 28 |
29 | * 도메인은 일반최상위도메인(gTLD: Generic Top Level Domain)과 국가최상위도메인(ccTLD: Country Code Top Level Domain)로 구분할 수 있으며 여기서 일반최상위도메인은 다시 스폰서도메인(Sponsored TLD)과 언스폰서도메인(Unsponsored TLD)으로 구분됩니다.
30 |
31 |
28 |
29 | * 도메인은 일반최상위도메인(gTLD: Generic Top Level Domain)과 국가최상위도메인(ccTLD: Country Code Top Level Domain)로 구분할 수 있으며 여기서 일반최상위도메인은 다시 스폰서도메인(Sponsored TLD)과 언스폰서도메인(Unsponsored TLD)으로 구분됩니다.
30 |
31 | 



 7 |
8 | * Doman Name System의 약자로 도메인 네임을 IP주소로 매핑하는 시스템입니다.
9 | * client 컴퓨터가 도메인 이름의 ip주소를 물어보면 알려주고, 서버 컴퓨터는 자신의 이름과 IP주소를 DNS서버에 저장합니다.
10 |
11 |
12 | #### 💡 Domain Name 구조를 설명해주세요.
13 |
7 |
8 | * Doman Name System의 약자로 도메인 네임을 IP주소로 매핑하는 시스템입니다.
9 | * client 컴퓨터가 도메인 이름의 ip주소를 물어보면 알려주고, 서버 컴퓨터는 자신의 이름과 IP주소를 DNS서버에 저장합니다.
10 |
11 |
12 | #### 💡 Domain Name 구조를 설명해주세요.
13 |  14 |
15 |
16 | * Root DNS server는 Top level의 주소 목록을 알고 있습니다.
17 |
18 | * Top level 서버는 Second level의 주소 목록을 알고 있습니다.
19 |
20 | * Second level 서버는 sub의 주소 목록을 알고 있습니다.
21 |
22 | * 모든 dns서버는 루트의 주소를 알고 있고, sub 서버가 Doman Name의 최종 ip 주소를 알려줍니다.
23 |
24 | #### 💡 Domain Name System 과정을 설명해주세요.
25 |
26 | * 사용자 컴퓨터의 운영체제가 hosts에 ip주소가 저장되었는지 확인합니다.
27 | * 없으면 로컬 DNS서버에 묻습니다. 로컬 DNS서버도 모르면 root서버에게 묻습니다.
28 | 1. 처음에 사용자가 root 서버에게 주소를 물어봅니다.
29 | root서버는 "com"의 top level 서버 주소를 알려줍니다.
30 |
31 | 2. 사용자는 top level 서버에게 주소를 물어봅니다.
32 | top level 서버는 "example.com"의 second level 서버 주소를 알려줍니다.
33 |
34 | 3. 사용자는 second level 서버에게 주소를 물어봅니다.
35 | second level 서버는 "blog.example.com"의 sub 서버 주소를 알려줍니다.
36 |
37 | 4. 사용자는 sub 서버에게 주소를 물어봅니다.
38 | sub 서버는 사용자에게 최종적으로 "blog.example.com"의 ip주소를 알려줍니다.
39 |
40 |
41 |
14 |
15 |
16 | * Root DNS server는 Top level의 주소 목록을 알고 있습니다.
17 |
18 | * Top level 서버는 Second level의 주소 목록을 알고 있습니다.
19 |
20 | * Second level 서버는 sub의 주소 목록을 알고 있습니다.
21 |
22 | * 모든 dns서버는 루트의 주소를 알고 있고, sub 서버가 Doman Name의 최종 ip 주소를 알려줍니다.
23 |
24 | #### 💡 Domain Name System 과정을 설명해주세요.
25 |
26 | * 사용자 컴퓨터의 운영체제가 hosts에 ip주소가 저장되었는지 확인합니다.
27 | * 없으면 로컬 DNS서버에 묻습니다. 로컬 DNS서버도 모르면 root서버에게 묻습니다.
28 | 1. 처음에 사용자가 root 서버에게 주소를 물어봅니다.
29 | root서버는 "com"의 top level 서버 주소를 알려줍니다.
30 |
31 | 2. 사용자는 top level 서버에게 주소를 물어봅니다.
32 | top level 서버는 "example.com"의 second level 서버 주소를 알려줍니다.
33 |
34 | 3. 사용자는 second level 서버에게 주소를 물어봅니다.
35 | second level 서버는 "blog.example.com"의 sub 서버 주소를 알려줍니다.
36 |
37 | 4. 사용자는 sub 서버에게 주소를 물어봅니다.
38 | sub 서버는 사용자에게 최종적으로 "blog.example.com"의 ip주소를 알려줍니다.
39 |
40 |
41 |  61 |
62 | * __Contents Delevery Network__ 의 약자입니다.
63 | * 지리, 물리적으로 떨어져있는 사용자에게 컨텐츠를 더 빠르게 제공할 수 있는 기술입니다.
64 | * 서버를 여러곳에 두고 사용자가 요청했을 때 제일 근접한 서버에서 처리합니다. 그러기 위해서 사용자와 가까운 Cache Server 에 해당 데이터를 캐싱합니다. 그래서 1개의 서버가 망가지더라도 다른 서버에서 데이터를 제공할 수 있습니다.
65 |
66 | * 단점
67 | * OriginServer 들은 모든 사용자의 요청에 일일이 응답해야 합니다. 그래서 트래픽이 과도하게 증가하면 장애가 발생할 확률이 큽니다.
68 |
69 | * 작동 원리
70 | 1. 최초 요청은 서버로 부터 컨텐츠를 가져와 고객에게 전송하며 동시에 CDN 캐싱장비에 저장한다.
71 | 2. 두번째 이후 모든 요청은 만료 시점까지 CDN캐싱장비에 저장된 컨텐츠를 전송한다.
72 | 3. 자주 사용하는 페이지에 한해서 CDN장비에 캐싱이 되며, 해당 컨텐츠 호출이 없을 경우 주기적으로 삭제된다.
73 |
74 | 4. 서버가 파일을 찾는 데 실패하는 경우 CDN 플랫폼의 다른 서버에서 콘텐츠를 찾아 엔드유저에게 응답을 전송한다.
75 |
76 | 5. 콘텐츠를 사용할 수 없거나 콘텐츠가 오래된 경우, CDN은 서버에 대한 요청을 프록시로 작동하여 향후 요청에 대해 응답할 수 있도록 새로운 콘텐츠를 저장한다.
77 |
78 | 출처: https://goddaehee.tistory.com/173 [갓대희의 작은공간]
79 |
61 |
62 | * __Contents Delevery Network__ 의 약자입니다.
63 | * 지리, 물리적으로 떨어져있는 사용자에게 컨텐츠를 더 빠르게 제공할 수 있는 기술입니다.
64 | * 서버를 여러곳에 두고 사용자가 요청했을 때 제일 근접한 서버에서 처리합니다. 그러기 위해서 사용자와 가까운 Cache Server 에 해당 데이터를 캐싱합니다. 그래서 1개의 서버가 망가지더라도 다른 서버에서 데이터를 제공할 수 있습니다.
65 |
66 | * 단점
67 | * OriginServer 들은 모든 사용자의 요청에 일일이 응답해야 합니다. 그래서 트래픽이 과도하게 증가하면 장애가 발생할 확률이 큽니다.
68 |
69 | * 작동 원리
70 | 1. 최초 요청은 서버로 부터 컨텐츠를 가져와 고객에게 전송하며 동시에 CDN 캐싱장비에 저장한다.
71 | 2. 두번째 이후 모든 요청은 만료 시점까지 CDN캐싱장비에 저장된 컨텐츠를 전송한다.
72 | 3. 자주 사용하는 페이지에 한해서 CDN장비에 캐싱이 되며, 해당 컨텐츠 호출이 없을 경우 주기적으로 삭제된다.
73 |
74 | 4. 서버가 파일을 찾는 데 실패하는 경우 CDN 플랫폼의 다른 서버에서 콘텐츠를 찾아 엔드유저에게 응답을 전송한다.
75 |
76 | 5. 콘텐츠를 사용할 수 없거나 콘텐츠가 오래된 경우, CDN은 서버에 대한 요청을 프록시로 작동하여 향후 요청에 대해 응답할 수 있도록 새로운 콘텐츠를 저장한다.
77 |
78 | 출처: https://goddaehee.tistory.com/173 [갓대희의 작은공간]
79 |  60 |
61 | * OSI 7 계층 구조와 흐름
62 |
63 |
60 |
61 | * OSI 7 계층 구조와 흐름
62 |
63 |  64 |
65 |
64 |
65 |  76 |
77 | * Encapsulation/Decapsulation
78 |
79 |
76 |
77 | * Encapsulation/Decapsulation
78 |
79 |  80 |
81 |
82 | * IP 프로토콜 in 인터넷 계층
83 |
84 | IP 프로토콜은 라우팅 방법을 정의하는 것입니다. 상위 계층인 전송 계층이 데이터 전달의 신뢰성을 책임진다는 가정하에 어떤 경로로 패킷을 전송할 것인가에 초점을 둡니다.
85 |
86 | * TCP 프로토콜 in 전송 계층
87 |
88 | **TCP 프로토콜**은 신뢰성 있는 데이터의 전송을 담당합니다.
89 |
90 | IP 프로토콜은 TCP가 데이터를 보낼 때 기반이 되는 프로토콜입니다. IP 계층은 문제가 발생해도 해결해주지 않는 신뢰되지 않은 프로토콜입니다.
91 |
92 | 이 문저젬을 해결해 주는 것이 TCP 프로토콜입니다.
93 | TCP 프로토콜은 데이터가 순서에 맞게 올바르게 전송이 갔는지 확인을 해줍니다. 즉, TCP는 신뢰성 없는 IP에 신뢰성을 부여한 프로토콜입니다.
94 |
--------------------------------------------------------------------------------
/01.network/lyj/21.01.13.md:
--------------------------------------------------------------------------------
1 | # 21.01.13
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 질문1. 프로토콜이란 무엇인가요?
6 | * 컴퓨터간 데이터 통신을 원활하게 하기 위해 규정한 규약입니다. 프로토콜에는 신호 송신의 순서나 표현법, 오류 검출법 등을 정해둡니다.
7 |
8 | #### 💡 [질문2. TCP와 UDP의 차이점은 무엇인가요?](#개념1)
9 | * TCP 프로토콜은 연결 지향적이며, 신뢰성이 보장된다는 특징이 있습니다.
10 |
11 | 이와 달리, UDP 프로토콜은 비연결 지향적이며, 성능이 빠르다는 특징이 있습니다.
12 |
13 |
14 | #### 💡 [질문3. TCP 3 way handshaking이 무엇인가요?](#개념2)
15 |
16 | * 클라이언트와 서버가 통신을 하기전 정확한 전송을 보장하기 위해 컴퓨터간 세션을 수립하는 과정으로서 TCP 프로토콜에서 신뢰성을 보장하기 위해 사용됩니다.
17 |
18 | #### 💡 [질문4. TCP 4 way handshaking이 무엇인가요?](#개념2)
19 |
20 | * 클라이언트와 서버가 연결하기 위해 3-way handshaking 과정이 필요하듯이 연결을 종료할때에도 데이터 손실없는 전송을 보장하기 위해 handshaking 과정이 필요한데 이것이 4-way handshaking 입니다.
21 |
22 |
80 |
81 |
82 | * IP 프로토콜 in 인터넷 계층
83 |
84 | IP 프로토콜은 라우팅 방법을 정의하는 것입니다. 상위 계층인 전송 계층이 데이터 전달의 신뢰성을 책임진다는 가정하에 어떤 경로로 패킷을 전송할 것인가에 초점을 둡니다.
85 |
86 | * TCP 프로토콜 in 전송 계층
87 |
88 | **TCP 프로토콜**은 신뢰성 있는 데이터의 전송을 담당합니다.
89 |
90 | IP 프로토콜은 TCP가 데이터를 보낼 때 기반이 되는 프로토콜입니다. IP 계층은 문제가 발생해도 해결해주지 않는 신뢰되지 않은 프로토콜입니다.
91 |
92 | 이 문저젬을 해결해 주는 것이 TCP 프로토콜입니다.
93 | TCP 프로토콜은 데이터가 순서에 맞게 올바르게 전송이 갔는지 확인을 해줍니다. 즉, TCP는 신뢰성 없는 IP에 신뢰성을 부여한 프로토콜입니다.
94 |
--------------------------------------------------------------------------------
/01.network/lyj/21.01.13.md:
--------------------------------------------------------------------------------
1 | # 21.01.13
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 질문1. 프로토콜이란 무엇인가요?
6 | * 컴퓨터간 데이터 통신을 원활하게 하기 위해 규정한 규약입니다. 프로토콜에는 신호 송신의 순서나 표현법, 오류 검출법 등을 정해둡니다.
7 |
8 | #### 💡 [질문2. TCP와 UDP의 차이점은 무엇인가요?](#개념1)
9 | * TCP 프로토콜은 연결 지향적이며, 신뢰성이 보장된다는 특징이 있습니다.
10 |
11 | 이와 달리, UDP 프로토콜은 비연결 지향적이며, 성능이 빠르다는 특징이 있습니다.
12 |
13 |
14 | #### 💡 [질문3. TCP 3 way handshaking이 무엇인가요?](#개념2)
15 |
16 | * 클라이언트와 서버가 통신을 하기전 정확한 전송을 보장하기 위해 컴퓨터간 세션을 수립하는 과정으로서 TCP 프로토콜에서 신뢰성을 보장하기 위해 사용됩니다.
17 |
18 | #### 💡 [질문4. TCP 4 way handshaking이 무엇인가요?](#개념2)
19 |
20 | * 클라이언트와 서버가 연결하기 위해 3-way handshaking 과정이 필요하듯이 연결을 종료할때에도 데이터 손실없는 전송을 보장하기 위해 handshaking 과정이 필요한데 이것이 4-way handshaking 입니다.
21 |
22 |  60 |
61 | * RUDP
62 |
63 | 추가 필요
64 |
65 |
60 |
61 | * RUDP
62 |
63 | 추가 필요
64 |
65 |  78 |
79 | TCP는 세그먼트를 이용하여 시스템의 데이터 수신 준비를 확인하고 다음과 같은 절차를 밟은 후 데이터를 보내게 됩니다.
80 |
81 | >1. 송신 : 통신하고 싶어요. SYN를 보낼게요.
82 | >
83 | >2. 수신 : 그래? 나도 통신 준비 됬어요! SYN-ACK
84 | >
85 | >3. 송신 : 그래? 그러면 보낼게 ACK
86 |
87 | TCP 초기 연결 과정 이후에는 송신 TCP는 다른 ACK세그먼트를 보낸 다음 계속 데이터를 보내게 됩니다.
88 |
89 | * 4 way handshaking
90 |
91 | ✅ TCP 연결 종료
92 |
93 |
78 |
79 | TCP는 세그먼트를 이용하여 시스템의 데이터 수신 준비를 확인하고 다음과 같은 절차를 밟은 후 데이터를 보내게 됩니다.
80 |
81 | >1. 송신 : 통신하고 싶어요. SYN를 보낼게요.
82 | >
83 | >2. 수신 : 그래? 나도 통신 준비 됬어요! SYN-ACK
84 | >
85 | >3. 송신 : 그래? 그러면 보낼게 ACK
86 |
87 | TCP 초기 연결 과정 이후에는 송신 TCP는 다른 ACK세그먼트를 보낸 다음 계속 데이터를 보내게 됩니다.
88 |
89 | * 4 way handshaking
90 |
91 | ✅ TCP 연결 종료
92 |
93 |  94 |
95 | >1. 먼저 클라이언트가 연결을 닫으려 할 떄 FIN 으로 설정된 세그먼트를 보냅니다.
96 | >
97 | >2. 클라이언트는 FIN_WAIT_1상태로 들어가고 서버의 응답을 기다립니다.
98 | >
99 | >3. 서버는 클라이언트로 ACK라는 승인 세그먼트를 보냅니다.
100 | >
101 | >4. 클라이언트가 세그먼트를 받으면 FIN_WAIT_2상태에 들어갑니다.
102 | >
103 | >5. 서버는 ACK를 보낸 후 일정시간 이후에 FIN이라는 세그먼트를 보냅니다.
104 | >
105 | >6. 클라이언트는 받게 되면 TIME_WAIT상태가 되고 다시 서버로 ACK를 보내서 서버는 CLOSED상태가 됩니다.
106 | >
107 | >7. 클라이언트는 30초에서 2분동안 대기 후 연결이 공식적으로 닫히고 클라이언트 측의 모든 자원의 연결이 해제 됩니다.
108 |
109 |
94 |
95 | >1. 먼저 클라이언트가 연결을 닫으려 할 떄 FIN 으로 설정된 세그먼트를 보냅니다.
96 | >
97 | >2. 클라이언트는 FIN_WAIT_1상태로 들어가고 서버의 응답을 기다립니다.
98 | >
99 | >3. 서버는 클라이언트로 ACK라는 승인 세그먼트를 보냅니다.
100 | >
101 | >4. 클라이언트가 세그먼트를 받으면 FIN_WAIT_2상태에 들어갑니다.
102 | >
103 | >5. 서버는 ACK를 보낸 후 일정시간 이후에 FIN이라는 세그먼트를 보냅니다.
104 | >
105 | >6. 클라이언트는 받게 되면 TIME_WAIT상태가 되고 다시 서버로 ACK를 보내서 서버는 CLOSED상태가 됩니다.
106 | >
107 | >7. 클라이언트는 30초에서 2분동안 대기 후 연결이 공식적으로 닫히고 클라이언트 측의 모든 자원의 연결이 해제 됩니다.
108 |
109 |  61 |
62 | - Long Polling
63 |
64 | **HTTP 프로토콜 "Stateless"**
65 |
66 | - Client가 요청을 보내는 경우에만 Server가 응답하는 단방향적 통신
67 |
68 | **HTTP로 일단 request를 보내놓고 timeout날 때까지 기다리다 중간에 보낼 데이터가 있다면 response를 보내주는 방식**
69 |
70 | - 클라이언트가 웹 서버에게 새로운 내용이 있는지 물어보았을 때 웹 서버에서 새로운 내용이 없다면 대답해 주지 않다가 새로운 내용이 생기면 이 때 대답해 준다.
71 |
72 | 클라이언트에서 서버로 일단 http request를 날린다. 이 상태로 계속 기다리다가 서버에서 해당 클라이언트로 전달할 이벤트가 있다면 그순간 response 메시지를 전달하면서 연결이 종료된다. 클라이언트에서는 곧바로 다시 http request를 날려서 서버의 다음 이벤트를 기다린다.
73 |
74 | **한계**
75 |
76 | - 클라이언트로 보내는 이벤트들의 시간간격이 좁다면 polling 과 별 차이가 없게 되며, 다수의 클라이언트에게 동시에 이벤트가 발생될 경우에는 곧바로 다수의 클라이언트가 서버로 접속을 시도하면서 서버의 부담이 급증하게 된다.
77 |
78 |
79 |
80 |
61 |
62 | - Long Polling
63 |
64 | **HTTP 프로토콜 "Stateless"**
65 |
66 | - Client가 요청을 보내는 경우에만 Server가 응답하는 단방향적 통신
67 |
68 | **HTTP로 일단 request를 보내놓고 timeout날 때까지 기다리다 중간에 보낼 데이터가 있다면 response를 보내주는 방식**
69 |
70 | - 클라이언트가 웹 서버에게 새로운 내용이 있는지 물어보았을 때 웹 서버에서 새로운 내용이 없다면 대답해 주지 않다가 새로운 내용이 생기면 이 때 대답해 준다.
71 |
72 | 클라이언트에서 서버로 일단 http request를 날린다. 이 상태로 계속 기다리다가 서버에서 해당 클라이언트로 전달할 이벤트가 있다면 그순간 response 메시지를 전달하면서 연결이 종료된다. 클라이언트에서는 곧바로 다시 http request를 날려서 서버의 다음 이벤트를 기다린다.
73 |
74 | **한계**
75 |
76 | - 클라이언트로 보내는 이벤트들의 시간간격이 좁다면 polling 과 별 차이가 없게 되며, 다수의 클라이언트에게 동시에 이벤트가 발생될 경우에는 곧바로 다수의 클라이언트가 서버로 접속을 시도하면서 서버의 부담이 급증하게 된다.
77 |
78 |
79 |
80 |  81 |
82 |
83 |
84 |
85 |
86 |
81 |
82 |
83 |
84 |
85 |
86 |  --------------------------------------------------------------------------------
/01.network/lyj/21.01.16.md:
--------------------------------------------------------------------------------
1 | # 21.01.16
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 [질문1. blocking과 non-blocking 차이점은 무엇인가요?](#개념1)
6 |
7 | #### 💡 [질문2. non-blocking과 asynchronous의 차이점은 무엇인가요?](#개념1)
8 |
9 | #### 💡 [질문3. 통신 프로토콜 기능은 무엇이 있나요?](#개념2)
10 |
11 |
--------------------------------------------------------------------------------
/01.network/lyj/21.01.16.md:
--------------------------------------------------------------------------------
1 | # 21.01.16
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 [질문1. blocking과 non-blocking 차이점은 무엇인가요?](#개념1)
6 |
7 | #### 💡 [질문2. non-blocking과 asynchronous의 차이점은 무엇인가요?](#개념1)
8 |
9 | #### 💡 [질문3. 통신 프로토콜 기능은 무엇이 있나요?](#개념2)
10 |
11 |  50 |
51 | - Sync/Blocking IO
52 |
53 | - Ex) 멀티 스레드 서버 (Thread vs Socket = 1 vs 1)
54 |
55 | - Sync/Non-Blocking IO
56 |
57 | - Ex) select(), epoll() 함수
58 | - Ex) future.isDone()
59 |
60 | - Async/Non-Blocking IO (AIO)
61 |
62 | - Ex) Window IOCP
63 |
64 | - Async/Blocking IO
65 |
66 | - 이와 같은 사례는 거의 없어 무시 가능
67 |
68 | Ex) **Node.js + MySQL** 조합
69 |
70 | - Blocking-Async는 별다른 장점이 없어서 일부러 사용할 필요는 없지만, NonBlocking-Async 방식을 쓰는데 그 과정 중에 하나라도 Blocking으로 동작하는 놈이 포함되어 있다면 의도하지 않게 Blocking-Async로 동작할 수 있다.
71 |
72 |
50 |
51 | - Sync/Blocking IO
52 |
53 | - Ex) 멀티 스레드 서버 (Thread vs Socket = 1 vs 1)
54 |
55 | - Sync/Non-Blocking IO
56 |
57 | - Ex) select(), epoll() 함수
58 | - Ex) future.isDone()
59 |
60 | - Async/Non-Blocking IO (AIO)
61 |
62 | - Ex) Window IOCP
63 |
64 | - Async/Blocking IO
65 |
66 | - 이와 같은 사례는 거의 없어 무시 가능
67 |
68 | Ex) **Node.js + MySQL** 조합
69 |
70 | - Blocking-Async는 별다른 장점이 없어서 일부러 사용할 필요는 없지만, NonBlocking-Async 방식을 쓰는데 그 과정 중에 하나라도 Blocking으로 동작하는 놈이 포함되어 있다면 의도하지 않게 Blocking-Async로 동작할 수 있다.
71 |
72 | 출처
116 | https://m.post.naver.com/viewer/postView.nhn?volumeNo=27046347&memberNo=2521903 117 |
118 |
--------------------------------------------------------------------------------
/01.network/phb/21.01.26.md:
--------------------------------------------------------------------------------
1 | # 21.01.26
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 [질문1](#개념1)
6 | * 답변
7 |
8 | #### 💡 질문2
9 | * 답변
10 |
11 | #### 💡 질문3
12 | * 답변
13 |
14 |
15 |
16 |
17 | 18 | ## ⭐ 개념 정리 (보충 필요) 19 | 20 | ### HTTP/1.1 vs HTTP/2.0 21 | ||HTTP/1.1|HTTP/2.0| 22 | |-|-|-| 23 | |Connection|하나의 요청만 처리|여러개 요청 처리 (Multiplexed Streams)| 24 | |Header|많은 메타 정보 저장|압축 정보| 25 | |Resource|Client 요청 시 전송|Server Push| 26 | 27 |
28 | 29 |  30 | 31 | 32 |
33 | 34 |
40 | 41 | ### Block/Non-Block 42 | * Block의 뜻은 **행위자가 취한 행위가 막힌 상태**를 의미하며 제한되고 대기하는 상태를 의미 43 | * Blocking : 호출된 함수가 자신의 일을 마칠 때까지 제어권을 계속 가지고 있으며 호출한 함수에게 돌려주지 않는 것 44 | * Non-Block : 호출된 함수가 자신의 일을 마치지 않았더라도 제어권을 호출한 함수에게 return 해주어 다른 다른 일을 진행할 수 있도록 하는 것 45 | 46 | 47 | ### Synchronous/Asynchronous 48 | * Synchronous : 호출된 함수의 작업 완료 여부를 호출한 함수가 신경 쓰는 경우 49 | * Asynchronous : 호출된 함수의 작업 완료 여부를 호출한 함수가 신경 쓰지 않는 경우 50 | 51 |
57 | -------------------------------------------------------------------------------- /01.network/phb/21.01.27.md: -------------------------------------------------------------------------------- 1 | # 21.01.27 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [웹 소켓과 TCP 소켓의 차이점](#웹-소켓과-tcp/ip-소켓) 6 | * http 통신은 단방향 통신이기 때문에 클라이언트의 요청이 있을 때만 서버의 응답을 받을 수 있습니다. 웹 소켓은 실시간 양방향 통신으로 클라이언트에게 필요한 정보를 캐시했다가 클라이언트의 요청 없이도 요청을 보낼 수 있습니다. 7 | 8 | #### 💡 [CORS](#corscross-origin-resource-sharing) 9 | * 프로토콜, 호스트, 포트번호가 다른 서버를 요청하면 발생하는 이슈입니다. 추가 http 헤더를 사용하여 권한을 부여하도록 브라우저에게 알려주는 체계입니다. 10 | 11 |
12 | 13 | ## ⭐ 개념 정리 14 | 15 | ### 소켓 16 | * 프로세스가 네트워크를 통해 데이터를 주고 받기 위해 필요한 창구 17 | * 동작원리(Web socket) 18 |  19 | 20 |
21 | 22 | ### 웹 소켓과 TCP/IP 소켓 23 | * 공통점 24 | * IP, PORT 사용하여 통신 25 | * 차이점 26 | |웹 소켓|TCP 소켓| 27 | |-|-| 28 | |실시간 양방향 통신|단방향 통신| 29 | |[Push] Client→Server, Client←Server|[Polling] Client→Server| 30 | |실시간 스트리밍|Android App 개발| 31 | 32 |
33 | 34 |  35 | 36 |
37 | 38 | ### CORS(Cross-Origin Resource Sharing) 39 | * 출처 = 프로토콜 + 호스트 + 포트번호 40 |  41 | 42 | * 도메인 또는 포트가 다른 서버의 자원을 요청하면 발생하는 이슈 43 | * 추가 HTTP 헤더를 사용하여 실행 중인 웹 애플리케이션이 다른 자원에 접근할 수 있는 권한을 부여하도록 브라우저에게 알려주는 체제 44 | 45 | 46 |
47 |
13 | 14 | ## ⭐ 개념 정리 (보충 필요) 15 | 16 | ### IPv4 17 | * IPv4는 인터넷 프로토콜 4번째 판이며 전 세계적으로 사용된 첫 번째 인터넷 프로토콜 18 | * 네트워크 상에서 데이터 교환을 위한 프로토콜 19 | * 구성단위 (32bit) 20 |  21 | 22 |
23 | 24 | ### IPv6 25 | * IP 주소의 길이가 128bit 26 | * 특성 27 | * IP 주소의 확장 28 | * 호스트 주소 자동 설정 29 | * 패킷 확장 30 | * 보안성 31 | * etc 32 | 33 | ### IPv4/IPv6 34 |  35 | 36 | 37 | * 주소변환 (아래 두개 이해 안 됨...) 38 | * 헤더변환방식 (IP계층) 39 | IPv4, IPv6 패킷에서 헤더를 제외한 상위 계층은 동일한 구조로 생성되어 있기 때문에 헤더 부분을 전환하여 그대로 데이터를 전송 40 | 41 | * 전송 릴레이 방식 (전송계층) 42 | TCP 두 개 만듬...? 43 | 44 | * 수송 계층 게이트웨이 방식 (응용계층) 45 |
46 | -------------------------------------------------------------------------------- /01.network/phb/21.01.29.md: -------------------------------------------------------------------------------- 1 | # 21.01.29 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [Ajax를 왜 사용하는가?](#ajax) 6 | * 기본적으로 HTTP 프로토콜은 클라이언트가 요청을 보내고 서버가 응답 받으면 연결이 종료되고 화면 갱신을 위해서는 다시 요청-응답을 하면서 페이지를 전체 갱신해야합니다. 페이지 일부만 갱신 할 경우에도 전체 페이지를 다시 로드해야하는데 이는 엄청난 자원과 시간을 낭비합니다. ajax를 사용하면 일부만 갱신이 가능하여 자원과 시간을 아낄 수 있습니다. 7 | 8 | #### 💡 Ajax 심화 질문 넣고 싶다... 9 | * 답변 10 | 11 | 12 | #### 💡 [JWT가 무엇인가?](#jwt) 13 | * json으로 이루어진 헤더, 내용, 서명에 필요한 정보를 담아 안전하게 정보를 전달하는 방법입니다. 14 | 15 | 16 | 17 |
18 | 19 | ## ⭐ 개념 정리 20 | ### SPA 21 | * 웹 애플리케이션에 필요한 모든 정적 리소스를 최초에 한번 다운로드하고 이후 페이지 갱신에 필요한 데이터만 전달받아 페이지를 갱신하는 웹 패러다임 22 | 23 | 24 | ### Ajax 25 | * 전체 페이지를 새로 고치지 않고 일부 데이터만 로드하는 웹 개발 기법 26 | * 일반적으로 jQuery와 함께 사용 27 | * jQuery : HTML의 클라이언트 처리 조작을 단순화 하도록 설계된 js 라이브러리 28 | * 동작원리 29 | 30 |  31 | 32 | * 장점 33 | * 페이지 이동없이 화면 전환 34 | * 비동기 요청 35 | * 속도 향상 36 | 37 | * 단점 38 | * 연속 데이터 요청 시에 서버 부하 증가 가능성 39 | * 보안 취약 40 | * 서버 푸시 사용 불가능 41 | 42 | 43 |
49 | 50 | 51 | ### DOM 52 | * HTML, XML 문서의 프로그래밍 인터페이스 53 | * 문서의 구조화된 표현 제공하여 동일한 문서를 표현, 저장, 조작하는 방법을 제공 54 | * 프로그래밍 언어-문서 사이의 매개체 역할 55 | 56 |
62 | 63 | ### JWT 64 | * JSON Web Token의 약자로 두 객체가 JSON객체를 사용해 필요한 모든 정보를 안전하게 전달하는 방법 65 | * 모양 66 |  67 | * 헤더 : 토큰 타입(typ)과 해싱 알고리즘(alg) 지정 68 | ```json 69 | { 70 | "typ" : "JWT", 71 | "alg" : "HS256" // 보통 SHA256, RSA 사용 72 | } 73 | ``` 74 | 75 |
76 | 77 | * 내용 : 내용에 담는 정보의 한 조각을 클레임이라 부르고 (name-value)의 쌍으로 이루어져 있다. 78 | * 등록된 클레임 : 토큰에 대한 정보를 담기 위해 이미 정해진 클레임 79 | * 공개 클레임 : 충돌 방지를 위한 이름을 가져야하며 URI 형식으로 지음 80 | * 비공개 클레임 : 클라이언트-서버 협의 하에 사용되는 클레임 이름 81 | ```javascript 82 | { 83 | "iss": "example.com", // 토큰 발급자 (등록된 클레임) 84 | "exp": "155550000000", // 토큰 만료기간 (등록된 클레임) 85 | "https://example.com/jwt": true, // URI (공개 클레임) 86 | "userId": "11235482", // 사용자 id (비공개 클레임) 87 | "username": "bin_park" // 사용자 이름 (비공개 클레임) 88 | } 89 | ``` 90 | 91 |
92 | 93 | 94 | * 서명 : 헤더와 정보의 인코딩 값을 합친 뒤 비밀키로 해쉬하여 생성 95 | 96 |
33 | 34 | ## 심화 질문 35 | 36 | #### 💡 Database를 사용하는 이유 37 | 38 | * 데이터베이스는 파일처리시스템의 문제점을 해결하기 위한 목적으로 만들어졌다. 데이터베이스가 존재하기 이전에는 파일 시스템을 이용하여 데이터를 관리하였고 데이터의 무결성을 유지하고 생산성을 늘리기 위하여 데이터베이스를 사용한다. 39 | 40 |
41 | 42 | ## 개념 정리 43 | 44 | ### ⭐ Database 속성 45 | 46 | 1. 독립성 47 | 48 | - 물리적 독립성 : 데이터베이스 사이즈를 늘리거나 성능 향상을 위해 데이터 파일을 늘리거나 새롭게 추가하더라도 관련된 응용 프로그램을 수정할 필요가 없다. 49 | 50 | - 논리적 독립성 : 데이터베이스는 논리적인 구조로 다양한 응용 프로그램의 논리적 요구를 만족시켜줄 수 있다. 51 | 52 | 2. 무결성 : 데이터베이스에 들어 있는 데이터의 정확성을 보장하기 위해 데이터의 변경이나 수정시 제한을 두어 안정성을 저해하는 요소를 막아 데이터 상태들을 항상 옳게 유지하는 것을 의미한다. 53 | 54 | 3. 보안성 : 인가된 사용자들만 데이터베이스나 데이터베이스 내의 자원에 접근할 수 있도록 계정 관리 또는 접근 권한을 설정함으로써 모든 데이터에 보안을 구현할 수 있다. 55 | 56 | 4. 일관성 : 연관된 정보를 논리적은 구조로 관리함으로써 어떤 하나의 데이터만 변경했을 경우 발생할 수 있는 데이터의 불일치성을 배제할 수 있다. 또한 작업 중 일부 데이터만 변경되어 나머지 데이터와 일치하지 않는 경우의 수를 배제할 수 있다. 57 | 58 | 5. 중복 최소화 : 데이터베이스는 데이터를 통합해서 관리함으로써 파일 시스템의 단점 중 하나인 자료의 중복과 데이터의 중복성 문제를 해결할 수 있다. 59 | 60 |
70 | 71 | ### ⭐ Schema 특징 72 |
- 각각의 사용자가 원하는 형태의 논리적 구조를 정의
- 조직 일부분을 정의
- 여러 개가 존재
- 응용 프로그래머나 사용자와 관련된 개체, 그 개체들의 관계 및 제약조건|⋅ **개념 스키마**
- 데이터를 통합하여 조직 전체의 논리적 구조를 정의
- 기관(조직) 전체를 표현
- 하나만 존재
- 한 기관 전체에 필요한 모든 개체, 모든 개체의 관계 및 제약 사항|⋅ **내부 스키마**
- 전체 DB의 물리적 저장 구조를 정의
- 개념 스키마의 물리적 저장 형태를 정의하는 개념 - 하나만 존재
- 저장될 내부(저장) 레코드의 형식| 78 | 79 | * 요약 80 | - 외부 스키마 : 실세계에 존재하는 데이터들을 어떤 형식, 구조, 배치 화면을 통해 사용자에게 보여줄 것인가 81 | - 개념 스키마 : 데이터 베이스의 전체적인 논리적 구조 (개체간의 관계, 제약조건 등) 82 | - 내부 스키마 : 데이터 베이스의 물리적 저장구조를 정의 83 | 84 | 85 |
92 | 93 | ### ⭐ DBMS 특징 94 | 95 | |DBMS 장점|DBMS 단점| 96 | |---------|---------| 97 | |⋅ 데이터 중복 최소화
⋅ 데이터 공유
⋅ 데이터 표준화
⋅ 데이터 보안 유지
⋅ 데이터 무결성 유지
⋅ 데이터 통합적 관리
⋅ 데이터 일관성 유지|⋅ 구축이 복잡하다. ( 규모가 방대하고 복잡한 관리 체계를 유지해야 하므로 )
⋅ 구축 비용이 많이 든다.
⋅ 예비(Backup자료)와 회복(원상복귀) 절차 수립이 어렵다.
⋅ 한 부분의 장애로 전체 시스템에 영향을 주는 취약성이 있다. 98 | 99 |
100 |
26 | 27 | ## 심화 질문 28 | 29 | #### 💡 반정규화란? 30 | * 반 정규화는 정규화 되어있는 것을 다시 정규화 이전 상태로 돌리는 것을 말한다. 31 | 데이터 무결성이 위배되는 위험을 감수하고 적용하는 이유는 데이터 조회 시 디스크 I/O 량이 많거나, 여러테이블의 조인에 의해 성능이 저하되거나 업무적인 조회에 대한 처리성능이 중요하다고 생각 될때 부분적인 반정규화를 고려 하게 된다. 32 | 33 | 34 | 35 |
36 | 37 | ## 개념 정리 38 | 39 | ### ⭐ 정규화 40 | 41 | * Normalization Process 42 |
64 | 65 | 66 | 67 | -------------------------------------------------------------------------------- /02.database/hsh/21.01.16.md: -------------------------------------------------------------------------------- 1 | 2 | # 21.01.16 3 | 4 | 5 | 6 | ## 주요 질문 7 | 8 | #### 💡 트랜잭션이란? 9 | 10 | * DB의 상태를 하나의 일관된 상태에서 또 다른 일관된 상태로 변환시켜주는 일련의 논리적 연산의 집합 11 | 12 | * 트랜잭션은 DB 서버에 여러 개의 클라이언트가 동시에 액세스 하거나 응용프로그램이 갱신을 처리하는 과정에서 중단될 수 있는 경우 등 데이터 부정합을 방지하고자 할 때 사용합니다. 13 | 14 | 15 | #### 💡 트랜잭션 특징 16 | 17 | * 트랜잭션의 특징은 크게 4가지 **(ACID)** 로 구분된다. 18 | - **원자성 (Atomicity)**: 트랜잭션이 데이터베이스에 모두 반영되던가, 아니면 전혀 반영되지 않아야 한다. 19 | - **일관성 (Consistency)**: 트랜잭션의 작업 처리 결과가 항상 일관성이 있어야 한다. 20 | 송금 예제에서 금액의 데이터 타입이 정수형(integer)인데, 갑자기 문자열(string)이 되지 않는 것을 말합니다. 21 | - **독립성 (Isolation)**: 둘 이상의 트랜잭션이 동시에 실행되고 있을 경우 어떤 하나의 트랜잭션이라도, 다른 트랜잭션의 연산에 끼어들 수 없다는 점을 가리킨다. 22 | - **지속성 (Durability)**: 트랜잭션이 성공적으로 완료됬을 경우, 결과는 영구적으로 반영되어야 한다 23 | 24 | 25 | #### 💡 잠금(Locking) 기법이란? 26 | 27 | * 잠금(Locking)은 하나의 트랜잭션이 실행하는 동안 특정 데이터 항목에 대해서 다른 트랜잭션이 동시에 접근하지 못하도록 상호배제(Mutual Exclusive) 기능을 제공하는 기법이다. 하나의 트랜잭션이 데이터 항목에 대하여 잠금(lock)을 설정하면, 잠금을 설정한 트랜잭션이 해제(unlock)할 때까지 데이터를 독점적으로 사용할 수 있다. 28 | 29 | #### 💡 교착상태(deadlock) 이란? 30 | * 교착 상태(Dead Lock)란 여러 개의 트랜잭션(Transaction)들이 실행을 하지 못하고 서로 무한정 기다리는 상태를 의미합니다. 31 | * 기본적으로 데이터베이스에서는 트랜잭션들의 '동시성'을 제어하기 위한 기법으로 로킹(Locking)을 사용합니다. 이러한 로킹이 데이터가 엉망진창이 되는 것을 막아주겠지만 반면에 그 부작용으로 교착 상태를 일으킬 수 있다. 32 | 33 |
34 | 35 | ## 심화 질문 36 | 37 | #### 💡 교착상태(deadlock) 해결 방법 38 | 39 | - 예방 기법 : 예방 기법은 각 트랜잭션이 실행되기 전에 필요한 데이터를 모두 로킹(Locking) 해주는 것입니다. 다만 예방 기법은 데이터가 많이 필요하면 사실상 모든 데이터를 전부 로킹 해주어야 하므로 트랜잭션의 병행성을 보장하지 못합니다. 뿐만 아니라 몇몇 트랜잭션은 계속해서 처리를 못 하게 되는 기아 상태가 발생할 수 있습니다. 40 | - 회피 기법 : 회피 기법은 자원을 할당할 때 시간 스탬프(Time Stamp)를 사용하여 교착상태가 일어나지 않도록 회피하는 방법입니다. 이러한 회피 기법으로는 Wait-Die 방식과 Wound-Wait 방식이 있습니다. 41 |
44 | 45 | ## 개념 정리 46 | 47 | ### ⭐ 트랜잭션 상태 48 | 49 | - Active : 트랜잭션의 활동 상태. 트랜잭션이 실행중이며 동작중인 상태를 말한다. 50 | - Failed : 트랜잭션 실패 상태. 트랜잭션이 더이상 정상적으로 진행 할 수 없는 상태를 말한다. 51 | - Partially Committed : 트랜잭션의 Commit 명령이 도착한 상태. 트랜잭션의 commit이전 sql문이 수행되고 commit만 남은 상태를 말한다. 52 | - Committed : 트랜잭션 완료 상태. 트랜잭션이 정상적으로 완료된 상태를 말한다. 53 | - Aborted : 트랜잭션이 취소 상태. 트랜잭션이 취소되고 트랜잭션 실행 이전 데이터로 돌아간 상태를 말한다.
54 |  55 | 56 |
57 | 58 | - Partially Committed 와 Committed 의 차이점
59 | : Commit 요청이 들어오면 상태는 Partial Commited 상태가 된다. 이후 Commit을 문제없이 수행할 수 있으면 Committed 상태로 전이되고, 만약 오류가 발생하면 Failed 상태가 된다. 즉, Partial Commited는 Commit 요청이 들어왔을때를 말하며, Commited는 Commit을 정상적으로 완료한 상태를 말한다. 60 | 61 |
70 | 71 | 72 | ### ⭐ DB 회복(Recovery) 73 | * 어떤 외부적 혹은 내부적 장애 요인으로 DB의 상태가 일관성을 유지할 수 없을 때, 장애 이전의 일관된 상태가 되도록 복원하는 일 74 |  75 | 76 |
83 | -------------------------------------------------------------------------------- /02.database/hsh/21.01.17.md: -------------------------------------------------------------------------------- 1 | 2 | # 21.01.17 3 | 4 | 5 | ## 주요 질문 6 | #### 💡 Index란? 7 | 8 | * 인덱스란 추가적인 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 방법입니다. 9 | 10 | 11 | #### 💡 데이터베이스의 Index 구조에 대해 설명하시오. 12 | 13 | * DB의 Index는 가장 대표적인 해시 테이블과 B+Tree로 이루어져 있다. 하지만 DB 인덱스에서 해시 테이블이 사용되는 경우는 제한적인데, 그러한 이유는 해시가 등호(=) 연산에만 특화되었기 때문이다. 데이터베이스의 인덱스 컬럼은 부등호를 이용한 순차 검색 연산이 자주 발생될 수 있다. 이러한 이유로 B-Tree의 리프노드들을 LinkedList로 연결하여 순차검색을 용이하게 하는 등 B-Tree를 인덱스에 맞게 최적화하였다. 이러한 이유로 해시테이블보다 인덱싱에 더욱 적합한 자료구조가 되었다. 14 | 15 | #### 💡 Index의 특징에 대해 설명하시오. 16 | - 장점 17 | 1. 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다. 18 | 2. 전반적인 시스템의 부하를 줄일 수 있다. 19 | - 단점 20 | 1. 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다. 21 | 2. 인덱스를 관리하기 위해 추가 작업이 필요하다. 22 | 3. 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다. 23 | 24 | _만약 CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 걸게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있다._ 25 | 26 | 27 |
28 | 29 | ## 심화 질문 30 | 31 | #### 💡 B-tree 와 B+Tree의 차이 32 | - B-tree의 각 노드에서는 key 뿐만 아니라 data도 들어갈 수 있다. 여기서 data는 disk block으로의 포인터가 될 수 있다. 33 | B+tree는 각 node에서는 key만 들어가야 한다. 그러므로 B+tree에서는 data는 오직 leaf에만 존재한다. 34 | - B+tree는 B-tree와는 달리 add, delete가 leaf에서만 이루어진다. 35 | - B+ tree는 leaf node 끼리 linked list로 연결되어 있다. 36 |
39 | 40 | ## 개념 정리 41 | 42 | #### ⭐ Index를 사용하면 좋은 경우 43 | - 규모가 작지 않은 테이블 44 | - INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼 45 | - JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼 46 | - 데이터의 중복도가 낮은 컬럼
47 | _인덱스를 사용하는 것 만큼이나 생성된 인덱스를 관리해주는 것도 중요하다.
그렇기 때문에 사용하지 않는 인덱스는 바로 제거를 해주어야 한다._ 48 | -------------------------------------------------------------------------------- /02.database/hsh/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.01.12|Database 개념|[✅보러가기](/02.database/hsh/21.01.12.md)| 6 | |21.01.13|정규화|[✅보러가기](/02.database/hsh/21.01.13.md)| 7 | |21.01.14|RDBMS|[✅보러가기](/02.database/hsh/21.01.14.md)| 8 | |21.01.16|트랜잭션|[✅보러가기](/02.database/hsh/21.01.16.md)| 9 | |21.01.17|Index|[✅보러가기](/02.database/hsh/21.01.17.md)| 10 | |-|-|-| 11 | 12 | -------------------------------------------------------------------------------- /02.database/hsh/img/DB_recovery.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/hsh/img/DB_recovery.jpg -------------------------------------------------------------------------------- /02.database/hsh/img/State_transaction.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/hsh/img/State_transaction.png -------------------------------------------------------------------------------- /02.database/hsh/img/_sql.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/hsh/img/_sql.png -------------------------------------------------------------------------------- /02.database/hsh/img/database2.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/hsh/img/database2.png -------------------------------------------------------------------------------- /02.database/hsh/img/database_key.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/hsh/img/database_key.jpg -------------------------------------------------------------------------------- /02.database/kmj/21.01.24.md: -------------------------------------------------------------------------------- 1 | # 21.01.24 2 | * 데이터베이스 개념 3 | 4 |
5 | 6 | ## 주요 질문 7 | #### 💡 데이터베이스를 사용하는 이유? 8 | * 데이터베이스가 존재하기 전에는 파일 시스템을 이용해서 데이터를 관리했습니다. 데이터를 각각의 파일로 저장해서 처리하면 데이터의 중복성, 무결성 문제가 발생할 수 있습니다. 그래서 데이터베이스를 사용합니다. 9 | 10 | 11 |
12 | 13 | 14 | 15 |
16 | 17 | ## ⭐ 개념 정리 18 | ### 데이터베이스의 특징 19 | 20 | * 물리적 독립성 21 | * 데이터베이스의 데이터를 새롭게 추가하더라도 관련된 응용 프로그램을 수정할 필요가 없다. 22 | * 논리적 독립성 23 | * 데이터베이스는 논리적인 구조로 다양항 응용 프로그램의 논리적 요구를 만족시켜줄 수 있다. 24 | * 데이터의 무결성 25 | * 여러 경로를 통해 잘못된 데이터가 발생하는 것을 방지한다. 26 | * 데이터의 보안성 27 | * 인가된 사용자들만 데이터베이스와 자원에 접근할 수 있다. 28 | * 데이터의 일관성 29 | * 연관된 정보를 논리적인 구조로 관리해서 특정 데이터만 변경했을 경우 발생할 수 있는 데이터의 불일치성을 배제할 수 있다. 30 | * 데이터 중복 최소화 31 | * 데이터를 통합해서 관리함으로써 파일 시스템의 단점인 자료와 데이터의 중복성 문제를 해결할 수 있다. 32 | 33 | ### 데이터의 무결성 34 | * 개체 무결성 35 | * 참조 무결성 36 | * 도메인 무결성 37 | 38 | 39 | 40 |
41 | 42 | 43 | 44 | 45 | 46 |
47 | [출처] -------------------------------------------------------------------------------- /02.database/kmj/21.01.25.md: -------------------------------------------------------------------------------- 1 | # 21.01.25 2 | * RDBMS 3 | * KEY 4 | * JOIN 5 | 6 | 7 | ## 주요 질문 8 | 9 | #### 💡 [JOIN에 대해서 설명해주세요.](#Join) 10 | * Join은 2개 테이블의 연관된 튜플들을 결합하여 하나의 새로운 릴레이션을 반환하는 개념입니다. 11 | * Join은 크게 Inner Join과 Outer Join으로 구분됩니다. Inner Join은 두 릴레이션에서 관련있는 튜플만 표시하고, Outer Join은 Join조건에 만족하지 않는 튜플도 결과로 출력합니다. 12 | 13 | 14 | 15 | 16 | 17 | 18 |
19 | 20 | ## 심화 질문 21 | 22 |
23 | 24 | ## ⭐ 개념 정리 25 | 26 | 27 | ### RDBMS 구조 28 | 29 | 30 |
31 | ### 키(Key)
32 | * Key란? : 검색, 정렬시 Tuple을 구분할 수 있는 기준이 되는 Attribute.
33 |
34 |
35 | 1. 후보키: Candidate Key
36 | * Tuple을 유일하게 식별하기 위해 사용하는 속성들의 부분 집합이다. 기본키로 사용할 수 있다.
37 |
38 | * 2가지 조건 만족해야 한다.
39 |
40 | * 유일성 : 하나의 Key로 하나의 Tuple을 유일하게 식별할 수 있어야 한다.
41 | * 최소성 : 꼭 필요한 속성으로만 구성되어야 한다.
42 |
43 | 2. 기본키: Primary Key
44 | * 후보키 중에서 선택한 Main Key로 중복된 값을 가질 수 없다.
45 |
46 | * 특징
47 | * 후보키의 성질을 가진다.(유일성, 최소성)
48 | * 특정 튜플을 유일하게 구별할 수 있는 속성이다.
49 |
50 | 3. 대체키: Alternate Key
51 | * 후보키 중 기본키를 제외한 나머지 Key를 말한다. = 보조키
52 |
53 |
54 | 4. 슈퍼키: Super Key
55 | * 한 릴레이션 내에 있는 속성들의 집합이다.
56 | * 유일성은 만족하지만, 최소성은 만족하지 않는다.
57 | ### Join
58 |
59 | * 조인이란?
60 | * 두 개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법이다.
61 | 테이블을 연결하려면, 적어도 하나의 Attribute를 서로 공유하고 있어야 한다.
62 |
63 |
64 | * JOIN 종류
65 | * INNER JOIN
66 | * LEFT OUTER JOIN
67 | * RIGHT OUTER JOIN
68 | * FULL OUTER JOIN
69 | * CROSS JOIN
70 | * SELF JOIN
71 |
72 |
73 | * INNER JOIN
74 |
75 | * 교집합으로, 기준 테이블과 join 테이블의 중복된 값을 보여준다.
76 | ```sql
77 | SELECT
78 | A.NAME, B.AGE
79 | FROM EX_TABLE A
80 | INNER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
81 | ```
82 | * LEFT OUTER JOIN
83 |
84 | * Inner join 결과를 구한 후, 우측 릴레이션의 어떤 튜플과도 맞지 않는 좌측 릴레이션의 튜플들에 NULL값을 붙인다.
85 | ```sql
86 | SELECT
87 | A.NAME, B.AGE
88 | FROM EX_TABLE A
89 | LEFT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
90 | ```
91 | * RIGHT OUTER JOIN
92 |
93 | * LEFT OUTER JOIN과는 반대로 우측 릴레이션의 튜플에 NULL을 붙인다.
94 | ```sql
95 | SELECT
96 | A.NAME, B.AGE
97 | FROM EX_TABLE A
98 | RIGHT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
99 | ```
100 | * FULL OUTER JOIN
101 |
102 | * Left outer join + Right outer join 이다.
103 | * Inner join의 결과를 구한 후 우측 항의 릴레이션에 NULL값을 추가한다. 그 후 좌측 항의 릴레이션에 NULL값을 추가한다.
104 | ```sql
105 | SELECT
106 | A.NAME, B.AGE
107 | FROM EX_TABLE A
108 | FULL OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
109 | ```
110 | * CROSS JOIN
111 |
112 | * 조인 테이블에 있는 튜플들의 순서쌍을 반환한다.
113 |
114 | * 결과 행의 수: A 테이블, B 테이블의 행 수를 곱한 것과 같다.
115 |
116 | ```sql
117 | SELECT
118 | A.NAME, B.AGE
119 | FROM EX_TABLE A
120 | CROSS JOIN JOIN_TABLE B
121 | ```
122 | * SELF JOIN
123 |
124 | * 같은 테이블에서 2개의 속성을 연결하여 EQUI JOIN하는 것이다.
125 | * 자기자신과 자기자신을 조인하는 것이다.
126 |
127 | ```sql
128 | SELECT
129 | A.NAME, B.AGE
130 | FROM EX_TABLE A, EX_TABLE B
131 | ```
132 |
133 |
134 |
135 |
30 |
31 | ### 키(Key)
32 | * Key란? : 검색, 정렬시 Tuple을 구분할 수 있는 기준이 되는 Attribute.
33 |
34 |
35 | 1. 후보키: Candidate Key
36 | * Tuple을 유일하게 식별하기 위해 사용하는 속성들의 부분 집합이다. 기본키로 사용할 수 있다.
37 |
38 | * 2가지 조건 만족해야 한다.
39 |
40 | * 유일성 : 하나의 Key로 하나의 Tuple을 유일하게 식별할 수 있어야 한다.
41 | * 최소성 : 꼭 필요한 속성으로만 구성되어야 한다.
42 |
43 | 2. 기본키: Primary Key
44 | * 후보키 중에서 선택한 Main Key로 중복된 값을 가질 수 없다.
45 |
46 | * 특징
47 | * 후보키의 성질을 가진다.(유일성, 최소성)
48 | * 특정 튜플을 유일하게 구별할 수 있는 속성이다.
49 |
50 | 3. 대체키: Alternate Key
51 | * 후보키 중 기본키를 제외한 나머지 Key를 말한다. = 보조키
52 |
53 |
54 | 4. 슈퍼키: Super Key
55 | * 한 릴레이션 내에 있는 속성들의 집합이다.
56 | * 유일성은 만족하지만, 최소성은 만족하지 않는다.
57 | ### Join
58 |
59 | * 조인이란?
60 | * 두 개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법이다.
61 | 테이블을 연결하려면, 적어도 하나의 Attribute를 서로 공유하고 있어야 한다.
62 |
63 |
64 | * JOIN 종류
65 | * INNER JOIN
66 | * LEFT OUTER JOIN
67 | * RIGHT OUTER JOIN
68 | * FULL OUTER JOIN
69 | * CROSS JOIN
70 | * SELF JOIN
71 |
72 |
73 | * INNER JOIN
74 |
75 | * 교집합으로, 기준 테이블과 join 테이블의 중복된 값을 보여준다.
76 | ```sql
77 | SELECT
78 | A.NAME, B.AGE
79 | FROM EX_TABLE A
80 | INNER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
81 | ```
82 | * LEFT OUTER JOIN
83 |
84 | * Inner join 결과를 구한 후, 우측 릴레이션의 어떤 튜플과도 맞지 않는 좌측 릴레이션의 튜플들에 NULL값을 붙인다.
85 | ```sql
86 | SELECT
87 | A.NAME, B.AGE
88 | FROM EX_TABLE A
89 | LEFT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
90 | ```
91 | * RIGHT OUTER JOIN
92 |
93 | * LEFT OUTER JOIN과는 반대로 우측 릴레이션의 튜플에 NULL을 붙인다.
94 | ```sql
95 | SELECT
96 | A.NAME, B.AGE
97 | FROM EX_TABLE A
98 | RIGHT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
99 | ```
100 | * FULL OUTER JOIN
101 |
102 | * Left outer join + Right outer join 이다.
103 | * Inner join의 결과를 구한 후 우측 항의 릴레이션에 NULL값을 추가한다. 그 후 좌측 항의 릴레이션에 NULL값을 추가한다.
104 | ```sql
105 | SELECT
106 | A.NAME, B.AGE
107 | FROM EX_TABLE A
108 | FULL OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
109 | ```
110 | * CROSS JOIN
111 |
112 | * 조인 테이블에 있는 튜플들의 순서쌍을 반환한다.
113 |
114 | * 결과 행의 수: A 테이블, B 테이블의 행 수를 곱한 것과 같다.
115 |
116 | ```sql
117 | SELECT
118 | A.NAME, B.AGE
119 | FROM EX_TABLE A
120 | CROSS JOIN JOIN_TABLE B
121 | ```
122 | * SELF JOIN
123 |
124 | * 같은 테이블에서 2개의 속성을 연결하여 EQUI JOIN하는 것이다.
125 | * 자기자신과 자기자신을 조인하는 것이다.
126 |
127 | ```sql
128 | SELECT
129 | A.NAME, B.AGE
130 | FROM EX_TABLE A, EX_TABLE B
131 | ```
132 |
133 |
134 |
135 |
136 | [출처] -------------------------------------------------------------------------------- /02.database/kmj/21.01.26.md: -------------------------------------------------------------------------------- 1 | # 21.01.26 2 | * 정규화 3 | 4 | 5 | ## 주요 질문 6 | 7 | #### 💡 [정규화에 대해서 설명해주세요.](#정규화) 8 | 9 | * 정규화는 종속적으로 설계된 관계형 스키마가 하나의 릴레이션에 표현될 수 있도록 분해하는 과정입니다. 10 | * 데이터의 중복성을 최소화하고 일관성을 보장하기 위한 과정입니다. 11 | * 정규화를 거치지 않으면 [이상(Anormaly)](#이상(Anormaly)) 문제가 발생합니다. 12 | 13 | 14 | 15 |
16 | 17 | ## 심화 질문 18 | 19 | 20 | #### 💡 정규화의 장단점은 무엇인가요? 21 | * 장점 22 | * 데이터베이스 변경 시 이상 현상(Anomaly) 문제점을 해결할 수 있습니다. 23 | * 새로운 데이터 형의 추가로 인한 확장 시, 구조를 최소한으로 변경할 수 있습니다. 24 | * 단점 25 | * 릴레이션의 분해로 인해 릴레이션 간 Join연산이 많아집니다. 26 | * 따라서 질의 응답시간이 느려질 수 있습니다. 이러한 경우 반정규화를 적용해볼 수 있습니다. 27 | 28 | 29 | #### 💡 반정규화란? 30 | * 정규화된 데이터 모델을 통합, 중복, 분리하는 과정입니다. 31 | * 의도적으로 정규화 원칙을 위배하는 방법입니다. 32 | * 사용예시 33 | * 조인 많을 때: 테이블 통합 34 | * 레코드별 사용빈도 차이가 클 때: 테이블 수평분할 35 | * 테이블에 속성이 많을 때: 테이블 수직분할 36 | * 특정 데이터 자주 처리할 때: 중복 테이블 추가 37 | * 접근 경로가 복잡할 때: 중복속성 추가 38 | * 주의할 점 39 | * 데이터의 일관성이 떨어질 수 있습니다. 40 | 출처 https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/Database#transaction 41 | 42 |
43 | 44 | ## ⭐ 개념 정리 45 | 46 | 47 | 48 | ### 이상(Anormaly) 49 | * 정규화를 거치지 않아 데이터가 불필요하게 중복되어 생기는 예기치 않은 문제 50 | * 종류 51 | * 삽입 이상: 릴레이션에 데이터를 삽입할 때 원하지 않은 값들도 함께 삽입되는 현상 52 | * 삭제 이상: 릴레이션에서 튜플을 삭제할 때 다른 값들도 함께 삭제되는 현상 53 | * 갱신 이상: 릴레이션에서 튜플의 속성값을 갱신할 때 일부 튜플만 갱신되는 현상 54 | 55 | 56 | 57 |
58 | 59 | ### 정규화 60 | * 61 | * 1NF - 제 1정규형
62 | * 릴레이션에 속한 모든 도메인(속성값)이 더이상 쪼갤 수 없는 원자값이어야 한다.
63 | * 2NF - 제 2정규형
64 | * 기본키에 대해 다른 모든 속성이 [완전 함수적 종속](#완전-함수적-종속)을 만족해야 한다.
65 | * 3NF - 제 3정규형
66 | * 무손실조인 또는 종속성 보존을 저해하지 않고 항상 3NF를 얻을 수 있어야 한다.
67 | * BCNF - Boyce - Codd 정규형
68 | * [결정자](#결정자)가 모두 후보키여야 한다.
69 | * 후보키가 서로 중첩되는 경우에 적용한다.
70 | * 4NF - 제 4정규형
71 | * 릴레이션에 [다치종속](#다치종속)이 성립하는 경우(A->->B), 릴레이션의 모든 속성이 A에 [함수적 종속 관계](#함수적-종속-관계)를 만족해야 한다.
72 | * 5NF - 제 5정규형
73 | * 릴레이션 R의 모든 조인종속이 R의 후보키를 통해서만 성립되어야 한다.
74 |
75 | ### 함수적 종속 관계
76 | * 수강(학번, 과목명, 이름, )
77 | * 학번이 정해지면 과목명 상관없이 이름이 대응되는 경우
78 | * 이름을 학번에 함수 종속적이라고 한다.
79 | * 학번 -> 이름 과 같이 표기
80 |
81 | ### 완전 함수적 종속
82 | * 수강(학번, 과목명, 이름, 성적)
83 | * 어떤 속성이 기본키에 대해 완전히 종속적
84 | * 성적은 학번+과목명에 의해서만 결정됨
85 | ### 부분 함수적 종속
86 | * 수강(학번, 과목명, 이름, 성적, 학년)
87 | * 기본키의 일부인 학번에 의해 학년이 결정됨
88 | * 학년은 부분 함수적 종속
89 | ### 결정자
90 | * 수강(학번, 과목명, 이름, 성적)
91 | * 학번에 의해 이름이 결정된다고 하자.
92 | * 학번: 결정자
93 | * 이름: 종속자
94 | ### 다치종속
95 | * R(A,B,C)에서 (A,C)에 대응하는 B의 집합이 A에만 종속되고 C에는 무관할 때
96 | * B는 A의 다치종속
97 | * A ->-> B 로 표기
98 |
99 |
100 |
61 | * 1NF - 제 1정규형
62 | * 릴레이션에 속한 모든 도메인(속성값)이 더이상 쪼갤 수 없는 원자값이어야 한다.
63 | * 2NF - 제 2정규형
64 | * 기본키에 대해 다른 모든 속성이 [완전 함수적 종속](#완전-함수적-종속)을 만족해야 한다.
65 | * 3NF - 제 3정규형
66 | * 무손실조인 또는 종속성 보존을 저해하지 않고 항상 3NF를 얻을 수 있어야 한다.
67 | * BCNF - Boyce - Codd 정규형
68 | * [결정자](#결정자)가 모두 후보키여야 한다.
69 | * 후보키가 서로 중첩되는 경우에 적용한다.
70 | * 4NF - 제 4정규형
71 | * 릴레이션에 [다치종속](#다치종속)이 성립하는 경우(A->->B), 릴레이션의 모든 속성이 A에 [함수적 종속 관계](#함수적-종속-관계)를 만족해야 한다.
72 | * 5NF - 제 5정규형
73 | * 릴레이션 R의 모든 조인종속이 R의 후보키를 통해서만 성립되어야 한다.
74 |
75 | ### 함수적 종속 관계
76 | * 수강(학번, 과목명, 이름, )
77 | * 학번이 정해지면 과목명 상관없이 이름이 대응되는 경우
78 | * 이름을 학번에 함수 종속적이라고 한다.
79 | * 학번 -> 이름 과 같이 표기
80 |
81 | ### 완전 함수적 종속
82 | * 수강(학번, 과목명, 이름, 성적)
83 | * 어떤 속성이 기본키에 대해 완전히 종속적
84 | * 성적은 학번+과목명에 의해서만 결정됨
85 | ### 부분 함수적 종속
86 | * 수강(학번, 과목명, 이름, 성적, 학년)
87 | * 기본키의 일부인 학번에 의해 학년이 결정됨
88 | * 학년은 부분 함수적 종속
89 | ### 결정자
90 | * 수강(학번, 과목명, 이름, 성적)
91 | * 학번에 의해 이름이 결정된다고 하자.
