├── A-Simple-App-with-ChainLit
├── chainlit.md
├── __pycache__
│ └── app.cpython-310.pyc
├── app.py
└── .chainlit
│ └── config.toml
├── Build-a-Simple-Chatbot
├── requirements.txt
└── my-chatbot.py
├── LangChain-Apps
├── requirements.txt
└── demo.ipynb
├── Build-an-ChatGPT-Clone
├── requirements.txt
└── app.py
├── RAG-with-Chat-History
├── requirements.txt
└── RAG-with-Chat-History.ipynb
├── Chat-with-CSV
├── requirements.txt
├── population.csv
└── app.py
├── RAG-with-Ollama
├── requirements.txt
└── rag.ipynb
├── SQL-Agent
├── my_demo.db
├── requirements.txt
└── app.py
├── Pandas-Dataframe-Agent
├── requirements.txt
├── population.csv
└── pandas.ipynb
├── README.md
├── LangChain-Models.ipynb
├── Prompt-Templates.ipynb
├── Groq-Api-Tutorial.ipynb
├── A-Gentle-Intro-to-LangChain.ipynb
├── Creating-a-Vector-Store.ipynb
├── Chat-With-Any-Document.ipynb
└── Quickstart-Guide.ipynb
/A-Simple-App-with-ChainLit/chainlit.md:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/Build-a-Simple-Chatbot/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain
2 | langchain-ollama
3 | streamlit
--------------------------------------------------------------------------------
/LangChain-Apps/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain
2 | langchain-openai
3 | python-dotenv
--------------------------------------------------------------------------------
/Build-an-ChatGPT-Clone/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain
2 | langchain_community
3 | streamlit
--------------------------------------------------------------------------------
/RAG-with-Chat-History/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain
2 | langchain-community
3 | chromadb
4 | bs4
--------------------------------------------------------------------------------
/Chat-with-CSV/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain
2 | langchain-experimental
3 | langchain-anthropic
4 | streamlit
--------------------------------------------------------------------------------
/RAG-with-Ollama/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain
2 | langchain-community
3 | langchainhub
4 | chromadb
5 | bs4
--------------------------------------------------------------------------------
/SQL-Agent/my_demo.db:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TirendazAcademy/LangChain-Tutorials/HEAD/SQL-Agent/my_demo.db
--------------------------------------------------------------------------------
/SQL-Agent/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain
2 | langchain_community
3 | langchain_openai
4 | streamlit
5 | python-dotenv
--------------------------------------------------------------------------------
/Pandas-Dataframe-Agent/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain
2 | langchain-experimental
3 | langchain_openai
4 | pandas
5 | python-dotenv
--------------------------------------------------------------------------------
/A-Simple-App-with-ChainLit/__pycache__/app.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/TirendazAcademy/LangChain-Tutorials/HEAD/A-Simple-App-with-ChainLit/__pycache__/app.cpython-310.pyc
--------------------------------------------------------------------------------
/Chat-with-CSV/population.csv:
--------------------------------------------------------------------------------
1 | Country,Population
2 | India,1428627663
3 | China,1425671352
4 | United States,339996563
5 | Indonesia,277534122
6 | Pakistan,240485658
7 | Nigeria,223804632
8 | Brazil,216422446
9 | Bangladesh,172954319
10 | Russia,144444359
11 | Mexico,128455567
--------------------------------------------------------------------------------
/Pandas-Dataframe-Agent/population.csv:
--------------------------------------------------------------------------------
1 | Country,Population
2 | India,1428627663
3 | China,1425671352
4 | USA,339996563
5 | Indonesia,277534122
6 | Pakistan,240485658
7 | Nigeria,223804632
8 | Brazil,216422446
9 | Bangladesh,172954319
10 | Russia,144444359
11 | Mexico,128455567
12 | Ethiopia,126527060
13 | Japan,123294513
14 | Philippines,117337368
15 | Egypt,112716598
16 | Congo,102262808
17 | Vietnam,98858950
18 | Iran,89172767
19 | Turkey,85816199
20 | Germany,83294633
21 | Thailand,71801279
22 |
--------------------------------------------------------------------------------
/Build-a-Simple-Chatbot/my-chatbot.py:
--------------------------------------------------------------------------------
1 | from langchain_ollama import OllamaLLM
2 | from langchain_core.prompts import ChatPromptTemplate
3 | import streamlit as st
4 |
5 | model = OllamaLLM(model="gemma3")
6 |
7 | template = """Question : {question}
8 | Answer: Let's think step by step."""
9 |
10 | prompt = ChatPromptTemplate.from_template(template)
11 |
12 | chain = prompt | model
13 |
14 | st.title("Chatbot with Ollama")
15 |
16 | user_input = st.text_input("Type a question:")
17 |
18 | if user_input:
19 | response = chain.invoke({"question":user_input})
20 | st.write("Response:", response)
21 |
22 |
23 |
24 |
--------------------------------------------------------------------------------
/A-Simple-App-with-ChainLit/app.py:
--------------------------------------------------------------------------------
1 | import os
2 | import chainlit as cl
3 | from langchain.prompts import PromptTemplate
4 | from langchain.chains import LLMChain
5 | from langchain.llms import OpenAI
6 |
7 | os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
8 |
9 | template = """Question: {question}
10 | Answer: Let's think step by step"""
11 |
12 | @cl.langchain_factory(use_async=True)
13 | def factory():
14 | prompt = PromptTemplate(
15 | template=template, input_variables=["question"])
16 | llm_chain = LLMChain(
17 | prompt = prompt,
18 | llm = OpenAI(temperature = 0),
19 | verbose = True)
20 | return llm_chain
--------------------------------------------------------------------------------
/SQL-Agent/app.py:
--------------------------------------------------------------------------------
1 | from dotenv import load_dotenv
2 | import streamlit as st
3 | from langchain_community.utilities.sql_database import SQLDatabase
4 | from langchain_openai import ChatOpenAI
5 | from langchain_community.agent_toolkits import create_sql_agent
6 |
7 | load_dotenv()
8 |
9 | st.set_page_config(page_title="Talk to your Database")
10 | st.header("Talk to your database")
11 |
12 | db = SQLDatabase.from_uri("sqlite:///my_demo.db")
13 |
14 | llm = ChatOpenAI(temperature=0)
15 |
16 | agent_executor = create_sql_agent(
17 | llm, db = db, agent_type = "openai-tools", verbose = True
18 | )
19 |
20 | user_question = st.text_input("Ask a question about your database:")
21 |
22 | if user_question is not None and user_question != "":
23 | with st.spinner(text="In progress..."):
24 | response = agent_executor.invoke(user_question)
25 | st.write(response["output"])
26 |
27 |
28 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Welcome to LangChain Tutorials
2 |
3 | This repo contains quick step-by-step guides to building an end-to-end language model application with [LangChain](https://python.langchain.com/en/latest/index.html).
4 |
5 | ## YouTube Videos
6 | - [What is LangChain](https://youtu.be/xLDadqb3BQQ)
7 | - [Getting started with LangChain](https://youtu.be/91W52Wl4wG8)
8 | - [RAG with Ollama and LangChain](https://youtu.be/BLR1FgFqbRo)
9 | - [RAG with Chat History](https://youtu.be/fvq1LoMI0co)
10 | - [Build a ChatGPT clone](https://youtu.be/npsQMJk7IH4)
11 | - [Data Analysis with Agents](https://youtu.be/Nzh0XcO_XuM)
12 | - [LangChain Pandas DataFrame Agent](https://youtu.be/fh6C_4yz5-M)
13 | - [LangChain SQL Agent](https://youtu.be/JXiBzpw7dAE)
14 |
15 | ## Blog Post
16 | - [Getting Started with LangChain for Beginners](https://medium.com/gitconnected/getting-started-with-langchain-for-beginners-f3841119e357)
17 |
--------------------------------------------------------------------------------
/Chat-with-CSV/app.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | from langchain_experimental.agents.agent_toolkits import create_csv_agent
3 | from langchain_anthropic import ChatAnthropic
4 | from langchain.agents.agent_types import AgentType
5 | from dotenv import load_dotenv
6 | load_dotenv()
7 | st.set_page_config(page_title="Talk to your CSV")
8 | st.header("Talk to your CSV")
9 | csv_file = st.file_uploader("Upload a CSV file", type="csv")
10 |
11 | if csv_file is not None:
12 | agent = create_csv_agent(
13 | ChatAnthropic(
14 | model_name="claude-3-haiku-20240307"
15 | ),
16 | csv_file,
17 | verbose = True,
18 | agent_type = AgentType.ZERO_SHOT_REACT_DESCRIPTION,
19 | )
20 |
21 | user_question = st.text_input("Ask a question about your CSV:")
22 |
23 | if user_question is not None and user_question != "":
24 | with st.spinner(text = "In progress..."):
25 | response = agent.invoke(user_question)
26 | st.write(response["output"])
--------------------------------------------------------------------------------
/A-Simple-App-with-ChainLit/.chainlit/config.toml:
--------------------------------------------------------------------------------
1 | [project]
2 | # If true (default), the app will be available to anonymous users.
3 | # If false, users will need to authenticate and be part of the project to use the app.
4 | public = true
5 |
6 | # The project ID (found on https://cloud.chainlit.io).
7 | # If provided, all the message data will be stored in the cloud.
8 | # The project ID is required when public is set to false.
9 | #id = ""
10 |
11 | # Whether to enable telemetry (default: true). No personal data is collected.
12 | enable_telemetry = true
13 |
14 | # List of environment variables to be provided by each user to use the app.
15 | user_env = []
16 |
17 | [UI]
18 | # Name of the app and chatbot.
19 | name = "Chatbot"
20 |
21 | # Description of the app and chatbot. This is used for HTML tags.
22 | # description = ""
23 |
24 | # The default value for the expand messages settings.
25 | default_expand_messages = false
26 |
27 | # Hide the chain of thought details from the user in the UI.
28 | hide_cot = false
29 |
30 | # Link to your github repo. This will add a github button in the UI's header.
31 | # github = ""
32 |
33 | [meta]
34 | generated_by = "0.4.0"
35 |
--------------------------------------------------------------------------------
/Build-an-ChatGPT-Clone/app.py:
--------------------------------------------------------------------------------
1 | from langchain_community.chat_models import ChatOllama
2 | from langchain_core.prompts import ChatPromptTemplate
3 | from langchain_core.output_parsers import StrOutputParser
4 | import streamlit as st
5 | from langchain_core.messages import AIMessage, HumanMessage
6 |
7 | def get_response(user_query, chat_history):
8 |
9 | llm = ChatOllama(model = "mistral")
10 |
11 | template = """
12 | You are a helpful assistant.
13 | Answer the following questions considering the history of the conversation:
14 | Chat history: {chat_history}
15 | User question: {user_question}
16 | """
17 | prompt = ChatPromptTemplate.from_template(template)
18 |
19 | chain = prompt | llm | StrOutputParser()
20 |
21 | return chain.stream({
22 | "chat_history": chat_history,
23 | "user_question": user_query
24 | })
25 |
26 | st.set_page_config(page_title="Streamlit Chatbot", page_icon="🤖")
27 | st.title("ChatGPT-like clone")
28 |
29 | if "chat_history" not in st.session_state:
30 | st.session_state.chat_history = [
31 | AIMessage(content="Hi, I'm a bot. How can I help you?")]
32 |
33 | for message in st.session_state.chat_history:
34 | if isinstance(message, AIMessage):
35 | with st.chat_message("AI"):
36 | st.write(message.content)
37 | elif isinstance(message, HumanMessage):
38 | with st.chat_message("Human"):
39 | st.write(message.content)
40 |
41 | user_query = st.chat_input("Type your message here...")
42 |
43 | if user_query is not None and user_query != "":
44 | st.session_state.chat_history.append(HumanMessage(content=user_query))
45 |
46 | with st.chat_message("Human"):
47 | st.markdown(user_query)
48 |
49 | with st.chat_message("AI"):
50 | response = st.write_stream(get_response(user_query, st.session_state.chat_history))
51 |
52 | st.session_state.chat_history.append(AIMessage(content=response))
53 |
54 |
55 |
56 |
57 |
--------------------------------------------------------------------------------
/LangChain-Apps/demo.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [
8 | {
9 | "data": {
10 | "text/plain": [
11 | "True"
12 | ]
13 | },
14 | "execution_count": 1,
15 | "metadata": {},
16 | "output_type": "execute_result"
17 | }
18 | ],
19 | "source": [
20 | "from dotenv import load_dotenv \n",
21 | "load_dotenv()"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 2,
27 | "metadata": {},
28 | "outputs": [
29 | {
30 | "name": "stdout",
31 | "output_type": "stream",
32 | "text": [
33 | "blue and scattered with fluffy white clouds on this sunny day.\n"
34 | ]
35 | }
36 | ],
37 | "source": [
38 | "from langchain_openai.chat_models import ChatOpenAI \n",
39 | "\n",
40 | "model = ChatOpenAI(model = \"gpt-3.5-turbo\") \n",
41 | "\n",
42 | "response = model.invoke(\"The sky is\")\n",
43 | "\n",
44 | "print(response.content)"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 3,
50 | "metadata": {},
51 | "outputs": [
52 | {
53 | "name": "stdout",
54 | "output_type": "stream",
55 | "text": [
56 | "The capital of France is Paris.\n"
57 | ]
58 | }
59 | ],
60 | "source": [
61 | "from langchain_openai.chat_models import ChatOpenAI \n",
62 | "\n",
63 | "from langchain_core.messages import HumanMessage \n",
64 | "\n",
65 | "model = ChatOpenAI()\n",
66 | "\n",
67 | "prompt= [HumanMessage(\"What is the capital of France?\")]\n",
68 | "\n",
69 | "response = model.invoke(prompt)\n",
70 | "\n",
71 | "print(response.content)"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": 6,
77 | "metadata": {},
78 | "outputs": [
79 | {
80 | "name": "stdout",
81 | "output_type": "stream",
82 | "text": [
83 | "Paris!!!\n"
84 | ]
85 | }
86 | ],
87 | "source": [
88 | "from langchain_openai.chat_models import ChatOpenAI \n",
89 | "from langchain_core.messages import HumanMessage, SystemMessage\n",
90 | "\n",
91 | "model = ChatOpenAI()\n",
92 | "\n",
93 | "human_msg = HumanMessage(\"What is the capital of France?\")\n",
94 | "\n",
95 | "system_msg= SystemMessage(\n",
96 | " \"You are a helpful assistant that responds to questions with three exclamation marks\"\n",
97 | ")\n",
98 | "\n",
99 | "response = model.invoke([system_msg, human_msg])\n",
100 | "\n",
101 | "print(response.content)"
102 | ]
103 | },
104 | {
105 | "cell_type": "code",
106 | "execution_count": 8,
107 | "metadata": {},
108 | "outputs": [
109 | {
110 | "data": {
111 | "text/plain": [
112 | "ChatPromptValue(messages=[SystemMessage(content='Translate the following form English into Turkish', additional_kwargs={}, response_metadata={}), HumanMessage(content='Hi!', additional_kwargs={}, response_metadata={})])"
113 | ]
114 | },
115 | "execution_count": 8,
116 | "metadata": {},
117 | "output_type": "execute_result"
118 | }
119 | ],
120 | "source": [
121 | "from langchain_core.prompts import ChatPromptTemplate \n",
122 | "\n",
123 | "system_template = \"Translate the following form English into {language}\" \n",
124 | "\n",
125 | "prompt_template = ChatPromptTemplate.from_messages(\n",
126 | " [(\"system\", system_template),(\"user\", \"{text}\")]\n",
127 | ")\n",
128 | "\n",
129 | "prompt = prompt_template.invoke({\"language\": \"Turkish\", \"text\": \"Hi!\"})\n",
130 | "\n",
131 | "prompt"
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": 9,
137 | "metadata": {},
138 | "outputs": [
139 | {
140 | "data": {
141 | "text/plain": [
142 | "[SystemMessage(content='Translate the following form English into Turkish', additional_kwargs={}, response_metadata={}),\n",
143 | " HumanMessage(content='Hi!', additional_kwargs={}, response_metadata={})]"
144 | ]
145 | },
146 | "execution_count": 9,
147 | "metadata": {},
148 | "output_type": "execute_result"
149 | }
150 | ],
151 | "source": [
152 | "prompt.to_messages()"
153 | ]
154 | },
155 | {
156 | "cell_type": "code",
157 | "execution_count": 10,
158 | "metadata": {},
159 | "outputs": [
160 | {
161 | "name": "stdout",
162 | "output_type": "stream",
163 | "text": [
164 | "Merhaba!\n"
165 | ]
166 | }
167 | ],
168 | "source": [
169 | "response = model.invoke(prompt)\n",
170 | "print(response.content)"
171 | ]
172 | },
173 | {
174 | "cell_type": "code",
175 | "execution_count": null,
176 | "metadata": {},
177 | "outputs": [],
178 | "source": []
179 | }
180 | ],
181 | "metadata": {
182 | "kernelspec": {
183 | "display_name": "langchain",
184 | "language": "python",
185 | "name": "python3"
186 | },
187 | "language_info": {
188 | "codemirror_mode": {
189 | "name": "ipython",
190 | "version": 3
191 | },
192 | "file_extension": ".py",
193 | "mimetype": "text/x-python",
194 | "name": "python",
195 | "nbconvert_exporter": "python",
196 | "pygments_lexer": "ipython3",
197 | "version": "3.10.16"
198 | }
199 | },
200 | "nbformat": 4,
201 | "nbformat_minor": 2
202 | }
203 |
--------------------------------------------------------------------------------
/LangChain-Models.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [
8 | {
9 | "data": {
10 | "text/plain": [
11 | "True"
12 | ]
13 | },
14 | "execution_count": 1,
15 | "metadata": {},
16 | "output_type": "execute_result"
17 | }
18 | ],
19 | "source": [
20 | "from dotenv import load_dotenv\n",
21 | "\n",
22 | "load_dotenv()"
23 | ]
24 | },
25 | {
26 | "cell_type": "code",
27 | "execution_count": 2,
28 | "metadata": {},
29 | "outputs": [],
30 | "source": [
31 | "from langchain_openai import OpenAI \n",
32 | "\n",
33 | "llm = OpenAI()"
34 | ]
35 | },
36 | {
37 | "cell_type": "code",
38 | "execution_count": 3,
39 | "metadata": {},
40 | "outputs": [
41 | {
42 | "data": {
43 | "text/plain": [
44 | "'\\n\\nThe capital of USA is Washington, D.C.'"
45 | ]
46 | },
47 | "execution_count": 3,
48 | "metadata": {},
49 | "output_type": "execute_result"
50 | }
51 | ],
52 | "source": [
53 | "text = \"What is the capital of USA\"\n",
54 | "\n",
55 | "llm.invoke(text)"
56 | ]
57 | },
58 | {
59 | "cell_type": "code",
60 | "execution_count": 4,
61 | "metadata": {},
62 | "outputs": [
63 | {
64 | "data": {
65 | "text/plain": [
66 | "'\\n\\nWhy did Elon Musk name his car company Tesla?\\n\\nBecause he couldn\\'t afford to call it \"Edison\"!'"
67 | ]
68 | },
69 | "execution_count": 4,
70 | "metadata": {},
71 | "output_type": "execute_result"
72 | }
73 | ],
74 | "source": [
75 | "text = \"tell me a joke about Elon Musk\"\n",
76 | "\n",
77 | "llm.invoke(text)"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 5,
83 | "metadata": {},
84 | "outputs": [
85 | {
86 | "name": "stdout",
87 | "output_type": "stream",
88 | "text": [
89 | "\n",
90 | "\n",
91 | "Why was Elon Musk always so tired?\n",
92 | "\n",
93 | "Because he was always Elon-\"Musking\" himself to success!\n"
94 | ]
95 | }
96 | ],
97 | "source": [
98 | "print(llm.invoke(text))"
99 | ]
100 | },
101 | {
102 | "cell_type": "code",
103 | "execution_count": 6,
104 | "metadata": {},
105 | "outputs": [],
106 | "source": [
107 | "from langchain_openai import ChatOpenAI \n",
108 | "\n",
109 | "chat_model = ChatOpenAI()"
110 | ]
111 | },
112 | {
113 | "cell_type": "code",
114 | "execution_count": 7,
115 | "metadata": {},
116 | "outputs": [],
117 | "source": [
118 | "from langchain.schema import HumanMessage\n",
119 | "\n",
120 | "messages = [HumanMessage(content=text)]"
121 | ]
122 | },
123 | {
124 | "cell_type": "code",
125 | "execution_count": 8,
126 | "metadata": {},
127 | "outputs": [
128 | {
129 | "data": {
130 | "text/plain": [
131 | "AIMessage(content='Why did Elon Musk become an astronaut?\\n\\nBecause he wanted to launch his own car into space and call it a \"Tesla-naut\"!')"
132 | ]
133 | },
134 | "execution_count": 8,
135 | "metadata": {},
136 | "output_type": "execute_result"
137 | }
138 | ],
139 | "source": [
140 | "chat_model.invoke(messages)"
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": 9,
146 | "metadata": {},
147 | "outputs": [],
148 | "source": [
149 | "from langchain_community.llms import Ollama \n",
150 | "\n",
151 | "llm = Ollama(model=\"llama2\")"
152 | ]
153 | },
154 | {
155 | "cell_type": "code",
156 | "execution_count": 10,
157 | "metadata": {},
158 | "outputs": [
159 | {
160 | "name": "stdout",
161 | "output_type": "stream",
162 | "text": [
163 | "The capital of the United States of America is Washington, D.C. (District of Columbia).\n"
164 | ]
165 | }
166 | ],
167 | "source": [
168 | "text = \"What is the capital of USA\"\n",
169 | "\n",
170 | "print(llm.invoke(text))"
171 | ]
172 | },
173 | {
174 | "cell_type": "code",
175 | "execution_count": 11,
176 | "metadata": {},
177 | "outputs": [],
178 | "source": [
179 | "from langchain_community.chat_models import ChatOllama \n",
180 | "\n",
181 | "chat_model = ChatOllama()"
182 | ]
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": 12,
187 | "metadata": {},
188 | "outputs": [
189 | {
190 | "data": {
191 | "text/plain": [
192 | "AIMessage(content='\\nThe capital of the United States of America is Washington, D.C. (abbreviation for District of Columbia).')"
193 | ]
194 | },
195 | "execution_count": 12,
196 | "metadata": {},
197 | "output_type": "execute_result"
198 | }
199 | ],
200 | "source": [
201 | "messages = [HumanMessage(content=text)]\n",
202 | "\n",
203 | "chat_model.invoke(messages)"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": null,
209 | "metadata": {},
210 | "outputs": [],
211 | "source": []
212 | }
213 | ],
214 | "metadata": {
215 | "kernelspec": {
216 | "display_name": "genai",
217 | "language": "python",
218 | "name": "python3"
219 | },
220 | "language_info": {
221 | "codemirror_mode": {
222 | "name": "ipython",
223 | "version": 3
224 | },
225 | "file_extension": ".py",
226 | "mimetype": "text/x-python",
227 | "name": "python",
228 | "nbconvert_exporter": "python",
229 | "pygments_lexer": "ipython3",
230 | "version": "3.10.13"
231 | }
232 | },
233 | "nbformat": 4,
234 | "nbformat_minor": 2
235 | }
236 |
--------------------------------------------------------------------------------
/Prompt-Templates.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Propmt Template"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "from langchain.prompts import PromptTemplate\n",
17 | "\n",
18 | "prompt_template = PromptTemplate.from_template(\n",
19 | " \"Explain {topic} like I am a {number} year old.\"\n",
20 | ")"
21 | ]
22 | },
23 | {
24 | "cell_type": "code",
25 | "execution_count": 2,
26 | "metadata": {},
27 | "outputs": [
28 | {
29 | "data": {
30 | "text/plain": [
31 | "'Explain generative AI like I am a five year old.'"
32 | ]
33 | },
34 | "execution_count": 2,
35 | "metadata": {},
36 | "output_type": "execute_result"
37 | }
38 | ],
39 | "source": [
40 | "prompt_template.format(\n",
41 | " topic = \"generative AI\",\n",
42 | " number = \"five\"\n",
43 | ")"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {},
49 | "source": [
50 | "## Chat Prompt Template"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 3,
56 | "metadata": {},
57 | "outputs": [],
58 | "source": [
59 | "from langchain_core.prompts import ChatPromptTemplate\n",
60 | "\n",
61 | "chat_template = ChatPromptTemplate.from_messages(\n",
62 | " [\n",
63 | " (\"system\", \"You are a helpful AI bot. Your name is {name}\"),\n",
64 | " (\"human\", \"Hello, how are you doing?\"),\n",
65 | " (\"ai\", \"I am doing well, thanks!\"),\n",
66 | " (\"human\", \"{user_input}\"),\n",
67 | " ]\n",
68 | ")"
69 | ]
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": 4,
74 | "metadata": {},
75 | "outputs": [
76 | {
77 | "data": {
78 | "text/plain": [
79 | "[SystemMessage(content='You are a helpful AI bot. Your name is Tim'),\n",
80 | " HumanMessage(content='Hello, how are you doing?'),\n",
81 | " AIMessage(content='I am doing well, thanks!'),\n",
82 | " HumanMessage(content='What is your name?')]"
83 | ]
84 | },
85 | "execution_count": 4,
86 | "metadata": {},
87 | "output_type": "execute_result"
88 | }
89 | ],
90 | "source": [
91 | "messages = chat_template.format_messages(\n",
92 | " name = \"Tim\",\n",
93 | " user_input = \"What is your name?\",\n",
94 | ")\n",
95 | "\n",
96 | "messages"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": 6,
102 | "metadata": {},
103 | "outputs": [],
104 | "source": [
105 | "from langchain.prompts import HumanMessagePromptTemplate \n",
106 | "from langchain_core.messages import SystemMessage"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": 9,
112 | "metadata": {},
113 | "outputs": [],
114 | "source": [
115 | "chat_template = ChatPromptTemplate.from_messages(\n",
116 | " [\n",
117 | " SystemMessage(\n",
118 | " content=(\"You are a helpful assistant.\")\n",
119 | " ),\n",
120 | " HumanMessagePromptTemplate.from_template(\"{text}\"),\n",
121 | " ]\n",
122 | ")"
123 | ]
124 | },
125 | {
126 | "cell_type": "code",
127 | "execution_count": 10,
128 | "metadata": {},
129 | "outputs": [
130 | {
131 | "name": "stdout",
132 | "output_type": "stream",
133 | "text": [
134 | "[SystemMessage(content='You are a helpful assistant.'), HumanMessage(content='Tell me five color.')]\n"
135 | ]
136 | }
137 | ],
138 | "source": [
139 | "messages = chat_template.format_messages(\n",
140 | " text = \"Tell me five color.\"\n",
141 | ")\n",
142 | "\n",
143 | "print(messages)"
144 | ]
145 | },
146 | {
147 | "cell_type": "code",
148 | "execution_count": 11,
149 | "metadata": {},
150 | "outputs": [],
151 | "source": [
152 | "prompt_template = PromptTemplate.from_template(\n",
153 | " \"Explain {topic} like I am a {number} year old.\"\n",
154 | ")"
155 | ]
156 | },
157 | {
158 | "cell_type": "markdown",
159 | "metadata": {},
160 | "source": [
161 | "## Chain"
162 | ]
163 | },
164 | {
165 | "cell_type": "code",
166 | "execution_count": 12,
167 | "metadata": {},
168 | "outputs": [],
169 | "source": [
170 | "from langchain_community.llms import Ollama \n",
171 | "\n",
172 | "llm = Ollama(model = \"llama2\")"
173 | ]
174 | },
175 | {
176 | "cell_type": "code",
177 | "execution_count": 13,
178 | "metadata": {},
179 | "outputs": [],
180 | "source": [
181 | "chain = prompt_template | llm "
182 | ]
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": 14,
187 | "metadata": {},
188 | "outputs": [
189 | {
190 | "name": "stdout",
191 | "output_type": "stream",
192 | "text": [
193 | "\n",
194 | "Oh, wow! *excitedly* Generative AI is like a magic box that can make new things that have never existed before! 🤯 It's like when you play with blocks and build a new tower, but instead of blocks, it's using magic to create something completely new and amazing. 🏗️\n",
195 | "\n",
196 | "Imagine you have a toy box full of different things like cars, dogs, and flowers. Generative AI is like a special tool that can take one of those things, like a car, and suddenly turn it into a whole new thing, like a unicorn! 🦄 It's like magic!\n",
197 | "\n",
198 | "But wait, there's more! Not only can it create new things, but it can also make them look and act like they were real. It's like the unicorn is a real living creature that you can see and touch! 🎨\n",
199 | "\n",
200 | "Generative AI is like a superhero that can create anything you can imagine! It's so cool, right? *excitedly* 😍\n"
201 | ]
202 | }
203 | ],
204 | "source": [
205 | "print(\n",
206 | " chain.invoke({\n",
207 | " \"topic\":\"What is generative AI?\",\n",
208 | " \"number\": \"five\"\n",
209 | " })\n",
210 | ")"
211 | ]
212 | },
213 | {
214 | "cell_type": "code",
215 | "execution_count": null,
216 | "metadata": {},
217 | "outputs": [],
218 | "source": []
219 | }
220 | ],
221 | "metadata": {
222 | "kernelspec": {
223 | "display_name": "genai",
224 | "language": "python",
225 | "name": "python3"
226 | },
227 | "language_info": {
228 | "codemirror_mode": {
229 | "name": "ipython",
230 | "version": 3
231 | },
232 | "file_extension": ".py",
233 | "mimetype": "text/x-python",
234 | "name": "python",
235 | "nbconvert_exporter": "python",
236 | "pygments_lexer": "ipython3",
237 | "version": "3.10.13"
238 | }
239 | },
240 | "nbformat": 4,
241 | "nbformat_minor": 2
242 | }
243 |
--------------------------------------------------------------------------------
/Pandas-Dataframe-Agent/pandas.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [
8 | {
9 | "data": {
10 | "text/plain": [
11 | "True"
12 | ]
13 | },
14 | "execution_count": 1,
15 | "metadata": {},
16 | "output_type": "execute_result"
17 | }
18 | ],
19 | "source": [
20 | "from dotenv import load_dotenv\n",
21 | "load_dotenv()"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 2,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "import pandas as pd \n",
31 | "\n",
32 | "df = pd.read_csv(\"population.csv\")"
33 | ]
34 | },
35 | {
36 | "cell_type": "code",
37 | "execution_count": 3,
38 | "metadata": {},
39 | "outputs": [
40 | {
41 | "data": {
42 | "text/html": [
43 | "\n",
44 | "\n",
57 | "
\n",
58 | " \n",
59 | " \n",
60 | " | \n",
61 | " Country | \n",
62 | " Population | \n",
63 | "
\n",
64 | " \n",
65 | " \n",
66 | " \n",
67 | " | 0 | \n",
68 | " India | \n",
69 | " 1428627663 | \n",
70 | "
\n",
71 | " \n",
72 | " | 1 | \n",
73 | " China | \n",
74 | " 1425671352 | \n",
75 | "
\n",
76 | " \n",
77 | " | 2 | \n",
78 | " USA | \n",
79 | " 339996563 | \n",
80 | "
\n",
81 | " \n",
82 | " | 3 | \n",
83 | " Indonesia | \n",
84 | " 277534122 | \n",
85 | "
\n",
86 | " \n",
87 | " | 4 | \n",
88 | " Pakistan | \n",
89 | " 240485658 | \n",
90 | "
\n",
91 | " \n",
92 | "
\n",
93 | "
 "
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 1,
32 | "metadata": {
33 | "id": "d_pvDMrgq0IP"
34 | },
35 | "outputs": [],
36 | "source": [
37 | "!pip install -q -U langchain langchain_core langchain_groq gradio"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "source": [
43 | "from google.colab import userdata\n",
44 | "groq_api_key = userdata.get('GROQ_API_KEY')"
45 | ],
46 | "metadata": {
47 | "id": "1BBWBEFc0G9J"
48 | },
49 | "execution_count": 2,
50 | "outputs": []
51 | },
52 | {
53 | "cell_type": "code",
54 | "source": [
55 | "from langchain_groq import ChatGroq\n",
56 | "\n",
57 | "chat = ChatGroq(\n",
58 | " api_key = groq_api_key,\n",
59 | " model_name = \"mixtral-8x7b-32768\"\n",
60 | ")"
61 | ],
62 | "metadata": {
63 | "id": "vPfbfzOC1qE8"
64 | },
65 | "execution_count": 3,
66 | "outputs": []
67 | },
68 | {
69 | "cell_type": "code",
70 | "source": [
71 | "from langchain_core.prompts import ChatPromptTemplate\n",
72 | "\n",
73 | "system = \"You are a helpful assistant.\"\n",
74 | "human = \"{text}\"\n",
75 | "\n",
76 | "prompt = ChatPromptTemplate.from_messages(\n",
77 | " [\n",
78 | " (\"system\", system), (\"human\", human)\n",
79 | " ]\n",
80 | ")"
81 | ],
82 | "metadata": {
83 | "id": "3VIDCzMm3Yh3"
84 | },
85 | "execution_count": 4,
86 | "outputs": []
87 | },
88 | {
89 | "cell_type": "code",
90 | "source": [
91 | "from langchain_core.output_parsers import StrOutputParser"
92 | ],
93 | "metadata": {
94 | "id": "4PajMIZS3w3B"
95 | },
96 | "execution_count": 5,
97 | "outputs": []
98 | },
99 | {
100 | "cell_type": "code",
101 | "source": [
102 | "chain = prompt | chat | StrOutputParser()"
103 | ],
104 | "metadata": {
105 | "id": "VtpYCfMW35Wr"
106 | },
107 | "execution_count": 6,
108 | "outputs": []
109 | },
110 | {
111 | "cell_type": "code",
112 | "source": [
113 | "chain.invoke(\n",
114 | " {\"text\":\"Why is the sky blue?\"}\n",
115 | ")"
116 | ],
117 | "metadata": {
118 | "colab": {
119 | "base_uri": "https://localhost:8080/",
120 | "height": 106
121 | },
122 | "id": "Q_r5ofV04adl",
123 | "outputId": "cc029596-a6ea-4126-ebfc-5134b27e21fa"
124 | },
125 | "execution_count": 7,
126 | "outputs": [
127 | {
128 | "output_type": "execute_result",
129 | "data": {
130 | "text/plain": [
131 | "\"The phenomenon that causes the sky to appear blue is known as Rayleigh scattering. As sunlight reaches Earth's atmosphere, it is made up of different colors, which are essentially different wavelengths of light. Shorter wavelengths (like blue and violet) are scattered in all directions more than longer wavelengths (like red, orange, and yellow).\\n\\nEven though violet light is scattered more than blue light, the sky appears blue, not violet, because our eyes are more sensitive to blue light and because sunlight reaches us more at the blue part of the spectrum, rather than the violet part. Additionally, some of the violet light gets absorbed by the ozone layer in the atmosphere. This combination results in the sky we typically observe as blue.\""
132 | ],
133 | "application/vnd.google.colaboratory.intrinsic+json": {
134 | "type": "string"
135 | }
136 | },
137 | "metadata": {},
138 | "execution_count": 7
139 | }
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "source": [
145 | "import gradio as gr"
146 | ],
147 | "metadata": {
148 | "id": "xJFwzG9p4fDK"
149 | },
150 | "execution_count": 8,
151 | "outputs": []
152 | },
153 | {
154 | "cell_type": "code",
155 | "source": [
156 | "def fetch_response(user_input):\n",
157 | " chat = ChatGroq(\n",
158 | " api_key = groq_api_key,\n",
159 | " model_name = \"mixtral-8x7b-32768\"\n",
160 | " )\n",
161 | " system = \"You are a helpful assistant.\"\n",
162 | " human = \"{text}\"\n",
163 | "\n",
164 | " prompt = ChatPromptTemplate.from_messages(\n",
165 | " [\n",
166 | " (\"system\", system), (\"human\", human)\n",
167 | " ]\n",
168 | " )\n",
169 | " chain = prompt | chat | StrOutputParser()\n",
170 | " output = chain.invoke({\"text\": user_input})\n",
171 | " return output"
172 | ],
173 | "metadata": {
174 | "id": "cgf7Uvaw5wfg"
175 | },
176 | "execution_count": 9,
177 | "outputs": []
178 | },
179 | {
180 | "cell_type": "code",
181 | "source": [
182 | "user_input = \"Why is the sky blue?\"\n",
183 | "\n",
184 | "fetch_response(user_input)"
185 | ],
186 | "metadata": {
187 | "colab": {
188 | "base_uri": "https://localhost:8080/",
189 | "height": 106
190 | },
191 | "id": "UYPZSCJW6sNE",
192 | "outputId": "da48cc76-0925-4aa1-806a-0877328dafef"
193 | },
194 | "execution_count": 10,
195 | "outputs": [
196 | {
197 | "output_type": "execute_result",
198 | "data": {
199 | "text/plain": [
200 | "\"The phenomenon that causes the sky to appear blue is known as Rayleigh scattering. As sunlight reaches Earth's atmosphere, it is made up of different colors, which are represented in the light spectrum as having different wavelengths. Blue and violet light have the shortest wavelengths and are scattered in all directions by the gas molecules in Earth's atmosphere. \\n\\nThis scattered blue and violet light reaches our eyes from all directions, giving the sky its blue appearance. You might wonder why we don't see a violet sky, given that violet light is scattered more than blue light. This is because our eyes are more sensitive to blue light and because sunlight reaches us with less violet light to begin with. Additionally, some of the violet light gets absorbed by the ozone layer in the atmosphere. Therefore, the sky appears blue to us during the daytime.\""
201 | ],
202 | "application/vnd.google.colaboratory.intrinsic+json": {
203 | "type": "string"
204 | }
205 | },
206 | "metadata": {},
207 | "execution_count": 10
208 | }
209 | ]
210 | },
211 | {
212 | "cell_type": "code",
213 | "source": [
214 | "iface = gr.Interface(\n",
215 | " fn = fetch_response,\n",
216 | " inputs = \"text\",\n",
217 | " outputs = \"text\",\n",
218 | " title = \"Groq Chatbot\",\n",
219 | " description=\"Ask a question and get a response.\"\n",
220 | ")"
221 | ],
222 | "metadata": {
223 | "id": "sSmvFUjL67SK"
224 | },
225 | "execution_count": 11,
226 | "outputs": []
227 | },
228 | {
229 | "cell_type": "code",
230 | "source": [
231 | "iface.launch()"
232 | ],
233 | "metadata": {
234 | "colab": {
235 | "base_uri": "https://localhost:8080/",
236 | "height": 627
237 | },
238 | "id": "Y0JVF_zB7fl8",
239 | "outputId": "7aeccd71-31de-4853-b5db-3923a79913af"
240 | },
241 | "execution_count": 12,
242 | "outputs": [
243 | {
244 | "output_type": "stream",
245 | "name": "stdout",
246 | "text": [
247 | "Setting queue=True in a Colab notebook requires sharing enabled. Setting `share=True` (you can turn this off by setting `share=False` in `launch()` explicitly).\n",
248 | "\n",
249 | "Colab notebook detected. To show errors in colab notebook, set debug=True in launch()\n",
250 | "Running on public URL: https://ba64a37776f78dbb6a.gradio.live\n",
251 | "\n",
252 | "This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)\n"
253 | ]
254 | },
255 | {
256 | "output_type": "display_data",
257 | "data": {
258 | "text/plain": [
259 | ""
260 | ],
261 | "text/html": [
262 | ""
263 | ]
264 | },
265 | "metadata": {}
266 | },
267 | {
268 | "output_type": "execute_result",
269 | "data": {
270 | "text/plain": []
271 | },
272 | "metadata": {},
273 | "execution_count": 12
274 | }
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "source": [
280 | "Let's connect [YouTube](http://youtube.com/tirendazacademy) | [Medium](http://tirendazacademy.medium.com) | [X](http://x.com/tirendazacademy) | [Linkedin](https://www.linkedin.com/in/tirendaz-academy) 😎"
281 | ],
282 | "metadata": {
283 | "id": "y08h2aQU--Ya"
284 | }
285 | }
286 | ]
287 | }
--------------------------------------------------------------------------------
/A-Gentle-Intro-to-LangChain.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyPSEIyI6+A7Q2yj360qdARd",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Installation"
33 | ],
34 | "metadata": {
35 | "id": "DrueKvwYZvVM"
36 | }
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 1,
41 | "metadata": {
42 | "id": "5uc9A7WP7gQx"
43 | },
44 | "outputs": [],
45 | "source": [
46 | "!pip install -q langchain\n",
47 | "!pip install -q openai"
48 | ]
49 | },
50 | {
51 | "cell_type": "markdown",
52 | "source": [
53 | "# Environment Setup"
54 | ],
55 | "metadata": {
56 | "id": "mWJrFgzyZzHy"
57 | }
58 | },
59 | {
60 | "cell_type": "code",
61 | "source": [
62 | "import os\n",
63 | "os.environ[\"OPENAI_API_KEY\"]=\"Your-API-Key\""
64 | ],
65 | "metadata": {
66 | "id": "y8cKMsGA8ZVp"
67 | },
68 | "execution_count": 2,
69 | "outputs": []
70 | },
71 | {
72 | "cell_type": "markdown",
73 | "source": [
74 | "# Building a Language Model Application"
75 | ],
76 | "metadata": {
77 | "id": "AgBeqAqxZ4tA"
78 | }
79 | },
80 | {
81 | "cell_type": "code",
82 | "source": [
83 | "from langchain.llms import OpenAI"
84 | ],
85 | "metadata": {
86 | "id": "rQfOeXbD882O"
87 | },
88 | "execution_count": 3,
89 | "outputs": []
90 | },
91 | {
92 | "cell_type": "code",
93 | "source": [
94 | "llm = OpenAI(temperature=0.7)"
95 | ],
96 | "metadata": {
97 | "id": "5bi0W54KH8nS"
98 | },
99 | "execution_count": 4,
100 | "outputs": []
101 | },
102 | {
103 | "cell_type": "code",
104 | "source": [
105 | "text = \"what are the 5 most expensive capital cities?\""
106 | ],
107 | "metadata": {
108 | "id": "zkPDSnBWID7D"
109 | },
110 | "execution_count": 5,
111 | "outputs": []
112 | },
113 | {
114 | "cell_type": "code",
115 | "source": [
116 | "print(llm(text))"
117 | ],
118 | "metadata": {
119 | "colab": {
120 | "base_uri": "https://localhost:8080/"
121 | },
122 | "id": "OaxHKf6yIOSq",
123 | "outputId": "b2b78f51-6dd9-484e-e571-703e5b70be7e"
124 | },
125 | "execution_count": 6,
126 | "outputs": [
127 | {
128 | "output_type": "stream",
129 | "name": "stdout",
130 | "text": [
131 | "\n",
132 | "\n",
133 | "1. Tokyo, Japan\n",
134 | "2. Beijing, China\n",
135 | "3. Singapore\n",
136 | "4. Zurich, Switzerland\n",
137 | "5. Hong Kong, China\n"
138 | ]
139 | }
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "source": [
145 | "llm_1 = OpenAI(model_name=\"gpt-3.5-turbo\")"
146 | ],
147 | "metadata": {
148 | "id": "ccY2Pm5MIX-7"
149 | },
150 | "execution_count": null,
151 | "outputs": []
152 | },
153 | {
154 | "cell_type": "code",
155 | "source": [
156 | "print(llm_1(\"Tell me a joke\"))"
157 | ],
158 | "metadata": {
159 | "colab": {
160 | "base_uri": "https://localhost:8080/"
161 | },
162 | "id": "4-vtyaxqIt9N",
163 | "outputId": "213d117e-e3dd-46c7-d28a-91c66bd95f33"
164 | },
165 | "execution_count": 8,
166 | "outputs": [
167 | {
168 | "output_type": "stream",
169 | "name": "stdout",
170 | "text": [
171 | "Why don't scientists trust atoms? \n",
172 | "Because they make up everything!\n"
173 | ]
174 | }
175 | ]
176 | },
177 | {
178 | "cell_type": "markdown",
179 | "source": [
180 | "# Prompt Templates & Chains"
181 | ],
182 | "metadata": {
183 | "id": "aeqNlevBaAn6"
184 | }
185 | },
186 | {
187 | "cell_type": "code",
188 | "source": [
189 | "from langchain.prompts import PromptTemplate"
190 | ],
191 | "metadata": {
192 | "id": "w7oLfzVvJIrK"
193 | },
194 | "execution_count": 9,
195 | "outputs": []
196 | },
197 | {
198 | "cell_type": "code",
199 | "source": [
200 | "prompt = PromptTemplate(\n",
201 | " input_variables=[\"input\"],\n",
202 | " template = \"Which are the 5 most {input} capital cities?\"\n",
203 | ")"
204 | ],
205 | "metadata": {
206 | "id": "jAeR5an0JcwT"
207 | },
208 | "execution_count": 10,
209 | "outputs": []
210 | },
211 | {
212 | "cell_type": "code",
213 | "source": [
214 | "print(prompt.format(input=\"popular\"))"
215 | ],
216 | "metadata": {
217 | "colab": {
218 | "base_uri": "https://localhost:8080/"
219 | },
220 | "id": "jnBacugyKDgw",
221 | "outputId": "eb12b493-fd55-448b-9e84-2d20143cd0a1"
222 | },
223 | "execution_count": 11,
224 | "outputs": [
225 | {
226 | "output_type": "stream",
227 | "name": "stdout",
228 | "text": [
229 | "Which are the 5 most popular capital cities?\n"
230 | ]
231 | }
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "source": [
237 | "# Creating Chains"
238 | ],
239 | "metadata": {
240 | "id": "UozkgL4TaJAd"
241 | }
242 | },
243 | {
244 | "cell_type": "code",
245 | "source": [
246 | "from langchain.chains import LLMChain"
247 | ],
248 | "metadata": {
249 | "id": "FmFLhs5aLB5X"
250 | },
251 | "execution_count": 12,
252 | "outputs": []
253 | },
254 | {
255 | "cell_type": "code",
256 | "source": [
257 | "llm = OpenAI(temperature=0.7)"
258 | ],
259 | "metadata": {
260 | "id": "BhKV3ZeOLLuE"
261 | },
262 | "execution_count": 13,
263 | "outputs": []
264 | },
265 | {
266 | "cell_type": "code",
267 | "source": [
268 | "prompt=PromptTemplate(\n",
269 | " input_variables=[\"country\"],\n",
270 | " template=\"where is the capital of {country}\"\n",
271 | ")"
272 | ],
273 | "metadata": {
274 | "id": "fs7oIdqwSKRR"
275 | },
276 | "execution_count": 14,
277 | "outputs": []
278 | },
279 | {
280 | "cell_type": "code",
281 | "source": [
282 | "chain = LLMChain(llm=llm, prompt=prompt)"
283 | ],
284 | "metadata": {
285 | "id": "N-j3BRkhSvVA"
286 | },
287 | "execution_count": 15,
288 | "outputs": []
289 | },
290 | {
291 | "cell_type": "code",
292 | "source": [
293 | "print(chain.run(\"USA\"))"
294 | ],
295 | "metadata": {
296 | "colab": {
297 | "base_uri": "https://localhost:8080/"
298 | },
299 | "id": "E5k6F7_YS93-",
300 | "outputId": "e946aef3-ce3d-4442-86cf-d682433d3577"
301 | },
302 | "execution_count": 16,
303 | "outputs": [
304 | {
305 | "output_type": "stream",
306 | "name": "stdout",
307 | "text": [
308 | "\n",
309 | "\n",
310 | "Washington, D.C. is the capital of the United States of America.\n"
311 | ]
312 | }
313 | ]
314 | },
315 | {
316 | "cell_type": "markdown",
317 | "source": [
318 | "# Combining Chains"
319 | ],
320 | "metadata": {
321 | "id": "TbiTlAJ4aMr2"
322 | }
323 | },
324 | {
325 | "cell_type": "code",
326 | "source": [
327 | "llm = OpenAI(temperature=0)"
328 | ],
329 | "metadata": {
330 | "id": "4aTVCQsTTMlk"
331 | },
332 | "execution_count": 17,
333 | "outputs": []
334 | },
335 | {
336 | "cell_type": "code",
337 | "source": [
338 | "from langchain.agents import load_tools"
339 | ],
340 | "metadata": {
341 | "id": "0WIvU9iMTds5"
342 | },
343 | "execution_count": 18,
344 | "outputs": []
345 | },
346 | {
347 | "cell_type": "code",
348 | "source": [
349 | "!pip install -q google-search-results"
350 | ],
351 | "metadata": {
352 | "id": "zhE5nBzXXMG4"
353 | },
354 | "execution_count": 19,
355 | "outputs": []
356 | },
357 | {
358 | "cell_type": "code",
359 | "source": [
360 | "os.environ[\"SERPAPI_API_KEY\"]=\"Your-API-Key\""
361 | ],
362 | "metadata": {
363 | "id": "apWCa-yoXY-o"
364 | },
365 | "execution_count": 20,
366 | "outputs": []
367 | },
368 | {
369 | "cell_type": "code",
370 | "source": [
371 | "tools = load_tools([\"serpapi\",\"llm-math\"], llm=llm)"
372 | ],
373 | "metadata": {
374 | "id": "Gr8ZdtBSYA3C"
375 | },
376 | "execution_count": 21,
377 | "outputs": []
378 | },
379 | {
380 | "cell_type": "code",
381 | "source": [
382 | "from langchain.agents import initialize_agent\n",
383 | "from langchain.agents import AgentType"
384 | ],
385 | "metadata": {
386 | "id": "t2mWKkToYTJ-"
387 | },
388 | "execution_count": 22,
389 | "outputs": []
390 | },
391 | {
392 | "cell_type": "code",
393 | "source": [
394 | "agent=initialize_agent(tools, llm,\n",
395 | " agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,\n",
396 | " verbose=True)"
397 | ],
398 | "metadata": {
399 | "id": "Cvn7yshvYfbV"
400 | },
401 | "execution_count": 23,
402 | "outputs": []
403 | },
404 | {
405 | "cell_type": "code",
406 | "source": [
407 | "agent.run(\"who is the director of the walking dead series? what is his current age raised to the 0.35 power\")"
408 | ],
409 | "metadata": {
410 | "colab": {
411 | "base_uri": "https://localhost:8080/",
412 | "height": 354
413 | },
414 | "id": "HLtWXKZ2YvW-",
415 | "outputId": "b00d82cc-9861-4087-a6b2-3684cca34c92"
416 | },
417 | "execution_count": 24,
418 | "outputs": [
419 | {
420 | "output_type": "stream",
421 | "name": "stderr",
422 | "text": [
423 | "WARNING:langchain.callbacks.manager:Error in on_chain_start callback: 'name'\n"
424 | ]
425 | },
426 | {
427 | "output_type": "stream",
428 | "name": "stdout",
429 | "text": [
430 | "\u001b[32;1m\u001b[1;3m I need to find out who the director is and then calculate his age raised to the 0.35 power\n",
431 | "Action: Search\n",
432 | "Action Input: \"director of the walking dead series\"\u001b[0m\n",
433 | "Observation: \u001b[36;1m\u001b[1;3mDarabont Ferenc, better known as Frank Darabont, is an Academy Award winning Hungarian-American director, screenwriter and producer.\u001b[0m\n",
434 | "Thought:\u001b[32;1m\u001b[1;3m I need to find out his age\n",
435 | "Action: Search\n",
436 | "Action Input: \"Frank Darabont age\"\u001b[0m\n",
437 | "Observation: \u001b[36;1m\u001b[1;3m64 years\u001b[0m\n",
438 | "Thought:\u001b[32;1m\u001b[1;3m I need to calculate his age raised to the 0.35 power\n",
439 | "Action: Calculator\n",
440 | "Action Input: 64^0.35\u001b[0m\n",
441 | "Observation: \u001b[33;1m\u001b[1;3mAnswer: 4.2870938501451725\u001b[0m\n",
442 | "Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
443 | "Final Answer: Frank Darabont is 64 years old and his age raised to the 0.35 power is 4.2870938501451725.\u001b[0m\n",
444 | "\n",
445 | "\u001b[1m> Finished chain.\u001b[0m\n"
446 | ]
447 | },
448 | {
449 | "output_type": "execute_result",
450 | "data": {
451 | "text/plain": [
452 | "'Frank Darabont is 64 years old and his age raised to the 0.35 power is 4.2870938501451725.'"
453 | ],
454 | "application/vnd.google.colaboratory.intrinsic+json": {
455 | "type": "string"
456 | }
457 | },
458 | "metadata": {},
459 | "execution_count": 24
460 | }
461 | ]
462 | },
463 | {
464 | "cell_type": "markdown",
465 | "source": [
466 | "Thanks for reading.\n",
467 | "\n",
468 | "Let's connect [YouTube](http://youtube.com/tirendazacademy) | [Medium](http://tirendazacademy.medium.com) | [Twitter](http://twitter.com/tirendazacademy) | [Linkedin](https://www.linkedin.com/in/tirendaz-academy)"
469 | ],
470 | "metadata": {
471 | "id": "ZvhoWvMCaPh8"
472 | }
473 | }
474 | ]
475 | }
--------------------------------------------------------------------------------
/Creating-a-Vector-Store.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyOStgzUDPpKri0l9rJ30dJG",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Creating a Vector Store (Vector Database)"
33 | ],
34 | "metadata": {
35 | "id": "xHVC_PSQoT_T"
36 | }
37 | },
38 | {
39 | "cell_type": "code",
40 | "source": [
41 | "%pip install -q langchain openai chromadb tiktoken"
42 | ],
43 | "metadata": {
44 | "colab": {
45 | "base_uri": "https://localhost:8080/"
46 | },
47 | "id": "HY0JZuTPnRKW",
48 | "outputId": "7a909860-13fd-4f0e-f60a-a12ccedc2d95"
49 | },
50 | "execution_count": 1,
51 | "outputs": [
52 | {
53 | "output_type": "stream",
54 | "name": "stdout",
55 | "text": [
56 | "\u001b[?25l \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m0.0/1.3 MB\u001b[0m \u001b[31m?\u001b[0m eta \u001b[36m-:--:--\u001b[0m\r\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m1.3/1.3 MB\u001b[0m \u001b[31m48.5 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
57 | "\u001b[?25h\u001b[?25l \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m0.0/73.6 kB\u001b[0m \u001b[31m?\u001b[0m eta \u001b[36m-:--:--\u001b[0m\r\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m73.6/73.6 kB\u001b[0m \u001b[31m6.5 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
58 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m396.4/396.4 kB\u001b[0m \u001b[31m29.5 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
59 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m1.7/1.7 MB\u001b[0m \u001b[31m81.4 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
60 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m90.0/90.0 kB\u001b[0m \u001b[31m8.8 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
61 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m62.6/62.6 kB\u001b[0m \u001b[31m6.2 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
62 | "\u001b[?25h Installing build dependencies ... \u001b[?25l\u001b[?25hdone\n",
63 | " Getting requirements to build wheel ... \u001b[?25l\u001b[?25hdone\n",
64 | " Preparing metadata (pyproject.toml) ... \u001b[?25l\u001b[?25hdone\n",
65 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m966.7/966.7 kB\u001b[0m \u001b[31m3.6 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
66 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m55.4/55.4 kB\u001b[0m \u001b[31m5.0 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
67 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m59.6/59.6 kB\u001b[0m \u001b[31m5.1 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
68 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m5.3/5.3 MB\u001b[0m \u001b[31m94.4 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
69 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m5.9/5.9 MB\u001b[0m \u001b[31m106.2 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
70 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m7.8/7.8 MB\u001b[0m \u001b[31m105.9 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
71 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m63.6/63.6 kB\u001b[0m \u001b[31m5.4 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
72 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m2.7/2.7 MB\u001b[0m \u001b[31m90.1 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
73 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m1.3/1.3 MB\u001b[0m \u001b[31m73.8 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
74 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m49.1/49.1 kB\u001b[0m \u001b[31m3.9 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
75 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m46.0/46.0 kB\u001b[0m \u001b[31m2.9 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
76 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m58.3/58.3 kB\u001b[0m \u001b[31m5.4 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
77 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m428.8/428.8 kB\u001b[0m \u001b[31m29.7 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
78 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m4.1/4.1 MB\u001b[0m \u001b[31m92.2 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
79 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m1.3/1.3 MB\u001b[0m \u001b[31m74.3 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
80 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m129.9/129.9 kB\u001b[0m \u001b[31m12.6 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
81 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m86.8/86.8 kB\u001b[0m \u001b[31m7.0 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
82 | "\u001b[?25h Building wheel for hnswlib (pyproject.toml) ... \u001b[?25l\u001b[?25hdone\n",
83 | "\u001b[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\n",
84 | "google-colab 1.0.0 requires requests==2.27.1, but you have requests 2.31.0 which is incompatible.\u001b[0m\u001b[31m\n",
85 | "\u001b[0m"
86 | ]
87 | }
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "source": [
93 | "import openai\n",
94 | "import os\n",
95 | "\n",
96 | "os.environ[\"OPENAI_API_KEY\"] = \"...\"\n",
97 | "openai.api_key = os.getenv(\"OPENAI_API_KEY\")"
98 | ],
99 | "metadata": {
100 | "id": "3szTdoSdlu8b"
101 | },
102 | "execution_count": 2,
103 | "outputs": []
104 | },
105 | {
106 | "cell_type": "markdown",
107 | "source": [
108 | "## Collect data that we want to use to answer the users’ questions\n",
109 | "\n",
110 | "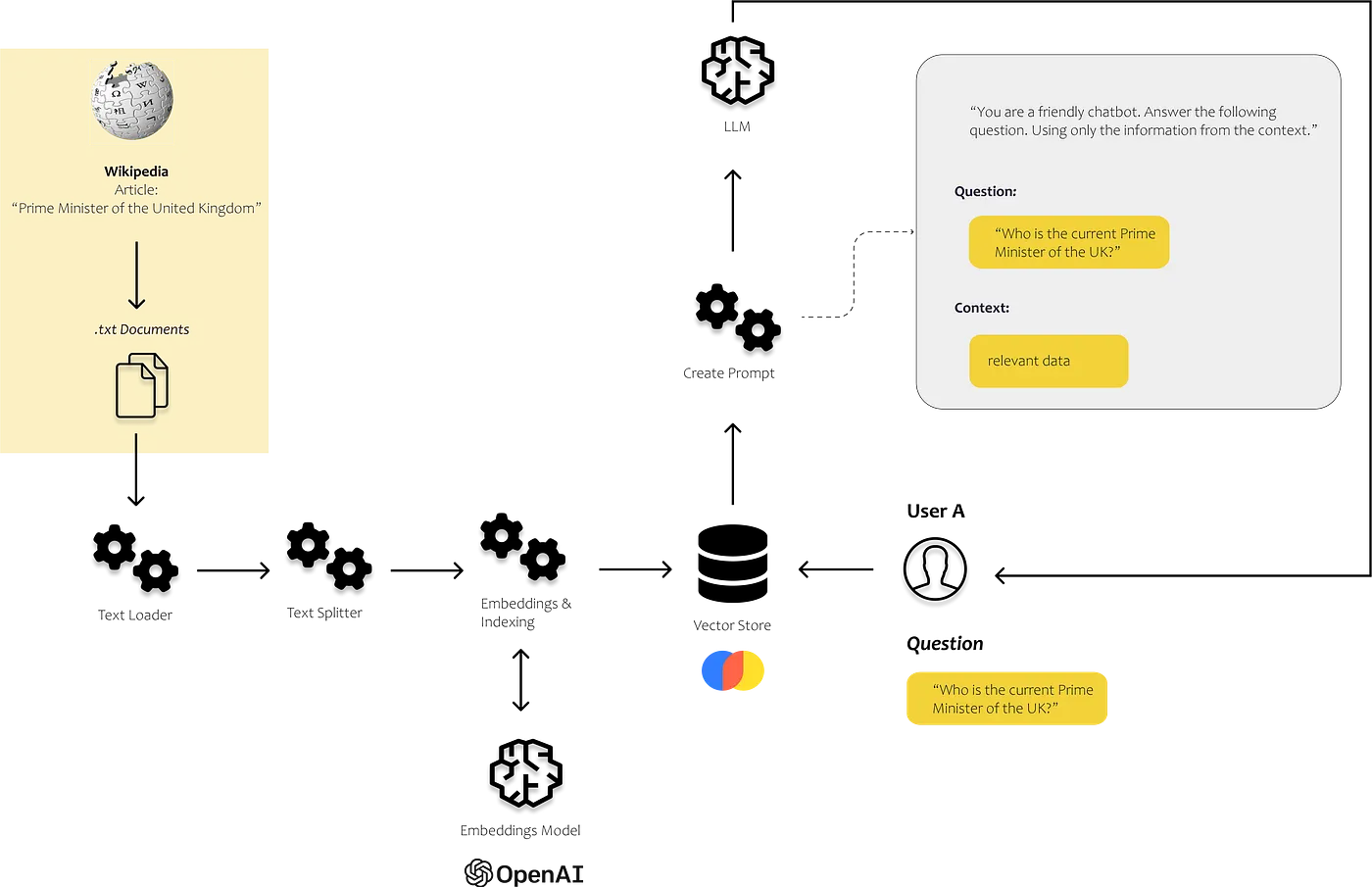"
111 | ],
112 | "metadata": {
113 | "id": "ju-ndba0olal"
114 | }
115 | },
116 | {
117 | "cell_type": "code",
118 | "source": [
119 | "import requests\n",
120 | "from bs4 import BeautifulSoup\n",
121 | "from langchain.embeddings.openai import OpenAIEmbeddings\n",
122 | "from langchain.text_splitter import CharacterTextSplitter\n",
123 | "from langchain.vectorstores import Chroma\n",
124 | "from langchain.document_loaders import TextLoader\n",
125 | "\n",
126 | "# URL of the Wikipedia page to scrape\n",
127 | "url = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'\n",
128 | "\n",
129 | "# Send a GET request to the URL\n",
130 | "response = requests.get(url)\n",
131 | "\n",
132 | "# Parse the HTML content using BeautifulSoup\n",
133 | "soup = BeautifulSoup(response.content, 'html.parser')\n",
134 | "\n",
135 | "# Find all the text on the page\n",
136 | "text = soup.get_text()\n",
137 | "text = text.replace('\\n', '')\n",
138 | "\n",
139 | "# Open a new file called 'output.txt' in write mode and store the file object in a variable\n",
140 | "with open('output.txt', 'w', encoding='utf-8') as file:\n",
141 | " # Write the string to the file\n",
142 | " file.write(text)"
143 | ],
144 | "metadata": {
145 | "id": "uAjB4BUZoFlT"
146 | },
147 | "execution_count": 3,
148 | "outputs": []
149 | },
150 | {
151 | "cell_type": "code",
152 | "source": [
153 | "text[:100]"
154 | ],
155 | "metadata": {
156 | "colab": {
157 | "base_uri": "https://localhost:8080/",
158 | "height": 35
159 | },
160 | "id": "kW9CzRDao4AJ",
161 | "outputId": "1addbbc4-0d22-4689-88ed-72abc60fec30"
162 | },
163 | "execution_count": 4,
164 | "outputs": [
165 | {
166 | "output_type": "execute_result",
167 | "data": {
168 | "text/plain": [
169 | "'Prime Minister of the United Kingdom - WikipediaJump to contentMain menuMain menumove to sidebarhide'"
170 | ],
171 | "application/vnd.google.colaboratory.intrinsic+json": {
172 | "type": "string"
173 | }
174 | },
175 | "metadata": {},
176 | "execution_count": 4
177 | }
178 | ]
179 | },
180 | {
181 | "cell_type": "markdown",
182 | "source": [
183 | "## Load the data and define how you want to split the data into text chunks\n",
184 | "\n",
185 | "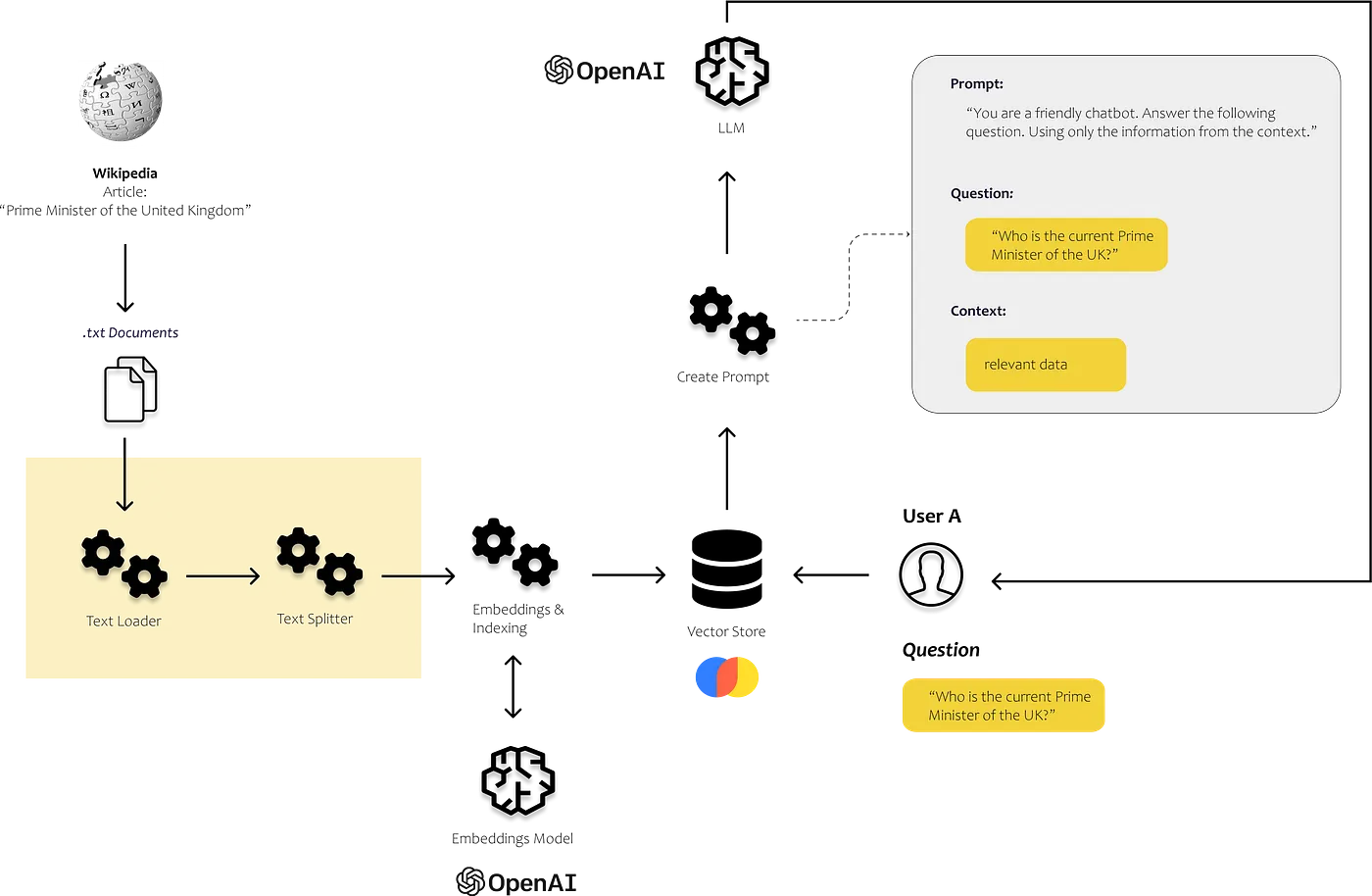"
186 | ],
187 | "metadata": {
188 | "id": "aAXUUfrOpLLg"
189 | }
190 | },
191 | {
192 | "cell_type": "code",
193 | "source": [
194 | "from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
195 | "\n",
196 | "# load the document\n",
197 | "with open('./output.txt', encoding='utf-8') as f:\n",
198 | " text = f.read()\n",
199 | "\n",
200 | "# define the text splitter\n",
201 | "text_splitter = RecursiveCharacterTextSplitter(\n",
202 | " chunk_size = 500,\n",
203 | " chunk_overlap = 100,\n",
204 | " length_function = len,\n",
205 | ")\n",
206 | "\n",
207 | "texts = text_splitter.create_documents([text])"
208 | ],
209 | "metadata": {
210 | "id": "1a35DSGbo8Ty"
211 | },
212 | "execution_count": 5,
213 | "outputs": []
214 | },
215 | {
216 | "cell_type": "code",
217 | "source": [
218 | "for text in texts[:3]:\n",
219 | " print(text)"
220 | ],
221 | "metadata": {
222 | "colab": {
223 | "base_uri": "https://localhost:8080/"
224 | },
225 | "id": "89WR4YZfqL1H",
226 | "outputId": "a0d0f778-6f16-4c8c-c6a5-283d271f5436"
227 | },
228 | "execution_count": 6,
229 | "outputs": [
230 | {
231 | "output_type": "stream",
232 | "name": "stdout",
233 | "text": [
234 | "page_content='Prime Minister of the United Kingdom - WikipediaJump to contentMain menuMain menumove to sidebarhide\\t\\tNavigation\\tMain pageContentsCurrent eventsRandom articleAbout WikipediaContact usDonate\\t\\tContribute\\tHelpLearn to editCommunity portalRecent changesUpload fileLanguagesLanguage links are at the top of the page across from the title.SearchSearchCreate accountLog inPersonal tools Create account Log inPages for logged out editors learn moreContributionsTalkContentsmove to' metadata={}\n",
235 | "page_content=\"tools Create account Log inPages for logged out editors learn moreContributionsTalkContentsmove to sidebarhide(Top)1History2Authority, powers and constraints3Constitutional background4Modern premiershipToggle Modern premiership subsection4.1Appointment4.2Prime Minister's Office4.3Prime Minister's Questions4.4Security and transport4.5International role4.6Deputy4.6.1Succession4.7Resignation5Precedence, privileges and form of address6Retirement honours7Public Duty Costs Allowance (PDCA)8See\" metadata={}\n",
236 | "page_content='privileges and form of address6Retirement honours7Public Duty Costs Allowance (PDCA)8See alsoToggle See also subsection8.1Lists of prime ministers by different criteria8.2Other related pages9Notes10ReferencesToggle References subsection10.1Works cited11Further reading12External linksToggle the table of contentsToggle the table of contentsPrime Minister of the United Kingdom84' metadata={}\n"
237 | ]
238 | }
239 | ]
240 | },
241 | {
242 | "cell_type": "markdown",
243 | "source": [
244 | "## Define the Embeddings Model you want to use to calculate the embeddings for your text chunks and store them in a vector store\n",
245 | "\n",
246 | ""
247 | ],
248 | "metadata": {
249 | "id": "tRa1L9Vtqjqt"
250 | }
251 | },
252 | {
253 | "cell_type": "code",
254 | "source": [
255 | "from langchain.embeddings.openai import OpenAIEmbeddings\n",
256 | "from langchain.vectorstores import Chroma\n",
257 | "\n",
258 | "# define the embeddings model\n",
259 | "embeddings = OpenAIEmbeddings()\n",
260 | "\n",
261 | "# use the text chunks and the embeddings model to fill our vector store\n",
262 | "db = Chroma.from_documents(texts, embeddings)"
263 | ],
264 | "metadata": {
265 | "id": "brqCzXQLqjcq"
266 | },
267 | "execution_count": 7,
268 | "outputs": []
269 | },
270 | {
271 | "cell_type": "markdown",
272 | "source": [
273 | "## Calculate the embeddings for the user’s question, find similar text chunks in our vector store and use them to build our prompt\n",
274 | "\n",
275 | "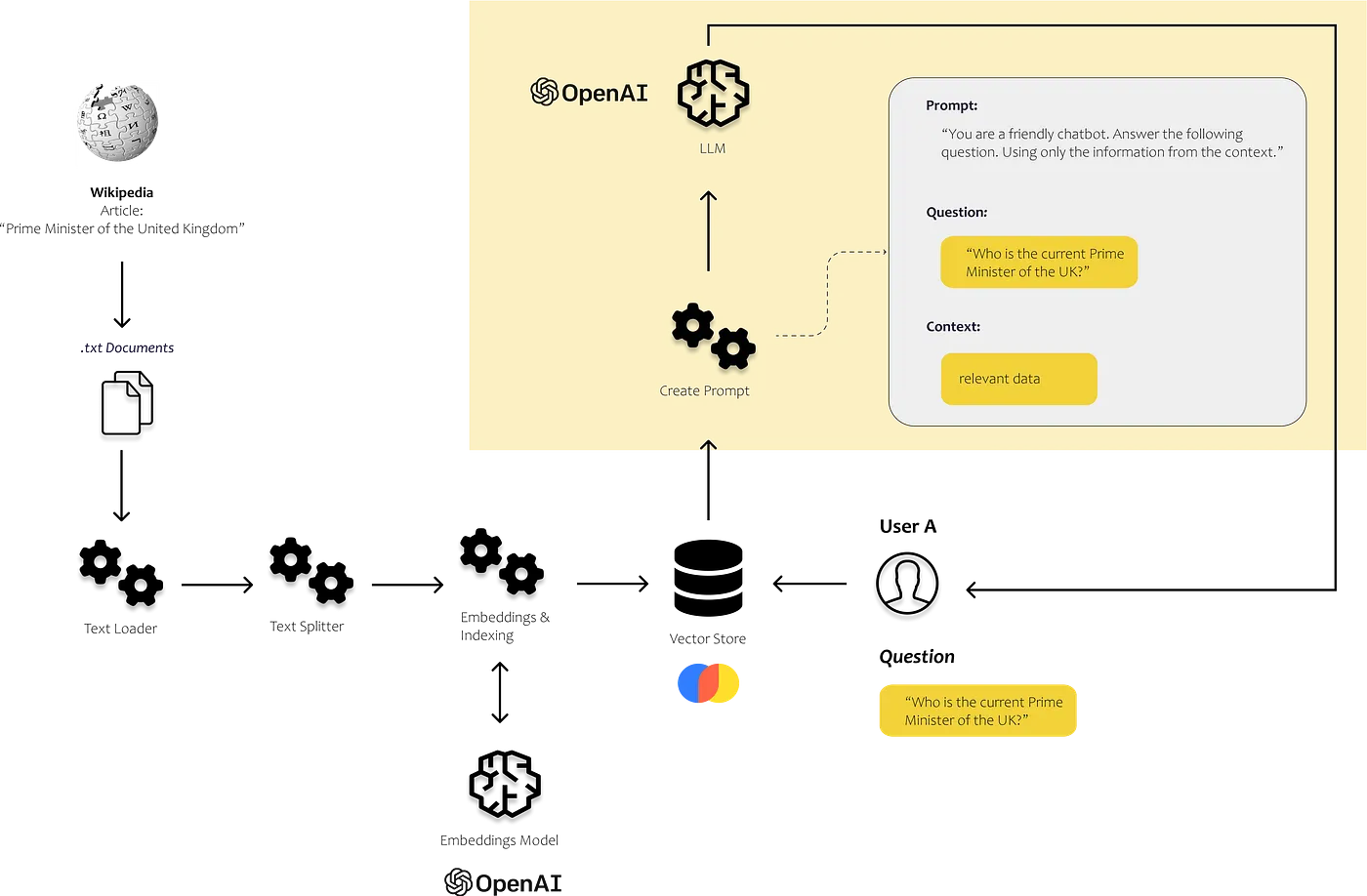"
276 | ],
277 | "metadata": {
278 | "id": "5ari5pv7uFE_"
279 | }
280 | },
281 | {
282 | "cell_type": "code",
283 | "source": [
284 | "from langchain.llms import OpenAI\n",
285 | "from langchain import PromptTemplate\n",
286 | "\n",
287 | "users_question = \"Who is the current Prime Minister of the UK?\"\n",
288 | "\n",
289 | "# use our vector store to find similar text chunks\n",
290 | "results = db.similarity_search(\n",
291 | " query=users_question,\n",
292 | " n_results=5\n",
293 | ")\n",
294 | "\n",
295 | "# define the prompt template\n",
296 | "template = \"\"\"\n",
297 | "You are a chat bot who loves to help people! Given the following context sections, answer the\n",
298 | "question using only the given context. If you are unsure and the answer is not\n",
299 | "explicitly writting in the documentation, say \"Sorry, I don't know how to help with that.\"\n",
300 | "\n",
301 | "Context sections:\n",
302 | "{context}\n",
303 | "\n",
304 | "Question:\n",
305 | "{users_question}\n",
306 | "\n",
307 | "Answer:\n",
308 | "\"\"\"\n",
309 | "\n",
310 | "prompt = PromptTemplate(template=template, input_variables=[\"context\", \"users_question\"])\n",
311 | "\n",
312 | "# fill the prompt template\n",
313 | "prompt_text = prompt.format(context = results, users_question = users_question)\n",
314 | "\n",
315 | "# ask the defined LLM\n",
316 | "llm = OpenAI(temperature=1)\n",
317 | "llm(prompt_text)"
318 | ],
319 | "metadata": {
320 | "colab": {
321 | "base_uri": "https://localhost:8080/",
322 | "height": 35
323 | },
324 | "id": "zkUj84BdtVlP",
325 | "outputId": "4a7184f4-47cb-4c49-8f3e-dd39ee45b2b3"
326 | },
327 | "execution_count": 8,
328 | "outputs": [
329 | {
330 | "output_type": "execute_result",
331 | "data": {
332 | "text/plain": [
333 | "'The current Prime Minister of the UK is Rishi Sunak, since 25 October 2022.'"
334 | ],
335 | "application/vnd.google.colaboratory.intrinsic+json": {
336 | "type": "string"
337 | }
338 | },
339 | "metadata": {},
340 | "execution_count": 8
341 | }
342 | ]
343 | },
344 | {
345 | "cell_type": "markdown",
346 | "source": [
347 | "### Resources\n",
348 | "\n",
349 | "- [All You Need to Know to Build Your First LLM App](https://towardsdatascience.com/all-you-need-to-know-to-build-your-first-llm-app-eb982c78ffac)"
350 | ],
351 | "metadata": {
352 | "id": "d34LhEpSvmlQ"
353 | }
354 | }
355 | ]
356 | }
--------------------------------------------------------------------------------
/RAG-with-Chat-History/RAG-with-Chat-History.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Initialize the local model"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "from langchain_community.llms import Ollama \n",
17 | "\n",
18 | "llm = Ollama(model = \"mistral\")"
19 | ]
20 | },
21 | {
22 | "cell_type": "code",
23 | "execution_count": 2,
24 | "metadata": {},
25 | "outputs": [
26 | {
27 | "data": {
28 | "text/plain": [
29 | "\" Why don't scientists trust atoms?\\n\\nBecause they make up everything!\""
30 | ]
31 | },
32 | "execution_count": 2,
33 | "metadata": {},
34 | "output_type": "execute_result"
35 | }
36 | ],
37 | "source": [
38 | "llm.invoke(\"Tell me a short joke\")"
39 | ]
40 | },
41 | {
42 | "cell_type": "markdown",
43 | "metadata": {},
44 | "source": [
45 | "## Load data for RAG"
46 | ]
47 | },
48 | {
49 | "cell_type": "code",
50 | "execution_count": 3,
51 | "metadata": {},
52 | "outputs": [],
53 | "source": [
54 | "from langchain_community.document_loaders import WebBaseLoader \n",
55 | "\n",
56 | "loader = WebBaseLoader(\n",
57 | " web_path=\"https://blog.langchain.dev/langgraph/\"\n",
58 | ")\n",
59 | "\n",
60 | "docs = loader.load()"
61 | ]
62 | },
63 | {
64 | "cell_type": "markdown",
65 | "metadata": {},
66 | "source": [
67 | "## Index the data"
68 | ]
69 | },
70 | {
71 | "cell_type": "code",
72 | "execution_count": 4,
73 | "metadata": {},
74 | "outputs": [],
75 | "source": [
76 | "from langchain_text_splitters import RecursiveCharacterTextSplitter \n",
77 | "\n",
78 | "text_splitter = RecursiveCharacterTextSplitter(\n",
79 | " chunk_size = 1000,\n",
80 | " chunk_overlap = 200,\n",
81 | " add_start_index = True \n",
82 | ")"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 5,
88 | "metadata": {},
89 | "outputs": [],
90 | "source": [
91 | "all_splits = text_splitter.split_documents(docs)"
92 | ]
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": 6,
97 | "metadata": {},
98 | "outputs": [],
99 | "source": [
100 | "from langchain_community import embeddings \n",
101 | "\n",
102 | "embedding = embeddings.ollama.OllamaEmbeddings(\n",
103 | " model=\"nomic-embed-text\"\n",
104 | ")"
105 | ]
106 | },
107 | {
108 | "cell_type": "code",
109 | "execution_count": 7,
110 | "metadata": {},
111 | "outputs": [],
112 | "source": [
113 | "from langchain_community.vectorstores import Chroma \n",
114 | "\n",
115 | "vectorstore = Chroma.from_documents(\n",
116 | " documents = all_splits,\n",
117 | " embedding = embedding\n",
118 | ")"
119 | ]
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": 8,
124 | "metadata": {},
125 | "outputs": [],
126 | "source": [
127 | "retriever = vectorstore.as_retriever(\n",
128 | " search_type = \"similarity\",\n",
129 | " search_kwargs = {\"k\":6}\n",
130 | ")"
131 | ]
132 | },
133 | {
134 | "cell_type": "code",
135 | "execution_count": 9,
136 | "metadata": {},
137 | "outputs": [
138 | {
139 | "data": {
140 | "text/plain": [
141 | "[Document(page_content='\"model\",\\n should_continue,\\n {\\n \"end\": END,\\n \"continue\": \"tools\"\\n }\\n)CompileAfter we define our graph, we can compile it into a runnable! This simply takes the graph definition we\\'ve created so far an returns a runnable. This runnable exposes all the same method as LangChain runnables (.invoke, .stream, .astream_log, etc) allowing it to be called in the same manner as a chain.app = graph.compile()Agent ExecutorWe\\'ve recreated the canonical LangChain AgentExecutor with LangGraph. This will allow you to use existing LangChain agents, but allow you to more easily modify the internals of the AgentExecutor. The state of this graph by default contains concepts that should be familiar to you if you\\'ve used LangChain agents: input, chat_history, intermediate_steps (and agent_outcome to represent the most recent agent outcome)from typing import TypedDict, Annotated, List, Union\\nfrom langchain_core.agents import AgentAction, AgentFinish', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 7622, 'title': 'LangGraph'}),\n",
142 | " Document(page_content='LangGraph\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nSkip to content\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nBy LangChain\\n\\n\\n\\n\\nRelease Notes\\n\\n\\n\\n\\nCase Studies\\n\\n\\n\\n\\nLangChain\\n\\n\\n\\n\\nGitHub\\n\\n\\n\\n\\nDocs\\n\\n\\n\\n\\n\\nSign in\\nSubscribe\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nLangGraph\\n\\nBy LangChain\\n7 min read\\nJan 17, 2024', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 3, 'title': 'LangGraph'}),\n",
143 | " Document(page_content=\"agent return output in a specific format using function calling. Only for Chat Agent Executor.Dynamically Returning the Output of a Tool DirectlySometimes you may want to return the output of a tool directly. We provide an easy way to do with the return_direct parameter in LangChain. However, this makes it so that the output of a tool is ALWAYS returned directly. Sometimes, you may want to let the LLM choose whether to return the response directly or not. Only for Chat Agent Executor.Future WorkWe're incredibly excited about the possibility of LangGraph enabling more custom and powerful agent runtimes. Some of the things we are looking to implement in the near future:More advanced agent runtimes from academia (LLM Compiler, plan-and-solve, etc)Stateful tools (allowing tools to modify some state)More controlled human-in-the-loop workflowsMulti-agent workflowsIf any of these resonate with you, please feel free to add an example notebook in the LangGraph repo, or reach out to us at\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 10390, 'title': 'LangGraph'}),\n",
144 | " Document(page_content=\"messages: Annotated[Sequence[BaseMessage], operator.add] See this notebook for how to get startedModificationsOne of the big benefits of LangGraph is that it exposes the logic of AgentExecutor in a far more natural and modifiable way. We've provided a few examples of modifications that we've heard requests for:Force Calling a ToolFor when you always want to make an agent call a tool first. For Agent Executor and Chat Agent Executor.Human-in-the-loopHow to add a human-in-the-loop step before calling tools. For Agent Executor and Chat Agent Executor.Managing Agent StepsFor adding custom logic on how to handle the intermediate steps an agent might take (useful for when there's a lot of steps). For Agent Executor and Chat Agent Executor.Returning Output in a Specific FormatHow to make the agent return output in a specific format using function calling. Only for Chat Agent Executor.Dynamically Returning the Output of a Tool DirectlySometimes you may want to return the output of a tool\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 9594, 'title': 'LangGraph'}),\n",
145 | " Document(page_content=\"TL;DR: LangGraph is module built on top of LangChain to better enable creation of cyclical graphs, often needed for agent runtimes.Python RepoPython YouTube PlaylistJS RepoIntroductionOne of the things we highlighted in our LangChain v0.1 announcement was the introduction of a new library: LangGraph. LangGraph is built on top of LangChain and completely interoperable with the LangChain ecosystem. It adds new value primarily through the introduction of an easy way to create cyclical graphs. This is often useful when creating agent runtimes.In this blog post, we will first walk through the motivations for LangGraph. We will then cover the basic functionality it provides. We will then spotlight two agent runtimes we've implemented already. We will then highlight a few of the common modifications to these runtimes we've heard requests for, and examples of implementing those. We will finish with a preview of what we will be releasing next.MotivationOne of the big value props of LangChain\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 273, 'title': 'LangGraph'}),\n",
146 | " Document(page_content='thing we\\'ve seen in practice as we\\'ve worked the community and companies to put agents into production is that often times more control is needed. You may want to always force an agent to call particular tool first. You may want have more control over how tools are called. You may want to have different prompts for the agent, depending on that state it is in.When talking about these more controlled flows, we internally refer to them as \"state machines\". See the below diagram from our blog on cognitive architectures.These state machines have the power of being able to loop - allowing for handling of more ambiguous inputs than simple chains. However, there is still an element of human guidance in terms of how that loop is constructed.LangGraph is a way to create these state machines by specifying them as graphs.FunctionalityAt it\\'s core, LangGraph exposes a pretty narrow interface on top of LangChain.StateGraphStateGraph is a class that represents the graph. You initialize this class by', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 3476, 'title': 'LangGraph'})]"
147 | ]
148 | },
149 | "execution_count": 9,
150 | "metadata": {},
151 | "output_type": "execute_result"
152 | }
153 | ],
154 | "source": [
155 | "retriever.get_relevant_documents(\"What is LangGraph?\")"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "metadata": {},
161 | "source": [
162 | "## Create a chain to contextualize"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 10,
168 | "metadata": {},
169 | "outputs": [],
170 | "source": [
171 | "from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder \n",
172 | "\n",
173 | "contextualize_q_system_prompt = \"\"\"Given a chat history and the latest user question \\\n",
174 | "which might reference context in the chat history, formulate a standalone question \\\n",
175 | "which can be understood without the chat history. Do NOT answer the question, \\\n",
176 | "just reformulate it if needed and otherwise return it as is.\"\"\""
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": 11,
182 | "metadata": {},
183 | "outputs": [],
184 | "source": [
185 | "contextualize_q_prompt= ChatPromptTemplate.from_messages(\n",
186 | " [\n",
187 | " (\"system\", contextualize_q_system_prompt),\n",
188 | " MessagesPlaceholder(variable_name=\"chat_history\"),\n",
189 | " (\"human\", \"{question}\"),\n",
190 | " ]\n",
191 | ")"
192 | ]
193 | },
194 | {
195 | "cell_type": "code",
196 | "execution_count": 12,
197 | "metadata": {},
198 | "outputs": [],
199 | "source": [
200 | "from langchain_core.output_parsers import StrOutputParser\n",
201 | "\n",
202 | "contextualize_q_chain = contextualize_q_prompt | llm | StrOutputParser()"
203 | ]
204 | },
205 | {
206 | "cell_type": "code",
207 | "execution_count": 13,
208 | "metadata": {},
209 | "outputs": [
210 | {
211 | "data": {
212 | "text/plain": [
213 | "' Question: What do you mean by \"large\" in the context of a \"large language model\"?'"
214 | ]
215 | },
216 | "execution_count": 13,
217 | "metadata": {},
218 | "output_type": "execute_result"
219 | }
220 | ],
221 | "source": [
222 | "from langchain_core.messages import AIMessage, HumanMessage\n",
223 | "\n",
224 | "contextualize_q_chain.invoke(\n",
225 | " {\n",
226 | " \"chat_history\":[\n",
227 | " HumanMessage(content=\"What does LLM stand for?\"),\n",
228 | " AIMessage(content=\"Large language model\"),\n",
229 | " ],\n",
230 | " \"question\": \"What is meant by large?\",\n",
231 | " }\n",
232 | ")"
233 | ]
234 | },
235 | {
236 | "cell_type": "markdown",
237 | "metadata": {},
238 | "source": [
239 | "## Create a chain for chat history"
240 | ]
241 | },
242 | {
243 | "cell_type": "code",
244 | "execution_count": 14,
245 | "metadata": {},
246 | "outputs": [],
247 | "source": [
248 | "qa_system_prompt = \"\"\"You are an assistant for question-answering tasks. \\\n",
249 | "Use the following pieces of retrieved context to answer the question. \\\n",
250 | "If you don't know the answer, just say that you don't know. \\\n",
251 | "Use three sentences maximum and keep the answer concise.\\\n",
252 | "\n",
253 | "{context}\"\"\""
254 | ]
255 | },
256 | {
257 | "cell_type": "code",
258 | "execution_count": 15,
259 | "metadata": {},
260 | "outputs": [],
261 | "source": [
262 | "qa_prompt = ChatPromptTemplate.from_messages(\n",
263 | " [\n",
264 | " (\"system\", qa_system_prompt),\n",
265 | " MessagesPlaceholder(variable_name=\"chat_history\"),\n",
266 | " (\"human\", \"{question}\"),\n",
267 | " ]\n",
268 | ")"
269 | ]
270 | },
271 | {
272 | "cell_type": "code",
273 | "execution_count": 16,
274 | "metadata": {},
275 | "outputs": [],
276 | "source": [
277 | "def format_docs(docs):\n",
278 | " return \"\\n\\n\".join(doc.page_content for doc in docs)"
279 | ]
280 | },
281 | {
282 | "cell_type": "code",
283 | "execution_count": 17,
284 | "metadata": {},
285 | "outputs": [],
286 | "source": [
287 | "def contextualized_question(input: dict):\n",
288 | " if input.get(\"chat_history\"):\n",
289 | " return contextualize_q_chain\n",
290 | " else:\n",
291 | " return input[\"question\"]"
292 | ]
293 | },
294 | {
295 | "cell_type": "code",
296 | "execution_count": 18,
297 | "metadata": {},
298 | "outputs": [],
299 | "source": [
300 | "from langchain_core.runnables import RunnablePassthrough\n",
301 | "\n",
302 | "rag_chain = (\n",
303 | " RunnablePassthrough.assign(\n",
304 | " context = contextualized_question | retriever | format_docs\n",
305 | " )\n",
306 | " | qa_prompt \n",
307 | " | llm\n",
308 | ")"
309 | ]
310 | },
311 | {
312 | "cell_type": "markdown",
313 | "metadata": {},
314 | "source": [
315 | "## Inference"
316 | ]
317 | },
318 | {
319 | "cell_type": "code",
320 | "execution_count": 19,
321 | "metadata": {},
322 | "outputs": [],
323 | "source": [
324 | "chat_history = []\n",
325 | "\n",
326 | "question = \"What is LangGraph?\"\n",
327 | "ai_msg = rag_chain.invoke(\n",
328 | " {\n",
329 | " \"question\": question,\n",
330 | " \"chat_history\": chat_history\n",
331 | " }\n",
332 | ")"
333 | ]
334 | },
335 | {
336 | "cell_type": "code",
337 | "execution_count": 20,
338 | "metadata": {},
339 | "outputs": [
340 | {
341 | "data": {
342 | "text/plain": [
343 | "' LangGraph is a module built on top of LangChain, allowing for the creation of cyclical graphs which is useful for agent runtimes. It provides an interface to create state machines specified as graphs and exposes a narrow interface over LangChain.'"
344 | ]
345 | },
346 | "execution_count": 20,
347 | "metadata": {},
348 | "output_type": "execute_result"
349 | }
350 | ],
351 | "source": [
352 | "ai_msg "
353 | ]
354 | },
355 | {
356 | "cell_type": "code",
357 | "execution_count": 21,
358 | "metadata": {},
359 | "outputs": [],
360 | "source": [
361 | "chat_history.extend(\n",
362 | " [\n",
363 | " HumanMessage(content=question), ai_msg\n",
364 | " ]\n",
365 | ")"
366 | ]
367 | },
368 | {
369 | "cell_type": "code",
370 | "execution_count": 22,
371 | "metadata": {},
372 | "outputs": [
373 | {
374 | "data": {
375 | "text/plain": [
376 | "' LangGraph is a Python module built on top of LangChain, designed to enable the creation of cyclical graphs, which is particularly useful for agent runtimes. It provides an interface to create state machines specified as graphs and exposes a narrow interface over LangChain. LangGraph allows for modifications such as forcing tool calls, adding human-in-the-loop steps, managing agent steps, and returning output in specific formats, among other things.'"
377 | ]
378 | },
379 | "execution_count": 22,
380 | "metadata": {},
381 | "output_type": "execute_result"
382 | }
383 | ],
384 | "source": [
385 | "second_question = \"What is it used for?\"\n",
386 | "\n",
387 | "rag_chain.invoke(\n",
388 | " {\n",
389 | " \"question\": second_question,\n",
390 | " \"chat_history\": chat_history\n",
391 | " }\n",
392 | ")"
393 | ]
394 | },
395 | {
396 | "cell_type": "markdown",
397 | "metadata": {},
398 | "source": [
399 | "Let's connect [YouTube](http://youtube.com/tirendazacademy) | [Medium](http://tirendazacademy.medium.com) | [X](http://x.com/tirendazacademy) | [Linkedin](https://www.linkedin.com/in/tirendaz-academy) 😎"
400 | ]
401 | }
402 | ],
403 | "metadata": {
404 | "kernelspec": {
405 | "display_name": "genai",
406 | "language": "python",
407 | "name": "python3"
408 | },
409 | "language_info": {
410 | "codemirror_mode": {
411 | "name": "ipython",
412 | "version": 3
413 | },
414 | "file_extension": ".py",
415 | "mimetype": "text/x-python",
416 | "name": "python",
417 | "nbconvert_exporter": "python",
418 | "pygments_lexer": "ipython3",
419 | "version": "3.11.8"
420 | }
421 | },
422 | "nbformat": 4,
423 | "nbformat_minor": 2
424 | }
425 |
--------------------------------------------------------------------------------
/Chat-With-Any-Document.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "id": "view-in-github",
7 | "colab_type": "text"
8 | },
9 | "source": [
10 | ""
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "metadata": {
16 | "id": "7XaaAFk6QG3Y"
17 | },
18 | "source": [
19 | "# Chat With Anything - From PDFs Files to Image Documents:\n"
20 | ]
21 | },
22 | {
23 | "cell_type": "markdown",
24 | "metadata": {
25 | "id": "tKQRUTBYQG3b"
26 | },
27 | "source": [
28 | "### Install the requirements"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 2,
34 | "metadata": {
35 | "id": "RRYSu48huSUW"
36 | },
37 | "outputs": [],
38 | "source": [
39 | "%%bash\n",
40 | "\n",
41 | "pip -q install langchain faiss-cpu unstructured\n",
42 | "pip -q install openai tiktoken\n",
43 | "pip -q install pytesseract pypdf\n",
44 | "pip -q install unstructured==0.7.12"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "source": [
50 | "!sudo apt install tesseract-ocr"
51 | ],
52 | "metadata": {
53 | "id": "sr6ppS0za7TH"
54 | },
55 | "execution_count": null,
56 | "outputs": []
57 | },
58 | {
59 | "cell_type": "markdown",
60 | "metadata": {
61 | "id": "pX3ndyD8E9hN"
62 | },
63 | "source": [
64 | "# Chat & Query your PDF files"
65 | ]
66 | },
67 | {
68 | "cell_type": "markdown",
69 | "metadata": {
70 | "id": "yhoMomdzQG3c"
71 | },
72 | "source": [
73 | "## Detect Document Type"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 4,
79 | "metadata": {
80 | "id": "vRy_fppZQG3d"
81 | },
82 | "outputs": [],
83 | "source": [
84 | "from filetype import guess\n",
85 | "\n",
86 | "def detect_document_type(document_path):\n",
87 | "\n",
88 | " guess_file = guess(document_path)\n",
89 | " file_type = \"\"\n",
90 | " image_types = ['jpg', 'jpeg', 'png', 'gif']\n",
91 | "\n",
92 | " if(guess_file.extension.lower() == \"pdf\"):\n",
93 | " file_type = \"pdf\"\n",
94 | "\n",
95 | " elif(guess_file.extension.lower() in image_types):\n",
96 | " file_type = \"image\"\n",
97 | "\n",
98 | " else:\n",
99 | " file_type = \"unkown\"\n",
100 | "\n",
101 | " return file_type\n",
102 | ""
103 | ]
104 | },
105 | {
106 | "cell_type": "code",
107 | "execution_count": 5,
108 | "metadata": {
109 | "colab": {
110 | "base_uri": "https://localhost:8080/"
111 | },
112 | "id": "vwfpliJxQG3d",
113 | "outputId": "bdf7e6f3-1397-4ecc-8fae-b03552fdf05c"
114 | },
115 | "outputs": [
116 | {
117 | "output_type": "stream",
118 | "name": "stdout",
119 | "text": [
120 | "Research Paper Type: pdf\n",
121 | "Article Information Document Type: image\n"
122 | ]
123 | }
124 | ],
125 | "source": [
126 | "research_paper_path = \"/content/transformer_paper.pdf\"\n",
127 | "article_information_path = \"/content/rticle_information.png\"\n",
128 | "\n",
129 | "print(f\"Research Paper Type: {detect_document_type(research_paper_path)}\")\n",
130 | "print(f\"Article Information Document Type: {detect_document_type(article_information_path)}\")"
131 | ]
132 | },
133 | {
134 | "cell_type": "markdown",
135 | "metadata": {
136 | "id": "7LGFFT0hQG3e"
137 | },
138 | "source": [
139 | "## Extract Documents Content"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 6,
145 | "metadata": {
146 | "id": "t9_3mkbBQG3f"
147 | },
148 | "outputs": [],
149 | "source": [
150 | "from langchain.document_loaders.image import UnstructuredImageLoader\n",
151 | "from langchain.document_loaders import UnstructuredFileLoader\n",
152 | "\n",
153 | "\"\"\"\n",
154 | "YOU CAN UNCOMMENT THE CODE BELOW TO UNDERSTAND THE LOGIC OF THE FUNCTIONS\n",
155 | "\"\"\"\n",
156 | "\"\"\"\n",
157 | "\n",
158 | "def extract_text_from_pdf(pdf_file):\n",
159 | "\n",
160 | " loader = UnstructuredFileLoader(pdf_file)\n",
161 | " documents = loader.load()\n",
162 | " pdf_pages_content = '\\n'.join(doc.page_content for doc in documents)\n",
163 | "\n",
164 | " return pdf_pages_content\n",
165 | "\n",
166 | "def extract_text_from_image(image_file):\n",
167 | "\n",
168 | " loader = UnstructuredImageLoader(image_file)\n",
169 | " documents = loader.load()\n",
170 | "\n",
171 | " image_content = '\\n'.join(doc.page_content for doc in documents)\n",
172 | "\n",
173 | " return image_content\n",
174 | "\n",
175 | "\n",
176 | "\"\"\"\n",
177 | "\n",
178 | "def extract_file_content(file_path):\n",
179 | "\n",
180 | " file_type = detect_document_type(file_path)\n",
181 | "\n",
182 | " if(file_type == \"pdf\"):\n",
183 | " loader = UnstructuredFileLoader(file_path)\n",
184 | "\n",
185 | " elif(file_type == \"image\"):\n",
186 | " loader = UnstructuredImageLoader(file_path)\n",
187 | "\n",
188 | " documents = loader.load()\n",
189 | " documents_content = '\\n'.join(doc.page_content for doc in documents)\n",
190 | "\n",
191 | " return documents_content"
192 | ]
193 | },
194 | {
195 | "cell_type": "code",
196 | "execution_count": 9,
197 | "metadata": {
198 | "id": "FydMC-fXQG3f"
199 | },
200 | "outputs": [],
201 | "source": [
202 | "#research_paper_content = extract_text_from_pdf(research_paper_path)\n",
203 | "#article_information_content = extract_text_from_image(article_information_path)\n",
204 | "\n",
205 | "\n",
206 | "research_paper_content = extract_file_content(research_paper_path)\n",
207 | "article_information_content = extract_file_content(article_information_path)"
208 | ]
209 | },
210 | {
211 | "cell_type": "code",
212 | "execution_count": 10,
213 | "metadata": {
214 | "colab": {
215 | "base_uri": "https://localhost:8080/"
216 | },
217 | "id": "u9kGWp-hQG3g",
218 | "outputId": "f56460c3-8146-442d-dbdc-e0c00b14b6db"
219 | },
220 | "outputs": [
221 | {
222 | "output_type": "stream",
223 | "name": "stdout",
224 | "text": [
225 | "First 400 Characters of the Paper: \n",
226 | "Provided proper attribution is provided, Google hereby grants permission to reproduce the tables and figures in this paper solely for use in journalistic or scholarly works.\n",
227 | "\n",
228 | "Attention Is All You Need\n",
229 | "\n",
230 | "3 2 0 2\n",
231 | "\n",
232 | "Ashish Vaswani∗ Google Brain avaswani@google.com\n",
233 | "\n",
234 | "Noam Shazeer∗ Google Brain noam@google.com\n",
235 | "\n",
236 | "Niki Parmar∗ Google Research nikip@google.com\n",
237 | "\n",
238 | "Jakob Uszkoreit∗ Google Research usz@google.com\n",
239 | "...\n",
240 | "---------------\n",
241 | "First 400 Characters of Article Information Document :\n",
242 | " Input Files e ‘ File Content in\n",
243 | "\n",
244 | "Raw Format\n",
245 | "\n",
246 | "Raw Bata Splitter\n",
247 | "\n",
248 | "PDF,\n",
249 | "\n",
250 | "File Tyee Detector File Content Extractor DifRerent Chunks of the Raw Data\n",
251 | "\n",
252 | "°\n",
253 | "\n",
254 | "<< }/ oO <\n",
255 | "\n",
256 | "© 6 6\n",
257 | "\n",
258 | "Chunk\n",
259 | "\n",
260 | "Vector Index Transformer\n",
261 | "\n",
262 | "Chunks, Embedlelings\n",
263 | "\n",
264 | "t\n",
265 | "\n",
266 | "See]\n",
267 | "\n",
268 | "Response\n",
269 | "\n",
270 | "‘ =] Q — Author: Zoumana Keita User...\n"
271 | ]
272 | }
273 | ],
274 | "source": [
275 | "nb_characters = 400\n",
276 | "\n",
277 | "print(f\"First {nb_characters} Characters of the Paper: \\n{research_paper_content[:nb_characters]}...\")\n",
278 | "print(\"---\"*5)\n",
279 | "print(f\"First {nb_characters} Characters of Article Information Document :\\n {article_information_content[:nb_characters]}...\")\n"
280 | ]
281 | },
282 | {
283 | "cell_type": "markdown",
284 | "metadata": {
285 | "id": "Ovyvwo4VQG3g"
286 | },
287 | "source": [
288 | "## Chat Implementation"
289 | ]
290 | },
291 | {
292 | "cell_type": "markdown",
293 | "metadata": {
294 | "id": "OjjVV0RnQG3h"
295 | },
296 | "source": [
297 | "### Create Chunks"
298 | ]
299 | },
300 | {
301 | "cell_type": "code",
302 | "execution_count": 11,
303 | "metadata": {
304 | "id": "-Brvp2ACQG3h"
305 | },
306 | "outputs": [],
307 | "source": [
308 | "from langchain.text_splitter import CharacterTextSplitter\n",
309 | "\n",
310 | "text_splitter = CharacterTextSplitter(\n",
311 | " separator = \"\\n\\n\",\n",
312 | " chunk_size = 1000,\n",
313 | " chunk_overlap = 200,\n",
314 | " length_function = len,\n",
315 | ")"
316 | ]
317 | },
318 | {
319 | "cell_type": "code",
320 | "execution_count": 12,
321 | "metadata": {
322 | "colab": {
323 | "base_uri": "https://localhost:8080/"
324 | },
325 | "id": "zkzN5YJ-QG3i",
326 | "outputId": "c81b34c7-12d0-40dc-c388-28659989c4f3"
327 | },
328 | "outputs": [
329 | {
330 | "output_type": "stream",
331 | "name": "stderr",
332 | "text": [
333 | "WARNING:langchain.text_splitter:Created a chunk of size 1140, which is longer than the specified 1000\n"
334 | ]
335 | },
336 | {
337 | "output_type": "stream",
338 | "name": "stdout",
339 | "text": [
340 | "# Chunks in Research Paper: 51\n",
341 | "# Chunks in Article Document: 1\n"
342 | ]
343 | }
344 | ],
345 | "source": [
346 | "research_paper_chunks = text_splitter.split_text(research_paper_content)\n",
347 | "article_information_chunks = text_splitter.split_text(article_information_content)\n",
348 | "\n",
349 | "print(f\"# Chunks in Research Paper: {len(research_paper_chunks)}\")\n",
350 | "print(f\"# Chunks in Article Document: {len(article_information_chunks)}\")"
351 | ]
352 | },
353 | {
354 | "cell_type": "markdown",
355 | "metadata": {
356 | "id": "X0fTb1OXQG3i"
357 | },
358 | "source": [
359 | "### Create Embeddings"
360 | ]
361 | },
362 | {
363 | "cell_type": "code",
364 | "execution_count": 13,
365 | "metadata": {
366 | "id": "2j_TWA_xQG3i"
367 | },
368 | "outputs": [],
369 | "source": [
370 | "from langchain.embeddings.openai import OpenAIEmbeddings\n",
371 | "import os\n",
372 | "\n",
373 | "os.environ[\"OPENAI_API_KEY\"] = \"\"\n",
374 | "\n",
375 | "embeddings = OpenAIEmbeddings()"
376 | ]
377 | },
378 | {
379 | "cell_type": "markdown",
380 | "metadata": {
381 | "id": "DJ16VESDQG3i"
382 | },
383 | "source": [
384 | "### Create Vector Index"
385 | ]
386 | },
387 | {
388 | "cell_type": "code",
389 | "execution_count": 14,
390 | "metadata": {
391 | "id": "YhGwAt_GQG3j"
392 | },
393 | "outputs": [],
394 | "source": [
395 | "from langchain.vectorstores import FAISS\n",
396 | "\n",
397 | "def get_doc_search(text_splitter):\n",
398 | "\n",
399 | " return FAISS.from_texts(text_splitter, embeddings)"
400 | ]
401 | },
402 | {
403 | "cell_type": "code",
404 | "execution_count": 15,
405 | "metadata": {
406 | "colab": {
407 | "base_uri": "https://localhost:8080/"
408 | },
409 | "id": "MeYNtWtoQG3j",
410 | "outputId": "323bf4ca-ca28-45dd-efeb-5eea12620d71"
411 | },
412 | "outputs": [
413 | {
414 | "output_type": "stream",
415 | "name": "stdout",
416 | "text": [
417 | "\n"
418 | ]
419 | }
420 | ],
421 | "source": [
422 | "doc_search_paper = get_doc_search(research_paper_chunks)\n",
423 | "print(doc_search_paper)"
424 | ]
425 | },
426 | {
427 | "cell_type": "markdown",
428 | "metadata": {
429 | "id": "MCAYKPq2QG3j"
430 | },
431 | "source": [
432 | "### Start chatting with your document"
433 | ]
434 | },
435 | {
436 | "cell_type": "code",
437 | "execution_count": 16,
438 | "metadata": {
439 | "id": "dNA4TsHpu6OM"
440 | },
441 | "outputs": [],
442 | "source": [
443 | "from langchain.llms import OpenAI\n",
444 | "from langchain.chains.question_answering import load_qa_chain\n",
445 | "chain = load_qa_chain(OpenAI(), chain_type = \"map_rerank\",\n",
446 | " return_intermediate_steps=True)\n",
447 | "\n",
448 | "def chat_with_file(file_path, query):\n",
449 | "\n",
450 | " file_content = extract_file_content(file_path)\n",
451 | " file_splitter = text_splitter.split_text(file_content)\n",
452 | "\n",
453 | " document_search = get_doc_search(file_splitter)\n",
454 | " documents = document_search.similarity_search(query)\n",
455 | "\n",
456 | " results = chain({\n",
457 | " \"input_documents\":documents,\n",
458 | " \"question\": query\n",
459 | " },\n",
460 | " return_only_outputs=True)\n",
461 | " results = results['intermediate_steps'][0]\n",
462 | "\n",
463 | " return results"
464 | ]
465 | },
466 | {
467 | "cell_type": "markdown",
468 | "metadata": {
469 | "id": "av7cFJ8PQG3k"
470 | },
471 | "source": [
472 | "##### Chat with the image file"
473 | ]
474 | },
475 | {
476 | "cell_type": "code",
477 | "execution_count": 17,
478 | "metadata": {
479 | "colab": {
480 | "base_uri": "https://localhost:8080/"
481 | },
482 | "id": "MvVMW_0DQG3k",
483 | "outputId": "54cdcb47-bb8a-4695-d476-448eebc6e36a"
484 | },
485 | "outputs": [
486 | {
487 | "output_type": "stream",
488 | "name": "stderr",
489 | "text": [
490 | "/usr/local/lib/python3.10/dist-packages/langchain/chains/llm.py:303: UserWarning: The apply_and_parse method is deprecated, instead pass an output parser directly to LLMChain.\n",
491 | " warnings.warn(\n"
492 | ]
493 | },
494 | {
495 | "output_type": "stream",
496 | "name": "stdout",
497 | "text": [
498 | "Answer: This document is about the process of extracting information from raw data, including splitting the data into chunks, detecting the type of file, extracting the content, and creating a vector index and embeddings.\n",
499 | "\n",
500 | "Confidence Score: 100\n"
501 | ]
502 | }
503 | ],
504 | "source": [
505 | "query = \"What is the document about\"\n",
506 | "\n",
507 | "results = chat_with_file(article_information_path, query)\n",
508 | "\n",
509 | "answer = results[\"answer\"]\n",
510 | "confidence_score = results[\"score\"]\n",
511 | "\n",
512 | "print(f\"Answer: {answer}\\n\\nConfidence Score: {confidence_score}\")"
513 | ]
514 | },
515 | {
516 | "cell_type": "markdown",
517 | "metadata": {
518 | "id": "9edAr_8eQG3k"
519 | },
520 | "source": [
521 | "##### Chat with the PDF file"
522 | ]
523 | },
524 | {
525 | "cell_type": "code",
526 | "execution_count": 18,
527 | "metadata": {
528 | "colab": {
529 | "base_uri": "https://localhost:8080/"
530 | },
531 | "id": "_k64BYyeQG3l",
532 | "outputId": "5d31a95a-7c1a-4c57-9857-52634f6b53fd"
533 | },
534 | "outputs": [
535 | {
536 | "output_type": "stream",
537 | "name": "stderr",
538 | "text": [
539 | "WARNING:langchain.text_splitter:Created a chunk of size 1140, which is longer than the specified 1000\n"
540 | ]
541 | },
542 | {
543 | "output_type": "stream",
544 | "name": "stdout",
545 | "text": [
546 | "Answer: Self-attention is used to compute a representation of the sequence, allowing for the construction of the Transformer which relies entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.\n",
547 | "\n",
548 | "Confidence Score: 100\n"
549 | ]
550 | }
551 | ],
552 | "source": [
553 | "query = \"Why is the self-attention approach used in this document?\"\n",
554 | "\n",
555 | "results = chat_with_file(research_paper_path, query)\n",
556 | "\n",
557 | "answer = results[\"answer\"]\n",
558 | "confidence_score = results[\"score\"]\n",
559 | "\n",
560 | "print(f\"Answer: {answer}\\n\\nConfidence Score: {confidence_score}\")"
561 | ]
562 | },
563 | {
564 | "cell_type": "markdown",
565 | "metadata": {
566 | "id": "wi_kh1faQG3l"
567 | },
568 | "source": [
569 | "# Resources\n",
570 | "\n",
571 | "- [How to Chat With Any PDFs and Image Files Using Large Language Models — With Code](https://towardsdatascience.com/how-to-chat-with-any-file-from-pdfs-to-images-using-large-language-models-with-code-4bcfd7e440bc)\n",
572 | "\n"
573 | ]
574 | }
575 | ],
576 | "metadata": {
577 | "colab": {
578 | "provenance": [],
579 | "include_colab_link": true
580 | },
581 | "kernelspec": {
582 | "display_name": "pandas_benchmark",
583 | "language": "python",
584 | "name": "pandas_benchmark"
585 | },
586 | "language_info": {
587 | "codemirror_mode": {
588 | "name": "ipython",
589 | "version": 3
590 | },
591 | "file_extension": ".py",
592 | "mimetype": "text/x-python",
593 | "name": "python",
594 | "nbconvert_exporter": "python",
595 | "pygments_lexer": "ipython3",
596 | "version": "3.9.15"
597 | },
598 | "toc": {
599 | "base_numbering": 1,
600 | "nav_menu": {},
601 | "number_sections": true,
602 | "sideBar": true,
603 | "skip_h1_title": false,
604 | "title_cell": "Table of Contents",
605 | "title_sidebar": "Contents",
606 | "toc_cell": false,
607 | "toc_position": {},
608 | "toc_section_display": true,
609 | "toc_window_display": false
610 | }
611 | },
612 | "nbformat": 4,
613 | "nbformat_minor": 0
614 | }
--------------------------------------------------------------------------------
/RAG-with-Ollama/rag.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Initializing the Local Model"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "from langchain_community.llms import Ollama \n",
17 | "llm = Ollama(model=\"mistral\", temperature = 0)"
18 | ]
19 | },
20 | {
21 | "cell_type": "code",
22 | "execution_count": 2,
23 | "metadata": {},
24 | "outputs": [
25 | {
26 | "data": {
27 | "text/plain": [
28 | "\" LangGraph is a large-scale graph database specifically designed for natural language processing (NLP) and information retrieval tasks. It was developed by Microsoft Research and is part of the Microsoft Open Data Initiative.\\n\\nLangGraph aims to provide a more efficient way to store, query, and process large amounts of text data compared to traditional relational databases or file-based storage systems. By representing text data as graphs, LangGraph enables advanced NLP tasks such as entity recognition, relation extraction, and semantic similarity analysis to be performed directly on the graph, rather than requiring separate preprocessing steps and external tools.\\n\\nLangGraph's key features include:\\n\\n1. Scalability: It can handle large volumes of data and complex queries with high performance.\\n2. Flexibility: It supports various data models, including property graphs and RDF triples, allowing for diverse use cases.\\n3. Integration: It integrates well with other Microsoft Azure services such as Cognitive Services, Power BI, and Azure Machine Learning.\\n4. Querying: It provides a powerful query language called Gremlin (Graph Query Language) that enables complex graph traversals and data manipulation tasks.\\n5. Indexing: It supports indexing on various properties, enabling efficient querying based on property values.\\n6. Security: It offers built-in security features to protect sensitive data.\\n7. Real-time processing: It can handle real-time data ingestion and processing, making it suitable for applications that require low latency.\\n\\nLangGraph is particularly useful in industries such as healthcare, finance, and e-commerce, where handling large volumes of text data and performing advanced NLP tasks are essential.\""
29 | ]
30 | },
31 | "execution_count": 2,
32 | "metadata": {},
33 | "output_type": "execute_result"
34 | }
35 | ],
36 | "source": [
37 | "llm.invoke(\"What is LangGraph?\")"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "## Indexing: Load"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 3,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "from langchain_community.document_loaders import WebBaseLoader \n",
54 | "\n",
55 | "loader = WebBaseLoader(\n",
56 | " web_path=(\"https://blog.langchain.dev/langgraph/\"),\n",
57 | ")\n",
58 | "docs= loader.load()"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": 4,
64 | "metadata": {},
65 | "outputs": [
66 | {
67 | "data": {
68 | "text/plain": [
69 | "'\\n\\n\\nLangGraph\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nSkip to content\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nBy LangChain\\n\\n\\n\\n\\nRelease Notes\\n\\n\\n\\n\\nCase Studies\\n\\n\\n\\n\\nLangChain\\n\\n\\n\\n\\nGitHub\\n\\n\\n\\n\\nDocs\\n\\n\\n\\n\\n\\nSign in\\nSubscribe\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nLangGraph\\n\\nBy LangChain\\n7 min read\\nJan 17, 2024\\n\\n\\n\\n\\n\\nTL;DR: LangGraph is module built on top of LangChain to better enable creation of cyclical graphs, often needed for agent runtimes.Python RepoPython YouTube PlaylistJS RepoIntroductionOne of the things we highlighted in our LangChain v0.1 announcement was the introduction of a new library: LangGraph. LangGraph is built on top of LangChain and completely interoperable with the LangChain ecosystem. It adds new value primarily through the introduction of an easy way to create cyclical graphs. This is often useful when creating agent runtimes.In this blog post, we will first walk through the motivations for LangGraph. We will then cover the basic functionality it provides. We will then spotlight two agent runtimes we\\'ve implemented already. We will then highlight a few of the common modifications to these runtimes we\\'ve heard requests for, and examples of implementing those. We will finish with a preview of what we will be releasing next.MotivationOne of the big value props of LangChain is the ability to easily create custom chains. We\\'ve invested heavily in the functionality for this with LangChain Expression Language. However, so far we\\'ve lacked a method for easily introducing cycles into these chains. Effectively, these chains are directed acyclic graphs (DAGs) - as are most data orchestration frameworks.One of the common patterns we see when people are creating more complex LLM applications is the introduction of cycles into the runtime. These cycles often use the LLM to reason about what to do next in the cycle. A big unlock of LLMs is the ability to use them for these reasoning tasks. This can essentially be thought of as running an LLM in a for-loop. These types of systems are often called agents.An example of why this agentic behavior can be so powerful can be found when considering a typical retrieval augmented generation (RAG) application. In a typical RAG application, a call to a retriever is made that returns some documents. These documents are then passed to an LLM to generate a final answer. While this is often effective, it breaks down in cases when the first retrieval step fails to return any useful results. In this case, it\\'s often ideal if the LLM can reason that the results returned from the retriever are poor, and maybe issue a second (more refined) query to the retriever, and use those results instead. Essentially, running an LLM in a loop helps create applications that are more flexible and thus can accomplish more vague use-cases that may not be predefined.These types of applications are often called agents. The simplest - but at the same time most ambitious - form of these is a loop that essentially has two steps:Call the LLM to determine either (a) what actions to take, or (b) what response to give the userTake given actions, and pass back to step 1These steps are repeated until a final response is generated. This is essentially the loop that powers our core AgentExecutor, and is the same logic that caused projects like AutoGPT to rise in prominence. This is simple because it is a relatively simple loop. It is the most ambitious because it offloads pretty much ALL of the decision making and reasoning ability to the LLM.One thing we\\'ve seen in practice as we\\'ve worked the community and companies to put agents into production is that often times more control is needed. You may want to always force an agent to call particular tool first. You may want have more control over how tools are called. You may want to have different prompts for the agent, depending on that state it is in.When talking about these more controlled flows, we internally refer to them as \"state machines\". See the below diagram from our blog on cognitive architectures.These state machines have the power of being able to loop - allowing for handling of more ambiguous inputs than simple chains. However, there is still an element of human guidance in terms of how that loop is constructed.LangGraph is a way to create these state machines by specifying them as graphs.FunctionalityAt it\\'s core, LangGraph exposes a pretty narrow interface on top of LangChain.StateGraphStateGraph is a class that represents the graph. You initialize this class by passing in a state definition. This state definition represents a central state object that is updated over time. This state is updated by nodes in the graph, which return operations to attributes of this state (in the form of a key-value store).The attributes of this state can be updated in two ways. First, an attribute could be overridden completely. This is useful if you want to nodes to return the new value of an attribute. Second, an attribute could be updated by adding to its value. This is useful if an attribute is a list of actions taken (or something similar) and you want nodes to return new actions taken (and have those automatically added to the attribute).You specify whether an attribute should be overridden or added to when creating the initial state definition. See an example in pseudocode below.from langgraph.graph import StateGraph\\nfrom typing import TypedDict, List, Annotated\\nimport Operator\\n\\n\\nclass State(TypedDict):\\n input: str\\n all_actions: Annotated[List[str], operator.add]\\n\\n\\ngraph = StateGraph(State)NodesAfter creating a StateGraph, you then add nodes with graph.add_node(name, value) syntax. The name parameter should be a string that we will use to refer to the node when adding edges. The value parameter should be either a function or LCEL runnable that will be called. This function/LCEL should accept a dictionary in the same form as the State object as input, and output a dictionary with keys of the State object to update.See an example in pseudocode below.graph.add_node(\"model\", model)\\ngraph.add_node(\"tools\", tool_executor)There is also a special END node that is used to represent the end of the graph. It is important that your cycles be able to end eventually!from langgraph.graph import ENDEdgesAfter adding nodes, you can then add edges to create the graph. There are a few types of edges.The Starting EdgeThis is the edge that connects the start of the graph to a particular node. This will make it so that that node is the first one called when input is passed to the graph. Pseudocode for that is:graph.set_entry_point(\"model\")Normal EdgesThese are edges where one node should ALWAYS be called after another. An example of this may be in the basic agent runtime, where we always want the model to be called after we call a tool.graph.add_edge(\"tools\", \"model\")Conditional EdgesThese are where a function (often powered by an LLM) is used to determine which node to go to first. To create this edge, you need to pass in three things:The upstream node: the output of this node will be looked at to determine what to do nextA function: this will be called to determine which node to call next. It should return a stringA mapping: this mapping will be used to map the output of the function in (2) to another node. The keys should be possible values that the function in (2) could return. The values should be names of nodes to go to if that value is returned.An example of this could be that after a model is called we either exit the graph and return to the user, or we call a tool - depending on what a user decides! See an example in pseudocode below:graph.add_conditional_edge(\\n \"model\",\\n should_continue,\\n {\\n \"end\": END,\\n \"continue\": \"tools\"\\n }\\n)CompileAfter we define our graph, we can compile it into a runnable! This simply takes the graph definition we\\'ve created so far an returns a runnable. This runnable exposes all the same method as LangChain runnables (.invoke, .stream, .astream_log, etc) allowing it to be called in the same manner as a chain.app = graph.compile()Agent ExecutorWe\\'ve recreated the canonical LangChain AgentExecutor with LangGraph. This will allow you to use existing LangChain agents, but allow you to more easily modify the internals of the AgentExecutor. The state of this graph by default contains concepts that should be familiar to you if you\\'ve used LangChain agents: input, chat_history, intermediate_steps (and agent_outcome to represent the most recent agent outcome)from typing import TypedDict, Annotated, List, Union\\nfrom langchain_core.agents import AgentAction, AgentFinish\\nfrom langchain_core.messages import BaseMessage\\nimport operator\\n\\n\\nclass AgentState(TypedDict):\\n input: str\\n chat_history: list[BaseMessage]\\n agent_outcome: Union[AgentAction, AgentFinish, None]\\n intermediate_steps: Annotated[list[tuple[AgentAction, str]], operator.add] See this notebook for how to get startedChat Agent ExecutorOne common trend we\\'ve seen is that more and more models are \"chat\" models which operate on a list of messages. This models are often the ones equipped with things like function calling, which make agent-like experiences much more feasible. When working with these types of models, it is often intuitive to represent the state of an agent as a list of messages.As such, we\\'ve created an agent runtime that works with this state. The input is a list of messages, and nodes just simply add to this list of messages over time.from typing import TypedDict, Annotated, Sequence\\nimport operator\\nfrom langchain_core.messages import BaseMessage\\n\\n\\nclass AgentState(TypedDict):\\n messages: Annotated[Sequence[BaseMessage], operator.add] See this notebook for how to get startedModificationsOne of the big benefits of LangGraph is that it exposes the logic of AgentExecutor in a far more natural and modifiable way. We\\'ve provided a few examples of modifications that we\\'ve heard requests for:Force Calling a ToolFor when you always want to make an agent call a tool first. For Agent Executor and Chat Agent Executor.Human-in-the-loopHow to add a human-in-the-loop step before calling tools. For Agent Executor and Chat Agent Executor.Managing Agent StepsFor adding custom logic on how to handle the intermediate steps an agent might take (useful for when there\\'s a lot of steps). For Agent Executor and Chat Agent Executor.Returning Output in a Specific FormatHow to make the agent return output in a specific format using function calling. Only for Chat Agent Executor.Dynamically Returning the Output of a Tool DirectlySometimes you may want to return the output of a tool directly. We provide an easy way to do with the return_direct parameter in LangChain. However, this makes it so that the output of a tool is ALWAYS returned directly. Sometimes, you may want to let the LLM choose whether to return the response directly or not. Only for Chat Agent Executor.Future WorkWe\\'re incredibly excited about the possibility of LangGraph enabling more custom and powerful agent runtimes. Some of the things we are looking to implement in the near future:More advanced agent runtimes from academia (LLM Compiler, plan-and-solve, etc)Stateful tools (allowing tools to modify some state)More controlled human-in-the-loop workflowsMulti-agent workflowsIf any of these resonate with you, please feel free to add an example notebook in the LangGraph repo, or reach out to us at hello@langchain.dev for more involved collaboration!\\n\\n\\nTags\\nBy LangChain\\n\\n\\nJoin our newsletter\\nUpdates from the LangChain team and community\\n\\n\\nEnter your email\\n\\nSubscribe\\n\\nProcessing your application...\\nSuccess! Please check your inbox and click the link to confirm your subscription.\\nSorry, something went wrong. Please try again.\\n\\n\\n\\n\\n\\nYou might also like\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nReflection Agents\\n\\n\\nagents\\n6 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nPlan-and-Execute Agents\\n\\n\\nBy LangChain\\n5 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n[Week of 2/19] LangChain Release Notes\\n\\n\\nBy LangChain\\n1 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nRakuten Group builds with LangChain and LangSmith to deliver premium products for its business clients and employees\\n\\n\\nBy LangChain\\n3 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n[Week of 2/5] LangChain Release Notes\\n\\n\\nBy LangChain\\n4 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nLangChain Partners with CommandBar on their Copilot User Assistant\\n\\n\\nBy LangChain\\n2 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nSign up\\n\\n\\n\\n\\n\\n © LangChain Blog 2024\\n \\n\\n\\n\\n\\n\\n\\n'"
70 | ]
71 | },
72 | "execution_count": 4,
73 | "metadata": {},
74 | "output_type": "execute_result"
75 | }
76 | ],
77 | "source": [
78 | "docs[0].page_content"
79 | ]
80 | },
81 | {
82 | "cell_type": "code",
83 | "execution_count": 5,
84 | "metadata": {},
85 | "outputs": [
86 | {
87 | "data": {
88 | "text/plain": [
89 | "12341"
90 | ]
91 | },
92 | "execution_count": 5,
93 | "metadata": {},
94 | "output_type": "execute_result"
95 | }
96 | ],
97 | "source": [
98 | "len(docs[0].page_content)"
99 | ]
100 | },
101 | {
102 | "cell_type": "markdown",
103 | "metadata": {},
104 | "source": [
105 | "## Indexing: Split"
106 | ]
107 | },
108 | {
109 | "cell_type": "code",
110 | "execution_count": 6,
111 | "metadata": {},
112 | "outputs": [],
113 | "source": [
114 | "from langchain_text_splitters import RecursiveCharacterTextSplitter\n",
115 | "\n",
116 | "text_splitter= RecursiveCharacterTextSplitter(\n",
117 | " chunk_size = 1000,\n",
118 | " chunk_overlap = 200,\n",
119 | " add_start_index = True,\n",
120 | ")"
121 | ]
122 | },
123 | {
124 | "cell_type": "code",
125 | "execution_count": 7,
126 | "metadata": {},
127 | "outputs": [],
128 | "source": [
129 | "all_splits = text_splitter.split_documents(docs)"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 8,
135 | "metadata": {},
136 | "outputs": [
137 | {
138 | "data": {
139 | "text/plain": [
140 | "21"
141 | ]
142 | },
143 | "execution_count": 8,
144 | "metadata": {},
145 | "output_type": "execute_result"
146 | }
147 | ],
148 | "source": [
149 | "len(all_splits)"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": 9,
155 | "metadata": {},
156 | "outputs": [
157 | {
158 | "data": {
159 | "text/plain": [
160 | "997"
161 | ]
162 | },
163 | "execution_count": 9,
164 | "metadata": {},
165 | "output_type": "execute_result"
166 | }
167 | ],
168 | "source": [
169 | "len(all_splits[1].page_content)"
170 | ]
171 | },
172 | {
173 | "cell_type": "markdown",
174 | "metadata": {},
175 | "source": [
176 | "## Indexing: Store"
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": 10,
182 | "metadata": {},
183 | "outputs": [],
184 | "source": [
185 | "from langchain_community.embeddings import OllamaEmbeddings\n",
186 | "\n",
187 | "embedding = OllamaEmbeddings(\n",
188 | " model=\"nomic-embed-text\",\n",
189 | ")"
190 | ]
191 | },
192 | {
193 | "cell_type": "code",
194 | "execution_count": 11,
195 | "metadata": {},
196 | "outputs": [],
197 | "source": [
198 | "from langchain_community.vectorstores import Chroma\n",
199 | "\n",
200 | "vectorstore = Chroma.from_documents(\n",
201 | " documents = all_splits,\n",
202 | " embedding = embedding,\n",
203 | ")"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": 12,
209 | "metadata": {},
210 | "outputs": [],
211 | "source": [
212 | "retriever = vectorstore.as_retriever(\n",
213 | " search_type = \"similarity\",\n",
214 | " search_kwargs = {\"k\":6}\n",
215 | ")"
216 | ]
217 | },
218 | {
219 | "cell_type": "code",
220 | "execution_count": 13,
221 | "metadata": {},
222 | "outputs": [
223 | {
224 | "data": {
225 | "text/plain": [
226 | "[Document(page_content='\"model\",\\n should_continue,\\n {\\n \"end\": END,\\n \"continue\": \"tools\"\\n }\\n)CompileAfter we define our graph, we can compile it into a runnable! This simply takes the graph definition we\\'ve created so far an returns a runnable. This runnable exposes all the same method as LangChain runnables (.invoke, .stream, .astream_log, etc) allowing it to be called in the same manner as a chain.app = graph.compile()Agent ExecutorWe\\'ve recreated the canonical LangChain AgentExecutor with LangGraph. This will allow you to use existing LangChain agents, but allow you to more easily modify the internals of the AgentExecutor. The state of this graph by default contains concepts that should be familiar to you if you\\'ve used LangChain agents: input, chat_history, intermediate_steps (and agent_outcome to represent the most recent agent outcome)from typing import TypedDict, Annotated, List, Union\\nfrom langchain_core.agents import AgentAction, AgentFinish', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 7622, 'title': 'LangGraph'}),\n",
227 | " Document(page_content='LangGraph\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nSkip to content\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nBy LangChain\\n\\n\\n\\n\\nRelease Notes\\n\\n\\n\\n\\nCase Studies\\n\\n\\n\\n\\nLangChain\\n\\n\\n\\n\\nGitHub\\n\\n\\n\\n\\nDocs\\n\\n\\n\\n\\n\\nSign in\\nSubscribe\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nLangGraph\\n\\nBy LangChain\\n7 min read\\nJan 17, 2024', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 3, 'title': 'LangGraph'}),\n",
228 | " Document(page_content=\"agent return output in a specific format using function calling. Only for Chat Agent Executor.Dynamically Returning the Output of a Tool DirectlySometimes you may want to return the output of a tool directly. We provide an easy way to do with the return_direct parameter in LangChain. However, this makes it so that the output of a tool is ALWAYS returned directly. Sometimes, you may want to let the LLM choose whether to return the response directly or not. Only for Chat Agent Executor.Future WorkWe're incredibly excited about the possibility of LangGraph enabling more custom and powerful agent runtimes. Some of the things we are looking to implement in the near future:More advanced agent runtimes from academia (LLM Compiler, plan-and-solve, etc)Stateful tools (allowing tools to modify some state)More controlled human-in-the-loop workflowsMulti-agent workflowsIf any of these resonate with you, please feel free to add an example notebook in the LangGraph repo, or reach out to us at\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 10390, 'title': 'LangGraph'}),\n",
229 | " Document(page_content=\"messages: Annotated[Sequence[BaseMessage], operator.add] See this notebook for how to get startedModificationsOne of the big benefits of LangGraph is that it exposes the logic of AgentExecutor in a far more natural and modifiable way. We've provided a few examples of modifications that we've heard requests for:Force Calling a ToolFor when you always want to make an agent call a tool first. For Agent Executor and Chat Agent Executor.Human-in-the-loopHow to add a human-in-the-loop step before calling tools. For Agent Executor and Chat Agent Executor.Managing Agent StepsFor adding custom logic on how to handle the intermediate steps an agent might take (useful for when there's a lot of steps). For Agent Executor and Chat Agent Executor.Returning Output in a Specific FormatHow to make the agent return output in a specific format using function calling. Only for Chat Agent Executor.Dynamically Returning the Output of a Tool DirectlySometimes you may want to return the output of a tool\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 9594, 'title': 'LangGraph'}),\n",
230 | " Document(page_content=\"TL;DR: LangGraph is module built on top of LangChain to better enable creation of cyclical graphs, often needed for agent runtimes.Python RepoPython YouTube PlaylistJS RepoIntroductionOne of the things we highlighted in our LangChain v0.1 announcement was the introduction of a new library: LangGraph. LangGraph is built on top of LangChain and completely interoperable with the LangChain ecosystem. It adds new value primarily through the introduction of an easy way to create cyclical graphs. This is often useful when creating agent runtimes.In this blog post, we will first walk through the motivations for LangGraph. We will then cover the basic functionality it provides. We will then spotlight two agent runtimes we've implemented already. We will then highlight a few of the common modifications to these runtimes we've heard requests for, and examples of implementing those. We will finish with a preview of what we will be releasing next.MotivationOne of the big value props of LangChain\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 273, 'title': 'LangGraph'}),\n",
231 | " Document(page_content='thing we\\'ve seen in practice as we\\'ve worked the community and companies to put agents into production is that often times more control is needed. You may want to always force an agent to call particular tool first. You may want have more control over how tools are called. You may want to have different prompts for the agent, depending on that state it is in.When talking about these more controlled flows, we internally refer to them as \"state machines\". See the below diagram from our blog on cognitive architectures.These state machines have the power of being able to loop - allowing for handling of more ambiguous inputs than simple chains. However, there is still an element of human guidance in terms of how that loop is constructed.LangGraph is a way to create these state machines by specifying them as graphs.FunctionalityAt it\\'s core, LangGraph exposes a pretty narrow interface on top of LangChain.StateGraphStateGraph is a class that represents the graph. You initialize this class by', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 3476, 'title': 'LangGraph'})]"
232 | ]
233 | },
234 | "execution_count": 13,
235 | "metadata": {},
236 | "output_type": "execute_result"
237 | }
238 | ],
239 | "source": [
240 | "retriever.get_relevant_documents(\n",
241 | " \"what is LangGraph?\"\n",
242 | ")"
243 | ]
244 | },
245 | {
246 | "cell_type": "markdown",
247 | "metadata": {},
248 | "source": [
249 | "## Retrieval and Generation: Generate"
250 | ]
251 | },
252 | {
253 | "cell_type": "code",
254 | "execution_count": 14,
255 | "metadata": {},
256 | "outputs": [],
257 | "source": [
258 | "from langchain import hub \n",
259 | "\n",
260 | "prompt= hub.pull(\"rlm/rag-prompt\")"
261 | ]
262 | },
263 | {
264 | "cell_type": "code",
265 | "execution_count": 15,
266 | "metadata": {},
267 | "outputs": [],
268 | "source": [
269 | "def format_docs(docs):\n",
270 | " return \"\\n\\n\".join(doc.page_content for doc in docs)"
271 | ]
272 | },
273 | {
274 | "cell_type": "code",
275 | "execution_count": 16,
276 | "metadata": {},
277 | "outputs": [],
278 | "source": [
279 | "from langchain_core.runnables import RunnablePassthrough\n",
280 | "from langchain_core.output_parsers import StrOutputParser\n",
281 | "\n",
282 | "rag_chain = (\n",
283 | " {\"context\": retriever | format_docs, \"question\": RunnablePassthrough()}\n",
284 | " | prompt \n",
285 | " | llm \n",
286 | " | StrOutputParser()\n",
287 | ")"
288 | ]
289 | },
290 | {
291 | "cell_type": "code",
292 | "execution_count": 17,
293 | "metadata": {},
294 | "outputs": [
295 | {
296 | "data": {
297 | "text/plain": [
298 | "' LangGraph is a Python module built on top of LangChain, providing easier creation of cyclical graphs for agent runtimes. It enables more control over agent flow and the calling of tools.'"
299 | ]
300 | },
301 | "execution_count": 17,
302 | "metadata": {},
303 | "output_type": "execute_result"
304 | }
305 | ],
306 | "source": [
307 | "rag_chain.invoke(\"What is LangGraph?\")"
308 | ]
309 | },
310 | {
311 | "cell_type": "code",
312 | "execution_count": 18,
313 | "metadata": {},
314 | "outputs": [
315 | {
316 | "data": {
317 | "text/plain": [
318 | "' LangGraph is a module developed on top of LangChain, enhancing its capabilities for creating cyclical graphs, particularly useful for agent runtimes. It allows the creation of nodes and edges with different types such as starting edges, normal edges, and conditional edges. The motivation behind LangGraph is to provide an easier way to build complex agent runtime graphs.'"
319 | ]
320 | },
321 | "execution_count": 18,
322 | "metadata": {},
323 | "output_type": "execute_result"
324 | }
325 | ],
326 | "source": [
327 | "rag_chain.invoke(\"What is LangGraph used for?\")"
328 | ]
329 | },
330 | {
331 | "cell_type": "markdown",
332 | "metadata": {},
333 | "source": [
334 | "Thanks for reading 😀\n",
335 | "\n",
336 | "Let's connect [YouTube](http://youtube.com/tirendazacademy) | [Medium](http://tirendazacademy.medium.com) | [X](http://x.com/tirendazacademy) | [Linkedin](https://www.linkedin.com/in/tirendaz-academy) 😎"
337 | ]
338 | }
339 | ],
340 | "metadata": {
341 | "kernelspec": {
342 | "display_name": "genai",
343 | "language": "python",
344 | "name": "python3"
345 | },
346 | "language_info": {
347 | "codemirror_mode": {
348 | "name": "ipython",
349 | "version": 3
350 | },
351 | "file_extension": ".py",
352 | "mimetype": "text/x-python",
353 | "name": "python",
354 | "nbconvert_exporter": "python",
355 | "pygments_lexer": "ipython3",
356 | "version": "3.11.8"
357 | }
358 | },
359 | "nbformat": 4,
360 | "nbformat_minor": 2
361 | }
362 |
--------------------------------------------------------------------------------
/Quickstart-Guide.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyOw4c0esr4QYXlq4/nOyYpP",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# LangChain Tutorial"
33 | ],
34 | "metadata": {
35 | "id": "5wjtV2JN9Cvg"
36 | }
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "source": [
41 | "This tutorial walks you through how to use LangChain."
42 | ],
43 | "metadata": {
44 | "id": "qoLu0W0H_oGU"
45 | }
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "source": [
50 | "# Installation"
51 | ],
52 | "metadata": {
53 | "id": "1pBexl6Y_fx8"
54 | }
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": null,
59 | "metadata": {
60 | "id": "WCvj819Yf8tu"
61 | },
62 | "outputs": [],
63 | "source": [
64 | "!pip install langchain \n",
65 | "!pip install openai \n",
66 | "!pip install google-search-results "
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "source": [
72 | "# Importing the Necessary Libraries"
73 | ],
74 | "metadata": {
75 | "id": "SVcHX_dW_jxc"
76 | }
77 | },
78 | {
79 | "cell_type": "code",
80 | "source": [
81 | "import os\n",
82 | "from langchain import ConversationChain\n",
83 | "from langchain.llms import OpenAI\n",
84 | "from langchain.chat_models import ChatOpenAI\n",
85 | "from langchain.prompts import (PromptTemplate, \n",
86 | " ChatPromptTemplate, \n",
87 | " MessagesPlaceholder, \n",
88 | " SystemMessagePromptTemplate, \n",
89 | " HumanMessagePromptTemplate)\n",
90 | "from langchain.chains import LLMChain\n",
91 | "from langchain.agents import (load_tools, \n",
92 | " initialize_agent, \n",
93 | " AgentType)\n",
94 | "from langchain.schema import (AIMessage, \n",
95 | " HumanMessage, \n",
96 | " SystemMessage)\n",
97 | "from langchain.prompts.chat import (ChatPromptTemplate, \n",
98 | " SystemMessagePromptTemplate,\n",
99 | " HumanMessagePromptTemplate)\n",
100 | "from langchain.memory import ConversationBufferMemory"
101 | ],
102 | "metadata": {
103 | "id": "yXIA5lVtgT6z"
104 | },
105 | "execution_count": 13,
106 | "outputs": []
107 | },
108 | {
109 | "cell_type": "markdown",
110 | "source": [
111 | "# Environment Setup"
112 | ],
113 | "metadata": {
114 | "id": "vgAQvzaq9XdE"
115 | }
116 | },
117 | {
118 | "cell_type": "code",
119 | "source": [
120 | "os.environ[\"OPENAI_API_KEY\"] = \"...\"\n",
121 | "os.environ[\"SERPAPI_API_KEY\"] = \"...\""
122 | ],
123 | "metadata": {
124 | "id": "qX-No2tp9ZXA"
125 | },
126 | "execution_count": null,
127 | "outputs": []
128 | },
129 | {
130 | "cell_type": "markdown",
131 | "source": [
132 | "# LLMs: Get predictions from a language model"
133 | ],
134 | "metadata": {
135 | "id": "kCyGJkdR9izy"
136 | }
137 | },
138 | {
139 | "cell_type": "code",
140 | "source": [
141 | "llm = OpenAI(temperature=0.9)"
142 | ],
143 | "metadata": {
144 | "id": "wWWtvD4NqqLT"
145 | },
146 | "execution_count": 14,
147 | "outputs": []
148 | },
149 | {
150 | "cell_type": "code",
151 | "source": [
152 | "text = \"Suggest a youtube name for AI\"\n",
153 | "print(llm(text))"
154 | ],
155 | "metadata": {
156 | "colab": {
157 | "base_uri": "https://localhost:8080/"
158 | },
159 | "id": "Gqdjoc3jq0J6",
160 | "outputId": "86d34972-e239-4d48-efbb-7eed1a4b3444"
161 | },
162 | "execution_count": 15,
163 | "outputs": [
164 | {
165 | "output_type": "stream",
166 | "name": "stdout",
167 | "text": [
168 | "\n",
169 | "\n",
170 | "AI Wiz\n"
171 | ]
172 | }
173 | ]
174 | },
175 | {
176 | "cell_type": "markdown",
177 | "source": [
178 | "# Prompt Templates: Manage prompts for LLMs"
179 | ],
180 | "metadata": {
181 | "id": "1QwCEOev9oQL"
182 | }
183 | },
184 | {
185 | "cell_type": "code",
186 | "source": [
187 | "prompt = PromptTemplate(\n",
188 | " input_variables=[\"topic\"],\n",
189 | " template=\"Recommend a youtube name for {topic}?\",\n",
190 | ")"
191 | ],
192 | "metadata": {
193 | "id": "eVniyzSzuzWd"
194 | },
195 | "execution_count": 40,
196 | "outputs": []
197 | },
198 | {
199 | "cell_type": "code",
200 | "source": [
201 | "print(prompt.format(topic=\"AI\"))"
202 | ],
203 | "metadata": {
204 | "colab": {
205 | "base_uri": "https://localhost:8080/"
206 | },
207 | "id": "XrF0PjyJvLGi",
208 | "outputId": "4e3cbfa3-bd9f-4285-98c9-cefe482c9f07"
209 | },
210 | "execution_count": 19,
211 | "outputs": [
212 | {
213 | "output_type": "stream",
214 | "name": "stdout",
215 | "text": [
216 | "Recommend a youtube name for AI?\n"
217 | ]
218 | }
219 | ]
220 | },
221 | {
222 | "cell_type": "code",
223 | "source": [
224 | "chain = LLMChain(llm=llm, prompt=prompt)"
225 | ],
226 | "metadata": {
227 | "id": "KGzNVlL90yuh"
228 | },
229 | "execution_count": 20,
230 | "outputs": []
231 | },
232 | {
233 | "cell_type": "code",
234 | "source": [
235 | "chain.run(\"data science\")"
236 | ],
237 | "metadata": {
238 | "colab": {
239 | "base_uri": "https://localhost:8080/",
240 | "height": 35
241 | },
242 | "id": "qDKcioiO096W",
243 | "outputId": "023cd793-6cc8-4451-d1ac-1a466f5d149b"
244 | },
245 | "execution_count": 21,
246 | "outputs": [
247 | {
248 | "output_type": "execute_result",
249 | "data": {
250 | "text/plain": [
251 | "'\\n\\nDataScienceTube'"
252 | ],
253 | "application/vnd.google.colaboratory.intrinsic+json": {
254 | "type": "string"
255 | }
256 | },
257 | "metadata": {},
258 | "execution_count": 21
259 | }
260 | ]
261 | },
262 | {
263 | "cell_type": "markdown",
264 | "source": [
265 | "# Agents: Dynamically Call Chains Based on User Input"
266 | ],
267 | "metadata": {
268 | "id": "YJvBK6jv2gW1"
269 | }
270 | },
271 | {
272 | "cell_type": "code",
273 | "source": [
274 | "# First, let's load the language model we're going to use to control the agent.\n",
275 | "llm = OpenAI(temperature=0)\n",
276 | "\n",
277 | "# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.\n",
278 | "tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm)\n",
279 | "\n",
280 | "# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.\n",
281 | "agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)\n",
282 | "\n",
283 | "# Now let's test it out!\n",
284 | "agent.run(\"What was the high temperature in SF yesterday in Fahrenheit? What is that number raised to the .023 power?\")"
285 | ],
286 | "metadata": {
287 | "colab": {
288 | "base_uri": "https://localhost:8080/",
289 | "height": 264
290 | },
291 | "id": "CF46aDoU2y3d",
292 | "outputId": "79ed61ea-5a2f-4214-89fc-3322c9aa0169"
293 | },
294 | "execution_count": 42,
295 | "outputs": [
296 | {
297 | "output_type": "stream",
298 | "name": "stderr",
299 | "text": [
300 | "WARNING:langchain.callbacks.manager:Error in on_chain_start callback: 'name'\n"
301 | ]
302 | },
303 | {
304 | "output_type": "stream",
305 | "name": "stdout",
306 | "text": [
307 | "\u001b[32;1m\u001b[1;3m I need to find the temperature first, then use the calculator to raise it to the .023 power.\n",
308 | "Action: Search\n",
309 | "Action Input: \"High temperature in SF yesterday\"\u001b[0m\n",
310 | "Observation: \u001b[36;1m\u001b[1;3mHigh: 69.8ºf @3:45 PM Low: 55.04ºf @5:56 AM Approx.\u001b[0m\n",
311 | "Thought:\u001b[32;1m\u001b[1;3m I need to use the calculator to raise 69.8 to the .023 power\n",
312 | "Action: Calculator\n",
313 | "Action Input: 69.8^.023\u001b[0m\n",
314 | "Observation: \u001b[33;1m\u001b[1;3mAnswer: 1.1025763550530143\u001b[0m\n",
315 | "Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
316 | "Final Answer: 1.1025763550530143\u001b[0m\n",
317 | "\n",
318 | "\u001b[1m> Finished chain.\u001b[0m\n"
319 | ]
320 | },
321 | {
322 | "output_type": "execute_result",
323 | "data": {
324 | "text/plain": [
325 | "'1.1025763550530143'"
326 | ],
327 | "application/vnd.google.colaboratory.intrinsic+json": {
328 | "type": "string"
329 | }
330 | },
331 | "metadata": {},
332 | "execution_count": 42
333 | }
334 | ]
335 | },
336 | {
337 | "cell_type": "markdown",
338 | "source": [
339 | "# Memory: Add State to Chains and Agents"
340 | ],
341 | "metadata": {
342 | "id": "i6pY8bCd3gEM"
343 | }
344 | },
345 | {
346 | "cell_type": "code",
347 | "source": [
348 | "llm = OpenAI(temperature=0)\n",
349 | "conversation = ConversationChain(llm=llm, verbose=True)\n",
350 | "\n",
351 | "output = conversation.predict(input=\"Hi there!\")\n",
352 | "print(output)"
353 | ],
354 | "metadata": {
355 | "colab": {
356 | "base_uri": "https://localhost:8080/"
357 | },
358 | "id": "wH13BtWd3hDV",
359 | "outputId": "8ac609c8-4cf1-4c16-d0ee-678f6ed5ed8d"
360 | },
361 | "execution_count": 25,
362 | "outputs": [
363 | {
364 | "output_type": "stream",
365 | "name": "stderr",
366 | "text": [
367 | "WARNING:langchain.callbacks.manager:Error in on_chain_start callback: 'name'\n"
368 | ]
369 | },
370 | {
371 | "output_type": "stream",
372 | "name": "stdout",
373 | "text": [
374 | "Prompt after formatting:\n",
375 | "\u001b[32;1m\u001b[1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n",
376 | "\n",
377 | "Current conversation:\n",
378 | "\n",
379 | "Human: Hi there!\n",
380 | "AI:\u001b[0m\n",
381 | "\n",
382 | "\u001b[1m> Finished chain.\u001b[0m\n",
383 | " Hi there! It's nice to meet you. How can I help you today?\n"
384 | ]
385 | }
386 | ]
387 | },
388 | {
389 | "cell_type": "code",
390 | "source": [
391 | "output = conversation.predict(input=\"I'm doing well! Just having a conversation with an AI.\")\n",
392 | "print(output)"
393 | ],
394 | "metadata": {
395 | "colab": {
396 | "base_uri": "https://localhost:8080/"
397 | },
398 | "id": "0D-8v4Ks5JAs",
399 | "outputId": "d6170741-0391-480e-97e5-4d41f837ffde"
400 | },
401 | "execution_count": 26,
402 | "outputs": [
403 | {
404 | "output_type": "stream",
405 | "name": "stderr",
406 | "text": [
407 | "WARNING:langchain.callbacks.manager:Error in on_chain_start callback: 'name'\n"
408 | ]
409 | },
410 | {
411 | "output_type": "stream",
412 | "name": "stdout",
413 | "text": [
414 | "Prompt after formatting:\n",
415 | "\u001b[32;1m\u001b[1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n",
416 | "\n",
417 | "Current conversation:\n",
418 | "Human: Hi there!\n",
419 | "AI: Hi there! It's nice to meet you. How can I help you today?\n",
420 | "Human: I'm doing well! Just having a conversation with an AI.\n",
421 | "AI:\u001b[0m\n",
422 | "\n",
423 | "\u001b[1m> Finished chain.\u001b[0m\n",
424 | " That's great! It's always nice to have a conversation with someone new. What would you like to talk about?\n"
425 | ]
426 | }
427 | ]
428 | },
429 | {
430 | "cell_type": "markdown",
431 | "source": [
432 | "# Get Message Completions from a Chat Model"
433 | ],
434 | "metadata": {
435 | "id": "zFzRZipF5bAI"
436 | }
437 | },
438 | {
439 | "cell_type": "code",
440 | "source": [
441 | "chat = ChatOpenAI(temperature=0)"
442 | ],
443 | "metadata": {
444 | "id": "W2VjRzo35Ri1"
445 | },
446 | "execution_count": 27,
447 | "outputs": []
448 | },
449 | {
450 | "cell_type": "code",
451 | "source": [
452 | "chat([HumanMessage(content=\"Translate this sentence from English to Turkish. I love programming.\")])"
453 | ],
454 | "metadata": {
455 | "colab": {
456 | "base_uri": "https://localhost:8080/"
457 | },
458 | "id": "2YwJK9Kd5r1d",
459 | "outputId": "a8cd8649-b2bd-46ee-e605-ae8f213121d0"
460 | },
461 | "execution_count": 29,
462 | "outputs": [
463 | {
464 | "output_type": "stream",
465 | "name": "stderr",
466 | "text": [
467 | "WARNING:langchain.chat_models.openai:Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.._completion_with_retry in 1.0 seconds as it raised RateLimitError: That model is currently overloaded with other requests. You can retry your request, or contact us through our help center at help.openai.com if the error persists. (Please include the request ID 618b332d89201832b2c4c918db5a7651 in your message.).\n"
468 | ]
469 | },
470 | {
471 | "output_type": "execute_result",
472 | "data": {
473 | "text/plain": [
474 | "AIMessage(lc_kwargs={'content': 'Ben programlamayı seviyorum.'}, content='Ben programlamayı seviyorum.', additional_kwargs={}, example=False)"
475 | ]
476 | },
477 | "metadata": {},
478 | "execution_count": 29
479 | }
480 | ]
481 | },
482 | {
483 | "cell_type": "code",
484 | "source": [
485 | "messages = [\n",
486 | " SystemMessage(content=\"You are a helpful assistant that translates English to Turkish.\"),\n",
487 | " HumanMessage(content=\"I love programming.\")\n",
488 | "]\n",
489 | "chat(messages)"
490 | ],
491 | "metadata": {
492 | "colab": {
493 | "base_uri": "https://localhost:8080/"
494 | },
495 | "id": "CMx4rU_J5vXU",
496 | "outputId": "406f7a92-e5f2-4a27-f6a8-068862027b1a"
497 | },
498 | "execution_count": 30,
499 | "outputs": [
500 | {
501 | "output_type": "execute_result",
502 | "data": {
503 | "text/plain": [
504 | "AIMessage(lc_kwargs={'content': 'Ben programlamayı seviyorum.'}, content='Ben programlamayı seviyorum.', additional_kwargs={}, example=False)"
505 | ]
506 | },
507 | "metadata": {},
508 | "execution_count": 30
509 | }
510 | ]
511 | },
512 | {
513 | "cell_type": "code",
514 | "source": [
515 | "batch_messages = [\n",
516 | " [\n",
517 | " SystemMessage(content=\"You are a helpful assistant that translates English to French.\"),\n",
518 | " HumanMessage(content=\"I love programming.\")\n",
519 | " ],\n",
520 | " [\n",
521 | " SystemMessage(content=\"You are a helpful assistant that translates English to French.\"),\n",
522 | " HumanMessage(content=\"I love artificial intelligence.\")\n",
523 | " ],\n",
524 | "]\n",
525 | "result = chat.generate(batch_messages)\n",
526 | "result"
527 | ],
528 | "metadata": {
529 | "colab": {
530 | "base_uri": "https://localhost:8080/"
531 | },
532 | "id": "WBfdrMQA6a4L",
533 | "outputId": "6d51c154-f1c7-4e97-e5fb-f7996abab77a"
534 | },
535 | "execution_count": 31,
536 | "outputs": [
537 | {
538 | "output_type": "execute_result",
539 | "data": {
540 | "text/plain": [
541 | "LLMResult(generations=[[ChatGeneration(lc_kwargs={'message': AIMessage(lc_kwargs={'content': \"J'adore la programmation.\"}, content=\"J'adore la programmation.\", additional_kwargs={}, example=False)}, text=\"J'adore la programmation.\", generation_info=None, message=AIMessage(lc_kwargs={'content': \"J'adore la programmation.\"}, content=\"J'adore la programmation.\", additional_kwargs={}, example=False))], [ChatGeneration(lc_kwargs={'message': AIMessage(lc_kwargs={'content': \"J'adore l'intelligence artificielle.\"}, content=\"J'adore l'intelligence artificielle.\", additional_kwargs={}, example=False)}, text=\"J'adore l'intelligence artificielle.\", generation_info=None, message=AIMessage(lc_kwargs={'content': \"J'adore l'intelligence artificielle.\"}, content=\"J'adore l'intelligence artificielle.\", additional_kwargs={}, example=False))]], llm_output={'token_usage': {'prompt_tokens': 57, 'completion_tokens': 20, 'total_tokens': 77}, 'model_name': 'gpt-3.5-turbo'}, run=RunInfo(run_id=UUID('cd379524-dc22-475c-ba5f-db2ef7722036')))"
542 | ]
543 | },
544 | "metadata": {},
545 | "execution_count": 31
546 | }
547 | ]
548 | },
549 | {
550 | "cell_type": "code",
551 | "source": [
552 | "result.llm_output['token_usage']"
553 | ],
554 | "metadata": {
555 | "colab": {
556 | "base_uri": "https://localhost:8080/"
557 | },
558 | "id": "f8JG9eQr6iO9",
559 | "outputId": "b0c229a0-8238-48de-daa9-acaf94a9ddd0"
560 | },
561 | "execution_count": 32,
562 | "outputs": [
563 | {
564 | "output_type": "execute_result",
565 | "data": {
566 | "text/plain": [
567 | "{'prompt_tokens': 57, 'completion_tokens': 20, 'total_tokens': 77}"
568 | ]
569 | },
570 | "metadata": {},
571 | "execution_count": 32
572 | }
573 | ]
574 | },
575 | {
576 | "cell_type": "markdown",
577 | "source": [
578 | "# Chat Prompt Templates"
579 | ],
580 | "metadata": {
581 | "id": "HSaHRDiz6pLM"
582 | }
583 | },
584 | {
585 | "cell_type": "code",
586 | "source": [
587 | "chat = ChatOpenAI(temperature=0)\n",
588 | "\n",
589 | "template = \"You are a helpful assistant that translates {input_language} to {output_language}.\"\n",
590 | "system_message_prompt = SystemMessagePromptTemplate.from_template(template)\n",
591 | "human_template = \"{text}\"\n",
592 | "human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)\n",
593 | "\n",
594 | "chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])\n",
595 | "\n",
596 | "# get a chat completion from the formatted messages\n",
597 | "chat(chat_prompt.format_prompt(input_language=\"English\", \n",
598 | " output_language=\"Turkish\", \n",
599 | " text=\"I love programming.\").to_messages())"
600 | ],
601 | "metadata": {
602 | "colab": {
603 | "base_uri": "https://localhost:8080/"
604 | },
605 | "id": "_FbafofP6mgD",
606 | "outputId": "f2cb965e-d2d6-432e-9728-2db6b65ee250"
607 | },
608 | "execution_count": 33,
609 | "outputs": [
610 | {
611 | "output_type": "execute_result",
612 | "data": {
613 | "text/plain": [
614 | "AIMessage(lc_kwargs={'content': 'Ben programlamayı seviyorum.'}, content='Ben programlamayı seviyorum.', additional_kwargs={}, example=False)"
615 | ]
616 | },
617 | "metadata": {},
618 | "execution_count": 33
619 | }
620 | ]
621 | },
622 | {
623 | "cell_type": "markdown",
624 | "source": [
625 | "# Chains with Chat Models"
626 | ],
627 | "metadata": {
628 | "id": "c8xDm2_J7IGi"
629 | }
630 | },
631 | {
632 | "cell_type": "code",
633 | "source": [
634 | "chat = ChatOpenAI(temperature=0)\n",
635 | "\n",
636 | "template = \"You are a helpful assistant that translates {input_language} to {output_language}.\"\n",
637 | "system_message_prompt = SystemMessagePromptTemplate.from_template(template)\n",
638 | "human_template = \"{text}\"\n",
639 | "human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)\n",
640 | "chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])\n",
641 | "\n",
642 | "chain = LLMChain(llm=chat, prompt=chat_prompt)\n",
643 | "chain.run(input_language=\"English\", output_language=\"Turkish\", text=\"I love programming.\")"
644 | ],
645 | "metadata": {
646 | "colab": {
647 | "base_uri": "https://localhost:8080/",
648 | "height": 35
649 | },
650 | "id": "a8mX8BGO7JJb",
651 | "outputId": "726ba550-83df-4c44-c903-43eebb6b202a"
652 | },
653 | "execution_count": 34,
654 | "outputs": [
655 | {
656 | "output_type": "execute_result",
657 | "data": {
658 | "text/plain": [
659 | "'Ben programlamayı seviyorum.'"
660 | ],
661 | "application/vnd.google.colaboratory.intrinsic+json": {
662 | "type": "string"
663 | }
664 | },
665 | "metadata": {},
666 | "execution_count": 34
667 | }
668 | ]
669 | },
670 | {
671 | "cell_type": "markdown",
672 | "source": [
673 | "# Agents with Chat Models"
674 | ],
675 | "metadata": {
676 | "id": "JYvB5BdY7Yps"
677 | }
678 | },
679 | {
680 | "cell_type": "code",
681 | "source": [
682 | "# First, let's load the language model we're going to use to control the agent.\n",
683 | "chat = ChatOpenAI(temperature=0)\n",
684 | "\n",
685 | "# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.\n",
686 | "llm = OpenAI(temperature=0)\n",
687 | "tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm)\n",
688 | "\n",
689 | "# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.\n",
690 | "agent = initialize_agent(tools, chat, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)\n",
691 | "\n",
692 | "# Now let's test it out!\n",
693 | "agent.run(\"Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?\")"
694 | ],
695 | "metadata": {
696 | "colab": {
697 | "base_uri": "https://localhost:8080/",
698 | "height": 513
699 | },
700 | "id": "k886YmjY7aEp",
701 | "outputId": "70b88cc3-a46c-41e1-e966-cefbac7767f1"
702 | },
703 | "execution_count": 35,
704 | "outputs": [
705 | {
706 | "output_type": "stream",
707 | "name": "stderr",
708 | "text": [
709 | "WARNING:langchain.callbacks.manager:Error in on_chain_start callback: 'name'\n"
710 | ]
711 | },
712 | {
713 | "output_type": "stream",
714 | "name": "stdout",
715 | "text": [
716 | "\u001b[32;1m\u001b[1;3mThought: I need to use a search engine to find Olivia Wilde's boyfriend and a calculator to raise his age to the 0.23 power.\n",
717 | "Action:\n",
718 | "```\n",
719 | "{\n",
720 | " \"action\": \"Search\",\n",
721 | " \"action_input\": \"Olivia Wilde boyfriend\"\n",
722 | "}\n",
723 | "```\n",
724 | "\u001b[0m\n",
725 | "Observation: \u001b[36;1m\u001b[1;3mLooks like Olivia Wilde and Jason Sudeikis are starting 2023 on good terms. Amid their highly publicized custody battle – and the actress' ...\u001b[0m\n",
726 | "Thought:\u001b[32;1m\u001b[1;3mNow I need to use a calculator to raise Jason Sudeikis' age to the 0.23 power.\n",
727 | "Action:\n",
728 | "```\n",
729 | "{\n",
730 | " \"action\": \"Calculator\",\n",
731 | " \"action_input\": \"47^0.23\"\n",
732 | "}\n",
733 | "```\n",
734 | "\n",
735 | "\u001b[0m\n",
736 | "Observation: \u001b[33;1m\u001b[1;3mAnswer: 2.4242784855673896\u001b[0m\n",
737 | "Thought:\u001b[32;1m\u001b[1;3mI now know that Jason Sudeikis' current age raised to the 0.23 power is 2.4242784855673896.\n",
738 | "Final Answer: Jason Sudeikis' current age raised to the 0.23 power is 2.4242784855673896.\u001b[0m\n",
739 | "\n",
740 | "\u001b[1m> Finished chain.\u001b[0m\n"
741 | ]
742 | },
743 | {
744 | "output_type": "execute_result",
745 | "data": {
746 | "text/plain": [
747 | "\"Jason Sudeikis' current age raised to the 0.23 power is 2.4242784855673896.\""
748 | ],
749 | "application/vnd.google.colaboratory.intrinsic+json": {
750 | "type": "string"
751 | }
752 | },
753 | "metadata": {},
754 | "execution_count": 35
755 | }
756 | ]
757 | },
758 | {
759 | "cell_type": "markdown",
760 | "source": [
761 | "# Memory: Add State to Chains and Agents"
762 | ],
763 | "metadata": {
764 | "id": "emKLYRiz8Aws"
765 | }
766 | },
767 | {
768 | "cell_type": "code",
769 | "source": [
770 | "prompt = ChatPromptTemplate.from_messages([\n",
771 | " SystemMessagePromptTemplate.from_template(\n",
772 | " \"The following is a friendly conversation between a human and an AI.\"),\n",
773 | " MessagesPlaceholder(variable_name=\"history\"),\n",
774 | " HumanMessagePromptTemplate.from_template(\"{input}\")\n",
775 | "])\n",
776 | "\n",
777 | "llm = ChatOpenAI(temperature=0)\n",
778 | "memory = ConversationBufferMemory(return_messages=True)\n",
779 | "conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)\n",
780 | "\n",
781 | "conversation.predict(input=\"Hi there!\")\n",
782 | "# -> 'Hello! How can I assist you today?'\n",
783 | "\n",
784 | "\n",
785 | "conversation.predict(input=\"I'm doing well! Just having a conversation with an AI.\")\n",
786 | "# -> \"That sounds like fun! I'm happy to chat with you. Is there anything specific you'd like to talk about?\"\n",
787 | "\n",
788 | "conversation.predict(input=\"Tell me about yourself.\")"
789 | ],
790 | "metadata": {
791 | "colab": {
792 | "base_uri": "https://localhost:8080/",
793 | "height": 70
794 | },
795 | "id": "PC9zwbTH8DLB",
796 | "outputId": "276e0f98-1bd2-40a8-e788-2dbd0c1f7e71"
797 | },
798 | "execution_count": 38,
799 | "outputs": [
800 | {
801 | "output_type": "execute_result",
802 | "data": {
803 | "text/plain": [
804 | "'I am an AI language model designed to assist with various tasks such as answering questions, generating text, and providing recommendations. I am constantly learning and improving my abilities through machine learning algorithms. Is there anything specific you would like to know about me?'"
805 | ],
806 | "application/vnd.google.colaboratory.intrinsic+json": {
807 | "type": "string"
808 | }
809 | },
810 | "metadata": {},
811 | "execution_count": 38
812 | }
813 | ]
814 | },
815 | {
816 | "cell_type": "markdown",
817 | "source": [
818 | "# Resource\n",
819 | "\n",
820 | "- [LangChain Doc](https://python.langchain.com/en/latest/getting_started/getting_started.html#environment-setup)"
821 | ],
822 | "metadata": {
823 | "id": "L6HvwP4h_7Zx"
824 | }
825 | }
826 | ]
827 | }
--------------------------------------------------------------------------------
"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 1,
32 | "metadata": {
33 | "id": "d_pvDMrgq0IP"
34 | },
35 | "outputs": [],
36 | "source": [
37 | "!pip install -q -U langchain langchain_core langchain_groq gradio"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "source": [
43 | "from google.colab import userdata\n",
44 | "groq_api_key = userdata.get('GROQ_API_KEY')"
45 | ],
46 | "metadata": {
47 | "id": "1BBWBEFc0G9J"
48 | },
49 | "execution_count": 2,
50 | "outputs": []
51 | },
52 | {
53 | "cell_type": "code",
54 | "source": [
55 | "from langchain_groq import ChatGroq\n",
56 | "\n",
57 | "chat = ChatGroq(\n",
58 | " api_key = groq_api_key,\n",
59 | " model_name = \"mixtral-8x7b-32768\"\n",
60 | ")"
61 | ],
62 | "metadata": {
63 | "id": "vPfbfzOC1qE8"
64 | },
65 | "execution_count": 3,
66 | "outputs": []
67 | },
68 | {
69 | "cell_type": "code",
70 | "source": [
71 | "from langchain_core.prompts import ChatPromptTemplate\n",
72 | "\n",
73 | "system = \"You are a helpful assistant.\"\n",
74 | "human = \"{text}\"\n",
75 | "\n",
76 | "prompt = ChatPromptTemplate.from_messages(\n",
77 | " [\n",
78 | " (\"system\", system), (\"human\", human)\n",
79 | " ]\n",
80 | ")"
81 | ],
82 | "metadata": {
83 | "id": "3VIDCzMm3Yh3"
84 | },
85 | "execution_count": 4,
86 | "outputs": []
87 | },
88 | {
89 | "cell_type": "code",
90 | "source": [
91 | "from langchain_core.output_parsers import StrOutputParser"
92 | ],
93 | "metadata": {
94 | "id": "4PajMIZS3w3B"
95 | },
96 | "execution_count": 5,
97 | "outputs": []
98 | },
99 | {
100 | "cell_type": "code",
101 | "source": [
102 | "chain = prompt | chat | StrOutputParser()"
103 | ],
104 | "metadata": {
105 | "id": "VtpYCfMW35Wr"
106 | },
107 | "execution_count": 6,
108 | "outputs": []
109 | },
110 | {
111 | "cell_type": "code",
112 | "source": [
113 | "chain.invoke(\n",
114 | " {\"text\":\"Why is the sky blue?\"}\n",
115 | ")"
116 | ],
117 | "metadata": {
118 | "colab": {
119 | "base_uri": "https://localhost:8080/",
120 | "height": 106
121 | },
122 | "id": "Q_r5ofV04adl",
123 | "outputId": "cc029596-a6ea-4126-ebfc-5134b27e21fa"
124 | },
125 | "execution_count": 7,
126 | "outputs": [
127 | {
128 | "output_type": "execute_result",
129 | "data": {
130 | "text/plain": [
131 | "\"The phenomenon that causes the sky to appear blue is known as Rayleigh scattering. As sunlight reaches Earth's atmosphere, it is made up of different colors, which are essentially different wavelengths of light. Shorter wavelengths (like blue and violet) are scattered in all directions more than longer wavelengths (like red, orange, and yellow).\\n\\nEven though violet light is scattered more than blue light, the sky appears blue, not violet, because our eyes are more sensitive to blue light and because sunlight reaches us more at the blue part of the spectrum, rather than the violet part. Additionally, some of the violet light gets absorbed by the ozone layer in the atmosphere. This combination results in the sky we typically observe as blue.\""
132 | ],
133 | "application/vnd.google.colaboratory.intrinsic+json": {
134 | "type": "string"
135 | }
136 | },
137 | "metadata": {},
138 | "execution_count": 7
139 | }
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "source": [
145 | "import gradio as gr"
146 | ],
147 | "metadata": {
148 | "id": "xJFwzG9p4fDK"
149 | },
150 | "execution_count": 8,
151 | "outputs": []
152 | },
153 | {
154 | "cell_type": "code",
155 | "source": [
156 | "def fetch_response(user_input):\n",
157 | " chat = ChatGroq(\n",
158 | " api_key = groq_api_key,\n",
159 | " model_name = \"mixtral-8x7b-32768\"\n",
160 | " )\n",
161 | " system = \"You are a helpful assistant.\"\n",
162 | " human = \"{text}\"\n",
163 | "\n",
164 | " prompt = ChatPromptTemplate.from_messages(\n",
165 | " [\n",
166 | " (\"system\", system), (\"human\", human)\n",
167 | " ]\n",
168 | " )\n",
169 | " chain = prompt | chat | StrOutputParser()\n",
170 | " output = chain.invoke({\"text\": user_input})\n",
171 | " return output"
172 | ],
173 | "metadata": {
174 | "id": "cgf7Uvaw5wfg"
175 | },
176 | "execution_count": 9,
177 | "outputs": []
178 | },
179 | {
180 | "cell_type": "code",
181 | "source": [
182 | "user_input = \"Why is the sky blue?\"\n",
183 | "\n",
184 | "fetch_response(user_input)"
185 | ],
186 | "metadata": {
187 | "colab": {
188 | "base_uri": "https://localhost:8080/",
189 | "height": 106
190 | },
191 | "id": "UYPZSCJW6sNE",
192 | "outputId": "da48cc76-0925-4aa1-806a-0877328dafef"
193 | },
194 | "execution_count": 10,
195 | "outputs": [
196 | {
197 | "output_type": "execute_result",
198 | "data": {
199 | "text/plain": [
200 | "\"The phenomenon that causes the sky to appear blue is known as Rayleigh scattering. As sunlight reaches Earth's atmosphere, it is made up of different colors, which are represented in the light spectrum as having different wavelengths. Blue and violet light have the shortest wavelengths and are scattered in all directions by the gas molecules in Earth's atmosphere. \\n\\nThis scattered blue and violet light reaches our eyes from all directions, giving the sky its blue appearance. You might wonder why we don't see a violet sky, given that violet light is scattered more than blue light. This is because our eyes are more sensitive to blue light and because sunlight reaches us with less violet light to begin with. Additionally, some of the violet light gets absorbed by the ozone layer in the atmosphere. Therefore, the sky appears blue to us during the daytime.\""
201 | ],
202 | "application/vnd.google.colaboratory.intrinsic+json": {
203 | "type": "string"
204 | }
205 | },
206 | "metadata": {},
207 | "execution_count": 10
208 | }
209 | ]
210 | },
211 | {
212 | "cell_type": "code",
213 | "source": [
214 | "iface = gr.Interface(\n",
215 | " fn = fetch_response,\n",
216 | " inputs = \"text\",\n",
217 | " outputs = \"text\",\n",
218 | " title = \"Groq Chatbot\",\n",
219 | " description=\"Ask a question and get a response.\"\n",
220 | ")"
221 | ],
222 | "metadata": {
223 | "id": "sSmvFUjL67SK"
224 | },
225 | "execution_count": 11,
226 | "outputs": []
227 | },
228 | {
229 | "cell_type": "code",
230 | "source": [
231 | "iface.launch()"
232 | ],
233 | "metadata": {
234 | "colab": {
235 | "base_uri": "https://localhost:8080/",
236 | "height": 627
237 | },
238 | "id": "Y0JVF_zB7fl8",
239 | "outputId": "7aeccd71-31de-4853-b5db-3923a79913af"
240 | },
241 | "execution_count": 12,
242 | "outputs": [
243 | {
244 | "output_type": "stream",
245 | "name": "stdout",
246 | "text": [
247 | "Setting queue=True in a Colab notebook requires sharing enabled. Setting `share=True` (you can turn this off by setting `share=False` in `launch()` explicitly).\n",
248 | "\n",
249 | "Colab notebook detected. To show errors in colab notebook, set debug=True in launch()\n",
250 | "Running on public URL: https://ba64a37776f78dbb6a.gradio.live\n",
251 | "\n",
252 | "This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)\n"
253 | ]
254 | },
255 | {
256 | "output_type": "display_data",
257 | "data": {
258 | "text/plain": [
259 | ""
260 | ],
261 | "text/html": [
262 | ""
263 | ]
264 | },
265 | "metadata": {}
266 | },
267 | {
268 | "output_type": "execute_result",
269 | "data": {
270 | "text/plain": []
271 | },
272 | "metadata": {},
273 | "execution_count": 12
274 | }
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "source": [
280 | "Let's connect [YouTube](http://youtube.com/tirendazacademy) | [Medium](http://tirendazacademy.medium.com) | [X](http://x.com/tirendazacademy) | [Linkedin](https://www.linkedin.com/in/tirendaz-academy) 😎"
281 | ],
282 | "metadata": {
283 | "id": "y08h2aQU--Ya"
284 | }
285 | }
286 | ]
287 | }
--------------------------------------------------------------------------------
/A-Gentle-Intro-to-LangChain.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyPSEIyI6+A7Q2yj360qdARd",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Installation"
33 | ],
34 | "metadata": {
35 | "id": "DrueKvwYZvVM"
36 | }
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 1,
41 | "metadata": {
42 | "id": "5uc9A7WP7gQx"
43 | },
44 | "outputs": [],
45 | "source": [
46 | "!pip install -q langchain\n",
47 | "!pip install -q openai"
48 | ]
49 | },
50 | {
51 | "cell_type": "markdown",
52 | "source": [
53 | "# Environment Setup"
54 | ],
55 | "metadata": {
56 | "id": "mWJrFgzyZzHy"
57 | }
58 | },
59 | {
60 | "cell_type": "code",
61 | "source": [
62 | "import os\n",
63 | "os.environ[\"OPENAI_API_KEY\"]=\"Your-API-Key\""
64 | ],
65 | "metadata": {
66 | "id": "y8cKMsGA8ZVp"
67 | },
68 | "execution_count": 2,
69 | "outputs": []
70 | },
71 | {
72 | "cell_type": "markdown",
73 | "source": [
74 | "# Building a Language Model Application"
75 | ],
76 | "metadata": {
77 | "id": "AgBeqAqxZ4tA"
78 | }
79 | },
80 | {
81 | "cell_type": "code",
82 | "source": [
83 | "from langchain.llms import OpenAI"
84 | ],
85 | "metadata": {
86 | "id": "rQfOeXbD882O"
87 | },
88 | "execution_count": 3,
89 | "outputs": []
90 | },
91 | {
92 | "cell_type": "code",
93 | "source": [
94 | "llm = OpenAI(temperature=0.7)"
95 | ],
96 | "metadata": {
97 | "id": "5bi0W54KH8nS"
98 | },
99 | "execution_count": 4,
100 | "outputs": []
101 | },
102 | {
103 | "cell_type": "code",
104 | "source": [
105 | "text = \"what are the 5 most expensive capital cities?\""
106 | ],
107 | "metadata": {
108 | "id": "zkPDSnBWID7D"
109 | },
110 | "execution_count": 5,
111 | "outputs": []
112 | },
113 | {
114 | "cell_type": "code",
115 | "source": [
116 | "print(llm(text))"
117 | ],
118 | "metadata": {
119 | "colab": {
120 | "base_uri": "https://localhost:8080/"
121 | },
122 | "id": "OaxHKf6yIOSq",
123 | "outputId": "b2b78f51-6dd9-484e-e571-703e5b70be7e"
124 | },
125 | "execution_count": 6,
126 | "outputs": [
127 | {
128 | "output_type": "stream",
129 | "name": "stdout",
130 | "text": [
131 | "\n",
132 | "\n",
133 | "1. Tokyo, Japan\n",
134 | "2. Beijing, China\n",
135 | "3. Singapore\n",
136 | "4. Zurich, Switzerland\n",
137 | "5. Hong Kong, China\n"
138 | ]
139 | }
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "source": [
145 | "llm_1 = OpenAI(model_name=\"gpt-3.5-turbo\")"
146 | ],
147 | "metadata": {
148 | "id": "ccY2Pm5MIX-7"
149 | },
150 | "execution_count": null,
151 | "outputs": []
152 | },
153 | {
154 | "cell_type": "code",
155 | "source": [
156 | "print(llm_1(\"Tell me a joke\"))"
157 | ],
158 | "metadata": {
159 | "colab": {
160 | "base_uri": "https://localhost:8080/"
161 | },
162 | "id": "4-vtyaxqIt9N",
163 | "outputId": "213d117e-e3dd-46c7-d28a-91c66bd95f33"
164 | },
165 | "execution_count": 8,
166 | "outputs": [
167 | {
168 | "output_type": "stream",
169 | "name": "stdout",
170 | "text": [
171 | "Why don't scientists trust atoms? \n",
172 | "Because they make up everything!\n"
173 | ]
174 | }
175 | ]
176 | },
177 | {
178 | "cell_type": "markdown",
179 | "source": [
180 | "# Prompt Templates & Chains"
181 | ],
182 | "metadata": {
183 | "id": "aeqNlevBaAn6"
184 | }
185 | },
186 | {
187 | "cell_type": "code",
188 | "source": [
189 | "from langchain.prompts import PromptTemplate"
190 | ],
191 | "metadata": {
192 | "id": "w7oLfzVvJIrK"
193 | },
194 | "execution_count": 9,
195 | "outputs": []
196 | },
197 | {
198 | "cell_type": "code",
199 | "source": [
200 | "prompt = PromptTemplate(\n",
201 | " input_variables=[\"input\"],\n",
202 | " template = \"Which are the 5 most {input} capital cities?\"\n",
203 | ")"
204 | ],
205 | "metadata": {
206 | "id": "jAeR5an0JcwT"
207 | },
208 | "execution_count": 10,
209 | "outputs": []
210 | },
211 | {
212 | "cell_type": "code",
213 | "source": [
214 | "print(prompt.format(input=\"popular\"))"
215 | ],
216 | "metadata": {
217 | "colab": {
218 | "base_uri": "https://localhost:8080/"
219 | },
220 | "id": "jnBacugyKDgw",
221 | "outputId": "eb12b493-fd55-448b-9e84-2d20143cd0a1"
222 | },
223 | "execution_count": 11,
224 | "outputs": [
225 | {
226 | "output_type": "stream",
227 | "name": "stdout",
228 | "text": [
229 | "Which are the 5 most popular capital cities?\n"
230 | ]
231 | }
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "source": [
237 | "# Creating Chains"
238 | ],
239 | "metadata": {
240 | "id": "UozkgL4TaJAd"
241 | }
242 | },
243 | {
244 | "cell_type": "code",
245 | "source": [
246 | "from langchain.chains import LLMChain"
247 | ],
248 | "metadata": {
249 | "id": "FmFLhs5aLB5X"
250 | },
251 | "execution_count": 12,
252 | "outputs": []
253 | },
254 | {
255 | "cell_type": "code",
256 | "source": [
257 | "llm = OpenAI(temperature=0.7)"
258 | ],
259 | "metadata": {
260 | "id": "BhKV3ZeOLLuE"
261 | },
262 | "execution_count": 13,
263 | "outputs": []
264 | },
265 | {
266 | "cell_type": "code",
267 | "source": [
268 | "prompt=PromptTemplate(\n",
269 | " input_variables=[\"country\"],\n",
270 | " template=\"where is the capital of {country}\"\n",
271 | ")"
272 | ],
273 | "metadata": {
274 | "id": "fs7oIdqwSKRR"
275 | },
276 | "execution_count": 14,
277 | "outputs": []
278 | },
279 | {
280 | "cell_type": "code",
281 | "source": [
282 | "chain = LLMChain(llm=llm, prompt=prompt)"
283 | ],
284 | "metadata": {
285 | "id": "N-j3BRkhSvVA"
286 | },
287 | "execution_count": 15,
288 | "outputs": []
289 | },
290 | {
291 | "cell_type": "code",
292 | "source": [
293 | "print(chain.run(\"USA\"))"
294 | ],
295 | "metadata": {
296 | "colab": {
297 | "base_uri": "https://localhost:8080/"
298 | },
299 | "id": "E5k6F7_YS93-",
300 | "outputId": "e946aef3-ce3d-4442-86cf-d682433d3577"
301 | },
302 | "execution_count": 16,
303 | "outputs": [
304 | {
305 | "output_type": "stream",
306 | "name": "stdout",
307 | "text": [
308 | "\n",
309 | "\n",
310 | "Washington, D.C. is the capital of the United States of America.\n"
311 | ]
312 | }
313 | ]
314 | },
315 | {
316 | "cell_type": "markdown",
317 | "source": [
318 | "# Combining Chains"
319 | ],
320 | "metadata": {
321 | "id": "TbiTlAJ4aMr2"
322 | }
323 | },
324 | {
325 | "cell_type": "code",
326 | "source": [
327 | "llm = OpenAI(temperature=0)"
328 | ],
329 | "metadata": {
330 | "id": "4aTVCQsTTMlk"
331 | },
332 | "execution_count": 17,
333 | "outputs": []
334 | },
335 | {
336 | "cell_type": "code",
337 | "source": [
338 | "from langchain.agents import load_tools"
339 | ],
340 | "metadata": {
341 | "id": "0WIvU9iMTds5"
342 | },
343 | "execution_count": 18,
344 | "outputs": []
345 | },
346 | {
347 | "cell_type": "code",
348 | "source": [
349 | "!pip install -q google-search-results"
350 | ],
351 | "metadata": {
352 | "id": "zhE5nBzXXMG4"
353 | },
354 | "execution_count": 19,
355 | "outputs": []
356 | },
357 | {
358 | "cell_type": "code",
359 | "source": [
360 | "os.environ[\"SERPAPI_API_KEY\"]=\"Your-API-Key\""
361 | ],
362 | "metadata": {
363 | "id": "apWCa-yoXY-o"
364 | },
365 | "execution_count": 20,
366 | "outputs": []
367 | },
368 | {
369 | "cell_type": "code",
370 | "source": [
371 | "tools = load_tools([\"serpapi\",\"llm-math\"], llm=llm)"
372 | ],
373 | "metadata": {
374 | "id": "Gr8ZdtBSYA3C"
375 | },
376 | "execution_count": 21,
377 | "outputs": []
378 | },
379 | {
380 | "cell_type": "code",
381 | "source": [
382 | "from langchain.agents import initialize_agent\n",
383 | "from langchain.agents import AgentType"
384 | ],
385 | "metadata": {
386 | "id": "t2mWKkToYTJ-"
387 | },
388 | "execution_count": 22,
389 | "outputs": []
390 | },
391 | {
392 | "cell_type": "code",
393 | "source": [
394 | "agent=initialize_agent(tools, llm,\n",
395 | " agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,\n",
396 | " verbose=True)"
397 | ],
398 | "metadata": {
399 | "id": "Cvn7yshvYfbV"
400 | },
401 | "execution_count": 23,
402 | "outputs": []
403 | },
404 | {
405 | "cell_type": "code",
406 | "source": [
407 | "agent.run(\"who is the director of the walking dead series? what is his current age raised to the 0.35 power\")"
408 | ],
409 | "metadata": {
410 | "colab": {
411 | "base_uri": "https://localhost:8080/",
412 | "height": 354
413 | },
414 | "id": "HLtWXKZ2YvW-",
415 | "outputId": "b00d82cc-9861-4087-a6b2-3684cca34c92"
416 | },
417 | "execution_count": 24,
418 | "outputs": [
419 | {
420 | "output_type": "stream",
421 | "name": "stderr",
422 | "text": [
423 | "WARNING:langchain.callbacks.manager:Error in on_chain_start callback: 'name'\n"
424 | ]
425 | },
426 | {
427 | "output_type": "stream",
428 | "name": "stdout",
429 | "text": [
430 | "\u001b[32;1m\u001b[1;3m I need to find out who the director is and then calculate his age raised to the 0.35 power\n",
431 | "Action: Search\n",
432 | "Action Input: \"director of the walking dead series\"\u001b[0m\n",
433 | "Observation: \u001b[36;1m\u001b[1;3mDarabont Ferenc, better known as Frank Darabont, is an Academy Award winning Hungarian-American director, screenwriter and producer.\u001b[0m\n",
434 | "Thought:\u001b[32;1m\u001b[1;3m I need to find out his age\n",
435 | "Action: Search\n",
436 | "Action Input: \"Frank Darabont age\"\u001b[0m\n",
437 | "Observation: \u001b[36;1m\u001b[1;3m64 years\u001b[0m\n",
438 | "Thought:\u001b[32;1m\u001b[1;3m I need to calculate his age raised to the 0.35 power\n",
439 | "Action: Calculator\n",
440 | "Action Input: 64^0.35\u001b[0m\n",
441 | "Observation: \u001b[33;1m\u001b[1;3mAnswer: 4.2870938501451725\u001b[0m\n",
442 | "Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
443 | "Final Answer: Frank Darabont is 64 years old and his age raised to the 0.35 power is 4.2870938501451725.\u001b[0m\n",
444 | "\n",
445 | "\u001b[1m> Finished chain.\u001b[0m\n"
446 | ]
447 | },
448 | {
449 | "output_type": "execute_result",
450 | "data": {
451 | "text/plain": [
452 | "'Frank Darabont is 64 years old and his age raised to the 0.35 power is 4.2870938501451725.'"
453 | ],
454 | "application/vnd.google.colaboratory.intrinsic+json": {
455 | "type": "string"
456 | }
457 | },
458 | "metadata": {},
459 | "execution_count": 24
460 | }
461 | ]
462 | },
463 | {
464 | "cell_type": "markdown",
465 | "source": [
466 | "Thanks for reading.\n",
467 | "\n",
468 | "Let's connect [YouTube](http://youtube.com/tirendazacademy) | [Medium](http://tirendazacademy.medium.com) | [Twitter](http://twitter.com/tirendazacademy) | [Linkedin](https://www.linkedin.com/in/tirendaz-academy)"
469 | ],
470 | "metadata": {
471 | "id": "ZvhoWvMCaPh8"
472 | }
473 | }
474 | ]
475 | }
--------------------------------------------------------------------------------
/Creating-a-Vector-Store.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyOStgzUDPpKri0l9rJ30dJG",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# Creating a Vector Store (Vector Database)"
33 | ],
34 | "metadata": {
35 | "id": "xHVC_PSQoT_T"
36 | }
37 | },
38 | {
39 | "cell_type": "code",
40 | "source": [
41 | "%pip install -q langchain openai chromadb tiktoken"
42 | ],
43 | "metadata": {
44 | "colab": {
45 | "base_uri": "https://localhost:8080/"
46 | },
47 | "id": "HY0JZuTPnRKW",
48 | "outputId": "7a909860-13fd-4f0e-f60a-a12ccedc2d95"
49 | },
50 | "execution_count": 1,
51 | "outputs": [
52 | {
53 | "output_type": "stream",
54 | "name": "stdout",
55 | "text": [
56 | "\u001b[?25l \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m0.0/1.3 MB\u001b[0m \u001b[31m?\u001b[0m eta \u001b[36m-:--:--\u001b[0m\r\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m1.3/1.3 MB\u001b[0m \u001b[31m48.5 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
57 | "\u001b[?25h\u001b[?25l \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m0.0/73.6 kB\u001b[0m \u001b[31m?\u001b[0m eta \u001b[36m-:--:--\u001b[0m\r\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m73.6/73.6 kB\u001b[0m \u001b[31m6.5 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
58 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m396.4/396.4 kB\u001b[0m \u001b[31m29.5 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
59 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m1.7/1.7 MB\u001b[0m \u001b[31m81.4 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
60 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m90.0/90.0 kB\u001b[0m \u001b[31m8.8 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
61 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m62.6/62.6 kB\u001b[0m \u001b[31m6.2 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
62 | "\u001b[?25h Installing build dependencies ... \u001b[?25l\u001b[?25hdone\n",
63 | " Getting requirements to build wheel ... \u001b[?25l\u001b[?25hdone\n",
64 | " Preparing metadata (pyproject.toml) ... \u001b[?25l\u001b[?25hdone\n",
65 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m966.7/966.7 kB\u001b[0m \u001b[31m3.6 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
66 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m55.4/55.4 kB\u001b[0m \u001b[31m5.0 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
67 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m59.6/59.6 kB\u001b[0m \u001b[31m5.1 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
68 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m5.3/5.3 MB\u001b[0m \u001b[31m94.4 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
69 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m5.9/5.9 MB\u001b[0m \u001b[31m106.2 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
70 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m7.8/7.8 MB\u001b[0m \u001b[31m105.9 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
71 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m63.6/63.6 kB\u001b[0m \u001b[31m5.4 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
72 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m2.7/2.7 MB\u001b[0m \u001b[31m90.1 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
73 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m1.3/1.3 MB\u001b[0m \u001b[31m73.8 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
74 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m49.1/49.1 kB\u001b[0m \u001b[31m3.9 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
75 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m46.0/46.0 kB\u001b[0m \u001b[31m2.9 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
76 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m58.3/58.3 kB\u001b[0m \u001b[31m5.4 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
77 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m428.8/428.8 kB\u001b[0m \u001b[31m29.7 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
78 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m4.1/4.1 MB\u001b[0m \u001b[31m92.2 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
79 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m1.3/1.3 MB\u001b[0m \u001b[31m74.3 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
80 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m129.9/129.9 kB\u001b[0m \u001b[31m12.6 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
81 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m86.8/86.8 kB\u001b[0m \u001b[31m7.0 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
82 | "\u001b[?25h Building wheel for hnswlib (pyproject.toml) ... \u001b[?25l\u001b[?25hdone\n",
83 | "\u001b[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\n",
84 | "google-colab 1.0.0 requires requests==2.27.1, but you have requests 2.31.0 which is incompatible.\u001b[0m\u001b[31m\n",
85 | "\u001b[0m"
86 | ]
87 | }
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "source": [
93 | "import openai\n",
94 | "import os\n",
95 | "\n",
96 | "os.environ[\"OPENAI_API_KEY\"] = \"...\"\n",
97 | "openai.api_key = os.getenv(\"OPENAI_API_KEY\")"
98 | ],
99 | "metadata": {
100 | "id": "3szTdoSdlu8b"
101 | },
102 | "execution_count": 2,
103 | "outputs": []
104 | },
105 | {
106 | "cell_type": "markdown",
107 | "source": [
108 | "## Collect data that we want to use to answer the users’ questions\n",
109 | "\n",
110 | ""
111 | ],
112 | "metadata": {
113 | "id": "ju-ndba0olal"
114 | }
115 | },
116 | {
117 | "cell_type": "code",
118 | "source": [
119 | "import requests\n",
120 | "from bs4 import BeautifulSoup\n",
121 | "from langchain.embeddings.openai import OpenAIEmbeddings\n",
122 | "from langchain.text_splitter import CharacterTextSplitter\n",
123 | "from langchain.vectorstores import Chroma\n",
124 | "from langchain.document_loaders import TextLoader\n",
125 | "\n",
126 | "# URL of the Wikipedia page to scrape\n",
127 | "url = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'\n",
128 | "\n",
129 | "# Send a GET request to the URL\n",
130 | "response = requests.get(url)\n",
131 | "\n",
132 | "# Parse the HTML content using BeautifulSoup\n",
133 | "soup = BeautifulSoup(response.content, 'html.parser')\n",
134 | "\n",
135 | "# Find all the text on the page\n",
136 | "text = soup.get_text()\n",
137 | "text = text.replace('\\n', '')\n",
138 | "\n",
139 | "# Open a new file called 'output.txt' in write mode and store the file object in a variable\n",
140 | "with open('output.txt', 'w', encoding='utf-8') as file:\n",
141 | " # Write the string to the file\n",
142 | " file.write(text)"
143 | ],
144 | "metadata": {
145 | "id": "uAjB4BUZoFlT"
146 | },
147 | "execution_count": 3,
148 | "outputs": []
149 | },
150 | {
151 | "cell_type": "code",
152 | "source": [
153 | "text[:100]"
154 | ],
155 | "metadata": {
156 | "colab": {
157 | "base_uri": "https://localhost:8080/",
158 | "height": 35
159 | },
160 | "id": "kW9CzRDao4AJ",
161 | "outputId": "1addbbc4-0d22-4689-88ed-72abc60fec30"
162 | },
163 | "execution_count": 4,
164 | "outputs": [
165 | {
166 | "output_type": "execute_result",
167 | "data": {
168 | "text/plain": [
169 | "'Prime Minister of the United Kingdom - WikipediaJump to contentMain menuMain menumove to sidebarhide'"
170 | ],
171 | "application/vnd.google.colaboratory.intrinsic+json": {
172 | "type": "string"
173 | }
174 | },
175 | "metadata": {},
176 | "execution_count": 4
177 | }
178 | ]
179 | },
180 | {
181 | "cell_type": "markdown",
182 | "source": [
183 | "## Load the data and define how you want to split the data into text chunks\n",
184 | "\n",
185 | ""
186 | ],
187 | "metadata": {
188 | "id": "aAXUUfrOpLLg"
189 | }
190 | },
191 | {
192 | "cell_type": "code",
193 | "source": [
194 | "from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
195 | "\n",
196 | "# load the document\n",
197 | "with open('./output.txt', encoding='utf-8') as f:\n",
198 | " text = f.read()\n",
199 | "\n",
200 | "# define the text splitter\n",
201 | "text_splitter = RecursiveCharacterTextSplitter(\n",
202 | " chunk_size = 500,\n",
203 | " chunk_overlap = 100,\n",
204 | " length_function = len,\n",
205 | ")\n",
206 | "\n",
207 | "texts = text_splitter.create_documents([text])"
208 | ],
209 | "metadata": {
210 | "id": "1a35DSGbo8Ty"
211 | },
212 | "execution_count": 5,
213 | "outputs": []
214 | },
215 | {
216 | "cell_type": "code",
217 | "source": [
218 | "for text in texts[:3]:\n",
219 | " print(text)"
220 | ],
221 | "metadata": {
222 | "colab": {
223 | "base_uri": "https://localhost:8080/"
224 | },
225 | "id": "89WR4YZfqL1H",
226 | "outputId": "a0d0f778-6f16-4c8c-c6a5-283d271f5436"
227 | },
228 | "execution_count": 6,
229 | "outputs": [
230 | {
231 | "output_type": "stream",
232 | "name": "stdout",
233 | "text": [
234 | "page_content='Prime Minister of the United Kingdom - WikipediaJump to contentMain menuMain menumove to sidebarhide\\t\\tNavigation\\tMain pageContentsCurrent eventsRandom articleAbout WikipediaContact usDonate\\t\\tContribute\\tHelpLearn to editCommunity portalRecent changesUpload fileLanguagesLanguage links are at the top of the page across from the title.SearchSearchCreate accountLog inPersonal tools Create account Log inPages for logged out editors learn moreContributionsTalkContentsmove to' metadata={}\n",
235 | "page_content=\"tools Create account Log inPages for logged out editors learn moreContributionsTalkContentsmove to sidebarhide(Top)1History2Authority, powers and constraints3Constitutional background4Modern premiershipToggle Modern premiership subsection4.1Appointment4.2Prime Minister's Office4.3Prime Minister's Questions4.4Security and transport4.5International role4.6Deputy4.6.1Succession4.7Resignation5Precedence, privileges and form of address6Retirement honours7Public Duty Costs Allowance (PDCA)8See\" metadata={}\n",
236 | "page_content='privileges and form of address6Retirement honours7Public Duty Costs Allowance (PDCA)8See alsoToggle See also subsection8.1Lists of prime ministers by different criteria8.2Other related pages9Notes10ReferencesToggle References subsection10.1Works cited11Further reading12External linksToggle the table of contentsToggle the table of contentsPrime Minister of the United Kingdom84' metadata={}\n"
237 | ]
238 | }
239 | ]
240 | },
241 | {
242 | "cell_type": "markdown",
243 | "source": [
244 | "## Define the Embeddings Model you want to use to calculate the embeddings for your text chunks and store them in a vector store\n",
245 | "\n",
246 | ""
247 | ],
248 | "metadata": {
249 | "id": "tRa1L9Vtqjqt"
250 | }
251 | },
252 | {
253 | "cell_type": "code",
254 | "source": [
255 | "from langchain.embeddings.openai import OpenAIEmbeddings\n",
256 | "from langchain.vectorstores import Chroma\n",
257 | "\n",
258 | "# define the embeddings model\n",
259 | "embeddings = OpenAIEmbeddings()\n",
260 | "\n",
261 | "# use the text chunks and the embeddings model to fill our vector store\n",
262 | "db = Chroma.from_documents(texts, embeddings)"
263 | ],
264 | "metadata": {
265 | "id": "brqCzXQLqjcq"
266 | },
267 | "execution_count": 7,
268 | "outputs": []
269 | },
270 | {
271 | "cell_type": "markdown",
272 | "source": [
273 | "## Calculate the embeddings for the user’s question, find similar text chunks in our vector store and use them to build our prompt\n",
274 | "\n",
275 | ""
276 | ],
277 | "metadata": {
278 | "id": "5ari5pv7uFE_"
279 | }
280 | },
281 | {
282 | "cell_type": "code",
283 | "source": [
284 | "from langchain.llms import OpenAI\n",
285 | "from langchain import PromptTemplate\n",
286 | "\n",
287 | "users_question = \"Who is the current Prime Minister of the UK?\"\n",
288 | "\n",
289 | "# use our vector store to find similar text chunks\n",
290 | "results = db.similarity_search(\n",
291 | " query=users_question,\n",
292 | " n_results=5\n",
293 | ")\n",
294 | "\n",
295 | "# define the prompt template\n",
296 | "template = \"\"\"\n",
297 | "You are a chat bot who loves to help people! Given the following context sections, answer the\n",
298 | "question using only the given context. If you are unsure and the answer is not\n",
299 | "explicitly writting in the documentation, say \"Sorry, I don't know how to help with that.\"\n",
300 | "\n",
301 | "Context sections:\n",
302 | "{context}\n",
303 | "\n",
304 | "Question:\n",
305 | "{users_question}\n",
306 | "\n",
307 | "Answer:\n",
308 | "\"\"\"\n",
309 | "\n",
310 | "prompt = PromptTemplate(template=template, input_variables=[\"context\", \"users_question\"])\n",
311 | "\n",
312 | "# fill the prompt template\n",
313 | "prompt_text = prompt.format(context = results, users_question = users_question)\n",
314 | "\n",
315 | "# ask the defined LLM\n",
316 | "llm = OpenAI(temperature=1)\n",
317 | "llm(prompt_text)"
318 | ],
319 | "metadata": {
320 | "colab": {
321 | "base_uri": "https://localhost:8080/",
322 | "height": 35
323 | },
324 | "id": "zkUj84BdtVlP",
325 | "outputId": "4a7184f4-47cb-4c49-8f3e-dd39ee45b2b3"
326 | },
327 | "execution_count": 8,
328 | "outputs": [
329 | {
330 | "output_type": "execute_result",
331 | "data": {
332 | "text/plain": [
333 | "'The current Prime Minister of the UK is Rishi Sunak, since 25 October 2022.'"
334 | ],
335 | "application/vnd.google.colaboratory.intrinsic+json": {
336 | "type": "string"
337 | }
338 | },
339 | "metadata": {},
340 | "execution_count": 8
341 | }
342 | ]
343 | },
344 | {
345 | "cell_type": "markdown",
346 | "source": [
347 | "### Resources\n",
348 | "\n",
349 | "- [All You Need to Know to Build Your First LLM App](https://towardsdatascience.com/all-you-need-to-know-to-build-your-first-llm-app-eb982c78ffac)"
350 | ],
351 | "metadata": {
352 | "id": "d34LhEpSvmlQ"
353 | }
354 | }
355 | ]
356 | }
--------------------------------------------------------------------------------
/RAG-with-Chat-History/RAG-with-Chat-History.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Initialize the local model"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "from langchain_community.llms import Ollama \n",
17 | "\n",
18 | "llm = Ollama(model = \"mistral\")"
19 | ]
20 | },
21 | {
22 | "cell_type": "code",
23 | "execution_count": 2,
24 | "metadata": {},
25 | "outputs": [
26 | {
27 | "data": {
28 | "text/plain": [
29 | "\" Why don't scientists trust atoms?\\n\\nBecause they make up everything!\""
30 | ]
31 | },
32 | "execution_count": 2,
33 | "metadata": {},
34 | "output_type": "execute_result"
35 | }
36 | ],
37 | "source": [
38 | "llm.invoke(\"Tell me a short joke\")"
39 | ]
40 | },
41 | {
42 | "cell_type": "markdown",
43 | "metadata": {},
44 | "source": [
45 | "## Load data for RAG"
46 | ]
47 | },
48 | {
49 | "cell_type": "code",
50 | "execution_count": 3,
51 | "metadata": {},
52 | "outputs": [],
53 | "source": [
54 | "from langchain_community.document_loaders import WebBaseLoader \n",
55 | "\n",
56 | "loader = WebBaseLoader(\n",
57 | " web_path=\"https://blog.langchain.dev/langgraph/\"\n",
58 | ")\n",
59 | "\n",
60 | "docs = loader.load()"
61 | ]
62 | },
63 | {
64 | "cell_type": "markdown",
65 | "metadata": {},
66 | "source": [
67 | "## Index the data"
68 | ]
69 | },
70 | {
71 | "cell_type": "code",
72 | "execution_count": 4,
73 | "metadata": {},
74 | "outputs": [],
75 | "source": [
76 | "from langchain_text_splitters import RecursiveCharacterTextSplitter \n",
77 | "\n",
78 | "text_splitter = RecursiveCharacterTextSplitter(\n",
79 | " chunk_size = 1000,\n",
80 | " chunk_overlap = 200,\n",
81 | " add_start_index = True \n",
82 | ")"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 5,
88 | "metadata": {},
89 | "outputs": [],
90 | "source": [
91 | "all_splits = text_splitter.split_documents(docs)"
92 | ]
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": 6,
97 | "metadata": {},
98 | "outputs": [],
99 | "source": [
100 | "from langchain_community import embeddings \n",
101 | "\n",
102 | "embedding = embeddings.ollama.OllamaEmbeddings(\n",
103 | " model=\"nomic-embed-text\"\n",
104 | ")"
105 | ]
106 | },
107 | {
108 | "cell_type": "code",
109 | "execution_count": 7,
110 | "metadata": {},
111 | "outputs": [],
112 | "source": [
113 | "from langchain_community.vectorstores import Chroma \n",
114 | "\n",
115 | "vectorstore = Chroma.from_documents(\n",
116 | " documents = all_splits,\n",
117 | " embedding = embedding\n",
118 | ")"
119 | ]
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": 8,
124 | "metadata": {},
125 | "outputs": [],
126 | "source": [
127 | "retriever = vectorstore.as_retriever(\n",
128 | " search_type = \"similarity\",\n",
129 | " search_kwargs = {\"k\":6}\n",
130 | ")"
131 | ]
132 | },
133 | {
134 | "cell_type": "code",
135 | "execution_count": 9,
136 | "metadata": {},
137 | "outputs": [
138 | {
139 | "data": {
140 | "text/plain": [
141 | "[Document(page_content='\"model\",\\n should_continue,\\n {\\n \"end\": END,\\n \"continue\": \"tools\"\\n }\\n)CompileAfter we define our graph, we can compile it into a runnable! This simply takes the graph definition we\\'ve created so far an returns a runnable. This runnable exposes all the same method as LangChain runnables (.invoke, .stream, .astream_log, etc) allowing it to be called in the same manner as a chain.app = graph.compile()Agent ExecutorWe\\'ve recreated the canonical LangChain AgentExecutor with LangGraph. This will allow you to use existing LangChain agents, but allow you to more easily modify the internals of the AgentExecutor. The state of this graph by default contains concepts that should be familiar to you if you\\'ve used LangChain agents: input, chat_history, intermediate_steps (and agent_outcome to represent the most recent agent outcome)from typing import TypedDict, Annotated, List, Union\\nfrom langchain_core.agents import AgentAction, AgentFinish', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 7622, 'title': 'LangGraph'}),\n",
142 | " Document(page_content='LangGraph\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nSkip to content\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nBy LangChain\\n\\n\\n\\n\\nRelease Notes\\n\\n\\n\\n\\nCase Studies\\n\\n\\n\\n\\nLangChain\\n\\n\\n\\n\\nGitHub\\n\\n\\n\\n\\nDocs\\n\\n\\n\\n\\n\\nSign in\\nSubscribe\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nLangGraph\\n\\nBy LangChain\\n7 min read\\nJan 17, 2024', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 3, 'title': 'LangGraph'}),\n",
143 | " Document(page_content=\"agent return output in a specific format using function calling. Only for Chat Agent Executor.Dynamically Returning the Output of a Tool DirectlySometimes you may want to return the output of a tool directly. We provide an easy way to do with the return_direct parameter in LangChain. However, this makes it so that the output of a tool is ALWAYS returned directly. Sometimes, you may want to let the LLM choose whether to return the response directly or not. Only for Chat Agent Executor.Future WorkWe're incredibly excited about the possibility of LangGraph enabling more custom and powerful agent runtimes. Some of the things we are looking to implement in the near future:More advanced agent runtimes from academia (LLM Compiler, plan-and-solve, etc)Stateful tools (allowing tools to modify some state)More controlled human-in-the-loop workflowsMulti-agent workflowsIf any of these resonate with you, please feel free to add an example notebook in the LangGraph repo, or reach out to us at\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 10390, 'title': 'LangGraph'}),\n",
144 | " Document(page_content=\"messages: Annotated[Sequence[BaseMessage], operator.add] See this notebook for how to get startedModificationsOne of the big benefits of LangGraph is that it exposes the logic of AgentExecutor in a far more natural and modifiable way. We've provided a few examples of modifications that we've heard requests for:Force Calling a ToolFor when you always want to make an agent call a tool first. For Agent Executor and Chat Agent Executor.Human-in-the-loopHow to add a human-in-the-loop step before calling tools. For Agent Executor and Chat Agent Executor.Managing Agent StepsFor adding custom logic on how to handle the intermediate steps an agent might take (useful for when there's a lot of steps). For Agent Executor and Chat Agent Executor.Returning Output in a Specific FormatHow to make the agent return output in a specific format using function calling. Only for Chat Agent Executor.Dynamically Returning the Output of a Tool DirectlySometimes you may want to return the output of a tool\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 9594, 'title': 'LangGraph'}),\n",
145 | " Document(page_content=\"TL;DR: LangGraph is module built on top of LangChain to better enable creation of cyclical graphs, often needed for agent runtimes.Python RepoPython YouTube PlaylistJS RepoIntroductionOne of the things we highlighted in our LangChain v0.1 announcement was the introduction of a new library: LangGraph. LangGraph is built on top of LangChain and completely interoperable with the LangChain ecosystem. It adds new value primarily through the introduction of an easy way to create cyclical graphs. This is often useful when creating agent runtimes.In this blog post, we will first walk through the motivations for LangGraph. We will then cover the basic functionality it provides. We will then spotlight two agent runtimes we've implemented already. We will then highlight a few of the common modifications to these runtimes we've heard requests for, and examples of implementing those. We will finish with a preview of what we will be releasing next.MotivationOne of the big value props of LangChain\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 273, 'title': 'LangGraph'}),\n",
146 | " Document(page_content='thing we\\'ve seen in practice as we\\'ve worked the community and companies to put agents into production is that often times more control is needed. You may want to always force an agent to call particular tool first. You may want have more control over how tools are called. You may want to have different prompts for the agent, depending on that state it is in.When talking about these more controlled flows, we internally refer to them as \"state machines\". See the below diagram from our blog on cognitive architectures.These state machines have the power of being able to loop - allowing for handling of more ambiguous inputs than simple chains. However, there is still an element of human guidance in terms of how that loop is constructed.LangGraph is a way to create these state machines by specifying them as graphs.FunctionalityAt it\\'s core, LangGraph exposes a pretty narrow interface on top of LangChain.StateGraphStateGraph is a class that represents the graph. You initialize this class by', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 3476, 'title': 'LangGraph'})]"
147 | ]
148 | },
149 | "execution_count": 9,
150 | "metadata": {},
151 | "output_type": "execute_result"
152 | }
153 | ],
154 | "source": [
155 | "retriever.get_relevant_documents(\"What is LangGraph?\")"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "metadata": {},
161 | "source": [
162 | "## Create a chain to contextualize"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 10,
168 | "metadata": {},
169 | "outputs": [],
170 | "source": [
171 | "from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder \n",
172 | "\n",
173 | "contextualize_q_system_prompt = \"\"\"Given a chat history and the latest user question \\\n",
174 | "which might reference context in the chat history, formulate a standalone question \\\n",
175 | "which can be understood without the chat history. Do NOT answer the question, \\\n",
176 | "just reformulate it if needed and otherwise return it as is.\"\"\""
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": 11,
182 | "metadata": {},
183 | "outputs": [],
184 | "source": [
185 | "contextualize_q_prompt= ChatPromptTemplate.from_messages(\n",
186 | " [\n",
187 | " (\"system\", contextualize_q_system_prompt),\n",
188 | " MessagesPlaceholder(variable_name=\"chat_history\"),\n",
189 | " (\"human\", \"{question}\"),\n",
190 | " ]\n",
191 | ")"
192 | ]
193 | },
194 | {
195 | "cell_type": "code",
196 | "execution_count": 12,
197 | "metadata": {},
198 | "outputs": [],
199 | "source": [
200 | "from langchain_core.output_parsers import StrOutputParser\n",
201 | "\n",
202 | "contextualize_q_chain = contextualize_q_prompt | llm | StrOutputParser()"
203 | ]
204 | },
205 | {
206 | "cell_type": "code",
207 | "execution_count": 13,
208 | "metadata": {},
209 | "outputs": [
210 | {
211 | "data": {
212 | "text/plain": [
213 | "' Question: What do you mean by \"large\" in the context of a \"large language model\"?'"
214 | ]
215 | },
216 | "execution_count": 13,
217 | "metadata": {},
218 | "output_type": "execute_result"
219 | }
220 | ],
221 | "source": [
222 | "from langchain_core.messages import AIMessage, HumanMessage\n",
223 | "\n",
224 | "contextualize_q_chain.invoke(\n",
225 | " {\n",
226 | " \"chat_history\":[\n",
227 | " HumanMessage(content=\"What does LLM stand for?\"),\n",
228 | " AIMessage(content=\"Large language model\"),\n",
229 | " ],\n",
230 | " \"question\": \"What is meant by large?\",\n",
231 | " }\n",
232 | ")"
233 | ]
234 | },
235 | {
236 | "cell_type": "markdown",
237 | "metadata": {},
238 | "source": [
239 | "## Create a chain for chat history"
240 | ]
241 | },
242 | {
243 | "cell_type": "code",
244 | "execution_count": 14,
245 | "metadata": {},
246 | "outputs": [],
247 | "source": [
248 | "qa_system_prompt = \"\"\"You are an assistant for question-answering tasks. \\\n",
249 | "Use the following pieces of retrieved context to answer the question. \\\n",
250 | "If you don't know the answer, just say that you don't know. \\\n",
251 | "Use three sentences maximum and keep the answer concise.\\\n",
252 | "\n",
253 | "{context}\"\"\""
254 | ]
255 | },
256 | {
257 | "cell_type": "code",
258 | "execution_count": 15,
259 | "metadata": {},
260 | "outputs": [],
261 | "source": [
262 | "qa_prompt = ChatPromptTemplate.from_messages(\n",
263 | " [\n",
264 | " (\"system\", qa_system_prompt),\n",
265 | " MessagesPlaceholder(variable_name=\"chat_history\"),\n",
266 | " (\"human\", \"{question}\"),\n",
267 | " ]\n",
268 | ")"
269 | ]
270 | },
271 | {
272 | "cell_type": "code",
273 | "execution_count": 16,
274 | "metadata": {},
275 | "outputs": [],
276 | "source": [
277 | "def format_docs(docs):\n",
278 | " return \"\\n\\n\".join(doc.page_content for doc in docs)"
279 | ]
280 | },
281 | {
282 | "cell_type": "code",
283 | "execution_count": 17,
284 | "metadata": {},
285 | "outputs": [],
286 | "source": [
287 | "def contextualized_question(input: dict):\n",
288 | " if input.get(\"chat_history\"):\n",
289 | " return contextualize_q_chain\n",
290 | " else:\n",
291 | " return input[\"question\"]"
292 | ]
293 | },
294 | {
295 | "cell_type": "code",
296 | "execution_count": 18,
297 | "metadata": {},
298 | "outputs": [],
299 | "source": [
300 | "from langchain_core.runnables import RunnablePassthrough\n",
301 | "\n",
302 | "rag_chain = (\n",
303 | " RunnablePassthrough.assign(\n",
304 | " context = contextualized_question | retriever | format_docs\n",
305 | " )\n",
306 | " | qa_prompt \n",
307 | " | llm\n",
308 | ")"
309 | ]
310 | },
311 | {
312 | "cell_type": "markdown",
313 | "metadata": {},
314 | "source": [
315 | "## Inference"
316 | ]
317 | },
318 | {
319 | "cell_type": "code",
320 | "execution_count": 19,
321 | "metadata": {},
322 | "outputs": [],
323 | "source": [
324 | "chat_history = []\n",
325 | "\n",
326 | "question = \"What is LangGraph?\"\n",
327 | "ai_msg = rag_chain.invoke(\n",
328 | " {\n",
329 | " \"question\": question,\n",
330 | " \"chat_history\": chat_history\n",
331 | " }\n",
332 | ")"
333 | ]
334 | },
335 | {
336 | "cell_type": "code",
337 | "execution_count": 20,
338 | "metadata": {},
339 | "outputs": [
340 | {
341 | "data": {
342 | "text/plain": [
343 | "' LangGraph is a module built on top of LangChain, allowing for the creation of cyclical graphs which is useful for agent runtimes. It provides an interface to create state machines specified as graphs and exposes a narrow interface over LangChain.'"
344 | ]
345 | },
346 | "execution_count": 20,
347 | "metadata": {},
348 | "output_type": "execute_result"
349 | }
350 | ],
351 | "source": [
352 | "ai_msg "
353 | ]
354 | },
355 | {
356 | "cell_type": "code",
357 | "execution_count": 21,
358 | "metadata": {},
359 | "outputs": [],
360 | "source": [
361 | "chat_history.extend(\n",
362 | " [\n",
363 | " HumanMessage(content=question), ai_msg\n",
364 | " ]\n",
365 | ")"
366 | ]
367 | },
368 | {
369 | "cell_type": "code",
370 | "execution_count": 22,
371 | "metadata": {},
372 | "outputs": [
373 | {
374 | "data": {
375 | "text/plain": [
376 | "' LangGraph is a Python module built on top of LangChain, designed to enable the creation of cyclical graphs, which is particularly useful for agent runtimes. It provides an interface to create state machines specified as graphs and exposes a narrow interface over LangChain. LangGraph allows for modifications such as forcing tool calls, adding human-in-the-loop steps, managing agent steps, and returning output in specific formats, among other things.'"
377 | ]
378 | },
379 | "execution_count": 22,
380 | "metadata": {},
381 | "output_type": "execute_result"
382 | }
383 | ],
384 | "source": [
385 | "second_question = \"What is it used for?\"\n",
386 | "\n",
387 | "rag_chain.invoke(\n",
388 | " {\n",
389 | " \"question\": second_question,\n",
390 | " \"chat_history\": chat_history\n",
391 | " }\n",
392 | ")"
393 | ]
394 | },
395 | {
396 | "cell_type": "markdown",
397 | "metadata": {},
398 | "source": [
399 | "Let's connect [YouTube](http://youtube.com/tirendazacademy) | [Medium](http://tirendazacademy.medium.com) | [X](http://x.com/tirendazacademy) | [Linkedin](https://www.linkedin.com/in/tirendaz-academy) 😎"
400 | ]
401 | }
402 | ],
403 | "metadata": {
404 | "kernelspec": {
405 | "display_name": "genai",
406 | "language": "python",
407 | "name": "python3"
408 | },
409 | "language_info": {
410 | "codemirror_mode": {
411 | "name": "ipython",
412 | "version": 3
413 | },
414 | "file_extension": ".py",
415 | "mimetype": "text/x-python",
416 | "name": "python",
417 | "nbconvert_exporter": "python",
418 | "pygments_lexer": "ipython3",
419 | "version": "3.11.8"
420 | }
421 | },
422 | "nbformat": 4,
423 | "nbformat_minor": 2
424 | }
425 |
--------------------------------------------------------------------------------
/Chat-With-Any-Document.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "id": "view-in-github",
7 | "colab_type": "text"
8 | },
9 | "source": [
10 | ""
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "metadata": {
16 | "id": "7XaaAFk6QG3Y"
17 | },
18 | "source": [
19 | "# Chat With Anything - From PDFs Files to Image Documents:\n"
20 | ]
21 | },
22 | {
23 | "cell_type": "markdown",
24 | "metadata": {
25 | "id": "tKQRUTBYQG3b"
26 | },
27 | "source": [
28 | "### Install the requirements"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 2,
34 | "metadata": {
35 | "id": "RRYSu48huSUW"
36 | },
37 | "outputs": [],
38 | "source": [
39 | "%%bash\n",
40 | "\n",
41 | "pip -q install langchain faiss-cpu unstructured\n",
42 | "pip -q install openai tiktoken\n",
43 | "pip -q install pytesseract pypdf\n",
44 | "pip -q install unstructured==0.7.12"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "source": [
50 | "!sudo apt install tesseract-ocr"
51 | ],
52 | "metadata": {
53 | "id": "sr6ppS0za7TH"
54 | },
55 | "execution_count": null,
56 | "outputs": []
57 | },
58 | {
59 | "cell_type": "markdown",
60 | "metadata": {
61 | "id": "pX3ndyD8E9hN"
62 | },
63 | "source": [
64 | "# Chat & Query your PDF files"
65 | ]
66 | },
67 | {
68 | "cell_type": "markdown",
69 | "metadata": {
70 | "id": "yhoMomdzQG3c"
71 | },
72 | "source": [
73 | "## Detect Document Type"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 4,
79 | "metadata": {
80 | "id": "vRy_fppZQG3d"
81 | },
82 | "outputs": [],
83 | "source": [
84 | "from filetype import guess\n",
85 | "\n",
86 | "def detect_document_type(document_path):\n",
87 | "\n",
88 | " guess_file = guess(document_path)\n",
89 | " file_type = \"\"\n",
90 | " image_types = ['jpg', 'jpeg', 'png', 'gif']\n",
91 | "\n",
92 | " if(guess_file.extension.lower() == \"pdf\"):\n",
93 | " file_type = \"pdf\"\n",
94 | "\n",
95 | " elif(guess_file.extension.lower() in image_types):\n",
96 | " file_type = \"image\"\n",
97 | "\n",
98 | " else:\n",
99 | " file_type = \"unkown\"\n",
100 | "\n",
101 | " return file_type\n",
102 | ""
103 | ]
104 | },
105 | {
106 | "cell_type": "code",
107 | "execution_count": 5,
108 | "metadata": {
109 | "colab": {
110 | "base_uri": "https://localhost:8080/"
111 | },
112 | "id": "vwfpliJxQG3d",
113 | "outputId": "bdf7e6f3-1397-4ecc-8fae-b03552fdf05c"
114 | },
115 | "outputs": [
116 | {
117 | "output_type": "stream",
118 | "name": "stdout",
119 | "text": [
120 | "Research Paper Type: pdf\n",
121 | "Article Information Document Type: image\n"
122 | ]
123 | }
124 | ],
125 | "source": [
126 | "research_paper_path = \"/content/transformer_paper.pdf\"\n",
127 | "article_information_path = \"/content/rticle_information.png\"\n",
128 | "\n",
129 | "print(f\"Research Paper Type: {detect_document_type(research_paper_path)}\")\n",
130 | "print(f\"Article Information Document Type: {detect_document_type(article_information_path)}\")"
131 | ]
132 | },
133 | {
134 | "cell_type": "markdown",
135 | "metadata": {
136 | "id": "7LGFFT0hQG3e"
137 | },
138 | "source": [
139 | "## Extract Documents Content"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 6,
145 | "metadata": {
146 | "id": "t9_3mkbBQG3f"
147 | },
148 | "outputs": [],
149 | "source": [
150 | "from langchain.document_loaders.image import UnstructuredImageLoader\n",
151 | "from langchain.document_loaders import UnstructuredFileLoader\n",
152 | "\n",
153 | "\"\"\"\n",
154 | "YOU CAN UNCOMMENT THE CODE BELOW TO UNDERSTAND THE LOGIC OF THE FUNCTIONS\n",
155 | "\"\"\"\n",
156 | "\"\"\"\n",
157 | "\n",
158 | "def extract_text_from_pdf(pdf_file):\n",
159 | "\n",
160 | " loader = UnstructuredFileLoader(pdf_file)\n",
161 | " documents = loader.load()\n",
162 | " pdf_pages_content = '\\n'.join(doc.page_content for doc in documents)\n",
163 | "\n",
164 | " return pdf_pages_content\n",
165 | "\n",
166 | "def extract_text_from_image(image_file):\n",
167 | "\n",
168 | " loader = UnstructuredImageLoader(image_file)\n",
169 | " documents = loader.load()\n",
170 | "\n",
171 | " image_content = '\\n'.join(doc.page_content for doc in documents)\n",
172 | "\n",
173 | " return image_content\n",
174 | "\n",
175 | "\n",
176 | "\"\"\"\n",
177 | "\n",
178 | "def extract_file_content(file_path):\n",
179 | "\n",
180 | " file_type = detect_document_type(file_path)\n",
181 | "\n",
182 | " if(file_type == \"pdf\"):\n",
183 | " loader = UnstructuredFileLoader(file_path)\n",
184 | "\n",
185 | " elif(file_type == \"image\"):\n",
186 | " loader = UnstructuredImageLoader(file_path)\n",
187 | "\n",
188 | " documents = loader.load()\n",
189 | " documents_content = '\\n'.join(doc.page_content for doc in documents)\n",
190 | "\n",
191 | " return documents_content"
192 | ]
193 | },
194 | {
195 | "cell_type": "code",
196 | "execution_count": 9,
197 | "metadata": {
198 | "id": "FydMC-fXQG3f"
199 | },
200 | "outputs": [],
201 | "source": [
202 | "#research_paper_content = extract_text_from_pdf(research_paper_path)\n",
203 | "#article_information_content = extract_text_from_image(article_information_path)\n",
204 | "\n",
205 | "\n",
206 | "research_paper_content = extract_file_content(research_paper_path)\n",
207 | "article_information_content = extract_file_content(article_information_path)"
208 | ]
209 | },
210 | {
211 | "cell_type": "code",
212 | "execution_count": 10,
213 | "metadata": {
214 | "colab": {
215 | "base_uri": "https://localhost:8080/"
216 | },
217 | "id": "u9kGWp-hQG3g",
218 | "outputId": "f56460c3-8146-442d-dbdc-e0c00b14b6db"
219 | },
220 | "outputs": [
221 | {
222 | "output_type": "stream",
223 | "name": "stdout",
224 | "text": [
225 | "First 400 Characters of the Paper: \n",
226 | "Provided proper attribution is provided, Google hereby grants permission to reproduce the tables and figures in this paper solely for use in journalistic or scholarly works.\n",
227 | "\n",
228 | "Attention Is All You Need\n",
229 | "\n",
230 | "3 2 0 2\n",
231 | "\n",
232 | "Ashish Vaswani∗ Google Brain avaswani@google.com\n",
233 | "\n",
234 | "Noam Shazeer∗ Google Brain noam@google.com\n",
235 | "\n",
236 | "Niki Parmar∗ Google Research nikip@google.com\n",
237 | "\n",
238 | "Jakob Uszkoreit∗ Google Research usz@google.com\n",
239 | "...\n",
240 | "---------------\n",
241 | "First 400 Characters of Article Information Document :\n",
242 | " Input Files e ‘ File Content in\n",
243 | "\n",
244 | "Raw Format\n",
245 | "\n",
246 | "Raw Bata Splitter\n",
247 | "\n",
248 | "PDF,\n",
249 | "\n",
250 | "File Tyee Detector File Content Extractor DifRerent Chunks of the Raw Data\n",
251 | "\n",
252 | "°\n",
253 | "\n",
254 | "<< }/ oO <\n",
255 | "\n",
256 | "© 6 6\n",
257 | "\n",
258 | "Chunk\n",
259 | "\n",
260 | "Vector Index Transformer\n",
261 | "\n",
262 | "Chunks, Embedlelings\n",
263 | "\n",
264 | "t\n",
265 | "\n",
266 | "See]\n",
267 | "\n",
268 | "Response\n",
269 | "\n",
270 | "‘ =] Q — Author: Zoumana Keita User...\n"
271 | ]
272 | }
273 | ],
274 | "source": [
275 | "nb_characters = 400\n",
276 | "\n",
277 | "print(f\"First {nb_characters} Characters of the Paper: \\n{research_paper_content[:nb_characters]}...\")\n",
278 | "print(\"---\"*5)\n",
279 | "print(f\"First {nb_characters} Characters of Article Information Document :\\n {article_information_content[:nb_characters]}...\")\n"
280 | ]
281 | },
282 | {
283 | "cell_type": "markdown",
284 | "metadata": {
285 | "id": "Ovyvwo4VQG3g"
286 | },
287 | "source": [
288 | "## Chat Implementation"
289 | ]
290 | },
291 | {
292 | "cell_type": "markdown",
293 | "metadata": {
294 | "id": "OjjVV0RnQG3h"
295 | },
296 | "source": [
297 | "### Create Chunks"
298 | ]
299 | },
300 | {
301 | "cell_type": "code",
302 | "execution_count": 11,
303 | "metadata": {
304 | "id": "-Brvp2ACQG3h"
305 | },
306 | "outputs": [],
307 | "source": [
308 | "from langchain.text_splitter import CharacterTextSplitter\n",
309 | "\n",
310 | "text_splitter = CharacterTextSplitter(\n",
311 | " separator = \"\\n\\n\",\n",
312 | " chunk_size = 1000,\n",
313 | " chunk_overlap = 200,\n",
314 | " length_function = len,\n",
315 | ")"
316 | ]
317 | },
318 | {
319 | "cell_type": "code",
320 | "execution_count": 12,
321 | "metadata": {
322 | "colab": {
323 | "base_uri": "https://localhost:8080/"
324 | },
325 | "id": "zkzN5YJ-QG3i",
326 | "outputId": "c81b34c7-12d0-40dc-c388-28659989c4f3"
327 | },
328 | "outputs": [
329 | {
330 | "output_type": "stream",
331 | "name": "stderr",
332 | "text": [
333 | "WARNING:langchain.text_splitter:Created a chunk of size 1140, which is longer than the specified 1000\n"
334 | ]
335 | },
336 | {
337 | "output_type": "stream",
338 | "name": "stdout",
339 | "text": [
340 | "# Chunks in Research Paper: 51\n",
341 | "# Chunks in Article Document: 1\n"
342 | ]
343 | }
344 | ],
345 | "source": [
346 | "research_paper_chunks = text_splitter.split_text(research_paper_content)\n",
347 | "article_information_chunks = text_splitter.split_text(article_information_content)\n",
348 | "\n",
349 | "print(f\"# Chunks in Research Paper: {len(research_paper_chunks)}\")\n",
350 | "print(f\"# Chunks in Article Document: {len(article_information_chunks)}\")"
351 | ]
352 | },
353 | {
354 | "cell_type": "markdown",
355 | "metadata": {
356 | "id": "X0fTb1OXQG3i"
357 | },
358 | "source": [
359 | "### Create Embeddings"
360 | ]
361 | },
362 | {
363 | "cell_type": "code",
364 | "execution_count": 13,
365 | "metadata": {
366 | "id": "2j_TWA_xQG3i"
367 | },
368 | "outputs": [],
369 | "source": [
370 | "from langchain.embeddings.openai import OpenAIEmbeddings\n",
371 | "import os\n",
372 | "\n",
373 | "os.environ[\"OPENAI_API_KEY\"] = \"\"\n",
374 | "\n",
375 | "embeddings = OpenAIEmbeddings()"
376 | ]
377 | },
378 | {
379 | "cell_type": "markdown",
380 | "metadata": {
381 | "id": "DJ16VESDQG3i"
382 | },
383 | "source": [
384 | "### Create Vector Index"
385 | ]
386 | },
387 | {
388 | "cell_type": "code",
389 | "execution_count": 14,
390 | "metadata": {
391 | "id": "YhGwAt_GQG3j"
392 | },
393 | "outputs": [],
394 | "source": [
395 | "from langchain.vectorstores import FAISS\n",
396 | "\n",
397 | "def get_doc_search(text_splitter):\n",
398 | "\n",
399 | " return FAISS.from_texts(text_splitter, embeddings)"
400 | ]
401 | },
402 | {
403 | "cell_type": "code",
404 | "execution_count": 15,
405 | "metadata": {
406 | "colab": {
407 | "base_uri": "https://localhost:8080/"
408 | },
409 | "id": "MeYNtWtoQG3j",
410 | "outputId": "323bf4ca-ca28-45dd-efeb-5eea12620d71"
411 | },
412 | "outputs": [
413 | {
414 | "output_type": "stream",
415 | "name": "stdout",
416 | "text": [
417 | "\n"
418 | ]
419 | }
420 | ],
421 | "source": [
422 | "doc_search_paper = get_doc_search(research_paper_chunks)\n",
423 | "print(doc_search_paper)"
424 | ]
425 | },
426 | {
427 | "cell_type": "markdown",
428 | "metadata": {
429 | "id": "MCAYKPq2QG3j"
430 | },
431 | "source": [
432 | "### Start chatting with your document"
433 | ]
434 | },
435 | {
436 | "cell_type": "code",
437 | "execution_count": 16,
438 | "metadata": {
439 | "id": "dNA4TsHpu6OM"
440 | },
441 | "outputs": [],
442 | "source": [
443 | "from langchain.llms import OpenAI\n",
444 | "from langchain.chains.question_answering import load_qa_chain\n",
445 | "chain = load_qa_chain(OpenAI(), chain_type = \"map_rerank\",\n",
446 | " return_intermediate_steps=True)\n",
447 | "\n",
448 | "def chat_with_file(file_path, query):\n",
449 | "\n",
450 | " file_content = extract_file_content(file_path)\n",
451 | " file_splitter = text_splitter.split_text(file_content)\n",
452 | "\n",
453 | " document_search = get_doc_search(file_splitter)\n",
454 | " documents = document_search.similarity_search(query)\n",
455 | "\n",
456 | " results = chain({\n",
457 | " \"input_documents\":documents,\n",
458 | " \"question\": query\n",
459 | " },\n",
460 | " return_only_outputs=True)\n",
461 | " results = results['intermediate_steps'][0]\n",
462 | "\n",
463 | " return results"
464 | ]
465 | },
466 | {
467 | "cell_type": "markdown",
468 | "metadata": {
469 | "id": "av7cFJ8PQG3k"
470 | },
471 | "source": [
472 | "##### Chat with the image file"
473 | ]
474 | },
475 | {
476 | "cell_type": "code",
477 | "execution_count": 17,
478 | "metadata": {
479 | "colab": {
480 | "base_uri": "https://localhost:8080/"
481 | },
482 | "id": "MvVMW_0DQG3k",
483 | "outputId": "54cdcb47-bb8a-4695-d476-448eebc6e36a"
484 | },
485 | "outputs": [
486 | {
487 | "output_type": "stream",
488 | "name": "stderr",
489 | "text": [
490 | "/usr/local/lib/python3.10/dist-packages/langchain/chains/llm.py:303: UserWarning: The apply_and_parse method is deprecated, instead pass an output parser directly to LLMChain.\n",
491 | " warnings.warn(\n"
492 | ]
493 | },
494 | {
495 | "output_type": "stream",
496 | "name": "stdout",
497 | "text": [
498 | "Answer: This document is about the process of extracting information from raw data, including splitting the data into chunks, detecting the type of file, extracting the content, and creating a vector index and embeddings.\n",
499 | "\n",
500 | "Confidence Score: 100\n"
501 | ]
502 | }
503 | ],
504 | "source": [
505 | "query = \"What is the document about\"\n",
506 | "\n",
507 | "results = chat_with_file(article_information_path, query)\n",
508 | "\n",
509 | "answer = results[\"answer\"]\n",
510 | "confidence_score = results[\"score\"]\n",
511 | "\n",
512 | "print(f\"Answer: {answer}\\n\\nConfidence Score: {confidence_score}\")"
513 | ]
514 | },
515 | {
516 | "cell_type": "markdown",
517 | "metadata": {
518 | "id": "9edAr_8eQG3k"
519 | },
520 | "source": [
521 | "##### Chat with the PDF file"
522 | ]
523 | },
524 | {
525 | "cell_type": "code",
526 | "execution_count": 18,
527 | "metadata": {
528 | "colab": {
529 | "base_uri": "https://localhost:8080/"
530 | },
531 | "id": "_k64BYyeQG3l",
532 | "outputId": "5d31a95a-7c1a-4c57-9857-52634f6b53fd"
533 | },
534 | "outputs": [
535 | {
536 | "output_type": "stream",
537 | "name": "stderr",
538 | "text": [
539 | "WARNING:langchain.text_splitter:Created a chunk of size 1140, which is longer than the specified 1000\n"
540 | ]
541 | },
542 | {
543 | "output_type": "stream",
544 | "name": "stdout",
545 | "text": [
546 | "Answer: Self-attention is used to compute a representation of the sequence, allowing for the construction of the Transformer which relies entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.\n",
547 | "\n",
548 | "Confidence Score: 100\n"
549 | ]
550 | }
551 | ],
552 | "source": [
553 | "query = \"Why is the self-attention approach used in this document?\"\n",
554 | "\n",
555 | "results = chat_with_file(research_paper_path, query)\n",
556 | "\n",
557 | "answer = results[\"answer\"]\n",
558 | "confidence_score = results[\"score\"]\n",
559 | "\n",
560 | "print(f\"Answer: {answer}\\n\\nConfidence Score: {confidence_score}\")"
561 | ]
562 | },
563 | {
564 | "cell_type": "markdown",
565 | "metadata": {
566 | "id": "wi_kh1faQG3l"
567 | },
568 | "source": [
569 | "# Resources\n",
570 | "\n",
571 | "- [How to Chat With Any PDFs and Image Files Using Large Language Models — With Code](https://towardsdatascience.com/how-to-chat-with-any-file-from-pdfs-to-images-using-large-language-models-with-code-4bcfd7e440bc)\n",
572 | "\n"
573 | ]
574 | }
575 | ],
576 | "metadata": {
577 | "colab": {
578 | "provenance": [],
579 | "include_colab_link": true
580 | },
581 | "kernelspec": {
582 | "display_name": "pandas_benchmark",
583 | "language": "python",
584 | "name": "pandas_benchmark"
585 | },
586 | "language_info": {
587 | "codemirror_mode": {
588 | "name": "ipython",
589 | "version": 3
590 | },
591 | "file_extension": ".py",
592 | "mimetype": "text/x-python",
593 | "name": "python",
594 | "nbconvert_exporter": "python",
595 | "pygments_lexer": "ipython3",
596 | "version": "3.9.15"
597 | },
598 | "toc": {
599 | "base_numbering": 1,
600 | "nav_menu": {},
601 | "number_sections": true,
602 | "sideBar": true,
603 | "skip_h1_title": false,
604 | "title_cell": "Table of Contents",
605 | "title_sidebar": "Contents",
606 | "toc_cell": false,
607 | "toc_position": {},
608 | "toc_section_display": true,
609 | "toc_window_display": false
610 | }
611 | },
612 | "nbformat": 4,
613 | "nbformat_minor": 0
614 | }
--------------------------------------------------------------------------------
/RAG-with-Ollama/rag.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Initializing the Local Model"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "from langchain_community.llms import Ollama \n",
17 | "llm = Ollama(model=\"mistral\", temperature = 0)"
18 | ]
19 | },
20 | {
21 | "cell_type": "code",
22 | "execution_count": 2,
23 | "metadata": {},
24 | "outputs": [
25 | {
26 | "data": {
27 | "text/plain": [
28 | "\" LangGraph is a large-scale graph database specifically designed for natural language processing (NLP) and information retrieval tasks. It was developed by Microsoft Research and is part of the Microsoft Open Data Initiative.\\n\\nLangGraph aims to provide a more efficient way to store, query, and process large amounts of text data compared to traditional relational databases or file-based storage systems. By representing text data as graphs, LangGraph enables advanced NLP tasks such as entity recognition, relation extraction, and semantic similarity analysis to be performed directly on the graph, rather than requiring separate preprocessing steps and external tools.\\n\\nLangGraph's key features include:\\n\\n1. Scalability: It can handle large volumes of data and complex queries with high performance.\\n2. Flexibility: It supports various data models, including property graphs and RDF triples, allowing for diverse use cases.\\n3. Integration: It integrates well with other Microsoft Azure services such as Cognitive Services, Power BI, and Azure Machine Learning.\\n4. Querying: It provides a powerful query language called Gremlin (Graph Query Language) that enables complex graph traversals and data manipulation tasks.\\n5. Indexing: It supports indexing on various properties, enabling efficient querying based on property values.\\n6. Security: It offers built-in security features to protect sensitive data.\\n7. Real-time processing: It can handle real-time data ingestion and processing, making it suitable for applications that require low latency.\\n\\nLangGraph is particularly useful in industries such as healthcare, finance, and e-commerce, where handling large volumes of text data and performing advanced NLP tasks are essential.\""
29 | ]
30 | },
31 | "execution_count": 2,
32 | "metadata": {},
33 | "output_type": "execute_result"
34 | }
35 | ],
36 | "source": [
37 | "llm.invoke(\"What is LangGraph?\")"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "## Indexing: Load"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 3,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "from langchain_community.document_loaders import WebBaseLoader \n",
54 | "\n",
55 | "loader = WebBaseLoader(\n",
56 | " web_path=(\"https://blog.langchain.dev/langgraph/\"),\n",
57 | ")\n",
58 | "docs= loader.load()"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": 4,
64 | "metadata": {},
65 | "outputs": [
66 | {
67 | "data": {
68 | "text/plain": [
69 | "'\\n\\n\\nLangGraph\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nSkip to content\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nBy LangChain\\n\\n\\n\\n\\nRelease Notes\\n\\n\\n\\n\\nCase Studies\\n\\n\\n\\n\\nLangChain\\n\\n\\n\\n\\nGitHub\\n\\n\\n\\n\\nDocs\\n\\n\\n\\n\\n\\nSign in\\nSubscribe\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nLangGraph\\n\\nBy LangChain\\n7 min read\\nJan 17, 2024\\n\\n\\n\\n\\n\\nTL;DR: LangGraph is module built on top of LangChain to better enable creation of cyclical graphs, often needed for agent runtimes.Python RepoPython YouTube PlaylistJS RepoIntroductionOne of the things we highlighted in our LangChain v0.1 announcement was the introduction of a new library: LangGraph. LangGraph is built on top of LangChain and completely interoperable with the LangChain ecosystem. It adds new value primarily through the introduction of an easy way to create cyclical graphs. This is often useful when creating agent runtimes.In this blog post, we will first walk through the motivations for LangGraph. We will then cover the basic functionality it provides. We will then spotlight two agent runtimes we\\'ve implemented already. We will then highlight a few of the common modifications to these runtimes we\\'ve heard requests for, and examples of implementing those. We will finish with a preview of what we will be releasing next.MotivationOne of the big value props of LangChain is the ability to easily create custom chains. We\\'ve invested heavily in the functionality for this with LangChain Expression Language. However, so far we\\'ve lacked a method for easily introducing cycles into these chains. Effectively, these chains are directed acyclic graphs (DAGs) - as are most data orchestration frameworks.One of the common patterns we see when people are creating more complex LLM applications is the introduction of cycles into the runtime. These cycles often use the LLM to reason about what to do next in the cycle. A big unlock of LLMs is the ability to use them for these reasoning tasks. This can essentially be thought of as running an LLM in a for-loop. These types of systems are often called agents.An example of why this agentic behavior can be so powerful can be found when considering a typical retrieval augmented generation (RAG) application. In a typical RAG application, a call to a retriever is made that returns some documents. These documents are then passed to an LLM to generate a final answer. While this is often effective, it breaks down in cases when the first retrieval step fails to return any useful results. In this case, it\\'s often ideal if the LLM can reason that the results returned from the retriever are poor, and maybe issue a second (more refined) query to the retriever, and use those results instead. Essentially, running an LLM in a loop helps create applications that are more flexible and thus can accomplish more vague use-cases that may not be predefined.These types of applications are often called agents. The simplest - but at the same time most ambitious - form of these is a loop that essentially has two steps:Call the LLM to determine either (a) what actions to take, or (b) what response to give the userTake given actions, and pass back to step 1These steps are repeated until a final response is generated. This is essentially the loop that powers our core AgentExecutor, and is the same logic that caused projects like AutoGPT to rise in prominence. This is simple because it is a relatively simple loop. It is the most ambitious because it offloads pretty much ALL of the decision making and reasoning ability to the LLM.One thing we\\'ve seen in practice as we\\'ve worked the community and companies to put agents into production is that often times more control is needed. You may want to always force an agent to call particular tool first. You may want have more control over how tools are called. You may want to have different prompts for the agent, depending on that state it is in.When talking about these more controlled flows, we internally refer to them as \"state machines\". See the below diagram from our blog on cognitive architectures.These state machines have the power of being able to loop - allowing for handling of more ambiguous inputs than simple chains. However, there is still an element of human guidance in terms of how that loop is constructed.LangGraph is a way to create these state machines by specifying them as graphs.FunctionalityAt it\\'s core, LangGraph exposes a pretty narrow interface on top of LangChain.StateGraphStateGraph is a class that represents the graph. You initialize this class by passing in a state definition. This state definition represents a central state object that is updated over time. This state is updated by nodes in the graph, which return operations to attributes of this state (in the form of a key-value store).The attributes of this state can be updated in two ways. First, an attribute could be overridden completely. This is useful if you want to nodes to return the new value of an attribute. Second, an attribute could be updated by adding to its value. This is useful if an attribute is a list of actions taken (or something similar) and you want nodes to return new actions taken (and have those automatically added to the attribute).You specify whether an attribute should be overridden or added to when creating the initial state definition. See an example in pseudocode below.from langgraph.graph import StateGraph\\nfrom typing import TypedDict, List, Annotated\\nimport Operator\\n\\n\\nclass State(TypedDict):\\n input: str\\n all_actions: Annotated[List[str], operator.add]\\n\\n\\ngraph = StateGraph(State)NodesAfter creating a StateGraph, you then add nodes with graph.add_node(name, value) syntax. The name parameter should be a string that we will use to refer to the node when adding edges. The value parameter should be either a function or LCEL runnable that will be called. This function/LCEL should accept a dictionary in the same form as the State object as input, and output a dictionary with keys of the State object to update.See an example in pseudocode below.graph.add_node(\"model\", model)\\ngraph.add_node(\"tools\", tool_executor)There is also a special END node that is used to represent the end of the graph. It is important that your cycles be able to end eventually!from langgraph.graph import ENDEdgesAfter adding nodes, you can then add edges to create the graph. There are a few types of edges.The Starting EdgeThis is the edge that connects the start of the graph to a particular node. This will make it so that that node is the first one called when input is passed to the graph. Pseudocode for that is:graph.set_entry_point(\"model\")Normal EdgesThese are edges where one node should ALWAYS be called after another. An example of this may be in the basic agent runtime, where we always want the model to be called after we call a tool.graph.add_edge(\"tools\", \"model\")Conditional EdgesThese are where a function (often powered by an LLM) is used to determine which node to go to first. To create this edge, you need to pass in three things:The upstream node: the output of this node will be looked at to determine what to do nextA function: this will be called to determine which node to call next. It should return a stringA mapping: this mapping will be used to map the output of the function in (2) to another node. The keys should be possible values that the function in (2) could return. The values should be names of nodes to go to if that value is returned.An example of this could be that after a model is called we either exit the graph and return to the user, or we call a tool - depending on what a user decides! See an example in pseudocode below:graph.add_conditional_edge(\\n \"model\",\\n should_continue,\\n {\\n \"end\": END,\\n \"continue\": \"tools\"\\n }\\n)CompileAfter we define our graph, we can compile it into a runnable! This simply takes the graph definition we\\'ve created so far an returns a runnable. This runnable exposes all the same method as LangChain runnables (.invoke, .stream, .astream_log, etc) allowing it to be called in the same manner as a chain.app = graph.compile()Agent ExecutorWe\\'ve recreated the canonical LangChain AgentExecutor with LangGraph. This will allow you to use existing LangChain agents, but allow you to more easily modify the internals of the AgentExecutor. The state of this graph by default contains concepts that should be familiar to you if you\\'ve used LangChain agents: input, chat_history, intermediate_steps (and agent_outcome to represent the most recent agent outcome)from typing import TypedDict, Annotated, List, Union\\nfrom langchain_core.agents import AgentAction, AgentFinish\\nfrom langchain_core.messages import BaseMessage\\nimport operator\\n\\n\\nclass AgentState(TypedDict):\\n input: str\\n chat_history: list[BaseMessage]\\n agent_outcome: Union[AgentAction, AgentFinish, None]\\n intermediate_steps: Annotated[list[tuple[AgentAction, str]], operator.add] See this notebook for how to get startedChat Agent ExecutorOne common trend we\\'ve seen is that more and more models are \"chat\" models which operate on a list of messages. This models are often the ones equipped with things like function calling, which make agent-like experiences much more feasible. When working with these types of models, it is often intuitive to represent the state of an agent as a list of messages.As such, we\\'ve created an agent runtime that works with this state. The input is a list of messages, and nodes just simply add to this list of messages over time.from typing import TypedDict, Annotated, Sequence\\nimport operator\\nfrom langchain_core.messages import BaseMessage\\n\\n\\nclass AgentState(TypedDict):\\n messages: Annotated[Sequence[BaseMessage], operator.add] See this notebook for how to get startedModificationsOne of the big benefits of LangGraph is that it exposes the logic of AgentExecutor in a far more natural and modifiable way. We\\'ve provided a few examples of modifications that we\\'ve heard requests for:Force Calling a ToolFor when you always want to make an agent call a tool first. For Agent Executor and Chat Agent Executor.Human-in-the-loopHow to add a human-in-the-loop step before calling tools. For Agent Executor and Chat Agent Executor.Managing Agent StepsFor adding custom logic on how to handle the intermediate steps an agent might take (useful for when there\\'s a lot of steps). For Agent Executor and Chat Agent Executor.Returning Output in a Specific FormatHow to make the agent return output in a specific format using function calling. Only for Chat Agent Executor.Dynamically Returning the Output of a Tool DirectlySometimes you may want to return the output of a tool directly. We provide an easy way to do with the return_direct parameter in LangChain. However, this makes it so that the output of a tool is ALWAYS returned directly. Sometimes, you may want to let the LLM choose whether to return the response directly or not. Only for Chat Agent Executor.Future WorkWe\\'re incredibly excited about the possibility of LangGraph enabling more custom and powerful agent runtimes. Some of the things we are looking to implement in the near future:More advanced agent runtimes from academia (LLM Compiler, plan-and-solve, etc)Stateful tools (allowing tools to modify some state)More controlled human-in-the-loop workflowsMulti-agent workflowsIf any of these resonate with you, please feel free to add an example notebook in the LangGraph repo, or reach out to us at hello@langchain.dev for more involved collaboration!\\n\\n\\nTags\\nBy LangChain\\n\\n\\nJoin our newsletter\\nUpdates from the LangChain team and community\\n\\n\\nEnter your email\\n\\nSubscribe\\n\\nProcessing your application...\\nSuccess! Please check your inbox and click the link to confirm your subscription.\\nSorry, something went wrong. Please try again.\\n\\n\\n\\n\\n\\nYou might also like\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nReflection Agents\\n\\n\\nagents\\n6 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nPlan-and-Execute Agents\\n\\n\\nBy LangChain\\n5 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n[Week of 2/19] LangChain Release Notes\\n\\n\\nBy LangChain\\n1 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nRakuten Group builds with LangChain and LangSmith to deliver premium products for its business clients and employees\\n\\n\\nBy LangChain\\n3 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n[Week of 2/5] LangChain Release Notes\\n\\n\\nBy LangChain\\n4 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nLangChain Partners with CommandBar on their Copilot User Assistant\\n\\n\\nBy LangChain\\n2 min read\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nSign up\\n\\n\\n\\n\\n\\n © LangChain Blog 2024\\n \\n\\n\\n\\n\\n\\n\\n'"
70 | ]
71 | },
72 | "execution_count": 4,
73 | "metadata": {},
74 | "output_type": "execute_result"
75 | }
76 | ],
77 | "source": [
78 | "docs[0].page_content"
79 | ]
80 | },
81 | {
82 | "cell_type": "code",
83 | "execution_count": 5,
84 | "metadata": {},
85 | "outputs": [
86 | {
87 | "data": {
88 | "text/plain": [
89 | "12341"
90 | ]
91 | },
92 | "execution_count": 5,
93 | "metadata": {},
94 | "output_type": "execute_result"
95 | }
96 | ],
97 | "source": [
98 | "len(docs[0].page_content)"
99 | ]
100 | },
101 | {
102 | "cell_type": "markdown",
103 | "metadata": {},
104 | "source": [
105 | "## Indexing: Split"
106 | ]
107 | },
108 | {
109 | "cell_type": "code",
110 | "execution_count": 6,
111 | "metadata": {},
112 | "outputs": [],
113 | "source": [
114 | "from langchain_text_splitters import RecursiveCharacterTextSplitter\n",
115 | "\n",
116 | "text_splitter= RecursiveCharacterTextSplitter(\n",
117 | " chunk_size = 1000,\n",
118 | " chunk_overlap = 200,\n",
119 | " add_start_index = True,\n",
120 | ")"
121 | ]
122 | },
123 | {
124 | "cell_type": "code",
125 | "execution_count": 7,
126 | "metadata": {},
127 | "outputs": [],
128 | "source": [
129 | "all_splits = text_splitter.split_documents(docs)"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 8,
135 | "metadata": {},
136 | "outputs": [
137 | {
138 | "data": {
139 | "text/plain": [
140 | "21"
141 | ]
142 | },
143 | "execution_count": 8,
144 | "metadata": {},
145 | "output_type": "execute_result"
146 | }
147 | ],
148 | "source": [
149 | "len(all_splits)"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": 9,
155 | "metadata": {},
156 | "outputs": [
157 | {
158 | "data": {
159 | "text/plain": [
160 | "997"
161 | ]
162 | },
163 | "execution_count": 9,
164 | "metadata": {},
165 | "output_type": "execute_result"
166 | }
167 | ],
168 | "source": [
169 | "len(all_splits[1].page_content)"
170 | ]
171 | },
172 | {
173 | "cell_type": "markdown",
174 | "metadata": {},
175 | "source": [
176 | "## Indexing: Store"
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": 10,
182 | "metadata": {},
183 | "outputs": [],
184 | "source": [
185 | "from langchain_community.embeddings import OllamaEmbeddings\n",
186 | "\n",
187 | "embedding = OllamaEmbeddings(\n",
188 | " model=\"nomic-embed-text\",\n",
189 | ")"
190 | ]
191 | },
192 | {
193 | "cell_type": "code",
194 | "execution_count": 11,
195 | "metadata": {},
196 | "outputs": [],
197 | "source": [
198 | "from langchain_community.vectorstores import Chroma\n",
199 | "\n",
200 | "vectorstore = Chroma.from_documents(\n",
201 | " documents = all_splits,\n",
202 | " embedding = embedding,\n",
203 | ")"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": 12,
209 | "metadata": {},
210 | "outputs": [],
211 | "source": [
212 | "retriever = vectorstore.as_retriever(\n",
213 | " search_type = \"similarity\",\n",
214 | " search_kwargs = {\"k\":6}\n",
215 | ")"
216 | ]
217 | },
218 | {
219 | "cell_type": "code",
220 | "execution_count": 13,
221 | "metadata": {},
222 | "outputs": [
223 | {
224 | "data": {
225 | "text/plain": [
226 | "[Document(page_content='\"model\",\\n should_continue,\\n {\\n \"end\": END,\\n \"continue\": \"tools\"\\n }\\n)CompileAfter we define our graph, we can compile it into a runnable! This simply takes the graph definition we\\'ve created so far an returns a runnable. This runnable exposes all the same method as LangChain runnables (.invoke, .stream, .astream_log, etc) allowing it to be called in the same manner as a chain.app = graph.compile()Agent ExecutorWe\\'ve recreated the canonical LangChain AgentExecutor with LangGraph. This will allow you to use existing LangChain agents, but allow you to more easily modify the internals of the AgentExecutor. The state of this graph by default contains concepts that should be familiar to you if you\\'ve used LangChain agents: input, chat_history, intermediate_steps (and agent_outcome to represent the most recent agent outcome)from typing import TypedDict, Annotated, List, Union\\nfrom langchain_core.agents import AgentAction, AgentFinish', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 7622, 'title': 'LangGraph'}),\n",
227 | " Document(page_content='LangGraph\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nSkip to content\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nBy LangChain\\n\\n\\n\\n\\nRelease Notes\\n\\n\\n\\n\\nCase Studies\\n\\n\\n\\n\\nLangChain\\n\\n\\n\\n\\nGitHub\\n\\n\\n\\n\\nDocs\\n\\n\\n\\n\\n\\nSign in\\nSubscribe\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\n\\nLangGraph\\n\\nBy LangChain\\n7 min read\\nJan 17, 2024', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 3, 'title': 'LangGraph'}),\n",
228 | " Document(page_content=\"agent return output in a specific format using function calling. Only for Chat Agent Executor.Dynamically Returning the Output of a Tool DirectlySometimes you may want to return the output of a tool directly. We provide an easy way to do with the return_direct parameter in LangChain. However, this makes it so that the output of a tool is ALWAYS returned directly. Sometimes, you may want to let the LLM choose whether to return the response directly or not. Only for Chat Agent Executor.Future WorkWe're incredibly excited about the possibility of LangGraph enabling more custom and powerful agent runtimes. Some of the things we are looking to implement in the near future:More advanced agent runtimes from academia (LLM Compiler, plan-and-solve, etc)Stateful tools (allowing tools to modify some state)More controlled human-in-the-loop workflowsMulti-agent workflowsIf any of these resonate with you, please feel free to add an example notebook in the LangGraph repo, or reach out to us at\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 10390, 'title': 'LangGraph'}),\n",
229 | " Document(page_content=\"messages: Annotated[Sequence[BaseMessage], operator.add] See this notebook for how to get startedModificationsOne of the big benefits of LangGraph is that it exposes the logic of AgentExecutor in a far more natural and modifiable way. We've provided a few examples of modifications that we've heard requests for:Force Calling a ToolFor when you always want to make an agent call a tool first. For Agent Executor and Chat Agent Executor.Human-in-the-loopHow to add a human-in-the-loop step before calling tools. For Agent Executor and Chat Agent Executor.Managing Agent StepsFor adding custom logic on how to handle the intermediate steps an agent might take (useful for when there's a lot of steps). For Agent Executor and Chat Agent Executor.Returning Output in a Specific FormatHow to make the agent return output in a specific format using function calling. Only for Chat Agent Executor.Dynamically Returning the Output of a Tool DirectlySometimes you may want to return the output of a tool\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 9594, 'title': 'LangGraph'}),\n",
230 | " Document(page_content=\"TL;DR: LangGraph is module built on top of LangChain to better enable creation of cyclical graphs, often needed for agent runtimes.Python RepoPython YouTube PlaylistJS RepoIntroductionOne of the things we highlighted in our LangChain v0.1 announcement was the introduction of a new library: LangGraph. LangGraph is built on top of LangChain and completely interoperable with the LangChain ecosystem. It adds new value primarily through the introduction of an easy way to create cyclical graphs. This is often useful when creating agent runtimes.In this blog post, we will first walk through the motivations for LangGraph. We will then cover the basic functionality it provides. We will then spotlight two agent runtimes we've implemented already. We will then highlight a few of the common modifications to these runtimes we've heard requests for, and examples of implementing those. We will finish with a preview of what we will be releasing next.MotivationOne of the big value props of LangChain\", metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 273, 'title': 'LangGraph'}),\n",
231 | " Document(page_content='thing we\\'ve seen in practice as we\\'ve worked the community and companies to put agents into production is that often times more control is needed. You may want to always force an agent to call particular tool first. You may want have more control over how tools are called. You may want to have different prompts for the agent, depending on that state it is in.When talking about these more controlled flows, we internally refer to them as \"state machines\". See the below diagram from our blog on cognitive architectures.These state machines have the power of being able to loop - allowing for handling of more ambiguous inputs than simple chains. However, there is still an element of human guidance in terms of how that loop is constructed.LangGraph is a way to create these state machines by specifying them as graphs.FunctionalityAt it\\'s core, LangGraph exposes a pretty narrow interface on top of LangChain.StateGraphStateGraph is a class that represents the graph. You initialize this class by', metadata={'language': 'en', 'source': 'https://blog.langchain.dev/langgraph/', 'start_index': 3476, 'title': 'LangGraph'})]"
232 | ]
233 | },
234 | "execution_count": 13,
235 | "metadata": {},
236 | "output_type": "execute_result"
237 | }
238 | ],
239 | "source": [
240 | "retriever.get_relevant_documents(\n",
241 | " \"what is LangGraph?\"\n",
242 | ")"
243 | ]
244 | },
245 | {
246 | "cell_type": "markdown",
247 | "metadata": {},
248 | "source": [
249 | "## Retrieval and Generation: Generate"
250 | ]
251 | },
252 | {
253 | "cell_type": "code",
254 | "execution_count": 14,
255 | "metadata": {},
256 | "outputs": [],
257 | "source": [
258 | "from langchain import hub \n",
259 | "\n",
260 | "prompt= hub.pull(\"rlm/rag-prompt\")"
261 | ]
262 | },
263 | {
264 | "cell_type": "code",
265 | "execution_count": 15,
266 | "metadata": {},
267 | "outputs": [],
268 | "source": [
269 | "def format_docs(docs):\n",
270 | " return \"\\n\\n\".join(doc.page_content for doc in docs)"
271 | ]
272 | },
273 | {
274 | "cell_type": "code",
275 | "execution_count": 16,
276 | "metadata": {},
277 | "outputs": [],
278 | "source": [
279 | "from langchain_core.runnables import RunnablePassthrough\n",
280 | "from langchain_core.output_parsers import StrOutputParser\n",
281 | "\n",
282 | "rag_chain = (\n",
283 | " {\"context\": retriever | format_docs, \"question\": RunnablePassthrough()}\n",
284 | " | prompt \n",
285 | " | llm \n",
286 | " | StrOutputParser()\n",
287 | ")"
288 | ]
289 | },
290 | {
291 | "cell_type": "code",
292 | "execution_count": 17,
293 | "metadata": {},
294 | "outputs": [
295 | {
296 | "data": {
297 | "text/plain": [
298 | "' LangGraph is a Python module built on top of LangChain, providing easier creation of cyclical graphs for agent runtimes. It enables more control over agent flow and the calling of tools.'"
299 | ]
300 | },
301 | "execution_count": 17,
302 | "metadata": {},
303 | "output_type": "execute_result"
304 | }
305 | ],
306 | "source": [
307 | "rag_chain.invoke(\"What is LangGraph?\")"
308 | ]
309 | },
310 | {
311 | "cell_type": "code",
312 | "execution_count": 18,
313 | "metadata": {},
314 | "outputs": [
315 | {
316 | "data": {
317 | "text/plain": [
318 | "' LangGraph is a module developed on top of LangChain, enhancing its capabilities for creating cyclical graphs, particularly useful for agent runtimes. It allows the creation of nodes and edges with different types such as starting edges, normal edges, and conditional edges. The motivation behind LangGraph is to provide an easier way to build complex agent runtime graphs.'"
319 | ]
320 | },
321 | "execution_count": 18,
322 | "metadata": {},
323 | "output_type": "execute_result"
324 | }
325 | ],
326 | "source": [
327 | "rag_chain.invoke(\"What is LangGraph used for?\")"
328 | ]
329 | },
330 | {
331 | "cell_type": "markdown",
332 | "metadata": {},
333 | "source": [
334 | "Thanks for reading 😀\n",
335 | "\n",
336 | "Let's connect [YouTube](http://youtube.com/tirendazacademy) | [Medium](http://tirendazacademy.medium.com) | [X](http://x.com/tirendazacademy) | [Linkedin](https://www.linkedin.com/in/tirendaz-academy) 😎"
337 | ]
338 | }
339 | ],
340 | "metadata": {
341 | "kernelspec": {
342 | "display_name": "genai",
343 | "language": "python",
344 | "name": "python3"
345 | },
346 | "language_info": {
347 | "codemirror_mode": {
348 | "name": "ipython",
349 | "version": 3
350 | },
351 | "file_extension": ".py",
352 | "mimetype": "text/x-python",
353 | "name": "python",
354 | "nbconvert_exporter": "python",
355 | "pygments_lexer": "ipython3",
356 | "version": "3.11.8"
357 | }
358 | },
359 | "nbformat": 4,
360 | "nbformat_minor": 2
361 | }
362 |
--------------------------------------------------------------------------------
/Quickstart-Guide.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyOw4c0esr4QYXlq4/nOyYpP",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "# LangChain Tutorial"
33 | ],
34 | "metadata": {
35 | "id": "5wjtV2JN9Cvg"
36 | }
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "source": [
41 | "This tutorial walks you through how to use LangChain."
42 | ],
43 | "metadata": {
44 | "id": "qoLu0W0H_oGU"
45 | }
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "source": [
50 | "# Installation"
51 | ],
52 | "metadata": {
53 | "id": "1pBexl6Y_fx8"
54 | }
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": null,
59 | "metadata": {
60 | "id": "WCvj819Yf8tu"
61 | },
62 | "outputs": [],
63 | "source": [
64 | "!pip install langchain \n",
65 | "!pip install openai \n",
66 | "!pip install google-search-results "
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "source": [
72 | "# Importing the Necessary Libraries"
73 | ],
74 | "metadata": {
75 | "id": "SVcHX_dW_jxc"
76 | }
77 | },
78 | {
79 | "cell_type": "code",
80 | "source": [
81 | "import os\n",
82 | "from langchain import ConversationChain\n",
83 | "from langchain.llms import OpenAI\n",
84 | "from langchain.chat_models import ChatOpenAI\n",
85 | "from langchain.prompts import (PromptTemplate, \n",
86 | " ChatPromptTemplate, \n",
87 | " MessagesPlaceholder, \n",
88 | " SystemMessagePromptTemplate, \n",
89 | " HumanMessagePromptTemplate)\n",
90 | "from langchain.chains import LLMChain\n",
91 | "from langchain.agents import (load_tools, \n",
92 | " initialize_agent, \n",
93 | " AgentType)\n",
94 | "from langchain.schema import (AIMessage, \n",
95 | " HumanMessage, \n",
96 | " SystemMessage)\n",
97 | "from langchain.prompts.chat import (ChatPromptTemplate, \n",
98 | " SystemMessagePromptTemplate,\n",
99 | " HumanMessagePromptTemplate)\n",
100 | "from langchain.memory import ConversationBufferMemory"
101 | ],
102 | "metadata": {
103 | "id": "yXIA5lVtgT6z"
104 | },
105 | "execution_count": 13,
106 | "outputs": []
107 | },
108 | {
109 | "cell_type": "markdown",
110 | "source": [
111 | "# Environment Setup"
112 | ],
113 | "metadata": {
114 | "id": "vgAQvzaq9XdE"
115 | }
116 | },
117 | {
118 | "cell_type": "code",
119 | "source": [
120 | "os.environ[\"OPENAI_API_KEY\"] = \"...\"\n",
121 | "os.environ[\"SERPAPI_API_KEY\"] = \"...\""
122 | ],
123 | "metadata": {
124 | "id": "qX-No2tp9ZXA"
125 | },
126 | "execution_count": null,
127 | "outputs": []
128 | },
129 | {
130 | "cell_type": "markdown",
131 | "source": [
132 | "# LLMs: Get predictions from a language model"
133 | ],
134 | "metadata": {
135 | "id": "kCyGJkdR9izy"
136 | }
137 | },
138 | {
139 | "cell_type": "code",
140 | "source": [
141 | "llm = OpenAI(temperature=0.9)"
142 | ],
143 | "metadata": {
144 | "id": "wWWtvD4NqqLT"
145 | },
146 | "execution_count": 14,
147 | "outputs": []
148 | },
149 | {
150 | "cell_type": "code",
151 | "source": [
152 | "text = \"Suggest a youtube name for AI\"\n",
153 | "print(llm(text))"
154 | ],
155 | "metadata": {
156 | "colab": {
157 | "base_uri": "https://localhost:8080/"
158 | },
159 | "id": "Gqdjoc3jq0J6",
160 | "outputId": "86d34972-e239-4d48-efbb-7eed1a4b3444"
161 | },
162 | "execution_count": 15,
163 | "outputs": [
164 | {
165 | "output_type": "stream",
166 | "name": "stdout",
167 | "text": [
168 | "\n",
169 | "\n",
170 | "AI Wiz\n"
171 | ]
172 | }
173 | ]
174 | },
175 | {
176 | "cell_type": "markdown",
177 | "source": [
178 | "# Prompt Templates: Manage prompts for LLMs"
179 | ],
180 | "metadata": {
181 | "id": "1QwCEOev9oQL"
182 | }
183 | },
184 | {
185 | "cell_type": "code",
186 | "source": [
187 | "prompt = PromptTemplate(\n",
188 | " input_variables=[\"topic\"],\n",
189 | " template=\"Recommend a youtube name for {topic}?\",\n",
190 | ")"
191 | ],
192 | "metadata": {
193 | "id": "eVniyzSzuzWd"
194 | },
195 | "execution_count": 40,
196 | "outputs": []
197 | },
198 | {
199 | "cell_type": "code",
200 | "source": [
201 | "print(prompt.format(topic=\"AI\"))"
202 | ],
203 | "metadata": {
204 | "colab": {
205 | "base_uri": "https://localhost:8080/"
206 | },
207 | "id": "XrF0PjyJvLGi",
208 | "outputId": "4e3cbfa3-bd9f-4285-98c9-cefe482c9f07"
209 | },
210 | "execution_count": 19,
211 | "outputs": [
212 | {
213 | "output_type": "stream",
214 | "name": "stdout",
215 | "text": [
216 | "Recommend a youtube name for AI?\n"
217 | ]
218 | }
219 | ]
220 | },
221 | {
222 | "cell_type": "code",
223 | "source": [
224 | "chain = LLMChain(llm=llm, prompt=prompt)"
225 | ],
226 | "metadata": {
227 | "id": "KGzNVlL90yuh"
228 | },
229 | "execution_count": 20,
230 | "outputs": []
231 | },
232 | {
233 | "cell_type": "code",
234 | "source": [
235 | "chain.run(\"data science\")"
236 | ],
237 | "metadata": {
238 | "colab": {
239 | "base_uri": "https://localhost:8080/",
240 | "height": 35
241 | },
242 | "id": "qDKcioiO096W",
243 | "outputId": "023cd793-6cc8-4451-d1ac-1a466f5d149b"
244 | },
245 | "execution_count": 21,
246 | "outputs": [
247 | {
248 | "output_type": "execute_result",
249 | "data": {
250 | "text/plain": [
251 | "'\\n\\nDataScienceTube'"
252 | ],
253 | "application/vnd.google.colaboratory.intrinsic+json": {
254 | "type": "string"
255 | }
256 | },
257 | "metadata": {},
258 | "execution_count": 21
259 | }
260 | ]
261 | },
262 | {
263 | "cell_type": "markdown",
264 | "source": [
265 | "# Agents: Dynamically Call Chains Based on User Input"
266 | ],
267 | "metadata": {
268 | "id": "YJvBK6jv2gW1"
269 | }
270 | },
271 | {
272 | "cell_type": "code",
273 | "source": [
274 | "# First, let's load the language model we're going to use to control the agent.\n",
275 | "llm = OpenAI(temperature=0)\n",
276 | "\n",
277 | "# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.\n",
278 | "tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm)\n",
279 | "\n",
280 | "# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.\n",
281 | "agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)\n",
282 | "\n",
283 | "# Now let's test it out!\n",
284 | "agent.run(\"What was the high temperature in SF yesterday in Fahrenheit? What is that number raised to the .023 power?\")"
285 | ],
286 | "metadata": {
287 | "colab": {
288 | "base_uri": "https://localhost:8080/",
289 | "height": 264
290 | },
291 | "id": "CF46aDoU2y3d",
292 | "outputId": "79ed61ea-5a2f-4214-89fc-3322c9aa0169"
293 | },
294 | "execution_count": 42,
295 | "outputs": [
296 | {
297 | "output_type": "stream",
298 | "name": "stderr",
299 | "text": [
300 | "WARNING:langchain.callbacks.manager:Error in on_chain_start callback: 'name'\n"
301 | ]
302 | },
303 | {
304 | "output_type": "stream",
305 | "name": "stdout",
306 | "text": [
307 | "\u001b[32;1m\u001b[1;3m I need to find the temperature first, then use the calculator to raise it to the .023 power.\n",
308 | "Action: Search\n",
309 | "Action Input: \"High temperature in SF yesterday\"\u001b[0m\n",
310 | "Observation: \u001b[36;1m\u001b[1;3mHigh: 69.8ºf @3:45 PM Low: 55.04ºf @5:56 AM Approx.\u001b[0m\n",
311 | "Thought:\u001b[32;1m\u001b[1;3m I need to use the calculator to raise 69.8 to the .023 power\n",
312 | "Action: Calculator\n",
313 | "Action Input: 69.8^.023\u001b[0m\n",
314 | "Observation: \u001b[33;1m\u001b[1;3mAnswer: 1.1025763550530143\u001b[0m\n",
315 | "Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
316 | "Final Answer: 1.1025763550530143\u001b[0m\n",
317 | "\n",
318 | "\u001b[1m> Finished chain.\u001b[0m\n"
319 | ]
320 | },
321 | {
322 | "output_type": "execute_result",
323 | "data": {
324 | "text/plain": [
325 | "'1.1025763550530143'"
326 | ],
327 | "application/vnd.google.colaboratory.intrinsic+json": {
328 | "type": "string"
329 | }
330 | },
331 | "metadata": {},
332 | "execution_count": 42
333 | }
334 | ]
335 | },
336 | {
337 | "cell_type": "markdown",
338 | "source": [
339 | "# Memory: Add State to Chains and Agents"
340 | ],
341 | "metadata": {
342 | "id": "i6pY8bCd3gEM"
343 | }
344 | },
345 | {
346 | "cell_type": "code",
347 | "source": [
348 | "llm = OpenAI(temperature=0)\n",
349 | "conversation = ConversationChain(llm=llm, verbose=True)\n",
350 | "\n",
351 | "output = conversation.predict(input=\"Hi there!\")\n",
352 | "print(output)"
353 | ],
354 | "metadata": {
355 | "colab": {
356 | "base_uri": "https://localhost:8080/"
357 | },
358 | "id": "wH13BtWd3hDV",
359 | "outputId": "8ac609c8-4cf1-4c16-d0ee-678f6ed5ed8d"
360 | },
361 | "execution_count": 25,
362 | "outputs": [
363 | {
364 | "output_type": "stream",
365 | "name": "stderr",
366 | "text": [
367 | "WARNING:langchain.callbacks.manager:Error in on_chain_start callback: 'name'\n"
368 | ]
369 | },
370 | {
371 | "output_type": "stream",
372 | "name": "stdout",
373 | "text": [
374 | "Prompt after formatting:\n",
375 | "\u001b[32;1m\u001b[1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n",
376 | "\n",
377 | "Current conversation:\n",
378 | "\n",
379 | "Human: Hi there!\n",
380 | "AI:\u001b[0m\n",
381 | "\n",
382 | "\u001b[1m> Finished chain.\u001b[0m\n",
383 | " Hi there! It's nice to meet you. How can I help you today?\n"
384 | ]
385 | }
386 | ]
387 | },
388 | {
389 | "cell_type": "code",
390 | "source": [
391 | "output = conversation.predict(input=\"I'm doing well! Just having a conversation with an AI.\")\n",
392 | "print(output)"
393 | ],
394 | "metadata": {
395 | "colab": {
396 | "base_uri": "https://localhost:8080/"
397 | },
398 | "id": "0D-8v4Ks5JAs",
399 | "outputId": "d6170741-0391-480e-97e5-4d41f837ffde"
400 | },
401 | "execution_count": 26,
402 | "outputs": [
403 | {
404 | "output_type": "stream",
405 | "name": "stderr",
406 | "text": [
407 | "WARNING:langchain.callbacks.manager:Error in on_chain_start callback: 'name'\n"
408 | ]
409 | },
410 | {
411 | "output_type": "stream",
412 | "name": "stdout",
413 | "text": [
414 | "Prompt after formatting:\n",
415 | "\u001b[32;1m\u001b[1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n",
416 | "\n",
417 | "Current conversation:\n",
418 | "Human: Hi there!\n",
419 | "AI: Hi there! It's nice to meet you. How can I help you today?\n",
420 | "Human: I'm doing well! Just having a conversation with an AI.\n",
421 | "AI:\u001b[0m\n",
422 | "\n",
423 | "\u001b[1m> Finished chain.\u001b[0m\n",
424 | " That's great! It's always nice to have a conversation with someone new. What would you like to talk about?\n"
425 | ]
426 | }
427 | ]
428 | },
429 | {
430 | "cell_type": "markdown",
431 | "source": [
432 | "# Get Message Completions from a Chat Model"
433 | ],
434 | "metadata": {
435 | "id": "zFzRZipF5bAI"
436 | }
437 | },
438 | {
439 | "cell_type": "code",
440 | "source": [
441 | "chat = ChatOpenAI(temperature=0)"
442 | ],
443 | "metadata": {
444 | "id": "W2VjRzo35Ri1"
445 | },
446 | "execution_count": 27,
447 | "outputs": []
448 | },
449 | {
450 | "cell_type": "code",
451 | "source": [
452 | "chat([HumanMessage(content=\"Translate this sentence from English to Turkish. I love programming.\")])"
453 | ],
454 | "metadata": {
455 | "colab": {
456 | "base_uri": "https://localhost:8080/"
457 | },
458 | "id": "2YwJK9Kd5r1d",
459 | "outputId": "a8cd8649-b2bd-46ee-e605-ae8f213121d0"
460 | },
461 | "execution_count": 29,
462 | "outputs": [
463 | {
464 | "output_type": "stream",
465 | "name": "stderr",
466 | "text": [
467 | "WARNING:langchain.chat_models.openai:Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.._completion_with_retry in 1.0 seconds as it raised RateLimitError: That model is currently overloaded with other requests. You can retry your request, or contact us through our help center at help.openai.com if the error persists. (Please include the request ID 618b332d89201832b2c4c918db5a7651 in your message.).\n"
468 | ]
469 | },
470 | {
471 | "output_type": "execute_result",
472 | "data": {
473 | "text/plain": [
474 | "AIMessage(lc_kwargs={'content': 'Ben programlamayı seviyorum.'}, content='Ben programlamayı seviyorum.', additional_kwargs={}, example=False)"
475 | ]
476 | },
477 | "metadata": {},
478 | "execution_count": 29
479 | }
480 | ]
481 | },
482 | {
483 | "cell_type": "code",
484 | "source": [
485 | "messages = [\n",
486 | " SystemMessage(content=\"You are a helpful assistant that translates English to Turkish.\"),\n",
487 | " HumanMessage(content=\"I love programming.\")\n",
488 | "]\n",
489 | "chat(messages)"
490 | ],
491 | "metadata": {
492 | "colab": {
493 | "base_uri": "https://localhost:8080/"
494 | },
495 | "id": "CMx4rU_J5vXU",
496 | "outputId": "406f7a92-e5f2-4a27-f6a8-068862027b1a"
497 | },
498 | "execution_count": 30,
499 | "outputs": [
500 | {
501 | "output_type": "execute_result",
502 | "data": {
503 | "text/plain": [
504 | "AIMessage(lc_kwargs={'content': 'Ben programlamayı seviyorum.'}, content='Ben programlamayı seviyorum.', additional_kwargs={}, example=False)"
505 | ]
506 | },
507 | "metadata": {},
508 | "execution_count": 30
509 | }
510 | ]
511 | },
512 | {
513 | "cell_type": "code",
514 | "source": [
515 | "batch_messages = [\n",
516 | " [\n",
517 | " SystemMessage(content=\"You are a helpful assistant that translates English to French.\"),\n",
518 | " HumanMessage(content=\"I love programming.\")\n",
519 | " ],\n",
520 | " [\n",
521 | " SystemMessage(content=\"You are a helpful assistant that translates English to French.\"),\n",
522 | " HumanMessage(content=\"I love artificial intelligence.\")\n",
523 | " ],\n",
524 | "]\n",
525 | "result = chat.generate(batch_messages)\n",
526 | "result"
527 | ],
528 | "metadata": {
529 | "colab": {
530 | "base_uri": "https://localhost:8080/"
531 | },
532 | "id": "WBfdrMQA6a4L",
533 | "outputId": "6d51c154-f1c7-4e97-e5fb-f7996abab77a"
534 | },
535 | "execution_count": 31,
536 | "outputs": [
537 | {
538 | "output_type": "execute_result",
539 | "data": {
540 | "text/plain": [
541 | "LLMResult(generations=[[ChatGeneration(lc_kwargs={'message': AIMessage(lc_kwargs={'content': \"J'adore la programmation.\"}, content=\"J'adore la programmation.\", additional_kwargs={}, example=False)}, text=\"J'adore la programmation.\", generation_info=None, message=AIMessage(lc_kwargs={'content': \"J'adore la programmation.\"}, content=\"J'adore la programmation.\", additional_kwargs={}, example=False))], [ChatGeneration(lc_kwargs={'message': AIMessage(lc_kwargs={'content': \"J'adore l'intelligence artificielle.\"}, content=\"J'adore l'intelligence artificielle.\", additional_kwargs={}, example=False)}, text=\"J'adore l'intelligence artificielle.\", generation_info=None, message=AIMessage(lc_kwargs={'content': \"J'adore l'intelligence artificielle.\"}, content=\"J'adore l'intelligence artificielle.\", additional_kwargs={}, example=False))]], llm_output={'token_usage': {'prompt_tokens': 57, 'completion_tokens': 20, 'total_tokens': 77}, 'model_name': 'gpt-3.5-turbo'}, run=RunInfo(run_id=UUID('cd379524-dc22-475c-ba5f-db2ef7722036')))"
542 | ]
543 | },
544 | "metadata": {},
545 | "execution_count": 31
546 | }
547 | ]
548 | },
549 | {
550 | "cell_type": "code",
551 | "source": [
552 | "result.llm_output['token_usage']"
553 | ],
554 | "metadata": {
555 | "colab": {
556 | "base_uri": "https://localhost:8080/"
557 | },
558 | "id": "f8JG9eQr6iO9",
559 | "outputId": "b0c229a0-8238-48de-daa9-acaf94a9ddd0"
560 | },
561 | "execution_count": 32,
562 | "outputs": [
563 | {
564 | "output_type": "execute_result",
565 | "data": {
566 | "text/plain": [
567 | "{'prompt_tokens': 57, 'completion_tokens': 20, 'total_tokens': 77}"
568 | ]
569 | },
570 | "metadata": {},
571 | "execution_count": 32
572 | }
573 | ]
574 | },
575 | {
576 | "cell_type": "markdown",
577 | "source": [
578 | "# Chat Prompt Templates"
579 | ],
580 | "metadata": {
581 | "id": "HSaHRDiz6pLM"
582 | }
583 | },
584 | {
585 | "cell_type": "code",
586 | "source": [
587 | "chat = ChatOpenAI(temperature=0)\n",
588 | "\n",
589 | "template = \"You are a helpful assistant that translates {input_language} to {output_language}.\"\n",
590 | "system_message_prompt = SystemMessagePromptTemplate.from_template(template)\n",
591 | "human_template = \"{text}\"\n",
592 | "human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)\n",
593 | "\n",
594 | "chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])\n",
595 | "\n",
596 | "# get a chat completion from the formatted messages\n",
597 | "chat(chat_prompt.format_prompt(input_language=\"English\", \n",
598 | " output_language=\"Turkish\", \n",
599 | " text=\"I love programming.\").to_messages())"
600 | ],
601 | "metadata": {
602 | "colab": {
603 | "base_uri": "https://localhost:8080/"
604 | },
605 | "id": "_FbafofP6mgD",
606 | "outputId": "f2cb965e-d2d6-432e-9728-2db6b65ee250"
607 | },
608 | "execution_count": 33,
609 | "outputs": [
610 | {
611 | "output_type": "execute_result",
612 | "data": {
613 | "text/plain": [
614 | "AIMessage(lc_kwargs={'content': 'Ben programlamayı seviyorum.'}, content='Ben programlamayı seviyorum.', additional_kwargs={}, example=False)"
615 | ]
616 | },
617 | "metadata": {},
618 | "execution_count": 33
619 | }
620 | ]
621 | },
622 | {
623 | "cell_type": "markdown",
624 | "source": [
625 | "# Chains with Chat Models"
626 | ],
627 | "metadata": {
628 | "id": "c8xDm2_J7IGi"
629 | }
630 | },
631 | {
632 | "cell_type": "code",
633 | "source": [
634 | "chat = ChatOpenAI(temperature=0)\n",
635 | "\n",
636 | "template = \"You are a helpful assistant that translates {input_language} to {output_language}.\"\n",
637 | "system_message_prompt = SystemMessagePromptTemplate.from_template(template)\n",
638 | "human_template = \"{text}\"\n",
639 | "human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)\n",
640 | "chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])\n",
641 | "\n",
642 | "chain = LLMChain(llm=chat, prompt=chat_prompt)\n",
643 | "chain.run(input_language=\"English\", output_language=\"Turkish\", text=\"I love programming.\")"
644 | ],
645 | "metadata": {
646 | "colab": {
647 | "base_uri": "https://localhost:8080/",
648 | "height": 35
649 | },
650 | "id": "a8mX8BGO7JJb",
651 | "outputId": "726ba550-83df-4c44-c903-43eebb6b202a"
652 | },
653 | "execution_count": 34,
654 | "outputs": [
655 | {
656 | "output_type": "execute_result",
657 | "data": {
658 | "text/plain": [
659 | "'Ben programlamayı seviyorum.'"
660 | ],
661 | "application/vnd.google.colaboratory.intrinsic+json": {
662 | "type": "string"
663 | }
664 | },
665 | "metadata": {},
666 | "execution_count": 34
667 | }
668 | ]
669 | },
670 | {
671 | "cell_type": "markdown",
672 | "source": [
673 | "# Agents with Chat Models"
674 | ],
675 | "metadata": {
676 | "id": "JYvB5BdY7Yps"
677 | }
678 | },
679 | {
680 | "cell_type": "code",
681 | "source": [
682 | "# First, let's load the language model we're going to use to control the agent.\n",
683 | "chat = ChatOpenAI(temperature=0)\n",
684 | "\n",
685 | "# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.\n",
686 | "llm = OpenAI(temperature=0)\n",
687 | "tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm)\n",
688 | "\n",
689 | "# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.\n",
690 | "agent = initialize_agent(tools, chat, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)\n",
691 | "\n",
692 | "# Now let's test it out!\n",
693 | "agent.run(\"Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?\")"
694 | ],
695 | "metadata": {
696 | "colab": {
697 | "base_uri": "https://localhost:8080/",
698 | "height": 513
699 | },
700 | "id": "k886YmjY7aEp",
701 | "outputId": "70b88cc3-a46c-41e1-e966-cefbac7767f1"
702 | },
703 | "execution_count": 35,
704 | "outputs": [
705 | {
706 | "output_type": "stream",
707 | "name": "stderr",
708 | "text": [
709 | "WARNING:langchain.callbacks.manager:Error in on_chain_start callback: 'name'\n"
710 | ]
711 | },
712 | {
713 | "output_type": "stream",
714 | "name": "stdout",
715 | "text": [
716 | "\u001b[32;1m\u001b[1;3mThought: I need to use a search engine to find Olivia Wilde's boyfriend and a calculator to raise his age to the 0.23 power.\n",
717 | "Action:\n",
718 | "```\n",
719 | "{\n",
720 | " \"action\": \"Search\",\n",
721 | " \"action_input\": \"Olivia Wilde boyfriend\"\n",
722 | "}\n",
723 | "```\n",
724 | "\u001b[0m\n",
725 | "Observation: \u001b[36;1m\u001b[1;3mLooks like Olivia Wilde and Jason Sudeikis are starting 2023 on good terms. Amid their highly publicized custody battle – and the actress' ...\u001b[0m\n",
726 | "Thought:\u001b[32;1m\u001b[1;3mNow I need to use a calculator to raise Jason Sudeikis' age to the 0.23 power.\n",
727 | "Action:\n",
728 | "```\n",
729 | "{\n",
730 | " \"action\": \"Calculator\",\n",
731 | " \"action_input\": \"47^0.23\"\n",
732 | "}\n",
733 | "```\n",
734 | "\n",
735 | "\u001b[0m\n",
736 | "Observation: \u001b[33;1m\u001b[1;3mAnswer: 2.4242784855673896\u001b[0m\n",
737 | "Thought:\u001b[32;1m\u001b[1;3mI now know that Jason Sudeikis' current age raised to the 0.23 power is 2.4242784855673896.\n",
738 | "Final Answer: Jason Sudeikis' current age raised to the 0.23 power is 2.4242784855673896.\u001b[0m\n",
739 | "\n",
740 | "\u001b[1m> Finished chain.\u001b[0m\n"
741 | ]
742 | },
743 | {
744 | "output_type": "execute_result",
745 | "data": {
746 | "text/plain": [
747 | "\"Jason Sudeikis' current age raised to the 0.23 power is 2.4242784855673896.\""
748 | ],
749 | "application/vnd.google.colaboratory.intrinsic+json": {
750 | "type": "string"
751 | }
752 | },
753 | "metadata": {},
754 | "execution_count": 35
755 | }
756 | ]
757 | },
758 | {
759 | "cell_type": "markdown",
760 | "source": [
761 | "# Memory: Add State to Chains and Agents"
762 | ],
763 | "metadata": {
764 | "id": "emKLYRiz8Aws"
765 | }
766 | },
767 | {
768 | "cell_type": "code",
769 | "source": [
770 | "prompt = ChatPromptTemplate.from_messages([\n",
771 | " SystemMessagePromptTemplate.from_template(\n",
772 | " \"The following is a friendly conversation between a human and an AI.\"),\n",
773 | " MessagesPlaceholder(variable_name=\"history\"),\n",
774 | " HumanMessagePromptTemplate.from_template(\"{input}\")\n",
775 | "])\n",
776 | "\n",
777 | "llm = ChatOpenAI(temperature=0)\n",
778 | "memory = ConversationBufferMemory(return_messages=True)\n",
779 | "conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)\n",
780 | "\n",
781 | "conversation.predict(input=\"Hi there!\")\n",
782 | "# -> 'Hello! How can I assist you today?'\n",
783 | "\n",
784 | "\n",
785 | "conversation.predict(input=\"I'm doing well! Just having a conversation with an AI.\")\n",
786 | "# -> \"That sounds like fun! I'm happy to chat with you. Is there anything specific you'd like to talk about?\"\n",
787 | "\n",
788 | "conversation.predict(input=\"Tell me about yourself.\")"
789 | ],
790 | "metadata": {
791 | "colab": {
792 | "base_uri": "https://localhost:8080/",
793 | "height": 70
794 | },
795 | "id": "PC9zwbTH8DLB",
796 | "outputId": "276e0f98-1bd2-40a8-e788-2dbd0c1f7e71"
797 | },
798 | "execution_count": 38,
799 | "outputs": [
800 | {
801 | "output_type": "execute_result",
802 | "data": {
803 | "text/plain": [
804 | "'I am an AI language model designed to assist with various tasks such as answering questions, generating text, and providing recommendations. I am constantly learning and improving my abilities through machine learning algorithms. Is there anything specific you would like to know about me?'"
805 | ],
806 | "application/vnd.google.colaboratory.intrinsic+json": {
807 | "type": "string"
808 | }
809 | },
810 | "metadata": {},
811 | "execution_count": 38
812 | }
813 | ]
814 | },
815 | {
816 | "cell_type": "markdown",
817 | "source": [
818 | "# Resource\n",
819 | "\n",
820 | "- [LangChain Doc](https://python.langchain.com/en/latest/getting_started/getting_started.html#environment-setup)"
821 | ],
822 | "metadata": {
823 | "id": "L6HvwP4h_7Zx"
824 | }
825 | }
826 | ]
827 | }
--------------------------------------------------------------------------------