├── pytorch_ssim
├── LICENSE.txt
├── setup.cfg
├── einstein.png
├── max_ssim.gif
├── .gitignore
├── setup.py
├── max_ssim.py
├── README.md
└── pytorch_ssim
│ └── __init__.py
├── PerceptualSimilarity
├── data
│ ├── __init__.py
│ ├── dataset
│ │ ├── __init__.py
│ │ ├── base_dataset.py
│ │ ├── jnd_dataset.py
│ │ └── twoafc_dataset.py
│ ├── base_data_loader.py
│ ├── data_loader.py
│ ├── custom_dataset_data_loader.py
│ └── image_folder.py
├── util
│ ├── __init__.py
│ ├── util.py
│ ├── html.py
│ └── visualizer.py
├── .gitignore
├── imgs
│ ├── ex_p0.png
│ ├── ex_p1.png
│ ├── ex_ref.png
│ ├── fig1.png
│ ├── ex_dir0
│ │ ├── 0.png
│ │ └── 1.png
│ ├── ex_dir1
│ │ ├── 0.png
│ │ └── 1.png
│ └── ex_dir_pair
│ │ ├── ex_p0.png
│ │ ├── ex_p1.png
│ │ └── ex_ref.png
├── scripts
│ ├── eval_valsets.sh
│ ├── train_test_metric.sh
│ ├── train_test_metric_tune.sh
│ ├── train_test_metric_scratch.sh
│ ├── download_dataset_valonly.sh
│ └── download_dataset.sh
├── lpips
│ ├── weights
│ │ ├── v0.0
│ │ │ ├── alex.pth
│ │ │ ├── vgg.pth
│ │ │ └── squeeze.pth
│ │ └── v0.1
│ │ │ ├── alex.pth
│ │ │ ├── vgg.pth
│ │ │ └── squeeze.pth
│ ├── __init__.py
│ ├── pretrained_networks.py
│ ├── lpips.py
│ └── trainer.py
├── requirements.txt
├── setup.py
├── lpips_2imgs.py
├── lpips_2dirs.py
├── LICENSE
├── test_network.py
├── lpips_loss.py
├── Dockerfile
├── lpips_1dir_allpairs.py
├── test_dataset_model.py
├── train.py
└── README.md
├── pytorch_msssim
├── LICENSE.txt
├── try1.py
├── setup.cfg
├── einstein.png
├── .gitignore
├── setup.py
├── max_ssim.py
├── README.md
└── pytorch_msssim
│ └── __init__.py
├── Examples
└── BRViT_sample1.jfif
├── LICENSE
├── README.md
├── evaluate.py
├── store_results.py
├── train.py
├── Bokeh_Data
└── test.csv
└── model.py
/pytorch_ssim/LICENSE.txt:
--------------------------------------------------------------------------------
1 | MIT
2 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/util/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/pytorch_msssim/LICENSE.txt:
--------------------------------------------------------------------------------
1 | MIT
2 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/dataset/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/pytorch_msssim/try1.py:
--------------------------------------------------------------------------------
1 | import pytorch_msssim
2 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
2 |
3 | checkpoints/*
4 |
--------------------------------------------------------------------------------
/pytorch_msssim/setup.cfg:
--------------------------------------------------------------------------------
1 | [metadata]
2 | description-file = README.md
3 |
--------------------------------------------------------------------------------
/pytorch_ssim/setup.cfg:
--------------------------------------------------------------------------------
1 | [metadata]
2 | description-file = README.md
3 |
--------------------------------------------------------------------------------
/pytorch_ssim/einstein.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/pytorch_ssim/einstein.png
--------------------------------------------------------------------------------
/pytorch_ssim/max_ssim.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/pytorch_ssim/max_ssim.gif
--------------------------------------------------------------------------------
/Examples/BRViT_sample1.jfif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/Examples/BRViT_sample1.jfif
--------------------------------------------------------------------------------
/pytorch_msssim/einstein.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/pytorch_msssim/einstein.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/ex_p0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/ex_p0.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/ex_p1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/ex_p1.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/ex_ref.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/ex_ref.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/fig1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/fig1.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/scripts/eval_valsets.sh:
--------------------------------------------------------------------------------
1 |
2 | python ./test_dataset_model.py --dataset_mode 2afc --model lpips --net alex --use_gpu --batch_size 50
3 |
4 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/ex_dir0/0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/ex_dir0/0.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/ex_dir0/1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/ex_dir0/1.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/ex_dir1/0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/ex_dir1/0.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/ex_dir1/1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/ex_dir1/1.png
--------------------------------------------------------------------------------
/pytorch_msssim/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
2 | *.gif
3 | *.png
4 | *.jpg
5 | test*
6 | !einstein.png
7 | !max_ssim.gif
8 | MANIFEST
9 | dist/*
10 | .sync-config.cson
11 |
--------------------------------------------------------------------------------
/pytorch_ssim/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
2 | *.gif
3 | *.png
4 | *.jpg
5 | test*
6 | !einstein.png
7 | !max_ssim.gif
8 | MANIFEST
9 | dist/*
10 | .sync-config.cson
11 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/ex_dir_pair/ex_p0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/ex_dir_pair/ex_p0.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/ex_dir_pair/ex_p1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/ex_dir_pair/ex_p1.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/imgs/ex_dir_pair/ex_ref.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/imgs/ex_dir_pair/ex_ref.png
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/weights/v0.0/alex.pth:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/lpips/weights/v0.0/alex.pth
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/weights/v0.0/vgg.pth:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/lpips/weights/v0.0/vgg.pth
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/weights/v0.1/alex.pth:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/lpips/weights/v0.1/alex.pth
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/weights/v0.1/vgg.pth:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/lpips/weights/v0.1/vgg.pth
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/weights/v0.0/squeeze.pth:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/lpips/weights/v0.0/squeeze.pth
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/weights/v0.1/squeeze.pth:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Soester10/Bokeh-Rendering-with-Vision-Transformers/HEAD/PerceptualSimilarity/lpips/weights/v0.1/squeeze.pth
--------------------------------------------------------------------------------
/PerceptualSimilarity/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=0.4.0
2 | torchvision>=0.2.1
3 | numpy>=1.14.3
4 | scipy>=1.0.1
5 | scikit-image>=0.13.0
6 | opencv>=2.4.11
7 | matplotlib>=1.5.1
8 | tqdm>=4.28.1
9 | jupyter
10 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/base_data_loader.py:
--------------------------------------------------------------------------------
1 |
2 | class BaseDataLoader():
3 | def __init__(self):
4 | pass
5 |
6 | def initialize(self):
7 | pass
8 |
9 | def load_data():
10 | return None
11 |
12 |
13 |
14 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/scripts/train_test_metric.sh:
--------------------------------------------------------------------------------
1 |
2 | TRIAL=${1}
3 | NET=${2}
4 | mkdir checkpoints
5 | mkdir checkpoints/${NET}_${TRIAL}
6 | python ./train.py --use_gpu --net ${NET} --name ${NET}_${TRIAL}
7 | python ./test_dataset_model.py --use_gpu --net ${NET} --model_path ./checkpoints/${NET}_${TRIAL}/latest_net_.pth
8 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/dataset/base_dataset.py:
--------------------------------------------------------------------------------
1 | import torch.utils.data as data
2 |
3 | class BaseDataset(data.Dataset):
4 | def __init__(self):
5 | super(BaseDataset, self).__init__()
6 |
7 | def name(self):
8 | return 'BaseDataset'
9 |
10 | def initialize(self):
11 | pass
12 |
13 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/scripts/train_test_metric_tune.sh:
--------------------------------------------------------------------------------
1 |
2 | TRIAL=${1}
3 | NET=${2}
4 | mkdir checkpoints
5 | mkdir checkpoints/${NET}_${TRIAL}_tune
6 | python ./train.py --train_trunk --use_gpu --net ${NET} --name ${NET}_${TRIAL}_tune
7 | python ./test_dataset_model.py --train_trunk --use_gpu --net ${NET} --model_path ./checkpoints/${NET}_${TRIAL}_tune/latest_net_.pth
8 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/scripts/train_test_metric_scratch.sh:
--------------------------------------------------------------------------------
1 |
2 | TRIAL=${1}
3 | NET=${2}
4 | mkdir checkpoints
5 | mkdir checkpoints/${NET}_${TRIAL}_scratch
6 | python ./train.py --from_scratch --train_trunk --use_gpu --net ${NET} --name ${NET}_${TRIAL}_scratch
7 | python ./test_dataset_model.py --from_scratch --train_trunk --use_gpu --net ${NET} --model_path ./checkpoints/${NET}_${TRIAL}_scratch/latest_net_.pth
8 |
9 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/data_loader.py:
--------------------------------------------------------------------------------
1 | def CreateDataLoader(datafolder,dataroot='./dataset',dataset_mode='2afc',load_size=64,batch_size=1,serial_batches=True,nThreads=4):
2 | from data.custom_dataset_data_loader import CustomDatasetDataLoader
3 | data_loader = CustomDatasetDataLoader()
4 | # print(data_loader.name())
5 | data_loader.initialize(datafolder,dataroot=dataroot+'/'+dataset_mode,dataset_mode=dataset_mode,load_size=load_size,batch_size=batch_size,serial_batches=serial_batches, nThreads=nThreads)
6 | return data_loader
7 |
--------------------------------------------------------------------------------
/pytorch_msssim/setup.py:
--------------------------------------------------------------------------------
1 | from distutils.core import setup
2 |
3 | setup(
4 | name = 'pytorch_msssim',
5 | packages = ['pytorch_msssim'], # this must be the same as the name above
6 | version = '0.1',
7 | description = 'Differentiable multi-scale structural similarity (MS-SSIM) index',
8 | author = 'Jorge Pessoa',
9 | author_email = 'jpessoa.on@gmail.com',
10 | url = 'https://github.com/jorge-pessoa/pytorch-msssim', # use the URL to the github repo
11 | keywords = ['pytorch', 'image-processing', 'deep-learning', 'ms-ssim'], # arbitrary keywords
12 | classifiers = [],
13 | )
14 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/scripts/download_dataset_valonly.sh:
--------------------------------------------------------------------------------
1 |
2 | mkdir dataset
3 |
4 | # JND Dataset
5 | wget https://people.eecs.berkeley.edu/~rich.zhang/projects/2018_perceptual/dataset/jnd.tar.gz -O ./dataset/jnd.tar.gz
6 |
7 | mkdir dataset/jnd
8 | tar -xzf ./dataset/jnd.tar.gz -C ./dataset
9 | rm ./dataset/jnd.tar.gz
10 |
11 | # 2AFC Val set
12 | mkdir dataset/2afc/
13 | wget https://people.eecs.berkeley.edu/~rich.zhang/projects/2018_perceptual/dataset/twoafc_val.tar.gz -O ./dataset/twoafc_val.tar.gz
14 |
15 | mkdir dataset/2afc/val
16 | tar -xzf ./dataset/twoafc_val.tar.gz -C ./dataset/2afc
17 | rm ./dataset/twoafc_val.tar.gz
18 |
--------------------------------------------------------------------------------
/pytorch_ssim/setup.py:
--------------------------------------------------------------------------------
1 | from distutils.core import setup
2 | setup(
3 | name = 'pytorch_ssim',
4 | packages = ['pytorch_ssim'], # this must be the same as the name above
5 | version = '0.1',
6 | description = 'Differentiable structural similarity (SSIM) index',
7 | author = 'Po-Hsun (Evan) Su',
8 | author_email = 'evan.pohsun.su@gmail.com',
9 | url = 'https://github.com/Po-Hsun-Su/pytorch-ssim', # use the URL to the github repo
10 | download_url = 'https://github.com/Po-Hsun-Su/pytorch-ssim/archive/0.1.tar.gz', # I'll explain this in a second
11 | keywords = ['pytorch', 'image-processing', 'deep-learning'], # arbitrary keywords
12 | classifiers = [],
13 | )
14 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/setup.py:
--------------------------------------------------------------------------------
1 |
2 | import setuptools
3 | with open("README.md", "r") as fh:
4 | long_description = fh.read()
5 | setuptools.setup(
6 | name='lpips',
7 | version='0.1.2',
8 | author="Richard Zhang",
9 | author_email="rizhang@adobe.com",
10 | description="LPIPS Similarity metric",
11 | long_description=long_description,
12 | long_description_content_type="text/markdown",
13 | url="https://github.com/richzhang/PerceptualSimilarity",
14 | packages=['lpips'],
15 | package_data={'lpips': ['weights/v0.0/*.pth','weights/v0.1/*.pth']},
16 | include_package_data=True,
17 | classifiers=[
18 | "Programming Language :: Python :: 3",
19 | "License :: OSI Approved :: BSD License",
20 | "Operating System :: OS Independent",
21 | ],
22 | )
23 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/scripts/download_dataset.sh:
--------------------------------------------------------------------------------
1 |
2 | mkdir dataset
3 |
4 | # JND Dataset
5 | wget https://people.eecs.berkeley.edu/~rich.zhang/projects/2018_perceptual/dataset/jnd.tar.gz -O ./dataset/jnd.tar.gz
6 |
7 | mkdir dataset/jnd
8 | tar -xzf ./dataset/jnd.tar.gz -C ./dataset
9 | rm ./dataset/jnd.tar.gz
10 |
11 | # 2AFC Val set
12 | mkdir dataset/2afc/
13 | wget https://people.eecs.berkeley.edu/~rich.zhang/projects/2018_perceptual/dataset/twoafc_val.tar.gz -O ./dataset/twoafc_val.tar.gz
14 |
15 | mkdir dataset/2afc/val
16 | tar -xzf ./dataset/twoafc_val.tar.gz -C ./dataset/2afc
17 | rm ./dataset/twoafc_val.tar.gz
18 |
19 | # 2AFC Train set
20 | mkdir dataset/2afc/
21 | wget https://people.eecs.berkeley.edu/~rich.zhang/projects/2018_perceptual/dataset/twoafc_train.tar.gz -O ./dataset/twoafc_train.tar.gz
22 |
23 | mkdir dataset/2afc/train
24 | tar -xzf ./dataset/twoafc_train.tar.gz -C ./dataset/2afc
25 | rm ./dataset/twoafc_train.tar.gz
26 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips_2imgs.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import lpips
3 |
4 | parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
5 | parser.add_argument('-p0','--path0', type=str, default='./imgs/ex_ref.png')
6 | parser.add_argument('-p1','--path1', type=str, default='./imgs/ex_p0.png')
7 | parser.add_argument('-v','--version', type=str, default='0.1')
8 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
9 |
10 | opt = parser.parse_args()
11 |
12 | ## Initializing the model
13 | loss_fn = lpips.LPIPS(net='alex',version=opt.version)
14 |
15 | if(opt.use_gpu):
16 | loss_fn.cuda()
17 |
18 | # Load images
19 | img0 = lpips.im2tensor(lpips.load_image(opt.path0)) # RGB image from [-1,1]
20 | img1 = lpips.im2tensor(lpips.load_image(opt.path1))
21 |
22 | if(opt.use_gpu):
23 | img0 = img0.cuda()
24 | img1 = img1.cuda()
25 |
26 | # Compute distance
27 | dist01 = loss_fn.forward(img0,img1)
28 | print('Distance: %.3f'%dist01)
29 |
--------------------------------------------------------------------------------
/pytorch_ssim/max_ssim.py:
--------------------------------------------------------------------------------
1 | import pytorch_ssim
2 | import torch
3 | from torch.autograd import Variable
4 | from torch import optim
5 | import cv2
6 | import numpy as np
7 |
8 | npImg1 = cv2.imread("einstein.png")
9 |
10 | img1 = torch.from_numpy(np.rollaxis(npImg1, 2)).float().unsqueeze(0)/255.0
11 | img2 = torch.rand(img1.size())
12 |
13 | if torch.cuda.is_available():
14 | img1 = img1.cuda()
15 | img2 = img2.cuda()
16 |
17 |
18 | img1 = Variable( img1, requires_grad=False)
19 | img2 = Variable( img2, requires_grad = True)
20 |
21 |
22 | # Functional: pytorch_ssim.ssim(img1, img2, window_size = 11, size_average = True)
23 | ssim_value = pytorch_ssim.ssim(img1, img2).data[0]
24 | print("Initial ssim:", ssim_value)
25 |
26 | # Module: pytorch_ssim.SSIM(window_size = 11, size_average = True)
27 | ssim_loss = pytorch_ssim.SSIM()
28 |
29 | optimizer = optim.Adam([img2], lr=0.01)
30 |
31 | while ssim_value < 0.95:
32 | optimizer.zero_grad()
33 | ssim_out = -ssim_loss(img1, img2)
34 | ssim_value = - ssim_out.data[0]
35 | print(ssim_value)
36 | ssim_out.backward()
37 | optimizer.step()
38 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2021 Hariharan N
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips_2dirs.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import lpips
4 |
5 | parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
6 | parser.add_argument('-d0','--dir0', type=str, default='./imgs/ex_dir0')
7 | parser.add_argument('-d1','--dir1', type=str, default='./imgs/ex_dir1')
8 | parser.add_argument('-o','--out', type=str, default='./imgs/example_dists.txt')
9 | parser.add_argument('-v','--version', type=str, default='0.1')
10 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
11 |
12 | opt = parser.parse_args()
13 |
14 | ## Initializing the model
15 | loss_fn = lpips.LPIPS(net='alex',version=opt.version)
16 | if(opt.use_gpu):
17 | loss_fn.cuda()
18 |
19 | # crawl directories
20 | f = open(opt.out,'w')
21 | files = os.listdir(opt.dir0)
22 |
23 | for file in files:
24 | if(os.path.exists(os.path.join(opt.dir1,file))):
25 | # Load images
26 | img0 = lpips.im2tensor(lpips.load_image(os.path.join(opt.dir0,file))) # RGB image from [-1,1]
27 | img1 = lpips.im2tensor(lpips.load_image(os.path.join(opt.dir1,file)))
28 |
29 | if(opt.use_gpu):
30 | img0 = img0.cuda()
31 | img1 = img1.cuda()
32 |
33 | # Compute distance
34 | dist01 = loss_fn.forward(img0,img1)
35 | print('%s: %.3f'%(file,dist01))
36 | f.writelines('%s: %.6f\n'%(file,dist01))
37 |
38 | f.close()
39 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/LICENSE:
--------------------------------------------------------------------------------
1 | Copyright (c) 2018, Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, Oliver Wang
2 | All rights reserved.
3 |
4 | Redistribution and use in source and binary forms, with or without
5 | modification, are permitted provided that the following conditions are met:
6 |
7 | * Redistributions of source code must retain the above copyright notice, this
8 | list of conditions and the following disclaimer.
9 |
10 | * Redistributions in binary form must reproduce the above copyright notice,
11 | this list of conditions and the following disclaimer in the documentation
12 | and/or other materials provided with the distribution.
13 |
14 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
15 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
16 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
17 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
18 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
19 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
20 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
21 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
22 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
23 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
24 |
25 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Bokeh-Rendering-with-Vision-Transformers
2 | Establishing new state-of-the-art results for Bokeh Rendering on the EBB! Dataset. The preprint of our work can be found [here](https://www.techrxiv.org/articles/preprint/Bokeh_Effect_Rendering_with_Vision_Transformers/17714849).
3 |
4 | ### Sample:
5 |
6 |  7 |
8 |
9 | ### References
10 |
11 | Model adapted from https://github.com/isl-org/DPT
12 |
13 | SSIM loss can be found at https://github.com/Po-Hsun-Su/pytorch-ssim
14 |
15 | MSSSIM loss can be found at https://github.com/jorge-pessoa/pytorch-msssim
16 |
17 | LPIPS can be found at https://github.com/richzhang/PerceptualSimilarity
18 |
19 |
20 | ### BRViT Weights
21 |
22 | Our latest model weights can be downloaded from [here](https://drive.google.com/file/d/1V4oX1fARjaIujXQ7Vf4UDwxJhm9ubVG-/view?usp=sharing).
23 |
24 |
25 | ### BRViT Metrics
26 |
27 | Common Metrics with the latest weights for model comparison:
28 |
29 | 1. PSNR: 24.76
30 | 2. SSIM: 0.8904
31 | 3. LPIPS: 0.1924
32 |
33 |
34 | ### Dataset
35 |
36 | Training: [https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/Training.zip](https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/Training.zip)
37 |
38 | Validation: [https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/ValidationBokehFree.zip](https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/ValidationBokehFree.zip)
39 |
40 | Testing: [https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/TestBokehFree.zip](https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/TestBokehFree.zip)
41 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/util/util.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 |
3 | import numpy as np
4 | from PIL import Image
5 | import numpy as np
6 | import os
7 | import matplotlib.pyplot as plt
8 | import torch
9 |
10 | def load_image(path):
11 | if(path[-3:] == 'dng'):
12 | import rawpy
13 | with rawpy.imread(path) as raw:
14 | img = raw.postprocess()
15 | elif(path[-3:]=='bmp' or path[-3:]=='jpg' or path[-3:]=='png'):
16 | import cv2
17 | return cv2.imread(path)[:,:,::-1]
18 | else:
19 | img = (255*plt.imread(path)[:,:,:3]).astype('uint8')
20 |
21 | return img
22 |
23 | def save_image(image_numpy, image_path, ):
24 | image_pil = Image.fromarray(image_numpy)
25 | image_pil.save(image_path)
26 |
27 | def mkdirs(paths):
28 | if isinstance(paths, list) and not isinstance(paths, str):
29 | for path in paths:
30 | mkdir(path)
31 | else:
32 | mkdir(paths)
33 |
34 | def mkdir(path):
35 | if not os.path.exists(path):
36 | os.makedirs(path)
37 |
38 |
39 | def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
40 | # def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
41 | image_numpy = image_tensor[0].cpu().float().numpy()
42 | image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
43 | return image_numpy.astype(imtype)
44 |
45 | def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
46 | # def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
47 | return torch.Tensor((image / factor - cent)
48 | [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
49 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/test_network.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import lpips
3 | from IPython import embed
4 |
5 | use_gpu = False # Whether to use GPU
6 | spatial = True # Return a spatial map of perceptual distance.
7 |
8 | # Linearly calibrated models (LPIPS)
9 | loss_fn = lpips.LPIPS(net='alex', spatial=spatial) # Can also set net = 'squeeze' or 'vgg'
10 | # loss_fn = lpips.LPIPS(net='alex', spatial=spatial, lpips=False) # Can also set net = 'squeeze' or 'vgg'
11 |
12 | if(use_gpu):
13 | loss_fn.cuda()
14 |
15 | ## Example usage with dummy tensors
16 | dummy_im0 = torch.zeros(1,3,64,64) # image should be RGB, normalized to [-1,1]
17 | dummy_im1 = torch.zeros(1,3,64,64)
18 | if(use_gpu):
19 | dummy_im0 = dummy_im0.cuda()
20 | dummy_im1 = dummy_im1.cuda()
21 | dist = loss_fn.forward(dummy_im0,dummy_im1)
22 |
23 | ## Example usage with images
24 | ex_ref = lpips.im2tensor(lpips.load_image('./imgs/ex_ref.png'))
25 | ex_p0 = lpips.im2tensor(lpips.load_image('./imgs/ex_p0.png'))
26 | ex_p1 = lpips.im2tensor(lpips.load_image('./imgs/ex_p1.png'))
27 | if(use_gpu):
28 | ex_ref = ex_ref.cuda()
29 | ex_p0 = ex_p0.cuda()
30 | ex_p1 = ex_p1.cuda()
31 |
32 | ex_d0 = loss_fn.forward(ex_ref,ex_p0)
33 | ex_d1 = loss_fn.forward(ex_ref,ex_p1)
34 |
35 | if not spatial:
36 | print('Distances: (%.3f, %.3f)'%(ex_d0, ex_d1))
37 | else:
38 | print('Distances: (%.3f, %.3f)'%(ex_d0.mean(), ex_d1.mean())) # The mean distance is approximately the same as the non-spatial distance
39 |
40 | # Visualize a spatially-varying distance map between ex_p0 and ex_ref
41 | import pylab
42 | pylab.imshow(ex_d0[0,0,...].data.cpu().numpy())
43 | pylab.show()
44 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/custom_dataset_data_loader.py:
--------------------------------------------------------------------------------
1 | import torch.utils.data
2 | from data.base_data_loader import BaseDataLoader
3 | import os
4 |
5 | def CreateDataset(dataroots,dataset_mode='2afc',load_size=64,):
6 | dataset = None
7 | if dataset_mode=='2afc': # human judgements
8 | from data.dataset.twoafc_dataset import TwoAFCDataset
9 | dataset = TwoAFCDataset()
10 | elif dataset_mode=='jnd': # human judgements
11 | from data.dataset.jnd_dataset import JNDDataset
12 | dataset = JNDDataset()
13 | else:
14 | raise ValueError("Dataset Mode [%s] not recognized."%self.dataset_mode)
15 |
16 | dataset.initialize(dataroots,load_size=load_size)
17 | return dataset
18 |
19 | class CustomDatasetDataLoader(BaseDataLoader):
20 | def name(self):
21 | return 'CustomDatasetDataLoader'
22 |
23 | def initialize(self, datafolders, dataroot='./dataset',dataset_mode='2afc',load_size=64,batch_size=1,serial_batches=True, nThreads=1):
24 | BaseDataLoader.initialize(self)
25 | if(not isinstance(datafolders,list)):
26 | datafolders = [datafolders,]
27 | data_root_folders = [os.path.join(dataroot,datafolder) for datafolder in datafolders]
28 | self.dataset = CreateDataset(data_root_folders,dataset_mode=dataset_mode,load_size=load_size)
29 | self.dataloader = torch.utils.data.DataLoader(
30 | self.dataset,
31 | batch_size=batch_size,
32 | shuffle=not serial_batches,
33 | num_workers=int(nThreads))
34 |
35 | def load_data(self):
36 | return self.dataloader
37 |
38 | def __len__(self):
39 | return len(self.dataset)
40 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips_loss.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from torch.autograd import Variable
4 | import matplotlib.pyplot as plt
5 | import argparse
6 | import lpips
7 |
8 | parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
9 | parser.add_argument('--ref_path', type=str, default='./imgs/ex_ref.png')
10 | parser.add_argument('--pred_path', type=str, default='./imgs/ex_p1.png')
11 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
12 |
13 | opt = parser.parse_args()
14 |
15 | loss_fn = lpips.LPIPS(net='vgg')
16 | if(opt.use_gpu):
17 | loss_fn.cuda()
18 |
19 | ref = lpips.im2tensor(lpips.load_image(opt.ref_path))
20 | pred = Variable(lpips.im2tensor(lpips.load_image(opt.pred_path)), requires_grad=True)
21 | if(opt.use_gpu):
22 | with torch.no_grad():
23 | ref = ref.cuda()
24 | pred = pred.cuda()
25 |
26 | optimizer = torch.optim.Adam([pred,], lr=1e-3, betas=(0.9, 0.999))
27 |
28 | plt.ion()
29 | fig = plt.figure(1)
30 | ax = fig.add_subplot(131)
31 | ax.imshow(lpips.tensor2im(ref))
32 | ax.set_title('target')
33 | ax = fig.add_subplot(133)
34 | ax.imshow(lpips.tensor2im(pred.data))
35 | ax.set_title('initialization')
36 |
37 | for i in range(1000):
38 | dist = loss_fn.forward(pred, ref)
39 | optimizer.zero_grad()
40 | dist.backward()
41 | optimizer.step()
42 | pred.data = torch.clamp(pred.data, -1, 1)
43 |
44 | if i % 10 == 0:
45 | print('iter %d, dist %.3g' % (i, dist.view(-1).data.cpu().numpy()[0]))
46 | pred.data = torch.clamp(pred.data, -1, 1)
47 | pred_img = lpips.tensor2im(pred.data)
48 |
49 | ax = fig.add_subplot(132)
50 | ax.imshow(pred_img)
51 | ax.set_title('iter %d, dist %.3f' % (i, dist.view(-1).data.cpu().numpy()[0]))
52 | plt.pause(5e-2)
53 | # plt.imsave('imgs_saved/%04d.jpg'%i,pred_img)
54 |
55 |
56 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM nvidia/cuda:9.0-base-ubuntu16.04
2 |
3 | LABEL maintainer="Seyoung Park "
4 |
5 | # This Dockerfile is forked from Tensorflow Dockerfile
6 |
7 | # Pick up some PyTorch gpu dependencies
8 | RUN apt-get update && apt-get install -y --no-install-recommends \
9 | build-essential \
10 | cuda-command-line-tools-9-0 \
11 | cuda-cublas-9-0 \
12 | cuda-cufft-9-0 \
13 | cuda-curand-9-0 \
14 | cuda-cusolver-9-0 \
15 | cuda-cusparse-9-0 \
16 | curl \
17 | libcudnn7=7.1.4.18-1+cuda9.0 \
18 | libfreetype6-dev \
19 | libhdf5-serial-dev \
20 | libpng12-dev \
21 | libzmq3-dev \
22 | pkg-config \
23 | python \
24 | python-dev \
25 | rsync \
26 | software-properties-common \
27 | unzip \
28 | && \
29 | apt-get clean && \
30 | rm -rf /var/lib/apt/lists/*
31 |
32 |
33 | # Install miniconda
34 | RUN apt-get update && apt-get install -y --no-install-recommends \
35 | wget && \
36 | MINICONDA="Miniconda3-latest-Linux-x86_64.sh" && \
37 | wget --quiet https://repo.continuum.io/miniconda/$MINICONDA && \
38 | bash $MINICONDA -b -p /miniconda && \
39 | rm -f $MINICONDA
40 | ENV PATH /miniconda/bin:$PATH
41 |
42 | # Install PyTorch
43 | RUN conda update -n base conda && \
44 | conda install pytorch torchvision cuda90 -c pytorch
45 |
46 | # Install PerceptualSimilarity dependencies
47 | RUN conda install numpy scipy jupyter matplotlib && \
48 | conda install -c conda-forge scikit-image && \
49 | apt-get install -y python-qt4 && \
50 | pip install opencv-python
51 |
52 | # For CUDA profiling, TensorFlow requires CUPTI. Maybe PyTorch needs this too.
