├── .gitignore
├── CONTRIBUTING.md
├── LICENSE
├── README.md
└── automation
├── data.csv
├── generate.py
└── requirements.txt
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea/
2 | .vscode/
3 |
4 | env/
5 | venv/
6 |
7 | .DS_Store
8 | .ipynb_checkpoints
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | ## 🦸 contributor guide
2 |
3 | - fork and clone the repository (command below clones the original repository)
4 |
5 | ```bash
6 | git clone https://github.com/SkalskiP/top-cvpr-2024-papers.git
7 | ```
8 |
9 | - navigate to the `automation` directory
10 |
11 | ```bash
12 | cd top-cvpr-2024-papers/automation
13 | ```
14 |
15 | - setup and activate python environment (optional, but recommended)
16 |
17 | ```bash
18 | python3 -m venv venv
19 | source venv/bin/activate
20 | ```
21 |
22 | - install dependencies
23 |
24 | ```bash
25 | pip install -r requirements.txt
26 | ```
27 |
28 | - update `data.csv` with awesome CVPR 2024 papers
29 |
30 | - update `README.md` with the following command
31 |
32 | ```bash
33 | python automation/generate.py
34 | ```
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Creative Commons Legal Code
2 |
3 | CC0 1.0 Universal
4 |
5 | CREATIVE COMMONS CORPORATION IS NOT A LAW FIRM AND DOES NOT PROVIDE
6 | LEGAL SERVICES. DISTRIBUTION OF THIS DOCUMENT DOES NOT CREATE AN
7 | ATTORNEY-CLIENT RELATIONSHIP. CREATIVE COMMONS PROVIDES THIS
8 | INFORMATION ON AN "AS-IS" BASIS. CREATIVE COMMONS MAKES NO WARRANTIES
9 | REGARDING THE USE OF THIS DOCUMENT OR THE INFORMATION OR WORKS
10 | PROVIDED HEREUNDER, AND DISCLAIMS LIABILITY FOR DAMAGES RESULTING FROM
11 | THE USE OF THIS DOCUMENT OR THE INFORMATION OR WORKS PROVIDED
12 | HEREUNDER.
13 |
14 | Statement of Purpose
15 |
16 | The laws of most jurisdictions throughout the world automatically confer
17 | exclusive Copyright and Related Rights (defined below) upon the creator
18 | and subsequent owner(s) (each and all, an "owner") of an original work of
19 | authorship and/or a database (each, a "Work").
20 |
21 | Certain owners wish to permanently relinquish those rights to a Work for
22 | the purpose of contributing to a commons of creative, cultural and
23 | scientific works ("Commons") that the public can reliably and without fear
24 | of later claims of infringement build upon, modify, incorporate in other
25 | works, reuse and redistribute as freely as possible in any form whatsoever
26 | and for any purposes, including without limitation commercial purposes.
27 | These owners may contribute to the Commons to promote the ideal of a free
28 | culture and the further production of creative, cultural and scientific
29 | works, or to gain reputation or greater distribution for their Work in
30 | part through the use and efforts of others.
31 |
32 | For these and/or other purposes and motivations, and without any
33 | expectation of additional consideration or compensation, the person
34 | associating CC0 with a Work (the "Affirmer"), to the extent that he or she
35 | is an owner of Copyright and Related Rights in the Work, voluntarily
36 | elects to apply CC0 to the Work and publicly distribute the Work under its
37 | terms, with knowledge of his or her Copyright and Related Rights in the
38 | Work and the meaning and intended legal effect of CC0 on those rights.
39 |
40 | 1. Copyright and Related Rights. A Work made available under CC0 may be
41 | protected by copyright and related or neighboring rights ("Copyright and
42 | Related Rights"). Copyright and Related Rights include, but are not
43 | limited to, the following:
44 |
45 | i. the right to reproduce, adapt, distribute, perform, display,
46 | communicate, and translate a Work;
47 | ii. moral rights retained by the original author(s) and/or performer(s);
48 | iii. publicity and privacy rights pertaining to a person's image or
49 | likeness depicted in a Work;
50 | iv. rights protecting against unfair competition in regards to a Work,
51 | subject to the limitations in paragraph 4(a), below;
52 | v. rights protecting the extraction, dissemination, use and reuse of data
53 | in a Work;
54 | vi. database rights (such as those arising under Directive 96/9/EC of the
55 | European Parliament and of the Council of 11 March 1996 on the legal
56 | protection of databases, and under any national implementation
57 | thereof, including any amended or successor version of such
58 | directive); and
59 | vii. other similar, equivalent or corresponding rights throughout the
60 | world based on applicable law or treaty, and any national
61 | implementations thereof.
62 |
63 | 2. Waiver. To the greatest extent permitted by, but not in contravention
64 | of, applicable law, Affirmer hereby overtly, fully, permanently,
65 | irrevocably and unconditionally waives, abandons, and surrenders all of
66 | Affirmer's Copyright and Related Rights and associated claims and causes
67 | of action, whether now known or unknown (including existing as well as
68 | future claims and causes of action), in the Work (i) in all territories
69 | worldwide, (ii) for the maximum duration provided by applicable law or
70 | treaty (including future time extensions), (iii) in any current or future
71 | medium and for any number of copies, and (iv) for any purpose whatsoever,
72 | including without limitation commercial, advertising or promotional
73 | purposes (the "Waiver"). Affirmer makes the Waiver for the benefit of each
74 | member of the public at large and to the detriment of Affirmer's heirs and
75 | successors, fully intending that such Waiver shall not be subject to
76 | revocation, rescission, cancellation, termination, or any other legal or
77 | equitable action to disrupt the quiet enjoyment of the Work by the public
78 | as contemplated by Affirmer's express Statement of Purpose.
79 |
80 | 3. Public License Fallback. Should any part of the Waiver for any reason
81 | be judged legally invalid or ineffective under applicable law, then the
82 | Waiver shall be preserved to the maximum extent permitted taking into
83 | account Affirmer's express Statement of Purpose. In addition, to the
84 | extent the Waiver is so judged Affirmer hereby grants to each affected
85 | person a royalty-free, non transferable, non sublicensable, non exclusive,
86 | irrevocable and unconditional license to exercise Affirmer's Copyright and
87 | Related Rights in the Work (i) in all territories worldwide, (ii) for the
88 | maximum duration provided by applicable law or treaty (including future
89 | time extensions), (iii) in any current or future medium and for any number
90 | of copies, and (iv) for any purpose whatsoever, including without
91 | limitation commercial, advertising or promotional purposes (the
92 | "License"). The License shall be deemed effective as of the date CC0 was
93 | applied by Affirmer to the Work. Should any part of the License for any
94 | reason be judged legally invalid or ineffective under applicable law, such
95 | partial invalidity or ineffectiveness shall not invalidate the remainder
96 | of the License, and in such case Affirmer hereby affirms that he or she
97 | will not (i) exercise any of his or her remaining Copyright and Related
98 | Rights in the Work or (ii) assert any associated claims and causes of
99 | action with respect to the Work, in either case contrary to Affirmer's
100 | express Statement of Purpose.
101 |
102 | 4. Limitations and Disclaimers.
103 |
104 | a. No trademark or patent rights held by Affirmer are waived, abandoned,
105 | surrendered, licensed or otherwise affected by this document.
106 | b. Affirmer offers the Work as-is and makes no representations or
107 | warranties of any kind concerning the Work, express, implied,
108 | statutory or otherwise, including without limitation warranties of
109 | title, merchantability, fitness for a particular purpose, non
110 | infringement, or the absence of latent or other defects, accuracy, or
111 | the present or absence of errors, whether or not discoverable, all to
112 | the greatest extent permissible under applicable law.
