", "version": VERSION},
28 | )
29 |
30 |
31 | def check_first_connect(_: LifecycleMetaEvent) -> bool:
32 | return True
33 |
34 |
35 | start_metaevent = on_metaevent(rule=check_first_connect, temp=True)
36 | FIRST_BOOT_MESSAGE = (
37 | "首次启动,目前没有订阅,请添加!\n另外,请检查配置文件的内容(详见部署教程)!"
38 | )
39 | BOOT_SUCCESS_MESSAGE = "ELF_RSS 订阅器启动成功!"
40 |
41 |
42 | # 启动时发送启动成功信息
43 | @start_metaevent.handle()
44 | async def start(bot: Bot) -> None:
45 | # 启动后检查 data 目录,不存在就创建
46 | if not DATA_PATH.is_dir():
47 | DATA_PATH.mkdir()
48 |
49 | boot_message = (
50 | f"Version: v{VERSION}\nAuthor:Quan666\nhttps://github.com/Quan666/ELF_RSS"
51 | )
52 |
53 | rss_list = Rss.read_rss() # 读取list
54 | if not rss_list:
55 | await send_message_to_admin(f"{FIRST_BOOT_MESSAGE}\n{boot_message}", bot)
56 | logger.info(FIRST_BOOT_MESSAGE)
57 | if plugin_config.enable_boot_message:
58 | await send_message_to_admin(f"{BOOT_SUCCESS_MESSAGE}\n{boot_message}", bot)
59 | logger.info(BOOT_SUCCESS_MESSAGE)
60 | # 创建检查更新任务
61 | await asyncio.gather(*[tr.add_job(rss) for rss in rss_list if not rss.stop])
62 |
--------------------------------------------------------------------------------
/docs/更新日志.md:
--------------------------------------------------------------------------------
1 | # 更新日志
2 |
3 | ## 2.0
4 |
5 | 请查看 commit 记录
6 |
7 | ### 2020年12月21日
8 |
9 | #### 全新 2.0 正式版
10 |
11 | > 新特性:
12 | >
13 | > 1. 更易使用的命令
14 | > 2. 更简洁的代码,方便移植到你自己的机器人
15 | > 3. 使用全新的 Nonebot2 框架
16 |
17 | ### 2022年1月25日
18 |
19 | #### `nonebot2 2.0.0b1` 适配
20 |
21 | 适配 `nonebot2 2.0.0b1`,其余未修改。
22 |
23 | ### 2022年1月25日
24 |
25 | #### 频道适配
26 |
27 | 适配 QQ 频道,需使用 `gocqhttp v1.0.0-beta8-fix2` 及以上版本。
28 |
29 | ## 1.0
30 |
31 | ### 2020年6月8日
32 |
33 | [v1.3.1](https://github.com/Quan666/ELF_RSS/commit/4d6f9e45849e14c15849eaa871f4e79364b42256) 修复bug
34 |
35 | ### 2020年6月17日
36 |
37 | [v1.3.2](https://github.com/Quan666/ELF_RSS/commit/3b47c06ef0d90319c3de0fbeb728fb035fb67f82) 修复拉取失败 bug
38 |
39 | ### 2020年6月18日
40 |
41 | [v1.3.3](https://github.com/Quan666/ELF_RSS/commit/50935b3b8fae783027e007237ba4cf3388779f8f) 修复修改订阅地址时,订阅地址带有“=”号导致的bug
42 |
43 | ### 2020年8月8日
44 |
45 | [v1.3.4](https://github.com/Quan666/ELF_RSS/commit/c115e76499cdf308f129a13cfeb9d07fa4bae270) 修复一些 bug,新增图片压缩,默认压缩大于 3MB 的图片
46 |
47 | ### 2020年8月19日
48 |
49 | [v1.3.5](https://github.com/Quan666/ELF_RSS/commit/dbac5337f66c786ed97c286a503840871e6ffc7f)
50 |
51 | * 适配Linux
52 | * 修复图片压缩导致的图片丢失,以及优化压缩方式
53 | * 修复一些其他 bug
54 | * 新增配置项 `ZIP_SIZE` 图片压缩大小 kb * 1024 = MB
55 | * 删除配置项 `IsAir` `Linux_Path`
56 |
57 | [v1.3.7](https://github.com/Quan666/ELF_RSS/commit/a125119f3ea2c2d5c967e863b067fda145fcacc9)
58 |
59 | * 新增 [只转发包含图片的推特](https://github.com/Quan666/ELF_RSS/issues/5)
60 | * 新增 百度翻译,需自己申请相应api
61 | * 修复一些其他 bug
62 | * 新增配置项 `blockquote = True` #是否显示转发的内容,默认打开
63 | * 新增配置项 `showlottery = True` #是否显示互动抽奖信息,默认打开
64 | * 新增配置项 `UseBaidu = False` `BaiduID = ''` `BaiduKEY = ''`
65 |
66 | * 添加了retry来防止获取外网rss时超时
67 |
68 | [v1.3.8](https://github.com/Quan666/ELF_RSS/commit/b47e3da5a6cf2a7c7abd1ed96a05ad1d9c8d3cba)
69 |
70 | * 弃用 第三方属性,但添加订阅(add)等命令还保留该属性,预计 2 个版本后删除
71 | * 弃用 配置项 ROOTUSER, 只使用 SUPERUSERS
72 | * 新增 分群管理,即在群聊使用命令时,优先作用于群聊
73 |
74 | 如果群组添加的订阅名或者订阅地址已经存在于后台,会只添加进订阅群,不修改其他参数
75 |
76 | * 修复一些其他 bug
77 | * 新增配置项
78 |
79 | ```text
80 | #群组订阅的默认参数
81 | add_uptime = 10 #默认订阅更新时间
82 | add_proxy = False #默认是否启用代理
83 |
84 | ···
85 |
86 | Blockword = ["互动抽奖","微博抽奖平台"] #屏蔽词填写 支持正则,看里面格式就明白怎么添加了吧(
87 | ```
88 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/command/add_dy.py:
--------------------------------------------------------------------------------
1 | import re
2 |
3 | from nonebot import on_command
4 | from nonebot.adapters.onebot.v11 import (
5 | GroupMessageEvent,
6 | Message,
7 | MessageEvent,
8 | PrivateMessageEvent,
9 | )
10 | from nonebot.adapters.onebot.v11.permission import GROUP_ADMIN, GROUP_OWNER
11 | from nonebot.matcher import Matcher
12 | from nonebot.params import ArgPlainText, CommandArg
13 | from nonebot.permission import SUPERUSER
14 | from nonebot.rule import to_me
15 |
16 | from .. import my_trigger as tr
17 | from ..rss_class import Rss
18 |
19 | RSS_ADD = on_command(
20 | "add",
21 | aliases={"添加订阅", "sub"},
22 | rule=to_me(),
23 | priority=5,
24 | permission=GROUP_ADMIN | GROUP_OWNER | SUPERUSER,
25 | )
26 |
27 |
28 | @RSS_ADD.handle()
29 | async def handle_first_receive(matcher: Matcher, args: Message = CommandArg()) -> None:
30 | plain_text = args.extract_plain_text().strip()
31 | if plain_text and re.match(r"^\S+\s\S+$", plain_text):
32 | matcher.set_arg("RSS_ADD", args)
33 |
34 |
35 | prompt = """\
36 | 请输入
37 | 名称 订阅地址
38 | 空格分割
39 | 私聊默认订阅到当前账号,群聊默认订阅到当前群组
40 | 更多信息可通过 change 命令修改\
41 | """
42 |
43 |
44 | @RSS_ADD.got("RSS_ADD", prompt=prompt)
45 | async def handle_rss_add(
46 | event: MessageEvent, name_and_url: str = ArgPlainText("RSS_ADD")
47 | ) -> None:
48 | try:
49 | name, url = name_and_url.strip().split(" ")
50 | except ValueError:
51 | await RSS_ADD.reject(prompt)
52 | return
53 | if not name or not url:
54 | await RSS_ADD.reject(prompt)
55 | return
56 |
57 | if _ := Rss.get_one_by_name(name):
58 | await RSS_ADD.finish(f"已存在订阅名为 {name} 的订阅")
59 | return
60 |
61 | await add_feed(name, url, event)
62 |
63 |
64 | async def add_feed(
65 | name: str,
66 | url: str,
67 | event: MessageEvent,
68 | ) -> None:
69 | rss = Rss()
70 | rss.name = name
71 | rss.url = url
72 | user = str(event.user_id) if isinstance(event, PrivateMessageEvent) else None
73 | group = str(event.group_id) if isinstance(event, GroupMessageEvent) else None
74 | guild_channel = None
75 | rss.add_user_or_group_or_channel(user, group, guild_channel)
76 | await RSS_ADD.send(f"👏 已成功添加订阅 {name} !")
77 | await tr.add_job(rss)
78 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/command/show_dy.py:
--------------------------------------------------------------------------------
1 | from typing import List, Optional
2 |
3 | from nonebot import on_command
4 | from nonebot.adapters.onebot.v11 import GroupMessageEvent, Message, MessageEvent
5 | from nonebot.adapters.onebot.v11.permission import GROUP_ADMIN, GROUP_OWNER
6 | from nonebot.params import CommandArg
7 | from nonebot.permission import SUPERUSER
8 | from nonebot.rule import to_me
9 |
10 | from ..rss_class import Rss
11 |
12 | RSS_SHOW = on_command(
13 | "show",
14 | aliases={"查看订阅"},
15 | rule=to_me(),
16 | priority=5,
17 | permission=GROUP_ADMIN | GROUP_OWNER | SUPERUSER,
18 | )
19 |
20 |
21 | def handle_rss_list(rss_list: List[Rss]) -> str:
22 | rss_info_list = [
23 | f"(已停止){i.name}:{i.url}" if i.stop else f"{i.name}:{i.url}"
24 | for i in rss_list
25 | ]
26 | return "\n\n".join(rss_info_list)
27 |
28 |
29 | async def show_rss_by_name(
30 | rss_name: str, group_id: Optional[int], guild_channel_id: Optional[str]
31 | ) -> str:
32 | rss = Rss.get_one_by_name(rss_name)
33 | if (
34 | rss is None
35 | or (group_id and str(group_id) not in rss.group_id)
36 | or (guild_channel_id and guild_channel_id not in rss.guild_channel_id)
37 | ):
38 | return f"❌ 订阅 {rss_name} 不存在或未订阅!"
39 | else:
40 | # 隐私考虑,不展示除当前群组或频道外的群组、频道和QQ
41 | return str(rss.hide_some_infos(group_id, guild_channel_id))
42 |
43 |
44 | # 不带订阅名称默认展示当前群组或账号的订阅,带订阅名称就显示该订阅的
45 | @RSS_SHOW.handle()
46 | async def handle_rss_show(event: MessageEvent, args: Message = CommandArg()) -> None:
47 | rss_name = args.extract_plain_text().strip()
48 |
49 | user_id = event.get_user_id()
50 | group_id = event.group_id if isinstance(event, GroupMessageEvent) else None
51 | guild_channel_id = None
52 |
53 | if rss_name:
54 | rss_msg = await show_rss_by_name(rss_name, group_id, guild_channel_id)
55 | await RSS_SHOW.finish(rss_msg)
56 |
57 | if group_id:
58 | rss_list = Rss.get_by_group(group_id=group_id)
59 | elif guild_channel_id:
60 | rss_list = Rss.get_by_guild_channel(guild_channel_id=guild_channel_id)
61 | else:
62 | rss_list = Rss.get_by_user(user=user_id)
63 |
64 | if rss_list:
65 | msg_str = handle_rss_list(rss_list)
66 | await RSS_SHOW.finish(msg_str)
67 | else:
68 | await RSS_SHOW.finish("❌ 当前没有任何订阅!")
69 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/config.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 | from typing import List, Optional
3 |
4 | from nonebot import get_driver
5 | from nonebot.config import Config
6 | from nonebot.log import logger
7 | from pydantic import AnyHttpUrl
8 |
9 | DATA_PATH = Path.cwd() / "data"
10 | JSON_PATH = DATA_PATH / "rss.json"
11 |
12 |
13 | class ELFConfig(Config):
14 | class Config:
15 | extra = "allow"
16 |
17 | # 代理地址
18 | rss_proxy: Optional[str] = None
19 | rsshub: AnyHttpUrl = "https://rsshub.app" # type: ignore
20 | # 备用 rsshub 地址
21 | rsshub_backup: List[AnyHttpUrl] = []
22 | db_cache_expire: int = 30
23 | limit: int = 200
24 | max_length: int = 1024 # 正文长度限制,防止消息太长刷屏,以及消息过长发送失败的情况
25 | enable_boot_message: bool = True # 是否启用启动时的提示消息推送
26 | debug: bool = (
27 | False # 是否开启 debug 模式,开启后会打印更多的日志信息,同时检查更新时不会使用缓存,便于调试
28 | )
29 |
30 | zip_size: int = 2 * 1024
31 | gif_zip_size: int = 6 * 1024
32 | img_format: Optional[str] = None
33 | img_down_path: Optional[str] = None
34 |
35 | blockquote: bool = True
36 | black_word: Optional[List[str]] = None
37 |
38 | # 百度翻译的 appid 和 key
39 | baidu_id: Optional[str] = None
40 | baidu_key: Optional[str] = None
41 | deepl_translator_api_key: Optional[str] = None
42 | # 配合 deepl_translator 使用的语言检测接口,前往 https://detectlanguage.com/documentation 注册获取 api_key
43 | single_detection_api_key: Optional[str] = None
44 |
45 | qb_username: Optional[str] = None # qbittorrent 用户名
46 | qb_password: Optional[str] = None # qbittorrent 密码
47 | qb_web_url: Optional[str] = None # qbittorrent 的 web 地址
48 | qb_down_path: Optional[str] = (
49 | None # qb 的文件下载地址,这个地址必须是 go-cqhttp 能访问到的
50 | )
51 | down_status_msg_group: Optional[List[int]] = None # 下载进度消息提示群组
52 | down_status_msg_date: int = 10 # 下载进度检查及提示间隔时间,单位秒
53 |
54 | pikpak_username: Optional[str] = None # pikpak 用户名
55 | pikpak_password: Optional[str] = None # pikpak 密码
56 | # pikpak 离线保存的目录, 默认是根目录,示例: ELF_RSS/Downloads ,目录不存在会自动创建, 不能/结尾
57 | pikpak_download_path: str = ""
58 |
59 | telegram_admin_ids: List[int] = (
60 | []
61 | ) # Telegram 管理员 ID 列表,用于接收离线通知和管理机器人
62 | telegram_bot_token: Optional[str] = None # Telegram 机器人的 token
63 |
64 |
65 | config = ELFConfig(**get_driver().config.dict())
66 | logger.debug(f"RSS Config loaded: {config!r}")
67 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/routes/weibo.py:
--------------------------------------------------------------------------------
1 | from typing import Any, Dict
2 |
3 | from nonebot.log import logger
4 | from pyquery import PyQuery as Pq
5 |
6 | from ...config import config
7 | from ...rss_class import Rss
8 | from .. import ParsingBase, handle_html_tag
9 | from ..handle_images import handle_img_combo, handle_img_combo_with_content
10 | from ..utils import get_summary
11 |
12 |
13 | # 处理正文 处理网页 tag
14 | @ParsingBase.append_handler(parsing_type="summary", rex="/weibo/")
15 | async def handle_summary(item: Dict[str, Any], tmp: str) -> str:
16 | summary_html = Pq(get_summary(item))
17 |
18 | # 判断是否保留转发内容
19 | if not config.blockquote:
20 | summary_html.remove("blockquote")
21 |
22 | tmp += handle_html_tag(html=summary_html)
23 |
24 | return tmp
25 |
26 |
27 | # 处理图片
28 | @ParsingBase.append_handler(parsing_type="picture", rex="/weibo/")
29 | async def handle_picture(rss: Rss, item: Dict[str, Any], tmp: str) -> str:
30 | # 判断是否开启了只推送标题
31 | if rss.only_title:
32 | return ""
33 |
34 | res = ""
35 | try:
36 | res += await handle_img(
37 | item=item,
38 | img_proxy=rss.img_proxy,
39 | img_num=rss.max_image_number,
40 | )
41 | except Exception as e:
42 | logger.warning(f"{rss.name} 没有正文内容!{e}")
43 |
44 | # 判断是否开启了只推送图片
45 | return f"{res}\n" if rss.only_pic else f"{tmp + res}\n"
46 |
47 |
48 | # 处理图片、视频
49 | async def handle_img(item: Dict[str, Any], img_proxy: bool, img_num: int) -> str:
50 | if item.get("image_content"):
51 | return await handle_img_combo_with_content(
52 | item.get("gif_url", ""), item["image_content"]
53 | )
54 | html = Pq(get_summary(item))
55 | # 移除多余图标
56 | html.remove("span.url-icon")
57 | img_str = ""
58 | # 处理图片
59 | doc_img = list(html("img").items())
60 | # 只发送限定数量的图片,防止刷屏
61 | if 0 < img_num < len(doc_img):
62 | img_str += f"\n因启用图片数量限制,目前只有 {img_num} 张图片:"
63 | doc_img = doc_img[:img_num]
64 | for img in doc_img:
65 | url = img.attr("src")
66 | img_str += await handle_img_combo(url, img_proxy)
67 |
68 | # 处理视频
69 | if doc_video := html("video"):
70 | img_str += "\n视频封面:"
71 | for video in doc_video.items():
72 | url = video.attr("poster")
73 | img_str += await handle_img_combo(url, img_proxy)
74 |
75 | return img_str
76 |
--------------------------------------------------------------------------------
/.env.dev:
--------------------------------------------------------------------------------
1 | # 配置 NoneBot 监听的 IP/主机名
2 | HOST=0.0.0.0
3 | # 配置 NoneBot 监听的端口
4 | PORT=8080
5 | # 开启 debug 模式 **请勿在生产环境开启**
6 | DEBUG=false
7 | # 配置 NoneBot 超级用户:管理员qq,支持多管理员,逗号分隔 注意,启动消息只发送给第一个管理员
8 | SUPERUSERS=["123123123"]
9 | # 配置机器人的昵称
10 | NICKNAME=["elf","ELF"]
11 | # 配置命令起始字符
12 | COMMAND_START=["","/"]
13 | # 配置命令分割字符
14 | COMMAND_SEP=["."]
15 |
16 | # 代理地址
17 | #RSS_PROXY="127.0.0.1:7890"
18 | # rsshub订阅地址
19 | RSSHUB="https://rsshub.app"
20 | # 备用 rsshub 地址 示例: ["https://rsshub.app","https://rsshub.app"] 务必使用双引号!!!
21 | RSSHUB_BACKUP=[]
22 | # 去重数据库的记录清理限定天数
23 | DB_CACHE_EXPIRE=30
24 | # 缓存rss条数
25 | LIMIT=200
26 | # 正文长度限制,防止消息太长刷屏,以及消息过长发送失败的情况
27 | MAX_LENGTH=1024
28 | # 是否启用启动时的提示消息推送
29 | ENABLE_BOOT_MESSAGE=true
30 |
31 | # 图片压缩
32 | # 非 GIF 图片压缩后的最大长宽值,单位 px
33 | ZIP_SIZE=2048
34 | # GIF 图片压缩临界值,单位 KB
35 | GIF_ZIP_SIZE=6144
36 | # 保存图片的文件名,可使用 {subs}:订阅名 {name}:文件名 {ext}:文件后缀(可省略)
37 | IMG_FORMAT="{subs}/{name}{ext}"
38 | # 图片的下载路径,默认为./data/image 可以为相对路径(./test)或绝对路径(/home)
39 | IMG_DOWN_PATH=""
40 |
41 | # 是否显示转发的内容(主要是微博),默认打开,如果关闭还有转发的信息的话,可以自行添加进屏蔽词(但是这整条消息就会没)
42 | BLOCKQUOTE=true
43 | # 屏蔽词填写 支持正则,如 ["互动抽奖","微博抽奖平台"] 务必使用双引号!!!
44 | BLACK_WORD=[]
45 |
46 | # 使用百度翻译API 可选,填的话两个都要填,不填默认使用谷歌翻译(需墙外?)
47 | # 百度翻译接口appid和secretKey,前往http://api.fanyi.baidu.com/获取
48 | # 一般来说申请标准版免费就够了,想要好一点可以认证上高级版,有月限额,rss用也足够了
49 | BAIDU_ID=""
50 | BAIDU_KEY=""
51 | # DEEPL 翻译API 可选,不填默认使用谷歌翻译(需墙外?)
52 | DEEPL_TRANSLATOR_API_KEY=""
53 | # 配合 deepl_translator 使用的语言检测接口,前往 https://detectlanguage.com/documentation 注册获取 api_key
54 | SINGLE_DETECTION_API_KEY=""
55 |
56 | # qbittorrent 相关设置(文件下载位置等更多设置请在qbittorrent软件中设置)
57 | # qbittorrent 用户名
58 | QB_USERNAME=""
59 | # qbittorrent 密码
60 | QB_PASSWORD=""
61 | # qbittorrent 客户端默认是关闭状态,请打开并设置端口号为 8081,同时勾选 “对本地主机上的客户端跳过身份验证”
62 | #QB_WEB_URL="http://127.0.0.1:8081"
63 | # qb的文件下载地址,这个地址必须是 go-cqhttp能访问到的
64 | QB_DOWN_PATH=""
65 | # 下载进度消息提示群组 示例 [12345678] 注意:最好是将该群设置为免打扰
66 | DOWN_STATUS_MSG_GROUP=[]
67 | # 下载进度检查及提示间隔时间,单位秒,不建议小于 10
68 | DOWN_STATUS_MSG_DATE=10
69 |
70 | # pikpak 相关设置
71 | # pikpak 用户名
72 | PIKPAK_USERNAME=""
73 | # pikpak 密码
74 | PIKPAK_PASSWORD=""
75 | # pikpak 离线保存的目录, 默认是根目录,示例: ELF_RSS/Downloads ,目录不存在会自动创建, 不能/结尾
76 | PIKPAK_DOWNLOAD_PATH=""
77 |
78 | # Telegram 相关设置
79 | # Telegram 管理员 ID 列表,用于接收离线通知和管理机器人
80 | TELEGRAM_ADMIN_IDS=[]
81 | # Telegram 机器人的 token
82 | TELEGRAM_BOT_TOKEN=""
83 |
84 | # MYELF博客地址 https://myelf.club
85 | # 出现问题请在 GitHub 上提 issues
86 | # 项目地址 https://github.com/Quan666/ELF_RSS
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # ELF_RSS
2 |
3 | [](https://www.codacy.com/gh/Quan666/ELF_RSS/dashboard?utm_source=github.com&utm_medium=referral&utm_content=Quan666/ELF_RSS&utm_campaign=Badge_Grade)
4 | [](https://jq.qq.com/?_wv=1027&k=sST08Nkd)
5 |
6 | > 1. 容易使用的命令
7 | > 2. 更规范的代码,方便移植到你自己的机器人
8 | > 3. 使用全新的 [Nonebot2](https://v2.nonebot.dev/guide/) 框架
9 |
10 | 这是一个以 Python 编写的 QQ 机器人插件,用于订阅 RSS 并实时以 QQ消息推送。
11 |
12 | 算是第一次用 Python 写出来的比较完整、实用的项目。代码比较难看,正在重构中
13 |
14 | ---
15 |
16 | 当然也有很多插件能够做到订阅 RSS ,但不同的是,大多数都需要在服务器上修改相应配置才能添加订阅,而该插件只需要发送QQ消息给机器人就能动态添加订阅。
17 |
18 | 对于订阅,支持QQ、QQ群、QQ频道的单个、多个订阅。
19 |
20 | 每个订阅的个性化设置丰富,能够应付多种场景。
21 |
22 | ## 功能介绍
23 |
24 | * 发送命令添加、删除、查询、修改 RSS 订阅
25 | * 交互式添加 RSSHub 订阅
26 | * 订阅内容翻译(使用谷歌机翻,可设置为百度翻译)
27 | * 个性化订阅设置(更新频率、翻译、仅标题、仅图片等)
28 | * 多平台支持
29 | * 图片压缩后发送
30 | * 种子下载并上传到群文件
31 | * 离线下载到 PikPak 网盘(方便追番)
32 | * 消息支持根据链接、标题、图片去重
33 | * 可设置只发送限定数量的图片,防止刷屏
34 | * 可设置从正文中要移除的指定内容,支持正则
35 |
36 | ## 文档目录
37 |
38 | > 注意:推荐 Python 3.8.3+ 版本 Windows版安装包下载地址:[https://www.python.org/ftp/python/3.8.3/python-3.8.3-amd64.exe](https://www.python.org/ftp/python/3.8.3/python-3.8.3-amd64.exe)
39 | >
40 | > * [部署教程](docs/部署教程.md)
41 | > * [使用教程](docs/2.0%20使用教程.md)
42 | > * [使用教程 旧版](docs/1.0%20使用教程.md)
43 | > * [常见问题](docs/常见问题.md)
44 | > * [更新日志](docs/更新日志.md)
45 |
46 | ## 效果预览
47 |
48 | 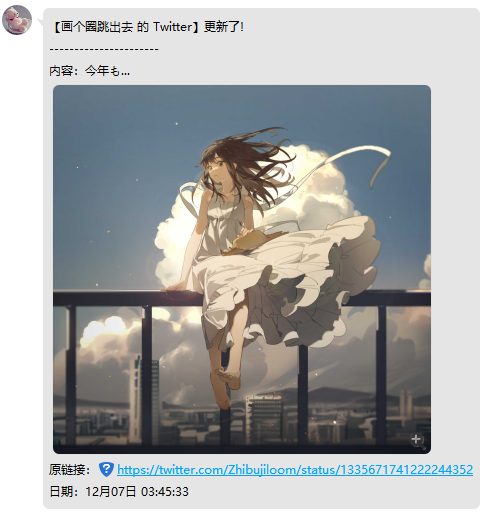
49 |
50 | 
51 |
52 | 
53 |
54 | 
55 |
56 | ## TODO
57 |
58 | * [x] 1. 订阅信息保护,不在群组中输出订阅QQ、群组
59 | * [x] 2. 更为强大的检查更新时间设置
60 | * [x] 3. RSS 源中 torrent 自动下载并上传至订阅群(适合番剧订阅)
61 | * [x] 4. 暂停检查订阅更新
62 | * [x] 5. 正则匹配订阅名
63 | * [x] 6. 性能优化,尽可能替换为异步操作
64 |
65 | ## 感谢以下项目或服务
66 |
67 | 不分先后
68 |
69 | * [RSSHub](https://github.com/DIYgod/RSSHub)
70 | * [Nonebot](https://github.com/nonebot/nonebot2)
71 | * [酷Q(R. I. P)](https://cqp.cc/)
72 | * [coolq-http-api](https://github.com/richardchien/coolq-http-api)
73 | * [go-cqhttp](https://github.com/Mrs4s/go-cqhttp)
74 |
75 | ## Star History
76 |
77 | [](https://starchart.cc/Quan666/ELF_RSS)
78 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/my_trigger.py:
--------------------------------------------------------------------------------
1 | import asyncio
2 | import re
3 |
4 | from apscheduler.executors.pool import ProcessPoolExecutor, ThreadPoolExecutor
5 | from apscheduler.triggers.cron import CronTrigger
6 | from apscheduler.triggers.interval import IntervalTrigger
7 | from async_timeout import timeout
8 | from nonebot.log import logger
9 | from nonebot_plugin_apscheduler import scheduler
10 |
11 | from . import rss_parsing
12 | from .rss_class import Rss
13 |
14 |
15 | # 检测某个rss更新
16 | async def check_update(rss: Rss) -> None:
17 | logger.info(f"{rss.name} 检查更新")
18 | try:
19 | wait_for = 5 * 60 if re.search(r"[_*/,-]", rss.time) else int(rss.time) * 60
20 | async with timeout(wait_for):
21 | await rss_parsing.start(rss)
22 | except asyncio.TimeoutError:
23 | logger.error(f"{rss.name} 检查更新超时,结束此次任务!")
