6 | 📃 Paper • 🌐 Project Page 7 |
8 | 9 | > **AlphaTablets: A Generic Plane Representation for 3D Planar Reconstruction from Monocular Videos** 10 | > 11 | > [Yuze He](https://hyzcluster.github.io), [Wang Zhao](https://github.com/thuzhaowang), [Shaohui Liu](http://b1ueber2y.me/), [Yubin Hu](https://github.com/AlbertHuyb), [Yushi Bai](https://bys0318.github.io/), Yu-Hui Wen, Yong-Jin Liu 12 | > 13 | > NeurIPS 2024 14 | 15 | **AlphaTablets** is a novel and generic representation of 3D planes that features continuous 3D surface and precise boundary delineation. By representing 3D planes as rectangles with alpha channels, AlphaTablets combine the advantages of current 2D and 3D plane representations, enabling accurate, consistent and flexible modeling of 3D planes. 16 | 17 | We propose a novel bottom-up pipeline for 3D planar reconstruction from monocular videos. Starting with 2D superpixels and geometric cues from pre-trained models, we initialize 3D planes as AlphaTablets and optimize them via differentiable rendering. An effective merging scheme is introduced to facilitate the growth and refinement of AlphaTablets. Through iterative optimization and merging, we reconstruct complete and accurate 3D planes with solid surfaces and clear boundaries. 18 | 19 |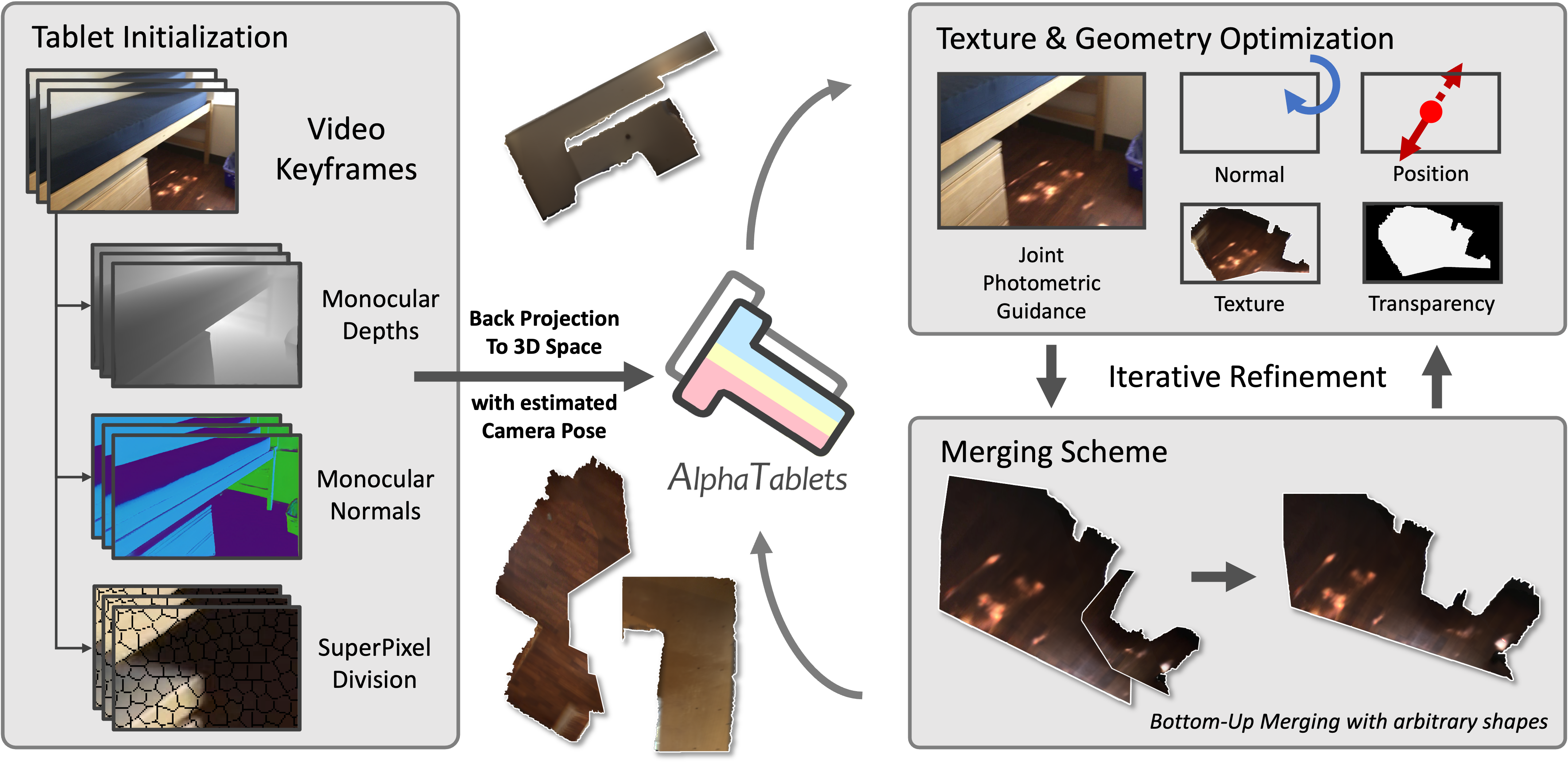 20 |
21 |
22 |
23 | ## Quick Start
24 |
25 | ### 1. Clone the Repository
26 |
27 | Make sure to clone the repository along with its submodules:
28 |
29 | ```bash
30 | git clone --recursive https://github.com/THU-LYJ-Lab/AlphaTablets
31 | ```
32 |
33 | ### 2. Install Dependencies
34 |
35 | Set up a Python environment and install the required packages:
36 |
37 | ```bash
38 | conda create -n alphatablets python=3.9
39 | conda activate alphatablets
40 |
41 | # Install PyTorch based on your machine configuration
42 | pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118
43 |
44 | # Install other dependencies
45 | # Note: mmcv package also requires CUDA. To avoid potential errors, set the CUDA_HOME environment variable and download a CUDA-compatible version of the library.
46 | # Example: python -m pip install mmcv==2.2.0 -f https://download.openmmlab.com/mmcv/dist/cu118/torch2.1/index.html
47 | pip install -r requirements.txt
48 | ```
49 |
50 | ### 3. Download Pretrained Weights
51 |
52 | #### Monocular Normal Estimation Weights
53 |
54 | Download **Omnidata** pretrained weights:
55 |
56 | - File: `omnidata_dpt_normal_v2.ckpt`
57 | - Link: [Download Here](https://www.dropbox.com/scl/fo/348s01x0trt0yxb934cwe/h?rlkey=a96g2incso7g53evzamzo0j0y&e=2&dl=0)
58 |
59 | Place the file in the directory:
60 |
61 | ```plaintext
62 | ./recon/third_party/omnidata/omnidata_tools/torch/pretrained_models
63 | ```
64 |
65 | #### Depth Estimation Weights
66 |
67 | Download **Metric3D** pretrained weights:
68 |
69 | - File: `metric_depth_vit_giant2_800k.pth`
70 | - Link: [Download Here](https://huggingface.co/JUGGHM/Metric3D/blob/main/metric_depth_vit_giant2_800k.pth)
71 |
72 | Place the file in the directory:
73 |
74 | ```plaintext
75 | ./recon/third_party/metric3d/weight
76 | ```
77 |
78 | ### 4. Running Demos
79 |
80 | #### ScanNet Demo
81 |
82 | 1. Download the `scene0684_01` demo scene from [here](https://drive.google.com/drive/folders/13rYkek_CQuOk_N5erJL08R26B1BkYmwD?usp=sharing) and extract it to `./data/`.
83 | 2. Run the demo with the following command:
84 |
85 | ```bash
86 | python run.py --job scene0684_01
87 | ```
88 |
89 | #### Replica Demo
90 |
91 | 1. Download the `office0` demo scene from [here](https://drive.google.com/drive/folders/13rYkek_CQuOk_N5erJL08R26B1BkYmwD?usp=sharing) and extract it to `./data/`.
92 | 2. Run the demo using the specified configuration:
93 |
94 | ```bash
95 | python run.py --config configs/replica.yaml --job office0
96 | ```
97 |
98 | ### Tips
99 |
100 | - **Out-of-Memory (OOM):** Reduce `batch_size` if you encounter memory issues.
101 | - **Low Frame Rate Sequences:** Increase `weight_decay`, or set it to `-1` for an automatic decay. The default value is `0.9` (works well for ScanNet and Replica), but it can go up to larger values (no more than `1.0`).
102 | - **Scene Scaling Issues:** If the scene scale differs significantly from real-world dimensions, adjust merging parameters such as `dist_thres` (maximum allowable distance for tablet merging).
103 |
104 |
105 |
106 | ## Evaluation on the ScanNet v2 dataset
107 |
108 | 1. **Download and Extract ScanNet**:
109 | Follow the instructions provided on the [ScanNet website](http://www.scan-net.org/) to download and extract the dataset.
110 |
111 | 2. **Prepare the Data**:
112 | Use the data preparation script to parse the raw ScanNet data into a processed pickle format and generate ground truth planes using code modified from [PlaneRCNN](https://github.com/NVlabs/planercnn/blob/master/data_prep/parse.py) and [PlanarRecon](https://github.com/neu-vi/PlanarRecon/tree/main).
113 |
114 | Run the following command under the PlanarRecon environment:
115 |
116 | ```bash
117 | python tools/generate_gt.py --data_path PATH_TO_SCANNET --save_name planes_9/ --window_size 9 --n_proc 2 --n_gpu 1
118 | python tools/prepare_inst_gt_txt.py --val_list PATH_TO_SCANNET/scannetv2_val.txt --plane_mesh_path ./planes_9
119 | ```
120 |
121 | 3. **Process Scenes in the Validation Set**:
122 | You can use the following command to process each scene in the validation set. Update `scene????_??` with the specific scene name. Train/val/test split information is available [here](https://github.com/ScanNet/ScanNet/tree/master/Tasks/Benchmark):
123 |
124 | ```bash
125 | python run.py --job scene????_?? --input_dir PATH_TO_SCANNET/scene????_??
126 | ```
127 |
128 | 4. **Run the Test Script**:
129 | Finally, execute the test script to evaluate the processed data:
130 |
131 | ```bash
132 | python test.py
133 | ```
134 |
135 |
136 |
137 | ## Citation
138 |
139 | If you find our work useful, please kindly cite:
140 |
141 | ```
142 | @article{he2024alphatablets,
143 | title={AlphaTablets: A Generic Plane Representation for 3D Planar Reconstruction from Monocular Videos},
144 | author={Yuze He and Wang Zhao and Shaohui Liu and Yubin Hu and Yushi Bai and Yu-Hui Wen and Yong-Jin Liu},
145 | journal={arXiv preprint arXiv:2411.19950},
146 | year={2024}
147 | }
148 | ```
149 |
150 |
151 |
152 | ## Acknowledgements
153 |
154 | Some of the test code and installation guide in this repo is borrowed from [NeuralRecon](https://github.com/zju3dv/NeuralRecon), [PlanarRecon](https://github.com/neu-vi/PlanarRecon/tree/main) and [ParticleSfM](https://github.com/bytedance/particle-sfm)! We sincerely thank them all.
155 |
--------------------------------------------------------------------------------
/configs/default.yaml:
--------------------------------------------------------------------------------
1 | data:
2 | dataset_type: 'scannet'
3 | input_dir: './data/scene0684_01'
4 |
5 | init:
6 | depth_model_type: 'metric3d'
7 | normal_model_type: 'omnidata'
8 |
9 | crop: 20
--------------------------------------------------------------------------------
/configs/replica.yaml:
--------------------------------------------------------------------------------
1 | data:
2 | dataset_type: 'replica'
3 | input_dir: './data/office0'
4 |
5 | init:
6 | depth_model_type: 'metric3d'
7 | normal_model_type: 'omnidata'
8 |
9 | crop: 20
--------------------------------------------------------------------------------
/dataset/dataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.utils.data import Dataset
3 |
4 | class CustomDataset(Dataset):
5 | def __init__(self, images, mvp_mtxs, normals, depths):
6 | self.images = images
7 | self.mvp_mtxs = mvp_mtxs
8 | self.normals = normals
9 | self.depths = depths
10 |
11 | def __len__(self):
12 | return len(self.images)
13 |
14 | def __getitem__(self, idx):
15 | img = torch.from_numpy(self.images[idx])
16 | mvp_mtx = torch.from_numpy(self.mvp_mtxs[idx]).float()
17 | normal = torch.from_numpy(self.normals[idx])
18 | depth = torch.from_numpy(self.depths[idx])
19 |
20 | return img, mvp_mtx, normal, depth
21 |
--------------------------------------------------------------------------------
/geom/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THU-LYJ-Lab/AlphaTablets/735cbfe6aa7f03f7bc37f48303045fe71ffa042a/geom/__init__.py
--------------------------------------------------------------------------------
/geom/plane_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 |
4 | from sklearn.neighbors import KDTree
5 | from tqdm import trange
6 |
7 |
8 | class DisjointSet:
9 | def __init__(self, size, params, mean_colors):
10 | self.parent = [i for i in range(size)]
11 | self.rank = [0] * size
12 | self.accum_normal = [_ for _ in params[:, :3].copy()]
13 | self.accum_center = [_ for _ in params[:, 3:].copy()]
14 | self.accum_color = [_ for _ in mean_colors.copy()]
15 | self.accum_num = [1] * size
16 |
17 | def find(self, x):
18 | if self.parent[x] != x:
19 | self.parent[x] = self.find(self.parent[x])
20 | return self.parent[x]
21 |
22 | def union(self, x, y, normal_thres=0.9, dis_thres=0.1, color_thres=1.):
23 | root_x = self.find(x)
24 | root_y = self.find(y)
25 | if root_x != root_y and np.abs(
26 | np.sum(self.accum_normal[root_x] * self.accum_normal[root_y]) /
27 | np.linalg.norm(self.accum_normal[root_x]) /
28 | np.linalg.norm(self.accum_normal[root_y])
29 | ) > normal_thres and np.linalg.norm(
30 | (self.accum_center[root_x] / self.accum_num[root_x] -
31 | self.accum_center[root_y] / self.accum_num[root_y])
32 | * self.accum_normal[root_x] / np.linalg.norm(self.accum_normal[root_x])
33 | ) < dis_thres and np.linalg.norm(
34 | self.accum_color[root_x] / self.accum_num[root_x] -
35 | self.accum_color[root_y] / self.accum_num[root_y]
36 | ) < color_thres:
37 | if self.rank[root_x] < self.rank[root_y]:
38 | self.parent[root_x] = root_y
39 | self.accum_normal[root_y] += self.accum_normal[root_x]
40 | self.accum_center[root_y] += self.accum_center[root_x]
41 | self.accum_color[root_y] += self.accum_color[root_x]
42 | self.accum_num[root_y] += self.accum_num[root_x]
43 | elif self.rank[root_x] > self.rank[root_y]:
44 | self.parent[root_y] = root_x
45 | self.accum_normal[root_x] += self.accum_normal[root_y]
46 | self.accum_center[root_x] += self.accum_center[root_y]
47 | self.accum_color[root_x] += self.accum_color[root_y]
48 | self.accum_num[root_x] += self.accum_num[root_y]
49 | else:
50 | self.parent[root_x] = root_y
51 | self.rank[root_y] += 1
52 | self.accum_normal[root_y] += self.accum_normal[root_x]
53 | self.accum_center[root_y] += self.accum_center[root_x]
54 | self.accum_color[root_y] += self.accum_color[root_x]
55 | self.accum_num[root_y] += self.accum_num[root_x]
56 |
57 |
58 | def calc_plane(K, pose, depth, dis, mask, x_range_uv, y_range_uv, plane_normal=None):
59 | """Calculate the plane parameters from the camera pose and the pixel plane parameters.
60 | Args:
61 | K: camera intrinsic matrix, [3, 3]
62 | pose: camera pose, world-to-cam, [4, 4]
63 | dis: pixel plane distance to camera, scalar
64 | x_range_uv: pixel x range, [2]
65 | y_range_uv: pixel y range, [2]
66 | plane_normal: plane normal vector, [3], optional
67 | Returns:
68 | plane: plane parameters, [4]
69 | plane_up_vec: plane up vector, [3]
70 | resol: pixel plane resolution, [2]
71 | new_x_range_uv: new pixel x range, [2]
72 | new_y_range_uv: new pixel y range, [2]
73 | """
74 |
75 | # create a pixel grid in the image plane
76 | u = np.linspace(x_range_uv[0], x_range_uv[1], int(x_range_uv[1]-x_range_uv[0]+1))
77 | v = np.linspace(y_range_uv[0], y_range_uv[1], int(y_range_uv[1]-y_range_uv[0]+1))
78 | U, V = np.meshgrid(u, v)
79 |
80 | # back project the pixel grid to 3D space
81 | X = depth * (U + 0.5 - K[0, 2]) / K[0, 0]
82 | Y = -depth * (V + 0.5 - K[1, 2]) / K[1, 1]
83 | Z = -depth * np.ones(U.shape)
84 |
85 | # transform the points from camera coordinate to world coordinate
86 | points = np.stack((X, Y, Z, np.ones(U.shape)), axis=-1)
87 | points_world = np.matmul(points, np.linalg.inv(pose).T)
88 | points_world = points_world[:, :, :3] / points_world[:, :, 3:]
89 |
90 | # use PCA to fit a plane to these points
91 | points_world_flat = points_world[mask]
92 | mean = np.mean(points_world_flat, axis=0)
93 | points_world_zero_centroid = points_world_flat - mean
94 |
95 | if plane_normal is not None:
96 | plane_normal = np.matmul(plane_normal, np.linalg.inv(pose[:3, :3]).T)
97 | plane_normal = plane_normal / np.linalg.norm(plane_normal)
98 |
99 | else:
100 | if len(points_world_zero_centroid) < 10000:
101 | _, _, v = np.linalg.svd(points_world_zero_centroid)
102 | else:
103 | import random
104 | _, _, v = np.linalg.svd(random.sample(list(points_world_zero_centroid), 10000))
105 |
106 | # plane parameters
107 | plane_normal = v[-1, :] / np.linalg.norm(v[-1, :])
108 | if np.abs(plane_normal).max() != plane_normal.max():
109 | plane_normal = -plane_normal
110 |
111 | plane = np.concatenate((plane_normal, mean))
112 |
113 | resol = np.array([K[0,0]/dis, K[1,1]/dis])
114 |
115 | # calculate plane_up_vector according to the plane_normal
116 | pose_up_vec = np.array([0, 0, 1])
117 | if np.abs(np.sum(plane_normal * pose_up_vec)) > 0.8:
118 | pose_up_vec = np.array([0, 1, 0])
119 | plane_up_vec = pose_up_vec - np.sum(plane_normal * pose_up_vec) * plane_normal
120 | plane_up_vec = plane_up_vec / np.linalg.norm(plane_up_vec)
121 |
122 | U, V = U[mask], V[mask]
123 |
124 | plane_right = np.cross(plane_normal, plane_up_vec)
125 |
126 | new_x_argmin =np.matmul(points_world_flat, plane_right).argmin()
127 | new_x_argmax =np.matmul(points_world_flat, plane_right).argmax()
128 | new_y_argmin =np.matmul(points_world_flat, plane_up_vec).argmin()
129 | new_y_argmax =np.matmul(points_world_flat, plane_up_vec).argmax()
130 |
131 | new_x_width = np.sqrt((U[new_x_argmin] - U[new_x_argmax])**2 + (V[new_x_argmin] - V[new_x_argmax])**2)
132 | new_y_width = np.sqrt((U[new_y_argmin] - U[new_y_argmax])**2 + (V[new_y_argmin] - V[new_y_argmax])**2)
133 |
134 | new_x_range_uv = [-new_x_width/2 - 2, new_x_width/2 + 2]
135 | new_y_range_uv = [-new_y_width/2 - 2, new_y_width/2 + 2]
136 |
137 | y_range_3d = np.matmul(points_world_flat, plane_up_vec).max() - np.matmul(points_world_flat, plane_up_vec).min()
138 | x_range_3d = np.matmul(points_world_flat, plane_right).max() - np.matmul(points_world_flat, plane_right).min()
139 |
140 | resol = np.array([
141 | new_x_width / (x_range_3d + 1e-6),
142 | new_y_width / (y_range_3d + 1e-6)
143 | ])
144 |
145 | if resol[0] < K[0,0]/dis / 10 or resol[1] < K[1,1]/dis / 10:
146 | return None
147 |
148 | xy_min = np.array([new_x_range_uv[0], new_y_range_uv[0]])
149 | xy_max = np.array([new_x_range_uv[1], new_y_range_uv[1]])
150 |
151 | return plane, plane_up_vec, resol, xy_min, xy_max
152 |
153 |
154 | def ray_plane_intersect(plane, ray_origin, ray_direction):
155 | """Calculate the intersection of a ray and a plane.
156 | Args:
157 | plane: plane parameters, [4]
158 | ray_origin: ray origin, [3]
159 | ray_direction: ray direction, [3]
160 |
161 | Returns:
162 | intersection: intersection point, [3]
163 | """
164 |
165 | # calculate intersection
166 | t = -(plane[3] + np.dot(plane[:3], ray_origin)) / np.dot(plane[:3], ray_direction)
167 | intersection = ray_origin + t * ray_direction
168 |
169 | return intersection
170 |
171 |
172 | def points_xyz_to_plane_uv(points, plane, resol, plane_up):
173 | """Project 3D points to the pixel plane.
174 | Args:
175 | points: 3D points, [N, 3]
176 | plane: plane parameters, [4]
177 | resol: pixel plane resolution, [2]
178 | plane_up: plane up vector, [3]
179 | Returns:
180 | uv: pixel plane coordinates, [N, 2]
181 | """
182 |
183 | # plane normal vector
184 | plane_normal = np.asarray(plane[:3])
185 | # projection points of 'points' on the plane
186 | points_proj = points - np.outer( np.sum(points*plane_normal, axis=1)+plane[3] , plane_normal) / np.linalg.norm(plane_normal)
187 | mean_proj = np.mean(points_proj, axis=0)
188 | uvw_right = np.cross(plane_normal, plane_up)
189 | uvw_up = plane_up
190 | # calculate the uv coordinates
191 | uv = np.c_[np.sum((points_proj-mean_proj) * uvw_right, axis=-1), np.sum((points_proj-mean_proj) * uvw_up, axis=-1)]
192 | uv = uv * resol
193 | return uv
194 |
195 |
196 | def points_xyz_to_plane_uv_torch(points, plane, resol, plane_up):
197 | """Project 3D points to the pixel plane.
198 | Args:
199 | points: 3D points, [N, 3]
200 | plane: plane parameters, [4]
201 | resol: pixel plane resolution, [2]
202 | plane_up: plane up vector, [3]
203 | Returns:
204 | uv: pixel plane coordinates, [N, 2]
205 | """
206 |
207 | # plane normal vector
208 | plane_normal = plane[:3]
209 | # projection points of 'points' on the plane
210 | points_proj = points - torch.outer( torch.sum(points*plane_normal, dim=1)+plane[3] , plane_normal) / torch.norm(plane_normal)
211 | mean_proj = torch.mean(points_proj, dim=0)
212 | uvw_right = torch.cross(plane_normal, plane_up)
213 | uvw_up = plane_up
214 | # calculate the uv coordinates
215 | uv = torch.cat([torch.sum((points_proj-mean_proj) * uvw_right, dim=-1, keepdim=True), torch.sum((points_proj-mean_proj) * uvw_up, dim=-1, keepdim=True)], dim=-1)
216 | uv = uv * resol
217 | return uv
218 |
219 |
220 | def simple_distribute_planes_2D(uv_ranges, gap=2, min_H=8192):
221 | """Distribute pixel planes in 2D space.
