├── .gitignore
├── CNAME
├── README.md
├── docs
├── .vuepress
│ ├── config.ts
│ ├── enhanceApp.js
│ ├── navbar.ts
│ ├── sidebar.ts
│ ├── styles
│ │ ├── index.scss
│ │ └── palette.scss
│ ├── theme.ts
│ └── vuepress-sidebar-auto
│ │ └── vuepress-sidebar-auto.js
├── README.md
├── about
│ ├── contact.md
│ └── introduce.md
├── advance
│ ├── concurrent
│ │ ├── 1-current-limiting.md
│ │ ├── 2-load-balance.md
│ │ └── README.md
│ ├── design-pattern-all.md
│ ├── design-pattern
│ │ ├── 1-principle.md
│ │ ├── 10-observer.md
│ │ ├── 11-proxy.md
│ │ ├── 12-builder.md
│ │ ├── 2-singleton.md
│ │ ├── 3-factory.md
│ │ ├── 4-template.md
│ │ ├── 5-strategy.md
│ │ ├── 6-chain.md
│ │ ├── 7-iterator.md
│ │ ├── 8-decorator.md
│ │ ├── 9-adapter.md
│ │ └── README.md
│ ├── distributed
│ │ ├── 1-global-unique-id.md
│ │ ├── 2-distributed-lock.md
│ │ ├── 3-rpc.md
│ │ ├── 4-micro-service.md
│ │ ├── 5-distibuted-arch.md
│ │ ├── 6-distributed-transaction.md
│ │ ├── README.md
│ │ └── article
│ │ │ └── distributed-lock.md
│ ├── excellent-article
│ │ ├── 1-redis-stock-minus.md
│ │ ├── 10-file-upload.md
│ │ ├── 11-8-architect-pattern.md
│ │ ├── 12-mysql-table-max-rows.md
│ │ ├── 13-order-by-work.md
│ │ ├── 14-architect-forward.md
│ │ ├── 15-http-vs-rpc.md
│ │ ├── 16-what-is-jwt.md
│ │ ├── 17-limit-scheme.md
│ │ ├── 18-db-connect-resource.md
│ │ ├── 19-java19.md
│ │ ├── 2-spring-transaction.md
│ │ ├── 20-architect-pattern.md
│ │ ├── 22-distributed-scheduled-task.md
│ │ ├── 23-arthas-intro.md
│ │ ├── 24-generic.md
│ │ ├── 25-select-count-slow-query.md
│ │ ├── 26-java-stream.md
│ │ ├── 27-mq-usage.md
│ │ ├── 28-springboot-forbid-tomcat.md
│ │ ├── 29-idempotent-design.md
│ │ ├── 3-springboot-auto-assembly.md
│ │ ├── 30-yi-di-duo-huo.md
│ │ ├── 31-mysql-data-sync-es.md
│ │ ├── 4-remove-duplicate-code.md
│ │ ├── 5-jvm-optimize.md
│ │ ├── 6-spring-three-cache.md
│ │ ├── 7-sql-optimize.md
│ │ ├── 8-interface-idempotent.md
│ │ ├── 9-jvm-optimize-param.md
│ │ ├── MySQL中N个写SQL的好习惯.md
│ │ ├── README.md
│ │ └── 实现异步编程,我有八种方式!.md
│ └── system-design
│ │ ├── 1-scan-code-login.md
│ │ ├── 10-pdd-visit-statistics.md
│ │ ├── 11-realtime-subscribe-push.md
│ │ ├── 12-second-kill-5-point.md
│ │ ├── 13-permission-system.md
│ │ ├── 15-red-packet.md
│ │ ├── 16-mq-design.md
│ │ ├── 17-shopping-car.md
│ │ ├── 18-register-center.md
│ │ ├── 19-high-concurrent-system-design.md
│ │ ├── 2-order-timeout-auto-cancel.md
│ │ ├── 20-sharding-smooth-migration.md
│ │ ├── 21-excel-import.md
│ │ ├── 3-file-send.md
│ │ ├── 3-short-url.md
│ │ ├── 4-oversold.md
│ │ ├── 5-second-kill.md
│ │ ├── 6-wechat-redpacket-design.md
│ │ ├── 8-sso-design.md
│ │ ├── 9-coupon-design.md
│ │ └── README.md
├── campus-recruit
│ ├── README.md
│ ├── biggest-difficulty.md
│ ├── career-plan.md
│ ├── company
│ │ └── 1-shanghai-it-company.md
│ ├── hr-ask-offers.md
│ ├── interview-question-career-plan.md
│ ├── interview
│ │ ├── 1-byte-and-dance.md
│ │ ├── 10-netease.md
│ │ ├── 11-lixiang-car.md
│ │ ├── 2-tencent.md
│ │ ├── 3-baidu.md
│ │ ├── 4-ali.md
│ │ ├── 5-kuaishou.md
│ │ ├── 6-meituan.md
│ │ ├── 7-shopee.md
│ │ ├── 8-jingdong.md
│ │ ├── 9-huawei.md
│ │ └── README.md
│ ├── lack-project-experience.md
│ ├── layoffs-solution.md
│ ├── leetcode-guide.md
│ ├── program-language
│ │ ├── README.md
│ │ ├── java-or-c++.md
│ │ └── java-or-golang.md
│ ├── project-experience.md
│ ├── question-ask-me.md
│ ├── resume.md
│ └── share
│ │ ├── 1-23-backend.md
│ │ ├── 2-no-offer.md
│ │ ├── 2-years-tech-upgrade.md
│ │ ├── 3-power-grid-vs-pdd.md
│ │ ├── 4-agricultural-bank.md
│ │ ├── 5-feizhu-meituan-internship.md
│ │ ├── 6-2023-autumn-recruit.md
│ │ └── README.md
├── career-plan
│ ├── 3-years-reflect.md
│ ├── 4-years-reflect.md
│ ├── guoqi-programmer.md
│ ├── how-to-prepare-job-hopping.md
│ └── java-or-bigdata.md
├── computer-basic
│ ├── algorithm.md
│ ├── data-structure.md
│ ├── network.md
│ ├── operate-system.md
│ ├── tcp.md
│ └── 图解HTTP.md
├── database
│ ├── es
│ │ ├── 1-es-architect.md
│ │ └── es-basic.md
│ ├── mongodb.md
│ ├── mysql-basic-all.md
│ ├── mysql-basic
│ │ ├── 1-data-type.md
│ │ ├── 10-view.md
│ │ ├── 11-procedure.md
│ │ ├── 12-cursor.md
│ │ ├── 13-trigger.md
│ │ ├── 14-transaction.md
│ │ ├── 15-permission.md
│ │ ├── 16-performace-optimization.md
│ │ ├── 17-index.md
│ │ ├── 2-basic-command.md
│ │ ├── 3-function.md
│ │ ├── 4-sum.md
│ │ ├── 5-group.md
│ │ ├── 6-join.md
│ │ ├── 7-full-text-query.md
│ │ ├── 8-table-operate.md
│ │ ├── 9-column-operate.md
│ │ └── README.md
│ ├── mysql-execution-plan.md
│ ├── mysql-lock.md
│ ├── mysql.md
│ ├── sharding-id.md
│ ├── sql-optimize.md
│ └── 一条 SQL 查询语句如何执行的.md
├── framework
│ ├── Apollo配置中心.md
│ ├── mybatis.md
│ ├── netty-overview.md
│ ├── netty
│ │ ├── 1-overview.md
│ │ ├── 10-encoder-decoder.md
│ │ ├── 11-preset-channel-handler.md
│ │ ├── 2-make-your-app.md
│ │ ├── 3-component.md
│ │ ├── 4-transport.md
│ │ ├── 6-channel-handler.md
│ │ ├── 7-channel-pipeline.md
│ │ ├── 8-eventloop-thread-model.md
│ │ ├── 9-guide.md
│ │ └── README.md
│ ├── spring.md
│ ├── spring
│ │ └── transaction-propagation.md
│ ├── springboot.md
│ ├── springboot
│ │ ├── springboot-contract.md
│ │ ├── springboot-cross-domain.md
│ │ ├── springboot-dev-tools.md
│ │ └── springboot-websocket-monitor.md
│ ├── springcloud-interview.md
│ ├── springcloud-overview.md
│ ├── springcloud
│ │ ├── 1-basic.md
│ │ ├── 10-bus.md
│ │ ├── 11-security.md
│ │ ├── 2-springboot-springcloud-diff.md
│ │ ├── 3-eureka.md
│ │ ├── 4-ribbon.md
│ │ ├── 5-hystrix.md
│ │ ├── 6-feign.md
│ │ ├── 7-zuul.md
│ │ ├── 8-gateway.md
│ │ ├── 9-config.md
│ │ └── README.md
│ └── springmvc.md
├── interview
│ ├── concurrent
│ │ └── 1-forbid-default-executor.md
│ ├── java
│ │ ├── 1-create-object.md
│ │ ├── 2-3rd-interface.md
│ │ ├── 3-design-interface.md
│ │ ├── 4-interface-slow.md
│ │ ├── 5-comparable-vs-comparator.md
│ │ └── README.md
│ ├── javaweb
│ │ └── 1-interceptor-filter.md
│ ├── mq
│ │ └── 1-why-to-use-mq.md
│ └── network
│ │ ├── 1-input-url-return-page.md
│ │ └── 2-http-status-code.md
├── java
│ ├── basic
│ │ ├── reflect-affect-permance.md
│ │ └── serialization.md
│ ├── java-basic.md
│ ├── java-collection.md
│ ├── java-concurrent.md
│ ├── java8-all.md
│ ├── java8
│ │ ├── 1-functional-program.md
│ │ ├── 2-lambda.md
│ │ ├── 3-functional-interface.md
│ │ ├── 4-inner-functional-interface.md
│ │ ├── 5-stream.md
│ │ ├── 6-parallel-stream.md
│ │ ├── 7-map.md
│ │ └── README.md
│ ├── jvm.md
│ └── jvm
│ │ └── jvm-heap-memory-share.md
├── learn
│ ├── ghelper.md
│ ├── leetcode.md
│ └── manual.md
├── learning-resources
│ ├── chang-gou-mall.md
│ ├── cs-learn-guide.md
│ ├── java-learn-guide.md
│ ├── leetcode-note.md
│ ├── mysql-top.md
│ ├── mysql45-section.md
│ ├── sgg-java-learn.md
│ ├── shang-chou.md
│ └── springboot-guide.md
├── leetcode
│ ├── README.md
│ ├── hot120
│ │ ├── 1-two-sum.md
│ │ ├── 103-binary-tree-zigzag-level-order-traversal.md
│ │ ├── 104-maximum-depth-of-binary-tree.md
│ │ ├── 11-container-with-most-water.md
│ │ ├── 1143-longest-common-subquence.md
│ │ ├── 120-triangle.md
│ │ ├── 121-best-time-to-buy-and-sell-stock.md
│ │ ├── 122-best-time-to-buy-and-sell-stock-ii.md
│ │ ├── 128-longest-consecutive-sequence.md
│ │ ├── 131-palindrome-partion.md
│ │ ├── 133-clone-graph.md
│ │ ├── 134-gas-station.md
│ │ ├── 141-linked-list-cycle.md
│ │ ├── 148-sort-list.md
│ │ ├── 15-3sum.md
│ │ ├── 152-maximum-product-subarray.md
│ │ ├── 160-intersection-of-two-linked-lists.md
│ │ ├── 169-majority-element.md
│ │ ├── 18-4sum .md
│ │ ├── 19-remove-nth-node-from-end-of-list.md
│ │ ├── 199-binary-tree-right-side-view.md
│ │ ├── 20-valid-parentheses.md
│ │ ├── 200-number-of-islands.md
│ │ ├── 206-reverse-linked-list.md
│ │ ├── 21-merge-two-sorted-lists.md
│ │ ├── 215-kth-largest-element-in-an-array.md
│ │ ├── 22-generate-parentheses.md
│ │ ├── 234-palindrome-linked-list.md
│ │ ├── 236-lowest-common-ancestor-of-a-binary-tree.md
│ │ ├── 24-swap-nodes-in-pairs.md
│ │ ├── 26-remove-duplicates-from-sorted-array.md
│ │ ├── 27-remove-element.md
│ │ ├── 28-mirror-binary-tree.md
│ │ ├── 29-divide-two-integers.md
│ │ ├── 3-longest-substring-without-repeating-characters.md
│ │ ├── 31-next-permutation.md
│ │ ├── 34-find-first-and-last-position-of-element-in-sorted-array.md
│ │ ├── 36-valid-sudoku.md
│ │ ├── 40-combination-sum-ii.md
│ │ ├── 415-add-strings.md
│ │ ├── 43-multiply-strings.md
│ │ ├── 46-permutations.md
│ │ ├── 47-permutations-ii.md
│ │ ├── 48-rotate-image.md
│ │ ├── 49-group-anagrams.md
│ │ ├── 5-longest-palindromic-substring.md
│ │ ├── 50-powx-n.md
│ │ ├── 53-maximum-subarray.md
│ │ ├── 54-spiral-matrix.md
│ │ ├── 543-diameter-of-binary-tree.md
│ │ ├── 55-jump-game.md
│ │ ├── 56-merge-intervals.md
│ │ ├── 59-spiral-matrix-ii.md
│ │ ├── 62-unique-paths.md
│ │ ├── 7-reverse-integer.md
│ │ ├── 71-simplify-path.md
│ │ ├── 73-set-matrix-zeroes.md
│ │ ├── 74-search-a-2d-matrix.md
│ │ ├── 75-sort-colors.md
│ │ ├── 77-combinations.md
│ │ ├── 83-remove-duplicates-from-sorted-list.md
│ │ ├── 9-palindrome-number.md
│ │ ├── 92-reverse-linked-list-ii.md
│ │ ├── 958-check-completeness-of-a-binary-tree.md
│ │ ├── 98-validate-binary-search-tree.md
│ │ └── README.md
│ └── leetcode-share.md
├── mass-data
│ ├── 1-count-phone-num.md
│ ├── 2-find-hign-frequency-word.md
│ ├── 3-find-same-url.md
│ ├── 4-find-mid-num.md
│ ├── 5-find-hot-string.md
│ ├── 6-top-500-num.md
│ ├── 7-query-frequency-sort.md
│ ├── 8-topk-template.md
│ ├── 9-sort-500-million-large-files.md
│ └── README.md
├── message-queue
│ ├── kafka.md
│ ├── mq.md
│ ├── mq
│ │ └── consume-by-order.md
│ └── rabbitmq.md
├── note
│ ├── README.md
│ ├── computer-blogger.md
│ ├── computer-course.md
│ ├── computer-site.md
│ ├── computer-teacher.md
│ ├── computor-advice.md
│ ├── crash-course-computer-science.md
│ ├── docker-note.md
│ ├── freshman-planning.md
│ ├── redis-note.md
│ └── write-sql.md
├── other
│ ├── leave-a-message.md
│ ├── log-print.md
│ └── site-diary.md
├── practice
│ └── service-performance-optimization.md
├── redis
│ ├── article
│ │ ├── cache-db-consistency.md
│ │ ├── redis-cluster-work.md
│ │ ├── redis-duration.md
│ │ └── redis-multi-thread.md
│ ├── redis-basic-all.md
│ ├── redis-basic
│ │ ├── 1-introduce.md
│ │ ├── 10-lua.md
│ │ ├── 11-deletion-policy.md
│ │ ├── 12-others.md
│ │ ├── 2-data-type.md
│ │ ├── 3-data-structure.md
│ │ ├── 4-implement.md
│ │ ├── 5-sort.md
│ │ ├── 6-transaction.md
│ │ ├── 7-message-queue.md
│ │ ├── 8-persistence.md
│ │ ├── 9-cluster.md
│ │ └── README.md
│ └── redis.md
├── resource
│ └── 1-cs-books.md
├── snippets
│ └── ads.md
├── source
│ ├── mybatis
│ │ ├── # MyBatis 源码分析(七):接口层.md
│ │ ├── 1-overview.md
│ │ ├── 2-reflect.md
│ │ ├── MyBatis 源码分析3--基础支持模块.md
│ │ ├── MyBatis 源码分析4--运行时配置解析.md
│ │ ├── MyBatis 源码分析5--Mapper 通用配置解析.md
│ │ ├── MyBatis 源码分析6--statement 解析.md
│ │ └── MyBatis 源码分析8--执行器.md
│ ├── spring-mvc
│ │ ├── 1-overview.md
│ │ ├── 2-guide.md
│ │ ├── 3-scene.md
│ │ └── 4-fileupload-interceptor.md
│ └── spring
│ │ ├── 1-architect.md
│ │ ├── 10-bean-initial.md
│ │ ├── 11-application-refresh.md
│ │ ├── 12-aop-custom-tag.md
│ │ ├── 13-aop-proxy-advisor.md
│ │ ├── 14-aop-proxy-create.md
│ │ ├── 15-aop-advice-create.md
│ │ ├── 16-transactional.md
│ │ ├── 17-spring-transaction-aop.md
│ │ ├── 18-transaction-advice.md
│ │ ├── 19-transaction-rollback-commit.md
│ │ ├── 2-ioc-overview.md
│ │ ├── 3-ioc-tag-parse-1.md
│ │ ├── 4-ioc-tag-parse-2.md
│ │ ├── 5-ioc-tag-custom.md.md
│ │ ├── 6-bean-load.md
│ │ ├── 7-bean-build.md
│ │ ├── 8-ioc-attribute-fill.md
│ │ └── 9-ioc-circular-dependency.md
├── system-design
│ ├── 2-order-timeout-auto-cancel.md
│ └── README.md
├── tools
│ ├── docker-overview.md
│ ├── docker
│ │ ├── 1-introduce.md
│ │ ├── 2-image-command.md
│ │ ├── 3-container-command.md
│ │ ├── 4-docker-compose.md
│ │ ├── 5-maven-build.md
│ │ ├── 6-other.md
│ │ └── README.md
│ ├── git-overview.md
│ ├── git.md
│ ├── git
│ │ ├── 1-introduce.md
│ │ ├── 2-basic.md
│ │ ├── 3-remote-repo.md
│ │ ├── 4-label.md
│ │ ├── 5-branch.md
│ │ └── README.md
│ ├── linux-overview.md
│ ├── linux
│ │ ├── 1-basic.md
│ │ ├── 2-disk-file.md
│ │ ├── 3-search.md
│ │ ├── 4-net.md
│ │ ├── 5-monitor.md
│ │ └── README.md
│ ├── maven-overview.md
│ ├── maven
│ │ ├── 1-introduce.md
│ │ ├── 2-basic.md
│ │ ├── 3-dependency.md
│ │ ├── 4-repo.md
│ │ ├── 5-lifecycle.md
│ │ ├── 6-plugin.md
│ │ ├── 7-aggregator.md
│ │ ├── 8-inherit.md
│ │ └── README.md
│ ├── nginx.md
│ └── typora-overview.md
├── web
│ └── tomcat.md
├── zookeeper
│ ├── zk-usage.md
│ └── zk.md
└── zsxq
│ ├── article
│ ├── select-max-rows.md
│ ├── sideline-guide.md
│ ├── site-hack.md
│ ├── sql-optimize.md
│ └── 每年到年底总结工作述职的时候感觉自己好像啥都没干.md
│ ├── inner-material.md
│ ├── introduce.md
│ ├── mianshishouce.md
│ ├── question
│ ├── 2-years-tech-no-upgrade.md
│ ├── 3-years-confusion.md
│ ├── VO, BO, PO, DO, DTO.md
│ ├── familiarize-new-project-qucikly.md
│ ├── frontend-or-backend.md
│ ├── how-to-learn.md
│ ├── how-to-prepare-job-hopping.md
│ ├── java-or-bigdata.md
│ ├── offer选择:小红书vs阿里.md
│ ├── personality-test.md
│ ├── qa-or-java.md
│ ├── tech
│ │ └── service-expansion.md
│ ├── 三年测开转后端.md
│ ├── 二本学历,想出国读研.md
│ ├── 如何谈薪.md
│ ├── 怎样准备才能找到一份实习工作?.md
│ ├── 想跳槽进大厂,怎么提升技术.md
│ ├── 放弃大厂去外包.md
│ ├── 星球技术问题汇总.md
│ ├── 秋招0offer,打算去上培训班了....md
│ ├── 读博还是找工作.md
│ └── 非科班,想补基础.md
│ ├── share
│ ├── Java开发的16个小建议.md
│ ├── completable-future-bug.md
│ ├── oom.md
│ ├── slow-query.md
│ ├── spring-upgrade-copy-problem.md
│ ├── 分享10个高级SQL写法.md
│ └── 由“ YYYY-MM-dd ”引发的bug.md
│ ├── springboot-inner-material.md
│ ├── 春招来了,大家都在偷偷卷!.md
│ ├── 线上CPU飙升100%问题排查.md
│ ├── 这可能是最全民的面试题库了.md
│ └── 面试真题共享群.md
├── package-lock.json
└── package.json
/.gitignore:
--------------------------------------------------------------------------------
1 | .DS_Store
2 | *.log
3 | node_modules/
4 | *.bat
5 | *.sh
6 | .idea/
7 | *.py
8 | public/
9 | docs/.vuepress/.temp/
10 | docs/.vuepress/.cache/
11 | ByteDanceVerify.html
12 | google053c90e5a7354c40.html
13 | sogousiteverification.txt
--------------------------------------------------------------------------------
/CNAME:
--------------------------------------------------------------------------------
1 | topjavaer.cn
2 |
--------------------------------------------------------------------------------
/docs/.vuepress/enhanceApp.js:
--------------------------------------------------------------------------------
1 | export default ({router}) => {
2 | router.beforeEach((to, from, next) => {
3 | //对每个页面点击添加百度统计
4 | if(typeof _hmt!='undefined'){
5 | if (to.path) {
6 | _hmt.push(['_trackPageview', to.fullPath]);
7 | }
8 | }
9 |
10 | // continue
11 | next();
12 | })
13 | };
14 |
--------------------------------------------------------------------------------
/docs/.vuepress/styles/index.scss:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tyson0314/Java-learning/9690a43241c7d21a77faa0928a27499d46d47c6d/docs/.vuepress/styles/index.scss
--------------------------------------------------------------------------------
/docs/.vuepress/styles/palette.scss:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tyson0314/Java-learning/9690a43241c7d21a77faa0928a27499d46d47c6d/docs/.vuepress/styles/palette.scss
--------------------------------------------------------------------------------
/docs/about/contact.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | ---
4 |
5 | ## 联系我
6 |
7 | 如果有什么疑问或者建议,欢迎添加大彬微信进行交流~
8 |
9 | 
10 |
11 |
 21 |
22 | 
23 |
24 |
21 |
22 | 
23 |
24 |  25 |
26 | 感兴趣的小伙伴可以扫描下方的二维码**加我微信**,**备注加群**,我拉你进群,一起学习成长!
27 |
28 | 
29 |
--------------------------------------------------------------------------------
/docs/advance/concurrent/README.md:
--------------------------------------------------------------------------------
1 | ## 高并发专题(更新中)
2 |
3 | - [限流算法](./1-current-limiting.md)
4 | - [负载均衡](./2-load-balance.md)
5 |
--------------------------------------------------------------------------------
/docs/advance/design-pattern/1-principle.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 设计模式的六大原则
4 | category: 设计模式
5 | tag:
6 | - 设计模式
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 设计模式的六大原则,设计模式,设计模式面试题
11 | - - meta
12 | - name: description
13 | content: 设计模式常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 设计模式的六大原则
17 |
18 | - 开闭原则:对扩展开放,对修改关闭,多使用抽象类和接口。
19 | - 里氏替换原则:基类可以被子类替换,使用抽象类继承,不使用具体类继承。
20 | - 依赖倒转原则:要依赖于抽象,不要依赖于具体,针对接口编程,不针对实现编程。
21 | - 接口隔离原则:使用多个隔离的接口,比使用单个接口好,建立最小的接口。
22 | - 迪米特法则:一个软件实体应当尽可能少地与其他实体发生相互作用,通过中间类建立联系。
23 | - 合成复用原则:尽量使用合成/聚合,而不是使用继承。
24 |
25 |
--------------------------------------------------------------------------------
/docs/advance/design-pattern/7-iterator.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 设计模式之迭代器模式
4 | category: 设计模式
5 | tag:
6 | - 设计模式
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 迭代器模式,设计模式,迭代器
11 | - - meta
12 | - name: description
13 | content: 设计模式常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 迭代器模式
17 |
18 | 提供一种方法顺序访问一个聚合对象中的各个元素, 而又不暴露其内部的表示。
19 |
20 | 把在元素之间游走的责任交给迭代器,而不是聚合对象。
21 |
22 | **应用实例:**JAVA 中的 iterator。
23 |
24 | **优点:** 1、它支持以不同的方式遍历一个聚合对象。 2、迭代器简化了聚合类。 3、在同一个聚合上可以有多个遍历。 4、在迭代器模式中,增加新的聚合类和迭代器类都很方便,无须修改原有代码。
25 |
26 | **缺点:**由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
27 |
28 | **使用场景:** 1、访问一个聚合对象的内容而无须暴露它的内部表示。 2、需要为聚合对象提供多种遍历方式。 3、为遍历不同的聚合结构提供一个统一的接口。
29 |
30 | **迭代器模式在JDK中的应用**
31 |
32 | ArrayList的遍历:
33 |
34 | ```java
35 | Iterator iter = null;
36 |
37 | System.out.println("ArrayList:");
38 | iter = arrayList.iterator();
39 | while (iter.hasNext()) {
40 | System.out.print(iter.next() + "\t");
41 | }
42 | ```
43 |
44 |
45 |
46 |
--------------------------------------------------------------------------------
/docs/advance/design-pattern/9-adapter.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 设计模式之适配器模式
4 | category: 设计模式
5 | tag:
6 | - 设计模式
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 适配器模式,设计模式,适配器
11 | - - meta
12 | - name: description
13 | content: 设计模式常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 适配器模式
17 | 适配器模式将现成的对象通过适配变成我们需要的接口。 适配器让原本接口不兼容的类可以合作。
18 |
19 | 适配器模式有类的适配器模式和对象的适配器模式两种不同的形式。
20 |
21 | 对象适配器模式通过组合对象进行适配。
22 |
23 | 
24 |
25 | 类适配器通过继承来完成适配。
26 |
27 | 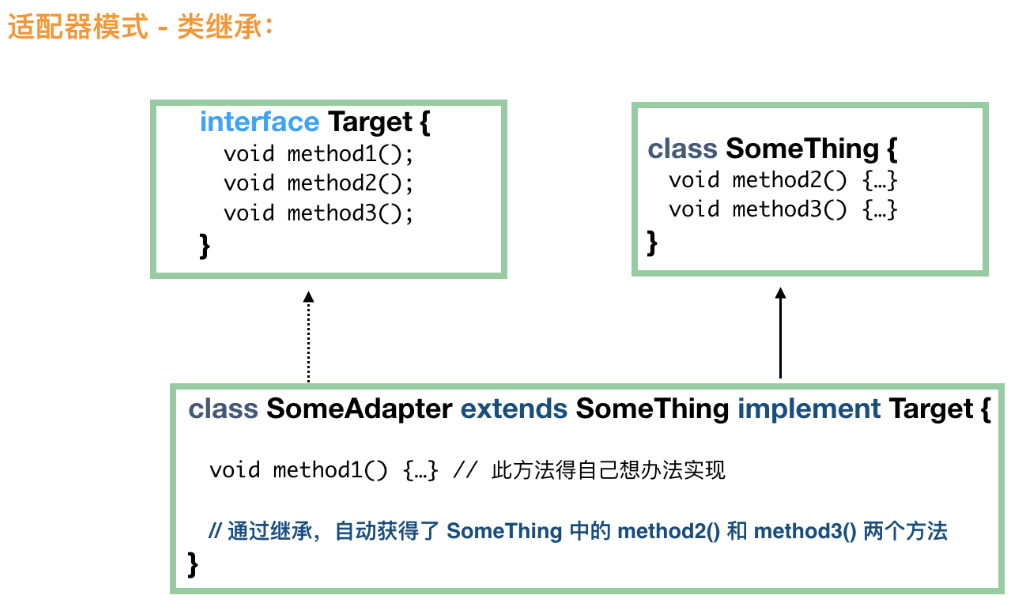
28 |
29 | 适配器模式的**优点**:
30 |
31 | 1. 更好的复用性。系统需要使用现有的类,而此类的接口不符合系统的需要。那么通过适配器模式就可以让这些功能得到更好的复用。
32 | 2. 更好的扩展性。在实现适配器功能的时候,可以调用自己开发的功能,从而自然地扩展系统的功能。
33 |
34 |
--------------------------------------------------------------------------------
/docs/advance/design-pattern/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 设计模式
3 | icon: design
4 | date: 2022-08-07
5 | category: 设计模式
6 | star: true
7 | ---
8 |
9 | ::: tip 这是一则或许对你有帮助的信息
10 |
11 | - **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
12 | - **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
13 |
14 | :::
15 |
16 | **本专栏是大彬学习设计模式基础知识的学习笔记,如有错误,可以在评论区指出**~
17 |
18 | ## 设计模式详解
19 |
20 | - [设计模式的六大原则](./1-principle.md)
21 | - [单例模式](./2-singleton.md)
22 | - [工厂模式](./3-factory.md)
23 | - [模板模式](./4-template.md)
24 | - [策略模式](./5-strategy.md)
25 | - [责任链模式](./6-chain.md)
26 | - [迭代器模式](./7-iterator.md)
27 | - [装饰模式](./8-decorator.md)
28 | - [适配器模式](./9-adapter.md)
29 | - [观察者模式](./10-observer.md)
30 | - [代理模式](./11-proxy.md)
31 | - [建造者模式](./12-builder.md)
32 |
--------------------------------------------------------------------------------
/docs/advance/distributed/5-distibuted-arch.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 分布式架构
4 | category: 分布式
5 | tag:
6 | - 分布式架构
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 分布式架构,限流,熔断
11 | - - meta
12 | - name: description
13 | content: 分布式常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 分布式架构,微服务、限流、熔断....
17 |
18 | [分布式架构,微服务、限流、熔断....](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247490543&idx=1&sn=ee34bee96511d5e548381e0576f8b484&chksm=ce98e6a9f9ef6fbf7db9c2b6d2fed26853a3bc13a50c3228ab57bea55afe0772008cdb1f957b&token=1594696656&lang=zh_CN#rd)
19 |
--------------------------------------------------------------------------------
/docs/advance/distributed/README.md:
--------------------------------------------------------------------------------
1 | ## 目录
2 |
3 | - [全局唯一ID生成方案](./1-global-unique-id.md)
4 | - [分布式锁](./2-distributed-lock.md)
5 | - [RPC](./3-rpc.md)
6 | - [微服务](./4-micro-service.md)
7 | - [分布式架构,微服务、限流、熔断....](./6-distibuted-arch.md)
8 | - [分布式事务](./7-distributed-transaction.md)
9 |
--------------------------------------------------------------------------------
/docs/advance/excellent-article/11-8-architect-pattern.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 8种架构模式
4 | category: 优质文章
5 | tag:
6 | - 架构
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 架构模式
11 | - - meta
12 | - name: description
13 | content: 优质文章汇总
14 | ---
15 |
16 | # 8种架构模式
17 |
18 | [8种架构模式](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247490779&idx=2&sn=eff9e8cf9b15c29630514a137f102701&chksm=ce98e19df9ef688bd9c7b775658c704a51b7961347a7aabf70e6c555cb57560aa5e8b1e497a1&token=1170645384&lang=zh_CN#rd)
19 |
--------------------------------------------------------------------------------
/docs/advance/excellent-article/29-idempotent-design.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 接口的幂等性如何设计?
4 | category: 优质文章
5 | tag:
6 | - Spring Boot
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 接口幂等,幂等性
11 | - - meta
12 | - name: description
13 | content: 努力打造最优质的Java学习网站
14 | ---
15 |
16 | ## 接口的幂等性如何设计?
17 |
18 | 分布式系统中的某个接口,该如何保证幂等性?
19 |
20 | 假如有个服务提供一个付款接口供外部调用,这个服务部署在了 5 台机器上。然后用户在前端上操作的时候,不小心发起了两次支付请求,然后这俩请求分散在了这个服务部署的不同的机器上,结果一个订单扣款扣两次。
21 |
22 | 这就是典型的接口幂等性问题。
23 |
24 | 所谓幂等性,就是说一个接口,多次发起同一个请求,你这个接口得保证结果是准确的,比如不能多扣款、不能多插入一条数据、不能将统计值多加了 1。这就是幂等性。
25 |
26 | 其实保证幂等性主要是三点:
27 |
28 | 对于每个请求必须有一个唯一的标识,举个例子:订单支付请求,肯定得包含订单 id,一个订单 id 最多支付一次。每次处理完请求之后,必须有一个记录标识这个请求处理过了。常见的方案是在数据库中记录一个状态,比如支付之前记录一条这个订单的支付流水。
29 |
30 | 每次接收请求需要进行判断,判断之前是否处理过。如果订单已经支付了,就已经有了一条支付流水,那么如果重复发送这个请求,则此时先插入支付流水,orderId 已经存在了,唯一键约束生效,报错插入不进去的。然后你就不用再扣款了。
31 |
32 | 实际运作过程中,你要结合自己的业务来,比如说利用 Redis,用 orderId 作为唯一键。只有成功插入这个支付流水,才可以执行实际的支付扣款。
33 |
34 | 要求是支付一个订单,必须插入一条支付流水,order_id 建一个唯一键 unique key 。你在支付一个订单之前,先插入一条支付流水,order_id 就已经进去了。你就可以写一个标识到 Redis 里面去, set order_id payed ,下一次重复请求过来了,先查 Redis 的 order_id 对应的 value,如果是 payed 就说明已经支付过了,就别重复支付了。
35 |
--------------------------------------------------------------------------------
/docs/advance/excellent-article/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## 优质文章汇总
3 |
4 | - [Redis如何实现库存扣减操作和防止被超卖?](./1-redis-stock-minus.md)
5 | - [@Transactional事务注解详解](./2-spring-transaction.md)
6 | - [SpringBoot自动装配原理](./3-springboot-auto-assembly.md)
7 | - [干掉“重复代码”的技巧有哪些](./4-remove-duplicate-code.md)
8 | - [一次简单的 *JVM* 调优,拿去写到简历里](./5-jvm-optimize.md)
9 | - [Spring为何需要三级缓存解决循环依赖,而不是二级缓存?](./6-spring-three-cache.md)
10 | - [8种最坑SQL语法](./7-sql-optimize.md)
11 | - [面试官:如何保证接口幂等性?一口气说了12种方法!](./8-interface-idempotent.md)
12 | - [美团面试:熟悉哪些JVM调优参数?](./9-jvm-optimize-param.md)
13 | - [大文件上传时如何做到秒传?](./10-file-upload.md)
14 | - [8种架构模式](./11-8-architect-pattern.md)
15 | - [MySQL最大建议行数 2000w,靠谱吗?](./12-mysql-table-max-rows.md)
16 | - [order by是怎么工作的?](./13-order-by-work.md)
17 | - [架构的演进](./14-architect-forward.md)
18 | - [有了HTTP,为啥还要用RPC](./15-http-vs-rpc.md)
19 | - [什么是JWT](./16-what-is-jwt.md)
20 | - [限流的几种方案](./17-limit-scheme.md)
21 | - [为什么说数据库连接很消耗资源](./18-db-connect-resource.md)
22 | - [Java19新特性](./19-java19.md)
23 | - [几种常见的架构模式](./20-architect-pattern.md)
24 | - [新一代分布式任务调度框架](./22-distributed-scheduled-task.md)
25 | - [Arthas 常用命令](./23-arthas-intro.md)
--------------------------------------------------------------------------------
/docs/advance/system-design/19-high-concurrent-system-design.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何设计一个高并发系统?
4 | category: 场景设计
5 | tag:
6 | - 场景设计
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 场景设计面试题,高并发系统,高并发系统设计,场景设计
11 | - - meta
12 | - name: description
13 | content: 场景设计常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 如何设计一个高并发系统?
17 |
18 | ## 总览
19 |
20 | 在高并发的情景下进行系统设计,
21 |
22 | 可以分为以下 6 点:
23 |
24 | - 系统拆分
25 | - 熔断
26 | - 降级
27 | - 缓存
28 | - MQ
29 | - 分库分表
30 | - 读写分离
31 | - ElasticSearch
32 |
33 | 
34 |
35 | ### 系统拆分
36 |
37 | 将一个系统拆分为多个子系统,用 RPC 来搞。然后每个系统连一个数据库,这样本来就一个库,现在多个数据库,分担系统压力。
38 |
39 | ### 缓存
40 |
41 | 大部分的高并发场景,都是读多写少,那你完全可以在数据库和缓存里都写一份,然后读的时候大量走缓存就可以了。毕竟 Redis 轻轻松松单机几万的并发。所以你可以考虑你的项目里,那些承载主要请求的读场景,怎么用缓存来抗高并发。
42 |
43 | ### MQ
44 |
45 | 可能你还是会出现高并发写的场景,比如说一个业务操作里要频繁搞数据库几十次,增删改增删改。那高并发绝对搞挂你的系统,你要是用 Redis 来承载写那肯定不行,人家是缓存,数据随时就被 LRU 了,数据格式还很简单,没有事务支持。所以该用 MySQL 还得用 MySQL 啊。那你咋办?用 MQ 吧,大量的写请求灌入 MQ 里,后边系统消费后慢慢写,控制在 MySQL 承载范围之内。所以你可以考虑你的项目里,那些承载复杂写业务逻辑的场景里,如何用 MQ 来异步写,提升并发性。
46 |
47 | ### 分库分表
48 |
49 | 分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就将一个数据库拆分为多个库,多个库来扛更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高 SQL 执行的性能。
50 |
51 | ### 读写分离
52 |
53 | 读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。
54 |
55 | ### ElasticSearch
56 |
57 | ES 是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来扛更高的并发。那么一些比较简单的查询、统计类的操作,可以考虑用 ES 来承载,还有一些全文搜索类的操作,也可以考虑用 ES 来承载。
58 |
59 |
60 |
61 |
62 |
63 | > 参考链接:https://hadyang.com/interview/docs/architecture/concurrent/design/
64 |
--------------------------------------------------------------------------------
/docs/advance/system-design/3-file-send.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何把一个文件较快的发送到100w个服务器?
4 | category: 场景设计
5 | tag:
6 | - 场景设计
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 场景设计面试题,文件发送,场景设计
11 | - - meta
12 | - name: description
13 | content: 场景设计常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | ## 如何把一个文件较快的发送到100w个服务器?
17 |
18 | 可以采用p2p网络形式,比如树状形式,单个节点既可以从其他节点接收服务又可以向其他节点提供服务。
19 |
20 | 不过,树状结构会有什么问题呢?
21 |
22 | 第一,如果树上的某一个节点坏掉了,那么从这个节点往下的所有服务器全部接收不到文件。
23 |
24 | 第二,如果树中的某条路径,因为网络因素等原因,传递速度比较慢,导致传递时间比较长,这样会使传递效率退化。
25 |
26 | 改进的方案如下:
27 |
28 | 可以使用**连通图**。100W台服务器相当于有100W个节点的连通图。我们可以在图里生成多颗不同的生成树,在进行数据下发时,同时按照多颗不同的树去传递数据。这样就可以避免某个中间节点宕机,影响到后续的节点。同时这种传递方法实际上是一种依据时间的广度优先遍历,可以避免某条路径过长造成的效率低下。
29 |
--------------------------------------------------------------------------------
/docs/advance/system-design/4-oversold.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 超卖问题
4 | category: 场景设计
5 | tag:
6 | - 场景设计
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 场景设计面试题,超卖问题,场景设计
11 | - - meta
12 | - name: description
13 | content: 场景设计常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 超卖问题
17 |
18 | 先到数据库查询库存,在减库存。不是原子操作,会有超卖问题。
19 |
20 | 通过加排他锁解决该问题。
21 |
22 | - 开始事务。
23 | - 查询库存,并显式的设置排他锁:SELECT * FROM table_name WHERE … FOR UPDATE
24 | - 生成订单。
25 | - 去库存,update会隐式的设置排他锁:UPDATE products SET count=count-1 WHERE id=1
26 | - commit,释放锁。
27 |
28 | 也可以通过乐观锁实现。使用版本号实现乐观锁。
29 |
30 | 假设此时version = 100, num = 1; 100个线程进入到了这里,同时他们select出来版本号都是version = 100。
31 |
32 | 然后直接update的时候,只有其中一个先update了,同时更新了版本号。
33 |
34 | 那么其他99个在更新的时候,会发觉version并不等于上次select的version,就说明version被其他线程修改过了,则放弃此次update,重试直到成功。
35 |
36 | ```mysql
37 | select version from goods WHERE id= 1001
38 | update goods set num = num - 1, version = version + 1 WHERE id= 1001 AND num > 0 AND version = @version(上面查到的version);
39 | ```
40 |
--------------------------------------------------------------------------------
/docs/advance/system-design/README.md:
--------------------------------------------------------------------------------
1 | **系统设计高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到Java面试手册**完整版**。
2 |
3 | 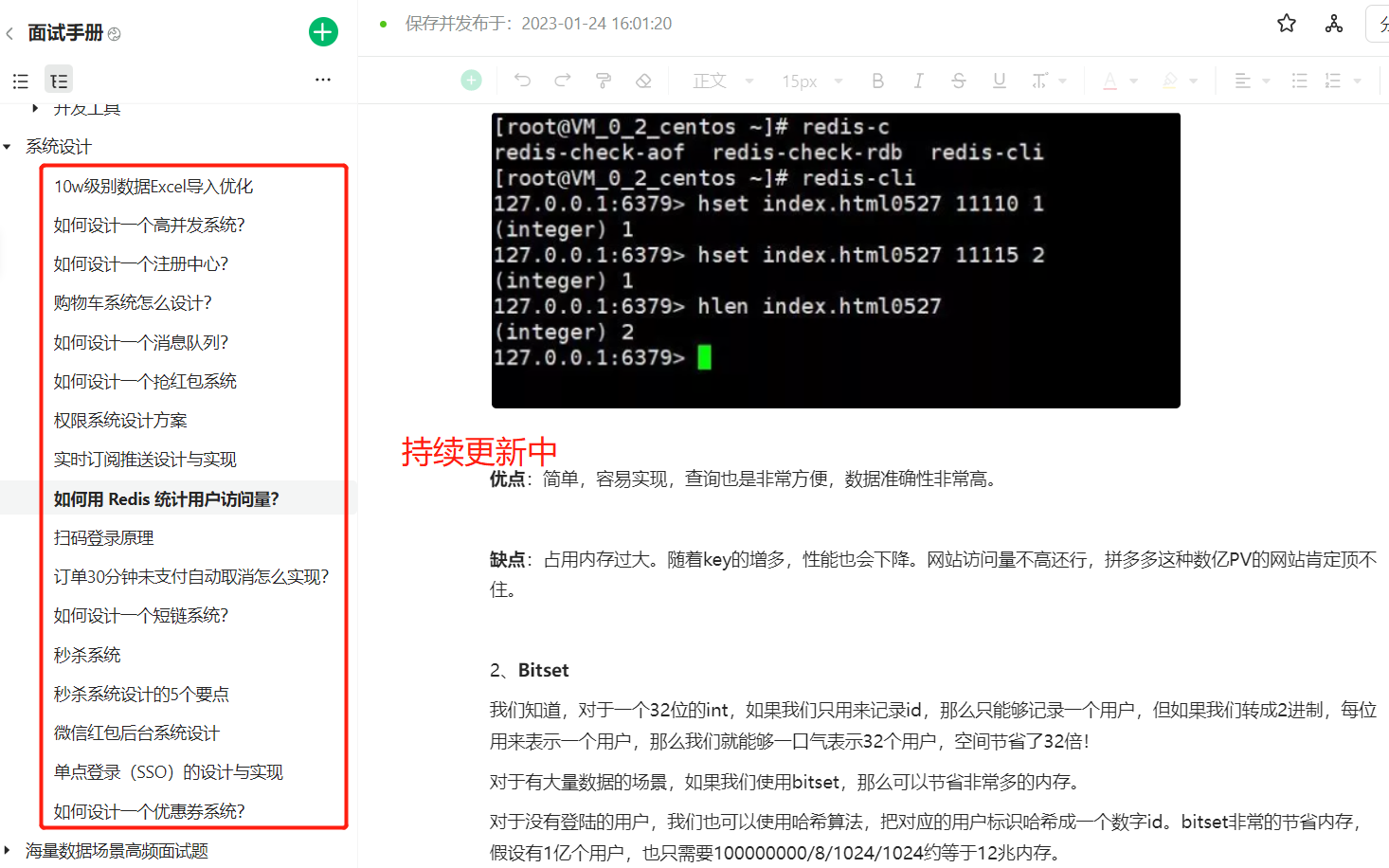
4 |
5 | 另外星球提供**专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
6 |
7 | 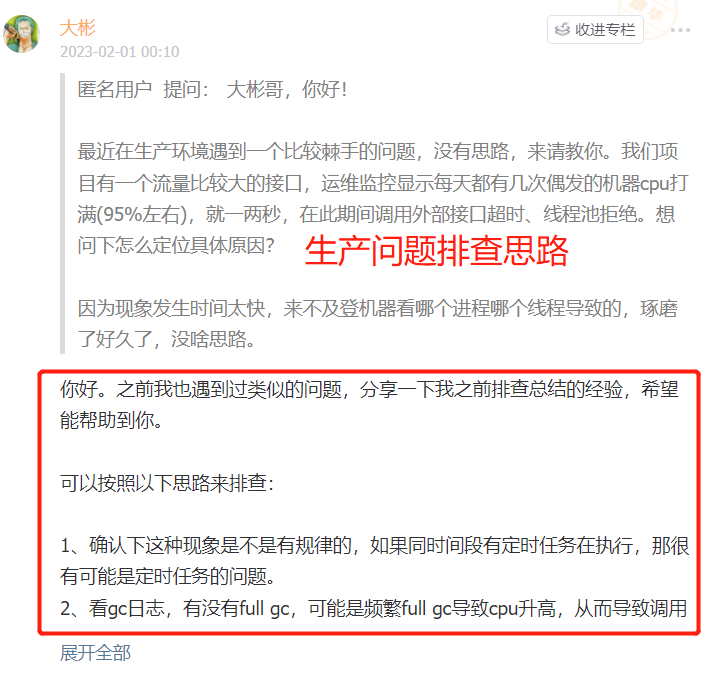
8 |
9 | 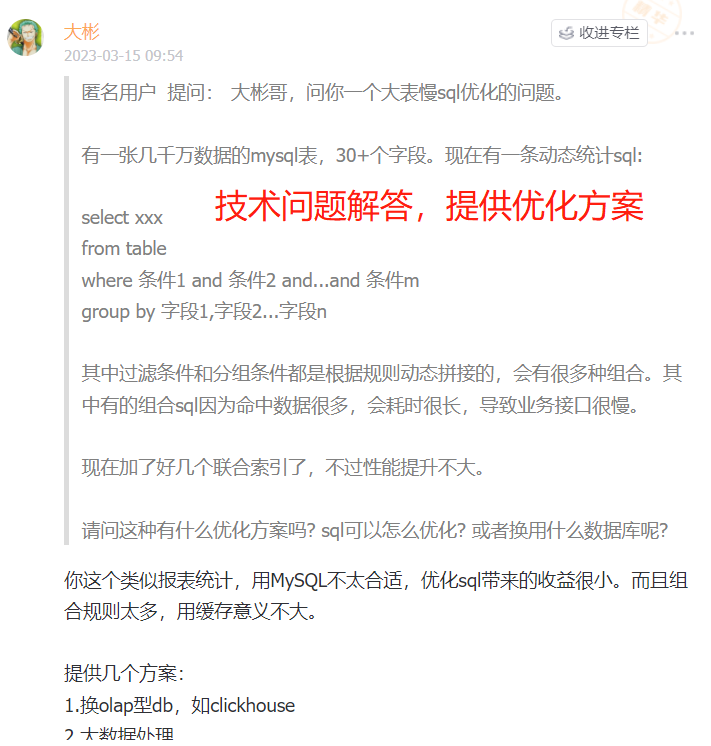
10 |
11 | 
12 |
13 | 如果你正在打算准备跳槽、面试,星球还提供**简历指导、修改服务**,大彬已经帮**120**+个小伙伴修改了简历,相对还是比较有经验的。
14 |
15 | 
16 |
17 | 
18 |
19 | 星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
20 |
21 | 
22 |
23 | 
24 |
25 | 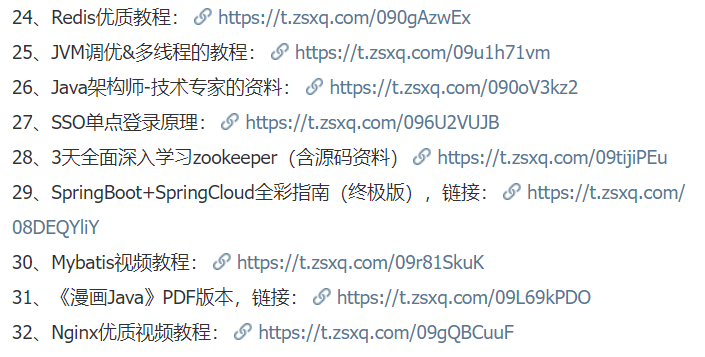
26 |
27 | 怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
28 |
29 | **扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
30 |
31 | 随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
32 |
33 | 
--------------------------------------------------------------------------------
/docs/campus-recruit/README.md:
--------------------------------------------------------------------------------
1 | 分享校招公司招聘信息,写简历技巧、面试技巧。
2 |
3 | 愿所有正在参与秋招的小伙伴能够找到一份满意的好工作!