24 |
25 |
26 | def delete_job(rss: Rss) -> None:
27 | if scheduler.get_job(rss.name):
28 | scheduler.remove_job(rss.name)
29 |
30 |
31 | # 加入订阅任务队列并立即执行一次
32 | async def add_job(rss: Rss) -> None:
33 | delete_job(rss)
34 | # 加入前判断是否存在子频道或群组或用户,三者不能同时为空
35 | if any([rss.user_id, rss.group_id, rss.guild_channel_id]):
36 | rss_trigger(rss)
37 | await check_update(rss)
38 |
39 |
40 | def rss_trigger(rss: Rss) -> None:
41 | if re.search(r"[_*/,-]", rss.time):
42 | my_trigger_cron(rss)
43 | return
44 | # 制作一个“time分钟/次”触发器
45 | trigger = IntervalTrigger(minutes=int(rss.time), jitter=10)
46 | # 添加任务
47 | scheduler.add_job(
48 | func=check_update, # 要添加任务的函数,不要带参数
49 | trigger=trigger, # 触发器
50 | args=(rss,), # 函数的参数列表,注意:只有一个值时,不能省略末尾的逗号
51 | id=rss.name,
52 | misfire_grace_time=30, # 允许的误差时间,建议不要省略
53 | max_instances=1, # 最大并发
54 | default=ThreadPoolExecutor(64), # 最大线程
55 | processpool=ProcessPoolExecutor(8), # 最大进程
56 | coalesce=True, # 积攒的任务是否只跑一次,是否合并所有错过的Job
57 | )
58 | logger.info(f"定时任务 {rss.name} 添加成功")
59 |
60 |
61 | # cron 表达式
62 | # 参考 https://www.runoob.com/linux/linux-comm-crontab.html
63 |
64 |
65 | def my_trigger_cron(rss: Rss) -> None:
66 | # 解析参数
67 | tmp_list = rss.time.split("_")
68 | times_list = ["*/5", "*", "*", "*", "*"]
69 | for index, value in enumerate(tmp_list):
70 | if value:
71 | times_list[index] = value
72 | try:
73 | # 制作一个触发器
74 | trigger = CronTrigger(
75 | minute=times_list[0],
76 | hour=times_list[1],
77 | day=times_list[2],
78 | month=times_list[3],
79 | day_of_week=times_list[4],
80 | )
81 | except Exception:
82 | logger.exception(f"创建定时器错误!cron:{times_list}")
83 | return
84 |
85 | # 添加任务
86 | scheduler.add_job(
87 | func=check_update, # 要添加任务的函数,不要带参数
88 | trigger=trigger, # 触发器
89 | args=(rss,), # 函数的参数列表,注意:只有一个值时,不能省略末尾的逗号
90 | id=rss.name,
91 | misfire_grace_time=30, # 允许的误差时间,建议不要省略
92 | max_instances=1, # 最大并发
93 | default=ThreadPoolExecutor(64), # 最大线程
94 | processpool=ProcessPoolExecutor(8), # 最大进程
95 | coalesce=True, # 积攒的任务是否只跑一次,是否合并所有错过的Job
96 | )
97 | logger.info(f"定时任务 {rss.name} 添加成功")
98 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/command/show_all.py:
--------------------------------------------------------------------------------
1 | import asyncio
2 | import re
3 | from typing import List, Optional
4 |
5 | from nonebot import on_command
6 | from nonebot.adapters.onebot.v11 import (
7 | ActionFailed,
8 | GroupMessageEvent,
9 | Message,
10 | MessageEvent,
11 | )
12 | from nonebot.adapters.onebot.v11.permission import GROUP_ADMIN, GROUP_OWNER
13 | from nonebot.params import CommandArg
14 | from nonebot.permission import SUPERUSER
15 | from nonebot.rule import to_me
16 |
17 | from ..rss_class import Rss
18 | from .show_dy import handle_rss_list
19 |
20 | RSS_SHOW_ALL = on_command(
21 | "show_all",
22 | aliases={"showall", "select_all", "selectall", "所有订阅"},
23 | rule=to_me(),
24 | priority=5,
25 | permission=GROUP_ADMIN | GROUP_OWNER | SUPERUSER,
26 | )
27 |
28 |
29 | def filter_results_by_keyword(
30 | rss_list: List[Rss],
31 | search_keyword: str,
32 | group_id: Optional[int],
33 | guild_channel_id: Optional[str],
34 | ) -> List[Rss]:
35 | return [
36 | i
37 | for i in rss_list
38 | if (
39 | re.search(search_keyword, i.name, flags=re.I)
40 | or re.search(search_keyword, i.url, flags=re.I)
41 | or (
42 | search_keyword.isdigit()
43 | and not group_id
44 | and not guild_channel_id
45 | and (
46 | (i.user_id and search_keyword in i.user_id)
47 | or (i.group_id and search_keyword in i.group_id)
48 | or (i.guild_channel_id and search_keyword in i.guild_channel_id)
49 | )
50 | )
51 | )
52 | ]
53 |
54 |
55 | def get_rss_list(group_id: Optional[int], guild_channel_id: Optional[str]) -> List[Rss]:
56 | if group_id:
57 | return Rss.get_by_group(group_id=group_id)
58 | elif guild_channel_id:
59 | return Rss.get_by_guild_channel(guild_channel_id=guild_channel_id)
60 | else:
61 | return Rss.read_rss()
62 |
63 |
64 | @RSS_SHOW_ALL.handle()
65 | async def handle_rss_show_all(
66 | event: MessageEvent, args: Message = CommandArg()
67 | ) -> None:
68 | search_keyword = args.extract_plain_text().strip()
69 |
70 | group_id = event.group_id if isinstance(event, GroupMessageEvent) else None
71 | guild_channel_id = None
72 |
73 | if not (rss_list := get_rss_list(group_id, guild_channel_id)):
74 | await RSS_SHOW_ALL.finish("❌ 当前没有任何订阅!")
75 | return
76 |
77 | result = (
78 | filter_results_by_keyword(rss_list, search_keyword, group_id, guild_channel_id)
79 | if search_keyword
80 | else rss_list
81 | )
82 |
83 | if result:
84 | await RSS_SHOW_ALL.send(f"当前共有 {len(result)} 条订阅")
85 | result.sort(key=lambda x: x.get_url())
86 | await asyncio.sleep(0.5)
87 | page_size = 30
88 | while result:
89 | current_page = result[:page_size]
90 | msg_str = handle_rss_list(current_page)
91 | try:
92 | await RSS_SHOW_ALL.send(msg_str)
93 | except ActionFailed:
94 | page_size -= 5
95 | continue
96 | result = result[page_size:]
97 | else:
98 | await RSS_SHOW_ALL.finish("❌ 当前没有任何订阅!")
99 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 |
2 | # Created by https://www.toptal.com/developers/gitignore/api/python
3 | # Edit at https://www.toptal.com/developers/gitignore?templates=python
4 |
5 | ### Python ###
6 | # Byte-compiled / optimized / DLL files
7 | __pycache__/
8 | *.py[cod]
9 | *$py.class
10 |
11 | # C extensions
12 | *.so
13 |
14 | # Distribution / packaging
15 | .Python
16 | build/
17 | develop-eggs/
18 | dist/
19 | downloads/
20 | eggs/
21 | .eggs/
22 | lib/
23 | lib64/
24 | parts/
25 | sdist/
26 | var/
27 | wheels/
28 | pip-wheel-metadata/
29 | share/python-wheels/
30 | *.egg-info/
31 | .installed.cfg
32 | *.egg
33 | MANIFEST
34 |
35 | # PyInstaller
36 | # Usually these files are written by a python script from a template
37 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
38 | *.manifest
39 | *.spec
40 |
41 | # Installer logs
42 | pip-log.txt
43 | pip-delete-this-directory.txt
44 |
45 | # Unit test / coverage reports
46 | htmlcov/
47 | .tox/
48 | .nox/
49 | .coverage
50 | .coverage.*
51 | .cache
52 | nosetests.xml
53 | coverage.xml
54 | *.cover
55 | *.py,cover
56 | .hypothesis/
57 | .pytest_cache/
58 | pytestdebug.log
59 |
60 | # Translations
61 | *.mo
62 | *.pot
63 |
64 | # Django stuff:
65 | *.log
66 | local_settings.py
67 | db.sqlite3
68 | db.sqlite3-journal
69 |
70 | # Flask stuff:
71 | instance/
72 | .webassets-cache
73 |
74 | # Scrapy stuff:
75 | .scrapy
76 |
77 | # Sphinx documentation
78 | docs/_build/
79 | doc/_build/
80 |
81 | # PyBuilder
82 | target/
83 |
84 | # Jupyter Notebook
85 | .ipynb_checkpoints
86 |
87 | # IPython
88 | profile_default/
89 | ipython_config.py
90 |
91 | # pyenv
92 | .python-version
93 |
94 | # pipenv
95 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
96 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
97 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
98 | # install all needed dependencies.
99 | #Pipfile.lock
100 |
101 | # poetry
102 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
103 | # This is especially recommended for binary packages to ensure reproducibility, and is more
104 | # commonly ignored for libraries.
105 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
106 | poetry.lock
107 |
108 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
109 | __pypackages__/
110 |
111 | # Celery stuff
112 | celerybeat-schedule
113 | celerybeat.pid
114 |
115 | # SageMath parsed files
116 | *.sage.py
117 |
118 | # Environments
119 | .env
120 | .venv
121 | env/
122 | venv/
123 | ENV/
124 | env.bak/
125 | venv.bak/
126 |
127 | # Spyder project settings
128 | .spyderproject
129 | .spyproject
130 |
131 | # Rope project settings
132 | .ropeproject
133 |
134 | # mkdocs documentation
135 | /site
136 |
137 | # mypy
138 | .mypy_cache/
139 | .dmypy.json
140 | dmypy.json
141 |
142 | # Pyre type checker
143 | .pyre/
144 |
145 | # pytype static type analyzer
146 | .pytype/
147 | .idea/
148 | .env.prod
149 | data/
150 |
151 | # vscode
152 | .vscode
153 | # End of https://www.toptal.com/developers/gitignore/api/python
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/command/del_dy.py:
--------------------------------------------------------------------------------
1 | from typing import List, Optional, Tuple
2 |
3 | from nonebot import on_command
4 | from nonebot.adapters.onebot.v11 import GroupMessageEvent, Message, MessageEvent
5 | from nonebot.adapters.onebot.v11.permission import GROUP_ADMIN, GROUP_OWNER
6 | from nonebot.matcher import Matcher
7 | from nonebot.params import ArgPlainText, CommandArg
8 | from nonebot.permission import SUPERUSER
9 | from nonebot.rule import to_me
10 |
11 | from .. import my_trigger as tr
12 | from ..rss_class import Rss
13 |
14 | RSS_DELETE = on_command(
15 | "deldy",
16 | aliases={"drop", "unsub", "删除订阅"},
17 | rule=to_me(),
18 | priority=5,
19 | permission=GROUP_ADMIN | GROUP_OWNER | SUPERUSER,
20 | )
21 |
22 |
23 | @RSS_DELETE.handle()
24 | async def handle_first_receive(matcher: Matcher, args: Message = CommandArg()) -> None:
25 | if args.extract_plain_text():
26 | matcher.set_arg("RSS_DELETE", args)
27 |
28 |
29 | async def process_rss_deletion(
30 | rss_name_list: List[str], group_id: Optional[int], guild_channel_id: Optional[str]
31 | ) -> Tuple[List[str], List[str]]:
32 | delete_successes = []
33 | delete_failures = []
34 |
35 | for rss_name in rss_name_list:
36 | rss = Rss.get_one_by_name(name=rss_name)
37 | if rss is None:
38 | delete_failures.append(rss_name)
39 | elif guild_channel_id:
40 | if rss.delete_guild_channel(guild_channel=guild_channel_id):
41 | if not any([rss.group_id, rss.user_id, rss.guild_channel_id]):
42 | rss.delete_rss()
43 | tr.delete_job(rss)
44 | else:
45 | await tr.add_job(rss)
46 | delete_successes.append(rss_name)
47 | else:
48 | delete_failures.append(rss_name)
49 | elif group_id:
50 | if rss.delete_group(group=str(group_id)):
51 | if not any([rss.group_id, rss.user_id, rss.guild_channel_id]):
52 | rss.delete_rss()
53 | tr.delete_job(rss)
54 | else:
55 | await tr.add_job(rss)
56 | delete_successes.append(rss_name)
57 | else:
58 | delete_failures.append(rss_name)
59 | else:
60 | rss.delete_rss()
61 | tr.delete_job(rss)
62 | delete_successes.append(rss_name)
63 |
64 | return delete_successes, delete_failures
65 |
66 |
67 | @RSS_DELETE.got("RSS_DELETE", prompt="输入要删除的订阅名")
68 | async def handle_rss_delete(
69 | event: MessageEvent, rss_name: str = ArgPlainText("RSS_DELETE")
70 | ) -> None:
71 | group_id = event.group_id if isinstance(event, GroupMessageEvent) else None
72 | guild_channel_id = None
73 |
74 | rss_name_list = rss_name.strip().split(" ")
75 |
76 | delete_successes, delete_failures = await process_rss_deletion(
77 | rss_name_list, group_id, guild_channel_id
78 | )
79 |
80 | result = []
81 | if delete_successes:
82 | if guild_channel_id:
83 | result.append(
84 | f'👏 当前子频道成功取消订阅: {"、".join(delete_successes)} !'
85 | )
86 | elif group_id:
87 | result.append(f'👏 当前群组成功取消订阅: {"、".join(delete_successes)} !')
88 | else:
89 | result.append(f'👏 成功删除订阅: {"、".join(delete_successes)} !')
90 | if delete_failures:
91 | if guild_channel_id:
92 | result.append(f'❌ 当前子频道没有订阅: {"、".join(delete_successes)} !')
93 | elif group_id:
94 | result.append(f'❌ 当前群组没有订阅: {"、".join(delete_successes)} !')
95 | else:
96 | result.append(f'❌ 未找到订阅: {"、".join(delete_successes)} !')
97 |
98 | await RSS_DELETE.finish("\n".join(result))
99 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/pikpak_offline.py:
--------------------------------------------------------------------------------
1 | from typing import Any, Dict, List, Optional
2 |
3 | from nonebot.log import logger
4 | from pikpakapi import PikPakApi
5 | from pikpakapi.PikpakException import PikpakException
6 |
7 | from .config import config
8 |
9 | pikpak_client: Optional[PikPakApi] = None
10 | if config.pikpak_username and config.pikpak_password:
11 | pikpak_client = PikPakApi(
12 | username=config.pikpak_username,
13 | password=config.pikpak_password,
14 | )
15 |
16 |
17 | async def refresh_access_token() -> None:
18 | """
19 | Login or Refresh access_token PikPak
20 |
21 | """
22 | try:
23 | await pikpak_client.refresh_access_token()
24 | except PikpakException as e:
25 | logger.warning(f"refresh_access_token {e}")
26 | await pikpak_client.login()
27 |
28 |
29 | async def login() -> None:
30 | if not pikpak_client.access_token:
31 | await pikpak_client.login()
32 |
33 |
34 | async def path_to_id(
35 | path: Optional[str] = None, create: bool = False
36 | ) -> List[Dict[str, Any]]:
37 | """
38 | path: str like "/1/2/3"
39 | create: bool create path if not exist
40 | 将形如 /path/a/b 的路径转换为 文件夹的id
41 | """
42 | if not path:
43 | return []
44 | paths = [p.strip() for p in path.split("/") if len(p) > 0]
45 | path_ids = []
46 | count = 0
47 | next_page_token = None
48 | parent_id = None
49 | while count < len(paths):
50 | data = await pikpak_client.file_list(
51 | parent_id=parent_id, next_page_token=next_page_token
52 | )
53 | if _id := next(
54 | (
55 | f.get("id")
56 | for f in data.get("files", [])
57 | if f.get("kind", "") == "drive#folder" and f.get("name") == paths[count]
58 | ),
59 | "",
60 | ):
61 | path_ids.append(
62 | {
63 | "id": _id,
64 | "name": paths[count],
65 | }
66 | )
67 | count += 1
68 | parent_id = _id
69 | elif data.get("next_page_token"):
70 | next_page_token = data.get("next_page_token")
71 | elif create:
72 | data = await pikpak_client.create_folder(
73 | name=paths[count], parent_id=parent_id
74 | )
75 | _id = data.get("file").get("id")
76 | path_ids.append(
77 | {
78 | "id": _id,
79 | "name": paths[count],
80 | }
81 | )
82 | count += 1
83 | parent_id = _id
84 | else:
85 | break
86 | return path_ids
87 |
88 |
89 | async def pikpak_offline_download(
90 | url: str,
91 | path: Optional[str] = None,
92 | parent_id: Optional[str] = None,
93 | name: Optional[str] = None,
94 | ) -> Dict[str, Any]:
95 | """
96 | Offline download
97 | 当有path时, 表示下载到指定的文件夹, 否则下载到根目录
98 | 如果存在 parent_id, 以 parent_id 为准
99 | """
100 | await login()
101 | try:
102 | if not parent_id:
103 | path_ids = await path_to_id(path, create=True)
104 | if path_ids and len(path_ids) > 0:
105 | parent_id = path_ids[-1].get("id")
106 | return await pikpak_client.offline_download(url, parent_id=parent_id, name=name) # type: ignore
107 | except PikpakException as e:
108 | logger.warning(e)
109 | await refresh_access_token()
110 | return await pikpak_offline_download(
111 | url=url, path=path, parent_id=parent_id, name=name
112 | )
113 | except Exception as e:
114 | msg = f"PikPak Offline Download Error: {e}"
115 | logger.error(msg)
116 | raise Exception(msg) from e
117 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/download_torrent.py:
--------------------------------------------------------------------------------
1 | import re
2 | from typing import Any, Dict, List, Optional
3 |
4 | import aiohttp
5 | from nonebot.adapters.onebot.v11 import Bot
6 | from nonebot.log import logger
7 |
8 | from ..config import config
9 | from ..parsing.utils import get_summary
10 | from ..pikpak_offline import pikpak_offline_download
11 | from ..qbittorrent_download import start_down
12 | from ..rss_class import Rss
13 | from ..utils import convert_size, get_bot, get_torrent_b16_hash, send_msg
14 |
15 |
16 | async def down_torrent(
17 | rss: Rss, item: Dict[str, Any], proxy: Optional[str]
18 | ) -> List[str]:
19 | """
20 | 创建下载种子任务
21 | """
22 | bot: Bot = await get_bot() # type: ignore
23 | if bot is None:
24 | raise ValueError("There are not bots to get.")
25 | hash_list = []
26 | for tmp in item["links"]:
27 | if (
28 | tmp["type"] == "application/x-bittorrent"
29 | or tmp["href"].find(".torrent") > 0
30 | ):
31 | hash_list.append(
32 | await start_down(
33 | bot=bot,
34 | url=tmp["href"],
35 | group_ids=rss.group_id,
36 | name=rss.name,
37 | proxy=proxy,
38 | )
39 | )
40 | return hash_list
41 |
42 |
43 | async def fetch_magnet_link(rss: Rss, url: str, proxy: Optional[str]) -> Optional[str]:
44 | try:
45 | async with aiohttp.ClientSession(
46 | timeout=aiohttp.ClientTimeout(total=100)
47 | ) as session:
48 | resp = await session.get(url, proxy=proxy)
49 | content = await resp.read()
50 | return f"magnet:?xt=urn:btih:{get_torrent_b16_hash(content)}"
51 | except Exception as e:
52 | msg = f"{rss.name} 下载种子失败: {e}"
53 | logger.error(msg)
54 | await send_msg(msg=msg, user_ids=rss.user_id, group_ids=rss.group_id)
55 | return None
56 |
57 |
58 | async def pikpak_offline(
59 | rss: Rss, item: Dict[str, Any], proxy: Optional[str]
60 | ) -> List[Dict[str, Any]]:
61 | """
62 | 创建pikpak 离线下载任务
63 | 下载到 config.pikpak_download_path/rss.name or find rss.pikpak_path_rex
64 | """
65 | download_infos = []
66 | for tmp in item["links"]:
67 | if (
68 | tmp["type"] == "application/x-bittorrent"
69 | or tmp["href"].find(".torrent") > 0
70 | ):
71 | url = tmp["href"]
72 | if not re.search(r"magnet:\?xt=urn:btih:", url):
73 | if not (url := await fetch_magnet_link(rss, url, proxy)):
74 | continue
75 | try:
76 | path = f"{config.pikpak_download_path}/{rss.name}"
77 | summary = get_summary(item)
78 | if rss.pikpak_path_key and (
79 | result := re.findall(rss.pikpak_path_key, summary)
80 | ):
81 | path = (
82 | config.pikpak_download_path
83 | + "/"
84 | + re.sub(r'[?*:"<>\\/|]', "_", result[0])
85 | )
86 | logger.info(f"Offline download {url} to {path}")
87 | info = await pikpak_offline_download(url=url, path=path)
88 | download_infos.append(
89 | {
90 | "name": info["task"]["name"],
91 | "file_size": convert_size(int(info["task"]["file_size"])),
92 | "path": path,
93 | }
94 | )
95 | except Exception as e:
96 | msg = f"{rss.name} PikPak 离线下载失败: {e}"
97 | logger.error(msg)
98 | await send_msg(msg=msg, user_ids=rss.user_id, group_ids=rss.group_id)
99 | return download_infos
100 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/handle_translation.py:
--------------------------------------------------------------------------------
1 | import hashlib
2 | import random
3 | import re
4 | from typing import Dict, Optional
5 |
6 | import aiohttp
7 | import emoji
8 | from deep_translator import DeeplTranslator, GoogleTranslator, single_detection
9 | from nonebot.log import logger
10 |
11 | from ..config import config
12 |
13 |
14 | async def baidu_translator(content: str, appid: str, secret_key: str) -> str:
15 | url = "https://api.fanyi.baidu.com/api/trans/vip/translate"
16 | salt = str(random.randint(32768, 65536))
17 | sign = hashlib.md5((appid + content + salt + secret_key).encode()).hexdigest()
18 | params = {
19 | "q": content,
20 | "from": "auto",
21 | "to": "zh",
22 | "appid": appid,
23 | "salt": salt,
24 | "sign": sign,
25 | }
26 | async with aiohttp.ClientSession() as session:
27 | resp = await session.get(url, params=params, timeout=aiohttp.ClientTimeout(10))
28 | data = await resp.json()
29 | try:
30 | content = "".join(i["dst"] + "\n" for i in data["trans_result"])
31 | return "\n百度翻译:\n" + content[:-1]
32 | except Exception as e:
33 | error_msg = f"百度翻译失败:{data['error_msg']}"
34 | logger.warning(error_msg)
35 | raise Exception(error_msg) from e
36 |
37 |
38 | async def google_translation(text: str, proxies: Optional[Dict[str, str]]) -> str:
39 | # text 是处理过emoji的
40 | try:
41 | translator = GoogleTranslator(source="auto", target="zh-CN", proxies=proxies)
42 | return "\n谷歌翻译:\n" + str(translator.translate(re.escape(text)))
43 | except Exception as e:
44 | error_msg = "\nGoogle翻译失败:" + str(e) + "\n"
45 | logger.warning(error_msg)
46 | raise Exception(error_msg) from e
47 |
48 |
49 | async def deepl_translator(text: str, proxies: Optional[Dict[str, str]]) -> str:
50 | try:
51 | lang = None
52 | if config.single_detection_api_key:
53 | lang = single_detection(text, api_key=config.single_detection_api_key)
54 | translator = DeeplTranslator(
55 | api_key=config.deepl_translator_api_key,
56 | source=lang,
57 | target="zh",
58 | use_free_api=True,
59 | proxies=proxies,
60 | )
61 | return "\nDeepl翻译:\n" + str(translator.translate(re.escape(text)))
62 | except Exception as e:
63 | error_msg = "\nDeeplTranslator翻译失败:" + str(e) + "\n"
64 | logger.warning(error_msg)
65 | raise Exception(error_msg) from e
66 |
67 |
68 | # 翻译
69 | async def handle_translation(content: str) -> str:
70 | proxies = (
71 | {
72 | "https": config.rss_proxy,
73 | "http": config.rss_proxy,
74 | }
75 | if config.rss_proxy
76 | else None
77 | )
78 |
79 | text = emoji.demojize(content)
80 | text = re.sub(r":[A-Za-z_]*:", " ", text)
81 | try:
82 | # 优先级 DeeplTranslator > 百度翻译 > GoogleTranslator
83 | # 异常时使用 GoogleTranslator 重试
84 | google_translator_flag = False
85 | try:
86 | if config.deepl_translator_api_key:
87 | text = await deepl_translator(text=text, proxies=proxies)
88 | elif config.baidu_id and config.baidu_key:
89 | text = await baidu_translator(
90 | content, config.baidu_id, config.baidu_key
91 | )
92 | else:
93 | google_translator_flag = True
94 | except Exception:
95 | google_translator_flag = True
96 | if google_translator_flag:
97 | text = await google_translation(text=text, proxies=proxies)
98 | except Exception as e:
99 | logger.error(e)
100 | text = str(e)
101 |
102 | text = text.replace("\\", "")
103 | return text
104 |
--------------------------------------------------------------------------------
/docs/迁移到 go-cqhttp.md:
--------------------------------------------------------------------------------
1 | # 迁移到 go-cqhttp
2 |
3 | > **前提:已经按照部署流程部署好 ELF_RSS**
4 |
5 | 准备工作
6 |
7 | - 下载 [go-cqhttp](https://github.com/Mrs4s/go-cqhttp/releases)
8 |
9 | ## 开始
10 |
11 | 1. 解压并运行 `go-cqhttp`,选择使用 `反向 WS` 方式连接,之后会生成配置文件,关闭 `go-cqhttp`
12 | 2. 修改 `config.yml` 文件,参考配置如下: 其中 `uin` 处填写 QQ 号
13 |
14 | ```yaml
15 | # go-cqhttp 默认配置文件
16 |
17 | account: # 账号相关
18 | uin: 1122334455 # QQ账号
19 | password: '' # 密码为空时使用扫码登录
20 | encrypt: false # 是否开启密码加密
21 | status: 0 # 在线状态 请参考 https://github.com/Mrs4s/go-cqhttp/blob/dev/docs/config.md#在线状态
22 | relogin: # 重连设置
23 | delay: 3 # 首次重连延迟, 单位秒
24 | interval: 3 # 重连间隔
25 | max-times: 0 # 最大重连次数, 0为无限制
26 |
27 | # 是否使用服务器下发的新地址进行重连
28 | # 注意, 此设置可能导致在海外服务器上连接情况更差
29 | use-sso-address: true
30 |
31 | heartbeat:
32 | # 心跳频率, 单位秒
33 | # -1 为关闭心跳
34 | interval: 5
35 |
36 | message:
37 | # 上报数据类型
38 | # 可选: string,array
39 | post-format: string
40 | # 是否忽略无效的CQ码, 如果为假将原样发送
41 | ignore-invalid-cqcode: false
42 | # 是否强制分片发送消息
43 | # 分片发送将会带来更快的速度
44 | # 但是兼容性会有些问题
45 | force-fragment: false
46 | # 是否将url分片发送
47 | fix-url: false
48 | # 下载图片等请求网络代理
49 | proxy-rewrite: ''
50 | # 是否上报自身消息
51 | report-self-message: false
52 | # 移除服务端的Reply附带的At
53 | remove-reply-at: false
54 | # 为Reply附加更多信息
55 | extra-reply-data: false
56 |
57 | output:
58 | # 日志等级 trace,debug,info,warn,error
59 | log-level: warn
60 | # 是否启用 DEBUG
61 | debug: false # 开启调试模式
62 |
63 | # 默认中间件锚点
64 | default-middlewares: &default
65 | # 访问密钥, 强烈推荐在公网的服务器设置
66 | access-token: ''
67 | # 事件过滤器文件目录
68 | filter: ''
69 | # API限速设置
70 | # 该设置为全局生效
71 | # 原 cqhttp 虽然启用了 rate_limit 后缀, 但是基本没插件适配
72 | # 目前该限速设置为令牌桶算法, 请参考:
73 | # https://baike.baidu.com/item/%E4%BB%A4%E7%89%8C%E6%A1%B6%E7%AE%97%E6%B3%95/6597000?fr=aladdin
74 | rate-limit:
75 | enabled: false # 是否启用限速
76 | frequency: 1 # 令牌回复频率, 单位秒
77 | bucket: 1 # 令牌桶大小
78 |
79 | database: # 数据库相关设置
80 | leveldb:
81 | # 是否启用内置leveldb数据库
82 | # 启用将会增加10-20MB的内存占用和一定的磁盘空间
83 | # 关闭将无法使用 撤回 回复 get_msg 等上下文相关功能
84 | enable: true
85 |
86 | # 连接服务列表
87 | servers:
88 | # HTTP 通信设置
89 | - http:
90 | # 服务端监听地址
91 | host: 127.0.0.1
92 | # 服务端监听端口
93 | port: 5700
94 | # 反向HTTP超时时间, 单位秒
95 | # 最小值为5,小于5将会忽略本项设置
96 | timeout: 5
97 | middlewares:
98 | <<: *default # 引用默认中间件
99 | # 反向HTTP POST地址列表
100 | post:
101 | #- url: '' # 地址
102 | # secret: '' # 密钥
103 | #- url: 127.0.0.1:5701 # 地址
104 | # secret: '' # 密钥
105 | # 正向WS设置
106 | - ws:
107 | # 正向WS服务器监听地址
108 | host: 127.0.0.1
109 | # 正向WS服务器监听端口
110 | port: 6700
111 | middlewares:
112 | <<: *default # 引用默认中间件
113 | # 反向WS设置
114 | - ws-reverse:
115 | # 反向WS Universal 地址
116 | # 注意 设置了此项地址后下面两项将会被忽略
117 | universal: ws://127.0.0.1:8080/onebot/v11/ws/
118 | # 反向WS API 地址
119 | api: ws://your_websocket_api.server
120 | # 反向WS Event 地址
121 | event: ws://your_websocket_event.server
122 | # 重连间隔 单位毫秒
123 | reconnect-interval: 3000
124 | middlewares:
125 | <<: *default # 引用默认中间件
126 | # pprof 性能分析服务器, 一般情况下不需要启用.
