 8 |
9 | 点击首页中的天启平台体验入口:
10 |
8 |
9 | 点击首页中的天启平台体验入口:
10 |  11 | 点击API应用:
12 |
11 | 点击API应用:
12 |  13 | 输入任意名称,创建API应用。创建后会得到API Key/Secret,用于调用API:
14 |
13 | 输入任意名称,创建API应用。创建后会得到API Key/Secret,用于调用API:
14 |  15 |
16 | 在API信息中,可以查看代码生成/代码翻译的请求地址和使用文档:
17 |
15 |
16 | 在API信息中,可以查看代码生成/代码翻译的请求地址和使用文档:
17 |  18 |
19 | 根据文档中的描述使用API,Python版参考目录``api/codegeex-api-example-python``;JAVA版参考工程:``api/codegeex-api-example-java``
20 |
--------------------------------------------------------------------------------
/api/codegeex-api-example-java/pom.xml:
--------------------------------------------------------------------------------
1 |
2 |
18 |
19 | 根据文档中的描述使用API,Python版参考目录``api/codegeex-api-example-python``;JAVA版参考工程:``api/codegeex-api-example-java``
20 |
--------------------------------------------------------------------------------
/api/codegeex-api-example-java/pom.xml:
--------------------------------------------------------------------------------
1 |
2 |  8 |
9 |
8 |
9 | HumanEval-X支持的任务示例。声明、描述、解答分别用红、绿、蓝色标注。代码生成将声明与描述作为输入,输出解答。代码翻译将两种语言的声明与源语言的解答作为输入,输出目标语言的解答。
10 | 11 | HumanEval-X中每个语言的样本,包含了声明、描述和解答,它们之间的组合可以支持不同的下游任务,包括生成、翻译、概括等。我们目前关注两个任务:**代码生成**与**代码翻译**。对于代码生成任务,模型将函数声明与文档字符串作为输入,输出函数实现;对于代码翻译任务,模型将两种语言的函数声明与源语言的实现作为输入,输出目标语言上的实现。我们在代码翻译任务中不将文档字符串输入模型,以避免模型直接通过描述生成答案。在两种任务下,我们都采用[Codex](https://arxiv.org/abs/2107.03374)所使用的无偏pass@k指标:$\text{pass}@k:= \mathbb{E}[1-\frac{\tbinom{n-c}{k}}{\tbinom{n}{k}}]$, $n=200$, $k\in(1,10,100)$。 12 | 13 | ## 如何使用HumanEval-X 14 | 15 | 样本使用JSON列表格式存储在``codegeex/benchmark/humaneval-x/[LANG]/data/humaneval_[LANG].jsonl.gz``,每条样本包含6个部分: 16 | 17 | * ``task_id``: 题目的目标语言与ID。语言为["Python", "Java", "JavaScript", "CPP", "Go"]中之一。 18 | * ``prompt``: 函数声明与描述,用于代码生成。 19 | * ``declaration``: 仅有函数声明,用于代码翻译。 20 | * ``canonical_solution``: 手写的示例解答。 21 | * ``test``: 隐藏测例,用于评测。 22 | * ``example_test``: 提示中出现的公开测例,用于评测。 23 | 24 | ### 评测环境 25 | 26 | 评测生成的代码需要使用多种语言编译、运行。我们使用的各编程语言依赖及所用包的版本如下: 27 | 28 | | 依赖 | 版本 | 29 | | ------- | -------- | 30 | | Python | 3.8.12 | 31 | | JDK | 18.0.2.1 | 32 | | Node.js | 16.14.0 | 33 | | js-md5 | 0.7.3 | 34 | | C++ | 11 | 35 | | g++ | 7.5.0 | 36 | | Boost | 1.71.0 | 37 | | OpenSSL | 3.0.0 | 38 | | go | 1.18.4 | 39 | 40 | 为了省去使用者配置这些语言环境的麻烦,我们构建了一个Docker镜像,并在其中配置了所需要的环境。 41 | 42 | 可以直接从Docker Hub拉取镜像: 43 | 44 | ```bash 45 | docker pull rishubi/codegeex:latest 46 | ``` 47 | 48 | 如果您熟悉Dockerfile,也可以从`codegeex/docker/Dockerfile`构建镜像,或者修改之以定制自己的配置: 49 | 50 | ```bash 51 | cd codegeex/docker 52 | docker build [OPTIONS] . 53 | ``` 54 | 55 | 获取镜像后,使用如下命令创建容器: 56 | 57 | ```bash 58 | docker run -it --gpus all --mount type=bind,source=", "langauge": "HTML"}
7 | {"code": "// Write a function that returns the sum of the numbers from 1 to n.\n// For example, if n is 5, then the function should return 1 + 2 + 3 + 4 + 5.\n// If n is 0, then the function should return 0.\n// If n is less than 0, then the function should return -1.\n/**\n * @param {number} n\n * @return {number}\n */\nfunction sum ($n) {", "langauge": "PHP"}
8 | {"code": "// Write a function that returns the sum of the numbers from 1 to n.\n// For example, if n is 5, then the function should return 1 + 2 + 3 + 4 + 5.\n\nfunction sum(n) {", "langauge": "JavaScript"}
9 | {"code": "// Write a function that returns the sum of the numbers from 1 to n,\n// but using a for loop instead of a while loop.\n\nfunction sumForLoop(n) {", "langauge": "TypeScript"}
10 | {"code": "// Write a function that returns the sum of the numbers from 1 to n,\n// but using a for loop instead of a while loop.\n\nfunc sumN(n int) int {", "langauge": "Go"}
11 | {"code": "// Write a function that returns the sum of the numbers from 1 to n,\n// but using a for loop instead of a while loop.\n\nfn sum_numbers(n: usize) -> usize {", "langauge": "Rust"}
12 | {"code": "-- Search all the records from the table CodeGeeX\n-- Delete iterms with odd indices", "langauge": "SQL"}
13 | {"code": "// Write a function that returns the sum of the numbers from 1 to n.\n// For example, if n is 5, then the function should return 1 + 2 + 3 + 4 + 5.\n\nfun sum(n: Int): Int {", "langauge": "Kotlin"}
14 | {"code": "! Write a function that returns the sum of the numbers from 1 to n.\n! For example, if n is 5, then the function should return 1 + 2 + 3 + 4 + 5.\n\n! Use the following header:\n! module sum_numbers\n! end\nmodule sum_numbers", "langauge": "Fortran"}
15 | {"code": "# Write a function that returns the sum of the numbers from 1 to n.\n# For example, if n is 5, then the function should return 1 + 2 + 3 + 4 + 5.\nsum_numbers <- function(n) {", "langauge": "R"}
16 |
--------------------------------------------------------------------------------
/generations/humaneval_python_generations.jsonl.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/generations/humaneval_python_generations.jsonl.gz
--------------------------------------------------------------------------------
/generations/humaneval_rust_generations.jsonl.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/generations/humaneval_rust_generations.jsonl.gz
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | fire>=0.4.0
2 | ipython>=8.4.0
3 | numpy>=1.22.0
4 | pandas>=1.3.5
5 | pyzmq>=23.2.1
6 | regex>=2022.3.15
7 | setuptools>=58.0.4
8 | transformers>=4.22.0
9 | torch>=1.10.0
10 | tqdm>=4.63.0
11 | cpm_kernels
12 | deepspeed>0.6.1
--------------------------------------------------------------------------------
/resources/api/api_step_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/api/api_step_1.png
--------------------------------------------------------------------------------
/resources/api/api_step_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/api/api_step_2.png
--------------------------------------------------------------------------------
/resources/api/api_step_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/api/api_step_3.png
--------------------------------------------------------------------------------
/resources/api/api_step_4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/api/api_step_4.png
--------------------------------------------------------------------------------
/resources/api/api_step_5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/api/api_step_5.png
--------------------------------------------------------------------------------
/resources/en/codegeex_training.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/en/codegeex_training.png
--------------------------------------------------------------------------------
/resources/en/hx_boxplot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/en/hx_boxplot.png
--------------------------------------------------------------------------------
/resources/en/hx_examples.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/en/hx_examples.png
--------------------------------------------------------------------------------
/resources/en/hx_generattion_radar_horizon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/en/hx_generattion_radar_horizon.png
--------------------------------------------------------------------------------
/resources/en/hx_pass_rate_vs_language.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/en/hx_pass_rate_vs_language.png
--------------------------------------------------------------------------------
/resources/en/hx_tasks.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/en/hx_tasks.png
--------------------------------------------------------------------------------
/resources/en/hx_translation.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/en/hx_translation.png
--------------------------------------------------------------------------------
/resources/logo/codegeex_logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/logo/codegeex_logo.png
--------------------------------------------------------------------------------
/resources/zh/hx_boxplot_zh.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/zh/hx_boxplot_zh.png
--------------------------------------------------------------------------------
/resources/zh/hx_generattion_radar_horizon_zh.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/zh/hx_generattion_radar_horizon_zh.png
--------------------------------------------------------------------------------
/resources/zh/hx_pass_rate_vs_language_zh.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/zh/hx_pass_rate_vs_language_zh.png
--------------------------------------------------------------------------------
/resources/zh/hx_tasks_zh.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/zh/hx_tasks_zh.png
--------------------------------------------------------------------------------
/resources/zh/hx_translation_zh.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/zh/hx_translation_zh.png
--------------------------------------------------------------------------------
/resources/zh/join_wechat.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/THUDM/CodeGeeX/2838420b7b4492cf3d16bce5320e26e65960c9e2/resources/zh/join_wechat.png
--------------------------------------------------------------------------------
/resources/zh/wechat.md:
--------------------------------------------------------------------------------
1 | "
12 | MASTER_IP=$(cat $HOSTFILE | head -n 1)
13 | cat $HOSTFILE | awk '{print $1 " slots=8"}' > $SCRIPT_DIR/hostfile
14 | echo "MASTER_IP=$MASTER_IP"
15 |
16 | # ====== Parameters ======
17 | DATA_PATH=""
18 | CKPT_PATH=""
19 | DS_CONFIG=ds_config.json
20 | # - 13b
21 | TP=1
22 | PP=1
23 | NLAYERS=39
24 | HIDDEN=5120
25 | NATTN_HEAD=40
26 | EMBED_VOCAB=52224
27 | GLOBAL_BATCH=560
28 | MICRO_BATCH=10
29 | NTRAIN_ITERS=100000
30 | EVAL_INT=10
31 | SAVE_INT=10
32 | TRIAL_TAG="13b-test"
33 | # - trial
34 | TRIAL_NAME="pretrain-codegeex"
35 | # - zero stage
36 | ZERO_STAGE=2
37 | # - logging & output
38 | NOW=$(date +"%Y%m%d_%H%M%S")
39 | OUTPUT_DIR="-$TRIAL_NAME-$TRIAL_TAG"
40 | TB_DIR=$OUTPUT_DIR/tb$NOW
41 | mkdir -p $OUTPUT_DIR
42 | mkdir -p $TB_DIR
43 |
44 | # Deepspeed config
45 | cat < $DS_CONFIG
46 | {
47 | "train_batch_size" : $GLOBAL_BATCH,
48 | "train_micro_batch_size_per_gpu": $MICRO_BATCH,
49 | "steps_per_print": 5,
50 | "zero_optimization": {
51 | "stage": $ZERO_STAGE,
52 | "reduce_bucket_size": 50000000,
53 | "allgather_bucket_size": 50000000,
54 | "overlap_comm": true,
55 | "contiguous_gradients": false
56 | },
57 | "fp16": {
58 | "enabled": true,
59 | "loss_scale": 0,
60 | "loss_scale_window": 500,
61 | "hysteresis": 2,
62 | "min_loss_scale": 1,
63 | "initial_scale_power": 12
64 | },
65 | "wall_clock_breakdown" : true
66 | }
67 | EOT
68 |
69 | ds_args=""
70 | ds_args=" --deepspeed ${ds_args}"
71 | ds_args=" --no-pipeline-parallel ${ds_args}"
72 | ds_args=" --deepspeed_config=$DS_CONFIG ${ds_args}"
73 | ds_args=" --zero-stage=$ZERO_STAGE ${ds_args}"
74 | ds_args=" --deepspeed-activation-checkpointing ${ds_args}"
75 |
76 | echo "Launching deepspeed"
77 | deepspeed \
78 | --hostfile hostfile \
79 | --master_addr $MASTER_IP \
80 | $MAIN_DIR/codegeex/megatron/tools/pretrain_codegeex.py \
81 | --tensor-model-parallel-size $TP \
82 | --pipeline-model-parallel-size $PP \
83 | --no-pipeline-parallel \
84 | --num-layers $NLAYERS \
85 | --hidden-size $HIDDEN \
86 | --make-vocab-size-divisible-by $EMBED_VOCAB \
87 | --num-attention-heads $NATTN_HEAD \
88 | --seq-length 512 \
89 | --loss-scale 12 \
90 | --max-position-embeddings 2048 \
91 | --micro-batch-size $MICRO_BATCH \
92 | --global-batch-size $GLOBAL_BATCH \
93 | --train-iters $NTRAIN_ITERS \
94 | --lr 1e-6 \
95 | --min-lr 1e-7 \
96 | --lr-decay-iters 100000 \
97 | --lr-decay-style cosine \
98 | --lr-warmup-iters 1000 \
99 | --log-interval 1 \
100 | --eval-iters 10 \
101 | --eval-interval $EVAL_INT \
102 | --data-path $DATA_PATH \
103 | --vocab-file $MAIN_DIR/codegeex/tokenizer/vocab.json \
104 | --merge-file $MAIN_DIR/codegeex/tokenizer/merges.txt \
105 | --save-interval $SAVE_INT \
106 | --save $OUTPUT_DIR \
107 | --load $OUTPUT_DIR \
108 | --load-state $CKPT_PATH \
109 | --split 98,2,0 \
110 | --clip-grad 1.0 \
111 | --weight-decay 0.1 \
112 | --adam-beta1 0.9 \
113 | --adam-beta2 0.95 \
114 | --fp16 \
115 | --ln-fp16 \
116 | --attention-softmax-in-fp32 \
117 | --checkpoint-activations \
118 | --override-lr-scheduler \
119 | --tensorboard-dir $TB_DIR \
120 | $ds_args |& tee ${OUTPUT_DIR}/$NOW.log
--------------------------------------------------------------------------------
/scripts/gather_output.sh:
--------------------------------------------------------------------------------
1 | # This script is used to gather the distributed outputs of different ranks.