--------------------------------------------------------------------------------
/docs/campus-recruit/biggest-difficulty.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 你在项目里遇到的最大困难是什么,如何解决的?
4 | category: 分享
5 | tag:
6 | - 面试题
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 项目里遇到的最大困难是什么
11 | - - meta
12 | - name: description
13 | content: 你在项目里遇到的最大困难是什么,如何解决的?
14 | ---
15 |
16 | ## 你在项目里遇到的最大困难是什么,如何解决的?
17 |
18 | 这是一道面试高频题,但是很多人都没能回答好,或者说没有准备好怎么去回答。
19 |
20 | 今天跟大家分享我是如何去回答这个问题的。
21 |
22 | 很多人可能觉得,自己每天都是干着CRUD的工作,难一点,再加个缓存,没有什么困难的地方。就算当时真的觉得有困难,做完了也就不觉得困难了。
23 |
24 | 其实,大部分人都是这样的状态,没有谁天天能遇到一些框架上的疑难杂症、超乎意外的生产问题,这种疑难问题很少,出现了可能也轮不到你处理。不过如果遇到这种问题的话,不管你是不是主要处理人,我建议你能主动参与进去,去分析问题产生的问题,应该怎么去处理,事后做好**复盘总结**。做好这些之后,面试就有的吹水了。
25 |
26 | 再者,平时开发过程多多少少也是会遇到一些问题,可以把遇到的这些问题记录下来,多去思考、网上搜索,或者跟别人请教,无论是怎样解决,解决以后,需要对问题进行**复盘总结**。比如下面就是我工作中遇到的OOM问题复盘总结,建议大家也养成记录的习惯。
27 |
28 | 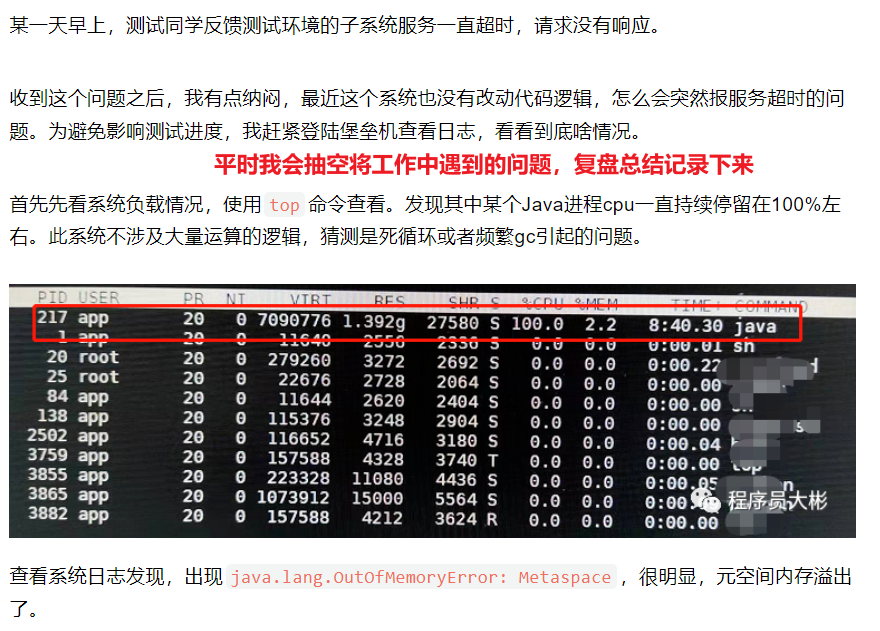
29 |
30 | 另外,关于“你在项目里遇到的最大困难是什么,如何解决的?”这个问题,可以使用 star 法则去回答:
31 |
32 | - Situation(背景信息):事情是在什么情况下发生,比如在生产环境遇到xxx问题
33 | - Target(目标任务):你的目标任务是什么,比如保证线上服务稳定、分析问题产生原因等
34 | - Action(采取的行动):针对这样的情况分析,你采用了什么行动方式,比如先重启保证服务正常,之后再进行分析等
35 | - Result(取得的成果):结果怎样,在这样的情况下你学习到了什么
36 |
37 |
38 |
39 | 最后总结一下,最重要是平时要多复盘总结,积累面试素材。不管是多小的问题,只要你认真对待,总能学到一些知识。大部分面试官也不会期待你有处理过多大的问题,毕竟大部分人都是普通人。只要能从你的回答中看出你的思考,解决问题的方式,那么面试官的问这个问题的目的也就达到了。
40 |
--------------------------------------------------------------------------------
/docs/campus-recruit/career-plan.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 程序员职业规划分享
4 | category: 分享
5 | tag:
6 | - 面试题
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 职业规划
11 | - - meta
12 | - name: description
13 | content: 面试高频题,职业规划
14 | ---
15 |
16 | 分享一下我的看法。
17 |
18 | 程序员的职业未来分为三个阶段,每个阶段都会遇到一个区分门槛。
19 |
20 | ## 第一阶段:前三年
21 |
22 | 工作前三年是程序员的第一道门槛,这三年会逐渐淘汰一批不适合写代码的人。
23 |
24 | 在这个阶段,我们走出校园,迈入社会,成为一名程序员,开始把书本上的知识应用到的真正的企业级开发。我们学会了如何团队协作、如何使用项目管理工具、项目版本如何控制、写的代码如何测试、如何在线上运行等等。
25 |
26 | 前三年,积累了一定的开发经验,也对代码有了一定深入的认识,是一个比较纯粹的码农阶段。
27 |
28 |
29 |
30 | ## 第二阶段:第五年
31 |
32 | 第五年是程序员的第二个门槛,这一年程序员的工作已经基本定型。
33 |
34 | 有些人在这五年里,除了完成工作,闲余时间就不会研究别的东西,这些人永远就是个码农。等到年纪大了便会被年轻人给替代。
35 |
36 | 有些人在这五年里,除了写代码,还热衷于研究各种技术实现细节、看了很多好书、写一些博客分享技术,这些人在五年后必然具备在技术上独当一面的能力并且清楚自己未来的发展方向,从一个码农逐步走向系统分析师或是架构师,成为项目组中不可或缺的人物。
37 |
38 |
39 |
40 | ## 第三阶段:第十年
41 |
42 | 第十年是程序的第三个门槛,转行或是继续做一名程序员就在这个节点上。
43 |
44 | 如果在前几年就抱定不转行的思路并且为之努力的话,那么在十年的这个节点上,有些人必然成长为一名对行业有着深入认识、对技术有着深入认识、能从零开始对一个产品进行分析的程序员,这样的人在公司基本担任的都是CTO、技术专家、首席架构师等最关键的职位。在这个阶段,还需要有趋势预判的能力,能够提前看到市场在未来几年的红利和缺口,提前进行布局,学习将来会稀缺的技术,积极主动去探索。
45 |
46 |
47 |
48 | > 参考:https://segmentfault.com/a/1190000040241465
49 |
--------------------------------------------------------------------------------
/docs/campus-recruit/hr-ask-offers.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: HR问目前拿到哪几个offer了,怎么回答好?
4 | category: 分享
5 | tag:
6 | - 面试题
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 面试题
11 | - - meta
12 | - name: description
13 | content: HR问目前拿到哪几个offer了,怎么回答好?
14 | ---
15 |
16 | ## HR问目前拿到哪几个offer了,怎么回答好?
17 |
18 | 这是比较常见的面试问题。
19 |
20 | HR提问的目的是要把握候选人的求职进展情况。
21 |
22 | 如果你手里已经有Offer了,公司综合评估你是比较适合的候选人,就会争取尽快和你进行薪酬谈判,尽快发Offer,推进的速度可以很快。
23 |
24 | HR也会根据你拿到的Offer的情况,评估你在市场上对标的位置一一有助于HR评估你接公司Offer,并且顺利入职的可能性。假如你拿到的offer是30w左右,而HR根据你前边面试情况定级,最高只能给到20w,那么这种情况大概率你会选择30w年薪的offer,HR可能就不会给你发offer了,而是考虑其他有可能入职的应聘者。
25 |
26 | 那么你该如何回答这个问题呢。
27 |
28 | ### 没有Offer
29 |
30 | 如果你目前还没有offer,可以说“目前没有,有两家公司在谈,还没发书面Offer。”
31 |
32 | 或者说:“还没有,我刚刚开始看机会。”
33 |
34 | 如果你真的是面试很多家,但是都没有什么成果。这个千万不要让对方知道,不然对方通过该信息得出的结论就是:这个人可能水平不是很高,没啥竞争力。可能HR面试你就被挂了。
35 |
36 | 不管面了多少家,只要没有Offer,都可以说刚刚开始面试。
37 |
38 | ### 手头有Offer,还在择优选择中
39 |
40 | 如果你手里有Offer,可以坦诚说大体信息。我们的目的是拿到所有Offer, 所以,一定要表达,我更倾向你公司Offer。
41 |
42 | 比如我目前手里有两个Offer, 但是我更倾向加入咱们公司,因为咱们公司发展前景更好之类的话,让HR相信你是想加入他们公司的。
43 |
44 | 如果对方没有问你什么公司,Offer多少。你就不要继续讲具体的内容。
45 |
46 | 可能HR会追问“是哪家公司? 给你Offer多少?”
47 |
48 | 这个时候,我建议不要诱露公司具体的名字。可以说某行业,比如“我有两个Offer,一个是金融行业独角兽,一个是互联网公司的”。这样含糊回答即可。
49 |
50 | 另外,不要说有太多Offer,即便你真的有很多,就说2-3个。站在HR的角度,候选人手里那么多Offer,还没确定去哪家,在市场上不断面试,大概率是来练手的。这种情况在HR面试估计就被pass了。
51 |
52 |
53 |
54 | 总之,回答要往对自己有利的方向进行,还有就是要自信。
55 |
56 |
57 |
58 | > 参考链接:https://www.zhihu.com/question/23751641
59 |
--------------------------------------------------------------------------------
/docs/campus-recruit/interview-question-career-plan.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 面试时问你的职业规划,该怎么回答?
4 | category: 分享
5 | tag:
6 | - 面试题
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 面试题,职业规划
11 | - - meta
12 | - name: description
13 | content: 面试时问你的职业规划,该怎么回答?
14 | ---
15 |
16 | ## 面试时问你的职业规划,该怎么回答?
17 |
18 | 建议紧扣工作和学习两个维度回答
19 |
20 | **第一点**: 介绍自己认真思考过这个问题,自己的规划是基于目前的实际情况来设计的,不是凭空想的。加分!加分! 加分!
21 |
22 | **第二点**:工作方面,突出自己打算通过积极完成工作任务,积累各方面的经验,让自己成为这个领域的专业人士,也希望有机会能够带领团队,成为优秀的管理者,为单位做出更大贡献,获得双赢。加分!加分! 加分!
23 |
24 | **第三点**: 在学习方面,打算在专业领域做进一步学习和研究,将实践经验与专业知识只相结合,为自己的职业成长做好铺垫,打好基础。加分!加分!加分!
25 |
26 | 根据以上的关键点,参考回复:
27 |
28 | **参考回复1**:
29 |
30 | 首先,自己认真思考过这个问题,自己的规划是基于目前的实际情况来设计的,不是凭空想的,自已毕竟刚毕业或者工作时间不长,经验还欠缺
31 |
32 | 其次,在工作方面,我打算通过积极完成工作任务,积累各方面的经验,让自己成为这个领域的专业人士,也希望有机会能够带领团队,成为优秀的管理者,为单位做出更大贡献
33 |
34 | 第三,在学习方面,打算在专业领域做进一步学习和研究,将实践经验与专业知识相结合,为自己的职业成长做好铺垫,打好基础。谢谢!
35 |
36 | **参考回复2**:
37 |
38 | 未来一年:我希望通过自己的学习和实践,加深对行业和岗位的理解,能够独立完成一些小项目,推动业务的发展。对此,我会针对性的看一些相关的书籍,与公司和行业的前辈多沟通交流,多调研用户加深业务的熟悉程度,并有机会成为业务本身的用户。
39 |
40 | 未来三年:可以同时独立负责几个项目,在完成任务本身的基础上主动做优化和迭代,总结形成自己的方法论和工作方式。对此,我会多整理复盘学习成果,延伸学习产品、技术等专业知识。
41 |
42 | 未来五年:可以带自己的team或者实习生,将所学所得与他们进行沟通交流,从团队协作和业务两方面共同提升团队效益;同时有机会跟业内的大牛老师交流学习共事。对此,我会学习一些心理学、管理学等相关知识,拓宽对团队管理方面的学习,并拓展在业务本身和上下游各联动产业的学习。
43 |
44 | > Tips: 回答这个问题强调你稳定性,踏实工作的态度,重点在工作技能方面的提升与内在积累,不要描述外在的东西,比如职位,薪资。
45 |
46 |
47 |
48 | 参考链接:https://www.zhihu.com/question/20054953
49 |
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/11-lixiang-car.md:
--------------------------------------------------------------------------------
1 | ## 理想汽车面经
2 |
3 | 一面:
4 |
5 | 1. 谈谈你常用的集合
6 | 2. arrarylist与linkedlist区别
7 | 3. hashmap扩容机制
8 | 4. 为什么用红黑树?
9 | 5. 线程安全吗? 怎么不安全?
10 | 6. 具体场景如何优化
11 | 7. concurrentHashMap实现原理
12 | 8. CAS自旋ABA问题
13 | 9. 乐观锁悲观锁的实现
14 | 10. Svnchronized与lock的区别
15 | 11. ReentrantLocklock中可公平锁是如何实现的
16 | 12. 如何理解Java对象头与Monitor
17 | 13. 说一下你知道的线程池
18 | 14. 线程池的七个参数
19 | 15. 核心线程数五个,最大线程数十个,现在有八个线程,如何分配?
20 | 16. 它的队列是做什么的?
21 | 17. 说一下拒绝策略说一下ivm组成吧
22 | 18. 哪些是公有的,哪些是私有的
23 | 19. 类加载过程双亲委派原理
24 | 20. 如何实现自定义类加载器
25 | 21. 对象创建的主要流程
26 | 22. 常用的垃圾回收器
27 | 23. 简单说一下垃圾回收算法
28 | 24. 你常用的索引(B树、哈希)
29 | 25. 在各种树里面为什么选择B+树 (AVL、红黑树、二叉树)
30 | 26. 索引失效的情况
31 | 27. 最左匹配原则
32 | 28. 谈谈mvcc
33 | 29. 内连接怎么实现
34 | 30. 事务的特性隔离级别
35 | 31. 什么是幻读
36 | 32. MVISAM与InnoDB区别
37 | 33. 引擎是如何实现事务四个特性的
38 |
39 | 二面:
40 | 1. 随着学习,项目中哪些点有更好的实现方式了吗
41 | 2. 实习项目说了消息中间件问了几种消息中间件的区别
42 | 3. sprngboot的常用注解以及含义
43 | 4. 你对spring的iocaop的理解
44 | 5. #几和$的区别说一下
45 | 6. mvbatis的一级缓存与二级缓存
46 | 7. Java四种引用
47 | 8. string与stringbuilder与stringbuffer说一下
48 | 9. 实现链表冒泡排序的思路
49 | 10. 了解的设计模式说一下
50 | 11. 单例模式懒汉饿汉的应用场景
51 | 12. 还有一道算法题(时间太久忘了)
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/2-tencent.md:
--------------------------------------------------------------------------------
1 | # 腾讯
2 |
3 | ## 一面
4 | 1. mysql索引结构?
5 | 2. redis持久化策略?
6 | 3. zookeeper节点类型说一下;
7 | 4. zookeeper选举机制?
8 | 5. zookeeper主节点故障,如何重新选举?
9 | 6. syn机制?
10 | 7. 线程池的核心参数;
11 | 8. threadlocal的实现,原理,业务用来做什么?
12 | 9. spring DI的原理;
13 | 10. 四次挥手;
14 | 11. gc root选择;
15 | 12. 标记清除算法的过程,标记清楚算法如何给对象分配内存空间?
16 | 13. cms算法的缺点;
17 | ## 二面
18 | 1. CorruntHashmap理解
19 | 2. ThreadLocal原理
20 | 3. hashmap;
21 | 4. Java数据类型,同步机制;
22 | 5. 讲讲贪心算法;
23 | 6. 如果线上用户出现502错误你怎么排查?
24 | 7. 并发量很大,服务器宕机。你会怎么做?
25 | ## 三面
26 | 1. syn和lock的区别,哪个更好?怎么选择?
27 | 2. hashmap源码,为什么8个节点变成红黑树又为什么到了6个节点才恢复为链表?
28 | 3. 缓存穿透,怎么解决?
29 | 4. 负载均衡算法,实现;
30 | 5. 轮询和随机的缺点;
31 | 6. 分布式服务治理;
32 | 7. dns迭代和递归的区别;
33 | 8. 算法题:最长回文串
34 | 9. 为什么连接的时候是三次握手,关闭的时候却是四次握手?
35 | ## 四面
36 | 1. 自我介绍
37 | 2. 简单说说计算机网络
38 | 3. 简单描述一下从浏览器输入一个地址到服务端整个交互过程
39 | 4. 说说数据结构
40 | 5. 操作系统用过吗
41 | 6. 用过 linux 的哪些命令
42 | 7. 查看一个进程监听了哪些端口
43 | 8. 详细介绍项目(简历上的域名访问不了)
44 | 9. 讲解之前工作经历中做的东西
45 | 10.做一道算法题(判断二叉树是否对称)
46 | 10. java 如何从源代码转换成机器码执行的
47 | 11. java 的击穿
48 | 12. 网络的七层结构
49 | 13. tcp\udp 详解 区别
50 | 14. https 协议的交互过程
51 | 15. linux 基础命令
52 | 16. linux 开机过程
53 | 17. 了解现在市面上主流的 cpu 架构
54 | 18. fpga 概念了解吗
55 | 19. 市面上的图数据库
56 | 20. rdf 讲解
57 | 21. 图数据库底层存储
58 | 22. b 树,b+树的概念和区别
59 | 23. 红黑树平衡二叉树优缺点和应用场景
60 | 24. 有没有了解 docker 等云技术
61 |
62 |
63 |
64 | **最后给大家分享一份精心整理的大厂高频面试题PDF,需要的小伙伴可以自行下载:**
65 |
66 | [大厂面试手册](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247485445&idx=1&sn=1c6e224b9bb3da457f5ee03894493dbc&chksm=ce98f543f9ef7c55325e3bf336607a370935a6c78dbb68cf86e59f5d68f4c51d175365a189f8#rd)
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/7-shopee.md:
--------------------------------------------------------------------------------
1 | # shopee
2 |
3 | ## 面经1
4 |
5 | 消息队列如何保证可靠性
6 | 消息队列如何保证消息幂等性
7 | 消息队列的优缺点
8 | 为什么用b+树
9 | 聚集索引和主键区别,其他引擎怎么做的
10 | 平时数据库编码
11 | explain参数
12 | http报文参数有哪些吗?
13 | 做题,链表奇偶有序输出
14 |
15 | ## 面经2
16 |
17 | 1. 自我介绍
18 | 2. 有哪些排序算法?
19 | 3. 介绍下快排/堆排/归并排序。
20 | 4. 数据库中的索引应该如何设计?
21 | 5. 有哪些索引失效的情况?
22 | 6. 你们用到的HTTP接口用到了什么提交方式?
23 | 7. GET/POST的区别?
24 | 8. 除了GET/POST还有哪些?
25 | 9. 面向对象的基本原则?再详细说下依赖倒转。
26 | 10. 介绍下策略模式和观察者模式?
27 | 11. 如何保证用户请求的等幂性?等幂性指的是用户可能连点提交三次支付请求,返回同样的结果(支付成功),但实际后台只执行一次,保持一致性。
28 | 12. 介绍下TCP四次挥手?
29 | 13. 第四次挥手后客户端是立刻就关闭了吗?是什么状态?
30 | 14. 两个大文件,分别每行都存一个url,查找两个文件中重复的url。
31 | 15. 一个大文件中,每一行有一个整数,怎么找第100大的数?
32 | 16. 一个大文件中,每一行有一个整数,怎么找中位数?
33 | 17. redis的基本数据结构?
34 | 18. zset是怎么实现的?有哪些命令?
35 | 19. 算法题 力扣221. 最大正方形
36 |
37 | ## 面经3
38 |
39 | 自我介绍、项目介绍,问了数据量
40 |
41 | 了解微服务吗?(有没有自己在做项目时进行调研,了解企业目前常用的工具、方法)
42 |
43 | 了解springcloud吗?
44 |
45 | 一台机器无法满足运载需求,怎么办呢?答:多搞几台机器,问:多台机器如何协同工作?
46 |
47 | 开始瞎答:mapreduce
48 |
49 | 解释一下mapreduce
50 |
51 | 如果有一个很大的文件,TB级别,文件里是乱序的数字,如何排序?mapreduce如何实现?
52 |
53 | 排序过程中的归并排序,请描述一下其过程?时间复杂度
54 |
55 | 进程、线程区别,问使用Java时,里面多线程的概念和os里的线程进程的区别是什么?真正使用时,Java里的线程和进程是如何调度?
56 |
57 | 多线程的同步互斥的方法?答了信号量,问具体怎么实现,答pv操作,给了具体的场景,问变量如何初始化(等同于口述代码)
58 |
59 | 有哪些索引?(mysql为例)
60 |
61 | b树、b+树是什么样的树结构,查询复杂度?是平衡二叉树吗?
62 |
63 | 使用过redis吗?具体做什么?
64 |
65 | 手撕代码:LRU算法;正反序层序遍历二叉树
66 |
67 |
68 |
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/8-jingdong.md:
--------------------------------------------------------------------------------
1 | # 京东
2 |
3 | ## 一面
4 |
5 | - kafka在应用场景以及 项目 里的实现
6 | - bitmap底层
7 | - object里有哪些方法
8 | - hashmap相关
9 | - sychronized和reentrantlock相关问题以及锁升级
10 | - cas和volatile
11 | - 线程几种状态以及转化
12 | - jvm内存模型
13 | - mybatis相关问题
14 | - Redis数据结构,问了下跳表的底层
15 | - RDB和AOF
16 | - MySQL索引有哪些
17 | - b+树底层实现
18 | - 最左前缀原理
19 |
20 | ## 二面
21 |
22 | - 线程的状态
23 | - cms
24 | - 增量更新法
25 | - GcRoots是哪些
26 | - java基础
27 | - mysql索引
28 | - 项目具体实现
29 |
30 | ## 三面
31 |
32 | - 索引
33 | - 谈谈多线程
34 | - jvm如何调优
35 | - mq在项目中的用法
36 | - 遇到的多线程问题,如何解决
37 | - 最长无重复字串
38 | - 找到A^2+B^2 = C
39 |
40 | ## 四面
41 |
42 | - 数据库乐观锁、悲观锁
43 | - 为啥用Redis
44 | - sql语句执行顺序
45 | - SpringMVC优点,原理
46 | - aop优点,原理
47 | - ioc优点,原理
48 | - 面向对象概念
49 | - 封装
50 | - 项目中封装如何体现
51 | - 高内聚,低耦合啥意思,如何去设计
52 | - 设计一个电梯场景,实现面向对象,高内聚,低耦合的情况
53 | - 统计学校内共享单车数量,你有啥想法(开放题)
54 |
55 | **最后分享一个BAT大佬总结的高频面试题PDF,需要的小伙伴可以自行下载(复制链接到浏览器打开):**
56 |
57 | 链接:https://pan.baidu.com/s/16GnVoALA1r6BhumuUrXIRg
58 | 提取码:6666
59 |
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/9-huawei.md:
--------------------------------------------------------------------------------
1 | # 华为
2 |
3 | 最近越来越多公司校招进入面试流程了,为了帮助大家更好的应对面试,大彬整理了往年华为校招面试的题目,供大家参考~
4 |
5 | ## 面经1
6 |
7 | ### 技术一面
8 |
9 | 1. 自我介绍
10 | 2. 说下项目中的难点
11 | 3. volatile和synchronized的区别, 问的比较细
12 | 4. 大顶堆小顶堆怎么删除根节点
13 | 5. CSRF攻击是什么,怎么预防
14 | 6. 线程通信方式。
15 | 7. Volitate关键字。
16 | 8. Java 高效拷贝数组。
17 | 9. 算法题 跳跃游戏 leetcode 55。
18 |
19 |
20 | ### 技术二面
21 | 1. 上来就手撕代码 ,奇偶链表,leetcode原题,先说思路,然后打开ide共享屏幕撕代码
22 | 2. 手写单例模式,并说为什么这样写,会不会有什么问题,涉及到volatile原理
23 | 3. mysql常用的数据类型
24 | 4. Java集合框架的主类是什么,HashSet有没有继承Collection软件工程学过哪些课程
25 | 5. 软件工程学过哪些课程
26 | 6. 进程和线程的区别
27 | 7. 知道哪些排序算法,快排的时间复杂度是多少,是稳定的排序算法吗
28 | 8. 编程题/算法
29 | 题目大概:请输出两个字符串a和b相减的结果(a>b,a和b的字符串长度介于1~50之间)。
30 | 例:输入a:“99999”,b=“99998”
31 | 输出:“1”
32 |
33 |
34 | ## 面经2
35 | ### 华为一面
36 | 1. 项目、论文。
37 | 2. String能否被继承。
38 | 3. Java内存泄露和排查。
39 | 4. Hash方式和Hash冲突解决。
40 | 5. 静态代理和动态代理。
41 | 6. spring boot常用的注解有哪些
42 | 7. spring boot的配置文件
43 | 8. redis集群的几种方式详细说一下
44 | 9. redis缓存雪崩,缓存击穿,缓存穿透是什么,怎么解决
45 | 10. mysql索引相关,为什么用B+树
46 | 11. 手撕代码,链表求和,leetcode原题
47 |
48 | ### 华为二面
49 | - 是否用过Java、Python做系统的项目
50 | - 平时熟练使用哪种语言
51 | - HashMap、HashSet、HashTable、StringBuffer、StringBuilder哪些是线程安全,哪些是线程不安全
52 | - HashSet数据结构,跟HashMap有什么区别
53 | - char和varchar的区别
54 | - mysql建索引的原则,索引是不是越多越好,为什么
55 | - spring boot用到了哪些设计模式,从源码层面说说你熟悉的以及实现
56 | - jvm调优你用什么工具,具体怎么做的,怎么调优
57 |
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## 大厂面经汇总
3 |
4 | - [字节跳动](./1-byte-and-dance.md)
5 | - [腾讯](./2-tencent.md)
6 | - [百度](./3-baidu.md)
7 | - [阿里](./4-ali.md)
8 | - [快手](./5-kuaishou.md)
9 | - [美团](./6-meituan.md)
10 | - [shopee](./7-shopee.md)
11 | - [京东](./8-jingdong.md)
12 | - [华为](./9-huawei.md)
13 | - [网易](./10-netease.md)
14 |
--------------------------------------------------------------------------------
/docs/campus-recruit/layoffs-solution.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | ---
4 |
5 | 今年确实是互联网寒冬啊!
6 |
7 | 从2022年5月中旬以来,包括腾讯、阿里巴巴、字节跳动、美团、拼多多、快手、百度、京东、网易等在内的十余家企业被爆出裁员消息。
8 |
9 | 也有一些校招毁约的公司,真的是。。。
10 |
11 | 对于2023届的同学,这里给几个建议:
12 |
13 | 1. **准备充足**,再去面试!今年行情不好,很多互联网中大厂都在缩招,hc比往年少,所以更要准备充分,争取多拿几个offer,才有主动选择的余地!
14 | 2. **多投简历**,不要有“非大厂不进”的心态。今年秋招会比往年难些,毕竟僧多粥少,建议海投简历,争取多一些面试机会。
15 | 3. 找师兄师姐**内推**。内推可以避免在简历关被筛掉,见过太多学历不好的同学,投了很多简历,最终面试的机会寥寥无几。多找一些内推渠道,包括你的师兄师姐、牛客网、一些求职交流裙等。
16 | 4. **选择好方向**,不要“三心二意”。有些同学没有规划好自己的职业发展,在秋招会投递多个方向,比如前段时间我的读者就投了嵌入式工程师、Java后台工程师、测试工程师,大彬不建议大家这么做。虽然投递多个岗位方向,可以多几个面试机会,但是相应的你得多准备几个岗位的知识复习,精力会分散。就Java后台的知识点,没有半个月一个月的时间,是复习不完的(大佬除外)。因此,建议大家秋招之前就定好方向,专注一个方向进行复习。
17 | 5. 多看看银行、研究所等**国企**的机会,相对稳定。近两年很多公司爆出校招毁约的劣迹,而国企一般不会轻易毁约,这算是一个优势。
18 | 6. **打好基础**。校招比较注重基础知识,包括操作系统、计算机网络、数据结构与算法等(针对开发岗位),小伙伴们一定要把基础巩固好,不要等到面试的时候,一问三不知,成了秋招的“炮灰”。
19 |
20 |
21 |
22 | 最后,互联网行业,**年年都是最难的一年**,大家放好心态,面试没过也不用气馁,面试通过与否跟很多因素相关(自身知识储备、竞争者的水平等等),面试完多复盘,相信大家最终都能找到自己满意的offer!
23 |
24 |
25 |
--------------------------------------------------------------------------------
/docs/campus-recruit/program-language/README.md:
--------------------------------------------------------------------------------
1 | # 编程语言(更新中)
2 |
3 | - [Java和Golang怎么选?](./java-or-golang.md)
4 | - [Java和C++怎么选?](./java-or-c++.md)
5 |
6 |
--------------------------------------------------------------------------------
/docs/campus-recruit/program-language/java-or-c++.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Java和C++怎么选?
4 | category: 分享
5 | tag:
6 | - 职业规划
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: java和c++,语言选择
11 | - - meta
12 | - name: description
13 | content: 努力打造最优质的Java学习网站
14 | ---
15 |
16 | # Java和C++怎么选?
17 |
18 | 很多读者私底下问过我这个问题:Java和c++应该选择哪个?哪个好就业、前景更好?
19 |
20 | 首先,Java和C++都是主流的编程语言,不存在哪个好哪个差的说法,学得好的话,都很有前途。
21 |
22 | 下面我从几个方面来比较Java和C++的差异。
23 |
24 | ## 学习难度
25 |
26 | 毫无疑问,C++相对于Java更难学。C++面向底层,而Java面向上层。C++要求对于计算机底层的知识更高,更难,学习C++更有利于理解计算机基础。
27 |
28 | ## 使用场景
29 |
30 | Java 是大型 web 应用后台的首选语言,像淘宝和京东这些大型电商系统的 web 服务器都选用Java技术栈。很多大数据相关的框架,都是用 Java 开发的,所以在大数据领域 Java 有着天然的优势。另外,移动端安卓APP开发语言也是Java。
31 |
32 | C++在人工智能、机器学习、计算机视觉与图像识别、自动驾驶等新兴技术领域运用更多,这些领域对性能、效率要求更高。
33 |
34 | ## 市场需求
35 |
36 | 从招聘网站的数据来看,Java开发需求是大于C++的,而且相比于C++,Java更好入门,比Java简单一些,很适合短期学习快速上手工作。如果你想从事后台开发方向,那么建议你选择Java,因为互联网公司在后台开发方向招的 Java 程序员会更多一些。C++ 主要是底层应用开发、语音、图形图像、音视频、游戏等方面用得多。
37 |
38 | ## 发展前景
39 |
40 | Java 和 C++是两门主流的热门开发语言,一直名列世界编程语言排行榜的前几位。在 TIOBE2022 年 5 月最新的世界编程语言排行榜中,C++和 Java 依然稳定在前几位。两者目前发展前景都很好,暂时不存在谁替代谁或者被其他编程语言替代的情况。
41 |
42 |
43 |
44 | 最后,每个人学习能力、职业规划、兴趣不一样,对于选择哪种编程语言,应该根据自身的具体情况,选择相应的编程语言,做出最优的选择。
45 |
46 |
--------------------------------------------------------------------------------
/docs/campus-recruit/share/2-no-offer.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 非科班,秋招还没offer,该怎么办
4 | category: 分享
5 | tag:
6 | - 校招
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 非科班转码,秋招没offer,23秋招,秋招
11 | - - meta
12 | - name: description
13 | content: 秋招经验分享
14 | ---
15 |
16 | # 非科班,秋招还没offer,该怎么办
17 |
18 | 前两天有个学弟微信私聊我,他是非科班的(985硕士,机械专业),因为秋招准备的比较晚,目前还没拿offer,感觉秋招已经没希望了,只能春招再战了。学弟很焦虑,作为一个985硕士,周围很多人都拿到offer了,只有他还在“苦苦挣扎”,问我有没有什么**学习建议**?
19 |
20 | 学弟目前**基本情况**如下:
21 |
22 | **已经学习的知识**:
23 |
24 | - 计算机基础:操作系统、数据结构 、计网、组成原理、数据库
25 | - Java 基础、集合、JVM、Java并发
26 | - 框架:Spring Boot、Mybatis、SpringMVC、Spring Cloud
27 | - LeetCode 刷了几百道题
28 | - 其他的像Redis、RabbitMQ、Kafka这些都学了
29 |
30 | 项目经验是烂大街的秒杀系统,没有什么亮点。
31 |
32 | 因为我也是非科班出身,比较了解转码人秋招的“**痛**”,周末花了时间整理了一下,给了几点**建议**:
33 |
34 | ## 校招是最好的机会
35 |
36 | 一定要明白**校招的重要性**,如果校招没拿到offer,那么只能走社招,而社招跟校招的难度不是一个级别的,看重的是你的项目经历,只会更难。无论是秋招,还是春招,对于应届毕业生来说,都是拿offer的最好机会,一定要抓住这个机会!秋招没把握住机会,那么春招更应该加足马力,争取拿到满意的offer。
37 |
38 | ## 实习经验很重要
39 |
40 | **特别对于非科班同学**。如果现在还没有实习经验,最好找一下实习。非科班选手,如果不是名校出身,学历不够突出,没有相关实习经验,可能简历都过不了。
41 |
42 | ## 项目经验同样很重要
43 |
44 | 现在大部分应届生简历上的项目都是秒杀商城、RPC、外卖系统等等,这些项目也不是说没亮点,只是亮点都差不多,给人的感觉就是抄网上现成的,不是从头到尾自己实现的。假如面试时让你介绍一下这个项目,**你觉得这个项目亮点在哪里?你自己实现的功能有哪些?有没有其他解决方案**?这些都是需要自己仔细去考虑的。
45 |
46 | 可以看看类似的开源项目,取长补短,**包装**自己的项目经验,当然,包装要适度,要经得住面试的“灵魂拷问”,否则得不偿失。
47 |
48 | ## 面向面试准备
49 |
50 | 多在网上搜索面经,看看心仪的公司面试是个什么难度,喜欢考察什么类型的问题,思考怎么去准备,有**针对性**的进行查漏补缺。
51 |
52 | ## 关于算法题
53 |
54 | 学弟刷了400道LeetCode题目了,如果不是“无效刷题”,其实已经完全够用了。挺多人刷题量非常大,但是到最后发现还是效果不好,一道题做完之后,隔了半个月再来看,依旧一头雾水,这样刷再多题也没用。**建议是每刷完一道题,将解题思路写下来**,方便后续复习查看,这样刷题的效率会更高。
55 |
56 | ## 抓住秋招的尾巴
57 |
58 | **秋招尚未结束,抓住秋招的尾巴**。11月-12月这个时间段,会有公司针对秋招时没有招满的岗位进行补录,要抓住这个机会。秋招补录的流程很快,一般只有整个流程几天内可以走完。
59 |
60 |
61 |
62 |
63 |
64 | 最后,如果秋招面试过程有疑问、offer抉择问题、简历问题等,可以扫码加大彬的微信交流~
65 |
66 | 
67 |
68 |
--------------------------------------------------------------------------------
/docs/campus-recruit/share/README.md:
--------------------------------------------------------------------------------
1 | # 校招分享(持续更新中)
2 |
3 | - [双非本,非科班的自我救赎之路](./1-23-backend.md)
4 | - [非科班,秋招还没offer,该怎么办](./2-no-offer.md)
5 |
6 |
--------------------------------------------------------------------------------
/docs/career-plan/java-or-bigdata.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 24届校招,Java开发和大数据开发怎么选
4 | category: 分享
5 | tag:
6 | - 星球
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 职业规划,岗位选择,Java还是大数据
11 | - - meta
12 | - name: description
13 | content: 星球问题摘录
14 | ---
15 |
16 | ## 24届校招,Java开发和大数据开发怎么选
17 |
18 | 最近在大彬的[学习圈](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247492252&idx=1&sn=8fc12e97763e3b994b0dd0e717a4b674&chksm=ce9b1fdaf9ec96cca6c03cb6e7b61156d3226dbb587f81cea27b71be6671b81b537c9b7e9b2d#rd)中,有小伙伴提了一个关于方向选择的问题:**24届校招,Java开发和大数据开发怎么选**?
19 |
20 | **原问题如下**:
21 |
22 | 想请教一下大彬,对于**java开发和大数据开发**的明年秋招情况的预测。java岗位多卷度也高,每家公司基本都有相关的职位,大数据开发的话培训班比岗位多,只有大公司和数据公司会有这类岗位。24年秋招的话**选择哪个方向**会比较合适呢?
23 |
24 | ---
25 |
26 | **大彬的回答**:
27 |
28 | 建议选大数据吧。就这几年校招来看,大数据岗位拿offer的**难度**相比Java还是比较小一些的。而且距离24年秋招还有一年多时间,转大数据完全来得及,而且有了Java基础,再来学大数据,应该会比较快入门。
29 |
30 | 再说下大数据和后端的**差异**。大数据门槛比Java高,除了熟悉数据库的操作之外,还要学习大数据整个生态,需要会分布式、数仓、数据分析统计等知识。因为大数据的学习门槛比 Java 高,所以市场上培训大数据的相比Java会少一些,**竞争也相对小**,没有Java那么卷。
31 |
32 | 另外,大数据**薪资**总体会比Java开发高一些(同一家公司同一级别,普通开发岗比大数据开发薪资会少一点),这也是大数据方向的一个优势。
33 |
34 | 不过呢,小点的公司,可能没有大数据的需求,毕竟业务量不大(小公司通常也不建议去,坑多)。
35 |
36 | 综上所述,还是建议你选择**大数据**方向。
37 |
38 |
39 |
40 | ---
41 |
42 | 最后,推荐大家加入我的[学习圈](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247492252&idx=1&sn=8fc12e97763e3b994b0dd0e717a4b674&chksm=ce9b1fdaf9ec96cca6c03cb6e7b61156d3226dbb587f81cea27b71be6671b81b537c9b7e9b2d&scene=21#wechat_redirect),目前已经有140多位小伙伴加入了,文末有50元的**优惠券**,**扫描文末二维码**领取优惠券加入。
43 |
44 | 学习圈提供以下这些**服务**:
45 |
46 | 1、学习圈内部**知识图谱**,汇总了**优质资源、面试高频问题、大厂面经、踩坑分享**,让你少走一些弯路
47 |
48 | 2、四个**优质专栏**、Java**面试手册完整版**(包含场景设计、系统设计、分布式、微服务等),持续更新
49 |
50 | 3、**一对一答疑**,我会尽自己最大努力为你答疑解惑
51 |
52 | 4、**免费的简历修改、面试指导服务**,绝对赚回门票
53 |
54 | 5、各个阶段的优质**学习资源**(新手小白到架构师),超值
55 |
56 | 6、打卡学习,**大学自习室的氛围**,一起蜕变成长
57 |
58 |
59 |
60 | **加入方式**:**扫描二维码**领取优惠券加入(**即将恢复原价**)~
61 |
62 | 
63 |
--------------------------------------------------------------------------------
/docs/computer-basic/network.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 计算机网络常见面试题
4 | category: 计算机基础
5 | tag:
6 | - 网络
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 计算机网络常见面试题
11 | - - meta
12 | - name: description
13 | content: 计算机网络常见面试题,努力打造最优质的Java学习网站
14 | ---
15 |
16 | **计算机网络重要知识点&高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到**Java面试手册完整版**。
17 |
18 | 
19 |
20 | 如果你正在打算准备跳槽、面试,星球还提供**简历指导、修改服务**,大彬已经帮**120**+个小伙伴修改了简历,相对还是比较有经验的。
21 |
22 | 
23 |
24 | 
25 |
26 | 另外星球也提供**专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
27 |
28 | 
29 |
30 | 
31 |
32 | 
33 |
34 | 星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
35 |
36 | 
37 |
38 | 
39 |
40 | 
41 |
42 | 怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
43 |
44 | **扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
45 |
46 | 随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
47 |
48 | 
49 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/10-view.md:
--------------------------------------------------------------------------------
1 | # 视图
2 |
3 | 视图为虚拟的表。视图提供了一种MySQL的SELECT语句层次的封装,可用来简化数据处理以及重新格式化基础数据或保护基础数据。
4 |
5 | ## 应用
6 |
7 | - 重用SQL语句。
8 | - 保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限。
9 | - 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
10 |
11 | ## 限制
12 |
13 | - 与表一样,视图必须唯一命名
14 | - 视图不能索引,也不能有关联的触发器或默认值。
15 | - 视图可以和表一起使用。例如,编写一条联结表和视图的SELECT语句。
16 | - ORDER BY可以用在视图中,但如果从该视图检索数据SELECT中也含有ORDER BY,那么该视图中的ORDER BY将被覆盖。
17 |
18 | ## 语法
19 |
20 | `CREATE VIEW`:创建视图
21 |
22 | `SHOW CREATE VIEW viewname`:查看创建视图的语句
23 |
24 | `DROP VIEW viewname`:删除视图
25 |
26 | `CREATE ORREPLACE VIEW`:更新视图,相当于先用`DROP`再用`CREATE`
27 |
28 | ## 简化复杂连接
29 |
30 | 创建一个视图,返回订购了任意产品的客户列表。
31 |
32 | ```mysql
33 | CREATE VIEW productcustomers AS
34 | SELECT cust_name, orders, orderitems
35 | FROM customers, orders, orderitems
36 | WHERE orderitems.order_num = orders.order_num
37 | AND customers.cust_id = orders.cust_id;
38 | ```
39 |
40 | 使用视图:
41 |
42 | ```mysql
43 | SELECT cust_name, cust_contact
44 | FROM productcustomers
45 | WHERE prod_id = 'nike';
46 | ```
47 |
48 | ## 更新视图
49 |
50 | 对视图增加或删除行,实际上是对其基表增加或删除行。视图主要用于数据检索。
--------------------------------------------------------------------------------
/docs/database/mysql-basic/12-cursor.md:
--------------------------------------------------------------------------------
1 | # 游标
2 |
3 | 存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。MySQL游标只能用于存储过程(和函数)。
4 |
5 | ## 创建游标
6 |
7 | DECLARE 命名游标。存储过程处理完成后,游标便消失(游标只存在于存储过程)。定义游标之后,便可以打开它。
8 |
9 | ```mysql
10 | CREATE PROCEDURE processorders()
11 | BEGIN
12 | DECLARE ordernumbers CURSOR
13 | FOR
14 | SELECT order_num FROM orders;
15 | END;
16 | ```
17 |
18 | ## 使用游标
19 |
20 | `OPEN ordernumbers` 打开游标。
21 | `CLOSE ordernumbers` CLOSE释放游标使用的所有内部内存和资源。
22 |
23 | ```mysql
24 | CREATE PROCEDURE processorders()
25 | BEGIN
26 |
27 | DECLARE done BOOLEAN DEFAULT 0;
28 | DECLARE o INT;
29 | DECLARE t DECIMAL(8, 2);
30 |
31 | DECLARE ordernumbers CURSOR
32 | FOR
33 | SELECT order_num FROM orders;
34 |
35 | DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done=1; #游标移到最后
36 |
37 | CREATE TABLE IF NOT EXISTS ordertotals
38 | (order_num INT, total DECIMAL(8,2));
39 | -- 打开游标
40 | OPEN ordernumbers;
41 |
42 | -- 循环
43 | REPEAT
44 | FETCH ordernumbers INTO o;
45 | CALL ordertotal(o, 1, t);
46 |
47 | -- 插入订单号和订单金额
48 | INSERT INTO ordertotals(order_num, total)
49 | VALUES(o, t);
50 |
51 | -- done为1结束循环
52 | UNTIL done END REPEAT;
53 |
54 | CLOSE ordernumbers;
55 | END;
56 | ```
57 |
58 | 存储过程还在运行中创建了一个新表,。这个表将保存存储过程生成的结果。FETCH取每个order_num,然后用CALL执行另一个存储过程,计算每个订单税后金额。最后,用INSERT保存每个订单的订单号和金额。
--------------------------------------------------------------------------------
/docs/database/mysql-basic/13-trigger.md:
--------------------------------------------------------------------------------
1 | # 触发器
2 |
3 | 触发器提供SQL语句自动执行的功能。DELETE/INSERT/UPDATE支持触发器,其他SQL语句不支持。
4 |
5 | ## 创建
6 |
7 | 创建触发器四要素:1.唯一的触发器名(MySQL5规定触发器名在表中唯一,数据库没要求);2.触发器关联的表;3.相应的SQL语句;4.何时执行(处理之前或者之后)。
8 |
9 | ```mysql
10 | CREATE TRIGGER newproduct AFTER INSERT ON products #插入之后执行
11 | FOR EACH ROW SELECT 'product added'; #对每个插入行执行
12 | ```
13 |
14 | 只有表支持触发器,视图不支持。单一触发器不能与多个事件或多个表关联,如果需要对INSERT和UPDATE操作执行触发器,则应该定义两个触发器。
15 |
16 | ## 删除
17 |
18 | `DROP TRIGGER newproduct`
19 |
20 | ## 使用
21 |
22 | INSERT 触发器可饮用名为 NEW 的虚拟表,访问被插入的行。NEW中的值也可以被更新(允许更改被插入的值)。
23 |
24 | ```mysql
25 | CREATE TRIGGER neworder AFTER INSERT ON order
26 | FOR EACH ROW SELECT NEW.order_num; #返回新的订单号
27 | ```
28 |
29 | DELETE 触发器可以引用名为 OLD 的虚拟表,访问被删除的行。OLD中的值全都是只读的,不能更新。
30 |
31 | ```mysql
32 | CREATE TRIGGER deleteorder BEFORE DELETE ON orders
33 | FOR EACH ROW
34 | BEGIN
35 | INSERT INTO archive_orders(order_num, cust_id)
36 | VALUES(OLD.order_num, OLD.cust_id);
37 | END;
38 | ```
39 |
40 | 订单删除之前保存订单信息到存档表。
41 |
42 | UPDATE 触发器可以引用名为 OLD 的虚拟表访问以前的值,引用一个名为NEW的虚拟表访问新更新的值。NEW 值可被更新,OLD 值是只读的。
43 |
44 | 下面的例子保证州名缩写总是大写。
45 |
46 | ```mysql
47 | CREATE TRIGGER updatevendor BEFORE UPDATE ON vendor
48 | FOR EACH ROW SET NEW.vend_state = Upper(NEW.vend_state);
49 | ```
50 |
51 |
52 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/14-transaction.md:
--------------------------------------------------------------------------------
1 | # 事务处理
2 |
3 | 事务处理可以用来维护数据库的完整性。它保证成批的MySQL操作要么完全执行,要么完全不执行。
4 |
5 | CREATE/DROP 操作不能回退,即便可以执行回退操作,回退不会有效果。
6 |
7 | 执行事务过程,一旦某个SQL失败,则之前执行成功的SQL会被自动撤销。
8 |
9 | ## 语法
10 |
11 | ```mysql
12 | START TRANSACTION;
13 | DELETE FROM orderitems WHERE order_num = 20010;
14 | DELETE FROM orders WHERE order_num = 20010;
15 | COMMIT;
16 | ```
17 |
18 | 当COMMIT或ROLLBACK语句执行后,事务会自动关闭。
19 |
20 | ## 保留点
21 |
22 | 为了支持回退部分事务处理,必须能在事务处理块中合适的位置放置占位符。这样,如果需要回退,可以回退到某个占位符。
23 |
24 | 保留点在事务处理完成后自动释放。
25 |
26 | ```mysql
27 | ...