92 | * 학번: 결정자
93 | * 이름: 종속자
94 | ### 다치종속
95 | * R(A,B,C)에서 (A,C)에 대응하는 B의 집합이 A에만 종속되고 C에는 무관할 때
96 | * B는 A의 다치종속
97 | * A ->-> B 로 표기
98 |
99 |
100 |
101 | [출처] -------------------------------------------------------------------------------- /02.database/kmj/21.01.27.md: -------------------------------------------------------------------------------- 1 | # 21.01.27 2 | * 트랜잭션 3 | ## 주요 질문 4 | 5 | 6 | #### 💡 트랜잭션에 대해서 설명해주세요. 7 | * 트랜잭션이란 데이터베이스의 상태를 변화시키기 위해 한번에 수행되어야 할 연산들입니다. 8 | * 트랜잭션은 수행중에 한 작업이라도 실패하면 전부 실패하고, 모두 성공해야 성공이라고 할 수 있습니다. 9 | 10 | 11 | #### 💡 ACID에 대해서 설명해주세요. 12 | 13 | * ACID는 트랜잭션의 무결성을 보장하기 위한 특성입니다. 14 | 15 | * Atomicity(원자성): 트랜잭션의 연산은 모든 연산이 완벽히 수행되어야 하며, 한 연산이라도 실패하면 트랜잭션은 실패해야 합니다. 16 | * Consistency(일관성): 언제나 일관성 있는 데이터베이스 상태로 변환합니다. 17 | * Isolation(고립성): 트랜잭션은 동시에 실행될 경우 다른 트랜잭션에 의해 영향을 받지 않습니다. 18 | * Durability(내구성): 트랜잭션이 커밋된 이후에는 시스템 오류가 발생하더라도 커밋된 상태로 유지되는 것을 보장해야 합니다. 19 | 20 | 21 | 22 | 23 |
24 | 25 | ## 심화 질문 26 | 27 | 28 | 29 | #### 💡 트랜잭션 격리 수준(Transaction Isolation Levels)에 대해서 설명해주세요. 30 | 31 | * 트랜잭션에서 일관성 없는 데이터를 허용하는 수준입니다. 32 | * 독립성을 유지하기 위해 동시에 수행되는 수많은 트랜잭션들을 순서대로 처리하게 되면 성능이 떨어집니다. 따라서 효율적인 Locking 방법이 필요합니다. 33 | * 종류(밑으로 갈수록 엄격함) 34 | * READ UNCOMMITTED: 트랜잭션에서 처리중이거나 커밋안된 내용을 다른 트랜잭션이 읽을 수 있다. 35 | * READ COMMITTED: 트랜잭션이 수행되는 동안 다른 트랜잭션이 접근할 수 없다. 36 | * REPEATABLE READ: 트랜잭션에 진입하기 이전에 커밋된 내용만 참조할 수 있다. 37 | * SERIALIZABLE: 트랜잭션에 진입하면 락을 걸어 다른 트랜잭션이 접근하지 못하게 한다.(성능 매우 떨어짐) 38 | 39 | [출처] https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/Transaction%20Isolation%20Level.md 40 | 41 | 42 | 43 | 44 |
45 | 46 | ## ⭐ 개념 정리 47 | 48 | ### 개념1 49 | * 설명 50 | 51 | 52 | 53 |
54 | 55 | ### 개념2 56 | * 설명 57 | 58 | 59 |
60 | [출처] -------------------------------------------------------------------------------- /02.database/kmj/21.01.28.md: -------------------------------------------------------------------------------- 1 | # 21.01.28 2 | * 인덱스 3 | 4 | ## 주요 질문 5 | 6 | #### 💡 인덱스란? 7 | * 데이터에 빠르게 접근하기 위해 <키값, 포인터> 쌍으로 구성되는 데이터 구조입니다. 8 | 9 | #### 💡 인덱스를 모든 속성에 추가할 경우 성능이 좋아질까요? 10 | * 그렇지 않습니다. 11 | 12 | #### 데이터베이스에서 조회만 일어난다고 할 때, 모든 속성에 인덱스를 추가하면 성능에 좋을까요? 13 | 14 | 15 | #### 💡 인덱스를 사용하면 좋은 경우는 무엇일까요? 16 | * 규모가 작지 않은 테이블에 사용하면 조회 속도가 빨라집니다. 17 | * Insert, Update, Delete 가 자주 발생하지 않는 컬럼이 좋습니다. 18 | * where구문, join문에 자주 사용되는 컬럼이 좋습니다. 19 | * 데이터의 중복도가 낮은 컬럼이 좋습니다. 20 | 21 | 22 | 23 | 24 | 25 |
26 | 27 | ## ⭐ 개념 정리 28 | 29 | ### 클러스터드 인덱스 vs 넌클러스터드 인덱스 30 | * 클러스터드 인덱스는 데이터를 PK에 따라서 순서대로 저장합니다. 범위탐색은 빠르지만 테이블 중간에 있는 데이터를 삭제하거나, 삽입할 때 느립니다. 31 | * 넌클러스터드 인덱스는 인덱스와 hashcode를 이용해서 데이터를 저장합니다. hashcode 또한 저장해야 하기 때문에 추가저장공간이 필요합니다. 그리고 데이터를 insert할 때 인덱스를 생성해줘야 하는 추가 작업이 필요합니다. 32 | 33 | 34 | 35 |
36 | 37 | ### B+Tree 38 | * RDBMS 에서 사용하는 INDEX는 B-Tree 에서 파생된 B+Tree를 사용합니다. 39 | * Index Node, Data Node로 구성되어 있다. 40 | Data Node: Leaf Node 41 | Index Node: Data Node 를 제외한 나머지 노드 42 | 43 | ### B-Tree 44 | * 45 | 46 | 47 |
48 | [출처] -------------------------------------------------------------------------------- /02.database/kmj/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.01.24|DATABASE 개념|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/kmj/21.01.24.md)| 6 | |21.01.25|RDBMS, KEY, JOIN|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/kmj/21.01.25.md)| 7 | |21.01.26|정규화|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/kmj/21.01.26.md)| 8 | |21.01.27|트랜잭션|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/kmj/21.01.27.md)| 9 | |21.01.28|INDEX|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/kmj/21.01.28.md)| 10 | -------------------------------------------------------------------------------- /02.database/kmj/images/normalization.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/kmj/images/normalization.png -------------------------------------------------------------------------------- /02.database/kmj/images/rdbms_relation.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/kmj/images/rdbms_relation.png -------------------------------------------------------------------------------- /02.database/kmj/기타.md: -------------------------------------------------------------------------------- 1 | * Injection 2 | * DB 풀 3 | 4 | ### SQL Injection 5 | 해커에 의해 조작된 SQL 쿼리문이 데이터베이스에 그대로 전달되어 비정상적 명령을 실행시키는 공격 기법 6 | 7 | 8 | 공격 방법 9 | 1) 인증 우회 10 | 보통 로그인을 할 때, 아이디와 비밀번호를 input 창에 입력하게 된다. 쉽게 이해하기 위해 가벼운 예를 들어보자. 아이디가 abc, 비밀번호가 만약 1234일 때 쿼리는 아래와 같은 방식으로 전송될 것이다. 11 | 12 | SELECT * FROM USER WHERE ID = "abc" AND PASSWORD = "1234"; 13 | SQL Injection으로 공격할 때, input 창에 비밀번호를 입력함과 동시에 다른 쿼리문을 함께 입력하는 것이다. 14 | 15 | 1234; DELETE * USER FROM ID = "1"; 16 | 보안이 완벽하지 않은 경우, 이처럼 비밀번호가 아이디와 일치해서 True가 되고 뒤에 작성한 DELETE 문도 데이터베이스에 영향을 줄 수도 있게 되는 치명적인 상황이다. 17 | 18 | 이 밖에도 기본 쿼리문의 WHERE 절에 OR문을 추가하여 '1' = '1'과 같은 true문을 작성하여 무조건 적용되도록 수정한 뒤 DB를 마음대로 조작할 수도 있다. 19 | 20 | 21 | 2) 데이터 노출 22 | 시스템에서 발생하는 에러 메시지를 이용해 공격하는 방법이다. 보통 에러는 개발자가 버그를 수정하는 면에서 도움을 받을 수 있는 존재다. 해커들은 이를 역이용해 악의적인 구문을 삽입하여 에러를 유발시킨다. 23 | 24 | 즉 예를 들면, 해커는 GET 방식으로 동작하는 URL 쿼리 스트링을 추가하여 에러를 발생시킨다. 이에 해당하는 오류가 발생하면, 이를 통해 해당 웹앱의 데이터베이스 구조를 유추할 수 있고 해킹에 활용한다. 25 | 26 | 27 | 28 | 방어 방법 29 | 1) input 값을 받을 때, 특수문자 여부 검사하기 30 | 로그인 전, 검증 로직을 추가하여 미리 설정한 특수문자들이 들어왔을 때 요청을 막아낸다. 31 | 32 | 2) SQL 서버 오류 발생 시, 해당하는 에러 메시지 감추기 33 | view를 활용하여 원본 데이터베이스 테이블에는 접근 권한을 높인다. 일반 사용자는 view로만 접근하여 에러를 볼 수 없도록 만든다. 34 | 35 | 3) preparestatement 사용하기 36 | preparestatement를 사용하면, 특수문자를 자동으로 escaping 해준다. (statement와는 다르게 쿼리문에서 전달인자 값을 ?로 받는 것) 이를 활용해 서버 측에서 필터링 과정을 통해서 공격을 방어한다. 37 | 38 | ### 데이터베이스 풀 39 | Connection Pool 40 | 클라이언트의 요청에 따라 각 어플리케이션의 스레드에서 데이터베이스에 접근하기 위해서는 Connection이 필요하다. 41 | Connection pool은 이런 Connection을 여러 개 생성해 두어 저장해 놓은 공간(캐시), 또는 이 공간의 Connection을 필요할 때 꺼내 쓰고 반환하는 기법을 말한다. 42 | 43 | DB에 접근하는 단계 44 | 웹 컨테이너가 실행되면서 DB와 연결된 Connection 객체들을 미리 생성하여 pool에 저장한다. 45 | DB에 요청 시, pool에서 Connection 객체를 가져와 DB에 접근한다. 46 | 처리가 끝나면 다시 pool에 반환한다. 47 | Connction이 부족하면? 48 | 모든 요청이 DB에 접근하고 있고 남은 Conncetion이 없다면, 해당 클라이언트는 대기 상태로 전환시키고 Pool에 Connection이 반환되면 대기 상태에 있는 클라이언트에게 순차적으로 제공된다. 49 | 왜 사용할까? 50 | 매 연결마다 Connection 객체를 생성하고 소멸시키는 비용을 줄일 수 있다. 51 | 미리 생성된 Connection 객체를 사용하기 때문에, DB 접근 시간이 단축된다. 52 | DB에 접근하는 Connection의 수를 제한하여, 메모리와 DB에 걸리는 부하를 조정할 수 있다. 53 | Thread Pool 54 | 비슷한 맥락으로 Thread pool이라는 개념도 있다. 55 | 이 역시 매 요청마다 요청을 처리할 Thread를 만드는것이 아닌, 미리 생성한 pool 내의 Thread를 소멸시키지 않고 재사용하여 효율적으로 자원을 활용하는 기법. 56 | Thread Pool과 Connection pool 57 | WAS에서 Thread pool과 Connection pool내의 Thread와 Connection의 수는 직접적으로 메모리와 관련이 있기 때문에, 많이 사용하면 할 수록 메모리를 많이 점유하게 된다. 그렇다고 반대로 메모리를 위해 적게 지정한다면, 서버에서는 많은 요청을 처리하지 못하고 대기 할 수 밖에 없다. 58 | 보통 WAS의 Thread의 수가 Conncetion의 수보다 많은 것이 좋은데, 그 이유는 모든 요청이 DB에 접근하는 작업이 아니기 때문이다. 59 | 60 | #### 데이터베이스의 성능? 61 | 데이터베이스의 성능 이슈는 디스크 I/O 를 어떻게 줄이느냐에서 시작된다. 디스크 I/O 란 디스크 드라이브의 플래터(원판)을 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것을 의미한다. 이 때 데이터를 읽는데 걸리는 시간은 디스크 헤더를 움직여서 읽고 쓸 위치로 옮기는 단계에서 결정된다. 즉 디스크의 성능은 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한 번에 기록하느냐에 따라 결정된다고 볼 수 있다. 62 | 63 | 그렇기 때문에 순차 I/O 가 랜덤 I/O 보다 빠를 수 밖에 없다. 하지만 현실에서는 대부분의 I/O 작업이 랜덤 I/O 이다. 랜덤 I/O 를 순차 I/O 로 바꿔서 실행할 수는 없을까? 이러한 생각에서부터 시작되는 데이터베이스 쿼리 튜닝은 랜덤 I/O 자체를 줄여주는 것이 목적이라고 할 수 있다. 64 | * 답변 -------------------------------------------------------------------------------- /02.database/lyj/21.01.13.md: -------------------------------------------------------------------------------- 1 | # 21.00.00 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [질문1](#개념1) 6 | * 답변 7 | 8 | #### 💡 질문2 9 | * 답변 10 | 11 | #### 💡 질문3 12 | * 답변 13 | 14 | 15 | 16 |
17 | 18 | ## 심화 질문 19 | 20 | #### 💡 질문1 21 | * 답변 22 | 23 | #### 💡 질문2 24 | * 답변 25 | 26 | #### 💡 질문3 27 | * 답변 28 | 29 | 30 |
31 | 32 | ## 개념 정리 33 | 34 | ### ⭐ 개념1 35 | * 설명 36 | 37 |
44 | 45 | #### ⭐ 개념2 46 | * 설명 47 | 48 | 49 |
50 | -------------------------------------------------------------------------------- /02.database/lyj/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.01.13|OSI 7 Layers|[✅보러가기](https://github.com/ACmolar/Tech_interview#21-01-13)| 6 | |21.01.14|TCP/IP|[✅보러가기](https://github.com/ACmolar/Tech_interview#21-01-14)| 7 | |21.01.15|테스트2|[✅보러가기](https://github.com/ACmolar/Tech_interview#21-01-15)| -------------------------------------------------------------------------------- /02.database/phb/21.01.12.md: -------------------------------------------------------------------------------- 1 | # 21.01.12 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [데이터베이스의 특징은 무엇인가?](#데이터베이스) 6 | * 일관성 있는 데이터를 실시간으로 여러 사람들에게 공유할 수 있습니다. 7 | 8 | #### 💡 [데이터베이스 설계 시 고려할 점은 무엇인가?](#데이터베이스) 9 | * 데이터의 무결성, 일관성을 유지하여 정확한 데이터를 제공해야합니다. 시스템 장애 발생시에 장애 발생 전으로 복구할 수 있어야합니다. 불법적 데이터 노출이나 변경 및 손실로부터 데이터를 보호할 수 있어야 합니다. 10 | 11 | #### 💡 [스키마란?](#스키마) 12 | * 데이터베이스의 자료 구조, 관계, 제약조건 등을 정의한 것입니다. 13 | 14 |
15 | 16 | ## ⭐ 개념 정리 17 | 18 | ### 데이터베이스 19 | * 조직에 필요한 데이터를 저장해 놓은 것 20 | * 특징 21 | * 공유데이터 : 동시공유 가능 22 | * 운영데이터 : 항상 최신 데이터를 유지하며 실시간 접근이 가능 23 | * 통합데이터 : 데이터 중복의 최소화 24 | * 저장데이터 : 내용에 의한 접근 25 | * 설계 고려사항 26 | * 데이터의 무결성 유지 27 | * 데이터의 일관성 유지 28 | * 데이터의 회복성 유지 29 | * 데이터의 보안성 유지 30 | * 데이터의 효율성 유지 31 | * 데이터베이스의 확장성 유지 32 | * 생명주기 33 | * 요구사항 분석 - 설계 - 구현 - 운영 - 유지보수 34 | 35 | 36 |
37 | 38 | ### DBMS 39 | * 데이터베이스를 관리하는 소프트웨어 40 | 41 | 42 |
43 | 44 | ### 스키마 45 | * 데이터베이스의 자료 구조, 관계 등을 정의한 구조 46 | * 데이터베이스 스키마 47 | 48 |  49 | 50 | 51 | 52 |
53 | 54 | ### 데이터모델링 55 | * 복잡한 현실 세계를 정해진 구조 및 제약조건에 따라 추상화하는 과정 56 | * 모델링 과정 57 | 58 |  59 | 60 | * 개념 모델링 : 핵심 엔티티 도출 및 관계를 정의 (개념 E-R모델) 61 | * 논리 모델링 : 엔티티-속성 관계 구조 설계 및 정규화 수행 (상세 E-R모델) 62 | * 물리 모델링 : 사용할 DBMS, 데이터 타입 선정 등 실제 DB 저장을 위한 내용 정의 63 | 64 | 65 |
66 | -------------------------------------------------------------------------------- /02.database/phb/21.01.13.md: -------------------------------------------------------------------------------- 1 | # 21.01.13 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [정규화란?](#정규화) 6 | * 종속 이론을 기반으로 하여 잘못 설계된 관계형 스키마를 작은 속성 집합으로 쪼개는 과정입니다. 7 | 8 | #### 💡 [정규화 과정 간단하게 알려주세요](#정규화) 9 | * 정규화되지 않은 릴레이션에서 도메인을 원자값으로 쪼개면 제 1정규형이 됩니다. 제 1 정규형에서 부분 함수 종속을 제거하면 제 2정규형이되고 이행적 함수 종속을 제거하면 제 3정규형을 만족하게 됩니다. 10 | 11 | #### 💡 모든 테이블을 정규화하는 것이 좋은가요? 12 | * 아닙니다. 항상 같이 사용되는 칼럼값이 정규화로 쪼개진다면 두 테이블을 항상 join하여 사용해야 합니다. 이 과정은 오히려 연산 횟수가 증가하여 성능의 저하가 발생할 수 있어 역정규화를 실행합니다. 13 | 14 | 15 | #### 💡 [이상현상 설명해주세요](#이상현상) 16 | * 정규화되지 않은 릴레이션에서 예기치 않게 발생하는 문제로 삽입이상, 갱신이상, 삭제이상이 있습니다. 17 | 18 |
19 | 20 | ## ⭐ 개념 정리 21 | 22 | ### 정규화 23 | * 종속 이론을 기반으로 하여 잘못 설계된 관계형 스키마를 작은 속성 집합으로 쪼개는 과정 24 | * 데이터베이스 설계 시, 중복을 최소화하여 구조 설계 하는 것 25 | 26 | * 목적 27 | * 데이터베이스 구조 안정화 28 | * 효과적인 검색 29 | * 이상현상 방지 30 | * 과정 31 | 32 |  33 | 34 |
35 | 36 | ### 이상현상 37 | * 정규화되지 않은 릴레이션에서 예기치 않게 발생하는 문제 38 | * 종류 39 | * 삽입이상 : 원하지 않는 값이 삽입 40 | * 삭제이상 : 원하지 않는 값이 연쇄 삭제 41 | * 갱신이상 : 일부 데이터만 변경 42 | 43 |
44 | 45 | 46 | -------------------------------------------------------------------------------- /02.database/phb/21.01.14.md: -------------------------------------------------------------------------------- 1 | # 21.01.14 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [PK랑 FK 설명해주세요](#키key) 6 | * PK는 릴레이션에서 최소성, 유일성을 지키고 있으며 null 값을 가질 수 없는 키입니다. 7 | * FK는 릴레이션 간의 관계를 표시하는 키로 null값이거나 참조하는 테이블의 PK 값이어야 합니다. 8 | 9 | #### 💡 [뷰 설명해주세요](#뷰view) 10 | * 뷰는 기본 테이블에서 유도된 가상테이블입니다. 중요한 정보는 제외하고 사용자에게 보여줄 수 있습니다. 11 | 12 | #### 💡 서브 쿼리의 성능은? 13 | * MySQL 5.5 이하의 버전에서 IN절에 사용하는 경우 EXISTS로 테이블을 FULL SCAN 하여 속도가 느립니다. MySQL 5.6부터는 최적화가 되어 있지만 다양한 조건에 최적화되어 있지 않아 가능한 join문 2개로 푸는 것이 성능적으로 효과적입니다. 14 | 15 |
16 | 17 | #### 💡 RDBMS와 NoSQL의 차이는? 18 | |RDBMS|NoSQL| 19 | |------|---| 20 | |- 스키마에 따라 데이터를 관리 | - 스키마가 없어 유연한 데이터 저장| 21 | |- 정교한 검색이 가능 | - 규격화된 데이터 값을 얻기 힘듬| 22 | |- 부하의 분산이 어려움 | - 분산형 구조| 23 | 24 |
25 | 26 | 27 | ## ⭐개념 정리 28 | 29 | ### 관계형 데이터베이스의 구조 30 |  31 | 32 | * 속성(Attribue) : 릴레이션을 구성하는 각각의 열 33 | * 차수(Degree) : 속성의 수 34 | * 튜플 : 릴레이션을 구성하는 각각의 행 35 | * 카디널리티(Cardinality) : 튜플의 수 36 | * 도메인 : 하나의 속성이 취할 수 있는 같은 원자값들의 집합 37 | 38 | 39 |
40 | 41 | #### 키(KEY) 42 | 43 | * 기본키(PK) : 후보키에서 선택된 1개의 키, 유일성과 최소성을 만족하며 null값을 가질 수 없다. (개체 무결성) 44 | * 외래키(FK) : 릴레이션을 참조하기 위한 키, null값 또는 참조하는 릴레이션의 PK값이어야 한다. (참조 무결성) 45 | 46 | * 후보키 : 유일성과 최소성을 만족하는 키 47 | * 대체키 : 후보키에서 기본키를 제외한 나머지 키 48 | * 슈퍼키 : 유일성을 만족하며 2개 이상의 속성으로 이루어진 키 49 | 50 | 51 |
52 | 53 | #### SQL 54 | * DDL 55 | * CREATE : 테이블 생성 56 | > CREATE TABLE 테이블명 ( 칼럼명1 DATATYPE, 칼럼명2 DATATYPE, ... [CONSTRAINT]); 57 | 58 |
59 | 60 | * DROP : 테이블 삭제 61 | > DROP TABLE FROM 테이블명 [WHERE 조건]; 62 | 63 |
64 | 65 | * ALTER : 테이블 수정 66 | > ALTER TABLE 테이블명 ADD/DROP/MODIFY/RENAME 칼럼명/칼럼내용 ; 67 | 68 | * DML 69 | * SELECT : 검색 70 | > SELECT 칼럼명1, ... FROM 테이블명 [WHERE 조건]; 71 | 72 |
73 | 74 | * UPDATE : 수정 75 | > UPDATE 테이블명 SET 조건 WHERE 조건; 76 | 77 |
78 | 79 | * DELETE : 삭제 80 | > DELETE FROM 테이블명 [WHERE 조건]; 81 | 82 |
83 | 84 | * INSERT : 삽입 85 | > INSERT 테이블명 INTO VALUES(값1, 값2, ...); 86 | > INSERT 테이블명(칼럼명1, 칼럼명2, ...) INTO VALUE(값1, 값2, ...); 87 | 88 | * DCL 89 | * GRANT : 시스템 권한 부여 90 | > GRANT 권한명 ON 객체명 TO 유저명 [WITH ADMIN OPTION]; 91 | 92 |
93 | 94 | * REVOKE : 시스템 권환 회수 95 | > REVOKE 권한명 ON 객체명 FROM 유저명; 96 | 97 |
98 | 99 | * COMMIT : 트랜잭션이 정상적으로 처리됐음을 의미 100 | * ROLLBACK : 트랜잭션에 문제가 생겨 이전 상태로 돌아감을 의미 101 | 102 |
103 | 104 | #### 뷰(VIEW) 105 | > CREATE VIEW 뷰이름(속성1, 속성2, ...) AS SELECT문; 106 | * 기본 테이블에서 유도된 가상테이블 107 | * 원하는 정보만 사용자에게 보여줄 수 있음 108 | * 물리적으로 존재하지 않음 109 | * 물리적으로 존재하지 않기 때문에 독립적인 인덱스를 가질 수 없음 110 | * 삽입, 삭제, 갱신 등 연산에 제약이 있음 111 | 112 | 113 |
114 | 115 | #### 서브쿼리 116 | * 하나의 sql문 안에 포함되어 있는 또 다른 sql 117 | * 서브쿼리 내부에 order by 사용 불가능 118 | * 서브쿼리는 메인 쿼리의 칼럼을 사용할 수 있지만 메인쿼리는 서브쿼리의 칼럼 사용 불가능 119 | * 성능 (MySQL 5.5이하 버전 구림) 120 | * MySQL 5.5 이하 버전에서 IN절 내에 서브쿼리가 존재할 경우, EXISTS 형태로 변환되어 실행되어 최적화 되지 못하고 외부 쿼리는 테이블 FULL SCAN 동작 121 | * join문으로 풀어서 사용하는 것이 좋음 -> 쿼리 성능 비교 후 적용 122 | 123 |
19 | 20 | ## ⭐ 개념 정리 21 | 22 | ### 트랜잭션(Transaction) 23 | * 데이터베이스의 논리적 작업 단위 24 | * 특징 (ACID) 25 | * 원자성 : All or Nothing, 결과가 모두 반영되거나 아무것도 반영되지 않아야 함 26 | * 일관성 : 트랜잭션 후에도 데이터베이스 상태는 무결성을 유지 27 | * 고립성 : 한 트랜잭션 중간에 다른 트랜잭션이 끼어들 수 없음 28 | * 지속성 : 트랜잭션으로 변화된 상태는 계속 유지되어야 함 29 | * TCL 30 | * COMMIT : 트랜잭션 성공하여 DB에 상태 반영 31 | * ROLLBACK : 트랜잭션 실패하여 기존 상태로 복구 32 | 33 | 34 |
35 | 36 | ### 회복 37 | * 외부/내부 장애로 데이터베이스가 일관성을 유지하지 못할 때 이를 유지하기 위한 방법 38 | * 회복 연산자 39 | * REDO : 백업본으로 변경 후, 로그 기록에 남은 성공 데이터를 DB에 적용 40 | * UNDO : 변경된 데이터를 취소하고 예전 데이터로 복구 41 | 42 | 43 |
44 | 45 | ### 동시성 제어 46 | * 여러 트랜잭션 간의 문제가 발생하지 않도록 트랜잭션의 실행 순서를 제어하는 기법 47 | 48 | | |T1|T2|발생문제| 허용여부| 49 | |---|---|---|---|---| 50 | |CASE1|READ|READ|X|허용| 51 | |CASE2|READ|WRITE|오손읽기, 유령데이터 읽기|허용/불가 선택| 52 | |CASE3|WRITE|WRITE| 갱신손실, 연쇄복구, 모순성| 절대 불가| 53 | 54 |
55 | 56 | ### 로킹(Locking) 57 | * 동시성 제어 방법으로 트랜잭션에 LOCK을 설정하여 LOCK 상태에서 다른 트랜잭션이 실행하지 못하도록 하는 기법 58 | * 2단계 로킹 59 | * 확장 단계 : LOCK을 걸 수만 있음 60 | * 축소 단계 : UNLOCK만 가능 61 | * 문제점 : 데이터가 많은 경우 교착상태에 빠질 수 있음 62 |
63 | 64 | ### 교착상태(DeadLock) 65 | * 여러 트랜잭션이 실행되지 못하고 무기한 대기 중인 상태 66 | * 해결 방법 67 | * 예방기법 : 트랜잭션 시작 전, 필요한 데이터에 LOCK을 모두 걸어주는 기법. 필요한 데이터가 많은 경우 무쓸모 68 | * 회복기법 : 자원 할당 시에 타임스탬프를 사용하여 시간 순서대로 제어하는 기법. 69 | -------------------------------------------------------------------------------- /02.database/phb/21.01.17.md: -------------------------------------------------------------------------------- 1 | # 21.01.17 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [인덱스란?](#인덱스index) 6 | * 책의 목차처럼 지정한 칼럼을 정렬하여 데이터를 쉽게 찾을 수 있도록 만든 테이블입니다. 7 | 8 | #### 💡 [인덱스 구조는?](#인덱스-구조) 9 | * 해쉬테이블과 B+Tree 구조가 있습니다. 해쉬테이블은 키 값에 해쉬함수를 적용하여 나온 주소값과 매칭하는 기법입니다. 하지만 부등호 연산이 많은 db에는 효과적이지 않은 방법입니다. B+Tree는 LinkedList로 연결된 구조입니다. 연결된 노드를 따라가면서 일치하는 값으로 가서 읽고 일치하지 않는 값이 나오면 즉시 중지합니다. B+Tree는 부등호 연산에 효율적입니다. 10 | 11 | #### 💡 [Index는 어디에 사용하는게 좋나요?](#인덱스를-사용하면-좋은-테이블) 12 | * 연산이 거의 없고 검색을 많이 하는 테이블에 사용하면 좋고 칼럼의 중복도가 낮은 곳에 사용하면 좋습니다. 13 | 14 | #### 💡 중복도가 높은 칼럼 예시 하나만 들어주세요. 15 | * 성별입니다. 사람은 여자, 남자밖에 없어서 최악의 경우 full scan을 해야합니다. 이 경우 인덱스를 설정하지 않는 것이 좋습니다. 16 | 17 | #### 💡 [인덱스를 따로 설정하지 않으면 어떻게 되는가?](#인덱스index) 18 | * 인덱스를 설정하지 않아도 기본적으로 PK값이 인덱스로 설정되어 있습니다. 19 | 20 | #### 💡 [속도를 위해 모든 칼럼에 인덱스를 넣으면 되지 않는가?](#인덱스index) 21 | * 인덱스는 인덱스 설정된 칼럼을 추가 저장 공간에 저장하고 재정렬해서 사용합니다. 그렇기 때문에 모든 칼럼에 인덱스를 넣게 되면 저장 공간을 많이 차지하게 됩니다. 또한, 데이터를 재정렬하기 때문에 삽입, 삭제, 갱신이 발생하게 되면 인덱스 테이블은 이 데이터에 대해 재정렬을 다시 수행해야하므로 오히려 성능 저하로 이어지게 됩니다. 22 | 23 | 24 |
25 | 26 | ## ⭐ 개념 정리 27 | 28 | ### 인덱스(Index) 29 | > CREATE INDEX 인덱스명 ON 테이블명(칼럼명) 30 | * 책의 목차와 같은 개념 31 | * 추가 저장 공간에 인덱스 테이블을 생성하고 데이터 정렬해서 사용 32 | * 검색 속도 향상 33 | * 인덱스를 설정하지 않은 경우, 기본적으로 PK값이 인덱스로 사용 34 | 35 | 36 |
37 | 38 | ### 인덱스를 사용하면 좋은 테이블 39 | * 규모가 작지 않은 테이블 40 | * 삽입, 삭제, 갱신이 자주 발생하지 않는 테이블 41 | * 데이터 중복도가 낮은 칼럼 42 | 43 | 44 |
45 | 46 | ### 인덱스 구조 47 | * 해쉬테이블 48 |  49 | 50 | 51 | * 해쉬함수에 의해 값이 주소값에 매핑된다. 52 | * equal 관계에서는 효율적이지만, 범위 연산이 많은 DB 연산에서는 비효율적 53 | 54 |
55 | 56 | * B+Tree 57 |  58 | 59 | * LinkedList로 연결 60 | * 일치하지 않는 값이 나오면 탐색을 중지 61 | * 만약 위의 그림에서 52번이 9번 블록 끝까지 있다면 10번 노드도 탐색 62 | 63 |
64 | 65 |
24 | 25 | ## 개념 정리 26 | 27 | ### ⭐ 메모리 관리 전략 28 | - 메모리 용량이 증가함에 따라 프로그램의 크기 또한 계속 증가하고 있기 때문에 메모리는 언제나 부족 29 | - 제한된 물리 메모리의 효율적인 사용과 메모리 참조 방식을 제공하기 위한 전략 30 | 31 | #### 논리 대 물리주소 공간 32 | * CPU가 생성하는 주소를 논리 주소, 메모리가 취급하는 주소를 물리 주소라 한다. 프로그램 실행 중에는 이와 같은 가상 주소를 물리 주소로 바꿔줘야 하는데, 이 매핑 작업은 메모리 관리기(Memory Management Unit)에서 실행된다. 33 | 34 | #### 관리 전략 35 | * Swapping(스와핑) 36 | * 프로세스가 실행되기 위해서는 메모리에 있어야 하지만, 프로세스는 실행 중에 임시로 예비저장장치(backup store)에 내보내여 졌다가 실행을 계속하기 위해 다시 메모리로 돌아올 수 있다. 37 |  38 | * 프로세스를 불러들이기 위한 공간이 메모리에 부족하다면 현재 메모리에 적재된 프로세스들을 내보내고(swap out) 원하는 프로세스를 불러들인다(swap in) 39 | * 상당한 Context-switching time이 발생한다. 또한 스와핑을 위해서는 현재 메모리의 프로세스가 완전히 휴지상태(idle)임을 확인해야 한다. 40 | 41 | 42 | #### Fragmentation(단편화) 43 | * 메모리 단편화란 메모리 공간이 비효율적으로 사용되어 저장 공간이 낭비되는 것을 말한다. 44 | #### 내부 단편화 45 |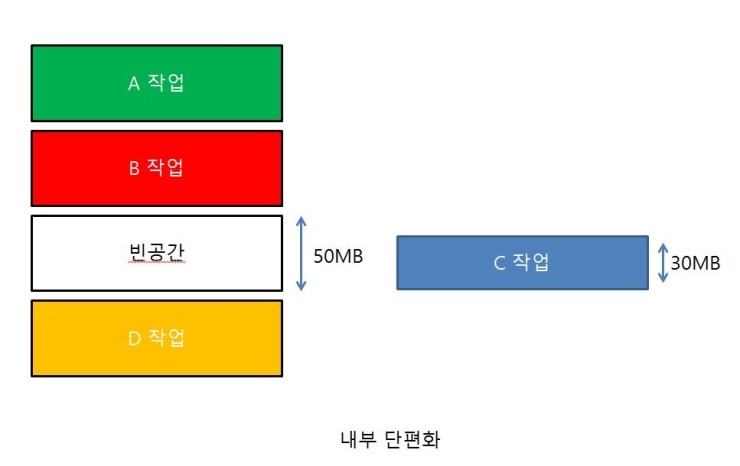
46 | * 할당한 영역 중 사용되지 않는 공간으로 인해 공간이 낭비되는 것을 의미한다. 47 | * '내부'라는 용어는 할당한 영역 내부에 사용되지 않는 공간이 있다는 것을 뜻한다. 48 | * ex) 페이징 기법에서 한 페이지를 크게 할 경우 내부 단편화가 발생할 수 있다. 49 | * ex) 배열을 너무 크게 잡은 경우 50 | 51 | #### 외부 단편화 52 | * 메모리 여유 공간이 띄엄 띄엄 존재해서 실제로 사용할 수 없는 경우를 의미한다. 53 | * '외부'라는 용어는 사용할 수 없는 기억 장소가 할당된 영역 밖에 있다는 것을 뜻한다. 54 | * ex) 동적 메모리 할당 해제를 자주 하는 경우 55 | *  56 | * 57 | * 메모리 단편화로 일어날 수 있는 현상 58 | 1. 총 메모리 공간은 충분 하지만 실제 사용이 불가능할 수 있다. 59 | 2. 실제 사용 가능한 공간이 줄어들어 시스템 성능의 저하를 일으킬 수 있다. 60 | 3. 실제 사용할 수 있는 공간을 찾는 과정이 필요 61 | 4. 잦은 페이지 교체 62 | 63 | #### 메모리 단편화 해결 기법 64 | * 페이징/세그멘테이션 65 | * 세그멘테이션(segmentation) : 내부 단편화 해결, 외부 단편화 존재 66 | * 페이징(paing) : 외부 단편화 해결, 내부 단편화 존재 67 | 68 | * Segmentation(세그멘테이션)이란? 69 | * 메모리를 서로 크기가 다른 논리적인 블록 단위인 '세그먼트(segment)'로 분할하고 메모리를 할당하여 물리 주소를 논리 주소로 변환하는 것을 말한다. 미리 분할하는 것이 아니고 메모리를 사용할 시점에 할당된다. 70 | 71 | * Paging(페이징)이란? 72 | * 하나의 프로세스가 사용하는 메모리 공간이 연속적이어야 한다는 제약을 없애는 메모리 관리 방법이다. 외부 단편화와 압축 작업을 해소 하기 위해 생긴 방법론으로, 물리 메모리는 Frame 이라는 고정 크기로 분리되어 있고, 논리 메모리(프로세스가 점유하는)는 페이지라 불리는 고정 크기의 블록으로 분리된다.(페이지 교체 알고리즘에 들어가는 페이지) 73 |
74 | 75 | > https://m.blog.naver.com/s2kiess/220149980093 -------------------------------------------------------------------------------- /03.Operating_system/hsh/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.02.15|Process & Thread|[✅보러가기](/03.Operating_system/hsh/21.02.15.md)| 6 | |21.02.16|스케줄링|[✅보러가기](/03.Operating_system/hsh/21.02.16.md)| 7 | |21.02.17|메모리 관리|[✅보러가기](/03.Operating_system/hsh/21.02.17.md)| 8 | |21.02.20|가상 메모리|[✅보러가기](/03.Operating_system/hsh/21.02.20.md)| 9 | |21.02.23|Kernel|[✅보러가기](/03.Operating_system/hsh/21.02.23.md)| 10 | |-|-|-| 11 | 12 | 13 | -------------------------------------------------------------------------------- /03.Operating_system/hsh/images/Swapping.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/hsh/images/Swapping.png -------------------------------------------------------------------------------- /03.Operating_system/kmj/21.02.15.md: -------------------------------------------------------------------------------- 1 | # 21.02.15 2 | * 프로세스와 쓰레드 차이 3 | * 멀티쓰레드 4 | * ThreadSafe 5 | * 뮤텍스 vs 세마포어 6 | ## 주요 질문 7 | 8 | #### 💡 프로세스와 쓰레드 차이 9 | * 프로세스는 실행되고 있는 프로그램을 의미합니다. 10 | * 쓰레드는 프로세스 내부에서 실행되는 여러 흐름의 단위입니다. 11 | * 프로세스가 쓰레드보다 큰 단위입니다. 프로세스는 데이터를 공유할 수 없습니다. 반면, 스레드는 같은 프로세스 내부에 있는 stack 영역을 제외한 모든 영역을 공유할 수 있습니다. 12 | 13 | 14 | 15 | #### 💡 멀티 프로세스 vs 멀티 쓰레드 16 | 17 | 멀티 프로세스는 하나의 CPU를 여러 프로세스가 번갈아가면서 사용하는 방식입니다. 이 방식은 문맥교환 시 속도가 느려집니다. 18 | 반면 멀티 스레드는 CPU 1개로 여러 스레드를 생성하여 시스템의 컴퓨팅 속도를 높일 수 있습니다. 19 | 20 | #### 💡 context switching이란? 21 | 문맥 교환(context switch)이란 하나의 프로세스가 CPU를 사용 중인 상태에서 다른 프로세스가 CPU를 사용하도록 하기 위해, 이전의 프로세스의 상태(문맥)를 보관하고 새로운 프로세스의 상태를 적재하는 작업을 말합니다. 22 | 23 | 24 | #### 💡 PCB: Process Control Block 25 | * 특정 프로세스에 대한 중요한 정보를 저장하고 있는 운영체제의 자료구조입니다. 26 | * Context Switch 작업이 발생할 때 진행하던 작업을 PCB에 저장하고 CPU를 반환합니다. 27 | * 이후 CPU를 할당받게 되면 PCB에 저장되었던 내용을 불러와서 이전에 종료됐던 시점부터 다시 작업을 수행합니다. 28 | 29 | > https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/OS 30 | 31 | #### 💡 멀티쓰레드 장점 및 단점 32 | * 장점 33 | * 컨텍스트 스위칭(Context Switching) 시에 공유 메모리 만큼의 시간(자원) 손실이 줄어듭니다. 34 | 35 | * Stack을 제외한 모든 메모리를 공유합니다. 36 | 37 | * 단점 38 | * 하나의 스레드가 자신이 사용하던 데이터 공간을 망가뜨린다면, 그 공간을 공유하는 모든 스레드를 작동불능 상태가 된다는 점입니다. 39 | 40 | 41 | 42 | 43 | 44 | > https://blog.xeros.dev/63 45 | > https://you9010.tistory.com/136 [본질을 알고픈 개발자] 46 | 47 | #### 💡 ThreadSafe 48 | * 멀티 스레드 프로그래밍에서 데이터가 여러 쓰레드로부터 동시에 접근이 이루어져도 프로그램 실행에 문제가 없는 상태를 말합니다. 49 | * 자바에서 concurrent hash map, concurrent linked queue 를 사용함 50 | synchronized 키워드 추가하면 됨. 51 | * 추가로 reentranlock, atomicinteger 가 있다는데 안써봄 52 | 53 | * c++ 에서는 critical session 개념을 도입해서 연산들을 직렬화해준다고 함. 54 | https://heowc.dev/programming-study/repo/java/thread_safe%ED%95%98%EA%B2%8C_%EB%8D%B0%EC%9D%B4%ED%84%B0_%EA%B0%B1%EC%8B%A0%ED%95%98%EA%B8%B0 55 | ## 심화 질문 56 | #### 💡 쓰레드와 프로세스의 공통점 57 | * 쓰레드와 프로세스는 모두 각자의 스택 영역을 가집니다. 58 | 그리고 각각의 영역을 관리하는 ControlBlock이 존재합니다. 59 | * 쓰레드의 control block 은 TCB, 프로세스의 control block 은 PCB 60 | 61 | #### 💡 스레드를 사용할 때의 장단점이 뭔가요? 62 | 63 | * 장점 64 | 65 | 1. 스레드 간의 컨텍스트 스위칭이나 통신은 프로세스 대비 오버헤드가 적습니다. 66 | 67 | 68 | * 단점 69 | 70 | 1. 한 프로세스 내의 여러 스레드 중 스레드 하나가 잘못되면, 다른 스레드 모두가 영향을 받습니다. 71 | 2. 공유하는 변수를 여러 스레드가 동시에 변경하는 경우, 이상 동작의 발생 가능성이 높습니다. 72 | 73 | 74 | #### 💡 스레드에 스택을 독립적으로 할당하는 이유 75 | * 스택: 인자, 변수 등을 저장하는 메모리 공간 76 | * 스레드마다 독립적인 함수 호출, 실행을 하기 위해서 스레드에 스택을 독립적으로 할당합니다. 77 | #### 💡 PC레지스터를 스레드마다 독립적으로 할당하는 이유 78 | * PC레지스터: 스레드가 명령어의 어디까지 수행했는지 79 | * Context Switch 할 때 이전에 어디 부분까지 작업을 수행했는지 기억하기 위해서 PC 레지스터를 스레드마다 독립적으로 할당합니다. 80 | 81 | #### 💡 자바 스레드란? 82 | * 자바는 프로세스가 존재하지 않고 스레드만 존재합니다. 83 | * 자바 스레드는 JVM에 의해 스케줄링되는 코드블록입니다. 84 | * 개발자는 스레드 코드를 작성하고 JVM에 실행을 요청합니다. 85 |
86 | 87 | ## ⭐ 개념 정리 88 | 89 | 90 | 91 | ### 운영체제 92 | 하드웨어와 소프트웨어를 연결해주는 인터페이스 역할을 수행합니다. 93 | 94 | ### 프로세스 vs 스레드 95 | 96 | 97 |
98 |
97 |
98 |  99 |
100 |
101 |
102 |
99 |
100 |
101 |
102 |
103 | 104 | ### 프로세스의 주소공간 105 | 프로그램이 CPU에 의해 실행되면 프로세스가 생성되고 메모리에 '프로세스 주소 공간'이 할당됩니다. 이 때 프로세스 주소 공간은 코드, 데이터, 스택, 힙 영역으로 이루어져 있습니다. 106 | * 코드 : 프로그램 소스 코드 저장 107 | * 데이터 : 전역 변수 저장 108 | * 스택 : 함수, 지역 변수 저장 109 | * 힙: 동적 할당 시 사용 110 | 111 | ### 뮤텍스 vs 세마포어 112 | * 뮤텍스: 공유된 자원을 여러 스레드가 접근하는 것을 막음 113 | * synchronized, lock 사용 114 | * 동기화 대상이 1개 115 | * 세마포어: 공유된 자원의 데이터를 여러 프로세스가 접근하는 것을 막음 116 | * 공유 자원에 접근할 수 있는 프로세스의 최대 개수를 설정할 수 있다. 117 | * 동기화 대상이 1개 이상 118 |
119 | [출처] -------------------------------------------------------------------------------- /03.Operating_system/kmj/21.02.16.md: -------------------------------------------------------------------------------- 1 | # 21.02.16 2 | * 스케줄러 (장기,중기,단기) 3 | * CPU 스케줄러 (FCFS, SJF, SRT, Priority Scheduling, RR) 4 | 5 | ## 주요 질문 6 | 7 | #### 💡 스케줄러란? 8 | * 어떤 프로세스에게 자원을 할당할지 결정하는 운영체제의 커널 모듈입니다. 9 | 10 |
11 | #### 💡 장기 스케줄러
12 | * 작업 스케줄러라고도 부르며 어떤 프로세스를 Ready 단계에 넣을지 결정합니다. 디스크에서 어떤 프로그램을 가져와 커널(Ready Queue)에 등록할지 결정합니다.
13 | * 현대의 운영체제에서는 장기 스케줄러 없이 바로 프로세스에 메모리를 할당해 Ready Queue 에 넣습니다.
14 |
15 | #### 💡 중기 스케줄러
16 | * 메모리에 적재된 프로세스의 수를 관리합니다.
17 | * 메모리에 많은 수의 프로세스가 적재되면 프로세스 당 보유하는 메모리 양이 적어집니다. 그러면 CPU 수행이 필요한 프로세스의 주소도 메모리에 올려놓지 못하게 되어 성능이 저하됩니다.
18 | * 이 경우 SWAP OUT 작업을 통해 Ready상태에서 Suspended Ready상태로, Blocked 상태에서 Suspended Blocked 상태로 프로세스들을 옮깁니다.
19 | * 중지준비: suspended ready: 준비->디스크
20 | * 봉쇄준비: suspended block: 봉쇄->디스크
21 |
22 | #### 💡 단기 스케줄러
23 | * 어떤 프로세스를 다음번에 실행(Running) 상태로 만들 것인지 결정합니다.
24 | * 단기 스케줄러는 미리 정한 스케줄링 알고리즘에 따라 CPU를 할당할 프로세스를 선택합니다.
25 |
26 |
27 | #### 💡 CPU 스케줄링 알고리즘
28 | * Ready Queue 에 있는 프로세스들 중 어떤 프로세스를 CPU에 할당할 것인지 정하는 알고리즘입니다.
29 | * 이 알고리즘에는 선점 알고리즘과 비선점 알고리즘이 있습니다.
30 | * 선점 알고리즘은 우선순위가 높은 작업이 진행중인 작업을 중단시키고 CPU를 사용할 수 있는 알고리즘입니다.
31 | * 비선점 알고리즘은 CPU를 할당받은 작업이 끝날때까지 다른 작업이 CPU 를 사용할 수 없는 알고리즘입니다.
32 |
10 |
11 | #### 💡 장기 스케줄러
12 | * 작업 스케줄러라고도 부르며 어떤 프로세스를 Ready 단계에 넣을지 결정합니다. 디스크에서 어떤 프로그램을 가져와 커널(Ready Queue)에 등록할지 결정합니다.
13 | * 현대의 운영체제에서는 장기 스케줄러 없이 바로 프로세스에 메모리를 할당해 Ready Queue 에 넣습니다.
14 |
15 | #### 💡 중기 스케줄러
16 | * 메모리에 적재된 프로세스의 수를 관리합니다.
17 | * 메모리에 많은 수의 프로세스가 적재되면 프로세스 당 보유하는 메모리 양이 적어집니다. 그러면 CPU 수행이 필요한 프로세스의 주소도 메모리에 올려놓지 못하게 되어 성능이 저하됩니다.
18 | * 이 경우 SWAP OUT 작업을 통해 Ready상태에서 Suspended Ready상태로, Blocked 상태에서 Suspended Blocked 상태로 프로세스들을 옮깁니다.
19 | * 중지준비: suspended ready: 준비->디스크
20 | * 봉쇄준비: suspended block: 봉쇄->디스크
21 |
22 | #### 💡 단기 스케줄러
23 | * 어떤 프로세스를 다음번에 실행(Running) 상태로 만들 것인지 결정합니다.
24 | * 단기 스케줄러는 미리 정한 스케줄링 알고리즘에 따라 CPU를 할당할 프로세스를 선택합니다.
25 |
26 |
27 | #### 💡 CPU 스케줄링 알고리즘
28 | * Ready Queue 에 있는 프로세스들 중 어떤 프로세스를 CPU에 할당할 것인지 정하는 알고리즘입니다.
29 | * 이 알고리즘에는 선점 알고리즘과 비선점 알고리즘이 있습니다.
30 | * 선점 알고리즘은 우선순위가 높은 작업이 진행중인 작업을 중단시키고 CPU를 사용할 수 있는 알고리즘입니다.
31 | * 비선점 알고리즘은 CPU를 할당받은 작업이 끝날때까지 다른 작업이 CPU 를 사용할 수 없는 알고리즘입니다.
32 |
33 | 34 | #### 💡 CPU 스케줄링은 언제 발생하는가? 35 | 36 | 실행상태에서 대기상태로 전환될 때 (예, 입출력 요청) - Non preemptive(비선점) 37 | 실행상태에서 준비상태로 전환될 때 (예, 인터럽트 발생) - preemptive(선점) 38 | 대기상태에서 준비상태로 전환될 때(예, 입출력이 종료될 때) 39 | 종료될 때(Terminated) 40 | 41 | 42 | 43 | 44 | 45 | ## 심화 질문 46 | 47 | ### 비선점형 48 | #### 💡 FCFS(First Come First Served) 49 | * 먼저 들어온 프로세스가 CPU 를 먼저 할당받습니다. 50 | * 짧은 시간이 걸리는 프로세스가 CPU 를 오래 기다릴 수 있어 비효율적입니다. 51 | 52 | #### 💡 SJF(Shortest Job First) 53 | 54 | * 짧은 시간이 걸리는 프로세스가 CPU를 우선으로 할당하는 방법입니다. 55 | * 최소 평균 대기시간을 보장하지만 기아 현상이 발생할 수 있습니다. 56 | 57 | 58 | ### 선점형 59 | #### 💡 SRT(Shortest Remaining Time) 60 | * 짧은 시간이 걸리는 프로세스가 CPU를 우선으로 할당받는 방식입니다. 이 때, 프로세스의 남은 CPU사용시간(burst time) 보다 짧은 process 가 도착하면 cpu 를 선점합니다. 61 | * 단점: CPU 사용 시간을 정확하게 예측하기 어렵습니다. 62 | #### 💡 Priority Scheduling 63 | * 높은 우선순위를 가진 프로세스에게 CPU를 할당합니다. 64 | * 단점: 기아현상, 무한정지 상태가 발생할 수 있습니다. 65 | #### 💡 RR(Round Robin) 66 | * 프로세스의 할당시간이 지나면 다른 프로세스에게 CPU를 선점당하고 Ready queue 의 맨 뒤로 가는 방식입니다. 67 | * 어떤 프로세스도 할당 시간 이상 기다리지 않는 공정한 알고리즘입니다. 68 | * 평균 대기시간은 길어질 수 있지만, 응답시간은 짧아집니다. 69 | * 단점 70 | * 할당시간이 크면 FCFS와 같아집니다. 71 | * 할당시간이 작으면 문맥교환이 많이 발생해 오버헤드가 증가합니다. 72 | > https://velog.io/@ss-won/OS-CPU-Scheduling-Algorithm 73 |
74 | 75 | ## ⭐ 개념 정리 76 | 77 | ### 알고리즘에 대한 성능평가 기준 5가지 78 | * 프로세서 이용률(CPU Utilization) 79 | * 시간당 CPU를 사용한 시간의 비율 80 | 81 | * 처리율(Throughput) 82 | * 시간당 처리한 작업의 비율 83 | 84 | * 반환시간 또는 소요시간(Turnaround Time) 85 | * CPU burst time(쓰고 나갈때까지의 시간, 누적되지 않음) 86 | * 작업 제출 후 완료되는 순간까지의 소요시간 87 | * 대기시간(Waiting Time) 88 | * 대기열에 들어와 CPU를 할당받기까지 기다린 시간 89 | 90 | * 반응시간 또는 응답시간(Response Time) 91 | * 대기열에서 처음으로 CPU를 얻을때까지 걸린시간 92 | 93 | ### 주체별 CPU 성능 척도 94 | * 시스템 입장 95 | 👉🏻 CPU Utilization + Throughput 96 | 97 | * 사용자 입장 98 | 👉🏻 Turnaround Time + Waiting Time + Response Time 99 | 100 | 101 |
102 | -------------------------------------------------------------------------------- /03.Operating_system/kmj/21.02.17.md: -------------------------------------------------------------------------------- 1 | # 21.02.17 2 | * 교착상태 vs 기아상태 3 | * 메모리 관리전략 4 | * 메모리 관리 배경 5 | * Paging 6 | * Segmentation 7 | 8 | 9 | ## 질문 10 | 11 | #### 💡 [교착상태 vs 기아상태](#교착상태) 12 | * 교착상태는 각 프로세스가 다른 프로세스에 의해 획득된 리소스를 기다릴 때 발생합니다. 13 | 14 |
15 | * 기아상태는 우선순위가 높은 프로세스가 우선순위가 낮은 프로세스가 실행되는 것을 계속 막는 상태입니다.
16 | #### 💡 교착상태
17 | 발생조건
18 | * 다음 네 가지 조건이 모두 성립할 때 교착상태 발생 가능성 있음.
19 | * 상호배제(Mutual exclusion) : 프로세스들이 필요로 하는 자원에 대해 배타적인 통제권을 요구한다.
20 | * 점유대기(Hold and wait) : 프로세스가 할당된 자원을 가진 상태에서 다른 자원을 기다린다.
21 | * 비선점(No preemption) : 프로세스가 어떤 자원의 사용을 끝낼 때까지 그 자원을 뺏을 수 없다.
22 | * 순환대기(Circular wait) : 각 프로세스는 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있다.
23 |
24 | 해결방안
25 | * 위 4가지 발생조건 중 1개라도 성립되지 않으면 된다.
26 |
27 | #### 💡 기아상태
28 | * 해결방안
29 | * 오래 기다린 프로세스의 우선순위 높이기
30 | * 우선순위가 아닌 요청 순서대로 처리하는 큐 사용하기
31 |
32 | #### 💡 운영 체제에서 기아(Starvation) 란 무엇입니까?
33 | 특정 프로세스의 우선순위가 낮아서 원하는 자원을 계속 할당 받지 못하는 상태이다.
34 |
35 | 기아상태는 자원 관리 문제이다. 이 문제에서 대기중인 프로세스는 리소스가 다른 프로세스에 할당되어 있기 때문에 오랫동안 필요한 리소스를 얻지 못한다.
36 |
37 |
38 |
39 |
40 | #### 💡 운영 체제에서 에이징(Aging)는 무엇입니까?
41 | 에이징은 자원 스케줄링 시스템에서 기아를 방지하기 위해 사용되는 기술이다. 특정 프로세스의 우선순위가 낮아 무한정 기다리게되는 경우, 한번 양보하거나 기다린 시간에 비례하여 일정 시간이 지나면 우선순위를 한 단계씩 높여 가까운 시간 안에 자원을 할당받도록 하는 기법을 말한다.
42 |
43 | #### 💡 메모리 관리전략이란?
44 | * 제한된 메모리를 효율적으로 사용하기 위한 전략입니다.
45 | 효율적인 메모리 사용을 위해서 [반입전략](#반입전략), [배치전략](#배치전략), 교체전략이 있습니다.
46 |
47 | #### 💡 교체전략: Replacement
48 |
49 | * 주기억장치의 영역이 모두 사용중일 때, 사용중인 영역중 어느 영역이랑 교체해서 사용할 것인지 결정하는 전략입니다.
50 | * 종류에는 FIFO, OPT, LRU, LFU, NUR, SCR 등이 있습니다.
51 |
52 | #### 💡 가상기억장치
53 | * 보조기억장치의 일부를 주기억장치처럼 사용하는 장치입니다.
54 | * 주기억장치의 용량보다 큰 프로그램을 실행하기 위해 사용합니다.
55 | * 가상기억장치의 구현 방법에는 페이징 기법과 세그먼테이션 기법이 있습니다.
56 |
57 | #### 💡 페이징 기법
58 | * 영역을 동일한 크기로 나눈 후 크기가 동일한 페이지를 영역에 적재시켜 실행하는 기법입니다.
59 | * 페이지: 일정한 크기로 나눈 단위.
60 | * 내부 단편화 발생 가능
61 |
62 | 단편화: 빈 기억공간
63 | #### 💡 페이징의 장점과 단점은?
64 |
65 | 장점: 메모리를 페이지단위로 가져와서, 프로세스의 효율적인 운영이 가능하다.
66 |
67 | 단점: 페이지 크기별, 단위별로 페이지 폴트 현상이 발생할 수 있다.
68 | #### 💡 세그멘테이션 기법
69 | * 가상 기억장치의 프로그램을 다양한 크기로 나눈 후 주기억장치에 적재시켜 실행하는 방법입니다.
70 | * 세그먼터: 다양한 크기로 나눈 단위
71 | * 외부 단편화 발생 가능
72 | #### 💡 페이지 교체 알고리즘
73 | * FIFO(first in first out)
74 | * 메모리에 올라온지 가장 오래된 페이지 교체
75 | * 최적(Optimal) 페이지 교체
76 | * 앞으로 가장 오랫동안 사용되지 않을 페이지 교체
77 | * LRU(Least Recently Used)
78 | * 최근에 가장 오랫동안 사용하지 않은 페이지 교체
79 | * LFU(Least Frequently Used)
80 | * 사용 빈도가 가장 적은 페이지 교체
81 | * NUR(Not Used Recently)
82 | * 최근에 사용하지 않은 페이지 교체
83 | * 변형비트, 참조비트 사용
84 | * 변형비트: 변경시 1, 아니면 0
85 | * 참조비트: 호출시 1, 아니면 0
86 |
87 |
14 |
15 | * 기아상태는 우선순위가 높은 프로세스가 우선순위가 낮은 프로세스가 실행되는 것을 계속 막는 상태입니다.
16 | #### 💡 교착상태
17 | 발생조건
18 | * 다음 네 가지 조건이 모두 성립할 때 교착상태 발생 가능성 있음.
19 | * 상호배제(Mutual exclusion) : 프로세스들이 필요로 하는 자원에 대해 배타적인 통제권을 요구한다.
20 | * 점유대기(Hold and wait) : 프로세스가 할당된 자원을 가진 상태에서 다른 자원을 기다린다.
21 | * 비선점(No preemption) : 프로세스가 어떤 자원의 사용을 끝낼 때까지 그 자원을 뺏을 수 없다.
22 | * 순환대기(Circular wait) : 각 프로세스는 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있다.
23 |
24 | 해결방안
25 | * 위 4가지 발생조건 중 1개라도 성립되지 않으면 된다.
26 |
27 | #### 💡 기아상태
28 | * 해결방안
29 | * 오래 기다린 프로세스의 우선순위 높이기
30 | * 우선순위가 아닌 요청 순서대로 처리하는 큐 사용하기
31 |
32 | #### 💡 운영 체제에서 기아(Starvation) 란 무엇입니까?
33 | 특정 프로세스의 우선순위가 낮아서 원하는 자원을 계속 할당 받지 못하는 상태이다.
34 |
35 | 기아상태는 자원 관리 문제이다. 이 문제에서 대기중인 프로세스는 리소스가 다른 프로세스에 할당되어 있기 때문에 오랫동안 필요한 리소스를 얻지 못한다.
36 |
37 |
38 |
39 |
40 | #### 💡 운영 체제에서 에이징(Aging)는 무엇입니까?
41 | 에이징은 자원 스케줄링 시스템에서 기아를 방지하기 위해 사용되는 기술이다. 특정 프로세스의 우선순위가 낮아 무한정 기다리게되는 경우, 한번 양보하거나 기다린 시간에 비례하여 일정 시간이 지나면 우선순위를 한 단계씩 높여 가까운 시간 안에 자원을 할당받도록 하는 기법을 말한다.
42 |
43 | #### 💡 메모리 관리전략이란?
44 | * 제한된 메모리를 효율적으로 사용하기 위한 전략입니다.
45 | 효율적인 메모리 사용을 위해서 [반입전략](#반입전략), [배치전략](#배치전략), 교체전략이 있습니다.
46 |
47 | #### 💡 교체전략: Replacement
48 |
49 | * 주기억장치의 영역이 모두 사용중일 때, 사용중인 영역중 어느 영역이랑 교체해서 사용할 것인지 결정하는 전략입니다.
50 | * 종류에는 FIFO, OPT, LRU, LFU, NUR, SCR 등이 있습니다.
51 |
52 | #### 💡 가상기억장치
53 | * 보조기억장치의 일부를 주기억장치처럼 사용하는 장치입니다.
54 | * 주기억장치의 용량보다 큰 프로그램을 실행하기 위해 사용합니다.
55 | * 가상기억장치의 구현 방법에는 페이징 기법과 세그먼테이션 기법이 있습니다.
56 |
57 | #### 💡 페이징 기법
58 | * 영역을 동일한 크기로 나눈 후 크기가 동일한 페이지를 영역에 적재시켜 실행하는 기법입니다.
59 | * 페이지: 일정한 크기로 나눈 단위.
60 | * 내부 단편화 발생 가능
61 |
62 | 단편화: 빈 기억공간
63 | #### 💡 페이징의 장점과 단점은?
64 |
65 | 장점: 메모리를 페이지단위로 가져와서, 프로세스의 효율적인 운영이 가능하다.
66 |
67 | 단점: 페이지 크기별, 단위별로 페이지 폴트 현상이 발생할 수 있다.
68 | #### 💡 세그멘테이션 기법
69 | * 가상 기억장치의 프로그램을 다양한 크기로 나눈 후 주기억장치에 적재시켜 실행하는 방법입니다.
70 | * 세그먼터: 다양한 크기로 나눈 단위
71 | * 외부 단편화 발생 가능
72 | #### 💡 페이지 교체 알고리즘
73 | * FIFO(first in first out)
74 | * 메모리에 올라온지 가장 오래된 페이지 교체
75 | * 최적(Optimal) 페이지 교체
76 | * 앞으로 가장 오랫동안 사용되지 않을 페이지 교체
77 | * LRU(Least Recently Used)
78 | * 최근에 가장 오랫동안 사용하지 않은 페이지 교체
79 | * LFU(Least Frequently Used)
80 | * 사용 빈도가 가장 적은 페이지 교체
81 | * NUR(Not Used Recently)
82 | * 최근에 사용하지 않은 페이지 교체
83 | * 변형비트, 참조비트 사용
84 | * 변형비트: 변경시 1, 아니면 0
85 | * 참조비트: 호출시 1, 아니면 0
86 |
87 |  88 |
89 | * SCR(Second Chance Replacement, 2차 기회 교체)
90 | * 가장 오랫동안 주기억장치에 있던 페이지 중 자주 사용되는 페이지 교체 방지
91 | * FIFO 단점 보완
92 |
93 |
94 | #### 💡 메모리 단편화 란 무엇인가?
95 |
96 | 메모리의 빈 공간 또는 자료가 여러 개의 조각으로 나뉘는 현상을 말한다. 할당한 메모리를 해제를 하게 되면 그 메모리 공간이 빈 공간(사용하지 않는 공간)이 되고 그 빈공간의 크기보다 큰 메모리는 사용할 수 없다. 그리하여 이 공간들이 하나 둘 쌓이게 되면 수치상으로는 많은 메모리 공간이 남았음에도 불구하고, 실제로 사용할 수 없는 메모리가 발생한다.
97 |
98 |
99 |
100 |
101 |
102 | #### 💡 내부단편화와 내부단편화란?
103 |
104 | - 내부단편화
105 |
106 | : 분할된 영역이 할당된 프로그램의 크기보다 커서 사용되지 않고 남아 있는 빈 공간을 말한다.
107 |
108 | : 내부 단편화는 페이징에서 발생한다.
109 |
110 |
111 |
112 | - 외부단편화
113 |
114 | : 분할된 영역이 할당될 프로그램의 크기보다 작아서 모두 빈 공간으로 남아 있는 전체 영역을 말한다.
115 |
116 | : 외부 단편화는 세그먼테이션에서 발생한다.
117 |
118 |
119 |
120 |
121 |
122 | #### 💡 메모리 단편화 해결방법은?
123 |
124 | 메모리 압축(디스크 조각 모음), 메모리 통합(단편화가 발생된 공간들을 하나로 통합시켜 큰 공간으로 만드는 기법)
125 |
126 |
88 |
89 | * SCR(Second Chance Replacement, 2차 기회 교체)
90 | * 가장 오랫동안 주기억장치에 있던 페이지 중 자주 사용되는 페이지 교체 방지
91 | * FIFO 단점 보완
92 |
93 |
94 | #### 💡 메모리 단편화 란 무엇인가?
95 |
96 | 메모리의 빈 공간 또는 자료가 여러 개의 조각으로 나뉘는 현상을 말한다. 할당한 메모리를 해제를 하게 되면 그 메모리 공간이 빈 공간(사용하지 않는 공간)이 되고 그 빈공간의 크기보다 큰 메모리는 사용할 수 없다. 그리하여 이 공간들이 하나 둘 쌓이게 되면 수치상으로는 많은 메모리 공간이 남았음에도 불구하고, 실제로 사용할 수 없는 메모리가 발생한다.
97 |
98 |
99 |
100 |
101 |
102 | #### 💡 내부단편화와 내부단편화란?
103 |
104 | - 내부단편화
105 |
106 | : 분할된 영역이 할당된 프로그램의 크기보다 커서 사용되지 않고 남아 있는 빈 공간을 말한다.
107 |
108 | : 내부 단편화는 페이징에서 발생한다.
109 |
110 |
111 |
112 | - 외부단편화
113 |
114 | : 분할된 영역이 할당될 프로그램의 크기보다 작아서 모두 빈 공간으로 남아 있는 전체 영역을 말한다.
115 |
116 | : 외부 단편화는 세그먼테이션에서 발생한다.
117 |
118 |
119 |
120 |
121 |
122 | #### 💡 메모리 단편화 해결방법은?
