63 |
64 | Overview
65 | -------------
66 |
67 | Trustee is a framework to extract decision tree explanation from black-box ML models.
68 |
69 | .. figure:: _static/flowchart.png
70 | :align: center
71 | :alt: Trustee Flowchart
72 |
73 | Standard AI/ML development pipeline extended by Trustee.
74 |
75 |
76 | Getting Started
77 | ---------------
78 | This section contains basic information and instructions to get started with Trustee.
79 |
80 | Python Version
81 | ***************
82 |
83 | Trustee supports Python >=3.7.
84 |
85 | Install Trustee
86 | ***************
87 |
88 | Use the following command to install Trustee:
89 |
90 | .. code-block:: sh
91 |
92 | $ pip install trustee
93 |
94 |
95 | Sample Code
96 | *******************
97 |
98 | .. code:: python
99 |
100 | from sklearn import datasets
101 | from sklearn.ensemble import RandomForestClassifier
102 | from sklearn.model_selection import train_test_split
103 | from sklearn.metrics import classification_report
104 |
105 | from trustee import ClassificationTrustee
106 |
107 | X, y = datasets.load_iris(return_X_y=True)
108 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
109 |
110 | clf = RandomForestClassifier(n_estimators=100)
111 | clf.fit(X_train, y_train)
112 | y_pred = clf.predict(X_test)
113 |
114 | trustee = ClassificationTrustee(expert=clf)
115 | trustee.fit(X_train, y_train, num_iter=50, num_stability_iter=10, samples_size=0.3, verbose=True)
116 | dt, pruned_dt, agreement, reward = trustee.explain()
117 | dt_y_pred = dt.predict(X_test)
118 |
119 | print("Model explanation global fidelity report:")
120 | print(classification_report(y_pred, dt_y_pred))
121 | print("Model explanation score report:")
122 | print(classification_report(y_test, dt_y_pred))
123 |
124 |
125 | Other Use Cases
126 | *******************
127 | For other examples and use cases of how Trustee can used to scrutinize ML models, listed in the table below, please check our `Use Cases repository `_.
128 |
129 | .. table::
130 | :class: align-left
131 |
132 | ===================== ===========================================================================================================================================================
133 | Use Case Description
134 | ===================== ===========================================================================================================================================================
135 | `heartbleed_case/` Trustee application to a Random Forest Classifier for an Intrustion Detection System, trained with CIC-IDS-2017 dataset pre-computed features.
136 | `kitsune_case/` Trustee application to Kitsune model for anomaly detection in network traffic, trained with features extracted from Kitsune's Mirai attack trace.
137 | `iot_case/` Trustee application to Random Forest Classifier to distguish IoT devices, trained with features extracted from the pcaps from the UNSW IoT Dataset.
138 | `moon_star_case/` Trustee application to Neural Network Moon and Stars Shortcut learning toy example.
139 | `nprint_ids_case/` Trustee application to the nPrintML AutoGluon Tabular Predictor for an Intrustion Detection System, also trained using pcaps from the CIC-IDS-2017 dataset.
140 | `nprint_os_case/` Trustee application to the nPrintML AutoGluon Tabular Predictor for OS Fingerprinting, also trained using with pcaps from the CIC-IDS-2017 dataset.
141 | `pensieve_case/` Trustee application to the Pensieve RL model for adaptive bit-rate prediction, and comparison to related work Metis.
142 | `vpn_case/` Trustee application the 1D-CNN trained to detect VPN traffic trained with the ISCX VPN-nonVPN dataset.
143 | ===================== ===========================================================================================================================================================
144 |
145 | Supported AI/ML Libraries
146 | *************************
147 |
148 | .. table::
149 | :class: align-left
150 |
151 | ============== ===================
152 | Library Supported
153 | ============== ===================
154 | `scikit-learn` |:white_check_mark:|
155 | `Keras` |:white_check_mark:|
156 | `Tensorflow` |:white_check_mark:|
157 | `PyTorch` |:white_check_mark:|
158 | `AutoGluon` |:white_check_mark:|
159 | ============== ===================
160 |
161 | API Reference
162 | -------------
163 |
164 | If you are looking for information on a specific function, class or
165 | method, this part of the documentation is for you.
166 |
167 | .. toctree::
168 | :maxdepth: 2
169 |
170 | api
171 | auto_examples/index
172 |
173 |
174 | Citing Us
175 | ---------
176 |
177 | .. code::
178 |
179 | @inproceedings{Jacobs2022,
180 | title = {AI/ML and Network Security: The Emperor has no Clothes},
181 | author = {A. S. Jacobs and R. Beltiukov and W. Willinger and R. A. Ferreira and A. Gupta and L. Z. Granville},
182 | year = 2022,
183 | booktitle = {Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security},
184 | location = {Los Angeles, CA, USA},
185 | publisher = {Association for Computing Machinery},
186 | address = {New York, NY, USA},
187 | series = {CCS '22}
188 | }
189 |
190 |
--------------------------------------------------------------------------------
/trustee/utils/plot.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import matplotlib
3 | import matplotlib.pyplot as plt
4 | import matplotlib.patches as mpatches
5 |
6 | from matplotlib import rcParams
7 |
8 | FONT_NAME = "Roboto"
9 | FONT_WEIGHT = "light"
10 |
11 | rcParams["font.family"] = "serif"
12 | rcParams["font.serif"] = [FONT_NAME]
13 | rcParams["font.weight"] = FONT_WEIGHT
14 |
15 |
16 | def plot_heatmap(matrix, labels=[], path=None):
17 | """Util function to plot confusion matrix"""
18 | cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", ["#d75d5b", "#a7c3cd"])
19 | fig, ax = plt.subplots(figsize=(15, 15))
20 | ax.matshow(matrix, cmap=cmap, alpha=0.3)
21 | for i in range(matrix.shape[0]):
22 | for j in range(matrix.shape[1]):
23 | ax.text(
24 | x=j,
25 | y=i,
26 | s=f"{matrix[i, j]:.2f}",
27 | va="center",
28 | ha="center",
29 | # size="xx-large",
30 | )
31 |
32 | plt.xticks(ticks=range(len(labels)), labels=labels)
33 | plt.yticks(ticks=range(len(labels)), labels=labels)
34 | plt.tight_layout()
35 | if path:
36 | plt.savefig(path)
37 | else:
38 | plt.show()
39 | plt.close()
40 |
41 |
42 | def plot_lines(x, y, xlim=None, ylim=None, labels=[], title=None, xlabel=None, ylabel=None, size=(), path=None):
43 | """Util function to plot lines"""
44 | plt.figure(figsize=size if size else (4, 1.5)) # width:20, height:3
45 | # plt.figure(figsize=size if size else (3, 2)) # width:20, height:3
46 | markers = [
47 | "o",
48 | "v",
49 | "^",
50 | "<",
51 | ">",
52 | "1",
53 | "2",
54 | "3",
55 | "4",
56 | "8",
57 | "s",
58 | "p",
59 | "P",
60 | "*",
61 | "h",
62 | "H",
63 | "+",
64 | "x",
65 | "X",
66 | "D",
67 | "d",
68 | "|",
69 | "_",
70 | ]
71 | colors = [
72 | "#a7c3cd",
73 | "#8a4444",
74 | "#524a47",
75 | "#d75d5b",
76 | "#c8c5c3",
77 | "#f5f0ed",
78 | "#edeef0",
79 | ]
80 |
81 | if np.shape(x)[0] == 1:
82 | x = np.ravel(x)
83 |
84 | if np.shape(x) and np.shape(x)[0] > 1 and not isinstance(x[0], str) and np.shape(x[0]) and np.shape(x[0])[0] >= 1:
85 | for idx, (x_values, y_values) in enumerate(zip(x, y)):
86 | plt.plot(
87 | x_values,
88 | y_values,
89 | color=colors[idx] if idx < len(colors) else None,
90 | # marker=markers[idx] if idx < len(markers) else None,
91 | label=labels[idx] if idx < len(labels) else "",
92 | )
93 | else:
94 | for idx, values in enumerate(y):
95 | plt.plot(
96 | x,
97 | values,
98 | color=colors[idx] if idx < len(colors) else None,
99 | # marker=markers[idx] if idx < len(markers) else None,
100 | label=labels[idx] if idx < len(labels) else "",
101 | )
102 |
103 | if len(labels) > 1:
104 | plt.legend(loc="lower right", ncol=2)
105 |
106 | if xlabel:
107 | plt.xlabel(xlabel, fontname=FONT_NAME, fontweight=FONT_WEIGHT)
108 |
109 | if ylabel:
110 | plt.ylabel(ylabel, fontname=FONT_NAME, fontweight=FONT_WEIGHT)
111 |
112 | if xlim:
113 | plt.xlim(xlim)
114 |
115 | if ylim:
116 | plt.ylim(ylim)
117 |
118 | if title:
119 | plt.title(title)
120 |
121 | _, end = plt.xlim()
122 | end = int(end)
123 | plt.xticks(np.arange(0, end + 1, max(1, int(end / 10))))
124 |
125 | plt.tight_layout()
126 | if path:
127 | plt.savefig(path)
128 | else:
129 | plt.show()
130 | plt.close()
131 |
132 |
133 | def plot_bars(x, y, ylim=None, xlabel=None, ylabel=None, labels=[], title=None, path=None):
134 | """Util function to plot bars"""
135 | plt.figure(figsize=(30, 3)) # width:20, height:3
136 | width = 0.4
137 | fig, ax = plt.subplots()
138 | locs = np.arange(len(x)) # the label locations
139 | colors = [
140 | "#d75d5b",
141 | "#a7c3cd",
142 | "#524a47",
143 | "#8a4444",
144 | "#c8c5c3",
145 | "#524a47",
146 | "#edeef0",
147 | ]
148 |
149 | for idx, values in enumerate(y):
150 | ax.bar(
151 | locs - (width / 2) if idx % 2 == 0 else locs + (width / 2),
152 | values,
153 | width,
154 | color=colors[idx] if idx <= len(colors) else None,
155 | label=labels[idx] if idx < len(labels) else "",
156 | )
157 |
158 | ax.set_xticks(locs)
159 | ax.set_xticklabels(x, rotation=60)
160 | if labels:
161 | ax.legend()
162 |
163 | if xlabel:
164 | plt.xlabel(xlabel)
165 |
166 | if ylabel:
167 | plt.ylabel(ylabel)
168 |
169 | if ylim:
170 | ax.set_ylim(ylim)
171 |
172 | if title:
173 | plt.title(title)
174 |
175 | fig.tight_layout()
176 | if path:
177 | plt.savefig(path)
178 | else:
179 | plt.show()
180 | plt.close()
181 |
182 |
183 | def plot_lines_and_bars(
184 | x,
185 | lines,
186 | bars,
187 | ylim=None,
188 | xlabel=None,
189 | ylabel=None,
190 | second_x_axis=None,
191 | second_x_axis_label=None,
192 | labels=[],
193 | legend=[],
194 | colors_by_x=[],
195 | title=None,
196 | path=None,
197 | ):
198 | """Util function to plot lines"""
199 | plt.figure(figsize=(40, 3)) # width:20, height:3
200 |
201 | width = 0.4
202 | fig, ax = plt.subplots()
203 | locs = np.arange(len(x)) # the label locations
204 | colors = [
205 | "#d75d5b",
206 | "#a7c3cd",
207 | "#f5f0ed",
208 | "#524a47",
209 | "#8a4444",
210 | "#edeef0",
211 | "#c8c5c3",
212 | ]
213 |
214 | for idx, values in enumerate(lines):
215 | ax.plot(
216 | x,
217 | values,
218 | color=colors[idx] if idx < len(colors) else None,
219 | label=labels[idx] if idx < len(labels) else "",
220 | )
221 |
222 | for idx, values in enumerate(bars):
223 | if colors_by_x:
224 | ax.bar(
225 | locs,
226 | values,
227 | width if len(bars) > 1 else 1,
228 | color=colors_by_x,
229 | )
230 | else:
231 | ax.bar(
232 | locs - (width / 2) if idx % 2 == 0 else locs + (width / 2),
233 | values,
234 | width if len(bars) > 1 else 1,
235 | color=colors[len(colors) - idx - 1] if len(colors) - idx - 1 >= 0 else None,
236 | label=labels[idx] if idx < len(labels) else "",
237 | )
238 |
239 | patches = []
240 | if legend:
241 | for label, color in legend.items():
242 | patches.append(mpatches.Patch(color=color, label=label))
243 |
244 | ax.set_xticks(locs)
245 | ax.set_xticklabels(x, rotation=60)
246 |
247 | if second_x_axis is not None:
248 | ax2 = ax.twiny()
249 | ax2.set_xlim(ax.get_xlim())
250 | ax2.set_xticks(locs)
251 | ax2.set_xticklabels(second_x_axis, rotation=60)
252 |
253 | if second_x_axis_label:
254 | ax2.set_xlabel(second_x_axis_label)
255 |
256 | if patches:
257 | plt.legend(handles=patches)
258 | elif labels:
259 | plt.legend()
260 |
261 | if xlabel:
262 | ax.set_xlabel(xlabel)
263 |
264 | if ylabel:
265 | ax.set_ylabel(ylabel)
266 |
267 | if ylim:
268 | plt.ylim(ylim)
269 |
270 | if title:
271 | plt.title(title)
272 |
273 | plt.tight_layout()
274 | if path:
275 | plt.savefig(path)
276 | else:
277 | plt.show()
278 | plt.close()
279 |
280 |
281 | def plot_stacked_bars(x, y, y_placeholder=None, ylim=None, xlabel=None, ylabel=None, labels=[], title=None, path=None):
282 | plt.figure(figsize=(50, 10)) # width:20, height:3
283 | """Util function to plot stacker bars"""
284 | fig, ax = plt.subplots()
285 | width = 0.8
286 | colors = [
287 | "#a7c3cd",
288 | "#8a4444",
289 | "#c8c5c3",
290 | "#f5f0ed",
291 | "#d75d5b",
292 | ]
293 | # hatches = ["/", "-", "+", ".", "*"]
294 |
295 | y_placeholder = np.sort(y_placeholder, axis=0)[::-1] if y_placeholder else None
296 | labels = [label for _, label in (sorted(zip(y, labels), key=lambda pair: np.sum(pair[0]))[::-1])]
297 | y = np.sort(y, axis=0)[::-1]
298 |
299 | if y_placeholder is not None:
300 | previous_stack = 0
301 | for i, stack in enumerate(y_placeholder):
302 | if i > 0:
303 | previous_stack += y_placeholder[i - 1]
304 |
305 | rects = ax.bar(
306 | x,
307 | stack,
308 | width,
309 | color="#edeef0",
310 | edgecolor="#524a47",
311 | linewidth=0.25,
312 | bottom=previous_stack,
313 | )
314 | sum_y = [sum(val) for val in zip(*y)]
315 | # ax.bar_label(rects, labels=[f"{val:.2f}" for val in sum_y], padding=1)
316 |
317 | bottom_by_y = {}
318 | if y_placeholder is not None:
319 | for i, stack in enumerate(y_placeholder):
320 | if i == 0:
321 | bottom_by_y[i] = stack
322 | else:
323 | bottom_by_y[i] = stack + bottom_by_y[i - 1]
324 | else:
325 | for i, stack in enumerate(y):
326 | if i == 0:
327 | bottom_by_y[i] = stack
328 | else:
329 | bottom_by_y[i] = stack + bottom_by_y[i - 1]
330 |
331 | for i, values in enumerate(y):
332 | rects = ax.bar(
333 | x,
334 | values,
335 | width,
336 | bottom=bottom_by_y[i - 1] if i > 0 and bottom_by_y else 0,
337 | # hatch=hatches[i] if i < len(hatches) else None,
338 | color=colors[i] if i < len(colors) else None,
339 | label=labels[i] if labels else "",
340 | )
341 | # ax.bar_label(rects, label_type="center", fmt="%.2f", padding=5)
342 |
343 | if labels:
344 | ax.legend()
345 |
346 | if xlabel:
347 | plt.xlabel(xlabel)
348 |
349 | if ylabel:
350 | plt.ylabel(ylabel)
351 |
352 | if ylim:
353 | ax.set_ylim(ylim)
354 |
355 | plt.xticks(rotation=60)
356 | if title:
357 | plt.title(title)
358 |
359 | fig.tight_layout()
360 | plt.tight_layout()
361 |
362 | if path:
363 | plt.savefig(path)
364 | else:
365 | plt.show()
366 | plt.close()
367 |
368 |
369 | def plot_stacked_bars_split(
370 | x, y_a, y_b, y_placeholder=None, ylim=None, xlabel=None, ylabel=None, labels=[], title=None, path=None
371 | ):
372 | """Util function to plot stacker bars"""
373 | plt.figure(figsize=(50, 3)) # width:50, height:3
374 | fig, ax = plt.subplots()
375 | width = 0.8
376 | colors = [
377 | "#a7c3cd",
378 | "#8a4444",
379 | "#c8c5c3",
380 | "#f5f0ed",
381 | "#d75d5b",
382 | ]
383 | # hatches = ["/", "-", "+", ".", "*"]
384 |
385 | labels = [label for _, label in sorted(zip(y_a, labels), key=lambda pair: np.sum(pair[0]))[::-1]]
386 | y_a = np.sort(y_a, axis=0)[::-1]
387 | y_b = np.sort(y_b, axis=0)[::-1]
388 | x = np.sort(x, axis=0)[::-1]
389 | y_placeholder = np.sort(y_placeholder, axis=0)[::-1] if y_placeholder else None
390 |
391 | locs = np.arange(len(x)) # the label locations
392 | new_locs = np.array([2 * i for i in locs])
393 | if y_placeholder is not None:
394 | previous_stack = 0
395 | for i, stack in enumerate(y_placeholder):
396 | if i > 0:
397 | previous_stack += y_placeholder[i - 1]
398 |
399 | rects1 = ax.bar(
400 | new_locs - (width / 2),
401 | stack,
402 | width,
403 | color="#edeef0",
404 | edgecolor="#524a47",
405 | linewidth=0.25,
406 | bottom=previous_stack,
407 | )
408 | rects2 = ax.bar(
409 | new_locs + (width / 2),
410 | stack,
411 | width,
412 | color="#edeef0",
413 | edgecolor="#524a47",
414 | linewidth=0.25,
415 | bottom=previous_stack,
416 | )
417 | sum_y_a = [sum(val) for val in zip(*y_a)]
418 | sum_y_b = [sum(val) for val in zip(*y_b)]
419 | # ax.bar_label(rects1, labels=[f"{val:.2f}" for val in sum_y_a], padding=1, rotation=60)
420 | # ax.bar_label(rects2, labels=[f"{val:.2f}" for val in sum_y_b], padding=1, rotation=60)
421 |
422 | bottom_by_y = {}
423 | bottom_by_y_a = {}
424 | bottom_by_y_b = {}
425 | if y_placeholder is not None:
426 | for i, stack in enumerate(y_placeholder):
427 | if i == 0:
428 | bottom_by_y[i] = stack
429 | else:
430 | bottom_by_y[i] = stack + bottom_by_y[i - 1]
431 | else:
432 | for i, (values_a, values_b) in enumerate(zip(y_a, y_b)):
433 | if i == 0:
434 | bottom_by_y_a[i] = np.array(values_a)
435 | bottom_by_y_b[i] = np.array(values_b)
436 | else:
437 | bottom_by_y_a[i] = np.array(values_a) + bottom_by_y_a[i - 1]
438 | bottom_by_y_b[i] = np.array(values_b) + bottom_by_y_b[i - 1]
439 |
440 | for i, (values_a, values_b) in enumerate(zip(y_a, y_b)):
441 | rects1 = ax.bar(
442 | new_locs - (width / 2),
443 | values_a,
444 | width,
445 | bottom=bottom_by_y[i - 1]
446 | if i > 0 and bottom_by_y
447 | else bottom_by_y_a[i - 1]
448 | if i > 0 and bottom_by_y_a
449 | else 0,
450 | # hatch=hatches[i] if i < len(hatches) else None,
451 | color=colors[i] if i < len(colors) else None,
452 | label=labels[i] if labels and i < len(labels) else None,
453 | )
454 | rects2 = ax.bar(
455 | new_locs + (width / 2),
456 | values_b,
457 | width,
458 | bottom=bottom_by_y[i - 1]
459 | if i > 0 and bottom_by_y
460 | else bottom_by_y_b[i - 1]
461 | if i > 0 and bottom_by_y_b
462 | else 0,
463 | # hatch=hatches[i] if i < len(hatches) else None,
464 | color=colors[i] if i < len(colors) else None,
465 | # label=labels[i] if labels else "",
466 | )
467 | # ax.bar_label(rects1, label_type="center", fmt="%.2f", padding=5)
468 | # ax.bar_label(rects2, label_type="center", fmt="%.2f", padding=5)
469 |
470 | ax.set_xticks(new_locs)
471 | ax.set_xticklabels(x, rotation=60)
472 | if labels:
473 | ax.legend()
474 |
475 | if xlabel:
476 | plt.xlabel(xlabel)
477 |
478 | if ylabel:
479 | plt.ylabel(ylabel)
480 |
481 | if ylim:
482 | ax.set_ylim(ylim)
483 |
484 | if title:
485 | plt.title(title)
486 |
487 | fig.tight_layout()
488 | plt.tight_layout()
489 |
490 | if path:
491 | plt.savefig(path)
492 | else:
493 | plt.show()
494 | plt.close()
495 |
--------------------------------------------------------------------------------
/trustee/utils/const.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | from . import rootpath
4 | from trustee.enums.feature_type import FeatureType
5 |
6 | WINE_DATASET_META = {
7 | "name": "wine",
8 | "path": f"{rootpath.detect()}/res/dataset/wine.csv",
9 | "has_header": True,
10 | "delimiter": ";",
11 | "fields": [
12 | ("fixed acidity", FeatureType.NUMERICAL, None, False),
13 | ("volatile acidity", FeatureType.NUMERICAL, None, False),
14 | ("citric acid", FeatureType.NUMERICAL, None, False),
15 | ("residual sugar", FeatureType.NUMERICAL, None, False),
16 | ("chlorides", FeatureType.NUMERICAL, None, False),
17 | ("free sulfur dioxide", FeatureType.NUMERICAL, None, False),
18 | ("total sulfur dioxide", FeatureType.NUMERICAL, None, False),
19 | ("density", FeatureType.NUMERICAL, None, False),
20 | ("pH", FeatureType.NUMERICAL, None, False),
21 | ("sulphates", FeatureType.NUMERICAL, None, False),
22 | ("alcohol", FeatureType.NUMERICAL, None, False),
23 | ("quality", FeatureType.NUMERICAL, None, True),
24 | ],
25 | "type": "regression",
26 | "url": "https://archive.ics.uci.edu/ml/datasets/wine",
27 | }
28 |
29 | DIABETES_DATASET_META = {
30 | "name": "diabetes",
31 | "path": f"{rootpath.detect()}/res/dataset/diabetes/diabetic_data.csv",
32 | "has_header": True,
33 | "delimiter": ",",
34 | "fields": [
35 | ("encounter_id", FeatureType.IDENTIFIER, None, False),
36 | ("patient_nbr", FeatureType.IDENTIFIER, None, False),
37 | ("race", FeatureType.CATEGORICAL, None, False),
38 | ("gender", FeatureType.CATEGORICAL, None, False),
39 | ("age", FeatureType.CATEGORICAL, None, False),
40 | ("weight", FeatureType.CATEGORICAL, None, False),
41 | ("admission_type_id", FeatureType.CATEGORICAL, None, False),
42 | ("discharge_disposition_id", FeatureType.CATEGORICAL, None, False),
43 | ("admission_source_id", FeatureType.CATEGORICAL, None, False),
44 | ("time_in_hospital", FeatureType.NUMERICAL, None, False),
45 | ("payer_code", FeatureType.CATEGORICAL, None, False),
46 | ("medical_specialty", FeatureType.CATEGORICAL, None, False),
47 | ("num_lab_procedures", FeatureType.NUMERICAL, None, False),
48 | ("num_procedures", FeatureType.NUMERICAL, None, False),
49 | ("num_medications", FeatureType.NUMERICAL, None, False),
50 | ("number_outpatient", FeatureType.NUMERICAL, None, False),
51 | ("number_emergency", FeatureType.NUMERICAL, None, False),
52 | ("number_inpatient", FeatureType.NUMERICAL, None, False),
53 | ("diag_1", FeatureType.CATEGORICAL, None, False),
54 | ("diag_2", FeatureType.CATEGORICAL, None, False),
55 | ("diag_3", FeatureType.CATEGORICAL, None, False),
56 | ("number_diagnoses", FeatureType.NUMERICAL, None, False),
57 | ("max_glu_serum", FeatureType.CATEGORICAL, None, False),
58 | ("A1Cresult", FeatureType.CATEGORICAL, None, False),
59 | ("metformin", FeatureType.CATEGORICAL, None, False),
60 | ("repaglinide", FeatureType.CATEGORICAL, None, False),
61 | ("nateglinide", FeatureType.CATEGORICAL, None, False),
62 | ("chlorpropamide", FeatureType.CATEGORICAL, None, False),
63 | ("glimepiride", FeatureType.CATEGORICAL, None, False),
64 | ("acetohexamide", FeatureType.CATEGORICAL, None, False),
65 | ("glipizide", FeatureType.CATEGORICAL, None, False),
66 | ("glyburide", FeatureType.CATEGORICAL, None, False),
67 | ("tolbutamide", FeatureType.CATEGORICAL, None, False),
68 | ("pioglitazone", FeatureType.CATEGORICAL, None, False),
69 | ("rosiglitazone", FeatureType.CATEGORICAL, None, False),
70 | ("acarbose", FeatureType.CATEGORICAL, None, False),
71 | ("miglitol", FeatureType.CATEGORICAL, None, False),
72 | ("troglitazone", FeatureType.CATEGORICAL, None, False),
73 | ("tolazamide", FeatureType.CATEGORICAL, None, False),
74 | ("examide", FeatureType.CATEGORICAL, None, False),
75 | ("citoglipton", FeatureType.CATEGORICAL, None, False),
76 | ("insulin", FeatureType.CATEGORICAL, None, False),
77 | ("glyburide-metformin", FeatureType.CATEGORICAL, None, False),
78 | ("glipizide-metformin", FeatureType.CATEGORICAL, None, False),
79 | ("glimepiride-pioglitazone", FeatureType.CATEGORICAL, None, False),
80 | ("metformin-rosiglitazone", FeatureType.CATEGORICAL, None, False),
81 | ("metformin-pioglitazone", FeatureType.CATEGORICAL, None, False),
82 | ("change", FeatureType.CATEGORICAL, None, False),
83 | ("diabetesMed", FeatureType.CATEGORICAL, None, False),
84 | ("readmitted", FeatureType.CATEGORICAL, None, True),
85 | ],
86 | "type": "classification",
87 | "url": "https://www.kaggle.com/brandao/diabetes?select=diabetic_data.csv",
88 | }
89 |
90 | IOT_DATASET_META = {
91 | "name": "iot",
92 | # "path": "{}/res/dataset/iot/csv_files/16-09-23-labeled.csv".format(rootpath.detect()),
93 | "path": f"{rootpath.detect()}/res/dataset/iot/csv_files/",
94 | "is_dir": True,
95 | "has_header": False,
96 | "fields": [
97 | ("Frame Length", FeatureType.NUMERICAL, None, False),
98 | ("Ethernet Type", FeatureType.NUMERICAL, None, False),
99 | ("IP Protocol", FeatureType.CATEGORICAL, None, False),
100 | ("IPv4 Flags", FeatureType.CATEGORICAL, None, False),
101 | ("IPv6 Next Header", FeatureType.CATEGORICAL, None, False),
102 | ("IPv6 Option", FeatureType.CATEGORICAL, None, False),
103 | ("TCP Src Port", FeatureType.NUMERICAL, None, False),
104 | ("TCP Dst Port", FeatureType.NUMERICAL, None, False),
105 | ("TCP Flags", FeatureType.CATEGORICAL, None, False),
106 | ("UDP Src Port", FeatureType.NUMERICAL, None, False),
107 | ("UDP Dst Port", FeatureType.NUMERICAL, None, False),
108 | ("IoT Device Type", FeatureType.CATEGORICAL, None, True),
109 | ],
110 | "classes": ["Smart Static", "Sensor", "Audio", "Video", "Other"],
111 | "converters": {
112 | 1: lambda x: int(x, 16) if x else None,
113 | 3: lambda x: int(x, 16) if x else None,
114 | 8: lambda x: int(x, 16) if x else None,
115 | },
116 | "type": "classification",
117 | "categories": {
118 | "IP Protocol": [-1, 0, 1, 2, 6, 17, 145, 242],
119 | "IPv4 Flags": [
120 | -1,
121 | 0,
122 | 185,
123 | 925,
124 | 8192,
125 | 8377,
126 | 8562,
127 | 8747,
128 | 8932,
129 | 16384,
130 | 48299,
131 | 60692,
132 | ],
133 | "IPv6 Next Header": [-1, 0, 6, 17, 44, 58],
134 | "IPv6 Option": [-1, 1],
135 | "TCP Flags": [
136 | -1,
137 | 1,
138 | 2,
139 | 4,
140 | 16,
141 | 17,
142 | 18,
143 | 20,
144 | 24,
145 | 25,
146 | 28,
147 | 47,
148 | 49,
149 | 56,
150 | 82,
151 | 144,
152 | 152,
153 | 153,
154 | 168,
155 | 194,
156 | 210,
157 | 1041,
158 | 2050,
159 | 2051,
160 | 2513,
161 | 3345,
162 | 3610,
163 | ],
164 | },
165 | "url": "https://iotanalytics.unsw.edu.au/iottraces.html",
166 | }
167 |
168 | BOSTON_DATASET_META = {
169 | "name": "boston",
170 | "path": f"{rootpath.detect()}/res/dataset/boston.csv",
171 | "has_header": True,
172 | "fields": [
173 | ("CRIM", FeatureType.NUMERICAL, None, False),
174 | ("ZN", FeatureType.NUMERICAL, None, False),
175 | ("INDUS", FeatureType.NUMERICAL, None, False),
176 | ("CHAS", FeatureType.CATEGORICAL, None, False),
177 | ("NOX", FeatureType.NUMERICAL, None, False),
178 | ("RM", FeatureType.NUMERICAL, None, False),
179 | ("AGE", FeatureType.NUMERICAL, None, False),
180 | ("DIS", FeatureType.NUMERICAL, None, False),
181 | ("RAD", FeatureType.NUMERICAL, None, False),
182 | ("TAX", FeatureType.NUMERICAL, None, False),
183 | ("PTRATIO", FeatureType.NUMERICAL, None, False),
184 | ("B", FeatureType.NUMERICAL, None, False),
185 | ("LSTAT", FeatureType.NUMERICAL, None, False),
186 | ("MEDV", FeatureType.CATEGORICAL, None, True),
187 | ],
188 | "type": "regression",
189 | "url": "https://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html",
190 | }
191 |
192 |
193 | def cic_ids_2017_label_converter(label):
194 | value = -1
195 | labels = {
196 | "BENIGN": 0,
197 | "Bot": 1,
198 | "DDoS": 2,
199 | "DoS GoldenEye": 3,
200 | "DoS Hulk": 4,
201 | "DoS Slowhttptest": 5,
202 | "DoS slowloris": 6,
203 | "FTP-Patator": 7,
204 | "Heartbleed": 8,
205 | "Infiltration": 9,
206 | "PortScan": 10,
207 | "SSH-Patator": 11,
208 | "Web Attack Brute Force": 12,
209 | "Web Attack Sql Injection": 13,
210 | "Web Attack XSS": 14,
211 | }
212 |
213 | try:
214 | value = labels[label.strip()]
215 | except Exception as err:
216 | print("Exception", err, label)
217 |
218 | return np.uint8(value)
219 |
220 |
221 | CIC_IDS_2017_DATASET_META = {
222 | "name": "cic_ids_2017",
223 | "path": f"{rootpath.detect()}/res/dataset/CIC-IDS-2017/MachineLearningCVE/",
224 | "is_dir": True,
225 | "oversampled_path": f"{rootpath.detect()}/res/dataset/CIC-IDS-2017/MachineLearningCVE_OverSampled.csv.zip",
226 | "undersampled_path": f"{rootpath.detect()}/res/dataset/CIC-IDS-2017/MachineLearningCVE_UnderSampled.csv",
227 | "has_header": True,
228 | "fields": [
229 | ("Destination Port", FeatureType.NUMERICAL, "uint32", False),
230 | ("Flow Duration", FeatureType.NUMERICAL, "uint32", False),
231 | ("Total Fwd Packets", FeatureType.NUMERICAL, "uint32", False),
232 | ("Total Backward Packets", FeatureType.NUMERICAL, "uint32", False),
233 | ("Total Length of Fwd Packets", FeatureType.NUMERICAL, "uint32", False),
234 | ("Total Length of Bwd Packets", FeatureType.NUMERICAL, "uint32", False),
235 | ("Fwd Packet Length Max", FeatureType.NUMERICAL, "uint16", False),
236 | ("Fwd Packet Length Min", FeatureType.NUMERICAL, "uint16", False),
237 | ("Fwd Packet Length Mean", FeatureType.NUMERICAL, "float16", False),
238 | ("Fwd Packet Length Std", FeatureType.NUMERICAL, "float16", False),
239 | ("Bwd Packet Length Max", FeatureType.NUMERICAL, "uint16", False),
240 | ("Bwd Packet Length Min", FeatureType.NUMERICAL, "uint16", False),
241 | ("Bwd Packet Length Mean", FeatureType.NUMERICAL, "float16", False),
242 | ("Bwd Packet Length Std", FeatureType.NUMERICAL, "float16", False),
243 | ("Flow Bytes/s", FeatureType.NUMERICAL, "float32", False),
244 | ("Flow Packets/s", FeatureType.NUMERICAL, "float32", False),
245 | ("Flow IAT Mean", FeatureType.NUMERICAL, "float32", False),
246 | ("Flow IAT Std", FeatureType.NUMERICAL, "float32", False),
247 | ("Flow IAT Max", FeatureType.NUMERICAL, "uint32", False),
248 | ("Flow IAT Min", FeatureType.NUMERICAL, "uint32", False),
249 | ("Fwd IAT Total", FeatureType.NUMERICAL, "uint32", False),
250 | ("Fwd IAT Mean", FeatureType.NUMERICAL, "float32", False),
251 | ("Fwd IAT Std", FeatureType.NUMERICAL, "float32", False),
252 | ("Fwd IAT Max", FeatureType.NUMERICAL, "uint32", False),
253 | ("Fwd IAT Min", FeatureType.NUMERICAL, "uint32", False),
254 | ("Bwd IAT Total", FeatureType.NUMERICAL, "uint32", False),
255 | ("Bwd IAT Mean", FeatureType.NUMERICAL, "float32", False),
256 | ("Bwd IAT Std", FeatureType.NUMERICAL, "float32", False),
257 | ("Bwd IAT Max", FeatureType.NUMERICAL, "uint32", False),
258 | ("Bwd IAT Min", FeatureType.NUMERICAL, "uint32", False),
259 | ("Fwd PSH Flags", FeatureType.CATEGORICAL, "uint8", False),
260 | ("Bwd PSH Flags", FeatureType.IDENTIFIER, "uint8", False),
261 | ("Fwd URG Flags", FeatureType.CATEGORICAL, "uint8", False),
262 | ("Bwd URG Flags", FeatureType.IDENTIFIER, "uint8", False),
263 | (
264 | "Fwd Header Length 2",
265 | FeatureType.IDENTIFIER,
266 | "uint32",
267 | False,
268 | ), # duplicate column, so ignore it
269 | ("Bwd Header Length", FeatureType.NUMERICAL, "uint32", False),
270 | ("Fwd Packets/s", FeatureType.NUMERICAL, "float16", False),
271 | ("Bwd Packets/s", FeatureType.NUMERICAL, "float16", False),
272 | ("Min Packet Length", FeatureType.NUMERICAL, "float16", False),
273 | ("Max Packet Length", FeatureType.NUMERICAL, "float16", False),
274 | ("Packet Length Mean", FeatureType.NUMERICAL, "float16", False),
275 | ("Packet Length Std", FeatureType.NUMERICAL, "float16", False),
276 | ("Packet Length Variance", FeatureType.NUMERICAL, "float32", False),
277 | ("FIN Flag Count", FeatureType.NUMERICAL, "uint8", False),
278 | ("SYN Flag Count", FeatureType.NUMERICAL, "uint8", False),
279 | ("RST Flag Count", FeatureType.NUMERICAL, "uint8", False),
280 | ("PSH Flag Count", FeatureType.NUMERICAL, "uint8", False),
281 | ("ACK Flag Count", FeatureType.NUMERICAL, "uint8", False),
282 | ("URG Flag Count", FeatureType.NUMERICAL, "uint8", False),
283 | ("CWE Flag Count", FeatureType.NUMERICAL, "uint8", False),
284 | ("ECE Flag Count", FeatureType.NUMERICAL, "uint8", False),
285 | ("Down/Up Ratio", FeatureType.NUMERICAL, "float16", False),
286 | ("Average Packet Size", FeatureType.NUMERICAL, "float16", False),
287 | ("Avg Fwd Segment Size", FeatureType.NUMERICAL, "float16", False),
288 | ("Avg Bwd Segment Size", FeatureType.NUMERICAL, "float16", False),
289 | ("Fwd Header Length", FeatureType.NUMERICAL, "uint32", False),
290 | ("Fwd Avg Bytes/Bulk", FeatureType.NUMERICAL, "uint8", False),
291 | ("Fwd Avg Packets/Bulk", FeatureType.NUMERICAL, "uint8", False),
292 | ("Fwd Avg Bulk Rate", FeatureType.NUMERICAL, "uint8", False),
293 | ("Bwd Avg Bytes/Bulk", FeatureType.NUMERICAL, "uint8", False),
294 | ("Bwd Avg Packets/Bulk", FeatureType.NUMERICAL, "uint8", False),
295 | ("Bwd Avg Bulk Rate", FeatureType.NUMERICAL, "uint8", False),
296 | ("Subflow Fwd Packets", FeatureType.NUMERICAL, "uint32", False),
297 | ("Subflow Fwd Bytes", FeatureType.NUMERICAL, "uint32", False),
298 | ("Subflow Bwd Packets", FeatureType.NUMERICAL, "uint32", False),
299 | ("Subflow Bwd Bytes", FeatureType.NUMERICAL, "uint32", False),
300 | ("Init_Win_bytes_forward", FeatureType.NUMERICAL, "uint32", False),
301 | ("Init_Win_bytes_backward", FeatureType.NUMERICAL, "uint32", False),
302 | ("act_data_pkt_fwd", FeatureType.NUMERICAL, "uint16", False),
303 | ("min_seg_size_forward", FeatureType.NUMERICAL, "uint16", False),
304 | ("Active Mean", FeatureType.NUMERICAL, "float32", False),
305 | ("Active Std", FeatureType.NUMERICAL, "float32", False),
306 | ("Active Max", FeatureType.NUMERICAL, "uint32", False),
307 | ("Active Min", FeatureType.NUMERICAL, "uint32", False),
308 | ("Idle Mean", FeatureType.NUMERICAL, "float32", False),
309 | ("Idle Std", FeatureType.NUMERICAL, "float32", False),
310 | ("Idle Max", FeatureType.NUMERICAL, "uint32", False),
311 | ("Idle Min", FeatureType.NUMERICAL, "uint32", False),
312 | ("Label", FeatureType.CATEGORICAL, "uint8", True),
313 | ],
314 | "categories": {
315 | "Fwd PSH Flags": [np.uint8(0), np.uint8(1)],
316 | # "Bwd PSH Flags": [np.uint8(0)],
317 | "Fwd URG Flags": [np.uint8(0), np.uint8(1)],
318 | # "Bwd URG Flags": [np.uint8(0)],
319 | },
320 | "classes": [
321 | "BENIGN",
322 | "Bot",
323 | "DDoS",
324 | "DoS GoldenEye",
325 | "DoS Hulk",
326 | "DoS Slowhttptest",
327 | "DoS slowloris",
328 | "FTP-Patator",
329 | "Heartbleed",
330 | "Infiltration",
331 | "PortScan",
332 | "SSH-Patator",
333 | "Web Attack Brute Force",
334 | "Web Attack Sql Injection",
335 | "Web Attack XSS",
336 | ],
337 | "converters": {"Label": lambda x: cic_ids_2017_label_converter(x)},
338 | "type": "classification",
339 | "url": "https://www.unb.ca/cic/datasets/ids-2017.html",
340 | }
341 |
--------------------------------------------------------------------------------
/trustee/report/plot.py:
--------------------------------------------------------------------------------
1 | import os
2 | import re
3 | import math
4 | import numbers
5 | import numpy as np
6 | import pandas as pd
7 |
8 | from copy import deepcopy
9 | from pandas.api.types import is_numeric_dtype
10 |
11 | import matplotlib.pyplot as plt
12 | from matplotlib.ticker import PercentFormatter
13 | from sklearn.metrics import f1_score, r2_score
14 |
15 | from trustee.utils import plot
16 | from trustee.utils.tree import get_dt_info
17 |
18 |
19 | def plot_top_features(top_features, dt_sum_samples, dt_nodes, output_dir, feature_names=[]):
20 | """Uses top features information and plots CDF with it"""
21 | if not np.array(top_features).size or not np.array(dt_sum_samples).size or not np.array(dt_nodes).size:
22 | return
23 |
24 | features = [feature_names[feat] if feature_names else str(feat) for (feat, _) in top_features]
25 | count = [(values["count"] / dt_nodes) * 100 for (_, values) in top_features]
26 | count_sum = np.cumsum(count)
27 | data = [(values["samples"] / dt_sum_samples) * 100 for (_, values) in top_features]
28 | data_sum = np.cumsum(data)
29 |
30 | plot.plot_lines(
31 | features,
32 | [count_sum, data_sum],
33 | ylim=(0, 100),
34 | xlabel="Feature",
35 | ylabel="% of total",
36 | labels=["Nodes", "Samples"],
37 | path=f"{output_dir}/top_features_lines.pdf",
38 | )
39 | plot.plot_bars(
40 | features,
41 | [count_sum, data_sum],
42 | ylim=(0, 100),
43 | xlabel="Feature",
44 | ylabel="% of total",
45 | labels=["Nodes", "Samples"],
46 | path=f"{output_dir}/top_features_bars.pdf",
47 | )
48 |
49 | plot.plot_lines_and_bars(
50 | features,
51 | [count_sum, data_sum],
52 | [count, data],
53 | ylim=(0, 100),
54 | xlabel="Feature",
55 | ylabel="% of total",
56 | labels=["Nodes", "Samples"],
57 | path=f"{output_dir}/top_features_lines_bars.pdf",
58 | )
59 |
60 |
61 | def plot_top_nodes(top_nodes, dt_samples_by_class, dt_samples, output_dir, feature_names=[], class_names=[]):
62 | """Uses top features information and plots CDF with it"""
63 | if not np.array(top_nodes).size or not np.array(dt_samples_by_class).size or not np.array(dt_samples).size:
64 | return
65 |
66 | plot.plot_stacked_bars_split(
67 | [
68 | "{} <= {:.2f}".format(
69 | feature_names[node["feature"]] if feature_names else node["feature"],
70 | node["threshold"],
71 | )
72 | for node in top_nodes
73 | ],
74 | [[(node["data_split"][0] / dt_samples) * 100 for node in top_nodes]],
75 | [[(node["data_split"][1] / dt_samples) * 100 for node in top_nodes]],
76 | y_placeholder=[100],
77 | ylim=(0, 100),
78 | xlabel="Node",
79 | ylabel="% of total samples",
80 | path=f"{output_dir}/top_nodes.pdf",
81 | )
82 |
83 | plot.plot_stacked_bars_split(
84 | [
85 | "{} <= {:.2f}".format(
86 | feature_names[node["feature"]] if feature_names else node["feature"],
87 | node["threshold"],
88 | )
89 | for node in top_nodes
90 | ],
91 | [
92 | [(node["data_split_by_class"][idx][0] / dt_samples) * 100 for node in top_nodes]
93 | for idx in range(len(dt_samples_by_class))
94 | ],
95 | [
96 | [(node["data_split_by_class"][idx][1] / dt_samples) * 100 for node in top_nodes]
97 | for idx in range(len(dt_samples_by_class))
98 | ],
99 | y_placeholder=[(samples / dt_samples) * 100 for samples in dt_samples_by_class],
100 | ylim=(0, 100),
101 | xlabel="Node",
102 | ylabel="% of total samples",
103 | labels=class_names if class_names is not None else [],
104 | path=f"{output_dir}/top_nodes_by_class.pdf",
105 | )
106 |
107 |
108 | def plot_top_branches(
109 | top_branches,
110 | dt_samples_by_class,
111 | dt_samples,
112 | output_dir,
113 | filename="top_branches",
114 | class_names=[],
115 | is_classify=True,
116 | ):
117 | """Uses top features information and plots CDF with it"""
118 | if not np.array(top_branches).size or not np.array(dt_samples_by_class).size or not np.array(dt_samples).size:
119 | return
120 |
121 | colors = [
122 | "#d75d5b",
123 | "#524a47",
124 | "#8a4444",
125 | "#edeef0",
126 | "#c8c5c3",
127 | "#f5f0ed",
128 | "#a7c3cd",
129 | ]
130 |
131 | samples = []
132 | colors_by_class = {}
133 | colors_by_samples = []
134 | for branch in top_branches:
135 | class_label = class_names[branch["class"]] if class_names is not None else branch["class"]
136 | if class_label not in colors_by_class:
137 | colors_by_class[class_label] = (
138 | colors.pop() if colors else "#%02x%02x%02x" % tuple(np.random.randint(256, size=3))
139 | )
140 | samples.append((branch["samples"] / dt_samples) * 100)
141 | colors_by_samples.append(colors_by_class[class_label])
142 |
143 | plot.plot_lines(
144 | range(len(top_branches[:600])),
145 | [np.cumsum(samples[:600])],
146 | ylim=(0, 100),
147 | xlabel="Top-k Branches",
148 | ylabel="% of Samples",
149 | path=f"{output_dir}/{filename}.pdf",
150 | )
151 |
152 | plot.plot_lines_and_bars(
153 | [f"Top {idx + 1}" for idx in range(len(top_branches))] if len(top_branches) < 20 else range(len(top_branches)),
154 | [np.cumsum(samples)],
155 | [samples],
156 | ylim=(0, 100),
157 | xlabel="Branches",
158 | ylabel="% of total samples",
159 | legend={"CDF": "#d75d5b", **colors_by_class},
160 | colors_by_x=colors_by_samples,
161 | path=f"{output_dir}/{filename}_by_class.pdf",
162 | )
163 |
164 | # TODO: This only works for classification problems, fix for refression in the future.
165 | if is_classify:
166 | plot.plot_stacked_bars(
167 | [f"Top {idx + 1}" for idx in range(len(top_branches))]
168 | if len(top_branches) < 20
169 | else range(len(top_branches)),
170 | [np.cumsum(samples)],
171 | y_placeholder=[100],
172 | ylim=(0, 100),
173 | xlabel="Branches",
174 | ylabel="% of total samples",
175 | path=f"{output_dir}/{filename}_bars.pdf",
176 | )
177 |
178 | plot.plot_stacked_bars(
179 | [f"Top {idx + 1}" for idx in range(len(top_branches))]
180 | if len(top_branches) < 20
181 | else range(len(top_branches)),
182 | [
183 | np.cumsum(
184 | [
185 | ((branch["samples"] / dt_samples) * 100) if idx == branch["class"] else 0
186 | for branch in top_branches
187 | ]
188 | )
189 | for idx, _ in enumerate(dt_samples_by_class)
190 | ],
191 | y_placeholder=[(samples / dt_samples) * 100 for samples in dt_samples_by_class],
192 | ylim=(0, 100),
193 | xlabel="Branches",
194 | ylabel="% of total samples",
195 | labels=class_names,
196 | path=f"{output_dir}/cum_{filename}_by_class.pdf",
197 | )
198 |
199 |
200 | def plot_all_branches(top_branches, dt_samples_by_class, dt_samples, output_dir, class_names=[], is_classify=True):
201 | """Uses all features information and plots CDF with it"""
202 | plot_top_branches(
203 | top_branches,
204 | dt_samples_by_class,
205 | dt_samples,
206 | output_dir,
207 | filename="all_branches",
208 | class_names=class_names,
209 | is_classify=is_classify,
210 | )
211 |
212 |
213 | def plot_samples_by_level(dt_samples_by_level, dt_nodes_by_level, dt_samples, output_dir):
214 | """Uses dt information to plot number of samples per level"""
215 | if not np.array(dt_nodes_by_level).size or not np.array(dt_nodes_by_level).size or not np.array(dt_samples).size:
216 | return
217 |
218 | samples = []
219 | for idx, level_samples in enumerate(dt_samples_by_level):
220 | if idx < len(dt_samples_by_level) - 1:
221 | samples.append(((level_samples - dt_samples_by_level[idx + 1]) / dt_samples) * 100)
222 | else:
223 | samples.append((level_samples / dt_samples) * 100)
224 |
225 | plot.plot_lines_and_bars(
226 | [level for level, _ in enumerate(dt_samples_by_level)],
227 | [np.cumsum(samples)],
228 | [samples],
229 | ylim=(0, 100),
230 | xlabel="Level",
231 | ylabel="% of total samples",
232 | second_x_axis=dt_nodes_by_level,
233 | second_x_axis_label="Leaves at Level",
234 | labels=["Samples"],
235 | legend={"CDF": "#d75d5b", "Samples": "#c8c5c3"},
236 | path=f"{output_dir}/samples_by_level.pdf",
237 | )
238 |
239 |
240 | def plot_dts_fidelity_by_size(pruning_list, output_dir, filename="dts"):
241 | """Uses pruning information to plot fidelity vs size of decision trees"""
242 | if not np.array(pruning_list).size:
243 | return
244 |
245 | num_leaves = {}
246 | depth = {}
247 | fidelity = {}
248 |
249 | for pr in pruning_list:
250 | for i in pr["iter"]:
251 | if pr["type"] not in num_leaves:
252 | num_leaves[pr["type"]] = []
253 | depth[pr["type"]] = []
254 | fidelity[pr["type"]] = []
255 |
256 | num_leaves[pr["type"]].append(i["dt"].get_n_leaves())
257 | depth[pr["type"]].append(i["dt"].get_depth())
258 | fidelity[pr["type"]].append(i["fidelity"])
259 |
260 | plot.plot_lines(
261 | list(num_leaves.values()),
262 | list(fidelity.values()),
263 | ylim=(0, 1),
264 | xlim=(0, 50),
265 | xlabel="Number of Branches",
266 | ylabel="Fidelity",
267 | labels=list(num_leaves.keys()),
268 | path=f"{output_dir}/{filename}_fidelity_x_leaves.pdf",
269 | )
270 |
271 | plot.plot_lines(
272 | list(depth.values()),
273 | list(fidelity.values()),
274 | ylim=(0, 1),
275 | xlabel="Depth",
276 | ylabel="Fidelity",
277 | labels=list(depth.keys()),
278 | path=f"{output_dir}/{filename}_fidelity_x_depth.pdf",
279 | )
280 |
281 |
282 | def plot_stability(
283 | stability_iter,
284 | X_test,
285 | y_test,
286 | base_tree,
287 | base_tree_key,
288 | top_branches,
289 | output_dir,
290 | class_names=[],
291 | is_classify=True,
292 | ):
293 | """Uses stability information to plot the edit-distance between decision trees"""
294 | if not np.array(stability_iter).size:
295 | return
296 |
297 | agreement = []
298 | agreement_by_class = {}
299 | nodes = {}
300 | features = {}
301 | features_by_it = {}
302 | total_nodes = 0
303 | number_of_splits = []
304 | fidelity = []
305 | base_y_pred = base_tree.predict(X_test.values)
306 | base_df = pd.DataFrame(deepcopy(X_test))
307 | base_df["label"] = y_test
308 | grouped_df = base_df.groupby("label") if is_classify else []
309 |
310 | for idx, it in enumerate(stability_iter):
311 | iter_tree = it[f"{base_tree_key}"]
312 | _, splits, _ = get_dt_info(iter_tree)
313 | total_nodes += len(splits)
314 | features_by_it[idx] = 0
315 | number_of_splits.append(len(splits))
316 |
317 | for split in splits:
318 | split_str = f"{split['feature']}-{split['threshold']}"
319 | if split_str not in nodes:
320 | nodes[split_str] = 0
321 | nodes[split_str] += 1
322 |
323 | if split["feature"] not in features:
324 | features[split["feature"]] = {}
325 |
326 | if idx not in features[split["feature"]]:
327 | features[split["feature"]][idx] = 0
328 | features_by_it[idx] += 1
329 | features[split["feature"]][idx] += 1
330 |
331 | y_pred = iter_tree.predict(X_test.values)
332 | fidelity.append(it[f"{base_tree_key}_fidelity"])
333 | agreement.append(
334 | f1_score(y_pred, base_y_pred, average="weighted") if is_classify else r2_score(y_pred, base_y_pred)
335 | )
336 |
337 | for group, data in grouped_df:
338 | y_pred_class = iter_tree.predict(data.drop("label", axis=1).values)
339 | base_y_pred_class = base_tree.predict(data.drop("label", axis=1).values)
340 | if group not in agreement_by_class:
341 | agreement_by_class[group] = []
342 |
343 | agreement_by_class[group].append(f1_score(y_pred_class, base_y_pred_class, average="weighted"))
344 |
345 | plot.plot_lines(
346 | range(len(number_of_splits)),
347 | [number_of_splits],
348 | xlabel="Iteration",
349 | ylabel="Number of Splits",
350 | path=f"{output_dir}/{base_tree_key}_num_nodes_stability.pdf",
351 | )
352 |
353 | plot.plot_lines(
354 | range(len(features_by_it.keys())),
355 | [features_by_it.values()],
356 | xlabel="Iteration",
357 | ylabel="Stability",
358 | labels=["Features"],
359 | path=f"{output_dir}/{base_tree_key}_feature_stability.pdf",
360 | )
361 |
362 | plot.plot_lines(
363 | range(len(stability_iter)),
364 | [agreement, fidelity],
365 | ylim=(0, 1),
366 | xlabel="Iteration",
367 | ylabel="Score",
368 | labels=["Agreement", "Fidelity"],
369 | path=f"{output_dir}/{base_tree_key}_stability.pdf",
370 | )
371 |
372 | if is_classify:
373 | top_branch_agreement = {}
374 | for branch in top_branches[:5]:
375 | class_name = class_names[branch["class"]] if class_names is not None else branch["class"]
376 | class_id = class_name if class_name in agreement_by_class else branch["class"]
377 | top_branch_agreement[class_id] = agreement_by_class[class_id]
378 |
379 | plot.plot_lines(
380 | range(len(stability_iter)),
381 | [agreement for _, agreement in top_branch_agreement.items()],
382 | ylim=(0, 1),
383 | xlabel="Iteration",
384 | ylabel="Agreement (Score)",
385 | labels=[
386 | class_names[group] if class_names is not None and not isinstance(group, str) else group
387 | for group, _ in top_branch_agreement.items()
388 | ],
389 | path=f"{output_dir}/{base_tree_key}_stability_by_class.pdf",
390 | size=(6, 4),
391 | )
392 |
393 |
394 | def plot_stability_heatmap(
395 | stability_iter,
396 | X_test,
397 | y_test,
398 | tree_key,
399 | top_branches,
400 | output_dir,
401 | class_names=[],
402 | is_classify=True,
403 | ):
404 | """Uses stability information to plot the edit-distance between decision trees"""
405 | if not np.array(stability_iter).size:
406 | return
407 |
408 | heatmap_size = 30
409 | agreement = []
410 | fidelity = []
411 | mean_agreement = []
412 | agreement_by_class = {}
413 | base_df = pd.DataFrame(deepcopy(X_test))
414 | base_df["label"] = y_test
415 | grouped_df = base_df.groupby("label") if is_classify else []
416 |
417 | for i, _ in enumerate(stability_iter):
418 | base_tree = stability_iter[i][f"{tree_key}"]
419 | fidelity.append(stability_iter[i][f"{tree_key}_fidelity"])
420 | agreement.append([])
421 |
422 | for j, _ in enumerate(stability_iter):
423 | iter_tree = stability_iter[j][f"{tree_key}"]
424 |
425 | iter_y_pred = iter_tree.predict(X_test.values)
426 | base_y_pred = base_tree.predict(X_test.values)
427 |
428 | agreement[i].append(
429 | f1_score(iter_y_pred, base_y_pred, average="weighted")
430 | if is_classify
431 | else r2_score(iter_y_pred, base_y_pred)
432 | )
433 |
434 | for group, data in grouped_df:
435 | y_pred_class = iter_tree.predict(data.drop("label", axis=1).values)
436 | base_y_pred_class = base_tree.predict(data.drop("label", axis=1).values)
437 | if group not in agreement_by_class:
438 | agreement_by_class[group] = []
439 |
440 | if i >= len(agreement_by_class[group]):
441 | agreement_by_class[group].append([])
442 |
443 | agreement_by_class[group][i].append(
444 | f1_score(y_pred_class, base_y_pred_class, average="weighted")
445 | if is_classify
446 | else r2_score(y_pred_class, base_y_pred_class)
447 | )
448 | mean_agreement.append(np.mean(agreement[i]))
449 |
450 | plot.plot_lines(
451 | range(len(stability_iter)),
452 | [mean_agreement, fidelity],
453 | ylim=(0, 1),
454 | xlim=(0, 50),
455 | xlabel="Iteration",
456 | ylabel="Score",
457 | labels=["Mean Agreement", "Fidelity"],
458 | path=f"{output_dir}/{tree_key}_mean_stability.pdf",
459 | )
460 |
461 | plot.plot_heatmap(
462 | np.array([arr[:heatmap_size] for arr in agreement[:heatmap_size]]),
463 | labels=range(min(len(stability_iter), heatmap_size)),
464 | path=f"{output_dir}/{tree_key}_stability_heatmap.pdf",
465 | )
466 |
467 | if is_classify:
468 | top_branch_agreement = {}
469 | for branch in top_branches[:5]:
470 | class_name = class_names[branch["class"]] if class_names is not None else branch["class"]
471 | class_id = class_name if class_name in agreement_by_class else branch["class"]
472 | top_branch_agreement[class_id] = agreement_by_class[class_id]
473 |
474 | for group, group_agreement in top_branch_agreement.items():
475 | plot.plot_heatmap(
476 | np.array(group_agreement[:heatmap_size]),
477 | labels=range(min(len(stability_iter), heatmap_size)),
478 | path=f"{output_dir}/{tree_key}_{class_names[group] if class_names is not None and not isinstance(group, str) else group}_stability_heatmap.pdf",
479 | )
480 |
481 |
482 | def plot_accuracy_by_feature_removed(whitebox_iter, output_dir, feature_names=[]):
483 | """Uses iterative analysis information to plot f1-score from the trained blackbox vs number of features removed"""
484 | if not np.array(whitebox_iter).size:
485 | return
486 |
487 | blackbox_scores = [i["score"] * 100 for i in whitebox_iter]
488 | fidelity = [i["fidelity"] * 100 for i in whitebox_iter]
489 | features = [feature_names[i["feature_removed"]] if feature_names else i["feature_removed"] for i in whitebox_iter]
490 | plot.plot_lines(
491 | features,
492 | [blackbox_scores, fidelity],
493 | ylim=(0, 100),
494 | xlabel="Features removed",
495 | ylabel="Metric (%)",
496 | labels=["Blackbox Score", "DT Fidelity"],
497 | path=f"{output_dir}/accuracy_by_feature_removed.pdf",
498 | )
499 |
500 |
501 | def plot_distribution(X, y, top_branches, output_dir, aggregate=False, feature_names=[], class_names=[]):
502 | if isinstance(X, pd.DataFrame):
503 | X = X.values
504 | if isinstance(y, pd.Series):
505 | y = y.values
506 |
507 | """Plots the distribution of the data based on the top branches"""
508 | if not np.array(X).size or not np.array(y).size or not np.array(top_branches).size:
509 | return
510 |
511 | plots_output_dir = f"{output_dir}/dist" if not aggregate else f"{output_dir}/aggr_dist"
512 | if not os.path.exists(plots_output_dir):
513 | os.makedirs(plots_output_dir)
514 |
515 | colors = [
516 | "#d75d5b",
517 | "#524a47",
518 | "#8a4444",
519 | "#edeef0",
520 | "#c8c5c3",
521 | "#f5f0ed",
522 | "#a7c3cd",
523 | ]
524 |
525 | df = pd.DataFrame(X, columns=feature_names if feature_names else None)
526 | if isinstance(df.columns[0], numbers.Number):
527 | df.columns = [str(i) for i in range(len(df.columns))]
528 |
529 | if aggregate:
530 | col_regex = "([\w_]+)_([0-9]+)"
531 | opt_prefixes = set({})
532 | non_opt_prefixes = set({})
533 | field_size = {}
534 | non_aggr_cols = df.columns # for plotting
535 | for col in df.columns:
536 | match_groups = re.findall(col_regex, col)[0]
537 | prefix = match_groups[0]
538 | bit = int(match_groups[1])
539 | if "opt" in col:
540 | opt_prefixes.add(prefix)
541 | else:
542 | non_opt_prefixes.add(prefix)
543 |
544 | if prefix not in field_size:
545 | field_size[prefix] = bit
546 |
547 | if field_size[prefix] < bit:
548 | field_size[prefix] = bit
549 |
550 | # we need to treat option differently
551 | opt_df = df[[col for col in df.columns if "opt" in col]]
552 | non_opt_df = df[[col for col in df.columns if "opt" not in col]]
553 |
554 | def bin_to_int(num):
555 | try:
556 | return int(num, 2)
557 | except:
558 | return -1
559 |
560 | grouper = [next(p for p in non_opt_prefixes if p in c) for c in non_opt_df.columns]
561 | non_opt_df = non_opt_df.groupby(grouper, axis=1).apply(
562 | lambda x: x.astype(str).apply("".join, axis=1).apply(bin_to_int)
563 | )
564 | df = pd.concat([non_opt_df, opt_df], axis=1)
565 |
566 | df["label"] = y
567 | if class_names is not None and is_numeric_dtype(df["label"]):
568 | df["label"] = df["label"].map(lambda x: class_names[int(x)])
569 |
570 | num_classes = len(np.unique(y))
571 | split_dfs = [x for _, x in df.groupby("label")]
572 |
573 | for idx, branch in enumerate(top_branches):
574 | branch_class = class_names[branch["class"]] if class_names is not None else str(branch["class"])
575 | branch_output_dir = f"{plots_output_dir}/{idx}_branch_{branch_class}"
576 |
577 | if not os.path.exists(branch_output_dir):
578 | os.makedirs(branch_output_dir)
579 |
580 | filtered_dfs = [x.copy(deep=True) for _, x in df.groupby("label")]
581 | for rule_idx, (_, feat, op, thresh) in enumerate(branch["path"]):
582 | if aggregate:
583 | column = non_aggr_cols[int(feat)] if (isinstance(feat, numbers.Number) or feat.isdigit()) else feat
584 | if "opt" not in column:
585 | match_groups = re.findall(col_regex, column)[0]
586 | column = match_groups[0]
587 | bit = match_groups[1]
588 | shift = field_size[column]
589 | thresh = (1 << (shift - int(bit))) - (1 - int(thresh))
590 | else:
591 | column = df.columns[int(feat)] if (isinstance(feat, numbers.Number) or feat.isdigit()) else feat
592 |
593 | plots_per_row = 5
594 | if num_classes > plots_per_row:
595 | n_rows = math.gcd(num_classes, plots_per_row)
596 | n_cols = num_classes if num_classes <= plots_per_row else int(num_classes / n_rows)
597 | else:
598 | n_rows = num_classes
599 | n_cols = 1
600 |
601 | fig, axes = plt.subplots(nrows=n_rows, ncols=n_cols)
602 | axes = axes.flatten()
603 | for df_idx, split_df in enumerate(split_dfs):
604 | df_class = split_df["label"].unique()[0]
605 |
606 | ax = axes[df_idx]
607 | ax.hist(
608 | split_df[column].values,
609 | histtype="bar",
610 | label="All" if df_idx == 0 else None,
611 | color=colors[0],
612 | )
613 | ax.yaxis.set_major_formatter(PercentFormatter(xmax=split_df.shape[0]))
614 | ax.tick_params(axis="both", labelsize=6)
615 | ax.set_title(df_class, fontsize=8)
616 |
617 | tlt = fig.suptitle(f"{column} {op} {thresh:.3f}")
618 | lgd = fig.legend(loc="lower center", bbox_to_anchor=(0.5, -0.05), fancybox=True, ncol=5)
619 | plt.tight_layout()
620 | plt.savefig(
621 | f"{branch_output_dir}/{rule_idx}_{column.replace('/', '_')}_hist_all.pdf",
622 | bbox_extra_artists=(lgd, tlt),
623 | bbox_inches="tight",
624 | )
625 | plt.close()
626 |
627 | fig, axes = plt.subplots(nrows=n_rows, ncols=n_cols)
628 | axes = axes.flatten()
629 | for df_idx, split_df in enumerate(split_dfs):
630 | branch_filter = f"filtered_dfs[{df_idx}]['{column}'] {op} {thresh}"
631 | filtered_dfs[df_idx] = filtered_dfs[df_idx][eval(branch_filter)]
632 | df_class = split_df["label"].unique()[0]
633 |
634 | ax = axes[df_idx]
635 | ax.hist(
636 | filtered_dfs[df_idx][column].values,
637 | histtype="bar",
638 | label=f"Branch ({branch_class.strip()})" if df_idx == 0 else None,
639 | color=colors[-1],
640 | )
641 | ax.yaxis.set_major_formatter(PercentFormatter(xmax=split_df.shape[0]))
642 | ax.tick_params(axis="both", labelsize=6)
643 | ax.set_title(df_class, fontsize=8)
644 |
645 | tlt = fig.suptitle(f"{column} {op} {thresh:.3f}")
646 | lgd = fig.legend(loc="lower center", bbox_to_anchor=(0.5, -0.05), fancybox=True, ncol=5)
647 | plt.tight_layout()
648 | plt.savefig(
649 | f"{branch_output_dir}/{rule_idx}_{column.replace('/', '_')}_hist_branch.pdf",
650 | bbox_extra_artists=(lgd, tlt),
651 | bbox_inches="tight",
652 | )
653 | plt.close()
654 |
655 | fig, axes = plt.subplots(nrows=n_rows, ncols=n_cols)
656 | axes = axes.flatten()
657 | for df_idx, split_df in enumerate(split_dfs):
658 | df_class = split_df["label"].unique()[0]
659 | branch_filter = f"filtered_dfs[{df_idx}]['{column}'] {op} {thresh}"
660 | filtered_dfs[df_idx] = filtered_dfs[df_idx][eval(branch_filter)]
661 |
662 | ax = axes[df_idx]
663 | ax.hist(
664 | split_df[column].values,
665 | histtype="bar",
666 | label="All" if df_idx == 0 else None,
667 | color=colors[0],
668 | )
669 | ax.hist(
670 | filtered_dfs[df_idx][column].values,
671 | histtype="bar",
672 | label=f"Branch ({branch_class.strip()})" if df_idx == 0 else None,
673 | color=colors[-1],
674 | )
675 | ax.yaxis.set_major_formatter(PercentFormatter(xmax=split_df.shape[0]))
676 | ax.tick_params(axis="both", labelsize=6)
677 | ax.set_title(df_class, fontsize=8)
678 |
679 | tlt = fig.suptitle(f"{column} {op} {thresh:.3f}")
680 | lgd = fig.legend(loc="lower center", bbox_to_anchor=(0.5, -0.05), fancybox=True, ncol=5)
681 | plt.tight_layout()
682 | plt.savefig(
683 | f"{branch_output_dir}/{rule_idx}_{column.replace('/', '_')}_hist.pdf",
684 | bbox_extra_artists=(lgd, tlt),
685 | bbox_inches="tight",
686 | )
687 | plt.close()
688 |
--------------------------------------------------------------------------------
/trustee/main.py:
--------------------------------------------------------------------------------
1 | """
2 | Trustee
3 | ====================================
4 | The core module of the Trustee project
5 | """
6 | import abc
7 | import functools
8 | import numpy as np
9 | import pandas as pd
10 |
11 | from copy import deepcopy
12 |
13 |
14 | from sklearn.metrics import f1_score, r2_score
15 | from sklearn.model_selection import train_test_split
16 | from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
17 |
18 | from trustee.utils.tree import get_dt_info, top_k_prune
19 | from trustee.utils.dataset import convert_to_df, convert_to_series
20 |
21 |
22 | def _check_if_trained(func):
23 | """
24 | Checks whether the Trustee is already fitted and self._best_student exists
25 |
26 | Parameters
27 | ----------
28 | func: callable
29 | Function to apply decorator to.
30 | *args: tuple
31 | Additional arguments should be passed as keyword arguments to `func`.
32 | **kwargs: dict, optional
33 | Extra arguments to `func`: refer to each func documentation for a list of all possible arguments.
34 | """
35 |
36 | @functools.wraps(func)
37 | def wrapper(self, *args, **kwargs):
38 | if len(self._top_students) == 0:
39 | raise ValueError("No student models have been trained yet. Please fit() Trustee explainer first.")
40 | return func(self, *args, **kwargs)
41 |
42 | return wrapper
43 |
44 |
45 | class Trustee(abc.ABC):
46 | """
47 | Base implementation the Trust-oriented Decision Tree Extraction (Trustee)
48 | algorithm to train student model based on observations from an Expert model.
49 | """
50 |
51 | def __init__(self, expert, student_class, logger=None):
52 | """
53 | Trustee constructor.
54 |
55 | Parameters
56 | ----------
57 | expert: object
58 | The ML blackbox model to analyze. The expert model must have a `predict` method call implemented for
59 | Trustee to work properly, unless explicitly stated otherwise using the `predict_method_name` argument
60 | in the fit() method.
61 |
62 | student_class: Class
63 | Class of student to train based on blackbox model predictions. The given Class must implement a `fit()
64 | and a `predict()` method interface for Trustee to work properly. The current implementation has been
65 | tested using the DecisionTreeClassifier and DecisionTreeRegressor from scikit-learn.
66 |
67 | logger: Logger object , default=None
68 | A logger object to log messages to. If none is given, the print() method will be used to log messages.
69 | """
70 | self.log = logger.log if logger else print
71 | self.expert = expert
72 | self.student_class = student_class
73 |
74 | self._students_by_iter = []
75 | self._top_students = []
76 | self._stable_students = []
77 |
78 | self._X_train = []
79 | self._X_test = []
80 | self._y_train = []
81 | self._y_test = []
82 |
83 | self._best_student = None
84 | self._features = None
85 | self._nodes = None
86 | self._branches = None
87 |
88 | self._student_use_features: np.array = []
89 |
90 | @abc.abstractmethod
91 | def _score(self, y_true, y_pred):
92 | """
93 | Score function for student models. Compares the ground-truth predictions
94 | of a blackbox model with the predictions of a student model.
95 |
96 | Parameters
97 | ----------
98 | y_true: array-like of shape (n_samples,) or (n_samples, n_outputs)
99 | The ground-truth target values (class labels in classification, real numbers in regression).
100 |
101 | y_pred: array-like of shape (n_samples,) or (n_samples, n_outputs)
102 | The predicted target values (class labels in classification, real numbers in regression).
103 |
104 | Returns
105 | -------
106 | score: float
107 | Calculated student model score.
108 | """
109 |
110 | def fit(
111 | self,
112 | X,
113 | y,
114 | top_k=10,
115 | max_leaf_nodes=None,
116 | max_depth=None,
117 | ccp_alpha=0.0,
118 | train_size=0.7,
119 | num_iter=50,
120 | num_stability_iter=5,
121 | num_samples=2000,
122 | samples_size=None,
123 | use_features=None,
124 | predict_method_name="predict",
125 | optimization="fidelity", # for comparative purposes only
126 | aggregate=True, # for comparative purposes only
127 | verbose=False,
128 | ):
129 | """
130 | Trains Decision Tree Regressor to imitate Expert model.
131 |
132 | Parameters
133 | ----------
134 | X: {array-like, sparse matrix} of shape (n_samples, n_features)
135 | The training input samples. Internally, it will be converted to a pandas DataFrame.
136 |
137 | y: array-like of shape (n_samples,) or (n_samples, n_outputs)
138 | The target values for X (class labels in classification, real numbers in regression).
139 | Internally, it will be converted to a pandas Series.
140 |
141 | top_k: int, default=10
142 | Number of top-k branches, sorted by number of samples per branch, to keep after finding
143 | decision tree with highest fidelity.
144 |
145 | max_leaf_nodes: int, default=None
146 | Grow a tree with max_leaf_nodes in best-first fashion. Best nodes are defined as
147 | relative reduction in impurity. If None then unlimited number of leaf nodes.
148 |
149 | max_depth: int, default=None
150 | The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure.
151 |
152 | ccp_alpha: float, default=0.0
153 | Complexity parameter used for Minimal Cost-Complexity Pruning. The subtree with the
154 | largest cost complexity that is smaller than ccp_alpha will be chosen. By default,
155 | no pruning is performed. See Minimal Cost-Complexity Pruning here for details:
156 | https://scikit-learn.org/stable/modules/tree.html#minimal-cost-complexity-pruning
157 |
158 | train_size: float or int, default=0.7
159 | If float, should be between 0.0 and 1.0 and represent the proportion of the dataset
160 | to include in the train split. If int, represents the absolute number of train samples.
161 |
162 | num_iter: int, default=50
163 | Number of iterations to repeat Trustee inner-loop for.
164 |
165 | num_stability_iter: int, default=5
166 | Number of stability to repeat Trustee stabilization outer-loop for.
167 |
168 | num_samples: int, default=2000
169 | The absolute number of samples to fetch from the training dataset split to train the
170 | student decision tree model. If the `samples_size` argument is provided, this arg is
171 | ignored.
172 |
173 | samples_size: float, default=None
174 | The fraction of the training dataset to use to train the student decision tree model.
175 | If None, the value is automatically set to the `num_samples` provided value.
176 |
177 | use_features: array-like, default=None
178 | Array-like of integers representing the indexes of features from the `X` training samples.
179 | If not None, only the features indicated by the provided indexes will be used to train the
180 | student decision tree model.
181 |
182 | predict_method_name: str, default="predict"
183 | The method interface to use to get predictions from the expert model.
184 | If no value is passed, the default `predict` interface is used.
185 |
186 | optimization: {"fidelity", "accuracy"}, default="fidelity"
187 | The comparison criteria to optimize the decision tree students in Trustee inner-loop.
188 | Used for ablation study only.
189 |
190 | aggregate: bool, default=True
191 | Boolean indicating whether dataset aggregation should be used in Trustee inner-loop.
192 | Used for ablation study only.
193 |
194 | verbose: bool, default=False
195 | Boolean indicating whether to log messages.
196 | """
197 | if verbose:
198 | self.log(f"Initializing training dataset using {self.expert} as expert model")
199 |
200 | if len(X) != len(y):
201 | raise ValueError("Features (X) and target (y) values should have the same length.")
202 |
203 | # convert data to np array to facilitate processing
204 | X = convert_to_df(X)
205 | y = convert_to_series(y)
206 |
207 | self._student_use_features = use_features if use_features is not None else np.arange(0, len(X.columns))
208 |
209 | # split input array to train DTs and evaluate agreement
210 | self._X_train, self._X_test, self._y_train, self._y_test = train_test_split(X, y, train_size=train_size)
211 |
212 | features = self._X_train
213 | targets = convert_to_series(getattr(self.expert, predict_method_name)(self._X_train))
214 |
215 | if hasattr(targets, "shape") and len(targets.shape) >= 2:
216 | targets = targets.ravel()
217 |
218 | student = self.student_class(
219 | random_state=0, max_leaf_nodes=max_leaf_nodes, max_depth=max_depth, ccp_alpha=ccp_alpha
220 | )
221 |
222 | if verbose:
223 | self.log(f"Expert model score: {self._score(self._y_train, targets)}")
224 | self.log(f"Initializing Trustee outer-loop with {num_stability_iter} iterations")
225 |
226 | # Trustee outer-loop
227 | for i in range(num_stability_iter):
228 | self._students_by_iter.append([])
229 | if verbose:
230 | self.log("#" * 10, f"Outer-loop Iteration {i}/{num_stability_iter}", "#" * 10)
231 | self.log(f"Initializing Trustee inner-loop with {num_stability_iter} iterations")
232 |
233 | # Trustee inner-loop
234 | for j in range(num_iter):
235 | if verbose:
236 | self.log("#" * 10, f"Inner-loop Iteration {j}/{num_iter}", "#" * 10)
237 |
238 | dataset_size = len(features)
239 | size = int(int(len(self._X_train)) * samples_size) if samples_size else num_samples
240 | # Step 1: Sample predictions from training dataset
241 | if verbose:
242 | self.log(
243 | f"Sampling {size} points from training dataset with ({len(features)}, {len(targets)}) entries"
244 | )
245 |
246 | samples_idxs = np.random.choice(dataset_size, size=size, replace=False)
247 | X_iter, y_iter = features.iloc[samples_idxs], targets.iloc[samples_idxs]
248 | X_iter_train, X_iter_test, y_iter_train, y_iter_test = train_test_split(
249 | X_iter, y_iter, train_size=train_size
250 | )
251 | X_train_student = X_iter_train.iloc[:, self._student_use_features]
252 | X_test_student = X_iter_test.iloc[:, self._student_use_features]
253 |
254 | # Step 2: Training DecisionTreeRegressor with sampled data
255 | student.fit(X_train_student.values, y_iter_train.values)
256 | student_pred = student.predict(X_test_student.values)
257 |
258 | if verbose:
259 | self.log(
260 | f"Student model {i}-{j} trained with depth {student.get_depth()} "
261 | f"and {student.get_n_leaves()} leaves:"
262 | )
263 | self.log(f"Student model score: {self._score(y_iter_test, student_pred)}")
264 |
265 | # Step 3: Use expert model predictions to aggregate original dataset
266 | expert_pred = pd.Series(getattr(self.expert, predict_method_name)(X_iter_test))
267 | if hasattr(expert_pred, "shape") and len(expert_pred.shape) >= 2:
268 | expert_pred = expert_pred.ravel()
269 |
270 | if aggregate:
271 | features = pd.concat([features, X_iter_test])
272 | targets = pd.concat([targets, expert_pred])
273 |
274 | if optimization == "accuracy":
275 | # Step 4: Calculate reward based on Decision Tree Classifier accuracy
276 | reward = self._score(y_iter_test, student_pred)
277 | else:
278 | # Step 4: Calculate reward based on Decision Tree Classifier fidelity to the Expert model
279 | reward = self._score(expert_pred, student_pred)
280 |
281 | if verbose:
282 | self.log(f"Student model {i}-{j} fidelity: {reward}")
283 |
284 | # Save student to list of iterations dt
285 | self._students_by_iter[i].append((deepcopy(student), reward))
286 |
287 | # Save student with highest fidelity to list of top students by iteration
288 | self._top_students.append(max(self._students_by_iter[i], key=lambda item: item[1]))
289 |
290 | # Get best overall student based on mean agreement
291 | self._best_student = self.explain(top_k=top_k)[0]
292 |
293 | @_check_if_trained
294 | def explain(self, top_k=10):
295 | """
296 | Returns explainable model that best imitates Expert model, based on highest mean agreement and highest fidelity.
297 |
298 | Returns
299 | -------
300 | top_student: tuple
301 | (dt, pruned_dt, agreement, reward)
302 |
303 | - dt: {DecisionTreeClassifier, DecisionTreeRegressor}
304 | Unconstrained fitted student model.
305 |
306 | - pruned_dt: {DecisionTreeClassifier, DecisionTreeRegressor}
307 | Top-k pruned fitted student model.
308 |
309 | - agreement: float
310 | Mean agreement of pruned student model with respect to others.
311 |
312 | - reward: float
313 | Fidelity of student model to the expert model.
314 | """
315 | stable = self.get_stable(top_k=top_k, threshold=0, sort=False)
316 | return max(stable, key=lambda item: item[2])
317 |
318 | @_check_if_trained
319 | def get_stable(self, top_k=10, threshold=0.9, sort=True):
320 | """
321 | Filters out explanations from Trustee stability analysis with less than threshold agreement.
322 |
323 | Parameters
324 | ----------
325 | top_k: int, default=10
326 | Number of top-k branches, sorted by number of samples per branch, to keep after finding
327 | decision tree with highest fidelity.
328 |
329 | threshold: float, default=0.9
330 | Remove any student decision tree explanation if their mean agreement goes below given threshold.
331 | To keep all students regardless of mean agreement, pass 0.
332 |
333 | sort: bool, default=True
334 | Boolean indicating whether to sort returned stable student explanation based on mean agreement.
335 |
336 | Returns
337 | -------
338 | stable_explanations: array-like of tuple
339 | [(dt, pruned_dt, agreement, reward), ...]
340 |
341 | - dt: {DecisionTreeClassifier, DecisionTreeRegressor}
342 | Unconstrained fitted student model.
343 |
344 | - pruned_dt: {DecisionTreeClassifier, DecisionTreeRegressor}
345 | Top-k pruned fitted student model.
346 |
347 | - agreement: float
348 | Mean agreement of pruned student model with respect to others.
349 |
350 | - reward: float
351 | Fidelity of student model to the expert model.
352 | """
353 | if len(self._stable_students) == 0:
354 | agreement = []
355 | # Calculate pair-wise agreement of all top students generated during inner loop
356 | for i, _ in enumerate(self._top_students):
357 | agreement.append([])
358 | # Apply top-k pruning before calculating agreement
359 | base_tree = top_k_prune(self._top_students[i][0], top_k=top_k)
360 | for j, _ in enumerate(self._top_students):
361 | # Apply top-k pruning before calculating agreement
362 | iter_tree = top_k_prune(self._top_students[j][0], top_k=top_k)
363 |
364 | iter_y_pred = iter_tree.predict(self._X_test.iloc[:, self._student_use_features].values)
365 | base_y_pred = base_tree.predict(self._X_test.iloc[:, self._student_use_features].values)
366 |
367 | agreement[i].append(self._score(iter_y_pred, base_y_pred))
368 |
369 | # Save complete dt, top-k prune dt, mean agreement and fidelity
370 | self._stable_students.append(
371 | (
372 | self._top_students[i][0],
373 | base_tree,
374 | np.mean(agreement[i]),
375 | self._top_students[i][1],
376 | )
377 | )
378 |
379 | stable = self._stable_students
380 | if threshold > 0:
381 | stable = filter(lambda item: item[2] >= threshold, stable)
382 |
383 | if sort:
384 | return sorted(stable, key=lambda item: item[2], reverse=True)
385 |
386 | return stable
387 |
388 | @_check_if_trained
389 | def get_all_students(self):
390 | """
391 | Get list of all (student, reward) obtained during the inner-loop process.
392 |
393 | Returns
394 | -------
395 | students_by_iter: array-like of shape (num_stability_iter, num_iter) of tuple (dt, reward)
396 | Matrix with all student models trained during `fit()`.
397 |
398 | - dt: {DecisionTreeClassifier, DecisionTreeRegressor}
399 | Unconstrained fitted student model.
400 |
401 | - reward: float
402 | Fidelity of student model to the expert model.
403 | """
404 | return self._students_by_iter
405 |
406 | @_check_if_trained
407 | def get_top_students(self):
408 | """
409 | Get list of top (students, reward) obtained during the outer-loop process.
410 |
411 | Returns
412 | -------
413 | top_students: array-like of shape (num_stability_iter,) of tuple (dt, reward)
414 | List with top student models trained during `fit()`.
415 |
416 | - dt: {DecisionTreeClassifier, DecisionTreeRegressor}
417 | Unconstrained fitted student model.
418 |
419 | - reward: float
420 | Fidelity of student model to the expert model.
421 | """
422 | return self._top_students
423 |
424 | @_check_if_trained
425 | def get_n_features(self):
426 | """
427 | Returns number of features used in the top student model.
428 |
429 | Returns
430 | -------
431 | n_features: int
432 | Number of features used in top student model.
433 | """
434 | if not self._features:
435 | self._features, self._nodes, self._branches = get_dt_info(self._best_student)
436 |
437 | return len(self._features.keys())
438 |
439 | @_check_if_trained
440 | def get_n_classes(self):
441 | """
442 | Returns number of classes used in the top student model.
443 |
444 | Returns
445 | -------
446 | n_classes: int
447 | Number of classes outputted in top student model.
448 | """
449 | return self._best_student.tree_.n_classes[0]
450 |
451 | @_check_if_trained
452 | def get_samples_sum(self):
453 | """
454 | Get the sum of all samples in all non-leaf _nodes in best student model.
455 |
456 | Returns
457 | -------
458 | samples_sum: int
459 | Sum of all samples covered by non-leaf nodes in top student model.
460 | """
461 | left = self._best_student.tree_.children_left
462 | right = self._best_student.tree_.children_right
463 | samples = self._best_student.tree_.n_node_samples
464 |
465 | return np.sum([n_samples if left[node] != right[node] else 0 for node, n_samples in enumerate(samples)])
466 |
467 | @_check_if_trained
468 | def get_top_branches(self, top_k=10):
469 | """
470 | Returns list of top-k _branches of the best student, sorted by the number of samples the branch classifies.
471 |
472 | Parameters
473 | ----------
474 | top_k: int, default=10
475 | Number of top-k branches, sorted by number of samples per branch, to return.
476 |
477 | Returns
478 | -------
479 | top_branches: array-like of dict
480 | Dict of top-k branches from top student model.
481 |
482 | - dict: { "level": int, "path": array-like of dict, "class": int, "prob": float, "samples": int}
483 | """
484 | if not self._branches:
485 | self._features, self._nodes, self._branches = get_dt_info(self._best_student)
486 |
487 | return sorted(self._branches, key=lambda p: p["samples"], reverse=True)[:top_k]
488 |
489 | @_check_if_trained
490 | def get_top_features(self, top_k=10):
491 | """
492 | Get list of top _features of the best student, sorted by the number of samples the feature is used to classify.
493 |
494 | Parameters
495 | ----------
496 | top_k: int, default=10
497 | Number of top-k features, sorted by number of samples per branch, to return.
498 |
499 |
500 | Returns
501 | -------
502 | top_features: array-like of dict
503 | List of top-k features from top student model.
504 |
505 | - dict {"(int)" : {"count": int"samples": int}}
506 | """
507 | if not self._features:
508 | self._features, self._nodes, self._branches = get_dt_info(self._best_student)
509 |
510 | return sorted(self._features.items(), key=lambda p: p[1]["samples"], reverse=True)[:top_k]
511 |
512 | @_check_if_trained
513 | def get_top_nodes(self, top_k=10):
514 | """
515 | Returns list of top _nodes of the best student, sorted by the proportion of samples split by each node.
516 |
517 | The proportion of samples is calculated based on the impurity decrease equation is the following::
518 | n_samples * abs(left_impurity - right_impurity)
519 |
520 | Parameters
521 | ----------
522 | top_k: int, default=10
523 | Number of top-k nodes, sorted by number of samples per branch, to return.
524 |
525 | Returns
526 | -------
527 | top_nodes: array-like of dict
528 | List of top-k nodes from top student model.
529 |
530 | - dict: {"idx": int, "level": int, "feature": int, "threshold": float, "samples": int,
531 | "values": tuple of int, "gini_split": tuple of float, "data_split": tuple of float,
532 | "data_split_by_class": array-like of tuple of float}
533 | """
534 | if not self._nodes:
535 | self._features, self._nodes, self._branches = get_dt_info(self._best_student)
536 |
537 | return sorted(
538 | self._nodes, key=lambda p: p["samples"] * abs(p["gini_split"][0] - p["gini_split"][1]), reverse=True
539 | )[:top_k]
540 |
541 | @_check_if_trained
542 | def get_samples_by_level(self):
543 | """
544 | Get number of samples by level of the best student.
545 |
546 | Returns
547 | -------
548 | samples_by_level: dict of int
549 | Dict of samples by level. {"(int)": (int)}
550 | """
551 | if not self._nodes:
552 | self._features, self._nodes, self._branches = get_dt_info(self._best_student)
553 |
554 | samples_by_level = list(np.zeros(self._best_student.get_depth() + 1))
555 | for node in self._nodes:
556 | samples_by_level[node["level"]] += node["samples"]
557 |
558 | for node in self._branches:
559 | samples_by_level[node["level"]] += node["samples"]
560 |
561 | return samples_by_level
562 |
563 | @_check_if_trained
564 | def get_leaves_by_level(self):
565 | """
566 | Returns number of leaves by level of the best student.
567 |
568 | Returns
569 | -------
570 | leaves_by_level: dict of int
571 | Dict of leaves by level. {"(int)": (int)}
572 | """
573 | if not self._branches:
574 | self._features, self._nodes, self._branches = get_dt_info(self._best_student)
575 |
576 | leaves_by_level = list(np.zeros(self._best_student.get_depth() + 1).astype(int))
577 | for node in self._branches:
578 | leaves_by_level[node["level"]] += 1
579 |
580 | return leaves_by_level
581 |
582 | @_check_if_trained
583 | def prune(self, top_k=10, max_impurity=0.10):
584 | """
585 | Prunes and returns the best student model explanation from the list of _students_by_iter.
586 |
587 | Parameters
588 | ----------
589 | top_k: int, default=10
590 | Number of top-k branches, sorted by number of samples per branch, to return.
591 |
592 | max_impurity: float, default=0.10
593 | Maximum impurity allowed in a branch. Will prune anything below that impurity level.
594 |
595 | Returns
596 | -------
597 | top_k_pruned_student: {DecisionTreeClassifier, DecisionTreeRegressor}
598 | Top-k pruned best fitted student model.
599 | """
600 | return top_k_prune(self._best_student, top_k=top_k, max_impurity=max_impurity)
601 |
602 |
603 | class ClassificationTrustee(Trustee):
604 | """
605 | Implements the Trust-oriented Decision Tree Extraction (Trustee) algorithm to train
606 | a student DecisionTreeClassifier based on observations from an Expert classification model.
607 | """
608 |
609 | def __init__(self, expert, logger=None):
610 | """
611 | Classification Trustee constructor
612 |
613 | Parameters
614 | ----------
615 | expert: object
616 | The ML blackbox model to analyze. The expert model must have a `predict` method call implemented for
617 | Trustee to work properly, unless explicitly stated otherwise using the `predict_method_name` argument
618 | in the fit() method.
619 | logger: Logger object , default=None
620 | A logger object to log messages to. If none is given, the print() method will be used to log messages.
621 | """
622 | super().__init__(expert, student_class=DecisionTreeClassifier, logger=logger)
623 |
624 | def _score(self, y_true, y_pred, average="macro"):
625 | """
626 | Score function for student models. Compares the ground-truth predictions
627 | of a blackbox model with the predictions of a student model, using F1-score.
628 |
629 | Parameters
630 | ----------
631 | y_true: array-like of shape (n_samples,) or (n_samples, n_outputs)
632 | The ground-truth target values (class labels in classification, real numbers in regression).
633 |
634 | y_pred: array-like of shape (n_samples,) or (n_samples, n_outputs)
635 | The predicted target values (class labels in classification, real numbers in regression).
636 |
637 | Returns
638 | -------
639 | score: float
640 | Calculated F1-score between student model predictions and expert model ground-truth.
641 | """
642 | return f1_score(y_true, y_pred, average=average)
643 |
644 |
645 | class RegressionTrustee(Trustee):
646 | """
647 | Implements the Trust-oriented Decision Tree Extraction (Trustee) algorithm to train a
648 | student DecisionTreeRegressor based on observations from an Expert regression model.
649 | """
650 |
651 | def __init__(self, expert, logger=None):
652 | """
653 | Regression Trustee constructor
654 |
655 | Parameters
656 | ----------
657 | expert: object
658 | The ML blackbox model to analyze. The expert model must have a `predict` method call implemented for
659 | Trustee to work properly, unless explicitly stated otherwise using the `predict_method_name` argument
660 | in the fit() method.
661 | logger: Logger object , default=None
662 | A logger object to log messages to. If none is given, the print() method will be used to log messages.
663 | """
664 | super().__init__(expert=expert, student_class=DecisionTreeRegressor, logger=logger)
665 |
666 | def _score(self, y_true, y_pred):
667 | """
668 | Score function for student models. Compares the ground-truth predictions
669 | of a blackbox model with the predictions of a student model, using R2-score.
670 |
671 | Parameters
672 | ----------
673 | y_true: array-like of shape (n_samples,) or (n_samples, n_outputs)
674 | The ground-truth target values (class labels in classification, real numbers in regression).
675 |
676 | y_pred: array-like of shape (n_samples,) or (n_samples, n_outputs)
677 | The predicted target values (class labels in classification, real numbers in regression).
678 |
679 | Returns
680 | -------
681 | score: float
682 | Calculated R2-score between student model predictions and expert model ground-truth.
683 | """
684 | return r2_score(y_true, y_pred)
685 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | GNU GENERAL PUBLIC LICENSE
2 | Version 3, 29 June 2007
3 |
4 | Copyright (C) 2007 Free Software Foundation, Inc.
5 | Everyone is permitted to copy and distribute verbatim copies
6 | of this license document, but changing it is not allowed.
7 |
8 | Preamble
9 |
10 | The GNU General Public License is a free, copyleft license for
11 | software and other kinds of works.
12 |
13 | The licenses for most software and other practical works are designed
14 | to take away your freedom to share and change the works. By contrast,
15 | the GNU General Public License is intended to guarantee your freedom to
16 | share and change all versions of a program--to make sure it remains free
17 | software for all its users. We, the Free Software Foundation, use the
18 | GNU General Public License for most of our software; it applies also to
19 | any other work released this way by its authors. You can apply it to
20 | your programs, too.
21 |
22 | When we speak of free software, we are referring to freedom, not
23 | price. Our General Public Licenses are designed to make sure that you
24 | have the freedom to distribute copies of free software (and charge for
25 | them if you wish), that you receive source code or can get it if you
26 | want it, that you can change the software or use pieces of it in new
27 | free programs, and that you know you can do these things.
28 |
29 | To protect your rights, we need to prevent others from denying you
30 | these rights or asking you to surrender the rights. Therefore, you have
31 | certain responsibilities if you distribute copies of the software, or if
32 | you modify it: responsibilities to respect the freedom of others.
33 |
34 | For example, if you distribute copies of such a program, whether
35 | gratis or for a fee, you must pass on to the recipients the same
36 | freedoms that you received. You must make sure that they, too, receive
37 | or can get the source code. And you must show them these terms so they
38 | know their rights.
39 |
40 | Developers that use the GNU GPL protect your rights with two steps:
41 | (1) assert copyright on the software, and (2) offer you this License
42 | giving you legal permission to copy, distribute and/or modify it.
43 |
44 | For the developers' and authors' protection, the GPL clearly explains
45 | that there is no warranty for this free software. For both users' and
46 | authors' sake, the GPL requires that modified versions be marked as
47 | changed, so that their problems will not be attributed erroneously to
48 | authors of previous versions.
49 |
50 | Some devices are designed to deny users access to install or run
51 | modified versions of the software inside them, although the manufacturer
52 | can do so. This is fundamentally incompatible with the aim of
53 | protecting users' freedom to change the software. The systematic
54 | pattern of such abuse occurs in the area of products for individuals to
55 | use, which is precisely where it is most unacceptable. Therefore, we
56 | have designed this version of the GPL to prohibit the practice for those
57 | products. If such problems arise substantially in other domains, we
58 | stand ready to extend this provision to those domains in future versions
59 | of the GPL, as needed to protect the freedom of users.
60 |
61 | Finally, every program is threatened constantly by software patents.
62 | States should not allow patents to restrict development and use of
63 | software on general-purpose computers, but in those that do, we wish to
64 | avoid the special danger that patents applied to a free program could
65 | make it effectively proprietary. To prevent this, the GPL assures that
66 | patents cannot be used to render the program non-free.
67 |
68 | The precise terms and conditions for copying, distribution and
69 | modification follow.
70 |
71 | TERMS AND CONDITIONS
72 |
73 | 0. Definitions.
74 |
75 | "This License" refers to version 3 of the GNU General Public License.
76 |
77 | "Copyright" also means copyright-like laws that apply to other kinds of
78 | works, such as semiconductor masks.
79 |
80 | "The Program" refers to any copyrightable work licensed under this
81 | License. Each licensee is addressed as "you". "Licensees" and
82 | "recipients" may be individuals or organizations.
83 |
84 | To "modify" a work means to copy from or adapt all or part of the work
85 | in a fashion requiring copyright permission, other than the making of an
86 | exact copy. The resulting work is called a "modified version" of the
87 | earlier work or a work "based on" the earlier work.
88 |
89 | A "covered work" means either the unmodified Program or a work based
90 | on the Program.
91 |
92 | To "propagate" a work means to do anything with it that, without
93 | permission, would make you directly or secondarily liable for
94 | infringement under applicable copyright law, except executing it on a
95 | computer or modifying a private copy. Propagation includes copying,
96 | distribution (with or without modification), making available to the
97 | public, and in some countries other activities as well.
98 |
99 | To "convey" a work means any kind of propagation that enables other
100 | parties to make or receive copies. Mere interaction with a user through
101 | a computer network, with no transfer of a copy, is not conveying.
102 |
103 | An interactive user interface displays "Appropriate Legal Notices"
104 | to the extent that it includes a convenient and prominently visible
105 | feature that (1) displays an appropriate copyright notice, and (2)
106 | tells the user that there is no warranty for the work (except to the
107 | extent that warranties are provided), that licensees may convey the
108 | work under this License, and how to view a copy of this License. If
109 | the interface presents a list of user commands or options, such as a
110 | menu, a prominent item in the list meets this criterion.
111 |
112 | 1. Source Code.
113 |
114 | The "source code" for a work means the preferred form of the work
115 | for making modifications to it. "Object code" means any non-source
116 | form of a work.
117 |
118 | A "Standard Interface" means an interface that either is an official
119 | standard defined by a recognized standards body, or, in the case of
120 | interfaces specified for a particular programming language, one that
121 | is widely used among developers working in that language.
122 |
123 | The "System Libraries" of an executable work include anything, other
124 | than the work as a whole, that (a) is included in the normal form of
125 | packaging a Major Component, but which is not part of that Major
126 | Component, and (b) serves only to enable use of the work with that
127 | Major Component, or to implement a Standard Interface for which an
128 | implementation is available to the public in source code form. A
129 | "Major Component", in this context, means a major essential component
130 | (kernel, window system, and so on) of the specific operating system
131 | (if any) on which the executable work runs, or a compiler used to
132 | produce the work, or an object code interpreter used to run it.
133 |
134 | The "Corresponding Source" for a work in object code form means all
135 | the source code needed to generate, install, and (for an executable
136 | work) run the object code and to modify the work, including scripts to
137 | control those activities. However, it does not include the work's
138 | System Libraries, or general-purpose tools or generally available free
139 | programs which are used unmodified in performing those activities but
140 | which are not part of the work. For example, Corresponding Source
141 | includes interface definition files associated with source files for
142 | the work, and the source code for shared libraries and dynamically
143 | linked subprograms that the work is specifically designed to require,
144 | such as by intimate data communication or control flow between those
145 | subprograms and other parts of the work.
146 |
147 | The Corresponding Source need not include anything that users
148 | can regenerate automatically from other parts of the Corresponding
149 | Source.
150 |
151 | The Corresponding Source for a work in source code form is that
152 | same work.
153 |
154 | 2. Basic Permissions.
155 |
156 | All rights granted under this License are granted for the term of
157 | copyright on the Program, and are irrevocable provided the stated
158 | conditions are met. This License explicitly affirms your unlimited
159 | permission to run the unmodified Program. The output from running a
160 | covered work is covered by this License only if the output, given its
161 | content, constitutes a covered work. This License acknowledges your
162 | rights of fair use or other equivalent, as provided by copyright law.
163 |
164 | You may make, run and propagate covered works that you do not
165 | convey, without conditions so long as your license otherwise remains
166 | in force. You may convey covered works to others for the sole purpose
167 | of having them make modifications exclusively for you, or provide you
168 | with facilities for running those works, provided that you comply with
169 | the terms of this License in conveying all material for which you do
170 | not control copyright. Those thus making or running the covered works
171 | for you must do so exclusively on your behalf, under your direction
172 | and control, on terms that prohibit them from making any copies of
173 | your copyrighted material outside their relationship with you.
174 |
175 | Conveying under any other circumstances is permitted solely under
176 | the conditions stated below. Sublicensing is not allowed; section 10
177 | makes it unnecessary.
178 |
179 | 3. Protecting Users' Legal Rights From Anti-Circumvention Law.
180 |
181 | No covered work shall be deemed part of an effective technological
182 | measure under any applicable law fulfilling obligations under article
183 | 11 of the WIPO copyright treaty adopted on 20 December 1996, or
184 | similar laws prohibiting or restricting circumvention of such
185 | measures.
186 |
187 | When you convey a covered work, you waive any legal power to forbid
188 | circumvention of technological measures to the extent such circumvention
189 | is effected by exercising rights under this License with respect to
190 | the covered work, and you disclaim any intention to limit operation or
191 | modification of the work as a means of enforcing, against the work's
192 | users, your or third parties' legal rights to forbid circumvention of
193 | technological measures.
194 |
195 | 4. Conveying Verbatim Copies.
196 |
197 | You may convey verbatim copies of the Program's source code as you
198 | receive it, in any medium, provided that you conspicuously and
199 | appropriately publish on each copy an appropriate copyright notice;
200 | keep intact all notices stating that this License and any
201 | non-permissive terms added in accord with section 7 apply to the code;
202 | keep intact all notices of the absence of any warranty; and give all
203 | recipients a copy of this License along with the Program.
204 |
205 | You may charge any price or no price for each copy that you convey,
206 | and you may offer support or warranty protection for a fee.
207 |
208 | 5. Conveying Modified Source Versions.
209 |
210 | You may convey a work based on the Program, or the modifications to
211 | produce it from the Program, in the form of source code under the
212 | terms of section 4, provided that you also meet all of these conditions:
213 |
214 | a) The work must carry prominent notices stating that you modified
215 | it, and giving a relevant date.
216 |
217 | b) The work must carry prominent notices stating that it is
218 | released under this License and any conditions added under section
219 | 7. This requirement modifies the requirement in section 4 to
220 | "keep intact all notices".
221 |
222 | c) You must license the entire work, as a whole, under this
223 | License to anyone who comes into possession of a copy. This
224 | License will therefore apply, along with any applicable section 7
225 | additional terms, to the whole of the work, and all its parts,
226 | regardless of how they are packaged. This License gives no
227 | permission to license the work in any other way, but it does not
228 | invalidate such permission if you have separately received it.
229 |
230 | d) If the work has interactive user interfaces, each must display
231 | Appropriate Legal Notices; however, if the Program has interactive
232 | interfaces that do not display Appropriate Legal Notices, your
233 | work need not make them do so.
234 |
235 | A compilation of a covered work with other separate and independent
236 | works, which are not by their nature extensions of the covered work,
237 | and which are not combined with it such as to form a larger program,
238 | in or on a volume of a storage or distribution medium, is called an
239 | "aggregate" if the compilation and its resulting copyright are not
240 | used to limit the access or legal rights of the compilation's users
241 | beyond what the individual works permit. Inclusion of a covered work
242 | in an aggregate does not cause this License to apply to the other
243 | parts of the aggregate.
244 |
245 | 6. Conveying Non-Source Forms.
246 |
247 | You may convey a covered work in object code form under the terms
248 | of sections 4 and 5, provided that you also convey the
249 | machine-readable Corresponding Source under the terms of this License,
250 | in one of these ways:
251 |
252 | a) Convey the object code in, or embodied in, a physical product
253 | (including a physical distribution medium), accompanied by the
254 | Corresponding Source fixed on a durable physical medium
255 | customarily used for software interchange.
256 |
257 | b) Convey the object code in, or embodied in, a physical product
258 | (including a physical distribution medium), accompanied by a
259 | written offer, valid for at least three years and valid for as
260 | long as you offer spare parts or customer support for that product
261 | model, to give anyone who possesses the object code either (1) a
262 | copy of the Corresponding Source for all the software in the
263 | product that is covered by this License, on a durable physical
264 | medium customarily used for software interchange, for a price no
265 | more than your reasonable cost of physically performing this
266 | conveying of source, or (2) access to copy the
267 | Corresponding Source from a network server at no charge.
268 |
269 | c) Convey individual copies of the object code with a copy of the
270 | written offer to provide the Corresponding Source. This
271 | alternative is allowed only occasionally and noncommercially, and
272 | only if you received the object code with such an offer, in accord
273 | with subsection 6b.
274 |
275 | d) Convey the object code by offering access from a designated
276 | place (gratis or for a charge), and offer equivalent access to the
277 | Corresponding Source in the same way through the same place at no
278 | further charge. You need not require recipients to copy the
279 | Corresponding Source along with the object code. If the place to
280 | copy the object code is a network server, the Corresponding Source
281 | may be on a different server (operated by you or a third party)
282 | that supports equivalent copying facilities, provided you maintain
283 | clear directions next to the object code saying where to find the
284 | Corresponding Source. Regardless of what server hosts the
285 | Corresponding Source, you remain obligated to ensure that it is
286 | available for as long as needed to satisfy these requirements.
287 |
288 | e) Convey the object code using peer-to-peer transmission, provided
289 | you inform other peers where the object code and Corresponding
290 | Source of the work are being offered to the general public at no
291 | charge under subsection 6d.
292 |
293 | A separable portion of the object code, whose source code is excluded
294 | from the Corresponding Source as a System Library, need not be
295 | included in conveying the object code work.
296 |
297 | A "User Product" is either (1) a "consumer product", which means any
298 | tangible personal property which is normally used for personal, family,
299 | or household purposes, or (2) anything designed or sold for incorporation
300 | into a dwelling. In determining whether a product is a consumer product,
301 | doubtful cases shall be resolved in favor of coverage. For a particular
302 | product received by a particular user, "normally used" refers to a
303 | typical or common use of that class of product, regardless of the status
304 | of the particular user or of the way in which the particular user
305 | actually uses, or expects or is expected to use, the product. A product
306 | is a consumer product regardless of whether the product has substantial
307 | commercial, industrial or non-consumer uses, unless such uses represent
308 | the only significant mode of use of the product.
309 |
310 | "Installation Information" for a User Product means any methods,
311 | procedures, authorization keys, or other information required to install
312 | and execute modified versions of a covered work in that User Product from
313 | a modified version of its Corresponding Source. The information must
314 | suffice to ensure that the continued functioning of the modified object
315 | code is in no case prevented or interfered with solely because
316 | modification has been made.
317 |
318 | If you convey an object code work under this section in, or with, or
319 | specifically for use in, a User Product, and the conveying occurs as
320 | part of a transaction in which the right of possession and use of the
321 | User Product is transferred to the recipient in perpetuity or for a
322 | fixed term (regardless of how the transaction is characterized), the
323 | Corresponding Source conveyed under this section must be accompanied
324 | by the Installation Information. But this requirement does not apply
325 | if neither you nor any third party retains the ability to install
326 | modified object code on the User Product (for example, the work has
327 | been installed in ROM).
328 |
329 | The requirement to provide Installation Information does not include a
330 | requirement to continue to provide support service, warranty, or updates
331 | for a work that has been modified or installed by the recipient, or for
332 | the User Product in which it has been modified or installed. Access to a
333 | network may be denied when the modification itself materially and
334 | adversely affects the operation of the network or violates the rules and
335 | protocols for communication across the network.
336 |
337 | Corresponding Source conveyed, and Installation Information provided,
338 | in accord with this section must be in a format that is publicly
339 | documented (and with an implementation available to the public in
340 | source code form), and must require no special password or key for
341 | unpacking, reading or copying.
342 |
343 | 7. Additional Terms.
344 |
345 | "Additional permissions" are terms that supplement the terms of this
346 | License by making exceptions from one or more of its conditions.
347 | Additional permissions that are applicable to the entire Program shall
348 | be treated as though they were included in this License, to the extent
349 | that they are valid under applicable law. If additional permissions
350 | apply only to part of the Program, that part may be used separately
351 | under those permissions, but the entire Program remains governed by
352 | this License without regard to the additional permissions.
353 |
354 | When you convey a copy of a covered work, you may at your option
355 | remove any additional permissions from that copy, or from any part of
356 | it. (Additional permissions may be written to require their own
357 | removal in certain cases when you modify the work.) You may place
358 | additional permissions on material, added by you to a covered work,
359 | for which you have or can give appropriate copyright permission.
360 |
361 | Notwithstanding any other provision of this License, for material you
362 | add to a covered work, you may (if authorized by the copyright holders of
363 | that material) supplement the terms of this License with terms:
364 |
365 | a) Disclaiming warranty or limiting liability differently from the
366 | terms of sections 15 and 16 of this License; or
367 |
368 | b) Requiring preservation of specified reasonable legal notices or
369 | author attributions in that material or in the Appropriate Legal
370 | Notices displayed by works containing it; or
371 |
372 | c) Prohibiting misrepresentation of the origin of that material, or
373 | requiring that modified versions of such material be marked in
374 | reasonable ways as different from the original version; or
375 |
376 | d) Limiting the use for publicity purposes of names of licensors or
377 | authors of the material; or
378 |
379 | e) Declining to grant rights under trademark law for use of some
380 | trade names, trademarks, or service marks; or
381 |
382 | f) Requiring indemnification of licensors and authors of that
383 | material by anyone who conveys the material (or modified versions of
384 | it) with contractual assumptions of liability to the recipient, for
385 | any liability that these contractual assumptions directly impose on
386 | those licensors and authors.
387 |
388 | All other non-permissive additional terms are considered "further
389 | restrictions" within the meaning of section 10. If the Program as you
390 | received it, or any part of it, contains a notice stating that it is
391 | governed by this License along with a term that is a further
392 | restriction, you may remove that term. If a license document contains
393 | a further restriction but permits relicensing or conveying under this
394 | License, you may add to a covered work material governed by the terms
395 | of that license document, provided that the further restriction does
396 | not survive such relicensing or conveying.
397 |
398 | If you add terms to a covered work in accord with this section, you
399 | must place, in the relevant source files, a statement of the
400 | additional terms that apply to those files, or a notice indicating
401 | where to find the applicable terms.
402 |
403 | Additional terms, permissive or non-permissive, may be stated in the
404 | form of a separately written license, or stated as exceptions;
405 | the above requirements apply either way.
406 |
407 | 8. Termination.
408 |
409 | You may not propagate or modify a covered work except as expressly
410 | provided under this License. Any attempt otherwise to propagate or
411 | modify it is void, and will automatically terminate your rights under
412 | this License (including any patent licenses granted under the third
413 | paragraph of section 11).
414 |
415 | However, if you cease all violation of this License, then your
416 | license from a particular copyright holder is reinstated (a)
417 | provisionally, unless and until the copyright holder explicitly and
418 | finally terminates your license, and (b) permanently, if the copyright
419 | holder fails to notify you of the violation by some reasonable means
420 | prior to 60 days after the cessation.
421 |
422 | Moreover, your license from a particular copyright holder is
423 | reinstated permanently if the copyright holder notifies you of the
424 | violation by some reasonable means, this is the first time you have
425 | received notice of violation of this License (for any work) from that
426 | copyright holder, and you cure the violation prior to 30 days after
427 | your receipt of the notice.
428 |
429 | Termination of your rights under this section does not terminate the
430 | licenses of parties who have received copies or rights from you under
431 | this License. If your rights have been terminated and not permanently
432 | reinstated, you do not qualify to receive new licenses for the same
433 | material under section 10.
434 |
435 | 9. Acceptance Not Required for Having Copies.
436 |
437 | You are not required to accept this License in order to receive or
438 | run a copy of the Program. Ancillary propagation of a covered work
439 | occurring solely as a consequence of using peer-to-peer transmission
440 | to receive a copy likewise does not require acceptance. However,
441 | nothing other than this License grants you permission to propagate or
442 | modify any covered work. These actions infringe copyright if you do
443 | not accept this License. Therefore, by modifying or propagating a
444 | covered work, you indicate your acceptance of this License to do so.
445 |
446 | 10. Automatic Licensing of Downstream Recipients.
447 |
448 | Each time you convey a covered work, the recipient automatically
449 | receives a license from the original licensors, to run, modify and
450 | propagate that work, subject to this License. You are not responsible
451 | for enforcing compliance by third parties with this License.
452 |
453 | An "entity transaction" is a transaction transferring control of an
454 | organization, or substantially all assets of one, or subdividing an
455 | organization, or merging organizations. If propagation of a covered
456 | work results from an entity transaction, each party to that
457 | transaction who receives a copy of the work also receives whatever
458 | licenses to the work the party's predecessor in interest had or could
459 | give under the previous paragraph, plus a right to possession of the
460 | Corresponding Source of the work from the predecessor in interest, if
461 | the predecessor has it or can get it with reasonable efforts.
462 |
463 | You may not impose any further restrictions on the exercise of the
464 | rights granted or affirmed under this License. For example, you may
465 | not impose a license fee, royalty, or other charge for exercise of
466 | rights granted under this License, and you may not initiate litigation
467 | (including a cross-claim or counterclaim in a lawsuit) alleging that
468 | any patent claim is infringed by making, using, selling, offering for
469 | sale, or importing the Program or any portion of it.
470 |
471 | 11. Patents.
472 |
473 | A "contributor" is a copyright holder who authorizes use under this
474 | License of the Program or a work on which the Program is based. The
475 | work thus licensed is called the contributor's "contributor version".
476 |
477 | A contributor's "essential patent claims" are all patent claims
478 | owned or controlled by the contributor, whether already acquired or
479 | hereafter acquired, that would be infringed by some manner, permitted
480 | by this License, of making, using, or selling its contributor version,
481 | but do not include claims that would be infringed only as a
482 | consequence of further modification of the contributor version. For
483 | purposes of this definition, "control" includes the right to grant
484 | patent sublicenses in a manner consistent with the requirements of
485 | this License.
486 |
487 | Each contributor grants you a non-exclusive, worldwide, royalty-free
488 | patent license under the contributor's essential patent claims, to
489 | make, use, sell, offer for sale, import and otherwise run, modify and
490 | propagate the contents of its contributor version.
491 |
492 | In the following three paragraphs, a "patent license" is any express
493 | agreement or commitment, however denominated, not to enforce a patent
494 | (such as an express permission to practice a patent or covenant not to
495 | sue for patent infringement). To "grant" such a patent license to a
496 | party means to make such an agreement or commitment not to enforce a
497 | patent against the party.
498 |
499 | If you convey a covered work, knowingly relying on a patent license,
500 | and the Corresponding Source of the work is not available for anyone
501 | to copy, free of charge and under the terms of this License, through a
502 | publicly available network server or other readily accessible means,
503 | then you must either (1) cause the Corresponding Source to be so
504 | available, or (2) arrange to deprive yourself of the benefit of the
505 | patent license for this particular work, or (3) arrange, in a manner
506 | consistent with the requirements of this License, to extend the patent
507 | license to downstream recipients. "Knowingly relying" means you have
508 | actual knowledge that, but for the patent license, your conveying the
509 | covered work in a country, or your recipient's use of the covered work
510 | in a country, would infringe one or more identifiable patents in that
511 | country that you have reason to believe are valid.
512 |
513 | If, pursuant to or in connection with a single transaction or
514 | arrangement, you convey, or propagate by procuring conveyance of, a
515 | covered work, and grant a patent license to some of the parties
516 | receiving the covered work authorizing them to use, propagate, modify
517 | or convey a specific copy of the covered work, then the patent license
518 | you grant is automatically extended to all recipients of the covered
519 | work and works based on it.
520 |
521 | A patent license is "discriminatory" if it does not include within
522 | the scope of its coverage, prohibits the exercise of, or is
523 | conditioned on the non-exercise of one or more of the rights that are
524 | specifically granted under this License. You may not convey a covered
525 | work if you are a party to an arrangement with a third party that is
526 | in the business of distributing software, under which you make payment
527 | to the third party based on the extent of your activity of conveying
528 | the work, and under which the third party grants, to any of the
529 | parties who would receive the covered work from you, a discriminatory
530 | patent license (a) in connection with copies of the covered work
531 | conveyed by you (or copies made from those copies), or (b) primarily
532 | for and in connection with specific products or compilations that
533 | contain the covered work, unless you entered into that arrangement,
534 | or that patent license was granted, prior to 28 March 2007.
535 |
536 | Nothing in this License shall be construed as excluding or limiting
537 | any implied license or other defenses to infringement that may
538 | otherwise be available to you under applicable patent law.
539 |
540 | 12. No Surrender of Others' Freedom.
541 |
542 | If conditions are imposed on you (whether by court order, agreement or
543 | otherwise) that contradict the conditions of this License, they do not
544 | excuse you from the conditions of this License. If you cannot convey a
545 | covered work so as to satisfy simultaneously your obligations under this
546 | License and any other pertinent obligations, then as a consequence you may
547 | not convey it at all. For example, if you agree to terms that obligate you
548 | to collect a royalty for further conveying from those to whom you convey
549 | the Program, the only way you could satisfy both those terms and this
550 | License would be to refrain entirely from conveying the Program.
551 |
552 | 13. Use with the GNU Affero General Public License.
553 |
554 | Notwithstanding any other provision of this License, you have
555 | permission to link or combine any covered work with a work licensed
556 | under version 3 of the GNU Affero General Public License into a single
557 | combined work, and to convey the resulting work. The terms of this
558 | License will continue to apply to the part which is the covered work,
559 | but the special requirements of the GNU Affero General Public License,
560 | section 13, concerning interaction through a network will apply to the
561 | combination as such.
562 |
563 | 14. Revised Versions of this License.
564 |
565 | The Free Software Foundation may publish revised and/or new versions of
566 | the GNU General Public License from time to time. Such new versions will
567 | be similar in spirit to the present version, but may differ in detail to
568 | address new problems or concerns.
569 |
570 | Each version is given a distinguishing version number. If the
571 | Program specifies that a certain numbered version of the GNU General
572 | Public License "or any later version" applies to it, you have the
573 | option of following the terms and conditions either of that numbered
574 | version or of any later version published by the Free Software
575 | Foundation. If the Program does not specify a version number of the
576 | GNU General Public License, you may choose any version ever published
577 | by the Free Software Foundation.
578 |
579 | If the Program specifies that a proxy can decide which future
580 | versions of the GNU General Public License can be used, that proxy's
581 | public statement of acceptance of a version permanently authorizes you
582 | to choose that version for the Program.
583 |
584 | Later license versions may give you additional or different
585 | permissions. However, no additional obligations are imposed on any
586 | author or copyright holder as a result of your choosing to follow a
587 | later version.
588 |
589 | 15. Disclaimer of Warranty.
590 |
591 | THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
592 | APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
593 | HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
594 | OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
595 | THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
596 | PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
597 | IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
598 | ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
599 |
600 | 16. Limitation of Liability.
601 |
602 | IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
603 | WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
604 | THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
605 | GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
606 | USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
607 | DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
608 | PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
609 | EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
610 | SUCH DAMAGES.
611 |
612 | 17. Interpretation of Sections 15 and 16.
613 |
614 | If the disclaimer of warranty and limitation of liability provided
615 | above cannot be given local legal effect according to their terms,
616 | reviewing courts shall apply local law that most closely approximates
617 | an absolute waiver of all civil liability in connection with the
618 | Program, unless a warranty or assumption of liability accompanies a
619 | copy of the Program in return for a fee.
620 |
621 | END OF TERMS AND CONDITIONS
622 |
623 | How to Apply These Terms to Your New Programs
624 |
625 | If you develop a new program, and you want it to be of the greatest
626 | possible use to the public, the best way to achieve this is to make it
627 | free software which everyone can redistribute and change under these terms.
628 |
629 | To do so, attach the following notices to the program. It is safest
630 | to attach them to the start of each source file to most effectively
631 | state the exclusion of warranty; and each file should have at least
632 | the "copyright" line and a pointer to where the full notice is found.
633 |
634 |
635 | Copyright (C)
636 |
637 | This program is free software: you can redistribute it and/or modify
638 | it under the terms of the GNU General Public License as published by
639 | the Free Software Foundation, either version 3 of the License, or
640 | (at your option) any later version.
641 |
642 | This program is distributed in the hope that it will be useful,
643 | but WITHOUT ANY WARRANTY; without even the implied warranty of
644 | MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
645 | GNU General Public License for more details.
646 |
647 | You should have received a copy of the GNU General Public License
648 | along with this program. If not, see .
649 |
650 | Also add information on how to contact you by electronic and paper mail.
651 |
652 | If the program does terminal interaction, make it output a short
653 | notice like this when it starts in an interactive mode:
654 |
655 | Copyright (C)
656 | This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
657 | This is free software, and you are welcome to redistribute it
658 | under certain conditions; type `show c' for details.
659 |
660 | The hypothetical commands `show w' and `show c' should show the appropriate
661 | parts of the General Public License. Of course, your program's commands
662 | might be different; for a GUI interface, you would use an "about box".
663 |
664 | You should also get your employer (if you work as a programmer) or school,
665 | if any, to sign a "copyright disclaimer" for the program, if necessary.
666 | For more information on this, and how to apply and follow the GNU GPL, see
667 | .
668 |
669 | The GNU General Public License does not permit incorporating your program
670 | into proprietary programs. If your program is a subroutine library, you
671 | may consider it more useful to permit linking proprietary applications with
672 | the library. If this is what you want to do, use the GNU Lesser General
673 | Public License instead of this License. But first, please read
674 | .
675 |
--------------------------------------------------------------------------------
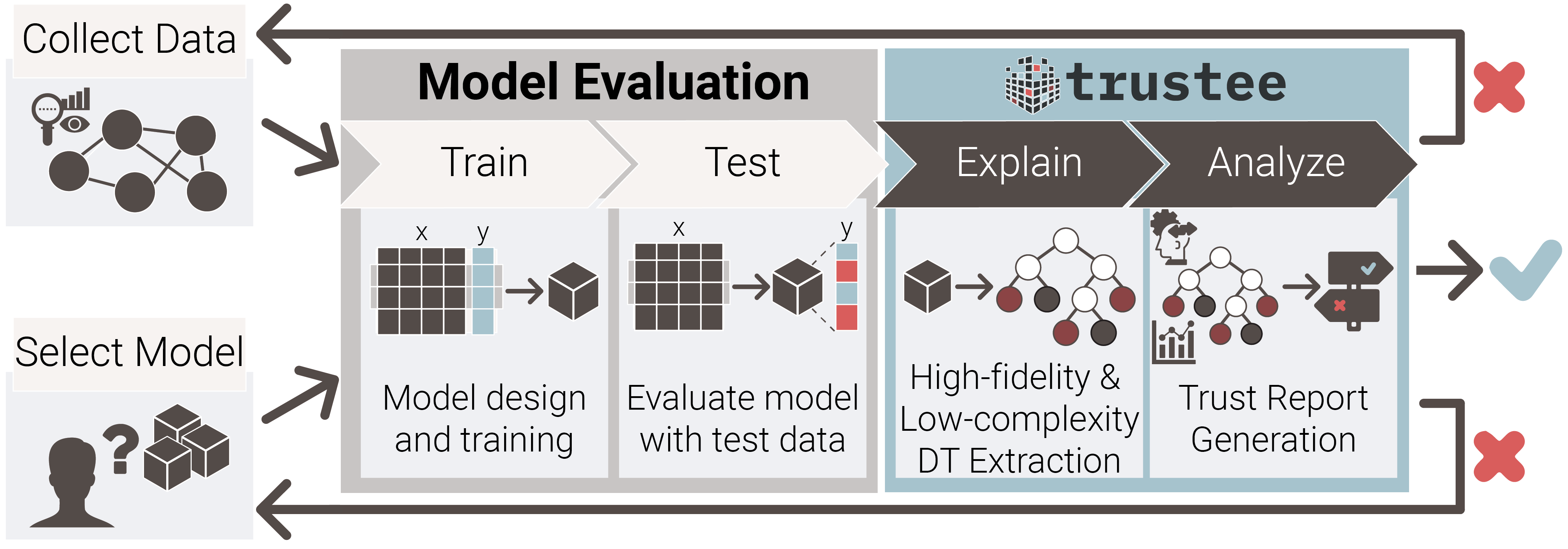 11 |
12 | Getting Started
13 | ---------------
14 |
15 | This section contains basic information and instructions to get started with Trustee.
16 |
17 | ### Python Version
18 |
19 | Trustee supports `Python >=3.7`.
20 |
21 | ### Install Trustee
22 |
23 | Use the following command to install Trustee:
24 |
25 | ```
26 | $ pip install trustee
27 | ```
28 |
29 | ### Sample Code
30 |
31 | ```
32 | from sklearn import datasets
33 | from sklearn.ensemble import RandomForestClassifier
34 | from sklearn.model_selection import train_test_split
35 | from sklearn.metrics import classification_report
36 |
37 | from trustee import ClassificationTrustee
38 |
39 | X, y = datasets.load_iris(return_X_y=True)
40 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
41 |
42 | clf = RandomForestClassifier(n_estimators=100)
43 | clf.fit(X_train, y_train)
44 | y_pred = clf.predict(X_test)
45 |
46 | trustee = ClassificationTrustee(expert=clf)
47 | trustee.fit(X_train, y_train, num_iter=50, num_stability_iter=10, samples_size=0.3, verbose=True)
48 | dt, pruned_dt, agreement, reward = trustee.explain()
49 | dt_y_pred = dt.predict(X_test)
50 |
51 | print("Model explanation global fidelity report:")
52 | print(classification_report(y_pred, dt_y_pred))
53 | print("Model explanation score report:")
54 | print(classification_report(y_test, dt_y_pred))
55 | ```
56 |
57 | ### Usage Examples
58 |
59 | For simple usage examples of Trustee and TrustReport, please check the `examples/` directory.
60 |
61 | ### Other Use Cases
62 |
63 | For other examples and use cases of how Trustee can used to scrutinize ML models, listed in the table below, please check our [Use Cases repository](https://github.com/TrusteeML/emperor).
64 |
65 | | Use Case | Description |
66 | | ------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
67 | | heartbleed\_case/ | Trustee application to a Random Forest Classifier for an Intrustion Detection System, trained with CIC-IDS-2017 dataset pre-computed features. |
68 | | kitsune\_case/ | Trustee application to Kitsune model for anomaly detection in network traffic, trained with features extracted from Kitsune\'s Mirai attack trace. |
69 | | iot\_case/ | Trustee application to Random Forest Classifier to distguish IoT devices, trained with features extracted from the pcaps from the UNSW IoT Dataset. |
70 | | moon\_star\_case/ | Trustee application to Neural Network Moon and Stars Shortcut learning toy example. |
71 | | nprint\_ids\_case/ | Trustee application to the nPrintML AutoGluon Tabular Predictor for an Intrustion Detection System, also trained using pcaps from the CIC-IDS-2017 dataset. |
72 | | nprint\_os\_case/ | Trustee application to the nPrintML AutoGluon Tabular Predictor for OS Fingerprinting, also trained using with pcaps from the CIC-IDS-2017 dataset. |
73 | | pensieve\_case/ | Trustee application to the Pensieve RL model for adaptive bit-rate prediction, and comparison to related work Metis. |
74 | | vpn\_case/ | Trustee application the 1D-CNN trained to detect VPN traffic trained with the ISCX VPN-nonVPN dataset. |
75 |
76 | ### Supported AI/ML Libraries
77 |
78 | | Library | Supported |
79 | | ------------ | ------------------ |
80 | | scikit-learn | :white_check_mark: |
81 | | Keras | :white_check_mark: |
82 | | Tensorflow | :white_check_mark: |
83 | | PyTorch | :white_check_mark: |
84 | | AutoGluon | :white_check_mark: |
85 |
86 | ## Citing us
87 |
88 | ```
89 | @inproceedings{Jacobs2022,
90 | title = {AI/ML and Network Security: The Emperor has no Clothes},
91 | author = {A. S. Jacobs and R. Beltiukov and W. Willinger and R. A. Ferreira and A. Gupta and L. Z. Granville},
92 | year = 2022,
93 | booktitle = {Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security},
94 | location = {Los Angeles, CA, USA},
95 | publisher = {Association for Computing Machinery},
96 | address = {New York, NY, USA},
97 | series = {CCS '22}
98 | }
99 | ```
100 |
--------------------------------------------------------------------------------
/trustee/utils/tree.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | from copy import deepcopy
4 |
5 | from sklearn.tree._tree import TREE_LEAF, TREE_UNDEFINED, NODE_DTYPE
6 |
7 |
8 | def prune_index(dt, index, prune_level):
9 | """Prunes the given decision tree at the given index and returns the number of pruned nodes"""
10 | if index < 0:
11 | return 0
12 |
13 | left_idx = dt.tree_.children_left[index]
14 | right_idx = dt.tree_.children_right[index]
15 |
16 | # turn node into a leaf by "unlinking" its children
17 | dt.tree_.children_left[index] = TREE_LEAF if prune_level == 0 else TREE_UNDEFINED
18 | dt.tree_.children_right[index] = TREE_LEAF if prune_level == 0 else TREE_UNDEFINED
19 |
20 | # if there are children, visit them as well
21 | if left_idx != TREE_LEAF and right_idx != TREE_LEAF:
22 | prune_index(dt, left_idx, prune_level + 1)
23 | prune_index(dt, right_idx, prune_level + 1)
24 |
25 |
26 | def get_dt_dict(dt):
27 | """Iterates through the given Decision Tree to collect updated tree node structure"""
28 | children_left = dt.tree_.children_left
29 | children_right = dt.tree_.children_right
30 | dt_state = dt.tree_.__getstate__()
31 | nodes_arr = dt_state["nodes"]
32 | values_arr = dt_state["values"]
33 |
34 | idx_inc = 0
35 | nodes = []
36 |
37 | def walk_tree(node, level, idx):
38 | """Recursively iterates through all nodes in given decision tree and returns them as a list."""
39 | left = children_left[node]
40 | right = children_right[node]
41 |
42 | nonlocal idx_inc
43 | if left != right: # if not leaf node
44 | idx_inc += 1
45 | left = walk_tree(left, level + 1, idx_inc)
46 | idx_inc += 1
47 | right = walk_tree(right, level + 1, idx_inc)
48 |
49 | nodes.append(
50 | {
51 | "idx": idx,
52 | "node": node,
53 | "left": left,
54 | "right": right,
55 | "level": level,
56 | "node_tuple": nodes_arr[node],
57 | "values_tuple": values_arr[node],
58 | }
59 | )
60 |
61 | return idx
62 |
63 | walk_tree(0, 0, idx_inc)
64 |
65 | max_depth = 0
66 | node_values = []
67 | node_ndarray = np.array([], dtype=NODE_DTYPE)
68 |
69 | for node in sorted(nodes, key=lambda x: x["idx"]):
70 | if node["level"] > max_depth:
71 | max_depth = node["level"]
72 |
73 | node_tuple = (node["left"], node["right"], *tuple(node["node_tuple"])[2:])
74 | node_ndarray = np.append(node_ndarray, np.array([node_tuple], dtype=NODE_DTYPE))
75 | node_values.append(node["values_tuple"])
76 |
77 | value_ndarray = np.array(node_values, dtype=np.float64)
78 |
79 | dt_dict = {
80 | "max_depth": max_depth,
81 | "node_count": len(node_ndarray),
82 | "nodes": node_ndarray,
83 | "values": value_ndarray,
84 | }
85 |
86 | return dt_dict
87 |
88 |
89 | def get_dt_info(dt):
90 | """Iterates through the given Decision Tree to collect relevant information."""
91 | children_left = dt.tree_.children_left
92 | children_right = dt.tree_.children_right
93 | features = dt.tree_.feature
94 | thresholds = dt.tree_.threshold
95 | values = dt.tree_.value
96 | samples = dt.tree_.n_node_samples
97 | impurity = dt.tree_.impurity
98 |
99 | splits = []
100 | features_used = {}
101 |
102 | def walk_tree(node, level, path):
103 | """Recursively iterates through all nodes in given decision tree and returns them as a list."""
104 | if children_left[node] == children_right[node]: # if leaf node
105 | node_class = np.argmax(values[node][0]) if len(np.array(values[node][0])) > 1 else values[node][0][0]
106 | node_prob = (
107 | (values[node][0][node_class] / np.sum(values[node][0])) * 100
108 | if np.array(values[node][0]).ndim > 1
109 | else 0
110 | )
111 | return [
112 | {
113 | "level": level,
114 | "path": path,
115 | "class": node_class,
116 | "prob": node_prob,
117 | "samples": samples[node],
118 | }
119 | ]
120 |
121 | feature = features[node]
122 | threshold = thresholds[node]
123 | left = children_left[node]
124 | right = children_right[node]
125 |
126 | if feature not in features_used:
127 | features_used[feature] = {"count": 0, "samples": 0}
128 |
129 | features_used[feature]["count"] += 1
130 | features_used[feature]["samples"] += samples[node]
131 |
132 | splits.append(
133 | {
134 | "idx": node,
135 | "level": level,
136 | "feature": feature,
137 | "threshold": threshold,
138 | "samples": samples[node],
139 | "values": values[node],
140 | "gini_split": (impurity[left], impurity[right]),
141 | "data_split": (np.sum(values[left]), np.sum(values[right])),
142 | "data_split_by_class": [
143 | (c_left, c_right) for (c_left, c_right) in zip(values[left][0], values[right][0])
144 | ],
145 | }
146 | )
147 |
148 | return walk_tree(left, level + 1, path + [(node, feature, "<=", threshold)]) + walk_tree(
149 | right, level + 1, path + [(node, feature, ">", threshold)]
150 | )
151 |
152 | branches = walk_tree(0, 0, [])
153 | return features_used, splits, branches
154 |
155 |
156 | def top_k_prune(dt, top_k, max_impurity=0.1):
157 | """Prunes a given decision tree down to its top-k branches, sorted by number of samples covered"""
158 | _, nodes, branches = get_dt_info(dt)
159 | top_branches = sorted(branches, key=lambda p: p["samples"], reverse=True)[:top_k]
160 | prunned_dt = deepcopy(dt)
161 |
162 | nodes_to_keep = set({})
163 | for branch in top_branches:
164 | for node, _, _, _ in branch["path"]:
165 | if dt.tree_.impurity[node] > max_impurity:
166 | nodes_to_keep.add(node)
167 |
168 | for node in nodes:
169 | if node["idx"] not in nodes_to_keep:
170 | prune_index(prunned_dt, node["idx"], 0)
171 |
172 | # update classifier with prunned model
173 | prunned_dt.tree_.__setstate__(get_dt_dict(prunned_dt))
174 |
175 | return prunned_dt
176 |
--------------------------------------------------------------------------------
/trustee/utils/dataset.py:
--------------------------------------------------------------------------------
1 | import io
2 | import glob
3 | import numpy as np
4 | import pandas as pd
5 |
6 | from pandas.api.types import CategoricalDtype
7 |
8 | from trustee.enums.feature_type import FeatureType
9 |
10 |
11 | def convert_to_df(data):
12 | """
13 | Converts data to a pandas DataFrame.
14 |
15 | Args:
16 | - data
17 | Data to be converted
18 |
19 | Returns: pd.DataFrame
20 | """
21 | if isinstance(data, pd.DataFrame):
22 | return data
23 | elif isinstance(data, pd.Series):
24 | return pd.DataFrame(data)
25 | elif isinstance(data, np.ndarray):
26 | return pd.DataFrame(data)
27 | else:
28 | raise ValueError("Data must be a pandas dataframe or numpy array")
29 |
30 |
31 | def convert_to_series(data):
32 | """
33 | Converts data to a pandas Series.
34 |
35 | Args:
36 | - data
37 | Data to be converted
38 |
39 | Returns: pd.Series
40 | """
41 | if isinstance(data, pd.Series):
42 | return data
43 | elif isinstance(data, pd.DataFrame):
44 | return data.iloc[:, 0]
45 | elif isinstance(data, np.ndarray):
46 | return pd.Series(data.flatten())
47 | else:
48 | raise ValueError("Data must be a pandas dataframe or numpy array")
49 |
50 |
51 | def read(path_or_buffer, metadata={}, verbose=False, logger=None, as_df=False):
52 | """
53 | Reads dataset from a CSV and returns it as dataframe
54 |
55 | Args:
56 | - path
57 | Path to read dataset from
58 | Returns:
59 | - X
60 | Features from dataset as an np.array or dataframe (if as_df == True)
61 | - y
62 | Target variable from dataset as an np.array or dataframe (if as_df == True)
63 | - feature_names
64 | Feature names, if any were extracted from csv or metadata
65 | """
66 |
67 | log = logger.log if logger else print
68 |
69 | X = []
70 | y = []
71 |
72 | idx_offset = 0 # cant use enumerate because of skipping ID features
73 | names = []
74 | dtypes = {}
75 | numerical = []
76 | categorical = []
77 | dummies = []
78 | use_cols = []
79 | result = []
80 |
81 | for idx, (name, type, dtype, is_result) in enumerate(metadata["fields"]):
82 | if type != FeatureType.IDENTIFIER:
83 | use_cols.append(idx)
84 |
85 | if dtype:
86 | dtypes[name] = dtype
87 |
88 | if name:
89 | names.append(name)
90 |
91 | if type == FeatureType.NUMERICAL and not is_result:
92 | numerical.append(idx - idx_offset)
93 |
94 | if type == FeatureType.CATEGORICAL and not is_result:
95 | dummies.append(idx - idx_offset)
96 |
97 | if is_result:
98 | result.append(idx - idx_offset)
99 | else:
100 | idx_offset += 1
101 |
102 | if verbose:
103 | log(10 * "=", "Metadata start.", 10 * "=")
104 | log("Names:", names)
105 | log("Dummies:", dummies)
106 | log("Use cols:", use_cols)
107 | log("Result variable:", result)
108 | log(10 * "=", "Metadata end.", 10 * "=")
109 | log("") # skip line
110 |
111 | if "is_dir" in metadata and metadata["is_dir"] and not isinstance(path_or_buffer, io.TextIOBase):
112 | df_list = []
113 |
114 | datasets = glob.glob(path_or_buffer + "/*.csv")
115 | if not datasets:
116 | datasets = glob.glob(path_or_buffer + "/*.zip")
117 |
118 | for dataset_path in datasets:
119 | df = pd.read_csv(
120 | dataset_path,
121 | delimiter=metadata["delimiter"] if "delimiter" in metadata else ",",
122 | header=0 if "has_header" in metadata and metadata["has_header"] else None,
123 | names=names if names else None,
124 | dtype=dtypes if dtypes else None,
125 | usecols=use_cols,
126 | converters=metadata["converters"] if "converters" in metadata else None,
127 | ).fillna(-1)
128 | df_list.append(df)
129 | df = pd.concat(df_list, axis=0, ignore_index=True)
130 | else:
131 | df = pd.read_csv(
132 | path_or_buffer,
133 | delimiter=metadata["delimiter"] if "delimiter" in metadata else ",",
134 | header=0 if "has_header" in metadata and metadata["has_header"] else None,
135 | names=names if names else None,
136 | dtype=dtypes if dtypes else None,
137 | usecols=use_cols,
138 | converters=metadata["converters"] if "converters" in metadata else None,
139 | ).fillna(-1)
140 |
141 | names = df.columns # guaranteing names will be filled, even if read from csv
142 | if verbose:
143 | log("Pandas read_csv complete.")
144 |
145 | if "categories" in metadata:
146 | for (column, categories) in metadata["categories"].items():
147 | category = CategoricalDtype(categories=categories, ordered=True)
148 | df[column] = df[column].astype(category)
149 |
150 | if verbose:
151 | log("CSV dataset read:")
152 | log(df)
153 | log(df.shape)
154 | log("Any NAN?", df.isnull().sum().sum())
155 | total_usage_b = df.memory_usage(deep=True).sum()
156 | total_usage_mb = total_usage_b / 1024**2
157 | mean_usage_b = df.memory_usage(deep=True).mean()
158 | mean_usage_mb = mean_usage_b / 1024**2
159 | log(f"Total memory usage: {total_usage_mb:03.2f} MB")
160 | log(f"Average memory usage: {mean_usage_mb:03.2f} MB")
161 |
162 | # if no result varibles is passed in metadata, we assume the last column as the result
163 | if not result:
164 | result = [len(df.columns) - 1]
165 |
166 | y = df[names[result]].copy()
167 |
168 | X = df.drop(columns=names[result], axis=1)
169 | # resulting dataset corresponds to feature variables only, so encode it if necessary
170 | if dummies:
171 | dummy_cols = [names[i] for i in dummies]
172 | categorical = [[] for _ in dummy_cols]
173 | X = pd.get_dummies(X, columns=dummy_cols)
174 | for i, _ in enumerate(X.columns):
175 | for j, _ in enumerate(dummy_cols):
176 | cat_feat = dummy_cols[j]
177 | if str(X.columns[i]).startswith(f"{str(cat_feat)}_"):
178 | categorical[j].append(i)
179 |
180 | if verbose:
181 | log("Features Shape:", X.shape)
182 | column_names = "".join(f"{str(i)}: {str(col)}\n" for (i, col) in zip(list(range(len(X.columns))), X.columns))
183 | log(f"Column names:\n{column_names}")
184 | log("Targets shape:", y.shape, y.columns)
185 |
186 | X = X.replace([np.inf, -np.inf], np.nan).fillna(-1)
187 |
188 | return (
189 | X if as_df else np.nan_to_num(X.to_numpy()),
190 | y if as_df else y.to_numpy(),
191 | X.columns,
192 | numerical,
193 | categorical,
194 | )
195 |
--------------------------------------------------------------------------------
/docs/index.rst:
--------------------------------------------------------------------------------
1 | .. image:: _static/logo.png
2 | :width: 400px
3 | :align: center
4 | :alt: Trustee
5 | :class: only-light
6 |
7 | .. image:: _static/logo-alt.png
8 | :width: 400px
9 | :align: center
10 | :alt: Trustee
11 | :class: only-dark
12 |
13 | Welcome to Trustee's documentation. Get started with `installation`
14 | and then get an overview with the `quickstart`. The rest of the docs
15 | describe each component of Trustee in detail, with a full reference in
16 | the :doc:`api` section.
17 |
18 | .. raw:: html
19 |
20 |
43 |
63 |
64 | Overview
65 | -------------
66 |
67 | Trustee is a framework to extract decision tree explanation from black-box ML models.
68 |
69 | .. figure:: _static/flowchart.png
70 | :align: center
71 | :alt: Trustee Flowchart
72 |
73 | Standard AI/ML development pipeline extended by Trustee.
74 |
75 |
76 | Getting Started
77 | ---------------
78 | This section contains basic information and instructions to get started with Trustee.
79 |
80 | Python Version
81 | ***************
82 |
83 | Trustee supports Python >=3.7.
84 |
85 | Install Trustee
86 | ***************
87 |
88 | Use the following command to install Trustee:
89 |
90 | .. code-block:: sh
91 |
92 | $ pip install trustee
93 |
94 |
95 | Sample Code
96 | *******************
97 |
98 | .. code:: python
99 |
100 | from sklearn import datasets
101 | from sklearn.ensemble import RandomForestClassifier
102 | from sklearn.model_selection import train_test_split
103 | from sklearn.metrics import classification_report
104 |
105 | from trustee import ClassificationTrustee
106 |
107 | X, y = datasets.load_iris(return_X_y=True)
108 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
109 |
110 | clf = RandomForestClassifier(n_estimators=100)
111 | clf.fit(X_train, y_train)
112 | y_pred = clf.predict(X_test)
113 |
114 | trustee = ClassificationTrustee(expert=clf)
115 | trustee.fit(X_train, y_train, num_iter=50, num_stability_iter=10, samples_size=0.3, verbose=True)
116 | dt, pruned_dt, agreement, reward = trustee.explain()
117 | dt_y_pred = dt.predict(X_test)
118 |
119 | print("Model explanation global fidelity report:")
120 | print(classification_report(y_pred, dt_y_pred))
121 | print("Model explanation score report:")
122 | print(classification_report(y_test, dt_y_pred))
123 |
124 |
125 | Other Use Cases
126 | *******************
127 | For other examples and use cases of how Trustee can used to scrutinize ML models, listed in the table below, please check our `Use Cases repository
11 |
12 | Getting Started
13 | ---------------
14 |
15 | This section contains basic information and instructions to get started with Trustee.
16 |
17 | ### Python Version
18 |
19 | Trustee supports `Python >=3.7`.
20 |
21 | ### Install Trustee
22 |
23 | Use the following command to install Trustee:
24 |
25 | ```
26 | $ pip install trustee
27 | ```
28 |
29 | ### Sample Code
30 |
31 | ```
32 | from sklearn import datasets
33 | from sklearn.ensemble import RandomForestClassifier
34 | from sklearn.model_selection import train_test_split
35 | from sklearn.metrics import classification_report
36 |
37 | from trustee import ClassificationTrustee
38 |
39 | X, y = datasets.load_iris(return_X_y=True)
40 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
41 |
42 | clf = RandomForestClassifier(n_estimators=100)
43 | clf.fit(X_train, y_train)
44 | y_pred = clf.predict(X_test)
45 |
46 | trustee = ClassificationTrustee(expert=clf)
47 | trustee.fit(X_train, y_train, num_iter=50, num_stability_iter=10, samples_size=0.3, verbose=True)
48 | dt, pruned_dt, agreement, reward = trustee.explain()
49 | dt_y_pred = dt.predict(X_test)
50 |
51 | print("Model explanation global fidelity report:")
52 | print(classification_report(y_pred, dt_y_pred))
53 | print("Model explanation score report:")
54 | print(classification_report(y_test, dt_y_pred))
55 | ```
56 |
57 | ### Usage Examples
58 |
59 | For simple usage examples of Trustee and TrustReport, please check the `examples/` directory.
60 |
61 | ### Other Use Cases
62 |
63 | For other examples and use cases of how Trustee can used to scrutinize ML models, listed in the table below, please check our [Use Cases repository](https://github.com/TrusteeML/emperor).
64 |
65 | | Use Case | Description |
66 | | ------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
67 | | heartbleed\_case/ | Trustee application to a Random Forest Classifier for an Intrustion Detection System, trained with CIC-IDS-2017 dataset pre-computed features. |
68 | | kitsune\_case/ | Trustee application to Kitsune model for anomaly detection in network traffic, trained with features extracted from Kitsune\'s Mirai attack trace. |
69 | | iot\_case/ | Trustee application to Random Forest Classifier to distguish IoT devices, trained with features extracted from the pcaps from the UNSW IoT Dataset. |
70 | | moon\_star\_case/ | Trustee application to Neural Network Moon and Stars Shortcut learning toy example. |
71 | | nprint\_ids\_case/ | Trustee application to the nPrintML AutoGluon Tabular Predictor for an Intrustion Detection System, also trained using pcaps from the CIC-IDS-2017 dataset. |
72 | | nprint\_os\_case/ | Trustee application to the nPrintML AutoGluon Tabular Predictor for OS Fingerprinting, also trained using with pcaps from the CIC-IDS-2017 dataset. |
73 | | pensieve\_case/ | Trustee application to the Pensieve RL model for adaptive bit-rate prediction, and comparison to related work Metis. |
74 | | vpn\_case/ | Trustee application the 1D-CNN trained to detect VPN traffic trained with the ISCX VPN-nonVPN dataset. |
75 |
76 | ### Supported AI/ML Libraries
77 |
78 | | Library | Supported |
79 | | ------------ | ------------------ |
80 | | scikit-learn | :white_check_mark: |
81 | | Keras | :white_check_mark: |
82 | | Tensorflow | :white_check_mark: |
83 | | PyTorch | :white_check_mark: |
84 | | AutoGluon | :white_check_mark: |
85 |
86 | ## Citing us
87 |
88 | ```
89 | @inproceedings{Jacobs2022,
90 | title = {AI/ML and Network Security: The Emperor has no Clothes},
91 | author = {A. S. Jacobs and R. Beltiukov and W. Willinger and R. A. Ferreira and A. Gupta and L. Z. Granville},
92 | year = 2022,
93 | booktitle = {Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security},
94 | location = {Los Angeles, CA, USA},
95 | publisher = {Association for Computing Machinery},
96 | address = {New York, NY, USA},
97 | series = {CCS '22}
98 | }
99 | ```
100 |
--------------------------------------------------------------------------------
/trustee/utils/tree.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | from copy import deepcopy
4 |
5 | from sklearn.tree._tree import TREE_LEAF, TREE_UNDEFINED, NODE_DTYPE
6 |
7 |
8 | def prune_index(dt, index, prune_level):
9 | """Prunes the given decision tree at the given index and returns the number of pruned nodes"""
10 | if index < 0:
11 | return 0
12 |
13 | left_idx = dt.tree_.children_left[index]
14 | right_idx = dt.tree_.children_right[index]
15 |
16 | # turn node into a leaf by "unlinking" its children
17 | dt.tree_.children_left[index] = TREE_LEAF if prune_level == 0 else TREE_UNDEFINED
18 | dt.tree_.children_right[index] = TREE_LEAF if prune_level == 0 else TREE_UNDEFINED
19 |
20 | # if there are children, visit them as well
21 | if left_idx != TREE_LEAF and right_idx != TREE_LEAF:
22 | prune_index(dt, left_idx, prune_level + 1)
23 | prune_index(dt, right_idx, prune_level + 1)
24 |
25 |
26 | def get_dt_dict(dt):
27 | """Iterates through the given Decision Tree to collect updated tree node structure"""
28 | children_left = dt.tree_.children_left
29 | children_right = dt.tree_.children_right
30 | dt_state = dt.tree_.__getstate__()
31 | nodes_arr = dt_state["nodes"]
32 | values_arr = dt_state["values"]
33 |
34 | idx_inc = 0
35 | nodes = []
36 |
37 | def walk_tree(node, level, idx):
38 | """Recursively iterates through all nodes in given decision tree and returns them as a list."""
39 | left = children_left[node]
40 | right = children_right[node]
41 |
42 | nonlocal idx_inc
43 | if left != right: # if not leaf node
44 | idx_inc += 1
45 | left = walk_tree(left, level + 1, idx_inc)
46 | idx_inc += 1
47 | right = walk_tree(right, level + 1, idx_inc)
48 |
49 | nodes.append(
50 | {
51 | "idx": idx,
52 | "node": node,
53 | "left": left,
54 | "right": right,
55 | "level": level,
56 | "node_tuple": nodes_arr[node],
57 | "values_tuple": values_arr[node],
58 | }
59 | )
60 |
61 | return idx
62 |
63 | walk_tree(0, 0, idx_inc)
64 |
65 | max_depth = 0
66 | node_values = []
67 | node_ndarray = np.array([], dtype=NODE_DTYPE)
68 |
69 | for node in sorted(nodes, key=lambda x: x["idx"]):
70 | if node["level"] > max_depth:
71 | max_depth = node["level"]
72 |
73 | node_tuple = (node["left"], node["right"], *tuple(node["node_tuple"])[2:])
74 | node_ndarray = np.append(node_ndarray, np.array([node_tuple], dtype=NODE_DTYPE))
75 | node_values.append(node["values_tuple"])
76 |
77 | value_ndarray = np.array(node_values, dtype=np.float64)
78 |
79 | dt_dict = {
80 | "max_depth": max_depth,
81 | "node_count": len(node_ndarray),
82 | "nodes": node_ndarray,
83 | "values": value_ndarray,
84 | }
85 |
86 | return dt_dict
87 |
88 |
89 | def get_dt_info(dt):
90 | """Iterates through the given Decision Tree to collect relevant information."""
91 | children_left = dt.tree_.children_left
92 | children_right = dt.tree_.children_right
93 | features = dt.tree_.feature
94 | thresholds = dt.tree_.threshold
95 | values = dt.tree_.value
96 | samples = dt.tree_.n_node_samples
97 | impurity = dt.tree_.impurity
98 |
99 | splits = []
100 | features_used = {}
101 |
102 | def walk_tree(node, level, path):
103 | """Recursively iterates through all nodes in given decision tree and returns them as a list."""
104 | if children_left[node] == children_right[node]: # if leaf node
105 | node_class = np.argmax(values[node][0]) if len(np.array(values[node][0])) > 1 else values[node][0][0]
106 | node_prob = (
107 | (values[node][0][node_class] / np.sum(values[node][0])) * 100
108 | if np.array(values[node][0]).ndim > 1
109 | else 0
110 | )
111 | return [
112 | {
113 | "level": level,
114 | "path": path,
115 | "class": node_class,
116 | "prob": node_prob,
117 | "samples": samples[node],
118 | }
119 | ]
120 |
121 | feature = features[node]
122 | threshold = thresholds[node]
123 | left = children_left[node]
124 | right = children_right[node]
125 |
126 | if feature not in features_used:
127 | features_used[feature] = {"count": 0, "samples": 0}
128 |
129 | features_used[feature]["count"] += 1
130 | features_used[feature]["samples"] += samples[node]
131 |
132 | splits.append(
133 | {
134 | "idx": node,
135 | "level": level,
136 | "feature": feature,
137 | "threshold": threshold,
138 | "samples": samples[node],
139 | "values": values[node],
140 | "gini_split": (impurity[left], impurity[right]),
141 | "data_split": (np.sum(values[left]), np.sum(values[right])),
142 | "data_split_by_class": [
143 | (c_left, c_right) for (c_left, c_right) in zip(values[left][0], values[right][0])
144 | ],
145 | }
146 | )
147 |
148 | return walk_tree(left, level + 1, path + [(node, feature, "<=", threshold)]) + walk_tree(
149 | right, level + 1, path + [(node, feature, ">", threshold)]
150 | )
151 |
152 | branches = walk_tree(0, 0, [])
153 | return features_used, splits, branches
154 |
155 |
156 | def top_k_prune(dt, top_k, max_impurity=0.1):
157 | """Prunes a given decision tree down to its top-k branches, sorted by number of samples covered"""
158 | _, nodes, branches = get_dt_info(dt)
159 | top_branches = sorted(branches, key=lambda p: p["samples"], reverse=True)[:top_k]
160 | prunned_dt = deepcopy(dt)
161 |
162 | nodes_to_keep = set({})
163 | for branch in top_branches:
164 | for node, _, _, _ in branch["path"]:
165 | if dt.tree_.impurity[node] > max_impurity:
166 | nodes_to_keep.add(node)
167 |
168 | for node in nodes:
169 | if node["idx"] not in nodes_to_keep:
170 | prune_index(prunned_dt, node["idx"], 0)
171 |
172 | # update classifier with prunned model
173 | prunned_dt.tree_.__setstate__(get_dt_dict(prunned_dt))
174 |
175 | return prunned_dt
176 |
--------------------------------------------------------------------------------
/trustee/utils/dataset.py:
--------------------------------------------------------------------------------
1 | import io
2 | import glob
3 | import numpy as np
4 | import pandas as pd
5 |
6 | from pandas.api.types import CategoricalDtype
7 |
8 | from trustee.enums.feature_type import FeatureType
9 |
10 |
11 | def convert_to_df(data):
12 | """
13 | Converts data to a pandas DataFrame.
14 |
15 | Args:
16 | - data
17 | Data to be converted
18 |
19 | Returns: pd.DataFrame
20 | """
21 | if isinstance(data, pd.DataFrame):
22 | return data
23 | elif isinstance(data, pd.Series):
24 | return pd.DataFrame(data)
25 | elif isinstance(data, np.ndarray):
26 | return pd.DataFrame(data)
27 | else:
28 | raise ValueError("Data must be a pandas dataframe or numpy array")
29 |
30 |
31 | def convert_to_series(data):
32 | """
33 | Converts data to a pandas Series.
34 |
35 | Args:
36 | - data
37 | Data to be converted
38 |
39 | Returns: pd.Series
40 | """
41 | if isinstance(data, pd.Series):
42 | return data
43 | elif isinstance(data, pd.DataFrame):
44 | return data.iloc[:, 0]
45 | elif isinstance(data, np.ndarray):
46 | return pd.Series(data.flatten())
47 | else:
48 | raise ValueError("Data must be a pandas dataframe or numpy array")
49 |
50 |
51 | def read(path_or_buffer, metadata={}, verbose=False, logger=None, as_df=False):
52 | """
53 | Reads dataset from a CSV and returns it as dataframe
54 |
55 | Args:
56 | - path
57 | Path to read dataset from
58 | Returns:
59 | - X
60 | Features from dataset as an np.array or dataframe (if as_df == True)
61 | - y
62 | Target variable from dataset as an np.array or dataframe (if as_df == True)
63 | - feature_names
64 | Feature names, if any were extracted from csv or metadata
65 | """
66 |
67 | log = logger.log if logger else print
68 |
69 | X = []
70 | y = []
71 |
72 | idx_offset = 0 # cant use enumerate because of skipping ID features
73 | names = []
74 | dtypes = {}
75 | numerical = []
76 | categorical = []
77 | dummies = []
78 | use_cols = []
79 | result = []
80 |
81 | for idx, (name, type, dtype, is_result) in enumerate(metadata["fields"]):
82 | if type != FeatureType.IDENTIFIER:
83 | use_cols.append(idx)
84 |
85 | if dtype:
86 | dtypes[name] = dtype
87 |
88 | if name:
89 | names.append(name)
90 |
91 | if type == FeatureType.NUMERICAL and not is_result:
92 | numerical.append(idx - idx_offset)
93 |
94 | if type == FeatureType.CATEGORICAL and not is_result:
95 | dummies.append(idx - idx_offset)
96 |
97 | if is_result:
98 | result.append(idx - idx_offset)
99 | else:
100 | idx_offset += 1
101 |
102 | if verbose:
103 | log(10 * "=", "Metadata start.", 10 * "=")
104 | log("Names:", names)
105 | log("Dummies:", dummies)
106 | log("Use cols:", use_cols)
107 | log("Result variable:", result)
108 | log(10 * "=", "Metadata end.", 10 * "=")
109 | log("") # skip line
110 |
111 | if "is_dir" in metadata and metadata["is_dir"] and not isinstance(path_or_buffer, io.TextIOBase):
112 | df_list = []
113 |
114 | datasets = glob.glob(path_or_buffer + "/*.csv")
115 | if not datasets:
116 | datasets = glob.glob(path_or_buffer + "/*.zip")
117 |
118 | for dataset_path in datasets:
119 | df = pd.read_csv(
120 | dataset_path,
121 | delimiter=metadata["delimiter"] if "delimiter" in metadata else ",",
122 | header=0 if "has_header" in metadata and metadata["has_header"] else None,
123 | names=names if names else None,
124 | dtype=dtypes if dtypes else None,
125 | usecols=use_cols,
126 | converters=metadata["converters"] if "converters" in metadata else None,
127 | ).fillna(-1)
128 | df_list.append(df)
129 | df = pd.concat(df_list, axis=0, ignore_index=True)
130 | else:
131 | df = pd.read_csv(
132 | path_or_buffer,
133 | delimiter=metadata["delimiter"] if "delimiter" in metadata else ",",
134 | header=0 if "has_header" in metadata and metadata["has_header"] else None,
135 | names=names if names else None,
136 | dtype=dtypes if dtypes else None,
137 | usecols=use_cols,
138 | converters=metadata["converters"] if "converters" in metadata else None,
139 | ).fillna(-1)
140 |
141 | names = df.columns # guaranteing names will be filled, even if read from csv
142 | if verbose:
143 | log("Pandas read_csv complete.")
144 |
145 | if "categories" in metadata:
146 | for (column, categories) in metadata["categories"].items():
147 | category = CategoricalDtype(categories=categories, ordered=True)
148 | df[column] = df[column].astype(category)
149 |
150 | if verbose:
151 | log("CSV dataset read:")
152 | log(df)
153 | log(df.shape)
154 | log("Any NAN?", df.isnull().sum().sum())
155 | total_usage_b = df.memory_usage(deep=True).sum()
156 | total_usage_mb = total_usage_b / 1024**2
157 | mean_usage_b = df.memory_usage(deep=True).mean()
158 | mean_usage_mb = mean_usage_b / 1024**2
159 | log(f"Total memory usage: {total_usage_mb:03.2f} MB")
160 | log(f"Average memory usage: {mean_usage_mb:03.2f} MB")
161 |
162 | # if no result varibles is passed in metadata, we assume the last column as the result
163 | if not result:
164 | result = [len(df.columns) - 1]
165 |
166 | y = df[names[result]].copy()
167 |
168 | X = df.drop(columns=names[result], axis=1)
169 | # resulting dataset corresponds to feature variables only, so encode it if necessary
170 | if dummies:
171 | dummy_cols = [names[i] for i in dummies]
172 | categorical = [[] for _ in dummy_cols]
173 | X = pd.get_dummies(X, columns=dummy_cols)
174 | for i, _ in enumerate(X.columns):
175 | for j, _ in enumerate(dummy_cols):
176 | cat_feat = dummy_cols[j]
177 | if str(X.columns[i]).startswith(f"{str(cat_feat)}_"):
178 | categorical[j].append(i)
179 |
180 | if verbose:
181 | log("Features Shape:", X.shape)
182 | column_names = "".join(f"{str(i)}: {str(col)}\n" for (i, col) in zip(list(range(len(X.columns))), X.columns))
183 | log(f"Column names:\n{column_names}")
184 | log("Targets shape:", y.shape, y.columns)
185 |
186 | X = X.replace([np.inf, -np.inf], np.nan).fillna(-1)
187 |
188 | return (
189 | X if as_df else np.nan_to_num(X.to_numpy()),
190 | y if as_df else y.to_numpy(),
191 | X.columns,
192 | numerical,
193 | categorical,
194 | )
195 |
--------------------------------------------------------------------------------
/docs/index.rst:
--------------------------------------------------------------------------------
1 | .. image:: _static/logo.png
2 | :width: 400px
3 | :align: center
4 | :alt: Trustee
5 | :class: only-light
6 |
7 | .. image:: _static/logo-alt.png
8 | :width: 400px
9 | :align: center
10 | :alt: Trustee
11 | :class: only-dark
12 |
13 | Welcome to Trustee's documentation. Get started with `installation`
14 | and then get an overview with the `quickstart`. The rest of the docs
15 | describe each component of Trustee in detail, with a full reference in
16 | the :doc:`api` section.
17 |
18 | .. raw:: html
19 |
20 |
43 |
63 |
64 | Overview
65 | -------------
66 |
67 | Trustee is a framework to extract decision tree explanation from black-box ML models.
68 |
69 | .. figure:: _static/flowchart.png
70 | :align: center
71 | :alt: Trustee Flowchart
72 |
73 | Standard AI/ML development pipeline extended by Trustee.
74 |
75 |
76 | Getting Started
77 | ---------------
78 | This section contains basic information and instructions to get started with Trustee.
79 |
80 | Python Version
81 | ***************
82 |
83 | Trustee supports Python >=3.7.
84 |
85 | Install Trustee
86 | ***************
87 |
88 | Use the following command to install Trustee:
89 |
90 | .. code-block:: sh
91 |
92 | $ pip install trustee
93 |
94 |
95 | Sample Code
96 | *******************
97 |
98 | .. code:: python
99 |
100 | from sklearn import datasets
101 | from sklearn.ensemble import RandomForestClassifier
102 | from sklearn.model_selection import train_test_split
103 | from sklearn.metrics import classification_report
104 |
105 | from trustee import ClassificationTrustee
106 |
107 | X, y = datasets.load_iris(return_X_y=True)
108 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
109 |
110 | clf = RandomForestClassifier(n_estimators=100)
111 | clf.fit(X_train, y_train)
112 | y_pred = clf.predict(X_test)
113 |
114 | trustee = ClassificationTrustee(expert=clf)
115 | trustee.fit(X_train, y_train, num_iter=50, num_stability_iter=10, samples_size=0.3, verbose=True)
116 | dt, pruned_dt, agreement, reward = trustee.explain()
117 | dt_y_pred = dt.predict(X_test)
118 |
119 | print("Model explanation global fidelity report:")
120 | print(classification_report(y_pred, dt_y_pred))
121 | print("Model explanation score report:")
122 | print(classification_report(y_test, dt_y_pred))
123 |
124 |
125 | Other Use Cases
126 | *******************
127 | For other examples and use cases of how Trustee can used to scrutinize ML models, listed in the table below, please check our `Use Cases repository