给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
4 | 5 |6 | 7 |
示例 1:
8 |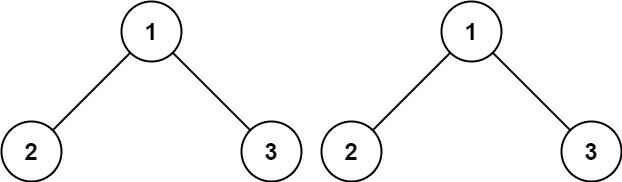 9 |
9 | 10 | 输入:p = [1,2,3], q = [1,2,3] 11 | 输出:true 12 |13 | 14 |
示例 2:
15 |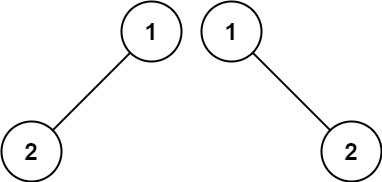 16 |
16 | 17 | 输入:p = [1,2], q = [1,null,2] 18 | 输出:false 19 |20 | 21 |
示例 3:
22 |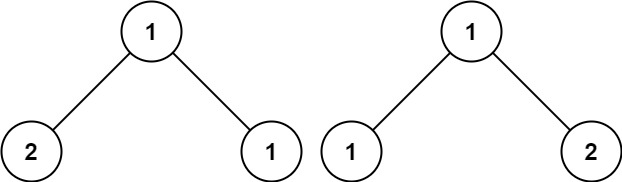 23 |
23 | 24 | 输入:p = [1,2,1], q = [1,1,2] 25 | 输出:false 26 |27 | 28 |
29 | 30 |
提示:
31 | 32 |-
33 |
- 两棵树上的节点数目都在范围
[0, 100]内
34 | -104 <= Node.val <= 104
35 |
给你一个二叉树的根节点 root , 检查它是否轴对称。
4 | 5 |
示例 1:
6 |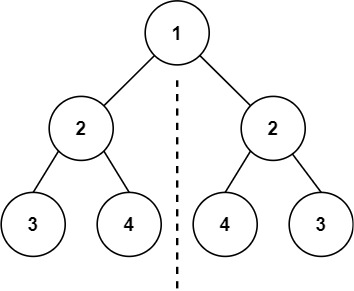 7 |
7 | 8 | 输入:root = [1,2,2,3,4,4,3] 9 | 输出:true 10 |11 | 12 |
示例 2:
13 |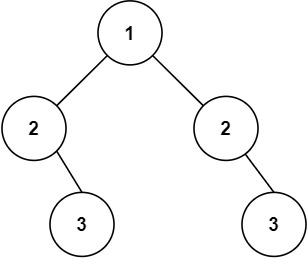 14 |
14 | 15 | 输入:root = [1,2,2,null,3,null,3] 16 | 输出:false 17 |18 | 19 |
20 | 21 |
提示:
22 | 23 |-
24 |
- 树中节点数目在范围
[1, 1000]内
25 | -100 <= Node.val <= 100
26 |
29 | 30 |
进阶:你可以运用递归和迭代两种方法解决这个问题吗?
31 | 32 |给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
4 | 5 |
示例 1:
6 | 7 |
7 | 8 | 输入:root = [3,9,20,null,null,15,7] 9 | 输出:[[3],[9,20],[15,7]] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:root = [1] 16 | 输出:[[1]] 17 |18 | 19 |
示例 3:
20 | 21 |22 | 输入:root = [] 23 | 输出:[] 24 |25 | 26 |
27 | 28 |
提示:
29 | 30 |-
31 |
- 树中节点数目在范围
[0, 2000]内
32 | -1000 <= Node.val <= 1000
33 |
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
4 | 5 |在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
6 | 7 |8 | 9 |
示例:
10 | 11 |输入:"abbaca" 12 | 输出:"ca" 13 | 解释: 14 | 例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。 15 |16 | 17 |
18 | 19 |
提示:
20 | 21 |-
22 |
1 <= S.length <= 20000
23 | S仅由小写英文字母组成。
24 |
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
4 | 5 |6 | 7 |
示例 1:
8 | 9 |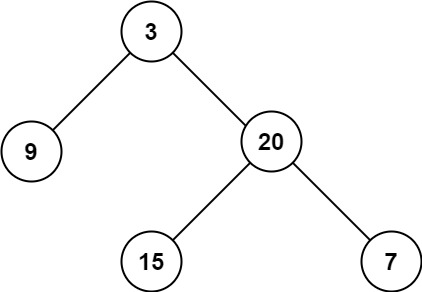
12 | 13 |
14 | 输入:root = [3,9,20,null,null,15,7] 15 | 输出:3 16 |17 | 18 |
示例 2:
19 | 20 |21 | 输入:root = [1,null,2] 22 | 输出:2 23 |24 | 25 |
26 | 27 |
提示:
28 | 29 |-
30 |
- 树中节点的数量在
[0, 104]区间内。
31 | -100 <= Node.val <= 100
32 |
给你二叉树的根节点 root ,返回其节点值 自底向上的层序遍历 。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
4 | 5 |
示例 1:
6 |
7 | 8 | 输入:root = [3,9,20,null,null,15,7] 9 | 输出:[[15,7],[9,20],[3]] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:root = [1] 16 | 输出:[[1]] 17 |18 | 19 |
示例 3:
20 | 21 |22 | 输入:root = [] 23 | 输出:[] 24 |25 | 26 |
27 | 28 |
提示:
29 | 30 |-
31 |
- 树中节点数目在范围
[0, 2000]内
32 | -1000 <= Node.val <= 1000
33 |
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
4 | 5 |6 | 7 |
示例 1:
8 |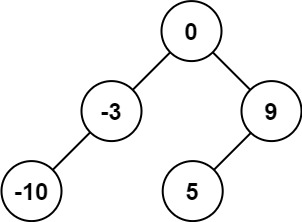 9 |
9 | 10 | 输入:nums = [-10,-3,0,5,9] 11 | 输出:[0,-3,9,-10,null,5] 12 | 解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案: 13 |15 | 16 |14 |
示例 2:
17 |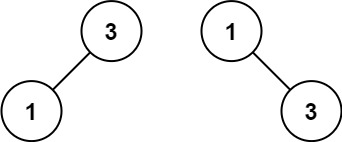 18 |
18 | 19 | 输入:nums = [1,3] 20 | 输出:[3,1] 21 | 解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树。 22 |23 | 24 |
