├── Adapter
├── Sampling.py
├── extra_condition
│ ├── api.py
│ ├── model_edge.py
│ └── openpose
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── __init__.cpython-310.pyc
│ │ ├── api.cpython-310.pyc
│ │ ├── body.cpython-310.pyc
│ │ ├── model.cpython-310.pyc
│ │ └── util.cpython-310.pyc
│ │ ├── api.py
│ │ ├── body.py
│ │ ├── hand.py
│ │ ├── model.py
│ │ └── util.py
├── inference_base.py
├── models
│ └── adapters.py
└── utils.py
├── README.md
├── app.py
├── assets
└── logo3.png
├── configs
├── inference
│ ├── Adapter-XL-canny.yaml
│ ├── Adapter-XL-openpose.yaml
│ └── Adapter-XL-sketch.yaml
├── train
│ └── Adapter-XL-sketch.yaml
└── utils.py
├── dataset
├── dataset_laion.py
└── utils.py
├── demo.py
├── examples
├── dog.png
├── people.jpg
└── room.jpg
├── models
└── unet.py
├── requirements.txt
├── test.py
└── train_sketch.py
/Adapter/Sampling.py:
--------------------------------------------------------------------------------
1 | from transformers import AutoTokenizer
2 | from diffusers import DDPMScheduler, AutoencoderKL
3 | import torch
4 | from pytorch_lightning import seed_everything
5 | import tqdm
6 | import copy
7 | import random
8 | from basicsr.utils import tensor2img
9 | import numpy as np
10 |
11 | from Adapter.utils import import_model_class_from_model_name_or_path
12 | from models.unet import UNet
13 |
14 | class diffusion_inference:
15 | def __init__(self, model_id):
16 | self.device = 'cuda'
17 | self.model_id = model_id
18 |
19 | # load unet model
20 | self.scheduler = DDPMScheduler.from_pretrained(model_id, subfolder="scheduler")
21 | self.model = UNet.from_pretrained(model_id, subfolder="unet").to(self.device)
22 | try:
23 | self.model.enable_xformers_memory_efficient_attention()
24 | except:
25 | print('The current xformers is not compatible, please reinstall xformers to speed up.')
26 | self.scheduler.set_timesteps(50)
27 |
28 | tokenizer_one = AutoTokenizer.from_pretrained(
29 | self.model_id, subfolder="tokenizer", revision=None, use_fast=False
30 | )
31 | tokenizer_two = AutoTokenizer.from_pretrained(
32 | self.model_id, subfolder="tokenizer_2", revision=None, use_fast=False
33 | )
34 |
35 | # import correct text encoder classes
36 | text_encoder_cls_one = import_model_class_from_model_name_or_path(
37 | self.model_id, None
38 | )
39 | text_encoder_cls_two = import_model_class_from_model_name_or_path(
40 | self.model_id, None, subfolder="text_encoder_2"
41 | )
42 |
43 | # Load scheduler and models
44 | text_encoder_one = text_encoder_cls_one.from_pretrained(
45 | self.model_id, subfolder="text_encoder", revision=None
46 | )
47 | text_encoder_two = text_encoder_cls_two.from_pretrained(
48 | self.model_id, subfolder="text_encoder_2", revision=None
49 | )
50 | # self.text_encoders = [text_encoder_one.to(self.device), text_encoder_two.to(self.device)]
51 | self.text_encoders = [text_encoder_one, text_encoder_two]
52 | self.tokenizers = [tokenizer_one, tokenizer_two]
53 | self.vae = AutoencoderKL.from_pretrained(
54 | self.model_id,
55 | subfolder="vae",
56 | revision=None,
57 | )#.to(self.device)
58 |
59 | def reset_schedule(self, timesteps):
60 | self.scheduler.set_timesteps(timesteps)
61 |
62 | def inference(self, prompt, size, prompt_n='', adapter_features=None, guidance_scale=7.5, seed=-1, steps=50):
63 | prompt_batch = [prompt_n, prompt]
64 | prompt_embeds, unet_added_cond_kwargs = self.compute_embeddings(
65 | prompt_batch=prompt_batch,proportion_empty_prompts=0,text_encoders=self.text_encoders,tokenizers=self.tokenizers,size=size
66 | )
67 | self.reset_schedule(steps)
68 | if seed != -1:
69 | seed_everything(seed)
70 | noisy_latents = torch.randn((1, 4, size[0]//8, size[1]//8)).to("cuda")
71 |
72 | with torch.no_grad():
73 | for t in tqdm.tqdm(self.scheduler.timesteps):
74 | with torch.no_grad():
75 | input = torch.cat([noisy_latents]*2)
76 | noise_pred = self.model(
77 | input,
78 | t,
79 | encoder_hidden_states=prompt_embeds["prompt_embeds"],
80 | added_cond_kwargs=unet_added_cond_kwargs,
81 | down_block_additional_residuals=copy.deepcopy(adapter_features),
82 | )[0]
83 | noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
84 | noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
85 | noisy_latents = self.scheduler.step(noise_pred, t, noisy_latents)[0]
86 |
87 | image = self.vae.decode(noisy_latents.cpu() / self.vae.config.scaling_factor, return_dict=False)[0]
88 | image = (image / 2 + 0.5).clamp(0, 1)
89 | image = tensor2img(image)
90 |
91 | return image
92 |
93 |
94 | def encode_prompt(self, prompt_batch, proportion_empty_prompts, is_train=True):
95 | prompt_embeds_list = []
96 |
97 | captions = []
98 | for caption in prompt_batch:
99 | if random.random() < proportion_empty_prompts:
100 | captions.append("")
101 | elif isinstance(caption, str):
102 | captions.append(caption)
103 | elif isinstance(caption, (list, np.ndarray)):
104 | # take a random caption if there are multiple
105 | captions.append(random.choice(caption) if is_train else caption[0])
106 |
107 | with torch.no_grad():
108 | for tokenizer, text_encoder in zip(self.tokenizers, self.text_encoders):
109 | text_inputs = tokenizer(
110 | captions,
111 | padding="max_length",
112 | max_length=tokenizer.model_max_length,
113 | truncation=True,
114 | return_tensors="pt",
115 | )
116 | text_input_ids = text_inputs.input_ids
117 | prompt_embeds = text_encoder(
118 | text_input_ids.to(text_encoder.device),
119 | output_hidden_states=True,
120 | )
121 |
122 | # We are only ALWAYS interested in the pooled output of the final text encoder
123 | pooled_prompt_embeds = prompt_embeds[0]
124 | prompt_embeds = prompt_embeds.hidden_states[-2]
125 | bs_embed, seq_len, _ = prompt_embeds.shape
126 | prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
127 | prompt_embeds_list.append(prompt_embeds)
128 |
129 | prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
130 | pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
131 | return prompt_embeds, pooled_prompt_embeds
132 |
133 | def compute_embeddings(self, prompt_batch, proportion_empty_prompts, text_encoders, tokenizers, size, is_train=True):
134 | original_size = size
135 | target_size = size
136 | crops_coords_top_left = (0, 0)
137 |
138 | prompt_embeds, pooled_prompt_embeds = self.encode_prompt(
139 | prompt_batch, proportion_empty_prompts, is_train
140 | )
141 | add_text_embeds = pooled_prompt_embeds
142 |
143 | # Adapted from pipeline.StableDiffusionXLPipeline._get_add_time_ids
144 | add_time_ids = list(original_size + crops_coords_top_left + target_size)
145 | add_time_ids = torch.tensor([add_time_ids])
146 |
147 | prompt_embeds = prompt_embeds.to(self.device)
148 | add_text_embeds = add_text_embeds.to(self.device)
149 | add_time_ids = add_time_ids.repeat(len(prompt_batch), 1)
150 | add_time_ids = add_time_ids.to(self.device, dtype=prompt_embeds.dtype)
151 | unet_added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
152 |
153 | return {"prompt_embeds": prompt_embeds}, unet_added_cond_kwargs
154 |
155 |
156 |
--------------------------------------------------------------------------------
/Adapter/extra_condition/api.py:
--------------------------------------------------------------------------------
1 | from enum import Enum, unique
2 | import cv2
3 | import torch
4 | from basicsr.utils import img2tensor
5 | from PIL import Image
6 | from torch import autocast
7 |
8 | from Adapter.utils import resize_numpy_image
9 |
10 | @unique
11 | class ExtraCondition(Enum):
12 | sketch = 0
13 | keypose = 1
14 | seg = 2
15 | depth = 3
16 | canny = 4
17 | style = 5
18 | color = 6
19 | openpose = 7
20 | edge = 8
21 | zoedepth = 9
22 |
23 |
24 | def get_cond_model(opt, cond_type: ExtraCondition):
25 | if cond_type == ExtraCondition.sketch:
26 | from Adapter.extra_condition.model_edge import pidinet
27 | model = pidinet()
28 | ckp = torch.load('checkpoints/table5_pidinet.pth', map_location='cpu')['state_dict']
29 | model.load_state_dict({k.replace('module.', ''): v for k, v in ckp.items()}, strict=True)
30 | model.to(opt.device)
31 | return model
32 | elif cond_type == ExtraCondition.seg:
33 | raise NotImplementedError
34 | elif cond_type == ExtraCondition.keypose:
35 | import mmcv
36 | from mmdet.apis import init_detector
37 | from mmpose.apis import init_pose_model
38 | det_config = 'configs/mm/faster_rcnn_r50_fpn_coco.py'
39 | det_checkpoint = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
40 | pose_config = 'configs/mm/hrnet_w48_coco_256x192.py'
41 | pose_checkpoint = 'checkpoints/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth'
42 | det_config_mmcv = mmcv.Config.fromfile(det_config)
43 | det_model = init_detector(det_config_mmcv, det_checkpoint, device=opt.device)
44 | pose_config_mmcv = mmcv.Config.fromfile(pose_config)
45 | pose_model = init_pose_model(pose_config_mmcv, pose_checkpoint, device=opt.device)
46 | return {'pose_model': pose_model, 'det_model': det_model}
47 | elif cond_type == ExtraCondition.depth:
48 | from Adapter.extra_condition.midas.api import MiDaSInference
49 | model = MiDaSInference(model_type='dpt_hybrid').to(opt.device)
50 | return model
51 | elif cond_type == ExtraCondition.zoedepth:
52 | from handyinfer.depth_estimation import init_depth_estimation_model
53 | model = init_depth_estimation_model('ZoeD_N', device=opt.device)
54 | return model
55 | elif cond_type == ExtraCondition.canny:
56 | return None
57 | elif cond_type == ExtraCondition.style:
58 | from transformers import CLIPProcessor, CLIPVisionModel
59 | version = 'openai/clip-vit-large-patch14'
60 | processor = CLIPProcessor.from_pretrained(version)
61 | clip_vision_model = CLIPVisionModel.from_pretrained(version).to(opt.device)
62 | return {'processor': processor, 'clip_vision_model': clip_vision_model}
63 | elif cond_type == ExtraCondition.color:
64 | return None
65 | elif cond_type == ExtraCondition.openpose:
66 | from Adapter.extra_condition.openpose.api import OpenposeInference
67 | model = OpenposeInference().to(opt.device)
68 | return model
69 | elif cond_type == ExtraCondition.edge:
70 | return None
71 | else:
72 | raise NotImplementedError
73 |
74 |
75 | def get_cond_sketch(opt, cond_image, cond_inp_type, cond_model=None):
76 | if isinstance(cond_image, str):
77 | edge = cv2.imread(cond_image)
78 | else:
79 | # for gradio input, pay attention, it's rgb numpy
80 | edge = cv2.cvtColor(cond_image, cv2.COLOR_RGB2BGR)
81 | edge = resize_numpy_image(edge, max_resolution=opt.max_resolution, resize_short_edge=opt.resize_short_edge)
82 | opt.H, opt.W = edge.shape[:2]
83 | if cond_inp_type == 'sketch':
84 | edge = img2tensor(edge)[0].unsqueeze(0).unsqueeze(0) / 255.
85 | edge = edge.to(opt.device)
86 | elif cond_inp_type == 'image':
87 | edge = img2tensor(edge).unsqueeze(0) / 255.
88 | edge = cond_model(edge.to(opt.device))[-1]
89 | else:
90 | raise NotImplementedError
91 |
92 | # edge = 1-edge # for white background
93 | edge = edge > 0.5
94 | edge = edge.float()
95 |
96 | return edge
97 |
98 |
99 | def get_cond_seg(opt, cond_image, cond_inp_type='image', cond_model=None):
100 | if isinstance(cond_image, str):
101 | seg = cv2.imread(cond_image)
102 | else:
103 | seg = cv2.cvtColor(cond_image, cv2.COLOR_RGB2BGR)
104 | seg = resize_numpy_image(seg, max_resolution=opt.max_resolution, resize_short_edge=opt.resize_short_edge)
105 | opt.H, opt.W = seg.shape[:2]
106 | if cond_inp_type == 'seg':
107 | seg = img2tensor(seg).unsqueeze(0) / 255.
108 | seg = seg.to(opt.device)
109 | else:
110 | raise NotImplementedError
111 |
112 | return seg
113 |
114 |
115 | def get_cond_keypose(opt, cond_image, cond_inp_type='image', cond_model=None):
116 | if isinstance(cond_image, str):
117 | pose = cv2.imread(cond_image)
118 | else:
119 | pose = cv2.cvtColor(cond_image, cv2.COLOR_RGB2BGR)
120 | pose = resize_numpy_image(pose, max_resolution=opt.max_resolution, resize_short_edge=opt.resize_short_edge)
121 | opt.H, opt.W = pose.shape[:2]
122 | if cond_inp_type == 'keypose':
123 | pose = img2tensor(pose).unsqueeze(0) / 255.
124 | pose = pose.to(opt.device)
125 | elif cond_inp_type == 'image':
126 | from Adapter.extra_condition.utils import imshow_keypoints
127 | from mmdet.apis import inference_detector
128 | from mmpose.apis import (inference_top_down_pose_model, process_mmdet_results)
129 |
130 | # mmpose seems not compatible with autocast fp16
131 | with autocast("cuda", dtype=torch.float32):
132 | mmdet_results = inference_detector(cond_model['det_model'], pose)
133 | # keep the person class bounding boxes.
134 | person_results = process_mmdet_results(mmdet_results, 1)
135 |
136 | # optional
137 | return_heatmap = False
138 | dataset = cond_model['pose_model'].cfg.data['test']['type']
139 |
140 | # e.g. use ('backbone', ) to return backbone feature
141 | output_layer_names = None
142 | pose_results, returned_outputs = inference_top_down_pose_model(
143 | cond_model['pose_model'],
144 | pose,
145 | person_results,
146 | bbox_thr=0.2,
147 | format='xyxy',
148 | dataset=dataset,
149 | dataset_info=None,
150 | return_heatmap=return_heatmap,
151 | outputs=output_layer_names)
152 |
153 | # show the results
154 | pose = imshow_keypoints(pose, pose_results, radius=2, thickness=2)
155 | pose = img2tensor(pose).unsqueeze(0) / 255.
156 | pose = pose.to(opt.device)
157 | else:
158 | raise NotImplementedError
159 |
160 | return pose
161 |
162 |
163 | def get_cond_depth(opt, cond_image, cond_inp_type='image', cond_model=None):
164 | if isinstance(cond_image, str):
165 | depth = cv2.imread(cond_image)
166 | else:
167 | depth = cv2.cvtColor(cond_image, cv2.COLOR_RGB2BGR)
168 | depth = resize_numpy_image(depth, max_resolution=opt.max_resolution, resize_short_edge=opt.resize_short_edge)
169 | opt.H, opt.W = depth.shape[:2]
170 | if cond_inp_type == 'depth':
171 | depth = img2tensor(depth).unsqueeze(0) / 255.
172 | depth = depth.to(opt.device)
173 | elif cond_inp_type == 'image':
174 | depth = img2tensor(depth).unsqueeze(0) / 127.5 - 1.0
175 | depth = cond_model(depth.to(opt.device)).repeat(1, 3, 1, 1)
176 | depth -= torch.min(depth)
177 | depth /= torch.max(depth)
178 | else:
179 | raise NotImplementedError
180 |
181 | return depth
182 |
183 |
184 | def get_cond_zoedepth(opt, cond_image, cond_inp_type='image', cond_model=None):
185 | if isinstance(cond_image, str):
186 | depth = cv2.imread(cond_image)
187 | else:
188 | depth = cv2.cvtColor(cond_image, cv2.COLOR_RGB2BGR)
189 | depth = resize_numpy_image(depth, max_resolution=opt.max_resolution, resize_short_edge=opt.resize_short_edge)
190 | opt.H, opt.W = depth.shape[:2]
191 | if cond_inp_type == 'zoedepth':
192 | depth = img2tensor(depth).unsqueeze(0) / 255.
193 | depth = depth.to(opt.device)
194 | elif cond_inp_type == 'image':
195 | depth = img2tensor(depth).unsqueeze(0) / 255.
196 |
197 | with autocast("cuda", dtype=torch.float32):
198 | depth = cond_model.infer(depth.to(opt.device))
199 | depth = depth.repeat(1, 3, 1, 1)
200 | else:
201 | raise NotImplementedError
202 |
203 | return depth
204 |
205 |
206 | def get_cond_canny(opt, cond_image, cond_inp_type='image', cond_model=None):
207 | if isinstance(cond_image, str):
208 | canny = cv2.imread(cond_image)
209 | else:
210 | canny = cv2.cvtColor(cond_image, cv2.COLOR_RGB2BGR)
211 | canny = resize_numpy_image(canny, max_resolution=opt.max_resolution, resize_short_edge=opt.resize_short_edge)
212 | opt.H, opt.W = canny.shape[:2]
213 | if cond_inp_type == 'canny':
214 | canny = img2tensor(canny)[0:1].unsqueeze(0) / 255.
215 | canny = canny.to(opt.device)
216 | elif cond_inp_type == 'image':
217 | canny = cv2.Canny(canny, 100, 200)[..., None]
218 | canny = img2tensor(canny).unsqueeze(0) / 255.
219 | canny = canny.to(opt.device)
220 | else:
221 | raise NotImplementedError
222 |
223 | return canny
224 |
225 |
226 | def get_cond_style(opt, cond_image, cond_inp_type='image', cond_model=None):
227 | assert cond_inp_type == 'image'
228 | if isinstance(cond_image, str):
229 | style = Image.open(cond_image)
230 | else:
231 | # numpy image to PIL image
232 | style = Image.fromarray(cond_image)
233 |
234 | style_for_clip = cond_model['processor'](images=style, return_tensors="pt")['pixel_values']
235 | style_feat = cond_model['clip_vision_model'](style_for_clip.to(opt.device))['last_hidden_state']
236 |
237 | return style_feat
238 |
239 |
240 | def get_cond_color(opt, cond_image, cond_inp_type='image', cond_model=None):
241 | if isinstance(cond_image, str):
242 | color = cv2.imread(cond_image)
243 | else:
244 | color = cv2.cvtColor(cond_image, cv2.COLOR_RGB2BGR)
245 | color = resize_numpy_image(color, max_resolution=opt.max_resolution, resize_short_edge=opt.resize_short_edge)
246 | opt.H, opt.W = color.shape[:2]
247 | if cond_inp_type == 'image':
248 | color = cv2.resize(color, (opt.W // 64, opt.H // 64), interpolation=cv2.INTER_CUBIC)
249 | color = cv2.resize(color, (opt.W, opt.H), interpolation=cv2.INTER_NEAREST)
250 | color = img2tensor(color).unsqueeze(0) / 255.
251 | color = color.to(opt.device)
252 | return color
253 |
254 |
255 | def get_cond_openpose(opt, cond_image, cond_inp_type='image', cond_model=None):
256 | if isinstance(cond_image, str):
257 | openpose_keypose = cv2.imread(cond_image)
258 | else:
259 | openpose_keypose = cv2.cvtColor(cond_image, cv2.COLOR_RGB2BGR)
260 | openpose_keypose = resize_numpy_image(
261 | openpose_keypose, max_resolution=opt.max_resolution, resize_short_edge=opt.resize_short_edge)
262 | opt.H, opt.W = openpose_keypose.shape[:2]
263 | if cond_inp_type == 'openpose':
264 | openpose_keypose = img2tensor(openpose_keypose).unsqueeze(0) / 255.
265 | openpose_keypose = openpose_keypose.to(opt.device)
266 | elif cond_inp_type == 'image':
267 | with autocast('cuda', dtype=torch.float32):
268 | w, h = openpose_keypose.shape[:2]
269 | openpose_keypose = cv2.resize(openpose_keypose, (h//2, w//2))
270 | openpose_keypose = cond_model(openpose_keypose)
271 | openpose_keypose = cv2.resize(openpose_keypose, (h, w))[:,:,::-1]
272 | openpose_keypose = img2tensor(openpose_keypose).unsqueeze(0) / 255.
273 | openpose_keypose = openpose_keypose.to(opt.device)
274 |
275 | else:
276 | raise NotImplementedError
277 |
278 | return openpose_keypose
279 |
280 |
281 | def get_cond_edge(opt, cond_image, cond_inp_type='image', cond_model=None):
282 | if isinstance(cond_image, str):
283 | edge = cv2.imread(cond_image)
284 | else:
285 | edge = cv2.cvtColor(cond_image, cv2.COLOR_RGB2BGR)
286 | edge = resize_numpy_image(edge, max_resolution=opt.max_resolution, resize_short_edge=opt.resize_short_edge)
287 | opt.H, opt.W = edge.shape[:2]
288 | if cond_inp_type == 'edge':
289 | edge = img2tensor(edge)[0:1].unsqueeze(0) / 255.
290 | edge = edge.to(opt.device)
291 | elif cond_inp_type == 'image':
292 | edge = cv2.cvtColor(edge, cv2.COLOR_RGB2GRAY) / 1.0
293 | blur = cv2.blur(edge, (4, 4))
294 | edge = ((edge - blur) + 128)[..., None]
295 | edge = img2tensor(edge).unsqueeze(0) / 255.
296 | edge = edge.to(opt.device)
297 | else:
298 | raise NotImplementedError
299 |
300 | return edge
301 |
302 |
303 | def get_adapter_feature(inputs, adapters):
304 | ret_feat_map = None
305 | ret_feat_seq = None
306 | if not isinstance(inputs, list):
307 | inputs = [inputs]
308 | adapters = [adapters]
309 |
310 | for input, adapter in zip(inputs, adapters):
311 | cur_feature = adapter['model'](input)
312 | if isinstance(cur_feature, list):
313 | if ret_feat_map is None:
314 | ret_feat_map = list(map(lambda x: x * adapter['cond_weight'], cur_feature))
315 | else:
316 | ret_feat_map = list(map(lambda x, y: x + y * adapter['cond_weight'], ret_feat_map, cur_feature))
317 | else:
318 | if ret_feat_seq is None:
319 | ret_feat_seq = cur_feature * adapter['cond_weight']
320 | else:
321 | ret_feat_seq = torch.cat([ret_feat_seq, cur_feature * adapter['cond_weight']], dim=1)
322 |
323 | return ret_feat_map, ret_feat_seq
324 |
--------------------------------------------------------------------------------
/Adapter/extra_condition/model_edge.py:
--------------------------------------------------------------------------------
1 | """
2 | Author: Zhuo Su, Wenzhe Liu
3 | Date: Feb 18, 2021
4 | """
5 |
6 | import math
7 |
8 | import cv2
9 | import numpy as np
10 | import torch
11 | import torch.nn as nn
12 | import torch.nn.functional as F
13 | from basicsr.utils import img2tensor
14 |
15 | nets = {
16 | 'baseline': {
17 | 'layer0': 'cv',
18 | 'layer1': 'cv',
19 | 'layer2': 'cv',
20 | 'layer3': 'cv',
21 | 'layer4': 'cv',
22 | 'layer5': 'cv',
23 | 'layer6': 'cv',
24 | 'layer7': 'cv',
25 | 'layer8': 'cv',
26 | 'layer9': 'cv',
27 | 'layer10': 'cv',
28 | 'layer11': 'cv',
29 | 'layer12': 'cv',
30 | 'layer13': 'cv',
31 | 'layer14': 'cv',
32 | 'layer15': 'cv',
33 | },
34 | 'c-v15': {
35 | 'layer0': 'cd',
36 | 'layer1': 'cv',
37 | 'layer2': 'cv',
38 | 'layer3': 'cv',
39 | 'layer4': 'cv',
40 | 'layer5': 'cv',
41 | 'layer6': 'cv',
42 | 'layer7': 'cv',
43 | 'layer8': 'cv',
44 | 'layer9': 'cv',
45 | 'layer10': 'cv',
46 | 'layer11': 'cv',
47 | 'layer12': 'cv',
48 | 'layer13': 'cv',
49 | 'layer14': 'cv',
50 | 'layer15': 'cv',
51 | },
52 | 'a-v15': {
53 | 'layer0': 'ad',
54 | 'layer1': 'cv',
55 | 'layer2': 'cv',
56 | 'layer3': 'cv',
57 | 'layer4': 'cv',
58 | 'layer5': 'cv',
59 | 'layer6': 'cv',
60 | 'layer7': 'cv',
61 | 'layer8': 'cv',
62 | 'layer9': 'cv',
63 | 'layer10': 'cv',
64 | 'layer11': 'cv',
65 | 'layer12': 'cv',
66 | 'layer13': 'cv',
67 | 'layer14': 'cv',
68 | 'layer15': 'cv',
69 | },
70 | 'r-v15': {
71 | 'layer0': 'rd',
72 | 'layer1': 'cv',
73 | 'layer2': 'cv',
74 | 'layer3': 'cv',
75 | 'layer4': 'cv',
76 | 'layer5': 'cv',
77 | 'layer6': 'cv',
78 | 'layer7': 'cv',
79 | 'layer8': 'cv',
80 | 'layer9': 'cv',
81 | 'layer10': 'cv',
82 | 'layer11': 'cv',
83 | 'layer12': 'cv',
84 | 'layer13': 'cv',
85 | 'layer14': 'cv',
86 | 'layer15': 'cv',
87 | },
88 | 'cvvv4': {
89 | 'layer0': 'cd',
90 | 'layer1': 'cv',
91 | 'layer2': 'cv',
92 | 'layer3': 'cv',
93 | 'layer4': 'cd',
94 | 'layer5': 'cv',
95 | 'layer6': 'cv',
96 | 'layer7': 'cv',
97 | 'layer8': 'cd',
98 | 'layer9': 'cv',
99 | 'layer10': 'cv',
100 | 'layer11': 'cv',
101 | 'layer12': 'cd',
102 | 'layer13': 'cv',
103 | 'layer14': 'cv',
104 | 'layer15': 'cv',
105 | },
106 | 'avvv4': {
107 | 'layer0': 'ad',
108 | 'layer1': 'cv',
109 | 'layer2': 'cv',
110 | 'layer3': 'cv',
111 | 'layer4': 'ad',
112 | 'layer5': 'cv',
113 | 'layer6': 'cv',
114 | 'layer7': 'cv',
115 | 'layer8': 'ad',
116 | 'layer9': 'cv',
117 | 'layer10': 'cv',
118 | 'layer11': 'cv',
119 | 'layer12': 'ad',
120 | 'layer13': 'cv',
121 | 'layer14': 'cv',
122 | 'layer15': 'cv',
123 | },
124 | 'rvvv4': {
125 | 'layer0': 'rd',
126 | 'layer1': 'cv',
127 | 'layer2': 'cv',
128 | 'layer3': 'cv',
129 | 'layer4': 'rd',
130 | 'layer5': 'cv',
131 | 'layer6': 'cv',
132 | 'layer7': 'cv',
133 | 'layer8': 'rd',
134 | 'layer9': 'cv',
135 | 'layer10': 'cv',
136 | 'layer11': 'cv',
137 | 'layer12': 'rd',
138 | 'layer13': 'cv',
139 | 'layer14': 'cv',
140 | 'layer15': 'cv',
141 | },
142 | 'cccv4': {
143 | 'layer0': 'cd',
144 | 'layer1': 'cd',
145 | 'layer2': 'cd',
146 | 'layer3': 'cv',
147 | 'layer4': 'cd',
148 | 'layer5': 'cd',
149 | 'layer6': 'cd',
150 | 'layer7': 'cv',
151 | 'layer8': 'cd',
152 | 'layer9': 'cd',
153 | 'layer10': 'cd',
154 | 'layer11': 'cv',
155 | 'layer12': 'cd',
156 | 'layer13': 'cd',
157 | 'layer14': 'cd',
158 | 'layer15': 'cv',
159 | },
160 | 'aaav4': {
161 | 'layer0': 'ad',
162 | 'layer1': 'ad',
163 | 'layer2': 'ad',
164 | 'layer3': 'cv',
165 | 'layer4': 'ad',
166 | 'layer5': 'ad',
167 | 'layer6': 'ad',
168 | 'layer7': 'cv',
169 | 'layer8': 'ad',
170 | 'layer9': 'ad',
171 | 'layer10': 'ad',
172 | 'layer11': 'cv',
173 | 'layer12': 'ad',
174 | 'layer13': 'ad',
175 | 'layer14': 'ad',
176 | 'layer15': 'cv',
177 | },
178 | 'rrrv4': {
179 | 'layer0': 'rd',
180 | 'layer1': 'rd',
181 | 'layer2': 'rd',
182 | 'layer3': 'cv',
183 | 'layer4': 'rd',
184 | 'layer5': 'rd',
185 | 'layer6': 'rd',
186 | 'layer7': 'cv',
187 | 'layer8': 'rd',
188 | 'layer9': 'rd',
189 | 'layer10': 'rd',
190 | 'layer11': 'cv',
191 | 'layer12': 'rd',
192 | 'layer13': 'rd',
193 | 'layer14': 'rd',
194 | 'layer15': 'cv',
195 | },
196 | 'c16': {
197 | 'layer0': 'cd',
198 | 'layer1': 'cd',
199 | 'layer2': 'cd',
200 | 'layer3': 'cd',
201 | 'layer4': 'cd',
202 | 'layer5': 'cd',
203 | 'layer6': 'cd',
204 | 'layer7': 'cd',
205 | 'layer8': 'cd',
206 | 'layer9': 'cd',
207 | 'layer10': 'cd',
208 | 'layer11': 'cd',
209 | 'layer12': 'cd',
210 | 'layer13': 'cd',
211 | 'layer14': 'cd',
212 | 'layer15': 'cd',
213 | },
214 | 'a16': {
215 | 'layer0': 'ad',
216 | 'layer1': 'ad',
217 | 'layer2': 'ad',
218 | 'layer3': 'ad',
219 | 'layer4': 'ad',
220 | 'layer5': 'ad',
221 | 'layer6': 'ad',
222 | 'layer7': 'ad',
223 | 'layer8': 'ad',
224 | 'layer9': 'ad',
225 | 'layer10': 'ad',
226 | 'layer11': 'ad',
227 | 'layer12': 'ad',
228 | 'layer13': 'ad',
229 | 'layer14': 'ad',
230 | 'layer15': 'ad',
231 | },
232 | 'r16': {
233 | 'layer0': 'rd',
234 | 'layer1': 'rd',
235 | 'layer2': 'rd',
236 | 'layer3': 'rd',
237 | 'layer4': 'rd',
238 | 'layer5': 'rd',
239 | 'layer6': 'rd',
240 | 'layer7': 'rd',
241 | 'layer8': 'rd',
242 | 'layer9': 'rd',
243 | 'layer10': 'rd',
244 | 'layer11': 'rd',
245 | 'layer12': 'rd',
246 | 'layer13': 'rd',
247 | 'layer14': 'rd',
248 | 'layer15': 'rd',
249 | },
250 | 'carv4': {
251 | 'layer0': 'cd',
252 | 'layer1': 'ad',
253 | 'layer2': 'rd',
254 | 'layer3': 'cv',
255 | 'layer4': 'cd',
256 | 'layer5': 'ad',
257 | 'layer6': 'rd',
258 | 'layer7': 'cv',
259 | 'layer8': 'cd',
260 | 'layer9': 'ad',
261 | 'layer10': 'rd',
262 | 'layer11': 'cv',
263 | 'layer12': 'cd',
264 | 'layer13': 'ad',
265 | 'layer14': 'rd',
266 | 'layer15': 'cv',
267 | },
268 | }
269 |
270 | def createConvFunc(op_type):
271 | assert op_type in ['cv', 'cd', 'ad', 'rd'], 'unknown op type: %s' % str(op_type)
272 | if op_type == 'cv':
273 | return F.conv2d
274 |
275 | if op_type == 'cd':
276 | def func(x, weights, bias=None, stride=1, padding=0, dilation=1, groups=1):
277 | assert dilation in [1, 2], 'dilation for cd_conv should be in 1 or 2'
278 | assert weights.size(2) == 3 and weights.size(3) == 3, 'kernel size for cd_conv should be 3x3'
279 | assert padding == dilation, 'padding for cd_conv set wrong'
280 |
281 | weights_c = weights.sum(dim=[2, 3], keepdim=True)
282 | # print(x.device, weights_c.device)
283 | yc = F.conv2d(x, weights_c, stride=stride, padding=0, groups=groups)
284 | y = F.conv2d(x, weights, bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
285 | return y - yc
286 | return func
287 | elif op_type == 'ad':
288 | def func(x, weights, bias=None, stride=1, padding=0, dilation=1, groups=1):
289 | assert dilation in [1, 2], 'dilation for ad_conv should be in 1 or 2'
290 | assert weights.size(2) == 3 and weights.size(3) == 3, 'kernel size for ad_conv should be 3x3'
291 | assert padding == dilation, 'padding for ad_conv set wrong'
292 |
293 | shape = weights.shape
294 | weights = weights.view(shape[0], shape[1], -1)
295 | weights_conv = (weights - weights[:, :, [3, 0, 1, 6, 4, 2, 7, 8, 5]]).view(shape) # clock-wise
296 | y = F.conv2d(x, weights_conv, bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
297 | return y
298 | return func
299 | elif op_type == 'rd':
300 | def func(x, weights, bias=None, stride=1, padding=0, dilation=1, groups=1):
301 | assert dilation in [1, 2], 'dilation for rd_conv should be in 1 or 2'
302 | assert weights.size(2) == 3 and weights.size(3) == 3, 'kernel size for rd_conv should be 3x3'
303 | padding = 2 * dilation
304 |
305 | shape = weights.shape
306 | if weights.is_cuda:
307 | buffer = torch.cuda.FloatTensor(shape[0], shape[1], 5 * 5).fill_(0)
308 | else:
309 | buffer = torch.zeros(shape[0], shape[1], 5 * 5)
310 | buffer = buffer.to(dtype=weights.dtype)
311 | weights = weights.view(shape[0], shape[1], -1)
312 | buffer[:, :, [0, 2, 4, 10, 14, 20, 22, 24]] = weights[:, :, 1:]
313 | buffer[:, :, [6, 7, 8, 11, 13, 16, 17, 18]] = -weights[:, :, 1:]
314 | buffer[:, :, 12] = 0
315 | buffer = buffer.view(shape[0], shape[1], 5, 5)
316 | y = F.conv2d(x, buffer, bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
317 | return y
318 | return func
319 | else:
320 | print('impossible to be here unless you force that')
321 | return None
322 |
323 | class Conv2d(nn.Module):
324 | def __init__(self, pdc, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=False):
325 | super(Conv2d, self).__init__()
326 | if in_channels % groups != 0:
327 | raise ValueError('in_channels must be divisible by groups')
328 | if out_channels % groups != 0:
329 | raise ValueError('out_channels must be divisible by groups')
330 | self.in_channels = in_channels
331 | self.out_channels = out_channels
332 | self.kernel_size = kernel_size
333 | self.stride = stride
334 | self.padding = padding
335 | self.dilation = dilation
336 | self.groups = groups
337 | self.weight = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, kernel_size, kernel_size))
338 | if bias:
339 | self.bias = nn.Parameter(torch.Tensor(out_channels))
340 | else:
341 | self.register_parameter('bias', None)
342 | self.reset_parameters()
343 | self.pdc = pdc
344 |
345 | def reset_parameters(self):
346 | nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
347 | if self.bias is not None:
348 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.weight)
349 | bound = 1 / math.sqrt(fan_in)
350 | nn.init.uniform_(self.bias, -bound, bound)
351 |
352 | def forward(self, input):
353 |
354 | return self.pdc(input, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
355 |
356 | class CSAM(nn.Module):
357 | """
358 | Compact Spatial Attention Module
359 | """
360 | def __init__(self, channels):
361 | super(CSAM, self).__init__()
362 |
363 | mid_channels = 4
364 | self.relu1 = nn.ReLU()
365 | self.conv1 = nn.Conv2d(channels, mid_channels, kernel_size=1, padding=0)
366 | self.conv2 = nn.Conv2d(mid_channels, 1, kernel_size=3, padding=1, bias=False)
367 | self.sigmoid = nn.Sigmoid()
368 | nn.init.constant_(self.conv1.bias, 0)
369 |
370 | def forward(self, x):
371 | y = self.relu1(x)
372 | y = self.conv1(y)
373 | y = self.conv2(y)
374 | y = self.sigmoid(y)
375 |
376 | return x * y
377 |
378 | class CDCM(nn.Module):
379 | """
380 | Compact Dilation Convolution based Module
381 | """
382 | def __init__(self, in_channels, out_channels):
383 | super(CDCM, self).__init__()
384 |
385 | self.relu1 = nn.ReLU()
386 | self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0)
387 | self.conv2_1 = nn.Conv2d(out_channels, out_channels, kernel_size=3, dilation=5, padding=5, bias=False)
388 | self.conv2_2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, dilation=7, padding=7, bias=False)
389 | self.conv2_3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, dilation=9, padding=9, bias=False)
390 | self.conv2_4 = nn.Conv2d(out_channels, out_channels, kernel_size=3, dilation=11, padding=11, bias=False)
391 | nn.init.constant_(self.conv1.bias, 0)
392 |
393 | def forward(self, x):
394 | x = self.relu1(x)
395 | x = self.conv1(x)
396 | x1 = self.conv2_1(x)
397 | x2 = self.conv2_2(x)
398 | x3 = self.conv2_3(x)
399 | x4 = self.conv2_4(x)
400 | return x1 + x2 + x3 + x4
401 |
402 |
403 | class MapReduce(nn.Module):
404 | """
405 | Reduce feature maps into a single edge map
406 | """
407 | def __init__(self, channels):
408 | super(MapReduce, self).__init__()
409 | self.conv = nn.Conv2d(channels, 1, kernel_size=1, padding=0)
410 | nn.init.constant_(self.conv.bias, 0)
411 |
412 | def forward(self, x):
413 | return self.conv(x)
414 |
415 |
416 | class PDCBlock(nn.Module):
417 | def __init__(self, pdc, inplane, ouplane, stride=1):
418 | super(PDCBlock, self).__init__()
419 | self.stride=stride
420 |
421 | self.stride=stride
422 | if self.stride > 1:
423 | self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
424 | self.shortcut = nn.Conv2d(inplane, ouplane, kernel_size=1, padding=0)
425 | self.conv1 = Conv2d(pdc, inplane, inplane, kernel_size=3, padding=1, groups=inplane, bias=False)
426 | self.relu2 = nn.ReLU()
427 | self.conv2 = nn.Conv2d(inplane, ouplane, kernel_size=1, padding=0, bias=False)
428 |
429 | def forward(self, x):
430 | if self.stride > 1:
431 | x = self.pool(x)
432 | y = self.conv1(x)
433 | y = self.relu2(y)
434 | y = self.conv2(y)
435 | if self.stride > 1:
436 | x = self.shortcut(x)
437 | y = y + x
438 | return y
439 |
440 | class PDCBlock_converted(nn.Module):
441 | """
442 | CPDC, APDC can be converted to vanilla 3x3 convolution
443 | RPDC can be converted to vanilla 5x5 convolution
444 | """
445 | def __init__(self, pdc, inplane, ouplane, stride=1):
446 | super(PDCBlock_converted, self).__init__()
447 | self.stride=stride
448 |
449 | if self.stride > 1:
450 | self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
451 | self.shortcut = nn.Conv2d(inplane, ouplane, kernel_size=1, padding=0)
452 | if pdc == 'rd':
453 | self.conv1 = nn.Conv2d(inplane, inplane, kernel_size=5, padding=2, groups=inplane, bias=False)
454 | else:
455 | self.conv1 = nn.Conv2d(inplane, inplane, kernel_size=3, padding=1, groups=inplane, bias=False)
456 | self.relu2 = nn.ReLU()
457 | self.conv2 = nn.Conv2d(inplane, ouplane, kernel_size=1, padding=0, bias=False)
458 |
459 | def forward(self, x):
460 | if self.stride > 1:
461 | x = self.pool(x)
462 | y = self.conv1(x)
463 | y = self.relu2(y)
464 | y = self.conv2(y)
465 | if self.stride > 1:
466 | x = self.shortcut(x)
467 | y = y + x
468 | return y
469 |
470 | class PiDiNet(nn.Module):
471 | def __init__(self, inplane, pdcs, dil=None, sa=False, convert=False):
472 | super(PiDiNet, self).__init__()
473 | self.sa = sa
474 | if dil is not None:
475 | assert isinstance(dil, int), 'dil should be an int'
476 | self.dil = dil
477 |
478 | self.fuseplanes = []
479 |
480 | self.inplane = inplane
481 | if convert:
482 | if pdcs[0] == 'rd':
483 | init_kernel_size = 5
484 | init_padding = 2
485 | else:
486 | init_kernel_size = 3
487 | init_padding = 1
488 | self.init_block = nn.Conv2d(3, self.inplane,
489 | kernel_size=init_kernel_size, padding=init_padding, bias=False)
490 | block_class = PDCBlock_converted
491 | else:
492 | self.init_block = Conv2d(pdcs[0], 3, self.inplane, kernel_size=3, padding=1)
493 | block_class = PDCBlock
494 |
495 | self.block1_1 = block_class(pdcs[1], self.inplane, self.inplane)
496 | self.block1_2 = block_class(pdcs[2], self.inplane, self.inplane)
497 | self.block1_3 = block_class(pdcs[3], self.inplane, self.inplane)
498 | self.fuseplanes.append(self.inplane) # C
499 |
500 | inplane = self.inplane
501 | self.inplane = self.inplane * 2
502 | self.block2_1 = block_class(pdcs[4], inplane, self.inplane, stride=2)
503 | self.block2_2 = block_class(pdcs[5], self.inplane, self.inplane)
504 | self.block2_3 = block_class(pdcs[6], self.inplane, self.inplane)
505 | self.block2_4 = block_class(pdcs[7], self.inplane, self.inplane)
506 | self.fuseplanes.append(self.inplane) # 2C
507 |
508 | inplane = self.inplane
509 | self.inplane = self.inplane * 2
510 | self.block3_1 = block_class(pdcs[8], inplane, self.inplane, stride=2)
511 | self.block3_2 = block_class(pdcs[9], self.inplane, self.inplane)
512 | self.block3_3 = block_class(pdcs[10], self.inplane, self.inplane)
513 | self.block3_4 = block_class(pdcs[11], self.inplane, self.inplane)
514 | self.fuseplanes.append(self.inplane) # 4C
515 |
516 | self.block4_1 = block_class(pdcs[12], self.inplane, self.inplane, stride=2)
517 | self.block4_2 = block_class(pdcs[13], self.inplane, self.inplane)
518 | self.block4_3 = block_class(pdcs[14], self.inplane, self.inplane)
519 | self.block4_4 = block_class(pdcs[15], self.inplane, self.inplane)
520 | self.fuseplanes.append(self.inplane) # 4C
521 |
522 | self.conv_reduces = nn.ModuleList()
523 | if self.sa and self.dil is not None:
524 | self.attentions = nn.ModuleList()
525 | self.dilations = nn.ModuleList()
526 | for i in range(4):
527 | self.dilations.append(CDCM(self.fuseplanes[i], self.dil))
528 | self.attentions.append(CSAM(self.dil))
529 | self.conv_reduces.append(MapReduce(self.dil))
530 | elif self.sa:
531 | self.attentions = nn.ModuleList()
532 | for i in range(4):
533 | self.attentions.append(CSAM(self.fuseplanes[i]))
534 | self.conv_reduces.append(MapReduce(self.fuseplanes[i]))
535 | elif self.dil is not None:
536 | self.dilations = nn.ModuleList()
537 | for i in range(4):
538 | self.dilations.append(CDCM(self.fuseplanes[i], self.dil))
539 | self.conv_reduces.append(MapReduce(self.dil))
540 | else:
541 | for i in range(4):
542 | self.conv_reduces.append(MapReduce(self.fuseplanes[i]))
543 |
544 | self.classifier = nn.Conv2d(4, 1, kernel_size=1) # has bias
545 | nn.init.constant_(self.classifier.weight, 0.25)
546 | nn.init.constant_(self.classifier.bias, 0)
547 |
548 | # print('initialization done')
549 |
550 | def get_weights(self):
551 | conv_weights = []
552 | bn_weights = []
553 | relu_weights = []
554 | for pname, p in self.named_parameters():
555 | if 'bn' in pname:
556 | bn_weights.append(p)
557 | elif 'relu' in pname:
558 | relu_weights.append(p)
559 | else:
560 | conv_weights.append(p)
561 |
562 | return conv_weights, bn_weights, relu_weights
563 |
564 | def forward(self, x):
565 | H, W = x.size()[2:]
566 |
567 | x = self.init_block(x)
568 |
569 | x1 = self.block1_1(x)
570 | x1 = self.block1_2(x1)
571 | x1 = self.block1_3(x1)
572 |
573 | x2 = self.block2_1(x1)
574 | x2 = self.block2_2(x2)
575 | x2 = self.block2_3(x2)
576 | x2 = self.block2_4(x2)
577 |
578 | x3 = self.block3_1(x2)
579 | x3 = self.block3_2(x3)
580 | x3 = self.block3_3(x3)
581 | x3 = self.block3_4(x3)
582 |
583 | x4 = self.block4_1(x3)
584 | x4 = self.block4_2(x4)
585 | x4 = self.block4_3(x4)
586 | x4 = self.block4_4(x4)
587 |
588 | x_fuses = []
589 | if self.sa and self.dil is not None:
590 | for i, xi in enumerate([x1, x2, x3, x4]):
591 | x_fuses.append(self.attentions[i](self.dilations[i](xi)))
592 | elif self.sa:
593 | for i, xi in enumerate([x1, x2, x3, x4]):
594 | x_fuses.append(self.attentions[i](xi))
595 | elif self.dil is not None:
596 | for i, xi in enumerate([x1, x2, x3, x4]):
597 | x_fuses.append(self.dilations[i](xi))
598 | else:
599 | x_fuses = [x1, x2, x3, x4]
600 |
601 | e1 = self.conv_reduces[0](x_fuses[0])
602 | e1 = F.interpolate(e1, (H, W), mode="bilinear", align_corners=False)
603 |
604 | e2 = self.conv_reduces[1](x_fuses[1])
605 | e2 = F.interpolate(e2, (H, W), mode="bilinear", align_corners=False)
606 |
607 | e3 = self.conv_reduces[2](x_fuses[2])
608 | e3 = F.interpolate(e3, (H, W), mode="bilinear", align_corners=False)
609 |
610 | e4 = self.conv_reduces[3](x_fuses[3])
611 | e4 = F.interpolate(e4, (H, W), mode="bilinear", align_corners=False)
612 |
613 | outputs = [e1, e2, e3, e4]
614 |
615 | output = self.classifier(torch.cat(outputs, dim=1))
616 | #if not self.training:
617 | # return torch.sigmoid(output)
618 |
619 | outputs.append(output)
620 | outputs = [torch.sigmoid(r) for r in outputs]
621 | return outputs
622 |
623 | def config_model(model):
624 | model_options = list(nets.keys())
625 | assert model in model_options, \
626 | 'unrecognized model, please choose from %s' % str(model_options)
627 |
628 | # print(str(nets[model]))
629 |
630 | pdcs = []
631 | for i in range(16):
632 | layer_name = 'layer%d' % i
633 | op = nets[model][layer_name]
634 | pdcs.append(createConvFunc(op))
635 |
636 | return pdcs
637 |
638 | def pidinet():
639 | pdcs = config_model('carv4')
640 | dil = 24 #if args.dil else None
641 | return PiDiNet(60, pdcs, dil=dil, sa=True)
642 |
643 |
644 | if __name__ == '__main__':
645 | model = pidinet()
646 | ckp = torch.load('table5_pidinet.pth')['state_dict']
647 | model.load_state_dict({k.replace('module.',''):v for k, v in ckp.items()})
648 | im = cv2.imread('examples/test_my/cat_v4.png')
649 | im = img2tensor(im).unsqueeze(0)/255.
650 | res = model(im)[-1]
651 | res = res>0.5
652 | res = res.float()
653 | res = (res[0,0].cpu().data.numpy()*255.).astype(np.uint8)
654 | print(res.shape)
655 | cv2.imwrite('edge.png', res)
656 |
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TencentARC/T2I-Adapter/c408b059c36e3f9ce336b66746bd606edaa5483a/Adapter/extra_condition/openpose/__init__.py
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TencentARC/T2I-Adapter/c408b059c36e3f9ce336b66746bd606edaa5483a/Adapter/extra_condition/openpose/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/__pycache__/api.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TencentARC/T2I-Adapter/c408b059c36e3f9ce336b66746bd606edaa5483a/Adapter/extra_condition/openpose/__pycache__/api.cpython-310.pyc
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/__pycache__/body.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TencentARC/T2I-Adapter/c408b059c36e3f9ce336b66746bd606edaa5483a/Adapter/extra_condition/openpose/__pycache__/body.cpython-310.pyc
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/__pycache__/model.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TencentARC/T2I-Adapter/c408b059c36e3f9ce336b66746bd606edaa5483a/Adapter/extra_condition/openpose/__pycache__/model.cpython-310.pyc
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/__pycache__/util.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TencentARC/T2I-Adapter/c408b059c36e3f9ce336b66746bd606edaa5483a/Adapter/extra_condition/openpose/__pycache__/util.cpython-310.pyc
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/api.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import os
3 | import torch.nn as nn
4 |
5 | os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
6 |
7 | import cv2
8 | import torch
9 |
10 | from . import util
11 | from .body import Body
12 |
13 | remote_model_path = "https://huggingface.co/TencentARC/T2I-Adapter/blob/main/third-party-models/body_pose_model.pth"
14 |
15 |
16 | class OpenposeInference(nn.Module):
17 |
18 | def __init__(self):
19 | super().__init__()
20 | body_modelpath = os.path.join('checkpoints', "body_pose_model.pth")
21 |
22 | if not os.path.exists(body_modelpath):
23 | from basicsr.utils.download_util import load_file_from_url
24 | load_file_from_url(remote_model_path, model_dir='checkpoints')
25 |
26 | self.body_estimation = Body(body_modelpath)
27 |
28 | def forward(self, x):
29 | x = x[:, :, ::-1].copy()
30 | with torch.no_grad():
31 | candidate, subset = self.body_estimation(x)
32 | # print(candidate.shape)
33 | # print(subset.shape)
34 | canvas = np.zeros_like(x)
35 | canvas = util.draw_bodypose(canvas, candidate, subset)
36 | canvas = cv2.cvtColor(canvas, cv2.COLOR_RGB2BGR)
37 | return canvas
38 |
39 |
40 | class OpenposeInference_count(nn.Module):
41 |
42 | def __init__(self):
43 | super().__init__()
44 | body_modelpath = os.path.join('checkpoints', "body_pose_model.pth")
45 |
46 | if not os.path.exists(body_modelpath):
47 | from basicsr.utils.download_util import load_file_from_url
48 | load_file_from_url(remote_model_path, model_dir='checkpoints')
49 |
50 | self.body_estimation = Body(body_modelpath)
51 |
52 | def forward(self, x):
53 | x = x[:, :, ::-1].copy()
54 | with torch.no_grad():
55 | candidate, subset = self.body_estimation(x)
56 | return subset.shape[0]
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/body.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import math
3 | import matplotlib
4 | import matplotlib.pyplot as plt
5 | import numpy as np
6 | import time
7 | import torch
8 | from scipy.ndimage.filters import gaussian_filter
9 | from torchvision import transforms
10 |
11 | from . import util
12 | from .model import bodypose_model
13 |
14 |
15 | class Body(object):
16 |
17 | def __init__(self, model_path):
18 | self.model = bodypose_model()
19 | if torch.cuda.is_available():
20 | self.model = self.model.cuda()
21 | print('cuda')
22 | model_dict = util.transfer(self.model, torch.load(model_path))
23 | self.model.load_state_dict(model_dict)
24 | self.model.eval()
25 |
26 | def __call__(self, oriImg):
27 | # scale_search = [0.5, 1.0, 1.5, 2.0]
28 | scale_search = [0.5]
29 | boxsize = 368
30 | stride = 8
31 | padValue = 128
32 | thre1 = 0.1
33 | thre2 = 0.05
34 | multiplier = [x * boxsize / oriImg.shape[0] for x in scale_search]
35 | heatmap_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 19))
36 | paf_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 38))
37 |
38 | for m in range(len(multiplier)):
39 | scale = multiplier[m]
40 | imageToTest = cv2.resize(oriImg, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC)
41 | imageToTest_padded, pad = util.padRightDownCorner(imageToTest, stride, padValue)
42 | im = np.transpose(np.float32(imageToTest_padded[:, :, :, np.newaxis]), (3, 2, 0, 1)) / 256 - 0.5
43 | im = np.ascontiguousarray(im)
44 |
45 | data = torch.from_numpy(im).float()
46 | if torch.cuda.is_available():
47 | data = data.cuda()
48 | # data = data.permute([2, 0, 1]).unsqueeze(0).float()
49 | with torch.no_grad():
50 | Mconv7_stage6_L1, Mconv7_stage6_L2 = self.model(data)
51 | Mconv7_stage6_L1 = Mconv7_stage6_L1.cpu().numpy()
52 | Mconv7_stage6_L2 = Mconv7_stage6_L2.cpu().numpy()
53 |
54 | # extract outputs, resize, and remove padding
55 | # heatmap = np.transpose(np.squeeze(net.blobs[output_blobs.keys()[1]].data), (1, 2, 0)) # output 1 is heatmaps
56 | heatmap = np.transpose(np.squeeze(Mconv7_stage6_L2), (1, 2, 0)) # output 1 is heatmaps
57 | heatmap = cv2.resize(heatmap, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC)
58 | heatmap = heatmap[:imageToTest_padded.shape[0] - pad[2], :imageToTest_padded.shape[1] - pad[3], :]
59 | heatmap = cv2.resize(heatmap, (oriImg.shape[1], oriImg.shape[0]), interpolation=cv2.INTER_CUBIC)
60 |
61 | # paf = np.transpose(np.squeeze(net.blobs[output_blobs.keys()[0]].data), (1, 2, 0)) # output 0 is PAFs
62 | paf = np.transpose(np.squeeze(Mconv7_stage6_L1), (1, 2, 0)) # output 0 is PAFs
63 | paf = cv2.resize(paf, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC)
64 | paf = paf[:imageToTest_padded.shape[0] - pad[2], :imageToTest_padded.shape[1] - pad[3], :]
65 | paf = cv2.resize(paf, (oriImg.shape[1], oriImg.shape[0]), interpolation=cv2.INTER_CUBIC)
66 |
67 | heatmap_avg += heatmap_avg + heatmap / len(multiplier)
68 | paf_avg += +paf / len(multiplier)
69 |
70 | all_peaks = []
71 | peak_counter = 0
72 |
73 | for part in range(18):
74 | map_ori = heatmap_avg[:, :, part]
75 | one_heatmap = gaussian_filter(map_ori, sigma=3)
76 |
77 | map_left = np.zeros(one_heatmap.shape)
78 | map_left[1:, :] = one_heatmap[:-1, :]
79 | map_right = np.zeros(one_heatmap.shape)
80 | map_right[:-1, :] = one_heatmap[1:, :]
81 | map_up = np.zeros(one_heatmap.shape)
82 | map_up[:, 1:] = one_heatmap[:, :-1]
83 | map_down = np.zeros(one_heatmap.shape)
84 | map_down[:, :-1] = one_heatmap[:, 1:]
85 |
86 | peaks_binary = np.logical_and.reduce((one_heatmap >= map_left, one_heatmap >= map_right,
87 | one_heatmap >= map_up, one_heatmap >= map_down, one_heatmap > thre1))
88 | peaks = list(zip(np.nonzero(peaks_binary)[1], np.nonzero(peaks_binary)[0])) # note reverse
89 | peaks_with_score = [x + (map_ori[x[1], x[0]], ) for x in peaks]
90 | peak_id = range(peak_counter, peak_counter + len(peaks))
91 | peaks_with_score_and_id = [peaks_with_score[i] + (peak_id[i], ) for i in range(len(peak_id))]
92 |
93 | all_peaks.append(peaks_with_score_and_id)
94 | peak_counter += len(peaks)
95 |
96 | # find connection in the specified sequence, center 29 is in the position 15
97 | limbSeq = [[2, 3], [2, 6], [3, 4], [4, 5], [6, 7], [7, 8], [2, 9], [9, 10], \
98 | [10, 11], [2, 12], [12, 13], [13, 14], [2, 1], [1, 15], [15, 17], \
99 | [1, 16], [16, 18], [3, 17], [6, 18]]
100 | # the middle joints heatmap correpondence
101 | mapIdx = [[31, 32], [39, 40], [33, 34], [35, 36], [41, 42], [43, 44], [19, 20], [21, 22], \
102 | [23, 24], [25, 26], [27, 28], [29, 30], [47, 48], [49, 50], [53, 54], [51, 52], \
103 | [55, 56], [37, 38], [45, 46]]
104 |
105 | connection_all = []
106 | special_k = []
107 | mid_num = 10
108 |
109 | for k in range(len(mapIdx)):
110 | score_mid = paf_avg[:, :, [x - 19 for x in mapIdx[k]]]
111 | candA = all_peaks[limbSeq[k][0] - 1]
112 | candB = all_peaks[limbSeq[k][1] - 1]
113 | nA = len(candA)
114 | nB = len(candB)
115 | indexA, indexB = limbSeq[k]
116 | if (nA != 0 and nB != 0):
117 | connection_candidate = []
118 | for i in range(nA):
119 | for j in range(nB):
120 | vec = np.subtract(candB[j][:2], candA[i][:2])
121 | norm = math.sqrt(vec[0] * vec[0] + vec[1] * vec[1])
122 | norm = max(0.001, norm)
123 | vec = np.divide(vec, norm)
124 |
125 | startend = list(zip(np.linspace(candA[i][0], candB[j][0], num=mid_num), \
126 | np.linspace(candA[i][1], candB[j][1], num=mid_num)))
127 |
128 | vec_x = np.array([score_mid[int(round(startend[I][1])), int(round(startend[I][0])), 0] \
129 | for I in range(len(startend))])
130 | vec_y = np.array([score_mid[int(round(startend[I][1])), int(round(startend[I][0])), 1] \
131 | for I in range(len(startend))])
132 |
133 | score_midpts = np.multiply(vec_x, vec[0]) + np.multiply(vec_y, vec[1])
134 | score_with_dist_prior = sum(score_midpts) / len(score_midpts) + min(
135 | 0.5 * oriImg.shape[0] / norm - 1, 0)
136 | criterion1 = len(np.nonzero(score_midpts > thre2)[0]) > 0.8 * len(score_midpts)
137 | criterion2 = score_with_dist_prior > 0
138 | if criterion1 and criterion2:
139 | connection_candidate.append(
140 | [i, j, score_with_dist_prior, score_with_dist_prior + candA[i][2] + candB[j][2]])
141 |
142 | connection_candidate = sorted(connection_candidate, key=lambda x: x[2], reverse=True)
143 | connection = np.zeros((0, 5))
144 | for c in range(len(connection_candidate)):
145 | i, j, s = connection_candidate[c][0:3]
146 | if (i not in connection[:, 3] and j not in connection[:, 4]):
147 | connection = np.vstack([connection, [candA[i][3], candB[j][3], s, i, j]])
148 | if (len(connection) >= min(nA, nB)):
149 | break
150 |
151 | connection_all.append(connection)
152 | else:
153 | special_k.append(k)
154 | connection_all.append([])
155 |
156 | # last number in each row is the total parts number of that person
157 | # the second last number in each row is the score of the overall configuration
158 | subset = -1 * np.ones((0, 20))
159 | candidate = np.array([item for sublist in all_peaks for item in sublist])
160 |
161 | for k in range(len(mapIdx)):
162 | if k not in special_k:
163 | partAs = connection_all[k][:, 0]
164 | partBs = connection_all[k][:, 1]
165 | indexA, indexB = np.array(limbSeq[k]) - 1
166 |
167 | for i in range(len(connection_all[k])): # = 1:size(temp,1)
168 | found = 0
169 | subset_idx = [-1, -1]
170 | for j in range(len(subset)): # 1:size(subset,1):
171 | if subset[j][indexA] == partAs[i] or subset[j][indexB] == partBs[i]:
172 | subset_idx[found] = j
173 | found += 1
174 |
175 | if found == 1:
176 | j = subset_idx[0]
177 | if subset[j][indexB] != partBs[i]:
178 | subset[j][indexB] = partBs[i]
179 | subset[j][-1] += 1
180 | subset[j][-2] += candidate[partBs[i].astype(int), 2] + connection_all[k][i][2]
181 | elif found == 2: # if found 2 and disjoint, merge them
182 | j1, j2 = subset_idx
183 | membership = ((subset[j1] >= 0).astype(int) + (subset[j2] >= 0).astype(int))[:-2]
184 | if len(np.nonzero(membership == 2)[0]) == 0: # merge
185 | subset[j1][:-2] += (subset[j2][:-2] + 1)
186 | subset[j1][-2:] += subset[j2][-2:]
187 | subset[j1][-2] += connection_all[k][i][2]
188 | subset = np.delete(subset, j2, 0)
189 | else: # as like found == 1
190 | subset[j1][indexB] = partBs[i]
191 | subset[j1][-1] += 1
192 | subset[j1][-2] += candidate[partBs[i].astype(int), 2] + connection_all[k][i][2]
193 |
194 | # if find no partA in the subset, create a new subset
195 | elif not found and k < 17:
196 | row = -1 * np.ones(20)
197 | row[indexA] = partAs[i]
198 | row[indexB] = partBs[i]
199 | row[-1] = 2
200 | row[-2] = sum(candidate[connection_all[k][i, :2].astype(int), 2]) + connection_all[k][i][2]
201 | subset = np.vstack([subset, row])
202 | # delete some rows of subset which has few parts occur
203 | deleteIdx = []
204 | for i in range(len(subset)):
205 | if subset[i][-1] < 4 or subset[i][-2] / subset[i][-1] < 0.4:
206 | deleteIdx.append(i)
207 | subset = np.delete(subset, deleteIdx, axis=0)
208 |
209 | # subset: n*20 array, 0-17 is the index in candidate, 18 is the total score, 19 is the total parts
210 | # candidate: x, y, score, id
211 | return candidate, subset
212 |
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/hand.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import json
3 | import math
4 | import matplotlib
5 | import matplotlib.pyplot as plt
6 | import numpy as np
7 | import time
8 | import torch
9 | from scipy.ndimage.filters import gaussian_filter
10 | from skimage.measure import label
11 |
12 | from . import util
13 | from .model import handpose_model
14 |
15 |
16 | class Hand(object):
17 |
18 | def __init__(self, model_path):
19 | self.model = handpose_model()
20 | if torch.cuda.is_available():
21 | self.model = self.model.cuda()
22 | print('cuda')
23 | model_dict = util.transfer(self.model, torch.load(model_path))
24 | self.model.load_state_dict(model_dict)
25 | self.model.eval()
26 |
27 | def __call__(self, oriImg):
28 | scale_search = [0.5, 1.0, 1.5, 2.0]
29 | # scale_search = [0.5]
30 | boxsize = 368
31 | stride = 8
32 | padValue = 128
33 | thre = 0.05
34 | multiplier = [x * boxsize / oriImg.shape[0] for x in scale_search]
35 | heatmap_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 22))
36 | # paf_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 38))
37 |
38 | for m in range(len(multiplier)):
39 | scale = multiplier[m]
40 | imageToTest = cv2.resize(oriImg, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC)
41 | imageToTest_padded, pad = util.padRightDownCorner(imageToTest, stride, padValue)
42 | im = np.transpose(np.float32(imageToTest_padded[:, :, :, np.newaxis]), (3, 2, 0, 1)) / 256 - 0.5
43 | im = np.ascontiguousarray(im)
44 |
45 | data = torch.from_numpy(im).float()
46 | if torch.cuda.is_available():
47 | data = data.cuda()
48 | # data = data.permute([2, 0, 1]).unsqueeze(0).float()
49 | with torch.no_grad():
50 | output = self.model(data).cpu().numpy()
51 | # output = self.model(data).numpy()q
52 |
53 | # extract outputs, resize, and remove padding
54 | heatmap = np.transpose(np.squeeze(output), (1, 2, 0)) # output 1 is heatmaps
55 | heatmap = cv2.resize(heatmap, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC)
56 | heatmap = heatmap[:imageToTest_padded.shape[0] - pad[2], :imageToTest_padded.shape[1] - pad[3], :]
57 | heatmap = cv2.resize(heatmap, (oriImg.shape[1], oriImg.shape[0]), interpolation=cv2.INTER_CUBIC)
58 |
59 | heatmap_avg += heatmap / len(multiplier)
60 |
61 | all_peaks = []
62 | for part in range(21):
63 | map_ori = heatmap_avg[:, :, part]
64 | one_heatmap = gaussian_filter(map_ori, sigma=3)
65 | binary = np.ascontiguousarray(one_heatmap > thre, dtype=np.uint8)
66 | # 全部小于阈值
67 | if np.sum(binary) == 0:
68 | all_peaks.append([0, 0])
69 | continue
70 | label_img, label_numbers = label(binary, return_num=True, connectivity=binary.ndim)
71 | max_index = np.argmax([np.sum(map_ori[label_img == i]) for i in range(1, label_numbers + 1)]) + 1
72 | label_img[label_img != max_index] = 0
73 | map_ori[label_img == 0] = 0
74 |
75 | y, x = util.npmax(map_ori)
76 | all_peaks.append([x, y])
77 | return np.array(all_peaks)
78 |
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/model.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from collections import OrderedDict
4 |
5 |
6 | def make_layers(block, no_relu_layers):
7 | layers = []
8 | for layer_name, v in block.items():
9 | if 'pool' in layer_name:
10 | layer = nn.MaxPool2d(kernel_size=v[0], stride=v[1], padding=v[2])
11 | layers.append((layer_name, layer))
12 | else:
13 | conv2d = nn.Conv2d(in_channels=v[0], out_channels=v[1], kernel_size=v[2], stride=v[3], padding=v[4])
14 | layers.append((layer_name, conv2d))
15 | if layer_name not in no_relu_layers:
16 | layers.append(('relu_' + layer_name, nn.ReLU(inplace=True)))
17 |
18 | return nn.Sequential(OrderedDict(layers))
19 |
20 |
21 | class bodypose_model(nn.Module):
22 |
23 | def __init__(self):
24 | super(bodypose_model, self).__init__()
25 |
26 | # these layers have no relu layer
27 | no_relu_layers = ['conv5_5_CPM_L1', 'conv5_5_CPM_L2', 'Mconv7_stage2_L1',\
28 | 'Mconv7_stage2_L2', 'Mconv7_stage3_L1', 'Mconv7_stage3_L2',\
29 | 'Mconv7_stage4_L1', 'Mconv7_stage4_L2', 'Mconv7_stage5_L1',\
30 | 'Mconv7_stage5_L2', 'Mconv7_stage6_L1', 'Mconv7_stage6_L1']
31 | blocks = {}
32 | block0 = OrderedDict([('conv1_1', [3, 64, 3, 1, 1]), ('conv1_2', [64, 64, 3, 1, 1]), ('pool1_stage1', [2, 2,
33 | 0]),
34 | ('conv2_1', [64, 128, 3, 1, 1]), ('conv2_2', [128, 128, 3, 1, 1]),
35 | ('pool2_stage1', [2, 2, 0]), ('conv3_1', [128, 256, 3, 1, 1]),
36 | ('conv3_2', [256, 256, 3, 1, 1]), ('conv3_3', [256, 256, 3, 1, 1]),
37 | ('conv3_4', [256, 256, 3, 1, 1]), ('pool3_stage1', [2, 2, 0]),
38 | ('conv4_1', [256, 512, 3, 1, 1]), ('conv4_2', [512, 512, 3, 1, 1]),
39 | ('conv4_3_CPM', [512, 256, 3, 1, 1]), ('conv4_4_CPM', [256, 128, 3, 1, 1])])
40 |
41 | # Stage 1
42 | block1_1 = OrderedDict([('conv5_1_CPM_L1', [128, 128, 3, 1, 1]), ('conv5_2_CPM_L1', [128, 128, 3, 1, 1]),
43 | ('conv5_3_CPM_L1', [128, 128, 3, 1, 1]), ('conv5_4_CPM_L1', [128, 512, 1, 1, 0]),
44 | ('conv5_5_CPM_L1', [512, 38, 1, 1, 0])])
45 |
46 | block1_2 = OrderedDict([('conv5_1_CPM_L2', [128, 128, 3, 1, 1]), ('conv5_2_CPM_L2', [128, 128, 3, 1, 1]),
47 | ('conv5_3_CPM_L2', [128, 128, 3, 1, 1]), ('conv5_4_CPM_L2', [128, 512, 1, 1, 0]),
48 | ('conv5_5_CPM_L2', [512, 19, 1, 1, 0])])
49 | blocks['block1_1'] = block1_1
50 | blocks['block1_2'] = block1_2
51 |
52 | self.model0 = make_layers(block0, no_relu_layers)
53 |
54 | # Stages 2 - 6
55 | for i in range(2, 7):
56 | blocks['block%d_1' % i] = OrderedDict([('Mconv1_stage%d_L1' % i, [185, 128, 7, 1, 3]),
57 | ('Mconv2_stage%d_L1' % i, [128, 128, 7, 1, 3]),
58 | ('Mconv3_stage%d_L1' % i, [128, 128, 7, 1, 3]),
59 | ('Mconv4_stage%d_L1' % i, [128, 128, 7, 1, 3]),
60 | ('Mconv5_stage%d_L1' % i, [128, 128, 7, 1, 3]),
61 | ('Mconv6_stage%d_L1' % i, [128, 128, 1, 1, 0]),
62 | ('Mconv7_stage%d_L1' % i, [128, 38, 1, 1, 0])])
63 |
64 | blocks['block%d_2' % i] = OrderedDict([('Mconv1_stage%d_L2' % i, [185, 128, 7, 1, 3]),
65 | ('Mconv2_stage%d_L2' % i, [128, 128, 7, 1, 3]),
66 | ('Mconv3_stage%d_L2' % i, [128, 128, 7, 1, 3]),
67 | ('Mconv4_stage%d_L2' % i, [128, 128, 7, 1, 3]),
68 | ('Mconv5_stage%d_L2' % i, [128, 128, 7, 1, 3]),
69 | ('Mconv6_stage%d_L2' % i, [128, 128, 1, 1, 0]),
70 | ('Mconv7_stage%d_L2' % i, [128, 19, 1, 1, 0])])
71 |
72 | for k in blocks.keys():
73 | blocks[k] = make_layers(blocks[k], no_relu_layers)
74 |
75 | self.model1_1 = blocks['block1_1']
76 | self.model2_1 = blocks['block2_1']
77 | self.model3_1 = blocks['block3_1']
78 | self.model4_1 = blocks['block4_1']
79 | self.model5_1 = blocks['block5_1']
80 | self.model6_1 = blocks['block6_1']
81 |
82 | self.model1_2 = blocks['block1_2']
83 | self.model2_2 = blocks['block2_2']
84 | self.model3_2 = blocks['block3_2']
85 | self.model4_2 = blocks['block4_2']
86 | self.model5_2 = blocks['block5_2']
87 | self.model6_2 = blocks['block6_2']
88 |
89 | def forward(self, x):
90 |
91 | out1 = self.model0(x)
92 |
93 | out1_1 = self.model1_1(out1)
94 | out1_2 = self.model1_2(out1)
95 | out2 = torch.cat([out1_1, out1_2, out1], 1)
96 |
97 | out2_1 = self.model2_1(out2)
98 | out2_2 = self.model2_2(out2)
99 | out3 = torch.cat([out2_1, out2_2, out1], 1)
100 |
101 | out3_1 = self.model3_1(out3)
102 | out3_2 = self.model3_2(out3)
103 | out4 = torch.cat([out3_1, out3_2, out1], 1)
104 |
105 | out4_1 = self.model4_1(out4)
106 | out4_2 = self.model4_2(out4)
107 | out5 = torch.cat([out4_1, out4_2, out1], 1)
108 |
109 | out5_1 = self.model5_1(out5)
110 | out5_2 = self.model5_2(out5)
111 | out6 = torch.cat([out5_1, out5_2, out1], 1)
112 |
113 | out6_1 = self.model6_1(out6)
114 | out6_2 = self.model6_2(out6)
115 |
116 | return out6_1, out6_2
117 |
118 |
119 | class handpose_model(nn.Module):
120 |
121 | def __init__(self):
122 | super(handpose_model, self).__init__()
123 |
124 | # these layers have no relu layer
125 | no_relu_layers = ['conv6_2_CPM', 'Mconv7_stage2', 'Mconv7_stage3',\
126 | 'Mconv7_stage4', 'Mconv7_stage5', 'Mconv7_stage6']
127 | # stage 1
128 | block1_0 = OrderedDict([('conv1_1', [3, 64, 3, 1, 1]), ('conv1_2', [64, 64, 3, 1, 1]),
129 | ('pool1_stage1', [2, 2, 0]), ('conv2_1', [64, 128, 3, 1, 1]),
130 | ('conv2_2', [128, 128, 3, 1, 1]), ('pool2_stage1', [2, 2, 0]),
131 | ('conv3_1', [128, 256, 3, 1, 1]), ('conv3_2', [256, 256, 3, 1, 1]),
132 | ('conv3_3', [256, 256, 3, 1, 1]), ('conv3_4', [256, 256, 3, 1, 1]),
133 | ('pool3_stage1', [2, 2, 0]), ('conv4_1', [256, 512, 3, 1, 1]),
134 | ('conv4_2', [512, 512, 3, 1, 1]), ('conv4_3', [512, 512, 3, 1, 1]),
135 | ('conv4_4', [512, 512, 3, 1, 1]), ('conv5_1', [512, 512, 3, 1, 1]),
136 | ('conv5_2', [512, 512, 3, 1, 1]), ('conv5_3_CPM', [512, 128, 3, 1, 1])])
137 |
138 | block1_1 = OrderedDict([('conv6_1_CPM', [128, 512, 1, 1, 0]), ('conv6_2_CPM', [512, 22, 1, 1, 0])])
139 |
140 | blocks = {}
141 | blocks['block1_0'] = block1_0
142 | blocks['block1_1'] = block1_1
143 |
144 | # stage 2-6
145 | for i in range(2, 7):
146 | blocks['block%d' % i] = OrderedDict([('Mconv1_stage%d' % i, [150, 128, 7, 1, 3]),
147 | ('Mconv2_stage%d' % i, [128, 128, 7, 1, 3]),
148 | ('Mconv3_stage%d' % i, [128, 128, 7, 1, 3]),
149 | ('Mconv4_stage%d' % i, [128, 128, 7, 1, 3]),
150 | ('Mconv5_stage%d' % i, [128, 128, 7, 1, 3]),
151 | ('Mconv6_stage%d' % i, [128, 128, 1, 1, 0]),
152 | ('Mconv7_stage%d' % i, [128, 22, 1, 1, 0])])
153 |
154 | for k in blocks.keys():
155 | blocks[k] = make_layers(blocks[k], no_relu_layers)
156 |
157 | self.model1_0 = blocks['block1_0']
158 | self.model1_1 = blocks['block1_1']
159 | self.model2 = blocks['block2']
160 | self.model3 = blocks['block3']
161 | self.model4 = blocks['block4']
162 | self.model5 = blocks['block5']
163 | self.model6 = blocks['block6']
164 |
165 | def forward(self, x):
166 | out1_0 = self.model1_0(x)
167 | out1_1 = self.model1_1(out1_0)
168 | concat_stage2 = torch.cat([out1_1, out1_0], 1)
169 | out_stage2 = self.model2(concat_stage2)
170 | concat_stage3 = torch.cat([out_stage2, out1_0], 1)
171 | out_stage3 = self.model3(concat_stage3)
172 | concat_stage4 = torch.cat([out_stage3, out1_0], 1)
173 | out_stage4 = self.model4(concat_stage4)
174 | concat_stage5 = torch.cat([out_stage4, out1_0], 1)
175 | out_stage5 = self.model5(concat_stage5)
176 | concat_stage6 = torch.cat([out_stage5, out1_0], 1)
177 | out_stage6 = self.model6(concat_stage6)
178 | return out_stage6
179 |
--------------------------------------------------------------------------------
/Adapter/extra_condition/openpose/util.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import cv2
4 | import matplotlib
5 | import numpy as np
6 |
7 |
8 | def padRightDownCorner(img, stride, padValue):
9 | h = img.shape[0]
10 | w = img.shape[1]
11 |
12 | pad = 4 * [None]
13 | pad[0] = 0 # up
14 | pad[1] = 0 # left
15 | pad[2] = 0 if (h % stride == 0) else stride - (h % stride) # down
16 | pad[3] = 0 if (w % stride == 0) else stride - (w % stride) # right
17 |
18 | img_padded = img
19 | pad_up = np.tile(img_padded[0:1, :, :] * 0 + padValue, (pad[0], 1, 1))
20 | img_padded = np.concatenate((pad_up, img_padded), axis=0)
21 | pad_left = np.tile(img_padded[:, 0:1, :] * 0 + padValue, (1, pad[1], 1))
22 | img_padded = np.concatenate((pad_left, img_padded), axis=1)
23 | pad_down = np.tile(img_padded[-2:-1, :, :] * 0 + padValue, (pad[2], 1, 1))
24 | img_padded = np.concatenate((img_padded, pad_down), axis=0)
25 | pad_right = np.tile(img_padded[:, -2:-1, :] * 0 + padValue, (1, pad[3], 1))
26 | img_padded = np.concatenate((img_padded, pad_right), axis=1)
27 |
28 | return img_padded, pad
29 |
30 |
31 | # transfer caffe model to pytorch which will match the layer name
32 | def transfer(model, model_weights):
33 | transfered_model_weights = {}
34 | for weights_name in model.state_dict().keys():
35 | transfered_model_weights[weights_name] = model_weights['.'.join(weights_name.split('.')[1:])]
36 | return transfered_model_weights
37 |
38 |
39 | # draw the body keypoint and lims
40 | def draw_bodypose(canvas, candidate, subset):
41 | stickwidth = 4
42 | limbSeq = [[2, 3], [2, 6], [3, 4], [4, 5], [6, 7], [7, 8], [2, 9], [9, 10], \
43 | [10, 11], [2, 12], [12, 13], [13, 14], [2, 1], [1, 15], [15, 17], \
44 | [1, 16], [16, 18], [3, 17], [6, 18]]
45 |
46 | colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
47 | [0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], \
48 | [170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
49 | for i in range(18):
50 | for n in range(len(subset)):
51 | index = int(subset[n][i])
52 | if index == -1:
53 | continue
54 | x, y = candidate[index][0:2]
55 | cv2.circle(canvas, (int(x), int(y)), 4, colors[i], thickness=-1)
56 | for i in range(17):
57 | for n in range(len(subset)):
58 | index = subset[n][np.array(limbSeq[i]) - 1]
59 | if -1 in index:
60 | continue
61 | cur_canvas = canvas.copy()
62 | Y = candidate[index.astype(int), 0]
63 | X = candidate[index.astype(int), 1]
64 | mX = np.mean(X)
65 | mY = np.mean(Y)
66 | length = ((X[0] - X[1])**2 + (Y[0] - Y[1])**2)**0.5
67 | angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1]))
68 | polygon = cv2.ellipse2Poly((int(mY), int(mX)), (int(length / 2), stickwidth), int(angle), 0, 360, 1)
69 | cv2.fillConvexPoly(cur_canvas, polygon, colors[i])
70 | canvas = cv2.addWeighted(canvas, 0.4, cur_canvas, 0.6, 0)
71 | # plt.imsave("preview.jpg", canvas[:, :, [2, 1, 0]])
72 | # plt.imshow(canvas[:, :, [2, 1, 0]])
73 | return canvas
74 |
75 |
76 | # image drawed by opencv is not good.
77 | def draw_handpose(canvas, all_hand_peaks, show_number=False):
78 | edges = [[0, 1], [1, 2], [2, 3], [3, 4], [0, 5], [5, 6], [6, 7], [7, 8], [0, 9], [9, 10], \
79 | [10, 11], [11, 12], [0, 13], [13, 14], [14, 15], [15, 16], [0, 17], [17, 18], [18, 19], [19, 20]]
80 |
81 | for peaks in all_hand_peaks:
82 | for ie, e in enumerate(edges):
83 | if np.sum(np.all(peaks[e], axis=1) == 0) == 0:
84 | x1, y1 = peaks[e[0]]
85 | x2, y2 = peaks[e[1]]
86 | cv2.line(
87 | canvas, (x1, y1), (x2, y2),
88 | matplotlib.colors.hsv_to_rgb([ie / float(len(edges)), 1.0, 1.0]) * 255,
89 | thickness=2)
90 |
91 | for i, keyponit in enumerate(peaks):
92 | x, y = keyponit
93 | cv2.circle(canvas, (x, y), 4, (0, 0, 255), thickness=-1)
94 | if show_number:
95 | cv2.putText(canvas, str(i), (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.3, (0, 0, 0), lineType=cv2.LINE_AA)
96 | return canvas
97 |
98 |
99 | # detect hand according to body pose keypoints
100 | # please refer to https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/src/openpose/hand/handDetector.cpp
101 | def handDetect(candidate, subset, oriImg):
102 | # right hand: wrist 4, elbow 3, shoulder 2
103 | # left hand: wrist 7, elbow 6, shoulder 5
104 | ratioWristElbow = 0.33
105 | detect_result = []
106 | image_height, image_width = oriImg.shape[0:2]
107 | for person in subset.astype(int):
108 | # if any of three not detected
109 | has_left = np.sum(person[[5, 6, 7]] == -1) == 0
110 | has_right = np.sum(person[[2, 3, 4]] == -1) == 0
111 | if not (has_left or has_right):
112 | continue
113 | hands = []
114 | #left hand
115 | if has_left:
116 | left_shoulder_index, left_elbow_index, left_wrist_index = person[[5, 6, 7]]
117 | x1, y1 = candidate[left_shoulder_index][:2]
118 | x2, y2 = candidate[left_elbow_index][:2]
119 | x3, y3 = candidate[left_wrist_index][:2]
120 | hands.append([x1, y1, x2, y2, x3, y3, True])
121 | # right hand
122 | if has_right:
123 | right_shoulder_index, right_elbow_index, right_wrist_index = person[[2, 3, 4]]
124 | x1, y1 = candidate[right_shoulder_index][:2]
125 | x2, y2 = candidate[right_elbow_index][:2]
126 | x3, y3 = candidate[right_wrist_index][:2]
127 | hands.append([x1, y1, x2, y2, x3, y3, False])
128 |
129 | for x1, y1, x2, y2, x3, y3, is_left in hands:
130 | # pos_hand = pos_wrist + ratio * (pos_wrist - pos_elbox) = (1 + ratio) * pos_wrist - ratio * pos_elbox
131 | # handRectangle.x = posePtr[wrist*3] + ratioWristElbow * (posePtr[wrist*3] - posePtr[elbow*3]);
132 | # handRectangle.y = posePtr[wrist*3+1] + ratioWristElbow * (posePtr[wrist*3+1] - posePtr[elbow*3+1]);
133 | # const auto distanceWristElbow = getDistance(poseKeypoints, person, wrist, elbow);
134 | # const auto distanceElbowShoulder = getDistance(poseKeypoints, person, elbow, shoulder);
135 | # handRectangle.width = 1.5f * fastMax(distanceWristElbow, 0.9f * distanceElbowShoulder);
136 | x = x3 + ratioWristElbow * (x3 - x2)
137 | y = y3 + ratioWristElbow * (y3 - y2)
138 | distanceWristElbow = math.sqrt((x3 - x2)**2 + (y3 - y2)**2)
139 | distanceElbowShoulder = math.sqrt((x2 - x1)**2 + (y2 - y1)**2)
140 | width = 1.5 * max(distanceWristElbow, 0.9 * distanceElbowShoulder)
141 | # x-y refers to the center --> offset to topLeft point
142 | # handRectangle.x -= handRectangle.width / 2.f;
143 | # handRectangle.y -= handRectangle.height / 2.f;
144 | x -= width / 2
145 | y -= width / 2 # width = height
146 | # overflow the image
147 | if x < 0: x = 0
148 | if y < 0: y = 0
149 | width1 = width
150 | width2 = width
151 | if x + width > image_width: width1 = image_width - x
152 | if y + width > image_height: width2 = image_height - y
153 | width = min(width1, width2)
154 | # the max hand box value is 20 pixels
155 | if width >= 20:
156 | detect_result.append([int(x), int(y), int(width), is_left])
157 | '''
158 | return value: [[x, y, w, True if left hand else False]].
159 | width=height since the network require squared input.
160 | x, y is the coordinate of top left
161 | '''
162 | return detect_result
163 |
164 |
165 | # get max index of 2d array
166 | def npmax(array):
167 | arrayindex = array.argmax(1)
168 | arrayvalue = array.max(1)
169 | i = arrayvalue.argmax()
170 | j = arrayindex[i]
171 | return i, j
172 |
173 |
174 | def HWC3(x):
175 | assert x.dtype == np.uint8
176 | if x.ndim == 2:
177 | x = x[:, :, None]
178 | assert x.ndim == 3
179 | H, W, C = x.shape
180 | assert C == 1 or C == 3 or C == 4
181 | if C == 3:
182 | return x
183 | if C == 1:
184 | return np.concatenate([x, x, x], axis=2)
185 | if C == 4:
186 | color = x[:, :, 0:3].astype(np.float32)
187 | alpha = x[:, :, 3:4].astype(np.float32) / 255.0
188 | y = color * alpha + 255.0 * (1.0 - alpha)
189 | y = y.clip(0, 255).astype(np.uint8)
190 | return y
191 |
192 |
193 | def resize_image(input_image, resolution):
194 | H, W, C = input_image.shape
195 | H = float(H)
196 | W = float(W)
197 | k = float(resolution) / min(H, W)
198 | H *= k
199 | W *= k
200 | H = int(np.round(H / 64.0)) * 64
201 | W = int(np.round(W / 64.0)) * 64
202 | img = cv2.resize(input_image, (W, H), interpolation=cv2.INTER_LANCZOS4 if k > 1 else cv2.INTER_AREA)
203 | return img
204 |
--------------------------------------------------------------------------------
/Adapter/inference_base.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | from omegaconf import OmegaConf
4 |
5 | DEFAULT_NEGATIVE_PROMPT = 'extra digit, fewer digits, cropped, worst quality, low quality'
6 |
7 | def get_base_argument_parser() -> argparse.ArgumentParser:
8 | """get the base argument parser for inference scripts"""
9 | parser = argparse.ArgumentParser()
10 | parser.add_argument(
11 | '--outdir',
12 | type=str,
13 | help='dir to write results to',
14 | default=None,
15 | )
16 |
17 | parser.add_argument(
18 | '--prompt',
19 | type=str,
20 | default='',
21 | help='positive prompt',
22 | )
23 |
24 | parser.add_argument(
25 | '--neg_prompt',
26 | type=str,
27 | default=DEFAULT_NEGATIVE_PROMPT,
28 | help='negative prompt',
29 | )
30 |
31 | parser.add_argument(
32 | '--cond_path',
33 | type=str,
34 | default=None,
35 | help='condition image path',
36 | )
37 |
38 | parser.add_argument(
39 | '--cond_inp_type',
40 | type=str,
41 | default='image',
42 | help='the type of the input condition image, take depth T2I as example, the input can be raw image, '
43 | 'which depth will be calculated, or the input can be a directly a depth map image',
44 | )
45 |
46 | parser.add_argument(
47 | '--sampler',
48 | type=str,
49 | default='ddim',
50 | choices=['ddim', 'plms'],
51 | help='sampling algorithm, currently, only ddim and plms are supported, more are on the way',
52 | )
53 |
54 | parser.add_argument(
55 | '--steps',
56 | type=int,
57 | default=50,
58 | help='number of sampling steps',
59 | )
60 |
61 | parser.add_argument(
62 | '--max_resolution',
63 | type=float,
64 | default=1024 * 1024,
65 | help='max image height * width, only for computer with limited vram',
66 | )
67 |
68 | parser.add_argument(
69 | '--resize_short_edge',
70 | type=int,
71 | default=None,
72 | help='resize short edge of the input image, if this arg is set, max_resolution will not be used',
73 | )
74 |
75 | parser.add_argument(
76 | '--C',
77 | type=int,
78 | default=4,
79 | help='latent channels',
80 | )
81 |
82 | parser.add_argument(
83 | '--f',
84 | type=int,
85 | default=8,
86 | help='downsampling factor',
87 | )
88 |
89 | parser.add_argument(
90 | '--scale',
91 | type=float,
92 | default=7.5,
93 | help='unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))',
94 | )
95 |
96 | parser.add_argument(
97 | '--cond_tau',
98 | type=float,
99 | default=1.0,
100 | help='timestamp parameter that determines until which step the adapter is applied, '
101 | 'similar as Prompt-to-Prompt tau',
102 | )
103 |
104 | parser.add_argument(
105 | '--cond_weight',
106 | type=float,
107 | default=1.0,
108 | help='the adapter features are multiplied by the cond_weight. The larger the cond_weight, the more aligned '
109 | 'the generated image and condition will be, but the generated quality may be reduced',
110 | )
111 |
112 | parser.add_argument(
113 | '--seed',
114 | type=int,
115 | default=42,
116 | )
117 |
118 | parser.add_argument(
119 | '--n_samples',
120 | type=int,
121 | default=4,
122 | help='# of samples to generate',
123 | )
124 |
125 | return parser
126 |
127 |
--------------------------------------------------------------------------------
/Adapter/models/adapters.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from collections import OrderedDict
4 |
5 |
6 | def conv_nd(dims, *args, **kwargs):
7 | """
8 | Create a 1D, 2D, or 3D convolution module.
9 | """
10 | if dims == 1:
11 | return nn.Conv1d(*args, **kwargs)
12 | elif dims == 2:
13 | return nn.Conv2d(*args, **kwargs)
14 | elif dims == 3:
15 | return nn.Conv3d(*args, **kwargs)
16 | raise ValueError(f"unsupported dimensions: {dims}")
17 |
18 |
19 | def avg_pool_nd(dims, *args, **kwargs):
20 | """
21 | Create a 1D, 2D, or 3D average pooling module.
22 | """
23 | if dims == 1:
24 | return nn.AvgPool1d(*args, **kwargs)
25 | elif dims == 2:
26 | return nn.AvgPool2d(*args, **kwargs)
27 | elif dims == 3:
28 | return nn.AvgPool3d(*args, **kwargs)
29 | raise ValueError(f"unsupported dimensions: {dims}")
30 |
31 | def get_parameter_dtype(parameter: torch.nn.Module):
32 | try:
33 | params = tuple(parameter.parameters())
34 | if len(params) > 0:
35 | return params[0].dtype
36 |
37 | buffers = tuple(parameter.buffers())
38 | if len(buffers) > 0:
39 | return buffers[0].dtype
40 |
41 | except StopIteration:
42 | # For torch.nn.DataParallel compatibility in PyTorch 1.5
43 |
44 | def find_tensor_attributes(module: torch.nn.Module) -> List[Tuple[str, Tensor]]:
45 | tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
46 | return tuples
47 |
48 | gen = parameter._named_members(get_members_fn=find_tensor_attributes)
49 | first_tuple = next(gen)
50 | return first_tuple[1].dtype
51 |
52 | class Downsample(nn.Module):
53 | """
54 | A downsampling layer with an optional convolution.
55 | :param channels: channels in the inputs and outputs.
56 | :param use_conv: a bool determining if a convolution is applied.
57 | :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
58 | downsampling occurs in the inner-two dimensions.
59 | """
60 |
61 | def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
62 | super().__init__()
63 | self.channels = channels
64 | self.out_channels = out_channels or channels
65 | self.use_conv = use_conv
66 | self.dims = dims
67 | stride = 2 if dims != 3 else (1, 2, 2)
68 | if use_conv:
69 | self.op = conv_nd(dims, self.channels, self.out_channels, 3, stride=stride, padding=padding)
70 | else:
71 | assert self.channels == self.out_channels
72 | self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
73 |
74 | def forward(self, x):
75 | assert x.shape[1] == self.channels
76 | return self.op(x)
77 |
78 |
79 | class ResnetBlock(nn.Module):
80 |
81 | def __init__(self, in_c, out_c, down, ksize=3, sk=False, use_conv=True):
82 | super().__init__()
83 | ps = ksize // 2
84 | if in_c != out_c or sk == False:
85 | self.in_conv = nn.Conv2d(in_c, out_c, ksize, 1, ps)
86 | else:
87 | self.in_conv = None
88 | self.block1 = nn.Conv2d(out_c, out_c, 3, 1, 1)
89 | self.act = nn.ReLU()
90 | self.block2 = nn.Conv2d(out_c, out_c, ksize, 1, ps)
91 | if sk == False:
92 | self.skep = nn.Conv2d(in_c, out_c, ksize, 1, ps)
93 | else:
94 | self.skep = None
95 |
96 | self.down = down
97 | if self.down == True:
98 | self.down_opt = Downsample(in_c, use_conv=use_conv)
99 |
100 | def forward(self, x):
101 | if self.down == True:
102 | x = self.down_opt(x)
103 | if self.in_conv is not None: # edit
104 | x = self.in_conv(x)
105 |
106 | h = self.block1(x)
107 | h = self.act(h)
108 | h = self.block2(h)
109 | if self.skep is not None:
110 | return h + self.skep(x)
111 | else:
112 | return h + x
113 |
114 |
115 | class Adapter_XL(nn.Module):
116 |
117 | def __init__(self, channels=[320, 640, 1280, 1280], nums_rb=3, cin=64, ksize=3, sk=False, use_conv=True):
118 | super(Adapter_XL, self).__init__()
119 | self.unshuffle = nn.PixelUnshuffle(16)
120 | self.channels = channels
121 | self.nums_rb = nums_rb
122 | self.body = []
123 | for i in range(len(channels)):
124 | for j in range(nums_rb):
125 | if (i == 2) and (j == 0):
126 | self.body.append(
127 | ResnetBlock(channels[i - 1], channels[i], down=True, ksize=ksize, sk=sk, use_conv=use_conv))
128 | elif (i == 1) and (j == 0):
129 | self.body.append(
130 | ResnetBlock(channels[i - 1], channels[i], down=False, ksize=ksize, sk=sk, use_conv=use_conv))
131 | else:
132 | self.body.append(
133 | ResnetBlock(channels[i], channels[i], down=False, ksize=ksize, sk=sk, use_conv=use_conv))
134 | self.body = nn.ModuleList(self.body)
135 | self.conv_in = nn.Conv2d(cin, channels[0], 3, 1, 1)
136 |
137 | @property
138 | def dtype(self) -> torch.dtype:
139 | """
140 | `torch.dtype`: The dtype of the module (assuming that all the module parameters have the same dtype).
141 | """
142 | return get_parameter_dtype(self)
143 |
144 | def forward(self, x):
145 | # unshuffle
146 | x = self.unshuffle(x)
147 | # extract features
148 | features = []
149 | x = self.conv_in(x)
150 | for i in range(len(self.channels)):
151 | for j in range(self.nums_rb):
152 | idx = i * self.nums_rb + j
153 | x = self.body[idx](x)
154 | features.append(x)
155 |
156 | return features
157 |
158 |
--------------------------------------------------------------------------------
/Adapter/utils.py:
--------------------------------------------------------------------------------
1 | from transformers import PretrainedConfig
2 | import numpy as np
3 | import cv2
4 |
5 | def import_model_class_from_model_name_or_path(
6 | pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
7 | ):
8 | text_encoder_config = PretrainedConfig.from_pretrained(
9 | pretrained_model_name_or_path, subfolder=subfolder, revision=revision
10 | )
11 | model_class = text_encoder_config.architectures[0]
12 |
13 | if model_class == "CLIPTextModel":
14 | from transformers import CLIPTextModel
15 |
16 | return CLIPTextModel
17 | elif model_class == "CLIPTextModelWithProjection":
18 | from transformers import CLIPTextModelWithProjection
19 |
20 | return CLIPTextModelWithProjection
21 | else:
22 | raise ValueError(f"{model_class} is not supported.")
23 |
24 | def resize_numpy_image(image, max_resolution=1024 * 1024, resize_short_edge=None):
25 | h, w = image.shape[:2]
26 | if resize_short_edge is not None:
27 | k = resize_short_edge / min(h, w)
28 | else:
29 | k = max_resolution / (h * w)
30 | k = k**0.5
31 | h = int(np.round(h * k / 64)) * 64
32 | w = int(np.round(w * k / 64)) * 64
33 | image = cv2.resize(image, (w, h), interpolation=cv2.INTER_LANCZOS4)
34 | return image
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |  3 |
3 |
4 |
5 |
6 | ###
7 |
8 |
9 |
10 | [](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL) [](https://huggingface.co/blog/t2i-sdxl-adapters) [](https://arxiv.org/abs/2302.08453)
11 |
12 |
13 |
14 | ---
15 |
16 | Official implementation of **[T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.08453)** based on [Stable Diffusion-XL](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0).
17 |
18 | The diffusers team and the T2I-Adapter authors have been collaborating to bring the support of T2I-Adapters for Stable Diffusion XL (SDXL) in diffusers! It achieves impressive results in both performance and efficiency.
19 |
20 | ---
21 | 
22 |
23 | ## 🚩 **New Features/Updates**
24 | - ✅ Sep. 8, 2023. We collaborate with the diffusers team to bring the support of T2I-Adapters for Stable Diffusion XL (SDXL) in diffusers! It achieves impressive results in both performance and efficiency. We release T2I-Adapter-SDXL models for [sketch](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0), [canny](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0), [lineart](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0), [openpose](https://huggingface.co/TencentARC/t2i-adapter-openpose-sdxl-1.0), [depth-zoe](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0), and [depth-mid](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0). We release two online demos: [](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL) and [](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL-Sketch).
25 | - ✅ Aug. 21, 2023. We release [T2I-Adapter-SDXL](https://github.com/TencentARC/T2I-Adapter/), including sketch, canny, and keypoint. We still use the original recipe (77M parameters, a single inference) to drive [StableDiffusion-XL](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0). Due to the limited computing resources, those adapters still need further improvement. We are collaborating with [HuggingFace](https://huggingface.co/), and a more powerful adapter is in the works.
26 |
27 | - ✅ Jul. 13, 2023. [Stability AI](https://stability.ai/) release [Stable Doodle](https://stability.ai/blog/clipdrop-launches-stable-doodle), a groundbreaking sketch-to-image tool based on T2I-Adapter and [SDXL](https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9). It makes drawing easier.
28 |
29 | - ✅ Mar. 16, 2023. We add **CoAdapter** (**Co**mposable **Adapter**). The online Huggingface Gadio has been updated [](https://huggingface.co/spaces/Adapter/CoAdapter). You can also try the [local gradio demo](app_coadapter.py).
30 | - ✅ Mar. 16, 2023. We have shrunk the git repo with [bfg](https://rtyley.github.io/bfg-repo-cleaner/). If you encounter any issues when pulling or pushing, you can try re-cloning the repository. Sorry for the inconvenience.
31 | - ✅ Mar. 3, 2023. Add a [*color adapter (spatial palette)*](https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models), which has only **17M parameters**.
32 | - ✅ Mar. 3, 2023. Add four new adapters [*style, color, openpose and canny*](https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models). See more info in the **[Adapter Zoo](https://github.com/TencentARC/T2I-Adapter/blob/SD/docs/AdapterZoo.md)**.
33 | - ✅ Feb. 23, 2023. Add the depth adapter [*t2iadapter_depth_sd14v1.pth*](https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models). See more info in the **[Adapter Zoo](https://github.com/TencentARC/T2I-Adapter/blob/SD/docs/AdapterZoo.md)**.
34 | - ✅ Feb. 15, 2023. Release [T2I-Adapter](https://github.com/TencentARC/T2I-Adapter/tree/SD).
35 |
36 | ---
37 |
38 | # 🔥🔥🔥 Why T2I-Adapter-SDXL?
39 | ## The Original Recipe Drives Larger SD.
40 |
41 | | | SD-V1.4/1.5 | SD-XL | T2I-Adapter | T2I-Adapter-SDXL |
42 | | --- | --- |--- |--- |--- |
43 | | Parameters | 860M | 2.6B |77 M | 77/79 M | |
44 |
45 | ## Inherit High-quality Generation from SDXL.
46 |
47 | - Lineart-guided
48 |
49 | Model from [TencentARC/t2i-adapter-lineart-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0)
50 |
51 |  52 |
52 |
53 |
54 | - Keypoint-guided
55 |
56 | Model from [openpose_sdxl_1.0](https://huggingface.co/Adapter/t2iadapter/tree/main/openpose_sdxl_1.0)
57 |
58 |  59 |
59 |
60 |
61 | - Sketch-guided
62 |
63 | Model from [TencentARC/t2i-adapter-sketch-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0)
64 |
65 |  66 |
66 |
67 |
68 | - Canny-guided
69 | Model from [TencentARC/t2i-adapter-canny-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0)
70 |
71 |  72 |
72 |
73 |
74 | - Depth-guided
75 |
76 | Depth guided models from [TencentARC/t2i-adapter-depth-midas-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0) and [TencentARC/t2i-adapter-depth-zoe-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0) respectively
77 |
78 |  79 |
79 |
80 |
81 | # 🔧 Dependencies and Installation
82 |
83 | - Python >= 3.8 (Recommend to use [Anaconda](https://www.anaconda.com/download/#linux) or [Miniconda](https://docs.conda.io/en/latest/miniconda.html))
84 | - [PyTorch >= 2.0.1](https://pytorch.org/)
85 | ```bash
86 | pip install -r requirements.txt
87 | ```
88 |
89 | # ⏬ Download Models
90 | All models will be automatically downloaded. You can also choose to download manually from this [url](https://huggingface.co/TencentARC).
91 |
92 | # 🔥 How to Train
93 | Here we take sketch guidance as an example, but of course, you can also prepare your own dataset following this method.
94 | ```bash
95 | accelerate launch train_sketch.py --pretrained_model_name_or_path stabilityai/stable-diffusion-xl-base-1.0 --output_dir experiments/adapter_sketch_xl --config configs/train/Adapter-XL-sketch.yaml --mixed_precision="fp16" --resolution=1024 --learning_rate=1e-5 --max_train_steps=60000 --train_batch_size=1 --gradient_accumulation_steps=4 --report_to="wandb" --seed=42 --num_train_epochs 100
96 | ```
97 |
98 | We train with `FP16` data precision on `4` NVIDIA `A100` GPUs.
99 |
100 | # 💻 How to Test
101 | Inference requires at least `15GB` of GPU memory.
102 |
103 | ## Quick start with [diffusers](https://github.com/huggingface/diffusers)
104 |
105 | To get started, first install the required dependencies:
106 |
107 | ```bash
108 | pip install git+https://github.com/huggingface/diffusers.git@t2iadapterxl # for now
109 | pip install -U controlnet_aux==0.0.7 # for conditioning models and detectors
110 | pip install transformers accelerate safetensors
111 | ```
112 |
113 | 1. Images are first downloaded into the appropriate *control image* format.
114 | 2. The *control image* and *prompt* are passed to the [`StableDiffusionXLAdapterPipeline`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py#L125).
115 |
116 | Let's have a look at a simple example using the [LineArt Adapter](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0).
117 |
118 | - Dependency
119 | ```py
120 | from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, EulerAncestralDiscreteScheduler, AutoencoderKL
121 | from diffusers.utils import load_image, make_image_grid
122 | from controlnet_aux.lineart import LineartDetector
123 | import torch
124 |
125 | # load adapter
126 | adapter = T2IAdapter.from_pretrained(
127 | "TencentARC/t2i-adapter-lineart-sdxl-1.0", torch_dtype=torch.float16, varient="fp16"
128 | ).to("cuda")
129 |
130 | # load euler_a scheduler
131 | model_id = 'stabilityai/stable-diffusion-xl-base-1.0'
132 | euler_a = EulerAncestralDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
133 | vae=AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
134 | pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
135 | model_id, vae=vae, adapter=adapter, scheduler=euler_a, torch_dtype=torch.float16, variant="fp16",
136 | ).to("cuda")
137 | pipe.enable_xformers_memory_efficient_attention()
138 |
139 | line_detector = LineartDetector.from_pretrained("lllyasviel/Annotators").to("cuda")
140 | ```
141 |
142 | - Condition Image
143 | ```py
144 | url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_lin.jpg"
145 | image = load_image(url)
146 | image = line_detector(
147 | image, detect_resolution=384, image_resolution=1024
148 | )
149 | ```
150 |  151 |
152 | - Generation
153 | ```py
154 | prompt = "Ice dragon roar, 4k photo"
155 | negative_prompt = "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"
156 | gen_images = pipe(
157 | prompt=prompt,
158 | negative_prompt=negative_prompt,
159 | image=image,
160 | num_inference_steps=30,
161 | adapter_conditioning_scale=0.8,
162 | guidance_scale=7.5,
163 | ).images[0]
164 | gen_images.save('out_lin.png')
165 | ```
166 |
151 |
152 | - Generation
153 | ```py
154 | prompt = "Ice dragon roar, 4k photo"
155 | negative_prompt = "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"
156 | gen_images = pipe(
157 | prompt=prompt,
158 | negative_prompt=negative_prompt,
159 | image=image,
160 | num_inference_steps=30,
161 | adapter_conditioning_scale=0.8,
162 | guidance_scale=7.5,
163 | ).images[0]
164 | gen_images.save('out_lin.png')
165 | ```
166 |  167 |
168 | ## Online Demo [](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL)
169 |
167 |
168 | ## Online Demo [](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL)
169 | 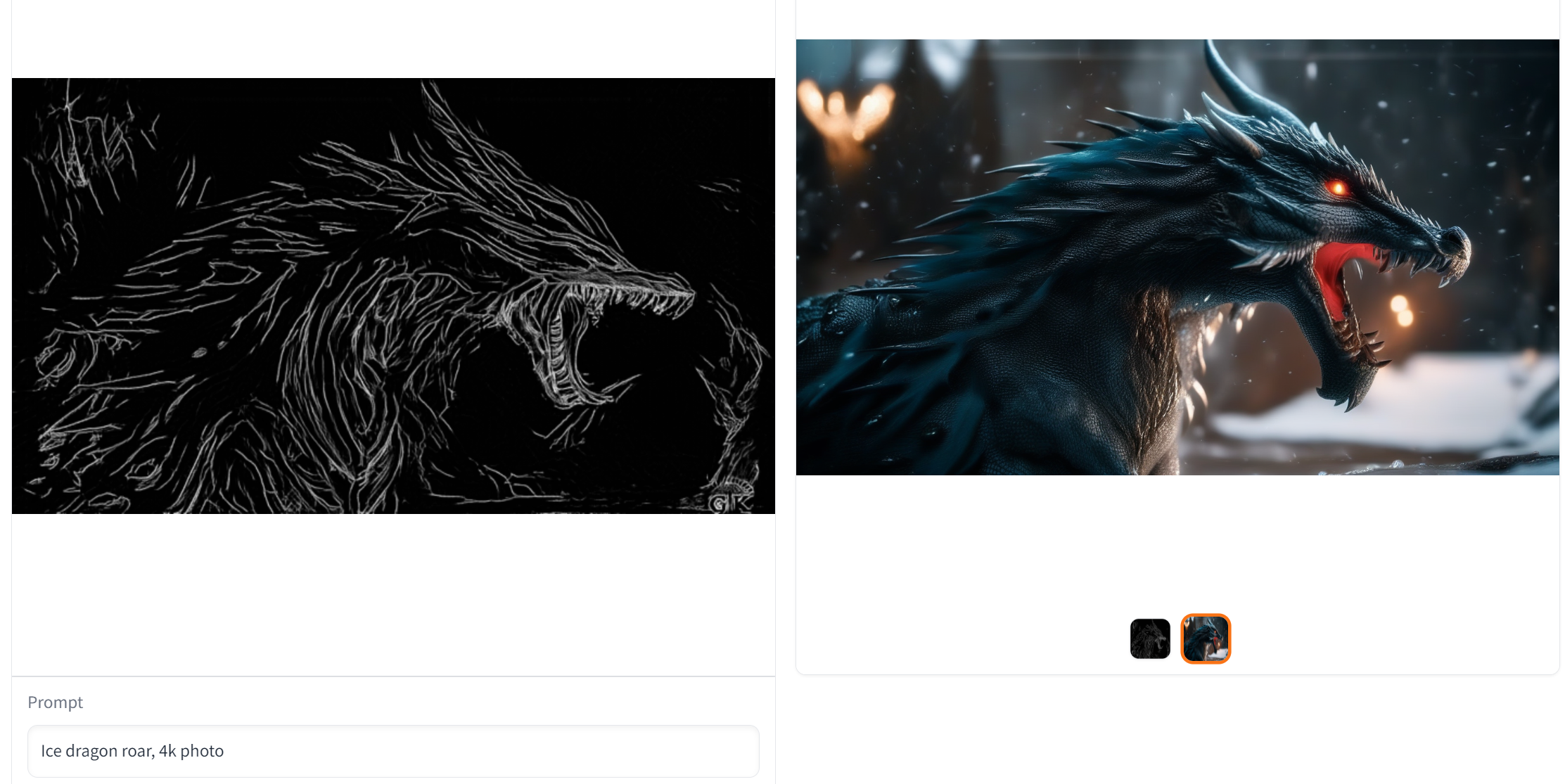 170 |
171 | ## Online Doodly Demo [](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL-Sketch)
172 |
170 |
171 | ## Online Doodly Demo [](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL-Sketch)
172 | 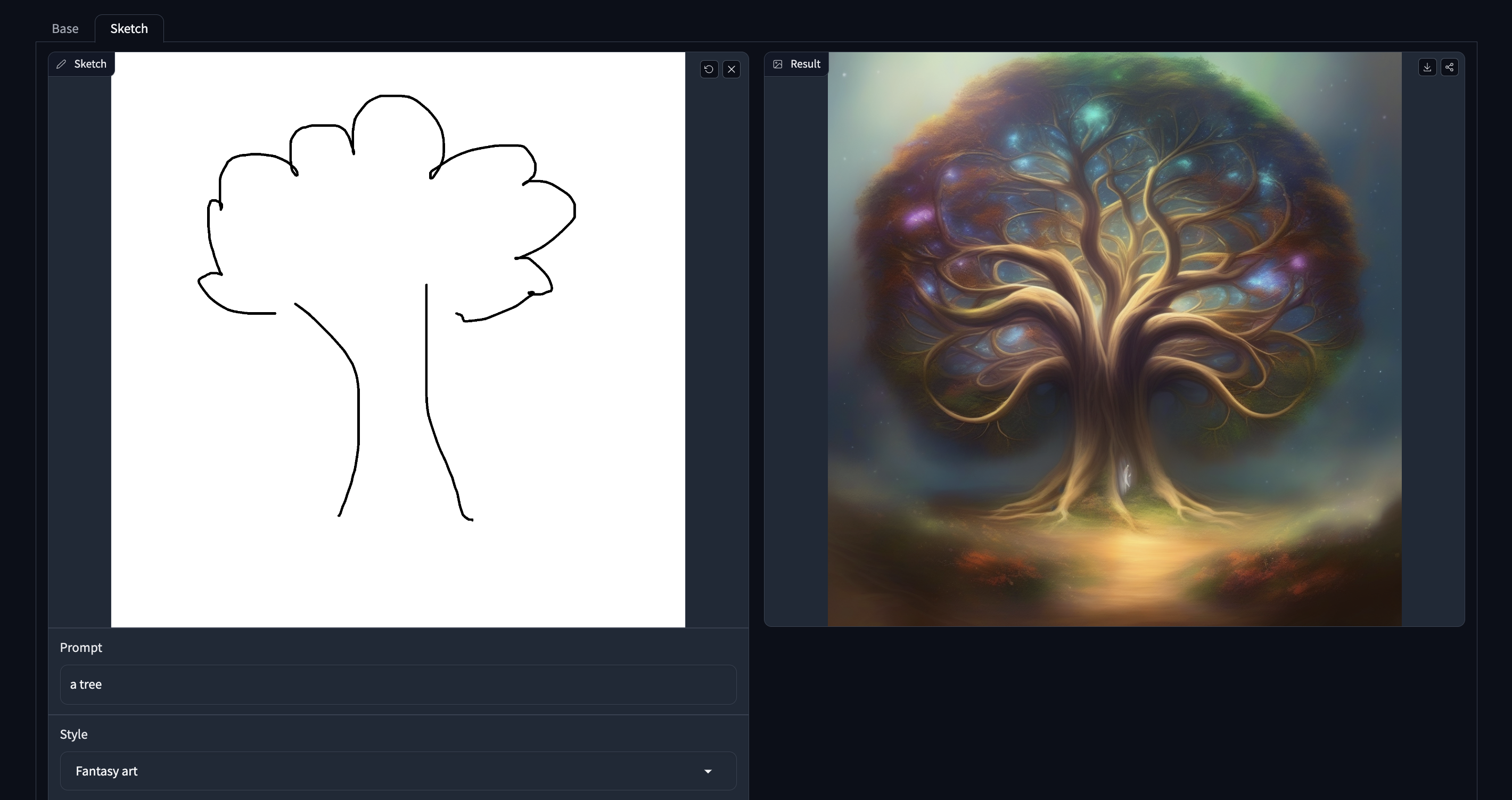 173 |
173 |  174 |
175 |
176 | # Tutorials on HuggingFace:
177 | - Sketch: [https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0)
178 | - Canny: [https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0)
179 | - Lineart: [https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0)
180 | - Openpose: [https://huggingface.co/TencentARC/t2i-adapter-openpose-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-openpose-sdxl-1.0)
181 | - Depth-mid: [https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0)
182 | - Depth-zoe: [https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0)
183 |
184 | ...
185 |
186 | # Other Source
187 | Jul. 13, 2023. [Stability AI](https://stability.ai/) release [Stable Doodle](https://stability.ai/blog/clipdrop-launches-stable-doodle), a groundbreaking sketch-to-image tool based on T2I-Adapter and [SDXL](https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9). It makes drawing easier.
188 |
189 | https://user-images.githubusercontent.com/73707470/253800159-c7e12362-1ea1-4b20-a44e-bd6c8d546765.mp4
190 |
191 | # 🤗 Acknowledgements
192 | - Thanks to HuggingFace for their support of T2I-Adapter.
193 | - T2I-Adapter is co-hosted by Tencent ARC Lab and Peking University [VILLA](https://villa.jianzhang.tech/).
194 |
195 | # BibTeX
196 |
197 | @article{mou2023t2i,
198 | title={T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models},
199 | author={Mou, Chong and Wang, Xintao and Xie, Liangbin and Wu, Yanze and Zhang, Jian and Qi, Zhongang and Shan, Ying and Qie, Xiaohu},
200 | journal={arXiv preprint arXiv:2302.08453},
201 | year={2023}
202 | }
203 |
--------------------------------------------------------------------------------
/app.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import gradio as gr
3 | import torch
4 | from basicsr.utils import tensor2img
5 | import os
6 | from huggingface_hub import hf_hub_url
7 | import subprocess
8 | import shlex
9 | import cv2
10 | from omegaconf import OmegaConf
11 |
12 | from demo import create_demo_sketch, create_demo_canny, create_demo_pose
13 | from Adapter.Sampling import diffusion_inference
14 | from configs.utils import instantiate_from_config
15 | from Adapter.extra_condition.api import get_cond_model, ExtraCondition
16 | from Adapter.extra_condition import api
17 | from Adapter.inference_base import get_base_argument_parser
18 |
19 | torch.set_grad_enabled(False)
20 |
21 | urls = {
22 | 'TencentARC/T2I-Adapter':[
23 | 'models_XL/adapter-xl-canny.pth', 'models_XL/adapter-xl-sketch.pth',
24 | 'models_XL/adapter-xl-openpose.pth', 'third-party-models/body_pose_model.pth',
25 | 'third-party-models/table5_pidinet.pth'
26 | ]
27 | }
28 |
29 | if os.path.exists('checkpoints') == False:
30 | os.mkdir('checkpoints')
31 | for repo in urls:
32 | files = urls[repo]
33 | for file in files:
34 | url = hf_hub_url(repo, file)
35 | name_ckp = url.split('/')[-1]
36 | save_path = os.path.join('checkpoints',name_ckp)
37 | if os.path.exists(save_path) == False:
38 | subprocess.run(shlex.split(f'wget {url} -O {save_path}'))
39 |
40 | parser = get_base_argument_parser()
41 | global_opt = parser.parse_args()
42 | global_opt.device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
43 |
44 | DESCRIPTION = '# [T2I-Adapter-XL](https://github.com/TencentARC/T2I-Adapter)'
45 |
46 | DESCRIPTION += f'
174 |
175 |
176 | # Tutorials on HuggingFace:
177 | - Sketch: [https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0)
178 | - Canny: [https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0)
179 | - Lineart: [https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0)
180 | - Openpose: [https://huggingface.co/TencentARC/t2i-adapter-openpose-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-openpose-sdxl-1.0)
181 | - Depth-mid: [https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0)
182 | - Depth-zoe: [https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0)
183 |
184 | ...
185 |
186 | # Other Source
187 | Jul. 13, 2023. [Stability AI](https://stability.ai/) release [Stable Doodle](https://stability.ai/blog/clipdrop-launches-stable-doodle), a groundbreaking sketch-to-image tool based on T2I-Adapter and [SDXL](https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9). It makes drawing easier.
188 |
189 | https://user-images.githubusercontent.com/73707470/253800159-c7e12362-1ea1-4b20-a44e-bd6c8d546765.mp4
190 |
191 | # 🤗 Acknowledgements
192 | - Thanks to HuggingFace for their support of T2I-Adapter.
193 | - T2I-Adapter is co-hosted by Tencent ARC Lab and Peking University [VILLA](https://villa.jianzhang.tech/).
194 |
195 | # BibTeX
196 |
197 | @article{mou2023t2i,
198 | title={T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models},
199 | author={Mou, Chong and Wang, Xintao and Xie, Liangbin and Wu, Yanze and Zhang, Jian and Qi, Zhongang and Shan, Ying and Qie, Xiaohu},
200 | journal={arXiv preprint arXiv:2302.08453},
201 | year={2023}
202 | }
203 |
--------------------------------------------------------------------------------
/app.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import gradio as gr
3 | import torch
4 | from basicsr.utils import tensor2img
5 | import os
6 | from huggingface_hub import hf_hub_url
7 | import subprocess
8 | import shlex
9 | import cv2
10 | from omegaconf import OmegaConf
11 |
12 | from demo import create_demo_sketch, create_demo_canny, create_demo_pose
13 | from Adapter.Sampling import diffusion_inference
14 | from configs.utils import instantiate_from_config
15 | from Adapter.extra_condition.api import get_cond_model, ExtraCondition
16 | from Adapter.extra_condition import api
17 | from Adapter.inference_base import get_base_argument_parser
18 |
19 | torch.set_grad_enabled(False)
20 |
21 | urls = {
22 | 'TencentARC/T2I-Adapter':[
23 | 'models_XL/adapter-xl-canny.pth', 'models_XL/adapter-xl-sketch.pth',
24 | 'models_XL/adapter-xl-openpose.pth', 'third-party-models/body_pose_model.pth',
25 | 'third-party-models/table5_pidinet.pth'
26 | ]
27 | }
28 |
29 | if os.path.exists('checkpoints') == False:
30 | os.mkdir('checkpoints')
31 | for repo in urls:
32 | files = urls[repo]
33 | for file in files:
34 | url = hf_hub_url(repo, file)
35 | name_ckp = url.split('/')[-1]
36 | save_path = os.path.join('checkpoints',name_ckp)
37 | if os.path.exists(save_path) == False:
38 | subprocess.run(shlex.split(f'wget {url} -O {save_path}'))
39 |
40 | parser = get_base_argument_parser()
41 | global_opt = parser.parse_args()
42 | global_opt.device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
43 |
44 | DESCRIPTION = '# [T2I-Adapter-XL](https://github.com/TencentARC/T2I-Adapter)'
45 |
46 | DESCRIPTION += f'Gradio demo for **T2I-Adapter-XL**: [[GitHub]](https://github.com/TencentARC/T2I-Adapter). If T2I-Adapter-XL is helpful, please help to ⭐ the [Github Repo](https://github.com/TencentARC/T2I-Adapter) and recommend it to your friends 😊
'
47 |
48 | # DESCRIPTION += f'For faster inference without waiting in queue, you may duplicate the space and upgrade to GPU in settings. 
'
49 |
50 | # diffusion sampler creation
51 | sampler = diffusion_inference('stabilityai/stable-diffusion-xl-base-1.0')
52 |
53 | def run(input_image, in_type, prompt, a_prompt, n_prompt, ddim_steps, scale, seed, cond_name, con_strength):
54 | in_type = in_type.lower()
55 | prompt = prompt+', '+a_prompt
56 | config = OmegaConf.load(f'configs/inference/Adapter-XL-{cond_name}.yaml')
57 | # Adapter creation
58 | adapter_config = config.model.params.adapter_config
59 | adapter = instantiate_from_config(adapter_config).cuda()
60 | adapter.load_state_dict(torch.load(config.model.params.adapter_config.pretrained))
61 | cond_model = get_cond_model(global_opt, getattr(ExtraCondition, cond_name))
62 | process_cond_module = getattr(api, f'get_cond_{cond_name}')
63 |
64 | # diffusion generation
65 | cond = process_cond_module(
66 | global_opt,
67 | input_image,
68 | cond_inp_type = in_type,
69 | cond_model = cond_model
70 | )
71 | with torch.no_grad():
72 | adapter_features = adapter(cond)
73 |
74 | for i in range(len(adapter_features)):
75 | adapter_features[i] = adapter_features[i]*con_strength
76 |
77 | result = sampler.inference(
78 | prompt = prompt,
79 | prompt_n = n_prompt,
80 | steps = ddim_steps,
81 | adapter_features = copy.deepcopy(adapter_features),
82 | guidance_scale = scale,
83 | size = (cond.shape[-2], cond.shape[-1]),
84 | seed= seed,
85 | )
86 | im_cond = tensor2img(cond)
87 |
88 | return result[:,:,::-1], im_cond
89 |
90 | with gr.Blocks(css='style.css') as demo:
91 | gr.Markdown(DESCRIPTION)
92 | with gr.Tabs():
93 | with gr.TabItem('Sketch guided'):
94 | create_demo_sketch(run)
95 | with gr.TabItem('Canny guided'):
96 | create_demo_canny(run)
97 | with gr.TabItem('Keypoint guided'):
98 | create_demo_pose(run)
99 |
100 | demo.queue(concurrency_count=3, max_size=20)
101 | demo.launch(server_name="0.0.0.0")
102 |
--------------------------------------------------------------------------------
/assets/logo3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TencentARC/T2I-Adapter/c408b059c36e3f9ce336b66746bd606edaa5483a/assets/logo3.png
--------------------------------------------------------------------------------
/configs/inference/Adapter-XL-canny.yaml:
--------------------------------------------------------------------------------
1 | model:
2 | params:
3 | adapter_config:
4 | name: canny
5 | target: Adapter.models.adapters.Adapter_XL
6 | params:
7 | cin: 256
8 | channels: [320, 640, 1280, 1280]
9 | nums_rb: 2
10 | ksize: 1
11 | sk: true
12 | use_conv: false
13 | pretrained: checkpoints/adapter-xl-canny.pth
--------------------------------------------------------------------------------
/configs/inference/Adapter-XL-openpose.yaml:
--------------------------------------------------------------------------------
1 | model:
2 | params:
3 | adapter_config:
4 | name: openpose
5 | target: Adapter.models.adapters.Adapter_XL
6 | params:
7 | cin: 768
8 | channels: [320, 640, 1280, 1280]
9 | nums_rb: 2
10 | ksize: 1
11 | sk: true
12 | use_conv: false
13 | # pretrained: /group/30042/chongmou/ft_local/Diffusion_part2/T2I-Adapter-XL/experiments/adapter_encoder_mid_openpose_extream_ft/checkpoint-9000/model_00.pth
14 | pretrained: checkpoints/adapter-xl-openpose.pth
--------------------------------------------------------------------------------
/configs/inference/Adapter-XL-sketch.yaml:
--------------------------------------------------------------------------------
1 | model:
2 | params:
3 | adapter_config:
4 | name: sketch
5 | target: Adapter.models.adapters.Adapter_XL
6 | params:
7 | cin: 256
8 | channels: [320, 640, 1280, 1280]
9 | nums_rb: 2
10 | ksize: 1
11 | sk: true
12 | use_conv: false
13 | pretrained: checkpoints/adapter-xl-sketch.pth
--------------------------------------------------------------------------------
/configs/train/Adapter-XL-sketch.yaml:
--------------------------------------------------------------------------------
1 | model:
2 | params:
3 | adapter_config:
4 | name: sketch
5 | target: Adapter.models.adapters.Adapter_XL
6 | params:
7 | cin: 256
8 | channels: [320, 640, 1280, 1280]
9 | nums_rb: 2
10 | ksize: 1
11 | sk: true
12 | use_conv: false
13 | pretrained: checkpoints/adapter-xl-sketch.pth
14 | data:
15 | target: dataset.dataset_laion.WebDataModuleFromConfig_Laion_Lexica
16 | params:
17 | tar_base1: "data/LAION_6plus"
18 | tar_base2: "data/WebDataset"
19 | batch_size: 2
20 | num_workers: 8
21 | multinode: True
22 | train:
23 | shards1: 'train_{00000..00006}/{00000..00171}.tar'
24 | shards2: 'lexica-{000000..000099}.tar'
25 | shards1_prob: 0.7
26 | shards2_prob: 0.3
27 | shuffle: 10000
28 | image_key: jpg
29 | image_transforms:
30 | - target: torchvision.transforms.Resize
31 | params:
32 | size: 1024
33 | interpolation: 3
34 | - target: torchvision.transforms.RandomCrop
35 | params:
36 | size: 1024
37 | process:
38 | target: dataset.utils.AddEqual_fp16
--------------------------------------------------------------------------------
/configs/utils.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | import math
3 |
4 | import cv2
5 | import torch
6 | import numpy as np
7 |
8 | import os
9 | from safetensors.torch import load_file
10 |
11 | from inspect import isfunction
12 | from PIL import Image, ImageDraw, ImageFont
13 |
14 |
15 | def log_txt_as_img(wh, xc, size=10):
16 | # wh a tuple of (width, height)
17 | # xc a list of captions to plot
18 | b = len(xc)
19 | txts = list()
20 | for bi in range(b):
21 | txt = Image.new("RGB", wh, color="white")
22 | draw = ImageDraw.Draw(txt)
23 | font = ImageFont.truetype('assets/DejaVuSans.ttf', size=size)
24 | nc = int(40 * (wh[0] / 256))
25 | lines = "\n".join(xc[bi][start:start + nc] for start in range(0, len(xc[bi]), nc))
26 |
27 | try:
28 | draw.text((0, 0), lines, fill="black", font=font)
29 | except UnicodeEncodeError:
30 | print("Cant encode string for logging. Skipping.")
31 |
32 | txt = np.array(txt).transpose(2, 0, 1) / 127.5 - 1.0
33 | txts.append(txt)
34 | txts = np.stack(txts)
35 | txts = torch.tensor(txts)
36 | return txts
37 |
38 |
39 | def ismap(x):
40 | if not isinstance(x, torch.Tensor):
41 | return False
42 | return (len(x.shape) == 4) and (x.shape[1] > 3)
43 |
44 |
45 | def isimage(x):
46 | if not isinstance(x, torch.Tensor):
47 | return False
48 | return (len(x.shape) == 4) and (x.shape[1] == 3 or x.shape[1] == 1)
49 |
50 |
51 | def exists(x):
52 | return x is not None
53 |
54 |
55 | def default(val, d):
56 | if exists(val):
57 | return val
58 | return d() if isfunction(d) else d
59 |
60 |
61 | def mean_flat(tensor):
62 | """
63 | https://github.com/openai/guided-diffusion/blob/27c20a8fab9cb472df5d6bdd6c8d11c8f430b924/guided_diffusion/nn.py#L86
64 | Take the mean over all non-batch dimensions.
65 | """
66 | return tensor.mean(dim=list(range(1, len(tensor.shape))))
67 |
68 |
69 | def count_params(model, verbose=False):
70 | total_params = sum(p.numel() for p in model.parameters())
71 | if verbose:
72 | print(f"{model.__class__.__name__} has {total_params * 1.e-6:.2f} M params.")
73 | return total_params
74 |
75 |
76 | def instantiate_from_config(config):
77 | if not "target" in config:
78 | if config == '__is_first_stage__':
79 | return None
80 | elif config == "__is_unconditional__":
81 | return None
82 | raise KeyError("Expected key `target` to instantiate.")
83 | return get_obj_from_str(config["target"])(**config.get("params", dict()))
84 |
85 |
86 | def get_obj_from_str(string, reload=False):
87 | module, cls = string.rsplit(".", 1)
88 | if reload:
89 | module_imp = importlib.import_module(module)
90 | importlib.reload(module_imp)
91 | return getattr(importlib.import_module(module, package=None), cls)
92 |
93 |
94 | checkpoint_dict_replacements = {
95 | 'cond_stage_model.transformer.text_model.embeddings.': 'cond_stage_model.transformer.embeddings.',
96 | 'cond_stage_model.transformer.text_model.encoder.': 'cond_stage_model.transformer.encoder.',
97 | 'cond_stage_model.transformer.text_model.final_layer_norm.': 'cond_stage_model.transformer.final_layer_norm.',
98 | }
99 |
100 |
101 | def transform_checkpoint_dict_key(k):
102 | for text, replacement in checkpoint_dict_replacements.items():
103 | if k.startswith(text):
104 | k = replacement + k[len(text):]
105 |
106 | return k
107 |
108 |
109 | def get_state_dict_from_checkpoint(pl_sd):
110 | pl_sd = pl_sd.pop("state_dict", pl_sd)
111 | pl_sd.pop("state_dict", None)
112 |
113 | sd = {}
114 | for k, v in pl_sd.items():
115 | new_key = transform_checkpoint_dict_key(k)
116 |
117 | if new_key is not None:
118 | sd[new_key] = v
119 |
120 | pl_sd.clear()
121 | pl_sd.update(sd)
122 |
123 | return pl_sd
124 |
125 |
126 | def read_state_dict(checkpoint_file, print_global_state=False):
127 | _, extension = os.path.splitext(checkpoint_file)
128 | if extension.lower() == ".safetensors":
129 | pl_sd = load_file(checkpoint_file, device='cpu')
130 | else:
131 | pl_sd = torch.load(checkpoint_file, map_location='cpu')
132 |
133 | if print_global_state and "global_step" in pl_sd:
134 | print(f"Global Step: {pl_sd['global_step']}")
135 |
136 | sd = get_state_dict_from_checkpoint(pl_sd)
137 | return sd
138 |
139 |
140 | def load_model_from_config(config, ckpt, vae_ckpt=None, verbose=False):
141 | print(f"Loading model from {ckpt}")
142 | sd = read_state_dict(ckpt)
143 | model = instantiate_from_config(config.model)
144 | m, u = model.load_state_dict(sd, strict=False)
145 | if len(m) > 0 and verbose:
146 | print("missing keys:")
147 | print(m)
148 | if len(u) > 0 and verbose:
149 | print("unexpected keys:")
150 | print(u)
151 |
152 | if 'anything' in ckpt.lower() and vae_ckpt is None:
153 | vae_ckpt = 'models/anything-v4.0.vae.pt'
154 |
155 | if vae_ckpt is not None and vae_ckpt != 'None':
156 | print(f"Loading vae model from {vae_ckpt}")
157 | vae_sd = torch.load(vae_ckpt, map_location="cpu")
158 | if "global_step" in vae_sd:
159 | print(f"Global Step: {vae_sd['global_step']}")
160 | sd = vae_sd["state_dict"]
161 | m, u = model.first_stage_model.load_state_dict(sd, strict=False)
162 | if len(m) > 0 and verbose:
163 | print("missing keys:")
164 | print(m)
165 | if len(u) > 0 and verbose:
166 | print("unexpected keys:")
167 | print(u)
168 |
169 | model.cuda()
170 | model.eval()
171 | return model
172 |
--------------------------------------------------------------------------------
/dataset/dataset_laion.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | import numpy as np
4 | import os
5 | import pytorch_lightning as pl
6 | import torch
7 | import webdataset as wds
8 | from torchvision.transforms import transforms
9 |
10 | from configs.utils import instantiate_from_config
11 |
12 |
13 | def dict_collation_fn(samples, combine_tensors=True, combine_scalars=True):
14 | """Take a list of samples (as dictionary) and create a batch, preserving the keys.
15 | If `tensors` is True, `ndarray` objects are combined into
16 | tensor batches.
17 | :param dict samples: list of samples
18 | :param bool tensors: whether to turn lists of ndarrays into a single ndarray
19 | :returns: single sample consisting of a batch
20 | :rtype: dict
21 | """
22 | keys = set.intersection(*[set(sample.keys()) for sample in samples])
23 | batched = {key: [] for key in keys}
24 |
25 | for s in samples:
26 | [batched[key].append(s[key]) for key in batched]
27 |
28 | result = {}
29 | for key in batched:
30 | if isinstance(batched[key][0], (int, float)):
31 | if combine_scalars:
32 | result[key] = np.array(list(batched[key]))
33 | elif isinstance(batched[key][0], torch.Tensor):
34 | if combine_tensors:
35 | result[key] = torch.stack(list(batched[key]))
36 | elif isinstance(batched[key][0], np.ndarray):
37 | if combine_tensors:
38 | result[key] = np.array(list(batched[key]))
39 | else:
40 | result[key] = list(batched[key])
41 | return result
42 |
43 |
44 | class WebDataModuleFromConfig_Laion_Lexica(pl.LightningDataModule):
45 |
46 | def __init__(self,
47 | tar_base1,
48 | tar_base2,
49 | batch_size,
50 | train=None,
51 | validation=None,
52 | test=None,
53 | num_workers=4,
54 | multinode=True,
55 | min_size=None,
56 | max_pwatermark=1.0,
57 | **kwargs):
58 | super().__init__()
59 | print(f'Setting tar base to {tar_base1} and {tar_base2}')
60 | self.tar_base1 = tar_base1
61 | self.tar_base2 = tar_base2
62 | self.batch_size = batch_size
63 | self.num_workers = num_workers
64 | self.train = train
65 | self.validation = validation
66 | self.test = test
67 | self.multinode = multinode
68 | self.min_size = min_size # filter out very small images
69 | self.max_pwatermark = max_pwatermark # filter out watermarked images
70 |
71 | def make_loader(self, dataset_config):
72 | image_transforms = [instantiate_from_config(tt) for tt in dataset_config.image_transforms]
73 | image_transforms = transforms.Compose(image_transforms)
74 |
75 | process = instantiate_from_config(dataset_config['process'])
76 |
77 | shuffle = dataset_config.get('shuffle', 0)
78 | shardshuffle = shuffle > 0
79 |
80 | nodesplitter = wds.shardlists.split_by_node if self.multinode else wds.shardlists.single_node_only
81 |
82 | # make dataset for laion
83 | tars_1 = os.path.join(self.tar_base1, dataset_config.shards1)
84 |
85 | dset1 = wds.WebDataset(
86 | tars_1, nodesplitter=nodesplitter, shardshuffle=shardshuffle,
87 | handler=wds.warn_and_continue).repeat().shuffle(shuffle)
88 | print(f'Loading webdataset with {len(dset1.pipeline[0].urls)} shards.')
89 |
90 | dset1 = (
91 | dset1.select(self.filter_keys).decode('pil',
92 | handler=wds.warn_and_continue).select(self.filter_size).map_dict(
93 | jpg=image_transforms, handler=wds.warn_and_continue).map(process))
94 | dset1 = (dset1.batched(self.batch_size, partial=False, collation_fn=dict_collation_fn))
95 |
96 | # make dataset for lexica
97 | tars_2 = os.path.join(self.tar_base2, dataset_config.shards2)
98 |
99 | dset2 = wds.WebDataset(
100 | tars_2, nodesplitter=nodesplitter, shardshuffle=shardshuffle,
101 | handler=wds.warn_and_continue).repeat().shuffle(shuffle)
102 |
103 | dset2 = (
104 | dset2.decode('pil',
105 | handler=wds.warn_and_continue).map_dict(jpg=image_transforms,
106 | handler=wds.warn_and_continue).map(process))
107 | dset2 = (dset2.batched(self.batch_size, partial=False, collation_fn=dict_collation_fn))
108 |
109 | # get the corresponding prob
110 | shards1_prob = dataset_config.get('shards1_prob', 0)
111 | shards2_prob = dataset_config.get('shards2_prob', 0)
112 | dataset = wds.RandomMix([dset1, dset2], [shards1_prob, shards2_prob])
113 |
114 | loader = wds.WebLoader(dataset, batch_size=None, shuffle=False, num_workers=self.num_workers)
115 |
116 | return loader
117 |
118 | def filter_size(self, x):
119 | if self.min_size is None:
120 | return True
121 | try:
122 | return x['json']['original_width'] >= self.min_size and x['json']['original_height'] >= self.min_size and x[
123 | 'json']['pwatermark'] <= self.max_pwatermark
124 | except Exception:
125 | return False
126 |
127 | def filter_keys(self, x):
128 | try:
129 | return ("jpg" in x) and ("txt" in x)
130 | except Exception:
131 | return False
132 |
133 | def train_dataloader(self):
134 | return self.make_loader(self.train)
135 |
136 | def val_dataloader(self):
137 | return None
138 |
139 | def test_dataloader(self):
140 | return None
--------------------------------------------------------------------------------
/dataset/utils.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | import cv2
4 | import numpy as np
5 | import random
6 | from torchvision.transforms import transforms
7 | from torchvision.transforms.functional import to_tensor
8 | from transformers import CLIPProcessor
9 | from basicsr.utils import img2tensor
10 | import torch
11 |
12 |
13 | class AddEqual_fp16(object):
14 |
15 | def __init__(self):
16 | print('There is no specific process function')
17 |
18 | def __call__(self, sample):
19 | # sample['jpg'] is PIL image
20 | x = sample['jpg']
21 | sample['jpg'] = to_tensor(x)#.to(torch.float16)
22 | return sample
23 |
24 |
25 | class AddCannyRandomThreshold(object):
26 |
27 | def __init__(self, low_threshold=100, high_threshold=200, shift_range=50):
28 | self.low_threshold = low_threshold
29 | self.high_threshold = high_threshold
30 | self.threshold_prng = np.random.RandomState()
31 | self.shift_range = shift_range
32 |
33 | def __call__(self, sample):
34 | # sample['jpg'] is PIL image
35 | x = sample['jpg']
36 | img = cv2.cvtColor(np.array(x), cv2.COLOR_RGB2BGR)
37 | low_threshold = self.low_threshold + self.threshold_prng.randint(-self.shift_range, self.shift_range)
38 | high_threshold = self.high_threshold + self.threshold_prng.randint(-self.shift_range, self.shift_range)
39 | canny = cv2.Canny(img, low_threshold, high_threshold)[..., None]
40 | sample['canny'] = img2tensor(canny, bgr2rgb=True, float32=True) / 255.
41 | sample['jpg'] = to_tensor(x)
42 | return sample
--------------------------------------------------------------------------------
/demo.py:
--------------------------------------------------------------------------------
1 | import gradio as gr
2 |
3 | def create_demo_sketch(run):
4 | cond_name = gr.State(value='sketch')
5 | with gr.Blocks() as demo:
6 | with gr.Row():
7 | gr.Markdown('## Control Stable Diffusion-XL with Sketch Maps')
8 | with gr.Row():
9 | with gr.Column():
10 | input_image = gr.Image(source='upload', type='numpy')
11 | prompt = gr.Textbox(label='Prompt')
12 | run_button = gr.Button(label='Run')
13 | in_type = gr.Radio(
14 | choices=["Image", "Sketch"],
15 | label=f"Input type for Sketch",
16 | interactive=True,
17 | value="Image",
18 | )
19 | with gr.Accordion('Advanced options', open=False):
20 | con_strength = gr.Slider(label='Control Strength',
21 | minimum=0.0,
22 | maximum=1.0,
23 | value=1.0,
24 | step=0.1)
25 | ddim_steps = gr.Slider(label='Steps',
26 | minimum=1,
27 | maximum=100,
28 | value=20,
29 | step=1)
30 | scale = gr.Slider(label='Guidance Scale',
31 | minimum=0.1,
32 | maximum=30.0,
33 | value=7.5,
34 | step=0.1)
35 | seed = gr.Slider(label='Seed',
36 | minimum=-1,
37 | maximum=2147483647,
38 | step=1,
39 | randomize=True)
40 | a_prompt = gr.Textbox(
41 | label='Added Prompt',
42 | value='in real world, high quality')
43 | n_prompt = gr.Textbox(
44 | label='Negative Prompt',
45 | value='extra digit, fewer digits, cropped, worst quality, low quality'
46 | )
47 | with gr.Column():
48 | result_gallery = gr.Gallery(label='Output',
49 | show_label=False,
50 | elem_id='gallery').style(
51 | grid=2, height='auto')
52 | ips = [
53 | input_image, in_type, prompt, a_prompt, n_prompt,
54 | ddim_steps, scale, seed, cond_name, con_strength
55 | ]
56 | run_button.click(fn=run,
57 | inputs=ips,
58 | outputs=[result_gallery],
59 | api_name='sketch')
60 | return demo
61 |
62 | def create_demo_canny(run):
63 | cond_name = gr.State(value='canny')
64 | with gr.Blocks() as demo:
65 | with gr.Row():
66 | gr.Markdown('## Control Stable Diffusion-XL with Canny Maps')
67 | with gr.Row():
68 | with gr.Column():
69 | input_image = gr.Image(source='upload', type='numpy')
70 | prompt = gr.Textbox(label='Prompt')
71 | run_button = gr.Button(label='Run')
72 | in_type = gr.Radio(
73 | choices=["Image", "Canny"],
74 | label=f"Input type for Canny",
75 | interactive=True,
76 | value="Image",
77 | )
78 | with gr.Accordion('Advanced options', open=False):
79 | con_strength = gr.Slider(label='Control Strength',
80 | minimum=0.0,
81 | maximum=1.0,
82 | value=1.0,
83 | step=0.1)
84 | ddim_steps = gr.Slider(label='Steps',
85 | minimum=1,
86 | maximum=100,
87 | value=20,
88 | step=1)
89 | scale = gr.Slider(label='Guidance Scale',
90 | minimum=0.1,
91 | maximum=30.0,
92 | value=7.5,
93 | step=0.1)
94 | seed = gr.Slider(label='Seed',
95 | minimum=-1,
96 | maximum=2147483647,
97 | step=1,
98 | randomize=True)
99 | a_prompt = gr.Textbox(
100 | label='Added Prompt',
101 | value='in real world, high quality')
102 | n_prompt = gr.Textbox(
103 | label='Negative Prompt',
104 | value='extra digit, fewer digits, cropped, worst quality, low quality'
105 | )
106 | with gr.Column():
107 | result_gallery = gr.Gallery(label='Output',
108 | show_label=False,
109 | elem_id='gallery').style(
110 | grid=2, height='auto')
111 | ips = [
112 | input_image, in_type, prompt, a_prompt, n_prompt,
113 | ddim_steps, scale, seed, cond_name, con_strength
114 | ]
115 | run_button.click(fn=run,
116 | inputs=ips,
117 | outputs=[result_gallery],
118 | api_name='canny')
119 | return demo
120 |
121 | def create_demo_pose(run):
122 | cond_name = gr.State(value='openpose')
123 | in_type = gr.State(value='Image')
124 | with gr.Blocks() as demo:
125 | with gr.Row():
126 | gr.Markdown('## Control Stable Diffusion-XL with Keypoint Maps')
127 | with gr.Row():
128 | with gr.Column():
129 | input_image = gr.Image(source='upload', type='numpy')
130 | prompt = gr.Textbox(label='Prompt')
131 | run_button = gr.Button(label='Run')
132 | with gr.Accordion('Advanced options', open=False):
133 | con_strength = gr.Slider(label='Control Strength',
134 | minimum=0.0,
135 | maximum=1.0,
136 | value=1.0,
137 | step=0.1)
138 | ddim_steps = gr.Slider(label='Steps',
139 | minimum=1,
140 | maximum=100,
141 | value=20,
142 | step=1)
143 | scale = gr.Slider(label='Guidance Scale',
144 | minimum=0.1,
145 | maximum=30.0,
146 | value=7.5,
147 | step=0.1)
148 | seed = gr.Slider(label='Seed',
149 | minimum=-1,
150 | maximum=2147483647,
151 | step=1,
152 | randomize=True)
153 | a_prompt = gr.Textbox(
154 | label='Added Prompt',
155 | value='in real world, high quality')
156 | n_prompt = gr.Textbox(
157 | label='Negative Prompt',
158 | value='extra digit, fewer digits, cropped, worst quality, low quality'
159 | )
160 | with gr.Column():
161 | result_gallery = gr.Gallery(label='Output',
162 | show_label=False,
163 | elem_id='gallery').style(
164 | grid=2, height='auto')
165 | ips = [
166 | input_image, in_type, prompt, a_prompt, n_prompt,
167 | ddim_steps, scale, seed, cond_name, con_strength
168 | ]
169 | run_button.click(fn=run,
170 | inputs=ips,
171 | outputs=[result_gallery],
172 | api_name='openpose')
173 | return demo
--------------------------------------------------------------------------------
/examples/dog.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TencentARC/T2I-Adapter/c408b059c36e3f9ce336b66746bd606edaa5483a/examples/dog.png
--------------------------------------------------------------------------------
/examples/people.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TencentARC/T2I-Adapter/c408b059c36e3f9ce336b66746bd606edaa5483a/examples/people.jpg
--------------------------------------------------------------------------------
/examples/room.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TencentARC/T2I-Adapter/c408b059c36e3f9ce336b66746bd606edaa5483a/examples/room.jpg
--------------------------------------------------------------------------------
/models/unet.py:
--------------------------------------------------------------------------------
1 | from diffusers.models.unet_2d_condition import UNet2DConditionModel, UNet2DConditionOutput, logger
2 | import torch
3 | from typing import Any, Dict, List, Optional, Tuple, Union
4 |
5 | class UNet(UNet2DConditionModel):
6 | def forward(
7 | self,
8 | sample: torch.FloatTensor,
9 | timestep: Union[torch.Tensor, float, int],
10 | encoder_hidden_states: torch.Tensor,
11 | class_labels: Optional[torch.Tensor] = None,
12 | timestep_cond: Optional[torch.Tensor] = None,
13 | attention_mask: Optional[torch.Tensor] = None,
14 | cross_attention_kwargs: Optional[Dict[str, Any]] = None,
15 | added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
16 | down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
17 | mid_block_additional_residual: Optional[torch.Tensor] = None,
18 | encoder_attention_mask: Optional[torch.Tensor] = None,
19 | return_dict: bool = True,
20 | ) -> Union[UNet2DConditionOutput, Tuple]:
21 | r"""
22 | The [`UNet2DConditionModel`] forward method.
23 |
24 | Args:
25 | sample (`torch.FloatTensor`):
26 | The noisy input tensor with the following shape `(batch, channel, height, width)`.
27 | timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
28 | encoder_hidden_states (`torch.FloatTensor`):
29 | The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
30 | encoder_attention_mask (`torch.Tensor`):
31 | A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
32 | `True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
33 | which adds large negative values to the attention scores corresponding to "discard" tokens.
34 | return_dict (`bool`, *optional*, defaults to `True`):
35 | Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
36 | tuple.
37 | cross_attention_kwargs (`dict`, *optional*):
38 | A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
39 | added_cond_kwargs: (`dict`, *optional*):
40 | A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
41 | are passed along to the UNet blocks.
42 |
43 | Returns:
44 | [`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
45 | If `return_dict` is True, an [`~models.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
46 | a `tuple` is returned where the first element is the sample tensor.
47 | """
48 | # By default samples have to be AT least a multiple of the overall upsampling factor.
49 | # The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
50 | # However, the upsampling interpolation output size can be forced to fit any upsampling size
51 | # on the fly if necessary.
52 | default_overall_up_factor = 2**self.num_upsamplers
53 |
54 | # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
55 | forward_upsample_size = False
56 | upsample_size = None
57 |
58 | if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
59 | logger.info("Forward upsample size to force interpolation output size.")
60 | forward_upsample_size = True
61 |
62 | # ensure attention_mask is a bias, and give it a singleton query_tokens dimension
63 | # expects mask of shape:
64 | # [batch, key_tokens]
65 | # adds singleton query_tokens dimension:
66 | # [batch, 1, key_tokens]
67 | # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
68 | # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
69 | # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
70 | if attention_mask is not None:
71 | # assume that mask is expressed as:
72 | # (1 = keep, 0 = discard)
73 | # convert mask into a bias that can be added to attention scores:
74 | # (keep = +0, discard = -10000.0)
75 | attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
76 | attention_mask = attention_mask.unsqueeze(1)
77 |
78 | # convert encoder_attention_mask to a bias the same way we do for attention_mask
79 | if encoder_attention_mask is not None:
80 | encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
81 | encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
82 |
83 | # 0. center input if necessary
84 | if self.config.center_input_sample:
85 | sample = 2 * sample - 1.0
86 |
87 | # 1. time
88 | timesteps = timestep
89 | if not torch.is_tensor(timesteps):
90 | # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
91 | # This would be a good case for the `match` statement (Python 3.10+)
92 | is_mps = sample.device.type == "mps"
93 | if isinstance(timestep, float):
94 | dtype = torch.float32 if is_mps else torch.float64
95 | else:
96 | dtype = torch.int32 if is_mps else torch.int64
97 | timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
98 | elif len(timesteps.shape) == 0:
99 | timesteps = timesteps[None].to(sample.device)
100 |
101 | # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
102 | timesteps = timesteps.expand(sample.shape[0])
103 |
104 | t_emb = self.time_proj(timesteps)
105 |
106 | # `Timesteps` does not contain any weights and will always return f32 tensors
107 | # but time_embedding might actually be running in fp16. so we need to cast here.
108 | # there might be better ways to encapsulate this.
109 | t_emb = t_emb.to(dtype=sample.dtype)
110 |
111 | emb = self.time_embedding(t_emb, timestep_cond)
112 | aug_emb = None
113 |
114 | if self.class_embedding is not None:
115 | if class_labels is None:
116 | raise ValueError("class_labels should be provided when num_class_embeds > 0")
117 |
118 | if self.config.class_embed_type == "timestep":
119 | class_labels = self.time_proj(class_labels)
120 |
121 | # `Timesteps` does not contain any weights and will always return f32 tensors
122 | # there might be better ways to encapsulate this.
123 | class_labels = class_labels.to(dtype=sample.dtype)
124 |
125 | class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
126 |
127 | if self.config.class_embeddings_concat:
128 | emb = torch.cat([emb, class_emb], dim=-1)
129 | else:
130 | emb = emb + class_emb
131 |
132 | if self.config.addition_embed_type == "text":
133 | aug_emb = self.add_embedding(encoder_hidden_states)
134 | elif self.config.addition_embed_type == "text_image":
135 | # Kandinsky 2.1 - style
136 | if "image_embeds" not in added_cond_kwargs:
137 | raise ValueError(
138 | f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
139 | )
140 |
141 | image_embs = added_cond_kwargs.get("image_embeds")
142 | text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
143 | aug_emb = self.add_embedding(text_embs, image_embs)
144 | elif self.config.addition_embed_type == "text_time":
145 | # SDXL - style
146 | if "text_embeds" not in added_cond_kwargs:
147 | raise ValueError(
148 | f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
149 | )
150 | text_embeds = added_cond_kwargs.get("text_embeds")
151 | if "time_ids" not in added_cond_kwargs:
152 | raise ValueError(
153 | f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
154 | )
155 | time_ids = added_cond_kwargs.get("time_ids")
156 | time_embeds = self.add_time_proj(time_ids.flatten())
157 | time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
158 |
159 | add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
160 | add_embeds = add_embeds.to(emb.dtype)
161 | aug_emb = self.add_embedding(add_embeds)
162 | elif self.config.addition_embed_type == "image":
163 | # Kandinsky 2.2 - style
164 | if "image_embeds" not in added_cond_kwargs:
165 | raise ValueError(
166 | f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
167 | )
168 | image_embs = added_cond_kwargs.get("image_embeds")
169 | aug_emb = self.add_embedding(image_embs)
170 | elif self.config.addition_embed_type == "image_hint":
171 | # Kandinsky 2.2 - style
172 | if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
173 | raise ValueError(
174 | f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
175 | )
176 | image_embs = added_cond_kwargs.get("image_embeds")
177 | hint = added_cond_kwargs.get("hint")
178 | aug_emb, hint = self.add_embedding(image_embs, hint)
179 | sample = torch.cat([sample, hint], dim=1)
180 |
181 | emb = emb + aug_emb if aug_emb is not None else emb
182 |
183 | if self.time_embed_act is not None:
184 | emb = self.time_embed_act(emb)
185 |
186 | if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
187 | encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
188 | elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
189 | # Kadinsky 2.1 - style
190 | if "image_embeds" not in added_cond_kwargs:
191 | raise ValueError(
192 | f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
193 | )
194 |
195 | image_embeds = added_cond_kwargs.get("image_embeds")
196 | encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
197 | elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
198 | # Kandinsky 2.2 - style
199 | if "image_embeds" not in added_cond_kwargs:
200 | raise ValueError(
201 | f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
202 | )
203 | image_embeds = added_cond_kwargs.get("image_embeds")
204 | encoder_hidden_states = self.encoder_hid_proj(image_embeds)
205 | # 2. pre-process
206 | sample = self.conv_in(sample)
207 |
208 | # 3. down
209 |
210 | is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
211 | is_adapter = mid_block_additional_residual is None and down_block_additional_residuals is not None
212 |
213 | down_block_res_samples = (sample,)
214 | for downsample_block in self.down_blocks:
215 | if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
216 | # For t2i-adapter CrossAttnDownBlock2D
217 | additional_residuals = {}
218 | if is_adapter and len(down_block_additional_residuals) > 0:
219 | additional_residuals["additional_residuals"] = down_block_additional_residuals.pop(0)
220 |
221 | sample, res_samples = downsample_block(
222 | hidden_states=sample,
223 | temb=emb,
224 | encoder_hidden_states=encoder_hidden_states,
225 | attention_mask=attention_mask,
226 | cross_attention_kwargs=cross_attention_kwargs,
227 | encoder_attention_mask=encoder_attention_mask,
228 | **additional_residuals,
229 | )
230 | else:
231 | sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
232 |
233 | if is_adapter and len(down_block_additional_residuals) > 0:
234 | sample += down_block_additional_residuals.pop(0)
235 | down_block_res_samples += res_samples
236 |
237 | if is_controlnet:
238 | new_down_block_res_samples = ()
239 |
240 | for down_block_res_sample, down_block_additional_residual in zip(
241 | down_block_res_samples, down_block_additional_residuals
242 | ):
243 | down_block_res_sample = down_block_res_sample + down_block_additional_residual
244 | new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
245 |
246 | down_block_res_samples = new_down_block_res_samples
247 |
248 | # 4. mid
249 | if self.mid_block is not None:
250 | sample = self.mid_block(
251 | sample,
252 | emb,
253 | encoder_hidden_states=encoder_hidden_states,
254 | attention_mask=attention_mask,
255 | cross_attention_kwargs=cross_attention_kwargs,
256 | encoder_attention_mask=encoder_attention_mask,
257 | )
258 | # only add this two lines to support T2I-Adapter-XL
259 | if is_adapter and len(down_block_additional_residuals) > 0:
260 | sample += down_block_additional_residuals.pop(0)
261 |
262 | if is_controlnet:
263 | sample = sample + mid_block_additional_residual
264 |
265 | # 5. up
266 | for i, upsample_block in enumerate(self.up_blocks):
267 | is_final_block = i == len(self.up_blocks) - 1
268 |
269 | res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
270 | down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
271 |
272 | # if we have not reached the final block and need to forward the
273 | # upsample size, we do it here
274 | if not is_final_block and forward_upsample_size:
275 | upsample_size = down_block_res_samples[-1].shape[2:]
276 |
277 | if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
278 | sample = upsample_block(
279 | hidden_states=sample,
280 | temb=emb,
281 | res_hidden_states_tuple=res_samples,
282 | encoder_hidden_states=encoder_hidden_states,
283 | cross_attention_kwargs=cross_attention_kwargs,
284 | upsample_size=upsample_size,
285 | attention_mask=attention_mask,
286 | encoder_attention_mask=encoder_attention_mask,
287 | )
288 | else:
289 | sample = upsample_block(
290 | hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
291 | )
292 |
293 | # 6. post-process
294 | if self.conv_norm_out:
295 | sample = self.conv_norm_out(sample)
296 | sample = self.conv_act(sample)
297 | sample = self.conv_out(sample)
298 |
299 | if not return_dict:
300 | return (sample,)
301 |
302 | return UNet2DConditionOutput(sample=sample)
303 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==2.0.1
2 | diffusers==0.19.3
3 | omegaconf
4 | transformers
5 | datasets
6 | pytorch_lightning
7 | gradio
8 | accelerate
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, EulerAncestralDiscreteScheduler, AutoencoderKL
2 | from diffusers.utils import load_image, make_image_grid
3 | from controlnet_aux.lineart import LineartDetector
4 | import torch
5 |
6 | if __name__ == '__main__':
7 | # load adapter
8 | adapter = T2IAdapter.from_pretrained(
9 | "TencentARC/t2i-adapter-lineart-sdxl-1.0", torch_dtype=torch.float16, varient="fp16"
10 | ).to("cuda")
11 |
12 | # load euler_a scheduler
13 | model_id = 'stabilityai/stable-diffusion-xl-base-1.0'
14 | euler_a = EulerAncestralDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
15 | vae=AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
16 | pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
17 | model_id, vae=vae, adapter=adapter, scheduler=euler_a, torch_dtype=torch.float16, variant="fp16",
18 | ).to("cuda")
19 | pipe.enable_xformers_memory_efficient_attention()
20 |
21 | line_detector = LineartDetector.from_pretrained("lllyasviel/Annotators").to("cuda")
22 |
23 | url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_lin.jpg"
24 | image = load_image(url)
25 | image = line_detector(
26 | image, detect_resolution=384, image_resolution=1024
27 | )
28 |
29 | prompt = "Ice dragon roar, 4k photo"
30 | negative_prompt = "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"
31 | gen_images = pipe(
32 | prompt=prompt,
33 | negative_prompt=negative_prompt,
34 | image=image,
35 | num_inference_steps=30,
36 | adapter_conditioning_scale=0.8,
37 | guidance_scale=7.5,
38 | ).images[0]
39 | gen_images.save('out_lin.png')
40 |
--------------------------------------------------------------------------------
/train_sketch.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding=utf-8
3 | # Copyright 2023 The HuggingFace Inc. team. All rights reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 |
16 | import argparse
17 | import functools
18 | import gc
19 | import logging
20 | import math
21 | import os
22 | import random
23 | import shutil
24 | from pathlib import Path
25 |
26 | import accelerate
27 | import numpy as np
28 | import torch
29 | import torch.nn.functional as F
30 | import torch.utils.checkpoint
31 | import transformers
32 | from accelerate import Accelerator
33 | from accelerate.logging import get_logger
34 | from accelerate.utils import ProjectConfiguration, set_seed
35 | from datasets import load_dataset
36 | from huggingface_hub import create_repo, upload_folder
37 | from packaging import version
38 | from PIL import Image
39 | from torchvision import transforms
40 | from tqdm.auto import tqdm
41 | from transformers import AutoTokenizer, PretrainedConfig
42 |
43 | import diffusers
44 | from diffusers import (
45 | AutoencoderKL,
46 | DDPMScheduler,
47 | UNet2DConditionModel,
48 | UniPCMultistepScheduler,
49 | )
50 | from diffusers.optimization import get_scheduler
51 | from diffusers.utils import check_min_version, is_wandb_available
52 | from diffusers.utils.import_utils import is_xformers_available
53 |
54 | from configs.utils import instantiate_from_config
55 | from omegaconf import OmegaConf
56 | from Adapter.extra_condition.model_edge import pidinet
57 | from models.unet import UNet
58 | from basicsr.utils import tensor2img
59 | import cv2
60 | from huggingface_hub import hf_hub_url
61 | import subprocess
62 | import shlex
63 |
64 | urls = {
65 | 'TencentARC/T2I-Adapter':[
66 | 'third-party-models/body_pose_model.pth', 'third-party-models/table5_pidinet.pth'
67 | ]
68 | }
69 |
70 | if os.path.exists('checkpoints') == False:
71 | os.mkdir('checkpoints')
72 | for repo in urls:
73 | files = urls[repo]
74 | for file in files:
75 | url = hf_hub_url(repo, file)
76 | name_ckp = url.split('/')[-1]
77 | save_path = os.path.join('checkpoints',name_ckp)
78 | if os.path.exists(save_path) == False:
79 | subprocess.run(shlex.split(f'wget {url} -O {save_path}'))
80 |
81 |
82 | if is_wandb_available():
83 | import wandb
84 |
85 | # Will error if the minimal version of diffusers is not installed. Remove at your own risks.
86 | # check_min_version("0.20.0.dev0")
87 |
88 | logger = get_logger(__name__)
89 |
90 | def import_model_class_from_model_name_or_path(
91 | pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
92 | ):
93 | text_encoder_config = PretrainedConfig.from_pretrained(
94 | pretrained_model_name_or_path, subfolder=subfolder, revision=revision
95 | )
96 | model_class = text_encoder_config.architectures[0]
97 |
98 | if model_class == "CLIPTextModel":
99 | from transformers import CLIPTextModel
100 |
101 | return CLIPTextModel
102 | elif model_class == "CLIPTextModelWithProjection":
103 | from transformers import CLIPTextModelWithProjection
104 |
105 | return CLIPTextModelWithProjection
106 | else:
107 | raise ValueError(f"{model_class} is not supported.")
108 |
109 |
110 | def parse_args(input_args=None):
111 | parser = argparse.ArgumentParser(description="Simple example of a T2I-Adapter training script.")
112 | parser.add_argument(
113 | "--pretrained_model_name_or_path",
114 | type=str,
115 | default=None,
116 | required=True,
117 | help="Path to pretrained model or model identifier from huggingface.co/models.",
118 | )
119 | parser.add_argument(
120 | "--pretrained_vae_model_name_or_path",
121 | type=str,
122 | default=None,
123 | help="Path to an improved VAE to stabilize training. For more details check out: https://github.com/huggingface/diffusers/pull/4038.",
124 | )
125 | parser.add_argument(
126 | "--revision",
127 | type=str,
128 | default=None,
129 | required=False,
130 | help=(
131 | "Revision of pretrained model identifier from huggingface.co/models. Trainable model components should be"
132 | " float32 precision."
133 | ),
134 | )
135 | parser.add_argument(
136 | "--tokenizer_name",
137 | type=str,
138 | default=None,
139 | help="Pretrained tokenizer name or path if not the same as model_name",
140 | )
141 | parser.add_argument(
142 | "--output_dir",
143 | type=str,
144 | default="experiments/adapter_xl_sketch",
145 | help="The output directory where the model predictions and checkpoints will be written.",
146 | )
147 | parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
148 | parser.add_argument(
149 | "--resolution",
150 | type=int,
151 | default=1024,
152 | help=(
153 | "The resolution for input images, all the images in the train/validation dataset will be resized to this"
154 | " resolution"
155 | ),
156 | )
157 | parser.add_argument(
158 | "--crops_coords_top_left_h",
159 | type=int,
160 | default=0,
161 | help=("Coordinate for (the height) to be included in the crop coordinate embeddings needed by SDXL UNet."),
162 | )
163 | parser.add_argument(
164 | "--crops_coords_top_left_w",
165 | type=int,
166 | default=0,
167 | help=("Coordinate for (the height) to be included in the crop coordinate embeddings needed by SDXL UNet."),
168 | )
169 | parser.add_argument(
170 | "--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
171 | )
172 | parser.add_argument("--num_train_epochs", type=int, default=1)
173 | parser.add_argument(
174 | "--max_train_steps",
175 | type=int,
176 | default=None,
177 | help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
178 | )
179 | parser.add_argument(
180 | "--checkpointing_steps",
181 | type=int,
182 | default=1000,
183 | help=(
184 | "Save a checkpoint of the training state every X updates. Checkpoints can be used for resuming training via `--resume_from_checkpoint`. "
185 | "In the case that the checkpoint is better than the final trained model, the checkpoint can also be used for inference."
186 | "Using a checkpoint for inference requires separate loading of the original pipeline and the individual checkpointed model components."
187 | "See https://huggingface.co/docs/diffusers/main/en/training/dreambooth#performing-inference-using-a-saved-checkpoint for step by step"
188 | "instructions."
189 | ),
190 | )
191 | parser.add_argument(
192 | "--gradient_accumulation_steps",
193 | type=int,
194 | default=1,
195 | help="Number of updates steps to accumulate before performing a backward/update pass.",
196 | )
197 | parser.add_argument(
198 | "--gradient_checkpointing",
199 | action="store_true",
200 | help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
201 | )
202 | parser.add_argument(
203 | "--learning_rate",
204 | type=float,
205 | default=5e-6,
206 | help="Initial learning rate (after the potential warmup period) to use.",
207 | )
208 | parser.add_argument(
209 | "--scale_lr",
210 | action="store_true",
211 | default=False,
212 | help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
213 | )
214 | parser.add_argument(
215 | "--config",
216 | type=str,
217 | default="configs/train/Adapter-XL-sketch.yaml",
218 | help=('config to load the train model and dataset'),
219 | )
220 | parser.add_argument(
221 | "--lr_scheduler",
222 | type=str,
223 | default="constant",
224 | help=(
225 | 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
226 | ' "constant", "constant_with_warmup"]'
227 | ),
228 | )
229 | parser.add_argument(
230 | "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
231 | )
232 | parser.add_argument(
233 | "--lr_num_cycles",
234 | type=int,
235 | default=1,
236 | help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
237 | )
238 | parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
239 | parser.add_argument(
240 | "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
241 | )
242 | parser.add_argument(
243 | "--dataloader_num_workers",
244 | type=int,
245 | default=0,
246 | help=(
247 | "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
248 | ),
249 | )
250 | parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
251 | parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
252 | parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
253 | parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
254 | parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
255 | parser.add_argument(
256 | "--logging_dir",
257 | type=str,
258 | default="logs",
259 | help=(
260 | "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
261 | " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
262 | ),
263 | )
264 | parser.add_argument(
265 | "--allow_tf32",
266 | action="store_true",
267 | help=(
268 | "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
269 | " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
270 | ),
271 | )
272 | parser.add_argument(
273 | "--report_to",
274 | type=str,
275 | default="tensorboard",
276 | help=(
277 | 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
278 | ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
279 | ),
280 | )
281 | parser.add_argument(
282 | "--mixed_precision",
283 | type=str,
284 | default=None,
285 | choices=["no", "fp16", "bf16"],
286 | help=(
287 | "Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
288 | " 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
289 | " flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
290 | ),
291 | )
292 | parser.add_argument(
293 | "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
294 | )
295 | parser.add_argument(
296 | "--set_grads_to_none",
297 | action="store_true",
298 | help=(
299 | "Save more memory by using setting grads to None instead of zero. Be aware, that this changes certain"
300 | " behaviors, so disable this argument if it causes any problems. More info:"
301 | " https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html"
302 | ),
303 | )
304 | parser.add_argument(
305 | "--proportion_empty_prompts",
306 | type=float,
307 | default=0,
308 | help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
309 | )
310 | parser.add_argument(
311 | "--tracker_project_name",
312 | type=str,
313 | default="sd_xl_train_t2i_adapter ",
314 | help=(
315 | "The `project_name` argument passed to Accelerator.init_trackers for"
316 | " more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
317 | ),
318 | )
319 |
320 | if input_args is not None:
321 | args = parser.parse_args(input_args)
322 | else:
323 | args = parser.parse_args()
324 |
325 | if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
326 | raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
327 |
328 | if args.resolution % 8 != 0:
329 | raise ValueError(
330 | "`--resolution` must be divisible by 8 for consistently sized encoded images between the VAE and T2I-Adapter."
331 | )
332 |
333 | return args
334 |
335 |
336 | # Adapted from pipelines.StableDiffusionXLPipeline.encode_prompt
337 | def encode_prompt(prompt_batch, text_encoders, tokenizers, proportion_empty_prompts, is_train=True):
338 | prompt_embeds_list = []
339 |
340 | captions = []
341 | for caption in prompt_batch:
342 | if random.random() < proportion_empty_prompts:
343 | captions.append("")
344 | elif isinstance(caption, str):
345 | captions.append(caption)
346 | elif isinstance(caption, (list, np.ndarray)):
347 | # take a random caption if there are multiple
348 | captions.append(random.choice(caption) if is_train else caption[0])
349 |
350 | with torch.no_grad():
351 | for tokenizer, text_encoder in zip(tokenizers, text_encoders):
352 | text_inputs = tokenizer(
353 | captions,
354 | padding="max_length",
355 | max_length=tokenizer.model_max_length,
356 | truncation=True,
357 | return_tensors="pt",
358 | )
359 | text_input_ids = text_inputs.input_ids
360 | prompt_embeds = text_encoder(
361 | text_input_ids.to(text_encoder.device),
362 | output_hidden_states=True,
363 | )
364 |
365 | # We are only ALWAYS interested in the pooled output of the final text encoder
366 | pooled_prompt_embeds = prompt_embeds[0]
367 | prompt_embeds = prompt_embeds.hidden_states[-2]
368 | bs_embed, seq_len, _ = prompt_embeds.shape
369 | prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
370 | prompt_embeds_list.append(prompt_embeds)
371 |
372 | prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
373 | pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
374 | return prompt_embeds, pooled_prompt_embeds
375 |
376 |
377 | def random_threshold(edge, low_threshold=0.3, high_threshold=0.8):
378 | threshold = round(random.uniform(low_threshold, high_threshold), 1)
379 | edge = edge > threshold
380 | return edge
381 |
382 |
383 | def main(args):
384 | logging_dir = Path(args.output_dir, args.logging_dir)
385 |
386 | accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
387 |
388 | accelerator = Accelerator(
389 | gradient_accumulation_steps=args.gradient_accumulation_steps,
390 | mixed_precision=args.mixed_precision,
391 | log_with=args.report_to,
392 | project_config=accelerator_project_config,
393 | )
394 |
395 | # Make one log on every process with the configuration for debugging.
396 | logging.basicConfig(
397 | format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
398 | datefmt="%m/%d/%Y %H:%M:%S",
399 | level=logging.INFO,
400 | )
401 | logger.info(accelerator.state, main_process_only=False)
402 | if accelerator.is_local_main_process:
403 | transformers.utils.logging.set_verbosity_warning()
404 | diffusers.utils.logging.set_verbosity_info()
405 | else:
406 | transformers.utils.logging.set_verbosity_error()
407 | diffusers.utils.logging.set_verbosity_error()
408 |
409 | # If passed along, set the training seed now.
410 | if args.seed is not None:
411 | set_seed(args.seed)
412 |
413 | # Handle the repository creation
414 | if accelerator.is_main_process:
415 | if args.output_dir is not None:
416 | os.makedirs(args.output_dir, exist_ok=True)
417 |
418 | # Load the tokenizers
419 | tokenizer_one = AutoTokenizer.from_pretrained(
420 | args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision, use_fast=False
421 | )
422 | tokenizer_two = AutoTokenizer.from_pretrained(
423 | args.pretrained_model_name_or_path, subfolder="tokenizer_2", revision=args.revision, use_fast=False
424 | )
425 |
426 | # import correct text encoder classes
427 | text_encoder_cls_one = import_model_class_from_model_name_or_path(
428 | args.pretrained_model_name_or_path, args.revision
429 | )
430 | text_encoder_cls_two = import_model_class_from_model_name_or_path(
431 | args.pretrained_model_name_or_path, args.revision, subfolder="text_encoder_2"
432 | )
433 |
434 | # Load scheduler and models
435 | noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
436 | text_encoder_one = text_encoder_cls_one.from_pretrained(
437 | args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
438 | )
439 | text_encoder_two = text_encoder_cls_two.from_pretrained(
440 | args.pretrained_model_name_or_path, subfolder="text_encoder_2", revision=args.revision
441 | )
442 | vae_path = (
443 | args.pretrained_model_name_or_path
444 | if args.pretrained_vae_model_name_or_path is None
445 | else args.pretrained_vae_model_name_or_path
446 | )
447 | vae = AutoencoderKL.from_pretrained(
448 | vae_path,
449 | subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
450 | revision=args.revision,
451 | )
452 | unet = UNet.from_pretrained(
453 | args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
454 | )
455 |
456 | # `accelerate` 0.16.0 will have better support for customized saving
457 | if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
458 | # create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
459 | def save_model_hook(models, weights, output_dir):
460 | i = len(weights) - 1
461 |
462 | while len(weights) > 0:
463 | weights.pop()
464 | model = models[i]
465 | torch.save(model.state_dict(), os.path.join(output_dir, 'model_%02d.pth'%i))
466 | i -= 1
467 |
468 | accelerator.register_save_state_pre_hook(save_model_hook)
469 |
470 | vae.requires_grad_(False)
471 | text_encoder_one.requires_grad_(False)
472 | text_encoder_two.requires_grad_(False)
473 |
474 | if args.enable_xformers_memory_efficient_attention:
475 | if is_xformers_available():
476 | import xformers
477 |
478 | xformers_version = version.parse(xformers.__version__)
479 | if xformers_version == version.parse("0.0.16"):
480 | logger.warn(
481 | "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
482 | )
483 | unet.enable_xformers_memory_efficient_attention()
484 | else:
485 | raise ValueError("xformers is not available. Make sure it is installed correctly")
486 |
487 | if args.gradient_checkpointing:
488 | unet.enable_gradient_checkpointing()
489 |
490 | # Enable TF32 for faster training on Ampere GPUs,
491 | # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
492 | if args.allow_tf32:
493 | torch.backends.cuda.matmul.allow_tf32 = True
494 |
495 | if args.scale_lr:
496 | args.learning_rate = (
497 | args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
498 | )
499 |
500 | # Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
501 | if args.use_8bit_adam:
502 | try:
503 | import bitsandbytes as bnb
504 | except ImportError:
505 | raise ImportError(
506 | "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
507 | )
508 |
509 | optimizer_class = bnb.optim.AdamW8bit
510 | else:
511 | optimizer_class = torch.optim.AdamW
512 |
513 | # configs
514 | config = OmegaConf.load(args.config)
515 | # Optimizer creation
516 | adapter_config = config.model.params.adapter_config
517 | adapter = instantiate_from_config(adapter_config).cuda()
518 | params_to_optimize = adapter.parameters()
519 | optimizer = optimizer_class(
520 | params_to_optimize,
521 | lr=args.learning_rate,
522 | betas=(args.adam_beta1, args.adam_beta2),
523 | weight_decay=args.adam_weight_decay,
524 | eps=args.adam_epsilon,
525 | )
526 | # load sketch model
527 | sketch_model = pidinet()
528 | ckp = torch.load('checkpoints/table5_pidinet.pth', map_location='cpu')['state_dict']
529 | sketch_model.load_state_dict({k.replace('module.', ''): v for k, v in ckp.items()}, strict=True)
530 | sketch_model = sketch_model.cuda()
531 | for param in sketch_model.parameters():
532 | param.required_grad = False
533 |
534 | # For mixed precision training we cast the text_encoder and vae weights to half-precision
535 | # as these models are only used for inference, keeping weights in full precision is not required.
536 | weight_dtype = torch.float32
537 | if accelerator.mixed_precision == "fp16":
538 | weight_dtype = torch.float16
539 | elif accelerator.mixed_precision == "bf16":
540 | weight_dtype = torch.bfloat16
541 |
542 | # Move vae, unet and text_encoder to device and cast to weight_dtype
543 | # The VAE is in float32 to avoid NaN losses.
544 | if args.pretrained_vae_model_name_or_path is not None:
545 | vae.to(accelerator.device, dtype=weight_dtype)
546 | else:
547 | vae.to(accelerator.device, dtype=torch.float32)
548 | unet.to(accelerator.device, dtype=weight_dtype)
549 | text_encoder_one.to(accelerator.device, dtype=weight_dtype)
550 | text_encoder_two.to(accelerator.device, dtype=weight_dtype)
551 |
552 | # Here, we compute not just the text embeddings but also the additional embeddings
553 | # needed for the SD XL UNet to operate.
554 | def compute_embeddings(batch, proportion_empty_prompts, text_encoders, tokenizers, is_train=True):
555 | original_size = (args.resolution, args.resolution)
556 | target_size = (args.resolution, args.resolution)
557 | crops_coords_top_left = (args.crops_coords_top_left_h, args.crops_coords_top_left_w)
558 | prompt_batch = batch['txt']
559 |
560 | prompt_embeds, pooled_prompt_embeds = encode_prompt(
561 | prompt_batch, text_encoders, tokenizers, proportion_empty_prompts, is_train
562 | )
563 | add_text_embeds = pooled_prompt_embeds
564 |
565 | # Adapted from pipeline.StableDiffusionXLPipeline._get_add_time_ids
566 | add_time_ids = list(original_size + crops_coords_top_left + target_size)
567 | add_time_ids = torch.tensor([add_time_ids])
568 |
569 | prompt_embeds = prompt_embeds.to(accelerator.device)
570 | add_text_embeds = add_text_embeds.to(accelerator.device)
571 | add_time_ids = add_time_ids.repeat(len(prompt_batch), 1)
572 | add_time_ids = add_time_ids.to(accelerator.device, dtype=prompt_embeds.dtype)
573 | unet_added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
574 |
575 | return {"prompt_embeds": prompt_embeds}, unet_added_cond_kwargs#, **unet_added_cond_kwargs}
576 |
577 | # Let's first compute all the embeddings so that we can free up the text encoders
578 | # from memory.
579 | text_encoders = [text_encoder_one, text_encoder_two]
580 | tokenizers = [tokenizer_one, tokenizer_two]
581 | gc.collect()
582 | torch.cuda.empty_cache()
583 |
584 | # data
585 | data = instantiate_from_config(config.data)
586 | train_dataloader = data.train_dataloader()
587 |
588 | # Scheduler and math around the number of training steps.
589 | overrode_max_train_steps = False
590 | # num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
591 | num_update_steps_per_epoch = math.ceil(1e7 / args.gradient_accumulation_steps)
592 | if args.max_train_steps is None:
593 | args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
594 | overrode_max_train_steps = True
595 |
596 | lr_scheduler = get_scheduler(
597 | args.lr_scheduler,
598 | optimizer=optimizer,
599 | num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
600 | num_training_steps=args.max_train_steps * accelerator.num_processes,
601 | num_cycles=args.lr_num_cycles,
602 | power=args.lr_power,
603 | )
604 |
605 | # Prepare everything with our `accelerator`.
606 | adapter, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
607 | adapter, optimizer, train_dataloader, lr_scheduler
608 | )
609 |
610 | # We need to recalculate our total training steps as the size of the training dataloader may have changed.
611 | # num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
612 | # if overrode_max_train_steps:
613 | # args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
614 | # # Afterwards we recalculate our number of training epochs
615 | # args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
616 |
617 | # We need to initialize the trackers we use, and also store our configuration.
618 | # The trackers initializes automatically on the main process.
619 | if accelerator.is_main_process:
620 | tracker_config = dict(vars(args))
621 |
622 | accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
623 |
624 | # Train!
625 | total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
626 |
627 | logger.info("***** Running training *****")
628 | logger.info(f" Num Epochs = {args.num_train_epochs}")
629 | logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
630 | logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
631 | logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
632 | logger.info(f" Total optimization steps = {args.max_train_steps}")
633 | global_step = 0
634 | first_epoch = 0
635 |
636 | initial_global_step = 0
637 |
638 | progress_bar = tqdm(
639 | range(0, args.max_train_steps),
640 | initial=initial_global_step,
641 | desc="Steps",
642 | # Only show the progress bar once on each machine.
643 | disable=not accelerator.is_local_main_process,
644 | )
645 |
646 | image_logs = None
647 | for epoch in range(first_epoch, args.num_train_epochs):
648 | for step, batch in enumerate(train_dataloader):
649 | with accelerator.accumulate(adapter):
650 | # norm input
651 | batch["jpg"] = batch["jpg"].cuda()
652 | batch["jpg"] = batch["jpg"]*2.-1.
653 | # get sketch
654 | edge = 0.5 * batch['jpg'] + 0.5
655 | edge = sketch_model(edge)[-1]
656 | # add random threshold and random masking
657 | edge = random_threshold(edge).to(dtype=weight_dtype)
658 |
659 | # Convert images to latent space
660 | if args.pretrained_vae_model_name_or_path is not None:
661 | pixel_values = batch["jpg"].to(dtype=weight_dtype)
662 | else:
663 | pixel_values = batch["jpg"]
664 | latents = vae.encode(pixel_values).latent_dist.sample()
665 | latents = latents * vae.config.scaling_factor
666 | if args.pretrained_vae_model_name_or_path is None:
667 | latents = latents.to(weight_dtype)
668 |
669 | # Sample noise that we'll add to the latents
670 | noise = torch.randn_like(latents)
671 | bsz = latents.shape[0]
672 |
673 | # Cubic sampling to sample a random timestep for each image
674 | timesteps = torch.rand((bsz, ), device=latents.device)
675 | timesteps = (1 - timesteps**3) * noise_scheduler.config.num_train_timesteps
676 | timesteps = timesteps.long()
677 |
678 | # Add noise to the latents according to the noise magnitude at each timestep
679 | # (this is the forward diffusion process)
680 | noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
681 |
682 | # get text embedding
683 | prompt_embeds, unet_added_cond_kwargs = compute_embeddings(
684 | batch=batch,proportion_empty_prompts=0,text_encoders=text_encoders,tokenizers=tokenizers
685 | )
686 |
687 | # Adapter conditioning.
688 | down_block_additional_residuals = adapter(
689 | edge
690 | )
691 |
692 | # Predict the noise residual
693 | model_pred = unet(
694 | noisy_latents,
695 | timesteps,
696 | encoder_hidden_states=prompt_embeds["prompt_embeds"],
697 | added_cond_kwargs=unet_added_cond_kwargs,
698 | down_block_additional_residuals=[
699 | sample.to(dtype=weight_dtype) for sample in down_block_additional_residuals
700 | ]
701 | # down_block_additional_residuals,
702 | ).sample
703 |
704 | # Get the target for loss depending on the prediction type
705 | if noise_scheduler.config.prediction_type == "epsilon":
706 | target = noise
707 | elif noise_scheduler.config.prediction_type == "v_prediction":
708 | target = noise_scheduler.get_velocity(latents, noise, timesteps)
709 | else:
710 | raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
711 | loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
712 |
713 | accelerator.backward(loss)
714 | if accelerator.sync_gradients:
715 | params_to_clip = adapter.parameters()
716 | accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
717 | optimizer.step()
718 | lr_scheduler.step()
719 | optimizer.zero_grad(set_to_none=args.set_grads_to_none)
720 |
721 |
722 | # Checks if the accelerator has performed an optimization step behind the scenes
723 | if accelerator.sync_gradients:
724 | progress_bar.update(1)
725 | global_step += 1
726 |
727 | if accelerator.is_main_process:
728 | if global_step % args.checkpointing_steps == 0:
729 | save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
730 | accelerator.save_state(save_path)
731 | logger.info(f"Saved state to {save_path}")
732 |
733 | logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
734 | progress_bar.set_postfix(**logs)
735 | accelerator.log(logs, step=global_step)
736 |
737 | if global_step >= args.max_train_steps:
738 | save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
739 | accelerator.save_state(save_path)
740 | logger.info(f"Saved state to {save_path}")
741 | break
742 |
743 | save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
744 | accelerator.save_state(save_path)
745 | logger.info(f"Saved state to {save_path}")
746 |
747 |
748 | if __name__ == "__main__":
749 | args = parse_args()
750 | main(args)
751 |
--------------------------------------------------------------------------------