123 |
124 | 메모리 압축(디스크 조각 모음), 메모리 통합(단편화가 발생된 공간들을 하나로 통합시켜 큰 공간으로 만드는 기법)
125 |
126 |
127 | 128 | 129 |
130 | 131 | ## ⭐ 개념 정리 132 | 133 | ### 반입전략 134 | * Fetch 135 | * 보조 기억장치에 보관중인 데이터를 언제 주기억장치로 옮길 것인지 136 | * 요구반입: 요구할때 옮긴다. 137 | * 예상반입: 사용될 것을 미리 예상해서 옮긴다. 138 | 139 | ### 배치전략 140 | * Placement 141 | * 새로 반입되는 데이터를 주기억장치의 어느 위치에 놓을것인지 142 | * 최초 적합: FirstFit: 프로그램이나 데이터가 들어갈 수 있는 크기의 빈 영역 중 첫번째 영역에 배치 143 | * 최적 적합 BestFit : 단편화를 가장 작게 남기는 영역에 배치 144 | * 최악적합: WorstFit : 단편화를 가장 많이 남기는 분할영역에 배치 145 | 146 | 147 | 148 | -------------------------------------------------------------------------------- /03.Operating_system/kmj/21.02.20.md: -------------------------------------------------------------------------------- 1 | # 21.02.20 2 | * 가상 메모리 3 | * 캐시의 지역성 4 | * 파일 시스템 5 | 6 | ## 주요 질문 7 | 8 |
9 | 10 | ## 심화 질문 11 | #### 💡 파일 시스템이란 12 | * 컴퓨터에서 파일이나 자료를 쉽게 발견할 수 있도록 유지 및 관리하는 방법입니다. 13 | #### 💡 파일 시스템 개발 목적 14 | * 하드디스크와 메인 메모리의 속도 차이를 줄이기 위함입니다. 15 | * 하드디스크 용량을 효율적으로 이용하기 위함입니다. 16 | 17 |
18 | 19 | ## ⭐ 개념 정리 20 | 21 | ### 가상메모리 22 | * 가상 메모리가 하는 일 23 | * 주기억장치의 용량보다 큰 프로그램을 실행하기 위해 사용합니다. 24 | * Demand Paging 25 | * 메모리 관리 메커니즘(MMU 메커니즘)을 사용해서 여러 프로세스가 시스템의 메모리를 효율적으로 공유할 수 있도록 하는 기술 26 | 27 | > https://jennysgap.tistory.com/entry/운영체제의-기초-17-Demand-Paging-1 [jennysgap] 28 | 29 | * 페이지 교체 알고리즘 30 | * FIFO(first in first out) 31 | * 메모리에 올라온지 가장 오래된 페이지 교체 32 | * 최적(Optimal) 페이지 교체 33 | * 앞으로 가장 오랫동안 사용되지 않을 페이지 교체 34 | * LRU(Least Recently Used) 35 | * 최근에 가장 오랫동안 사용하지 않은 페이지 교체 36 | * LFU(Least Frequently Used) 37 | * 사용 빈도가 가장 적은 페이지 교체 38 | * NUR(Not Used Recently) 39 | * 최근에 사용하지 않은 페이지 교체 40 | * 변형비트, 참조비트 사용 41 | * 변형비트: 변경시 1, 아니면 0 42 | * 참조비트: 호출시 1, 아니면 0 43 | 44 |
45 |
46 | * SCR(Second Chance Replacement, 2차 기회 교체)
47 | * 가장 오랫동안 주기억장치에 있던 페이지 중 자주 사용되는 페이지 교체 방지
48 | * FIFO 단점 보완
49 |
50 |
51 | 52 | ### 캐시(Cache) 53 | * 정의: 캐시란 프로세서와 메인 메모리간의 처리 속도 차이를 보완하기 위한 고속 버퍼입니다. 54 | (버퍼: 데이터를 A에서 B 로 전송하는 동안 일시적으로 그 데이터를 보관하는 메모리) 55 | * 캐시는 메인 메모리에서 데이터를 가져와서 프로세서에 전달합니다. 56 | 57 | ### 캐시 적중, 캐시 실패 58 | * 캐시 적중(Cache Hit) 59 | * 프로세서에 있는 데이터가 참조하려는 데이터인 경우 60 | * 캐시 실패(Cache Miss) 61 | * 프로세서에 있는 데이터가 참조하려는 데이터가 아닌 경우 62 | 63 | ### 캐시의 지역성 64 | * 지역성이란? 65 | * 기억장치의 특정 영역에만 참조가 집중적으로 발생하는 특성 66 | * 캐시의 적중률을 극대화하기 위해 지역성 원리를 사용합니다. 67 | * 공간 지역성, 시간 지역성으로 구분된다. 68 | * 공간 지역성 69 | * 의미: 참조된 주소와 인접한 주소의 데이터가 참조되는 특성 70 | * 발생상황 71 | * 프로그램이 명령어를 순차적으로 실행할 때 72 | * 배열 순회 73 | * 시간 지역성 74 | * 의미: 최근에 참조된 주소의 데이터를 가까운 시간 내에 계속 참조하는 특성 75 | * 발생 상황 76 | * for문 77 | * while문 78 | >https://blackjellybear.tistory.com/31 79 | 80 | ### 파일 시스템 81 | * 정의 82 | * 운영체제가 저장 매체에 파일을 쓰기 위한 자료구조 또는 알고리즘 83 | * 디스크에 존재하는 데이터와 프로그램을 저장하고, 접근할 수 있는 기법 84 | * 파일 시스템의 디스크 할당 방식 85 | * 연속 할당 방식 86 | * 인접한 연속의 공간에 할당 87 | * 요구되는 크기만큼의 인접한 공간이 존재해야 함 88 | * 파일의 크기가 변하면 문제가 됨 89 | * 불연속할당 방식보다 빠름 90 | * 불연속 할당 방식 91 | * 인접하지 않은 공간에 할당 92 | * 해당 정보가 어디에 흩어져 있는지 위치정보를 따로 저장, 관리해야함. 93 | * 파일의 크기가 커져도 할당이 비교적 쉬움 94 | * 일반적으로 불연속 할당방식이 사용됨 95 | 96 | * 저장매체에 효율적으로 파일을 저장하는 방법 97 | * 블록체인 기법 98 | * 같은 파일정보를 저장하는 블록을 체인(포인터)로 연결 99 | * 원하는 정보를 검색할 때 처음부터 읽어야 함 100 | * 인덱스 블록 기법 101 | * 위치정보를 인덱스 블록이라는 별도의 공간에 관리 102 | * 파일마다 인덱스 블록을 가짐 103 | * 데이터를 처음부터 읽을 필요가 없어서 검색 속도가 비교적 빠름 104 | * 단점: 파일 수가 늘어날수록 인덱스 블록을 저장하는 공간이 많이 소비됨 105 | * FAT(File Allocation Table) 106 | * 파일 시스템마다 위치정보를 FAT라는 자료구조에 저장 107 | * FAT 정보를 유실하면 손해가 크기 때문에 중복으로 관리 108 | * 데이터를 처음부터 읽을 필요가 없어서 검색 속도가 비교적 빠름 109 | >https://jiming.tistory.com/359 110 | >https://www.notion.so/File-System-9ce6c463b6e54484aeb497c96c8edaf7 111 | 112 |
113 | 114 | -------------------------------------------------------------------------------- /03.Operating_system/kmj/21.02.25.md: -------------------------------------------------------------------------------- 1 | # 21.02.25 2 | * 시스템 콜 3 | * IPC 4 | * 인터럽트 5 | ## 주요 질문 6 | 7 | 8 | 9 |
10 | 11 | ## 심화 질문 12 | 13 | 14 | 15 |
16 | 17 | ## ⭐ 개념 정리 18 | 19 | ## 시스템 호출 (System Calls) 20 | * 커널 영역의 기능을 사용자 모드가 사용할 수 있게 함 21 | = 22 | * 프로세스가 하드웨어에 접근해서 필요한 기능을 사용할 수 있게 함 23 | >https://luckyyowu.tistory.com/133 24 | ### 유형 25 | * 프로세스 제어 26 | * 파일 조작 27 | * 장치 관리 28 | * 정보 유지 29 | * 통신 30 | 31 |
32 | 33 | ## IPC (Interprocess Communication) 34 | * 여러 프로세스간 데이터를 주고받을 수 있도록 하는 메커니즘이다. 35 | * 종류 36 | * 공유 메모리 37 | * 메시지 시스템 38 | ### 공유 메모리 39 | * 다수의 프로세스에 의해 공유되는 메모리 영역 40 | > 프로세스는 공유 메모리 영역을 생성 41 | > 프로세스가 다른 프로세스의 공유 메모리 영역에 연결 42 | ### 메시지 시스템 43 | * 공유데이터 없이 데이터를 송수신할 수 있는 통신 44 | ### 직접통신 45 | ### 간접통신 46 | ### 동기화 47 |
48 | 49 | ## 인터럽트 50 | * 의미 51 | * CPU 가 프로그램을 실행하고 있을 때 예외상황이 발생하여 실행중인 일을 중단하고 다른 일을 하게끔 하는 것 52 | 53 | * 인터럽트 하는 이유 54 | * 입출력 연산이 CPU 명령 수행속도보다 느리기 때문 55 | 56 | ### 하드웨어 인터럽트 57 | * 하드웨엉가 발생시키는 인터럽트 58 | * CPU -> 하드웨어에게 일을 시킬 때 59 | * 하드웨어 -> CPU 에게 어떤 사실을 알려줄 떄 발생 60 | ### 소프트웨어 인터럽트 61 | * 소프트웨어가 발생시키는 인터럽트 62 | * 예외상황, System call 호출 시 발생 63 | ### 인터럽트 과정 64 | > process A 실행 중 디스크에서 어떤 데이터를 읽어오라는 명령을 받았다 65 | 66 | 1. process A는 system call을 통해 인터럽트를 발생시킨다. 67 | 2. CPU는 현재 진행 중인 기계어 코드를 완료한다. 68 | 3. 현재까지 수행중이었던 상태를 해당 process의 PCB(Process Control Block)에 저장한다. (수행중이던 MEMORY주소, 레지스터 값, 하드웨어 상태 등...) 69 | 4. PC(Program Counter, IP)에 다음에 실행할 명령의 주소를 저장한다. 70 | 인터럽트 벡터를 읽고 ISR 주소값을 얻어 ISR(Interrupt Service Routine)로 점프하여 루틴을 실행한다. 71 | 5. 해당 코드를 실행한다. 72 | 6. 해당 일을 다 처리하면, 대피시킨 레지스터를 복원한다. 73 | 7. ISR의 끝에 IRET 명령어에 의해 인터럽트가 해제 된다. 74 | 8. IRET 명령어가 실행되면, 대피시킨 PC 값을 복원하여 이전 실행 위치로 복원한다. 75 | 76 | >https://velog.io/@adam2/%EC%9D%B8%ED%84%B0%EB%9F%BD%ED%8A%B8 77 |
78 | 79 | 80 | 81 |
82 |
39 | 40 | ## ⭐ 개념 정리 41 | 42 | ## 프로세스/스레드 43 | ### 1. 프로세스(Process) 44 | * 실행 중인 프로그램 45 | * 메모리에 올라와 실행되고 있는 독립적인 인스턴스 46 | 47 | ### 2. 스레드(Thread) 48 | * 프로세스 내에 실행되는 작업 흐름의 단위 49 | 50 |  51 | 52 | #### 2-1. 사용자 수준 스레드 53 | * [유저모드](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.22.md#2-io-protection)에서 수행되는 스레드 연산 54 | * 다대일 스레드 매핑 55 | * 장점 56 | * 유연한 스케줄링 57 | * 높은 이식성 58 | * 낮은 오버헤드 59 | * 단점 60 | * 시스템 동시성 미지원 61 | * 스케줄링 우선 순위 미지원 62 | * 확장 제약 63 | 64 | #### 2-2. 커널 수준 스레드 65 | * [커널모드](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.22.md#2-io-protection)에서 수행되는 스레드 연산 66 | * 장점 67 | * 멀티 프로세서 환경에서 빠른 동작 68 | * 각 스레드를 개별 관리 69 | * 안정성과 다양한 기능 제공 70 | * 단점 71 | * 높은 오버헤드 72 | * 더 많은 자원 소비 73 | 74 |
75 | 76 |
83 | 84 | ## 멀티 프로세스/멀티 스레드 85 | ### 1. 멀티 프로세스 86 | * 하나의 응용 프로그램을 여러 프로세스로 처리 87 | * 장점 88 | * 하나의 프로세스에 문제가 생겨도 다른 영향을 끼치지 않는다. 89 | * 단점 90 | * 문맥 교환 오버헤드 91 | * 시스템 콜 증가 92 | 93 | >**문맥 교환(Context Switching)** 94 | >* 하나의 프로세스가 CPU를 사용 중인 상태에서 다른 프로세스가 CPU를 사용하도록 하기 위해, **이전의 프로세스의 상태를 PCB에 보관하고 새로운 프로세스의 상태를 적재**하는 작업 95 | 96 |
97 | 98 | ### 2. 멀티 스레드 99 | * 하나의 응용 프로그램을 여러 스레드로 처리 100 | * 장점 101 | * 시스템 자원 효율성 증대 102 | * 자원을 공유 103 | * 응답시간 단축 104 | * 처리시간 감소 105 | * 단점 106 | * 프로세스 밖에서 스레드 제어 불가능 107 | * 자원 공유의 문제 108 | * 하나의 스레드 문제 발생 시, 프로세스 전체에 문제 109 | 110 | ### 3. Thread-safe 111 | * 멀티 스레드 환경에서 공유 자원에 여러 스레드의 접근이 있어도 프로그램 실행에 문제가 없음을 의미 112 | * 해결방법 (자세한 내용은 출처) 113 | * Re-entrancy 114 | * Thread-local storage 115 | * Mutual exclusion 116 | * Atomic operations 117 | 118 |
125 | 126 | ## 뮤텍스/세마포어 127 | ### 1. 상호배제(Mutual exclusive) 128 | * 병행 처리를 위한 프로세스 동기화 기법 129 | * 자원의 동시 공유를 피하기 위해 사용되는 알고리즘으로 임계 영역이라 불리는 코드 영역에 의해 구현 130 | > 임계영역(Critical Section) 131 | > 서로 다른 프로세스 혹은 스레드 등의 처리 단위가 같이 접근해서는 안 되는 공유 영역 132 | 133 | ### 2. 뮤텍스(Mutex) 134 | * lock/unlock 만을 지원 135 | * lock : 임계 구역에 들어갈 권한 부여 → 종료까지 대기 136 | * unlock : 임계 구역을 모두 사용 → 다른 프로세스/스레드 진입 가능 137 | 138 | ### 3. 세마포어(Semaphore) 139 | * 카운트를 조절하여 진입 가능한 프로세스/스레드 수를 조절 140 | 141 | ### 차이점 142 | * 뮤텍스는 오직 1개의 접근만 허용 143 | * 세마포어는 설정한 카운트만큼 접근이 허용 144 | -------------------------------------------------------------------------------- /03.Operating_system/phb/21.02.16.md: -------------------------------------------------------------------------------- 1 | # 21.02.16 2 | 3 | ## 주요 질문 4 | #### 💡 [라운드 로빈이 뭐에요?](#선점) 5 | * 스케줄링 방식 중 시분할 시스템을 위해 설계된 선점 방식의 알고리즘 입니다. 각 프로세스는 같은 크기의 CPU 시간을 할당받게 됩니다. 할당된 시간 안에 작업이 끝나지 않으면 해당 프로세스는 ready 큐에 들어가는 선입선출 방식입니다. 6 | 7 | #### 💡 [스케쥴링이 무엇인지와 목적을 설명해주세요](#1-스케줄링) 8 | * 스케줄링은 프로세서에게 필요한 자원을 어떻게 할당할 것인지 선택하는 알고리즘 입니다. 9 | * 단위 시간당 처리량을 최대화하고 효율적으로 자원을 할당하기 위한 목적을 가지고 있습니다. 10 | 11 | #### 💡 [비선점방식과 선점방식을 설명해주세요.](#3-스케줄링-방식) 12 | * 비선점 방식은 프로세스가 CPU를 점유하고 있는 경우 다른 프로세스가 CPU를 빼앗지 못하는 방식입니다. 비선점방식은 CPU를 중간에 가로채지 않기 때문에 응답시간 예측이 용이하다는 장점이 있지만 중요한 작업이 오래 기다리는 경우가 발생할 수 있다는 단점이 있습니다. 13 | * 선점 방식은 프로세스가 CPU를 점유하고 있어도 우선 순위가 높은 프로세스가 오면 CPU를 빼앗을 수 있는 방식입니다. 선점방식은 우선 순위가 높은 프로세스가 빠르게 처리할 수 있다는 장점이 있지만 잦은 Context Switching으로 오버헤드가 증가한다는 단점이 있습니다. 14 | 15 | #### 💡 [스케줄링 단계를 설명해주세요.](#4-스케줄링-단계) 16 | * 장기 스케줄러에 의해 어떤 프로세스가 준비 큐에 삽입될지 결정합니다. 단기 스케줄러는 스케줄링 알고리즘에 따라 CPU를 할당할 프로세스를 선택합니다. 선택된 프로세스는 Running 상태가 되고 작업이 끝나면 terminated 상태가 됩니다. 17 | 18 |
19 | 20 | ## ⭐ 개념 정리 21 | ### 1. 스케줄링 22 | #### Process Scheduling 23 | * 여러 프로세스에게 제한된 자원을 어떻게 나눠줄 것인지 선택하는 알고리즘 24 | 25 | #### CPU Scheduling 26 | * 하나의 프로세스 작업이 끝나면 CPU는 다음으로 어떤 프로세스를 작업할 것인지 선택하는 알고리즘 27 | 28 |
29 | 30 | ### 2. 스케줄링 목적 31 | * 자원 할당의 공정성 32 | * 단위 시간당 처리량 최대화 33 | * 적절한 반환시간 보장 34 | * 예측 가능성 보장 35 | * 오버헤드 최소화 36 | * 외 여러가지 목적 有 37 | 38 |
39 | 40 | ### 3. 스케줄링 방식 41 | #### 비선점 42 | * 한 프로세스가 CPU를 점유하는 동안 인터럽트 발생, I/O 또는 프로세스 종료 전까지는 다른 프로세스가 CPU를 점유 불가능 43 | * 장점 : 응답시간 예측 용이 44 | * 단점 : 중요한 작업이 기다리는 경우 발생 45 | 46 | |종류|설명| 47 | |-|-| 48 | |FCFS|먼저 들어온 것을 먼저 처리하는 FIFO 구조의 알고리즘| 49 | |SJF|Ready 큐에 있는 프로세스 중 실행 시간이 가장 작은 프로세스에게 자원 할당| 50 | |HRN|우선순위 계산식을 활용해 자원할당| 51 | 52 |
53 | 54 | #### 선점 55 | * 한 프로세스가 CPU를 점유하는 동안 다른 프로세스가 해당 CPU를 강제로 점유 가능 56 | * 장점 : 우선 순위가 높은 프로세스를 빠르게 처리 가능 57 | * 단점 : 잦은 문맥교환으로 오버헤드 증가 58 | 59 | |종류|설명| 60 | |-|-| 61 | |SRT|짧은 시간 순서대로 프로세스를 수행| 62 | |RR|각 프로세스는 같은 크기의 CPU 시간을 할당 받고 선입선출에 의해 수행| 63 | |다단계 큐|Ready 큐를 여러개 사용하는 기법| 64 | 65 |
66 | 67 | ### 4. 스케줄링 단계 68 |  69 | 70 | * 장기 스케줄러 71 | 메모리-디스크 사이의 스케줄링 - 속도, 호출 빈도↓ 72 | 어떤 프로세스를 준비 큐에 삽입할지 결정하며 메모리에 동시에 올라가는 프로세스 수를 조절 73 | 74 | * 중기 스케줄러 75 | 메모리에 적재된 프로세스의 수를 동적으로 조절 76 | 스와핑 : CPU 경쟁이 심해진 경우, 우선 순위가 낮은 프로세스를 잠시 제거하고 경쟁이 완화되었을 때 디스크에서 메모리로 불러와 중단된 부분부터 처리 77 | 78 | * 단기 스케줄러(CPU 스케줄러) 79 | CPU-메모리 사이의 스케줄링 - 속도, 호출 빈도↑ 80 | 스케줄링 알고리즘에 따라 CPU를 할당할 프로세스를 선택 81 | 82 | 83 |
84 | 85 | 86 |
19 | 20 | ## ⭐ 개념 정리 21 | ## **가상메모리** 22 | ### 1. 가상메모리 23 | * 물리 메모리 크기의 한계를 극복하기 위한 기술로 물리 메모리보다 큰 프로세스를 수행하기 위해 사용 24 | * 동적 할당으로 프로세스 실행 시 필요한 부분만 메모리에 적재 25 | 26 | ### 2. 요구 페이징(Demading Page) 27 | * 필요한 페이지만 메모리에 올리는 것 28 | * 동작 원리 29 |  30 | 1. CPU에서 페이지를 찾는다. 31 | 2. 페이지 테이블의 Valid bit 값이 1면 존재, 0이면 존재하지 않는다. 32 | 3. Valid bit가 0인 경우, 인터럽트가 발생하여 필요한 페이지에 메모리를 할당한다. 33 | 34 |
35 | 36 | > **인터럽트(interrupt)** 37 | > CPU가 프로그램을 실행하고 있는 중간에 I/O 장치나 예외 상황이 발생하여 처리가 필요한 경우 CPU에게 알려 처리할 수 있도록 하는 작업 38 | 39 | 40 |
48 | 49 | ## **페이지 교체 알고리즘** 50 | * 페이지를 요구했을 때, 메모리가 가득 차있고 요구하는 페이지가 메모리에 없으면 어떤 페이지를 디스크로 내리고 요구 페이지를 가져올 것인지 정하는 알고리즘 51 | 52 | * 페이징 교체 알고리즘 53 | |종류|설명| 54 | |-|-| 55 | |FIFO|들어온 순서대로 메모리에서 페이지를 내리고 요구하는 페이지를 적재| 56 | |OPT|가장 오랫동안 사용되지 않을 페이지를 제거 (현실적으로 불가능)| 57 | |LRU| 최근에 사용하지 않은 페이지는 나중에도 사용하지 않을 것이라는 개념으로 가장 오랫동안 사용되지 않은 페이지를 교체| 58 | |LFU|참조 횟수가 가장 작은 페이지를 교체| 59 | |MFU|참조 횟수가 가장 많은 페이지를 교체| 60 | 61 |
12 | 13 | ## ⭐ 개념 정리 14 | ## **캐시 메모리(Cache Memory)** 15 | ### 1. 캐시(Cache) 16 | * 데이터의 임시 보관소 17 | * 메인 메모리-CPU 사이에 존재하며 둘 간의 속도 차이를 극복하는 중간 버퍼 역할 18 | * 자주 사용하는 파일들을 가까운 곳에 저장 19 | * 휘발성 메모리 20 | 21 | ### 2. 캐싱 라인(Caching Line) 22 | * 캐시에 저장된 데이터의 자료구조(태그)의 묶음 23 | 24 | ### 3. 지역성(Locality Of Reference) 25 | * 적중율(Hit Ratio)을 극대화 시키기 위한 방법 26 | * 지역성의 원리 27 | |종류|설명| 28 | |-|-| 29 | |시간 지역성|최근에 참조된 주소의 내용은 곧 다음에 다시 참조된다는 특성| 30 | |공간 지역성|한 번 참조한 메모리의 옆에 있는 메모리를 다시 참조할 확률이 높다는 특성| 31 | 32 | ### 4. 캐시 사상 기법(Memory Mapping) 33 | * CPU의 가상 주소를 물리 주소로 변환하여 메모리에 전달하는 기법 34 | * 사상 기법 (이해 잘 안 감 다시 봐야할 듯...) 35 | |종류|설명| 36 | |-|-| 37 | |직접 매핑|메인 메모리와 캐시를 똑같은 크기로 나누고 순서대로 매핑하는 방법| 38 | |연관 매핑|캐시에 저장된 데이터들은 메모리 순서와 상관 없이 매핑하는 방법| 39 | |집합 연관 매핑|직접 사상과 연관 사상 방식을 조합한 방식| 40 | 41 | 42 | ### 5. 쓰기 정책(Write Policy) 43 | * CPU가 메모리에 쓰기를 실행할 때, 주기억장치를 갱신하는 절차에 관한 정책 44 | * 즉시 쓰기(Write-though) 45 | * CPU의 연산 결과가 캐시기억장치와 주기억장치 동시에 발생 46 | * 데이터의 일관성 보장 47 | * 매번 캐시와 주기억장치에 접근하므로 쓰기 시간이 길어짐 48 | 49 | * 나중 쓰기(Write-back) 50 | * 새롭게 생성된 데이터를 캐시기억장치에만 기록하고 주기억 장치는 나중에 기록 51 | * 새로운 블록에 의해 캐시기억장치에서 삭제되는 교체가 이뤄지기 전 주기억장치로 복사 52 | * 주기억장치에 기록하는 동작을 최소화 53 | 54 |
62 | 63 | ## **파일 시스템** 64 | ### 1. 파일 시스템 65 | * 하드디스크가 데이터를 관리 66 | * 하드디스크는 블록 단위로 읽고 쓴다. 67 | 68 | ### 2. 파일 할당 69 | #### 2.1 연속 할당 (Contiguous Allocation) 70 |  71 | 72 | * 연속된 블록에 파일을 할당 73 | * 디스크 헤더의 이동을 최소화하여 I/O 성능 향상 74 | * 순차 접근과 직접 접근이 가능 75 | * 외부단편화 76 | 77 | #### 2.2 연결 할당 (Linked Allocation) 78 |  79 | 80 | * LinkedList 방식으로 파일을 할당 81 | * 블록마다 주소를 저장하는 포인터 공간이 존재하며 다음 블록을 가리킨다. 82 | * 순차 접근은 가능하지만 직접 접근이 불가능 83 | * 낮은 신뢰성과 느린 속도 84 | 85 | #### 2.2.1 FAT (File Allocation Table) 86 |  87 | 88 | * 연결 할당의 문제점을 개선하기 위한 방법 89 | * 다음 블록으로 가리키는 포인터만 모아서 하나의 테이블을 만들어 블록에 저장 90 | * 테이블의 인덱스는 전체 디스크의 블록 91 | * 직접 접근이 가능 92 | 93 | #### 2.3 색인 할당 (Indexed Allocation) 94 |  95 | 96 | * 랜덤한 블록에 데이터를 할당 97 | * 인덱스 블록 : 할당된 블록번호를 하나의 블록에 테이블 형식으로 저장 98 | * 디렉토리 정보에 시작 블록이 아닌 인덱스 블록 번호를 저장 99 | 100 |
19 | 20 | ## ⭐ 개념 정리 21 | ## 인터럽트(Interrupt) 22 | ### 1. 인터럽트 23 | * CPU가 프로그램을 실행하고 있을 때, I/O장치나 예외가 발생하여 처리가 필요할 경우 CPU에게 알려 일을 처리할 수 있도록 하는 것 24 | * 인터럽트 종류 25 | |종류|설명|예| 26 | |-|-|-| 27 | |하드웨어
인터럽트|CPU 외 주변장치나 디스크 컨트롤러에 의해 발생|입출력 인터럽트, 외부 인터럽트 등| 28 | |소프트웨어
인터럽트|CPU가 내린 명령이나 관련 모듈이 변하는 경우 발생|시스템콜, 예외처리 등| 29 | 30 |
31 | 32 | ### 2. 인터럽트 과정 33 |  34 | 35 | 1. 프로그램 실행 36 | 2. 인터럽트 요청 37 | 3. 프로그램 중단 38 | * 수행중이던 상태를 PCB블록에 저장 39 | * PC에 다음에 실행할 명령 주소 저장 40 | 4. 인터럽트 처리 41 | * 인터럽트 벡터를 읽고 ISR 주소를 얻어 ISR로 점프 42 | * 해당 코드 처리 43 | 5. PC값 복원하여 이전 실행 위치로 복원 44 | 6. 수행중이던 프로그램 재실행 45 | 46 |
47 | 48 | ## 커널(Kernel) 49 | ### 1. 커널 50 | * 컴퓨터 자원들을 관리하는 역할 51 | * HW-SW간의 커뮤니케이션을 관리하는 프로그램 52 | * 입출력을 관리하고 시스템 콜을 통해 컴퓨터에 있는 하드웨어가 처리할 수 있도록 요청을 변환하는 역할 → 사용자가 컴퓨터 자원 사용 가능 53 | * 구성요소 54 | |관리자|기능| 55 | |-|-| 56 | |테스크 관리자|물리적 자원인 CPU를 추상적인 태스크로 제공| 57 | |메모리 관리자|물리적 자원인 메모리를 추상적 자원인 페이지나 세그먼트로 제공| 58 | |파일 시스템 관리자|물리적 자원인 디스크를 추상적 자원인 파일로 제공| 59 | |네트워크 관리자|물리적 자원인 네트워크 장치를 추상적 자원인 소켓으로 제공| 60 | |디바이스 드라이버 관리자|각종 외부 장치에 대한 접근| 61 | * 커널 역할 (외에도 여러 기능 有) 62 | |역할|기능| 63 | |-|-| 64 | |프로세서 관리|처리속도 향상을 위해 여러 프로세서를 병렬로 연결
OS 처리 요구에 맞춰 동작할 수 있도록 각 프로세스에 필요한 프로세서를 효율적으로 할당하고
수행하도록 관리| 65 | |프로세스 관리|스케줄러를 이용하여 여러 프로세스가 동작 가능하도록 하며 외부 환경과 프로세스를 연결하고 관리| 66 | |메모리 관리|각 프로세스가 독립적인 공간에서 수행될 수 있도록 가상 주소 공간 제공| 67 | 68 |
69 | 70 | ### 2. I/O Protection 71 | #### 2.1 유저 모드(User Mode) 72 | * 어플리케이션 프로그램이 수행되는 모드 73 | * 시스템 데이터에 제한된 접근만이 허용되며 하드웨어에 직접 접근 불가 74 | * 시스템 서비스를 호출하면 커널 모드로 전환 75 | * mode bit 1 76 | 77 | #### 2.2 커널 모드(Kernel Mode) 78 | * 프로그램이 수행되다가 인터럽트에 걸려 운영체제가 호출되어 수행되는 모드 79 | * 시스템의 모든 메모리에 접근 가능하며 모든 CPU 명령을 실행 가능 80 | * 운영체제 코드나 디바이스 드라이버 같은 커널 모드 코드를 실행 81 | * mode bit 0 82 | 83 |  84 | 85 | > 시스템 콜(System Call) 86 | > 운영체제한테 요청하는 interface 87 | -------------------------------------------------------------------------------- /03.Operating_system/phb/21.02.23.md: -------------------------------------------------------------------------------- 1 | # 21.02.23 2 | 3 | ## 주요 질문 4 | #### 💡 [시스템 콜 처리 방식을 설명해주세요](#2-처리방식) 5 | * 시스템 콜 요청이 들어오면 유저 모드에서 커널모드로 변경됩니다. 커널은 요청받은 시스템 콜에 대한 서비스 루틴을 호출합니다. 서비스 루틴 처리 후에 커널모드에서 다시 유저모드로 돌아오게 됩니다. 6 | 7 |
8 | 9 | 10 | ## ⭐ 개념 정리 11 | 12 | ## 시스템 호출(System Calls) 13 | ### 1. 시스템 콜 14 | * 응용 프로그램에서 운영체제에게 시스템 자원을 요청하는 인터페이스 15 | 16 | ### 2. 처리방식 17 | 1. 사용자 프로세스가 시스템 콜 요청 (유저 모드 → 커널 모드) 18 | 2. 시스템 콜 구분을 위해 기능별로 고유번호를 할당하고 번호에 해당하는 제어루틴을 커널 내부에 정의 19 | 3. 커널은 요청받은 시스템 콜에 대응하는 기능 번호 확인 20 | 4. 기능 번호에 맞는 서비스 루틴 호출 21 | 5. 서비스 루틴 처리 후 유저 모드로 전환 22 | 23 | ### 3. 종류 24 | * 프로세스 제어 25 | * 파일 조작 26 | * 장치 관리 27 | * 시스템 정보 및 자원 관리 28 | * 통신 관련 29 | 30 |
39 | 40 | ## IPC (Inter Process Communication) 41 | ### 1. IPC 42 |  43 | * 독립된 실행객체인 내부 프로세스 간의 통신 44 | * 커널 영역에 존재 45 | 46 |
47 | 48 | ### 2. IPC 설비 49 | * 데이터를 주고 받을 수 있는 공유 메모리가 필요 50 | 51 | |종류|사용 시기|공유 매개체|통신 단위|통신 방향|통신 가능 범위| 52 | |-|-|-|-|-|-| 53 | |PIPE|부모-자식|파일|stream|단방향|동일 시스템| 54 | |Named PIPE|모든 프로세스|파일|stream|단방향|동일 시스템| 55 | |Meesage
Queue|모든 프로세스|메모리|구조체|단방향|동일시스템| 56 | |Shared
Memory|모든 프로세스|메모리|구조체|양방향|동일시스템| 57 | |Memory Map|모든 프로세스|파일 + 메모리|페이지|양방향|동일시스템| 58 | |Socket|모든 프로세스|소켓|stream|양방향|동일 + 외부시스템| 59 | 60 |
16 | 17 | ## ⭐ 개념 정리 18 | ### 리눅스 부팅 과정 19 | * **0단계 : 전원 공급** 20 | * CPU 전원 공급과 메인보드 BIOS 프로그램 자동 실행 21 | > BIOS : 컴퓨터 켤 때 나오는 까만 배경에 흰 글씨이며 PC에 존재하는 모든 하드웨어와 소프트웨어의 기본 동작을 제어한다. 22 | 23 | * **1단계 : BIOS 단계** 24 | * 자체진단기능(POST(Post On Self Test)) 실행 25 | * 디스크로부터 부트 로더를 가져오기 26 | * 시스템 제어권을 부팅 로더에게 전달 27 | 28 | * **2단계 : 부트로더 단계** 29 | * 부트로더는 커널을 메모리에 올리는 역할 30 | * 커널 이미지를 불러오고 지배권을 커널에게 전달 31 | 32 | * **3단계 : 커널 로딩** 33 | * swapper 프로세스 호출 34 | * 커널이 사용할 장치 드라이브들을 초기화 35 | * init 프로세스 실행 36 | * **4단계 : init 프로세스 실행** 37 | * /etc/inittab 파일에 정의된 순서에 따라 시스템 초기화 38 | * 로그인 프롬프트가 나오는 화면까지 init 프로세스에 의해 실행 39 | 40 |
41 | 42 | 43 | ## CPU 아키텍처 44 | ### 1. RISC(Reduced Instruction Set Computer) 45 | * 축소 명령어 집합 컴퓨터 46 | * 명령어 개수가 적은 것을 의미 47 | * 파이프라이닝 기법을 적용 48 | * 간단한 명령어와 빠른 동작 속도 49 | * 프로그램 구성 시 상대적으로 많은 명령어 필요 50 | * 워드, 데이터 버스 크기, 실행 사이클 모두 동일 51 | * 회로 구성 단순 52 | * 단순한 컴파일러 53 | 54 | >파이프라이닝 : 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태로 연결된 구조. 55 | 56 | ### 2. CISC(Complex Instruction Set Computer) 57 | * 복잡 명령어 집합 컴퓨터 58 | * 복잡한 명령어가 수백개 이상으로 내부구조가 복잡 59 | * 다양한 명령어 길이 60 | * 프로그램 구성 시 적은 명령어로 구현 가능 61 | * 컴파일러 복잡 62 | * CISC를 사용하는 이유 63 | * 많은 프로세서가 CISC로 구축되어 있어 이것을 모두 변경하기에 많은 비용 소모 64 | * RISC에 비해 호환성이 좋음 65 | -------------------------------------------------------------------------------- /03.Operating_system/phb/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.02.15|프로세스/스레드|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.15.md)| 6 | |21.02.16|스케줄링|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.16.md)| 7 | |21.02.17|메모리 관리 전략|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.17.md)| 8 | |21.02.19|가상메모리 및 페이지 교체 알고리즘|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.19.md)| 9 | |21.02.20|캐시 및 파일 시스템|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.20.md)| 10 | |21.02.22|인터럽트, 커널|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.22.md) 11 | |21.02.23|IPC, 시스템콜|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.23.md) 12 | |21.02.25|리눅스 부팅과정, RISC/CISC|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.25.md) 13 | 14 | -------------------------------------------------------------------------------- /04.Java/hsh/21.03.23.md: -------------------------------------------------------------------------------- 1 | # 21.03.23 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [객체지향 프로그래밍의 장점과 단점에 대해 설명하시오.](#oop의-4가지-특징) 6 | * 코드의 재사용성이 높아지고 유지보수가 쉬운 장점이 있습니다. 다만, 처리 시간이 비교적 오래 걸린다. 7 | 8 | #### 💡 [객체지향 프로그래밍의 5원칙에 대해 설명하시오.](#oop의-5원칙-solid) 9 | * SRP(단일 책임 원칙), OCP(개방-폐쇄 원칙), LSP(리스코프 치환 원칙), DIP(의존 역전 원칙), ISP(인터페이스 분리 원칙)을 말하며, 앞자를 따서 SOILD 원칙이라고 부릅니다. 프로그래머가 시간이 지나도 유지 보수와 확장이 쉬운 소프트웨어를 만드는데 이 원칙들을 적용할 수 있다. 10 | 11 | #### 💡 [객체지향 프로그래밍의 특징에 대해 설명하시오.](#oop의-4가지-특징) 12 | * 캡슐화, 상속, 추상화, 다형성 4가지 특징을 가지고 있습니다. 13 | * 캡슐화는 연관 있는 변수와 함수를 클래스로 묶는 작업을 의미합니다. 14 | * 상속은 자식 클래스가 부모 클래스의 특성과 기능을 물려받아 재사용성을 높이는 역할을 합니다. 15 | * 추상화란 인터페이스로 공통적인 특성들을 묶어 표현하는 것을 의미합니다. 16 | * 다형성의 대표적인 특징으로는 오버로딩, 오버라이딩이 있습니다. 17 | * 오버로딩은 같은 이름의 메서드가 매개변수의 유형과 개수에 다르도록 하는 기술입니다. 18 | * 오버라이딩은 상위 클래스가 가지고 있는 메서드를 하위 클래스가 재정의하는 기술입니다. 19 | 20 | #### 💡 [객체지향 설계 5원칙에 대해 설명해보시오.](#oop의-5원칙-solid) 21 | * SRP( Single Responsibility Principle ), 단일 책임 원칙 22 | * 객체는 단 하나의 책임만 가져야 한다는 원칙을 말합니다. 23 | * 시스템에 변화가 생기더라도 영향을 최소화 할 수 있다는 장점이 있습니다. 24 | * OCP ( Open-Closed Principle ), 개방-폐쇄 원칙 25 | * 기존의 코드를 변경하지 않으면서, 기능을 추가할 수 있도록 설계가 되어야 한다는 원칙을 말합니다. 26 | * 확장에 대해서는 개방적이고 수정에 대해서는 폐쇄적으로 설계해야 한다는 의미입니다. 27 | * L (LSP : Liskov’s Substitution Principle) 28 | * 자식 클래스는 최소한 자신의 부모 클래스에서 가능한 행위는 수행할 수 있어야 한다는 설계 원칙입니다. 29 | * I (ISP : Interface Segregation Principle) 30 | * 자신이 사용하지 않는 인터페이스는 구현하지 말아야 한다는 설계 원칙입니다. 31 | * D (DIP : ependency Inversion Principle) 32 | * 객체들이 서로 정보를 주고 받을 때 의존 관계가 형성되는데, 이 때 객체들은 나름대로의 원칙을 갖고 정보를 주고 받아야 한다는 설계 원칙입니다. 33 | 34 |
35 | 36 | ## ⭐ 개념 정리 37 | 38 | ### OOP(Object-Oriented Programming) 39 | --- 40 | #### OOP 이전의 프로그래밍 방식은? 41 | * 절차적 프로그래밍 방식 42 | * 입력을 받아 명시된 순서대로만 처리하고 결과를 내는 방식 43 | 44 | * 구조적 프로그래밍 방식 45 | * 절차적 프로그래밍 방식의 개선된 형태 46 | * 프로그램을 함수단위로 나누고 함수끼리 호출하는 방식 47 | * 큰 문제를 해결하기 위해 문제를 작은 단위들로 나누어 해결하는 방식 48 | * Top-Down 방식이라고도 한다. 49 | 50 | * 객체 지향 프로그래밍 방식 51 | * 구조적 프로그래밍 방식의 개선된 형태 52 | * 큰 문제를 작게 쪼개는 것이 아니라, 작은 문제들을 해결하는 객체를 만든다. 53 | * 객체들을 조합해 큰 문제를 해결하는 Bottom-Up 방식 54 | 55 | #### OOP의 장점과 단점 56 | * 장점 57 | * 코드의 재사용성이 높아진다. 58 | * 유지보수가 쉽다. 59 | * 코드가 간결해진다. 60 | * 단점 61 | * 처리 시간이 비교적 오래 걸린다. 62 | * 프로그램 설계할 때 많은 고민과 시간을 투자해야한다. 63 | 64 | #### OOP의 5원칙 (SOLID) 65 | * S (SRP : Single Responsibility Principle) 66 | * 한 클래스는 하나의 책임만 가져야 한다. 67 | * 시스템에 변화가 생기더라도 그 영향을 최소화 할 수 있음. 68 | * 응집도(구성 요소들의 응집력) ⬆️ 69 | * 결합도(프로그램 구성 요소들 사이의 의존성) ⬇️ 70 | 71 | * O (OCP : Open/Closed Principle) 72 | * 확장에는 열려(Open) 있으나, 변경에는 닫혀(Closed)있어야 한다. 73 | * 기존의 코드를 변경하지 않으면서(closed), 기능을 추가할 수 있도록(open) 설계가 되어야 한다는 원칙 74 | 75 | * L (LSP : Liskov’s Substitution Principle) 76 | * 프로그램의 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다. 77 | 78 | * I (ISP : Interface Segregation Principle) 79 | * 특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다. 80 | 81 | * D (DIP : ependency Inversion Principle) 82 | * 추상화에 의존한다. 구체화에 의존하면 안된다. 83 | 84 | > https://victorydntmd.tistory.com/291 상세설명 85 | 86 | #### OOP의 4가지 특징 87 | 1. 캡슐화 88 | * 실제로 구현 부분을 외부에 드러나지 않도록 하는 것 89 | * 변수와 메소드를 하나로 묶음 90 | * 데이터를 외부에서 직접 접근하지 않고 함수를 통해서만 접근 91 | * ex) public, private, protected 92 | * public : 클래스 외부에서 접근 가능 93 | * private : 클래스 내부에서만 접근 가능 94 | * protected : 상속받은 자식 클래스에서만 접근 가능 95 | 2. 상속 96 | * 자식 클래스가 부모 클래스의 특성과 기능을 물려받는 것 97 | * 기능의 일부분을 변경하는 경우 자식 클래스에서 상속받아 수정 및 사용함 98 | * 상속은 캡슐화를 유지, 클래스의 재사용이 용이하도록 해 준다. 99 | 3. 추상화 100 | * 인터페이스로 클래스들의 공통적인 특성(변수, 메소드)들을 묶어 표현하는 것 101 | 4. 다형성 102 | * 어떤 변수,메소드가 상황에 따라 다른 결과를 내는 것 103 | * 오버로딩(Overloading) : 하나의 클래스에서 메소드의 이름이 같지만, 파라메터가 다른 것 104 | * 오버라이딩(Overriding) : 부모 클래스의 메소드를 자식 클래스의 용도에 맞게 재정의하여 코드의 재사용성을 높임 105 | -------------------------------------------------------------------------------- /04.Java/hsh/21.03.25.md: -------------------------------------------------------------------------------- 1 | # 21.03.25 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [non-static 멤버와 static 멤버의 차이](#-non-static-멤버와-static-멤버의-차이) 6 | * static 멤버는 클래스 당 하나만 생성되고 non-static 멤버는 객체마다 별도로 존재합니다. 따라서 static 멤버는 동일한 클래스의 모든 객체들에 의해 공유되는 특성을 가지고 있습니다. 7 | 8 | #### 💡 [Final 키워드의 용도에 대해 설명하시오.](#-final-키워드의-용도에-대해-설명하시오) 9 | * 변수, 메서드, 클래스에 사용 할 수 있으며 변수에 사용 시 값이 변경 불가능하고 메서드에 사용 시 오버라이딩을 못하게 만들며 클래스에 사용할 시에 상속을 할 수 없게 만든다. 10 | 11 | #### 💡 [Generic에 대해 설명하시오.](#-generic에-대해-설명하시오) 12 | * 자바에서 제네릭(generic)이란 데이터의 타입(data type)을 일반화한다(generalize)는 것을 의미합니다. 제네릭은 클래스나 메소드에서 사용할 내부 데이터 타입을 컴파일 시에 미리 지정하는 방법입니다. 13 | 14 | #### 💡 [Generic의 장점에 대해 설명하시오.] 15 | * 컬렉션 클래스에서 제네릭을 사용하면 컴파일러는 특정 타입만 포함 될 수 있도록 컬렉션을 제한합니다. 컬렉션 클래스에 저장하는 인스턴스 타입을 제한하여 런타임에 발생할 수 있는 잠재적인 모든 예외를 컴파일타임에 잡아낼 수 있도록 도와줍니다. 16 | 17 | 18 |
19 | 20 | ## ⭐ 개념 정리 21 | 22 | ### non-static VS static 23 | * non-static 멤버 24 | * 공간적 특성: 멤버는 객체마다 별도로 존재한다. 25 | * 인스턴스 멤버 라고 부른다. 26 | * 시간적 특성: 객체 생성 시에 멤버가 생성된다. 27 | * 객체가 생길 때 멤버도 생성된다. 28 | * 객체 생성 후 멤버 사용이 가능하다. 29 | * 객체가 사라지면 멤버도 사라진다. 30 | * 공유의 특성: 공유되지 않는다. 31 | * 멤버는 객체 내에 각각의 공간을 유지한다. 32 | 33 | * static 멤버 34 | * 공간적 특성: 멤버는 클래스당 하나가 생성된다. 35 | * 멤버는 객체 내부가 아닌 별도의 공간에 생성된다. 36 | * 클래스 멤버 라고 부른다. 37 | * 시간적 특성: 클래스 로딩 시에 멤버가 생성된다. 38 | * 객체가 생기기 전에 이미 생성된다. 39 | * 객체가 생기기 전에도 사용이 가능하다. (즉, 객체를 생성하지 않고도 사용할 수 있다.) 40 | * 객체가 사라져도 멤버는 사라지지 않는다. 41 | * 멤버는 프로그램이 종료될 때 사라진다. 42 | * 공유의 특성: 동일한 클래스의 모든 객체들에 의해 공유된다. 43 | 44 | > https://gmlwjd9405.github.io/2018/08/04/java-static.html 45 | 46 | ### Final 키워드 47 | * 상수정의에 사용 48 | * 상수에 언제든 값을 한번 저장하고 다음에 다시 바꾸지 않을때 사용한다. 49 | 50 | * 메서드에 사용 51 | * 오버라이딩(재정의)을 못하게 만든다. 52 | 53 | * 클래스에 사용 54 | * 상속을 못하게 만든다. 55 | 56 | * static final 57 | * 객체마다 값이 바뀌는 것이 아닌 클래스에 존재하는 상수이므로 선언과 동시에 초기화를 해 주어야하는 클래스 상수이다. 58 | 59 | ### java Generic(제네릭) 60 | * 모든 종류의 타입을 다룰 수 있도록 일반화된 타입 매개 변수(generic type)로 클래스나 메서드를 선언하는 기법 61 | -------------------------------------------------------------------------------- /04.Java/hsh/21.04.10.md: -------------------------------------------------------------------------------- 1 | # 21.04.10 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [동등연산자(==)와 equals()의 차이에 대해 설명하세요.](#--equals-compareto-의-차이) 6 | * 동등연산자는 두 객체가 같은 메모리 공간을 가르키는지 확인을 할 때 사용하고 equals() 연산자는 두 객체의 값이 같은지를 확인할 떄 사용하는 메서드입니다. 7 | 8 | #### 💡 [java Reflection에 대해 설명하시오.](#java-reflection) 9 | * java reflection은 구체적인 클래스 타입을 알지 못해도, 그 클래스의 메소드, 타입, 변수들에 접근할 수 있도록 해주는 자바 API 입니다. 10 | 11 | #### 💡 [Lambda란 무엇이고 어떠한 장점이 있는가?](#java-lambda) 12 | * "식별자없이 실행가능한 함수" 함수인데 함수를 따로 만들지 않고 코드한줄에 함수를 써서 그것을 호출하는 방식입니다. 코드를 줄여 간단하게 작성 가능하고 가독성이 증가합니다. 13 | 14 | ## ⭐ 개념 정리 15 | 16 | ### Java 동기화, 비동기화 17 | * 동기화 방식(Syncronous) 18 | * 한 자원에 동시에 접근하는 것 제한 -> 순차적으로 진행 19 | * syncronized 키워드 사용 : 멀티 스레드 접근 제한 keyword 20 | * 비동기화 방식(Asyncronous) 21 | * 현재 실행 중인 명령이 종료되지 않아도 다음 명령 실행 가능 22 | 23 | 24 | ### == , equals(), compareTo() 의 차이 25 | 26 | * **==** 27 | * 항등 연산자(Operator) 이다. 28 | * 참조 비교(Reference Comparison), 주소 비교(Address Comparision) 29 | * 두 객체가 같은 메모리 공간을 가르키는지 확인한다. 30 | * **equals()** 31 | * 객체 비교 메서드이다. 32 | * 내용 비교 (Content Comparison) 33 | * 두 객체의 값이 같은지 확인한다. 34 | * 즉, 문자열의 데이터/내용을 기반으로 비교한다. 35 | * 기본 유형(Primitive Types)에 대해서는 적용할 수 없다. 36 | * 반환 형태: boolean type 37 | * 같으면 true, 다르면 false 38 | * **compareTo()** 39 | * Interface Comparable 가 구현되어 있는 객체에서 사용가능한 객체 비교 메서드(Method)
40 | * 사용자가 정의한 정렬 기준에 맞춰 정렬하기 위한 용도 로 compareTo() 메서드를 오버라이드하여 구현한다.
41 |
42 | ### java Reflection
43 | * 자바에서 제공하는 리플렉션(Reflection)은 C, C++과 같은 언어를 비롯한 다른 언어에서는 볼 수 없는 기능입니다. 이미 로딩이 완료된 클래스에서 또 다른 클래스를 동적으로 로딩(Dynamic Loading)하여 생성자(Constructor), 멤버 필드(Member Variables) 그리고 멤버 메서드(Member Method) 등을 사용할 수 있도록 합니다.
44 |
45 | * 컴파일 시간(Compile Time)이 아니라 실행 시간(Run Time)에 동적으로 특정 클래스의 정보를 객체화를 통해 분석 및 추출해낼 수 있는 프로그래밍 기법이라고 표현할 수 있습니다.
46 |
47 | ```text
48 | 내가 짠 코든데 내가 만든 클래스의 이름도 모르는게 말이 되나? 라는 의문이 생깁니다.
49 | 하지만 가끔 어떤 타입의 클래스나 변수 혹은 메소드를 사용할지 모르는 경우가 생깁니다.
50 | 예를 들어 변수의 값을 조건에 따라서 다르게 사용해야하는 경우라던가.
51 | 어플리케이션이 실행되고 나서 생성되는 클래스라던가. 이럴경우에 리플렉션을 사용할 수 있습니다.
52 |
53 | 출처 : https://kingname.tistory.com/164
54 | ```
55 | ### java Stream
56 | * 자바에서는 파일이나 콘솔의 입출력을 직접 다루지 않고, 스트림(stream)이라는 흐름을 통해 다룹니다.
57 | * 스트림(stream)이란 실제의 입력이나 출력이 표현된 데이터의 이상화된 흐름을 의미합니다.
58 | * 즉, 스트림은 운영체제에 의해 생성되는 가상의 연결 고리를 의미하며, 중간 매개자 역할을 합니다.
59 |  60 |
61 | * 스트림은 사용 목적에 따라 입력 스트림과 출력 스트림으로 구분됩니다.
62 |
63 | ### java Lambda
64 | 1. 람다 함수(Lambda Function)란?
65 | * 람다 함수는 함수형 프로그래밍 언어에서 사용되는 개념으로 익명 함수라고도 한다.
66 | * Java 8 부터 지원되며, 불필요한 코드를 줄이고 가독성을 향상시키는 것을 목적으로 두고있다.
67 |
68 | 2. 람다 함수의 특징
69 | * 메소드의 매개변수로 전달될 수 있고, 변수에 저장될 수 있다.
70 | * 즉, 어떤 전달되는 매개변수에 따라서 행위가 결정될 수 있음을 의미한다.
71 | * 컴파일러 추론에 의지하고 추론이 가능한 코드는 모두 제거해 코드를 간결하게 한다.
72 | 3. 람다식 표현
73 | * 파라미터와 몸체로 구분된다.
74 | * 파라미터와 몸체 사이에 -> 구분을 추가하여 람다식을 완성시킨다.
75 | * 몸체 부분이 단일 행일 경우 중괄호와 return문을 생략할 수 있다.
76 |
77 | * 기존 방법
78 | ```java
79 | new Thread(new Runnable() {
80 | @Override
81 | public void run() {
82 | System.out.println("Thread!");
83 | }
84 | }).start();
85 | ```
86 |
87 | * 람다식
88 | ```java
89 | new Thread(() -> {
90 | System.out.println("Thread!");
91 | }).start();
92 | ```
--------------------------------------------------------------------------------
/04.Java/hsh/21.04.17.md:
--------------------------------------------------------------------------------
1 | # 21.04.10
2 |
3 | ## 주요 질문
4 | #### 💡 직렬화와 역직렬화에 대해 설명하시오.
5 | * 자바에서 직렬화와 역직렬화는 객체를 파일로 저장하거나 네트워크를 통해 전송하기 위해 제공되는 기능입니다.
6 | * 직렬화는 객체를 파일에 저장하거나 네트워크를 통해 전달 할 수 있도록 변환하는 과정입니다.
7 | * 역직렬화는 직렬화된 데이터를 불러와 다시 객체로 변환하는 과정입니다.
8 |
9 | #### 💡 클래스와 객체의 차이는 무엇인가요?
10 | * 클래스는 ‘설계도’, 객체는 ‘설계도로 구현한 모든 대상’을 의미합니다.
11 |
12 | #### 💡 객체와 인스턴스의 차이는 무엇인가요?
13 | * 클래스의 타입으로 선언되었을 때 객체라고 부르고, 그 객체가 메모리에 할당되어 실제 사용될 때 인스턴스라고 부른다.
14 |
15 |
16 | ## ⭐ 개념 정리
17 |
18 | ### java Garbage Collection(GC)
19 | * Java Application은 JVM(Java Viirtual Machine) 위에서 구동됩니다. JVM에서는 Java Application이 사용하는 메모리를 관리하고 있는데 이 JVM의 기능중 더 이상 사용하지 않는 객체를 청소하여 공간을 확보하는 GC라는 작업이 있습니다.
20 |
21 | * GC란 Garbage Collection(쓰레기 객체 정리, 이하 GC)의 약자입니다. Java Runtime시 Heap 영역에 저장되는 객체들은 따로 정리하지 않으면 계속해서 쌓이게되어 OutOfMemmory Exception이 발생할 수 있습니다. 이를 방지하기 위하여 JVM에서는 주기적으로 사용하지 않는 객체를 수집하여 정리하는 GC를 진행합니다.
22 |
23 | * Garbage Collector 역할
24 | 1. 메모리 할당
25 | 2. 사용중인 메모리를 인식
26 | 3. 사용하지 않는 메모리를 인식
27 |
28 | * GC 동작 방식
29 | > https://mangkyu.tistory.com/118
30 |
31 |
32 | ### java 직렬화, 역직렬화
33 | * 자바에서 직렬화와 역직렬화는 객체를 파일로 저장하거나 네트워크를 통해 전송하기 위해 제공되는 기능이다.
34 | * 객체는 '인스턴스 변수의 집합'이므로 객체를 저장/전송하는 것은 객체의 인스턴스 변수의 값을 저장/전송하는 것과 동일하다.
35 | * 궁극적으로 객체의 직렬화는 서드파티에서 객체를 사용하기 위한 것이다.
36 | * **직렬화**
37 | - 객체에 저장된 데이터를 I/O 스트림에 쓰기(출력) 위해 연속적인(serial) 데이터로 변환하는 것
38 |
39 | * **역직렬화**
40 | - I/O 스트림에서 데이터를 읽어서(입력) 객체를 만드는 것
41 |
42 | ```java
43 | // 객체를 직렬화하여 파일에 저장
44 | ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("objectfile.ser"));
45 | oos.writeObject(new Member());
46 |
47 | // 파일로부터 객체를 읽어 객체 생성
48 | ObjectInputStream ois = new ObjectInputStream(new FileInputStream("objectfile.ser"));
49 | Member member = (Member) ois.readObject(); // Object로 리턴되므로 명시적 형변환 필요
50 | ```
51 |
52 | ### 클래스,객체,인스턴스의 차이
53 | * 클래스(Class)
54 | * 객체를 만들어 내기 위한 **설계도** 혹은 틀
55 | * 연관되어 있는 변수와 메서드의 집합
56 | * 객체(Object)
57 | * 소프트웨어 세계에 **구현할 대상**
58 | * 클래스에 선언된 모양 그대로 생성된 실체
59 |
61 | * ***'클래스의 인스턴스(instance)'*** 라고도 부른다.
62 | * 객체는 모든 인스턴스를 대표하는 포괄적인 의미를 갖는다.
63 | * oop의 관점에서 클래스의 타입으로 선언되었을 때 '객체'라고 부른다.
64 | * 인스턴스(Instance)
65 | * 설계도를 바탕으로 소프트웨어 세계에 **구현된 구체적인 실체**
66 | * 즉, 객체를 소프트웨어에 실체화 하면 그것을 '인스턴스'라고 부른다.
67 | * 실체화된 인스턴스는 메모리에 할당된다.
68 | * 인스턴스는 객체에 포함된다고 볼 수 있다.
69 | * oop의 관점에서 객체가 메모리에 할당되어 실제 사용될 때 '인스턴스'라고 부른다.
70 | * 추상적인 개념(또는 명세)과 구체적인 객체 사이의 **관계** 에 초점을 맞출 경우에 사용한다.
71 | * *'~의 인스턴스'* 의 형태로 사용된다.
72 | * 객체는 클래스의 인스턴스다.
73 | * 객체 간의 링크는 클래스 간의 연관 관계의 인스턴스다.
74 | * 실행 프로세스는 프로그램의 인스턴스다.
75 | * 즉, 인스턴스라는 용어는 반드시 클래스와 객체 사이의 관계로 한정지어서 사용할 필요는 없다.
76 | * 인스턴스는 어떤 원본(추상적인 개념)으로부터 '생성된 복제본'을 의미한다.
--------------------------------------------------------------------------------
/04.Java/hsh/21.04.18.md:
--------------------------------------------------------------------------------
1 | # 21.04.18
2 |
3 | ## 주요 질문
4 | #### 💡 [오버로딩과 오버라이딩에 대해 설명하시오.](#overloading-overriding)
5 | * 오버로딩은 메서드의 이름은 같고 매개변수의 갯수나 타입이 다른 함수를 정의하는 것을 의미합니다.
6 | * 오버라이딩은 상위 클래스의 메서드를 하위 클래스에서 재정의 하는 것을 의미합니다.
7 |
8 | #### 💡 Call by Reference와 Call by Value의 차이에 대해 설명하시오.
9 | * Call by Value는 메소드의 매개변수의 값을 복사를 하여 처리를 하느냐, 아니면 직접 참조를 하느냐 차이를 의미합니다. Call by Value의 경우 인자로 받은 값이 보존되고 Call by reference의 경우에 메소드에 의해 원래의 값이 영향을 받게 됩니다.
10 |
11 | #### 💡 추상 클래스와 인터페이스의 차이에 대해 설명하시오.
12 | * 추상 클래스는 클래스 내 '추상 메소드'가 하나 이상 포함되거나 abstract로 정의된 경우를 말합니다. 반면 인터페이스는 모든 메소드가 추상 메소드인 경우입니다.
13 | * 추상 클래스는 그 추상 클래스를 상속받아서 기능을 이용하고, 확장시키는 데 있습니다. 반면에 인터페이스는 함수의 껍데기만 있는데, 그 이유는 그 함수의 구현을 강제하기 위해서 입니다.
14 |
15 |
16 | ## ⭐ 개념 정리
17 |
18 | ### Overloading, Overriding
19 | * Overloading
20 | * 두 메서드가 같은 이름을 갖고 있으나 인자의 수나 자료형이 다른 경우
21 | * Overriding
22 | * 상위 클래스의 메서드와 이름과 용례(signature)가 같은 함수를 하위 클래스에 재정의하는 것
23 |
24 | ### Call by Value, Call by Reference
25 | * Call by value(값에 의한 호출)
26 | * 메소드로 인자값을 넘길때 그 값을 복사하여 넘기는 형태이다. 따라서 이 방식으로 메소드 호출을 하면 메소드 내에서는 복사된 값으로 작업을 하기 때문에 원래의 값을 변경시키지 않는다.
27 | * Call by reference(참조에 의한 호출)
28 | * 인자값을 메소드로 넘겨 줄때 그 객체를 참조하는 주소를 넘겨주는 형태이다. 따라서 메소드 내에서도 원래의 값에 접근이 가능하다.
29 |
30 | > https://hyoje420.tistory.com/6
31 |
32 | ### 인터페이스(Interface)와 추상 클래스(Abstract class)의 차이
33 | * 추상클래스란?
34 | * 추상클래스는 일반 클래스와 별 다를 것이 없습니다. 단지, 추상 메서드를 선언하여 상속을 통해서 자손 클래스에서 완성하도록 유도하는 클래스입니다. 그래서 미완성 설계도라고도 표현합니다. 상속을 위한 클래스이기 때문에 따로 객체를 생성할 수 없습니다.
35 |
36 | * class 앞에 "abstract" 예약어를 사용하여 상속을 통해서 구현해야한다는 것을 알려주고 선언부만 작성하는 추상메서드를 선언할 수 있습니다.
37 | ```java
38 | abstract class 클래스이름 {
39 | ...
40 | public abstract void 메서드이름();
41 | }
42 | ```
43 |
44 | * 인터페이스란?
45 | * 추상클래스가 미완성 설계도라면 인터페이스는 기본 설계도라고 할 수 있습니다. 인터페이스도 추상클래스처럼 다른 클래스를 작성하는데 도움을 주는 목적으로 작성하고 클래스와 다르게 다중상속(구현)이 가능합니다.
46 |
47 | * 클래스는 크게 일반 클래스와 추상 클래스로 나뉘는데 추상 클래스는 클래스 내 '추상 메소드'가 하나 이상 포함되거나 abstract로 정의된 경우를 말합니다. 반면 인터페이스는 모든 메소드가 추상 메소드인 경우입니다. (자바 8에서는 default 키워드를 이용해서 일반 메소드의 구현도 가능합니다.)
48 |
49 | ```java
50 | interface 인터페이스이름 {
51 | public static final 상수이름 = 값;
52 | public abstract void 메서드이름();
53 | }
54 | ```
55 |
56 | * 목적의 차이
57 | * 인터페이스와 추상 클래스는 존재 목적이 다릅니다. 추상 클래스는 그 추상 클래스를 상속받아서 기능을 이용하고, 확장시키는 데 있습니다. 반면에 인터페이스는 함수의 껍데기만 있는데, 그 이유는 그 함수의 구현을 강제하기 위해서 입니다. 구현을 강제함으로써 구현 객체의 같은 동작을 보장할 수 있습니다.
58 |
59 | > https://brunch.co.kr/@kd4/6
--------------------------------------------------------------------------------
/04.Java/hsh/README.md:
--------------------------------------------------------------------------------
1 | # 진행사항
2 |
3 | |날짜|설명|링크|
4 | |------|---|---|
5 | |21.03.22|JAVA|[✅보러가기](/04.Java/hsh/21.03.22.md)|
6 | |21.03.23|OOP|[✅보러가기](/04.Java/hsh/21.03.23.md)|
7 | |21.03.25|-|[✅보러가기](/04.Java/hsh/21.03.25.md)|
8 | |21.04.10|-|[✅보러가기](/04.Java/hsh/21.04.10.md)|
9 | |21.04.17|-|[✅보러가기](/04.Java/hsh/21.04.17.md)|
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/04.Java/kmj/21.03.25.md:
--------------------------------------------------------------------------------
1 | # 21.03.25
2 |
3 | ## 주요 질문
4 | * non-static vs static
5 | * final
6 | * generic
7 | #### 💡 [질문1](#개념1)
8 | * 답변
9 |
10 | #### 💡 질문2
11 | * 답변
12 |
13 | #### 💡 질문3
14 | * 답변
15 |
16 |
17 |
18 |
60 |
61 | * 스트림은 사용 목적에 따라 입력 스트림과 출력 스트림으로 구분됩니다.
62 |
63 | ### java Lambda
64 | 1. 람다 함수(Lambda Function)란?
65 | * 람다 함수는 함수형 프로그래밍 언어에서 사용되는 개념으로 익명 함수라고도 한다.
66 | * Java 8 부터 지원되며, 불필요한 코드를 줄이고 가독성을 향상시키는 것을 목적으로 두고있다.
67 |
68 | 2. 람다 함수의 특징
69 | * 메소드의 매개변수로 전달될 수 있고, 변수에 저장될 수 있다.
70 | * 즉, 어떤 전달되는 매개변수에 따라서 행위가 결정될 수 있음을 의미한다.
71 | * 컴파일러 추론에 의지하고 추론이 가능한 코드는 모두 제거해 코드를 간결하게 한다.
72 | 3. 람다식 표현
73 | * 파라미터와 몸체로 구분된다.
74 | * 파라미터와 몸체 사이에 -> 구분을 추가하여 람다식을 완성시킨다.
75 | * 몸체 부분이 단일 행일 경우 중괄호와 return문을 생략할 수 있다.
76 |
77 | * 기존 방법
78 | ```java
79 | new Thread(new Runnable() {
80 | @Override
81 | public void run() {
82 | System.out.println("Thread!");
83 | }
84 | }).start();
85 | ```
86 |
87 | * 람다식
88 | ```java
89 | new Thread(() -> {
90 | System.out.println("Thread!");
91 | }).start();
92 | ```
--------------------------------------------------------------------------------
/04.Java/hsh/21.04.17.md:
--------------------------------------------------------------------------------
1 | # 21.04.10
2 |
3 | ## 주요 질문
4 | #### 💡 직렬화와 역직렬화에 대해 설명하시오.
5 | * 자바에서 직렬화와 역직렬화는 객체를 파일로 저장하거나 네트워크를 통해 전송하기 위해 제공되는 기능입니다.
6 | * 직렬화는 객체를 파일에 저장하거나 네트워크를 통해 전달 할 수 있도록 변환하는 과정입니다.
7 | * 역직렬화는 직렬화된 데이터를 불러와 다시 객체로 변환하는 과정입니다.
8 |
9 | #### 💡 클래스와 객체의 차이는 무엇인가요?
10 | * 클래스는 ‘설계도’, 객체는 ‘설계도로 구현한 모든 대상’을 의미합니다.
11 |
12 | #### 💡 객체와 인스턴스의 차이는 무엇인가요?
13 | * 클래스의 타입으로 선언되었을 때 객체라고 부르고, 그 객체가 메모리에 할당되어 실제 사용될 때 인스턴스라고 부른다.
14 |
15 |
16 | ## ⭐ 개념 정리
17 |
18 | ### java Garbage Collection(GC)
19 | * Java Application은 JVM(Java Viirtual Machine) 위에서 구동됩니다. JVM에서는 Java Application이 사용하는 메모리를 관리하고 있는데 이 JVM의 기능중 더 이상 사용하지 않는 객체를 청소하여 공간을 확보하는 GC라는 작업이 있습니다.
20 |
21 | * GC란 Garbage Collection(쓰레기 객체 정리, 이하 GC)의 약자입니다. Java Runtime시 Heap 영역에 저장되는 객체들은 따로 정리하지 않으면 계속해서 쌓이게되어 OutOfMemmory Exception이 발생할 수 있습니다. 이를 방지하기 위하여 JVM에서는 주기적으로 사용하지 않는 객체를 수집하여 정리하는 GC를 진행합니다.
22 |
23 | * Garbage Collector 역할
24 | 1. 메모리 할당
25 | 2. 사용중인 메모리를 인식
26 | 3. 사용하지 않는 메모리를 인식
27 |
28 | * GC 동작 방식
29 | > https://mangkyu.tistory.com/118
30 |
31 |
32 | ### java 직렬화, 역직렬화
33 | * 자바에서 직렬화와 역직렬화는 객체를 파일로 저장하거나 네트워크를 통해 전송하기 위해 제공되는 기능이다.
34 | * 객체는 '인스턴스 변수의 집합'이므로 객체를 저장/전송하는 것은 객체의 인스턴스 변수의 값을 저장/전송하는 것과 동일하다.
35 | * 궁극적으로 객체의 직렬화는 서드파티에서 객체를 사용하기 위한 것이다.
36 | * **직렬화**
37 | - 객체에 저장된 데이터를 I/O 스트림에 쓰기(출력) 위해 연속적인(serial) 데이터로 변환하는 것
38 |
39 | * **역직렬화**
40 | - I/O 스트림에서 데이터를 읽어서(입력) 객체를 만드는 것
41 |
42 | ```java
43 | // 객체를 직렬화하여 파일에 저장
44 | ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("objectfile.ser"));
45 | oos.writeObject(new Member());
46 |
47 | // 파일로부터 객체를 읽어 객체 생성
48 | ObjectInputStream ois = new ObjectInputStream(new FileInputStream("objectfile.ser"));
49 | Member member = (Member) ois.readObject(); // Object로 리턴되므로 명시적 형변환 필요
50 | ```
51 |
52 | ### 클래스,객체,인스턴스의 차이
53 | * 클래스(Class)
54 | * 객체를 만들어 내기 위한 **설계도** 혹은 틀
55 | * 연관되어 있는 변수와 메서드의 집합
56 | * 객체(Object)
57 | * 소프트웨어 세계에 **구현할 대상**
58 | * 클래스에 선언된 모양 그대로 생성된 실체
59 |
61 | * ***'클래스의 인스턴스(instance)'*** 라고도 부른다.
62 | * 객체는 모든 인스턴스를 대표하는 포괄적인 의미를 갖는다.
63 | * oop의 관점에서 클래스의 타입으로 선언되었을 때 '객체'라고 부른다.
64 | * 인스턴스(Instance)
65 | * 설계도를 바탕으로 소프트웨어 세계에 **구현된 구체적인 실체**
66 | * 즉, 객체를 소프트웨어에 실체화 하면 그것을 '인스턴스'라고 부른다.
67 | * 실체화된 인스턴스는 메모리에 할당된다.
68 | * 인스턴스는 객체에 포함된다고 볼 수 있다.
69 | * oop의 관점에서 객체가 메모리에 할당되어 실제 사용될 때 '인스턴스'라고 부른다.
70 | * 추상적인 개념(또는 명세)과 구체적인 객체 사이의 **관계** 에 초점을 맞출 경우에 사용한다.
71 | * *'~의 인스턴스'* 의 형태로 사용된다.
72 | * 객체는 클래스의 인스턴스다.
73 | * 객체 간의 링크는 클래스 간의 연관 관계의 인스턴스다.
74 | * 실행 프로세스는 프로그램의 인스턴스다.
75 | * 즉, 인스턴스라는 용어는 반드시 클래스와 객체 사이의 관계로 한정지어서 사용할 필요는 없다.
76 | * 인스턴스는 어떤 원본(추상적인 개념)으로부터 '생성된 복제본'을 의미한다.
--------------------------------------------------------------------------------
/04.Java/hsh/21.04.18.md:
--------------------------------------------------------------------------------
1 | # 21.04.18
2 |
3 | ## 주요 질문
4 | #### 💡 [오버로딩과 오버라이딩에 대해 설명하시오.](#overloading-overriding)
5 | * 오버로딩은 메서드의 이름은 같고 매개변수의 갯수나 타입이 다른 함수를 정의하는 것을 의미합니다.
6 | * 오버라이딩은 상위 클래스의 메서드를 하위 클래스에서 재정의 하는 것을 의미합니다.
7 |
8 | #### 💡 Call by Reference와 Call by Value의 차이에 대해 설명하시오.
9 | * Call by Value는 메소드의 매개변수의 값을 복사를 하여 처리를 하느냐, 아니면 직접 참조를 하느냐 차이를 의미합니다. Call by Value의 경우 인자로 받은 값이 보존되고 Call by reference의 경우에 메소드에 의해 원래의 값이 영향을 받게 됩니다.
10 |
11 | #### 💡 추상 클래스와 인터페이스의 차이에 대해 설명하시오.
12 | * 추상 클래스는 클래스 내 '추상 메소드'가 하나 이상 포함되거나 abstract로 정의된 경우를 말합니다. 반면 인터페이스는 모든 메소드가 추상 메소드인 경우입니다.
13 | * 추상 클래스는 그 추상 클래스를 상속받아서 기능을 이용하고, 확장시키는 데 있습니다. 반면에 인터페이스는 함수의 껍데기만 있는데, 그 이유는 그 함수의 구현을 강제하기 위해서 입니다.
14 |
15 |
16 | ## ⭐ 개념 정리
17 |
18 | ### Overloading, Overriding
19 | * Overloading
20 | * 두 메서드가 같은 이름을 갖고 있으나 인자의 수나 자료형이 다른 경우
21 | * Overriding
22 | * 상위 클래스의 메서드와 이름과 용례(signature)가 같은 함수를 하위 클래스에 재정의하는 것
23 |
24 | ### Call by Value, Call by Reference
25 | * Call by value(값에 의한 호출)
26 | * 메소드로 인자값을 넘길때 그 값을 복사하여 넘기는 형태이다. 따라서 이 방식으로 메소드 호출을 하면 메소드 내에서는 복사된 값으로 작업을 하기 때문에 원래의 값을 변경시키지 않는다.
27 | * Call by reference(참조에 의한 호출)
28 | * 인자값을 메소드로 넘겨 줄때 그 객체를 참조하는 주소를 넘겨주는 형태이다. 따라서 메소드 내에서도 원래의 값에 접근이 가능하다.
29 |
30 | > https://hyoje420.tistory.com/6
31 |
32 | ### 인터페이스(Interface)와 추상 클래스(Abstract class)의 차이
33 | * 추상클래스란?
34 | * 추상클래스는 일반 클래스와 별 다를 것이 없습니다. 단지, 추상 메서드를 선언하여 상속을 통해서 자손 클래스에서 완성하도록 유도하는 클래스입니다. 그래서 미완성 설계도라고도 표현합니다. 상속을 위한 클래스이기 때문에 따로 객체를 생성할 수 없습니다.
35 |
36 | * class 앞에 "abstract" 예약어를 사용하여 상속을 통해서 구현해야한다는 것을 알려주고 선언부만 작성하는 추상메서드를 선언할 수 있습니다.
37 | ```java
38 | abstract class 클래스이름 {
39 | ...
40 | public abstract void 메서드이름();
41 | }
42 | ```
43 |
44 | * 인터페이스란?
45 | * 추상클래스가 미완성 설계도라면 인터페이스는 기본 설계도라고 할 수 있습니다. 인터페이스도 추상클래스처럼 다른 클래스를 작성하는데 도움을 주는 목적으로 작성하고 클래스와 다르게 다중상속(구현)이 가능합니다.
46 |
47 | * 클래스는 크게 일반 클래스와 추상 클래스로 나뉘는데 추상 클래스는 클래스 내 '추상 메소드'가 하나 이상 포함되거나 abstract로 정의된 경우를 말합니다. 반면 인터페이스는 모든 메소드가 추상 메소드인 경우입니다. (자바 8에서는 default 키워드를 이용해서 일반 메소드의 구현도 가능합니다.)
48 |
49 | ```java
50 | interface 인터페이스이름 {
51 | public static final 상수이름 = 값;
52 | public abstract void 메서드이름();
53 | }
54 | ```
55 |
56 | * 목적의 차이
57 | * 인터페이스와 추상 클래스는 존재 목적이 다릅니다. 추상 클래스는 그 추상 클래스를 상속받아서 기능을 이용하고, 확장시키는 데 있습니다. 반면에 인터페이스는 함수의 껍데기만 있는데, 그 이유는 그 함수의 구현을 강제하기 위해서 입니다. 구현을 강제함으로써 구현 객체의 같은 동작을 보장할 수 있습니다.