113 | c. Affirmer disclaims responsibility for clearing rights of other persons
114 | that may apply to the Work or any use thereof, including without
115 | limitation any person's Copyright and Related Rights in the Work.
116 | Further, Affirmer disclaims responsibility for obtaining any necessary
117 | consents, permissions or other rights required for any use of the
118 | Work.
119 | d. Affirmer understands and acknowledges that Creative Commons is not a
120 | party to this document and has no duty or obligation with respect to
121 | this CC0 or use of the Work.
122 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 |
7 |
8 |
9 |
10 |
11 |

12 |
34 |
35 |  36 |
37 |
38 | 🔥 SpatialTracker: Tracking Any 2D Pixels in 3D Space
39 |
40 |
36 |
37 |
38 | 🔥 SpatialTracker: Tracking Any 2D Pixels in 3D Space
39 |
40 |
41 | Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, Xiaowei Zhou
42 |
43 | [paper] [code]
44 |
45 | Topic: 3D from multi-view and sensors
46 |
47 | Session: Fri 21 Jun 1:30 p.m. EDT — 3 p.m. EDT #84
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |  56 |
57 |
58 | ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
59 |
60 |
56 |
57 |
58 | ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
59 |
60 |
61 | Lukas Höllein, Aljaž Božič, Norman Müller, David Novotny, Hung-Yu Tseng, Christian Richardt, Michael Zollhöfer, Matthias Nießner
62 |
63 | [paper] [code] [video]
64 |
65 | Topic: 3D from multi-view and sensors
66 |
67 | Session: Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #20
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 | OmniGlue: Generalizable Feature Matching with Foundation Model Guidance
76 |
77 |
78 | Hanwen Jiang, Arjun Karpur, Bingyi Cao, Qixing Huang, Andre Araujo
79 |
80 | [paper] [code] [demo]
81 |
82 | Topic: 3D from multi-view and sensors
83 |
84 | Session: Fri 21 Jun 1:30 p.m. EDT — 3 p.m. EDT #32
85 |
86 |
87 |
88 | ### deep learning architectures and techniques
89 |
90 |
91 |
92 |  93 |
94 |
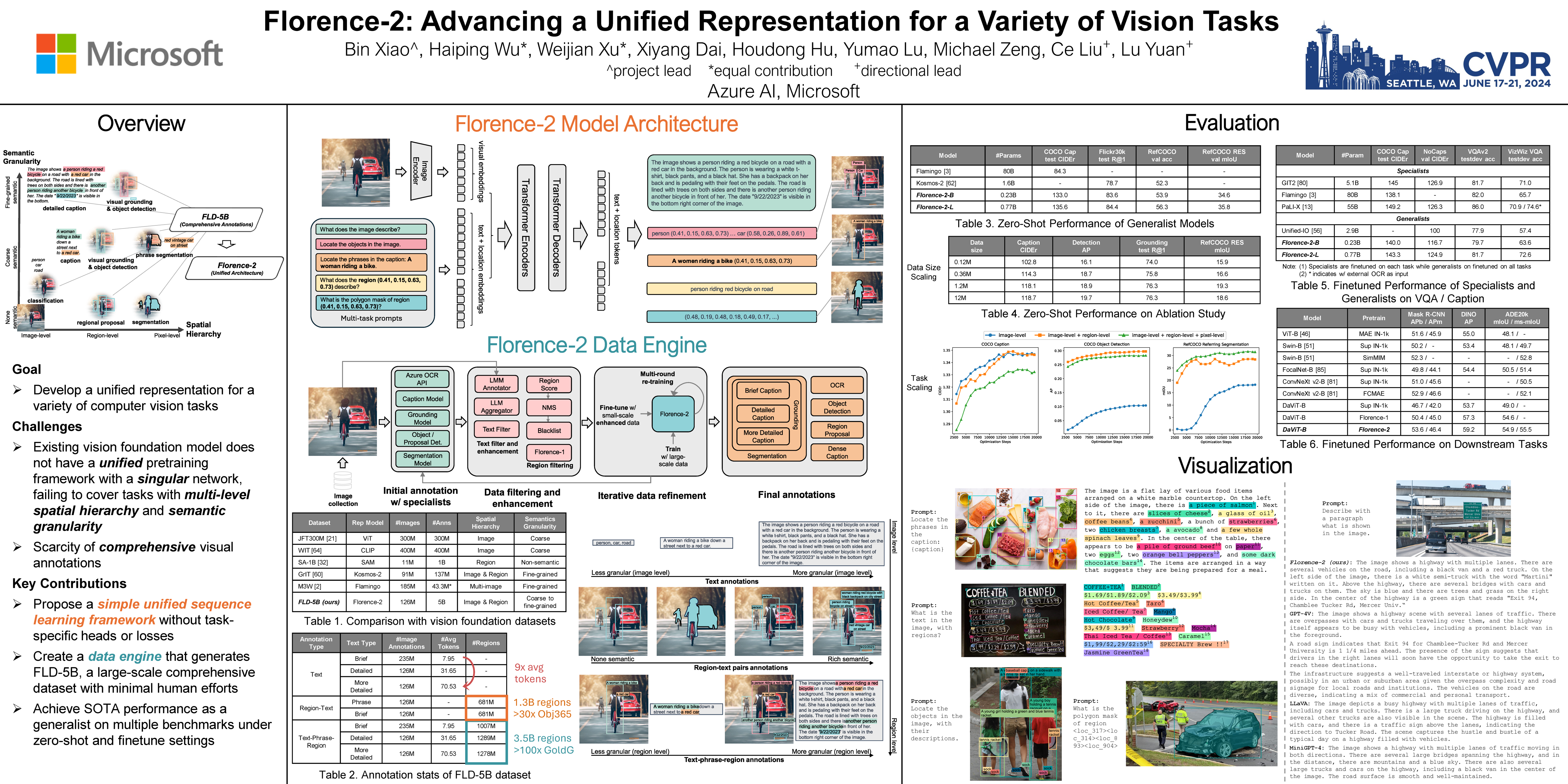
95 | 🔥 Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
96 |
97 |
93 |
94 |
95 | 🔥 Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
96 |
97 |
98 | Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan
99 |
100 | [paper] [video] [demo] [colab]
101 |
102 | Topic: Deep learning architectures and techniques
103 |
104 | Session: Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #102
105 |
106 |
107 |
108 |
109 | ### document analysis and understanding
110 |
111 |
112 |
113 | DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks
114 |
115 |
116 | Jiaxin Zhang, Dezhi Peng, Chongyu Liu, Peirong Zhang, Lianwen Jin
117 |
118 | [paper] [code] [demo]
119 |
120 | Topic: Document analysis and understanding
121 |
122 | Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #101
123 |
124 |
125 |
126 | ### efficient and scalable vision
127 |
128 |
129 |
130 |  131 |
132 |
133 | 🔥 EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
134 |
135 |
131 |
132 |
133 | 🔥 EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
134 |
135 |
136 | Yunyang Xiong, Bala Varadarajan, Lemeng Wu, Xiaoyu Xiang, Fanyi Xiao, Chenchen Zhu, Xiaoliang Dai, Dilin Wang, Fei Sun, Forrest Iandola, Raghuraman Krishnamoorthi, Vikas Chandra
137 |
138 | [paper] [code] [demo]
139 |
140 | Topic: Efficient and scalable vision
141 |
142 | Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #144
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 | 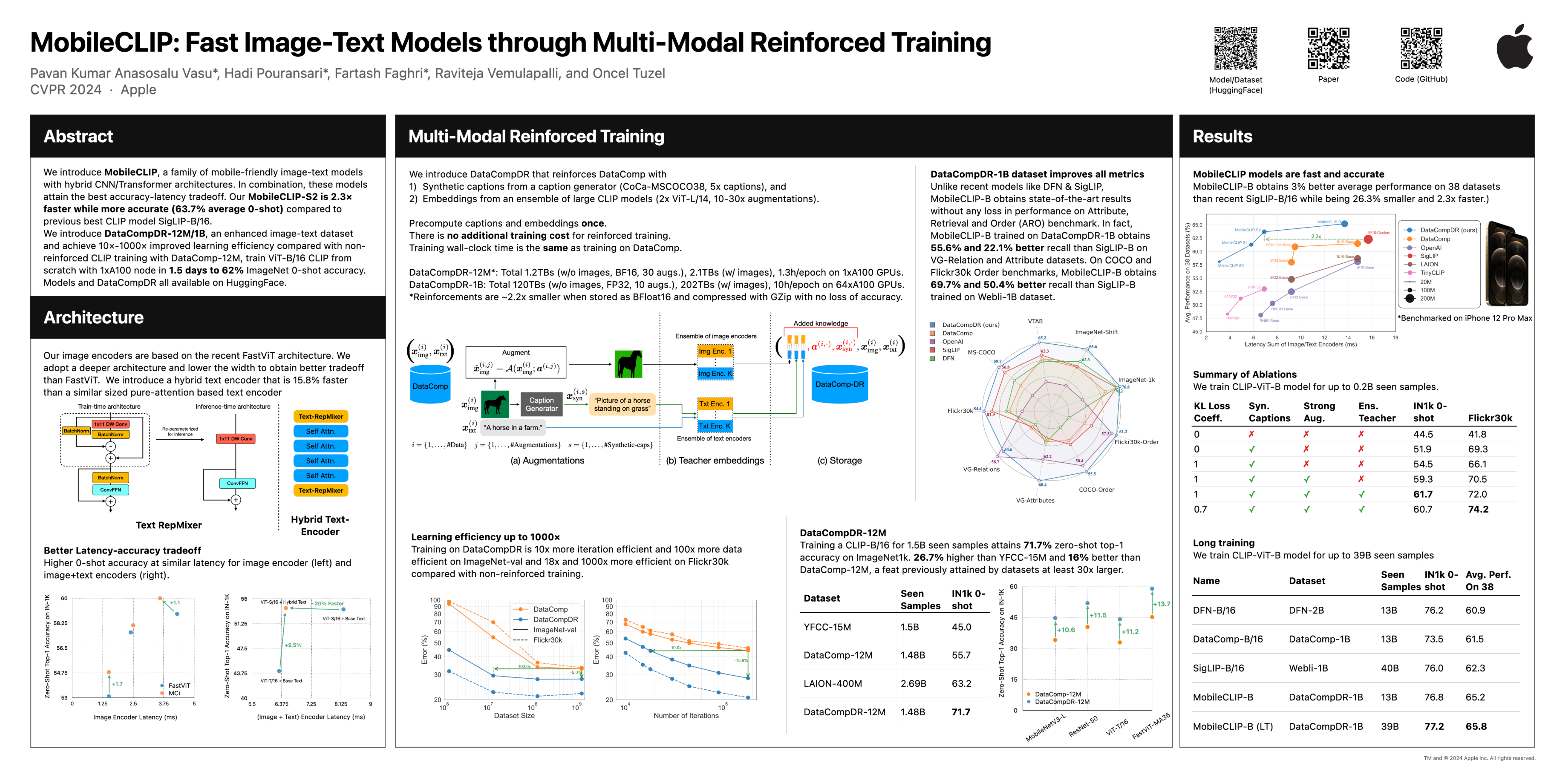 151 |
152 |
153 | MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
154 |
155 |
151 |
152 |
153 | MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
154 |
155 |
156 | Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel
157 |
158 | [paper] [code] [demo]