2 |
3 | OUTPUT_DIR=$1
4 | OUTPUT_PREFIX=$2
5 | IF_REMOVE_RANK_FILES=$3
6 |
7 | echo "$OUTPUT_DIR"
8 | echo "$OUTPUT_PREFIX"
9 |
10 | if [ -z "$IF_REMOVE_RANK_FILES" ]
11 | then
12 | IF_REMOVE_RANK_FILES=0
13 | fi
14 |
15 | SCRIPT_PATH=$(realpath "$0")
16 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
17 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
18 |
19 |
20 | CMD="python $MAIN_DIR/codegeex/benchmark/gather_output.py \
21 | --output_dir $OUTPUT_DIR \
22 | --output_prefix $OUTPUT_PREFIX \
23 | --if_remove_rank_files $IF_REMOVE_RANK_FILES"
24 |
25 | echo "$CMD"
26 | eval "$CMD"
--------------------------------------------------------------------------------
/scripts/generate_humaneval_x.sh:
--------------------------------------------------------------------------------
1 | # This script is used to generate solutions of HumanEval-X.
2 |
3 | LANGUAGE=$1 # Target programming language, currently support one of ["python", "java", "cpp", "js", "go"]
4 | OUTPUT_PATH=$2 # Output path of the generated programs.
5 | HOSTLIST=$3 # Provide hostfile if generating distributedly
6 |
7 | SCRIPT_PATH=$(realpath "$0")
8 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
9 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
10 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
11 |
12 | # export CUDA settings
13 | export CUDA_HOME=/usr/local/cuda-11.1/
14 |
15 | # import model configuration
16 | source "$MAIN_DIR/configs/codegeex_13b.sh"
17 |
18 | # nccl options
19 | OPTIONS_NCCL="export NCCL_DEBUG=warn; export NCCL_IB_DISABLE=0; export NCCL_IB_GID_INDEX=3"
20 | OPTIONS_PATH="export PATH=$PATH; export LD_LIBRARY_PATH=$LD_LIBRARY_PATH"
21 | CWD=$(pwd)
22 |
23 | # set master ip for zmq server
24 | if [ -z "$HOSTLIST" ]; then
25 | ZMQ_ADDR=$(hostname -i)
26 | echo "$ZMQ_ADDR" > "./hostfile"
27 | HOSTLIST="./hostfile"
28 | else
29 | ZMQ_ADDR=$(cat $HOSTLIST | head -n 1)
30 | fi
31 | echo "master_ip: $ZMQ_ADDR"
32 |
33 | NUM_SAMPLES=1
34 | MICRO_BSZ=1
35 | WORLD_SIZE=1
36 | TEMP=0.8
37 | TOPP=0.95
38 | SEED=42
39 | DATASET=humaneval
40 | TODAY=$(date +%y%m%d)
41 | CHANNEL_PORT=$(expr $RANDOM + 5000)
42 | MASTER_PORT=$(expr $RANDOM + 8000)
43 |
44 | # save log file
45 | LOG_DIR=$MAIN_DIR/log
46 | mkdir -p "$LOG_DIR"
47 | LOG_PATH="$LOG_DIR/$TODAY-generation.log"
48 |
49 | if [ -z "$LANGUAGE" ]; then
50 | LANGUAGE=python
51 | fi
52 |
53 | if [ -z "$INPUT_PATH" ]; then
54 | INPUT_PATH=$MAIN_DIR/codegeex/benchmark/humaneval-x/$LANGUAGE/data/humaneval_$LANGUAGE.jsonl.gz
55 | fi
56 |
57 | if [ -z "$OUTPUT_PATH" ]; then
58 | OUTPUT_PATH=$MAIN_DIR/codegeex/benchmark/output/humaneval-x/codegeex/
59 | mkdir -p "$OUTPUT_PATH"
60 | fi
61 |
62 | JOB_ID=codegeex-ns$NUM_SAMPLES-t$TEMP-topp$TOPP-seed$SEED-$LANGUAGE
63 |
64 | RUN_CMD="python \
65 | $MAIN_DIR/codegeex/benchmark/humaneval-x/generate_humaneval_x.py \
66 | --hostfile $HOSTLIST \
67 | --channel-ip $ZMQ_ADDR \
68 | --channel-port $CHANNEL_PORT \
69 | --master-port $MASTER_PORT \
70 | --tokenizer-path $TOKENIZER_PATH \
71 | --load-deepspeed \
72 | --temperature $TEMP \
73 | --top-p $TOPP \
74 | --out-seq-length 1024 \
75 | --micro-batch-size $MICRO_BSZ \
76 | --samples-per-problem $NUM_SAMPLES \
77 | --language-type $LANGUAGE \
78 | --dataset $DATASET \
79 | --input-path $INPUT_PATH \
80 | --output-prefix $OUTPUT_PATH/$JOB_ID \
81 | --gen-node-world-size $WORLD_SIZE \
82 | --seed $SEED \
83 | $MODEL_ARGS"
84 |
85 | RUN_CMD="$OPTIONS_NCCL; $OPTIONS_PATH; $RUN_CMD"
86 | RUN_CMD="cd $CWD; $RUN_CMD"
87 |
88 | if (( WORLD_SIZE != 1 )); then
89 | RUN_CMD="pdsh -R ssh -w ^$HOSTLIST \"$RUN_CMD\""
90 | fi
91 |
92 | echo "$RUN_CMD"
93 | echo "Writing log to $LOG_PATH"
94 | eval "$RUN_CMD" > "$LOG_PATH"
95 | bash $MAIN_DIR/scripts/gather_output.sh $OUTPUT_PATH $JOB_ID 1
96 |
--------------------------------------------------------------------------------
/scripts/pretrain_codegeex.sh:
--------------------------------------------------------------------------------
1 | SCRIPT_PATH=$(realpath "$0")
2 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
3 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
4 |
5 | # ====== Environment ======
6 | # - NCCL & IB
7 | export NCCL_DEBUG=info
8 | export NCCL_IB_DISABLE=0
9 | export NCCL_IB_GID_INDEX=3
10 |
11 | HOSTFILE=""
12 | MASTER_IP=$(cat $HOSTFILE | head -n 1)
13 | cat $HOSTFILE | awk '{print $1 " slots=8"}' > $SCRIPT_DIR/hostfile
14 | echo "MASTER_IP=$MASTER_IP"
15 |
16 | # ====== Parameters ======
17 | DATA_PATH=""
18 | CKPT_PATH=""
19 | DS_CONFIG=ds_config.json
20 | # - 13b
21 | TP=1
22 | PP=1
23 | NLAYERS=39
24 | HIDDEN=5120
25 | NATTN_HEAD=40
26 | EMBED_VOCAB=52224
27 | GLOBAL_BATCH=560
28 | MICRO_BATCH=10
29 | NTRAIN_ITERS=100000
30 | EVAL_INT=10
31 | SAVE_INT=10
32 | TRIAL_TAG="13b-test"
33 | # - trial
34 | TRIAL_NAME="pretrain-codegeex"
35 | # - zero stage
36 | ZERO_STAGE=2
37 | # - logging & output
38 | NOW=$(date +"%Y%m%d_%H%M%S")
39 | OUTPUT_DIR="-$TRIAL_NAME-$TRIAL_TAG"
40 | TB_DIR=$OUTPUT_DIR/tb$NOW
41 | mkdir -p $OUTPUT_DIR
42 | mkdir -p $TB_DIR
43 |
44 | # Deepspeed config
45 | cat < $DS_CONFIG
46 | {
47 | "train_batch_size" : $GLOBAL_BATCH,
48 | "train_micro_batch_size_per_gpu": $MICRO_BATCH,
49 | "steps_per_print": 5,
50 | "zero_optimization": {
51 | "stage": $ZERO_STAGE,
52 | "reduce_bucket_size": 50000000,
53 | "allgather_bucket_size": 50000000,
54 | "overlap_comm": true,
55 | "contiguous_gradients": false
56 | },
57 | "fp16": {
58 | "enabled": true,
59 | "loss_scale": 0,
60 | "loss_scale_window": 500,
61 | "hysteresis": 2,
62 | "min_loss_scale": 1,
63 | "initial_scale_power": 12
64 | },
65 | "wall_clock_breakdown" : true
66 | }
67 | EOT
68 |
69 | ds_args=""
70 | ds_args=" --deepspeed ${ds_args}"
71 | ds_args=" --no-pipeline-parallel ${ds_args}"
72 | ds_args=" --deepspeed_config=$DS_CONFIG ${ds_args}"
73 | ds_args=" --zero-stage=$ZERO_STAGE ${ds_args}"
74 | ds_args=" --deepspeed-activation-checkpointing ${ds_args}"
75 |
76 | echo "Launching deepspeed"
77 | deepspeed \
78 | --hostfile hostfile \
79 | --master_addr $MASTER_IP \
80 | $MAIN_DIR/codegeex/megatron/tools/pretrain_codegeex.py \
81 | --tensor-model-parallel-size $TP \
82 | --pipeline-model-parallel-size $PP \
83 | --no-pipeline-parallel \
84 | --num-layers $NLAYERS \
85 | --hidden-size $HIDDEN \
86 | --make-vocab-size-divisible-by $EMBED_VOCAB \
87 | --num-attention-heads $NATTN_HEAD \
88 | --seq-length 512 \
89 | --loss-scale 12 \
90 | --max-position-embeddings 2048 \
91 | --micro-batch-size $MICRO_BATCH \
92 | --global-batch-size $GLOBAL_BATCH \
93 | --train-iters $NTRAIN_ITERS \
94 | --lr 2e-4 \
95 | --min-lr 1e-7 \
96 | --lr-decay-iters 100000 \
97 | --lr-decay-style cosine \
98 | --lr-warmup-iters 1500 \
99 | --log-interval 1 \
100 | --eval-iters 10 \
101 | --eval-interval $EVAL_INT \
102 | --data-path $DATA_PATH \
103 | --vocab-file $MAIN_DIR/codegeex/tokenizer/vocab.json \
104 | --merge-file $MAIN_DIR/codegeex/tokenizer/merges.txt \
105 | --save-interval $SAVE_INT \
106 | --save $OUTPUT_DIR \
107 | --load $OUTPUT_DIR \
108 | --load-state $CKPT_PATH \
109 | --split 98,2,0 \
110 | --clip-grad 1.0 \
111 | --weight-decay 0.1 \
112 | --adam-beta1 0.9 \
113 | --adam-beta2 0.95 \
114 | --fp16 \
115 | --ln-fp16 \
116 | --attention-softmax-in-fp32 \
117 | --checkpoint-activations \
118 | --override-lr-scheduler \
119 | --tensorboard-dir $TB_DIR \
120 | $ds_args |& tee ${OUTPUT_DIR}/$NOW.log
121 |
122 |
--------------------------------------------------------------------------------
/scripts/process_pretrain_dataset.sh:
--------------------------------------------------------------------------------
1 | # Process dataset for CodeGeeX pretraining
2 |
3 | DATASET_PATH=$1
4 | OUTPUT_PATH=$2
5 | LANGUAGE=$3
6 |
7 | SCRIPT_PATH=$(realpath "$0")
8 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
9 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
10 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
11 |
12 | if [ -z "$LANGUAGE" ]; then
13 | LANGUAGE=python
14 | fi
15 |
16 | CMD="python $MAIN_DIR/codegeex/data/process_pretrain_dataset.py \
17 | --dataset_path $DATASET_PATH \
18 | --tokenizer_path $TOKENIZER_PATH \
19 | --output_prefix $OUTPUT_PATH \
20 | --language $LANGUAGE \
21 | --mode pretrain \
22 | --seq_len 2048"
23 |
24 | echo "$CMD"
25 | eval "$CMD"
--------------------------------------------------------------------------------
/scripts/test_inference.sh:
--------------------------------------------------------------------------------
1 | # This script is used to test the inference of CodeGeeX.
