 16 |
17 |
18 | ### Dataset Statistics
19 | To split the dataset, we separated the entities into 4 mutually exclusive sets. Due to the nature of news collections, some entities tend to dominate the collection. In our collection,there were four entities which were the main entity in nearly 800 articles. To avoid these entities from dominating the train or test splits, we moved them to a separate test collection. We split the remaining into a training, dev, and test sets at random. Thus our collection includes one standard test set consisting of articles drawn at random (Test Standard), while the other is a test set which contains multiple articles about a small number of popular entities (Test Frequent).
20 |
16 |
17 |
18 | ### Dataset Statistics
19 | To split the dataset, we separated the entities into 4 mutually exclusive sets. Due to the nature of news collections, some entities tend to dominate the collection. In our collection,there were four entities which were the main entity in nearly 800 articles. To avoid these entities from dominating the train or test splits, we moved them to a separate test collection. We split the remaining into a training, dev, and test sets at random. Thus our collection includes one standard test set consisting of articles drawn at random (Test Standard), while the other is a test set which contains multiple articles about a small number of popular entities (Test Frequent).
20 | 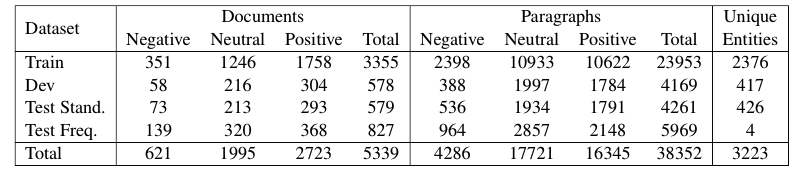 21 |
22 | ### Download the data
23 | You can download the data set URLs from [here](https://github.com/MHDBST/PerSenT/blob/main/train_dev_test_URLs.pkl)
24 |
25 | The processed version of the dataset which contains used paragraphs, document-level, and paragraph-level labels can be download separately as [train](https://github.com/MHDBST/PerSenT/blob/main/train.csv), [dev](https://github.com/MHDBST/PerSenT/blob/main/dev.csv), [random test](https://github.com/MHDBST/PerSenT/blob/main/random_test.csv), and [fixed test](https://github.com/MHDBST/PerSenT/blob/main/fixed_test.csv).
26 |
27 | To recreat the results from the paper you can follow the instructions in the readme file from the [source code](https://github.com/StonyBrookNLP/PerSenT/tree/main/pre_post_processing_steps).
28 |
29 | ### Liked us? Cite us!
30 |
31 | Please use the following bibtex entry:
32 |
33 | ```
34 | @inproceedings{bastan-etal-2020-authors,
35 | title = "Author{'}s Sentiment Prediction",
36 | author = "Bastan, Mohaddeseh and
37 | Koupaee, Mahnaz and
38 | Son, Youngseo and
39 | Sicoli, Richard and
40 | Balasubramanian, Niranjan",
41 | booktitle = "Proceedings of the 28th International Conference on Computational Linguistics",
42 | month = dec,
43 | year = "2020",
44 | address = "Barcelona, Spain (Online)",
45 | publisher = "International Committee on Computational Linguistics",
46 | url = "https://aclanthology.org/2020.coling-main.52",
47 | doi = "10.18653/v1/2020.coling-main.52",
48 | pages = "604--615",
49 | }
50 | ```
51 |
52 |
53 |
54 |
55 |
--------------------------------------------------------------------------------
/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-slate
2 |
--------------------------------------------------------------------------------
/pre_post_processing_steps/10_data_stats.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import collections
3 | import random
4 | import matplotlib.pyplot as plt
5 | import matplotlib.pylab as pylab
6 |
7 | train_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_train.csv')
8 | dev_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_dev.csv')
9 | random_test_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_random_test.csv')
10 | fixed_test_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_fixed_test.csv')
11 |
12 | def count_entities(df):
13 | entities = df['TARGET_ENTITY']
14 | unique_entities = entities.unique().tolist()
15 | return unique_entities
16 |
17 | def plot_class_distribution(dataset,negative,positive,neutral):
18 | print('distribution of %s set among three classes"'%dataset)
19 | print('negative:\n ', negative)
20 | print('positive:\n ', positive)
21 | print('neutral:\n ', neutral)
22 | # Data to plot
23 | plt.figure()
24 | labels = 'Negative', 'Positive', 'Neutral'
25 | sizes = [negative,
26 | positive
27 | , neutral]
28 |
29 | colors = ['Red', 'Green', 'Yellow']
30 |
31 | # Plot
32 | plt.pie(sizes, labels=labels, colors=colors,
33 | autopct='%1.1f%%', shadow=True, startangle=140)
34 |
35 | plt.axis('equal')
36 | plt.title(dataset, horizontalalignment='center', verticalalignment='bottom')
37 | # plt.show()
38 | pylab.savefig('%s.png'%dataset)
39 |
40 |
41 | def entity_frequency(df):
42 | plt.figure()
43 | entities = df['TARGET_ENTITY']
44 | entity_count = collections.Counter(entities)
45 | data = entity_count.most_common(10)
46 | plot_df = pd.DataFrame(data, columns=['entity', 'frequency'])
47 | plot_df.plot(kind='bar', x='entity')
48 | pylab.savefig('%s.png' % 'entity_frequency')
49 |
50 | def paragraph_distribution(df,plot=True):
51 | # plot sentence information
52 | plt.figure()
53 | documents = df['DOCUMENT'].tolist()
54 | doc_length = []
55 | for document in documents:
56 | try:
57 | doc_length.append(len(document.split('\n')))
58 | except:
59 | continue
60 | if plot:
61 | plt.hist(doc_length,len(set(doc_length)))
62 | plt.xlabel('Number of Paragraphs')
63 | plt.ylabel('Frequency')
64 | plt.axis([0, 25, 0, 4000])
65 | pylab.savefig('%s.png' % 'paragraph_freq')
66 | # plt.legend()
67 | print('total number of sentences:%d'% sum(doc_length))
68 | print('plot done')
69 | return doc_length
70 |
71 | def word_distribution(df,plot=True,plot_name='train_words'):
72 | # plot sentence information
73 | plt.figure()
74 | documents = df['DOCUMENT'].tolist()
75 | sentence_length = []
76 | for document in documents:
77 | try:
78 | sentences = document.split('\n')
79 |
80 | except:
81 | continue
82 | for sentence in sentences:
83 | sentence_length.append(len(sentence.split()))
84 | if plot:
85 | plt.hist(sentence_length,len(set(sentence_length)))
86 | plt.xlabel('Number of Words in a Sentence')
87 | plt.ylabel('Frequency')
88 | plt.axis([0, 120, 0, 7500])
89 | pylab.savefig('%s.png' % plot_name)
90 | # plt.legend()
91 | print('total number of sentences:%d'% sum(sentence_length))
92 | print('plot done')
93 | return sentence_length
94 |
95 |
96 | train_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_train.csv')
97 | dev_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_dev.csv')
98 | random_test_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_random_test.csv')
99 | fixed_test_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_fixed_test.csv')
100 |
101 | train_entities = count_entities(train_set)