53 | ENV LD_LIBRARY_PATH /usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
54 |
55 | # IPython
56 | EXPOSE 8888
57 |
58 | WORKDIR "/notebooks"
59 |
60 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips_1dir_allpairs.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import lpips
4 | import numpy as np
5 |
6 | parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
7 | parser.add_argument('-d','--dir', type=str, default='./imgs/ex_dir_pair')
8 | parser.add_argument('-o','--out', type=str, default='./imgs/example_dists.txt')
9 | parser.add_argument('-v','--version', type=str, default='0.1')
10 | parser.add_argument('--all-pairs', action='store_true', help='turn on to test all N(N-1)/2 pairs, leave off to just do consecutive pairs (N-1)')
11 | parser.add_argument('-N', type=int, default=None)
12 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
13 |
14 | opt = parser.parse_args()
15 |
16 | ## Initializing the model
17 | loss_fn = lpips.LPIPS(net='alex',version=opt.version)
18 | if(opt.use_gpu):
19 | loss_fn.cuda()
20 |
21 | # crawl directories
22 | f = open(opt.out,'w')
23 | files = os.listdir(opt.dir)
24 | if(opt.N is not None):
25 | files = files[:opt.N]
26 | F = len(files)
27 |
28 | dists = []
29 | for (ff,file) in enumerate(files[:-1]):
30 | img0 = lpips.im2tensor(lpips.load_image(os.path.join(opt.dir,file))) # RGB image from [-1,1]
31 | if(opt.use_gpu):
32 | img0 = img0.cuda()
33 |
34 | if(opt.all_pairs):
35 | files1 = files[ff+1:]
36 | else:
37 | files1 = [files[ff+1],]
38 |
39 | for file1 in files1:
40 | img1 = lpips.im2tensor(lpips.load_image(os.path.join(opt.dir,file1)))
41 |
42 | if(opt.use_gpu):
43 | img1 = img1.cuda()
44 |
45 | # Compute distance
46 | dist01 = loss_fn.forward(img0,img1)
47 | print('(%s,%s): %.3f'%(file,file1,dist01))
48 | f.writelines('(%s,%s): %.6f\n'%(file,file1,dist01))
49 |
50 | dists.append(dist01.item())
51 |
52 | avg_dist = np.mean(np.array(dists))
53 | stderr_dist = np.std(np.array(dists))/np.sqrt(len(dists))
54 |
55 | print('Avg: %.5f +/- %.5f'%(avg_dist,stderr_dist))
56 | f.writelines('Avg: %.6f +/- %.6f'%(avg_dist,stderr_dist))
57 |
58 | f.close()
59 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/dataset/jnd_dataset.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | import torchvision.transforms as transforms
3 | from data.dataset.base_dataset import BaseDataset
4 | from data.image_folder import make_dataset
5 | from PIL import Image
6 | import numpy as np
7 | import torch
8 | from IPython import embed
9 |
10 | class JNDDataset(BaseDataset):
11 | def initialize(self, dataroot, load_size=64):
12 | self.root = dataroot
13 | self.load_size = load_size
14 |
15 | self.dir_p0 = os.path.join(self.root, 'p0')
16 | self.p0_paths = make_dataset(self.dir_p0)
17 | self.p0_paths = sorted(self.p0_paths)
18 |
19 | self.dir_p1 = os.path.join(self.root, 'p1')
20 | self.p1_paths = make_dataset(self.dir_p1)
21 | self.p1_paths = sorted(self.p1_paths)
22 |
23 | transform_list = []
24 | transform_list.append(transforms.Scale(load_size))
25 | transform_list += [transforms.ToTensor(),
26 | transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))]
27 |
28 | self.transform = transforms.Compose(transform_list)
29 |
30 | # judgement directory
31 | self.dir_S = os.path.join(self.root, 'same')
32 | self.same_paths = make_dataset(self.dir_S,mode='np')
33 | self.same_paths = sorted(self.same_paths)
34 |
35 | def __getitem__(self, index):
36 | p0_path = self.p0_paths[index]
37 | p0_img_ = Image.open(p0_path).convert('RGB')
38 | p0_img = self.transform(p0_img_)
39 |
40 | p1_path = self.p1_paths[index]
41 | p1_img_ = Image.open(p1_path).convert('RGB')
42 | p1_img = self.transform(p1_img_)
43 |
44 | same_path = self.same_paths[index]
45 | same_img = np.load(same_path).reshape((1,1,1,)) # [0,1]
46 |
47 | same_img = torch.FloatTensor(same_img)
48 |
49 | return {'p0': p0_img, 'p1': p1_img, 'same': same_img,
50 | 'p0_path': p0_path, 'p1_path': p1_path, 'same_path': same_path}
51 |
52 | def __len__(self):
53 | return len(self.p0_paths)
54 |
--------------------------------------------------------------------------------
/pytorch_ssim/README.md:
--------------------------------------------------------------------------------
1 | # pytorch-ssim
2 |
3 | ### Differentiable structural similarity (SSIM) index.
4 |  
5 |
6 | ## Installation
7 | 1. Clone this repo.
8 | 2. Copy "pytorch_ssim" folder in your project.
9 |
10 | ## Example
11 | ### basic usage
12 | ```python
13 | import pytorch_ssim
14 | import torch
15 | from torch.autograd import Variable
16 |
17 | img1 = Variable(torch.rand(1, 1, 256, 256))
18 | img2 = Variable(torch.rand(1, 1, 256, 256))
19 |
20 | if torch.cuda.is_available():
21 | img1 = img1.cuda()
22 | img2 = img2.cuda()
23 |
24 | print(pytorch_ssim.ssim(img1, img2))
25 |
26 | ssim_loss = pytorch_ssim.SSIM(window_size = 11)
27 |
28 | print(ssim_loss(img1, img2))
29 |
30 | ```
31 | ### maximize ssim
32 | ```python
33 | import pytorch_ssim
34 | import torch
35 | from torch.autograd import Variable
36 | from torch import optim
37 | import cv2
38 | import numpy as np
39 |
40 | npImg1 = cv2.imread("einstein.png")
41 |
42 | img1 = torch.from_numpy(np.rollaxis(npImg1, 2)).float().unsqueeze(0)/255.0
43 | img2 = torch.rand(img1.size())
44 |
45 | if torch.cuda.is_available():
46 | img1 = img1.cuda()
47 | img2 = img2.cuda()
48 |
49 |
50 | img1 = Variable( img1, requires_grad=False)
51 | img2 = Variable( img2, requires_grad = True)
52 |
53 |
54 | # Functional: pytorch_ssim.ssim(img1, img2, window_size = 11, size_average = True)
55 | ssim_value = pytorch_ssim.ssim(img1, img2).data[0]
56 | print("Initial ssim:", ssim_value)
57 |
58 | # Module: pytorch_ssim.SSIM(window_size = 11, size_average = True)
59 | ssim_loss = pytorch_ssim.SSIM()
60 |
61 | optimizer = optim.Adam([img2], lr=0.01)
62 |
63 | while ssim_value < 0.95:
64 | optimizer.zero_grad()
65 | ssim_out = -ssim_loss(img1, img2)
66 | ssim_value = - ssim_out.data[0]
67 | print(ssim_value)
68 | ssim_out.backward()
69 | optimizer.step()
70 |
71 | ```
72 |
73 | ## Reference
74 | https://ece.uwaterloo.ca/~z70wang/research/ssim/
75 |
--------------------------------------------------------------------------------
/pytorch_msssim/max_ssim.py:
--------------------------------------------------------------------------------
1 | from pytorch_msssim import msssim, ssim
2 | import torch
3 | from torch import optim
4 |
5 | from PIL import Image
6 | from torchvision.transforms.functional import to_tensor
7 | import numpy as np
8 |
9 | # display = True requires matplotlib
10 | display = True
11 | metric = 'MSSSIM' # MSSSIM or SSIM
12 | device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
13 |
14 | def post_process(img):
15 | img = img.detach().cpu().numpy()
16 | img = np.transpose(np.squeeze(img, axis=0), (1, 2, 0))
17 | img = np.squeeze(img) # works if grayscale
18 | return img
19 |
20 | # Preprocessing
21 | img1 = to_tensor(Image.open('einstein.png')).unsqueeze(0).type(torch.FloatTensor)
22 |
23 | img2 = torch.rand(img1.size())
24 | img2 = torch.nn.functional.sigmoid(img2) # use sigmoid to clamp between [0, 1]
25 |
26 | img1 = img1.to(device)
27 | img2 = img2.to(device)
28 |
29 | img1.requires_grad = False
30 | img2.requires_grad = True
31 |
32 | loss_func = msssim if metric == 'MSSSIM' else ssim
33 |
34 | value = loss_func(img1, img2)
35 | print("Initial %s: %.5f" % (metric, value.item()))
36 |
37 | optimizer = optim.Adam([img2], lr=0.01)
38 |
39 | # MSSSIM yields higher values for worse results, because noise is removed in scales with lower resolutions
40 | threshold = 0.999 if metric == 'MSSSIM' else 0.9
41 |
42 | while value < threshold:
43 | optimizer.zero_grad()
44 | msssim_out = -loss_func(img1, img2)
45 | value = -msssim_out.item()
46 | print('Current MS-SSIM = %.5f' % value)
47 | msssim_out.backward()
48 | optimizer.step()
49 |
50 | if display:
51 | # Post processing
52 | img1np = post_process(img1)
53 | img2 = torch.nn.functional.sigmoid(img2)
54 | img2np = post_process(img2)
55 | import matplotlib.pyplot as plt
56 | cmap = 'gray' if len(img1np.shape) == 2 else None
57 | plt.subplot(1, 2, 1)
58 | plt.imshow(img1np, cmap=cmap)
59 | plt.title('Original')
60 | plt.subplot(1, 2, 2)
61 | plt.imshow(img2np, cmap=cmap)
62 | plt.title('Generated, {:s}: {:.3f}'.format(metric, value))
63 | plt.show()
64 |
--------------------------------------------------------------------------------
/evaluate.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 |
5 | import timm
6 | import types
7 | import math
8 | import numpy as np
9 | from PIL import Image
10 | import PIL.Image as pil
11 | from torchvision import transforms, datasets
12 | from torch.utils.data import Dataset, DataLoader
13 | import torch.utils.data as data
14 | import PerceptualSimilarity.lpips.lpips as lpips
15 | import glob
16 | import gc
17 | import pytorch_msssim.pytorch_msssim as pytorch_msssim
18 | from torch.cuda.amp import autocast
19 | from model import BRViT
20 | import matplotlib.pyplot as plt
21 | from pytorch_ssim.pytorch_ssim import ssim
22 | from torchvision.utils import save_image
23 | from PerceptualSimilarity.util import util
24 |
25 |
26 | import pandas as pd
27 | from tqdm import tqdm
28 | import sys
29 | import cv2
30 |
31 | from skimage.metrics import peak_signal_noise_ratio as compare_psnr
32 | from skimage.metrics import structural_similarity as compare_ssim
33 |
34 | batch_size = 1
35 | feed_width = 1536
36 | feed_height = 1024
37 |
38 |
39 |
40 | def evaluate():
41 | tot_lpips_loss = 0.0
42 | total_psnr = 0.0
43 | total_ssim = 0.0
44 |
45 | device = torch.device("cuda")
46 | loss_fn = lpips.LPIPS(net='alex').to(device)
47 |
48 | for i in tqdm(range(294)):
49 | csv_file = "Bokeh_Data/test.csv"
50 | root_dir = "."
51 | dataa = pd.read_csv(csv_file)
52 | idx = i
53 |
54 | img0 = util.im2tensor(util.load_image(root_dir + dataa.iloc[idx, 0][1:])) # RGB image from [-1,1]
55 | img1 = util.im2tensor(util.load_image(f"Results/{4400+i}.png"))
56 | img0 = img0.to(device)
57 | img1 = img1.to(device)
58 |
59 | lpips_loss = loss_fn.forward(img0, img1)
60 | tot_lpips_loss += lpips_loss.item()
61 |
62 |
63 | total_psnr += compare_psnr(I0,I1)
64 | total_ssim += compare_ssim(I0, I1, multichannel=True)
65 |
66 |
67 | print("TOTAL LPIPS:",":", tot_lpips_loss / 294)
68 | print("TOTAL PSNR",":", total_psnr / 294)
69 | print("TOTAL SSIM",":", total_ssim / 294)
70 |
71 |
72 | if __name__ == "__main__":
73 | evaluate()
74 |
75 |
76 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/util/html.py:
--------------------------------------------------------------------------------
1 | import dominate
2 | from dominate.tags import *
3 | import os
4 |
5 |
6 | class HTML:
7 | def __init__(self, web_dir, title, image_subdir='', reflesh=0):
8 | self.title = title
9 | self.web_dir = web_dir
10 | # self.img_dir = os.path.join(self.web_dir, )
11 | self.img_subdir = image_subdir
12 | self.img_dir = os.path.join(self.web_dir, image_subdir)
13 | if not os.path.exists(self.web_dir):
14 | os.makedirs(self.web_dir)
15 | if not os.path.exists(self.img_dir):
16 | os.makedirs(self.img_dir)
17 | # print(self.img_dir)
18 |
19 | self.doc = dominate.document(title=title)
20 | if reflesh > 0:
21 | with self.doc.head:
22 | meta(http_equiv="reflesh", content=str(reflesh))
23 |
24 | def get_image_dir(self):
25 | return self.img_dir
26 |
27 | def add_header(self, str):
28 | with self.doc:
29 | h3(str)
30 |
31 | def add_table(self, border=1):
32 | self.t = table(border=border, style="table-layout: fixed;")
33 | self.doc.add(self.t)
34 |
35 | def add_images(self, ims, txts, links, width=400):
36 | self.add_table()
37 | with self.t:
38 | with tr():
39 | for im, txt, link in zip(ims, txts, links):
40 | with td(style="word-wrap: break-word;", halign="center", valign="top"):
41 | with p():
42 | with a(href=os.path.join(link)):
43 | img(style="width:%dpx" % width, src=os.path.join(im))
44 | br()
45 | p(txt)
46 |
47 | def save(self,file='index'):
48 | html_file = '%s/%s.html' % (self.web_dir,file)
49 | f = open(html_file, 'wt')
50 | f.write(self.doc.render())
51 | f.close()
52 |
53 |
54 | if __name__ == '__main__':
55 | html = HTML('web/', 'test_html')
56 | html.add_header('hello world')
57 |
58 | ims = []
59 | txts = []
60 | links = []
61 | for n in range(4):
62 | ims.append('image_%d.png' % n)
63 | txts.append('text_%d' % n)
64 | links.append('image_%d.png' % n)
65 | html.add_images(ims, txts, links)
66 | html.save()
67 |
--------------------------------------------------------------------------------
/store_results.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 |
5 | import timm
6 | import types
7 | import math
8 | import numpy as np
9 | from PIL import Image
10 | import PIL.Image as pil
11 | from torchvision import transforms, datasets
12 | from torch.utils.data import Dataset, DataLoader
13 | import torch.utils.data as data
14 | import PerceptualSimilarity.lpips.lpips as lpips
15 | import glob
16 | import gc
17 | import pytorch_msssim.pytorch_msssim as pytorch_msssim
18 | from torch.cuda.amp import autocast
19 | from model import BRViT
20 | import matplotlib.pyplot as plt
21 | from pytorch_ssim.pytorch_ssim import ssim
22 | from torchvision.utils import save_image
23 |
24 | import pandas as pd
25 | from tqdm import tqdm
26 | import sys
27 | import cv2
28 | import time
29 | import scipy.misc
30 |
31 | from skimage.metrics import peak_signal_noise_ratio as compare_psnr
32 | from skimage.metrics import structural_similarity as compare_ssim
33 |
34 |
35 | feed_width = 1536
36 | feed_height = 1024
37 |
38 |
39 | #to store results
40 | def store_results():
41 | device = torch.device("cuda")
42 |
43 | model = BRViT().to(device)
44 |
45 | PATH = "weights/BRViT_53_0.pt"
46 | model.load_state_dict(torch.load(PATH), strict=True)
47 |
48 | with torch.no_grad():
49 | for i in tqdm(range(4400,4694)):
50 | csv_file = "Bokeh_Data/test.csv"
51 | data = pd.read_csv(csv_file)
52 | root_dir = "."
53 | idx = i - 4400
54 | bok = pil.open(root_dir + data.iloc[idx, 0][1:]).convert('RGB')
55 | input_image = pil.open(root_dir + data.iloc[idx, 1][1:]).convert('RGB')
56 | original_width, original_height = input_image.size
57 |
58 | org_image = input_image
59 | org_image = transforms.ToTensor()(org_image).unsqueeze(0)
60 |
61 | input_image = input_image.resize((feed_width, feed_height), pil.LANCZOS)
62 | input_image = transforms.ToTensor()(input_image).unsqueeze(0)
63 |
64 | # prediction
65 | org_image = org_image.to(device)
66 | input_image = input_image.to(device)
67 |
68 | bok_pred = model(input_image)
69 |
70 | bok_pred = F.interpolate(bok_pred,(original_height,original_width),mode = 'bilinear')
71 |
72 | save_image(bok_pred,'Results/'+ str(i) +'.png')
73 |
74 |
75 |
76 | if __name__ == "__main__":
77 | store_results()
78 |
79 |
80 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/image_folder.py:
--------------------------------------------------------------------------------
1 | ################################################################################
2 | # Code from
3 | # https://github.com/pytorch/vision/blob/master/torchvision/datasets/folder.py
4 | # Modified the original code so that it also loads images from the current
5 | # directory as well as the subdirectories
6 | ################################################################################
7 |
8 | import torch.utils.data as data
9 |
10 | from PIL import Image
11 | import os
12 | import os.path
13 |
14 | IMG_EXTENSIONS = [
15 | '.jpg', '.JPG', '.jpeg', '.JPEG',
16 | '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP',
17 | ]
18 |
19 | NP_EXTENSIONS = ['.npy',]
20 |
21 | def is_image_file(filename, mode='img'):
22 | if(mode=='img'):
23 | return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
24 | elif(mode=='np'):
25 | return any(filename.endswith(extension) for extension in NP_EXTENSIONS)
26 |
27 | def make_dataset(dirs, mode='img'):
28 | if(not isinstance(dirs,list)):
29 | dirs = [dirs,]
30 |
31 | images = []
32 | for dir in dirs:
33 | assert os.path.isdir(dir), '%s is not a valid directory' % dir
34 | for root, _, fnames in sorted(os.walk(dir)):
35 | for fname in fnames:
36 | if is_image_file(fname, mode=mode):
37 | path = os.path.join(root, fname)
38 | images.append(path)
39 |
40 | # print("Found %i images in %s"%(len(images),root))
41 | return images
42 |
43 | def default_loader(path):
44 | return Image.open(path).convert('RGB')
45 |
46 | class ImageFolder(data.Dataset):
47 | def __init__(self, root, transform=None, return_paths=False,
48 | loader=default_loader):
49 | imgs = make_dataset(root)
50 | if len(imgs) == 0:
51 | raise(RuntimeError("Found 0 images in: " + root + "\n"
52 | "Supported image extensions are: " + ",".join(IMG_EXTENSIONS)))
53 |
54 | self.root = root
55 | self.imgs = imgs
56 | self.transform = transform
57 | self.return_paths = return_paths
58 | self.loader = loader
59 |
60 | def __getitem__(self, index):
61 | path = self.imgs[index]
62 | img = self.loader(path)
63 | if self.transform is not None:
64 | img = self.transform(img)
65 | if self.return_paths:
66 | return img, path
67 | else:
68 | return img
69 |
70 | def __len__(self):
71 | return len(self.imgs)
72 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/dataset/twoafc_dataset.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | import torchvision.transforms as transforms
3 | from data.dataset.base_dataset import BaseDataset
4 | from data.image_folder import make_dataset
5 | from PIL import Image
6 | import numpy as np
7 | import torch
8 | # from IPython import embed
9 |
10 | class TwoAFCDataset(BaseDataset):
11 | def initialize(self, dataroots, load_size=64):
12 | if(not isinstance(dataroots,list)):
13 | dataroots = [dataroots,]
14 | self.roots = dataroots
15 | self.load_size = load_size
16 |
17 | # image directory
18 | self.dir_ref = [os.path.join(root, 'ref') for root in self.roots]
19 | self.ref_paths = make_dataset(self.dir_ref)
20 | self.ref_paths = sorted(self.ref_paths)
21 |
22 | self.dir_p0 = [os.path.join(root, 'p0') for root in self.roots]
23 | self.p0_paths = make_dataset(self.dir_p0)
24 | self.p0_paths = sorted(self.p0_paths)
25 |
26 | self.dir_p1 = [os.path.join(root, 'p1') for root in self.roots]
27 | self.p1_paths = make_dataset(self.dir_p1)
28 | self.p1_paths = sorted(self.p1_paths)
29 |
30 | transform_list = []
31 | transform_list.append(transforms.Scale(load_size))
32 | transform_list += [transforms.ToTensor(),
33 | transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))]
34 |
35 | self.transform = transforms.Compose(transform_list)
36 |
37 | # judgement directory
38 | self.dir_J = [os.path.join(root, 'judge') for root in self.roots]
39 | self.judge_paths = make_dataset(self.dir_J,mode='np')
40 | self.judge_paths = sorted(self.judge_paths)
41 |
42 | def __getitem__(self, index):
43 | p0_path = self.p0_paths[index]
44 | p0_img_ = Image.open(p0_path).convert('RGB')
45 | p0_img = self.transform(p0_img_)
46 |
47 | p1_path = self.p1_paths[index]
48 | p1_img_ = Image.open(p1_path).convert('RGB')
49 | p1_img = self.transform(p1_img_)
50 |
51 | ref_path = self.ref_paths[index]
52 | ref_img_ = Image.open(ref_path).convert('RGB')
53 | ref_img = self.transform(ref_img_)
54 |
55 | judge_path = self.judge_paths[index]
56 | # judge_img = (np.load(judge_path)*2.-1.).reshape((1,1,1,)) # [-1,1]
57 | judge_img = np.load(judge_path).reshape((1,1,1,)) # [0,1]
58 |
59 | judge_img = torch.FloatTensor(judge_img)
60 |
61 | return {'p0': p0_img, 'p1': p1_img, 'ref': ref_img, 'judge': judge_img,
62 | 'p0_path': p0_path, 'p1_path': p1_path, 'ref_path': ref_path, 'judge_path': judge_path}
63 |
64 | def __len__(self):
65 | return len(self.p0_paths)
66 |
--------------------------------------------------------------------------------
/pytorch_msssim/README.md:
--------------------------------------------------------------------------------
1 | # pytorch-msssim
2 |
3 | ### Differentiable Multi-Scale Structural Similarity (SSIM) index
4 |
5 | This small utiliy provides a differentiable MS-SSIM implementation for PyTorch based on Po Hsun Su's implementation of SSIM @ https://github.com/Po-Hsun-Su/pytorch-ssim.
6 | At the moment only the product method for MS-SSIM is supported.
7 |
8 | ## Installation
9 |
10 | Master branch now only supports PyTorch 0.4 or higher. All development occurs in the dev branch (`git checkout dev` after cloning the repository to get the latest development version).
11 |
12 | To install the current version of pytorch_mssim:
13 |
14 | 1. Clone this repo.
15 | 2. Go to the repo directory.
16 | 3. Run `python setup.py install`
17 |
18 | or
19 |
20 | 1. Clone this repo.
21 | 2. Copy "pytorch_msssim" folder in your project.
22 |
23 | To install a version of of pytorch_mssim that runs in PyTorch 0.3.1 or lower use the tag checkpoint-0.3. To do so, run the following commands after cloning the repository:
24 |
25 | ```
26 | git fetch --all --tags
27 | git checkout tags/checkpoint-0.3
28 | ```
29 |
30 | ## Example
31 |
32 | ### Basic usage
33 | ```python
34 | import pytorch_msssim
35 | import torch
36 |
37 | device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
38 | m = pytorch_msssim.MSSSIM()
39 |
40 | img1 = torch.rand(1, 1, 256, 256)
41 | img2 = torch.rand(1, 1, 256, 256)
42 |
43 | print(pytorch_msssim.msssim(img1, img2))
44 | print(m(img1, img2))
45 |
46 |
47 | ```
48 |
49 | ### Training
50 |
51 | For a detailed example on how to use msssim for optimization, take a look at the file max_ssim.py.
52 |
53 |
54 | ### Stability and normalization
55 |
56 | MS-SSIM is a particularly unstable metric when used for some architectures and may result in NaN values early on during the training. The msssim method provides a normalize attribute to help in these cases. There are three possible values. We recommend using the value normalized="relu" when training.
57 |
58 | - None : no normalization method is used and should be used for evaluation
59 | - "relu" : the `ssim`and `mc` values of each level during the calculation are rectified using a relu ensuring that negative values are zeroed
60 | - "simple" : the `ssim`result of each iteration is averaged with 1 for an expected lower bound of 0.5 - should ONLY be used for the initial iterations of your training or when averaging below 0.6 normalized score
61 |
62 | Currently and due to backward compability, a value of True will equal the "simple" normalization.
63 |
64 | ## Reference
65 | https://ece.uwaterloo.ca/~z70wang/research/ssim/
66 |
67 | https://github.com/Po-Hsun-Su/pytorch-ssim
68 |
69 | Thanks to z70wang for proposing MS-SSIM and providing the initial implementation, and Po-Hsun-Su for the initial differentiable SSIM implementation for Pytorch.
70 |
--------------------------------------------------------------------------------
/pytorch_ssim/pytorch_ssim/__init__.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | from torch.autograd import Variable
4 | import numpy as np
5 | from math import exp
6 |
7 | def gaussian(window_size, sigma):
8 | gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
9 | return gauss/gauss.sum()
10 |
11 | def create_window(window_size, channel):
12 | _1D_window = gaussian(window_size, 1.5).unsqueeze(1)
13 | _2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
14 | window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
15 | return window
16 |
17 | def _ssim(img1, img2, window, window_size, channel, size_average = True):
18 | mu1 = F.conv2d(img1, window, padding = window_size//2, groups = channel)
19 | mu2 = F.conv2d(img2, window, padding = window_size//2, groups = channel)
20 |
21 | mu1_sq = mu1.pow(2)
22 | mu2_sq = mu2.pow(2)
23 | mu1_mu2 = mu1*mu2
24 |
25 | sigma1_sq = F.conv2d(img1*img1, window, padding = window_size//2, groups = channel) - mu1_sq
26 | sigma2_sq = F.conv2d(img2*img2, window, padding = window_size//2, groups = channel) - mu2_sq
27 | sigma12 = F.conv2d(img1*img2, window, padding = window_size//2, groups = channel) - mu1_mu2
28 |
29 | C1 = 0.01**2
30 | C2 = 0.03**2
31 |
32 | ssim_map = ((2*mu1_mu2 + C1)*(2*sigma12 + C2))/((mu1_sq + mu2_sq + C1)*(sigma1_sq + sigma2_sq + C2))
33 |
34 | if size_average:
35 | return ssim_map.mean()
36 | else:
37 | return ssim_map.mean(1).mean(1).mean(1)
38 |
39 | class SSIM(torch.nn.Module):
40 | def __init__(self, window_size = 11, size_average = True):
41 | super(SSIM, self).__init__()
42 | self.window_size = window_size
43 | self.size_average = size_average
44 | self.channel = 1
45 | self.window = create_window(window_size, self.channel)
46 |
47 | def forward(self, img1, img2):
48 | (_, channel, _, _) = img1.size()
49 |
50 | if channel == self.channel and self.window.data.type() == img1.data.type():
51 | window = self.window
52 | else:
53 | window = create_window(self.window_size, channel)
54 |
55 | if img1.is_cuda:
56 | window = window.cuda(img1.get_device())
57 | window = window.type_as(img1)
58 |
59 | self.window = window
60 | self.channel = channel
61 |
62 |
63 | return _ssim(img1, img2, window, self.window_size, channel, self.size_average)
64 |
65 | def ssim(img1, img2, window_size = 11, size_average = True):
66 | (_, channel, _, _) = img1.size()
67 | window = create_window(window_size, channel)
68 |
69 | if img1.is_cuda:
70 | window = window.cuda(img1.get_device())
71 | window = window.type_as(img1)
72 |
73 | return _ssim(img1, img2, window, window_size, channel, size_average)
74 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/test_dataset_model.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import lpips
3 | from data import data_loader as dl
4 | import argparse
5 | from IPython import embed
6 |
7 | parser = argparse.ArgumentParser()
8 | parser.add_argument('--dataset_mode', type=str, default='2afc', help='[2afc,jnd]')
9 | parser.add_argument('--datasets', type=str, nargs='+', default=['val/traditional','val/cnn','val/superres','val/deblur','val/color','val/frameinterp'], help='datasets to test - for jnd mode: [val/traditional],[val/cnn]; for 2afc mode: [train/traditional],[train/cnn],[train/mix],[val/traditional],[val/cnn],[val/color],[val/deblur],[val/frameinterp],[val/superres]')
10 | parser.add_argument('--model', type=str, default='lpips', help='distance model type [lpips] for linearly calibrated net, [baseline] for off-the-shelf network, [l2] for euclidean distance, [ssim] for Structured Similarity Image Metric')
11 | parser.add_argument('--net', type=str, default='alex', help='[squeeze], [alex], or [vgg] for network architectures')
12 | parser.add_argument('--colorspace', type=str, default='Lab', help='[Lab] or [RGB] for colorspace to use for l2, ssim model types')
13 | parser.add_argument('--batch_size', type=int, default=50, help='batch size to test image patches in')
14 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
15 | parser.add_argument('--gpu_ids', type=int, nargs='+', default=[0], help='gpus to use')
16 | parser.add_argument('--nThreads', type=int, default=4, help='number of threads to use in data loader')
17 |
18 | parser.add_argument('--model_path', type=str, default=None, help='location of model, will default to ./weights/v[version]/[net_name].pth')
19 |
20 | parser.add_argument('--from_scratch', action='store_true', help='model was initialized from scratch')
21 | parser.add_argument('--train_trunk', action='store_true', help='model trunk was trained/tuned')
22 | parser.add_argument('--version', type=str, default='0.1', help='v0.1 is latest, v0.0 was original release')
23 |
24 | opt = parser.parse_args()
25 | if(opt.model in ['l2','ssim']):
26 | opt.batch_size = 1
27 |
28 | # initialize model
29 | trainer = lpips.Trainer()
30 | # trainer.initialize(model=opt.model,net=opt.net,colorspace=opt.colorspace,model_path=opt.model_path,use_gpu=opt.use_gpu)
31 | trainer.initialize(model=opt.model, net=opt.net, colorspace=opt.colorspace,
32 | model_path=opt.model_path, use_gpu=opt.use_gpu, pnet_rand=opt.from_scratch, pnet_tune=opt.train_trunk,
33 | version=opt.version, gpu_ids=opt.gpu_ids)
34 |
35 | if(opt.model in ['net-lin','net']):
36 | print('Testing model [%s]-[%s]'%(opt.model,opt.net))
37 | elif(opt.model in ['l2','ssim']):
38 | print('Testing model [%s]-[%s]'%(opt.model,opt.colorspace))
39 |
40 | # initialize data loader
41 | for dataset in opt.datasets:
42 | data_loader = dl.CreateDataLoader(dataset,dataset_mode=opt.dataset_mode, batch_size=opt.batch_size, nThreads=opt.nThreads)
43 |
44 | # evaluate model on data
45 | if(opt.dataset_mode=='2afc'):
46 | (score, results_verbose) = lpips.score_2afc_dataset(data_loader, trainer.forward, name=dataset)
47 | elif(opt.dataset_mode=='jnd'):
48 | (score, results_verbose) = lpips.score_jnd_dataset(data_loader, trainer.forward, name=dataset)
49 |
50 | # print results
51 | print(' Dataset [%s]: %.2f'%(dataset,100.*score))
52 |
53 |
--------------------------------------------------------------------------------
/pytorch_msssim/pytorch_msssim/__init__.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | from math import exp
4 | import numpy as np
5 |
6 |
7 | def gaussian(window_size, sigma):
8 | gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
9 | return gauss/gauss.sum()
10 |
11 |
12 | def create_window(window_size, channel=1):
13 | _1D_window = gaussian(window_size, 1.5).unsqueeze(1)
14 | _2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
15 | window = _2D_window.expand(channel, 1, window_size, window_size).contiguous()
16 | return window
17 |
18 |
19 | def ssim(img1, img2, window_size=11, window=None, size_average=True, full=False, val_range=None):
20 | # Value range can be different from 255. Other common ranges are 1 (sigmoid) and 2 (tanh).