28 | SAVEPOINT delete1;
29 | ...
30 | ROLLBACK TO delete1;
31 | ```
32 |
33 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/15-permission.md:
--------------------------------------------------------------------------------
1 | # 权限
2 |
3 | MySQL用户账号和信息存储在名为mysql的MySQL数据库中。
4 |
5 | 获取用户账号列表:
6 |
7 | ```mysql
8 | USE mysql;
9 | SELECT user FROM user;
10 | ```
11 |
12 | 创建用户账号:`CREATE USER tyson IDENTIFIED BY 'abc123'`
13 |
14 | 修改密码:`SET PASSWORD FOR tyson = Password('xxx');`,新密码需传递到Password()函数进行加密。
15 |
16 | 设置当前用户密码:`SET PASSWORD = Password('xxx');`
17 |
18 | 重命名账号:`RENAME USER tyson TO tom`
19 |
20 | 删除用户账号:`DROP USER tyson`
21 |
22 | 查看访问权限:`SHOW GRANTS FOR tyson`,返回`USAGE ON *.*`则表示没有权限。
23 |
24 | 授予访问权限:`GRANT SELECT ON mall.# TO tyson`,允许用户在mall数据库所有表使用SELECT。
25 |
26 | 撤销权限:`REVOKE SELECT, INSERT ON mall.* FROM tyson`,被撤销的访问权限必须存在,否则会出错。
27 |
28 | GRANT和REVOKE可在几个层次上控制访问权限:
29 |
30 | - 整个服务器,使用GRANT ALL和REVOKE ALL;
31 | - 整个数据库,使用ON database.*;
32 | - 特定的表,使用ON database.table;
33 | - 特定的列;
34 | - 特定的存储过程。
35 |
36 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/16-performace-optimization.md:
--------------------------------------------------------------------------------
1 | # 性能优化
2 |
3 | 使用EXPLAIN语句让MySQL解释它将如何执行一条SELECT语句。
4 |
5 | 如果一个简单的WHERE子句返回结果所花的时间太长,则可以断定其中使用的某些列就是需要索引的对象。
6 |
7 | 避免使用OR。通过使用多条SELECT语句和连接它们的UNION语句,会有极大的性能改进。
8 |
9 | LIKE很慢,最好是使用FULLTEXT而不是LIKE。
10 |
11 | 很多高性能的应用都会对关联查询进行分解,有如下的优势:
12 |
13 | 1 、让缓存效率更高。如果某张表很少变化,那么基于该表的查询就可以重复利用查询缓存结果。
14 | 2 、将查询分解后,执行单个查询可以减少锁的竞争。
15 | 3 、在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展。
16 | 4 、查询本身效率也可能会有所提升。例如 IN()代替关联查询,可能比随机的关联更高效。
17 | 5 、减少冗余记录得查询。
18 | 6 、更进一步,这样做相当于在应用中实现了哈希关联,而不是使用 MySQL 得嵌套循环关联。某些场景哈希关联得效率要高很多。
--------------------------------------------------------------------------------
/docs/database/mysql-basic/17-index.md:
--------------------------------------------------------------------------------
1 | # 索引
2 |
3 | ## 创建索引
4 |
5 | ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
6 |
7 | ```mysql
8 | ALTER TABLE table_name ADD INDEX index_name (column_list)
9 | ALTER TABLE table_name ADD UNIQUE (column_list)
10 | ALTER TABLE table_name ADD PRIMARY KEY (column_list)
11 | ```
12 |
13 | CREATE INDEX可对表增加普通索引或UNIQUE索引。
14 |
15 | ```mysql
16 | CREATE INDEX index_name ON table_name (column_list)
17 | CREATE UNIQUE INDEX index_name ON table_name (column_list)
18 | ```
19 |
20 | 在创建索引时,可以规定索引能否包含重复值。如果不包含,则索引应该创建为PRIMARY KEY或UNIQUE索引。
21 |
22 | ## 删除索引
23 |
24 | ```mysql
25 | DROP INDEX index_name ON talbe_name
26 | ALTER TABLE table_name DROP INDEX index_name
27 | ALTER TABLE table_name DROP PRIMARY KEY #只有一个主键,不需要指定索引名
28 | ```
29 |
30 | ## 查看索引
31 |
32 | ```mysql
33 | show index from tblname;
34 | show keys from tblname;
35 | ```
36 |
37 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/3-function.md:
--------------------------------------------------------------------------------
1 | # 函数
2 | ## 文本处理
3 |
4 | ```mysql
5 | SELECT vend_name, Upper(vend_name) AS vend_name_upcase
6 | FROM vendors
7 | ORDER BY vend_name;
8 | ```
9 |
10 | Soundex()函数,匹配所有同音字符串。
11 |
12 | ```mysql
13 | SELECT cust_name, cust_contact
14 | FROM customers
15 | WHERE Soundex(cust_contact) = Soundex('Y Lie');
16 | ```
17 |
18 | 返回数据:`Tyson Y lee`
19 |
20 | ## 日期处理函数
21 |
22 | 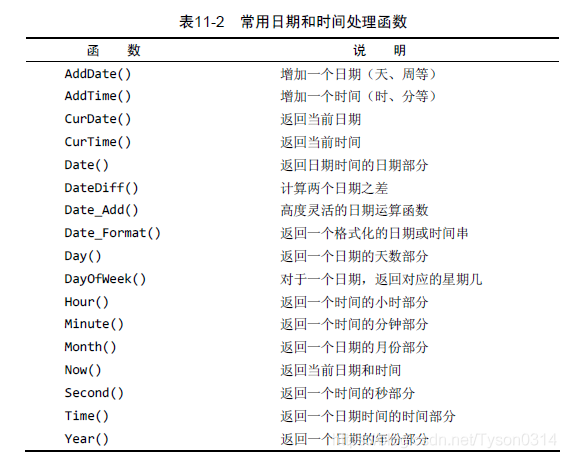
23 | 查找2005年9月的所有订单:
24 |
25 | ```mysql
26 | SELECT cust_id, order_num
27 | FROM orders
28 | WHERE Date(order_date) BETWEEN '2005-09-01' AND '2005-09-30';
29 | ```
30 |
31 | 或者
32 |
33 | ```mysql
34 | SELECT cust_id, order_num
35 | FROM orders
36 | WHERE Year(order_date) = 2005 AND Month(order_date) = 9;
37 | ```
38 |
39 | ## 数值处理函数
40 |
41 | 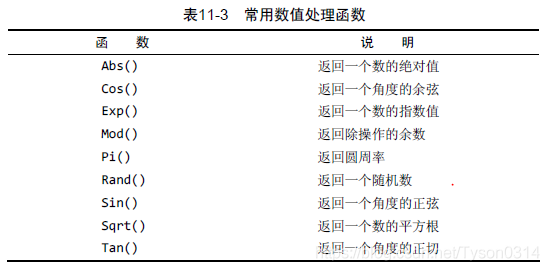
42 |
43 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/4-sum.md:
--------------------------------------------------------------------------------
1 | # 聚集函数
2 |
3 | Sum:求和
4 | Avg:求平均数
5 | Max:求最大值
6 | Min:求最小值
7 | Count:求记录
8 |
9 | ```mysql
10 | SELECT SUM(item_price*quanlity) AS total_price
11 | FROM orderitems
12 | WHERE order_num = 2005;
13 | ```
14 |
15 | 聚集不同值:
16 |
17 | ```mysql
18 | SELECT AVG(DISTINCT prod_price) AS avg_price #只考虑不同价格
19 | FROM products
20 | WHERE vend_id = 1003;
21 | ```
22 |
23 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/5-group.md:
--------------------------------------------------------------------------------
1 | # 分组
2 |
3 | 单独地使用group by没意义,它只能显示出每组记录的第一条记录。
4 |
5 | ```mysql
6 | SELECT * FROM orders
7 | GROUP BY cust_id;
8 | ```
9 |
10 | 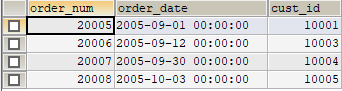
11 |
12 | 除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出。
13 |
14 | ```mysql
15 | SELECT vend_id, COUNT(*) AS num_prods #vend_id在GROUP BY子句给出
16 | FROM products
17 | GROUP BY vend_id;
18 | ```
19 |
20 | GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
21 |
22 | ## 过滤分组
23 |
24 | having 用来分组查询后指定一些条件来输出查询结果,having作用和where类似,但是having只能用在group by场合,并且必须位于group by之后order by之前。
25 |
26 | ```mysql
27 | SELECT cust_id, COUNT(*) AS orders
28 | FROM orders
29 | GROUP BY cust_id
30 | HAVING COUNT(*) >= 2;
31 | ```
32 |
33 | ## having和where区别
34 |
35 | ```mysql
36 | SELECT cust_id FROM orders GROUP BY cust_id HAVING COUNT(cust_id) >= 2;
37 | SELECT cust_id FROM orders GROUP BY cust_id WHERE COUNT(cust_id) >= 2; #Error Code : 1064
38 | ```
39 |
40 | 第一个sql语句可以执行,但是第二个会报错。
41 |
42 | - WHERE子句不起作用,因为过滤是基于分组聚集值而不是特定行值的。
43 |
44 | - 二者作用的对象不同,where子句作用于表和视图,having作用于组。
45 |
46 | - WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。
47 |
48 | ```mysql
49 | SELECT vend_id, COUNT(*) AS num_prods
50 | FROM products
51 | WHERE prod_price >= 10
52 | GROUP BY vend_id
53 | HAVING COUNT(*) >= 2;
54 | ```
55 |
56 | WHERE子句过滤所有prod_price至少为10的行。然后按vend_id分组数据,HAVING子句过滤计数为2或2以上的分组。
57 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/7-full-text-query.md:
--------------------------------------------------------------------------------
1 | # 全文搜索
2 | 为了进行全文本搜索,必须索引被搜索的列,而且要随着数据的改变不断地重新索引。在对表列进行适当设计后,MySQL会自动进行所有的索引和重新索引。
3 |
4 | 启动全文搜索(仅在MyISAM数据库引擎中支持全文本搜索):
5 |
6 | ```mysql
7 | CREATE TABLE productnotes
8 | (
9 | note_id int NOT NULL AUTO_INCREMENT,
10 | note_text text NULL,
11 | PRIMARY KEY(note_id),
12 | FULLTEXT(note_text)
13 | ) ENGINE=MyISAM;
14 | ```
15 |
16 | 在定义之后,MySQL自动维护该索引。在增加、更新或删除行时,索引随之自动更新。
17 |
18 | 不要在导入数据时使用FULLTEXT,。应该首先导入所有数据,然后再修改表,定义FULLTEXT,这样可以更快导入数据。
19 |
20 | 使用全文搜索:
21 |
22 | ```mysql
23 | SELECT note_text
24 | FROM productnotes
25 | WHERE Match(note_text) Against('shoe'); #Match指定搜索列,Against指定搜索词
26 | ```
27 |
28 | 返回结果:`nike shoes is good`,搜索不区分大小写。
29 |
30 | 全文搜索会对返回结果进行排序,具有高等级的行先返回:
31 |
32 | ```mysql
33 | SELECT note_text,
34 | Match(note_text) Against('shoes') AS rank #等级由MySQL根据行中词的数目、唯一词的数目、整个索引中词的总数以及包含该词的行的数目计算出来。
35 | FROM productnotes;
36 | ```
37 |
38 | 全文搜索数据是有索引的,速度快。
39 |
40 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/8-table-operate.md:
--------------------------------------------------------------------------------
1 | # 表操作
2 |
3 | ## 创建表
4 |
5 | ```mysql
6 | CREATE TABLE productnotes
7 | (
8 | note_id int NOT NULL AUTO_INCREMENT,
9 | note_text text NULL,
10 | quanlity int NOT NULL DEFAULT 1, # 默认值,只支持常量
11 | PRIMARY KEY(note_id),
12 | FULLTEXT(note_text)
13 | ) ENGINE=MyISAM;
14 | ```
15 |
16 | 主键中只能使用NOT NULL值的列。
17 |
18 | ## 更新表
19 |
20 | 数据库表的更改不能撤销,应先做好备份。
21 |
22 | 添加列:
23 |
24 | ```mysql
25 | ALTER TABLE vendors
26 | ADD vend_phone CHAR(20);
27 | ```
28 |
29 | 删除列:
30 |
31 | ```mysql
32 | ALTER TABLE vendors
33 | DROP COLUMN vend_phone;
34 | ```
35 |
36 | 更改列属性:
37 |
38 | ```mysql
39 | ALTER TABLE vendors
40 | MODIFY vend_phone CHAR(16);
41 | ```
42 |
43 | 复杂的表结构更改一般需要手动删除过程:
44 |
45 | - 用新的列布局创建一个新表;
46 |
47 | - 使用INSERT SELECT语句,从旧表复制数据到新表;
48 |
49 | - 检验包含所需数据的新表;
50 | - 重命名旧表(如果确定,可以删除它);
51 |
52 | - 用旧表原来的名字重命名新表;
53 |
54 | - 重新创建触发器、存储过程、索引和外键。
55 |
56 | ## 约束
57 |
58 | 添加主键约束:
59 |
60 | ```mysql
61 | ALTER TABLE vendors
62 | ADD CONSTRAINT pk_vendors PRIMARY KEY(vend_id);
63 | ```
64 |
65 | 删除主键约束:
66 |
67 | ```mysql
68 | ALTER TABLE vendors
69 | DROP PRIMARY KEY;
70 | ```
71 |
72 | 添加外键约束:
73 |
74 | ```mysql
75 | ALTER TABLE products
76 | ADD FOREIGN KEY(vendor_id) REFERENCES vendors(vendor_id);
77 | ```
78 |
79 | 删除外键约束:
80 |
81 | ```mysql
82 | ALTER TABLE products DROP FOREIGN KEY vendor_id;
83 | ```
84 |
85 | ## 删除表
86 |
87 | `DROP TABLE cumstomers`
88 |
89 | ## truncate、delete与drop区别
90 |
91 | **相同点:**
92 |
93 | 1. truncate和不带where子句的delete、以及drop都会删除表内的数据。
94 |
95 | 2. drop、truncate都是DDL语句(数据定义语言),执行后会自动提交。
96 |
97 | **不同点:**
98 |
99 | 1. truncate 和 delete 只删除数据不删除表的结构;drop 语句将删除表的结构被依赖的约束、触发器、索引;
100 |
101 | 2. 速度,一般来说: drop> truncate > delete。
102 |
103 | ## 重命名表
104 |
105 | `RENAME TABLE cusmtomers TO cust`
106 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/9-column-operate.md:
--------------------------------------------------------------------------------
1 | # 列操作
2 |
3 | ## 插入数据
4 |
5 | MySQL用单条INSERT语句处理多个插入比使用多条INSERT语句快。
6 |
7 | ```mysql
8 | INSERT INTO customers(cust_name, cust_city)
9 | VALUES('Tyson', 'GD'),
10 | ('sophia','GZ');
11 | ```
12 |
13 | INSERT操作可能很耗时(特别是有很多索引需要更新时),而且它可能降低等待处理的SELECT语句的性能。降低INSERT语句的优先级:`INSERT LOW_PRIORITY INTO`
14 |
15 | ## 更新数据
16 |
17 | 如果用UPDATE语句更新多行,并且在更新这些行中的一行或多行时出一个现错误,则整个UPDATE操作被取消。为了在发生错误时也继续进行更新,可使用IGNORE关键字:`UPDATE IGNORE customers...`
18 |
19 | ```mysql
20 | UPDATE customers
21 | SET cust_city = NULL
22 | WHERE cust_id = 1005;
23 | ```
24 |
25 | 返回值是受影响的记录数。
26 |
27 | ## 删除数据
28 |
29 | 如果想从表中删除所有行,不要使用DELETE。可使用TRUNCATE TABLE语句,它完成相同的工作,但速度更快(TRUNCATE实际是删除原来的表并重新创建一个表,而不是逐行删除表中的数据)。
30 |
31 | ```mysql
32 | DELETE FROM customers
33 | WHERE cust_id = 1006;
34 | ```
35 |
36 | 如果执行DELETE语句而不带WHERE子句,表的所有数据都将被删除。MySQL没有撤销操作,应该非常小心地使用UPDATE和DELETE。
37 |
38 | delete使用别名的时候,要在delete和from间加上删除表的别名。
39 |
40 | ```mysql
41 | DELETE a #加上删除表的别名
42 | FROM table1 a
43 | WHERE a.status = 0
44 | AND EXISTS
45 | (SELECT b.id FROM table2 b
46 | WHERE b.id = a.id);
47 | ```
48 |
49 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: MySQL基础
3 | icon: linux
4 | date: 2022-08-06
5 | category: MySQL
6 | star: true
7 | ---
8 |
9 | **本专栏是大彬学习MySQL基础知识的学习笔记,如有错误,可以在评论区指出**~
10 |
11 | 
12 |
13 | ## MySQL基础总结
14 |
15 | - [数据类型](./1-data-type.md)
16 | - [基本命令](./2-basic-command.md)
17 | - [函数](./3-function.md)
18 | - [聚集函数](./4-sum.md)
19 | - [分组](./5-group.md)
20 | - [连接](./6-join.md)
21 | - [全文搜索](./7-full-text-query.md)
22 | - [表操作](./8-table-operate.md)
23 | - [列操作](./9-column-operate.md)
24 | - [视图](./10-view.md)
25 | - [存储过程](./11-procedure.md)
26 | - [游标](./12-cursor.md)
27 | - [触发器](./13-trigger.md)
28 | - [事务处理](./14-transaction.md)
29 | - [权限](./15-permission.md)
30 | - [性能优化](./16-performace-optimization.md)
31 | - [索引](./17-index.md)
32 |
--------------------------------------------------------------------------------
/docs/database/一条 SQL 查询语句如何执行的.md:
--------------------------------------------------------------------------------
1 | 一条 SQL 查询语句如何执行的
2 |
3 | 在平常的开发中,可能很多人都是 CRUD,对 SQL 语句的语法很熟练,但是说起一条 SQL 语句在 MySQL 中是怎么执行的却浑然不知,今天大彬就由浅入深,带大家一点点剖析一条 SQL 语句在 MySQL 中是怎么执行的。
4 |
5 | 比如你执行下面这个 SQL 语句时,我们看到的只是输入一条语句,返回一个结果,却不知道 MySQL 内部的执行过程:
6 |
7 | ```mysql
8 | mysql> select * from T where ID=10;
9 | ```
10 |
11 | 在剖析这个语句怎么执行之前,我们先看一下 MySQL 的基本架构示意图,能更清楚的看到 SQL 语句在 MySQL 的各个功能模块中的执行过程。
12 |
13 | 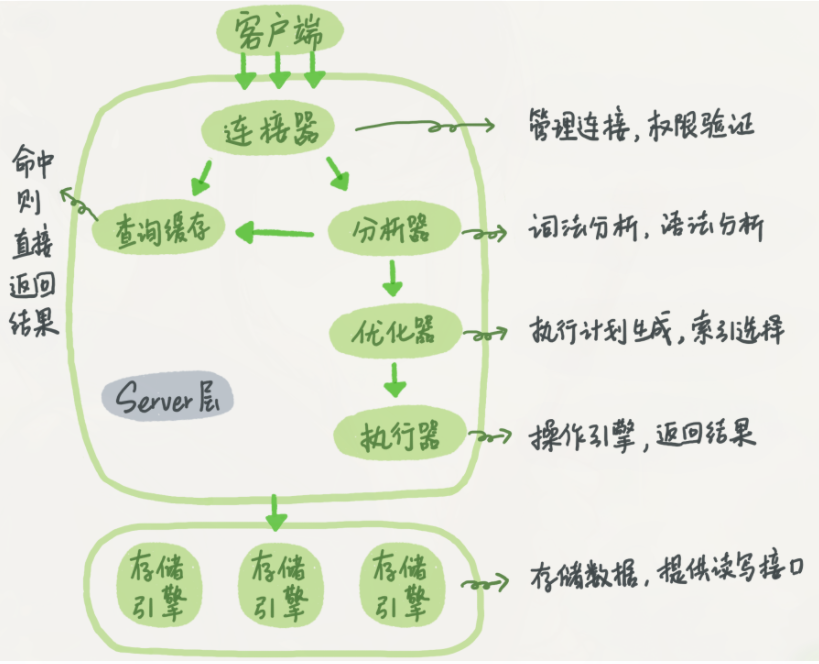
14 |
15 | 整体来说,MySQL 可以分为 Server 层和存储引擎两部分。
16 |
17 | Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
18 |
19 | ### 连接器
20 |
21 | 如果要操作 MySQL 数据库,我们必须使用 MySQL 客户端来连接 MySQL 服务器,这时候就是服务器中的连接器来负责根客户端建立连接、获取权限、维持和管理连接。
22 |
23 | 在和服务端完成 TCP 连接后,连接器就要认证身份,需要用到用户名和密码,确保用户有足够的权限执行该SQL语句。
24 |
25 | ### 查询缓存
26 |
27 | 建立完连接后,就可以执行查询语句了,来到第二步:查询缓存。
28 |
29 | MySQL 拿到第一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中,如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
30 |
31 | 如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
32 |
33 | ### 分析器
34 |
35 | 如果没有命中缓存,就要开始真正执行语句了,MySQL 首先会对 SQL 语句做解析。
36 |
37 | 分析器会先做 “词法分析”,MySQL 需要识别出 SQL 里面的字符串分别是什么,代表什么。
38 |
39 | 做完之后就要做“语法分析”,根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。若果语句不对,就会收到错误提醒。
40 |
41 | ### 优化器
42 |
43 | 经过了分析器,MySQL 就知道要做什么了,但是在开始执行之前,要先经过优化器的处理。
44 |
45 | 比如:优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
46 |
47 | MySQL 会帮我去使用他自己认为的最好的方式去优化这条 SQL 语句,并生成一条条的执行计划,比如你创建了多个索引,MySQL 会依据**成本最小原则**来选择使用对应的索引,这里的成本主要包括两个方面, IO 成本和 CPU 成本。
48 |
49 | ### 执行器
50 |
51 | 执行优化之后的执行计划,在开始执行之前,先判断一下用户对这个表有没有执行查询的权限,如果没有,就会返回没有权限的错误;如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
52 |
53 | ### 存储引擎
54 |
55 | 执行器将查询请求发送给存储引擎组件。
56 |
57 | 存储引擎组件负责具体的数据存储、检索和修改操作。
58 |
59 | 存储引擎根据执行器的请求,从磁盘或内存中读取或写入相关数据。
60 |
61 | ### 返回结果
62 |
63 | 存储引擎将查询结果返回给执行器。
64 |
65 | 执行器将结果返回给连接器。
66 |
67 | 最后,连接器将结果发送回客户端,完成整个执行过程。
--------------------------------------------------------------------------------
/docs/framework/Apollo配置中心.md:
--------------------------------------------------------------------------------
1 | Apollo从设计之初就立志于成为一个有治理能力的配置发布平台,目前提供了以下的特性
2 |
3 | - **统一管理不同环境、不同集群的配置**
4 |
5 | - - Apollo提供了一个统一界面集中式管理不同环境(Environment)、不同集群(Cluster)、不同命名空间(Namespace)的配置
6 | - 同一份代码部署在不同的集群,可以有不同的配置
7 | - 通过命名空间可以很方便地支持多个不同应用共享同一份配置,同时还允许应用对共享的配置进行覆盖
8 |
9 | - **热发布--配置修改实时生效** 用户在Apollo修改完配置并发布后,客户端能实时(1秒)接收到最新的配置,并通知到应用程序
10 |
11 | - **版本发布管理** 所有的配置发布都有版本概念,从而可以方便地支持配置的回滚
12 |
13 | - **灰度发布** 支持配置的灰度发布,比如点了发布后,只对部分应用实例生效,等观察一段时间没问题后再推给所有应用实例
14 |
15 | - **权限管理、发布审核、操作审计**
16 |
17 | - - 应用和配置的管理都有完善的权限管理机制,对配置的管理还分为了编辑和发布两个环节,从而减少人为的错误
18 | - 所有的操作都有审计日志,可以方便地追踪问题
19 |
20 | - **客户端配置信息监控** 可以在界面上方便地看到配置在被哪些实例使用
21 |
22 | - **提供Java和.Net原生客户端**
23 |
24 | - - 提供了Java和.Net的原生客户端,方便应用集成
25 | - 支持Spring Placeholder, Annotation和Spring Boot的ConfigurationProperties,方便应用使用(需要Spring 3.1.1+)
26 | - 同时提供了Http接口,非Java和.Net应用也可以方便地使用
27 |
28 | - 提供开放平台API
29 |
30 | - 部署简单
31 |
32 |
33 |
34 | **基础模型**
35 |
36 | - 用户在配置中心对配置进行修改并发布
37 | - 配置中心通知Apollo客户端有配置更新
38 | - Apollo客户端从配置中心拉取最新的配置、更新本地配置并通知到应用
39 |
40 |
41 |
42 |
43 |
44 | **配置中心如何做到实时更新并且通知到客户端的?**
--------------------------------------------------------------------------------
/docs/framework/netty/1-overview.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | ## netty 核心组件
4 |
5 | - Channel:传入和传出数据的载体,它可以连接或者断开连接。
6 |
7 | - 回调:操作完成后通知相关方。
8 | - Future:提供了另一种在操作完成时通知应用程序的方式。
9 | - 事件和 ChannelHandler
10 |
11 | ## NIO
12 |
13 | 当一个 socket 建立好之后,Thread 会把这个连接请求交给 Selector,Selector 会不断去遍历所有的 Socket,一旦有一个 Socket 建立完成,它就会通知 Thread,然后 Thread 处理完数据在返回给客户端,这个过程是不阻塞的。
14 |
15 |
16 |
17 |
--------------------------------------------------------------------------------
/docs/framework/netty/8-eventloop-thread-model.md:
--------------------------------------------------------------------------------
1 | # EventLoop 和线程模型
2 |
3 | ## EventLoop 接口
4 |
5 | EventLoop 构建在 java.util.concurrent 和 io.netty.channel 之上。EventLoop 继承了 ScheduledExecutorService。EventLoop 由一个永远不会改变的 Thread 驱动,同时任务可以直接提交给 EventLoop 实现。EventLoop 可能服务于多个 Channel。
6 |
7 | Netty4中所有的 io 操作和事件都由 EventLoop 的 Thread 处理。Netty3只保证入站事件在 EventLoop(io 线程)执行,所有出站事件都由调用线程处理,可能是 io 线程或者别的线程,因此需要在 ChannelHandler 中对出站事件进行同步。
8 |
9 | Netty 4 中所采用的线程模型,通过在同一个线程中处理某个给定的EventLoop 中所产生的所有事件,解决了这个问题。这提供了一个更加简单的执行体系架构,并且消除了在多个ChannelHandler 中进行同步的需要
10 |
11 | ## 任务调度
12 |
13 | 使用 EventLoop 调度任务:
14 |
15 | ```java
16 | Channel ch = ...
17 | ScheduledFuture future = ch.eventLoop().schedule(
18 | new Runnable() {
19 | @Override
20 | public void run() {
21 | //逻辑
22 | }
23 | }, 60, TimeUnit.SECONDS);
24 | ```
25 |
26 | 周期性任务:
27 |
28 | ```java
29 | Channel ch = ...
30 | ScheduledFuture future = ch.eventLoop().scheduleAtFixedRate(
31 | new Runnable() {
32 | @Override
33 | public void run() {
34 | //逻辑
35 | }
36 | }, 60, 60, TimeUnit.SECONDES);
37 | ```
38 |
39 | ## 实现细节
40 |
41 | 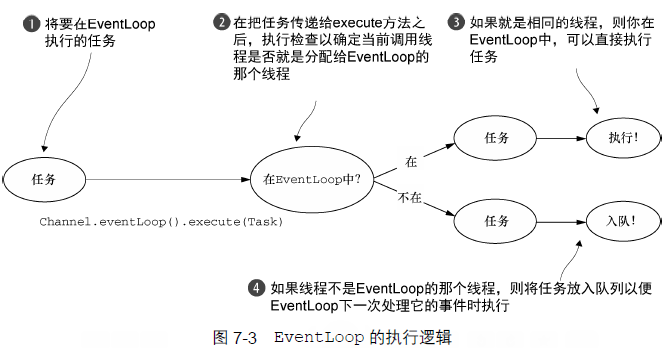
42 |
43 |
44 |
45 |
46 |
47 |
--------------------------------------------------------------------------------
/docs/framework/netty/9-guide.md:
--------------------------------------------------------------------------------
1 | # 引导
2 |
3 | 配置 netty 应用程序,使它运行起来。服务器使用一个父 Channel 接受来自客户端的连接,并创建子 Channel 以用于它们之间的通信。客户端只需要一个 Channel 完成所有的网络交互。
4 |
5 | 引导类是 cloneable 的,在引导类实例上调用 clone() 就可以创建多个具有类似配置或者完全相同配置的 Channel。
6 |
7 | ## 引导客户端
8 |
9 | BootStrap 类被用于客户端或者使用了无连接协议的应用程序中。
10 |
11 | ## 引导服务器
12 |
13 | 
14 |
15 | 在基类AbstractBootstrap有handler方法,目的是添加一个handler,监听Bootstrap的动作。
16 |
17 | 在服务端的ServerBootstrap中增加了一个方法childHandler,它的目的是添加handler,用来监听已经连接的客户端的Channel的动作和状态。
18 |
19 | **handler在初始化时就会执行,而childHandler会在客户端成功connect后才执行。**
20 |
21 | ## 在引导过程添加多个 ChannelHandler
22 |
23 | 在 handler 传入 ChannelInitializer 的实现类,重写 initChannel 方法,在这个方法中添加多个 ChannelHandler。
24 |
25 | ```java
26 | EventLoopGroup group = new NioEventLoopGroup();
27 | try {
28 | Bootstrap bootstrap = new Bootstrap();
29 | bootstrap.group(group)
30 | .channel(NioSocketChannel.class)//适用于nio传输的channel类型
31 | .remoteAddress(new InetSocketAddress(host, port))
32 | .handler(new ChannelInitializer() {
33 | @Override
34 | protected void initChannel(SocketChannel socketChannel) throws Exception {
35 | socketChannel.pipeline().addLast(
36 | new EchoClientHandler());
37 | }
38 | });
39 | ChannelFuture future = bootstrap.connect().sync();//连接到远程节点,阻塞等待
40 | future.channel().closeFuture().sync();//阻塞直到channel关闭
41 | } finally {
42 | group.shutdownGracefully().sync();//关闭线程池并释放所有的资源
43 | }
44 | ```
45 |
46 | ## 关闭
47 |
48 | 关闭 EventLoopGroup,它将处理任何挂起的事件和任务,随后释放所有活动的线程。
49 |
50 | ```java
51 | Future future = group.shutdownGracefully();//释放所有资源,关闭Channel
52 | // block until the group has shutdown
53 | future.syncUninterruptibly();
54 | ```
55 |
56 |
57 |
58 |
--------------------------------------------------------------------------------
/docs/framework/netty/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Netty基础
3 | icon: netty
4 | date: 2022-08-06
5 | category: netty
6 | star: true
7 | ---
8 |
9 | 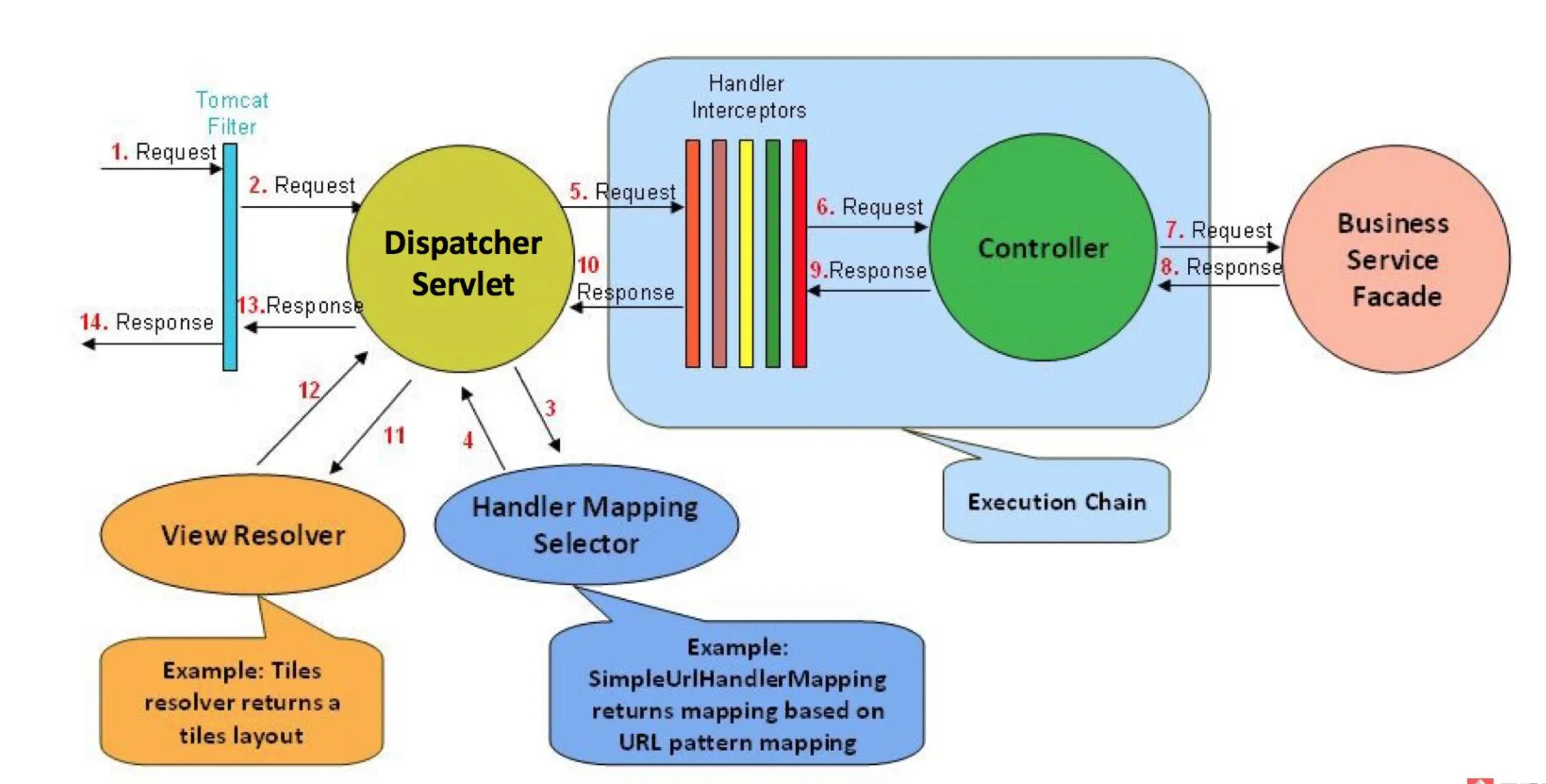
10 |
11 |
12 |
13 | ## Netty总结
14 |
15 | - [简介](./1-overview.md)
16 | - [简单的netty应用程序](./2-make-your-app.md)
17 | - [Netty的组件和设计](./3-component.md)
18 | - [传输](./4-transport.md)
19 | - [ChannelHandler](./6-channel-handler.md)
20 | - [ChannelPipeline接口](./7-channel-pipeline.md)
21 | - [EventLoop和线程模型](./8-eventloop-thread-model.md)
22 | - [引导](./9-guide.md)
23 | - [编解码器](./10-encoder-decoder.md)
24 | - [预置的ChannelHandler和编解码器](./11-preset-channel-handler.md)
25 |
--------------------------------------------------------------------------------
/docs/framework/springcloud/1-basic.md:
--------------------------------------------------------------------------------
1 | # 基础知识
2 |
3 | 微服务是将一个原本独立的系统拆分成多个小型服务,这些小型服务都在各自独立的进程中运行。
4 |
5 | [从单体应用到微服务](https://www.zhihu.com/question/65502802/answer/802678798)
6 |
7 | 单体系统的缺点:
8 |
9 | 1. 修改一个小功能,就需要将整个系统重新部署上线,影响其他功能的运行;
10 | 2. 功能模块互相依赖,强耦合,扩展困难。如果出现性能瓶颈,需要对整体应用进行升级,虽然影响性能的可能只是其中一个小模块;
11 |
12 | 单体系统的优点:
13 |
14 | 1. 容易部署,程序单一,不存在分布式集群的复杂部署环境;
15 | 2. 容易测试,没有复杂的服务调用关系。
16 |
17 | 微服务的优点:
18 |
19 | 1. 不同的服务可以使用不同的技术;
20 | 2. 隔离性。一个服务不可用不会导致其他服务不可用;
21 | 3. 可扩展性。某个服务出现性能瓶颈,只需对此服务进行升级即可;
22 | 4. 简化部署。服务的部署是独立的,哪个服务出现问题,只需对此服务进行修改重新部署;
23 |
24 | 微服务的缺点:
25 |
26 | 1. 网络调用频繁。性能相对函数调用较差。
27 | 2. 运维成本增加。系统由多个独立运行的微服务构成,需要设计一个良好的监控系统对各个微服务的运行状态进行监控。
28 |
29 | springcloud是一个基于Spring Boot实现的微服务架构开发工具。spring cloud包含多个子项目:
30 |
31 | - Spring Cloud Config:配置管理工具,支持使用Git存储配置内容, 可以使用它实现应用配置的外部化存储, 并支持客户端配置信息刷新、加密/解密配置内容等。
32 | - Spring Cloud Netflix:核心 组件,对多个Netflix OSS开源套件进行整合。
33 | - Eureka: 服务治理组件, 包含服务注册中心、服务注册与发现机制的实现。
34 | - Hystrix: 容错管理组件,实现断路器模式, 帮助服务依赖中出现的延迟和为故障提供强大的容错能力。
35 | - Ribbon: 客户端负载均衡的服务调用组件。
36 | - Feign: 基于Ribbon 和Hystrix 的声明式服务调用组件。
37 | - Zuul: 网关组件, 提供智能路由、访问过滤等功能。
38 | - Archaius: 外部化配置组件。
39 | - Spring Cloud Bus: 事件、消息总线, 用于传播集群中的状态变化或事件, 以触发后续的处理, 比如用来动态刷新配置等。
40 | - Spring Cloud Cluster: 针对ZooKeeper、Redis、Hazelcast、Consul 的选举算法和通用状态模式的实现。
41 | - Spring Cloud Consul: 服务发现与配置管理工具。
42 | - Spring Cloud ZooKeeper: 基于ZooKeeper 的服务发现与配置管理组件。
43 | - Spring Cloud Security:Spring Security组件封装,提供用户验证和权限验证,一般与Spring Security OAuth2 组一起使用,通过搭建授权服务,验证Token或者JWT这种形式对整个微服务系统进行安全验证
44 | - Spring Cloud Sleuth:分布式链路追踪组件,他分封装了Dapper、Zipkin、Kibana 的组件
45 | - Spring Cloud Stream:Spring Cloud框架的数据流操作包,可以封装RabbitMq,ActiveMq,Kafka,Redis等消息组件,利用Spring Cloud Stream可以实现消息的接收和发送
46 |
47 | spring-boot-starter-actuator:该模块能够自动为Spring Boot 构建的应用提供一系列用于监控的端点。
48 |
49 |
--------------------------------------------------------------------------------
/docs/framework/springcloud/10-bus.md:
--------------------------------------------------------------------------------
1 | # Spring Cloud Bus
2 |
3 | 我们通常会使用消息代理来构建一个主题,然后把微服务架构中的所有服务都连接到这个主题上去,当我们向该主题发送消息时,所有订阅该主题的服务都会收到消息并进行消费。使用 Spring Cloud Bus 可以方便地构建起这套机制,所以 Spring Cloud Bus 又被称为消息总线。Spring Cloud Bus 配合 Spring Cloud Config 使用可以实现配置的动态刷新。
4 |
5 |
6 |
7 |
--------------------------------------------------------------------------------
/docs/framework/springcloud/11-security.md:
--------------------------------------------------------------------------------
1 | # Spring Cloud Security
2 |
3 | Spring Cloud Security 为构建安全的SpringBoot应用提供了一系列解决方案,结合Oauth2可以实现单点登录、令牌中继、令牌交换等功能。
4 |
5 | OAuth 是一个验证授权(Authorization)的开放标准,所有人都有基于这个标准实现自己的OAuth。在OAuth之前,使用的是`HTTP Basic Authentication`(在浏览网页时候,浏览器会弹出一个登录验证的对话框),需要用户输入用户名和密码的形式进行验证, 这种形式是不安全的。OAuth的出现就是为了解决访问资源的安全性以及灵活性。OAuth使得第三方应用对资源的访问更加安全。
6 |
7 | 适用场景:[OAuth 2.0](https://www.ruanyifeng.com/blog/2014/05/oauth_2_0.html)
8 |
9 | 有一个"云冲印"的网站,可以将用户储存在Google的照片,冲印出来。用户为了使用该服务,必须让"云冲印"读取自己储存在Google上的照片。传统方法是,用户将自己的Google用户名和密码,告诉"云冲印",后者就可以读取用户的照片了。但是这种方法可能会导致用户密码泄露等问题。
10 |
11 | OAuth在"客户端"(云冲印)与"服务提供商"(谷歌)之间,设置了一个授权层(authorization layer)。"客户端"不能直接登录"服务提供商",只能登录授权层,以此将用户与客户端区分开来。"客户端"登录授权层所用的令牌(token),与用户的密码不同。用户可以在登录的时候,指定授权层令牌的权限范围和有效期。
12 |
13 | "客户端"登录授权层以后,"服务提供商"根据令牌的权限范围和有效期,向"客户端"开放用户储存的资料。
14 |
15 | 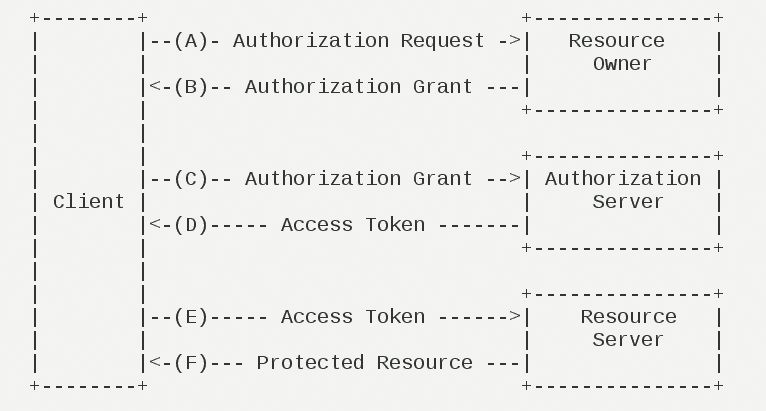
16 |
17 | (A)用户打开客户端以后,客户端要求用户给予授权。
18 |
19 | (B)用户同意给予客户端授权。
20 |
21 | (C)客户端使用上一步获得的授权,向认证服务器申请令牌。
22 |
23 | (D)认证服务器对客户端进行认证以后,确认无误,同意发放令牌。
24 |
25 | (E)客户端使用令牌,向资源服务器申请获取资源。
26 |
27 | (F)资源服务器确认令牌无误,同意向客户端开放资源。
28 |
29 |
--------------------------------------------------------------------------------
/docs/framework/springcloud/2-springboot-springcloud-diff.md:
--------------------------------------------------------------------------------
1 | # 说说对SpringBoot 和SpringCloud的理解
2 |
3 | - SpringBoot专注于快速方便的开发单个个体微服务。
4 | - SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来,为各个微服务之间提供,配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等集成服务
5 | - SpringBoot可以离开SpringCloud独立使用开发项目,但是SpringCloud离不开SpringBoot,属于依赖的关系。
6 | - SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架。
7 |
8 | Spring Boot可以离开Spring Cloud独立使用开发项目,但是Spring Cloud离不开Spring Boot,属于依赖的关系。
9 |
10 |
--------------------------------------------------------------------------------
/docs/framework/springcloud/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: SpringCloud基础
3 | icon: cloud
4 | date: 2022-08-06
5 | category: springcloud
6 | star: true
7 | ---
8 |
9 |
10 | ## SpringCloud总结
11 |
12 | - [基础知识](./1-basic.md)
13 | - [说说对SpringBoot和SpringCloud的理解](./2-springboot-springcloud-diff.md)
14 | - [SpringCloudEureka](./3-eureka.md)
15 | - [SpringCloudRibbon](./4-ribbon.md)
16 | - [SpringCloudHystrix](./5-hystrix.md)
17 | - [SpringCloudFeign](./6-feign.md)
18 | - [SpringCloudZuul](./7-zuul.md)
19 | - [SpringCloudGateway](./8-gateway.md)
20 | - [SpringCloudConfig](./9-config.md)
21 | - [SpringCloudBus](./10-bus.md)
22 | - [SpringCloudSecurity](./11-security.md)
23 |
--------------------------------------------------------------------------------
/docs/framework/springmvc.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Spring MVC常见面试题总结
4 | category: 框架
5 | tag:
6 | - Spring MVC
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Spring MVC面试题,MVC模式,Spring MVC和Struts,Spring MVC工作原理,Spring MVC常用注解,Spring MVC异常处理,Spring MVC拦截器,REST
11 | - - meta
12 | - name: description
13 | content: 高质量的Spring MVC常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 |
17 |
18 | **Spring MVC高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到**Java面试手册完整版**。
19 |
20 | 
21 |
22 | 如果你正在打算准备跳槽、面试,星球还提供**简历指导、修改服务**,大彬已经帮**120**+个小伙伴修改了简历,相对还是比较有经验的。
23 |
24 | 
25 |
26 | 
27 |
28 | 另外星球也提供**专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
29 |
30 | 
31 |
32 | 
33 |
34 | 
35 |
36 | 星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
37 |
38 | 
39 |
40 | 
41 |
42 | 
43 |
44 | 怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
45 |
46 | **扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
47 |
48 | 随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
49 |
50 | 
--------------------------------------------------------------------------------
/docs/interview/concurrent/1-forbid-default-executor.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 为什么阿里禁止使用Java内置线程池?
4 | category: Java
5 | tag:
6 | - Java并发
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Java并发,多线程,线程池,为什么禁止使用Java内置线程池
11 | - - meta
12 | - name: description
13 | content: 高质量的Java并发常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | ## 为什么阿里禁止使用Java内置线程池?
17 |
18 | 首先要了解一下线程池 ThreadPoolExecutor 的参数及其作用。
19 |
20 | ThreadPoolExecutor有以下这些参数。
21 |
22 | 1. **corePoolSize** 指定了线程池里的线程数量,核心线程池大小
23 |
24 | 2. maximumPoolSize 指定了线程池里的最大线程数量
25 |
26 | 3. **keepAliveTime** 当线程池线程数量大于corePoolSize时候,多出来的空闲线程,多长时间会被销毁。
27 |
28 | 4. **TimeUnit**时间单位。
29 |
30 | 5. workQueue 任务队列,用于存放提交但是尚未被执行的任务。
31 |
32 | 6. **threadFactory** 线程工厂,用于创建线程,一般可以用默认的
33 |
34 | 7. **RejectedExecutionHandler** 拒绝策略,所谓拒绝策略,是指将任务添加到线程池中时,线程池拒绝该任务所采取的相应策略。
35 |
36 | 阿里规约之所以强制要求手动创建线程池,也是和这些参数有关。
37 |
38 | 阿里规约上指出,线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的**运行规则**,规避资源耗尽的风险。
39 |
40 | 虽然Executor提供的四个静态方法创建线程池,但是不建议去使用这些静态方法创建线程池,因为这些方法创建的线程池,如果使用不当,可能会有OOM的风险。
41 |
42 | 比如**newFixedThreadPool**和**newSingleThreadExecutor**的问题是堆积的请求处理队列可能会耗费非常大的内存,甚至**OOM**。
43 |
44 | **newCachedThreadPool**和**newScheduledThreadPool**的问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至**OOM**。
45 |
46 |
47 |
48 | --end--
49 |
50 | 最后分享一份大彬精心整理的**大厂面试手册**,包含**操作系统、计算机网络、Java基础、JVM、分布式**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
51 |
52 | 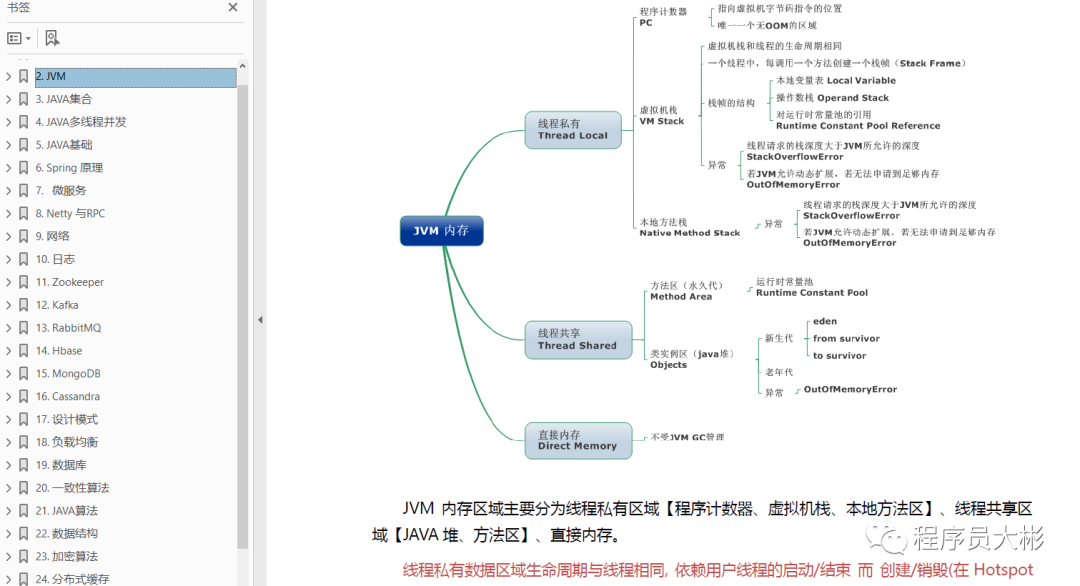
53 |
54 | 
55 |
56 | **手册获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**手册**」就可以找到下载链接了(**无套路,无解压密码**)。
57 |
58 | 
59 |
--------------------------------------------------------------------------------
/docs/interview/java/1-create-object.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Java创建对象有几种方式?