58 |
59 | > https://brunch.co.kr/@kd4/6
--------------------------------------------------------------------------------
/04.Java/hsh/README.md:
--------------------------------------------------------------------------------
1 | # 진행사항
2 |
3 | |날짜|설명|링크|
4 | |------|---|---|
5 | |21.03.22|JAVA|[✅보러가기](/04.Java/hsh/21.03.22.md)|
6 | |21.03.23|OOP|[✅보러가기](/04.Java/hsh/21.03.23.md)|
7 | |21.03.25|-|[✅보러가기](/04.Java/hsh/21.03.25.md)|
8 | |21.04.10|-|[✅보러가기](/04.Java/hsh/21.04.10.md)|
9 | |21.04.17|-|[✅보러가기](/04.Java/hsh/21.04.17.md)|
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/04.Java/kmj/21.03.25.md:
--------------------------------------------------------------------------------
1 | # 21.03.25
2 |
3 | ## 주요 질문
4 | * non-static vs static
5 | * final
6 | * generic
7 | #### 💡 [질문1](#개념1)
8 | * 답변
9 |
10 | #### 💡 질문2
11 | * 답변
12 |
13 | #### 💡 질문3
14 | * 답변
15 |
16 |
17 |
18 |
19 | 20 | ## 심화 질문 21 | 22 | #### 💡 질문1 23 | * 답변 24 | 25 | #### 💡 질문2 26 | * 답변 27 | 28 | #### 💡 질문3 29 | * 답변 30 | 31 | 32 |
33 | 34 | ## ⭐ 개념 정리 35 | 36 | ### java의 non-static 멤버와 static 멤버의 차이 37 | * non-static (인스턴스 멤버) 38 | * 객체마다 갖고 있어야 하는 성질 39 | * 각 객체마다 1개씩 생긴다. 40 | * static 멤버(클래스 멤버) 41 | * 오직 1개여야하는 성질 42 | * 클래스마다 1개씩 생긴다. 43 |  44 | 45 | ### java의 main메서드가 static인 이유 46 | * main메서드는 가장 먼저 실행돼야 하기 때문이다. 47 | #### public을 붙이는 이유 48 | * 어떤 패키지의 어떤 클래스에 선언될지 모르는 main메서드를 호출하기 위해서 49 | ### java의 final 키워드 (final, finally, finalize) 50 | #### 사용의도 51 | * 변수, 함수, 클래스를 명시적으로 제한하기 위해서 52 | * 코드 가독성을 증가하기 위해서 53 | #### final 54 | * final 클래스는 상속하지 못한다. 55 | * final 메서드는 자식클래스에서 재정의하지 못한다. 56 | * final 변수는 선언 이후 변경하지 못한다. 57 | #### finally 58 | * try-catch와 함께 사용되며 필수 요소는 아니다. 59 | * 예외 발생 유무와 상관없이 무조건 수행된다. 60 | #### finalize 61 | * Object클래스에 포함된 메서드로 Garbage Collection이 수행될 때 더이상 사용되지 않는 자원을 종료하는 메서드이다. 62 | ### java의 제네릭과 c++의 템플릿 차이 63 | * java의 제네릭 64 | * 클래스 내부에서 사용할 데이터 타입을 인스턴스를 생성할 때 확정하는 것이다. 65 | * 객체 타입을 컴파일 시에 확인하기 때문에 타입 안정성을 높이고, 형변환의 번거로움이 줄어든다. 66 | * c++의 템플릿 67 | * 기능은 명확하지만 자료형을 모호하게 선언하는 것이다. 68 | * 나중에 호출할 때 어떤 자료형을 쓸건지 표시한다. 69 |  70 | * 차이점 71 | * 컴파일 시 타입 체크 72 | * 자바는 체크하지만, C++는 체크하지 않는다. 73 | * 컴파일 된 코드 생성 개수 74 | * 자바는 1개의 컴파일 된 코드를 생성하지만, C++는 사용되는 데이터 개수만큼 컴파일 코드를 생성한다. 75 | 76 |
77 |
21 | 22 | ## ⭐ 개념 정리 23 | 24 | ### 동기화 vs 비동기화 25 | * 동기화 (Synchronous) 26 | * 요청과 결과가 동시에 일어난다. 27 | * 장점: 설계가 간단하다. 28 | * 단점: 결과가 주어질 때까지 대기해야 한다. 29 | * 비동기화 (Asynchronous) 30 | * 요청과 결과가 동시에 일어나지 않는다. 31 | * 장점: 결과를 기다리는 동안 다른 일을 할 수 있다. -> 자원을 효울적으로 활용 32 | * 단점: 설계가 복잡하다. 33 | 34 | ### 블럭 vs 넌블럭 35 | * 블럭: 호출된 함수가 자신이 할 일을 모두 마칠 때까지 제어권을 계속 가지고서 호출한 함수에게 바로 돌려주지 않는 상태 36 | * 넌블럭: 호출된 함수가 자신이 할 일을 채 마치지 않았더라도 바로 제어권을 건네주어(return) 호출한 함수가 다른 일을 진행할 수 있도록 해주는 상태 37 | 38 | > https://private.tistory.com/24 [공부해서 남 주자] 39 | > https://musma.github.io/2019/04/17/blocking-and-synchronous.html 40 | ### 자바의 == vs equals 41 | * == 42 | * 주소값 비교 43 | * equals 44 | * 비교대상의 내용을 비교 45 | 46 |  47 |  48 | 49 | * a, b => ==, equals로 비교 가능 50 | * a, c => equals로 비교해야 true 나옴 51 | >https://ojava.tistory.com/15 52 | ### 자바의 리플렉션 53 | * 구체적인 클래스 타입을 알지 못해도, 클래스의 메서드, 변수들에 접근할 수 있도록 하는 자바 API 54 | 55 | ### Stream 56 | * 데이터의 흐름 57 | * 배열 또는 컬렉션 인스턴스에 함수들을 조합해서 원하는 결과를 만들 수 있다. 58 | ### Lambda 59 | * 이름이 없는 함수형 인터페이스 60 | * 타입의 언급이 없다. 61 | * 타입추론은 컴파일러가 대신 해준다. 62 | * 타입추론시 필요한 정보는 제네릭을 이용해서 얻는다. 63 | > https://javabom.tistory.com/66 64 |
65 | 66 | 67 | 68 | -------------------------------------------------------------------------------- /04.Java/lyj/21.03.30.md: -------------------------------------------------------------------------------- 1 | ## String, StringBuilder, StringBuffer의 차이 2 | 3 | **String 객체** 4 | 5 | - **immutable.** 즉 **한번 생성이 되면 변경이 불가능**. 6 | - 객체를 한 번 할당할시 메모리 공간에 변동 없음. **Heap String Pool 영역**에 생성되어 **그 값을 계속 사용**. 7 | - 동기화 관리 필요 없음 8 | 9 | **StringBuffer** 10 | 11 | - mutable 12 | - 멀티쓰레드 환경에서 동기화 지원 13 | 14 | **StringBuilder** 15 | 16 | - mutable 17 | - 멀티쓰레드 환경에서 동기화 지원 안함 18 | 19 | ## ==와 equals 차이 20 | 21 | ### equals 22 | 23 | 값 자체를 비교 24 | 25 | ### == 26 | 27 | 주소값을 비교 28 | 29 | ```java 30 | String basket1 = "Ya-Ong"; 31 | String basket2 = "Ya-Ong"; 32 | System.out.println(basket1==basket2); // false 33 | System.out.println(basket1.equals(basket2)); // true 34 | ``` 35 | 36 | ## try-with-resource 37 | 38 | 자동으로 자원을 해제 39 | 40 | try에서 선언된 객체가 AutoCloseable을 구현하였다면 Java는 try구문이 종료될 때 객체의 close() 메소드를 자동으로 호출 41 | 42 | ## Collection 43 | 44 | ### Collection 45 | 46 | - 데이터의 집합, 그룹 47 | - 데이터를 저장하고 연산할 수 있는 집합 48 | 49 | ### Collection 특징 50 | 51 | - **크기가 가변적**이다. 52 | 53 | - **모든 객체를 원소로 저장가능**하다. 54 | 55 | Primitive type → Wrapper Class 56 | 57 | ### Collection 종류 58 | 59 | 1. Collection 인터페이스 60 | - 순서나 집합적인 저장 공간 명세 61 | - Set, List, Queue 62 | 2. Map 인터페이스 63 | - 키와 값으로 데이터를 다룰 수 있는 공간 명세 64 | - HashMap, TreeMap 65 | 66 | ### Set, List, Queue 67 | 68 | **List 인터페이스** 69 | 70 | - 객체의 순서 있음 71 | - 원소가 중복될 수 있음 72 | - ArrayList - 동기화 보장안됨 73 | 74 | **Queue 인터페이스** 75 | 76 | - 객체를 입력한 순서대로 저장 77 | - 원소가 중복될 수 있음 78 | - LinkedList, ArrayDeque 79 | 80 | **Set 인터페이스** 81 | 82 | - 객체의 순서가 없음 83 | - 동일한 원소를 중복 저장 불가 84 | - HashSet, TreeSet 등 85 | 86 | ### LinkedList와 ArrayList 87 | 88 | **ArrayList** 89 | 90 | - 내부적으로 특정 데이터 타입의 배열에서 데이터를 관리 91 | - 삽입 및 삭제 시간복잡도 O(n) 92 | - 검색 시간복잡도 O(n) 93 | 94 | **LinkedList** 95 | 96 | - 노드에 데이터를 저장하고 앞 뒤 노드의 주소값을 연결지어 데이터를 관리 97 | - 삽입 및 삭제 시간복잡도 O(1) 98 | - 검색 시간복잡도 O(n) 99 | 100 | ### HashMap 101 | 102 | - Hashing을 사용해서 Map 데이터를 관리 및 연산하는 데이터 구조 103 | - hash 함수를 이용해서 key 값을 hash code로 바꿔서 데이터 저장 104 | - hashcode를 기반으로 검색 105 | 106 | ### HashMap과 HashTable 107 | 108 | **HashMap** 109 | 110 | - 동기화 기능 제공안함 111 | - 멀티 스레드 환경에서 스레드 세이프 하지 않음 112 | 113 | **HashTable** 114 | 115 | - 동기화 기능 제공 116 | - 멀티 스레드 환경에서 스레드 세이프 117 | 118 | ### TreeMap과 TreeSet 119 | 120 | **공통점** 121 | 122 | Red Black Tree 기반으로 구성. red black tree는 balanced binary search tree의 한 종류 로써 BST에서 발생하는 불균형 문제를 색깔을 통해서 자체적으로 해결하는 자료구조 입니다. 123 | 124 | **차이점** 125 | 126 | TreeSet은 Collection 인터페이스를 구현한 클래스이고 TreeMap은 Map 인터페이스를 구현한 클래스이다. -------------------------------------------------------------------------------- /04.Java/lyj/21.04.05.md: -------------------------------------------------------------------------------- 1 | ## Reflection 2 | 3 | - 정의된 클래스 / 메소드 / annotation 정보를 확인하고 참조하기 4 | - 인스턴스를 생성하고, 필드값을 변경하며, 메소드를 실행할 수 있는 방법. 5 | 6 | 구체적인 클래스 타입을 알지 못해도 그 클래스의 메소드, 타입, 변수에 접근할 수 있도록 해준다. 7 | 8 | ### 장점 9 | 10 | 리플렉션을 사용하면, String 값을 통해 class를 얻어올 수 있고, 그 생성자를 얻어올 수 있다. 11 | 12 | 그 생성자를 통해 인스턴스를 생성할 수 있고, 생성된 인스턴스를 이용하여 메소드나 속성에 접근할 수 있다. 13 | 14 | 15 | 16 | ## Java 8 특징 17 | 18 | - Stream API 19 | - Lamda 표현식, **함수형 프로그래밍**이 처음으로 도입 20 | - 나즈혼이라는 자비스크립트의 엔진 추가 21 | - Method Reference, Default Method, Optional Class 22 | - java.time 패키지 추가 23 | 24 | ### Stream API 25 | 26 | 데이터 요소인 배열이나 컬렉션 등의 데이터를 처리하기 위한 API 27 | 28 | **Stream API 장점** 29 | 30 | - 멀티 스레드를 활용하여 병렬로 연산 수행 가능 31 | 32 | - 내부 반복으로 연산을 수행하기 때문에 코드 단순화 가능 33 | 34 | 데이터 저장시 배열이나 컬렉션을 사용하는데 이에 접근하기 위해서는 반복문을 사용해야 했다. 또한 데이터마다 접근하는 방식도 달랐다. 35 | 36 | Stream API로 데이터를 추상화하여 공통된 방법으로 데이터를 읽고 쓰는 게 가능해졌다. 37 | 38 | ### Lambda 39 | 40 | **람다표현식** 41 | 42 | - 메소드를 하나의 식으로 표현 43 | - 익명함수. 이름없이 실행할 수 있는 함수 표현식. 44 | 45 | **Lambda 예시** 46 | 47 | - 자바에서 Thread를 만들때 Runnable()객체를 할당하고 run 메소드를 실행하는데 이를 축약하여 ()로 나타낼 수 있다. 48 | 49 | **Lambda 장점** 50 | 51 | - 불필요한 코드 줄일 수 있다. 52 | - 가독성을 높일 수 있다. 53 | 54 | ### 나즈혼 엔진 55 | 56 | JAVA 8 이전에는 모질라의 리노 자바스크립트 엔진을 사용하였다. 이는 java의 최신 개선사항 등을 반영하지 못해 성능이나 메모리상으로 크게 향상된 나즈혼 엔진으로 업데이트 되었다. 57 | 58 | -------------------------------------------------------------------------------- /04.Java/lyj/21.04.10.md: -------------------------------------------------------------------------------- 1 | ## 디자인 패턴 2 | 3 | **소프트웨어를 설계할 때 특정 문맥에서 자주 발생하는 고질적인 문제들이 또 발생했을 때 재사용할 수 있는 설계 패턴**을 의미합니다. 4 | 5 | ### Singleton Pattern 6 | 7 | - **인스턴스가 오직 1개만 생성되어야 하는 경우에 사용되는 패턴** 8 | - **동시성 문제 고려**해야한다 9 | 10 | ### **자바와 스프링의 싱글톤 차이**점 11 | 12 | 싱글톤 객체의 생명주기가 다르다 13 | 14 | - 자바 싱글톤 객체의 범위는 **클래스 로더**가 기준 15 | 16 | - 스프링에서는 **어플리케이션 컨텍스트**가 기준 17 | 18 | Bean을 등록할 때 범위의 default는 Singleton다. 싱글톤 이외 범위는 prototype, request, session이 있다. 19 | 20 | ### Proxy Pattern 21 | 22 | - 특정 객체를 대신해서 프록시 객체가 해당 역할을 수행 23 | - 클라이언트가 최종적으로 받는 리턴값을 조작하지 않고 그대로 전달 24 | 25 | ### Decorator Pattern 26 | 27 | - 클라이언트가 받는 반환값에 장식 추가 28 | - 프록시 패턴과 구현 방법 유사 29 | 30 | ### Adapter Pattern 31 | 32 | - 클래스의 인터페이스를 사용자가 기대하는 다른 인터페이스로 변환 33 | 34 | ### Template Method Pattern 35 | 36 | - 알고리즘의 구조를 바꾸지 않고 서브클래스에서 알고리즘의 특정 단계를 재정의 37 | - 상속을 통해 슈퍼클래스의 기능을 확장할 때 사용 38 | 39 | ### Strategy Pattern 40 | 41 | - 전략 객체를 통해서 알고리즘의 구조를 바꾼다. -------------------------------------------------------------------------------- /04.Java/phb/21.03.15.md: -------------------------------------------------------------------------------- 1 | # 21.03.15 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 Override과 Overload의 차이점을 설명해주세요. 6 | * Overriding은 메소드를 새롭게 재정의하는 것이고 Overload는 같은 이름의 메소드를 여러개 정의하는 것입니다. 7 | 8 | #### 💡 SOLID 원칙 중 개방-폐쇄 원칙에 대해서 설명해주세요. 9 | * 개방-폐쇄 원칙은 기존 코드를 변경하지 않고 기능을 수정 및 추가할 수 있어야한다는 원칙입니다. 10 | 11 |
12 | 13 | ## ⭐ Java 14 | 15 | ### 1. Java 특징 16 | * 높은 이식성을 가진 언어 (OS에 구애받지 않음) 17 | * 객체 지향 언어 18 | * Garbage Collector 19 | * 등등 20 | 21 | ### 2. 객체지향 프로그래밍 언어(OOP) 22 | * 구성 요소 23 | * 클래스 24 | * 객체 25 | * 메소드 26 | * 특징 27 | * 추상화 28 | * 정보 은닉 29 | * 상속 30 | * 다형성 31 | 32 | ### 2-1. OOP의 5대 원칙 SOLID 33 | * Single Responsibility Principle (단일 책임 원칙) 34 | * 객체(클래스, 함수 등)는 단 하나의 책임(기능)만 가져야 한다. 35 | * 응지도는 높고 결합도가 낮은 프로그램 36 | * Open Closed Principle (개방-폐쇄 원칙) 37 | * 기존 코드를 변경하지 않고 기능을 수정 및 추가할 수 있도록 설계해야 한다. 38 | * Liskov Substitution Principle (리스코프 치환 원칙) 39 | * 자식 클래스는 부모 클래스에서 가능한 행위를 수행할 수 있어야 한다. 40 | * Interface Segregation Principle (인터페이스 분리 원칙) 41 | * 특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다. 42 | * 인터페이스들을 구체적이고 작은 단위로 분리시킴으로써 클라이언트들에게 필요한 메소드만 이용할 수 있게 한다. 43 | * Dependency Inversion Principle (의존 역전 원칙) 44 | * 의존 관계를 맺을 때, 변화하기 쉬운 것 보다 변화하기 어려운 것에 의존해야 한다. 45 | 46 | ### 2-2. 다형성 47 | ||오버라이딩(Overriding)|오버로드(Overloading)| 48 | |-|-|-| 49 | |정의|상위 클래스의 메소드를 하위 클래서에서 재정의|같은 이름의 함수를 여러개 정의| 50 | |메소드명|동일|동일| 51 | |매개변수|동일|다름| 52 | |리턴타입|동일|상관없음| 53 | 54 | 55 | -------------------------------------------------------------------------------- /04.Java/phb/21.03.16.md: -------------------------------------------------------------------------------- 1 | # 21.03.16 2 | 3 | ## 주요 질문 4 | ## ⭐ Java 5 | 6 | ### 1. 접근제어자 7 | * 접근 범위: private < default < protected < public 8 | 9 | ||private|(default)|protected|public| 10 | |-|-|-|-|-| 11 | |동일 클래스|O|O|O|O| 12 | |동일 패키지|X|O|O|O| 13 | |자손 클래스|X|X|O|O| 14 | |전체|X|X|X|O| 15 | 16 |
17 | 18 | ### 2. 데이터 타입 19 | 20 | |타입|구분|데이터형|바이트 수| 21 | |-|-|-|-| 22 | |기본형|정수형|byte|1바이트| 23 | |||short|2바이트| 24 | |||int|4바이트| 25 | |||long|8바이트| 26 | ||실수형|float|4바이트| 27 | |||double|8바이트| 28 | ||자료형|char|2바이트| 29 | ||논리형|boolean|4바이트| 30 | |참조형|배열| 31 | ||열거| 32 | ||클래스| 33 | ||인터페이스| 34 | 35 | 36 |
37 | 38 | ### 3. 래퍼 클래스(Wrapper Class) 39 | * 기본형을 객체로 다루기 위해 사용하는 클래스 40 | * 박싱(Boxing) : 기본타입 → 래퍼 클래스 41 | * 언박싱(UnBoxing) : 래퍼 클래스 → 기본타입 42 | 43 |  44 | 45 | 46 |
14 | 15 | ## ⭐ 개념 정리 16 | 17 | ### static/non-static 18 | * **static** 19 | ```java 20 | static int i = 3; 21 | ``` 22 | * 프로그램 실행 시 메모리에 적재 23 | * 값의 중복을 피하게 해주고 찾는 시간이 줄어 프로그램의 효율성을 증가 24 | 25 | * **non-static** 26 | ```java 27 | int i = 3; 28 | ``` 29 | * new로 객체를 생성하면 메모리에 적재 30 | 31 |
32 | 33 | ### final/finally/finalize 34 | * **final** 35 | * 키워드를 명시하여 한 번만 할당하고 싶을 때 사용 36 | * classes : 상속불가 37 | * methods : Override 불가 38 | * variables : 값 변경 불가 39 | * **finally** 40 | * try-catch와 함께 사용되며 예외 발생 유무와 상관없이 무조건 수행되는 것들을 작성 41 | * **fianlize** 42 | * JVM에서 GC이 수행될 때 사용하지 않는 자원에 대한 정리 작업 진행을 위해 호출되는 종료자 메소드 43 | 44 |
45 | 46 | ### Generics 47 | * 데이터의 타입을 인스턴스를 생성할 때 결정하는 것을 의미 48 | * 객체 타입을 컴파일 시점에 체크하므로 타입 안정성을 높이고 형변환의 번거로움을 감소 49 | ```java 50 | // 제네릭 사용 X → 타입 변환이 필요 51 | ArrayList list = new ArrayList(); 52 | list.add("test"); 53 | String a = (String) list.get(0); 54 | ``` 55 | 56 | ```java 57 | // 제네릭 사용 → 타입 변환이 필요 X 58 | ArrayList list = new ArrayList<>();
59 | list.add("test");
60 | String a = list.get(0);
61 | ```
62 |
63 | ### C++ Template vs Java Generics
64 | * Java Generics
65 | * 특정 타입이 되도록 제한할 수 있음
66 | * 기본형 타입을 인자로 받을 수 없음
67 | * static 선언하는데 사용될 수 없음
68 |
69 | * C++ Template
70 | * 기본형 타입을 인자로 넘길 수 있음
71 | * 인자로 주어진 타입으로부터 객체 생성이 가능
72 | * static 선언하는데 사용 가능
73 |
--------------------------------------------------------------------------------
/04.Java/phb/21.03.29.md:
--------------------------------------------------------------------------------
1 | # 21.03.29
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 Call by reference와 value의 차이점이 무엇인가요?
6 | * call by reference 주소값을 호출
7 | * call by value 실제 값을 호출
8 |
9 |
10 | 11 | ## ⭐ Java 12 | 13 | ## Call by Reference/Value 14 | |**Call by Reference**|**Call by Value**| 15 | |-|-| 16 | |참조에 의한 호출|값에 의한 호출| 17 | |복사하지 않고 실제 값을 직접 참조 → 빠른 속도|실제 값을 복사하여 처리 → 복사에 의해 메모리 사용량 증가| 18 | |직접 참조하므로 원래 값이 영향을 받음|원래 값 보존| 19 | 20 |
21 | 22 | ## Abstract/Interface 23 | ||**추상클래스**|**인터페이스**| 24 | |-|-|-| 25 | |선언 예약어|abstract|interface| 26 | |미구현 메소드 포함 가능 여부|O|O| 27 | |구현 메소드 포함 가능 여부|O|X| 28 | |static 메소드 선언 가능 여부|O|X| 29 | |final 메소드 선언 가능 여부|O|X| 30 | |상속(extends) 가능 여부|O|X| 31 | |구현(implements) 가능 여부|O|X| 32 | 33 | * 추상클래스는 다중상속이 불가능 34 | * 인터페이스로 다중상속처럼 구현 가능 (실제 다중상속 아님) 35 | 36 | 37 | -------------------------------------------------------------------------------- /04.Java/phb/21.03.30.md: -------------------------------------------------------------------------------- 1 | # 21.03.30 2 | 3 | ## ⭐ 개념 정리 4 | 5 | ## JVM(Java Virtual Machine) 6 | 7 | ### 1. JAVA 실행과정 8 |  9 | 10 | 1. 프로그램 실행되면 JVM은 OS로부터 프로그램에 필요한 메모리를 할당받는다. 11 | JVM은 이 메모리를 용도에 따라 여러 영역으로 나누어 관리한다. 12 | 2. 자바 컴파일러(.javac)가 자바 소스코드(.java)를 읽어들여 자바 바이트코드(.class)로 변환시킨다. 13 | 3. Class Loader로 class파일들을 JVM에 로딩한다. 14 | 4. 해석된 바이트코드는 Runtime Data Areas에 배치되어 실질적인 수행을 한다. 15 | 필요에 따라 JVM은 GC 관리작업을 수행한다. 16 | 17 |
18 | 19 | ### 2. JVM 20 |  21 | * Java-운영체제 사이에서 중개자 역할 22 | * Java Application을 Class loader로 읽어서 Java API와 함께 실행하는 역할 23 | * 특징 24 | * 스택 기반의 가상 머신 25 | * 심볼릭 레퍼런스 26 | * Garbage Collection 27 | * 플랫폼 독립성 보장 28 | * 네트워크 바이트 오더 29 | 30 |
31 | 32 | ### 3. JVM 구성 33 |  34 | 35 | * **Class Loader** 36 | * 클래스(.class)를 로드하고 링크를 통해 배치하는 작업을 수행하는 모듈 37 | * Runtime 시에 동적으로 로드 38 | 39 |
40 | 41 | * **Execution Engine** 42 | * 클래스 로더에 의해 메모리에 적재된 클래스를 실행시키는 역할 43 | * 바이트코드를 기계어로 변경 44 | * 방식 45 | * 인터프리터(Interpreter) 46 | * 명령어 단위로 읽어서 실행 47 | * 한 줄씩 수행하므로 속도가 느림 48 | * JIT(Just In Time) 49 | * 인터프리터 방식의 단점을 보완하기 위한 컴파일러 50 | * 인터프리터 방식으로 실행하다가 적절한 시점에 바이트코드 전체를 컴파일하여 네이티브 코드로 변경 51 | 52 |
53 | 54 | * **Runtime Data Area** 55 | * PC Register 56 | * Thread가 시작될 때마다 생성되는 공간 57 | * Thread가 어떤 부분을 어떤 명령으로 실행할 지에 대한 기록으로 JVM 명령의 주소를 가짐 58 | * stack 59 | * 메소드 안에서 사용되는 값을 저장 (변수, 매개변수, 지역변수, 리턴 값 등) 60 | * Native method stack 61 | * 기계어로 작성된 프로그램을 실행시키는 영역 62 | * Method Area (= Class area = Static area) 63 | * 클래스 정보를 처음 메모리에 올릴 때 초기화되는 대상을 저장하기 위한 메모리 공간 64 | * 내부에 Runtime Constant Pool 존재하며 상수 자료형을 저장 65 | * heap 66 | * 객체를 저장하는 가상 메모리 공간 67 | 68 |
69 | 70 |
16 | * 순서가 있는 데이터 집합으로 중복을 허용
17 | * 종류
18 | * Vector
19 | * ArrayList
20 | * LinkedList
21 | * Set
22 | * 순서가 없는 데이터 집합으로 데이터 중복을 허용하지 않음
23 | * 종류
24 | * HashSet
25 | * TreeSet
26 | * Map
27 | * 키-값의 쌍으로 이루어진 데이터 집합으로 순서가 없음
28 | * 키는 중복을 허용하지 않지만 값은 중복 가능
29 | * 종류
30 | * HashMap
31 | * TreeMap
32 |
33 |
34 | 35 | ### Collection 주요 메소드 36 |  37 | 38 |
39 | 40 | ## Annotation 41 | * @ 42 | * 자바 소스 코드에 추가하여 사용하는 메타 데이터 43 | * JDK 1.5 버전 이상에서 사용 가능 44 | * Java에서 제공하는 기본 Annotation 45 | |Annotation|내용| 46 | |-|-| 47 | |@Override|선언 메소드 재정의| 48 | |@Deprecated|해당 메소드가 더 이상 사용되지 않음| 49 | |@SuppressWarnings|선언한 곳의 컴파일 경로를 무시| 50 | |@SafeVarargs|Java7부터 지원, 제너릭 같은 가변인자의 매개변수를 사용할 때 경고를 무시| 51 | |@FunctionalInterface|Java8부터 지원, 함수형 인터페이스 지정| 52 | 53 |
54 |
61 | 62 | ## String/StringBuilder/StringBuffer 63 | ||String|StringBuilder|StringBuffer| 64 | |-|-|-|-| 65 | |가변성|immutable|mutable|mutable| 66 | |동기화|X|X|O| 67 | |Thread-Safe|O|X|O| 68 | |속도|제일 느림|빠름|제일 빠름| 69 | 70 |
71 | 72 | ### 언제 사용하면 유용할까? 73 | * String: 짧은 문자열을 더할 경우 사용 74 | * StringBuilder : Thread-safe 여부 관계 없는 프로그램 개발 시 사용 75 | * StringBuffer : Thread-safe를 보장해야하는 프로그램 개발 시 사용 76 | -------------------------------------------------------------------------------- /04.Java/phb/21.04.15.md: -------------------------------------------------------------------------------- 1 | # 21.00.00 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 Java 8에 추가된 기능은 무엇이 있나요? 6 | * time 라이브러리와 Stream API, 람다식이 있습니다. 7 | 8 | #### 💡 Stream API 특징이나 장점은 무엇이 있나요? 9 | * Stream API는 원본 데이터를 변경하지 않고 가공된 데이터를 추출합니다. 10 | * Stream API는 컬렉션의 요소를 람다식으로 처리하여 코드의 가독성이 높일 수 있고 Collection 요소를 모두 동일한 방식으로 데이터 처리할 수 있습니다. 11 | 12 |
13 | 14 | ## 동기화/비동기화 15 | * 동기화 (Synchronized) 16 | * 한 자원에 대해 동시에 접근하는 것을 제한하는 방식 17 | * System Call이 끝날 때 까지 다른 스레드의 접근 제한 18 | * ```public synchronized void add()```처럼 synchronized 키워드를 사용하여 선언 19 | * 비동기화 (Asynchronized) 20 | * System call과 상관없이 계속 호출 가능 21 | * Callback 함수로 결과값 리턴 22 | 23 |
24 | 25 | ## ==/equals 26 | * == 27 | * 비교 연산자 28 | * call by reference 29 | * equals 30 | * 대상의 내용을 비교하는 메소드 31 | * call by value 32 | 33 |
34 | 35 | ## Reflection 36 | * 런타임 시 동적으로 특정 클래스의 정보를 객체화하여 분석 및 추출해낼 수 있는 프로그래밍 기법 37 | * 사용법 38 | * ```Class.forName()```로 클래스 객체 가져옴. 39 | * 메소드로 클래스 반환 40 | |메소드|설명| 41 | |-|-| 42 | |class.getSuperClass()|슈퍼 클래스를 반환| 43 | |class.getClass()|상속된 클래스를 포함하여 모든 공용 클래스, 인터페이스 및 열거형을 반환| 44 | |class.getDeclaredClass()|명시적으로 선언된 모든 클래스 및 인터페이스, 열거형을 반환| 45 | |class.getDeclaringClass()|클래스에 구성된 클래스 반환| 46 | |class.getEnclosingClass()|클래스의 즉시 동봉된 클래스를 반환| 47 | * 주의할 점 48 | * ```Field.setAccessible()```을 true값으로 주게 되면 private 멤버도 접근 가능 49 | 50 | 51 |
59 | 60 | ## Stream/Lambda 61 | * Java 8 62 | * Stream 63 | * 데이터의 흐름 64 | * 파이프구조로 데이터를 조합, 필터링하고 가공된 결과 추출 65 | * 병렬 스트림(parallel 지원 66 | 67 |
17 | 18 | ### 추상클래스와 인터페이스 차이 19 | 20 | - 추상클래스의 목적은 **공통점을 찾아 추상화** 21 | - 인터페이스의 목적은 **구현 객체가 같은 동작하는 것을 보장** 22 | 23 |
24 | 25 | ### Java Reflection 26 | 27 |
28 | 29 | ### GC 변수 초기화 30 | 31 | - GC 동작 원리 32 |  33 | 34 |  35 | 36 | 1. 처음 생성된 객체는 Eden에 위치 37 | 2. Minor GC 발생 후에 살아있다면 Survivor 영역으로 이동 38 | 3. Survivor에서 살아남은 객체는 Old Generation 영역으로 이동 39 | 40 |
41 | 42 | ### CheckedException, UnCheckedException 43 | 44 |  45 | 46 | | 구분 | Checked Exception | Unchecked Exception | 47 | | ------------ | -------------------------- | ---------------------------- | 48 | | 확인시점 | 컴파일 시점 | 런타임 시점 | 49 | | 처리여부 | 반드시 예외 처리해야한다. | 명시적으로 하지 않아도 된다. | 50 | | 트랜잭션처리 | 예외 발생 시 롤백하지 않음 | 예외 발생시 롤백 | 51 | 52 |
59 | 60 | ### JVM 질문 61 | 62 | ### 1. GC가 무엇인가요? 63 | 64 | - 힙 영역에서 사용하지 않는 객체들을 제거하는 작업을 의미합니다. 65 | 66 | ### 2. JVM 메모리 구조에 대해 설명해주세요. 67 | 68 | - JVM 메모리는 메소드, 힙, 스택, PC 레지스터, 네이티브 메소드 스택 총 5개로 구성되어 있습니다. 69 | 70 | * 메소드 영역은 클래스와 관련된 정보가 저장됩니다. 71 | * 힙 영역은 new로 생성된 객체와 배열의 인스턴스를 저장합니다. 72 | * 스택 영역은 지역변수, 매개변수, 리턴 값 등이 저장됩니다. 73 | * PC 레지스터는 현재 스레드가 실행되는 부분의 주소와 명령을 저장한다. 74 | * 네이티브 메소드는 자바 외의 언어로 작성된 코드를 위한 메모리 영역입니다. 75 | 76 |
77 | 78 | ### 예외 질문 79 | -------------------------------------------------------------------------------- /04.Java/phb/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.03.15|Java 특징|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.15.md)| 6 | |21.03.16||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.16.md)| 7 | |21.03.25||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.25.md)| 8 | |21.03.29||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.29.md)| 9 | |21.03.30||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.30.md)| 10 | |21.04.05||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.04.05.md)| 11 | |21.04.15||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.04.15.md)| 12 | |21.05.10||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.05.10.md)| 13 | -------------------------------------------------------------------------------- /05.Spring/README.md: -------------------------------------------------------------------------------- 1 | # Part 05.Spring 2 | 3 | Made by. [김민지](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/04.Java/kmj) [박혜빈](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/04.Java/phb) [이연주](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/04.Java/lyj) [황성현](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/04.Java/hsh) 4 | -------------------------------------------------------------------------------- /05.Spring/hsh/21.06.22.md: -------------------------------------------------------------------------------- 1 | # 21.06.22 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 6 |
7 | 8 | ## ⭐ 개념 정리 9 | 10 | ## Spring Framework란? 11 | * JAVA의 웹 프레임워크로 JAVA 언어를 기반으로 사용한다. JAVA로 다양한 어플리케이션을 만들기 위한 프로그래밍 틀이라 할 수 있다. 12 | * 옛날에 비교하면 지금은 JAVA의 활용도가 높아졌고 따라서 프로젝트 규모도 커졌다. JAVA를 이용한 기술은 JSP, MyBatis, JPA 등 여러가지가 있는데 즉, 이 기술들이 프로젝트에 많이 쓰인다고 할 수 있다. Spring은 이 기술들을 더 편하게 사용하기 위해 만들어진 것이다. 13 | * 프로젝트를 진행하다 보면 아무리 분업을 해도 분명 중복되는 코드가 있기 마련이다. **Spring은 이런 중복코드의 사용률을 줄여주고, 비즈니스 로직을 더 간단**하게 해줄 수 있다. 14 | - Spring을 사용하면 다른 사람의 코드를 참조하여 쓰기 편리한데 이말의 의미는 오픈소스를 좀더 효율적으로 가져다 쓰기 좋은 구조라는 것이다. 15 | 16 | - 결론적으로 **Spring이란 JAVA 기술들을 더 쉽게 사용할 수 있게 해주는 오픈소스 프레임 워크**이다. 17 | 18 | > Spring이란? : https://jerryjerryjerry.tistory.com/62 19 | 20 | ### Spring 주요 특징 21 | #### IoC(Inversion of Control, 제어 반전) 22 | * "제어의 역전" 이라는 의미는 말 그대로 메소드나 객체의 호출작업을 개발자가 결정하는 것이 아니라, 외부에서 결정되는 것을 의미한다. (Object간의 연결 관계를 런타임에 결정) 23 | 24 | * 스프링 컨테이너 차원에서는 엔터프라이즈 개발에 적합하게 수많은 객체 생명주기를 관리 하고 의존 관계를 설정해주고 그 외 많은 기능들을 제공하여 **개발자는 비지니스 로직에 집중 할 수 있게 해줌.** 25 | * 스프링에서 IoC를 담당하는 컨테이너에는 BeanFactory, ApplicationContext가 있다. 26 | * Spring DI Container가 관리하는 객체를 Bean이라고 함. 27 | 28 | * 빈(Bean) 29 | * 스프링이 IoC방식으로 관리하는 객체 30 | * 빈 팩토리(BeanFactory) 31 | * 스프링이 IoC를 담당하는 Bean들의 핵심 컨테이너 32 | * 애플리케이션 컨텍스트(ApplicationContext) 33 | * BeanFactory를 확장한 IoC 컨테이너. BeanFactory + 스프링 제공 각종 부가 서비스 34 | 35 | #### DI(Dependency Injection, 의존성 주입) 36 | * IoC의 구현 방법 중 하나가 DI이다. 37 | * 의존성 주입은 제어의 역전이 일어날때 스프링 내부에 있는 객체들간의 관계를 관리할 때 사용하는 기법이다. 자바에서는 일반적으로 인터페이스를 이용해서 의존적인 객체의 관계를 최대한 유연하게 처리할 수 있도록 한다. 38 | 39 | * 의존성 주입은 의존적인 객체를 직접 생성하거나 제어하는것이 아닌, 특정 객체에 필요한 객체를 외부에서 결정해서 연결 시키는 것을 의미한다. 우리는 클래스의 기능을 추상적으로 묶어둔 인터페이스를 갖다 쓰면 되는 것 이다. 이러한 **의존성 주입으로인해 모듈간의 결합도가 낮아지고 유연성이 높아진다.** 40 | 41 | #### AOP(Aspect Object Programming, 관점 지향 프로그래밍) 42 | * AOP는 Aspect Oriented Programming의 약자로 관점 지향 프로그래밍이라고 불린다. 관점 지향은 쉽게 말해 어떤 로직을 기준으로 핵심적인 관점, 부가적인 관점으로 나누어서 보고 그 관점을 기준으로 각각 모듈화하겠다는 것이다. 여기서 모듈화란 어떤 공통된 로직이나 기능을 하나의 단위로 묶는 것을 말한다. 43 |
44 | 45 | #### POJO(Plain Old Java Object) 지원 46 | - POJO는 Java EE를 사용하면서 해당 플랫폼에 종속되어 있는 무거운 객체들을 만드는 것에 반발하여 나타난 용어이다. 47 | - 별도의 프레임 워크 없이 Java EE를 사용할 때에 비해 인터페이스를 직접 구현하거나 상속받을 필요가 없어 기존 라이브러리를 지원하기 용이하고, 객체가 가볍다. 48 | - 즉, getter/setter를 가진 단순한 자바 오브젝트를 말한다. -------------------------------------------------------------------------------- /05.Spring/hsh/21.06.24.md: -------------------------------------------------------------------------------- 1 | # 21.06.24 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 6 |
7 | 8 | ## ⭐ 개념 정리 9 | 10 | ## Spring Web MVC 11 | 12 | #### MVC(Model-View-Controller) Pattern 13 | 14 |
15 | * 모델, Model
16 | * 애플리케이션의 정보, 데이터를 나타냅니다. 데이터베이스, 처음의 정의하는 상수, 초기화값, 변수 등을 뜻합니다. 또한 이러한 DATA, 정보들의 가공을 책임지는 컴포넌트를 말합니다.
17 | * Java Beans
18 |
19 | * 뷰, View
20 | * input 텍스트, 체크박스 항목 등과 같은 사용자 인터페이스 요소를 나타냅니다. 다시 말해 데이터 및 객체의 입력, 그리고 보여주는 출력을 담당합니다. 데이타를 기반으로 사용자들이 볼 수 있는 화면입니다.
21 | * JSP
22 |
23 |
24 | * 컨트롤러, Controller
25 | * 데이터와 사용자인터페이스 요소들을 잇는 다리역할을 합니다. 즉, 사용자가 데이터를 클릭하고, 수정하는 것에 대한 "이벤트"들을 처리하는 부분을 뜻합니다.
26 | * Servlet
27 |
28 | #### 왜 MVC 패턴을 사용해야 할까?
29 | * **서로 분리되어 각자의 역할에 집중할 수 있게끔하여 개발**을 하고 그렇게 애플리케이션을 만든다면, 유지보수성, 애플리케이션의 확장성, 그리고 유연성이 증가하고, 중복코딩이라는 문제점 또한 사라지게 되는 것입니다. 그러기 위한 MVC패턴입니다.
30 | * *단, 개발과정이 복잡해 초기 개발속도가 늦음*
31 | > https://m.blog.naver.com/jhc9639/220967034588
32 |
33 |
34 | ### Spring MVC
35 |
36 |
14 |
15 | * 모델, Model
16 | * 애플리케이션의 정보, 데이터를 나타냅니다. 데이터베이스, 처음의 정의하는 상수, 초기화값, 변수 등을 뜻합니다. 또한 이러한 DATA, 정보들의 가공을 책임지는 컴포넌트를 말합니다.
17 | * Java Beans
18 |
19 | * 뷰, View
20 | * input 텍스트, 체크박스 항목 등과 같은 사용자 인터페이스 요소를 나타냅니다. 다시 말해 데이터 및 객체의 입력, 그리고 보여주는 출력을 담당합니다. 데이타를 기반으로 사용자들이 볼 수 있는 화면입니다.
21 | * JSP
22 |
23 |
24 | * 컨트롤러, Controller
25 | * 데이터와 사용자인터페이스 요소들을 잇는 다리역할을 합니다. 즉, 사용자가 데이터를 클릭하고, 수정하는 것에 대한 "이벤트"들을 처리하는 부분을 뜻합니다.
26 | * Servlet
27 |
28 | #### 왜 MVC 패턴을 사용해야 할까?
29 | * **서로 분리되어 각자의 역할에 집중할 수 있게끔하여 개발**을 하고 그렇게 애플리케이션을 만든다면, 유지보수성, 애플리케이션의 확장성, 그리고 유연성이 증가하고, 중복코딩이라는 문제점 또한 사라지게 되는 것입니다. 그러기 위한 MVC패턴입니다.
30 | * *단, 개발과정이 복잡해 초기 개발속도가 늦음*
31 | > https://m.blog.naver.com/jhc9639/220967034588
32 |
33 |
34 | ### Spring MVC
35 |
36 |  37 |
38 | * DispatcherServlet (Front Controller)
39 | * 기본적인 처리 흐름을 제어하는 **사령탑 역할**
40 | * 모든 클라이언트의 요청을 전달받음.
41 | * Controller에게 클라이언트의 요청을 전달하고, Controller가 리턴 한 결과값을 View에게 전달하여 알맞은 응답을 생성.
42 |
43 | * HandlerMapping
44 | * 클라이언트의 요청 URL을 어떤 Controller가 처리할지를 결정.
45 | * URL과 요청 정보를 기준으로 어떤 핸들러 객체를 사용할지를 결정하는 객체이며, DispatcherServlet은 하나 이상의 핸들러 매핑을 가질 수 있음.
46 |
47 | * ViewResolver
48 | * 클라이언트의 요청을 처리한 뒤, Model을 호출하고 그 결과를 DispatcherServlet에 알려준다.
49 |
50 | * ModelAndView
51 | * Controller가 처리한 데이터 및 화면에 대해 정보를 보유한 객체
52 |
53 | * ViewResolver
54 | * Controller가 리턴 한 View 이름을 기반으로 Controller의 처리 결과를 보여줄 View를 결정
55 |
56 | * View
57 | * Controller의 처리 결과를 보여줄 응답화면을 생성
58 |
59 |
60 | ### 기본 Project Structure
61 |
37 |
38 | * DispatcherServlet (Front Controller)
39 | * 기본적인 처리 흐름을 제어하는 **사령탑 역할**
40 | * 모든 클라이언트의 요청을 전달받음.
41 | * Controller에게 클라이언트의 요청을 전달하고, Controller가 리턴 한 결과값을 View에게 전달하여 알맞은 응답을 생성.
42 |
43 | * HandlerMapping
44 | * 클라이언트의 요청 URL을 어떤 Controller가 처리할지를 결정.
45 | * URL과 요청 정보를 기준으로 어떤 핸들러 객체를 사용할지를 결정하는 객체이며, DispatcherServlet은 하나 이상의 핸들러 매핑을 가질 수 있음.
46 |
47 | * ViewResolver
48 | * 클라이언트의 요청을 처리한 뒤, Model을 호출하고 그 결과를 DispatcherServlet에 알려준다.
49 |
50 | * ModelAndView
51 | * Controller가 처리한 데이터 및 화면에 대해 정보를 보유한 객체
52 |
53 | * ViewResolver
54 | * Controller가 리턴 한 View 이름을 기반으로 Controller의 처리 결과를 보여줄 View를 결정
55 |
56 | * View
57 | * Controller의 처리 결과를 보여줄 응답화면을 생성
58 |
59 |
60 | ### 기본 Project Structure
61 |  62 |
63 |
64 | * src
65 | * 개발자가 작성한 Servlet 코드가 저장된다.
66 | * Controller, Model, Service, Dao
67 | * src/main/java
68 | * 개발되는 Java 코드의 경로
69 | * src/main/resources
70 | * 서버가 실행될 때 필요한 파일들의 경로
71 | * src/test/java
72 | * 테스트 전용 경로 (각 테스트 코드 작성 경로)
73 | * src/test/resource
74 | * 테스트 시에만 사용되는 파일들의 경로
75 | * Libraries
76 | * Servlet이나 JSP에서 추가로 사용하는 라이브러리 또는 드라이버
77 | * jar로 압축한 파일이어야 한다.
78 | * WebContent (**전체 ROOT**) - webapp
79 | * Deploy할 때 WebContent 디렉터리 전체가 .war로 묶어서 보내진다.
80 | * resources
81 | * 정적인 데이터 (ex. image file, css, js, fonts)
82 | * WEB-INF
83 | * classes: 작성한 Java Servlet 파일이 나중에 .class로 이곳에 모두 저장된다.
84 | * lib: 추가한 모든 라이브러리 또는 드라이버가 이곳에 모두 저장된다.
85 | * props: property file을 저장한다.
86 | * spring: **spring configuration files**을 저장한다. (Spring과 관련된 설정 파일을 모아둔 것)
87 | * dispatcher-servlet.xml
88 | * applicationContext.xml
89 | * dao-context.xml, service-context.xml 등
90 | * views: Controller와 매핑되는 .jsp 파일들을 저장한다. (JSP 파일의 경로)
91 | * web.xml: web application의 설정을 위한 **web deployment descriptor**
92 | * DispatcherServlet, ContextLoadListener 설정
93 | * pom.xml
94 | * **maven configuration file**
95 | * 어떤 lib를 쓸지 명시한다.
96 |
97 | > https://gmlwjd9405.github.io/2018/12/20/spring-mvc-framework.html
--------------------------------------------------------------------------------
/05.Spring/hsh/21.06.25.md:
--------------------------------------------------------------------------------
1 | # 21.06.24
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 Spring툴을 사용하면서 Service와 Dao를 나누어 사용하는 이유
6 |
7 | * DAO - 단일 데이터의 접근과 갱신만 처리한다(CRUD)
8 | * Service - 여러 DAO를 호출하여 사용자의 요구에 맞게 가공한다.
9 |
10 | * DAO는 단일 데이터 접근/갱신만 처리합니다.Service는 여러 DAO를 호출하여 여러번의 데이터 접근/갱신을 하며 그렇게 읽은 데이터에 대한 비즈니스 로직을 수행하고, 그것을 하나의(혹은 여러개의) 트랜잭션으로 묶습니다.
11 |
12 | #### 💡 forward 와 redirect 차이
13 | * [ Forward 방식 ]
14 |
62 |
63 |
64 | * src
65 | * 개발자가 작성한 Servlet 코드가 저장된다.
66 | * Controller, Model, Service, Dao
67 | * src/main/java
68 | * 개발되는 Java 코드의 경로
69 | * src/main/resources
70 | * 서버가 실행될 때 필요한 파일들의 경로
71 | * src/test/java
72 | * 테스트 전용 경로 (각 테스트 코드 작성 경로)
73 | * src/test/resource
74 | * 테스트 시에만 사용되는 파일들의 경로
75 | * Libraries
76 | * Servlet이나 JSP에서 추가로 사용하는 라이브러리 또는 드라이버
77 | * jar로 압축한 파일이어야 한다.
78 | * WebContent (**전체 ROOT**) - webapp
79 | * Deploy할 때 WebContent 디렉터리 전체가 .war로 묶어서 보내진다.
80 | * resources
81 | * 정적인 데이터 (ex. image file, css, js, fonts)
82 | * WEB-INF
83 | * classes: 작성한 Java Servlet 파일이 나중에 .class로 이곳에 모두 저장된다.
84 | * lib: 추가한 모든 라이브러리 또는 드라이버가 이곳에 모두 저장된다.
85 | * props: property file을 저장한다.
86 | * spring: **spring configuration files**을 저장한다. (Spring과 관련된 설정 파일을 모아둔 것)
87 | * dispatcher-servlet.xml
88 | * applicationContext.xml
89 | * dao-context.xml, service-context.xml 등
90 | * views: Controller와 매핑되는 .jsp 파일들을 저장한다. (JSP 파일의 경로)
91 | * web.xml: web application의 설정을 위한 **web deployment descriptor**
92 | * DispatcherServlet, ContextLoadListener 설정
93 | * pom.xml
94 | * **maven configuration file**
95 | * 어떤 lib를 쓸지 명시한다.
96 |
97 | > https://gmlwjd9405.github.io/2018/12/20/spring-mvc-framework.html
--------------------------------------------------------------------------------
/05.Spring/hsh/21.06.25.md:
--------------------------------------------------------------------------------
1 | # 21.06.24
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 Spring툴을 사용하면서 Service와 Dao를 나누어 사용하는 이유
6 |
7 | * DAO - 단일 데이터의 접근과 갱신만 처리한다(CRUD)
8 | * Service - 여러 DAO를 호출하여 사용자의 요구에 맞게 가공한다.
9 |
10 | * DAO는 단일 데이터 접근/갱신만 처리합니다.Service는 여러 DAO를 호출하여 여러번의 데이터 접근/갱신을 하며 그렇게 읽은 데이터에 대한 비즈니스 로직을 수행하고, 그것을 하나의(혹은 여러개의) 트랜잭션으로 묶습니다.
11 |
12 | #### 💡 forward 와 redirect 차이
13 | * [ Forward 방식 ]
14 |  15 | * Forward는 Web Container 차원에서 페이지의 이동만 존재합니다. 실제로 웹 브라우저는 다른 페이지로 이동했음을 알 수 없습니다. 그렇기 때문에 웹 브라우저에는 최초에 호출한 URL이 표시되고, 이동한 페이지의 URL 정보는 확인할 수 없습니다. 또한 현재 실행중인 페이지와 forward에 의해 호출될 페이지는 **Request 객체와 Response 객체를 공유**합니다.
16 |
17 | * [ Redirect 방식 ]
18 |
15 | * Forward는 Web Container 차원에서 페이지의 이동만 존재합니다. 실제로 웹 브라우저는 다른 페이지로 이동했음을 알 수 없습니다. 그렇기 때문에 웹 브라우저에는 최초에 호출한 URL이 표시되고, 이동한 페이지의 URL 정보는 확인할 수 없습니다. 또한 현재 실행중인 페이지와 forward에 의해 호출될 페이지는 **Request 객체와 Response 객체를 공유**합니다.
16 |
17 | * [ Redirect 방식 ]
18 |  19 | * Redirect는 Web Container로 명령이 들어오면, 웹 브라우저에게 다른 페이지로 이동하라고 명령을 내립니다. 그러면 웹 브라우저는 URL을 지시된 주소로 바꾸고 해당 주소로 이동합니다. 다른 웹 컨테이너에 있는 주소로 이동하며 새로운 페이지에서는 Request와 Response객체가 **새롭게 생성**됩니다.
20 |
19 | * Redirect는 Web Container로 명령이 들어오면, 웹 브라우저에게 다른 페이지로 이동하라고 명령을 내립니다. 그러면 웹 브라우저는 URL을 지시된 주소로 바꾸고 해당 주소로 이동합니다. 다른 웹 컨테이너에 있는 주소로 이동하며 새로운 페이지에서는 Request와 Response객체가 **새롭게 생성**됩니다.
20 |
21 | 22 | ## ⭐ 개념 정리 23 | 24 | ### JDBC? MyBatis? 25 | * JDBC(Java Database Connectivity)는 자바에서 데이터베이스에 접속할 수 있도록 하는 자바 API이다. JDBC는 데이터베이스에서 자료를 쿼리하거나 업데이트 하는 방법을 제공한다.자바는 JDBC를 통해 mysql, oracle에 접근한다. jdbc는 1개 클래스에 반복된 코드가 존재, 한 파일에 java언어와 sql언어가 있어 재사용성 등 안좋은 단점이 있다. 26 | 27 | * Mybatis는 JDBC의 작업을 간편하게 해주는 프레임워크이다. SQL문을 자바 코드에서 분리하여 xml 파일로 따로 관리한다. spring에서 jdbc를 사용할 수 있지만 , mybatis 를 사용 하는것이 보통이다. jdbc에서 사용해야 하는 Connection, Statement등을 mybatis가 직접 관리해서 코드를 줄여준다. jdbc의 PrepareStatment와 같은 sql injection을 고려하지 않아도 된다. 28 | 29 | ### MyBatis란? 30 | * Mybatis는 자바 오브젝트와 SQL사이의 자동 매핑 기능을 지원하는 ORM(Object relational Mapping)프레임워크이다. 31 | 32 | ### MyBatis 특징 33 | 1. 쉬운 접근성과 코드의 간결함 JDBC의 모든 기능을 Mybatis가 대부분 제공한다.복잡한 JDBC코드를 걷어내며 깔끔한 소스코드를 유지할 수 있다. 수동적인 파라미터 설정과 쿼리 결과에 대한 맵핑 구문을 제거할 수 있다. 34 | 35 | 2. SQL문과 프로그래밍 코드의 분리, SQL에 변경이 있을 때마다 자바 코드를 수정하거나 컴파일하지 않아도 된다. 36 | 37 | 3. 다양한 프로그래밍 언어로 구현가능 (Java, C#, .NET, Ruby) 38 | 39 | ### Mybatis-Spring의 주요 컴포넌트 40 | 41 |
42 | * MyBatis 설정파일(SqlMapConfig.xml) : VO 객체의 정보를 설정한다.
43 |
44 | * SqlSessionFactory : MyBatis 설정파일을 바탕으로 SqlSessionFactory를 생성한다, Spring Bean으로 등록해야 한다.
45 |
46 | * SqlSessionTemplate : 핵심적인 역할을 하는 클래스로서 SQL 실행이나 트랜잭션 관리를 실행한다. SqlSession 인터페이스를 구현하며, Thread-safe 하다. Spring Bean으로 등록해야 한다.
47 |
48 | * Mapping 파일 (user.xml) : SQL문과 OR Mapping을 설정한다.
49 |
50 | * Spring Bean 설정 파일 (mybatisBeans.xml) : SqlSessionFactoryBean을 Bean 등록할 때 DataSource 정보와 MyBatis Config 파일정보, Mapping 파일의 정보를 함께 설정한다. SqlSessionTemplate을 Bean으로 등록한다.
51 |
52 | ## REST(Representational State Transfer) API
53 | * Restful 서비스(API)란 REST 아키텍쳐를 준수하는 서비스
54 | * 일반적인 서비스의 경우 요청받은 내용을 처리하고 데이터를 가공해서 처리 결과를 특정 플랫폼에 적합한 형태의 View로 만들어 되돌려주는 반면, Restful 서비스에서는 그냥 데이터만 처리하고 끝내거나 되돌려줄 데이터가 있다면 **JSON이나 XML 형식**으로 전달해줍니다. View에 대해서는 전혀 신경쓰지 않습니다.
55 |
56 | * 따라서 요청하는 클라이언트는 규칙에 맞게 작업을 요청하고, 서버는 어떤 플랫폼에서 어떻게 사용할 것인지 신경쓰지 않고 요청받은 데이터만 처리하고 만들어서 되돌려주면 됩니다. 클라이언트는 받은 데이터를 알아서 가공해서 사용합니다. 즉, **멀티 플랫폼에서 사용이 가능**하다는 의미입니다.
57 |
58 | ## Spring Boot
59 | * 스프링 프레임워크는 기능이 많은만큼 환경설정이 복잡한 편이다. 이에 어려움을 느끼는 사용자들을 위해 나온 것이 바로 스프링 부트다. 스프링 부트는 스프링 프레임워크를 사용하기 위한 설정의 많은 부분을 자동화하여 사용자가 정말 편하게 스프링을 활용할 수 있도록 돕는다.
--------------------------------------------------------------------------------
/05.Spring/hsh/README.md:
--------------------------------------------------------------------------------
1 | # 진행사항
2 |
3 | | 날짜 | 설명 | 링크 |
4 | | -------- | -------------- | ------------------------------------------------------------------------------------------- |
5 | | 21.06.22 | IoC/DI | [✅보러가기](21.06.22.md) |
6 | | 21.06.24 | Spring Web MVC | [✅보러가기](21.06.24.md) |
7 | | 21.06.25 | MyBatis & REST Api | [✅보러가기](21.06.25.md) |
8 |
--------------------------------------------------------------------------------
/05.Spring/kmj/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/05.Spring/kmj/.DS_Store
--------------------------------------------------------------------------------
/05.Spring/lyj/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/05.Spring/lyj/.DS_Store
--------------------------------------------------------------------------------
/05.Spring/lyj/21.06.22.md:
--------------------------------------------------------------------------------
1 | # [21.06.22] Spring Framework 01
2 |
3 | ## Spring
4 | 1. 기존 EJB(Enterprise Java Beans) + WAS
5 | - 한계 : 개발 유지보수 복잡해져서 다양한 디자인패턴에 대한 이해 등 시간이 많이 소요된다.
6 | 2. Spring
7 | 특정 프레임워크나 기술에 의존적이지 않은 자바 객체 POJO 사용하여 EJB 서비스 지원 가능!
8 |
9 | Spring은 **IoC와 AOP 지원하는 경량 컨테이너 프레임워크**
10 | > 프레임워크
11 | > - 개발 구조나 설계시 제공되는 인터페이스 집합
12 | > - 앱 개발시 코드 품질, 필수 코드, DB 연동 등의 어느정도 기능이 구성된 뼈대를 제공한다.
13 | >
14 | > 라이브러리
15 | > - 특정기능에 대한 API 집합
16 |
17 | ## **OOP 설계원칙**
18 | 1. 결합도 낮추기
19 |
20 | 클래스 간의 의존성(상대방에게 영향을 주는 정도) 낮추기
21 |
22 | = **디커플링** : 변경될 때 다른 부분에 영향을 주는 정도 최소화
23 |
24 | 2. 응집도 높이기
25 |
26 | 클래스의 책임에 맞는 내용들로 클래스 설계
27 |
28 | = 한 클래스의 책임을 3-5개 이내로
29 |
30 | - 1개의 책임 : 1~3개 메소드로 구현
31 |
32 | ## 디커플링 방법
33 | 1. **Interface** : 구현과 사용의 분리
34 | - 구현 객체가 달라져도 그릇이 바뀌지 않도록!
35 |
36 | ```java
37 | // 그릇 a = new 알맹이();
38 | // 상위타입 참조변수를 사용하자
39 | // 인터페이스 타입 a = new 구현클래스();
40 | OutputService os1 = new OutputServiceConsole();
41 | OutputService os2 = new OutputServiceFile();
42 |
43 | // 01 GreetingService 내부
44 | OutputService os = new OutputServiceConsole();
45 |
46 | // 02 XXXService 내부
47 | // 해당 서비스에서 OutputServiceConsole을 썼지만 OutputServiceFile로 바꾸고 싶을 때 문제점 발생!
48 | OutputService os = new OutputServiceConsole();
49 | ```
50 | - 한계
51 | - new 연산자로 만들어지는 객체를 바꾸기 위해서 하나씩 다 바꾸어주어야한다.
52 | - 손이 많이 간다.
53 |
54 | 2. **팩토리 패턴** : 생성되는 객체 교체 용이
55 | - 팩토리 reference가 있다면 객체 생성을 new로 하지 않고 `OutputService oc = factory.getGreeting();`으로 바꾸면 된다.
56 |
57 | ```java
58 | // 싱글톤 패턴
59 | class GreetingFactory {
60 | // 상위타입으로 리턴
61 | OutputService getGreetingFactory(){
62 | return OutputServiceFile();
63 | }
64 | }
65 |
66 | // 01 GreetingService 내부
67 | OutputService os = factory.getGreeingFactory();
68 |
69 | // 02 XXXService 내부
70 | OutputService os = factory.getGreeingFactory();
71 |
72 | // new 연산자로 생성되는 클래스 일일이 바꿀 필요가 없어졌다
73 | ```
74 |
41 |
42 | * MyBatis 설정파일(SqlMapConfig.xml) : VO 객체의 정보를 설정한다.
43 |
44 | * SqlSessionFactory : MyBatis 설정파일을 바탕으로 SqlSessionFactory를 생성한다, Spring Bean으로 등록해야 한다.
45 |
46 | * SqlSessionTemplate : 핵심적인 역할을 하는 클래스로서 SQL 실행이나 트랜잭션 관리를 실행한다. SqlSession 인터페이스를 구현하며, Thread-safe 하다. Spring Bean으로 등록해야 한다.
47 |
48 | * Mapping 파일 (user.xml) : SQL문과 OR Mapping을 설정한다.
49 |
50 | * Spring Bean 설정 파일 (mybatisBeans.xml) : SqlSessionFactoryBean을 Bean 등록할 때 DataSource 정보와 MyBatis Config 파일정보, Mapping 파일의 정보를 함께 설정한다. SqlSessionTemplate을 Bean으로 등록한다.
51 |
52 | ## REST(Representational State Transfer) API
53 | * Restful 서비스(API)란 REST 아키텍쳐를 준수하는 서비스
54 | * 일반적인 서비스의 경우 요청받은 내용을 처리하고 데이터를 가공해서 처리 결과를 특정 플랫폼에 적합한 형태의 View로 만들어 되돌려주는 반면, Restful 서비스에서는 그냥 데이터만 처리하고 끝내거나 되돌려줄 데이터가 있다면 **JSON이나 XML 형식**으로 전달해줍니다. View에 대해서는 전혀 신경쓰지 않습니다.
55 |
56 | * 따라서 요청하는 클라이언트는 규칙에 맞게 작업을 요청하고, 서버는 어떤 플랫폼에서 어떻게 사용할 것인지 신경쓰지 않고 요청받은 데이터만 처리하고 만들어서 되돌려주면 됩니다. 클라이언트는 받은 데이터를 알아서 가공해서 사용합니다. 즉, **멀티 플랫폼에서 사용이 가능**하다는 의미입니다.
57 |
58 | ## Spring Boot
59 | * 스프링 프레임워크는 기능이 많은만큼 환경설정이 복잡한 편이다. 이에 어려움을 느끼는 사용자들을 위해 나온 것이 바로 스프링 부트다. 스프링 부트는 스프링 프레임워크를 사용하기 위한 설정의 많은 부분을 자동화하여 사용자가 정말 편하게 스프링을 활용할 수 있도록 돕는다.
--------------------------------------------------------------------------------
/05.Spring/hsh/README.md:
--------------------------------------------------------------------------------
1 | # 진행사항
2 |
3 | | 날짜 | 설명 | 링크 |
4 | | -------- | -------------- | ------------------------------------------------------------------------------------------- |
5 | | 21.06.22 | IoC/DI | [✅보러가기](21.06.22.md) |
6 | | 21.06.24 | Spring Web MVC | [✅보러가기](21.06.24.md) |
7 | | 21.06.25 | MyBatis & REST Api | [✅보러가기](21.06.25.md) |
8 |
--------------------------------------------------------------------------------
/05.Spring/kmj/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/05.Spring/kmj/.DS_Store
--------------------------------------------------------------------------------
/05.Spring/lyj/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/05.Spring/lyj/.DS_Store
--------------------------------------------------------------------------------
/05.Spring/lyj/21.06.22.md:
--------------------------------------------------------------------------------
1 | # [21.06.22] Spring Framework 01
2 |
3 | ## Spring
4 | 1. 기존 EJB(Enterprise Java Beans) + WAS
5 | - 한계 : 개발 유지보수 복잡해져서 다양한 디자인패턴에 대한 이해 등 시간이 많이 소요된다.
6 | 2. Spring
7 | 특정 프레임워크나 기술에 의존적이지 않은 자바 객체 POJO 사용하여 EJB 서비스 지원 가능!
8 |
9 | Spring은 **IoC와 AOP 지원하는 경량 컨테이너 프레임워크**
10 | > 프레임워크
11 | > - 개발 구조나 설계시 제공되는 인터페이스 집합
12 | > - 앱 개발시 코드 품질, 필수 코드, DB 연동 등의 어느정도 기능이 구성된 뼈대를 제공한다.
13 | >
14 | > 라이브러리
15 | > - 특정기능에 대한 API 집합
16 |
17 | ## **OOP 설계원칙**
18 | 1. 결합도 낮추기
19 |
20 | 클래스 간의 의존성(상대방에게 영향을 주는 정도) 낮추기
21 |
22 | = **디커플링** : 변경될 때 다른 부분에 영향을 주는 정도 최소화
23 |
24 | 2. 응집도 높이기
25 |
26 | 클래스의 책임에 맞는 내용들로 클래스 설계
27 |
28 | = 한 클래스의 책임을 3-5개 이내로
29 |
30 | - 1개의 책임 : 1~3개 메소드로 구현
31 |
32 | ## 디커플링 방법
33 | 1. **Interface** : 구현과 사용의 분리
34 | - 구현 객체가 달라져도 그릇이 바뀌지 않도록!
35 |
36 | ```java
37 | // 그릇 a = new 알맹이();
38 | // 상위타입 참조변수를 사용하자
39 | // 인터페이스 타입 a = new 구현클래스();
40 | OutputService os1 = new OutputServiceConsole();
41 | OutputService os2 = new OutputServiceFile();
42 |
43 | // 01 GreetingService 내부
44 | OutputService os = new OutputServiceConsole();
45 |
46 | // 02 XXXService 내부
47 | // 해당 서비스에서 OutputServiceConsole을 썼지만 OutputServiceFile로 바꾸고 싶을 때 문제점 발생!
48 | OutputService os = new OutputServiceConsole();
49 | ```
50 | - 한계
51 | - new 연산자로 만들어지는 객체를 바꾸기 위해서 하나씩 다 바꾸어주어야한다.
52 | - 손이 많이 간다.
53 |
54 | 2. **팩토리 패턴** : 생성되는 객체 교체 용이
55 | - 팩토리 reference가 있다면 객체 생성을 new로 하지 않고 `OutputService oc = factory.getGreeting();`으로 바꾸면 된다.
56 |
57 | ```java
58 | // 싱글톤 패턴
59 | class GreetingFactory {
60 | // 상위타입으로 리턴
61 | OutputService getGreetingFactory(){
62 | return OutputServiceFile();
63 | }
64 | }
65 |
66 | // 01 GreetingService 내부
67 | OutputService os = factory.getGreeingFactory();
68 |
69 | // 02 XXXService 내부
70 | OutputService os = factory.getGreeingFactory();
71 |
72 | // new 연산자로 생성되는 클래스 일일이 바꿀 필요가 없어졌다
73 | ```
74 |  75 |
76 | ## **IOC**
77 | 인스턴스의 생성부터 소멸까지 개발자가 아닌 컨테이너가 대신 관리해주는 것을 말합니다. 컨테이너가 제어권을 갖음으로써, DI와 AOP 등이 가능하게 됩니다.
78 |
79 | ### Spring IoC 지원
80 | 1. Dependency Lookup
81 | 2. Dependency Injection
82 |
83 | ## **DI(Dependency Injection)**
84 | 의존 관계 주입이며, 어떤 객체가 사용하는 의존 객체를 직접 만들어 사용하는 것이 아니라, 주입 받아 사용하는 방법입니다.
85 | 즉, 의존관계를 스프링 설정파일에 등록된 정보로 컨테이너가 자동 처리합니다.
86 |
87 | **1. 직접 객체 생성 또는 팩토리 객체를 이용하여 객체 생성에 대한 제어권을 내가 가지고 있느냐**
88 |
89 | **2. 나 대신 객체 제어를 해주는 제 3자가 있느냐 (Inversion Of Conversion)**
90 |
91 | 즉, 스프링 설정 파일만 변경해도 변경사항이 반영되는 것이다. 이러한 점으로 유지보수가 용이해진다.
92 |
93 | ### DI 종류
94 | 1. 의존객체 상위타입 변수 선언만
95 | 2. 객체 받아들일 방법 선택
96 | - 생성자 : 필수 객체는 생성자에서 주로 해준다
97 |
75 |
76 | ## **IOC**
77 | 인스턴스의 생성부터 소멸까지 개발자가 아닌 컨테이너가 대신 관리해주는 것을 말합니다. 컨테이너가 제어권을 갖음으로써, DI와 AOP 등이 가능하게 됩니다.
78 |
79 | ### Spring IoC 지원
80 | 1. Dependency Lookup
81 | 2. Dependency Injection
82 |
83 | ## **DI(Dependency Injection)**
84 | 의존 관계 주입이며, 어떤 객체가 사용하는 의존 객체를 직접 만들어 사용하는 것이 아니라, 주입 받아 사용하는 방법입니다.
85 | 즉, 의존관계를 스프링 설정파일에 등록된 정보로 컨테이너가 자동 처리합니다.
86 |
87 | **1. 직접 객체 생성 또는 팩토리 객체를 이용하여 객체 생성에 대한 제어권을 내가 가지고 있느냐**
88 |
89 | **2. 나 대신 객체 제어를 해주는 제 3자가 있느냐 (Inversion Of Conversion)**
90 |
91 | 즉, 스프링 설정 파일만 변경해도 변경사항이 반영되는 것이다. 이러한 점으로 유지보수가 용이해진다.
92 |
93 | ### DI 종류
94 | 1. 의존객체 상위타입 변수 선언만
95 | 2. 객체 받아들일 방법 선택
96 | - 생성자 : 필수 객체는 생성자에서 주로 해준다
97 |  98 |
99 | - 세터
100 |
98 |
99 | - 세터
100 |  101 |
102 | 3. 의존객체 관련 설정
103 | - 방법1 **XML**
104 |
105 | ```
106 |
101 |
102 | 3. 의존객체 관련 설정
103 | - 방법1 **XML**
104 |
105 | ```
106 |
107 |
108 | // DI 정보 설정
109 | // 01 constructor 주입
110 |
115 |
116 | ```
117 |
118 | - 방법2 **Annotation**
119 | - XML의 ``
120 |
121 | `@Component`
122 |
123 | - `@Service`
124 | -
125 | - XML의 정보설정 `` 또는``
126 |
127 | `@Autowired`
128 |
129 | - 방법3 **Java Source**
130 |
131 |
132 | ### AOP
133 | OOP를 보완하는 수단으로, 흩어진 관심사들을 하나로 모아서 Aspect로 모듈화하는 기법입니다.
134 | Aspect를 이용해서 핵심 로직을 구현한 각 클래스에 공통 기능을 적용합니다.
135 | 이를 사용하면 공통의 관심 사항을 적용해서 발생하는 복잡성과 코드 중복을 해결할 수 있습니다.
136 |
137 | 스프링 AOP는 프록시 기반의 AOP 구현체로, 런타임 시 A객체의 빈을 만들 때, 이를 감싸는 proxy 빈을 만들어서 등록합니다.
138 | > 프록시 패턴이란?
139 | > 기존 코드의 변경 없이 기능 추가가 가능
140 |
141 | - Aspect : 공통 관심 사항으로, 트랜잭션, 로깅 등
142 | - Advice : 해야할 일
143 | - Join Point : 합류지점으로, Advice 적용이 가능한 지점
144 | - Pointcut : 실제로 Advice가 적용되는 지점
145 |
--------------------------------------------------------------------------------
/05.Spring/phb/21.06.22.md:
--------------------------------------------------------------------------------
1 | # [21.06.22] Spring Framework 01 - DI
2 |
3 | ### 💡 Singleton의 문제점
4 |
5 | - 싱글톤 인스턴스가 많은 일을 하거나 많은 데이터를 공유시킬 경우 인스턴스들 간의 결합도가 높아진다. 이 때, 수정 및 테스트가 어려워진다.
6 | - Lifecycle 제어가 어렵다. 싱글톤이 제대로 GC 되지 않는다면 끝까지 메모리를 먹는다.