2 |
3 | GPU=$1
4 | PROMPT_FILE=$2
5 |
6 | SCRIPT_PATH=$(realpath "$0")
7 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
8 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
9 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
10 |
11 | # import model configuration
12 | source "$MAIN_DIR/configs/codegeex_13b.sh"
13 |
14 | # export CUDA settings
15 | if [ -z "$GPU" ]; then
16 | GPU=0
17 | fi
18 |
19 | export CUDA_HOME=/usr/local/cuda-11.1/
20 | export CUDA_VISIBLE_DEVICES=$GPU
21 |
22 | if [ -z "$PROMPT_FILE" ]; then
23 | PROMPT_FILE=$MAIN_DIR/tests/test_prompt.txt
24 | fi
25 |
26 | # remove --greedy if using sampling
27 | CMD="python $MAIN_DIR/tests/test_inference.py \
28 | --prompt-file $PROMPT_FILE \
29 | --tokenizer-path $TOKENIZER_PATH \
30 | --micro-batch-size 1 \
31 | --out-seq-length 1024 \
32 | --temperature 0.8 \
33 | --top-p 0.95 \
34 | --top-k 0 \
35 | --greedy \
36 | $MODEL_ARGS"
37 |
38 | echo "$CMD"
39 | eval "$CMD"
40 |
--------------------------------------------------------------------------------
/scripts/test_inference_oneflow.sh:
--------------------------------------------------------------------------------
1 | # This script is used to test the inference of CodeGeeX.
2 |
3 | GPU=$1
4 | PROMPT_FILE=$2
5 |
6 | SCRIPT_PATH=$(realpath "$0")
7 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
8 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
9 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
10 |
11 | # import model configuration
12 | source "$MAIN_DIR/configs/codegeex_13b.sh"
13 |
14 | # export CUDA settings
15 | if [ -z "$GPU" ]; then
16 | GPU=0
17 | fi
18 |
19 | export CUDA_HOME=/usr/local/cuda-11.1/
20 | export CUDA_VISIBLE_DEVICES=$GPU
21 |
22 | if [ -z "$PROMPT_FILE" ]; then
23 | PROMPT_FILE=$MAIN_DIR/tests/test_prompt.txt
24 | fi
25 |
26 | # remove --greedy if using sampling
27 | CMD="python $MAIN_DIR/tests/test_inference_oneflow.py \
28 | --prompt-file $PROMPT_FILE \
29 | --tokenizer-path $TOKENIZER_PATH \
30 | --micro-batch-size 1 \
31 | --out-seq-length 1024 \
32 | --temperature 0.8 \
33 | --top-p 0.95 \
34 | --top-k 0 \
35 | --greedy \
36 | $MODEL_ARGS"
37 |
38 | echo "$CMD"
39 | eval "$CMD"
40 |
--------------------------------------------------------------------------------
/scripts/test_inference_oneflow_quantized.sh:
--------------------------------------------------------------------------------
1 | # This script is used to test the inference of CodeGeeX.
2 |
3 | GPU=$1
4 | PROMPT_FILE=$2
5 |
6 | SCRIPT_PATH=$(realpath "$0")
7 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
8 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
9 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
10 |
11 | # import model configuration
12 | source "$MAIN_DIR/configs/codegeex_13b.sh"
13 |
14 | # export CUDA settings
15 | if [ -z "$GPU" ]; then
16 | GPU=1
17 | fi
18 |
19 | export CUDA_HOME=/usr/local/cuda-11.1/
20 | export CUDA_VISIBLE_DEVICES=$GPU
21 |
22 | if [ -z "$PROMPT_FILE" ]; then
23 | PROMPT_FILE=$MAIN_DIR/tests/test_prompt.txt
24 | fi
25 |
26 | # remove --greedy if using sampling
27 | CMD="python $MAIN_DIR/tests/test_inference_oneflow.py \
28 | --prompt-file $PROMPT_FILE \
29 | --tokenizer-path $TOKENIZER_PATH \
30 | --micro-batch-size 1 \
31 | --out-seq-length 1024 \
32 | --temperature 0.2 \
33 | --top-p 0.95 \
34 | --top-k 0 \
35 | --quantize \
36 | $MODEL_ARGS"
37 |
38 | echo "$CMD"
39 | eval "$CMD"
40 |
--------------------------------------------------------------------------------
/scripts/test_inference_paddle.sh:
--------------------------------------------------------------------------------
1 | # This script is used to test the inference of CodeGeeX.
2 |
3 | GPU=$1
4 | PROMPT_FILE=$2
5 |
6 | SCRIPT_PATH=$(realpath "$0")
7 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
8 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
9 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
10 |
11 | # import model configuration
12 | source "$MAIN_DIR/configs/codegeex_13b_paddle.sh"
13 |
14 | # export CUDA settings
15 | if [ -z "$GPU" ]; then
16 | GPU=0
17 | fi
18 |
19 | export CUDA_HOME=/usr/local/cuda-11.1/
20 | export CUDA_VISIBLE_DEVICES=$GPU
21 |
22 | if [ -z "$PROMPT_FILE" ]; then
23 | PROMPT_FILE=$MAIN_DIR/tests/test_prompt.txt
24 | fi
25 |
26 | # remove --greedy if using sampling
27 | CMD="python $MAIN_DIR/tests/test_inference_paddle.py \
28 | --prompt-file $PROMPT_FILE \
29 | --tokenizer-path $TOKENIZER_PATH \
30 | --micro-batch-size 1 \
31 | --out-seq-length 1024 \
32 | --temperature 0.8 \
33 | --top-p 0.95 \
34 | --top-k 0 \
35 | --greedy \
36 | $MODEL_ARGS"
37 |
38 | echo "$CMD"
39 | eval "$CMD"
40 |
--------------------------------------------------------------------------------
/scripts/test_inference_parallel.sh:
--------------------------------------------------------------------------------
1 | # This script is used to test the inference of CodeGeeX.
2 |
3 | MP_SIZE=$1
4 | PROMPT_FILE=$2
5 |
6 | SCRIPT_PATH=$(realpath "$0")
7 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
8 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
9 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
10 |
11 | if [ -z "$MP_SIZE" ]; then
12 | MP_SIZE=1
13 | fi
14 |
15 | if [ "$MP_SIZE" -eq 1 ]; then
16 | source "$MAIN_DIR/configs/codegeex_13b.sh"
17 | echo "Load config from $MAIN_DIR/configs/codegeex_13b.sh"
18 | else
19 | source "$MAIN_DIR/configs/codegeex_13b_parallel.sh"
20 | echo "Load config from $MAIN_DIR/configs/codegeex_13b_parallel.sh"
21 | fi
22 |
23 | # export CUDA settings
24 | export CUDA_HOME=/usr/local/cuda-11.1/
25 | # export CUDA_VISIBLE_DEVICES=0,1
26 |
27 | if [ -z "$PROMPT_FILE" ]; then
28 | PROMPT_FILE=$MAIN_DIR/tests/test_prompt.txt
29 | fi
30 |
31 | # remove --greedy if using sampling
32 | CMD="torchrun --nproc_per_node $MP_SIZE $MAIN_DIR/tests/test_inference_megatron.py \
33 | --tensor-model-parallel-size $MP_SIZE \
34 | --prompt-file $PROMPT_FILE \
35 | --tokenizer-path $TOKENIZER_PATH \
36 | --micro-batch-size 1 \
37 | --out-seq-length 1024 \
38 | --temperature 0.8 \
39 | --top-p 0.95 \
40 | --top-k 0 \
41 | --greedy \
42 | --use-cpu-initialization \
43 | --ln-fp16 \
44 | $MODEL_ARGS"
45 |
46 | echo "$CMD"
47 | eval "$CMD"
48 |
--------------------------------------------------------------------------------
/scripts/test_inference_quantized.sh:
--------------------------------------------------------------------------------
1 | # This script is used to test the inference of CodeGeeX.
2 |
3 | GPU=$1
4 | PROMPT_FILE=$2
5 |
6 | SCRIPT_PATH=$(realpath "$0")
7 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
8 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
9 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
10 |
11 | # import model configuration
12 | source "$MAIN_DIR/configs/codegeex_13b.sh"
13 |
14 | # export CUDA settings
15 | if [ -z "$GPU" ]; then
16 | GPU=0
17 | fi
18 |
19 | export CUDA_HOME=/usr/local/cuda-11.1/
20 | export CUDA_VISIBLE_DEVICES=$GPU
21 |
22 | if [ -z "$PROMPT_FILE" ]; then
23 | PROMPT_FILE=$MAIN_DIR/tests/test_prompt.txt
24 | fi
25 |
26 | # remove --greedy if using sampling
27 | CMD="python $MAIN_DIR/tests/test_inference.py \
28 | --prompt-file $PROMPT_FILE \
29 | --tokenizer-path $TOKENIZER_PATH \
30 | --micro-batch-size 1 \
31 | --out-seq-length 1024 \
32 | --temperature 0.2 \
33 | --top-p 0.95 \
34 | --top-k 0 \
35 | --quantize \
36 | $MODEL_ARGS"
37 |
38 | echo "$CMD"
39 | eval "$CMD"
40 |
--------------------------------------------------------------------------------
/scripts/translate_humaneval_x.sh:
--------------------------------------------------------------------------------
1 | # This script is used to translate solutions of HumanEval-X.