25 | 26 |
提示:
27 | 28 |-
29 |
1 <= nums.length <= 104
30 | -104 <= nums[i] <= 104
31 | nums按 严格递增 顺序排列
32 |
给定一个单链表的头节点 head ,其中的元素 按升序排序 ,将其转换为高度平衡的二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差不超过 1。
4 | 5 |6 | 7 |
示例 1:
8 | 9 |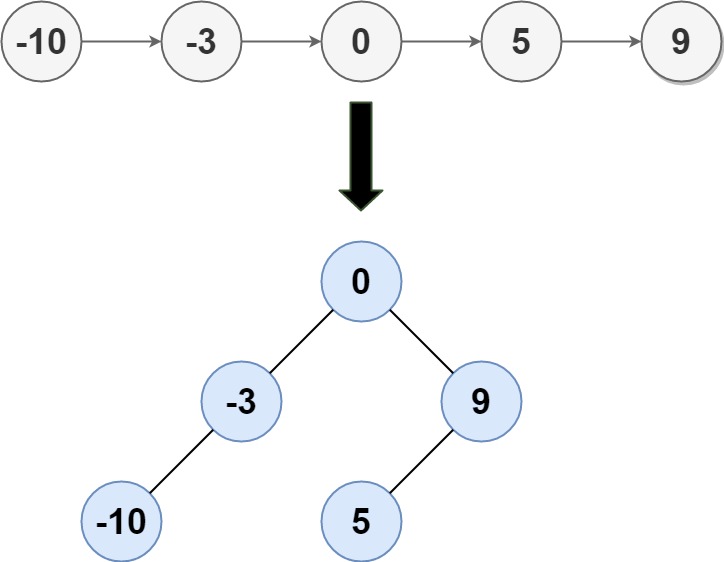
12 | 输入: head = [-10,-3,0,5,9] 13 | 输出: [0,-3,9,-10,null,5] 14 | 解释: 一个可能的答案是[0,-3,9,-10,null,5],它表示所示的高度平衡的二叉搜索树。 15 |16 | 17 |
示例 2:
18 | 19 |20 | 输入: head = [] 21 | 输出: [] 22 |23 | 24 |
25 | 26 |
提示:
27 | 28 |-
29 |
head中的节点数在[0, 2 * 104]范围内
30 | -105 <= Node.val <= 105
31 |
给定一个二叉树,判断它是否是高度平衡的二叉树。
2 | 3 |本题中,一棵高度平衡二叉树定义为:
4 | 5 |6 |8 | 9 |一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
7 |
10 | 11 |
示例 1:
12 |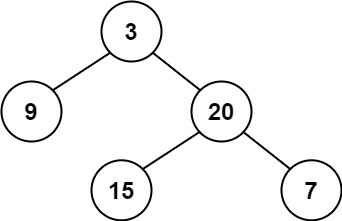 13 |
13 | 14 | 输入:root = [3,9,20,null,null,15,7] 15 | 输出:true 16 |17 | 18 |
示例 2:
19 |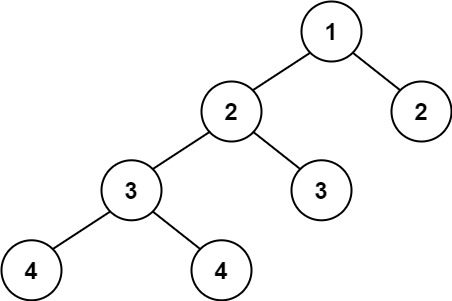 20 |
20 | 21 | 输入:root = [1,2,2,3,3,null,null,4,4] 22 | 输出:false 23 |24 | 25 |
示例 3:
26 | 27 |28 | 输入:root = [] 29 | 输出:true 30 |31 | 32 |
33 | 34 |
提示:
35 | 36 |-
37 |
- 树中的节点数在范围
[0, 5000]内
38 | -104 <= Node.val <= 104
39 |
给定一个二叉树,找出其最小深度。
2 | 3 |最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
4 | 5 |说明:叶子节点是指没有子节点的节点。
6 | 7 |8 | 9 |
示例 1:
10 |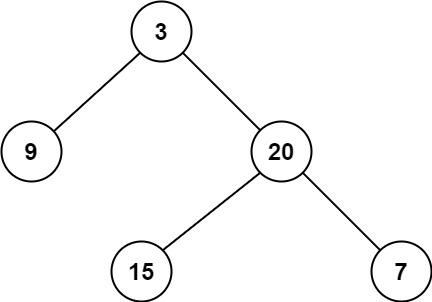 11 |
11 | 12 | 输入:root = [3,9,20,null,null,15,7] 13 | 输出:2 14 |15 | 16 |
示例 2:
17 | 18 |19 | 输入:root = [2,null,3,null,4,null,5,null,6] 20 | 输出:5 21 |22 | 23 |
24 | 25 |
提示:
26 | 27 |-
28 |
- 树中节点数的范围在
[0, 105]内
29 | -1000 <= Node.val <= 1000
30 |
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
4 | 5 |6 | 7 |
示例 1:
8 |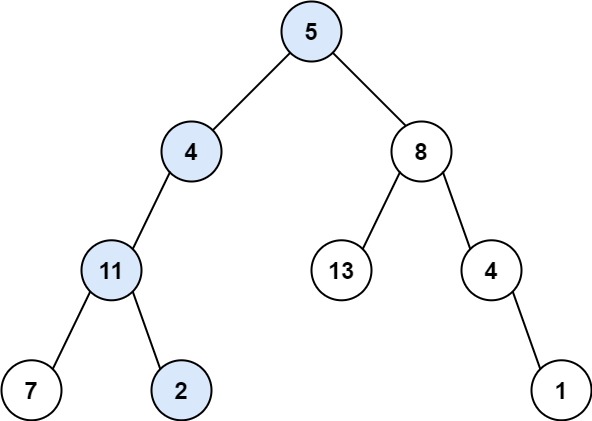 9 |
9 | 10 | 输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22 11 | 输出:true 12 | 解释:等于目标和的根节点到叶节点路径如上图所示。 13 |14 | 15 |
示例 2:
16 |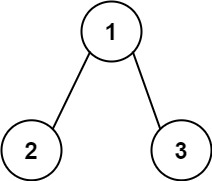 17 |
17 | 18 | 输入:root = [1,2,3], targetSum = 5 19 | 输出:false 20 | 解释:树中存在两条根节点到叶子节点的路径: 21 | (1 --> 2): 和为 3 22 | (1 --> 3): 和为 4 23 | 不存在 sum = 5 的根节点到叶子节点的路径。24 | 25 |
示例 3:
26 | 27 |28 | 输入:root = [], targetSum = 0 29 | 输出:false 30 | 解释:由于树是空的,所以不存在根节点到叶子节点的路径。 31 |32 | 33 |
34 | 35 |
提示:
36 | 37 |-
38 |
- 树中节点的数目在范围
[0, 5000]内
39 | -1000 <= Node.val <= 1000
40 | -1000 <= targetSum <= 1000
41 |
给你二叉树的根结点 root ,请你将它展开为一个单链表:
-
4 |
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。
5 | - 展开后的单链表应该与二叉树 先序遍历 顺序相同。 6 |
9 | 10 |
示例 1:
11 |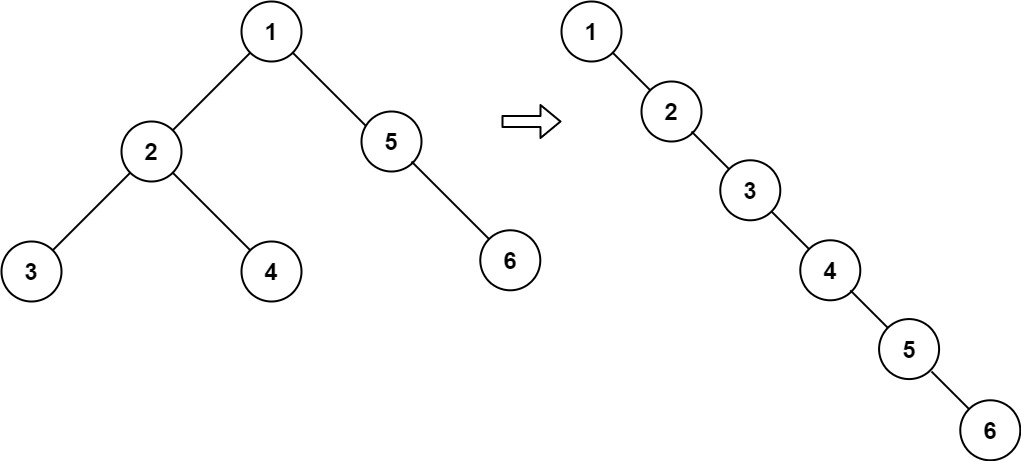 12 |
12 | 13 | 输入:root = [1,2,5,3,4,null,6] 14 | 输出:[1,null,2,null,3,null,4,null,5,null,6] 15 |16 | 17 |
示例 2:
18 | 19 |20 | 输入:root = [] 21 | 输出:[] 22 |23 | 24 |
示例 3:
25 | 26 |27 | 输入:root = [0] 28 | 输出:[0] 29 |30 | 31 |
32 | 33 |
提示:
34 | 35 |-
36 |
- 树中结点数在范围
[0, 2000]内
37 | -100 <= Node.val <= 100
38 |
41 | 42 |
进阶:你可以使用原地算法(O(1) 额外空间)展开这棵树吗?