21 | if val_range is None:
22 | if torch.max(img1) > 128:
23 | max_val = 255
24 | else:
25 | max_val = 1
26 |
27 | if torch.min(img1) < -0.5:
28 | min_val = -1
29 | else:
30 | min_val = 0
31 | L = max_val - min_val
32 | else:
33 | L = val_range
34 |
35 | padd = 0
36 | (_, channel, height, width) = img1.size()
37 | if window is None:
38 | real_size = min(window_size, height, width)
39 | window = create_window(real_size, channel=channel).to(img1.device)
40 |
41 | mu1 = F.conv2d(img1, window, padding=padd, groups=channel)
42 | mu2 = F.conv2d(img2, window, padding=padd, groups=channel)
43 |
44 | mu1_sq = mu1.pow(2)
45 | mu2_sq = mu2.pow(2)
46 | mu1_mu2 = mu1 * mu2
47 |
48 | sigma1_sq = F.conv2d(img1 * img1, window, padding=padd, groups=channel) - mu1_sq
49 | sigma2_sq = F.conv2d(img2 * img2, window, padding=padd, groups=channel) - mu2_sq
50 | sigma12 = F.conv2d(img1 * img2, window, padding=padd, groups=channel) - mu1_mu2
51 |
52 | C1 = (0.01 * L) ** 2
53 | C2 = (0.03 * L) ** 2
54 |
55 | v1 = 2.0 * sigma12 + C2
56 | v2 = sigma1_sq + sigma2_sq + C2
57 | cs = v1 / v2 # contrast sensitivity
58 |
59 | ssim_map = ((2 * mu1_mu2 + C1) * v1) / ((mu1_sq + mu2_sq + C1) * v2)
60 |
61 | if size_average:
62 | cs = cs.mean()
63 | ret = ssim_map.mean()
64 | else:
65 | cs = cs.mean(1).mean(1).mean(1)
66 | ret = ssim_map.mean(1).mean(1).mean(1)
67 |
68 | if full:
69 | return ret, cs
70 | return ret
71 |
72 |
73 | def msssim(img1, img2, window_size=11, size_average=True, val_range=None, normalize=None):
74 | device = img1.device
75 | weights = torch.FloatTensor([0.0448, 0.2856, 0.3001, 0.2363, 0.1333]).to(device)
76 | levels = weights.size()[0]
77 | ssims = []
78 | mcs = []
79 | for _ in range(levels):
80 | sim, cs = ssim(img1, img2, window_size=window_size, size_average=size_average, full=True, val_range=val_range)
81 |
82 | # Relu normalize (not compliant with original definition)
83 | if normalize == "relu":
84 | ssims.append(torch.relu(sim))
85 | mcs.append(torch.relu(cs))
86 | else:
87 | ssims.append(sim)
88 | mcs.append(cs)
89 |
90 | img1 = F.avg_pool2d(img1, (2, 2))
91 | img2 = F.avg_pool2d(img2, (2, 2))
92 |
93 | ssims = torch.stack(ssims)
94 | mcs = torch.stack(mcs)
95 |
96 | # Simple normalize (not compliant with original definition)
97 | # TODO: remove support for normalize == True (kept for backward support)
98 | if normalize == "simple" or normalize == True:
99 | ssims = (ssims + 1) / 2
100 | mcs = (mcs + 1) / 2
101 |
102 | pow1 = mcs ** weights
103 | pow2 = ssims ** weights
104 |
105 | # From Matlab implementation https://ece.uwaterloo.ca/~z70wang/research/iwssim/
106 | output = torch.prod(pow1[:-1]) * pow2[-1]
107 | ## output = torch.prod(pow1[:-1] * pow2[-1])
108 | return output
109 |
110 |
111 | # Classes to re-use window
112 | class SSIM(torch.nn.Module):
113 | def __init__(self, window_size=11, size_average=True, val_range=None):
114 | super(SSIM, self).__init__()
115 | self.window_size = window_size
116 | self.size_average = size_average
117 | self.val_range = val_range
118 |
119 | # Assume 1 channel for SSIM
120 | self.channel = 1
121 | self.window = create_window(window_size)
122 |
123 | def forward(self, img1, img2):
124 | (_, channel, _, _) = img1.size()
125 |
126 | if channel == self.channel and self.window.dtype == img1.dtype:
127 | window = self.window
128 | else:
129 | window = create_window(self.window_size, channel).to(img1.device).type(img1.dtype)
130 | self.window = window
131 | self.channel = channel
132 |
133 | return ssim(img1, img2, window=window, window_size=self.window_size, size_average=self.size_average)
134 |
135 | class MSSSIM(torch.nn.Module):
136 | def __init__(self, window_size=11, size_average=True, channel=3):
137 | super(MSSSIM, self).__init__()
138 | self.window_size = window_size
139 | self.size_average = size_average
140 | self.channel = channel
141 |
142 | def forward(self, img1, img2):
143 | # TODO: store window between calls if possible
144 | return msssim(img1, img2, window_size=self.window_size, size_average=self.size_average)
145 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import, division, print_function
2 | import cv2
3 | import numbers
4 | import math
5 | import os
6 | import sys
7 | import glob
8 | import argparse
9 | import numpy as np
10 | import PIL.Image as pil
11 | import matplotlib as mpl
12 | import matplotlib.cm as cm
13 | import torch
14 | from torchvision import transforms, datasets
15 | from torch.utils.data import Dataset, DataLoader
16 | import pandas as pd
17 | import torch.nn as nn
18 | import torch.optim as optim
19 | import torch.nn.functional as F
20 | import math
21 | from pytorch_msssim.pytorch_msssim import msssim
22 | import torchvision
23 | from torch.autograd import Variable
24 | from pytorch_ssim.pytorch_ssim import ssim
25 | import PerceptualSimilarity.lpips.lpips as lpips
26 |
27 | from tqdm import tqdm
28 |
29 | device = torch.device("cuda:0")
30 |
31 | from model import BRViT
32 |
33 |
34 | feed_width = 768
35 | feed_height = 512
36 |
37 |
38 | bokehnet = BRViT().to(device)
39 | batch_size = 1
40 |
41 |
42 | PATH = "BRViT_53_0.pt"
43 | bokehnet.load_state_dict(torch.load(PATH), strict=False)
44 |
45 | print("weights loaded!!")
46 |
47 |
48 | class bokehDataset(Dataset):
49 |
50 | def __init__(self, csv_file,root_dir, transform=None):
51 |
52 | self.data = pd.read_csv(csv_file)
53 | self.transform = transform
54 | self.root_dir = root_dir
55 |
56 | def __len__(self):
57 | return len(self.data)
58 |
59 | def __getitem__(self, idx):
60 |
61 | bok = pil.open(self.root_dir + self.data.iloc[idx, 0][1:]).convert('RGB')
62 | org = pil.open(self.root_dir + self.data.iloc[idx, 1][1:]).convert('RGB')
63 |
64 | bok = bok.resize((feed_width, feed_height), pil.LANCZOS)
65 | org = org.resize((feed_width, feed_height), pil.LANCZOS)
66 | if self.transform :
67 | bok_dep = self.transform(bok)
68 | org_dep = self.transform(org)
69 | return (bok_dep, org_dep)
70 |
71 | transform1 = transforms.Compose(
72 | [
73 | transforms.ToTensor(),
74 | ])
75 |
76 |
77 | transform2 = transforms.Compose(
78 | [
79 | transforms.RandomHorizontalFlip(p=1),
80 | transforms.ToTensor(),
81 | ])
82 |
83 |
84 | transform3 = transforms.Compose(
85 | [
86 | transforms.RandomVerticalFlip(p=1),
87 | transforms.ToTensor(),
88 | ])
89 |
90 |
91 |
92 | trainset1 = bokehDataset(csv_file = './Bokeh_Data/train.csv', root_dir = '.',transform = transform1)
93 | trainset2 = bokehDataset(csv_file = './Bokeh_Data/train.csv', root_dir = '.',transform = transform2)
94 | trainset3 = bokehDataset(csv_file = './Bokeh_Data/train.csv', root_dir = '.',transform = transform3)
95 |
96 |
97 | trainloader = torch.utils.data.DataLoader(torch.utils.data.ConcatDataset([trainset1,trainset2,trainset3]), batch_size=batch_size,
98 | shuffle=True, num_workers=0)
99 |
100 | testset = bokehDataset(csv_file = './Bokeh_Data/test.csv', root_dir = '.', transform = transform1)
101 | testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
102 | shuffle=False, num_workers=0)
103 |
104 |
105 | learning_rate = 0.00001
106 |
107 | optimizer = optim.Adam(bokehnet.parameters(), lr=learning_rate, betas=(0.9, 0.999))
108 |
109 |
110 | sm = nn.Softmax(dim=1)
111 |
112 | MSE_LossFn = nn.MSELoss()
113 | L1_LossFn = nn.L1Loss()
114 |
115 |
116 | def train(dataloader):
117 | running_l1_loss = 0
118 | running_ms_loss = 0
119 | running_sal_loss = 0
120 | running_loss = 0
121 |
122 | for i,data in enumerate(dataloader,0) :
123 | bok , org = data
124 | bok , org = bok.to(device) , org.to(device)
125 |
126 | optimizer.zero_grad()
127 |
128 | bok_pred = bokehnet(org)
129 |
130 | loss = (1-msssim(bok_pred, bok))
131 |
132 | ## loss = L1_LossFn(bok_pred, bok)
133 |
134 | running_loss += loss.item()
135 |
136 | loss.backward()
137 | optimizer.step()
138 | if (i % 10 == 0):
139 | print ('Batch: ',i,'/',len(dataloader),' Loss:', loss.item())
140 |
141 |
142 | if ((i+1)%8000==0):
143 | torch.save(bokehnet.state_dict(), './weights/BRViT_' + str(epoch) + '_' + str(i) + '.pt')
144 | print(loss.item())
145 |
146 | print (running_loss/len(dataloader))
147 |
148 |
149 |
150 |
151 | def val(dataloader):
152 | running_l1_loss = 0
153 | running_ms_loss = 0
154 | running_lips_loss = 0
155 |
156 | with torch.no_grad():
157 | for i,data in enumerate(tqdm(dataloader),0) :
158 | bok , org = data
159 | bok , org = bok.to(device) , org.to(device)
160 |
161 | bok_pred = bokehnet(org)
162 |
163 | try:
164 | l1_loss = L1_LossFn(bok_pred, bok)
165 | except:
166 | l1_loss = L1_LossFn(bok_pred[0], bok)
167 |
168 | ms_loss = 1-ssim(bok_pred, bok)
169 |
170 |
171 | running_l1_loss += l1_loss.item()
172 | running_ms_loss += ms_loss.item()
173 |
174 |
175 | print ('Validation l1 Loss: ',running_l1_loss/len(dataloader))
176 | print ('Validation ms Loss: ',running_ms_loss/len(dataloader))
177 |
178 | ## torch.save(bokehnet.state_dict(), './weights/BRViT_'+str(epoch)+'.pt')
179 |
180 | try:
181 | with open("log.txt", 'a') as f:
182 | f.write(f"{running_ms_loss/len(dataloader)}\n")
183 | except:
184 | pass
185 |
186 |
187 |
188 | start_ep = 0
189 | for epoch in range(start_ep, 40):
190 | print (epoch)
191 |
192 | train(trainloader)
193 |
194 | with torch.no_grad():
195 | val(testloader)
196 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/train.py:
--------------------------------------------------------------------------------
1 | import torch.backends.cudnn as cudnn
2 | cudnn.benchmark=False
3 |
4 | import numpy as np
5 | import time
6 | import os
7 | import lpips
8 | from data import data_loader as dl
9 | import argparse
10 | from util.visualizer import Visualizer
11 | from IPython import embed
12 |
13 | parser = argparse.ArgumentParser()
14 | parser.add_argument('--datasets', type=str, nargs='+', default=['train/traditional','train/cnn','train/mix'], help='datasets to train on: [train/traditional],[train/cnn],[train/mix],[val/traditional],[val/cnn],[val/color],[val/deblur],[val/frameinterp],[val/superres]')
15 | parser.add_argument('--model', type=str, default='lpips', help='distance model type [lpips] for linearly calibrated net, [baseline] for off-the-shelf network, [l2] for euclidean distance, [ssim] for Structured Similarity Image Metric')
16 | parser.add_argument('--net', type=str, default='alex', help='[squeeze], [alex], or [vgg] for network architectures')
17 | parser.add_argument('--batch_size', type=int, default=50, help='batch size to test image patches in')
18 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
19 | parser.add_argument('--gpu_ids', type=int, nargs='+', default=[0], help='gpus to use')
20 |
21 | parser.add_argument('--nThreads', type=int, default=4, help='number of threads to use in data loader')
22 | parser.add_argument('--nepoch', type=int, default=5, help='# epochs at base learning rate')
23 | parser.add_argument('--nepoch_decay', type=int, default=5, help='# additional epochs at linearly learning rate')
24 | parser.add_argument('--display_freq', type=int, default=5000, help='frequency (in instances) of showing training results on screen')
25 | parser.add_argument('--print_freq', type=int, default=5000, help='frequency (in instances) of showing training results on console')
26 | parser.add_argument('--save_latest_freq', type=int, default=20000, help='frequency (in instances) of saving the latest results')
27 | parser.add_argument('--save_epoch_freq', type=int, default=1, help='frequency of saving checkpoints at the end of epochs')
28 | parser.add_argument('--display_id', type=int, default=0, help='window id of the visdom display, [0] for no displaying')
29 | parser.add_argument('--display_winsize', type=int, default=256, help='display window size')
30 | parser.add_argument('--display_port', type=int, default=8001, help='visdom display port')
31 | parser.add_argument('--use_html', action='store_true', help='save off html pages')
32 | parser.add_argument('--checkpoints_dir', type=str, default='checkpoints', help='checkpoints directory')
33 | parser.add_argument('--name', type=str, default='tmp', help='directory name for training')
34 |
35 | parser.add_argument('--from_scratch', action='store_true', help='model was initialized from scratch')
36 | parser.add_argument('--train_trunk', action='store_true', help='model trunk was trained/tuned')
37 | parser.add_argument('--train_plot', action='store_true', help='plot saving')
38 |
39 | opt = parser.parse_args()
40 | opt.save_dir = os.path.join(opt.checkpoints_dir,opt.name)
41 | if(not os.path.exists(opt.save_dir)):
42 | os.mkdir(opt.save_dir)
43 |
44 | # initialize model
45 | trainer = lpips.Trainer()
46 | trainer.initialize(model=opt.model, net=opt.net, use_gpu=opt.use_gpu, is_train=True,
47 | pnet_rand=opt.from_scratch, pnet_tune=opt.train_trunk, gpu_ids=opt.gpu_ids)
48 |
49 | # load data from all training sets
50 | data_loader = dl.CreateDataLoader(opt.datasets,dataset_mode='2afc', batch_size=opt.batch_size, serial_batches=False, nThreads=opt.nThreads)
51 | dataset = data_loader.load_data()
52 | dataset_size = len(data_loader)
53 | D = len(dataset)
54 | print('Loading %i instances from'%dataset_size,opt.datasets)
55 | visualizer = Visualizer(opt)
56 |
57 | total_steps = 0
58 | fid = open(os.path.join(opt.checkpoints_dir,opt.name,'train_log.txt'),'w+')
59 | for epoch in range(1, opt.nepoch + opt.nepoch_decay + 1):
60 | epoch_start_time = time.time()
61 | for i, data in enumerate(dataset):
62 | iter_start_time = time.time()
63 | total_steps += opt.batch_size
64 | epoch_iter = total_steps - dataset_size * (epoch - 1)
65 |
66 | trainer.set_input(data)
67 | trainer.optimize_parameters()
68 |
69 | if total_steps % opt.display_freq == 0:
70 | visualizer.display_current_results(trainer.get_current_visuals(), epoch)
71 |
72 | if total_steps % opt.print_freq == 0:
73 | errors = trainer.get_current_errors()
74 | t = (time.time()-iter_start_time)/opt.batch_size
75 | t2o = (time.time()-epoch_start_time)/3600.
76 | t2 = t2o*D/(i+.0001)
77 | visualizer.print_current_errors(epoch, epoch_iter, errors, t, t2=t2, t2o=t2o, fid=fid)
78 |
79 | for key in errors.keys():
80 | visualizer.plot_current_errors_save(epoch, float(epoch_iter)/dataset_size, opt, errors, keys=[key,], name=key, to_plot=opt.train_plot)
81 |
82 | if opt.display_id > 0:
83 | visualizer.plot_current_errors(epoch, float(epoch_iter)/dataset_size, opt, errors)
84 |
85 | if total_steps % opt.save_latest_freq == 0:
86 | print('saving the latest model (epoch %d, total_steps %d)' %
87 | (epoch, total_steps))
88 | trainer.save(opt.save_dir, 'latest')
89 |
90 | if epoch % opt.save_epoch_freq == 0:
91 | print('saving the model at the end of epoch %d, iters %d' %
92 | (epoch, total_steps))
93 | trainer.save(opt.save_dir, 'latest')
94 | trainer.save(opt.save_dir, epoch)
95 |
96 | print('End of epoch %d / %d \t Time Taken: %d sec' %
97 | (epoch, opt.nepoch + opt.nepoch_decay, time.time() - epoch_start_time))
98 |
99 | if epoch > opt.nepoch:
100 | trainer.update_learning_rate(opt.nepoch_decay)
101 |
102 | # trainer.save_done(True)
103 | fid.close()
104 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/__init__.py:
--------------------------------------------------------------------------------
1 |
2 | from __future__ import absolute_import
3 | from __future__ import division
4 | from __future__ import print_function
5 |
6 | import numpy as np
7 | import torch
8 | # from torch.autograd import Variable
9 |
10 | from PerceptualSimilarity.lpips.trainer import *
11 | from PerceptualSimilarity.lpips.lpips import *
12 |
13 | # class PerceptualLoss(torch.nn.Module):
14 | # def __init__(self, model='lpips', net='alex', spatial=False, use_gpu=False, gpu_ids=[0], version='0.1'): # VGG using our perceptually-learned weights (LPIPS metric)
15 | # # def __init__(self, model='net', net='vgg', use_gpu=True): # "default" way of using VGG as a perceptual loss
16 | # super(PerceptualLoss, self).__init__()
17 | # print('Setting up Perceptual loss...')
18 | # self.use_gpu = use_gpu
19 | # self.spatial = spatial
20 | # self.gpu_ids = gpu_ids
21 | # self.model = dist_model.DistModel()
22 | # self.model.initialize(model=model, net=net, use_gpu=use_gpu, spatial=self.spatial, gpu_ids=gpu_ids, version=version)
23 | # print('...[%s] initialized'%self.model.name())
24 | # print('...Done')
25 |
26 | # def forward(self, pred, target, normalize=False):
27 | # """
28 | # Pred and target are Variables.
29 | # If normalize is True, assumes the images are between [0,1] and then scales them between [-1,+1]
30 | # If normalize is False, assumes the images are already between [-1,+1]
31 |
32 | # Inputs pred and target are Nx3xHxW
33 | # Output pytorch Variable N long
34 | # """
35 |
36 | # if normalize:
37 | # target = 2 * target - 1
38 | # pred = 2 * pred - 1
39 |
40 | # return self.model.forward(target, pred)
41 |
42 | def normalize_tensor(in_feat,eps=1e-10):
43 | norm_factor = torch.sqrt(torch.sum(in_feat**2,dim=1,keepdim=True))
44 | return in_feat/(norm_factor+eps)
45 |
46 | def l2(p0, p1, range=255.):
47 | return .5*np.mean((p0 / range - p1 / range)**2)
48 |
49 | def psnr(p0, p1, peak=255.):
50 | return 10*np.log10(peak**2/np.mean((1.*p0-1.*p1)**2))
51 |
52 | def dssim(p0, p1, range=255.):
53 | from skimage.measure import compare_ssim
54 | return (1 - compare_ssim(p0, p1, data_range=range, multichannel=True)) / 2.
55 |
56 | def rgb2lab(in_img,mean_cent=False):
57 | from skimage import color
58 | img_lab = color.rgb2lab(in_img)
59 | if(mean_cent):
60 | img_lab[:,:,0] = img_lab[:,:,0]-50
61 | return img_lab
62 |
63 | def tensor2np(tensor_obj):
64 | # change dimension of a tensor object into a numpy array
65 | return tensor_obj[0].cpu().float().numpy().transpose((1,2,0))
66 |
67 | def np2tensor(np_obj):
68 | # change dimenion of np array into tensor array
69 | return torch.Tensor(np_obj[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
70 |
71 | def tensor2tensorlab(image_tensor,to_norm=True,mc_only=False):
72 | # image tensor to lab tensor
73 | from skimage import color
74 |
75 | img = tensor2im(image_tensor)
76 | img_lab = color.rgb2lab(img)
77 | if(mc_only):
78 | img_lab[:,:,0] = img_lab[:,:,0]-50
79 | if(to_norm and not mc_only):
80 | img_lab[:,:,0] = img_lab[:,:,0]-50
81 | img_lab = img_lab/100.
82 |
83 | return np2tensor(img_lab)
84 |
85 | def tensorlab2tensor(lab_tensor,return_inbnd=False):
86 | from skimage import color
87 | import warnings
88 | warnings.filterwarnings("ignore")
89 |
90 | lab = tensor2np(lab_tensor)*100.
91 | lab[:,:,0] = lab[:,:,0]+50
92 |
93 | rgb_back = 255.*np.clip(color.lab2rgb(lab.astype('float')),0,1)
94 | if(return_inbnd):
95 | # convert back to lab, see if we match
96 | lab_back = color.rgb2lab(rgb_back.astype('uint8'))
97 | mask = 1.*np.isclose(lab_back,lab,atol=2.)
98 | mask = np2tensor(np.prod(mask,axis=2)[:,:,np.newaxis])
99 | return (im2tensor(rgb_back),mask)
100 | else:
101 | return im2tensor(rgb_back)
102 |
103 | def load_image(path):
104 | if(path[-3:] == 'dng'):
105 | import rawpy
106 | with rawpy.imread(path) as raw:
107 | img = raw.postprocess()
108 | elif(path[-3:]=='bmp' or path[-3:]=='jpg' or path[-3:]=='png' or path[-4:]=='jpeg'):
109 | import cv2
110 | return cv2.imread(path)[:,:,::-1]
111 | else:
112 | img = (255*plt.imread(path)[:,:,:3]).astype('uint8')
113 |
114 | return img
115 |
116 | def rgb2lab(input):
117 | from skimage import color
118 | return color.rgb2lab(input / 255.)
119 |
120 | def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
121 | image_numpy = image_tensor[0].cpu().float().numpy()
122 | image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
123 | return image_numpy.astype(imtype)
124 |
125 | def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
126 | return torch.Tensor((image / factor - cent)
127 | [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
128 |
129 | def tensor2vec(vector_tensor):
130 | return vector_tensor.data.cpu().numpy()[:, :, 0, 0]
131 |
132 |
133 | def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
134 | # def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
135 | image_numpy = image_tensor[0].cpu().float().numpy()
136 | image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
137 | return image_numpy.astype(imtype)
138 |
139 | def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
140 | # def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
141 | return torch.Tensor((image / factor - cent)
142 | [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
143 |
144 |
145 |
146 | def voc_ap(rec, prec, use_07_metric=False):
147 | """ ap = voc_ap(rec, prec, [use_07_metric])
148 | Compute VOC AP given precision and recall.
149 | If use_07_metric is true, uses the
150 | VOC 07 11 point method (default:False).
151 | """
152 | if use_07_metric:
153 | # 11 point metric
154 | ap = 0.
155 | for t in np.arange(0., 1.1, 0.1):
156 | if np.sum(rec >= t) == 0:
157 | p = 0
158 | else:
159 | p = np.max(prec[rec >= t])
160 | ap = ap + p / 11.
161 | else:
162 | # correct AP calculation
163 | # first append sentinel values at the end
164 | mrec = np.concatenate(([0.], rec, [1.]))
165 | mpre = np.concatenate(([0.], prec, [0.]))
166 |
167 | # compute the precision envelope
168 | for i in range(mpre.size - 1, 0, -1):
169 | mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
170 |
171 | # to calculate area under PR curve, look for points
172 | # where X axis (recall) changes value
173 | i = np.where(mrec[1:] != mrec[:-1])[0]
174 |
175 | # and sum (\Delta recall) * prec
176 | ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
177 | return ap
178 |
179 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/pretrained_networks.py:
--------------------------------------------------------------------------------
1 | from collections import namedtuple
2 | import torch
3 | from torchvision import models as tv
4 |
5 | class squeezenet(torch.nn.Module):
6 | def __init__(self, requires_grad=False, pretrained=True):
7 | super(squeezenet, self).__init__()
8 | pretrained_features = tv.squeezenet1_1(pretrained=pretrained).features
9 | self.slice1 = torch.nn.Sequential()
10 | self.slice2 = torch.nn.Sequential()
11 | self.slice3 = torch.nn.Sequential()
12 | self.slice4 = torch.nn.Sequential()
13 | self.slice5 = torch.nn.Sequential()
14 | self.slice6 = torch.nn.Sequential()
15 | self.slice7 = torch.nn.Sequential()
16 | self.N_slices = 7
17 | for x in range(2):
18 | self.slice1.add_module(str(x), pretrained_features[x])
19 | for x in range(2,5):
20 | self.slice2.add_module(str(x), pretrained_features[x])
21 | for x in range(5, 8):
22 | self.slice3.add_module(str(x), pretrained_features[x])
23 | for x in range(8, 10):
24 | self.slice4.add_module(str(x), pretrained_features[x])
25 | for x in range(10, 11):
26 | self.slice5.add_module(str(x), pretrained_features[x])
27 | for x in range(11, 12):
28 | self.slice6.add_module(str(x), pretrained_features[x])
29 | for x in range(12, 13):
30 | self.slice7.add_module(str(x), pretrained_features[x])
31 | if not requires_grad:
32 | for param in self.parameters():
33 | param.requires_grad = False
34 |
35 | def forward(self, X):
36 | h = self.slice1(X)
37 | h_relu1 = h
38 | h = self.slice2(h)
39 | h_relu2 = h
40 | h = self.slice3(h)
41 | h_relu3 = h
42 | h = self.slice4(h)
43 | h_relu4 = h
44 | h = self.slice5(h)
45 | h_relu5 = h
46 | h = self.slice6(h)
47 | h_relu6 = h
48 | h = self.slice7(h)
49 | h_relu7 = h
50 | vgg_outputs = namedtuple("SqueezeOutputs", ['relu1','relu2','relu3','relu4','relu5','relu6','relu7'])
51 | out = vgg_outputs(h_relu1,h_relu2,h_relu3,h_relu4,h_relu5,h_relu6,h_relu7)
52 |
53 | return out
54 |
55 |
56 | class alexnet(torch.nn.Module):
57 | def __init__(self, requires_grad=False, pretrained=True):
58 | super(alexnet, self).__init__()
59 | alexnet_pretrained_features = tv.alexnet(pretrained=pretrained).features
60 | self.slice1 = torch.nn.Sequential()
61 | self.slice2 = torch.nn.Sequential()
62 | self.slice3 = torch.nn.Sequential()
63 | self.slice4 = torch.nn.Sequential()
64 | self.slice5 = torch.nn.Sequential()
65 | self.N_slices = 5
66 | for x in range(2):
67 | self.slice1.add_module(str(x), alexnet_pretrained_features[x])
68 | for x in range(2, 5):
69 | self.slice2.add_module(str(x), alexnet_pretrained_features[x])
70 | for x in range(5, 8):
71 | self.slice3.add_module(str(x), alexnet_pretrained_features[x])
72 | for x in range(8, 10):
73 | self.slice4.add_module(str(x), alexnet_pretrained_features[x])
74 | for x in range(10, 12):
75 | self.slice5.add_module(str(x), alexnet_pretrained_features[x])
76 | if not requires_grad:
77 | for param in self.parameters():
78 | param.requires_grad = False
79 |
80 | def forward(self, X):
81 | h = self.slice1(X)
82 | h_relu1 = h
83 | h = self.slice2(h)
84 | h_relu2 = h
85 | h = self.slice3(h)
86 | h_relu3 = h
87 | h = self.slice4(h)
88 | h_relu4 = h
89 | h = self.slice5(h)
90 | h_relu5 = h
91 | alexnet_outputs = namedtuple("AlexnetOutputs", ['relu1', 'relu2', 'relu3', 'relu4', 'relu5'])
92 | out = alexnet_outputs(h_relu1, h_relu2, h_relu3, h_relu4, h_relu5)
93 |
94 | return out
95 |
96 | class vgg16(torch.nn.Module):
97 | def __init__(self, requires_grad=False, pretrained=True):
98 | super(vgg16, self).__init__()
99 | vgg_pretrained_features = tv.vgg16(pretrained=pretrained).features
100 | self.slice1 = torch.nn.Sequential()
101 | self.slice2 = torch.nn.Sequential()
102 | self.slice3 = torch.nn.Sequential()
103 | self.slice4 = torch.nn.Sequential()
104 | self.slice5 = torch.nn.Sequential()
105 | self.N_slices = 5
106 | for x in range(4):
107 | self.slice1.add_module(str(x), vgg_pretrained_features[x])
108 | for x in range(4, 9):
109 | self.slice2.add_module(str(x), vgg_pretrained_features[x])
110 | for x in range(9, 16):
111 | self.slice3.add_module(str(x), vgg_pretrained_features[x])
112 | for x in range(16, 23):
113 | self.slice4.add_module(str(x), vgg_pretrained_features[x])
114 | for x in range(23, 30):
115 | self.slice5.add_module(str(x), vgg_pretrained_features[x])
116 | if not requires_grad:
117 | for param in self.parameters():
118 | param.requires_grad = False
119 |
120 | def forward(self, X):
121 | h = self.slice1(X)
122 | h_relu1_2 = h
123 | h = self.slice2(h)
124 | h_relu2_2 = h
125 | h = self.slice3(h)
126 | h_relu3_3 = h
127 | h = self.slice4(h)
128 | h_relu4_3 = h
129 | h = self.slice5(h)
130 | h_relu5_3 = h
131 | vgg_outputs = namedtuple("VggOutputs", ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3', 'relu5_3'])
132 | out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3)
133 |
134 | return out
135 |
136 |
137 |
138 | class resnet(torch.nn.Module):
139 | def __init__(self, requires_grad=False, pretrained=True, num=18):
140 | super(resnet, self).__init__()
141 | if(num==18):
142 | self.net = tv.resnet18(pretrained=pretrained)
143 | elif(num==34):
144 | self.net = tv.resnet34(pretrained=pretrained)
145 | elif(num==50):
146 | self.net = tv.resnet50(pretrained=pretrained)
147 | elif(num==101):
148 | self.net = tv.resnet101(pretrained=pretrained)
149 | elif(num==152):
150 | self.net = tv.resnet152(pretrained=pretrained)
151 | self.N_slices = 5
152 |
153 | self.conv1 = self.net.conv1
154 | self.bn1 = self.net.bn1
155 | self.relu = self.net.relu
156 | self.maxpool = self.net.maxpool
157 | self.layer1 = self.net.layer1
158 | self.layer2 = self.net.layer2
159 | self.layer3 = self.net.layer3
160 | self.layer4 = self.net.layer4
161 |
162 | def forward(self, X):
163 | h = self.conv1(X)
164 | h = self.bn1(h)
165 | h = self.relu(h)
166 | h_relu1 = h
167 | h = self.maxpool(h)
168 | h = self.layer1(h)
169 | h_conv2 = h
170 | h = self.layer2(h)
171 | h_conv3 = h
172 | h = self.layer3(h)
173 | h_conv4 = h
174 | h = self.layer4(h)
175 | h_conv5 = h
176 |
177 | outputs = namedtuple("Outputs", ['relu1','conv2','conv3','conv4','conv5'])
178 | out = outputs(h_relu1, h_conv2, h_conv3, h_conv4, h_conv5)
179 |
180 | return out
181 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/util/visualizer.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import os
3 | import time
4 | from . import util
5 | from . import html
6 | import matplotlib.pyplot as plt
7 | import math
8 | # from IPython import embed
9 |
10 | def zoom_to_res(img,res=256,order=0,axis=0):
11 | # img 3xXxX
12 | from scipy.ndimage import zoom
13 | zoom_factor = res/img.shape[1]
14 | if(axis==0):
15 | return zoom(img,[1,zoom_factor,zoom_factor],order=order)
16 | elif(axis==2):
17 | return zoom(img,[zoom_factor,zoom_factor,1],order=order)
18 |
19 | class Visualizer():
20 | def __init__(self, opt):
21 | # self.opt = opt
22 | self.display_id = opt.display_id
23 | # self.use_html = opt.is_train and not opt.no_html
24 | self.win_size = opt.display_winsize
25 | self.name = opt.name
26 | self.display_cnt = 0 # display_current_results counter
27 | self.display_cnt_high = 0
28 | self.use_html = opt.use_html
29 |
30 | if self.display_id > 0:
31 | import visdom
32 | self.vis = visdom.Visdom(port = opt.display_port)
33 |
34 | self.web_dir = os.path.join(opt.checkpoints_dir, opt.name, 'web')
35 | util.mkdirs([self.web_dir,])
36 | if self.use_html:
37 | self.img_dir = os.path.join(self.web_dir, 'images')
38 | print('create web directory %s...' % self.web_dir)
39 | util.mkdirs([self.img_dir,])
40 |
41 | # |visuals|: dictionary of images to display or save
42 | def display_current_results(self, visuals, epoch, nrows=None, res=256):
43 | if self.display_id > 0: # show images in the browser
44 | title = self.name
45 | if(nrows is None):
46 | nrows = int(math.ceil(len(visuals.items()) / 2.0))
47 | images = []
48 | idx = 0
49 | for label, image_numpy in visuals.items():
50 | title += " | " if idx % nrows == 0 else ", "
51 | title += label
52 | img = image_numpy.transpose([2, 0, 1])
53 | img = zoom_to_res(img,res=res,order=0)
54 | images.append(img)
55 | idx += 1
56 | if len(visuals.items()) % 2 != 0:
57 | white_image = np.ones_like(image_numpy.transpose([2, 0, 1]))*255
58 | white_image = zoom_to_res(white_image,res=res,order=0)
59 | images.append(white_image)
60 | self.vis.images(images, nrow=nrows, win=self.display_id + 1,
61 | opts=dict(title=title))
62 |
63 | if self.use_html: # save images to a html file
64 | for label, image_numpy in visuals.items():
65 | img_path = os.path.join(self.img_dir, 'epoch%.3d_cnt%.6d_%s.png' % (epoch, self.display_cnt, label))
66 | util.save_image(zoom_to_res(image_numpy, res=res, axis=2), img_path)
67 |
68 | self.display_cnt += 1
69 | self.display_cnt_high = np.maximum(self.display_cnt_high, self.display_cnt)
70 |
71 | # update website
72 | webpage = html.HTML(self.web_dir, 'Experiment name = %s' % self.name, reflesh=1)
73 | for n in range(epoch, 0, -1):
74 | webpage.add_header('epoch [%d]' % n)
75 | if(n==epoch):
76 | high = self.display_cnt
77 | else:
78 | high = self.display_cnt_high
79 | for c in range(high-1,-1,-1):
80 | ims = []
81 | txts = []
82 | links = []
83 |
84 | for label, image_numpy in visuals.items():
85 | img_path = 'epoch%.3d_cnt%.6d_%s.png' % (n, c, label)
86 | ims.append(os.path.join('images',img_path))
87 | txts.append(label)
88 | links.append(os.path.join('images',img_path))
89 | webpage.add_images(ims, txts, links, width=self.win_size)
90 | webpage.save()
91 |
92 | # save errors into a directory
93 | def plot_current_errors_save(self, epoch, counter_ratio, opt, errors,keys='+ALL',name='loss', to_plot=False):
94 | if not hasattr(self, 'plot_data'):
95 | self.plot_data = {'X':[],'Y':[], 'legend':list(errors.keys())}
96 | self.plot_data['X'].append(epoch + counter_ratio)
97 | self.plot_data['Y'].append([errors[k] for k in self.plot_data['legend']])
98 |
99 | # embed()
100 | if(keys=='+ALL'):
101 | plot_keys = self.plot_data['legend']
102 | else:
103 | plot_keys = keys
104 |
105 | if(to_plot):
106 | (f,ax) = plt.subplots(1,1)
107 | for (k,kname) in enumerate(plot_keys):
108 | kk = np.where(np.array(self.plot_data['legend'])==kname)[0][0]
109 | x = self.plot_data['X']
110 | y = np.array(self.plot_data['Y'])[:,kk]
111 | if(to_plot):
112 | ax.plot(x, y, 'o-', label=kname)
113 | np.save(os.path.join(self.web_dir,'%s_x')%kname,x)
114 | np.save(os.path.join(self.web_dir,'%s_y')%kname,y)
115 |
116 | if(to_plot):
117 | plt.legend(loc=0,fontsize='small')
118 | plt.xlabel('epoch')
119 | plt.ylabel('Value')
120 | f.savefig(os.path.join(self.web_dir,'%s.png'%name))
121 | f.clf()
122 | plt.close()
123 |
124 | # errors: dictionary of error labels and values
125 | def plot_current_errors(self, epoch, counter_ratio, opt, errors):
126 | if not hasattr(self, 'plot_data'):
127 | self.plot_data = {'X':[],'Y':[], 'legend':list(errors.keys())}
128 | self.plot_data['X'].append(epoch + counter_ratio)
129 | self.plot_data['Y'].append([errors[k] for k in self.plot_data['legend']])
130 | self.vis.line(
131 | X=np.stack([np.array(self.plot_data['X'])]*len(self.plot_data['legend']),1),
132 | Y=np.array(self.plot_data['Y']),
133 | opts={
134 | 'title': self.name + ' loss over time',
135 | 'legend': self.plot_data['legend'],
136 | 'xlabel': 'epoch',
137 | 'ylabel': 'loss'},
138 | win=self.display_id)
139 |
140 | # errors: same format as |errors| of plotCurrentErrors
141 | def print_current_errors(self, epoch, i, errors, t, t2=-1, t2o=-1, fid=None):
142 | message = '(ep: %d, it: %d, t: %.3f[s], ept: %.2f/%.2f[h]) ' % (epoch, i, t, t2o, t2)
143 | message += (', ').join(['%s: %.3f' % (k, v) for k, v in errors.items()])
144 |
145 | print(message)
146 | if(fid is not None):
147 | fid.write('%s\n'%message)
148 |
149 |
150 | # save image to the disk
151 | def save_images_simple(self, webpage, images, names, in_txts, prefix='', res=256):
152 | image_dir = webpage.get_image_dir()
153 | ims = []
154 | txts = []
155 | links = []
156 |
157 | for name, image_numpy, txt in zip(names, images, in_txts):
158 | image_name = '%s_%s.png' % (prefix, name)
159 | save_path = os.path.join(image_dir, image_name)
160 | if(res is not None):
161 | util.save_image(zoom_to_res(image_numpy,res=res,axis=2), save_path)
162 | else:
163 | util.save_image(image_numpy, save_path)
164 |
165 | ims.append(os.path.join(webpage.img_subdir,image_name))
166 | # txts.append(name)
167 | txts.append(txt)
168 | links.append(os.path.join(webpage.img_subdir,image_name))
169 | # embed()
170 | webpage.add_images(ims, txts, links, width=self.win_size)
171 |
172 | # save image to the disk
173 | def save_images(self, webpage, images, names, image_path, title=''):
174 | image_dir = webpage.get_image_dir()
175 | # short_path = ntpath.basename(image_path)
176 | # name = os.path.splitext(short_path)[0]
177 | # name = short_path
178 | # webpage.add_header('%s, %s' % (name, title))
179 | ims = []
180 | txts = []
181 | links = []
182 |
183 | for label, image_numpy in zip(names, images):
184 | image_name = '%s.jpg' % (label,)
185 | save_path = os.path.join(image_dir, image_name)
186 | util.save_image(image_numpy, save_path)
187 |
188 | ims.append(image_name)
189 | txts.append(label)
190 | links.append(image_name)
191 | webpage.add_images(ims, txts, links, width=self.win_size)
192 |
193 | # save image to the disk
194 | # def save_images(self, webpage, visuals, image_path, short=False):
195 | # image_dir = webpage.get_image_dir()
196 | # if short:
197 | # short_path = ntpath.basename(image_path)
198 | # name = os.path.splitext(short_path)[0]
199 | # else:
200 | # name = image_path
201 |
202 | # webpage.add_header(name)
203 | # ims = []
204 | # txts = []
205 | # links = []
206 |
207 | # for label, image_numpy in visuals.items():
208 | # image_name = '%s_%s.png' % (name, label)
209 | # save_path = os.path.join(image_dir, image_name)
210 | # util.save_image(image_numpy, save_path)
211 |
212 | # ims.append(image_name)
213 | # txts.append(label)
214 | # links.append(image_name)
215 | # webpage.add_images(ims, txts, links, width=self.win_size)
216 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/lpips.py:
--------------------------------------------------------------------------------
1 |
2 | from __future__ import absolute_import
3 |
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.init as init
7 | from torch.autograd import Variable
8 | import numpy as np
9 | from . import pretrained_networks as pn
10 | import torch.nn
11 |
12 | import PerceptualSimilarity.lpips as lpips
13 |
14 | def spatial_average(in_tens, keepdim=True):
15 | return in_tens.mean([2,3],keepdim=keepdim)
16 |
17 | def upsample(in_tens, out_HW=(64,64)): # assumes scale factor is same for H and W
18 | in_H, in_W = in_tens.shape[2], in_tens.shape[3]
19 | return nn.Upsample(size=out_HW, mode='bilinear', align_corners=False)(in_tens)
20 |
21 | # Learned perceptual metric
22 | class LPIPS(nn.Module):
23 | def __init__(self, pretrained=True, net='alex', version='0.1', lpips=True, spatial=False,
24 | pnet_rand=False, pnet_tune=False, use_dropout=True, model_path=None, eval_mode=True, verbose=True):
25 | # lpips - [True] means with linear calibration on top of base network
26 | # pretrained - [True] means load linear weights
27 |
28 | super(LPIPS, self).__init__()
29 | if(verbose):
30 | print('Setting up [%s] perceptual loss: trunk [%s], v[%s], spatial [%s]'%
31 | ('LPIPS' if lpips else 'baseline', net, version, 'on' if spatial else 'off'))
32 |
33 | self.pnet_type = net
34 | self.pnet_tune = pnet_tune
35 | self.pnet_rand = pnet_rand
36 | self.spatial = spatial
37 | self.lpips = lpips # false means baseline of just averaging all layers
38 | self.version = version
39 | self.scaling_layer = ScalingLayer()
40 |
41 | if(self.pnet_type in ['vgg','vgg16']):
42 | net_type = pn.vgg16
43 | self.chns = [64,128,256,512,512]
44 | elif(self.pnet_type=='alex'):
45 | net_type = pn.alexnet
46 | self.chns = [64,192,384,256,256]
47 | elif(self.pnet_type=='squeeze'):
48 | net_type = pn.squeezenet
49 | self.chns = [64,128,256,384,384,512,512]
50 | self.L = len(self.chns)
51 |
52 | self.net = net_type(pretrained=not self.pnet_rand, requires_grad=self.pnet_tune)
53 |
54 | if(lpips):
55 | self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
56 | self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
57 | self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
58 | self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
59 | self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
60 | self.lins = [self.lin0,self.lin1,self.lin2,self.lin3,self.lin4]
61 | if(self.pnet_type=='squeeze'): # 7 layers for squeezenet
62 | self.lin5 = NetLinLayer(self.chns[5], use_dropout=use_dropout)
63 | self.lin6 = NetLinLayer(self.chns[6], use_dropout=use_dropout)
64 | self.lins+=[self.lin5,self.lin6]
65 | self.lins = nn.ModuleList(self.lins)
66 |
67 | if(pretrained):
68 | if(model_path is None):
69 | import inspect
70 | import os
71 | model_path = os.path.abspath(os.path.join(inspect.getfile(self.__init__), '..', 'weights/v%s/%s.pth'%(version,net)))
72 |
73 | if(verbose):
74 | print('Loading model from: %s'%model_path)
75 | self.load_state_dict(torch.load(model_path, map_location='cpu'), strict=False)
76 |
77 | if(eval_mode):
78 | self.eval()
79 |
80 | def forward(self, in0, in1, retPerLayer=False, normalize=False):
81 | if normalize: # turn on this flag if input is [0,1] so it can be adjusted to [-1, +1]
82 | in0 = 2 * in0 - 1
83 | in1 = 2 * in1 - 1
84 |
85 | # v0.0 - original release had a bug, where input was not scaled
86 | in0_input, in1_input = (self.scaling_layer(in0), self.scaling_layer(in1)) if self.version=='0.1' else (in0, in1)
87 | outs0, outs1 = self.net.forward(in0_input), self.net.forward(in1_input)
88 | feats0, feats1, diffs = {}, {}, {}
89 |
90 | for kk in range(self.L):
91 | feats0[kk], feats1[kk] = lpips.normalize_tensor(outs0[kk]), lpips.normalize_tensor(outs1[kk])
92 | diffs[kk] = (feats0[kk]-feats1[kk])**2
93 |
94 | if(self.lpips):
95 | if(self.spatial):
96 | res = [upsample(self.lins[kk](diffs[kk]), out_HW=in0.shape[2:]) for kk in range(self.L)]
97 | else:
98 | res = [spatial_average(self.lins[kk](diffs[kk]), keepdim=True) for kk in range(self.L)]
99 | else:
100 | if(self.spatial):
101 | res = [upsample(diffs[kk].sum(dim=1,keepdim=True), out_HW=in0.shape[2:]) for kk in range(self.L)]
102 | else:
103 | res = [spatial_average(diffs[kk].sum(dim=1,keepdim=True), keepdim=True) for kk in range(self.L)]
104 |
105 | val = res[0]
106 | for l in range(1,self.L):
107 | val += res[l]
108 |
109 | # a = spatial_average(self.lins[kk](diffs[kk]), keepdim=True)
110 | # b = torch.max(self.lins[kk](feats0[kk]**2))
111 | # for kk in range(self.L):
112 | # a += spatial_average(self.lins[kk](diffs[kk]), keepdim=True)
113 | # b = torch.max(b,torch.max(self.lins[kk](feats0[kk]**2)))
114 | # a = a/self.L
115 | # from IPython import embed
116 | # embed()
117 | # return 10*torch.log10(b/a)
118 |
119 | if(retPerLayer):
120 | return (val, res)
121 | else:
122 | return val
123 |
124 |
125 | class ScalingLayer(nn.Module):
126 | def __init__(self):
127 | super(ScalingLayer, self).__init__()
128 | self.register_buffer('shift', torch.Tensor([-.030,-.088,-.188])[None,:,None,None])
129 | self.register_buffer('scale', torch.Tensor([.458,.448,.450])[None,:,None,None])
130 |
131 | def forward(self, inp):
132 | return (inp - self.shift) / self.scale
133 |
134 |
135 | class NetLinLayer(nn.Module):
136 | ''' A single linear layer which does a 1x1 conv '''
137 | def __init__(self, chn_in, chn_out=1, use_dropout=False):
138 | super(NetLinLayer, self).__init__()
139 |
140 | layers = [nn.Dropout(),] if(use_dropout) else []
141 | layers += [nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False),]
142 | self.model = nn.Sequential(*layers)
143 |
144 | def forward(self, x):
145 | return self.model(x)
146 |
147 | class Dist2LogitLayer(nn.Module):
148 | ''' takes 2 distances, puts through fc layers, spits out value between [0,1] (if use_sigmoid is True) '''
149 | def __init__(self, chn_mid=32, use_sigmoid=True):
150 | super(Dist2LogitLayer, self).__init__()
151 |
152 | layers = [nn.Conv2d(5, chn_mid, 1, stride=1, padding=0, bias=True),]
153 | layers += [nn.LeakyReLU(0.2,True),]
154 | layers += [nn.Conv2d(chn_mid, chn_mid, 1, stride=1, padding=0, bias=True),]
155 | layers += [nn.LeakyReLU(0.2,True),]
156 | layers += [nn.Conv2d(chn_mid, 1, 1, stride=1, padding=0, bias=True),]
157 | if(use_sigmoid):
158 | layers += [nn.Sigmoid(),]
159 | self.model = nn.Sequential(*layers)
160 |
161 | def forward(self,d0,d1,eps=0.1):
162 | return self.model.forward(torch.cat((d0,d1,d0-d1,d0/(d1+eps),d1/(d0+eps)),dim=1))
163 |
164 | class BCERankingLoss(nn.Module):
165 | def __init__(self, chn_mid=32):
166 | super(BCERankingLoss, self).__init__()
167 | self.net = Dist2LogitLayer(chn_mid=chn_mid)
168 | # self.parameters = list(self.net.parameters())
169 | self.loss = torch.nn.BCELoss()
170 |
171 | def forward(self, d0, d1, judge):
172 | per = (judge+1.)/2.
173 | self.logit = self.net.forward(d0,d1)
174 | return self.loss(self.logit, per)
175 |
176 | # L2, DSSIM metrics
177 | class FakeNet(nn.Module):
178 | def __init__(self, use_gpu=True, colorspace='Lab'):
179 | super(FakeNet, self).__init__()
180 | self.use_gpu = use_gpu
181 | self.colorspace = colorspace
182 |
183 | class L2(FakeNet):
184 | def forward(self, in0, in1, retPerLayer=None):
185 | assert(in0.size()[0]==1) # currently only supports batchSize 1
186 |
187 | if(self.colorspace=='RGB'):
188 | (N,C,X,Y) = in0.size()
189 | value = torch.mean(torch.mean(torch.mean((in0-in1)**2,dim=1).view(N,1,X,Y),dim=2).view(N,1,1,Y),dim=3).view(N)
190 | return value
191 | elif(self.colorspace=='Lab'):
192 | value = lpips.l2(lpips.tensor2np(lpips.tensor2tensorlab(in0.data,to_norm=False)),
193 | lpips.tensor2np(lpips.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
194 | ret_var = Variable( torch.Tensor((value,) ) )
195 | if(self.use_gpu):
196 | ret_var = ret_var.cuda()
197 | return ret_var
198 |
199 | class DSSIM(FakeNet):
200 |
201 | def forward(self, in0, in1, retPerLayer=None):
202 | assert(in0.size()[0]==1) # currently only supports batchSize 1
203 |
204 | if(self.colorspace=='RGB'):
205 | value = lpips.dssim(1.*lpips.tensor2im(in0.data), 1.*lpips.tensor2im(in1.data), range=255.).astype('float')
206 | elif(self.colorspace=='Lab'):
207 | value = lpips.dssim(lpips.tensor2np(lpips.tensor2tensorlab(in0.data,to_norm=False)),
208 | lpips.tensor2np(lpips.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
209 | ret_var = Variable( torch.Tensor((value,) ) )
210 | if(self.use_gpu):
211 | ret_var = ret_var.cuda()
212 | return ret_var
213 |
214 | def print_network(net):
215 | num_params = 0
216 | for param in net.parameters():
217 | num_params += param.numel()
218 | print('Network',net)
219 | print('Total number of parameters: %d' % num_params)
220 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## Perceptual Similarity Metric and Dataset [[Project Page]](http://richzhang.github.io/PerceptualSimilarity/)
3 |
4 | **The Unreasonable Effectiveness of Deep Features as a Perceptual Metric**
5 | [Richard Zhang](https://richzhang.github.io/), [Phillip Isola](http://web.mit.edu/phillipi/), [Alexei A. Efros](http://www.eecs.berkeley.edu/~efros/), [Eli Shechtman](https://research.adobe.com/person/eli-shechtman/), [Oliver Wang](http://www.oliverwang.info/). In [CVPR](https://arxiv.org/abs/1801.03924), 2018.
6 |
7 |
7 |
8 |
9 | ### References
10 |
11 | Model adapted from https://github.com/isl-org/DPT
12 |
13 | SSIM loss can be found at https://github.com/Po-Hsun-Su/pytorch-ssim
14 |
15 | MSSSIM loss can be found at https://github.com/jorge-pessoa/pytorch-msssim
16 |
17 | LPIPS can be found at https://github.com/richzhang/PerceptualSimilarity
18 |
19 |
20 | ### BRViT Weights
21 |
22 | Our latest model weights can be downloaded from [here](https://drive.google.com/file/d/1V4oX1fARjaIujXQ7Vf4UDwxJhm9ubVG-/view?usp=sharing).
23 |
24 |
25 | ### BRViT Metrics
26 |
27 | Common Metrics with the latest weights for model comparison:
28 |
29 | 1. PSNR: 24.76
30 | 2. SSIM: 0.8904
31 | 3. LPIPS: 0.1924
32 |
33 |
34 | ### Dataset
35 |
36 | Training: [https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/Training.zip](https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/Training.zip)
37 |
38 | Validation: [https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/ValidationBokehFree.zip](https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/ValidationBokehFree.zip)
39 |
40 | Testing: [https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/TestBokehFree.zip](https://data.vision.ee.ethz.ch/timofter/AIM19Bokeh/TestBokehFree.zip)
41 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/util/util.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 |
3 | import numpy as np
4 | from PIL import Image
5 | import numpy as np
6 | import os
7 | import matplotlib.pyplot as plt
8 | import torch
9 |
10 | def load_image(path):
11 | if(path[-3:] == 'dng'):
12 | import rawpy
13 | with rawpy.imread(path) as raw:
14 | img = raw.postprocess()
15 | elif(path[-3:]=='bmp' or path[-3:]=='jpg' or path[-3:]=='png'):
16 | import cv2
17 | return cv2.imread(path)[:,:,::-1]
18 | else:
19 | img = (255*plt.imread(path)[:,:,:3]).astype('uint8')
20 |
21 | return img
22 |
23 | def save_image(image_numpy, image_path, ):
24 | image_pil = Image.fromarray(image_numpy)
25 | image_pil.save(image_path)
26 |
27 | def mkdirs(paths):
28 | if isinstance(paths, list) and not isinstance(paths, str):
29 | for path in paths:
30 | mkdir(path)
31 | else:
32 | mkdir(paths)
33 |
34 | def mkdir(path):
35 | if not os.path.exists(path):
36 | os.makedirs(path)
37 |
38 |
39 | def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
40 | # def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
41 | image_numpy = image_tensor[0].cpu().float().numpy()
42 | image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
43 | return image_numpy.astype(imtype)
44 |
45 | def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
46 | # def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
47 | return torch.Tensor((image / factor - cent)
48 | [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
49 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/test_network.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import lpips
3 | from IPython import embed
4 |
5 | use_gpu = False # Whether to use GPU
6 | spatial = True # Return a spatial map of perceptual distance.
