├── .gitpod.Dockerfile
├── .gitpod.yml
├── Building_Your_First_Machine_Learning_Model.ipynb
├── Built_In_Functions_Exercise_Questions.ipynb
├── Cheat_sheet_for_Google_Colab.ipynb
├── Data Scraping from the Web
├── README.md
├── Scraping YouTube accounts with python.ipynb
├── Web_Scraping_Rate_My_Professor_Website.ipynb
├── Web_Scraping_Vs_API.md
└── the_knot.md
├── Data_Analysis.ipynb
├── Data_Cleaning
└── Data_Cleaning_using_Python_with_Pandas_Library.ipynb
├── Data_Preprocessing_with_Pandas.md
├── Demystifying_Feature_Engineering.ipynb
├── Dependency_Inversion_Principle_in_Python.ipynb
├── Dictionary
└── Python_Dictionary.ipynb
├── Eval_built_in_function.ipynb
├── Excel_to_PDF_conversion_using_Python_libraries.md
├── Exercises
├── Built-InFunctionsPracticeProblemsSolutions.pdf
├── Built-InFunctionsProblems.pdf
├── CommentsAndMathOperatorsPracticeProblemsSolutions.pdf
├── CommentsandMathOperatorsProblems.pdf
├── FlowControlandComparatorsPracticeProblemsSolutions.pdf
├── FlowControlandComparatorsProblems.pdf
├── ForLoopsandTuplesPracticeProblemsSolutions.pdf
├── ForLoopsandTuplesProblems.pdf
├── FunctionsPracticeProblemsSolutions.pdf
├── FunctionsProblems.pdf
├── IfElseandElifPracticeProblemsSolutions.pdf
├── IfElseandElifProblems.pdf
├── ImportingModulesPracticeProblemsSolutions.pdf
├── ImportingModulesProblems.pdf
├── ListsPracticeProblemsSolutions.pdf
├── ListsProblems.pdf
├── StringMethodsPracticeProblemsSolutions.pdf
├── StringMethodsProblems.pdf
├── StringsAndEscapeSequencesPracticeProblemsSolutions.pdf
├── StringsAndEscapeSequencesProblems.pdf
├── UsingFunctionsWithListsPracticeProblemsSolutions.pdf
├── UsingFunctionsWithListsProblems.pdf
├── VariablesAndDataTypesPracticeProblemsSolutions.pdf
├── VariablesandDataTypesProblems.pdf
└── printPracticeProblemsSolutions.pdf
├── Exploratory Data Analysis
├── Exploratory_data_Analysis_1.ipynb
├── Exploratory_data_Analysis_2.ipynb
└── README.md
├── Exploratory_data_Analysis.ipynb
├── Global,_Local_and_Nonlocal_variables_in_Python.ipynb
├── Google Translate API
├── Dataset
│ └── Vegetables_names_in_hindi.csv
└── Google_Translate_API_for_Python.ipynb
├── Google_Trends_API.ipynb
├── Hacker_Rank_Exercises
├── HackerRanK_Exercises.ipynb
├── Img
│ └── hackerrank.png
└── README.md
├── Hidden_Layers_of_Understanding_CNN.ipynb
├── Hidden_Markov_Models_in_Python.ipynb
├── How_to_Efficiently_Compute_Euclidean_Distance_in_Python_Using_NumPy.ipynb
├── How_to_Handle_Missing_Data_in_Pandas_Like_a_Pro.ipynb
├── How_to_Structure_Machine_Learning_Projects_with_Clean_Code_Principles_in_Python.ipynb
├── How_to_create_NumPy_arrays_from_scratch?.ipynb
├── How_to_get_started_coding_in_Python?.ipynb
├── How_to_handle_JSON_in_Python?.ipynb
├── Img
├── 1745257696486.png
├── CNN.png
├── Data.PNG
├── Jupyter.PNG
├── Python.PNG
├── Python.jpeg
├── Tanu.jpeg
├── Time Series Forecasting with Pandas.png
├── api.png
├── brecht-corbeel-qHx3w6Gwz9k-unsplash.jpg
├── choong-deng-xiang--WXQm_NTK0U-unsplash.jpg
├── christina-wocintechchat-com-SqmaKDvcIso-unsplash.jpg
├── decoraters.png
├── gaelle-marcel-vrkSVpOwchk-unsplash.jpg
├── hackerrank.png
├── james-harrison-vpOeXr5wmR4-unsplash.jpg
├── logo.jpg
├── luke-chesser-JKUTrJ4vK00-unsplash.jpg
├── markov models.png
├── mlmodel!.png
├── model.png
├── ray-rui-SyzQ5aByJnE-unsplash.jpg
├── resume_ranker.png
├── rubaitul-azad-ZIPFteu-R8k-unsplash.jpg
├── rule_based.png
├── sebastian-herrmann-O2o1hzDA7iE-unsplash.jpg
├── uml.png
├── uml_dip.png
├── uml_isp.png
├── uml_lsp.png
├── umlopenclose.png
├── umlsrp.png
├── virtual_env.png
└── zach-graves-wtpTL_SzmhM-unsplash.jpg
├── Interface_Segregation_Principle.ipynb
├── Is_Python_object_oriented?.ipynb
├── Learn_the_Python_Math_Module.ipynb
├── Learning_One_Hot_Encoding_in_Python_the_Easy_Way.ipynb
├── Liskov_Substitution_Principle_in_Python.ipynb
├── Lists
├── Lists.ipynb
└── README.md
├── Manipulating_the_data_with_Pandas_using_Python.ipynb
├── Mastering_Python_Decorators.ipynb
├── Mastering_the_Bar_Plot_in_Python.ipynb
├── Normalization_vs_Standardization.ipynb
├── Numpy
├── How_to_create_NumPy_arrays_from_scratch?.ipynb
├── Numpy_1.ipynb
├── Numpy_Arrays.ipynb
├── Numpy_Examples3.ipynb
└── Numpy_Examples4.ipynb
├── Oil Refineries
└── Readme.md
├── Open_Closed_Principle_in_Python.ipynb
├── Optimizing_Python_Code_with_List_Comprehensions.ipynb
├── Pandas
└── Pandas_DataFrame.ipynb
├── Pick_up_Line_Generator.ipynb
├── Playing_with_Titanic_Dataset.ipynb
├── Predicting_Loan_Default_Using_Decision_Trees.ipynb
├── Predicting_PewDiePie's_daily_subscribers_using_Machine_Learning_.ipynb
├── Presenting_Python_code_using_RISE.ipynb
├── Python Coding Interview Prep
├── 35 Python interview questions for experienced.md
├── Basic_calculator.ipynb
├── Children_with_candy.ipynb
├── Crack Python Interviews Like a Pro!.md
├── Draw_polygon.ipynb
├── Python Coding Interview Questions (Beginner to Advanced).md
├── Python_Interview_Questions_and_Answers.md
├── Python_Interview_Questions_and_Answers_Strings.md
├── Python_Theoritical_Interview_Questions.md
├── README.md
├── Remove_Element.ipynb
├── Sentimental_Analysis.ipynb
├── Text_Justification.ipynb
├── Vowel_Count.ipynb
└── pick_up_line_generator_sentiments.ipynb
├── Python Coding Interview Questions And Answers Fixed.py
├── Python_Input,_Output_and_Import.ipynb
├── Python_Lambda_Function.ipynb
├── Python_Operators.ipynb
├── Python_Variables.ipynb
├── Python_enumerate()_built_in_function.ipynb
├── Python_len()_built_in_function.ipynb
├── Quiz
├── Python_Quiz_1.ipynb
├── Python_Quiz_2.ipynb
└── Python_Quiz_3.ipynb
├── README.md
├── Range_built_in_function.ipynb
├── Reading_An_Image_In_Python_(Without_Using_Special_Libraries).ipynb
├── Rendering_Images_inside_a_Pandas_DataFrame.ipynb
├── Rule_Based_System_with_Python.ipynb
├── Single_Responsibility_Principle.ipynb
├── Smart_Resume_Ranker_with_Python.ipynb
├── Speech_Recognition_using_Python.ipynb
├── Splitting_the_dataset_into_three_sets.ipynb
├── Src
├── Section1_Introduction.ipynb
└── Section2.ipynb
├── String_Concatenation_Exercise_Answers.ipynb
├── String_Concatenation_Exercise_Questions.ipynb
├── Strings
├── String
└── Strings.ipynb
├── The_two_Google_Search_Python_Libraries_you_should_never_miss.ipynb
├── Time_Series_Forecasting_with_Pandas.ipynb
├── Top_Python_Libraries_Used_In_Data Science.ipynb
├── Transit_Data_Calgary_2025.ipynb
├── Tuples
└── Tuples.ipynb
├── Understanding_Virtual_Environments_in_Python.ipynb
├── University_of_Regina_Professor's_salary.ipynb
├── Unlocking_Time_Series_Forecasting_with_Facebook_Prophet.ipynb
├── Using_the_Pandas_DataFrame_in_Day_To_Day_Life.ipynb
├── Using_the_Pandas_Data_Frame_as_a_Database_.ipynb
├── Vowel_Count.ipynb
├── Wikipedia_API_for_Python.ipynb
├── data_load.md
└── src
├── 2D_Matrix_Multiplication.py
├── Accessing_By_Index.py
├── Slicing_A_String
├── String_Concat_Using_Print.py
├── Strings.py
├── Vending_Machine.py
├── control_Statements.py
├── dictionary.py
├── for_loop.py
├── functions.py
├── helloWorld.py
├── input().py
├── length_of_name.py
├── list.py
├── list_functions1.py
├── lists_and_functions.py
├── numpy_examples.py
├── panda_examples.py
├── tuples.py
├── using_%s_format_operator.py
├── variables.py
└── variables1.py
/.gitpod.Dockerfile:
--------------------------------------------------------------------------------
1 | FROM gitpod/workspace-full
2 |
3 | # Install custom tools, runtimes, etc.
4 | # For example "bastet", a command-line tetris clone:
5 | # RUN brew install bastet
6 | #
7 | # More information: https://www.gitpod.io/docs/config-docker/
8 |
--------------------------------------------------------------------------------
/.gitpod.yml:
--------------------------------------------------------------------------------
1 | image:
2 | file: .gitpod.Dockerfile
3 |
4 | tasks:
5 | - init: 'echo "TODO: Replace with init/build command"'
6 | command: 'echo "TODO: Replace with command to start project"'
7 |
--------------------------------------------------------------------------------
/Building_Your_First_Machine_Learning_Model.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyPQkbM1IouCRwgPSAqq7OmT",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | " "
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Building Your First Machine Learning Model with scikit-learn\n",
33 | "\n",
34 | "## Understand the essentials of model training and evaluation in Python\n",
35 | "\n",
36 | "\n",
37 | "|  |\n",
38 | "|:--:|\n",
39 | "| Image Generated Using Canva|\n",
40 | "\n",
41 | "### Introduction\n",
42 | "Machine learning sounds complicated, but getting started with it is easier than you think! Today, you'll build a simple yet powerful machine-learning model using Python’s scikit-learn library. We'll walk through loading data, training a model, making predictions, and evaluating performance in a clean and beginner-friendly way.\n",
43 | "\n",
44 | "---\n",
45 | "\n",
46 | "### Code Implementation"
47 | ],
48 | "metadata": {
49 | "id": "eC0Qz4bv80Ko"
50 | }
51 | },
52 | {
53 | "cell_type": "code",
54 | "source": [
55 | "# Step 1: Import necessary libraries\n",
56 | "from sklearn.datasets import load_iris\n",
57 | "from sklearn.model_selection import train_test_split\n",
58 | "from sklearn.ensemble import RandomForestClassifier\n",
59 | "from sklearn.metrics import accuracy_score\n",
60 | "\n",
61 | "# Step 2: Load the dataset\n",
62 | "iris = load_iris()\n",
63 | "X = iris.data\n",
64 | "y = iris.target\n",
65 | "\n",
66 | "# Step 3: Split the dataset into training and testing sets\n",
67 | "X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)\n",
68 | "\n",
69 | "# Step 4: Initialize and train the model\n",
70 | "model = RandomForestClassifier()\n",
71 | "model.fit(X_train, y_train)\n",
72 | "\n",
73 | "# Step 5: Make predictions\n",
74 | "y_pred = model.predict(X_test)\n",
75 | "\n",
76 | "# Step 6: Evaluate the model\n",
77 | "accuracy = accuracy_score(y_test, y_pred)\n",
78 | "print(f\"Model Accuracy: {accuracy:.2f}\")"
79 | ],
80 | "metadata": {
81 | "colab": {
82 | "base_uri": "https://localhost:8080/"
83 | },
84 | "id": "MOPJd24H9XDF",
85 | "outputId": "3858aeed-8240-44fe-8c4e-14f970d397d5"
86 | },
87 | "execution_count": 1,
88 | "outputs": [
89 | {
90 | "output_type": "stream",
91 | "name": "stdout",
92 | "text": [
93 | "Model Accuracy: 1.00\n"
94 | ]
95 | }
96 | ]
97 | },
98 | {
99 | "cell_type": "markdown",
100 | "source": [
101 | "### What this code does\n",
102 | "* Loads the famous Iris dataset.\n",
103 | "* Splits it into training and testing parts.\n",
104 | "* Trains a Random Forest Classifier.\n",
105 | "* Evaluates how well the model performs.\n",
106 | "\n",
107 | "---\n",
108 | "\n",
109 | "### Conclusion\n",
110 | "You just built your first machine-learning model! This simple project introduces you to real-world workflows like data splitting, model training, and accuracy evaluation. With scikit-learn, machine learning becomes a lot less intimidating and a lot more fun. Keep experimenting with different datasets and models. Thanks for reading my article, let me know if you have any suggestions or similar implementations via the comment section. Until then, see you next time. Happy coding!\n",
111 | "\n",
112 | "---\n",
113 | "\n",
114 | "#### Before you go\n",
115 | "* Be sure to Like and Connect Me\n",
116 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
117 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
118 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!"
119 | ],
120 | "metadata": {
121 | "id": "cTFA0NJr9hAY"
122 | }
123 | }
124 | ]
125 | }
--------------------------------------------------------------------------------
/Data Scraping from the Web/README.md:
--------------------------------------------------------------------------------
1 | # Data Scraping from the Web
2 |
"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Building Your First Machine Learning Model with scikit-learn\n",
33 | "\n",
34 | "## Understand the essentials of model training and evaluation in Python\n",
35 | "\n",
36 | "\n",
37 | "|  |\n",
38 | "|:--:|\n",
39 | "| Image Generated Using Canva|\n",
40 | "\n",
41 | "### Introduction\n",
42 | "Machine learning sounds complicated, but getting started with it is easier than you think! Today, you'll build a simple yet powerful machine-learning model using Python’s scikit-learn library. We'll walk through loading data, training a model, making predictions, and evaluating performance in a clean and beginner-friendly way.\n",
43 | "\n",
44 | "---\n",
45 | "\n",
46 | "### Code Implementation"
47 | ],
48 | "metadata": {
49 | "id": "eC0Qz4bv80Ko"
50 | }
51 | },
52 | {
53 | "cell_type": "code",
54 | "source": [
55 | "# Step 1: Import necessary libraries\n",
56 | "from sklearn.datasets import load_iris\n",
57 | "from sklearn.model_selection import train_test_split\n",
58 | "from sklearn.ensemble import RandomForestClassifier\n",
59 | "from sklearn.metrics import accuracy_score\n",
60 | "\n",
61 | "# Step 2: Load the dataset\n",
62 | "iris = load_iris()\n",
63 | "X = iris.data\n",
64 | "y = iris.target\n",
65 | "\n",
66 | "# Step 3: Split the dataset into training and testing sets\n",
67 | "X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)\n",
68 | "\n",
69 | "# Step 4: Initialize and train the model\n",
70 | "model = RandomForestClassifier()\n",
71 | "model.fit(X_train, y_train)\n",
72 | "\n",
73 | "# Step 5: Make predictions\n",
74 | "y_pred = model.predict(X_test)\n",
75 | "\n",
76 | "# Step 6: Evaluate the model\n",
77 | "accuracy = accuracy_score(y_test, y_pred)\n",
78 | "print(f\"Model Accuracy: {accuracy:.2f}\")"
79 | ],
80 | "metadata": {
81 | "colab": {
82 | "base_uri": "https://localhost:8080/"
83 | },
84 | "id": "MOPJd24H9XDF",
85 | "outputId": "3858aeed-8240-44fe-8c4e-14f970d397d5"
86 | },
87 | "execution_count": 1,
88 | "outputs": [
89 | {
90 | "output_type": "stream",
91 | "name": "stdout",
92 | "text": [
93 | "Model Accuracy: 1.00\n"
94 | ]
95 | }
96 | ]
97 | },
98 | {
99 | "cell_type": "markdown",
100 | "source": [
101 | "### What this code does\n",
102 | "* Loads the famous Iris dataset.\n",
103 | "* Splits it into training and testing parts.\n",
104 | "* Trains a Random Forest Classifier.\n",
105 | "* Evaluates how well the model performs.\n",
106 | "\n",
107 | "---\n",
108 | "\n",
109 | "### Conclusion\n",
110 | "You just built your first machine-learning model! This simple project introduces you to real-world workflows like data splitting, model training, and accuracy evaluation. With scikit-learn, machine learning becomes a lot less intimidating and a lot more fun. Keep experimenting with different datasets and models. Thanks for reading my article, let me know if you have any suggestions or similar implementations via the comment section. Until then, see you next time. Happy coding!\n",
111 | "\n",
112 | "---\n",
113 | "\n",
114 | "#### Before you go\n",
115 | "* Be sure to Like and Connect Me\n",
116 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
117 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
118 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!"
119 | ],
120 | "metadata": {
121 | "id": "cTFA0NJr9hAY"
122 | }
123 | }
124 | ]
125 | }
--------------------------------------------------------------------------------
/Data Scraping from the Web/README.md:
--------------------------------------------------------------------------------
1 | # Data Scraping from the Web
2 |  3 |
--------------------------------------------------------------------------------
/Data Scraping from the Web/Web_Scraping_Vs_API.md:
--------------------------------------------------------------------------------
1 | # Web Scraping vs API: Which Data Extraction Method is Best for Your Needs?
2 | ## Understanding the pros, cons, and best use cases of web scraping and API for data extraction
3 |
4 |
3 |
--------------------------------------------------------------------------------
/Data Scraping from the Web/Web_Scraping_Vs_API.md:
--------------------------------------------------------------------------------
1 | # Web Scraping vs API: Which Data Extraction Method is Best for Your Needs?
2 | ## Understanding the pros, cons, and best use cases of web scraping and API for data extraction
3 |
4 |
5 |  6 |
6 |
7 |
8 | Photo by Luke Chesser on Unsplash
9 |
10 |
11 | ## Problem Statement
12 | Efficiently extracting and using online data is vital in our data-driven world. The two primary data acquisition methods are APIs and web scraping. Web scraping pulls data from websites by parsing HTML, unlike APIs, which provide structured data access directly from the source.
13 |
14 | We must analyze, compare, and contrast the two data extraction methods, noting their strengths and weaknesses. This includes a specific analysis of each method’s best use, trustworthiness, performance, legal implications, and restrictions. Furthermore, the task is to build a solution that efficiently, compliantly, and scalably extracts dynamic data (like the current world population) from online sources such as websites and APIs.
15 |
16 | ---
17 |
18 | ## Web scraping
19 | Scraping the data from the web is called web scraping. In this approach, we can use the requests to fetch the webpage content and `BeautifulSoup` to parse and extract the content. Let’s use the [Worldometer](https://www.worldometers.info/world-population/) website to get the dynamic population count.
20 |
21 | ```Python
22 |
23 | # Python Libraries used for Web Scraping
24 | import requests
25 | from bs4 import BeautifulSoup
26 |
27 | # URL of the page to scrape
28 | url = "https://www.worldometers.info/world-population/"
29 |
30 | # Send a GET request to the webpage
31 | response = requests.get(url)
32 |
33 | # Check if the request was successful
34 | # Don't Run this multiple time, as doing so
35 | # You will send too many request.
36 | # Will lead to blocking of the site.
37 | if response.status_code == 200:
38 | # Parse the HTML content
39 | soup = BeautifulSoup(response.text, 'html.parser')
40 |
41 | # Find the element that contains the world population
42 | # Sometimes the tags might change keep an eye
43 | population_element = soup.select_one(".maincounter-number span")
44 |
45 | if population_element:
46 | # Extract and print the population
47 | population = population_element.text.strip()
48 | print(f"The Current World Population is : {population}")
49 | else:
50 | print("Population data not found.")
51 | else:
52 |
53 | print(f"Failed to retrieve the page. HTTP Status Code: {response.status_code}")
54 |
55 | ```
56 |
57 | ## Explanation
58 | You send an HTTP request to the Worldometer website and we use the beautiful soup library to parse and extract the data from the HTML element. This is dynamic data, meaning you will get updated results every time you refresh.
59 |
60 | ---
61 | ## Output
62 | Upon executing this program, you will get the result as `The Current World Population is: 8,196,543,067`. But what I noticed when I executed it on Google Colab I got the output as `Current World Population: retrieving data…` Do you know why is this? Let me know in the comment section.
63 |
64 | ## Reason
65 | If the program is stuck while executing “retrieving data” it may be because of the following reasons.
66 |
67 | 1. **Blocking** — Worldometer will block if it detects an automated behavior
68 | 2. **Incorrect HTML Structure** — The scraper cannot scrape the correct form of data. Check the selectors and their attributes.
69 | 3. **Slow Network** — If your internet is slow, then it can cause a delay in fetching the data.
70 |
71 | ---
72 |
73 | ## API
74 | An Application Program Interface is an intermediate software that allows applications to talk to each other. For example, your phone’s weather app uses APIs to communicate with this system, providing daily weather updates. We shall use the [World Bank API](https://datahelpdesk.worldbank.org/knowledgebase/articles/889392-about-the-indicators-api) to access the population data.
75 |
76 | ```Python
77 |
78 | # Requests allows you to send HTTP/1.1 requests extremely easily
79 | import requests
80 |
81 | # API endpoint for World Bank population data
82 | url = "http://api.worldbank.org/v2/country/WLD/indicator/SP.POP.TOTL?format=json"
83 |
84 | # Send a GET request to the API
85 | response = requests.get(url)
86 |
87 | # Check if the request was successful
88 | if response.status_code == 200:
89 | # Parse JSON response
90 | data = response.json()
91 | # Extract population value
92 | population = data[1][0]["value"]
93 | print(f"The World Population is: {population}")
94 | else:
95 | print(f"Failed to fetch data. HTTP Status Code: {response.status_code}")
96 |
97 | ```
98 |
99 | ## Explanation
100 | You fetch the data from the API using `requests` and use the `json()` to parse the response and access the first element when the data is returned. This can be done using `data[1][0][“value”]`
101 |
102 | ---
103 |
104 |
105 | ## Output
106 | Upon executing this program, the result will be `The World Population is: 8061876001`. Unlike web scraping, the execution was quick and never prompted `retrieving data`. This is why I love the API. They make our jobs so much easier and better.
107 |
108 | ---
109 |
110 | ## Benefits of Leveraging APIs
111 |
112 | 1. **Structured Data** — APIs' well-defined formats (JSON, XML, etc.) make their data easy to parse and use.
113 | 2. **Reliability** — API formats are less prone to frequent changes than HTML.
114 | 3. **Speed** — API data retrieval proved significantly faster than web scraping, as the example above demonstrates.
115 | 4. **Regulatory Adherence** — APIs usually include simple terms of service, thus offering better legal protection.
116 | 5. **Documentation** — Each available API includes comprehensive documentation. This significantly improves API understanding.
117 | 6. **Accessibility** — APIs let you access and use data and services from countless different sources.
118 |
119 | For more on real-time API usage, see the article below.
120 |
121 | [What is API? Use Case and Benefits](https://konghq.com/blog/learning-center/what-is-api?source=post_page-----c578464d6083--------------------------------)
122 |
123 | ---
124 |
125 | ## Limitations of APIs
126 |
127 | 1. **Restricted Access** — To gain access to certain APIs, you may need to register, purchase API keys, or pay.
128 | 2. **Less Flexibility** — Customization may be limited by APIs’ inability to supply all of the data that is displayed on a webpage.
129 | 3. **Rate Limits** — The maximum number of queries you may make in a given second, hour, or day is frequently limited by APIs.
130 |
131 | ---
132 |
133 | ## Benefits of Web Scraping
134 |
135 | 1. **Dependency** — Scraping may be the sole choice if there is no API or if the API does not provide the necessary data.
136 | 2. **Visibility** — Any information seen on the webpage, including dynamically loaded content, can be captured via scraping.
137 | 3. **Access Without Registration** — Often, scraping doesn’t require you to sign up or pay for
138 |
139 | ---
140 |
141 | ## Limitations of Web Scraping
142 |
143 | 1. **Fragility** — When the structure of a website changes, web scraping scripts are prone to breaking.
144 | 2. **Legal and Ethical Issues** — Depending on the jurisdiction, scraping may be against local laws or even a website’s terms of service.
145 | 3. **Performance Overhead** — Scraping can be resource-intensive and slow because it requires downloading and parsing whole HTML pages.
146 | 4. **Error Handling** — It can be difficult to handle edge circumstances, like dynamic JavaScript content.
147 |
148 | ---
149 |
150 | ## Opinion
151 | Whenever feasible, use the API if it's available. It is more dependable, quicker, and safer from a legal standpoint. If not then use Web Scraping. To stay out of trouble with the law, review the website’s terms of service. For scripts that are effective and maintainable, use scraping libraries such as `BeautifulSoup`, `Selenium`, or `Scrapy`. Use tools such as `Playwright` or `Selenium` to manage dynamic content. For more information about the law standpoint I would highly recommend you guys read the below-listed article by [Lisa R. Lifshitz](https://www.canadianlawyermag.com/external-contributors/lisa-r.-lifshitz)
152 |
153 | [Federal Court Makes Clear: Website Scraping is Illegal](https://www.canadianlawyermag.com/news/opinion/federal-court-makes-clear-website-scraping-is-illegal/276128?source=post_page-----c578464d6083--------------------------------)
154 |
155 | ---
156 |
157 | ## Conclusion
158 | For population data, APIs such as the World Bank API are more reliable and efficient than scraping the [Worldometer](https://www.worldometers.info/world-population/), which should only be used as a last resort. Prioritize APIs for accurate and dependable data retrieval. I hope you enjoyed reading my article. Suggestions are always welcomed. Until then, see you next time. Happy Writing!
159 |
--------------------------------------------------------------------------------
/Data Scraping from the Web/the_knot.md:
--------------------------------------------------------------------------------
1 | # Pick-Up Lines Scraper Using Beautiful Soup
2 | ## This might get you more matches, just kidding!
