70 | pairs_file_train = pd.read_csv(pairLst)
71 | size = len(pairs_file_train)
72 | pairs = []
73 | print('Loading data pairs ...')
74 | for i in range(size):
75 | pair = [pairs_file_train.iloc[i]['from'], pairs_file_train.iloc[i]['to']]
76 | pairs.append(pair)
77 |
78 | print('Loading data pairs finished ...')
79 | return pairs
80 |
81 | def getRandomAffineParam(self):
82 | if self.opt.angle is not False:
83 | angle = np.random.uniform(low=self.opt.angle[0], high=self.opt.angle[1])
84 | else:
85 | angle = 0
86 | if self.opt.scale is not False:
87 | scale = np.random.uniform(low=self.opt.scale[0], high=self.opt.scale[1])
88 | else:
89 | scale = 1
90 | if self.opt.shift is not False:
91 | shift_x = np.random.uniform(low=self.opt.shift[0], high=self.opt.shift[1])
92 | shift_y = np.random.uniform(low=self.opt.shift[0], high=self.opt.shift[1])
93 | else:
94 | shift_x = 0
95 | shift_y = 0
96 | return angle, (shift_x, shift_y), scale
97 |
98 | def obtain_bone(self, name):
99 | string = self.annotation_file.loc[name]
100 | array = pose_utils.load_pose_cords_from_strings(string['keypoints_y'], string['keypoints_x'])
101 | pose = pose_utils.cords_to_map(array, self.load_size, self.opt.old_size)
102 | pose = np.transpose(pose,(2, 0, 1))
103 | pose = torch.Tensor(pose)
104 | return pose
105 |
106 | def obtain_bone_affine(self, name, affine_matrix):
107 | string = self.annotation_file.loc[name]
108 | array = pose_utils.load_pose_cords_from_strings(string['keypoints_y'], string['keypoints_x'])
109 | pose = pose_utils.cords_to_map(array, self.load_size, self.opt.old_size, affine_matrix)
110 | pose = np.transpose(pose,(2, 0, 1))
111 | pose = torch.Tensor(pose)
112 | return pose
113 |
114 | def __len__(self):
115 | return len(self.name_pairs) // self.opt.batchSize * self.opt.batchSize
116 |
117 | def name(self):
118 | return 'FashionDataset'
--------------------------------------------------------------------------------
/metrics/inception.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 | from torchvision import models
4 |
5 |
6 | class InceptionV3(nn.Module):
7 | """Pretrained InceptionV3 network returning feature maps"""
8 |
9 | # Index of default block of inception to return,
10 | # corresponds to output of final average pooling
11 | DEFAULT_BLOCK_INDEX = 3
12 |
13 | # Maps feature dimensionality to their output blocks indices
14 | BLOCK_INDEX_BY_DIM = {
15 | 64: 0, # First max pooling features
16 | 192: 1, # Second max pooling featurs
17 | 768: 2, # Pre-aux classifier features
18 | 2048: 3 # Final average pooling features
19 | }
20 |
21 | def __init__(self,
22 | output_blocks=[DEFAULT_BLOCK_INDEX],
23 | resize_input=True,
24 | normalize_input=True,
25 | requires_grad=False):
26 | """Build pretrained InceptionV3
27 | Parameters
28 | ----------
29 | output_blocks : list of int
30 | Indices of blocks to return features of. Possible values are:
31 | - 0: corresponds to output of first max pooling
32 | - 1: corresponds to output of second max pooling
33 | - 2: corresponds to output which is fed to aux classifier
34 | - 3: corresponds to output of final average pooling
35 | resize_input : bool
36 | If true, bilinearly resizes input to width and height 299 before
37 | feeding input to model. As the network without fully connected
38 | layers is fully convolutional, it should be able to handle inputs
39 | of arbitrary size, so resizing might not be strictly needed
40 | normalize_input : bool
41 | If true, normalizes the input to the statistics the pretrained
42 | Inception network expects
43 | requires_grad : bool
44 | If true, parameters of the model require gradient. Possibly useful
45 | for finetuning the network
46 | """
47 | super(InceptionV3, self).__init__()
48 |
49 | self.resize_input = resize_input
50 | self.normalize_input = normalize_input
51 | self.output_blocks = sorted(output_blocks)
52 | self.last_needed_block = max(output_blocks)
53 |
54 | assert self.last_needed_block <= 3, \
55 | 'Last possible output block index is 3'
56 |
57 | self.blocks = nn.ModuleList()
58 |
59 | inception = models.inception_v3(pretrained=True)
60 |
61 | # Block 0: input to maxpool1
62 | block0 = [
63 | inception.Conv2d_1a_3x3,
64 | inception.Conv2d_2a_3x3,
65 | inception.Conv2d_2b_3x3,
66 | nn.MaxPool2d(kernel_size=3, stride=2)
67 | ]
68 | self.blocks.append(nn.Sequential(*block0))
69 |
70 | # Block 1: maxpool1 to maxpool2
71 | if self.last_needed_block >= 1:
72 | block1 = [
73 | inception.Conv2d_3b_1x1,
74 | inception.Conv2d_4a_3x3,
75 | nn.MaxPool2d(kernel_size=3, stride=2)
76 | ]
77 | self.blocks.append(nn.Sequential(*block1))
78 |
79 | # Block 2: maxpool2 to aux classifier
80 | if self.last_needed_block >= 2:
81 | block2 = [
82 | inception.Mixed_5b,
83 | inception.Mixed_5c,
84 | inception.Mixed_5d,
85 | inception.Mixed_6a,
86 | inception.Mixed_6b,
87 | inception.Mixed_6c,
88 | inception.Mixed_6d,
89 | inception.Mixed_6e,
90 | ]
91 | self.blocks.append(nn.Sequential(*block2))
92 |
93 | # Block 3: aux classifier to final avgpool
94 | if self.last_needed_block >= 3:
95 | block3 = [
96 | inception.Mixed_7a,
97 | inception.Mixed_7b,
98 | inception.Mixed_7c,
99 | nn.AdaptiveAvgPool2d(output_size=(1, 1))
100 | ]
101 | self.blocks.append(nn.Sequential(*block3))
102 |
103 | for param in self.parameters():
104 | param.requires_grad = requires_grad
105 |
106 | def forward(self, inp):
107 | """Get Inception feature maps
108 | Parameters
109 | ----------
110 | inp : torch.autograd.Variable
111 | Input tensor of shape Bx3xHxW. Values are expected to be in
112 | range (0, 1)
113 | Returns
114 | -------
115 | List of torch.autograd.Variable, corresponding to the selected output
116 | block, sorted ascending by index
117 | """
118 | outp = []
119 | x = inp
120 |
121 | if self.resize_input:
122 | x = F.upsample(x, size=(299, 299), mode='bilinear')
123 |
124 | if self.normalize_input:
125 | x = x.clone()
126 | x[:, 0] = x[:, 0] * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
127 | x[:, 1] = x[:, 1] * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
128 | x[:, 2] = x[:, 2] * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
129 |
130 | for idx, block in enumerate(self.blocks):
131 | x = block(x)
132 | if idx in self.output_blocks:
133 | outp.append(x)
134 |
135 | if idx == self.last_needed_block:
136 | break
137 |
138 | return outp
139 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | import time
2 | import os
3 | import numpy as np
4 | import torch
5 | from torch.autograd import Variable
6 | from collections import OrderedDict
7 | from subprocess import call
8 | import fractions
9 | def lcm(a,b): return abs(a * b)/fractions.gcd(a,b) if a and b else 0
10 |
11 | from options.train_options import TrainOptions
12 | from data.data_loader import CreateDataLoader
13 | from models.models import create_model
14 | import util.util as util
15 | from util.visualizer import Visualizer
16 | from torch.utils.tensorboard import SummaryWriter
17 |
18 | opt = TrainOptions().parse()
19 | iter_path = os.path.join(opt.checkpoints_dir, opt.name, 'iter.txt')
20 | if opt.continue_train:
21 | try:
22 | start_epoch, epoch_iter = np.loadtxt(iter_path , delimiter=',', dtype=int)
23 | except:
24 | start_epoch, epoch_iter = 1, 0
25 | print('Resuming from epoch %d at iteration %d' % (start_epoch, epoch_iter))
26 | else:
27 | start_epoch, epoch_iter = 1, 0
28 |
29 | opt.iter_start = start_epoch
30 |
31 | opt.print_freq = lcm(opt.print_freq, opt.batchSize)
32 | if opt.debug:
33 | opt.display_freq = 1
34 | opt.print_freq = 1
35 | opt.niter = 1
36 | opt.niter_decay = 0
37 | opt.max_dataset_size = 10
38 |
39 | data_loader = CreateDataLoader(opt)
40 | dataset = data_loader.load_data()
41 | dataset_size = len(data_loader)
42 | print('#training images = %d' % dataset_size)
43 | writer = SummaryWriter(comment=opt.name)
44 |
45 | model = create_model(opt)
46 | visualizer = Visualizer(opt)
47 |
48 | total_steps = (start_epoch-1) * dataset_size + epoch_iter
49 |
50 | display_delta = total_steps % opt.display_freq
51 | print_delta = total_steps % opt.print_freq
52 | save_delta = total_steps % opt.save_latest_freq
53 |
54 | for epoch in range(start_epoch, opt.niter + opt.niter_decay + 1):
55 | epoch_start_time = time.time()
56 | if epoch != start_epoch:
57 | epoch_iter = epoch_iter % dataset_size
58 | for i, data in enumerate(dataset, start=epoch_iter):
59 | print("epoch: ", epoch, "iter: ", epoch_iter, "total_iteration: ", total_steps, end=" ")
60 | if total_steps % opt.print_freq == print_delta:
61 | iter_start_time = time.time()
62 | total_steps += opt.batchSize
63 | epoch_iter += opt.batchSize
64 |
65 | save_fake = total_steps % opt.display_freq == display_delta
66 |
67 | model.set_input(data)
68 | model.optimize_parameters()
69 |
70 | losses = model.get_current_errors()
71 | for k, v in losses.items():
72 | print(k, ": ", '%.2f' % v, end=" ")
73 | lr_G, lr_D = model.get_current_learning_rate()
74 | print("learning rate G: %.7f" % lr_G, end=" ")
75 | print("learning rate D: %.7f" % lr_D, end=" ")
76 | print('\n')
77 |
78 |
79 | writer.add_scalar('Loss/app_gen_s', losses['app_gen_s'], total_steps)
80 | writer.add_scalar('Loss/content_gen_s', losses['content_gen_s'], total_steps)
81 | writer.add_scalar('Loss/style_gen_s', losses['style_gen_s'], total_steps)
82 | writer.add_scalar('Loss/app_gen_t', losses['app_gen_t'], total_steps)
83 | writer.add_scalar('Loss/ad_gen_t', losses['ad_gen_t'], total_steps)
84 | writer.add_scalar('Loss/dis_img_gen_t', losses['dis_img_gen_t'], total_steps)
85 | writer.add_scalar('Loss/content_gen_t', losses['content_gen_t'], total_steps)
86 | writer.add_scalar('Loss/style_gen_t', losses['style_gen_t'], total_steps)
87 | writer.add_scalar('LR/G', lr_G, total_steps)
88 | writer.add_scalar('LR/D', lr_D, total_steps)
89 |
90 |
91 | ############## Display results and errors ##########
92 | if total_steps % opt.print_freq == print_delta:
93 | losses = model.get_current_errors()
94 | t = (time.time() - iter_start_time) / opt.batchSize
95 | visualizer.print_current_errors(epoch, epoch_iter, total_steps, losses, lr_G, lr_D, t)
96 | if opt.display_id > 0:
97 | visualizer.plot_current_errors(total_steps, losses)
98 |
99 | if total_steps % opt.display_freq == display_delta:
100 | visualizer.display_current_results(model.get_current_visuals(), epoch)
101 | if hasattr(model, 'distribution'):
102 | visualizer.plot_current_distribution(model.get_current_dis())
103 |
104 | if total_steps % opt.save_latest_freq == save_delta:
105 | print('saving the latest model (epoch %d, total_steps %d)' % (epoch, total_steps))
106 | model.save_networks('latest')
107 | if opt.dataset_mode == 'market':
108 | model.save_networks(total_steps)
109 | np.savetxt(iter_path, (epoch, epoch_iter), delimiter=',', fmt='%d')
110 |
111 | if epoch_iter >= dataset_size:
112 | break
113 |
114 | # end of epoch
115 | iter_end_time = time.time()
116 | print('End of epoch %d / %d \t Time Taken: %d sec' %
117 | (epoch, opt.niter + opt.niter_decay, time.time() - epoch_start_time))
118 |
119 | ### save model for this epoch
120 | if epoch % opt.save_epoch_freq == 0 or (epoch > opt.niter and epoch % (opt.save_epoch_freq//2) == 0):
121 | print('saving the model at the end of epoch %d, iters %d' % (epoch, total_steps))
122 | model.save_networks('latest')
123 | model.save_networks(epoch)
124 | np.savetxt(iter_path, (epoch+1, 0), delimiter=',', fmt='%d')
125 |
126 | ### linearly decay learning rate after certain iterations
127 | model.update_learning_rate()
128 |
--------------------------------------------------------------------------------
/util/pose_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from scipy.ndimage.filters import gaussian_filter
3 | from skimage.draw import circle, line_aa, polygon
4 | import json
5 |
6 | import matplotlib
7 | matplotlib.use('Agg')
8 | import matplotlib.pyplot as plt
9 | import matplotlib.patches as mpatches
10 | from collections import defaultdict
11 | import skimage.measure, skimage.transform
12 | import sys
13 |
14 | LIMB_SEQ = [[1,2], [1,5], [2,3], [3,4], [5,6], [6,7], [1,8], [8,9],
15 | [9,10], [1,11], [11,12], [12,13], [1,0], [0,14], [14,16],
16 | [0,15], [15,17], [2,16], [5,17]]
17 |
18 | COLORS = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0],
19 | [0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255],
20 | [170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
21 |
22 |
23 | LABELS = ['nose', 'neck', 'Rsho', 'Relb', 'Rwri', 'Lsho', 'Lelb', 'Lwri',
24 | 'Rhip', 'Rkne', 'Rank', 'Lhip', 'Lkne', 'Lank', 'Leye', 'Reye', 'Lear', 'Rear']
25 |
26 | MISSING_VALUE = -1
27 |
28 |
29 | def map_to_cord(pose_map, threshold=0.1):
30 | all_peaks = [[] for i in range(18)]
31 | pose_map = pose_map[..., :18]
32 |
33 | y, x, z = np.where(np.logical_and(pose_map == pose_map.max(axis = (0, 1)),
34 | pose_map > threshold))
35 | for x_i, y_i, z_i in zip(x, y, z):
36 | all_peaks[z_i].append([x_i, y_i])
37 |
38 | x_values = []
39 | y_values = []
40 |
41 | for i in range(18):
42 | if len(all_peaks[i]) != 0:
43 | x_values.append(all_peaks[i][0][0])
44 | y_values.append(all_peaks[i][0][1])
45 | else:
46 | x_values.append(MISSING_VALUE)
47 | y_values.append(MISSING_VALUE)
48 |
49 | return np.concatenate([np.expand_dims(y_values, -1), np.expand_dims(x_values, -1)], axis=1)
50 |
51 |
52 | def cords_to_map(cords, img_size, old_size=None, affine_matrix=None, sigma=6):
53 | old_size = img_size if old_size is None else old_size
54 | cords = cords.astype(float)
55 | result = np.zeros(img_size + cords.shape[0:1], dtype='float32')
56 | for i, point in enumerate(cords):
57 | if point[0] == MISSING_VALUE or point[1] == MISSING_VALUE:
58 | continue
59 | point[0] = point[0]/old_size[0] * img_size[0]
60 | point[1] = point[1]/old_size[1] * img_size[1]
61 | if affine_matrix is not None:
62 | point_ =np.dot(affine_matrix, np.matrix([point[1], point[0], 1]).reshape(3,1))
63 | point_0 = int(point_[1])
64 | point_1 = int(point_[0])
65 | else:
66 | point_0 = int(point[0])
67 | point_1 = int(point[1])
68 | xx, yy = np.meshgrid(np.arange(img_size[1]), np.arange(img_size[0]))
69 | result[..., i] = np.exp(-((yy - point_0) ** 2 + (xx - point_1) ** 2) / (2 * sigma ** 2))
70 | return result
71 |
72 |
73 | def draw_pose_from_cords(pose_joints, img_size, radius=2, draw_joints=True):
74 | colors = np.zeros(shape=img_size + (3, ), dtype=np.uint8)
75 | mask = np.zeros(shape=img_size, dtype=bool)
76 |
77 | if draw_joints:
78 | for f, t in LIMB_SEQ:
79 | from_missing = pose_joints[f][0] == MISSING_VALUE or pose_joints[f][1] == MISSING_VALUE
80 | to_missing = pose_joints[t][0] == MISSING_VALUE or pose_joints[t][1] == MISSING_VALUE
81 | if from_missing or to_missing:
82 | continue
83 | yy, xx, val = line_aa(pose_joints[f][0], pose_joints[f][1], pose_joints[t][0], pose_joints[t][1])
84 | colors[yy, xx] = np.expand_dims(val, 1) * 255
85 | mask[yy, xx] = True
86 |
87 | for i, joint in enumerate(pose_joints):
88 | if pose_joints[i][0] == MISSING_VALUE or pose_joints[i][1] == MISSING_VALUE:
89 | continue
90 | yy, xx = circle(joint[0], joint[1], radius=radius, shape=img_size)
91 | colors[yy, xx] = COLORS[i]
92 | mask[yy, xx] = True
93 |
94 | return colors, mask
95 |
96 |
97 | def draw_pose_from_map(pose_map, threshold=0.1, **kwargs):
98 | cords = map_to_cord(pose_map, threshold=threshold)
99 | return draw_pose_from_cords(cords, pose_map.shape[:2], **kwargs)
100 |
101 |
102 | def load_pose_cords_from_strings(y_str, x_str):
103 | y_cords = json.loads(y_str)
104 | x_cords = json.loads(x_str)
105 | return np.concatenate([np.expand_dims(y_cords, -1), np.expand_dims(x_cords, -1)], axis=1)
106 |
107 | def mean_inputation(X):
108 | X = X.copy()
109 | for i in range(X.shape[1]):
110 | for j in range(X.shape[2]):
111 | val = np.mean(X[:, i, j][X[:, i, j] != -1])
112 | X[:, i, j][X[:, i, j] == -1] = val
113 | return X
114 |
115 | def draw_legend():
116 | handles = [mpatches.Patch(color=np.array(color) / 255.0, label=name) for color, name in zip(COLORS, LABELS)]
117 | plt.legend(handles=handles, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
118 |
119 | def produce_ma_mask(kp_array, img_size, point_radius=4):
120 | from skimage.morphology import dilation, erosion, square
121 | mask = np.zeros(shape=img_size, dtype=bool)
122 | limbs = [[2,3], [2,6], [3,4], [4,5], [6,7], [7,8], [2,9], [9,10],
123 | [10,11], [2,12], [12,13], [13,14], [2,1], [1,15], [15,17],
124 | [1,16], [16,18], [2,17], [2,18], [9,12], [12,6], [9,3], [17,18]]
125 | limbs = np.array(limbs) - 1
126 | for f, t in limbs:
127 | from_missing = kp_array[f][0] == MISSING_VALUE or kp_array[f][1] == MISSING_VALUE
128 | to_missing = kp_array[t][0] == MISSING_VALUE or kp_array[t][1] == MISSING_VALUE
129 | if from_missing or to_missing:
130 | continue
131 |
132 | norm_vec = kp_array[f] - kp_array[t]
133 | norm_vec = np.array([-norm_vec[1], norm_vec[0]])
134 | norm_vec = point_radius * norm_vec / np.linalg.norm(norm_vec)
135 |
136 |
137 | vetexes = np.array([
138 | kp_array[f] + norm_vec,
139 | kp_array[f] - norm_vec,
140 | kp_array[t] - norm_vec,
141 | kp_array[t] + norm_vec
142 | ])
143 | yy, xx = polygon(vetexes[:, 0], vetexes[:, 1], shape=img_size)
144 | mask[yy, xx] = True
145 |
146 | for i, joint in enumerate(kp_array):
147 | if kp_array[i][0] == MISSING_VALUE or kp_array[i][1] == MISSING_VALUE:
148 | continue
149 | yy, xx = circle(joint[0], joint[1], radius=point_radius, shape=img_size)
150 | mask[yy, xx] = True
151 |
152 | mask = dilation(mask, square(5))
153 | mask = erosion(mask, square(5))
154 | return mask
155 |
156 | if __name__ == "__main__":
157 | import pandas as pd
158 | from skimage.io import imread
159 | import pylab as plt
160 | import os
161 | i = 5
162 | df = pd.read_csv('data/market-annotation-train.csv', sep=':')
163 |
164 | for index, row in df.iterrows():
165 | pose_cords = load_pose_cords_from_strings(row['keypoints_y'], row['keypoints_x'])
166 |
167 | colors, mask = draw_pose_from_cords(pose_cords, (128, 64))
168 |
169 | mmm = produce_ma_mask(pose_cords, (128, 64)).astype(float)[..., np.newaxis].repeat(3, axis=-1)
170 | print(mmm.shape)
171 | img = imread('data/market-dataset/train/' + row['name'])
172 |
173 | mmm[mask] = colors[mask]
174 |
175 | print (mmm)
176 | plt.subplot(1, 1, 1)
177 | plt.imshow(mmm)
178 | plt.show()
179 |
--------------------------------------------------------------------------------
/options/base_options.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | from util import util
4 | import torch
5 | import data
6 | import models
7 |
8 | class BaseOptions():
9 | def __init__(self):
10 | self.parser = argparse.ArgumentParser()
11 | self.initialized = False
12 |
13 | def initialize(self):
14 | # experiment specifics
15 | self.parser.add_argument('--name', type=str, default='label2city', help='name of the experiment. It decides where to store samples and models')
16 | self.parser.add_argument('--gpu_ids', type=str, default='0', help='gpu ids: e.g. 0 0,1,2, 0,2. use -1 for CPU')
17 | self.parser.add_argument('--checkpoints_dir', type=str, default='./checkpoints', help='models are saved here')
18 | self.parser.add_argument('--model', type=str, default='pix2pixHD', help='which model to use')
19 | self.parser.add_argument('--norm', type=str, default='instance', help='instance normalization or batch normalization')
20 | self.parser.add_argument('--use_dropout', action='store_true', help='use dropout for the generator')
21 | self.parser.add_argument('--data_type', default=32, type=int, choices=[8, 16, 32], help="Supported data type i.e. 8, 16, 32 bit")
22 | self.parser.add_argument('--verbose', action='store_true', default=False, help='toggles verbose')
23 | self.parser.add_argument('--fp16', action='store_true', default=False, help='train with AMP')
24 | self.parser.add_argument('--local_rank', type=int, default=0, help='local rank for distributed training')
25 |
26 | # input/output sizes
27 | self.parser.add_argument('--image_nc', type=int, default=3)
28 | self.parser.add_argument('--pose_nc', type=int, default=18)
29 | self.parser.add_argument('--batchSize', type=int, default=1, help='input batch size')
30 | self.parser.add_argument('--old_size', type=int, default=(256, 176), help='Scale images to this size. The final image will be cropped to --crop_size.')
31 | self.parser.add_argument('--loadSize', type=int, default=256, help='scale images to this size')
32 | self.parser.add_argument('--fineSize', type=int, default=512, help='then crop to this size')
33 | self.parser.add_argument('--label_nc', type=int, default=35, help='# of input label channels')
34 | self.parser.add_argument('--input_nc', type=int, default=3, help='# of input image channels')
35 | self.parser.add_argument('--output_nc', type=int, default=3, help='# of output image channels')
36 |
37 | # for setting inputs
38 | self.parser.add_argument('--dataset_mode', type=str, default='fashion')
39 | self.parser.add_argument('--dataroot', type=str, default='/media/data2/zhangpz/DataSet/Fashion')
40 | self.parser.add_argument('--resize_or_crop', type=str, default='scale_width', help='scaling and cropping of images at load time [resize_and_crop|crop|scale_width|scale_width_and_crop]')
41 | self.parser.add_argument('--serial_batches', action='store_true', help='if true, takes images in order to make batches, otherwise takes them randomly')
42 | self.parser.add_argument('--no_flip', action='store_true', help='if specified, do not flip the images for data argumentation')
43 | self.parser.add_argument('--nThreads', default=2, type=int, help='# threads for loading data')
44 | self.parser.add_argument('--max_dataset_size', type=int, default=float("inf"), help='Maximum number of samples allowed per dataset. If the dataset directory contains more than max_dataset_size, only a subset is loaded.')
45 |
46 | # for displays
47 | self.parser.add_argument('--display_winsize', type=int, default=512, help='display window size')
48 | self.parser.add_argument('--tf_log', action='store_true', help='if specified, use tensorboard logging. Requires tensorflow installed')
49 | self.parser.add_argument('--display_id', type=int, default=0, help='display id of the web') # 1
50 | self.parser.add_argument('--display_port', type=int, default=8096, help='visidom port of the web display')
51 | self.parser.add_argument('--display_single_pane_ncols', type=int, default=0,
52 | help='if positive, display all images in a single visidom web panel')
53 | self.parser.add_argument('--display_env', type=str, default=self.parser.parse_known_args()[0].name.replace('_', ''),
54 | help='the environment of visidom display')
55 | # for instance-wise features
56 | self.parser.add_argument('--no_instance', action='store_true', help='if specified, do *not* add instance map as input')
57 | self.parser.add_argument('--instance_feat', action='store_true', help='if specified, add encoded instance features as input')
58 | self.parser.add_argument('--label_feat', action='store_true', help='if specified, add encoded label features as input')
59 | self.parser.add_argument('--feat_num', type=int, default=3, help='vector length for encoded features')
60 | self.parser.add_argument('--load_features', action='store_true', help='if specified, load precomputed feature maps')
61 | self.parser.add_argument('--n_downsample_E', type=int, default=4, help='# of downsampling layers in encoder')
62 | self.parser.add_argument('--nef', type=int, default=16, help='# of encoder filters in the first conv layer')
63 | self.parser.add_argument('--n_clusters', type=int, default=10, help='number of clusters for features')
64 |
65 | self.initialized = True
66 |
67 | def parse(self, save=True):
68 | if not self.initialized:
69 | self.initialize()
70 | opt, _ = self.parser.parse_known_args()
71 | # modify the options for different models
72 | model_option_set = models.get_option_setter(opt.model)
73 | self.parser = model_option_set(self.parser, self.isTrain)
74 |
75 | data_option_set = data.get_option_setter(opt.dataset_mode)
76 | self.parser = data_option_set(self.parser, self.isTrain)
77 |
78 | self.opt = self.parser.parse_args()
79 | self.opt.isTrain = self.isTrain # train or test
80 |
81 | if torch.cuda.is_available():
82 | self.opt.device = torch.device("cuda")
83 | torch.backends.cudnn.benchmark = True # cudnn auto-tuner
84 | else:
85 | self.opt.device = torch.device("cpu")
86 |
87 | str_ids = self.opt.gpu_ids.split(',')
88 | self.opt.gpu_ids = []
89 | for str_id in str_ids:
90 | id = int(str_id)
91 | if id >= 0:
92 | self.opt.gpu_ids.append(id)
93 |
94 | # set gpu ids
95 | if len(self.opt.gpu_ids) > 0:
96 | torch.cuda.set_device(self.opt.gpu_ids[0])
97 |
98 | args = vars(self.opt)
99 |
100 | print('------------ Options -------------')
101 | for k, v in sorted(args.items()):
102 | print('%s: %s' % (str(k), str(v)))
103 | print('-------------- End ----------------')
104 |
105 | # save to the disk
106 | expr_dir = os.path.join(self.opt.checkpoints_dir, self.opt.name)
107 | util.mkdirs(expr_dir)
108 | if save and not (self.isTrain and self.opt.continue_train):
109 | name = 'train' if self.isTrain else 'test'
110 | file_name = os.path.join(expr_dir, name+'_opt.txt')
111 | with open(file_name, 'wt') as opt_file:
112 | opt_file.write('------------ Options -------------\n')
113 | for k, v in sorted(args.items()):
114 | opt_file.write('%s: %s\n' % (str(k), str(v)))
115 | opt_file.write('-------------- End ----------------\n')
116 | return self.opt
117 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Dual-task Pose Transformer Network
2 | The source code for our paper "[Exploring Dual-task Correlation for Pose Guided Person Image Generation](https://openaccess.thecvf.com/content/CVPR2022/papers/Zhang_Exploring_Dual-Task_Correlation_for_Pose_Guided_Person_Image_Generation_CVPR_2022_paper.pdf)“, Pengze Zhang, Lingxiao Yang, Jianhuang Lai, and Xiaohua Xie, CVPR 2022. Video: [[Chinese](https://www.koushare.com/video/videodetail/35887)] [[English](https://www.youtube.com/watch?v=p9o3lOlZBSE)]
3 | 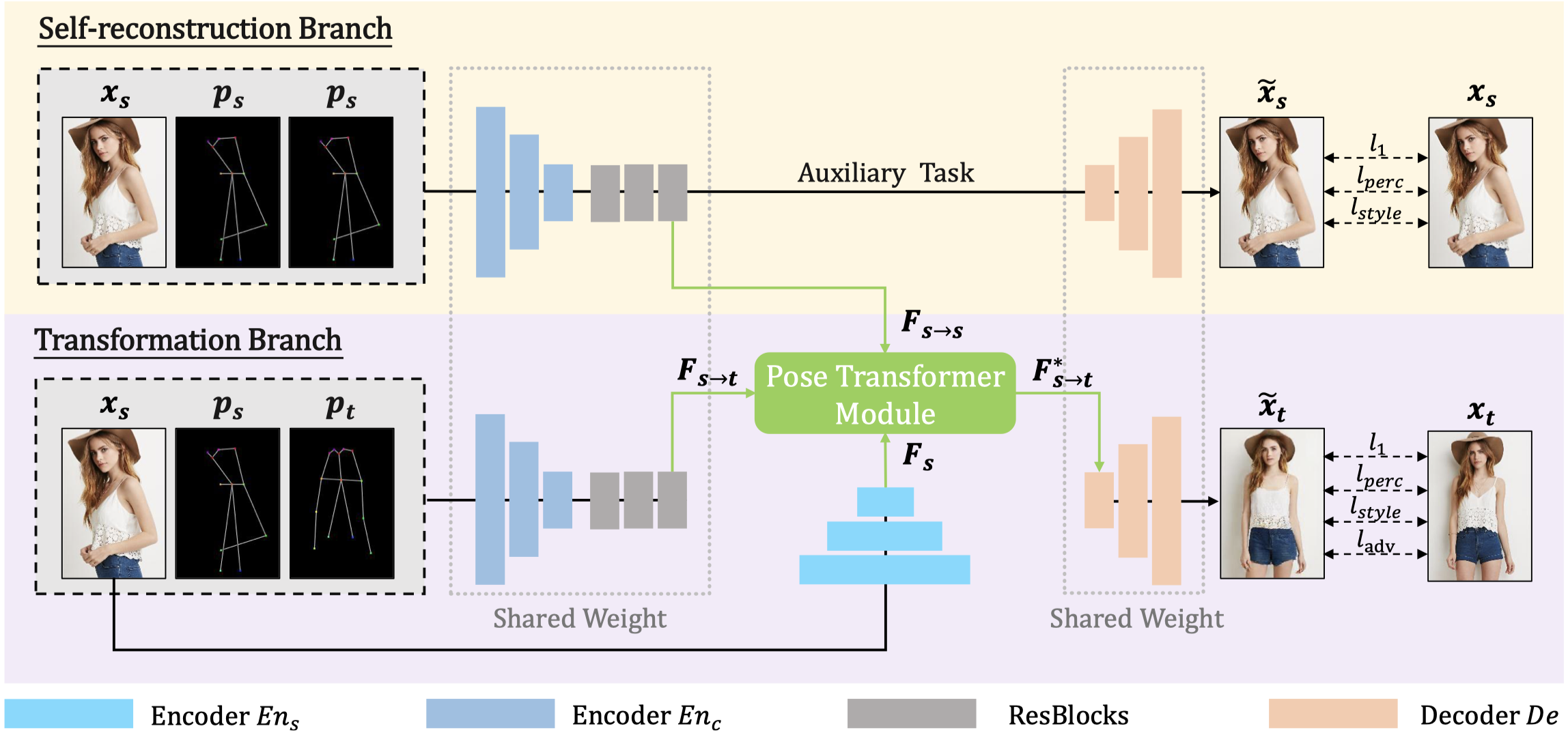 4 |
5 | ## Abstract
6 |
7 | Pose Guided Person Image Generation (PGPIG) is the task of transforming a person image from the source pose to a given target pose. Most of the existing methods only focus on the ill-posed source-to-target task and fail to capture reasonable texture mapping. To address this problem, we propose a novel Dual-task Pose Transformer Network (DPTN), which introduces an auxiliary task (i.e., source-tosource task) and exploits the dual-task correlation to promote the performance of PGPIG. The DPTN is of a Siamese structure, containing a source-to-source self-reconstruction branch, and a transformation branch for source-to-target generation. By sharing partial weights between them, the knowledge learned by the source-to-source task can effectively assist the source-to-target learning. Furthermore, we bridge the two branches with a proposed Pose Transformer Module (PTM) to adaptively explore the correlation between features from dual tasks. Such correlation can establish the fine-grained mapping of all the pixels between the sources and the targets, and promote the source texture transmission to enhance the details of the generated target images. Extensive experiments show that our DPTN outperforms state-of-the-arts in terms of both PSNR and LPIPS. In addition, our DPTN only contains 9.79 million parameters, which is significantly smaller than other approaches.
8 |
9 |
10 | ## Get Start
11 |
12 | ### 1) Requirement
13 |
14 | * Python 3.7.9
15 | * Pytorch 1.7.1
16 | * torchvision 0.8.2
17 | * CUDA 11.1
18 | * NVIDIA A100 40GB PCIe
19 |
20 | ### 2) Data Preperation
21 |
22 | Following **[PATN](https://github.com/tengteng95/Pose-Transfer)**, the dataset split files and extracted keypoints files can be obtained as follows:
23 |
24 | **DeepFashion**
25 |
26 |
27 | * Download the DeepFashion dataset **[in-shop clothes retrival benchmark](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/InShopRetrieval.html)**, and put them under the `./dataset/fashion` directory.
28 |
29 | * Download train/test pairs and train/test keypoints annotations from **[Google Drive](https://drive.google.com/drive/folders/1qZDod3QDD7PaBxnNyHCuLBR7ftTSkSE1?usp=sharing)**, including **fasion-resize-pairs-train.csv, fasion-resize-pairs-test.csv, fasion-resize-annotation-train.csv, fasion-resize-annotation-train.csv, train.lst, test.lst**, and put them under the `./dataset/fashion` directory.
30 |
31 | * Split the raw image into the training set (`./dataset/fashion/train`) and test set (`./dataset/fashion/test`):
32 | ``` bash
33 | python data/generate_fashion_datasets.py
34 | ```
35 |
36 | **Market1501**
37 |
38 | * Download the Market1501 dataset from **[here](http://zheng-lab.cecs.anu.edu.au/Project/project_reid.html)**. Rename **bounding_box_train** and **bounding_box_test** as **train** and **test**, and put them under the `./dataset/market` directory.
39 |
40 | * Download train/test key points annotations from **[Google Drive](https://drive.google.com/drive/folders/1zzkimhX_D5gR1G8txTQkPXwdZPRcnrAx?usp=sharing)** including **market-pairs-train.csv, market-pairs-test.csv, market-annotation-train.csv, market-annotation-train.csv**. Put these files under the `./dataset/market` directory.
41 |
42 | ### 3) Train a model
43 |
44 | **DeepFashion**
45 | ``` bash
46 | python train.py --name=DPTN_fashion --model=DPTN --dataset_mode=fashion --dataroot=./dataset/fashion --batchSize 32 --gpu_id=0
47 | ```
48 | **Market1501**
49 |
50 | ``` bash
51 | python train.py --name=DPTN_market --model=DPTN --dataset_mode=market --dataroot=./dataset/market --dis_layers=3 --lambda_g=5 --lambda_rec 2 --t_s_ratio=0.8 --save_latest_freq=10400 --batchSize 32 --gpu_id=0
52 | ```
53 |
54 | ### 4) Test the model
55 |
56 | You can directly download our test results from Google Drive: **[Deepfashion](https://drive.google.com/drive/folders/1Y_Ar7w_CAYRgG2gzBg2vfxTCCen7q7k2?usp=sharing)**, **[Market1501](https://drive.google.com/drive/folders/15UBWEtGAqYaoEREIIeIuD-P4dRgsys19?usp=sharing)**.
57 |
58 | **DeepFashion**
59 | ``` bash
60 | python test.py --name=DPTN_fashion --model=DPTN --dataset_mode=fashion --dataroot=./dataset/fashion --which_epoch latest --results_dir ./results/DPTN_fashion --batchSize 1 --gpu_id=0
61 | ```
62 |
63 | **Market1501**
64 |
65 | ``` bash
66 | python test.py --name=DPTN_market --model=DPTN --dataset_mode=market --dataroot=./dataset/market --which_epoch latest --results_dir=./results/DPTN_market --batchSize 1 --gpu_id=0
67 | ```
68 |
69 | ### 5) Evaluation
70 |
71 | We adopt SSIM, PSNR, FID, LPIPS and person re-identification (re-id) system for the evaluation. Please clone the official repository **[PerceptualSimilarity](https://github.com/richzhang/PerceptualSimilarity/tree/future)** of the LPIPS score, and put the folder PerceptualSimilarity to the folder **[metrics](https://github.com/PangzeCheung/Dual-task-Pose-Transformer-Network/tree/main/metrics)**.
72 |
73 | * For SSIM, PSNR, FID and LPIPS:
74 |
75 | **DeepFashion**
76 | ``` bash
77 | python -m metrics.metrics --gt_path=./dataset/fashion/test --distorated_path=./results/DPTN_fashion --fid_real_path=./dataset/fashion/train --name=./fashion
78 | ```
79 |
80 | **Market1501**
81 |
82 | ``` bash
83 | python -m metrics.metrics --gt_path=./dataset/market/test --distorated_path=./results/DPTN_market --fid_real_path=./dataset/market/train --name=./market --market
84 | ```
85 |
86 | * For person re-id system:
87 |
88 | Clone the code of the **[fast-reid](https://github.com/JDAI-CV/fast-reid)** to this project (`./fast-reid-master`). Move the **[config](https://drive.google.com/file/d/1xWCnNpcNrgjEMDKuK29Gre3sYEE1yWTV/view?usp=sharing)** and **[loader](https://drive.google.com/file/d/1axMKB7QlYQgo7f1ZWigTh3uLIDvXRxro/view?usp=sharing)** of the DeepFashion dataset to (`./fast-reid-master/configs/Fashion/bagtricks_R50.yml`) and (`./fast-reid-master/fastreid/data/datasets/fashion.py`) respectively. Download the **[pre-trained network](https://drive.google.com/file/d/1Co6NVWN6OSqPVUd7ut8xCwsQQDIOcypV/view?usp=sharing)** and put it under the `./fast-reid-master/logs/Fashion/bagtricks_R50-ibn/` directory. And then launch:
89 |
90 | ``` bash
91 | python ./tools/train_net.py --config-file ./configs/Fashion/bagtricks_R50.yml --eval-only MODEL.WEIGHTS ./logs/Fashion/bagtricks_R50-ibn/model_final.pth MODEL.DEVICE "cuda:0"
92 | ```
93 |
94 | ### 6) Pre-trained Model
95 |
96 | Our pre-trained models and logs can be downloaded from Google Drive: **[Deepfashion](https://drive.google.com/drive/folders/12Ufr8jkOwAIGVEamDedJy_ZWPvJZn8WG?usp=sharing)**[**[log](https://drive.google.com/drive/folders/16ZYYl_jVdK8E9FtnQi6oi6JGfBuD2jCt?usp=sharing)**], **[Market1501](https://drive.google.com/drive/folders/1YY_U2pMzLrZMTKoK8oBkMylR6KXnZJKP?usp=sharing)**[**[log](https://drive.google.com/drive/folders/1ujlvhz7JILULRVRJsLruT9ZAz2JCT74G?usp=sharing)**].
97 |
98 | ## Citation
99 |
100 | ```tex
101 | @InProceedings{Zhang_2022_CVPR,
102 | author = {Zhang, Pengze and Yang, Lingxiao and Lai, Jian-Huang and Xie, Xiaohua},
103 | title = {Exploring Dual-Task Correlation for Pose Guided Person Image Generation},
104 | booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
105 | month = {June},
106 | year = {2022},
107 | pages = {7713-7722}
108 | }
109 | ```
110 | ## Acknowledgement
111 |
112 | We build our project based on **[pix2pix](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix)**. Some dataset preprocessing methods are derived from **[PATN](https://github.com/tengteng95/Pose-Transfer)**.
113 |
114 |
--------------------------------------------------------------------------------
/models/PTM.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import torch
3 | from torch import nn
4 | from .base_function import *
5 |
6 | class PTM(nn.Module):
7 | """
8 | Pose Transformer Module (PTM)
9 | :param d_model: number of channels in input
10 | :param nhead: number of heads in attention module
11 | :param num_CABs: number of CABs
12 | :param num_TTBs: number of TTBs
13 | :param dim_feedforward: dimension in feedforward
14 | :param activation: activation function 'ReLU, SELU, LeakyReLU, PReLU'
15 | :param affine: affine in normalization
16 | :param norm: normalization function 'instance, batch'
17 | """
18 | def __init__(self, d_model=512, nhead=8, num_CABs=6,
19 | num_TTBs=6, dim_feedforward=2048,
20 | activation="LeakyReLU",
21 | affine=True, norm='instance'):
22 | super().__init__()
23 | encoder_layer = CAB(d_model, nhead, dim_feedforward,
24 | activation, affine, norm)
25 | if norm == 'batch':
26 | encoder_norm = None
27 | decoder_norm = nn.BatchNorm1d(d_model, affine=affine)
28 | elif norm == 'instance':
29 | encoder_norm = None
30 | decoder_norm = nn.InstanceNorm1d(d_model, affine=affine)
31 |
32 | self.encoder = CABs(encoder_layer, num_CABs, encoder_norm)
33 |
34 | decoder_layer = TTB(d_model, nhead, dim_feedforward,
35 | activation, affine, norm)
36 |
37 | self.decoder = TTBs(decoder_layer, num_TTBs, decoder_norm)
38 |
39 | self._reset_parameters()
40 |
41 | self.d_model = d_model
42 | self.nhead = nhead
43 |
44 | def _reset_parameters(self):
45 | for p in self.parameters():
46 | if p.dim() > 1:
47 | nn.init.xavier_uniform_(p)
48 |
49 | def forward(self, src, tgt, val, pos_embed=None):
50 | bs, c, h, w = src.shape
51 | src = src.flatten(2).permute(2, 0, 1)
52 | tgt = tgt.flatten(2).permute(2, 0, 1)
53 | val = val.flatten(2).permute(2, 0, 1)
54 | if pos_embed != None:
55 | pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
56 | memory = self.encoder(src, pos=pos_embed)
57 | hs = self.decoder(tgt, memory, val, pos=pos_embed)
58 | return hs.view(bs, c, h, w)
59 |
60 |
61 | class CABs(nn.Module):
62 | """
63 | Context Augment Blocks (CABs)
64 | :param encoder_layer: CAB
65 | :param num_CABS: number of CABs
66 | :param norm: normalization function 'instance, batch'
67 | """
68 | def __init__(self, encoder_layer, num_CABs, norm=None):
69 | super().__init__()
70 | self.layers = _get_clones(encoder_layer, num_CABs)
71 | self.norm = norm
72 |
73 | def forward(self, src, pos = None):
74 | output = src
75 |
76 | for layer in self.layers:
77 | output = layer(output, pos=pos)
78 |
79 | if self.norm is not None:
80 | output = self.norm(output.permute(1, 2, 0)).permute(2, 0, 1)
81 |
82 | return output
83 |
84 |
85 | class TTBs(nn.Module):
86 | """
87 | Texture Transfer Blocks (TTBs)
88 | :param decoder_layer: TTB
89 | :param num_layers: number of TTBs
90 | :param norm: normalization function 'instance, batch'
91 | """
92 | def __init__(self, decoder_layer, num_TTBs, norm=None):
93 | super().__init__()
94 | self.layers = _get_clones(decoder_layer, num_TTBs)
95 | self.norm = norm
96 |
97 | def forward(self, tgt, memory, val, pos = None):
98 | output = tgt
99 |
100 | for layer in self.layers:
101 | output = layer(output, memory, val, pos=pos)
102 |
103 | if self.norm is not None:
104 | output = self.norm(output.permute(1, 2, 0))
105 | return output
106 |
107 |
108 | class CAB(nn.Module):
109 | """
110 | Context Augment Block (CAB)
111 | :param d_model: number of channels in input
112 | :param nhead: number of heads in attention module
113 | :param dim_feedforward: dimension in feedforward
114 | :param activation: activation function 'ReLU, SELU, LeakyReLU, PReLU'
115 | :param affine: affine in normalization
116 | :param norm: normalization function 'instance, batch'
117 | """
118 | def __init__(self, d_model, nhead, dim_feedforward=2048,
119 | activation="LeakyReLU", affine=True, norm='instance'):
120 | super().__init__()
121 | self.self_attn = nn.MultiheadAttention(d_model, nhead)
122 | self.linear1 = nn.Linear(d_model, dim_feedforward)
123 | self.linear2 = nn.Linear(dim_feedforward, d_model)
124 |
125 | if norm == 'batch':
126 | self.norm1 = nn.BatchNorm1d(d_model, affine=affine)
127 | self.norm2 = nn.BatchNorm1d(d_model, affine=affine)
128 | else:
129 | self.norm1 = nn.InstanceNorm1d(d_model, affine=affine)
130 | self.norm2 = nn.InstanceNorm1d(d_model, affine=affine)
131 |
132 | self.activation = get_nonlinearity_layer(activation)
133 |
134 | def with_pos_embed(self, tensor, pos):
135 | return tensor if pos is None else tensor + pos
136 |
137 | def forward(self, src, pos = None):
138 | q = k = self.with_pos_embed(src, pos)
139 | src2 = self.self_attn(q, k, value=src)[0]
140 | src = src + src2
141 | src = self.norm1(src.permute(1, 2, 0)).permute(2, 0, 1)
142 | src2 = self.linear2(self.activation(self.linear1(src)))
143 | src = src + src2
144 | src = self.norm2(src.permute(1, 2, 0)).permute(2, 0, 1)
145 | return src
146 |
147 |
148 | class TTB(nn.Module):
149 | """
150 | Texture Transfer Block (TTB)
151 | :param d_model: number of channels in input
152 | :param nhead: number of heads in attention module
153 | :param dim_feedforward: dimension in feedforward
154 | :param activation: activation function 'ReLU, SELU, LeakyReLU, PReLU'
155 | :param affine: affine in normalization
156 | :param norm: normalization function 'instance, batch'
157 | """
158 | def __init__(self, d_model, nhead, dim_feedforward=2048,
159 | activation="LeakyReLU", affine=True, norm='instance'):
160 | super().__init__()
161 | self.self_attn = nn.MultiheadAttention(d_model, nhead)
162 | self.multihead_attn = nn.MultiheadAttention(d_model, nhead)
163 | self.linear1 = nn.Linear(d_model, dim_feedforward)
164 | self.linear2 = nn.Linear(dim_feedforward, d_model)
165 |
166 | if norm == 'batch':
167 | self.norm1 = nn.BatchNorm1d(d_model, affine=affine)
168 | self.norm2 = nn.BatchNorm1d(d_model, affine=affine)
169 | self.norm3 = nn.BatchNorm1d(d_model, affine=affine)
170 | else:
171 | self.norm1 = nn.InstanceNorm1d(d_model, affine=affine)
172 | self.norm2 = nn.InstanceNorm1d(d_model, affine=affine)
173 | self.norm3 = nn.InstanceNorm1d(d_model, affine=affine)
174 |
175 | self.activation = get_nonlinearity_layer(activation)
176 |
177 | def with_pos_embed(self, tensor, pos):
178 | return tensor if pos is None else tensor + pos
179 |
180 | def forward(self, tgt, memory, val, pos = None):
181 | q = k = self.with_pos_embed(tgt, pos)
182 | tgt2 = self.self_attn(q, k, value=tgt)[0]
183 | tgt = tgt + tgt2
184 | tgt = self.norm1(tgt.permute(1, 2, 0)).permute(2, 0, 1)
185 | tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, pos),
186 | key=self.with_pos_embed(memory, pos),
187 | value=val)[0]
188 | tgt = tgt + tgt2
189 | tgt = self.norm2(tgt.permute(1, 2, 0)).permute(2, 0, 1)
190 | tgt2 = self.linear2(self.activation(self.linear1(tgt)))
191 | tgt = tgt + tgt2
192 | tgt = self.norm3(tgt.permute(1, 2, 0)).permute(2, 0, 1)
193 | return tgt
194 |
195 |
196 | def _get_clones(module, N):
197 | return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
198 |
199 |
200 |
--------------------------------------------------------------------------------
/util/visualizer.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import os
3 | import ntpath
4 | import time
5 | from . import util
6 | from . import html
7 | import scipy.misc
8 | try:
9 | from StringIO import StringIO # Python 2.7
10 | except ImportError:
11 | from io import BytesIO # Python 3.x
12 |
13 | class Visualizer():
14 | def __init__(self, opt):
15 | # self.opt = opt
16 | self.display_id = opt.display_id
17 | self.use_html = opt.isTrain and not opt.no_html
18 | self.win_size = opt.display_winsize
19 | self.name = opt.name
20 | if self.display_id > 0:
21 | import visdom
22 | self.vis = visdom.Visdom(port=opt.display_port, env=opt.display_env)
23 | self.display_single_pane_ncols = opt.display_single_pane_ncols
24 | self.use_html = 1
25 | if self.use_html:
26 | self.web_dir = os.path.join(opt.checkpoints_dir, opt.name, 'web')
27 | self.img_dir = os.path.join(self.web_dir, 'images')
28 | print('create web directory %s...' % self.web_dir)
29 | util.mkdirs([self.web_dir, self.img_dir])
30 | self.log_name = os.path.join(opt.checkpoints_dir, opt.name, 'loss_log.txt')
31 | self.eval_log_name = os.path.join(opt.checkpoints_dir, opt.name, 'eval_log.txt')
32 | with open(self.log_name, "a") as log_file:
33 | now = time.strftime("%c")
34 | log_file.write('================ Training Loss (%s) ================\n' % now)
35 |
36 | # |visuals|: dictionary of images to display or save
37 | def display_current_results(self, visuals, epoch):
38 | if self.display_id > 0: # show images in the browser
39 | if self.display_single_pane_ncols > 0:
40 | h, w = next(iter(visuals.values())).shape[:2]
41 | table_css = """""" % (w, h)
45 | ncols = self.display_single_pane_ncols
46 | title = self.name
47 | label_html = ''
48 | label_html_row = ''
49 | nrows = int(np.ceil(len(visuals.items()) / ncols))
50 | images = []
51 | idx = 0
52 | for label, image_numpy in visuals.items():
53 | label_html_row += '
4 |
5 | ## Abstract
6 |
7 | Pose Guided Person Image Generation (PGPIG) is the task of transforming a person image from the source pose to a given target pose. Most of the existing methods only focus on the ill-posed source-to-target task and fail to capture reasonable texture mapping. To address this problem, we propose a novel Dual-task Pose Transformer Network (DPTN), which introduces an auxiliary task (i.e., source-tosource task) and exploits the dual-task correlation to promote the performance of PGPIG. The DPTN is of a Siamese structure, containing a source-to-source self-reconstruction branch, and a transformation branch for source-to-target generation. By sharing partial weights between them, the knowledge learned by the source-to-source task can effectively assist the source-to-target learning. Furthermore, we bridge the two branches with a proposed Pose Transformer Module (PTM) to adaptively explore the correlation between features from dual tasks. Such correlation can establish the fine-grained mapping of all the pixels between the sources and the targets, and promote the source texture transmission to enhance the details of the generated target images. Extensive experiments show that our DPTN outperforms state-of-the-arts in terms of both PSNR and LPIPS. In addition, our DPTN only contains 9.79 million parameters, which is significantly smaller than other approaches.
8 |
9 |
10 | ## Get Start
11 |
12 | ### 1) Requirement
13 |
14 | * Python 3.7.9
15 | * Pytorch 1.7.1
16 | * torchvision 0.8.2
17 | * CUDA 11.1
18 | * NVIDIA A100 40GB PCIe
19 |
20 | ### 2) Data Preperation
21 |
22 | Following **[PATN](https://github.com/tengteng95/Pose-Transfer)**, the dataset split files and extracted keypoints files can be obtained as follows:
23 |
24 | **DeepFashion**
25 |
26 |
27 | * Download the DeepFashion dataset **[in-shop clothes retrival benchmark](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/InShopRetrieval.html)**, and put them under the `./dataset/fashion` directory.
28 |
29 | * Download train/test pairs and train/test keypoints annotations from **[Google Drive](https://drive.google.com/drive/folders/1qZDod3QDD7PaBxnNyHCuLBR7ftTSkSE1?usp=sharing)**, including **fasion-resize-pairs-train.csv, fasion-resize-pairs-test.csv, fasion-resize-annotation-train.csv, fasion-resize-annotation-train.csv, train.lst, test.lst**, and put them under the `./dataset/fashion` directory.
30 |
31 | * Split the raw image into the training set (`./dataset/fashion/train`) and test set (`./dataset/fashion/test`):
32 | ``` bash
33 | python data/generate_fashion_datasets.py
34 | ```
35 |
36 | **Market1501**
37 |
38 | * Download the Market1501 dataset from **[here](http://zheng-lab.cecs.anu.edu.au/Project/project_reid.html)**. Rename **bounding_box_train** and **bounding_box_test** as **train** and **test**, and put them under the `./dataset/market` directory.
39 |
40 | * Download train/test key points annotations from **[Google Drive](https://drive.google.com/drive/folders/1zzkimhX_D5gR1G8txTQkPXwdZPRcnrAx?usp=sharing)** including **market-pairs-train.csv, market-pairs-test.csv, market-annotation-train.csv, market-annotation-train.csv**. Put these files under the `./dataset/market` directory.
41 |
42 | ### 3) Train a model
43 |
44 | **DeepFashion**
45 | ``` bash
46 | python train.py --name=DPTN_fashion --model=DPTN --dataset_mode=fashion --dataroot=./dataset/fashion --batchSize 32 --gpu_id=0
47 | ```
48 | **Market1501**
49 |
50 | ``` bash
51 | python train.py --name=DPTN_market --model=DPTN --dataset_mode=market --dataroot=./dataset/market --dis_layers=3 --lambda_g=5 --lambda_rec 2 --t_s_ratio=0.8 --save_latest_freq=10400 --batchSize 32 --gpu_id=0
52 | ```
53 |
54 | ### 4) Test the model
55 |
56 | You can directly download our test results from Google Drive: **[Deepfashion](https://drive.google.com/drive/folders/1Y_Ar7w_CAYRgG2gzBg2vfxTCCen7q7k2?usp=sharing)**, **[Market1501](https://drive.google.com/drive/folders/15UBWEtGAqYaoEREIIeIuD-P4dRgsys19?usp=sharing)**.
57 |
58 | **DeepFashion**
59 | ``` bash
60 | python test.py --name=DPTN_fashion --model=DPTN --dataset_mode=fashion --dataroot=./dataset/fashion --which_epoch latest --results_dir ./results/DPTN_fashion --batchSize 1 --gpu_id=0
61 | ```
62 |
63 | **Market1501**
64 |
65 | ``` bash
66 | python test.py --name=DPTN_market --model=DPTN --dataset_mode=market --dataroot=./dataset/market --which_epoch latest --results_dir=./results/DPTN_market --batchSize 1 --gpu_id=0
67 | ```
68 |
69 | ### 5) Evaluation
70 |
71 | We adopt SSIM, PSNR, FID, LPIPS and person re-identification (re-id) system for the evaluation. Please clone the official repository **[PerceptualSimilarity](https://github.com/richzhang/PerceptualSimilarity/tree/future)** of the LPIPS score, and put the folder PerceptualSimilarity to the folder **[metrics](https://github.com/PangzeCheung/Dual-task-Pose-Transformer-Network/tree/main/metrics)**.
72 |
73 | * For SSIM, PSNR, FID and LPIPS:
74 |
75 | **DeepFashion**
76 | ``` bash
77 | python -m metrics.metrics --gt_path=./dataset/fashion/test --distorated_path=./results/DPTN_fashion --fid_real_path=./dataset/fashion/train --name=./fashion
78 | ```
79 |
80 | **Market1501**
81 |
82 | ``` bash
83 | python -m metrics.metrics --gt_path=./dataset/market/test --distorated_path=./results/DPTN_market --fid_real_path=./dataset/market/train --name=./market --market
84 | ```
85 |
86 | * For person re-id system:
87 |
88 | Clone the code of the **[fast-reid](https://github.com/JDAI-CV/fast-reid)** to this project (`./fast-reid-master`). Move the **[config](https://drive.google.com/file/d/1xWCnNpcNrgjEMDKuK29Gre3sYEE1yWTV/view?usp=sharing)** and **[loader](https://drive.google.com/file/d/1axMKB7QlYQgo7f1ZWigTh3uLIDvXRxro/view?usp=sharing)** of the DeepFashion dataset to (`./fast-reid-master/configs/Fashion/bagtricks_R50.yml`) and (`./fast-reid-master/fastreid/data/datasets/fashion.py`) respectively. Download the **[pre-trained network](https://drive.google.com/file/d/1Co6NVWN6OSqPVUd7ut8xCwsQQDIOcypV/view?usp=sharing)** and put it under the `./fast-reid-master/logs/Fashion/bagtricks_R50-ibn/` directory. And then launch:
89 |
90 | ``` bash
91 | python ./tools/train_net.py --config-file ./configs/Fashion/bagtricks_R50.yml --eval-only MODEL.WEIGHTS ./logs/Fashion/bagtricks_R50-ibn/model_final.pth MODEL.DEVICE "cuda:0"
92 | ```
93 |
94 | ### 6) Pre-trained Model
95 |
96 | Our pre-trained models and logs can be downloaded from Google Drive: **[Deepfashion](https://drive.google.com/drive/folders/12Ufr8jkOwAIGVEamDedJy_ZWPvJZn8WG?usp=sharing)**[**[log](https://drive.google.com/drive/folders/16ZYYl_jVdK8E9FtnQi6oi6JGfBuD2jCt?usp=sharing)**], **[Market1501](https://drive.google.com/drive/folders/1YY_U2pMzLrZMTKoK8oBkMylR6KXnZJKP?usp=sharing)**[**[log](https://drive.google.com/drive/folders/1ujlvhz7JILULRVRJsLruT9ZAz2JCT74G?usp=sharing)**].
97 |
98 | ## Citation
99 |
100 | ```tex
101 | @InProceedings{Zhang_2022_CVPR,
102 | author = {Zhang, Pengze and Yang, Lingxiao and Lai, Jian-Huang and Xie, Xiaohua},
103 | title = {Exploring Dual-Task Correlation for Pose Guided Person Image Generation},
104 | booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
105 | month = {June},
106 | year = {2022},
107 | pages = {7713-7722}
108 | }
109 | ```
110 | ## Acknowledgement
111 |
112 | We build our project based on **[pix2pix](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix)**. Some dataset preprocessing methods are derived from **[PATN](https://github.com/tengteng95/Pose-Transfer)**.
113 |
114 |
--------------------------------------------------------------------------------
/models/PTM.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import torch
3 | from torch import nn
4 | from .base_function import *
5 |
6 | class PTM(nn.Module):
7 | """
8 | Pose Transformer Module (PTM)
9 | :param d_model: number of channels in input
10 | :param nhead: number of heads in attention module
11 | :param num_CABs: number of CABs
12 | :param num_TTBs: number of TTBs
13 | :param dim_feedforward: dimension in feedforward
14 | :param activation: activation function 'ReLU, SELU, LeakyReLU, PReLU'
15 | :param affine: affine in normalization
16 | :param norm: normalization function 'instance, batch'
17 | """
18 | def __init__(self, d_model=512, nhead=8, num_CABs=6,
19 | num_TTBs=6, dim_feedforward=2048,
20 | activation="LeakyReLU",
21 | affine=True, norm='instance'):
22 | super().__init__()
23 | encoder_layer = CAB(d_model, nhead, dim_feedforward,
24 | activation, affine, norm)
25 | if norm == 'batch':
26 | encoder_norm = None
27 | decoder_norm = nn.BatchNorm1d(d_model, affine=affine)
28 | elif norm == 'instance':
29 | encoder_norm = None
30 | decoder_norm = nn.InstanceNorm1d(d_model, affine=affine)
31 |
32 | self.encoder = CABs(encoder_layer, num_CABs, encoder_norm)
33 |
34 | decoder_layer = TTB(d_model, nhead, dim_feedforward,
35 | activation, affine, norm)
36 |
37 | self.decoder = TTBs(decoder_layer, num_TTBs, decoder_norm)
38 |
39 | self._reset_parameters()
40 |
41 | self.d_model = d_model
42 | self.nhead = nhead
43 |
44 | def _reset_parameters(self):
45 | for p in self.parameters():
46 | if p.dim() > 1:
47 | nn.init.xavier_uniform_(p)
48 |
49 | def forward(self, src, tgt, val, pos_embed=None):
50 | bs, c, h, w = src.shape
51 | src = src.flatten(2).permute(2, 0, 1)
52 | tgt = tgt.flatten(2).permute(2, 0, 1)
53 | val = val.flatten(2).permute(2, 0, 1)
54 | if pos_embed != None:
55 | pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
56 | memory = self.encoder(src, pos=pos_embed)
57 | hs = self.decoder(tgt, memory, val, pos=pos_embed)
58 | return hs.view(bs, c, h, w)
59 |
60 |
61 | class CABs(nn.Module):
62 | """
63 | Context Augment Blocks (CABs)
64 | :param encoder_layer: CAB
65 | :param num_CABS: number of CABs
66 | :param norm: normalization function 'instance, batch'
67 | """
68 | def __init__(self, encoder_layer, num_CABs, norm=None):
69 | super().__init__()
70 | self.layers = _get_clones(encoder_layer, num_CABs)
71 | self.norm = norm
72 |
73 | def forward(self, src, pos = None):
74 | output = src
75 |
76 | for layer in self.layers:
77 | output = layer(output, pos=pos)
78 |
79 | if self.norm is not None:
80 | output = self.norm(output.permute(1, 2, 0)).permute(2, 0, 1)
81 |
82 | return output
83 |
84 |
85 | class TTBs(nn.Module):
86 | """
87 | Texture Transfer Blocks (TTBs)
88 | :param decoder_layer: TTB
89 | :param num_layers: number of TTBs
90 | :param norm: normalization function 'instance, batch'
91 | """
92 | def __init__(self, decoder_layer, num_TTBs, norm=None):
93 | super().__init__()
94 | self.layers = _get_clones(decoder_layer, num_TTBs)
95 | self.norm = norm
96 |
97 | def forward(self, tgt, memory, val, pos = None):
98 | output = tgt
99 |
100 | for layer in self.layers:
101 | output = layer(output, memory, val, pos=pos)
102 |
103 | if self.norm is not None:
104 | output = self.norm(output.permute(1, 2, 0))
105 | return output
106 |
107 |
108 | class CAB(nn.Module):
109 | """
110 | Context Augment Block (CAB)
111 | :param d_model: number of channels in input
112 | :param nhead: number of heads in attention module
113 | :param dim_feedforward: dimension in feedforward
114 | :param activation: activation function 'ReLU, SELU, LeakyReLU, PReLU'
115 | :param affine: affine in normalization
116 | :param norm: normalization function 'instance, batch'
117 | """
118 | def __init__(self, d_model, nhead, dim_feedforward=2048,
119 | activation="LeakyReLU", affine=True, norm='instance'):
120 | super().__init__()
121 | self.self_attn = nn.MultiheadAttention(d_model, nhead)
122 | self.linear1 = nn.Linear(d_model, dim_feedforward)
123 | self.linear2 = nn.Linear(dim_feedforward, d_model)
124 |
125 | if norm == 'batch':
126 | self.norm1 = nn.BatchNorm1d(d_model, affine=affine)
127 | self.norm2 = nn.BatchNorm1d(d_model, affine=affine)
128 | else:
129 | self.norm1 = nn.InstanceNorm1d(d_model, affine=affine)
130 | self.norm2 = nn.InstanceNorm1d(d_model, affine=affine)
131 |
132 | self.activation = get_nonlinearity_layer(activation)
133 |
134 | def with_pos_embed(self, tensor, pos):
135 | return tensor if pos is None else tensor + pos
136 |
137 | def forward(self, src, pos = None):
138 | q = k = self.with_pos_embed(src, pos)
139 | src2 = self.self_attn(q, k, value=src)[0]
140 | src = src + src2
141 | src = self.norm1(src.permute(1, 2, 0)).permute(2, 0, 1)
142 | src2 = self.linear2(self.activation(self.linear1(src)))
143 | src = src + src2
144 | src = self.norm2(src.permute(1, 2, 0)).permute(2, 0, 1)
145 | return src
146 |
147 |
148 | class TTB(nn.Module):
149 | """
150 | Texture Transfer Block (TTB)
151 | :param d_model: number of channels in input
152 | :param nhead: number of heads in attention module
153 | :param dim_feedforward: dimension in feedforward
154 | :param activation: activation function 'ReLU, SELU, LeakyReLU, PReLU'
155 | :param affine: affine in normalization
156 | :param norm: normalization function 'instance, batch'
157 | """
158 | def __init__(self, d_model, nhead, dim_feedforward=2048,
159 | activation="LeakyReLU", affine=True, norm='instance'):
160 | super().__init__()
161 | self.self_attn = nn.MultiheadAttention(d_model, nhead)
162 | self.multihead_attn = nn.MultiheadAttention(d_model, nhead)
163 | self.linear1 = nn.Linear(d_model, dim_feedforward)
164 | self.linear2 = nn.Linear(dim_feedforward, d_model)
165 |
166 | if norm == 'batch':
167 | self.norm1 = nn.BatchNorm1d(d_model, affine=affine)
168 | self.norm2 = nn.BatchNorm1d(d_model, affine=affine)
169 | self.norm3 = nn.BatchNorm1d(d_model, affine=affine)
170 | else:
171 | self.norm1 = nn.InstanceNorm1d(d_model, affine=affine)
172 | self.norm2 = nn.InstanceNorm1d(d_model, affine=affine)
173 | self.norm3 = nn.InstanceNorm1d(d_model, affine=affine)
174 |
175 | self.activation = get_nonlinearity_layer(activation)
176 |
177 | def with_pos_embed(self, tensor, pos):
178 | return tensor if pos is None else tensor + pos
179 |
180 | def forward(self, tgt, memory, val, pos = None):
181 | q = k = self.with_pos_embed(tgt, pos)
182 | tgt2 = self.self_attn(q, k, value=tgt)[0]
183 | tgt = tgt + tgt2
184 | tgt = self.norm1(tgt.permute(1, 2, 0)).permute(2, 0, 1)
185 | tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, pos),
186 | key=self.with_pos_embed(memory, pos),
187 | value=val)[0]
188 | tgt = tgt + tgt2
189 | tgt = self.norm2(tgt.permute(1, 2, 0)).permute(2, 0, 1)
190 | tgt2 = self.linear2(self.activation(self.linear1(tgt)))
191 | tgt = tgt + tgt2
192 | tgt = self.norm3(tgt.permute(1, 2, 0)).permute(2, 0, 1)
193 | return tgt
194 |
195 |
196 | def _get_clones(module, N):
197 | return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
198 |
199 |
200 |
--------------------------------------------------------------------------------
/util/visualizer.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import os
3 | import ntpath
4 | import time
5 | from . import util
6 | from . import html
7 | import scipy.misc
8 | try:
9 | from StringIO import StringIO # Python 2.7
10 | except ImportError:
11 | from io import BytesIO # Python 3.x
12 |
13 | class Visualizer():
14 | def __init__(self, opt):
15 | # self.opt = opt
16 | self.display_id = opt.display_id
17 | self.use_html = opt.isTrain and not opt.no_html
18 | self.win_size = opt.display_winsize
19 | self.name = opt.name
20 | if self.display_id > 0:
21 | import visdom
22 | self.vis = visdom.Visdom(port=opt.display_port, env=opt.display_env)
23 | self.display_single_pane_ncols = opt.display_single_pane_ncols
24 | self.use_html = 1
25 | if self.use_html:
26 | self.web_dir = os.path.join(opt.checkpoints_dir, opt.name, 'web')
27 | self.img_dir = os.path.join(self.web_dir, 'images')
28 | print('create web directory %s...' % self.web_dir)
29 | util.mkdirs([self.web_dir, self.img_dir])
30 | self.log_name = os.path.join(opt.checkpoints_dir, opt.name, 'loss_log.txt')
31 | self.eval_log_name = os.path.join(opt.checkpoints_dir, opt.name, 'eval_log.txt')
32 | with open(self.log_name, "a") as log_file:
33 | now = time.strftime("%c")
34 | log_file.write('================ Training Loss (%s) ================\n' % now)
35 |
36 | # |visuals|: dictionary of images to display or save
37 | def display_current_results(self, visuals, epoch):
38 | if self.display_id > 0: # show images in the browser
39 | if self.display_single_pane_ncols > 0:
40 | h, w = next(iter(visuals.values())).shape[:2]
41 | table_css = """""" % (w, h)
45 | ncols = self.display_single_pane_ncols
46 | title = self.name
47 | label_html = ''
48 | label_html_row = ''
49 | nrows = int(np.ceil(len(visuals.items()) / ncols))
50 | images = []
51 | idx = 0
52 | for label, image_numpy in visuals.items():
53 | label_html_row += '%s | ' % label
54 | images.append(image_numpy.transpose([2, 0, 1]))
55 | idx += 1
56 | if idx % ncols == 0:
57 | label_html += '%s
' % label_html_row
58 | label_html_row = ''
59 | white_image = np.ones_like(image_numpy.transpose([2, 0, 1]))*255
60 | while idx % ncols != 0:
61 | images.append(white_image)
62 | label_html_row += ' | '
63 | idx += 1
64 | if label_html_row != '':
65 | label_html += '%s
' % label_html_row
66 | # pane col = image row
67 | self.vis.images(images, nrow=ncols, win=self.display_id + 1,
68 | padding=2, opts=dict(title=title + ' images'))
69 | label_html = '' % label_html
70 | self.vis.text(table_css + label_html, win = self.display_id + 2,
71 | opts=dict(title=title + ' labels'))
72 | else:
73 | idx = 1
74 | for label, image_numpy in visuals.items():
75 | #image_numpy = np.flipud(image_numpy)
76 | self.vis.image(image_numpy.transpose([2,0,1]), opts=dict(title=label),
77 | win=self.display_id + idx)
78 | idx += 1
79 | if self.use_html: # save images to a html file
80 | for label, image_numpy in visuals.items():
81 | img_path = os.path.join(self.img_dir, 'epoch%.3d_%s.png' % (epoch, label))
82 | util.save_image(image_numpy, img_path)
83 | # update website
84 | webpage = html.HTML(self.web_dir, 'Experiment name = %s' % self.name, refresh=1)
85 | for n in range(epoch, 0, -1):
86 | webpage.add_header('epoch [%d]' % n)
87 | ims = []
88 | txts = []
89 | links = []
90 |
91 | for label, image_numpy in visuals.items():
92 | img_path = 'epoch%.3d_%s.png' % (n, label)
93 | ims.append(img_path)
94 | txts.append(label)
95 | links.append(img_path)
96 | webpage.add_images(ims, txts, links, width=self.win_size)
97 | webpage.save()
98 |
99 | # errors: dictionary of error labels and values
100 | def plot_current_errors(self, iters, errors):
101 | if not hasattr(self, 'plot_data'):
102 | self.plot_data = {'X': [], 'Y': [], 'legend': list(errors.keys())}
103 | self.plot_data['X'].append(iters)
104 | self.plot_data['Y'].append([errors[k] for k in self.plot_data['legend']])
105 | '''
106 | self.vis.line(
107 | X=np.stack([np.array(self.plot_data['X'])] * len(self.plot_data['legend']), 1),
108 | Y=np.array(self.plot_data['Y']),
109 | opts={'title': self.name + ' loss over time',
110 | 'legend': self.plot_data['legend'],
111 | 'xlabel': 'iterations',
112 | 'ylabel': 'loss'},
113 | win=self.display_id)
114 | '''
115 |
116 | def plot_current_score(self, iters, scores):
117 | if not hasattr(self, 'plot_score'):
118 | self.plot_score = {'X':[],'Y':[], 'legend':list(scores.keys())}
119 | self.plot_score['X'].append(iters)
120 | self.plot_score['Y'].append([scores[k] for k in self.plot_score['legend']])
121 | '''
122 | self.vis.line(
123 | X=np.stack([np.array(self.plot_score['X'])] * len(self.plot_score['legend']), 1),
124 | Y=np.array(self.plot_score['Y']),
125 | opts={
126 | 'title': self.name + ' Evaluation Score over time',
127 | 'legend': self.plot_score['legend'],
128 | 'xlabel': 'iters',
129 | 'ylabel': 'score'},
130 | win=self.display_id + 29
131 | )
132 | '''
133 |
134 | # statistics distribution: draw data histogram
135 | def plot_current_distribution(self, distribution):
136 | name = list(distribution.keys())
137 | value = np.array(list(distribution.values())).swapaxes(1, 0)
138 | self.vis.boxplot(
139 | X=value,
140 | opts=dict(legend=name),
141 | win=self.display_id+30
142 | )
143 |
144 | # errors: same format as |errors| of plotCurrentErrors
145 | def print_current_errors(self, epoch, iter, i, errors, lr_G, lr_D, t):
146 | message = '(epoch: %d, iters: %d, total iters: %d, time: %.3f) ' % (epoch, iter, i, t)
147 | for k, v in errors.items():
148 | message += '%s: %.3f ' % (k, v)
149 | message += 'learning_rate_g: %.10f' % lr_G
150 | message += ' learning_rate_d: %.10f' % lr_D
151 | print(message)
152 | with open(self.log_name, "a") as log_file:
153 | log_file.write('%s\n' % message)
154 |
155 | def print_current_eval(self, epoch, i, score):
156 | message = '(epoch: %d, iters: %d)' % (epoch, i)
157 | for k, v in score.items():
158 | message += '%s: %.3f ' % (k, v)
159 |
160 | print(message)
161 | with open(self.eval_log_name, "a") as log_file:
162 | log_file.write('%s\n' % message)
163 |
164 | # save image to the disk
165 | def save_images(self, webpage, visuals, image_path):
166 | image_dir = webpage.get_image_dir()
167 | short_path = ntpath.basename(image_path[0])
168 | name = os.path.splitext(short_path)[0]
169 |
170 | webpage.add_header(name)
171 | ims = []
172 | txts = []
173 | links = []
174 |
175 | for label, image_numpy in visuals.items():
176 | image_name = '%s_%s.png' % (name, label)
177 | save_path = os.path.join(image_dir, image_name)
178 | util.save_image(image_numpy, save_path)
179 |
180 | ims.append(image_name)
181 | txts.append(label)
182 | links.append(image_name)
183 | webpage.add_images(ims, txts, links, width=self.win_size)
--------------------------------------------------------------------------------
/models/base_model.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | import sys
4 | from collections import OrderedDict
5 | from util import util
6 | from util import pose_utils
7 | import numpy as np
8 | import ntpath
9 | import cv2
10 |
11 | class BaseModel():
12 | def name(self):
13 | return 'BaseModel'
14 |
15 | def __init__(self, opt):
16 | self.opt = opt
17 | self.gpu_ids = opt.gpu_ids
18 | self.isTrain = opt.isTrain
19 | self.Tensor = torch.cuda.FloatTensor if self.gpu_ids else torch.Tensor
20 | self.save_dir = os.path.join(opt.checkpoints_dir, opt.name)
21 |
22 | def set_input(self, input):
23 | self.input = input
24 |
25 | def forward(self):
26 | pass
27 |
28 | # used in test time, no backprop
29 | def test(self):
30 | pass
31 |
32 | def get_image_paths(self):
33 | return self.image_paths
34 |
35 | def optimize_parameters(self):
36 | pass
37 |
38 | def get_current_visuals(self):
39 | """Return visualization images"""
40 | visual_ret = OrderedDict()
41 | for name in self.visual_names:
42 | if isinstance(name, str):
43 | value = getattr(self, name)
44 | if isinstance(value, list):
45 | # visual multi-scale ouputs
46 | for i in range(len(value)):
47 | visual_ret[name + str(i)] = self.convert2im(value[i], name)
48 | else:
49 | visual_ret[name] =self.convert2im(value, name)
50 | return visual_ret
51 |
52 | def convert2im(self, value, name):
53 | if 'label' in name:
54 | convert = getattr(self, 'label2color')
55 | value = convert(value)
56 |
57 | if 'flow' in name: # flow_field
58 | convert = getattr(self, 'flow2color')
59 | value = convert(value)
60 |
61 | if value.size(1) == 18: # bone_map
62 | value = np.transpose(value[0].detach().cpu().numpy(),(1,2,0))
63 | value = pose_utils.draw_pose_from_map(value)[0]
64 | result = value
65 |
66 | elif value.size(1) == 21: # bone_map + color image
67 | value = np.transpose(value[0,-3:,...].detach().cpu().numpy(),(1,2,0))
68 | # value = pose_utils.draw_pose_from_map(value)[0]
69 | result = value.astype(np.uint8)
70 |
71 | else:
72 | result = util.tensor2im(value.data)
73 | return result
74 |
75 | def get_current_errors(self):
76 | """Return training loss"""
77 | errors_ret = OrderedDict()
78 | for name in self.loss_names:
79 | if isinstance(name, str):
80 | errors_ret[name] = getattr(self, 'loss_' + name).item()
81 | return errors_ret
82 |
83 | def save(self, label):
84 | pass
85 |
86 | # save model
87 | def save_networks(self, which_epoch):
88 | """Save all the networks to the disk"""
89 | for name in self.model_names:
90 | if isinstance(name, str):
91 | save_filename = '%s_net_%s.pth' % (which_epoch, name)
92 | save_path = os.path.join(self.save_dir, save_filename)
93 | net = getattr(self, 'net_' + name)
94 | torch.save(net.cpu().state_dict(), save_path)
95 | if len(self.gpu_ids) > 0 and torch.cuda.is_available():
96 | net.cuda()
97 |
98 | # load models
99 | def load_networks(self, which_epoch):
100 | """Load all the networks from the disk"""
101 | for name in self.model_names:
102 | if isinstance(name, str):
103 | filename = '%s_net_%s.pth' % (which_epoch, name)
104 | path = os.path.join(self.save_dir, filename)
105 | net = getattr(self, 'net_' + name)
106 | try:
107 | '''
108 | new_dict = {}
109 | pretrained_dict = torch.load(path)
110 | for k, v in pretrained_dict.items():
111 | if 'transformer' in k:
112 | new_dict[k.replace('transformer', 'PTM')] = v
113 | else:
114 | new_dict[k] = v
115 |
116 | net.load_state_dict(new_dict)
117 | '''
118 | net.load_state_dict(torch.load(path))
119 | print('load %s from %s' % (name, filename))
120 | except FileNotFoundError:
121 | print('do not find checkpoint for network %s'%name)
122 | continue
123 | except:
124 | pretrained_dict = torch.load(path)
125 | model_dict = net.state_dict()
126 | try:
127 | pretrained_dict_ = {k: v for k, v in pretrained_dict.items() if k in model_dict}
128 | if len(pretrained_dict_) == 0:
129 | pretrained_dict_ = {k.replace('module.', ''): v for k, v in pretrained_dict.items() if
130 | k.replace('module.', '') in model_dict}
131 | if len(pretrained_dict_) == 0:
132 | pretrained_dict_ = {('module.' + k): v for k, v in pretrained_dict.items() if
133 | 'module.' + k in model_dict}
134 |
135 | pretrained_dict = pretrained_dict_
136 | net.load_state_dict(pretrained_dict)
137 | print('Pretrained network %s has excessive layers; Only loading layers that are used' % name)
138 | except:
139 | print('Pretrained network %s has fewer layers; The following are not initialized:' % name)
140 | not_initialized = set()
141 | for k, v in pretrained_dict.items():
142 | if v.size() == model_dict[k].size():
143 | model_dict[k] = v
144 |
145 | for k, v in model_dict.items():
146 | if k not in pretrained_dict or v.size() != pretrained_dict[k].size():
147 | # not_initialized.add(k)
148 | not_initialized.add(k.split('.')[0])
149 | print(sorted(not_initialized))
150 | net.load_state_dict(model_dict)
151 | if len(self.gpu_ids) > 0 and torch.cuda.is_available():
152 | net.cuda()
153 | if not self.isTrain:
154 | net.eval()
155 |
156 | def update_learning_rate(self, epoch=None):
157 | """Update learning rate"""
158 | for scheduler in self.schedulers:
159 | if epoch == None:
160 | scheduler.step()
161 | else:
162 | scheduler.step(epoch)
163 | lr = self.optimizers[0].param_groups[0]['lr']
164 | print('learning rate=%.7f' % lr)
165 |
166 | def get_current_learning_rate(self):
167 | lr_G = self.optimizers[0].param_groups[0]['lr']
168 | lr_D = self.optimizers[1].param_groups[0]['lr']
169 | return lr_G, lr_D
170 |
171 | def save_results(self, save_data, old_size, data_name='none', data_ext='jpg'):
172 | """Save the training or testing results to disk"""
173 | img_paths = self.get_image_paths()
174 |
175 | for i in range(save_data.size(0)):
176 | print('process image ...... %s' % img_paths[i])
177 | short_path = ntpath.basename(img_paths[i]) # get image path
178 | name = os.path.splitext(short_path)[0]
179 | img_name = '%s_%s.%s' % (name, data_name, data_ext)
180 |
181 | util.mkdir(self.opt.results_dir)
182 | img_path = os.path.join(self.opt.results_dir, img_name)
183 | img_numpy = util.tensor2im(save_data[i].data)
184 | img_numpy = cv2.resize(img_numpy, (old_size[1], old_size[0]))
185 | util.save_image(img_numpy, img_path)
186 |
187 | def save_chair_results(self, save_data, old_size, img_path, data_name='none', data_ext='jpg'):
188 | """Save the training or testing results to disk"""
189 | img_paths = self.get_image_paths()
190 | print(save_data.shape)
191 | for i in range(save_data.size(0)):
192 | print('process image ...... %s' % img_paths[i])
193 | short_path = ntpath.basename(img_paths[i]) # get image path
194 | name = os.path.splitext(short_path)[0]
195 | img_name = '%s_%s.%s' % (name, data_name, data_ext)
196 |
197 | util.mkdir(self.opt.results_dir)
198 | img_numpy = util.tensor2im(save_data[i].data)
199 | img_numpy = cv2.resize(img_numpy, (old_size[1], old_size[0]))
200 | util.save_image(img_numpy, img_path)
201 |
--------------------------------------------------------------------------------
/models/DPTN_model.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | import os
4 | import itertools
5 | from torch.autograd import Variable
6 | from util.image_pool import ImagePool
7 | from .base_model import BaseModel
8 | from . import networks
9 | from . import external_function
10 | from . import base_function
11 |
12 |
13 | class DPTNModel(BaseModel):
14 | def name(self):
15 | return 'DPTNModel'
16 |
17 | @staticmethod
18 | def modify_options(parser, is_train=True):
19 | """Add new options and rewrite default values for existing options"""
20 | parser.add_argument('--init_type', type=str, default='orthogonal', help='initial type')
21 | parser.add_argument('--use_spect_g', action='store_false', help='use spectual normalization in generator')
22 | parser.add_argument('--use_spect_d', action='store_false', help='use spectual normalization in generator')
23 | parser.add_argument('--use_coord', action='store_true', help='use coordconv')
24 | parser.add_argument('--lambda_style', type=float, default=500, help='weight for the VGG19 style loss')
25 | parser.add_argument('--lambda_content', type=float, default=0.5, help='weight for the VGG19 content loss')
26 | parser.add_argument('--layers_g', type=int, default=3, help='number of layers in G')
27 | parser.add_argument('--save_input', action='store_true', help="whether save the input images when testing")
28 | parser.add_argument('--num_blocks', type=int, default=3, help="number of resblocks")
29 | parser.add_argument('--affine', action='store_true', default=True, help="affine in PTM")
30 | parser.add_argument('--nhead', type=int, default=2, help="number of heads in PTM")
31 | parser.add_argument('--num_CABs', type=int, default=2, help="number of CABs in PTM")
32 | parser.add_argument('--num_TTBs', type=int, default=2, help="number of CABs in PTM")
33 |
34 | # if is_train:
35 | parser.add_argument('--ratio_g2d', type=float, default=0.1, help='learning rate ratio G to D')
36 | parser.add_argument('--lambda_rec', type=float, default=5.0, help='weight for image reconstruction loss')
37 | parser.add_argument('--lambda_g', type=float, default=2.0, help='weight for generation loss')
38 | parser.add_argument('--t_s_ratio', type=float, default=0.5, help='loss ratio between dual tasks')
39 | parser.add_argument('--dis_layers', type=int, default=4, help='number of layers in D')
40 | parser.set_defaults(use_spect_g=False)
41 | parser.set_defaults(use_spect_d=True)
42 | return parser
43 |
44 | def __init__(self, opt):
45 | BaseModel.__init__(self, opt)
46 | self.old_size = opt.old_size
47 | self.t_s_ratio = opt.t_s_ratio
48 | self.loss_names = ['app_gen_s', 'content_gen_s', 'style_gen_s', 'app_gen_t', 'ad_gen_t', 'dis_img_gen_t', 'content_gen_t', 'style_gen_t']
49 | self.model_names = ['G']
50 | self.visual_names = ['source_image', 'source_pose', 'target_image', 'target_pose', 'fake_image_s', 'fake_image_t']
51 |
52 | self.net_G = networks.define_G(opt, image_nc=opt.image_nc, pose_nc=opt.structure_nc, ngf=64, img_f=512,
53 | encoder_layer=3, norm=opt.norm, activation='LeakyReLU',
54 | use_spect=opt.use_spect_g, use_coord=opt.use_coord, output_nc=3, num_blocks=3, affine=True, nhead=opt.nhead, num_CABs=opt.num_CABs, num_TTBs=opt.num_TTBs)
55 |
56 | # Discriminator network
57 | if self.isTrain:
58 | self.model_names = ['G', 'D']
59 | self.net_D = networks.define_D(opt, ndf=32, img_f=128, layers=opt.dis_layers, use_spect=opt.use_spect_d)
60 |
61 | if self.opt.verbose:
62 | print('---------- Networks initialized -------------')
63 | # set loss functions and optimizers
64 | if self.isTrain:
65 | if opt.pool_size > 0 and (len(self.gpu_ids)) > 1:
66 | raise NotImplementedError("Fake Pool Not Implemented for MultiGPU")
67 | #self.fake_pool = ImagePool(opt.pool_size)
68 | self.old_lr = opt.lr
69 |
70 | self.GANloss = external_function.GANLoss(opt.gan_mode).to(opt.device)
71 | self.L1loss = torch.nn.L1Loss()
72 | self.Vggloss = external_function.VGGLoss().to(opt.device)
73 |
74 | # define the optimizer
75 | self.optimizer_G = torch.optim.Adam(itertools.chain(
76 | filter(lambda p: p.requires_grad, self.net_G.parameters())),
77 | lr=opt.lr, betas=(opt.beta1, 0.999))
78 | self.optimizers = []
79 | self.optimizers.append(self.optimizer_G)
80 | self.optimizer_D = torch.optim.Adam(itertools.chain(
81 | filter(lambda p: p.requires_grad, self.net_D.parameters())),
82 | lr=opt.lr * opt.ratio_g2d, betas=(opt.beta1, 0.999))
83 | self.optimizers.append(self.optimizer_D)
84 |
85 | self.schedulers = [base_function.get_scheduler(optimizer, opt) for optimizer in self.optimizers]
86 | else:
87 | self.net_G.eval()
88 |
89 | if not self.isTrain or opt.continue_train:
90 | print('model resumed from latest')
91 | self.load_networks(opt.which_epoch)
92 |
93 | def set_input(self, input):
94 | self.input = input
95 | source_image, source_pose = input['Xs'], input['Ps']
96 | target_image, target_pose = input['Xt'], input['Pt']
97 | if len(self.gpu_ids) > 0:
98 | self.source_image = source_image.cuda()
99 | self.source_pose = source_pose.cuda()
100 | self.target_image = target_image.cuda()
101 | self.target_pose = target_pose.cuda()
102 |
103 | self.image_paths = []
104 | for i in range(self.source_image.size(0)):
105 | self.image_paths.append(os.path.splitext(input['Xs_path'][i])[0] + '_2_' + input['Xt_path'][i])
106 |
107 | def forward(self):
108 | # Encode Inputs
109 | self.fake_image_t, self.fake_image_s = self.net_G(self.source_image, self.source_pose, self.target_pose)
110 |
111 | def test(self):
112 | """Forward function used in test time"""
113 | fake_image_t, fake_image_s = self.net_G(self.source_image, self.source_pose, self.target_pose, False)
114 | self.save_results(fake_image_t, self.old_size, data_name='vis')
115 |
116 | def backward_D_basic(self, netD, real, fake):
117 | # Real
118 | D_real = netD(real)
119 | D_real_loss = self.GANloss(D_real, True, True)
120 | # fake
121 | D_fake = netD(fake.detach())
122 | D_fake_loss = self.GANloss(D_fake, False, True)
123 | # loss for discriminator
124 | D_loss = (D_real_loss + D_fake_loss) * 0.5
125 | # gradient penalty for wgan-gp
126 | if self.opt.gan_mode == 'wgangp':
127 | gradient_penalty, gradients = external_function.cal_gradient_penalty(netD, real, fake.detach())
128 | D_loss += gradient_penalty
129 |
130 | return D_loss
131 |
132 | def backward_D(self):
133 | base_function._unfreeze(self.net_D)
134 | self.loss_dis_img_gen_t = self.backward_D_basic(self.net_D, self.target_image, self.fake_image_t)
135 | D_loss = self.loss_dis_img_gen_t
136 | D_loss.backward()
137 |
138 | def backward_G_basic(self, fake_image, target_image, use_d):
139 | # Calculate reconstruction loss
140 | loss_app_gen = self.L1loss(fake_image, target_image)
141 | loss_app_gen = loss_app_gen * self.opt.lambda_rec
142 |
143 | # Calculate GAN loss
144 | loss_ad_gen = None
145 | if use_d:
146 | base_function._freeze(self.net_D)
147 | D_fake = self.net_D(fake_image)
148 | loss_ad_gen = self.GANloss(D_fake, True, False) * self.opt.lambda_g
149 |
150 | # Calculate perceptual loss
151 | loss_content_gen, loss_style_gen = self.Vggloss(fake_image, target_image)
152 | loss_style_gen = loss_style_gen * self.opt.lambda_style
153 | loss_content_gen = loss_content_gen * self.opt.lambda_content
154 |
155 | return loss_app_gen, loss_ad_gen, loss_style_gen, loss_content_gen
156 |
157 | def backward_G(self):
158 | base_function._unfreeze(self.net_D)
159 |
160 | self.loss_app_gen_t, self.loss_ad_gen_t, self.loss_style_gen_t, self.loss_content_gen_t = self.backward_G_basic(self.fake_image_t, self.target_image, use_d = True)
161 |
162 | self.loss_app_gen_s, self.loss_ad_gen_s, self.loss_style_gen_s, self.loss_content_gen_s = self.backward_G_basic(self.fake_image_s, self.source_image, use_d = False)
163 | G_loss = self.t_s_ratio*(self.loss_app_gen_t+self.loss_style_gen_t+self.loss_content_gen_t) + (1-self.t_s_ratio)*(self.loss_app_gen_s+self.loss_style_gen_s+self.loss_content_gen_s)+self.loss_ad_gen_t
164 | G_loss.backward()
165 |
166 | def optimize_parameters(self):
167 | self.forward()
168 |
169 | self.optimizer_D.zero_grad()
170 | self.backward_D()
171 | self.optimizer_D.step()
172 |
173 | self.optimizer_G.zero_grad()
174 | self.backward_G()
175 | self.optimizer_G.step()
176 |
177 |
--------------------------------------------------------------------------------
/util/util.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | import torch
3 | import numpy as np
4 | from PIL import Image
5 | import numpy as np
6 | import os
7 | import imageio
8 |
9 | # Converts a Tensor into a Numpy array
10 | # |imtype|: the desired type of the converted numpy array
11 | def tensor2im(image_tensor, imtype=np.uint8, normalize=True):
12 | if isinstance(image_tensor, list):
13 | image_numpy = []
14 | for i in range(len(image_tensor)):
15 | image_numpy.append(tensor2im(image_tensor[i], imtype, normalize))
16 | return image_numpy
17 | if image_tensor.dim() == 3:
18 | image_numpy = image_tensor.cpu().float().numpy()
19 | else:
20 | image_numpy = image_tensor[0].cpu().float().numpy()
21 | if normalize:
22 | image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + 1) / 2.0 * 255.0
23 | else:
24 | image_numpy = np.transpose(image_numpy, (1, 2, 0)) * 255.0
25 | image_numpy = np.clip(image_numpy, 0, 255)
26 | if image_numpy.shape[2] == 1 or image_numpy.shape[2] > 3:
27 | image_numpy = image_numpy[:,:,0]
28 | return image_numpy.astype(imtype)
29 |
30 | # Converts a one-hot tensor into a colorful label map
31 | def tensor2label(label_tensor, n_label, imtype=np.uint8):
32 | if n_label == 0:
33 | return tensor2im(label_tensor, imtype)
34 | label_tensor = label_tensor.cpu().float()
35 | if label_tensor.size()[0] > 1:
36 | label_tensor = label_tensor.max(0, keepdim=True)[1]
37 | label_tensor = Colorize(n_label)(label_tensor)
38 | label_numpy = np.transpose(label_tensor.numpy(), (1, 2, 0))
39 | return label_numpy.astype(imtype)
40 |
41 | def save_image(image_numpy, image_path):
42 | image_pil = Image.fromarray(image_numpy)
43 | image_pil.save(image_path)
44 |
45 | def mkdirs(paths):
46 | if isinstance(paths, list) and not isinstance(paths, str):
47 | for path in paths:
48 | mkdir(path)
49 | else:
50 | mkdir(paths)
51 |
52 | def mkdir(path):
53 | if not os.path.exists(path):
54 | os.makedirs(path)
55 |
56 | ###############################################################################
57 | # Code from
58 | # https://github.com/ycszen/pytorch-seg/blob/master/transform.py
59 | # Modified so it complies with the Citscape label map colors
60 | ###############################################################################
61 | def uint82bin(n, count=8):
62 | """returns the binary of integer n, count refers to amount of bits"""
63 | return ''.join([str((n >> y) & 1) for y in range(count-1, -1, -1)])
64 |
65 | def labelcolormap(N):
66 | if N == 35: # cityscape
67 | cmap = np.array([( 0, 0, 0), ( 0, 0, 0), ( 0, 0, 0), ( 0, 0, 0), ( 0, 0, 0), (111, 74, 0), ( 81, 0, 81),
68 | (128, 64,128), (244, 35,232), (250,170,160), (230,150,140), ( 70, 70, 70), (102,102,156), (190,153,153),
69 | (180,165,180), (150,100,100), (150,120, 90), (153,153,153), (153,153,153), (250,170, 30), (220,220, 0),
70 | (107,142, 35), (152,251,152), ( 70,130,180), (220, 20, 60), (255, 0, 0), ( 0, 0,142), ( 0, 0, 70),
71 | ( 0, 60,100), ( 0, 0, 90), ( 0, 0,110), ( 0, 80,100), ( 0, 0,230), (119, 11, 32), ( 0, 0,142)],
72 | dtype=np.uint8)
73 | else:
74 | cmap = np.zeros((N, 3), dtype=np.uint8)
75 | for i in range(N):
76 | r, g, b = 0, 0, 0
77 | id = i
78 | for j in range(7):
79 | str_id = uint82bin(id)
80 | r = r ^ (np.uint8(str_id[-1]) << (7-j))
81 | g = g ^ (np.uint8(str_id[-2]) << (7-j))
82 | b = b ^ (np.uint8(str_id[-3]) << (7-j))
83 | id = id >> 3
84 | cmap[i, 0] = r
85 | cmap[i, 1] = g
86 | cmap[i, 2] = b
87 | return cmap
88 |
89 | class Colorize(object):
90 | def __init__(self, n=35):
91 | self.cmap = labelcolormap(n)
92 | self.cmap = torch.from_numpy(self.cmap[:n])
93 |
94 | def __call__(self, gray_image):
95 | size = gray_image.size()
96 | color_image = torch.ByteTensor(3, size[1], size[2]).fill_(0)
97 |
98 | for label in range(0, len(self.cmap)):
99 | mask = (label == gray_image[0]).cpu()
100 | color_image[0][mask] = self.cmap[label][0]
101 | color_image[1][mask] = self.cmap[label][1]
102 | color_image[2][mask] = self.cmap[label][2]
103 |
104 | return color_image
105 |
106 | def make_colorwheel():
107 | '''
108 | Generates a color wheel for optical flow visualization as presented in:
109 | Baker et al. "A Database and Evaluation Methodology for Optical Flow" (ICCV, 2007)
110 | URL: http://vision.middlebury.edu/flow/flowEval-iccv07.pdf
111 | According to the C++ source code of Daniel Scharstein
112 | According to the Matlab source code of Deqing Sun
113 | '''
114 | RY = 15
115 | YG = 6
116 | GC = 4
117 | CB = 11
118 | BM = 13
119 | MR = 6
120 |
121 | ncols = RY + YG + GC + CB + BM + MR
122 | colorwheel = np.zeros((ncols, 3))
123 | col = 0
124 |
125 | # RY
126 | colorwheel[0:RY, 0] = 255
127 | colorwheel[0:RY, 1] = np.floor(255 * np.arange(0, RY) / RY)
128 | col = col + RY
129 | # YG
130 | colorwheel[col:col + YG, 0] = 255 - np.floor(255 * np.arange(0, YG) / YG)
131 | colorwheel[col:col + YG, 1] = 255
132 | col = col + YG
133 | # GC
134 | colorwheel[col:col + GC, 1] = 255
135 | colorwheel[col:col + GC, 2] = np.floor(255 * np.arange(0, GC) / GC)
136 | col = col + GC
137 | # CB
138 | colorwheel[col:col + CB, 1] = 255 - np.floor(255 * np.arange(CB) / CB)
139 | colorwheel[col:col + CB, 2] = 255
140 | col = col + CB
141 | # BM
142 | colorwheel[col:col + BM, 2] = 255
143 | colorwheel[col:col + BM, 0] = np.floor(255 * np.arange(0, BM) / BM)
144 | col = col + BM
145 | # MR
146 | colorwheel[col:col + MR, 2] = 255 - np.floor(255 * np.arange(MR) / MR)
147 | colorwheel[col:col + MR, 0] = 255
148 | return colorwheel
149 |
150 |
151 | class flow2color():
152 | # code from: https://github.com/tomrunia/OpticalFlow_Visualization
153 | # MIT License
154 | #
155 | # Copyright (c) 2018 Tom Runia
156 | #
157 | # Permission is hereby granted, free of charge, to any person obtaining a copy
158 | # of this software and associated documentation files (the "Software"), to deal
159 | # in the Software without restriction, including without limitation the rights
160 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
161 | # copies of the Software, and to permit persons to whom the Software is
162 | # furnished to do so, subject to conditions.
163 | #
164 | # Author: Tom Runia
165 | # Date Created: 2018-08-03
166 | def __init__(self):
167 | self.colorwheel = make_colorwheel()
168 |
169 | def flow_compute_color(self, u, v, convert_to_bgr=False):
170 | '''
171 | Applies the flow color wheel to (possibly clipped) flow components u and v.
172 | According to the C++ source code of Daniel Scharstein
173 | According to the Matlab source code of Deqing Sun
174 | :param u: np.ndarray, input horizontal flow
175 | :param v: np.ndarray, input vertical flow
176 | :param convert_to_bgr: bool, whether to change ordering and output BGR instead of RGB
177 | :return:
178 | '''
179 | flow_image = np.zeros((u.shape[0], u.shape[1], 3), np.uint8)
180 | ncols = self.colorwheel.shape[0]
181 |
182 | rad = np.sqrt(np.square(u) + np.square(v))
183 | a = np.arctan2(-v, -u) / np.pi
184 | fk = (a + 1) / 2 * (ncols - 1)
185 | k0 = np.floor(fk).astype(np.int32)
186 | k1 = k0 + 1
187 | k1[k1 == ncols] = 0
188 | f = fk - k0
189 |
190 | for i in range(self.colorwheel.shape[1]):
191 | tmp = self.colorwheel[:, i]
192 | col0 = tmp[k0] / 255.0
193 | col1 = tmp[k1] / 255.0
194 | col = (1 - f) * col0 + f * col1
195 |
196 | idx = (rad <= 1)
197 | col[idx] = 1 - rad[idx] * (1 - col[idx])
198 | col[~idx] = col[~idx] * 0.75 # out of range?
199 |
200 | # Note the 2-i => BGR instead of RGB
201 | ch_idx = 2 - i if convert_to_bgr else i
202 | flow_image[:, :, ch_idx] = np.floor(255 * col)
203 |
204 | return flow_image
205 |
206 | def __call__(self, flow_uv, clip_flow=None, convert_to_bgr=False):
207 | '''
208 | Expects a two dimensional flow image of shape [H,W,2]
209 | According to the C++ source code of Daniel Scharstein
210 | According to the Matlab source code of Deqing Sun
211 | :param flow_uv: np.ndarray of shape [H,W,2]
212 | :param clip_flow: float, maximum clipping value for flow
213 | :return:
214 | '''
215 | if len(flow_uv.size()) != 3:
216 | flow_uv = flow_uv[0]
217 | flow_uv = flow_uv.permute(1, 2, 0).cpu().detach().numpy()
218 |
219 | assert flow_uv.ndim == 3, 'input flow must have three dimensions'
220 | assert flow_uv.shape[2] == 2, 'input flow must have shape [H,W,2]'
221 |
222 | if clip_flow is not None:
223 | flow_uv = np.clip(flow_uv, 0, clip_flow)
224 |
225 | u = flow_uv[:, :, 1]
226 | v = flow_uv[:, :, 0]
227 |
228 | rad = np.sqrt(np.square(u) + np.square(v))
229 | rad_max = np.max(rad)
230 |
231 | epsilon = 1e-5
232 | u = u / (rad_max + epsilon)
233 | v = v / (rad_max + epsilon)
234 | image = self.flow_compute_color(u, v, convert_to_bgr)
235 | image = torch.tensor(image).float().permute(2, 0, 1) / 255.0 * 2 - 1
236 | return image
237 |
238 |
239 | def save_image(image_numpy, image_path):
240 | if image_numpy.shape[2] == 1:
241 | image_numpy = image_numpy.reshape(image_numpy.shape[0], image_numpy.shape[1])
242 | #image_numpy = cv2.resize(image_numpy, (176,256))
243 |
244 | imageio.imwrite(image_path, image_numpy)
--------------------------------------------------------------------------------
/models/networks.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import functools
4 | from torch.autograd import Variable
5 | import numpy as np
6 | from .base_function import *
7 | from .PTM import PTM
8 |
9 |
10 | ###############################################################################
11 | # Functions
12 | ###############################################################################
13 | def define_G(opt, image_nc, pose_nc, ngf=64, img_f=1024, encoder_layer=3, norm='batch',
14 | activation='ReLU', use_spect=True, use_coord=False, output_nc=3, num_blocks=3, affine=True, nhead=2, num_CABs=2, num_TTBs=2):
15 | print(opt.model)
16 | if opt.model == 'DPTN':
17 | netG = DPTNGenerator(image_nc, pose_nc, ngf, img_f, encoder_layer, norm, activation, use_spect, use_coord, output_nc, num_blocks, affine, nhead, num_CABs, num_TTBs)
18 | else:
19 | raise('generator not implemented!')
20 | return init_net(netG, opt.init_type, opt.gpu_ids)
21 |
22 |
23 | def define_D(opt, input_nc=3, ndf=64, img_f=1024, layers=3, norm='none', activation='LeakyReLU', use_spect=True,):
24 | netD = ResDiscriminator(input_nc, ndf, img_f, layers, norm, activation, use_spect)
25 | return init_net(netD, opt.init_type, opt.gpu_ids)
26 |
27 |
28 | def print_network(net):
29 | if isinstance(net, list):
30 | net = net[0]
31 | num_params = 0
32 | for param in net.parameters():
33 | num_params += param.numel()
34 | print(net)
35 | print('Total number of parameters: %d' % num_params)
36 |
37 |
38 | ##############################################################################
39 | # Generator
40 | ##############################################################################
41 | class SourceEncoder(nn.Module):
42 | """
43 | Source Image Encoder (En_s)
44 | :param image_nc: number of channels in input image
45 | :param ngf: base filter channel
46 | :param img_f: the largest feature channels
47 | :param encoder_layer: encoder layers
48 | :param norm: normalization function 'instance, batch, group'
49 | :param activation: activation function 'ReLU, SELU, LeakyReLU, PReLU'
50 | :param use_spect: use spectual normalization
51 | :param use_coord: use coordConv operation
52 | """
53 | def __init__(self, image_nc, ngf=64, img_f=1024, encoder_layer=3, norm='batch',
54 | activation='ReLU', use_spect=True, use_coord=False):
55 | super(SourceEncoder, self).__init__()
56 |
57 | self.encoder_layer = encoder_layer
58 |
59 | norm_layer = get_norm_layer(norm_type=norm)
60 | nonlinearity = get_nonlinearity_layer(activation_type=activation)
61 | input_nc = image_nc
62 |
63 | self.block0 = EncoderBlockOptimized(input_nc, ngf, norm_layer,
64 | nonlinearity, use_spect, use_coord)
65 | mult = 1
66 | for i in range(encoder_layer - 1):
67 | mult_prev = mult
68 | mult = min(2 ** (i + 1), img_f // ngf)
69 | block = EncoderBlock(ngf * mult_prev, ngf * mult, norm_layer,
70 | nonlinearity, use_spect, use_coord)
71 | setattr(self, 'encoder' + str(i), block)
72 |
73 | def forward(self, source):
74 | inputs = source
75 | out = self.block0(inputs)
76 | for i in range(self.encoder_layer - 1):
77 | model = getattr(self, 'encoder' + str(i))
78 | out = model(out)
79 | return out
80 |
81 |
82 | class DPTNGenerator(nn.Module):
83 | """
84 | Dual-task Pose Transformer Network (DPTN)
85 | :param image_nc: number of channels in input image
86 | :param pose_nc: number of channels in input pose
87 | :param ngf: base filter channel
88 | :param img_f: the largest feature channels
89 | :param layers: down and up sample layers
90 | :param norm: normalization function 'instance, batch, group'
91 | :param activation: activation function 'ReLU, SELU, LeakyReLU, PReLU'
92 | :param use_spect: use spectual normalization
93 | :param use_coord: use coordConv operation
94 | :param output_nc: number of channels in output image
95 | :param num_blocks: number of ResBlocks
96 | :param affine: affine in Pose Transformer Module
97 | :param nhead: number of heads in attention module
98 | :param num_CABs: number of CABs
99 | :param num_TTBs: number of TTBs
100 | """
101 | def __init__(self, image_nc, pose_nc, ngf=64, img_f=256, layers=3, norm='batch',
102 | activation='ReLU', use_spect=True, use_coord=False, output_nc=3, num_blocks=3, affine=True, nhead=2, num_CABs=2, num_TTBs=2):
103 | super(DPTNGenerator, self).__init__()
104 |
105 | self.layers = layers
106 | norm_layer = get_norm_layer(norm_type=norm)
107 | nonlinearity = get_nonlinearity_layer(activation_type=activation)
108 | input_nc = 2 * pose_nc + image_nc
109 |
110 | # Encoder En_c
111 | self.block0 = EncoderBlockOptimized(input_nc, ngf, norm_layer,
112 | nonlinearity, use_spect, use_coord)
113 | mult = 1
114 | for i in range(self.layers - 1):
115 | mult_prev = mult
116 | mult = min(2 ** (i + 1), img_f // ngf)
117 | block = EncoderBlock(ngf * mult_prev, ngf * mult, norm_layer,
118 | nonlinearity, use_spect, use_coord)
119 | setattr(self, 'encoder' + str(i), block)
120 |
121 | # ResBlocks
122 | self.num_blocks = num_blocks
123 | for i in range(num_blocks):
124 | block = ResBlock(ngf * mult, ngf * mult, norm_layer=norm_layer,
125 | nonlinearity=nonlinearity, use_spect=use_spect, use_coord=use_coord)
126 | setattr(self, 'mblock' + str(i), block)
127 |
128 | # Pose Transformer Module (PTM)
129 | self.PTM = PTM(d_model=ngf * mult, nhead=nhead, num_CABs=num_CABs,
130 | num_TTBs=num_TTBs, dim_feedforward=ngf * mult,
131 | activation="LeakyReLU", affine=affine, norm=norm)
132 |
133 | # Encoder En_s
134 | self.source_encoder = SourceEncoder(image_nc, ngf, img_f, layers, norm, activation, use_spect, use_coord)
135 |
136 | # Decoder
137 | for i in range(self.layers):
138 | mult_prev = mult
139 | mult = min(2 ** (self.layers - i - 2), img_f // ngf) if i != self.layers - 1 else 1
140 | up = ResBlockDecoder(ngf * mult_prev, ngf * mult, ngf * mult, norm_layer,
141 | nonlinearity, use_spect, use_coord)
142 | setattr(self, 'decoder' + str(i), up)
143 | self.outconv = Output(ngf, output_nc, 3, None, nonlinearity, use_spect, use_coord)
144 |
145 | def forward(self, source, source_B, target_B, is_train=True):
146 | # Self-reconstruction Branch
147 | # Source-to-source Inputs
148 | input_s_s = torch.cat((source, source_B, source_B), 1)
149 | # Source-to-source Encoder
150 | F_s_s = self.block0(input_s_s)
151 | for i in range(self.layers - 1):
152 | model = getattr(self, 'encoder' + str(i))
153 | F_s_s = model(F_s_s)
154 | # Source-to-source Resblocks
155 | for i in range(self.num_blocks):
156 | model = getattr(self, 'mblock' + str(i))
157 | F_s_s = model(F_s_s)
158 |
159 | # Transformation Branch
160 | # Source-to-target Inputs
161 | input_s_t = torch.cat((source, source_B, target_B), 1)
162 | # Source-to-target Encoder
163 | F_s_t = self.block0(input_s_t)
164 | for i in range(self.layers - 1):
165 | model = getattr(self, 'encoder' + str(i))
166 | F_s_t = model(F_s_t)
167 | # Source-to-target Resblocks
168 | for i in range(self.num_blocks):
169 | model = getattr(self, 'mblock' + str(i))
170 | F_s_t = model(F_s_t)
171 |
172 | # Source Image Encoding
173 | F_s = self.source_encoder(source)
174 |
175 | # Pose Transformer Module for Dual-task Correlation
176 | F_s_t = self.PTM(F_s_s, F_s_t, F_s)
177 |
178 | # Source-to-source Decoder (only for training)
179 | out_image_s = None
180 | if is_train:
181 | for i in range(self.layers):
182 | model = getattr(self, 'decoder' + str(i))
183 | F_s_s = model(F_s_s)
184 | out_image_s = self.outconv(F_s_s)
185 |
186 | # Source-to-target Decoder
187 | for i in range(self.layers):
188 | model = getattr(self, 'decoder' + str(i))
189 | F_s_t = model(F_s_t)
190 | out_image_t = self.outconv(F_s_t)
191 |
192 | return out_image_t, out_image_s
193 |
194 |
195 | ##############################################################################
196 | # Discriminator
197 | ##############################################################################
198 | class ResDiscriminator(nn.Module):
199 | """
200 | ResNet Discriminator Network
201 | :param input_nc: number of channels in input
202 | :param ndf: base filter channel
203 | :param layers: down and up sample layers
204 | :param img_f: the largest feature channels
205 | :param norm: normalization function 'instance, batch, group'
206 | :param activation: activation function 'ReLU, SELU, LeakyReLU, PReLU'
207 | :param use_spect: use spectual normalization
208 | :param use_coord: use coordConv operation
209 | """
210 | def __init__(self, input_nc=3, ndf=64, img_f=1024, layers=3, norm='none', activation='LeakyReLU', use_spect=True,
211 | use_coord=False):
212 | super(ResDiscriminator, self).__init__()
213 |
214 | self.layers = layers
215 |
216 | norm_layer = get_norm_layer(norm_type=norm)
217 | nonlinearity = get_nonlinearity_layer(activation_type=activation)
218 | self.nonlinearity = nonlinearity
219 |
220 | # encoder part
221 | self.block0 = ResBlockEncoderOptimized(input_nc, ndf, ndf, norm_layer, nonlinearity, use_spect, use_coord)
222 |
223 | mult = 1
224 | for i in range(layers - 1):
225 | mult_prev = mult
226 | mult = min(2 ** (i + 1), img_f//ndf)
227 | block = ResBlockEncoder(ndf*mult_prev, ndf*mult, ndf*mult_prev, norm_layer, nonlinearity, use_spect, use_coord)
228 | setattr(self, 'encoder' + str(i), block)
229 | self.conv = SpectralNorm(nn.Conv2d(ndf*mult, 1, 1))
230 |
231 | def forward(self, x):
232 | out = self.block0(x)
233 | for i in range(self.layers - 1):
234 | model = getattr(self, 'encoder' + str(i))
235 | out = model(out)
236 | out = self.conv(self.nonlinearity(out))
237 | return out
--------------------------------------------------------------------------------
/models/external_function.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 | import torchvision.models as models
4 | from torch.nn import Parameter
5 | import torch.nn.functional as F
6 | import copy
7 |
8 |
9 | ####################################################################################################
10 | # adversarial loss for different gan mode
11 | ####################################################################################################
12 |
13 |
14 | class GANLoss(nn.Module):
15 | """Define different GAN objectives.
16 | The GANLoss class abstracts away the need to create the target label tensor
17 | that has the same size as the input.
18 | """
19 |
20 | def __init__(self, gan_mode, target_real_label=1.0, target_fake_label=0.0):
21 | """ Initialize the GANLoss class.
22 | Parameters:
23 | gan_mode (str) - - the type of GAN objective. It currently supports vanilla, lsgan, and wgangp.
24 | target_real_label (bool) - - label for a real image
25 | target_fake_label (bool) - - label of a fake image
26 | Note: Do not use sigmoid as the last layer of Discriminator.
27 | LSGAN needs no sigmoid. vanilla GANs will handle it with BCEWithLogitsLoss.
28 | """
29 | super(GANLoss, self).__init__()
30 | self.register_buffer('real_label', torch.tensor(target_real_label))
31 | self.register_buffer('fake_label', torch.tensor(target_fake_label))
32 | self.gan_mode = gan_mode
33 | if gan_mode == 'lsgan':
34 | self.loss = nn.MSELoss()
35 | elif gan_mode == 'vanilla':
36 | self.loss = nn.BCEWithLogitsLoss()
37 | elif gan_mode == 'hinge':
38 | self.loss = nn.ReLU()
39 | elif gan_mode == 'wgangp':
40 | self.loss = None
41 | else:
42 | raise NotImplementedError('gan mode %s not implemented' % gan_mode)
43 |
44 | def __call__(self, prediction, target_is_real, is_disc=False):
45 | """Calculate loss given Discriminator's output and grount truth labels.
46 | Parameters:
47 | prediction (tensor) - - tpyically the prediction output from a discriminator
48 | target_is_real (bool) - - if the ground truth label is for real images or fake images
49 | Returns:
50 | the calculated loss.
51 | """
52 | if self.gan_mode in ['lsgan', 'vanilla']:
53 | labels = (self.real_label if target_is_real else self.fake_label).expand_as(prediction).type_as(prediction)
54 | loss = self.loss(prediction, labels)
55 | elif self.gan_mode in ['hinge', 'wgangp']:
56 | if is_disc:
57 | if target_is_real:
58 | prediction = -prediction
59 | if self.gan_mode == 'hinge':
60 | loss = self.loss(1 + prediction).mean()
61 | elif self.gan_mode == 'wgangp':
62 | loss = prediction.mean()
63 | else:
64 | loss = -prediction.mean()
65 | return loss
66 |
67 |
68 | def cal_gradient_penalty(netD, real_data, fake_data, type='mixed', constant=1.0, lambda_gp=10.0):
69 | """Calculate the gradient penalty loss, used in WGAN-GP paper https://arxiv.org/abs/1704.00028
70 | Arguments:
71 | netD (network) -- discriminator network
72 | real_data (tensor array) -- real images
73 | fake_data (tensor array) -- generated images from the generator
74 | type (str) -- if we mix real and fake data or not [real | fake | mixed].
75 | constant (float) -- the constant used in formula ( | |gradient||_2 - constant)^2
76 | lambda_gp (float) -- weight for this loss
77 | Returns the gradient penalty loss
78 | """
79 | if lambda_gp > 0.0:
80 | if type == 'real': # either use real images, fake images, or a linear interpolation of two.
81 | interpolatesv = real_data
82 | elif type == 'fake':
83 | interpolatesv = fake_data
84 | elif type == 'mixed':
85 | alpha = torch.rand(real_data.shape[0], 1)
86 | alpha = alpha.expand(real_data.shape[0], real_data.nelement() // real_data.shape[0]).contiguous().view(*real_data.shape)
87 | alpha = alpha.type_as(real_data)
88 | interpolatesv = alpha * real_data + ((1 - alpha) * fake_data)
89 | else:
90 | raise NotImplementedError('{} not implemented'.format(type))
91 | interpolatesv.requires_grad_(True)
92 | disc_interpolates = netD(interpolatesv)
93 | gradients = torch.autograd.grad(outputs=disc_interpolates, inputs=interpolatesv,
94 | grad_outputs=torch.ones(disc_interpolates.size()).type_as(real_data),
95 | create_graph=True, retain_graph=True, only_inputs=True)
96 | gradients = gradients[0].view(real_data.size(0), -1) # flat the data
97 | gradient_penalty = (((gradients + 1e-16).norm(2, dim=1) - constant) ** 2).mean() * lambda_gp # added eps
98 | return gradient_penalty, gradients
99 | else:
100 | return 0.0, None
101 |
102 |
103 | class VGGLoss(nn.Module):
104 | r"""
105 | Perceptual loss, VGG-based
106 | https://arxiv.org/abs/1603.08155
107 | https://github.com/dxyang/StyleTransfer/blob/master/utils.py
108 | """
109 |
110 | def __init__(self, weights=[1.0, 1.0, 1.0, 1.0, 1.0]):
111 | super(VGGLoss, self).__init__()
112 | self.add_module('vgg', VGG19())
113 | self.criterion = torch.nn.L1Loss()
114 | self.weights = weights
115 |
116 | def compute_gram(self, x):
117 | b, ch, h, w = x.size()
118 | f = x.view(b, ch, w * h)
119 | f_T = f.transpose(1, 2)
120 | G = f.bmm(f_T) / (h * w * ch)
121 | return G
122 |
123 | def __call__(self, x, y):
124 | # Compute features
125 | x_vgg, y_vgg = self.vgg(x), self.vgg(y)
126 |
127 | content_loss = 0.0
128 | content_loss += self.weights[0] * self.criterion(x_vgg['relu1_1'], y_vgg['relu1_1'])
129 | content_loss += self.weights[1] * self.criterion(x_vgg['relu2_1'], y_vgg['relu2_1'])
130 | content_loss += self.weights[2] * self.criterion(x_vgg['relu3_1'], y_vgg['relu3_1'])
131 | content_loss += self.weights[3] * self.criterion(x_vgg['relu4_1'], y_vgg['relu4_1'])
132 | content_loss += self.weights[4] * self.criterion(x_vgg['relu5_1'], y_vgg['relu5_1'])
133 |
134 | # Compute loss
135 | style_loss = 0.0
136 | style_loss += self.criterion(self.compute_gram(x_vgg['relu2_2']), self.compute_gram(y_vgg['relu2_2']))
137 | style_loss += self.criterion(self.compute_gram(x_vgg['relu3_4']), self.compute_gram(y_vgg['relu3_4']))
138 | style_loss += self.criterion(self.compute_gram(x_vgg['relu4_4']), self.compute_gram(y_vgg['relu4_4']))
139 | style_loss += self.criterion(self.compute_gram(x_vgg['relu5_2']), self.compute_gram(y_vgg['relu5_2']))
140 |
141 | return content_loss, style_loss
142 |
143 |
144 | def reduce_sum(x, axis=None, keepdim=False):
145 | if not axis:
146 | axis = range(len(x.shape))
147 | for i in sorted(axis, reverse=True):
148 | x = torch.sum(x, dim=i, keepdim=keepdim)
149 | return x
150 |
151 |
152 | ####################################################################################################
153 | # neural style transform loss from neural_style_tutorial of pytorch
154 | ####################################################################################################
155 |
156 |
157 | class StyleLoss(nn.Module):
158 | r"""
159 | Perceptual loss, VGG-based
160 | https://arxiv.org/abs/1603.08155
161 | https://github.com/dxyang/StyleTransfer/blob/master/utils.py
162 | """
163 |
164 | def __init__(self):
165 | super(StyleLoss, self).__init__()
166 | self.add_module('vgg', VGG19())
167 | self.criterion = torch.nn.L1Loss()
168 |
169 | def compute_gram(self, x):
170 | b, ch, h, w = x.size()
171 | f = x.view(b, ch, w * h)
172 | f_T = f.transpose(1, 2)
173 | G = f.bmm(f_T) / (h * w * ch)
174 |
175 | return G
176 |
177 | def __call__(self, x, y):
178 | # Compute features
179 | x_vgg, y_vgg = self.vgg(x), self.vgg(y)
180 |
181 | # Compute loss
182 | style_loss = 0.0
183 | style_loss += self.criterion(self.compute_gram(x_vgg['relu2_2']), self.compute_gram(y_vgg['relu2_2']))
184 | style_loss += self.criterion(self.compute_gram(x_vgg['relu3_4']), self.compute_gram(y_vgg['relu3_4']))
185 | style_loss += self.criterion(self.compute_gram(x_vgg['relu4_4']), self.compute_gram(y_vgg['relu4_4']))
186 | style_loss += self.criterion(self.compute_gram(x_vgg['relu5_2']), self.compute_gram(y_vgg['relu5_2']))
187 |
188 | return style_loss
189 |
190 |
191 |
192 | class PerceptualLoss(nn.Module):
193 | r"""
194 | Perceptual loss, VGG-based
195 | https://arxiv.org/abs/1603.08155
196 | https://github.com/dxyang/StyleTransfer/blob/master/utils.py
197 | """
198 |
199 | def __init__(self, weights=[1.0, 1.0, 1.0, 1.0, 1.0]):
200 | super(PerceptualLoss, self).__init__()
201 | self.add_module('vgg', VGG19())
202 | self.criterion = torch.nn.L1Loss()
203 | self.weights = weights
204 |
205 | def __call__(self, x, y):
206 | # Compute features
207 | x_vgg, y_vgg = self.vgg(x), self.vgg(y)
208 |
209 | content_loss = 0.0
210 | content_loss += self.weights[0] * self.criterion(x_vgg['relu1_1'], y_vgg['relu1_1'])
211 | content_loss += self.weights[1] * self.criterion(x_vgg['relu2_1'], y_vgg['relu2_1'])
212 | content_loss += self.weights[2] * self.criterion(x_vgg['relu3_1'], y_vgg['relu3_1'])
213 | content_loss += self.weights[3] * self.criterion(x_vgg['relu4_1'], y_vgg['relu4_1'])
214 | content_loss += self.weights[4] * self.criterion(x_vgg['relu5_1'], y_vgg['relu5_1'])
215 |
216 |
217 | return content_loss
218 |
219 |
220 |
221 | class VGG19(torch.nn.Module):
222 | def __init__(self):
223 | super(VGG19, self).__init__()
224 | features = models.vgg19(pretrained=True).features
225 | self.relu1_1 = torch.nn.Sequential()
226 | self.relu1_2 = torch.nn.Sequential()
227 |
228 | self.relu2_1 = torch.nn.Sequential()
229 | self.relu2_2 = torch.nn.Sequential()
230 |
231 | self.relu3_1 = torch.nn.Sequential()
232 | self.relu3_2 = torch.nn.Sequential()
233 | self.relu3_3 = torch.nn.Sequential()
234 | self.relu3_4 = torch.nn.Sequential()
235 |
236 | self.relu4_1 = torch.nn.Sequential()
237 | self.relu4_2 = torch.nn.Sequential()
238 | self.relu4_3 = torch.nn.Sequential()
239 | self.relu4_4 = torch.nn.Sequential()
240 |
241 | self.relu5_1 = torch.nn.Sequential()
242 | self.relu5_2 = torch.nn.Sequential()
243 | self.relu5_3 = torch.nn.Sequential()
244 | self.relu5_4 = torch.nn.Sequential()
245 |
246 | for x in range(2):
247 | self.relu1_1.add_module(str(x), features[x])
248 |
249 | for x in range(2, 4):
250 | self.relu1_2.add_module(str(x), features[x])
251 |
252 | for x in range(4, 7):
253 | self.relu2_1.add_module(str(x), features[x])
254 |
255 | for x in range(7, 9):
256 | self.relu2_2.add_module(str(x), features[x])
257 |
258 | for x in range(9, 12):
259 | self.relu3_1.add_module(str(x), features[x])
260 |
261 | for x in range(12, 14):
262 | self.relu3_2.add_module(str(x), features[x])
263 |
264 | for x in range(14, 16):
265 | self.relu3_3.add_module(str(x), features[x])
266 |
267 | for x in range(16, 18):
268 | self.relu3_4.add_module(str(x), features[x])
269 |
270 | for x in range(18, 21):
271 | self.relu4_1.add_module(str(x), features[x])
272 |
273 | for x in range(21, 23):
274 | self.relu4_2.add_module(str(x), features[x])
275 |
276 | for x in range(23, 25):
277 | self.relu4_3.add_module(str(x), features[x])
278 |
279 | for x in range(25, 27):
280 | self.relu4_4.add_module(str(x), features[x])
281 |
282 | for x in range(27, 30):
283 | self.relu5_1.add_module(str(x), features[x])
284 |
285 | for x in range(30, 32):
286 | self.relu5_2.add_module(str(x), features[x])
287 |
288 | for x in range(32, 34):
289 | self.relu5_3.add_module(str(x), features[x])
290 |
291 | for x in range(34, 36):
292 | self.relu5_4.add_module(str(x), features[x])
293 |
294 | # don't need the gradients, just want the features
295 | for param in self.parameters():
296 | param.requires_grad = False
297 |
298 | def forward(self, x):
299 | relu1_1 = self.relu1_1(x)
300 | relu1_2 = self.relu1_2(relu1_1)
301 |
302 | relu2_1 = self.relu2_1(relu1_2)
303 | relu2_2 = self.relu2_2(relu2_1)
304 |
305 | relu3_1 = self.relu3_1(relu2_2)
306 | relu3_2 = self.relu3_2(relu3_1)
307 | relu3_3 = self.relu3_3(relu3_2)
308 | relu3_4 = self.relu3_4(relu3_3)
309 |
310 | relu4_1 = self.relu4_1(relu3_4)
311 | relu4_2 = self.relu4_2(relu4_1)
312 | relu4_3 = self.relu4_3(relu4_2)
313 | relu4_4 = self.relu4_4(relu4_3)
314 |
315 | relu5_1 = self.relu5_1(relu4_4)
316 | relu5_2 = self.relu5_2(relu5_1)
317 | relu5_3 = self.relu5_3(relu5_2)
318 | relu5_4 = self.relu5_4(relu5_3)
319 |
320 | out = {
321 | 'relu1_1': relu1_1,
322 | 'relu1_2': relu1_2,
323 |
324 | 'relu2_1': relu2_1,
325 | 'relu2_2': relu2_2,
326 |
327 | 'relu3_1': relu3_1,
328 | 'relu3_2': relu3_2,
329 | 'relu3_3': relu3_3,
330 | 'relu3_4': relu3_4,
331 |
332 | 'relu4_1': relu4_1,
333 | 'relu4_2': relu4_2,
334 | 'relu4_3': relu4_3,
335 | 'relu4_4': relu4_4,
336 |
337 | 'relu5_1': relu5_1,
338 | 'relu5_2': relu5_2,
339 | 'relu5_3': relu5_3,
340 | 'relu5_4': relu5_4,
341 | }
342 | return out
343 |
--------------------------------------------------------------------------------
/LICENSE.md:
--------------------------------------------------------------------------------
1 | ## creative commons
2 |
3 | # Attribution-NonCommercial 4.0 International
4 |
5 | Creative Commons Corporation (“Creative Commons”) is not a law firm and does not provide legal services or legal advice. Distribution of Creative Commons public licenses does not create a lawyer-client or other relationship. Creative Commons makes its licenses and related information available on an “as-is” basis. Creative Commons gives no warranties regarding its licenses, any material licensed under their terms and conditions, or any related information. Creative Commons disclaims all liability for damages resulting from their use to the fullest extent possible.
6 |
7 | ### Using Creative Commons Public Licenses
8 |
9 | Creative Commons public licenses provide a standard set of terms and conditions that creators and other rights holders may use to share original works of authorship and other material subject to copyright and certain other rights specified in the public license below. The following considerations are for informational purposes only, are not exhaustive, and do not form part of our licenses.
10 |
11 | * __Considerations for licensors:__ Our public licenses are intended for use by those authorized to give the public permission to use material in ways otherwise restricted by copyright and certain other rights. Our licenses are irrevocable. Licensors should read and understand the terms and conditions of the license they choose before applying it. Licensors should also secure all rights necessary before applying our licenses so that the public can reuse the material as expected. Licensors should clearly mark any material not subject to the license. This includes other CC-licensed material, or material used under an exception or limitation to copyright. [More considerations for licensors](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensors).
12 |
13 | * __Considerations for the public:__ By using one of our public licenses, a licensor grants the public permission to use the licensed material under specified terms and conditions. If the licensor’s permission is not necessary for any reason–for example, because of any applicable exception or limitation to copyright–then that use is not regulated by the license. Our licenses grant only permissions under copyright and certain other rights that a licensor has authority to grant. Use of the licensed material may still be restricted for other reasons, including because others have copyright or other rights in the material. A licensor may make special requests, such as asking that all changes be marked or described. Although not required by our licenses, you are encouraged to respect those requests where reasonable. [More considerations for the public](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensees).
14 |
15 | ## Creative Commons Attribution-NonCommercial 4.0 International Public License
16 |
17 | By exercising the Licensed Rights (defined below), You accept and agree to be bound by the terms and conditions of this Creative Commons Attribution-NonCommercial 4.0 International Public License ("Public License"). To the extent this Public License may be interpreted as a contract, You are granted the Licensed Rights in consideration of Your acceptance of these terms and conditions, and the Licensor grants You such rights in consideration of benefits the Licensor receives from making the Licensed Material available under these terms and conditions.
18 |
19 | ### Section 1 – Definitions.
20 |
21 | a. __Adapted Material__ means material subject to Copyright and Similar Rights that is derived from or based upon the Licensed Material and in which the Licensed Material is translated, altered, arranged, transformed, or otherwise modified in a manner requiring permission under the Copyright and Similar Rights held by the Licensor. For purposes of this Public License, where the Licensed Material is a musical work, performance, or sound recording, Adapted Material is always produced where the Licensed Material is synched in timed relation with a moving image.
22 |
23 | b. __Adapter's License__ means the license You apply to Your Copyright and Similar Rights in Your contributions to Adapted Material in accordance with the terms and conditions of this Public License.
24 |
25 | c. __Copyright and Similar Rights__ means copyright and/or similar rights closely related to copyright including, without limitation, performance, broadcast, sound recording, and Sui Generis Database Rights, without regard to how the rights are labeled or categorized. For purposes of this Public License, the rights specified in Section 2(b)(1)-(2) are not Copyright and Similar Rights.
26 |
27 | d. __Effective Technological Measures__ means those measures that, in the absence of proper authority, may not be circumvented under laws fulfilling obligations under Article 11 of the WIPO Copyright Treaty adopted on December 20, 1996, and/or similar international agreements.
28 |
29 | e. __Exceptions and Limitations__ means fair use, fair dealing, and/or any other exception or limitation to Copyright and Similar Rights that applies to Your use of the Licensed Material.
30 |
31 | f. __Licensed Material__ means the artistic or literary work, database, or other material to which the Licensor applied this Public License.
32 |
33 | g. __Licensed Rights__ means the rights granted to You subject to the terms and conditions of this Public License, which are limited to all Copyright and Similar Rights that apply to Your use of the Licensed Material and that the Licensor has authority to license.
34 |
35 | h. __Licensor__ means the individual(s) or entity(ies) granting rights under this Public License.
36 |
37 | i. __NonCommercial__ means not primarily intended for or directed towards commercial advantage or monetary compensation. For purposes of this Public License, the exchange of the Licensed Material for other material subject to Copyright and Similar Rights by digital file-sharing or similar means is NonCommercial provided there is no payment of monetary compensation in connection with the exchange.
38 |
39 | j. __Share__ means to provide material to the public by any means or process that requires permission under the Licensed Rights, such as reproduction, public display, public performance, distribution, dissemination, communication, or importation, and to make material available to the public including in ways that members of the public may access the material from a place and at a time individually chosen by them.
40 |
41 | k. __Sui Generis Database Rights__ means rights other than copyright resulting from Directive 96/9/EC of the European Parliament and of the Council of 11 March 1996 on the legal protection of databases, as amended and/or succeeded, as well as other essentially equivalent rights anywhere in the world.
42 |
43 | l. __You__ means the individual or entity exercising the Licensed Rights under this Public License. Your has a corresponding meaning.
44 |
45 | ### Section 2 – Scope.
46 |
47 | a. ___License grant.___
48 |
49 | 1. Subject to the terms and conditions of this Public License, the Licensor hereby grants You a worldwide, royalty-free, non-sublicensable, non-exclusive, irrevocable license to exercise the Licensed Rights in the Licensed Material to:
50 |
51 | A. reproduce and Share the Licensed Material, in whole or in part, for NonCommercial purposes only; and
52 |
53 | B. produce, reproduce, and Share Adapted Material for NonCommercial purposes only.
54 |
55 | 2. __Exceptions and Limitations.__ For the avoidance of doubt, where Exceptions and Limitations apply to Your use, this Public License does not apply, and You do not need to comply with its terms and conditions.
56 |
57 | 3. __Term.__ The term of this Public License is specified in Section 6(a).
58 |
59 | 4. __Media and formats; technical modifications allowed.__ The Licensor authorizes You to exercise the Licensed Rights in all media and formats whether now known or hereafter created, and to make technical modifications necessary to do so. The Licensor waives and/or agrees not to assert any right or authority to forbid You from making technical modifications necessary to exercise the Licensed Rights, including technical modifications necessary to circumvent Effective Technological Measures. For purposes of this Public License, simply making modifications authorized by this Section 2(a)(4) never produces Adapted Material.
60 |
61 | 5. __Downstream recipients.__
62 |
63 | A. __Offer from the Licensor – Licensed Material.__ Every recipient of the Licensed Material automatically receives an offer from the Licensor to exercise the Licensed Rights under the terms and conditions of this Public License.
64 |
65 | B. __No downstream restrictions.__ You may not offer or impose any additional or different terms or conditions on, or apply any Effective Technological Measures to, the Licensed Material if doing so restricts exercise of the Licensed Rights by any recipient of the Licensed Material.
66 |
67 | 6. __No endorsement.__ Nothing in this Public License constitutes or may be construed as permission to assert or imply that You are, or that Your use of the Licensed Material is, connected with, or sponsored, endorsed, or granted official status by, the Licensor or others designated to receive attribution as provided in Section 3(a)(1)(A)(i).
68 |
69 | b. ___Other rights.___
70 |
71 | 1. Moral rights, such as the right of integrity, are not licensed under this Public License, nor are publicity, privacy, and/or other similar personality rights; however, to the extent possible, the Licensor waives and/or agrees not to assert any such rights held by the Licensor to the limited extent necessary to allow You to exercise the Licensed Rights, but not otherwise.
72 |
73 | 2. Patent and trademark rights are not licensed under this Public License.
74 |
75 | 3. To the extent possible, the Licensor waives any right to collect royalties from You for the exercise of the Licensed Rights, whether directly or through a collecting society under any voluntary or waivable statutory or compulsory licensing scheme. In all other cases the Licensor expressly reserves any right to collect such royalties, including when the Licensed Material is used other than for NonCommercial purposes.
76 |
77 | ### Section 3 – License Conditions.
78 |
79 | Your exercise of the Licensed Rights is expressly made subject to the following conditions.
80 |
81 | a. ___Attribution.___
82 |
83 | 1. If You Share the Licensed Material (including in modified form), You must:
84 |
85 | A. retain the following if it is supplied by the Licensor with the Licensed Material:
86 |
87 | i. identification of the creator(s) of the Licensed Material and any others designated to receive attribution, in any reasonable manner requested by the Licensor (including by pseudonym if designated);
88 |
89 | ii. a copyright notice;
90 |
91 | iii. a notice that refers to this Public License;
92 |
93 | iv. a notice that refers to the disclaimer of warranties;
94 |
95 | v. a URI or hyperlink to the Licensed Material to the extent reasonably practicable;
96 |
97 | B. indicate if You modified the Licensed Material and retain an indication of any previous modifications; and
98 |
99 | C. indicate the Licensed Material is licensed under this Public License, and include the text of, or the URI or hyperlink to, this Public License.
100 |
101 | 2. You may satisfy the conditions in Section 3(a)(1) in any reasonable manner based on the medium, means, and context in which You Share the Licensed Material. For example, it may be reasonable to satisfy the conditions by providing a URI or hyperlink to a resource that includes the required information.
102 |
103 | 3. If requested by the Licensor, You must remove any of the information required by Section 3(a)(1)(A) to the extent reasonably practicable.
104 |
105 | 4. If You Share Adapted Material You produce, the Adapter's License You apply must not prevent recipients of the Adapted Material from complying with this Public License.
106 |
107 | ### Section 4 – Sui Generis Database Rights.
108 |
109 | Where the Licensed Rights include Sui Generis Database Rights that apply to Your use of the Licensed Material:
110 |
111 | a. for the avoidance of doubt, Section 2(a)(1) grants You the right to extract, reuse, reproduce, and Share all or a substantial portion of the contents of the database for NonCommercial purposes only;
112 |
113 | b. if You include all or a substantial portion of the database contents in a database in which You have Sui Generis Database Rights, then the database in which You have Sui Generis Database Rights (but not its individual contents) is Adapted Material; and
114 |
115 | c. You must comply with the conditions in Section 3(a) if You Share all or a substantial portion of the contents of the database.
116 |
117 | For the avoidance of doubt, this Section 4 supplements and does not replace Your obligations under this Public License where the Licensed Rights include other Copyright and Similar Rights.
118 |
119 | ### Section 5 – Disclaimer of Warranties and Limitation of Liability.
120 |
121 | a. __Unless otherwise separately undertaken by the Licensor, to the extent possible, the Licensor offers the Licensed Material as-is and as-available, and makes no representations or warranties of any kind concerning the Licensed Material, whether express, implied, statutory, or other. This includes, without limitation, warranties of title, merchantability, fitness for a particular purpose, non-infringement, absence of latent or other defects, accuracy, or the presence or absence of errors, whether or not known or discoverable. Where disclaimers of warranties are not allowed in full or in part, this disclaimer may not apply to You.__
122 |
123 | b. __To the extent possible, in no event will the Licensor be liable to You on any legal theory (including, without limitation, negligence) or otherwise for any direct, special, indirect, incidental, consequential, punitive, exemplary, or other losses, costs, expenses, or damages arising out of this Public License or use of the Licensed Material, even if the Licensor has been advised of the possibility of such losses, costs, expenses, or damages. Where a limitation of liability is not allowed in full or in part, this limitation may not apply to You.__
124 |
125 | c. The disclaimer of warranties and limitation of liability provided above shall be interpreted in a manner that, to the extent possible, most closely approximates an absolute disclaimer and waiver of all liability.
126 |
127 | ### Section 6 – Term and Termination.
128 |
129 | a. This Public License applies for the term of the Copyright and Similar Rights licensed here. However, if You fail to comply with this Public License, then Your rights under this Public License terminate automatically.
130 |
131 | b. Where Your right to use the Licensed Material has terminated under Section 6(a), it reinstates:
132 |
133 | 1. automatically as of the date the violation is cured, provided it is cured within 30 days of Your discovery of the violation; or
134 |
135 | 2. upon express reinstatement by the Licensor.
136 |
137 | For the avoidance of doubt, this Section 6(b) does not affect any right the Licensor may have to seek remedies for Your violations of this Public License.
138 |
139 | c. For the avoidance of doubt, the Licensor may also offer the Licensed Material under separate terms or conditions or stop distributing the Licensed Material at any time; however, doing so will not terminate this Public License.
140 |
141 | d. Sections 1, 5, 6, 7, and 8 survive termination of this Public License.
142 |
143 | ### Section 7 – Other Terms and Conditions.
144 |
145 | a. The Licensor shall not be bound by any additional or different terms or conditions communicated by You unless expressly agreed.
146 |
147 | b. Any arrangements, understandings, or agreements regarding the Licensed Material not stated herein are separate from and independent of the terms and conditions of this Public License.
148 |
149 | ### Section 8 – Interpretation.
150 |
151 | a. For the avoidance of doubt, this Public License does not, and shall not be interpreted to, reduce, limit, restrict, or impose conditions on any use of the Licensed Material that could lawfully be made without permission under this Public License.
152 |
153 | b. To the extent possible, if any provision of this Public License is deemed unenforceable, it shall be automatically reformed to the minimum extent necessary to make it enforceable. If the provision cannot be reformed, it shall be severed from this Public License without affecting the enforceability of the remaining terms and conditions.
154 |
155 | c. No term or condition of this Public License will be waived and no failure to comply consented to unless expressly agreed to by the Licensor.
156 |
157 | d. Nothing in this Public License constitutes or may be interpreted as a limitation upon, or waiver of, any privileges and immunities that apply to the Licensor or You, including from the legal processes of any jurisdiction or authority.
158 |
159 | > Creative Commons is not a party to its public licenses. Notwithstanding, Creative Commons may elect to apply one of its public licenses to material it publishes and in those instances will be considered the “Licensor.” Except for the limited purpose of indicating that material is shared under a Creative Commons public license or as otherwise permitted by the Creative Commons policies published at [creativecommons.org/policies](http://creativecommons.org/policies), Creative Commons does not authorize the use of the trademark “Creative Commons” or any other trademark or logo of Creative Commons without its prior written consent including, without limitation, in connection with any unauthorized modifications to any of its public licenses or any other arrangements, understandings, or agreements concerning use of licensed material. For the avoidance of doubt, this paragraph does not form part of the public licenses.
160 | >
161 | > Creative Commons may be contacted at creativecommons.org
162 |
--------------------------------------------------------------------------------
/models/base_function.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from torch.nn import init
4 | import functools
5 | from torch.optim import lr_scheduler
6 | from torch.nn.utils.spectral_norm import spectral_norm as SpectralNorm
7 |
8 | ######################################################################################
9 | # base function for network structure
10 | ######################################################################################
11 |
12 |
13 | def init_weights(net, init_type='normal', gain=0.02):
14 | """Get different initial method for the network weights"""
15 | def init_func(m):
16 | classname = m.__class__.__name__
17 | if hasattr(m, 'weight') and (classname.find('Conv')!=-1 or classname.find('Linear')!=-1):
18 | if init_type == 'normal':
19 | init.normal_(m.weight.data, 0.0, gain)
20 | elif init_type == 'xavier':
21 | init.xavier_normal_(m.weight.data, gain=gain)
22 | elif init_type == 'kaiming':
23 | init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
24 | elif init_type == 'orthogonal':
25 | init.orthogonal_(m.weight.data, gain=gain)
26 | else:
27 | raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
28 | if hasattr(m, 'bias') and m.bias is not None:
29 | init.constant_(m.bias.data, 0.0)
30 | elif classname.find('BatchNorm2d') != -1:
31 | init.normal_(m.weight.data, 1.0, 0.02)
32 | init.constant_(m.bias.data, 0.0)
33 |
34 | print('initialize network with %s' % init_type)
35 | net.apply(init_func)
36 |
37 |
38 | def get_norm_layer(norm_type='batch'):
39 | """Get the normalization layer for the networks"""
40 | if norm_type == 'batch':
41 | norm_layer = functools.partial(nn.BatchNorm2d, momentum=0.1, affine=True)
42 | elif norm_type == 'instance':
43 | norm_layer = functools.partial(nn.InstanceNorm2d, affine=True)
44 | elif norm_type == 'none':
45 | norm_layer = None
46 | else:
47 | raise NotImplementedError('normalization layer [%s] is not found' % norm_type)
48 | return norm_layer
49 |
50 |
51 | def get_nonlinearity_layer(activation_type='PReLU'):
52 | """Get the activation layer for the networks"""
53 | if activation_type == 'ReLU':
54 | nonlinearity_layer = nn.ReLU()
55 | elif activation_type == 'SELU':
56 | nonlinearity_layer = nn.SELU()
57 | elif activation_type == 'LeakyReLU':
58 | nonlinearity_layer = nn.LeakyReLU(0.1)
59 | elif activation_type == 'PReLU':
60 | nonlinearity_layer = nn.PReLU()
61 | else:
62 | raise NotImplementedError('activation layer [%s] is not found' % activation_type)
63 | return nonlinearity_layer
64 |
65 |
66 | def get_scheduler(optimizer, opt):
67 | """Get the training learning rate for different epoch"""
68 | if opt.lr_policy == 'lambda':
69 | def lambda_rule(epoch):
70 | lr_l = 1.0 - max(0, epoch+opt.iter_start-opt.niter) / float(opt.niter_decay+1)
71 | return lr_l
72 | scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda_rule)
73 | elif opt.lr_policy == 'step':
74 | scheduler = lr_scheduler.StepLR(optimizer, step_size=opt.lr_decay_iters, gamma=0.1)
75 | elif opt.lr_policy == 'exponent':
76 | scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
77 | elif opt.lr_policy == 'cosine':
78 | scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=32, eta_min=0)
79 | else:
80 | raise NotImplementedError('learning rate policy [%s] is not implemented', opt.lr_policy)
81 | return scheduler
82 |
83 |
84 | def print_network(net):
85 | """print the network"""
86 | num_params = 0
87 | for param in net.parameters():
88 | num_params += param.numel()
89 | print(net)
90 | print('total number of parameters: %.3f M' % (num_params/1e6))
91 |
92 |
93 | def init_net(net, init_type='normal', gpu_ids=[]):
94 | """print the network structure and initial the network"""
95 | print_network(net)
96 |
97 | if len(gpu_ids) > 0:
98 | assert(torch.cuda.is_available())
99 | net.cuda()
100 | net = torch.nn.DataParallel(net, gpu_ids)
101 | init_weights(net, init_type)
102 | return net
103 |
104 |
105 | def _freeze(*args):
106 | """freeze the network for forward process"""
107 | for module in args:
108 | if module:
109 | for p in module.parameters():
110 | p.requires_grad = False
111 |
112 |
113 | def _unfreeze(*args):
114 | """ unfreeze the network for parameter update"""
115 | for module in args:
116 | if module:
117 | for p in module.parameters():
118 | p.requires_grad = True
119 |
120 |
121 | def spectral_norm(module, use_spect=True):
122 | """use spectral normal layer to stable the training process"""
123 | if use_spect:
124 | return SpectralNorm(module)
125 | else:
126 | return module
127 |
128 |
129 | def coord_conv(input_nc, output_nc, use_spect=False, use_coord=False, with_r=False, **kwargs):
130 | """use coord convolution layer to add position information"""
131 | if use_coord:
132 | print("ERROR! #### ERROR! #### ERROR! #### ERROR! #### ERROR! #### ERROR! #### ERROR! #### ")
133 | return CoordConv(input_nc, output_nc, with_r, use_spect, **kwargs)
134 | else:
135 | return spectral_norm(nn.Conv2d(input_nc, output_nc, **kwargs), use_spect)
136 |
137 |
138 | ######################################################################################
139 | # Network basic function
140 | ######################################################################################
141 | class AddCoords(nn.Module):
142 | """
143 | Add Coords to a tensor
144 | """
145 | def __init__(self, with_r=False):
146 | super(AddCoords, self).__init__()
147 | self.with_r = with_r
148 |
149 | def forward(self, x):
150 | """
151 | :param x: shape (batch, channel, x_dim, y_dim)
152 | :return: shape (batch, channel+2, x_dim, y_dim)
153 | """
154 | B, _, x_dim, y_dim = x.size()
155 |
156 | # coord calculate
157 | xx_channel = torch.arange(x_dim).repeat(B, 1, y_dim, 1).type_as(x)
158 | yy_cahnnel = torch.arange(y_dim).repeat(B, 1, x_dim, 1).permute(0, 1, 3, 2).type_as(x)
159 | # normalization
160 | xx_channel = xx_channel.float() / (x_dim-1)
161 | yy_cahnnel = yy_cahnnel.float() / (y_dim-1)
162 | xx_channel = xx_channel * 2 - 1
163 | yy_cahnnel = yy_cahnnel * 2 - 1
164 |
165 | ret = torch.cat([x, xx_channel, yy_cahnnel], dim=1)
166 |
167 | if self.with_r:
168 | rr = torch.sqrt(xx_channel ** 2 + yy_cahnnel ** 2)
169 | ret = torch.cat([ret, rr], dim=1)
170 |
171 | return ret
172 |
173 |
174 | class CoordConv(nn.Module):
175 | """
176 | CoordConv operation
177 | """
178 | def __init__(self, input_nc, output_nc, with_r=False, use_spect=False, **kwargs):
179 | super(CoordConv, self).__init__()
180 | self.addcoords = AddCoords(with_r=with_r)
181 | input_nc = input_nc + 2
182 | if with_r:
183 | input_nc = input_nc + 1
184 | self.conv = spectral_norm(nn.Conv2d(input_nc, output_nc, **kwargs), use_spect)
185 |
186 | def forward(self, x):
187 | ret = self.addcoords(x)
188 | ret = self.conv(ret)
189 |
190 | return ret
191 |
192 |
193 | class ResBlock(nn.Module):
194 | """
195 | Define an Residual block for different types
196 | """
197 | def __init__(self, input_nc, output_nc, hidden_nc=None, norm_layer=nn.BatchNorm2d, nonlinearity= nn.LeakyReLU(),
198 | sample_type='none', use_spect=False, use_coord=False):
199 | super(ResBlock, self).__init__()
200 |
201 | hidden_nc = output_nc if hidden_nc is None else hidden_nc
202 | self.sample = True
203 | if sample_type == 'none':
204 | self.sample = False
205 | elif sample_type == 'up':
206 | output_nc = output_nc * 4
207 | self.pool = nn.PixelShuffle(upscale_factor=2)
208 | elif sample_type == 'down':
209 | self.pool = nn.AvgPool2d(kernel_size=2, stride=2)
210 | else:
211 | raise NotImplementedError('sample type [%s] is not found' % sample_type)
212 |
213 | kwargs = {'kernel_size': 3, 'stride': 1, 'padding': 1}
214 | kwargs_short = {'kernel_size': 1, 'stride': 1, 'padding': 0}
215 |
216 | self.conv1 = coord_conv(input_nc, hidden_nc, use_spect, use_coord, **kwargs)
217 | self.conv2 = coord_conv(hidden_nc, output_nc, use_spect, use_coord, **kwargs)
218 | self.bypass = coord_conv(input_nc, output_nc, use_spect, use_coord, **kwargs_short)
219 |
220 | if type(norm_layer) == type(None):
221 | self.model = nn.Sequential(nonlinearity, self.conv1, nonlinearity, self.conv2,)
222 | else:
223 | self.model = nn.Sequential(norm_layer(input_nc), nonlinearity, self.conv1, norm_layer(hidden_nc), nonlinearity, self.conv2,)
224 |
225 | self.shortcut = nn.Sequential(self.bypass,)
226 |
227 | def forward(self, x):
228 | if self.sample:
229 | out = self.pool(self.model(x)) + self.pool(self.shortcut(x))
230 | else:
231 | out = self.model(x) + self.shortcut(x)
232 |
233 | return out
234 |
235 |
236 | class EncoderBlockOptimized(nn.Module):
237 | """
238 | Define an Encoder block for the first layer of the generator
239 | """
240 | def __init__(self, input_nc, output_nc, norm_layer=nn.BatchNorm2d, nonlinearity=nn.LeakyReLU(),
241 | use_spect=False, use_coord=False):
242 | super(EncoderBlockOptimized, self).__init__()
243 |
244 | kwargs_down = {'kernel_size': 4, 'stride': 2, 'padding': 1}
245 | kwargs_fine = {'kernel_size': 3, 'stride': 1, 'padding': 1}
246 |
247 | conv1 = coord_conv(input_nc, output_nc, use_spect, use_coord, **kwargs_down)
248 | conv2 = coord_conv(output_nc, output_nc, use_spect, use_coord, **kwargs_fine)
249 |
250 | if type(norm_layer) == type(None):
251 | self.model = nn.Sequential(conv1, nonlinearity, conv2)
252 | else:
253 | self.model = nn.Sequential(conv1, norm_layer(output_nc), nonlinearity, conv2)
254 |
255 | def forward(self, x):
256 | out = self.model(x)
257 | return out
258 |
259 |
260 | class EncoderBlock(nn.Module):
261 | """
262 | Define an Encoder block for the medium layer of the generator
263 | """
264 | def __init__(self, input_nc, output_nc, norm_layer=nn.BatchNorm2d, nonlinearity=nn.LeakyReLU(),
265 | use_spect=False, use_coord=False):
266 | super(EncoderBlock, self).__init__()
267 |
268 |
269 | kwargs_down = {'kernel_size': 4, 'stride': 2, 'padding': 1}
270 | kwargs_fine = {'kernel_size': 3, 'stride': 1, 'padding': 1}
271 |
272 | conv1 = coord_conv(input_nc, output_nc, use_spect, use_coord, **kwargs_down)
273 | conv2 = coord_conv(output_nc, output_nc, use_spect, use_coord, **kwargs_fine)
274 |
275 | if type(norm_layer) == type(None):
276 | self.model = nn.Sequential(conv1, nonlinearity, conv2, nonlinearity)
277 | else:
278 | self.model = nn.Sequential(norm_layer(input_nc), nonlinearity, conv1,
279 | norm_layer(output_nc), nonlinearity, conv2)
280 |
281 | def forward(self, x):
282 | out = self.model(x)
283 | return out
284 |
285 |
286 | class ResBlockDecoder(nn.Module):
287 | """
288 | Define a decoder block
289 | """
290 | def __init__(self, input_nc, output_nc, hidden_nc=None, norm_layer=nn.BatchNorm2d, nonlinearity= nn.LeakyReLU(),
291 | use_spect=False, use_coord=False):
292 | super(ResBlockDecoder, self).__init__()
293 |
294 | hidden_nc = output_nc if hidden_nc is None else hidden_nc
295 |
296 | conv1 = spectral_norm(nn.Conv2d(input_nc, hidden_nc, kernel_size=3, stride=1, padding=1), use_spect)
297 | conv2 = spectral_norm(nn.ConvTranspose2d(hidden_nc, output_nc, kernel_size=3, stride=2, padding=1, output_padding=1), use_spect)
298 | bypass = spectral_norm(nn.ConvTranspose2d(input_nc, output_nc, kernel_size=3, stride=2, padding=1, output_padding=1), use_spect)
299 |
300 | if type(norm_layer) == type(None):
301 | self.model = nn.Sequential(nonlinearity, conv1, nonlinearity, conv2,)
302 | else:
303 | self.model = nn.Sequential(norm_layer(input_nc), nonlinearity, conv1, norm_layer(hidden_nc), nonlinearity, conv2,)
304 |
305 | self.shortcut = nn.Sequential(bypass)
306 |
307 | def forward(self, x):
308 | out = self.model(x) + self.shortcut(x)
309 |
310 | return out
311 |
312 |
313 | class ResBlockEncoderOptimized(nn.Module):
314 | """
315 | Define an Encoder block for the first layer of the discriminator
316 | """
317 | def __init__(self, input_nc, output_nc, hidden_nc=None, norm_layer=nn.BatchNorm2d, nonlinearity= nn.LeakyReLU(),
318 | use_spect=False, use_coord=False):
319 | super(ResBlockEncoderOptimized, self).__init__()
320 |
321 | hidden_nc = input_nc if hidden_nc is None else hidden_nc
322 |
323 | conv1 = spectral_norm(nn.Conv2d(input_nc, hidden_nc, kernel_size=3, stride=1, padding=1), use_spect)
324 | conv2 = spectral_norm(nn.Conv2d(hidden_nc, output_nc, kernel_size=4, stride=2, padding=1), use_spect)
325 | bypass = spectral_norm(nn.Conv2d(input_nc, output_nc, kernel_size=1, stride=1, padding=0), use_spect)
326 |
327 | if type(norm_layer) == type(None):
328 | self.model = nn.Sequential(conv1, nonlinearity, conv2,)
329 | else:
330 | self.model = nn.Sequential(conv1, norm_layer(hidden_nc), nonlinearity, conv2,)
331 | self.shortcut = nn.Sequential(nn.AvgPool2d(kernel_size=2, stride=2), bypass)
332 |
333 | def forward(self, x):
334 | out = self.model(x) + self.shortcut(x)
335 | return out
336 |
337 |
338 | class ResBlockEncoder(nn.Module):
339 | """
340 | Define an Encoder block for the medium layer of the discriminator
341 | """
342 | def __init__(self, input_nc, output_nc, hidden_nc=None, norm_layer=nn.BatchNorm2d, nonlinearity= nn.LeakyReLU(),
343 | use_spect=False, use_coord=False):
344 | super(ResBlockEncoder, self).__init__()
345 |
346 | hidden_nc = input_nc if hidden_nc is None else hidden_nc
347 |
348 | conv1 = spectral_norm(nn.Conv2d(input_nc, hidden_nc, kernel_size=3, stride=1, padding=1), use_spect)
349 | conv2 = spectral_norm(nn.Conv2d(hidden_nc, output_nc, kernel_size=4, stride=2, padding=1), use_spect)
350 | bypass = spectral_norm(nn.Conv2d(input_nc, output_nc, kernel_size=1, stride=1, padding=0), use_spect)
351 |
352 | if type(norm_layer) == type(None):
353 | self.model = nn.Sequential(nonlinearity, conv1, nonlinearity, conv2,)
354 | else:
355 | self.model = nn.Sequential(norm_layer(input_nc), nonlinearity, conv1,
356 | norm_layer(hidden_nc), nonlinearity, conv2,)
357 | self.shortcut = nn.Sequential(nn.AvgPool2d(kernel_size=2, stride=2), bypass)
358 |
359 | def forward(self, x):
360 | out = self.model(x) + self.shortcut(x)
361 | return out
362 |
363 |
364 | class Output(nn.Module):
365 | """
366 | Define the output layer
367 | """
368 | def __init__(self, input_nc, output_nc, kernel_size = 3, norm_layer=nn.BatchNorm2d, nonlinearity= nn.LeakyReLU(),
369 | use_spect=False, use_coord=False):
370 | super(Output, self).__init__()
371 |
372 | kwargs = {'kernel_size': kernel_size, 'padding':0, 'bias': True}
373 |
374 | self.conv1 = coord_conv(input_nc, output_nc, use_spect, use_coord, **kwargs)
375 |
376 | if type(norm_layer) == type(None):
377 | self.model = nn.Sequential(nonlinearity, nn.ReflectionPad2d(int(kernel_size/2)), self.conv1, nn.Tanh())
378 | else:
379 | self.model = nn.Sequential(norm_layer(input_nc), nonlinearity, nn.ReflectionPad2d(int(kernel_size / 2)), self.conv1, nn.Tanh())
380 |
381 | def forward(self, x):
382 | out = self.model(x)
383 |
384 | return out
385 |
386 |
387 | class Auto_Attn(nn.Module):
388 | """ Short+Long attention Layer"""
389 |
390 | def __init__(self, input_nc, norm_layer=nn.BatchNorm2d):
391 | super(Auto_Attn, self).__init__()
392 | self.input_nc = input_nc
393 |
394 | self.query_conv = nn.Conv2d(input_nc, input_nc // 4, kernel_size=1)
395 | self.gamma = nn.Parameter(torch.zeros(1))
396 | self.alpha = nn.Parameter(torch.zeros(1))
397 |
398 | self.softmax = nn.Softmax(dim=-1)
399 |
400 | self.model = ResBlock(int(input_nc*2), input_nc, input_nc, norm_layer=norm_layer, use_spect=True)
401 |
402 | def forward(self, x, pre=None, mask=None):
403 | """
404 | inputs :
405 | x : input feature maps( B X C X W X H)
406 | returns :
407 | out : self attention value + input feature
408 | attention: B X N X N (N is Width*Height)
409 | """
410 | B, C, W, H = x.size()
411 | proj_query = self.query_conv(x).view(B, -1, W * H) # B X (N)X C
412 | proj_key = proj_query # B X C x (N)
413 |
414 | energy = torch.bmm(proj_query.permute(0, 2, 1), proj_key) # transpose check
415 | attention = self.softmax(energy) # BX (N) X (N)
416 | proj_value = x.view(B, -1, W * H) # B X C X N
417 |
418 | out = torch.bmm(proj_value, attention.permute(0, 2, 1))
419 | out = out.view(B, C, W, H)
420 |
421 | out = self.gamma * out + x
422 |
423 | if type(pre) != type(None):
424 | # using long distance attention layer to copy information from valid regions
425 | context_flow = torch.bmm(pre.view(B, -1, W*H), attention.permute(0, 2, 1)).view(B, -1, W, H)
426 | context_flow = self.alpha * (1-mask) * context_flow + (mask) * pre
427 | out = self.model(torch.cat([out, context_flow], dim=1))
428 |
429 | return out, attention
430 |
--------------------------------------------------------------------------------
/models/ui_model.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.autograd import Variable
3 | from collections import OrderedDict
4 | import numpy as np
5 | import os
6 | from PIL import Image
7 | import util.util as util
8 | from .base_model import BaseModel
9 | from . import networks
10 |
11 | class UIModel(BaseModel):
12 | def name(self):
13 | return 'UIModel'
14 |
15 | def initialize(self, opt):
16 | assert(not opt.isTrain)
17 | BaseModel.initialize(self, opt)
18 | self.use_features = opt.instance_feat or opt.label_feat
19 |
20 | netG_input_nc = opt.label_nc
21 | if not opt.no_instance:
22 | netG_input_nc += 1
23 | if self.use_features:
24 | netG_input_nc += opt.feat_num
25 |
26 | self.netG = networks.define_G(netG_input_nc, opt.output_nc, opt.ngf, opt.netG,
27 | opt.n_downsample_global, opt.n_blocks_global, opt.n_local_enhancers,
28 | opt.n_blocks_local, opt.norm, gpu_ids=self.gpu_ids)
29 | self.load_network(self.netG, 'G', opt.which_epoch)
30 |
31 | print('---------- Networks initialized -------------')
32 |
33 | def toTensor(self, img, normalize=False):
34 | tensor = torch.from_numpy(np.array(img, np.int32, copy=False))
35 | tensor = tensor.view(1, img.size[1], img.size[0], len(img.mode))
36 | tensor = tensor.transpose(1, 2).transpose(1, 3).contiguous()
37 | if normalize:
38 | return (tensor.float()/255.0 - 0.5) / 0.5
39 | return tensor.float()
40 |
41 | def load_image(self, label_path, inst_path, feat_path):
42 | opt = self.opt
43 | # read label map
44 | label_img = Image.open(label_path)
45 | if label_path.find('face') != -1:
46 | label_img = label_img.convert('L')
47 | ow, oh = label_img.size
48 | w = opt.loadSize
49 | h = int(w * oh / ow)
50 | label_img = label_img.resize((w, h), Image.NEAREST)
51 | label_map = self.toTensor(label_img)
52 |
53 | # onehot vector input for label map
54 | self.label_map = label_map.cuda()
55 | oneHot_size = (1, opt.label_nc, h, w)
56 | input_label = self.Tensor(torch.Size(oneHot_size)).zero_()
57 | self.input_label = input_label.scatter_(1, label_map.long().cuda(), 1.0)
58 |
59 | # read instance map
60 | if not opt.no_instance:
61 | inst_img = Image.open(inst_path)
62 | inst_img = inst_img.resize((w, h), Image.NEAREST)
63 | self.inst_map = self.toTensor(inst_img).cuda()
64 | self.edge_map = self.get_edges(self.inst_map)
65 | self.net_input = Variable(torch.cat((self.input_label, self.edge_map), dim=1), volatile=True)
66 | else:
67 | self.net_input = Variable(self.input_label, volatile=True)
68 |
69 | self.features_clustered = np.load(feat_path).item()
70 | self.object_map = self.inst_map if opt.instance_feat else self.label_map
71 |
72 | object_np = self.object_map.cpu().numpy().astype(int)
73 | self.feat_map = self.Tensor(1, opt.feat_num, h, w).zero_()
74 | self.cluster_indices = np.zeros(self.opt.label_nc, np.uint8)
75 | for i in np.unique(object_np):
76 | label = i if i < 1000 else i//1000
77 | if label in self.features_clustered:
78 | feat = self.features_clustered[label]
79 | np.random.seed(i+1)
80 | cluster_idx = np.random.randint(0, feat.shape[0])
81 | self.cluster_indices[label] = cluster_idx
82 | idx = (self.object_map == i).nonzero()
83 | self.set_features(idx, feat, cluster_idx)
84 |
85 | self.net_input_original = self.net_input.clone()
86 | self.label_map_original = self.label_map.clone()
87 | self.feat_map_original = self.feat_map.clone()
88 | if not opt.no_instance:
89 | self.inst_map_original = self.inst_map.clone()
90 |
91 | def reset(self):
92 | self.net_input = self.net_input_prev = self.net_input_original.clone()
93 | self.label_map = self.label_map_prev = self.label_map_original.clone()
94 | self.feat_map = self.feat_map_prev = self.feat_map_original.clone()
95 | if not self.opt.no_instance:
96 | self.inst_map = self.inst_map_prev = self.inst_map_original.clone()
97 | self.object_map = self.inst_map if self.opt.instance_feat else self.label_map
98 |
99 | def undo(self):
100 | self.net_input = self.net_input_prev
101 | self.label_map = self.label_map_prev
102 | self.feat_map = self.feat_map_prev
103 | if not self.opt.no_instance:
104 | self.inst_map = self.inst_map_prev
105 | self.object_map = self.inst_map if self.opt.instance_feat else self.label_map
106 |
107 | # get boundary map from instance map
108 | def get_edges(self, t):
109 | edge = torch.cuda.ByteTensor(t.size()).zero_()
110 | edge[:,:,:,1:] = edge[:,:,:,1:] | (t[:,:,:,1:] != t[:,:,:,:-1])
111 | edge[:,:,:,:-1] = edge[:,:,:,:-1] | (t[:,:,:,1:] != t[:,:,:,:-1])
112 | edge[:,:,1:,:] = edge[:,:,1:,:] | (t[:,:,1:,:] != t[:,:,:-1,:])
113 | edge[:,:,:-1,:] = edge[:,:,:-1,:] | (t[:,:,1:,:] != t[:,:,:-1,:])
114 | return edge.float()
115 |
116 | # change the label at the source position to the label at the target position
117 | def change_labels(self, click_src, click_tgt):
118 | y_src, x_src = click_src[0], click_src[1]
119 | y_tgt, x_tgt = click_tgt[0], click_tgt[1]
120 | label_src = int(self.label_map[0, 0, y_src, x_src])
121 | inst_src = self.inst_map[0, 0, y_src, x_src]
122 | label_tgt = int(self.label_map[0, 0, y_tgt, x_tgt])
123 | inst_tgt = self.inst_map[0, 0, y_tgt, x_tgt]
124 |
125 | idx_src = (self.inst_map == inst_src).nonzero()
126 | # need to change 3 things: label map, instance map, and feature map
127 | if idx_src.shape:
128 | # backup current maps
129 | self.backup_current_state()
130 |
131 | # change both the label map and the network input
132 | self.label_map[idx_src[:,0], idx_src[:,1], idx_src[:,2], idx_src[:,3]] = label_tgt
133 | self.net_input[idx_src[:,0], idx_src[:,1] + label_src, idx_src[:,2], idx_src[:,3]] = 0
134 | self.net_input[idx_src[:,0], idx_src[:,1] + label_tgt, idx_src[:,2], idx_src[:,3]] = 1
135 |
136 | # update the instance map (and the network input)
137 | if inst_tgt > 1000:
138 | # if different instances have different ids, give the new object a new id
139 | tgt_indices = (self.inst_map > label_tgt * 1000) & (self.inst_map < (label_tgt+1) * 1000)
140 | inst_tgt = self.inst_map[tgt_indices].max() + 1
141 | self.inst_map[idx_src[:,0], idx_src[:,1], idx_src[:,2], idx_src[:,3]] = inst_tgt
142 | self.net_input[:,-1,:,:] = self.get_edges(self.inst_map)
143 |
144 | # also copy the source features to the target position
145 | idx_tgt = (self.inst_map == inst_tgt).nonzero()
146 | if idx_tgt.shape:
147 | self.copy_features(idx_src, idx_tgt[0,:])
148 |
149 | self.fake_image = util.tensor2im(self.single_forward(self.net_input, self.feat_map))
150 |
151 | # add strokes of target label in the image
152 | def add_strokes(self, click_src, label_tgt, bw, save):
153 | # get the region of the new strokes (bw is the brush width)
154 | size = self.net_input.size()
155 | h, w = size[2], size[3]
156 | idx_src = torch.LongTensor(bw**2, 4).fill_(0)
157 | for i in range(bw):
158 | idx_src[i*bw:(i+1)*bw, 2] = min(h-1, max(0, click_src[0]-bw//2 + i))
159 | for j in range(bw):
160 | idx_src[i*bw+j, 3] = min(w-1, max(0, click_src[1]-bw//2 + j))
161 | idx_src = idx_src.cuda()
162 |
163 | # again, need to update 3 things
164 | if idx_src.shape:
165 | # backup current maps
166 | if save:
167 | self.backup_current_state()
168 |
169 | # update the label map (and the network input) in the stroke region
170 | self.label_map[idx_src[:,0], idx_src[:,1], idx_src[:,2], idx_src[:,3]] = label_tgt
171 | for k in range(self.opt.label_nc):
172 | self.net_input[idx_src[:,0], idx_src[:,1] + k, idx_src[:,2], idx_src[:,3]] = 0
173 | self.net_input[idx_src[:,0], idx_src[:,1] + label_tgt, idx_src[:,2], idx_src[:,3]] = 1
174 |
175 | # update the instance map (and the network input)
176 | self.inst_map[idx_src[:,0], idx_src[:,1], idx_src[:,2], idx_src[:,3]] = label_tgt
177 | self.net_input[:,-1,:,:] = self.get_edges(self.inst_map)
178 |
179 | # also update the features if available
180 | if self.opt.instance_feat:
181 | feat = self.features_clustered[label_tgt]
182 | #np.random.seed(label_tgt+1)
183 | #cluster_idx = np.random.randint(0, feat.shape[0])
184 | cluster_idx = self.cluster_indices[label_tgt]
185 | self.set_features(idx_src, feat, cluster_idx)
186 |
187 | self.fake_image = util.tensor2im(self.single_forward(self.net_input, self.feat_map))
188 |
189 | # add an object to the clicked position with selected style
190 | def add_objects(self, click_src, label_tgt, mask, style_id=0):
191 | y, x = click_src[0], click_src[1]
192 | mask = np.transpose(mask, (2, 0, 1))[np.newaxis,...]
193 | idx_src = torch.from_numpy(mask).cuda().nonzero()
194 | idx_src[:,2] += y
195 | idx_src[:,3] += x
196 |
197 | # backup current maps
198 | self.backup_current_state()
199 |
200 | # update label map
201 | self.label_map[idx_src[:,0], idx_src[:,1], idx_src[:,2], idx_src[:,3]] = label_tgt
202 | for k in range(self.opt.label_nc):
203 | self.net_input[idx_src[:,0], idx_src[:,1] + k, idx_src[:,2], idx_src[:,3]] = 0
204 | self.net_input[idx_src[:,0], idx_src[:,1] + label_tgt, idx_src[:,2], idx_src[:,3]] = 1
205 |
206 | # update instance map
207 | self.inst_map[idx_src[:,0], idx_src[:,1], idx_src[:,2], idx_src[:,3]] = label_tgt
208 | self.net_input[:,-1,:,:] = self.get_edges(self.inst_map)
209 |
210 | # update feature map
211 | self.set_features(idx_src, self.feat, style_id)
212 |
213 | self.fake_image = util.tensor2im(self.single_forward(self.net_input, self.feat_map))
214 |
215 | def single_forward(self, net_input, feat_map):
216 | net_input = torch.cat((net_input, feat_map), dim=1)
217 | fake_image = self.netG.forward(net_input)
218 |
219 | if fake_image.size()[0] == 1:
220 | return fake_image.data[0]
221 | return fake_image.data
222 |
223 |
224 | # generate all outputs for different styles
225 | def style_forward(self, click_pt, style_id=-1):
226 | if click_pt is None:
227 | self.fake_image = util.tensor2im(self.single_forward(self.net_input, self.feat_map))
228 | self.crop = None
229 | self.mask = None
230 | else:
231 | instToChange = int(self.object_map[0, 0, click_pt[0], click_pt[1]])
232 | self.instToChange = instToChange
233 | label = instToChange if instToChange < 1000 else instToChange//1000
234 | self.feat = self.features_clustered[label]
235 | self.fake_image = []
236 | self.mask = self.object_map == instToChange
237 | idx = self.mask.nonzero()
238 | self.get_crop_region(idx)
239 | if idx.size():
240 | if style_id == -1:
241 | (min_y, min_x, max_y, max_x) = self.crop
242 | ### original
243 | for cluster_idx in range(self.opt.multiple_output):
244 | self.set_features(idx, self.feat, cluster_idx)
245 | fake_image = self.single_forward(self.net_input, self.feat_map)
246 | fake_image = util.tensor2im(fake_image[:,min_y:max_y,min_x:max_x])
247 | self.fake_image.append(fake_image)
248 | """### To speed up previewing different style results, either crop or downsample the label maps
249 | if instToChange > 1000:
250 | (min_y, min_x, max_y, max_x) = self.crop
251 | ### crop
252 | _, _, h, w = self.net_input.size()
253 | offset = 512
254 | y_start, x_start = max(0, min_y-offset), max(0, min_x-offset)
255 | y_end, x_end = min(h, (max_y + offset)), min(w, (max_x + offset))
256 | y_region = slice(y_start, y_start+(y_end-y_start)//16*16)
257 | x_region = slice(x_start, x_start+(x_end-x_start)//16*16)
258 | net_input = self.net_input[:,:,y_region,x_region]
259 | for cluster_idx in range(self.opt.multiple_output):
260 | self.set_features(idx, self.feat, cluster_idx)
261 | fake_image = self.single_forward(net_input, self.feat_map[:,:,y_region,x_region])
262 | fake_image = util.tensor2im(fake_image[:,min_y-y_start:max_y-y_start,min_x-x_start:max_x-x_start])
263 | self.fake_image.append(fake_image)
264 | else:
265 | ### downsample
266 | (min_y, min_x, max_y, max_x) = [crop//2 for crop in self.crop]
267 | net_input = self.net_input[:,:,::2,::2]
268 | size = net_input.size()
269 | net_input_batch = net_input.expand(self.opt.multiple_output, size[1], size[2], size[3])
270 | for cluster_idx in range(self.opt.multiple_output):
271 | self.set_features(idx, self.feat, cluster_idx)
272 | feat_map = self.feat_map[:,:,::2,::2]
273 | if cluster_idx == 0:
274 | feat_map_batch = feat_map
275 | else:
276 | feat_map_batch = torch.cat((feat_map_batch, feat_map), dim=0)
277 | fake_image_batch = self.single_forward(net_input_batch, feat_map_batch)
278 | for i in range(self.opt.multiple_output):
279 | self.fake_image.append(util.tensor2im(fake_image_batch[i,:,min_y:max_y,min_x:max_x]))"""
280 |
281 | else:
282 | self.set_features(idx, self.feat, style_id)
283 | self.cluster_indices[label] = style_id
284 | self.fake_image = util.tensor2im(self.single_forward(self.net_input, self.feat_map))
285 |
286 | def backup_current_state(self):
287 | self.net_input_prev = self.net_input.clone()
288 | self.label_map_prev = self.label_map.clone()
289 | self.inst_map_prev = self.inst_map.clone()
290 | self.feat_map_prev = self.feat_map.clone()
291 |
292 | # crop the ROI and get the mask of the object
293 | def get_crop_region(self, idx):
294 | size = self.net_input.size()
295 | h, w = size[2], size[3]
296 | min_y, min_x = idx[:,2].min(), idx[:,3].min()
297 | max_y, max_x = idx[:,2].max(), idx[:,3].max()
298 | crop_min = 128
299 | if max_y - min_y < crop_min:
300 | min_y = max(0, (max_y + min_y) // 2 - crop_min // 2)
301 | max_y = min(h-1, min_y + crop_min)
302 | if max_x - min_x < crop_min:
303 | min_x = max(0, (max_x + min_x) // 2 - crop_min // 2)
304 | max_x = min(w-1, min_x + crop_min)
305 | self.crop = (min_y, min_x, max_y, max_x)
306 | self.mask = self.mask[:,:, min_y:max_y, min_x:max_x]
307 |
308 | # update the feature map once a new object is added or the label is changed
309 | def update_features(self, cluster_idx, mask=None, click_pt=None):
310 | self.feat_map_prev = self.feat_map.clone()
311 | # adding a new object
312 | if mask is not None:
313 | y, x = click_pt[0], click_pt[1]
314 | mask = np.transpose(mask, (2,0,1))[np.newaxis,...]
315 | idx = torch.from_numpy(mask).cuda().nonzero()
316 | idx[:,2] += y
317 | idx[:,3] += x
318 | # changing the label of an existing object
319 | else:
320 | idx = (self.object_map == self.instToChange).nonzero()
321 |
322 | # update feature map
323 | self.set_features(idx, self.feat, cluster_idx)
324 |
325 | # set the class features to the target feature
326 | def set_features(self, idx, feat, cluster_idx):
327 | for k in range(self.opt.feat_num):
328 | self.feat_map[idx[:,0], idx[:,1] + k, idx[:,2], idx[:,3]] = feat[cluster_idx, k]
329 |
330 | # copy the features at the target position to the source position
331 | def copy_features(self, idx_src, idx_tgt):
332 | for k in range(self.opt.feat_num):
333 | val = self.feat_map[idx_tgt[0], idx_tgt[1] + k, idx_tgt[2], idx_tgt[3]]
334 | self.feat_map[idx_src[:,0], idx_src[:,1] + k, idx_src[:,2], idx_src[:,3]] = val
335 |
336 | def get_current_visuals(self, getLabel=False):
337 | mask = self.mask
338 | if self.mask is not None:
339 | mask = np.transpose(self.mask[0].cpu().float().numpy(), (1,2,0)).astype(np.uint8)
340 |
341 | dict_list = [('fake_image', self.fake_image), ('mask', mask)]
342 |
343 | if getLabel: # only output label map if needed to save bandwidth
344 | label = util.tensor2label(self.net_input.data[0], self.opt.label_nc)
345 | dict_list += [('label', label)]
346 |
347 | return OrderedDict(dict_list)
--------------------------------------------------------------------------------
/metrics/metrics.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pathlib
3 | import torch
4 | import numpy as np
5 | from imageio import imread
6 | from scipy import linalg
7 | from torch.nn.functional import adaptive_avg_pool2d
8 | from skimage.measure import compare_ssim
9 | from skimage.measure import compare_psnr
10 | import glob
11 | import argparse
12 | import matplotlib.pyplot as plt
13 | from metrics.inception import InceptionV3
14 | from metrics.PerceptualSimilarity.models import dist_model as dm
15 | import pandas as pd
16 | import json
17 | import imageio
18 | from skimage.draw import circle, line_aa, polygon
19 |
20 |
21 | def pad_256(img):
22 | result = np.ones((256, 256, 3), dtype=float) * 255
23 | result[:,40:216,:] = img
24 | return result
25 |
26 |
27 | class FID():
28 | """docstring for FID
29 | Calculates the Frechet Inception Distance (FID) to evalulate GANs
30 | The FID metric calculates the distance between two distributions of images.
31 | Typically, we have summary statistics (mean & covariance matrix) of one
32 | of these distributions, while the 2nd distribution is given by a GAN.
33 | When run as a stand-alone program, it compares the distribution of
34 | images that are stored as PNG/JPEG at a specified location with a
35 | distribution given by summary statistics (in pickle format).
36 | The FID is calculated by assuming that X_1 and X_2 are the activations of
37 | the pool_3 layer of the inception net for generated samples and real world
38 | samples respectivly.
39 | See --help to see further details.
40 | Code apapted from https://github.com/bioinf-jku/TTUR to use PyTorch instead
41 | of Tensorflow
42 | Copyright 2018 Institute of Bioinformatics, JKU Linz
43 | Licensed under the Apache License, Version 2.0 (the "License");
44 | you may not use this file except in compliance with the License.
45 | You may obtain a copy of the License at
46 | http://www.apache.org/licenses/LICENSE-2.0
47 | Unless required by applicable law or agreed to in writing, software
48 | distributed under the License is distributed on an "AS IS" BASIS,
49 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
50 | See the License for the specific language governing permissions and
51 | limitations under the License.
52 | """
53 | def __init__(self):
54 | self.dims = 2048
55 | self.batch_size = 64
56 | self.cuda = True
57 | self.verbose=False
58 |
59 | block_idx = InceptionV3.BLOCK_INDEX_BY_DIM[self.dims]
60 | self.model = InceptionV3([block_idx])
61 | if self.cuda:
62 | # TODO: put model into specific GPU
63 | self.model.cuda()
64 |
65 | def __call__(self, images, gt_path):
66 | """ images: list of the generated image. The values must lie between 0 and 1.
67 | gt_path: the path of the ground truth images. The values must lie between 0 and 1.
68 | """
69 | if not os.path.exists(gt_path):
70 | raise RuntimeError('Invalid path: %s' % gt_path)
71 |
72 | print('calculate gt_path statistics...')
73 | m1, s1 = self.compute_statistics_of_path(gt_path, self.verbose)
74 | print('calculate generated_images statistics...')
75 | m2, s2 = self.calculate_activation_statistics(images, self.verbose)
76 | fid_value = self.calculate_frechet_distance(m1, s1, m2, s2)
77 | return fid_value
78 |
79 | def calculate_from_disk(self, generated_path, gt_path):
80 | """
81 | """
82 | if not os.path.exists(gt_path):
83 | raise RuntimeError('Invalid path: %s' % gt_path)
84 | if not os.path.exists(generated_path):
85 | raise RuntimeError('Invalid path: %s' % generated_path)
86 |
87 | print('calculate gt_path statistics...')
88 | m1, s1 = self.compute_statistics_of_path(gt_path, self.verbose)
89 | print('calculate generated_path statistics...')
90 | m2, s2 = self.compute_statistics_of_path(generated_path, self.verbose)
91 | print('calculate frechet distance...')
92 | fid_value = self.calculate_frechet_distance(m1, s1, m2, s2)
93 | print('fid_distance %f' % (fid_value))
94 | return fid_value
95 |
96 | def compute_statistics_of_path(self, path, verbose):
97 | npz_file = os.path.join(path, 'statistics.npz')
98 | if os.path.exists(npz_file):
99 | f = np.load(npz_file)
100 | m, s = f['mu'][:], f['sigma'][:]
101 | f.close()
102 | else:
103 | path = pathlib.Path(path)
104 | files = list(path.glob('*.jpg')) + list(path.glob('*.png'))
105 |
106 | imgs = np.array([imread(str(fn)).astype(np.float32) for fn in files])
107 |
108 | # Bring images to shape (B, 3, H, W)
109 | imgs = imgs.transpose((0, 3, 1, 2))
110 |
111 | # Rescale images to be between 0 and 1
112 | imgs /= 255
113 |
114 | m, s = self.calculate_activation_statistics(imgs, verbose)
115 | np.savez(npz_file, mu=m, sigma=s)
116 |
117 | return m, s
118 |
119 | def calculate_activation_statistics(self, images, verbose):
120 | """Calculation of the statistics used by the FID.
121 | Params:
122 | -- images : Numpy array of dimension (n_images, 3, hi, wi). The values
123 | must lie between 0 and 1.
124 | -- model : Instance of inception model
125 | -- batch_size : The images numpy array is split into batches with
126 | batch size batch_size. A reasonable batch size
127 | depends on the hardware.
128 | -- dims : Dimensionality of features returned by Inception
129 | -- cuda : If set to True, use GPU
130 | -- verbose : If set to True and parameter out_step is given, the
131 | number of calculated batches is reported.
132 | Returns:
133 | -- mu : The mean over samples of the activations of the pool_3 layer of
134 | the inception model.
135 | -- sigma : The covariance matrix of the activations of the pool_3 layer of
136 | the inception model.
137 | """
138 | act = self.get_activations(images, verbose)
139 | mu = np.mean(act, axis=0)
140 | sigma = np.cov(act, rowvar=False)
141 | return mu, sigma
142 |
143 | def get_activations(self, images, verbose=False):
144 | """Calculates the activations of the pool_3 layer for all images.
145 | Params:
146 | -- images : Numpy array of dimension (n_images, 3, hi, wi). The values
147 | must lie between 0 and 1.
148 | -- model : Instance of inception model
149 | -- batch_size : the images numpy array is split into batches with
150 | batch size batch_size. A reasonable batch size depends
151 | on the hardware.
152 | -- dims : Dimensionality of features returned by Inception
153 | -- cuda : If set to True, use GPU
154 | -- verbose : If set to True and parameter out_step is given, the number
155 | of calculated batches is reported.
156 | Returns:
157 | -- A numpy array of dimension (num images, dims) that contains the
158 | activations of the given tensor when feeding inception with the
159 | query tensor.
160 | """
161 | self.model.eval()
162 |
163 | d0 = images.shape[0]
164 | if self.batch_size > d0:
165 | print(('Warning: batch size is bigger than the data size. '
166 | 'Setting batch size to data size'))
167 | self.batch_size = d0
168 |
169 | n_batches = d0 // self.batch_size
170 | n_used_imgs = n_batches * self.batch_size
171 |
172 | pred_arr = np.empty((n_used_imgs, self.dims))
173 | for i in range(n_batches):
174 | if verbose:
175 | print('\rPropagating batch %d/%d' % (i + 1, n_batches))
176 | start = i * self.batch_size
177 | end = start + self.batch_size
178 |
179 | batch = torch.from_numpy(images[start:end]).type(torch.FloatTensor)
180 | if self.cuda:
181 | batch = batch.cuda()
182 |
183 | pred = self.model(batch)[0]
184 |
185 | # If model output is not scalar, apply global spatial average pooling.
186 | # This happens if you choose a dimensionality not equal 2048.
187 | if pred.shape[2] != 1 or pred.shape[3] != 1:
188 | pred = adaptive_avg_pool2d(pred, output_size=(1, 1))
189 |
190 | pred_arr[start:end] = pred.cpu().data.numpy().reshape(self.batch_size, -1)
191 |
192 | if verbose:
193 | print(' done')
194 |
195 | return pred_arr
196 |
197 | def calculate_frechet_distance(self, mu1, sigma1, mu2, sigma2, eps=1e-6):
198 | """Numpy implementation of the Frechet Distance.
199 | The Frechet distance between two multivariate Gaussians X_1 ~ N(mu_1, C_1)
200 | and X_2 ~ N(mu_2, C_2) is
201 | d^2 = ||mu_1 - mu_2||^2 + Tr(C_1 + C_2 - 2*sqrt(C_1*C_2)).
202 | Stable version by Dougal J. Sutherland.
203 | Params:
204 | -- mu1 : Numpy array containing the activations of a layer of the
205 | inception net (like returned by the function 'get_predictions')
206 | for generated samples.
207 | -- mu2 : The sample mean over activations, precalculated on an
208 | representive data set.
209 | -- sigma1: The covariance matrix over activations for generated samples.
210 | -- sigma2: The covariance matrix over activations, precalculated on an
211 | representive data set.
212 | Returns:
213 | -- : The Frechet Distance.
214 | """
215 |
216 | mu1 = np.atleast_1d(mu1)
217 | mu2 = np.atleast_1d(mu2)
218 |
219 | sigma1 = np.atleast_2d(sigma1)
220 | sigma2 = np.atleast_2d(sigma2)
221 |
222 | assert mu1.shape == mu2.shape, \
223 | 'Training and test mean vectors have different lengths'
224 | assert sigma1.shape == sigma2.shape, \
225 | 'Training and test covariances have different dimensions'
226 |
227 | diff = mu1 - mu2
228 |
229 | # Product might be almost singular
230 | covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
231 | if not np.isfinite(covmean).all():
232 | msg = ('fid calculation produces singular product; '
233 | 'adding %s to diagonal of cov estimates') % eps
234 | print(msg)
235 | offset = np.eye(sigma1.shape[0]) * eps
236 | covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
237 |
238 | # Numerical error might give slight imaginary component
239 | if np.iscomplexobj(covmean):
240 | if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
241 | m = np.max(np.abs(covmean.imag))
242 | raise ValueError('Imaginary component {}'.format(m))
243 | covmean = covmean.real
244 |
245 | tr_covmean = np.trace(covmean)
246 |
247 | return (diff.dot(diff) + np.trace(sigma1) +
248 | np.trace(sigma2) - 2 * tr_covmean)
249 |
250 |
251 | class Reconstruction_Metrics():
252 | def __init__(self, metric_list=['ssim', 'psnr', 'l1', 'mae'], data_range=1, win_size=51, multichannel=True):
253 | self.data_range = data_range
254 | self.win_size = win_size
255 | self.multichannel = multichannel
256 | for metric in metric_list:
257 | if metric in ['ssim', 'psnr', 'l1', 'mae']:
258 | setattr(self, metric, True)
259 | else:
260 | print('unsupport reconstruction metric: %s'%metric)
261 |
262 | def __call__(self, inputs, gts):
263 | """
264 | inputs: the generated image, size (b,c,w,h), data range(0, data_range)
265 | gts: the ground-truth image, size (b,c,w,h), data range(0, data_range)
266 | """
267 | result = dict()
268 | [b,n,w,h] = inputs.size()
269 | inputs = inputs.view(b*n, w, h).detach().cpu().numpy().astype(np.float32).transpose(1,2,0)
270 | gts = gts.view(b*n, w, h).detach().cpu().numpy().astype(np.float32).transpose(1,2,0)
271 |
272 | if hasattr(self, 'ssim'):
273 | ssim_value = compare_ssim(inputs, gts, data_range=self.data_range,
274 | win_size=self.win_size, multichannel=self.multichannel)
275 | result['ssim'] = ssim_value
276 |
277 |
278 | if hasattr(self, 'psnr'):
279 | psnr_value = compare_psnr(inputs, gts, self.data_range)
280 | result['psnr'] = psnr_value
281 |
282 | if hasattr(self, 'l1'):
283 | l1_value = compare_l1(inputs, gts)
284 | result['l1'] = l1_value
285 |
286 | if hasattr(self, 'mae'):
287 | mae_value = compare_mae(inputs, gts)
288 | result['mae'] = mae_value
289 | return result
290 |
291 | def calculate_from_disk(self, inputs, gts, save_path=None, sort=True, debug=0):
292 | """
293 | inputs: .txt files, floders, image files (string), image files (list)
294 | gts: .txt files, floders, image files (string), image files (list)
295 | """
296 | if sort:
297 | input_image_list = sorted(get_image_list(inputs))
298 | gt_image_list = sorted(get_image_list(gts))
299 | else:
300 | input_image_list = get_image_list(inputs)
301 | gt_image_list = get_image_list(gts)
302 | npz_file = os.path.join(save_path, 'metrics.npz')
303 | if os.path.exists(npz_file):
304 | f = np.load(npz_file)
305 | psnr,ssim,ssim_256,mae,l1=f['psnr'],f['ssim'],f['ssim_256'],f['mae'],f['l1']
306 | else:
307 | psnr = []
308 | ssim = []
309 | ssim_256 = []
310 | mae = []
311 | l1 = []
312 | names = []
313 |
314 | for index in range(len(input_image_list)):
315 | name = os.path.basename(input_image_list[index])
316 | names.append(name)
317 |
318 | img_gt = pad_256(imread(str(gt_image_list[index]))).astype(np.float32) / 255.0
319 | img_pred = pad_256(imread(str(input_image_list[index]))).astype(np.float32) / 255.0
320 |
321 |
322 | if debug != 0:
323 | plt.subplot('121')
324 | plt.imshow(img_gt)
325 | plt.title('Groud truth')
326 | plt.subplot('122')
327 | plt.imshow(img_pred)
328 | plt.title('Output')
329 | plt.show()
330 |
331 | psnr.append(compare_psnr(img_gt, img_pred, data_range=self.data_range))
332 | ssim.append(compare_ssim(img_gt, img_pred, data_range=self.data_range,
333 | win_size=self.win_size,multichannel=self.multichannel))
334 | mae.append(compare_mae(img_gt, img_pred))
335 | l1.append(compare_l1(img_gt, img_pred))
336 |
337 | img_gt_256 = img_gt*255.0
338 | img_pred_256 = img_pred*255.0
339 | ssim_256.append(compare_ssim(img_gt_256, img_pred_256, gaussian_weights=True, sigma=1.5,
340 | use_sample_covariance=False, multichannel=True,
341 | data_range=img_pred_256.max() - img_pred_256.min()))
342 | if np.mod(index, 200) == 0:
343 | print(
344 | str(index) + ' images processed',
345 | "PSNR: %.4f" % round(np.mean(psnr), 4),
346 | "SSIM: %.4f" % round(np.mean(ssim), 4),
347 | "SSIM_256: %.4f" % round(np.mean(ssim_256), 4),
348 | "MAE: %.4f" % round(np.mean(mae), 4),
349 | "l1: %.4f" % round(np.mean(l1), 4),
350 | )
351 |
352 | if save_path:
353 | np.savez(save_path + '/metrics.npz', psnr=psnr, ssim=ssim, ssim_256=ssim_256, mae=mae, l1=l1, names=names)
354 |
355 | print(
356 | "PSNR: %.4f" % round(np.mean(psnr), 4),
357 | "PSNR Variance: %.4f" % round(np.var(psnr), 4),
358 | "SSIM: %.4f" % round(np.mean(ssim), 4),
359 | "SSIM Variance: %.4f" % round(np.var(ssim), 4),
360 | "SSIM_256: %.4f" % round(np.mean(ssim_256), 4),
361 | "SSIM_256 Variance: %.4f" % round(np.var(ssim_256), 4),
362 | "MAE: %.4f" % round(np.mean(mae), 4),
363 | "MAE Variance: %.4f" % round(np.var(mae), 4),
364 | "l1: %.4f" % round(np.mean(l1), 4),
365 | "l1 Variance: %.4f" % round(np.var(l1), 4)
366 | )
367 |
368 | dic = {"psnr":[round(np.mean(psnr), 6)],
369 | "psnr_variance": [round(np.var(psnr), 6)],
370 | "ssim": [round(np.mean(ssim), 6)],
371 | "ssim_variance": [round(np.var(ssim), 6)],
372 | "ssim_256": [round(np.mean(ssim_256), 6)],
373 | "ssim_256_variance": [round(np.var(ssim_256), 6)],
374 | "mae": [round(np.mean(mae), 6)],
375 | "mae_variance": [round(np.var(mae), 6)],
376 | "l1": [round(np.mean(l1), 6)],
377 | "l1_variance": [round(np.var(l1), 6)] }
378 |
379 | return dic
380 |
381 |
382 | class Reconstruction_Market_Metrics():
383 | def __init__(self, metric_list=['ssim', 'psnr', 'l1', 'mae'], data_range=1, win_size=51, multichannel=True):
384 | self.data_range = data_range
385 | self.win_size = win_size
386 | self.multichannel = multichannel
387 | for metric in metric_list:
388 | if metric in ['ssim', 'psnr', 'l1', 'mae']:
389 | setattr(self, metric, True)
390 | else:
391 | print('unsupport reconstruction metric: %s' % metric)
392 |
393 | def __call__(self, inputs, gts):
394 | """
395 | inputs: the generated image, size (b,c,w,h), data range(0, data_range)
396 | gts: the ground-truth image, size (b,c,w,h), data range(0, data_range)
397 | """
398 | result = dict()
399 | [b, n, w, h] = inputs.size()
400 | inputs = inputs.view(b * n, w, h).detach().cpu().numpy().astype(np.float32).transpose(1, 2, 0)
401 | gts = gts.view(b * n, w, h).detach().cpu().numpy().astype(np.float32).transpose(1, 2, 0)
402 |
403 | if hasattr(self, 'ssim'):
404 | ssim_value = compare_ssim(inputs, gts, data_range=self.data_range,
405 | win_size=self.win_size, multichannel=self.multichannel)
406 | result['ssim'] = ssim_value
407 |
408 | if hasattr(self, 'psnr'):
409 | psnr_value = compare_psnr(inputs, gts, self.data_range)
410 | result['psnr'] = psnr_value
411 |
412 | if hasattr(self, 'l1'):
413 | l1_value = compare_l1(inputs, gts)
414 | result['l1'] = l1_value
415 |
416 | if hasattr(self, 'mae'):
417 | mae_value = compare_mae(inputs, gts)
418 | result['mae'] = mae_value
419 | return result
420 |
421 | def calculate_from_disk(self, inputs, gts, save_path=None, sort=True, debug=0):
422 | """
423 | inputs: .txt files, floders, image files (string), image files (list)
424 | gts: .txt files, floders, image files (string), image files (list)
425 | """
426 | if sort:
427 | input_image_list = sorted(get_image_list(inputs))
428 | gt_image_list = sorted(get_image_list(gts))
429 | else:
430 | input_image_list = get_image_list(inputs)
431 | gt_image_list = get_image_list(gts)
432 | npz_file = os.path.join(save_path, 'metrics.npz')
433 | if os.path.exists(npz_file):
434 | f = np.load(npz_file)
435 | psnr, ssim, ssim_256, mae, l1 = f['psnr'], f['ssim'], f['ssim_256'], f['mae'], f['l1']
436 | else:
437 | psnr = []
438 | ssim = []
439 | ssim_256 = []
440 | mae = []
441 | l1 = []
442 | names = []
443 |
444 | for index in range(len(input_image_list)):
445 | name = os.path.basename(input_image_list[index])
446 | names.append(name)
447 |
448 | img_gt = imread(str(gt_image_list[index])).astype(np.float32) / 255.0
449 | img_pred = imread(str(input_image_list[index])).astype(np.float32) / 255.0
450 |
451 | if debug != 0:
452 | plt.subplot('121')
453 | plt.imshow(img_gt)
454 | plt.title('Groud truth')
455 | plt.subplot('122')
456 | plt.imshow(img_pred)
457 | plt.title('Output')
458 | plt.show()
459 |
460 | psnr.append(compare_psnr(img_gt, img_pred, data_range=self.data_range))
461 | ssim.append(compare_ssim(img_gt, img_pred, data_range=self.data_range,
462 | win_size=self.win_size, multichannel=self.multichannel))
463 | mae.append(compare_mae(img_gt, img_pred))
464 | l1.append(compare_l1(img_gt, img_pred))
465 |
466 | img_gt_256 = img_gt * 255.0
467 | img_pred_256 = img_pred * 255.0
468 | ssim_256.append(compare_ssim(img_gt_256, img_pred_256, gaussian_weights=True, sigma=1.5,
469 | use_sample_covariance=False, multichannel=True,
470 | data_range=img_pred_256.max() - img_pred_256.min()))
471 | if np.mod(index, 200) == 0:
472 | print(
473 | str(index) + ' images processed',
474 | "PSNR: %.4f" % round(np.mean(psnr), 4),
475 | "SSIM: %.4f" % round(np.mean(ssim), 4),
476 | "SSIM_256: %.4f" % round(np.mean(ssim_256), 4),
477 | "MAE: %.4f" % round(np.mean(mae), 4),
478 | "l1: %.4f" % round(np.mean(l1), 4),
479 | )
480 |
481 | if save_path:
482 | np.savez(save_path + '/metrics.npz', psnr=psnr, ssim=ssim, ssim_256=ssim_256, mae=mae, l1=l1,
483 | names=names)
484 |
485 | print(
486 | "PSNR: %.4f" % round(np.mean(psnr), 4),
487 | "PSNR Variance: %.4f" % round(np.var(psnr), 4),
488 | "SSIM: %.4f" % round(np.mean(ssim), 4),
489 | "SSIM Variance: %.4f" % round(np.var(ssim), 4),
490 | "SSIM_256: %.4f" % round(np.mean(ssim_256), 4),
491 | "SSIM_256 Variance: %.4f" % round(np.var(ssim_256), 4),
492 | "MAE: %.4f" % round(np.mean(mae), 4),
493 | "MAE Variance: %.4f" % round(np.var(mae), 4),
494 | "l1: %.4f" % round(np.mean(l1), 4),
495 | "l1 Variance: %.4f" % round(np.var(l1), 4)
496 | )
497 |
498 | dic = {"psnr": [round(np.mean(psnr), 6)],
499 | "psnr_variance": [round(np.var(psnr), 6)],
500 | "ssim": [round(np.mean(ssim), 6)],
501 | "ssim_variance": [round(np.var(ssim), 6)],
502 | "ssim_256": [round(np.mean(ssim_256), 6)],
503 | "ssim_256_variance": [round(np.var(ssim_256), 6)],
504 | "mae": [round(np.mean(mae), 6)],
505 | "mae_variance": [round(np.var(mae), 6)],
506 | "l1": [round(np.mean(l1), 6)],
507 | "l1_variance": [round(np.var(l1), 6)]}
508 |
509 | return dic
510 |
511 |
512 | def get_image_list(flist):
513 | if isinstance(flist, list):
514 | return flist
515 |
516 | # flist: image file path, image directory path, text file flist path
517 | if isinstance(flist, str):
518 | if os.path.isdir(flist):
519 | flist = list(glob.glob(flist + '/*.jpg')) + list(glob.glob(flist + '/*.png'))
520 | flist.sort()
521 | return flist
522 |
523 | if os.path.isfile(flist):
524 | try:
525 | return np.genfromtxt(flist, dtype=np.str)
526 | except:
527 | return [flist]
528 | print('can not read files from %s return empty list'%flist)
529 | return []
530 |
531 |
532 | def compare_l1(img_true, img_test):
533 | img_true = img_true.astype(np.float32)
534 | img_test = img_test.astype(np.float32)
535 | return np.mean(np.abs(img_true - img_test))
536 |
537 |
538 | def compare_mae(img_true, img_test):
539 | img_true = img_true.astype(np.float32)
540 | img_test = img_test.astype(np.float32)
541 | return np.sum(np.abs(img_true - img_test)) / np.sum(img_true + img_test)
542 |
543 |
544 | def preprocess_path_for_deform_task(gt_path, distorted_path):
545 | distorted_image_list = sorted(get_image_list(distorted_path))
546 | gt_list=[]
547 | distorated_list=[]
548 |
549 | for distorted_image in distorted_image_list:
550 | image = os.path.basename(distorted_image)
551 | image = image.split('_2_')[-1]
552 | image = image.split('_vis')[0] +'.jpg'
553 | gt_image = os.path.join(gt_path, image)
554 | if not os.path.isfile(gt_image):
555 | print("hhhhhhhhh")
556 | print(gt_image)
557 | continue
558 | gt_list.append(gt_image)
559 | distorated_list.append(distorted_image)
560 |
561 | return gt_list, distorated_list
562 |
563 |
564 |
565 | class LPIPS():
566 | def __init__(self, use_gpu=True):
567 | self.model = dm.DistModel()
568 | self.model.initialize(model='net-lin', net='alex',use_gpu=use_gpu)
569 | self.use_gpu=use_gpu
570 |
571 | def __call__(self, image_1, image_2):
572 | """
573 | image_1: images with size (n, 3, w, h) with value [-1, 1]
574 | image_2: images with size (n, 3, w, h) with value [-1, 1]
575 | """
576 | result = self.model.forward(image_1, image_2)
577 | return result
578 |
579 | def calculate_from_disk(self, path_1, path_2, batch_size=1, verbose=False, sort=True):
580 | if sort:
581 | files_1 = sorted(get_image_list(path_1))
582 | files_2 = sorted(get_image_list(path_2))
583 | else:
584 | files_1 = get_image_list(path_1)
585 | files_2 = get_image_list(path_2)
586 |
587 |
588 | imgs_1 = np.array([imread(str(fn)).astype(np.float32)/127.5-1 for fn in files_1])
589 | imgs_2 = np.array([imread(str(fn)).astype(np.float32)/127.5-1 for fn in files_2])
590 |
591 | # Bring images to shape (B, 3, H, W)
592 | imgs_1 = imgs_1.transpose((0, 3, 1, 2))
593 | imgs_2 = imgs_2.transpose((0, 3, 1, 2))
594 |
595 | result=[]
596 |
597 |
598 | d0 = imgs_1.shape[0]
599 | if batch_size > d0:
600 | print(('Warning: batch size is bigger than the data size. '
601 | 'Setting batch size to data size'))
602 | batch_size = d0
603 |
604 | n_batches = d0 // batch_size
605 |
606 | for i in range(n_batches):
607 | if verbose:
608 | print('\rPropagating batch %d/%d' % (i + 1, n_batches))
609 | start = i * batch_size
610 | end = start + batch_size
611 |
612 | img_1_batch = torch.from_numpy(imgs_1[start:end]).type(torch.FloatTensor)
613 | img_2_batch = torch.from_numpy(imgs_2[start:end]).type(torch.FloatTensor)
614 |
615 | if self.use_gpu:
616 | img_1_batch = img_1_batch.cuda()
617 | img_2_batch = img_2_batch.cuda()
618 |
619 | a = self.model.forward(img_1_batch, img_2_batch).item()
620 | result.append(a)
621 |
622 |
623 | distance = np.average(result)
624 | print('lpips: ', distance)
625 | return distance
626 |
627 | def calculate_mask_lpips(self, path_1, path_2, batch_size=64, verbose=False, sort=True):
628 | if sort:
629 | files_1 = sorted(get_image_list(path_1))
630 | files_2 = sorted(get_image_list(path_2))
631 | else:
632 | files_1 = get_image_list(path_1)
633 | files_2 = get_image_list(path_2)
634 |
635 | imgs_1=[]
636 | imgs_2=[]
637 | bonesLst = '/media/data1/zhangpz/DataSet/Market/market-annotation-test.csv'
638 | annotation_file = pd.read_csv(bonesLst, sep=':')
639 | annotation_file = annotation_file.set_index('name')
640 |
641 | for i in range(len(files_1)):
642 | string = annotation_file.loc[os.path.basename(files_2[i])]
643 | mask = np.tile(np.expand_dims(create_masked_image(string).astype(np.float32), -1), (1,1,3))#.repeat(1,1,3)
644 | imgs_1.append((imread(str(files_1[i])).astype(np.float32)/127.5-1)*mask)
645 | imgs_2.append((imread(str(files_2[i])).astype(np.float32)/127.5-1)*mask)
646 |
647 | # Bring images to shape (B, 3, H, W)
648 | imgs_1 = np.array(imgs_1)
649 | imgs_2 = np.array(imgs_2)
650 | imgs_1 = imgs_1.transpose((0, 3, 1, 2))
651 | imgs_2 = imgs_2.transpose((0, 3, 1, 2))
652 |
653 | result=[]
654 |
655 |
656 | d0 = imgs_1.shape[0]
657 | if batch_size > d0:
658 | print(('Warning: batch size is bigger than the data size. '
659 | 'Setting batch size to data size'))
660 | batch_size = d0
661 |
662 | n_batches = d0 // batch_size
663 |
664 | for i in range(n_batches):
665 | if verbose:
666 | print('\rPropagating batch %d/%d' % (i + 1, n_batches))
667 | start = i * batch_size
668 | end = start + batch_size
669 |
670 | img_1_batch = torch.from_numpy(imgs_1[start:end]).type(torch.FloatTensor)
671 | img_2_batch = torch.from_numpy(imgs_2[start:end]).type(torch.FloatTensor)
672 |
673 | if self.use_gpu:
674 | img_1_batch = img_1_batch.cuda()
675 | img_2_batch = img_2_batch.cuda()
676 |
677 |
678 | result.append(self.model.forward(img_1_batch, img_2_batch))
679 |
680 |
681 | distance = torch.mean(torch.stack(result))
682 | print('lpips_mask: ', distance)
683 | return distance
684 |
685 |
686 | def produce_ma_mask(kp_array, img_size=(128, 64), point_radius=4):
687 | MISSING_VALUE = -1
688 | from skimage.morphology import dilation, erosion, square
689 | mask = np.zeros(shape=img_size, dtype=bool)
690 | limbs = [[2,3], [2,6], [3,4], [4,5], [6,7], [7,8], [2,9], [9,10],
691 | [10,11], [2,12], [12,13], [13,14], [2,1], [1,15], [15,17],
692 | [1,16], [16,18], [2,17], [2,18], [9,12], [12,6], [9,3], [17,18]]
693 | limbs = np.array(limbs) - 1
694 | for f, t in limbs:
695 | from_missing = kp_array[f][0] == MISSING_VALUE or kp_array[f][1] == MISSING_VALUE
696 | to_missing = kp_array[t][0] == MISSING_VALUE or kp_array[t][1] == MISSING_VALUE
697 | if from_missing or to_missing:
698 | continue
699 |
700 | norm_vec = kp_array[f] - kp_array[t]
701 | norm_vec = np.array([-norm_vec[1], norm_vec[0]])
702 | norm_vec = point_radius * norm_vec / np.linalg.norm(norm_vec)
703 |
704 |
705 | vetexes = np.array([
706 | kp_array[f] + norm_vec,
707 | kp_array[f] - norm_vec,
708 | kp_array[t] - norm_vec,
709 | kp_array[t] + norm_vec
710 | ])
711 | yy, xx = polygon(vetexes[:, 0], vetexes[:, 1], shape=img_size)
712 | mask[yy, xx] = True
713 |
714 | for i, joint in enumerate(kp_array):
715 | if kp_array[i][0] == MISSING_VALUE or kp_array[i][1] == MISSING_VALUE:
716 | continue
717 | yy, xx = circle(joint[0], joint[1], radius=point_radius, shape=img_size)
718 | mask[yy, xx] = True
719 |
720 | mask = dilation(mask, square(5))
721 | mask = erosion(mask, square(5))
722 | return mask
723 |
724 |
725 | def load_pose_cords_from_strings(y_str, x_str):
726 | y_cords = json.loads(y_str)
727 | x_cords = json.loads(x_str)
728 | return np.concatenate([np.expand_dims(y_cords, -1), np.expand_dims(x_cords, -1)], axis=1)
729 |
730 |
731 | def create_masked_image(ano_to):
732 | kp_to = load_pose_cords_from_strings(ano_to['keypoints_y'], ano_to['keypoints_x'])
733 | mask = produce_ma_mask(kp_to)
734 | return mask
735 |
736 |
737 | if __name__ == "__main__":
738 | parser = argparse.ArgumentParser(description='script to compute all statistics')
739 | parser.add_argument('--gt_path', help='Path to ground truth data', type=str)
740 | parser.add_argument('--distorated_path', help='Path to output data', type=str)
741 | parser.add_argument('--fid_real_path', help='Path to real images when calculate FID', type=str)
742 | parser.add_argument('--name', help='name of the experiment', type=str)
743 | parser.add_argument('--calculate_mask', action='store_true')
744 | parser.add_argument('--market', action='store_true')
745 | args = parser.parse_args()
746 |
747 | print('load start')
748 |
749 | fid = FID()
750 | print('load FID')
751 |
752 | if args.market:
753 | rec = Reconstruction_Market_Metrics()
754 | print('load market rec')
755 | else:
756 | rec = Reconstruction_Metrics()
757 | print('load rec')
758 |
759 | lpips = LPIPS()
760 | print('load LPIPS')
761 |
762 | for arg in vars(args):
763 | print('[%s] =' % arg, getattr(args, arg))
764 |
765 | print('calculate LPIPS...')
766 | gt_list, distorated_list = preprocess_path_for_deform_task(args.gt_path, args.distorated_path)
767 | lpips_score = lpips.calculate_from_disk(distorated_list, gt_list, sort=False)
768 |
769 | print('calculate fid metric...')
770 | fid_score = fid.calculate_from_disk(args.distorated_path, args.fid_real_path)
771 |
772 | print('calculate reconstruction metric...')
773 | rec_dic = rec.calculate_from_disk(distorated_list, gt_list, save_path=args.distorated_path, sort=False, debug=False)
774 |
775 | if args.calculate_mask:
776 | mask_lpips_score = lpips.calculate_mask_lpips(distorated_list, gt_list, sort=False)
777 |
778 | dic = {}
779 | dic['name'] = [args.name]
780 | for key in rec_dic:
781 | dic[key] = rec_dic[key]
782 | dic['fid'] = [fid_score]
783 |
784 | print('fid', fid_score)
785 |
786 | dic['lpips']=[lpips_score]
787 | print('lpips_score', lpips_score)
788 |
789 | if args.calculate_mask:
790 | dic['mask_lpips']=[mask_lpips_score]
791 |
792 |
793 |
794 |
795 |
796 |
797 |
798 |
799 |
--------------------------------------------------------------------------------