102 | dev_entities = count_entities(dev_set)
103 | random_test_entities = count_entities(random_test_set)
104 | fixed_test_entities = count_entities(fixed_test_set)
105 |
106 | print('number of unique entities in train set is %d' % len(train_entities))
107 | print('number of unique entities in dev set is %d' %len(dev_entities))
108 | print('number of unique entities in random test set is %d'%len(random_test_entities))
109 | print('number of unique entities in fixed test set is %d'%len(fixed_test_entities))
110 |
111 |
112 | #
113 | #
114 | plot_class_distribution('train',len(train_set[train_set['TRUE_SENTIMENT']=='Negative']),
115 | len(train_set[train_set['TRUE_SENTIMENT'] == 'Positive']),
116 | len(train_set[train_set['TRUE_SENTIMENT'] == 'Neutral']))
117 |
118 | plot_class_distribution('dev',len(dev_set[dev_set['TRUE_SENTIMENT']=='Negative']),
119 | len(dev_set[dev_set['TRUE_SENTIMENT'] == 'Positive']),
120 | len(dev_set[dev_set['TRUE_SENTIMENT'] == 'Neutral']))
121 |
122 | plot_class_distribution('random_test',len(random_test_set[random_test_set['TRUE_SENTIMENT']=='Negative']),
123 | len(random_test_set[random_test_set['TRUE_SENTIMENT'] == 'Positive']),
124 | len(random_test_set[random_test_set['TRUE_SENTIMENT'] == 'Neutral']))
125 |
126 | plot_class_distribution('fixed_test',len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT']=='Negative']),
127 | len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT'] == 'Positive']),
128 | len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT'] == 'Neutral']))
129 |
130 |
131 | all_used_docs = train_set.append(dev_set).append(random_test_set).append(fixed_test_set)
132 | plot_class_distribution('fixed_test',len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT']=='Negative']),
133 | len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT'] == 'Positive']),
134 | len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT'] == 'Neutral']))
135 |
136 | paragraph_distribution(all_used_docs,plot=True)
137 |
138 | para_train = paragraph_distribution(train_set,plot=False)
139 | para_dev = paragraph_distribution(dev_set,plot=False)
140 | para_fixed_test = paragraph_distribution(fixed_test_set,plot=False)
141 | para_random_test = paragraph_distribution(random_test_set,plot=False)
142 | print('paragraphs in train: %d, dev %d, fixed test %d, random test %d' %(sum(para_train),sum(para_dev),sum(para_fixed_test),sum(para_random_test)))
143 | print('max paragraphs in train: %d, dev %d, fixed test %d, random test %d' %(max(para_train),max(para_dev),max(para_fixed_test),max(para_random_test)))
144 |
145 | word_distribution(all_used_docs,plot=True)
146 |
147 | sent_train = word_distribution(train_set.append(dev_set),plot=False)
148 | sent_dev = word_distribution(dev_set,plot=False)
149 | sent_fixed_test = word_distribution(fixed_test_set,plot=False)
150 | sent_random_test = word_distribution(random_test_set,plot=False)
151 | print('words in train: %d, dev %d, fixed test %d, random test %d' %(sum(sent_train),sum(sent_dev),sum(sent_fixed_test),sum(sent_random_test)))
152 | print('max wordsin train: %d, dev %d, fixed test %d, random test %d' %(max(sent_train),max(sent_dev),max(sent_fixed_test),max(sent_random_test)))
153 |
154 |
155 |
--------------------------------------------------------------------------------
/pre_post_processing_steps/11_masked_lm_prepare_datasets.py:
--------------------------------------------------------------------------------
1 | ##### create mask data set from the main dataset
2 | ##### for each document, replace all occurences of the main entity with [TGT], for each document, replace
3 | ##### one of the [TGT] occurrences with [MASK] and add the new document to the new dataset with label TRUE
4 | ##### for each document, replace each occurrences of all other entities with [MASK] and add the new document
5 | ##### to the dataset with FALSE label.
6 | import pandas as pd
7 | from nltk.tag import StanfordNERTagger
8 | from nltk.tokenize import word_tokenize
9 | import time
10 | st = StanfordNERTagger('../entityRecognition/stanford-ner-2018-02-27/classifiers/english.all.3class.distsim.crf.ser.gz',
11 | '../entityRecognition/stanford-ner-2018-02-27/stanford-ner.jar',
12 | encoding='utf-8')
13 |
14 | def prepare_date(df):
15 |
16 |
17 | ### new dataframe has 3 columnds, the initial data document id, the masked document(new) and the new label (true or false)
18 | mask_lm_df = pd.DataFrame(columns=['DOCUMENT_INDEX','DOCUMENT','LABEL'])
19 | ind = -1
20 |
21 | now = time.time()
22 | for doc in list(df['MASKED_DOCUMENT']):
23 | if ind %100 == 0:
24 | print('document %d processed'%ind)
25 | true_docs = []
26 | ind += 1
27 | doc_id = df['DOCUMENT_INDEX'].iloc[ind]
28 | mask_count = doc.count('[TGT]')
29 | for i in range(1,mask_count+1):
30 | ## replace [TGT] one by one based on the occurrence number
31 | true_doc = doc.replace('[TGT]','[MASK]',i).replace('[MASK]','[TGT]',i-1)
32 | if not true_doc in true_docs:
33 | true_docs.append(true_doc)
34 | try:
35 | tokenized_text = word_tokenize(doc)
36 | except:
37 | tokenized_text = word_tokenize(doc.decode('utf-8'))
38 | classified_text = st.tag(tokenized_text)
39 | false_docs = []
40 | i = 0
41 |
42 | previous_entity = ("","")
43 | entity = ""
44 | # read all entities in document and their entity tags
45 | for pair in classified_text:
46 |
47 | # if the entity is person, find the whole person name, replace it with mask add it to the false arrays and keep going
48 | if (pair[1] != 'PERSON' and previous_entity[1] == 'PERSON'):
49 | false_doc = doc.replace(entity,'[MASK]')
50 | if not false_doc in false_docs :
51 | false_docs.append(false_doc)
52 | if (pair[1] == 'PERSON' and previous_entity[1] != 'PERSON'):
53 | entity = pair[0]
54 | elif (pair[1] == 'PERSON' and previous_entity[1] == 'PERSON'):
55 | entity += " "+ pair[0]
56 |
57 | previous_entity = pair
58 | ### add all documents in the false/true array to the data frame with False/True labels
59 | for item in true_docs:
60 | mask_lm_df = mask_lm_df.append({'DOCUMENT_INDEX':doc_id,'DOCUMENT': item,'LABEL':'TRUE'}, ignore_index=True)
61 | for item in false_docs:
62 | mask_lm_df = mask_lm_df.append({'DOCUMENT_INDEX':doc_id,'DOCUMENT': item,'LABEL':'FALSE'}, ignore_index=True)
63 |
64 | print('processing took %d seconds'%(time.time()-now))
65 | print(len(mask_lm_df[mask_lm_df['LABEL']=='TRUE']))
66 | print(len(mask_lm_df[mask_lm_df['LABEL']=='FALSE']))
67 |
68 | return mask_lm_df
69 |
70 |
71 |
72 | ##### load data set with MASKED_ENTITY column where main entities are replaced with [TGT]
73 | #df_train = pd.read_csv('combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_reindex_train.csv', encoding='latin-1')
74 | #mask_train = prepare_date(df_train)