127 | # 如果遇到性能问题请上传报告给开发者处理
128 | # 注意: pprof服务不支持中间件、不支持鉴权. 请不要开放到公网
129 | - pprof:
130 | # 是否禁用pprof性能分析服务器
131 | disabled: true
132 | # pprof服务器监听地址
133 | host: 127.0.0.1
134 | # pprof服务器监听端口
135 | port: 7700
136 |
137 | # 可添加更多
138 | # 添加方式,同一连接方式可添加多个,具体配置说明请查看 go-cqhttp 文档
139 | #- http: # http 通信
140 | #- ws: # 正向 Websocket
141 | #- ws-reverse: # 反向 Websocket
142 | #- pprof: #性能分析服务器
143 | ```
144 |
145 | 3. 再次运行 go-cqhttp
146 | 4. 到此基本就迁移完毕
147 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/command/rsshub_add.py:
--------------------------------------------------------------------------------
1 | from typing import Any, Dict
2 |
3 | import aiohttp
4 | from nonebot import on_command
5 | from nonebot.adapters.onebot.v11 import Message, MessageEvent
6 | from nonebot.adapters.onebot.v11.permission import GROUP_ADMIN, GROUP_OWNER
7 | from nonebot.matcher import Matcher
8 | from nonebot.params import ArgPlainText, CommandArg
9 | from nonebot.permission import SUPERUSER
10 | from nonebot.rule import to_me
11 | from nonebot.typing import T_State
12 | from yarl import URL
13 |
14 | from ..config import config
15 | from ..rss_class import Rss
16 | from .add_dy import add_feed
17 |
18 | rsshub_routes: Dict[str, Any] = {}
19 |
20 |
21 | RSSHUB_ADD = on_command(
22 | "rsshub_add",
23 | rule=to_me(),
24 | priority=5,
25 | permission=GROUP_ADMIN | GROUP_OWNER | SUPERUSER,
26 | )
27 |
28 |
29 | @RSSHUB_ADD.handle()
30 | async def handle_first_receive(matcher: Matcher, args: Message = CommandArg()) -> None:
31 | if args.extract_plain_text().strip():
32 | matcher.set_arg("route", args)
33 |
34 |
35 | @RSSHUB_ADD.got("name", prompt="请输入要订阅的订阅名")
36 | async def handle_feed_name(name: str = ArgPlainText("name")) -> None:
37 | if not name.strip():
38 | await RSSHUB_ADD.reject("订阅名不能为空,请重新输入")
39 | return
40 |
41 | if _ := Rss.get_one_by_name(name=name):
42 | await RSSHUB_ADD.reject(f"已存在名为 {name} 的订阅,请重新输入")
43 |
44 |
45 | @RSSHUB_ADD.got("route", prompt="请输入要订阅的 RSSHub 路由名")
46 | async def handle_rsshub_routes(
47 | state: T_State, route: str = ArgPlainText("route")
48 | ) -> None:
49 | if not route.strip():
50 | await RSSHUB_ADD.reject("路由名不能为空,请重新输入")
51 | return
52 |
53 | rsshub_url = URL(str(config.rsshub))
54 | # 对本机部署的 RSSHub 不使用代理
55 | local_host = [
56 | "localhost",
57 | "127.0.0.1",
58 | ]
59 | if config.rss_proxy and rsshub_url.host not in local_host:
60 | proxy = f"http://{config.rss_proxy}"
61 | else:
62 | proxy = None
63 |
64 | global rsshub_routes
65 | if not rsshub_routes:
66 | async with aiohttp.ClientSession() as session:
67 | resp = await session.get(rsshub_url.with_path("api/routes"), proxy=proxy)
68 | if resp.status != 200:
69 | await RSSHUB_ADD.finish(
70 | "获取路由数据失败,请检查 RSSHub 的地址配置及网络连接"
71 | )
72 | rsshub_routes = await resp.json()
73 |
74 | if route not in rsshub_routes["data"]:
75 | await RSSHUB_ADD.reject(f"未找到名为 {route} 的 RSSHub 路由,请重新输入")
76 | else:
77 | route_list = state["route_list"] = rsshub_routes["data"][route]["routes"]
78 | if len(route_list) > 1:
79 | await RSSHUB_ADD.send(
80 | "请输入序号来选择要订阅的 RSSHub 路由:\n"
81 | + "\n".join(
82 | f"{index + 1}. {_route}" for index, _route in enumerate(route_list)
83 | )
84 | )
85 | else:
86 | state["route_index"] = Message("0")
87 |
88 |
89 | @RSSHUB_ADD.got("route_index")
90 | async def handle_route_index(
91 | state: T_State, route_index: str = ArgPlainText("route_index")
92 | ) -> None:
93 | route = state["route_list"][int(route_index) - 1]
94 | if args := [i for i in route.split("/") if i.startswith(":")]:
95 | await RSSHUB_ADD.send(
96 | '请依次输入要订阅的 RSSHub 路由参数,并用 "/" 分隔:\n'
97 | + "/".join(
98 | f"{i.rstrip('?')}(可选)" if i.endswith("?") else f"{i}" for i in args
99 | )
100 | + "\n要置空请输入#或直接留空"
101 | )
102 | else:
103 | state["route_args"] = Message()
104 |
105 |
106 | @RSSHUB_ADD.got("route_args")
107 | async def handle_route_args(
108 | event: MessageEvent,
109 | state: T_State,
110 | name: str = ArgPlainText("name"),
111 | route_index: str = ArgPlainText("route_index"),
112 | route_args: str = ArgPlainText("route_args"),
113 | ) -> None:
114 | route = state["route_list"][int(route_index) - 1]
115 | feed_url = "/".join([i for i in route.split("/") if not i.startswith(":")])
116 | for i in route_args.split("/"):
117 | if len(i.strip("#")) > 0:
118 | feed_url += f"/{i}"
119 |
120 | await add_feed(name, feed_url.lstrip("/"), event)
121 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/routes/danbooru.py:
--------------------------------------------------------------------------------
1 | import sqlite3
2 | from typing import Any, Dict
3 |
4 | import aiohttp
5 | from nonebot.log import logger
6 | from pyquery import PyQuery as Pq
7 | from tenacity import RetryError, retry, stop_after_attempt, stop_after_delay
8 |
9 | from ...config import DATA_PATH
10 | from ...rss_class import Rss
11 | from .. import ParsingBase, cache_db_manage, duplicate_exists, write_item
12 | from ..handle_images import (
13 | get_preview_gif_from_video,
14 | handle_img_combo,
15 | handle_img_combo_with_content,
16 | )
17 | from ..utils import get_proxy
18 |
19 |
20 | # 处理图片
21 | @ParsingBase.append_handler(parsing_type="picture", rex="danbooru")
22 | async def handle_picture(rss: Rss, item: Dict[str, Any], tmp: str) -> str:
23 | # 判断是否开启了只推送标题
24 | if rss.only_title:
25 | return ""
26 |
27 | try:
28 | res = await handle_img(
29 | item=item,
30 | img_proxy=rss.img_proxy,
31 | )
32 | except RetryError:
33 | res = "预览图获取失败"
34 | logger.warning(f"[{item['link']}]的预览图获取失败")
35 |
36 | # 判断是否开启了只推送图片
37 | return f"{res}\n" if rss.only_pic else f"{tmp + res}\n"
38 |
39 |
40 | # 处理图片、视频
41 | @retry(stop=(stop_after_attempt(5) | stop_after_delay(30)))
42 | async def handle_img(item: Dict[str, Any], img_proxy: bool) -> str:
43 | if item.get("image_content"):
44 | return await handle_img_combo_with_content(
45 | item.get("gif_url", ""), item["image_content"]
46 | )
47 | img_str = ""
48 |
49 | # 处理图片
50 | async with aiohttp.ClientSession() as session:
51 | resp = await session.get(item["link"], proxy=get_proxy(img_proxy))
52 | d = Pq(await resp.text())
53 | if img := d("img#image"):
54 | url = img.attr("src")
55 | else:
56 | img_str += "视频预览:"
57 | url = d("video#image").attr("src")
58 | try:
59 | url = await get_preview_gif_from_video(url)
60 | except RetryError:
61 | logger.warning("视频预览获取失败,将发送原视频封面")
62 | url = d("meta[property='og:image']").attr("content")
63 | img_str += await handle_img_combo(url, img_proxy)
64 |
65 | return img_str
66 |
67 |
68 | # 如果启用了去重模式,对推送列表进行过滤
69 | @ParsingBase.append_before_handler(rex="danbooru", priority=12)
70 | async def handle_check_update(rss: Rss, state: Dict[str, Any]) -> Dict[str, Any]:
71 | change_data = state["change_data"]
72 | conn = state["conn"]
73 | db = state["tinydb"]
74 |
75 | # 检查是否启用去重 使用 duplicate_filter_mode 字段
76 | if not rss.duplicate_filter_mode:
77 | return {"change_data": change_data}
78 |
79 | if not conn:
80 | conn = sqlite3.connect(str(DATA_PATH / "cache.db"))
81 | conn.set_trace_callback(logger.debug)
82 |
83 | cache_db_manage(conn)
84 |
85 | delete = []
86 | for index, item in enumerate(change_data):
87 | try:
88 | summary = await get_summary(item, rss.img_proxy)
89 | except RetryError:
90 | logger.warning(f"[{item['link']}]的预览图获取失败")
91 | continue
92 | is_duplicate, image_hash = await duplicate_exists(
93 | rss=rss,
94 | conn=conn,
95 | item=item,
96 | summary=summary,
97 | )
98 | if is_duplicate:
99 | write_item(db, item)
100 | delete.append(index)
101 | else:
102 | change_data[index]["image_hash"] = str(image_hash)
103 |
104 | change_data = [
105 | item for index, item in enumerate(change_data) if index not in delete
106 | ]
107 |
108 | return {
109 | "change_data": change_data,
110 | "conn": conn,
111 | }
112 |
113 |
114 | # 获取正文
115 | @retry(stop=(stop_after_attempt(5) | stop_after_delay(30)))
116 | async def get_summary(item: Dict[str, Any], img_proxy: bool) -> str:
117 | summary = (
118 | item["content"][0].get("value") if item.get("content") else item["summary"]
119 | )
120 | # 如果图片非视频封面,替换为更清晰的预览图;否则移除,以此跳过图片去重检查
121 | summary_doc = Pq(summary)
122 | async with aiohttp.ClientSession() as session:
123 | resp = await session.get(item["link"], proxy=get_proxy(img_proxy))
124 | d = Pq(await resp.text())
125 | if img := d("img#image"):
126 | summary_doc("img").attr("src", img.attr("src"))
127 | else:
128 | summary_doc.remove("img")
129 | return str(summary_doc)
130 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/routes/pixiv.py:
--------------------------------------------------------------------------------
1 | import re
2 | import sqlite3
3 | from typing import Any, Dict
4 |
5 | import aiohttp
6 | from nonebot.log import logger
7 | from pyquery import PyQuery as Pq
8 | from tenacity import RetryError, TryAgain, retry, stop_after_attempt, stop_after_delay
9 |
10 | from ...config import DATA_PATH
11 | from ...rss_class import Rss
12 | from .. import ParsingBase, cache_db_manage, duplicate_exists, write_item
13 | from ..handle_images import (
14 | get_preview_gif_from_video,
15 | handle_img_combo,
16 | handle_img_combo_with_content,
17 | )
18 | from ..utils import get_summary
19 |
20 |
21 | # 如果启用了去重模式,对推送列表进行过滤
22 | @ParsingBase.append_before_handler(rex="/pixiv/", priority=12)
23 | async def handle_check_update(rss: Rss, state: Dict[str, Any]) -> Dict[str, Any]:
24 | change_data = state["change_data"]
25 | conn = state["conn"]
26 | db = state["tinydb"]
27 |
28 | # 检查是否启用去重 使用 duplicate_filter_mode 字段
29 | if not rss.duplicate_filter_mode:
30 | return {"change_data": change_data}
31 |
32 | if not conn:
33 | conn = sqlite3.connect(str(DATA_PATH / "cache.db"))
34 | conn.set_trace_callback(logger.debug)
35 |
36 | cache_db_manage(conn)
37 |
38 | delete = []
39 | for index, item in enumerate(change_data):
40 | summary = get_summary(item)
41 | try:
42 | summary_doc = Pq(summary)
43 | # 如果图片为动图,通过移除来跳过图片去重检查
44 | if re.search("类型:ugoira", str(summary_doc)):
45 | summary_doc.remove("img")
46 | summary = str(summary_doc)
47 | except Exception as e:
48 | logger.warning(e)
49 | is_duplicate, image_hash = await duplicate_exists(
50 | rss=rss,
51 | conn=conn,
52 | item=item,
53 | summary=summary,
54 | )
55 | if is_duplicate:
56 | write_item(db, item)
57 | delete.append(index)
58 | else:
59 | change_data[index]["image_hash"] = str(image_hash)
60 |
61 | change_data = [
62 | item for index, item in enumerate(change_data) if index not in delete
63 | ]
64 |
65 | return {
66 | "change_data": change_data,
67 | "conn": conn,
68 | }
69 |
70 |
71 | # 处理图片
72 | @ParsingBase.append_handler(parsing_type="picture", rex="/pixiv/")
73 | async def handle_picture(rss: Rss, item: Dict[str, Any], tmp: str) -> str:
74 | # 判断是否开启了只推送标题
75 | if rss.only_title:
76 | return ""
77 |
78 | res = ""
79 | try:
80 | res += await handle_img(
81 | item=item, img_proxy=rss.img_proxy, img_num=rss.max_image_number, rss=rss
82 | )
83 | except Exception as e:
84 | logger.warning(f"{rss.name} 没有正文内容!{e}")
85 |
86 | # 判断是否开启了只推送图片
87 | return f"{res}\n" if rss.only_pic else f"{tmp + res}\n"
88 |
89 |
90 | # 处理图片、视频
91 | @retry(stop=(stop_after_attempt(5) | stop_after_delay(30)))
92 | async def handle_img(
93 | item: Dict[str, Any], img_proxy: bool, img_num: int, rss: Rss
94 | ) -> str:
95 | if item.get("image_content"):
96 | return await handle_img_combo_with_content(
97 | item.get("gif_url", ""), item["image_content"]
98 | )
99 | html = Pq(get_summary(item))
100 | link = item["link"]
101 | img_str = ""
102 | # 处理动图
103 | if re.search("类型:ugoira", str(html)):
104 | ugoira_id = re.search(r"\d+", link).group() # type: ignore
105 | try:
106 | url = await get_ugoira_video(ugoira_id)
107 | url = await get_preview_gif_from_video(url)
108 | img_str += await handle_img_combo(url, img_proxy)
109 | except RetryError:
110 | logger.warning(f"动图[{link}]的预览图获取失败,将发送原动图封面")
111 | url = html("img").attr("src")
112 | img_str += await handle_img_combo(url, img_proxy)
113 | else:
114 | # 处理图片
115 | doc_img = list(html("img").items())
116 | # 只发送限定数量的图片,防止刷屏
117 | if 0 < img_num < len(doc_img):
118 | img_str += f"\n因启用图片数量限制,目前只有 {img_num} 张图片:"
119 | doc_img = doc_img[:img_num]
120 | for img in doc_img:
121 | url = img.attr("src")
122 | img_str += await handle_img_combo(url, img_proxy, rss)
123 |
124 | return img_str
125 |
126 |
127 | # 获取动图为视频
128 | @retry(stop=(stop_after_attempt(5) | stop_after_delay(30)))
129 | async def get_ugoira_video(ugoira_id: str) -> Any:
130 | async with aiohttp.ClientSession() as session:
131 | data = {"id": ugoira_id, "type": "ugoira"}
132 | resp = await session.post("https://ugoira.huggy.moe/api/illusts", data=data)
133 | url = (await resp.json()).get("data")[0].get("url")
134 | if not url:
135 | raise TryAgain
136 | return url
137 |
138 |
139 | # 处理来源
140 | @ParsingBase.append_handler(parsing_type="source", rex="/pixiv/")
141 | async def handle_source(item: Dict[str, Any]) -> str:
142 | source = item["link"]
143 | # 缩短 pixiv 链接
144 | str_link = re.sub("https://www.pixiv.net/artworks/", "https://pixiv.net/i/", source)
145 | return f"链接:{str_link}\n"
146 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/cache_manage.py:
--------------------------------------------------------------------------------
1 | from io import BytesIO
2 | from sqlite3 import Connection
3 | from typing import Any, Dict, Optional, Tuple
4 |
5 | import imagehash
6 | from nonebot.log import logger
7 | from PIL import Image, UnidentifiedImageError
8 | from pyquery import PyQuery as Pq
9 | from tinydb import Query, TinyDB
10 | from tinydb.operations import delete
11 |
12 | from ..config import config
13 | from ..rss_class import Rss
14 | from .check_update import get_item_date
15 | from .handle_images import download_image
16 |
17 |
18 | # 精简 xxx.json (缓存) 中的字段
19 | def cache_filter(data: Dict[str, Any]) -> Dict[str, Any]:
20 | keys = [
21 | "guid",
22 | "link",
23 | "published",
24 | "updated",
25 | "title",
26 | "hash",
27 | ]
28 | if data.get("to_send"):
29 | keys += [
30 | "content",
31 | "summary",
32 | "to_send",
33 | ]
34 | return {k: v for k in keys if (v := data.get(k))}
35 |
36 |
37 | # 对去重数据库进行管理
38 | def cache_db_manage(conn: Connection) -> None:
39 | cursor = conn.cursor()
40 | # 用来去重的 sqlite3 数据表如果不存在就创建一个
41 | cursor.execute(
42 | """
43 | CREATE TABLE IF NOT EXISTS main (
44 | "id" INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
45 | "link" TEXT,
46 | "title" TEXT,
47 | "image_hash" TEXT,
48 | "datetime" TEXT DEFAULT (DATETIME('Now', 'LocalTime'))
49 | );
50 | """
51 | )
52 | cursor.close()
53 | conn.commit()
54 | cursor = conn.cursor()
55 | # 移除超过 config.db_cache_expire 天没重复过的记录
56 | cursor.execute(
57 | "DELETE FROM main WHERE datetime <= DATETIME('Now', 'LocalTime', ?);",
58 | (f"-{config.db_cache_expire} Day",),
59 | )
60 | cursor.close()
61 | conn.commit()
62 |
63 |
64 | # 对缓存 json 进行管理
65 | def cache_json_manage(db: TinyDB, new_data_length: int) -> None:
66 | # 只保留最多 config.limit + new_data_length 条的记录
67 | limit = config.limit + new_data_length
68 | retains = db.all()
69 | retains.sort(key=get_item_date)
70 | retains = retains[-limit:]
71 | db.truncate()
72 | db.insert_multiple(retains)
73 |
74 |
75 | async def get_image_hash(rss: Rss, summary: str, item: Dict[str, Any]) -> Optional[str]:
76 | try:
77 | summary_doc = Pq(summary)
78 | except Exception as e:
79 | logger.warning(e)
80 | # 没有正文内容直接跳过
81 | return None
82 |
83 | img_doc = summary_doc("img")
84 | # 只处理仅有一张图片的情况
85 | if len(img_doc) != 1:
86 | return None
87 |
88 | url = img_doc.attr("src")
89 | # 通过图像的指纹来判断是否实际是同一张图片
90 | content = await download_image(url, rss.img_proxy)
91 |
92 | if not content:
93 | return None
94 |
95 | try:
96 | im = Image.open(BytesIO(content))
97 | except UnidentifiedImageError:
98 | return None
99 |
100 | item["image_content"] = content
101 | # GIF 图片的 image_hash 实际上是第一帧的值,为了避免误伤直接跳过
102 | if im.format == "GIF":
103 | item["gif_url"] = url
104 | return None
105 |
106 | return str(imagehash.dhash(im))
107 |
108 |
109 | # 去重判断
110 | async def duplicate_exists(
111 | rss: Rss, conn: Connection, item: Dict[str, Any], summary: str
112 | ) -> Tuple[bool, Optional[str]]:
113 | flag = False
114 | link = item["link"].replace("'", "''")
115 | title = item["title"].replace("'", "''")
116 | image_hash = None
117 | cursor = conn.cursor()
118 | sql = "SELECT * FROM main WHERE 1=1"
119 | args = []
120 |
121 | for mode in rss.duplicate_filter_mode:
122 | if mode == "image":
123 | image_hash = await get_image_hash(rss, summary, item)
124 | if image_hash:
125 | sql += " AND image_hash=?"
126 | args.append(image_hash)
127 | elif mode == "link":
128 | sql += " AND link=?"
129 | args.append(link)
130 | elif mode == "title":
131 | sql += " AND title=?"