3 |
4 | 
5 |
6 |
7 | # Introduction
8 | This article explains you scraping the first 10 pick-up lines
9 |
--------------------------------------------------------------------------------
/Data_Preprocessing_with_Pandas.md:
--------------------------------------------------------------------------------
1 | # Mastering the Art of Data Preprocessing with Pandas
2 | ## Build cleaner, faster, and smarter ML pipelines with real-world data techniques
3 |
4 | | [](https://discord.gg/qFryjbX) |  |  |  | | [](https://gitpod.io/#https://github.com/Tanu-N-Prabhu/Python)| [](https://github.com/Tanu-N-Prabhu/Python/commits/main?icon=github&color=green)|||
5 | |:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
6 |
7 |
8 | |  |
9 | |:--:|
10 | | Image Generated Using Canva |
11 |
12 | Written by Tanu Nanda Prabhu
13 |
14 |
15 | # Introduction
16 | Raw data is rarely clean or usable straight out of the box. Whether you're working on a machine learning project, a data analysis dashboard, or a backend system. How you preprocess your data determines the quality of your results.
17 |
18 | In this post, we’ll walk through the must-know techniques in pandas for handling missing data, transforming features, and preparing datasets that are ready to power any model or insight.
19 |
20 | ---
21 |
22 | # Why Preprocessing is a Game-Changer
23 | * Garbage in = garbage out. Clean data ensures better predictions.
24 | * Saves time in the long run by eliminating inconsistencies early.
25 | * Helps models converge faster and perform better.
26 | * Makes your data pipeline robust and production-ready.
27 |
28 | ---
29 |
30 | # Common Data Preprocessing Tasks (with Code)
31 | Let’s break it down into real-world tasks you’ll face and how to solve them using Pandas.
32 |
33 | ## 1. Handling Missing Values
34 |
35 | ```python
36 | import pandas as pd
37 | import numpy as np
38 |
39 | # Sample dataset
40 | df = pd.DataFrame({
41 | 'Age': [25, 28, np.nan, 35],
42 | 'Income': [50000, 60000, 65000, np.nan]
43 | })
44 |
45 | # Fill missing values
46 | df['Age'].fillna(df['Age'].mean(), inplace=True)
47 | df['Income'].fillna(df['Income'].median(), inplace=True)
48 | ```
49 |
50 | > Tip: Use `.mean()` for normally distributed values, and `.median()` for skewed ones.
51 |
52 | ## 2. Encoding Categorical Variables
53 |
54 | ```python
55 | df = pd.DataFrame({
56 | 'Department': ['HR', 'Finance', 'IT', 'HR']
57 | })
58 |
59 | # One-hot encoding
60 | df_encoded = pd.get_dummies(df, columns=['Department'])
61 |
62 | ```
63 | > Use `get_dummies` for nominal data. For ordinal data, consider LabelEncoder.
64 |
65 | ## 3. Scaling Numerical Features
66 |
67 | ```python
68 |
69 | from sklearn.preprocessing import StandardScaler
70 |
71 | df = pd.DataFrame({
72 | 'Height': [150, 160, 170],
73 | 'Weight': [60, 70, 80]
74 | })
75 |
76 | scaler = StandardScaler()
77 | scaled = scaler.fit_transform(df)
78 |
79 | ```
80 | > Standardizing helps algorithms like SVM, KNN, and Gradient Boosting.
81 |
82 | ## 4. Detecting and Removing Outliers
83 |
84 | ```python
85 |
86 | # Using Z-score
87 | from scipy import stats
88 |
89 | z_scores = stats.zscore(df)
90 | df_no_outliers = df[(np.abs(z_scores) < 3).all(axis=1)]
91 | ```
92 |
93 | > Z-score method is simple and effective for normally distributed data.
94 |
95 | ## 5. Feature Engineering, DateTime Example
96 |
97 | ```python
98 |
99 | df = pd.DataFrame({
100 | 'Timestamp': pd.to_datetime([
101 | '2023-01-01', '2023-02-15', '2023-03-30'
102 | ])
103 | })
104 |
105 | df['Month'] = df['Timestamp'].dt.month
106 | df['Weekday'] = df['Timestamp'].dt.weekday
107 |
108 | ```
109 |
110 | > Extracting features from dates can boost model performance in time-related problems.
111 |
112 | ## Bonus Tip: Pipeline It!
113 |
114 |
115 | > Use `sklearn.pipeline.Pipeline` or `make_column_transformer` to wrap all preprocessing steps into one clean object.
116 |
117 | ```python
118 |
119 | from sklearn.pipeline import Pipeline
120 | from sklearn.impute import SimpleImputer
121 | from sklearn.preprocessing import StandardScaler
122 |
123 | pipeline = Pipeline([
124 | ('imputer', SimpleImputer(strategy='mean')),
125 | ('scaler', StandardScaler())
126 | ])
127 |
128 | ```
129 | ---
130 |
131 | # Real-World Use Case
132 | In any ML competition or project, preprocessing is where the top performers gain the edge. They know how to clean and transform messy real-world data into a form the model can understand. Even a 1% improvement in data cleaning can lead to huge gains in model performance.
133 |
134 | ---
135 | # Conclusion
136 | Data preprocessing isn’t a “boring” step, it’s the backbone of all successful projects. Mastering tools like pandas, sklearn, and some domain intuition can help you scale your skills from beginner to expert.
137 |
138 | ---
139 |
140 | # Stay Connected & Level Up!
141 | Loved this challenge? Smash that like, drop a comment, and hit follow for daily mind-bending Python questions! Want more in-depth explanations?
142 |
143 | Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!
144 |
--------------------------------------------------------------------------------
/Excel_to_PDF_conversion_using_Python_libraries.md:
--------------------------------------------------------------------------------
1 | # Comparision of Excel to PDF Conversion Methods
2 |
3 | ### **Comparison of Excel to PDF Conversion Methods**
4 |
5 | | Features | **`pywin32`** | **`libreoffice`**| **`pdfkit`** |
6 | |:-----------------------------|:----------------------|:----------------------|:----------------|
7 | | **Usability** | ⚠️ Windows-only and requires Excel installed | ✅ Command Line Interface Based | ✅ Easy to Use |
8 | | **Formatting** | ✅ Preserves Excel formatting | ✅ Preserves Excel formatting | ✅ Basic Table|
9 | | **Dependencies** | ⚠️ Requires MS Office (Excel) Installed | ⚠️ Requires `libreOffice` | ✅ Needs `pdfkit` + `wkhtmltopdf` |
10 | | **Performance** | ⚠️ Can be slow for large files | ✅ Very fast | ✅ Fast for small tables |
11 | | **Images/Charts** | ✅ Yes | ✅ Yes | ❌ No |
12 | | **Google Colab Compatibility** | ❌ No (Windows-only) | ✅ Yes | ✅ Yes|
13 | | **Quality** | ✅ High-quality, preserves formatting | ✅ High-quality, preserves formatting | ✅ Good for plain tables |
14 |
--------------------------------------------------------------------------------
/Exercises/Built-InFunctionsPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/Built-InFunctionsPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/Built-InFunctionsProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/Built-InFunctionsProblems.pdf
--------------------------------------------------------------------------------
/Exercises/CommentsAndMathOperatorsPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/CommentsAndMathOperatorsPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/CommentsandMathOperatorsProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/CommentsandMathOperatorsProblems.pdf
--------------------------------------------------------------------------------
/Exercises/FlowControlandComparatorsPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/FlowControlandComparatorsPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/FlowControlandComparatorsProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/FlowControlandComparatorsProblems.pdf
--------------------------------------------------------------------------------
/Exercises/ForLoopsandTuplesPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/ForLoopsandTuplesPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/ForLoopsandTuplesProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/ForLoopsandTuplesProblems.pdf
--------------------------------------------------------------------------------
/Exercises/FunctionsPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/FunctionsPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/FunctionsProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/FunctionsProblems.pdf
--------------------------------------------------------------------------------
/Exercises/IfElseandElifPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/IfElseandElifPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/IfElseandElifProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/IfElseandElifProblems.pdf
--------------------------------------------------------------------------------
/Exercises/ImportingModulesPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/ImportingModulesPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/ImportingModulesProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/ImportingModulesProblems.pdf
--------------------------------------------------------------------------------
/Exercises/ListsPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/ListsPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/ListsProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/ListsProblems.pdf
--------------------------------------------------------------------------------
/Exercises/StringMethodsPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/StringMethodsPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/StringMethodsProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/StringMethodsProblems.pdf
--------------------------------------------------------------------------------
/Exercises/StringsAndEscapeSequencesPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/StringsAndEscapeSequencesPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/StringsAndEscapeSequencesProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/StringsAndEscapeSequencesProblems.pdf
--------------------------------------------------------------------------------
/Exercises/UsingFunctionsWithListsPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/UsingFunctionsWithListsPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/UsingFunctionsWithListsProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/UsingFunctionsWithListsProblems.pdf
--------------------------------------------------------------------------------
/Exercises/VariablesAndDataTypesPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/VariablesAndDataTypesPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exercises/VariablesandDataTypesProblems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/VariablesandDataTypesProblems.pdf
--------------------------------------------------------------------------------
/Exercises/printPracticeProblemsSolutions.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Exercises/printPracticeProblemsSolutions.pdf
--------------------------------------------------------------------------------
/Exploratory Data Analysis/README.md:
--------------------------------------------------------------------------------
1 | # Exploratory Data Analysis in Python.
2 |
3 |  4 |
--------------------------------------------------------------------------------
/Google Translate API/Dataset/Vegetables_names_in_hindi.csv:
--------------------------------------------------------------------------------
1 | Vegetable Names
2 | गाजर
3 | शिमला मिर्च
4 | भिन्डी
5 | मक्का
6 | लाल मिर्च
7 | खीरा
8 | कढ़ी पत्ता
9 | बैगन
10 | लहसुन
11 | अदरक
12 |
--------------------------------------------------------------------------------
/Hacker_Rank_Exercises/Img/hackerrank.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Hacker_Rank_Exercises/Img/hackerrank.png
--------------------------------------------------------------------------------
/Hacker_Rank_Exercises/README.md:
--------------------------------------------------------------------------------
1 | # This page deals with solved HackerRank exercises.
2 |
3 |
4 |
--------------------------------------------------------------------------------
/Google Translate API/Dataset/Vegetables_names_in_hindi.csv:
--------------------------------------------------------------------------------
1 | Vegetable Names
2 | गाजर
3 | शिमला मिर्च
4 | भिन्डी
5 | मक्का
6 | लाल मिर्च
7 | खीरा
8 | कढ़ी पत्ता
9 | बैगन
10 | लहसुन
11 | अदरक
12 |
--------------------------------------------------------------------------------
/Hacker_Rank_Exercises/Img/hackerrank.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Hacker_Rank_Exercises/Img/hackerrank.png
--------------------------------------------------------------------------------
/Hacker_Rank_Exercises/README.md:
--------------------------------------------------------------------------------
1 | # This page deals with solved HackerRank exercises.
2 |
3 |  4 |
5 |
4 |
5 | HackerRank is a technology company that focuses on competitive programming challenges for both consumers and businesses, where developers compete by trying to program according to provided specifications. HackerRank's programming challenges can be solved in a variety of programming languages (including Java, C++, PHP, Python, SQL, JavaScript) and span multiple computer science domains (Copied from Wikipedia).
6 |
7 | Getting started with HackerRank
8 |
9 | 1. Sign-In/ Sign-Up: (https://www.hackerrank.com/dashboard).
10 |
11 | 2. My Profile at HackerRank: (https://www.hackerrank.com/TanuPrabhu)
12 |
13 | Configuring HackerRank is quite trivial, but solving problems in it is the most the complicated part (The problems are not straightforward, you have to use your brain). Well, I spend some time everyday in it, just to sharpen my programming skills. I hope even you spend quite some time with it. All the best !!!
14 |
--------------------------------------------------------------------------------
/How_to_Efficiently_Compute_Euclidean_Distance_in_Python_Using_NumPy.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyNu/nXCSJtRoaMmdp8Ef5T7",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# How to Efficiently Compute Euclidean Distance in Python Using NumPy (No Loops Needed)\n",
33 | "\n",
34 | "## A faster, cleaner, production-ready method for distance calculations in ML workflows\n",
35 | "\n",
36 | "|  |\n",
37 | "|:--:|\n",
38 | "| Photo by James Harrison on Unsplash|\n",
39 | "\n",
40 | "### Introduction\n",
41 | "When working with high-dimensional datasets, calculating distances between points is a common task in many machine learning applications. However, relying on traditional Python loops can be painfully slow, especially with large datasets. In this post, you'll learn how to replace loops with vectorized operations using NumPy; the industry-standard approach for high-performance numerical computing in Python.\n",
42 | "\n",
43 | "---\n",
44 | "\n",
45 | "### Problem\n",
46 | "Suppose you have a dataset of thousands of points, and you need to calculate the Euclidean distance from each point to a fixed query vector. A for-loop might work for small datasets, but for real-world ML tasks, it's simply too slow.\n",
47 | "\n",
48 | "---\n",
49 | "\n",
50 | "### Code Implementation\n",
51 | "\n",
52 | "\n",
53 | "\n",
54 | "\n",
55 | "\n",
56 | "\n",
57 | "\n",
58 | "\n"
59 | ],
60 | "metadata": {
61 | "id": "bo2FG0K7tRAn"
62 | }
63 | },
64 | {
65 | "cell_type": "code",
66 | "source": [
67 | "import numpy as np\n",
68 | "\n",
69 | "# Generate sample data: 10,000 points with 3 features\n",
70 | "data = np.random.rand(10000, 3)\n",
71 | "\n",
72 | "# Define a query vector\n",
73 | "query = np.array([0.5, 0.5, 0.5])\n",
74 | "\n",
75 | "# Vectorized Euclidean distance computation\n",
76 | "distances = np.linalg.norm(data - query, axis=1)\n",
77 | "\n",
78 | "# Get the indices of the 5 closest points\n",
79 | "top_indices = np.argsort(distances)[:5]\n",
80 | "print(\"Closest 5 points:\\n\", data[top_indices])"
81 | ],
82 | "metadata": {
83 | "colab": {
84 | "base_uri": "https://localhost:8080/"
85 | },
86 | "id": "YUdKVEAXvlx8",
87 | "outputId": "9443e38e-d4b2-4a3c-861b-847c31651e83"
88 | },
89 | "execution_count": 1,
90 | "outputs": [
91 | {
92 | "output_type": "stream",
93 | "name": "stdout",
94 | "text": [
95 | "Closest 5 points:\n",
96 | " [[0.49876677 0.48344345 0.49651103]\n",
97 | " [0.5117045 0.47720221 0.49312307]\n",
98 | " [0.48753621 0.46997124 0.52821116]\n",
99 | " [0.46658145 0.5168309 0.46931167]\n",
100 | " [0.50022365 0.54906596 0.50488196]]\n"
101 | ]
102 | }
103 | ]
104 | },
105 | {
106 | "cell_type": "markdown",
107 | "source": [
108 | "### Code Explanation\n",
109 | "\n",
110 | "* Uses `np.random.rand()` to generate synthetic 3D data.\n",
111 | "\n",
112 | "* The query vector represents the point to which distances are calculated.\n",
113 | "\n",
114 | "* `np.linalg.norm()` computes vectorized Euclidean distances.\n",
115 | "\n",
116 | "* `np.argsort()` returns indices of the 5 smallest distances.\n",
117 | "\n",
118 | "* Entire calculation is done without any Python `for` loops.\n",
119 | "\n",
120 | "---\n",
121 | "\n",
122 | "### Why it’s so important\n",
123 | "\n",
124 | "* Vectorization using NumPy is 10x–100x faster than Python loops.\n",
125 | "\n",
126 | "* Cleaner, more maintainable code for production ML systems.\n",
127 | "\n",
128 | "* Reduces runtime, memory usage, and improves model deployment speed.\n",
129 | "\n",
130 | "---\n",
131 | "\n",
132 | "### Applications\n",
133 | "\n",
134 | "* K-Nearest Neighbors (KNN) and clustering algorithms.\n",
135 | "\n",
136 | "* Real-time recommendation engines.\n",
137 | "\n",
138 | "* Feature similarity and anomaly detection.\n",
139 | "\n",
140 | "* Any task involving proximity or distance metrics in ML.\n",
141 | "\n",
142 | "---\n",
143 | "\n",
144 | "### Conclusion\n",
145 | "Replacing loops with NumPy vectorization is one of the simplest yet most powerful ways to accelerate your machine learning workflows. This approach is production-ready, scalable, and widely adopted across the data science and AI industry. Mastering this technique will significantly improve your ability to write efficient, clean, and high-performing Python code. Thanks for reading my article, let me know if you have any suggestions or similar implementations via the comment section. Until then, see you next time. Happy coding!\n",
146 | "\n",
147 | "---\n",
148 | "\n",
149 | "### Before you go\n",
150 | "* Be sure to Like and Connect Me\n",
151 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
152 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
153 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!\n"
154 | ],
155 | "metadata": {
156 | "id": "qfuKFW_EwKv2"
157 | }
158 | }
159 | ]
160 | }
--------------------------------------------------------------------------------
/Img/1745257696486.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/1745257696486.png
--------------------------------------------------------------------------------
/Img/CNN.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/CNN.png
--------------------------------------------------------------------------------
/Img/Data.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/Data.PNG
--------------------------------------------------------------------------------
/Img/Jupyter.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/Jupyter.PNG
--------------------------------------------------------------------------------
/Img/Python.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/Python.PNG
--------------------------------------------------------------------------------
/Img/Python.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/Python.jpeg
--------------------------------------------------------------------------------
/Img/Tanu.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/Tanu.jpeg
--------------------------------------------------------------------------------
/Img/Time Series Forecasting with Pandas.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/Time Series Forecasting with Pandas.png
--------------------------------------------------------------------------------
/Img/api.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/api.png
--------------------------------------------------------------------------------
/Img/brecht-corbeel-qHx3w6Gwz9k-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/brecht-corbeel-qHx3w6Gwz9k-unsplash.jpg
--------------------------------------------------------------------------------
/Img/choong-deng-xiang--WXQm_NTK0U-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/choong-deng-xiang--WXQm_NTK0U-unsplash.jpg
--------------------------------------------------------------------------------
/Img/christina-wocintechchat-com-SqmaKDvcIso-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/christina-wocintechchat-com-SqmaKDvcIso-unsplash.jpg
--------------------------------------------------------------------------------
/Img/decoraters.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/decoraters.png
--------------------------------------------------------------------------------
/Img/gaelle-marcel-vrkSVpOwchk-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/gaelle-marcel-vrkSVpOwchk-unsplash.jpg
--------------------------------------------------------------------------------
/Img/hackerrank.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/hackerrank.png
--------------------------------------------------------------------------------
/Img/james-harrison-vpOeXr5wmR4-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/james-harrison-vpOeXr5wmR4-unsplash.jpg
--------------------------------------------------------------------------------
/Img/logo.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/logo.jpg
--------------------------------------------------------------------------------
/Img/luke-chesser-JKUTrJ4vK00-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/luke-chesser-JKUTrJ4vK00-unsplash.jpg
--------------------------------------------------------------------------------
/Img/markov models.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/markov models.png
--------------------------------------------------------------------------------
/Img/mlmodel!.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/mlmodel!.png
--------------------------------------------------------------------------------
/Img/model.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/model.png
--------------------------------------------------------------------------------
/Img/ray-rui-SyzQ5aByJnE-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/ray-rui-SyzQ5aByJnE-unsplash.jpg
--------------------------------------------------------------------------------
/Img/resume_ranker.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/resume_ranker.png
--------------------------------------------------------------------------------
/Img/rubaitul-azad-ZIPFteu-R8k-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/rubaitul-azad-ZIPFteu-R8k-unsplash.jpg
--------------------------------------------------------------------------------
/Img/rule_based.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/rule_based.png
--------------------------------------------------------------------------------
/Img/sebastian-herrmann-O2o1hzDA7iE-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/sebastian-herrmann-O2o1hzDA7iE-unsplash.jpg
--------------------------------------------------------------------------------
/Img/uml.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/uml.png
--------------------------------------------------------------------------------
/Img/uml_dip.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/uml_dip.png
--------------------------------------------------------------------------------
/Img/uml_isp.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/uml_isp.png
--------------------------------------------------------------------------------
/Img/uml_lsp.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/uml_lsp.png
--------------------------------------------------------------------------------
/Img/umlopenclose.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/umlopenclose.png
--------------------------------------------------------------------------------
/Img/umlsrp.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/umlsrp.png
--------------------------------------------------------------------------------
/Img/virtual_env.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/virtual_env.png
--------------------------------------------------------------------------------
/Img/zach-graves-wtpTL_SzmhM-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tanu-N-Prabhu/Python/b2e1bf53d5ca95cc798bd73210f2d8f76307ab9e/Img/zach-graves-wtpTL_SzmhM-unsplash.jpg
--------------------------------------------------------------------------------
/Lists/README.md:
--------------------------------------------------------------------------------
1 | # Python Lists.