75 | #mask_train.to_csv('masked_lm/mask_lm_combined_shuffled_3Dec_7Dec_aug19_reindex_train.csv', encoding='latin-1')
76 | #
77 | #df_dev = pd.read_csv('combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_reindex_dev.csv', encoding='latin-1')
78 | #mask_dev = prepare_date(df_dev)
79 | #mask_dev.to_csv('masked_lm/mask_lm_combined_shuffled_3Dec_7Dec_aug19_reindex_dev.csv', encoding='latin-1')
80 | #
81 | df_rTest = pd.read_csv('combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_reindex_random_test.csv', encoding='latin-1')
82 | mask_rTest = prepare_date(df_rTest)
83 | mask_rTest.to_csv('masked_lm/mask_lm_combined_shuffled_3Dec_7Dec_aug19_reindex_random_test.csv', encoding='latin-1')
84 |
85 | #df_fTest = pd.read_csv('combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_reindex_fixed_test.csv', encoding='latin-1')
86 | #mask_fTest = prepare_date(df_fTest)
87 | #mask_fTest.to_csv('masked_lm/mask_lm_combined_shuffled_3Dec_7Dec_aug19_reindex_fixed_test.csv', encoding='latin-1')
88 |
--------------------------------------------------------------------------------
/pre_post_processing_steps/1_preprocess_EMNLP.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import json
3 | import random
4 | import os
5 |
6 | source_path = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/data_resource/EMNLP_Data_Junting'
7 | train_input = source_path + '/content_df_test_filtered.csv'
8 | title_train_input = source_path + '/titles/title_selected_sources_ids_with_targets_test.csv'
9 |
10 |
11 |
12 |
13 | text_df = pd.read_csv(train_input, error_bad_lines=False,delimiter='\t')
14 | title_df = pd.read_csv(title_train_input, error_bad_lines=False,delimiter='\t')
15 |
16 | input_json = json.load(open(source_path + '/raw_docs.json'))
17 | title_input = source_path + '/titles/title_selected_sources_ids_with_targets_train.csv'#'emnlp18_data/titles/title_selected_sources_ids_with_targets_train.csv'
18 | title_df = pd.read_csv(open(title_input ), error_bad_lines=False,delimiter='\t')
19 |
20 |
21 | data_path = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/emnlp18_data/'
22 | subdir= 'emnlp_paragraph_seperated_Aug19_part2/'
23 |
24 |
25 |
26 | ##select No_of_samples random documents
27 | No_of_samples = 5000
28 | doc_ids = random.sample(input_json.keys(), No_of_samples)
29 | for index in doc_ids:
30 |
31 |
32 | for root, dirs, files in os.walk(data_path):
33 |
34 | if index in files:
35 | print ("File exists")
36 | continue
37 |
38 | # if the file exsits, don't create it again
39 | try:
40 | # if it has been chosen previously, don't choose it again
41 | out_file = open(data_path+subdir+str(index))
42 | # out_file = open('./masked_entity_lm/'+str(index))
43 | continue
44 | except:
45 | pass
46 | # select random documents from source file and read the main document
47 | paragraphs = input_json[index].split('\n\n')
48 |
49 | if len(paragraphs) < 3:
50 | continue
51 |
52 | title = title_df[title_df['docid'] == int(index)]
53 | try:
54 | main_title = title.iloc[0]['title']
55 | out_file = open(data_path+subdir+str(index),'w')
56 | # out_file = open('./masked_entity_lm/'+str(index),'w')
57 | out_file.write(main_title)
58 | out_file.write('\n')
59 |
60 | except: # this index is not in title file
61 | continue
62 | for paragraph in paragraphs:
63 |
64 | try:
65 | out_file.write(paragraph)
66 | except:
67 | out_file.write(paragraph.encode('utf-8'))
68 | out_file.write('\n')
69 | out_file.close()
70 |
--------------------------------------------------------------------------------
/pre_post_processing_steps/2_core.py:
--------------------------------------------------------------------------------
1 | # This Python file uses the following encoding: utf-8
2 | # import en_coref_lg
3 | import spacy
4 | import neuralcoref
5 | import os
6 | import re
7 | # coref = en_coref_lg.load()
8 | coref = spacy.load('en')
9 | neuralcoref.add_to_pipe(coref)
10 | #source = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/LDC2014E13_output/'
11 | source = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/emnlp18_data/'
12 | # source = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/'
13 | # subdir = 'crowdsource/'
14 | # subdir = 'KBP/'
15 | # subdir = 'emnlp/'
16 | # subdir = 'emnlp_paragraph_seperated_batch3/'
17 | # subdir = 'masked_entity_lm/'
18 | subdir = 'emnlp_paragraph_seperated_Aug19_part2/'
19 | # read all files in directory (the reports)
20 | for filename in os.listdir(source+subdir):
21 |
22 | # print(filename)
23 | textfile = open(source+subdir + filename)
24 |
25 |
26 | text = textfile.read()
27 | text = re.sub('[^0-9a-zA-Z.\n,!?@#$%^&*()_+\"\';:=<>[]}{\|~`]+', ' ', text)
28 | indd = 0
29 | if os.path.exists(source+'coref_%s/'%subdir+filename):
30 | continue
31 | try:
32 | doc = coref(text.decode('utf-8'))
33 |
34 | except Exception as e:
35 | print('error occured: %s'%str(e))
36 | doc = coref(text)
37 | # continue
38 | try:
39 | outputText = doc._.coref_resolved
40 | except:
41 | print('not being processed %s'%filename)
42 | continue
43 |
44 | indd = indd+1
45 | outputfile = open(source+'coref_%s/'%subdir+filename,'w')
46 | try:
47 | outputfile.write(outputText)
48 | except:
49 | outputfile.write(outputText.encode('utf-8'))
50 | outputfile.write('\n')
51 | outputfile.close()
52 | del doc
53 |
54 | print('all coreferences found')
55 |
56 | print('output table created')
57 |
58 |
59 |
60 |
61 |
62 |
--------------------------------------------------------------------------------
/pre_post_processing_steps/3_entity_recognition.py:
--------------------------------------------------------------------------------
1 | #-*- coding: utf-8 -*-
2 | from nltk.tag import StanfordNERTagger
3 | from nltk.tokenize import word_tokenize
4 | import spacy
5 | import neuralcoref
6 | import os
7 | import re
8 | coref = spacy.load('en')
9 | neuralcoref.add_to_pipe(coref)
10 | st = StanfordNERTagger('/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/entityRecognition/stanford-ner-2018-02-27/classifiers/english.all.3class.distsim.crf.ser.gz',
11 | '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/entityRecognition/stanford-ner-2018-02-27/stanford-ner.jar',
12 | encoding='utf-8')
13 |
14 |
15 | # find the most frequent entity in document and write them on file
16 | import os
17 |
18 |
19 | source = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/emnlp18_data/'
20 | subdir = 'emnlp_paragraph_seperated_Aug19_part2'
21 |
22 | ### reads all the file in a subdirectory and process one by one
23 | for filename in os.listdir(source+'coref_%s/'%subdir):
24 |
25 | ### if the entity recognition for on document is solved (it is saved in another direcotry) skip that document
26 | if os.path.exists(source +'pairentity_%s/'%subdir +filename):
27 | continue
28 | print(filename)
29 | text = open(source+'coref_%s/'%subdir + filename)