132 | args.append(title)
133 |
134 | if "or" in rss.duplicate_filter_mode:
135 | sql = sql.replace("AND", "OR").replace("OR", "AND", 1)
136 |
137 | cursor.execute(f"{sql};", args)
138 | result = cursor.fetchone()
139 |
140 | if result is not None:
141 | result_id = result[0]
142 | cursor.execute(
143 | "UPDATE main SET datetime = DATETIME('Now','LocalTime') WHERE id = ?;",
144 | (result_id,),
145 | )
146 | cursor.close()
147 | conn.commit()
148 | flag = True
149 |
150 | return flag, image_hash
151 |
152 |
153 | # 消息发送后存入去重数据库
154 | def insert_into_cache_db(
155 | conn: Connection, item: Dict[str, Any], image_hash: str
156 | ) -> None:
157 | cursor = conn.cursor()
158 | link = item["link"].replace("'", "''")
159 | title = item["title"].replace("'", "''")
160 | cursor.execute(
161 | "INSERT INTO main (link, title, image_hash) VALUES (?, ?, ?);",
162 | (link, title, image_hash),
163 | )
164 | cursor.close()
165 | conn.commit()
166 |
167 |
168 | # 写入缓存 json
169 | def write_item(db: TinyDB, new_item: Dict[str, Any]) -> None:
170 | if not new_item.get("to_send"):
171 | db.update(delete("to_send"), Query().hash == str(new_item.get("hash"))) # type: ignore
172 | db.upsert(cache_filter(new_item), Query().hash == str(new_item.get("hash")))
173 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/handle_html_tag.py:
--------------------------------------------------------------------------------
1 | import re
2 | from html import unescape as html_unescape
3 |
4 | import bbcode
5 | from pyquery import PyQuery as Pq
6 | from yarl import URL
7 |
8 | from ..config import config
9 |
10 |
11 | # 处理 bbcode
12 | def handle_bbcode(html: Pq) -> str:
13 | rss_str = html_unescape(str(html))
14 |
15 | # issue 36 处理 bbcode
16 | rss_str = re.sub(
17 | r"(\[url=[^]]+])?\[img[^]]*].+\[/img](\[/url])?", "", rss_str, flags=re.I
18 | )
19 |
20 | # 处理一些 bbcode 标签
21 | bbcode_tags = [
22 | "align",
23 | "b",
24 | "backcolor",
25 | "color",
26 | "font",
27 | "size",
28 | "table",
29 | "tbody",
30 | "td",
31 | "tr",
32 | "u",
33 | "url",
34 | ]
35 |
36 | for i in bbcode_tags:
37 | rss_str = re.sub(rf"\[{i}=[^]]+]", "", rss_str, flags=re.I)
38 | rss_str = re.sub(rf"\[/?{i}]", "", rss_str, flags=re.I)
39 |
40 | # 去掉结尾被截断的信息
41 | rss_str = re.sub(
42 | r"(\[[^]]+|\[img][^\[\]]+) \.\.\n?", "", rss_str, flags=re.I
43 | )
44 |
45 | # 检查正文是否为 bbcode ,没有成对的标签也当作不是,从而不进行处理
46 | bbcode_search = re.search(r"\[/(\w+)]", rss_str)
47 | if bbcode_search and re.search(f"\\[{bbcode_search[1]}", rss_str):
48 | parser = bbcode.Parser()
49 | parser.escape_html = False
50 | rss_str = parser.format(rss_str)
51 |
52 | return rss_str
53 |
54 |
55 | def handle_lists(html: Pq, rss_str: str) -> str:
56 | # 有序/无序列表 标签处理
57 | for ul in html("ul").items():
58 | for li in ul("li").items():
59 | li_str_search = re.search("(.+)", repr(str(li)))
60 | rss_str = rss_str.replace(
61 | str(li), f"\n- {li_str_search[1]}" # type: ignore
62 | ).replace("\\n", "\n")
63 | for ol in html("ol").items():
64 | for index, li in enumerate(ol("li").items()):
65 | li_str_search = re.search("(.+)", repr(str(li)))
66 | rss_str = rss_str.replace(
67 | str(li), f"\n{index + 1}. {li_str_search[1]}" # type: ignore
68 | ).replace("\\n", "\n")
69 | rss_str = re.sub("", "\n", rss_str)
70 | # 处理没有被 ul / ol 标签包围的 li 标签
71 | rss_str = rss_str.replace("", "- ").replace("", "")
72 | return rss_str
73 |
74 |
75 | # 标签处理
76 | def handle_links(html: Pq, rss_str: str) -> str:
77 | for a in html("a").items():
78 | a_str = re.search(
79 | r"]+>.*?", html_unescape(str(a)), flags=re.DOTALL
80 | ).group() # type: ignore
81 | if a.text() and str(a.text()) != a.attr("href"):
82 | # 去除微博超话
83 | if re.search(
84 | r"https://m\.weibo\.cn/p/index\?extparam=\S+&containerid=\w+",
85 | a.attr("href"),
86 | ):
87 | rss_str = rss_str.replace(a_str, "")
88 | # 去除微博话题对应链接 及 微博用户主页链接,只保留文本
89 | elif (
90 | a.attr("href").startswith("https://m.weibo.cn/search?containerid=")
91 | and re.search("#.+#", a.text())
92 | ) or (
93 | a.attr("href").startswith("https://weibo.com/")
94 | and a.text().startswith("@")
95 | ):
96 | rss_str = rss_str.replace(a_str, a.text())
97 | else:
98 | if a.attr("href").startswith("https://weibo.cn/sinaurl?u="):
99 | a.attr("href", URL(a.attr("href")).query["u"])
100 | rss_str = rss_str.replace(a_str, f" {a.text()}: {a.attr('href')}\n")
101 | else:
102 | rss_str = rss_str.replace(a_str, f" {a.attr('href')}\n")
103 | return rss_str
104 |
105 |
106 | # HTML标签等处理
107 | def handle_html_tag(html: Pq) -> str:
108 | rss_str = html_unescape(str(html))
109 |
110 | rss_str = handle_lists(html, rss_str)
111 | rss_str = handle_links(html, rss_str)
112 |
113 | # 处理一些 HTML 标签
114 | html_tags = [
115 | "b",
116 | "blockquote",
117 | "code",
118 | "dd",
119 | "del",
120 | "div",
121 | "dl",
122 | "dt",
123 | "em",
124 | "figure",
125 | "font",
126 | "i",
127 | "iframe",
128 | "ol",
129 | "p",
130 | "pre",
131 | "s",
132 | "small",
133 | "span",
134 | "strong",
135 | "sub",
136 | "table",
137 | "tbody",
138 | "td",
139 | "th",
140 | "thead",
141 | "tr",
142 | "u",
143 | "ul",
144 | ]
145 |
146 | #
标签后增加俩个换行
147 | for i in ["p", "pre"]:
148 | rss_str = re.sub(f"", f"\n\n", rss_str)
149 |
150 | # 直接去掉标签,留下内部文本信息
151 | for i in html_tags:
152 | rss_str = re.sub(f"<{i} [^>]+>", "", rss_str)
153 | rss_str = re.sub(f"", "", rss_str)
154 |
155 | rss_str = re.sub(r"<(br|hr)\s?/?>|<(br|hr) [^>]+>", "\n", rss_str)
156 | rss_str = re.sub(r"]+>", "\n", rss_str)
157 | rss_str = re.sub(r"", "\n", rss_str)
158 |
159 | # 删除图片、视频标签
160 | rss_str = re.sub(
161 | r"]*>(.*?)?|]+>", "", rss_str, flags=re.DOTALL
162 | )
163 |
164 | # 去掉多余换行
165 | while "\n\n\n" in rss_str:
166 | rss_str = rss_str.replace("\n\n\n", "\n\n")
167 | rss_str = rss_str.strip()
168 |
169 | if 0 < config.max_length < len(rss_str):
170 | rss_str = f"{rss_str[: config.max_length]}..."
171 |
172 | return rss_str
173 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/rss_parsing.py:
--------------------------------------------------------------------------------
1 | from typing import Any, Dict, Optional, Tuple
2 |
3 | import aiohttp
4 | import feedparser
5 | from nonebot.adapters.onebot.v11 import Bot
6 | from nonebot.log import logger
7 | from tinydb import TinyDB
8 | from yarl import URL
9 |
10 | from . import my_trigger as tr
11 | from .config import DATA_PATH, config
12 | from .parsing import get_proxy
13 | from .parsing.cache_manage import cache_filter
14 | from .parsing.check_update import dict_hash
15 | from .parsing.parsing_rss import ParsingRss
16 | from .rss_class import Rss
17 | from .utils import (
18 | filter_valid_group_id_list,
19 | filter_valid_guild_channel_id_list,
20 | filter_valid_user_id_list,
21 | get_bot,
22 | get_http_caching_headers,
23 | send_message_to_admin,
24 | )
25 |
26 | HEADERS = {
27 | "Accept": "application/xhtml+xml,application/xml,*/*",
28 | "Accept-Language": "en-US,en;q=0.9",
29 | "Cache-Control": "max-age=0",
30 | "User-Agent": (
31 | "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
32 | "AppleWebKit/537.36 (KHTML, like Gecko) "
33 | "Chrome/111.0.0.0 Safari/537.36"
34 | ),
35 | "Connection": "keep-alive",
36 | "Content-Type": "application/xml; charset=utf-8",
37 | }
38 |
39 |
40 | async def filter_and_validate_rss(rss: Rss, bot: Bot) -> Rss:
41 | if rss.user_id:
42 | rss.user_id = await filter_valid_user_id_list(bot, rss.user_id)
43 | if rss.group_id:
44 | rss.group_id = await filter_valid_group_id_list(bot, rss.group_id)
45 | if rss.guild_channel_id:
46 | rss.guild_channel_id = await filter_valid_guild_channel_id_list(
47 | bot, rss.guild_channel_id
48 | )
49 | return rss
50 |
51 |
52 | async def save_first_time_fetch(rss: Rss, new_rss: Dict[str, Any]) -> None:
53 | _file = DATA_PATH / f"{Rss.handle_name(rss.name)}.json"
54 | result = [cache_filter(entry) for entry in new_rss["entries"]]
55 | for r in result:
56 | r["hash"] = dict_hash(r)
57 |
58 | with TinyDB(
59 | _file,
60 | encoding="utf-8",
61 | sort_keys=True,
62 | indent=4,
63 | ensure_ascii=False,
64 | ) as db:
65 | db.insert_multiple(result)
66 |
67 | logger.info(f"{rss.name} 第一次抓取成功!")
68 |
69 |
70 | # 抓取 feed,读取缓存,检查更新,对更新进行处理
71 | async def start(rss: Rss) -> None:
72 | bot: Bot = await get_bot() # type: ignore
73 | if bot is None:
74 | return
75 |
76 | # 先检查订阅者是否合法
77 | rss = await filter_and_validate_rss(rss, bot)
78 | if not any([rss.user_id, rss.group_id, rss.guild_channel_id]):
79 | await auto_stop_and_notify_admin(rss, bot)
80 | return
81 |
82 | new_rss, cached = await fetch_rss(rss)
83 | # 检查是否存在rss记录
84 | _file = DATA_PATH / f"{Rss.handle_name(rss.name)}.json"
85 | first_time_fetch = not _file.exists()
86 |
87 | if cached:
88 | logger.info(f"{rss.name} 没有新信息")
89 | return
90 |
91 | if not new_rss or not new_rss.get("feed"):
92 | rss.error_count += 1
93 | logger.warning(f"{rss.name} 抓取失败!")
94 |
95 | if first_time_fetch:
96 | if config.rss_proxy and not rss.img_proxy:
97 | rss.img_proxy = True
98 | logger.info(f"{rss.name} 第一次抓取失败,自动使用代理抓取")
99 | await start(rss)
100 | else:
101 | await auto_stop_and_notify_admin(rss, bot)
102 |
103 | if rss.error_count >= 100:
104 | await auto_stop_and_notify_admin(rss, bot)
105 | return
106 |
107 | if new_rss.get("feed") and rss.error_count > 0:
108 | rss.error_count = 0
109 |
110 | if first_time_fetch:
111 | await save_first_time_fetch(rss, new_rss)
112 | return
113 |
114 | pr = ParsingRss(rss=rss)
115 | await pr.start(rss_name=rss.name, new_rss=new_rss)
116 |
117 |
118 | async def auto_stop_and_notify_admin(rss: Rss, bot: Bot) -> None:
119 | rss.stop = True
120 | rss.upsert()
121 | tr.delete_job(rss)
122 | cookies_str = "及 cookies " if rss.cookies else ""
123 | if not any([rss.user_id, rss.group_id, rss.guild_channel_id]):
124 | msg = f"{rss.name}[{rss.get_url()}]无人订阅!已自动停止更新!"
125 | elif rss.error_count >= 100:
126 | msg = f"{rss.name}[{rss.get_url()}]已经连续抓取失败超过 100 次!已自动停止更新!请检查订阅地址{cookies_str}!"
127 | else:
128 | msg = f"{rss.name}[{rss.get_url()}]第一次抓取失败!已自动停止更新!请检查订阅地址{cookies_str}!"
129 | await send_message_to_admin(msg, bot)
130 |
131 |
132 | async def fetch_rss_backup(
133 | rss: Rss, session: aiohttp.ClientSession, proxy: Optional[str]
134 | ) -> Dict[str, Any]:
135 | d = {}
136 | for rsshub_url in config.rsshub_backup:
137 | rss_url = rss.get_url(rsshub=str(rsshub_url))
138 | try:
139 | resp = await session.get(rss_url, proxy=proxy)
140 | d = feedparser.parse(await resp.text())
141 | if d.get("feed"):
142 | logger.info(f"[{rss_url}]抓取成功!")
143 | break
144 | except Exception:
145 | logger.debug(f"[{rss_url}]访问失败!将使用备用 RSSHub 地址!")
146 | continue
147 | return d
148 |
149 |
150 | # 获取 RSS 并解析为 json
151 | async def fetch_rss(rss: Rss) -> Tuple[Dict[str, Any], bool]:
152 | rss_url = rss.get_url()
153 | # 对本机部署的 RSSHub 不使用代理
154 | local_host = ["localhost", "127.0.0.1"]
155 | proxy = get_proxy(rss.img_proxy) if URL(rss_url).host not in local_host else None
156 | cookies = rss.cookies or None
157 | headers = HEADERS.copy()
158 | if cookies:
159 | headers["cookie"] = cookies
160 | d = {}
161 | cached = False
162 |
163 | if not config.rsshub_backup and not config.debug:
164 | if rss.etag:
165 | headers["If-None-Match"] = rss.etag
166 | if rss.last_modified:
167 | headers["If-Modified-Since"] = rss.last_modified
168 |
169 | async with aiohttp.ClientSession(
170 | headers=headers,
171 | raise_for_status=True,
172 | timeout=aiohttp.ClientTimeout(10),
173 | ) as session:
174 | try:
175 | resp = await session.get(rss_url, proxy=proxy)
176 | if not config.rsshub_backup:
177 | http_caching_headers = get_http_caching_headers(resp.headers)
178 | rss.etag = http_caching_headers["ETag"]
179 | rss.last_modified = http_caching_headers["Last-Modified"]
180 | rss.upsert()
181 | if (
182 | resp.status == 200 and int(resp.headers.get("Content-Length", "1")) == 0
183 | ) or resp.status == 304:
184 | cached = True
185 | d = feedparser.parse(await resp.text())
186 | except Exception:
187 | if not URL(rss.url).scheme and config.rsshub_backup:
188 | logger.debug(f"[{rss_url}]访问失败!将使用备用 RSSHub 地址!")
189 | d = await fetch_rss_backup(rss, session, proxy)
190 | else:
191 | logger.error(f"[{rss_url}]访问失败!")
192 | return d, cached
193 |
--------------------------------------------------------------------------------
/docs/部署教程.md:
--------------------------------------------------------------------------------
1 | # 2.0 部署教程
2 |
3 | ## 手动部署
4 |
5 | ### 配置 QQ 协议端
6 |
7 | 目前支持的协议有:
8 |
9 | - [OneBot(CQHTTP)](https://github.com/howmanybots/onebot/blob/master/README.md)
10 |
11 | QQ 协议端举例:
12 |
13 | - [go-cqhttp](https://github.com/Mrs4s/go-cqhttp)(基于 [MiraiGo](https://github.com/Mrs4s/MiraiGo))
14 | - [cqhttp-mirai-embedded](https://github.com/yyuueexxiinngg/cqhttp-mirai/tree/embedded)
15 | - [Mirai](https://github.com/mamoe/mirai)+ [cqhttp-mirai](https://github.com/yyuueexxiinngg/cqhttp-mirai)
16 | - [Mirai](https://github.com/mamoe/mirai)+ [Mirai Native](https://github.com/iTXTech/mirai-native)+ [CQHTTP](https://github.com/richardchien/coolq-http-api)
17 | - [OICQ-http-api](https://github.com/takayama-lily/onebot)(基于 [OICQ](https://github.com/takayama-lily/oicq))
18 |
19 | **本插件主要以 [`go-cqhttp`](https://github.com/Mrs4s/go-cqhttp) 为主要适配对象,其他协议端存在兼容性问题,不保证可用性!**
20 |
21 | 1. 下载 `go-cqhttp` 对应平台的 release 文件,建议使用 `v1.0.0-beta8-fix2` [点此前往](https://github.com/Mrs4s/go-cqhttp/releases)
22 |
23 | 2. 运行 `go-cqhttp.exe` 或者使用 `./go-cqhttp` 启动
24 |
25 | 3. 选择 `反向 WS` 方式连接,生成配置文件 `config.yml` 并按修改以下几行内容
26 |
27 | ```yaml
28 | account: # 账号相关
29 | uin: 1233456 # 修改为 QQ 账号
30 |
31 | # 连接服务列表
32 | servers:
33 | # 反向WS设置
34 | - ws-reverse:
35 | # 反向WS Universal 地址
36 | universal: ws://127.0.0.1:8080/onebot/v11/ws/
37 | ```
38 |
39 | 其中 `ws://127.0.0.1:8080/onebot/v11/ws/` 中的 `127.0.0.1` 和 `8080` 应分别对应 nonebot2 配置文件的 `HOST` 和 `PORT`
40 |
41 | 4. 运行 `go-cqhttp.exe` 或者使用 `./go-cqhttp` 启动,扫码登陆
42 |
43 | ### 配置 `ELF_RSS`
44 |
45 | 注意:推荐 Python 3.8.3+ 版本
46 |
47 | Windows版安装包下载地址:[https://www.python.org/ftp/python/3.8.3/python-3.8.3-amd64.exe](https://www.python.org/ftp/python/3.8.3/python-3.8.3-amd64.exe)
48 |
49 | #### 第一次部署
50 |
51 | ##### 不使用脚手架
52 |
53 | 1. 下载代码到本地
54 |
55 | 2. 运行 `pip install -r requirements.txt` 或者 运行 `pip install .`
56 |
57 | 3. 复制 `.env.dev` 文件,并改名为 `.env.prod`,按照注释修改配置
58 |
59 | ```bash
60 | cp .env.dev .env.prod
61 | ```
62 |
63 | 注意配置
64 | ```dotenv
65 | COMMAND_START=["","/"] # 配置命令起始字符
66 | ```
67 |
68 | "" 和 "/" 分别对应指令前不需要前缀和前缀是 "/" ,也就是 "add" 和 "/add" 的区别。 [#382](https://github.com/Quan666/ELF_RSS/issues/382)
69 |
70 | 4. 运行 `nb run`
71 |
72 | 5. 收到机器人发送的启动成功消息
73 |
74 | ##### 使用脚手架
75 |
76 | 1. 安装 `nb-cli`
77 |
78 | ```bash
79 | pip install nb-cli
80 | ```
81 |
82 | 2. 使用 `nb-cli` 新建工程
83 |
84 | ```bash
85 | nb create
86 | ```
87 |
88 | 3. 选择 `OneBot V11` 适配器创建工程
89 |
90 | 4. 切换到工程目录,安装 `ELF-RSS`
91 |
92 | ```bash
93 | nb plugin install ELF-RSS
94 | ```
95 |
96 | 5. 复制本仓库中 `.env.dev` 文件内容到工程目录下的 `.env.prod` 文件,并根据注释修改
97 |
98 | #### 已经部署过其它 Nonebot2 机器人
99 |
100 | 1. 下载 `src/plugins/ELF_RSS2` 文件夹 到你部署好了的机器人 `plugins` 目录
101 |
102 | 2. 下载 `requirements.txt` 文件,并运行 `pip install -r requirements.txt`
103 |
104 | 3. 同 `第一次部署` 一样,修改配置文件
105 |
106 | 4. 运行 `nb run`
107 |
108 | 5. 收到机器人发送的启动成功消息
109 |
110 | #### 从 Nonebot1 到 NoneBot2
111 |
112 | > 注意:go-cqhttp 的配置需要有所变动!,**`config.yml`务必按照下方样式修改!**
113 | > ```yaml
114 | > # yml 注意缩进!!!
115 | > - ws-reverse:
116 | > # 是否禁用当前反向WS服务
117 | > disabled: false
118 | > # 反向WS Universal 地址
119 | > universal: ws://127.0.0.1:8080/onebot/v11/ws/
120 | > ```
121 |
122 | 1. 卸载 nonebot1
123 |
124 | ```bash
125 | pip uninstall nonebot
126 | ```
127 |
128 | 2. 运行
129 |
130 | ```bash
131 | pip install -r requirements.txt
132 | ```
133 |
134 | 3. 参照 `第一次部署`
135 |
136 | ---
137 |
138 | > ### RSS 源中 torrent 自动下载并上传至订阅群 相关设置
139 | >
140 | > #### 1. 配置 qbittorrent
141 | >
142 | > ##### - Windows安装配置
143 | >
144 | > 1. 下载并安装 [qbittorrent](https://www.qbittorrent.org/download.php)
145 | >
146 | > 2. 设置 qbittorrent
147 | >
148 | > 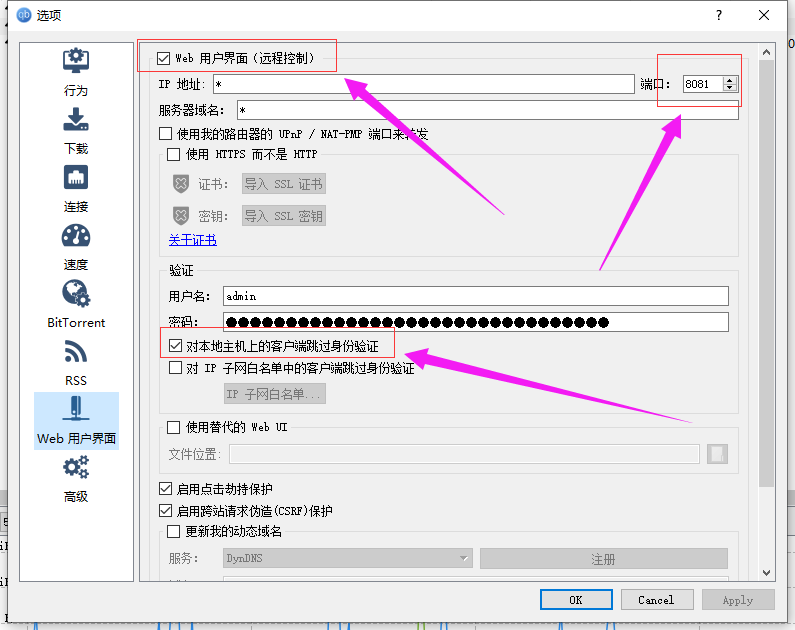
149 | >
150 | > ##### - Linux安装配置
151 | >
152 | > 1. 说明:由于Linux各发行版本软件包管理器差异较大,这里以ubuntu2004和centos7.9为例,其他发行版方法大同小异。如想体验最新版qbittorrent或找不到软件源,可以参考[官方教程](https://github.com/qbittorrent/qBittorrent/wiki/Running-qBittorrent-without-X-server-(WebUI-only))进行编译安装
153 | >
154 | > 2. 对于centos,可以使用epel软件源安装qbittorrent-nox
155 | >
156 | > ```bash
157 | > yum -y install epel-release
158 | > yum -y install qbittorrent-nox.x86_64
159 | > ```
160 | >
161 | > 3. 对于ubuntu,建议使用qbittorrent官方ppa安装qbittorrent-nox
162 | >
163 | > ```bash
164 | > sudo add-apt-repository ppa:qbittorrent-team/qbittorrent-stable
165 | > sudo apt -y install qbittorrent-nox
166 | > ```
167 | >
168 | > 4. 设置qbittorrent
169 | >
170 | > 安装完成后,运行
171 | >
172 | > ```bash
173 | > qbittorrent-nox
174 | > ```
175 | >
176 | > 此时 qbittorrent-nox 会显示“Legal Notice”(法律通告),告诉你使用 qbittorrent 会上传数据,需要自己承担责任。
177 | >
178 | > 输入y表示接受
179 | >
180 | > 接下来的会显示一段信息:
181 | >
182 | > ```text
183 | > ******** Information ********
184 | > To control qBittorrent, access the Web UI at http://localhost:8080
185 | > The Web UI administrator user name is: admin
186 | > The Web UI administrator password is still the default one: adminadmin
187 | > This is a security risk, please consider changing your password from program preferences.