7 | - 멀티 스레드 환경에서 동기화 처리를 하지 않으면 인스턴스가 여러개 생성될 가능성이 있다.
8 |
9 |
15 |
16 | 17 | ## Spring 18 | 19 | ### 구조 20 | 21 | 1. POJO (Plain Old Java Object) 22 | 23 | - 특정 기술에 종속되지 않은 순수한 자바객체 24 | - Spring 기술에서 이것이 가능한 이유는 PSA 25 | 26 | 2. PSA (Portable Service Abstraction) 27 | 28 | - 하나의 추상화로 여러 서비스를 묶어둔 것 29 | - 일관된 방식으로 기술에 접근 가능하도록 해주는 설계 원칙 30 |
44 | 45 | ## IoC & Container 46 | 47 | ### IoC 유형 48 | 49 |  50 | 51 | - DL (Dependency Lookup) 52 | 53 | - 의존성 검색 54 | - IoC 컨테이너는 각 컨테이너에서 관리해야 하는 별도의 저장소(객체 저장소)에서 객체를 검색하여 참조하는 방법 55 | 56 | - DI (Dependency Injection) 57 | - 의존성 주입 58 | - 클래스 간의 의존성을 외부(컨테이너)에서 주입하는 개념 59 | 60 |
66 | 67 | ### Container 68 | 69 | 객체의 생성, 사용, 소멸에 해당하는 라이프 사이클을 담당하며 애플리케이션 사용에 필요한 주요 기능을 제공 70 | 71 |
72 | 73 | ## 의존성 주입 (Dependency Injection, DI) 74 | 75 | ### 빈(Bean) 76 | 77 | - 애플리케이션의 핵심을 이루는 객체 78 | - Spring IoC Container에 의해 인스턴스화, 관리, 생성됨 79 | - 기본적인 빈 스코프는 싱글톤 80 | - XML 파일에 정의 81 | 82 | ```xml 83 |
84 |
87 | ```
88 |
89 | - Annotation으로 정의
90 | - component-scan을 반드시 설정해야함
91 |
92 | ```java
93 | @Component
94 | public class ComponentExample {
95 | ...
96 | }
97 | ```
98 |
99 |
100 | 101 | ### 빈 스코프(Bean Scope) 102 | 103 | | Scope | Description | 104 | | ----------------- | ---------------------------------------------------------------------------------------- | 105 | | singleton | 스프링 컨테이너 내에 하나의 인스턴스 빈만 생성 | 106 | | prototype | 컨테이너에 빈을 요청할 때마다 새로운 인스턴스 생성 | 107 | | request | HTTP Request별로 새로운 인스턴스 생성 | 108 | | session | HTTP Session별로 새로운 인스턴스 생성 | 109 | | ✍ global session | global HTTP SESSION별로 새로운 인스턴스 생성
일반적으로 portlet context 안에서 유효 | 110 | 111 |
112 | 113 | ✍ Bean Life Cycle / BeanFactory & ApplicationContext 114 | ✍ singleton을 사용하는 경우와 아닌 경우 115 | -------------------------------------------------------------------------------- /05.Spring/phb/21.06.24.md: -------------------------------------------------------------------------------- 1 | # [21.06.22] Spring Framework 02 - MVC 2 | 3 | # Spring Web MVC 4 | 5 | ## MVC Pattern 6 | 7 | - Model 8 | 9 | - 앱이 포함해야할 데이터가 무엇인지 정의 10 | - 비즈니스 로직 처리 11 | - 데이터 상태 변경되면 view에게 알림 12 | - 규칙 13 | - 사용자가 편집하길 원하는 모든 데이터를 가지고 있어야만 한다. 14 | - 뷰나 컨트롤러에 대해서 어떤 정보도 알지 말아야한다. 15 | - 변경이 일어나면, 변경 통지에 대한 처리 방법을 구현해야만 한다. 16 | 17 | - View 18 | 19 | - 앱의 데이터를 보여주는 방식 20 | - 표시할 데이터를 모델로부터 받음 21 | - 규칙 22 | - 모델이 가지고 있는 정보를 따로 저장해서는 안된다. 23 | - 다른 구성 요소를 몰라야한다. 24 | - 변경이 일어나면, 변경 통지에 대한 처리 방법을 구현해야만 한다. 25 | 26 | - Controller 27 | - 앱의 사용자로부터 입력에 대한 응답으로 모델 및 뷰를 업데이트하는 로직 포함 28 | - 규칙 29 | - 모델이나 뷰에 대해서 알고 있어야한다. 30 | - 모델이나 뷰의 변경을 모니터링 해야 한다. 31 | 32 | * 동작순서 33 |  34 | 35 |
16 |
17 | 18 | ### Mybatis 19 | 20 | - Java와 RDBMS 사이의 자동 매핑을 지원하는 ORM 프레임워크 21 | - 개발자가 작성한 sql문(xml 파일)을 자바 객체를 매핑 22 | - 특징 23 | 24 | - 코드의 간결함 25 | - 객체-RDBMS 코드의 분리 26 | - 다양한 프로그래밍 언어 구현 가능 27 | 28 | - 주요 컴포넌트 29 |  30 | - SqlSessionFactory : singleton 31 | - sqlSession : request scope 32 | 33 | ``` 34 | ORM 35 | Object-Relational Mapping(객체 관계 매핑)이란 의미로 객체는 객체대로 설계하며 RDBMS는 RDBMS대로 설계하면 중간에서 매핑해주는 기술 36 | ``` 37 | 38 |
48 |
49 | 50 | # [21.06.25] Spring Framework 04 - REST API 51 | 52 | ### REST (Representational State Transfer) 53 | 54 | - HTTP URI + HTTP Method 55 | - URI로 자원을 명시하고 Method로 자원을 제어하는 명령을 내리는 아키텍처 56 | - 구성 57 | 58 | - 자원(Resource) - URI 59 | - 행위(Verb) - HTTP Method 60 | - 표현(Representations) 61 | 62 | - Method 63 | |Method|작업|비고| 64 | |-|-|-| 65 | |POST|Create(insert)|쓰기| 66 | |GET|Read(select)|읽기| 67 | |PUT|Update(update)|수정| 68 | |DELETE|Delete(delete)|삭제| 69 | 70 | - 특징 71 | - 클라이언트-서버 구조 72 | - stateless 73 | - Cacheable 74 | - 자기 기술적(self-descriptive) 75 | - 계층화 76 | - Code-On-Demand 77 | - Uniform Interface 78 | 79 |
80 | 81 |
89 |
90 | 91 | # [21.06.25] Spring Framework 05 - SpringBoot 92 | 93 | ✍ REST는 왜 쓰고 REST 외에 다른 아키텍처는 무엇이 있을까? 94 | ✍ REST API는 Java말고 다른 언어로는 어떻게 구현할까? 95 | ✍ 왜 대부분의 API는 Spring Framework를 사용할까? 96 | ✍ 자동 설정이 완전 편한데 어떤 경우에 Spring을 사용하는 걸까? 97 | -------------------------------------------------------------------------------- /05.Spring/phb/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | | 날짜 | 설명 | 링크 | 4 | | -------- | -------------- | ------------------------------------------------------------------------------------------- | 5 | | 21.06.22 | IoC/DI | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/05.Spring/phb/21.06.22.md) | 6 | | 21.06.24 | Spring Web MVC | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/05.Spring/phb/21.06.24.md) | 7 | | 21.03.25 |MyBatis/REST API/SpringBoot| [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/05.Spring/phb/21.06.25.md) | 8 | | 21.03.29 | | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.29.md) | 9 | | 21.03.30 | | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.30.md) | 10 | | 21.04.05 | | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.04.05.md) | 11 | | 21.04.15 | | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.04.15.md) | 12 | | 21.05.10 | | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.05.10.md) | 13 | -------------------------------------------------------------------------------- /README.md: -------------------------------------------------------------------------------- 1 |  2 | 3 | 4 | 5 | ## 📣 소개 6 | - SSAFY 5기생들이 만든 CS 스터디 Repo입니다.🤸♀️🤸♂️🤸♀️🤸 **(21.01.11 ~ 21.06)** 7 | - SW 전공자들이 필수적으로 알아야 하는 지식을 공부하고, 다른 사람에게 설명할 수 있는 SKILL을 기르기 위한 스터디 입니다. 8 | 9 | ## 📝 스터디 방식 10 | - 주 2회 (수, 금) 회의 및 발표를 진행합니다. 11 | - 한 과목이 끝나면 모의 면접을 진행합니다. 12 | 13 | 14 | ## 📁 면접질문모음 15 | |**과목명**|**질문보기**|기간|모의면접| 16 | |-|-|-|-| 17 | |**Database**|[📃질문보기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/README.md)|2021.01.11 ~ 2021.01.21|O| 18 | |**Network**|[📃질문보기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/01.network/README.md)|2021.01.22 ~ 2021.02.09|O| 19 | |**Operating System**|[📃질문보기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/03.Operating_system/README.md)|2021.02.15 ~ 2021.03.03|O| 20 | |**Java**|[📃질문보기](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/04.Java/README.md)|2021.03.15 ~ 2021.05.12|-| 21 | |**Spring**|[📃질문보기](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/05.Spring/README.md)|-|-| 22 |
23 | 24 | ## 📑 문서구조 25 | ```sh 26 | ├─CS과목명 27 | │ ├─hsh 28 | │ ├─kmj 29 | │ ├─lyj 30 | │ ├─phb 31 | │ ├─면접질문모음 (README.md) 32 | │ │ ├─ 날짜별 공부 내용 33 | │ │ ├─ 공부목차 (README.md) 34 | ``` 35 | 36 | ## REFERENCE 37 | * https://github.com/WeareSoft 38 | * https://github.com/JaeYeopHan/Interview_Question_for_Beginner 39 | * https://github.com/gyoogle/tech-interview-for-developer 40 | 41 | 42 | ## ⭐️ 도움을 주신 분들 43 | [](https://hits.seeyoufarm.com) 44 | 45 | 46 | 47 | 48 |
49 |
50 |
51 |
52 |
--------------------------------------------------------------------------------
/template/README.md:
--------------------------------------------------------------------------------
1 | # 21.00.00
2 |
3 |
4 | ## 주요 질문
5 |
6 | #### 💡 [질문1](#개념1)
7 | * 답변
8 |
9 | #### 💡 질문2
10 | * 답변
11 |
12 | #### 💡 질문3
13 | * 답변
14 |
15 |
16 |
48 |
49 |
50 |
51 |
52 |
--------------------------------------------------------------------------------
/template/README.md:
--------------------------------------------------------------------------------
1 | # 21.00.00
2 |
3 |
4 | ## 주요 질문
5 |
6 | #### 💡 [질문1](#개념1)
7 | * 답변
8 |
9 | #### 💡 질문2
10 | * 답변
11 |
12 | #### 💡 질문3
13 | * 답변
14 |
15 |
16 |
17 | 18 | ## ⭐ 개념 정리 19 | 20 | ### 개념1 21 | ### 개념2 22 | 23 |
24 | 25 | 26 | 27 | --------------------------------------------------------------------------------
17 | 18 | ## ⭐ 개념 정리 (보충 필요) 19 | 20 | ### HTTP/1.1 vs HTTP/2.0 21 | ||HTTP/1.1|HTTP/2.0| 22 | |-|-|-| 23 | |Connection|하나의 요청만 처리|여러개 요청 처리 (Multiplexed Streams)| 24 | |Header|많은 메타 정보 저장|압축 정보| 25 | |Resource|Client 요청 시 전송|Server Push| 26 | 27 |
28 | 29 |  30 | 31 | 32 |
33 | 34 |
35 |
38 |
39 | 출처
36 | https://lalwr.blogspot.com/2019/01/http1-vs-http2.html 37 |40 | 41 | ### Block/Non-Block 42 | * Block의 뜻은 **행위자가 취한 행위가 막힌 상태**를 의미하며 제한되고 대기하는 상태를 의미 43 | * Blocking : 호출된 함수가 자신의 일을 마칠 때까지 제어권을 계속 가지고 있으며 호출한 함수에게 돌려주지 않는 것 44 | * Non-Block : 호출된 함수가 자신의 일을 마치지 않았더라도 제어권을 호출한 함수에게 return 해주어 다른 다른 일을 진행할 수 있도록 하는 것 45 | 46 | 47 | ### Synchronous/Asynchronous 48 | * Synchronous : 호출된 함수의 작업 완료 여부를 호출한 함수가 신경 쓰는 경우 49 | * Asynchronous : 호출된 함수의 작업 완료 여부를 호출한 함수가 신경 쓰지 않는 경우 50 | 51 |
52 |
55 |
56 | 출처
53 | https://musma.github.io/2019/04/17/blocking-and-synchronous.html 54 |57 | -------------------------------------------------------------------------------- /01.network/phb/21.01.27.md: -------------------------------------------------------------------------------- 1 | # 21.01.27 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [웹 소켓과 TCP 소켓의 차이점](#웹-소켓과-tcp/ip-소켓) 6 | * http 통신은 단방향 통신이기 때문에 클라이언트의 요청이 있을 때만 서버의 응답을 받을 수 있습니다. 웹 소켓은 실시간 양방향 통신으로 클라이언트에게 필요한 정보를 캐시했다가 클라이언트의 요청 없이도 요청을 보낼 수 있습니다. 7 | 8 | #### 💡 [CORS](#corscross-origin-resource-sharing) 9 | * 프로토콜, 호스트, 포트번호가 다른 서버를 요청하면 발생하는 이슈입니다. 추가 http 헤더를 사용하여 권한을 부여하도록 브라우저에게 알려주는 체계입니다. 10 | 11 |
12 | 13 | ## ⭐ 개념 정리 14 | 15 | ### 소켓 16 | * 프로세스가 네트워크를 통해 데이터를 주고 받기 위해 필요한 창구 17 | * 동작원리(Web socket) 18 |  19 | 20 |
21 | 22 | ### 웹 소켓과 TCP/IP 소켓 23 | * 공통점 24 | * IP, PORT 사용하여 통신 25 | * 차이점 26 | |웹 소켓|TCP 소켓| 27 | |-|-| 28 | |실시간 양방향 통신|단방향 통신| 29 | |[Push] Client→Server, Client←Server|[Polling] Client→Server| 30 | |실시간 스트리밍|Android App 개발| 31 | 32 |
33 | 34 |  35 | 36 |
37 | 38 | ### CORS(Cross-Origin Resource Sharing) 39 | * 출처 = 프로토콜 + 호스트 + 포트번호 40 |  41 | 42 | * 도메인 또는 포트가 다른 서버의 자원을 요청하면 발생하는 이슈 43 | * 추가 HTTP 헤더를 사용하여 실행 중인 웹 애플리케이션이 다른 자원에 접근할 수 있는 권한을 부여하도록 브라우저에게 알려주는 체제 44 | 45 | 46 |
47 |
48 |
54 |
--------------------------------------------------------------------------------
/01.network/phb/21.01.28.md:
--------------------------------------------------------------------------------
1 | # 21.01.28
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 [IPv4와 IPv6를 설명하시오.](#IPv4/IPv6)
6 | * 이 둘은 인터넷 프로토콜입니다. 모바일, IoT 등 다양한 기기들과 인터넷이 결합되면서 현재 사용하고 있던 IPv4가 나타낼 수 있는 주소가 부족해져서 128bit인 IPv6가 나오게 됐습니다.
7 |
8 | #### 💡 [IPv4와 IPv6 연결](#개념1)
9 | * 미흡
10 |
11 |
12 | 출처
49 |-
50 |
- https://developer.mozilla.org/ko/docs/Web/HTTP/CORS 51 |
- https://evan-moon.github.io/2020/05/21/about-cors/ 52 |
13 | 14 | ## ⭐ 개념 정리 (보충 필요) 15 | 16 | ### IPv4 17 | * IPv4는 인터넷 프로토콜 4번째 판이며 전 세계적으로 사용된 첫 번째 인터넷 프로토콜 18 | * 네트워크 상에서 데이터 교환을 위한 프로토콜 19 | * 구성단위 (32bit) 20 |  21 | 22 |
23 | 24 | ### IPv6 25 | * IP 주소의 길이가 128bit 26 | * 특성 27 | * IP 주소의 확장 28 | * 호스트 주소 자동 설정 29 | * 패킷 확장 30 | * 보안성 31 | * etc 32 | 33 | ### IPv4/IPv6 34 |  35 | 36 | 37 | * 주소변환 (아래 두개 이해 안 됨...) 38 | * 헤더변환방식 (IP계층) 39 | IPv4, IPv6 패킷에서 헤더를 제외한 상위 계층은 동일한 구조로 생성되어 있기 때문에 헤더 부분을 전환하여 그대로 데이터를 전송 40 | 41 | * 전송 릴레이 방식 (전송계층) 42 | TCP 두 개 만듬...? 43 | 44 | * 수송 계층 게이트웨이 방식 (응용계층) 45 |
46 | -------------------------------------------------------------------------------- /01.network/phb/21.01.29.md: -------------------------------------------------------------------------------- 1 | # 21.01.29 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [Ajax를 왜 사용하는가?](#ajax) 6 | * 기본적으로 HTTP 프로토콜은 클라이언트가 요청을 보내고 서버가 응답 받으면 연결이 종료되고 화면 갱신을 위해서는 다시 요청-응답을 하면서 페이지를 전체 갱신해야합니다. 페이지 일부만 갱신 할 경우에도 전체 페이지를 다시 로드해야하는데 이는 엄청난 자원과 시간을 낭비합니다. ajax를 사용하면 일부만 갱신이 가능하여 자원과 시간을 아낄 수 있습니다. 7 | 8 | #### 💡 Ajax 심화 질문 넣고 싶다... 9 | * 답변 10 | 11 | 12 | #### 💡 [JWT가 무엇인가?](#jwt) 13 | * json으로 이루어진 헤더, 내용, 서명에 필요한 정보를 담아 안전하게 정보를 전달하는 방법입니다. 14 | 15 | 16 | 17 |
18 | 19 | ## ⭐ 개념 정리 20 | ### SPA 21 | * 웹 애플리케이션에 필요한 모든 정적 리소스를 최초에 한번 다운로드하고 이후 페이지 갱신에 필요한 데이터만 전달받아 페이지를 갱신하는 웹 패러다임 22 | 23 | 24 | ### Ajax 25 | * 전체 페이지를 새로 고치지 않고 일부 데이터만 로드하는 웹 개발 기법 26 | * 일반적으로 jQuery와 함께 사용 27 | * jQuery : HTML의 클라이언트 처리 조작을 단순화 하도록 설계된 js 라이브러리 28 | * 동작원리 29 | 30 |  31 | 32 | * 장점 33 | * 페이지 이동없이 화면 전환 34 | * 비동기 요청 35 | * 속도 향상 36 | 37 | * 단점 38 | * 연속 데이터 요청 시에 서버 부하 증가 가능성 39 | * 보안 취약 40 | * 서버 푸시 사용 불가능 41 | 42 | 43 |
44 |
47 |
48 | 출처
45 | https://coding-factory.tistory.com/143 46 |49 | 50 | 51 | ### DOM 52 | * HTML, XML 문서의 프로그래밍 인터페이스 53 | * 문서의 구조화된 표현 제공하여 동일한 문서를 표현, 저장, 조작하는 방법을 제공 54 | * 프로그래밍 언어-문서 사이의 매개체 역할 55 | 56 |
57 |
60 |
61 | 출처
58 | https://developer.mozilla.org/ko/docs/Web/API/Document_Object_Model/%EC%86%8C%EA%B0%9C 59 |62 | 63 | ### JWT 64 | * JSON Web Token의 약자로 두 객체가 JSON객체를 사용해 필요한 모든 정보를 안전하게 전달하는 방법 65 | * 모양 66 |  67 | * 헤더 : 토큰 타입(typ)과 해싱 알고리즘(alg) 지정 68 | ```json 69 | { 70 | "typ" : "JWT", 71 | "alg" : "HS256" // 보통 SHA256, RSA 사용 72 | } 73 | ``` 74 | 75 |
76 | 77 | * 내용 : 내용에 담는 정보의 한 조각을 클레임이라 부르고 (name-value)의 쌍으로 이루어져 있다. 78 | * 등록된 클레임 : 토큰에 대한 정보를 담기 위해 이미 정해진 클레임 79 | * 공개 클레임 : 충돌 방지를 위한 이름을 가져야하며 URI 형식으로 지음 80 | * 비공개 클레임 : 클라이언트-서버 협의 하에 사용되는 클레임 이름 81 | ```javascript 82 | { 83 | "iss": "example.com", // 토큰 발급자 (등록된 클레임) 84 | "exp": "155550000000", // 토큰 만료기간 (등록된 클레임) 85 | "https://example.com/jwt": true, // URI (공개 클레임) 86 | "userId": "11235482", // 사용자 id (비공개 클레임) 87 | "username": "bin_park" // 사용자 이름 (비공개 클레임) 88 | } 89 | ``` 90 | 91 |
92 | 93 | 94 | * 서명 : 헤더와 정보의 인코딩 값을 합친 뒤 비밀키로 해쉬하여 생성 95 | 96 |
97 |
100 |
--------------------------------------------------------------------------------
/01.network/phb/README.md:
--------------------------------------------------------------------------------
1 | # 진행사항
2 |
3 | |날짜|설명|링크|
4 | |------|---|---|
5 | |21.01.21|OSI 7, TCP/IP|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/01.network/phb/21.01.21.md)|
6 | |21.01.23|프로토콜, TCP/UDP|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/01.network/phb/21.01.23.md)|
7 | |21.01.24|HTTP/HTTPS|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/01.network/phb/21.01.24.md)|
8 | |21.01.25|DNS, REST|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/01.network/phb/21.01.25.md)|
9 | |21.01.26|HTTP/1.1, HTTP/2.0, Blocking/Non-Blocking, 동기/비동기|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/01.network/phb/21.01.26.md)|
10 | |21.01.27|소켓, CORS|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/01.network/phb/21.01.27.md)|
11 | |21.01.28|IPv4/IPv6|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/01.network/phb/21.01.28.md)|
12 | |21.01.29|Web|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/01.network/phb/21.01.29.md)|
13 |
--------------------------------------------------------------------------------
/02.database/hsh/21.01.12.md:
--------------------------------------------------------------------------------
1 |
2 | # 21.01.12
3 |
4 |
5 |
6 | ## 주요 질문
7 |
8 | #### 💡 Database란 무엇인가?
9 |
10 | * 데이터베이스란 여러 사람들이 공유하고 사용할 목적으로 통합 관리되는 **데이터들의 모임입니다.**
11 |
12 | #### 💡 [Database의 특징](#-database-속성)
13 |
14 | * 데이터베이스에는 **독립성, 무결성, 보안성, 중복 최소화** 총 4개의 특징이 있습니다.
15 |
16 |
17 | #### 💡 [Schema란?](#-schema-특징)
18 |
19 | * 스키마는 데이터베이스의 구조와 제약 조건에 관한 전반적인 명세를 기술한 **메타데이터의 집합이다.**
20 |
21 | 1. 스키마는 데이터베이스를 구성하는 데이터 개체(Entity), 속성(Attribute), 관계(Relationship) 및 **데이터 조작 시 데이터 값들이 갖는 제약 조건 등에 관해 전반적으로 정의한다.**
22 |
23 | 2. 스키마는 사용자의 관점에 따라 외부 스키마, 개념 스키마, 내부 스키마로 나눠진다.
24 |
25 |
26 | #### 💡 [DBMS란 무엇인가?](#-dbms-특징)
27 |
28 | * 데이터 집단과 데이터를 관리하는 프로그램의 집합체로 운영체제 위에서 작동된다. **데이터 정의, 조작, 제어 3가지 기능**을 가지고 있다.
29 |
30 |
31 |
32 | 출처
98 | https://velopert.com/2389 99 |33 | 34 | ## 심화 질문 35 | 36 | #### 💡 Database를 사용하는 이유 37 | 38 | * 데이터베이스는 파일처리시스템의 문제점을 해결하기 위한 목적으로 만들어졌다. 데이터베이스가 존재하기 이전에는 파일 시스템을 이용하여 데이터를 관리하였고 데이터의 무결성을 유지하고 생산성을 늘리기 위하여 데이터베이스를 사용한다. 39 | 40 |
41 | 42 | ## 개념 정리 43 | 44 | ### ⭐ Database 속성 45 | 46 | 1. 독립성 47 | 48 | - 물리적 독립성 : 데이터베이스 사이즈를 늘리거나 성능 향상을 위해 데이터 파일을 늘리거나 새롭게 추가하더라도 관련된 응용 프로그램을 수정할 필요가 없다. 49 | 50 | - 논리적 독립성 : 데이터베이스는 논리적인 구조로 다양한 응용 프로그램의 논리적 요구를 만족시켜줄 수 있다. 51 | 52 | 2. 무결성 : 데이터베이스에 들어 있는 데이터의 정확성을 보장하기 위해 데이터의 변경이나 수정시 제한을 두어 안정성을 저해하는 요소를 막아 데이터 상태들을 항상 옳게 유지하는 것을 의미한다. 53 | 54 | 3. 보안성 : 인가된 사용자들만 데이터베이스나 데이터베이스 내의 자원에 접근할 수 있도록 계정 관리 또는 접근 권한을 설정함으로써 모든 데이터에 보안을 구현할 수 있다. 55 | 56 | 4. 일관성 : 연관된 정보를 논리적은 구조로 관리함으로써 어떤 하나의 데이터만 변경했을 경우 발생할 수 있는 데이터의 불일치성을 배제할 수 있다. 또한 작업 중 일부 데이터만 변경되어 나머지 데이터와 일치하지 않는 경우의 수를 배제할 수 있다. 57 | 58 | 5. 중복 최소화 : 데이터베이스는 데이터를 통합해서 관리함으로써 파일 시스템의 단점 중 하나인 자료의 중복과 데이터의 중복성 문제를 해결할 수 있다. 59 | 60 |
61 |
62 |
69 | 출처
63 | 64 | 65 | 66 | https://coding-factory.tistory.com/216 67 | 68 |70 | 71 | ### ⭐ Schema 특징 72 |

- 각각의 사용자가 원하는 형태의 논리적 구조를 정의
- 조직 일부분을 정의
- 여러 개가 존재
- 응용 프로그래머나 사용자와 관련된 개체, 그 개체들의 관계 및 제약조건|⋅ **개념 스키마**
- 데이터를 통합하여 조직 전체의 논리적 구조를 정의
- 기관(조직) 전체를 표현
- 하나만 존재
- 한 기관 전체에 필요한 모든 개체, 모든 개체의 관계 및 제약 사항|⋅ **내부 스키마**
- 전체 DB의 물리적 저장 구조를 정의
- 개념 스키마의 물리적 저장 형태를 정의하는 개념 - 하나만 존재
- 저장될 내부(저장) 레코드의 형식| 78 | 79 | * 요약 80 | - 외부 스키마 : 실세계에 존재하는 데이터들을 어떤 형식, 구조, 배치 화면을 통해 사용자에게 보여줄 것인가 81 | - 개념 스키마 : 데이터 베이스의 전체적인 논리적 구조 (개체간의 관계, 제약조건 등) 82 | - 내부 스키마 : 데이터 베이스의 물리적 저장구조를 정의 83 | 84 | 85 |
86 |
90 |
91 | 출처
87 | 88 | https://coding-factory.tistory.com/216 89 |92 | 93 | ### ⭐ DBMS 특징 94 | 95 | |DBMS 장점|DBMS 단점| 96 | |---------|---------| 97 | |⋅ 데이터 중복 최소화
⋅ 데이터 공유
⋅ 데이터 표준화
⋅ 데이터 보안 유지
⋅ 데이터 무결성 유지
⋅ 데이터 통합적 관리
⋅ 데이터 일관성 유지|⋅ 구축이 복잡하다. ( 규모가 방대하고 복잡한 관리 체계를 유지해야 하므로 )
⋅ 구축 비용이 많이 든다.
⋅ 예비(Backup자료)와 회복(원상복귀) 절차 수립이 어렵다.
⋅ 한 부분의 장애로 전체 시스템에 영향을 주는 취약성이 있다. 98 | 99 |
100 |
101 |
105 |
--------------------------------------------------------------------------------
/02.database/hsh/21.01.13.md:
--------------------------------------------------------------------------------
1 |
2 | # 21.01.13
3 |
4 | ## 주요 질문
5 |
6 |
7 | #### 💡 [정규화란?](#-정규화)
8 |
9 | * 하나의 릴레이션에 하나의 의미만 존재할 수 있도록 릴레이션을 분해해 나가는 과정이 정규화이다. 일반적으로 테이블을 여러 개로 분해하면 속도는 상대적으로 느려 질 수 있지만, 분해하지 않으면 삽입 , 삭제, 갱신 시 이상 문제들이 발생 합니다. 정규화는 총 6단계가 있지만 대체로 1~3 정규화 과정을 거칩니다. (릴레이션 분해로 인한 속도 저하)
10 |
11 | - 저장 공간 최소화
12 | - 자료 구조 안정화
13 | - 자료 삽입, 삭제, 갱신 시 이상 현상 방지
14 |
15 | #### 💡 정규화 과정에 대해 설명하시오.
16 |
17 | * 정규화는 총 6단계로 이루어져 있습니다.
18 | * 제1정규형 (원자값이 아닌 속성 분해)
19 | * 제2정규형 (부분 함수 종속 제거)
20 | * 제3정규형 (이행 함수 종속 제거)
21 | * BCNF (결정자가 후보키가 아닌 함수 종속 제거)
22 | * 제4정규형 (다치 종속 제거)
23 | * 제5정규형 (후보키를 통하지 않는 조인 종속의 제거)
24 |
25 | 출처
102 | 103 | https://blog.naver.com/syunjae21/221984529819 104 |26 | 27 | ## 심화 질문 28 | 29 | #### 💡 반정규화란? 30 | * 반 정규화는 정규화 되어있는 것을 다시 정규화 이전 상태로 돌리는 것을 말한다. 31 | 데이터 무결성이 위배되는 위험을 감수하고 적용하는 이유는 데이터 조회 시 디스크 I/O 량이 많거나, 여러테이블의 조인에 의해 성능이 저하되거나 업무적인 조회에 대한 처리성능이 중요하다고 생각 될때 부분적인 반정규화를 고려 하게 된다. 32 | 33 | 34 | 35 |
36 | 37 | ## 개념 정리 38 | 39 | ### ⭐ 정규화 40 | 41 | * Normalization Process 42 |

52 |
53 |
58 | https://wkdtjsgur100.github.io/database-normalization/
59 | https://3months.tistory.com/193
60 | https://zzozzomin08.tistory.com/12 61 | 62 |
63 | 출처
54 | 55 | 56 | 57 | https://nirsa.tistory.com/10758 | https://wkdtjsgur100.github.io/database-normalization/
59 | https://3months.tistory.com/193
60 | https://zzozzomin08.tistory.com/12 61 | 62 |
64 | 65 | 66 | 67 | -------------------------------------------------------------------------------- /02.database/hsh/21.01.16.md: -------------------------------------------------------------------------------- 1 | 2 | # 21.01.16 3 | 4 | 5 | 6 | ## 주요 질문 7 | 8 | #### 💡 트랜잭션이란? 9 | 10 | * DB의 상태를 하나의 일관된 상태에서 또 다른 일관된 상태로 변환시켜주는 일련의 논리적 연산의 집합 11 | 12 | * 트랜잭션은 DB 서버에 여러 개의 클라이언트가 동시에 액세스 하거나 응용프로그램이 갱신을 처리하는 과정에서 중단될 수 있는 경우 등 데이터 부정합을 방지하고자 할 때 사용합니다. 13 | 14 | 15 | #### 💡 트랜잭션 특징 16 | 17 | * 트랜잭션의 특징은 크게 4가지 **(ACID)** 로 구분된다. 18 | - **원자성 (Atomicity)**: 트랜잭션이 데이터베이스에 모두 반영되던가, 아니면 전혀 반영되지 않아야 한다. 19 | - **일관성 (Consistency)**: 트랜잭션의 작업 처리 결과가 항상 일관성이 있어야 한다. 20 | 송금 예제에서 금액의 데이터 타입이 정수형(integer)인데, 갑자기 문자열(string)이 되지 않는 것을 말합니다. 21 | - **독립성 (Isolation)**: 둘 이상의 트랜잭션이 동시에 실행되고 있을 경우 어떤 하나의 트랜잭션이라도, 다른 트랜잭션의 연산에 끼어들 수 없다는 점을 가리킨다. 22 | - **지속성 (Durability)**: 트랜잭션이 성공적으로 완료됬을 경우, 결과는 영구적으로 반영되어야 한다 23 | 24 | 25 | #### 💡 잠금(Locking) 기법이란? 26 | 27 | * 잠금(Locking)은 하나의 트랜잭션이 실행하는 동안 특정 데이터 항목에 대해서 다른 트랜잭션이 동시에 접근하지 못하도록 상호배제(Mutual Exclusive) 기능을 제공하는 기법이다. 하나의 트랜잭션이 데이터 항목에 대하여 잠금(lock)을 설정하면, 잠금을 설정한 트랜잭션이 해제(unlock)할 때까지 데이터를 독점적으로 사용할 수 있다. 28 | 29 | #### 💡 교착상태(deadlock) 이란? 30 | * 교착 상태(Dead Lock)란 여러 개의 트랜잭션(Transaction)들이 실행을 하지 못하고 서로 무한정 기다리는 상태를 의미합니다. 31 | * 기본적으로 데이터베이스에서는 트랜잭션들의 '동시성'을 제어하기 위한 기법으로 로킹(Locking)을 사용합니다. 이러한 로킹이 데이터가 엉망진창이 되는 것을 막아주겠지만 반면에 그 부작용으로 교착 상태를 일으킬 수 있다. 32 | 33 |
34 | 35 | ## 심화 질문 36 | 37 | #### 💡 교착상태(deadlock) 해결 방법 38 | 39 | - 예방 기법 : 예방 기법은 각 트랜잭션이 실행되기 전에 필요한 데이터를 모두 로킹(Locking) 해주는 것입니다. 다만 예방 기법은 데이터가 많이 필요하면 사실상 모든 데이터를 전부 로킹 해주어야 하므로 트랜잭션의 병행성을 보장하지 못합니다. 뿐만 아니라 몇몇 트랜잭션은 계속해서 처리를 못 하게 되는 기아 상태가 발생할 수 있습니다. 40 | - 회피 기법 : 회피 기법은 자원을 할당할 때 시간 스탬프(Time Stamp)를 사용하여 교착상태가 일어나지 않도록 회피하는 방법입니다. 이러한 회피 기법으로는 Wait-Die 방식과 Wound-Wait 방식이 있습니다. 41 |

44 | 45 | ## 개념 정리 46 | 47 | ### ⭐ 트랜잭션 상태 48 | 49 | - Active : 트랜잭션의 활동 상태. 트랜잭션이 실행중이며 동작중인 상태를 말한다. 50 | - Failed : 트랜잭션 실패 상태. 트랜잭션이 더이상 정상적으로 진행 할 수 없는 상태를 말한다. 51 | - Partially Committed : 트랜잭션의 Commit 명령이 도착한 상태. 트랜잭션의 commit이전 sql문이 수행되고 commit만 남은 상태를 말한다. 52 | - Committed : 트랜잭션 완료 상태. 트랜잭션이 정상적으로 완료된 상태를 말한다. 53 | - Aborted : 트랜잭션이 취소 상태. 트랜잭션이 취소되고 트랜잭션 실행 이전 데이터로 돌아간 상태를 말한다.
54 |  55 | 56 |
57 | 58 | - Partially Committed 와 Committed 의 차이점
59 | : Commit 요청이 들어오면 상태는 Partial Commited 상태가 된다. 이후 Commit을 문제없이 수행할 수 있으면 Committed 상태로 전이되고, 만약 오류가 발생하면 Failed 상태가 된다. 즉, Partial Commited는 Commit 요청이 들어왔을때를 말하며, Commited는 Commit을 정상적으로 완료한 상태를 말한다. 60 | 61 |
62 |
65 | [https://medium.com/pocs/](https://medium.com/pocs/%EB%8F%99%EC%8B%9C%EC%84%B1-%EC%A0%9C%EC%96%B4-%EA%B8%B0%EB%B2%95-%EC%9E%A0%EA%B8%88-locking-%EA%B8%B0%EB%B2%95-319bd0e6a68a) 66 | 67 |
68 |
69 | 출처
63 | 64 | [https://victorydntmd.tistory.com/](https://victorydntmd.tistory.com/129)65 | [https://medium.com/pocs/](https://medium.com/pocs/%EB%8F%99%EC%8B%9C%EC%84%B1-%EC%A0%9C%EC%96%B4-%EA%B8%B0%EB%B2%95-%EC%9E%A0%EA%B8%88-locking-%EA%B8%B0%EB%B2%95-319bd0e6a68a) 66 | 67 |
70 | 71 | 72 | ### ⭐ DB 회복(Recovery) 73 | * 어떤 외부적 혹은 내부적 장애 요인으로 DB의 상태가 일관성을 유지할 수 없을 때, 장애 이전의 일관된 상태가 되도록 복원하는 일 74 |  75 | 76 |
77 |
81 |
82 | 출처
78 | 79 | https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/Transaction%20Isolation%20Level.md 80 |83 | -------------------------------------------------------------------------------- /02.database/hsh/21.01.17.md: -------------------------------------------------------------------------------- 1 | 2 | # 21.01.17 3 | 4 | 5 | ## 주요 질문 6 | #### 💡 Index란? 7 | 8 | * 인덱스란 추가적인 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 방법입니다. 9 | 10 | 11 | #### 💡 데이터베이스의 Index 구조에 대해 설명하시오. 12 | 13 | * DB의 Index는 가장 대표적인 해시 테이블과 B+Tree로 이루어져 있다. 하지만 DB 인덱스에서 해시 테이블이 사용되는 경우는 제한적인데, 그러한 이유는 해시가 등호(=) 연산에만 특화되었기 때문이다. 데이터베이스의 인덱스 컬럼은 부등호를 이용한 순차 검색 연산이 자주 발생될 수 있다. 이러한 이유로 B-Tree의 리프노드들을 LinkedList로 연결하여 순차검색을 용이하게 하는 등 B-Tree를 인덱스에 맞게 최적화하였다. 이러한 이유로 해시테이블보다 인덱싱에 더욱 적합한 자료구조가 되었다. 14 | 15 | #### 💡 Index의 특징에 대해 설명하시오. 16 | - 장점 17 | 1. 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다. 18 | 2. 전반적인 시스템의 부하를 줄일 수 있다. 19 | - 단점 20 | 1. 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다. 21 | 2. 인덱스를 관리하기 위해 추가 작업이 필요하다. 22 | 3. 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다. 23 | 24 | _만약 CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 걸게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있다._ 25 | 26 | 27 |
28 | 29 | ## 심화 질문 30 | 31 | #### 💡 B-tree 와 B+Tree의 차이 32 | - B-tree의 각 노드에서는 key 뿐만 아니라 data도 들어갈 수 있다. 여기서 data는 disk block으로의 포인터가 될 수 있다. 33 | B+tree는 각 node에서는 key만 들어가야 한다. 그러므로 B+tree에서는 data는 오직 leaf에만 존재한다. 34 | - B+tree는 B-tree와는 달리 add, delete가 leaf에서만 이루어진다. 35 | - B+ tree는 leaf node 끼리 linked list로 연결되어 있다. 36 |
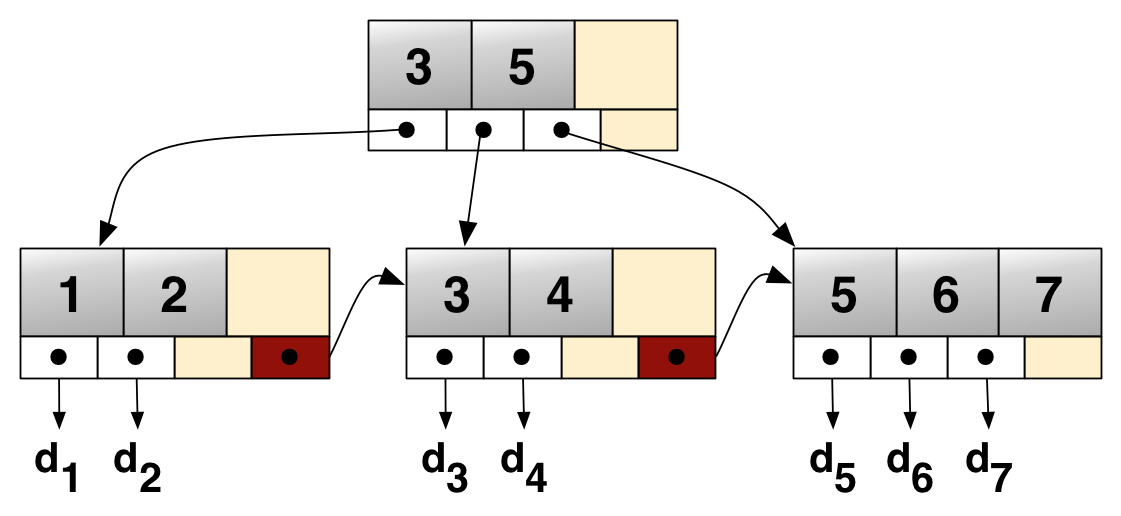
39 | 40 | ## 개념 정리 41 | 42 | #### ⭐ Index를 사용하면 좋은 경우 43 | - 규모가 작지 않은 테이블 44 | - INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼 45 | - JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼 46 | - 데이터의 중복도가 낮은 컬럼
47 | _인덱스를 사용하는 것 만큼이나 생성된 인덱스를 관리해주는 것도 중요하다.
그렇기 때문에 사용하지 않는 인덱스는 바로 제거를 해주어야 한다._ 48 | -------------------------------------------------------------------------------- /02.database/hsh/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.01.12|Database 개념|[✅보러가기](/02.database/hsh/21.01.12.md)| 6 | |21.01.13|정규화|[✅보러가기](/02.database/hsh/21.01.13.md)| 7 | |21.01.14|RDBMS|[✅보러가기](/02.database/hsh/21.01.14.md)| 8 | |21.01.16|트랜잭션|[✅보러가기](/02.database/hsh/21.01.16.md)| 9 | |21.01.17|Index|[✅보러가기](/02.database/hsh/21.01.17.md)| 10 | |-|-|-| 11 | 12 | -------------------------------------------------------------------------------- /02.database/hsh/img/DB_recovery.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/hsh/img/DB_recovery.jpg -------------------------------------------------------------------------------- /02.database/hsh/img/State_transaction.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/hsh/img/State_transaction.png -------------------------------------------------------------------------------- /02.database/hsh/img/_sql.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/hsh/img/_sql.png -------------------------------------------------------------------------------- /02.database/hsh/img/database2.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/hsh/img/database2.png -------------------------------------------------------------------------------- /02.database/hsh/img/database_key.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/hsh/img/database_key.jpg -------------------------------------------------------------------------------- /02.database/kmj/21.01.24.md: -------------------------------------------------------------------------------- 1 | # 21.01.24 2 | * 데이터베이스 개념 3 | 4 |
5 | 6 | ## 주요 질문 7 | #### 💡 데이터베이스를 사용하는 이유? 8 | * 데이터베이스가 존재하기 전에는 파일 시스템을 이용해서 데이터를 관리했습니다. 데이터를 각각의 파일로 저장해서 처리하면 데이터의 중복성, 무결성 문제가 발생할 수 있습니다. 그래서 데이터베이스를 사용합니다. 9 | 10 | 11 |
12 | 13 | 14 | 15 |
16 | 17 | ## ⭐ 개념 정리 18 | ### 데이터베이스의 특징 19 | 20 | * 물리적 독립성 21 | * 데이터베이스의 데이터를 새롭게 추가하더라도 관련된 응용 프로그램을 수정할 필요가 없다. 22 | * 논리적 독립성 23 | * 데이터베이스는 논리적인 구조로 다양항 응용 프로그램의 논리적 요구를 만족시켜줄 수 있다. 24 | * 데이터의 무결성 25 | * 여러 경로를 통해 잘못된 데이터가 발생하는 것을 방지한다. 26 | * 데이터의 보안성 27 | * 인가된 사용자들만 데이터베이스와 자원에 접근할 수 있다. 28 | * 데이터의 일관성 29 | * 연관된 정보를 논리적인 구조로 관리해서 특정 데이터만 변경했을 경우 발생할 수 있는 데이터의 불일치성을 배제할 수 있다. 30 | * 데이터 중복 최소화 31 | * 데이터를 통합해서 관리함으로써 파일 시스템의 단점인 자료와 데이터의 중복성 문제를 해결할 수 있다. 32 | 33 | ### 데이터의 무결성 34 | * 개체 무결성 35 | * 참조 무결성 36 | * 도메인 무결성 37 | 38 | 39 | 40 |
41 | 42 | 43 | 44 | 45 | 46 |
47 | [출처] -------------------------------------------------------------------------------- /02.database/kmj/21.01.25.md: -------------------------------------------------------------------------------- 1 | # 21.01.25 2 | * RDBMS 3 | * KEY 4 | * JOIN 5 | 6 | 7 | ## 주요 질문 8 | 9 | #### 💡 [JOIN에 대해서 설명해주세요.](#Join) 10 | * Join은 2개 테이블의 연관된 튜플들을 결합하여 하나의 새로운 릴레이션을 반환하는 개념입니다. 11 | * Join은 크게 Inner Join과 Outer Join으로 구분됩니다. Inner Join은 두 릴레이션에서 관련있는 튜플만 표시하고, Outer Join은 Join조건에 만족하지 않는 튜플도 결과로 출력합니다. 12 | 13 | 14 | 15 | 16 | 17 | 18 |
19 | 20 | ## 심화 질문 21 | 22 |
23 | 24 | ## ⭐ 개념 정리 25 | 26 | 27 | ### RDBMS 구조 28 | 29 |
30 |
31 | ### 키(Key)
32 | * Key란? : 검색, 정렬시 Tuple을 구분할 수 있는 기준이 되는 Attribute.
33 |
34 |
35 | 1. 후보키: Candidate Key
36 | * Tuple을 유일하게 식별하기 위해 사용하는 속성들의 부분 집합이다. 기본키로 사용할 수 있다.
37 |
38 | * 2가지 조건 만족해야 한다.
39 |
40 | * 유일성 : 하나의 Key로 하나의 Tuple을 유일하게 식별할 수 있어야 한다.
41 | * 최소성 : 꼭 필요한 속성으로만 구성되어야 한다.
42 |
43 | 2. 기본키: Primary Key
44 | * 후보키 중에서 선택한 Main Key로 중복된 값을 가질 수 없다.
45 |
46 | * 특징
47 | * 후보키의 성질을 가진다.(유일성, 최소성)
48 | * 특정 튜플을 유일하게 구별할 수 있는 속성이다.
49 |
50 | 3. 대체키: Alternate Key
51 | * 후보키 중 기본키를 제외한 나머지 Key를 말한다. = 보조키
52 |
53 |
54 | 4. 슈퍼키: Super Key
55 | * 한 릴레이션 내에 있는 속성들의 집합이다.
56 | * 유일성은 만족하지만, 최소성은 만족하지 않는다.
57 | ### Join
58 |
59 | * 조인이란?
60 | * 두 개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법이다.
61 | 테이블을 연결하려면, 적어도 하나의 Attribute를 서로 공유하고 있어야 한다.
62 |
63 |
64 | * JOIN 종류
65 | * INNER JOIN
66 | * LEFT OUTER JOIN
67 | * RIGHT OUTER JOIN
68 | * FULL OUTER JOIN
69 | * CROSS JOIN
70 | * SELF JOIN
71 |
72 |
73 | * INNER JOIN
74 |
75 | * 교집합으로, 기준 테이블과 join 테이블의 중복된 값을 보여준다.
76 | ```sql
77 | SELECT
78 | A.NAME, B.AGE
79 | FROM EX_TABLE A
80 | INNER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
81 | ```
82 | * LEFT OUTER JOIN
83 |
84 | * Inner join 결과를 구한 후, 우측 릴레이션의 어떤 튜플과도 맞지 않는 좌측 릴레이션의 튜플들에 NULL값을 붙인다.
85 | ```sql
86 | SELECT
87 | A.NAME, B.AGE
88 | FROM EX_TABLE A
89 | LEFT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
90 | ```
91 | * RIGHT OUTER JOIN
92 |
93 | * LEFT OUTER JOIN과는 반대로 우측 릴레이션의 튜플에 NULL을 붙인다.
94 | ```sql
95 | SELECT
96 | A.NAME, B.AGE
97 | FROM EX_TABLE A
98 | RIGHT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
99 | ```
100 | * FULL OUTER JOIN
101 |
102 | * Left outer join + Right outer join 이다.
103 | * Inner join의 결과를 구한 후 우측 항의 릴레이션에 NULL값을 추가한다. 그 후 좌측 항의 릴레이션에 NULL값을 추가한다.
104 | ```sql
105 | SELECT
106 | A.NAME, B.AGE
107 | FROM EX_TABLE A
108 | FULL OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
109 | ```
110 | * CROSS JOIN
111 |
112 | * 조인 테이블에 있는 튜플들의 순서쌍을 반환한다.
113 |
114 | * 결과 행의 수: A 테이블, B 테이블의 행 수를 곱한 것과 같다.
115 |
116 | ```sql
117 | SELECT
118 | A.NAME, B.AGE
119 | FROM EX_TABLE A
120 | CROSS JOIN JOIN_TABLE B
121 | ```
122 | * SELF JOIN
123 |
124 | * 같은 테이블에서 2개의 속성을 연결하여 EQUI JOIN하는 것이다.
125 | * 자기자신과 자기자신을 조인하는 것이다.
126 |
127 | ```sql
128 | SELECT
129 | A.NAME, B.AGE
130 | FROM EX_TABLE A, EX_TABLE B
131 | ```
132 |
133 |
134 |
135 | 136 | [출처] -------------------------------------------------------------------------------- /02.database/kmj/21.01.26.md: -------------------------------------------------------------------------------- 1 | # 21.01.26 2 | * 정규화 3 | 4 | 5 | ## 주요 질문 6 | 7 | #### 💡 [정규화에 대해서 설명해주세요.](#정규화) 8 | 9 | * 정규화는 종속적으로 설계된 관계형 스키마가 하나의 릴레이션에 표현될 수 있도록 분해하는 과정입니다. 10 | * 데이터의 중복성을 최소화하고 일관성을 보장하기 위한 과정입니다. 11 | * 정규화를 거치지 않으면 [이상(Anormaly)](#이상(Anormaly)) 문제가 발생합니다. 12 | 13 | 14 | 15 |
16 | 17 | ## 심화 질문 18 | 19 | 20 | #### 💡 정규화의 장단점은 무엇인가요? 21 | * 장점 22 | * 데이터베이스 변경 시 이상 현상(Anomaly) 문제점을 해결할 수 있습니다. 23 | * 새로운 데이터 형의 추가로 인한 확장 시, 구조를 최소한으로 변경할 수 있습니다. 24 | * 단점 25 | * 릴레이션의 분해로 인해 릴레이션 간 Join연산이 많아집니다. 26 | * 따라서 질의 응답시간이 느려질 수 있습니다. 이러한 경우 반정규화를 적용해볼 수 있습니다. 27 | 28 | 29 | #### 💡 반정규화란? 30 | * 정규화된 데이터 모델을 통합, 중복, 분리하는 과정입니다. 31 | * 의도적으로 정규화 원칙을 위배하는 방법입니다. 32 | * 사용예시 33 | * 조인 많을 때: 테이블 통합 34 | * 레코드별 사용빈도 차이가 클 때: 테이블 수평분할 35 | * 테이블에 속성이 많을 때: 테이블 수직분할 36 | * 특정 데이터 자주 처리할 때: 중복 테이블 추가 37 | * 접근 경로가 복잡할 때: 중복속성 추가 38 | * 주의할 점 39 | * 데이터의 일관성이 떨어질 수 있습니다. 40 | 출처 https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/Database#transaction 41 | 42 |
43 | 44 | ## ⭐ 개념 정리 45 | 46 | 47 | 48 | ### 이상(Anormaly) 49 | * 정규화를 거치지 않아 데이터가 불필요하게 중복되어 생기는 예기치 않은 문제 50 | * 종류 51 | * 삽입 이상: 릴레이션에 데이터를 삽입할 때 원하지 않은 값들도 함께 삽입되는 현상 52 | * 삭제 이상: 릴레이션에서 튜플을 삭제할 때 다른 값들도 함께 삭제되는 현상 53 | * 갱신 이상: 릴레이션에서 튜플의 속성값을 갱신할 때 일부 튜플만 갱신되는 현상 54 | 55 | 56 | 57 |
58 | 59 | ### 정규화 60 | *
61 | * 1NF - 제 1정규형
62 | * 릴레이션에 속한 모든 도메인(속성값)이 더이상 쪼갤 수 없는 원자값이어야 한다.
63 | * 2NF - 제 2정규형
64 | * 기본키에 대해 다른 모든 속성이 [완전 함수적 종속](#완전-함수적-종속)을 만족해야 한다.
65 | * 3NF - 제 3정규형
66 | * 무손실조인 또는 종속성 보존을 저해하지 않고 항상 3NF를 얻을 수 있어야 한다.
67 | * BCNF - Boyce - Codd 정규형
68 | * [결정자](#결정자)가 모두 후보키여야 한다.
69 | * 후보키가 서로 중첩되는 경우에 적용한다.
70 | * 4NF - 제 4정규형
71 | * 릴레이션에 [다치종속](#다치종속)이 성립하는 경우(A->->B), 릴레이션의 모든 속성이 A에 [함수적 종속 관계](#함수적-종속-관계)를 만족해야 한다.
72 | * 5NF - 제 5정규형
73 | * 릴레이션 R의 모든 조인종속이 R의 후보키를 통해서만 성립되어야 한다.
74 |
75 | ### 함수적 종속 관계
76 | * 수강(학번, 과목명, 이름, )
77 | * 학번이 정해지면 과목명 상관없이 이름이 대응되는 경우
78 | * 이름을 학번에 함수 종속적이라고 한다.
79 | * 학번 -> 이름 과 같이 표기
80 |
81 | ### 완전 함수적 종속
82 | * 수강(학번, 과목명, 이름, 성적)
83 | * 어떤 속성이 기본키에 대해 완전히 종속적
84 | * 성적은 학번+과목명에 의해서만 결정됨
85 | ### 부분 함수적 종속
86 | * 수강(학번, 과목명, 이름, 성적, 학년)
87 | * 기본키의 일부인 학번에 의해 학년이 결정됨
88 | * 학년은 부분 함수적 종속
89 | ### 결정자
90 | * 수강(학번, 과목명, 이름, 성적)
91 | * 학번에 의해 이름이 결정된다고 하자.
92 | * 학번: 결정자
93 | * 이름: 종속자
94 | ### 다치종속
95 | * R(A,B,C)에서 (A,C)에 대응하는 B의 집합이 A에만 종속되고 C에는 무관할 때
96 | * B는 A의 다치종속
97 | * A ->-> B 로 표기
98 |
99 |
100 | 101 | [출처] -------------------------------------------------------------------------------- /02.database/kmj/21.01.27.md: -------------------------------------------------------------------------------- 1 | # 21.01.27 2 | * 트랜잭션 3 | ## 주요 질문 4 | 5 | 6 | #### 💡 트랜잭션에 대해서 설명해주세요. 7 | * 트랜잭션이란 데이터베이스의 상태를 변화시키기 위해 한번에 수행되어야 할 연산들입니다. 8 | * 트랜잭션은 수행중에 한 작업이라도 실패하면 전부 실패하고, 모두 성공해야 성공이라고 할 수 있습니다. 9 | 10 | 11 | #### 💡 ACID에 대해서 설명해주세요. 12 | 13 | * ACID는 트랜잭션의 무결성을 보장하기 위한 특성입니다. 14 | 15 | * Atomicity(원자성): 트랜잭션의 연산은 모든 연산이 완벽히 수행되어야 하며, 한 연산이라도 실패하면 트랜잭션은 실패해야 합니다. 16 | * Consistency(일관성): 언제나 일관성 있는 데이터베이스 상태로 변환합니다. 17 | * Isolation(고립성): 트랜잭션은 동시에 실행될 경우 다른 트랜잭션에 의해 영향을 받지 않습니다. 18 | * Durability(내구성): 트랜잭션이 커밋된 이후에는 시스템 오류가 발생하더라도 커밋된 상태로 유지되는 것을 보장해야 합니다. 19 | 20 | 21 | 22 | 23 |
24 | 25 | ## 심화 질문 26 | 27 | 28 | 29 | #### 💡 트랜잭션 격리 수준(Transaction Isolation Levels)에 대해서 설명해주세요. 30 | 31 | * 트랜잭션에서 일관성 없는 데이터를 허용하는 수준입니다. 32 | * 독립성을 유지하기 위해 동시에 수행되는 수많은 트랜잭션들을 순서대로 처리하게 되면 성능이 떨어집니다. 따라서 효율적인 Locking 방법이 필요합니다. 33 | * 종류(밑으로 갈수록 엄격함) 34 | * READ UNCOMMITTED: 트랜잭션에서 처리중이거나 커밋안된 내용을 다른 트랜잭션이 읽을 수 있다. 35 | * READ COMMITTED: 트랜잭션이 수행되는 동안 다른 트랜잭션이 접근할 수 없다. 36 | * REPEATABLE READ: 트랜잭션에 진입하기 이전에 커밋된 내용만 참조할 수 있다. 37 | * SERIALIZABLE: 트랜잭션에 진입하면 락을 걸어 다른 트랜잭션이 접근하지 못하게 한다.(성능 매우 떨어짐) 38 | 39 | [출처] https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/Transaction%20Isolation%20Level.md 40 | 41 | 42 | 43 | 44 |
45 | 46 | ## ⭐ 개념 정리 47 | 48 | ### 개념1 49 | * 설명 50 | 51 | 52 | 53 |
54 | 55 | ### 개념2 56 | * 설명 57 | 58 | 59 |
60 | [출처] -------------------------------------------------------------------------------- /02.database/kmj/21.01.28.md: -------------------------------------------------------------------------------- 1 | # 21.01.28 2 | * 인덱스 3 | 4 | ## 주요 질문 5 | 6 | #### 💡 인덱스란? 7 | * 데이터에 빠르게 접근하기 위해 <키값, 포인터> 쌍으로 구성되는 데이터 구조입니다. 8 | 9 | #### 💡 인덱스를 모든 속성에 추가할 경우 성능이 좋아질까요? 10 | * 그렇지 않습니다. 11 | 12 | #### 데이터베이스에서 조회만 일어난다고 할 때, 모든 속성에 인덱스를 추가하면 성능에 좋을까요? 13 | 14 | 15 | #### 💡 인덱스를 사용하면 좋은 경우는 무엇일까요? 16 | * 규모가 작지 않은 테이블에 사용하면 조회 속도가 빨라집니다. 17 | * Insert, Update, Delete 가 자주 발생하지 않는 컬럼이 좋습니다. 18 | * where구문, join문에 자주 사용되는 컬럼이 좋습니다. 19 | * 데이터의 중복도가 낮은 컬럼이 좋습니다. 20 | 21 | 22 | 23 | 24 | 25 |
26 | 27 | ## ⭐ 개념 정리 28 | 29 | ### 클러스터드 인덱스 vs 넌클러스터드 인덱스 30 | * 클러스터드 인덱스는 데이터를 PK에 따라서 순서대로 저장합니다. 범위탐색은 빠르지만 테이블 중간에 있는 데이터를 삭제하거나, 삽입할 때 느립니다. 31 | * 넌클러스터드 인덱스는 인덱스와 hashcode를 이용해서 데이터를 저장합니다. hashcode 또한 저장해야 하기 때문에 추가저장공간이 필요합니다. 그리고 데이터를 insert할 때 인덱스를 생성해줘야 하는 추가 작업이 필요합니다. 32 | 33 | 34 | 35 |
36 | 37 | ### B+Tree 38 | * RDBMS 에서 사용하는 INDEX는 B-Tree 에서 파생된 B+Tree를 사용합니다. 39 | * Index Node, Data Node로 구성되어 있다. 40 | Data Node: Leaf Node 41 | Index Node: Data Node 를 제외한 나머지 노드 42 | 43 | ### B-Tree 44 | * 45 | 46 | 47 |
48 | [출처] -------------------------------------------------------------------------------- /02.database/kmj/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.01.24|DATABASE 개념|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/kmj/21.01.24.md)| 6 | |21.01.25|RDBMS, KEY, JOIN|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/kmj/21.01.25.md)| 7 | |21.01.26|정규화|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/kmj/21.01.26.md)| 8 | |21.01.27|트랜잭션|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/kmj/21.01.27.md)| 9 | |21.01.28|INDEX|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/kmj/21.01.28.md)| 10 | -------------------------------------------------------------------------------- /02.database/kmj/images/normalization.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/kmj/images/normalization.png -------------------------------------------------------------------------------- /02.database/kmj/images/rdbms_relation.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/02.database/kmj/images/rdbms_relation.png -------------------------------------------------------------------------------- /02.database/kmj/기타.md: -------------------------------------------------------------------------------- 1 | * Injection 2 | * DB 풀 3 | 4 | ### SQL Injection 5 | 해커에 의해 조작된 SQL 쿼리문이 데이터베이스에 그대로 전달되어 비정상적 명령을 실행시키는 공격 기법 6 | 7 | 8 | 공격 방법 9 | 1) 인증 우회 10 | 보통 로그인을 할 때, 아이디와 비밀번호를 input 창에 입력하게 된다. 쉽게 이해하기 위해 가벼운 예를 들어보자. 아이디가 abc, 비밀번호가 만약 1234일 때 쿼리는 아래와 같은 방식으로 전송될 것이다. 11 | 12 | SELECT * FROM USER WHERE ID = "abc" AND PASSWORD = "1234"; 13 | SQL Injection으로 공격할 때, input 창에 비밀번호를 입력함과 동시에 다른 쿼리문을 함께 입력하는 것이다. 14 | 15 | 1234; DELETE * USER FROM ID = "1"; 16 | 보안이 완벽하지 않은 경우, 이처럼 비밀번호가 아이디와 일치해서 True가 되고 뒤에 작성한 DELETE 문도 데이터베이스에 영향을 줄 수도 있게 되는 치명적인 상황이다. 17 | 18 | 이 밖에도 기본 쿼리문의 WHERE 절에 OR문을 추가하여 '1' = '1'과 같은 true문을 작성하여 무조건 적용되도록 수정한 뒤 DB를 마음대로 조작할 수도 있다. 19 | 20 | 21 | 2) 데이터 노출 22 | 시스템에서 발생하는 에러 메시지를 이용해 공격하는 방법이다. 보통 에러는 개발자가 버그를 수정하는 면에서 도움을 받을 수 있는 존재다. 해커들은 이를 역이용해 악의적인 구문을 삽입하여 에러를 유발시킨다. 23 | 24 | 즉 예를 들면, 해커는 GET 방식으로 동작하는 URL 쿼리 스트링을 추가하여 에러를 발생시킨다. 이에 해당하는 오류가 발생하면, 이를 통해 해당 웹앱의 데이터베이스 구조를 유추할 수 있고 해킹에 활용한다. 25 | 26 | 27 | 28 | 방어 방법 29 | 1) input 값을 받을 때, 특수문자 여부 검사하기 30 | 로그인 전, 검증 로직을 추가하여 미리 설정한 특수문자들이 들어왔을 때 요청을 막아낸다. 31 | 32 | 2) SQL 서버 오류 발생 시, 해당하는 에러 메시지 감추기 33 | view를 활용하여 원본 데이터베이스 테이블에는 접근 권한을 높인다. 일반 사용자는 view로만 접근하여 에러를 볼 수 없도록 만든다. 34 | 35 | 3) preparestatement 사용하기 36 | preparestatement를 사용하면, 특수문자를 자동으로 escaping 해준다. (statement와는 다르게 쿼리문에서 전달인자 값을 ?로 받는 것) 이를 활용해 서버 측에서 필터링 과정을 통해서 공격을 방어한다. 37 | 38 | ### 데이터베이스 풀 39 | Connection Pool 40 | 클라이언트의 요청에 따라 각 어플리케이션의 스레드에서 데이터베이스에 접근하기 위해서는 Connection이 필요하다. 41 | Connection pool은 이런 Connection을 여러 개 생성해 두어 저장해 놓은 공간(캐시), 또는 이 공간의 Connection을 필요할 때 꺼내 쓰고 반환하는 기법을 말한다. 42 | 43 | DB에 접근하는 단계 44 | 웹 컨테이너가 실행되면서 DB와 연결된 Connection 객체들을 미리 생성하여 pool에 저장한다. 45 | DB에 요청 시, pool에서 Connection 객체를 가져와 DB에 접근한다. 46 | 처리가 끝나면 다시 pool에 반환한다. 47 | Connction이 부족하면? 48 | 모든 요청이 DB에 접근하고 있고 남은 Conncetion이 없다면, 해당 클라이언트는 대기 상태로 전환시키고 Pool에 Connection이 반환되면 대기 상태에 있는 클라이언트에게 순차적으로 제공된다. 49 | 왜 사용할까? 50 | 매 연결마다 Connection 객체를 생성하고 소멸시키는 비용을 줄일 수 있다. 51 | 미리 생성된 Connection 객체를 사용하기 때문에, DB 접근 시간이 단축된다. 52 | DB에 접근하는 Connection의 수를 제한하여, 메모리와 DB에 걸리는 부하를 조정할 수 있다. 53 | Thread Pool 54 | 비슷한 맥락으로 Thread pool이라는 개념도 있다. 55 | 이 역시 매 요청마다 요청을 처리할 Thread를 만드는것이 아닌, 미리 생성한 pool 내의 Thread를 소멸시키지 않고 재사용하여 효율적으로 자원을 활용하는 기법. 56 | Thread Pool과 Connection pool 57 | WAS에서 Thread pool과 Connection pool내의 Thread와 Connection의 수는 직접적으로 메모리와 관련이 있기 때문에, 많이 사용하면 할 수록 메모리를 많이 점유하게 된다. 그렇다고 반대로 메모리를 위해 적게 지정한다면, 서버에서는 많은 요청을 처리하지 못하고 대기 할 수 밖에 없다. 58 | 보통 WAS의 Thread의 수가 Conncetion의 수보다 많은 것이 좋은데, 그 이유는 모든 요청이 DB에 접근하는 작업이 아니기 때문이다. 59 | 60 | #### 데이터베이스의 성능? 61 | 데이터베이스의 성능 이슈는 디스크 I/O 를 어떻게 줄이느냐에서 시작된다. 디스크 I/O 란 디스크 드라이브의 플래터(원판)을 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것을 의미한다. 이 때 데이터를 읽는데 걸리는 시간은 디스크 헤더를 움직여서 읽고 쓸 위치로 옮기는 단계에서 결정된다. 즉 디스크의 성능은 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한 번에 기록하느냐에 따라 결정된다고 볼 수 있다. 62 | 63 | 그렇기 때문에 순차 I/O 가 랜덤 I/O 보다 빠를 수 밖에 없다. 하지만 현실에서는 대부분의 I/O 작업이 랜덤 I/O 이다. 랜덤 I/O 를 순차 I/O 로 바꿔서 실행할 수는 없을까? 이러한 생각에서부터 시작되는 데이터베이스 쿼리 튜닝은 랜덤 I/O 자체를 줄여주는 것이 목적이라고 할 수 있다. 64 | * 답변 -------------------------------------------------------------------------------- /02.database/lyj/21.01.13.md: -------------------------------------------------------------------------------- 1 | # 21.00.00 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [질문1](#개념1) 6 | * 답변 7 | 8 | #### 💡 질문2 9 | * 답변 10 | 11 | #### 💡 질문3 12 | * 답변 13 | 14 | 15 | 16 |
17 | 18 | ## 심화 질문 19 | 20 | #### 💡 질문1 21 | * 답변 22 | 23 | #### 💡 질문2 24 | * 답변 25 | 26 | #### 💡 질문3 27 | * 답변 28 | 29 | 30 |
31 | 32 | ## 개념 정리 33 | 34 | ### ⭐ 개념1 35 | * 설명 36 | 37 |
38 |
42 |
43 | 출처
39 | 40 | 출처적어주세요 41 |44 | 45 | #### ⭐ 개념2 46 | * 설명 47 | 48 | 49 |
50 | -------------------------------------------------------------------------------- /02.database/lyj/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.01.13|OSI 7 Layers|[✅보러가기](https://github.com/ACmolar/Tech_interview#21-01-13)| 6 | |21.01.14|TCP/IP|[✅보러가기](https://github.com/ACmolar/Tech_interview#21-01-14)| 7 | |21.01.15|테스트2|[✅보러가기](https://github.com/ACmolar/Tech_interview#21-01-15)| -------------------------------------------------------------------------------- /02.database/phb/21.01.12.md: -------------------------------------------------------------------------------- 1 | # 21.01.12 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [데이터베이스의 특징은 무엇인가?](#데이터베이스) 6 | * 일관성 있는 데이터를 실시간으로 여러 사람들에게 공유할 수 있습니다. 7 | 8 | #### 💡 [데이터베이스 설계 시 고려할 점은 무엇인가?](#데이터베이스) 9 | * 데이터의 무결성, 일관성을 유지하여 정확한 데이터를 제공해야합니다. 시스템 장애 발생시에 장애 발생 전으로 복구할 수 있어야합니다. 불법적 데이터 노출이나 변경 및 손실로부터 데이터를 보호할 수 있어야 합니다. 10 | 11 | #### 💡 [스키마란?](#스키마) 12 | * 데이터베이스의 자료 구조, 관계, 제약조건 등을 정의한 것입니다. 13 | 14 |
15 | 16 | ## ⭐ 개념 정리 17 | 18 | ### 데이터베이스 19 | * 조직에 필요한 데이터를 저장해 놓은 것 20 | * 특징 21 | * 공유데이터 : 동시공유 가능 22 | * 운영데이터 : 항상 최신 데이터를 유지하며 실시간 접근이 가능 23 | * 통합데이터 : 데이터 중복의 최소화 24 | * 저장데이터 : 내용에 의한 접근 25 | * 설계 고려사항 26 | * 데이터의 무결성 유지 27 | * 데이터의 일관성 유지 28 | * 데이터의 회복성 유지 29 | * 데이터의 보안성 유지 30 | * 데이터의 효율성 유지 31 | * 데이터베이스의 확장성 유지 32 | * 생명주기 33 | * 요구사항 분석 - 설계 - 구현 - 운영 - 유지보수 34 | 35 | 36 |
37 | 38 | ### DBMS 39 | * 데이터베이스를 관리하는 소프트웨어 40 | 41 | 42 |
43 | 44 | ### 스키마 45 | * 데이터베이스의 자료 구조, 관계 등을 정의한 구조 46 | * 데이터베이스 스키마 47 | 48 |  49 | 50 | 51 | 52 |
53 | 54 | ### 데이터모델링 55 | * 복잡한 현실 세계를 정해진 구조 및 제약조건에 따라 추상화하는 과정 56 | * 모델링 과정 57 | 58 |  59 | 60 | * 개념 모델링 : 핵심 엔티티 도출 및 관계를 정의 (개념 E-R모델) 61 | * 논리 모델링 : 엔티티-속성 관계 구조 설계 및 정규화 수행 (상세 E-R모델) 62 | * 물리 모델링 : 사용할 DBMS, 데이터 타입 선정 등 실제 DB 저장을 위한 내용 정의 63 | 64 | 65 |
66 | -------------------------------------------------------------------------------- /02.database/phb/21.01.13.md: -------------------------------------------------------------------------------- 1 | # 21.01.13 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [정규화란?](#정규화) 6 | * 종속 이론을 기반으로 하여 잘못 설계된 관계형 스키마를 작은 속성 집합으로 쪼개는 과정입니다. 7 | 8 | #### 💡 [정규화 과정 간단하게 알려주세요](#정규화) 9 | * 정규화되지 않은 릴레이션에서 도메인을 원자값으로 쪼개면 제 1정규형이 됩니다. 제 1 정규형에서 부분 함수 종속을 제거하면 제 2정규형이되고 이행적 함수 종속을 제거하면 제 3정규형을 만족하게 됩니다. 10 | 11 | #### 💡 모든 테이블을 정규화하는 것이 좋은가요? 12 | * 아닙니다. 항상 같이 사용되는 칼럼값이 정규화로 쪼개진다면 두 테이블을 항상 join하여 사용해야 합니다. 이 과정은 오히려 연산 횟수가 증가하여 성능의 저하가 발생할 수 있어 역정규화를 실행합니다. 13 | 14 | 15 | #### 💡 [이상현상 설명해주세요](#이상현상) 16 | * 정규화되지 않은 릴레이션에서 예기치 않게 발생하는 문제로 삽입이상, 갱신이상, 삭제이상이 있습니다. 17 | 18 |
19 | 20 | ## ⭐ 개념 정리 21 | 22 | ### 정규화 23 | * 종속 이론을 기반으로 하여 잘못 설계된 관계형 스키마를 작은 속성 집합으로 쪼개는 과정 24 | * 데이터베이스 설계 시, 중복을 최소화하여 구조 설계 하는 것 25 | 26 | * 목적 27 | * 데이터베이스 구조 안정화 28 | * 효과적인 검색 29 | * 이상현상 방지 30 | * 과정 31 | 32 |  33 | 34 |
35 | 36 | ### 이상현상 37 | * 정규화되지 않은 릴레이션에서 예기치 않게 발생하는 문제 38 | * 종류 39 | * 삽입이상 : 원하지 않는 값이 삽입 40 | * 삭제이상 : 원하지 않는 값이 연쇄 삭제 41 | * 갱신이상 : 일부 데이터만 변경 42 | 43 |
44 | 45 | 46 | -------------------------------------------------------------------------------- /02.database/phb/21.01.14.md: -------------------------------------------------------------------------------- 1 | # 21.01.14 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [PK랑 FK 설명해주세요](#키key) 6 | * PK는 릴레이션에서 최소성, 유일성을 지키고 있으며 null 값을 가질 수 없는 키입니다. 7 | * FK는 릴레이션 간의 관계를 표시하는 키로 null값이거나 참조하는 테이블의 PK 값이어야 합니다. 8 | 9 | #### 💡 [뷰 설명해주세요](#뷰view) 10 | * 뷰는 기본 테이블에서 유도된 가상테이블입니다. 중요한 정보는 제외하고 사용자에게 보여줄 수 있습니다. 11 | 12 | #### 💡 서브 쿼리의 성능은? 13 | * MySQL 5.5 이하의 버전에서 IN절에 사용하는 경우 EXISTS로 테이블을 FULL SCAN 하여 속도가 느립니다. MySQL 5.6부터는 최적화가 되어 있지만 다양한 조건에 최적화되어 있지 않아 가능한 join문 2개로 푸는 것이 성능적으로 효과적입니다. 14 | 15 |
16 | 17 | #### 💡 RDBMS와 NoSQL의 차이는? 18 | |RDBMS|NoSQL| 19 | |------|---| 20 | |- 스키마에 따라 데이터를 관리 | - 스키마가 없어 유연한 데이터 저장| 21 | |- 정교한 검색이 가능 | - 규격화된 데이터 값을 얻기 힘듬| 22 | |- 부하의 분산이 어려움 | - 분산형 구조| 23 | 24 |
25 | 26 | 27 | ## ⭐개념 정리 28 | 29 | ### 관계형 데이터베이스의 구조 30 |  31 | 32 | * 속성(Attribue) : 릴레이션을 구성하는 각각의 열 33 | * 차수(Degree) : 속성의 수 34 | * 튜플 : 릴레이션을 구성하는 각각의 행 35 | * 카디널리티(Cardinality) : 튜플의 수 36 | * 도메인 : 하나의 속성이 취할 수 있는 같은 원자값들의 집합 37 | 38 | 39 |
40 | 41 | #### 키(KEY) 42 | 43 | * 기본키(PK) : 후보키에서 선택된 1개의 키, 유일성과 최소성을 만족하며 null값을 가질 수 없다. (개체 무결성) 44 | * 외래키(FK) : 릴레이션을 참조하기 위한 키, null값 또는 참조하는 릴레이션의 PK값이어야 한다. (참조 무결성) 45 | 46 | * 후보키 : 유일성과 최소성을 만족하는 키 47 | * 대체키 : 후보키에서 기본키를 제외한 나머지 키 48 | * 슈퍼키 : 유일성을 만족하며 2개 이상의 속성으로 이루어진 키 49 | 50 | 51 |
52 | 53 | #### SQL 54 | * DDL 55 | * CREATE : 테이블 생성 56 | > CREATE TABLE 테이블명 ( 칼럼명1 DATATYPE, 칼럼명2 DATATYPE, ... [CONSTRAINT]); 57 | 58 |
59 | 60 | * DROP : 테이블 삭제 61 | > DROP TABLE FROM 테이블명 [WHERE 조건]; 62 | 63 |
64 | 65 | * ALTER : 테이블 수정 66 | > ALTER TABLE 테이블명 ADD/DROP/MODIFY/RENAME 칼럼명/칼럼내용 ; 67 | 68 | * DML 69 | * SELECT : 검색 70 | > SELECT 칼럼명1, ... FROM 테이블명 [WHERE 조건]; 71 | 72 |
73 | 74 | * UPDATE : 수정 75 | > UPDATE 테이블명 SET 조건 WHERE 조건; 76 | 77 |
78 | 79 | * DELETE : 삭제 80 | > DELETE FROM 테이블명 [WHERE 조건]; 81 | 82 |
83 | 84 | * INSERT : 삽입 85 | > INSERT 테이블명 INTO VALUES(값1, 값2, ...); 86 | > INSERT 테이블명(칼럼명1, 칼럼명2, ...) INTO VALUE(값1, 값2, ...); 87 | 88 | * DCL 89 | * GRANT : 시스템 권한 부여 90 | > GRANT 권한명 ON 객체명 TO 유저명 [WITH ADMIN OPTION]; 91 | 92 |
93 | 94 | * REVOKE : 시스템 권환 회수 95 | > REVOKE 권한명 ON 객체명 FROM 유저명; 96 | 97 |
98 | 99 | * COMMIT : 트랜잭션이 정상적으로 처리됐음을 의미 100 | * ROLLBACK : 트랜잭션에 문제가 생겨 이전 상태로 돌아감을 의미 101 | 102 |
103 | 104 | #### 뷰(VIEW) 105 | > CREATE VIEW 뷰이름(속성1, 속성2, ...) AS SELECT문; 106 | * 기본 테이블에서 유도된 가상테이블 107 | * 원하는 정보만 사용자에게 보여줄 수 있음 108 | * 물리적으로 존재하지 않음 109 | * 물리적으로 존재하지 않기 때문에 독립적인 인덱스를 가질 수 없음 110 | * 삽입, 삭제, 갱신 등 연산에 제약이 있음 111 | 112 | 113 |
114 | 115 | #### 서브쿼리 116 | * 하나의 sql문 안에 포함되어 있는 또 다른 sql 117 | * 서브쿼리 내부에 order by 사용 불가능 118 | * 서브쿼리는 메인 쿼리의 칼럼을 사용할 수 있지만 메인쿼리는 서브쿼리의 칼럼 사용 불가능 119 | * 성능 (MySQL 5.5이하 버전 구림) 120 | * MySQL 5.5 이하 버전에서 IN절 내에 서브쿼리가 존재할 경우, EXISTS 형태로 변환되어 실행되어 최적화 되지 못하고 외부 쿼리는 테이블 FULL SCAN 동작 121 | * join문으로 풀어서 사용하는 것이 좋음 -> 쿼리 성능 비교 후 적용 122 | 123 |
124 |
128 |
129 |
--------------------------------------------------------------------------------
/02.database/phb/21.01.16.md:
--------------------------------------------------------------------------------
1 | # 21.01.16
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 [트랜잭션 설명해주세요.](#트랜잭션transaction)
6 | * DB 상태를 변화하는 흐름 단위이며 원자성, 일관성, 고립성, 지속성의 특징을 가지고 있습니다.