159 |
160 | Topic: Efficient and scalable vision
161 |
162 | Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #130
163 |
164 |
165 |
166 |
167 | ### explainable computer vision
168 |
169 |
170 |
171 |  172 |
173 |
174 | 🔥 Describing Differences in Image Sets with Natural Language
175 |
176 |
172 |
173 |
174 | 🔥 Describing Differences in Image Sets with Natural Language
175 |
176 |
177 | Lisa Dunlap, Yuhui Zhang, Xiaohan Wang, Ruiqi Zhong, Trevor Darrell, Jacob Steinhardt, Joseph E. Gonzalez, Serena Yeung-Levy
178 |
179 | [paper] [code]
180 |
181 | Topic: Explainable computer vision
182 |
183 | Session: Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #115
184 |
185 |
186 |
187 |
188 | ### image and video synthesis and generation
189 |
190 |
191 |
192 | DemoFusion: Democratising High-Resolution Image Generation With No $$$
193 |
194 |
195 | Ruoyi Du, Dongliang Chang, Timothy Hospedales, Yi-Zhe Song, Zhanyu Ma
196 |
197 | [paper] [code] [demo] [colab]
198 |
199 | Topic: Image and video synthesis and generation
200 |
201 | Session: Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #132
202 |
203 |
204 |
205 |
206 |
207 |
208 |  209 |
210 |
211 | 🔥 DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
212 |
213 |
209 |
210 |
211 | 🔥 DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
212 |
213 |
214 | Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Hanshu Yan, Wenqing Zhang, Vincent Y. F. Tan, Song Bai
215 |
216 | [paper] [code] [video]
217 |
218 | Topic: Image and video synthesis and generation
219 |
220 | Session: Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #392
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |  229 |
230 |
231 | 🔥 Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models
232 |
233 |
229 |
230 |
231 | 🔥 Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models
232 |
233 |
234 | Daniel Geng, Inbum Park, Andrew Owens
235 |
236 | [paper] [code] [colab]
237 |
238 | Topic: Image and video synthesis and generation
239 |
240 | Session: Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #118
241 |
242 |
243 |
244 |
245 | ### low-level vision
246 |
247 |
248 |
249 |  250 |
251 |
252 | XFeat: Accelerated Features for Lightweight Image Matching
253 |
254 |
250 |
251 |
252 | XFeat: Accelerated Features for Lightweight Image Matching
253 |
254 |
255 | Guilherme Potje, Felipe Cadar, Andre Araujo, Renato Martins, Erickson R. Nascimento
256 |
257 | [paper] [code] [video] [demo] [colab]
258 |
259 | Topic: Low-level vision
260 |
261 | Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #245
262 |
263 |
264 |
265 |
266 |
267 |
268 |
269 |  270 |
271 |
272 | Robust Image Denoising through Adversarial Frequency Mixup
273 |
274 |
270 |
271 |
272 | Robust Image Denoising through Adversarial Frequency Mixup
273 |
274 |
275 | Donghun Ryou, Inju Ha, Hyewon Yoo, Dongwan Kim, Bohyung Han
276 |
277 | [paper] [code] [video]
278 |
279 | Topic: Low-level vision
280 |
281 | Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #250
282 |
283 |
284 |
285 |
286 | ### multi-modal learning
287 |
288 |
289 |
290 | 🔥 Improved Baselines with Visual Instruction Tuning
291 |
292 |
293 | Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee
294 |
295 | [paper] [code]
296 |
297 | Topic: Multi-modal learning
298 |
299 | Session: Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #209
300 |
301 |
302 |
303 | ### recognition: categorization, detection, retrieval
304 |
305 |
306 |
307 |  308 |
309 |
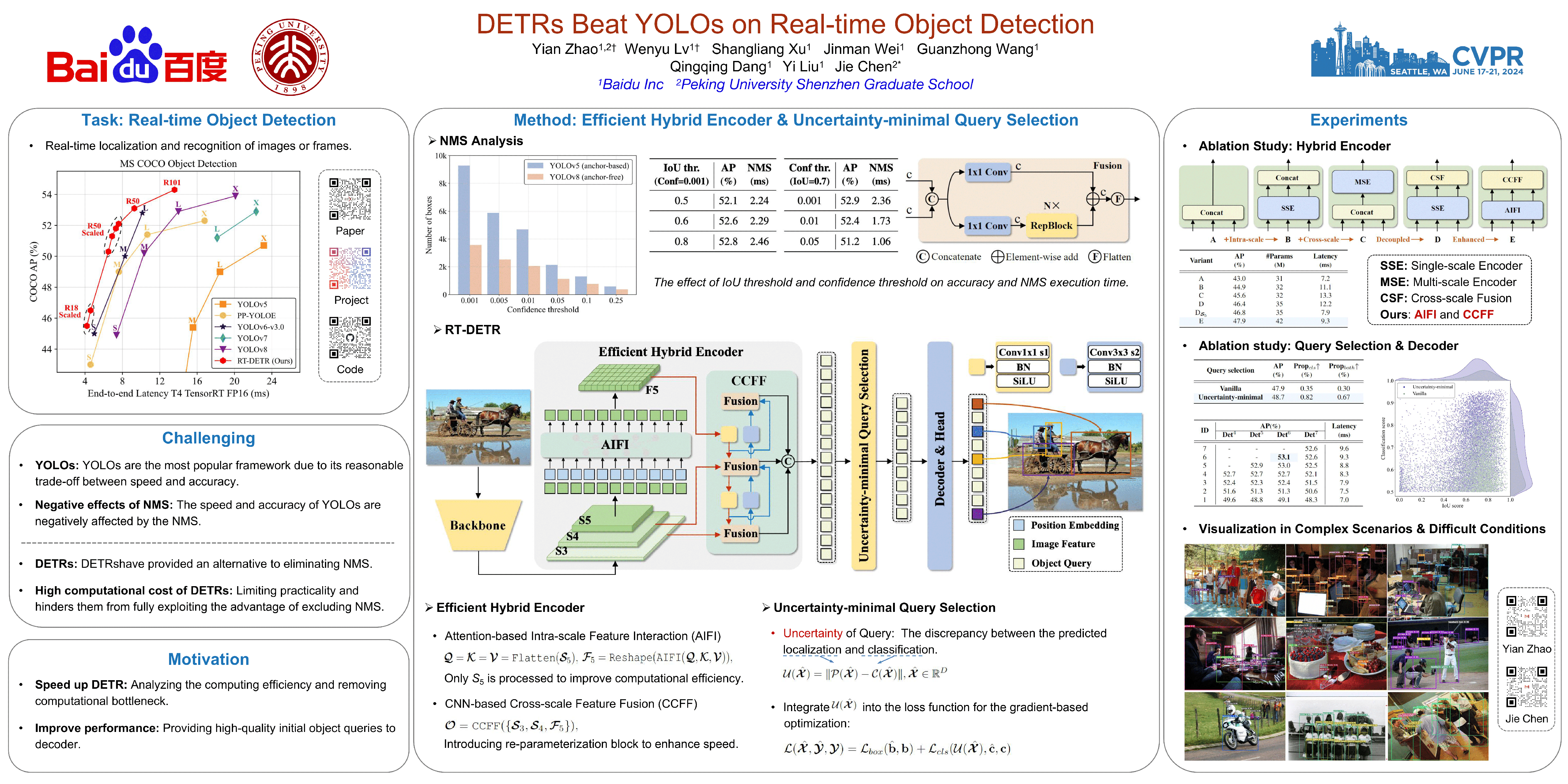
310 | DETRs Beat YOLOs on Real-time Object Detection
311 |
312 |
308 |
309 |
310 | DETRs Beat YOLOs on Real-time Object Detection
311 |
312 |
313 | Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen
314 |
315 | [paper] [code] [video]