7 |
8 | # Linearly calibrated models (LPIPS)
9 | loss_fn = lpips.LPIPS(net='alex', spatial=spatial) # Can also set net = 'squeeze' or 'vgg'
10 | # loss_fn = lpips.LPIPS(net='alex', spatial=spatial, lpips=False) # Can also set net = 'squeeze' or 'vgg'
11 |
12 | if(use_gpu):
13 | loss_fn.cuda()
14 |
15 | ## Example usage with dummy tensors
16 | dummy_im0 = torch.zeros(1,3,64,64) # image should be RGB, normalized to [-1,1]
17 | dummy_im1 = torch.zeros(1,3,64,64)
18 | if(use_gpu):
19 | dummy_im0 = dummy_im0.cuda()
20 | dummy_im1 = dummy_im1.cuda()
21 | dist = loss_fn.forward(dummy_im0,dummy_im1)
22 |
23 | ## Example usage with images
24 | ex_ref = lpips.im2tensor(lpips.load_image('./imgs/ex_ref.png'))
25 | ex_p0 = lpips.im2tensor(lpips.load_image('./imgs/ex_p0.png'))
26 | ex_p1 = lpips.im2tensor(lpips.load_image('./imgs/ex_p1.png'))
27 | if(use_gpu):
28 | ex_ref = ex_ref.cuda()
29 | ex_p0 = ex_p0.cuda()
30 | ex_p1 = ex_p1.cuda()
31 |
32 | ex_d0 = loss_fn.forward(ex_ref,ex_p0)
33 | ex_d1 = loss_fn.forward(ex_ref,ex_p1)
34 |
35 | if not spatial:
36 | print('Distances: (%.3f, %.3f)'%(ex_d0, ex_d1))
37 | else:
38 | print('Distances: (%.3f, %.3f)'%(ex_d0.mean(), ex_d1.mean())) # The mean distance is approximately the same as the non-spatial distance
39 |
40 | # Visualize a spatially-varying distance map between ex_p0 and ex_ref
41 | import pylab
42 | pylab.imshow(ex_d0[0,0,...].data.cpu().numpy())
43 | pylab.show()
44 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/custom_dataset_data_loader.py:
--------------------------------------------------------------------------------
1 | import torch.utils.data
2 | from data.base_data_loader import BaseDataLoader
3 | import os
4 |
5 | def CreateDataset(dataroots,dataset_mode='2afc',load_size=64,):
6 | dataset = None
7 | if dataset_mode=='2afc': # human judgements
8 | from data.dataset.twoafc_dataset import TwoAFCDataset
9 | dataset = TwoAFCDataset()
10 | elif dataset_mode=='jnd': # human judgements
11 | from data.dataset.jnd_dataset import JNDDataset
12 | dataset = JNDDataset()
13 | else:
14 | raise ValueError("Dataset Mode [%s] not recognized."%self.dataset_mode)
15 |
16 | dataset.initialize(dataroots,load_size=load_size)
17 | return dataset
18 |
19 | class CustomDatasetDataLoader(BaseDataLoader):
20 | def name(self):
21 | return 'CustomDatasetDataLoader'
22 |
23 | def initialize(self, datafolders, dataroot='./dataset',dataset_mode='2afc',load_size=64,batch_size=1,serial_batches=True, nThreads=1):
24 | BaseDataLoader.initialize(self)
25 | if(not isinstance(datafolders,list)):
26 | datafolders = [datafolders,]
27 | data_root_folders = [os.path.join(dataroot,datafolder) for datafolder in datafolders]
28 | self.dataset = CreateDataset(data_root_folders,dataset_mode=dataset_mode,load_size=load_size)
29 | self.dataloader = torch.utils.data.DataLoader(
30 | self.dataset,
31 | batch_size=batch_size,
32 | shuffle=not serial_batches,
33 | num_workers=int(nThreads))
34 |
35 | def load_data(self):
36 | return self.dataloader
37 |
38 | def __len__(self):
39 | return len(self.dataset)
40 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips_loss.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from torch.autograd import Variable
4 | import matplotlib.pyplot as plt
5 | import argparse
6 | import lpips
7 |
8 | parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
9 | parser.add_argument('--ref_path', type=str, default='./imgs/ex_ref.png')
10 | parser.add_argument('--pred_path', type=str, default='./imgs/ex_p1.png')
11 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
12 |
13 | opt = parser.parse_args()
14 |
15 | loss_fn = lpips.LPIPS(net='vgg')
16 | if(opt.use_gpu):
17 | loss_fn.cuda()
18 |
19 | ref = lpips.im2tensor(lpips.load_image(opt.ref_path))
20 | pred = Variable(lpips.im2tensor(lpips.load_image(opt.pred_path)), requires_grad=True)
21 | if(opt.use_gpu):
22 | with torch.no_grad():
23 | ref = ref.cuda()
24 | pred = pred.cuda()
25 |
26 | optimizer = torch.optim.Adam([pred,], lr=1e-3, betas=(0.9, 0.999))
27 |
28 | plt.ion()
29 | fig = plt.figure(1)
30 | ax = fig.add_subplot(131)
31 | ax.imshow(lpips.tensor2im(ref))
32 | ax.set_title('target')
33 | ax = fig.add_subplot(133)
34 | ax.imshow(lpips.tensor2im(pred.data))
35 | ax.set_title('initialization')
36 |
37 | for i in range(1000):
38 | dist = loss_fn.forward(pred, ref)
39 | optimizer.zero_grad()
40 | dist.backward()
41 | optimizer.step()
42 | pred.data = torch.clamp(pred.data, -1, 1)
43 |
44 | if i % 10 == 0:
45 | print('iter %d, dist %.3g' % (i, dist.view(-1).data.cpu().numpy()[0]))
46 | pred.data = torch.clamp(pred.data, -1, 1)
47 | pred_img = lpips.tensor2im(pred.data)
48 |
49 | ax = fig.add_subplot(132)
50 | ax.imshow(pred_img)
51 | ax.set_title('iter %d, dist %.3f' % (i, dist.view(-1).data.cpu().numpy()[0]))
52 | plt.pause(5e-2)
53 | # plt.imsave('imgs_saved/%04d.jpg'%i,pred_img)
54 |
55 |
56 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM nvidia/cuda:9.0-base-ubuntu16.04
2 |
3 | LABEL maintainer="Seyoung Park "
4 |
5 | # This Dockerfile is forked from Tensorflow Dockerfile
6 |
7 | # Pick up some PyTorch gpu dependencies
8 | RUN apt-get update && apt-get install -y --no-install-recommends \
9 | build-essential \
10 | cuda-command-line-tools-9-0 \
11 | cuda-cublas-9-0 \
12 | cuda-cufft-9-0 \
13 | cuda-curand-9-0 \
14 | cuda-cusolver-9-0 \
15 | cuda-cusparse-9-0 \
16 | curl \
17 | libcudnn7=7.1.4.18-1+cuda9.0 \
18 | libfreetype6-dev \
19 | libhdf5-serial-dev \
20 | libpng12-dev \
21 | libzmq3-dev \
22 | pkg-config \
23 | python \
24 | python-dev \
25 | rsync \
26 | software-properties-common \
27 | unzip \
28 | && \
29 | apt-get clean && \
30 | rm -rf /var/lib/apt/lists/*
31 |
32 |
33 | # Install miniconda
34 | RUN apt-get update && apt-get install -y --no-install-recommends \
35 | wget && \
36 | MINICONDA="Miniconda3-latest-Linux-x86_64.sh" && \
37 | wget --quiet https://repo.continuum.io/miniconda/$MINICONDA && \
38 | bash $MINICONDA -b -p /miniconda && \
39 | rm -f $MINICONDA
40 | ENV PATH /miniconda/bin:$PATH
41 |
42 | # Install PyTorch
43 | RUN conda update -n base conda && \
44 | conda install pytorch torchvision cuda90 -c pytorch
45 |
46 | # Install PerceptualSimilarity dependencies
47 | RUN conda install numpy scipy jupyter matplotlib && \
48 | conda install -c conda-forge scikit-image && \
49 | apt-get install -y python-qt4 && \
50 | pip install opencv-python
51 |
52 | # For CUDA profiling, TensorFlow requires CUPTI. Maybe PyTorch needs this too.
53 | ENV LD_LIBRARY_PATH /usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
54 |
55 | # IPython
56 | EXPOSE 8888
57 |
58 | WORKDIR "/notebooks"
59 |
60 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips_1dir_allpairs.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import lpips
4 | import numpy as np
5 |
6 | parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
7 | parser.add_argument('-d','--dir', type=str, default='./imgs/ex_dir_pair')
8 | parser.add_argument('-o','--out', type=str, default='./imgs/example_dists.txt')
9 | parser.add_argument('-v','--version', type=str, default='0.1')
10 | parser.add_argument('--all-pairs', action='store_true', help='turn on to test all N(N-1)/2 pairs, leave off to just do consecutive pairs (N-1)')
11 | parser.add_argument('-N', type=int, default=None)
12 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
13 |
14 | opt = parser.parse_args()
15 |
16 | ## Initializing the model
17 | loss_fn = lpips.LPIPS(net='alex',version=opt.version)
18 | if(opt.use_gpu):
19 | loss_fn.cuda()
20 |
21 | # crawl directories
22 | f = open(opt.out,'w')
23 | files = os.listdir(opt.dir)
24 | if(opt.N is not None):
25 | files = files[:opt.N]
26 | F = len(files)
27 |
28 | dists = []
29 | for (ff,file) in enumerate(files[:-1]):
30 | img0 = lpips.im2tensor(lpips.load_image(os.path.join(opt.dir,file))) # RGB image from [-1,1]
31 | if(opt.use_gpu):
32 | img0 = img0.cuda()
33 |
34 | if(opt.all_pairs):
35 | files1 = files[ff+1:]
36 | else:
37 | files1 = [files[ff+1],]
38 |
39 | for file1 in files1:
40 | img1 = lpips.im2tensor(lpips.load_image(os.path.join(opt.dir,file1)))
41 |
42 | if(opt.use_gpu):
43 | img1 = img1.cuda()
44 |
45 | # Compute distance
46 | dist01 = loss_fn.forward(img0,img1)
47 | print('(%s,%s): %.3f'%(file,file1,dist01))
48 | f.writelines('(%s,%s): %.6f\n'%(file,file1,dist01))
49 |
50 | dists.append(dist01.item())
51 |
52 | avg_dist = np.mean(np.array(dists))
53 | stderr_dist = np.std(np.array(dists))/np.sqrt(len(dists))
54 |
55 | print('Avg: %.5f +/- %.5f'%(avg_dist,stderr_dist))
56 | f.writelines('Avg: %.6f +/- %.6f'%(avg_dist,stderr_dist))
57 |
58 | f.close()
59 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/dataset/jnd_dataset.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | import torchvision.transforms as transforms
3 | from data.dataset.base_dataset import BaseDataset
4 | from data.image_folder import make_dataset
5 | from PIL import Image
6 | import numpy as np
7 | import torch
8 | from IPython import embed
9 |
10 | class JNDDataset(BaseDataset):
11 | def initialize(self, dataroot, load_size=64):
12 | self.root = dataroot
13 | self.load_size = load_size
14 |
15 | self.dir_p0 = os.path.join(self.root, 'p0')
16 | self.p0_paths = make_dataset(self.dir_p0)
17 | self.p0_paths = sorted(self.p0_paths)
18 |
19 | self.dir_p1 = os.path.join(self.root, 'p1')
20 | self.p1_paths = make_dataset(self.dir_p1)
21 | self.p1_paths = sorted(self.p1_paths)
22 |
23 | transform_list = []
24 | transform_list.append(transforms.Scale(load_size))
25 | transform_list += [transforms.ToTensor(),
26 | transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))]
27 |
28 | self.transform = transforms.Compose(transform_list)
29 |
30 | # judgement directory
31 | self.dir_S = os.path.join(self.root, 'same')
32 | self.same_paths = make_dataset(self.dir_S,mode='np')
33 | self.same_paths = sorted(self.same_paths)
34 |
35 | def __getitem__(self, index):
36 | p0_path = self.p0_paths[index]
37 | p0_img_ = Image.open(p0_path).convert('RGB')
38 | p0_img = self.transform(p0_img_)
39 |
40 | p1_path = self.p1_paths[index]
41 | p1_img_ = Image.open(p1_path).convert('RGB')
42 | p1_img = self.transform(p1_img_)
43 |
44 | same_path = self.same_paths[index]
45 | same_img = np.load(same_path).reshape((1,1,1,)) # [0,1]
46 |
47 | same_img = torch.FloatTensor(same_img)
48 |
49 | return {'p0': p0_img, 'p1': p1_img, 'same': same_img,
50 | 'p0_path': p0_path, 'p1_path': p1_path, 'same_path': same_path}
51 |
52 | def __len__(self):
53 | return len(self.p0_paths)
54 |
--------------------------------------------------------------------------------
/pytorch_ssim/README.md:
--------------------------------------------------------------------------------
1 | # pytorch-ssim
2 |
3 | ### Differentiable structural similarity (SSIM) index.
4 |  
5 |
6 | ## Installation
7 | 1. Clone this repo.
8 | 2. Copy "pytorch_ssim" folder in your project.
9 |
10 | ## Example
11 | ### basic usage
12 | ```python
13 | import pytorch_ssim
14 | import torch
15 | from torch.autograd import Variable
16 |
17 | img1 = Variable(torch.rand(1, 1, 256, 256))
18 | img2 = Variable(torch.rand(1, 1, 256, 256))
19 |
20 | if torch.cuda.is_available():
21 | img1 = img1.cuda()
22 | img2 = img2.cuda()
23 |
24 | print(pytorch_ssim.ssim(img1, img2))
25 |
26 | ssim_loss = pytorch_ssim.SSIM(window_size = 11)
27 |
28 | print(ssim_loss(img1, img2))
29 |
30 | ```
31 | ### maximize ssim
32 | ```python
33 | import pytorch_ssim
34 | import torch
35 | from torch.autograd import Variable
36 | from torch import optim
37 | import cv2
38 | import numpy as np
39 |
40 | npImg1 = cv2.imread("einstein.png")
41 |
42 | img1 = torch.from_numpy(np.rollaxis(npImg1, 2)).float().unsqueeze(0)/255.0
43 | img2 = torch.rand(img1.size())
44 |
45 | if torch.cuda.is_available():
46 | img1 = img1.cuda()
47 | img2 = img2.cuda()
48 |
49 |
50 | img1 = Variable( img1, requires_grad=False)
51 | img2 = Variable( img2, requires_grad = True)
52 |
53 |
54 | # Functional: pytorch_ssim.ssim(img1, img2, window_size = 11, size_average = True)
55 | ssim_value = pytorch_ssim.ssim(img1, img2).data[0]
56 | print("Initial ssim:", ssim_value)
57 |
58 | # Module: pytorch_ssim.SSIM(window_size = 11, size_average = True)
59 | ssim_loss = pytorch_ssim.SSIM()
60 |
61 | optimizer = optim.Adam([img2], lr=0.01)
62 |
63 | while ssim_value < 0.95:
64 | optimizer.zero_grad()
65 | ssim_out = -ssim_loss(img1, img2)
66 | ssim_value = - ssim_out.data[0]
67 | print(ssim_value)
68 | ssim_out.backward()
69 | optimizer.step()
70 |
71 | ```
72 |
73 | ## Reference
74 | https://ece.uwaterloo.ca/~z70wang/research/ssim/
75 |
--------------------------------------------------------------------------------
/pytorch_msssim/max_ssim.py:
--------------------------------------------------------------------------------
1 | from pytorch_msssim import msssim, ssim
2 | import torch
3 | from torch import optim
4 |
5 | from PIL import Image
6 | from torchvision.transforms.functional import to_tensor
7 | import numpy as np
8 |
9 | # display = True requires matplotlib
10 | display = True
11 | metric = 'MSSSIM' # MSSSIM or SSIM
12 | device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
13 |
14 | def post_process(img):
15 | img = img.detach().cpu().numpy()
16 | img = np.transpose(np.squeeze(img, axis=0), (1, 2, 0))
17 | img = np.squeeze(img) # works if grayscale
18 | return img
19 |
20 | # Preprocessing
21 | img1 = to_tensor(Image.open('einstein.png')).unsqueeze(0).type(torch.FloatTensor)
22 |
23 | img2 = torch.rand(img1.size())
24 | img2 = torch.nn.functional.sigmoid(img2) # use sigmoid to clamp between [0, 1]
25 |
26 | img1 = img1.to(device)
27 | img2 = img2.to(device)
28 |
29 | img1.requires_grad = False
30 | img2.requires_grad = True
31 |
32 | loss_func = msssim if metric == 'MSSSIM' else ssim
33 |
34 | value = loss_func(img1, img2)
35 | print("Initial %s: %.5f" % (metric, value.item()))
36 |
37 | optimizer = optim.Adam([img2], lr=0.01)
38 |
39 | # MSSSIM yields higher values for worse results, because noise is removed in scales with lower resolutions
40 | threshold = 0.999 if metric == 'MSSSIM' else 0.9
41 |
42 | while value < threshold:
43 | optimizer.zero_grad()
44 | msssim_out = -loss_func(img1, img2)
45 | value = -msssim_out.item()
46 | print('Current MS-SSIM = %.5f' % value)
47 | msssim_out.backward()
48 | optimizer.step()
49 |
50 | if display:
51 | # Post processing
52 | img1np = post_process(img1)
53 | img2 = torch.nn.functional.sigmoid(img2)
54 | img2np = post_process(img2)
55 | import matplotlib.pyplot as plt
56 | cmap = 'gray' if len(img1np.shape) == 2 else None
57 | plt.subplot(1, 2, 1)
58 | plt.imshow(img1np, cmap=cmap)
59 | plt.title('Original')
60 | plt.subplot(1, 2, 2)
61 | plt.imshow(img2np, cmap=cmap)
62 | plt.title('Generated, {:s}: {:.3f}'.format(metric, value))
63 | plt.show()
64 |
--------------------------------------------------------------------------------
/evaluate.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 |
5 | import timm
6 | import types
7 | import math
8 | import numpy as np
9 | from PIL import Image
10 | import PIL.Image as pil
11 | from torchvision import transforms, datasets
12 | from torch.utils.data import Dataset, DataLoader
13 | import torch.utils.data as data
14 | import PerceptualSimilarity.lpips.lpips as lpips
15 | import glob
16 | import gc
17 | import pytorch_msssim.pytorch_msssim as pytorch_msssim
18 | from torch.cuda.amp import autocast
19 | from model import BRViT
20 | import matplotlib.pyplot as plt
21 | from pytorch_ssim.pytorch_ssim import ssim
22 | from torchvision.utils import save_image
23 | from PerceptualSimilarity.util import util
24 |
25 |
26 | import pandas as pd
27 | from tqdm import tqdm
28 | import sys
29 | import cv2
30 |
31 | from skimage.metrics import peak_signal_noise_ratio as compare_psnr
32 | from skimage.metrics import structural_similarity as compare_ssim
33 |
34 | batch_size = 1
35 | feed_width = 1536
36 | feed_height = 1024
37 |
38 |
39 |
40 | def evaluate():
41 | tot_lpips_loss = 0.0
42 | total_psnr = 0.0
43 | total_ssim = 0.0
44 |
45 | device = torch.device("cuda")
46 | loss_fn = lpips.LPIPS(net='alex').to(device)
47 |
48 | for i in tqdm(range(294)):
49 | csv_file = "Bokeh_Data/test.csv"
50 | root_dir = "."
51 | dataa = pd.read_csv(csv_file)
52 | idx = i
53 |
54 | img0 = util.im2tensor(util.load_image(root_dir + dataa.iloc[idx, 0][1:])) # RGB image from [-1,1]
55 | img1 = util.im2tensor(util.load_image(f"Results/{4400+i}.png"))
56 | img0 = img0.to(device)
57 | img1 = img1.to(device)
58 |
59 | lpips_loss = loss_fn.forward(img0, img1)
60 | tot_lpips_loss += lpips_loss.item()
61 |
62 |
63 | total_psnr += compare_psnr(I0,I1)
64 | total_ssim += compare_ssim(I0, I1, multichannel=True)
65 |
66 |
67 | print("TOTAL LPIPS:",":", tot_lpips_loss / 294)
68 | print("TOTAL PSNR",":", total_psnr / 294)
69 | print("TOTAL SSIM",":", total_ssim / 294)
70 |
71 |
72 | if __name__ == "__main__":
73 | evaluate()
74 |
75 |
76 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/util/html.py:
--------------------------------------------------------------------------------
1 | import dominate
2 | from dominate.tags import *
3 | import os
4 |
5 |
6 | class HTML:
7 | def __init__(self, web_dir, title, image_subdir='', reflesh=0):
8 | self.title = title
9 | self.web_dir = web_dir
10 | # self.img_dir = os.path.join(self.web_dir, )
11 | self.img_subdir = image_subdir
12 | self.img_dir = os.path.join(self.web_dir, image_subdir)
13 | if not os.path.exists(self.web_dir):
14 | os.makedirs(self.web_dir)
15 | if not os.path.exists(self.img_dir):
16 | os.makedirs(self.img_dir)
17 | # print(self.img_dir)
18 |
19 | self.doc = dominate.document(title=title)
20 | if reflesh > 0:
21 | with self.doc.head:
22 | meta(http_equiv="reflesh", content=str(reflesh))
23 |
24 | def get_image_dir(self):
25 | return self.img_dir
26 |
27 | def add_header(self, str):
28 | with self.doc:
29 | h3(str)
30 |
31 | def add_table(self, border=1):
32 | self.t = table(border=border, style="table-layout: fixed;")
33 | self.doc.add(self.t)
34 |
35 | def add_images(self, ims, txts, links, width=400):
36 | self.add_table()
37 | with self.t:
38 | with tr():
39 | for im, txt, link in zip(ims, txts, links):
40 | with td(style="word-wrap: break-word;", halign="center", valign="top"):
41 | with p():
42 | with a(href=os.path.join(link)):
43 | img(style="width:%dpx" % width, src=os.path.join(im))
44 | br()
45 | p(txt)
46 |
47 | def save(self,file='index'):
48 | html_file = '%s/%s.html' % (self.web_dir,file)
49 | f = open(html_file, 'wt')
50 | f.write(self.doc.render())
51 | f.close()
52 |
53 |
54 | if __name__ == '__main__':
55 | html = HTML('web/', 'test_html')
56 | html.add_header('hello world')
57 |
58 | ims = []
59 | txts = []
60 | links = []
61 | for n in range(4):
62 | ims.append('image_%d.png' % n)
63 | txts.append('text_%d' % n)
64 | links.append('image_%d.png' % n)
65 | html.add_images(ims, txts, links)
66 | html.save()
67 |
--------------------------------------------------------------------------------
/store_results.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 |
5 | import timm
6 | import types
7 | import math
8 | import numpy as np
9 | from PIL import Image
10 | import PIL.Image as pil
11 | from torchvision import transforms, datasets
12 | from torch.utils.data import Dataset, DataLoader
13 | import torch.utils.data as data
14 | import PerceptualSimilarity.lpips.lpips as lpips
15 | import glob
16 | import gc
17 | import pytorch_msssim.pytorch_msssim as pytorch_msssim
18 | from torch.cuda.amp import autocast
19 | from model import BRViT
20 | import matplotlib.pyplot as plt
21 | from pytorch_ssim.pytorch_ssim import ssim
22 | from torchvision.utils import save_image
23 |
24 | import pandas as pd
25 | from tqdm import tqdm
26 | import sys
27 | import cv2
28 | import time
29 | import scipy.misc
30 |
31 | from skimage.metrics import peak_signal_noise_ratio as compare_psnr
32 | from skimage.metrics import structural_similarity as compare_ssim
33 |
34 |
35 | feed_width = 1536
36 | feed_height = 1024
37 |
38 |
39 | #to store results
40 | def store_results():
41 | device = torch.device("cuda")
42 |
43 | model = BRViT().to(device)
44 |
45 | PATH = "weights/BRViT_53_0.pt"
46 | model.load_state_dict(torch.load(PATH), strict=True)
47 |
48 | with torch.no_grad():
49 | for i in tqdm(range(4400,4694)):
50 | csv_file = "Bokeh_Data/test.csv"
51 | data = pd.read_csv(csv_file)
52 | root_dir = "."
53 | idx = i - 4400
54 | bok = pil.open(root_dir + data.iloc[idx, 0][1:]).convert('RGB')
55 | input_image = pil.open(root_dir + data.iloc[idx, 1][1:]).convert('RGB')
56 | original_width, original_height = input_image.size
57 |
58 | org_image = input_image
59 | org_image = transforms.ToTensor()(org_image).unsqueeze(0)
60 |
61 | input_image = input_image.resize((feed_width, feed_height), pil.LANCZOS)
62 | input_image = transforms.ToTensor()(input_image).unsqueeze(0)
63 |
64 | # prediction
65 | org_image = org_image.to(device)
66 | input_image = input_image.to(device)
67 |
68 | bok_pred = model(input_image)
69 |
70 | bok_pred = F.interpolate(bok_pred,(original_height,original_width),mode = 'bilinear')
71 |
72 | save_image(bok_pred,'Results/'+ str(i) +'.png')
73 |
74 |
75 |
76 | if __name__ == "__main__":
77 | store_results()
78 |
79 |
80 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/image_folder.py:
--------------------------------------------------------------------------------
1 | ################################################################################
2 | # Code from
3 | # https://github.com/pytorch/vision/blob/master/torchvision/datasets/folder.py
4 | # Modified the original code so that it also loads images from the current
5 | # directory as well as the subdirectories
6 | ################################################################################
7 |
8 | import torch.utils.data as data
9 |
10 | from PIL import Image
11 | import os
12 | import os.path
13 |
14 | IMG_EXTENSIONS = [
15 | '.jpg', '.JPG', '.jpeg', '.JPEG',
16 | '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP',
17 | ]
18 |
19 | NP_EXTENSIONS = ['.npy',]
20 |
21 | def is_image_file(filename, mode='img'):
22 | if(mode=='img'):
23 | return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
24 | elif(mode=='np'):
25 | return any(filename.endswith(extension) for extension in NP_EXTENSIONS)
26 |
27 | def make_dataset(dirs, mode='img'):
28 | if(not isinstance(dirs,list)):
29 | dirs = [dirs,]
30 |
31 | images = []
32 | for dir in dirs:
33 | assert os.path.isdir(dir), '%s is not a valid directory' % dir
34 | for root, _, fnames in sorted(os.walk(dir)):
35 | for fname in fnames:
36 | if is_image_file(fname, mode=mode):
37 | path = os.path.join(root, fname)
38 | images.append(path)
39 |
40 | # print("Found %i images in %s"%(len(images),root))
41 | return images
42 |
43 | def default_loader(path):
44 | return Image.open(path).convert('RGB')
45 |
46 | class ImageFolder(data.Dataset):
47 | def __init__(self, root, transform=None, return_paths=False,
48 | loader=default_loader):
49 | imgs = make_dataset(root)
50 | if len(imgs) == 0:
51 | raise(RuntimeError("Found 0 images in: " + root + "\n"
52 | "Supported image extensions are: " + ",".join(IMG_EXTENSIONS)))
53 |
54 | self.root = root
55 | self.imgs = imgs
56 | self.transform = transform
57 | self.return_paths = return_paths
58 | self.loader = loader
59 |
60 | def __getitem__(self, index):
61 | path = self.imgs[index]
62 | img = self.loader(path)
63 | if self.transform is not None:
64 | img = self.transform(img)
65 | if self.return_paths:
66 | return img, path
67 | else:
68 | return img
69 |
70 | def __len__(self):
71 | return len(self.imgs)
72 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/data/dataset/twoafc_dataset.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | import torchvision.transforms as transforms
3 | from data.dataset.base_dataset import BaseDataset
4 | from data.image_folder import make_dataset
5 | from PIL import Image
6 | import numpy as np
7 | import torch
8 | # from IPython import embed
9 |
10 | class TwoAFCDataset(BaseDataset):
11 | def initialize(self, dataroots, load_size=64):
12 | if(not isinstance(dataroots,list)):
13 | dataroots = [dataroots,]
14 | self.roots = dataroots
15 | self.load_size = load_size
16 |
17 | # image directory
18 | self.dir_ref = [os.path.join(root, 'ref') for root in self.roots]
19 | self.ref_paths = make_dataset(self.dir_ref)
20 | self.ref_paths = sorted(self.ref_paths)
21 |
22 | self.dir_p0 = [os.path.join(root, 'p0') for root in self.roots]
23 | self.p0_paths = make_dataset(self.dir_p0)
24 | self.p0_paths = sorted(self.p0_paths)
25 |
26 | self.dir_p1 = [os.path.join(root, 'p1') for root in self.roots]
27 | self.p1_paths = make_dataset(self.dir_p1)
28 | self.p1_paths = sorted(self.p1_paths)
29 |
30 | transform_list = []
31 | transform_list.append(transforms.Scale(load_size))
32 | transform_list += [transforms.ToTensor(),
33 | transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))]
34 |
35 | self.transform = transforms.Compose(transform_list)
36 |
37 | # judgement directory
38 | self.dir_J = [os.path.join(root, 'judge') for root in self.roots]
39 | self.judge_paths = make_dataset(self.dir_J,mode='np')
40 | self.judge_paths = sorted(self.judge_paths)
41 |
42 | def __getitem__(self, index):
43 | p0_path = self.p0_paths[index]
44 | p0_img_ = Image.open(p0_path).convert('RGB')
45 | p0_img = self.transform(p0_img_)
46 |
47 | p1_path = self.p1_paths[index]
48 | p1_img_ = Image.open(p1_path).convert('RGB')
49 | p1_img = self.transform(p1_img_)
50 |
51 | ref_path = self.ref_paths[index]
52 | ref_img_ = Image.open(ref_path).convert('RGB')
53 | ref_img = self.transform(ref_img_)
54 |
55 | judge_path = self.judge_paths[index]
56 | # judge_img = (np.load(judge_path)*2.-1.).reshape((1,1,1,)) # [-1,1]
57 | judge_img = np.load(judge_path).reshape((1,1,1,)) # [0,1]
58 |
59 | judge_img = torch.FloatTensor(judge_img)
60 |
61 | return {'p0': p0_img, 'p1': p1_img, 'ref': ref_img, 'judge': judge_img,
62 | 'p0_path': p0_path, 'p1_path': p1_path, 'ref_path': ref_path, 'judge_path': judge_path}
63 |
64 | def __len__(self):
65 | return len(self.p0_paths)
66 |
--------------------------------------------------------------------------------
/pytorch_msssim/README.md:
--------------------------------------------------------------------------------
1 | # pytorch-msssim
2 |
3 | ### Differentiable Multi-Scale Structural Similarity (SSIM) index
4 |
5 | This small utiliy provides a differentiable MS-SSIM implementation for PyTorch based on Po Hsun Su's implementation of SSIM @ https://github.com/Po-Hsun-Su/pytorch-ssim.
6 | At the moment only the product method for MS-SSIM is supported.
7 |
8 | ## Installation
9 |
10 | Master branch now only supports PyTorch 0.4 or higher. All development occurs in the dev branch (`git checkout dev` after cloning the repository to get the latest development version).
11 |
12 | To install the current version of pytorch_mssim:
13 |
14 | 1. Clone this repo.
15 | 2. Go to the repo directory.
16 | 3. Run `python setup.py install`
17 |
18 | or
19 |
20 | 1. Clone this repo.
21 | 2. Copy "pytorch_msssim" folder in your project.