2 |
3 |  4 |
5 |
--------------------------------------------------------------------------------
/Mastering_Python_Decorators.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyPFJTTvjD+8cdUJGQWvnXZT",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Mastering Python Decorators\n",
33 | "\n",
34 | "## Enhance your functions without changing their code\n",
35 | "\n",
36 | "|  |\n",
37 | "|:--:|\n",
38 | "| Image Generated Using Canva|\n",
39 | "\n",
40 | "#### Why It’s So Important\n",
41 | "Decorators in Python are one of the most powerful and useful tools, yet they are often underutilized. They allow you to \"wrap\" a function to extend its behavior without permanently modifying it. This becomes extremely handy when adding functionalities like logging, authentication, caching, or performance tracking. Mastering decorators boosts your ability to write clean, modular, and professional-grade code.\n",
42 | "\n",
43 | "---\n",
44 | "\n",
45 | "#### Key Highlights\n",
46 | "* Add functionality to existing code easily.\n",
47 | "* Keeps functions clean and readable.\n",
48 | "* Reusable and customizable behavior extensions.\n",
49 | "* Essential for building scalable applications.\n",
50 | "\n",
51 | "---\n",
52 | "\n",
53 | "#### What is a Decorator?\n",
54 | "A decorator is simply a function that takes another function as an argument, adds some functionality, and returns another function.\n",
55 | "\n",
56 | "##### Example\n",
57 | "\n",
58 | "\n"
59 | ],
60 | "metadata": {
61 | "id": "-KE5_qxI0rRu"
62 | }
63 | },
64 | {
65 | "cell_type": "code",
66 | "source": [
67 | "# Basic decorator that logs the execution of a function\n",
68 | "def log_decorator(func):\n",
69 | " def wrapper(*args, **kwargs):\n",
70 | " print(f\"Function '{func.__name__}' is being called\")\n",
71 | " result = func(*args, **kwargs)\n",
72 | " print(f\"Function '{func.__name__}' executed successfully\")\n",
73 | " return result\n",
74 | " return wrapper\n",
75 | "\n",
76 | "# Applying the decorator\n",
77 | "@log_decorator\n",
78 | "def greet(name):\n",
79 | " print(f\"Hello, {name}!\")\n",
80 | "\n",
81 | "# Function call\n",
82 | "greet(\"Tanu\")\n"
83 | ],
84 | "metadata": {
85 | "colab": {
86 | "base_uri": "https://localhost:8080/"
87 | },
88 | "id": "ZeWDeRFR1X8O",
89 | "outputId": "5485115d-f9b6-4827-ae0b-29dd235fcec3"
90 | },
91 | "execution_count": 1,
92 | "outputs": [
93 | {
94 | "output_type": "stream",
95 | "name": "stdout",
96 | "text": [
97 | "Function 'greet' is being called\n",
98 | "Hello, Tanu!\n",
99 | "Function 'greet' executed successfully\n"
100 | ]
101 | }
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "source": [
107 | "#### What this shows\n",
108 | "* `@log_decorator` automatically wraps the greet function.\n",
109 | "* When you call `greet(\"Tanu\")`, the wrapper runs first, logs the messages, then executes the actual function.\n",
110 | "\n",
111 | "---\n",
112 | "\n",
113 | "#### Fun Fact\n",
114 | "In Python, even built-in features like `@staticmethod` and `@classmethod` are implemented as decorators!\n",
115 | "\n",
116 | "---\n",
117 | "\n",
118 | "#### Conclusion\n",
119 | "Mastering decorators empowers you to write cleaner, more efficient Python code. By adding functionality without touching the core logic, decorators make your programs more modular, readable, and professional. Thanks for reading my article, let me know if you have any suggestions or similar implementations via the comment section. Until then, see you next time. Happy coding!\n",
120 | "\n",
121 | "---\n",
122 | "\n",
123 | "### Before you go\n",
124 | "* Be sure to **Like** and **Connect** Me\n",
125 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
126 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
127 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!\n"
128 | ],
129 | "metadata": {
130 | "id": "JODXLzbK1ael"
131 | }
132 | }
133 | ]
134 | }
--------------------------------------------------------------------------------
/Numpy/Numpy_Examples3.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 16,
6 | "metadata": {},
7 | "outputs": [
8 | {
9 | "name": "stdout",
10 | "output_type": "stream",
11 | "text": [
12 | "x = [0 1 2 3]\n",
13 | "x + 5 = [5 6 7 8]\n",
14 | "x - 5 = [-5 -4 -3 -2]\n",
15 | "x * 2 = [0 2 4 6]\n",
16 | "x / 2 = [0. 0.5 1. 1.5]\n",
17 | "x // 2 = [0 0 1 1]\n",
18 | "-x = [ 0 -1 -2 -3]\n",
19 | "x ** 2 = [0 1 4 9]\n",
20 | "x % 2 = [0 1 0 1]\n",
21 | "[2 3 4 5]\n"
22 | ]
23 | }
24 | ],
25 | "source": [
26 | "# Iam very sorry because I had to copy the problems given below directly from the textbook, because it is a redundant process.\n",
27 | "# Moreover the concept of numpy library is a never ending process, because there are a ton of different methods and functions.\n",
28 | "# I think this is more than enough to learn about numpy.\n",
29 | "import numpy as np\n",
30 | "x = np.arange(4)\n",
31 | "print(\"x =\", x)\n",
32 | "print(\"x + 5 =\", x + 5)\n",
33 | "print(\"x - 5 =\", x - 5)\n",
34 | "print(\"x * 2 =\", x * 2)\n",
35 | "print(\"x / 2 =\", x / 2)\n",
36 | "print(\"x // 2 =\", x // 2) # floor division\n",
37 | "print(\"-x = \", -x)\n",
38 | "print(\"x ** 2 = \", x ** 2)\n",
39 | "print(\"x % 2 = \", x % 2)\n",
40 | "print(np.add(x, 2))"
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": 18,
46 | "metadata": {},
47 | "outputs": [
48 | {
49 | "name": "stdout",
50 | "output_type": "stream",
51 | "text": [
52 | "[2 1 0 1 2]\n",
53 | "---------------------------\n",
54 | "[5. 5. 2. 1.]\n"
55 | ]
56 | }
57 | ],
58 | "source": [
59 | "# Absolute value\n",
60 | "x = np.array([-2, -1, 0, 1, 2])\n",
61 | "print(abs(x))\n",
62 | "print(\"---------------------------\")\n",
63 | "x = np.array([3 - 4j, 4 - 3j, 2 + 0j, 0 + 1j])\n",
64 | "print(np.abs(x))\n"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": 22,
70 | "metadata": {},
71 | "outputs": [
72 | {
73 | "name": "stdout",
74 | "output_type": "stream",
75 | "text": [
76 | "---------------------------\n",
77 | "theta = [0. 1.57079633 3.14159265]\n",
78 | "sin(theta) = [0.0000000e+00 1.0000000e+00 1.2246468e-16]\n",
79 | "cos(theta) = [ 1.000000e+00 6.123234e-17 -1.000000e+00]\n",
80 | "tan(theta) = [ 0.00000000e+00 1.63312394e+16 -1.22464680e-16]\n",
81 | "---------------------------\n",
82 | "x = [-1, 0, 1]\n",
83 | "arcsin(x) = [-1.57079633 0. 1.57079633]\n",
84 | "arccos(x) = [3.14159265 1.57079633 0. ]\n",
85 | "arctan(x) = [-0.78539816 0. 0.78539816]\n"
86 | ]
87 | }
88 | ],
89 | "source": [
90 | "# Trigonometric functions\n",
91 | "\n",
92 | "theta = np.linspace(0, np.pi, 3)\n",
93 | "print(\"---------------------------\")\n",
94 | "print(\"theta = \", theta)\n",
95 | "print(\"sin(theta) = \", np.sin(theta))\n",
96 | "print(\"cos(theta) = \", np.cos(theta))\n",
97 | "print(\"tan(theta) = \", np.tan(theta))\n",
98 | "print(\"---------------------------\")\n",
99 | "\n",
100 | "x = [-1, 0, 1]\n",
101 | "print(\"x = \", x)\n",
102 | "print(\"arcsin(x) = \", np.arcsin(x))\n",
103 | "print(\"arccos(x) = \", np.arccos(x))\n",
104 | "print(\"arctan(x) = \", np.arctan(x))"
105 | ]
106 | },
107 | {
108 | "cell_type": "code",
109 | "execution_count": 25,
110 | "metadata": {},
111 | "outputs": [
112 | {
113 | "name": "stdout",
114 | "output_type": "stream",
115 | "text": [
116 | "x = [1, 2, 3]\n",
117 | "e^x = [ 2.71828183 7.3890561 20.08553692]\n",
118 | "2^x = [2. 4. 8.]\n",
119 | "3^x = [ 3 9 27]\n",
120 | "---------------------------\n",
121 | "x = [1, 2, 4, 10]\n",
122 | "ln(x) = [0. 0.69314718 1.38629436 2.30258509]\n",
123 | "log2(x) = [0. 1. 2. 3.32192809]\n",
124 | "log10(x) = [0. 0.30103 0.60205999 1. ]\n",
125 | "---------------------------\n",
126 | "exp(x) - 1 = [0. 0.0010005 0.01005017 0.10517092]\n",
127 | "log(1 + x) = [0. 0.0009995 0.00995033 0.09531018]\n"
128 | ]
129 | }
130 | ],
131 | "source": [
132 | "# Exponents and logarithms\n",
133 | "x = [1, 2, 3]\n",
134 | "print(\"x =\", x)\n",
135 | "print(\"e^x =\", np.exp(x))\n",
136 | "print(\"2^x =\", np.exp2(x))\n",
137 | "print(\"3^x =\", np.power(3, x))\n",
138 | "print(\"---------------------------\")\n",
139 | "\n",
140 | "x = [1, 2, 4, 10]\n",
141 | "print(\"x =\", x)\n",
142 | "print(\"ln(x) =\", np.log(x))\n",
143 | "print(\"log2(x) =\", np.log2(x))\n",
144 | "print(\"log10(x) =\", np.log10(x))\n",
145 | "print(\"---------------------------\")\n",
146 | "\n",
147 | "x = [0, 0.001, 0.01, 0.1]\n",
148 | "print(\"exp(x) - 1 =\", np.expm1(x))\n",
149 | "print(\"log(1 + x) =\", np.log1p(x))"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": 29,
155 | "metadata": {},
156 | "outputs": [
157 | {
158 | "name": "stdout",
159 | "output_type": "stream",
160 | "text": [
161 | "gamma(x) = [1.0000e+00 2.4000e+01 3.6288e+05]\n",
162 | "ln|gamma(x)| = [ 0. 3.17805383 12.80182748]\n",
163 | "beta(x, 2) = [0.5 0.03333333 0.00909091]\n",
164 | "---------------------------\n",
165 | "erf(x) = [0. 0.32862676 0.67780119 0.84270079]\n",
166 | "erfc(x) = [1. 0.67137324 0.32219881 0.15729921]\n",
167 | "erfinv(x) = [0. 0.27246271 0.73286908 inf]\n"
168 | ]
169 | }
170 | ],
171 | "source": [
172 | "# Another excellent source for more specialized and obscure ufuncs is the submodule\n",
173 | "# scipy.special. If you want to compute some obscure mathematical function on\n",
174 | "# your data, chances are it is implemented in scipy.special.\n",
175 | "\n",
176 | "from scipy import special\n",
177 | "x = [1, 5, 10]\n",
178 | "print(\"gamma(x) =\", special.gamma(x))\n",
179 | "print(\"ln|gamma(x)| =\", special.gammaln(x))\n",
180 | "print(\"beta(x, 2) =\", special.beta(x, 2))\n",
181 | "print(\"---------------------------\")\n",
182 | "\n",
183 | "# Error function (integral of Gaussian)\n",
184 | "# its complement, and its inverse\n",
185 | "x = np.array([0, 0.3, 0.7, 1.0])\n",
186 | "print(\"erf(x) =\", special.erf(x))\n",
187 | "print(\"erfc(x) =\", special.erfc(x))\n",
188 | "print(\"erfinv(x) =\", special.erfinv(x))\n"
189 | ]
190 | },
191 | {
192 | "cell_type": "code",
193 | "execution_count": 31,
194 | "metadata": {},
195 | "outputs": [
196 | {
197 | "name": "stdout",
198 | "output_type": "stream",
199 | "text": [
200 | "[ 0. 10. 20. 30. 40.]\n",
201 | "---------------------------\n",
202 | "[ 1. 0. 2. 0. 4. 0. 8. 0. 16. 0.]\n"
203 | ]
204 | }
205 | ],
206 | "source": [
207 | "# Advanced Ufunc Features\n",
208 | "# Specifying output\n",
209 | "\n",
210 | "x = np.arange(5)\n",
211 | "y = np.empty(5)\n",
212 | "np.multiply(x, 10, out=y)\n",
213 | "print(y)\n",
214 | "print(\"---------------------------\")\n",
215 | "\n",
216 | "y = np.zeros(10)\n",
217 | "np.power(2, x, out=y[::2])\n",
218 | "print(y)"
219 | ]
220 | },
221 | {
222 | "cell_type": "code",
223 | "execution_count": 35,
224 | "metadata": {},
225 | "outputs": [
226 | {
227 | "name": "stdout",
228 | "output_type": "stream",
229 | "text": [
230 | "15\n",
231 | "---------------------------\n",
232 | "120\n",
233 | "---------------------------\n",
234 | "[ 1 3 6 10 15]\n",
235 | "---------------------------\n",
236 | "[ 1 2 6 24 120]\n"
237 | ]
238 | }
239 | ],
240 | "source": [
241 | "# Aggregates\n",
242 | "x = np.arange(1, 6)\n",
243 | "print(np.add.reduce(x))\n",
244 | "print(\"---------------------------\")\n",
245 | "\n",
246 | "print(np.multiply.reduce(x))\n",
247 | "print(\"---------------------------\")\n",
248 | "\n",
249 | "print(np.add.accumulate(x))\n",
250 | "print(\"---------------------------\")\n",
251 | "\n",
252 | "print(np.multiply.accumulate(x))"
253 | ]
254 | }
255 | ],
256 | "metadata": {
257 | "kernelspec": {
258 | "display_name": "Python 3",
259 | "language": "python",
260 | "name": "python3"
261 | },
262 | "language_info": {
263 | "codemirror_mode": {
264 | "name": "ipython",
265 | "version": 3
266 | },
267 | "file_extension": ".py",
268 | "mimetype": "text/x-python",
269 | "name": "python",
270 | "nbconvert_exporter": "python",
271 | "pygments_lexer": "ipython3",
272 | "version": "3.7.3"
273 | }
274 | },
275 | "nbformat": 4,
276 | "nbformat_minor": 2
277 | }
278 |
--------------------------------------------------------------------------------
/Numpy/Numpy_Examples4.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [
8 | {
9 | "name": "stdout",
10 | "output_type": "stream",
11 | "text": [
12 | "[0 1 3 5 7 9]\n"
13 | ]
14 | }
15 | ],
16 | "source": [
17 | "# Sorting Arrays\n",
18 | "# Fast Sorting in NumPy: np.sort and np.argsort\n",
19 | "\n",
20 | "import numpy as np\n",
21 | "\n",
22 | "a = np.array([1, 9, 0, 7, 3, 5])\n",
23 | "sort = np.sort(a)\n",
24 | "print(sort)\n"
25 | ]
26 | },
27 | {
28 | "cell_type": "code",
29 | "execution_count": 3,
30 | "metadata": {},
31 | "outputs": [
32 | {
33 | "name": "stdout",
34 | "output_type": "stream",
35 | "text": [
36 | "[2 0 4 5 3 1]\n"
37 | ]
38 | }
39 | ],
40 | "source": [
41 | "# If you want the sorted index then use np.argsort\n",
42 | "\n",
43 | "index = np.argsort(a)\n",
44 | "print(index)"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 11,
50 | "metadata": {},
51 | "outputs": [
52 | {
53 | "name": "stdout",
54 | "output_type": "stream",
55 | "text": [
56 | "[[7 8 7 3 4 8]\n",
57 | " [6 3 8 8 5 1]\n",
58 | " [3 3 3 2 6 5]\n",
59 | " [5 2 5 6 1 5]]\n",
60 | "-----------------------------------\n",
61 | "[[3 2 3 2 1 1]\n",
62 | " [5 3 5 3 4 5]\n",
63 | " [6 3 7 6 5 5]\n",
64 | " [7 8 8 8 6 8]]\n",
65 | "-----------------------------------\n",
66 | "[[3 4 7 7 8 8]\n",
67 | " [1 3 5 6 8 8]\n",
68 | " [2 3 3 3 5 6]\n",
69 | " [1 2 5 5 5 6]]\n"
70 | ]
71 | }
72 | ],
73 | "source": [
74 | "# Sorting along rows or columns\n",
75 | "\n",
76 | "X = rand.randint(0, 10, (4, 6)) \n",
77 | "print(X)\n",
78 | "print(\"-----------------------------------\")\n",
79 | "# sort each column of X\n",
80 | "a = np.sort(X, axis=0)\n",
81 | "print(a)\n",
82 | "print(\"-----------------------------------\")\n",
83 | "# sort each row of X \n",
84 | "b = np.sort(X, axis =1)\n",
85 | "print(b)"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": 13,
91 | "metadata": {},
92 | "outputs": [
93 | {
94 | "name": "stdout",
95 | "output_type": "stream",
96 | "text": [
97 | "[7 2 3 1 6 5 4]\n",
98 | "------------------------------\n",
99 | "[2 1 3 4 6 5 7]\n"
100 | ]
101 | }
102 | ],
103 | "source": [
104 | "# Partial Sorts: Partitioning\n",
105 | "x = np.array([7, 2, 3, 1, 6, 5, 4]) \n",
106 | "print(x)\n",
107 | "print(\"------------------------------\")\n",
108 | "a = np.partition(x, 3)\n",
109 | "print(a)\n",
110 | "\n",
111 | "# NumPy provides this in the np.partition function. \n",
112 | "# np.partition takes an array and a number K; the result is a new array with the smallest K values to the left of the partition,\n",
113 | "# and the remaining values to the right, in arbitrary order:\n"
114 | ]
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": 14,
119 | "metadata": {},
120 | "outputs": [
121 | {
122 | "name": "stdout",
123 | "output_type": "stream",
124 | "text": [
125 | "[[3 4 7 7 8 8]\n",
126 | " [1 3 5 8 8 6]\n",
127 | " [2 3 3 3 6 5]\n",
128 | " [1 2 5 6 5 5]]\n"
129 | ]
130 | }
131 | ],
132 | "source": [
133 | "b = np.partition(X, 2, axis=1)\n",
134 | "print(b)"
135 | ]
136 | }
137 | ],
138 | "metadata": {
139 | "kernelspec": {
140 | "display_name": "Python 3",
141 | "language": "python",
142 | "name": "python3"
143 | },
144 | "language_info": {
145 | "codemirror_mode": {
146 | "name": "ipython",
147 | "version": 3
148 | },
149 | "file_extension": ".py",
150 | "mimetype": "text/x-python",
151 | "name": "python",
152 | "nbconvert_exporter": "python",
153 | "pygments_lexer": "ipython3",
154 | "version": "3.7.3"
155 | }
156 | },
157 | "nbformat": 4,
158 | "nbformat_minor": 2
159 | }
160 |
--------------------------------------------------------------------------------
/Oil Refineries/Readme.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
--------------------------------------------------------------------------------
/Mastering_Python_Decorators.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyPFJTTvjD+8cdUJGQWvnXZT",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Mastering Python Decorators\n",
33 | "\n",
34 | "## Enhance your functions without changing their code\n",
35 | "\n",
36 | "|  |\n",
37 | "|:--:|\n",
38 | "| Image Generated Using Canva|\n",
39 | "\n",
40 | "#### Why It’s So Important\n",
41 | "Decorators in Python are one of the most powerful and useful tools, yet they are often underutilized. They allow you to \"wrap\" a function to extend its behavior without permanently modifying it. This becomes extremely handy when adding functionalities like logging, authentication, caching, or performance tracking. Mastering decorators boosts your ability to write clean, modular, and professional-grade code.\n",
42 | "\n",
43 | "---\n",
44 | "\n",
45 | "#### Key Highlights\n",
46 | "* Add functionality to existing code easily.\n",
47 | "* Keeps functions clean and readable.\n",
48 | "* Reusable and customizable behavior extensions.\n",
49 | "* Essential for building scalable applications.\n",
50 | "\n",
51 | "---\n",
52 | "\n",
53 | "#### What is a Decorator?\n",
54 | "A decorator is simply a function that takes another function as an argument, adds some functionality, and returns another function.\n",
55 | "\n",
56 | "##### Example\n",
57 | "\n",
58 | "\n"
59 | ],
60 | "metadata": {
61 | "id": "-KE5_qxI0rRu"
62 | }
63 | },
64 | {
65 | "cell_type": "code",
66 | "source": [
67 | "# Basic decorator that logs the execution of a function\n",
68 | "def log_decorator(func):\n",
69 | " def wrapper(*args, **kwargs):\n",
70 | " print(f\"Function '{func.__name__}' is being called\")\n",
71 | " result = func(*args, **kwargs)\n",
72 | " print(f\"Function '{func.__name__}' executed successfully\")\n",
73 | " return result\n",
74 | " return wrapper\n",
75 | "\n",
76 | "# Applying the decorator\n",
77 | "@log_decorator\n",
78 | "def greet(name):\n",
79 | " print(f\"Hello, {name}!\")\n",
80 | "\n",
81 | "# Function call\n",
82 | "greet(\"Tanu\")\n"
83 | ],
84 | "metadata": {
85 | "colab": {
86 | "base_uri": "https://localhost:8080/"
87 | },
88 | "id": "ZeWDeRFR1X8O",
89 | "outputId": "5485115d-f9b6-4827-ae0b-29dd235fcec3"
90 | },
91 | "execution_count": 1,
92 | "outputs": [
93 | {
94 | "output_type": "stream",
95 | "name": "stdout",
96 | "text": [
97 | "Function 'greet' is being called\n",
98 | "Hello, Tanu!\n",
99 | "Function 'greet' executed successfully\n"
100 | ]
101 | }
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "source": [
107 | "#### What this shows\n",
108 | "* `@log_decorator` automatically wraps the greet function.\n",
109 | "* When you call `greet(\"Tanu\")`, the wrapper runs first, logs the messages, then executes the actual function.\n",
110 | "\n",
111 | "---\n",
112 | "\n",
113 | "#### Fun Fact\n",
114 | "In Python, even built-in features like `@staticmethod` and `@classmethod` are implemented as decorators!\n",
115 | "\n",
116 | "---\n",
117 | "\n",
118 | "#### Conclusion\n",
119 | "Mastering decorators empowers you to write cleaner, more efficient Python code. By adding functionality without touching the core logic, decorators make your programs more modular, readable, and professional. Thanks for reading my article, let me know if you have any suggestions or similar implementations via the comment section. Until then, see you next time. Happy coding!\n",
120 | "\n",
121 | "---\n",
122 | "\n",
123 | "### Before you go\n",
124 | "* Be sure to **Like** and **Connect** Me\n",
125 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
126 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
127 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!\n"
128 | ],
129 | "metadata": {
130 | "id": "JODXLzbK1ael"
131 | }
132 | }
133 | ]
134 | }
--------------------------------------------------------------------------------
/Numpy/Numpy_Examples3.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 16,
6 | "metadata": {},
7 | "outputs": [
8 | {
9 | "name": "stdout",
10 | "output_type": "stream",
11 | "text": [
12 | "x = [0 1 2 3]\n",
13 | "x + 5 = [5 6 7 8]\n",
14 | "x - 5 = [-5 -4 -3 -2]\n",
15 | "x * 2 = [0 2 4 6]\n",
16 | "x / 2 = [0. 0.5 1. 1.5]\n",
17 | "x // 2 = [0 0 1 1]\n",
18 | "-x = [ 0 -1 -2 -3]\n",
19 | "x ** 2 = [0 1 4 9]\n",
20 | "x % 2 = [0 1 0 1]\n",
21 | "[2 3 4 5]\n"
22 | ]
23 | }
24 | ],
25 | "source": [
26 | "# Iam very sorry because I had to copy the problems given below directly from the textbook, because it is a redundant process.\n",
27 | "# Moreover the concept of numpy library is a never ending process, because there are a ton of different methods and functions.\n",
28 | "# I think this is more than enough to learn about numpy.\n",
29 | "import numpy as np\n",
30 | "x = np.arange(4)\n",
31 | "print(\"x =\", x)\n",
32 | "print(\"x + 5 =\", x + 5)\n",
33 | "print(\"x - 5 =\", x - 5)\n",
34 | "print(\"x * 2 =\", x * 2)\n",
35 | "print(\"x / 2 =\", x / 2)\n",
36 | "print(\"x // 2 =\", x // 2) # floor division\n",
37 | "print(\"-x = \", -x)\n",
38 | "print(\"x ** 2 = \", x ** 2)\n",
39 | "print(\"x % 2 = \", x % 2)\n",
40 | "print(np.add(x, 2))"
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": 18,
46 | "metadata": {},
47 | "outputs": [
48 | {
49 | "name": "stdout",
50 | "output_type": "stream",
51 | "text": [
52 | "[2 1 0 1 2]\n",
53 | "---------------------------\n",
54 | "[5. 5. 2. 1.]\n"
55 | ]
56 | }
57 | ],
58 | "source": [
59 | "# Absolute value\n",
60 | "x = np.array([-2, -1, 0, 1, 2])\n",
61 | "print(abs(x))\n",
62 | "print(\"---------------------------\")\n",
63 | "x = np.array([3 - 4j, 4 - 3j, 2 + 0j, 0 + 1j])\n",
64 | "print(np.abs(x))\n"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": 22,
70 | "metadata": {},
71 | "outputs": [
72 | {
73 | "name": "stdout",
74 | "output_type": "stream",
75 | "text": [
76 | "---------------------------\n",
77 | "theta = [0. 1.57079633 3.14159265]\n",
78 | "sin(theta) = [0.0000000e+00 1.0000000e+00 1.2246468e-16]\n",
79 | "cos(theta) = [ 1.000000e+00 6.123234e-17 -1.000000e+00]\n",
80 | "tan(theta) = [ 0.00000000e+00 1.63312394e+16 -1.22464680e-16]\n",
81 | "---------------------------\n",
82 | "x = [-1, 0, 1]\n",
83 | "arcsin(x) = [-1.57079633 0. 1.57079633]\n",
84 | "arccos(x) = [3.14159265 1.57079633 0. ]\n",
85 | "arctan(x) = [-0.78539816 0. 0.78539816]\n"
86 | ]
87 | }
88 | ],
89 | "source": [
90 | "# Trigonometric functions\n",
91 | "\n",
92 | "theta = np.linspace(0, np.pi, 3)\n",
93 | "print(\"---------------------------\")\n",
94 | "print(\"theta = \", theta)\n",
95 | "print(\"sin(theta) = \", np.sin(theta))\n",
96 | "print(\"cos(theta) = \", np.cos(theta))\n",
97 | "print(\"tan(theta) = \", np.tan(theta))\n",
98 | "print(\"---------------------------\")\n",
99 | "\n",
100 | "x = [-1, 0, 1]\n",
101 | "print(\"x = \", x)\n",
102 | "print(\"arcsin(x) = \", np.arcsin(x))\n",
103 | "print(\"arccos(x) = \", np.arccos(x))\n",
104 | "print(\"arctan(x) = \", np.arctan(x))"
105 | ]
106 | },
107 | {
108 | "cell_type": "code",
109 | "execution_count": 25,
110 | "metadata": {},
111 | "outputs": [
112 | {
113 | "name": "stdout",
114 | "output_type": "stream",
115 | "text": [
116 | "x = [1, 2, 3]\n",
117 | "e^x = [ 2.71828183 7.3890561 20.08553692]\n",
118 | "2^x = [2. 4. 8.]\n",
119 | "3^x = [ 3 9 27]\n",
120 | "---------------------------\n",
121 | "x = [1, 2, 4, 10]\n",
122 | "ln(x) = [0. 0.69314718 1.38629436 2.30258509]\n",
123 | "log2(x) = [0. 1. 2. 3.32192809]\n",
124 | "log10(x) = [0. 0.30103 0.60205999 1. ]\n",
125 | "---------------------------\n",
126 | "exp(x) - 1 = [0. 0.0010005 0.01005017 0.10517092]\n",
127 | "log(1 + x) = [0. 0.0009995 0.00995033 0.09531018]\n"
128 | ]
129 | }
130 | ],
131 | "source": [
132 | "# Exponents and logarithms\n",
133 | "x = [1, 2, 3]\n",
134 | "print(\"x =\", x)\n",
135 | "print(\"e^x =\", np.exp(x))\n",
136 | "print(\"2^x =\", np.exp2(x))\n",
137 | "print(\"3^x =\", np.power(3, x))\n",
138 | "print(\"---------------------------\")\n",
139 | "\n",
140 | "x = [1, 2, 4, 10]\n",
141 | "print(\"x =\", x)\n",
142 | "print(\"ln(x) =\", np.log(x))\n",
143 | "print(\"log2(x) =\", np.log2(x))\n",
144 | "print(\"log10(x) =\", np.log10(x))\n",
145 | "print(\"---------------------------\")\n",
146 | "\n",
147 | "x = [0, 0.001, 0.01, 0.1]\n",
148 | "print(\"exp(x) - 1 =\", np.expm1(x))\n",
149 | "print(\"log(1 + x) =\", np.log1p(x))"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": 29,
155 | "metadata": {},
156 | "outputs": [
157 | {
158 | "name": "stdout",
159 | "output_type": "stream",
160 | "text": [
161 | "gamma(x) = [1.0000e+00 2.4000e+01 3.6288e+05]\n",
162 | "ln|gamma(x)| = [ 0. 3.17805383 12.80182748]\n",
163 | "beta(x, 2) = [0.5 0.03333333 0.00909091]\n",
164 | "---------------------------\n",
165 | "erf(x) = [0. 0.32862676 0.67780119 0.84270079]\n",
166 | "erfc(x) = [1. 0.67137324 0.32219881 0.15729921]\n",
167 | "erfinv(x) = [0. 0.27246271 0.73286908 inf]\n"
168 | ]
169 | }
170 | ],
171 | "source": [
172 | "# Another excellent source for more specialized and obscure ufuncs is the submodule\n",
173 | "# scipy.special. If you want to compute some obscure mathematical function on\n",
174 | "# your data, chances are it is implemented in scipy.special.\n",
175 | "\n",
176 | "from scipy import special\n",
177 | "x = [1, 5, 10]\n",
178 | "print(\"gamma(x) =\", special.gamma(x))\n",
179 | "print(\"ln|gamma(x)| =\", special.gammaln(x))\n",
180 | "print(\"beta(x, 2) =\", special.beta(x, 2))\n",
181 | "print(\"---------------------------\")\n",
182 | "\n",
183 | "# Error function (integral of Gaussian)\n",
184 | "# its complement, and its inverse\n",
185 | "x = np.array([0, 0.3, 0.7, 1.0])\n",
186 | "print(\"erf(x) =\", special.erf(x))\n",
187 | "print(\"erfc(x) =\", special.erfc(x))\n",
188 | "print(\"erfinv(x) =\", special.erfinv(x))\n"
189 | ]
190 | },
191 | {
192 | "cell_type": "code",
193 | "execution_count": 31,
194 | "metadata": {},
195 | "outputs": [
196 | {
197 | "name": "stdout",
198 | "output_type": "stream",
199 | "text": [
200 | "[ 0. 10. 20. 30. 40.]\n",
201 | "---------------------------\n",
202 | "[ 1. 0. 2. 0. 4. 0. 8. 0. 16. 0.]\n"
203 | ]
204 | }
205 | ],
206 | "source": [
207 | "# Advanced Ufunc Features\n",
208 | "# Specifying output\n",
209 | "\n",
210 | "x = np.arange(5)\n",
211 | "y = np.empty(5)\n",
212 | "np.multiply(x, 10, out=y)\n",
213 | "print(y)\n",
214 | "print(\"---------------------------\")\n",
215 | "\n",
216 | "y = np.zeros(10)\n",
217 | "np.power(2, x, out=y[::2])\n",
218 | "print(y)"
219 | ]
220 | },
221 | {
222 | "cell_type": "code",
223 | "execution_count": 35,
224 | "metadata": {},
225 | "outputs": [
226 | {
227 | "name": "stdout",
228 | "output_type": "stream",
229 | "text": [
230 | "15\n",
231 | "---------------------------\n",
232 | "120\n",
233 | "---------------------------\n",
234 | "[ 1 3 6 10 15]\n",
235 | "---------------------------\n",
236 | "[ 1 2 6 24 120]\n"
237 | ]
238 | }
239 | ],
240 | "source": [
241 | "# Aggregates\n",
242 | "x = np.arange(1, 6)\n",
243 | "print(np.add.reduce(x))\n",
244 | "print(\"---------------------------\")\n",
245 | "\n",
246 | "print(np.multiply.reduce(x))\n",
247 | "print(\"---------------------------\")\n",
248 | "\n",
249 | "print(np.add.accumulate(x))\n",
250 | "print(\"---------------------------\")\n",
251 | "\n",
252 | "print(np.multiply.accumulate(x))"
253 | ]
254 | }
255 | ],
256 | "metadata": {
257 | "kernelspec": {
258 | "display_name": "Python 3",
259 | "language": "python",
260 | "name": "python3"
261 | },
262 | "language_info": {
263 | "codemirror_mode": {
264 | "name": "ipython",
265 | "version": 3
266 | },
267 | "file_extension": ".py",
268 | "mimetype": "text/x-python",
269 | "name": "python",
270 | "nbconvert_exporter": "python",
271 | "pygments_lexer": "ipython3",
272 | "version": "3.7.3"
273 | }
274 | },
275 | "nbformat": 4,
276 | "nbformat_minor": 2
277 | }
278 |
--------------------------------------------------------------------------------
/Numpy/Numpy_Examples4.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [
8 | {
9 | "name": "stdout",
10 | "output_type": "stream",
11 | "text": [
12 | "[0 1 3 5 7 9]\n"
13 | ]
14 | }
15 | ],
16 | "source": [
17 | "# Sorting Arrays\n",
18 | "# Fast Sorting in NumPy: np.sort and np.argsort\n",
19 | "\n",
20 | "import numpy as np\n",
21 | "\n",
22 | "a = np.array([1, 9, 0, 7, 3, 5])\n",
23 | "sort = np.sort(a)\n",
24 | "print(sort)\n"
25 | ]
26 | },
27 | {
28 | "cell_type": "code",
29 | "execution_count": 3,
30 | "metadata": {},
31 | "outputs": [
32 | {
33 | "name": "stdout",
34 | "output_type": "stream",
35 | "text": [
36 | "[2 0 4 5 3 1]\n"
37 | ]
38 | }
39 | ],
40 | "source": [
41 | "# If you want the sorted index then use np.argsort\n",
42 | "\n",
43 | "index = np.argsort(a)\n",
44 | "print(index)"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 11,
50 | "metadata": {},
51 | "outputs": [
52 | {
53 | "name": "stdout",
54 | "output_type": "stream",
55 | "text": [
56 | "[[7 8 7 3 4 8]\n",
57 | " [6 3 8 8 5 1]\n",
58 | " [3 3 3 2 6 5]\n",
59 | " [5 2 5 6 1 5]]\n",
60 | "-----------------------------------\n",
61 | "[[3 2 3 2 1 1]\n",
62 | " [5 3 5 3 4 5]\n",
63 | " [6 3 7 6 5 5]\n",
64 | " [7 8 8 8 6 8]]\n",
65 | "-----------------------------------\n",
66 | "[[3 4 7 7 8 8]\n",
67 | " [1 3 5 6 8 8]\n",
68 | " [2 3 3 3 5 6]\n",
69 | " [1 2 5 5 5 6]]\n"
70 | ]
71 | }
72 | ],
73 | "source": [
74 | "# Sorting along rows or columns\n",
75 | "\n",
76 | "X = rand.randint(0, 10, (4, 6)) \n",
77 | "print(X)\n",
78 | "print(\"-----------------------------------\")\n",
79 | "# sort each column of X\n",
80 | "a = np.sort(X, axis=0)\n",
81 | "print(a)\n",
82 | "print(\"-----------------------------------\")\n",
83 | "# sort each row of X \n",
84 | "b = np.sort(X, axis =1)\n",
85 | "print(b)"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": 13,
91 | "metadata": {},
92 | "outputs": [
93 | {
94 | "name": "stdout",
95 | "output_type": "stream",
96 | "text": [
97 | "[7 2 3 1 6 5 4]\n",
98 | "------------------------------\n",
99 | "[2 1 3 4 6 5 7]\n"
100 | ]
101 | }
102 | ],
103 | "source": [
104 | "# Partial Sorts: Partitioning\n",
105 | "x = np.array([7, 2, 3, 1, 6, 5, 4]) \n",
106 | "print(x)\n",
107 | "print(\"------------------------------\")\n",
108 | "a = np.partition(x, 3)\n",
109 | "print(a)\n",
110 | "\n",
111 | "# NumPy provides this in the np.partition function. \n",
112 | "# np.partition takes an array and a number K; the result is a new array with the smallest K values to the left of the partition,\n",
113 | "# and the remaining values to the right, in arbitrary order:\n"
114 | ]
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": 14,
119 | "metadata": {},
120 | "outputs": [
121 | {
122 | "name": "stdout",
123 | "output_type": "stream",
124 | "text": [
125 | "[[3 4 7 7 8 8]\n",
126 | " [1 3 5 8 8 6]\n",
127 | " [2 3 3 3 6 5]\n",
128 | " [1 2 5 6 5 5]]\n"
129 | ]
130 | }
131 | ],
132 | "source": [
133 | "b = np.partition(X, 2, axis=1)\n",
134 | "print(b)"
135 | ]
136 | }
137 | ],
138 | "metadata": {
139 | "kernelspec": {
140 | "display_name": "Python 3",
141 | "language": "python",
142 | "name": "python3"
143 | },
144 | "language_info": {
145 | "codemirror_mode": {
146 | "name": "ipython",
147 | "version": 3
148 | },
149 | "file_extension": ".py",
150 | "mimetype": "text/x-python",
151 | "name": "python",
152 | "nbconvert_exporter": "python",
153 | "pygments_lexer": "ipython3",
154 | "version": "3.7.3"
155 | }
156 | },
157 | "nbformat": 4,
158 | "nbformat_minor": 2
159 | }
160 |
--------------------------------------------------------------------------------
/Oil Refineries/Readme.md:
--------------------------------------------------------------------------------
1 | Oil Refineries
2 |
3 |
4 |  5 |
5 |
6 |
7 | ## What is a Oil Refinery?