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
2 | 3 |
4 | struct Node {
5 | int val;
6 | Node *left;
7 | Node *right;
8 | Node *next;
9 | }
10 |
11 | 填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
16 | 17 |
示例 1:
18 | 19 |
22 | 输入:root = [1,2,3,4,5,6,7] 23 | 输出:[1,#,2,3,#,4,5,6,7,#] 24 | 解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。 25 |26 | 27 |
28 |
29 | 30 |示例 2:
31 | 32 |33 | 输入:root = [] 34 | 输出:[] 35 |36 | 37 |
38 | 39 |
提示:
40 | 41 |-
42 |
- 树中节点的数量在
43 |
[0, 212 - 1]范围内
44 | -1000 <= node.val <= 1000
45 |
48 | 49 |
进阶:
50 | 51 |-
52 |
- 你只能使用常量级额外空间。 53 |
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。 54 |
给定一个二叉树:
2 | 3 |
4 | struct Node {
5 | int val;
6 | Node *left;
7 | Node *right;
8 | Node *next;
9 | }
10 |
11 | 填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL 。
初始状态下,所有 next 指针都被设置为 NULL 。
16 | 17 |
示例 1:
18 |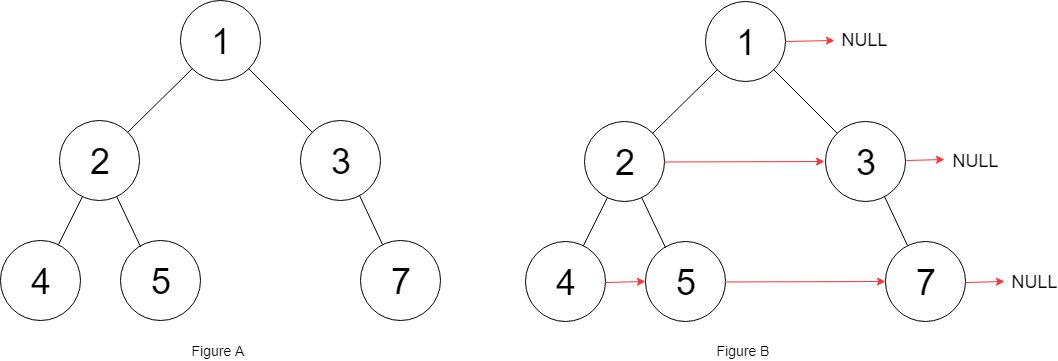 19 |
19 | 20 | 输入:root = [1,2,3,4,5,null,7] 21 | 输出:[1,#,2,3,#,4,5,7,#] 22 | 解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化输出按层序遍历顺序(由 next 指针连接),'#' 表示每层的末尾。23 | 24 |
示例 2:
25 | 26 |27 | 输入:root = [] 28 | 输出:[] 29 |30 | 31 |
32 | 33 |
提示:
34 | 35 |-
36 |
- 树中的节点数在范围
[0, 6000]内
37 | -100 <= Node.val <= 100
38 |
进阶:
41 | 42 |-
43 |
- 你只能使用常量级额外空间。 44 |
- 使用递归解题也符合要求,本题中递归程序的隐式栈空间不计入额外空间复杂度。 45 |
-
48 |
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
2 | 3 |字母和数字都属于字母数字字符。
4 | 5 |给你一个字符串 s,如果它是 回文串 ,返回 true ;否则,返回 false 。
8 | 9 |
示例 1:
10 | 11 |12 | 输入: s = "A man, a plan, a canal: Panama" 13 | 输出:true 14 | 解释:"amanaplanacanalpanama" 是回文串。 15 |16 | 17 |
示例 2:
18 | 19 |20 | 输入:s = "race a car" 21 | 输出:false 22 | 解释:"raceacar" 不是回文串。 23 |24 | 25 |
示例 3:
26 | 27 |28 | 输入:s = " " 29 | 输出:true 30 | 解释:在移除非字母数字字符之后,s 是一个空字符串 "" 。 31 | 由于空字符串正着反着读都一样,所以是回文串。 32 |33 | 34 |
35 | 36 |
提示:
37 | 38 |-
39 |
1 <= s.length <= 2 * 105
40 | s仅由可打印的 ASCII 字符组成
41 |
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
4 | 5 |
示例 1:
6 | 7 |8 | 输入:s = "aab" 9 | 输出:[["a","a","b"],["aa","b"]] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:s = "a" 16 | 输出:[["a"]] 17 |18 | 19 |
20 | 21 |
提示:
22 | 23 |-
24 |
1 <= s.length <= 16
25 | s仅由小写英文字母组成
26 |
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
4 | 5 |8 |
示例 1 :
12 | 13 |14 | 输入:nums = [2,2,1] 15 | 输出:1 16 |17 | 18 |
示例 2 :
19 | 20 |21 | 输入:nums = [4,1,2,1,2] 22 | 输出:4 23 |24 | 25 |
示例 3 :
26 | 27 |28 | 输入:nums = [1] 29 | 输出:1 30 |31 | 32 |
33 | 34 |
提示:
35 | 36 |-
37 |
1 <= nums.length <= 3 * 104
38 | -3 * 104 <= nums[i] <= 3 * 104
39 | - 除了某个元素只出现一次以外,其余每个元素均出现两次。 40 |
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
8 | 9 |
示例 1:
10 | 11 |
14 | 输入:head = [3,2,0,-4], pos = 1 15 | 输出:true 16 | 解释:链表中有一个环,其尾部连接到第二个节点。 17 |18 | 19 |
示例 2:
20 | 21 |
24 | 输入:head = [1,2], pos = 0 25 | 输出:true 26 | 解释:链表中有一个环,其尾部连接到第一个节点。 27 |28 | 29 |
示例 3:
30 | 31 |
34 | 输入:head = [1], pos = -1 35 | 输出:false 36 | 解释:链表中没有环。 37 |38 | 39 |
40 | 41 |
提示:
42 | 43 |-
44 |
- 链表中节点的数目范围是
[0, 104]
45 | -105 <= Node.val <= 105
46 | pos为-1或者链表中的一个 有效索引 。
47 |
50 | 51 |
进阶:你能用 O(1)(即,常量)内存解决此问题吗?
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
4 | 5 |
示例 1:
6 | 7 |
7 | 8 | 输入:root = [1,null,2,3] 9 | 输出:[1,2,3] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:root = [] 16 | 输出:[] 17 |18 | 19 |
示例 3:
20 | 21 |22 | 输入:root = [1] 23 | 输出:[1] 24 |25 | 26 |
示例 4:
27 | 28 |
28 | 29 | 输入:root = [1,2] 30 | 输出:[1,2] 31 |32 | 33 |
示例 5:
34 | 35 |
35 | 36 | 输入:root = [1,null,2] 37 | 输出:[1,2] 38 |39 | 40 |
41 | 42 |
提示:
43 | 44 |-
45 |
- 树中节点数目在范围
[0, 100]内
46 | -100 <= Node.val <= 100
47 |
50 | 51 |
进阶:递归算法很简单,你可以通过迭代算法完成吗?
52 | 53 |给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。
4 | 5 |
示例 1:
6 | 7 |
7 | 8 | 输入:root = [1,null,2,3] 9 | 输出:[3,2,1] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:root = [] 16 | 输出:[] 17 |18 | 19 |
示例 3:
20 | 21 |22 | 输入:root = [1] 23 | 输出:[1] 24 |25 | 26 |
27 | 28 |
提示:
29 | 30 |-
31 |
- 树中节点的数目在范围
[0, 100]内
32 | -100 <= Node.val <= 100
33 |
36 | 37 |
进阶:递归算法很简单,你可以通过迭代算法完成吗?
38 | 39 |给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
6 | 7 |注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
10 | 11 |
示例 1:
12 | 13 |14 | 输入:s = "17 | 18 |the sky is blue" 15 | 输出:"blue is sky the" 16 |
示例 2:
19 | 20 |21 | 输入:s = " hello world " 22 | 输出:"world hello" 23 | 解释:反转后的字符串中不能存在前导空格和尾随空格。 24 |25 | 26 |
示例 3:
27 | 28 |29 | 输入:s = "a good example" 30 | 输出:"example good a" 31 | 解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个。 32 |33 | 34 |
35 | 36 |
提示:
37 | 38 |-
39 |
1 <= s.length <= 104
40 | s包含英文大小写字母、数字和空格' '
41 | s中 至少存在一个 单词
42 |
-
45 |
48 | 49 |
进阶:如果字符串在你使用的编程语言中是一种可变数据类型,请尝试使用 O(1) 额外空间复杂度的 原地 解法。
n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,2,4,5,6,7] 在变化后可能得到:
2 |
3 | -
4 |
- 若旋转
4次,则可以得到[4,5,6,7,0,1,2]
5 | - 若旋转
7次,则可以得到[0,1,2,4,5,6,7]
6 |
注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
给你一个元素值 互不相同 的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
15 | 16 |
示例 1:
17 | 18 |19 | 输入:nums = [3,4,5,1,2] 20 | 输出:1 21 | 解释:原数组为 [1,2,3,4,5] ,旋转 3 次得到输入数组。 22 |23 | 24 |
示例 2:
25 | 26 |27 | 输入:nums = [4,5,6,7,0,1,2] 28 | 输出:0 29 | 解释:原数组为 [0,1,2,4,5,6,7] ,旋转 3 次得到输入数组。 30 |31 | 32 |
示例 3:
33 | 34 |35 | 输入:nums = [11,13,15,17] 36 | 输出:11 37 | 解释:原数组为 [11,13,15,17] ,旋转 4 次得到输入数组。 38 |39 | 40 |
41 | 42 |
提示:
43 | 44 |-
45 |
n == nums.length
46 | 1 <= n <= 5000
47 | -5000 <= nums[i] <= 5000
48 | nums中的所有整数 互不相同
49 | nums原来是一个升序排序的数组,并进行了1至n次旋转
50 |
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请
你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
6 | 7 |8 | 9 |
10 | 11 |
示例 1:
12 | 13 |14 | 输入:nums = [-1,0,1,2,-1,-4] 15 | 输出:[[-1,-1,2],[-1,0,1]] 16 | 解释: 17 | nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。 18 | nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。 19 | nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。 20 | 不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。 21 | 注意,输出的顺序和三元组的顺序并不重要。 22 |23 | 24 |
示例 2:
25 | 26 |27 | 输入:nums = [0,1,1] 28 | 输出:[] 29 | 解释:唯一可能的三元组和不为 0 。 30 |31 | 32 |
示例 3:
33 | 34 |35 | 输入:nums = [0,0,0] 36 | 输出:[[0,0,0]] 37 | 解释:唯一可能的三元组和为 0 。 38 |39 | 40 |
41 | 42 |
提示:
43 | 44 |-
45 |
3 <= nums.length <= 3000
46 | -105 <= nums[i] <= 105
47 |
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
4 | 5 |
8 | 9 |
示例 1:
10 | 11 |12 | 输入:digits = "23" 13 | 输出:["ad","ae","af","bd","be","bf","cd","ce","cf"] 14 |15 | 16 |
示例 2:
17 | 18 |19 | 输入:digits = "" 20 | 输出:[] 21 |22 | 23 |
示例 3:
24 | 25 |26 | 输入:digits = "2" 27 | 输出:["a","b","c"] 28 |29 | 30 |
31 | 32 |
提示:
33 | 34 |-
35 |
0 <= digits.length <= 4
36 | digits[i]是范围['2', '9']的一个数字。
37 |
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
4 | 5 |
示例 1:
6 | 7 |
10 | 输入: [1,2,3,null,5,null,4] 11 | 输出: [1,3,4] 12 |13 | 14 |
示例 2:
15 | 16 |17 | 输入: [1,null,3] 18 | 输出: [1,3] 19 |20 | 21 |
示例 3:
22 | 23 |24 | 输入: [] 25 | 输出: [] 26 |27 | 28 |
29 | 30 |
提示:
31 | 32 |-
33 |
- 二叉树的节点个数的范围是
[0,100]
34 | -
35 |
-100 <= Node.val <= 100
36 |
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
4 | 5 |你可以按任意顺序返回答案。
6 | 7 |8 | 9 |
示例 1:
10 | 11 |12 | 输入:nums = [2,7,11,15], target = 9 13 | 输出:[0,1] 14 | 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。 15 |16 | 17 |
示例 2:
18 | 19 |20 | 输入:nums = [3,2,4], target = 6 21 | 输出:[1,2] 22 |23 | 24 |
示例 3:
25 | 26 |27 | 输入:nums = [3,3], target = 6 28 | 输出:[0,1] 29 |30 | 31 |
32 | 33 |
提示:
34 | 35 |-
36 |
2 <= nums.length <= 104
37 | -109 <= nums[i] <= 109
38 | -109 <= target <= 109
39 | - 只会存在一个有效答案 40 |
43 | 44 |
进阶:你可以想出一个时间复杂度小于 O(n2) 的算法吗?