4 | category: Java
5 | tag:
6 | - Java基础
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: java创建对象的方式
11 | - - meta
12 | - name: description
13 | content: 高质量的Java基础常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | ## Java创建对象有几种方式?
17 |
18 | Java创建对象有以下几种方式:
19 |
20 | - 1、用new语句创建对象。
21 | - 2、使用反射机制创建对象,用Class类或Constructor类的newInstance()方法。
22 | - 3、调用对象的clone()方法。需要实现Cloneable接口,重写object类的clone方法。当调用一个对象的clone方法,JVM就会创建一个新的对象,将前面对象的内容全部拷贝进去。
23 | - 4、运用反序列化手段。需要让类实现Serializable接口,通过ObjectInputStream的readObject()方法反序列化类。当我们序列化和反序列化一个对象,JVM会给我们创建一个单独的对象。
24 |
25 |
--------------------------------------------------------------------------------
/docs/interview/java/2-3rd-interface.md:
--------------------------------------------------------------------------------
1 | ## 对接第三方接口要考虑什么?
2 |
3 | 嗯,需要考虑以下几点:
4 |
5 | 1. 确认接口对接的网络协议,是https/http或者自定义的私有协议等。
6 | 2. 约定好数据传参、响应格式(如application/json),弱类型对接强类型语言时要特别注意
7 | 3. 接口安全方面,要确定身份校验方式,使用token、证书校验等
8 | 4. 确认是否需要接口调用失败后的重试机制,保证数据传输的最终一致性。
9 | 5. 日志记录要全面。接口出入参数,以及解析之后的参数值,都要用日志记录下来,方便定位问题(甩锅)。
10 |
11 |
12 |
13 | 参考:https://blog.csdn.net/gzt19881123/article/details/108791034
--------------------------------------------------------------------------------
/docs/interview/java/3-design-interface.md:
--------------------------------------------------------------------------------
1 | ## 设计接口要注意什么?
2 |
3 | 1. 接口参数校验。接口必须校验参数,比如入参是否允许为空,入参长度是否符合预期。
4 | 2. 设计接口时,充分考虑接口的可扩展性。思考接口是否可以复用,怎样保持接口的可扩展性。
5 | 3. 串行调用考虑改并行调用。比如设计一个商城首页接口,需要查商品信息、营销信息、用户信息等等。如果是串行一个一个查,那耗时就比较大了。这种场景是可以改为并行调用的,降低接口耗时。
6 | 4. 接口是否需要防重处理。涉及到数据库修改的,要考虑防重处理,可以使用数据库防重表,以唯一流水号作为唯一索引。
7 | 5. 日志打印全面,入参出参,接口耗时,记录好日志,方便甩锅。
8 | 6. 修改旧接口时,注意兼容性设计。
9 | 7. 异常处理得当。使用finally关闭流资源、使用log打印而不是e.printStackTrace()、不要吞异常等等
10 | 8. 是否需要考虑限流。限流为了保护系统,防止流量洪峰超过系统的承载能力。
11 |
12 |
--------------------------------------------------------------------------------
/docs/interview/java/4-interface-slow.md:
--------------------------------------------------------------------------------
1 | ## 线上接口很慢怎么办?
2 |
3 | 使用调用链跟踪,如zipkin,查看每一条路线的耗时情况,甚至包括此时 CPU 性能,然后再针对性能差的服务接口进行分析。
4 |
5 | 针对数据库性能优化问题,从设计上来说,设计表之前考虑好引擎,数据量,字段格式,索引等。
6 |
7 | 从 SQL 层面要利用好索引覆盖,尽量不回表,优化好 SQL。
8 |
9 | 从架构上来说,采用高可用的架构,如 MySQL 扩展的 MHA 架构
10 |
11 | 从业务代码层面来说,分析是不是代码问题,比如查询 SQL 过慢,返回超时,或者限流不合理等情况
12 |
13 | 如果数据量比较大的话,千万以及上亿级别,做好分表分库或者选用分布式数据库等
14 |
15 | 如果下游处理能力薄弱或者调用链路很深,考虑是否能够使用消息队列方式处理。
16 |
17 |
18 |
19 | > 参考:https://youle.zhipin.com/questions/d260cce58d0333c9tnVy2tW8GFQ~.html
--------------------------------------------------------------------------------
/docs/interview/java/5-comparable-vs-comparator.md:
--------------------------------------------------------------------------------
1 | ## Comparable和Comparator有什么区别?
2 |
3 | Comparable 和 Comparator 都是用来进行元素排序的。它们之间的区别如下:
4 |
5 | 1、字面含义不同。Comparable 是“比较”的意思,而 Comparator 是“比较器”的意思。
6 |
7 | 2、Comparable 是通过重写 compareTo 方法实现排序的,而 Comparator 是通过重写compare 方法实现排序的。
8 |
9 | 3、Comparable 必须由自定义类内部实现排序方法,而 Comparator 是外部定义并实现排序的。
10 |
11 |
12 |
13 | 总结一下:Comparable 可以看作是“对内”进行排序接口,而 Comparator 是“对外”进行排序的接口。
14 |
15 |
--------------------------------------------------------------------------------
/docs/interview/java/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## 目录
3 |
4 | - [Java创建对象有几种方式?](./1-create-object.md)
5 | - [对接第三方接口要考虑什么?](./2-3rd-interface.md)
6 | - [设计接口要注意什么?](./3-design-interface.md)
7 | - [线上接口很慢怎么办?](./4-interface-slow.md)
8 |
--------------------------------------------------------------------------------
/docs/interview/javaweb/1-interceptor-filter.md:
--------------------------------------------------------------------------------
1 | ## 过滤器和拦截器有什么区别?
2 |
3 | 1、**实现原理不同**。
4 |
5 | 过滤器和拦截器底层实现不同。过滤器是基于函数回调的,拦截器是基于Java的反射机制(动态代理)实现的。一般自定义的过滤器中都会实现一个doFilter()方法,这个方法有一个FilterChain参数,而实际上它是一个回调接口。
6 |
7 | 2、**使用范围不同**。
8 |
9 | 过滤器实现的是 javax.servlet.Filter 接口,而这个接口是在Servlet规范中定义的,也就是说过滤器Filter的使用要依赖于Tomcat等容器,导致它只能在web程序中使用。而拦截器是一个Spring组件,并由Spring容器管理,并不依赖Tomcat等容器,是可以单独使用的。拦截器不仅能应用在web程序中,也可以用于Application、Swing等程序中。
10 |
11 | 3、**使用的场景不同**。
12 |
13 | 因为拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:日志记录、权限判断等业务。而过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、响应数据压缩等功能。
14 |
15 | 4、**触发时机不同**。
16 |
17 | 过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。
18 |
19 | 拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。
20 |
21 | 5、**拦截的请求范围不同**。
22 |
23 | 请求的执行顺序是:请求进入容器 -> 进入过滤器 -> 进入 Servlet -> 进入拦截器 -> 执行控制器。可以看到过滤器和拦截器的执行时机也是不同的,过滤器会先执行,然后才会执行拦截器,最后才会进入真正的要调用的方法。
24 |
25 |
26 |
27 | > 参考链接:https://segmentfault.com/a/1190000022833940
--------------------------------------------------------------------------------
/docs/interview/mq/1-why-to-use-mq.md:
--------------------------------------------------------------------------------
1 | ## 为什么要使用消息队列?
2 |
3 | 主要有以下几点原因:
4 |
5 | 1、解**耦**。比如,用户下单后,订单系统需要通知库存系统,假如库存系统无法访问,则订单减库存将失败,从而导致订单操作失败。订单系统与库存系统耦合,这个时候如果使用消息队列,可以返回给用户成功,先把消息持久化,等库存系统恢复后,就可以正常消费减去库存了。
6 |
7 | 2、**异步**。将消息写入消息队列,非必要的业务逻辑以异步的方式运行,不影响主流程业务。
8 |
9 | 3、**削峰**。消费端慢慢的按照数据库能处理的并发量,从消息队列中慢慢拉取消息。在生产中,这个短暂的高峰期积压是允许的。比如秒杀活动,一般会因为流量过大,从而导致流量暴增,应用挂掉。这个时候加上消息队列,服务器接收到用户的请求后,首先写入消息队列,如果消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面。
10 |
11 | 总结一下,主要三点原因:**解耦、异步、削峰**。
12 |
13 | ## 那使用了消息队列会有什么缺点
14 |
15 | - **系统可用性降低**。引入消息队列之后,如果消息队列挂了,可能会影响到业务系统的可用性。
16 | - **系统复杂性增加**。加入了消息队列,要多考虑很多方面的问题,比如:一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。
17 |
18 |
19 |
20 |
21 |
22 | ---
23 |
24 |
25 |
26 | [整理了200本计算机经典书籍,含下载方式](https://github.com/Tyson0314/java-books)
27 |
28 | [Github疯传!谷歌师兄的LeetCode刷题笔记](https://topjavaer.cn/learning-resources/leetcode-note.html)
29 |
30 | [大彬花了一周收集的简历模板](https://mp.weixin.qq.com/s/JEG11UnWdO_Wi8-Qib89VQ)
31 |
32 | [学弟靠这本大厂面试手册,拿了字节跳动offer!](https://mp.weixin.qq.com/s/LVa4H5feXrjZL-DUtQQ0Yg)
--------------------------------------------------------------------------------
/docs/interview/network/1-input-url-return-page.md:
--------------------------------------------------------------------------------
1 | ## 说说浏览器中输入URL返回页面过程
2 |
3 | 1. **解析域名**,找到主机 IP。
4 | 2. 浏览器利用 IP 直接与网站主机通信,**三次握手**,建立 TCP 连接。浏览器会以一个随机端口向服务端的 web 程序 80 端口发起 TCP 的连接。
5 | 3. 建立 TCP 连接后,浏览器向主机发起一个HTTP请求。
6 | 4. 参数从客户端传递到服务器端。
7 | 5. 服务器端得到客户端参数之后,进行相应的业务处理,再将结果封装成 HTTP 包,返回给客户端。
8 | 6. 服务器端和客户端的交互完成,断开 TCP 连接(4 次挥手)。
9 | 7. 浏览器**解析响应内容,进行渲染**,呈现给用户。
10 |
11 | 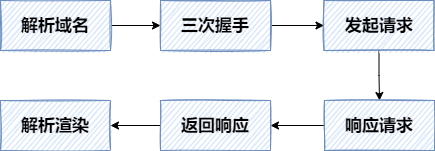
12 |
13 | ## DNS 域名解析的过程详细讲讲
14 |
15 | 在网络中定位是依靠 IP 进行身份定位的,所以 URL 访问的第一步便是先要得到服务器端的 IP 地址。而得到服务器的 IP 地址需要使用 DNS(Domain Name System,域名系统)域名解析,DNS 域名解析就是通过 URL 找到与之相对应的 IP 地址。
16 |
17 | DNS 域名解析的大致流程如下:
18 |
19 | 1. 先检**查浏览器中的 DNS 缓存**,如果浏览器中有对应的记录会直接使用,并完成解析;
20 | 2. 如果浏览器没有缓存,那就去**查询操作系统的缓存**,如果查询到记录就可以直接返回 IP 地址,完成解析;
21 | 3. 如果操作系统没有 DNS 缓存,就会去**查看本地 host 文件**,Windows 操作系统下,host 文件一般位于 "C:\Windows\System32\drivers\etc\hosts",如果 host 文件有记录则直接使用;
22 | 4. 如果本地 host 文件没有相应的记录,会**请求本地 DNS 服务器**,本地 DNS 服务器一般是由本地网络服务商如移动、联通等提供。通常情况下可通过 DHCP 自动分配,当然也可以自己手动配置。目前用的比较多的是谷歌提供的公用 DNS 是 8.8.8.8 和国内的公用 DNS 是 114.114.114.114。
23 | 5. 如果本地 DNS 服务器没有相应的记录,就会**去根域名服务器查询**了。为了能更高效完成全球所有域名的解析请求,根域名服务器本身并不会直接去解析域名,而是会把不同的解析请求分配给下面的其他服务器去完成。
24 |
25 | 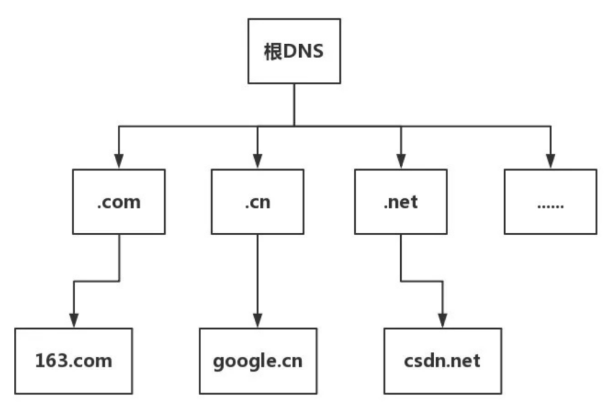
--------------------------------------------------------------------------------
/docs/java/java8/1-functional-program.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 函数式编程
4 | category: Java
5 | tag:
6 | - Java8
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 函数式编程
11 | - - meta
12 | - name: description
13 | content: 高质量的Java基础常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 函数式编程
17 |
18 | 面向对象编程:面向对象的语言,一切皆对象,如果想要调用一个函数,函数必须属于一个类或对象,然后在使用类或对象进行调用。面向对象编程可能需要多写很多重复的代码行。
19 |
20 | ```java
21 | Runnable runnable = new Runnable() {
22 | @Override
23 | public void run() {
24 | System.out.println("do something...");
25 | }
26 | };
27 |
28 | ```
29 |
30 | 函数式编程:在某些编程语言中,如js、c++,我们可以直接写一个函数,然后在需要的时候进行调用,即函数式编程。
31 |
32 |
--------------------------------------------------------------------------------
/docs/java/java8/2-lambda.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Lambda表达式
4 | category: Java
5 | tag:
6 | - Java8
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Lambda表达式
11 | - - meta
12 | - name: description
13 | content: 高质量的Java基础常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # Lambda 表达式
17 |
18 | 在Java8以前,使用`Collections`的sort方法对字符串排序的写法:
19 |
20 | ```java
21 | List names = Arrays.asList("dabin", "tyson", "sophia");
22 |
23 | Collections.sort(names, new Comparator() {
24 | @Override
25 | public int compare(String a, String b) {
26 | return b.compareTo(a);
27 | }
28 | });
29 | ```
30 |
31 | Java8 推荐使用lambda表达式,简化这种写法。
32 |
33 | ```java
34 | List names = Arrays.asList("dabin", "tyson", "sophia");
35 |
36 | Collections.sort(names, (String a, String b) -> b.compareTo(a)); //简化写法一
37 | names.sort((a, b) -> b.compareTo(a)); //简化写法二,省略入参类型,Java 编译器能够根据类型推断机制判断出参数类型
38 | ```
39 |
40 | 可以看到使用lambda表示式之后,代码变得很简短并且易于阅读。
41 |
42 |
--------------------------------------------------------------------------------
/docs/java/java8/3-functional-interface.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 函数式接口
4 | category: Java
5 | tag:
6 | - Java8
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 函数式接口
11 | - - meta
12 | - name: description
13 | content: 高质量的Java基础常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 函数式接口
17 |
18 | Functional Interface:函数式接口,只包含一个抽象方法的接口。只有函数式接口才能缩写成 Lambda 表达式。@FunctionalInterface 定义类为一个函数式接口,如果添加了第二个抽象方法,编译器会立刻抛出错误提示。
19 |
20 | ```java
21 | @FunctionalInterface
22 | interface Converter {
23 | T convert(F from);
24 | }
25 |
26 | public class FunctionalInterfaceTest {
27 | public static void main(String[] args) {
28 | Converter converter = (from) -> Integer.valueOf(from);
29 | Integer converted = converter.convert("666");
30 | System.out.println(converted);
31 | }
32 | /**
33 | * output
34 | * 666
35 | */
36 | }
37 | ```
38 |
39 |
40 |
41 |
--------------------------------------------------------------------------------
/docs/java/java8/6-parallel-stream.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Parallel-Streams
4 | category: Java
5 | tag:
6 | - Java8
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Parallel-Streams,并行流
11 | - - meta
12 | - name: description
13 | content: 高质量的Java基础常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # Parallel-Streams
17 |
18 | 并行流。`stream` 流是支持**顺序**和**并行**的。顺序流操作是单线程操作,串行化的流无法带来性能上的提升,通常我们会使用多线程来并行执行任务,处理速度更快。
19 |
20 | ```java
21 | /**
22 | * @description:
23 | * @author: 程序员大彬
24 | * @time: 2021-09-06 00:05
25 | */
26 | public class StreamTest7 {
27 | public static void main(String[] args) {
28 | int max = 100;
29 | List strs = new ArrayList<>(max);
30 | for (int i = 0; i < max; i++) {
31 | UUID uuid = UUID.randomUUID();
32 | strs.add(uuid.toString());
33 | }
34 |
35 | List sortedStrs = strs.stream().sorted().collect(Collectors.toList());
36 | System.out.println(sortedStrs);
37 | }
38 | /**
39 | * output
40 | * [029be6d0-e77e-4188-b511-f1571cdbf299, 02d97425-b696-483a-80c6-e2ef51c05d83, 0632f1e9-e749-4bce-8bac-1cf6c9e93afa, ...]
41 | */
42 | }
43 | ```
44 |
45 |
46 |
47 |
--------------------------------------------------------------------------------
/docs/java/java8/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## Java8总结
3 |
4 | - [函数式编程](./1-functional-program.md)
5 | - [Lambda表达式](./2-lambda.md)
6 | - [函数式接口](./3-functional-interface.md)
7 | - [内置的函数式接口](./4-inner-functional-interface.md)
8 | - [Stream](./5-stream.md)
9 | - [Parallel-Streams](./6-parallel-stream.md)
10 | - [Map集合](./7-map.md)
11 |
12 |
--------------------------------------------------------------------------------
/docs/java/jvm.md:
--------------------------------------------------------------------------------
1 | **JVM重要知识点&高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到Java面试手册**完整版**。
2 |
3 | 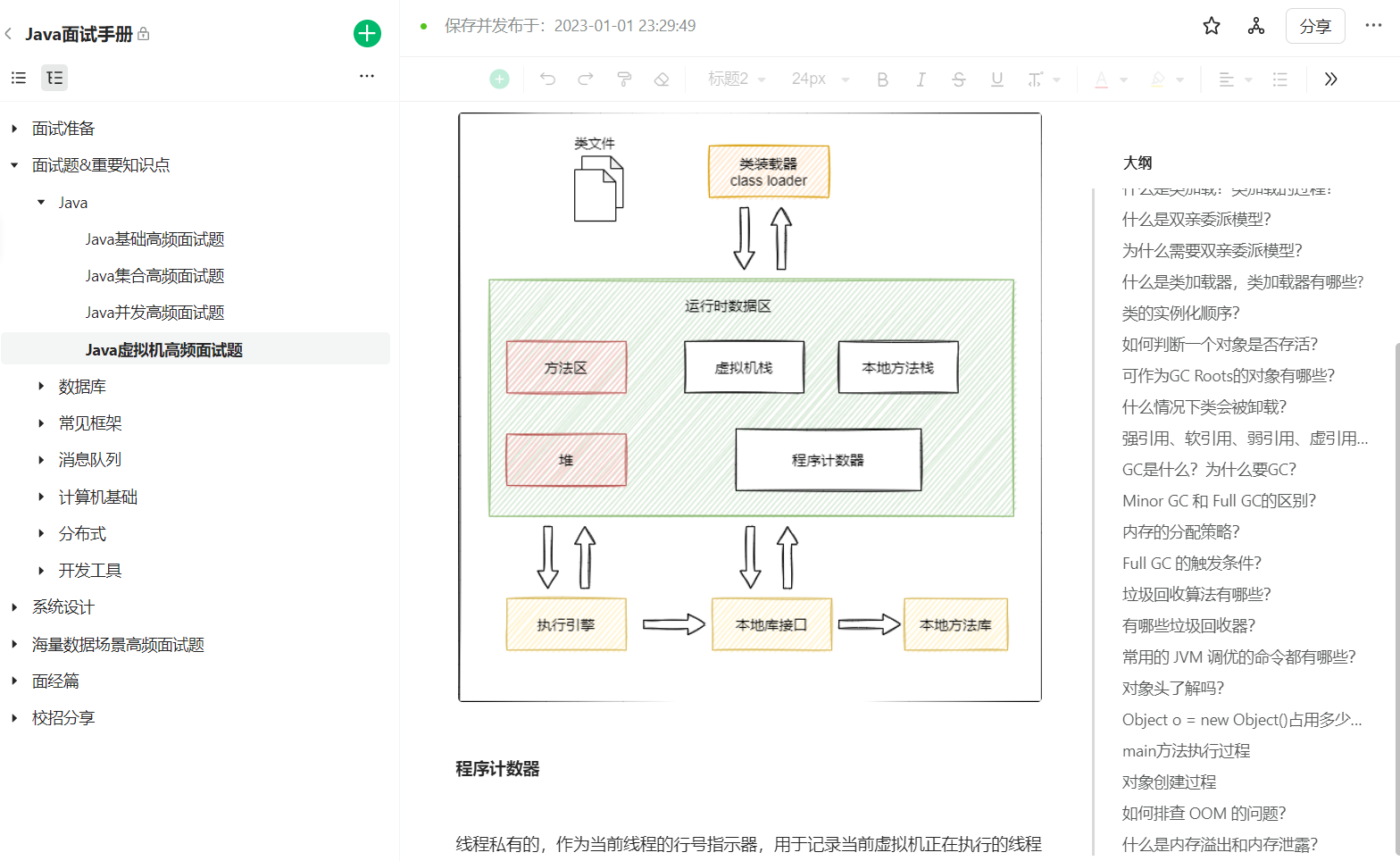
4 |
5 | 除了Java面试手册完整版之外,星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
6 |
7 | 
8 |
9 | 
10 |
11 | 
12 |
13 | **专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
14 |
15 | 
16 |
17 | 
18 |
19 | 
20 |
21 | 如果你正在打算准备跳槽、面试,星球还提供**简历指导、修改服务**,大彬已经帮**120**+个小伙伴修改了简历,相对还是比较有经验的。
22 |
23 | 
24 |
25 | 
26 |
27 | 怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
28 |
29 | **扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
30 |
31 | 随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
32 |
33 | 
--------------------------------------------------------------------------------
/docs/learn/leetcode.md:
--------------------------------------------------------------------------------
1 | 在学习数据结构和算法,或者准备面试的小伙伴们,千万不要错过这份宝藏算法笔记!
2 |
3 | 
4 |
5 | 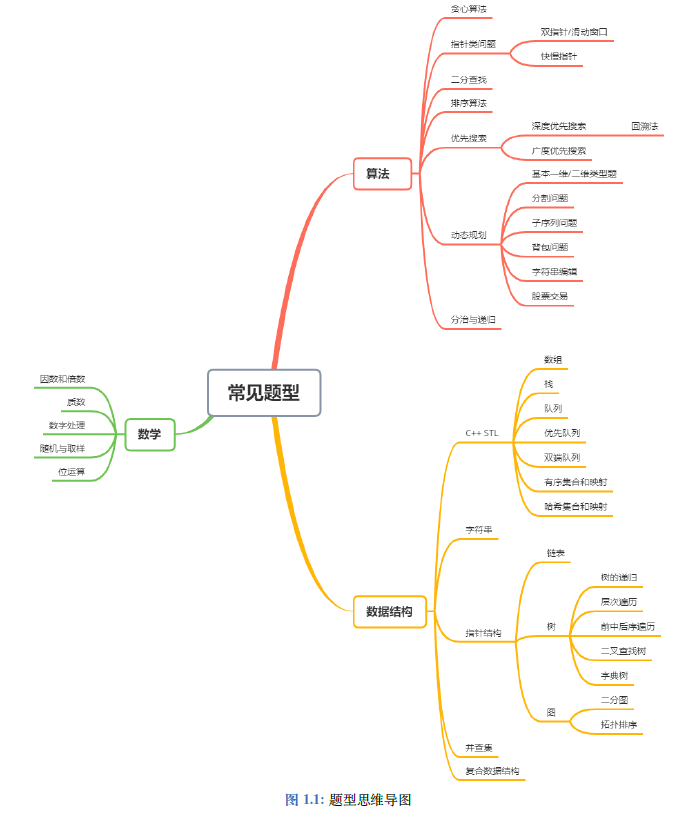
6 |
7 | **手册获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**谷歌**」就可以找到下载链接了(**无套路,无解压密码**)。
8 |
9 | 
10 |
11 |
12 |
13 |
14 |
15 | ---
16 |
17 |
18 |
19 | > 最后给大家分享一个Github仓库,上面有大彬整理的**300多本经典的计算机书籍PDF**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~
20 |
21 | 
22 |
23 | 
24 |
25 | **Github地址**:https://github.com/Tyson0314/java-books
--------------------------------------------------------------------------------
/docs/learn/manual.md:
--------------------------------------------------------------------------------
1 | 大家好,我是大彬~
2 |
3 | 最近抽空将小破站的**面试题汇总成PDF手册**了,方便小伙伴打印出来看。手册内容基本跟网站上的一致,包含**Java基础、MySQL、SpringBoot、MyBatis、Redis、RabbitMQ、计算机网络、数据结构与算法、微服务、场景题**等内容。
4 |
5 | 这份面试手册非常**详细**,并且有相应的**配图讲解**:
6 |
7 | 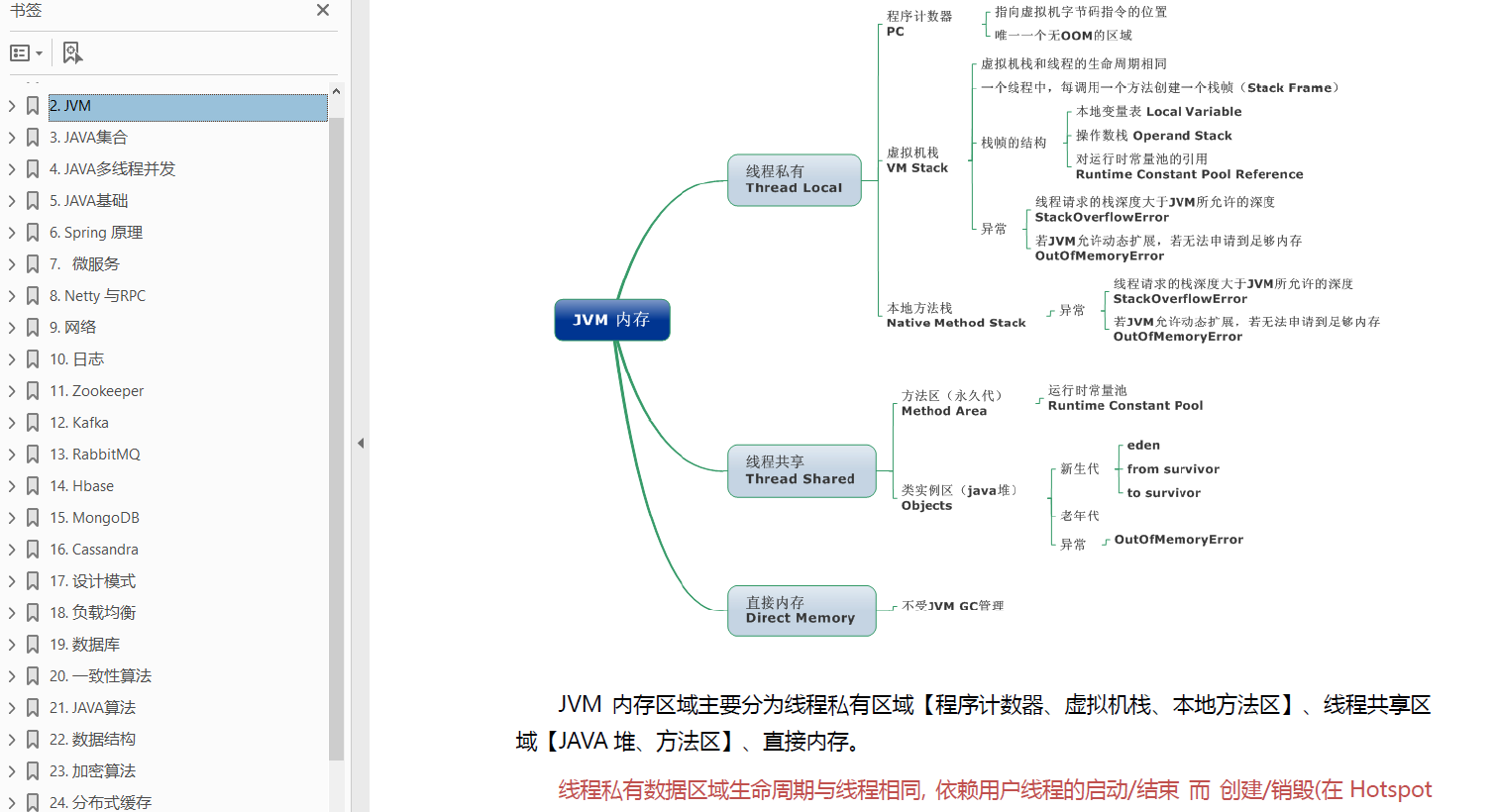
8 |
9 | 
10 |
11 | 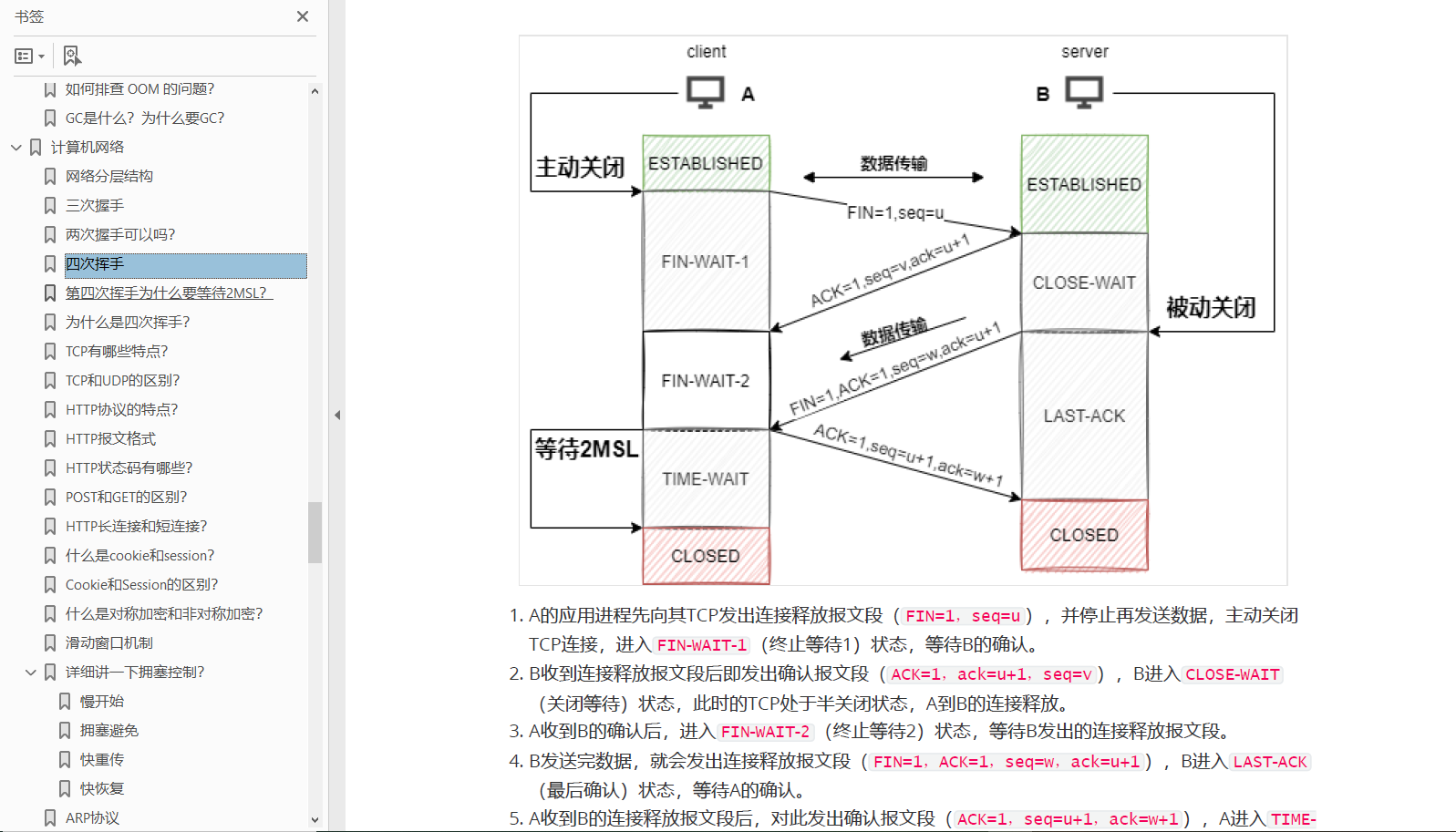
12 |
13 | 
14 |
15 | 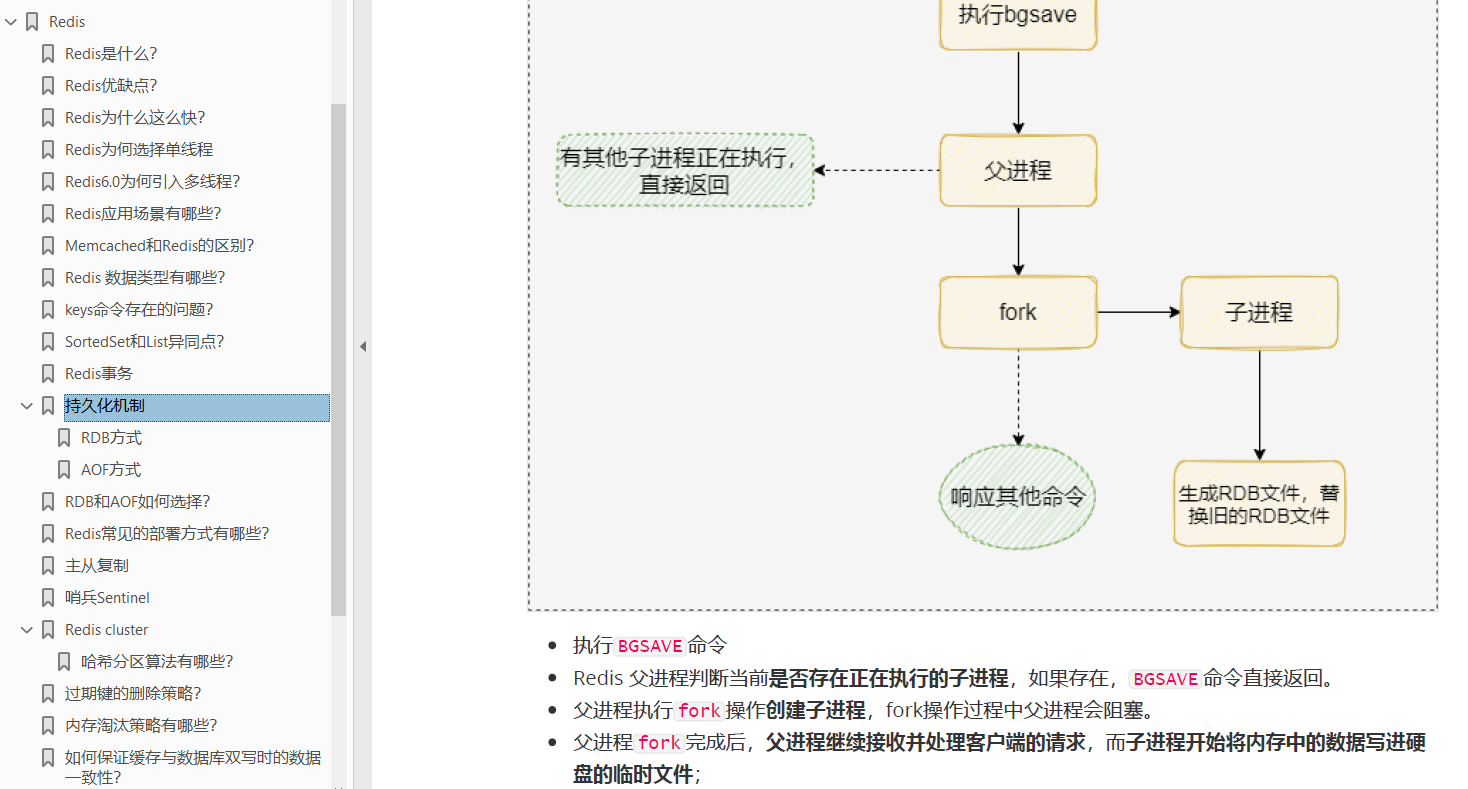
16 |
17 | **手册获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**手册**」就可以找到下载链接了(**无套路,无解压密码**)。
18 |
19 | 
20 |
21 | 祝大家学习愉快!
22 |
23 |
--------------------------------------------------------------------------------
/docs/learning-resources/chang-gou-mall.md:
--------------------------------------------------------------------------------
1 | 畅购商城项目是一个B2C的电商网站,采用了微服务架构,并且使用了前后端分离的方式进行开发。
2 |
3 | 整个微服务的开发是基于SpringBoot的,OAuth2.0是用来进行授权操作的,JWT用来封装用户的授权信息,Spring AMQP是消息队列协议。然后就是一套Spring Cloud的微服务框架。
4 |
5 | 持久化技术栈选用了MyBatis。数据库采用了MySQL,消息队列选用了RabbitMQ,还实现了MySQL读写分离。支付接口就选择了微信支付。
6 |
7 | 项目架构图如下:
8 |
9 | 
10 |
11 | 这个项目比较适合在校生学习,推荐给大家。
12 |
13 | **获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**畅购**」就可以找到下载链接了(**无套路,无解压密码**)。
14 |
15 | 
--------------------------------------------------------------------------------
/docs/learning-resources/leetcode-note.md:
--------------------------------------------------------------------------------
1 | 分享三份LeetCode刷题笔记,分别是**c/c++、Java、Go**版本的,每份笔记都挺详细,内容分别有**字符串、栈队列、树、排序、查找、BFS、DFS、贪心、动态规划**等等,每道题都包含解题思路、最佳解法、拓展题型等。
2 |
3 | 
4 |
5 | **c/c++版本**:
6 |
7 | 
8 |
9 | **Java版本**:
10 |
11 | 
12 |
13 | **Go版本**:
14 |
15 | 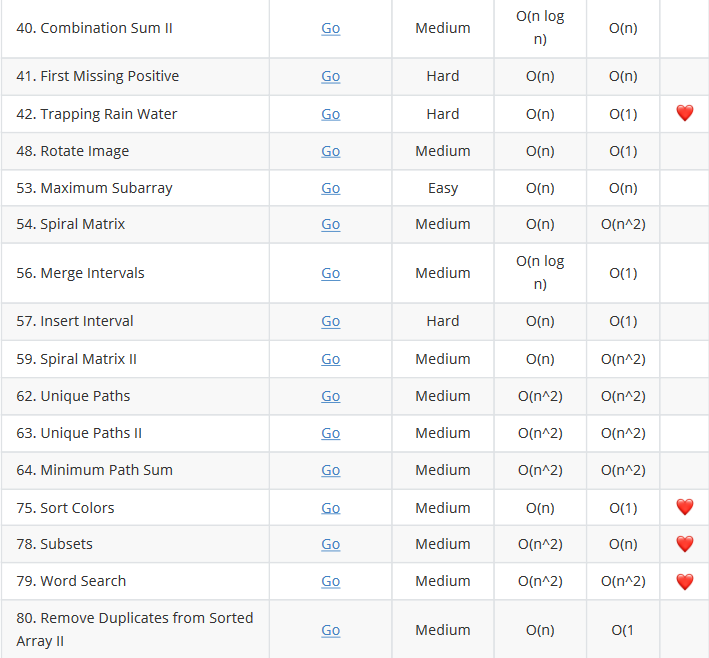
16 |
17 | 正在学习数据结构和算法,或者准备面试的小伙伴们,千万不要错过这几份**宝藏笔记**!
18 |
19 | **手册获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**力扣**」就可以找到下载链接了(**无套路,无解压密码**)。
20 |
21 | 
22 |
23 | 祝大家学习愉快!
24 |
25 |
26 |
27 |
--------------------------------------------------------------------------------
/docs/learning-resources/mysql45-section.md:
--------------------------------------------------------------------------------
1 | MySQL 使用和面试中遇到的问题,很多人会通过搜索别人的经验来解决 ,零散不成体系。实际上只要理解了 MySQL 的底层工作原理,就能很快地直戳问题的本质。
2 |
3 | MySQL45讲专栏通过探讨 MySQL 实战中最常见的 **36 个** 痛点问题,串起各个零散的知识点,配合 **100+** 手绘详解图,由线到面带你构建 MySQL 系统的学习路径。
4 |
5 | 专栏共包括两大模块。
6 |
7 | **模块一,基础篇**。为你深入浅出地讲述 MySQL 核心知识,涵盖 MySQL 基础架构、日志系统、事务隔离、锁等内容。
8 |
9 | **模块二,实践篇**。将从一个个关键的数据库问题出发,分析数据库原理,并给出实践指导。每个问题,都不只是简单地给出答案,而是从为什么要这么想、到底该怎样做出发,让你能够知其所以然,都将能够解决你平时工作中的一个疑惑点。
10 |
11 | 建议大家都去听听这个专栏,干货满满!
12 |
13 | 
14 |
15 |
16 |
17 | **手册获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**1003**」就可以找到下载链接了(**无套路,无解压密码**)。
18 |
19 | 
--------------------------------------------------------------------------------
/docs/learning-resources/sgg-java-learn.md:
--------------------------------------------------------------------------------
1 | 尚硅谷的 java 教程,不用多说,在行业内是排前面的,java 相关的所有技术,尚硅谷基本上都有对应的视频教程,这里给大家分享尚硅谷 java 全套教程,200多G,**文末直接获取**。
2 |
3 | ## 全套视频共5部分
4 |
5 | 
6 |
7 | ## 基础必备
8 |
9 | 
10 |
11 | ## 微服务核心
12 |
13 | 
14 |
15 | ## 微服务生态
16 |
17 | 
18 |
19 | 
20 |
21 | ## 项目实战
22 |
23 | 
24 |
25 | ## 选学技术
26 |
27 | 
28 |
29 | 
30 |
31 | ## 获取方式
32 |
33 | 百度云链接: https://pan.baidu.com/s/1F5HJKF9o455_1_oqMhMOEw?pwd=dv9s 提取码: dv9s
--------------------------------------------------------------------------------
/docs/learning-resources/shang-chou.md:
--------------------------------------------------------------------------------
1 | 尚筹网项目是一个众筹项目,整个项目分为后台管理与前台会员两大部分。其整体框架图如下:
2 |
3 | 
4 |
5 | 1、后台管理系统为单一架构,由SSM框架进行实现,同时整合SpringSecurity来对用户权限进行控制。
6 |
7 | 2、前台会员系统 前台会员系统为分布式微服务架构,由SpringBoot+SpringCloud进行实现,同时为了上传项目图片整合了oss服务,以及为了支付整合了阿里的支付API。
8 |
9 | 
10 |
11 | **获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**尚筹网**」就可以找到下载链接了(**无套路,无解压密码**)。
12 |
13 | 
--------------------------------------------------------------------------------
/docs/learning-resources/springboot-guide.md:
--------------------------------------------------------------------------------
1 | # Alibaba官方上线!SpringBoot+SpringCloud全彩指南(终极版)
2 |
3 | **Alibaba**作为国内一线互联网大厂,其中**SpringCloudAlibaba**更是阿里微服务最具代表性的技术之一,很多人只知道SpringCloudAlibaba其实面向微服务技术基本上都有的下面就给大家**推荐一份**Alibaba官网最新版:Spring+SpringBoot+SpringCloud微服务全栈开发小册,带你全面掌握Spring全家桶的知识。
4 |
5 | 下面直接给大家展示**目录**:
6 |
7 | **SpringBoot**
8 |
9 | 
10 |
11 | 
12 |
13 | **SpringCloudAlibaba**
14 |
15 | 
16 |
17 | 
18 |
19 | **高清pdf版获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**1001**」就可以找到下载链接了(**无套路,无解压密码**)。
20 |
21 | 
--------------------------------------------------------------------------------
/docs/leetcode/hot120/1-two-sum.md:
--------------------------------------------------------------------------------
1 | # 1. 两数之和
2 |
3 | [1. 两数之和](https://leetcode.cn/problems/two-sum/)
4 |
5 | **题目描述**
6 |
7 | 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
8 |
9 | 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
10 |
11 | 你可以按任意顺序返回答案。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:nums = [2,7,11,15], target = 9
17 | 输出:[0,1]
18 | 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
19 | ```
20 |
21 | **解题思路**
22 |
23 | - 遍历数组 nums,i 为当前下标,每个值都判断map中是否存在 `nums[i]` 的 key 值。
24 |
25 | - 如果存在则找到了两个值,如果不存在则将当前的 `(target - nums[i],i)` 存入 map 中,继续遍历直到找到为止。
26 |
27 | **参考代码**:
28 |
29 | ```java
30 | class Solution {
31 | public int[] twoSum(int[] nums, int target) {
32 | int[] result = new int[2];
33 | Map map = new HashMap<>();
34 |
35 | for (int i = 0; i < nums.length; i++) {
36 | if (map.containsKey(nums[i])) {
37 | result[0] = map.get(nums[i]);
38 | result[1] = i;
39 | return result;
40 | }
41 | map.put(target - nums[i], i);
42 | }
43 |
44 | return result;
45 | }
46 | }
47 | ```
48 |
49 |
50 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/104-maximum-depth-of-binary-tree.md:
--------------------------------------------------------------------------------
1 | # 104. 二叉树的最大深度
2 |
3 | [题目链接](https://leetcode.cn/problems/maximum-depth-of-binary-tree/)
4 |
5 | **题目描述**
6 |
7 | 给定一个二叉树,找出其最大深度。
8 |
9 | 二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
10 |
11 | **说明:** 叶子节点是指没有子节点的节点。
12 |
13 | **示例**
14 |
15 | ```java
16 | 给定二叉树 [3,9,20,null,null,15,7],
17 | 3
18 | / \
19 | 9 20
20 | / \
21 | 15 7
22 | 返回它的最大深度 3 。
23 | ```
24 |
25 | **解题思路**
26 |
27 | 找出终止条件:当前节点为空
28 | 找出返回值:节点为空时说明高度为 0,所以返回 0;节点不为空时则分别求左右子树的高度的最大值,同时加1表示当前节点的高度,返回该数值
29 |
30 | **参考代码**:
31 |
32 | ```java
33 | /**
34 | * Definition for a binary tree node.