30 | # a dictionary for each document to find the entity
31 | allEntities = {}
32 | lines = text.read()
33 | lines = lines.replace('”','"').replace('’','\'')
34 | try:
35 | tokenized_text = word_tokenize(lines)
36 | except:
37 | tokenized_text = word_tokenize(lines.decode('utf-8'))
38 | classified_text = st.tag(tokenized_text)
39 | i = 0
40 | previous_entity = ("","")
41 | two_previous_entity = ("","")
42 | # read all entities in document and double check to keep the PERSON ones
43 | for pair in classified_text:
44 | # if the entity is person, save it in hash
45 | if (pair[1] == 'PERSON' and previous_entity[1] != 'PERSON'):
46 | if pair[0] in allEntities:
47 | allEntities[pair[0]] = allEntities[pair[0]] +1
48 | else:
49 | allEntities[pair[0]] = 1
50 | elif (pair[1] == 'PERSON' and previous_entity[1] == 'PERSON' and two_previous_entity[1] != 'PERSON'):
51 | entity = previous_entity[0]+" "+pair[0]
52 | if entity in allEntities:
53 | allEntities[entity] = allEntities[entity] +1
54 | else:
55 | allEntities[entity] = 1
56 | elif (pair[1] == 'PERSON' and previous_entity[1] == 'PERSON' and two_previous_entity[1] == 'PERSON'):
57 | # then add the new pairs as new entity
58 | entity = two_previous_entity[0]+" "+ previous_entity[0]+" "+pair[0]
59 | if entity in allEntities:
60 | allEntities[entity] = allEntities[entity] +1
61 | else:
62 | allEntities[entity] = 1
63 | two_previous_entity = previous_entity
64 | previous_entity = pair
65 | if len(allEntities) ==0:
66 | print('no Entities in %s'%filename)
67 | continue
68 | sortedEntities = sorted(allEntities, key=allEntities.get, reverse=True)
69 | maxEntity = sortedEntities[0]
70 | counted = 0
71 | for item in sortedEntities:
72 | if maxEntity in item:
73 | counted += allEntities[item]
74 | maxEntity = item
75 | # if number of entities is less than 3 do not save that document
76 | if counted <3:
77 | print('number of dominate entity %d'%counted)
78 | continue
79 | print(maxEntity)
80 | outfile = open(source +'pairentity_%s/'%subdir +filename,'w')
81 | try:
82 | outfile.write(maxEntity)
83 | except:
84 | outfile.write(maxEntity.encode('utf-8'))
85 | outfile.write('\n')
86 | outfile.write(''.join(lines))
87 | outfile.close()
--------------------------------------------------------------------------------
/pre_post_processing_steps/4_prepare_mturk_input.py:
--------------------------------------------------------------------------------
1 | # create input file for mechanical turk, it has three types of columns, entity, title, content. content itself may be
2 | # at most 15 paragraphs and at least 5 paragraphs. we disregard the rest. Finally all entities are highlighted not from
3 | # the corefrenced document, from the main documents.
4 | import os
5 | import re
6 | source = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/emnlp18_data/'
7 | import csv
8 | import spacy
9 | import neuralcoref
10 |
11 |
12 |
13 | docStat= {}
14 | # subdir = 'crowdsource/'
15 | # subdir = 'KBP/'
16 | # subdir = 'emnlp/'
17 | # subdir = 'emnlp_paragraph_seperated/'
18 | # subdir = 'emnlp_paragraph_seperated_batch3/'
19 | subdir = 'emnlp_paragraph_seperated_Aug19_part2/'
20 |
21 | # read all files in directory (the reports)
22 |
23 | # csvfile = open('input_KBP.csv', 'wb')
24 | # csvfile = open('./input_emnlp_PS.csv', 'wb')
25 | csvfile = open('./input_emnlp_PS_Aug19_part3.csv', 'w')
26 |
27 | writer = csv.writer(csvfile, delimiter=',',quotechar='|', quoting=csv.QUOTE_MINIMAL)
28 | writer.writerow(['entity','title','content'])
29 | fileCounter = 0
30 | coref = spacy.load('en')
31 | neuralcoref.add_to_pipe(coref)
32 | cnt = 0
33 | longdocs = []
34 | shortdocs = []
35 | notFound = []
36 | countNF = 0
37 | for filename in os.listdir(source+subdir):
38 | fileCounter += 1
39 | if fileCounter%100 == 0:
40 | print('processing document: %d'%fileCounter)
41 |
42 | ### if the file is processes, skip it
43 | try:
44 | open(source+'used_documents_in_MTurk_%s'%subdir+filename)
45 | print('file found %s' %filename)
46 | continue
47 | except:
48 | pass
49 |
50 |
51 |
52 |
53 | try:
54 | coref_text = open(source+'pairentity_%s'%subdir + filename)
55 | except Exception as e:
56 | if str(e).startswith('[Errno 2]'):
57 | continue
58 | print('error darim: %s'%str(e))
59 | # print('pair entity file not found %s'%filename)
60 | # print(filename)
61 | notFound.append(filename)
62 | countNF += 1
63 | continue
64 | entity = coref_text.readline().rstrip().replace(',',' ')
65 |
66 | try:
67 | main_text = open(source+subdir+ filename)
68 | text = main_text.read().decode('utf-8').strip().replace(',',' ')
69 | except:
70 | main_text = open(source+subdir+ filename)
71 | text = main_text.read().strip().replace(',',' ')
72 | new_text = ""
73 | sc = 0
74 | try:
75 | doc = coref(text)
76 | except Exception as e:
77 | print('there is an error in %s which is %s'%(filename,str(e)))
78 | continue
79 | entity_in_coref = False
80 | corefs = []
81 | try:
82 | # find all mentions and coreferences
83 | for item in doc._.coref_clusters:
84 | # if the head of cluster is the intended entity then highlight all of the mentions
85 | if entity in item.main.text or item.main.text in entity:
86 |
87 | entity_in_coref = True
88 | for span in item:
89 | corefs.append(span)
90 | for item in sorted(corefs):
91 | pronoun = item.text
92 | ec = item.start_char
93 | if ec < sc:
94 | continue
95 | new_text += text[sc:ec] + ' '+pronoun+' '
96 | sc = item.end_char
97 | # print(new_text)
98 | new_text += text[sc:]
99 |
100 | new_text = new_text.replace(entity,''+entity+'' )
101 |
102 | new_text = new_text.rstrip().replace(',',' ')
103 | new_text = new_text.replace('|',' ')
104 | if not entity_in_coref:
105 | continue
106 |
107 | except Exception as e:
108 | print('the error is %s'%str(e))
109 | print('coreference not resolved %s' % filename)
110 | continue
111 |
112 | main_lines = new_text.split('\n')
113 | content = ""
114 | # if len( main_lines) < 3 :
115 | # continue
116 | header = main_lines[0]
117 | used_text = entity+ '\n'+ header.replace('','').replace('','') + '\n'
118 | ind=0
119 | for main_line in main_lines[1:]:
120 | ### for one paragraph text
121 | # if main_line.count('
21 |
22 | ### Download the data
23 | You can download the data set URLs from [here](https://github.com/MHDBST/PerSenT/blob/main/train_dev_test_URLs.pkl)
24 |
25 | The processed version of the dataset which contains used paragraphs, document-level, and paragraph-level labels can be download separately as [train](https://github.com/MHDBST/PerSenT/blob/main/train.csv), [dev](https://github.com/MHDBST/PerSenT/blob/main/dev.csv), [random test](https://github.com/MHDBST/PerSenT/blob/main/random_test.csv), and [fixed test](https://github.com/MHDBST/PerSenT/blob/main/fixed_test.csv).