head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
2 |
3 | 4 | 5 |
示例 1:
6 |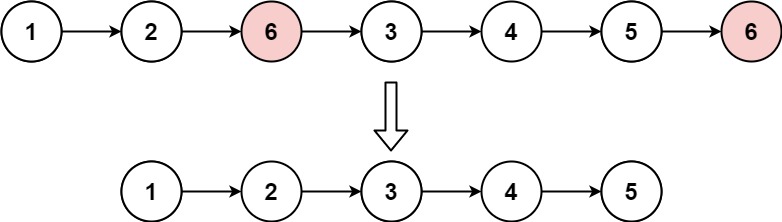 7 |
7 | 8 | 输入:head = [1,2,6,3,4,5,6], val = 6 9 | 输出:[1,2,3,4,5] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:head = [], val = 1 16 | 输出:[] 17 |18 | 19 |
示例 3:
20 | 21 |22 | 输入:head = [7,7,7,7], val = 7 23 | 输出:[] 24 |25 | 26 |
27 | 28 |
提示:
29 | 30 |-
31 |
- 列表中的节点数目在范围
[0, 104]内
32 | 1 <= Node.val <= 50
33 | 0 <= val <= 50
34 |
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
4 | 5 |-
6 |
- 左括号必须用相同类型的右括号闭合。 7 |
- 左括号必须以正确的顺序闭合。 8 |
- 每个右括号都有一个对应的相同类型的左括号。 9 |
12 | 13 |
示例 1:
14 | 15 |16 | 输入:s = "()" 17 | 输出:true 18 |19 | 20 |
示例 2:
21 | 22 |
23 | 输入:s = "()[]{}"
24 | 输出:true
25 |
26 |
27 | 示例 3:
28 | 29 |30 | 输入:s = "(]" 31 | 输出:false 32 |33 | 34 |
35 | 36 |
提示:
37 | 38 |-
39 |
1 <= s.length <= 104
40 | s仅由括号'()[]{}'组成
41 |
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
2 | 3 |4 | 5 |
示例 1:
6 | 7 |
7 | 8 | 输入:l1 = [1,2,4], l2 = [1,3,4] 9 | 输出:[1,1,2,3,4,4] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:l1 = [], l2 = [] 16 | 输出:[] 17 |18 | 19 |
示例 3:
20 | 21 |22 | 输入:l1 = [], l2 = [0] 23 | 输出:[0] 24 |25 | 26 |
27 | 28 |
提示:
29 | 30 |-
31 |
- 两个链表的节点数目范围是
[0, 50]
32 | -100 <= Node.val <= 100
33 | l1和l2均按 非递减顺序 排列
34 |
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。
完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
6 | 7 |
示例 1:
8 | 9 |
9 | 10 | 输入:root = [1,2,3,4,5,6] 11 | 输出:6 12 |13 | 14 |
示例 2:
15 | 16 |17 | 输入:root = [] 18 | 输出:0 19 |20 | 21 |
示例 3:
22 | 23 |24 | 输入:root = [1] 25 | 输出:1 26 |27 | 28 |
29 | 30 |
提示:
31 | 32 |-
33 |
- 树中节点的数目范围是
[0, 5 * 104]
34 | 0 <= Node.val <= 5 * 104
35 | - 题目数据保证输入的树是 完全二叉树 36 |
39 | 40 |
进阶:遍历树来统计节点是一种时间复杂度为 O(n) 的简单解决方案。你可以设计一个更快的算法吗?
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
-
6 |
void push(int x)将元素 x 压入栈顶。
7 | int pop()移除并返回栈顶元素。
8 | int top()返回栈顶元素。
9 | boolean empty()如果栈是空的,返回true;否则,返回false。
10 |
13 | 14 |
注意:
15 | 16 |-
17 |
- 你只能使用队列的标准操作 —— 也就是
push to back、peek/pop from front、size和is empty这些操作。
18 | - 你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。 19 |
22 | 23 |
示例:
24 | 25 |26 | 输入: 27 | ["MyStack", "push", "push", "top", "pop", "empty"] 28 | [[], [1], [2], [], [], []] 29 | 输出: 30 | [null, null, null, 2, 2, false] 31 | 32 | 解释: 33 | MyStack myStack = new MyStack(); 34 | myStack.push(1); 35 | myStack.push(2); 36 | myStack.top(); // 返回 2 37 | myStack.pop(); // 返回 2 38 | myStack.empty(); // 返回 False 39 |40 | 41 |
42 | 43 |
提示:
44 | 45 |-
46 |
1 <= x <= 9
47 | - 最多调用
100次push、pop、top和empty
48 | - 每次调用
pop和top都保证栈不为空
49 |
52 | 53 |
进阶:你能否仅用一个队列来实现栈。
54 | 55 |给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
4 | 5 |
示例 1:
6 | 7 |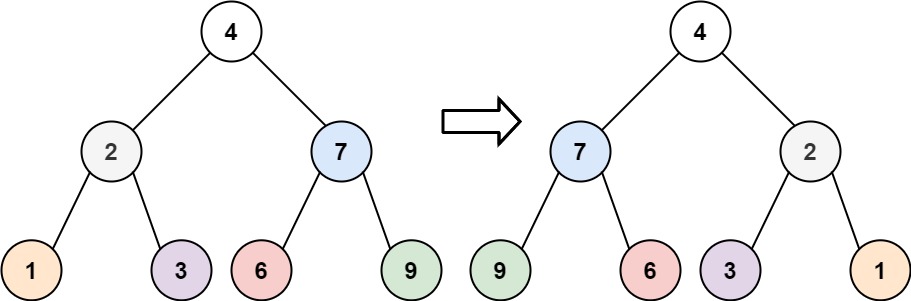
10 | 输入:root = [4,2,7,1,3,6,9] 11 | 输出:[4,7,2,9,6,3,1] 12 |13 | 14 |
示例 2:
15 | 16 |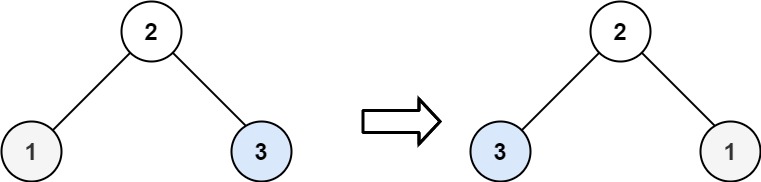
19 | 输入:root = [2,1,3] 20 | 输出:[2,3,1] 21 |22 | 23 |
示例 3:
24 | 25 |26 | 输入:root = [] 27 | 输出:[] 28 |29 | 30 |
31 | 32 |
提示:
33 | 34 |-
35 |
- 树中节点数目范围在
[0, 100]内
36 | -100 <= Node.val <= 100
37 |
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。
4 | 5 |
示例 1:
6 |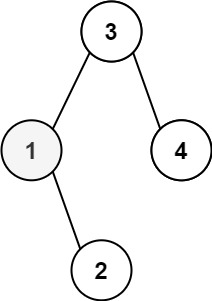 7 |
7 | 8 | 输入:root = [3,1,4,null,2], k = 1 9 | 输出:1 10 |11 | 12 |
示例 2:
13 |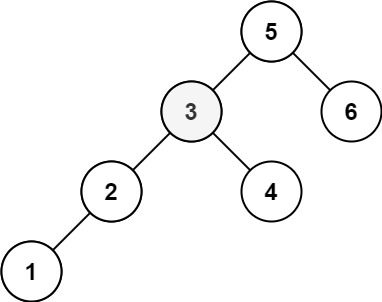 14 |
14 | 15 | 输入:root = [5,3,6,2,4,null,null,1], k = 3 16 | 输出:3 17 |18 | 19 |
20 | 21 |
22 | 23 |
提示:
24 | 25 |-
26 |
- 树中的节点数为
n。
27 | 1 <= k <= n <= 104
28 | 0 <= Node.val <= 104
29 |
32 | 33 |
进阶:如果二叉搜索树经常被修改(插入/删除操作)并且你需要频繁地查找第 k 小的值,你将如何优化算法?