316 |
317 | Topic: Recognition: Categorization, detection, retrieval
318 |
319 | Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #229
320 |
321 |
322 |
323 |
324 |
325 |
326 |
327 |  328 |
329 |
330 | YOLO-World: Real-Time Open-Vocabulary Object Detection
331 |
332 |
328 |
329 |
330 | YOLO-World: Real-Time Open-Vocabulary Object Detection
331 |
332 |
333 | Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, Ying Shan
334 |
335 | [paper] [code] [video] [demo] [colab]
336 |
337 | Topic: Recognition: Categorization, detection, retrieval
338 |
339 | Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #223
340 |
341 |
342 |
343 |
344 |
345 |
346 |
347 |  348 |
349 |
350 | 🔥 Object Recognition as Next Token Prediction
351 |
352 |
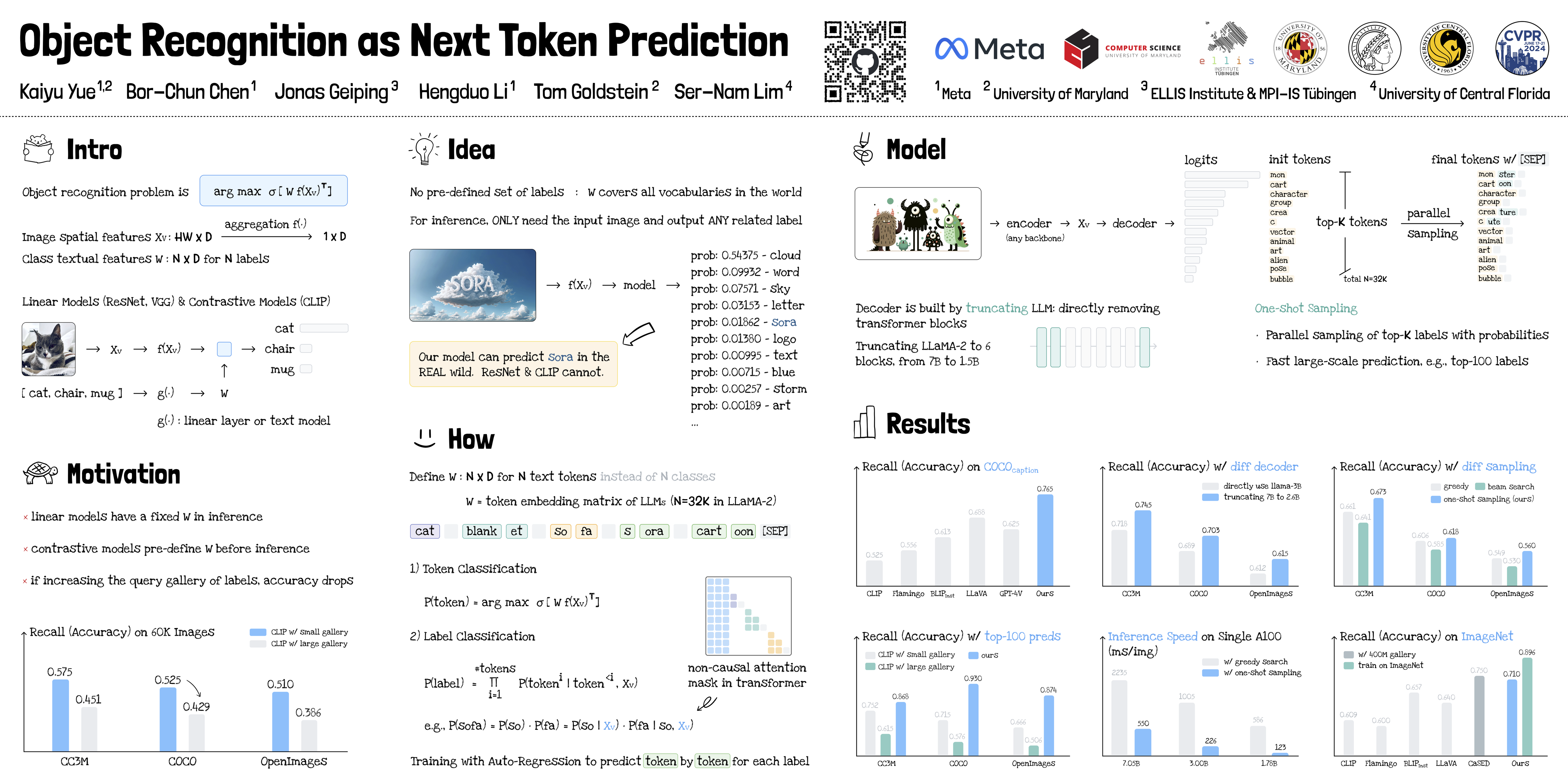
348 |
349 |
350 | 🔥 Object Recognition as Next Token Prediction
351 |
352 |
353 | Kaiyu Yue, Bor-Chun Chen, Jonas Geiping, Hengduo Li, Tom Goldstein, Ser-Nam Lim
354 |
355 | [paper] [code] [video] [colab]
356 |
357 | Topic: Recognition: Categorization, detection, retrieval
358 |
359 | Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #199
360 |
361 |
362 |
363 |
364 | ### segmentation, grouping and shape analysis
365 |
366 |
367 |
368 |  369 |
370 |
371 | 🔥 RobustSAM: Segment Anything Robustly on Degraded Images
372 |
373 |
369 |
370 |
371 | 🔥 RobustSAM: Segment Anything Robustly on Degraded Images
372 |
373 |
374 | Wei-Ting Chen, Yu-Jiet Vong, Sy-Yen Kuo, Sizhou Ma, Jian Wang
375 |
376 | [paper] [video]
377 |
378 | Topic: Segmentation, grouping and shape analysis
379 |
380 | Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #378
381 |
382 |
383 |
384 |
385 |
386 |
387 |
388 |  389 |
390 |
391 | 🔥 Frozen CLIP: A Strong Backbone for Weakly Supervised Semantic Segmentation
392 |
393 |
389 |
390 |
391 | 🔥 Frozen CLIP: A Strong Backbone for Weakly Supervised Semantic Segmentation
392 |
393 |
394 | Bingfeng Zhang, Siyue Yu, Yunchao Wei, Yao Zhao, Jimin Xiao
395 |
396 | [paper] [code] [video]
397 |
398 | Topic: Segmentation, grouping and shape analysis
399 |
400 | Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #351
401 |
402 |
403 |
404 |
405 |
406 |
407 |
408 |  409 |
410 |
411 | 🔥 Semantic-aware SAM for Point-Prompted Instance Segmentation
412 |
413 |
409 |
410 |
411 | 🔥 Semantic-aware SAM for Point-Prompted Instance Segmentation
412 |
413 |
414 | Zhaoyang Wei, Pengfei Chen, Xuehui Yu, Guorong Li, Jianbin Jiao, Zhenjun Han
415 |
416 | [paper] [code] [video]
417 |
418 | Topic: Segmentation, grouping and shape analysis
419 |
420 | Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #331
421 |
422 |
423 |
424 |
425 |
426 |
427 |
428 | 🔥 In-Context Matting
429 |
430 |
431 | He Guo, Zixuan Ye, Zhiguo Cao, Hao Lu
432 |
433 | [paper] [code]
434 |
435 | Topic: Segmentation, grouping and shape analysis
436 |
437 | Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #343
438 |
439 |
440 |
441 |
442 |
443 |
444 |  445 |
446 |
447 | 🔥 General Object Foundation Model for Images and Videos at Scale
448 |
449 |
445 |
446 |
447 | 🔥 General Object Foundation Model for Images and Videos at Scale
448 |
449 |
450 | Junfeng Wu, Yi Jiang, Qihao Liu, Zehuan Yuan, Xiang Bai, Song Bai
451 |
452 | [paper] [code] [video]
453 |
454 | Topic: Segmentation, grouping and shape analysis
455 |
456 | Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #350
457 |
458 |
459 |
460 |
461 | ### self-supervised or unsupervised representation learning
462 |
463 |
464 |
465 |  466 |
467 |
468 | 🔥 InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
469 |
470 |
466 |
467 |
468 | 🔥 InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
469 |
470 |
471 | Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, Jifeng Dai
472 |
473 | [paper] [code] [demo]
474 |
475 | Topic: Self-supervised or unsupervised representation learning
476 |
477 | Session: Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #412
478 |
479 |
480 |
481 |
482 | ### video: low-level analysis, motion, and tracking
483 |
484 |
485 |
486 |  487 |
488 |
489 | 🔥 Matching Anything by Segmenting Anything
490 |
491 |
487 |
488 |
489 | 🔥 Matching Anything by Segmenting Anything
490 |
491 |
492 | Siyuan Li, Lei Ke, Martin Danelljan, Luigi Piccinelli, Mattia Segu, Luc Van Gool, Fisher Yu
493 |
494 | [paper] [code] [video]
495 |
496 | Topic: Video: Low-level analysis, motion, and tracking
497 |
498 | Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #421
499 |
500 |
501 |
502 |
503 |
504 |
505 |
506 |  507 |
508 |
509 | DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction
510 |
511 |
507 |
508 |
509 | DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction
510 |
511 |
512 | Weiyi Lv, Yuhang Huang, Ning Zhang, Ruei-Sung Lin, Mei Han, Dan Zeng
513 |
514 | [paper] [code]
515 |
516 | Topic: Video: Low-level analysis, motion, and tracking
517 |
518 | Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #455
519 |
520 |
521 |
522 |
523 | ### vision, language, and reasoning
524 |
525 |
526 |
527 |  528 |
529 |
530 | Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
531 |
532 |
528 |
529 |
530 | Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
531 |
532 |
533 | Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, Jiaqi Wang
534 |
535 | [paper] [code] [video] [demo]
536 |
537 | Topic: Vision, language, and reasoning
538 |
539 | Session: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #327
540 |
541 |
542 |
543 |
544 |
545 |
546 |
547 | 🔥 Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
548 |
549 |
550 | Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, Saining Xie
551 |
552 | [paper] [code]
553 |
554 | Topic: Vision, language, and reasoning
555 |
556 | Session: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #390
557 |
558 |
559 |
560 |
561 |
562 |
563 |  564 |
565 |
566 | 🔥 LISA: Reasoning Segmentation via Large Language Model
567 |
568 |
564 |
565 |
566 | 🔥 LISA: Reasoning Segmentation via Large Language Model
567 |
568 |
569 | Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, Jiaya Jia
570 |
571 | [paper] [code] [demo]
572 |
573 | Topic: Vision, language, and reasoning
574 |
575 | Session: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #413
576 |
577 |
578 |
579 |
580 |
581 |
582 |
583 |  584 |
585 |
586 | ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
587 |
588 |
584 |
585 |
586 | ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
587 |
588 |
589 | Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee
590 |
591 | [paper] [code] [video] [demo]
592 |
593 | Topic: Vision, language, and reasoning
594 |
595 | Session: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #317
596 |
597 |
598 |
599 |
600 |
601 |
602 |
603 |  604 |
605 |
606 | 🔥 MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
607 |
608 |
604 |
605 |
606 | 🔥 MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
607 |
608 |
609 | Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, Wenhu Chen
610 |
611 | [paper]
612 |
613 | Topic: Vision, language, and reasoning
614 |
615 | Session: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #382
616 |
617 |
618 |
619 |
620 |
621 |
622 | ## 🦸 contribution
623 |
624 | We would love your help in making this repository even better! If you know of an amazing
625 | paper that isn't listed here, or if you have any suggestions for improvement, feel free
626 | to open an
627 | [issue](https://github.com/SkalskiP/top-cvpr-2024-papers/issues)
628 | or submit a
629 | [pull request](https://github.com/SkalskiP/top-cvpr-2024-papers/pulls).