26 |
27 | To recreat the results from the paper you can follow the instructions in the readme file from the [source code](https://github.com/StonyBrookNLP/PerSenT/tree/main/pre_post_processing_steps).
28 |
29 | ### Liked us? Cite us!
30 |
31 | Please use the following bibtex entry:
32 |
33 | ```
34 | @inproceedings{bastan-etal-2020-authors,
35 | title = "Author{'}s Sentiment Prediction",
36 | author = "Bastan, Mohaddeseh and
37 | Koupaee, Mahnaz and
38 | Son, Youngseo and
39 | Sicoli, Richard and
40 | Balasubramanian, Niranjan",
41 | booktitle = "Proceedings of the 28th International Conference on Computational Linguistics",
42 | month = dec,
43 | year = "2020",
44 | address = "Barcelona, Spain (Online)",
45 | publisher = "International Committee on Computational Linguistics",
46 | url = "https://aclanthology.org/2020.coling-main.52",
47 | doi = "10.18653/v1/2020.coling-main.52",
48 | pages = "604--615",
49 | }
50 | ```
51 |
52 |
53 |
54 |
55 |
--------------------------------------------------------------------------------
/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-slate
2 |
--------------------------------------------------------------------------------
/pre_post_processing_steps/10_data_stats.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import collections
3 | import random
4 | import matplotlib.pyplot as plt
5 | import matplotlib.pylab as pylab
6 |
7 | train_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_train.csv')
8 | dev_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_dev.csv')
9 | random_test_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_random_test.csv')
10 | fixed_test_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_fixed_test.csv')
11 |
12 | def count_entities(df):
13 | entities = df['TARGET_ENTITY']
14 | unique_entities = entities.unique().tolist()
15 | return unique_entities
16 |
17 | def plot_class_distribution(dataset,negative,positive,neutral):
18 | print('distribution of %s set among three classes"'%dataset)
19 | print('negative:\n ', negative)
20 | print('positive:\n ', positive)
21 | print('neutral:\n ', neutral)
22 | # Data to plot
23 | plt.figure()
24 | labels = 'Negative', 'Positive', 'Neutral'
25 | sizes = [negative,
26 | positive
27 | , neutral]
28 |
29 | colors = ['Red', 'Green', 'Yellow']
30 |
31 | # Plot
32 | plt.pie(sizes, labels=labels, colors=colors,
33 | autopct='%1.1f%%', shadow=True, startangle=140)
34 |
35 | plt.axis('equal')
36 | plt.title(dataset, horizontalalignment='center', verticalalignment='bottom')
37 | # plt.show()
38 | pylab.savefig('%s.png'%dataset)
39 |
40 |
41 | def entity_frequency(df):
42 | plt.figure()
43 | entities = df['TARGET_ENTITY']
44 | entity_count = collections.Counter(entities)
45 | data = entity_count.most_common(10)
46 | plot_df = pd.DataFrame(data, columns=['entity', 'frequency'])
47 | plot_df.plot(kind='bar', x='entity')
48 | pylab.savefig('%s.png' % 'entity_frequency')
49 |
50 | def paragraph_distribution(df,plot=True):
51 | # plot sentence information
52 | plt.figure()
53 | documents = df['DOCUMENT'].tolist()
54 | doc_length = []
55 | for document in documents:
56 | try:
57 | doc_length.append(len(document.split('\n')))
58 | except:
59 | continue
60 | if plot:
61 | plt.hist(doc_length,len(set(doc_length)))
62 | plt.xlabel('Number of Paragraphs')
63 | plt.ylabel('Frequency')
64 | plt.axis([0, 25, 0, 4000])
65 | pylab.savefig('%s.png' % 'paragraph_freq')
66 | # plt.legend()
67 | print('total number of sentences:%d'% sum(doc_length))
68 | print('plot done')
69 | return doc_length
70 |
71 | def word_distribution(df,plot=True,plot_name='train_words'):
72 | # plot sentence information
73 | plt.figure()
74 | documents = df['DOCUMENT'].tolist()
75 | sentence_length = []
76 | for document in documents:
77 | try:
78 | sentences = document.split('\n')
79 |
80 | except:
81 | continue
82 | for sentence in sentences:
83 | sentence_length.append(len(sentence.split()))
84 | if plot:
85 | plt.hist(sentence_length,len(set(sentence_length)))
86 | plt.xlabel('Number of Words in a Sentence')
87 | plt.ylabel('Frequency')
88 | plt.axis([0, 120, 0, 7500])
89 | pylab.savefig('%s.png' % plot_name)
90 | # plt.legend()
91 | print('total number of sentences:%d'% sum(sentence_length))
92 | print('plot done')
93 | return sentence_length
94 |
95 |
96 | train_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_train.csv')
97 | dev_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_dev.csv')
98 | random_test_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_random_test.csv')
99 | fixed_test_set = pd.read_csv('./combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_fixed_test.csv')
100 |
101 | train_entities = count_entities(train_set)
102 | dev_entities = count_entities(dev_set)
103 | random_test_entities = count_entities(random_test_set)
104 | fixed_test_entities = count_entities(fixed_test_set)
105 |
106 | print('number of unique entities in train set is %d' % len(train_entities))
107 | print('number of unique entities in dev set is %d' %len(dev_entities))
108 | print('number of unique entities in random test set is %d'%len(random_test_entities))
109 | print('number of unique entities in fixed test set is %d'%len(fixed_test_entities))
110 |
111 |
112 | #
113 | #
114 | plot_class_distribution('train',len(train_set[train_set['TRUE_SENTIMENT']=='Negative']),
115 | len(train_set[train_set['TRUE_SENTIMENT'] == 'Positive']),
116 | len(train_set[train_set['TRUE_SENTIMENT'] == 'Neutral']))
117 |
118 | plot_class_distribution('dev',len(dev_set[dev_set['TRUE_SENTIMENT']=='Negative']),
119 | len(dev_set[dev_set['TRUE_SENTIMENT'] == 'Positive']),
120 | len(dev_set[dev_set['TRUE_SENTIMENT'] == 'Neutral']))
121 |
122 | plot_class_distribution('random_test',len(random_test_set[random_test_set['TRUE_SENTIMENT']=='Negative']),
123 | len(random_test_set[random_test_set['TRUE_SENTIMENT'] == 'Positive']),
124 | len(random_test_set[random_test_set['TRUE_SENTIMENT'] == 'Neutral']))
125 |
126 | plot_class_distribution('fixed_test',len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT']=='Negative']),
127 | len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT'] == 'Positive']),
