├── README.md
├── Keras Transformer Tutorial.ipynb
├── Deep Learning Tutorial Using Keras Part_01_Basic.ipynb
├── Deep_Learning_Tutorial_Using_Keras_Part_02_CNN.ipynb
└── Deep_Learning_Tutorial_Using_Keras_Part_03_RNN.ipynb
/README.md:
--------------------------------------------------------------------------------
1 | # Keras_Tutorial_PCJ
2 |
3 | 인공지능, 머신러닝, 딥러닝에 기초 개념에 대해서 이론 뿐만 아니라 Keras 코드로 학습할 수 있게 만든 초보자를 위한 Tutorial 입니다.
4 | Colab에서 실행시켜 주세요.
5 |
6 | Part01: 인공지능, 머신러닝 , 딥러닝 기초에 대해서 학습할 수 있습니다.
7 | Part02: CNN(Convolution Neural Network)에 대해서 학습할 수 있습니다.
8 | Part03: RNN(Recureent Nerual Network)에 대해서 학습할 수 있습니다
9 |
10 | 번외)
11 | Keras Transformer: Keras를 이용한 Transformer Model Build 및 Translate 방법에 대해서 학습할 수 있습니다.
12 |
13 | ##
14 | 제작자: Park Chanjun (박찬준)
15 | 소속: Korea University Natural Language Processing & Artificial Intelligence Lab (고려대학교 자연언어처리&인공지능 연구실)
16 | Email: bcj1210@naver.com
17 |
18 | ##
19 | 참고자료: 케라스 창시자에게 배우는 딥러닝
20 |
--------------------------------------------------------------------------------
/Keras Transformer Tutorial.ipynb:
--------------------------------------------------------------------------------
1 | {"nbformat":4,"nbformat_minor":0,"metadata":{"colab":{"name":"Keras Transformer Tutorial.ipynb","provenance":[],"collapsed_sections":[]},"kernelspec":{"name":"python3","display_name":"Python 3"}},"cells":[{"cell_type":"markdown","metadata":{"id":"9BQrQg8rFaU5","colab_type":"text"},"source":["**제목**: Keras Transformer Tutorial
\n","**제작자**: Park Chanjun (박찬준)
\n","**소속**: Korea University Natural Language Processing & Artificial Intelligence Lab (고려대학교 자연언어처리&인공지능 연구실)
\n","**Email**: bcj1210@naver.com
"]},{"cell_type":"markdown","metadata":{"id":"hG0El7TwFjnt","colab_type":"text"},"source":["**Install keras-transformer**"]},{"cell_type":"code","metadata":{"id":"EufxtQh3ErCP","colab_type":"code","colab":{}},"source":["!pip install keras-transformer"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"rYOzUEVbFogl","colab_type":"text"},"source":["**Train Transformer Model**"]},{"cell_type":"code","metadata":{"id":"tx0AnKd-EuLI","colab_type":"code","colab":{}},"source":["import numpy as np\n","from keras_transformer import get_model\n","\n","#예시 문장\n","tokens = '안녕하세요 저의 이름은 박찬준입니다. 만나서 반갑습니다. 저는 자연언어처리를 전공으로 하고 있습니다.'.split(' ')\n","\n","#토큰 딕셔너리 생성\n","token_dict = {\n"," '': 0,\n"," '': 1,\n"," '': 2,\n","}\n","\n","#예시문장 토큰화 및 딕셔너리화\n","for token in tokens:\n"," if token not in token_dict:\n"," token_dict[token] = len(token_dict)\n","\n","#데이터 전처리 작업 (패딩 등)\n","encoder_inputs_no_padding = []\n","encoder_inputs, decoder_inputs, decoder_outputs = [], [], []\n","\n","for i in range(1, len(tokens) - 1):\n"," encode_tokens, decode_tokens = tokens[:i], tokens[i:]\n"," encode_tokens = [''] + encode_tokens + [''] + [''] * (len(tokens) - len(encode_tokens)) #패딩\n"," \n"," output_tokens = decode_tokens + ['', ''] + [''] * (len(tokens) - len(decode_tokens))\n"," \n"," decode_tokens = [''] + decode_tokens + [''] + [''] * (len(tokens) - len(decode_tokens))#패딩\n"," \n"," encode_tokens = list(map(lambda x: token_dict[x], encode_tokens))\n"," decode_tokens = list(map(lambda x: token_dict[x], decode_tokens))\n"," output_tokens = list(map(lambda x: [token_dict[x]], output_tokens))\n"," \n"," encoder_inputs_no_padding.append(encode_tokens[:i + 2])\n"," encoder_inputs.append(encode_tokens)\n"," \n"," decoder_inputs.append(decode_tokens)\n"," decoder_outputs.append(output_tokens)\n","\n","# 모델 생성 (keras_transformer 이용)\n","model = get_model(\n"," token_num=len(token_dict),\n"," embed_dim=30,\n"," encoder_num=3,\n"," decoder_num=2,\n"," head_num=3,\n"," hidden_dim=120,\n"," attention_activation='relu',\n"," feed_forward_activation='relu',\n"," dropout_rate=0.05,\n"," embed_weights=np.random.random((14, 30)),\n",")\n","\n","#모델 컴파일\n","model.compile(\n"," optimizer='adam',\n"," loss='sparse_categorical_crossentropy',\n",")\n","\n","#모델 써머리\n","model.summary()\n","\n","# 모델 훈련\n","model.fit(\n"," x=[np.asarray(encoder_inputs * 1000), np.asarray(decoder_inputs * 1000)],\n"," y=np.asarray(decoder_outputs * 1000),\n"," epochs=5,\n",")"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"GsjHc7FvGXGP","colab_type":"text"},"source":["**Translation**"]},{"cell_type":"code","metadata":{"id":"MYzOveCTExlX","colab_type":"code","colab":{}},"source":["import numpy as np\n","from keras_transformer import get_model, decode\n","\n","#소스 문장\n","source_tokens = [\n"," '안녕하세요 저의 이름은 박찬준입니다.'.split(' '),\n"," '저는 24살입니다.'.split(' '),\n","]\n","\n","#타겟 문장\n","target_tokens = [\n"," list('Hello My name is Park Chanjun.'),\n"," list('I am 24 years old.'),\n","]\n","\n","#토큰 딕셔너리화 함수\n","def build_token_dict(token_list):\n"," token_dict = {\n"," '': 0,\n"," '': 1,\n"," '': 2,\n"," }\n"," for tokens in token_list:\n"," for token in tokens:\n"," if token not in token_dict:\n"," token_dict[token] = len(token_dict)\n"," return token_dict\n","\n","\n","source_token_dict = build_token_dict(source_tokens) #딕셔너리화\n","target_token_dict = build_token_dict(target_tokens) #딕셔너리화\n","target_token_dict_inv = {v: k for k, v in target_token_dict.items()} #역으로.\n","\n","# ,와 같은 Special Token 추가\n","encode_tokens = [[''] + tokens + [''] for tokens in source_tokens]\n","decode_tokens = [[''] + tokens + [''] for tokens in target_tokens]\n","output_tokens = [tokens + ['', ''] for tokens in target_tokens]\n","\n","# 패딩\n","source_max_len = max(map(len, encode_tokens))\n","target_max_len = max(map(len, decode_tokens))\n","\n","encode_tokens = [tokens + [''] * (source_max_len - len(tokens)) for tokens in encode_tokens]\n","decode_tokens = [tokens + [''] * (target_max_len - len(tokens)) for tokens in decode_tokens]\n","output_tokens = [tokens + [''] * (target_max_len - len(tokens)) for tokens in output_tokens]\n","\n","encode_input = [list(map(lambda x: source_token_dict[x], tokens)) for tokens in encode_tokens]\n","decode_input = [list(map(lambda x: target_token_dict[x], tokens)) for tokens in decode_tokens]\n","decode_output = [list(map(lambda x: [target_token_dict[x]], tokens)) for tokens in output_tokens]\n","\n","\n","#모델 생성\n","model = get_model(\n"," token_num=max(len(source_token_dict), len(target_token_dict)),\n"," embed_dim=32,\n"," encoder_num=2,\n"," decoder_num=2,\n"," head_num=4,\n"," hidden_dim=128,\n"," dropout_rate=0.05,\n"," use_same_embed=False, # Use different embeddings for different languages\n",")\n","\n","#모델 컴파일\n","model.compile('adam', 'sparse_categorical_crossentropy')\n","\n","#모델 써머리 \n","model.summary()\n","\n","#모델 훈련\n","model.fit(\n"," x=[np.array(encode_input * 1024), np.array(decode_input * 1024)],\n"," y=np.array(decode_output * 1024),\n"," epochs=10,\n"," batch_size=32,\n",")\n","\n","# 번역 진행 (Predict)\n","decoded = decode(\n"," model,\n"," encode_input,\n"," start_token=target_token_dict[''],\n"," end_token=target_token_dict[''],\n"," pad_token=target_token_dict[''],\n",")\n","\n","print(''.join(map(lambda x: target_token_dict_inv[x], decoded[0][1:-1])))\n","print(''.join(map(lambda x: target_token_dict_inv[x], decoded[1][1:-1])))"],"execution_count":0,"outputs":[]}]}
--------------------------------------------------------------------------------
/Deep Learning Tutorial Using Keras Part_01_Basic.ipynb:
--------------------------------------------------------------------------------
1 | {"nbformat":4,"nbformat_minor":0,"metadata":{"colab":{"name":"Deep Learning Tutorial Using Keras Part01 - Basic.ipynb","provenance":[],"collapsed_sections":[]},"kernelspec":{"name":"python3","display_name":"Python 3"}},"cells":[{"cell_type":"markdown","metadata":{"id":"7BK95rFutQ3Q","colab_type":"text"},"source":["제목: Deep Learning Tutorial Using Keras Part01 - Basic (Keras로 배우는 딥러닝 튜토리얼 Part01 기초편)
\n","제작자: Park Chanjun (박찬준)
\n","소속: Korea University Natural Language Processing & Artificial Intelligence Lab (고려대학교 자연언어처리&인공지능 연구실)
\n","Email: bcj1210@naver.com
\n","참고자료: 케라스 창시자에게 배우는 딥러닝\n"]},{"cell_type":"markdown","metadata":{"id":"YpT34NjUt-gu","colab_type":"text"},"source":[""]},{"cell_type":"markdown","metadata":{"id":"JSjL2i1nuaWa","colab_type":"text"},"source":["**인공지능**
\n","보통의 사람이 수행하는 지능적인 작업을 자동화하기 위한 연구활동
\n","**심볼릭 AI(1950~1980)**
\n","명시적인 규칙을 충분하게 많이 만들어 지식을 다루면 인간 수준의 인공지능을 만들 수 있을 것이라는 패러다임
\n","대표적으로 전문가 시스템이 있다.
\n","이미지 분류, 기계번역 같은 불분명한 문제를 해결하기 위한 명확한 규칙을 찾는 것은 어렵다는 단점이 있다.
\n","**머신러닝**
\n","프로그래머가 직접 만든 데이터처리 규칙 대신 컴퓨터가 데이터를 보고 자동으로 이러한 규칙을 학습할 수 있을까? 라는 질문에서 시작.
\n","\n","기존) 규칙 + 데이터 = 해답
\n","머신러닝) 데이터 + 해답 = 규칙
\n","\n","머신러닝을 위해 필요한 것\n","1. 입력 데이터 \n","2. 기대 출력 (즉 정답)\n","3. 알고리즘의 성능을 측정하는 방법 = 알고리즘의 현재 출력과 기대 출력 간의 차이를 결정하기 위해 필요\n","\n","결론적으로 입력데이터를 기반으로 기대출력에 가깝게 만드는 유용한 표현을 학습 하는 것이다.\n","즉 학습이란 더 나은 표현을 찾는 자동화된 과정이다.\n","\n","즉 머신러닝은 가능성 있는 공간을 사전에 정의하고 피드백 신호의 도움을 받아 입력 데이터에 대한 유용한 변환을 찾는 것이다.
\n","\n","**딥러닝**
\n","딥러닝은 머신러닝의 한 분야로 연속된 층(Layer)에서 점진적으로 의미 있는 표현을 배우는 것.
\n","딥이란 결국 연속된 층으로 표현을 학습한다는 개념이다.
\n","즉 Layer Representations Learning, Hierarchical Representations Learning이다.
\n","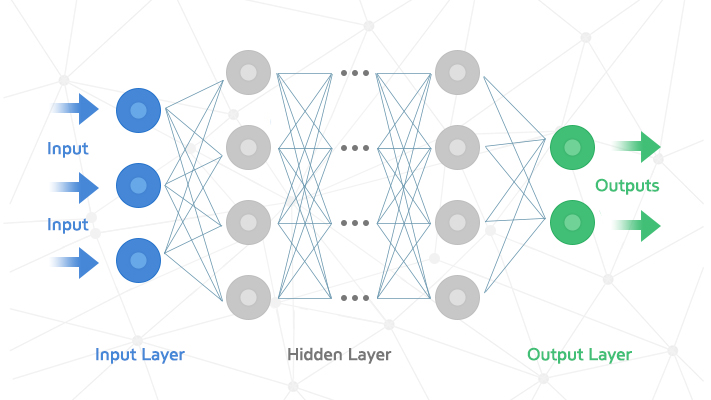
\n","\n","즉 딥러닝은 정보가 연속된 필터를 통과 하면서 순도 높게 정제되는 다단계 정보 추출 작업으로 생각할 수 있다.
\n","즉 데이터 표현을 학습하기 위한 다단계 처리방식을 말한다.
\n","\n","\n"]},{"cell_type":"markdown","metadata":{"id":"xr5blk_Fwb0G","colab_type":"text"},"source":["**학습(Learning)**
\n","\n","층에서 입력 데이터가 처리되는 상세 내용은 일련의 숫자로 이루어진 층의 가중치(Weight)에 저장되어 있다.
어떤 층에서 일어나는 변환은 그 층의 가중치를 파라미터로 가지는 함수로 표현 되는 것이다.
\n","\n","학습이란 주어진 입력을 정확한 타깃에 매칭하기 위해 신경망의 모든 층에 있는 가중치 값을 찾는 것을 의미한다.
\n","즉 학습이란 최적의 Weight 파라미터를 찾는 것이라 한마디로 정의해볼 수 있다.
\n","\n","**손실함수(Loss Function)**
\n","최적을 찾으려면 어떤 것을 계속 조정해보면서 찾아야 한다!
\n","즉 신경망의 출력을 제어하려면 출력이 기대하는 것보다 얼마나 벗어나는지를 먼저 측정해야한다.
\n","이는 신경망의 손실 함수(Loss Function) 또는 목적함수(Objective Function)이 담당한다.
\n","신경망이 한 샘플에 대해 얼마나 잘 예측했는지 측정하기 위해 손실함수가 신경망의 예측과 진짜 타깃의 차이를 점수로 계산한다!
\n","\n","**역전파와 옵티마이저(BackPropagation and Optimizer)**
\n","즉 기본적인 딥러닝 방식은 이 점수를 현재 샘플의 손실 점수가 감소되는 방향으로 가중치 값을 조금씩 수정하는 것이다.
\n","이 작업을 딥러닝의 역전파(Backpropagation)을 구현한 옵티마이저(Optimizer)가 담당한다.
\n",""]},{"cell_type":"markdown","metadata":{"id":"tSLct1iazsMP","colab_type":"text"},"source":["**한눈에 보는 딥러닝의 성과들**
\n",""]},{"cell_type":"markdown","metadata":{"id":"U_8uGWf91NPT","colab_type":"text"},"source":["**Why Deep Learning**\n","1. 하드웨어의 발전(GPU)\n","2. 대용량 데이터셋\n","3. 알고리즘의 향상\n","- 신경망 층에 더 잘 맞는 활성화 함수(Activation Function)\n","- 층별 사전 훈련(Pretraining)을 불필요하게 만든 가중치 초기화 (Weight initialization) 방법\n","- Adam 및 Radam과 같은 좋은 최적화 방법들.\n","4. 오픈소스"]},{"cell_type":"markdown","metadata":{"id":"L6b-t4RK2I8G","colab_type":"text"},"source":["이제 부터 Keras코드로 딥러닝을 배워보도록 하겠습니다.\n","기초부터 차근차근 !\n","\n","먼저 Mnist예제로 신경망의 기초를 배워보도록 하겠습니다."]},{"cell_type":"code","metadata":{"id":"kS8WOkpRtP5y","colab_type":"code","colab":{}},"source":["from keras.datasets import mnist\n","\n","(train_images,train_labels),(test_images,test_labels)= mnist.load_data() #데이터 로드하기 , 학습데이터와 테스트 데이터\n","\n","#먼저 모양을 한번 보도록 하겠습니다.\n","print(\"Shape: \",train_images.shape)\n","print(\"길이: \",len(train_images))\n","print(\"Shape: \",test_images.shape)\n","print(\"길이: \",len(test_images))\n","\n","#총 6만개의 학습데이터,1만개의 테스트 데이터 28*28(픽셀)임을 볼 수 있습니다."],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"UTnHMMNb3rwY","colab_type":"text"},"source":["데이터 정보를 알았으니 이제 모델을 만들어 보도록 하겠습니다.
\n","\n","신경망의 핵심 구성요소는 바로 층(Layer) 입니다.
\n","층은 주어진 문제에 더 의미있는 표현을 입력된 데이터로부터 추출합니다.