给你一个整数 n,请你判断该整数是否是 2 的幂次方。如果是,返回 true ;否则,返回 false 。
如果存在一个整数 x 使得 n == 2x ,则认为 n 是 2 的幂次方。
6 | 7 |
示例 1:
8 | 9 |10 | 输入:n = 1 11 | 输出:true 12 | 解释:20 = 1 13 |14 | 15 |
示例 2:
16 | 17 |18 | 输入:n = 16 19 | 输出:true 20 | 解释:24 = 16 21 |22 | 23 |
示例 3:
24 | 25 |26 | 输入:n = 3 27 | 输出:false 28 |29 | 30 |
示例 4:
31 | 32 |33 | 输入:n = 4 34 | 输出:true 35 |36 | 37 |
示例 5:
38 | 39 |40 | 输入:n = 5 41 | 输出:false 42 |43 | 44 |
45 | 46 |
提示:
47 | 48 |-
49 |
-231 <= n <= 231 - 1
50 |
53 | 54 |
进阶:你能够不使用循环/递归解决此问题吗?
55 | 56 |给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
4 | 5 |
示例 1:
6 | 7 |
7 | 8 | 输入:head = [1,2,2,1] 9 | 输出:true 10 |11 | 12 |
示例 2:
13 |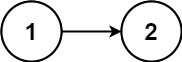 14 |
14 | 15 | 输入:head = [1,2] 16 | 输出:false 17 |18 | 19 |
20 | 21 |
提示:
22 | 23 |-
24 |
- 链表中节点数目在范围
[1, 105]内
25 | 0 <= Node.val <= 9
26 |
29 | 30 |
进阶:你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
2 | 3 |百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
4 | 5 |6 | 7 |
示例 1:
8 | 9 |
9 | 10 | 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 11 | 输出:3 12 | 解释:节点14 | 15 |5和节点1的最近公共祖先是节点3 。13 |
示例 2:
16 |
17 | 18 | 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 19 | 输出:5 20 | 解释:节点22 | 23 |5和节点4的最近公共祖先是节点5 。因为根据定义最近公共祖先节点可以为节点本身。 21 |
示例 3:
24 | 25 |26 | 输入:root = [1,2], p = 1, q = 2 27 | 输出:1 28 |29 | 30 |
31 | 32 |
提示:
33 | 34 |-
35 |
- 树中节点数目在范围
[2, 105]内。
36 | -109 <= Node.val <= 109
37 | - 所有
Node.val互不相同。
38 | p != q
39 | p和q均存在于给定的二叉树中。
40 |
给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
叶子节点 是指没有子节点的节点。
4 | 5 |示例 1:
6 |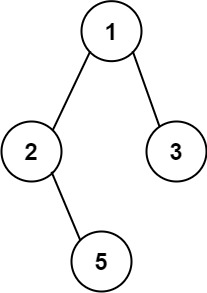 7 |
7 | 8 | 输入:root = [1,2,3,null,5] 9 | 输出:["1->2->5","1->3"] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:root = [1] 16 | 输出:["1"] 17 |18 | 19 |
20 | 21 |
提示:
22 | 23 |-
24 |
- 树中节点的数目在范围
[1, 100]内
25 | -100 <= Node.val <= 100
26 |
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
4 | 5 |6 | 7 |
示例 1:
8 | 9 |10 | 输入: nums =13 | 14 |[0,1,0,3,12]11 | 输出:[1,3,12,0,0]12 |
示例 2:
15 | 16 |17 | 输入: nums =19 | 20 |[0]18 | 输出:[0]
21 | 22 |
提示:
23 | 24 | 25 |-
26 |
1 <= nums.length <= 104
27 | -231 <= nums[i] <= 231 - 1
28 |
31 | 32 |
进阶:你能尽量减少完成的操作次数吗?
33 | 34 |给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
2 | 3 |请你将两个数相加,并以相同形式返回一个表示和的链表。
4 | 5 |你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
6 | 7 |8 | 9 |
示例 1:
10 |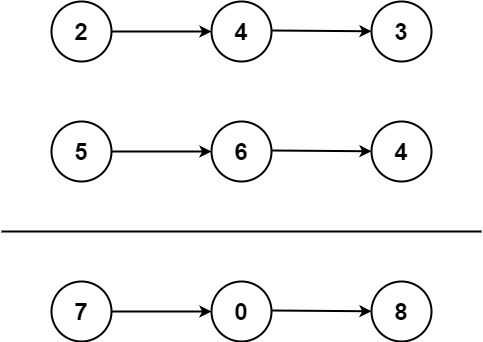 11 |
11 | 12 | 输入:l1 = [2,4,3], l2 = [5,6,4] 13 | 输出:[7,0,8] 14 | 解释:342 + 465 = 807. 15 |16 | 17 |
示例 2:
18 | 19 |20 | 输入:l1 = [0], l2 = [0] 21 | 输出:[0] 22 |23 | 24 |
示例 3:
25 | 26 |27 | 输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9] 28 | 输出:[8,9,9,9,0,0,0,1] 29 |30 | 31 |
32 | 33 |
提示:
34 | 35 |-
36 |
- 每个链表中的节点数在范围
[1, 100]内
37 | 0 <= Node.val <= 9
38 | - 题目数据保证列表表示的数字不含前导零 39 |
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
示例 1:
6 | 7 |8 | 输入:nums = [10,9,2,5,3,7,101,18] 9 | 输出:4 10 | 解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。 11 |12 | 13 |
示例 2:
14 | 15 |16 | 输入:nums = [0,1,0,3,2,3] 17 | 输出:4 18 |19 | 20 |
示例 3:
21 | 22 |23 | 输入:nums = [7,7,7,7,7,7,7] 24 | 输出:1 25 |26 | 27 |
28 | 29 |
提示:
30 | 31 |-
32 |
1 <= nums.length <= 2500
33 | -104 <= nums[i] <= 104
34 |
37 | 38 |
进阶:
39 | 40 |-
41 |
- 你能将算法的时间复杂度降低到
O(n log(n))吗?
42 |
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
6 | 7 |8 | 9 |
示例 1:
10 | 11 |12 | 输入:coins =15 | 16 |[1, 2, 5], amount =1113 | 输出:314 | 解释:11 = 5 + 5 + 1
示例 2:
17 | 18 |19 | 输入:coins =21 | 22 |[2], amount =320 | 输出:-1
示例 3:
23 | 24 |25 | 输入:coins = [1], amount = 0 26 | 输出:0 27 |28 | 29 |
30 | 31 |
提示:
32 | 33 |-
34 |
1 <= coins.length <= 12
35 | 1 <= coins[i] <= 231 - 1
36 | 0 <= amount <= 104
37 |
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
8 | 9 |
示例 1:
10 | 11 |12 | 输入:candidates =18 | 19 |[2,3,6,7],target =713 | 输出:[[2,2,3],[7]] 14 | 解释: 15 | 2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。 16 | 7 也是一个候选, 7 = 7 。 17 | 仅有这两种组合。
示例 2:
20 | 21 |
22 | 输入: candidates = [2,3,5], target = 8
23 | 输出: [[2,2,2,2],[2,3,3],[3,5]]
24 |
25 | 示例 3:
26 | 27 |
28 | 输入: candidates = [2], target = 1
29 | 输出: []
30 |
31 |
32 | 33 | 34 |
提示:
35 | 36 |-
37 |
1 <= candidates.length <= 30
38 | 2 <= candidates[i] <= 40
39 | candidates的所有元素 互不相同
40 | 1 <= target <= 40
41 |
给定二叉树的根节点 root ,返回所有左叶子之和。
4 | 5 |
示例 1:
6 | 7 |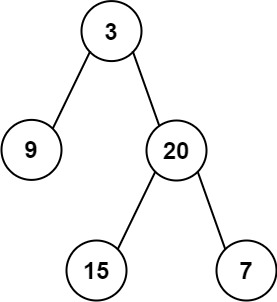
10 | 输入: root = [3,9,20,null,null,15,7] 11 | 输出: 24 12 | 解释: 在这个二叉树中,有两个左叶子,分别是 9 和 15,所以返回 24 13 |14 | 15 |
示例 2:
16 | 17 |18 | 输入: root = [1] 19 | 输出: 0 20 |21 | 22 |
23 | 24 |
提示:
25 | 26 |-
27 |
- 节点数在
[1, 1000]范围内
28 | -1000 <= Node.val <= 1000
29 |
32 | 33 |
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。
2 | 3 |树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。
4 | 5 |6 | 7 |
示例 1:
8 | 9 |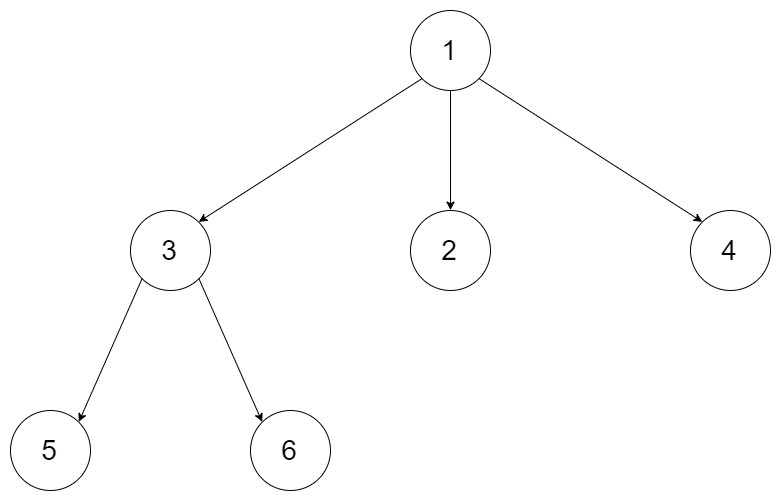
12 | 输入:root = [1,null,3,2,4,null,5,6] 13 | 输出:[[1],[3,2,4],[5,6]] 14 |15 | 16 |
示例 2:
17 | 18 |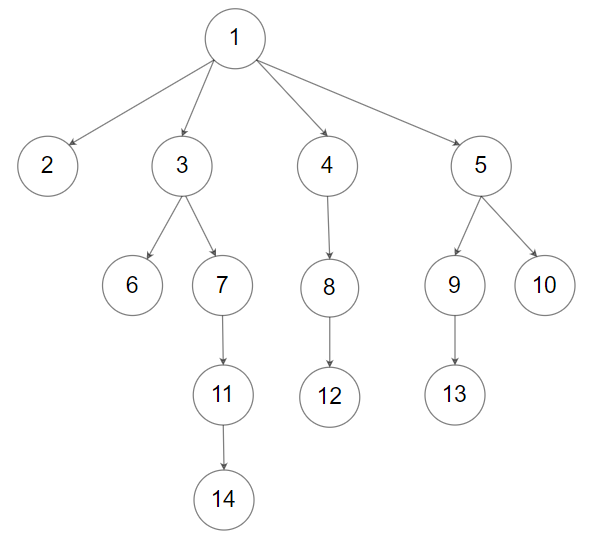
21 | 输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14] 22 | 输出:[[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]] 23 |24 | 25 |
26 | 27 |
提示:
28 | 29 |-
30 |
- 树的高度不会超过
1000
31 | - 树的节点总数在
[0, 10^4]之间
32 |
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
2 | 3 |对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
6 | 7 |8 | 输入: g = [1,2,3], s = [1,1] 9 | 输出: 1 10 | 解释: 11 | 你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。 12 | 虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。 13 | 所以你应该输出1。 14 |15 | 16 |
示例 2:
17 | 18 |19 | 输入: g = [1,2], s = [1,2,3] 20 | 输出: 2 21 | 解释: 22 | 你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。 23 | 你拥有的饼干数量和尺寸都足以让所有孩子满足。 24 | 所以你应该输出2. 25 |26 | 27 |
28 | 29 |
提示:
30 | 31 |-
32 |
1 <= g.length <= 3 * 104
33 | 0 <= s.length <= 3 * 104
34 | 1 <= g[i], s[j] <= 231 - 1
35 |
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
4 | 5 |
示例 1:
6 | 7 |8 | 输入:nums = [1,2,3] 9 | 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:nums = [0,1] 16 | 输出:[[0,1],[1,0]] 17 |18 | 19 |
示例 3:
20 | 21 |22 | 输入:nums = [1] 23 | 输出:[[1]] 24 |25 | 26 |
27 | 28 |
提示:
29 | 30 |-
31 |
1 <= nums.length <= 6
32 | -10 <= nums[i] <= 10
33 | nums中的所有整数 互不相同
34 |
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
4 | F(0) = 0,F(1) = 1 5 | F(n) = F(n - 1) + F(n - 2),其中 n > 1 6 |7 | 8 |
给定 n ,请计算 F(n) 。
11 | 12 |
示例 1:
13 | 14 |15 | 输入:n = 2 16 | 输出:1 17 | 解释:F(2) = F(1) + F(0) = 1 + 0 = 1 18 |19 | 20 |
示例 2:
21 | 22 |23 | 输入:n = 3 24 | 输出:2 25 | 解释:F(3) = F(2) + F(1) = 1 + 1 = 2 26 |27 | 28 |
示例 3:
29 | 30 |31 | 输入:n = 4 32 | 输出:3 33 | 解释:F(4) = F(3) + F(2) = 2 + 1 = 3 34 |35 | 36 |
37 | 38 |
提示:
39 | 40 |-
41 |
0 <= n <= 30
42 |
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。
4 | 5 |
示例1:
6 | 7 |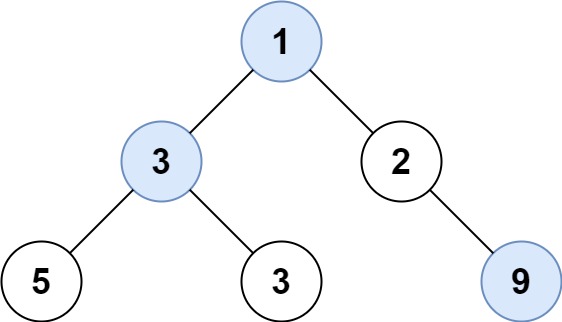
10 | 输入: root = [1,3,2,5,3,null,9] 11 | 输出: [1,3,9] 12 |13 | 14 |
示例2:
15 | 16 |17 | 输入: root = [1,2,3] 18 | 输出: [1,3] 19 |20 | 21 |
22 | 23 |
提示:
24 | 25 |-
26 |
- 二叉树的节点个数的范围是
[0,104]
27 | -
28 |
-231 <= Node.val <= 231 - 1
29 |
32 | 33 |
给你一棵二叉树的根节点,返回该树的 直径 。
2 | 3 |二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。
两节点之间路径的 长度 由它们之间边数表示。
6 | 7 |8 | 9 |
示例 1:
10 |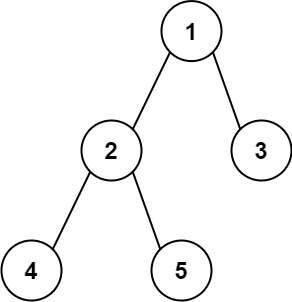 11 |
11 | 12 | 输入:root = [1,2,3,4,5] 13 | 输出:3 14 | 解释:3 ,取路径 [4,2,1,3] 或 [5,2,1,3] 的长度。 15 |16 | 17 |
示例 2:
18 | 19 |20 | 输入:root = [1,2] 21 | 输出:1 22 |23 | 24 |
25 | 26 |
提示:
27 | 28 |-
29 |
- 树中节点数目在范围
[1, 104]内
30 | -100 <= Node.val <= 100
31 |
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
6 | 7 |
示例 1:
8 | 9 |10 | 输入:nums = [2,3,1,1,4] 11 | 输出:true 12 | 解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。 13 |14 | 15 |
示例 2:
16 | 17 |18 | 输入:nums = [3,2,1,0,4] 19 | 输出:false 20 | 解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。 21 |22 | 23 |
24 | 25 |
提示:
26 | 27 |-
28 |
1 <= nums.length <= 104
29 | 0 <= nums[i] <= 105
30 |
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
10 | 11 |
示例 1:
12 |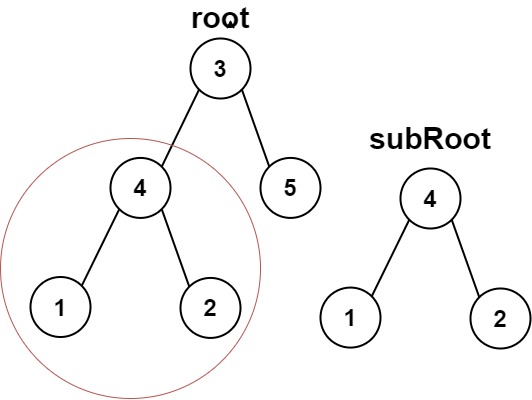 13 |