188 | > ```
189 | >
190 | > 此时qBittorrent Web UI就已经在8080端口运行了
191 | >
192 | > 访问面板,打开Tools>Options
193 | >
194 | > 
195 | >
196 | > 选择Web UI,在Port里修改为8081
197 | >
198 | > 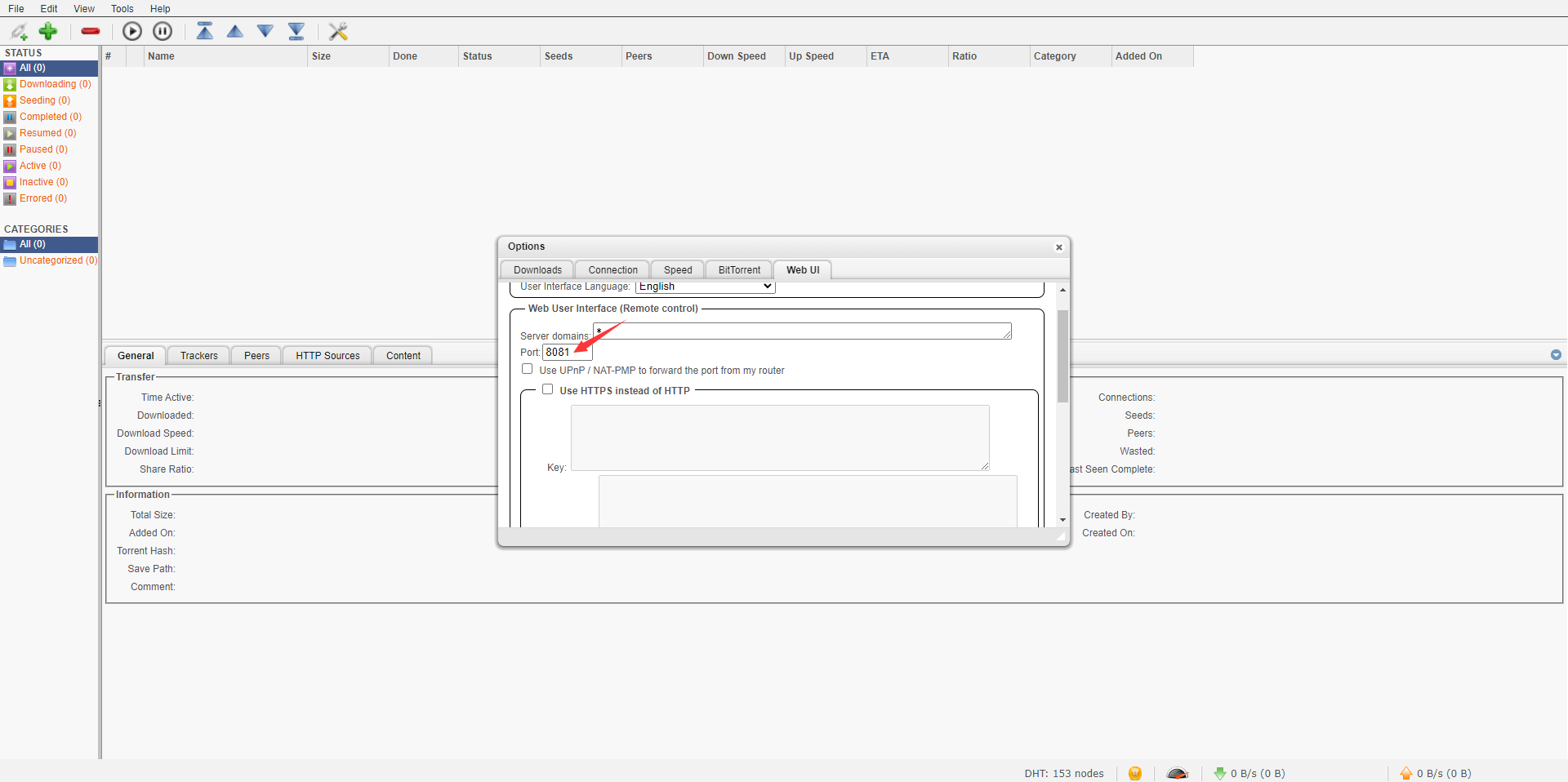
199 | >
200 | > 下滑,修改用户名和密码(可选),勾选Bypass authentication for localhost
201 | >
202 | > 
203 | >
204 | > 下滑,点击save保存,设置完成
205 | >
206 | > 5. qbittorrent-nox默认没有开机启动,建议通过systemctl配置开机启动
207 | >
208 | > #### 2. 设置API超时时间
209 | >
210 | > 在配置文件中新增 以下配置
211 | >
212 | > ```dotenv
213 | > API_TIMEOUT=3600 # 超时,单位 s,建议根据你上传带宽灵活配置
214 | > ```
215 | >
216 | > **注意:**
217 | >
218 | > **如果是容器部署qbittorrent,请将其下载路径挂载到宿主机,以及确保go-cqhttp能访问到下载的文件**
219 | >
220 | > **要么保证挂载路径与容器内路径一致,要么配置 qb_down_path 配置项为挂载路径**
221 |
222 | ---
223 |
224 | ## 1.x 部署教程
225 |
226 | ### 要求
227 |
228 | 1. python3.8+
229 |
230 | ### 开始安装
231 |
232 | 1. 安装有关依赖
233 |
234 | ```bash
235 | # 国内
236 | pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
237 |
238 | # 国外服务器
239 | # pip3 install -r requirements.txt
240 |
241 | # 如果pip3安装不了,将pip换成pip再全部重新安装
242 | # 建议使用pip3
243 | ```
244 |
245 | 2. 下载插件文件
246 | [ELF_RSS 项目地址](https://github.com/Quan666/ELF_RSS "ELF_RSS 项目地址")
247 |
248 | 3. 修改配置文件
249 | 解压打开后修改`config.py` 文件,以记事本打开就行
250 |
251 | ```python
252 | from nonebot.default_config import *
253 |
254 | HOST = '0.0.0.0'
255 | PORT = 8080
256 |
257 | NICKNAME = {'ELF', 'elf'}
258 |
259 | COMMAND_START = {'', '/', '!', '/', '!'}
260 |
261 | SUPERUSERS = {123456789} # 管理员(你)的QQ号
262 |
263 | API_ROOT = 'http://127.0.0.1:5700' #
264 | RSS_PROXY = '127.0.0.1:7890' # 代理地址
265 | ROOTUSER=[123456] # 管理员qq,支持多管理员,逗号分隔 如 [1,2,3] 注意,启动消息只发送给第一个管理员
266 | DEBUG = False
267 | RSSHUB='https://rsshub.app' # rsshub订阅地址
268 | DELCACHE=3 #缓存删除间隔 天
269 | ```
270 |
271 | > **修改完后记得保存**
272 |
273 | ### 机器人相关配置
274 |
275 | 移步 [迁移到 go-cqhttp](迁移到%20go-cqhttp.md)
276 |
277 | ### 运行插件
278 |
279 | shift+右键打开powershell或命令行输入
280 |
281 | ```bash
282 | hypercorn run:app -b 0.0.0.0:8080
283 |
284 | # 或者使用(不推荐) python bot.py
285 | # 或者 python3 bot.py
286 | ```
287 |
288 | 运行后qq会收到消息
289 |
290 | > **第一次运行要先添加订阅**
291 | > **不要关闭窗口**
292 | > **CTRL+C可以结束运行**
293 | > **如果某次运行无法使用命令,请多次按CTRL+C**
294 |
295 | ### 更新
296 |
297 | `git pull`
298 | 或者下载代码覆盖
299 |
--------------------------------------------------------------------------------
/docs/2.0 使用教程.md:
--------------------------------------------------------------------------------
1 | # 2.0 使用教程
2 |
3 | > 注意:
4 | >
5 | > 1. 所有命令均分群组、子频道和私聊三种情况,执行结果也会不同
6 | > 2. [] 包起来的参数表示可选,但某些情况下为必须参数
7 | > 3. 所有订阅命令群管都可使用(但是有一定限制)
8 | > 4. 私聊直接发送命令即可,群聊和子频道需在消息首部或尾部添加 **机器人昵称** 或者 **@机器人**
9 | > 5. 群聊中也可以回复机器人发的消息执行命令,子频道暂不支持
10 | > 6. 所有参数之间均用空格分割,符号为英文标点
11 |
12 | ## 添加订阅
13 |
14 | > 命令:add (添加订阅、sub)
15 | >
16 | > 参数:订阅名 [RSS 地址]
17 | >
18 | > 示例: `add test twitter/user/huagequan`
19 | >
20 | > 使用技巧:先快速添加订阅,之后再通过 `change` 命令修改
21 | >
22 | > 命令解释:
23 | >
24 | > 必需 `订阅名` 及 `RSS地址(RSSHub订阅源可以省略域名,其余需要完整的URL地址)` 两个参数,
25 | > 订阅到当前 `群组` 、 `频道` 或 `QQ`。
26 |
27 | ## 添加 RSSHub 订阅
28 |
29 | > 命令:rsshub_add
30 | >
31 | > 参数:[RSSHub 路由名] [订阅名]
32 | >
33 | > 示例: `rsshub_add github`
34 | >
35 | > 命令解释:
36 | >
37 | > 发送命令后,按照提示依次输入 RSSHub 路由、订阅名和路由参数
38 |
39 | ## 删除订阅
40 |
41 | > 命令:deldy (删除订阅、drop、unsub)
42 | >
43 | > 参数:订阅名 [订阅名 ...](支持批量操作)
44 | >
45 | > 示例: `deldy test` `deldy test1 test2`
46 | >
47 | > 命令解释:
48 | >
49 | > 1. 在超级管理员私聊使用该命令时,可完全删除订阅
50 | > 2. 在群组使用该命令时,将该群组从订阅群组中删除
51 | > 3. 在子频道使用该命令时,将该子频道从订阅子频道中删除
52 |
53 | ## 所有订阅
54 |
55 | > 命令:show_all(showall,select_all,selectall,所有订阅)
56 | >
57 | > 参数:[关键词](支持正则,过滤生效范围:订阅名、订阅地址、QQ 号、群号)
58 | >
59 | > 示例: `showall test` `showall 123`
60 | >
61 | > 命令解释:
62 | >
63 | > 1. 携带 `关键词` 参数时,展示该群组或子频道或所有订阅中含有关键词的订阅
64 | > 2. 不携带 `关键词` 参数时,展示该群组或子频道或所有订阅
65 | > 3. 当 `关键词` 参数为整数时候,只对超级管理员用户额外展示所有订阅中 `QQ号` 或 `群号` 含有关键词的订阅
66 |
67 | ## 查看订阅
68 |
69 | > 命令:show(查看订阅)
70 | >
71 | > 参数:[订阅名]
72 | >
73 | > 示例: `show test`
74 | >
75 | > 命令解释:
76 | >
77 | > 1. 携带 `订阅名` 参数时,展示该订阅的详细信息
78 | > 2. 不携带 `订阅名` 参数时,展示该群组或子频道或 QQ 的订阅详情
79 |
80 | ## 修改订阅
81 |
82 | > 命令:change(修改订阅,moddy)
83 | >
84 | > 参数:订阅名[, 订阅名,...] 属性=值[ 属性=值 ...]
85 | >
86 | > 示例: `change test1[,test2,...] qq=,123,234 qun=-1`
87 | >
88 | > 使用技巧:可以先只发送 `change` ,机器人会返回提示信息,无需记住复杂的参数列表
89 | >
90 | > 对应参数:
91 | >
92 | > | 修改项 | 参数名 | 值范围 | 备注 |
93 | > |-----------------|-----------|--------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------|
94 | > | 订阅名 | -name | 无空格字符串 | 禁止将多个订阅批量改名,会因为名称相同起冲突 |
95 | > | 订阅链接 | -url | 无空格字符串 | RSSHub 订阅源可以省略域名,其余需要完整的 URL 地址 |
96 | > | QQ 号 | -qq | 正整数 / -1 | 需要先加该对象好友;前加英文逗号表示追加;-1 设为空 |
97 | > | QQ 群 | -qun | 正整数 / -1 | 需要先加入该群组;前加英文逗号表示追加;-1 设为空 |
98 | > | 更新频率 | -time | 正整数 / crontab 字符串 | 值为整数时表示每 x 分钟进行一次检查更新,且必须大于等于 1
值为 crontab 字符串时,详见表格下方的补充说明 |
99 | > | 代理 | -proxy | 1 / 0 | 是否启用代理 |
100 | > | 翻译 | -tl | 1 / 0 | 是否翻译正文内容 |
101 | > | 仅标题 | -ot | 1 / 0 | 是否仅发送标题 |
102 | > | 仅图片 | -op | 1 / 0 | 是否仅发送图片 (正文中只保留图片) |
103 | > | 仅含有图片 | -ohp | 1 / 0 | 仅含有图片不同于仅图片,除了图片还会发送正文中的其他文本信息 |
104 | > | 下载种子 | -downopen | 1 / 0 | 是否进行 BT 下载 (需要配置 qBittorrent,参考:[第一次部署](部署教程.md#第一次部署)) |
105 | > | 白名单关键词 | -wkey | 无空格字符串 / 空 | 支持正则表达式,匹配时推送消息及下载
设为空 (wkey=) 时不生效
前面加 +/- 表示追加/去除,详见表格下方的补充说明 |
106 | > | 黑名单关键词 | -bkey | 无空格字符串 / 空 | 同白名单关键词,但匹配时不推送,可在避免冲突的情况下组合使用 |
107 | > | 种子上传到群 | -upgroup | 1 / 0 | 是否将 BT 下载完成的文件上传到群 (需要配置 qBittorrent,参考:[第一次部署](部署教程.md#第一次部署)) |
108 | > | 去重模式 | -mode | link / title / image / or / -1 | 分为按链接 (link)、标题 (title)、图片 (image) 判断
其中 image 模式,出于性能考虑以及避免误伤情况发生,生效对象限定为只带 1 张图片的消息
此外,如果属性中带有 or 说明判断逻辑是任一匹配即去重,默认为全匹配
-1 设为禁用 |
109 | > | 图片数量限制 | -img_num | 正整数 | 只发送限定数量的图片,防止刷屏 |
110 | > | 正文待移除内容 | -rm_list | 无空格字符串 / -1 | 从正文中要移除的指定内容,支持正则表达式
因为参数解析的缘故,格式必须如:`rm_list='a'` 或 `rm_list='a','b'`
该处理过程是在解析 html 标签后进行的
要将该参数设为空,使用 `rm_list='-1'` |
111 | > | 停止更新 | -stop | 1 / 0 | 对订阅停止、恢复检查更新 |
112 | > | PikPak 离线下载 | -pikpak | 1 / 0 | 将磁力链接离线到 PikPak 网盘,方便追番 |
113 | > | PikPak 离线下载路径匹配 | -ppk | 无空格字符串 | 匹配正文中的关键字作为目录 |
114 | > | 发送合并消息 | -forward | 1 / 0 | 当一次更新多条消息时,尝试发送合并消息 |
115 | >
116 | > **注:**
117 | >
118 | > 各个属性之间使用**空格**分割
119 | >
120 | > wkey / bkey 前面加 +/- 表示追加/去除,最终处理为格式如 `a` 、 `a|b` 、 `a|b|c` ……
121 | >
122 | > 如要使用,请在修改后检查处理后的正则表达式是否正确
123 | >
124 | > time 属性兼容 Linux crontab 格式,**但不同的是,crontab 中的空格应该替换为 `_` 即下划线**
125 | >
126 | > 可以参考 [Linux crontab 命令](https://www.runoob.com/linux/linux-comm-crontab.html) 务必理解!但实际有少许不同,主要是设置第 5 个字段时,即每周有不同。
127 | >
128 | > 时间格式如下:
129 | >
130 | > ```text
131 | > f1_f2_f3_f4_f5
132 | > ```
133 | >
134 | > - 其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份中的第几日,f4 表示月份,f5 表示一个星期中的第几天。program 表示要执行的程序。
135 | > - 当 f1 为 *时表示每分钟都要执行 program,f2 为* 时表示每小时都要执行程序,其馀类推
136 | > - 当 f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行,f2 为 a-b 时表示从第 a 到第 b 小时都要执行,其馀类推
137 | > - 当 f1 为 */n 时表示每 n 分钟个时间间隔执行一次,f2 为*/n 表示每 n 小时个时间间隔执行一次,其馀类推
138 | > - 当 f1 为 a, b, c, ... 时表示第 a, b, c, ... 分钟要执行,f2 为 a, b, c, ... 时表示第 a, b, c... 个小时要执行,其馀类推
139 | >
140 | > ```text
141 | > * * * * *
142 | > - - - - -
143 | > | | | | |
144 | > | | | | +----- 星期中星期几 (0 - 6) (星期一为 0,星期天为 6) (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun)
145 | > | | | +---------- 月份 (1 - 12)
146 | > | | +--------------- 一个月中的第几天 (1 - 31)
147 | > | +-------------------- 小时 (0 - 23)
148 | > +------------------------- 分钟 (0 - 59)
149 | > ```
150 | >
151 | > 以下是一些示例:
152 | >
153 | > ``` text
154 | > 1 # 每分钟执行一次(普通)
155 | > 1_ # 每小时的第一分钟运行(cron)
156 | > */1 # 每分钟执行一次
157 | > *_*/1 # 每小时执行一次(注意,均在整点运行)
158 | > *_*_*_*_0, 1, 2, 6 # 每周 1、2、3、日运行,周日为 6
159 | > 0_6-12/3_*_12_* #在 12 月内, 每天的早上 6 点到 12 点,每隔 3 个小时 0 分钟执行一次
160 | > *_12_* # 每天 12 点运行
161 | > # 如果不生效请查看控制台输出
162 | > ```
163 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/parsing_rss.py:
--------------------------------------------------------------------------------
1 | import re
2 | from inspect import signature
3 | from typing import Any, Callable, Dict, List, Optional, Tuple
4 |
5 | from tinydb import TinyDB
6 |
7 | from ..config import DATA_PATH
8 | from ..rss_class import Rss
9 | from ..utils import partition_list
10 |
11 |
12 | # 订阅器启动的时候将解析器注册到rss实例类?,避免每次推送时再匹配
13 | class ParsingItem:
14 | def __init__(
15 | self,
16 | func: Callable[..., Any],
17 | rex: str = "(.*)",
18 | priority: int = 10,
19 | block: bool = False,
20 | ):
21 | # 解析函数
22 | self.func: Callable[..., Any] = func
23 | # 匹配的订阅地址正则,"(.*)" 是全都匹配
24 | self.rex: str = rex
25 | # 优先级,数字越小优先级越高。优先级相同时,会抛弃默认处理方式,即抛弃 rex="(.*)"
26 | self.priority: int = priority
27 | # 是否阻止执行之后的处理,默认不阻止。抛弃默认处理方式,只需要 block==True and priority<10
28 | self.block: bool = block
29 |
30 |
31 | # 解析器排序
32 | def _sort(_list: List[ParsingItem]) -> List[ParsingItem]:
33 | _list.sort(key=lambda x: x.priority)
34 | return _list
35 |
36 |
37 | # rss 解析类 ,需要将特殊处理的订阅注册到该类
38 | class ParsingBase:
39 | """
40 | - **类型**: ``List[ParsingItem]``
41 | - **说明**: 最先执行的解析器,定义了检查更新等前置步骤
42 | """
43 |
44 | before_handler: List[ParsingItem] = []
45 |
46 | """
47 | - **类型**: ``Dict[str, List[ParsingItem]]``
48 | - **说明**: 解析器
49 | """
50 | handler: Dict[str, List[ParsingItem]] = {
51 | "title": [],
52 | "summary": [],
53 | "picture": [],
54 | "source": [],
55 | "date": [],
56 | "torrent": [],
57 | "after": [], # item的最后处理,此处调用消息截取、发送
58 | }
59 |
60 | """
61 | - **类型**: ``List[ParsingItem]``
62 | - **说明**: 最后执行的解析器,在消息发送后,也可以多条消息合并发送
63 | """
64 | after_handler: List[ParsingItem] = []
65 |
66 | # 增加解析器
67 | @classmethod
68 | def append_handler(
69 | cls,
70 | parsing_type: str,
71 | rex: str = "(.*)",
72 | priority: int = 10,
73 | block: bool = False,
74 | ) -> Callable[..., Any]:
75 | def _decorator(func: Callable[..., Any]) -> Callable[..., Any]:
76 | cls.handler[parsing_type].append(ParsingItem(func, rex, priority, block))
77 | cls.handler.update({parsing_type: _sort(cls.handler[parsing_type])})
78 | return func
79 |
80 | return _decorator
81 |
82 | @classmethod
83 | def append_before_handler(
84 | cls, rex: str = "(.*)", priority: int = 10, block: bool = False
85 | ) -> Callable[..., Any]:
86 | """
87 | 装饰一个方法,作为将其一个前置处理器
88 | 参数:
89 | rex: 用于正则匹配目标订阅地址,匹配成功后执行器将适用
90 | priority: 执行器优先级,自定义执行器会覆盖掉相同优先级的默认执行器
91 | block: 是否要阻断后续执行器进行
92 | """
93 |
94 | def _decorator(func: Callable[..., Any]) -> Callable[..., Any]:
95 | cls.before_handler.append(ParsingItem(func, rex, priority, block))
96 | cls.before_handler = _sort(cls.before_handler)
97 | return func
98 |
99 | return _decorator
100 |
101 | @classmethod
102 | def append_after_handler(
103 | cls, rex: str = "(.*)", priority: int = 10, block: bool = False
104 | ) -> Callable[..., Any]:
105 | """
106 | 装饰一个方法,作为将其一个后置处理器
107 | 参数:
108 | rex: 用于正则匹配目标订阅地址,匹配成功后执行器将适用
109 | priority: 执行器优先级,自定义执行器会覆盖掉相同优先级的默认执行器
110 | block: 是否要阻断后续执行器进行
111 | """
112 |
113 | def _decorator(func: Callable[..., Any]) -> Callable[..., Any]:
114 | cls.after_handler.append(ParsingItem(func, rex, priority, block))
115 | cls.after_handler = _sort(cls.after_handler)
116 | return func
117 |
118 | return _decorator
119 |
120 |
121 | # 对处理器进行过滤
122 | def _handler_filter(_handler_list: List[ParsingItem], _url: str) -> List[ParsingItem]:
123 | _result = [h for h in _handler_list if re.search(h.rex, _url)]
124 | # 删除优先级相同时默认的处理器
125 | _delete = [
126 | (h.func.__name__, "(.*)", h.priority) for h in _result if h.rex != "(.*)"
127 | ]
128 | _result = [
129 | h for h in _result if (h.func.__name__, h.rex, h.priority) not in _delete
130 | ]
131 | return _result
132 |
133 |
134 | async def _run_handlers(
135 | handlers: List[ParsingItem],
136 | rss: Rss,
137 | state: Dict[str, Any],
138 | item: Optional[Dict[str, Any]] = None,
139 | item_msg: Optional[str] = None,
140 | tmp: Optional[str] = None,
141 | tmp_state: Optional[Dict[str, Any]] = None,
142 | ) -> Tuple[Dict[str, Any], str]:
143 | for handler in handlers:
144 | kwargs = {
145 | "rss": rss,
146 | "state": state,
147 | "item": item,
148 | "item_msg": item_msg,
149 | "tmp": tmp,
150 | "tmp_state": tmp_state,
151 | }
152 | handler_params = signature(handler.func).parameters
153 | handler_kwargs = {k: v for k, v in kwargs.items() if k in handler_params}
154 |
155 | if any((item, item_msg, tmp, tmp_state)):
156 | tmp = await handler.func(**handler_kwargs)
157 | else:
158 | state.update(await handler.func(**handler_kwargs))
159 | if handler.block or (tmp_state is not None and not tmp_state["continue"]):
160 | break
161 | return state, tmp or ""
162 |
163 |
164 | # 解析实例
165 | class ParsingRss:
166 | # 初始化解析实例
167 | def __init__(self, rss: Rss):
168 | self.state: Dict[str, Any] = {} # 用于存储实例处理中上下文数据
169 | self.rss: Rss = rss
170 |
171 | # 对处理器进行过滤
172 | self.before_handler: List[ParsingItem] = _handler_filter(
173 | ParsingBase.before_handler, self.rss.get_url()
174 | )
175 | self.handler: Dict[str, List[ParsingItem]] = {}
176 | for k, v in ParsingBase.handler.items():
177 | self.handler[k] = _handler_filter(v, self.rss.get_url())
178 | self.after_handler: List[ParsingItem] = _handler_filter(
179 | ParsingBase.after_handler, self.rss.get_url()
180 | )
181 |
182 | # 开始解析
183 | async def start(self, rss_name: str, new_rss: Dict[str, Any]) -> None:
184 | # new_data 是完整的 rss 解析后的 dict
185 | # 前置处理
186 | rss_title = new_rss["feed"]["title"]
187 | new_data = new_rss["entries"]
188 | _file = DATA_PATH / f"{Rss.handle_name(rss_name)}.json"
189 | db = TinyDB(
190 | _file,
191 | encoding="utf-8",
192 | sort_keys=True,
193 | indent=4,
194 | ensure_ascii=False,
195 | )
196 | self.state.update(
197 | {
198 | "rss_title": rss_title,
199 | "new_data": new_data,
200 | "change_data": [], # 更新的消息列表
201 | "conn": None, # 数据库连接
202 | "tinydb": db, # 缓存 json
203 | "error_count": 0, # 消息发送失败计数
204 | }
205 | )
206 | self.state, _ = await _run_handlers(self.before_handler, self.rss, self.state)
207 |
208 | # 分条处理
209 | self.state.update(
210 | {
211 | "header_message": f"【{rss_title}】更新了!",
212 | "messages": [],
213 | "items": [],
214 | }
215 | )
216 | if change_data := self.state["change_data"]:
217 | for parted_item_list in partition_list(change_data, 10):
218 | for item in parted_item_list:
219 | item_msg = ""
220 | for handler_list in self.handler.values():
221 | # 用于保存上一次处理结果
222 | tmp = ""
223 | tmp_state = {"continue": True} # 是否继续执行后续处理
224 |
225 | # 某一个内容的处理如正文,传入原文与上一次处理结果,此次处理完后覆盖
226 | _, tmp = await _run_handlers(
227 | handler_list,
228 | self.rss,
229 | self.state,
230 | item=item,
231 | item_msg=item_msg,
232 | tmp=tmp,
233 | tmp_state=tmp_state,
234 | )
235 | item_msg += tmp
236 | self.state["messages"].append(item_msg)
237 | self.state["items"].append(item)
238 |
239 | _, _ = await _run_handlers(self.after_handler, self.rss, self.state)
240 | self.state["messages"] = self.state["items"] = []
241 | else:
242 | _, _ = await _run_handlers(self.after_handler, self.rss, self.state)
243 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/utils.py:
--------------------------------------------------------------------------------
1 | import base64
2 | import functools
3 | import math
4 | import re
5 | from contextlib import suppress
6 | from typing import Any, Dict, Generator, List, Mapping, Optional
7 |
8 | from aiohttp import ClientSession
9 | from cachetools import TTLCache
10 | from cachetools.keys import hashkey
11 | from nonebot import get_bot as nonebot_get_bot
12 | from nonebot.adapters.onebot.v11 import Bot
13 | from nonebot.log import logger
14 |
15 | from .config import config
16 | from .parsing.utils import get_proxy
17 |
18 | bot_offline = False
19 |
20 |
21 | def get_http_caching_headers(
22 | headers: Optional[Mapping[str, Any]],
23 | ) -> Dict[str, Optional[str]]:
24 | return (
25 | {
26 | "Last-Modified": headers.get("Last-Modified") or headers.get("Date"),
27 | "ETag": headers.get("ETag"),
28 | }
29 | if headers
30 | else {"Last-Modified": None, "ETag": None}
31 | )
32 |
33 |
34 | def convert_size(size_bytes: int) -> str:
35 | if size_bytes == 0:
36 | return "0 B"
37 | size_name = ("B", "KB", "MB", "GB", "TB")
38 | i = int(math.floor(math.log(size_bytes, 1024)))
39 | p = math.pow(1024, i)
40 | s = round(size_bytes / p, 2)
41 | return f"{s} {size_name[i]}"
42 |
43 |
44 | def cached_async(cache, key=hashkey): # type: ignore
45 | """
46 | https://github.com/tkem/cachetools/commit/3f073633ed4f36f05b57838a3e5655e14d3e3524
47 | """
48 |
49 | def decorator(func): # type: ignore
50 | if cache is None:
51 |
52 | async def wrapper(*args, **kwargs): # type: ignore
53 | return await func(*args, **kwargs)
54 |
55 | else:
56 |
57 | async def wrapper(*args, **kwargs): # type: ignore
58 | k = key(*args, **kwargs)
59 | with suppress(KeyError): # key not found
60 | return cache[k]
61 | v = await func(*args, **kwargs)
62 | with suppress(ValueError): # value too large
63 | cache[k] = v
64 | return v
65 |
66 | return functools.update_wrapper(wrapper, func)
67 |
68 | return decorator
69 |
70 |
71 | @cached_async(TTLCache(maxsize=1, ttl=300)) # type: ignore
72 | async def get_bot_friend_list(bot: Bot) -> List[int]:
73 | friend_list = await bot.get_friend_list()
74 | return [i["user_id"] for i in friend_list]
75 |
76 |
77 | @cached_async(TTLCache(maxsize=1, ttl=300)) # type: ignore
78 | async def get_bot_group_list(bot: Bot) -> List[int]:
79 | group_list = await bot.get_group_list()
80 | return [i["group_id"] for i in group_list]
81 |
82 |
83 | @cached_async(TTLCache(maxsize=1, ttl=300)) # type: ignore
84 | async def get_bot_guild_channel_list(
85 | bot: Bot, guild_id: Optional[str] = None
86 | ) -> List[str]:
87 | guild_list = await bot.get_guild_list()
88 | if guild_id is None:
89 | return [i["guild_id"] for i in guild_list]
90 | elif guild_id in [i["guild_id"] for i in guild_list]:
91 | channel_list = await bot.get_guild_channel_list(guild_id=guild_id)
92 | return [i["channel_id"] for i in channel_list]
93 | return []
94 |
95 |
96 | def get_torrent_b16_hash(content: bytes) -> str:
97 | import magneturi
98 |
99 | # mangetlink = magneturi.from_torrent_file(torrentname)
100 | manget_link = magneturi.from_torrent_data(content)
101 | # print(mangetlink)
102 | ch = ""
103 | n = 20
104 | b32_hash = n * ch + manget_link[20:52]
105 | # print(b32Hash)
106 | b16_hash = base64.b16encode(base64.b32decode(b32_hash))
107 | b16_hash = b16_hash.lower()
108 | # print("40位info hash值:" + '\n' + b16Hash)
109 | # print("磁力链:" + '\n' + "magnet:?xt=urn:btih:" + b16Hash)
110 | return str(b16_hash, "utf-8")
111 |
112 |
113 | async def send_message_to_admin(message: str, bot: Optional[Bot] = None) -> None:
114 | if bot is None:
115 | bot = await get_bot()
116 | if bot is None:
117 | return
118 | try:
119 | await bot.send_private_msg(
120 | user_id=int(list(config.superusers)[0]), message=message
121 | )
122 | except Exception as e:
123 | logger.error(f"管理员消息推送失败:{e}")
124 | logger.error(f"消息内容:{message}")
125 |
126 |
127 | async def send_msg(
128 | msg: str,
129 | user_ids: Optional[List[str]] = None,
130 | group_ids: Optional[List[str]] = None,
131 | ) -> List[Dict[str, Any]]:
132 | """
133 | msg: str
134 | user: List[str]
135 | group: List[str]
136 |
137 | 发送消息到私聊或群聊
138 | """
139 | bot: Bot = await get_bot() # type: ignore
140 | if bot is None:
141 | raise ValueError("There are not bots to get.")