35 | * public class TreeNode {
36 | * int val;
37 | * TreeNode left;
38 | * TreeNode right;
39 | * TreeNode(int x) { val = x; }
40 | * }
41 | */
42 | class Solution {
43 | public int maxDepth(TreeNode root) {
44 | if (root == null) {
45 | return 0;
46 | }
47 | return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
48 | }
49 | }
50 | ```
51 |
52 |
53 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/11-container-with-most-water.md:
--------------------------------------------------------------------------------
1 | # 11. 盛最多水的容器
2 |
3 | [11. 盛最多水的容器](https://leetcode.cn/problems/container-with-most-water/)
4 |
5 | **题目描述**
6 |
7 | 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
8 |
9 | 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
10 |
11 | 返回容器可以储存的最大水量。
12 |
13 | 说明:你不能倾斜容器。
14 |
15 | 
16 |
17 | **示例**
18 |
19 | ```java
20 | 输入:[1,8,6,2,5,4,8,3,7]
21 | 输出:49
22 | 解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
23 |
24 | 输入:height = [1,1]
25 | 输出:1
26 | ```
27 |
28 | **解题思路**
29 |
30 | 左右指针,数字小的指针往数字大的指针移动,面积才有可能变大。注意左右指针数字相同的情况。
31 |
32 | ```java
33 | class Solution {
34 | public int maxArea(int[] height) {
35 | int maxArea = 0;
36 | int left = 0;
37 | int right = height.length - 1;
38 |
39 | while(left < right) {
40 | maxArea = Math.max(maxArea, Math.min(height[left], height[right]) * (right - left));
41 | if(height[left] > height[right]) {
42 | right--;
43 | } else {
44 | left++;
45 | }
46 | }
47 |
48 | return maxArea;
49 | }
50 | }
51 | ```
52 |
53 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/120-triangle.md:
--------------------------------------------------------------------------------
1 | # 120. 三角形最小路径和
2 |
3 | [题目链接](https://leetcode.cn/problems/triangle/)
4 |
5 | **题目描述**
6 |
7 | 给定一个三角形 triangle ,找出自顶向下的最小路径和。
8 |
9 | 每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。也就是说,如果正位于当前行的下标 i ,那么下一步可以移动到下一行的下标 i 或 i + 1 。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:triangle = [[2],[3,4],[6,5,7],[4,1,8,3]]
15 | 输出:11
16 | 解释:如下面简图所示:
17 | 2
18 | 3 4
19 | 6 5 7
20 | 4 1 8 3
21 | 自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
22 |
23 | 来源:力扣(LeetCode)
24 | 链接:https://leetcode.cn/problems/triangle
25 | 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
26 | ```
27 |
28 | **解题思路**
29 |
30 | 动态规划。
31 |
32 | ```java
33 | class Solution {
34 | public int minimumTotal(List> triangle) {
35 | int size = triangle.size();
36 | int[] minLen = new int[size + 1];//+1
37 | for (int i = size - 1; i >= 0 ; i--) {
38 | for (int j = 0; j <= i; j++) {
39 | minLen[j] = Math.min(minLen[j], minLen[j + 1]) + triangle.get(i).get(j);
40 | }
41 | }
42 |
43 | return minLen[0];
44 | }
45 | }
46 | ```
47 |
48 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/121-best-time-to-buy-and-sell-stock.md:
--------------------------------------------------------------------------------
1 | # 121. 买卖股票的最佳时机
2 |
3 | [原题链接](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/)
4 |
5 | ## 题目描述
6 |
7 | 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
8 |
9 | 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
10 |
11 | 返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
12 |
13 | **示例**:
14 |
15 | ```java
16 | 输入:[7,1,5,3,6,4]
17 | 输出:5
18 | 解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
19 | 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
20 | ```
21 |
22 | ## 解题思路
23 |
24 | 动态规划。前i天的最大收益 = max{前i-1天的最大收益,第i天的价格-前i-1天中的最小价格}
25 |
26 | ```java
27 | class Solution {
28 | public int maxProfit(int[] prices) {
29 | int minPrice = Integer.MAX_VALUE;
30 | int maxProfit = 0;
31 | for (int i = 0; i < prices.length; i++) {
32 | if (prices[i] < minPrice) {
33 | minPrice = prices[i];
34 | }
35 | maxProfit = Math.max(prices[i] - minPrice, maxProfit);
36 | }
37 | return maxProfit;
38 | }
39 | }
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/122-best-time-to-buy-and-sell-stock-ii.md:
--------------------------------------------------------------------------------
1 | # 122. 买卖股票的最佳时机 II
2 |
3 | [题目链接](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-ii/)
4 |
5 | **题目描述**:
6 |
7 | 给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
8 |
9 | 在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
10 |
11 | 返回 你能获得的 最大 利润 。
12 |
13 | **示例**:
14 |
15 | ```java
16 | 输入:prices = [1,2,3,4,5]
17 | 输出:4
18 | 解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
19 | 总利润为 4 。
20 | ```
21 |
22 | **解题思路**
23 |
24 | 可以尽可能地完成更多的交易,但不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
25 |
26 | ```java
27 | //输入: [7,1,5,3,6,4]
28 | //输出: 7
29 | class Solution {
30 | public int maxProfit(int[] prices) {
31 | int profit = 0;
32 | for (int i = 1; i < prices.length; i++) {
33 | int tmp = prices[i] - prices[i - 1];
34 | if (tmp > 0) {
35 | profit += tmp;
36 | }
37 | }
38 |
39 | return profit;
40 | }
41 | }
42 | ```
43 |
44 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/128-longest-consecutive-sequence.md:
--------------------------------------------------------------------------------
1 | # 128. 最长连续序列
2 |
3 | [128. 最长连续序列](https://leetcode.cn/problems/longest-consecutive-sequence/)
4 |
5 | **题目描述**:
6 |
7 | 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
8 |
9 | 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
10 |
11 | **示例**:
12 |
13 | ```java
14 | 输入:nums = [100,4,200,1,3,2]
15 | 输出:4
16 | 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
17 | ```
18 |
19 | **解题思路**
20 |
21 | 将数组存入set。遍历数组,对`num[i]`前后连续的数字进行计数,并将set中的这些数字移除,避免重复计算。
22 |
23 | 比如`[10, 9, 8, 7, 11, 14]`,存入set。遍历第一个元素10,set移除10,10前面有7-8-9,后面有11,连续序列长度为5,将set中的7-8-9-11移除,后续遍历到7-8-9-11,直接跳过。
24 |
25 | ```java
26 | class Solution {
27 | public int longestConsecutive(int[] nums) {
28 | Set set = new HashSet<>();
29 | for (int num : nums) {
30 | set.add(num);
31 | }
32 |
33 | int len = 0;
34 | int maxLen = 0;
35 | for (int num : nums) {
36 | len = 1;
37 | if (set.remove(num)) {
38 | int cur = num;
39 | while (set.remove(--cur)) {
40 | len++;
41 | }
42 | cur = num;
43 | while (set.remove(++cur)) {
44 | len++;
45 | }
46 | maxLen = maxLen > len ? maxLen : len;
47 | }
48 | }
49 |
50 | return maxLen;
51 | }
52 | }
53 | ```
54 |
55 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/134-gas-station.md:
--------------------------------------------------------------------------------
1 | # 134. 加油站
2 |
3 | [134. 加油站](https://leetcode.cn/problems/gas-station/)
4 |
5 | **题目描述**
6 |
7 | 在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
8 |
9 | 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
10 |
11 | 给定两个整数数组 gas 和 cost ,如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入: gas = [1,2,3,4,5], cost = [3,4,5,1,2]
17 | 输出: 3
18 | 解释:
19 | 从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
20 | 开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
21 | 开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
22 | 开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
23 | 开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
24 | 开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
25 | 因此,3 可为起始索引。
26 | ```
27 |
28 | **解题思路**:
29 |
30 | 1. 遍历一周,总获得的油量少于要花掉的油量必然没有结果;
31 | 2. 先苦后甜,记录遍历时所存的油量最少的站点,由于题目有解只有唯一解,所以从当前站点的下一个站点开始是唯一可能成功开完全程的。
32 |
33 | ```java
34 | class Solution {
35 | public int canCompleteCircuit(int[] gas, int[] cost) {
36 | int minIdx=0;
37 | int sum=Integer.MAX_VALUE;
38 | int num=0;
39 | for (int i = 0; i < gas.length; i++) {
40 | num+=gas[i]-cost[i];
41 | if(num 作者:cxywushixiong
29 | > 链接:https://leetcode.cn/problems/remove-nth-node-from-end-of-list/solution/dong-hua-tu-jie-leetcode-di-19-hao-wen-ti-shan-chu/
30 | > 来源:力扣(LeetCode)
31 |
32 | **代码实现**
33 |
34 | ```java
35 | class Solution {
36 | public ListNode removeNthFromEnd(ListNode head, int n) {
37 | ListNode dummy = new ListNode(-1);
38 | dummy.next = head;
39 | ListNode pre = dummy;
40 | ListNode slow = head;
41 | ListNode fast = head;
42 | for(int i=0;i rightSideView(TreeNode root) {
23 | List res = new ArrayList<>();
24 | if (root == null) {
25 | return res;
26 | }
27 |
28 | Queue queue = new ArrayDeque<>();
29 | queue.offer(root);
30 |
31 | while (!queue.isEmpty()) {
32 | int size = queue.size();
33 | while (size-- > 0) { //先取size的值,再自减
34 | TreeNode node = queue.poll();
35 | if (node.left != null) {
36 | queue.offer(node.left);
37 | }
38 | if (node.right != null) {
39 | queue.offer(node.right);
40 | }
41 | if (size == 0) { //最右边的节点
42 | res.add(node.val);
43 | }
44 | }
45 | }
46 |
47 | return res;
48 | }
49 | }
50 | ```
51 |
52 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/20-valid-parentheses.md:
--------------------------------------------------------------------------------
1 | # 20. 有效的括号
2 |
3 | [20. 有效的括号](https://leetcode.cn/problems/valid-parentheses/)
4 |
5 | **题目描述**
6 |
7 | 给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
8 |
9 | 有效字符串需满足:
10 |
11 | - 左括号必须用相同类型的右括号闭合。
12 | - 左括号必须以正确的顺序闭合。
13 | - 每个右括号都有一个对应的相同类型的左括号。
14 |
15 | **示例**
16 |
17 | ```java
18 | 输入:s = "()"
19 | 输出:true
20 |
21 | 输入:s = "()[]{}"
22 | 输出:true
23 | ```
24 |
25 | **解题思路**
26 |
27 | 使用栈实现。
28 |
29 | ```java
30 | class Solution {
31 | public boolean isValid(String s) {
32 | Stack stack = new Stack<>();
33 |
34 | for (int i = 0; i < s.length(); i++) {
35 | switch (s.charAt(i)) {
36 | case '(':
37 | stack.push(')');//存进相反符号
38 | break;
39 | case '[':
40 | stack.push(']');
41 | break;
42 | case '{':
43 | stack.push('}');
44 | break;
45 | default:
46 | if (stack.isEmpty() || s.charAt(i) != stack.pop()) {
47 | return false;
48 | }
49 | break;
50 | }
51 | }
52 | return stack.isEmpty();
53 | }
54 | }
55 | ```
56 |
57 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/200-number-of-islands.md:
--------------------------------------------------------------------------------
1 | # 200. 岛屿数量
2 |
3 | [题目链接](https://leetcode.cn/problems/number-of-islands/)
4 |
5 | **题目描述**
6 |
7 | 给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
8 |
9 | 岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
10 |
11 | 此外,你可以假设该网格的四条边均被水包围。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:grid = [
17 | ["1","1","1","1","0"],
18 | ["1","1","0","1","0"],
19 | ["1","1","0","0","0"],
20 | ["0","0","0","0","0"]
21 | ]
22 | 输出:1
23 | ```
24 |
25 | **解题思路**
26 |
27 | 深度优先遍历,使用isVisited数组记录元素是否被访问过。
28 |
29 | ```java
30 | class Solution {
31 | public int numIslands(char[][] grid) {
32 | if (grid == null || grid.length == 0 || grid[0].length == 0) {
33 | return 0;
34 | }
35 |
36 | boolean[][] isVisited = new boolean[grid.length][grid[0].length];
37 | int count = 0;
38 |
39 | for (int i = 0; i < grid.length; i++) {
40 | for (int j = 0; j < grid[0].length; j++) {
41 | if (grid[i][j] == '1' && !isVisited[i][j]) {
42 | dfs(grid, isVisited, i, j);
43 | count++;
44 | }
45 | }
46 | }
47 |
48 | return count;
49 | }
50 |
51 | private void dfs(char[][] grid, boolean[][] isVisited, int i, int j) {
52 | if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == '0') {
53 | return;
54 | }
55 | if (!isVisited[i][j]) {
56 | isVisited[i][j] = true;
57 | dfs(grid, isVisited, i + 1, j);
58 | dfs(grid, isVisited, i - 1, j);
59 | dfs(grid, isVisited, i, j + 1);
60 | dfs(grid, isVisited, i, j - 1);
61 | }
62 | }
63 | }
64 | ```
65 |
66 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/206-reverse-linked-list.md:
--------------------------------------------------------------------------------
1 | # 206. 反转链表
2 |
3 | [原题链接](https://leetcode.cn/problems/reverse-linked-list/)
4 |
5 | **题目描述**
6 |
7 | 给你单链表的头节点 `head` ,请你反转链表,并返回反转后的链表。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:head = [1,2,3,4,5]
13 | 输出:[5,4,3,2,1]
14 | ```
15 |
16 | **解题思路**:
17 |
18 | 1. 定义两个指针,第一个指针叫 pre,最初是指向 null 的。
19 | 2. 第二个指针 cur 指向 head,然后不断遍历 cur。
20 | 3. 每次迭代到 cur,都将 cur 的 next 指向 pre,然后 pre 和 cur 前进一位。
21 | 4. 都迭代完了(cur 变成 null 了),pre 就是最后一个节点了。
22 |
23 | ```java
24 | class Solution {
25 | public ListNode reverseList(ListNode head) {
26 | if (head == null) {
27 | return null;
28 | }
29 |
30 | ListNode pre = null;
31 | ListNode cur = head;
32 | ListNode tmp = null;
33 | while (cur != null) {
34 | tmp = cur.next;
35 | cur.next = pre;
36 | pre = cur;
37 | cur = tmp;
38 | }
39 |
40 | return pre;
41 | }
42 | }
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/21-merge-two-sorted-lists.md:
--------------------------------------------------------------------------------
1 | # 21. 合并两个有序链表
2 |
3 | [21. 合并两个有序链表](https://leetcode.cn/problems/merge-two-sorted-lists/)
4 |
5 | **题目描述**
6 |
7 | 将两个升序链表合并为一个新的 **升序** 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:l1 = [1,2,4], l2 = [1,3,4]
13 | 输出:[1,1,2,3,4,4]
14 | ```
15 |
16 | **参考代码**
17 |
18 | ```java
19 | class Solution {
20 | public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
21 | ListNode ans = new ListNode(0);
22 | ListNode tmp = ans;
23 |
24 | while (l1 != null && l2!= null) {
25 | if (l1.val > l2.val) {
26 | tmp.next = l2; //tmp.next = new ListNode(l2.val); 没必要这么做
27 | l2 = l2.next;
28 | } else {
29 | tmp.next = l1;
30 | l1 = l1.next;
31 | }
32 | tmp = tmp.next;
33 | }
34 |
35 | tmp.next = l1 == null ? l2 : l1;
36 |
37 | return ans.next;
38 | }
39 | }
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/234-palindrome-linked-list.md:
--------------------------------------------------------------------------------
1 | # 234. 回文链表
2 |
3 | [234. 回文链表](https://leetcode.cn/problems/palindrome-linked-list/)
4 |
5 | **题目描述**
6 |
7 | 给你一个单链表的头节点 `head` ,请你判断该链表是否为回文链表。如果是,返回 `true` ;否则,返回 `false` 。
8 |
9 | **示例**
10 |
11 | ```java
12 | 给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
13 | ```
14 |
15 | **解题思路**
16 |
17 | 快慢指针。
18 |
19 | 快指针走到末尾,慢指针刚好到中间。其中慢指针将前半部分反转。然后比较。
20 |
21 | **参考代码**:
22 |
23 | ```java
24 | public boolean isPalindrome(ListNode head) {
25 | if(head == null || head.next == null) {
26 | return true;
27 | }
28 | ListNode slow = head, fast = head;
29 | ListNode pre = head, prepre = null;
30 | while(fast != null && fast.next != null) {
31 | pre = slow;
32 | slow = slow.next;
33 | fast = fast.next.next;
34 | pre.next = prepre;
35 | prepre = pre;
36 | }
37 | if(fast != null) {
38 | slow = slow.next;
39 | }
40 | while(pre != null && slow != null) {
41 | if(pre.val != slow.val) {
42 | return false;
43 | }
44 | pre = pre.next;
45 | slow = slow.next;
46 | }
47 | return true;
48 | }
49 |
50 | 作者:nuan
51 | 链接:https://leetcode.cn/problems/palindrome-linked-list/solution/wo-de-kuai-man-zhi-zhen-du-cong-tou-kai-shi-gan-ju/
52 | 来源:力扣(LeetCode)
53 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
54 | ```
55 |
56 |
57 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/236-lowest-common-ancestor-of-a-binary-tree.md:
--------------------------------------------------------------------------------
1 | # 236. 二叉树的最近公共祖先
2 |
3 | [题目链接](https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-tree/)
4 |
5 | **题目描述**
6 |
7 | 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
8 |
9 | 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
15 | 输出:3
16 | 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
17 | ```
18 |
19 | **解题思路**
20 |
21 | [后序遍历](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/solution/236-er-cha-shu-de-zui-jin-gong-gong-zu-xian-hou-xu/)
22 |
23 | ```java
24 | class Solution {
25 | public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
26 | if (root == null || root == p || root == q) {
27 | return root;
28 | }
29 |
30 | TreeNode left = lowestCommonAncestor(root.left, p, q);
31 | TreeNode right = lowestCommonAncestor(root.right, p, q);
32 |
33 | if (left != null && right != null) {
34 | return root;
35 | } else {
36 | return left == null ? right : left;
37 | }
38 | }
39 | }
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/24-swap-nodes-in-pairs.md:
--------------------------------------------------------------------------------
1 | # 24. 两两交换链表中的节点
2 |
3 | [两两交换链表中的节点](https://leetcode.cn/problems/swap-nodes-in-pairs/)
4 |
5 | **题目描述**
6 |
7 | 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
8 |
9 | 
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:head = [1,2,3,4]
15 | 输出:[2,1,4,3]
16 | ```
17 |
18 | **解题思路**
19 |
20 | 使用递归实现。
21 |
22 | ```java
23 | class Solution {
24 | public ListNode swapPairs(ListNode head) {
25 | if (head == null) {
26 | return head;
27 | }
28 | ListNode left = head;
29 | ListNode right = head.next;
30 |
31 | if (right == null) {
32 | right = left;
33 | } else {
34 | left.next = swapPairs(right.next);
35 | right.next = left;
36 | }
37 |
38 | return right;
39 | }
40 | }
41 | ```
42 |
43 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/26-remove-duplicates-from-sorted-array.md:
--------------------------------------------------------------------------------
1 | # 26. 删除有序数组中的重复项
2 |
3 | [题目链接](https://leetcode.cn/problems/remove-duplicates-from-sorted-array/)
4 |
5 | **题目描述**
6 |
7 | 给你一个 **升序排列** 的数组 `nums` ,请你**[ 原地](http://baike.baidu.com/item/原地算法)** 删除重复出现的元素,使每个元素 **只出现一次** ,返回删除后数组的新长度。元素的 **相对顺序** 应该保持 **一致** 。
8 |
9 | 由于在某些语言中不能改变数组的长度,所以必须将结果放在数组nums的第一部分。更规范地说,如果在删除重复项之后有 `k` 个元素,那么 `nums` 的前 `k` 个元素应该保存最终结果。
10 |
11 | 将最终结果插入 `nums` 的前 `k` 个位置后返回 `k` 。
12 |
13 | 不要使用额外的空间,你必须在 **[原地 ](https://baike.baidu.com/item/原地算法)修改输入数组** 并在使用 O(1) 额外空间的条件下完成。
14 |
15 | **示例**:
16 |
17 | ```java
18 | 输入:nums = [1,1,2]
19 | 输出:2, nums = [1,2,_]
20 | 解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
21 | ```
22 |
23 | **参考代码**
24 |
25 | ```java
26 | class Solution {
27 | public int removeDuplicates(int[] nums) {
28 | if (nums == null || nums.length == 0) {
29 | return 0;
30 | }
31 | int left = 0;
32 | int right = 1;
33 | int count = 1;
34 |
35 | while (right < nums.length) {
36 | if (nums[right] == nums[left]) {
37 | if (count < 2) {
38 | nums[++left] = nums[right++];
39 | } else {
40 | right++;
41 | }
42 | count++;
43 | } else {
44 | count = 1;
45 | nums[++left] = nums[right++];
46 | }
47 | }
48 | return left + 1;
49 | }
50 | }
51 | ```
52 |
53 |
54 |
55 |
56 |
57 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/27-remove-element.md:
--------------------------------------------------------------------------------
1 | # 27. 移除元素
2 |
3 | [移除元素](https://leetcode.cn/problems/remove-element/)
4 |
5 | **题目描述**
6 |
7 | 给你一个数组 `nums` 和一个值 `val`,你需要 **[原地](https://baike.baidu.com/item/原地算法)** 移除所有数值等于 `val` 的元素,并返回移除后数组的新长度。
8 |
9 | 不要使用额外的数组空间,你必须仅使用 `O(1)` 额外空间并 **[原地 ](https://baike.baidu.com/item/原地算法)修改输入数组**。
10 |
11 | 元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:nums = [3,2,2,3], val = 3
17 | 输出:2, nums = [2,2]
18 | 解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
19 | ```
20 |
21 | **解题思路**
22 |
23 | 
24 |
25 | > 作者:画手大鹏
26 | > 链接:https://leetcode.cn/problems/remove-element/solutions/10388/hua-jie-suan-fa-27-yi-chu-yuan-su-by-guanpengchn/
27 | > 来源:力扣(LeetCode)
28 | > 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
29 |
30 | ```java
31 | class Solution {
32 | public int removeElement(int[] nums, int val) {
33 | int ans = 0;
34 | for(int num: nums) {
35 | if(num != val) {
36 | nums[ans] = num;
37 | ans++;
38 | }
39 | }
40 | return ans;
41 | }
42 | }
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/28-mirror-binary-tree.md:
--------------------------------------------------------------------------------
1 | # 28. 对称的二叉树
2 |
3 | [28. 对称的二叉树](https://leetcode.cn/problems/dui-cheng-de-er-cha-shu-lcof/)
4 |
5 | **题目描述**
6 |
7 | 请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
8 |
9 | 例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:root = [1,2,2,3,4,4,3]
15 | 输出:true
16 | ```
17 |
18 | **解题思路**
19 |
20 | 从顶至底递归,判断每对节点是否对称,从而判断树是否为对称二叉树。
21 |
22 | ```java
23 | class Solution {
24 | public boolean isSymmetric(TreeNode root) {
25 | if (root == null) {
26 | return true;
27 | }
28 | return isMirror(root.left, root.right);
29 | }
30 |
31 | public boolean isMirror(TreeNode node1, TreeNode node2) {
32 | if (node1 == null && node2 == null) {
33 | return true;
34 | }
35 |
36 | if (node1 == null || node2 == null || node1.val != node2.val) {
37 | return false;
38 | }
39 |
40 | return isMirror(node1.left, node2.right) && isMirror(node1.right, node2.left);
41 | }
42 | }
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/29-divide-two-integers.md:
--------------------------------------------------------------------------------
1 | # 29. 两数相除
2 |
3 | [29. 两数相除](https://leetcode.cn/problems/divide-two-integers/)
4 |
5 | **题目描述**
6 |
7 | 给定两个整数,被除数 `dividend` 和除数 `divisor`。将两数相除,要求不使用乘法、除法和 mod 运算符。
8 |
9 | 返回被除数 `dividend` 除以除数 `divisor` 得到的商。
10 |
11 | 整数除法的结果应当截去(`truncate`)其小数部分,例如:`truncate(8.345) = 8` 以及 `truncate(-2.7335) = -2`
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入: dividend = 10, divisor = 3
17 | 输出: 3
18 | 解释: 10/3 = truncate(3.33333..) = truncate(3) = 3
19 | ```
20 |
21 | **解题思路**
22 |
23 | Integer.MIN_VALUE 转为正数会溢出,故将 dividend 和 divisor 都转化为负数。**两个负数相加溢出会大于0**。
24 |
25 | ```java
26 | class Solution {
27 | //dividend / divisor
28 | public int divide(int dividend, int divisor) {
29 | if (dividend == Integer.MIN_VALUE && divisor == -1) {
30 | return Integer.MAX_VALUE;
31 | }
32 | if (divisor == 1) { //不加上会超时
33 | return dividend;
34 | }
35 | int sign = 1;
36 | if ((dividend < 0 && divisor > 0) || (dividend > 0 && divisor < 0)) {
37 | sign = -1;
38 | }
39 | int a = dividend > 0 ? -dividend : dividend;
40 | int b = divisor > 0 ? -divisor : divisor;
41 | if (a > b) {
42 | return 0;
43 | }
44 | int ans = divideHelper(a, b);
45 |
46 | return sign > 0 ? ans : -ans;
47 | }
48 |
49 | private int divideHelper(int a, int b) {
50 | if (a > b) {
51 | return 0;
52 | }
53 |
54 | int count = 1;
55 | int tmp = b;
56 | while (tmp + tmp >= a && tmp + tmp < 0) { //两个负数相加溢出会大于0
57 | tmp += tmp;
58 | count += count;
59 | }
60 |
61 | return count + divideHelper(a - tmp, b);
62 | }
63 | }
64 | ```
65 |
66 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/3-longest-substring-without-repeating-characters.md:
--------------------------------------------------------------------------------
1 | # 3 . 无重复字符的最长子串
2 |
3 | [题目链接](https://leetcode.cn/problems/longest-substring-without-repeating-characters/)
4 |
5 | **题目描述**
6 |
7 | 给定一个字符串 `s` ,请你找出其中不含有重复字符的 **最长子串** 的长度。
8 |
9 | **示例**
10 |
11 | ```
12 | 输入: s = "abcabcbb"
13 | 输出: 3
14 | 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
15 | ```
16 |
17 | **解题思路**
18 |
19 | 这道题主要用到思路是:滑动窗口
20 |
21 | **什么是滑动窗口**?
22 |
23 | 其实就是一个队列,比如例题中的 abcabcbb,进入这个队列(窗口)为 abc 满足题目要求,当再进入 a,队列变成了 abca,这时候不满足要求。所以,我们要移动这个队列!
24 |
25 | **如何移动**?
26 |
27 | 我们只要把队列的左边的元素移出就行了,直到满足题目要求!
28 |
29 | 一直维持这样的队列,找出队列出现最长的长度时候,求出解!
30 |
31 | 时间复杂度:O(n)
32 |
33 | **代码实现**
34 |
35 | ```java
36 | class Solution {
37 | public int lengthOfLongestSubstring(String s) {
38 | if (s.length()==0) return 0;
39 | HashMap map = new HashMap();
40 | int max = 0;
41 | int left = 0;
42 | for(int i = 0; i < s.length(); i ++){
43 | if(map.containsKey(s.charAt(i))){
44 | left = Math.max(left,map.get(s.charAt(i)) + 1);
45 | }
46 | map.put(s.charAt(i),i);
47 | max = Math.max(max,i-left+1);
48 | }
49 | return max;
50 |
51 | }
52 | }
53 | ```
54 |
55 |
56 |
57 | > 作者:powcai
58 | > 链接:https://leetcode.cn/problems/longest-substring-without-repeating-characters/solution/hua-dong-chuang-kou-by-powcai/
59 | > 来源:力扣(LeetCode)
--------------------------------------------------------------------------------
/docs/leetcode/hot120/31-next-permutation.md:
--------------------------------------------------------------------------------
1 | # 31. 下一个排列
2 |
3 | [31. 下一个排列](https://leetcode.cn/problems/next-permutation/)
4 |
5 | **题目描述**
6 |
7 | 整数数组的一个 **排列** 就是将其所有成员以序列或线性顺序排列。
8 |
9 | - 例如,`arr = [1,2,3]` ,以下这些都可以视作 `arr` 的排列:`[1,2,3]`、`[1,3,2]`、`[3,1,2]`、`[2,3,1]` 。
10 |
11 | 整数数组的 **下一个排列** 是指其整数的下一个字典序更大的排列。更正式地,如果数组的所有排列根据其字典顺序从小到大排列在一个容器中,那么数组的 **下一个排列** 就是在这个有序容器中排在它后面的那个排列。如果不存在下一个更大的排列,那么这个数组必须重排为字典序最小的排列(即,其元素按升序排列)。
12 |
13 | - 例如,`arr = [1,2,3]` 的下一个排列是 `[1,3,2]` 。
14 | - 类似地,`arr = [2,3,1]` 的下一个排列是 `[3,1,2]` 。
15 | - 而 `arr = [3,2,1]` 的下一个排列是 `[1,2,3]` ,因为 `[3,2,1]` 不存在一个字典序更大的排列。
16 |
17 | 给你一个整数数组 `nums` ,找出 `nums` 的下一个排列。
18 |
19 | 必须**[ 原地 ](https://baike.baidu.com/item/原地算法)**修改,只允许使用额外常数空间。
20 |
21 | **示例**
22 |
23 | ```java
24 | 输入:nums = [1,2,3]
25 | 输出:[1,3,2]
26 | ```
27 |
28 | **参考代码**
29 |
30 | ```java
31 | class Solution {
32 | public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
33 | ListNode ans = new ListNode(0);
34 | ListNode tmp = ans;
35 |
36 | while (l1 != null && l2!= null) {
37 | if (l1.val > l2.val) {
38 | tmp.next = l2; //tmp.next = new ListNode(l2.val); 没必要这么做
39 | l2 = l2.next;
40 | } else {
41 | tmp.next = l1;
42 | l1 = l1.next;
43 | }
44 | tmp = tmp.next;
45 | }
46 |
47 | tmp.next = l1 == null ? l2 : l1;
48 |
49 | return ans.next;
50 | }
51 | }
52 | ```
53 |
54 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/34-find-first-and-last-position-of-element-in-sorted-array.md:
--------------------------------------------------------------------------------
1 | # 34. 在排序数组中查找元素的第一个和最后一个位置
2 |
3 | [34. 在排序数组中查找元素的第一个和最后一个位置](https://leetcode.cn/problems/find-first-and-last-position-of-element-in-sorted-array/)
4 |
5 | **题目描述**
6 |
7 | 给你一个按照非递减顺序排列的整数数组 `nums`,和一个目标值 `target`。请你找出给定目标值在数组中的开始位置和结束位置。
8 |
9 | 如果数组中不存在目标值 `target`,返回 `[-1, -1]`。
10 |
11 | 你必须设计并实现时间复杂度为 `O(log n)` 的算法解决此问题。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:nums = [5,7,7,8,8,10], target = 8
17 | 输出:[3,4]
18 | ```
19 |
20 | **参考代码**
21 |
22 | ```java
23 | //输入: nums = [5,7,7,8,8,10], target = 8
24 | //输出: [3,4]
25 |
26 | class Solution {
27 | public int[] searchRange(int[] nums, int target) {
28 | if (nums == null || nums.length == 0) {
29 | return new int[]{-1, -1};
30 | }
31 | int left = searchRangeHelper(nums, target);
32 | int right = searchRangeHelper(nums, target + 1);//复用代码
33 |
34 | if (left == nums.length || nums[left] != target) {//left==nums.length数组元素比target小
35 | return new int[]{-1, -1};
36 | }
37 | return new int[]{left, right - 1};
38 | }
39 |
40 | private int searchRangeHelper(int[] nums, int target) {
41 | int left = 0;
42 | int right = nums.length;//特殊情况[1] 1
43 | while (left < right) {
44 | int mid = (left + right) >> 1;
45 | if (nums[mid] < target) {
46 | left = mid + 1;
47 | } else {
48 | right = mid;
49 | }
50 | }
51 |
52 | return left;
53 | }
54 | }
55 | ```
56 |
57 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/40-combination-sum-ii.md:
--------------------------------------------------------------------------------
1 | # 40. 组合总和 II
2 |
3 | [40. 组合总和 II](https://leetcode.cn/problems/combination-sum-ii/)
4 |
5 | **题目描述**
6 |
7 | 给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
8 |
9 | candidates 中的每个数字在每个组合中只能使用 一次 。
10 |
11 | 注意:解集不能包含重复的组合。
12 |
13 | **示例**:
14 |
15 | ```
16 | 输入: candidates = [2,5,2,1,2], target = 5,
17 | 输出:
18 | [
19 | [1,2,2],
20 | [5]
21 | ]
22 | ```
23 |
24 | **解题思路**
25 |
26 | 数组元素可能重复。使用回溯算法。
27 |
28 | 剪枝:
29 |
30 | 
31 |
32 | 去重复组合:
33 |
34 | 
35 |
36 | ```java
37 | class Solution {
38 | private List> ans = new ArrayList<>();
39 | public List> combinationSum2(int[] candidates, int target) {
40 | if (candidates == null || candidates.length == 0) {
41 | return ans;
42 | }
43 | Arrays.sort(candidates);//排序方便回溯剪枝
44 | Deque path = new ArrayDeque<>();//作为栈来使用,效率高于Stack;也可以作为队列来使用,效率高于LinkedList;线程不安全
45 | combinationSum2Helper(candidates, target, 0, path);
46 | return ans;
47 | }
48 |
49 | public void combinationSum2Helper(int[] arr, int target, int start, Deque path) {
50 | if (target == 0) {
51 | ans.add(new ArrayList(path));
52 | }
53 |
54 | for (int i = start; i < arr.length; i++) {
55 | if (target < arr[i]) {//剪枝
56 | return;
57 | }
58 | if (i > start && arr[i] == arr[i - 1]) {//在一个层级,会产生重复
59 | continue;
60 | }
61 | path.addLast(arr[i]);
62 | combinationSum2Helper(arr, target - arr[i], i + 1, path);
63 | path.removeLast();
64 | }
65 | }
66 | }
67 | ```
68 |
69 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/415-add-strings.md:
--------------------------------------------------------------------------------
1 | # 415. 字符串相加
2 |
3 | [415. 字符串相加](https://leetcode.cn/problems/add-strings/)
4 |
5 | **题目描述**
6 |
7 | 给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。
8 |
9 | 你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直接将输入的字符串转换为整数形式。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:num1 = "11", num2 = "123"
15 | 输出:"134"
16 | ```
17 |
18 | **解题思路**
19 |
20 | 
21 |
22 | **参考代码**:
23 |
24 | ```java
25 | class Solution {
26 | public String addStrings(String num1, String num2) {
27 | StringBuilder res = new StringBuilder("");
28 | int i = num1.length() - 1, j = num2.length() - 1, carry = 0;
29 | while(i >= 0 || j >= 0){
30 | int n1 = i >= 0 ? num1.charAt(i) - '0' : 0;
31 | int n2 = j >= 0 ? num2.charAt(j) - '0' : 0;
32 | int tmp = n1 + n2 + carry;
33 | carry = tmp / 10;
34 | res.append(tmp % 10);
35 | i--; j--;
36 | }
37 | if(carry == 1) res.append(1);
38 | return res.reverse().toString();
39 | }
40 | }
41 |
42 | 作者:jyd
43 | 链接:https://leetcode.cn/problems/add-strings/solution/add-strings-shuang-zhi-zhen-fa-by-jyd/
44 | 来源:力扣(LeetCode)
45 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
46 | ```
47 |
48 |
49 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/43-multiply-strings.md:
--------------------------------------------------------------------------------
1 | # 43. 字符串相乘
2 |
3 | [43. 字符串相乘](https://leetcode.cn/problems/multiply-strings/)
4 |
5 | **题目描述**
6 |
7 | 给定两个以字符串形式表示的非负整数 `num1` 和 `num2`,返回 `num1` 和 `num2` 的乘积,它们的乘积也表示为字符串形式。
8 |
9 | **注意:**不能使用任何内置的 BigInteger 库或直接将输入转换为整数。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入: num1 = "2", num2 = "3"
15 | 输出: "6"
16 | ```
17 |
18 | **解题思路**
19 |
20 | 参考自:https://leetcode-cn.com/problems/multiply-strings/solution/you-hua-ban-shu-shi-da-bai-994-by-breezean/
21 |
22 | 
23 |
24 | ```java
25 | class Solution {
26 | public String multiply(String num1, String num2) {
27 | if (num1.equals("0") || num2.equals("0")) { //乘0
28 | return "0";
29 | }
30 | int[] arr = new int[num1.length() + num2.length()];
31 | for (int i = num1.length() - 1; i >= 0; i--) {
32 | int m = num1.charAt(i) - '0';
33 | for (int j = num2.length() - 1; j >= 0; j--) {
34 | int n = num2.charAt(j) - '0';
35 | int sum = arr[i + j + 1] + m * n;
36 | arr[i + j + 1] = sum % 10;
37 | arr[i + j] += sum / 10; //+=,不能忘了原先的数
38 | }
39 | }
40 |
41 | StringBuilder ans = new StringBuilder("");
42 | if (arr[0] != 0) {
43 | ans.append(arr[0]);
44 | }
45 | for (int i = 1; i < arr.length; i++) {
46 | ans.append(arr[i]);
47 | }
48 |
49 | return ans.toString();
50 | }
51 | }
52 | ```
53 |
54 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/46-permutations.md:
--------------------------------------------------------------------------------
1 | # 46. 全排列
2 |
3 | [题目链接](https://leetcode.cn/problems/permutations/)
4 |
5 | **题目描述**
6 |
7 | 给定一个不含重复数字的数组 `nums` ,返回其 *所有可能的全排列* 。你可以 **按任意顺序** 返回答案。
8 |
9 | 示例:
10 |
11 | ```
12 | 输入:nums = [1,2,3]
13 | 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
14 | ```
15 |
16 | **解题思路**
17 |
18 | 使用回溯。注意与组合总和的区别(数字有无顺序)。
19 |
20 | ```java
21 | class Solution {
22 | private List> ans = new ArrayList<>();
23 | public List> permute(int[] nums) {
24 | boolean[] flag = new boolean[nums.length];
25 | ArrayDeque path = new ArrayDeque<>();
26 | permuteHelper(nums, flag, path);
27 |
28 | return ans;
29 | }
30 |
31 | private void permuteHelper(int[] nums, boolean[] flag, ArrayDeque path) {
32 | if (path.size() == nums.length) {
33 | ans.add(new ArrayList<>(path));
34 | return;
35 | }
36 | for (int i = 0; i < nums.length; i++) {
37 | if (flag[i]) {
38 | continue;//继续循环
39 | }
40 | path.addLast(nums[i]);
41 | flag[i] = true;
42 | permuteHelper(nums, flag, path);
43 | path.removeLast();
44 | flag[i] = false;
45 | }
46 | }
47 | }
48 | ```
49 |
50 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/47-permutations-ii.md:
--------------------------------------------------------------------------------
1 | # 47. 全排列 II
2 |
3 | [题目链接](https://leetcode.cn/problems/permutations-ii/)
4 |
5 | **题目描述**
6 |
7 | 给定一个可包含重复数字的序列,返回所有不重复的全排列。注意与组合总和的区别。
8 |
9 | 示例:
10 |
11 | ```java
12 | 输入:nums = [1,2,3]
13 | 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
14 | ```
15 |
16 | **解题思路**
17 |
18 | 1、排序;
19 |
20 | 2、同一层级相同元素剪枝。
21 |
22 | > 参考自:https://leetcode-cn.com/problems/permutations-ii/solution/hui-su-suan-fa-python-dai-ma-java-dai-ma-by-liwe-2/
23 |
24 | 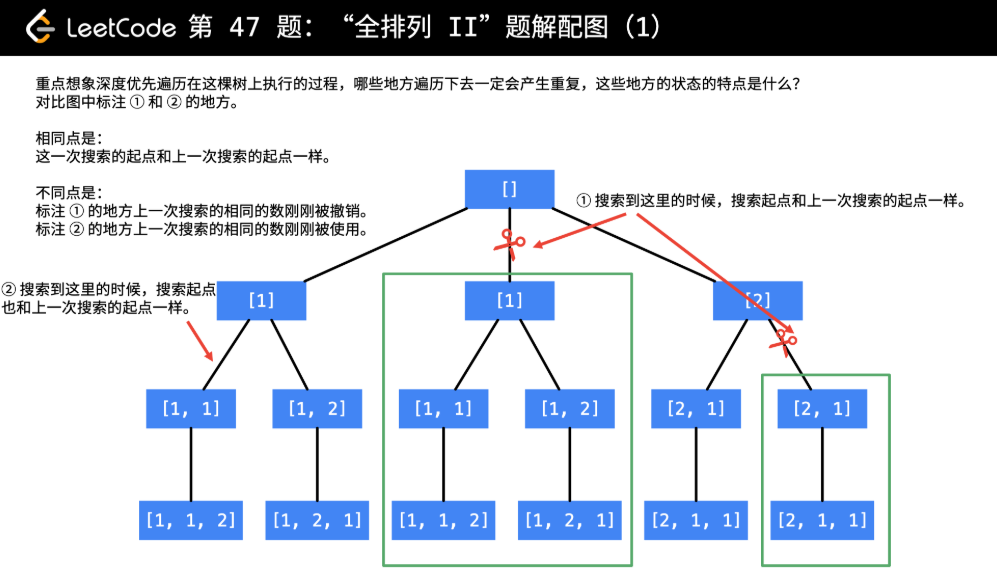
25 |
26 | ```java
27 | class Solution {
28 | private List> ans = new ArrayList<>();
29 | public List> permuteUnique(int[] nums) {
30 | if (nums == null || nums.length == 0) {
31 | return ans;
32 | }
33 | ArrayDeque path = new ArrayDeque<>();
34 | boolean[] used = new boolean[nums.length];
35 | Arrays.sort(nums);//切记
36 | dps(nums, used, path);
37 |
38 | return ans;
39 | }
40 |
41 | private void dps(int[] nums, boolean[] used, ArrayDeque path) {
42 | if (path.size() == nums.length) {
43 | ans.add(new ArrayList<>(path));
44 | return;
45 | }
46 | for (int i = 0; i < nums.length; i++) {
47 | if (used[i]) {
48 | continue;
49 | }
50 | if ((i > 0 && nums[i] == nums[i - 1]) && !used[i - 1]) {//同一层相同的元素,剪枝
51 | continue;//继续循环,不是return退出循环
52 | }
53 | path.addLast(nums[i]);
54 | used[i] = true;
55 | dps(nums, used, path);
56 | path.removeLast();
57 | used[i] = false;
58 | }
59 | }
60 | }
61 | ```
62 |
63 |
64 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/48-rotate-image.md:
--------------------------------------------------------------------------------
1 | # 48. 旋转图像
2 |
3 | [48. 旋转图像](https://leetcode.cn/problems/rotate-image/)
4 |
5 | **题目描述**
6 |
7 | 给定一个 *n* × *n* 的二维矩阵 `matrix` 表示一个图像。请你将图像顺时针旋转 90 度。
8 |
9 | 你必须在**[ 原地](https://baike.baidu.com/item/原地算法)** 旋转图像,这意味着你需要直接修改输入的二维矩阵。**请不要** 使用另一个矩阵来旋转图像。
10 |
11 | **示例**
12 |
13 | 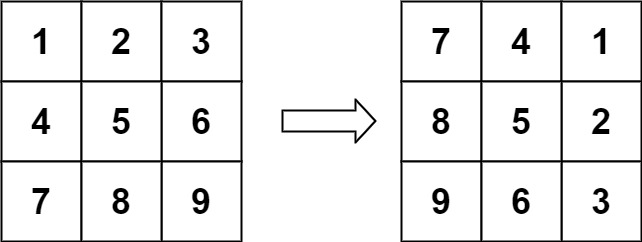
14 |
15 | ```java
16 | 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
17 | 输出:[[7,4,1],[8,5,2],[9,6,3]]
18 | ```
19 |
20 | **解题思路**
21 |
22 | 先转置,然后翻转每一行。
23 |
24 | ```java
25 | class Solution {
26 | public void rotate(int[][] matrix) {
27 | if (matrix == null || matrix.length <= 1) {
28 | return;
29 | }
30 | //转置
31 | for (int i = 0; i < matrix.length; i++) {
32 | for (int j = i + 1; j < matrix.length; j++) {
33 | int tmp = matrix[i][j];
34 | matrix[i][j] = matrix[j][i];
35 | matrix[j][i] = tmp;
36 | }
37 | }
38 | //翻转每一行
39 | for (int i = 0; i < matrix.length; i++) {
40 | for (int j = 0; j < matrix.length / 2; j++) {
41 | int tmp = matrix[i][j];
42 | matrix[i][j] = matrix[i][matrix.length - j - 1];
43 | matrix[i][matrix.length - j - 1] = tmp;
44 | }
45 | }
46 | }
47 | }
48 | ```
49 |
50 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/49-group-anagrams.md:
--------------------------------------------------------------------------------
1 | # 49. 字母异位词分组
2 |
3 | [49. 字母异位词分组](https://leetcode.cn/problems/group-anagrams/description/)
4 |
5 | **题目描述**
6 |
7 | 给你一个字符串数组,请你将 **字母异位词** 组合在一起。可以按任意顺序返回结果列表。
8 |
9 | **字母异位词** 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
15 | 输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
16 | ```
17 |
18 | **解题思路**
19 |
20 | 由于互为字母异位词的两个字符串包含的字母相同,因此对两个字符串分别进行排序之后得到的字符串一定是相同的,故可以将排序之后的字符串作为哈希表的键。
21 |
22 | ```java
23 | class Solution {
24 | public List> groupAnagrams(String[] strs) {
25 | if (strs == null || strs.length == 0) {
26 | return new ArrayList();
27 | }
28 |
29 | Map ans = new HashMap<>();
30 | for (String s : strs) {
31 | char[] arr = s.toCharArray();
32 | Arrays.sort(arr);
33 | String key = String.valueOf(arr);
34 | if (!ans.containsKey(key)) {
35 | ans.put(key, new ArrayList());
36 | }
37 | ans.get(key).add(s);
38 | }
39 |
40 | return new ArrayList(ans.values());//没有<>
41 | }
42 | }
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/50-powx-n.md:
--------------------------------------------------------------------------------
1 | # 50. Pow(x, n)
2 |
3 | [50. Pow(x, n)](https://leetcode.cn/problems/powx-n/)
4 |
5 | **题目描述**
6 |
7 | 实现 pow(x, n) ,即计算 `x` 的整数 `n` 次幂函数(即,`x^n` )。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:x = 2.00000, n = 10
13 | 输出:1024.00000
14 | ```
15 |
16 | **解题思路**
17 |
18 | 快速幂算法。
19 |
20 | ```java
21 | class Solution {
22 | public double myPow(double x, int n) {
23 | if (n == 0) {
24 | return 1.0;
25 | }
26 | if (n == -1) {//负数边界
27 | return 1 / x;
28 | }
29 | double res = myPow(x, n / 2);
30 | double ans = 0;
31 | if (n % 2 == 0) {
32 | ans = res * res;
33 | } else {
34 | ans = n > 0 ? res * res * x : res * res / x;
35 | }
36 |
37 | return ans;
38 | }
39 | }
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/53-maximum-subarray.md:
--------------------------------------------------------------------------------
1 | # 53. 最大子数组和
2 |
3 | [原题链接](https://leetcode.cn/problems/maximum-subarray/)
4 |
5 | ## 题目描述
6 |
7 | 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
8 |
9 | 子数组 是数组中的一个连续部分。
10 |
11 | ```java
12 | 示例 1:
13 |
14 | 输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
15 | 输出:6
16 | 解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
17 | ```
18 |
19 | ## 解题
20 |
21 | ```java
22 | class Solution {
23 | public int maxSubArray(int[] nums) {
24 | int res = nums[0];
25 | int sum = 0;
26 | for (int num : nums) {
27 | if (sum > 0)
28 | sum += num;
29 | else
30 | sum = num;
31 | res = Math.max(res, sum);
32 | }
33 | return res;
34 | }
35 | }
36 | ```
37 |
38 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/543-diameter-of-binary-tree.md:
--------------------------------------------------------------------------------
1 | # 543. 二叉树的直径
2 |
3 | [题目链接](https://leetcode.cn/problems/diameter-of-binary-tree/)
4 |
5 | **题目描述**
6 |
7 | 给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
8 |
9 | **示例**
10 |
11 | ```java
12 | 1
13 | / \
14 | 2 3
15 | / \
16 | 4 5
17 |
18 | 返回 3, 它的长度是路径 [4,2,1,3] 或者 [5,2,1,3]。
19 | ```
20 |
21 | **解题思路**
22 |
23 | **深度优先搜索**
24 |
25 | ```java
26 | class Solution {
27 | private int max = 0;
28 |
29 | public int diameterOfBinaryTree(TreeNode root) {
30 | depth(root);
31 | return max;
32 | }
33 |
34 | private int depth(TreeNode node) {
35 | if (node == null) {
36 | return 0;
37 | }
38 |
39 | int left = depth(node.left);
40 | int right = depth(node.right);
41 |
42 | max = Math.max(max, left + right);
43 | return Math.max(left, right) + 1;
44 | }
45 | }
46 | ```
47 |
48 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/55-jump-game.md:
--------------------------------------------------------------------------------
1 | # 55. 跳跃游戏
2 |
3 | [题目链接](https://leetcode.cn/problems/jump-game/)
4 |
5 | **题目描述**
6 |
7 | 给定一个非负整数数组 `nums` ,你最初位于数组的 **第一个下标** 。
8 |
9 | 数组中的每个元素代表你在该位置可以跳跃的最大长度。
10 |
11 | 判断你是否能够到达最后一个下标。
12 |
13 | **示例**:
14 |
15 | ```java
16 | 输入:nums = [2,3,1,1,4]
17 | 输出:true
18 | 解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
19 | ```
20 |
21 | **解题思路**:
22 |
23 | 1. 如果某一个作为 起跳点 的格子可以跳跃的距离是 3,那么表示后面 3 个格子都可以作为 起跳点
24 | 2. 可以对每一个能作为 起跳点 的格子都尝试跳一次,把 能跳到最远的距离 不断更新
25 | 3. 如果可以一直跳到最后,就成功了
26 |
27 | ```java
28 | class Solution {
29 | public boolean canJump(int[] nums) {
30 | if (nums == null || nums.length == 0) {
31 | return true;
32 | }
33 |
34 | int maxIndex = nums[0];
35 | for (int i = 1; i < nums.length; i++) {
36 | if (maxIndex >= i) {
37 | maxIndex = Math.max(maxIndex, i + nums[i]);
38 | } else {
39 | return false;
40 | }
41 | }
42 |
43 | return true;
44 | }
45 | }
46 | ```
47 |
48 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/56-merge-intervals.md:
--------------------------------------------------------------------------------
1 | # 56. 合并区间
2 |
3 | [56. 合并区间](https://leetcode.cn/problems/merge-intervals/)
4 |
5 | **题目描述**
6 |
7 | 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
13 | 输出:[[1,6],[8,10],[15,18]]
14 | 解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
15 | ```
16 |
17 | **解题思路**
18 |
19 | 先对区间左边界排序 `Array.sort(arr, (i1, i2) -> i1[0] - i2[0])`,然后新建数组进行合并。
20 |
21 | ```java
22 | class Solution {
23 | public int[][] merge(int[][] intervals) {
24 | if (intervals == null || intervals.length == 0) {
25 | throw new IllegalArgumentException("array is null or array is empty");
26 | }
27 |
28 | Arrays.sort(intervals, (a, b) -> a[0] - b[0]); //lambda表达式写法,返回值是int
29 |
30 | int index = 0;
31 | for (int i = 1; i < intervals.length; i++) {
32 | if (intervals[index][1] < intervals[i][0]) {
33 | intervals[++index] = intervals[i]; //++index,先自增,再取值
34 | } else {
35 | intervals[index][1] = Math.max(intervals[i][1], intervals[index][1]);
36 | }
37 | }
38 |
39 | return Arrays.copyOf(intervals, index + 1); //第二个参数是数组长度
40 | }
41 | }
42 | ```
43 |
44 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/59-spiral-matrix-ii.md:
--------------------------------------------------------------------------------
1 | # 59. 螺旋矩阵II
2 |
3 | [题目链接](https://leetcode.cn/problems/spiral-matrix-ii/)
4 |
5 | **题目描述**
6 |
7 | 给你一个正整数 `n` ,生成一个包含 `1` 到 `n2` 所有元素,且元素按顺时针顺序螺旋排列的 `n x n` 正方形矩阵 `matrix` 。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:n = 3
13 | 输出:[[1,2,3],[8,9,4],[7,6,5]]
14 | ```
15 |
16 | **解题思路**
17 |
18 | tips:定义上下左右边界。
19 |
20 | ```java
21 | class Solution {
22 | public int[][] generateMatrix(int n) {
23 | int left = 0;
24 | int right = n - 1;
25 | int top = 0;
26 | int bottom = n - 1;
27 |
28 | int[][] ans = new int[n][n];
29 | int num = 1;
30 | while (true) {
31 | for (int i = left; i <= right; i++) {
32 | ans[top][i] = num++;//注意下标顺序
33 | }
34 | if (++top > bottom) {
35 | break;
36 | }
37 | for (int j = top; j <= bottom; j++) {
38 | ans[j][right] = num++;
39 | }
40 | if (--right < left) {
41 | break;
42 | }
43 | for (int m = right; m >= left; m--) {
44 | ans[bottom][m] = num++;
45 | }
46 | if (--bottom < top) {
47 | break;
48 | }
49 | for (int k = bottom; k >= top; k--) {
50 | ans[k][left] = num++;
51 | }
52 | if (++left > right) {
53 | break;
54 | }
55 | }
56 | return ans;
57 | }
58 | }
59 | ```
60 |
61 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/7-reverse-integer.md:
--------------------------------------------------------------------------------
1 | # 7. 整数反转
2 |
3 | [题目链接](https://leetcode.cn/problems/reverse-integer/)
4 |
5 | **题目描述**
6 |
7 | 给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。
8 |
9 | 如果反转后整数超过 32 位的有符号整数的范围 [−231, 231 − 1] ,就返回 0。
10 |
11 | 假设环境不允许存储 64 位整数(有符号或无符号)。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:x = 123
17 | 输出:321
18 |
19 | 输入:x = 120
20 | 输出:21
21 | ```
22 |
23 | **解题思路**
24 |
25 | - 本题如果不考虑溢出问题,是非常简单的。解决溢出问题有两个思路,第一个思路是通过字符串转换加`try catch`的方式来解决,第二个思路就是通过数学计算来解决。
26 | - 由于字符串转换的效率较低且使用较多库函数,所以解题方案不考虑该方法,而是通过数学计算来解决。
27 | - 通过循环将数字`x`的每一位拆开,在计算新值时每一步都判断是否溢出。
28 | - 溢出条件有两个,一个是大于整数最大值`MAX_VALUE`,另一个是小于整数最小值`MIN_VALUE`,设当前计算结果为`ans`,下一位为`pop`。
29 | - 从`ans * 10 + pop > MAX_VALUE`这个溢出条件来看
30 | - 当出现 `ans > MAX_VALUE / 10` 且 `还有pop需要添加` 时,则一定溢出
31 | - 当出现 `ans == MAX_VALUE / 10` 且 `pop > 7` 时,则一定溢出,`7`是`2^31 - 1`的个位数
32 | - 从`ans * 10 + pop < MIN_VALUE`这个溢出条件来看
33 | - 当出现 `ans < MIN_VALUE / 10` 且 `还有pop需要添加` 时,则一定溢出
34 | - 当出现 `ans == MIN_VALUE / 10` 且 `pop < -8` 时,则一定溢出,`8`是`-2^31`的个位数
35 |
36 | > 作者:guanpengchn
37 | > 链接:https://leetcode.cn/problems/reverse-integer/solution/hua-jie-suan-fa-7-zheng-shu-fan-zhuan-by-guanpengc/
38 | > 来源:力扣(LeetCode)
39 | > 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
40 |
41 | ```java
42 | class Solution {
43 | public int reverse(int x) {
44 | int ans = 0;
45 | while (x != 0) {
46 | int pop = x % 10;
47 | if (ans > Integer.MAX_VALUE / 10 || (ans == Integer.MAX_VALUE / 10 && pop > 7))
48 | return 0;
49 | if (ans < Integer.MIN_VALUE / 10 || (ans == Integer.MIN_VALUE / 10 && pop < -8))
50 | return 0;
51 | ans = ans * 10 + pop;
52 | x /= 10;
53 | }
54 | return ans;
55 | }
56 | }
57 | ```
58 |
59 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/71-simplify-path.md:
--------------------------------------------------------------------------------
1 | # 71. 简化路径
2 |
3 | [题目链接](https://leetcode.cn/problems/simplify-path/)
4 |
5 | **题目描述**
6 |
7 | 给你一个字符串 `path` ,表示指向某一文件或目录的 Unix 风格 **绝对路径** (以 `'/'` 开头),请你将其转化为更加简洁的规范路径。
8 |
9 | 在 Unix 风格的文件系统中,一个点(`.`)表示当前目录本身;此外,两个点 (`..`) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,`'//'`)都被视为单个斜杠 `'/'` 。 对于此问题,任何其他格式的点(例如,`'...'`)均被视为文件/目录名称。
10 |
11 | 请注意,返回的 **规范路径** 必须遵循下述格式:
12 |
13 | - 始终以斜杠 `'/'` 开头。
14 | - 两个目录名之间必须只有一个斜杠 `'/'` 。
15 | - 最后一个目录名(如果存在)**不能** 以 `'/'` 结尾。
16 | - 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含 `'.'` 或 `'..'`)。
17 |
18 | 返回简化后得到的 **规范路径** 。
19 |
20 | **示例**:
21 |
22 | ```java
23 | 输入:path = "/home/"
24 | 输出:"/home"
25 | 解释:注意,最后一个目录名后面没有斜杠。
26 |
27 | 输入:path = "/../"
28 | 输出:"/"
29 | 解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。
30 | ```
31 |
32 | **解题思路**
33 |
34 | 使用栈实现。
35 |
36 | ```java
37 | //输入:"/a/./b/../../c/"
38 | //输出:"/c"
39 | class Solution {
40 | public String simplifyPath(String path) {
41 | Stack stack = new Stack<>();
42 | String[] strs = path.split("/");
43 |
44 | for (String s : strs) {
45 | if ("..".equals(s)) {
46 | if (!stack.isEmpty()) {
47 | stack.pop();
48 | }
49 | continue;//只要是"..",就执行下一个循环,不能放入栈
50 | }
51 | if (!"".equals(s) && !".".equals(s)) {
52 | stack.push(s);
53 | }
54 | }
55 |
56 | if (stack.isEmpty()) {
57 | return "/";
58 | }
59 |
60 | StringBuilder sb = new StringBuilder();
61 | int size = stack.size();
62 | for (int i = 0; i < size; i++) {
63 | sb.append("/").append(stack.get(i));//tips
64 | }
65 | return sb.toString();
66 | }
67 | }
68 | ```
69 |
70 |
71 |
72 |
73 |
74 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/74-search-a-2d-matrix.md:
--------------------------------------------------------------------------------
1 | # 74. 搜索二维矩阵
2 |
3 | [题目链接](https://leetcode.cn/problems/search-a-2d-matrix/)
4 |
5 | **题目描述**
6 |
7 | 编写一个高效的算法来判断 `m x n` 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
8 |
9 | - 每行中的整数从左到右按升序排列。
10 | - 每行的第一个整数大于前一行的最后一个整数。
11 |
12 | **示例**:
13 |
14 | 
15 |
16 | ```java
17 | 输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
18 | 输出:true
19 | ```
20 |
21 | **参考代码**
22 |
23 | ```java
24 | class Solution {
25 | public boolean searchMatrix(int[][] matrix, int target) {
26 | if (null == matrix || matrix.length == 0 || matrix[0].length == 0) {
27 | return false;
28 | }
29 | int rows = matrix.length;
30 | int cols = matrix[0].length;
31 | int left = 0;
32 | int right = rows * cols - 1;
33 |
34 | while (left <= right) {
35 | int mid = (left + right) >> 1; //!