2 |
3 | LANG_SRC_TYPE=$1 # Source programming language, currently support one of ["python", "java", "cpp", "js", "go"]
4 | LANG_TGT_TYPE=$2 # Target programming language, currently support one of ["python", "java", "cpp", "js", "go"]
5 | OUTPUT_PATH=$3 # Output path of the generated programs.
6 | HOSTLIST=$4 # Provide hostfile if generating distributedly
7 |
8 | SCRIPT_PATH=$(realpath "$0")
9 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
10 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
11 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
12 |
13 | # export CUDA settings
14 | export CUDA_HOME=/usr/local/cuda-11.1/
15 |
16 | # import model configuration
17 | source "$MAIN_DIR/configs/codegeex_13b.sh"
18 |
19 | # nccl options
20 | OPTIONS_NCCL="export NCCL_DEBUG=warn; export NCCL_IB_DISABLE=0; export NCCL_IB_GID_INDEX=3"
21 | OPTIONS_PATH="export PATH=$PATH; export LD_LIBRARY_PATH=$LD_LIBRARY_PATH"
22 | CWD=$(pwd)
23 |
24 | # set master ip for zmq server
25 | if [ -z "$HOSTLIST" ]; then
26 | ZMQ_ADDR=$(hostname -i)
27 | echo "$ZMQ_ADDR" > "./hostfile"
28 | HOSTLIST="./hostfile"
29 | else
30 | ZMQ_ADDR=$(cat $HOSTLIST | head -n 1)
31 | fi
32 | echo "master_ip: $ZMQ_ADDR"
33 |
34 | NUM_SAMPLES=1
35 | MICRO_BSZ=1
36 | WORLD_SIZE=1
37 | TEMP=0.8
38 | TOPP=0.95
39 | SEED=42
40 | DATASET=humaneval
41 | TODAY=$(date +%y%m%d)
42 | CHANNEL_PORT=$(expr $RANDOM + 5000)
43 | MASTER_PORT=$(expr $RANDOM + 8000)
44 |
45 | # save log file
46 | LOG_DIR=$MAIN_DIR/log
47 | mkdir -p "$LOG_DIR"
48 | LOG_PATH="$LOG_DIR/$TODAY-translation.log"
49 |
50 | if [ -z "$LANG_SRC_TYPE" ]
51 | then
52 | LANG_SRC_TYPE=python
53 | fi
54 |
55 | if [ -z "$LANG_TGT_TYPE" ]
56 | then
57 | LANG_TGT_TYPE=java
58 | fi
59 |
60 | if [ -z "$INPUT_SRC_PATH" ]
61 | then
62 | INPUT_SRC_PATH=$MAIN_DIR/codegeex/benchmark/humaneval-x/$LANG_SRC_TYPE/data/humaneval_$LANG_SRC_TYPE.jsonl.gz
63 | fi
64 |
65 | if [ -z "$INPUT_TGT_PATH" ]
66 | then
67 | INPUT_TGT_PATH=$MAIN_DIR/codegeex/benchmark/humaneval-x/$LANG_TGT_TYPE/data/humaneval_$LANG_TGT_TYPE.jsonl.gz
68 | fi
69 |
70 | if [ -z "$OUTPUT_PATH" ]; then
71 | OUTPUT_PATH=$MAIN_DIR/codegeex/benchmark/output/humaneval-x/codegeex/
72 | mkdir -p "$OUTPUT_PATH"
73 | fi
74 |
75 | JOB_ID=codegeex-ns$NUM_SAMPLES-t$TEMP-topp$TOPP-seed$SEED-$LANGUAGE
76 |
77 | RUN_CMD="python \
78 | $MAIN_DIR/codegeex/benchmark/humaneval-x/translate_humaneval_x.py \
79 | --hostfile $HOSTLIST \
80 | --channel-ip $ZMQ_ADDR \
81 | --channel-port $CHANNEL_PORT \
82 | --master-port $MASTER_PORT \
83 | --tokenizer-path $TOKENIZER_PATH \
84 | --load-deepspeed \
85 | --temperature $TEMP \
86 | --top-p $TOPP \
87 | --out-seq-length 1024 \
88 | --micro-batch-size $MICRO_BSZ \
89 | --samples-per-problem $NUM_SAMPLES \
90 | --language-src-type $LANG_SRC_TYPE \
91 | --language-tgt-type $LANG_TGT_TYPE \
92 | --src-path $INPUT_SRC_PATH \
93 | --tgt-path $INPUT_TGT_PATH \
94 | --dataset $DATASET \
95 | --output-prefix $OUTPUT_PATH/$JOB_ID \
96 | --gen-node-world-size $WORLD_SIZE \
97 | --seed $SEED \
98 | $MODEL_ARGS"
99 |
100 | RUN_CMD="$OPTIONS_NCCL; $OPTIONS_PATH; $RUN_CMD"
101 | RUN_CMD="cd $CWD; $RUN_CMD"
102 |
103 | if (( WORLD_SIZE != 1 )); then
104 | RUN_CMD="pdsh -R ssh -w ^$HOSTLIST \"$RUN_CMD\""
105 | fi
106 |
107 | echo "$RUN_CMD"
108 | echo "Writing log to $LOG_PATH"
109 | eval "$RUN_CMD" > "$LOG_PATH"
110 | bash $MAIN_DIR/scripts/gather_output.sh $OUTPUT_PATH $JOB_ID 1
111 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | setup(
4 | name="codegeex",
5 | py_modules=["codegeex"],
6 | version="1.0",
7 | description="CodeGeeX: A Open Multilingual Code Generation Model.",
8 | author="Qinkai Zheng",
9 | packages=find_packages(),
10 | install_requires=[
11 | "fire>=0.4.0",
12 | "ipython>=8.4.0",
13 | "numpy>=1.22.0",
14 | "pandas>=1.3.5",
15 | "pyzmq>=23.2.1",
16 | "regex>=2022.3.15",
17 | "setuptools>=58.0.4",
18 | "transformers>=4.22.0",
19 | "tokenizers>=0.11.0",
20 | "torch>=1.10.0",
21 | "tqdm>=4.63.0",
22 | "cpm_kernels",
23 | "deepspeed>0.6.1",
24 | ],
25 | entry_points={}
26 | )
27 |
--------------------------------------------------------------------------------
/tests/test_inference.py:
--------------------------------------------------------------------------------
1 | import time
2 | import torch
3 | import argparse
4 | import numpy as np
5 |
6 | import codegeex
7 | from codegeex.torch import CodeGeeXModel
8 | from codegeex.tokenizer import CodeGeeXTokenizer
9 | from codegeex.quantization import quantize
10 |
11 |
12 | def model_provider(args):
13 | """Build the model."""
14 |
15 | model = CodeGeeXModel(
16 | args.hidden_size,
17 | args.num_layers,
18 | args.num_attention_heads,
19 | args.padded_vocab_size,
20 | args.max_position_embeddings
21 | )
22 |
23 | return model
24 |
25 |
26 | def add_code_generation_args(parser):
27 | group = parser.add_argument_group(title="code generation")
28 | group.add_argument(
29 | "--num-layers",
30 | type=int,
31 | default=39,
32 | )
33 | group.add_argument(
34 | "--hidden-size",
35 | type=int,
36 | default=5120,
37 | )
38 | group.add_argument(
39 | "--num-attention-heads",
40 | type=int,
41 | default=40,
42 | )
43 | group.add_argument(
44 | "--padded-vocab-size",
45 | type=int,
46 | default=52224,
47 | )
48 | group.add_argument(
49 | "--max-position-embeddings",
50 | type=int,
51 | default=2048,
52 | )
53 | group.add_argument(
54 | "--temperature",
55 | type=float,
56 | default=1.0,
57 | help="Sampling temperature.",
58 | )
59 | group.add_argument(
60 | "--greedy",
61 | action="store_true",
62 | default=False,
63 | help="Use greedy sampling.",
64 | )
65 | group.add_argument(
66 | "--top-p",
67 | type=float,
68 | default=0.0,
69 | help="Top p sampling.",
70 | )
71 | group.add_argument(
72 | "--top-k",
73 | type=int,
74 | default=0,
75 | help="Top k sampling.",
76 | )
77 | group.add_argument(
78 | "--out-seq-length",
79 | type=int,
80 | default=2048,
81 | help="Size of the output generated text.",
82 | )
83 | group.add_argument(
84 | "--prompt-file",
85 | type=str,
86 | default="./test_prompt.txt",
87 | )
88 | group.add_argument(
89 | "--tokenizer-path",
90 | type=str,
91 | default="./tokenizer",
92 | )
93 | group.add_argument(
94 | "--load",
95 | type=str,
96 | )
97 | group.add_argument(
98 | "--state-dict-path",
99 | type=str,
100 | )
101 | group.add_argument(
102 | "--micro-batch-size",
103 | type=int,
104 | default=1,
105 | )
106 | group.add_argument(
107 | "--quantize",
108 | action="store_true",
109 | )
110 | group.add_argument(
111 | "--interative",
112 | action="store_true",
113 | )
114 |
115 | return parser
116 |
117 |
118 | def main():
119 | parser = argparse.ArgumentParser()
120 | parser = add_code_generation_args(parser)
121 | args, _ = parser.parse_known_args()
122 |
123 | print("Loading tokenizer ...")
124 | tokenizer = CodeGeeXTokenizer(
125 | tokenizer_path=args.tokenizer_path,
126 | mode="codegeex-13b")
127 |
128 | print("Loading state dict ...")
129 | state_dict = torch.load(args.load, map_location="cpu")
130 | state_dict = state_dict["module"]
131 |
132 | print("Building CodeGeeX model ...")
133 | model = model_provider(args)
134 | model.load_state_dict(state_dict)
135 | model.eval()
136 | model.half()
137 | if args.quantize:
138 | model = quantize(model, weight_bit_width=8, backend="torch")
139 | model.cuda()
140 | torch.cuda.synchronize()
141 |
142 | with open(args.prompt_file, "r") as f:
143 | prompt = f.readlines()
144 | prompt = "".join(prompt)
145 |
146 | out_seq_lengths = [args.out_seq_length]
147 | for out_seq_length in out_seq_lengths:
148 | print(f"Generating with out_seq_len {out_seq_length}...")
149 | while True:
150 | print("\nPlease Input Query (Ctrl-D to save multiple lines, 'stop' to exit) >>> ")
151 | prompts = []
152 | while True:
153 | try:
154 | line = input()
155 | except EOFError:
156 | break
157 | prompts.append(line)
158 | prompt = "\n".join(prompts)
159 | prompt = prompt.strip()
160 | if not prompt:
161 | print('Query should not be empty!')
162 | continue
163 | if prompt == "stop":
164 | return
165 | try:
166 | t0 = time.perf_counter()
167 | generated_code = codegeex.generate(
168 | model,
169 | tokenizer,
170 | prompt,
171 | out_seq_length=out_seq_length,
172 | seq_length=args.max_position_embeddings,
173 | top_k=args.top_k,
174 | top_p=args.top_p,
175 | temperature=args.temperature,
176 | micro_batch_size=args.micro_batch_size,
177 | backend="megatron",
178 | verbose=True,
179 | )
180 | t1 = time.perf_counter()
181 | print("Total generation time:", t1 - t0)
182 | except (ValueError, FileNotFoundError) as e:
183 | print(e)
184 | continue
185 |
186 | print("Generation finished.")
187 |
188 |
189 | if __name__ == "__main__":
190 | main()
--------------------------------------------------------------------------------
/tests/test_prompt.txt:
--------------------------------------------------------------------------------
1 | code translation
2 | Java:
3 | public class Solution {
4 | public static boolean hasCloseElements(int[] nums, int threshold) {
5 | for (int i = 0; i < nums.length - 1; i++) {
6 | for (int j = i + 1; j < nums.length; j++) {
7 | if (Math.abs(nums[i] - nums[j]) < threshold) {
8 | return true;
9 | }
10 | }
11 | }
12 | return false;
13 | }
14 | }
15 | Python:
16 |
--------------------------------------------------------------------------------
/vscode-extension/README_zh.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | 🌐 English
4 |
5 | 
6 | 
7 | 
8 | 
9 | 
10 |
11 | CodeGeeX是一个具有130亿参数的多编程语言代码生成预训练模型,使用超过二十种编程语言训练得到。基于CodeGeeX开发的插件可以实现通过描述生成代码、补全代码、代码翻译等一系列功能。CodeGeeX同样提供可以定制的**提示模式(Prompt Mode)**,构建专属的编程助手。Happy Coding!
12 |
13 | VS Code插件市场搜索"codegeex"即可免费使用(需要VS Code版本不低于1.68.0),更多关于CodeGeeX信息请见我们的[主页](https://models.aminer.cn/codegeex/) and [GitHub仓库](https://github.com/THUDM/CodeGeeX)。
14 |
15 | 如使用过程中遇到问题或有任何改进意见,欢迎发送邮件到[codegeex@aminer.cn](mailto:codegeex@aminer.cn)反馈!
16 |
17 | - [基本用法](#基本用法)
18 | - [隐私声明](#隐私声明)
19 | - [使用指南](#使用指南)
20 | - [隐匿模式](#隐匿模式)
21 | - [交互模式](#交互模式)
22 | - [翻译模式](#翻译模式)
23 | - [提示模式(实验功能)](#提示模式实验功能)
24 |
25 | ## 基本用法
26 | 需要保证VS Code版本 >= 1.68.0。安装插件并全局激活CodeGeeX,有以下四种使用模式:
27 |
28 | - **隐匿模式**: 保持CodeGeeX处于激活状态,当您停止输入时,会从当前光标处开始生成(右下角CodeGeeX图标转圈表示正在生成)。 生成完毕之后会以灰色显示,按``Tab``即可插入生成结果。
29 | - **交互模式**: 按``Ctrl+Enter``激活交互模式,CodeGeeX将生成``X``个候选,并显示在右侧窗口中(``X`` 数量可以在设置的``Candidate Num``中修改)。 点击候选代码上方的``use code``即可插入。
30 | - **翻译模式**: 选择代码,然后按下``Ctrl+Alt+T``激活翻译模式,CodeGeeX会把该代码翻译成匹配您当前编辑器语言的代码。点击翻译结果上方的``use code``插入。您还可以在设置中选择您希望插入的时候如何处理被翻译的代码,您可以选择注释它们或者覆盖它们。
31 | - **提示模式(实验功能)**: 选择需要作为输入的代码,按``Alt/Option+t``触发提示模式,会显示预定义模板列表,选择其中一个模板,即可将代码插入到模板中进行生成。 这个模式高度自定义,可以在设置中 ``Prompt Templates``修改或添加模板内容,为模型加入额外的提示。
32 |
33 | ## 隐私声明
34 |
35 | 我们高度尊重用户代码的隐私,代码仅用来辅助编程。在您第一次使用时,我们会询问您是否同意将生成的代码用于研究用途,帮助CodeGeeX变得更好(该选项默认**关闭**)。
36 | ## 使用指南
37 |
38 | 以下是CodeGeeX几种模式的详细用法:
39 |
40 | ### 隐匿模式
41 |
42 | 在该模式中,CodeGeeX将在您停止输入时,从光标处开始生成(右下角CodeGeeX图标转圈表示正在生成)。生成完毕之后会以灰色显示,按``Tab``即可插入生成结果。 在生成多个候选的情况下,可以使用``Alt/Option+[`` 或 ``]``在几个候选间进行切换。如果你对现有建议不满意,可以使用``Alt/Option+N``去获得新的候选。可以在设置中改变``Candidate Num``(增加个数会导致生成速度相对变慢)。**注意**:生成总是从当前光标位置开始,如果您在生成结束前移动光标位置,可能会导致一些bugs。我们正在努力使生成速度变得更快以提升用户体验。
43 |
44 | 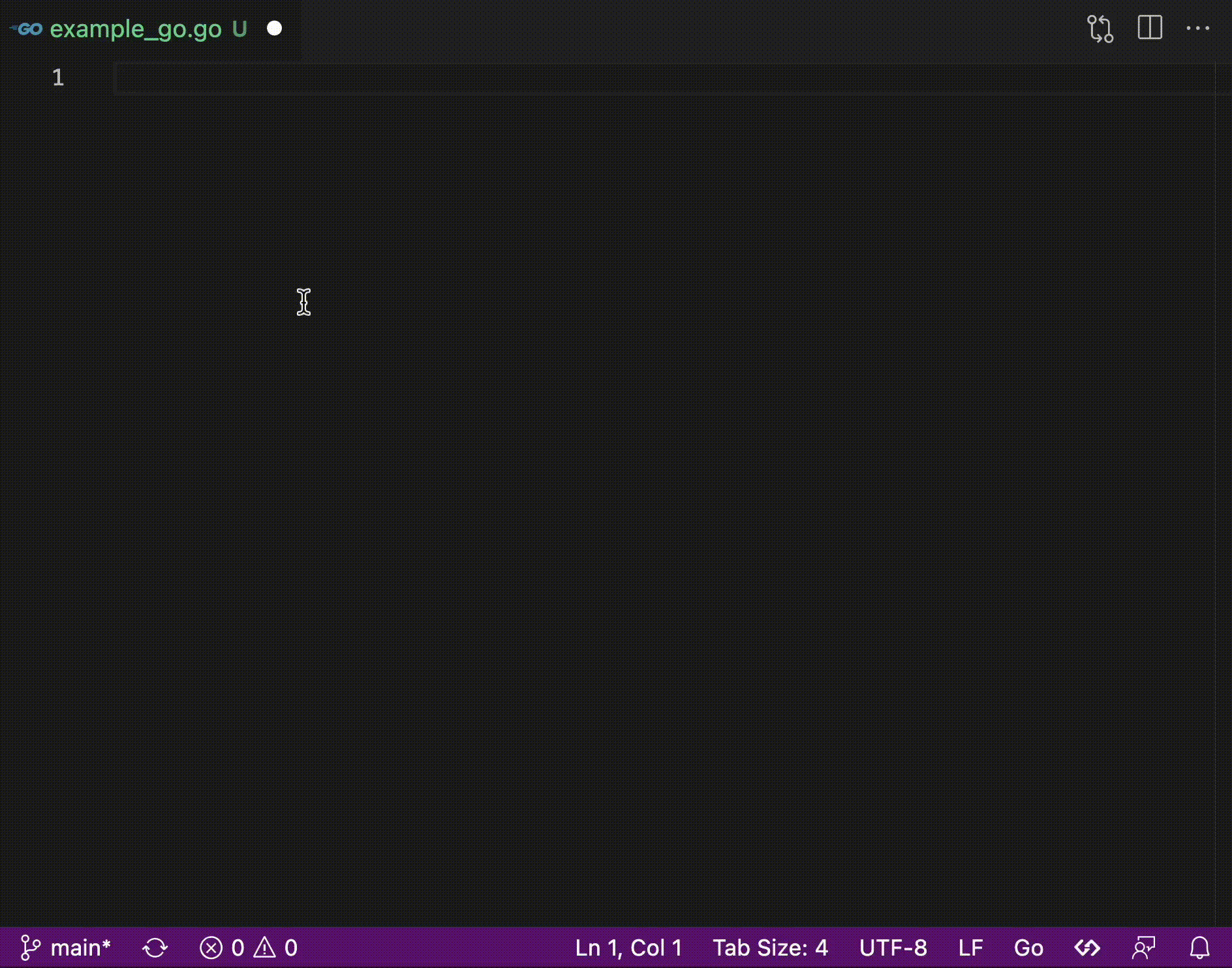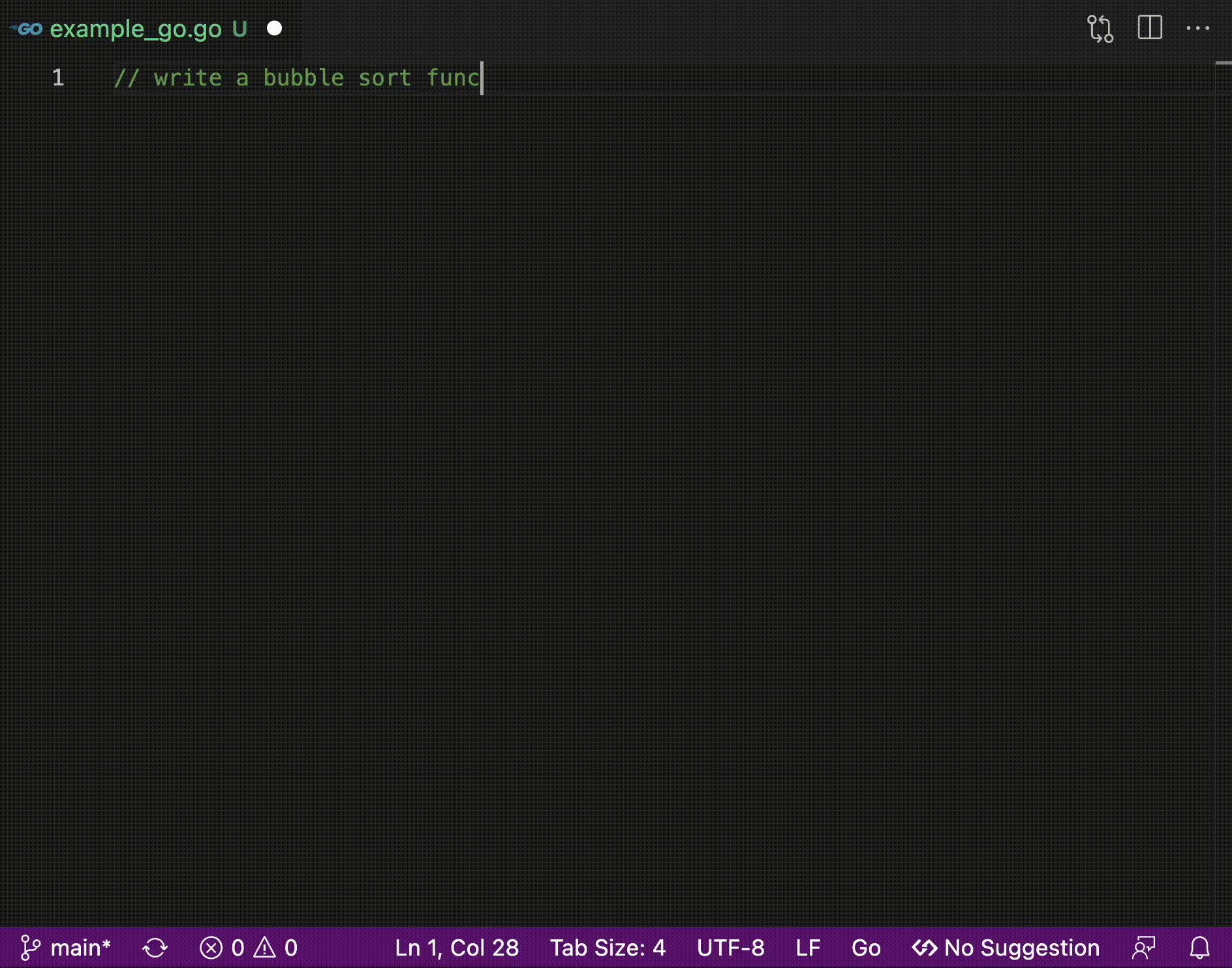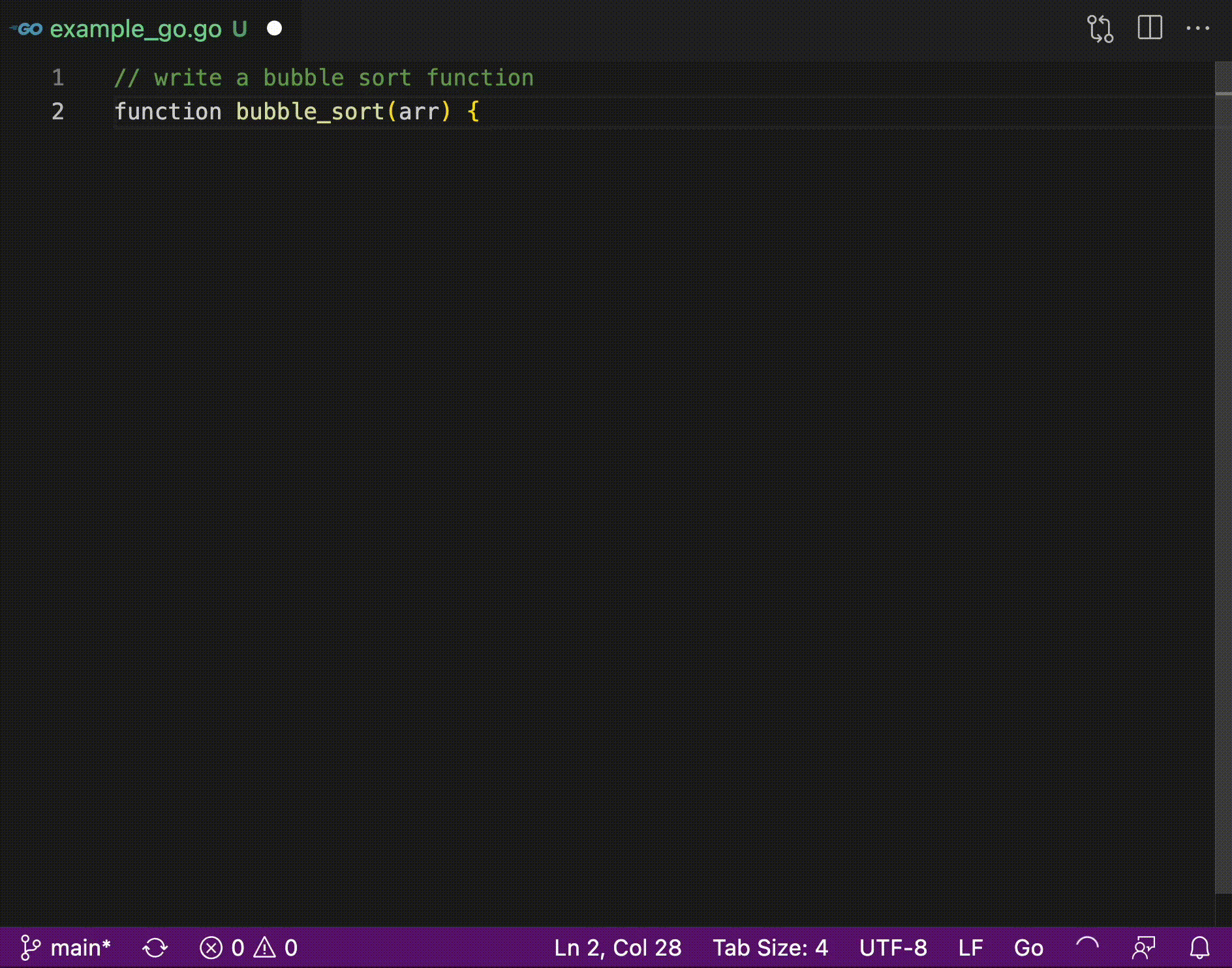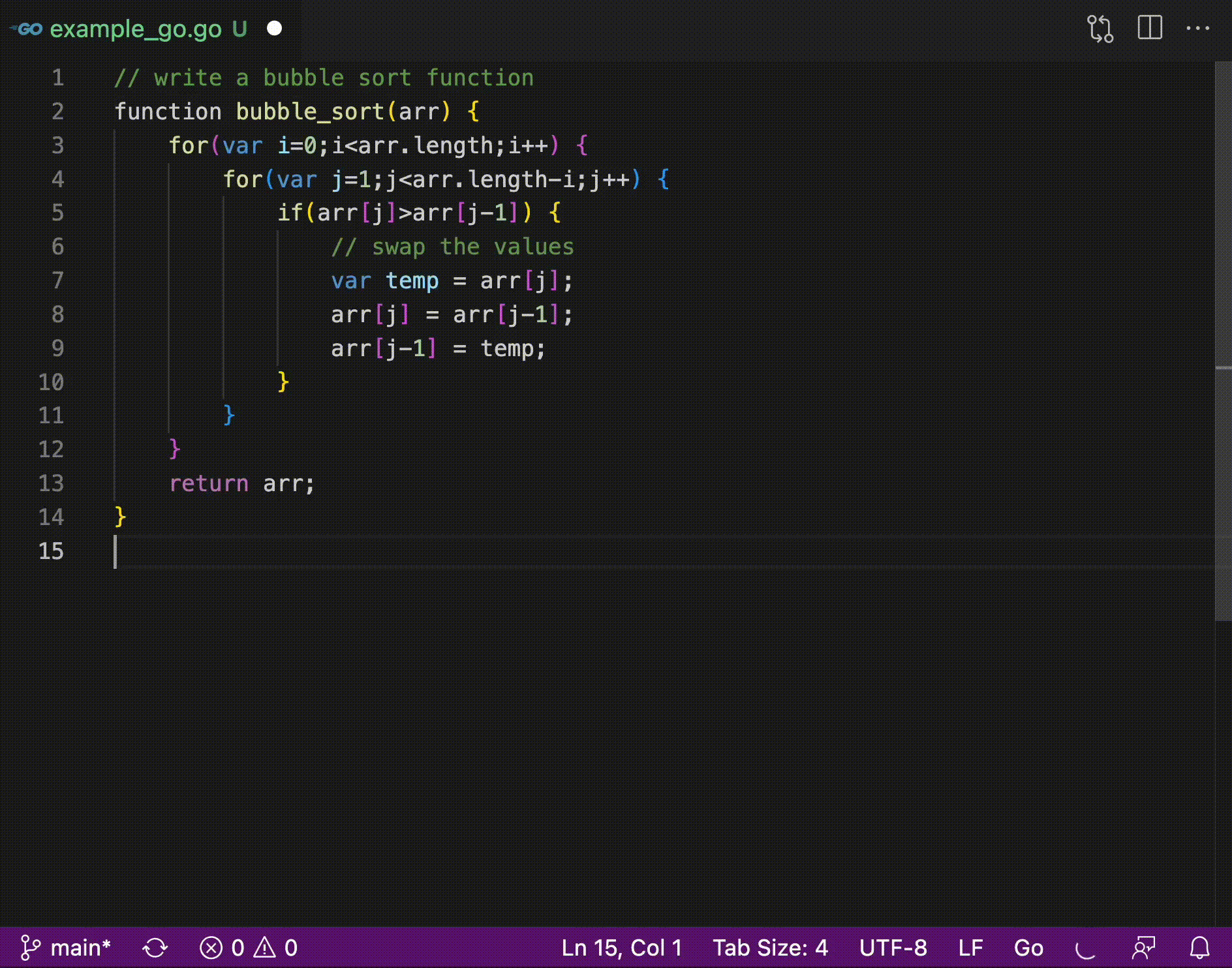
45 |
46 | ### 交互模式
47 |
48 | 在该模式中,按``Ctrl+Enter``激活交互模式,CodeGeeX将生成``X``个候选,并显示在右侧窗口中(``X`` 数量可以在设置的``Candidate Num``中修改)。 点击候选代码上方的``use code``即可插入结果到为当前光标位置。
49 |
50 | 
51 |
52 | ### 翻译模式
53 |
54 | 在当前的语言的文本编辑器中输入或者粘贴其他语言的代码,您用鼠标选择这些代码,然后按下``Ctrl+Alt+T``激活翻译模式,您根据提示选择该代码的语言,然后CodeGeeX会帮您把该代码翻译成匹配您当前编辑器语言的代码。点击翻译结果上方的``use code``即可插入。您还可以在设置中选择您希望插入的时候如何处理被翻译的代码,您可以选择注释它们或者覆盖它们。
55 |
56 | 
57 |
58 | ### 提示模式(实验功能)
59 |
60 | 在该模式中,您可以在输入中添加额外的提示来实现一些有趣的功能,包括并不限于代码解释、概括、以特定风格生成等。该模式的原理是利用了CodeGeeX强大的少样本生成能力。当您在输入中提供一些例子时,CodeGeeX会模仿这些例子并实现相应的功能。比如,您可以自定义模板中提供一段逐行解释代码的例子。选择您想要解释的代码,按``Alt/Option+t``触发提示模式,选择您写好的模板(如``explanation``),CodeGeeX就会解释您输入的代码。以下我们会详细介绍如何制作模板。
61 |
62 | 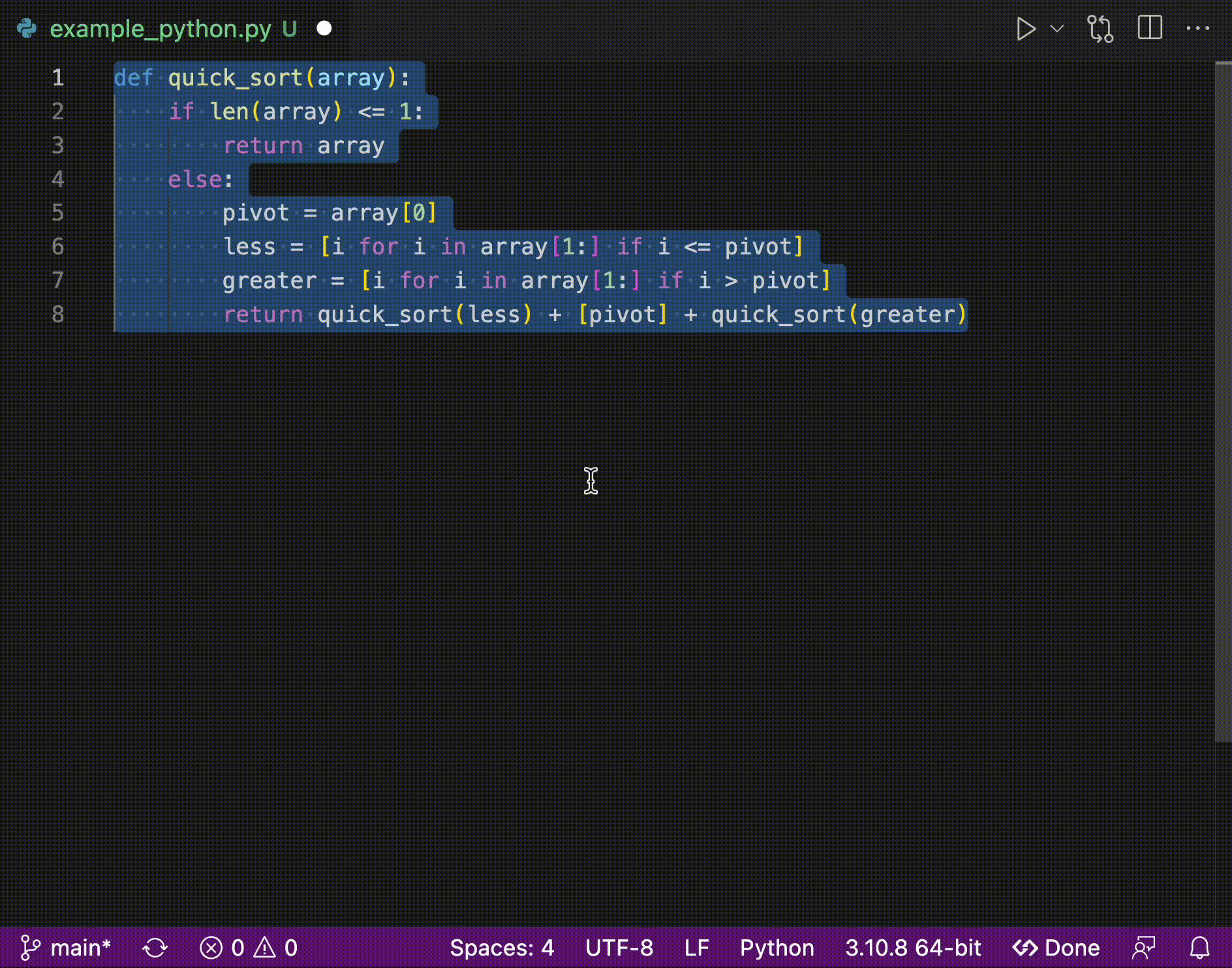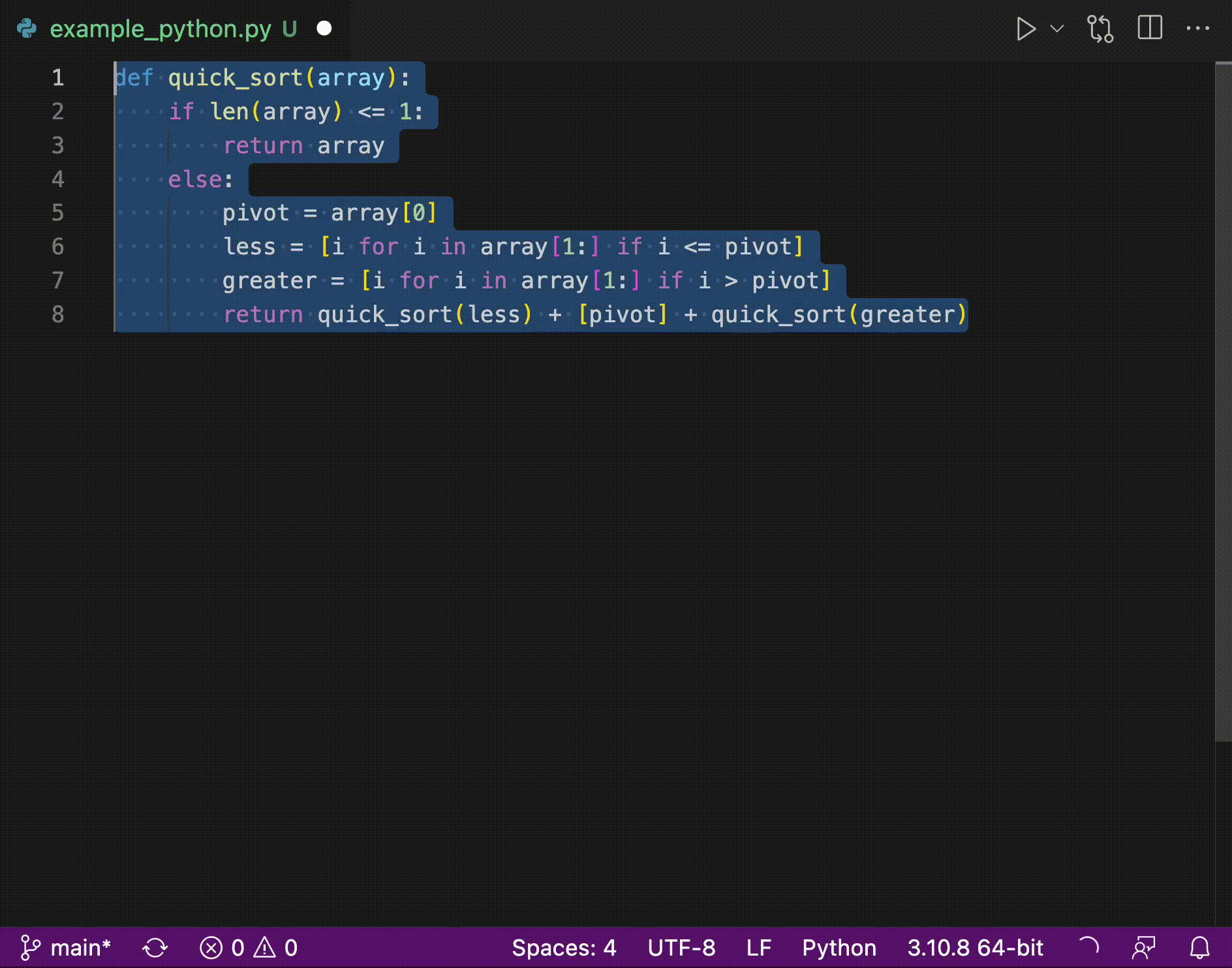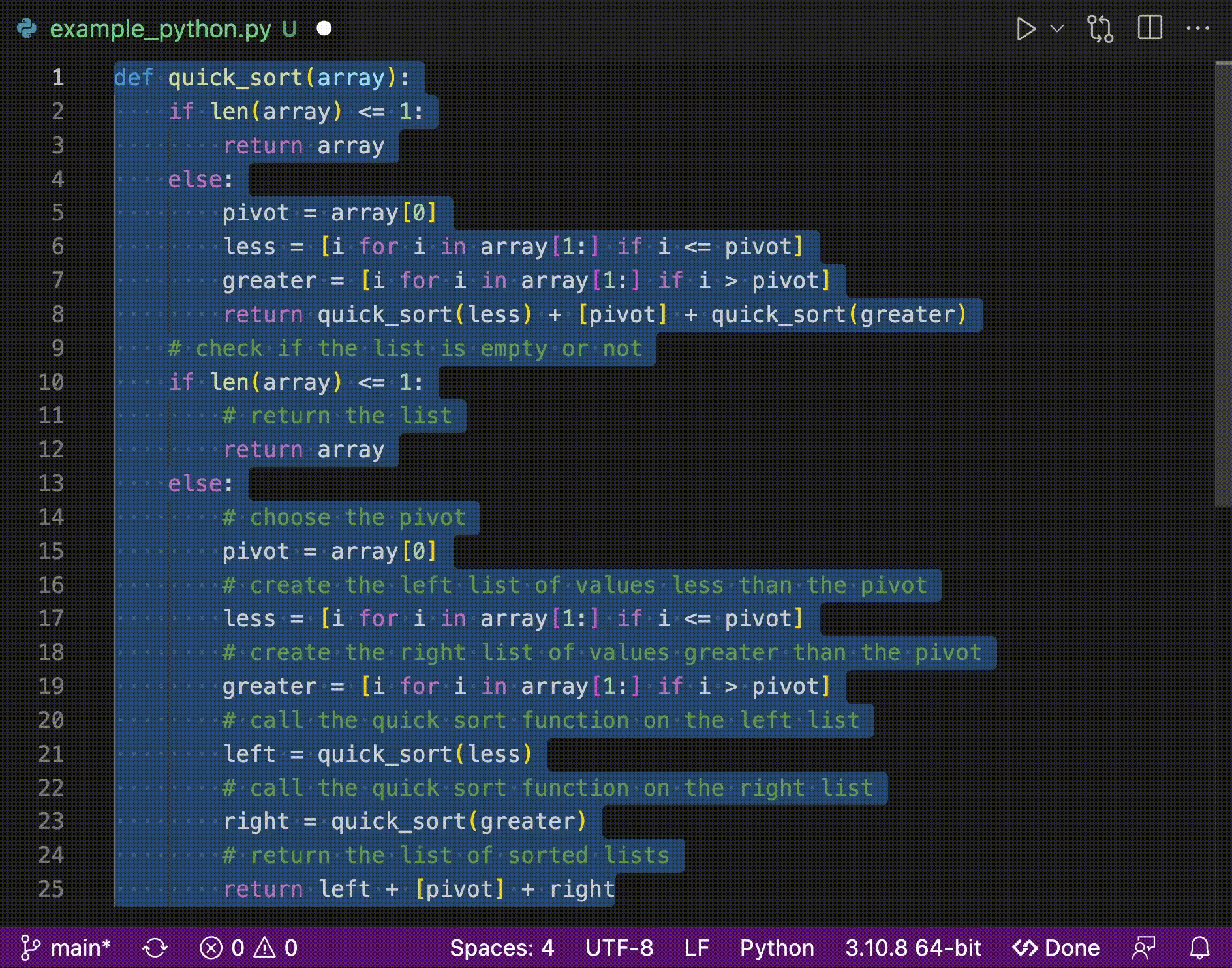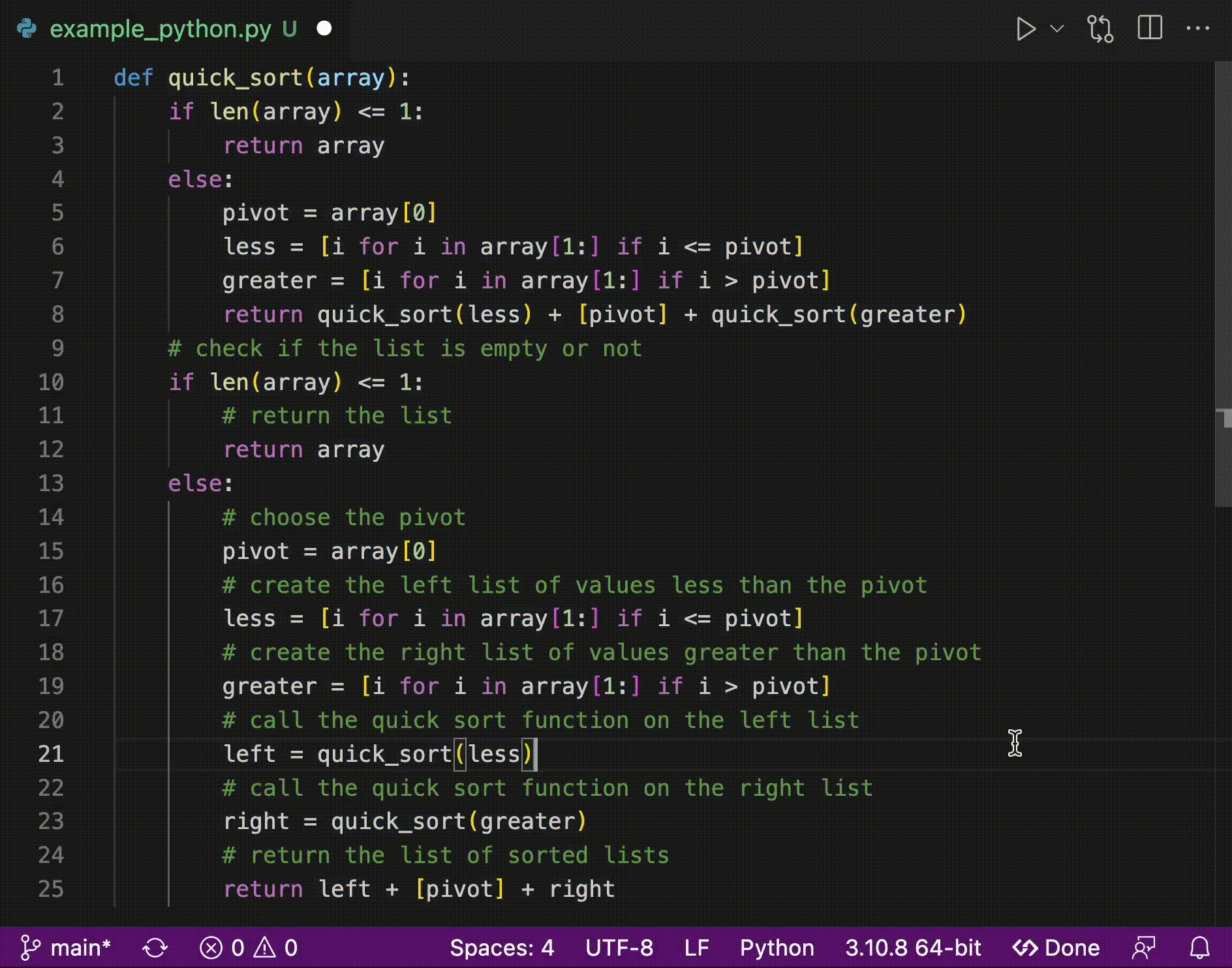
63 |
64 | 上述例子中的模板如下图所示,由``[示例代码]``, ````, ``[带解释的示例代码]`` and ``[输出函数头]`` 。````表示您选中的代码将会插入的位置。 ```` 这一句用来保证模型解释的是同一个函数。当使用提示模式时,CodeGeeX会将您选择的代码(插入到部分)和模板代码相结合,一起作为模型的输入。
65 |
66 | ```python
67 | # language: Python
68 |
69 | def sum_squares(lst):
70 | sum = 0
71 | for i in range(len(lst)):
72 | if i % 3 == 0:
73 | lst[i] = lst[i]**2
74 | elif i % 4 == 0:
75 | lst[i] = lst[i]**3
76 | sum += lst[i]
77 | return sum
78 |
79 |
80 |
81 | # Explain the code line by line
82 | def sum_squares(lst):
83 | # initialize sum
84 | sum = 0
85 | # loop through the list
86 | for i in range(len(lst)):
87 | # if the index is a multiple of 3
88 | if i % 3 == 0:
89 | # square the entry
90 | lst[i] = lst[i]**2
91 | # if the index is a multiple of 4
92 | elif i % 4 == 0:
93 | # cube the entry
94 | lst[i] = lst[i]**3
95 | # add the entry to the sum
96 | sum += lst[i]
97 | # return the sum
98 | return sum
99 |
100 | # Explain the code line by line
101 |
102 | ```
103 |
104 | 以下是另一个Python文档字符串生成的例子,CodeGeeX在您写新函数时会模仿该注释的格式:
105 | ```python
106 | def add_binary(a, b):
107 | '''
108 | Returns the sum of two decimal numbers in binary digits.