\n","\n","아래의 예시는 Fully Connected된 신경망 층이 2개가 연소되어 있으며 2번째 층은 10개의 확률 점수가 들어 있는 배열을 반환하는 소프트맥스(Softmax) 층입니다.
\n","10개인 이유는 MNIST가 숫자 0~9까지 구분하는 예제이기 때문입니다."]},{"cell_type":"code","metadata":{"id":"K461DDd1tPRK","colab_type":"code","colab":{}},"source":["from keras import models\n","from keras import layers\n","\n","model=models.Sequential()\n","model.add(layers.Dense(512,activation=\"relu\",input_shape=(28*28,)))\n","model.add(layers.Dense(10,activation=\"softmax\"))\n"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"S4aQyHZB4u-X","colab_type":"text"},"source":["신경망이 훈련 준비를 마치기 위해서 컴파일 단계에 총 3가지 정보가 필요합니다.\n","\n","1. 손실함수(Loss Function) : 훈련 데이터에서 신경망의 성능을 측정하는 방법으로 네트워크가 옳은 방향으로 학습될 수 있도록 도와준다.\n","\n","2. 옵티마이저(Optimizer): 입력된 데이터와 손실함수를 기반으로 네트워크를 업데이트하는 매커니즘\n","\n","3. 훈련과 테스트 과정을 모니터링할 지표: 정확도를 의미!"]},{"cell_type":"code","metadata":{"id":"uPZonEjD5Kl0","colab_type":"code","colab":{}},"source":["model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"h1-FhzjS5W02","colab_type":"text"},"source":["훈련을 시작하기 전 !!!!
\n","데이터를 네트워크에 맞는 크기로 바꾸고 모든 갑을 0과 1 사이로 스케일을 조정해보겠습니다.\n","\n","또한 레이블을 범주형으로 변경해보겠습니다 . (one hot)\n"]},{"cell_type":"code","metadata":{"id":"JqANl9Fg5fWr","colab_type":"code","colab":{}},"source":["train_images=train_images.reshape((60000,28*28))\n","train_images=train_images.astype('float32')/255\n","\n","test_images=test_images.reshape((10000,28*28))\n","test_images=test_images.astype('float32')/255\n","\n","from keras.utils import to_categorical\n","\n","train_labels=to_categorical(train_labels)\n","test_labels=to_categorical(test_labels)"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"xiiaQys-6HGn","colab_type":"text"},"source":["이제 훈련을 실제 해보도록 하겠습니다.
\n","keras에서는 fit 함수를 이용해 훈련을 진행합니다."]},{"cell_type":"code","metadata":{"id":"NLY9i_op6NDG","colab_type":"code","colab":{}},"source":["model.fit(train_images,train_labels,epochs=5,batch_size=128)"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"hePK7_976tF2","colab_type":"text"},"source":["이제 성능을 측정해보도록 하겠습니다.\n"]},{"cell_type":"code","metadata":{"id":"2B5x_91b6vzT","colab_type":"code","colab":{}},"source":["test_loss,test_acc=model.evaluate(test_images,test_labels)\n","print(\"정확도: \",test_acc)"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Yi6-6_h-7XYR","colab_type":"text"},"source":["이제 모든 코드를 한눈에 보도록 하겠습니다."]},{"cell_type":"code","metadata":{"id":"XIVflgVH7aE8","colab_type":"code","colab":{}},"source":["from keras.datasets import mnist\n","from keras import models\n","from keras import layers\n","from keras.utils import to_categorical\n","\n","#데이터 로드하기 , 학습데이터와 테스트 데이터\n","(train_images,train_labels),(test_images,test_labels)= mnist.load_data() \n","\n","#데이터 전처리\n","train_images=train_images.reshape((60000,28*28))\n","train_images=train_images.astype('float32')/255\n","\n","test_images=test_images.reshape((10000,28*28))\n","test_images=test_images.astype('float32')/255\n","\n","train_labels=to_categorical(train_labels)\n","test_labels=to_categorical(test_labels)\n","\n","#모델 설계\n","model=models.Sequential()\n","model.add(layers.Dense(512,activation=\"relu\",input_shape=(28*28,)))\n","model.add(layers.Dense(10,activation=\"softmax\"))\n","\n","#모델 컴파일\n","model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])\n","\n","#모델 훈련\n","model.fit(train_images,train_labels,epochs=5,batch_size=128)\n","\n","#정확도 측정\n","test_loss,test_acc=model.evaluate(test_images,test_labels)\n","print(\"정확도: \",test_acc)\n"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"V1H_sMMl8B1-","colab_type":"text"},"source":["**텐서**
\n","텐서는 데이터를 위한 Container이다.
\n","텐서에서 차원을 종종 축(Axis)라고 부르기도 한다.\n","텐서의 축 개수: 랭크(Rank)\n","\n","**중요 개념**\n","1. 축의 개수(랭크): 예를 들어 3D 텐서에서는 3개의 축이 있고, 행렬에는 2개의 축이 있는 것.
넘파이의 ndim 속성에 저장되어 있는 값.\n","\n","2. 크기(Shape): 텐서의 각 축을 따라 얼마나 많은 차원이 있는지를 나타낸 파이썬의 튜플 값.
벡터의 크기는 (5,)처럼 1개의 원소로 이루어진 튜플 !, 스칼라는 크기가 없음.\n","\n","3. 데이터 타입: 넘파이의 dtype에 저장된 값. 텐서에 포함된 데이터의 타입이다.\n","\n","\n","\n","**스칼라(0D 텐서)**
\n","하나의 숫자만 담고 있는 텐서를 스칼라라고 한다.
\n","스칼라 텐서, 0차원 텐서, 0D텐서라고 한다.
\n","\n","**벡터(1D 텐서)**
\n","숫자의 배열
\n","\n","**행렬(2D 텐서)**
\n","행렬은 2D 텐서이다.
\n","행(row)과 열(column)으로 이루어짐
\n","\n","**3D텐서와 고차원 텐서**
\n","3D 텐서들을 하나의 배열로 합치면 4D 텐서를 만드는 식으로 이루어짐 !!
\n","딥러닝에서는 보통 0D~4D까지의 텐서를 다룬다.
\n","동영상의 경우 5D까지 텐서를 다루기도 한다.
\n","\n","**텐서의 실제 사례**\n","1. 벡터 데이터: (sample,features)크기의 2D 텐서\n","2. 시계열 데이터 또는 시퀀스 데이터: (sample,timesteps,features) 크기의 텐서\n","3. 이미지: (samples, height,width,channels) 또는 (samples,channels, height,width) 크기의 3D 텐서 (채널 마지막(channel-last) 방식과 (channel-first) 방식)\n","4. 동영상 (samples,frames,height,width,channels) 또는 (samples,frames,channels,height,width) 크기의 5D 텐서 \n","\n","**Transpose(전치)**
\n","행렬의 전치란 행과 열을 바꾸는 것을 의미한다.\n"]},{"cell_type":"code","metadata":{"id":"klxX16kY_B0v","colab_type":"code","colab":{}},"source":["#넘파이로 텐서 조작해보기\n","from keras.datasets import mnist\n","\n","(train_images,train_labels),(test_images,test_labels)= mnist.load_data() \n","print(train_images.shape)\n","\n","slice_data=train_images[10:100]#11번째 데이터부터 101번째 전까지 !!, 즉 (90,28,28)\n","print(slice_data.shape)\n","\n","slice_data=train_images[10:100,:,:]#더 자세한 표기법 !! \":\" 는 전체를 의미한다.\n","print(slice_data.shape)\n","\n","slice_data=train_images[10:100,0:28,0:28]#더더 자세한 표기법 \n","\n","\n"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"AAoukQo8ADmj","colab_type":"text"},"source":["일반적으로 딥러닝에서 사용하는 모든 데이터 텐서의 첫번째 축(0번째 축)은 샘플 축(sample axis)이다. 샘플 차원(sample dimension)이라고 부르기도 한다.\n","\n","왜 이 개념을 말하는가?\n","\n","바로 딥러닝 모델은 한번에 전체 데이터 셋 전체를 처리하지 않기 때문이다.\n","작은 batch(배치)로 나누어 학습하게 된다.
\n","이런 배치 데이터를 다룰 때는 첫번째 축을 배치 축(batch axis) 또는 배치 차원(batch dimension)이라고 부른다."]},{"cell_type":"code","metadata":{"id":"4ukRafk_AeGF","colab_type":"code","colab":{}},"source":["batch=train_images[:128]\n","batch=train_images[128:256]\n","\n","batch=train_images[128*n:128*(n+1)]"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"3j2f64RJG2VJ","colab_type":"text"},"source":["훈련에 대해서 더 자세히 알아보자\n","output=relu(dot(W,input)*b)\n","\n","W는 가중치 또는 훈련되는 파라미터(trainable parameter)라고 부른다.\n","초기에는 가중치 행렬이 작은 난수로 채워져 있다. 이는 무작위 초기화(random initialization)단계라고 부른다.\n","즉 의미없는 표현이 만들어지며 이 표현을 점진적으로 조정하면서 훈련을 진행하는 것이다.\n","\n","1. 훈련 샘플 x와 이에 상응하는 정답 y의 배치를 추출한다.\n","2. x를 사용하여 네트워크를 실행하고(forward) , 예측 값 y_pred를 구한다.\n","3. y_pred와 y의 차이를 측정하여 이 배치에 대한 네트워크 손실을 계산한다.즉 손실함수의 그레디언트 계산(backward)\n","4. 배치에 대한 손실이 조금 감소되도록 네트워크의 모든 가중치를 업데이트 한다. 즉 그레디언트의 반대 방향으로 파라미터를 조금 씩 이동시킨다. W= W- step*gradient\n","5. 이렇게 되면 결국 훈련 데이터에서 네트워크의 손실, 즉 예측 y_ped와 정답 y의 오차가 매우 작아질 것이다.\n","\n","\n","\n","\n","\n",""]},{"cell_type":"markdown","metadata":{"id":"VNWqMpnSHa_a","colab_type":"text"},"source":["**본격적인 Keras 실습 및 신경망 시작하기**
\n","\n","keras 자체에 대한 특징 및 자세한 설명은 구글링을 해주세요.\n","\n","1. 입력 텐서와 타겟 텐서로 이루어진 훈련 데이터를 정의한다.\n","2. 입력과 타겟을 매핑하는 층으로 이루어진 모델(혹은 네트워크)를 정의한다.\n","3. 손실함수, 옵티마이저, 모니터링을 하기 위한 측정 지표를 선택하여 학습과정을 설정한다.\n","4. 훈련 데이터에 대해 모델의 fit() 메서드를 반복적으로 호출하여 훈련을 시작한다.\n","\n","
\n","Keras의 코딩 방법은 크게 Sequential 클래스를 이용하거나 함수형 API를 사용하는 방법이 있다. (모델 구조 정의에 한함)"]},{"cell_type":"code","metadata":{"id":"2rjXk1wDKKHH","colab_type":"code","colab":{}},"source":["#Sequential 클래스 이용\n","model=model.Sequential()\n","model.add(layers.Dense(32,activation='relu',input_shape=(784,)))\n","model.add(layers.Dense(10,activation='softmax'))\n","\n","#함수형 API 이용\n","input_tensor=layers.Input(shape=(784,))\n","x=layers.Dense(32,activation='relu')(input_tensor)\n","output_tensor=layers.Dense(10,activation='softmax')(x)\n","\n","model=models.Model(inputs=input_tensor,outputs=output_tensor)"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"lPMj5h4DLitA","colab_type":"text"},"source":["**영화 리뷰 분류해보기: 이진 분류**\n","\n","본 실습은 imdb 데이터를 이용하여 영화평이 긍정인지 부정인지 분류하는 딥러닝 모델을 만드는 것을 실습한다.\n","\n","\n","신경망에 숫자 리스트를 그대로 주입할 수 없다.
\n","리스트를 텐서로 바꾸어 주어야 하는데 크게 2가지 방식이 있다.\n","\n","1. 같은 길이가 되도록 리스트에 패딩(padding)을 추가하고 (samples,sequence_length)크기의 정수 텐서로 변환한다. 그 다음 이 정수 텐서를 embedding층으로 사용한다.\n","\n","2. 리스트를 One-hot Encoding하여 0과 1의 벡터로 변환한다.\n","\n","**왜 활성화 함수를 쓰는가?**
\n","층을 깊게 만드는 장점을 살리기 위해서는 비선형성 또는 활성화 함수를 추가해야 한다. 주로 relu를 많이 사용한다.\n"]},{"cell_type":"code","metadata":{"id":"pahbXdHULr1R","colab_type":"code","colab":{}},"source":["from keras.datasets import imdb\n","from keras import models\n","from keras import layers\n","import numpy as np\n","\n","(train_data,train_labels),(test_data,test_labels)=imdb.load_data(num_words=10000) #데이터 로딩 + 자주 나타나는 단어 1만개만 사용하겠다. => 적절한 크기의 벡터 데이터를 얻기 위함.\n","\n","def make_one_hot(sequences,dimension=10000):\n"," results=np.zeros((len(sequences),dimension))\n","\n"," for i,sequence in enumerate(sequences):\n"," results[i,sequence]=1. #one-hot encoding\n"," return results\n","\n","\n","#전처리 \n","x_train=make_one_hot(train_data)\n","x_test=make_one_hot(test_data)\n","\n","y_train=np.asarray(train_labels).astype('float32')\n","y_test=np.asarray(test_labels).astype('float32')\n","\n","#모델 정의\n","model=models.Sequential()\n","model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))\n","model.add(layers.Dense(16,activation='relu'))\n","model.add(layers.Dense(1,activation='sigmoid'))\n","\n","#크로스앤트로피는 정보이론에서 온 개념으로 확률 분포간의 차이를 측정한다.(이진 분류에서 사용한다)\n","model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])\n","\n","#또 다른 방법\n","from keras import optimizers\n","model.compile(optimizer=optimizers.RMSprop(lr=0.001),loss='binary_crossentropy',metrics=['accuracy'])\n","\n","#또 다른 방법\n","from keras import losses\n","from keras import metrics\n","model.compile(optimizer=optimizers.RMSprop(lr=0.001),loss=losses.binary_crossentropy,metrics=[metrics.binary_accuracy])\n","\n","#검증 데이터 만들기\n","x_val=x_train[:10000]\n","partial_x_train=x_train[10000:]\n","\n","y_val=y_train[:10000]\n","partial_y_train=y_train[10000:]\n","\n","#훈련하기\n","#model.fit이 History객체를 반환한다.\n","#객체는 (acc,loss,val_acc,val_loss))를 딕셔너리 형태로 가지고 있다.\n","#검증 데이터는 validation_data에 전달한다.\n","history=model.fit(partial_x_train,partial_y_train,epochs=20,batch_size=512,validation_data=(x_val,y_val))\n","\n","#시각화 하기 - 훈련과 검증 손실\n","import matplotlib.pyplot as plt\n","\n","history_dict=history.history\n","loss=history_dict['loss']\n","val_loss=history_dict['val_loss']\n","\n","epochs=range(1,len(loss)+1)\n","\n","plt.plot(epochs,loss,'bo',label='Training loss')\n","plt.plot(epochs,val_loss,'b',label='Validatin_loss')\n","\n","plt.title('Training and Validation Loss')\n","plt.xlabel('Epochs')\n","plt.ylabel('Loss')\n","\n","plt.legend()\n","\n","plt.show()\n","\n","\n","#성능 측정\n","results=model.evaluate(x_test,y_test)\n","print(results)\n","\n","#훈련된 모델로 새로운 데이터에 대해서 예측해보기\n","model.predict(x_test)"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"SqywKMmFTtY5","colab_type":"text"},"source":["**뉴스기사 분류해보기: 다중 분류 문제**\n","\n","이번 실습은 단일 레이블 다중 분류 문제이다.
\n","로이터 데이터셋을 사용하여 46개의 토픽으로 분류해볼 예정이다.
"]},{"cell_type":"code","metadata":{"id":"hxNGnBnZNXRW","colab_type":"code","colab":{}},"source":["from keras.datasets import reuters\n","from keras.utils.np_utils import to_categorical\n","from keras import models\n","from keras import layers\n","import numpy as np\n","\n","(train_data,train_labels),(test_data,test_labels)=reuters.load_data(num_words=10000) #데이터 로딩 + 자주 나타나는 단어 1만개만 사용하겠다. => 적절한 크기의 벡터 데이터를 얻기 위함.\n","\n","\n","def make_one_hot(sequences,dimension=10000):\n"," results=np.zeros((len(sequences),dimension))\n","\n"," for i,sequence in enumerate(sequences):\n"," results[i,sequence]=1. #one-hot encoding\n"," return results\n","\n","\n","#전처리 \n","x_train=make_one_hot(train_data)\n","x_test=make_one_hot(test_data)\n","\n","y_train=to_categorical(train_labels)#원핫 인코딩 하기 (범주형 인코딩)\n","y_test=to_categorical(test_labels) #원핫 인코딩 하기 (범주형 인코딩)\n","\n","#모델 구성\n","model=models.Sequential()\n","model.add(layers.Dense(64,activation='relu',input_shape=(10000,)))\n","model.add(layers.Dense(64,activation='relu'))\n","model.add(layers.Dense(46,activation='softmax')) #46개로 분류하는 것이기에 !!!!!!!\n","\n","#컴파일\n","model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy']) #categorical_crossentropy는 두 확률 분포 사이의 거리를 측정한다.\n","\n","#검증 데이터 만들기\n","x_val=x_train[:1000]\n","partial_x_train=x_train[1000:]\n","\n","y_val=y_train[:1000]\n","partial_y_train=y_train[1000:]\n","\n","#훈련하기 \n","history=model.fit(partial_x_train,partial_y_train, epochs=20, batch_size=512, validation_data=(x_val,y_val))\n","\n","\n","#시각화 하기 - 훈련과 검증 손실\n","import matplotlib.pyplot as plt\n","\n","history_dict=history.history\n","loss=history_dict['loss']\n","val_loss=history_dict['val_loss']\n","\n","epochs=range(1,len(loss)+1)\n","\n","plt.plot(epochs,loss,'bo',label='Training loss')\n","plt.plot(epochs,val_loss,'b',label='Validatin_loss')\n","\n","plt.title('Training and Validation Loss')\n","plt.xlabel('Epochs')\n","plt.ylabel('Loss')\n","\n","plt.legend()\n","\n","plt.show()\n","\n","#성능 측정\n","results=model.evaluate(x_test,y_test)\n","print(\"성능:\",results)\n","\n","#훈련된 모델로 새로운 데이터에 대해서 예측해보기\n","predictions=model.predict(x_test)\n","print(\"Predictions Shape: \",predictions[0].shape)\n","print(\"Sum:\", np.sum(predictions[0]))\n","print(\"Argmax: \",np.argmax(predictions[0]))\n","\n"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"ocIWJk9JXq7f","colab_type":"text"},"source":["**회귀 문제: 주택 가격 예측 그리고 K-fold Cross Validation**
\n","\n","회귀와 로지스틱 회귀를 혼동하지 말것.
\n","로지스틱 회귀는 분류 알고리즘이다!!!!
\n","\n","개별적인 레이블 대신에 연속적인 !! 값을 예측하는 것이 회귀이다.
\n","\n","K-겹 교차 검증 (K-fold Cross validation)\n","데이터를 K개의 분할로 나누고 K개의 모델을 만들어 K-1개의 분할에서 훈련하고 나머지 분할에서 평가하는 방법\n","모델의 검증 점수는 K개의 검증 점수 평균이 된다."]},{"cell_type":"code","metadata":{"id":"QI_YO6pXYbTA","colab_type":"code","colab":{}},"source":["from keras.datasets import boston_housing\n","from keras.utils.np_utils import to_categorical\n","from keras import models\n","from keras import layers\n","import numpy as np\n","\n","(train_data,train_targets),(test_data,test_targets)=boston_housing.load_data() #데이터 로딩 + 자주 나타나는 단어 1만개만 사용하겠다. => 적절한 크기의 벡터 데이터를 얻기 위함.\n","print(\"학습 데이터 shape: \",train_data.shape)\n","print(\"테스트 데이터 shape: \",test_data.shape)\n","\n","\n","#정규화!!!!\n","#상이한 스케일을 가진 값을 신경망에 넣어주면 문제가 된다.\n","#따라서 정규화를 해주어야 한다.\n","#입력데이터에 있는 각 특성에 대해서 특성의 평균을 빼고 표준편차로 나누어 준다\n","#이렇게 되면 특성의 중앙이 0 근처에 맞추어 지고 표준편차가 1이 된다.\n","mean=train_data.mean(axis=0)\n","train_data-=mean\n","std=train_data.std(axis=0)\n","train_data/=std\n","\n","test_data-=mean\n","test_data/=std\n","\n","#모델 구성\n","#마지막 층에 활성화 함수가 없다. 이것이 전형적인 스칼라 회귀를 위한 구성이다.\n","#mse는 평균 제곱 오차(mean squared error)의 약어로 예측과 타깃 사이의 거리의 제곱이다. 이는 회귀 문제에서 널리 사용되는 loss 함수이다.\n","#mae는 Mean Absolute Error의 약자로 MAE가 0.5이면 예측이 평균적으로 500달러 정도 차이가 난다는 뜻이다.\n","def build_model():\n"," model=models.Sequential()\n"," model.add(layers.Dense(64,activation='relu',input_shape=(train_data.shape[1],))) #train_data.shape[1] ==> 13\n"," model.add(layers.Dense(64,activation='relu'))\n"," model.add(layers.Dense(1))\n"," model.compile(optimizer='rmsprop',loss='mse',metrics=['mae'])\n"," return model\n","\n","#K-겹 교차 검증 (K-fold Cross validation)\n","#데이터를 K개의 분할로 나누고 K개의 모델을 만들어 K-1개의 분할에서 훈련하고 나머지 분할에서 평가하는 방법\n","#모델의 검증 점수는 K개의 검증 점수 평균이 된다.\n","k=4\n","num_val_samples=len(train_data)//k #k만큼 학습데이터 분할\n","num_epochs=100\n","\n","all_scores=[]\n","\n","for i in range(k):\n"," print(\"처리중인 fold\",i)\n"," val_data = train_data[i * num_val_samples : (i+1) * num_val_samples] #검증 데이터\n"," val_targets=train_targets[i * num_val_samples : (i+1) * num_val_samples] #검증 데이터ㅏ\n","\n"," partial_train_data=np.concatenate([train_data[:i*num_val_samples],\n"," train_data[(i+1)*num_val_samples:]]\n"," ,axis=0) #학습데이터 concat\n"," partial_train_targets=np.concatenate([train_targets[:i*num_val_samples],\n"," train_targets[(i+1)*num_val_samples:]]\n"," ,axis=0) #학습데이터 concat\n"," \n"," model=build_model()\n"," model.fit(partial_train_data,partial_train_targets,epochs=num_epochs,batch_size=1,verbose=0) #verbose=0이면 훈련과정을 출력하지 않는다.\n","\n"," val_mse,val_mae=model.evaluate(val_data,val_targets,verbose=0)\n"," all_scores.append(val_mae)\n","\n","print(\"전체 점수: \",all_scores)\n","print(\"평균: \",np.mean(all_scores))"],"execution_count":0,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"dmllLj5XffFj","colab_type":"text"},"source":["**머신러닝 깊게 알아보기**
\n","\n","**지도학습(Supervised Learning)**: 현재까지 실습한 예제 코드 모두 지도학습의 예들이다. 샘플 데이터가 주어지면 알고있는 타깃에 입력 데이터를 매핑하는 방법을 학습하는 것!\n","\n","**비지도학습(Unsupervised Learning)**: 어떤 타깃도 사용하지 않고 입력 데이터에 대한 변환을 찾아낸다. 차원 축소(Dimensionality reduction)와 군집(Clustering)이 비지도 학습의 예이다.\n","\n","**자기지도학습(Self Supervised Learning)**: 지도학습이나 사람이 만든 레이블을 사용하지 않는 것이 특징이다. 즉 학습과정에 사람이 개입하지 않는 지도학습. 레이블이 여전히 필요하지만 보통 Heuristic한 알고리즘을 사용해서 입력데이터로부터 생성한다.\n","대표적인 예시로 오토인코더(Autoencoder)가 있다.\n","\n","**강화학습(Reinforcement Learning)**: 구글 딥마인드의 알파고에 사용된 기법. 에이전트(Agent)는 환경에 대한 정보를 최대화하는 행동을 선택하도록 학습된다. \n","
\n","
\n","**머신러닝의 목표**: 처음 본 데이터에서 잘 작동하는 일반화 된 모델을 얻는 것.\n","
\n","\n","**학습데이터, 검증데이터, 테스트 데이터**ㅣ\n","학습 데이터로 모델을 훈련하고 검증 데이터로 모델을 평가한다. 모델을 출시할 준비가 되면 테스트 데이터에서 최종적으로 모델을 테스트 한다.\n","\n","**어떻게 나누어줄까?** \n","1. 단순 홀드 아웃 검증(Hold-out Validation)\n","2. K-겹 교차 검증(K-fold-Cross-Validation)\n","3. 셔플링(Shuffle)을 이용한 반복 K-겹 교차 검증 => K-겹 교차 검증을 여러 번 적용하되 K개의 분할로 나누기 전에 매번 데이터를 무작위로 썪는 것 !\n","
\n","
\n","\n","**신경망을 위한 데이터 전처리**\n","1. 벡터화: 신경망에서 모든 입력과 타깃은 부동 소수 데이터로 이루어진 텐서여야 한다.\n","2. 값 정규화: 작은 값을 취할 수록 좋다. 일반적으로 대부분의 값이 0~1사이여야 한다. 또한 균일해야 한다. 즉 모든 특성이 대체로 비슷한 범위를 가져야 한다.\n","\n","**과대 적합과 과소 적합**\n","1. 최적화: 가능한 훈련 데이터에서 최고의 성능을 얻으려고 모델을 조정하는 과정\n","2. 일반화: 훈련된 모델이 이전에 본적 없는 데이터에서 얼마나 잘 수행 되는지\n","\n","\n","\n","**어떻게 완화시킬까?** => 가중치 규제 추가(Weight Regularization)
\n","L1 규제: 가중치의 절대값에 비례하는 비용이 추가 (L1 No rm)
\n","L2 규제: 가중치의 제곱에 비례하는 비용이 추가 (L2 Norm) Weight Decay라고도 부름.
\n","\n","keras 예시 L1 규제
\n","model.add(layers.Dense(16,kernel_regularizer.l1(0.001),activation='relu',input_shape=(10000,)))
\n","\n","keras 예시 L2 규제
\n","model.add(layers.Dense(16,kernel_regularizer.l2(0.001),activation='relu',input_shape=(10000,)))\n","\n","\n","**어떻게 완화시킬까?** ==> 드롭아웃\n","
\n","네트워크 층에 드롭아웃을 적용하면 훈련하는 동안 무작위로 층의 일부 출력 특성을 제외시킴.\n","
\n","keras 예시
\n","model.add(layers.Dropout(0.5))\n","\n","**머신러닝의 흐름**\n","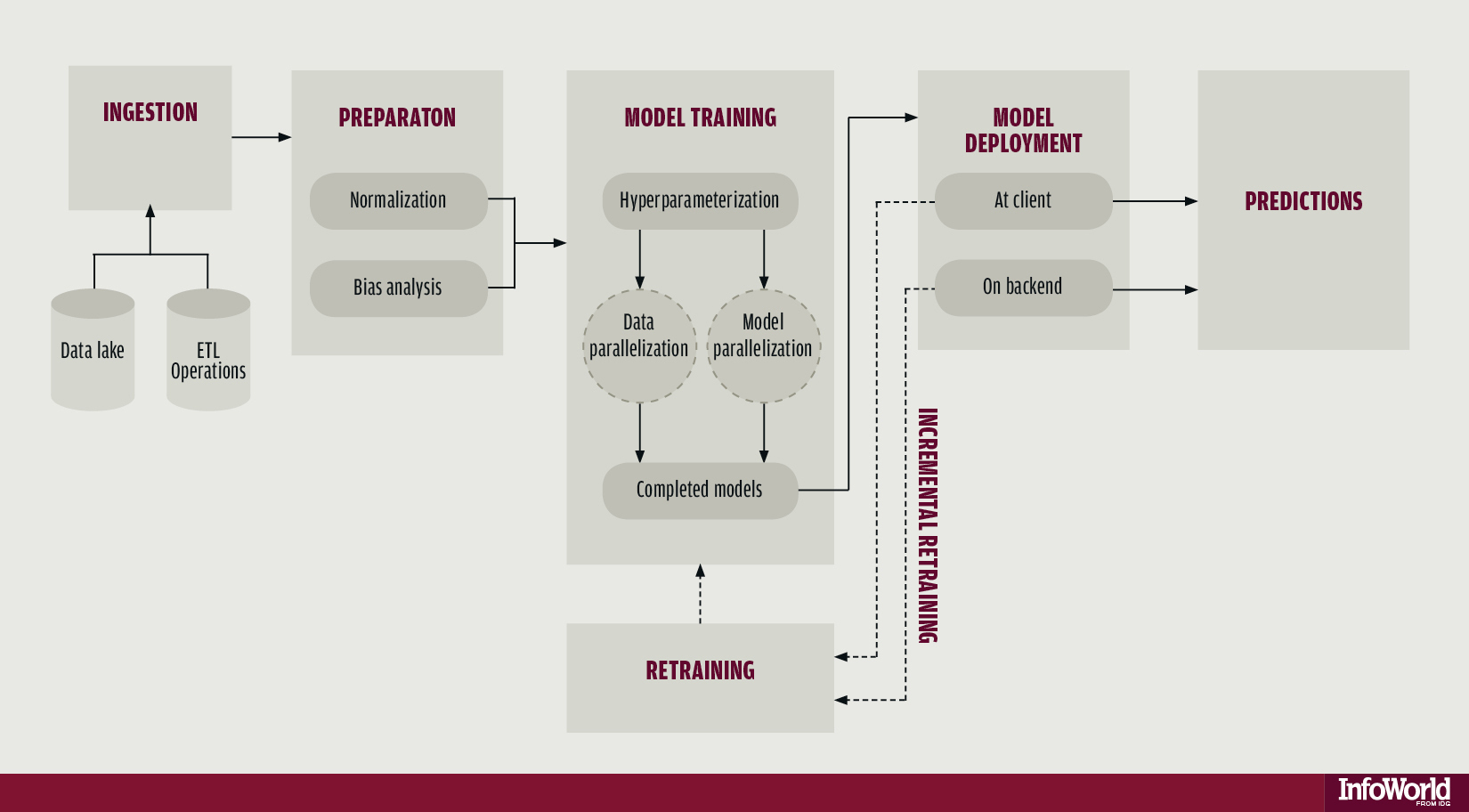\n"]}]}
--------------------------------------------------------------------------------
/Deep_Learning_Tutorial_Using_Keras_Part_02_CNN.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "name": "Deep Learning Tutorial Using Keras Part 02 - CNN.ipynb",
7 | "provenance": [],
8 | "collapsed_sections": []
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | }
14 | },
15 | "cells": [
16 | {
17 | "cell_type": "markdown",
18 | "metadata": {
19 | "id": "64auTbN6wEa2",
20 | "colab_type": "text"
21 | },
22 | "source": [
23 | "**제목**: Deep Learning Tutorial Using Keras Part02 - CNN (Keras로 배우는 딥러닝 튜토리얼 Part02 CNN편)
\n",
24 | "**제작자**: Park Chanjun (박찬준)
\n",
25 | "**소속**: Korea University Natural Language Processing & Artificial Intelligence Lab (고려대학교 자연언어처리&인공지능 연구실)
\n",
26 | "**Email**: bcj1210@naver.com
\n",
27 | "**참고자료**: 케라스 창시자에게 배우는 딥러닝"
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {
33 | "id": "ajj76oRnwR69",
34 | "colab_type": "text"
35 | },
36 | "source": [
37 | "**컴퓨터 비전을 위한 딥러닝 (Convolution Neural Network)**\n",
38 | "
\n",
39 | "**CNN**\n",
40 | "먼저 컨브넷(Convnet)으로 불리는 합성곱 신경망(CNN)에 대해서 배운다
\n",
41 | "Convnet은 (image_height,image_width,image_channels) 크기의 입력 텐서를 사용한다.
\n",
42 | "예를 들어 MNIST 같은 경우 (28,28,1)
\n",
43 | "\n",
44 | "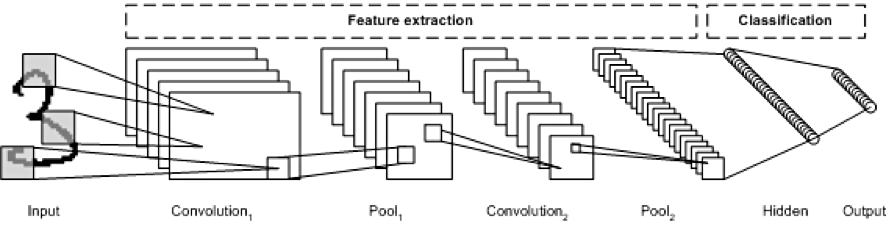\n",
45 | "\n",
46 | "
\n",
47 | "**CNN 특징**\n",
48 | "Dense층은 입력 특성 공간에 있는 전역 패턴을 학습
\n",
49 | "합성곱층은 지역 패턴을 학습한다.
\n",
50 | "\n",
51 | "1. 학습된 패턴은 평행 이동 불변성을 지닌다. 컨브넷이 이미지의 오른쪽 아래 모서리에서 어떤 패턴을 학습했다면 다른 곳에서도 이 패턴을 인식할 수 있다.\n",
52 | "\n",
53 | "2. 컨브넷은 패턴의 공간적 계층 구조를 학습할 수 있다. 1번째 합성곱은 에지 같은 작은 지역 패턴을 학습, 2번째 합성곱 층은 첫 번째 층의 특성으로 구성된 더 큰 패턴을 학습하는 식이다. 이러한 방식을 이용하여 컨브넷은 매우 복잡하고 추상적인 시각적 개념을 효과적으로 학습할 수 있다.
\n",
54 | "\n",
55 | "**Feature Map, Filter**
\n",
56 | "합성곱 연산은 특성 맵(Feature Map)이라고 부르는 3D 텐서에 적용됩니다.