36 | int val = matrix[mid / cols][mid % cols]; //cols!不是rows
37 | if (target == val) {
38 | return true;
39 | } else if (target > val) {
40 | left = mid + 1;
41 | } else {
42 | right = mid - 1;
43 | }
44 | }
45 |
46 | return false;
47 | }
48 | }
49 | ```
50 |
51 |
52 |
53 |
54 |
55 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/75-sort-colors.md:
--------------------------------------------------------------------------------
1 | # 75. 颜色分类
2 |
3 | [题目链接](https://leetcode.cn/problems/sort-colors/)
4 |
5 | **题目描述**
6 |
7 | 给定一个包含红色、白色和蓝色、共 `n` 个元素的数组 `nums` ,**[原地](https://baike.baidu.com/item/原地算法)**对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
8 |
9 | 我们使用整数 `0`、 `1` 和 `2` 分别表示红色、白色和蓝色。
10 |
11 | > 必须在不使用库的sort函数的情况下解决这个问题。
12 |
13 | **示例**:
14 |
15 | ```java
16 | 输入:nums = [2,0,2,1,1,0]
17 | 输出:[0,0,1,1,2,2]
18 | ```
19 |
20 | **解题思路**
21 |
22 | 三指针。
23 |
24 | ```java
25 | class Solution {
26 | public void sortColors(int[] nums) {
27 | if (nums == null || nums.length == 0) {
28 | return;
29 | }
30 | int p1 = 0, cur = 0, p2 = nums.length - 1;
31 | while (cur <= p2) { //边界,nums全为1的情况
32 | if (nums[cur] == 0) {
33 | int tmp = nums[p1];
34 | nums[p1++] = 0;
35 | nums[cur++] = tmp; //cur++
36 | } else if (nums[cur] == 2) {
37 | int tmp = nums[p2];
38 | nums[p2--] = 2;
39 | nums[cur] = tmp; //nums[cur]可能为2,不自增
40 | } else {
41 | cur++;
42 | }
43 | }
44 | }
45 | }
46 | ```
47 |
48 |
49 |
50 |
51 |
52 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/77-combinations.md:
--------------------------------------------------------------------------------
1 | # 77. 组合
2 |
3 | [题目链接](https://leetcode.cn/problems/combinations/)
4 |
5 | **题目描述**
6 |
7 | 给定两个整数 `n` 和 `k`,返回范围 `[1, n]` 中所有可能的 `k` 个数的组合。
8 |
9 | 你可以按 **任何顺序** 返回答案。
10 |
11 | **示例**:
12 |
13 | ```java
14 | 输入:n = 4, k = 2
15 | 输出:
16 | [
17 | [2,4],
18 | [3,4],
19 | [2,3],
20 | [1,2],
21 | [1,3],
22 | [1,4],
23 | ]
24 |
25 | 输入:n = 1, k = 1
26 | 输出:[[1]]
27 | ```
28 |
29 | **解题思路**
30 |
31 | 回溯。剪枝优化。
32 |
33 | 
34 |
35 | ```java
36 | class Solution {
37 | public List> combine(int n, int k) {
38 | List> res = new ArrayList<>();
39 | if (n <= 0 || k <= 0 || n < k) {
40 | return res;
41 | }
42 | Stack stack = new Stack<>();
43 | combineHelper(res, stack, 1, n, k);
44 | return res;
45 | }
46 |
47 | public void combineHelper(List> res, Stack stack, int index,int n, int k) {
48 | if (stack.size() == k) {
49 | res.add(new ArrayList<>(stack));
50 | return;
51 | }
52 | // i 的极限值满足: n - i + 1 = (k - pre.size())。
53 | // 【关键】n - i + 1 是闭区间 [i,n] 的长度。
54 | // k - pre.size() 是剩下还要寻找的数的个数。
55 | for (int i = index; i <= n - (k - stack.size()) + 1; i++) {
56 | stack.push(i);
57 | combineHelper(res, stack, i + 1, n, k);
58 | stack.pop();
59 | }
60 | }
61 | }
62 | ```
63 |
64 |
65 |
66 |
67 |
68 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/83-remove-duplicates-from-sorted-list.md:
--------------------------------------------------------------------------------
1 | # 83. 删除排序链表中的重复元素
2 |
3 | [83. 删除排序链表中的重复元素](https://leetcode.cn/problems/remove-duplicates-from-sorted-list/)
4 |
5 | **题目描述**
6 |
7 | 给定一个已排序的链表的头 `head` , *删除所有重复的元素,使每个元素只出现一次* 。返回 *已排序的链表* 。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:head = [1,1,2]
13 | 输出:[1,2]
14 | ```
15 |
16 | **解题思路**
17 |
18 | 使用快慢指针。
19 |
20 | ```java
21 | class Solution {
22 | public int removeDuplicates(int[] nums) {
23 | if (nums == null || nums.length <= 0) {
24 | return 0;
25 | }
26 |
27 | int slow = 0;
28 | for (int fast = 1; fast < nums.length; fast++) {
29 | if (nums[slow] != nums[fast]) {
30 | slow++;
31 | nums[slow] = nums[fast];
32 | }
33 | }
34 |
35 | return slow + 1;
36 | }
37 | }
38 | ```
39 |
40 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/9-palindrome-number.md:
--------------------------------------------------------------------------------
1 | # 9. 回文数
2 |
3 | [9. 回文数](https://leetcode.cn/problems/palindrome-number/)
4 |
5 | **题目描述**
6 |
7 | 给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。
8 |
9 | 回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
10 |
11 | 例如,121 是回文,而 123 不是。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:x = 121
17 | 输出:true
18 |
19 | 输入:x = -121
20 | 输出:false
21 | 解释:从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
22 | ```
23 |
24 | **解题思路**
25 |
26 | 将数字后半段反转,跟数字前半段相比即可。
27 |
28 | ```java
29 | class Solution {
30 | public boolean isPalindrome(int x) {
31 | //排除负数和整十的数
32 | if (x < 0 || (x % 10 == 0 && x != 0)) {
33 | return false;
34 | }
35 |
36 | int reverseNum = 0;
37 | //反转x的后半段数字,再做比较即可
38 | while(x > reverseNum) {
39 | reverseNum = reverseNum * 10 + x % 10;
40 | x /= 10;
41 | }
42 |
43 | //x为奇数位时,转换后reverseNum会比x多一位
44 | //如x为1234321,转换后reverseNum为1234,x为123
45 | return x == reverseNum || x == reverseNum / 10;
46 | }
47 | }
48 | ```
49 |
50 |
51 |
52 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/92-reverse-linked-list-ii.md:
--------------------------------------------------------------------------------
1 | # 92. 反转链表 II
2 |
3 | [原题链接](https://leetcode.cn/problems/reverse-linked-list-ii/)
4 |
5 | **题目描述**
6 |
7 | 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:head = [1,2,3,4,5], left = 2, right = 4
13 | 输出:[1,4,3,2,5]
14 | ```
15 |
16 | **解题思路**
17 |
18 | 双指针+头插法。
19 |
20 | ```java
21 | class Solution {
22 | public ListNode reverseBetween(ListNode head, int m, int n) {
23 | ListNode dummy = new ListNode(0);
24 | dummy.next = head;
25 | ListNode pre = dummy;
26 | for (int i = 1; i < m; i++) {
27 | pre = pre.next;
28 | }
29 | head = pre.next;
30 | for (int i = m; i < n; i++) {
31 | ListNode cur = head.next;
32 | head.next = cur.next;
33 | cur.next = pre.next;
34 | pre.next = cur;
35 | }
36 |
37 | return dummy.next;
38 | }
39 | }
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/958-check-completeness-of-a-binary-tree.md:
--------------------------------------------------------------------------------
1 | # 28. 对称的二叉树
2 |
3 | [28. 对称的二叉树](https://leetcode.cn/problems/dui-cheng-de-er-cha-shu-lcof/)
4 |
5 | **题目描述**
6 |
7 | 给定一个二叉树的 root ,确定它是否是一个 完全二叉树 。
8 |
9 | 在一个 完全二叉树 中,除了最后一个关卡外,所有关卡都是完全被填满的,并且最后一个关卡中的所有节点都是尽可能靠左的。它可以包含 1 到 2^h 节点之间的最后一级 h 。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:root = [1,2,3,4,5,6]
15 | 输出:true
16 | 解释:最后一层前的每一层都是满的(即,结点值为 {1} 和 {2,3} 的两层),且最后一层中的所有结点({4,5,6})都尽可能地向左。
17 | ```
18 |
19 | **解题思路**
20 |
21 | 层序遍历,当且仅当存在两个相邻节点:前一个为null,后一个不为null时,则不是完全二叉树。
22 |
23 | ```
24 | 1
25 | / \
26 | 2 3
27 | / \ \
28 | 4 5 6
29 | 层序遍历序列为:[1, 2, 3, 4, 5, null, 6],其中 null 出现在了6前面,所以不是完全二叉树
30 | ```
31 |
32 | 代码实现:
33 |
34 | ```java
35 | class Solution {
36 | public boolean isCompleteTree(TreeNode root) {
37 | LinkedList list = new LinkedList<>();
38 | TreeNode pre = root;
39 | TreeNode cur = root;
40 | list.addLast(root);
41 |
42 | while (!list.isEmpty()) {
43 | cur = list.removeFirst();
44 | if (cur != null) {
45 | if (pre == null) {
46 | return false;
47 | }
48 | list.addLast(cur.left);
49 | list.addLast(cur.right);
50 | }
51 | pre = cur;
52 | }
53 | return true;
54 | }
55 | }
56 | ```
57 |
58 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/98-validate-binary-search-tree.md:
--------------------------------------------------------------------------------
1 | # 98. 验证二叉搜索树
2 |
3 | [题目链接](https://leetcode.cn/problems/validate-binary-search-tree/)
4 |
5 | **题目描述**
6 |
7 | 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
8 |
9 | 有效 二叉搜索树定义如下:
10 |
11 | - 节点的左子树只包含 小于 当前节点的数。
12 | - 节点的右子树只包含 大于 当前节点的数。
13 | - 所有左子树和右子树自身必须也是二叉搜索树。
14 |
15 | **示例**
16 |
17 | ```java
18 | 输入:root = [2,1,3]
19 | 输出:true
20 |
21 | 输入:root = [5,1,4,null,null,3,6]
22 | 输出:false
23 | 解释:根节点的值是 5 ,但是右子节点的值是 4 。
24 | ```
25 |
26 | **解题思路**
27 |
28 | 中序遍历时,判断当前节点是否大于中序遍历的前一个节点,如果大于,说明满足 BST,继续遍历;否则直接返回 false。
29 |
30 | > 作者:sweetiee
31 | > 链接:https://leetcode.cn/problems/validate-binary-search-tree/solution/zhong-xu-bian-li-qing-song-na-xia-bi-xu-miao-dong-/
32 | > 来源:力扣(LeetCode)
33 | > 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
34 |
35 | ```java
36 | class Solution {
37 | long pre = Long.MIN_VALUE;
38 | public boolean isValidBST(TreeNode root) {
39 | if (root == null) {
40 | return true;
41 | }
42 | // 访问左子树
43 | if (!isValidBST(root.left)) {
44 | return false;
45 | }
46 | // 访问当前节点:如果当前节点小于等于中序遍历的前一个节点,说明不满足BST,返回 false;否则继续遍历。
47 | if (root.val <= pre) {
48 | return false;
49 | }
50 | pre = root.val;
51 | // 访问右子树
52 | return isValidBST(root.right);
53 | }
54 | }
55 | ```
56 |
57 |
--------------------------------------------------------------------------------
/docs/mass-data/3-find-same-url.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 查找两个大文件共同的URL
4 | category: 海量数据
5 | tag:
6 | - 海量数据
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 海量数据面试题,大文件共同的URL,海量数据
11 | - - meta
12 | - name: description
13 | content: 海量数据常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 查找两个大文件共同的URL
17 |
18 | ## 题目
19 |
20 | 给定 a、b 两个文件,各存放 50 亿个 URL,每个 URL 各占 64B,找出 a、b 两个文件共同的 URL。内存限制是 4G。
21 |
22 | ## 分析
23 |
24 | 每个 URL 占 64B,那么 50 亿个 URL占用的空间大小约为 320GB。
25 |
26 | 5,000,000,000 * 64B ≈ 320GB
27 |
28 | 由于内存大小只有 4G,因此,不可能一次性把所有 URL 加载到内存中处理。
29 |
30 | 可以采用分治策略,也就是把一个文件中的 URL 按照某个特征划分为多个小文件,使得每个小文件大小不超过 4G,这样就可以把这个小文件读到内存中进行处理了。
31 |
32 | 首先遍历文件a,对遍历到的 URL 进行哈希取余 `hash(URL) % 1000`,根据计算结果把遍历到的 URL 存储到 a0, a1,a2, ..., a999,这样每个大小约为 300MB。使用同样的方法遍历文件 b,把文件 b 中的 URL 分别存储到文件 b0, b1, b2, ..., b999 中。这样处理过后,所有可能相同的 URL 都在对应的小文件中,即 a0 对应 b0, ..., a999 对应 b999,不对应的小文件不可能有相同的 URL。那么接下来,我们只需要求出这 1000 对小文件中相同的 URL 就好了。
33 |
34 | 接着遍历 ai( `i∈[0,999]`),把 URL 存储到一个 HashSet 集合中。然后遍历 bi 中每个 URL,看在 HashSet 集合中是否存在,若存在,说明这就是共同的 URL,可以把这个 URL 保存到一个单独的文件中。
35 |
36 | ## 总结
37 |
38 | 最后总结一下:
39 |
40 | 1. 分而治之,进行哈希取余;
41 | 2. 对每个子文件进行 HashSet 统计。
42 |
--------------------------------------------------------------------------------
/docs/mass-data/4-find-mid-num.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何在100亿数据中找到中位数?
4 | category: 海量数据
5 | tag:
6 | - 海量数据
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 海量数据面试题,100亿数据找中位数,海量数据
11 | - - meta
12 | - name: description
13 | content: 海量数据常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 如何在100亿数据中找到中位数?
17 |
18 | ## 题目描述
19 |
20 | 给定100亿个无符号的乱序的整数序列,如何求出这100亿个数的中位数(中位数指的是排序后最中间那个数),内存只有**512M**。
21 |
22 | ## 分析
23 |
24 | 中位数问题可以看做一个统计问题,而不是排序问题,无符号整数大小为4B,则能表示的数的范围为为0 ~ 2^32 - 1(40亿),如果没有限制内存大小,则可以用一个2^32(4GB)大小的数组(也叫做桶)来保存100亿个数中每个无符号数出现的次数。遍历这100亿个数,当元素值等于桶元素索引时,桶元素的值加1。当统计完100亿个数以后,则从索引为0的值开始累加桶的元素值,当累加值等于50亿时,这个值对应的索引为中位数。时间复杂度为O(n)。
25 |
26 | 因为题目要求内存限制512M,所以上述解法不合适。
27 |
28 | 下面分享另一种解法(**分治法**的思想)
29 |
30 | 如果100亿个数字保存在一个大文件中,可以依次读一部分文件到内存(不超过内存限制),将每个数字用二进制表示,比较二进制的最高位(第32位,符号位,0是正,1是负)。
31 |
32 | 如果数字的最高位为0,则将这个数字写入 file_0文件中;如果最高位为 1,则将该数字写入file_1文件中。 从而将100亿个数字分成了两个文件。
33 |
34 | 假设 file_0文件中有 60亿 个数字,file_1文件中有 40亿 个数字。那么中位数就在 file_0 文件中,并且是 file_0 文件中所有数字排序之后的第 10亿 个数字。因为file_1中的数都是负数,file_0中的数都是正数,也即这里一共只有40亿个负数,那么排序之后的第50亿个数一定位于file_0中。
35 |
36 | 现在,我们只需要处理 file_0 文件了,不需要再考虑file_1文件。对于 file_0 文件,同样采取上面的措施处理:将file_0文件依次读一部分到内存(不超过内存限制),将每个数字用二进制表示,比较二进制的 次高位(第31位),如果数字的次高位为0,写入file_0_0文件中;如果次高位为1,写入file_0_1文件 中。
37 |
38 | 现假设 file_0_0文件中有30亿个数字,file_0_1中也有30亿个数字,则中位数就是:file_0_0文件中的数字从小到大排序之后的第10亿个数字。
39 |
40 | 抛弃file_0_1文件,继续对 file_0_0文件 根据 次次高位(第30位) 划分,假设此次划分的两个文件为:file_0_0_0中有5亿个数字,file_0_0_1中有25亿个数字,那么中位数就是 file_0_0_1文件中的所有数字排序之后的 第 5亿 个数。
41 |
42 | 按照上述思路,直到划分的文件可直接加载进内存时,就可以直接对数字进行快速排序,找出中位数了。
43 |
44 |
45 |
46 | > 参考链接:https://blog.csdn.net/qq_41306849/article/details/119828746
47 |
--------------------------------------------------------------------------------
/docs/mass-data/5-find-hot-string.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何查询最热门的查询串?
4 | category: 海量数据
5 | tag:
6 | - 海量数据
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 海量数据面试题,查询最热门的查询串,海量数据
11 | - - meta
12 | - name: description
13 | content: 海量数据常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 如何查询最热门的查询串?
17 |
18 | ## 题目描述
19 |
20 | 搜索引擎会通过日志文件把用户每次检索使用的所有查询串都记录下来,每个查询床的长度不超过 255 字节。
21 |
22 | 假设目前有 1000w 个记录(这些查询串的重复度比较高,虽然总数是 1000w,但如果除去重复后,则不超过 300w 个)。请统计最热门的 10 个查询串,要求使用的内存不能超过 1G。(一个查询串的重复度越高,说明查询它的用户越多,也就越热门。)
23 |
24 | ## 解答思路
25 |
26 | 每个查询串最长为 255B,1000w 个串需要占用 约 2.55G 内存,因此,我们无法将所有字符串全部读入到内存中处理。
27 |
28 | ### 方法一:分治法
29 |
30 | 分治法依然是一个非常实用的方法。
31 |
32 | 划分为多个小文件,保证单个小文件中的字符串能被直接加载到内存中处理,然后求出每个文件中出现次数最多的 10 个字符串;最后通过一个小顶堆统计出所有文件中出现最多的 10 个字符串。
33 |
34 | 方法可行,但不是最好,下面介绍其他方法。
35 |
36 | ### 方法二:HashMap 法
37 |
38 | 虽然字符串总数比较多,但去重后不超过 300w,因此,可以考虑把所有字符串及出现次数保存在一个 HashMap 中,所占用的空间为 300w*(255+4)≈777M(其中,4表示整数占用的4个字节)。由此可见,1G 的内存空间完全够用。
39 |
40 | **思路如下**:
41 |
42 | 首先,遍历字符串,若不在 map 中,直接存入 map,value 记为 1;若在 map 中,则把对应的 value 加 1,这一步时间复杂度 `O(N)`。
43 |
44 | 接着遍历 map,构建一个 10 个元素的小顶堆,若遍历到的字符串的出现次数大于堆顶字符串的出现次数,则进行替换,并将堆调整为小顶堆。
45 |
46 | 遍历结束后,堆中 10 个字符串就是出现次数最多的字符串。这一步时间复杂度 `O(Nlog10)`。
47 |
48 | ### 方法三:前缀树法
49 |
50 | 方法二使用了 HashMap 来统计次数,当这些字符串有大量相同前缀时,可以考虑使用前缀树来统计字符串出现的次数,树的结点保存字符串出现次数,0 表示没有出现。
51 |
52 | **思路如下**:
53 |
54 | 在遍历字符串时,在前缀树中查找,如果找到,则把结点中保存的字符串次数加 1,否则为这个字符串构建新结点,构建完成后把叶子结点中字符串的出现次数置为 1。
55 |
56 | 最后依然使用小顶堆来对字符串的出现次数进行排序。
57 |
58 | ## 方法总结
59 |
60 | 前缀树经常被用来统计字符串的出现次数。它的另外一个大的用途是字符串查找,判断是否有重复的字符串等。
61 |
62 |
63 |
64 | > 作者:yanglbme
65 | > 链接:https://juejin.cn/post/6844904003998842887
66 |
--------------------------------------------------------------------------------
/docs/mass-data/7-query-frequency-sort.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何按照 query 的频度排序?
4 | category: 海量数据
5 | tag:
6 | - 海量数据
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 海量数据面试题,海量数据
11 | - - meta
12 | - name: description
13 | content: 海量数据常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | ## 如何按照 query 的频度排序?
17 |
18 | ### 题目描述
19 |
20 | 有 10 个文件,每个文件大小为 1G,每个文件的每一行存放的都是用户的 query,每个文件的 query 都可能重复。要求按照 query 的频度排序。
21 |
22 | ### 解答思路
23 |
24 | 如果 query 的重复度比较大,可以考虑一次性把所有 query 读入内存中处理;如果 query 的重复率不高,那么可用内存不足以容纳所有的 query,这时候就需要采用分治法或其他的方法来解决。
25 |
26 | #### 方法一:HashMap 法
27 |
28 | 如果 query 重复率高,说明不同 query 总数比较小,可以考虑把所有的 query 都加载到内存中的 HashMap 中。接着就可以按照 query 出现的次数进行排序。
29 |
30 | #### 方法二:分治法
31 |
32 | 分治法需要根据数据量大小以及可用内存的大小来确定问题划分的规模。对于这道题,可以顺序遍历 10 个文件中的 query,通过 Hash 函数 `hash(query) % 10` 把这些 query 划分到 10 个小文件中。之后对每个小文件使用 HashMap 统计 query 出现次数,根据次数排序并写入到零外一个单独文件中。
33 |
34 | 接着对所有文件按照 query 的次数进行排序,这里可以使用归并排序(由于无法把所有 query 都读入内存,因此需要使用外排序)。
35 |
36 | ### 方法总结
37 |
38 | - 内存若够,直接读入进行排序;
39 | - 内存不够,先划分为小文件,小文件排好序后,整理使用外排序进行归并。
40 |
41 |
42 |
43 | > 作者:yanglbme
44 | > 链接:https://juejin.cn/post/6844904003998842887
45 |
--------------------------------------------------------------------------------
/docs/mass-data/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## 海量数据面试题(更新中)
3 |
4 | - [如何查询最热门的查询串?](./5-find-hot-string.md)
5 | - [统计不同号码的个数](./1-count-phone-num.md)
6 | - [出现频率最高的100个词](./2-find-hign-frequency-word.md)
7 | - [查找两个大文件共同的URL](./3-find-same-url.md)
8 | - [如何在100亿数据中找到中位数?](./4-find-mid-num)
9 | - [如何查询最热门的查询串?](./5-find-hot-string)
10 | - [如何找出排名前 500 的数?](./6-top-500-num)
11 | - [如何按照 query 的频度排序?](./7-query-frequency-sort)
12 | - [大数据中 TopK 问题的常用套路](./8-topk-template)
13 |
--------------------------------------------------------------------------------
/docs/message-queue/mq/consume-by-order.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何保证消息的顺序性?
4 | category: 消息队列
5 | tag:
6 | - 消息队列
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 消息队列面试题,如何保证消息消费的顺序性
11 | - - meta
12 | - name: description
13 | content: 高质量的消息队列常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | ## 如何保证消息的顺序性?
17 |
18 | 假设有这样一个场景,使用 MySQL `binlog` 将数据从一个 MySQL 库原封不动地同步到另一个 MySQL 库里面去。
19 |
20 | 你在 MySQL 里增删改一条数据,对应出来了增删改 3 条 `binlog` 日志,接着这三条 `binlog` 发送到 MQ 里面,再消费出来依次执行,这时需要保证按照顺序去执行,不然本来是:增加、修改、删除;调换了顺序变成执行成删除、修改、增加,这就有问题了。
21 |
22 | 本来这个数据同步过来,应该最后这个数据被删除了;结果搞错了这个顺序,最后这个数据保留下来了,数据同步就出错了。
23 |
24 | 先看看顺序会错乱的俩场景:
25 |
26 | - **RabbitMQ**:一个 queue,多个 consumer。比如,生产者向 RabbitMQ 里发送了三条数据,顺序依次是 data1/data2/data3,压入的是 RabbitMQ 的一个内存队列。有三个消费者分别从 MQ 中消费这三条数据中的一条,结果消费者 2 先执行完操作,把 data2 存入数据库,然后是 data1/data3。这明显就乱了。
27 |
28 | 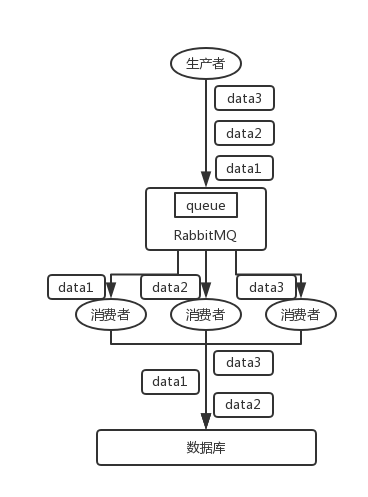
29 |
30 | - **Kafka**:比如说我们建了一个 topic,有三个 partition。生产者在写的时候,其实可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
31 | - 消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还是 ok 的,没有错乱。接着,我们在消费者里可能会搞**多个线程来并发处理消息**。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。
32 |
33 | 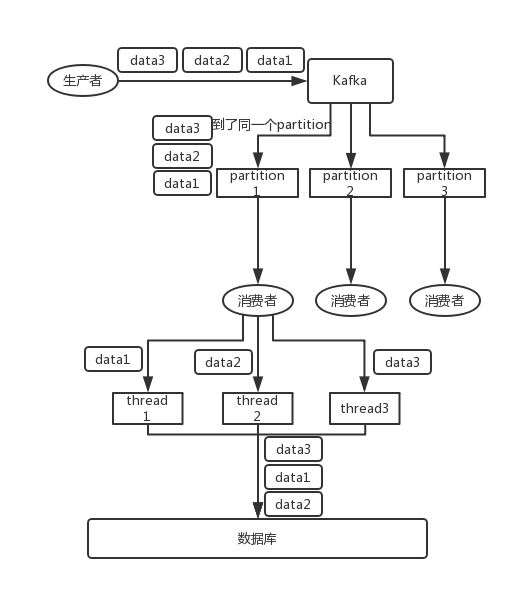
34 |
35 | ### 解决方案
36 |
37 | #### RabbitMQ
38 |
39 | 拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点,这样也会造成吞吐量下降,可以在消费者内部采用多线程的方式取消费。
40 |
41 | 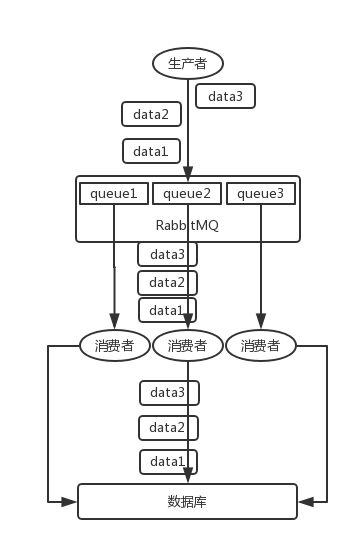
42 |
43 | 或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
44 |
45 | 注意,这里消费者不直接消费消息,而是将消息根据关键值(比如:订单 id)进行哈希,哈希值相同的消息保存到相同的内存队列里。也就是说,需要保证顺序的消息存到了相同的内存队列,然后由一个唯一的 worker 去处理。
46 |
47 | #### Kafka
48 |
49 | - 一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
50 | - 写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
51 |
52 | 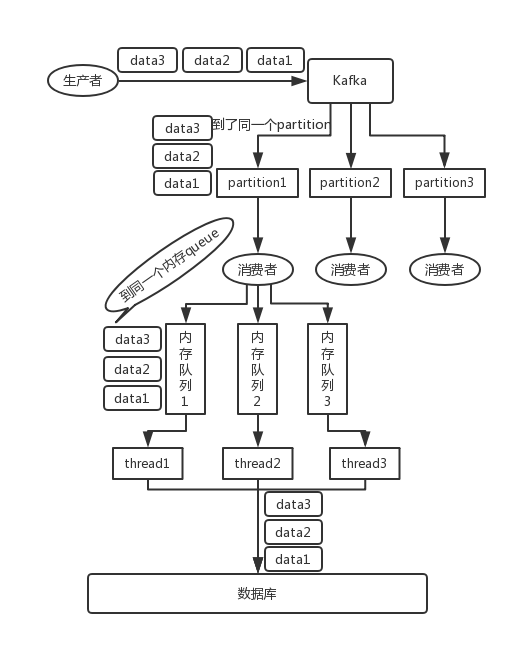
53 |
--------------------------------------------------------------------------------
/docs/note/README.md:
--------------------------------------------------------------------------------
1 | - [一小时彻底吃透Redis](https://topjavaer.cn/note/redis-note.html)
2 | - [21个写SQL的好习惯](https://topjavaer.cn/note/write-sql.html)
3 | - [Docker详解与部署微服务实战](https://topjavaer.cn/note/docker-note.html)
4 | - [计算机专业的同学都看看这几点建议](https://topjavaer.cn/note/computor-advice.html)
5 | - [建议计算机专业同学都看看这门课](https://topjavaer.cn/note/computor-advice.html)
6 |
7 |
--------------------------------------------------------------------------------
/docs/note/computer-blogger.md:
--------------------------------------------------------------------------------
1 | ## 湖科大教书匠——计算机网络
2 |
3 | “宝藏老师”、“干货满满”、“羡慕湖科大”...这些都是网友对这门网课的评价,可见网课质量之高!
4 |
5 | 湖南科技大学《计算机网络》微课堂是该校高军老师精心制作的视频课程,用简单的语言描述复杂的问题,用生动的动画演示抽象概念,更加便于学生理解和记忆。推荐初学者去看看,一定不会亏!
6 |
7 | 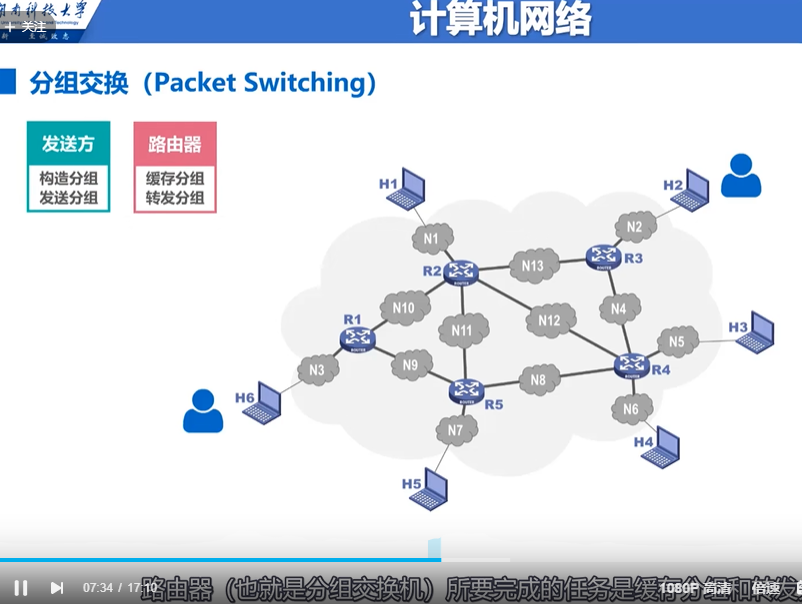
8 |
9 |
10 |
11 | ## 鱼C-小甲鱼——带你学C带你飞
12 |
13 | 小甲鱼的课程是很多转码人的第一门编程课,非常不错,对于自学的初学者来说挺友好。小甲鱼会从学生的角度思考问题,会针对一些初学者的疑惑进行解答,比很多大学老师教学水平强太多!
14 |
15 | 另外,小甲鱼的零基础入门学习python系列课程也很不错,推荐~
16 |
17 | 
18 |
19 | ## 跟李沐学AI——机器学习
20 |
21 | bilibili 2021新人奖UP主、亚马逊资深首席科学家,李沐老师的机器学习课程,可以说是机器学习入门课程的天花板,非常适合新手入门,没有很复杂的推导过程和数学知识,偏向于运用的角度。
22 |
23 | 
24 |
25 | ## 莫烦Python——Python
26 |
27 | 莫烦python的Python基础课程非常适合刚入门, 或者是以前使用过其语言的朋友,每一段视频都不会很长,节节相连,对于迅速掌握基础的使用方法很有帮助。
28 |
29 | 
30 |
31 |
32 |
33 | ## 懒猫老师——用动画讲编程
34 |
35 | 每个视频都用心制作,形象生动,用动画讲编程,在快乐中学习编程,太赞了。
36 |
37 | 
38 |
39 | ## 尚硅谷——Java教程
40 |
41 | 虽然是培训机构,但是尚硅谷也在某站上传了很多编程入门的视频,质量相对还是不错的,Java入门教程的播放量达到千万了,很多人都是看尚硅谷的视频学Java的哈哈(尚硅谷打qian!)。
42 |
43 | 
44 |
45 |
--------------------------------------------------------------------------------
/docs/note/computer-course.md:
--------------------------------------------------------------------------------
1 | ## GitHub
2 |
3 | 
4 |
5 | GitHub是一个面向开源及私有软件项目的托管平台,因为只支持Git作为唯一的版本库格式进行托管,故名GitHub。
6 |
7 | 作为开源代码库以及版本控制系统,Github拥有超过900万开发者用户。随着越来越多的应用程序转移到了云上,Github已经成为了管理软件开发以及发现已有代码的首选方法。
8 |
9 | 在GitHub,用户甚至可以十分轻易地找到海量的开源代码。
10 |
11 |
12 |
13 | ## LeetCode
14 |
15 | 
16 |
17 | 力扣,强推!力扣虐我千百遍,我待力扣如初恋!
18 |
19 | LeetCode是一个集合了大量算法面试题和AI面试题的网站,它为全世界的码农提供了练习自我技能的良好平台。
20 |
21 | 除了在题库中直接找题目之外,还可以根据该网站提供的阶梯训练进行练习。阶梯训练板块收纳了中美等不同公司的面试真题并以关卡的形式呈现给挑战者
22 |
23 | ## GeeksforGeeks
24 |
25 | 
26 |
27 | GeeksforGeeks是一个主要专注于计算机科学的网站。它有大量的算法,解决方案和编程问题。该网站也有很多面试中经常问到的问题。由于该网站更多地涉及计算机科学,因此你可以找到很多编程问题在大多数著名语言下的解决方案。
28 |
29 | ## StackOverflow
30 |
31 | 
32 |
33 | 程序员最痛苦的事莫过于深陷于BUG的泥潭,而stack overflow作为全球最大的技术问答网站,可以说每个搞过技术的人是必上的网站。开发过程中遇到什么 bug,上去搜一下,只要搜索的方式对,百分之 99 的问题都能搜到答案。
34 |
35 | 在 Stackoverflow 你也可以看到很多经典的问题,我们也可以从这些问题中学习如何去提问,如何和答题者沟通。
36 |
37 | ## Codebeautify
38 |
39 | 
40 |
41 | 由于我们是程序员,所以美不是我们所关心的。很多时候,我们的代码很难被其他人阅读。Codebeautify可以使你的代码易于阅读。该网站有大多数可以美化的语言。另外,如果你想让你的代码不能被某人读取,你也可以这样做。
42 |
43 |
44 |
45 | ## 菜鸟教程
46 |
47 | 菜鸟教程提供了编程的基础技术教程, 介绍了HTML、CSS、Javascript、Python,Java,Ruby,C,PHP , MySQL等各种编程语言的基础知识,对于计算机小白和初学者非常有用!
48 |
49 | 
50 |
51 |
52 |
53 | ## 中国大学MOOC
54 |
55 | 
56 |
57 | 中国大学MOOC(慕课) 是国内优质的中文MOOC学习平台,由网易有道与高教社携手推出的中国大学生MOOC承载了一万多门开放课、1400多门国家级精品课,与803所高校开展合作,已经成为最大的中文慕课平台。课程相对比较优质,推荐。
58 |
59 |
60 |
61 | ## 牛客网
62 |
63 | 
64 |
65 | 牛客网是一个集笔面试系统、题库、课程教育、社群交流、招聘内推于一体的招聘类网站。牛客网题库中包含几万道题目,题库涵盖六类行业题目,包含:IT技术类、硬件类、产品运营类、金融财会类、市场营销类、管理类、职能类。而且牛客网每年都会组织往年求职者分享面试经验,以供后来者学习、参考、交流。
--------------------------------------------------------------------------------
/docs/note/computor-advice.md:
--------------------------------------------------------------------------------
1 | 计算机专业的同学都看看这几点建议!