8 |
9 | An oil refinery or petroleum refinery is an industrial process plant where petroleum (crude oil) is transformed and refined into useful products such as gasoline (petrol), diesel fuel, asphalt base, fuel oils, heating oil, kerosene, liquefied petroleum gas and petroleum naphtha. Petrochemicals feedstock like ethylene and propylene can also be produced directly by cracking crude oil without the need of using refined products of crude oil such as naphtha. Source - Wiki
10 |
11 | ---
12 |
13 | ## What do oil refineries do?
14 |
15 | Petroleum refineries convert (refine) crude oil into petroleum products for use as fuels for transportation, heating, paving roads, and generating electricity and as feedstocks for making chemicals. Refining breaks crude oil down into its various components, which are then selectively reconfigured into new products
16 |
17 | ---
18 |
19 | ## How many oil refineries does Canada has?
20 |
21 | Canada is home to 15 refineries, all of which are operated by Canadian Fuels members and represent the country's refining capacity. Canada is a net exporter, mainly to the United States, of refined petroleum products and crude oil
22 |
23 |
24 | ---
25 |
26 | ## List of Canadian Oil Refineries
27 |
28 |
29 | 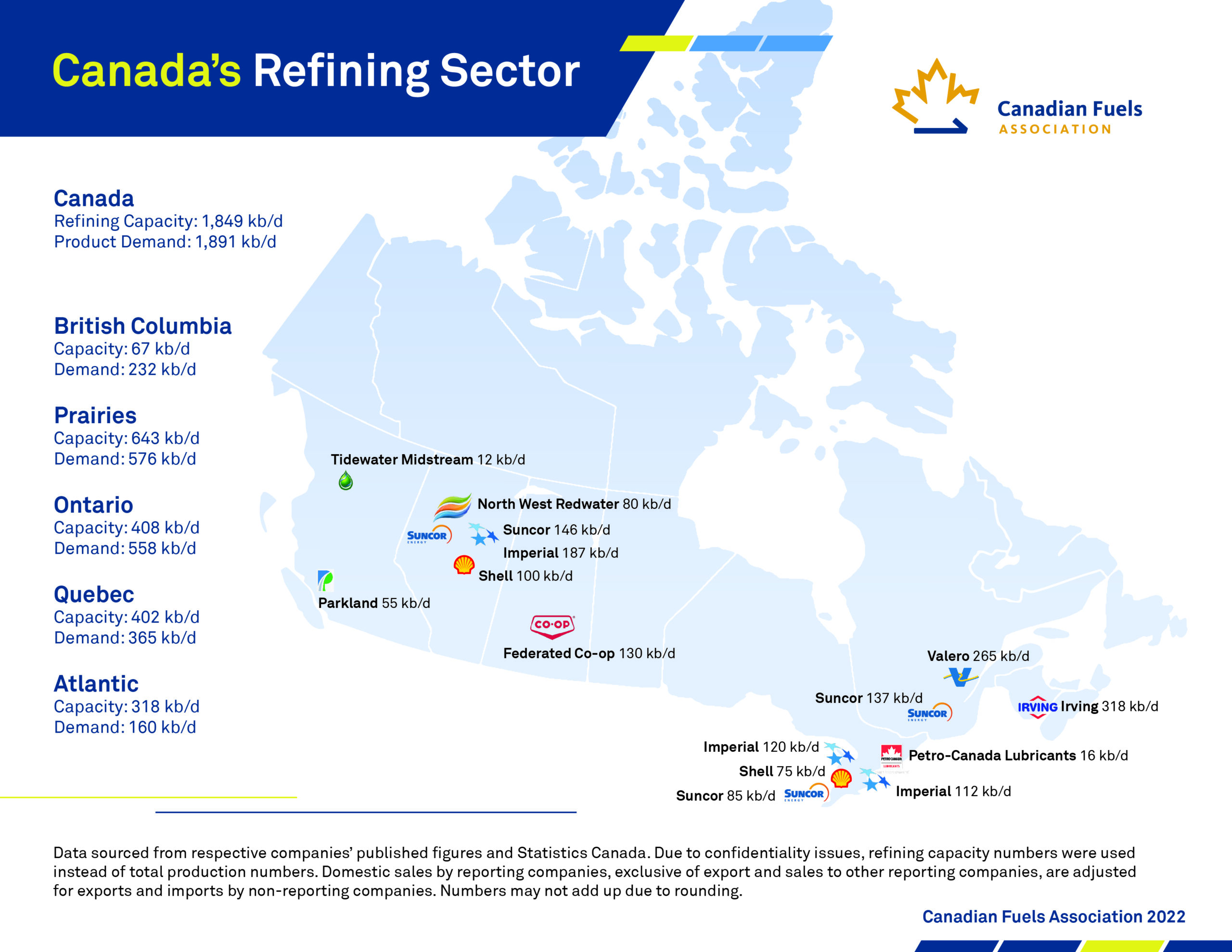 30 |
30 |
31 |
32 | I have gathered the below list of Canadian Oil Refineries by provinces. Thanks to [Oil Sand Magazine](https://www.oilsandsmagazine.com/projects/canadian-refineries) for the data.
33 |
34 | | Name | Province | City | Year | Capacity |
35 | | :---------------- |:---------------- | :---------------- | :---------------- | :---------------- |
36 | | Irving Oil Refinery | New Brunswick | Saint John | 1960 | 300,000 |
37 | | Jean-Gaulin Refinery | Quebec | Lévis | 1971 | 235000 |
38 | | Strathcona Refinery | Alberta | Edmonton | 1974 | 191000 |
39 | | Edmonton Refinery | Alberta | Edmonton | 1951 | 146000 |
40 | | Co-op Refinery | Saskatchewan | Regina | 1935 | 145000 |
41 | | Montreal Refinery | Quebec | Montreal | 1955 | 137000 |
42 | | North Atlantic Refinery | Newfoundland and Labrador | Come By Chance | 1973 | 130000 |
43 | | Sarnia Refinery | Ontario | Sarnia | 1897 | 127000 |
44 | | Scotford Refinery | Alberta | Strathcona County | 1984 | 114000 |
45 | | Nanticoke Refinery | Ontario | Nanticoke | 1978 | 112000 |
46 | | Sarnia Refinery | Ontario | Sarnia | 1953 | 85000 |
47 | | Sturgeon Refinery | Alberta | Sturgeon County | 2020 | 79000 |
48 | | Corunna Refinery | Ontario | Saint Clair | 1952 | 75000 |
49 | | Burnaby Refinery | British Columbia | Burnaby | 1936 | 55000 |
50 | | Lloydminster Refinery | Alberta | Lloydminister | 1947 | 30000 |
51 | | Moose Jaw Refinery | Saskatchewan | Moose Jaw | 1934 | 22000 |
52 | | Clarkson Refinery | Ontario | Mississauga | 1943 | 15600 |
53 | | Prince George Refinery | British Columbia | Prince George | 1967 | 12000 |
54 |
55 | ---
56 |
57 | ## World's largest refineries
58 |
59 |
60 |  61 |
61 |
62 |
63 | | Name | State | City | Country | Capacity |
64 | | :---------------- |:---------------- | :---------------- | :---------------- | :---------------- |
65 | | Jamnagar Refinery (Reliance Industries) | Gujarat | Jamnagar | India | 1,240,000 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
--------------------------------------------------------------------------------
/Optimizing_Python_Code_with_List_Comprehensions.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyNyEEzMdqD+qPu/0YOpVtei",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Optimizing Python Code with List Comprehensions\n",
33 | "\n",
34 | "## Write faster and cleaner loops the Pythonic way\n",
35 | "\n",
36 | "|  |\n",
37 | "|:--:|\n",
38 | "| Photo by Brecht Corbeel on Unsplash|\n",
39 | "\n",
40 | "\n",
41 | "#### Introduction\n",
42 | "\n",
43 | "When you first learn Python, you’re introduced to `for` loops. They work fine, but once you want faster, cleaner, and more professional-looking code, Python offers a beautiful shortcut called List Comprehensions.\n",
44 | "\n",
45 | "List comprehensions condense loops into a single line without sacrificing readability, and in many cases, they make your code more intuitive.\n",
46 | "\n",
47 | "---\n",
48 | "\n",
49 | "#### What is a List Comprehension?\n",
50 | "In simple terms, list comprehension is a concise way to create lists based on existing lists (or any iterable). Instead of writing multiple lines to build a list, you do it all in one elegant line.\n",
51 | "\n",
52 | "##### Syntax\n",
53 | "\n",
54 | "```\n",
55 | "new_list = [expression for item in iterable if condition]\n",
56 | "```\n",
57 | "---\n",
58 | "\n",
59 | "#### Why is it so important\n",
60 | "* Cleaner Code: Reduces boilerplate and improves readability.\n",
61 | "* Better Performance: Executes faster than traditional for loops.\n",
62 | "* Pythonic Style: This shows you understand and embrace Python's philosophy of simplicity.\n",
63 | "* Conditional Logic: Easily add conditions inside comprehensions.\n",
64 | "* Nesting Possible: You can even nest comprehensions for multidimensional data (carefully!).\n",
65 | "\n",
66 | "---\n",
67 | "\n",
68 | "#### Implementation\n",
69 | "##### Traditional For Loop\n",
70 | "\n",
71 | "\n",
72 | "\n"
73 | ],
74 | "metadata": {
75 | "id": "xybDgq3b4wRb"
76 | }
77 | },
78 | {
79 | "cell_type": "code",
80 | "source": [
81 | "squares = []\n",
82 | "for i in range(10):\n",
83 | " squares.append(i ** 2)\n",
84 | "\n",
85 | "squares"
86 | ],
87 | "metadata": {
88 | "colab": {
89 | "base_uri": "https://localhost:8080/"
90 | },
91 | "id": "ryvVtZ935Pki",
92 | "outputId": "b1dd9032-ebad-4775-e9aa-489d066c729f"
93 | },
94 | "execution_count": 3,
95 | "outputs": [
96 | {
97 | "output_type": "execute_result",
98 | "data": {
99 | "text/plain": [
100 | "[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]"
101 | ]
102 | },
103 | "metadata": {},
104 | "execution_count": 3
105 | }
106 | ]
107 | },
108 | {
109 | "cell_type": "markdown",
110 | "source": [
111 | "##### Using List Comprehension\n",
112 | "\n"
113 | ],
114 | "metadata": {
115 | "id": "Wms5iQ2N5Vdu"
116 | }
117 | },
118 | {
119 | "cell_type": "code",
120 | "source": [
121 | "squares = [i ** 2 for i in range(10)]\n",
122 | "squares"
123 | ],
124 | "metadata": {
125 | "colab": {
126 | "base_uri": "https://localhost:8080/"
127 | },
128 | "id": "NRPKBNGl5We_",
129 | "outputId": "437844cf-83c4-4c46-ff5f-55709d55ef6f"
130 | },
131 | "execution_count": 4,
132 | "outputs": [
133 | {
134 | "output_type": "execute_result",
135 | "data": {
136 | "text/plain": [
137 | "[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]"
138 | ]
139 | },
140 | "metadata": {},
141 | "execution_count": 4
142 | }
143 | ]
144 | },
145 | {
146 | "cell_type": "markdown",
147 | "source": [
148 | "> ***Did you see how shorter and cleaner it is?***\n",
149 | "\n",
150 | "##### Adding Conditions (Let's step it up)\n",
151 | "\n",
152 | "Suppose you want only even squares"
153 | ],
154 | "metadata": {
155 | "id": "XcyqfMg_5bJO"
156 | }
157 | },
158 | {
159 | "cell_type": "code",
160 | "source": [
161 | "even_squares = [i ** 2 for i in range(10) if i % 2 == 0]\n",
162 | "even_squares"
163 | ],
164 | "metadata": {
165 | "colab": {
166 | "base_uri": "https://localhost:8080/"
167 | },
168 | "id": "fCAU8hDg5fzB",
169 | "outputId": "b0f803c0-980a-44fe-8543-dd94fa4b893a"
170 | },
171 | "execution_count": 5,
172 | "outputs": [
173 | {
174 | "output_type": "execute_result",
175 | "data": {
176 | "text/plain": [
177 | "[0, 4, 16, 36, 64]"
178 | ]
179 | },
180 | "metadata": {},
181 | "execution_count": 5
182 | }
183 | ]
184 | },
185 | {
186 | "cell_type": "markdown",
187 | "source": [
188 | "> ***This is what called as a one-liner!***\n",
189 | "\n",
190 | "---\n",
191 | "\n",
192 | "#### Common Mistakes to Avoid\n",
193 | "* **Overcomplicating**: If comprehension looks confusing, use a normal loop instead.\n",
194 | "* **Too Many Nestings**: Nesting 2 or more comprehensions can get messy. I prefer breaking into separate steps when needed. Whatever you do, choose wisely!\n",
195 | "\n",
196 | "---\n",
197 | "\n",
198 | "#### Fun Fact\n",
199 | "List comprehension can be nearly twice as fast as traditional `for` loops because they’re optimized at the C level internally by Python!\n",
200 | "\n",
201 | "---\n",
202 | "\n",
203 | "#### Conclusion\n",
204 | "List comprehensions are a must-know technique for anyone who wants to write efficient, clean, and Pythonic code. Master them, and you’ll instantly level up the quality (and speed) of your Python scripts. I hope you learned something new today! Suggestions and comments are welcomed in the comment section. Until then, see you next time. Happy Coding!\n",
205 | "\n",
206 | "---\n",
207 | "\n",
208 | "#### Before you go\n",
209 | "* Be sure to Like and Connect Me\n",
210 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
211 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
212 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!\n"
213 | ],
214 | "metadata": {
215 | "id": "ccFA7LZx5i0Y"
216 | }
217 | }
218 | ]
219 | }
--------------------------------------------------------------------------------
/Python Coding Interview Prep/35 Python interview questions for experienced.md:
--------------------------------------------------------------------------------
1 | # Python Coding Interview Questions And Answers - Experienced
2 |
3 | Here Coding compiler sharing a list of 35 Python interview questions for experienced. These Python questions are prepared by expert Python developers. This list of interview questions on Python will help you to crack your next Python job interview. All the best for your future and happy [python learning](https://codingcompiler.com/python-coding-interview-questions-answers/)
4 |
5 | [](https://hits.seeyoufarm.com)
6 |
7 |
8 | ## 1. Debugging a Python Program
9 |
10 | ```python
11 | # By using this command we can debug a python program
12 | python -m pdb python-script.py
13 | ```
14 |
15 | ---
16 |
17 | ## 2. Yield Keyword in Python
18 | ### The keyword in Python can turn any function into a generator. Yields work like a standard return keyword.
19 |
20 | ```python
21 | def days(index):
22 | day = ['S','M','T','W','Tr','F','St']
23 | yield day[index]
24 | yield day[index+1]
25 |
26 | res = days(0)
27 | print(next(res), next(res))
28 |
29 | > S M
30 | ```
31 | ----
32 |
33 | ## 3. Converting a List into a String
34 | ### When we want to convert a list into a string, we can use the `<.join()>` method which joins all the elements into one and returns as a string.
35 |
36 | ```python
37 | days = ['S','M','T','W','Tr','F','St']
38 | ltos = ' '.join(days)
39 | print(ltos)
40 |
41 | > S M T W Tr F St
42 | ```
43 | ---
44 |
45 | ## 4. Converting a List into a Tuple
46 | ### By using Python `` function we can convert a list into a tuple. But we can’t change the list after turning it into tuple, because it becomes immutable.
47 |
48 | ```python
49 | days = ['S','M','T','W','Tr','F','St']
50 | ltos = tuple(days)
51 | print(ltos)
52 |
53 | > ('S', 'M', 'T', 'W', 'Tr', 'F', 'St')
54 | ```
55 | ---
56 |
57 |
58 | ## 5. Converting a List into a Set
59 | ### User can convert list into set by using `` function.
60 |
61 | ```python
62 | days = ['S','M','T','W','Tr','F','St']
63 | ltos = set(days)
64 | print(ltos)
65 |
66 | > {'T', 'W', 'M', 'F', 'S', 'Tr', 'St'}
67 | ```
68 | ---
69 |
70 | ## 6. Counting the occurrences of a particular element in the list
71 | ### We can count the occurrences of an individual element by using a `` function.
72 |
73 | ```python
74 | days = ['S','M','W', 'M','M','F','S']
75 |
76 | print(days.count('M'))
77 |
78 | > 3
79 | ```
80 | ---
81 |
82 | ### 6.1. Counting the occurrences of elements in the list
83 |
84 | ```python
85 | days = ['S','M','M','M','F','S']
86 | y = set(days)
87 |
88 | print([[x,days.count(x)] for x in y])
89 |
90 | > [['M', 3], ['S', 2], ['F', 1]]
91 | ```
92 |
93 | ---
94 |
95 | ## 7. Creating a NumPy Array in Python
96 | ### NumPy arrays are more flexible then lists in Python.
97 |
98 | ```python
99 | import numpy as np
100 |
101 | arr = np.array([1, 2, 3, 4, 5])
102 |
103 | print(arr)
104 | print(type(arr))
105 |
106 | > [1 2 3 4 5]
107 |
108 |
109 | ```
110 | ---
111 |
112 | ## 8. Implement a LRU (Least Recently Used) Cache
113 |
114 | ```python
115 | from collections import OrderedDict
116 |
117 | class LRUCache:
118 | def __init__(self, capacity: int):
119 | self.cache = OrderedDict()
120 | self.capacity = capacity
121 |
122 | def get(self, key: int) -> int:
123 | if key not in self.cache:
124 | return -1
125 | else:
126 | self.cache.move_to_end(key)
127 | return self.cache[key]
128 |
129 | def put(self, key: int, value: int) -> None:
130 | if key in self.cache:
131 | self.cache.move_to_end(key)
132 | self.cache[key] = value
133 | if len(self.cache) > self.capacity:
134 | self.cache.popitem(last=False)
135 |
136 | # Example usage:
137 | lru = LRUCache(2)
138 | lru.put(1, 1)
139 | lru.put(2, 2)
140 | print(lru.get(1))
141 | lru.put(3, 3)
142 |
143 | > 1
144 | ```
145 | ---
146 |
147 | ## 9. Find the Longest Substring Without Repeating Characters
148 |
149 | ```python
150 | def length_of_longest_substring(s: str) -> int:
151 | char_index_map = {}
152 | start = max_length = 0
153 |
154 | for i, char in enumerate(s):
155 | if char in char_index_map and char_index_map[char] >= start:
156 | start = char_index_map[char] + 1
157 | char_index_map[char] = i
158 | max_length = max(max_length, i - start + 1)
159 |
160 | return max_length
161 |
162 | # Example usage:
163 | print(length_of_longest_substring("abcabcbb"))
164 |
165 | > 3
166 |
167 | ```
168 | ---
169 |
170 | ## 10. Find the Kth Largest Element in an Array
171 |
172 | ```python
173 | import heapq
174 |
175 | def find_kth_largest(nums: list, k: int) -> int:
176 | return heapq.nlargest(k, nums)[-1]
177 |
178 | # Example usage:
179 | print(find_kth_largest([3, 2, 1, 5, 6, 4], 2))
180 |
181 | > 5
182 |
183 | ```
184 |
185 | ---
186 |
187 | ## 11. Detect a Cycle in a Linked List
188 |
189 | ```python
190 |
191 | class ListNode:
192 | def __init__(self, value=0, next=None):
193 | self.value = value
194 | self.next = next
195 |
196 | def has_cycle(head: ListNode) -> bool:
197 | slow = fast = head
198 | while fast and fast.next:
199 | slow = slow.next
200 | fast = fast.next.next
201 | if slow == fast:
202 | return True
203 | return False
204 |
205 | # Example usage:
206 | # Creating a linked list with a cycle for demonstration:
207 | node1 = ListNode(1)
208 | node2 = ListNode(2)
209 | node3 = ListNode(3)
210 | node1.next = node2
211 | node2.next = node3
212 | node3.next = node1 # Cycle here
213 | print(has_cycle(node1))
214 |
215 | > True
216 |
217 | ```
218 | ---
219 |
220 | ## 12. Serialize and Deserialize a Binary Tree
221 |
222 | ```python
223 |
224 | class TreeNode:
225 | def __init__(self, val=0, left=None, right=None):
226 | self.val = val
227 | self.left = left
228 | self.right = right
229 |
230 | class Codec:
231 | def serialize(self, root: TreeNode) -> str:
232 | def dfs(node):
233 | if not node:
234 | result.append("None")
235 | else:
236 | result.append(str(node.val))
237 | dfs(node.left)
238 | dfs(node.right)
239 | result = []
240 | dfs(root)
241 | return ','.join(result)
242 |
243 | def deserialize(self, data: str) -> TreeNode:
244 | def dfs():
245 | val = next(values)
246 | if val == "None":
247 | return None
248 | node = TreeNode(int(val))
249 | node.left = dfs()
250 | node.right = dfs()
251 | return node
252 | values = iter(data.split(','))
253 | return dfs()
254 |
255 | # Example usage:
256 | codec = Codec()
257 | tree = TreeNode(1, TreeNode(2), TreeNode(3, TreeNode(4), TreeNode(5)))
258 | serialized = codec.serialize(tree)
259 | print(serialized)
260 | deserialized = codec.deserialize(serialized)
261 |
262 | > "1,2,None,None,3,4,None,None,5,None,None"
263 |
264 | ```
265 | ---
266 |
267 |
268 |
269 |
270 |
271 | [](https://opensource.org/)
272 | [](https://tanu-n-prabhu.github.io/myWebsite.io/)
273 | [](http://commonmark.org)
274 |
275 |
276 |
277 |
278 |
--------------------------------------------------------------------------------
/Python Coding Interview Prep/Basic_calculator.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyMKvR+DF9qlkhkkPrzv+zEK",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Basic Calculator\n",
33 | "\n",
34 | "## Problem\n",
35 | "\n",
36 | "Given a string s representing a valid expression, implement a basic calculator to evaluate it, and return the result of the evaluation.\n",
37 | "\n",
38 | "> Note: You are not allowed to use any built-in function which evaluates strings as mathematical expressions, such as eval().\n",
39 | "\n",
40 | "```\n",
41 | "Example 1\n",
42 | "Input: s = \"1 + 1\"\n",
43 | "Output: 2\n",
44 | "\n",
45 | "Example 2\n",
46 | "Input: s = \"2-1 + 2\"\n",
47 | "Output: 3\n",
48 | "\n",
49 | "Example 3\n",
50 | "Input: s = \"(1+(4+5+2)-3)+(6+8)\"\n",
51 | "Output: 23\n",
52 | "\n",
53 | "Constraints\n",
54 | "1 <= s.length <= 3 * 105\n",
55 | "s consists of digits, '+', '-', '(', ')', and ' '.\n",
56 | "s represents a valid expression.\n",
57 | "'+' is not used as a unary operation (i.e., \"+1\" and \"+(2 + 3)\" is invalid).\n",
58 | "'-' could be used as a unary operation (i.e., \"-1\" and \"-(2 + 3)\" is valid).\n",
59 | "\n",
60 | "There will be no two consecutive operators in the input.\n",
61 | "Every number and running calculation will fit in a signed 32-bit integer.\n"
62 | ],
63 | "metadata": {
64 | "id": "YpjYRBtSkCUr"
65 | }
66 | },
67 | {
68 | "cell_type": "markdown",
69 | "source": [
70 | "## Solution"
71 | ],
72 | "metadata": {
73 | "id": "7P0B3DxAlDNW"
74 | }
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 1,
79 | "metadata": {
80 | "colab": {
81 | "base_uri": "https://localhost:8080/"
82 | },
83 | "id": "hXwpq4W-jVXC",
84 | "outputId": "5190701d-9b85-49b2-9326-09ca5650df91"
85 | },
86 | "outputs": [
87 | {
88 | "output_type": "stream",
89 | "name": "stdout",
90 | "text": [
91 | "23\n"
92 | ]
93 | }
94 | ],
95 | "source": [
96 | "class Solution:\n",
97 | " def calculate(self, s: str) -> int:\n",
98 | " stack = []\n",
99 | " num = 0\n",
100 | " sign = 1\n",
101 | " result = 0\n",
102 | "\n",
103 | " for char in s:\n",
104 | " if char.isdigit():\n",
105 | " num = num * 10 + int(char)\n",
106 | " elif char == \"+\":\n",
107 | " result += sign * num\n",
108 | " num = 0\n",
109 | " sign = 1\n",
110 | " elif char == \"-\":\n",
111 | " result += sign * num\n",
112 | " num = 0\n",
113 | " sign = -1\n",
114 | " elif char == \"(\":\n",
115 | " stack.append(result)\n",
116 | " stack.append(sign)\n",
117 | " result = 0\n",
118 | " sign = 1\n",
119 | " elif char == \")\":\n",
120 | " result += sign * num\n",
121 | " num = 0\n",
122 | " result *= stack.pop() # Pop the sign.\n",
123 | " result += stack.pop() # Pop the preceding result.\n",
124 | "\n",
125 | " result += sign * num\n",
126 | " return result\n",
127 | "\n",
128 | "\n",
129 | "# Example usage:\n",
130 | "solution = Solution()\n",
131 | "s = \"(1+(4+5+2)-3)+(6+8)\"\n",
132 | "result = solution.calculate(s)\n",
133 | "print(result) # Output: 23"
134 | ]
135 | },
136 | {
137 | "cell_type": "markdown",
138 | "source": [
139 | "## Credits\n",
140 | "\n",
141 | "I would like to thank [Dhirajpatra](https://github.com/dhirajpatra) for writing this piece of code. Feel free to reach him out if you have any questions about Python Programming.\n"
142 | ],
143 | "metadata": {
144 | "id": "xF26di99lOJd"
145 | }
146 | }
147 | ]
148 | }
--------------------------------------------------------------------------------
/Python Coding Interview Prep/Children_with_candy.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyPKS8ATQwYGAld9M5c891zB",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "Assigning Candies to Childrens\n",
33 | "\n",
34 | "## Problem Statement\n",
35 | "\n",
36 | "There are n children standing in a line. Each child is assigned a rating value given in the integer array ratings.\n",
37 | "You are giving candies to these children subjected to the following requirements:\n",
38 | "Each child must have at least one candy.\n",
39 | "Children with a higher rating get more candies than their neighbors.\n",
40 | "Return the minimum number of candies you need to have to distribute the candies to the children.\n",
41 | "\n",
42 | "## Example\n",
43 | "\n",
44 | "```\n",
45 | "Example 1:**bold text**\n",
46 | "Input: ratings = [1,0,2]\n",
47 | "Output: 5\n",
48 | "Explanation: You can allocate to the first, second and third child with 2, 1, 2 candies respectively.\n",
49 | "\n",
50 | "Example 2:\n",
51 | "Input: ratings = [1,2,2]\n",
52 | "Output: 4\n",
53 | "Explanation: You can allocate to the first, second and third child with 1, 2, 1 candies respectively.\n",
54 | "The third child gets 1 candy because it satisfies the above two conditions.\n",
55 | "\n",
56 | "Constraints:\n",
57 | "n == ratings.length\n",
58 | "1 <= n <= 2 * 104\n",
59 | "0 <= ratings[i] <= 2 * 104\n",
60 | "```\n",
61 | "\n",
62 | "## Solution"
63 | ],
64 | "metadata": {
65 | "id": "CpCMQv8CXrWL"
66 | }
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": null,
71 | "metadata": {
72 | "colab": {
73 | "base_uri": "https://localhost:8080/"
74 | },
75 | "id": "s26tYMsXWoiD",
76 | "outputId": "d0e766e6-871e-411f-baad-750ba04eab12"
77 | },
78 | "outputs": [
79 | {
80 | "output_type": "stream",
81 | "name": "stdout",
82 | "text": [
83 | "5\n",
84 | "4\n"
85 | ]
86 | }
87 | ],
88 | "source": [
89 | "from typing import List\n",
90 | "\n",
91 | "class Solution:\n",
92 | " def candy(self, ratings: List[int]) -> int:\n",
93 | " n = len(ratings)\n",
94 | " candies = [1] * n\n",
95 | "\n",
96 | " # Iterate from left to right\n",
97 | " for i in range(1, n):\n",
98 | " if ratings[i] > ratings[i - 1]:\n",
99 | " candies[i] = candies[i - 1] + 1\n",
100 | "\n",
101 | " total_candies = candies[n - 1]\n",
102 | "\n",
103 | " # Iterate from right to left and update candies\n",
104 | " for i in range(n - 2, -1, -1):\n",
105 | " if ratings[i] > ratings[i + 1]:\n",
106 | " candies[i] = max(candies[i], candies[i + 1] + 1)\n",
107 | " total_candies += candies[i]\n",
108 | "\n",
109 | " return total_candies\n",
110 | "\n",
111 | "# Example usage\n",
112 | "if __name__ == \"__main__\":\n",
113 | " solution = Solution()\n",
114 | " ratings1 = [1, 0, 2]\n",
115 | " ratings2 = [1, 2, 2]\n",
116 | " print(solution.candy(ratings1)) # Expected output: 5\n",
117 | " print(solution.candy(ratings2)) # Expected output: 4\n"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "source": [
123 | "## Credits\n",
124 | "\n",
125 | "I would like to thank [Dhirajpatra](https://github.com/dhirajpatra) for writing this piece of code. Feel free to reach him out if you have any questions about Python Programming."
126 | ],
127 | "metadata": {
128 | "id": "3_di5W04imv6"
129 | }
130 | }
131 | ]
132 | }
--------------------------------------------------------------------------------
/Python Coding Interview Prep/Python_Interview_Questions_and_Answers.md:
--------------------------------------------------------------------------------
1 | # Mastering Python Interviews: Essential Questions and Expert Answers
2 | ## Your Ultimate Guide to Acing Python Coding Interviews with Confidence
3 |
4 |
5 | |  |
6 | |:--:|
7 | | Photo by Zach Graves on Unsplash|
8 |
9 |
10 | [](https://hits.seeyoufarm.com)
11 |
12 | ## Introduction
13 | In the ever-evolving world of software development, Python has emerged as one of the most popular programming languages, thanks to its simplicity, versatility, and extensive community support. Whether you're a seasoned developer or a beginner, Python’s readable syntax and robust libraries make it a preferred choice for tasks ranging from web development to data science and machine learning.
14 |
15 | As the demand for Python developers continues to grow, so does the competition in landing a role in this field. Preparing for Python coding interviews requires not only a strong grasp of fundamental concepts but also the ability to solve problems efficiently. This article aims to equip you with a comprehensive set of Python interview questions and answers, covering everything from basic syntax to advanced topics. Whether you're gearing up for your first coding interview or looking to refine your skills, this guide will help you navigate the key concepts and strategies to succeed in your next Python interview.
16 |
17 | This introduction sets the stage by highlighting Python’s importance and the value of preparing for coding interviews, appealing to both newcomers and experienced developers.
18 |
19 | ---
20 |
21 | ## 1. Discuss some characteristics of the Python programming language.
22 |
23 | Python is object-oriented, it's easy to read and makes complex tasks simple. It's a Rapid Application Development (RAD) program, and I often use it as a scripting language. It's an interpreted language, dynamically typed, and its functions are first-class objects. You can use any text editor to write Python. Python uses third-party modules, is compatible with all major operating systems, and dynamically uses variables. Other reasons it's popular are its outstanding library, it's ability to support big data, and that it can expedite test-driven development.
24 |
25 | ---
26 |
27 | ## 2. What are some of Python's core default modules?
28 |
29 | Default modules include email, which is parsed and generated by Python. Other default modules are XML support, string, and databases.
30 |
31 | ---
32 |
33 | ## 3. Discuss the frameworks for app development that are popular with Python users.
34 |
35 | Python is an excellent general-purpose dynamic language because it's easy to understand and implement. It's popular for creating various apps for mobile phones because of its interactive environment. It runs on the major operating systems, and there are many frameworks for using Python. For instance, Pyramid, Circuits, and CherryPy as well as other frameworks are Flask, Web2Py, Pycnic, and Django.
36 |
37 | ---
38 |
39 | ## 4. How does Python manage memory?
40 |
41 | Python manages memory with private heap space. The private heap holds Python objects and data structures. The memory manager assigns objects. The garbage collector recycles any unused memory and routes it to the heap space.
42 |
43 | ---
44 |
45 | ## 5. Explain and give an example of inheritance
46 |
47 | The inheritance function gives one class the characteristics and methods of another class. The child class, or the derived class, gains the characteristics. Super-class is the data sending the characteristics. The reason for inheritance is to create and maintain apps and deliver code reusability. Python supports three types of inheritance. One is the single inheritance where a derived class obtains a single superclass. The second Python inheritance is multi-faceted where data can inherit a derived class from another. Finally, multiple inheritance means that a child class receives all the methods and attributes from one or more base, or parent, classes.
48 |
49 | ---
50 |
51 | ## 6. What are arrays in Python?
52 |
53 | An array is a special variable that holds more than one value at a time. Python doesn't have built-in arrays, so instead, we can use lists. Alternatively, to develop arrays in Python I might import a library like NumPy. Arrays contain mixed data types, and the numarray module even provides support for IDL-style array operations, multi-dimensional arrays, and the 'where' function. The numarray only works with numbers, and its length is the highest array index plus one. Lists support objects and strings but can also convert to arrays.
54 |
55 | ---
56 |
57 | ## 7. What are Python’s key features?
58 |
59 | * **Interpreted** - Python code is executed line-by-line.
60 | * **Dynamically Typed** - No need to declare the data type of variables.
61 | Garbage Collection: Automatic memory management.
62 | Extensive Libraries: Large standard library and third-party modules.
63 | Object-Oriented: Supports OOP with classes and objects.
64 | Cross-Platform: Runs on various platforms without modification.
65 | 2. Explain Python’s memory management.
66 | Python uses a private heap to store objects and data structures.
67 | Memory management includes reference counting for garbage collection.
68 | The gc (garbage collector) module can be used to manually manage memory.
69 | 3. What are Python’s data types?
70 | Numeric Types: int, float, complex
71 | Sequence Types: list, tuple, range
72 | Text Type: str
73 | Set Types: set, frozenset
74 | Mapping Type: dict
75 | Boolean Type: bool
76 | None Type: NoneType
77 | 4. How is memory managed in Python?
78 | Memory management is handled by the Python memory manager.
79 | It includes private heap space and garbage collection.
80 | Python’s memory manager automatically handles the allocation and deallocation of memory.
81 | 5. What is the difference between deep copy and shallow copy?
82 | Shallow Copy: Creates a new object but inserts references to the same objects in the original.
83 | python
84 | Copy code
85 | import copy
86 | original_list = [[1, 2], [3, 4]]
87 | shallow_copy = copy.copy(original_list)
88 | Deep Copy: Creates a new object and recursively copies all objects found in the original.
89 | python
90 | Copy code
91 | deep_copy = copy.deepcopy(original_list)
92 | 6. What are Python decorators?
93 | Decorators are functions that modify the behavior of another function or method.
94 | They are commonly used for logging, enforcing access control, instrumentation, etc.
95 | python
96 | Copy code
97 | def decorator(func):
98 | def wrapper():
99 | print("Something before the function.")
100 | func()
101 | print("Something after the function.")
102 | return wrapper
103 |
104 | @decorator
105 | def say_hello():
106 | print("Hello!")
107 | 7. What are Python’s built-in data structures?
108 | List: Ordered, mutable, allows duplicates.
109 | Tuple: Ordered, immutable, allows duplicates.
110 | Set: Unordered, mutable, no duplicates.
111 | Dictionary: Key-value pairs, unordered, mutable.
112 | 8. Explain the use of Python’s with statement.
113 | The with statement simplifies exception handling by encapsulating standard uses of try/finally statements in so-called context managers.
114 | Example with file handling:
115 | python
116 | Copy code
117 | with open('file.txt', 'r') as file:
118 | data = file.read()
119 | 9. How does Python handle exceptions?
120 | Python uses try, except, finally, and else blocks to handle exceptions.
121 | python
122 | Copy code
123 | try:
124 | result = 10 / 0
125 | except ZeroDivisionError:
126 | print("Cannot divide by zero!")
127 | finally:
128 | print("Execution complete.")
129 | 10. What are Python’s lambda functions?
130 | Anonymous functions defined using the lambda keyword.
131 | python
132 | Copy code
133 | add = lambda x, y: x + y
134 | print(add(2, 3)) # Output: 5
135 | 11. Explain list comprehension.
136 | A concise way to create lists using a single line of code.
137 | python
138 | Copy code
139 | squares = [x**2 for x in range(10)]
140 | 12. What are Python’s *args and **kwargs?
141 | *args is used to pass a variable number of positional arguments.
142 | **kwargs is used to pass a variable number of keyword arguments.
143 | python
144 | Copy code
145 | def example_function(*args, **kwargs):
146 | print(args)
147 | print(kwargs)
148 | example_function(1, 2, 3, name="John", age=30)
149 | 13. What is Python’s GIL (Global Interpreter Lock)?
150 | The GIL is a mutex that protects access to Python objects, preventing multiple native threads from executing Python bytecodes simultaneously in CPython.
151 | It simplifies memory management but can be a bottleneck in CPU-bound multi-threaded programs.
152 | 14. How is Python different from other programming languages?
153 | Python emphasizes readability and simplicity.
154 | It is dynamically typed and interpreted.
155 | It has extensive libraries and is often considered more beginner-friendly.
156 | 15. What is the difference between Python 2 and Python 3?
157 | Print Statement: Python 2 uses print, Python 3 uses print().
158 | Integer Division: Python 2’s division of integers truncates the decimal, Python 3 returns a float.
159 | Unicode: Python 3 uses Unicode by default for strings.
160 | These questions cover fundamental concepts and common practices in Python, providing a solid foundation for coding interviews.
161 |
162 |
--------------------------------------------------------------------------------
/Python Coding Interview Prep/Python_Interview_Questions_and_Answers_Strings.md:
--------------------------------------------------------------------------------
1 | # Python Interview Questions and Answers - Strings 2025
2 | ## Master Advanced String Manipulation Techniques for Python Interviews
3 |
4 | | |
5 | |:--:|
6 | | Photo by Gaelle Marcel on Unsplash |
7 |
8 |
9 |
10 | [](https://hits.seeyoufarm.com)
11 |
12 | # Introduction
13 |
14 | Strings are a fundamental aspect of Python programming, playing a crucial role in many applications, from web development to data analysis. In technical interviews, string manipulation questions are commonly asked to evaluate a candidate’s problem-solving abilities and understanding of key programming concepts.
15 |
16 | This repository focuses on advanced Python string interview questions and their solutions. It covers a wide range of topics, including permutations, palindromes, anagram grouping, regular expression matching, and more. Whether you're preparing for a coding interview or looking to enhance your Python skills, these examples will provide valuable insights and practical techniques to handle complex string problems efficiently.
17 |
18 | Dive into these advanced string challenges and sharpen your skills to ace your next technical interview!
19 |
20 | ---
21 |
22 | ## 1. Python program to remove characters from a string
23 |
24 |
25 | Hint
26 |
27 |
28 | > **Input** - Python
29 | >
30 | > **Input Character** - o
31 | >
32 | > **Output** - Pythn
33 |
34 |
35 | Hint
51 |
52 |
53 | > **Input** - Python
54 | >
55 | > **Input Character** - o
56 | >
57 | > **Output** - 1
58 |
59 |
60 | Hint
79 |
80 |
81 | > Input - Python
82 | >
83 | > Input Character - onypth
84 | >
85 | > Output - Anagrams
86 |
87 |
88 | Hint
107 |
108 |
109 | > Input - madam
110 | >
111 | > Output - Palindrome
112 |
113 |
114 | Hint
131 |
132 |
133 | > Input - a
134 | >
135 | > Output - Not a Digit
136 |
137 |
138 | Hint
156 |
157 |
158 | > Input - m m
159 | >
160 | > Input charcter - a
161 | >
162 | > Output - mam
163 |
164 |
165 |
270 |
271 |
272 | [](https://opensource.org/)
273 | [](https://tanu-n-prabhu.github.io/myWebsite.io/)
274 | [](http://commonmark.org)
275 |
276 |
277 |
--------------------------------------------------------------------------------
/Python Coding Interview Prep/README.md:
--------------------------------------------------------------------------------
1 | # Python Coding Interview Preparation 2024
2 | ## Last Minute Python Review
3 | |  |
4 | |:--:|
5 | | Image Credits [Omada Search](https://www.google.com/url?sa=i&url=https%3A%2F%2Fwww.omadasearch.com%2F2020%2F03%2F7-interview-questions-to-help-determine-the-best-candidate%2F&psig=AOvVaw3IMwK6o41H_A9XbVmeV72D&ust=1649477361590000&source=images&cd=vfe&ved=0CAsQjhxqFwoTCIDshZfMg_cCFQAAAAAdAAAAABAX) |
6 |
7 | 
8 |
9 | ### Table of Contents
10 |
11 | 1. [35 Python interview questions for experienced](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/35%20Python%20interview%20questions%20for%20experienced.md)
12 |
13 | 2. [Crack Python Interviews Like a Pro!](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Crack%20Python%20Interviews%20Like%20a%20Pro!.md)
14 |
15 | 3. [Python Coding Interview Questions (Beginner to Advanced)](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Python%20Coding%20Interview%20Questions%20(Beginner%20to%20Advanced).md)
16 |
17 | 4. [Python Interview Questions - Strings](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Python_Interview_Questions_and_Answers_Strings.md)
18 |
19 | 5. [Python Theoretical Interview Questions](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Python_Theoritical_Interview_Questions.md)
20 |
21 |
22 | 6. [Python Interview Questions and Answers 2025 ](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Python_Interview_Questions_and_Answers.md)
23 |
24 | 7. [Assigning Candies to Children Problem with Solution](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Children_with_candy.ipynb)
25 |
26 | 8. [Basic Calculator](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Basic_calculator.ipynb)
27 |
28 | 9. [Text Justification](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Text_Justification.ipynb)
29 |
30 | 10. [Removing an Element](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Remove_Element.ipynb)
31 |
32 | 11. [Vowel Count in a Sentence](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Vowel_Count.ipynb)
33 |
34 | 12. [Pick-Up Line Generator - Based on Sentiments](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/pick_up_line_generator_sentiments.ipynb)
35 |
36 | 13. [Sentimental Analysis](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Sentimental_Analysis.ipynb)
37 |
38 | 14. [Creating a Regular Polygon Visualizer Using Matplotlib in Python](https://github.com/Tanu-N-Prabhu/Python/blob/master/Python%20Coding%20Interview%20Prep/Draw_polygon.ipynb)
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 | > Note - This page is dynamic, new content and snippets will be added every hour/day. Stay Tuned!
49 |
--------------------------------------------------------------------------------
/Python Coding Interview Prep/Remove_Element.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyOYQMaKnPTttORNM3cYKBx4",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Removing an Element\n",
33 | "\n",
34 | "## Problem\n",
35 | "\n",
36 | "Given an integer array nums and an integer val, remove all occurrences of val in nums in-place. The order of the elements may be changed. Then return the number of elements in nums which are not equal to val.\n",
37 | "\n",
38 | "Consider the number of elements in nums which are not equal to val be k, to get accepted, you need to do the following things:\n",
39 | "\n",
40 | "Change the array nums such that the first k elements of nums contain the elements which are not equal to val. The remaining elements of nums are not important as well as the size of nums.\n",
41 | "Return k.\n",
42 | "\n",
43 | "```\n",
44 | "Custom Judge:\n",
45 | "\n",
46 | "The judge will test your solution with the following code:\n",
47 | "int[] nums = [...]; // Input array\n",
48 | "int val = ...; // Value to remove\n",
49 | "int[] expectedNums = [...]; // The expected answer with correct length.\n",
50 | " // It is sorted with no values equaling val.\n",
51 | "int k = removeElement(nums, val); // Calls your implementation\n",
52 | "assert k == expectedNums.length;\n",
53 | "sort(nums, 0, k); // Sort the first k elements of nums\n",
54 | "for (int i = 0; i < actualLength; i++) {\n",
55 | " assert nums[i] == expectedNums[i];\n",
56 | "}\n",
57 | "\n",
58 | "If all assertions pass, then your solution will be accepted.\n",
59 | "Example 1:\n",
60 | "Input: nums = [3,2,2,3], val = 3\n",
61 | "Output: 2, nums = [2,2,_,_]\n",
62 | "Explanation: Your function should return k = 2, with the first two elements of nums being 2.\n",
63 | "It does not matter what you leave beyond the returned k (hence they are underscores).\n",
64 | "Example 2:\n",
65 | "Input: nums = [0,1,2,2,3,0,4,2], val = 2\n",
66 | "Output: 5, nums = [0,1,4,0,3,_,_,_]\n",
67 | "Explanation: Your function should return k = 5, with the first five elements of nums containing 0, 0, 1, 3, and 4.\n",
68 | "Note that the five elements can be returned in any order.\n",
69 | "It does not matter what you leave beyond the returned k (hence they are underscores).\n",
70 | "Constraints:\n",
71 | "0 <= nums.length <= 100\n",
72 | "0 <= nums[i] <= 50\n",
73 | "0 <= val <= 100\n",
74 | "\n",
75 | "```\n",
76 | "\n",
77 | "## Solution\n"
78 | ],
79 | "metadata": {
80 | "id": "VXIFNA8N5w_r"
81 | }
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": 4,
86 | "metadata": {
87 | "colab": {
88 | "base_uri": "https://localhost:8080/"
89 | },
90 | "id": "OGhBr5xF5l6h",
91 | "outputId": "9807ea09-e7d8-4f34-b32c-2eb5b3cb7e4f"
92 | },
93 | "outputs": [
94 | {
95 | "output_type": "stream",
96 | "name": "stdout",
97 | "text": [
98 | "2\n",
99 | "[2, 2]\n",
100 | "5\n",
101 | "[0, 1, 3, 0, 4]\n"
102 | ]
103 | }
104 | ],
105 | "source": [
106 | "from typing import List\n",
107 | "\n",
108 | "class Solution:\n",
109 | " def removeElement(self, nums: List[int], val: int) -> int:\n",
110 | " # Initialize two pointers, one for iterating the list and one for the insertion point.\n",
111 | " i = 0\n",
112 | " k = 0\n",
113 | "\n",
114 | " while i < len(nums):\n",
115 | " if nums[i] != val:\n",
116 | " # If the current element is not equal to val, copy it to the insertion point.\n",
117 | " nums[k] = nums[i]\n",
118 | " k += 1\n",
119 | " i += 1\n",
120 | "\n",
121 | " return k\n",
122 | "\n",
123 | "# Example usage and custom judge test\n",
124 | "if __name__ == \"__main__\":\n",
125 | " solution = Solution()\n",
126 | "\n",
127 | " # Test case 1\n",
128 | " nums1 = [3, 2, 2, 3]\n",
129 | " val1 = 3\n",
130 | " k1 = solution.removeElement(nums1, val1)\n",
131 | " print(k1) # Expected output: 2\n",
132 | " print(nums1[:k1]) # Expected output: [2, 2]\n",
133 | "\n",
134 | " # Test case 2\n",
135 | " nums2 = [0, 1, 2, 2, 3, 0, 4, 2]\n",
136 | " val2 = 2\n",
137 | " k2 = solution.removeElement(nums2, val2)\n",
138 | " print(k2) # Expected output: 5\n",
139 | " print(nums2[:k2]) # Expected output: [0, 1, 4, 0, 3]"
140 | ]
141 | }
142 | ]
143 | }
--------------------------------------------------------------------------------
/Python Coding Interview Prep/Sentimental_Analysis.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyMjUJE1hCPosygYRij3Dr+a",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Problem Statement: Sentiment Analysis\n",
33 | "\n",
34 | "Develop a Python program that analyzes the sentiment of a given text input. Sentiment analysis involves determining whether a piece of text expresses positive, negative, or neutral sentiments. The program should utilize the TextBlob library, which provides a simple API for sentiment analysis.\n",
35 | "\n",
36 | "## Requirements:\n",
37 | "\n",
38 | "1. The program should prompt the user to input a text for sentiment analysis.\n",
39 | "2. It should analyze the sentiment of the input text using TextBlob.\n",
40 | "3. The sentiment analysis should include determining the polarity and subjectivity of the text.\n",
41 | "4. The program should categorize the sentiment as positive, negative, or neutral based on the polarity.\n",
42 | "5. It should display the sentiment category (positive, negative, or neutral), the polarity value (ranging from -1 to 1), and the subjectivity value (ranging from 0 to 1).\n",
43 | "\n",
44 | "\n",
45 | "```\n",
46 | "Enter text to analyze sentiment: I love this movie, it's fantastic!\n",
47 | "Sentiment: Positive\n",
48 | "Polarity: 0.8\n",
49 | "Subjectivity: 0.9\n",
50 | "```\n",
51 | "\n",
52 | "> **Note**: Ensure error handling is implemented to handle unexpected inputs or errors during sentiment analysis."
53 | ],
54 | "metadata": {
55 | "id": "mEjFkntDjnWu"
56 | }
57 | },
58 | {
59 | "cell_type": "code",
60 | "execution_count": 3,
61 | "metadata": {
62 | "colab": {
63 | "base_uri": "https://localhost:8080/"
64 | },
65 | "id": "-qpc20bSjTRV",
66 | "outputId": "1ca4fb88-2bbd-4437-fb8d-7d98f8372b9c"
67 | },
68 | "outputs": [
69 | {
70 | "output_type": "stream",
71 | "name": "stdout",
72 | "text": [
73 | "Enter text to analyze sentiment: Happy\n",
74 | "Sentiment: Positive\n",
75 | "Polarity: 0.8\n",
76 | "Subjectivity: 1.0\n"
77 | ]
78 | }
79 | ],
80 | "source": [
81 | "from textblob import TextBlob\n",
82 | "\n",
83 | "def analyze_sentiment(text):\n",
84 | " analysis = TextBlob(text)\n",
85 | "\n",
86 | " # Get polarity and subjectivity\n",
87 | " polarity = analysis.sentiment.polarity\n",
88 | " subjectivity = analysis.sentiment.subjectivity\n",
89 | "\n",
90 | " # Determine sentiment\n",
91 | " if polarity > 0:\n",
92 | " sentiment = \"Positive\"\n",
93 | " elif polarity < 0:\n",
94 | " sentiment = \"Negative\"\n",
95 | " else:\n",
96 | " sentiment = \"Neutral\"\n",
97 | "\n",
98 | " return sentiment, polarity, subjectivity\n",
99 | "\n",
100 | "text = input(\"Enter text to analyze sentiment: \")\n",
101 | "sentiment, polarity, subjectivity = analyze_sentiment(text)\n",
102 | "print(f\"Sentiment: {sentiment}\")\n",
103 | "print(f\"Polarity: {polarity}\")\n",
104 | "print(f\"Subjectivity: {subjectivity}\")\n"
105 | ]
106 | }
107 | ]
108 | }
--------------------------------------------------------------------------------
/Python Coding Interview Prep/Text_Justification.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyN4KVKP11K8h3IJFKwyJG/H",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Text Justification\n",
33 | "\n",
34 | "## Problem\n",
35 | "\n",
36 | "Given an array of strings words and a width maxWidth, format the text such that each line has exactly maxWidth characters and is fully (left and right) justified.\n",
37 | "\n",
38 | "You should pack your words in a greedy approach; that is, pack as many words as you can in each line. Pad extra spaces ' ' when necessary so that each line has exactly maxWidth characters.\n",
39 | "Extra spaces between words should be distributed as evenly as possible. If the number of spaces on a line does not divide evenly between words, the empty slots on the left will be assigned more spaces than the slots on the right.\n",
40 | "For the last line of text, it should be left-justified, and no extra space is inserted between words.\n",
41 | "\n",
42 | "> **Note**: A word is defined as a character sequence consisting of non-space characters only.\n",
43 | "Each word's length is guaranteed to be greater than 0 and not exceed maxWidth.\n",
44 | "The input array words contains at least one word.\n",
45 | "\n",
46 | "```\n",
47 | "\n",
48 | "Example 1:\n",
49 | "Input: words = [\"This\", \"is\", \"an\", \"example\", \"of\", \"text\", \"justification.\"], maxWidth = 16\n",
50 | "Output:\n",
51 | "[\n",
52 | " \"This is an\",\n",
53 | " \"example of text\",\n",
54 | " \"justification. \"\n",
55 | "]\n",
56 | "\n",
57 | "Example 2:\n",
58 | "Input: words = [\"What\",\"must\",\"be\",\"acknowledgment\",\"shall\",\"be\"], maxWidth = 16\n",
59 | "Output:\n",
60 | "[\n",
61 | " \"What must be\",\n",
62 | " \"acknowledgment \",\n",
63 | " \"shall be \"\n",
64 | "]\n",
65 | "\n",
66 | "Explanation: Note that the last line is \"shall be \" instead of \"shall be\", because the last line must be left-justified instead of fully-justified.\n",
67 | "Note that the second line is also left-justified because it contains only one word.\n",
68 | "\n",
69 | "Example 3:\n",
70 | "Input: words = [\"Science\",\"is\",\"what\",\"we\",\"understand\",\"well\",\"enough\",\"to\",\"explain\",\"to\",\"a\",\"computer.\",\"Art\",\"is\",\"everything\",\"else\",\"we\",\"do\"], maxWidth = 20\n",
71 | "Output:\n",
72 | "[\n",
73 | " \"Science is what we\",\n",
74 | " \"understand well\",\n",
75 | " \"enough to explain to\",\n",
76 | " \"a computer. Art is\",\n",
77 | " \"everything else we\",\n",
78 | " \"do \"\n",
79 | "]\n",
80 | "\n",
81 | "Constraints:\n",
82 | "1 <= words.length <= 300\n",
83 | "1 <= words[i].length <= 20\n",
84 | "words[i] consists of only English letters and symbols.\n",
85 | "1 <= maxWidth <= 100\n",
86 | "words[i].length <= maxWidth\n",
87 | "\n",
88 | "```\n",
89 | "\n",
90 | "## Solution"
91 | ],
92 | "metadata": {
93 | "id": "5r-EUJ-HPl06"
94 | }
95 | },
96 | {
97 | "cell_type": "code",
98 | "execution_count": 3,
99 | "metadata": {
100 | "colab": {
101 | "base_uri": "https://localhost:8080/"
102 | },
103 | "id": "aWMvEJ7kPgiJ",
104 | "outputId": "aa7bd169-8371-4ce6-f6e0-7e2a9d8dd88d"
105 | },
106 | "outputs": [
107 | {
108 | "output_type": "stream",
109 | "name": "stdout",
110 | "text": [
111 | "This is an\n",
112 | "example of text\n",
113 | "justification. \n",
114 | "What must be\n",
115 | "acknowledgment \n",
116 | "shall be \n",
117 | "Science is what\n",
118 | "we understand\n",
119 | "well enough to\n",
120 | "explain to a\n",
121 | "computer. Art is\n",
122 | "everything else\n",
123 | "we do \n"
124 | ]
125 | }
126 | ],
127 | "source": [
128 | "class Solution:\n",
129 | " def fullJustify(self, words, maxWidth):\n",
130 | " result = []\n",
131 | " line, line_length = [], 0\n",
132 | "\n",
133 | " for word in words:\n",
134 | " if line_length + len(word) + len(line) <= maxWidth:\n",
135 | " line.append(word)\n",
136 | " line_length += len(word)\n",
137 | " else:\n",
138 | " spaces_needed = maxWidth - line_length\n",
139 | " if len(line) == 1:\n",
140 | " result.append(line[0] + ' ' * spaces_needed)\n",
141 | " else:\n",
142 | " space_between_words, extra_spaces = divmod(spaces_needed, len(line) - 1)\n",
143 | " line_str = ''\n",
144 | " for i in range(len(line) - 1):\n",
145 | " line_str += line[i] + ' ' * (space_between_words + (1 if i < extra_spaces else 0))\n",
146 | " line_str += line[-1]\n",
147 | " result.append(line_str)\n",
148 | "\n",
149 | " line, line_length = [word], len(word)\n",
150 | "\n",
151 | " result.append(' '.join(line).ljust(maxWidth))\n",
152 | " return result\n",
153 | "\n",
154 | "\n",
155 | "# Example usage\n",
156 | "if __name__ == \"__main__\":\n",
157 | " solution = Solution()\n",
158 | " words1 = [\"This\", \"is\", \"an\", \"example\", \"of\", \"text\", \"justification.\"]\n",
159 | " words2 = [\"What\", \"must\", \"be\", \"acknowledgment\", \"shall\", \"be\"]\n",
160 | " words3 = [\"Science\", \"is\", \"what\", \"we\", \"understand\", \"well\", \"enough\", \"to\", \"explain\", \"to\", \"a\", \"computer.\",\n",
161 | " \"Art\", \"is\", \"everything\", \"else\", \"we\", \"do\"]\n",
162 | "\n",
163 | " maxWidth = 16\n",
164 | "\n",
165 | " result1 = solution.fullJustify(words1, maxWidth)\n",
166 | " result2 = solution.fullJustify(words2, maxWidth)\n",
167 | " result3 = solution.fullJustify(words3, maxWidth)\n",
168 | "\n",
169 | " for line in result1:\n",
170 | " print(line)\n",
171 | "\n",
172 | " for line in result2:\n",
173 | " print(line)\n",
174 | "\n",
175 | " for line in result3:\n",
176 | " print(line)"
177 | ]
178 | },
179 | {
180 | "cell_type": "markdown",
181 | "source": [
182 | "## Credits\n",
183 | "\n",
184 | "I would like to thank [Dhirajpatra](https://github.com/dhirajpatra) for writing this piece of code. Feel free to reach him out if you have any questions about Python Programming."
185 | ],
186 | "metadata": {
187 | "id": "rMlLUZrKRRyz"
188 | }
189 | }
190 | ]
191 | }
--------------------------------------------------------------------------------
/Python Coding Interview Prep/Vowel_Count.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyOqQvMYSVHffQwcSDCIXmsN",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Counting Vowels in a Sentence\n",
33 | "\n",
34 | "\n",
35 | "## Problem\n",
36 | "\n",
37 | "You are tasked with creating a Python script that counts the number of vowels in a given sentence. Your program should prompt the user to enter a sentence, and then output the total count of vowels present in that sentence. The program should treat both uppercase and lowercase vowels as equivalent.\n",
38 | "\n",
39 | "Your task is to write a Python script that accomplishes this, utilizing functions and loops as necessary."
40 | ],
41 | "metadata": {
42 | "id": "oQbsz2YwDc_f"
43 | }
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 1,
48 | "metadata": {
49 | "colab": {
50 | "base_uri": "https://localhost:8080/"
51 | },
52 | "id": "XAU5DlE0DZpU",
53 | "outputId": "43f94197-a8b0-42c5-fb3b-248340f81b1d"
54 | },
55 | "outputs": [
56 | {
57 | "output_type": "stream",
58 | "name": "stdout",
59 | "text": [
60 | "Enter a sentence: Hello I am a Sales Expert\n",
61 | "Number of vowels: 9\n"
62 | ]
63 | }
64 | ],
65 | "source": [
66 | "def count_vowels(sentence):\n",
67 | " vowels = 'aeiouAEIOU'\n",
68 | " vowel_count = 0\n",
69 | " for char in sentence:\n",
70 | " if char in vowels:\n",
71 | " vowel_count += 1\n",
72 | " return vowel_count\n",
73 | "\n",
74 | "sentence = input(\"Enter a sentence: \")\n",
75 | "print(\"Number of vowels:\", count_vowels(sentence))\n"
76 | ]
77 | },
78 | {
79 | "cell_type": "markdown",
80 | "source": [
81 | "This script defines a function count_vowels that takes a sentence as input and returns the count of vowels in it. It iterates over each character in the sentence and checks if it is a vowel. If it is, it increments the count. Finally, it prints out the total count of vowels in the sentence.\n",
82 | "\n",
83 | "\n"
84 | ],
85 | "metadata": {
86 | "id": "euH9m_htD6tG"
87 | }
88 | }
89 | ]
90 | }
--------------------------------------------------------------------------------
/Python Coding Interview Prep/pick_up_line_generator_sentiments.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyOXEOuU+2MwSdeSjS6kYtev",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Pick-up Line Generator - Sentimental Analysis\n",
33 | "\n",
34 | "## Problem Statement\n",
35 | "\n",
36 | "You are tasked with creating a Python script for a pick-up line generator. The program should generate pick-up lines based on different sentiments such as romantic, funny, cheesy, or flirty.\n",
37 | "\n",
38 | "### Requirements:\n",
39 | "\n",
40 | "The script should contain a function generate_pickup_line(sentiment) that takes a sentiment as input and returns a randomly selected pick-up line from the corresponding sentiment category.\n",
41 | "The sentiment categories and pick-up lines should be organized in a dictionary or a similar data structure within the script.\n",
42 | "The program should allow users to specify the sentiment category for the pick-up line they want to generate.\n",
43 | "The script should include a main section where it prompts the user to enter a sentiment category, calls the generate_pickup_line function with the specified sentiment, and prints the generated pick-up line.\n",
44 | "\n",
45 | "\n",
46 | "```\n",
47 | "Enter the sentiment category for the pick-up line (romantic/funny/cheesy/flirty): flirty\n",
48 | "Generated pick-up line: Are you a magician? Because whenever I look at you, everyone else disappears.\n",
49 | "```\n"
50 | ],
51 | "metadata": {
52 | "id": "viG6NBRUzlpg"
53 | }
54 | },
55 | {
56 | "cell_type": "code",
57 | "execution_count": 2,
58 | "metadata": {
59 | "colab": {
60 | "base_uri": "https://localhost:8080/"
61 | },
62 | "id": "gAJgWyq9zfyQ",
63 | "outputId": "ed1fb610-1301-40f0-f1b8-d2f498012afc"
64 | },
65 | "outputs": [
66 | {
67 | "output_type": "stream",
68 | "name": "stdout",
69 | "text": [
70 | "You are the reason for my smile.\n"
71 | ]
72 | }
73 | ],
74 | "source": [
75 | "import random\n",
76 | "\n",
77 | "def generate_pickup_line(sentiment):\n",
78 | " # Dictionary of pick-up lines categorized by sentiment\n",
79 | " pickup_lines = {\n",
80 | " \"romantic\": [\n",
81 | " \"You are the reason for my smile.\",\n",
82 | " \"I never believed in love at first sight until I saw you.\",\n",
83 | " \"You must be a shooting star because you light up my life.\",\n",
84 | " \"I want to be the reason you look down at your phone and smile.\"\n",
85 | " ],\n",
86 | " \"funny\": [\n",
87 | " \"Do you have a name, or can I call you mine?\",\n",
88 | " \"Are you made of copper and tellurium? Because you're Cu-Te.\",\n",
89 | " \"If you were a vegetable, you'd be a cute-cumber.\",\n",
90 | " \"Do you have a sunburn, or are you always this hot?\"\n",
91 | " ],\n",
92 | " \"cheesy\": [\n",
93 | " \"Do you have a map? I keep getting lost in your eyes.\",\n",
94 | " \"Is your name Google? Because you have everything I've been searching for.\",\n",
95 | " \"Are you a bank loan? Because you have my interest.\",\n",
96 | " \"Do you believe in love at first sight, or should I walk by again?\"\n",
97 | " ],\n",
98 | " \"flirty\": [\n",
99 | " \"Are you a magician? Because whenever I look at you, everyone else disappears.\",\n",
100 | " \"Do you have a Band-Aid? Because I just scraped my knee falling for you.\",\n",
101 | " \"Are you a camera? Because every time I look at you, I smile.\",\n",
102 | " \"If beauty were a crime, you'd be serving a life sentence.\"\n",
103 | " ]\n",
104 | " }\n",
105 | "\n",
106 | " # Select a pick-up line based on the specified sentiment\n",
107 | " return random.choice(pickup_lines[sentiment])\n",
108 | "\n",
109 | "if __name__ == \"__main__\":\n",
110 | " # Specify the sentiment category\n",
111 | " sentiment = \"romantic\" # Change this to \"romantic\", \"funny\", or \"cheesy\" as desired\n",
112 | " print(generate_pickup_line(sentiment))\n"
113 | ]
114 | }
115 | ]
116 | }
--------------------------------------------------------------------------------
/Python Coding Interview Questions And Answers Fixed.py:
--------------------------------------------------------------------------------
1 | import numpy as np # Import NumPy for efficient arrays (habit for numerical tasks)
2 |
3 | def debug_script(filename): # Reusable debugging function with clear naming
4 | """Starts the Python debugger for the given script."""
5 | import pdb # Import pdb for debugging
6 | pdb.runfile(filename) # Concise way to start debugging
7 |
8 | def days_generator(start_index=0): # Generator function for day names
9 | """Yields day names sequentially, starting from the given index."""
10 | days = ['S', 'M', 'T', 'W', 'Tr', 'F', 'St']
11 | for day in days[start_index:]:
12 | yield day
13 |
14 | def list_to_string(data): # Function to handle various data types
15 | """Converts a list, tuple, or set to a string with spaces between elements."""
16 | if isinstance(data, (list, tuple, set)):
17 | return ' '.join(data)
18 | raise TypeError("Input must be a list, tuple, or set") # Handle invalid input
19 |
20 | def count_occurrences(data, element): # Function for counting occurrences
21 | """Counts the number of times 'element' appears in 'data' (list or tuple)."""
22 | if not isinstance(data, (list, tuple)):
23 | raise TypeError("Input must be a list or tuple")
24 | return data.count(element)
25 |
26 | def create_numpy_array(data): # Function for array creation (flexible for different data types)
27 | """Creates a NumPy array from a list, tuple, or even another NumPy array."""
28 | return np.array(data)
29 |
30 | # Example usage (can be refactored into a more modular structure if needed)
31 | day_gen = days_generator(2) # Get day names starting from index 2 (Wednesday)
32 | print(next(day_gen)) # Print the first day
33 |
34 | weekdays = ['M', 'W', 'F']
35 | print(list_to_string(weekdays)) # Print weekdays as a string
36 |
37 | my_list = [1, 2, 2, 3, 4]
38 | print(count_occurrences(my_list, 2)) # Count occurrences of 2
39 |
40 | data = [5, 6, 7]
41 | arr = create_numpy_array(data)
42 | print(arr.dtype) # Check the array's data type (habit for type awareness)
43 |
--------------------------------------------------------------------------------
/Python_Variables.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "name": "Python Variables.ipynb",
7 | "provenance": [],
8 | "authorship_tag": "ABX9TyNaHyzT8vEu+M5zbjDt87/W",
9 | "include_colab_link": true
10 | },
11 | "kernelspec": {
12 | "name": "python3",
13 | "display_name": "Python 3"
14 | }
15 | },
16 | "cells": [
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {
20 | "id": "view-in-github",
21 | "colab_type": "text"
22 | },
23 | "source": [
24 | ""
25 | ]
26 | },
27 | {
28 | "cell_type": "markdown",
29 | "metadata": {
30 | "id": "yRgHPumxce8E",
31 | "colab_type": "text"
32 | },
33 | "source": [
34 | "# **Python Variables**\n",
35 | "\n",
36 | "\n",
37 | "\n",
38 | "\n",
39 | "In programming languages like C/C++, every time a variable is declared simultaneously a memory would be allocated this would allocation would completely depend on the variable type. Therefore, the programmers must specify the variable type while creating a variable. But luckily in Python, you don’t have to do that. Python doesn’t have a variable type declaration. Like pointers in C, variables in Python don’t store values legitimately; they work with references highlighting objects in memory.\n",
40 | "\n",
41 | "## **Variables**\n",
42 | "\n",
43 | "A variable is more likely a ***container*** to store the values. Now the values to be stored depends on the programmer whether to use integer, float, string or **[etc](https://www.w3schools.com/python/python_datatypes.asp)**.\n",
44 | "\n",
45 | "\n",
46 | "\n",
47 | "> ***A Variable is like a box in the computer’s memory where you can store a single value. — Al Sweigart***\n",
48 | "\n",
49 | "\n",
50 | "Unlike in other programming languages, in Python, you need not declare any variables or initialize them. Please read [this](https://stackoverflow.com/a/11008311/11646278).\n",
51 | "\n",
52 | "\n",
53 | "### **Syntax**\n",
54 | "\n",
55 | "\n",
56 | "The general syntax to create a variable in Python is as shown below:\n",
57 | "\n",
58 | "`variable_name = value`\n",
59 | "\n",
60 | "The `variable_name` in Python can be short as sweet as `a, b, x, y, ...` or can be very informative such as `age, height, name, student_name, covid, ...`\n",
61 | "\n",
62 | "\n",
63 | "> ***Although it is recommended keeping a very descriptive variable name to improve the readability.***\n",
64 | "\n",
65 | "\n",
66 | "\n",
67 | "### **Rules**\n",
68 | "\n",
69 | "**All set and done, there are some rules that you need to follow while naming a variable:**\n",
70 | "\n",
71 | "* A variable name must start with a ***letter*** or the ***underscore character***\n",
72 | "\n",
73 | "* A variable name cannot start with a ***number***\n",
74 | "\n",
75 | "* A variable name can only contain ***alpha-numeric characters*** and ***underscores***. For example, anything like this is valid: ***A-z, 0–9, and _***\n",
76 | "\n",
77 | "* Variable names are ***case-sensitive*** ***(height, Height***, and ***HEIGHT*** are three different variables names)\n",
78 | "\n",
79 | "### **Example**\n",
80 | "\n",
81 | "Below given is an example to properly initialize a value to a variable:"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "metadata": {
87 | "id": "NQKdREzkdw76",
88 | "colab_type": "code",
89 | "colab": {
90 | "base_uri": "https://localhost:8080/",
91 | "height": 35
92 | },
93 | "outputId": "70b43a3d-c3b4-4846-f786-64b07890bb4d"
94 | },
95 | "source": [
96 | "# This is a valid and good way to assign a value to a variable\n",
97 | "# For example you might want to assign values to variables to calculate the area of a circle\n",
98 | "\n",
99 | "pi = 3.142 # I could have also used \"math\" library (math.pi)\n",
100 | "radius = 5 # Interger value for radius\n",
101 | "area_of_circle = 0 # Used to store the value of area of circle\n",
102 | "\n",
103 | "area_of_circle = pi * (radius) ** 2 # Area = (PI * R^2)\n",
104 | "\n",
105 | "print(\"The area of the circle based on the given data is: \", area_of_circle)"
106 | ],
107 | "execution_count": 1,
108 | "outputs": [
109 | {
110 | "output_type": "stream",
111 | "text": [
112 | "The area of the circle based on the given data is: 78.55\n"
113 | ],
114 | "name": "stdout"
115 | }
116 | ]
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "metadata": {
121 | "id": "DIyEuUw8d3aU",
122 | "colab_type": "text"
123 | },
124 | "source": [
125 | "### **Pictorial Example (Skim it quickly)**\n",
126 | "I# believe just by seeing a picture or an image, the concepts can be understood more quickly. Below is the pictorial representation of a variable and it being stored in the memory.\n",
127 | "\n",
128 | "\n",
129 | "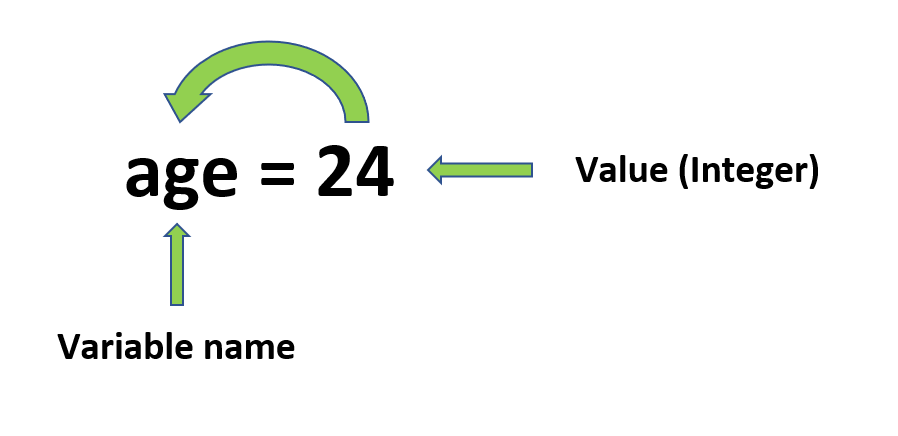\n",
130 | "\n",
131 | "\n",
132 | "\n",
133 | "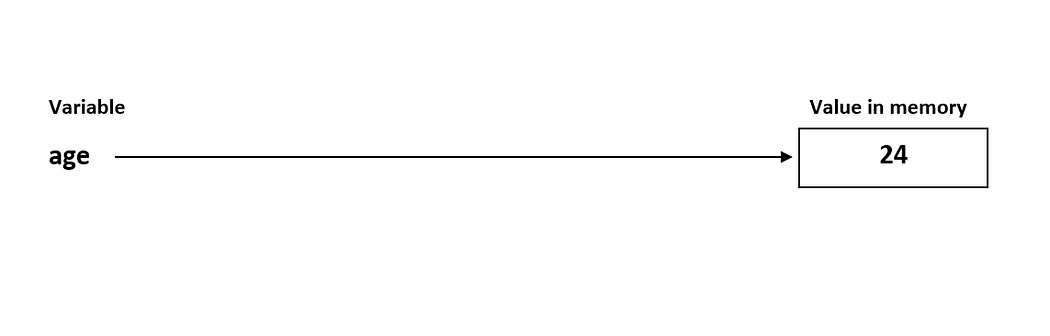\n",
134 | "\n",
135 | "\n",
136 | "---"
137 | ]
138 | }
139 | ]
140 | }
--------------------------------------------------------------------------------
/Rule_Based_System_with_Python.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyNCZyT2Cwhm58Z84c/3fVJD",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Build a Rule-Based System with Python\n",
33 | "\n",
34 | "## Learn how to simulate expert systems using Python dictionaries and logic\n",
35 | "\n",
36 | "|  |\n",
37 | "|:--:|\n",
38 | "| Image Generated Using Canva|\n",
39 | "\n",
40 | "### Introduction\n",
41 | "Rule-based systems are at the heart of many decision-making engines; from medical diagnosis to recommendation engines. These systems apply a set of predefined \"if-then\" rules to derive conclusions. In this article, you'll learn how to build a basic rule-based engine in Python that mimics real-world decision-making.\n",
42 | "\n",
43 | "---\n",
44 | "\n",
45 | "### What's Covered\n",
46 | "* What is a rule-based system\n",
47 | "\n",
48 | "* How to represent rules in Python\n",
49 | "\n",
50 | "* Building a mini inference engine\n",
51 | "\n",
52 | "* Testing it on a real-world example\n",
53 | "\n",
54 | "\n",
55 | "---\n",
56 | "\n",
57 | "### Code Implementation\n",
58 | "\n",
59 | "\n"
60 | ],
61 | "metadata": {
62 | "id": "AM4JNYqhSdqd"
63 | }
64 | },
65 | {
66 | "cell_type": "code",
67 | "source": [
68 | "# Step 1: Define rules as functions\n",
69 | "def is_fever(temp):\n",
70 | " return temp > 99.5\n",
71 | "\n",
72 | "def is_cough(symptoms):\n",
73 | " return 'cough' in symptoms\n",
74 | "\n",
75 | "def is_sore_throat(symptoms):\n",
76 | " return 'sore throat' in symptoms\n",
77 | "\n",
78 | "# Step 2: Define the rule engine\n",
79 | "def diagnose(symptoms, temperature):\n",
80 | " rules = {\n",
81 | " \"Flu\": is_fever(temperature) and is_cough(symptoms),\n",
82 | " \"Common Cold\": is_cough(symptoms) and is_sore_throat(symptoms),\n",
83 | " \"Healthy\": not is_fever(temperature) and not is_cough(symptoms)\n",
84 | " }\n",
85 | "\n",
86 | " for condition, result in rules.items():\n",
87 | " if result:\n",
88 | " return condition\n",
89 | " return \"Unknown Condition\"\n",
90 | "\n",
91 | "# Step 3: Run the engine\n",
92 | "symptoms = ['cough', 'sore throat']\n",
93 | "temperature = 100.2\n",
94 | "\n",
95 | "diagnosis = diagnose(symptoms, temperature)\n",
96 | "print(\"Diagnosis:\", diagnosis)"
97 | ],
98 | "metadata": {
99 | "colab": {
100 | "base_uri": "https://localhost:8080/"
101 | },
102 | "id": "7dG0e5AAaYp_",
103 | "outputId": "816b73cb-9ae4-47ee-aa28-e755a1268eef"
104 | },
105 | "execution_count": 1,
106 | "outputs": [
107 | {
108 | "output_type": "stream",
109 | "name": "stdout",
110 | "text": [
111 | "Diagnosis: Flu\n"
112 | ]
113 | }
114 | ]
115 | },
116 | {
117 | "cell_type": "markdown",
118 | "source": [
119 | "### Conclusion\n",
120 | "You’ve just built a basic rule-based system, the backbone of many early AI applications. While this example is simple, the principles can be extended with complex logic, probabilistic reasoning, or even natural language processing for intelligent decision-making systems. Thanks for reading my article, let me know if you have any suggestions or similar implementations via the comment section. Until then, see you next time. Happy coding!\n",
121 | "\n",
122 | "---\n",
123 | "\n",
124 | "### Before you go\n",
125 | "* Be sure to Like and Connect Me\n",
126 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
127 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
128 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!"