222 | Args:
223 | uv_ranges: pixel ranges of each plane, [N, 2]
224 | Returns:
225 | plane_leftup: left-up pixel of each plane, [N, 2]
226 | """
227 |
228 | # calculate the left-up pixel of each plane
229 | plane_leftup = torch.zeros_like(uv_ranges)
230 |
231 | H = (int(torch.max(uv_ranges[:, 1]).item()) + 2) // gap * gap + gap
232 | H = max(H, min_H)
233 |
234 | # sort the planes by the height
235 | _, sort_idx = torch.sort(uv_ranges[:, 1], descending=True)
236 |
237 | # distribute the planes
238 | idx = 0
239 | now_H = 0
240 | now_W = 0
241 | prev_W = 0
242 | while idx < len(sort_idx):
243 | now_leftup = torch.tensor((prev_W+1, now_H+1))
244 | plane_leftup[sort_idx[idx]] = now_leftup
245 | now_W = max(now_W, uv_ranges[sort_idx[idx], 0] + 1 + prev_W)
246 | now_H += uv_ranges[sort_idx[idx], 1] + 1
247 |
248 | if idx + 1 < len(sort_idx) and now_H + uv_ranges[sort_idx[idx+1], 1] + 1 > H:
249 | prev_W = now_W
250 | now_H = 0
251 |
252 | idx += 1
253 |
254 | W = (int(now_W.item()) + 2) // gap * gap + gap
255 |
256 | return plane_leftup, W, H
257 |
258 |
259 | def cluster_planes(planes, K=2, thres=0.999,
260 | color_thres_1=0.3, color_thres_2=0.2,
261 | dis_thres_1=0.5, dis_thres_2=0.1,
262 | merge_edge_planes=False,
263 | init_plane_sets=None):
264 | # planes[:, :3]: plane normal vector
265 | # planes[:, 3:6]: plane center
266 |
267 | # create disjoint set
268 | ds = DisjointSet(len(planes), planes[:, :6], planes[:, 17:20])
269 |
270 | if init_plane_sets is not None:
271 | for plane_set in init_plane_sets:
272 | for i in range(len(plane_set)-1):
273 | ds.union(plane_set[i], plane_set[i+1], normal_thres=0.99, dis_thres=1, color_thres=114514)
274 |
275 | # construct kd-tree for plane center
276 | print('clustering tablets ...')
277 | tree = KDTree(planes[:, 3:6])
278 |
279 | # find the nearest K neighbors for each plane
280 | _, ind = tree.query(planes[:, 3:6], k=K+1)
281 |
282 | # calculate the angle between each plane and its neighbors
283 | neighbor_normals = planes[ind[:, 1:], :3]
284 | plane_normals = planes[:, :3]
285 | cos = np.sum(neighbor_normals * plane_normals[:, None, :], axis=-1)
286 |
287 | # merge planes that have cos > thres
288 | for i in trange(len(planes)):
289 | if not merge_edge_planes and planes[i, 15] == True:
290 | continue
291 |
292 | for j in range(K):
293 | if not merge_edge_planes and planes[ind[i, j+1], 15] == True:
294 | continue
295 | if cos[i, j] > thres:
296 | ds.union(i, ind[i, j+1], normal_thres=0.99, dis_thres=dis_thres_1, color_thres=color_thres_1)
297 |
298 | # merge planes that have cos > thres
299 | for i in trange(len(planes)):
300 | if not merge_edge_planes and planes[i, 15] == True:
301 | continue
302 |
303 | for j in range(K):
304 | if not merge_edge_planes and planes[ind[i, j+1], 15] == True:
305 | continue
306 | if cos[i, j] > thres:
307 | ds.union(i, ind[i, j+1], normal_thres=0.9, dis_thres=dis_thres_2, color_thres=color_thres_2)
308 |
309 | root2idx = {}
310 | for i in range(len(planes)):
311 | root = ds.find(i)
312 | if root not in root2idx:
313 | root2idx[root] = []
314 | root2idx[root].append(i)
315 |
316 | plane_sets = []
317 | for root in root2idx:
318 | plane_sets.append(root2idx[root])
319 |
320 | return plane_sets
321 |
322 |
--------------------------------------------------------------------------------
/lib/keyframe.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import glob
3 | import os
4 | from datetime import datetime
5 |
6 |
7 | def get_keyframes(folder, min_angle=15, min_distance=0.2, window_size=9,
8 | min_mean=0.2, max_mean=10):
9 | txt_list = sorted(glob.glob(f'{folder}/pose/*.txt'), key=lambda x: int(x.split('/')[-1].split('.')[0]))
10 | if len(txt_list) != 0:
11 | last_pose = np.loadtxt(txt_list[0])
12 | image_skip = np.ceil(len(txt_list) / 2000)
13 | txt_list = txt_list[::int(image_skip)]
14 | pose_num = len(txt_list)
15 | else:
16 | extrs = np.loadtxt(os.path.join(folder, 'traj.txt')).reshape(-1, 4, 4)
17 | last_pose = extrs[0]
18 | image_skip = np.ceil(len(extrs) / 2000)
19 | extrs = extrs[::int(image_skip)]
20 | pose_num = len(extrs)
21 |
22 | count = 1
23 | all_ids = []
24 |
25 | if len(txt_list) != 0:
26 | depth_list = [ pname.replace('pose', 'aligned_dense_depths').replace('.txt', '.npy') for pname in txt_list ]
27 | else:
28 | depth_list = sorted(glob.glob(f'{folder}/aligned_dense_depths/*.npy'))
29 | for i, j in zip(txt_list, depth_list):
30 | if int(i.split('/')[-1].split('.')[0]) != int(j.split('/')[-1].split('.')[0]):
31 | print(i, j)
32 | raise ValueError('pose and depth not match')
33 | depth_list = depth_list[::int(image_skip)]
34 |
35 | depth_list = np.array([ np.load(i).mean() for i in depth_list ])
36 | id_list = np.linspace(0, len(depth_list)-1, pose_num).astype(int)[::int(image_skip)]
37 | id_list = id_list[np.logical_and(depth_list > min_mean, depth_list < max_mean)]
38 | depth_list = depth_list[np.logical_and(depth_list > min_mean, depth_list < max_mean)]
39 |
40 | from scipy.signal import medfilt
41 | filtered_depth_list = medfilt(depth_list, kernel_size=29)
42 |
43 | # filtered out the depth_list
44 | id_list = id_list[
45 | np.logical_and(
46 | depth_list > filtered_depth_list * 0.85,
47 | depth_list < filtered_depth_list * 1.15
48 | )
49 | ]
50 |
51 | depth_list = depth_list[
52 | np.logical_and(
53 | depth_list > filtered_depth_list * 0.85,
54 | depth_list < filtered_depth_list * 1.15
55 | )
56 | ]
57 |
58 | print(str(datetime.now()) + ': \033[92mI', 'filtered out depth_list', len(id_list), '/', pose_num, '\033[0m')
59 |
60 | ids = [id_list[0]]
61 |
62 | for idx_pos, idx in enumerate(id_list[1:]):
63 | if len(txt_list) != 0:
64 | i = txt_list[idx]
65 | with open(i, 'r') as f:
66 | cam_pose = np.loadtxt(i)
67 | else:
68 | cam_pose = extrs[idx]
69 | angle = np.arccos(
70 | ((np.linalg.inv(cam_pose[:3, :3]) @ last_pose[:3, :3] @ np.array([0, 0, 1]).T) * np.array(
71 | [0, 0, 1])).sum())
72 | dis = np.linalg.norm(cam_pose[:3, 3] - last_pose[:3, 3])
73 | if angle > (min_angle / 180) * np.pi or dis > min_distance:
74 | ids.append(idx)
75 | last_pose = cam_pose
76 | # Compute camera view frustum and extend convex hull
77 | count += 1
78 | if count == window_size:
79 | ids = [i * int(image_skip) for i in ids]
80 | all_ids.append(ids)
81 | ids = []
82 | count = 0
83 |
84 | if len(ids) > 2:
85 | ids = [i * int(image_skip) for i in ids]
86 | all_ids.append(ids)
87 | else:
88 | ids = [i * int(image_skip) for i in ids]
89 | all_ids[-1].extend(ids)
90 |
91 | return all_ids, int(image_skip)
92 |
93 |
94 | if __name__ == '__main__':
95 | folder = '/data0/bys/Hex/PixelPlane/data/scene0709_01'
96 | keyframes, image_skip = get_keyframes(folder)
97 | print(keyframes, image_skip)
98 |
--------------------------------------------------------------------------------
/lib/load_colmap.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime
2 | import os
3 | import cv2
4 | import glob
5 | import numpy as np
6 | from tqdm import tqdm
7 |
8 | from recon.utils import load_sfm_pose, load_scannet_pose
9 |
10 | from geom.plane_utils import calc_plane
11 |
12 | import torch
13 | import torch.nn.functional as F
14 |
15 |
16 | def dilate(img):
17 | kernel = torch.ones(3, 3).cuda().double()
18 | img = torch.tensor(img.astype('int32')).cuda().double()
19 |
20 | while True:
21 | mask = img > 0
22 | if torch.logical_not(mask).sum() == 0:
23 | break
24 | mask = mask.double()
25 |
26 | mask_dilated = F.conv2d(mask[None, None], kernel[None, None], padding=1).squeeze(0).squeeze(0)
27 |
28 | img_dilated = F.conv2d(img[None, None], kernel[None, None], padding=1).squeeze(0).squeeze(0)
29 | img_dilated = torch.where(mask_dilated == 0, img_dilated, img_dilated / mask_dilated)
30 |
31 | img = torch.where(mask == 0, img_dilated, img)
32 |
33 | img = img.cpu().numpy()
34 |
35 | return img
36 |
37 |
38 | def parse_sp(sp, intr, pose, depth, normal, img_sp, edge_thres=0.95, crop=20):
39 | """Parse the superpixel segmentation into planes
40 | """
41 | sp = torch.from_numpy(sp).cuda()
42 | depth = torch.from_numpy(depth).cuda()
43 | normal = (torch.from_numpy(normal).cuda() - 0.5) * 2
44 | normal = normal.permute(1, 2, 0)
45 | img_sp = torch.from_numpy(img_sp).cuda()
46 | sp = sp.int()
47 | sp_ids = torch.unique(sp)
48 | planes = []
49 | mean_colors = []
50 |
51 | # mask crop to -1
52 | sp[:crop] = -1
53 | sp[-crop:] = -1
54 | sp[:, :crop] = -1
55 | sp[:, -crop:] = -1
56 |
57 | new_sp = torch.ones_like(sp).cuda() * -1
58 |
59 | sp_id_cnt = 0
60 |
61 | for sp_id in tqdm(sp_ids):
62 | sp_mask = sp == sp_id
63 |
64 | if sp_mask.sum() <= 15:
65 | continue
66 |
67 | new_sp[sp_mask] = sp_id_cnt
68 | mean_color = torch.mean(img_sp[sp_mask], dim=0)
69 |
70 | sp_dis = depth[sp_mask]
71 | sp_dis = torch.median(sp_dis)
72 | if sp_dis < 0:
73 | continue
74 | sp_normal = normal[sp_mask]
75 |
76 | sp_coeff = torch.einsum('ij,kj->ik', sp_normal, sp_normal)
77 | if sp_coeff.min() < edge_thres:
78 | is_edge_plane = True
79 | else:
80 | is_edge_plane = False
81 |
82 | sp_normal = torch.mean(sp_normal, dim=0)
83 | sp_normal = sp_normal / torch.norm(sp_normal)
84 | sp_normal[1] = -sp_normal[1]
85 | sp_normal[2] = -sp_normal[2]
86 |
87 | x_accum = torch.sum(sp_mask, dim=0)
88 | y_accum = torch.sum(sp_mask, dim=1)
89 | x_range_uv = [torch.min(torch.nonzero(x_accum)).item(), torch.max(torch.nonzero(x_accum)).item()]
90 | y_range_uv = [torch.min(torch.nonzero(y_accum)).item(), torch.max(torch.nonzero(y_accum)).item()]
91 |
92 | sp_dis = sp_dis.cpu().numpy()
93 | sp_depth = depth[y_range_uv[0]:y_range_uv[1]+1, x_range_uv[0]:x_range_uv[1]+1].cpu().numpy()
94 | sp_mask = sp_mask[y_range_uv[0]:y_range_uv[1]+1, x_range_uv[0]:x_range_uv[1]+1].cpu().numpy()
95 |
96 | ret = calc_plane(intr, pose, sp_depth, sp_dis, sp_mask, x_range_uv, y_range_uv, plane_normal=sp_normal.cpu().numpy())
97 | if ret is None:
98 | continue
99 | plane, plane_up, resol, new_x_range_uv, new_y_range_uv = ret
100 |
101 | plane = np.concatenate([plane, plane_up, resol, new_x_range_uv, new_y_range_uv, [is_edge_plane]])
102 | planes.append(plane)
103 | mean_colors.append(mean_color.cpu().numpy())
104 |
105 | sp_id_cnt += 1
106 |
107 | return planes, new_sp.cpu().numpy(), mean_colors
108 |
109 |
110 | def get_projection_matrix(fovy: float, aspect_wh: float, near: float, far: float):
111 | proj_mtx = np.zeros((4, 4), dtype=np.float32)
112 | proj_mtx[0, 0] = 1.0 / (np.tan(fovy / 2.0) * aspect_wh)
113 | proj_mtx[1, 1] = -1.0 / np.tan(
114 | fovy / 2.0
115 | ) # add a negative sign here as the y axis is flipped in nvdiffrast output
116 | proj_mtx[2, 2] = -(far + near) / (far - near)
117 | proj_mtx[2, 3] = -2.0 * far * near / (far - near)
118 | proj_mtx[3, 2] = -1.0
119 | return proj_mtx
120 |
121 |
122 | def get_mvp_matrix(c2w, proj_mtx):
123 | # calculate w2c from c2w: R' = Rt, t' = -Rt * t
124 | # mathematically equivalent to (c2w)^-1
125 | w2c = np.zeros((c2w.shape[0], 4, 4))
126 | w2c[:, :3, :3] = np.transpose(c2w[:, :3, :3], (0, 2, 1))
127 | w2c[:, :3, 3:] = np.transpose(-c2w[:, :3, :3], (0, 2, 1)) @ c2w[:, :3, 3:]
128 | w2c[:, 3, 3] = 1.0
129 |
130 | # calculate mvp matrix by proj_mtx @ w2c (mv_mtx)
131 | mvp_mtx = proj_mtx @ w2c
132 |
133 | return mvp_mtx
134 |
135 |
136 | def load_colmap_data(args, kf_list=[], image_skip=1, load_plane=True, scannet_pose=True):
137 | imgs = []
138 | image_dir = os.path.join(args.input_dir, "images")
139 | start = kf_list[0]
140 | end = kf_list[-1] + 1 if kf_list[-1] != -1 else len(glob.glob(os.path.join(image_dir, "*")))
141 | image_names = sorted(glob.glob(os.path.join(image_dir, "*")), key=lambda x: int(x.split('/')[-1][:-4]))
142 |
143 | image_names_sp = [image_names[i] for i in kf_list]
144 | image_names = image_names[start:end:image_skip]
145 |
146 | print(str(datetime.now()) + ': \033[92mI', 'loading images ...', '\033[0m')
147 | for name in tqdm(image_names):
148 | img = cv2.imread(name)
149 | img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
150 | imgs.append(img.astype(np.float32) / 255.)
151 |
152 | imgs_sp = []
153 | for name in image_names_sp:
154 | img = cv2.imread(name)
155 | # convert to ycbcr using cv2
156 | img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
157 | imgs_sp.append(img.astype(np.float32) / 255.)
158 |
159 | imgs_sp = np.stack(imgs_sp, 0)
160 |
161 | if scannet_pose:
162 | print(str(datetime.now()) + ': \033[92mI', 'loading scannet poses ...', '\033[0m')
163 | intr_scannet, sfm_poses_scannet, sfm_camprojs_scannet = load_scannet_pose(args.input_dir)
164 | intr = intr_scannet
165 | sfm_poses, sfm_camprojs = sfm_poses_scannet, sfm_camprojs_scannet
166 | else:
167 | print(str(datetime.now()) + ': \033[92mI', 'loading colmap poses ...', '\033[0m')
168 | intr, sfm_poses, sfm_camprojs = load_sfm_pose(os.path.join(args.input_dir, "sfm"))
169 |
170 |
171 | sfm_poses_sp = np.array(sfm_poses)[kf_list]
172 | sfm_poses = np.array(sfm_poses)[start:end:image_skip]
173 | sfm_camprojs = np.array(sfm_camprojs)[start:end:image_skip]
174 |
175 | normal_dir = os.path.join(args.input_dir, "omnidata_normal")
176 | normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")), key=lambda x: int(x.split('/')[-1][:-4]))
177 | depth_names = [ iname.replace('omnidata_normal', 'aligned_dense_depths') for iname in normal_names ]
178 | depth_names = [depth_names[i] for i in kf_list]
179 |
180 | print(str(datetime.now()) + ': \033[92mI', 'loading depths ...', '\033[0m')
181 | depths = []
182 | for name in tqdm(depth_names):
183 | depth = np.load(name)
184 | depths.append(depth)
185 |
186 | depths = np.stack(depths, 0)
187 | aligned_depth_dir = os.path.join(args.input_dir, "aligned_dense_depths")
188 | all_depth_names = sorted(glob.glob(os.path.join(aligned_depth_dir, "*")), key=lambda x: int(x.split('/')[-1][:-4]))[start:end:image_skip]
189 | all_depths = []
190 |
191 | for name, pose in tqdm(zip(all_depth_names, sfm_poses)):
192 | depth = np.load(name)
193 | all_depths.append(depth)
194 |
195 | if args.init.normal_model_type == 'omnidata':
196 | normal_dir = os.path.join(args.input_dir, "omnidata_normal")
197 | else:
198 | raise NotImplementedError(f'Unknown normal model type {args.init.normal_model_type} exiting')
199 |
200 | normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")), key=lambda x: int(x.split('/')[-1][:-4]))
201 | normal_names = [normal_names[i] for i in kf_list]
202 |
203 | print(str(datetime.now()) + ': \033[92mI', 'loading normals ...', '\033[0m')
204 | normals = []
205 | for name in tqdm(normal_names):
206 | normal = np.load(name)[:3]
207 | normals.append(normal)
208 |
209 | normals = np.stack(normals, 0)
210 |
211 | all_normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")), key=lambda x: int(x.split('/')[-1][:-4]))[start:end:image_skip]
212 | all_normals = []
213 |
214 | for name, pose in tqdm(zip(all_normal_names, sfm_poses)):
215 | normal = np.load(name)
216 | normal = normal[:3]
217 |
218 | normal = torch.from_numpy(normal).cuda()
219 | normal = (normal - 0.5) * 2
220 | normal = normal / torch.norm(normal, dim=0, keepdim=True)
221 | normal = normal.permute(1, 2, 0)
222 | normal[:, :, 1] = -normal[:, :, 1]
223 | normal[:, :, 2] = -normal[:, :, 2]
224 | normal = torch.einsum('ijk,kl->ijl', normal, torch.from_numpy(np.linalg.inv(pose[:3, :3]).T).cuda().float())
225 | normal = F.interpolate(normal.permute(2, 0, 1).unsqueeze(0),
226 | (int(imgs[0].shape[0]/64)*8, int(imgs[0].shape[1]/64)*8),
227 | mode='bilinear', align_corners=False).squeeze(0).permute(1, 2, 0)
228 | all_normals.append(normal.cpu().numpy())
229 |
230 | sp_dir = os.path.join(args.input_dir, "sp")
231 | sp_names = [os.path.join(sp_dir, os.path.split(name)[-1].replace('.jpg', '.npy').replace('.png', '.npy')) for name in image_names_sp]
232 |
233 | if load_plane:
234 | print(str(datetime.now()) + ': \033[92mI', 'loading superpixels ...', '\033[0m')
235 | planes_all = []
236 | new_sp_all = []
237 | mean_colors_all = []
238 | plane_index_start = 0
239 | for plane_idx, (sp_name, depth, normal, pose, img_sp) in tqdm(enumerate(zip(sp_names, depths, normals, sfm_poses_sp, imgs_sp))):
240 | sp = np.load(sp_name)
241 | planes, new_sp, mean_colors = parse_sp(sp, intr, pose, depth, normal, img_sp)
242 | planes = np.array(planes)
243 | planes_idx = np.ones((planes.shape[0], 1)) * plane_idx
244 | planes = np.concatenate([planes, planes_idx], 1)
245 | planes_all.extend(planes)
246 | new_sp_all.append(new_sp + plane_index_start)
247 | plane_index_start += planes.shape[0]
248 | mean_colors = np.array(mean_colors)
249 | mean_colors_all.extend(mean_colors)
250 |
251 | planes_all = np.array(planes_all)
252 | mean_colors_all = np.array(mean_colors_all)
253 |
254 | else:
255 | planes_all = None
256 | new_sp_all = None
257 | mean_colors_all = None
258 |
259 | # proj matrixs
260 | frames_proj = []
261 | frames_c2w = []
262 | frames_center = []
263 | for i in range(len(sfm_camprojs)):
264 | fovy = 2 * np.arctan(0.5 * imgs[0].shape[0] / intr[1, 1])
265 | proj = get_projection_matrix(
266 | fovy, imgs[0].shape[1] / imgs[0].shape[0], 0.1, 1000.0
267 | )
268 | proj = np.array(proj)
269 | frames_proj.append(proj)
270 | # sfm_poses is w2c
271 | c2w = np.linalg.inv(sfm_poses[i])
272 | frames_c2w.append(c2w)
273 | frames_center.append(c2w[:3, 3])
274 |
275 | frames_proj = np.stack(frames_proj, 0)
276 | frames_c2w = np.stack(frames_c2w, 0)
277 | frames_center = np.stack(frames_center, 0)
278 |
279 | mvp_mtxs = get_mvp_matrix(
280 | frames_c2w, frames_proj,
281 | )
282 |
283 | index_init = ((np.array(kf_list) - kf_list[0]) / image_skip).astype(np.int32)
284 |
285 | return imgs, intr, sfm_poses, sfm_camprojs, frames_center, all_depths, all_normals, planes_all, \
286 | mvp_mtxs, index_init, new_sp_all, mean_colors_all
287 |
--------------------------------------------------------------------------------
/lib/load_data.py:
--------------------------------------------------------------------------------
1 | from .load_colmap import load_colmap_data
2 | from .load_replica import load_replica_data
3 |
4 |
5 | def load_data(args, kf_list, image_skip, load_plane):
6 | if args.dataset_type == 'scannet':
7 | images, intr, sfm_poses, sfm_camprojs, cam_centers, \
8 | all_depths, normals, planes_all, mvp_mtxs, index_init, \
9 | new_sps, mean_colors = load_colmap_data(args, kf_list=kf_list,
10 | image_skip=image_skip,
11 | load_plane=load_plane)
12 | print('Loaded scannet', intr, len(images), sfm_poses.shape, sfm_camprojs.shape, args.input_dir)
13 |
14 | data_dict = dict(
15 | poses=sfm_poses, images=images,
16 | intr=intr, sfm_camprojs=sfm_camprojs,
17 | cam_centers=cam_centers,
18 | all_depths=all_depths,
19 | normals=normals, planes_all=planes_all,
20 | mvp_mtxs=mvp_mtxs,
21 | index_init=index_init,
22 | new_sps=new_sps,
23 | mean_colors=mean_colors,
24 | )
25 | return data_dict
26 |
27 |
28 | elif args.dataset_type == 'replica':
29 | images, intr, sfm_poses, sfm_camprojs, cam_centers, \
30 | all_depths, normals, planes_all, mvp_mtxs, index_init, \
31 | new_sps, mean_colors = load_replica_data(args, kf_list=kf_list,
32 | image_skip=image_skip,
33 | load_plane=load_plane)
34 |
35 | print('Loaded replica', intr, len(images), sfm_poses.shape, sfm_camprojs.shape, args.input_dir)
36 |
37 | data_dict = dict(
38 | poses=sfm_poses, images=images,
39 | intr=intr, sfm_camprojs=sfm_camprojs,
40 | cam_centers=cam_centers,
41 | all_depths=all_depths,
42 | normals=normals, planes_all=planes_all,
43 | mvp_mtxs=mvp_mtxs,
44 | index_init=index_init,
45 | new_sps=new_sps,
46 | mean_colors=mean_colors,
47 | )
48 | return data_dict
49 |
50 |
51 | else:
52 | raise NotImplementedError(f'Unknown dataset type {args.dataset_type} exiting')
53 |
54 |
--------------------------------------------------------------------------------
/lib/load_replica.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime
2 | import os
3 | import cv2
4 | import glob
5 | import numpy as np
6 | from tqdm import tqdm
7 |
8 | from recon.utils import load_sfm_pose, load_replica_pose
9 |
10 | from geom.plane_utils import calc_plane
11 |
12 | import torch
13 | import torch.nn.functional as F
14 |
15 |
16 | def dilate(img):