7 |
8 | #### 💡 [로킹기법 설명해주세요](#로킹locking)
9 | * 트랜잭션이 동시에 여러개가 진행되면 갱신 손실, 연쇄 복귀 등 여러 문제가 발생할 수 있습니다. 로킹기법은 이 문제를 해결하기 위해 트랜잭션에 LOCK을 설정하여 LOCK이 존재하는 경우 트랜잭션이 진행되지 않도록 하는 기법입니다.
10 |
11 | #### 💡 [로킹기법의 문제점은?](#로킹locking)
12 | * 트랜잭션들이 LOCK을 무기한 기다리는 교착 상태가 발생할 수 있습니다.
13 |
14 | #### 💡 [교착상태의 빈도를 낮추는 방법은 뭐가 있나요?](교착상태deadlock)
15 | * 예방과 회피기법이 있습니다. 예방은 트랜잭션 전에 필요한 모든 데이터에 Lock을 미리 걸어주는 방법입니다. 하지만 데이터가 많으면 이 역시 데드락이 발생할 수 있습니다. 회피기법은 타임스탬프 기법을 적용하여 데이터를 시간 순서대로 제어하는 방법입니다.
16 |
17 |
18 | 출처
125 |https://idea-sketch.tistory.com/54
126 |https://jojoldu.tistory.com/520
127 |19 | 20 | ## ⭐ 개념 정리 21 | 22 | ### 트랜잭션(Transaction) 23 | * 데이터베이스의 논리적 작업 단위 24 | * 특징 (ACID) 25 | * 원자성 : All or Nothing, 결과가 모두 반영되거나 아무것도 반영되지 않아야 함 26 | * 일관성 : 트랜잭션 후에도 데이터베이스 상태는 무결성을 유지 27 | * 고립성 : 한 트랜잭션 중간에 다른 트랜잭션이 끼어들 수 없음 28 | * 지속성 : 트랜잭션으로 변화된 상태는 계속 유지되어야 함 29 | * TCL 30 | * COMMIT : 트랜잭션 성공하여 DB에 상태 반영 31 | * ROLLBACK : 트랜잭션 실패하여 기존 상태로 복구 32 | 33 | 34 |
35 | 36 | ### 회복 37 | * 외부/내부 장애로 데이터베이스가 일관성을 유지하지 못할 때 이를 유지하기 위한 방법 38 | * 회복 연산자 39 | * REDO : 백업본으로 변경 후, 로그 기록에 남은 성공 데이터를 DB에 적용 40 | * UNDO : 변경된 데이터를 취소하고 예전 데이터로 복구 41 | 42 | 43 |
44 | 45 | ### 동시성 제어 46 | * 여러 트랜잭션 간의 문제가 발생하지 않도록 트랜잭션의 실행 순서를 제어하는 기법 47 | 48 | | |T1|T2|발생문제| 허용여부| 49 | |---|---|---|---|---| 50 | |CASE1|READ|READ|X|허용| 51 | |CASE2|READ|WRITE|오손읽기, 유령데이터 읽기|허용/불가 선택| 52 | |CASE3|WRITE|WRITE| 갱신손실, 연쇄복구, 모순성| 절대 불가| 53 | 54 |
55 | 56 | ### 로킹(Locking) 57 | * 동시성 제어 방법으로 트랜잭션에 LOCK을 설정하여 LOCK 상태에서 다른 트랜잭션이 실행하지 못하도록 하는 기법 58 | * 2단계 로킹 59 | * 확장 단계 : LOCK을 걸 수만 있음 60 | * 축소 단계 : UNLOCK만 가능 61 | * 문제점 : 데이터가 많은 경우 교착상태에 빠질 수 있음 62 |
63 | 64 | ### 교착상태(DeadLock) 65 | * 여러 트랜잭션이 실행되지 못하고 무기한 대기 중인 상태 66 | * 해결 방법 67 | * 예방기법 : 트랜잭션 시작 전, 필요한 데이터에 LOCK을 모두 걸어주는 기법. 필요한 데이터가 많은 경우 무쓸모 68 | * 회복기법 : 자원 할당 시에 타임스탬프를 사용하여 시간 순서대로 제어하는 기법. 69 | -------------------------------------------------------------------------------- /02.database/phb/21.01.17.md: -------------------------------------------------------------------------------- 1 | # 21.01.17 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [인덱스란?](#인덱스index) 6 | * 책의 목차처럼 지정한 칼럼을 정렬하여 데이터를 쉽게 찾을 수 있도록 만든 테이블입니다. 7 | 8 | #### 💡 [인덱스 구조는?](#인덱스-구조) 9 | * 해쉬테이블과 B+Tree 구조가 있습니다. 해쉬테이블은 키 값에 해쉬함수를 적용하여 나온 주소값과 매칭하는 기법입니다. 하지만 부등호 연산이 많은 db에는 효과적이지 않은 방법입니다. B+Tree는 LinkedList로 연결된 구조입니다. 연결된 노드를 따라가면서 일치하는 값으로 가서 읽고 일치하지 않는 값이 나오면 즉시 중지합니다. B+Tree는 부등호 연산에 효율적입니다. 10 | 11 | #### 💡 [Index는 어디에 사용하는게 좋나요?](#인덱스를-사용하면-좋은-테이블) 12 | * 연산이 거의 없고 검색을 많이 하는 테이블에 사용하면 좋고 칼럼의 중복도가 낮은 곳에 사용하면 좋습니다. 13 | 14 | #### 💡 중복도가 높은 칼럼 예시 하나만 들어주세요. 15 | * 성별입니다. 사람은 여자, 남자밖에 없어서 최악의 경우 full scan을 해야합니다. 이 경우 인덱스를 설정하지 않는 것이 좋습니다. 16 | 17 | #### 💡 [인덱스를 따로 설정하지 않으면 어떻게 되는가?](#인덱스index) 18 | * 인덱스를 설정하지 않아도 기본적으로 PK값이 인덱스로 설정되어 있습니다. 19 | 20 | #### 💡 [속도를 위해 모든 칼럼에 인덱스를 넣으면 되지 않는가?](#인덱스index) 21 | * 인덱스는 인덱스 설정된 칼럼을 추가 저장 공간에 저장하고 재정렬해서 사용합니다. 그렇기 때문에 모든 칼럼에 인덱스를 넣게 되면 저장 공간을 많이 차지하게 됩니다. 또한, 데이터를 재정렬하기 때문에 삽입, 삭제, 갱신이 발생하게 되면 인덱스 테이블은 이 데이터에 대해 재정렬을 다시 수행해야하므로 오히려 성능 저하로 이어지게 됩니다. 22 | 23 | 24 |
25 | 26 | ## ⭐ 개념 정리 27 | 28 | ### 인덱스(Index) 29 | > CREATE INDEX 인덱스명 ON 테이블명(칼럼명) 30 | * 책의 목차와 같은 개념 31 | * 추가 저장 공간에 인덱스 테이블을 생성하고 데이터 정렬해서 사용 32 | * 검색 속도 향상 33 | * 인덱스를 설정하지 않은 경우, 기본적으로 PK값이 인덱스로 사용 34 | 35 | 36 |
37 | 38 | ### 인덱스를 사용하면 좋은 테이블 39 | * 규모가 작지 않은 테이블 40 | * 삽입, 삭제, 갱신이 자주 발생하지 않는 테이블 41 | * 데이터 중복도가 낮은 칼럼 42 | 43 | 44 |
45 | 46 | ### 인덱스 구조 47 | * 해쉬테이블 48 |  49 | 50 | 51 | * 해쉬함수에 의해 값이 주소값에 매핑된다. 52 | * equal 관계에서는 효율적이지만, 범위 연산이 많은 DB 연산에서는 비효율적 53 | 54 |
55 | 56 | * B+Tree 57 |  58 | 59 | * LinkedList로 연결 60 | * 일치하지 않는 값이 나오면 탐색을 중지 61 | * 만약 위의 그림에서 52번이 9번 블록 끝까지 있다면 10번 노드도 탐색 62 | 63 |
64 | 65 |
66 |
69 |
--------------------------------------------------------------------------------
/02.database/phb/README.md:
--------------------------------------------------------------------------------
1 | # 진행사항
2 |
3 | |날짜|설명|링크|
4 | |------|---|---|
5 | |21.01.12|DB/데이터모델링|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/phb/21.01.12.md)|
6 | |21.01.13|정규화|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/phb/21.01.13.md)|
7 | |21.01.14|RDBMS|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/phb/21.01.14.md)|
8 | |21.01.16|트랜잭션|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/phb/21.01.16.md)|
9 | |21.01.17|인덱스|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/phb/21.01.17.md)|7
10 |
11 |
--------------------------------------------------------------------------------
/03.Operating_system/hsh/21.02.17.md:
--------------------------------------------------------------------------------
1 | # 21.02.17
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 메모리 Swapping에 대해 설명하시오.
6 | * 메모리 관리를 위해 사용되는 기법 중 하나입니다. 프로세스를 불러들이기 위한 공간이 메모리에 부족하다면 현재 메모리에 적재된 프로세스들을 내보내고(swap out) 원하는 프로세스를 불러들이는 (swap in) 방식입니다.
7 |
8 | #### 💡 Fragmentation(단편화)에 대해 설명하시오.
9 | * 메모리 단편화란 메모리 공간이 비효율적으로 사용되어 저장 공간이 낭비되는 것을 말합니다.
10 | * 단편화는 외부 단편화와 내부 단편화로 나누어 집니다.
11 | * 내부 단편화는 할당한 영역 중 사용되지 않는 공간으로 인해 공간이 낭비되는 것을 의미합니다.
12 | * 외부 단편화는 메모리 여유 공간이 있지만 연속적인 공간이 아니라 사용할 수 없는 경우를 뜻합니다.
13 |
14 | #### 💡 메모리 단편화 해결 기법에 대해 설명하시오.
15 | * 내부 단편화 기법을 해결하는 세그멘테이션과 외부 단편화를 해결하는 페이징 기법이 있습니다.
16 | * Segmentation은 메모리를 서로 크기가 다른 논리적인 블록 단위인 세그먼트로 분할하여 메모리를 할당하는 기법입니다.
17 | * Paging은 프로세스를 일정 크기인 페이지로 잘라서 메모리에 적재하는 방식이다.
18 | > https://copycode.tistory.com/98?category=740133
19 |
20 | ## 심화 질문
21 |
22 | #### 💡
23 | 출처
67 |http://wiki.gurubee.net/pages/viewpage.action?pageId=29065492
68 |24 | 25 | ## 개념 정리 26 | 27 | ### ⭐ 메모리 관리 전략 28 | - 메모리 용량이 증가함에 따라 프로그램의 크기 또한 계속 증가하고 있기 때문에 메모리는 언제나 부족 29 | - 제한된 물리 메모리의 효율적인 사용과 메모리 참조 방식을 제공하기 위한 전략 30 | 31 | #### 논리 대 물리주소 공간 32 | * CPU가 생성하는 주소를 논리 주소, 메모리가 취급하는 주소를 물리 주소라 한다. 프로그램 실행 중에는 이와 같은 가상 주소를 물리 주소로 바꿔줘야 하는데, 이 매핑 작업은 메모리 관리기(Memory Management Unit)에서 실행된다. 33 | 34 | #### 관리 전략 35 | * Swapping(스와핑) 36 | * 프로세스가 실행되기 위해서는 메모리에 있어야 하지만, 프로세스는 실행 중에 임시로 예비저장장치(backup store)에 내보내여 졌다가 실행을 계속하기 위해 다시 메모리로 돌아올 수 있다. 37 |  38 | * 프로세스를 불러들이기 위한 공간이 메모리에 부족하다면 현재 메모리에 적재된 프로세스들을 내보내고(swap out) 원하는 프로세스를 불러들인다(swap in) 39 | * 상당한 Context-switching time이 발생한다. 또한 스와핑을 위해서는 현재 메모리의 프로세스가 완전히 휴지상태(idle)임을 확인해야 한다. 40 | 41 | 42 | #### Fragmentation(단편화) 43 | * 메모리 단편화란 메모리 공간이 비효율적으로 사용되어 저장 공간이 낭비되는 것을 말한다. 44 | #### 내부 단편화 45 |
46 | * 할당한 영역 중 사용되지 않는 공간으로 인해 공간이 낭비되는 것을 의미한다. 47 | * '내부'라는 용어는 할당한 영역 내부에 사용되지 않는 공간이 있다는 것을 뜻한다. 48 | * ex) 페이징 기법에서 한 페이지를 크게 할 경우 내부 단편화가 발생할 수 있다. 49 | * ex) 배열을 너무 크게 잡은 경우 50 | 51 | #### 외부 단편화 52 | * 메모리 여유 공간이 띄엄 띄엄 존재해서 실제로 사용할 수 없는 경우를 의미한다. 53 | * '외부'라는 용어는 사용할 수 없는 기억 장소가 할당된 영역 밖에 있다는 것을 뜻한다. 54 | * ex) 동적 메모리 할당 해제를 자주 하는 경우 55 | *  56 | * 57 | * 메모리 단편화로 일어날 수 있는 현상 58 | 1. 총 메모리 공간은 충분 하지만 실제 사용이 불가능할 수 있다. 59 | 2. 실제 사용 가능한 공간이 줄어들어 시스템 성능의 저하를 일으킬 수 있다. 60 | 3. 실제 사용할 수 있는 공간을 찾는 과정이 필요 61 | 4. 잦은 페이지 교체 62 | 63 | #### 메모리 단편화 해결 기법 64 | * 페이징/세그멘테이션 65 | * 세그멘테이션(segmentation) : 내부 단편화 해결, 외부 단편화 존재 66 | * 페이징(paing) : 외부 단편화 해결, 내부 단편화 존재 67 | 68 | * Segmentation(세그멘테이션)이란? 69 | * 메모리를 서로 크기가 다른 논리적인 블록 단위인 '세그먼트(segment)'로 분할하고 메모리를 할당하여 물리 주소를 논리 주소로 변환하는 것을 말한다. 미리 분할하는 것이 아니고 메모리를 사용할 시점에 할당된다. 70 | 71 | * Paging(페이징)이란? 72 | * 하나의 프로세스가 사용하는 메모리 공간이 연속적이어야 한다는 제약을 없애는 메모리 관리 방법이다. 외부 단편화와 압축 작업을 해소 하기 위해 생긴 방법론으로, 물리 메모리는 Frame 이라는 고정 크기로 분리되어 있고, 논리 메모리(프로세스가 점유하는)는 페이지라 불리는 고정 크기의 블록으로 분리된다.(페이지 교체 알고리즘에 들어가는 페이지) 73 |
74 | 75 | > https://m.blog.naver.com/s2kiess/220149980093 -------------------------------------------------------------------------------- /03.Operating_system/hsh/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.02.15|Process & Thread|[✅보러가기](/03.Operating_system/hsh/21.02.15.md)| 6 | |21.02.16|스케줄링|[✅보러가기](/03.Operating_system/hsh/21.02.16.md)| 7 | |21.02.17|메모리 관리|[✅보러가기](/03.Operating_system/hsh/21.02.17.md)| 8 | |21.02.20|가상 메모리|[✅보러가기](/03.Operating_system/hsh/21.02.20.md)| 9 | |21.02.23|Kernel|[✅보러가기](/03.Operating_system/hsh/21.02.23.md)| 10 | |-|-|-| 11 | 12 | 13 | -------------------------------------------------------------------------------- /03.Operating_system/hsh/images/Swapping.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/hsh/images/Swapping.png -------------------------------------------------------------------------------- /03.Operating_system/kmj/21.02.15.md: -------------------------------------------------------------------------------- 1 | # 21.02.15 2 | * 프로세스와 쓰레드 차이 3 | * 멀티쓰레드 4 | * ThreadSafe 5 | * 뮤텍스 vs 세마포어 6 | ## 주요 질문 7 | 8 | #### 💡 프로세스와 쓰레드 차이 9 | * 프로세스는 실행되고 있는 프로그램을 의미합니다. 10 | * 쓰레드는 프로세스 내부에서 실행되는 여러 흐름의 단위입니다. 11 | * 프로세스가 쓰레드보다 큰 단위입니다. 프로세스는 데이터를 공유할 수 없습니다. 반면, 스레드는 같은 프로세스 내부에 있는 stack 영역을 제외한 모든 영역을 공유할 수 있습니다. 12 | 13 | 14 | 15 | #### 💡 멀티 프로세스 vs 멀티 쓰레드 16 | 17 | 멀티 프로세스는 하나의 CPU를 여러 프로세스가 번갈아가면서 사용하는 방식입니다. 이 방식은 문맥교환 시 속도가 느려집니다. 18 | 반면 멀티 스레드는 CPU 1개로 여러 스레드를 생성하여 시스템의 컴퓨팅 속도를 높일 수 있습니다. 19 | 20 | #### 💡 context switching이란? 21 | 문맥 교환(context switch)이란 하나의 프로세스가 CPU를 사용 중인 상태에서 다른 프로세스가 CPU를 사용하도록 하기 위해, 이전의 프로세스의 상태(문맥)를 보관하고 새로운 프로세스의 상태를 적재하는 작업을 말합니다. 22 | 23 | 24 | #### 💡 PCB: Process Control Block 25 | * 특정 프로세스에 대한 중요한 정보를 저장하고 있는 운영체제의 자료구조입니다. 26 | * Context Switch 작업이 발생할 때 진행하던 작업을 PCB에 저장하고 CPU를 반환합니다. 27 | * 이후 CPU를 할당받게 되면 PCB에 저장되었던 내용을 불러와서 이전에 종료됐던 시점부터 다시 작업을 수행합니다. 28 | 29 | > https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/OS 30 | 31 | #### 💡 멀티쓰레드 장점 및 단점 32 | * 장점 33 | * 컨텍스트 스위칭(Context Switching) 시에 공유 메모리 만큼의 시간(자원) 손실이 줄어듭니다. 34 | 35 | * Stack을 제외한 모든 메모리를 공유합니다. 36 | 37 | * 단점 38 | * 하나의 스레드가 자신이 사용하던 데이터 공간을 망가뜨린다면, 그 공간을 공유하는 모든 스레드를 작동불능 상태가 된다는 점입니다. 39 | 40 | 41 | 42 | 43 | 44 | > https://blog.xeros.dev/63 45 | > https://you9010.tistory.com/136 [본질을 알고픈 개발자] 46 | 47 | #### 💡 ThreadSafe 48 | * 멀티 스레드 프로그래밍에서 데이터가 여러 쓰레드로부터 동시에 접근이 이루어져도 프로그램 실행에 문제가 없는 상태를 말합니다. 49 | * 자바에서 concurrent hash map, concurrent linked queue 를 사용함 50 | synchronized 키워드 추가하면 됨. 51 | * 추가로 reentranlock, atomicinteger 가 있다는데 안써봄 52 | 53 | * c++ 에서는 critical session 개념을 도입해서 연산들을 직렬화해준다고 함. 54 | https://heowc.dev/programming-study/repo/java/thread_safe%ED%95%98%EA%B2%8C_%EB%8D%B0%EC%9D%B4%ED%84%B0_%EA%B0%B1%EC%8B%A0%ED%95%98%EA%B8%B0 55 | ## 심화 질문 56 | #### 💡 쓰레드와 프로세스의 공통점 57 | * 쓰레드와 프로세스는 모두 각자의 스택 영역을 가집니다. 58 | 그리고 각각의 영역을 관리하는 ControlBlock이 존재합니다. 59 | * 쓰레드의 control block 은 TCB, 프로세스의 control block 은 PCB 60 | 61 | #### 💡 스레드를 사용할 때의 장단점이 뭔가요? 62 | 63 | * 장점 64 | 65 | 1. 스레드 간의 컨텍스트 스위칭이나 통신은 프로세스 대비 오버헤드가 적습니다. 66 | 67 | 68 | * 단점 69 | 70 | 1. 한 프로세스 내의 여러 스레드 중 스레드 하나가 잘못되면, 다른 스레드 모두가 영향을 받습니다. 71 | 2. 공유하는 변수를 여러 스레드가 동시에 변경하는 경우, 이상 동작의 발생 가능성이 높습니다. 72 | 73 | 74 | #### 💡 스레드에 스택을 독립적으로 할당하는 이유 75 | * 스택: 인자, 변수 등을 저장하는 메모리 공간 76 | * 스레드마다 독립적인 함수 호출, 실행을 하기 위해서 스레드에 스택을 독립적으로 할당합니다. 77 | #### 💡 PC레지스터를 스레드마다 독립적으로 할당하는 이유 78 | * PC레지스터: 스레드가 명령어의 어디까지 수행했는지 79 | * Context Switch 할 때 이전에 어디 부분까지 작업을 수행했는지 기억하기 위해서 PC 레지스터를 스레드마다 독립적으로 할당합니다. 80 | 81 | #### 💡 자바 스레드란? 82 | * 자바는 프로세스가 존재하지 않고 스레드만 존재합니다. 83 | * 자바 스레드는 JVM에 의해 스케줄링되는 코드블록입니다. 84 | * 개발자는 스레드 코드를 작성하고 JVM에 실행을 요청합니다. 85 |
86 | 87 | ## ⭐ 개념 정리 88 | 89 | 90 | 91 | ### 운영체제 92 | 하드웨어와 소프트웨어를 연결해주는 인터페이스 역할을 수행합니다. 93 | 94 | ### 프로세스 vs 스레드 95 | 96 |
97 |
98 |
99 |
100 |
101 |
102 | 103 | 104 | ### 프로세스의 주소공간 105 | 프로그램이 CPU에 의해 실행되면 프로세스가 생성되고 메모리에 '프로세스 주소 공간'이 할당됩니다. 이 때 프로세스 주소 공간은 코드, 데이터, 스택, 힙 영역으로 이루어져 있습니다. 106 | * 코드 : 프로그램 소스 코드 저장 107 | * 데이터 : 전역 변수 저장 108 | * 스택 : 함수, 지역 변수 저장 109 | * 힙: 동적 할당 시 사용 110 | 111 | ### 뮤텍스 vs 세마포어 112 | * 뮤텍스: 공유된 자원을 여러 스레드가 접근하는 것을 막음 113 | * synchronized, lock 사용 114 | * 동기화 대상이 1개 115 | * 세마포어: 공유된 자원의 데이터를 여러 프로세스가 접근하는 것을 막음 116 | * 공유 자원에 접근할 수 있는 프로세스의 최대 개수를 설정할 수 있다. 117 | * 동기화 대상이 1개 이상 118 |
119 | [출처] -------------------------------------------------------------------------------- /03.Operating_system/kmj/21.02.16.md: -------------------------------------------------------------------------------- 1 | # 21.02.16 2 | * 스케줄러 (장기,중기,단기) 3 | * CPU 스케줄러 (FCFS, SJF, SRT, Priority Scheduling, RR) 4 | 5 | ## 주요 질문 6 | 7 | #### 💡 스케줄러란? 8 | * 어떤 프로세스에게 자원을 할당할지 결정하는 운영체제의 커널 모듈입니다. 9 |
10 |
11 | #### 💡 장기 스케줄러
12 | * 작업 스케줄러라고도 부르며 어떤 프로세스를 Ready 단계에 넣을지 결정합니다. 디스크에서 어떤 프로그램을 가져와 커널(Ready Queue)에 등록할지 결정합니다.
13 | * 현대의 운영체제에서는 장기 스케줄러 없이 바로 프로세스에 메모리를 할당해 Ready Queue 에 넣습니다.
14 |
15 | #### 💡 중기 스케줄러
16 | * 메모리에 적재된 프로세스의 수를 관리합니다.
17 | * 메모리에 많은 수의 프로세스가 적재되면 프로세스 당 보유하는 메모리 양이 적어집니다. 그러면 CPU 수행이 필요한 프로세스의 주소도 메모리에 올려놓지 못하게 되어 성능이 저하됩니다.
18 | * 이 경우 SWAP OUT 작업을 통해 Ready상태에서 Suspended Ready상태로, Blocked 상태에서 Suspended Blocked 상태로 프로세스들을 옮깁니다.
19 | * 중지준비: suspended ready: 준비->디스크
20 | * 봉쇄준비: suspended block: 봉쇄->디스크
21 |
22 | #### 💡 단기 스케줄러
23 | * 어떤 프로세스를 다음번에 실행(Running) 상태로 만들 것인지 결정합니다.
24 | * 단기 스케줄러는 미리 정한 스케줄링 알고리즘에 따라 CPU를 할당할 프로세스를 선택합니다.
25 |
26 |
27 | #### 💡 CPU 스케줄링 알고리즘
28 | * Ready Queue 에 있는 프로세스들 중 어떤 프로세스를 CPU에 할당할 것인지 정하는 알고리즘입니다.
29 | * 이 알고리즘에는 선점 알고리즘과 비선점 알고리즘이 있습니다.
30 | * 선점 알고리즘은 우선순위가 높은 작업이 진행중인 작업을 중단시키고 CPU를 사용할 수 있는 알고리즘입니다.
31 | * 비선점 알고리즘은 CPU를 할당받은 작업이 끝날때까지 다른 작업이 CPU 를 사용할 수 없는 알고리즘입니다.
32 | 33 | 34 | #### 💡 CPU 스케줄링은 언제 발생하는가? 35 | 36 | 실행상태에서 대기상태로 전환될 때 (예, 입출력 요청) - Non preemptive(비선점) 37 | 실행상태에서 준비상태로 전환될 때 (예, 인터럽트 발생) - preemptive(선점) 38 | 대기상태에서 준비상태로 전환될 때(예, 입출력이 종료될 때) 39 | 종료될 때(Terminated) 40 | 41 | 42 | 43 | 44 | 45 | ## 심화 질문 46 | 47 | ### 비선점형 48 | #### 💡 FCFS(First Come First Served) 49 | * 먼저 들어온 프로세스가 CPU 를 먼저 할당받습니다. 50 | * 짧은 시간이 걸리는 프로세스가 CPU 를 오래 기다릴 수 있어 비효율적입니다. 51 | 52 | #### 💡 SJF(Shortest Job First) 53 | 54 | * 짧은 시간이 걸리는 프로세스가 CPU를 우선으로 할당하는 방법입니다. 55 | * 최소 평균 대기시간을 보장하지만 기아 현상이 발생할 수 있습니다. 56 | 57 | 58 | ### 선점형 59 | #### 💡 SRT(Shortest Remaining Time) 60 | * 짧은 시간이 걸리는 프로세스가 CPU를 우선으로 할당받는 방식입니다. 이 때, 프로세스의 남은 CPU사용시간(burst time) 보다 짧은 process 가 도착하면 cpu 를 선점합니다. 61 | * 단점: CPU 사용 시간을 정확하게 예측하기 어렵습니다. 62 | #### 💡 Priority Scheduling 63 | * 높은 우선순위를 가진 프로세스에게 CPU를 할당합니다. 64 | * 단점: 기아현상, 무한정지 상태가 발생할 수 있습니다. 65 | #### 💡 RR(Round Robin) 66 | * 프로세스의 할당시간이 지나면 다른 프로세스에게 CPU를 선점당하고 Ready queue 의 맨 뒤로 가는 방식입니다. 67 | * 어떤 프로세스도 할당 시간 이상 기다리지 않는 공정한 알고리즘입니다. 68 | * 평균 대기시간은 길어질 수 있지만, 응답시간은 짧아집니다. 69 | * 단점 70 | * 할당시간이 크면 FCFS와 같아집니다. 71 | * 할당시간이 작으면 문맥교환이 많이 발생해 오버헤드가 증가합니다. 72 | > https://velog.io/@ss-won/OS-CPU-Scheduling-Algorithm 73 |
74 | 75 | ## ⭐ 개념 정리 76 | 77 | ### 알고리즘에 대한 성능평가 기준 5가지 78 | * 프로세서 이용률(CPU Utilization) 79 | * 시간당 CPU를 사용한 시간의 비율 80 | 81 | * 처리율(Throughput) 82 | * 시간당 처리한 작업의 비율 83 | 84 | * 반환시간 또는 소요시간(Turnaround Time) 85 | * CPU burst time(쓰고 나갈때까지의 시간, 누적되지 않음) 86 | * 작업 제출 후 완료되는 순간까지의 소요시간 87 | * 대기시간(Waiting Time) 88 | * 대기열에 들어와 CPU를 할당받기까지 기다린 시간 89 | 90 | * 반응시간 또는 응답시간(Response Time) 91 | * 대기열에서 처음으로 CPU를 얻을때까지 걸린시간 92 | 93 | ### 주체별 CPU 성능 척도 94 | * 시스템 입장 95 | 👉🏻 CPU Utilization + Throughput 96 | 97 | * 사용자 입장 98 | 👉🏻 Turnaround Time + Waiting Time + Response Time 99 | 100 | 101 |
102 | -------------------------------------------------------------------------------- /03.Operating_system/kmj/21.02.17.md: -------------------------------------------------------------------------------- 1 | # 21.02.17 2 | * 교착상태 vs 기아상태 3 | * 메모리 관리전략 4 | * 메모리 관리 배경 5 | * Paging 6 | * Segmentation 7 | 8 | 9 | ## 질문 10 | 11 | #### 💡 [교착상태 vs 기아상태](#교착상태) 12 | * 교착상태는 각 프로세스가 다른 프로세스에 의해 획득된 리소스를 기다릴 때 발생합니다. 13 |
14 |
15 | * 기아상태는 우선순위가 높은 프로세스가 우선순위가 낮은 프로세스가 실행되는 것을 계속 막는 상태입니다.
16 | #### 💡 교착상태
17 | 발생조건
18 | * 다음 네 가지 조건이 모두 성립할 때 교착상태 발생 가능성 있음.
19 | * 상호배제(Mutual exclusion) : 프로세스들이 필요로 하는 자원에 대해 배타적인 통제권을 요구한다.
20 | * 점유대기(Hold and wait) : 프로세스가 할당된 자원을 가진 상태에서 다른 자원을 기다린다.
21 | * 비선점(No preemption) : 프로세스가 어떤 자원의 사용을 끝낼 때까지 그 자원을 뺏을 수 없다.
22 | * 순환대기(Circular wait) : 각 프로세스는 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있다.
23 |
24 | 해결방안
25 | * 위 4가지 발생조건 중 1개라도 성립되지 않으면 된다.
26 |
27 | #### 💡 기아상태
28 | * 해결방안
29 | * 오래 기다린 프로세스의 우선순위 높이기
30 | * 우선순위가 아닌 요청 순서대로 처리하는 큐 사용하기
31 |
32 | #### 💡 운영 체제에서 기아(Starvation) 란 무엇입니까?
33 | 특정 프로세스의 우선순위가 낮아서 원하는 자원을 계속 할당 받지 못하는 상태이다.
34 |
35 | 기아상태는 자원 관리 문제이다. 이 문제에서 대기중인 프로세스는 리소스가 다른 프로세스에 할당되어 있기 때문에 오랫동안 필요한 리소스를 얻지 못한다.
36 |
37 |
38 |
39 |
40 | #### 💡 운영 체제에서 에이징(Aging)는 무엇입니까?
41 | 에이징은 자원 스케줄링 시스템에서 기아를 방지하기 위해 사용되는 기술이다. 특정 프로세스의 우선순위가 낮아 무한정 기다리게되는 경우, 한번 양보하거나 기다린 시간에 비례하여 일정 시간이 지나면 우선순위를 한 단계씩 높여 가까운 시간 안에 자원을 할당받도록 하는 기법을 말한다.
42 |
43 | #### 💡 메모리 관리전략이란?
44 | * 제한된 메모리를 효율적으로 사용하기 위한 전략입니다.
45 | 효율적인 메모리 사용을 위해서 [반입전략](#반입전략), [배치전략](#배치전략), 교체전략이 있습니다.
46 |
47 | #### 💡 교체전략: Replacement
48 |
49 | * 주기억장치의 영역이 모두 사용중일 때, 사용중인 영역중 어느 영역이랑 교체해서 사용할 것인지 결정하는 전략입니다.
50 | * 종류에는 FIFO, OPT, LRU, LFU, NUR, SCR 등이 있습니다.
51 |
52 | #### 💡 가상기억장치
53 | * 보조기억장치의 일부를 주기억장치처럼 사용하는 장치입니다.
54 | * 주기억장치의 용량보다 큰 프로그램을 실행하기 위해 사용합니다.
55 | * 가상기억장치의 구현 방법에는 페이징 기법과 세그먼테이션 기법이 있습니다.
56 |
57 | #### 💡 페이징 기법
58 | * 영역을 동일한 크기로 나눈 후 크기가 동일한 페이지를 영역에 적재시켜 실행하는 기법입니다.
59 | * 페이지: 일정한 크기로 나눈 단위.
60 | * 내부 단편화 발생 가능
61 |
62 | 단편화: 빈 기억공간
63 | #### 💡 페이징의 장점과 단점은?
64 |
65 | 장점: 메모리를 페이지단위로 가져와서, 프로세스의 효율적인 운영이 가능하다.
66 |
67 | 단점: 페이지 크기별, 단위별로 페이지 폴트 현상이 발생할 수 있다.
68 | #### 💡 세그멘테이션 기법
69 | * 가상 기억장치의 프로그램을 다양한 크기로 나눈 후 주기억장치에 적재시켜 실행하는 방법입니다.
70 | * 세그먼터: 다양한 크기로 나눈 단위
71 | * 외부 단편화 발생 가능
72 | #### 💡 페이지 교체 알고리즘
73 | * FIFO(first in first out)
74 | * 메모리에 올라온지 가장 오래된 페이지 교체
75 | * 최적(Optimal) 페이지 교체
76 | * 앞으로 가장 오랫동안 사용되지 않을 페이지 교체
77 | * LRU(Least Recently Used)
78 | * 최근에 가장 오랫동안 사용하지 않은 페이지 교체
79 | * LFU(Least Frequently Used)
80 | * 사용 빈도가 가장 적은 페이지 교체
81 | * NUR(Not Used Recently)
82 | * 최근에 사용하지 않은 페이지 교체
83 | * 변형비트, 참조비트 사용
84 | * 변형비트: 변경시 1, 아니면 0
85 | * 참조비트: 호출시 1, 아니면 0
86 |
87 |
88 |
89 | * SCR(Second Chance Replacement, 2차 기회 교체)
90 | * 가장 오랫동안 주기억장치에 있던 페이지 중 자주 사용되는 페이지 교체 방지
91 | * FIFO 단점 보완
92 |
93 |
94 | #### 💡 메모리 단편화 란 무엇인가?
95 |
96 | 메모리의 빈 공간 또는 자료가 여러 개의 조각으로 나뉘는 현상을 말한다. 할당한 메모리를 해제를 하게 되면 그 메모리 공간이 빈 공간(사용하지 않는 공간)이 되고 그 빈공간의 크기보다 큰 메모리는 사용할 수 없다. 그리하여 이 공간들이 하나 둘 쌓이게 되면 수치상으로는 많은 메모리 공간이 남았음에도 불구하고, 실제로 사용할 수 없는 메모리가 발생한다.
97 |
98 |
99 |
100 |
101 |
102 | #### 💡 내부단편화와 내부단편화란?
103 |
104 | - 내부단편화
105 |
106 | : 분할된 영역이 할당된 프로그램의 크기보다 커서 사용되지 않고 남아 있는 빈 공간을 말한다.
107 |
108 | : 내부 단편화는 페이징에서 발생한다.
109 |
110 |
111 |
112 | - 외부단편화
113 |
114 | : 분할된 영역이 할당될 프로그램의 크기보다 작아서 모두 빈 공간으로 남아 있는 전체 영역을 말한다.
115 |
116 | : 외부 단편화는 세그먼테이션에서 발생한다.
117 |
118 |
119 |
120 |
121 |
122 | #### 💡 메모리 단편화 해결방법은?
123 |
124 | 메모리 압축(디스크 조각 모음), 메모리 통합(단편화가 발생된 공간들을 하나로 통합시켜 큰 공간으로 만드는 기법)
125 |
126 | 127 | 128 | 129 |
130 | 131 | ## ⭐ 개념 정리 132 | 133 | ### 반입전략 134 | * Fetch 135 | * 보조 기억장치에 보관중인 데이터를 언제 주기억장치로 옮길 것인지 136 | * 요구반입: 요구할때 옮긴다. 137 | * 예상반입: 사용될 것을 미리 예상해서 옮긴다. 138 | 139 | ### 배치전략 140 | * Placement 141 | * 새로 반입되는 데이터를 주기억장치의 어느 위치에 놓을것인지 142 | * 최초 적합: FirstFit: 프로그램이나 데이터가 들어갈 수 있는 크기의 빈 영역 중 첫번째 영역에 배치 143 | * 최적 적합 BestFit : 단편화를 가장 작게 남기는 영역에 배치 144 | * 최악적합: WorstFit : 단편화를 가장 많이 남기는 분할영역에 배치 145 | 146 | 147 | 148 | -------------------------------------------------------------------------------- /03.Operating_system/kmj/21.02.20.md: -------------------------------------------------------------------------------- 1 | # 21.02.20 2 | * 가상 메모리 3 | * 캐시의 지역성 4 | * 파일 시스템 5 | 6 | ## 주요 질문 7 | 8 |
9 | 10 | ## 심화 질문 11 | #### 💡 파일 시스템이란 12 | * 컴퓨터에서 파일이나 자료를 쉽게 발견할 수 있도록 유지 및 관리하는 방법입니다. 13 | #### 💡 파일 시스템 개발 목적 14 | * 하드디스크와 메인 메모리의 속도 차이를 줄이기 위함입니다. 15 | * 하드디스크 용량을 효율적으로 이용하기 위함입니다. 16 | 17 |
18 | 19 | ## ⭐ 개념 정리 20 | 21 | ### 가상메모리 22 | * 가상 메모리가 하는 일 23 | * 주기억장치의 용량보다 큰 프로그램을 실행하기 위해 사용합니다. 24 | * Demand Paging 25 | * 메모리 관리 메커니즘(MMU 메커니즘)을 사용해서 여러 프로세스가 시스템의 메모리를 효율적으로 공유할 수 있도록 하는 기술 26 | 27 | > https://jennysgap.tistory.com/entry/운영체제의-기초-17-Demand-Paging-1 [jennysgap] 28 | 29 | * 페이지 교체 알고리즘 30 | * FIFO(first in first out) 31 | * 메모리에 올라온지 가장 오래된 페이지 교체 32 | * 최적(Optimal) 페이지 교체 33 | * 앞으로 가장 오랫동안 사용되지 않을 페이지 교체 34 | * LRU(Least Recently Used) 35 | * 최근에 가장 오랫동안 사용하지 않은 페이지 교체 36 | * LFU(Least Frequently Used) 37 | * 사용 빈도가 가장 적은 페이지 교체 38 | * NUR(Not Used Recently) 39 | * 최근에 사용하지 않은 페이지 교체 40 | * 변형비트, 참조비트 사용 41 | * 변형비트: 변경시 1, 아니면 0 42 | * 참조비트: 호출시 1, 아니면 0 43 | 44 |
45 |
46 | * SCR(Second Chance Replacement, 2차 기회 교체)
47 | * 가장 오랫동안 주기억장치에 있던 페이지 중 자주 사용되는 페이지 교체 방지
48 | * FIFO 단점 보완
49 |
50 | 51 | 52 | ### 캐시(Cache) 53 | * 정의: 캐시란 프로세서와 메인 메모리간의 처리 속도 차이를 보완하기 위한 고속 버퍼입니다. 54 | (버퍼: 데이터를 A에서 B 로 전송하는 동안 일시적으로 그 데이터를 보관하는 메모리) 55 | * 캐시는 메인 메모리에서 데이터를 가져와서 프로세서에 전달합니다. 56 | 57 | ### 캐시 적중, 캐시 실패 58 | * 캐시 적중(Cache Hit) 59 | * 프로세서에 있는 데이터가 참조하려는 데이터인 경우 60 | * 캐시 실패(Cache Miss) 61 | * 프로세서에 있는 데이터가 참조하려는 데이터가 아닌 경우 62 | 63 | ### 캐시의 지역성 64 | * 지역성이란? 65 | * 기억장치의 특정 영역에만 참조가 집중적으로 발생하는 특성 66 | * 캐시의 적중률을 극대화하기 위해 지역성 원리를 사용합니다. 67 | * 공간 지역성, 시간 지역성으로 구분된다. 68 | * 공간 지역성 69 | * 의미: 참조된 주소와 인접한 주소의 데이터가 참조되는 특성 70 | * 발생상황 71 | * 프로그램이 명령어를 순차적으로 실행할 때 72 | * 배열 순회 73 | * 시간 지역성 74 | * 의미: 최근에 참조된 주소의 데이터를 가까운 시간 내에 계속 참조하는 특성 75 | * 발생 상황 76 | * for문 77 | * while문 78 | >https://blackjellybear.tistory.com/31 79 | 80 | ### 파일 시스템 81 | * 정의 82 | * 운영체제가 저장 매체에 파일을 쓰기 위한 자료구조 또는 알고리즘 83 | * 디스크에 존재하는 데이터와 프로그램을 저장하고, 접근할 수 있는 기법 84 | * 파일 시스템의 디스크 할당 방식 85 | * 연속 할당 방식 86 | * 인접한 연속의 공간에 할당 87 | * 요구되는 크기만큼의 인접한 공간이 존재해야 함 88 | * 파일의 크기가 변하면 문제가 됨 89 | * 불연속할당 방식보다 빠름 90 | * 불연속 할당 방식 91 | * 인접하지 않은 공간에 할당 92 | * 해당 정보가 어디에 흩어져 있는지 위치정보를 따로 저장, 관리해야함. 93 | * 파일의 크기가 커져도 할당이 비교적 쉬움 94 | * 일반적으로 불연속 할당방식이 사용됨 95 | 96 | * 저장매체에 효율적으로 파일을 저장하는 방법 97 | * 블록체인 기법 98 | * 같은 파일정보를 저장하는 블록을 체인(포인터)로 연결 99 | * 원하는 정보를 검색할 때 처음부터 읽어야 함 100 | * 인덱스 블록 기법 101 | * 위치정보를 인덱스 블록이라는 별도의 공간에 관리 102 | * 파일마다 인덱스 블록을 가짐 103 | * 데이터를 처음부터 읽을 필요가 없어서 검색 속도가 비교적 빠름 104 | * 단점: 파일 수가 늘어날수록 인덱스 블록을 저장하는 공간이 많이 소비됨 105 | * FAT(File Allocation Table) 106 | * 파일 시스템마다 위치정보를 FAT라는 자료구조에 저장 107 | * FAT 정보를 유실하면 손해가 크기 때문에 중복으로 관리 108 | * 데이터를 처음부터 읽을 필요가 없어서 검색 속도가 비교적 빠름 109 | >https://jiming.tistory.com/359 110 | >https://www.notion.so/File-System-9ce6c463b6e54484aeb497c96c8edaf7 111 | 112 |
113 | 114 | -------------------------------------------------------------------------------- /03.Operating_system/kmj/21.02.25.md: -------------------------------------------------------------------------------- 1 | # 21.02.25 2 | * 시스템 콜 3 | * IPC 4 | * 인터럽트 5 | ## 주요 질문 6 | 7 | 8 | 9 |
10 | 11 | ## 심화 질문 12 | 13 | 14 | 15 |
16 | 17 | ## ⭐ 개념 정리 18 | 19 | ## 시스템 호출 (System Calls) 20 | * 커널 영역의 기능을 사용자 모드가 사용할 수 있게 함 21 | = 22 | * 프로세스가 하드웨어에 접근해서 필요한 기능을 사용할 수 있게 함 23 | >https://luckyyowu.tistory.com/133 24 | ### 유형 25 | * 프로세스 제어 26 | * 파일 조작 27 | * 장치 관리 28 | * 정보 유지 29 | * 통신 30 | 31 |
32 | 33 | ## IPC (Interprocess Communication) 34 | * 여러 프로세스간 데이터를 주고받을 수 있도록 하는 메커니즘이다. 35 | * 종류 36 | * 공유 메모리 37 | * 메시지 시스템 38 | ### 공유 메모리 39 | * 다수의 프로세스에 의해 공유되는 메모리 영역 40 | > 프로세스는 공유 메모리 영역을 생성 41 | > 프로세스가 다른 프로세스의 공유 메모리 영역에 연결 42 | ### 메시지 시스템 43 | * 공유데이터 없이 데이터를 송수신할 수 있는 통신 44 | ### 직접통신 45 | ### 간접통신 46 | ### 동기화 47 |
48 | 49 | ## 인터럽트 50 | * 의미 51 | * CPU 가 프로그램을 실행하고 있을 때 예외상황이 발생하여 실행중인 일을 중단하고 다른 일을 하게끔 하는 것 52 | 53 | * 인터럽트 하는 이유 54 | * 입출력 연산이 CPU 명령 수행속도보다 느리기 때문 55 | 56 | ### 하드웨어 인터럽트 57 | * 하드웨엉가 발생시키는 인터럽트 58 | * CPU -> 하드웨어에게 일을 시킬 때 59 | * 하드웨어 -> CPU 에게 어떤 사실을 알려줄 떄 발생 60 | ### 소프트웨어 인터럽트 61 | * 소프트웨어가 발생시키는 인터럽트 62 | * 예외상황, System call 호출 시 발생 63 | ### 인터럽트 과정 64 | > process A 실행 중 디스크에서 어떤 데이터를 읽어오라는 명령을 받았다 65 | 66 | 1. process A는 system call을 통해 인터럽트를 발생시킨다. 67 | 2. CPU는 현재 진행 중인 기계어 코드를 완료한다. 68 | 3. 현재까지 수행중이었던 상태를 해당 process의 PCB(Process Control Block)에 저장한다. (수행중이던 MEMORY주소, 레지스터 값, 하드웨어 상태 등...) 69 | 4. PC(Program Counter, IP)에 다음에 실행할 명령의 주소를 저장한다. 70 | 인터럽트 벡터를 읽고 ISR 주소값을 얻어 ISR(Interrupt Service Routine)로 점프하여 루틴을 실행한다. 71 | 5. 해당 코드를 실행한다. 72 | 6. 해당 일을 다 처리하면, 대피시킨 레지스터를 복원한다. 73 | 7. ISR의 끝에 IRET 명령어에 의해 인터럽트가 해제 된다. 74 | 8. IRET 명령어가 실행되면, 대피시킨 PC 값을 복원하여 이전 실행 위치로 복원한다. 75 | 76 | >https://velog.io/@adam2/%EC%9D%B8%ED%84%B0%EB%9F%BD%ED%8A%B8 77 |
78 | 79 | 80 | 81 |
82 |
83 |
--------------------------------------------------------------------------------
/03.Operating_system/kmj/README.md:
--------------------------------------------------------------------------------
1 | # 진행사항
2 |
3 | |날짜|설명|링크|
4 | |------|---|---|
5 | |21.02.15|프로세스 vs 쓰레드, 멀티쓰레드, ThreadSafe, 뮤텍스 vs 세마포어|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/03.Operating_system/kmj/21.02.15.md)|
6 | |21.02.16|스케줄러(장기, 중기, 단기), CPU 스케줄러|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/03.Operating_system/kmj/21.02.16.md)|
7 | |21.02.17|교착상태 vs 기아상태 , 메모리 관리전략|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/03.Operating_system/kmj/21.02.17.md)|
8 | |21.02.20|가상메모리, 캐시의 지역성, 파일시스템|[✅보러가기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/03.Operating_system/kmj/21.02.20.md)|
--------------------------------------------------------------------------------
/03.Operating_system/kmj/images/NUR.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/kmj/images/NUR.png
--------------------------------------------------------------------------------
/03.Operating_system/kmj/images/booting.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/kmj/images/booting.png
--------------------------------------------------------------------------------
/03.Operating_system/kmj/images/deadlock.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/kmj/images/deadlock.png
--------------------------------------------------------------------------------
/03.Operating_system/kmj/images/kernelthread.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/kmj/images/kernelthread.png
--------------------------------------------------------------------------------
/03.Operating_system/kmj/images/multi-thread.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/kmj/images/multi-thread.png
--------------------------------------------------------------------------------
/03.Operating_system/kmj/images/process.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/kmj/images/process.png
--------------------------------------------------------------------------------
/03.Operating_system/kmj/images/scheduler.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/kmj/images/scheduler.png
--------------------------------------------------------------------------------
/03.Operating_system/lyj/1일차.md:
--------------------------------------------------------------------------------
1 | # 운영체제 1일차
2 |
3 | ## 프로세스와 스레드 차이
4 |
5 | **프로세스**는 **실행 중인 프로그램**입니다. 즉, 프로세스는 **운영체제로부터** 자원을 할당받는 **최소한의 작업의 단위**입니다. 프로세스는 독립된 메모리 영역 **Code, Data, Stack, Heap**을 할당받습니다.
6 |
7 | **스레드**는 프로세스 내에서 **실행되는 여러 흐름의 단위**입니다. 스레드는 프로세스 내에서 Stack 메모리 영역을 제외한 다른 메모리 영역을 같은 프로세스 내 다른 스레드와 공유합니다.
8 |
9 | ## 스레드가 스택은 따로 독립적으로 할당받는 이유
10 |
11 | 스택은 **함수 호출 시 전달되는 인자, 되돌아갈 주소값 및 함수 내에서 선언하는 변수** 등을 저장하기 위해 사용되는 메모리 공간입니다.
12 |
13 | 스택 메모리 공간이 독립적이라는 것은 독립적인 함수 호출이 가능하다는 것이고 이는 **독립적인 실행 흐름이 추가**되는 것입니다.
14 |
15 | 따라서 스레드의 정의에 따라 **독립적인 실행 흐름을 추가하기 위한 최소 조건** 으로 독립된 스택을 할당합니다.
16 |
17 | ## 멀티스레드
18 |
19 | 하나의 프로세스에 하나의 스레드, 즉 메인 스레드가 함께 생성됩니다. 하나의 프로세스는 여러 개의 스레드를 가질 수 있습니다.
20 |
21 | - 장점
22 |
23 | 멀티 프로세스로 실행되는 작업을 멀티 스레드로 실행할 경우, 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있습니다.
24 | Context Switching시 스레드는 Stack 영역만 바꾸어주면 되기 때문에 프로세스 간의 전환 속도보다 스레드 간의 전환 속도가 빠릅니다.
25 |
26 | - 단점
27 |
28 | 여러 스레드가 함께 전역 변수를 사용할 경우 운영체제가 스케줄링을 자동으로 해주지 않기 때문에 충돌이 발생할 수 있습니다. 따라서 스레드 간에 통신할 경우에는 충돌 문제가 발생하지 않도록 **동기화 문제**를 해결해야 합니다.
29 |
30 | 멀티스레드는 스레드끼리 같은 코드 블럭을 공유 하기 때문에 디버깅이 어렵습니다.
31 |
32 | ## 멀티스레드 vs 멀티프로세스
33 |
34 | 멀티프로세스는 프로그램을 여러 개 키는 것입니다. 멀티스레드는 하나의 프로그램 안에서 여러 작업을 해결하는 것입니다.
35 |
36 | 부모 프로세스와 독립적인 메모리 공간을 갖습니다. 따라서 PCB블록이 다르므로 Context Switching 오버 헤드가 많습니다.
37 |
38 | ## Thread-safe
39 |
40 | Thread safe는 멀티 스레드 프로그래밍 환경에서 일반적으로 어떤 **함수나 변수, 혹은 객체**가 **여러 스레드로부터 동시에 접근이 이루어져도 프로그램의 실행에 문제가 없는 것**을 말합니다.
41 |
42 | Thread-safe한 코드를 만들기 위해서는 **Critical Session**을 통해 스레드 내부에서 처리되는 **연산들을 직렬화** 하여 한 번에 한 스레드에서 연산이 수행되도록 만들어 주어야 합니다.
43 |
44 | - 참고자료
45 |
46 | [https://velog.io/@raejoonee/프로세스와-스레드의-차이](https://velog.io/@raejoonee/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EC%99%80-%EC%8A%A4%EB%A0%88%EB%93%9C%EC%9D%98-%EC%B0%A8%EC%9D%B4)
47 |
48 | [https://ohcode.tistory.com/2](https://ohcode.tistory.com/2)
49 |
50 | [https://velog.io/@emily0_0/OS-Process-Thread](https://velog.io/@emily0_0/OS-Process-Thread)
--------------------------------------------------------------------------------
/03.Operating_system/lyj/2일차.md:
--------------------------------------------------------------------------------
1 | # 운영체제 2일차
2 |
3 | ### 프로세스 상태
4 |
5 | 
6 |
7 | - **New** : 메모리에 프로세스가 올라간 상태를 말합니다. 즉, PCB를 획득한 것입니다.
8 | - Ready : 프로세스가 프로세서를 할당받기 위해 기다리고 있는 상태 프로세스는 준비상태 큐(스케줄링 큐)에서 실행을 준비하고 있으며 접수 상태에서 준비 상태로의 전이는 Job 스케줄러에 의해 수행된다.
9 | - Running : 준비상태 큐에 있는 프로세스가 프로세서를 할당받아 실행되는 상태이며 프로세스 수행이 완료되기 전에 프로세스에게 주어진 프로세서 할당 시간이 종료 되면 프로세스는 준비상태로 전환됩니다.
10 | - Waiting : 프로세스에 입출력 처리가 필요하면 현재 실행중인 프로세스가 중단되고, 입출력 처리가 완료될때까지 대기하고 있는 상태입니다.
11 | - Terminated : 작업이 완료됨 PCB가 사라진 상태
12 |
13 | ```jsx
14 | Dispatch : 준비 상태에서 대기하고 있는 프로세스 중 하나가 프로세서를 할당받아 실행 상태로 전이되는 과정
15 | Timeout (Interrupt) : 주어진 타임 슬라이스 동안 수행 완료되지 않은 프로세스가 준비 상태로 돌아가는 것
16 | Process Control Block : 프로세스 처리와 관련된 정보가 들어있는 블록
17 | Event Wait (running -> waiting) : I/O 입출력 발생 (CPU 사용 중 I/O 행위가 필요하며 대기 상태로 이동)
18 | Wake-Up (waiting ->ready) : I/O 요청이 완료되면 다시 ready 상태로 전이
19 | ```
20 |
21 | ### Context Switching
22 |
23 | 기존 프로세스의 상태나 레지스터의 값을 저장하고 다음 프로세스를 실행할 수 있도록 새로운 프로세스의 상태나 레지스터의 값을 교체하는 작업입니다.
24 |
25 | ### 스케줄링
26 |
27 | 여러 **프로세스**가 생성되어 실행될 때 자원이 필요합니다. 스케줄링이란 **운영체제가 제한된 자원**을 **어떤 프로세스부터 자원을 할당해줄지 결정하는** **작업**을 말합니다.
28 |
29 | ### 스케줄러
30 |
31 | - **장기스케줄러** ( new → ready )
32 |
33 | 어떤 프로세스에게 어떤 리소스를 할당할지 결정하는 스케줄러입니다.
34 |
35 | - **단기스케줄러** ( ready → running → waiting → ready)
36 |
37 | ready queue에 있는 프로세스 중 어떤 프로세스를 running 시킬지 결정하는 스케줄러입니다.
38 |
39 | - **중기스케줄러** (ready → suspended)
40 |
41 | 실행 중인 프로세스의 수 제어하는 스케줄러입니다. 메모리 공간을 위해 프로세스를 통째로 메모리에서 디스크에 swapping을 진행합니다.
42 |
43 | ### CPU 스케줄러
44 |
45 | ### 비선점(Non-preemptive) 스케줄링 : FCFS, SJF
46 |
47 | 하나의 프로세스가 CPU를 할당받아 실행하고 있을 때 우선순위가 높은 다른 프로세스가 CPU를 강제로 빼앗아 사용할 수 있는 스케줄링 기법입니다.
48 |
49 | 비선점 스케줄링의 **장점**은 **빠르게 우선순위가 높은 프로세스를 처리**할 수 있다는 것입니다.
50 |
51 | 비선점 스케줄링의 **단점**은 ****우선순위가 높은 프로세스가 생길 때마다 문맥교환이 일어나므로 오버헤드가 크다.
52 |
53 | - **FCFS** (**first come first served**)
54 |
55 | **ready queue에 도착 순서에 따라 프로세스에게 자원 할당**
56 |
57 | 장점
58 |
59 | 처리중인 프로세스에게 할당된 시간을 타 프로세스가 뺏지 않으므로 **문맥 교환이 일어나지 않아** 오버헤드 발생하지
60 |
61 | 단점
62 |
63 | 평균 응답시간이 길어질 수 있음
64 |
65 | - **SJF (Shortest Job First)**
66 |
67 | **실행시간이 가장 짧은 프로세스**에 먼저 자원 할당
68 |
69 | 장점
70 |
71 | - 평균 대기 시간 최소화
72 | - 시스템 내의 대기 프로세스 수 최소화
73 | - 많은 프로세스들에게 바른 응답 시간 제공
74 |
75 | 단점
76 |
77 | - 기아 현상, 한 프로세스를 처리하지 못하고 계속 연기되는 현상 발생 가능
78 |
79 | → **에이징** 기법으로 해결
80 |
81 | ### 선점 스케줄링 : SRT, Priority Scheduling, RR
82 |
83 | 이미 할당된 CPU를 다른 프로세스가 **강제로 빼앗아 사용할 수 없는** 스케줄 기법입니다.
84 |
85 | 선점 스케줄링의 장점은 프로세스 응답 시간을 예측하기 쉽다.
86 |
87 | 선점 스케줄링의 단점은 중요한 작업(짧은 작업)이 중요하지 않은 작업(긴 작업)을 기다리는 경우가 발생합니다.
88 |
89 | - **SRT**
90 |
91 | 현재 실행 중인 프로세스의 남은 시간과 readt queue에 프로세스의 실행시간이 가장 짧은 프로세스에게 자원을 할당
92 |
93 | 단점
94 |
95 | - 프로세스 생성 시 총 실행 시간 추정 작업 필요
96 | - 잦은 선점으로 문맥 교환/오버헤드가 증가
97 | - 실행 시간이 긴 프로세스들의 평균 응답 시간 길어짐
98 | - **Priority Scheduling**
99 |
100 | ready queue에서 우선순위가 가장 높은 프로세스에게 먼저 자원 할당
101 |
102 | 단점
103 |
104 | - 우선순위가 낮은 프로세스는 무기한 대기 현상이 일어남
105 |
106 | → **에이징** 기법으로 해결
107 |
108 | - **RR (Round Robin)**
109 |
110 | FCFS의 선점 형태
111 |
112 | 장점
113 |
114 | - 각 프로세스에 대한 응답 시간이 짧음
115 | - 대화형 시스템에 적합
116 |
117 | 단점
118 |
119 | 시간이 작을 경우 문맥교환 및 오버헤드가 자주 발생 가능
--------------------------------------------------------------------------------
/03.Operating_system/lyj/3일차.md:
--------------------------------------------------------------------------------
1 | # 운영체제 3일차
2 |
3 | ## 교착상태와 기아상태
4 |
5 | ### 교착상태
6 |
7 | 모든 작업이 각 작업의 락(공유자원을 잡고 있는 상황)이 풀리길 기다리는 상황
8 |
9 | ### 교착상태 발생조건
10 |
11 | - **상호배제** : 공유자원의 사용은 한번에 한 프로세스만 사용가능하다. 여러 프로세스가 접근 할 수 없다.
12 | - **점유대기** : 공유자원에 접근중이 한 프로세스가 접근해제를 하지 않고 다른 자원에 접근하려고 기다린다.
13 | - **비선점** : 한 프로세스가 자원의 사용을 끝낼 때까지 그 자원을 뺏을 수 없다.
14 | - **순환대기** : 각 프로세스는 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있다.
15 |
16 | 네가지의 조건 중 하나라도 만족하지 않는다면 교착상태는 일어나지 않는다.
17 |
18 | ```markdown
19 | 나한테 남친이 있다 내 친구도 남친이 있어
20 | 갑자기 친구 남친 뺏고 싶어
21 | 내 친구가 내 남친도 뺏고 싶어해
22 | 옆에 각자 남친 있으니까 서로 못뻇고 대기하는 상황
23 | ```
24 |
25 | ### 기아상태
26 |
27 | 병행 프로세스에서 프로세스가 실행되는데에 필수적인 자원을 끊임없이 사용하지 못하는 상황입니다.
28 |
29 | 우선순위(Priority) 스케줄링(Scheduling) 알고리즘입니다.
30 |
31 | - 스케줄러나 상호배제 알고리즘의 에러로부터 발생
32 | - 자원 누수에 의해 발생
33 | - 서비스 거부 공격에 의해 발생
34 |
35 | ## 메모리 단편화
36 |
37 | 메모리 단편화는 메모리 공간이 여러 공간으로 나뉘어져 사용 가능한 메모리가 충분하지만 프로세스에 메모리 할당(사용)이 불가능한 상태
38 |
39 | - 내부 단편화
40 |
41 | 프로세스가 **필요한 양보다 더 큰 메모리**가 할당되어 **메모리 공간이 낭비**되는 것을 말합니다.
42 |
43 | - 외부 단편화
44 |
45 | 메모리 할당 및 해제 작업이 진행될 때 메모리 공간은 충분하지만 **중간에 사용하지 않는 메모리**가 있어 프로세스에 공간 할당을 못한 것입니다.
46 |
47 | ## 프레임과 페이지
48 |
49 | ### 프레임
50 |
51 | **물리 메모리**를 일정 크기의 블록으로 나눈 단위를 말합니다.
52 |
53 | ### 페이지
54 |
55 | 보조기억장치를 이용하여 **가상 메모리**를 일정 크기의 블록으로 나눈 단위를 말합니다.
56 |
57 | ## Paging과 Segmentation
58 |
59 | ### **페이징(Paging)**
60 |
61 | 페이징은 **사용하지 않는 프레임을 페이지에 옮기고** **필요한 메모리를 페이지 단위로 프레임에 옮기는** 기법입니다
62 |
63 | ```markdown
64 | 프레임 → 페이지 : 사용하지 않는 프레임을!
65 | 페이지 → 프레임 : 메모리를 필요할 때!
66 | ```
67 |
68 | **Page Table**을 이용하여 프레임과 페이징을 연결하는 **Page Mapping**을 진행합니다.
69 |
70 | 페이징 기법을 사용하게되면 **연속적이지 않은 공간도 연속적으로 활용할 수 있기 때문에 위의 외부 단편화 문제점을 해결**할 수 있습니다. **페이지 단위를 작게 하면 내부 단편화 문제도 해결**할 수 있습니다.
71 |
72 | 하지만 그만큼 Mapping 과정 또한 늘어나기 때문에 Trade-Off 가 발생할 수 있습니다. 그리고 보통 페이지 단위에 알맞게 꽉채워 쓰는게 아니므로 내부 단편화 문제는 여전히 있습니다.
73 |
74 | ### 세그멘테이션(Segmentation)
75 |
76 | 가상 메모리를 서로 크기가 다른 세그멘트(Segment)를 논리적 단위로 분할해 사용하는 기법입니다.
77 |
78 | 세그먼트 테이블이 존재하는데, 이 세그먼트 테이블에는 세그먼트 번호, 시작주소, 세그먼트 크기가 들어있습니다.
79 |
80 | 프로세서가 세그먼트 테이블에 **테이블 번호, 사용할 메모리 크기**를 전달하면, 세그먼트 테이블에서 물리 메모리로 가서 해당 테이블 번호의 base(시작주소) 와 limit(세그먼트 크기) 를 비교하여 limit보다 메모리 공간이 작으면 인터럽트를 발생시켜 해당 프로세스를 강제 종료합니다.
81 |
82 | 
83 |
84 |
--------------------------------------------------------------------------------
/03.Operating_system/lyj/README.md:
--------------------------------------------------------------------------------
1 | # 진행사항
2 |
3 | | 날짜 | 설명 | 링크 |
4 | | -------- | ------------------------------------------------ | ------------- |
5 | | 21.02.15 | 프로세스/스레드 | [✅보러가기](https://github.com/Joylish/Tech_interview/blob/main/03.Operating_system/lyj/1%EC%9D%BC%EC%B0%A8.md) |
6 | | 21.02.16 | 스케줄링 | [✅보러가기](https://github.com/Joylish/Tech_interview/blob/main/03.Operating_system/lyj/2%EC%9D%BC%EC%B0%A8.md) |
7 | | 21.02.17 | 교착상태와 기아상태, Page와 Frame, 메모리 단편화 | [✅보러가기](https://github.com/Joylish/Tech_interview/blob/main/03.Operating_system/lyj/3%EC%9D%BC%EC%B0%A8.md) |
8 | | 21.02.20 | 가상메모리, 페이지 교체, 캐시의 지역성 | [✅보러가기](https://github.com/Joylish/Tech_interview/blob/main/03.Operating_system/lyj/4%EC%9D%BC%EC%B0%A8.md) |
9 |
--------------------------------------------------------------------------------
/03.Operating_system/lyj/images/process-status.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/lyj/images/process-status.png
--------------------------------------------------------------------------------
/03.Operating_system/lyj/images/segmentation.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/03.Operating_system/lyj/images/segmentation.png
--------------------------------------------------------------------------------
/03.Operating_system/phb/21.02.15.md:
--------------------------------------------------------------------------------
1 | # 21.02.15
2 |
3 | ## 주요 질문
4 | #### 💡 운영체제란 무엇인가요?
5 | * 컴퓨터 하드웨어 위에 설치되며 HW와 SW을 연결시켜주는 계층으로 HW와 SW의 인터페이스 역할을 합니다.
6 |
7 | #### 💡 [프로세스와 스레드에 대해 설명해주세요.](#프로세스스레드)
8 | * 프로세스는 현재 실행 중인 프로그램을 의미하며 스레드는 프로세스 내부에서 실행되는 작업 흐름의 단위입니다.
9 |
10 | #### 💡 [왜 멀티 스레드를 사용하는가?](#2-멀티-스레드)
11 | * 프로세스는 자원을 공유하지 않기 때문에 문맥 교환 오버헤드가 큰 반면 스레드는 stack만 변경해주면 되기 때문에 멀티 프로세스보다 처리 시간과 응답 시간이 빨라 멀티 스레드를 사용합니다.
12 |
13 | #### 💡 [멀티 스레드의 단점은 무엇인가?](#2-멀티-스레드)
14 | * 스레드는 자원을 공유하기 때문에 동시에 자원에 접근했을 때 문제가 될 수 있다는 점이 단점입니다.
15 |
16 | #### 💡 [Thread-safe가 뭐에요?](#3-thread-safe)
17 | * 멀티 스레드 환경에서 공유 자원에 여러 스레드 접근이 있어도 프로그램 실행에 문제 없음을 의미합니다.
18 |
19 | #### 💡 [임계영역이 뭐에요?](#뮤텍스세마포어)
20 | * 동시에 공유 자원 접근이 불가능한 영역을 의미합니다.
21 |
22 | #### 💡 [세마포어와 뮤텍스를 설명해주세요.](#뮤텍스세마포어)
23 | * 세마포어와 뮤텍스는 병행 처리를 위한 프로세스 동기화 기법입니다.
24 | * 세마포어는 count를 주어 count 값만큼 프로세스/스레드가 접근 가능하도록 하는 기법이며 뮤텍스는 lock/unlock으로 권한을 가진 프로세스/스레드만 접근할 수 있도록하는 기법입니다.
25 |
26 | #### 💡 [세마포어와 뮤텍스의 차이점이 뭐에요?](#차이점)
27 | * 뮤텍스는 오직 하나의 프로세스/스레드만 자원에 접근이 가능하고 세마포어는 count를 준 만큼 프로세스/스레드가 접근 가능합니다.
28 |
29 | #### 💡 [문맥 교환이 뭐에요?](#멀티-프로세스)
30 | * 하나의 프로세스가 다른 프로세스를 사용하기 위해 현재 상태를 PCB에 저장하고 새로운 프로세스 상태를 적재하는 것입니다.
31 |
32 | #### 💡 사용자 수준 스레드는 왜 다대일 매핑인가요?
33 | * 운영체제는 멀티 스레드를 포함하는 프로세스 한 단위로 프로세서를 할당하기 때문입니다.
34 |
35 | #### 💡 사용자 수준 스레드에서 하나의 스레드가 블록되면 왜 전체가 블록되나요?
36 | * 운영체제에서 멀티 스레드를 포함하는 프로세스를 하나의 스레드로 인식하기 때문입니다.
37 |
38 | 출처
84 | 85 | 출처적어주세요 86 |39 | 40 | ## ⭐ 개념 정리 41 | 42 | ## 프로세스/스레드 43 | ### 1. 프로세스(Process) 44 | * 실행 중인 프로그램 45 | * 메모리에 올라와 실행되고 있는 독립적인 인스턴스 46 | 47 | ### 2. 스레드(Thread) 48 | * 프로세스 내에 실행되는 작업 흐름의 단위 49 | 50 |  51 | 52 | #### 2-1. 사용자 수준 스레드 53 | * [유저모드](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.22.md#2-io-protection)에서 수행되는 스레드 연산 54 | * 다대일 스레드 매핑 55 | * 장점 56 | * 유연한 스케줄링 57 | * 높은 이식성 58 | * 낮은 오버헤드 59 | * 단점 60 | * 시스템 동시성 미지원 61 | * 스케줄링 우선 순위 미지원 62 | * 확장 제약 63 | 64 | #### 2-2. 커널 수준 스레드 65 | * [커널모드](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.22.md#2-io-protection)에서 수행되는 스레드 연산 66 | * 장점 67 | * 멀티 프로세서 환경에서 빠른 동작 68 | * 각 스레드를 개별 관리 69 | * 안정성과 다양한 기능 제공 70 | * 단점 71 | * 높은 오버헤드 72 | * 더 많은 자원 소비 73 | 74 |
75 | 76 |
77 |
81 |
82 | 프로세스/스레드 자세히 보기
78 | 79 | https://velog.io/@raejoonee/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EC%99%80-%EC%8A%A4%EB%A0%88%EB%93%9C%EC%9D%98-%EC%B0%A8%EC%9D%B4 80 |83 | 84 | ## 멀티 프로세스/멀티 스레드 85 | ### 1. 멀티 프로세스 86 | * 하나의 응용 프로그램을 여러 프로세스로 처리 87 | * 장점 88 | * 하나의 프로세스에 문제가 생겨도 다른 영향을 끼치지 않는다. 89 | * 단점 90 | * 문맥 교환 오버헤드 91 | * 시스템 콜 증가 92 | 93 | >**문맥 교환(Context Switching)** 94 | >* 하나의 프로세스가 CPU를 사용 중인 상태에서 다른 프로세스가 CPU를 사용하도록 하기 위해, **이전의 프로세스의 상태를 PCB에 보관하고 새로운 프로세스의 상태를 적재**하는 작업 95 | 96 |
97 | 98 | ### 2. 멀티 스레드 99 | * 하나의 응용 프로그램을 여러 스레드로 처리 100 | * 장점 101 | * 시스템 자원 효율성 증대 102 | * 자원을 공유 103 | * 응답시간 단축 104 | * 처리시간 감소 105 | * 단점 106 | * 프로세스 밖에서 스레드 제어 불가능 107 | * 자원 공유의 문제 108 | * 하나의 스레드 문제 발생 시, 프로세스 전체에 문제 109 | 110 | ### 3. Thread-safe 111 | * 멀티 스레드 환경에서 공유 자원에 여러 스레드의 접근이 있어도 프로그램 실행에 문제가 없음을 의미 112 | * 해결방법 (자세한 내용은 출처) 113 | * Re-entrancy 114 | * Thread-local storage 115 | * Mutual exclusion 116 | * Atomic operations 117 | 118 |
119 |
123 |
124 | 출처
120 | 121 | https://greatleee.github.io/what_is_the_thread_safety 122 |125 | 126 | ## 뮤텍스/세마포어 127 | ### 1. 상호배제(Mutual exclusive) 128 | * 병행 처리를 위한 프로세스 동기화 기법 129 | * 자원의 동시 공유를 피하기 위해 사용되는 알고리즘으로 임계 영역이라 불리는 코드 영역에 의해 구현 130 | > 임계영역(Critical Section) 131 | > 서로 다른 프로세스 혹은 스레드 등의 처리 단위가 같이 접근해서는 안 되는 공유 영역 132 | 133 | ### 2. 뮤텍스(Mutex) 134 | * lock/unlock 만을 지원 135 | * lock : 임계 구역에 들어갈 권한 부여 → 종료까지 대기 136 | * unlock : 임계 구역을 모두 사용 → 다른 프로세스/스레드 진입 가능 137 | 138 | ### 3. 세마포어(Semaphore) 139 | * 카운트를 조절하여 진입 가능한 프로세스/스레드 수를 조절 140 | 141 | ### 차이점 142 | * 뮤텍스는 오직 1개의 접근만 허용 143 | * 세마포어는 설정한 카운트만큼 접근이 허용 144 | -------------------------------------------------------------------------------- /03.Operating_system/phb/21.02.16.md: -------------------------------------------------------------------------------- 1 | # 21.02.16 2 | 3 | ## 주요 질문 4 | #### 💡 [라운드 로빈이 뭐에요?](#선점) 5 | * 스케줄링 방식 중 시분할 시스템을 위해 설계된 선점 방식의 알고리즘 입니다. 각 프로세스는 같은 크기의 CPU 시간을 할당받게 됩니다. 할당된 시간 안에 작업이 끝나지 않으면 해당 프로세스는 ready 큐에 들어가는 선입선출 방식입니다. 6 | 7 | #### 💡 [스케쥴링이 무엇인지와 목적을 설명해주세요](#1-스케줄링) 8 | * 스케줄링은 프로세서에게 필요한 자원을 어떻게 할당할 것인지 선택하는 알고리즘 입니다. 9 | * 단위 시간당 처리량을 최대화하고 효율적으로 자원을 할당하기 위한 목적을 가지고 있습니다. 10 | 11 | #### 💡 [비선점방식과 선점방식을 설명해주세요.](#3-스케줄링-방식) 12 | * 비선점 방식은 프로세스가 CPU를 점유하고 있는 경우 다른 프로세스가 CPU를 빼앗지 못하는 방식입니다. 비선점방식은 CPU를 중간에 가로채지 않기 때문에 응답시간 예측이 용이하다는 장점이 있지만 중요한 작업이 오래 기다리는 경우가 발생할 수 있다는 단점이 있습니다. 13 | * 선점 방식은 프로세스가 CPU를 점유하고 있어도 우선 순위가 높은 프로세스가 오면 CPU를 빼앗을 수 있는 방식입니다. 선점방식은 우선 순위가 높은 프로세스가 빠르게 처리할 수 있다는 장점이 있지만 잦은 Context Switching으로 오버헤드가 증가한다는 단점이 있습니다. 14 | 15 | #### 💡 [스케줄링 단계를 설명해주세요.](#4-스케줄링-단계) 16 | * 장기 스케줄러에 의해 어떤 프로세스가 준비 큐에 삽입될지 결정합니다. 단기 스케줄러는 스케줄링 알고리즘에 따라 CPU를 할당할 프로세스를 선택합니다. 선택된 프로세스는 Running 상태가 되고 작업이 끝나면 terminated 상태가 됩니다. 17 | 18 |
19 | 20 | ## ⭐ 개념 정리 21 | ### 1. 스케줄링 22 | #### Process Scheduling 23 | * 여러 프로세스에게 제한된 자원을 어떻게 나눠줄 것인지 선택하는 알고리즘 24 | 25 | #### CPU Scheduling 26 | * 하나의 프로세스 작업이 끝나면 CPU는 다음으로 어떤 프로세스를 작업할 것인지 선택하는 알고리즘 27 | 28 |
29 | 30 | ### 2. 스케줄링 목적 31 | * 자원 할당의 공정성 32 | * 단위 시간당 처리량 최대화 33 | * 적절한 반환시간 보장 34 | * 예측 가능성 보장 35 | * 오버헤드 최소화 36 | * 외 여러가지 목적 有 37 | 38 |
39 | 40 | ### 3. 스케줄링 방식 41 | #### 비선점 42 | * 한 프로세스가 CPU를 점유하는 동안 인터럽트 발생, I/O 또는 프로세스 종료 전까지는 다른 프로세스가 CPU를 점유 불가능 43 | * 장점 : 응답시간 예측 용이 44 | * 단점 : 중요한 작업이 기다리는 경우 발생 45 | 46 | |종류|설명| 47 | |-|-| 48 | |FCFS|먼저 들어온 것을 먼저 처리하는 FIFO 구조의 알고리즘| 49 | |SJF|Ready 큐에 있는 프로세스 중 실행 시간이 가장 작은 프로세스에게 자원 할당| 50 | |HRN|우선순위 계산식을 활용해 자원할당| 51 | 52 |
53 | 54 | #### 선점 55 | * 한 프로세스가 CPU를 점유하는 동안 다른 프로세스가 해당 CPU를 강제로 점유 가능 56 | * 장점 : 우선 순위가 높은 프로세스를 빠르게 처리 가능 57 | * 단점 : 잦은 문맥교환으로 오버헤드 증가 58 | 59 | |종류|설명| 60 | |-|-| 61 | |SRT|짧은 시간 순서대로 프로세스를 수행| 62 | |RR|각 프로세스는 같은 크기의 CPU 시간을 할당 받고 선입선출에 의해 수행| 63 | |다단계 큐|Ready 큐를 여러개 사용하는 기법| 64 | 65 |
66 | 67 | ### 4. 스케줄링 단계 68 |  69 | 70 | * 장기 스케줄러 71 | 메모리-디스크 사이의 스케줄링 - 속도, 호출 빈도↓ 72 | 어떤 프로세스를 준비 큐에 삽입할지 결정하며 메모리에 동시에 올라가는 프로세스 수를 조절 73 | 74 | * 중기 스케줄러 75 | 메모리에 적재된 프로세스의 수를 동적으로 조절 76 | 스와핑 : CPU 경쟁이 심해진 경우, 우선 순위가 낮은 프로세스를 잠시 제거하고 경쟁이 완화되었을 때 디스크에서 메모리로 불러와 중단된 부분부터 처리 77 | 78 | * 단기 스케줄러(CPU 스케줄러) 79 | CPU-메모리 사이의 스케줄링 - 속도, 호출 빈도↑ 80 | 스케줄링 알고리즘에 따라 CPU를 할당할 프로세스를 선택 81 | 82 | 83 |
84 | 85 | 86 |
87 |
--------------------------------------------------------------------------------
/03.Operating_system/phb/21.02.19.md:
--------------------------------------------------------------------------------
1 | # 21.02.19
2 |
3 | ## 주요 질문
4 | #### 💡 [가상 메모리가 무엇인가요?](#1-가상메모리)
5 | * 프로세스 전체가 메모리에 올라오지 않더라도 실행 가능하도록 한 기법입니다.
6 |
7 | #### 💡 [요구 페이징 기법은 무엇인가요?](#2-요구-페이징demading-page)
8 | * 프로그램 전체가 아니라 필요한 것만 메모리에 적재하는 기법입니다.
9 |
10 |
11 | #### 💡 요구 페이징 기법의 장점을 알려주세요.
12 | * 사용하지 않을 페이지를 가져오는 시간과 메모리 낭비를 줄일 수 있습니다.
13 |
14 | #### 💡 [페이지 교체 알고리즘이 언제 발생하나요?](#페이징-교체-알고리즘)
15 | * 프로세스가 특정 페이지를 요구하는데 메모리에 페이지가 없고 빈 프레임이 존재하지 않는 상황을 직면했을 때 발생합니다.
16 |
17 |
18 | 출처
88 |-
89 |
- https://www.crocus.co.kr/1373 90 |
- https://velog.io/@raejoonee/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C%EC%9D%98-CPU-%EC%8A%A4%EC%BC%80%EC%A4%84%EB%A7%81 91 |
19 | 20 | ## ⭐ 개념 정리 21 | ## **가상메모리** 22 | ### 1. 가상메모리 23 | * 물리 메모리 크기의 한계를 극복하기 위한 기술로 물리 메모리보다 큰 프로세스를 수행하기 위해 사용 24 | * 동적 할당으로 프로세스 실행 시 필요한 부분만 메모리에 적재 25 | 26 | ### 2. 요구 페이징(Demading Page) 27 | * 필요한 페이지만 메모리에 올리는 것 28 | * 동작 원리 29 |  30 | 1. CPU에서 페이지를 찾는다. 31 | 2. 페이지 테이블의 Valid bit 값이 1면 존재, 0이면 존재하지 않는다. 32 | 3. Valid bit가 0인 경우, 인터럽트가 발생하여 필요한 페이지에 메모리를 할당한다. 33 | 34 |
35 | 36 | > **인터럽트(interrupt)** 37 | > CPU가 프로그램을 실행하고 있는 중간에 I/O 장치나 예외 상황이 발생하여 처리가 필요한 경우 CPU에게 알려 처리할 수 있도록 하는 작업 38 | 39 | 40 |
41 |
46 |
47 | 참고
42 |-
43 |
- https://velog.io/@codemcd/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9COS-15.-%EA%B0%80%EC%83%81%EB%A9%94%EB%AA%A8%EB%A6%AC 44 |
48 | 49 | ## **페이지 교체 알고리즘** 50 | * 페이지를 요구했을 때, 메모리가 가득 차있고 요구하는 페이지가 메모리에 없으면 어떤 페이지를 디스크로 내리고 요구 페이지를 가져올 것인지 정하는 알고리즘 51 | 52 | * 페이징 교체 알고리즘 53 | |종류|설명| 54 | |-|-| 55 | |FIFO|들어온 순서대로 메모리에서 페이지를 내리고 요구하는 페이지를 적재| 56 | |OPT|가장 오랫동안 사용되지 않을 페이지를 제거 (현실적으로 불가능)| 57 | |LRU| 최근에 사용하지 않은 페이지는 나중에도 사용하지 않을 것이라는 개념으로 가장 오랫동안 사용되지 않은 페이지를 교체| 58 | |LFU|참조 횟수가 가장 작은 페이지를 교체| 59 | |MFU|참조 횟수가 가장 많은 페이지를 교체| 60 | 61 |
62 |
67 |
--------------------------------------------------------------------------------
/03.Operating_system/phb/21.02.20.md:
--------------------------------------------------------------------------------
1 | # 21.02.20
2 |
3 | ## 주요 질문
4 | #### 💡 [캐시 메모리가 무엇인가요?](#1-캐시cache)
5 | * 캐시간 주기억장치와 CPU 사이에서 둘 간의 속도 차이를 극복하기 위해 사용되는 메모리입니다.
6 |
7 | #### 💡 [페이지 적중율을 극대화 시키기 위한 방법에는 무엇이 있는지 간략히 설명해주세요.](#3-지역성locality-of-reference)
8 | * 페이지 적중율을 높이지 위해 지역성을 사용합니다.
9 | * 한 번 참조된 메모리 옆에 있는 메모리를 참조할 확률이 높다는 공간 지역성과 최근에 참조된 주소 내용은 곧 다음에 다시 참조된다는 시간 지역성이 있습니다.
10 |
11 | 참고
63 |-
64 |
- https://velog.io/@codemcd/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9COS-16.-%ED%8E%98%EC%9D%B4%EC%A7%80-%EA%B5%90%EC%B2%B4-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98 65 |
12 | 13 | ## ⭐ 개념 정리 14 | ## **캐시 메모리(Cache Memory)** 15 | ### 1. 캐시(Cache) 16 | * 데이터의 임시 보관소 17 | * 메인 메모리-CPU 사이에 존재하며 둘 간의 속도 차이를 극복하는 중간 버퍼 역할 18 | * 자주 사용하는 파일들을 가까운 곳에 저장 19 | * 휘발성 메모리 20 | 21 | ### 2. 캐싱 라인(Caching Line) 22 | * 캐시에 저장된 데이터의 자료구조(태그)의 묶음 23 | 24 | ### 3. 지역성(Locality Of Reference) 25 | * 적중율(Hit Ratio)을 극대화 시키기 위한 방법 26 | * 지역성의 원리 27 | |종류|설명| 28 | |-|-| 29 | |시간 지역성|최근에 참조된 주소의 내용은 곧 다음에 다시 참조된다는 특성| 30 | |공간 지역성|한 번 참조한 메모리의 옆에 있는 메모리를 다시 참조할 확률이 높다는 특성| 31 | 32 | ### 4. 캐시 사상 기법(Memory Mapping) 33 | * CPU의 가상 주소를 물리 주소로 변환하여 메모리에 전달하는 기법 34 | * 사상 기법 (이해 잘 안 감 다시 봐야할 듯...) 35 | |종류|설명| 36 | |-|-| 37 | |직접 매핑|메인 메모리와 캐시를 똑같은 크기로 나누고 순서대로 매핑하는 방법| 38 | |연관 매핑|캐시에 저장된 데이터들은 메모리 순서와 상관 없이 매핑하는 방법| 39 | |집합 연관 매핑|직접 사상과 연관 사상 방식을 조합한 방식| 40 | 41 | 42 | ### 5. 쓰기 정책(Write Policy) 43 | * CPU가 메모리에 쓰기를 실행할 때, 주기억장치를 갱신하는 절차에 관한 정책 44 | * 즉시 쓰기(Write-though) 45 | * CPU의 연산 결과가 캐시기억장치와 주기억장치 동시에 발생 46 | * 데이터의 일관성 보장 47 | * 매번 캐시와 주기억장치에 접근하므로 쓰기 시간이 길어짐 48 | 49 | * 나중 쓰기(Write-back) 50 | * 새롭게 생성된 데이터를 캐시기억장치에만 기록하고 주기억 장치는 나중에 기록 51 | * 새로운 블록에 의해 캐시기억장치에서 삭제되는 교체가 이뤄지기 전 주기억장치로 복사 52 | * 주기억장치에 기록하는 동작을 최소화 53 | 54 |
55 |
60 |
61 | 참고
56 |-
57 |
- https://wikidocs.net/65523 58 |
62 | 63 | ## **파일 시스템** 64 | ### 1. 파일 시스템 65 | * 하드디스크가 데이터를 관리 66 | * 하드디스크는 블록 단위로 읽고 쓴다. 67 | 68 | ### 2. 파일 할당 69 | #### 2.1 연속 할당 (Contiguous Allocation) 70 |  71 | 72 | * 연속된 블록에 파일을 할당 73 | * 디스크 헤더의 이동을 최소화하여 I/O 성능 향상 74 | * 순차 접근과 직접 접근이 가능 75 | * 외부단편화 76 | 77 | #### 2.2 연결 할당 (Linked Allocation) 78 |  79 | 80 | * LinkedList 방식으로 파일을 할당 81 | * 블록마다 주소를 저장하는 포인터 공간이 존재하며 다음 블록을 가리킨다. 82 | * 순차 접근은 가능하지만 직접 접근이 불가능 83 | * 낮은 신뢰성과 느린 속도 84 | 85 | #### 2.2.1 FAT (File Allocation Table) 86 |  87 | 88 | * 연결 할당의 문제점을 개선하기 위한 방법 89 | * 다음 블록으로 가리키는 포인터만 모아서 하나의 테이블을 만들어 블록에 저장 90 | * 테이블의 인덱스는 전체 디스크의 블록 91 | * 직접 접근이 가능 92 | 93 | #### 2.3 색인 할당 (Indexed Allocation) 94 |  95 | 96 | * 랜덤한 블록에 데이터를 할당 97 | * 인덱스 블록 : 할당된 블록번호를 하나의 블록에 테이블 형식으로 저장 98 | * 디렉토리 정보에 시작 블록이 아닌 인덱스 블록 번호를 저장 99 | 100 |
101 |
106 |
--------------------------------------------------------------------------------
/03.Operating_system/phb/21.02.22.md:
--------------------------------------------------------------------------------
1 | # 21.02.22
2 |
3 | ## 주요 질문
4 | #### 💡 [인터럽트는 언제 발생되나요?](#1-인터럽트)
5 | * CPU가 프로그램 수행 중에 I/O장치나 예외가 발생한 경우에 발생합니다.
6 |
7 | #### 💡 [인터럽트 과정을 간략히 설명해주세요.](#2-인터럽트-과정)
8 | * CPU가 프로그램을 실행합니다.
9 | * 인터럽트 요청이 들어옵니다.
10 | * CPU는 프로그램을 중단하고 다음 실행할 명령어와 현재 상태를 PCB 블록에 저장합니다.
11 | * ISR을 실행합니다.
12 | * 인터럽트 종료 후 기존 상태를 복구합니다.
13 | * 프로그램을 계속 실행합니다.
14 |
15 | #### 💡 [커널의 역할이 무엇인가요?](#1-커널)
16 | * 커널은 컴퓨터 하드웨어와 프로세스의 보안을 책임지며 한정된 시스템 자원을 효율적으로 관리합니다.
17 |
18 | 참고
102 |-
103 |
- https://velog.io/@codemcd/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9COS-18.-%ED%8C%8C%EC%9D%BC-%ED%95%A0%EB%8B%B9 104 |
19 | 20 | ## ⭐ 개념 정리 21 | ## 인터럽트(Interrupt) 22 | ### 1. 인터럽트 23 | * CPU가 프로그램을 실행하고 있을 때, I/O장치나 예외가 발생하여 처리가 필요할 경우 CPU에게 알려 일을 처리할 수 있도록 하는 것 24 | * 인터럽트 종류 25 | |종류|설명|예| 26 | |-|-|-| 27 | |하드웨어
인터럽트|CPU 외 주변장치나 디스크 컨트롤러에 의해 발생|입출력 인터럽트, 외부 인터럽트 등| 28 | |소프트웨어
인터럽트|CPU가 내린 명령이나 관련 모듈이 변하는 경우 발생|시스템콜, 예외처리 등| 29 | 30 |
31 | 32 | ### 2. 인터럽트 과정 33 |  34 | 35 | 1. 프로그램 실행 36 | 2. 인터럽트 요청 37 | 3. 프로그램 중단 38 | * 수행중이던 상태를 PCB블록에 저장 39 | * PC에 다음에 실행할 명령 주소 저장 40 | 4. 인터럽트 처리 41 | * 인터럽트 벡터를 읽고 ISR 주소를 얻어 ISR로 점프 42 | * 해당 코드 처리 43 | 5. PC값 복원하여 이전 실행 위치로 복원 44 | 6. 수행중이던 프로그램 재실행 45 | 46 |
47 | 48 | ## 커널(Kernel) 49 | ### 1. 커널 50 | * 컴퓨터 자원들을 관리하는 역할 51 | * HW-SW간의 커뮤니케이션을 관리하는 프로그램 52 | * 입출력을 관리하고 시스템 콜을 통해 컴퓨터에 있는 하드웨어가 처리할 수 있도록 요청을 변환하는 역할 → 사용자가 컴퓨터 자원 사용 가능 53 | * 구성요소 54 | |관리자|기능| 55 | |-|-| 56 | |테스크 관리자|물리적 자원인 CPU를 추상적인 태스크로 제공| 57 | |메모리 관리자|물리적 자원인 메모리를 추상적 자원인 페이지나 세그먼트로 제공| 58 | |파일 시스템 관리자|물리적 자원인 디스크를 추상적 자원인 파일로 제공| 59 | |네트워크 관리자|물리적 자원인 네트워크 장치를 추상적 자원인 소켓으로 제공| 60 | |디바이스 드라이버 관리자|각종 외부 장치에 대한 접근| 61 | * 커널 역할 (외에도 여러 기능 有) 62 | |역할|기능| 63 | |-|-| 64 | |프로세서 관리|처리속도 향상을 위해 여러 프로세서를 병렬로 연결
OS 처리 요구에 맞춰 동작할 수 있도록 각 프로세스에 필요한 프로세서를 효율적으로 할당하고
수행하도록 관리| 65 | |프로세스 관리|스케줄러를 이용하여 여러 프로세스가 동작 가능하도록 하며 외부 환경과 프로세스를 연결하고 관리| 66 | |메모리 관리|각 프로세스가 독립적인 공간에서 수행될 수 있도록 가상 주소 공간 제공| 67 | 68 |
69 | 70 | ### 2. I/O Protection 71 | #### 2.1 유저 모드(User Mode) 72 | * 어플리케이션 프로그램이 수행되는 모드 73 | * 시스템 데이터에 제한된 접근만이 허용되며 하드웨어에 직접 접근 불가 74 | * 시스템 서비스를 호출하면 커널 모드로 전환 75 | * mode bit 1 76 | 77 | #### 2.2 커널 모드(Kernel Mode) 78 | * 프로그램이 수행되다가 인터럽트에 걸려 운영체제가 호출되어 수행되는 모드 79 | * 시스템의 모든 메모리에 접근 가능하며 모든 CPU 명령을 실행 가능 80 | * 운영체제 코드나 디바이스 드라이버 같은 커널 모드 코드를 실행 81 | * mode bit 0 82 | 83 |  84 | 85 | > 시스템 콜(System Call) 86 | > 운영체제한테 요청하는 interface 87 | -------------------------------------------------------------------------------- /03.Operating_system/phb/21.02.23.md: -------------------------------------------------------------------------------- 1 | # 21.02.23 2 | 3 | ## 주요 질문 4 | #### 💡 [시스템 콜 처리 방식을 설명해주세요](#2-처리방식) 5 | * 시스템 콜 요청이 들어오면 유저 모드에서 커널모드로 변경됩니다. 커널은 요청받은 시스템 콜에 대한 서비스 루틴을 호출합니다. 서비스 루틴 처리 후에 커널모드에서 다시 유저모드로 돌아오게 됩니다. 6 | 7 |
8 | 9 | 10 | ## ⭐ 개념 정리 11 | 12 | ## 시스템 호출(System Calls) 13 | ### 1. 시스템 콜 14 | * 응용 프로그램에서 운영체제에게 시스템 자원을 요청하는 인터페이스 15 | 16 | ### 2. 처리방식 17 | 1. 사용자 프로세스가 시스템 콜 요청 (유저 모드 → 커널 모드) 18 | 2. 시스템 콜 구분을 위해 기능별로 고유번호를 할당하고 번호에 해당하는 제어루틴을 커널 내부에 정의 19 | 3. 커널은 요청받은 시스템 콜에 대응하는 기능 번호 확인 20 | 4. 기능 번호에 맞는 서비스 루틴 호출 21 | 5. 서비스 루틴 처리 후 유저 모드로 전환 22 | 23 | ### 3. 종류 24 | * 프로세스 제어 25 | * 파일 조작 26 | * 장치 관리 27 | * 시스템 정보 및 자원 관리 28 | * 통신 관련 29 | 30 |
31 |
37 |
38 | 참고
32 |-
33 |
- https://ypangtrouble.tistory.com/entry/%EC%8B%9C%EC%8A%A4%ED%85%9C-%EC%BD%9CSystem-Call 34 |
- https://medium.com/pocs/%EB%A6%AC%EB%88%85%EC%8A%A4-%EC%BB%A4%EB%84%90-%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%EA%B0%95%EC%9D%98%EB%85%B8%ED%8A%B8-2-78406a13c5c9 35 |
39 | 40 | ## IPC (Inter Process Communication) 41 | ### 1. IPC 42 |  43 | * 독립된 실행객체인 내부 프로세스 간의 통신 44 | * 커널 영역에 존재 45 | 46 |
47 | 48 | ### 2. IPC 설비 49 | * 데이터를 주고 받을 수 있는 공유 메모리가 필요 50 | 51 | |종류|사용 시기|공유 매개체|통신 단위|통신 방향|통신 가능 범위| 52 | |-|-|-|-|-|-| 53 | |PIPE|부모-자식|파일|stream|단방향|동일 시스템| 54 | |Named PIPE|모든 프로세스|파일|stream|단방향|동일 시스템| 55 | |Meesage
Queue|모든 프로세스|메모리|구조체|단방향|동일시스템| 56 | |Shared
Memory|모든 프로세스|메모리|구조체|양방향|동일시스템| 57 | |Memory Map|모든 프로세스|파일 + 메모리|페이지|양방향|동일시스템| 58 | |Socket|모든 프로세스|소켓|stream|양방향|동일 + 외부시스템| 59 | 60 |
61 |
67 |
--------------------------------------------------------------------------------
/03.Operating_system/phb/21.02.25.md:
--------------------------------------------------------------------------------
1 | # 21.02.25
2 |
3 | ## 주요 질문
4 | #### 💡 [리눅스 부팅 과정을 간단히 설명해주세요](#리눅스-부팅-과정)
5 | * 리눅스 부팅은 0단계부터 4단계까지 있습니다. 전원 공급, BIOS 단계, 부트로더 단계, 커널 로딩, init 프로세스 실행의 순서로 진행됩니다.
6 |
7 | #### 💡 [RISC와 CISC의 차이점을 알려주세요.](#CPU-아키텍처)
8 | * CISC는 복잡한 명령어 집합이며 RISC는 파이프라이닝 구조로 빠르고 단순한 명령어 집합입니다.
9 |
10 | #### 💡 [RISC가 단순하고 빠른 구조인데 왜 CISC를 사용하나요?](#2-cisccomplex-instruction-set-computer)
11 | * 많은 프로세서가 CISC로 구축되어 있어 모두 RISC로 변경하기에는 많은 비용이 소모되기 때문입니다.
12 | * 또, 호환성이 RISC보다 높습니다.
13 |
14 |
15 | 참고
62 |-
63 |
- https://doitnow-man.tistory.com/110 64 |
- https://mangkyu.tistory.com/9 65 |
16 | 17 | ## ⭐ 개념 정리 18 | ### 리눅스 부팅 과정 19 | * **0단계 : 전원 공급** 20 | * CPU 전원 공급과 메인보드 BIOS 프로그램 자동 실행 21 | > BIOS : 컴퓨터 켤 때 나오는 까만 배경에 흰 글씨이며 PC에 존재하는 모든 하드웨어와 소프트웨어의 기본 동작을 제어한다. 22 | 23 | * **1단계 : BIOS 단계** 24 | * 자체진단기능(POST(Post On Self Test)) 실행 25 | * 디스크로부터 부트 로더를 가져오기 26 | * 시스템 제어권을 부팅 로더에게 전달 27 | 28 | * **2단계 : 부트로더 단계** 29 | * 부트로더는 커널을 메모리에 올리는 역할 30 | * 커널 이미지를 불러오고 지배권을 커널에게 전달 31 | 32 | * **3단계 : 커널 로딩** 33 | * swapper 프로세스 호출 34 | * 커널이 사용할 장치 드라이브들을 초기화 35 | * init 프로세스 실행 36 | * **4단계 : init 프로세스 실행** 37 | * /etc/inittab 파일에 정의된 순서에 따라 시스템 초기화 38 | * 로그인 프롬프트가 나오는 화면까지 init 프로세스에 의해 실행 39 | 40 |
41 | 42 | 43 | ## CPU 아키텍처 44 | ### 1. RISC(Reduced Instruction Set Computer) 45 | * 축소 명령어 집합 컴퓨터 46 | * 명령어 개수가 적은 것을 의미 47 | * 파이프라이닝 기법을 적용 48 | * 간단한 명령어와 빠른 동작 속도 49 | * 프로그램 구성 시 상대적으로 많은 명령어 필요 50 | * 워드, 데이터 버스 크기, 실행 사이클 모두 동일 51 | * 회로 구성 단순 52 | * 단순한 컴파일러 53 | 54 | >파이프라이닝 : 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태로 연결된 구조. 55 | 56 | ### 2. CISC(Complex Instruction Set Computer) 57 | * 복잡 명령어 집합 컴퓨터 58 | * 복잡한 명령어가 수백개 이상으로 내부구조가 복잡 59 | * 다양한 명령어 길이 60 | * 프로그램 구성 시 적은 명령어로 구현 가능 61 | * 컴파일러 복잡 62 | * CISC를 사용하는 이유 63 | * 많은 프로세서가 CISC로 구축되어 있어 이것을 모두 변경하기에 많은 비용 소모 64 | * RISC에 비해 호환성이 좋음 65 | -------------------------------------------------------------------------------- /03.Operating_system/phb/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.02.15|프로세스/스레드|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.15.md)| 6 | |21.02.16|스케줄링|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.16.md)| 7 | |21.02.17|메모리 관리 전략|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.17.md)| 8 | |21.02.19|가상메모리 및 페이지 교체 알고리즘|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.19.md)| 9 | |21.02.20|캐시 및 파일 시스템|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.20.md)| 10 | |21.02.22|인터럽트, 커널|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.22.md) 11 | |21.02.23|IPC, 시스템콜|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.23.md) 12 | |21.02.25|리눅스 부팅과정, RISC/CISC|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/03.Operating_system/phb/21.02.25.md) 13 | 14 | -------------------------------------------------------------------------------- /04.Java/hsh/21.03.23.md: -------------------------------------------------------------------------------- 1 | # 21.03.23 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [객체지향 프로그래밍의 장점과 단점에 대해 설명하시오.](#oop의-4가지-특징) 6 | * 코드의 재사용성이 높아지고 유지보수가 쉬운 장점이 있습니다. 다만, 처리 시간이 비교적 오래 걸린다. 7 | 8 | #### 💡 [객체지향 프로그래밍의 5원칙에 대해 설명하시오.](#oop의-5원칙-solid) 9 | * SRP(단일 책임 원칙), OCP(개방-폐쇄 원칙), LSP(리스코프 치환 원칙), DIP(의존 역전 원칙), ISP(인터페이스 분리 원칙)을 말하며, 앞자를 따서 SOILD 원칙이라고 부릅니다. 프로그래머가 시간이 지나도 유지 보수와 확장이 쉬운 소프트웨어를 만드는데 이 원칙들을 적용할 수 있다. 10 | 11 | #### 💡 [객체지향 프로그래밍의 특징에 대해 설명하시오.](#oop의-4가지-특징) 12 | * 캡슐화, 상속, 추상화, 다형성 4가지 특징을 가지고 있습니다. 13 | * 캡슐화는 연관 있는 변수와 함수를 클래스로 묶는 작업을 의미합니다. 14 | * 상속은 자식 클래스가 부모 클래스의 특성과 기능을 물려받아 재사용성을 높이는 역할을 합니다. 15 | * 추상화란 인터페이스로 공통적인 특성들을 묶어 표현하는 것을 의미합니다. 16 | * 다형성의 대표적인 특징으로는 오버로딩, 오버라이딩이 있습니다. 17 | * 오버로딩은 같은 이름의 메서드가 매개변수의 유형과 개수에 다르도록 하는 기술입니다. 18 | * 오버라이딩은 상위 클래스가 가지고 있는 메서드를 하위 클래스가 재정의하는 기술입니다. 19 | 20 | #### 💡 [객체지향 설계 5원칙에 대해 설명해보시오.](#oop의-5원칙-solid) 21 | * SRP( Single Responsibility Principle ), 단일 책임 원칙 22 | * 객체는 단 하나의 책임만 가져야 한다는 원칙을 말합니다. 23 | * 시스템에 변화가 생기더라도 영향을 최소화 할 수 있다는 장점이 있습니다. 24 | * OCP ( Open-Closed Principle ), 개방-폐쇄 원칙 25 | * 기존의 코드를 변경하지 않으면서, 기능을 추가할 수 있도록 설계가 되어야 한다는 원칙을 말합니다. 26 | * 확장에 대해서는 개방적이고 수정에 대해서는 폐쇄적으로 설계해야 한다는 의미입니다. 27 | * L (LSP : Liskov’s Substitution Principle) 28 | * 자식 클래스는 최소한 자신의 부모 클래스에서 가능한 행위는 수행할 수 있어야 한다는 설계 원칙입니다. 29 | * I (ISP : Interface Segregation Principle) 30 | * 자신이 사용하지 않는 인터페이스는 구현하지 말아야 한다는 설계 원칙입니다. 31 | * D (DIP : ependency Inversion Principle) 32 | * 객체들이 서로 정보를 주고 받을 때 의존 관계가 형성되는데, 이 때 객체들은 나름대로의 원칙을 갖고 정보를 주고 받아야 한다는 설계 원칙입니다. 33 | 34 |
35 | 36 | ## ⭐ 개념 정리 37 | 38 | ### OOP(Object-Oriented Programming) 39 | --- 40 | #### OOP 이전의 프로그래밍 방식은? 41 | * 절차적 프로그래밍 방식 42 | * 입력을 받아 명시된 순서대로만 처리하고 결과를 내는 방식 43 | 44 | * 구조적 프로그래밍 방식 45 | * 절차적 프로그래밍 방식의 개선된 형태 46 | * 프로그램을 함수단위로 나누고 함수끼리 호출하는 방식 47 | * 큰 문제를 해결하기 위해 문제를 작은 단위들로 나누어 해결하는 방식 48 | * Top-Down 방식이라고도 한다. 49 | 50 | * 객체 지향 프로그래밍 방식 51 | * 구조적 프로그래밍 방식의 개선된 형태 52 | * 큰 문제를 작게 쪼개는 것이 아니라, 작은 문제들을 해결하는 객체를 만든다. 53 | * 객체들을 조합해 큰 문제를 해결하는 Bottom-Up 방식 54 | 55 | #### OOP의 장점과 단점 56 | * 장점 57 | * 코드의 재사용성이 높아진다. 58 | * 유지보수가 쉽다. 59 | * 코드가 간결해진다. 60 | * 단점 61 | * 처리 시간이 비교적 오래 걸린다. 62 | * 프로그램 설계할 때 많은 고민과 시간을 투자해야한다. 63 | 64 | #### OOP의 5원칙 (SOLID) 65 | * S (SRP : Single Responsibility Principle) 66 | * 한 클래스는 하나의 책임만 가져야 한다. 67 | * 시스템에 변화가 생기더라도 그 영향을 최소화 할 수 있음. 68 | * 응집도(구성 요소들의 응집력) ⬆️ 69 | * 결합도(프로그램 구성 요소들 사이의 의존성) ⬇️ 70 | 71 | * O (OCP : Open/Closed Principle) 72 | * 확장에는 열려(Open) 있으나, 변경에는 닫혀(Closed)있어야 한다. 73 | * 기존의 코드를 변경하지 않으면서(closed), 기능을 추가할 수 있도록(open) 설계가 되어야 한다는 원칙 74 | 75 | * L (LSP : Liskov’s Substitution Principle) 76 | * 프로그램의 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다. 77 | 78 | * I (ISP : Interface Segregation Principle) 79 | * 특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다. 80 | 81 | * D (DIP : ependency Inversion Principle) 82 | * 추상화에 의존한다. 구체화에 의존하면 안된다. 83 | 84 | > https://victorydntmd.tistory.com/291 상세설명 85 | 86 | #### OOP의 4가지 특징 87 | 1. 캡슐화 88 | * 실제로 구현 부분을 외부에 드러나지 않도록 하는 것 89 | * 변수와 메소드를 하나로 묶음 90 | * 데이터를 외부에서 직접 접근하지 않고 함수를 통해서만 접근 91 | * ex) public, private, protected 92 | * public : 클래스 외부에서 접근 가능 93 | * private : 클래스 내부에서만 접근 가능 94 | * protected : 상속받은 자식 클래스에서만 접근 가능 95 | 2. 상속 96 | * 자식 클래스가 부모 클래스의 특성과 기능을 물려받는 것 97 | * 기능의 일부분을 변경하는 경우 자식 클래스에서 상속받아 수정 및 사용함 98 | * 상속은 캡슐화를 유지, 클래스의 재사용이 용이하도록 해 준다. 99 | 3. 추상화 100 | * 인터페이스로 클래스들의 공통적인 특성(변수, 메소드)들을 묶어 표현하는 것 101 | 4. 다형성 102 | * 어떤 변수,메소드가 상황에 따라 다른 결과를 내는 것 103 | * 오버로딩(Overloading) : 하나의 클래스에서 메소드의 이름이 같지만, 파라메터가 다른 것 104 | * 오버라이딩(Overriding) : 부모 클래스의 메소드를 자식 클래스의 용도에 맞게 재정의하여 코드의 재사용성을 높임 105 | -------------------------------------------------------------------------------- /04.Java/hsh/21.03.25.md: -------------------------------------------------------------------------------- 1 | # 21.03.25 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [non-static 멤버와 static 멤버의 차이](#-non-static-멤버와-static-멤버의-차이) 6 | * static 멤버는 클래스 당 하나만 생성되고 non-static 멤버는 객체마다 별도로 존재합니다. 따라서 static 멤버는 동일한 클래스의 모든 객체들에 의해 공유되는 특성을 가지고 있습니다. 7 | 8 | #### 💡 [Final 키워드의 용도에 대해 설명하시오.](#-final-키워드의-용도에-대해-설명하시오) 9 | * 변수, 메서드, 클래스에 사용 할 수 있으며 변수에 사용 시 값이 변경 불가능하고 메서드에 사용 시 오버라이딩을 못하게 만들며 클래스에 사용할 시에 상속을 할 수 없게 만든다. 10 | 11 | #### 💡 [Generic에 대해 설명하시오.](#-generic에-대해-설명하시오) 12 | * 자바에서 제네릭(generic)이란 데이터의 타입(data type)을 일반화한다(generalize)는 것을 의미합니다. 제네릭은 클래스나 메소드에서 사용할 내부 데이터 타입을 컴파일 시에 미리 지정하는 방법입니다. 13 | 14 | #### 💡 [Generic의 장점에 대해 설명하시오.] 15 | * 컬렉션 클래스에서 제네릭을 사용하면 컴파일러는 특정 타입만 포함 될 수 있도록 컬렉션을 제한합니다. 컬렉션 클래스에 저장하는 인스턴스 타입을 제한하여 런타임에 발생할 수 있는 잠재적인 모든 예외를 컴파일타임에 잡아낼 수 있도록 도와줍니다. 16 | 17 | 18 |
19 | 20 | ## ⭐ 개념 정리 21 | 22 | ### non-static VS static 23 | * non-static 멤버 24 | * 공간적 특성: 멤버는 객체마다 별도로 존재한다. 25 | * 인스턴스 멤버 라고 부른다. 26 | * 시간적 특성: 객체 생성 시에 멤버가 생성된다. 27 | * 객체가 생길 때 멤버도 생성된다. 28 | * 객체 생성 후 멤버 사용이 가능하다. 29 | * 객체가 사라지면 멤버도 사라진다. 30 | * 공유의 특성: 공유되지 않는다. 31 | * 멤버는 객체 내에 각각의 공간을 유지한다. 32 | 33 | * static 멤버 34 | * 공간적 특성: 멤버는 클래스당 하나가 생성된다. 35 | * 멤버는 객체 내부가 아닌 별도의 공간에 생성된다. 36 | * 클래스 멤버 라고 부른다. 37 | * 시간적 특성: 클래스 로딩 시에 멤버가 생성된다. 38 | * 객체가 생기기 전에 이미 생성된다. 39 | * 객체가 생기기 전에도 사용이 가능하다. (즉, 객체를 생성하지 않고도 사용할 수 있다.) 40 | * 객체가 사라져도 멤버는 사라지지 않는다. 41 | * 멤버는 프로그램이 종료될 때 사라진다. 42 | * 공유의 특성: 동일한 클래스의 모든 객체들에 의해 공유된다. 43 | 44 | > https://gmlwjd9405.github.io/2018/08/04/java-static.html 45 | 46 | ### Final 키워드 47 | * 상수정의에 사용 48 | * 상수에 언제든 값을 한번 저장하고 다음에 다시 바꾸지 않을때 사용한다. 49 | 50 | * 메서드에 사용 51 | * 오버라이딩(재정의)을 못하게 만든다. 52 | 53 | * 클래스에 사용 54 | * 상속을 못하게 만든다. 55 | 56 | * static final 57 | * 객체마다 값이 바뀌는 것이 아닌 클래스에 존재하는 상수이므로 선언과 동시에 초기화를 해 주어야하는 클래스 상수이다. 58 | 59 | ### java Generic(제네릭) 60 | * 모든 종류의 타입을 다룰 수 있도록 일반화된 타입 매개 변수(generic type)로 클래스나 메서드를 선언하는 기법 61 | -------------------------------------------------------------------------------- /04.Java/hsh/21.04.10.md: -------------------------------------------------------------------------------- 1 | # 21.04.10 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 [동등연산자(==)와 equals()의 차이에 대해 설명하세요.](#--equals-compareto-의-차이) 6 | * 동등연산자는 두 객체가 같은 메모리 공간을 가르키는지 확인을 할 때 사용하고 equals() 연산자는 두 객체의 값이 같은지를 확인할 떄 사용하는 메서드입니다. 7 | 8 | #### 💡 [java Reflection에 대해 설명하시오.](#java-reflection) 9 | * java reflection은 구체적인 클래스 타입을 알지 못해도, 그 클래스의 메소드, 타입, 변수들에 접근할 수 있도록 해주는 자바 API 입니다. 10 | 11 | #### 💡 [Lambda란 무엇이고 어떠한 장점이 있는가?](#java-lambda) 12 | * "식별자없이 실행가능한 함수" 함수인데 함수를 따로 만들지 않고 코드한줄에 함수를 써서 그것을 호출하는 방식입니다. 코드를 줄여 간단하게 작성 가능하고 가독성이 증가합니다. 13 | 14 | ## ⭐ 개념 정리 15 | 16 | ### Java 동기화, 비동기화 17 | * 동기화 방식(Syncronous) 18 | * 한 자원에 동시에 접근하는 것 제한 -> 순차적으로 진행 19 | * syncronized 키워드 사용 : 멀티 스레드 접근 제한 keyword 20 | * 비동기화 방식(Asyncronous) 21 | * 현재 실행 중인 명령이 종료되지 않아도 다음 명령 실행 가능 22 | 23 | 24 | ### == , equals(), compareTo() 의 차이 25 | 26 | * **==** 27 | * 항등 연산자(Operator) 이다. 28 | * 참조 비교(Reference Comparison), 주소 비교(Address Comparision) 29 | * 두 객체가 같은 메모리 공간을 가르키는지 확인한다. 30 | * **equals()** 31 | * 객체 비교 메서드이다. 32 | * 내용 비교 (Content Comparison) 33 | * 두 객체의 값이 같은지 확인한다. 34 | * 즉, 문자열의 데이터/내용을 기반으로 비교한다. 35 | * 기본 유형(Primitive Types)에 대해서는 적용할 수 없다. 36 | * 반환 형태: boolean type 37 | * 같으면 true, 다르면 false 38 | * **compareTo()** 39 | * Interface Comparable
60 |
61 | * 스트림은 사용 목적에 따라 입력 스트림과 출력 스트림으로 구분됩니다.
62 |
63 | ### java Lambda
64 | 1. 람다 함수(Lambda Function)란?
65 | * 람다 함수는 함수형 프로그래밍 언어에서 사용되는 개념으로 익명 함수라고도 한다.
66 | * Java 8 부터 지원되며, 불필요한 코드를 줄이고 가독성을 향상시키는 것을 목적으로 두고있다.
67 |
68 | 2. 람다 함수의 특징
69 | * 메소드의 매개변수로 전달될 수 있고, 변수에 저장될 수 있다.
70 | * 즉, 어떤 전달되는 매개변수에 따라서 행위가 결정될 수 있음을 의미한다.
71 | * 컴파일러 추론에 의지하고 추론이 가능한 코드는 모두 제거해 코드를 간결하게 한다.
72 | 3. 람다식 표현
73 | * 파라미터와 몸체로 구분된다.
74 | * 파라미터와 몸체 사이에 -> 구분을 추가하여 람다식을 완성시킨다.
75 | * 몸체 부분이 단일 행일 경우 중괄호와 return문을 생략할 수 있다.
76 |
77 | * 기존 방법
78 | ```java
79 | new Thread(new Runnable() {
80 | @Override
81 | public void run() {
82 | System.out.println("Thread!");
83 | }
84 | }).start();
85 | ```
86 |
87 | * 람다식
88 | ```java
89 | new Thread(() -> {
90 | System.out.println("Thread!");
91 | }).start();
92 | ```
--------------------------------------------------------------------------------
/04.Java/hsh/21.04.17.md:
--------------------------------------------------------------------------------
1 | # 21.04.10
2 |
3 | ## 주요 질문
4 | #### 💡 직렬화와 역직렬화에 대해 설명하시오.
5 | * 자바에서 직렬화와 역직렬화는 객체를 파일로 저장하거나 네트워크를 통해 전송하기 위해 제공되는 기능입니다.
6 | * 직렬화는 객체를 파일에 저장하거나 네트워크를 통해 전달 할 수 있도록 변환하는 과정입니다.
7 | * 역직렬화는 직렬화된 데이터를 불러와 다시 객체로 변환하는 과정입니다.
8 |
9 | #### 💡 클래스와 객체의 차이는 무엇인가요?
10 | * 클래스는 ‘설계도’, 객체는 ‘설계도로 구현한 모든 대상’을 의미합니다.
11 |
12 | #### 💡 객체와 인스턴스의 차이는 무엇인가요?
13 | * 클래스의 타입으로 선언되었을 때 객체라고 부르고, 그 객체가 메모리에 할당되어 실제 사용될 때 인스턴스라고 부른다.
14 |
15 |
16 | ## ⭐ 개념 정리
17 |
18 | ### java Garbage Collection(GC)
19 | * Java Application은 JVM(Java Viirtual Machine) 위에서 구동됩니다. JVM에서는 Java Application이 사용하는 메모리를 관리하고 있는데 이 JVM의 기능중 더 이상 사용하지 않는 객체를 청소하여 공간을 확보하는 GC라는 작업이 있습니다.
20 |
21 | * GC란 Garbage Collection(쓰레기 객체 정리, 이하 GC)의 약자입니다. Java Runtime시 Heap 영역에 저장되는 객체들은 따로 정리하지 않으면 계속해서 쌓이게되어 OutOfMemmory Exception이 발생할 수 있습니다. 이를 방지하기 위하여 JVM에서는 주기적으로 사용하지 않는 객체를 수집하여 정리하는 GC를 진행합니다.
22 |
23 | * Garbage Collector 역할
24 | 1. 메모리 할당
25 | 2. 사용중인 메모리를 인식
26 | 3. 사용하지 않는 메모리를 인식
27 |
28 | * GC 동작 방식
29 | > https://mangkyu.tistory.com/118
30 |
31 |
32 | ### java 직렬화, 역직렬화
33 | * 자바에서 직렬화와 역직렬화는 객체를 파일로 저장하거나 네트워크를 통해 전송하기 위해 제공되는 기능이다.
34 | * 객체는 '인스턴스 변수의 집합'이므로 객체를 저장/전송하는 것은 객체의 인스턴스 변수의 값을 저장/전송하는 것과 동일하다.
35 | * 궁극적으로 객체의 직렬화는 서드파티에서 객체를 사용하기 위한 것이다.
36 | * **직렬화**
37 | - 객체에 저장된 데이터를 I/O 스트림에 쓰기(출력) 위해 연속적인(serial) 데이터로 변환하는 것
38 |
39 | * **역직렬화**
40 | - I/O 스트림에서 데이터를 읽어서(입력) 객체를 만드는 것
41 |
42 | ```java
43 | // 객체를 직렬화하여 파일에 저장
44 | ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("objectfile.ser"));
45 | oos.writeObject(new Member());
46 |
47 | // 파일로부터 객체를 읽어 객체 생성
48 | ObjectInputStream ois = new ObjectInputStream(new FileInputStream("objectfile.ser"));
49 | Member member = (Member) ois.readObject(); // Object로 리턴되므로 명시적 형변환 필요
50 | ```
51 |
52 | ### 클래스,객체,인스턴스의 차이
53 | * 클래스(Class)
54 | * 객체를 만들어 내기 위한 **설계도** 혹은 틀
55 | * 연관되어 있는 변수와 메서드의 집합
56 | * 객체(Object)
57 | * 소프트웨어 세계에 **구현할 대상**
58 | * 클래스에 선언된 모양 그대로 생성된 실체
59 |
61 | * ***'클래스의 인스턴스(instance)'*** 라고도 부른다.
62 | * 객체는 모든 인스턴스를 대표하는 포괄적인 의미를 갖는다.
63 | * oop의 관점에서 클래스의 타입으로 선언되었을 때 '객체'라고 부른다.
64 | * 인스턴스(Instance)
65 | * 설계도를 바탕으로 소프트웨어 세계에 **구현된 구체적인 실체**
66 | * 즉, 객체를 소프트웨어에 실체화 하면 그것을 '인스턴스'라고 부른다.
67 | * 실체화된 인스턴스는 메모리에 할당된다.
68 | * 인스턴스는 객체에 포함된다고 볼 수 있다.
69 | * oop의 관점에서 객체가 메모리에 할당되어 실제 사용될 때 '인스턴스'라고 부른다.
70 | * 추상적인 개념(또는 명세)과 구체적인 객체 사이의 **관계** 에 초점을 맞출 경우에 사용한다.
71 | * *'~의 인스턴스'* 의 형태로 사용된다.
72 | * 객체는 클래스의 인스턴스다.
73 | * 객체 간의 링크는 클래스 간의 연관 관계의 인스턴스다.
74 | * 실행 프로세스는 프로그램의 인스턴스다.
75 | * 즉, 인스턴스라는 용어는 반드시 클래스와 객체 사이의 관계로 한정지어서 사용할 필요는 없다.
76 | * 인스턴스는 어떤 원본(추상적인 개념)으로부터 '생성된 복제본'을 의미한다.
--------------------------------------------------------------------------------
/04.Java/hsh/21.04.18.md:
--------------------------------------------------------------------------------
1 | # 21.04.18
2 |
3 | ## 주요 질문
4 | #### 💡 [오버로딩과 오버라이딩에 대해 설명하시오.](#overloading-overriding)
5 | * 오버로딩은 메서드의 이름은 같고 매개변수의 갯수나 타입이 다른 함수를 정의하는 것을 의미합니다.
6 | * 오버라이딩은 상위 클래스의 메서드를 하위 클래스에서 재정의 하는 것을 의미합니다.
7 |
8 | #### 💡 Call by Reference와 Call by Value의 차이에 대해 설명하시오.
9 | * Call by Value는 메소드의 매개변수의 값을 복사를 하여 처리를 하느냐, 아니면 직접 참조를 하느냐 차이를 의미합니다. Call by Value의 경우 인자로 받은 값이 보존되고 Call by reference의 경우에 메소드에 의해 원래의 값이 영향을 받게 됩니다.
10 |
11 | #### 💡 추상 클래스와 인터페이스의 차이에 대해 설명하시오.
12 | * 추상 클래스는 클래스 내 '추상 메소드'가 하나 이상 포함되거나 abstract로 정의된 경우를 말합니다. 반면 인터페이스는 모든 메소드가 추상 메소드인 경우입니다.
13 | * 추상 클래스는 그 추상 클래스를 상속받아서 기능을 이용하고, 확장시키는 데 있습니다. 반면에 인터페이스는 함수의 껍데기만 있는데, 그 이유는 그 함수의 구현을 강제하기 위해서 입니다.
14 |
15 |
16 | ## ⭐ 개념 정리
17 |
18 | ### Overloading, Overriding
19 | * Overloading
20 | * 두 메서드가 같은 이름을 갖고 있으나 인자의 수나 자료형이 다른 경우
21 | * Overriding
22 | * 상위 클래스의 메서드와 이름과 용례(signature)가 같은 함수를 하위 클래스에 재정의하는 것
23 |
24 | ### Call by Value, Call by Reference
25 | * Call by value(값에 의한 호출)
26 | * 메소드로 인자값을 넘길때 그 값을 복사하여 넘기는 형태이다. 따라서 이 방식으로 메소드 호출을 하면 메소드 내에서는 복사된 값으로 작업을 하기 때문에 원래의 값을 변경시키지 않는다.
27 | * Call by reference(참조에 의한 호출)
28 | * 인자값을 메소드로 넘겨 줄때 그 객체를 참조하는 주소를 넘겨주는 형태이다. 따라서 메소드 내에서도 원래의 값에 접근이 가능하다.
29 |
30 | > https://hyoje420.tistory.com/6
31 |
32 | ### 인터페이스(Interface)와 추상 클래스(Abstract class)의 차이
33 | * 추상클래스란?
34 | * 추상클래스는 일반 클래스와 별 다를 것이 없습니다. 단지, 추상 메서드를 선언하여 상속을 통해서 자손 클래스에서 완성하도록 유도하는 클래스입니다. 그래서 미완성 설계도라고도 표현합니다. 상속을 위한 클래스이기 때문에 따로 객체를 생성할 수 없습니다.
35 |
36 | * class 앞에 "abstract" 예약어를 사용하여 상속을 통해서 구현해야한다는 것을 알려주고 선언부만 작성하는 추상메서드를 선언할 수 있습니다.
37 | ```java
38 | abstract class 클래스이름 {
39 | ...
40 | public abstract void 메서드이름();
41 | }
42 | ```
43 |
44 | * 인터페이스란?
45 | * 추상클래스가 미완성 설계도라면 인터페이스는 기본 설계도라고 할 수 있습니다. 인터페이스도 추상클래스처럼 다른 클래스를 작성하는데 도움을 주는 목적으로 작성하고 클래스와 다르게 다중상속(구현)이 가능합니다.
46 |
47 | * 클래스는 크게 일반 클래스와 추상 클래스로 나뉘는데 추상 클래스는 클래스 내 '추상 메소드'가 하나 이상 포함되거나 abstract로 정의된 경우를 말합니다. 반면 인터페이스는 모든 메소드가 추상 메소드인 경우입니다. (자바 8에서는 default 키워드를 이용해서 일반 메소드의 구현도 가능합니다.)
48 |
49 | ```java
50 | interface 인터페이스이름 {
51 | public static final 상수이름 = 값;
52 | public abstract void 메서드이름();
53 | }
54 | ```
55 |
56 | * 목적의 차이
57 | * 인터페이스와 추상 클래스는 존재 목적이 다릅니다. 추상 클래스는 그 추상 클래스를 상속받아서 기능을 이용하고, 확장시키는 데 있습니다. 반면에 인터페이스는 함수의 껍데기만 있는데, 그 이유는 그 함수의 구현을 강제하기 위해서 입니다. 구현을 강제함으로써 구현 객체의 같은 동작을 보장할 수 있습니다.
58 |
59 | > https://brunch.co.kr/@kd4/6
--------------------------------------------------------------------------------
/04.Java/hsh/README.md:
--------------------------------------------------------------------------------
1 | # 진행사항
2 |
3 | |날짜|설명|링크|
4 | |------|---|---|
5 | |21.03.22|JAVA|[✅보러가기](/04.Java/hsh/21.03.22.md)|
6 | |21.03.23|OOP|[✅보러가기](/04.Java/hsh/21.03.23.md)|
7 | |21.03.25|-|[✅보러가기](/04.Java/hsh/21.03.25.md)|
8 | |21.04.10|-|[✅보러가기](/04.Java/hsh/21.04.10.md)|
9 | |21.04.17|-|[✅보러가기](/04.Java/hsh/21.04.17.md)|
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/04.Java/kmj/21.03.25.md:
--------------------------------------------------------------------------------
1 | # 21.03.25
2 |
3 | ## 주요 질문
4 | * non-static vs static
5 | * final
6 | * generic
7 | #### 💡 [질문1](#개념1)
8 | * 답변
9 |
10 | #### 💡 질문2
11 | * 답변
12 |
13 | #### 💡 질문3
14 | * 답변
15 |
16 |
17 |
18 | 19 | 20 | ## 심화 질문 21 | 22 | #### 💡 질문1 23 | * 답변 24 | 25 | #### 💡 질문2 26 | * 답변 27 | 28 | #### 💡 질문3 29 | * 답변 30 | 31 | 32 |
33 | 34 | ## ⭐ 개념 정리 35 | 36 | ### java의 non-static 멤버와 static 멤버의 차이 37 | * non-static (인스턴스 멤버) 38 | * 객체마다 갖고 있어야 하는 성질 39 | * 각 객체마다 1개씩 생긴다. 40 | * static 멤버(클래스 멤버) 41 | * 오직 1개여야하는 성질 42 | * 클래스마다 1개씩 생긴다. 43 |  44 | 45 | ### java의 main메서드가 static인 이유 46 | * main메서드는 가장 먼저 실행돼야 하기 때문이다. 47 | #### public을 붙이는 이유 48 | * 어떤 패키지의 어떤 클래스에 선언될지 모르는 main메서드를 호출하기 위해서 49 | ### java의 final 키워드 (final, finally, finalize) 50 | #### 사용의도 51 | * 변수, 함수, 클래스를 명시적으로 제한하기 위해서 52 | * 코드 가독성을 증가하기 위해서 53 | #### final 54 | * final 클래스는 상속하지 못한다. 55 | * final 메서드는 자식클래스에서 재정의하지 못한다. 56 | * final 변수는 선언 이후 변경하지 못한다. 57 | #### finally 58 | * try-catch와 함께 사용되며 필수 요소는 아니다. 59 | * 예외 발생 유무와 상관없이 무조건 수행된다. 60 | #### finalize 61 | * Object클래스에 포함된 메서드로 Garbage Collection이 수행될 때 더이상 사용되지 않는 자원을 종료하는 메서드이다. 62 | ### java의 제네릭과 c++의 템플릿 차이 63 | * java의 제네릭 64 | * 클래스 내부에서 사용할 데이터 타입을 인스턴스를 생성할 때 확정하는 것이다. 65 | * 객체 타입을 컴파일 시에 확인하기 때문에 타입 안정성을 높이고, 형변환의 번거로움이 줄어든다. 66 | * c++의 템플릿 67 | * 기능은 명확하지만 자료형을 모호하게 선언하는 것이다. 68 | * 나중에 호출할 때 어떤 자료형을 쓸건지 표시한다. 69 |  70 | * 차이점 71 | * 컴파일 시 타입 체크 72 | * 자바는 체크하지만, C++는 체크하지 않는다. 73 | * 컴파일 된 코드 생성 개수 74 | * 자바는 1개의 컴파일 된 코드를 생성하지만, C++는 사용되는 데이터 개수만큼 컴파일 코드를 생성한다. 75 | 76 |
77 |
78 |
--------------------------------------------------------------------------------
/04.Java/kmj/21.04.14.md:
--------------------------------------------------------------------------------
1 | # 21.04.14
2 | * 동기화 vs 비동기화
3 | * 자바의 == vs equals
4 | * 자바의 리플렉션
5 | * Stream
6 | * Lambda
7 |
8 | ## 주요 질문
9 |
10 | #### 💡 [질문1](#개념1)
11 | * 답변
12 |
13 | #### 💡 질문2
14 | * 답변
15 |
16 | #### 💡 질문3
17 | * 답변
18 |
19 |
20 | 출처
79 | 80 | 출처적어주세요 81 |21 | 22 | ## ⭐ 개념 정리 23 | 24 | ### 동기화 vs 비동기화 25 | * 동기화 (Synchronous) 26 | * 요청과 결과가 동시에 일어난다. 27 | * 장점: 설계가 간단하다. 28 | * 단점: 결과가 주어질 때까지 대기해야 한다. 29 | * 비동기화 (Asynchronous) 30 | * 요청과 결과가 동시에 일어나지 않는다. 31 | * 장점: 결과를 기다리는 동안 다른 일을 할 수 있다. -> 자원을 효울적으로 활용 32 | * 단점: 설계가 복잡하다. 33 | 34 | ### 블럭 vs 넌블럭 35 | * 블럭: 호출된 함수가 자신이 할 일을 모두 마칠 때까지 제어권을 계속 가지고서 호출한 함수에게 바로 돌려주지 않는 상태 36 | * 넌블럭: 호출된 함수가 자신이 할 일을 채 마치지 않았더라도 바로 제어권을 건네주어(return) 호출한 함수가 다른 일을 진행할 수 있도록 해주는 상태 37 | 38 | > https://private.tistory.com/24 [공부해서 남 주자] 39 | > https://musma.github.io/2019/04/17/blocking-and-synchronous.html 40 | ### 자바의 == vs equals 41 | * == 42 | * 주소값 비교 43 | * equals 44 | * 비교대상의 내용을 비교 45 | 46 |  47 |  48 | 49 | * a, b => ==, equals로 비교 가능 50 | * a, c => equals로 비교해야 true 나옴 51 | >https://ojava.tistory.com/15 52 | ### 자바의 리플렉션 53 | * 구체적인 클래스 타입을 알지 못해도, 클래스의 메서드, 변수들에 접근할 수 있도록 하는 자바 API 54 | 55 | ### Stream 56 | * 데이터의 흐름 57 | * 배열 또는 컬렉션 인스턴스에 함수들을 조합해서 원하는 결과를 만들 수 있다. 58 | ### Lambda 59 | * 이름이 없는 함수형 인터페이스 60 | * 타입의 언급이 없다. 61 | * 타입추론은 컴파일러가 대신 해준다. 62 | * 타입추론시 필요한 정보는 제네릭을 이용해서 얻는다. 63 | > https://javabom.tistory.com/66 64 |
65 | 66 | 67 | 68 | -------------------------------------------------------------------------------- /04.Java/lyj/21.03.30.md: -------------------------------------------------------------------------------- 1 | ## String, StringBuilder, StringBuffer의 차이 2 | 3 | **String 객체** 4 | 5 | - **immutable.** 즉 **한번 생성이 되면 변경이 불가능**. 6 | - 객체를 한 번 할당할시 메모리 공간에 변동 없음. **Heap String Pool 영역**에 생성되어 **그 값을 계속 사용**. 7 | - 동기화 관리 필요 없음 8 | 9 | **StringBuffer** 10 | 11 | - mutable 12 | - 멀티쓰레드 환경에서 동기화 지원 13 | 14 | **StringBuilder** 15 | 16 | - mutable 17 | - 멀티쓰레드 환경에서 동기화 지원 안함 18 | 19 | ## ==와 equals 차이 20 | 21 | ### equals 22 | 23 | 값 자체를 비교 24 | 25 | ### == 26 | 27 | 주소값을 비교 28 | 29 | ```java 30 | String basket1 = "Ya-Ong"; 31 | String basket2 = "Ya-Ong"; 32 | System.out.println(basket1==basket2); // false 33 | System.out.println(basket1.equals(basket2)); // true 34 | ``` 35 | 36 | ## try-with-resource 37 | 38 | 자동으로 자원을 해제 39 | 40 | try에서 선언된 객체가 AutoCloseable을 구현하였다면 Java는 try구문이 종료될 때 객체의 close() 메소드를 자동으로 호출 41 | 42 | ## Collection 43 | 44 | ### Collection 45 | 46 | - 데이터의 집합, 그룹 47 | - 데이터를 저장하고 연산할 수 있는 집합 48 | 49 | ### Collection 특징 50 | 51 | - **크기가 가변적**이다. 52 | 53 | - **모든 객체를 원소로 저장가능**하다. 54 | 55 | Primitive type → Wrapper Class 56 | 57 | ### Collection 종류 58 | 59 | 1. Collection 인터페이스 60 | - 순서나 집합적인 저장 공간 명세 61 | - Set, List, Queue 62 | 2. Map 인터페이스 63 | - 키와 값으로 데이터를 다룰 수 있는 공간 명세 64 | - HashMap, TreeMap 65 | 66 | ### Set, List, Queue 67 | 68 | **List 인터페이스** 69 | 70 | - 객체의 순서 있음 71 | - 원소가 중복될 수 있음 72 | - ArrayList - 동기화 보장안됨 73 | 74 | **Queue 인터페이스** 75 | 76 | - 객체를 입력한 순서대로 저장 77 | - 원소가 중복될 수 있음 78 | - LinkedList, ArrayDeque 79 | 80 | **Set 인터페이스** 81 | 82 | - 객체의 순서가 없음 83 | - 동일한 원소를 중복 저장 불가 84 | - HashSet, TreeSet 등 85 | 86 | ### LinkedList와 ArrayList 87 | 88 | **ArrayList** 89 | 90 | - 내부적으로 특정 데이터 타입의 배열에서 데이터를 관리 91 | - 삽입 및 삭제 시간복잡도 O(n) 92 | - 검색 시간복잡도 O(n) 93 | 94 | **LinkedList** 95 | 96 | - 노드에 데이터를 저장하고 앞 뒤 노드의 주소값을 연결지어 데이터를 관리 97 | - 삽입 및 삭제 시간복잡도 O(1) 98 | - 검색 시간복잡도 O(n) 99 | 100 | ### HashMap 101 | 102 | - Hashing을 사용해서 Map 데이터를 관리 및 연산하는 데이터 구조 103 | - hash 함수를 이용해서 key 값을 hash code로 바꿔서 데이터 저장 104 | - hashcode를 기반으로 검색 105 | 106 | ### HashMap과 HashTable 107 | 108 | **HashMap** 109 | 110 | - 동기화 기능 제공안함 111 | - 멀티 스레드 환경에서 스레드 세이프 하지 않음 112 | 113 | **HashTable** 114 | 115 | - 동기화 기능 제공 116 | - 멀티 스레드 환경에서 스레드 세이프 117 | 118 | ### TreeMap과 TreeSet 119 | 120 | **공통점** 121 | 122 | Red Black Tree 기반으로 구성. red black tree는 balanced binary search tree의 한 종류 로써 BST에서 발생하는 불균형 문제를 색깔을 통해서 자체적으로 해결하는 자료구조 입니다. 123 | 124 | **차이점** 125 | 126 | TreeSet은 Collection 인터페이스를 구현한 클래스이고 TreeMap은 Map 인터페이스를 구현한 클래스이다. -------------------------------------------------------------------------------- /04.Java/lyj/21.04.05.md: -------------------------------------------------------------------------------- 1 | ## Reflection 2 | 3 | - 정의된 클래스 / 메소드 / annotation 정보를 확인하고 참조하기 4 | - 인스턴스를 생성하고, 필드값을 변경하며, 메소드를 실행할 수 있는 방법. 5 | 6 | 구체적인 클래스 타입을 알지 못해도 그 클래스의 메소드, 타입, 변수에 접근할 수 있도록 해준다. 7 | 8 | ### 장점 9 | 10 | 리플렉션을 사용하면, String 값을 통해 class를 얻어올 수 있고, 그 생성자를 얻어올 수 있다. 11 | 12 | 그 생성자를 통해 인스턴스를 생성할 수 있고, 생성된 인스턴스를 이용하여 메소드나 속성에 접근할 수 있다. 13 | 14 | 15 | 16 | ## Java 8 특징 17 | 18 | - Stream API 19 | - Lamda 표현식, **함수형 프로그래밍**이 처음으로 도입 20 | - 나즈혼이라는 자비스크립트의 엔진 추가 21 | - Method Reference, Default Method, Optional Class 22 | - java.time 패키지 추가 23 | 24 | ### Stream API 25 | 26 | 데이터 요소인 배열이나 컬렉션 등의 데이터를 처리하기 위한 API 27 | 28 | **Stream API 장점** 29 | 30 | - 멀티 스레드를 활용하여 병렬로 연산 수행 가능 31 | 32 | - 내부 반복으로 연산을 수행하기 때문에 코드 단순화 가능 33 | 34 | 데이터 저장시 배열이나 컬렉션을 사용하는데 이에 접근하기 위해서는 반복문을 사용해야 했다. 또한 데이터마다 접근하는 방식도 달랐다. 35 | 36 | Stream API로 데이터를 추상화하여 공통된 방법으로 데이터를 읽고 쓰는 게 가능해졌다. 37 | 38 | ### Lambda 39 | 40 | **람다표현식** 41 | 42 | - 메소드를 하나의 식으로 표현 43 | - 익명함수. 이름없이 실행할 수 있는 함수 표현식. 44 | 45 | **Lambda 예시** 46 | 47 | - 자바에서 Thread를 만들때 Runnable()객체를 할당하고 run 메소드를 실행하는데 이를 축약하여 ()로 나타낼 수 있다. 48 | 49 | **Lambda 장점** 50 | 51 | - 불필요한 코드 줄일 수 있다. 52 | - 가독성을 높일 수 있다. 53 | 54 | ### 나즈혼 엔진 55 | 56 | JAVA 8 이전에는 모질라의 리노 자바스크립트 엔진을 사용하였다. 이는 java의 최신 개선사항 등을 반영하지 못해 성능이나 메모리상으로 크게 향상된 나즈혼 엔진으로 업데이트 되었다. 57 | 58 | -------------------------------------------------------------------------------- /04.Java/lyj/21.04.10.md: -------------------------------------------------------------------------------- 1 | ## 디자인 패턴 2 | 3 | **소프트웨어를 설계할 때 특정 문맥에서 자주 발생하는 고질적인 문제들이 또 발생했을 때 재사용할 수 있는 설계 패턴**을 의미합니다. 4 | 5 | ### Singleton Pattern 6 | 7 | - **인스턴스가 오직 1개만 생성되어야 하는 경우에 사용되는 패턴** 8 | - **동시성 문제 고려**해야한다 9 | 10 | ### **자바와 스프링의 싱글톤 차이**점 11 | 12 | 싱글톤 객체의 생명주기가 다르다 13 | 14 | - 자바 싱글톤 객체의 범위는 **클래스 로더**가 기준 15 | 16 | - 스프링에서는 **어플리케이션 컨텍스트**가 기준 17 | 18 | Bean을 등록할 때 범위의 default는 Singleton다. 싱글톤 이외 범위는 prototype, request, session이 있다. 19 | 20 | ### Proxy Pattern 21 | 22 | - 특정 객체를 대신해서 프록시 객체가 해당 역할을 수행 23 | - 클라이언트가 최종적으로 받는 리턴값을 조작하지 않고 그대로 전달 24 | 25 | ### Decorator Pattern 26 | 27 | - 클라이언트가 받는 반환값에 장식 추가 28 | - 프록시 패턴과 구현 방법 유사 29 | 30 | ### Adapter Pattern 31 | 32 | - 클래스의 인터페이스를 사용자가 기대하는 다른 인터페이스로 변환 33 | 34 | ### Template Method Pattern 35 | 36 | - 알고리즘의 구조를 바꾸지 않고 서브클래스에서 알고리즘의 특정 단계를 재정의 37 | - 상속을 통해 슈퍼클래스의 기능을 확장할 때 사용 38 | 39 | ### Strategy Pattern 40 | 41 | - 전략 객체를 통해서 알고리즘의 구조를 바꾼다. -------------------------------------------------------------------------------- /04.Java/phb/21.03.15.md: -------------------------------------------------------------------------------- 1 | # 21.03.15 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 Override과 Overload의 차이점을 설명해주세요. 6 | * Overriding은 메소드를 새롭게 재정의하는 것이고 Overload는 같은 이름의 메소드를 여러개 정의하는 것입니다. 7 | 8 | #### 💡 SOLID 원칙 중 개방-폐쇄 원칙에 대해서 설명해주세요. 9 | * 개방-폐쇄 원칙은 기존 코드를 변경하지 않고 기능을 수정 및 추가할 수 있어야한다는 원칙입니다. 10 | 11 |
12 | 13 | ## ⭐ Java 14 | 15 | ### 1. Java 특징 16 | * 높은 이식성을 가진 언어 (OS에 구애받지 않음) 17 | * 객체 지향 언어 18 | * Garbage Collector 19 | * 등등 20 | 21 | ### 2. 객체지향 프로그래밍 언어(OOP) 22 | * 구성 요소 23 | * 클래스 24 | * 객체 25 | * 메소드 26 | * 특징 27 | * 추상화 28 | * 정보 은닉 29 | * 상속 30 | * 다형성 31 | 32 | ### 2-1. OOP의 5대 원칙 SOLID 33 | * Single Responsibility Principle (단일 책임 원칙) 34 | * 객체(클래스, 함수 등)는 단 하나의 책임(기능)만 가져야 한다. 35 | * 응지도는 높고 결합도가 낮은 프로그램 36 | * Open Closed Principle (개방-폐쇄 원칙) 37 | * 기존 코드를 변경하지 않고 기능을 수정 및 추가할 수 있도록 설계해야 한다. 38 | * Liskov Substitution Principle (리스코프 치환 원칙) 39 | * 자식 클래스는 부모 클래스에서 가능한 행위를 수행할 수 있어야 한다. 40 | * Interface Segregation Principle (인터페이스 분리 원칙) 41 | * 특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다. 42 | * 인터페이스들을 구체적이고 작은 단위로 분리시킴으로써 클라이언트들에게 필요한 메소드만 이용할 수 있게 한다. 43 | * Dependency Inversion Principle (의존 역전 원칙) 44 | * 의존 관계를 맺을 때, 변화하기 쉬운 것 보다 변화하기 어려운 것에 의존해야 한다. 45 | 46 | ### 2-2. 다형성 47 | ||오버라이딩(Overriding)|오버로드(Overloading)| 48 | |-|-|-| 49 | |정의|상위 클래스의 메소드를 하위 클래서에서 재정의|같은 이름의 함수를 여러개 정의| 50 | |메소드명|동일|동일| 51 | |매개변수|동일|다름| 52 | |리턴타입|동일|상관없음| 53 | 54 | 55 | -------------------------------------------------------------------------------- /04.Java/phb/21.03.16.md: -------------------------------------------------------------------------------- 1 | # 21.03.16 2 | 3 | ## 주요 질문 4 | ## ⭐ Java 5 | 6 | ### 1. 접근제어자 7 | * 접근 범위: private < default < protected < public 8 | 9 | ||private|(default)|protected|public| 10 | |-|-|-|-|-| 11 | |동일 클래스|O|O|O|O| 12 | |동일 패키지|X|O|O|O| 13 | |자손 클래스|X|X|O|O| 14 | |전체|X|X|X|O| 15 | 16 |
17 | 18 | ### 2. 데이터 타입 19 | 20 | |타입|구분|데이터형|바이트 수| 21 | |-|-|-|-| 22 | |기본형|정수형|byte|1바이트| 23 | |||short|2바이트| 24 | |||int|4바이트| 25 | |||long|8바이트| 26 | ||실수형|float|4바이트| 27 | |||double|8바이트| 28 | ||자료형|char|2바이트| 29 | ||논리형|boolean|4바이트| 30 | |참조형|배열| 31 | ||열거| 32 | ||클래스| 33 | ||인터페이스| 34 | 35 | 36 |
37 | 38 | ### 3. 래퍼 클래스(Wrapper Class) 39 | * 기본형을 객체로 다루기 위해 사용하는 클래스 40 | * 박싱(Boxing) : 기본타입 → 래퍼 클래스 41 | * 언박싱(UnBoxing) : 래퍼 클래스 → 기본타입 42 | 43 |  44 | 45 | 46 |
47 |
--------------------------------------------------------------------------------
/04.Java/phb/21.03.25.md:
--------------------------------------------------------------------------------
1 | # 21.03.25
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 main 메소드가 public static인 이유는?
6 | * 어떤 패키지에 있던 main 메소드는 JVM에 의해서 가장 먼저 실행되야 하므로 public을 사용합니다.
7 | * 가장 먼저 실행되는 메소드이기 때문에 어딘가에서 호출이 일어나지 않습니다. 따라서 실행 전 main 메소드는 메모리에 적재되어 있어야 하므로 static으로 선언되어 있습니다.
8 |
9 | #### 💡 제네릭이 뭐에요?
10 | * 객체 타입을 컴파일 시에 체크해주는 것입니다.
11 | * 컴파일 시에 타입을 체크하므로 타입 안정성을 높이고 형변환의 번거로움을 줄일 수 있습니다.
12 |
13 | 출처
48 | 49 | 출처적어주세요 50 |14 | 15 | ## ⭐ 개념 정리 16 | 17 | ### static/non-static 18 | * **static** 19 | ```java 20 | static int i = 3; 21 | ``` 22 | * 프로그램 실행 시 메모리에 적재 23 | * 값의 중복을 피하게 해주고 찾는 시간이 줄어 프로그램의 효율성을 증가 24 | 25 | * **non-static** 26 | ```java 27 | int i = 3; 28 | ``` 29 | * new로 객체를 생성하면 메모리에 적재 30 | 31 |
32 | 33 | ### final/finally/finalize 34 | * **final** 35 | * 키워드를 명시하여 한 번만 할당하고 싶을 때 사용 36 | * classes : 상속불가 37 | * methods : Override 불가 38 | * variables : 값 변경 불가 39 | * **finally** 40 | * try-catch와 함께 사용되며 예외 발생 유무와 상관없이 무조건 수행되는 것들을 작성 41 | * **fianlize** 42 | * JVM에서 GC이 수행될 때 사용하지 않는 자원에 대한 정리 작업 진행을 위해 호출되는 종료자 메소드 43 | 44 |
45 | 46 | ### Generics 47 | * 데이터의 타입을 인스턴스를 생성할 때 결정하는 것을 의미 48 | * 객체 타입을 컴파일 시점에 체크하므로 타입 안정성을 높이고 형변환의 번거로움을 감소 49 | ```java 50 | // 제네릭 사용 X → 타입 변환이 필요 51 | ArrayList list = new ArrayList(); 52 | list.add("test"); 53 | String a = (String) list.get(0); 54 | ``` 55 | 56 | ```java 57 | // 제네릭 사용 → 타입 변환이 필요 X 58 | ArrayList
10 | 11 | ## ⭐ Java 12 | 13 | ## Call by Reference/Value 14 | |**Call by Reference**|**Call by Value**| 15 | |-|-| 16 | |참조에 의한 호출|값에 의한 호출| 17 | |복사하지 않고 실제 값을 직접 참조 → 빠른 속도|실제 값을 복사하여 처리 → 복사에 의해 메모리 사용량 증가| 18 | |직접 참조하므로 원래 값이 영향을 받음|원래 값 보존| 19 | 20 |
21 | 22 | ## Abstract/Interface 23 | ||**추상클래스**|**인터페이스**| 24 | |-|-|-| 25 | |선언 예약어|abstract|interface| 26 | |미구현 메소드 포함 가능 여부|O|O| 27 | |구현 메소드 포함 가능 여부|O|X| 28 | |static 메소드 선언 가능 여부|O|X| 29 | |final 메소드 선언 가능 여부|O|X| 30 | |상속(extends) 가능 여부|O|X| 31 | |구현(implements) 가능 여부|O|X| 32 | 33 | * 추상클래스는 다중상속이 불가능 34 | * 인터페이스로 다중상속처럼 구현 가능 (실제 다중상속 아님) 35 | 36 | 37 | -------------------------------------------------------------------------------- /04.Java/phb/21.03.30.md: -------------------------------------------------------------------------------- 1 | # 21.03.30 2 | 3 | ## ⭐ 개념 정리 4 | 5 | ## JVM(Java Virtual Machine) 6 | 7 | ### 1. JAVA 실행과정 8 |  9 | 10 | 1. 프로그램 실행되면 JVM은 OS로부터 프로그램에 필요한 메모리를 할당받는다. 11 | JVM은 이 메모리를 용도에 따라 여러 영역으로 나누어 관리한다. 12 | 2. 자바 컴파일러(.javac)가 자바 소스코드(.java)를 읽어들여 자바 바이트코드(.class)로 변환시킨다. 13 | 3. Class Loader로 class파일들을 JVM에 로딩한다. 14 | 4. 해석된 바이트코드는 Runtime Data Areas에 배치되어 실질적인 수행을 한다. 15 | 필요에 따라 JVM은 GC 관리작업을 수행한다. 16 | 17 |
18 | 19 | ### 2. JVM 20 |  21 | * Java-운영체제 사이에서 중개자 역할 22 | * Java Application을 Class loader로 읽어서 Java API와 함께 실행하는 역할 23 | * 특징 24 | * 스택 기반의 가상 머신 25 | * 심볼릭 레퍼런스 26 | * Garbage Collection 27 | * 플랫폼 독립성 보장 28 | * 네트워크 바이트 오더 29 | 30 |
31 | 32 | ### 3. JVM 구성 33 |  34 | 35 | * **Class Loader** 36 | * 클래스(.class)를 로드하고 링크를 통해 배치하는 작업을 수행하는 모듈 37 | * Runtime 시에 동적으로 로드 38 | 39 |
40 | 41 | * **Execution Engine** 42 | * 클래스 로더에 의해 메모리에 적재된 클래스를 실행시키는 역할 43 | * 바이트코드를 기계어로 변경 44 | * 방식 45 | * 인터프리터(Interpreter) 46 | * 명령어 단위로 읽어서 실행 47 | * 한 줄씩 수행하므로 속도가 느림 48 | * JIT(Just In Time) 49 | * 인터프리터 방식의 단점을 보완하기 위한 컴파일러 50 | * 인터프리터 방식으로 실행하다가 적절한 시점에 바이트코드 전체를 컴파일하여 네이티브 코드로 변경 51 | 52 |
53 | 54 | * **Runtime Data Area** 55 | * PC Register 56 | * Thread가 시작될 때마다 생성되는 공간 57 | * Thread가 어떤 부분을 어떤 명령으로 실행할 지에 대한 기록으로 JVM 명령의 주소를 가짐 58 | * stack 59 | * 메소드 안에서 사용되는 값을 저장 (변수, 매개변수, 지역변수, 리턴 값 등) 60 | * Native method stack 61 | * 기계어로 작성된 프로그램을 실행시키는 영역 62 | * Method Area (= Class area = Static area) 63 | * 클래스 정보를 처음 메모리에 올릴 때 초기화되는 대상을 저장하기 위한 메모리 공간 64 | * 내부에 Runtime Constant Pool 존재하며 상수 자료형을 저장 65 | * heap 66 | * 객체를 저장하는 가상 메모리 공간 67 | 68 |
69 | 70 |
71 |
--------------------------------------------------------------------------------
/04.Java/phb/21.04.05.md:
--------------------------------------------------------------------------------
1 | # 21.04.05
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 StringBuilder와 StringBuffer의 차이점을 설명해주세요.
6 | * 둘의 차이점은 동기화 처리 여부입니다.
7 | * StringBuilder는 동기화 처리를 하지 않아 StringBuffer보다 속도가 더 빠릅니다.
8 | * StringBuffer은 속도는 느리지만 멀티 스레드 환경에서 안전하게 사용할 수 있습니다.
9 |
10 | ## ⭐ Java Collection Framework
11 |
12 | ## Collection FrameWork
13 | * 데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현한 것
14 | * 종류
15 | * List참고
72 |-
73 |
- https://catsbi.oopy.io/df0df290-9188-45c1-b056-b8fe032d88ca 74 |
- https://asfirstalways.tistory.com/15 75 |
34 | 35 | ### Collection 주요 메소드 36 |  37 | 38 |
39 | 40 | ## Annotation 41 | * @ 42 | * 자바 소스 코드에 추가하여 사용하는 메타 데이터 43 | * JDK 1.5 버전 이상에서 사용 가능 44 | * Java에서 제공하는 기본 Annotation 45 | |Annotation|내용| 46 | |-|-| 47 | |@Override|선언 메소드 재정의| 48 | |@Deprecated|해당 메소드가 더 이상 사용되지 않음| 49 | |@SuppressWarnings|선언한 곳의 컴파일 경로를 무시| 50 | |@SafeVarargs|Java7부터 지원, 제너릭 같은 가변인자의 매개변수를 사용할 때 경고를 무시| 51 | |@FunctionalInterface|Java8부터 지원, 함수형 인터페이스 지정| 52 | 53 |
54 |
55 |
58 |
59 |
60 | 출처
56 | https://elfinlas.github.io/2017/12/14/java-annotation/ 57 |61 | 62 | ## String/StringBuilder/StringBuffer 63 | ||String|StringBuilder|StringBuffer| 64 | |-|-|-|-| 65 | |가변성|immutable|mutable|mutable| 66 | |동기화|X|X|O| 67 | |Thread-Safe|O|X|O| 68 | |속도|제일 느림|빠름|제일 빠름| 69 | 70 |
71 | 72 | ### 언제 사용하면 유용할까? 73 | * String: 짧은 문자열을 더할 경우 사용 74 | * StringBuilder : Thread-safe 여부 관계 없는 프로그램 개발 시 사용 75 | * StringBuffer : Thread-safe를 보장해야하는 프로그램 개발 시 사용 76 | -------------------------------------------------------------------------------- /04.Java/phb/21.04.15.md: -------------------------------------------------------------------------------- 1 | # 21.00.00 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 Java 8에 추가된 기능은 무엇이 있나요? 6 | * time 라이브러리와 Stream API, 람다식이 있습니다. 7 | 8 | #### 💡 Stream API 특징이나 장점은 무엇이 있나요? 9 | * Stream API는 원본 데이터를 변경하지 않고 가공된 데이터를 추출합니다. 10 | * Stream API는 컬렉션의 요소를 람다식으로 처리하여 코드의 가독성이 높일 수 있고 Collection 요소를 모두 동일한 방식으로 데이터 처리할 수 있습니다. 11 | 12 |
13 | 14 | ## 동기화/비동기화 15 | * 동기화 (Synchronized) 16 | * 한 자원에 대해 동시에 접근하는 것을 제한하는 방식 17 | * System Call이 끝날 때 까지 다른 스레드의 접근 제한 18 | * ```public synchronized void add()```처럼 synchronized 키워드를 사용하여 선언 19 | * 비동기화 (Asynchronized) 20 | * System call과 상관없이 계속 호출 가능 21 | * Callback 함수로 결과값 리턴 22 | 23 |
24 | 25 | ## ==/equals 26 | * == 27 | * 비교 연산자 28 | * call by reference 29 | * equals 30 | * 대상의 내용을 비교하는 메소드 31 | * call by value 32 | 33 |
34 | 35 | ## Reflection 36 | * 런타임 시 동적으로 특정 클래스의 정보를 객체화하여 분석 및 추출해낼 수 있는 프로그래밍 기법 37 | * 사용법 38 | * ```Class.forName()```로 클래스 객체 가져옴. 39 | * 메소드로 클래스 반환 40 | |메소드|설명| 41 | |-|-| 42 | |class.getSuperClass()|슈퍼 클래스를 반환| 43 | |class.getClass()|상속된 클래스를 포함하여 모든 공용 클래스, 인터페이스 및 열거형을 반환| 44 | |class.getDeclaredClass()|명시적으로 선언된 모든 클래스 및 인터페이스, 열거형을 반환| 45 | |class.getDeclaringClass()|클래스에 구성된 클래스 반환| 46 | |class.getEnclosingClass()|클래스의 즉시 동봉된 클래스를 반환| 47 | * 주의할 점 48 | * ```Field.setAccessible()```을 true값으로 주게 되면 private 멤버도 접근 가능 49 | 50 | 51 |
52 |
57 |
58 | 참고
53 |-
54 |
- https://pjh3749.tistory.com/250 55 |
59 | 60 | ## Stream/Lambda 61 | * Java 8 62 | * Stream 63 | * 데이터의 흐름 64 | * 파이프구조로 데이터를 조합, 필터링하고 가공된 결과 추출 65 | * 병렬 스트림(parallel 지원 66 | 67 |
68 |
73 |
74 | * Lambda
75 | * 함수형 프로그래밍
76 | * 자료 처리를 수학적 함수 계산으로 취급하고 데이터를 멀리하는 프로그래밍 패러다임
77 | * 순수 함수를 조합하고 소프트웨어를 만드는 방식
78 | * How 보다 What에 초점
79 | * 간결한 표현
80 | * 행위를 전달 받아서 제어 흐름 수행
81 | * 메소드 단위의 추상화 가능
82 | * ```(매개변수) -> {함수 로직}```
83 |
84 | 참고
69 |-
70 |
- https://futurecreator.github.io/2018/08/26/java-8-streams/ 71 |
85 |
91 |
92 |
--------------------------------------------------------------------------------
/04.Java/phb/21.05.10.md:
--------------------------------------------------------------------------------
1 | # 21.05.10
2 |
3 | ## 추가 공부
4 |
5 | ### Java Compile
6 |
7 | 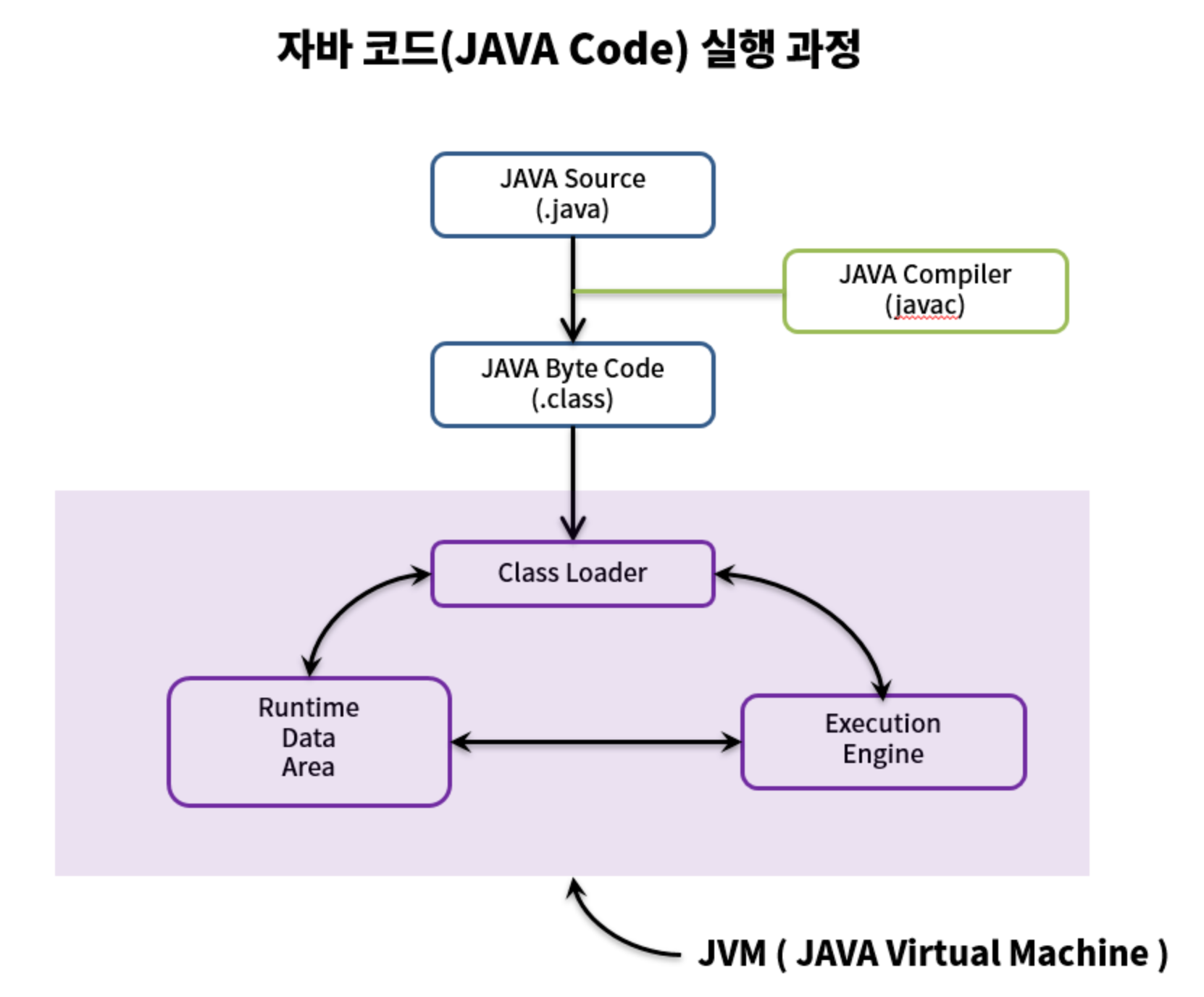
8 |
9 | 1. 개발자가 자바 소스코드(.java)를 작성한다.
10 | 2. 컴파일러에 의해 소스파일를 바이트코드(.class)로 컴파일한다.
11 | 3. 바이트코드를 클래스 로더에게 전달한다.
12 | 4. 클래스로더에 의해 import한 클래스 읽힌다.
13 | 5. 런타임 데이터 영역에 의해 JVM 메모리에 올라간다.
14 | 6. 실행엔진은 JVM 메모리에 올라온 바이트 코드를 하나식 가져와 실행한다. (Java 컴파일러 사용)
15 |
16 | 참고
86 |-
87 |
- https://skyoo2003.github.io/post/2016/11/09/java8-lambda-expression 88 |
- https://velog.io/@kyusung/%ED%95%A8%EC%88%98%ED%98%95-%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D-%EC%9A%94%EC%95%BD 89 |
17 | 18 | ### 추상클래스와 인터페이스 차이 19 | 20 | - 추상클래스의 목적은 **공통점을 찾아 추상화** 21 | - 인터페이스의 목적은 **구현 객체가 같은 동작하는 것을 보장** 22 | 23 |
24 | 25 | ### Java Reflection 26 | 27 |
28 | 29 | ### GC 변수 초기화 30 | 31 | - GC 동작 원리 32 |  33 | 34 |  35 | 36 | 1. 처음 생성된 객체는 Eden에 위치 37 | 2. Minor GC 발생 후에 살아있다면 Survivor 영역으로 이동 38 | 3. Survivor에서 살아남은 객체는 Old Generation 영역으로 이동 39 | 40 |
41 | 42 | ### CheckedException, UnCheckedException 43 | 44 |  45 | 46 | | 구분 | Checked Exception | Unchecked Exception | 47 | | ------------ | -------------------------- | ---------------------------- | 48 | | 확인시점 | 컴파일 시점 | 런타임 시점 | 49 | | 처리여부 | 반드시 예외 처리해야한다. | 명시적으로 하지 않아도 된다. | 50 | | 트랜잭션처리 | 예외 발생 시 롤백하지 않음 | 예외 발생시 롤백 | 51 | 52 |
53 |
58 | 참고
54 |-
55 |
- https://madplay.github.io/post/java-checked-unchecked-exceptions 56 |
59 | 60 | ### JVM 질문 61 | 62 | ### 1. GC가 무엇인가요? 63 | 64 | - 힙 영역에서 사용하지 않는 객체들을 제거하는 작업을 의미합니다. 65 | 66 | ### 2. JVM 메모리 구조에 대해 설명해주세요. 67 | 68 | - JVM 메모리는 메소드, 힙, 스택, PC 레지스터, 네이티브 메소드 스택 총 5개로 구성되어 있습니다. 69 | 70 | * 메소드 영역은 클래스와 관련된 정보가 저장됩니다. 71 | * 힙 영역은 new로 생성된 객체와 배열의 인스턴스를 저장합니다. 72 | * 스택 영역은 지역변수, 매개변수, 리턴 값 등이 저장됩니다. 73 | * PC 레지스터는 현재 스레드가 실행되는 부분의 주소와 명령을 저장한다. 74 | * 네이티브 메소드는 자바 외의 언어로 작성된 코드를 위한 메모리 영역입니다. 75 | 76 |
77 | 78 | ### 예외 질문 79 | -------------------------------------------------------------------------------- /04.Java/phb/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | |날짜|설명|링크| 4 | |------|---|---| 5 | |21.03.15|Java 특징|[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.15.md)| 6 | |21.03.16||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.16.md)| 7 | |21.03.25||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.25.md)| 8 | |21.03.29||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.29.md)| 9 | |21.03.30||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.30.md)| 10 | |21.04.05||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.04.05.md)| 11 | |21.04.15||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.04.15.md)| 12 | |21.05.10||[✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.05.10.md)| 13 | -------------------------------------------------------------------------------- /05.Spring/README.md: -------------------------------------------------------------------------------- 1 | # Part 05.Spring 2 | 3 | Made by. [김민지](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/04.Java/kmj) [박혜빈](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/04.Java/phb) [이연주](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/04.Java/lyj) [황성현](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/04.Java/hsh) 4 | -------------------------------------------------------------------------------- /05.Spring/hsh/21.06.22.md: -------------------------------------------------------------------------------- 1 | # 21.06.22 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 6 |
7 | 8 | ## ⭐ 개념 정리 9 | 10 | ## Spring Framework란? 11 | * JAVA의 웹 프레임워크로 JAVA 언어를 기반으로 사용한다. JAVA로 다양한 어플리케이션을 만들기 위한 프로그래밍 틀이라 할 수 있다. 12 | * 옛날에 비교하면 지금은 JAVA의 활용도가 높아졌고 따라서 프로젝트 규모도 커졌다. JAVA를 이용한 기술은 JSP, MyBatis, JPA 등 여러가지가 있는데 즉, 이 기술들이 프로젝트에 많이 쓰인다고 할 수 있다. Spring은 이 기술들을 더 편하게 사용하기 위해 만들어진 것이다. 13 | * 프로젝트를 진행하다 보면 아무리 분업을 해도 분명 중복되는 코드가 있기 마련이다. **Spring은 이런 중복코드의 사용률을 줄여주고, 비즈니스 로직을 더 간단**하게 해줄 수 있다. 14 | - Spring을 사용하면 다른 사람의 코드를 참조하여 쓰기 편리한데 이말의 의미는 오픈소스를 좀더 효율적으로 가져다 쓰기 좋은 구조라는 것이다. 15 | 16 | - 결론적으로 **Spring이란 JAVA 기술들을 더 쉽게 사용할 수 있게 해주는 오픈소스 프레임 워크**이다. 17 | 18 | > Spring이란? : https://jerryjerryjerry.tistory.com/62 19 | 20 | ### Spring 주요 특징 21 | #### IoC(Inversion of Control, 제어 반전) 22 | * "제어의 역전" 이라는 의미는 말 그대로 메소드나 객체의 호출작업을 개발자가 결정하는 것이 아니라, 외부에서 결정되는 것을 의미한다. (Object간의 연결 관계를 런타임에 결정) 23 | 24 | * 스프링 컨테이너 차원에서는 엔터프라이즈 개발에 적합하게 수많은 객체 생명주기를 관리 하고 의존 관계를 설정해주고 그 외 많은 기능들을 제공하여 **개발자는 비지니스 로직에 집중 할 수 있게 해줌.** 25 | * 스프링에서 IoC를 담당하는 컨테이너에는 BeanFactory, ApplicationContext가 있다. 26 | * Spring DI Container가 관리하는 객체를 Bean이라고 함. 27 | 28 | * 빈(Bean) 29 | * 스프링이 IoC방식으로 관리하는 객체 30 | * 빈 팩토리(BeanFactory) 31 | * 스프링이 IoC를 담당하는 Bean들의 핵심 컨테이너 32 | * 애플리케이션 컨텍스트(ApplicationContext) 33 | * BeanFactory를 확장한 IoC 컨테이너. BeanFactory + 스프링 제공 각종 부가 서비스 34 | 35 | #### DI(Dependency Injection, 의존성 주입) 36 | * IoC의 구현 방법 중 하나가 DI이다. 37 | * 의존성 주입은 제어의 역전이 일어날때 스프링 내부에 있는 객체들간의 관계를 관리할 때 사용하는 기법이다. 자바에서는 일반적으로 인터페이스를 이용해서 의존적인 객체의 관계를 최대한 유연하게 처리할 수 있도록 한다. 38 | 39 | * 의존성 주입은 의존적인 객체를 직접 생성하거나 제어하는것이 아닌, 특정 객체에 필요한 객체를 외부에서 결정해서 연결 시키는 것을 의미한다. 우리는 클래스의 기능을 추상적으로 묶어둔 인터페이스를 갖다 쓰면 되는 것 이다. 이러한 **의존성 주입으로인해 모듈간의 결합도가 낮아지고 유연성이 높아진다.** 40 | 41 | #### AOP(Aspect Object Programming, 관점 지향 프로그래밍) 42 | * AOP는 Aspect Oriented Programming의 약자로 관점 지향 프로그래밍이라고 불린다. 관점 지향은 쉽게 말해 어떤 로직을 기준으로 핵심적인 관점, 부가적인 관점으로 나누어서 보고 그 관점을 기준으로 각각 모듈화하겠다는 것이다. 여기서 모듈화란 어떤 공통된 로직이나 기능을 하나의 단위로 묶는 것을 말한다. 43 |
44 | 45 | #### POJO(Plain Old Java Object) 지원 46 | - POJO는 Java EE를 사용하면서 해당 플랫폼에 종속되어 있는 무거운 객체들을 만드는 것에 반발하여 나타난 용어이다. 47 | - 별도의 프레임 워크 없이 Java EE를 사용할 때에 비해 인터페이스를 직접 구현하거나 상속받을 필요가 없어 기존 라이브러리를 지원하기 용이하고, 객체가 가볍다. 48 | - 즉, getter/setter를 가진 단순한 자바 오브젝트를 말한다. -------------------------------------------------------------------------------- /05.Spring/hsh/21.06.24.md: -------------------------------------------------------------------------------- 1 | # 21.06.24 2 | 3 | ## 주요 질문 4 | 5 | #### 💡 6 |
7 | 8 | ## ⭐ 개념 정리 9 | 10 | ## Spring Web MVC 11 | 12 | #### MVC(Model-View-Controller) Pattern 13 |
14 |
15 | * 모델, Model
16 | * 애플리케이션의 정보, 데이터를 나타냅니다. 데이터베이스, 처음의 정의하는 상수, 초기화값, 변수 등을 뜻합니다. 또한 이러한 DATA, 정보들의 가공을 책임지는 컴포넌트를 말합니다.
17 | * Java Beans
18 |
19 | * 뷰, View
20 | * input 텍스트, 체크박스 항목 등과 같은 사용자 인터페이스 요소를 나타냅니다. 다시 말해 데이터 및 객체의 입력, 그리고 보여주는 출력을 담당합니다. 데이타를 기반으로 사용자들이 볼 수 있는 화면입니다.
21 | * JSP
22 |
23 |
24 | * 컨트롤러, Controller
25 | * 데이터와 사용자인터페이스 요소들을 잇는 다리역할을 합니다. 즉, 사용자가 데이터를 클릭하고, 수정하는 것에 대한 "이벤트"들을 처리하는 부분을 뜻합니다.
26 | * Servlet
27 |
28 | #### 왜 MVC 패턴을 사용해야 할까?
29 | * **서로 분리되어 각자의 역할에 집중할 수 있게끔하여 개발**을 하고 그렇게 애플리케이션을 만든다면, 유지보수성, 애플리케이션의 확장성, 그리고 유연성이 증가하고, 중복코딩이라는 문제점 또한 사라지게 되는 것입니다. 그러기 위한 MVC패턴입니다.
30 | * *단, 개발과정이 복잡해 초기 개발속도가 늦음*
31 | > https://m.blog.naver.com/jhc9639/220967034588
32 |
33 |
34 | ### Spring MVC
35 |
36 |
37 |
38 | * DispatcherServlet (Front Controller)
39 | * 기본적인 처리 흐름을 제어하는 **사령탑 역할**
40 | * 모든 클라이언트의 요청을 전달받음.
41 | * Controller에게 클라이언트의 요청을 전달하고, Controller가 리턴 한 결과값을 View에게 전달하여 알맞은 응답을 생성.
42 |
43 | * HandlerMapping
44 | * 클라이언트의 요청 URL을 어떤 Controller가 처리할지를 결정.
45 | * URL과 요청 정보를 기준으로 어떤 핸들러 객체를 사용할지를 결정하는 객체이며, DispatcherServlet은 하나 이상의 핸들러 매핑을 가질 수 있음.
46 |
47 | * ViewResolver
48 | * 클라이언트의 요청을 처리한 뒤, Model을 호출하고 그 결과를 DispatcherServlet에 알려준다.
49 |
50 | * ModelAndView
51 | * Controller가 처리한 데이터 및 화면에 대해 정보를 보유한 객체
52 |
53 | * ViewResolver
54 | * Controller가 리턴 한 View 이름을 기반으로 Controller의 처리 결과를 보여줄 View를 결정
55 |
56 | * View
57 | * Controller의 처리 결과를 보여줄 응답화면을 생성
58 |
59 |
60 | ### 기본 Project Structure
61 |
62 |
63 |
64 | * src
65 | * 개발자가 작성한 Servlet 코드가 저장된다.
66 | * Controller, Model, Service, Dao
67 | * src/main/java
68 | * 개발되는 Java 코드의 경로
69 | * src/main/resources
70 | * 서버가 실행될 때 필요한 파일들의 경로
71 | * src/test/java
72 | * 테스트 전용 경로 (각 테스트 코드 작성 경로)
73 | * src/test/resource
74 | * 테스트 시에만 사용되는 파일들의 경로
75 | * Libraries
76 | * Servlet이나 JSP에서 추가로 사용하는 라이브러리 또는 드라이버
77 | * jar로 압축한 파일이어야 한다.
78 | * WebContent (**전체 ROOT**) - webapp
79 | * Deploy할 때 WebContent 디렉터리 전체가 .war로 묶어서 보내진다.
80 | * resources
81 | * 정적인 데이터 (ex. image file, css, js, fonts)
82 | * WEB-INF
83 | * classes: 작성한 Java Servlet 파일이 나중에 .class로 이곳에 모두 저장된다.
84 | * lib: 추가한 모든 라이브러리 또는 드라이버가 이곳에 모두 저장된다.
85 | * props: property file을 저장한다.
86 | * spring: **spring configuration files**을 저장한다. (Spring과 관련된 설정 파일을 모아둔 것)
87 | * dispatcher-servlet.xml
88 | * applicationContext.xml
89 | * dao-context.xml, service-context.xml 등
90 | * views: Controller와 매핑되는 .jsp 파일들을 저장한다. (JSP 파일의 경로)
91 | * web.xml: web application의 설정을 위한 **web deployment descriptor**
92 | * DispatcherServlet, ContextLoadListener 설정
93 | * pom.xml
94 | * **maven configuration file**
95 | * 어떤 lib를 쓸지 명시한다.
96 |
97 | > https://gmlwjd9405.github.io/2018/12/20/spring-mvc-framework.html
--------------------------------------------------------------------------------
/05.Spring/hsh/21.06.25.md:
--------------------------------------------------------------------------------
1 | # 21.06.24
2 |
3 | ## 주요 질문
4 |
5 | #### 💡 Spring툴을 사용하면서 Service와 Dao를 나누어 사용하는 이유
6 |
7 | * DAO - 단일 데이터의 접근과 갱신만 처리한다(CRUD)
8 | * Service - 여러 DAO를 호출하여 사용자의 요구에 맞게 가공한다.
9 |
10 | * DAO는 단일 데이터 접근/갱신만 처리합니다.Service는 여러 DAO를 호출하여 여러번의 데이터 접근/갱신을 하며 그렇게 읽은 데이터에 대한 비즈니스 로직을 수행하고, 그것을 하나의(혹은 여러개의) 트랜잭션으로 묶습니다.
11 |
12 | #### 💡 forward 와 redirect 차이
13 | * [ Forward 방식 ]
14 |
15 | * Forward는 Web Container 차원에서 페이지의 이동만 존재합니다. 실제로 웹 브라우저는 다른 페이지로 이동했음을 알 수 없습니다. 그렇기 때문에 웹 브라우저에는 최초에 호출한 URL이 표시되고, 이동한 페이지의 URL 정보는 확인할 수 없습니다. 또한 현재 실행중인 페이지와 forward에 의해 호출될 페이지는 **Request 객체와 Response 객체를 공유**합니다.
16 |
17 | * [ Redirect 방식 ]
18 |
19 | * Redirect는 Web Container로 명령이 들어오면, 웹 브라우저에게 다른 페이지로 이동하라고 명령을 내립니다. 그러면 웹 브라우저는 URL을 지시된 주소로 바꾸고 해당 주소로 이동합니다. 다른 웹 컨테이너에 있는 주소로 이동하며 새로운 페이지에서는 Request와 Response객체가 **새롭게 생성**됩니다.
20 | 21 | 22 | ## ⭐ 개념 정리 23 | 24 | ### JDBC? MyBatis? 25 | * JDBC(Java Database Connectivity)는 자바에서 데이터베이스에 접속할 수 있도록 하는 자바 API이다. JDBC는 데이터베이스에서 자료를 쿼리하거나 업데이트 하는 방법을 제공한다.자바는 JDBC를 통해 mysql, oracle에 접근한다. jdbc는 1개 클래스에 반복된 코드가 존재, 한 파일에 java언어와 sql언어가 있어 재사용성 등 안좋은 단점이 있다. 26 | 27 | * Mybatis는 JDBC의 작업을 간편하게 해주는 프레임워크이다. SQL문을 자바 코드에서 분리하여 xml 파일로 따로 관리한다. spring에서 jdbc를 사용할 수 있지만 , mybatis 를 사용 하는것이 보통이다. jdbc에서 사용해야 하는 Connection, Statement등을 mybatis가 직접 관리해서 코드를 줄여준다. jdbc의 PrepareStatment와 같은 sql injection을 고려하지 않아도 된다. 28 | 29 | ### MyBatis란? 30 | * Mybatis는 자바 오브젝트와 SQL사이의 자동 매핑 기능을 지원하는 ORM(Object relational Mapping)프레임워크이다. 31 | 32 | ### MyBatis 특징 33 | 1. 쉬운 접근성과 코드의 간결함 JDBC의 모든 기능을 Mybatis가 대부분 제공한다.복잡한 JDBC코드를 걷어내며 깔끔한 소스코드를 유지할 수 있다. 수동적인 파라미터 설정과 쿼리 결과에 대한 맵핑 구문을 제거할 수 있다. 34 | 35 | 2. SQL문과 프로그래밍 코드의 분리, SQL에 변경이 있을 때마다 자바 코드를 수정하거나 컴파일하지 않아도 된다. 36 | 37 | 3. 다양한 프로그래밍 언어로 구현가능 (Java, C#, .NET, Ruby) 38 | 39 | ### Mybatis-Spring의 주요 컴포넌트 40 |
41 |
42 | * MyBatis 설정파일(SqlMapConfig.xml) : VO 객체의 정보를 설정한다.
43 |
44 | * SqlSessionFactory : MyBatis 설정파일을 바탕으로 SqlSessionFactory를 생성한다, Spring Bean으로 등록해야 한다.
45 |
46 | * SqlSessionTemplate : 핵심적인 역할을 하는 클래스로서 SQL 실행이나 트랜잭션 관리를 실행한다. SqlSession 인터페이스를 구현하며, Thread-safe 하다. Spring Bean으로 등록해야 한다.
47 |
48 | * Mapping 파일 (user.xml) : SQL문과 OR Mapping을 설정한다.
49 |
50 | * Spring Bean 설정 파일 (mybatisBeans.xml) : SqlSessionFactoryBean을 Bean 등록할 때 DataSource 정보와 MyBatis Config 파일정보, Mapping 파일의 정보를 함께 설정한다. SqlSessionTemplate을 Bean으로 등록한다.
51 |
52 | ## REST(Representational State Transfer) API
53 | * Restful 서비스(API)란 REST 아키텍쳐를 준수하는 서비스
54 | * 일반적인 서비스의 경우 요청받은 내용을 처리하고 데이터를 가공해서 처리 결과를 특정 플랫폼에 적합한 형태의 View로 만들어 되돌려주는 반면, Restful 서비스에서는 그냥 데이터만 처리하고 끝내거나 되돌려줄 데이터가 있다면 **JSON이나 XML 형식**으로 전달해줍니다. View에 대해서는 전혀 신경쓰지 않습니다.
55 |
56 | * 따라서 요청하는 클라이언트는 규칙에 맞게 작업을 요청하고, 서버는 어떤 플랫폼에서 어떻게 사용할 것인지 신경쓰지 않고 요청받은 데이터만 처리하고 만들어서 되돌려주면 됩니다. 클라이언트는 받은 데이터를 알아서 가공해서 사용합니다. 즉, **멀티 플랫폼에서 사용이 가능**하다는 의미입니다.
57 |
58 | ## Spring Boot
59 | * 스프링 프레임워크는 기능이 많은만큼 환경설정이 복잡한 편이다. 이에 어려움을 느끼는 사용자들을 위해 나온 것이 바로 스프링 부트다. 스프링 부트는 스프링 프레임워크를 사용하기 위한 설정의 많은 부분을 자동화하여 사용자가 정말 편하게 스프링을 활용할 수 있도록 돕는다.
--------------------------------------------------------------------------------
/05.Spring/hsh/README.md:
--------------------------------------------------------------------------------
1 | # 진행사항
2 |
3 | | 날짜 | 설명 | 링크 |
4 | | -------- | -------------- | ------------------------------------------------------------------------------------------- |
5 | | 21.06.22 | IoC/DI | [✅보러가기](21.06.22.md) |
6 | | 21.06.24 | Spring Web MVC | [✅보러가기](21.06.24.md) |
7 | | 21.06.25 | MyBatis & REST Api | [✅보러가기](21.06.25.md) |
8 |
--------------------------------------------------------------------------------
/05.Spring/kmj/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/05.Spring/kmj/.DS_Store
--------------------------------------------------------------------------------
/05.Spring/lyj/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/SSAFY-CS-STUDY/Tech_interview/c93d870cf8c3c2c65019517a7aaabb2d8bc79775/05.Spring/lyj/.DS_Store
--------------------------------------------------------------------------------
/05.Spring/lyj/21.06.22.md:
--------------------------------------------------------------------------------
1 | # [21.06.22] Spring Framework 01
2 |
3 | ## Spring
4 | 1. 기존 EJB(Enterprise Java Beans) + WAS
5 | - 한계 : 개발 유지보수 복잡해져서 다양한 디자인패턴에 대한 이해 등 시간이 많이 소요된다.
6 | 2. Spring
7 | 특정 프레임워크나 기술에 의존적이지 않은 자바 객체 POJO 사용하여 EJB 서비스 지원 가능!
8 |
9 | Spring은 **IoC와 AOP 지원하는 경량 컨테이너 프레임워크**
10 | > 프레임워크
11 | > - 개발 구조나 설계시 제공되는 인터페이스 집합
12 | > - 앱 개발시 코드 품질, 필수 코드, DB 연동 등의 어느정도 기능이 구성된 뼈대를 제공한다.
13 | >
14 | > 라이브러리
15 | > - 특정기능에 대한 API 집합
16 |
17 | ## **OOP 설계원칙**
18 | 1. 결합도 낮추기
19 |
20 | 클래스 간의 의존성(상대방에게 영향을 주는 정도) 낮추기
21 |
22 | = **디커플링** : 변경될 때 다른 부분에 영향을 주는 정도 최소화
23 |
24 | 2. 응집도 높이기
25 |
26 | 클래스의 책임에 맞는 내용들로 클래스 설계
27 |
28 | = 한 클래스의 책임을 3-5개 이내로
29 |
30 | - 1개의 책임 : 1~3개 메소드로 구현
31 |
32 | ## 디커플링 방법
33 | 1. **Interface** : 구현과 사용의 분리
34 | - 구현 객체가 달라져도 그릇이 바뀌지 않도록!
35 |
36 | ```java
37 | // 그릇 a = new 알맹이();
38 | // 상위타입 참조변수를 사용하자
39 | // 인터페이스 타입 a = new 구현클래스();
40 | OutputService os1 = new OutputServiceConsole();
41 | OutputService os2 = new OutputServiceFile();
42 |
43 | // 01 GreetingService 내부
44 | OutputService os = new OutputServiceConsole();
45 |
46 | // 02 XXXService 내부
47 | // 해당 서비스에서 OutputServiceConsole을 썼지만 OutputServiceFile로 바꾸고 싶을 때 문제점 발생!
48 | OutputService os = new OutputServiceConsole();
49 | ```
50 | - 한계
51 | - new 연산자로 만들어지는 객체를 바꾸기 위해서 하나씩 다 바꾸어주어야한다.
52 | - 손이 많이 간다.
53 |
54 | 2. **팩토리 패턴** : 생성되는 객체 교체 용이
55 | - 팩토리 reference가 있다면 객체 생성을 new로 하지 않고 `OutputService oc = factory.getGreeting();`으로 바꾸면 된다.
56 |
57 | ```java
58 | // 싱글톤 패턴
59 | class GreetingFactory {
60 | // 상위타입으로 리턴
61 | OutputService getGreetingFactory(){
62 | return OutputServiceFile();
63 | }
64 | }
65 |
66 | // 01 GreetingService 내부
67 | OutputService os = factory.getGreeingFactory();
68 |
69 | // 02 XXXService 내부
70 | OutputService os = factory.getGreeingFactory();
71 |
72 | // new 연산자로 생성되는 클래스 일일이 바꿀 필요가 없어졌다
73 | ```
74 |
75 |
76 | ## **IOC**
77 | 인스턴스의 생성부터 소멸까지 개발자가 아닌 컨테이너가 대신 관리해주는 것을 말합니다. 컨테이너가 제어권을 갖음으로써, DI와 AOP 등이 가능하게 됩니다.
78 |
79 | ### Spring IoC 지원
80 | 1. Dependency Lookup
81 | 2. Dependency Injection
82 |
83 | ## **DI(Dependency Injection)**
84 | 의존 관계 주입이며, 어떤 객체가 사용하는 의존 객체를 직접 만들어 사용하는 것이 아니라, 주입 받아 사용하는 방법입니다.
85 | 즉, 의존관계를 스프링 설정파일에 등록된 정보로 컨테이너가 자동 처리합니다.
86 |
87 | **1. 직접 객체 생성 또는 팩토리 객체를 이용하여 객체 생성에 대한 제어권을 내가 가지고 있느냐**
88 |
89 | **2. 나 대신 객체 제어를 해주는 제 3자가 있느냐 (Inversion Of Conversion)**
90 |
91 | 즉, 스프링 설정 파일만 변경해도 변경사항이 반영되는 것이다. 이러한 점으로 유지보수가 용이해진다.
92 |
93 | ### DI 종류
94 | 1. 의존객체 상위타입 변수 선언만
95 | 2. 객체 받아들일 방법 선택
96 | - 생성자 : 필수 객체는 생성자에서 주로 해준다
97 |
98 |
99 | - 세터
100 |
101 |
102 | 3. 의존객체 관련 설정
103 | - 방법1 **XML**
104 |
105 | ```
106 |
10 |
13 |
14 | 참고
11 | https://jeong-pro.tistory.com/86 12 |15 |
16 | 17 | ## Spring 18 | 19 | ### 구조 20 | 21 | 1. POJO (Plain Old Java Object) 22 | 23 | - 특정 기술에 종속되지 않은 순수한 자바객체 24 | - Spring 기술에서 이것이 가능한 이유는 PSA 25 | 26 | 2. PSA (Portable Service Abstraction) 27 | 28 | - 하나의 추상화로 여러 서비스를 묶어둔 것 29 | - 일관된 방식으로 기술에 접근 가능하도록 해주는 설계 원칙 30 |
31 |
34 |
35 | 3. IoC/DI
36 |
37 | - 클라이언트에게 무슨 서비스를 사용할 것인지 말해주는 것
38 | - 객체간의 의존성을 낮춰 유연한 확장이 가능
39 |
40 | 4. AOP
41 | - 관심사로 모듈화하고 핵심적인 비즈니스 로직을 분리하여 재사용
42 |
43 | 참고
32 | https://sabarada.tistory.com/127 33 |44 | 45 | ## IoC & Container 46 | 47 | ### IoC 유형 48 | 49 |  50 | 51 | - DL (Dependency Lookup) 52 | 53 | - 의존성 검색 54 | - IoC 컨테이너는 각 컨테이너에서 관리해야 하는 별도의 저장소(객체 저장소)에서 객체를 검색하여 참조하는 방법 55 | 56 | - DI (Dependency Injection) 57 | - 의존성 주입 58 | - 클래스 간의 의존성을 외부(컨테이너)에서 주입하는 개념 59 | 60 |
61 |
64 |
65 | 참고
62 | https://happy-playboy.tistory.com/entry/%EB%B0%B1%EC%88%98%EC%9D%98-%EC%8A%A4%ED%94%84%EB%A7%81-IoC%EC%99%80-DI%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C 63 |66 | 67 | ### Container 68 | 69 | 객체의 생성, 사용, 소멸에 해당하는 라이프 사이클을 담당하며 애플리케이션 사용에 필요한 주요 기능을 제공 70 | 71 |
72 | 73 | ## 의존성 주입 (Dependency Injection, DI) 74 | 75 | ### 빈(Bean) 76 | 77 | - 애플리케이션의 핵심을 이루는 객체 78 | - Spring IoC Container에 의해 인스턴스화, 관리, 생성됨 79 | - 기본적인 빈 스코프는 싱글톤 80 | - XML 파일에 정의 81 | 82 | ```xml 83 |
100 | 101 | ### 빈 스코프(Bean Scope) 102 | 103 | | Scope | Description | 104 | | ----------------- | ---------------------------------------------------------------------------------------- | 105 | | singleton | 스프링 컨테이너 내에 하나의 인스턴스 빈만 생성 | 106 | | prototype | 컨테이너에 빈을 요청할 때마다 새로운 인스턴스 생성 | 107 | | request | HTTP Request별로 새로운 인스턴스 생성 | 108 | | session | HTTP Session별로 새로운 인스턴스 생성 | 109 | | ✍ global session | global HTTP SESSION별로 새로운 인스턴스 생성
일반적으로 portlet context 안에서 유효 | 110 | 111 |
112 | 113 | ✍ Bean Life Cycle / BeanFactory & ApplicationContext 114 | ✍ singleton을 사용하는 경우와 아닌 경우 115 | -------------------------------------------------------------------------------- /05.Spring/phb/21.06.24.md: -------------------------------------------------------------------------------- 1 | # [21.06.22] Spring Framework 02 - MVC 2 | 3 | # Spring Web MVC 4 | 5 | ## MVC Pattern 6 | 7 | - Model 8 | 9 | - 앱이 포함해야할 데이터가 무엇인지 정의 10 | - 비즈니스 로직 처리 11 | - 데이터 상태 변경되면 view에게 알림 12 | - 규칙 13 | - 사용자가 편집하길 원하는 모든 데이터를 가지고 있어야만 한다. 14 | - 뷰나 컨트롤러에 대해서 어떤 정보도 알지 말아야한다. 15 | - 변경이 일어나면, 변경 통지에 대한 처리 방법을 구현해야만 한다. 16 | 17 | - View 18 | 19 | - 앱의 데이터를 보여주는 방식 20 | - 표시할 데이터를 모델로부터 받음 21 | - 규칙 22 | - 모델이 가지고 있는 정보를 따로 저장해서는 안된다. 23 | - 다른 구성 요소를 몰라야한다. 24 | - 변경이 일어나면, 변경 통지에 대한 처리 방법을 구현해야만 한다. 25 | 26 | - Controller 27 | - 앱의 사용자로부터 입력에 대한 응답으로 모델 및 뷰를 업데이트하는 로직 포함 28 | - 규칙 29 | - 모델이나 뷰에 대해서 알고 있어야한다. 30 | - 모델이나 뷰의 변경을 모니터링 해야 한다. 31 | 32 | * 동작순서 33 |  34 | 35 |
36 |
42 |
--------------------------------------------------------------------------------
/05.Spring/phb/21.06.25.md:
--------------------------------------------------------------------------------
1 | # [21.06.25] Spring Framework 03 - MyBatis
2 |
3 | ### 💡 REST Service와 기존 Service의 차이점
4 |
5 | - 기존 서비스는 플랫폼에 맞는 View를 전달했다면 REST 서비스는 JSON/XML 형식의 데이터만 전달
6 |
7 | ### 💡 RESTful?
8 |
9 | - REST 원리를 따르는 시스템
10 |
11 | ### 💡 Spring Vs Spring Boot
12 |
13 | - Spring Boot은 자동 설정을 지원하여 버전 관리를 자동으로 해준다.
14 |
15 | 참고
37 |-
38 |
- https://m.blog.naver.com/jhc9639/220967034588 39 |
- https://bsnippet.tistory.com/13 40 |
16 |
17 | 18 | ### Mybatis 19 | 20 | - Java와 RDBMS 사이의 자동 매핑을 지원하는 ORM 프레임워크 21 | - 개발자가 작성한 sql문(xml 파일)을 자바 객체를 매핑 22 | - 특징 23 | 24 | - 코드의 간결함 25 | - 객체-RDBMS 코드의 분리 26 | - 다양한 프로그래밍 언어 구현 가능 27 | 28 | - 주요 컴포넌트 29 |  30 | - SqlSessionFactory : singleton 31 | - sqlSession : request scope 32 | 33 | ``` 34 | ORM 35 | Object-Relational Mapping(객체 관계 매핑)이란 의미로 객체는 객체대로 설계하며 RDBMS는 RDBMS대로 설계하면 중간에서 매핑해주는 기술 36 | ``` 37 | 38 |
39 |
46 |
47 | 참고
40 |-
41 |
- http://mybatis.org/spring/ko/sqlsession.html 42 |
- https://opentutorials.org/module/3569/21223 43 |
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kd980311&logNo=220041128658 44 |
48 |
49 | 50 | # [21.06.25] Spring Framework 04 - REST API 51 | 52 | ### REST (Representational State Transfer) 53 | 54 | - HTTP URI + HTTP Method 55 | - URI로 자원을 명시하고 Method로 자원을 제어하는 명령을 내리는 아키텍처 56 | - 구성 57 | 58 | - 자원(Resource) - URI 59 | - 행위(Verb) - HTTP Method 60 | - 표현(Representations) 61 | 62 | - Method 63 | |Method|작업|비고| 64 | |-|-|-| 65 | |POST|Create(insert)|쓰기| 66 | |GET|Read(select)|읽기| 67 | |PUT|Update(update)|수정| 68 | |DELETE|Delete(delete)|삭제| 69 | 70 | - 특징 71 | - 클라이언트-서버 구조 72 | - stateless 73 | - Cacheable 74 | - 자기 기술적(self-descriptive) 75 | - 계층화 76 | - Code-On-Demand 77 | - Uniform Interface 78 | 79 |
80 | 81 |
82 |
87 |
88 | 참고
83 |-
84 |
- https://gmlwjd9405.github.io/2018/09/21/rest-and-restful.html 85 |
89 |
90 | 91 | # [21.06.25] Spring Framework 05 - SpringBoot 92 | 93 | ✍ REST는 왜 쓰고 REST 외에 다른 아키텍처는 무엇이 있을까? 94 | ✍ REST API는 Java말고 다른 언어로는 어떻게 구현할까? 95 | ✍ 왜 대부분의 API는 Spring Framework를 사용할까? 96 | ✍ 자동 설정이 완전 편한데 어떤 경우에 Spring을 사용하는 걸까? 97 | -------------------------------------------------------------------------------- /05.Spring/phb/README.md: -------------------------------------------------------------------------------- 1 | # 진행사항 2 | 3 | | 날짜 | 설명 | 링크 | 4 | | -------- | -------------- | ------------------------------------------------------------------------------------------- | 5 | | 21.06.22 | IoC/DI | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/05.Spring/phb/21.06.22.md) | 6 | | 21.06.24 | Spring Web MVC | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/05.Spring/phb/21.06.24.md) | 7 | | 21.03.25 |MyBatis/REST API/SpringBoot| [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/05.Spring/phb/21.06.25.md) | 8 | | 21.03.29 | | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.29.md) | 9 | | 21.03.30 | | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.03.30.md) | 10 | | 21.04.05 | | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.04.05.md) | 11 | | 21.04.15 | | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.04.15.md) | 12 | | 21.05.10 | | [✅보러가기](https://github.com/happ-in/Tech_interview/blob/main/04.Java/phb/21.05.10.md) | 13 | -------------------------------------------------------------------------------- /README.md: -------------------------------------------------------------------------------- 1 |  2 | 3 | 4 | 5 | ## 📣 소개 6 | - SSAFY 5기생들이 만든 CS 스터디 Repo입니다.🤸♀️🤸♂️🤸♀️🤸 **(21.01.11 ~ 21.06)** 7 | - SW 전공자들이 필수적으로 알아야 하는 지식을 공부하고, 다른 사람에게 설명할 수 있는 SKILL을 기르기 위한 스터디 입니다. 8 | 9 | ## 📝 스터디 방식 10 | - 주 2회 (수, 금) 회의 및 발표를 진행합니다. 11 | - 한 과목이 끝나면 모의 면접을 진행합니다. 12 | 13 | 14 | ## 📁 면접질문모음 15 | |**과목명**|**질문보기**|기간|모의면접| 16 | |-|-|-|-| 17 | |**Database**|[📃질문보기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/02.database/README.md)|2021.01.11 ~ 2021.01.21|O| 18 | |**Network**|[📃질문보기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/01.network/README.md)|2021.01.22 ~ 2021.02.09|O| 19 | |**Operating System**|[📃질문보기](https://github.com/SSAFY-CS-STUDY/Tech_interview/blob/main/03.Operating_system/README.md)|2021.02.15 ~ 2021.03.03|O| 20 | |**Java**|[📃질문보기](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/04.Java/README.md)|2021.03.15 ~ 2021.05.12|-| 21 | |**Spring**|[📃질문보기](https://github.com/SSAFY-CS-STUDY/Tech_interview/tree/main/05.Spring/README.md)|-|-| 22 |
23 | 24 | ## 📑 문서구조 25 | ```sh 26 | ├─CS과목명 27 | │ ├─hsh 28 | │ ├─kmj 29 | │ ├─lyj 30 | │ ├─phb 31 | │ ├─면접질문모음 (README.md) 32 | │ │ ├─ 날짜별 공부 내용 33 | │ │ ├─ 공부목차 (README.md) 34 | ``` 35 | 36 | ## REFERENCE 37 | * https://github.com/WeareSoft 38 | * https://github.com/JaeYeopHan/Interview_Question_for_Beginner 39 | * https://github.com/gyoogle/tech-interview-for-developer 40 | 41 | 42 | ## ⭐️ 도움을 주신 분들 43 | [](https://hits.seeyoufarm.com) 44 | 45 | 46 | 47 |
17 | 18 | ## ⭐ 개념 정리 19 | 20 | ### 개념1 21 | ### 개념2 22 | 23 |
24 | 25 | 26 | 27 | --------------------------------------------------------------------------------