2 |
3 | 
4 |
5 | 
6 |
7 | 
8 |
9 | 
--------------------------------------------------------------------------------
/docs/note/crash-course-computer-science.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | 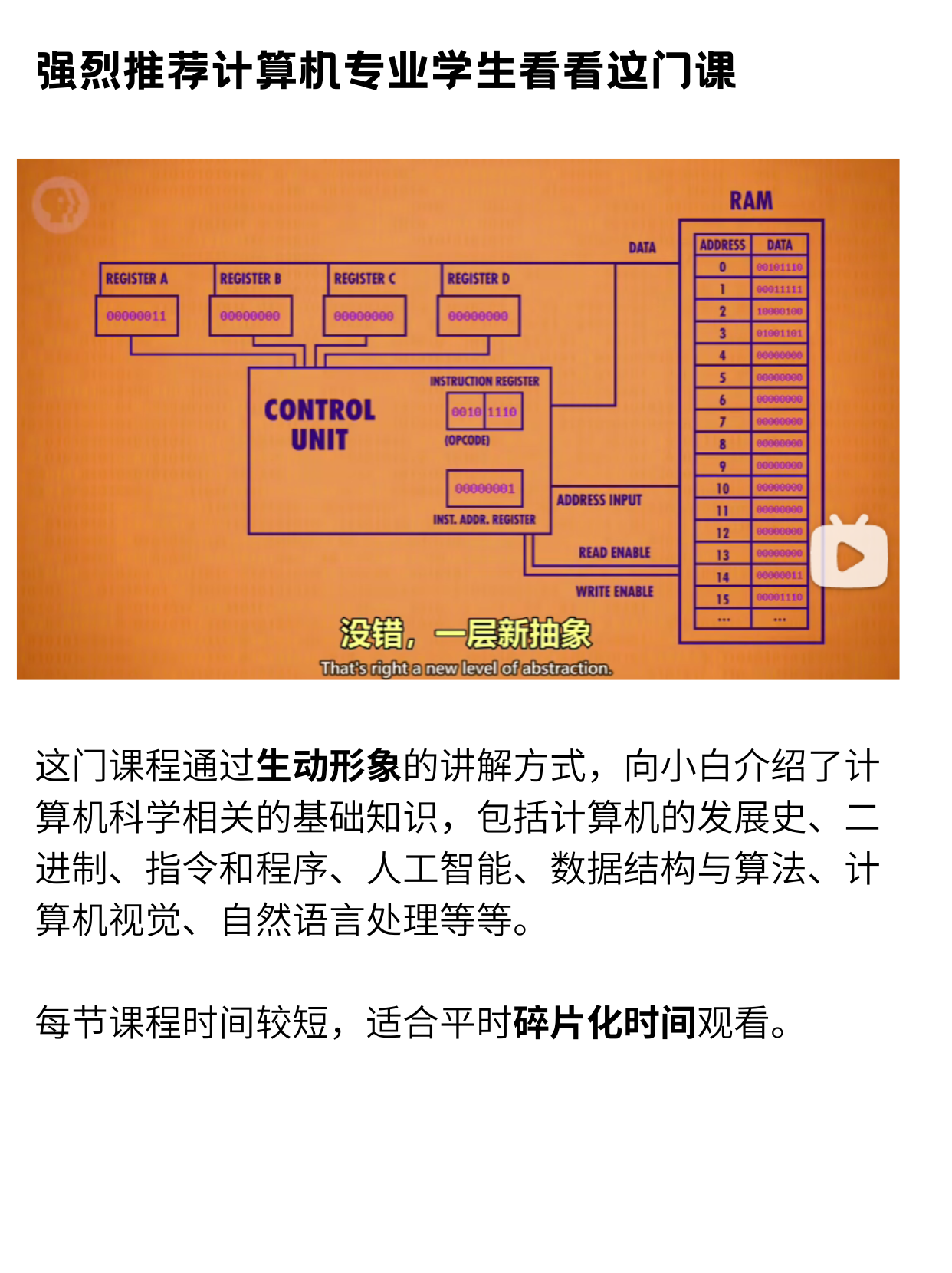
4 |
5 | 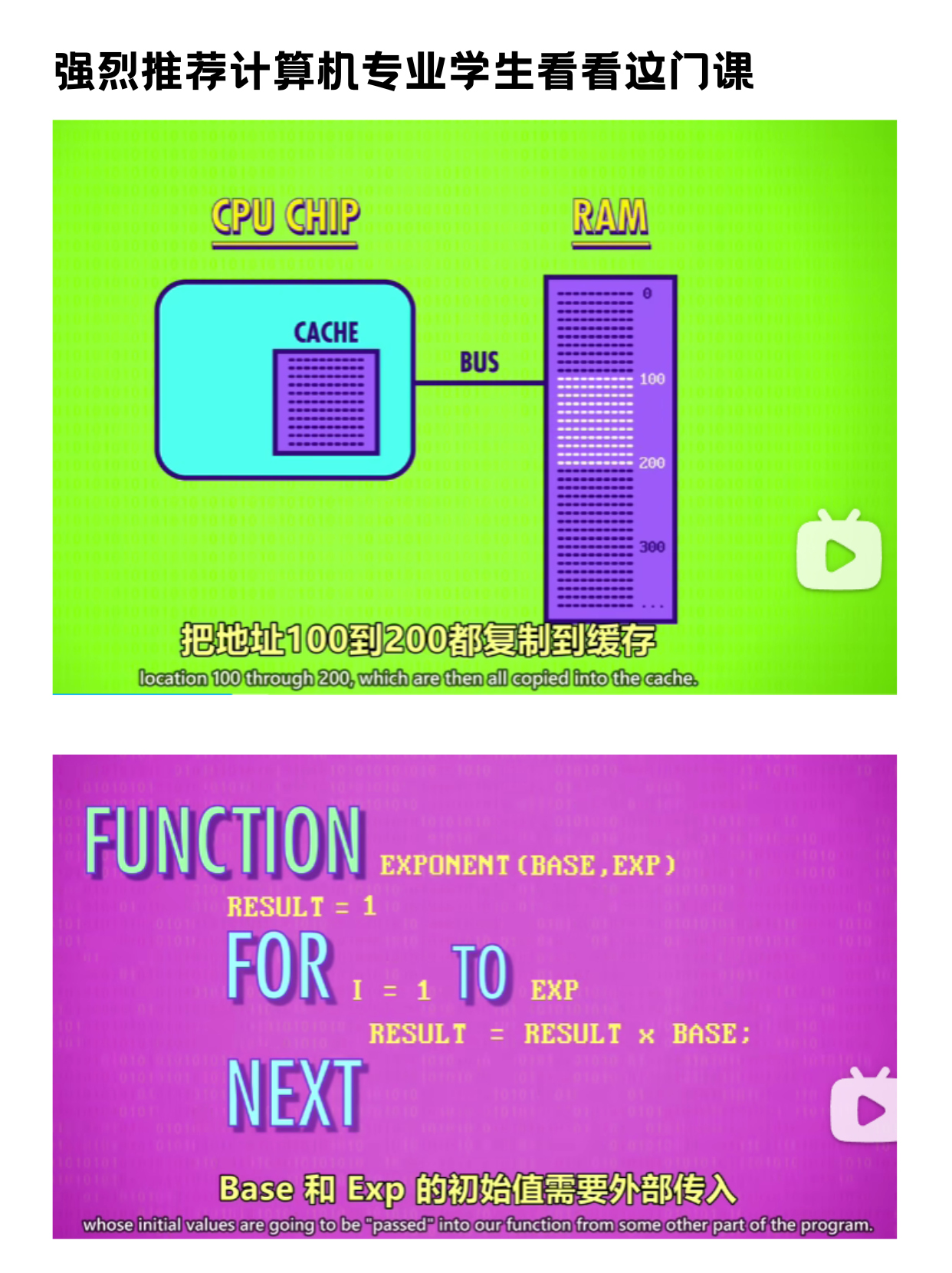
--------------------------------------------------------------------------------
/docs/note/docker-note.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | 
4 |
5 | 
6 |
7 | 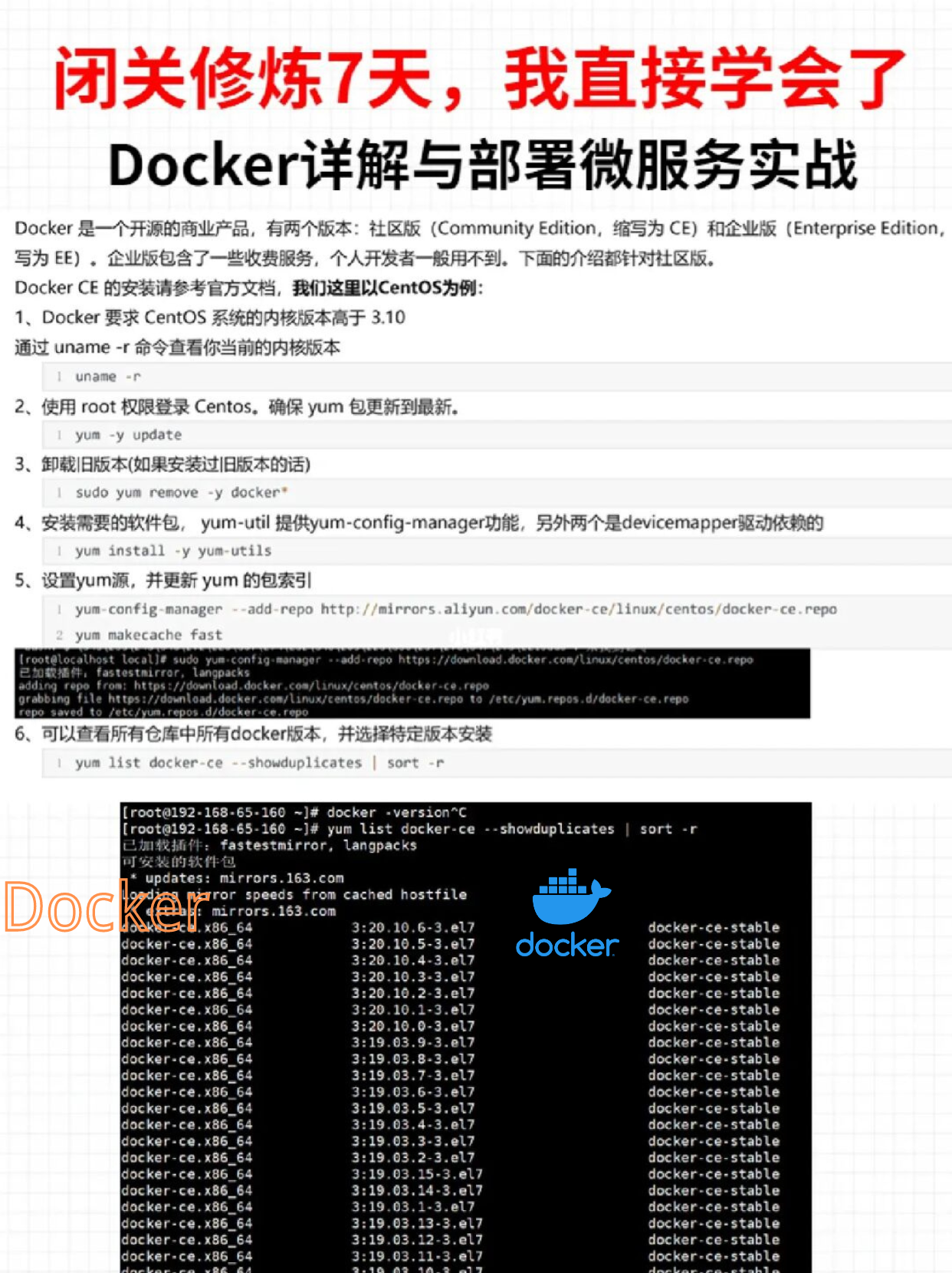
8 |
9 | 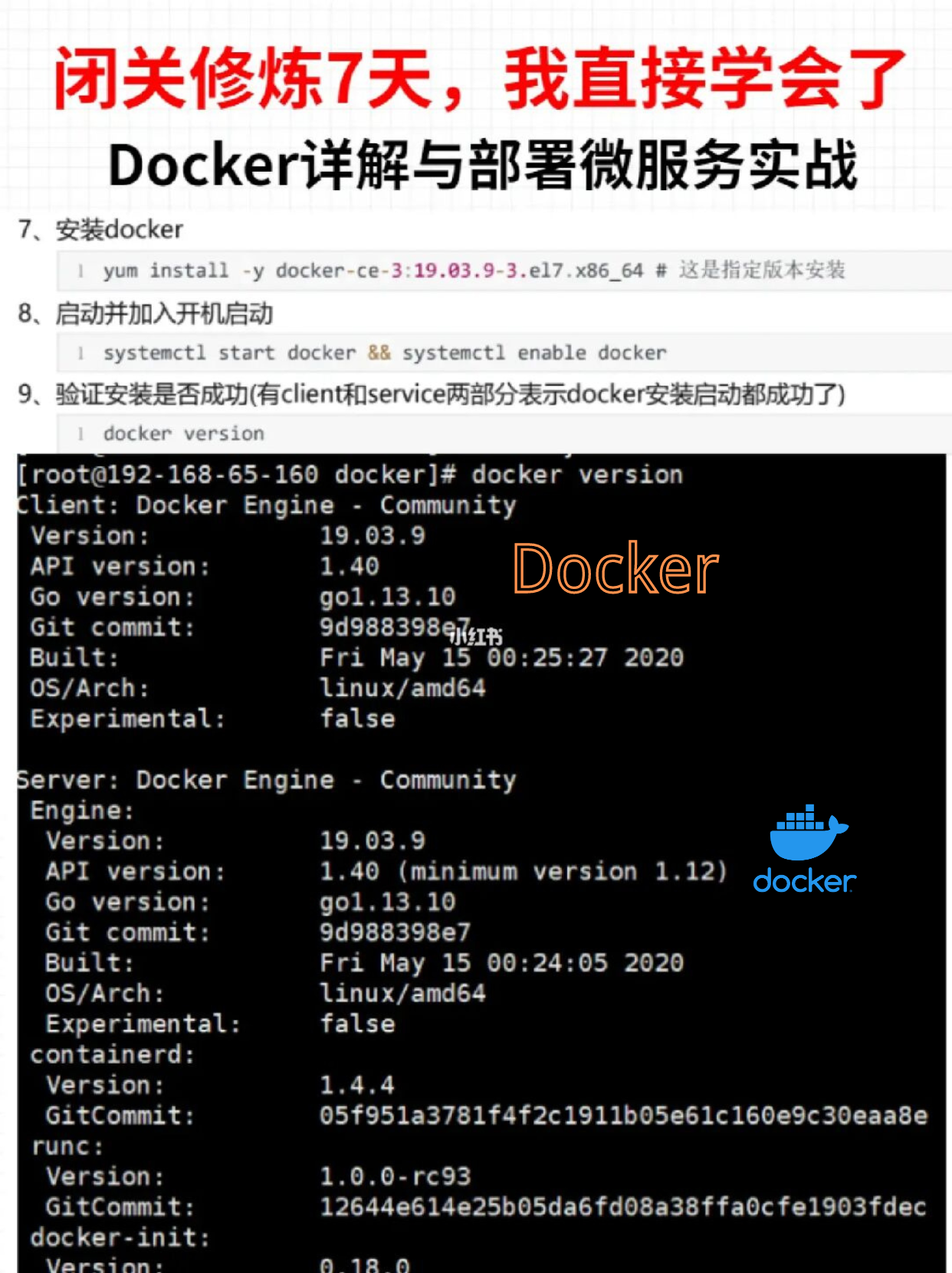
10 |
11 | 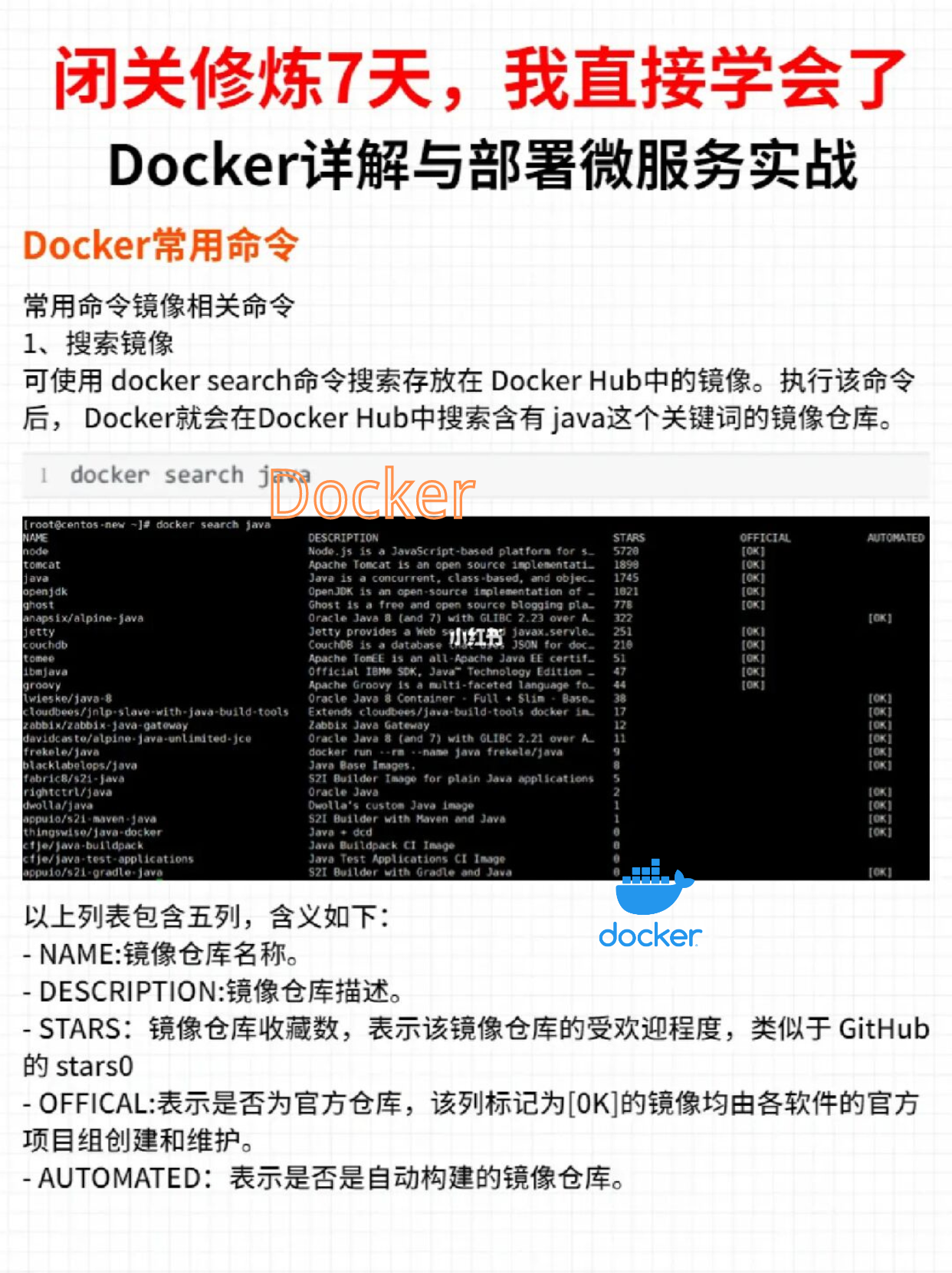
12 |
13 | 
14 |
15 | 
--------------------------------------------------------------------------------
/docs/note/freshman-planning.md:
--------------------------------------------------------------------------------
1 | 自学计算机的大彬来分享下几点宝贵经验。
2 |
3 | 1、看下**计算机科学速成课**,一门很全面的计算机原理入门课程,短短10分钟可以把大学老师十几节课讲的东西讲清楚!整个系列一共41个视频,B站上有中文字幕版。
4 |
5 | 每个视频都是一个特定的主题,例如软件工程、人工智能、操作系统等,主题之间都是紧密相连的,比国内很多大学计算机课程强太多!
6 |
7 | 这门课程通过生动形象的讲解方式,向普通人介绍了计算机科学相关的基础知识,包括**计算机的发展史、二进制、指令和程序、数据结构与算法、人工智能、计算机视觉、自然语言处理**等等。
8 |
9 | 每节课程短小精悍,只有短短十几分钟,适合平时碎片化时间观看。
10 |
11 | 
12 |
13 | 2、**学会使用google搜索**。很多同学遇到问题,不会利用好搜索引擎,而是在一些交流群咨询,往往“事倍功半”,问了半天也没得到想要的答案。建议题主学习下搜索的技巧,多用谷歌搜索,少用百度搜索,谷歌搜出来答案更准确,而不是通篇复制粘贴的“垃圾”。
14 |
15 | 
16 |
17 | 3、**多逛技术社区**。平时多逛逛全球最大的同xing交友社区Github、StackoverFlow等技术社区,关注最新的技术动态,尽量参与到开源项目建设,如果能给优秀的开源项目奉献自己的代码,那是非常nice的,对于以后找工作面试也有非常大的帮助。
18 |
19 | 
20 |
21 | 4、**多动手写代码**,切忌眼高手低!如果你确信自己对大多数的基础知识和概念足够熟悉,并且能够以某种方式将它们联系起来,那么你就可以进行下一步了,你可以开始尝试编写一些有趣的 Java 程序。刚开始动手编写程序时,请可能会困难重重。但是一旦挺过去,接下来即使这些问题再次出现,你也能轻松解决。
22 |
23 | 5、**阅读经典书籍**,比如《深入理解计算机系统》、《数据库系统概念》、《代码整洁之道》等等,这些都是非常优秀的书籍,每次阅读都会有新的收获。PS:不要看那种3天学会Java之类的垃圾书,内容很浅没深度!
24 |
25 | 6、学好英语,干计算机这行,要想走在前列,就必须学好英语。因为计算机很多术语都是英文,中文翻译的话经常翻译的非常生涩。而且很多前沿的东西都是国外的,国内教材资料需要等待一段时间才能跟上,因此良好的英语能力能让你快人一步获取一手资料。
26 |
27 | 7、**每天刷一道算法题**,养成刷题的习惯。很多互联网公司都会考察手写算法题,如果平时没有练习,那么笔试或面试的时候大概率会脑袋空白,game over。建议从大二开始,每天抽空到leetcode上刷刷题。
28 |
29 | 8、**参与计算机竞赛**。比如ACM国际大学生程序设计竞赛、GPLT团队程序设计天梯赛、蓝桥杯、中国大学生计算机设计大赛等,或者企业主办的比赛,如华为软件杯精英挑战赛、百度之星程序设计大赛等,参加这些比赛对找工作和保研都有加分,并且对你的代码能力、团队合作能力和逻辑思维能力也有很大的提升。
30 |
31 | 9、**绩点要刷高一点**,绩点高对你保研、考研或者找工作都有很大的帮助。尽量提高绩点,还有就是不能挂科!挂科对你以后发展影响挺大,切记!
32 |
33 | 10、**打牢计算机基础**
34 |
35 | 要特别重视计算机基础,无论以后是找工作还是考研,基础很重要。
36 |
37 | 计算机专业课程里边,**计算机基础课程无非以下几个:**
38 |
39 | 1. **计算机组成原理**
40 | 2. **操作系统**
41 | 3. **编译原理**
42 | 4. **计算机网络**
43 | 5. **数据结构与算法**
44 | 6. **数据库基础**
45 |
46 | 11、**培养写文档的能力**。写文档是计算机专业学生的必备技能。有空可以学习下markdown语法,比word好用太多了。markdown编辑器推荐Typora(最近收费了)、语雀。
--------------------------------------------------------------------------------
/docs/note/redis-note.md:
--------------------------------------------------------------------------------
1 | ::: tip 这是一则或许对你有帮助的信息
2 |
3 | - **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
4 | - **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
5 |
6 | :::
7 |
8 | ## 一小时彻底吃透Redis
9 |
10 | 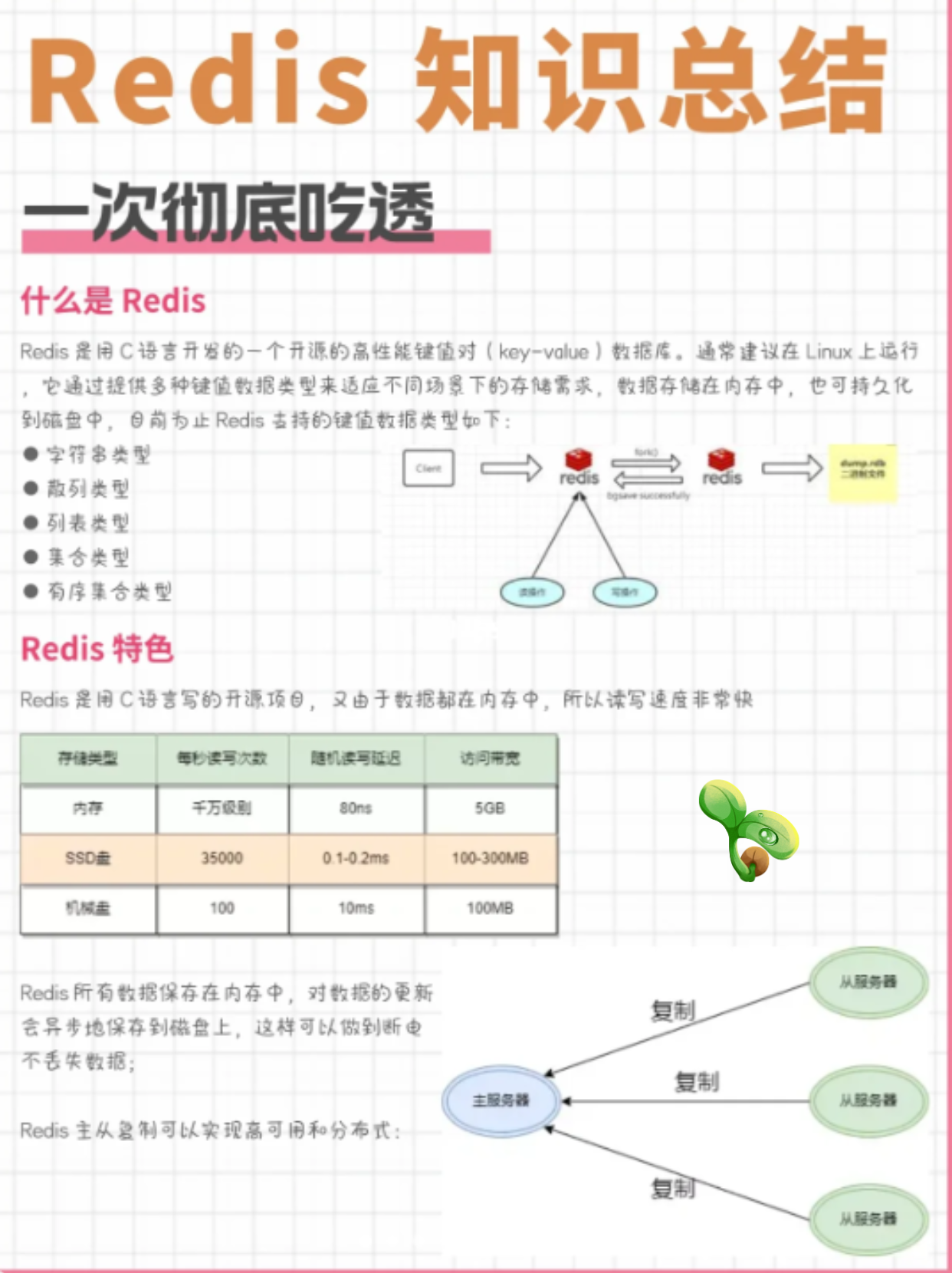
11 |
12 | 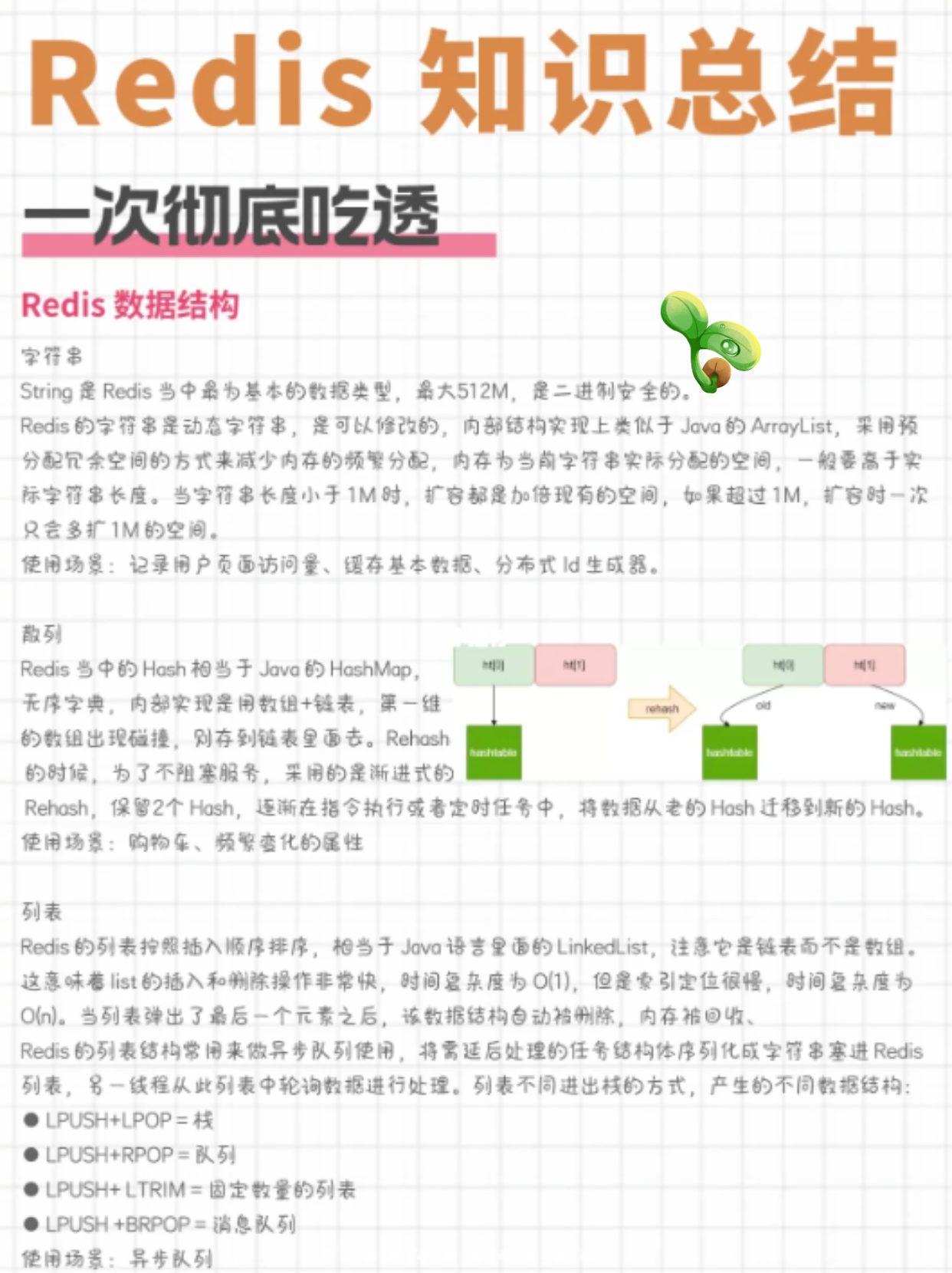
13 |
14 | 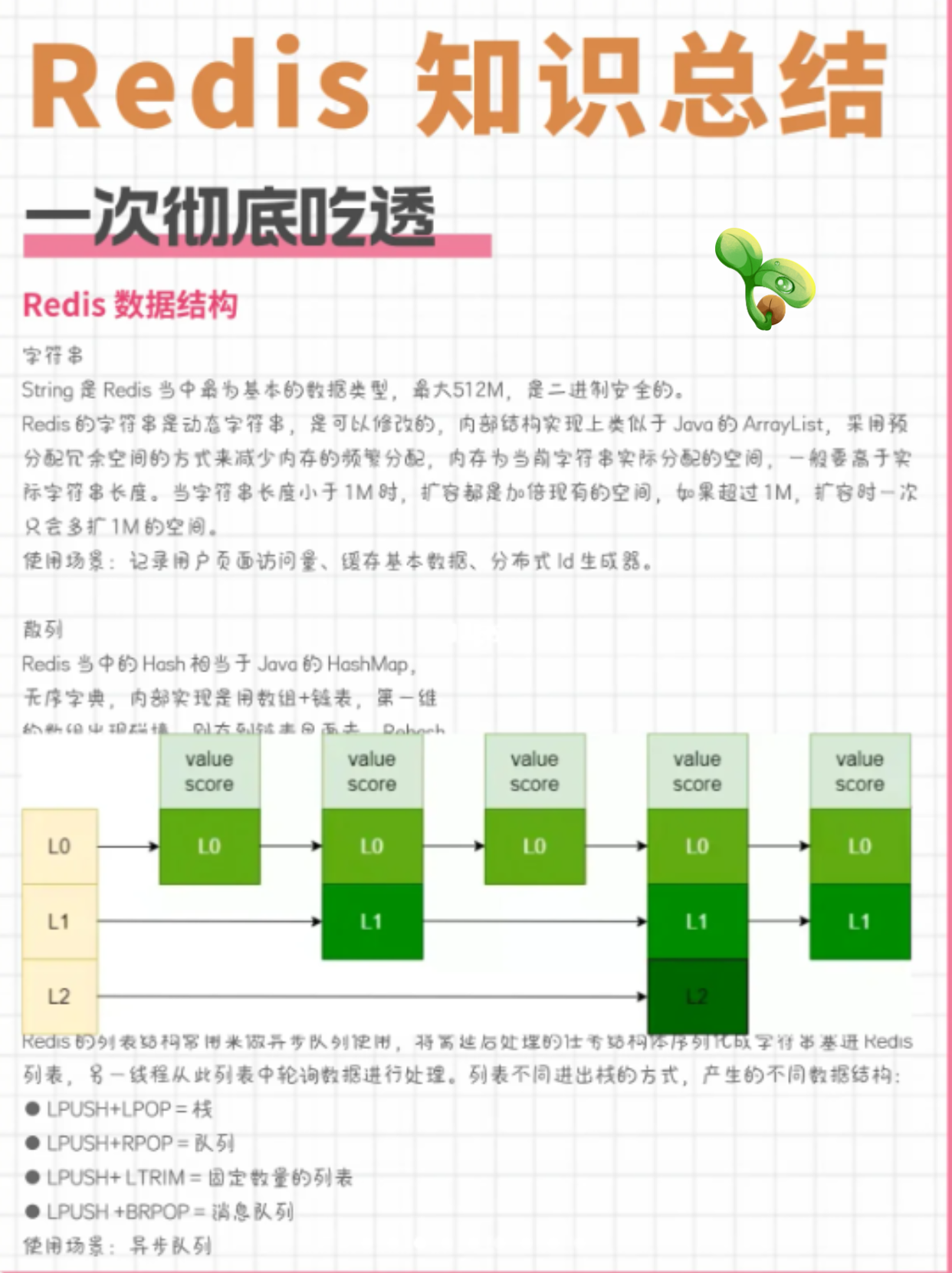
15 |
16 |
17 |
18 | 
19 |
20 | 
21 |
22 | 
23 |
24 | 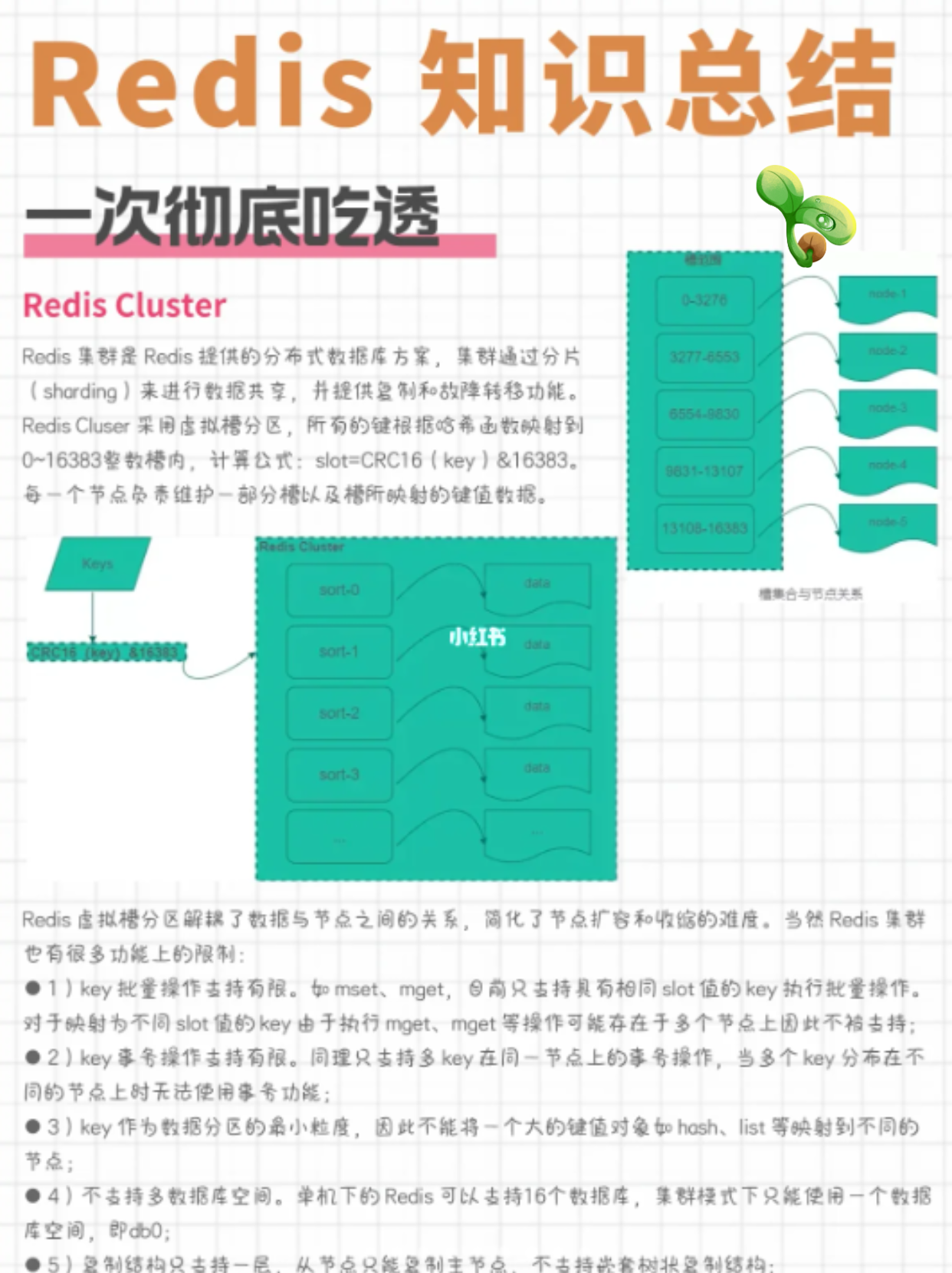
25 |
26 | 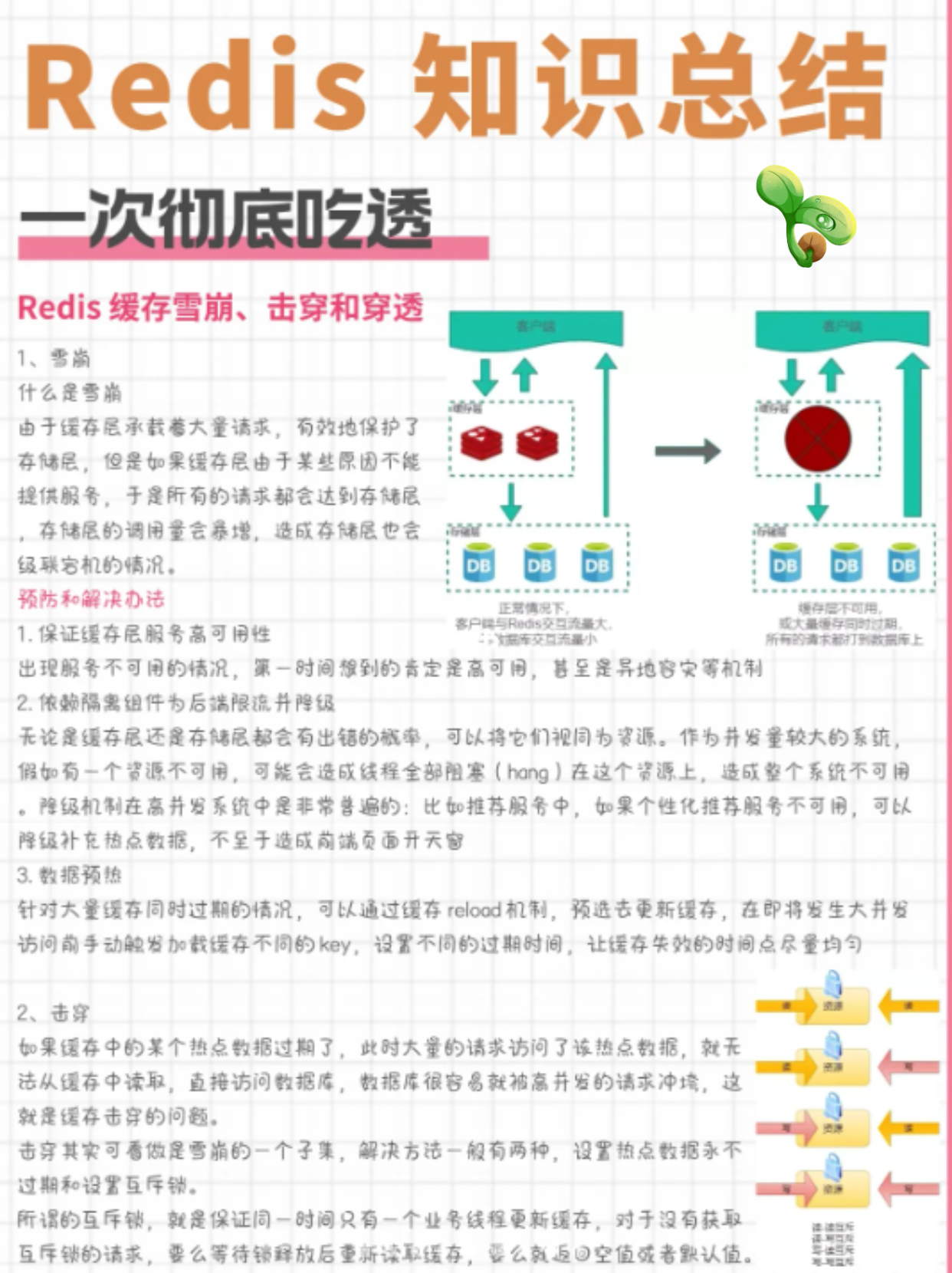
27 |
28 | 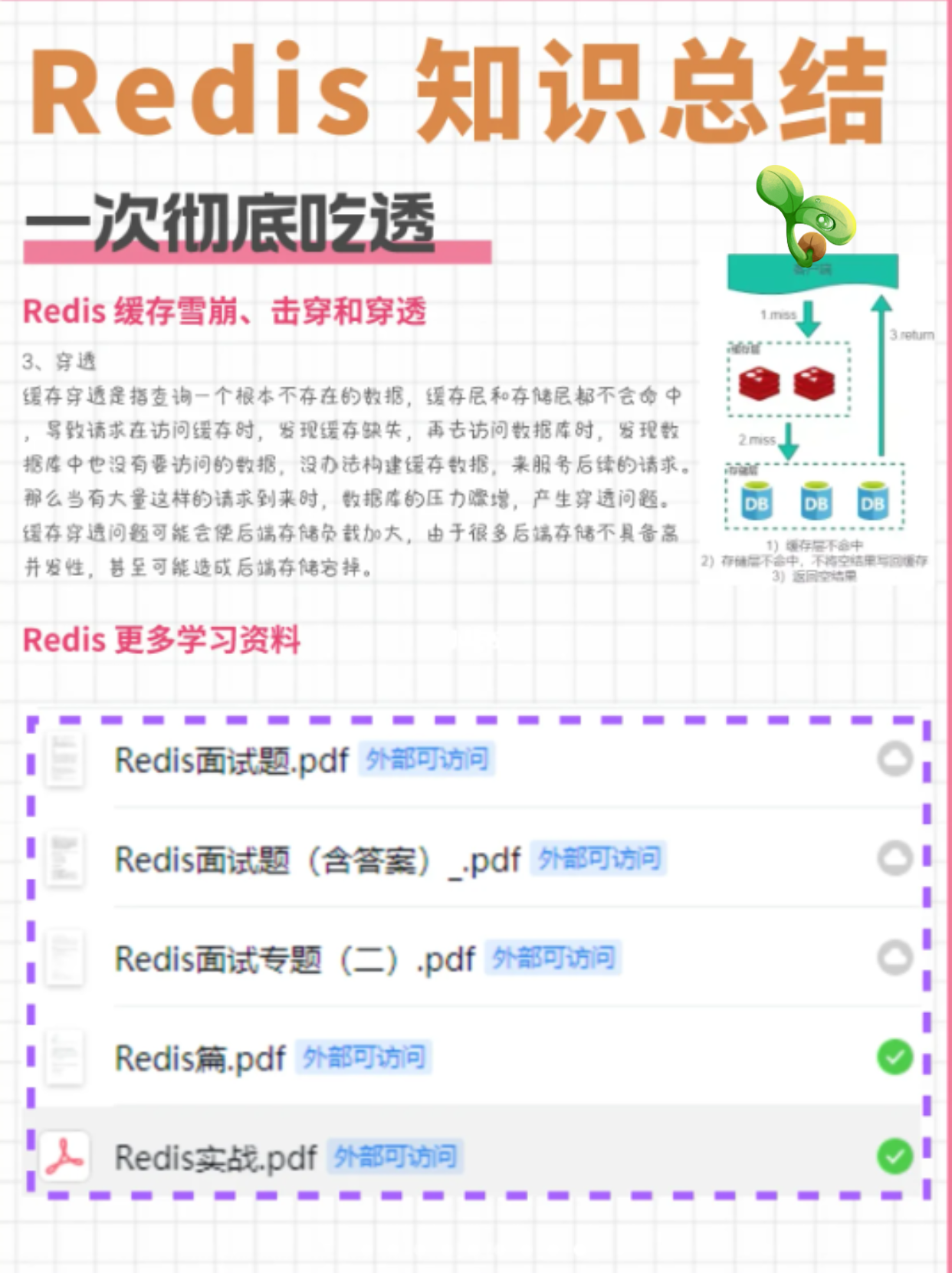
--------------------------------------------------------------------------------
/docs/other/leave-a-message.md:
--------------------------------------------------------------------------------
1 | # 留言区
2 |
3 | 大家有什么建议,或者觉得某个知识点理解有误的,欢迎到评论区留言~
4 |
5 |
--------------------------------------------------------------------------------
/docs/practice/service-performance-optimization.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 线上接口很慢怎么办?
4 | category: 实践经验
5 | tag:
6 | - 实践经验
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 线上接口很慢怎么处理
11 | - - meta
12 | - name: description
13 | content: 编程实践经验分享
14 | ---
15 |
16 | ## 线上接口很慢怎么办?