13 | 14 | 输入:root = [3,4,5,1,2], subRoot = [4,1,2] 15 | 输出:true 16 |17 | 18 |
示例 2:
19 |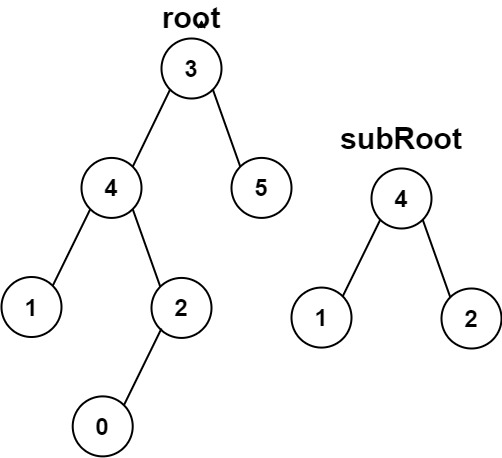 20 |
20 | 21 | 输入:root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2] 22 | 输出:false 23 |24 | 25 |
26 | 27 |
提示:
28 | 29 |-
30 |
root树上的节点数量范围是[1, 2000]
31 | subRoot树上的节点数量范围是[1, 1000]
32 | -104 <= root.val <= 104
33 | -104 <= subRoot.val <= 104
34 |
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
4 | 5 |返回合并后的二叉树。
6 | 7 |注意: 合并过程必须从两个树的根节点开始。
8 | 9 |10 | 11 |
示例 1:
12 | 13 |
13 | 14 | 输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7] 15 | 输出:[3,4,5,5,4,null,7] 16 |17 | 18 |
示例 2:
19 | 20 |21 | 输入:root1 = [1], root2 = [1,2] 22 | 输出:[2,2] 23 |24 | 25 |
26 | 27 |
提示:
28 | 29 |-
30 |
- 两棵树中的节点数目在范围
[0, 2000]内
31 | -104 <= Node.val <= 104
32 |
给定一个非空二叉树的根节点
2 | root , 以数组的形式返回每一层节点的平均值。与实际答案相差 10-5 以内的答案可以被接受。
5 | 6 |
示例 1:
7 | 8 |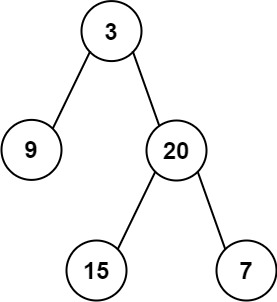
11 | 输入:root = [3,9,20,null,null,15,7] 12 | 输出:[3.00000,14.50000,11.00000] 13 | 解释:第 0 层的平均值为 3,第 1 层的平均值为 14.5,第 2 层的平均值为 11 。 14 | 因此返回 [3, 14.5, 11] 。 15 |16 | 17 |
示例 2:
18 | 19 |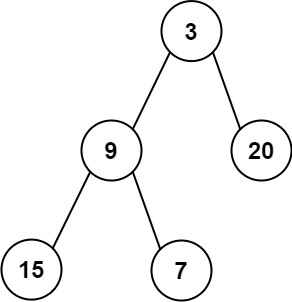
22 | 输入:root = [3,9,20,15,7] 23 | 输出:[3.00000,14.50000,11.00000] 24 |25 | 26 |
27 | 28 |
提示:
29 | 30 |31 |
32 | 33 |-
34 |
- 树中节点数量在
[1, 104]范围内
35 | -231 <= Node.val <= 231 - 1
36 |
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
-
4 |
- 创建一个根节点,其值为
nums中的最大值。
5 | - 递归地在最大值 左边 的 子数组前缀上 构建左子树。 6 |
- 递归地在最大值 右边 的 子数组后缀上 构建右子树。 7 |
返回 nums 构建的 最大二叉树 。
12 | 13 |
示例 1:
14 | 15 |
15 | 16 | 输入:nums = [3,2,1,6,0,5] 17 | 输出:[6,3,5,null,2,0,null,null,1] 18 | 解释:递归调用如下所示: 19 | - [3,2,1,6,0,5] 中的最大值是 6 ,左边部分是 [3,2,1] ,右边部分是 [0,5] 。 20 | - [3,2,1] 中的最大值是 3 ,左边部分是 [] ,右边部分是 [2,1] 。 21 | - 空数组,无子节点。 22 | - [2,1] 中的最大值是 2 ,左边部分是 [] ,右边部分是 [1] 。 23 | - 空数组,无子节点。 24 | - 只有一个元素,所以子节点是一个值为 1 的节点。 25 | - [0,5] 中的最大值是 5 ,左边部分是 [0] ,右边部分是 [] 。 26 | - 只有一个元素,所以子节点是一个值为 0 的节点。 27 | - 空数组,无子节点。 28 |29 | 30 |
示例 2:
31 | 32 |
32 | 33 | 输入:nums = [3,2,1] 34 | 输出:[3,null,2,null,1] 35 |36 | 37 |
38 | 39 |
提示:
40 | 41 |-
42 |
1 <= nums.length <= 1000
43 | 0 <= nums[i] <= 1000
44 | nums中的所有整数 互不相同
45 |
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
4 | 5 |注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
8 | 9 |
示例 1:
10 | 11 |12 | 输入:x = 4 13 | 输出:2 14 |15 | 16 |
示例 2:
17 | 18 |19 | 输入:x = 8 20 | 输出:2 21 | 解释:8 的算术平方根是 2.82842..., 由于返回类型是整数,小数部分将被舍去。 22 |23 | 24 |
25 | 26 |
提示:
27 | 28 |-
29 |
0 <= x <= 231 - 1
30 |
给定二叉搜索树(BST)的根节点
2 | root 和一个整数值
3 | val。
你需要在 BST 中找到节点值等于 val 的节点。 返回以该节点为根的子树。 如果节点不存在,则返回
6 | null 。
9 | 10 |
示例 1:
11 | 12 |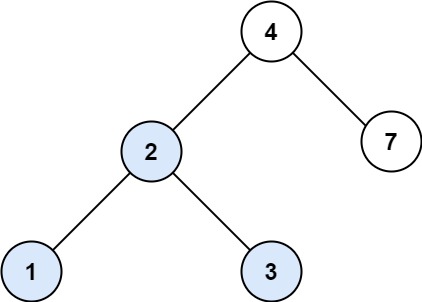 13 |
13 |
16 | 输入:root = [4,2,7,1,3], val = 2 17 | 输出:[2,1,3] 18 |19 | 20 |
示例 2:
21 |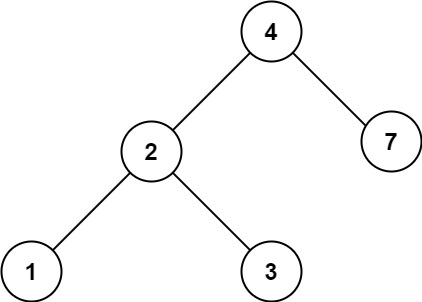 22 |
22 | 23 | 输入:root = [4,2,7,1,3], val = 5 24 | 输出:[] 25 |26 | 27 |
28 | 29 |
提示:
30 | 31 |-
32 |
- 树中节点数在
[1, 5000]范围内
33 | 1 <= Node.val <= 107
34 | root是二叉搜索树
35 | 1 <= val <= 107
36 |
给定二叉搜索树(BST)的根节点
2 | root 和要插入树中的值
3 | value ,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果 。
6 | 7 |8 | 9 |
示例 1:
10 |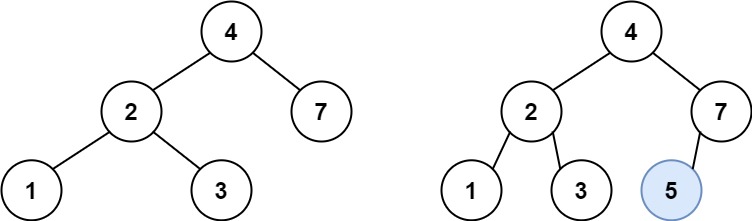 11 |
11 | 12 | 输入:root = [4,2,7,1,3], val = 5 13 | 输出:[4,2,7,1,3,5] 14 | 解释:另一个满足题目要求可以通过的树是: 15 |17 | 18 |16 |
示例 2:
19 | 20 |21 | 输入:root = [40,20,60,10,30,50,70], val = 25 22 | 输出:[40,20,60,10,30,50,70,null,null,25] 23 |24 | 25 |
示例 3:
26 | 27 |28 | 输入:root = [4,2,7,1,3,null,null,null,null,null,null], val = 5 29 | 输出:[4,2,7,1,3,5] 30 |31 | 32 |
33 | 34 |
提示:
35 | 36 |-
37 |
- 树中的节点数将在
38 |
[0, 104]的范围内。 39 |
40 | -108 <= Node.val <= 108
41 | - 所有值
42 |
Node.val是 独一无二 的。
43 | -108 <= val <= 108
44 | - 保证
val在原始BST中不存在。
45 |
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入:9 | 10 |nums= [-1,0,3,5,9,12],target= 9 6 | 输出: 4 7 | 解释: 9 出现在nums中并且下标为 4 8 |
示例 2:
11 | 12 |输入:16 | 17 |nums= [-1,0,3,5,9,12],target= 2 13 | 输出: -1 14 | 解释: 2 不存在nums中因此返回 -1 15 |
18 | 19 |
提示:
20 | 21 |-
22 |
- 你可以假设
nums中的所有元素是不重复的。
23 | n将在[1, 10000]之间。
24 | nums的每个元素都将在[-9999, 9999]之间。
25 |
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
6 | 7 |-
8 |
- 始终以斜杠
'/'开头。
9 | - 两个目录名之间必须只有一个斜杠
'/'。
10 | - 最后一个目录名(如果存在)不能 以
'/'结尾。
11 | - 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含
'.'或'..')。
12 |
返回简化后得到的 规范路径 。
15 | 16 |17 | 18 |
示例 1:
19 | 20 |21 | 输入:path = "/home/" 22 | 输出:"/home" 23 | 解释:注意,最后一个目录名后面没有斜杠。24 | 25 |
示例 2:
26 | 27 |28 | 输入:path = "/../" 29 | 输出:"/" 30 | 解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。 31 |32 | 33 |
示例 3:
34 | 35 |36 | 输入:path = "/home//foo/" 37 | 输出:"/home/foo" 38 | 解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。 39 |40 | 41 |
示例 4:
42 | 43 |44 | 输入:path = "/a/./b/../../c/" 45 | 输出:"/c" 46 |47 | 48 |
49 | 50 |
提示:
51 | 52 |-
53 |
1 <= path.length <= 3000
54 | path由英文字母,数字,'.','/'或'_'组成。
55 | path是一个有效的 Unix 风格绝对路径。
56 |
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
4 | 5 |6 | 7 |
示例 1:
8 | 9 |10 | 输入:n = 4, k = 2 11 | 输出: 12 | [ 13 | [2,4], 14 | [3,4], 15 | [2,3], 16 | [1,2], 17 | [1,3], 18 | [1,4], 19 | ]20 | 21 |
示例 2:
22 | 23 |24 | 输入:n = 1, k = 1 25 | 输出:[[1]]26 | 27 |
28 | 29 |
提示:
30 | 31 |-
32 |
1 <= n <= 20
33 | 1 <= k <= n
34 |
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
4 | 5 |6 | 7 |
示例 1:
8 | 9 |10 | 输入:nums = [1,2,3] 11 | 输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]] 12 |13 | 14 |
示例 2:
15 | 16 |17 | 输入:nums = [0] 18 | 输出:[[],[0]] 19 |20 | 21 |
22 | 23 |
提示:
24 | 25 |-
26 |
1 <= nums.length <= 10
27 | -10 <= nums[i] <= 10
28 | nums中的所有元素 互不相同
29 |
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
4 | 5 |6 | 7 |
示例 1:
8 | 9 |
9 | 10 | 输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED" 11 | 输出:true 12 |13 | 14 |
示例 2:
15 |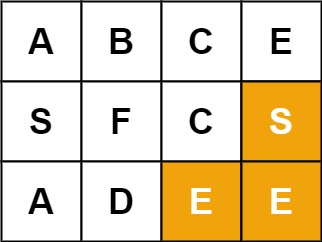 16 |
16 | 17 | 输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE" 18 | 输出:true 19 |20 | 21 |
示例 3:
22 | 23 |
23 | 24 | 输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB" 25 | 输出:false 26 |27 | 28 |
29 | 30 |
提示:
31 | 32 |-
33 |
m == board.length
34 | n = board[i].length
35 | 1 <= m, n <= 6
36 | 1 <= word.length <= 15
37 | board和word仅由大小写英文字母组成
38 |
41 | 42 |
进阶:你可以使用搜索剪枝的技术来优化解决方案,使其在 board 更大的情况下可以更快解决问题?
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
6 | 7 |给你一个整数数组 bills ,其中 bills[i] 是第 i 位顾客付的账。如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
10 | 11 |
示例 1:
12 | 13 |14 | 输入:bills = [5,5,5,10,20] 15 | 输出:true 16 | 解释: 17 | 前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。 18 | 第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。 19 | 第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。 20 | 由于所有客户都得到了正确的找零,所以我们输出 true。 21 |22 | 23 |
示例 2:
24 | 25 |26 | 输入:bills = [5,5,10,10,20] 27 | 输出:false 28 | 解释: 29 | 前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。 30 | 对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。 31 | 对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。 32 | 由于不是每位顾客都得到了正确的找零,所以答案是 false。 33 |34 | 35 |
36 | 37 |
提示:
38 | 39 |-
40 |
1 <= bills.length <= 105
41 | bills[i]不是5就是10或是20
42 |
给你单链表的头结点 head ,请你找出并返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
4 | 5 |6 | 7 |
示例 1:
8 | 9 |
9 | 10 | 输入:head = [1,2,3,4,5] 11 | 输出:[3,4,5] 12 | 解释:链表只有一个中间结点,值为 3 。 13 |14 | 15 |
示例 2:
16 | 17 |
17 | 18 | 输入:head = [1,2,3,4,5,6] 19 | 输出:[4,5,6] 20 | 解释:该链表有两个中间结点,值分别为 3 和 4 ,返回第二个结点。 21 |22 | 23 |
24 | 25 |
提示:
26 | 27 |-
28 |
- 链表的结点数范围是
[1, 100]
29 | 1 <= Node.val <= 100
30 |
head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
2 |
3 | 4 | 5 |
示例 1:
6 |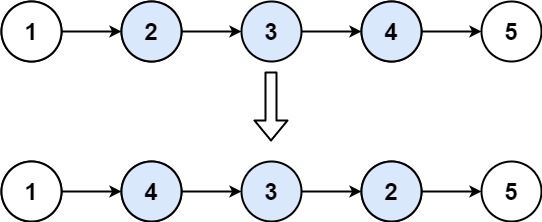 7 |
7 | 8 | 输入:head = [1,2,3,4,5], left = 2, right = 4 9 | 输出:[1,4,3,2,5] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:head = [5], left = 1, right = 1 16 | 输出:[5] 17 |18 | 19 |
20 | 21 |
提示:
22 | 23 |-
24 |
- 链表中节点数目为
n
25 | 1 <= n <= 500
26 | -500 <= Node.val <= 500
27 | 1 <= left <= right <= n
28 |
31 | 32 |
进阶: 你可以使用一趟扫描完成反转吗?
33 | 34 |给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
4 | 5 |
示例 1:
6 |
7 | 8 | 输入:root = [1,null,2,3] 9 | 输出:[1,3,2] 10 |11 | 12 |
示例 2:
13 | 14 |15 | 输入:root = [] 16 | 输出:[] 17 |18 | 19 |
示例 3:
20 | 21 |22 | 输入:root = [1] 23 | 输出:[1] 24 |25 | 26 |
27 | 28 |
提示:
29 | 30 |-
31 |
- 树中节点数目在范围
[0, 100]内
32 | -100 <= Node.val <= 100
33 |
36 | 37 |
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
38 | 39 |给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
4 | 5 |-
6 |
- 节点的左子树只包含 小于 当前节点的数。 7 |
- 节点的右子树只包含 大于 当前节点的数。 8 |
- 所有左子树和右子树自身必须也是二叉搜索树。 9 |
12 | 13 |
示例 1:
14 | 15 |
15 | 16 | 输入:root = [2,1,3] 17 | 输出:true 18 |19 | 20 |
示例 2:
21 | 22 |
22 | 23 | 输入:root = [5,1,4,null,null,3,6] 24 | 输出:false 25 | 解释:根节点的值是 5 ,但是右子节点的值是 4 。 26 |27 | 28 |
29 | 30 |
提示:
31 | 32 |-
33 |
- 树中节点数目范围在
[1, 104]内
34 | -231 <= Node.val <= 231 - 1
35 |
给你二叉搜索树的根节点 root ,该树中的 恰好 两个节点的值被错误地交换。请在不改变其结构的情况下,恢复这棵树 。
4 | 5 |
示例 1:
6 |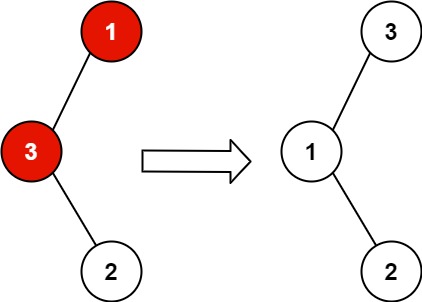 7 |
7 | 8 | 输入:root = [1,3,null,null,2] 9 | 输出:[3,1,null,null,2] 10 | 解释:3 不能是 1 的左孩子,因为 3 > 1 。交换 1 和 3 使二叉搜索树有效。 11 |12 | 13 |
示例 2:
14 |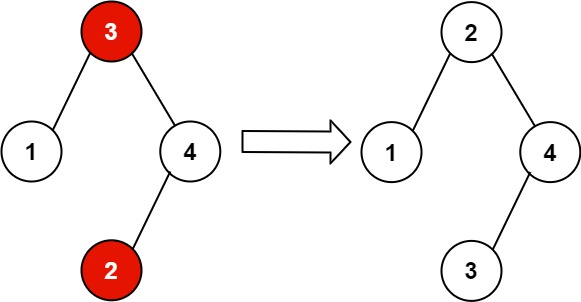 15 |
15 | 16 | 输入:root = [3,1,4,null,null,2] 17 | 输出:[2,1,4,null,null,3] 18 | 解释:2 不能在 3 的右子树中,因为 2 < 3 。交换 2 和 3 使二叉搜索树有效。19 | 20 |
21 | 22 |
提示:
23 | 24 |-
25 |
- 树上节点的数目在范围
[2, 1000]内
26 | -231 <= Node.val <= 231 - 1
27 |
30 | 31 |
进阶:使用 O(n) 空间复杂度的解法很容易实现。你能想出一个只使用 O(1) 空间的解决方案吗?