17 | kernel = torch.ones(3, 3).cuda().double()
18 | img = torch.tensor(img.astype('int32')).cuda().double()
19 |
20 | while True:
21 | mask = img > 0
22 | if torch.logical_not(mask).sum() == 0:
23 | break
24 | mask = mask.double()
25 |
26 | mask_dilated = F.conv2d(mask[None, None], kernel[None, None], padding=1).squeeze(0).squeeze(0)
27 |
28 | img_dilated = F.conv2d(img[None, None], kernel[None, None], padding=1).squeeze(0).squeeze(0)
29 | img_dilated = torch.where(mask_dilated == 0, img_dilated, img_dilated / mask_dilated)
30 |
31 | img = torch.where(mask == 0, img_dilated, img)
32 |
33 | img = img.cpu().numpy()
34 |
35 | return img
36 |
37 |
38 | def parse_sp(sp, intr, pose, depth, normal, img_sp, edge_thres=0.95, crop=20):
39 | """Parse the superpixel segmentation into planes
40 | """
41 | sp = torch.from_numpy(sp).cuda()
42 | depth = torch.from_numpy(depth).cuda()
43 | normal = (torch.from_numpy(normal).cuda() - 0.5) * 2
44 | normal = normal.permute(1, 2, 0)
45 | img_sp = torch.from_numpy(img_sp).cuda()
46 | sp = sp.int()
47 | sp_ids = torch.unique(sp)
48 | planes = []
49 | mean_colors = []
50 |
51 | # mask crop to -1
52 | sp[:crop] = -1
53 | sp[-crop:] = -1
54 | sp[:, :crop] = -1
55 | sp[:, -crop:] = -1
56 |
57 | new_sp = torch.ones_like(sp).cuda() * -1
58 | sp_id_cnt = 0
59 |
60 | for sp_id in tqdm(sp_ids):
61 | sp_mask = sp == sp_id
62 |
63 | if sp_mask.sum() <= 15:
64 | continue
65 |
66 | new_sp[sp_mask] = sp_id_cnt
67 | mean_color = torch.mean(img_sp[sp_mask], dim=0)
68 |
69 | sp_dis = depth[sp_mask]
70 | sp_dis = torch.median(sp_dis)
71 | if sp_dis < 0:
72 | continue
73 | sp_normal = normal[sp_mask]
74 |
75 | sp_coeff = torch.einsum('ij,kj->ik', sp_normal, sp_normal)
76 | if sp_coeff.min() < edge_thres:
77 | is_edge_plane = True
78 | else:
79 | is_edge_plane = False
80 |
81 | sp_normal = torch.mean(sp_normal, dim=0)
82 | sp_normal = sp_normal / torch.norm(sp_normal)
83 | sp_normal[1] = -sp_normal[1]
84 | sp_normal[2] = -sp_normal[2]
85 |
86 | x_accum = torch.sum(sp_mask, dim=0)
87 | y_accum = torch.sum(sp_mask, dim=1)
88 | x_range_uv = [torch.min(torch.nonzero(x_accum)).item(), torch.max(torch.nonzero(x_accum)).item()]
89 | y_range_uv = [torch.min(torch.nonzero(y_accum)).item(), torch.max(torch.nonzero(y_accum)).item()]
90 |
91 | sp_dis = sp_dis.cpu().numpy()
92 | sp_depth = depth[y_range_uv[0]:y_range_uv[1]+1, x_range_uv[0]:x_range_uv[1]+1].cpu().numpy()
93 | sp_mask = sp_mask[y_range_uv[0]:y_range_uv[1]+1, x_range_uv[0]:x_range_uv[1]+1].cpu().numpy()
94 |
95 | ret = calc_plane(intr, pose, sp_depth, sp_dis, sp_mask, x_range_uv, y_range_uv, plane_normal=sp_normal.cpu().numpy())
96 | if ret is None:
97 | continue
98 | plane, plane_up, resol, new_x_range_uv, new_y_range_uv = ret
99 |
100 | plane = np.concatenate([plane, plane_up, resol, new_x_range_uv, new_y_range_uv, [is_edge_plane]])
101 | planes.append(plane)
102 | mean_colors.append(mean_color.cpu().numpy())
103 |
104 | sp_id_cnt += 1
105 |
106 | return planes, new_sp.cpu().numpy(), mean_colors
107 |
108 |
109 | def get_projection_matrix(fovy: float, aspect_wh: float, near: float, far: float):
110 | proj_mtx = np.zeros((4, 4), dtype=np.float32)
111 | proj_mtx[0, 0] = 1.0 / (np.tan(fovy / 2.0) * aspect_wh)
112 | proj_mtx[1, 1] = -1.0 / np.tan(
113 | fovy / 2.0
114 | ) # add a negative sign here as the y axis is flipped in nvdiffrast output
115 | proj_mtx[2, 2] = -(far + near) / (far - near)
116 | proj_mtx[2, 3] = -2.0 * far * near / (far - near)
117 | proj_mtx[3, 2] = -1.0
118 | return proj_mtx
119 |
120 |
121 | def get_mvp_matrix(c2w, proj_mtx):
122 | # calculate w2c from c2w: R' = Rt, t' = -Rt * t
123 | # mathematically equivalent to (c2w)^-1
124 | w2c = np.zeros((c2w.shape[0], 4, 4))
125 | w2c[:, :3, :3] = np.transpose(c2w[:, :3, :3], (0, 2, 1))
126 | w2c[:, :3, 3:] = np.transpose(-c2w[:, :3, :3], (0, 2, 1)) @ c2w[:, :3, 3:]
127 | w2c[:, 3, 3] = 1.0
128 |
129 | # calculate mvp matrix by proj_mtx @ w2c (mv_mtx)
130 | mvp_mtx = proj_mtx @ w2c
131 |
132 | return mvp_mtx
133 |
134 |
135 | def load_replica_data(args, kf_list=[], image_skip=1, load_plane=True):
136 | imgs = []
137 | image_dir = os.path.join(args.input_dir, "images")
138 | start = kf_list[0]
139 | end = kf_list[-1] + 1 if kf_list[-1] != -1 else len(glob.glob(os.path.join(image_dir, "*")))
140 | image_names = sorted(glob.glob(os.path.join(image_dir, "*")))
141 |
142 | image_names_sp = [image_names[i] for i in kf_list]
143 | image_names = image_names[start:end:image_skip]
144 |
145 | print(str(datetime.now()) + ': \033[92mI', 'loading images ...', '\033[0m')
146 | for name in tqdm(image_names):
147 | img = cv2.imread(name)
148 | img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
149 | imgs.append(img.astype(np.float32) / 255.)
150 |
151 | imgs_sp = []
152 | for name in image_names_sp:
153 | img = cv2.imread(name)
154 | # convert to ycbcr using cv2
155 | img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
156 | imgs_sp.append(img.astype(np.float32) / 255.)
157 |
158 | imgs_sp = np.stack(imgs_sp, 0)
159 |
160 | intr, sfm_poses, sfm_camprojs = load_replica_pose(args.input_dir)
161 |
162 | sfm_poses_sp = np.array(sfm_poses)[kf_list]
163 | sfm_poses = np.array(sfm_poses)[start:end:image_skip]
164 | sfm_camprojs = np.array(sfm_camprojs)[start:end:image_skip]
165 |
166 | normal_dir = os.path.join(args.input_dir, "omnidata_normal")
167 | normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")))
168 | depth_names = [ iname.replace('omnidata_normal', 'aligned_dense_depths') for iname in normal_names ]
169 | depth_names = [depth_names[i] for i in kf_list]
170 |
171 | print(str(datetime.now()) + ': \033[92mI', 'loading depths ...', '\033[0m')
172 | depths = []
173 | for name in tqdm(depth_names):
174 | depth = np.load(name)
175 | depths.append(depth)
176 |
177 | depths = np.stack(depths, 0)
178 | aligned_depth_dir = os.path.join(args.input_dir, "aligned_dense_depths")
179 | all_depth_names = sorted(glob.glob(os.path.join(aligned_depth_dir, "*")))[start:end:image_skip]
180 | all_depths = []
181 |
182 | for name, pose in tqdm(zip(all_depth_names, sfm_poses)):
183 | depth = np.load(name)
184 | all_depths.append(depth)
185 |
186 | if args.init.normal_model_type == 'omnidata':
187 | normal_dir = os.path.join(args.input_dir, "omnidata_normal")
188 | else:
189 | raise NotImplementedError(f'Unknown normal model type {args.init.normal_model_type} exiting')
190 | normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")))
191 | normal_names = [normal_names[i] for i in kf_list]
192 |
193 | print(str(datetime.now()) + ': \033[92mI', 'loading normals ...', '\033[0m')
194 | normals = []
195 | for name in tqdm(normal_names):
196 | normal = np.load(name)[:3]
197 | normals.append(normal)
198 |
199 | normals = np.stack(normals, 0)
200 |
201 | all_normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")))[start:end:image_skip]
202 | all_normals = []
203 |
204 | for name, pose in tqdm(zip(all_normal_names, sfm_poses)):
205 | normal = np.load(name)
206 | normal = normal[:3]
207 |
208 | normal = torch.from_numpy(normal).cuda()
209 | normal = (normal - 0.5) * 2
210 | normal = normal / torch.norm(normal, dim=0, keepdim=True)
211 | normal = normal.permute(1, 2, 0)
212 | normal[:, :, 1] = -normal[:, :, 1]
213 | normal[:, :, 2] = -normal[:, :, 2]
214 | normal = torch.einsum('ijk,kl->ijl', normal, torch.from_numpy(np.linalg.inv(pose[:3, :3]).T).cuda().float())
215 | normal = F.interpolate(normal.permute(2, 0, 1).unsqueeze(0),
216 | (int(imgs[0].shape[0]/64)*8, int(imgs[0].shape[1]/64)*8),
217 | mode='bilinear', align_corners=False).squeeze(0).permute(1, 2, 0)
218 | all_normals.append(normal.cpu().numpy())
219 |
220 | sp_dir = os.path.join(args.input_dir, "sp")
221 | sp_names = [os.path.join(sp_dir, os.path.split(name)[-1].replace('.jpg', '.npy').replace('.png', '.npy')) for name in image_names_sp]
222 |
223 | if load_plane:
224 | print(str(datetime.now()) + ': \033[92mI', 'loading superpixels ...', '\033[0m')
225 | planes_all = []
226 | new_sp_all = []
227 | mean_colors_all = []
228 | plane_index_start = 0
229 | for plane_idx, (sp_name, depth, normal, pose, img_sp) in tqdm(enumerate(zip(sp_names, depths, normals, sfm_poses_sp, imgs_sp))):
230 | sp = np.load(sp_name)
231 | planes, new_sp, mean_colors = parse_sp(sp, intr, pose, depth, normal, img_sp)
232 | planes = np.array(planes)
233 | planes_idx = np.ones((planes.shape[0], 1)) * plane_idx
234 | planes = np.concatenate([planes, planes_idx], 1)
235 | planes_all.extend(planes)
236 | new_sp_all.append(new_sp + plane_index_start)
237 | plane_index_start += planes.shape[0]
238 | mean_colors = np.array(mean_colors)
239 | mean_colors_all.extend(mean_colors)
240 |
241 | planes_all = np.array(planes_all)
242 | mean_colors_all = np.array(mean_colors_all)
243 |
244 | else:
245 | planes_all = None
246 | new_sp_all = None
247 | mean_colors_all = None
248 |
249 | # proj matrixs
250 | frames_proj = []
251 | frames_c2w = []
252 | frames_center = []
253 | for i in range(len(sfm_camprojs)):
254 | fovy = 2 * np.arctan(0.5 * imgs[0].shape[0] / intr[1, 1])
255 | proj = get_projection_matrix(
256 | fovy, imgs[0].shape[1] / imgs[0].shape[0], 0.1, 1000.0
257 | )
258 | proj = np.array(proj)
259 | frames_proj.append(proj)
260 | # sfm_poses is w2c
261 | c2w = np.linalg.inv(sfm_poses[i])
262 | frames_c2w.append(c2w)
263 | frames_center.append(c2w[:3, 3])
264 |
265 | frames_proj = np.stack(frames_proj, 0)
266 | frames_c2w = np.stack(frames_c2w, 0)
267 | frames_center = np.stack(frames_center, 0)
268 |
269 | mvp_mtxs = get_mvp_matrix(
270 | frames_c2w, frames_proj,
271 | )
272 |
273 | index_init = ((np.array(kf_list) - kf_list[0]) / image_skip).astype(np.int32)
274 |
275 | return imgs, intr, sfm_poses, sfm_camprojs, frames_center, all_depths, all_normals, planes_all, \
276 | mvp_mtxs, index_init, new_sp_all, mean_colors_all
277 |
--------------------------------------------------------------------------------
/recon/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THU-LYJ-Lab/AlphaTablets/735cbfe6aa7f03f7bc37f48303045fe71ffa042a/recon/__init__.py
--------------------------------------------------------------------------------
/recon/run_depth.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import numpy as np
4 |
5 | from recon.third_party.omnidata.omnidata_tools.torch.demo_normal_custom_func import demo_normal_custom_func
6 | from recon.third_party.metric3d.depth_custom_func import depth_custom_func
7 |
8 |
9 | def metric3d_depth(img_dir, input_dir, depth_dir, dataset_type):
10 | """Initialize the dense depth of each image using single-image depth prediction
11 | """
12 | os.makedirs(depth_dir, exist_ok=True)
13 | if dataset_type == 'scannet':
14 | intr = np.loadtxt(f'{input_dir}/intrinsic/intrinsic_color.txt')
15 | fx, fy, cx, cy = intr[0, 0], intr[1, 1], intr[0, 2], intr[1, 2]
16 | elif dataset_type == 'replica':
17 | if os.path.exists(os.path.join(input_dir, 'cam_params.json')):
18 | cam_param_path = os.path.join(input_dir, 'cam_params.json')
19 | elif os.path.exists(os.path.join(input_dir, '../cam_params.json')):
20 | cam_param_path = os.path.join(input_dir, '../cam_params.json')
21 | else:
22 | raise FileNotFoundError('cam_params.json not found')
23 | with open(cam_param_path, 'r') as f:
24 | j = json.load(f)
25 | fx, fy, cx, cy = j["camera"]["fx"], j["camera"]["fy"], j["camera"]["cx"], j["camera"]["cy"]
26 | else:
27 | raise NotImplementedError(f'Unknown dataset type {dataset_type} exiting')
28 | indir = img_dir
29 | outdir = depth_dir
30 | depth_custom_func(fx, fy, cx, cy, indir, outdir)
31 |
32 |
33 | def omnidata_normal(img_dir, input_dir, normal_dir):
34 | """Initialize the dense normal of each image using single-image normal prediction
35 | """
36 | os.makedirs(normal_dir, exist_ok=True)
37 | demo_normal_custom_func(img_dir, normal_dir)
38 |
--------------------------------------------------------------------------------
/recon/run_recon.py:
--------------------------------------------------------------------------------
1 | import os
2 | import glob
3 | from datetime import datetime
4 |
5 |
6 | class Recon:
7 | def __init__(self, config, input_dir, dataset_type):
8 | self.config = config
9 | self.input_dir = input_dir
10 | self.image_dir = os.path.join(input_dir, "images")
11 | self.output_root = input_dir
12 | self.dataset_type = dataset_type
13 | self.preprocess()
14 |
15 | def preprocess(self):
16 | if not os.path.exists(self.image_dir):
17 | if self.dataset_type == 'scannet':
18 | original_image_dir = os.path.join(self.input_dir, "color")
19 | if not os.path.exists(original_image_dir):
20 | raise ValueError(f'Image directory {self.image_dir} not found')
21 | old_dir = os.getcwd()
22 | os.chdir(self.input_dir)
23 | os.symlink("color", "images")
24 | os.chdir(old_dir)
25 | print(str(datetime.now()) + ': \033[92mI', f'Linked {original_image_dir} to {self.image_dir}', '\033[0m')
26 | elif self.dataset_type == 'replica':
27 | original_image_dir = os.path.join(self.input_dir, "results")
28 | if not os.path.exists(original_image_dir):
29 | raise ValueError(f'Image directory {self.image_dir} not found')
30 | os.makedirs(self.image_dir)
31 | old_dir = os.getcwd()
32 | os.chdir(self.image_dir)
33 | for img in glob.glob(os.path.join("../results", "frame*")):
34 | os.symlink(os.path.join("../results", os.path.split(img)[-1]), os.path.split(img)[-1])
35 | os.chdir(old_dir)
36 | print(str(datetime.now()) + ': \033[92mI', f'Linked {original_image_dir} to {self.image_dir}', '\033[0m')
37 | else:
38 | raise NotImplementedError(f'Unknown dataset type {self.dataset_type} exiting')
39 |
40 |
41 | def recon(self):
42 | if os.path.exists(os.path.join(self.output_root, "recon.lock")):
43 | print(str(datetime.now()) + ': \033[92mI', 'Monocular estimation already done!', '\033[0m')
44 | return
45 |
46 | from .run_depth import omnidata_normal, metric3d_depth
47 |
48 | depth_dir = os.path.join(self.output_root, "aligned_dense_depths")
49 | print(str(datetime.now()) + ': \033[92mI', 'Running Depth Estimation ...', '\033[0m')
50 | metric3d_depth(self.image_dir, self.output_root, depth_dir, self.dataset_type)
51 | print(str(datetime.now()) + ': \033[92mI', 'Depth Estimation Done!', '\033[0m')
52 |
53 | normal_dir = os.path.join(self.output_root, "omnidata_normal")
54 | print(str(datetime.now()) + ': \033[92mI', 'Running Normal Estimation ...', '\033[0m')
55 | omnidata_normal(self.image_dir, self.output_root, normal_dir)
56 | print(str(datetime.now()) + ': \033[92mI', 'Normal Estimation Done!', '\033[0m')
57 |
58 | # create lock file
59 | open(os.path.join(self.output_root, "recon.lock"), "w").close()
60 |
61 | def run_sp(self, kf_list):
62 | from .run_sp import run_sp
63 | print(str(datetime.now()) + ': \033[92mI', 'Running SuperPixel Subdivision ...', '\033[0m')
64 | sp_dir = run_sp(self.image_dir, self.output_root, kf_list)
65 | print(str(datetime.now()) + ': \033[92mI', 'SuperPixel Subdivision Done!', '\033[0m')
66 | return sp_dir
67 |
--------------------------------------------------------------------------------
/recon/run_sp.py:
--------------------------------------------------------------------------------
1 | import os
2 | import cv2
3 | import numpy as np
4 | from tqdm import tqdm
5 |
6 |
7 | def sp_division(img):
8 | slic = cv2.ximgproc.createSuperpixelSLIC(img)
9 | slic.iterate(10)
10 | labels = slic.getLabels()
11 | # mask_slic = slic.getLabelContourMask() #获取Mask,超像素边缘Mask==1
12 | # number_slic = slic.getNumberOfSuperpixels() #获取超像素数目
13 | # mask_inv_slic = cv2.bitwise_not(mask_slic)
14 | # img_slic = cv2.bitwise_and(img,img,mask = mask_inv_slic) #在原图上绘制超像素边界
15 | # cv2.imwrite('3.png', img_slic)
16 | return labels
17 |
18 |
19 | def run_sp(image_dir, output_root, kf_list=None):
20 | sp_dir = os.path.join(output_root, "sp")
21 | os.makedirs(sp_dir, exist_ok=True)
22 | try:
23 | image_names = sorted(os.listdir(image_dir), key=lambda x: int(x.split('/')[-1][:-4]))
24 | except:
25 | image_names = sorted(os.listdir(image_dir))
26 | image_names = [image_names[k] for k in kf_list]
27 | for name in tqdm(image_names):
28 | if os.path.exists(os.path.join(sp_dir, name[:-4] + '.npy')):
29 | continue
30 | img = cv2.imread(os.path.join(image_dir, name))
31 | labels = sp_division(img)
32 | np.save(os.path.join(sp_dir, name[:-4]), labels)
33 |
34 |
35 | if __name__ == '__main__':
36 | img = cv2.imread('/home/hyz/git-plane/PixelPlane/data/scene0000_00/images/36.jpg')
37 | sp_division(img)
--------------------------------------------------------------------------------
/recon/utils.py:
--------------------------------------------------------------------------------
1 | import json
2 | import os
3 | import cv2
4 | import glob
5 | import numpy as np
6 |
7 |
8 | def load_images(img_dir):
9 | imgs = []
10 | image_names = sorted(os.listdir(img_dir))
11 | for name in image_names:
12 | img = cv2.imread(os.path.join(img_dir, name))
13 | img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
14 | imgs.append(img)
15 | return imgs, image_names
16 |
17 |
18 | def load_sfm(sfm_dir):
19 | """Load converted sfm world-to-cam depths and poses
20 | """
21 | depth_dir = os.path.join(sfm_dir, "colmap_outputs_converted/depths")
22 | pose_dir = os.path.join(sfm_dir, "colmap_outputs_converted/poses")
23 | depth_names = sorted(glob.glob(os.path.join(depth_dir, "*.npy")))
24 | pose_names = sorted(glob.glob(os.path.join(pose_dir, "*.txt")))
25 | sfm_depths, sfm_poses = [], []
26 | for dn, pn in zip(depth_names, pose_names):
27 | assert os.path.basename(dn)[:-4] == os.path.basename(pn)[:-4]
28 | depth = np.load(dn)
29 | pose = np.loadtxt(pn)
30 | sfm_depths.append(depth)
31 | sfm_poses.append(pose)
32 | return sfm_depths, sfm_poses
33 |
34 |
35 | def load_sfm_pose(sfm_dir):
36 | """Load sfm poses and then convert into proj mat
37 | """
38 | pose_dir = os.path.join(sfm_dir, "colmap_outputs_converted/poses")
39 | intr_dir = os.path.join(sfm_dir, "colmap_outputs_converted/intrinsics")
40 | pose_names = sorted(glob.glob(os.path.join(pose_dir, "*.txt")), key=lambda x: int(x.split('/')[-1][:-4]))
41 | intr_names = sorted(glob.glob(os.path.join(intr_dir, "*.txt")), key=lambda x: int(x.split('/')[-1][:-4]))
42 | K = np.loadtxt(intr_names[0])
43 | KH = np.eye(4)
44 | KH[:3,:3] = K
45 | sfm_poses, sfm_projmats = [], []
46 | for pn in pose_names:
47 | # world-to-cam
48 | pose = np.loadtxt(pn)
49 | pose = np.concatenate([pose, np.array([[0,0,0,1]])], 0)
50 | c2w = np.linalg.inv(pose)
51 | c2w[0:3, 1:3] *= -1
52 | pose = np.linalg.inv(c2w)
53 | sfm_poses.append(pose)
54 | # projmat
55 | projmat = KH @ pose
56 | sfm_projmats.append(projmat)
57 | return K, sfm_poses, sfm_projmats
58 |
59 |
60 | def load_scannet_pose(scannet_dir):
61 | """Load scannet poses and then convert into proj mat
62 | """
63 | pose_dir = os.path.join(scannet_dir, "pose")
64 | intr_dir = os.path.join(scannet_dir, "intrinsic")
65 | pose_names = sorted(glob.glob(os.path.join(pose_dir, "*.txt")), key=lambda x: int(x.split('/')[-1][:-4]))
66 | intr_name = os.path.join(intr_dir, "intrinsic_color.txt")
67 | KH = np.loadtxt(intr_name)
68 | scannet_poses, scannet_projmats = [], []
69 | for pn in pose_names:
70 | p = np.loadtxt(pn)
71 | R = p[:3, :3]
72 | R = np.matmul(R, np.array([
73 | [1, 0, 0],
74 | [0, -1, 0],
75 | [0, 0, -1]
76 | ]))
77 | p[:3, :3] = R
78 | p = np.linalg.inv(p)
79 | scannet_poses.append(p)
80 | # projmat
81 | projmat = KH @ p
82 | scannet_projmats.append(projmat)
83 | return KH[:3, :3], scannet_poses, scannet_projmats
84 |
85 |
86 | def load_replica_pose(replica_dir):
87 | """Load replica poses and then convert into proj mat
88 | """
89 | if os.path.exists(os.path.join(replica_dir, 'cam_params.json')):
90 | cam_param_path = os.path.join(replica_dir, 'cam_params.json')
91 | elif os.path.exists(os.path.join(replica_dir, '../cam_params.json')):
92 | cam_param_path = os.path.join(replica_dir, '../cam_params.json')
93 | else:
94 | raise FileNotFoundError('cam_params.json not found')
95 | with open(cam_param_path, 'r') as f:
96 | j = json.load(f)
97 | intrinsics = np.array([