22 |
23 | To install a version of of pytorch_mssim that runs in PyTorch 0.3.1 or lower use the tag checkpoint-0.3. To do so, run the following commands after cloning the repository:
24 |
25 | ```
26 | git fetch --all --tags
27 | git checkout tags/checkpoint-0.3
28 | ```
29 |
30 | ## Example
31 |
32 | ### Basic usage
33 | ```python
34 | import pytorch_msssim
35 | import torch
36 |
37 | device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
38 | m = pytorch_msssim.MSSSIM()
39 |
40 | img1 = torch.rand(1, 1, 256, 256)
41 | img2 = torch.rand(1, 1, 256, 256)
42 |
43 | print(pytorch_msssim.msssim(img1, img2))
44 | print(m(img1, img2))
45 |
46 |
47 | ```
48 |
49 | ### Training
50 |
51 | For a detailed example on how to use msssim for optimization, take a look at the file max_ssim.py.
52 |
53 |
54 | ### Stability and normalization
55 |
56 | MS-SSIM is a particularly unstable metric when used for some architectures and may result in NaN values early on during the training. The msssim method provides a normalize attribute to help in these cases. There are three possible values. We recommend using the value normalized="relu" when training.
57 |
58 | - None : no normalization method is used and should be used for evaluation
59 | - "relu" : the `ssim`and `mc` values of each level during the calculation are rectified using a relu ensuring that negative values are zeroed
60 | - "simple" : the `ssim`result of each iteration is averaged with 1 for an expected lower bound of 0.5 - should ONLY be used for the initial iterations of your training or when averaging below 0.6 normalized score
61 |
62 | Currently and due to backward compability, a value of True will equal the "simple" normalization.
63 |
64 | ## Reference
65 | https://ece.uwaterloo.ca/~z70wang/research/ssim/
66 |
67 | https://github.com/Po-Hsun-Su/pytorch-ssim
68 |
69 | Thanks to z70wang for proposing MS-SSIM and providing the initial implementation, and Po-Hsun-Su for the initial differentiable SSIM implementation for Pytorch.
70 |
--------------------------------------------------------------------------------
/pytorch_ssim/pytorch_ssim/__init__.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | from torch.autograd import Variable
4 | import numpy as np
5 | from math import exp
6 |
7 | def gaussian(window_size, sigma):
8 | gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
9 | return gauss/gauss.sum()
10 |
11 | def create_window(window_size, channel):
12 | _1D_window = gaussian(window_size, 1.5).unsqueeze(1)
13 | _2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
14 | window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
15 | return window
16 |
17 | def _ssim(img1, img2, window, window_size, channel, size_average = True):
18 | mu1 = F.conv2d(img1, window, padding = window_size//2, groups = channel)
19 | mu2 = F.conv2d(img2, window, padding = window_size//2, groups = channel)
20 |
21 | mu1_sq = mu1.pow(2)
22 | mu2_sq = mu2.pow(2)
23 | mu1_mu2 = mu1*mu2
24 |
25 | sigma1_sq = F.conv2d(img1*img1, window, padding = window_size//2, groups = channel) - mu1_sq
26 | sigma2_sq = F.conv2d(img2*img2, window, padding = window_size//2, groups = channel) - mu2_sq
27 | sigma12 = F.conv2d(img1*img2, window, padding = window_size//2, groups = channel) - mu1_mu2
28 |
29 | C1 = 0.01**2
30 | C2 = 0.03**2
31 |
32 | ssim_map = ((2*mu1_mu2 + C1)*(2*sigma12 + C2))/((mu1_sq + mu2_sq + C1)*(sigma1_sq + sigma2_sq + C2))
33 |
34 | if size_average:
35 | return ssim_map.mean()
36 | else:
37 | return ssim_map.mean(1).mean(1).mean(1)
38 |
39 | class SSIM(torch.nn.Module):
40 | def __init__(self, window_size = 11, size_average = True):
41 | super(SSIM, self).__init__()
42 | self.window_size = window_size
43 | self.size_average = size_average
44 | self.channel = 1
45 | self.window = create_window(window_size, self.channel)
46 |
47 | def forward(self, img1, img2):
48 | (_, channel, _, _) = img1.size()
49 |
50 | if channel == self.channel and self.window.data.type() == img1.data.type():
51 | window = self.window
52 | else:
53 | window = create_window(self.window_size, channel)
54 |
55 | if img1.is_cuda:
56 | window = window.cuda(img1.get_device())
57 | window = window.type_as(img1)
58 |
59 | self.window = window
60 | self.channel = channel
61 |
62 |
63 | return _ssim(img1, img2, window, self.window_size, channel, self.size_average)
64 |
65 | def ssim(img1, img2, window_size = 11, size_average = True):
66 | (_, channel, _, _) = img1.size()
67 | window = create_window(window_size, channel)
68 |
69 | if img1.is_cuda:
70 | window = window.cuda(img1.get_device())
71 | window = window.type_as(img1)
72 |
73 | return _ssim(img1, img2, window, window_size, channel, size_average)
74 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/test_dataset_model.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import lpips
3 | from data import data_loader as dl
4 | import argparse
5 | from IPython import embed
6 |
7 | parser = argparse.ArgumentParser()
8 | parser.add_argument('--dataset_mode', type=str, default='2afc', help='[2afc,jnd]')
9 | parser.add_argument('--datasets', type=str, nargs='+', default=['val/traditional','val/cnn','val/superres','val/deblur','val/color','val/frameinterp'], help='datasets to test - for jnd mode: [val/traditional],[val/cnn]; for 2afc mode: [train/traditional],[train/cnn],[train/mix],[val/traditional],[val/cnn],[val/color],[val/deblur],[val/frameinterp],[val/superres]')
10 | parser.add_argument('--model', type=str, default='lpips', help='distance model type [lpips] for linearly calibrated net, [baseline] for off-the-shelf network, [l2] for euclidean distance, [ssim] for Structured Similarity Image Metric')
11 | parser.add_argument('--net', type=str, default='alex', help='[squeeze], [alex], or [vgg] for network architectures')
12 | parser.add_argument('--colorspace', type=str, default='Lab', help='[Lab] or [RGB] for colorspace to use for l2, ssim model types')
13 | parser.add_argument('--batch_size', type=int, default=50, help='batch size to test image patches in')
14 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
15 | parser.add_argument('--gpu_ids', type=int, nargs='+', default=[0], help='gpus to use')
16 | parser.add_argument('--nThreads', type=int, default=4, help='number of threads to use in data loader')
17 |
18 | parser.add_argument('--model_path', type=str, default=None, help='location of model, will default to ./weights/v[version]/[net_name].pth')
19 |
20 | parser.add_argument('--from_scratch', action='store_true', help='model was initialized from scratch')
21 | parser.add_argument('--train_trunk', action='store_true', help='model trunk was trained/tuned')
22 | parser.add_argument('--version', type=str, default='0.1', help='v0.1 is latest, v0.0 was original release')
23 |
24 | opt = parser.parse_args()
25 | if(opt.model in ['l2','ssim']):
26 | opt.batch_size = 1
27 |
28 | # initialize model
29 | trainer = lpips.Trainer()
30 | # trainer.initialize(model=opt.model,net=opt.net,colorspace=opt.colorspace,model_path=opt.model_path,use_gpu=opt.use_gpu)
31 | trainer.initialize(model=opt.model, net=opt.net, colorspace=opt.colorspace,
32 | model_path=opt.model_path, use_gpu=opt.use_gpu, pnet_rand=opt.from_scratch, pnet_tune=opt.train_trunk,
33 | version=opt.version, gpu_ids=opt.gpu_ids)
34 |
35 | if(opt.model in ['net-lin','net']):
36 | print('Testing model [%s]-[%s]'%(opt.model,opt.net))
37 | elif(opt.model in ['l2','ssim']):
38 | print('Testing model [%s]-[%s]'%(opt.model,opt.colorspace))
39 |
40 | # initialize data loader
41 | for dataset in opt.datasets:
42 | data_loader = dl.CreateDataLoader(dataset,dataset_mode=opt.dataset_mode, batch_size=opt.batch_size, nThreads=opt.nThreads)
43 |
44 | # evaluate model on data
45 | if(opt.dataset_mode=='2afc'):
46 | (score, results_verbose) = lpips.score_2afc_dataset(data_loader, trainer.forward, name=dataset)
47 | elif(opt.dataset_mode=='jnd'):
48 | (score, results_verbose) = lpips.score_jnd_dataset(data_loader, trainer.forward, name=dataset)
49 |
50 | # print results
51 | print(' Dataset [%s]: %.2f'%(dataset,100.*score))
52 |
53 |
--------------------------------------------------------------------------------
/pytorch_msssim/pytorch_msssim/__init__.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | from math import exp
4 | import numpy as np
5 |
6 |
7 | def gaussian(window_size, sigma):
8 | gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
9 | return gauss/gauss.sum()
10 |
11 |
12 | def create_window(window_size, channel=1):
13 | _1D_window = gaussian(window_size, 1.5).unsqueeze(1)
14 | _2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
15 | window = _2D_window.expand(channel, 1, window_size, window_size).contiguous()
16 | return window
17 |
18 |
19 | def ssim(img1, img2, window_size=11, window=None, size_average=True, full=False, val_range=None):
20 | # Value range can be different from 255. Other common ranges are 1 (sigmoid) and 2 (tanh).
21 | if val_range is None:
22 | if torch.max(img1) > 128:
23 | max_val = 255
24 | else:
25 | max_val = 1
26 |
27 | if torch.min(img1) < -0.5:
28 | min_val = -1
29 | else:
30 | min_val = 0
31 | L = max_val - min_val
32 | else:
33 | L = val_range
34 |
35 | padd = 0
36 | (_, channel, height, width) = img1.size()
37 | if window is None:
38 | real_size = min(window_size, height, width)
39 | window = create_window(real_size, channel=channel).to(img1.device)
40 |
41 | mu1 = F.conv2d(img1, window, padding=padd, groups=channel)
42 | mu2 = F.conv2d(img2, window, padding=padd, groups=channel)
43 |
44 | mu1_sq = mu1.pow(2)
45 | mu2_sq = mu2.pow(2)
46 | mu1_mu2 = mu1 * mu2
47 |
48 | sigma1_sq = F.conv2d(img1 * img1, window, padding=padd, groups=channel) - mu1_sq
49 | sigma2_sq = F.conv2d(img2 * img2, window, padding=padd, groups=channel) - mu2_sq
50 | sigma12 = F.conv2d(img1 * img2, window, padding=padd, groups=channel) - mu1_mu2
51 |
52 | C1 = (0.01 * L) ** 2
53 | C2 = (0.03 * L) ** 2
54 |
55 | v1 = 2.0 * sigma12 + C2
56 | v2 = sigma1_sq + sigma2_sq + C2
57 | cs = v1 / v2 # contrast sensitivity
58 |
59 | ssim_map = ((2 * mu1_mu2 + C1) * v1) / ((mu1_sq + mu2_sq + C1) * v2)
60 |
61 | if size_average:
62 | cs = cs.mean()
63 | ret = ssim_map.mean()
64 | else:
65 | cs = cs.mean(1).mean(1).mean(1)
66 | ret = ssim_map.mean(1).mean(1).mean(1)
67 |
68 | if full:
69 | return ret, cs
70 | return ret
71 |
72 |
73 | def msssim(img1, img2, window_size=11, size_average=True, val_range=None, normalize=None):
74 | device = img1.device
75 | weights = torch.FloatTensor([0.0448, 0.2856, 0.3001, 0.2363, 0.1333]).to(device)
76 | levels = weights.size()[0]
77 | ssims = []
78 | mcs = []
79 | for _ in range(levels):
80 | sim, cs = ssim(img1, img2, window_size=window_size, size_average=size_average, full=True, val_range=val_range)
81 |
82 | # Relu normalize (not compliant with original definition)
83 | if normalize == "relu":
84 | ssims.append(torch.relu(sim))
85 | mcs.append(torch.relu(cs))
86 | else:
87 | ssims.append(sim)
88 | mcs.append(cs)
89 |
90 | img1 = F.avg_pool2d(img1, (2, 2))
91 | img2 = F.avg_pool2d(img2, (2, 2))
92 |
93 | ssims = torch.stack(ssims)
94 | mcs = torch.stack(mcs)
95 |
96 | # Simple normalize (not compliant with original definition)
97 | # TODO: remove support for normalize == True (kept for backward support)
98 | if normalize == "simple" or normalize == True:
99 | ssims = (ssims + 1) / 2
100 | mcs = (mcs + 1) / 2
101 |
102 | pow1 = mcs ** weights
103 | pow2 = ssims ** weights
104 |
105 | # From Matlab implementation https://ece.uwaterloo.ca/~z70wang/research/iwssim/
106 | output = torch.prod(pow1[:-1]) * pow2[-1]
107 | ## output = torch.prod(pow1[:-1] * pow2[-1])
108 | return output
109 |
110 |
111 | # Classes to re-use window
112 | class SSIM(torch.nn.Module):
113 | def __init__(self, window_size=11, size_average=True, val_range=None):
114 | super(SSIM, self).__init__()
115 | self.window_size = window_size
116 | self.size_average = size_average
117 | self.val_range = val_range
118 |
119 | # Assume 1 channel for SSIM
120 | self.channel = 1
121 | self.window = create_window(window_size)
122 |
123 | def forward(self, img1, img2):
124 | (_, channel, _, _) = img1.size()
125 |
126 | if channel == self.channel and self.window.dtype == img1.dtype:
127 | window = self.window
128 | else:
129 | window = create_window(self.window_size, channel).to(img1.device).type(img1.dtype)
130 | self.window = window
131 | self.channel = channel
132 |
133 | return ssim(img1, img2, window=window, window_size=self.window_size, size_average=self.size_average)
134 |
135 | class MSSSIM(torch.nn.Module):
136 | def __init__(self, window_size=11, size_average=True, channel=3):
137 | super(MSSSIM, self).__init__()
138 | self.window_size = window_size
139 | self.size_average = size_average
140 | self.channel = channel
141 |
142 | def forward(self, img1, img2):
143 | # TODO: store window between calls if possible
144 | return msssim(img1, img2, window_size=self.window_size, size_average=self.size_average)
145 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import, division, print_function
2 | import cv2
3 | import numbers
4 | import math
5 | import os
6 | import sys
7 | import glob
8 | import argparse
9 | import numpy as np
10 | import PIL.Image as pil
11 | import matplotlib as mpl
12 | import matplotlib.cm as cm
13 | import torch
14 | from torchvision import transforms, datasets
15 | from torch.utils.data import Dataset, DataLoader
16 | import pandas as pd
17 | import torch.nn as nn
18 | import torch.optim as optim
19 | import torch.nn.functional as F
20 | import math
21 | from pytorch_msssim.pytorch_msssim import msssim
22 | import torchvision
23 | from torch.autograd import Variable
24 | from pytorch_ssim.pytorch_ssim import ssim
25 | import PerceptualSimilarity.lpips.lpips as lpips
26 |
27 | from tqdm import tqdm
28 |
29 | device = torch.device("cuda:0")
30 |
31 | from model import BRViT
32 |
33 |
34 | feed_width = 768
35 | feed_height = 512
36 |
37 |
38 | bokehnet = BRViT().to(device)
39 | batch_size = 1
40 |
41 |
42 | PATH = "BRViT_53_0.pt"
43 | bokehnet.load_state_dict(torch.load(PATH), strict=False)
44 |
45 | print("weights loaded!!")
46 |
47 |
48 | class bokehDataset(Dataset):
49 |
50 | def __init__(self, csv_file,root_dir, transform=None):
51 |
52 | self.data = pd.read_csv(csv_file)
53 | self.transform = transform
54 | self.root_dir = root_dir
55 |
56 | def __len__(self):
57 | return len(self.data)
58 |
59 | def __getitem__(self, idx):
60 |
61 | bok = pil.open(self.root_dir + self.data.iloc[idx, 0][1:]).convert('RGB')
62 | org = pil.open(self.root_dir + self.data.iloc[idx, 1][1:]).convert('RGB')
63 |
64 | bok = bok.resize((feed_width, feed_height), pil.LANCZOS)
65 | org = org.resize((feed_width, feed_height), pil.LANCZOS)
66 | if self.transform :
67 | bok_dep = self.transform(bok)
68 | org_dep = self.transform(org)
69 | return (bok_dep, org_dep)
70 |
71 | transform1 = transforms.Compose(
72 | [
73 | transforms.ToTensor(),
74 | ])
75 |
76 |
77 | transform2 = transforms.Compose(
78 | [
79 | transforms.RandomHorizontalFlip(p=1),
80 | transforms.ToTensor(),
81 | ])
82 |
83 |
84 | transform3 = transforms.Compose(
85 | [
86 | transforms.RandomVerticalFlip(p=1),
87 | transforms.ToTensor(),
88 | ])
89 |
90 |
91 |
92 | trainset1 = bokehDataset(csv_file = './Bokeh_Data/train.csv', root_dir = '.',transform = transform1)
93 | trainset2 = bokehDataset(csv_file = './Bokeh_Data/train.csv', root_dir = '.',transform = transform2)
94 | trainset3 = bokehDataset(csv_file = './Bokeh_Data/train.csv', root_dir = '.',transform = transform3)
95 |
96 |
97 | trainloader = torch.utils.data.DataLoader(torch.utils.data.ConcatDataset([trainset1,trainset2,trainset3]), batch_size=batch_size,
98 | shuffle=True, num_workers=0)
99 |
100 | testset = bokehDataset(csv_file = './Bokeh_Data/test.csv', root_dir = '.', transform = transform1)
101 | testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
102 | shuffle=False, num_workers=0)
103 |
104 |
105 | learning_rate = 0.00001
106 |
107 | optimizer = optim.Adam(bokehnet.parameters(), lr=learning_rate, betas=(0.9, 0.999))
108 |
109 |
110 | sm = nn.Softmax(dim=1)
111 |
112 | MSE_LossFn = nn.MSELoss()
113 | L1_LossFn = nn.L1Loss()
114 |
115 |
116 | def train(dataloader):
117 | running_l1_loss = 0
118 | running_ms_loss = 0
119 | running_sal_loss = 0
120 | running_loss = 0
121 |
122 | for i,data in enumerate(dataloader,0) :
123 | bok , org = data
124 | bok , org = bok.to(device) , org.to(device)
125 |
126 | optimizer.zero_grad()
127 |
128 | bok_pred = bokehnet(org)
129 |
130 | loss = (1-msssim(bok_pred, bok))
131 |
132 | ## loss = L1_LossFn(bok_pred, bok)
133 |
134 | running_loss += loss.item()
135 |
136 | loss.backward()
137 | optimizer.step()
138 | if (i % 10 == 0):
139 | print ('Batch: ',i,'/',len(dataloader),' Loss:', loss.item())
140 |
141 |
142 | if ((i+1)%8000==0):
143 | torch.save(bokehnet.state_dict(), './weights/BRViT_' + str(epoch) + '_' + str(i) + '.pt')
144 | print(loss.item())
145 |
146 | print (running_loss/len(dataloader))
147 |
148 |
149 |
150 |
151 | def val(dataloader):
152 | running_l1_loss = 0
153 | running_ms_loss = 0
154 | running_lips_loss = 0
155 |
156 | with torch.no_grad():
157 | for i,data in enumerate(tqdm(dataloader),0) :
158 | bok , org = data
159 | bok , org = bok.to(device) , org.to(device)
160 |
161 | bok_pred = bokehnet(org)
162 |
163 | try:
164 | l1_loss = L1_LossFn(bok_pred, bok)
165 | except:
166 | l1_loss = L1_LossFn(bok_pred[0], bok)
167 |
168 | ms_loss = 1-ssim(bok_pred, bok)
169 |
170 |
171 | running_l1_loss += l1_loss.item()
172 | running_ms_loss += ms_loss.item()
173 |
174 |
175 | print ('Validation l1 Loss: ',running_l1_loss/len(dataloader))
176 | print ('Validation ms Loss: ',running_ms_loss/len(dataloader))
177 |
178 | ## torch.save(bokehnet.state_dict(), './weights/BRViT_'+str(epoch)+'.pt')
179 |
180 | try:
181 | with open("log.txt", 'a') as f:
182 | f.write(f"{running_ms_loss/len(dataloader)}\n")
183 | except:
184 | pass
185 |
186 |
187 |
188 | start_ep = 0
189 | for epoch in range(start_ep, 40):
190 | print (epoch)
191 |
192 | train(trainloader)
193 |
194 | with torch.no_grad():
195 | val(testloader)
196 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/train.py:
--------------------------------------------------------------------------------
1 | import torch.backends.cudnn as cudnn
2 | cudnn.benchmark=False
3 |
4 | import numpy as np
5 | import time
6 | import os
7 | import lpips
8 | from data import data_loader as dl
9 | import argparse
10 | from util.visualizer import Visualizer
11 | from IPython import embed
12 |
13 | parser = argparse.ArgumentParser()
14 | parser.add_argument('--datasets', type=str, nargs='+', default=['train/traditional','train/cnn','train/mix'], help='datasets to train on: [train/traditional],[train/cnn],[train/mix],[val/traditional],[val/cnn],[val/color],[val/deblur],[val/frameinterp],[val/superres]')
15 | parser.add_argument('--model', type=str, default='lpips', help='distance model type [lpips] for linearly calibrated net, [baseline] for off-the-shelf network, [l2] for euclidean distance, [ssim] for Structured Similarity Image Metric')
16 | parser.add_argument('--net', type=str, default='alex', help='[squeeze], [alex], or [vgg] for network architectures')
17 | parser.add_argument('--batch_size', type=int, default=50, help='batch size to test image patches in')
18 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
19 | parser.add_argument('--gpu_ids', type=int, nargs='+', default=[0], help='gpus to use')
20 |
21 | parser.add_argument('--nThreads', type=int, default=4, help='number of threads to use in data loader')
22 | parser.add_argument('--nepoch', type=int, default=5, help='# epochs at base learning rate')
23 | parser.add_argument('--nepoch_decay', type=int, default=5, help='# additional epochs at linearly learning rate')
24 | parser.add_argument('--display_freq', type=int, default=5000, help='frequency (in instances) of showing training results on screen')
25 | parser.add_argument('--print_freq', type=int, default=5000, help='frequency (in instances) of showing training results on console')
26 | parser.add_argument('--save_latest_freq', type=int, default=20000, help='frequency (in instances) of saving the latest results')
27 | parser.add_argument('--save_epoch_freq', type=int, default=1, help='frequency of saving checkpoints at the end of epochs')
28 | parser.add_argument('--display_id', type=int, default=0, help='window id of the visdom display, [0] for no displaying')
29 | parser.add_argument('--display_winsize', type=int, default=256, help='display window size')
30 | parser.add_argument('--display_port', type=int, default=8001, help='visdom display port')
31 | parser.add_argument('--use_html', action='store_true', help='save off html pages')
32 | parser.add_argument('--checkpoints_dir', type=str, default='checkpoints', help='checkpoints directory')
33 | parser.add_argument('--name', type=str, default='tmp', help='directory name for training')
34 |
35 | parser.add_argument('--from_scratch', action='store_true', help='model was initialized from scratch')
36 | parser.add_argument('--train_trunk', action='store_true', help='model trunk was trained/tuned')
37 | parser.add_argument('--train_plot', action='store_true', help='plot saving')
38 |
39 | opt = parser.parse_args()
40 | opt.save_dir = os.path.join(opt.checkpoints_dir,opt.name)
41 | if(not os.path.exists(opt.save_dir)):
42 | os.mkdir(opt.save_dir)
43 |
44 | # initialize model
45 | trainer = lpips.Trainer()
46 | trainer.initialize(model=opt.model, net=opt.net, use_gpu=opt.use_gpu, is_train=True,
47 | pnet_rand=opt.from_scratch, pnet_tune=opt.train_trunk, gpu_ids=opt.gpu_ids)
48 |
49 | # load data from all training sets
50 | data_loader = dl.CreateDataLoader(opt.datasets,dataset_mode='2afc', batch_size=opt.batch_size, serial_batches=False, nThreads=opt.nThreads)
51 | dataset = data_loader.load_data()
52 | dataset_size = len(data_loader)
53 | D = len(dataset)
54 | print('Loading %i instances from'%dataset_size,opt.datasets)
55 | visualizer = Visualizer(opt)
56 |
57 | total_steps = 0
58 | fid = open(os.path.join(opt.checkpoints_dir,opt.name,'train_log.txt'),'w+')
59 | for epoch in range(1, opt.nepoch + opt.nepoch_decay + 1):
60 | epoch_start_time = time.time()
61 | for i, data in enumerate(dataset):
62 | iter_start_time = time.time()
63 | total_steps += opt.batch_size
64 | epoch_iter = total_steps - dataset_size * (epoch - 1)
65 |
66 | trainer.set_input(data)
67 | trainer.optimize_parameters()
68 |
69 | if total_steps % opt.display_freq == 0:
70 | visualizer.display_current_results(trainer.get_current_visuals(), epoch)
71 |
72 | if total_steps % opt.print_freq == 0:
73 | errors = trainer.get_current_errors()
74 | t = (time.time()-iter_start_time)/opt.batch_size
75 | t2o = (time.time()-epoch_start_time)/3600.
76 | t2 = t2o*D/(i+.0001)
77 | visualizer.print_current_errors(epoch, epoch_iter, errors, t, t2=t2, t2o=t2o, fid=fid)
78 |
79 | for key in errors.keys():
80 | visualizer.plot_current_errors_save(epoch, float(epoch_iter)/dataset_size, opt, errors, keys=[key,], name=key, to_plot=opt.train_plot)
81 |
82 | if opt.display_id > 0:
83 | visualizer.plot_current_errors(epoch, float(epoch_iter)/dataset_size, opt, errors)
84 |
85 | if total_steps % opt.save_latest_freq == 0:
86 | print('saving the latest model (epoch %d, total_steps %d)' %
87 | (epoch, total_steps))
88 | trainer.save(opt.save_dir, 'latest')
89 |
90 | if epoch % opt.save_epoch_freq == 0:
91 | print('saving the model at the end of epoch %d, iters %d' %
92 | (epoch, total_steps))
93 | trainer.save(opt.save_dir, 'latest')
94 | trainer.save(opt.save_dir, epoch)
95 |
96 | print('End of epoch %d / %d \t Time Taken: %d sec' %
97 | (epoch, opt.nepoch + opt.nepoch_decay, time.time() - epoch_start_time))
98 |
99 | if epoch > opt.nepoch:
100 | trainer.update_learning_rate(opt.nepoch_decay)
101 |
102 | # trainer.save_done(True)
103 | fid.close()
104 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/__init__.py:
--------------------------------------------------------------------------------
1 |
2 | from __future__ import absolute_import
3 | from __future__ import division
4 | from __future__ import print_function
5 |
6 | import numpy as np
7 | import torch
8 | # from torch.autograd import Variable
9 |
10 | from PerceptualSimilarity.lpips.trainer import *
11 | from PerceptualSimilarity.lpips.lpips import *
12 |
13 | # class PerceptualLoss(torch.nn.Module):
14 | # def __init__(self, model='lpips', net='alex', spatial=False, use_gpu=False, gpu_ids=[0], version='0.1'): # VGG using our perceptually-learned weights (LPIPS metric)
15 | # # def __init__(self, model='net', net='vgg', use_gpu=True): # "default" way of using VGG as a perceptual loss
16 | # super(PerceptualLoss, self).__init__()
17 | # print('Setting up Perceptual loss...')
18 | # self.use_gpu = use_gpu
19 | # self.spatial = spatial
20 | # self.gpu_ids = gpu_ids
21 | # self.model = dist_model.DistModel()
22 | # self.model.initialize(model=model, net=net, use_gpu=use_gpu, spatial=self.spatial, gpu_ids=gpu_ids, version=version)
23 | # print('...[%s] initialized'%self.model.name())
24 | # print('...Done')
25 |
26 | # def forward(self, pred, target, normalize=False):
27 | # """
28 | # Pred and target are Variables.
29 | # If normalize is True, assumes the images are between [0,1] and then scales them between [-1,+1]
30 | # If normalize is False, assumes the images are already between [-1,+1]
31 |
32 | # Inputs pred and target are Nx3xHxW
33 | # Output pytorch Variable N long
34 | # """
35 |
36 | # if normalize:
37 | # target = 2 * target - 1
38 | # pred = 2 * pred - 1
39 |
40 | # return self.model.forward(target, pred)
41 |
42 | def normalize_tensor(in_feat,eps=1e-10):
43 | norm_factor = torch.sqrt(torch.sum(in_feat**2,dim=1,keepdim=True))
44 | return in_feat/(norm_factor+eps)
45 |
46 | def l2(p0, p1, range=255.):
47 | return .5*np.mean((p0 / range - p1 / range)**2)
48 |
49 | def psnr(p0, p1, peak=255.):
50 | return 10*np.log10(peak**2/np.mean((1.*p0-1.*p1)**2))
51 |
52 | def dssim(p0, p1, range=255.):
53 | from skimage.measure import compare_ssim
54 | return (1 - compare_ssim(p0, p1, data_range=range, multichannel=True)) / 2.
55 |
56 | def rgb2lab(in_img,mean_cent=False):
57 | from skimage import color
58 | img_lab = color.rgb2lab(in_img)
59 | if(mean_cent):
60 | img_lab[:,:,0] = img_lab[:,:,0]-50
61 | return img_lab
62 |
63 | def tensor2np(tensor_obj):
64 | # change dimension of a tensor object into a numpy array
65 | return tensor_obj[0].cpu().float().numpy().transpose((1,2,0))
66 |
67 | def np2tensor(np_obj):
68 | # change dimenion of np array into tensor array
69 | return torch.Tensor(np_obj[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
70 |
71 | def tensor2tensorlab(image_tensor,to_norm=True,mc_only=False):
72 | # image tensor to lab tensor
73 | from skimage import color
74 |
75 | img = tensor2im(image_tensor)
76 | img_lab = color.rgb2lab(img)
77 | if(mc_only):
78 | img_lab[:,:,0] = img_lab[:,:,0]-50
79 | if(to_norm and not mc_only):
80 | img_lab[:,:,0] = img_lab[:,:,0]-50
81 | img_lab = img_lab/100.