630 |
--------------------------------------------------------------------------------
/automation/data.csv:
--------------------------------------------------------------------------------
1 | "title","authors","paper","code","huggingface","colab","youtube","topic","poster","compressed_poster","session","is_highlighted"
2 | "DETRs Beat YOLOs on Real-time Object Detection","Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen",https://arxiv.org/abs/2304.08069,https://github.com/lyuwenyu/RT-DETR,,,https://www.youtube.com/watch?v=UOc0qMSX4Ac,"Recognition: Categorization, detection, retrieval",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/31301.png?t=1717420504.9897285,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/3732bfdd-4be4-45cd-8353-e056094f9fec,"Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #229",False
3 | "Alpha-CLIP: A CLIP Model Focusing on Wherever You Want","Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, Jiaqi Wang",https://arxiv.org/abs/2312.03818,https://github.com/SunzeY/AlphaCLIP,https://huggingface.co/spaces/Zery/Alpha-CLIP_LLaVA-1.5,,https://youtu.be/QCEIKPZpZz0,"Vision, language, and reasoning",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/31492.png?t=1717327133.6073072,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/4480d88a-7f8f-48c2-bcb0-bde3b694dfd8,"Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #327",False
4 | "YOLO-World: Real-Time Open-Vocabulary Object Detection","Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, Ying Shan",https://arxiv.org/abs/2401.17270,https://github.com/AILab-CVC/YOLO-World,https://huggingface.co/spaces/SkalskiP/YOLO-World,https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/zero-shot-object-detection-with-yolo-world.ipynb,https://youtu.be/X7gKBGVz4vs,"Recognition: Categorization, detection, retrieval",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/f9023a28-aca5-4965-a194-984c62348dc0,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/b9f0bb1e-91d4-4ea3-83c6-ee0817afc1bf,"Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #223",False
5 | "SpatialTracker: Tracking Any 2D Pixels in 3D Space","Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, Xiaowei Zhou",https://arxiv.org/abs/2404.04319,https://github.com/henry123-boy/SpaTracker,,,,"3D from multi-view and sensors",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/31668.png?t=1717417393.7589533,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/56498f78-2ca0-46ee-9231-6aa1806b6ebc,"Fri 21 Jun 1:30 p.m. EDT — 3 p.m. EDT #84",True
6 | "EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything","Yunyang Xiong, Bala Varadarajan, Lemeng Wu, Xiaoyu Xiang, Fanyi Xiao, Chenchen Zhu, Xiaoliang Dai, Dilin Wang, Fei Sun, Forrest Iandola, Raghuraman Krishnamoorthi, Vikas Chandra",https://arxiv.org/abs/2312.00863,https://github.com/yformer/EfficientSAM,https://huggingface.co/spaces/SkalskiP/EfficientSAM,,,"Efficient and scalable vision",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/e95eac04-5a45-402c-885d-14395879abd3,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/e95eac04-5a45-402c-885d-14395879abd3,"Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #144",True
7 | "DemoFusion: Democratising High-Resolution Image Generation With No $$$","Ruoyi Du, Dongliang Chang, Timothy Hospedales, Yi-Zhe Song, Zhanyu Ma",https://arxiv.org/abs/2311.16973,https://github.com/PRIS-CV/DemoFusion,https://huggingface.co/spaces/radames/Enhance-This-DemoFusion-SDXL,https://colab.research.google.com/github/camenduru/DemoFusion-colab/blob/main/DemoFusion_colab.ipynb,,"Image and video synthesis and generation",,,"Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #132",False
8 | "Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs","Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, Saining Xie",https://arxiv.org/abs/2401.06209,https://github.com/tsb0601/MMVP,,,,"Vision, language, and reasoning",,,"Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #390",True
9 | "ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models","Lukas Höllein, Aljaž Božič, Norman Müller, David Novotny, Hung-Yu Tseng, Christian Richardt, Michael Zollhöfer, Matthias Nießner",https://arxiv.org/abs/2403.01807,https://github.com/facebookresearch/ViewDiff,,,https://youtu.be/SdjoCqHzMMk,"3D from multi-view and sensors",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/31616.png?t=1716470830.0209699,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/0453bf88-9d54-4ecf-8a45-01af0f604faf,"Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #20",False
10 | "LISA: Reasoning Segmentation via Large Language Model","Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, Jiaya Jia",https://arxiv.org/abs/2308.00692,https://github.com/dvlab-research/LISA,http://103.170.5.190:7870/,,,"Vision, language, and reasoning",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/30109.png?t=1717509456.89997,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/fc2699d9-7bd2-4c3a-8e6c-4961505cc802,"Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #413",True
11 | "Matching Anything by Segmenting Anything","Siyuan Li, Lei Ke, Martin Danelljan, Luigi Piccinelli, Mattia Segu, Luc Van Gool, Fisher Yu",https://arxiv.org/abs/2406.04221,https://github.com/siyuanliii/masa,,,https://youtu.be/KDQVujKAWFQ,"Video: Low-level analysis, motion, and tracking",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/29590.png?t=1717456006.3308516,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/bb451f47-ba3e-4e34-a7c0-3410b64d9339,"Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #421",True
12 | "DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction","Weiyi Lv, Yuhang Huang, Ning Zhang, Ruei-Sung Lin, Mei Han, Dan Zeng",https://arxiv.org/abs/2403.02075,https://github.com/Kroery/DiffMOT,,,,"Video: Low-level analysis, motion, and tracking",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/9711186c-b05b-472d-b095-d98dbe386171,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/18caf2db-5dab-4251-9eeb-e2397c67eb3f,"Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #455",False
13 | "RobustSAM: Segment Anything Robustly on Degraded Images","Wei-Ting Chen, Yu-Jiet Vong, Sy-Yen Kuo, Sizhou Ma, Jian Wang",https://openaccess.thecvf.com/content/CVPR2024/html/Chen_RobustSAM_Segment_Anything_Robustly_on_Degraded_Images_CVPR_2024_paper.html,,,,https://www.youtube.com/watch?v=Awukqkbs6zM,"Segmentation, grouping and shape analysis",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/62d34981-73d6-49b2-8058-46ec99bac94d,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/ee15d3bc-c391-44f9-b35b-24af714ef119,"Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #378",True
14 | "Frozen CLIP: A Strong Backbone for Weakly Supervised Semantic Segmentation","Bingfeng Zhang, Siyue Yu, Yunchao Wei, Yao Zhao, Jimin Xiao",https://openaccess.thecvf.com/content/CVPR2024/html/Zhang_Frozen_CLIP_A_Strong_Backbone_for_Weakly_Supervised_Semantic_Segmentation_CVPR_2024_paper.html,https://github.com/zbf1991/WeCLIP,,,https://youtu.be/Lh489nTm_M0,"Segmentation, grouping and shape analysis",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/30253.png?t=1716781257.513028,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/0c43b789-f2e8-4ff9-ae46-b5a87de1b921,"Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #351",True
15 | "ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts","Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee",https://arxiv.org/abs/2312.00784,https://github.com/WisconsinAIVision/ViP-LLaVA,https://pages.cs.wisc.edu/~mucai/vip-llava.html,,https://youtu.be/j_l1bRQouzc,"Vision, language, and reasoning",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/53e03a08-4dd9-451a-975e-e3654fa5bc71,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/6d1536ae-3f96-49d9-a05f-9648b925cdb5,"Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #317",False
16 | "DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing","Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Hanshu Yan, Wenqing Zhang, Vincent Y. F. Tan, Song Bai",https://arxiv.org/abs/2306.14435,https://github.com/Yujun-Shi/DragDiffusion,,,https://youtu.be/rysOFTpDBhc,"Image and video synthesis and generation",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/b0833f6b-6924-4f28-b409-ae85aaaa4dd6,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/2a0219f5-9f1e-47e1-a968-d4d98154feb2,"Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #392",True
17 | "OmniGlue: Generalizable Feature Matching with Foundation Model Guidance","Hanwen Jiang, Arjun Karpur, Bingyi Cao, Qixing Huang, Andre Araujo",https://arxiv.org/abs/2405.12979,https://github.com/google-research/omniglue,https://huggingface.co/spaces/qubvel-hf/omniglue,,,"3D from multi-view and sensors",,,"Fri 21 Jun 1:30 p.m. EDT — 3 p.m. EDT #32",False
18 | "DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks","Jiaxin Zhang, Dezhi Peng, Chongyu Liu, Peirong Zhang, Lianwen Jin",https://arxiv.org/abs/2405.04408,https://github.com/ZZZHANG-jx/DocRes,https://huggingface.co/spaces/qubvel-hf/documents-restoration,,,"Document analysis and understanding",,,"Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #101",False
19 | "XFeat: Accelerated Features for Lightweight Image Matching","Guilherme Potje, Felipe Cadar, Andre Araujo, Renato Martins, Erickson R. Nascimento",https://arxiv.org/abs/2404.19174,https://github.com/verlab/accelerated_features,https://huggingface.co/spaces/qubvel-hf/xfeat,https://colab.research.google.com/github/verlab/accelerated_features/blob/main/notebooks/xfeat_matching.ipynb,https://youtu.be/RamC70IkZuI,"Low-level vision",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/8eb6b4f0-4ae6-4615-9921-f73fa2aa3766,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/50b6d16f-c2d8-49a4-8c15-a31d6f9a3c44,"Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #245",False
20 | "Improved Baselines with Visual Instruction Tuning","Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee",https://arxiv.org/abs/2310.03744,https://github.com/LLaVA-VL/LLaVA-NeXT,,,,"Multi-modal learning",,,"Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #209",True
21 | "Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks","Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan",https://arxiv.org/pdf/2311.06242,,https://huggingface.co/spaces/gokaygokay/Florence-2,https://youtu.be/cOlyA00K1ec,https://youtu.be/cOlyA00K1ec,"Deep learning architectures and techniques",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/30529.png?t=1717455193.7819567,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/4aaf3f87-cc62-4fa3-af99-c8c1c83c0069,"Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #102",True
22 | "Semantic-aware SAM for Point-Prompted Instance Segmentation","Zhaoyang Wei, Pengfei Chen, Xuehui Yu, Guorong Li, Jianbin Jiao, Zhenjun Han",https://arxiv.org/abs/2312.15895,https://github.com/zhaoyangwei123/SAPNet,,,https://youtu.be/42-tJFmT7Ao,"Segmentation, grouping and shape analysis",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/2f2bf794-3981-48c8-992d-04dd32ee9ced,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/f1ed2755-1df1-45fe-810b-5fc98b4b52e1,"Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #331",True
23 | "In-Context Matting","He Guo, Zixuan Ye, Zhiguo Cao, Hao Lu",https://arxiv.org/abs/2403.15789,https://github.com/tiny-smart/in-context-matting,,,,"Segmentation, grouping and shape analysis",,,"Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #343",True
24 | "Robust Image Denoising through Adversarial Frequency Mixup","Donghun Ryou, Inju Ha, Hyewon Yoo, Dongwan Kim, Bohyung Han",https://openaccess.thecvf.com/content/CVPR2024/html/Ryou_Robust_Image_Denoising_through_Adversarial_Frequency_Mixup_CVPR_2024_paper.html,https://github.com/dhryougit/AFM,,,https://youtu.be/zQ0pwFSk7uo,"Low-level vision",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/038bef8f-a6df-440d-9ebc-b58f69beb338,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/03cc753c-f875-479e-bca2-e0375e9929a6,"Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #250",False
25 | "General Object Foundation Model for Images and Videos at Scale","Junfeng Wu, Yi Jiang, Qihao Liu, Zehuan Yuan, Xiang Bai, Song Bai",https://arxiv.org/abs/2312.09158,https://github.com/FoundationVision/GLEE,,,https://www.youtube.com/watch?v=PSVhfTPx0GQ,"Segmentation, grouping and shape analysis",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/bfe79038-706d-491b-ac99-083f421dc5ec,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/4f0ed38d-28aa-4766-b290-940cbc6711d6,"Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #350",True
26 | "MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training","Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel",https://arxiv.org/abs/2311.17049,https://github.com/apple/ml-mobileclip,https://huggingface.co/spaces/Xenova/webgpu-mobileclip,,,"Efficient and scalable vision",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/30022.png?t=1718402790.003817,,"Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #130",False
27 | "Object Recognition as Next Token Prediction","Kaiyu Yue, Bor-Chun Chen, Jonas Geiping, Hengduo Li, Tom Goldstein, Ser-Nam Lim",https://arxiv.org/abs/2312.02142,https://github.com/kaiyuyue/nxtp,,https://colab.research.google.com/drive/1pJX37LP5xGLDzD3H7ztTmpq1RrIBeWX3?usp=sharing,https://youtu.be/xeI8dZIpoco,"Recognition: Categorization, detection, retrieval",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/31732.png?t=1717298372.5822952,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/bcdc1aba-8ecb-4e63-a8a7-d287ca728bbb,"Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #199",True
28 | "MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI","Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, Wenhu Chen",https://arxiv.org/abs/2311.16502,,,,,"Vision, language, and reasoning",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/31040.png?t=1718300473.5736258,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/8b9f69b7-3384-40e6-828f-90bf7b43e345,"Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #382",True
29 | "InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks","Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, Jifeng Dai",https://arxiv.org/abs/2312.14238,https://github.com/OpenGVLab/InternVL,https://huggingface.co/spaces/OpenGVLab/InternVL,,,"Self-supervised or unsupervised representation learning",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/30014.png?t=1717339970.9614518,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/9a03d726-0459-48f1-9f1e-5f12c7382084,"Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #412",True
30 | "Describing Differences in Image Sets with Natural Language","Lisa Dunlap, Yuhui Zhang, Xiaohan Wang, Ruiqi Zhong, Trevor Darrell, Jacob Steinhardt, Joseph E. Gonzalez, Serena Yeung-Levy",https://arxiv.org/abs/2312.02974,https://github.com/Understanding-Visual-Datasets/VisDiff,,,,"Explainable computer vision",https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/6d87318b-57c1-40c7-9de6-5cb47145e119,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/6d87318b-57c1-40c7-9de6-5cb47145e119,"Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #115",True
31 | "Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models","Daniel Geng, Inbum Park, Andrew Owens",https://arxiv.org/abs/2311.17919,https://github.com/dangeng/visual_anagrams,,https://colab.research.google.com/github/dangeng/visual_anagrams/blob/main/notebooks/colab_demo_free_tier.ipynb,,"Image and video synthesis and generation",https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202024/30657.png?t=1717473392.6694562,https://github.com/SkalskiP/top-cvpr-2024-papers/assets/26109316/709e3619-25d9-409e-b6ad-ca082611fe09,"Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #118",True
--------------------------------------------------------------------------------
/automation/generate.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from typing import List
3 |
4 | import pandas as pd
5 |
6 | from pandas.core.series import Series
7 |
8 | TITLE_COLUMN_NAME = "title"
9 | AUTHORS_COLUMN_NAME = "authors"
10 | TOPIC_COLUMN_NAME = "topic"
11 | SESSION_COLUMN_NAME = "session"
12 | POSTER_COLUMN_NAME = "poster"
13 | COMPRESSED_POSTER_COLUMN_NAME = "compressed_poster"
14 | PAPER_COLUMN_NAME = "paper"
15 | CODE_COLUMN_NAME = "code"
16 | HUGGINGFACE_SPACE_COLUMN_NAME = "huggingface"
17 | YOUTUBE_COLUMN_NAME = "youtube"
18 | COLAB_COLUMN_NAME = "colab"
19 | IS_HIGHLIGHTED_COLUMN_NAME = "is_highlighted"
20 |
21 | AUTOGENERATED_PAPERS_LIST_TOKEN = ""
22 |
23 | WARNING_HEADER = [
24 | ""
28 | ]
29 |
30 | ARXIV_BADGE_PATTERN = '[paper]'
31 | GITHUB_BADGE_PATTERN = '[code]'
32 | HUGGINGFACE_SPACE_BADGE_PATTERN = '[demo]'
33 | COLAB_BADGE_PATTERN = '[colab]'
34 | YOUTUBE_BADGE_PATTERN = '[video]'
35 |
36 | PAPER_WITHOUT_POSTER_PATTERN = """
37 |
38 |
39 | {}{}
40 |
41 |
42 | {}
43 |
44 | {}
45 |
46 | Topic: {}
47 |
48 | Session: {}
49 |
50 |
51 | """
52 |
53 | PAPER_WITH_POSTER_PATTERN = """
54 |
55 |
56 |  57 |
58 |
59 | {}{}
60 |
61 |
57 |
58 |
59 | {}{}
60 |
61 |
62 | {}
63 |
64 | {}
65 |
66 | Topic: {}
67 |
68 | Session: {}
69 |
70 |
71 |
72 | """
73 |
74 | def read_lines_from_file(path: str) -> List[str]:
75 | """
76 | Reads lines from file and strips trailing whitespaces.
77 | """
78 | with open(path) as file:
79 | return [line.rstrip() for line in file]
80 |
81 |
82 | def save_lines_to_file(path: str, lines: List[str]) -> None:
83 | """
84 | Saves lines to file.
85 | """
86 | with open(path, "w") as f:
87 | for line in lines:
88 | f.write("%s\n" % line)
89 |
90 |
91 | def format_entry(entry: Series) -> str:
92 | """
93 | Formats entry into Markdown table row, ensuring dates are formatted correctly.
94 | """
95 | title = entry.loc[TITLE_COLUMN_NAME]
96 | authors = entry.loc[AUTHORS_COLUMN_NAME]
97 | topics = entry.loc[TOPIC_COLUMN_NAME]
98 | session = entry.loc[SESSION_COLUMN_NAME]
99 | poster = entry.loc[POSTER_COLUMN_NAME]
100 | compressed_poster = entry.loc[COMPRESSED_POSTER_COLUMN_NAME]
101 | paper_id = entry.loc[PAPER_COLUMN_NAME]
102 | code_url = entry.loc[CODE_COLUMN_NAME]
103 | huggingface_url = entry.loc[HUGGINGFACE_SPACE_COLUMN_NAME]
104 | youtube_url = entry.loc[YOUTUBE_COLUMN_NAME]
105 | colab_url = entry.loc[COLAB_COLUMN_NAME]
106 | is_highlight = entry.loc[IS_HIGHLIGHTED_COLUMN_NAME]
107 | arxiv_badge = ARXIV_BADGE_PATTERN.format(paper_id) if paper_id else ""
108 | code_badge = GITHUB_BADGE_PATTERN.format(code_url) if code_url else ""
109 | youtube_badge = YOUTUBE_BADGE_PATTERN.format(youtube_url) if youtube_url else ""
110 | huggingface_badge = HUGGINGFACE_SPACE_BADGE_PATTERN.format(huggingface_url) if huggingface_url else ""
111 | colab_badge = COLAB_BADGE_PATTERN.format(colab_url) if colab_url else ""
112 | highlight_badge = "🔥 " if is_highlight == "True" else ""
113 | badges = " ".join([arxiv_badge, code_badge, youtube_badge, huggingface_badge, colab_badge])
114 | compressed_poster = compressed_poster if compressed_poster else poster
115 |
116 | if not poster:
117 | return PAPER_WITHOUT_POSTER_PATTERN.format(
118 | paper_id, title, highlight_badge, title, authors, badges, topics, session)
119 |
120 | return PAPER_WITH_POSTER_PATTERN.format(
121 | poster, title, compressed_poster, title, paper_id, title, highlight_badge, title, authors, badges, topics, session)
122 |
123 |
124 | def load_entries(path: str) -> List[str]:
125 | """
126 | Loads table entries from csv file, sorted by date in descending order and formats dates.
127 | """
128 | df = pd.read_csv(path, quotechar='"', dtype=str)
129 | df.columns = df.columns.str.strip()
130 | df = df.fillna("")
131 |
132 | entries = []
133 | df_dict = {topic: group_df for topic, group_df in df.groupby(TOPIC_COLUMN_NAME)}
134 | for topic, group_df in df_dict.items():
135 | entries.append(f"### {topic.lower()}")
136 | entries += [
137 | format_entry(row)
138 | for _, row
139 | in group_df.iterrows()
140 | ]
141 | return entries
142 |
143 |
144 | def search_lines_with_token(lines: List[str], token: str) -> List[int]:
145 | """
146 | Searches for lines with token.
147 | """
148 | result = []
149 | for line_index, line in enumerate(lines):
150 | if token in line:
151 | result.append(line_index)
152 | return result
153 |
154 |
155 | def inject_papers_list_into_readme(
156 | readme_lines: List[str],
157 | papers_list_lines: List[str]
158 | ) -> List[str]:
159 | """
160 | Injects papers list into README.md.
161 | """
162 | lines_with_token_indexes = search_lines_with_token(
163 | lines=readme_lines, token=AUTOGENERATED_PAPERS_LIST_TOKEN)
164 |
165 | if len(lines_with_token_indexes) != 2:
166 | raise Exception(f"Please inject two {AUTOGENERATED_PAPERS_LIST_TOKEN} "
167 | f"tokens to signal start and end of autogenerated table.")
168 |
169 | [start_index, end_index] = lines_with_token_indexes
170 | return readme_lines[:start_index + 1] + papers_list_lines + readme_lines[end_index:]
171 |
172 |
173 | if __name__ == "__main__":
174 | parser = argparse.ArgumentParser()
175 | parser.add_argument('-d', '--data_path', default='automation/data.csv')
176 | parser.add_argument('-r', '--readme_path', default='README.md')
177 | args = parser.parse_args()
178 |
179 | table_lines = load_entries(path=args.data_path)
180 | table_lines = WARNING_HEADER + table_lines
181 | readme_lines = read_lines_from_file(path=args.readme_path)
182 | readme_lines = inject_papers_list_into_readme(readme_lines=readme_lines,
183 | papers_list_lines=table_lines)
184 | save_lines_to_file(path=args.readme_path, lines=readme_lines)
--------------------------------------------------------------------------------
/automation/requirements.txt:
--------------------------------------------------------------------------------
1 | pandas
--------------------------------------------------------------------------------