142 | msg_id = []
143 | if group_ids:
144 | for group_id in group_ids:
145 | msg_id.append(await bot.send_group_msg(group_id=int(group_id), message=msg))
146 | if user_ids:
147 | for user_id in user_ids:
148 | msg_id.append(await bot.send_private_msg(user_id=int(user_id), message=msg))
149 | return msg_id
150 |
151 |
152 | # 校验正则表达式合法性
153 | def regex_validate(regex: str) -> bool:
154 | try:
155 | re.compile(regex)
156 | return True
157 | except re.error:
158 | return False
159 |
160 |
161 | # 过滤合法好友
162 | async def filter_valid_user_id_list(bot: Bot, user_id_list: List[str]) -> List[str]:
163 | friend_list = await get_bot_friend_list(bot)
164 | valid_user_id_list = [
165 | user_id for user_id in user_id_list if int(user_id) in friend_list
166 | ]
167 | if invalid_user_id_list := [
168 | user_id for user_id in user_id_list if user_id not in valid_user_id_list
169 | ]:
170 | logger.warning(
171 | f"QQ号[{','.join(invalid_user_id_list)}]不是Bot[{bot.self_id}]的好友"
172 | )
173 | return valid_user_id_list
174 |
175 |
176 | # 过滤合法群组
177 | async def filter_valid_group_id_list(bot: Bot, group_id_list: List[str]) -> List[str]:
178 | group_list = await get_bot_group_list(bot)
179 | valid_group_id_list = [
180 | group_id for group_id in group_id_list if int(group_id) in group_list
181 | ]
182 | if invalid_group_id_list := [
183 | group_id for group_id in group_id_list if group_id not in valid_group_id_list
184 | ]:
185 | logger.warning(
186 | f"Bot[{bot.self_id}]未加入群组[{','.join(invalid_group_id_list)}]"
187 | )
188 | return valid_group_id_list
189 |
190 |
191 | # 过滤合法频道
192 | async def filter_valid_guild_channel_id_list(
193 | bot: Bot, guild_channel_id_list: List[str]
194 | ) -> List[str]:
195 | valid_guild_channel_id_list = []
196 | for guild_channel_id in guild_channel_id_list:
197 | guild_id, channel_id = guild_channel_id.split("@")
198 | guild_list = await get_bot_guild_channel_list(bot)
199 | if guild_id not in guild_list:
200 | guild_name = (await bot.get_guild_meta_by_guest(guild_id=guild_id))[
201 | "guild_name"
202 | ]
203 | logger.warning(f"Bot[{bot.self_id}]未加入频道 {guild_name}[{guild_id}]")
204 | continue
205 |
206 | channel_list = await get_bot_guild_channel_list(bot, guild_id=guild_id)
207 | if channel_id not in channel_list:
208 | guild_name = (await bot.get_guild_meta_by_guest(guild_id=guild_id))[
209 | "guild_name"
210 | ]
211 | logger.warning(
212 | f"Bot[{bot.self_id}]未加入频道 {guild_name}[{guild_id}]的子频道[{channel_id}]"
213 | )
214 | continue
215 | valid_guild_channel_id_list.append(guild_channel_id)
216 | return valid_guild_channel_id_list
217 |
218 |
219 | def partition_list(
220 | input_list: List[Any], partition_size: int
221 | ) -> Generator[List[Any], None, None]:
222 | for i in range(0, len(input_list), partition_size):
223 | yield input_list[i : i + partition_size]
224 |
225 |
226 | async def send_message_to_telegram_admin(message: str) -> None:
227 | try:
228 | async with ClientSession(raise_for_status=True) as session:
229 | await session.post(
230 | f"https://api.telegram.org/bot{config.telegram_bot_token}/sendMessage",
231 | json={
232 | "chat_id": config.telegram_admin_ids[0],
233 | "text": message,
234 | },
235 | proxy=get_proxy(),
236 | )
237 | except Exception as e:
238 | logger.error(f"发送到 Telegram 失败:\n {e}")
239 |
240 |
241 | async def get_bot() -> Optional[Bot]:
242 | global bot_offline
243 | bot: Optional[Bot] = None
244 | try:
245 | bot = nonebot_get_bot() # type: ignore
246 | bot_offline = False
247 | except ValueError:
248 | if not bot_offline and config.telegram_admin_ids and config.telegram_bot_token:
249 | await send_message_to_telegram_admin("QQ Bot 已离线!")
250 | logger.warning("Bot 已离线!")
251 | bot_offline = True
252 | return bot
253 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/qbittorrent_download.py:
--------------------------------------------------------------------------------
1 | import asyncio
2 | import base64
3 | import re
4 | from pathlib import Path
5 | from typing import Any, Dict, List, Optional
6 |
7 | import aiohttp
8 | import arrow
9 | from apscheduler.triggers.interval import IntervalTrigger
10 | from nonebot.adapters.onebot.v11 import ActionFailed, Bot, NetworkError
11 | from nonebot.log import logger
12 | from nonebot_plugin_apscheduler import scheduler
13 | from qbittorrent import Client
14 |
15 | from .config import config
16 | from .utils import (
17 | convert_size,
18 | get_bot,
19 | get_bot_group_list,
20 | get_torrent_b16_hash,
21 | send_message_to_admin,
22 | )
23 |
24 | # 计划
25 | # 创建一个全局定时器用来检测种子下载情况
26 | # 群文件上传成功回调
27 | # 文件三种状态1.下载中2。上传中3.上传完成
28 | # 文件信息持久化存储
29 | # 关键词正则表达式
30 | # 下载开关
31 |
32 | DOWN_STATUS_DOWNING = 1 # 下载中
33 | DOWN_STATUS_UPLOADING = 2 # 上传中
34 | DOWN_STATUS_UPLOAD_OK = 3 # 上传完成
35 | down_info: Dict[str, Dict[str, Any]] = {}
36 |
37 | # 示例
38 | # {
39 | # "hash值": {
40 | # "status":DOWN_STATUS_DOWNING,
41 | # "start_time":None, # 下载开始时间
42 | # "downing_tips_msg_id":[] # 下载中通知群上一条通知的信息,用于撤回,防止刷屏
43 | # }
44 | # }
45 |
46 |
47 | # 发送通知
48 | async def send_msg(
49 | bot: Bot, msg: str, notice_group: Optional[List[str]] = None
50 | ) -> List[Dict[str, Any]]:
51 | logger.info(msg)
52 | msg_id = []
53 | group_list = await get_bot_group_list(bot)
54 | if down_status_msg_group := (notice_group or config.down_status_msg_group):
55 | for group_id in down_status_msg_group:
56 | if int(group_id) not in group_list:
57 | logger.error(f"Bot[{bot.self_id}]未加入群组[{group_id}]")
58 | continue
59 | msg_id.append(await bot.send_group_msg(group_id=int(group_id), message=msg))
60 | return msg_id
61 |
62 |
63 | async def get_qb_client() -> Optional[Client]:
64 | try:
65 | qb = Client(config.qb_web_url)
66 | if config.qb_username and config.qb_password:
67 | qb.login(config.qb_username, config.qb_password)
68 | else:
69 | qb.login()
70 | except Exception:
71 | msg = (
72 | "❌ 无法连接到 qbittorrent ,请检查:\n"
73 | "1. 是否启动程序\n"
74 | "2. 是否勾选了“Web用户界面(远程控制)”\n"
75 | "3. 连接地址、端口是否正确"
76 | )
77 | logger.exception(msg)
78 | await send_message_to_admin(msg)
79 | return None
80 | try:
81 | qb.get_default_save_path()
82 | except Exception:
83 | msg = "❌ 无法连登录到 qbittorrent ,请检查相关配置是否正确"
84 | logger.exception(msg)
85 | await send_message_to_admin(msg)
86 | return None
87 | return qb
88 |
89 |
90 | async def get_torrent_info_from_hash(
91 | bot: Bot, qb: Client, url: str, proxy: Optional[str]
92 | ) -> Dict[str, str]:
93 | info = None
94 | if re.search(r"magnet:\?xt=urn:btih:", url):
95 | qb.download_from_link(link=url)
96 | if _hash_str := re.search(r"[A-F\d]{40}", url, flags=re.I):
97 | hash_str = _hash_str[0].lower()
98 | else:
99 | hash_str = (
100 | base64.b16encode(
101 | base64.b32decode(re.search(r"[2-7A-Z]{32}", url, flags=re.I)[0]) # type: ignore
102 | )
103 | .decode("utf-8")
104 | .lower()
105 | )
106 |
107 | else:
108 | async with aiohttp.ClientSession(
109 | timeout=aiohttp.ClientTimeout(total=100)
110 | ) as session:
111 | try:
112 | resp = await session.get(url, proxy=proxy)
113 | content = await resp.read()
114 | qb.download_from_file(content)
115 | hash_str = get_torrent_b16_hash(content)
116 | except Exception as e:
117 | await send_msg(bot, f"下载种子失败,可能需要代理\n{e}")
118 | return {}
119 |
120 | while not info:
121 | for tmp_torrent in qb.torrents():
122 | if tmp_torrent["hash"] == hash_str and tmp_torrent["size"]:
123 | info = {
124 | "hash": tmp_torrent["hash"],
125 | "filename": tmp_torrent["name"],
126 | "size": convert_size(tmp_torrent["size"]),
127 | }
128 | await asyncio.sleep(1)
129 | return info
130 |
131 |
132 | # 种子地址,种子下载路径,群文件上传 群列表,订阅名称
133 | async def start_down(
134 | bot: Bot, url: str, group_ids: List[str], name: str, proxy: Optional[str]
135 | ) -> str:
136 | qb = await get_qb_client()
137 | if not qb:
138 | return ""
139 | # 获取种子 hash
140 | info = await get_torrent_info_from_hash(bot=bot, qb=qb, url=url, proxy=proxy)
141 | await rss_trigger(
142 | bot,
143 | hash_str=info["hash"],
144 | group_ids=group_ids,
145 | name=f"订阅:{name}\n{info['filename']}\n文件大小:{info['size']}",
146 | )
147 | down_info[info["hash"]] = {
148 | "status": DOWN_STATUS_DOWNING,
149 | "start_time": arrow.now(), # 下载开始时间
150 | "downing_tips_msg_id": [], # 下载中通知群上一条通知的信息,用于撤回,防止刷屏
151 | }
152 | return info["hash"]
153 |
154 |
155 | async def update_down_status_message(
156 | bot: Bot, hash_str: str, info: Dict[str, Any], name: str
157 | ) -> List[Dict[str, Any]]:
158 | return await send_msg(
159 | bot,
160 | f"{name}\n"
161 | f"Hash:{hash_str}\n"
162 | f"下载了 {round(info['total_downloaded'] / info['total_size'] * 100, 2)}%\n"
163 | f"平均下载速度: {round(info['dl_speed_avg'] / 1024, 2)} KB/s",
164 | )
165 |
166 |
167 | async def upload_files_to_groups(
168 | bot: Bot,
169 | group_ids: List[str],
170 | info: Dict[str, Any],
171 | files: List[Dict[str, Any]],
172 | name: str,
173 | hash_str: str,
174 | ) -> None:
175 | for group_id in group_ids:
176 | for tmp in files:
177 | path = Path(info.get("save_path", "")) / tmp["name"]
178 | if config.qb_down_path:
179 | if (_path := Path(config.qb_down_path)).is_dir():
180 | path = _path / tmp["name"]
181 |
182 | await send_msg(bot, f"{name}\nHash:{hash_str}\n开始上传到群:{group_id}")
183 |
184 | try:
185 | await bot.call_api(
186 | "upload_group_file",
187 | group_id=group_id,
188 | file=str(path),
189 | name=tmp["name"],
190 | )
191 | except ActionFailed:
192 | msg = (
193 | f"{name}\nHash:{hash_str}\n上传到群:{group_id}失败!请手动上传!"
194 | )
195 | await send_msg(bot, msg, [group_id])
196 | logger.exception(msg)
197 | except (NetworkError, TimeoutError) as e:
198 | logger.warning(e)
199 |
200 |
201 | # 检查下载状态
202 | async def check_down_status(
203 | bot: Bot, hash_str: str, group_ids: List[str], name: str
204 | ) -> None:
205 | qb = await get_qb_client()
206 | if not qb:
207 | return
208 | # 防止中途删掉任务,无限执行
209 | try:
210 | info = qb.get_torrent(hash_str)
211 | files = qb.get_torrent_files(hash_str)
212 | except Exception as e:
213 | logger.exception(e)
214 | scheduler.remove_job(hash_str)
215 | return
216 |
217 | if info["total_downloaded"] - info["total_size"] >= 0.000000:
218 | all_time = arrow.now() - down_info[hash_str]["start_time"]
219 | await send_msg(
220 | bot,
221 | f"👏 {name}\n"
222 | f"Hash:{hash_str}\n"
223 | f"下载完成!耗时:{str(all_time).split('.', 2)[0]}",
224 | )
225 | down_info[hash_str]["status"] = DOWN_STATUS_UPLOADING
226 |
227 | await upload_files_to_groups(bot, group_ids, info, files, name, hash_str)
228 |
229 | scheduler.remove_job(hash_str)
230 | down_info[hash_str]["status"] = DOWN_STATUS_UPLOAD_OK
231 | else:
232 | await delete_msg(bot, down_info[hash_str]["downing_tips_msg_id"])
233 | msg_id = await update_down_status_message(bot, hash_str, info, name)
234 | down_info[hash_str]["downing_tips_msg_id"] = msg_id
235 |
236 |
237 | # 撤回消息
238 | async def delete_msg(bot: Bot, msg_ids: List[Dict[str, Any]]) -> None:
239 | for msg_id in msg_ids:
240 | await bot.delete_msg(message_id=msg_id["message_id"])
241 |
242 |
243 | async def rss_trigger(bot: Bot, hash_str: str, group_ids: List[str], name: str) -> None:
244 | # 制作一个频率为“ n 秒 / 次”的触发器
245 | trigger = IntervalTrigger(seconds=int(config.down_status_msg_date), jitter=10)
246 | job_defaults = {"max_instances": 1}
247 | # 添加任务
248 | scheduler.add_job(
249 | func=check_down_status, # 要添加任务的函数,不要带参数
250 | trigger=trigger, # 触发器
251 | args=(
252 | bot,
253 | hash_str,
254 | group_ids,
255 | name,
256 | ), # 函数的参数列表,注意:只有一个值时,不能省略末尾的逗号
257 | id=hash_str,
258 | misfire_grace_time=60, # 允许的误差时间,建议不要省略
259 | job_defaults=job_defaults,
260 | )
261 | bot: Bot = await get_bot() # type: ignore
262 | if bot is None:
263 | return
264 | await send_msg(bot, f"👏 {name}\nHash:{hash_str}\n下载任务添加成功!", group_ids)
265 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/send_message.py:
--------------------------------------------------------------------------------
1 | import asyncio
2 | from collections import defaultdict
3 | from contextlib import suppress
4 | from typing import Any, Callable, Coroutine, DefaultDict, Dict, List, Tuple, Union
5 |
6 | import arrow
7 | from nonebot.adapters.onebot.v11 import Bot, Message, MessageSegment
8 | from nonebot.adapters.onebot.v11.exception import NetworkError
9 | from nonebot.log import logger
10 |
11 | from ..config import config
12 | from ..rss_class import Rss
13 | from ..utils import get_bot
14 | from .cache_manage import insert_into_cache_db, write_item
15 |
16 | sending_lock: DefaultDict[Tuple[Union[int, str], str], asyncio.Lock] = defaultdict(
17 | asyncio.Lock
18 | )
19 |
20 |
21 | # 发送消息
22 | async def send_msg(
23 | rss: Rss, messages: List[str], items: List[Dict[str, Any]], header_message: str
24 | ) -> bool:
25 | bot: Bot = await get_bot() # type: ignore
26 | if bot is None:
27 | return False
28 | if not messages:
29 | return False
30 | flag = False
31 | if rss.user_id:
32 | flag = any(
33 | await asyncio.gather(
34 | *[
35 | send_private_msg(
36 | bot,
37 | messages,
38 | int(user_id),
39 | items,
40 | header_message,
41 | rss.send_forward_msg,
42 | )
43 | for user_id in rss.user_id
44 | ]
45 | )
46 | )
47 | if rss.group_id:
48 | flag = (
49 | any(
50 | await asyncio.gather(
51 | *[
52 | send_group_msg(
53 | bot,
54 | messages,
55 | int(group_id),
56 | items,
57 | header_message,
58 | rss.send_forward_msg,
59 | )
60 | for group_id in rss.group_id
61 | ]
62 | )
63 | )
64 | or flag
65 | )
66 | if rss.guild_channel_id:
67 | flag = (
68 | any(
69 | await asyncio.gather(
70 | *[
71 | send_guild_channel_msg(
72 | bot, messages, guild_channel_id, items, header_message
73 | )
74 | for guild_channel_id in rss.guild_channel_id
75 | ]
76 | )
77 | )
78 | or flag
79 | )
80 | return flag
81 |
82 |
83 | # 发送私聊消息
84 | async def send_private_msg(
85 | bot: Bot,
86 | message: List[str],
87 | user_id: int,
88 | items: List[Dict[str, Any]],
89 | header_message: str,
90 | send_forward_msg: bool,
91 | ) -> bool:
92 | return await send_msgs_with_lock(
93 | bot=bot,
94 | messages=message,
95 | target_id=user_id,
96 | target_type="private",
97 | items=items,
98 | header_message=header_message,
99 | send_func=lambda user_id, message: bot.send_private_msg(
100 | user_id=user_id, message=message # type: ignore
101 | ),
102 | send_forward_msg=send_forward_msg,
103 | )
104 |
105 |
106 | # 发送群聊消息
107 | async def send_group_msg(
108 | bot: Bot,
109 | message: List[str],
110 | group_id: int,
111 | items: List[Dict[str, Any]],
112 | header_message: str,
113 | send_forward_msg: bool,
114 | ) -> bool:
115 | return await send_msgs_with_lock(
116 | bot=bot,
117 | messages=message,
118 | target_id=group_id,
119 | target_type="group",
120 | items=items,
121 | header_message=header_message,
122 | send_func=lambda group_id, message: bot.send_group_msg(
123 | group_id=group_id, message=message # type: ignore
124 | ),
125 | send_forward_msg=send_forward_msg,
126 | )
127 |
128 |
129 | # 发送频道消息
130 | async def send_guild_channel_msg(
131 | bot: Bot,
132 | message: List[str],
133 | guild_channel_id: str,
134 | items: List[Dict[str, Any]],
135 | header_message: str,
136 | ) -> bool:
137 | guild_id, channel_id = guild_channel_id.split("@")
138 | return await send_msgs_with_lock(
139 | bot=bot,
140 | messages=message,
141 | target_id=guild_channel_id,
142 | target_type="guild_channel",
143 | items=items,
144 | header_message=header_message,
145 | send_func=lambda guild_channel_id, message: bot.send_guild_channel_msg(
146 | message=message, guild_id=guild_id, channel_id=channel_id
147 | ),
148 | )
149 |
150 |
151 | async def send_single_msg(
152 | message: str,
153 | target_id: Union[int, str],
154 | item: Dict[str, Any],
155 | header_message: str,
156 | send_func: Callable[[Union[int, str], str], Coroutine[Any, Any, Dict[str, Any]]],
157 | ) -> bool:
158 | flag = False
159 | try:
160 | await send_func(
161 | target_id, f"{header_message}\n----------------------\n{message}"
162 | )
163 | flag = True
164 | except Exception as e:
165 | error_msg = f"E: {repr(e)}\n消息发送失败!\n链接:[{item.get('link')}]"
166 | logger.error(error_msg)
167 | if item.get("to_send"):
168 | flag = True
169 | with suppress(Exception):
170 | await send_func(target_id, error_msg)
171 | return flag
172 |
173 |
174 | async def send_multiple_msgs(
175 | messages: List[str],
176 | target_id: Union[int, str],
177 | items: List[Dict[str, Any]],
178 | header_message: str,
179 | send_func: Callable[[Union[int, str], str], Coroutine[Any, Any, Dict[str, Any]]],
180 | ) -> bool:
181 | flag = False
182 | for message, item in zip(messages, items):
183 | flag = (
184 | await send_single_msg(message, target_id, item, header_message, send_func)
185 | or flag
186 | )
187 | return flag
188 |
189 |
190 | async def send_msgs_with_lock(
191 | bot: Bot,
192 | messages: List[str],
193 | target_id: Union[int, str],
194 | target_type: str,
195 | items: List[Dict[str, Any]],
196 | header_message: str,
197 | send_func: Callable[[Union[int, str], str], Coroutine[Any, Any, Dict[str, Any]]],
198 | send_forward_msg: bool = False,
199 | ) -> bool:
200 | start_time = arrow.now()
201 | async with sending_lock[(target_id, target_type)]:
202 | if len(messages) == 1:
203 | flag = await send_single_msg(
204 | messages[0], target_id, items[0], header_message, send_func
205 | )
206 | elif send_forward_msg and target_type != "guild_channel":
207 | flag = await try_sending_forward_msg(
208 | bot, messages, target_id, target_type, items, header_message, send_func
209 | )
210 | else:
211 | flag = await send_multiple_msgs(
212 | messages, target_id, items, header_message, send_func
213 | )
214 | await asyncio.sleep(max(1 - (arrow.now() - start_time).total_seconds(), 0))
215 | return flag
216 |
217 |
218 | async def try_sending_forward_msg(
219 | bot: Bot,
220 | messages: List[str],
221 | target_id: Union[int, str],
222 | target_type: str,
223 | items: List[Dict[str, Any]],
224 | header_message: str,
225 | send_func: Callable[[Union[int, str], str], Coroutine[Any, Any, Dict[str, Any]]],
226 | ) -> bool:
227 | forward_messages = handle_forward_message(bot, [header_message] + messages)
228 | try:
229 | if target_type == "private":
230 | await bot.send_private_forward_msg(
231 | user_id=target_id, messages=forward_messages
232 | )
233 | elif target_type == "group":
234 | await bot.send_group_forward_msg(
235 | group_id=target_id, messages=forward_messages
236 | )
237 | flag = True
238 | except NetworkError:
239 | # 如果图片体积过大或数量过多,很可能触发这个错误,但实际上发送成功,不过高概率吞图,只警告不处理
240 | logger.warning("图片过大或数量过多,可能发送失败!")
241 | flag = True
242 | except Exception as e:
243 | logger.warning(f"E: {repr(e)}\n合并消息发送失败!将尝试逐条发送!")
244 | flag = await send_multiple_msgs(
245 | messages, target_id, items, header_message, send_func
246 | )
247 | return flag
248 |
249 |
250 | def handle_forward_message(bot: Bot, messages: List[str]) -> Message:
251 | return Message(
252 | [
253 | MessageSegment.node_custom(
254 | user_id=int(bot.self_id),
255 | nickname=list(config.nickname)[0] if config.nickname else "\u200b",
256 | content=message,
257 | )
258 | for message in messages
259 | ]
260 | )
261 |
262 |
263 | # 发送消息并写入文件
264 | async def handle_send_msgs(
265 | rss: Rss, messages: List[str], items: List[Dict[str, Any]], state: Dict[str, Any]
266 | ) -> None:
267 | db = state["tinydb"]
268 | header_message = state["header_message"]
269 |
270 | if await send_msg(rss, messages, items, header_message):
271 | if rss.duplicate_filter_mode:
272 | for item in items:
273 | insert_into_cache_db(
274 | conn=state["conn"], item=item, image_hash=item["image_hash"]
275 | )
276 |
277 | for item in items:
278 | if item.get("to_send"):
279 | item.pop("to_send")
280 |
281 | else:
282 | for item in items:
283 | item["to_send"] = True
284 |
285 | state["error_count"] += len(messages)
286 |
287 | for item in items:
288 | write_item(db, item)
289 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/rss_class.py:
--------------------------------------------------------------------------------
1 | import re
2 | from copy import deepcopy
3 | from typing import Any, Dict, List, Optional
4 |
5 | from tinydb import Query, TinyDB
6 | from tinydb.operations import set as tinydb_set
7 | from yarl import URL
8 |
9 | from .config import DATA_PATH, JSON_PATH, config
10 |
11 |
12 | class Rss:
13 | def __init__(self, data: Optional[Dict[str, Any]] = None):
14 | self.name: str = "" # 订阅名
15 | self.url: str = "" # 订阅地址
16 | self.user_id: List[str] = [] # 订阅用户(qq)
17 | self.group_id: List[str] = [] # 订阅群组
18 | self.guild_channel_id: List[str] = [] # 订阅子频道
19 | self.img_proxy: bool = False
20 | self.time: str = "5" # 更新频率 分钟/次
21 | self.translation: bool = False # 翻译
22 | self.only_title: bool = False # 仅标题
23 | self.only_pic: bool = False # 仅图片
24 | self.only_has_pic: bool = False # 仅含有图片
25 | self.download_pic: bool = False # 是否要下载图片
26 | self.cookies: str = ""
27 | self.down_torrent: bool = False # 是否下载种子
28 | self.down_torrent_keyword: str = "" # 过滤关键字,支持正则
29 | self.black_keyword: str = "" # 黑名单关键词
30 | self.is_open_upload_group: bool = True # 默认开启上传到群
31 | self.duplicate_filter_mode: List[str] = [] # 去重模式
32 | self.max_image_number: int = 0 # 图片数量限制,防止消息太长刷屏
33 | self.content_to_remove: Optional[str] = None # 正文待移除内容,支持正则
34 | self.etag: Optional[str] = None
35 | self.last_modified: Optional[str] = None # 上次更新时间
36 | self.error_count: int = 0 # 连续抓取失败的次数,超过 100 就停止更新
37 | self.stop: bool = False # 停止更新
38 | self.pikpak_offline: bool = False # 是否PikPak离线
39 | self.pikpak_path_key: str = (
40 | "" # PikPak 离线下载路径匹配正则表达式,用于自动归档文件 例如 r"(?:\[.*?\][\s\S])([\s\S]*)[\s\S]-"
41 | )
42 | self.send_forward_msg: bool = (
43 | False # 当一次更新多条消息时,是否尝试发送合并消息
44 | )
45 | if data:
46 | self.__dict__.update(data)
47 |
48 | # 返回订阅链接
49 | def get_url(self, rsshub: str = str(config.rsshub)) -> str:
50 | if URL(self.url).scheme in ["http", "https"]:
51 | return self.url
52 | # 去除 rsshub地址末尾的斜杠 和 订阅地址开头的斜杠
53 | return f"{rsshub.rstrip('/')}/{self.url.lstrip('/')}"
54 |
55 | # 读取记录
56 | @staticmethod
57 | def read_rss() -> List["Rss"]:
58 | # 如果文件不存在
59 | if not JSON_PATH.exists():
60 | return []
61 | with TinyDB(
62 | JSON_PATH,
63 | encoding="utf-8",
64 | sort_keys=True,
65 | indent=4,
66 | ensure_ascii=False,
67 | ) as db:
68 | rss_list = [Rss(rss) for rss in db.all()]
69 | return rss_list
70 |
71 | # 过滤订阅名中的特殊字符
72 | @staticmethod
73 | def handle_name(name: str) -> str:
74 | name = re.sub(r'[?*:"<>\\/|]', "_", name)
75 | if name == "rss":
76 | name = "rss_"
77 | return name
78 |
79 | # 查找是否存在当前订阅名 rss 要转换为 rss_
80 | @staticmethod
81 | def get_one_by_name(name: str) -> Optional["Rss"]:
82 | feed_list = Rss.read_rss()
83 | return next((feed for feed in feed_list if feed.name == name), None)
84 |
85 | # 添加订阅
86 | def add_user_or_group_or_channel(
87 | self,
88 | user: Optional[str] = None,
89 | group: Optional[str] = None,
90 | guild_channel: Optional[str] = None,
91 | ) -> None:
92 | if user:
93 | if user in self.user_id:
94 | return
95 | self.user_id.append(user)
96 | elif group:
97 | if group in self.group_id:
98 | return
99 | self.group_id.append(group)
100 | elif guild_channel:
101 | if guild_channel in self.guild_channel_id:
102 | return
103 | self.guild_channel_id.append(guild_channel)
104 | self.upsert()
105 |
106 | # 删除订阅 群组
107 | def delete_group(self, group: str) -> bool:
108 | if group not in self.group_id:
109 | return False
110 | self.group_id.remove(group)
111 | with TinyDB(
112 | JSON_PATH,
113 | encoding="utf-8",
114 | sort_keys=True,
115 | indent=4,
116 | ensure_ascii=False,
117 | ) as db:
118 | db.update(tinydb_set("group_id", self.group_id), Query().name == self.name) # type: ignore
119 | return True
120 |
121 | # 删除订阅 子频道
122 | def delete_guild_channel(self, guild_channel: str) -> bool:
123 | if guild_channel not in self.guild_channel_id:
124 | return False
125 | self.guild_channel_id.remove(guild_channel)
126 | with TinyDB(
127 | JSON_PATH,
128 | encoding="utf-8",
129 | sort_keys=True,
130 | indent=4,
131 | ensure_ascii=False,
132 | ) as db:
133 | db.update(
134 | tinydb_set("guild_channel_id", self.guild_channel_id), Query().name == self.name # type: ignore
135 | )
136 | return True
137 |
138 | # 删除整个订阅
139 | def delete_rss(self) -> None:
140 | with TinyDB(
141 | JSON_PATH,
142 | encoding="utf-8",
143 | sort_keys=True,
144 | indent=4,
145 | ensure_ascii=False,
146 | ) as db:
147 | db.remove(Query().name == self.name)
148 | self.delete_file()
149 |
150 | # 重命名订阅缓存 json 文件
151 | def rename_file(self, target: str) -> None:
152 | source = DATA_PATH / f"{Rss.handle_name(self.name)}.json"
153 | if source.exists():
154 | source.rename(target)
155 |
156 | # 删除订阅缓存 json 文件
157 | def delete_file(self) -> None:
158 | (DATA_PATH / f"{Rss.handle_name(self.name)}.json").unlink(missing_ok=True)
159 |
160 | # 隐私考虑,不展示除当前群组或频道外的群组、频道和QQ
161 | def hide_some_infos(
162 | self, group_id: Optional[int] = None, guild_channel_id: Optional[str] = None
163 | ) -> "Rss":
164 | if not group_id and not guild_channel_id:
165 | return self
166 | rss_tmp = deepcopy(self)
167 | rss_tmp.guild_channel_id = [guild_channel_id, "*"] if guild_channel_id else []
168 | rss_tmp.group_id = [str(group_id), "*"] if group_id else []
169 | rss_tmp.user_id = ["*"] if rss_tmp.user_id else []
170 | return rss_tmp
171 |
172 | @staticmethod
173 | def get_by_guild_channel(guild_channel_id: str) -> List["Rss"]:
174 | rss_old = Rss.read_rss()
175 | return [
176 | rss.hide_some_infos(guild_channel_id=guild_channel_id)
177 | for rss in rss_old
178 | if guild_channel_id in rss.guild_channel_id
179 | ]
180 |
181 | @staticmethod
182 | def get_by_group(group_id: int) -> List["Rss"]:
183 | rss_old = Rss.read_rss()
184 | return [
185 | rss.hide_some_infos(group_id=group_id)
186 | for rss in rss_old
187 | if str(group_id) in rss.group_id
188 | ]
189 |
190 | @staticmethod
191 | def get_by_user(user: str) -> List["Rss"]:
192 | rss_old = Rss.read_rss()
193 | return [rss for rss in rss_old if user in rss.user_id]
194 |
195 | def set_cookies(self, cookies: str) -> None:
196 | self.cookies = cookies
197 | with TinyDB(
198 | JSON_PATH,
199 | encoding="utf-8",
200 | sort_keys=True,
201 | indent=4,
202 | ensure_ascii=False,
203 | ) as db:
204 | db.update(tinydb_set("cookies", cookies), Query().name == self.name) # type: ignore
205 |
206 | def upsert(self, old_name: Optional[str] = None) -> None:
207 | with TinyDB(
208 | JSON_PATH,
209 | encoding="utf-8",
210 | sort_keys=True,
211 | indent=4,
212 | ensure_ascii=False,
213 | ) as db:
214 | if old_name:
215 | db.update(self.__dict__, Query().name == old_name)
216 | else:
217 | db.upsert(self.__dict__, Query().name == str(self.name))
218 |
219 | def __str__(self) -> str:
220 | def _generate_feature_string(feature: str, value: Any) -> str:
221 | return f"{feature}:{value}" if value else ""
222 |
223 | if self.duplicate_filter_mode:
224 | delimiter = " 或 " if "or" in self.duplicate_filter_mode else "、"
225 | mode_name = {"link": "链接", "title": "标题", "image": "图片"}
226 | mode_msg = (
227 | "已启用去重模式,"
228 | f"{delimiter.join(mode_name[i] for i in self.duplicate_filter_mode if i != 'or')} 相同时去重"
229 | )
230 | else:
231 | mode_msg = ""
232 |
233 | ret_list = [
234 | f"名称:{self.name}",
235 | f"订阅地址:{self.url}",
236 | _generate_feature_string("订阅QQ", self.user_id),
237 | _generate_feature_string("订阅群", self.group_id),
238 | _generate_feature_string("订阅子频道", self.guild_channel_id),
239 | f"更新时间:{self.time}",
240 | _generate_feature_string("代理", self.img_proxy),
241 | _generate_feature_string("翻译", self.translation),
242 | _generate_feature_string("仅标题", self.only_title),
243 | _generate_feature_string("仅图片", self.only_pic),
244 | _generate_feature_string("下载图片", self.download_pic),
245 | _generate_feature_string("仅含有图片", self.only_has_pic),
246 | _generate_feature_string("白名单关键词", self.down_torrent_keyword),
247 | _generate_feature_string("黑名单关键词", self.black_keyword),
248 | _generate_feature_string("cookies", self.cookies),
249 | "种子自动下载功能已启用" if self.down_torrent else "",
250 | (
251 | ""
252 | if self.is_open_upload_group
253 | else f"是否上传到群:{self.is_open_upload_group}"
254 | ),
255 | mode_msg,
256 | _generate_feature_string("图片数量限制", self.max_image_number),
257 | _generate_feature_string("正文待移除内容", self.content_to_remove),
258 | _generate_feature_string("连续抓取失败的次数", self.error_count),
259 | _generate_feature_string("停止更新", self.stop),
260 | _generate_feature_string("PikPak离线", self.pikpak_offline),
261 | _generate_feature_string("PikPak离线路径匹配", self.pikpak_path_key),
262 | ]
263 | return "\n".join([i for i in ret_list if i != ""])
264 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/__init__.py:
--------------------------------------------------------------------------------
1 | import re
2 | import sqlite3
3 | from difflib import SequenceMatcher
4 | from importlib import import_module
5 | from typing import Any, Dict, List
6 |
7 | import arrow
8 | import emoji
9 | from nonebot.log import logger
10 | from pyquery import PyQuery as Pq
11 |
12 | from ..config import DATA_PATH, config
13 | from ..rss_class import Rss
14 | from .cache_manage import (
15 | cache_db_manage,
16 | cache_json_manage,
17 | duplicate_exists,
18 | write_item,
19 | )
20 | from .check_update import check_update, get_item_date
21 | from .download_torrent import down_torrent, pikpak_offline
22 | from .handle_html_tag import handle_html_tag
23 | from .handle_images import handle_img
24 | from .handle_translation import handle_translation
25 | from .parsing_rss import ParsingBase
26 | from .routes import ALL_MODULES
27 | from .send_message import handle_send_msgs
28 | from .utils import get_proxy, get_summary
29 |
30 | for module in ALL_MODULES:
31 | import_module(f".routes.{module}", package=__name__)
32 |
33 |
34 | # 检查更新
35 | @ParsingBase.append_before_handler()
36 | async def handle_check_update(state: Dict[str, Any]):
37 | db = state.get("tinydb")
38 | change_data = check_update(db, state.get("new_data"))
39 | return {"change_data": change_data}
40 |
41 |
42 | # 判断是否满足推送条件
43 | @ParsingBase.append_before_handler(priority=11) # type: ignore
44 | async def handle_check_update(rss: Rss, state: Dict[str, Any]):
45 | change_data = state.get("change_data")
46 | db = state.get("tinydb")
47 | for item in change_data.copy():
48 | summary = get_summary(item)
49 | # 检查是否包含屏蔽词
50 | if config.black_word and re.findall("|".join(config.black_word), summary):
51 | logger.info("内含屏蔽词,已经取消推送该消息")
52 | write_item(db, item)
53 | change_data.remove(item)
54 | continue
55 | # 检查是否匹配关键词 使用 down_torrent_keyword 字段,命名是历史遗留导致,实际应该是白名单关键字
56 | if rss.down_torrent_keyword and not re.search(
57 | rss.down_torrent_keyword, summary
58 | ):
59 | write_item(db, item)
60 | change_data.remove(item)
61 | continue
62 | # 检查是否匹配黑名单关键词 使用 black_keyword 字段
63 | if rss.black_keyword and (
64 | re.search(rss.black_keyword, item["title"])
65 | or re.search(rss.black_keyword, summary)
66 | ):
67 | write_item(db, item)
68 | change_data.remove(item)
69 | continue
70 | # 检查是否只推送有图片的消息
71 | if (rss.only_pic or rss.only_has_pic) and not re.search(
72 | r"]+>|\[img]", summary
73 | ):
74 | logger.info(f"{rss.name} 已开启仅图片/仅含有图片,该消息没有图片,将跳过")
75 | write_item(db, item)
76 | change_data.remove(item)
77 |
78 | return {"change_data": change_data}
79 |
80 |
81 | # 如果启用了去重模式,对推送列表进行过滤
82 | @ParsingBase.append_before_handler(priority=12) # type: ignore
83 | async def handle_check_update(rss: Rss, state: Dict[str, Any]):
84 | change_data = state.get("change_data")
85 | conn = state.get("conn")
86 | db = state.get("tinydb")
87 |
88 | # 检查是否启用去重 使用 duplicate_filter_mode 字段
89 | if not rss.duplicate_filter_mode:
90 | return {"change_data": change_data}
91 |
92 | if not conn:
93 | conn = sqlite3.connect(str(DATA_PATH / "cache.db"))
94 | conn.set_trace_callback(logger.debug)
95 |
96 | cache_db_manage(conn)
97 |
98 | delete = []
99 | for index, item in enumerate(change_data):
100 | is_duplicate, image_hash = await duplicate_exists(
101 | rss=rss,
102 | conn=conn,
103 | item=item,
104 | summary=get_summary(item),
105 | )
106 | if is_duplicate:
107 | write_item(db, item)
108 | delete.append(index)
109 | else:
110 | change_data[index]["image_hash"] = str(image_hash)
111 |
112 | change_data = [
113 | item for index, item in enumerate(change_data) if index not in delete
114 | ]
115 |
116 | return {
117 | "change_data": change_data,
118 | "conn": conn,
119 | }
120 |
121 |
122 | # 处理标题
123 | @ParsingBase.append_handler(parsing_type="title")
124 | async def handle_title(rss: Rss, item: Dict[str, Any]) -> str:
125 | # 判断是否开启了只推送图片
126 | if rss.only_pic:
127 | return ""
128 |
129 | title = item["title"]
130 |
131 | if not config.blockquote:
132 | title = re.sub(r" - 转发 .*", "", title)
133 |
134 | res = f"标题:{title}\n"
135 | # 隔开标题和正文
136 | if not rss.only_title:
137 | res += "\n"
138 | if rss.translation:
139 | res += await handle_translation(content=title)
140 |
141 | # 如果开启了只推送标题,跳过下面判断标题与正文相似度的处理
142 | if rss.only_title:
143 | return emoji.emojize(res, language="alias")
144 |
145 | # 判断标题与正文相似度,避免标题正文一样,或者是标题为正文前N字等情况
146 | try:
147 | summary_html = Pq(get_summary(item))
148 | if not config.blockquote:
149 | summary_html.remove("blockquote")
150 | similarity = SequenceMatcher(None, summary_html.text()[: len(title)], title)
151 | # 标题正文相似度
152 | if similarity.ratio() > 0.6:
153 | res = ""
154 | except Exception as e:
155 | logger.warning(f"{rss.name} 没有正文内容!{e}")
156 |
157 | return emoji.emojize(res, language="alias")
158 |
159 |
160 | # 处理正文 判断是否是仅推送标题 、是否仅推送图片
161 | @ParsingBase.append_handler(parsing_type="summary", priority=1)
162 | async def handle_summary(rss: Rss, tmp_state: Dict[str, Any]) -> str:
163 | if rss.only_title or rss.only_pic:
164 | tmp_state["continue"] = False
165 | return ""
166 |
167 |
168 | # 处理正文 处理网页 tag
169 | @ParsingBase.append_handler(parsing_type="summary") # type: ignore
170 | async def handle_summary(rss: Rss, item: Dict[str, Any], tmp: str) -> str:
171 | try:
172 | tmp += handle_html_tag(html=Pq(get_summary(item)))
173 | except Exception as e:
174 | logger.warning(f"{rss.name} 没有正文内容!{e}")
175 | return tmp
176 |
177 |
178 | # 处理正文 移除指定内容
179 | @ParsingBase.append_handler(parsing_type="summary", priority=11) # type: ignore
180 | async def handle_summary(rss: Rss, tmp: str) -> str:
181 | # 移除指定内容
182 | if rss.content_to_remove:
183 | for pattern in rss.content_to_remove:
184 | tmp = re.sub(pattern, "", tmp)
185 | # 去除多余换行
186 | while "\n\n\n" in tmp:
187 | tmp = tmp.replace("\n\n\n", "\n\n")
188 | tmp = tmp.strip()
189 | return emoji.emojize(tmp, language="alias")
190 |
191 |
192 | # 处理正文 翻译
193 | @ParsingBase.append_handler(parsing_type="summary", priority=12) # type: ignore
194 | async def handle_summary(rss: Rss, tmp: str) -> str:
195 | if rss.translation:
196 | tmp += await handle_translation(tmp)
197 | return tmp
198 |
199 |
200 | # 处理图片
201 | @ParsingBase.append_handler(parsing_type="picture")
202 | async def handle_picture(rss: Rss, item: Dict[str, Any], tmp: str) -> str:
203 | # 判断是否开启了只推送标题
204 | if rss.only_title:
205 | return ""
206 |
207 | res = ""
208 | try:
209 | res += await handle_img(
210 | item=item,
211 | img_proxy=rss.img_proxy,
212 | img_num=rss.max_image_number,
213 | )
214 | except Exception as e:
215 | logger.warning(f"{rss.name} 没有正文内容!{e}")
216 |
217 | # 判断是否开启了只推送图片
218 | return f"{res}\n" if rss.only_pic else f"{tmp + res}\n"
219 |
220 |
221 | # 处理来源
222 | @ParsingBase.append_handler(parsing_type="source")
223 | async def handle_source(item: Dict[str, Any]) -> str:
224 | return f"链接:{item['link']}\n"
225 |
226 |
227 | # 处理种子
228 | @ParsingBase.append_handler(parsing_type="torrent")
229 | async def handle_torrent(rss: Rss, item: Dict[str, Any]) -> str:
230 | res: List[str] = []
231 | if not rss.is_open_upload_group:
232 | rss.group_id = []
233 | if rss.down_torrent:
234 | # 处理种子
235 | try:
236 | hash_list = await down_torrent(
237 | rss=rss, item=item, proxy=get_proxy(rss.img_proxy)
238 | )
239 | if hash_list and hash_list[0] is not None:
240 | res.append("\n磁力:")
241 | res.extend([f"magnet:?xt=urn:btih:{h}" for h in hash_list])
242 | except Exception:
243 | logger.exception("下载种子时出错")
244 | if rss.pikpak_offline:
245 | try:
246 | result = await pikpak_offline(
247 | rss=rss, item=item, proxy=get_proxy(rss.img_proxy)
248 | )
249 | if result:
250 | res.append("\nPikPak 离线成功")
251 | res.extend(
252 | [
253 | f"{r.get('name')}\n{r.get('file_size')} - {r.get('path')}"
254 | for r in result
255 | ]
256 | )
257 | except Exception:
258 | logger.exception("PikPak 离线时出错")
259 | return "\n".join(res)
260 |
261 |
262 | # 处理日期
263 | @ParsingBase.append_handler(parsing_type="date")
264 | async def handle_date(item: Dict[str, Any]) -> str:
265 | date = get_item_date(item)
266 | date = date.replace(tzinfo="local") if date > arrow.now() else date.to("local")
267 | return f"日期:{date.format('YYYY年MM月DD日 HH:mm:ss')}"
268 |
269 |
270 | # 发送消息
271 | @ParsingBase.append_handler(parsing_type="after")
272 | async def handle_message(
273 | rss: Rss,
274 | state: Dict[str, Any],
275 | item: Dict[str, Any],
276 | item_msg: str,
277 | ) -> str:
278 | if rss.send_forward_msg:
279 | return ""
280 |
281 | # 发送消息并写入文件
282 | await handle_send_msgs(rss=rss, messages=[item_msg], items=[item], state=state)
283 | return ""
284 |
285 |
286 | @ParsingBase.append_after_handler()
287 | async def after_handler(rss: Rss, state: Dict[str, Any]) -> Dict[str, Any]:
288 | if rss.send_forward_msg:
289 | # 发送消息并写入文件
290 | await handle_send_msgs(
291 | rss=rss, messages=state["messages"], items=state["items"], state=state
292 | )
293 |
294 | db = state["tinydb"]
295 | new_data_length = len(state["new_data"])
296 | cache_json_manage(db, new_data_length)
297 |
298 | message_count = len(state["change_data"])
299 | success_count = message_count - state["error_count"]
300 |
301 | if message_count > 10 and len(state["messages"]) == 10:
302 | return {}
303 |
304 | if success_count > 0:
305 | logger.info(f"{rss.name} 新消息推送完毕,共计:{success_count}/{message_count}")
306 | elif message_count > 0:
307 | logger.error(f"{rss.name} 新消息推送失败,共计:{message_count}")
308 | else:
309 | logger.info(f"{rss.name} 没有新信息")
310 |
311 | if conn := state["conn"]:
312 | conn.close()
313 |
314 | db.close()
315 |
316 | return {}
317 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/parsing/handle_images.py:
--------------------------------------------------------------------------------
1 | import base64
2 | import random
3 | import re
4 | from io import BytesIO
5 | from typing import Any, Dict, Optional, Tuple, Union
6 |
7 | import aiohttp
8 | from nonebot.log import logger
9 | from PIL import Image, UnidentifiedImageError
10 | from pyquery import PyQuery as Pq
11 | from tenacity import RetryError, retry, stop_after_attempt, stop_after_delay
12 | from yarl import URL
13 |
14 | from ..config import Path, config
15 | from ..rss_class import Rss
16 | from .utils import get_proxy, get_summary
17 |
18 |
19 | # 通过 ezgif 压缩 GIF
20 | @retry(stop=(stop_after_attempt(5) | stop_after_delay(30)))
21 | async def resize_gif(url: str, resize_ratio: int = 2) -> Optional[bytes]:
22 | async with aiohttp.ClientSession() as session:
23 | resp = await session.post(
24 | "https://s3.ezgif.com/resize",
25 | data={"new-image-url": url},
26 | )
27 | d = Pq(await resp.text())
28 | next_url = d("form").attr("action")
29 | _file = d("form > input[type=hidden]:nth-child(1)").attr("value")
30 | token = d("form > input[type=hidden]:nth-child(2)").attr("value")
31 | old_width = d("form > input[type=hidden]:nth-child(3)").attr("value")
32 | old_height = d("form > input[type=hidden]:nth-child(4)").attr("value")
33 | data = {
34 | "file": _file,
35 | "token": token,
36 | "old_width": old_width,
37 | "old_height": old_height,
38 | "width": str(int(old_width) // resize_ratio),
39 | "method": "gifsicle",
40 | "ar": "force",
41 | }
42 | resp = await session.post(next_url, params="ajax=true", data=data)
43 | d = Pq(await resp.text())
44 | output_img_url = "https:" + d("img:nth-child(1)").attr("src")
45 | return await download_image(output_img_url)
46 |
47 |
48 | # 通过 ezgif 把视频中间 4 秒转 GIF 作为预览
49 | @retry(stop=(stop_after_attempt(5) | stop_after_delay(30)))
50 | async def get_preview_gif_from_video(url: str) -> str:
51 | async with aiohttp.ClientSession() as session:
52 | resp = await session.post(
53 | "https://s3.ezgif.com/video-to-gif",
54 | data={"new-image-url": url},
55 | )
56 | d = Pq(await resp.text())
57 | video_length = re.search(
58 | r"\d\d:\d\d:\d\d", str(d("#main > p.filestats > strong"))
59 | ).group() # type: ignore
60 | hours = int(video_length.split(":")[0])
61 | minutes = int(video_length.split(":")[1])
62 | seconds = int(video_length.split(":")[2])
63 | video_length_median = (hours * 60 * 60 + minutes * 60 + seconds) // 2
64 | next_url = d("form").attr("action")
65 | _file = d("form > input[type=hidden]:nth-child(1)").attr("value")
66 | token = d("form > input[type=hidden]:nth-child(2)").attr("value")
67 | default_end = d("#end").attr("value")
68 | if float(default_end) >= 4:
69 | start = video_length_median - 2
70 | end = video_length_median + 2
71 | else:
72 | start = 0
73 | end = default_end
74 | data = {
75 | "file": _file,
76 | "token": token,
77 | "start": start,
78 | "end": end,
79 | "size": 320,
80 | "fps": 25,
81 | "method": "ffmpeg",
82 | }
83 | resp = await session.post(next_url, params="ajax=true", data=data)
84 | d = Pq(await resp.text())
85 | return f'https:{d("img:nth-child(1)").attr("src")}'
86 |
87 |
88 | # 图片压缩
89 | async def zip_pic(url: str, content: bytes) -> Union[Image.Image, bytes, None]:
90 | # 打开一个 JPEG/PNG/GIF/WEBP 图像文件
91 | try:
92 | im = Image.open(BytesIO(content))
93 | except UnidentifiedImageError:
94 | logger.error(f"无法识别图像文件 链接:[{url}]")
95 | return None
96 | if im.format != "GIF":
97 | # 先把 WEBP 图像转为 PNG
98 | if im.format == "WEBP":
99 | with BytesIO() as output:
100 | im.save(output, "PNG")
101 | im = Image.open(output)
102 | # 对图像文件进行缩小处理
103 | im.thumbnail((config.zip_size, config.zip_size))
104 | width, height = im.size
105 | logger.debug(f"Resize image to: {width} x {height}")
106 | # 和谐
107 | points = [(0, 0), (0, height - 1), (width - 1, 0), (width - 1, height - 1)]
108 | for x, y in points:
109 | im.putpixel((x, y), random.randint(0, 255))
110 | return im
111 | else:
112 | if len(content) > config.gif_zip_size * 1024:
113 | try:
114 | return await resize_gif(url)
115 | except RetryError:
116 | logger.error(f"GIF 图片[{url}]压缩失败,将发送原图")
117 | return content
118 |
119 |
120 | # 将图片转化为 base64
121 | def get_pic_base64(content: Union[Image.Image, bytes, None]) -> str:
122 | if not content:
123 | return ""
124 | if isinstance(content, Image.Image):
125 | with BytesIO() as output:
126 | content.save(output, format=content.format)
127 | content = output.getvalue()
128 | if isinstance(content, bytes):
129 | return str(base64.b64encode(content).decode())
130 | return ""
131 |
132 |
133 | # 去你的 pixiv.cat
134 | async def fuck_pixiv_cat(url: str) -> str:
135 | img_id = re.sub("https://pixiv.cat/", "", url)
136 | img_id = img_id[:-4]
137 | info_list = img_id.split("-")
138 | async with aiohttp.ClientSession() as session:
139 | try:
140 | resp = await session.get(
141 | f"https://api.obfs.dev/api/pixiv/illust?id={info_list[0]}"
142 | )
143 | resp_json = await resp.json()
144 | if len(info_list) >= 2:
145 | return str(
146 | resp_json["illust"]["meta_pages"][int(info_list[1]) - 1][
147 | "image_urls"
148 | ]["original"]
149 | )
150 | else:
151 | return str(
152 | resp_json["illust"]["meta_single_page"]["original_image_url"]
153 | )
154 | except Exception as e:
155 | logger.error(f"处理pixiv.cat链接时出现问题 :{e} 链接:[{url}]")
156 | return url
157 |
158 |
159 | @retry(stop=(stop_after_attempt(5) | stop_after_delay(30)))
160 | async def download_image_detail(url: str, proxy: bool) -> Optional[bytes]:
161 | async with aiohttp.ClientSession(raise_for_status=True) as session:
162 | referer = f"{URL(url).scheme}://{URL(url).host}/"
163 | headers = {"referer": referer}
164 | try:
165 | resp = await session.get(
166 | url, headers=headers, proxy=get_proxy(open_proxy=proxy)
167 | )
168 | # 如果图片无法获取到,直接返回
169 | if len(await resp.read()) == 0:
170 | if "pixiv.cat" in url:
171 | url = await fuck_pixiv_cat(url=url)
172 | return await download_image(url, proxy)
173 | logger.error(
174 | f"图片[{url}]下载失败! Content-Type: {resp.headers['Content-Type']} status: {resp.status}"
175 | )
176 | return None
177 | # 如果图片格式为 SVG ,先转换为 PNG
178 | if resp.headers["Content-Type"].startswith("image/svg+xml"):
179 | next_url = str(
180 | URL("https://images.weserv.nl/").with_query(f"url={url}&output=png")
181 | )
182 | return await download_image(next_url, proxy)
183 | return await resp.read()
184 | except Exception as e:
185 | logger.warning(f"图片[{url}]下载失败!将重试最多 5 次!\n{e}")
186 | raise
187 |
188 |
189 | async def download_image(url: str, proxy: bool = False) -> Optional[bytes]:
190 | try:
191 | return await download_image_detail(url=url, proxy=proxy)
192 | except RetryError:
193 | logger.error(f"图片[{url}]下载失败!已达最大重试次数!有可能需要开启代理!")
194 | return None
195 |
196 |
197 | async def handle_img_combo(url: str, img_proxy: bool, rss: Optional[Rss] = None) -> str:
198 | """'
199 | 下载图片并返回可用的CQ码
200 |
201 | 参数:
202 | url: 需要下载的图片地址
203 | img_proxy: 是否使用代理下载图片
204 | rss: Rss对象
205 | 返回值:
206 | 返回当前图片的CQ码,以base64格式编码发送
207 | 如获取图片失败将会提示图片走丢了
208 | """
209 | if content := await download_image(url, img_proxy):
210 | if rss is not None and rss.download_pic:
211 | _url = URL(url)
212 | logger.debug(f"正在保存图片: {url}")
213 | try:
214 | save_image(content=content, file_url=_url, rss=rss)
215 | except Exception as e:
216 | logger.warning(f"在保存图片到本地时出现错误\nE:{repr(e)}")
217 | if resize_content := await zip_pic(url, content):
218 | if img_base64 := get_pic_base64(resize_content):
219 | return f"[CQ:image,file=base64://{img_base64}]"
220 | return f"\n图片走丢啦 链接:[{url}]\n"
221 |
222 |
223 | async def handle_img_combo_with_content(url: str, content: bytes) -> str:
224 | if resize_content := await zip_pic(url, content):
225 | if img_base64 := get_pic_base64(resize_content):
226 | return f"[CQ:image,file=base64://{img_base64}]"
227 | return f"\n图片走丢啦 链接:[{url}]\n" if url else "\n图片走丢啦\n"
228 |
229 |
230 | # 处理图片、视频
231 | async def handle_img(item: Dict[str, Any], img_proxy: bool, img_num: int) -> str:
232 | if item.get("image_content"):
233 | return await handle_img_combo_with_content(
234 | item.get("gif_url", ""), item["image_content"]
235 | )
236 | html = Pq(get_summary(item))
237 | img_str = ""
238 | # 处理图片
239 | doc_img = list(html("img").items())
240 | # 只发送限定数量的图片,防止刷屏
241 | if 0 < img_num < len(doc_img):
242 | img_str += f"\n因启用图片数量限制,目前只有 {img_num} 张图片:"
243 | doc_img = doc_img[:img_num]
244 | for img in doc_img:
245 | url = img.attr("src")
246 | img_str += await handle_img_combo(url, img_proxy)
247 |
248 | # 处理视频
249 | if doc_video := html("video"):
250 | img_str += "\n视频封面:"
251 | for video in doc_video.items():
252 | url = video.attr("poster")
253 | img_str += await handle_img_combo(url, img_proxy)
254 |
255 | return img_str
256 |
257 |
258 | # 处理 bbcode 图片
259 | async def handle_bbcode_img(html: Pq, img_proxy: bool, img_num: int) -> str:
260 | img_str = ""
261 | # 处理图片
262 | img_list = re.findall(r"\[img[^]]*](.+)\[/img]", str(html), flags=re.I)
263 | # 只发送限定数量的图片,防止刷屏
264 | if 0 < img_num < len(img_list):
265 | img_str += f"\n因启用图片数量限制,目前只有 {img_num} 张图片:"
266 | img_list = img_list[:img_num]
267 | for img_tmp in img_list:
268 | img_str += await handle_img_combo(img_tmp, img_proxy)
269 |
270 | return img_str
271 |
272 |
273 | def file_name_format(file_url: URL, rss: Rss) -> Tuple[Path, str]:
274 | """
275 | 可以根据用户设置的规则来格式化文件名
276 | """
277 | format_rule = config.img_format or ""
278 | down_path = config.img_down_path or ""
279 | rules = { # 替换格式化字符串
280 | "{subs}": rss.name,
281 | "{name}": (
282 | file_url.name if "{ext}" not in format_rule else Path(file_url.name).stem
283 | ),
284 | "{ext}": file_url.suffix if "{ext}" in format_rule else "",
285 | }
286 | for k, v in rules.items():
287 | format_rule = format_rule.replace(k, v)
288 | if down_path == "": # 如果没设置保存路径的话,就保存到默认目录下
289 | save_path = Path().cwd() / "data" / "image"
290 | elif down_path[0] == ".":
291 | save_path = Path().cwd() / Path(down_path)
292 | else:
293 | save_path = Path(down_path)
294 | full_path = save_path / format_rule
295 | save_path = full_path.parents[0]
296 | save_name = full_path.name
297 | return save_path, save_name
298 |
299 |
300 | def save_image(content: bytes, file_url: URL, rss: Rss) -> None:
301 | """
302 | 将压缩之前的原图保存到本地的电脑上
303 | """
304 | save_path, save_name = file_name_format(file_url=file_url, rss=rss)
305 |
306 | full_save_path = save_path / save_name
307 | try:
308 | full_save_path.write_bytes(content)
309 | except FileNotFoundError:
310 | # 初次写入时文件夹不存在,需要创建一下
311 | save_path.mkdir(parents=True)
312 | full_save_path.write_bytes(content)
313 |
--------------------------------------------------------------------------------
/src/plugins/ELF_RSS2/command/change_dy.py:
--------------------------------------------------------------------------------
1 | import re
2 | from contextlib import suppress
3 | from copy import deepcopy
4 | from typing import Any, List, Match, Optional
5 |
6 | from nonebot import on_command
7 | from nonebot.adapters.onebot.v11 import GroupMessageEvent, Message, MessageEvent
8 | from nonebot.adapters.onebot.v11.permission import GROUP_ADMIN, GROUP_OWNER
9 | from nonebot.log import logger
10 | from nonebot.matcher import Matcher
11 | from nonebot.params import ArgPlainText, CommandArg
12 | from nonebot.permission import SUPERUSER
13 | from nonebot.rule import to_me
14 |
15 | from .. import my_trigger as tr
16 | from ..config import DATA_PATH
17 | from ..rss_class import Rss
18 | from ..utils import regex_validate
19 |
20 | RSS_CHANGE = on_command(
21 | "change",
22 | aliases={"修改订阅", "modify"},
23 | rule=to_me(),
24 | priority=5,
25 | permission=GROUP_ADMIN | GROUP_OWNER | SUPERUSER,
26 | )
27 |
28 |
29 | @RSS_CHANGE.handle()
30 | async def handle_first_receive(matcher: Matcher, args: Message = CommandArg()) -> None:
31 | if args.extract_plain_text():
32 | matcher.set_arg("RSS_CHANGE", args)
33 |
34 |
35 | # 处理带多个值的订阅参数
36 | def handle_property(value: str, property_list: List[Any]) -> List[Any]:
37 | # 清空
38 | if value == "-1":
39 | return []
40 | value_list = value.split(",")
41 | # 追加
42 | if value_list[0] == "":
43 | value_list.pop(0)
44 | return property_list + [i for i in value_list if i not in property_list]
45 | # 防止用户输入重复参数,去重并保持原来的顺序
46 | return list(dict.fromkeys(value_list))
47 |
48 |
49 | # 处理类型为正则表达式的订阅参数
50 | def handle_regex_property(value: str, old_value: str) -> Optional[str]:
51 | result = None
52 | if not value:
53 | result = None
54 | elif value.startswith("+"):
55 | result = f"{old_value}|{value.lstrip('+')}" if old_value else value.lstrip("+")
56 | elif value.startswith("-"):
57 | if regex_list := old_value.split("|"):
58 | with suppress(ValueError):
59 | regex_list.remove(value.lstrip("-"))
60 | result = "|".join(regex_list) if regex_list else None
61 | else:
62 | result = value
63 | if isinstance(result, str) and not regex_validate(result):
64 | result = None
65 | return result
66 |
67 |
68 | attribute_dict = {
69 | "name": "name",
70 | "url": "url",
71 | "qq": "user_id",
72 | "qun": "group_id",
73 | "channel": "guild_channel_id",
74 | "time": "time",
75 | "proxy": "img_proxy",
76 | "tl": "translation",
77 | "ot": "only_title",
78 | "op": "only_pic",
79 | "ohp": "only_has_pic",
80 | "downpic": "download_pic",
81 | "upgroup": "is_open_upload_group",
82 | "downopen": "down_torrent",
83 | "downkey": "down_torrent_keyword",
84 | "wkey": "down_torrent_keyword",
85 | "blackkey": "black_keyword",
86 | "bkey": "black_keyword",
87 | "mode": "duplicate_filter_mode",
88 | "img_num": "max_image_number",
89 | "stop": "stop",
90 | "pikpak": "pikpak_offline",
91 | "ppk": "pikpak_path_key",
92 | "forward": "send_forward_msg",
93 | }
94 |
95 |
96 | def handle_name_change(rss: Rss, value_to_change: str) -> None:
97 | tr.delete_job(rss)
98 | rss.rename_file(str(DATA_PATH / f"{Rss.handle_name(value_to_change)}.json"))
99 |
100 |
101 | def handle_time_change(value_to_change: str) -> str:
102 | if not re.search(r"[_*/,-]", value_to_change):
103 | if int(float(value_to_change)) < 1:
104 | return "1"
105 | else:
106 | return str(int(float(value_to_change)))
107 | return value_to_change
108 |
109 |
110 | # 处理要修改的订阅参数
111 | def handle_change_list(
112 | rss: Rss,
113 | key_to_change: str,
114 | value_to_change: str,
115 | group_id: Optional[int],
116 | guild_channel_id: Optional[str],
117 | ) -> None:
118 | if key_to_change == "name":
119 | handle_name_change(rss, value_to_change)
120 | elif (
121 | key_to_change in {"qq", "qun", "channel"}
122 | and not group_id
123 | and not guild_channel_id
124 | ) or key_to_change == "mode":
125 | value_to_change = handle_property(
126 | value_to_change, getattr(rss, attribute_dict[key_to_change])
127 | ) # type:ignore
128 | elif key_to_change == "time":
129 | value_to_change = handle_time_change(value_to_change)
130 | elif key_to_change in {
131 | "proxy",
132 | "tl",
133 | "ot",
134 | "op",
135 | "ohp",
136 | "downpic",
137 | "upgroup",
138 | "downopen",
139 | "stop",
140 | "pikpak",
141 | "forward",
142 | }:
143 | value_to_change = bool(int(value_to_change)) # type:ignore
144 | if key_to_change == "stop" and not value_to_change and rss.error_count > 0:
145 | rss.error_count = 0
146 | elif key_to_change in {"downkey", "wkey", "blackkey", "bkey"}:
147 | value_to_change = handle_regex_property(
148 | value_to_change, getattr(rss, attribute_dict[key_to_change])
149 | ) # type:ignore
150 | elif key_to_change == "ppk" and not value_to_change:
151 | value_to_change = None # type:ignore
152 | elif key_to_change == "img_num":
153 | value_to_change = int(value_to_change) # type:ignore
154 | setattr(rss, attribute_dict.get(key_to_change), value_to_change) # type:ignore
155 |
156 |
157 | prompt = """\
158 | 请输入要修改的订阅
159 | 订阅名[,订阅名,...] 属性=值[ 属性=值 ...]
160 | 如:
161 | test1[,test2,...] qq=,123,234 qun=-1
162 | 对应参数:
163 | 订阅名(-name): 禁止将多个订阅批量改名,名称相同会冲突
164 | 订阅链接(-url)
165 | QQ(-qq)
166 | 群(-qun)
167 | 更新频率(-time)
168 | 代理(-proxy)
169 | 翻译(-tl)
170 | 仅Title(ot)
171 | 仅图片(-op)
172 | 仅含图片(-ohp)
173 | 下载图片(-downpic): 下载图片到本地硬盘,仅pixiv有效
174 | 下载种子(-downopen)
175 | 白名单关键词(-wkey)
176 | 黑名单关键词(-bkey)
177 | 种子上传到群(-upgroup)
178 | 去重模式(-mode)
179 | 图片数量限制(-img_num): 只发送限定数量的图片,防止刷屏
180 | 正文移除内容(-rm_list): 从正文中移除指定内容,支持正则
181 | 停止更新(-stop): 停止更新订阅
182 | PikPak离线(-pikpak): 开启PikPak离线下载
183 | PikPak离线路径匹配(-ppk): 匹配离线下载的文件夹,设置该值后生效
184 | 发送合并消息(-forward): 当一次更新多条消息时,尝试发送合并消息
185 | 注:
186 | 1. 仅含有图片不同于仅图片,除了图片还会发送正文中的其他文本信息
187 | 2. proxy/tl/ot/op/ohp/downopen/upgroup/stop/pikpak 值为 1/0
188 | 3. 去重模式分为按链接(link)、标题(title)、图片(image)判断,其中 image 模式生效对象限定为只带 1 张图片的消息。如果属性中带有 or 说明判断逻辑是任一匹配即去重,默认为全匹配
189 | 4. 白名单关键词支持正则表达式,匹配时推送消息及下载,设为空(wkey=)时不生效
190 | 5. 黑名单关键词同白名单相似,匹配时不推送,两者可以一起用
191 | 6. 正文待移除内容格式必须如:rm_list='a' 或 rm_list='a','b'。该处理过程在解析 html 标签后进行,设为空使用 rm_list='-1'"
192 | 7. QQ、群号、去重模式前加英文逗号表示追加,-1设为空
193 | 8. 各个属性使用空格分割
194 | 9. downpic保存的文件位于程序根目录下 "data/image/订阅名/图片名"
195 | 详细用法请查阅文档。\
196 | """
197 |
198 |
199 | async def filter_rss_by_permissions(
200 | rss_list: List[Rss],
201 | change_info: str,
202 | group_id: Optional[int],
203 | guild_channel_id: Optional[str],
204 | ) -> List[Rss]:
205 | if group_id:
206 | if re.search(" (qq|qun|channel)=", change_info):
207 | await RSS_CHANGE.finish(
208 | "❌ 禁止在群组中修改订阅账号!如要取消订阅请使用 deldy 命令!"
209 | )
210 | rss_list = [
211 | rss
212 | for rss in rss_list
213 | if rss.group_id == [str(group_id)]
214 | and not rss.user_id
215 | and not rss.guild_channel_id
216 | ]
217 |
218 | if guild_channel_id:
219 | if re.search(" (qq|qun|channel)=", change_info):
220 | await RSS_CHANGE.finish(
221 | "❌ 禁止在子频道中修改订阅账号!如要取消订阅请使用 deldy 命令!"
222 | )
223 | rss_list = [
224 | rss
225 | for rss in rss_list
226 | if rss.guild_channel_id == [str(guild_channel_id)]
227 | and not rss.user_id
228 | and not rss.group_id
229 | ]
230 |
231 | if not rss_list:
232 | await RSS_CHANGE.finish(
233 | "❌ 请检查是否存在以下问题:\n1.要修改的订阅名不存在对应的记录\n2.当前群组或频道无权操作"
234 | )
235 |
236 | return rss_list
237 |
238 |
239 | @RSS_CHANGE.got("RSS_CHANGE", prompt=prompt)
240 | async def handle_rss_change(
241 | event: MessageEvent, change_info: str = ArgPlainText("RSS_CHANGE")
242 | ) -> None:
243 | group_id = event.group_id if isinstance(event, GroupMessageEvent) else None
244 | guild_channel_id = None
245 | name_list = change_info.split(" ")[0].split(",")
246 | rss_list: List[Rss] = []
247 | for name in name_list:
248 | if rss_tmp := Rss.get_one_by_name(name=name):
249 | rss_list.append(rss_tmp)
250 |
251 | # 出于公平考虑,限制订阅者只有当前群组或频道时才能修改订阅,否则只有超级管理员能修改
252 | rss_list = await filter_rss_by_permissions(
253 | rss_list, change_info, group_id, guild_channel_id
254 | )
255 |
256 | if len(rss_list) > 1 and " name=" in change_info:
257 | await RSS_CHANGE.finish("❌ 禁止将多个订阅批量改名!会因为名称相同起冲突!")
258 |
259 | # 参数特殊处理:正文待移除内容
260 | rm_list_exist = re.search("rm_list='.+'", change_info)
261 | change_list = handle_rm_list(rss_list, change_info, rm_list_exist)
262 |
263 | changed_rss_list = await batch_change_rss(
264 | change_list, group_id, guild_channel_id, rss_list, rm_list_exist
265 | )
266 | # 隐私考虑,不展示除当前群组或频道外的群组、频道和QQ
267 | rss_msg_list = [
268 | str(rss.hide_some_infos(group_id, guild_channel_id)) for rss in changed_rss_list
269 | ]
270 | result_msg = f"👏 修改了 {len(rss_msg_list)} 条订阅"
271 | if rss_msg_list:
272 | separator = "\n----------------------\n"
273 | result_msg += separator + separator.join(rss_msg_list)
274 | await RSS_CHANGE.finish(result_msg)
275 |
276 |
277 | async def validate_rss_change(key_to_change: str, value_to_change: str) -> None:
278 | # 对用户输入的去重模式参数进行校验
279 | mode_property_set = {"", "-1", "link", "title", "image", "or"}
280 | if key_to_change == "mode" and (
281 | set(value_to_change.split(",")) - mode_property_set or value_to_change == "or"
282 | ):
283 | await RSS_CHANGE.finish(
284 | f"❌ 去重模式参数错误!\n{key_to_change}={value_to_change}"
285 | )
286 | elif key_to_change in {
287 | "downkey",
288 | "wkey",
289 | "blackkey",
290 | "bkey",
291 | } and not regex_validate(value_to_change.lstrip("+-")):
292 | await RSS_CHANGE.finish(
293 | f"❌ 正则表达式错误!\n{key_to_change}={value_to_change}"
294 | )
295 | elif key_to_change == "ppk" and not regex_validate(value_to_change):
296 | await RSS_CHANGE.finish(
297 | f"❌ 正则表达式错误!\n{key_to_change}={value_to_change}"
298 | )
299 |
300 |
301 | async def batch_change_rss(
302 | change_list: List[str],
303 | group_id: Optional[int],
304 | guild_channel_id: Optional[str],
305 | rss_list: List[Rss],
306 | rm_list_exist: Optional[Match[str]] = None,
307 | ) -> List[Rss]:
308 | changed_rss_list = []
309 |
310 | for rss in rss_list:
311 | new_rss = deepcopy(rss)
312 | rss_name = rss.name
313 |
314 | for change_dict in change_list:
315 | key_to_change, value_to_change = change_dict.split("=", 1)
316 |
317 | if key_to_change in attribute_dict.keys():
318 | await validate_rss_change(key_to_change, value_to_change)
319 | handle_change_list(
320 | new_rss, key_to_change, value_to_change, group_id, guild_channel_id
321 | )
322 | else:
323 | await RSS_CHANGE.finish(f"❌ 参数错误!\n{change_dict}")
324 |
325 | if new_rss.__dict__ == rss.__dict__ and not rm_list_exist:
326 | continue
327 | changed_rss_list.append(new_rss)
328 |
329 | # 参数解析完毕,写入
330 | new_rss.upsert(rss_name)
331 |
332 | # 加入定时任务
333 | if not new_rss.stop:
334 | await tr.add_job(new_rss)
335 | elif not rss.stop:
336 | tr.delete_job(new_rss)
337 | logger.info(f"{rss_name} 已停止更新")
338 |
339 | return changed_rss_list
340 |
341 |
342 | # 参数特殊处理:正文待移除内容
343 | def handle_rm_list(
344 | rss_list: List[Rss], change_info: str, rm_list_exist: Optional[Match[str]] = None
345 | ) -> List[str]:
346 | rm_list = None
347 |
348 | if rm_list_exist:
349 | rm_list_str = rm_list_exist[0].lstrip().replace("rm_list=", "")
350 | rm_list = [i.strip("'") for i in rm_list_str.split("','")]
351 | change_info = change_info.replace(rm_list_exist[0], "").strip()
352 |
353 | if rm_list:
354 | for rss in rss_list:
355 | if len(rm_list) == 1 and rm_list[0] == "-1":
356 | setattr(rss, "content_to_remove", None)
357 | elif valid_rm_list := [i for i in rm_list if regex_validate(i)]:
358 | setattr(rss, "content_to_remove", valid_rm_list)
359 |
360 | change_list = [i.strip() for i in change_info.split(" ")]
361 | # 去掉订阅名
362 | change_list.pop(0)
363 |
364 | return change_list
365 |
--------------------------------------------------------------------------------