128 | len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT'] == 'Neutral']))
129 |
130 |
131 | all_used_docs = train_set.append(dev_set).append(random_test_set).append(fixed_test_set)
132 | plot_class_distribution('fixed_test',len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT']=='Negative']),
133 | len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT'] == 'Positive']),
134 | len(fixed_test_set[fixed_test_set['TRUE_SENTIMENT'] == 'Neutral']))
135 |
136 | paragraph_distribution(all_used_docs,plot=True)
137 |
138 | para_train = paragraph_distribution(train_set,plot=False)
139 | para_dev = paragraph_distribution(dev_set,plot=False)
140 | para_fixed_test = paragraph_distribution(fixed_test_set,plot=False)
141 | para_random_test = paragraph_distribution(random_test_set,plot=False)
142 | print('paragraphs in train: %d, dev %d, fixed test %d, random test %d' %(sum(para_train),sum(para_dev),sum(para_fixed_test),sum(para_random_test)))
143 | print('max paragraphs in train: %d, dev %d, fixed test %d, random test %d' %(max(para_train),max(para_dev),max(para_fixed_test),max(para_random_test)))
144 |
145 | word_distribution(all_used_docs,plot=True)
146 |
147 | sent_train = word_distribution(train_set.append(dev_set),plot=False)
148 | sent_dev = word_distribution(dev_set,plot=False)
149 | sent_fixed_test = word_distribution(fixed_test_set,plot=False)
150 | sent_random_test = word_distribution(random_test_set,plot=False)
151 | print('words in train: %d, dev %d, fixed test %d, random test %d' %(sum(sent_train),sum(sent_dev),sum(sent_fixed_test),sum(sent_random_test)))
152 | print('max wordsin train: %d, dev %d, fixed test %d, random test %d' %(max(sent_train),max(sent_dev),max(sent_fixed_test),max(sent_random_test)))
153 |
154 |
155 |
--------------------------------------------------------------------------------
/pre_post_processing_steps/11_masked_lm_prepare_datasets.py:
--------------------------------------------------------------------------------
1 | ##### create mask data set from the main dataset
2 | ##### for each document, replace all occurences of the main entity with [TGT], for each document, replace
3 | ##### one of the [TGT] occurrences with [MASK] and add the new document to the new dataset with label TRUE
4 | ##### for each document, replace each occurrences of all other entities with [MASK] and add the new document
5 | ##### to the dataset with FALSE label.
6 | import pandas as pd
7 | from nltk.tag import StanfordNERTagger
8 | from nltk.tokenize import word_tokenize
9 | import time
10 | st = StanfordNERTagger('../entityRecognition/stanford-ner-2018-02-27/classifiers/english.all.3class.distsim.crf.ser.gz',
11 | '../entityRecognition/stanford-ner-2018-02-27/stanford-ner.jar',
12 | encoding='utf-8')
13 |
14 | def prepare_date(df):
15 |
16 |
17 | ### new dataframe has 3 columnds, the initial data document id, the masked document(new) and the new label (true or false)
18 | mask_lm_df = pd.DataFrame(columns=['DOCUMENT_INDEX','DOCUMENT','LABEL'])
19 | ind = -1
20 |
21 | now = time.time()
22 | for doc in list(df['MASKED_DOCUMENT']):
23 | if ind %100 == 0:
24 | print('document %d processed'%ind)
25 | true_docs = []
26 | ind += 1
27 | doc_id = df['DOCUMENT_INDEX'].iloc[ind]
28 | mask_count = doc.count('[TGT]')
29 | for i in range(1,mask_count+1):
30 | ## replace [TGT] one by one based on the occurrence number
31 | true_doc = doc.replace('[TGT]','[MASK]',i).replace('[MASK]','[TGT]',i-1)
32 | if not true_doc in true_docs:
33 | true_docs.append(true_doc)
34 | try:
35 | tokenized_text = word_tokenize(doc)
36 | except:
37 | tokenized_text = word_tokenize(doc.decode('utf-8'))
38 | classified_text = st.tag(tokenized_text)
39 | false_docs = []
40 | i = 0
41 |
42 | previous_entity = ("","")
43 | entity = ""
44 | # read all entities in document and their entity tags
45 | for pair in classified_text:
46 |
47 | # if the entity is person, find the whole person name, replace it with mask add it to the false arrays and keep going
48 | if (pair[1] != 'PERSON' and previous_entity[1] == 'PERSON'):
49 | false_doc = doc.replace(entity,'[MASK]')
50 | if not false_doc in false_docs :
51 | false_docs.append(false_doc)
52 | if (pair[1] == 'PERSON' and previous_entity[1] != 'PERSON'):
53 | entity = pair[0]
54 | elif (pair[1] == 'PERSON' and previous_entity[1] == 'PERSON'):
55 | entity += " "+ pair[0]
56 |
57 | previous_entity = pair
58 | ### add all documents in the false/true array to the data frame with False/True labels
59 | for item in true_docs:
60 | mask_lm_df = mask_lm_df.append({'DOCUMENT_INDEX':doc_id,'DOCUMENT': item,'LABEL':'TRUE'}, ignore_index=True)
61 | for item in false_docs:
62 | mask_lm_df = mask_lm_df.append({'DOCUMENT_INDEX':doc_id,'DOCUMENT': item,'LABEL':'FALSE'}, ignore_index=True)
63 |
64 | print('processing took %d seconds'%(time.time()-now))
65 | print(len(mask_lm_df[mask_lm_df['LABEL']=='TRUE']))
66 | print(len(mask_lm_df[mask_lm_df['LABEL']=='FALSE']))
67 |
68 | return mask_lm_df
69 |
70 |
71 |
72 | ##### load data set with MASKED_ENTITY column where main entities are replaced with [TGT]
73 | #df_train = pd.read_csv('combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_reindex_train.csv', encoding='latin-1')
74 | #mask_train = prepare_date(df_train)
75 | #mask_train.to_csv('masked_lm/mask_lm_combined_shuffled_3Dec_7Dec_aug19_reindex_train.csv', encoding='latin-1')
76 | #
77 | #df_dev = pd.read_csv('combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_reindex_dev.csv', encoding='latin-1')
78 | #mask_dev = prepare_date(df_dev)
79 | #mask_dev.to_csv('masked_lm/mask_lm_combined_shuffled_3Dec_7Dec_aug19_reindex_dev.csv', encoding='latin-1')
80 | #
81 | df_rTest = pd.read_csv('combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_reindex_random_test.csv', encoding='latin-1')
82 | mask_rTest = prepare_date(df_rTest)
83 | mask_rTest.to_csv('masked_lm/mask_lm_combined_shuffled_3Dec_7Dec_aug19_reindex_random_test.csv', encoding='latin-1')
84 |
85 | #df_fTest = pd.read_csv('combined_set/all_data_combined_shuffled_3Dec_7Dec_aug19_reindex_fixed_test.csv', encoding='latin-1')