129 | ],
130 | "metadata": {
131 | "id": "s0kL_-OpagpT"
132 | }
133 | }
134 | ]
135 | }
--------------------------------------------------------------------------------
/Single_Responsibility_Principle.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyPvHA8hp0PpJQRRSppI7OPg",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Why the Single Responsibility Principle Will Clean Up Your Machine Learning Code\n",
33 | "\n",
34 | "## Stop writing bloated ML classes, keep each class laser-focused.\n",
35 | "\n",
36 | "|  |\n",
37 | "|:--:|\n",
38 | "|Photo by Christina @ wocintechchat.com on Unsplash|\n",
39 | "\n",
40 | "### Introduction\n",
41 | "In Machine Learning projects, classes often become massive, data loaders that also train, validate, log, and even save models. This leads to tightly coupled systems that are hard to debug or reuse. The Single Responsibility Principle (SRP) offers a clean, maintainable path forward.\n",
42 | "\n",
43 | "---\n",
44 | "\n",
45 | "### Problem\n",
46 | "Imagine a class `MLPipeline` that:\n",
47 | "\n",
48 | "* Loads data\n",
49 | "\n",
50 | "* Trains a model\n",
51 | "\n",
52 | "* Evaluates metrics\n",
53 | "\n",
54 | "* Logs output\n",
55 | "\n",
56 | "* Saves results\n",
57 | "\n",
58 | "Now imagine debugging it. Or reusing just the training logic for another model. It’s a nightmare.\n",
59 | "\n",
60 | "---\n",
61 | "\n",
62 | "### Code Implementation (with SRP)\n",
63 | "\n",
64 | "\n"
65 | ],
66 | "metadata": {
67 | "id": "e5VWiO0zFRR9"
68 | }
69 | },
70 | {
71 | "cell_type": "code",
72 | "source": [
73 | "from sklearn.linear_model import LogisticRegression\n",
74 | "import joblib\n",
75 | "\n",
76 | "class DataLoader:\n",
77 | " def load_data(self):\n",
78 | " from sklearn.datasets import load_iris\n",
79 | " data = load_iris()\n",
80 | " return data.data, data.target\n",
81 | "\n",
82 | "class ModelTrainer:\n",
83 | " def __init__(self):\n",
84 | " self.model = LogisticRegression()\n",
85 | "\n",
86 | " def train(self, X, y):\n",
87 | " self.model.fit(X, y)\n",
88 | " return self.model\n",
89 | "\n",
90 | "class Evaluator:\n",
91 | " def evaluate(self, model, X, y):\n",
92 | " accuracy = model.score(X, y)\n",
93 | " print(f\"Model Accuracy: {accuracy:.2f}\")\n",
94 | "\n",
95 | "class ModelSaver:\n",
96 | " def save(self, model, filepath=\"model.pkl\"):\n",
97 | " joblib.dump(model, filepath)\n",
98 | " print(f\"Model saved to {filepath}\")"
99 | ],
100 | "metadata": {
101 | "id": "UKz3WgSdHTe8"
102 | },
103 | "execution_count": null,
104 | "outputs": []
105 | },
106 | {
107 | "cell_type": "markdown",
108 | "source": [
109 | "### Output\n",
110 | "\n",
111 | "Model Accuracy: 0.97\n",
112 | "\n",
113 | "Model saved to model.pkl\n",
114 | "\n",
115 | "---\n",
116 | "\n",
117 | "\n",
118 | "### Code Explanation\n",
119 | "\n",
120 | "* `DataLoader`: Handles only data loading from the dataset.\n",
121 | "\n",
122 | "* `ModelTrainer`: Trains a `LogisticRegression` model.\n",
123 | "\n",
124 | "* `Evaluator`: Responsible for performance measurement.\n",
125 | "\n",
126 | "* `ModelSaver`: Handles model persistence to disk.\n",
127 | "\n",
128 | "* Each class has only one reason to change.\n",
129 | "\n",
130 | "---\n",
131 | "\n",
132 | "### UML Class Diagram\n",
133 | "\n",
134 | "\n",
135 | "|  |\n",
136 | "|:--:|\n",
137 | "|Designed by Author|\n",
138 | "\n",
139 | "#### UML Diagram Explanation\n",
140 | "\n",
141 | "* **DataLoader**\n",
142 | "\n",
143 | " * Method: `load_data()`\n",
144 | "\n",
145 | " * Responsibility: Load data from an external source or dataset like Iris.\n",
146 | "\n",
147 | "* **ModelTrainer**\n",
148 | "\n",
149 | " * Attributes: `model`\n",
150 | "\n",
151 | " * Method: `train(X, y)`\n",
152 | "\n",
153 | " * Responsibility: Fit the model on the data. Uses scikit-learn's `LogisticRegression`.\n",
154 | "\n",
155 | "* **Evaluator**\n",
156 | "\n",
157 | " * Method: `evaluate(model, X, y)`\n",
158 | "\n",
159 | " * Responsibility: Evaluate the model’s performance by calculating accuracy.\n",
160 | "\n",
161 | "* **ModelSaver**\n",
162 | "\n",
163 | " * Method: `save(model, filepath)`\n",
164 | "\n",
165 | " * Responsibility: Save the trained model to disk using `joblib.`\n",
166 | "\n",
167 | "Each class has one responsibility, adhering to SRP. The arrows/lines between classes represent collaboration, not inheritance or strong coupling. This decoupled architecture helps teams test, maintain, and expand the codebase more easily.\n",
168 | "\n",
169 | "\n",
170 | "---\n",
171 | "\n",
172 | "### Why It’s So Important\n",
173 | "\n",
174 | "* **Easier Testing**: You can unit test `Evaluator` or `ModelSaver` in isolation.\n",
175 | "\n",
176 | "* **Reusability**: Use `ModelTrainer` with different datasets without touching other logic.\n",
177 | "\n",
178 | "* **Maintenance**: If the save format changes (e.g., from `joblib` to `pickle`), only `ModelSaver` needs an update.\n",
179 | "\n",
180 | "* **Scalability**: Easily extend each component (e.g., add TensorBoard logging later without modifying training logic).\n",
181 | "\n",
182 | "\n",
183 | "---\n",
184 | "\n",
185 | "### Applications\n",
186 | "* Production ML pipelines (e.g., Airflow DAGs or Kubeflow components).\n",
187 | "\n",
188 | "* MLOps workflows where responsibilities are separated by teams.\n",
189 | "\n",
190 | "* Teaching ML to beginners in a clean, modular way.\n",
191 | "\n",
192 | "* Building reusable ML tooling in a team setting.\n",
193 | "\n",
194 | "---\n",
195 | "\n",
196 | "### Conclusion\n",
197 | "The Single Responsibility Principle isn’t just for backend systems. It’s your best friend in AI/ML projects too. Next time you build a pipeline, make each class do one thing only and do it well. Adopt these patterns early, and your ML projects will scale with confidence. Thanks for reading my article, let me know if you have any suggestions or similar implementations via the comment section. Until then, see you next time. Happy coding!\n",
198 | "\n",
199 | "---\n",
200 | "\n",
201 | "### Before you go\n",
202 | "* Be sure to Like and Connect Me\n",
203 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
204 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
205 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!\n",
206 | "\n",
207 | "\n",
208 | "\n"
209 | ],
210 | "metadata": {
211 | "id": "jGSL7BBXHXgn"
212 | }
213 | }
214 | ]
215 | }
--------------------------------------------------------------------------------
/Smart_Resume_Ranker_with_Python.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyMflk/ikTyYALqe18fySLnX",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Build a Smart Resume Ranker with Python and Natural Language Processing\n",
33 | "\n",
34 | "## Use AI to evaluate and score resumes against a job description\n",
35 | "\n",
36 | "|  |\n",
37 | "|:--:|\n",
38 | "| Image Generated Using Canva|\n",
39 | "\n",
40 | "### Introduction\n",
41 | "Tired of manually skimming through resumes to match the right candidate? In today’s world, AI can do a first-level screening by ranking resumes based on their relevance to a job description. In this project, we'll build a smart resume ranking system using TF-IDF and cosine similarity, simple NLP techniques that can save a lot of time.\n",
42 | "\n",
43 | "---\n",
44 | "\n",
45 | "### What You'll Learn\n",
46 | "* How to parse text from resumes and job descriptions\n",
47 | "* Clean and preprocess resume content\n",
48 | "* Convert documents into numerical form using TF-IDF\n",
49 | "* Calculate similarity scores using cosine similarity\n",
50 | "* Rank resumes based on relevance\n",
51 | "\n",
52 | "---\n",
53 | "\n",
54 | "### Code Implementation\n"
55 | ],
56 | "metadata": {
57 | "id": "ywY_EoH2-Fvc"
58 | }
59 | },
60 | {
61 | "cell_type": "code",
62 | "source": [
63 | "import os\n",
64 | "from sklearn.feature_extraction.text import TfidfVectorizer\n",
65 | "from sklearn.metrics.pairwise import cosine_similarity\n",
66 | "\n",
67 | "# Sample job description\n",
68 | "job_desc = \"\"\"\n",
69 | "We are looking for a Python developer with experience in data analysis, pandas, NumPy,\n",
70 | "machine learning, and writing clean, maintainable code.\n",
71 | "\"\"\"\n",
72 | "\n",
73 | "# Sample resumes\n",
74 | "resumes = [\n",
75 | " \"Experienced Python developer with knowledge of pandas, NumPy, and machine learning models.\",\n",
76 | " \"Software engineer skilled in Java, C++, and cloud services like AWS and Azure.\",\n",
77 | " \"Data scientist with strong Python skills, data cleaning, pandas, sklearn, and model evaluation.\",\n",
78 | " \"Content writer with a strong verbal and written skills.\",\n",
79 | " \"I have no experience in programming\",\n",
80 | " \"Python developer with experience in data analysis, pandas, NumPy, machine learning, and writing clean, maintainable code.\"\n",
81 | "]\n",
82 | "\n",
83 | "# Combine all documents\n",
84 | "documents = [job_desc] + resumes\n",
85 | "\n",
86 | "# TF-IDF Vectorization\n",
87 | "vectorizer = TfidfVectorizer()\n",
88 | "tfidf_matrix = vectorizer.fit_transform(documents)\n",
89 | "\n",
90 | "# Calculate cosine similarity between job description and each resume\n",
91 | "cosine_similarities = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix[1:]).flatten()\n",
92 | "\n",
93 | "# Rank resumes\n",
94 | "ranking = sorted(list(enumerate(cosine_similarities)), key=lambda x: x[1], reverse=True)\n",
95 | "\n",
96 | "# Display results\n",
97 | "print(\"Resume Ranking:\")\n",
98 | "for idx, score in ranking:\n",
99 | " print(f\"Resume {idx+1} - Relevance Score: {score:.2f}\")"
100 | ],
101 | "metadata": {
102 | "colab": {
103 | "base_uri": "https://localhost:8080/"
104 | },
105 | "id": "igiNh_VR_h-b",
106 | "outputId": "4c79870b-731e-49bb-92e6-deeb8df537f5"
107 | },
108 | "execution_count": 7,
109 | "outputs": [
110 | {
111 | "output_type": "stream",
112 | "name": "stdout",
113 | "text": [
114 | "Resume Ranking:\n",
115 | "Resume 6 - Relevance Score: 0.82\n",
116 | "Resume 1 - Relevance Score: 0.35\n",
117 | "Resume 3 - Relevance Score: 0.21\n",
118 | "Resume 5 - Relevance Score: 0.13\n",
119 | "Resume 2 - Relevance Score: 0.07\n",
120 | "Resume 4 - Relevance Score: 0.06\n"
121 | ]
122 | }
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "source": [
128 | "### Explanation\n",
129 | "* TF-IDF captures how important each word is in each resume relative to the job description.\n",
130 | "\n",
131 | "* Cosine similarity then measures how closely the resume matches the job.\n",
132 | "\n",
133 | "* This is a scalable way to automate initial screening in HR workflows or freelance platforms.\n",
134 | "\n",
135 | "---\n",
136 | "\n",
137 | "### Understanding Resume Scores\n",
138 | "Each resume is compared to the job description using text similarity, and a Relevance Score between 0 and 1 is generated:\n",
139 | "\n",
140 | "* A score closer to 1 means very relevant (e.g., 0.95 = strong match)\n",
141 | "\n",
142 | "* A score around 0.5 means moderately relevant\n",
143 | "\n",
144 | "* A score below 0.3 means weak or poor match\n",
145 | "\n",
146 | "Think of it as a percentage match: just multiply by 100 to get an idea:\n",
147 | "\n",
148 | "* 0.38 → 38% match\n",
149 | "\n",
150 | "* 0.23 → 23% match\n",
151 | "\n",
152 | "* 0.15 → 15% match\n",
153 | "\n",
154 | "---\n",
155 | "\n",
156 | "### Conclusion\n",
157 | "AI doesn’t always have to be complicated. This simple NLP-based resume ranker shows how machine learning concepts can create real-world impact, especially in recruitment, HR tech, or freelance hiring systems. You can expand this further by adding PDF parsing, named entity recognition (NER), or using large language models for deeper understanding. Thanks for reading my article, let me know if you have any suggestions or similar implementations via the comment section. Until then, see you next time. Happy coding!\n",
158 | "\n",
159 | "---\n",
160 | "\n",
161 | "### Before you go\n",
162 | "* Be sure to Like and Connect Me\n",
163 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
164 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
165 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!"
166 | ],
167 | "metadata": {
168 | "id": "FpxFJj3-BEFb"
169 | }
170 | }
171 | ]
172 | }
--------------------------------------------------------------------------------
/Src/Section1_Introduction.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "name": "Section1.ipynb",
7 | "provenance": [],
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | }
14 | },
15 | "cells": [
16 | {
17 | "cell_type": "markdown",
18 | "metadata": {
19 | "id": "view-in-github",
20 | "colab_type": "text"
21 | },
22 | "source": [
23 | ""
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {
29 | "id": "EbY2FS7z6ZyV",
30 | "colab_type": "text"
31 | },
32 | "source": [
33 | "# Python For Beginners "
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {
39 | "id": "ySn16e_D6dm5",
40 | "colab_type": "text"
41 | },
42 | "source": [
43 | "\n"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {
49 | "id": "QOsNQAl36hGT",
50 | "colab_type": "text"
51 | },
52 | "source": [
53 | "# Section 1: Introduction"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {
59 | "id": "kxnm8bmc6exd",
60 | "colab_type": "text"
61 | },
62 | "source": [
63 | "In this tutorial I will teach you guys python from a beginners perspective. If you guys want to know about Python and study the theory behind it then read the [documentation](https://www.python.org/). There is no point of me explaining the definition and giving introduction about Python. All you need to know given the problem what approach you should take in order to solve the problem.\n",
64 | "\n",
65 | "The introduction section contains only the installation procedures of python and its IDE, but I strongly recommend you guys to just use Notebooks instead. Yes you heard it right be a professional coder and start working in notebooks. Here throughout the tutorial I'll be using the [Google Colab](https://colab.research.google.com/notebooks/welcome.ipynb) notebook to type all my code, it's a really good notebook to type the code and so that I can focus on documentation. If you use Google Colab you don't have to install nothing no Python, no IDE and no external libraries etc. Let's start coding. "
66 | ]
67 | }
68 | ]
69 | }
70 |
--------------------------------------------------------------------------------
/Src/Section2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "name": "Section2.ipynb",
7 | "provenance": [],
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | }
14 | },
15 | "cells": [
16 | {
17 | "cell_type": "markdown",
18 | "metadata": {
19 | "id": "view-in-github",
20 | "colab_type": "text"
21 | },
22 | "source": [
23 | ""
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {
29 | "id": "-LXPbirj6_zH",
30 | "colab_type": "text"
31 | },
32 | "source": [
33 | "# Section 2: Python Basics"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {
39 | "id": "AkkJ7uwG7klL",
40 | "colab_type": "text"
41 | },
42 | "source": [
43 | ""
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {
49 | "id": "S7SFMRLM7AbN",
50 | "colab_type": "text"
51 | },
52 | "source": [
53 | "## 1. Variables and data types\n",
54 | "\n",
55 | "A variable is a name of the memory location where we store the data. For example think of box where you store all you belongings inside that box. \n"
56 | ]
57 | },
58 | {
59 | "cell_type": "code",
60 | "metadata": {
61 | "id": "cUWE7e3u7Dqu",
62 | "colab_type": "code",
63 | "colab": {}
64 | },
65 | "source": [
66 | "# Creating a bunch of variables with mixture of datatypes like int, float, boolean.\n",
67 | "var = 20 # Integer data\n",
68 | "var1 = 20.0 # Float data\n",
69 | "var2 = False # Boolean data\n",
70 | "var3 = -20 # Integer data"
71 | ],
72 | "execution_count": 0,
73 | "outputs": []
74 | },
75 | {
76 | "cell_type": "code",
77 | "metadata": {
78 | "id": "QpgAsB0Q7FWM",
79 | "colab_type": "code",
80 | "colab": {
81 | "base_uri": "https://localhost:8080/",
82 | "height": 139
83 | },
84 | "outputId": "1de99ff2-8473-48d7-a5df-6e4877f460a8"
85 | },
86 | "source": [
87 | "# Printing the variables \n",
88 | "\n",
89 | "print(var)\n",
90 | "print(\"-------------------------------------------------------------\")\n",
91 | "print(var1)\n",
92 | "print(\"-------------------------------------------------------------\")\n",
93 | "print(var2)\n",
94 | "print(\"-------------------------------------------------------------\")\n",
95 | "print(var3)"
96 | ],
97 | "execution_count": 8,
98 | "outputs": [
99 | {
100 | "output_type": "stream",
101 | "text": [
102 | "20\n",
103 | "-------------------------------------------------------------\n",
104 | "20.0\n",
105 | "-------------------------------------------------------------\n",
106 | "False\n",
107 | "-------------------------------------------------------------\n",
108 | "-20\n"
109 | ],
110 | "name": "stdout"
111 | }
112 | ]
113 | },
114 | {
115 | "cell_type": "markdown",
116 | "metadata": {
117 | "id": "5iqRB58Y7H5I",
118 | "colab_type": "text"
119 | },
120 | "source": [
121 | "A datatype refers to the type of data that we store inside a variable. For example we store integer datatype, float datatype and booleab datatype. \n"
122 | ]
123 | },
124 | {
125 | "cell_type": "code",
126 | "metadata": {
127 | "id": "L8mXWd-k7JKH",
128 | "colab_type": "code",
129 | "colab": {
130 | "base_uri": "https://localhost:8080/",
131 | "height": 139
132 | },
133 | "outputId": "82cd4b34-91a0-4a40-bdad-f9f1bdeb3713"
134 | },
135 | "source": [
136 | "# The type of the data can be determined by using type() method.\n",
137 | "\n",
138 | "print(type(var))\n",
139 | "print(\"-------------------------------------------------------------\")\n",
140 | "print(type(var1))\n",
141 | "print(\"-------------------------------------------------------------\")\n",
142 | "print(type(var2))\n",
143 | "print(\"-------------------------------------------------------------\")\n",
144 | "print(type(var3))"
145 | ],
146 | "execution_count": 9,
147 | "outputs": [
148 | {
149 | "output_type": "stream",
150 | "text": [
151 | "\n",
152 | "-------------------------------------------------------------\n",
153 | "\n",
154 | "-------------------------------------------------------------\n",
155 | "\n",
156 | "-------------------------------------------------------------\n",
157 | "\n"
158 | ],
159 | "name": "stdout"
160 | }
161 | ]
162 | },
163 | {
164 | "cell_type": "markdown",
165 | "metadata": {
166 | "id": "ebMioqef7Vux",
167 | "colab_type": "text"
168 | },
169 | "source": [
170 | "\n",
171 | "\n",
172 | "---\n",
173 | "\n"
174 | ]
175 | },
176 | {
177 | "cell_type": "markdown",
178 | "metadata": {
179 | "id": "-reTM9zI7Lst",
180 | "colab_type": "text"
181 | },
182 | "source": [
183 | "## 2. Comments and Mathematical operators\n",
184 | "\n",
185 | "Comments are very useful especially when you are stuck in understanding the code with the help of comments ypu can understand the code.Single line comments can be written by using \"#\" . It's a good practice to comment your code."
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "metadata": {
191 | "id": "cLmQahXA7Nib",
192 | "colab_type": "code",
193 | "colab": {}
194 | },
195 | "source": [
196 | "# This is a single line comment"
197 | ],
198 | "execution_count": 0,
199 | "outputs": []
200 | },
201 | {
202 | "cell_type": "markdown",
203 | "metadata": {
204 | "id": "Mo3Xzi__7PZ2",
205 | "colab_type": "text"
206 | },
207 | "source": [
208 | "Mathematical operators include additon, subtraction, multiplication, division etc. It is very easy to perform mathematical operations in python."
209 | ]
210 | },
211 | {
212 | "cell_type": "code",
213 | "metadata": {
214 | "id": "9BuhtN0X7Qer",
215 | "colab_type": "code",
216 | "colab": {}
217 | },
218 | "source": [
219 | "add = 10 + 5 # Addition\n",
220 | "sub = 10 - 5 # Subtraction\n",
221 | "mul = 10 * 5 # Multiplication\n",
222 | "div = 10 / 5 # Division\n",
223 | "exp = 10 ** 5 # Exponent\n",
224 | "floor = 13 // 5 # Floor division\n",
225 | "mod = 13 % 5 # Modulus operator"
226 | ],
227 | "execution_count": 0,
228 | "outputs": []
229 | },
230 | {
231 | "cell_type": "code",
232 | "metadata": {
233 | "id": "FcFF5tuf7R37",
234 | "colab_type": "code",
235 | "colab": {
236 | "base_uri": "https://localhost:8080/",
237 | "height": 243
238 | },
239 | "outputId": "5430dd3c-3bd0-4989-c333-a29ac4136568"
240 | },
241 | "source": [
242 | "print(add)\n",
243 | "print(\"-------------------------------------------------------------\")\n",
244 | "print(sub)\n",
245 | "print(\"-------------------------------------------------------------\")\n",
246 | "print(mul)\n",
247 | "print(\"-------------------------------------------------------------\")\n",
248 | "print(div)\n",
249 | "print(\"-------------------------------------------------------------\")\n",
250 | "print(exp)\n",
251 | "print(\"-------------------------------------------------------------\")\n",
252 | "print(floor)\n",
253 | "print(\"-------------------------------------------------------------\")\n",
254 | "print(mod)"
255 | ],
256 | "execution_count": 12,
257 | "outputs": [
258 | {
259 | "output_type": "stream",
260 | "text": [
261 | "15\n",
262 | "-------------------------------------------------------------\n",
263 | "5\n",
264 | "-------------------------------------------------------------\n",
265 | "50\n",
266 | "-------------------------------------------------------------\n",
267 | "2.0\n",
268 | "-------------------------------------------------------------\n",
269 | "100000\n",
270 | "-------------------------------------------------------------\n",
271 | "2\n",
272 | "-------------------------------------------------------------\n",
273 | "3\n"
274 | ],
275 | "name": "stdout"
276 | }
277 | ]
278 | },
279 | {
280 | "cell_type": "markdown",
281 | "metadata": {
282 | "id": "UuBRpiFt7UKl",
283 | "colab_type": "text"
284 | },
285 | "source": [
286 | "\n",
287 | "\n",
288 | "---\n",
289 | "\n"
290 | ]
291 | }
292 | ]
293 | }
--------------------------------------------------------------------------------
/Strings/String:
--------------------------------------------------------------------------------
1 | # Python Program for
2 | # Creation of String
3 |
4 | # Creating a String
5 | # with single Quotes
6 | String1 = 'Welcome to the Geeks World'
7 | print("String with the use of Single Quotes: ")
8 | print(String1)
9 |
10 | # Creating a String
11 | # with double Quotes
12 | String1 = "I'm a Geek"
13 | print("\nString with the use of Double Quotes: ")
14 | print(String1)
15 |
16 | # Creating a String
17 | # with triple Quotes
18 | String1 = '''I'm a Geek and I live in a world of "Geeks"'''
19 | print("\nString with the use of Triple Quotes: ")
20 | print(String1)
21 |
22 | # Creating String with triple
23 | # Quotes allows multiple lines
24 | String1 = '''Geeks
25 | For
26 | Life'''
27 | print("\nCreating a multiline String: ")
28 | print(String1)
29 |
--------------------------------------------------------------------------------
/Time_Series_Forecasting_with_Pandas.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyP4NJQtGdN2hKjuY6z95NLe",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Time Series Forecasting with Pandas\n",
33 | "## Learn how Python handles time-based data and lays the foundation for forecasting\n",
34 | "\n",
35 | "\n",
36 | "|  |\n",
37 | "|:--:|\n",
38 | "| Image Generated Using Canva|\n",
39 | "\n",
40 | "\n",
41 | "### Why it’s so important\n",
42 | "Time series data is everywhere; stock prices, weather reports, sensor data, website traffic. If you can master how to work with time, you can unlock powerful insights and predict the future.\n",
43 | "\n",
44 | "Pandas makes it incredibly intuitive to handle time-indexed data, re-sample it, and prep it for machine learning models.\n",
45 | "\n",
46 | "In this article, let’s explore Pandas’s core time series operations, laying the groundwork for real-world forecasting models.\n",
47 | "\n",
48 | "---\n",
49 | "\n",
50 | "### Key Concepts Covered\n",
51 | "* How `DateTimeIndex` supercharges time-aware operations\n",
52 | "* Resampling vs. frequency conversion: `resample() vs. asfreq()`\n",
53 | "* Rolling windows and moving averages for smoothing\n",
54 | "* Time-shifting data for lag analysis\n",
55 | "* Handling missing time entries cleanly\n",
56 | "\n",
57 | "---\n",
58 | "\n",
59 | "### Fun Fact\n",
60 | "Pandas can automatically parse date columns and even infer frequencies, making it possible to clean and analyze time data with just a few lines of code.\n",
61 | "\n",
62 | "---\n",
63 | "\n",
64 | "### Implementation"
65 | ],
66 | "metadata": {
67 | "id": "GR67xFgeYmr2"
68 | }
69 | },
70 | {
71 | "cell_type": "code",
72 | "execution_count": null,
73 | "metadata": {
74 | "colab": {
75 | "base_uri": "https://localhost:8080/"
76 | },
77 | "id": "IUDHmM3_Yc4c",
78 | "outputId": "707fceb7-5a4f-471e-b665-3c3c0af76f35"
79 | },
80 | "outputs": [
81 | {
82 | "output_type": "stream",
83 | "name": "stdout",
84 | "text": [
85 | " value rolling_avg prev_day\n",
86 | "2023-01-01 173 NaN NaN\n",
87 | "2023-01-02 139 NaN 173.0\n",
88 | "2023-01-03 176 162.666667 139.0\n",
89 | "2023-01-04 111 142.000000 176.0\n",
90 | "2023-01-05 172 153.000000 111.0\n",
91 | "2023-01-06 164 149.000000 172.0\n",
92 | "2023-01-07 179 171.666667 164.0\n",
93 | "2023-01-08 149 164.000000 179.0\n",
94 | "2023-01-09 109 145.666667 149.0\n",
95 | "2023-01-10 107 121.666667 109.0\n",
96 | "Resampled:\n",
97 | " value\n",
98 | "2023-01-01 162.666667\n",
99 | "2023-01-04 149.000000\n",
100 | "2023-01-07 145.666667\n",
101 | "2023-01-10 107.000000\n"
102 | ]
103 | }
104 | ],
105 | "source": [
106 | "import pandas as pd\n",
107 | "import numpy as np\n",
108 | "\n",
109 | "# Create time series data\n",
110 | "dates = pd.date_range(start=\"2023-01-01\", periods=10, freq=\"D\")\n",
111 | "data = np.random.randint(100, 200, size=(10,))\n",
112 | "df = pd.DataFrame({'value': data}, index=dates)\n",
113 | "\n",
114 | "# Resample to every 3 days and get the mean\n",
115 | "resampled = df.resample('3D').mean()\n",
116 | "\n",
117 | "# Calculate rolling average\n",
118 | "df['rolling_avg'] = df['value'].rolling(window=3).mean()\n",
119 | "\n",
120 | "# Shift data for comparison (e.g., yesterday’s value)\n",
121 | "df['prev_day'] = df['value'].shift(1)\n",
122 | "\n",
123 | "print(df)\n",
124 | "print(\"Resampled:\\n\", resampled)"
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "source": [
130 | "\n",
131 | "\n",
132 | "> ***This is the backbone of forecasting models. Whether you’re predicting sales or analyzing sensor patterns, these time-based manipulations are the first step toward insights!***\n",
133 | "\n",
134 | "---\n",
135 | "\n",
136 | "### Before you go\n",
137 | "* Be sure to Like and Connect Me\n",
138 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
139 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
140 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!\n",
141 | "\n",
142 | "\n",
143 | "\n"
144 | ],
145 | "metadata": {
146 | "id": "FuZbSrr8ZCoY"
147 | }
148 | }
149 | ]
150 | }
--------------------------------------------------------------------------------
/Understanding_Virtual_Environments_in_Python.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyMmQmdne96MzUKygHRgHbly",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Understanding Virtual Environments in Python\n",
33 | "\n",
34 | "## Master Efficient Data Storage and Retrieval with Python\n",
35 | "\n",
36 | "|  |\n",
37 | "|:--:|\n",
38 | "| Image Generated Using Canva|\n",
39 | "\n",
40 | "#### Introduction\n",
41 | "When you're working on multiple Python projects, you might run into version conflicts, one project needs `Django 3.x`, another needs `Django 4.x`. Virtual environments solve this problem! They create isolated spaces for each project, ensuring dependencies don’t clash and projects stay clean and manageable. Today, let's dive into how virtual environments work and why they're a must for professional development.\n",
42 | "\n",
43 | "---\n",
44 | "\n",
45 | "#### Why It’s So Important?\n",
46 | "* It keeps project dependencies isolated.\n",
47 | "* It avoids version conflicts.\n",
48 | "* It makes your projects easily reproducible.\n",
49 | "* The professional standard for real-world development.\n",
50 | "\n",
51 | "---\n",
52 | "\n",
53 | "#### Code Implementation"
54 | ],
55 | "metadata": {
56 | "id": "Gm7uUS7t-SeQ"
57 | }
58 | },
59 | {
60 | "cell_type": "code",
61 | "source": [
62 | "# Step 1: Install virtualenv (if you haven't)\n",
63 | "pip install virtualenv\n",
64 | "\n",
65 | "# Step 2: Create a virtual environment\n",
66 | "virtualenv myprojectenv\n",
67 | "\n",
68 | "# Step 3: Activate the environment\n",
69 | "# On Windows\n",
70 | "myprojectenv\\Scripts\\activate\n",
71 | "\n",
72 | "# On Mac/Linux\n",
73 | "source myprojectenv/bin/activate\n",
74 | "\n",
75 | "# Step 4: Install project dependencies\n",
76 | "pip install django==3.2\n",
77 | "\n",
78 | "# Step 5: To deactivate\n",
79 | "deactivate"
80 | ],
81 | "metadata": {
82 | "id": "kD0pzSME-raT"
83 | },
84 | "execution_count": null,
85 | "outputs": []
86 | },
87 | {
88 | "cell_type": "markdown",
89 | "source": [
90 | "##### Notes\n",
91 | "* Each environment has its own Python binary and can have different versions of libraries.\n",
92 | "* You can even have different Python versions inside environments using tools like pyenv.\n",
93 | "\n",
94 | "---\n",
95 | "\n",
96 | "#### Conclusion\n",
97 | "Virtual environments are not just a \"nice to have\", they are essential for clean, organized, and scalable Python development. Whether you're working solo or in a team, mastering virtual environments will make your coding life much smoother! Thanks for reading my article, let me know if you have any suggestions or similar implementations via the comment section. Until then, see you next time. Happy coding!\n",
98 | "\n",
99 | "---\n",
100 | "\n",
101 | "#### Before you go\n",
102 | "* Be sure to Like and Connect Me\n",
103 | "* Follow Me : [Medium](https://medium.com/@tanunprabhu95) | [GitHub](https://github.com/Tanu-N-Prabhu) | [LinkedIn](https://ca.linkedin.com/in/tanu-nanda-prabhu-a15a091b5) | [Python Hub](https://github.com/Tanu-N-Prabhu/Python)\n",
104 | "* [Check out my latest articles on Programming](https://medium.com/@tanunprabhu95)\n",
105 | "* Check out my [GitHub](https://github.com/Tanu-N-Prabhu) for code and [Medium](https://medium.com/@tanunprabhu95) for deep dives!"
106 | ],
107 | "metadata": {
108 | "id": "q-O_5Uza-t1P"
109 | }
110 | }
111 | ]
112 | }
--------------------------------------------------------------------------------
/Vowel_Count.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyOqQvMYSVHffQwcSDCIXmsN",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Counting Vowels in a Sentence\n",
33 | "\n",
34 | "\n",
35 | "## Problem\n",
36 | "\n",
37 | "You are tasked with creating a Python script that counts the number of vowels in a given sentence. Your program should prompt the user to enter a sentence, and then output the total count of vowels present in that sentence. The program should treat both uppercase and lowercase vowels as equivalent.\n",
38 | "\n",
39 | "Your task is to write a Python script that accomplishes this, utilizing functions and loops as necessary."
40 | ],
41 | "metadata": {
42 | "id": "oQbsz2YwDc_f"
43 | }
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 1,
48 | "metadata": {
49 | "colab": {
50 | "base_uri": "https://localhost:8080/"
51 | },
52 | "id": "XAU5DlE0DZpU",
53 | "outputId": "43f94197-a8b0-42c5-fb3b-248340f81b1d"
54 | },
55 | "outputs": [
56 | {
57 | "output_type": "stream",
58 | "name": "stdout",
59 | "text": [
60 | "Enter a sentence: Hello I am a Sales Expert\n",
61 | "Number of vowels: 9\n"
62 | ]
63 | }
64 | ],
65 | "source": [
66 | "def count_vowels(sentence):\n",
67 | " vowels = 'aeiouAEIOU'\n",
68 | " vowel_count = 0\n",
69 | " for char in sentence:\n",
70 | " if char in vowels:\n",
71 | " vowel_count += 1\n",
72 | " return vowel_count\n",
73 | "\n",
74 | "sentence = input(\"Enter a sentence: \")\n",
75 | "print(\"Number of vowels:\", count_vowels(sentence))\n"
76 | ]
77 | },
78 | {
79 | "cell_type": "markdown",
80 | "source": [
81 | "This script defines a function count_vowels that takes a sentence as input and returns the count of vowels in it. It iterates over each character in the sentence and checks if it is a vowel. If it is, it increments the count. Finally, it prints out the total count of vowels in the sentence.\n",
82 | "\n",
83 | "\n"
84 | ],
85 | "metadata": {
86 | "id": "euH9m_htD6tG"
87 | }
88 | }
89 | ]
90 | }
--------------------------------------------------------------------------------
/data_load.md:
--------------------------------------------------------------------------------
1 | # Loading a File using Pandas
2 | ## Watch out for different types of file formats!
3 |
4 | 
5 |
6 | [](https://hits.seeyoufarm.com)
7 |
8 | | Function | Description |
9 | | -------- | ------- |
10 | | read_csv | Read a comma-separated values (CSV) file into DataFrame |
11 | | read_table | Read general delimited file into DataFrame |
12 | | read_excel | $420 |
13 | | read_fwf | $420 |
14 | | read_clipboard | $420 |
15 | | read_excel | $420 |
16 |
17 |
--------------------------------------------------------------------------------
/src/2D_Matrix_Multiplication.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | print("Make sure that a should be equal to b * c")
4 | b = int(input("Enter the value of b ===> "))
5 | c = int(input("Enter the value of c ===> "))
6 | a = int(input("Enter the value of a ===> "))
7 |
8 | first = np.arange(a).reshape(b, c)
9 | print(first)
10 |
11 | second = np.arange(a).reshape(b, c)
12 | print(second)
13 |
14 | product = first * second
15 | print(product)
16 |
17 |
--------------------------------------------------------------------------------
/src/Accessing_By_Index.py:
--------------------------------------------------------------------------------
1 | str = "example"
2 | str1 = str[3]
3 | print(str1)
4 |
5 | str2 = "Tanu"[3]
6 | print(str2)
7 |
8 |
--------------------------------------------------------------------------------
/src/Slicing_A_String:
--------------------------------------------------------------------------------
1 | String = "Apple"
2 |
3 | a = String[:3]
4 | print(a)
5 |
6 | b = String[2:5]
7 | print(b)
8 |
9 | c = String[3:]
10 | print(c)
11 |
12 |
13 | d = "Orange"[:3]
14 | print(d)
15 |
16 | e = "Orange"[2:5]
17 | print(e)
18 |
19 | f = "Orange"[3:]
20 | print(f)
21 |
--------------------------------------------------------------------------------
/src/String_Concat_Using_Print.py:
--------------------------------------------------------------------------------
1 | String1 = "Tanu"
2 | String2 = "Nanda"
3 | String3 = "Prabhu"
4 |
5 | print(String1 + " " + String2 + " " + String3)
6 |
--------------------------------------------------------------------------------
/src/Strings.py:
--------------------------------------------------------------------------------
1 | String = " This is a string "
2 | print(String)
3 |
--------------------------------------------------------------------------------
/src/Vending_Machine.py:
--------------------------------------------------------------------------------
1 | import sys
2 |
3 | option = int(input("Enter the option as 1, 2 or 3"))
4 |
5 | if option == 1:
6 | charge = 1.00
7 | elif option == 2:
8 | charge = 1.50
9 | elif option ==3:
10 | charge = 2.00
11 | else:
12 | sys.exit("Invalid option: Try again !!!!!")
13 |
14 | quaters = int(input("Enter the quarters"))
15 | nickels = int(input("Enter the nickles"))
16 | dimes = int(input("Enter the dimes"))
17 | pennies = int(input("Enter the pennis"))
18 |
19 | total = quaters*0.25 + nickels+0.10 + dimes*0.05 + pennies*0.01
20 |
21 | print("You total money is: %f" %(total))
22 |
23 | if total >= charge:
24 | print("You change is: %f" % (total-charge))
25 |
26 | else:
27 | print("Please try again")
28 |
--------------------------------------------------------------------------------
/src/control_Statements.py:
--------------------------------------------------------------------------------
1 | a = input("Enter the value of a: ")
2 | b = input("Enter the value of b: ")
3 | c = input("Enter the value of c: ")
4 |
5 | if a > b > c:
6 | print("a is greater than b and c")
7 | elif b > c > a:
8 | print("b is greater than c and a")
9 | elif a == b == c:
10 | print("a, b, c are all equal")
11 | elif a == b:
12 | print("a and b are equal")
13 | elif b == c:
14 | print("b and c are equal")
15 | elif a == c:
16 | print("a and c are equal")
17 | else:
18 | print("c is greater than a and b")
19 |
20 |
--------------------------------------------------------------------------------
/src/dictionary.py:
--------------------------------------------------------------------------------
1 | name = {1: "Tanu", 2: "Nanda", 3: "Prabhu"}
2 |
3 | print(name[1])
4 | print(name[2])
5 | print(name[3])
6 | print(name)
7 |
8 | # Creating the new Dictinoary from an empty dictionary
9 |
10 | name1 = {}
11 | name1[1] = "Mercedes"
12 | name1[2] = "Benz"
13 |
14 | print(name1)
15 |
16 | # Calculating the length of the dictionary name1 can be done by
17 | length = len(name1)
18 | print(length)
19 |
20 |
21 | # Reassigning the key of the dictionary
22 |
23 | name[2] = "N"
24 | print(name)
25 |
26 | # Removing the key valur pair using a del:
27 |
28 | name2 = {1: "Newton", 2: "Einstein", 3: "Tanu"}
29 | del name2[3]
30 |
31 | print(name2)
32 |
--------------------------------------------------------------------------------
/src/for_loop.py:
--------------------------------------------------------------------------------
1 | list = [1, 2, 3, 4, 5]
2 | for item in list:
3 | print(item)
4 |
--------------------------------------------------------------------------------
/src/functions.py:
--------------------------------------------------------------------------------
1 |
2 | def add(c,d):
3 | e = c + d
4 | return e
5 |
6 |
7 | a = int(input("Enter the value of a:"))
8 | b = int(input("Enter the value of b:"))
9 |
10 | e = add (a, b)
11 | print(e)
12 |
--------------------------------------------------------------------------------
/src/helloWorld.py:
--------------------------------------------------------------------------------
1 | print("Hello World")
2 |
--------------------------------------------------------------------------------
/src/input().py:
--------------------------------------------------------------------------------
1 | firstName = input("Enter your first name")
2 | lastName = input("Enter your last name")
3 | age = input("Enter your age")
4 |
5 | print("Your firstname is: %s, lastname is: %s, and height is: %sl" %(firstName, lastName, age))
6 |
--------------------------------------------------------------------------------
/src/length_of_name.py:
--------------------------------------------------------------------------------
1 | name = input("Enter your name: ")
2 |
3 | length = len(name)
4 |
5 | print("The length of your name is: %s" %(length))
6 |
7 | if length < 4:
8 | print("The name is less than 4 characters")
9 |
10 | elif length < 10 :
11 | print("The name is greater than 4 but less thank 10")
12 | else:
13 | print("The name is very long")
14 |
--------------------------------------------------------------------------------
/src/list.py:
--------------------------------------------------------------------------------
1 | def list():
2 | List = ["Tanu", "Nanda", "Prabhu"]
3 | print(List)
4 |
5 | def byIndex():
6 | List = ["Tanu", "Nanda", "Prabhu"]
7 | Index = List[2]
8 | print(Index)
9 |
10 | def appending():
11 | adder = [1, 2, 3, 4]
12 | adder.append(5)
13 | print(adder)
14 |
15 | def slicing():
16 | slice = [1, 2, 3, 4, 5]
17 | slice1 = slice[:2]
18 | print(slice1)
19 |
20 | def index():
21 | index = [1, 2, 3, 4, 5]
22 | index1 = index.index(3)
23 | print(index1)
24 |
25 | def insert():
26 | insert = ["Tanu", "Nanda"]
27 | insert.insert(2, "Prabhu")
28 | print(insert)
29 |
30 | def remove():
31 | remove = ["Daimler", "Mercedes", "Benz"]
32 | remove.remove("Daimler")
33 | print(remove)
34 |
35 | def pop():
36 | popped = ["BMW", "Mercedes", "Mini"]
37 | pop1 = popped.pop(2)
38 | print(pop1)
39 |
40 | option = int(input("Enter the option such as 1, 2, 3, 4, 5, 6, 7, 8"))
41 |
42 | if option == 1:
43 | list()
44 | elif option == 2:
45 | byIndex()
46 | elif option == 3:
47 | appending()
48 | elif option == 4:
49 | slicing()
50 | elif option == 5:
51 | index()
52 | elif option == 6:
53 | insert()
54 | elif option == 7:
55 | remove()
56 | elif option == 8:
57 | pop()
58 | else:
59 | print("You have entered invalid option !!!!")
60 |
61 |
62 |
63 |
--------------------------------------------------------------------------------
/src/list_functions1.py:
--------------------------------------------------------------------------------
1 | # Passing the entire list as a parameter to the function
2 | list1 = [1, 2, 3, 4, 5, 6]
3 |
4 | def func1(l1):
5 | for item1 in list1:
6 | print(item1)
7 |
8 | func1(list1)
9 |
10 | # Generating the list using a range function
11 |
12 | # range (stop)
13 | list2 = range(5)
14 | print(list2)
15 |
16 | # range (start, stop)
17 | list3 = range(1, 10)
18 | print(list3)
19 |
20 | #range (start, step, stop)
21 | list4 = range(2, 10, 20)
22 | print(list4)
23 |
24 | # range function are innutable, they cannot be modified
25 |
26 | # Using range function in a for loop
27 |
28 | list5 = [1, 3, 5, 7]
29 |
30 | def fun2(l2):
31 | for item3 in range(0, 4):
32 | print(l2[item3])
33 |
34 | fun2(list5)
35 |
36 | # Modifying the list using the range function
37 |
38 | list6 = [1, 2, 3, 4, 5]
39 |
40 | def modify(list):
41 | for item4 in range(0, 5):
42 | list[item4] = list[item4] + 5
43 | print(list[item4])
44 |
45 | modify(list6)
46 |
47 | # Passing multiple lists into the function
48 |
49 | list7 = [1, 2, 3]
50 | list8 = [4, 5, 6]
51 |
52 | def multiple(a, b):
53 | print(a, b)
54 |
55 | multiple(list7, list8 )
56 |
57 | # Iterating through a list of list using a function
58 |
59 | listoflist = [[1, 2, 3], [4, 5, 6]]
60 |
61 | def makeOneList (a):
62 | bothLists = []
63 | for item in a:
64 | for element in item:
65 | bothLists.append(element)
66 | print(bothLists)
67 |
68 | makeOneList(listoflist)
--------------------------------------------------------------------------------
/src/lists_and_functions.py:
--------------------------------------------------------------------------------
1 | # passing a list as a parameter to a function
2 | list = ["Tanu", "Nanda", "Prabhu"]
3 |
4 | def call_list(li):
5 | return li
6 |
7 | print(call_list(list))
8 | print(call_list(list[2]))
9 |
10 | # Accessing an element in a list using a function
11 |
12 | list2 = [1, 2, 3, 4, 5]
13 |
14 | def listing(li1):
15 | return li1
16 |
17 | print(listing(list2[1]))
18 |
19 | # Modifing a list value in a function
20 |
21 | list3 = [4, 3, 2, 1, 0]
22 |
23 | def modify(l1):
24 | return l1[1]+1
25 |
26 | print(modify(list3))
27 |
28 | # Manipulating the list using the functions
29 |
30 | list4 = [1, 1, 3, 8]
31 |
32 | def list_manip(li):
33 | li.remove(3)
34 | li.insert(2,4)
35 | return li
36 |
37 | print(list_manip(list4))
--------------------------------------------------------------------------------
/src/numpy_examples.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | # For arrays of 3 zeros
4 | a = np.zeros(3)
5 | print(a)
6 | print(type(a[0])) # Indicates that a is of float type and the values inside it is of type float
7 |
8 |
9 | # For arrays of 10 zeros
10 | b = np.zeros(10)
11 | print(b)
12 |
13 | # For looking to the shape of the array
14 | print(b.shape)
15 |
16 | # changing the shape of the array from 10 to 1
17 |
18 | b.shape = (10, 1)
19 | print(b)
20 |
21 | # changing the zeros to ones
22 | c = np.ones(5)
23 | print(c)
24 |
25 | # Using line space
26 | d = np.linspace(2, 10, 5)
27 | print(d)
28 |
29 | # another way to create an array
30 | e = np.array([10, 20])
31 | print(e)
32 | print(type(e))
33 |
34 | # also we can add a list in a array
35 | list = [1, 2, 3, 4, 5]
36 | f = np.array([list])
37 | print(f)
38 |
39 | # creating a two dimension array
40 | list2 = [[1, 2, 3, 4],[5, 6, 7,]]
41 |
42 | g = np.array([list2])
43 | print(g)
44 |
45 | # creating a random array using random()
46 |
47 | np.random.seed(0) # if you remove this line then, you can rerun the code and check that the random array is same.
48 |
49 | h = np.random.randint(10, size=6)
50 | print(h)
51 | print(h[-1]) # gets the last element of the array
--------------------------------------------------------------------------------
/src/panda_examples.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import numpy as np
3 |
4 | # There are three datastructures in panda
5 | # 1. Series ==> They are a 1-D Matrix
6 | # 2. DataFrame ==> They are a 2-D Matrix
7 | # 3. Panel ==> They are a 3-D Matrix
8 |
9 |
10 | # Creating a Series Datastructure
11 | a = [1, 2, 3, 4, 5]
12 | series = pd.Series(a)
13 | print(series)
14 |
15 | # Creating the Dataframe Datastructure
16 | b = [['Ashika', 24], ['Tanu', 23], ['Ashwin', 22],['Mohith', 16], ['Sourabh', 10]]
17 | dataframe = pd.DataFrame(b, columns= ['Name', 'Age'], dtype= int)
18 | print(dataframe)
19 |
20 | # Creating the Panel Datastructure
21 | data = {'Item1' : pd.DataFrame(np.random.randn(4, 3)),
22 | 'Item2' : pd.DataFrame(np.random.randn(4, 2))}
23 | p = pd.Panel(data)
24 | print(p.minor_xs(1))
25 |
26 |
--------------------------------------------------------------------------------
/src/tuples.py:
--------------------------------------------------------------------------------
1 | tuple1 = (1, "Hi", True, 8.999)
2 |
3 | print(tuple1)
4 |
5 | tupleEmpty = ()
6 | print(tupleEmpty)
7 |
8 | # Accessing the tuple by Index
9 |
10 | tuple2 = (1, 2, 3, 4, 5)
11 |
12 | print(tuple2[4])
13 | print(tuple2[1])
14 |
15 | # Slicing the tuples
16 |
17 | print(tuple2[1:3])
18 | print(tuple2[:3])
19 |
--------------------------------------------------------------------------------
/src/using_%s_format_operator.py:
--------------------------------------------------------------------------------
1 | name = "Tanu"
2 | lastname = "Nanda_Prabhu"
3 | height = 6.1
4 |
5 | print("The name of the developer is %s %s and his height is %0.1f" %(name, lastname, height))
6 |
--------------------------------------------------------------------------------
/src/variables.py:
--------------------------------------------------------------------------------
1 | variableNamesCannotBeginWithANumber = True
2 | boolean = True
3 | posInt = 2
4 | zero = 0
5 | negFloat = -1
6 | initial = 3
7 | initial = 4
8 | print(initial)
9 |
--------------------------------------------------------------------------------
/src/variables1.py:
--------------------------------------------------------------------------------
1 | """
2 | comments practice:
3 | 1.create a single line comment
4 | 2.create a multiple line comment
5 | """
6 |
7 | # Hi this me
8 |
9 | """
10 | This is me
11 | """
12 |
13 | """
14 | basic mathematical operators practice:
15 | 1.create a variable called add and assign it the sum of two numbers
16 | 2.create a variable called sub and assign it the difference of two numbers
17 | 3.create a variable called mult and assign it the product of two numbers
18 | 4.create a variable called div and assign it the quotient of two numbers
19 | 5.create a variable called power and assign it the value of a number raised to a power
20 | 6.create a variable called mod and assign it the emainder of a quotient
21 | """
22 | add = 5+6
23 | print(add)
24 |
25 | sub = 7-6
26 | print(sub)
27 |
28 | mult = 9*8
29 | print(mult)
30 |
31 | div = 10/2
32 | print(div)
33 |
34 | power = 5**6
35 | print(power)
36 |
37 | mod = 9%4
38 | print(mod)
39 | """
40 | modulo practice:
41 | 1.create a variable called mod1 and assign it the result of 7 % 5
42 | 2.create a variable called mod2 and assign it the result of 16 % 6
43 | 3.create a variable called mod3 and assign it the result of 4 % 3
44 | """
45 | mod1 = 7%5
46 | print(mod1)
47 |
48 | mod2 = 16%6
49 | print(mod2)
50 |
51 | mod3 = 4%3
52 | print(mod3)
53 | """
54 | order of operations practice:
55 | 1.create and assign a variable called ordOp1 the result of 7 + 6 + 9 - 4 * ((9 - 2) ** 2) / 7
56 | 2.create and assign a variable called ordOp2 the result of (6 % 4 * (7 + (7 + 2) * 3)) ** 2
57 | """
58 |
59 | ordOp1 = 7 + 6 + 9 - 4 * ((9 - 2) ** 2) / 7
60 | print(ordOp1)
61 |
62 | ordOp2 = (6 % 4 * (7 + (7 + 2) * 3)) ** 2
63 | print(ordOp2)
64 |
--------------------------------------------------------------------------------