98 | j["camera"]["fx"], 0, j["camera"]["cx"],
99 | 0, j["camera"]["fy"], j["camera"]["cy"],
100 | 0, 0, 1
101 | ], dtype=np.float32).reshape(3, 3)
102 |
103 | KH = np.eye(4)
104 | KH[:3, :3] = intrinsics
105 |
106 | extrinsics = np.loadtxt(os.path.join(replica_dir, 'traj.txt')).reshape(-1, 4, 4)
107 | poses = []
108 | projmats = []
109 | for extrinsic in extrinsics:
110 | p = extrinsic
111 | R = p[:3, :3]
112 | R = np.matmul(R, np.array([
113 | [1, 0, 0],
114 | [0, -1, 0],
115 | [0, 0, -1]
116 | ]))
117 | p[:3, :3] = R
118 | p = np.linalg.inv(p)
119 | poses.append(p)
120 | # projmat
121 | projmat = KH @ p
122 | projmats.append(projmat)
123 |
124 | return intrinsics, poses, projmats
125 |
126 |
127 | def load_dense_depths(depth_dir):
128 | """Load initialized single-image dense depth predictions
129 | """
130 | depth_names = sorted(os.listdir(depth_dir))
131 | depths = []
132 | for dn in depth_names:
133 | depth = np.load(os.path.join(depth_dir, dn))
134 | depths.append(depth)
135 | return depths, depth_names
136 |
137 |
138 | def depth2disp(depth):
139 | """Convert depth map to disparity
140 | """
141 | disp = 1.0 / (depth + 1e-8)
142 | return disp
143 |
144 |
145 | def disp2depth(disp):
146 | """Convert disparity map to depth
147 | """
148 | depth = 1.0 / (disp + 1e-8)
149 | return depth
150 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | tqdm
2 | scikit-learn
3 | opencv-python
4 | opencv-contrib-python
5 | hydra-core
6 | matplotlib
7 | timm
8 | h5py
9 | pytorch_lightning
10 | mmengine
11 | mmcv
12 | ninja
13 | trimesh
14 | open3d
15 | git+https://github.com/NVlabs/nvdiffrast.git
--------------------------------------------------------------------------------
/run.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime
2 | import os, time, random, argparse
3 |
4 | import numpy as np
5 | import cv2
6 |
7 | from tqdm import tqdm, trange
8 |
9 | import torch
10 | import torch.nn.functional as F
11 | from torch.utils.data import DataLoader
12 | import torch.optim.lr_scheduler as lr_scheduler
13 |
14 | from lib.load_data import load_data
15 | from lib.alphatablets import AlphaTablets
16 | from dataset.dataset import CustomDataset
17 | from lib.keyframe import get_keyframes
18 | from recon.run_recon import Recon
19 |
20 |
21 | def config_parser():
22 | '''Define command line arguments
23 | '''
24 | parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
25 | parser.add_argument('--config', type=str, default='configs/default.yaml',
26 | help='config file path')
27 | parser.add_argument("--seed", type=int, default=777,
28 | help='Random seed')
29 | parser.add_argument("--job", type=str, default=str(time.time()),
30 | help='Job name')
31 |
32 | # learning options
33 | parser.add_argument("--lr_tex", type=float, default=0.01,
34 | help='Learning rate of texture color')
35 | parser.add_argument("--lr_alpha", type=float, default=0.03,
36 | help='Learning rate of texture alpha')
37 | parser.add_argument("--lr_plane_n", type=float, default=0.0001,
38 | help='Learning rate of plane normal')
39 | parser.add_argument("--lr_plane_dis", type=float, default=0.0005,
40 | help='Learning rate of plane distance')
41 | parser.add_argument("--lr_plane_dis_stage2", type=float, default=0.0002,
42 | help='Learning rate of plane distance in stage 2')
43 |
44 | # loss weights
45 | parser.add_argument("--weight_alpha_inv", type=float, default=1.0,
46 | help='Weight of alpha inv loss')
47 | parser.add_argument("--weight_normal", type=float, default=4.0,
48 | help='Weight of direct normal loss')
49 | parser.add_argument("--weight_depth", type=float, default=4.0,
50 | help='Weight of direct depth loss')
51 | parser.add_argument("--weight_distortion", type=float, default=20.0,
52 | help='Weight of distortion loss')
53 | parser.add_argument("--weight_decay", type=float, default=0.9,
54 | help='Weight of tablet alpha decay after a single step. -1 denotes automatic decay')
55 |
56 | # merging options
57 | parser.add_argument("--merge_normal_thres_init", type=float, default=0.97,
58 | help='Threshold of init merging planes')
59 | parser.add_argument("--merge_normal_thres", type=float, default=0.93,
60 | help='Threshold of merging planes')
61 | parser.add_argument("--merge_dist_thres1", type=float, default=0.5,
62 | help='Threshold of init merging planes')
63 | parser.add_argument("--merge_dist_thres2", type=float, default=0.1,
64 | help='Threshold of merging planes')
65 | parser.add_argument("--merge_color_thres1", type=float, default=0.3,
66 | help='Threshold of init merging planes')
67 | parser.add_argument("--merge_color_thres2", type=float, default=0.2,
68 | help='Threshold of merging planes')
69 | parser.add_argument("--merge_Y_decay", type=float, default=0.5,
70 | help='Decay rate of Y channel')
71 |
72 | # optimization options
73 | parser.add_argument("--batch_size", type=int, default=3,
74 | help='Batch size')
75 | parser.add_argument("--max_steps", type=int, default=32,
76 | help='Max optimization steps')
77 | parser.add_argument("--merge_interval", type=int, default=13,
78 | help='Merge interval')
79 | parser.add_argument("--max_steps_union", type=int, default=9,
80 | help='Max optimization steps for union optimization')
81 | parser.add_argument("--merge_interval_union", type=int, default=3,
82 | help='Merge interval for union optimization')
83 |
84 | parser.add_argument("--alpha_init", type=float, default=0.5,
85 | help='Initial alpha value')
86 | parser.add_argument("--alpha_init_empty", type=float, default=0.,
87 | help='Initial alpha value for empty pixels')
88 | parser.add_argument("--depth_inside_mask_alphathres", type=float, default=0.5,
89 | help='Threshold of alpha for inside mask')
90 |
91 | parser.add_argument("--max_rasterize_layers", type=int, default=15,
92 | help='Max rasterize layers')
93 |
94 | # logging/saving options
95 | parser.add_argument("--log_path", type=str, default='./logs',
96 | help='path to save logs')
97 | parser.add_argument("--dump_images", type=bool, default=False)
98 | parser.add_argument("--dump_interval", type=int, default=1,
99 | help='Dump interval')
100 |
101 | # update input
102 | parser.add_argument("--input_dir", type=str, default='',
103 | help='input directory')
104 |
105 | args = parser.parse_args()
106 |
107 | from hydra import compose, initialize
108 |
109 | initialize(version_base=None, config_path='./')
110 | ori_cfg = compose(config_name=args.config)['configs']
111 |
112 | class Struct:
113 | def __init__(self, **entries):
114 | self.__dict__.update(entries)
115 |
116 | cfg = Struct(**ori_cfg)
117 |
118 | # dump args and cfg
119 | import json
120 | os.makedirs(os.path.join(args.log_path, args.job), exist_ok=True)
121 | with open(os.path.join(args.log_path, args.job, 'args.json'), 'w') as f:
122 | args_json = {k: v for k, v in vars(args).items() if k != 'config'}
123 | json.dump(args_json, f, indent=4)
124 |
125 | import shutil
126 | shutil.copy(args.config, os.path.join(args.log_path, args.job, 'config.yaml'))
127 |
128 | if args.input_dir != '':
129 | cfg.data.input_dir = args.input_dir
130 |
131 | return args, cfg
132 |
133 |
134 | def seed_everything():
135 | '''Seed everything for better reproducibility.
136 | (some pytorch operation is non-deterministic like the backprop of grid_samples)
137 | '''
138 | torch.manual_seed(args.seed)
139 | np.random.seed(args.seed)
140 | random.seed(args.seed)
141 |
142 |
143 | def load_everything(cfg, kf_list, image_skip, load_plane=True):
144 | '''Load images / poses / camera settings / data split.
145 | '''
146 | data_dict = load_data(cfg.data, kf_list=kf_list, image_skip=image_skip, load_plane=load_plane)
147 | data_dict['poses'] = torch.Tensor(data_dict['poses'])
148 | return data_dict
149 |
150 |
151 | if __name__=='__main__':
152 | # load setup
153 | args, cfg = config_parser()
154 | merge_cfgs = {
155 | 'normal_thres_init': args.merge_normal_thres_init,
156 | 'normal_thres': args.merge_normal_thres,
157 | 'dist_thres1': args.merge_dist_thres1,
158 | 'dist_thres2': args.merge_dist_thres2,
159 | 'color_thres1': args.merge_color_thres1,
160 | 'color_thres2': args.merge_color_thres2,
161 | 'Y_decay': args.merge_Y_decay
162 | }
163 |
164 | # init enviroment
165 | if torch.cuda.is_available():
166 | torch.set_default_tensor_type('torch.cuda.FloatTensor')
167 | device = torch.device('cuda')
168 | else:
169 | torch.set_default_tensor_type('torch.FloatTensor')
170 | device = torch.device('cpu')
171 | torch.set_default_dtype(torch.float32)
172 | seed_everything()
173 |
174 | recon = Recon(cfg.data.init, cfg.data.input_dir, cfg.data.dataset_type)
175 | recon.recon()
176 |
177 | kf_lists, image_skip = get_keyframes(cfg.data.input_dir)
178 | subset_mean_len = np.mean([ k[-1]-k[0]+1 for k in kf_lists ])
179 | kf_lists.append([0, -1])
180 |
181 | for set_num, kf_list in enumerate(kf_lists):
182 | if set_num == len(kf_lists) - 1:
183 | print(str(datetime.now()) + f': \033[94mUnion Optimization', '\033[0m')
184 | else:
185 | print(str(datetime.now()) + f': \033[94mSubset {set_num+1}/{len(kf_lists)-1}, Keyframes', kf_list, '\033[0m')
186 |
187 | union_optimize = False
188 | if kf_list[0] == 0 and kf_list[1] == -1:
189 | union_optimize = True
190 | if os.path.exists(os.path.join(args.log_path, args.job, 'ckpt', f'./ckpt_{set_num:02d}_{args.max_steps_union-1}.pt')):
191 | print(str(datetime.now()) + f': \033[94mUnion optimization already done!', '\033[0m')
192 | continue
193 | else:
194 | if os.path.exists(os.path.join(args.log_path, args.job, 'ckpt', f'./ckpt_{set_num:02d}_{args.max_steps-1}.pt')):
195 | print(str(datetime.now()) + f': \033[94mSubset {set_num+1}/{len(kf_lists)-1} optimization already done!', '\033[0m')
196 | continue
197 |
198 | if kf_list[-1] != -1:
199 | recon.run_sp(kf_list)
200 |
201 | # load images / poses / camera settings / data split
202 | data_dict = load_everything(cfg=cfg, kf_list=kf_list, image_skip=image_skip,
203 | load_plane=not union_optimize)
204 |
205 | images, mvp_mtxs, K = data_dict['images'], data_dict['mvp_mtxs'], data_dict['intr']
206 | index_init = data_dict['index_init']
207 | new_sps = data_dict['new_sps']
208 | cam_centers = data_dict['cam_centers']
209 | normals = data_dict['normals']
210 | mean_colors = data_dict['mean_colors']
211 | depths = data_dict['all_depths']
212 |
213 | sp_images = np.stack([ images[idx] for idx in index_init ])
214 |
215 | if not union_optimize:
216 | pp = AlphaTablets(plane_params=data_dict['planes_all'],
217 | sp=[ sp_images , new_sps, mvp_mtxs[index_init]],
218 | cam_centers=cam_centers[index_init],
219 | mean_colors=mean_colors,
220 | HW=images[0].shape[0:2],
221 | alpha_init=args.alpha_init, alpha_init_empty=args.alpha_init_empty,
222 | inside_mask_alpha_thres=args.depth_inside_mask_alphathres,
223 | merge_cfgs=merge_cfgs)
224 | else:
225 | pp = AlphaTablets(ckpt_paths=[
226 | os.path.join(args.log_path, args.job, 'ckpt', f'./ckpt_{ii:02d}_{args.max_steps-1}.pt')
227 | for ii in range(len(kf_lists) - 1)
228 | ], merge_cfgs=merge_cfgs,
229 | alpha_init=args.alpha_init, alpha_init_empty=args.alpha_init_empty,
230 | inside_mask_alpha_thres=args.depth_inside_mask_alphathres)
231 |
232 | dataset = CustomDataset(images, mvp_mtxs, normals, depths)
233 | dataloader = DataLoader(dataset, batch_size=args.batch_size, shuffle=True, generator=torch.Generator(device=device))
234 |
235 | optimizer = torch.optim.Adam([
236 | {'params': pp.tex_color, 'lr': args.lr_tex},
237 | {'params': pp.tex_alpha, 'lr': args.lr_alpha},
238 | {'params': pp.plane_n, 'lr': args.lr_plane_n},
239 | {'params': pp.plane_dis, 'lr': args.lr_plane_dis},
240 | ])
241 |
242 | scheduler = lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.3)
243 | crop = cfg.data.crop
244 |
245 | max_steps = args.max_steps if not union_optimize else args.max_steps_union
246 | merge_interval = args.merge_interval if not union_optimize else args.merge_interval_union
247 |
248 | psnr_lst = []
249 | time0 = time.time()
250 | print(str(datetime.now()) + ': \033[92mI', 'Start AlphaTablets Optimization', '\033[0m')
251 | for global_step in trange(0, max_steps):
252 | avg_psnr = 0
253 | for batch_idx, (imgs, mvp_mtxs, normals, depths) in enumerate(dataloader):
254 | mvp_mtxs = mvp_mtxs.cuda()
255 | imgs = imgs.cuda()
256 | normals = normals.cuda()
257 | depths = depths.cuda()
258 |
259 | render_result = pp(mvp_mtxs,
260 | max_rasterize_layers=args.max_rasterize_layers)
261 |
262 | try:
263 | render_result, render_normal, render_depth, alpha_loss, distort_loss, inside_mask, plane_inside_mask = render_result
264 | except:
265 | continue
266 |
267 | # gradient descent step
268 | optimizer.zero_grad(set_to_none=True)
269 | crop_mask = torch.zeros_like(imgs)
270 | crop_mask[:, crop:-crop, crop:-crop] = 1
271 | mask = crop_mask * inside_mask
272 | loss = F.mse_loss(render_result * mask, imgs * mask)
273 | direct_normal_loss = F.mse_loss(render_normal, normals)
274 | direct_depth_loss = F.mse_loss(render_depth * mask[..., 0] * plane_inside_mask[..., 0], depths * mask[..., 0] * plane_inside_mask[..., 0])
275 | psnr = -10 * torch.log10(loss)
276 |
277 | loss += alpha_loss * args.weight_alpha_inv
278 | loss += distort_loss * args.weight_distortion
279 | loss += direct_normal_loss * args.weight_normal
280 | loss += direct_depth_loss * args.weight_depth
281 | avg_psnr += psnr.item()
282 |
283 | loss.backward()
284 | optimizer.step()
285 |
286 | if global_step % args.dump_interval == 0 and batch_idx == 0 and args.dump_images:
287 | optimizer.zero_grad(set_to_none=True)
288 | mvp_mtxs = torch.from_numpy(data_dict['mvp_mtxs'][0:1]).cuda().float()
289 | render_result, alpha_acc = pp(mvp_mtxs, return_alpha=True,
290 | max_rasterize_layers=args.max_rasterize_layers)
291 |
292 | os.makedirs(os.path.join(args.log_path, args.job, 'dump_images'), exist_ok=True)
293 |
294 | cv2.imwrite(os.path.join(args.log_path, args.job, 'dump_images', f'{set_num:02d}_{global_step:05d}.png'), render_result[0].detach().cpu().numpy() * 255)
295 | cv2.imwrite(os.path.join(args.log_path, args.job, 'dump_images', f'{set_num:02d}_{global_step:05d}_mask.png'), mask[0].detach().cpu().numpy() * 255)
296 | cv2.imwrite(os.path.join(args.log_path, args.job, 'dump_images', f'{set_num:02d}_{global_step:05d}_alpha.png'), alpha_acc[0].detach().cpu().numpy() * 255)
297 |
298 | error_map = torch.abs(render_result - torch.from_numpy(data_dict['images'][0][None, ...]).cuda().float())
299 | error_map = error_map[0].detach().cpu().numpy()
300 | # turn to red-blue, 0-255
301 | error_map = (error_map - error_map.min()) / (error_map.max() - error_map.min()) * 255
302 | error_map = cv2.applyColorMap(error_map.astype(np.uint8), cv2.COLORMAP_JET)
303 | cv2.imwrite(os.path.join(args.log_path, args.job, 'dump_images', f'{set_num:02d}_{global_step:05d}_error_map.png'), error_map)
304 |
305 | if global_step % merge_interval == 0 and batch_idx == 0 and global_step > 0:
306 | optimizer.zero_grad(set_to_none=True)
307 |
308 | pp.weightCheck(torch.from_numpy(data_dict['mvp_mtxs']).cuda().float())
309 |
310 | pp = AlphaTablets(pp=pp, merge_cfgs=merge_cfgs)
311 | del optimizer
312 | optimizer = torch.optim.Adam([
313 | {'params': pp.tex_color, 'lr': args.lr_tex},
314 | {'params': pp.tex_alpha, 'lr': args.lr_alpha},
315 | {'params': pp.plane_n, 'lr': args.lr_plane_n},
316 | {'params': pp.plane_dis, 'lr': args.lr_plane_dis_stage2},
317 | ])
318 |
319 | scheduler.step()
320 |
321 | if global_step == max_steps - 1:
322 | with torch.no_grad():
323 | os.makedirs(os.path.join(args.log_path, args.job, 'ckpt'), exist_ok=True)
324 | pp.save_ckpt(os.path.join(args.log_path, args.job, 'ckpt', f'ckpt_{set_num:02d}_{global_step}.pt'))
325 | optimizer.zero_grad(set_to_none=True)
326 |
327 | if union_optimize:
328 | with torch.no_grad():
329 | decay = args.weight_decay if args.weight_decay > 0 else max(1-0.00067*subset_mean_len, 0.8)
330 | pp.tex_alpha.data = torch.log( decay / (1 - decay + torch.exp(-pp.tex_alpha)) )
331 | elif global_step < args.merge_interval:
332 | with torch.no_grad():
333 | decay = args.weight_decay if args.weight_decay > 0 else max(1-0.00067*len(images), 0.8)
334 | pp.tex_alpha.data = torch.log( decay / (1 - decay + torch.exp(-pp.tex_alpha)) )
335 |
336 | if union_optimize:
337 | os.makedirs(os.path.join(args.log_path, args.job, 'results'), exist_ok=True)
338 | export_name_obj = os.path.join(args.log_path, args.job, 'results', f'{set_num:02d}_final.obj')
339 | pp.export_mesh_with_weight_check(torch.from_numpy(data_dict['mvp_mtxs']).cuda().float(), name=export_name_obj)
340 |
341 | os.makedirs(os.path.join(args.log_path, args.job, 'plys'), exist_ok=True)
342 | export_name = os.path.join(args.log_path, args.job, 'plys', f'{set_num:02d}_final.ply')
343 | pp.export_ply(torch.from_numpy(data_dict['mvp_mtxs'][::8]).cuda().float(), name=export_name)
344 |
345 | if set_num == len(kf_lists) - 1:
346 | print(str(datetime.now()) + f': \033[94mUnion optimization finished!', '\033[0m')
347 | else:
348 | print(str(datetime.now()) + f': \033[94mSubset {set_num+1}/{len(kf_lists)-1} optimization finished', '\033[0m')
349 |
350 | # create complete lock
351 | with open(os.path.join(args.log_path, args.job, 'complete.lock'), 'w') as f:
352 | f.write('done')
353 |
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | import numpy as np
4 | import open3d as o3d
5 | import trimesh
6 | from tqdm import tqdm
7 | from sklearn.metrics import rand_score
8 | from skimage.metrics import variation_of_information
9 |
10 | def compute_sc(gt_in, pred_in):
11 | # to be consistent with skimage sklearn input arrangment
12 |
13 | assert len(pred_in.shape) == 1 and len(gt_in.shape) == 1
14 |
15 | acc, pred, gt = match_seg(pred_in, gt_in) # n_gt * n_pred
16 |
17 | bestmatch_gt2pred = acc.max(axis=1)
18 | bestmatch_pred2gt = acc.max(axis=0)
19 |
20 | pred_id, pred_cnt = np.unique(pred, return_counts=True)
21 | gt_id, gt_cnt = np.unique(gt, return_counts=True)
22 |
23 | cnt_pred, sum_pred = 0, 0
24 | for i, _ in enumerate(pred_id):
25 | cnt_pred += bestmatch_pred2gt[i] * pred_cnt[i]
26 | sum_pred += pred_cnt[i]
27 |
28 | cnt_gt, sum_gt = 0, 0
29 | for i, _ in enumerate(gt_id):
30 | cnt_gt += bestmatch_gt2pred[i] * gt_cnt[i]
31 | sum_gt += gt_cnt[i]
32 |
33 | sc = (cnt_pred / sum_pred + cnt_gt / sum_gt) / 2
34 |
35 | return sc
36 |
37 | def match_seg(pred_in, gt_in):
38 | assert len(pred_in.shape) == 1 and len(gt_in.shape) == 1
39 |
40 | pred, gt = compact_segm(pred_in), compact_segm(gt_in)
41 | n_gt = gt.max() + 1
42 | n_pred = pred.max() + 1
43 |
44 | # this will offer the overlap between gt and pred
45 | # if gt == 1, we will later have conf[1, j] = gt(1) + pred(j) * n_gt
46 | # essential, we encode conf_mat[i, j] to overlap, and when we decode it we let row as gt, and col for pred
47 | # then assume we have 13 gt label, 6 pred label --> gt 1 will correspond to 14, 1+2*13 ... 1 + 6*13
48 | overlap = gt + n_gt * pred
49 | freq, bin_val = np.histogram(overlap, np.arange(0, n_gt * n_pred+1)) # hist given bins [1, 2, 3] --> return [1, 2), [2, 3)
50 | conf_mat = freq.reshape([ n_gt, n_pred], order='F') # column first reshape, like matlab
51 |
52 | acc = np.zeros([n_gt, n_pred])
53 | for i in range(n_gt):
54 | for j in range(n_pred):
55 | gt_i = conf_mat[i].sum()
56 | pred_j = conf_mat[:, j].sum()
57 | gt_pred = conf_mat[i, j]
58 | acc[i,j] = gt_pred / (gt_i + pred_j - gt_pred) if (gt_i + pred_j - gt_pred) != 0 else 0
59 | return acc[1:, 1:], pred, gt
60 |
61 | def compact_segm(seg_in):
62 | seg = seg_in.copy()
63 | uniq_id = np.unique(seg)
64 | cnt = 1
65 | for id in sorted(uniq_id):
66 | if id == 0:
67 | continue
68 | seg[seg==id] = cnt
69 | cnt += 1
70 |
71 | # every id (include non-plane should not be 0 for the later process in match_seg
72 | seg = seg + 1
73 | return seg
74 |
75 | def project_to_mesh(from_mesh, to_mesh, attribute, attr_name, color_mesh=None, dist_thresh=None):
76 | """ Transfers attributs from from_mesh to to_mesh using nearest neighbors
77 |
78 | Each vertex in to_mesh gets assigned the attribute of the nearest
79 | vertex in from mesh. Used for semantic evaluation.
80 |
81 | Args:
82 | from_mesh: Trimesh with known attributes
83 | to_mesh: Trimesh to be labeled
84 | attribute: Which attribute to transfer
85 | dist_thresh: Do not transfer attributes beyond this distance
86 | (None transfers regardless of distacne between from and to vertices)
87 |
88 | Returns:
89 | Trimesh containing transfered attribute
90 | """
91 |
92 | if len(from_mesh.vertices) == 0:
93 | to_mesh.vertex_attributes[attr_name] = np.zeros((0), dtype=np.uint8)
94 | to_mesh.visual.vertex_colors = np.zeros((0), dtype=np.uint8)
95 | return to_mesh
96 |
97 | pcd = o3d.geometry.PointCloud()
98 | pcd.points = o3d.utility.Vector3dVector(from_mesh.vertices)
99 | kdtree = o3d.geometry.KDTreeFlann(pcd)
100 |
101 | pred_ids = attribute.copy()
102 | pred_colors = from_mesh.visual.vertex_colors if color_mesh is None else color_mesh.visual.vertex_colors
103 |
104 | matched_ids = np.zeros((to_mesh.vertices.shape[0]), dtype=np.uint8)
105 | matched_colors = np.zeros((to_mesh.vertices.shape[0], 4), dtype=np.uint8)
106 |
107 | for i, vert in enumerate(to_mesh.vertices):
108 | _, inds, dist = kdtree.search_knn_vector_3d(vert, 1)
109 | if dist_thresh is None or dist[0]
20 |
21 |
22 |
23 | ## Quick Start
24 |
25 | ### 1. Clone the Repository
26 |
27 | Make sure to clone the repository along with its submodules:
28 |
29 | ```bash
30 | git clone --recursive https://github.com/THU-LYJ-Lab/AlphaTablets
31 | ```
32 |
33 | ### 2. Install Dependencies
34 |
35 | Set up a Python environment and install the required packages:
36 |
37 | ```bash
38 | conda create -n alphatablets python=3.9
39 | conda activate alphatablets
40 |
41 | # Install PyTorch based on your machine configuration
42 | pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118
43 |
44 | # Install other dependencies
45 | # Note: mmcv package also requires CUDA. To avoid potential errors, set the CUDA_HOME environment variable and download a CUDA-compatible version of the library.
46 | # Example: python -m pip install mmcv==2.2.0 -f https://download.openmmlab.com/mmcv/dist/cu118/torch2.1/index.html
47 | pip install -r requirements.txt
48 | ```
49 |
50 | ### 3. Download Pretrained Weights
51 |
52 | #### Monocular Normal Estimation Weights
53 |
54 | Download **Omnidata** pretrained weights:
55 |
56 | - File: `omnidata_dpt_normal_v2.ckpt`
57 | - Link: [Download Here](https://www.dropbox.com/scl/fo/348s01x0trt0yxb934cwe/h?rlkey=a96g2incso7g53evzamzo0j0y&e=2&dl=0)
58 |
59 | Place the file in the directory:
60 |
61 | ```plaintext
62 | ./recon/third_party/omnidata/omnidata_tools/torch/pretrained_models
63 | ```
64 |
65 | #### Depth Estimation Weights
66 |
67 | Download **Metric3D** pretrained weights:
68 |
69 | - File: `metric_depth_vit_giant2_800k.pth`
70 | - Link: [Download Here](https://huggingface.co/JUGGHM/Metric3D/blob/main/metric_depth_vit_giant2_800k.pth)
71 |
72 | Place the file in the directory:
73 |
74 | ```plaintext
75 | ./recon/third_party/metric3d/weight
76 | ```
77 |
78 | ### 4. Running Demos
79 |
80 | #### ScanNet Demo
81 |
82 | 1. Download the `scene0684_01` demo scene from [here](https://drive.google.com/drive/folders/13rYkek_CQuOk_N5erJL08R26B1BkYmwD?usp=sharing) and extract it to `./data/`.
83 | 2. Run the demo with the following command:
84 |
85 | ```bash
86 | python run.py --job scene0684_01
87 | ```
88 |
89 | #### Replica Demo
90 |
91 | 1. Download the `office0` demo scene from [here](https://drive.google.com/drive/folders/13rYkek_CQuOk_N5erJL08R26B1BkYmwD?usp=sharing) and extract it to `./data/`.
92 | 2. Run the demo using the specified configuration:
93 |
94 | ```bash
95 | python run.py --config configs/replica.yaml --job office0
96 | ```
97 |
98 | ### Tips
99 |
100 | - **Out-of-Memory (OOM):** Reduce `batch_size` if you encounter memory issues.
101 | - **Low Frame Rate Sequences:** Increase `weight_decay`, or set it to `-1` for an automatic decay. The default value is `0.9` (works well for ScanNet and Replica), but it can go up to larger values (no more than `1.0`).
102 | - **Scene Scaling Issues:** If the scene scale differs significantly from real-world dimensions, adjust merging parameters such as `dist_thres` (maximum allowable distance for tablet merging).
103 |
104 |
105 |
106 | ## Evaluation on the ScanNet v2 dataset
107 |
108 | 1. **Download and Extract ScanNet**:
109 | Follow the instructions provided on the [ScanNet website](http://www.scan-net.org/) to download and extract the dataset.
110 |
111 | 2. **Prepare the Data**:
112 | Use the data preparation script to parse the raw ScanNet data into a processed pickle format and generate ground truth planes using code modified from [PlaneRCNN](https://github.com/NVlabs/planercnn/blob/master/data_prep/parse.py) and [PlanarRecon](https://github.com/neu-vi/PlanarRecon/tree/main).
113 |
114 | Run the following command under the PlanarRecon environment:
115 |
116 | ```bash
117 | python tools/generate_gt.py --data_path PATH_TO_SCANNET --save_name planes_9/ --window_size 9 --n_proc 2 --n_gpu 1
118 | python tools/prepare_inst_gt_txt.py --val_list PATH_TO_SCANNET/scannetv2_val.txt --plane_mesh_path ./planes_9
119 | ```
120 |
121 | 3. **Process Scenes in the Validation Set**:
122 | You can use the following command to process each scene in the validation set. Update `scene????_??` with the specific scene name. Train/val/test split information is available [here](https://github.com/ScanNet/ScanNet/tree/master/Tasks/Benchmark):
123 |
124 | ```bash
125 | python run.py --job scene????_?? --input_dir PATH_TO_SCANNET/scene????_??
126 | ```
127 |
128 | 4. **Run the Test Script**:
129 | Finally, execute the test script to evaluate the processed data:
130 |
131 | ```bash
132 | python test.py
133 | ```
134 |
135 |
136 |
137 | ## Citation
138 |
139 | If you find our work useful, please kindly cite:
140 |
141 | ```
142 | @article{he2024alphatablets,
143 | title={AlphaTablets: A Generic Plane Representation for 3D Planar Reconstruction from Monocular Videos},
144 | author={Yuze He and Wang Zhao and Shaohui Liu and Yubin Hu and Yushi Bai and Yu-Hui Wen and Yong-Jin Liu},
145 | journal={arXiv preprint arXiv:2411.19950},
146 | year={2024}
147 | }
148 | ```
149 |
150 |
151 |
152 | ## Acknowledgements
153 |
154 | Some of the test code and installation guide in this repo is borrowed from [NeuralRecon](https://github.com/zju3dv/NeuralRecon), [PlanarRecon](https://github.com/neu-vi/PlanarRecon/tree/main) and [ParticleSfM](https://github.com/bytedance/particle-sfm)! We sincerely thank them all.
155 |
--------------------------------------------------------------------------------
/configs/default.yaml:
--------------------------------------------------------------------------------
1 | data:
2 | dataset_type: 'scannet'
3 | input_dir: './data/scene0684_01'
4 |
5 | init:
6 | depth_model_type: 'metric3d'
7 | normal_model_type: 'omnidata'
8 |
9 | crop: 20
--------------------------------------------------------------------------------
/configs/replica.yaml:
--------------------------------------------------------------------------------
1 | data:
2 | dataset_type: 'replica'
3 | input_dir: './data/office0'
4 |
5 | init:
6 | depth_model_type: 'metric3d'
7 | normal_model_type: 'omnidata'
8 |
9 | crop: 20
--------------------------------------------------------------------------------
/dataset/dataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.utils.data import Dataset
3 |
4 | class CustomDataset(Dataset):
5 | def __init__(self, images, mvp_mtxs, normals, depths):
6 | self.images = images
7 | self.mvp_mtxs = mvp_mtxs
8 | self.normals = normals
9 | self.depths = depths
10 |
11 | def __len__(self):
12 | return len(self.images)
13 |
14 | def __getitem__(self, idx):
15 | img = torch.from_numpy(self.images[idx])
16 | mvp_mtx = torch.from_numpy(self.mvp_mtxs[idx]).float()
17 | normal = torch.from_numpy(self.normals[idx])
18 | depth = torch.from_numpy(self.depths[idx])
19 |
20 | return img, mvp_mtx, normal, depth
21 |
--------------------------------------------------------------------------------
/geom/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THU-LYJ-Lab/AlphaTablets/735cbfe6aa7f03f7bc37f48303045fe71ffa042a/geom/__init__.py
--------------------------------------------------------------------------------
/geom/plane_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 |
4 | from sklearn.neighbors import KDTree
5 | from tqdm import trange
6 |
7 |
8 | class DisjointSet:
9 | def __init__(self, size, params, mean_colors):
10 | self.parent = [i for i in range(size)]
11 | self.rank = [0] * size
12 | self.accum_normal = [_ for _ in params[:, :3].copy()]
13 | self.accum_center = [_ for _ in params[:, 3:].copy()]
14 | self.accum_color = [_ for _ in mean_colors.copy()]
15 | self.accum_num = [1] * size
16 |
17 | def find(self, x):
18 | if self.parent[x] != x:
19 | self.parent[x] = self.find(self.parent[x])
20 | return self.parent[x]
21 |
22 | def union(self, x, y, normal_thres=0.9, dis_thres=0.1, color_thres=1.):
23 | root_x = self.find(x)
24 | root_y = self.find(y)
25 | if root_x != root_y and np.abs(
26 | np.sum(self.accum_normal[root_x] * self.accum_normal[root_y]) /
27 | np.linalg.norm(self.accum_normal[root_x]) /
28 | np.linalg.norm(self.accum_normal[root_y])
29 | ) > normal_thres and np.linalg.norm(
30 | (self.accum_center[root_x] / self.accum_num[root_x] -
31 | self.accum_center[root_y] / self.accum_num[root_y])
32 | * self.accum_normal[root_x] / np.linalg.norm(self.accum_normal[root_x])
33 | ) < dis_thres and np.linalg.norm(
34 | self.accum_color[root_x] / self.accum_num[root_x] -
35 | self.accum_color[root_y] / self.accum_num[root_y]
36 | ) < color_thres:
37 | if self.rank[root_x] < self.rank[root_y]:
38 | self.parent[root_x] = root_y
39 | self.accum_normal[root_y] += self.accum_normal[root_x]
40 | self.accum_center[root_y] += self.accum_center[root_x]
41 | self.accum_color[root_y] += self.accum_color[root_x]
42 | self.accum_num[root_y] += self.accum_num[root_x]
43 | elif self.rank[root_x] > self.rank[root_y]:
44 | self.parent[root_y] = root_x
45 | self.accum_normal[root_x] += self.accum_normal[root_y]
46 | self.accum_center[root_x] += self.accum_center[root_y]
47 | self.accum_color[root_x] += self.accum_color[root_y]
48 | self.accum_num[root_x] += self.accum_num[root_y]
49 | else:
50 | self.parent[root_x] = root_y
51 | self.rank[root_y] += 1
52 | self.accum_normal[root_y] += self.accum_normal[root_x]
53 | self.accum_center[root_y] += self.accum_center[root_x]
54 | self.accum_color[root_y] += self.accum_color[root_x]
55 | self.accum_num[root_y] += self.accum_num[root_x]
56 |
57 |
58 | def calc_plane(K, pose, depth, dis, mask, x_range_uv, y_range_uv, plane_normal=None):
59 | """Calculate the plane parameters from the camera pose and the pixel plane parameters.
60 | Args:
61 | K: camera intrinsic matrix, [3, 3]
62 | pose: camera pose, world-to-cam, [4, 4]
63 | dis: pixel plane distance to camera, scalar
64 | x_range_uv: pixel x range, [2]
65 | y_range_uv: pixel y range, [2]
66 | plane_normal: plane normal vector, [3], optional
67 | Returns:
68 | plane: plane parameters, [4]
69 | plane_up_vec: plane up vector, [3]
70 | resol: pixel plane resolution, [2]
71 | new_x_range_uv: new pixel x range, [2]
72 | new_y_range_uv: new pixel y range, [2]
73 | """
74 |
75 | # create a pixel grid in the image plane
76 | u = np.linspace(x_range_uv[0], x_range_uv[1], int(x_range_uv[1]-x_range_uv[0]+1))
77 | v = np.linspace(y_range_uv[0], y_range_uv[1], int(y_range_uv[1]-y_range_uv[0]+1))
78 | U, V = np.meshgrid(u, v)
79 |
80 | # back project the pixel grid to 3D space
81 | X = depth * (U + 0.5 - K[0, 2]) / K[0, 0]
82 | Y = -depth * (V + 0.5 - K[1, 2]) / K[1, 1]
83 | Z = -depth * np.ones(U.shape)
84 |
85 | # transform the points from camera coordinate to world coordinate
86 | points = np.stack((X, Y, Z, np.ones(U.shape)), axis=-1)
87 | points_world = np.matmul(points, np.linalg.inv(pose).T)
88 | points_world = points_world[:, :, :3] / points_world[:, :, 3:]
89 |
90 | # use PCA to fit a plane to these points
91 | points_world_flat = points_world[mask]
92 | mean = np.mean(points_world_flat, axis=0)
93 | points_world_zero_centroid = points_world_flat - mean
94 |
95 | if plane_normal is not None:
96 | plane_normal = np.matmul(plane_normal, np.linalg.inv(pose[:3, :3]).T)
97 | plane_normal = plane_normal / np.linalg.norm(plane_normal)
98 |
99 | else:
100 | if len(points_world_zero_centroid) < 10000:
101 | _, _, v = np.linalg.svd(points_world_zero_centroid)
102 | else:
103 | import random
104 | _, _, v = np.linalg.svd(random.sample(list(points_world_zero_centroid), 10000))
105 |
106 | # plane parameters
107 | plane_normal = v[-1, :] / np.linalg.norm(v[-1, :])
108 | if np.abs(plane_normal).max() != plane_normal.max():
109 | plane_normal = -plane_normal
110 |
111 | plane = np.concatenate((plane_normal, mean))
112 |
113 | resol = np.array([K[0,0]/dis, K[1,1]/dis])
114 |
115 | # calculate plane_up_vector according to the plane_normal
116 | pose_up_vec = np.array([0, 0, 1])
117 | if np.abs(np.sum(plane_normal * pose_up_vec)) > 0.8:
118 | pose_up_vec = np.array([0, 1, 0])
119 | plane_up_vec = pose_up_vec - np.sum(plane_normal * pose_up_vec) * plane_normal
120 | plane_up_vec = plane_up_vec / np.linalg.norm(plane_up_vec)
121 |
122 | U, V = U[mask], V[mask]
123 |
124 | plane_right = np.cross(plane_normal, plane_up_vec)
125 |
126 | new_x_argmin =np.matmul(points_world_flat, plane_right).argmin()
127 | new_x_argmax =np.matmul(points_world_flat, plane_right).argmax()
128 | new_y_argmin =np.matmul(points_world_flat, plane_up_vec).argmin()
129 | new_y_argmax =np.matmul(points_world_flat, plane_up_vec).argmax()
130 |
131 | new_x_width = np.sqrt((U[new_x_argmin] - U[new_x_argmax])**2 + (V[new_x_argmin] - V[new_x_argmax])**2)
132 | new_y_width = np.sqrt((U[new_y_argmin] - U[new_y_argmax])**2 + (V[new_y_argmin] - V[new_y_argmax])**2)
133 |
134 | new_x_range_uv = [-new_x_width/2 - 2, new_x_width/2 + 2]
135 | new_y_range_uv = [-new_y_width/2 - 2, new_y_width/2 + 2]
136 |
137 | y_range_3d = np.matmul(points_world_flat, plane_up_vec).max() - np.matmul(points_world_flat, plane_up_vec).min()
138 | x_range_3d = np.matmul(points_world_flat, plane_right).max() - np.matmul(points_world_flat, plane_right).min()
139 |
140 | resol = np.array([
141 | new_x_width / (x_range_3d + 1e-6),
142 | new_y_width / (y_range_3d + 1e-6)
143 | ])
144 |
145 | if resol[0] < K[0,0]/dis / 10 or resol[1] < K[1,1]/dis / 10:
146 | return None
147 |
148 | xy_min = np.array([new_x_range_uv[0], new_y_range_uv[0]])
149 | xy_max = np.array([new_x_range_uv[1], new_y_range_uv[1]])
150 |
151 | return plane, plane_up_vec, resol, xy_min, xy_max
152 |
153 |
154 | def ray_plane_intersect(plane, ray_origin, ray_direction):
155 | """Calculate the intersection of a ray and a plane.
156 | Args:
157 | plane: plane parameters, [4]
158 | ray_origin: ray origin, [3]
159 | ray_direction: ray direction, [3]
160 |
161 | Returns:
162 | intersection: intersection point, [3]
163 | """
164 |
165 | # calculate intersection
166 | t = -(plane[3] + np.dot(plane[:3], ray_origin)) / np.dot(plane[:3], ray_direction)
167 | intersection = ray_origin + t * ray_direction
168 |
169 | return intersection
170 |
171 |
172 | def points_xyz_to_plane_uv(points, plane, resol, plane_up):
173 | """Project 3D points to the pixel plane.
174 | Args:
175 | points: 3D points, [N, 3]
176 | plane: plane parameters, [4]
177 | resol: pixel plane resolution, [2]
178 | plane_up: plane up vector, [3]
179 | Returns:
180 | uv: pixel plane coordinates, [N, 2]
181 | """
182 |
183 | # plane normal vector
184 | plane_normal = np.asarray(plane[:3])
185 | # projection points of 'points' on the plane
186 | points_proj = points - np.outer( np.sum(points*plane_normal, axis=1)+plane[3] , plane_normal) / np.linalg.norm(plane_normal)
187 | mean_proj = np.mean(points_proj, axis=0)
188 | uvw_right = np.cross(plane_normal, plane_up)
189 | uvw_up = plane_up
190 | # calculate the uv coordinates
191 | uv = np.c_[np.sum((points_proj-mean_proj) * uvw_right, axis=-1), np.sum((points_proj-mean_proj) * uvw_up, axis=-1)]
192 | uv = uv * resol
193 | return uv
194 |
195 |
196 | def points_xyz_to_plane_uv_torch(points, plane, resol, plane_up):
197 | """Project 3D points to the pixel plane.
198 | Args:
199 | points: 3D points, [N, 3]
200 | plane: plane parameters, [4]
201 | resol: pixel plane resolution, [2]
202 | plane_up: plane up vector, [3]
203 | Returns:
204 | uv: pixel plane coordinates, [N, 2]
205 | """
206 |
207 | # plane normal vector
208 | plane_normal = plane[:3]
209 | # projection points of 'points' on the plane
210 | points_proj = points - torch.outer( torch.sum(points*plane_normal, dim=1)+plane[3] , plane_normal) / torch.norm(plane_normal)
211 | mean_proj = torch.mean(points_proj, dim=0)
212 | uvw_right = torch.cross(plane_normal, plane_up)
213 | uvw_up = plane_up
214 | # calculate the uv coordinates
215 | uv = torch.cat([torch.sum((points_proj-mean_proj) * uvw_right, dim=-1, keepdim=True), torch.sum((points_proj-mean_proj) * uvw_up, dim=-1, keepdim=True)], dim=-1)
216 | uv = uv * resol
217 | return uv
218 |
219 |
220 | def simple_distribute_planes_2D(uv_ranges, gap=2, min_H=8192):
221 | """Distribute pixel planes in 2D space.
222 | Args:
223 | uv_ranges: pixel ranges of each plane, [N, 2]
224 | Returns:
225 | plane_leftup: left-up pixel of each plane, [N, 2]
226 | """
227 |
228 | # calculate the left-up pixel of each plane
229 | plane_leftup = torch.zeros_like(uv_ranges)
230 |
231 | H = (int(torch.max(uv_ranges[:, 1]).item()) + 2) // gap * gap + gap
232 | H = max(H, min_H)
233 |
234 | # sort the planes by the height
235 | _, sort_idx = torch.sort(uv_ranges[:, 1], descending=True)
236 |
237 | # distribute the planes
238 | idx = 0
239 | now_H = 0
240 | now_W = 0
241 | prev_W = 0
242 | while idx < len(sort_idx):
243 | now_leftup = torch.tensor((prev_W+1, now_H+1))
244 | plane_leftup[sort_idx[idx]] = now_leftup
245 | now_W = max(now_W, uv_ranges[sort_idx[idx], 0] + 1 + prev_W)
246 | now_H += uv_ranges[sort_idx[idx], 1] + 1
247 |
248 | if idx + 1 < len(sort_idx) and now_H + uv_ranges[sort_idx[idx+1], 1] + 1 > H:
249 | prev_W = now_W
250 | now_H = 0
251 |
252 | idx += 1
253 |
254 | W = (int(now_W.item()) + 2) // gap * gap + gap
255 |
256 | return plane_leftup, W, H
257 |
258 |
259 | def cluster_planes(planes, K=2, thres=0.999,
260 | color_thres_1=0.3, color_thres_2=0.2,
261 | dis_thres_1=0.5, dis_thres_2=0.1,
262 | merge_edge_planes=False,
263 | init_plane_sets=None):
264 | # planes[:, :3]: plane normal vector
265 | # planes[:, 3:6]: plane center
266 |
267 | # create disjoint set
268 | ds = DisjointSet(len(planes), planes[:, :6], planes[:, 17:20])
269 |
270 | if init_plane_sets is not None:
271 | for plane_set in init_plane_sets:
272 | for i in range(len(plane_set)-1):
273 | ds.union(plane_set[i], plane_set[i+1], normal_thres=0.99, dis_thres=1, color_thres=114514)
274 |
275 | # construct kd-tree for plane center
276 | print('clustering tablets ...')
277 | tree = KDTree(planes[:, 3:6])
278 |
279 | # find the nearest K neighbors for each plane
280 | _, ind = tree.query(planes[:, 3:6], k=K+1)
281 |
282 | # calculate the angle between each plane and its neighbors
283 | neighbor_normals = planes[ind[:, 1:], :3]
284 | plane_normals = planes[:, :3]
285 | cos = np.sum(neighbor_normals * plane_normals[:, None, :], axis=-1)
286 |
287 | # merge planes that have cos > thres
288 | for i in trange(len(planes)):
289 | if not merge_edge_planes and planes[i, 15] == True:
290 | continue
291 |
292 | for j in range(K):
293 | if not merge_edge_planes and planes[ind[i, j+1], 15] == True:
294 | continue
295 | if cos[i, j] > thres:
296 | ds.union(i, ind[i, j+1], normal_thres=0.99, dis_thres=dis_thres_1, color_thres=color_thres_1)
297 |
298 | # merge planes that have cos > thres
299 | for i in trange(len(planes)):
300 | if not merge_edge_planes and planes[i, 15] == True:
301 | continue
302 |
303 | for j in range(K):
304 | if not merge_edge_planes and planes[ind[i, j+1], 15] == True:
305 | continue
306 | if cos[i, j] > thres:
307 | ds.union(i, ind[i, j+1], normal_thres=0.9, dis_thres=dis_thres_2, color_thres=color_thres_2)
308 |
309 | root2idx = {}
310 | for i in range(len(planes)):
311 | root = ds.find(i)
312 | if root not in root2idx:
313 | root2idx[root] = []
314 | root2idx[root].append(i)
315 |
316 | plane_sets = []
317 | for root in root2idx:
318 | plane_sets.append(root2idx[root])
319 |
320 | return plane_sets
321 |
322 |
--------------------------------------------------------------------------------
/lib/keyframe.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import glob
3 | import os
4 | from datetime import datetime
5 |
6 |
7 | def get_keyframes(folder, min_angle=15, min_distance=0.2, window_size=9,
8 | min_mean=0.2, max_mean=10):
9 | txt_list = sorted(glob.glob(f'{folder}/pose/*.txt'), key=lambda x: int(x.split('/')[-1].split('.')[0]))
10 | if len(txt_list) != 0:
11 | last_pose = np.loadtxt(txt_list[0])
12 | image_skip = np.ceil(len(txt_list) / 2000)
13 | txt_list = txt_list[::int(image_skip)]
14 | pose_num = len(txt_list)
15 | else:
16 | extrs = np.loadtxt(os.path.join(folder, 'traj.txt')).reshape(-1, 4, 4)
17 | last_pose = extrs[0]
18 | image_skip = np.ceil(len(extrs) / 2000)
19 | extrs = extrs[::int(image_skip)]
20 | pose_num = len(extrs)
21 |
22 | count = 1
23 | all_ids = []
24 |
25 | if len(txt_list) != 0:
26 | depth_list = [ pname.replace('pose', 'aligned_dense_depths').replace('.txt', '.npy') for pname in txt_list ]
27 | else:
28 | depth_list = sorted(glob.glob(f'{folder}/aligned_dense_depths/*.npy'))
29 | for i, j in zip(txt_list, depth_list):
30 | if int(i.split('/')[-1].split('.')[0]) != int(j.split('/')[-1].split('.')[0]):
31 | print(i, j)
32 | raise ValueError('pose and depth not match')
33 | depth_list = depth_list[::int(image_skip)]
34 |
35 | depth_list = np.array([ np.load(i).mean() for i in depth_list ])
36 | id_list = np.linspace(0, len(depth_list)-1, pose_num).astype(int)[::int(image_skip)]
37 | id_list = id_list[np.logical_and(depth_list > min_mean, depth_list < max_mean)]
38 | depth_list = depth_list[np.logical_and(depth_list > min_mean, depth_list < max_mean)]
39 |
40 | from scipy.signal import medfilt
41 | filtered_depth_list = medfilt(depth_list, kernel_size=29)
42 |
43 | # filtered out the depth_list
44 | id_list = id_list[
45 | np.logical_and(
46 | depth_list > filtered_depth_list * 0.85,
47 | depth_list < filtered_depth_list * 1.15
48 | )
49 | ]
50 |
51 | depth_list = depth_list[
52 | np.logical_and(
53 | depth_list > filtered_depth_list * 0.85,
54 | depth_list < filtered_depth_list * 1.15
55 | )
56 | ]
57 |
58 | print(str(datetime.now()) + ': \033[92mI', 'filtered out depth_list', len(id_list), '/', pose_num, '\033[0m')
59 |
60 | ids = [id_list[0]]
61 |
62 | for idx_pos, idx in enumerate(id_list[1:]):
63 | if len(txt_list) != 0:
64 | i = txt_list[idx]
65 | with open(i, 'r') as f:
66 | cam_pose = np.loadtxt(i)
67 | else:
68 | cam_pose = extrs[idx]
69 | angle = np.arccos(
70 | ((np.linalg.inv(cam_pose[:3, :3]) @ last_pose[:3, :3] @ np.array([0, 0, 1]).T) * np.array(
71 | [0, 0, 1])).sum())
72 | dis = np.linalg.norm(cam_pose[:3, 3] - last_pose[:3, 3])
73 | if angle > (min_angle / 180) * np.pi or dis > min_distance:
74 | ids.append(idx)
75 | last_pose = cam_pose
76 | # Compute camera view frustum and extend convex hull
77 | count += 1
78 | if count == window_size:
79 | ids = [i * int(image_skip) for i in ids]
80 | all_ids.append(ids)
81 | ids = []
82 | count = 0
83 |
84 | if len(ids) > 2:
85 | ids = [i * int(image_skip) for i in ids]
86 | all_ids.append(ids)
87 | else:
88 | ids = [i * int(image_skip) for i in ids]
89 | all_ids[-1].extend(ids)
90 |
91 | return all_ids, int(image_skip)
92 |
93 |
94 | if __name__ == '__main__':
95 | folder = '/data0/bys/Hex/PixelPlane/data/scene0709_01'
96 | keyframes, image_skip = get_keyframes(folder)
97 | print(keyframes, image_skip)
98 |
--------------------------------------------------------------------------------
/lib/load_colmap.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime
2 | import os
3 | import cv2
4 | import glob
5 | import numpy as np
6 | from tqdm import tqdm
7 |
8 | from recon.utils import load_sfm_pose, load_scannet_pose
9 |
10 | from geom.plane_utils import calc_plane
11 |
12 | import torch
13 | import torch.nn.functional as F
14 |
15 |
16 | def dilate(img):
17 | kernel = torch.ones(3, 3).cuda().double()
18 | img = torch.tensor(img.astype('int32')).cuda().double()
19 |
20 | while True:
21 | mask = img > 0
22 | if torch.logical_not(mask).sum() == 0:
23 | break
24 | mask = mask.double()
25 |
26 | mask_dilated = F.conv2d(mask[None, None], kernel[None, None], padding=1).squeeze(0).squeeze(0)
27 |
28 | img_dilated = F.conv2d(img[None, None], kernel[None, None], padding=1).squeeze(0).squeeze(0)
29 | img_dilated = torch.where(mask_dilated == 0, img_dilated, img_dilated / mask_dilated)
30 |
31 | img = torch.where(mask == 0, img_dilated, img)
32 |
33 | img = img.cpu().numpy()
34 |
35 | return img
36 |
37 |
38 | def parse_sp(sp, intr, pose, depth, normal, img_sp, edge_thres=0.95, crop=20):
39 | """Parse the superpixel segmentation into planes
40 | """
41 | sp = torch.from_numpy(sp).cuda()
42 | depth = torch.from_numpy(depth).cuda()
43 | normal = (torch.from_numpy(normal).cuda() - 0.5) * 2
44 | normal = normal.permute(1, 2, 0)
45 | img_sp = torch.from_numpy(img_sp).cuda()
46 | sp = sp.int()
47 | sp_ids = torch.unique(sp)
48 | planes = []
49 | mean_colors = []
50 |
51 | # mask crop to -1
52 | sp[:crop] = -1
53 | sp[-crop:] = -1
54 | sp[:, :crop] = -1
55 | sp[:, -crop:] = -1
56 |
57 | new_sp = torch.ones_like(sp).cuda() * -1
58 |
59 | sp_id_cnt = 0
60 |
61 | for sp_id in tqdm(sp_ids):
62 | sp_mask = sp == sp_id
63 |
64 | if sp_mask.sum() <= 15:
65 | continue
66 |
67 | new_sp[sp_mask] = sp_id_cnt
68 | mean_color = torch.mean(img_sp[sp_mask], dim=0)
69 |
70 | sp_dis = depth[sp_mask]
71 | sp_dis = torch.median(sp_dis)
72 | if sp_dis < 0:
73 | continue
74 | sp_normal = normal[sp_mask]
75 |
76 | sp_coeff = torch.einsum('ij,kj->ik', sp_normal, sp_normal)
77 | if sp_coeff.min() < edge_thres:
78 | is_edge_plane = True
79 | else:
80 | is_edge_plane = False
81 |
82 | sp_normal = torch.mean(sp_normal, dim=0)
83 | sp_normal = sp_normal / torch.norm(sp_normal)
84 | sp_normal[1] = -sp_normal[1]
85 | sp_normal[2] = -sp_normal[2]
86 |
87 | x_accum = torch.sum(sp_mask, dim=0)
88 | y_accum = torch.sum(sp_mask, dim=1)
89 | x_range_uv = [torch.min(torch.nonzero(x_accum)).item(), torch.max(torch.nonzero(x_accum)).item()]
90 | y_range_uv = [torch.min(torch.nonzero(y_accum)).item(), torch.max(torch.nonzero(y_accum)).item()]
91 |
92 | sp_dis = sp_dis.cpu().numpy()
93 | sp_depth = depth[y_range_uv[0]:y_range_uv[1]+1, x_range_uv[0]:x_range_uv[1]+1].cpu().numpy()
94 | sp_mask = sp_mask[y_range_uv[0]:y_range_uv[1]+1, x_range_uv[0]:x_range_uv[1]+1].cpu().numpy()
95 |
96 | ret = calc_plane(intr, pose, sp_depth, sp_dis, sp_mask, x_range_uv, y_range_uv, plane_normal=sp_normal.cpu().numpy())
97 | if ret is None:
98 | continue
99 | plane, plane_up, resol, new_x_range_uv, new_y_range_uv = ret
100 |
101 | plane = np.concatenate([plane, plane_up, resol, new_x_range_uv, new_y_range_uv, [is_edge_plane]])
102 | planes.append(plane)
103 | mean_colors.append(mean_color.cpu().numpy())
104 |
105 | sp_id_cnt += 1
106 |
107 | return planes, new_sp.cpu().numpy(), mean_colors
108 |
109 |
110 | def get_projection_matrix(fovy: float, aspect_wh: float, near: float, far: float):
111 | proj_mtx = np.zeros((4, 4), dtype=np.float32)
112 | proj_mtx[0, 0] = 1.0 / (np.tan(fovy / 2.0) * aspect_wh)
113 | proj_mtx[1, 1] = -1.0 / np.tan(
114 | fovy / 2.0
115 | ) # add a negative sign here as the y axis is flipped in nvdiffrast output
116 | proj_mtx[2, 2] = -(far + near) / (far - near)
117 | proj_mtx[2, 3] = -2.0 * far * near / (far - near)
118 | proj_mtx[3, 2] = -1.0
119 | return proj_mtx
120 |
121 |
122 | def get_mvp_matrix(c2w, proj_mtx):
123 | # calculate w2c from c2w: R' = Rt, t' = -Rt * t
124 | # mathematically equivalent to (c2w)^-1
125 | w2c = np.zeros((c2w.shape[0], 4, 4))
126 | w2c[:, :3, :3] = np.transpose(c2w[:, :3, :3], (0, 2, 1))
127 | w2c[:, :3, 3:] = np.transpose(-c2w[:, :3, :3], (0, 2, 1)) @ c2w[:, :3, 3:]
128 | w2c[:, 3, 3] = 1.0
129 |
130 | # calculate mvp matrix by proj_mtx @ w2c (mv_mtx)
131 | mvp_mtx = proj_mtx @ w2c
132 |
133 | return mvp_mtx
134 |
135 |
136 | def load_colmap_data(args, kf_list=[], image_skip=1, load_plane=True, scannet_pose=True):
137 | imgs = []
138 | image_dir = os.path.join(args.input_dir, "images")
139 | start = kf_list[0]
140 | end = kf_list[-1] + 1 if kf_list[-1] != -1 else len(glob.glob(os.path.join(image_dir, "*")))
141 | image_names = sorted(glob.glob(os.path.join(image_dir, "*")), key=lambda x: int(x.split('/')[-1][:-4]))
142 |
143 | image_names_sp = [image_names[i] for i in kf_list]
144 | image_names = image_names[start:end:image_skip]
145 |
146 | print(str(datetime.now()) + ': \033[92mI', 'loading images ...', '\033[0m')
147 | for name in tqdm(image_names):
148 | img = cv2.imread(name)
149 | img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
150 | imgs.append(img.astype(np.float32) / 255.)
151 |
152 | imgs_sp = []
153 | for name in image_names_sp:
154 | img = cv2.imread(name)
155 | # convert to ycbcr using cv2
156 | img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
157 | imgs_sp.append(img.astype(np.float32) / 255.)
158 |
159 | imgs_sp = np.stack(imgs_sp, 0)
160 |
161 | if scannet_pose:
162 | print(str(datetime.now()) + ': \033[92mI', 'loading scannet poses ...', '\033[0m')
163 | intr_scannet, sfm_poses_scannet, sfm_camprojs_scannet = load_scannet_pose(args.input_dir)
164 | intr = intr_scannet
165 | sfm_poses, sfm_camprojs = sfm_poses_scannet, sfm_camprojs_scannet
166 | else:
167 | print(str(datetime.now()) + ': \033[92mI', 'loading colmap poses ...', '\033[0m')
168 | intr, sfm_poses, sfm_camprojs = load_sfm_pose(os.path.join(args.input_dir, "sfm"))
169 |
170 |
171 | sfm_poses_sp = np.array(sfm_poses)[kf_list]
172 | sfm_poses = np.array(sfm_poses)[start:end:image_skip]
173 | sfm_camprojs = np.array(sfm_camprojs)[start:end:image_skip]
174 |
175 | normal_dir = os.path.join(args.input_dir, "omnidata_normal")
176 | normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")), key=lambda x: int(x.split('/')[-1][:-4]))
177 | depth_names = [ iname.replace('omnidata_normal', 'aligned_dense_depths') for iname in normal_names ]
178 | depth_names = [depth_names[i] for i in kf_list]
179 |
180 | print(str(datetime.now()) + ': \033[92mI', 'loading depths ...', '\033[0m')
181 | depths = []
182 | for name in tqdm(depth_names):
183 | depth = np.load(name)
184 | depths.append(depth)
185 |
186 | depths = np.stack(depths, 0)
187 | aligned_depth_dir = os.path.join(args.input_dir, "aligned_dense_depths")
188 | all_depth_names = sorted(glob.glob(os.path.join(aligned_depth_dir, "*")), key=lambda x: int(x.split('/')[-1][:-4]))[start:end:image_skip]
189 | all_depths = []
190 |
191 | for name, pose in tqdm(zip(all_depth_names, sfm_poses)):
192 | depth = np.load(name)
193 | all_depths.append(depth)
194 |
195 | if args.init.normal_model_type == 'omnidata':
196 | normal_dir = os.path.join(args.input_dir, "omnidata_normal")
197 | else:
198 | raise NotImplementedError(f'Unknown normal model type {args.init.normal_model_type} exiting')
199 |
200 | normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")), key=lambda x: int(x.split('/')[-1][:-4]))
201 | normal_names = [normal_names[i] for i in kf_list]
202 |
203 | print(str(datetime.now()) + ': \033[92mI', 'loading normals ...', '\033[0m')
204 | normals = []
205 | for name in tqdm(normal_names):
206 | normal = np.load(name)[:3]
207 | normals.append(normal)
208 |
209 | normals = np.stack(normals, 0)
210 |
211 | all_normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")), key=lambda x: int(x.split('/')[-1][:-4]))[start:end:image_skip]
212 | all_normals = []
213 |
214 | for name, pose in tqdm(zip(all_normal_names, sfm_poses)):
215 | normal = np.load(name)
216 | normal = normal[:3]
217 |
218 | normal = torch.from_numpy(normal).cuda()
219 | normal = (normal - 0.5) * 2
220 | normal = normal / torch.norm(normal, dim=0, keepdim=True)
221 | normal = normal.permute(1, 2, 0)
222 | normal[:, :, 1] = -normal[:, :, 1]
223 | normal[:, :, 2] = -normal[:, :, 2]
224 | normal = torch.einsum('ijk,kl->ijl', normal, torch.from_numpy(np.linalg.inv(pose[:3, :3]).T).cuda().float())
225 | normal = F.interpolate(normal.permute(2, 0, 1).unsqueeze(0),
226 | (int(imgs[0].shape[0]/64)*8, int(imgs[0].shape[1]/64)*8),
227 | mode='bilinear', align_corners=False).squeeze(0).permute(1, 2, 0)
228 | all_normals.append(normal.cpu().numpy())
229 |
230 | sp_dir = os.path.join(args.input_dir, "sp")
231 | sp_names = [os.path.join(sp_dir, os.path.split(name)[-1].replace('.jpg', '.npy').replace('.png', '.npy')) for name in image_names_sp]
232 |
233 | if load_plane:
234 | print(str(datetime.now()) + ': \033[92mI', 'loading superpixels ...', '\033[0m')
235 | planes_all = []
236 | new_sp_all = []
237 | mean_colors_all = []
238 | plane_index_start = 0
239 | for plane_idx, (sp_name, depth, normal, pose, img_sp) in tqdm(enumerate(zip(sp_names, depths, normals, sfm_poses_sp, imgs_sp))):
240 | sp = np.load(sp_name)
241 | planes, new_sp, mean_colors = parse_sp(sp, intr, pose, depth, normal, img_sp)
242 | planes = np.array(planes)
243 | planes_idx = np.ones((planes.shape[0], 1)) * plane_idx
244 | planes = np.concatenate([planes, planes_idx], 1)
245 | planes_all.extend(planes)
246 | new_sp_all.append(new_sp + plane_index_start)
247 | plane_index_start += planes.shape[0]
248 | mean_colors = np.array(mean_colors)
249 | mean_colors_all.extend(mean_colors)
250 |
251 | planes_all = np.array(planes_all)
252 | mean_colors_all = np.array(mean_colors_all)
253 |
254 | else:
255 | planes_all = None
256 | new_sp_all = None
257 | mean_colors_all = None
258 |
259 | # proj matrixs
260 | frames_proj = []
261 | frames_c2w = []
262 | frames_center = []
263 | for i in range(len(sfm_camprojs)):
264 | fovy = 2 * np.arctan(0.5 * imgs[0].shape[0] / intr[1, 1])
265 | proj = get_projection_matrix(
266 | fovy, imgs[0].shape[1] / imgs[0].shape[0], 0.1, 1000.0
267 | )
268 | proj = np.array(proj)
269 | frames_proj.append(proj)
270 | # sfm_poses is w2c
271 | c2w = np.linalg.inv(sfm_poses[i])
272 | frames_c2w.append(c2w)
273 | frames_center.append(c2w[:3, 3])
274 |
275 | frames_proj = np.stack(frames_proj, 0)
276 | frames_c2w = np.stack(frames_c2w, 0)
277 | frames_center = np.stack(frames_center, 0)
278 |
279 | mvp_mtxs = get_mvp_matrix(
280 | frames_c2w, frames_proj,
281 | )
282 |
283 | index_init = ((np.array(kf_list) - kf_list[0]) / image_skip).astype(np.int32)
284 |
285 | return imgs, intr, sfm_poses, sfm_camprojs, frames_center, all_depths, all_normals, planes_all, \
286 | mvp_mtxs, index_init, new_sp_all, mean_colors_all
287 |
--------------------------------------------------------------------------------
/lib/load_data.py:
--------------------------------------------------------------------------------
1 | from .load_colmap import load_colmap_data
2 | from .load_replica import load_replica_data
3 |
4 |
5 | def load_data(args, kf_list, image_skip, load_plane):
6 | if args.dataset_type == 'scannet':
7 | images, intr, sfm_poses, sfm_camprojs, cam_centers, \
8 | all_depths, normals, planes_all, mvp_mtxs, index_init, \
9 | new_sps, mean_colors = load_colmap_data(args, kf_list=kf_list,
10 | image_skip=image_skip,
11 | load_plane=load_plane)
12 | print('Loaded scannet', intr, len(images), sfm_poses.shape, sfm_camprojs.shape, args.input_dir)
13 |
14 | data_dict = dict(
15 | poses=sfm_poses, images=images,
16 | intr=intr, sfm_camprojs=sfm_camprojs,
17 | cam_centers=cam_centers,
18 | all_depths=all_depths,
19 | normals=normals, planes_all=planes_all,
20 | mvp_mtxs=mvp_mtxs,
21 | index_init=index_init,
22 | new_sps=new_sps,
23 | mean_colors=mean_colors,
24 | )
25 | return data_dict
26 |
27 |
28 | elif args.dataset_type == 'replica':
29 | images, intr, sfm_poses, sfm_camprojs, cam_centers, \
30 | all_depths, normals, planes_all, mvp_mtxs, index_init, \
31 | new_sps, mean_colors = load_replica_data(args, kf_list=kf_list,
32 | image_skip=image_skip,
33 | load_plane=load_plane)
34 |
35 | print('Loaded replica', intr, len(images), sfm_poses.shape, sfm_camprojs.shape, args.input_dir)
36 |
37 | data_dict = dict(
38 | poses=sfm_poses, images=images,
39 | intr=intr, sfm_camprojs=sfm_camprojs,
40 | cam_centers=cam_centers,
41 | all_depths=all_depths,
42 | normals=normals, planes_all=planes_all,
43 | mvp_mtxs=mvp_mtxs,
44 | index_init=index_init,
45 | new_sps=new_sps,
46 | mean_colors=mean_colors,
47 | )
48 | return data_dict
49 |
50 |
51 | else:
52 | raise NotImplementedError(f'Unknown dataset type {args.dataset_type} exiting')
53 |
54 |
--------------------------------------------------------------------------------
/lib/load_replica.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime
2 | import os
3 | import cv2
4 | import glob
5 | import numpy as np
6 | from tqdm import tqdm
7 |
8 | from recon.utils import load_sfm_pose, load_replica_pose
9 |
10 | from geom.plane_utils import calc_plane
11 |
12 | import torch
13 | import torch.nn.functional as F
14 |
15 |
16 | def dilate(img):
17 | kernel = torch.ones(3, 3).cuda().double()
18 | img = torch.tensor(img.astype('int32')).cuda().double()
19 |
20 | while True:
21 | mask = img > 0
22 | if torch.logical_not(mask).sum() == 0:
23 | break
24 | mask = mask.double()
25 |
26 | mask_dilated = F.conv2d(mask[None, None], kernel[None, None], padding=1).squeeze(0).squeeze(0)
27 |
28 | img_dilated = F.conv2d(img[None, None], kernel[None, None], padding=1).squeeze(0).squeeze(0)
29 | img_dilated = torch.where(mask_dilated == 0, img_dilated, img_dilated / mask_dilated)
30 |
31 | img = torch.where(mask == 0, img_dilated, img)
32 |
33 | img = img.cpu().numpy()
34 |
35 | return img
36 |
37 |
38 | def parse_sp(sp, intr, pose, depth, normal, img_sp, edge_thres=0.95, crop=20):
39 | """Parse the superpixel segmentation into planes
40 | """
41 | sp = torch.from_numpy(sp).cuda()
42 | depth = torch.from_numpy(depth).cuda()
43 | normal = (torch.from_numpy(normal).cuda() - 0.5) * 2
44 | normal = normal.permute(1, 2, 0)
45 | img_sp = torch.from_numpy(img_sp).cuda()
46 | sp = sp.int()
47 | sp_ids = torch.unique(sp)
48 | planes = []
49 | mean_colors = []
50 |
51 | # mask crop to -1
52 | sp[:crop] = -1
53 | sp[-crop:] = -1
54 | sp[:, :crop] = -1
55 | sp[:, -crop:] = -1
56 |
57 | new_sp = torch.ones_like(sp).cuda() * -1
58 | sp_id_cnt = 0
59 |
60 | for sp_id in tqdm(sp_ids):
61 | sp_mask = sp == sp_id
62 |
63 | if sp_mask.sum() <= 15:
64 | continue
65 |
66 | new_sp[sp_mask] = sp_id_cnt
67 | mean_color = torch.mean(img_sp[sp_mask], dim=0)
68 |
69 | sp_dis = depth[sp_mask]
70 | sp_dis = torch.median(sp_dis)
71 | if sp_dis < 0:
72 | continue
73 | sp_normal = normal[sp_mask]
74 |
75 | sp_coeff = torch.einsum('ij,kj->ik', sp_normal, sp_normal)
76 | if sp_coeff.min() < edge_thres:
77 | is_edge_plane = True
78 | else:
79 | is_edge_plane = False
80 |
81 | sp_normal = torch.mean(sp_normal, dim=0)
82 | sp_normal = sp_normal / torch.norm(sp_normal)
83 | sp_normal[1] = -sp_normal[1]
84 | sp_normal[2] = -sp_normal[2]
85 |
86 | x_accum = torch.sum(sp_mask, dim=0)
87 | y_accum = torch.sum(sp_mask, dim=1)
88 | x_range_uv = [torch.min(torch.nonzero(x_accum)).item(), torch.max(torch.nonzero(x_accum)).item()]
89 | y_range_uv = [torch.min(torch.nonzero(y_accum)).item(), torch.max(torch.nonzero(y_accum)).item()]
90 |
91 | sp_dis = sp_dis.cpu().numpy()
92 | sp_depth = depth[y_range_uv[0]:y_range_uv[1]+1, x_range_uv[0]:x_range_uv[1]+1].cpu().numpy()
93 | sp_mask = sp_mask[y_range_uv[0]:y_range_uv[1]+1, x_range_uv[0]:x_range_uv[1]+1].cpu().numpy()
94 |
95 | ret = calc_plane(intr, pose, sp_depth, sp_dis, sp_mask, x_range_uv, y_range_uv, plane_normal=sp_normal.cpu().numpy())
96 | if ret is None:
97 | continue
98 | plane, plane_up, resol, new_x_range_uv, new_y_range_uv = ret
99 |
100 | plane = np.concatenate([plane, plane_up, resol, new_x_range_uv, new_y_range_uv, [is_edge_plane]])
101 | planes.append(plane)
102 | mean_colors.append(mean_color.cpu().numpy())
103 |
104 | sp_id_cnt += 1
105 |
106 | return planes, new_sp.cpu().numpy(), mean_colors
107 |
108 |
109 | def get_projection_matrix(fovy: float, aspect_wh: float, near: float, far: float):
110 | proj_mtx = np.zeros((4, 4), dtype=np.float32)
111 | proj_mtx[0, 0] = 1.0 / (np.tan(fovy / 2.0) * aspect_wh)
112 | proj_mtx[1, 1] = -1.0 / np.tan(
113 | fovy / 2.0
114 | ) # add a negative sign here as the y axis is flipped in nvdiffrast output
115 | proj_mtx[2, 2] = -(far + near) / (far - near)
116 | proj_mtx[2, 3] = -2.0 * far * near / (far - near)
117 | proj_mtx[3, 2] = -1.0
118 | return proj_mtx
119 |
120 |
121 | def get_mvp_matrix(c2w, proj_mtx):
122 | # calculate w2c from c2w: R' = Rt, t' = -Rt * t
123 | # mathematically equivalent to (c2w)^-1
124 | w2c = np.zeros((c2w.shape[0], 4, 4))
125 | w2c[:, :3, :3] = np.transpose(c2w[:, :3, :3], (0, 2, 1))
126 | w2c[:, :3, 3:] = np.transpose(-c2w[:, :3, :3], (0, 2, 1)) @ c2w[:, :3, 3:]
127 | w2c[:, 3, 3] = 1.0
128 |
129 | # calculate mvp matrix by proj_mtx @ w2c (mv_mtx)
130 | mvp_mtx = proj_mtx @ w2c
131 |
132 | return mvp_mtx
133 |
134 |
135 | def load_replica_data(args, kf_list=[], image_skip=1, load_plane=True):
136 | imgs = []
137 | image_dir = os.path.join(args.input_dir, "images")
138 | start = kf_list[0]
139 | end = kf_list[-1] + 1 if kf_list[-1] != -1 else len(glob.glob(os.path.join(image_dir, "*")))
140 | image_names = sorted(glob.glob(os.path.join(image_dir, "*")))
141 |
142 | image_names_sp = [image_names[i] for i in kf_list]
143 | image_names = image_names[start:end:image_skip]
144 |
145 | print(str(datetime.now()) + ': \033[92mI', 'loading images ...', '\033[0m')
146 | for name in tqdm(image_names):
147 | img = cv2.imread(name)
148 | img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
149 | imgs.append(img.astype(np.float32) / 255.)
150 |
151 | imgs_sp = []
152 | for name in image_names_sp:
153 | img = cv2.imread(name)
154 | # convert to ycbcr using cv2
155 | img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
156 | imgs_sp.append(img.astype(np.float32) / 255.)
157 |
158 | imgs_sp = np.stack(imgs_sp, 0)
159 |
160 | intr, sfm_poses, sfm_camprojs = load_replica_pose(args.input_dir)
161 |
162 | sfm_poses_sp = np.array(sfm_poses)[kf_list]
163 | sfm_poses = np.array(sfm_poses)[start:end:image_skip]
164 | sfm_camprojs = np.array(sfm_camprojs)[start:end:image_skip]
165 |
166 | normal_dir = os.path.join(args.input_dir, "omnidata_normal")
167 | normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")))
168 | depth_names = [ iname.replace('omnidata_normal', 'aligned_dense_depths') for iname in normal_names ]
169 | depth_names = [depth_names[i] for i in kf_list]
170 |
171 | print(str(datetime.now()) + ': \033[92mI', 'loading depths ...', '\033[0m')
172 | depths = []
173 | for name in tqdm(depth_names):
174 | depth = np.load(name)
175 | depths.append(depth)
176 |
177 | depths = np.stack(depths, 0)
178 | aligned_depth_dir = os.path.join(args.input_dir, "aligned_dense_depths")
179 | all_depth_names = sorted(glob.glob(os.path.join(aligned_depth_dir, "*")))[start:end:image_skip]
180 | all_depths = []
181 |
182 | for name, pose in tqdm(zip(all_depth_names, sfm_poses)):
183 | depth = np.load(name)
184 | all_depths.append(depth)
185 |
186 | if args.init.normal_model_type == 'omnidata':
187 | normal_dir = os.path.join(args.input_dir, "omnidata_normal")
188 | else:
189 | raise NotImplementedError(f'Unknown normal model type {args.init.normal_model_type} exiting')
190 | normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")))
191 | normal_names = [normal_names[i] for i in kf_list]
192 |
193 | print(str(datetime.now()) + ': \033[92mI', 'loading normals ...', '\033[0m')
194 | normals = []
195 | for name in tqdm(normal_names):
196 | normal = np.load(name)[:3]
197 | normals.append(normal)
198 |
199 | normals = np.stack(normals, 0)
200 |
201 | all_normal_names = sorted(glob.glob(os.path.join(normal_dir, "*")))[start:end:image_skip]
202 | all_normals = []
203 |
204 | for name, pose in tqdm(zip(all_normal_names, sfm_poses)):
205 | normal = np.load(name)
206 | normal = normal[:3]
207 |
208 | normal = torch.from_numpy(normal).cuda()
209 | normal = (normal - 0.5) * 2
210 | normal = normal / torch.norm(normal, dim=0, keepdim=True)
211 | normal = normal.permute(1, 2, 0)
212 | normal[:, :, 1] = -normal[:, :, 1]
213 | normal[:, :, 2] = -normal[:, :, 2]
214 | normal = torch.einsum('ijk,kl->ijl', normal, torch.from_numpy(np.linalg.inv(pose[:3, :3]).T).cuda().float())
215 | normal = F.interpolate(normal.permute(2, 0, 1).unsqueeze(0),
216 | (int(imgs[0].shape[0]/64)*8, int(imgs[0].shape[1]/64)*8),
217 | mode='bilinear', align_corners=False).squeeze(0).permute(1, 2, 0)
218 | all_normals.append(normal.cpu().numpy())
219 |
220 | sp_dir = os.path.join(args.input_dir, "sp")
221 | sp_names = [os.path.join(sp_dir, os.path.split(name)[-1].replace('.jpg', '.npy').replace('.png', '.npy')) for name in image_names_sp]
222 |
223 | if load_plane:
224 | print(str(datetime.now()) + ': \033[92mI', 'loading superpixels ...', '\033[0m')
225 | planes_all = []
226 | new_sp_all = []
227 | mean_colors_all = []
228 | plane_index_start = 0
229 | for plane_idx, (sp_name, depth, normal, pose, img_sp) in tqdm(enumerate(zip(sp_names, depths, normals, sfm_poses_sp, imgs_sp))):
230 | sp = np.load(sp_name)
231 | planes, new_sp, mean_colors = parse_sp(sp, intr, pose, depth, normal, img_sp)
232 | planes = np.array(planes)
233 | planes_idx = np.ones((planes.shape[0], 1)) * plane_idx
234 | planes = np.concatenate([planes, planes_idx], 1)
235 | planes_all.extend(planes)
236 | new_sp_all.append(new_sp + plane_index_start)
237 | plane_index_start += planes.shape[0]
238 | mean_colors = np.array(mean_colors)
239 | mean_colors_all.extend(mean_colors)
240 |
241 | planes_all = np.array(planes_all)
242 | mean_colors_all = np.array(mean_colors_all)
243 |
244 | else:
245 | planes_all = None
246 | new_sp_all = None
247 | mean_colors_all = None
248 |
249 | # proj matrixs
250 | frames_proj = []
251 | frames_c2w = []
252 | frames_center = []
253 | for i in range(len(sfm_camprojs)):
254 | fovy = 2 * np.arctan(0.5 * imgs[0].shape[0] / intr[1, 1])
255 | proj = get_projection_matrix(
256 | fovy, imgs[0].shape[1] / imgs[0].shape[0], 0.1, 1000.0
257 | )
258 | proj = np.array(proj)
259 | frames_proj.append(proj)
260 | # sfm_poses is w2c
261 | c2w = np.linalg.inv(sfm_poses[i])
262 | frames_c2w.append(c2w)
263 | frames_center.append(c2w[:3, 3])
264 |
265 | frames_proj = np.stack(frames_proj, 0)
266 | frames_c2w = np.stack(frames_c2w, 0)
267 | frames_center = np.stack(frames_center, 0)
268 |
269 | mvp_mtxs = get_mvp_matrix(
270 | frames_c2w, frames_proj,
271 | )
272 |
273 | index_init = ((np.array(kf_list) - kf_list[0]) / image_skip).astype(np.int32)
274 |
275 | return imgs, intr, sfm_poses, sfm_camprojs, frames_center, all_depths, all_normals, planes_all, \
276 | mvp_mtxs, index_init, new_sp_all, mean_colors_all
277 |
--------------------------------------------------------------------------------
/recon/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THU-LYJ-Lab/AlphaTablets/735cbfe6aa7f03f7bc37f48303045fe71ffa042a/recon/__init__.py
--------------------------------------------------------------------------------
/recon/run_depth.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import numpy as np
4 |
5 | from recon.third_party.omnidata.omnidata_tools.torch.demo_normal_custom_func import demo_normal_custom_func
6 | from recon.third_party.metric3d.depth_custom_func import depth_custom_func
7 |
8 |
9 | def metric3d_depth(img_dir, input_dir, depth_dir, dataset_type):
10 | """Initialize the dense depth of each image using single-image depth prediction
11 | """
12 | os.makedirs(depth_dir, exist_ok=True)
13 | if dataset_type == 'scannet':
14 | intr = np.loadtxt(f'{input_dir}/intrinsic/intrinsic_color.txt')
15 | fx, fy, cx, cy = intr[0, 0], intr[1, 1], intr[0, 2], intr[1, 2]
16 | elif dataset_type == 'replica':
17 | if os.path.exists(os.path.join(input_dir, 'cam_params.json')):
18 | cam_param_path = os.path.join(input_dir, 'cam_params.json')
19 | elif os.path.exists(os.path.join(input_dir, '../cam_params.json')):
20 | cam_param_path = os.path.join(input_dir, '../cam_params.json')
21 | else:
22 | raise FileNotFoundError('cam_params.json not found')
23 | with open(cam_param_path, 'r') as f:
24 | j = json.load(f)
25 | fx, fy, cx, cy = j["camera"]["fx"], j["camera"]["fy"], j["camera"]["cx"], j["camera"]["cy"]
26 | else:
27 | raise NotImplementedError(f'Unknown dataset type {dataset_type} exiting')
28 | indir = img_dir
29 | outdir = depth_dir
30 | depth_custom_func(fx, fy, cx, cy, indir, outdir)
31 |
32 |
33 | def omnidata_normal(img_dir, input_dir, normal_dir):
34 | """Initialize the dense normal of each image using single-image normal prediction
35 | """
36 | os.makedirs(normal_dir, exist_ok=True)
37 | demo_normal_custom_func(img_dir, normal_dir)
38 |
--------------------------------------------------------------------------------
/recon/run_recon.py:
--------------------------------------------------------------------------------
1 | import os
2 | import glob
3 | from datetime import datetime
4 |
5 |
6 | class Recon:
7 | def __init__(self, config, input_dir, dataset_type):
8 | self.config = config
9 | self.input_dir = input_dir
10 | self.image_dir = os.path.join(input_dir, "images")
11 | self.output_root = input_dir
12 | self.dataset_type = dataset_type
13 | self.preprocess()
14 |
15 | def preprocess(self):
16 | if not os.path.exists(self.image_dir):
17 | if self.dataset_type == 'scannet':
18 | original_image_dir = os.path.join(self.input_dir, "color")
19 | if not os.path.exists(original_image_dir):
20 | raise ValueError(f'Image directory {self.image_dir} not found')
21 | old_dir = os.getcwd()
22 | os.chdir(self.input_dir)
23 | os.symlink("color", "images")
24 | os.chdir(old_dir)
25 | print(str(datetime.now()) + ': \033[92mI', f'Linked {original_image_dir} to {self.image_dir}', '\033[0m')
26 | elif self.dataset_type == 'replica':
27 | original_image_dir = os.path.join(self.input_dir, "results")
28 | if not os.path.exists(original_image_dir):
29 | raise ValueError(f'Image directory {self.image_dir} not found')
30 | os.makedirs(self.image_dir)
31 | old_dir = os.getcwd()
32 | os.chdir(self.image_dir)
33 | for img in glob.glob(os.path.join("../results", "frame*")):
34 | os.symlink(os.path.join("../results", os.path.split(img)[-1]), os.path.split(img)[-1])
35 | os.chdir(old_dir)
36 | print(str(datetime.now()) + ': \033[92mI', f'Linked {original_image_dir} to {self.image_dir}', '\033[0m')
37 | else:
38 | raise NotImplementedError(f'Unknown dataset type {self.dataset_type} exiting')
39 |
40 |
41 | def recon(self):
42 | if os.path.exists(os.path.join(self.output_root, "recon.lock")):
43 | print(str(datetime.now()) + ': \033[92mI', 'Monocular estimation already done!', '\033[0m')
44 | return
45 |
46 | from .run_depth import omnidata_normal, metric3d_depth
47 |
48 | depth_dir = os.path.join(self.output_root, "aligned_dense_depths")
49 | print(str(datetime.now()) + ': \033[92mI', 'Running Depth Estimation ...', '\033[0m')
50 | metric3d_depth(self.image_dir, self.output_root, depth_dir, self.dataset_type)
51 | print(str(datetime.now()) + ': \033[92mI', 'Depth Estimation Done!', '\033[0m')
52 |
53 | normal_dir = os.path.join(self.output_root, "omnidata_normal")
54 | print(str(datetime.now()) + ': \033[92mI', 'Running Normal Estimation ...', '\033[0m')
55 | omnidata_normal(self.image_dir, self.output_root, normal_dir)
56 | print(str(datetime.now()) + ': \033[92mI', 'Normal Estimation Done!', '\033[0m')
57 |
58 | # create lock file
59 | open(os.path.join(self.output_root, "recon.lock"), "w").close()
60 |
61 | def run_sp(self, kf_list):
62 | from .run_sp import run_sp
63 | print(str(datetime.now()) + ': \033[92mI', 'Running SuperPixel Subdivision ...', '\033[0m')
64 | sp_dir = run_sp(self.image_dir, self.output_root, kf_list)
65 | print(str(datetime.now()) + ': \033[92mI', 'SuperPixel Subdivision Done!', '\033[0m')
66 | return sp_dir
67 |
--------------------------------------------------------------------------------
/recon/run_sp.py:
--------------------------------------------------------------------------------
1 | import os
2 | import cv2
3 | import numpy as np
4 | from tqdm import tqdm
5 |
6 |
7 | def sp_division(img):
8 | slic = cv2.ximgproc.createSuperpixelSLIC(img)
9 | slic.iterate(10)
10 | labels = slic.getLabels()
11 | # mask_slic = slic.getLabelContourMask() #获取Mask,超像素边缘Mask==1
12 | # number_slic = slic.getNumberOfSuperpixels() #获取超像素数目
13 | # mask_inv_slic = cv2.bitwise_not(mask_slic)
14 | # img_slic = cv2.bitwise_and(img,img,mask = mask_inv_slic) #在原图上绘制超像素边界
15 | # cv2.imwrite('3.png', img_slic)
16 | return labels
17 |
18 |
19 | def run_sp(image_dir, output_root, kf_list=None):
20 | sp_dir = os.path.join(output_root, "sp")
21 | os.makedirs(sp_dir, exist_ok=True)
22 | try:
23 | image_names = sorted(os.listdir(image_dir), key=lambda x: int(x.split('/')[-1][:-4]))
24 | except:
25 | image_names = sorted(os.listdir(image_dir))
26 | image_names = [image_names[k] for k in kf_list]
27 | for name in tqdm(image_names):
28 | if os.path.exists(os.path.join(sp_dir, name[:-4] + '.npy')):
29 | continue
30 | img = cv2.imread(os.path.join(image_dir, name))
31 | labels = sp_division(img)
32 | np.save(os.path.join(sp_dir, name[:-4]), labels)
33 |
34 |
35 | if __name__ == '__main__':
36 | img = cv2.imread('/home/hyz/git-plane/PixelPlane/data/scene0000_00/images/36.jpg')
37 | sp_division(img)
--------------------------------------------------------------------------------
/recon/utils.py:
--------------------------------------------------------------------------------
1 | import json
2 | import os
3 | import cv2
4 | import glob
5 | import numpy as np
6 |
7 |
8 | def load_images(img_dir):
9 | imgs = []
10 | image_names = sorted(os.listdir(img_dir))
11 | for name in image_names:
12 | img = cv2.imread(os.path.join(img_dir, name))
13 | img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
14 | imgs.append(img)
15 | return imgs, image_names
16 |
17 |
18 | def load_sfm(sfm_dir):
19 | """Load converted sfm world-to-cam depths and poses
20 | """
21 | depth_dir = os.path.join(sfm_dir, "colmap_outputs_converted/depths")
22 | pose_dir = os.path.join(sfm_dir, "colmap_outputs_converted/poses")
23 | depth_names = sorted(glob.glob(os.path.join(depth_dir, "*.npy")))
24 | pose_names = sorted(glob.glob(os.path.join(pose_dir, "*.txt")))
25 | sfm_depths, sfm_poses = [], []
26 | for dn, pn in zip(depth_names, pose_names):
27 | assert os.path.basename(dn)[:-4] == os.path.basename(pn)[:-4]
28 | depth = np.load(dn)
29 | pose = np.loadtxt(pn)
30 | sfm_depths.append(depth)
31 | sfm_poses.append(pose)
32 | return sfm_depths, sfm_poses
33 |
34 |
35 | def load_sfm_pose(sfm_dir):
36 | """Load sfm poses and then convert into proj mat
37 | """
38 | pose_dir = os.path.join(sfm_dir, "colmap_outputs_converted/poses")
39 | intr_dir = os.path.join(sfm_dir, "colmap_outputs_converted/intrinsics")
40 | pose_names = sorted(glob.glob(os.path.join(pose_dir, "*.txt")), key=lambda x: int(x.split('/')[-1][:-4]))
41 | intr_names = sorted(glob.glob(os.path.join(intr_dir, "*.txt")), key=lambda x: int(x.split('/')[-1][:-4]))
42 | K = np.loadtxt(intr_names[0])
43 | KH = np.eye(4)
44 | KH[:3,:3] = K
45 | sfm_poses, sfm_projmats = [], []
46 | for pn in pose_names:
47 | # world-to-cam
48 | pose = np.loadtxt(pn)
49 | pose = np.concatenate([pose, np.array([[0,0,0,1]])], 0)
50 | c2w = np.linalg.inv(pose)
51 | c2w[0:3, 1:3] *= -1
52 | pose = np.linalg.inv(c2w)
53 | sfm_poses.append(pose)
54 | # projmat
55 | projmat = KH @ pose
56 | sfm_projmats.append(projmat)
57 | return K, sfm_poses, sfm_projmats
58 |
59 |
60 | def load_scannet_pose(scannet_dir):
61 | """Load scannet poses and then convert into proj mat
62 | """
63 | pose_dir = os.path.join(scannet_dir, "pose")
64 | intr_dir = os.path.join(scannet_dir, "intrinsic")
65 | pose_names = sorted(glob.glob(os.path.join(pose_dir, "*.txt")), key=lambda x: int(x.split('/')[-1][:-4]))
66 | intr_name = os.path.join(intr_dir, "intrinsic_color.txt")
67 | KH = np.loadtxt(intr_name)
68 | scannet_poses, scannet_projmats = [], []
69 | for pn in pose_names:
70 | p = np.loadtxt(pn)
71 | R = p[:3, :3]
72 | R = np.matmul(R, np.array([
73 | [1, 0, 0],
74 | [0, -1, 0],
75 | [0, 0, -1]
76 | ]))
77 | p[:3, :3] = R
78 | p = np.linalg.inv(p)
79 | scannet_poses.append(p)
80 | # projmat
81 | projmat = KH @ p
82 | scannet_projmats.append(projmat)
83 | return KH[:3, :3], scannet_poses, scannet_projmats
84 |
85 |
86 | def load_replica_pose(replica_dir):
87 | """Load replica poses and then convert into proj mat
88 | """
89 | if os.path.exists(os.path.join(replica_dir, 'cam_params.json')):
90 | cam_param_path = os.path.join(replica_dir, 'cam_params.json')
91 | elif os.path.exists(os.path.join(replica_dir, '../cam_params.json')):
92 | cam_param_path = os.path.join(replica_dir, '../cam_params.json')
93 | else:
94 | raise FileNotFoundError('cam_params.json not found')
95 | with open(cam_param_path, 'r') as f:
96 | j = json.load(f)
97 | intrinsics = np.array([
98 | j["camera"]["fx"], 0, j["camera"]["cx"],
99 | 0, j["camera"]["fy"], j["camera"]["cy"],
100 | 0, 0, 1
101 | ], dtype=np.float32).reshape(3, 3)
102 |
103 | KH = np.eye(4)
104 | KH[:3, :3] = intrinsics
105 |
106 | extrinsics = np.loadtxt(os.path.join(replica_dir, 'traj.txt')).reshape(-1, 4, 4)
107 | poses = []
108 | projmats = []
109 | for extrinsic in extrinsics:
110 | p = extrinsic
111 | R = p[:3, :3]
112 | R = np.matmul(R, np.array([
113 | [1, 0, 0],
114 | [0, -1, 0],
115 | [0, 0, -1]
116 | ]))
117 | p[:3, :3] = R
118 | p = np.linalg.inv(p)
119 | poses.append(p)
120 | # projmat
121 | projmat = KH @ p
122 | projmats.append(projmat)
123 |
124 | return intrinsics, poses, projmats
125 |
126 |
127 | def load_dense_depths(depth_dir):
128 | """Load initialized single-image dense depth predictions
129 | """
130 | depth_names = sorted(os.listdir(depth_dir))
131 | depths = []
132 | for dn in depth_names:
133 | depth = np.load(os.path.join(depth_dir, dn))
134 | depths.append(depth)
135 | return depths, depth_names
136 |
137 |
138 | def depth2disp(depth):
139 | """Convert depth map to disparity
140 | """
141 | disp = 1.0 / (depth + 1e-8)
142 | return disp
143 |
144 |
145 | def disp2depth(disp):
146 | """Convert disparity map to depth
147 | """
148 | depth = 1.0 / (disp + 1e-8)
149 | return depth
150 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | tqdm
2 | scikit-learn
3 | opencv-python
4 | opencv-contrib-python
5 | hydra-core
6 | matplotlib
7 | timm
8 | h5py
9 | pytorch_lightning
10 | mmengine
11 | mmcv
12 | ninja
13 | trimesh
14 | open3d
15 | git+https://github.com/NVlabs/nvdiffrast.git
--------------------------------------------------------------------------------
/run.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime
2 | import os, time, random, argparse
3 |
4 | import numpy as np
5 | import cv2
6 |
7 | from tqdm import tqdm, trange
8 |
9 | import torch
10 | import torch.nn.functional as F
11 | from torch.utils.data import DataLoader
12 | import torch.optim.lr_scheduler as lr_scheduler
13 |
14 | from lib.load_data import load_data
15 | from lib.alphatablets import AlphaTablets
16 | from dataset.dataset import CustomDataset
17 | from lib.keyframe import get_keyframes
18 | from recon.run_recon import Recon
19 |
20 |
21 | def config_parser():
22 | '''Define command line arguments
23 | '''
24 | parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
25 | parser.add_argument('--config', type=str, default='configs/default.yaml',
26 | help='config file path')
27 | parser.add_argument("--seed", type=int, default=777,
28 | help='Random seed')
29 | parser.add_argument("--job", type=str, default=str(time.time()),
30 | help='Job name')
31 |
32 | # learning options
33 | parser.add_argument("--lr_tex", type=float, default=0.01,
34 | help='Learning rate of texture color')
35 | parser.add_argument("--lr_alpha", type=float, default=0.03,
36 | help='Learning rate of texture alpha')
37 | parser.add_argument("--lr_plane_n", type=float, default=0.0001,
38 | help='Learning rate of plane normal')
39 | parser.add_argument("--lr_plane_dis", type=float, default=0.0005,
40 | help='Learning rate of plane distance')
41 | parser.add_argument("--lr_plane_dis_stage2", type=float, default=0.0002,
42 | help='Learning rate of plane distance in stage 2')
43 |
44 | # loss weights
45 | parser.add_argument("--weight_alpha_inv", type=float, default=1.0,
46 | help='Weight of alpha inv loss')
47 | parser.add_argument("--weight_normal", type=float, default=4.0,
48 | help='Weight of direct normal loss')
49 | parser.add_argument("--weight_depth", type=float, default=4.0,
50 | help='Weight of direct depth loss')
51 | parser.add_argument("--weight_distortion", type=float, default=20.0,
52 | help='Weight of distortion loss')
53 | parser.add_argument("--weight_decay", type=float, default=0.9,
54 | help='Weight of tablet alpha decay after a single step. -1 denotes automatic decay')
55 |
56 | # merging options
57 | parser.add_argument("--merge_normal_thres_init", type=float, default=0.97,
58 | help='Threshold of init merging planes')
59 | parser.add_argument("--merge_normal_thres", type=float, default=0.93,
60 | help='Threshold of merging planes')
61 | parser.add_argument("--merge_dist_thres1", type=float, default=0.5,
62 | help='Threshold of init merging planes')
63 | parser.add_argument("--merge_dist_thres2", type=float, default=0.1,
64 | help='Threshold of merging planes')
65 | parser.add_argument("--merge_color_thres1", type=float, default=0.3,
66 | help='Threshold of init merging planes')
67 | parser.add_argument("--merge_color_thres2", type=float, default=0.2,
68 | help='Threshold of merging planes')
69 | parser.add_argument("--merge_Y_decay", type=float, default=0.5,
70 | help='Decay rate of Y channel')
71 |
72 | # optimization options
73 | parser.add_argument("--batch_size", type=int, default=3,
74 | help='Batch size')
75 | parser.add_argument("--max_steps", type=int, default=32,
76 | help='Max optimization steps')
77 | parser.add_argument("--merge_interval", type=int, default=13,
78 | help='Merge interval')
79 | parser.add_argument("--max_steps_union", type=int, default=9,
80 | help='Max optimization steps for union optimization')
81 | parser.add_argument("--merge_interval_union", type=int, default=3,
82 | help='Merge interval for union optimization')
83 |
84 | parser.add_argument("--alpha_init", type=float, default=0.5,
85 | help='Initial alpha value')
86 | parser.add_argument("--alpha_init_empty", type=float, default=0.,
87 | help='Initial alpha value for empty pixels')
88 | parser.add_argument("--depth_inside_mask_alphathres", type=float, default=0.5,
89 | help='Threshold of alpha for inside mask')
90 |
91 | parser.add_argument("--max_rasterize_layers", type=int, default=15,
92 | help='Max rasterize layers')
93 |
94 | # logging/saving options
95 | parser.add_argument("--log_path", type=str, default='./logs',
96 | help='path to save logs')
97 | parser.add_argument("--dump_images", type=bool, default=False)
98 | parser.add_argument("--dump_interval", type=int, default=1,
99 | help='Dump interval')
100 |
101 | # update input
102 | parser.add_argument("--input_dir", type=str, default='',
103 | help='input directory')
104 |
105 | args = parser.parse_args()
106 |
107 | from hydra import compose, initialize
108 |
109 | initialize(version_base=None, config_path='./')
110 | ori_cfg = compose(config_name=args.config)['configs']
111 |
112 | class Struct:
113 | def __init__(self, **entries):
114 | self.__dict__.update(entries)
115 |
116 | cfg = Struct(**ori_cfg)
117 |
118 | # dump args and cfg
119 | import json
120 | os.makedirs(os.path.join(args.log_path, args.job), exist_ok=True)
121 | with open(os.path.join(args.log_path, args.job, 'args.json'), 'w') as f:
122 | args_json = {k: v for k, v in vars(args).items() if k != 'config'}
123 | json.dump(args_json, f, indent=4)
124 |
125 | import shutil
126 | shutil.copy(args.config, os.path.join(args.log_path, args.job, 'config.yaml'))
127 |
128 | if args.input_dir != '':
129 | cfg.data.input_dir = args.input_dir
130 |
131 | return args, cfg
132 |
133 |
134 | def seed_everything():
135 | '''Seed everything for better reproducibility.
136 | (some pytorch operation is non-deterministic like the backprop of grid_samples)
137 | '''
138 | torch.manual_seed(args.seed)
139 | np.random.seed(args.seed)
140 | random.seed(args.seed)
141 |
142 |
143 | def load_everything(cfg, kf_list, image_skip, load_plane=True):
144 | '''Load images / poses / camera settings / data split.
145 | '''
146 | data_dict = load_data(cfg.data, kf_list=kf_list, image_skip=image_skip, load_plane=load_plane)
147 | data_dict['poses'] = torch.Tensor(data_dict['poses'])
148 | return data_dict
149 |
150 |
151 | if __name__=='__main__':
152 | # load setup
153 | args, cfg = config_parser()
154 | merge_cfgs = {
155 | 'normal_thres_init': args.merge_normal_thres_init,
156 | 'normal_thres': args.merge_normal_thres,
157 | 'dist_thres1': args.merge_dist_thres1,
158 | 'dist_thres2': args.merge_dist_thres2,
159 | 'color_thres1': args.merge_color_thres1,
160 | 'color_thres2': args.merge_color_thres2,
161 | 'Y_decay': args.merge_Y_decay
162 | }
163 |
164 | # init enviroment
165 | if torch.cuda.is_available():
166 | torch.set_default_tensor_type('torch.cuda.FloatTensor')
167 | device = torch.device('cuda')
168 | else:
169 | torch.set_default_tensor_type('torch.FloatTensor')
170 | device = torch.device('cpu')
171 | torch.set_default_dtype(torch.float32)
172 | seed_everything()
173 |
174 | recon = Recon(cfg.data.init, cfg.data.input_dir, cfg.data.dataset_type)
175 | recon.recon()
176 |
177 | kf_lists, image_skip = get_keyframes(cfg.data.input_dir)
178 | subset_mean_len = np.mean([ k[-1]-k[0]+1 for k in kf_lists ])
179 | kf_lists.append([0, -1])
180 |
181 | for set_num, kf_list in enumerate(kf_lists):
182 | if set_num == len(kf_lists) - 1:
183 | print(str(datetime.now()) + f': \033[94mUnion Optimization', '\033[0m')
184 | else:
185 | print(str(datetime.now()) + f': \033[94mSubset {set_num+1}/{len(kf_lists)-1}, Keyframes', kf_list, '\033[0m')
186 |
187 | union_optimize = False
188 | if kf_list[0] == 0 and kf_list[1] == -1:
189 | union_optimize = True
190 | if os.path.exists(os.path.join(args.log_path, args.job, 'ckpt', f'./ckpt_{set_num:02d}_{args.max_steps_union-1}.pt')):
191 | print(str(datetime.now()) + f': \033[94mUnion optimization already done!', '\033[0m')
192 | continue
193 | else:
194 | if os.path.exists(os.path.join(args.log_path, args.job, 'ckpt', f'./ckpt_{set_num:02d}_{args.max_steps-1}.pt')):
195 | print(str(datetime.now()) + f': \033[94mSubset {set_num+1}/{len(kf_lists)-1} optimization already done!', '\033[0m')
196 | continue
197 |
198 | if kf_list[-1] != -1:
199 | recon.run_sp(kf_list)
200 |
201 | # load images / poses / camera settings / data split
202 | data_dict = load_everything(cfg=cfg, kf_list=kf_list, image_skip=image_skip,
203 | load_plane=not union_optimize)
204 |
205 | images, mvp_mtxs, K = data_dict['images'], data_dict['mvp_mtxs'], data_dict['intr']
206 | index_init = data_dict['index_init']
207 | new_sps = data_dict['new_sps']
208 | cam_centers = data_dict['cam_centers']
209 | normals = data_dict['normals']
210 | mean_colors = data_dict['mean_colors']
211 | depths = data_dict['all_depths']
212 |
213 | sp_images = np.stack([ images[idx] for idx in index_init ])
214 |
215 | if not union_optimize:
216 | pp = AlphaTablets(plane_params=data_dict['planes_all'],
217 | sp=[ sp_images , new_sps, mvp_mtxs[index_init]],
218 | cam_centers=cam_centers[index_init],
219 | mean_colors=mean_colors,
220 | HW=images[0].shape[0:2],
221 | alpha_init=args.alpha_init, alpha_init_empty=args.alpha_init_empty,
222 | inside_mask_alpha_thres=args.depth_inside_mask_alphathres,
223 | merge_cfgs=merge_cfgs)
224 | else:
225 | pp = AlphaTablets(ckpt_paths=[
226 | os.path.join(args.log_path, args.job, 'ckpt', f'./ckpt_{ii:02d}_{args.max_steps-1}.pt')
227 | for ii in range(len(kf_lists) - 1)
228 | ], merge_cfgs=merge_cfgs,
229 | alpha_init=args.alpha_init, alpha_init_empty=args.alpha_init_empty,
230 | inside_mask_alpha_thres=args.depth_inside_mask_alphathres)
231 |
232 | dataset = CustomDataset(images, mvp_mtxs, normals, depths)
233 | dataloader = DataLoader(dataset, batch_size=args.batch_size, shuffle=True, generator=torch.Generator(device=device))
234 |
235 | optimizer = torch.optim.Adam([
236 | {'params': pp.tex_color, 'lr': args.lr_tex},
237 | {'params': pp.tex_alpha, 'lr': args.lr_alpha},
238 | {'params': pp.plane_n, 'lr': args.lr_plane_n},
239 | {'params': pp.plane_dis, 'lr': args.lr_plane_dis},
240 | ])
241 |
242 | scheduler = lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.3)
243 | crop = cfg.data.crop
244 |
245 | max_steps = args.max_steps if not union_optimize else args.max_steps_union
246 | merge_interval = args.merge_interval if not union_optimize else args.merge_interval_union
247 |
248 | psnr_lst = []
249 | time0 = time.time()
250 | print(str(datetime.now()) + ': \033[92mI', 'Start AlphaTablets Optimization', '\033[0m')
251 | for global_step in trange(0, max_steps):
252 | avg_psnr = 0
253 | for batch_idx, (imgs, mvp_mtxs, normals, depths) in enumerate(dataloader):
254 | mvp_mtxs = mvp_mtxs.cuda()
255 | imgs = imgs.cuda()
256 | normals = normals.cuda()
257 | depths = depths.cuda()
258 |
259 | render_result = pp(mvp_mtxs,
260 | max_rasterize_layers=args.max_rasterize_layers)
261 |
262 | try:
263 | render_result, render_normal, render_depth, alpha_loss, distort_loss, inside_mask, plane_inside_mask = render_result
264 | except:
265 | continue
266 |
267 | # gradient descent step
268 | optimizer.zero_grad(set_to_none=True)
269 | crop_mask = torch.zeros_like(imgs)
270 | crop_mask[:, crop:-crop, crop:-crop] = 1
271 | mask = crop_mask * inside_mask
272 | loss = F.mse_loss(render_result * mask, imgs * mask)
273 | direct_normal_loss = F.mse_loss(render_normal, normals)
274 | direct_depth_loss = F.mse_loss(render_depth * mask[..., 0] * plane_inside_mask[..., 0], depths * mask[..., 0] * plane_inside_mask[..., 0])
275 | psnr = -10 * torch.log10(loss)
276 |
277 | loss += alpha_loss * args.weight_alpha_inv
278 | loss += distort_loss * args.weight_distortion
279 | loss += direct_normal_loss * args.weight_normal
280 | loss += direct_depth_loss * args.weight_depth
281 | avg_psnr += psnr.item()
282 |
283 | loss.backward()
284 | optimizer.step()
285 |
286 | if global_step % args.dump_interval == 0 and batch_idx == 0 and args.dump_images:
287 | optimizer.zero_grad(set_to_none=True)
288 | mvp_mtxs = torch.from_numpy(data_dict['mvp_mtxs'][0:1]).cuda().float()
289 | render_result, alpha_acc = pp(mvp_mtxs, return_alpha=True,
290 | max_rasterize_layers=args.max_rasterize_layers)
291 |
292 | os.makedirs(os.path.join(args.log_path, args.job, 'dump_images'), exist_ok=True)
293 |
294 | cv2.imwrite(os.path.join(args.log_path, args.job, 'dump_images', f'{set_num:02d}_{global_step:05d}.png'), render_result[0].detach().cpu().numpy() * 255)
295 | cv2.imwrite(os.path.join(args.log_path, args.job, 'dump_images', f'{set_num:02d}_{global_step:05d}_mask.png'), mask[0].detach().cpu().numpy() * 255)
296 | cv2.imwrite(os.path.join(args.log_path, args.job, 'dump_images', f'{set_num:02d}_{global_step:05d}_alpha.png'), alpha_acc[0].detach().cpu().numpy() * 255)
297 |
298 | error_map = torch.abs(render_result - torch.from_numpy(data_dict['images'][0][None, ...]).cuda().float())
299 | error_map = error_map[0].detach().cpu().numpy()
300 | # turn to red-blue, 0-255
301 | error_map = (error_map - error_map.min()) / (error_map.max() - error_map.min()) * 255
302 | error_map = cv2.applyColorMap(error_map.astype(np.uint8), cv2.COLORMAP_JET)
303 | cv2.imwrite(os.path.join(args.log_path, args.job, 'dump_images', f'{set_num:02d}_{global_step:05d}_error_map.png'), error_map)
304 |
305 | if global_step % merge_interval == 0 and batch_idx == 0 and global_step > 0:
306 | optimizer.zero_grad(set_to_none=True)
307 |
308 | pp.weightCheck(torch.from_numpy(data_dict['mvp_mtxs']).cuda().float())
309 |
310 | pp = AlphaTablets(pp=pp, merge_cfgs=merge_cfgs)
311 | del optimizer
312 | optimizer = torch.optim.Adam([
313 | {'params': pp.tex_color, 'lr': args.lr_tex},
314 | {'params': pp.tex_alpha, 'lr': args.lr_alpha},
315 | {'params': pp.plane_n, 'lr': args.lr_plane_n},
316 | {'params': pp.plane_dis, 'lr': args.lr_plane_dis_stage2},
317 | ])
318 |
319 | scheduler.step()
320 |
321 | if global_step == max_steps - 1:
322 | with torch.no_grad():
323 | os.makedirs(os.path.join(args.log_path, args.job, 'ckpt'), exist_ok=True)
324 | pp.save_ckpt(os.path.join(args.log_path, args.job, 'ckpt', f'ckpt_{set_num:02d}_{global_step}.pt'))
325 | optimizer.zero_grad(set_to_none=True)
326 |
327 | if union_optimize:
328 | with torch.no_grad():
329 | decay = args.weight_decay if args.weight_decay > 0 else max(1-0.00067*subset_mean_len, 0.8)
330 | pp.tex_alpha.data = torch.log( decay / (1 - decay + torch.exp(-pp.tex_alpha)) )
331 | elif global_step < args.merge_interval:
332 | with torch.no_grad():
333 | decay = args.weight_decay if args.weight_decay > 0 else max(1-0.00067*len(images), 0.8)
334 | pp.tex_alpha.data = torch.log( decay / (1 - decay + torch.exp(-pp.tex_alpha)) )
335 |
336 | if union_optimize:
337 | os.makedirs(os.path.join(args.log_path, args.job, 'results'), exist_ok=True)
338 | export_name_obj = os.path.join(args.log_path, args.job, 'results', f'{set_num:02d}_final.obj')
339 | pp.export_mesh_with_weight_check(torch.from_numpy(data_dict['mvp_mtxs']).cuda().float(), name=export_name_obj)
340 |
341 | os.makedirs(os.path.join(args.log_path, args.job, 'plys'), exist_ok=True)
342 | export_name = os.path.join(args.log_path, args.job, 'plys', f'{set_num:02d}_final.ply')
343 | pp.export_ply(torch.from_numpy(data_dict['mvp_mtxs'][::8]).cuda().float(), name=export_name)
344 |
345 | if set_num == len(kf_lists) - 1:
346 | print(str(datetime.now()) + f': \033[94mUnion optimization finished!', '\033[0m')
347 | else:
348 | print(str(datetime.now()) + f': \033[94mSubset {set_num+1}/{len(kf_lists)-1} optimization finished', '\033[0m')
349 |
350 | # create complete lock
351 | with open(os.path.join(args.log_path, args.job, 'complete.lock'), 'w') as f:
352 | f.write('done')
353 |
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | import numpy as np
4 | import open3d as o3d
5 | import trimesh
6 | from tqdm import tqdm
7 | from sklearn.metrics import rand_score
8 | from skimage.metrics import variation_of_information
9 |
10 | def compute_sc(gt_in, pred_in):
11 | # to be consistent with skimage sklearn input arrangment
12 |
13 | assert len(pred_in.shape) == 1 and len(gt_in.shape) == 1
14 |
15 | acc, pred, gt = match_seg(pred_in, gt_in) # n_gt * n_pred
16 |
17 | bestmatch_gt2pred = acc.max(axis=1)
18 | bestmatch_pred2gt = acc.max(axis=0)
19 |
20 | pred_id, pred_cnt = np.unique(pred, return_counts=True)
21 | gt_id, gt_cnt = np.unique(gt, return_counts=True)
22 |
23 | cnt_pred, sum_pred = 0, 0
24 | for i, _ in enumerate(pred_id):
25 | cnt_pred += bestmatch_pred2gt[i] * pred_cnt[i]
26 | sum_pred += pred_cnt[i]
27 |
28 | cnt_gt, sum_gt = 0, 0
29 | for i, _ in enumerate(gt_id):
30 | cnt_gt += bestmatch_gt2pred[i] * gt_cnt[i]
31 | sum_gt += gt_cnt[i]
32 |
33 | sc = (cnt_pred / sum_pred + cnt_gt / sum_gt) / 2
34 |
35 | return sc
36 |
37 | def match_seg(pred_in, gt_in):
38 | assert len(pred_in.shape) == 1 and len(gt_in.shape) == 1
39 |
40 | pred, gt = compact_segm(pred_in), compact_segm(gt_in)
41 | n_gt = gt.max() + 1
42 | n_pred = pred.max() + 1
43 |
44 | # this will offer the overlap between gt and pred
45 | # if gt == 1, we will later have conf[1, j] = gt(1) + pred(j) * n_gt
46 | # essential, we encode conf_mat[i, j] to overlap, and when we decode it we let row as gt, and col for pred
47 | # then assume we have 13 gt label, 6 pred label --> gt 1 will correspond to 14, 1+2*13 ... 1 + 6*13
48 | overlap = gt + n_gt * pred
49 | freq, bin_val = np.histogram(overlap, np.arange(0, n_gt * n_pred+1)) # hist given bins [1, 2, 3] --> return [1, 2), [2, 3)
50 | conf_mat = freq.reshape([ n_gt, n_pred], order='F') # column first reshape, like matlab
51 |
52 | acc = np.zeros([n_gt, n_pred])
53 | for i in range(n_gt):
54 | for j in range(n_pred):
55 | gt_i = conf_mat[i].sum()
56 | pred_j = conf_mat[:, j].sum()
57 | gt_pred = conf_mat[i, j]
58 | acc[i,j] = gt_pred / (gt_i + pred_j - gt_pred) if (gt_i + pred_j - gt_pred) != 0 else 0
59 | return acc[1:, 1:], pred, gt
60 |
61 | def compact_segm(seg_in):
62 | seg = seg_in.copy()
63 | uniq_id = np.unique(seg)
64 | cnt = 1
65 | for id in sorted(uniq_id):
66 | if id == 0:
67 | continue
68 | seg[seg==id] = cnt
69 | cnt += 1
70 |
71 | # every id (include non-plane should not be 0 for the later process in match_seg
72 | seg = seg + 1
73 | return seg
74 |
75 | def project_to_mesh(from_mesh, to_mesh, attribute, attr_name, color_mesh=None, dist_thresh=None):
76 | """ Transfers attributs from from_mesh to to_mesh using nearest neighbors
77 |
78 | Each vertex in to_mesh gets assigned the attribute of the nearest
79 | vertex in from mesh. Used for semantic evaluation.
80 |
81 | Args:
82 | from_mesh: Trimesh with known attributes
83 | to_mesh: Trimesh to be labeled
84 | attribute: Which attribute to transfer
85 | dist_thresh: Do not transfer attributes beyond this distance
86 | (None transfers regardless of distacne between from and to vertices)
87 |
88 | Returns:
89 | Trimesh containing transfered attribute
90 | """
91 |
92 | if len(from_mesh.vertices) == 0:
93 | to_mesh.vertex_attributes[attr_name] = np.zeros((0), dtype=np.uint8)
94 | to_mesh.visual.vertex_colors = np.zeros((0), dtype=np.uint8)
95 | return to_mesh
96 |
97 | pcd = o3d.geometry.PointCloud()
98 | pcd.points = o3d.utility.Vector3dVector(from_mesh.vertices)
99 | kdtree = o3d.geometry.KDTreeFlann(pcd)
100 |
101 | pred_ids = attribute.copy()
102 | pred_colors = from_mesh.visual.vertex_colors if color_mesh is None else color_mesh.visual.vertex_colors
103 |
104 | matched_ids = np.zeros((to_mesh.vertices.shape[0]), dtype=np.uint8)
105 | matched_colors = np.zeros((to_mesh.vertices.shape[0], 4), dtype=np.uint8)
106 |
107 | for i, vert in enumerate(to_mesh.vertices):
108 | _, inds, dist = kdtree.search_knn_vector_3d(vert, 1)
109 | if dist_thresh is None or dist[0]