82 |
83 | return np2tensor(img_lab)
84 |
85 | def tensorlab2tensor(lab_tensor,return_inbnd=False):
86 | from skimage import color
87 | import warnings
88 | warnings.filterwarnings("ignore")
89 |
90 | lab = tensor2np(lab_tensor)*100.
91 | lab[:,:,0] = lab[:,:,0]+50
92 |
93 | rgb_back = 255.*np.clip(color.lab2rgb(lab.astype('float')),0,1)
94 | if(return_inbnd):
95 | # convert back to lab, see if we match
96 | lab_back = color.rgb2lab(rgb_back.astype('uint8'))
97 | mask = 1.*np.isclose(lab_back,lab,atol=2.)
98 | mask = np2tensor(np.prod(mask,axis=2)[:,:,np.newaxis])
99 | return (im2tensor(rgb_back),mask)
100 | else:
101 | return im2tensor(rgb_back)
102 |
103 | def load_image(path):
104 | if(path[-3:] == 'dng'):
105 | import rawpy
106 | with rawpy.imread(path) as raw:
107 | img = raw.postprocess()
108 | elif(path[-3:]=='bmp' or path[-3:]=='jpg' or path[-3:]=='png' or path[-4:]=='jpeg'):
109 | import cv2
110 | return cv2.imread(path)[:,:,::-1]
111 | else:
112 | img = (255*plt.imread(path)[:,:,:3]).astype('uint8')
113 |
114 | return img
115 |
116 | def rgb2lab(input):
117 | from skimage import color
118 | return color.rgb2lab(input / 255.)
119 |
120 | def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
121 | image_numpy = image_tensor[0].cpu().float().numpy()
122 | image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
123 | return image_numpy.astype(imtype)
124 |
125 | def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
126 | return torch.Tensor((image / factor - cent)
127 | [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
128 |
129 | def tensor2vec(vector_tensor):
130 | return vector_tensor.data.cpu().numpy()[:, :, 0, 0]
131 |
132 |
133 | def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
134 | # def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
135 | image_numpy = image_tensor[0].cpu().float().numpy()
136 | image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
137 | return image_numpy.astype(imtype)
138 |
139 | def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
140 | # def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
141 | return torch.Tensor((image / factor - cent)
142 | [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
143 |
144 |
145 |
146 | def voc_ap(rec, prec, use_07_metric=False):
147 | """ ap = voc_ap(rec, prec, [use_07_metric])
148 | Compute VOC AP given precision and recall.
149 | If use_07_metric is true, uses the
150 | VOC 07 11 point method (default:False).
151 | """
152 | if use_07_metric:
153 | # 11 point metric
154 | ap = 0.
155 | for t in np.arange(0., 1.1, 0.1):
156 | if np.sum(rec >= t) == 0:
157 | p = 0
158 | else:
159 | p = np.max(prec[rec >= t])
160 | ap = ap + p / 11.
161 | else:
162 | # correct AP calculation
163 | # first append sentinel values at the end
164 | mrec = np.concatenate(([0.], rec, [1.]))
165 | mpre = np.concatenate(([0.], prec, [0.]))
166 |
167 | # compute the precision envelope
168 | for i in range(mpre.size - 1, 0, -1):
169 | mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
170 |
171 | # to calculate area under PR curve, look for points
172 | # where X axis (recall) changes value
173 | i = np.where(mrec[1:] != mrec[:-1])[0]
174 |
175 | # and sum (\Delta recall) * prec
176 | ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
177 | return ap
178 |
179 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/pretrained_networks.py:
--------------------------------------------------------------------------------
1 | from collections import namedtuple
2 | import torch
3 | from torchvision import models as tv
4 |
5 | class squeezenet(torch.nn.Module):
6 | def __init__(self, requires_grad=False, pretrained=True):
7 | super(squeezenet, self).__init__()
8 | pretrained_features = tv.squeezenet1_1(pretrained=pretrained).features
9 | self.slice1 = torch.nn.Sequential()
10 | self.slice2 = torch.nn.Sequential()
11 | self.slice3 = torch.nn.Sequential()
12 | self.slice4 = torch.nn.Sequential()
13 | self.slice5 = torch.nn.Sequential()
14 | self.slice6 = torch.nn.Sequential()
15 | self.slice7 = torch.nn.Sequential()
16 | self.N_slices = 7
17 | for x in range(2):
18 | self.slice1.add_module(str(x), pretrained_features[x])
19 | for x in range(2,5):
20 | self.slice2.add_module(str(x), pretrained_features[x])
21 | for x in range(5, 8):
22 | self.slice3.add_module(str(x), pretrained_features[x])
23 | for x in range(8, 10):
24 | self.slice4.add_module(str(x), pretrained_features[x])
25 | for x in range(10, 11):
26 | self.slice5.add_module(str(x), pretrained_features[x])
27 | for x in range(11, 12):
28 | self.slice6.add_module(str(x), pretrained_features[x])
29 | for x in range(12, 13):
30 | self.slice7.add_module(str(x), pretrained_features[x])
31 | if not requires_grad:
32 | for param in self.parameters():
33 | param.requires_grad = False
34 |
35 | def forward(self, X):
36 | h = self.slice1(X)
37 | h_relu1 = h
38 | h = self.slice2(h)
39 | h_relu2 = h
40 | h = self.slice3(h)
41 | h_relu3 = h
42 | h = self.slice4(h)
43 | h_relu4 = h
44 | h = self.slice5(h)
45 | h_relu5 = h
46 | h = self.slice6(h)
47 | h_relu6 = h
48 | h = self.slice7(h)
49 | h_relu7 = h
50 | vgg_outputs = namedtuple("SqueezeOutputs", ['relu1','relu2','relu3','relu4','relu5','relu6','relu7'])
51 | out = vgg_outputs(h_relu1,h_relu2,h_relu3,h_relu4,h_relu5,h_relu6,h_relu7)
52 |
53 | return out
54 |
55 |
56 | class alexnet(torch.nn.Module):
57 | def __init__(self, requires_grad=False, pretrained=True):
58 | super(alexnet, self).__init__()
59 | alexnet_pretrained_features = tv.alexnet(pretrained=pretrained).features
60 | self.slice1 = torch.nn.Sequential()
61 | self.slice2 = torch.nn.Sequential()
62 | self.slice3 = torch.nn.Sequential()
63 | self.slice4 = torch.nn.Sequential()
64 | self.slice5 = torch.nn.Sequential()
65 | self.N_slices = 5
66 | for x in range(2):
67 | self.slice1.add_module(str(x), alexnet_pretrained_features[x])
68 | for x in range(2, 5):
69 | self.slice2.add_module(str(x), alexnet_pretrained_features[x])
70 | for x in range(5, 8):
71 | self.slice3.add_module(str(x), alexnet_pretrained_features[x])
72 | for x in range(8, 10):
73 | self.slice4.add_module(str(x), alexnet_pretrained_features[x])
74 | for x in range(10, 12):
75 | self.slice5.add_module(str(x), alexnet_pretrained_features[x])
76 | if not requires_grad:
77 | for param in self.parameters():
78 | param.requires_grad = False
79 |
80 | def forward(self, X):
81 | h = self.slice1(X)
82 | h_relu1 = h
83 | h = self.slice2(h)
84 | h_relu2 = h
85 | h = self.slice3(h)
86 | h_relu3 = h
87 | h = self.slice4(h)
88 | h_relu4 = h
89 | h = self.slice5(h)
90 | h_relu5 = h
91 | alexnet_outputs = namedtuple("AlexnetOutputs", ['relu1', 'relu2', 'relu3', 'relu4', 'relu5'])
92 | out = alexnet_outputs(h_relu1, h_relu2, h_relu3, h_relu4, h_relu5)
93 |
94 | return out
95 |
96 | class vgg16(torch.nn.Module):
97 | def __init__(self, requires_grad=False, pretrained=True):
98 | super(vgg16, self).__init__()
99 | vgg_pretrained_features = tv.vgg16(pretrained=pretrained).features
100 | self.slice1 = torch.nn.Sequential()
101 | self.slice2 = torch.nn.Sequential()
102 | self.slice3 = torch.nn.Sequential()
103 | self.slice4 = torch.nn.Sequential()
104 | self.slice5 = torch.nn.Sequential()
105 | self.N_slices = 5
106 | for x in range(4):
107 | self.slice1.add_module(str(x), vgg_pretrained_features[x])
108 | for x in range(4, 9):
109 | self.slice2.add_module(str(x), vgg_pretrained_features[x])
110 | for x in range(9, 16):
111 | self.slice3.add_module(str(x), vgg_pretrained_features[x])
112 | for x in range(16, 23):
113 | self.slice4.add_module(str(x), vgg_pretrained_features[x])
114 | for x in range(23, 30):
115 | self.slice5.add_module(str(x), vgg_pretrained_features[x])
116 | if not requires_grad:
117 | for param in self.parameters():
118 | param.requires_grad = False
119 |
120 | def forward(self, X):
121 | h = self.slice1(X)
122 | h_relu1_2 = h
123 | h = self.slice2(h)
124 | h_relu2_2 = h
125 | h = self.slice3(h)
126 | h_relu3_3 = h
127 | h = self.slice4(h)
128 | h_relu4_3 = h
129 | h = self.slice5(h)
130 | h_relu5_3 = h
131 | vgg_outputs = namedtuple("VggOutputs", ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3', 'relu5_3'])
132 | out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3)
133 |
134 | return out
135 |
136 |
137 |
138 | class resnet(torch.nn.Module):
139 | def __init__(self, requires_grad=False, pretrained=True, num=18):
140 | super(resnet, self).__init__()
141 | if(num==18):
142 | self.net = tv.resnet18(pretrained=pretrained)
143 | elif(num==34):
144 | self.net = tv.resnet34(pretrained=pretrained)
145 | elif(num==50):
146 | self.net = tv.resnet50(pretrained=pretrained)
147 | elif(num==101):
148 | self.net = tv.resnet101(pretrained=pretrained)
149 | elif(num==152):
150 | self.net = tv.resnet152(pretrained=pretrained)
151 | self.N_slices = 5
152 |
153 | self.conv1 = self.net.conv1
154 | self.bn1 = self.net.bn1
155 | self.relu = self.net.relu
156 | self.maxpool = self.net.maxpool
157 | self.layer1 = self.net.layer1
158 | self.layer2 = self.net.layer2
159 | self.layer3 = self.net.layer3
160 | self.layer4 = self.net.layer4
161 |
162 | def forward(self, X):
163 | h = self.conv1(X)
164 | h = self.bn1(h)
165 | h = self.relu(h)
166 | h_relu1 = h
167 | h = self.maxpool(h)
168 | h = self.layer1(h)
169 | h_conv2 = h
170 | h = self.layer2(h)
171 | h_conv3 = h
172 | h = self.layer3(h)
173 | h_conv4 = h
174 | h = self.layer4(h)
175 | h_conv5 = h
176 |
177 | outputs = namedtuple("Outputs", ['relu1','conv2','conv3','conv4','conv5'])
178 | out = outputs(h_relu1, h_conv2, h_conv3, h_conv4, h_conv5)
179 |
180 | return out
181 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/util/visualizer.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import os
3 | import time
4 | from . import util
5 | from . import html
6 | import matplotlib.pyplot as plt
7 | import math
8 | # from IPython import embed
9 |
10 | def zoom_to_res(img,res=256,order=0,axis=0):
11 | # img 3xXxX
12 | from scipy.ndimage import zoom
13 | zoom_factor = res/img.shape[1]
14 | if(axis==0):
15 | return zoom(img,[1,zoom_factor,zoom_factor],order=order)
16 | elif(axis==2):
17 | return zoom(img,[zoom_factor,zoom_factor,1],order=order)
18 |
19 | class Visualizer():
20 | def __init__(self, opt):
21 | # self.opt = opt
22 | self.display_id = opt.display_id
23 | # self.use_html = opt.is_train and not opt.no_html
24 | self.win_size = opt.display_winsize
25 | self.name = opt.name
26 | self.display_cnt = 0 # display_current_results counter
27 | self.display_cnt_high = 0
28 | self.use_html = opt.use_html
29 |
30 | if self.display_id > 0:
31 | import visdom
32 | self.vis = visdom.Visdom(port = opt.display_port)
33 |
34 | self.web_dir = os.path.join(opt.checkpoints_dir, opt.name, 'web')
35 | util.mkdirs([self.web_dir,])
36 | if self.use_html:
37 | self.img_dir = os.path.join(self.web_dir, 'images')
38 | print('create web directory %s...' % self.web_dir)
39 | util.mkdirs([self.img_dir,])
40 |
41 | # |visuals|: dictionary of images to display or save
42 | def display_current_results(self, visuals, epoch, nrows=None, res=256):
43 | if self.display_id > 0: # show images in the browser
44 | title = self.name
45 | if(nrows is None):
46 | nrows = int(math.ceil(len(visuals.items()) / 2.0))
47 | images = []
48 | idx = 0
49 | for label, image_numpy in visuals.items():
50 | title += " | " if idx % nrows == 0 else ", "
51 | title += label
52 | img = image_numpy.transpose([2, 0, 1])
53 | img = zoom_to_res(img,res=res,order=0)
54 | images.append(img)
55 | idx += 1
56 | if len(visuals.items()) % 2 != 0:
57 | white_image = np.ones_like(image_numpy.transpose([2, 0, 1]))*255
58 | white_image = zoom_to_res(white_image,res=res,order=0)
59 | images.append(white_image)
60 | self.vis.images(images, nrow=nrows, win=self.display_id + 1,
61 | opts=dict(title=title))
62 |
63 | if self.use_html: # save images to a html file
64 | for label, image_numpy in visuals.items():
65 | img_path = os.path.join(self.img_dir, 'epoch%.3d_cnt%.6d_%s.png' % (epoch, self.display_cnt, label))
66 | util.save_image(zoom_to_res(image_numpy, res=res, axis=2), img_path)
67 |
68 | self.display_cnt += 1
69 | self.display_cnt_high = np.maximum(self.display_cnt_high, self.display_cnt)
70 |
71 | # update website
72 | webpage = html.HTML(self.web_dir, 'Experiment name = %s' % self.name, reflesh=1)
73 | for n in range(epoch, 0, -1):
74 | webpage.add_header('epoch [%d]' % n)
75 | if(n==epoch):
76 | high = self.display_cnt
77 | else:
78 | high = self.display_cnt_high
79 | for c in range(high-1,-1,-1):
80 | ims = []
81 | txts = []
82 | links = []
83 |
84 | for label, image_numpy in visuals.items():
85 | img_path = 'epoch%.3d_cnt%.6d_%s.png' % (n, c, label)
86 | ims.append(os.path.join('images',img_path))
87 | txts.append(label)
88 | links.append(os.path.join('images',img_path))
89 | webpage.add_images(ims, txts, links, width=self.win_size)
90 | webpage.save()
91 |
92 | # save errors into a directory
93 | def plot_current_errors_save(self, epoch, counter_ratio, opt, errors,keys='+ALL',name='loss', to_plot=False):
94 | if not hasattr(self, 'plot_data'):
95 | self.plot_data = {'X':[],'Y':[], 'legend':list(errors.keys())}
96 | self.plot_data['X'].append(epoch + counter_ratio)
97 | self.plot_data['Y'].append([errors[k] for k in self.plot_data['legend']])
98 |
99 | # embed()
100 | if(keys=='+ALL'):
101 | plot_keys = self.plot_data['legend']
102 | else:
103 | plot_keys = keys
104 |
105 | if(to_plot):
106 | (f,ax) = plt.subplots(1,1)
107 | for (k,kname) in enumerate(plot_keys):
108 | kk = np.where(np.array(self.plot_data['legend'])==kname)[0][0]
109 | x = self.plot_data['X']
110 | y = np.array(self.plot_data['Y'])[:,kk]
111 | if(to_plot):
112 | ax.plot(x, y, 'o-', label=kname)
113 | np.save(os.path.join(self.web_dir,'%s_x')%kname,x)
114 | np.save(os.path.join(self.web_dir,'%s_y')%kname,y)
115 |
116 | if(to_plot):
117 | plt.legend(loc=0,fontsize='small')
118 | plt.xlabel('epoch')
119 | plt.ylabel('Value')
120 | f.savefig(os.path.join(self.web_dir,'%s.png'%name))
121 | f.clf()
122 | plt.close()
123 |
124 | # errors: dictionary of error labels and values
125 | def plot_current_errors(self, epoch, counter_ratio, opt, errors):
126 | if not hasattr(self, 'plot_data'):
127 | self.plot_data = {'X':[],'Y':[], 'legend':list(errors.keys())}
128 | self.plot_data['X'].append(epoch + counter_ratio)
129 | self.plot_data['Y'].append([errors[k] for k in self.plot_data['legend']])
130 | self.vis.line(
131 | X=np.stack([np.array(self.plot_data['X'])]*len(self.plot_data['legend']),1),
132 | Y=np.array(self.plot_data['Y']),
133 | opts={
134 | 'title': self.name + ' loss over time',
135 | 'legend': self.plot_data['legend'],
136 | 'xlabel': 'epoch',
137 | 'ylabel': 'loss'},
138 | win=self.display_id)
139 |
140 | # errors: same format as |errors| of plotCurrentErrors
141 | def print_current_errors(self, epoch, i, errors, t, t2=-1, t2o=-1, fid=None):
142 | message = '(ep: %d, it: %d, t: %.3f[s], ept: %.2f/%.2f[h]) ' % (epoch, i, t, t2o, t2)
143 | message += (', ').join(['%s: %.3f' % (k, v) for k, v in errors.items()])
144 |
145 | print(message)
146 | if(fid is not None):
147 | fid.write('%s\n'%message)
148 |
149 |
150 | # save image to the disk
151 | def save_images_simple(self, webpage, images, names, in_txts, prefix='', res=256):
152 | image_dir = webpage.get_image_dir()
153 | ims = []
154 | txts = []
155 | links = []
156 |
157 | for name, image_numpy, txt in zip(names, images, in_txts):
158 | image_name = '%s_%s.png' % (prefix, name)
159 | save_path = os.path.join(image_dir, image_name)
160 | if(res is not None):
161 | util.save_image(zoom_to_res(image_numpy,res=res,axis=2), save_path)
162 | else:
163 | util.save_image(image_numpy, save_path)
164 |
165 | ims.append(os.path.join(webpage.img_subdir,image_name))
166 | # txts.append(name)
167 | txts.append(txt)
168 | links.append(os.path.join(webpage.img_subdir,image_name))
169 | # embed()
170 | webpage.add_images(ims, txts, links, width=self.win_size)
171 |
172 | # save image to the disk
173 | def save_images(self, webpage, images, names, image_path, title=''):
174 | image_dir = webpage.get_image_dir()
175 | # short_path = ntpath.basename(image_path)
176 | # name = os.path.splitext(short_path)[0]
177 | # name = short_path
178 | # webpage.add_header('%s, %s' % (name, title))
179 | ims = []
180 | txts = []
181 | links = []
182 |
183 | for label, image_numpy in zip(names, images):
184 | image_name = '%s.jpg' % (label,)
185 | save_path = os.path.join(image_dir, image_name)
186 | util.save_image(image_numpy, save_path)
187 |
188 | ims.append(image_name)
189 | txts.append(label)
190 | links.append(image_name)
191 | webpage.add_images(ims, txts, links, width=self.win_size)
192 |
193 | # save image to the disk
194 | # def save_images(self, webpage, visuals, image_path, short=False):
195 | # image_dir = webpage.get_image_dir()
196 | # if short:
197 | # short_path = ntpath.basename(image_path)
198 | # name = os.path.splitext(short_path)[0]
199 | # else:
200 | # name = image_path
201 |
202 | # webpage.add_header(name)
203 | # ims = []
204 | # txts = []
205 | # links = []
206 |
207 | # for label, image_numpy in visuals.items():
208 | # image_name = '%s_%s.png' % (name, label)
209 | # save_path = os.path.join(image_dir, image_name)
210 | # util.save_image(image_numpy, save_path)
211 |
212 | # ims.append(image_name)
213 | # txts.append(label)
214 | # links.append(image_name)
215 | # webpage.add_images(ims, txts, links, width=self.win_size)
216 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/lpips.py:
--------------------------------------------------------------------------------
1 |
2 | from __future__ import absolute_import
3 |
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.init as init
7 | from torch.autograd import Variable
8 | import numpy as np
9 | from . import pretrained_networks as pn
10 | import torch.nn
11 |
12 | import PerceptualSimilarity.lpips as lpips
13 |
14 | def spatial_average(in_tens, keepdim=True):
15 | return in_tens.mean([2,3],keepdim=keepdim)
16 |
17 | def upsample(in_tens, out_HW=(64,64)): # assumes scale factor is same for H and W
18 | in_H, in_W = in_tens.shape[2], in_tens.shape[3]
19 | return nn.Upsample(size=out_HW, mode='bilinear', align_corners=False)(in_tens)
20 |
21 | # Learned perceptual metric
22 | class LPIPS(nn.Module):
23 | def __init__(self, pretrained=True, net='alex', version='0.1', lpips=True, spatial=False,
24 | pnet_rand=False, pnet_tune=False, use_dropout=True, model_path=None, eval_mode=True, verbose=True):
25 | # lpips - [True] means with linear calibration on top of base network
26 | # pretrained - [True] means load linear weights
27 |
28 | super(LPIPS, self).__init__()
29 | if(verbose):
30 | print('Setting up [%s] perceptual loss: trunk [%s], v[%s], spatial [%s]'%
31 | ('LPIPS' if lpips else 'baseline', net, version, 'on' if spatial else 'off'))
32 |
33 | self.pnet_type = net
34 | self.pnet_tune = pnet_tune
35 | self.pnet_rand = pnet_rand
36 | self.spatial = spatial
37 | self.lpips = lpips # false means baseline of just averaging all layers
38 | self.version = version
39 | self.scaling_layer = ScalingLayer()
40 |
41 | if(self.pnet_type in ['vgg','vgg16']):
42 | net_type = pn.vgg16
43 | self.chns = [64,128,256,512,512]
44 | elif(self.pnet_type=='alex'):
45 | net_type = pn.alexnet
46 | self.chns = [64,192,384,256,256]
47 | elif(self.pnet_type=='squeeze'):
48 | net_type = pn.squeezenet
49 | self.chns = [64,128,256,384,384,512,512]
50 | self.L = len(self.chns)
51 |
52 | self.net = net_type(pretrained=not self.pnet_rand, requires_grad=self.pnet_tune)
53 |
54 | if(lpips):
55 | self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
56 | self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
57 | self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
58 | self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
59 | self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
60 | self.lins = [self.lin0,self.lin1,self.lin2,self.lin3,self.lin4]
61 | if(self.pnet_type=='squeeze'): # 7 layers for squeezenet
62 | self.lin5 = NetLinLayer(self.chns[5], use_dropout=use_dropout)
63 | self.lin6 = NetLinLayer(self.chns[6], use_dropout=use_dropout)
64 | self.lins+=[self.lin5,self.lin6]
65 | self.lins = nn.ModuleList(self.lins)
66 |
67 | if(pretrained):
68 | if(model_path is None):
69 | import inspect
70 | import os
71 | model_path = os.path.abspath(os.path.join(inspect.getfile(self.__init__), '..', 'weights/v%s/%s.pth'%(version,net)))
72 |
73 | if(verbose):
74 | print('Loading model from: %s'%model_path)
75 | self.load_state_dict(torch.load(model_path, map_location='cpu'), strict=False)
76 |
77 | if(eval_mode):
78 | self.eval()
79 |
80 | def forward(self, in0, in1, retPerLayer=False, normalize=False):
81 | if normalize: # turn on this flag if input is [0,1] so it can be adjusted to [-1, +1]
82 | in0 = 2 * in0 - 1
83 | in1 = 2 * in1 - 1
84 |
85 | # v0.0 - original release had a bug, where input was not scaled
86 | in0_input, in1_input = (self.scaling_layer(in0), self.scaling_layer(in1)) if self.version=='0.1' else (in0, in1)
87 | outs0, outs1 = self.net.forward(in0_input), self.net.forward(in1_input)
88 | feats0, feats1, diffs = {}, {}, {}
89 |
90 | for kk in range(self.L):
91 | feats0[kk], feats1[kk] = lpips.normalize_tensor(outs0[kk]), lpips.normalize_tensor(outs1[kk])
92 | diffs[kk] = (feats0[kk]-feats1[kk])**2
93 |
94 | if(self.lpips):
95 | if(self.spatial):
96 | res = [upsample(self.lins[kk](diffs[kk]), out_HW=in0.shape[2:]) for kk in range(self.L)]
97 | else:
98 | res = [spatial_average(self.lins[kk](diffs[kk]), keepdim=True) for kk in range(self.L)]
99 | else:
100 | if(self.spatial):
101 | res = [upsample(diffs[kk].sum(dim=1,keepdim=True), out_HW=in0.shape[2:]) for kk in range(self.L)]
102 | else:
103 | res = [spatial_average(diffs[kk].sum(dim=1,keepdim=True), keepdim=True) for kk in range(self.L)]
104 |
105 | val = res[0]
106 | for l in range(1,self.L):
107 | val += res[l]
108 |
109 | # a = spatial_average(self.lins[kk](diffs[kk]), keepdim=True)
110 | # b = torch.max(self.lins[kk](feats0[kk]**2))
111 | # for kk in range(self.L):
112 | # a += spatial_average(self.lins[kk](diffs[kk]), keepdim=True)
113 | # b = torch.max(b,torch.max(self.lins[kk](feats0[kk]**2)))
114 | # a = a/self.L
115 | # from IPython import embed
116 | # embed()
117 | # return 10*torch.log10(b/a)
118 |
119 | if(retPerLayer):
120 | return (val, res)
121 | else:
122 | return val
123 |
124 |
125 | class ScalingLayer(nn.Module):
126 | def __init__(self):
127 | super(ScalingLayer, self).__init__()
128 | self.register_buffer('shift', torch.Tensor([-.030,-.088,-.188])[None,:,None,None])
129 | self.register_buffer('scale', torch.Tensor([.458,.448,.450])[None,:,None,None])
130 |
131 | def forward(self, inp):
132 | return (inp - self.shift) / self.scale
133 |
134 |
135 | class NetLinLayer(nn.Module):
136 | ''' A single linear layer which does a 1x1 conv '''
137 | def __init__(self, chn_in, chn_out=1, use_dropout=False):
138 | super(NetLinLayer, self).__init__()
139 |
140 | layers = [nn.Dropout(),] if(use_dropout) else []
141 | layers += [nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False),]
142 | self.model = nn.Sequential(*layers)
143 |
144 | def forward(self, x):
145 | return self.model(x)
146 |
147 | class Dist2LogitLayer(nn.Module):
148 | ''' takes 2 distances, puts through fc layers, spits out value between [0,1] (if use_sigmoid is True) '''
149 | def __init__(self, chn_mid=32, use_sigmoid=True):
150 | super(Dist2LogitLayer, self).__init__()
151 |
152 | layers = [nn.Conv2d(5, chn_mid, 1, stride=1, padding=0, bias=True),]
153 | layers += [nn.LeakyReLU(0.2,True),]
154 | layers += [nn.Conv2d(chn_mid, chn_mid, 1, stride=1, padding=0, bias=True),]
155 | layers += [nn.LeakyReLU(0.2,True),]
156 | layers += [nn.Conv2d(chn_mid, 1, 1, stride=1, padding=0, bias=True),]
157 | if(use_sigmoid):
158 | layers += [nn.Sigmoid(),]
159 | self.model = nn.Sequential(*layers)
160 |
161 | def forward(self,d0,d1,eps=0.1):
162 | return self.model.forward(torch.cat((d0,d1,d0-d1,d0/(d1+eps),d1/(d0+eps)),dim=1))
163 |
164 | class BCERankingLoss(nn.Module):
165 | def __init__(self, chn_mid=32):
166 | super(BCERankingLoss, self).__init__()
167 | self.net = Dist2LogitLayer(chn_mid=chn_mid)
168 | # self.parameters = list(self.net.parameters())
169 | self.loss = torch.nn.BCELoss()
170 |
171 | def forward(self, d0, d1, judge):
172 | per = (judge+1.)/2.
173 | self.logit = self.net.forward(d0,d1)
174 | return self.loss(self.logit, per)
175 |
176 | # L2, DSSIM metrics
177 | class FakeNet(nn.Module):
178 | def __init__(self, use_gpu=True, colorspace='Lab'):
179 | super(FakeNet, self).__init__()
180 | self.use_gpu = use_gpu
181 | self.colorspace = colorspace
182 |
183 | class L2(FakeNet):
184 | def forward(self, in0, in1, retPerLayer=None):
185 | assert(in0.size()[0]==1) # currently only supports batchSize 1
186 |
187 | if(self.colorspace=='RGB'):
188 | (N,C,X,Y) = in0.size()
189 | value = torch.mean(torch.mean(torch.mean((in0-in1)**2,dim=1).view(N,1,X,Y),dim=2).view(N,1,1,Y),dim=3).view(N)
190 | return value
191 | elif(self.colorspace=='Lab'):
192 | value = lpips.l2(lpips.tensor2np(lpips.tensor2tensorlab(in0.data,to_norm=False)),
193 | lpips.tensor2np(lpips.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
194 | ret_var = Variable( torch.Tensor((value,) ) )
195 | if(self.use_gpu):
196 | ret_var = ret_var.cuda()
197 | return ret_var
198 |
199 | class DSSIM(FakeNet):
200 |
201 | def forward(self, in0, in1, retPerLayer=None):
202 | assert(in0.size()[0]==1) # currently only supports batchSize 1
203 |
204 | if(self.colorspace=='RGB'):
205 | value = lpips.dssim(1.*lpips.tensor2im(in0.data), 1.*lpips.tensor2im(in1.data), range=255.).astype('float')
206 | elif(self.colorspace=='Lab'):
207 | value = lpips.dssim(lpips.tensor2np(lpips.tensor2tensorlab(in0.data,to_norm=False)),
208 | lpips.tensor2np(lpips.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
209 | ret_var = Variable( torch.Tensor((value,) ) )
210 | if(self.use_gpu):
211 | ret_var = ret_var.cuda()
212 | return ret_var
213 |
214 | def print_network(net):
215 | num_params = 0
216 | for param in net.parameters():
217 | num_params += param.numel()
218 | print('Network',net)
219 | print('Total number of parameters: %d' % num_params)
220 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## Perceptual Similarity Metric and Dataset [[Project Page]](http://richzhang.github.io/PerceptualSimilarity/)
3 |
4 | **The Unreasonable Effectiveness of Deep Features as a Perceptual Metric**
5 | [Richard Zhang](https://richzhang.github.io/), [Phillip Isola](http://web.mit.edu/phillipi/), [Alexei A. Efros](http://www.eecs.berkeley.edu/~efros/), [Eli Shechtman](https://research.adobe.com/person/eli-shechtman/), [Oliver Wang](http://www.oliverwang.info/). In [CVPR](https://arxiv.org/abs/1801.03924), 2018.
6 |
7 | 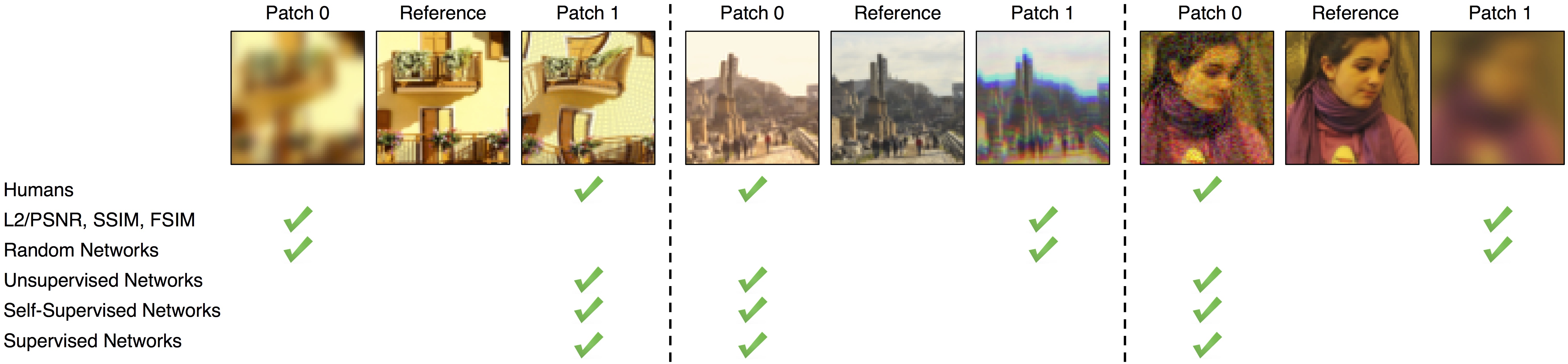 8 |
9 | ### Quick start
10 |
11 | Run `pip install lpips`. The following Python code is all you need.
12 |
13 | ```python
14 | import lpips
15 | loss_fn_alex = lpips.LPIPS(net='alex') # best forward scores
16 | loss_fn_vgg = lpips.LPIPS(net='vgg') # closer to "traditional" perceptual loss, when used for optimization
17 |
18 | import torch
19 | img0 = torch.zeros(1,3,64,64) # image should be RGB, IMPORTANT: normalized to [-1,1]
20 | img1 = torch.zeros(1,3,64,64)
21 | d = loss_fn_alex(img0, img1)
22 | ```
23 |
24 | More thorough information about variants is below. This repository contains our **perceptual metric (LPIPS)** and **dataset (BAPPS)**. It can also be used as a "perceptual loss". This uses PyTorch; a Tensorflow alternative is [here](https://github.com/alexlee-gk/lpips-tensorflow).
25 |
26 |
27 | **Table of Contents**
8 |
9 | ### Quick start
10 |
11 | Run `pip install lpips`. The following Python code is all you need.
12 |
13 | ```python
14 | import lpips
15 | loss_fn_alex = lpips.LPIPS(net='alex') # best forward scores
16 | loss_fn_vgg = lpips.LPIPS(net='vgg') # closer to "traditional" perceptual loss, when used for optimization
17 |
18 | import torch
19 | img0 = torch.zeros(1,3,64,64) # image should be RGB, IMPORTANT: normalized to [-1,1]
20 | img1 = torch.zeros(1,3,64,64)
21 | d = loss_fn_alex(img0, img1)
22 | ```
23 |
24 | More thorough information about variants is below. This repository contains our **perceptual metric (LPIPS)** and **dataset (BAPPS)**. It can also be used as a "perceptual loss". This uses PyTorch; a Tensorflow alternative is [here](https://github.com/alexlee-gk/lpips-tensorflow).
25 |
26 |
27 | **Table of Contents**
28 | 1. [Learned Perceptual Image Patch Similarity (LPIPS) metric](#1-learned-perceptual-image-patch-similarity-lpips-metric)
29 | a. [Basic Usage](#a-basic-usage) If you just want to run the metric through command line, this is all you need.
30 | b. ["Perceptual Loss" usage](#b-backpropping-through-the-metric)
31 | c. [About the metric](#c-about-the-metric)
32 | 2. [Berkeley-Adobe Perceptual Patch Similarity (BAPPS) dataset](#2-berkeley-adobe-perceptual-patch-similarity-bapps-dataset)
33 | a. [Download](#a-downloading-the-dataset)
34 | b. [Evaluation](#b-evaluating-a-perceptual-similarity-metric-on-a-dataset)
35 | c. [About the dataset](#c-about-the-dataset)
36 | d. [Train the metric using the dataset](#d-using-the-dataset-to-train-the-metric)
37 |
38 | ## (0) Dependencies/Setup
39 |
40 | ### Installation
41 | - Install PyTorch 1.0+ and torchvision fom http://pytorch.org
42 |
43 | ```bash
44 | pip install -r requirements.txt
45 | ```
46 | - Clone this repo:
47 | ```bash
48 | git clone https://github.com/richzhang/PerceptualSimilarity
49 | cd PerceptualSimilarity
50 | ```
51 |
52 | ## (1) Learned Perceptual Image Patch Similarity (LPIPS) metric
53 |
54 | Evaluate the distance between image patches. **Higher means further/more different. Lower means more similar.**
55 |
56 | ### (A) Basic Usage
57 |
58 | #### (A.I) Line commands
59 |
60 | Example scripts to take the distance between 2 specific images, all corresponding pairs of images in 2 directories, or all pairs of images within a directory:
61 |
62 | ```
63 | python lpips_2imgs.py -p0 imgs/ex_ref.png -p1 imgs/ex_p0.png --use_gpu
64 | python lpips_2dirs.py -d0 imgs/ex_dir0 -d1 imgs/ex_dir1 -o imgs/example_dists.txt --use_gpu
65 | python lpips_1dir_allpairs.py -d imgs/ex_dir_pair -o imgs/example_dists_pair.txt --use_gpu
66 | ```
67 |
68 | #### (A.II) Python code
69 |
70 | File [test_network.py](test_network.py) shows example usage. This snippet is all you really need.
71 |
72 | ```python
73 | import lpips
74 | loss_fn = lpips.LPIPS(net='alex')
75 | d = loss_fn.forward(im0,im1)
76 | ```
77 |
78 | Variables ```im0, im1``` is a PyTorch Tensor/Variable with shape ```Nx3xHxW``` (```N``` patches of size ```HxW```, RGB images scaled in `[-1,+1]`). This returns `d`, a length `N` Tensor/Variable.
79 |
80 | Run `python test_network.py` to take the distance between example reference image [`ex_ref.png`](imgs/ex_ref.png) to distorted images [`ex_p0.png`](./imgs/ex_p0.png) and [`ex_p1.png`](imgs/ex_p1.png). Before running it - which do you think *should* be closer?
81 |
82 | **Some Options** By default in `model.initialize`:
83 | - By default, `net='alex'`. Network `alex` is fastest, performs the best (as a forward metric), and is the default. For backpropping, `net='vgg'` loss is closer to the traditional "perceptual loss".
84 | - By default, `lpips=True`. This adds a linear calibration on top of intermediate features in the net. Set this to `lpips=False` to equally weight all the features.
85 |
86 | ### (B) Backpropping through the metric
87 |
88 | File [`lpips_loss.py`](lpips_loss.py) shows how to iteratively optimize using the metric. Run `python lpips_loss.py` for a demo. The code can also be used to implement vanilla VGG loss, without our learned weights.
89 |
90 | ### (C) About the metric
91 |
92 | **Higher means further/more different. Lower means more similar.**
93 |
94 | We found that deep network activations work surprisingly well as a perceptual similarity metric. This was true across network architectures (SqueezeNet [2.8 MB], AlexNet [9.1 MB], and VGG [58.9 MB] provided similar scores) and supervisory signals (unsupervised, self-supervised, and supervised all perform strongly). We slightly improved scores by linearly "calibrating" networks - adding a linear layer on top of off-the-shelf classification networks. We provide 3 variants, using linear layers on top of the SqueezeNet, AlexNet (default), and VGG networks.
95 |
96 | If you use LPIPS in your publication, please specify which version you are using. The current version is 0.1. You can set `version='0.0'` for the initial release.
97 |
98 | ## (2) Berkeley Adobe Perceptual Patch Similarity (BAPPS) dataset
99 |
100 | ### (A) Downloading the dataset
101 |
102 | Run `bash ./scripts/download_dataset.sh` to download and unzip the dataset into directory `./dataset`. It takes [6.6 GB] total. Alternatively, run `bash ./scripts/download_dataset_valonly.sh` to only download the validation set [1.3 GB].
103 | - 2AFC train [5.3 GB]
104 | - 2AFC val [1.1 GB]
105 | - JND val [0.2 GB]
106 |
107 | ### (B) Evaluating a perceptual similarity metric on a dataset
108 |
109 | Script `test_dataset_model.py` evaluates a perceptual model on a subset of the dataset.
110 |
111 | **Dataset flags**
112 | - `--dataset_mode`: `2afc` or `jnd`, which type of perceptual judgment to evaluate
113 | - `--datasets`: list the datasets to evaluate
114 | - if `--dataset_mode 2afc`: choices are [`train/traditional`, `train/cnn`, `val/traditional`, `val/cnn`, `val/superres`, `val/deblur`, `val/color`, `val/frameinterp`]
115 | - if `--dataset_mode jnd`: choices are [`val/traditional`, `val/cnn`]
116 |
117 | **Perceptual similarity model flags**
118 | - `--model`: perceptual similarity model to use
119 | - `lpips` for our LPIPS learned similarity model (linear network on top of internal activations of pretrained network)
120 | - `baseline` for a classification network (uncalibrated with all layers averaged)
121 | - `l2` for Euclidean distance
122 | - `ssim` for Structured Similarity Image Metric
123 | - `--net`: [`squeeze`,`alex`,`vgg`] for the `net-lin` and `net` models; ignored for `l2` and `ssim` models
124 | - `--colorspace`: choices are [`Lab`,`RGB`], used for the `l2` and `ssim` models; ignored for `net-lin` and `net` models
125 |
126 | **Misc flags**
127 | - `--batch_size`: evaluation batch size (will default to 1)
128 | - `--use_gpu`: turn on this flag for GPU usage
129 |
130 | An example usage is as follows: `python ./test_dataset_model.py --dataset_mode 2afc --datasets val/traditional val/cnn --model lpips --net alex --use_gpu --batch_size 50`. This would evaluate our model on the "traditional" and "cnn" validation datasets.
131 |
132 | ### (C) About the dataset
133 |
134 | The dataset contains two types of perceptual judgements: **Two Alternative Forced Choice (2AFC)** and **Just Noticeable Differences (JND)**.
135 |
136 | **(1) 2AFC** Evaluators were given a patch triplet (1 reference + 2 distorted). They were asked to select which of the distorted was "closer" to the reference.
137 |
138 | Training sets contain 2 judgments/triplet.
139 | - `train/traditional` [56.6k triplets]
140 | - `train/cnn` [38.1k triplets]
141 | - `train/mix` [56.6k triplets]
142 |
143 | Validation sets contain 5 judgments/triplet.
144 | - `val/traditional` [4.7k triplets]
145 | - `val/cnn` [4.7k triplets]
146 | - `val/superres` [10.9k triplets]
147 | - `val/deblur` [9.4k triplets]
148 | - `val/color` [4.7k triplets]
149 | - `val/frameinterp` [1.9k triplets]
150 |
151 | Each 2AFC subdirectory contains the following folders:
152 | - `ref`: original reference patches
153 | - `p0,p1`: two distorted patches
154 | - `judge`: human judgments - 0 if all preferred p0, 1 if all humans preferred p1
155 |
156 | **(2) JND** Evaluators were presented with two patches - a reference and a distorted - for a limited time. They were asked if the patches were the same (identically) or different.
157 |
158 | Each set contains 3 human evaluations/example.
159 | - `val/traditional` [4.8k pairs]
160 | - `val/cnn` [4.8k pairs]
161 |
162 | Each JND subdirectory contains the following folders:
163 | - `p0,p1`: two patches
164 | - `same`: human judgments: 0 if all humans thought patches were different, 1 if all humans thought patches were same
165 |
166 | ### (D) Using the dataset to train the metric
167 |
168 | See script `train_test_metric.sh` for an example of training and testing the metric. The script will train a model on the full training set for 10 epochs, and then test the learned metric on all of the validation sets. The numbers should roughly match the **Alex - lin** row in Table 5 in the [paper](https://arxiv.org/abs/1801.03924). The code supports training a linear layer on top of an existing representation. Training will add a subdirectory in the `checkpoints` directory.
169 |
170 | You can also train "scratch" and "tune" versions by running `train_test_metric_scratch.sh` and `train_test_metric_tune.sh`, respectively.
171 |
172 | ## Citation
173 |
174 | If you find this repository useful for your research, please use the following.
175 |
176 | ```
177 | @inproceedings{zhang2018perceptual,
178 | title={The Unreasonable Effectiveness of Deep Features as a Perceptual Metric},
179 | author={Zhang, Richard and Isola, Phillip and Efros, Alexei A and Shechtman, Eli and Wang, Oliver},
180 | booktitle={CVPR},
181 | year={2018}
182 | }
183 | ```
184 |
185 | ## Acknowledgements
186 |
187 | This repository borrows partially from the [pytorch-CycleGAN-and-pix2pix](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix) repository. The average precision (AP) code is borrowed from the [py-faster-rcnn](https://github.com/rbgirshick/py-faster-rcnn/blob/master/lib/datasets/voc_eval.py) repository. [Angjoo Kanazawa](https://github.com/akanazawa), [Connelly Barnes](http://www.connellybarnes.com/work/), [Gaurav Mittal](https://github.com/g1910), [wilhelmhb](https://github.com/wilhelmhb), [Filippo Mameli](https://github.com/mameli), [SuperShinyEyes](https://github.com/SuperShinyEyes), [Minyoung Huh](http://people.csail.mit.edu/minhuh/) helped to improve the codebase.
188 |
--------------------------------------------------------------------------------
/PerceptualSimilarity/lpips/trainer.py:
--------------------------------------------------------------------------------
1 |
2 | from __future__ import absolute_import
3 |
4 | import numpy as np
5 | import torch
6 | from torch import nn
7 | from collections import OrderedDict
8 | from torch.autograd import Variable
9 | from scipy.ndimage import zoom
10 | from tqdm import tqdm
11 | import PerceptualSimilarity.lpips as lpips
12 | import os
13 |
14 |
15 | class Trainer():
16 | def name(self):
17 | return self.model_name
18 |
19 | def initialize(self, model='lpips', net='alex', colorspace='Lab', pnet_rand=False, pnet_tune=False, model_path=None,
20 | use_gpu=True, printNet=False, spatial=False,
21 | is_train=False, lr=.0001, beta1=0.5, version='0.1', gpu_ids=[0]):
22 | '''
23 | INPUTS
24 | model - ['lpips'] for linearly calibrated network
25 | ['baseline'] for off-the-shelf network
26 | ['L2'] for L2 distance in Lab colorspace
27 | ['SSIM'] for ssim in RGB colorspace
28 | net - ['squeeze','alex','vgg']
29 | model_path - if None, will look in weights/[NET_NAME].pth
30 | colorspace - ['Lab','RGB'] colorspace to use for L2 and SSIM
31 | use_gpu - bool - whether or not to use a GPU
32 | printNet - bool - whether or not to print network architecture out
33 | spatial - bool - whether to output an array containing varying distances across spatial dimensions
34 | is_train - bool - [True] for training mode
35 | lr - float - initial learning rate
36 | beta1 - float - initial momentum term for adam
37 | version - 0.1 for latest, 0.0 was original (with a bug)
38 | gpu_ids - int array - [0] by default, gpus to use
39 | '''
40 | self.use_gpu = use_gpu
41 | self.gpu_ids = gpu_ids
42 | self.model = model
43 | self.net = net
44 | self.is_train = is_train
45 | self.spatial = spatial
46 | self.model_name = '%s [%s]'%(model,net)
47 |
48 | if(self.model == 'lpips'): # pretrained net + linear layer
49 | self.net = lpips.LPIPS(pretrained=not is_train, net=net, version=version, lpips=True, spatial=spatial,
50 | pnet_rand=pnet_rand, pnet_tune=pnet_tune,
51 | use_dropout=True, model_path=model_path, eval_mode=False)
52 | elif(self.model=='baseline'): # pretrained network
53 | self.net = lpips.LPIPS(pnet_rand=pnet_rand, net=net, lpips=False)
54 | elif(self.model in ['L2','l2']):
55 | self.net = lpips.L2(use_gpu=use_gpu,colorspace=colorspace) # not really a network, only for testing
56 | self.model_name = 'L2'
57 | elif(self.model in ['DSSIM','dssim','SSIM','ssim']):
58 | self.net = lpips.DSSIM(use_gpu=use_gpu,colorspace=colorspace)
59 | self.model_name = 'SSIM'
60 | else:
61 | raise ValueError("Model [%s] not recognized." % self.model)
62 |
63 | self.parameters = list(self.net.parameters())
64 |
65 | if self.is_train: # training mode
66 | # extra network on top to go from distances (d0,d1) => predicted human judgment (h*)
67 | self.rankLoss = lpips.BCERankingLoss()
68 | self.parameters += list(self.rankLoss.net.parameters())
69 | self.lr = lr
70 | self.old_lr = lr
71 | self.optimizer_net = torch.optim.Adam(self.parameters, lr=lr, betas=(beta1, 0.999))
72 | else: # test mode
73 | self.net.eval()
74 |
75 | if(use_gpu):
76 | self.net.to(gpu_ids[0])
77 | self.net = torch.nn.DataParallel(self.net, device_ids=gpu_ids)
78 | if(self.is_train):
79 | self.rankLoss = self.rankLoss.to(device=gpu_ids[0]) # just put this on GPU0
80 |
81 | if(printNet):
82 | print('---------- Networks initialized -------------')
83 | networks.print_network(self.net)
84 | print('-----------------------------------------------')
85 |
86 | def forward(self, in0, in1, retPerLayer=False):
87 | ''' Function computes the distance between image patches in0 and in1
88 | INPUTS
89 | in0, in1 - torch.Tensor object of shape Nx3xXxY - image patch scaled to [-1,1]
90 | OUTPUT
91 | computed distances between in0 and in1
92 | '''
93 |
94 | return self.net.forward(in0, in1, retPerLayer=retPerLayer)
95 |
96 | # ***** TRAINING FUNCTIONS *****
97 | def optimize_parameters(self):
98 | self.forward_train()
99 | self.optimizer_net.zero_grad()
100 | self.backward_train()
101 | self.optimizer_net.step()
102 | self.clamp_weights()
103 |
104 | def clamp_weights(self):
105 | for module in self.net.modules():
106 | if(hasattr(module, 'weight') and module.kernel_size==(1,1)):
107 | module.weight.data = torch.clamp(module.weight.data,min=0)
108 |
109 | def set_input(self, data):
110 | self.input_ref = data['ref']
111 | self.input_p0 = data['p0']
112 | self.input_p1 = data['p1']
113 | self.input_judge = data['judge']
114 |
115 | if(self.use_gpu):
116 | self.input_ref = self.input_ref.to(device=self.gpu_ids[0])
117 | self.input_p0 = self.input_p0.to(device=self.gpu_ids[0])
118 | self.input_p1 = self.input_p1.to(device=self.gpu_ids[0])
119 | self.input_judge = self.input_judge.to(device=self.gpu_ids[0])
120 |
121 | self.var_ref = Variable(self.input_ref,requires_grad=True)
122 | self.var_p0 = Variable(self.input_p0,requires_grad=True)
123 | self.var_p1 = Variable(self.input_p1,requires_grad=True)
124 |
125 | def forward_train(self): # run forward pass
126 | self.d0 = self.forward(self.var_ref, self.var_p0)
127 | self.d1 = self.forward(self.var_ref, self.var_p1)
128 | self.acc_r = self.compute_accuracy(self.d0,self.d1,self.input_judge)
129 |
130 | self.var_judge = Variable(1.*self.input_judge).view(self.d0.size())
131 |
132 | self.loss_total = self.rankLoss.forward(self.d0, self.d1, self.var_judge*2.-1.)
133 |
134 | return self.loss_total
135 |
136 | def backward_train(self):
137 | torch.mean(self.loss_total).backward()
138 |
139 | def compute_accuracy(self,d0,d1,judge):
140 | ''' d0, d1 are Variables, judge is a Tensor '''
141 | d1_lt_d0 = (d1 %f' % (type,self.old_lr, lr))
197 | self.old_lr = lr
198 |
199 |
200 | def get_image_paths(self):
201 | return self.image_paths
202 |
203 | def save_done(self, flag=False):
204 | np.save(os.path.join(self.save_dir, 'done_flag'),flag)
205 | np.savetxt(os.path.join(self.save_dir, 'done_flag'),[flag,],fmt='%i')
206 |
207 |
208 | def score_2afc_dataset(data_loader, func, name=''):
209 | ''' Function computes Two Alternative Forced Choice (2AFC) score using
210 | distance function 'func' in dataset 'data_loader'
211 | INPUTS
212 | data_loader - CustomDatasetDataLoader object - contains a TwoAFCDataset inside
213 | func - callable distance function - calling d=func(in0,in1) should take 2
214 | pytorch tensors with shape Nx3xXxY, and return numpy array of length N
215 | OUTPUTS
216 | [0] - 2AFC score in [0,1], fraction of time func agrees with human evaluators
217 | [1] - dictionary with following elements
218 | d0s,d1s - N arrays containing distances between reference patch to perturbed patches
219 | gts - N array in [0,1], preferred patch selected by human evaluators
220 | (closer to "0" for left patch p0, "1" for right patch p1,
221 | "0.6" means 60pct people preferred right patch, 40pct preferred left)
222 | scores - N array in [0,1], corresponding to what percentage function agreed with humans
223 | CONSTS
224 | N - number of test triplets in data_loader
225 | '''
226 |
227 | d0s = []
228 | d1s = []
229 | gts = []
230 |
231 | for data in tqdm(data_loader.load_data(), desc=name):
232 | d0s+=func(data['ref'],data['p0']).data.cpu().numpy().flatten().tolist()
233 | d1s+=func(data['ref'],data['p1']).data.cpu().numpy().flatten().tolist()
234 | gts+=data['judge'].cpu().numpy().flatten().tolist()
235 |
236 | d0s = np.array(d0s)
237 | d1s = np.array(d1s)
238 | gts = np.array(gts)
239 | scores = (d0s 1:
484 | out = self.conv_merge(out)
485 |
486 | return self.skip_add.add(out, x)
487 |
488 |
489 |
490 | class FeatureFusionBlock_custom(nn.Module):
491 | """Feature fusion block."""
492 |
493 | def __init__(
494 | self,
495 | features,
496 | activation,
497 | deconv=False,
498 | bn=False,
499 | expand=False,
500 | align_corners=True,
501 | ):
502 | """Init.
503 |
504 | Args:
505 | features (int): number of features
506 | """
507 | super(FeatureFusionBlock_custom, self).__init__()
508 |
509 | self.deconv = deconv
510 | self.align_corners = align_corners
511 |
512 | self.groups = 1
513 |
514 | self.expand = expand
515 | out_features = features
516 | if self.expand == True:
517 | out_features = features // 2
518 |
519 | self.out_conv = nn.Conv2d(
520 | features,
521 | out_features,
522 | kernel_size=1,
523 | stride=1,
524 | padding=0,
525 | bias=True,
526 | groups=1,
527 | )
528 |
529 | self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
530 | self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
531 |
532 | self.skip_add = nn.quantized.FloatFunctional()
533 |
534 | def forward(self, *xs):
535 | """Forward pass.
536 |
537 | Returns:
538 | tensor: output
539 | """
540 | output = xs[0]
541 |
542 | if len(xs) == 2:
543 | res = self.resConfUnit1(xs[1])
544 | output = self.skip_add.add(output, res)
545 |
546 | output = self.resConfUnit2(output)
547 |
548 | output = nn.functional.interpolate(
549 | output, scale_factor=2, mode="bilinear", align_corners=self.align_corners
550 | )
551 |
552 | output = self.out_conv(output)
553 |
554 | return output
555 |
556 |
557 |
558 | def _make_fusion_block(features, use_bn):
559 | return FeatureFusionBlock_custom(
560 | features,
561 | nn.ReLU(False),
562 | deconv=False,
563 | bn=use_bn,
564 | expand=False,
565 | align_corners=True,
566 | )
567 |
568 |
569 | class BaseModel(torch.nn.Module):
570 | def load(self, path):
571 | """Load model from file.
572 |
573 | Args:
574 | path (str): file path
575 | """
576 | parameters = torch.load(path, map_location=torch.device("cpu"))
577 |
578 | if "optimizer" in parameters:
579 | parameters = parameters["model"]
580 |
581 | self.load_state_dict(parameters)
582 |
583 |
584 | class Interpolate(nn.Module):
585 | """Interpolation module."""
586 |
587 | def __init__(self, scale_factor, mode, align_corners=False):
588 | """Init.
589 |
590 | Args:
591 | scale_factor (float): scaling
592 | mode (str): interpolation mode
593 | """
594 | super(Interpolate, self).__init__()
595 |
596 | self.interp = nn.functional.interpolate
597 | self.scale_factor = scale_factor
598 | self.mode = mode
599 | self.align_corners = align_corners
600 |
601 | def forward(self, x):
602 | """Forward pass.
603 |
604 | Args:
605 | x (tensor): input
606 |
607 | Returns:
608 | tensor: interpolated data
609 | """
610 |
611 | x = self.interp(
612 | x,
613 | scale_factor=self.scale_factor,
614 | mode=self.mode,
615 | align_corners=self.align_corners,
616 | )
617 |
618 | return x
619 |
620 |
621 |
622 | class BRViT(BaseModel):
623 | def __init__(
624 | self,
625 | features=256,
626 | backbone="vitb_rn50_384",
627 | non_negative=False,
628 | readout="project",
629 | channels_last=False,
630 | use_bn=False,
631 | enable_attention_hooks=False,
632 | ):
633 |
634 | super(BRViT, self).__init__()
635 |
636 | self.channels_last = channels_last
637 |
638 | hooks = {"vitb_rn50_384": [0, 1, 8, 11]}
639 |
640 | # Instantiate backbone and reassemble blocks
641 | self.pretrained, self.scratch = _make_encoder(
642 | backbone,
643 | features,
644 | True,
645 | groups=1,
646 | expand=False,
647 | exportable=False,
648 | hooks=hooks[backbone],
649 | use_readout=readout,
650 | enable_attention_hooks=enable_attention_hooks,
651 | )
652 |
653 | self.scratch.refinenet1 = _make_fusion_block(features, use_bn)
654 | self.scratch.refinenet2 = _make_fusion_block(features, use_bn)
655 | self.scratch.refinenet3 = _make_fusion_block(features, use_bn)
656 | self.scratch.refinenet4 = _make_fusion_block(features, use_bn)
657 |
658 | head = nn.Sequential(
659 | nn.Conv2d(features, features // 2, kernel_size=3, stride=1, padding=1),
660 | Interpolate(scale_factor=2, mode="bilinear", align_corners=True),
661 | nn.Conv2d(features // 2, 32, kernel_size=3, stride=1, padding=1),
662 | nn.ReLU(True),
663 | nn.Conv2d(32, 3, kernel_size=1, stride=1, padding=0),
664 | nn.ReLU(True) if non_negative else nn.Identity(),
665 | nn.Identity(),
666 | )
667 |
668 | self.scratch.output_conv = head
669 |
670 | def forward(self, x):
671 | layer_1, layer_2, layer_3, layer_4 = forward_vit(self.pretrained, x)
672 |
673 | layer_1_rn = self.scratch.layer1_rn(layer_1)
674 | layer_2_rn = self.scratch.layer2_rn(layer_2)
675 | layer_3_rn = self.scratch.layer3_rn(layer_3)
676 | layer_4_rn = self.scratch.layer4_rn(layer_4)
677 |
678 | path_4 = self.scratch.refinenet4(layer_4_rn)
679 | path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
680 | path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
681 | path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
682 |
683 | out = self.scratch.output_conv(path_1)
684 |
685 | return out
686 |
--------------------------------------------------------------------------------