109 |
110 | Parameters:
111 | a (int): A decimal integer
112 | b (int): Another decimal integer
113 |
114 | Returns:
115 | binary_sum (str): Binary string of the sum of a and b
116 | '''
117 | binary_sum = bin(a+b)[2:]
118 | return binary_sum
119 |
120 |
121 | ```
122 |
123 | 模板文件是高度自定义化的,您可以将自定义模板添加到插件设置中的``Prompt Templates``中。 ``key``表示模板的名字, ``value``是模板文件的路径(可以是您电脑上的任一路径,``.txt``, ``.py``, ``.h``, 等格式文件均可)。通过该功能,您可以让CodeGeeX生成具有特定风格或功能的代码,快尝试定义自己的专属模板吧!
--------------------------------------------------------------------------------
2 |  3 |
4 |
3 |
4 |
7 |
--------------------------------------------------------------------------------
/scripts/convert_ckpt_parallel.sh:
--------------------------------------------------------------------------------
1 | # This script is used to convert checkpoint model parallel partitions.
2 |
3 | LOAD_CKPT_PATH=$1 # Path to weights in .pt format.
4 | SAVE_CKPT_PATH=$2 # Path to save the output MP checkpoints.
5 | MP_SIZE=$3 # Model parallel size
6 |
7 | SCRIPT_PATH=$(realpath "$0")
8 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
9 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
10 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
11 |
12 | if [ -z "$MP_SIZE" ]; then
13 | MP_SIZE=1
14 | fi
15 |
16 | # export CUDA settings
17 | export CUDA_HOME=/usr/local/cuda-11.1/
18 | export CUDA_VISIBLE_DEVICES=0,1
19 |
20 |
21 | CMD="python $MAIN_DIR/codegeex/megatron/convert_ckpt_parallel.py \
22 | --load-ckpt-path $LOAD_CKPT_PATH \
23 | --save-ckpt-path $SAVE_CKPT_PATH \
24 | --tokenizer-path $TOKENIZER_PATH \
25 | --target-tensor-model-parallel-size $MP_SIZE \
26 | --num-layers 39 \
27 | --hidden-size 5120 \
28 | --num-attention-heads 40 \
29 | --max-position-embeddings 2048 \
30 | --attention-softmax-in-fp32 \
31 | --fp16 \
32 | --micro-batch-size 1 \
33 | --make-vocab-size-divisible-by 52224 \
34 | --seq-length 2048"
35 |
36 | echo "$CMD"
37 | eval "$CMD"
--------------------------------------------------------------------------------
/scripts/convert_mindspore_to_megatron.sh:
--------------------------------------------------------------------------------
1 | # This script is used to convert mindspore checkpoint to the megatron format.
2 |
3 | NPY_CKPT_PATH=$1 # Path to Mindspore exported weights in .npy format.
4 | SAVE_CKPT_PATH=$2 # Path to save the output .pt checkpoint.
5 | GPU=$3
6 |
7 | SCRIPT_PATH=$(realpath "$0")
8 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
9 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
10 | TOKENIZER_PATH="$MAIN_DIR/codegeex/tokenizer/"
11 |
12 | # export CUDA settings
13 | if [ -z "$GPU" ]; then
14 | GPU=0
15 | fi
16 |
17 | export CUDA_HOME=/usr/local/cuda-11.1/
18 | export CUDA_VISIBLE_DEVICES=$GPU
19 |
20 |
21 | CMD="python $MAIN_DIR/codegeex/megatron/mindspore_to_megatron.py \
22 | --npy-ckpt-path $NPY_CKPT_PATH \
23 | --save-ckpt-path $SAVE_CKPT_PATH \
24 | --tokenizer-path $TOKENIZER_PATH \
25 | $MODEL_ARGS"
26 |
27 | echo "$CMD"
28 | eval "$CMD"
--------------------------------------------------------------------------------
/scripts/evaluate_humaneval_x.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | from pathlib import Path
4 | from codegeex.benchmark.evaluate_humaneval_x import evaluate_functional_correctness
5 | #GLOBALS
6 | INPUT_FILE: str
7 | LANGUAGE: str
8 | N_WORKERS: int
9 | TIMEOUT: int
10 |
11 |
12 | parser = argparse.ArgumentParser("Debugging evaluate humaneval_x")
13 | # Path to the .jsonl file that contains the generated codes.
14 | parser.add_argument("-s","--samples", type=str)
15 |
16 | # Target programming language, currently support one of ["python", "java", "cpp", "js", "go"]
17 | parser.add_argument("-l","--language", default="python", type=str)
18 |
19 | # Number of parallel workers.
20 | parser.add_argument("-w","--workers", default=64, type=int)
21 |
22 | # Timeout in seconds.
23 | parser.add_argument("-t","--timeout", default=5, type=int)
24 |
25 | args = parser.parse_args()
26 |
27 | INPUT_FILE = args.samples
28 | LANGUAGE = args.language
29 | N_WORKERS = args.workers
30 | TIMEOUT= args.timeout
31 |
32 |
33 |
34 | SCRIPT_PATH: str = Path(os.path.abspath(__file__))
35 | print(SCRIPT_PATH)
36 | SCRIPT_DIR: str = os.path.dirname(SCRIPT_PATH)
37 | print(SCRIPT_DIR)
38 | MAIN_DIR: str = os.path.dirname(SCRIPT_DIR)
39 | print(MAIN_DIR)
40 |
41 | DATA_DIR=os.path.join(MAIN_DIR,"codegeex/benchmark/humaneval-x/" + LANGUAGE + "/data/humaneval_" + LANGUAGE + ".jsonl.gz")
42 | print(DATA_DIR)
43 |
44 | TMP_DIR=os.path.join(MAIN_DIR, "/codegeex/benchmark/humaneval-x/")
45 |
46 |
47 | #Debugging
48 | INPUT_FILE='/home/rog0d/Escritorio/CodeGeeX/generations/humaneval_rust_generations.jsonl.gz'
49 | LANGUAGE='rust'
50 | DATA_DIR=os.path.join(MAIN_DIR,"codegeex/benchmark/humaneval-x/" + LANGUAGE + "/data/humaneval_" + LANGUAGE + ".jsonl.gz")
51 |
52 | """
53 | input_file: str = None,
54 | tmp_dir: str = "./",
55 | n_workers: int = 32,
56 | timeout: float = 5.0,
57 | problem_file: str = "../data/humaneval_python.jsonl.gz",
58 | out_dir: str = None,
59 | k: List[int] = [1, 10, 100],
60 | test_groundtruth: bool = False,
61 | example_test: bool = False,
62 |
63 | """
64 |
65 | evaluate_functional_correctness(input_file=INPUT_FILE,
66 | n_workers=N_WORKERS,
67 | tmp_dir=TMP_DIR,
68 | problem_file=DATA_DIR,
69 | timeout=300.0)
70 |
71 |
72 |
--------------------------------------------------------------------------------
/scripts/evaluate_humaneval_x.sh:
--------------------------------------------------------------------------------
1 | # This script is for evaluating the functional correctness of the generated codes of HumanEval-X.
2 |
3 | INPUT_FILE=$1 # Path to the .jsonl file that contains the generated codes.
4 | LANGUAGE=$2 # Target programming language, currently support one of ["python", "java", "cpp", "js", "go"]
5 | N_WORKERS=$3 # Number of parallel workers.
6 | TIMEOUT=$4 # Timeout in seconds.
7 |
8 | SCRIPT_PATH=$(realpath "$0")
9 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
10 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
11 |
12 | echo "$INPUT_FILE"
13 |
14 | if [ -z "$N_WORKERS" ]
15 | then
16 | N_WORKERS=64
17 | fi
18 |
19 | if [ -z "$LANGUAGE" ]
20 | then
21 | LANGUAGE=python
22 | fi
23 |
24 | if [ -z "$TIMEOUT" ]
25 | then
26 | TIMEOUT=5
27 | fi
28 |
29 | DATA_DIR=$MAIN_DIR/codegeex/benchmark/humaneval-x/$LANGUAGE/data/humaneval_$LANGUAGE.jsonl.gz
30 |
31 | if [ $LANGUAGE = go ]; then
32 | export PATH=$PATH:/usr/local/go/bin
33 | fi
34 |
35 | if [ $LANGUAGE = cpp ]; then
36 | export PATH=$PATH:/usr/bin/openssl
37 | fi
38 |
39 | CMD="python $MAIN_DIR/codegeex/benchmark/humaneval-x/evaluate_humaneval_x.py \
40 | --input_file "$INPUT_FILE" \
41 | --n_workers $N_WORKERS \
42 | --tmp_dir $MAIN_DIR/codegeex/benchmark/humaneval-x/ \
43 | --problem_file $DATA_DIR \
44 | --timeout $TIMEOUT"
45 |
46 | echo "$CMD"
47 | eval "$CMD"
--------------------------------------------------------------------------------
/scripts/finetune_codegeex.sh:
--------------------------------------------------------------------------------
1 | SCRIPT_PATH=$(realpath "$0")
2 | SCRIPT_DIR=$(dirname "$SCRIPT_PATH")
3 | MAIN_DIR=$(dirname "$SCRIPT_DIR")
4 |
5 | # ====== Environment ======
6 | # - NCCL & IB
7 | export NCCL_DEBUG=info
8 | export NCCL_IB_DISABLE=0
9 | export NCCL_IB_GID_INDEX=3
10 |
11 | HOSTFILE="
3 |
4 | 扫码关注公众号加入「CodeGeeX交流群」
5 |Scan the QR code to join the "CodeGeeX WeChat Group"
6 |