\n",
57 | "이 텐서는 2개의 공간축(높이,넓이)과 깊이 축(채널 축)으로 구성.\n",
58 | "\n",
59 | "즉 합성곱 연산은 입력 특성 맵에서 작은 패치들을 추출하고 이런 모든 패치에 같은 변환을 적용하여 출력 특성 맵(Output Feature Map)을 만든다.\n",
60 | "\n",
61 | "필터 !!
\n",
62 | "필터는 입력 데이터의 어떤 특성을 인코딩하게 된다.
\n",
63 | "model.add(layers.Conv2D(32,(3,3),activation='relu',input_shape=(28,28,1)))
\n",
64 | "(28,28,1)크기의 특성 맵을 입력받아 (26,26,32) 크기의 특성 맵을 출력한다. 즉 입력에 대해서 32개의 필터를 적용한 것 !
\n",
65 | "이 값은 응답 맵(Response Map)이라고 한다. \n",
66 | "
\n",
67 | "\n",
68 | "**합성곱의 핵심 파라미터**
\n",
69 | "1. 입력으로 부터 뽑아낼 패치의 크기: 보통 3x3, 5x5를 많이 사용\n",
70 | "2. 특성 뱁의 출력 깊이: 합성곱으로 계산할 필터의 수이다. \n",
71 | "
\n",
72 | "**사용법**\n",
73 | "Conv2D(output_depth,(window_height,window_width))\n",
74 | "
\n",
75 | "**패딩(Padding)**: 입력과 동일한 높이와 넓이를 가진 출력 특성 맵을 얻고 싶다면 패딩을 해야한다. 정보 손실 방지\n",
76 | "
\n",
77 | "**스트라이드**: 출력 크기에 영향을 미치는 요소이다. 얼마나 움질일지. 스트라이드가 2 라는 것은 2의 배수로 다운 샘플링 되었다는 뜻.\n",
78 | "
\n",
79 | "**Max Pooling**: 스트라이드 합성곱과 마찬가지로 강제적으로 특성 맵을 다운샘플링을 하는 것이 Max Pooling의 역할. 입력 특성 맵에서 윈도우에 맞는 패치를 추출하고 각 채널별 최대값을 출력한다.\n",
80 | "\n",
81 | "**왜 하는가**: 처리할 특성맵의 가중치 개수를 줄이기 위해서.\n",
82 | "\n"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "metadata": {
88 | "id": "-fBkPj2Av4YC",
89 | "colab_type": "code",
90 | "colab": {}
91 | },
92 | "source": [
93 | "#MNIST 이미지에 컨브넷 훈련해보기\n",
94 | "\n",
95 | "from keras.datasets import mnist\n",
96 | "from keras.utils import to_categorical\n",
97 | "from keras import layers\n",
98 | "from keras import models\n",
99 | "\n",
100 | "#데이터 로딩\n",
101 | "(train_images,train_labels),(test_images,test_labels)=mnist.load_data()\n",
102 | "\n",
103 | "#데이터 전처리\n",
104 | "train_images=train_images.reshape((60000,28,28,1))\n",
105 | "train_images=train_images.astype('float32') /255\n",
106 | "\n",
107 | "test_images=test_images.reshape((10000,28,28,1))\n",
108 | "test_images=test_images.astype('float32') /255\n",
109 | "\n",
110 | "#One-hot Encoding\n",
111 | "train_labels=to_categorical(train_labels)\n",
112 | "test_labels=to_categorical(test_labels)\n",
113 | "\n",
114 | "#모델 구조\n",
115 | "model=models.Sequential()\n",
116 | "model.add(layers.Conv2D(32,(3,3),activation='relu',input_shape=(28,28,1)))\n",
117 | "model.add(layers.MaxPooling2D((2,2)))\n",
118 | "model.add(layers.Conv2D(64,(3,3),activation='relu'))\n",
119 | "model.add(layers.MaxPooling2D((2,2)))\n",
120 | "model.add(layers.Conv2D(64,(3,3),activation='relu'))\n",
121 | "\n",
122 | "model.add(layers.Flatten())\n",
123 | "model.add(layers.Dense(64,activation='relu'))\n",
124 | "model.add(layers.Dense(10,activation='softmax')) #MNIST이니 10\n",
125 | "\n",
126 | "#모델 정보 출력\n",
127 | "model.summary() \n",
128 | "\n",
129 | "#모델 컴파일\n",
130 | "model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])\n",
131 | "\n",
132 | "#모델 훈련\n",
133 | "model.fit(train_images,train_labels,epochs=5,batch_size=64)\n",
134 | "\n",
135 | "#모델 평가\n",
136 | "test_loss,test_acc=model.evaluate(test_images,test_labels)\n",
137 | "print(\"Test_acc: \",test_acc)"
138 | ],
139 | "execution_count": 0,
140 | "outputs": []
141 | },
142 | {
143 | "cell_type": "markdown",
144 | "metadata": {
145 | "id": "-QAwNEDBacMp",
146 | "colab_type": "text"
147 | },
148 | "source": [
149 | "**소규모 데이터셋에서 컨브넷 사용하기**
\n",
150 | "원본 데이터셋을 https://www.kaggle.com/c/dogs-vs-cats/data에서 내려받을 수 있습니다"
151 | ]
152 | },
153 | {
154 | "cell_type": "code",
155 | "metadata": {
156 | "id": "MVFObrAlacVn",
157 | "colab_type": "code",
158 | "colab": {}
159 | },
160 | "source": [
161 | "\"code from https://github.com/gilbutITbook/006975/blob/master/5.2-using-convnets-with-small-datasets.ipynb\"\n",
162 | "\n",
163 | "import os, shutil\n",
164 | "\n",
165 | "# 원본 데이터셋을 압축 해제한 디렉터리 경로\n",
166 | "original_dataset_dir = './datasets/cats_and_dogs/train'\n",
167 | "\n",
168 | "# 소규모 데이터셋을 저장할 디렉터리\n",
169 | "base_dir = './datasets/cats_and_dogs_small'\n",
170 | "if os.path.exists(base_dir): # 반복적인 실행을 위해 디렉토리를 삭제합니다.\n",
171 | " shutil.rmtree(base_dir) \n",
172 | "os.mkdir(base_dir)\n",
173 | "\n",
174 | "# 훈련, 검증, 테스트 분할을 위한 디렉터리\n",
175 | "train_dir = os.path.join(base_dir, 'train')\n",
176 | "os.mkdir(train_dir)\n",
177 | "validation_dir = os.path.join(base_dir, 'validation')\n",
178 | "os.mkdir(validation_dir)\n",
179 | "test_dir = os.path.join(base_dir, 'test')\n",
180 | "os.mkdir(test_dir)\n",
181 | "\n",
182 | "# 훈련용 고양이 사진 디렉터리\n",
183 | "train_cats_dir = os.path.join(train_dir, 'cats')\n",
184 | "os.mkdir(train_cats_dir)\n",
185 | "\n",
186 | "# 훈련용 강아지 사진 디렉터리\n",
187 | "train_dogs_dir = os.path.join(train_dir, 'dogs')\n",
188 | "os.mkdir(train_dogs_dir)\n",
189 | "\n",
190 | "# 검증용 고양이 사진 디렉터리\n",
191 | "validation_cats_dir = os.path.join(validation_dir, 'cats')\n",
192 | "os.mkdir(validation_cats_dir)\n",
193 | "\n",
194 | "# 검증용 강아지 사진 디렉터리\n",
195 | "validation_dogs_dir = os.path.join(validation_dir, 'dogs')\n",
196 | "os.mkdir(validation_dogs_dir)\n",
197 | "\n",
198 | "# 테스트용 고양이 사진 디렉터리\n",
199 | "test_cats_dir = os.path.join(test_dir, 'cats')\n",
200 | "os.mkdir(test_cats_dir)\n",
201 | "\n",
202 | "# 테스트용 강아지 사진 디렉터리\n",
203 | "test_dogs_dir = os.path.join(test_dir, 'dogs')\n",
204 | "os.mkdir(test_dogs_dir)\n",
205 | "\n",
206 | "# 처음 1,000개의 고양이 이미지를 train_cats_dir에 복사합니다\n",
207 | "fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]\n",
208 | "for fname in fnames:\n",
209 | " src = os.path.join(original_dataset_dir, fname)\n",
210 | " dst = os.path.join(train_cats_dir, fname)\n",
211 | " shutil.copyfile(src, dst)\n",
212 | "\n",
213 | "# 다음 500개 고양이 이미지를 validation_cats_dir에 복사합니다\n",
214 | "fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]\n",
215 | "for fname in fnames:\n",
216 | " src = os.path.join(original_dataset_dir, fname)\n",
217 | " dst = os.path.join(validation_cats_dir, fname)\n",
218 | " shutil.copyfile(src, dst)\n",
219 | " \n",
220 | "# 다음 500개 고양이 이미지를 test_cats_dir에 복사합니다\n",
221 | "fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]\n",
222 | "for fname in fnames:\n",
223 | " src = os.path.join(original_dataset_dir, fname)\n",
224 | " dst = os.path.join(test_cats_dir, fname)\n",
225 | " shutil.copyfile(src, dst)\n",
226 | " \n",
227 | "# 처음 1,000개의 강아지 이미지를 train_dogs_dir에 복사합니다\n",
228 | "fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]\n",
229 | "for fname in fnames:\n",
230 | " src = os.path.join(original_dataset_dir, fname)\n",
231 | " dst = os.path.join(train_dogs_dir, fname)\n",
232 | " shutil.copyfile(src, dst)\n",
233 | " \n",
234 | "# 다음 500개 강아지 이미지를 validation_dogs_dir에 복사합니다\n",
235 | "fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]\n",
236 | "for fname in fnames:\n",
237 | " src = os.path.join(original_dataset_dir, fname)\n",
238 | " dst = os.path.join(validation_dogs_dir, fname)\n",
239 | " shutil.copyfile(src, dst)\n",
240 | " \n",
241 | "# 다음 500개 강아지 이미지를 test_dogs_dir에 복사합니다\n",
242 | "fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]\n",
243 | "for fname in fnames:\n",
244 | " src = os.path.join(original_dataset_dir, fname)\n",
245 | " dst = os.path.join(test_dogs_dir, fname)\n",
246 | " shutil.copyfile(src, dst)\n",
247 | "\n",
248 | "print('훈련용 고양이 이미지 전체 개수:', len(os.listdir(train_cats_dir)))\n",
249 | "print('훈련용 강아지 이미지 전체 개수:', len(os.listdir(train_dogs_dir)))\n",
250 | "print('검증용 고양이 이미지 전체 개수:', len(os.listdir(validation_cats_dir)))\n",
251 | "print('검증용 강아지 이미지 전체 개수:', len(os.listdir(validation_dogs_dir)))\n",
252 | "print('테스트용 고양이 이미지 전체 개수:', len(os.listdir(test_cats_dir)))\n",
253 | "print('테스트용 강아지 이미지 전체 개수:', len(os.listdir(test_dogs_dir)))\n",
254 | "\n",
255 | "\n",
256 | "from keras import layers\n",
257 | "from keras import models\n",
258 | "\n",
259 | "#모델 생성 \n",
260 | "model = models.Sequential()\n",
261 | "model.add(layers.Conv2D(32, (3, 3), activation='relu',\n",
262 | " input_shape=(150, 150, 3)))\n",
263 | "model.add(layers.MaxPooling2D((2, 2)))\n",
264 | "model.add(layers.Conv2D(64, (3, 3), activation='relu'))\n",
265 | "model.add(layers.MaxPooling2D((2, 2)))\n",
266 | "model.add(layers.Conv2D(128, (3, 3), activation='relu'))\n",
267 | "model.add(layers.MaxPooling2D((2, 2)))\n",
268 | "model.add(layers.Conv2D(128, (3, 3), activation='relu'))\n",
269 | "model.add(layers.MaxPooling2D((2, 2)))\n",
270 | "model.add(layers.Flatten())\n",
271 | "model.add(layers.Dense(512, activation='relu'))\n",
272 | "model.add(layers.Dense(1, activation='sigmoid'))\n",
273 | "\n",
274 | "#모델 요약 \n",
275 | "model.summary()\n",
276 | "\n",
277 | "from keras import optimizers\n",
278 | "\n",
279 | "#모델 컴파일 \n",
280 | "model.compile(loss='binary_crossentropy',\n",
281 | " optimizer=optimizers.RMSprop(lr=1e-4),\n",
282 | " metrics=['acc'])"
283 | ],
284 | "execution_count": 0,
285 | "outputs": []
286 | },
287 | {
288 | "cell_type": "markdown",
289 | "metadata": {
290 | "id": "AuelycEqbmAW",
291 | "colab_type": "text"
292 | },
293 | "source": [
294 | "**데이터 전처리**\n",
295 | "\n",
296 | "1. 사진 파일을 읽습니다.\n",
297 | "2. JPEG 콘텐츠를 RGB 픽셀 값으로 디코딩합니다.\n",
298 | "3. 그다음 부동 소수 타입의 텐서로 변환합니다.\n",
299 | "4. 픽셀 값(0에서 255 사이)의 스케일을 [0, 1] 사이로 조정합니다(신경망은 작은 입력 값을 선호합니다).\n",
300 | "\n",
301 | "케라스는 keras.preprocessing.image에 이미지 처리를 위한 헬퍼 도구들을 가지고 있습니다.
특히 ImageDataGenerator 클래스는 디스크에 있는 이미지 파일을 전처리된 배치 텐서로 자동으로 바꾸어주는 파이썬 제너레이터를 만들어 줍니다. "
302 | ]
303 | },
304 | {
305 | "cell_type": "code",
306 | "metadata": {
307 | "id": "qgLu5B0ib35T",
308 | "colab_type": "code",
309 | "colab": {}
310 | },
311 | "source": [
312 | "from keras.preprocessing.image import ImageDataGenerator\n",
313 | "\n",
314 | "# 모든 이미지를 1/255로 스케일을 조정합니다\n",
315 | "train_datagen = ImageDataGenerator(rescale=1./255)\n",
316 | "test_datagen = ImageDataGenerator(rescale=1./255)\n",
317 | "\n",
318 | "train_generator = train_datagen.flow_from_directory(\n",
319 | " # 타깃 디렉터리\n",
320 | " train_dir,\n",
321 | " # 모든 이미지를 150 × 150 크기로 바꿉니다\n",
322 | " target_size=(150, 150),\n",
323 | " batch_size=20,\n",
324 | " # binary_crossentropy 손실을 사용하기 때문에 이진 레이블이 필요합니다\n",
325 | " class_mode='binary')\n",
326 | "\n",
327 | "validation_generator = test_datagen.flow_from_directory(\n",
328 | " validation_dir,\n",
329 | " target_size=(150, 150),\n",
330 | " batch_size=20,\n",
331 | " class_mode='binary')\n",
332 | "\n",
333 | "\n",
334 | "for data_batch, labels_batch in train_generator:\n",
335 | " print('배치 데이터 크기:', data_batch.shape)\n",
336 | " print('배치 레이블 크기:', labels_batch.shape)\n",
337 | " break\n",
338 | "\n",
339 | "#학습하기 \n",
340 | "history = model.fit_generator(\n",
341 | " train_generator, #제너레이터 \n",
342 | " steps_per_epoch=100,\n",
343 | " epochs=30,\n",
344 | " validation_data=validation_generator,#제너레이터\n",
345 | " validation_steps=50)\n",
346 | "\n",
347 | "model.save('cats_and_dogs_small_1.h5') #모델 저장하기 "
348 | ],
349 | "execution_count": 0,
350 | "outputs": []
351 | },
352 | {
353 | "cell_type": "markdown",
354 | "metadata": {
355 | "id": "X5c1brz2cKvJ",
356 | "colab_type": "text"
357 | },
358 | "source": [
359 | "**Data Augmentation(데이터 증식)**\n",
360 | "
\n",
361 | "과대적합은 학습할 샘플이 너무 적어 새로운 데이터에 일반화할 수 있는 모델을 훈련시킬 수 없기 때문에 발생.
\n",
362 | "무한히 많은 데이터가 주어지면 데이터 분포의 모든 가능한 측면을 모델이 학습할 수 있을 것.
데이터 증식은 기존의 훈련 샘플로부터 더 많은 훈련 데이터를 생성하는 방법.
이 방법은 그럴듯한 이미지를 생성하도록 여러 가지 랜덤한 변환을 적용하여 샘플을 늘림. "
363 | ]
364 | },
365 | {
366 | "cell_type": "code",
367 | "metadata": {
368 | "id": "mBmn-gaAcd-m",
369 | "colab_type": "code",
370 | "colab": {}
371 | },
372 | "source": [
373 | "#from https://github.com/gilbutITbook/006975/blob/master/5.2-using-convnets-with-small-datasets.ipynb\n",
374 | "\n",
375 | "#rotation_range는 랜덤하게 사진을 회전시킬 각도 범위입니다(0-180 사이).\n",
376 | "#width_shift_range와 height_shift_range는 사진을 수평과 수직으로 랜덤하게 평행 이동시킬 범위입니다(전체 넓이와 높이에 대한 비율).\n",
377 | "#shear_range는 랜덤하게 전단 변환을 적용할 각도 범위입니다.\n",
378 | "#zoom_range는 랜덤하게 사진을 확대할 범위입니다.\n",
379 | "#horizontal_flip은 랜덤하게 이미지를 수평으로 뒤집습니다. 수평 대칭을 가정할 수 있을 때 사용합니다(예를 들어, 풍경/인물 사진).\n",
380 | "#fill_mode는 회전이나 가로/세로 이동으로 인해 새롭게 생성해야 할 픽셀을 채울 전략입니다.\n",
381 | "\n",
382 | "datagen = ImageDataGenerator(\n",
383 | " rotation_range=40,\n",
384 | " width_shift_range=0.2,\n",
385 | " height_shift_range=0.2,\n",
386 | " shear_range=0.2,\n",
387 | " zoom_range=0.2,\n",
388 | " horizontal_flip=True,\n",
389 | " fill_mode='nearest')\n",
390 | "\n",
391 | "# 이미지 전처리 유틸리티 모듈\n",
392 | "from keras.preprocessing import image\n",
393 | "\n",
394 | "fnames = sorted([os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)])\n",
395 | "\n",
396 | "# 증식할 이미지 선택합니다\n",
397 | "img_path = fnames[3]\n",
398 | "\n",
399 | "# 이미지를 읽고 크기를 변경합니다\n",
400 | "img = image.load_img(img_path, target_size=(150, 150))\n",
401 | "\n",
402 | "# (150, 150, 3) 크기의 넘파이 배열로 변환합니다\n",
403 | "x = image.img_to_array(img)\n",
404 | "\n",
405 | "# (1, 150, 150, 3) 크기로 변환합니다\n",
406 | "x = x.reshape((1,) + x.shape)\n",
407 | "\n",
408 | "# flow() 메서드는 랜덤하게 변환된 이미지의 배치를 생성합니다.\n",
409 | "# 무한 반복되기 때문에 어느 지점에서 중지해야 합니다!\n",
410 | "i = 0\n",
411 | "for batch in datagen.flow(x, batch_size=1):\n",
412 | " plt.figure(i)\n",
413 | " imgplot = plt.imshow(image.array_to_img(batch[0]))\n",
414 | " i += 1\n",
415 | " if i % 4 == 0:\n",
416 | " break\n",
417 | "\n",
418 | "plt.show()\n",
419 | "\n",
420 | "#모델 생성 \n",
421 | "model = models.Sequential()\n",
422 | "model.add(layers.Conv2D(32, (3, 3), activation='relu',\n",
423 | " input_shape=(150, 150, 3)))\n",
424 | "model.add(layers.MaxPooling2D((2, 2)))\n",
425 | "model.add(layers.Conv2D(64, (3, 3), activation='relu'))\n",
426 | "model.add(layers.MaxPooling2D((2, 2)))\n",
427 | "model.add(layers.Conv2D(128, (3, 3), activation='relu'))\n",
428 | "model.add(layers.MaxPooling2D((2, 2)))\n",
429 | "model.add(layers.Conv2D(128, (3, 3), activation='relu'))\n",
430 | "model.add(layers.MaxPooling2D((2, 2)))\n",
431 | "\n",
432 | "model.add(layers.Flatten())\n",
433 | "model.add(layers.Dropout(0.5))\n",
434 | "model.add(layers.Dense(512, activation='relu'))\n",
435 | "model.add(layers.Dense(1, activation='sigmoid'))\n",
436 | "\n",
437 | "#모델 컴파일 \n",
438 | "model.compile(loss='binary_crossentropy',\n",
439 | " optimizer=optimizers.RMSprop(lr=1e-4),\n",
440 | " metrics=['acc'])\n",
441 | "\n",
442 | "#데이터 증식 \n",
443 | "train_datagen = ImageDataGenerator(\n",
444 | " rescale=1./255,\n",
445 | " rotation_range=40,\n",
446 | " width_shift_range=0.2,\n",
447 | " height_shift_range=0.2,\n",
448 | " shear_range=0.2,\n",
449 | " zoom_range=0.2,\n",
450 | " horizontal_flip=True,)\n",
451 | "\n",
452 | "# 검증 데이터는 증식되어서는 안 됩니다!\n",
453 | "test_datagen = ImageDataGenerator(rescale=1./255)\n",
454 | "\n",
455 | "#제너레이터 생성 \n",
456 | "train_generator = train_datagen.flow_from_directory(\n",
457 | " # 타깃 디렉터리\n",
458 | " train_dir,\n",
459 | " # 모든 이미지를 150 × 150 크기로 바꿉니다\n",
460 | " target_size=(150, 150),\n",
461 | " batch_size=32,\n",
462 | " # binary_crossentropy 손실을 사용하기 때문에 이진 레이블을 만들어야 합니다\n",
463 | " class_mode='binary')\n",
464 | "\n",
465 | "#제너레이터 생성 \n",
466 | "validation_generator = test_datagen.flow_from_directory(\n",
467 | " validation_dir,\n",
468 | " target_size=(150, 150),\n",
469 | " batch_size=32,\n",
470 | " class_mode='binary')\n",
471 | "\n",
472 | "#훈련\n",
473 | "history = model.fit_generator(\n",
474 | " train_generator,\n",
475 | " steps_per_epoch=100,\n",
476 | " epochs=100,\n",
477 | " validation_data=validation_generator,\n",
478 | " validation_steps=50)\n",
479 | "\n",
480 | "\n",
481 | "#모델 저장 \n",
482 | "model.save('cats_and_dogs_small_2.h5')\n",
483 | "\n",
484 | "\n",
485 | "#시각화 \n",
486 | "acc = history.history['acc']\n",
487 | "val_acc = history.history['val_acc']\n",
488 | "loss = history.history['loss']\n",
489 | "val_loss = history.history['val_loss']\n",
490 | "\n",
491 | "epochs = range(len(acc))\n",
492 | "\n",
493 | "plt.plot(epochs, acc, 'bo', label='Training acc')\n",
494 | "plt.plot(epochs, val_acc, 'b', label='Validation acc')\n",
495 | "plt.title('Training and validation accuracy')\n",
496 | "plt.legend()\n",
497 | "\n",
498 | "plt.figure()\n",
499 | "\n",
500 | "plt.plot(epochs, loss, 'bo', label='Training loss')\n",
501 | "plt.plot(epochs, val_loss, 'b', label='Validation loss')\n",
502 | "plt.title('Training and validation loss')\n",
503 | "plt.legend()\n",
504 | "\n",
505 | "plt.show()"
506 | ],
507 | "execution_count": 0,
508 | "outputs": []
509 | },
510 | {
511 | "cell_type": "markdown",
512 | "metadata": {
513 | "id": "CF1Ch91BV3iC",
514 | "colab_type": "text"
515 | },
516 | "source": [
517 | "**사전 훈련된 컨브넷**\n",
518 | "
\n",
519 | "대규모 이미지 분류 문제를 위해 대량의 데이터셋에서 미리 훈련되어 저장된 네트워크 이다.
\n",
520 | "VGG,ResNet,Inception,Inception-ResNet,Xception 등.
\n",
521 | "\n",
522 | "1. 특성 추출 (Feature Extraction): 사전에 학습된 네트워크의 표현을 사용하여 새로운 샘플에서 흥미로운 특성을 뽑아 내는 것.\n",
523 | "2. 미세 조정 (Fine Tuning): 특성 추출에서 사용했던 동결 모델의 사위 층 몇개를 동결에서 해제하고 모델에 새로 추가한 층과 함께 훈련하는 것.
\n",
524 | "a. 사전에 훈련된 기반 네트워크 위에 새로운 네트워크를 추가
\n",
525 | "b. 기반 네트워크를 동결
\n",
526 | "c. 새로 추가한 네트워크 훈련
\n",
527 | "d. 기반 네트워크에서 일부 층의 동결 해제
\n",
528 | "e. 동결을 해제한 층과 새로 추가한 층을 함께 훈련
"
529 | ]
530 | },
531 | {
532 | "cell_type": "code",
533 | "metadata": {
534 | "id": "v0R0dWiSWwtB",
535 | "colab_type": "code",
536 | "colab": {}
537 | },
538 | "source": [
539 | "#특성 추출 (Feature Extraction): 사전에 학습된 네트워크의 표현을 사용하여 새로운 샘플에서 흥미로운 특성을 뽑아 내는 것.\n",
540 | "#방법1) 새로운 데이터셋에서 합성곱 기반 층을 실행하고 출력을 넘파이 배열로 디스크에 저장., 그 다음 이 데이터를 독립된 완전 연결 분류기에 입력으로 사용 (비용이 적게 듬)\n",
541 | "\n",
542 | "\n",
543 | "from keras.applications import VGG16\n",
544 | "import os\n",
545 | "import numpy as np\n",
546 | "from keras.preprocessing.image import ImageDataGenerator\n",
547 | "\n",
548 | "#weights: 모델을 초기화할 가중치 체크포인트를 지정\n",
549 | "#include_top: 네트워크의 최상위 완전 연결 분류기를 포함할지 안할지\n",
550 | "#input_shape: 네트워크의 주입할 이미지의 텐서의 크기\n",
551 | "conv_base = VGG16(weights='imagenet',include_top=False,input_shape=(150,150,3))\n",
552 | "\n",
553 | "conv_base.summary()\n",
554 | "\n",
555 | "\n",
556 | "base_dir = './datasets/cats_and_dogs_small'\n",
557 | "\n",
558 | "train_dir = os.path.join(base_dir, 'train')\n",
559 | "validation_dir = os.path.join(base_dir, 'validation')\n",
560 | "test_dir = os.path.join(base_dir, 'test')\n",
561 | "\n",
562 | "datagen = ImageDataGenerator(rescale=1./255)\n",
563 | "batch_size = 20\n",
564 | "\n",
565 | "#Featur 추출 함수 \n",
566 | "def extract_features(directory, sample_count):\n",
567 | " features = np.zeros(shape=(sample_count, 4, 4, 512))\n",
568 | " labels = np.zeros(shape=(sample_count))\n",
569 | "\n",
570 | " generator = datagen.flow_from_directory(\n",
571 | " directory,\n",
572 | " target_size=(150, 150),\n",
573 | " batch_size=batch_size,\n",
574 | " class_mode='binary')\n",
575 | " \n",
576 | " i = 0\n",
577 | " \n",
578 | " for inputs_batch, labels_batch in generator:\n",
579 | " features_batch = conv_base.predict(inputs_batch)\n",
580 | " features[i * batch_size : (i + 1) * batch_size] = features_batch\n",
581 | " labels[i * batch_size : (i + 1) * batch_size] = labels_batch\n",
582 | " i += 1\n",
583 | " if i * batch_size >= sample_count:\n",
584 | " # 제너레이터는 루프 안에서 무한하게 데이터를 만들어내므로 모든 이미지를 한 번씩 처리하고 나면 중지합니다\n",
585 | " break\n",
586 | " return features, labels\n",
587 | "\n",
588 | "#적용 \n",
589 | "train_features, train_labels = extract_features(train_dir, 2000)\n",
590 | "validation_features, validation_labels = extract_features(validation_dir, 1000)\n",
591 | "test_features, test_labels = extract_features(test_dir, 1000)\n",
592 | "\n",
593 | "\n",
594 | "from keras import models\n",
595 | "from keras import layers\n",
596 | "from keras import optimizers\n",
597 | "\n",
598 | "#모델 정의\n",
599 | "model = models.Sequential()\n",
600 | "model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))\n",
601 | "model.add(layers.Dropout(0.5))\n",
602 | "model.add(layers.Dense(1, activation='sigmoid'))\n",
603 | "\n",
604 | "#모델 컴파일\n",
605 | "model.compile(optimizer=optimizers.RMSprop(lr=2e-5),\n",
606 | " loss='binary_crossentropy',\n",
607 | " metrics=['acc'])\n",
608 | "\n",
609 | "#모델 학습 \n",
610 | "history = model.fit(train_features, train_labels,\n",
611 | " epochs=30,\n",
612 | " batch_size=20,\n",
613 | " validation_data=(validation_features, validation_labels))"
614 | ],
615 | "execution_count": 0,
616 | "outputs": []
617 | },
618 | {
619 | "cell_type": "code",
620 | "metadata": {
621 | "id": "y7lSsNxzdW-K",
622 | "colab_type": "code",
623 | "colab": {}
624 | },
625 | "source": [
626 | "#방법2) 준비한 모델 위에 Dense층을 쌓아 확장. (비용이 많이 듬)\n",
627 | "\n",
628 | "from keras import models\n",
629 | "from keras import layers\n",
630 | "\n",
631 | "#모델 정의\n",
632 | "model = models.Sequential()\n",
633 | "\n",
634 | "model.add(conv_base) #준비한 모델!!\n",
635 | "\n",
636 | "model.add(layers.Flatten())\n",
637 | "model.add(layers.Dense(256, activation='relu'))\n",
638 | "model.add(layers.Dense(1, activation='sigmoid'))\n",
639 | "\n",
640 | "#모델 요약 \n",
641 | "model.summary()\n",
642 | "\n",
643 | "print('conv_base를 동결하기 전 훈련되는 가중치의 수:', \n",
644 | " len(model.trainable_weights))\n",
645 | "\n",
646 | "conv_base.trainable = False #동결하기 \n",
647 | "\n",
648 | "\n",
649 | "print('conv_base를 동결한 후 훈련되는 가중치의 수:', \n",
650 | " len(model.trainable_weights))\n",
651 | "\n",
652 | "\n",
653 | "from keras.preprocessing.image import ImageDataGenerator\n",
654 | "\n",
655 | "#데이터 증식 \n",
656 | "train_datagen = ImageDataGenerator(\n",
657 | " rescale=1./255,\n",
658 | " rotation_range=20,\n",
659 | " width_shift_range=0.1,\n",
660 | " height_shift_range=0.1,\n",
661 | " shear_range=0.1,\n",
662 | " zoom_range=0.1,\n",
663 | " horizontal_flip=True,\n",
664 | " fill_mode='nearest')\n",
665 | "\n",
666 | "# 검증 데이터는 증식되어서는 안 됩니다!\n",
667 | "test_datagen = ImageDataGenerator(rescale=1./255)\n",
668 | "\n",
669 | "#제너레이터 생성 \n",
670 | "train_generator = train_datagen.flow_from_directory(\n",
671 | " # 타깃 디렉터리\n",
672 | " train_dir,\n",
673 | " # 모든 이미지의 크기를 150 × 150로 변경합니다\n",
674 | " target_size=(150, 150),\n",
675 | " batch_size=20,\n",
676 | " # binary_crossentropy 손실을 사용하므로 이진 레이블이 필요합니다\n",
677 | " class_mode='binary')\n",
678 | "\n",
679 | "#제너레이터 생성 \n",
680 | "validation_generator = test_datagen.flow_from_directory(\n",
681 | " validation_dir,\n",
682 | " target_size=(150, 150),\n",
683 | " batch_size=20,\n",
684 | " class_mode='binary')\n",
685 | "\n",
686 | "#모델 컴파일 \n",
687 | "model.compile(loss='binary_crossentropy',\n",
688 | " optimizer=optimizers.RMSprop(lr=2e-5),\n",
689 | " metrics=['acc'])\n",
690 | "\n",
691 | "#모델 요약 \n",
692 | "history = model.fit_generator(\n",
693 | " train_generator,\n",
694 | " steps_per_epoch=100,\n",
695 | " epochs=30,\n",
696 | " validation_data=validation_generator,\n",
697 | " validation_steps=50,\n",
698 | " verbose=2)\n",
699 | "\n",
700 | "\n",
701 | "#모델 저장 \n",
702 | "model.save('cats_and_dogs_small_3.h5')\n",
703 | "\n"
704 | ],
705 | "execution_count": 0,
706 | "outputs": []
707 | },
708 | {
709 | "cell_type": "markdown",
710 | "metadata": {
711 | "id": "6uX0wP8Zd6kJ",
712 | "colab_type": "text"
713 | },
714 | "source": [
715 | "**미세조정 실습**
\n",
716 | "\n",
717 | "왜 더 많은 층을 미세조정 하지 않는 것인가?
\n",
718 | "1. 합성곱 기반 층에 있는 하위 층들은 좀 더 일반적이고 재사용 가능한 특성들을 인코딩한다. 반면에 상위 층은 좀 더 특화 된 특성을 인코딩 한다. 새로운 문제에 재활용 하도록 수정이 필요한 것은 구체적인 특성들이므로 이들을 미세조정하는 것이 좋음. 하위 층으로 갈 수록 미세 조정에 대한 효과가 감소한다.\n",
719 | "2. 훈련해야 할 파라미터가 많을 수록 고대적합 위험이 커지기에."
720 | ]
721 | },
722 | {
723 | "cell_type": "code",
724 | "metadata": {
725 | "id": "x8ob15Jbd77K",
726 | "colab_type": "code",
727 | "colab": {}
728 | },
729 | "source": [
730 | "conv_base.summary()\n",
731 | "\n",
732 | "conv_base.trainable = True\n",
733 | "\n",
734 | "set_trainable = False\n",
735 | "\n",
736 | "for layer in conv_base.layers:\n",
737 | " if layer.name == 'block5_conv1':\n",
738 | " set_trainable = True\n",
739 | " if set_trainable:\n",
740 | " layer.trainable = True\n",
741 | " else:\n",
742 | " layer.trainable = False\n",
743 | "\n",
744 | "model.compile(loss='binary_crossentropy',\n",
745 | " optimizer=optimizers.RMSprop(lr=1e-5),\n",
746 | " metrics=['acc'])\n",
747 | "\n",
748 | "history = model.fit_generator(\n",
749 | " train_generator,\n",
750 | " steps_per_epoch=100,\n",
751 | " epochs=100,\n",
752 | " validation_data=validation_generator,\n",
753 | " validation_steps=50)\n",
754 | "\n",
755 | "model.save('cats_and_dogs_small_4.h5')\n",
756 | "\n",
757 | "#시각화 \n",
758 | "acc = history.history['acc']\n",
759 | "val_acc = history.history['val_acc']\n",
760 | "loss = history.history['loss']\n",
761 | "val_loss = history.history['val_loss']\n",
762 | "\n",
763 | "epochs = range(len(acc))\n",
764 | "\n",
765 | "plt.plot(epochs, acc, 'bo', label='Training acc')\n",
766 | "plt.plot(epochs, val_acc, 'b', label='Validation acc')\n",
767 | "plt.title('Training and validation accuracy')\n",
768 | "plt.legend()\n",
769 | "\n",
770 | "plt.figure()\n",
771 | "\n",
772 | "plt.plot(epochs, loss, 'bo', label='Training loss')\n",
773 | "plt.plot(epochs, val_loss, 'b', label='Validation loss')\n",
774 | "plt.title('Training and validation loss')\n",
775 | "plt.legend()\n",
776 | "\n",
777 | "plt.show()\n",
778 | "\n",
779 | "\n",
780 | "#성능 측정 \n",
781 | "test_generator = test_datagen.flow_from_directory(\n",
782 | " test_dir,\n",
783 | " target_size=(150, 150),\n",
784 | " batch_size=20,\n",
785 | " class_mode='binary')\n",
786 | "\n",
787 | "test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)\n",
788 | "print('test acc:', test_acc)"
789 | ],
790 | "execution_count": 0,
791 | "outputs": []
792 | }
793 | ]
794 | }
--------------------------------------------------------------------------------
/Deep_Learning_Tutorial_Using_Keras_Part_03_RNN.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "name": "Deep Learning Tutorial Using Keras Part 03 - RNN.ipynb",
7 | "provenance": [],
8 | "collapsed_sections": []
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | }
14 | },
15 | "cells": [
16 | {
17 | "cell_type": "markdown",
18 | "metadata": {
19 | "id": "sMDPT3aUihg2",
20 | "colab_type": "text"
21 | },
22 | "source": [
23 | "**제목**: Deep Learning Tutorial Using Keras Part03 - RNN (Keras로 배우는 딥러닝 튜토리얼 Part03 RNN편)
\n",
24 | "**제작자**: Park Chanjun (박찬준)
\n",
25 | "**소속**: Korea University Natural Language Processing & Artificial Intelligence Lab (고려대학교 자연언어처리&인공지능 연구실)
\n",
26 | "**Email**: bcj1210@naver.com
\n",
27 | "**참고자료**: 케라스 창시자에게 배우는 딥러닝"
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {
33 | "id": "0EqNwJmJUHKe",
34 | "colab_type": "text"
35 | },
36 | "source": [
37 | "**텍스트와 시퀀스 데이터를 위한 딥러닝(자연언어처리)**\n",
38 | "
\n",
39 | "\n",
40 | "시퀀스 데이터를 처리하는 기본적인 딥러닝 모델은
\n",
41 | "1. Recurrent Neural Network \n",
42 | "2. 1D Convnet\n",
43 | "\n",
44 | "\n",
45 | "크게 2가지가 존재한다.\n",
46 | "\n",
47 | "딥러닝 모델은 수치형 텐서만 다룰 수 있다.
\n",
48 | "따라서 텍스트를 수치형 텐서로 변환해야 한다.
\n",
49 | "이 과정을 텍스트 벡터화(Vectorizing)이라고 한다.
\n",
50 | "텍스트를 나누는 단위에(Token) 따라 크게 3가지 방식으로 이루어진다.\n",
51 | "\n",
52 | "1. 텍스트를 단어로 나누고 각 단어를 하나의 벡터로 변환한다.\n",
53 | "2. 텍스트를 문자로 나누고 각 문자를 하나의 벡터로 변환한다.\n",
54 | "3. 텍스트에서 단어나 문자의 n-gram을 추출하여 n-gram을 하나의 벡터로 변환한다.\n",
55 | "n-gram이란 문장에서 추출한 N개의 연속된 단어 그룹을 의미한다.\n",
56 | "\n",
57 | "Token과 Vector를 연결하는 2가지 방법\n",
58 | "1. One Hot Encoding\n",
59 | "2. (Word or Char or Sentence or Document) Embedding
\n",
60 | "a. 문제와 함께 단어 임베딩을 학습, 랜덤한 단어 벡터로 시작하여 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습
\n",
61 | "b. 사전 훈련된 단어 임베딩(Pretrain word Embedding)사용
\n",
62 | "\n",
63 | "\n",
64 | "\n",
65 | "\n"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "metadata": {
71 | "id": "Vn0LVT3Lig5d",
72 | "colab_type": "code",
73 | "colab": {}
74 | },
75 | "source": [
76 | "#One-Hot Encoding 실습 (단어 수준)\n",
77 | "\n",
78 | "import numpy as np\n",
79 | "\n",
80 | "samples=[\"안녕하세요 저의 이름은 박찬준입니다.\",\"지금부터 자연언어처리 강의를 시작하도록 하겠습니다.\"] #샘플 데이터\n",
81 | "\n",
82 | "token_index={}#토큰 딕셔너리\n",
83 | "\n",
84 | "for sample in samples:\n",
85 | " for word in sample.split():#split을 이용하여 token으로 분리\n",
86 | " if word not in token_index:\n",
87 | " token_index[word]=len(token_index)+1 #단어마다 고유한 인덱스 부여, 인덱스 0은 사용하지 않기에 +1 을 하였음.\n",
88 | "\n",
89 | "max_length=10\n",
90 | "\n",
91 | "results=np.zeros(shape=(len(samples),\n",
92 | " max_length,\n",
93 | " max(token_index.values())+1))#결과를 저장할 배열\n",
94 | "\n",
95 | "for i,sample in enumerate(samples):\n",
96 | " for j,word in list(enumerate(sample.split()))[:max_length]:\n",
97 | " index=token_index.get(word)\n",
98 | " results[i,j,index]=1.\n",
99 | "\n",
100 | "print(results)\n",
101 | "\n"
102 | ],
103 | "execution_count": 0,
104 | "outputs": []
105 | },
106 | {
107 | "cell_type": "code",
108 | "metadata": {
109 | "id": "86sDMCoYihWQ",
110 | "colab_type": "code",
111 | "colab": {}
112 | },
113 | "source": [
114 | "#One-Hot Encoding 실습 (문자 수준)\n",
115 | "import numpy as np\n",
116 | "import string\n",
117 | "\n",
118 | "samples=[\"안녕하세요 저의 이름은 박찬준입니다.\",\"지금부터 자연언어처리 강의를 시작하도록 하겠습니다.\"] #샘플 데이터\n",
119 | "characters=string.printable #출력가능한 ASCII 문자\n",
120 | "\n",
121 | "token_index=dict(zip(characters, range(1,len(characters)+1))) #char 딕셔너리 생성\n",
122 | "\n",
123 | "max_length=50\n",
124 | "\n",
125 | "results=np.zeros(len(samples),max_length,max(token_index.values()+1))\n",
126 | "\n",
127 | "for i,sample in enumerate(samples):\n",
128 | " for i,character in enumerate(sample):\n",
129 | " index=token_index.get(character)\n",
130 | " results[i,j,index]=1."
131 | ],
132 | "execution_count": 0,
133 | "outputs": []
134 | },
135 | {
136 | "cell_type": "code",
137 | "metadata": {
138 | "id": "oB5RVWjUZAtr",
139 | "colab_type": "code",
140 | "colab": {}
141 | },
142 | "source": [
143 | "#One-Hot Encoding 실습 (Keras 이용)\n",
144 | "from keras.preprocessing.text import Tokenizer\n",
145 | "\n",
146 | "samples=[\"안녕하세요 저의 이름은 박찬준입니다.\",\"안녕하세요 지금부터 자연언어처리 강의를 시작하도록 하겠습니다.\"] #샘플 데이터\n",
147 | "\n",
148 | "tokenizer=Tokenizer(num_words=1000)#빈도수가 높은 1000개의 단어만 선택.\n",
149 | "tokenizer.fit_on_texts(samples)#단어 인덱스 구축\n",
150 | "\n",
151 | "sequences=tokenizer.texts_to_sequences(samples)#문자열을 정수 인덱스 리스트로 변환\n",
152 | "print(\"sequences: \",sequences)\n",
153 | "\n",
154 | "one_hot_results=tokenizer.texts_to_matrix(samples,mode='binary')#직접 one hot 이진 벡터 표현을 얻을 수 있다.\n",
155 | "print(\"one_hot_results: \",one_hot_results)\n",
156 | "\n",
157 | "word_index=tokenizer.word_index #단어 인덱스\n",
158 | "print(\"word_index: \",word_index)"
159 | ],
160 | "execution_count": 0,
161 | "outputs": []
162 | },
163 | {
164 | "cell_type": "markdown",
165 | "metadata": {
166 | "id": "vIxQA0V_egbA",
167 | "colab_type": "text"
168 | },
169 | "source": [
170 | "embedding_layer=Embedding(1000,64) #가능한 토큰의 개수(단어 인덱스 최대값+1), 임베딩 차원\n",
171 | "1. Embedding 층은 간단히 생각해 정수 인덱스를 밀집 벡터로 매핑하는 딕셔너리이다.\n",
172 | "2. 단어 인덱스 => Embedding층 => 연관된 단어 벡터\n",
173 | "3. 배치에 있는 모든 시퀀스는 길이가 같아야 하므로 작은 길이의 시퀀스는 0으로 패딩된다.\n",
174 | "\n",
175 | "4. Embedding 층은 (samples,sequence_length) 인 2D 정수 텐서를 입력으로 받는다.\n",
176 | "5. Embedding 층은 (sampels,sequence_length,embedding_dimensionality)인 3D 실수형 텐서를 반환한다."
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "metadata": {
182 | "id": "tXmBbxzaay8E",
183 | "colab_type": "code",
184 | "colab": {}
185 | },
186 | "source": [
187 | "#Word Embedding 실습 => 문제와 함께 단어 임베딩을 학습, 랜덤한 단어 벡터로 시작하여 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습\n",
188 | "#저차원의 실수벡터 (보통 256,512,1024차원 정도 사용)\n",
189 | "\n",
190 | "from keras.layers import Embedding\n",
191 | "from keras.datasets import imdb\n",
192 | "from keras import preprocessing\n",
193 | "from keras.models import Sequential\n",
194 | "from keras.layers import Flatten,Dense,Embedding\n",
195 | "\n",
196 | "max_features=10000 #특성으로 사용할 단어의 수\n",
197 | "maxlen=20 #사용할 텍스트 길이\n",
198 | "\n",
199 | "#데이터 로딩\n",
200 | "(x_train,y_train),(x_test,y_test)=imdb.load_data(num_words=max_features)\n",
201 | "\n",
202 | "#패딩\n",
203 | "x_train=preprocessing.sequence.pad_sequences(x_train,maxlen=maxlen) #패딩 , (sampels,maxlen)의 2D 텐서 반환\n",
204 | "x_test=preprocessing.sequence.pad_sequences(x_test,maxlen=maxlen) #패딩 , (sampels,maxlen)의 2D 텐서 반환\n",
205 | "\n",
206 | "#모델 생성\n",
207 | "model=Sequential()\n",
208 | "model.add(Embedding(10000, 8, input_length=maxlen)) #출력은 (samples,maxlen,8)\n",
209 | "\n",
210 | "model.add(Flatten()) #(samples,maxlen*8)의 2D 텐서로 펼친다.\n",
211 | "\n",
212 | "model.add(Dense(1,activation='sigmoid'))\n",
213 | "model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])\n",
214 | "\n",
215 | "model.summary()\n",
216 | "\n",
217 | "history=model.fit(x_train,y_train,epochs=10,batch_size=32,validation_split=0.2)\n",
218 | "\n",
219 | "test_loss,test_acc=model.evaluate(x_test,y_test)\n",
220 | "print(\"Test_acc: \",test_acc)"
221 | ],
222 | "execution_count": 0,
223 | "outputs": []
224 | },
225 | {
226 | "cell_type": "markdown",
227 | "metadata": {
228 | "id": "gneD3SfCgv86",
229 | "colab_type": "text"
230 | },
231 | "source": [
232 | "먼저 http://mng.bz/0tIo 에서 IMDB 원본 데이터셋을 다운로드하고 압축을 해제합니다."
233 | ]
234 | },
235 | {
236 | "cell_type": "code",
237 | "metadata": {
238 | "id": "aaobvmHRdqqs",
239 | "colab_type": "code",
240 | "colab": {}
241 | },
242 | "source": [
243 | "import os\n",
244 | "\n",
245 | "imdb_dir = './datasets/aclImdb'\n",
246 | "train_dir = os.path.join(imdb_dir, 'train')\n",
247 | "\n",
248 | "labels = []\n",
249 | "texts = []\n",
250 | "\n",
251 | "#훈련용 리뷰 하나를 문자열 하나로 만들어 훈련 데이터를 문자열의 리스트로 구성. 리뷰 레이블(긍정/부정)도 labels 리스트로 만듬.\n",
252 | "for label_type in ['neg', 'pos']:\n",
253 | " dir_name = os.path.join(train_dir, label_type)\n",
254 | " for fname in os.listdir(dir_name):\n",
255 | " if fname[-4:] == '.txt':\n",
256 | " f = open(os.path.join(dir_name, fname), encoding='utf8')\n",
257 | " texts.append(f.read())\n",
258 | " f.close()\n",
259 | " if label_type == 'neg':\n",
260 | " labels.append(0)\n",
261 | " else:\n",
262 | " labels.append(1)\n",
263 | "\n",
264 | "from keras.preprocessing.text import Tokenizer\n",
265 | "from keras.preprocessing.sequence import pad_sequences\n",
266 | "import numpy as np\n",
267 | "\n",
268 | "maxlen = 100 # 100개 단어 이후는 버립니다\n",
269 | "training_samples = 200 # 훈련 샘플은 200개입니다\n",
270 | "validation_samples = 10000 # 검증 샘플은 10,000개입니다\n",
271 | "max_words = 10000 # 데이터셋에서 가장 빈도 높은 10,000개의 단어만 사용합니다\n",
272 | "\n",
273 | "tokenizer = Tokenizer(num_words=max_words)\n",
274 | "tokenizer.fit_on_texts(texts)\n",
275 | "sequences = tokenizer.texts_to_sequences(texts)\n",
276 | "\n",
277 | "word_index = tokenizer.word_index\n",
278 | "print('%s개의 고유한 토큰을 찾았습니다.' % len(word_index))\n",
279 | "\n",
280 | "data = pad_sequences(sequences, maxlen=maxlen)\n",
281 | "\n",
282 | "labels = np.asarray(labels)\n",
283 | "print('데이터 텐서의 크기:', data.shape)\n",
284 | "print('레이블 텐서의 크기:', labels.shape)\n",
285 | "\n",
286 | "# 데이터를 훈련 세트와 검증 세트로 분할합니다.\n",
287 | "# 샘플이 순서대로 있기 때문에 (부정 샘플이 모두 나온 후에 긍정 샘플이 옵니다) \n",
288 | "# 먼저 데이터를 섞습니다.\n",
289 | "indices = np.arange(data.shape[0])\n",
290 | "np.random.shuffle(indices) #셔플링 \n",
291 | "data = data[indices]\n",
292 | "labels = labels[indices]\n",
293 | "\n",
294 | "x_train = data[:training_samples]\n",
295 | "y_train = labels[:training_samples]\n",
296 | "x_val = data[training_samples: training_samples + validation_samples]\n",
297 | "y_val = labels[training_samples: training_samples + validation_samples]"
298 | ],
299 | "execution_count": 0,
300 | "outputs": []
301 | },
302 | {
303 | "cell_type": "markdown",
304 | "metadata": {
305 | "id": "ZxJ-2NADhFws",
306 | "colab_type": "text"
307 | },
308 | "source": [
309 | "GloVe 단어 임베딩 내려받기\n",
310 | "https://nlp.stanford.edu/projects/glove 에서 2014년 영문 위키피디아를 사용해 사전에 계산된 임베딩을 내려받습니다. 이 파일의 이름은 glove.6B.zip이고 압축 파일 크기는 823MB입니다. 400,000만개의 단어(또는 단어가 아닌 토큰)에 대한 100차원의 임베딩 벡터를 포함하고 있습니다. datasets 폴더 아래에 파일 압축을 해제합니다.(이 저장소에는 이미 포함되어 있습니다)"
311 | ]
312 | },
313 | {
314 | "cell_type": "code",
315 | "metadata": {
316 | "id": "5PUp0Z_OhHGv",
317 | "colab_type": "code",
318 | "colab": {}
319 | },
320 | "source": [
321 | "glove_dir = './datasets/'\n",
322 | "\n",
323 | "#Glove 처리 \n",
324 | "embeddings_index = {}\n",
325 | "f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'), encoding=\"utf8\")\n",
326 | "for line in f:\n",
327 | " values = line.split()\n",
328 | " word = values[0] #단어\n",
329 | " coefs = np.asarray(values[1:], dtype='float32') #벡터값\n",
330 | " embeddings_index[word] = coefs #딕셔너리\n",
331 | "f.close()\n",
332 | "\n",
333 | "print('%s개의 단어 벡터를 찾았습니다.' % len(embeddings_index))\n",
334 | "\n",
335 | "\n",
336 | "#Embedding층에 주입할 수 있는 임베딩 행렬을 만들어야 한다.\n",
337 | "#행렬의 크기는 (max_words,embedding_dim)이어야 한다.\n",
338 | "embedding_dim = 100\n",
339 | "\n",
340 | "embedding_matrix = np.zeros((max_words, embedding_dim))\n",
341 | "\n",
342 | "for word, i in word_index.items():\n",
343 | " embedding_vector = embeddings_index.get(word)\n",
344 | " if i < max_words:\n",
345 | " if embedding_vector is not None:\n",
346 | " # 임베딩 인덱스에 없는 단어는 모두 0이 됩니다.\n",
347 | " embedding_matrix[i] = embedding_vector\n",
348 | "\n",
349 | "from keras.models import Sequential\n",
350 | "from keras.layers import Embedding, Flatten, Dense\n",
351 | "\n",
352 | "#모델 정의\n",
353 | "model = Sequential()\n",
354 | "model.add(Embedding(max_words, embedding_dim, input_length=maxlen))\n",
355 | "model.add(Flatten())\n",
356 | "model.add(Dense(32, activation='relu'))\n",
357 | "model.add(Dense(1, activation='sigmoid'))\n",
358 | "model.summary()\n",
359 | "\n",
360 | "#모델에 GloVe 임베딩 로드하기\n",
361 | "#Embedding 층은 하나의 가중치 행렬을 가집니다. 이 행렬은 2D 부동 소수 행렬이고 각 i번째 원소는 i번째 인덱스에 상응하는 단어 벡터입니다. 모델의 첫 번째 층인 Embedding 층에 준비된 GloVe 행렬을 로드\n",
362 | "model.layers[0].set_weights([embedding_matrix])\n",
363 | "model.layers[0].trainable = False #추가적으로 Embedding 층을 동결합니다\n",
364 | "\n",
365 | "#모델 컴파일\n",
366 | "model.compile(optimizer='rmsprop',\n",
367 | " loss='binary_crossentropy',\n",
368 | " metrics=['acc'])\n",
369 | "\n",
370 | "#모델 훈련\n",
371 | "history = model.fit(x_train, y_train,\n",
372 | " epochs=10,\n",
373 | " batch_size=32,\n",
374 | " validation_data=(x_val, y_val))\n",
375 | "#모델 저장\n",
376 | "model.save_weights('pre_trained_glove_model.h5')\n",
377 | "\n",
378 | "#테스트 \n",
379 | "test_dir = os.path.join(imdb_dir, 'test')\n",
380 | "\n",
381 | "labels = []\n",
382 | "texts = []\n",
383 | "\n",
384 | "for label_type in ['neg', 'pos']:\n",
385 | " dir_name = os.path.join(test_dir, label_type)\n",
386 | " for fname in sorted(os.listdir(dir_name)):\n",
387 | " if fname[-4:] == '.txt':\n",
388 | " f = open(os.path.join(dir_name, fname), encoding=\"utf8\")\n",
389 | " texts.append(f.read())\n",
390 | " f.close()\n",
391 | " if label_type == 'neg':\n",
392 | " labels.append(0)\n",
393 | " else:\n",
394 | " labels.append(1)\n",
395 | "\n",
396 | "sequences = tokenizer.texts_to_sequences(texts)\n",
397 | "x_test = pad_sequences(sequences, maxlen=maxlen)\n",
398 | "y_test = np.asarray(labels)\n",
399 | "\n",
400 | "model.load_weights('pre_trained_glove_model.h5')\n",
401 | "model.evaluate(x_test, y_test)"
402 | ],
403 | "execution_count": 0,
404 | "outputs": []
405 | },
406 | {
407 | "cell_type": "markdown",
408 | "metadata": {
409 | "id": "QOMaXmdNjolK",
410 | "colab_type": "text"
411 | },
412 | "source": [
413 | "**RNN**\n",
414 | "\n",
415 | "\n",
416 | "\n",
417 | "
\n",
418 | "RNN은 (batch_size, timesteps,input_features)인 2D 텐서로 인코딩 된 벡터의 시퀀스를 입력 받음."
419 | ]
420 | },
421 | {
422 | "cell_type": "code",
423 | "metadata": {
424 | "id": "kQSV4ip8mHf5",
425 | "colab_type": "code",
426 | "colab": {}
427 | },
428 | "source": [
429 | "from keras.datasets import imdb\n",
430 | "from keras.preprocessing import sequence\n",
431 | "\n",
432 | "from keras.models import Sequential\n",
433 | "from keras.layers import Embedding, SimpleRNN\n",
434 | "\n",
435 | "max_features = 10000 # 특성으로 사용할 단어의 수\n",
436 | "maxlen = 500 # 사용할 텍스트의 길이(가장 빈번한 max_features 개의 단어만 사용합니다)\n",
437 | "batch_size = 32\n",
438 | "\n",
439 | "#데이터 로딩\n",
440 | "(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_features)\n",
441 | "\n",
442 | "#패딩\n",
443 | "input_train = sequence.pad_sequences(input_train, maxlen=maxlen)\n",
444 | "input_test = sequence.pad_sequences(input_test, maxlen=maxlen)\n",
445 | "print('input_train 크기:', input_train.shape)\n",
446 | "print('input_test 크기:', input_test.shape)\n",
447 | "\n",
448 | "from keras.layers import Dense\n",
449 | "\n",
450 | "#모델 정의 \n",
451 | "model = Sequential()\n",
452 | "model.add(Embedding(max_features, 32))\n",
453 | "model.add(SimpleRNN(32))\n",
454 | "model.add(Dense(1, activation='sigmoid'))\n",
455 | "\n",
456 | "#모델 컴파일\n",
457 | "model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])\n",
458 | "\n",
459 | "#모델 훈련\n",
460 | "history = model.fit(input_train, y_train,\n",
461 | " epochs=10,\n",
462 | " batch_size=128,\n",
463 | " validation_split=0.2)\n",
464 | "\n",
465 | "import matplotlib.pyplot as plt\n",
466 | "\n",
467 | "#시각화 \n",
468 | "acc = history.history['acc']\n",
469 | "val_acc = history.history['val_acc']\n",
470 | "loss = history.history['loss']\n",
471 | "val_loss = history.history['val_loss']\n",
472 | "\n",
473 | "epochs = range(1, len(acc) + 1)\n",
474 | "\n",
475 | "plt.plot(epochs, acc, 'bo', label='Training acc')\n",
476 | "plt.plot(epochs, val_acc, 'b', label='Validation acc')\n",
477 | "plt.title('Training and validation accuracy')\n",
478 | "plt.legend()\n",
479 | "\n",
480 | "plt.figure()\n",
481 | "\n",
482 | "plt.plot(epochs, loss, 'bo', label='Training loss')\n",
483 | "plt.plot(epochs, val_loss, 'b', label='Validation loss')\n",
484 | "plt.title('Training and validation loss')\n",
485 | "plt.legend()\n",
486 | "\n",
487 | "plt.show()\n",
488 | "\n"
489 | ],
490 | "execution_count": 0,
491 | "outputs": []
492 | },
493 | {
494 | "cell_type": "markdown",
495 | "metadata": {
496 | "id": "EOXBqbPDmuGQ",
497 | "colab_type": "text"
498 | },
499 | "source": [
500 | "**LSTM과 GRU**\n",
501 | "
\n",
502 | "Simple RNN의 문제점은 Vanishing Gradient Problem 즉 기울기 소실 문제.
\n",
503 | "이 문제를 해결하기 위한 것이 LSTM,GRU이다
\n",
504 | "과거 정보를 나중에 다시 주입하여 기울기 소실 문제를 해결하려 하는 것 !\n",
505 | "\n",
506 | "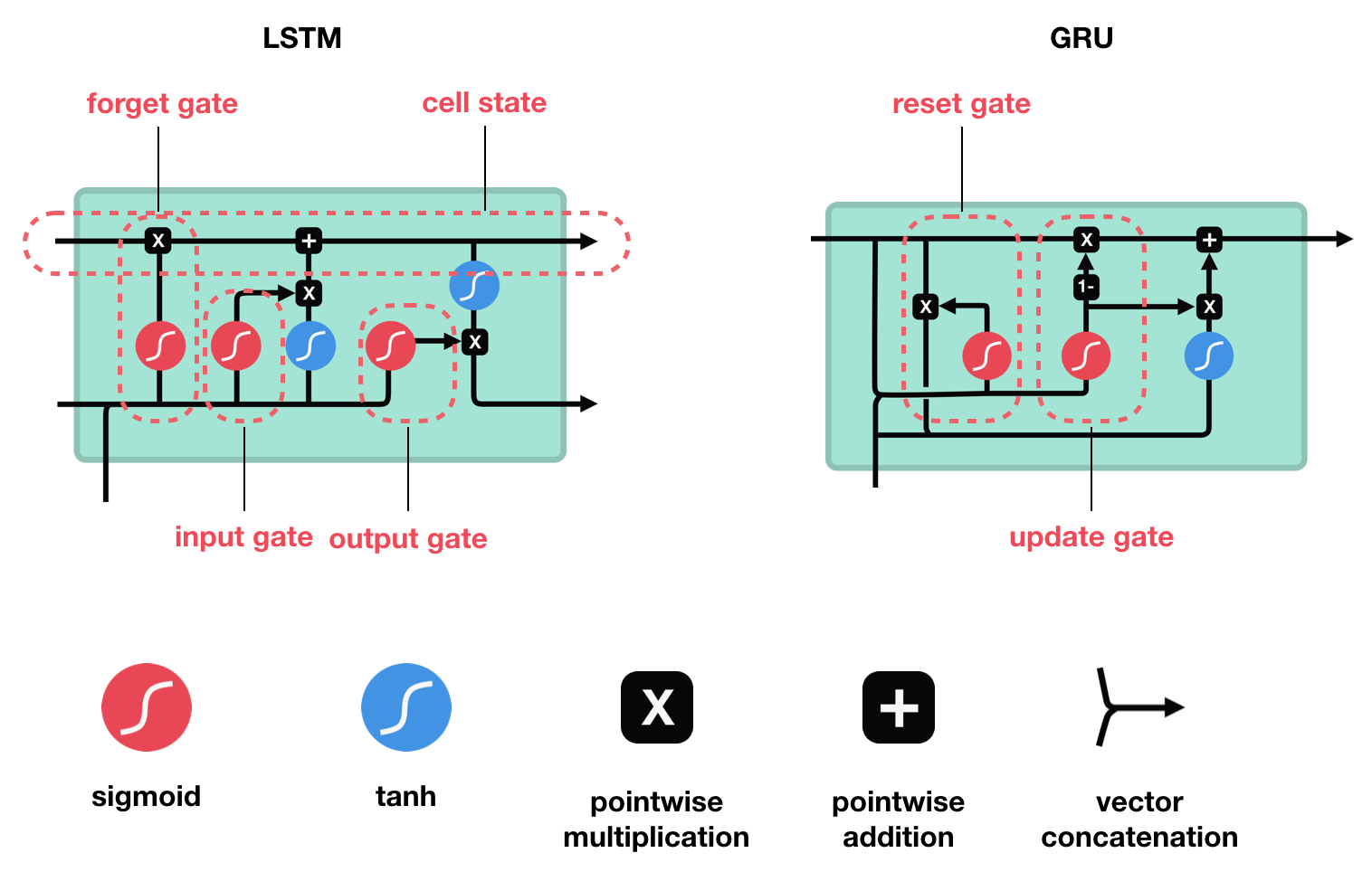"
507 | ]
508 | },
509 | {
510 | "cell_type": "code",
511 | "metadata": {
512 | "id": "3a7dTZVvnZ7s",
513 | "colab_type": "code",
514 | "colab": {}
515 | },
516 | "source": [
517 | "from keras.datasets import imdb\n",
518 | "from keras.preprocessing import sequence\n",
519 | "\n",
520 | "from keras.models import Sequential\n",
521 | "from keras.layers import Embedding, SimpleRNN\n",
522 | "\n",
523 | "max_features = 10000 # 특성으로 사용할 단어의 수\n",
524 | "maxlen = 500 # 사용할 텍스트의 길이(가장 빈번한 max_features 개의 단어만 사용합니다)\n",
525 | "batch_size = 32\n",
526 | "\n",
527 | "#데이터 로딩\n",
528 | "(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_features)\n",
529 | "\n",
530 | "#패딩\n",
531 | "input_train = sequence.pad_sequences(input_train, maxlen=maxlen)\n",
532 | "input_test = sequence.pad_sequences(input_test, maxlen=maxlen)\n",
533 | "print('input_train 크기:', input_train.shape)\n",
534 | "print('input_test 크기:', input_test.shape)\n",
535 | "\n",
536 | "\n",
537 | "#모델 정의 \n",
538 | "from keras.layers import Dense\n",
539 | "from keras.layers import LSTM\n",
540 | "\n",
541 | "model = Sequential()\n",
542 | "model.add(Embedding(max_features, 32))\n",
543 | "model.add(LSTM(32)) #LSTM 사용 !\n",
544 | "model.add(Dense(1, activation='sigmoid'))\n",
545 | "\n",
546 | "model.compile(optimizer='rmsprop',\n",
547 | " loss='binary_crossentropy',\n",
548 | " metrics=['acc'])\n",
549 | "history = model.fit(input_train, y_train,\n",
550 | " epochs=10,\n",
551 | " batch_size=128,\n",
552 | " validation_split=0.2)\n",
553 | "\n",
554 | "\n",
555 | "\n",
556 | "import matplotlib.pyplot as plt\n",
557 | "\n",
558 | "#시각화 \n",
559 | "acc = history.history['acc']\n",
560 | "val_acc = history.history['val_acc']\n",
561 | "loss = history.history['loss']\n",
562 | "val_loss = history.history['val_loss']\n",
563 | "\n",
564 | "epochs = range(1, len(acc) + 1)\n",
565 | "\n",
566 | "plt.plot(epochs, acc, 'bo', label='Training acc')\n",
567 | "plt.plot(epochs, val_acc, 'b', label='Validation acc')\n",
568 | "plt.title('Training and validation accuracy')\n",
569 | "plt.legend()\n",
570 | "\n",
571 | "plt.figure()\n",
572 | "\n",
573 | "plt.plot(epochs, loss, 'bo', label='Training loss')\n",
574 | "plt.plot(epochs, val_loss, 'b', label='Validation loss')\n",
575 | "plt.title('Training and validation loss')\n",
576 | "plt.legend()\n",
577 | "\n",
578 | "plt.show()\n"
579 | ],
580 | "execution_count": 0,
581 | "outputs": []
582 | },
583 | {
584 | "cell_type": "markdown",
585 | "metadata": {
586 | "id": "XJ763FUaoHHm",
587 | "colab_type": "text"
588 | },
589 | "source": [
590 | "**RNN 고급 사용법**\n",
591 | "\n",
592 | "1. 순환 드롭 아웃: Recurrent Dropout: 순환층에 과대적합 방지\n",
593 | "2. 스태킹 순환 층: Stacking Recurrent Layer: 네트워크 표현 능력 증가시킴\n",
594 | "3. Bidirectional Recurrent Layer: 양방향"
595 | ]
596 | },
597 | {
598 | "cell_type": "code",
599 | "metadata": {
600 | "id": "b38DIHOnogA3",
601 | "colab_type": "code",
602 | "colab": {}
603 | },
604 | "source": [
605 | "import os\n",
606 | "\n",
607 | "#데이터 받아오기 \n",
608 | "!mkdir ./datasets\n",
609 | "!mkdir ./datasets/jena_climate/\n",
610 | "!wget https://s3.amazonaws.com/keras-datasets/jena_climate_2009_2016.csv.zip\n",
611 | "!unzip jena_climate_2009_2016.csv.zip\n",
612 | "!mv jena_climate_2009_2016.csv ./datasets/jena_climate/\n",
613 | "\n",
614 | "#데이터 로딩\n",
615 | "data_dir = './datasets/jena_climate/'\n",
616 | "fname = os.path.join(data_dir, 'jena_climate_2009_2016.csv')\n",
617 | "\n",
618 | "f = open(fname)\n",
619 | "data = f.read()\n",
620 | "f.close()\n",
621 | "\n",
622 | "lines = data.split('\\n')\n",
623 | "header = lines[0].split(',')\n",
624 | "lines = lines[1:]\n",
625 | "\n",
626 | "print(header)\n",
627 | "print(len(lines))\n",
628 | "\n",
629 | "#데이터 파싱 \n",
630 | "import numpy as np\n",
631 | "\n",
632 | "float_data = np.zeros((len(lines), len(header) - 1))\n",
633 | "for i, line in enumerate(lines):\n",
634 | " values = [float(x) for x in line.split(',')[1:]]\n",
635 | " float_data[i, :] = values\n",
636 | "\n",
637 | "#정규화\n",
638 | "mean = float_data[:200000].mean(axis=0)\n",
639 | "float_data -= mean\n",
640 | "std = float_data[:200000].std(axis=0)\n",
641 | "float_data /= std\n",
642 | "\n",
643 | "#제너레이터 생성 \n",
644 | "def generator(data, lookback, delay, min_index, max_index,\n",
645 | " shuffle=False, batch_size=128, step=6):\n",
646 | " if max_index is None:\n",
647 | " max_index = len(data) - delay - 1\n",
648 | " i = min_index + lookback\n",
649 | " while 1:\n",
650 | " if shuffle:\n",
651 | " rows = np.random.randint(\n",
652 | " min_index + lookback, max_index, size=batch_size)\n",
653 | " else:\n",
654 | " if i + batch_size >= max_index:\n",
655 | " i = min_index + lookback\n",
656 | " rows = np.arange(i, min(i + batch_size, max_index))\n",
657 | " i += len(rows)\n",
658 | "\n",
659 | " samples = np.zeros((len(rows),\n",
660 | " lookback // step,\n",
661 | " data.shape[-1]))\n",
662 | " targets = np.zeros((len(rows),))\n",
663 | " for j, row in enumerate(rows):\n",
664 | " indices = range(rows[j] - lookback, rows[j], step)\n",
665 | " samples[j] = data[indices]\n",
666 | " targets[j] = data[rows[j] + delay][1]\n",
667 | " yield samples, targets\n",
668 | "\n",
669 | "lookback = 1440\n",
670 | "step = 6\n",
671 | "delay = 144\n",
672 | "batch_size = 128\n",
673 | "\n",
674 | "train_gen = generator(float_data,\n",
675 | " lookback=lookback,\n",
676 | " delay=delay,\n",
677 | " min_index=0,\n",
678 | " max_index=200000,\n",
679 | " shuffle=True,\n",
680 | " step=step, \n",
681 | " batch_size=batch_size)\n",
682 | "val_gen = generator(float_data,\n",
683 | " lookback=lookback,\n",
684 | " delay=delay,\n",
685 | " min_index=200001,\n",
686 | " max_index=300000,\n",
687 | " step=step,\n",
688 | " batch_size=batch_size)\n",
689 | "test_gen = generator(float_data,\n",
690 | " lookback=lookback,\n",
691 | " delay=delay,\n",
692 | " min_index=300001,\n",
693 | " max_index=None,\n",
694 | " step=step,\n",
695 | " batch_size=batch_size)\n",
696 | "\n",
697 | "# 전체 검증 세트를 순회하기 위해 val_gen에서 추출할 횟수\n",
698 | "val_steps = (300000 - 200001 - lookback) // batch_size\n",
699 | "\n",
700 | "# 전체 테스트 세트를 순회하기 위해 test_gen에서 추출할 횟수\n",
701 | "test_steps = (len(float_data) - 300001 - lookback) // batch_size\n",
702 | "\n",
703 | "\n",
704 | "def evaluate_naive_method():\n",
705 | " batch_maes = []\n",
706 | " for step in range(val_steps):\n",
707 | " samples, targets = next(val_gen)\n",
708 | " preds = samples[:, -1, 1]\n",
709 | " mae = np.mean(np.abs(preds - targets))\n",
710 | " batch_maes.append(mae)\n",
711 | " print(np.mean(batch_maes))\n",
712 | " \n",
713 | "evaluate_naive_method()\n",
714 | "\n",
715 | "\n",
716 | "#GRU 사용\n",
717 | "from keras.models import Sequential\n",
718 | "from keras import layers\n",
719 | "from keras.optimizers import RMSprop\n",
720 | "\n",
721 | "model = Sequential()\n",
722 | "model.add(layers.GRU(32, input_shape=(None, float_data.shape[-1])))#GRU\n",
723 | "model.add(layers.Dense(1))\n",
724 | "\n",
725 | "model.compile(optimizer=RMSprop(), loss='mae')\n",
726 | "history = model.fit_generator(train_gen,\n",
727 | " steps_per_epoch=500,\n",
728 | " epochs=20,\n",
729 | " validation_data=val_gen,\n",
730 | " validation_steps=val_steps)\n",
731 | "\n",
732 | "\n",
733 | "\n",
734 | "\n",
735 | "#드롭아웃 적용해보기 \n",
736 | "from keras.models import Sequential\n",
737 | "from keras import layers\n",
738 | "from keras.optimizers import RMSprop\n",
739 | "\n",
740 | "model = Sequential()\n",
741 | "model.add(layers.GRU(32,\n",
742 | " dropout=0.2, #드롭아웃\n",
743 | " recurrent_dropout=0.2, #드롭아웃 \n",
744 | " input_shape=(None, float_data.shape[-1])))\n",
745 | "model.add(layers.Dense(1))\n",
746 | "\n",
747 | "model.compile(optimizer=RMSprop(), loss='mae')\n",
748 | "\n",
749 | "history = model.fit_generator(train_gen,\n",
750 | " steps_per_epoch=500,\n",
751 | " epochs=40,\n",
752 | " validation_data=val_gen,\n",
753 | " validation_steps=val_steps)\n",
754 | "\n",
755 | "#스태킹 순환층\n",
756 | "from keras.models import Sequential\n",
757 | "from keras import layers\n",
758 | "from keras.optimizers import RMSprop\n",
759 | "\n",
760 | "model = Sequential()\n",
761 | "model.add(layers.GRU(32,\n",
762 | " dropout=0.1,\n",
763 | " recurrent_dropout=0.5,\n",
764 | " return_sequences=True,#요렇게 설정하면됨 !!!!!!!!!!!1\n",
765 | " input_shape=(None, float_data.shape[-1])))\n",
766 | "\n",
767 | "model.add(layers.GRU(64, activation='relu',\n",
768 | " dropout=0.1, \n",
769 | " recurrent_dropout=0.5))\n",
770 | "model.add(layers.Dense(1))\n",
771 | "\n",
772 | "model.compile(optimizer=RMSprop(), loss='mae')\n",
773 | "\n",
774 | "history = model.fit_generator(train_gen,\n",
775 | " steps_per_epoch=500,\n",
776 | " epochs=40,\n",
777 | " validation_data=val_gen,\n",
778 | " validation_steps=val_steps)\n",
779 | "\n",
780 | "\n",
781 | "\n",
782 | "#거꾸로 된 시퀀스를 가지고 훈련해보기 \n",
783 | "from keras.datasets import imdb\n",
784 | "from keras.preprocessing import sequence\n",
785 | "from keras import layers\n",
786 | "from keras.models import Sequential\n",
787 | "\n",
788 | "# 특성으로 사용할 단어의 수\n",
789 | "max_features = 10000\n",
790 | "# 사용할 텍스트의 길이(가장 빈번한 max_features 개의 단어만 사용합니다)\n",
791 | "maxlen = 500\n",
792 | "\n",
793 | "# 데이터 로드\n",
794 | "(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)\n",
795 | "\n",
796 | "# 시퀀스를 뒤집습니다!!!!!!!!!!!!!!!!!!!!!1\n",
797 | "x_train = [x[::-1] for x in x_train]\n",
798 | "x_test = [x[::-1] for x in x_test]\n",
799 | "\n",
800 | "# 시퀀스에 패딩을 추가합니다\n",
801 | "x_train = sequence.pad_sequences(x_train, maxlen=maxlen)\n",
802 | "x_test = sequence.pad_sequences(x_test, maxlen=maxlen)\n",
803 | "\n",
804 | "model = Sequential()\n",
805 | "model.add(layers.Embedding(max_features, 128))\n",
806 | "model.add(layers.LSTM(32))\n",
807 | "model.add(layers.Dense(1, activation='sigmoid'))\n",
808 | "\n",
809 | "model.compile(optimizer='rmsprop',\n",
810 | " loss='binary_crossentropy',\n",
811 | " metrics=['acc'])\n",
812 | "history = model.fit(x_train, y_train,\n",
813 | " epochs=10,\n",
814 | " batch_size=128,\n",
815 | " validation_split=0.2)\n",
816 | "\n",
817 | "\n",
818 | "#양방향 LSTM\n",
819 | "from keras import backend as K\n",
820 | "K.clear_session()\n",
821 | "\n",
822 | "model = Sequential()\n",
823 | "model.add(layers.Embedding(max_features, 32))\n",
824 | "model.add(layers.Bidirectional(layers.LSTM(32)))#Bidirectional!!!!!!!!!\n",
825 | "model.add(layers.Dense(1, activation='sigmoid'))\n",
826 | "\n",
827 | "model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])\n",
828 | "history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)\n",
829 | "\n",
830 | "\n",
831 | "from keras.models import Sequential\n",
832 | "from keras import layers\n",
833 | "from keras.optimizers import RMSprop\n",
834 | "\n",
835 | "model = Sequential()\n",
836 | "model.add(layers.Bidirectional(\n",
837 | " layers.GRU(32), input_shape=(None, float_data.shape[-1])))\n",
838 | "model.add(layers.Dense(1))\n",
839 | "\n",
840 | "model.compile(optimizer=RMSprop(), loss='mae')\n",
841 | "history = model.fit_generator(train_gen,\n",
842 | " steps_per_epoch=500,\n",
843 | " epochs=40,\n",
844 | " validation_data=val_gen,\n",
845 | " validation_steps=val_steps)\n",
846 | "\n",
847 | "\n"
848 | ],
849 | "execution_count": 0,
850 | "outputs": []
851 | },
852 | {
853 | "cell_type": "markdown",
854 | "metadata": {
855 | "id": "YSN9v9VbtNTB",
856 | "colab_type": "text"
857 | },
858 | "source": [
859 | "**CNN을 이용한 시퀀스 처리**\n",
860 | "
\n",
861 | ""
862 | ]
863 | },
864 | {
865 | "cell_type": "code",
866 | "metadata": {
867 | "id": "slAcTC_cpS6r",
868 | "colab_type": "code",
869 | "colab": {}
870 | },
871 | "source": [
872 | "from keras.datasets import imdb\n",
873 | "from keras.preprocessing import sequence\n",
874 | "\n",
875 | "max_features = 10000 # 특성으로 사용할 단어의 수\n",
876 | "max_len = 500 # 사용할 텍스트의 길이(가장 빈번한 max_features 개의 단어만 사용합니다)\n",
877 | "\n",
878 | "#데이터 로딩\n",
879 | "(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)\n",
880 | "\n",
881 | "\n",
882 | "#패딩\n",
883 | "x_train = sequence.pad_sequences(x_train, maxlen=max_len)\n",
884 | "x_test = sequence.pad_sequences(x_test, maxlen=max_len)\n",
885 | "print('x_train 크기:', x_train.shape)\n",
886 | "print('x_test 크기:', x_test.shape)\n",
887 | "\n",
888 | "from keras.models import Sequential\n",
889 | "from keras import layers\n",
890 | "from keras.optimizers import RMSprop\n",
891 | "\n",
892 | "#모델 정의 \n",
893 | "model = Sequential()\n",
894 | "model.add(layers.Embedding(max_features, 128, input_length=max_len))\n",
895 | "model.add(layers.Conv1D(32, 7, activation='relu'))\n",
896 | "model.add(layers.MaxPooling1D(5))\n",
897 | "model.add(layers.Conv1D(32, 7, activation='relu'))\n",
898 | "model.add(layers.GlobalMaxPooling1D())\n",
899 | "model.add(layers.Dense(1))\n",
900 | "\n",
901 | "#모델 출력\n",
902 | "model.summary()\n",
903 | "\n",
904 | "#모델 컴파일\n",
905 | "model.compile(optimizer=RMSprop(lr=1e-4),\n",
906 | " loss='binary_crossentropy',\n",
907 | " metrics=['acc'])\n",
908 | "\n",
909 | "#모델 훈련\n",
910 | "history = model.fit(x_train, y_train,\n",
911 | " epochs=10,\n",
912 | " batch_size=128,\n",
913 | " validation_split=0.2)\n",
914 | "\n",
915 | "\n",
916 | "test_loss,test_acc=model.evaluate(x_test,y_test)\n",
917 | "print(\"Test_acc: \",test_acc)\n"
918 | ],
919 | "execution_count": 0,
920 | "outputs": []
921 | },
922 | {
923 | "cell_type": "markdown",
924 | "metadata": {
925 | "id": "BhoKVV2fuWQc",
926 | "colab_type": "text"
927 | },
928 | "source": [
929 | "**CNN과 RNN 연결하여 긴 시퀀스 처리하기**\n"
930 | ]
931 | },
932 | {
933 | "cell_type": "code",
934 | "metadata": {
935 | "id": "pxUgu1sLuc7z",
936 | "colab_type": "code",
937 | "colab": {}
938 | },
939 | "source": [
940 | "import os\n",
941 | "import numpy as np\n",
942 | "\n",
943 | "data_dir = './datasets/jena_climate/'\n",
944 | "fname = os.path.join(data_dir, 'jena_climate_2009_2016.csv')\n",
945 | "\n",
946 | "f = open(fname)\n",
947 | "data = f.read()\n",
948 | "f.close()\n",
949 | "\n",
950 | "lines = data.split('\\n')\n",
951 | "header = lines[0].split(',')\n",
952 | "lines = lines[1:]\n",
953 | "\n",
954 | "float_data = np.zeros((len(lines), len(header) - 1))\n",
955 | "for i, line in enumerate(lines):\n",
956 | " values = [float(x) for x in line.split(',')[1:]]\n",
957 | " float_data[i, :] = values\n",
958 | " \n",
959 | "mean = float_data[:200000].mean(axis=0)\n",
960 | "float_data -= mean\n",
961 | "std = float_data[:200000].std(axis=0)\n",
962 | "float_data /= std\n",
963 | "\n",
964 | "def generator(data, lookback, delay, min_index, max_index,\n",
965 | " shuffle=False, batch_size=128, step=6):\n",
966 | " if max_index is None:\n",
967 | " max_index = len(data) - delay - 1\n",
968 | " i = min_index + lookback\n",
969 | " while 1:\n",
970 | " if shuffle:\n",
971 | " rows = np.random.randint(\n",
972 | " min_index + lookback, max_index, size=batch_size)\n",
973 | " else:\n",
974 | " if i + batch_size >= max_index:\n",
975 | " i = min_index + lookback\n",
976 | " rows = np.arange(i, min(i + batch_size, max_index))\n",
977 | " i += len(rows)\n",
978 | "\n",
979 | " samples = np.zeros((len(rows),\n",
980 | " lookback // step,\n",
981 | " data.shape[-1]))\n",
982 | " targets = np.zeros((len(rows),))\n",
983 | " for j, row in enumerate(rows):\n",
984 | " indices = range(rows[j] - lookback, rows[j], step)\n",
985 | " samples[j] = data[indices]\n",
986 | " targets[j] = data[rows[j] + delay][1]\n",
987 | " yield samples, targets\n",
988 | " \n",
989 | "lookback = 1440\n",
990 | "step = 6\n",
991 | "delay = 144\n",
992 | "batch_size = 128\n",
993 | "\n",
994 | "train_gen = generator(float_data,\n",
995 | " lookback=lookback,\n",
996 | " delay=delay,\n",
997 | " min_index=0,\n",
998 | " max_index=200000,\n",
999 | " shuffle=True,\n",
1000 | " step=step, \n",
1001 | " batch_size=batch_size)\n",
1002 | "\n",
1003 | "val_gen = generator(float_data,\n",
1004 | " lookback=lookback,\n",
1005 | " delay=delay,\n",
1006 | " min_index=200001,\n",
1007 | " max_index=300000,\n",
1008 | " step=step,\n",
1009 | " batch_size=batch_size)\n",
1010 | "\n",
1011 | "test_gen = generator(float_data,\n",
1012 | " lookback=lookback,\n",
1013 | " delay=delay,\n",
1014 | " min_index=300001,\n",
1015 | " max_index=None,\n",
1016 | " step=step,\n",
1017 | " batch_size=batch_size)\n",
1018 | "\n",
1019 | "# 전체 검증 세트를 순회하기 위해 val_gen에서 추출할 횟수\n",
1020 | "val_steps = (300000 - 200001 - lookback) // batch_size\n",
1021 | "\n",
1022 | "# 전체 테스트 세트를 순회하기 위해 test_gen에서 추출할 횟수\n",
1023 | "test_steps = (len(float_data) - 300001 - lookback) // batch_size\n",
1024 | "\n",
1025 | "from keras.models import Sequential\n",
1026 | "from keras import layers\n",
1027 | "from keras.optimizers import RMSprop\n",
1028 | "\n",
1029 | "#모델 정의\n",
1030 | "model = Sequential()\n",
1031 | "\n",
1032 | "#Conv 1D\n",
1033 | "model.add(layers.Conv1D(32, 5, activation='relu',\n",
1034 | " input_shape=(None, float_data.shape[-1])))\n",
1035 | "model.add(layers.MaxPooling1D(3))\n",
1036 | "model.add(layers.Conv1D(32, 5, activation='relu'))\n",
1037 | "\n",
1038 | "#GRU\n",
1039 | "model.add(layers.GRU(32, dropout=0.1, recurrent_dropout=0.5))\n",
1040 | "model.add(layers.Dense(1))\n",
1041 | "\n",
1042 | "model.summary()\n",
1043 | "\n",
1044 | "model.compile(optimizer=RMSprop(), loss='mae')\n",
1045 | "history = model.fit_generator(train_gen,\n",
1046 | " steps_per_epoch=500,\n",
1047 | " epochs=20,\n",
1048 | " validation_data=val_gen,\n",
1049 | " validation_steps=val_steps)\n",
1050 | "\n"
1051 | ],
1052 | "execution_count": 0,
1053 | "outputs": []
1054 | }
1055 | ]
1056 | }
--------------------------------------------------------------------------------