86 | #mask_fTest = prepare_date(df_fTest)
87 | #mask_fTest.to_csv('masked_lm/mask_lm_combined_shuffled_3Dec_7Dec_aug19_reindex_fixed_test.csv', encoding='latin-1')
88 |
--------------------------------------------------------------------------------
/pre_post_processing_steps/1_preprocess_EMNLP.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import json
3 | import random
4 | import os
5 |
6 | source_path = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/data_resource/EMNLP_Data_Junting'
7 | train_input = source_path + '/content_df_test_filtered.csv'
8 | title_train_input = source_path + '/titles/title_selected_sources_ids_with_targets_test.csv'
9 |
10 |
11 |
12 |
13 | text_df = pd.read_csv(train_input, error_bad_lines=False,delimiter='\t')
14 | title_df = pd.read_csv(title_train_input, error_bad_lines=False,delimiter='\t')
15 |
16 | input_json = json.load(open(source_path + '/raw_docs.json'))
17 | title_input = source_path + '/titles/title_selected_sources_ids_with_targets_train.csv'#'emnlp18_data/titles/title_selected_sources_ids_with_targets_train.csv'
18 | title_df = pd.read_csv(open(title_input ), error_bad_lines=False,delimiter='\t')
19 |
20 |
21 | data_path = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/emnlp18_data/'
22 | subdir= 'emnlp_paragraph_seperated_Aug19_part2/'
23 |
24 |
25 |
26 | ##select No_of_samples random documents
27 | No_of_samples = 5000
28 | doc_ids = random.sample(input_json.keys(), No_of_samples)
29 | for index in doc_ids:
30 |
31 |
32 | for root, dirs, files in os.walk(data_path):
33 |
34 | if index in files:
35 | print ("File exists")
36 | continue
37 |
38 | # if the file exsits, don't create it again
39 | try:
40 | # if it has been chosen previously, don't choose it again
41 | out_file = open(data_path+subdir+str(index))
42 | # out_file = open('./masked_entity_lm/'+str(index))
43 | continue
44 | except:
45 | pass
46 | # select random documents from source file and read the main document
47 | paragraphs = input_json[index].split('\n\n')
48 |
49 | if len(paragraphs) < 3:
50 | continue
51 |
52 | title = title_df[title_df['docid'] == int(index)]
53 | try:
54 | main_title = title.iloc[0]['title']
55 | out_file = open(data_path+subdir+str(index),'w')
56 | # out_file = open('./masked_entity_lm/'+str(index),'w')
57 | out_file.write(main_title)
58 | out_file.write('\n')
59 |
60 | except: # this index is not in title file
61 | continue
62 | for paragraph in paragraphs:
63 |
64 | try:
65 | out_file.write(paragraph)
66 | except:
67 | out_file.write(paragraph.encode('utf-8'))
68 | out_file.write('\n')
69 | out_file.close()
70 |
--------------------------------------------------------------------------------
/pre_post_processing_steps/2_core.py:
--------------------------------------------------------------------------------
1 | # This Python file uses the following encoding: utf-8
2 | # import en_coref_lg
3 | import spacy
4 | import neuralcoref
5 | import os
6 | import re
7 | # coref = en_coref_lg.load()
8 | coref = spacy.load('en')
9 | neuralcoref.add_to_pipe(coref)
10 | #source = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/LDC2014E13_output/'
11 | source = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/emnlp18_data/'
12 | # source = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/'
13 | # subdir = 'crowdsource/'
14 | # subdir = 'KBP/'
15 | # subdir = 'emnlp/'
16 | # subdir = 'emnlp_paragraph_seperated_batch3/'
17 | # subdir = 'masked_entity_lm/'
18 | subdir = 'emnlp_paragraph_seperated_Aug19_part2/'
19 | # read all files in directory (the reports)
20 | for filename in os.listdir(source+subdir):
21 |
22 | # print(filename)
23 | textfile = open(source+subdir + filename)
24 |
25 |
26 | text = textfile.read()
27 | text = re.sub('[^0-9a-zA-Z.\n,!?@#$%^&*()_+\"\';:=<>[]}{\|~`]+', ' ', text)
28 | indd = 0
29 | if os.path.exists(source+'coref_%s/'%subdir+filename):
30 | continue
31 | try:
32 | doc = coref(text.decode('utf-8'))
33 |
34 | except Exception as e:
35 | print('error occured: %s'%str(e))
36 | doc = coref(text)
37 | # continue
38 | try:
39 | outputText = doc._.coref_resolved
40 | except:
41 | print('not being processed %s'%filename)
42 | continue
43 |
44 | indd = indd+1
45 | outputfile = open(source+'coref_%s/'%subdir+filename,'w')
46 | try:
47 | outputfile.write(outputText)
48 | except:
49 | outputfile.write(outputText.encode('utf-8'))
50 | outputfile.write('\n')
51 | outputfile.close()
52 | del doc
53 |
54 | print('all coreferences found')
55 |
56 | print('output table created')
57 |
58 |
59 |
60 |
61 |
62 |
--------------------------------------------------------------------------------
/pre_post_processing_steps/3_entity_recognition.py:
--------------------------------------------------------------------------------
1 | #-*- coding: utf-8 -*-
2 | from nltk.tag import StanfordNERTagger
3 | from nltk.tokenize import word_tokenize
4 | import spacy
5 | import neuralcoref
6 | import os
7 | import re
8 | coref = spacy.load('en')
9 | neuralcoref.add_to_pipe(coref)
10 | st = StanfordNERTagger('/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/entityRecognition/stanford-ner-2018-02-27/classifiers/english.all.3class.distsim.crf.ser.gz',
11 | '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/entityRecognition/stanford-ner-2018-02-27/stanford-ner.jar',
12 | encoding='utf-8')
13 |
14 |
15 | # find the most frequent entity in document and write them on file
16 | import os
17 |
18 |
19 | source = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/emnlp18_data/'
20 | subdir = 'emnlp_paragraph_seperated_Aug19_part2'
21 |
22 | ### reads all the file in a subdirectory and process one by one
23 | for filename in os.listdir(source+'coref_%s/'%subdir):
24 |
25 | ### if the entity recognition for on document is solved (it is saved in another direcotry) skip that document
26 | if os.path.exists(source +'pairentity_%s/'%subdir +filename):
27 | continue
28 | print(filename)
29 | text = open(source+'coref_%s/'%subdir + filename)
30 | # a dictionary for each document to find the entity
31 | allEntities = {}
32 | lines = text.read()
33 | lines = lines.replace('”','"').replace('’','\'')
34 | try:
35 | tokenized_text = word_tokenize(lines)
36 | except:
37 | tokenized_text = word_tokenize(lines.decode('utf-8'))
38 | classified_text = st.tag(tokenized_text)
39 | i = 0
40 | previous_entity = ("","")
41 | two_previous_entity = ("","")
42 | # read all entities in document and double check to keep the PERSON ones
43 | for pair in classified_text:
44 | # if the entity is person, save it in hash
45 | if (pair[1] == 'PERSON' and previous_entity[1] != 'PERSON'):
46 | if pair[0] in allEntities:
47 | allEntities[pair[0]] = allEntities[pair[0]] +1
48 | else:
49 | allEntities[pair[0]] = 1
50 | elif (pair[1] == 'PERSON' and previous_entity[1] == 'PERSON' and two_previous_entity[1] != 'PERSON'):
51 | entity = previous_entity[0]+" "+pair[0]
52 | if entity in allEntities:
53 | allEntities[entity] = allEntities[entity] +1
54 | else:
55 | allEntities[entity] = 1
56 | elif (pair[1] == 'PERSON' and previous_entity[1] == 'PERSON' and two_previous_entity[1] == 'PERSON'):
57 | # then add the new pairs as new entity
58 | entity = two_previous_entity[0]+" "+ previous_entity[0]+" "+pair[0]
59 | if entity in allEntities:
60 | allEntities[entity] = allEntities[entity] +1
61 | else:
62 | allEntities[entity] = 1
63 | two_previous_entity = previous_entity
64 | previous_entity = pair
65 | if len(allEntities) ==0:
66 | print('no Entities in %s'%filename)
67 | continue
68 | sortedEntities = sorted(allEntities, key=allEntities.get, reverse=True)
69 | maxEntity = sortedEntities[0]
70 | counted = 0
71 | for item in sortedEntities:
72 | if maxEntity in item:
73 | counted += allEntities[item]
74 | maxEntity = item
75 | # if number of entities is less than 3 do not save that document
76 | if counted <3:
77 | print('number of dominate entity %d'%counted)
78 | continue
79 | print(maxEntity)
80 | outfile = open(source +'pairentity_%s/'%subdir +filename,'w')
81 | try:
82 | outfile.write(maxEntity)
83 | except:
84 | outfile.write(maxEntity.encode('utf-8'))
85 | outfile.write('\n')
86 | outfile.write(''.join(lines))
87 | outfile.close()
--------------------------------------------------------------------------------
/pre_post_processing_steps/4_prepare_mturk_input.py:
--------------------------------------------------------------------------------
1 | # create input file for mechanical turk, it has three types of columns, entity, title, content. content itself may be
2 | # at most 15 paragraphs and at least 5 paragraphs. we disregard the rest. Finally all entities are highlighted not from
3 | # the corefrenced document, from the main documents.
4 | import os
5 | import re
6 | source = '/Users/mohaddeseh/Documents/EntitySentimentAnalyzer-master/dataAnalysis/emnlp18_data/'
7 | import csv
8 | import spacy
9 | import neuralcoref
10 |
11 |
12 |
13 | docStat= {}
14 | # subdir = 'crowdsource/'
15 | # subdir = 'KBP/'
16 | # subdir = 'emnlp/'
17 | # subdir = 'emnlp_paragraph_seperated/'
18 | # subdir = 'emnlp_paragraph_seperated_batch3/'
19 | subdir = 'emnlp_paragraph_seperated_Aug19_part2/'
20 |
21 | # read all files in directory (the reports)
22 |
23 | # csvfile = open('input_KBP.csv', 'wb')
24 | # csvfile = open('./input_emnlp_PS.csv', 'wb')
25 | csvfile = open('./input_emnlp_PS_Aug19_part3.csv', 'w')
26 |
27 | writer = csv.writer(csvfile, delimiter=',',quotechar='|', quoting=csv.QUOTE_MINIMAL)
28 | writer.writerow(['entity','title','content'])
29 | fileCounter = 0
30 | coref = spacy.load('en')
31 | neuralcoref.add_to_pipe(coref)
32 | cnt = 0
33 | longdocs = []
34 | shortdocs = []
35 | notFound = []
36 | countNF = 0
37 | for filename in os.listdir(source+subdir):
38 | fileCounter += 1
39 | if fileCounter%100 == 0:
40 | print('processing document: %d'%fileCounter)
41 |
42 | ### if the file is processes, skip it
43 | try:
44 | open(source+'used_documents_in_MTurk_%s'%subdir+filename)
45 | print('file found %s' %filename)
46 | continue
47 | except:
48 | pass
49 |
50 |
51 |
52 |
53 | try:
54 | coref_text = open(source+'pairentity_%s'%subdir + filename)
55 | except Exception as e:
56 | if str(e).startswith('[Errno 2]'):
57 | continue
58 | print('error darim: %s'%str(e))
59 | # print('pair entity file not found %s'%filename)
60 | # print(filename)
61 | notFound.append(filename)
62 | countNF += 1
63 | continue
64 | entity = coref_text.readline().rstrip().replace(',',' ')
65 |
66 | try:
67 | main_text = open(source+subdir+ filename)
68 | text = main_text.read().decode('utf-8').strip().replace(',',' ')
69 | except:
70 | main_text = open(source+subdir+ filename)
71 | text = main_text.read().strip().replace(',',' ')
72 | new_text = ""
73 | sc = 0
74 | try:
75 | doc = coref(text)
76 | except Exception as e:
77 | print('there is an error in %s which is %s'%(filename,str(e)))
78 | continue
79 | entity_in_coref = False
80 | corefs = []
81 | try:
82 | # find all mentions and coreferences
83 | for item in doc._.coref_clusters:
84 | # if the head of cluster is the intended entity then highlight all of the mentions
85 | if entity in item.main.text or item.main.text in entity:
86 |
87 | entity_in_coref = True
88 | for span in item:
89 | corefs.append(span)
90 | for item in sorted(corefs):
91 | pronoun = item.text
92 | ec = item.start_char
93 | if ec < sc:
94 | continue
95 | new_text += text[sc:ec] + ' '+pronoun+' '
96 | sc = item.end_char
97 | # print(new_text)
98 | new_text += text[sc:]
99 |
100 | new_text = new_text.replace(entity,''+entity+'' )
101 |
102 | new_text = new_text.rstrip().replace(',',' ')
103 | new_text = new_text.replace('|',' ')
104 | if not entity_in_coref:
105 | continue
106 |
107 | except Exception as e:
108 | print('the error is %s'%str(e))
109 | print('coreference not resolved %s' % filename)
110 | continue
111 |
112 | main_lines = new_text.split('\n')
113 | content = ""
114 | # if len( main_lines) < 3 :
115 | # continue
116 | header = main_lines[0]
117 | used_text = entity+ '\n'+ header.replace('','').replace('','') + '\n'
118 | ind=0
119 | for main_line in main_lines[1:]:
120 | ### for one paragraph text
121 | # if main_line.count('' + main_line + '
' 133 | ##### for multiple paragraph documents 134 | SENTIMENT = '' + main_line + '
The whole article\'s view towards '+entity +' is: