├── .github
└── workflows
│ └── clmr.yml
├── .gitignore
├── LICENSE
├── README.md
├── _config.yml
├── clmr
├── data.py
├── datasets
│ ├── __init__.py
│ ├── audio.py
│ ├── dataset.py
│ ├── gtzan.py
│ ├── librispeech.py
│ ├── magnatagatune.py
│ └── million_song_dataset.py
├── evaluation.py
├── models
│ ├── __init__.py
│ ├── model.py
│ ├── sample_cnn.py
│ ├── sample_cnn_xl.py
│ ├── shortchunk_cnn.py
│ └── sinc_net.py
├── modules
│ ├── __init__.py
│ ├── callbacks.py
│ ├── contrastive_learning.py
│ ├── linear_evaluation.py
│ └── supervised_learning.py
└── utils
│ ├── __init__.py
│ ├── checkpoint.py
│ └── yaml_config_hook.py
├── config
└── config.yaml
├── examples
├── .DS_Store
└── clmr-onnxruntime-web
│ ├── .DS_Store
│ ├── clmr_sample-cnn.onnx
│ ├── data
│ ├── .DS_Store
│ ├── fisher_losing_it.mp3
│ ├── fisher_losing_it_22050.mp3
│ ├── john_lennon_imagine.mp3
│ ├── john_lennon_imagine_22050.mp3
│ ├── nirvana_smells_like_teen_spirit.mp3
│ ├── nirvana_smells_like_teen_spirit_22050.mp3
│ ├── queen_love_of_my_life.mp3
│ └── queen_love_of_my_life_22050.mp3
│ └── index.html
├── export.py
├── linear_evaluation.py
├── main.py
├── media
└── clmr_model.png
├── preprocess.py
├── requirements.txt
├── setup.py
└── tests
├── .DS_Store
├── __init__.py
├── data
└── audioset
│ └── 1272-128104-0000.wav
├── test_audioset.py
├── test_dataset.py
└── test_spectogram.py
/.github/workflows/clmr.yml:
--------------------------------------------------------------------------------
1 | # This workflow will install Python dependencies, run tests and lint with a single version of Python
2 | # For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
3 |
4 | name: CLMR
5 |
6 | on:
7 | push:
8 | branches: [ master ]
9 | pull_request:
10 | branches: [ master ]
11 |
12 | jobs:
13 | build:
14 |
15 | runs-on: ubuntu-latest
16 |
17 | steps:
18 | - uses: actions/checkout@v2
19 | - name: Set up Python 3.9
20 | uses: actions/setup-python@v2
21 | with:
22 | python-version: 3.9
23 | - name: Install dependencies
24 | run: |
25 | sudo apt-get install libsndfile1
26 | python -m pip install --upgrade pip
27 | pip install black pytest
28 | if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
29 | - name: Lint with black
30 | run: |
31 | black --check .
32 | - name: Test with pytest
33 | run: |
34 | pytest
35 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .vscode
2 | __pycache__
3 | /data
4 | runs/
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
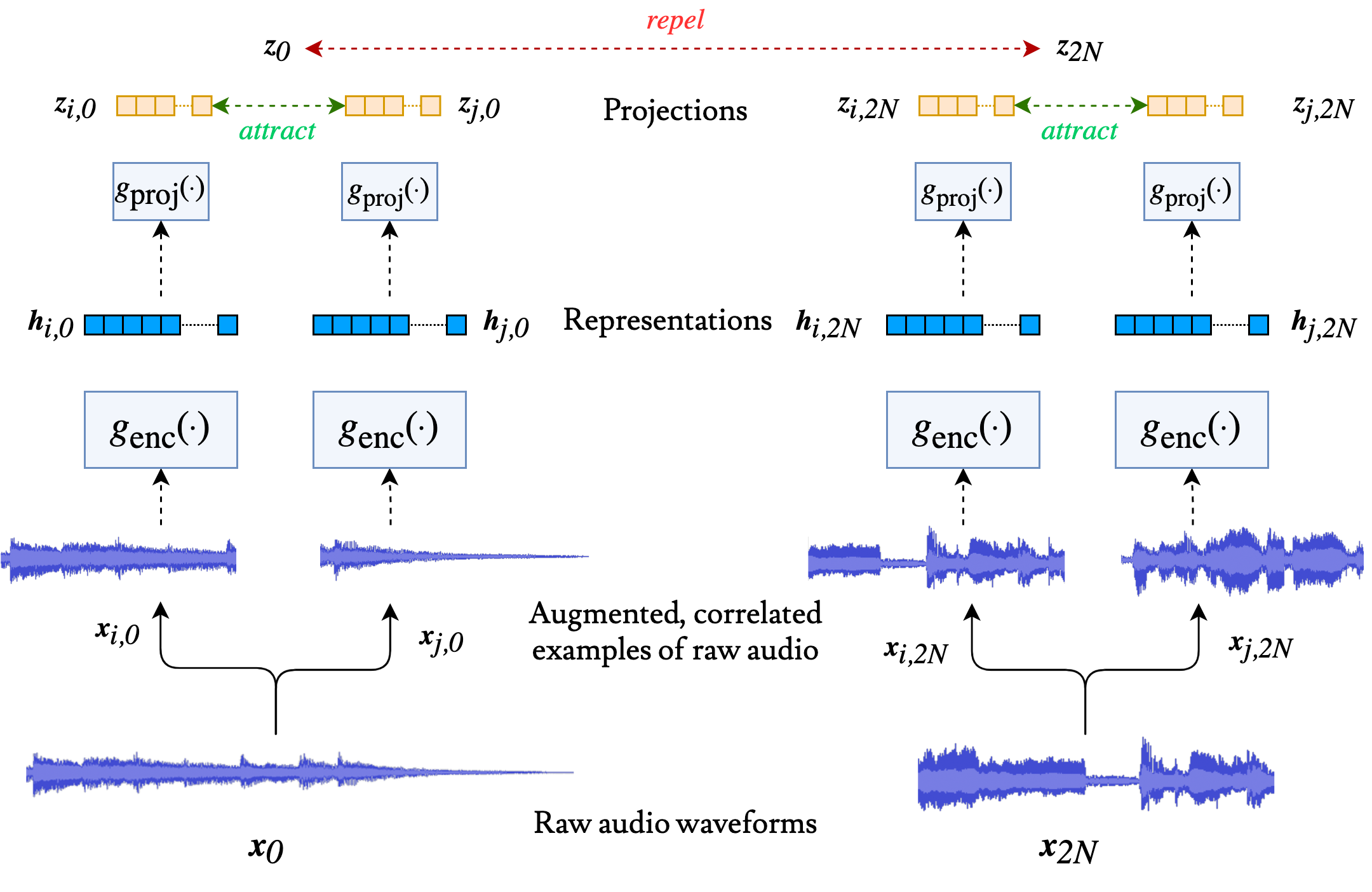
1 | # Contrastive Learning of Musical Representations
2 |
3 | PyTorch implementation of [Contrastive Learning of Musical Representations](https://arxiv.org/abs/2103.09410) by Janne Spijkervet and John Ashley Burgoyne.
4 |
5 | 
6 | [](https://colab.research.google.com/drive/1Njz8EoN4br587xjpRKcssMuqQY6Cc5nj#scrollTo=aeKVT59FhWzV)
7 |
8 | [](https://arxiv.org/abs/2103.09410)
9 | [](https://github.com/Spijkervet/CLMR/releases/download/2.1/CLMR.-.Supplementary.Material.pdf)
10 |
11 |
17 |
18 | You can run a pre-trained CLMR model directly from within your browser using ONNX Runtime: [here](https://spijkervet.github.io/CLMR/examples/clmr-onnxruntime-web).
19 |
20 |
21 | In this work, we introduce SimCLR to the music domain and contribute a large chain of audio data augmentations, to form a simple framework for self-supervised learning of raw waveforms of music: CLMR. We evaluate the performance of the self-supervised learned representations on the task of music classification.
22 |
23 | - We achieve competitive results on the MagnaTagATune and Million Song Datasets relative to fully supervised training, despite only using a linear classifier on self-supervised learned representations, i.e., representations that were learned task-agnostically without any labels.
24 | - CLMR enables efficient classification: with only 1% of the labeled data, we achieve similar scores compared to using 100% of the labeled data.
25 | - CLMR is able to generalise to out-of-domain datasets: when training on entirely different music datasets, it is still able to perform competitively compared to fully supervised training on the target dataset.
26 |
27 | *This is the CLMR v2 implementation, for the original implementation go to the [`v1`](https://github.com/Spijkervet/CLMR/tree/v1) branch*
28 |
29 |
92 | On this page, you are running a CLMR model on the ONNX Runtime in your browser.
93 | No data is sent to a server, all predictions are done on your device!
94 |
95 | In short, the following happens under the hood:
96 |
97 |
It will first load a pre-trained model in the background.
98 |
The model extracts audio representations from raw samples from the audio buffer.
99 |
The audio representations are given to a linear classifier, which predicts the corresponding audio tags.
100 |
The multi-label predictions are shown in the bar plot.
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
117 |
118 |
119 |
120 |
121 |
122 |
123 | No data is uploaded to the server.Ideally, the sample rate of the file should be 22,050Hz. But smaller / higher sample rates also work.
124 |
 31 |
31 |