17 |
18 | 首先需要明确一个问题,是只有**一个接口**变慢,还是**多个接口**变慢。
19 |
20 | 如果系统中有多个服务的接口都变慢,那可能是**系统共用的资源不足**导致的。比如数据库连接数太多、数据库有大量慢查询、共同依赖的下游服务性能问题等。
21 |
22 | 可以查看系统中调用量突然增多的服务,它的调用量是否导致数据库的并发达到了瓶颈,是不是共同调用的下游服务出现了性能问题,数据库中是不是有大量这个服务引起的慢查询等。
23 |
24 | 可以有以下针对性优化:
25 |
26 | - 如果数据库并发达到瓶颈,可以考虑用**读写分离、分库分表、加读缓存**等方式来解决
27 | - 如果下游接口出现性能问题,需要通知下游服务做优化,同时要加**降级开关**
28 | - 如果数据库中有大量慢查询,需要**优化sql**或**加索引**等
29 |
30 | 如果是只有一个服务的接口变慢,那就要针对这个服务做分析,查看它的cpu占用率和gc频率是不是异常,做针对性的优化。
31 |
32 | 1. 比如在循环里获取远程数据,可以改成只调用一次,**批量获取数据**
33 | 2. 比如在链路中多次调用同一个远程接口获取相同数据,可以第一次调用之后就把数据**缓存**起来,后续直接从缓存中获取
34 | 3. 比如如果多个比较耗时的操作是串行执行的,但它们又没有依赖关系,就可以把串行改成**并行**,可以用countDownLatch
35 | 4. 还有如果实在无法再缩短请求处理耗时的话,也可以考虑从产品逻辑上进行优化,比如把原来的同步请求改为**异步**的,前端再去轮询请求处理结果
36 | 5. 比如为了得到一个复杂的model,需要调多个接口获取信息,但当前接口只需要其中部分比较简单的数据,那么需要根据实际情况,**重新写**一个简单model的获取方法
37 |
38 |
39 |
40 | > 参考链接:https://juejin.cn/post/7064140627578978334
41 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/1-introduce.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Redis简介
4 | category: 缓存
5 | tag:
6 | - Redis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Redis简介,redis优缺点,io多路复用,Memcached和Redis的区别,redis应用场景
11 | - - meta
12 | - name: description
13 | content: Redis常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 简介
17 |
18 | Redis是一个高性能的key-value数据库。Redis对数据的操作都是原子性的。
19 |
20 | ## 优缺点
21 |
22 | 优点:
23 |
24 | 1. 基于内存操作,内存读写速度快。
25 | 2. Redis是单线程的,避免线程切换开销及多线程的竞争问题。单线程是指在处理网络请求(一个或多个redis客户端连接)的时候只有一个线程来处理,redis运行时不止有一个线程,数据持久化或者向slave同步aof时会另起线程。
26 | 3. 支持多种数据类型,包括String、Hash、List、Set、ZSet等
27 | 4. 支持持久化。Redis支持RDB和AOF两种持久化机制,持久化功能有效地避免数据丢失问题。
28 | 5. redis 采用IO多路复用技术。多路指的是多个socket连接,复用指的是复用一个线程。redis使用单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。
29 |
30 | 缺点:对join或其他结构化查询的支持就比较差。
31 |
32 | ## io多路复用
33 |
34 | 将用户socket对应的文件描述符(file description)注册进epoll,然后epoll帮你监听哪些socket上有消息到达。当某个socket可读或者可写的时候,它可以给你一个通知。只有当系统通知哪个描述符可读了,才去执行read操作,可以保证每次read都能读到有效数据。这样,多个描述符的I/O操作都能在一个线程内并发交替地顺序完成,这就叫I/O多路复用,这里的复用指的是复用同一个线程。
35 |
36 | ## 应用场景
37 |
38 | 1. 缓存热点数据,缓解数据库的压力。
39 | 2. 利用Redis中原子性的自增操作,可以用使用实现计算器的功能,比如统计用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力。
40 | 3. 简单消息队列,不要求高可靠的情况下,可以使用Redis自身的发布/订阅模式或者List来实现一个队列,实现异步操作。
41 | 4. 好友关系,利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好友、共同爱好之类的功能。
42 | 5. 限速器,比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力。
43 |
44 | ## Memcached和Redis的区别
45 |
46 | 1. Redis只使用单核,而Memcached可以使用多核。
47 | 2. MemCached数据结构单一,仅用来缓存数据,而Redis支持更加丰富的数据类型,也可以在服务器端直接对数据进行丰富的操作,这样可以减少网络IO次数和数据体积。
48 | 3. MemCached不支持数据持久化,断电或重启后数据消失。Redis支持数据持久化和数据恢复,允许单点故障。
49 |
50 |
51 |
52 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/11-deletion-policy.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Redis删除策略
4 | category: 缓存
5 | tag:
6 | - Redis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Redis删除策略
11 | - - meta
12 | - name: description
13 | content: Redis常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 删除策略
17 |
18 | 1. 被动删除。在访问key时,如果发现key已经过期,那么会将key删除。
19 | 2. 主动删除。定时清理key,每次清理会依次遍历所有DB,从db随机取出20个key,如果过期就删除,如果其中有5个key过期,那么就继续对这个db进行清理,否则开始清理下一个db。
20 |
21 | 3. 内存不够时清理。Redis有最大内存的限制,通过maxmemory参数可以设置最大内存,当使用的内存超过了设置的最大内存,就要进行内存释放, 在进行内存释放的时候,会按照配置的淘汰策略清理内存,淘汰策略一般有6种,Redis4.0版本后又增加了2种,主要由分为三类:
22 |
23 | - 第一类 不处理 noeviction。发现内存不够时,不删除key,执行写入命令时直接返回错误信息。(默认的配置)
24 |
25 | - 第二类 从所有结果集中的key中挑选,进行淘汰
26 |
27 | - allkeys-random 就是从所有的key中随机挑选key,进行淘汰
28 | - allkeys-lru 就是从所有的key中挑选最近最少使用的数据淘汰
29 | - allkeys-lfu 就是从所有的key中挑选使用频率最低的key,进行淘汰。(这是Redis 4.0版本后新增的策略)
30 |
31 | - 第三类 从设置了过期时间的key中挑选,进行淘汰
32 |
33 | 这种就是从设置了expires过期时间的结果集中选出一部分key淘汰,挑选的算法有:
34 |
35 | - volatile-random 从设置了过期时间的结果集中随机挑选key删除。
36 | - volatile-lru 从设置了过期时间的结果集中挑选最近最少使用的数据淘汰
37 | - volatile-ttl 从设置了过期时间的结果集中挑选可存活时间最短的key开始删除(也就是从哪些快要过期的key中先删除)
38 | - volatile-lfu 从过期时间的结果集中选择使用频率最低的key开始删除(这是Redis 4.0版本后新增的策略)
39 |
40 |
41 |
42 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/5-sort.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Redis排序
4 | category: 缓存
5 | tag:
6 | - Redis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Redis排序
11 | - - meta
12 | - name: description
13 | content: Redis常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 排序
17 |
18 | ```
19 | LPUSH myList 4 8 2 3 6
20 | SORT myList DESC
21 | ```
22 |
23 | ```
24 | LPUSH letters f l d n c
25 | SORT letters ALPHA
26 | ```
27 |
28 | **BY参数**
29 |
30 | ```
31 | LPUSH list1 1 2 3
32 | SET score:1 50
33 | SET score:2 100
34 | SET score:3 10
35 | SORT list1 BY score:* DESC
36 | ```
37 |
38 | **GET参数**
39 |
40 | GET参数命令作用是使SORT命令的返回结果是GET参数指定的键值。
41 |
42 | `SORT tag:Java:posts BY post:*->time DESC GET post:*->title GET post:*->time GET #`
43 |
44 | GET #返回文章ID。
45 |
46 | **STORE参数**
47 |
48 | `SORT tag:Java:posts BY post:*->time DESC GET post:*->title STORE resultCache`
49 |
50 | `EXPIRE resultCache 10 //STORE结合EXPIRE可以缓存排序结果`
51 |
52 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/6-transaction.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Redis事务
4 | category: 缓存
5 | tag:
6 | - Redis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Redis事务
11 | - - meta
12 | - name: description
13 | content: Redis常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 事务
17 |
18 | 事务的原理是将一个事务范围内的若干命令发送给Redis,然后再让Redis依次执行这些命令。
19 |
20 | 事务的生命周期:
21 |
22 | 1. 使用MULTI开启一个事务
23 | 2. 在开启事务的时候,每次操作的命令将会被插入到一个队列中,同时这个命令并不会被真的执行
24 |
25 | 3. EXEC命令进行提交事务
26 |
27 | 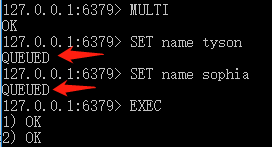
28 |
29 | DISCARD:放弃事务,即该事务内的所有命令都将取消
30 |
31 | 一个事务范围内某个命令出错不会影响其他命令的执行,不保证原子性:
32 |
33 | ```
34 | 127.0.0.1:6379> multi
35 | OK
36 | 127.0.0.1:6379> set a 1
37 | QUEUED
38 | 127.0.0.1:6379> set b 1 2
39 | QUEUED
40 | 127.0.0.1:6379> set c 3
41 | QUEUED
42 | 127.0.0.1:6379> exec
43 | 1) OK
44 | 2) (error) ERR syntax error
45 | 3) OK
46 | ```
47 |
48 | 事务里的命令执行时会读取最新的值:
49 |
50 | 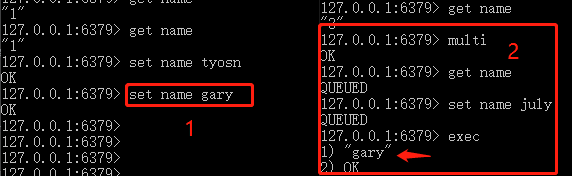
51 |
52 | ## WATCH命令
53 |
54 | WATCH命令可以监控一个或多个键,一旦其中有一个键被修改,之后的事务就不会执行(类似于乐观锁)。执行EXEC命令之后,就会自动取消监控。
55 |
56 | ```
57 | 127.0.0.1:6379> watch name
58 | OK
59 | 127.0.0.1:6379> set name 1
60 | OK
61 | 127.0.0.1:6379> multi
62 | OK
63 | 127.0.0.1:6379> set name 2
64 | QUEUED
65 | 127.0.0.1:6379> set gender 1
66 | QUEUED
67 | 127.0.0.1:6379> exec
68 | (nil)
69 | 127.0.0.1:6379> get gender
70 | (nil)
71 | ```
72 |
73 | UNWATCH:取消WATCH命令对多有key的监控,所有监控锁将会被取消。
74 |
75 |
76 |
77 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/7-message-queue.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Redis实现消息队列
4 | category: 缓存
5 | tag:
6 | - Redis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Redis实现消息队列
11 | - - meta
12 | - name: description
13 | content: Redis常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 消息队列
17 |
18 | 使用一个列表,让生产者将任务使用LPUSH命令放进列表,消费者不断用RPOP从列表取出任务。
19 |
20 | BRPOP和RPOP命令相似,唯一的区别就是当列表没有元素时BRPOP命令会一直阻塞连接,直到有新元素加入。
21 | `BRPOP queue 0 //0表示不限制等待时间`
22 |
23 | ## 优先级队列
24 |
25 | `BLPOP queue:1 queue:2 queue:3 0`
26 | 如果多个键都有元素,则按照从左到右的顺序取元素
27 |
28 | ## 发布/订阅模式
29 |
30 | ```
31 | PUBLISH channel1 hi
32 | SUBSCRIBE channel1
33 | UNSUBSCRIBE channel1 //退订通过SUBSCRIBE命令订阅的频道。
34 | ```
35 |
36 | `PSUBSCRIBE channel?*` 按照规则订阅
37 | `PUNSUBSCRIBE channel?*` 退订通过PSUBSCRIBE命令按照某种规则订阅的频道。其中订阅规则要进行严格的字符串匹配,`PUNSUBSCRIBE *`无法退订`channel?*`规则。
38 |
39 | 缺点:在消费者下线的情况下,生产的消息会丢失。
40 |
41 | ## 延时队列
42 |
43 | 使用sortedset,拿时间戳作为score,消息内容作为key,调用zadd来生产消息,消费者用`zrangebyscore`指令获取N秒之前的数据轮询进行处理。
44 |
45 |
46 |
47 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis基础
3 | icon: redis
4 | date: 2022-08-06
5 | category: redis
6 | star: true
7 | ---
8 |
9 | **本专栏是大彬学习MySQL基础知识的学习笔记,如有错误,可以在评论区指出**~
10 |
11 | 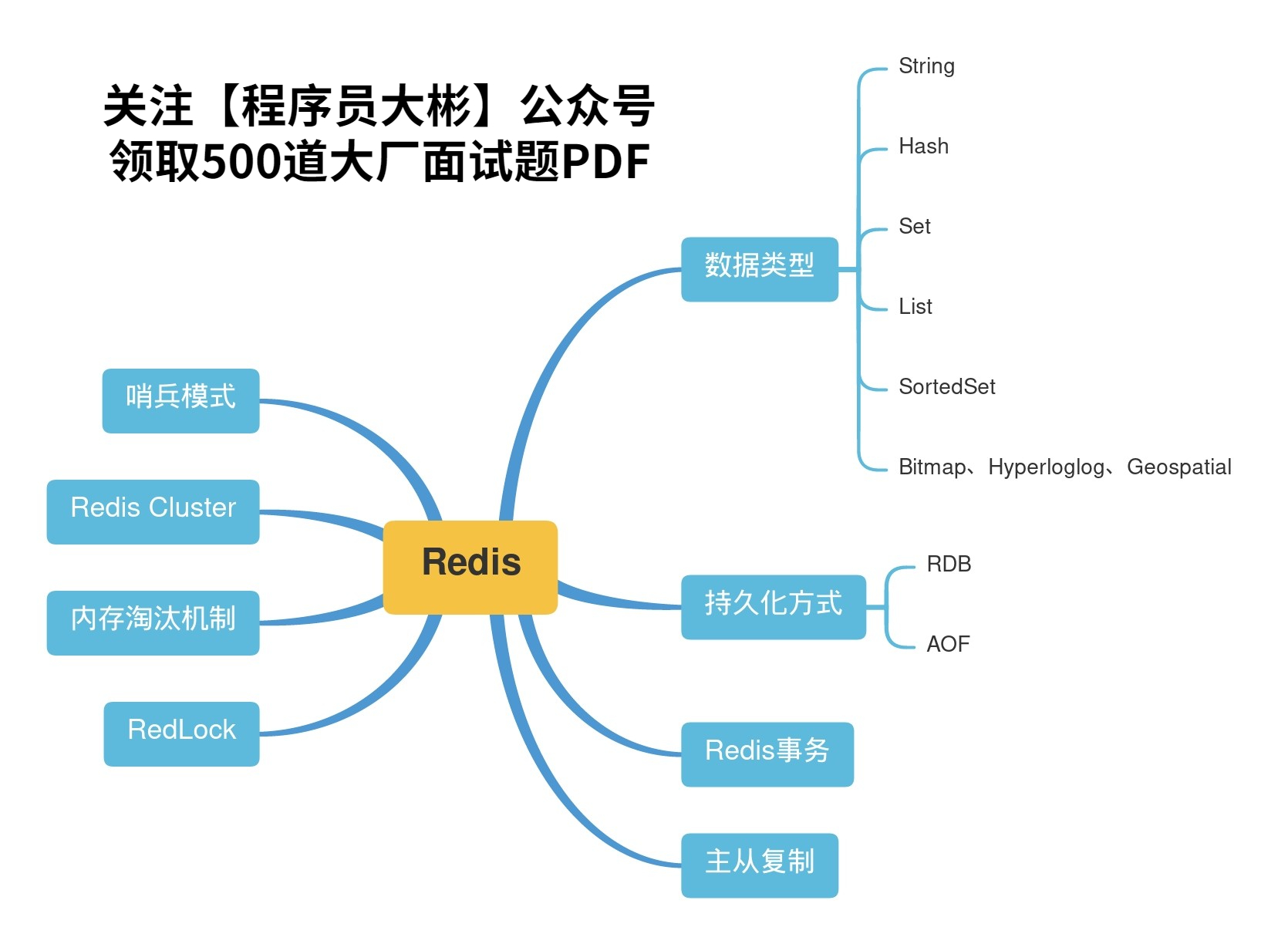
12 |
13 | ## Redis总结
14 |
15 | - [简介](./1-introduce.md)
16 | - [数据类型](./2-data-type.md)
17 | - [数据结构](./3-data-structure.md)
18 | - [底层实现](./4-implement.md)
19 | - [排序](./5-sort.md)
20 | - [事务](./6-transaction.md)
21 | - [消息队列](./7-message-queue.md)
22 | - [持久化](./8-persistence.md)
23 | - [集群](./9-cluster.md)
24 | - [LUA脚本](./10-lua.md)
25 | - [删除策略](./11-deletion-policy.md)
26 | - [其他](./12-others.md)
27 |
--------------------------------------------------------------------------------
/docs/snippets/ads.md:
--------------------------------------------------------------------------------
1 | ::: tip 这是一则或许对你有帮助的信息
2 |
3 | - **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
4 | - **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
5 |
6 | :::
--------------------------------------------------------------------------------
/docs/source/mybatis/1-overview.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: MyBatis源码分析
4 | category: 源码分析
5 | tag:
6 | - MyBatis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: MyBatis面试题,MyBatis源码分析,MyBatis整体架构,MyBatis源码,Hibernate,Executor,MyBatis分页,MyBatis插件运行原理,MyBatis延迟加载,MyBatis预编译,一级缓存和二级缓存
11 | - - meta
12 | - name: description
13 | content: 高质量的MyBatis源码分析总结
14 | ---
15 |
16 | `MyBatis` 是一款旨在帮助开发人员屏蔽底层重复性原生 `JDBC` 代码的持久化框架,其支持通过映射文件配置或注解将 `ResultSet` 映射为 `Java` 对象。相对于其它 `ORM` 框架,`MyBatis` 更为轻量级,支持定制化 `SQL` 和动态 `SQL`,方便优化查询性能,同时包含了良好的缓存机制。
17 |
18 | ## MyBatis 整体架构
19 |
20 | 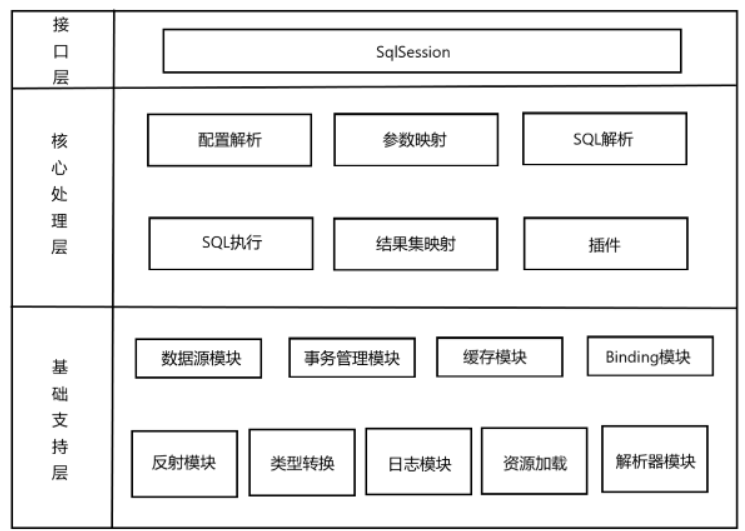
21 |
22 | ### 基础支持层
23 |
24 | - 反射模块:提供封装的反射 `API`,方便上层调用。
25 | - 类型转换:为简化配置文件提供了别名机制,并且实现了 `Java` 类型和 `JDBC` 类型的互转。
26 | - 日志模块:能够集成多种第三方日志框架。
27 | - 资源加载模块:对类加载器进行封装,提供加载类文件和其它资源文件的功能。
28 | - 数据源模块:提供数据源实现并能够集成第三方数据源模块。
29 | - 事务管理:可以和 `Spring` 集成开发,对事务进行管理。
30 | - 缓存模块:提供一级缓存和二级缓存,将部分请求拦截在缓存层。
31 | - `Binding` 模块:在调用 `SqlSession` 相应方法执行数据库操作时,需要指定映射文件中的 `SQL` 节点,`MyBatis` 通过 `Binding` 模块将自定义 `Mapper` 接口与映射文件关联,避免拼写等错误导致在运行时才发现相应异常。
32 |
33 | ### 核心处理层
34 |
35 | - 配置解析:`MyBatis` 初始化时会加载配置文件、映射文件和 `Mapper` 接口的注解信息,解析后会以对象的形式保存到 `Configuration` 对象中。
36 | - `SQL` 解析与 `scripting` 模块:`MyBatis` 支持通过配置实现动态 `SQL`,即根据不同入参生成 `SQL`。
37 | - `SQL` 执行与结果解析:`Executor` 负责维护缓存和事务管理,并将数据库相关操作委托给 `StatementHandler`,`ParmeterHadler` 负责完成 `SQL` 语句的实参绑定并通过 `Statement` 对象执行 `SQL`,通过 `ResultSet` 返回结果,交由 `ResultSetHandler` 处理。
38 |
39 | - 插件:支持开发者通过插件接口对 `MyBatis` 进行扩展。
40 |
41 | ### 接口层
42 |
43 | `SqlSession` 接口定义了暴露给应用程序调用的 `API`,接口层在收到请求时会调用核心处理层的相应模块完成具体的数据库操作。
--------------------------------------------------------------------------------
/docs/system-design/README.md:
--------------------------------------------------------------------------------
1 | **系统设计高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到Java面试手册**完整版**。
2 |
3 | 
4 |
5 | 除了Java面试手册完整版之外,星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
6 |
7 | 
8 |
9 | 
10 |
11 | 
12 |
13 | **专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
14 |
15 | 
16 |
17 | 
18 |
19 | 另外星球还提供**简历指导、修改服务**,大彬已经帮**90**+个小伙伴修改了简历,相对还是比较有经验的。
20 |
21 | 
22 |
23 | 
24 |
25 | [知识星球](https://topjavaer.cn/zsxq/introduce.html)**加入方式**:
26 |
27 | 
--------------------------------------------------------------------------------
/docs/tools/docker/1-introduce.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | Docker是一个开源的应用容器引擎,通过容器可以隔离应用程序的运行时环境(程序运行时依赖的各种库和配置),比虚拟机更轻量(虚拟机在操作系统层面进行隔离)。docker的另一个优点就是build once, run everywhere,只编译一次,就可以在各个平台(windows、linux等)运行。
4 |
5 | ## 基本概念
6 |
7 | docker的基本概念:
8 |
9 | 1. 镜像(image),类似于虚拟机中的镜像,可以理解为可执行程序。
10 |
11 | 2. 容器(container),类似于一个轻量级的沙盒,可以将其看作一个极简的Linux系统环境。Docker引擎利用容器来运行、隔离各个应用。容器是镜像创建的应用实例,可以创建、启动、停止、删除容器,各个容器之间是是相互隔离的,互不影响。
12 |
13 | 3. 镜像仓库(repository),是Docker用来集中存放镜像文件的地方。注意与注册服务器(Registry)的区别:注册服务器是存放仓库的地方,一般会有多个仓库;而仓库是存放镜像的地方,一般每个仓库存放一类镜像,每个镜像利用tag进行区分,比如Ubuntu仓库存放有多个版本(12.04、14.04等)的Ubuntu镜像。
14 | 4. dockerfile,image的编译配置文件,docker就是"编译器"。
15 |
16 | docker的基本命令:
17 |
18 | 1、docker build:我们只需要在dockerfile中指定需要哪些程序、依赖什么样的配置,之后把dockerfile交给“编译器”docker进行“编译”,生成的可执行程序就是image。
19 |
20 | 2、docker run:运行image,运行起来后就是docker container。
21 |
22 | 3、docker pull:到Docker Hub(docker registry)下载别人写好的image。
23 |
24 | 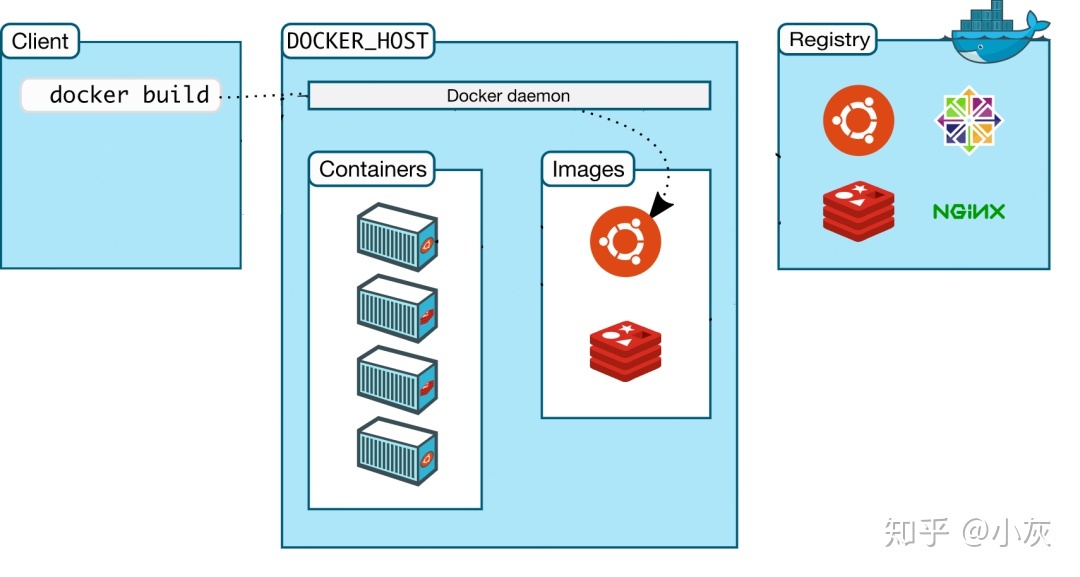
25 |
26 | > 图片来源:知乎小灰
27 |
28 |
--------------------------------------------------------------------------------
/docs/tools/docker/6-other.md:
--------------------------------------------------------------------------------
1 | # 其他
2 |
3 | ## 给nginx增加端口映射
4 |
5 | nginx一开始只映射了80端口,后面载部署项目的时候,需要用到其他端口,不想重新部署容器,所以通过修改配置文件的方式给容器添加其他端口。
6 |
7 | 1、执行命令`docker inspect nginx`,找到容器id
8 |
9 | 2、停止容器`docker stop nginx`,不然修改了配置会自动还原
10 |
11 | 3、修改hostconfig.json
12 |
13 | ```java
14 | cd /var/lib/docker/containers/135254e3429d1e75aa68569137c753b789416256f2ced52b4c5a85ec3849db87 # container id
15 | vim hostconfig.json
16 | ```
17 |
18 | 添加端口:
19 |
20 | ```java
21 | "PortBindings": {
22 | "80/tcp": [
23 | {
24 | "HostIp": "",
25 | "HostPort": "80"
26 | }
27 | ],
28 | "8080/tcp": [
29 | {
30 | "HostIp": "",
31 | "HostPort": "8080"
32 | }
33 | ]
34 | },
35 | ```
36 |
37 | 4、修改同目录下 config.v2.json
38 |
39 | ```java
40 | "ExposedPorts": {
41 | "80/tcp": {},
42 | "8080/tcp": {},
43 | "8189/tcp": {}
44 | },
45 | ```
46 |
47 | 5、重启容器
48 |
49 | ```java
50 | systemctl restart docker.service # 重启docker服务
51 | docker start nginx
52 | ```
53 |
54 |
--------------------------------------------------------------------------------
/docs/tools/docker/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Docker基础
3 | icon: docker
4 | date: 2022-08-06
5 | category: docker
6 | star: true
7 | ---
8 |
9 | 
10 | ## Docker总结
11 |
12 | - [简介](./1-introduce.md)
13 | - [docker镜像常用命令](./2-image-command.md)
14 | - [docker容器常用命令](./3-container-command.md)
15 | - [docker-compose](./4-docker-compose.md)
16 | - [maven插件构建docker镜像](./5-maven-build.md)
17 | - [其他](./6-other.md)
18 |
--------------------------------------------------------------------------------
/docs/tools/git/1-introduce.md:
--------------------------------------------------------------------------------
1 | # Git 简介
2 |
3 | Git 是一个开源的分布式版本控制系统,可以有效、快速的进行项目版本管理。Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
4 |
5 | ## Git工作流程
6 |
7 | Git工作流程如下:
8 |
9 | - 从远程仓库中克隆资源作为本地仓库;
10 | - 在本地仓库中进行代码修改;
11 | - 在提交本地仓库前先将代码提交到暂存区;
12 | - 提交修改,提交到本地仓库。本地仓库中保存修改的所有历史版本;
13 | - 在需要和团队成员共享代码时,可以将修改的代码push到远程仓库。
14 |
15 | Git 的工作流程图如下:
16 |
17 | 
18 |
19 | > 图片来源:https://blog.csdn.net/ThinkWon/article/details/94346816
20 |
21 | ## 存储原理
22 |
23 | Git 在保存项目状态时,它主要对全部文件制作一个快照并保存这个快照的索引,如果文件没有被修改,Git 不会重新存储这个文件,而是只保留一个链接指向之前存储的文件。
24 |
25 | ## Git 快照
26 |
27 | 快照就是将旧文件所占的空间保留下来,并且保存一个引用,而新文件中会继续使用与旧文件内容相同部分的磁盘空间,不同部分则写入新的磁盘空间。
28 |
29 | ## 三种状态
30 |
31 | Git 的三种状态:已修改(modified)、已暂存(staged)和已提交(committed)。已修改表示修改了文件,但还没保存到数据库。已暂存表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。已提交表示数据已经安全的保存到本地数据库。
32 |
33 | 基本的 Git 工作流程:在工作目录修改文件;暂存文件,将文件快照放到暂存区域;提交更新到本地库。暂存区保存了下次将要提交的文件列表信息,一般在 Git 仓库目录中。
34 |
35 | 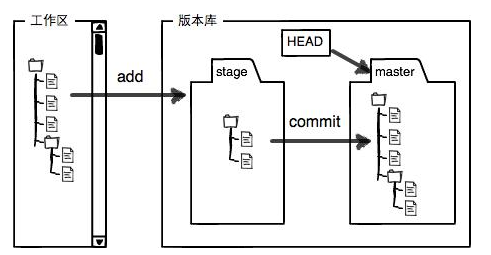
36 |
37 | > 图片来源:`https://img2018.cnblogs.com/blog/1252910/201907/1252910-20190726163829113-2056815874.png`
38 |
39 | 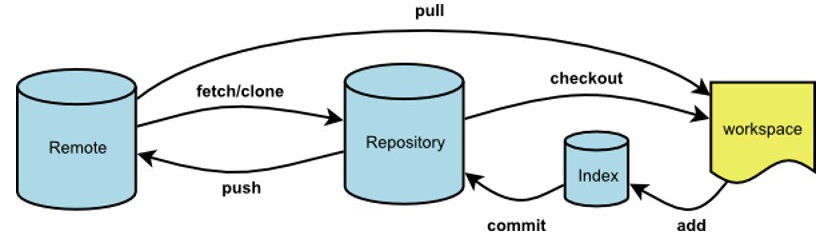
40 |
41 | ## 配置
42 |
43 | 设置用户名和邮箱地址:
44 |
45 | ```bash
46 | git config --global user.name "dabin"
47 | git config --global user.email xxx@xxx.com
48 | ```
49 |
50 | 如果使用了 --global 选项,那么该命令只需要运行一次,因为之后无论你在该系统上做任何事情,Git 都会使用那些信息。 当你想针对特定项目使用不同的用户名称与邮件地址时,可以在那个项目目录下运行没有 --global 选项的命令来配置。
51 |
52 | 查看配置信息:
53 |
54 | ```bash
55 | git config --list
56 | ```
57 |
58 | 查看某一项配置:
59 |
60 | ```bash
61 | git config user.name
62 | ```
63 |
64 | ## 获取帮助
65 |
66 | 获取 config 命令的手册:
67 |
68 | ```bash
69 | git help config
70 | ```
71 |
72 |
--------------------------------------------------------------------------------
/docs/tools/git/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Git基础
3 | icon: git
4 | date: 2022-08-06
5 | category: git
6 | star: true
7 | ---
8 |
9 | 
10 |
11 | ## Git总结
12 |
13 | - [Git简介](./1-introduce.md)
14 | - [Git基础](./2-basic.md)
15 | - [远程仓库](./3-remote-repo.md)
16 | - [标签](./4-label.md)
17 | - [git分支](./5-branch.md)
18 |
--------------------------------------------------------------------------------
/docs/tools/linux/3-search.md:
--------------------------------------------------------------------------------
1 | # 检索相关
2 |
3 | ## grep
4 |
5 | ```
6 | #反向匹配, 查找不包含xxx的内容
7 | grep -v xxx
8 |
9 | #排除所有空行
10 | grep -v '^/pre>
11 |
12 | #返回结果 2,则说明第二行是空行
13 | grep -n “^$” 111.txt
14 |
15 | #查询以abc开头的行
16 | grep -n “^abc” 111.txt
17 |
18 | #同时列出该词语出现在文章的第几行
19 | grep 'xxx' -n xxx.log
20 |
21 | #计算一下该字串出现的次数
22 | grep 'xxx' -c xxx.log
23 |
24 | #比对的时候,不计较大小写的不同
25 | grep 'xxx' -i xxx.log
26 | ```
27 |
28 | ## awk
29 |
30 | ```
31 | #以':' 为分隔符,如果第五域有user则输出该行
32 | awk -F ':' '{if ($5 ~ /user/) print $0}' /etc/passwd
33 |
34 | #统计单个文件中某个字符(串)(中文无效)出现的次数
35 | awk -v RS='character' 'END {print --NR}' xxx.txt
36 | ```
37 |
38 | ## find检索命令
39 |
40 | ```
41 | #在目录下找后缀是.mysql的文件
42 | find /home/eagleye -name '*.mysql' -print
43 |
44 | #会从 /usr 目录开始往下找,找最近3天之内存取过的文件。
45 | find /usr -atime 3 –print
46 |
47 | #会从 /usr 目录开始往下找,找最近5天之内修改过的文件。
48 | find /usr -ctime 5 –print
49 |
50 | #会从 /doc 目录开始往下找,找jacky 的、文件名开头是 j的文件。
51 | find /doc -user jacky -name 'j*' –print
52 |
53 | #会从 /doc 目录开始往下找,找寻文件名是 ja 开头或者 ma开头的文件。
54 | find /doc \( -name 'ja*' -o- -name 'ma*' \) –print
55 |
56 | #会从 /doc 目录开始往下找,找到凡是文件名结尾为 bak的文件,把它删除掉。-exec 选项是执行的意思,rm 是删除命令,{ } 表示文件名,“\;”是规定的命令结尾。
57 | find /doc -name '*bak' -exec rm {} \;
58 | ```
59 |
60 |
--------------------------------------------------------------------------------
/docs/tools/linux/README.md:
--------------------------------------------------------------------------------
1 | 虽然平时大部分工作都是和Java相关的开发, 但是每天都会接触Linux系统, 尤其是使用了Mac之后, 每天都是工作在黑色背景的命令行环境中. 自己记忆力不好, 很多有用的Linux命令不能很好的记忆, 现在逐渐总结一下, 以便后续查看。
2 |
3 | > 来源:siye1982.github.io/2016/02/25/linux-list
4 |
5 |
6 | ## Linux基础命令
7 |
8 | - [基本操作](./1-basic.md)
9 | - [磁盘,文件,目录相关操作](./2-disk-file.md)
10 | - [检索相关](./3-search.md)
11 | - [网络相关](./4-net.md)
12 | - [监控linux性能命令](./5-monitor.md)
13 |
--------------------------------------------------------------------------------
/docs/tools/maven/1-introduce.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | Maven 是强大的构建工具,能够帮我们自动化构建过程--清理、编译、测试、打包和部署。比如测试,我们无需告诉 maven 如何去测试,只需遵循 maven 的约定编写好测试用例,当我们运行构建的时候,这些测试就会自动运行。
4 |
5 | Maven 不仅是构建工具,还是一个依赖管理工具和项目信息管理工具。它提供了中央仓库,能帮助我们自动下载构件。
6 |
7 | ## 配置
8 |
9 | 配置用户范围 settings.xml。M2_HOME/conf/settings.xml 是全局范围的,而~/.m2/settings.xml 是用户范围的。配置成用户范围便于 Maven 升级。若直接修改 conf 目录下的 settings.xml,每次 Maven 升级时,都需要直接 settings.xml 文件。
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/docs/tools/maven/3-dependency.md:
--------------------------------------------------------------------------------
1 | # 依赖
2 |
3 | ```xml
4 |
5 | junit
6 | junit
7 | 4.7
8 | test
9 |
10 | ```
11 |
12 | - scope:依赖的范围
13 |
14 | - type:依赖的类型,jar 或者 war
15 |
16 | - exclusions:用来排除传递性依赖
17 |
18 | ## 依赖范围 scope
19 |
20 | maven 在编译、测试和运行项目时会使用不同的 classpath(编译classpath、测试 classpath、运行 classpath)。依赖范围就是用来控制依赖和这三种 classpath 的关系。maven 中有以下几种依赖范围:
21 |
22 | - compile:默认值,使用该依赖范围的 maven 依赖,在编译、测试和运行时都需要使用该依赖
23 | - test:只对测试 classpath 有效,在编译主代码和运行项目时无法使用此类依赖。如 JUnit 只在编译测试代码和运行测试的时候才需要此类依赖
24 | - provided:已提供依赖范围。对于编译和测试 classpath 有效,但在运行时无效。如 servlet-api,编译和测试时需要该依赖,但在运行项目时,由于容器已经提供此依赖,故不需要 maven重复引入
25 | - runtime:运行时依赖范围。对于测试和运行 classpath 有效,但在编译主代码时无效。如 JDBC 驱动实现,项目主代码的编译只需要 JDK 提供的 JDBC接口,只有在测试和运行时才需要实现 JDBC 接口的具体实现
26 | - system:系统依赖范围
27 | - import:导入依赖范围 [import 导入依赖管理](#import-导入依赖管理)
28 |
29 |
30 | ## 传递性依赖
31 |
32 | 假如项目 account 有一个 compile 范围的 spring-core 依赖,而 spring-core 有一个 compile 范围的 common-logging 依赖,那么 common-logging 就会成为 account 的 compile 范围依赖,common-logging 是 account 的一个传递性依赖。maven 会直接解析各个直接依赖的 POM,将那些必要的间接依赖,以传递性依赖的形式引入到项目中。
33 |
34 | spring-core 是 account 的第一直接依赖,common-logging 是 spring-core 的第二直接依赖,common-logging 是 account 的传递性依赖。第一直接依赖的范围和第二直接依赖的范围共同决定了传递性依赖的范围。下表左边是第一直接依赖的范围,上面一行是第二直接依赖的范围,中间部分是传递依赖的范围
35 |
36 | 
37 |
38 | ## 排除依赖
39 |
40 | 传递性依赖可能会带来一些问题,像引入一些类库的 SNAPSHOT 版本,会影响到当前项目的稳定性。此时可以通过 exclusions 元素声明排除传递性依赖,exclusions 元素可以包含一个或多个 exclusion 元素,因此可以排除多个传递性依赖。声明 exclusion 时只需要 groupId 和 artifactId,而不需要 version 元素。
41 |
42 | 
43 |
44 | ## 优化依赖
45 |
46 | 查看当前项目的依赖:`mvn dependency:list`
47 |
48 | 查看依赖树:`mvn dependency:tree`
49 |
50 | 分析依赖:`mvn dependency:analyze`
51 |
52 |
53 |
54 |
--------------------------------------------------------------------------------
/docs/tools/maven/5-lifecycle.md:
--------------------------------------------------------------------------------
1 | # 生命周期
2 |
3 | 项目构建过程包括:清理项目- 编译-测试-打包-部署
4 |
5 | ## 三套生命周期
6 |
7 | clean 生命周期:pre-clean、clean 和 post-clean;
8 |
9 | default 生命周期;
10 |
11 | site 生命周期:pre-site、site、post-site 和 site-deploy
12 |
13 | ## 命令行与生命周期
14 |
15 | `mvn clean`:调用 clean 生命周期的 clean 阶段,实际上执行的是 clean 的 pre-clean 和 clean 阶段;
16 |
17 | `mvn test`:调用 default 生命周期的 test 阶段;
18 |
19 | `mvn clean install`:调用 clean 生命周期的 clean 阶段和 default 生命周期的 install 阶段;
20 |
21 | `mvn clean deploy site-deploy`:调用 clean 生命周期的 clean 阶段、default 生命周期的 deploy 阶段,以及 site 生命周期的 site-deploy 阶段。
22 |
23 |
24 |
25 |
--------------------------------------------------------------------------------
/docs/tools/maven/6-plugin.md:
--------------------------------------------------------------------------------
1 | # 插件
2 |
3 | maven 的生命周期和插件相互绑定,用以完成具体的构建任务。
4 |
5 | ## 内置绑定
6 |
7 | 
8 |
9 | 
10 |
11 | ## 自定义绑定
12 |
13 | 内置绑定无法完成一些任务,如创建项目的源码 jar 包,此时需要用户自行配置。maven-source-plugin 可以完成这个任务,它的 jar-no-fork 目标能够将项目的主代码打包成 jar 文件,可以将其绑定到 default 生命周期的 verify 阶段,在执行完测试和安装构件之前创建源码 jar 包。
14 |
15 | ```xml
16 |
17 |
18 |
19 | org.apache.maven.plugins
20 | maven-source-plugin
21 | 2.1.1
22 |
23 |
24 | attach-sources
25 | verify
26 |
27 | jar-no-fork
28 |
29 |
30 |
31 |
32 |
33 |
34 | ```
35 |
36 | ## 命令行插件配置
37 |
38 | maven-surefire-plugin 提供了一个 maven.test.skip 参数,当其值为 true 时,就会跳过执行测试。
39 |
40 | `mvn install -Dmaven.test.skip=true` -D 是 Java 自带的。
41 |
42 | ## 插件全局配置
43 |
44 | 有些参数值从项目创建到发布都不会改变,可以在 pom 中一次性配置,避免重新在命令行输入。如配置 maven-compiler-plugin ,生成与 JVM1.5 兼容的字节码文件。
45 |
46 | ```xml
47 |
48 |
49 |
50 | org.apache.maven.plugins
51 | maven-compiler-plugin
52 | 2.1
53 |
54 | 1.5
55 | 1.5
56 |
57 |
58 |
59 |
60 | ```
61 |
62 |
63 |
64 |
--------------------------------------------------------------------------------
/docs/tools/maven/7-aggregator.md:
--------------------------------------------------------------------------------
1 | # 聚合
2 |
3 | 项目有多个模块时,使用一个聚合体将这些模块聚合起来,通过聚合体就可以一次构建全部模块。
4 |
5 | 
6 |
7 | accout-aggregator 的版本号要跟各个模块版本号相同,packaging 的值必须为 pom。module 标签的值是模块根目录名字(为了方便,模块根目录名字常与 artifactId 同名)。这样聚合模块和其他模块的目录结构是父子关系。如果使用平行目录结构,聚合模块的 pom 文件需要做相应的修改。
8 |
9 | ```xml
10 |
11 | ../account-register
12 | ../account-persist
13 |
14 | ```
15 |
16 |
17 |
18 |
--------------------------------------------------------------------------------
/docs/tools/maven/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Maven基础
3 | icon: build
4 | date: 2022-08-08
5 | category: maven
6 | star: true
7 | ---
8 |
9 | 
10 |
11 | ## Maven总结
12 |
13 | - [简介](./1-introduce.md)
14 | - [入门](./2-basic.md)
15 | - [依赖](./3-dependency.md)
16 | - [仓库](./4-repo.md)
17 | - [生命周期](./5-lifecycle.md)
18 | - [插件](./6-plugin.md)
19 | - [聚合](./7-aggregator.md)
20 | - [继承](./8-inherit.md)
21 |
--------------------------------------------------------------------------------
/docs/zookeeper/zk-usage.md:
--------------------------------------------------------------------------------
1 | ## Zookeeper有哪些使用场景?
2 |
3 | zookeeper 的使用场景有:
4 |
5 | - 分布式协调
6 | - 分布式锁
7 | - 元数据/配置信息管理
8 | - HA 高可用性
9 |
10 | ### 分布式协调
11 |
12 | 这个其实是 zookeeper 很经典的一个用法,简单来说,比如 A 系统发送个请求到 mq,然后 B 系统消息消费之后处理了。那 A 系统如何知道 B 系统的处理结果?用 zookeeper 就可以实现分布式系统之间的协调工作。A 系统发送请求之后可以在 zookeeper 上**对某个节点的值注册个监听器**,一旦 B 系统处理完了就修改 zookeeper 那个节点的值,A 系统立马就可以收到通知。
13 |
14 | 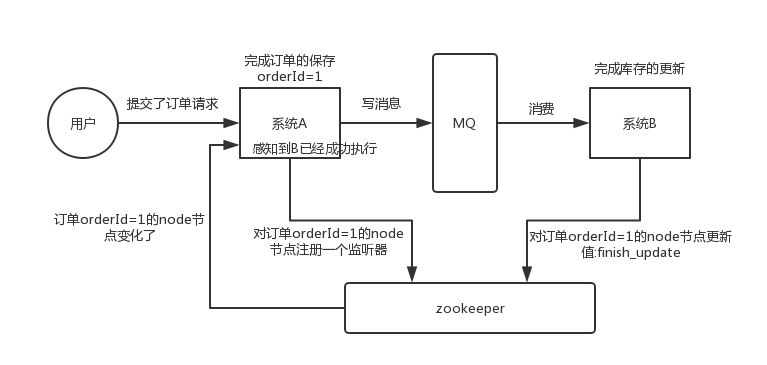
15 |
16 | ### 分布式锁
17 |
18 | 比如对某一个数据连续发出两个修改操作,两台机器同时收到了请求,但是只能一台机器先执行完另外一个机器再执行。那么此时就可以使用 zookeeper 分布式锁,一个机器接收到了请求之后先获取 zookeeper 上的一把分布式锁,就是可以去创建一个 znode,接着执行操作;然后另外一个机器也**尝试去创建**那个 znode,结果发现自己创建不了,因为被别人创建了,那只能等着,等第一个机器执行完了自己再执行。
19 |
20 | 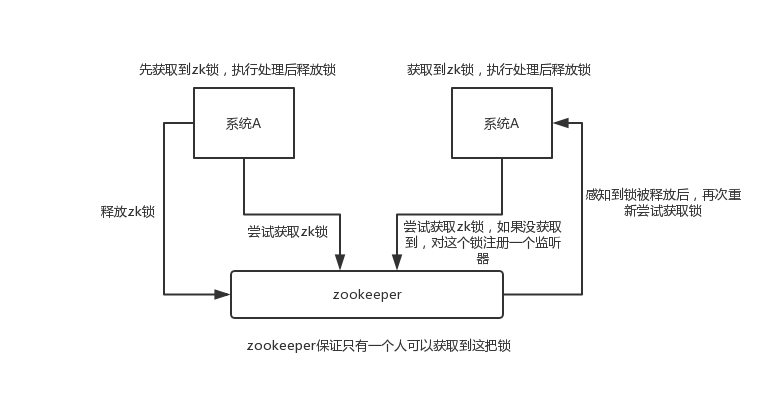
21 |
22 | ### 元数据/配置信息管理
23 |
24 | zookeeper 可以用作很多系统的配置信息的管理,比如 kafka、storm 等等很多分布式系统都会选用 zookeeper 来做一些元数据、配置信息的管理。
25 |
26 | 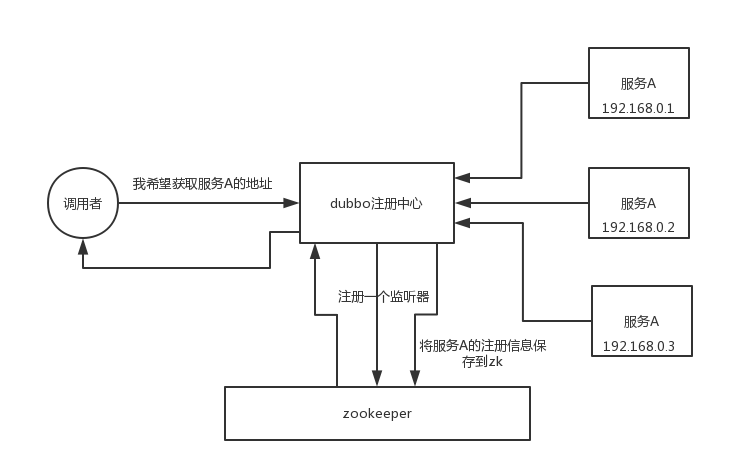
27 |
28 | ### HA 高可用性
29 |
30 | 这个应该是很常见的,比如 hadoop、hdfs、yarn 等很多大数据系统,都选择基于 zookeeper 来开发 HA 高可用机制,就是一个**重要进程一般会做主备**两个,主进程挂了立马通过 zookeeper 感知到切换到备用进程。
31 |
32 | 
33 |
34 |
35 |
36 | **参考资料**
37 |
38 | https://zhuanlan.zhihu.com/p/59669985
39 |
40 | https://doocs.github.io/
--------------------------------------------------------------------------------
/docs/zsxq/inner-material.md:
--------------------------------------------------------------------------------
1 | **JVM重要知识点&高频面试题**是我的**[知识星球](https://topjavaer.cn/zsxq/introduce.html)内部专属资料**,已经整理到Java面试手册完整版。除了Java面试手册完整版之外,星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
2 |
3 | 
4 |
5 | 
6 |
7 | 
8 |
9 | 
10 |
11 | 另外星球还提供**简历指导、修改服务**,大彬已经帮**90**+个小伙伴修改了简历,相对还是比较有经验的。
12 |
13 | 
14 |
15 | 
16 |
17 | **专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会优先解答球友的问题。
18 |
19 | 
20 |
21 | 
22 |
23 | [知识星球](https://topjavaer.cn/zsxq/introduce.html)**加入方式**:
24 |
25 | 
--------------------------------------------------------------------------------
/docs/zsxq/question/VO, BO, PO, DO, DTO.md:
--------------------------------------------------------------------------------
1 | 最近[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)有小伙伴提出了关于性格测试的疑问:
2 |
3 | **球友提问**:
4 |
5 | 大彬大佬,请教一个概念和具体应用上的问题, VO, BO, PO, DO, DTO 这些概念和具体应用是怎样的?
6 |
7 | ---
8 |
9 | **大彬的回答**:
10 |
11 | 你好,这个问题要结合实际业务来讲更好理解。
12 |
13 | 比如现在有一个用户登录的业务。 有一张表user存用户数据,这个表里面有 id ,name ,password。首先说说PO,PO比较好理解,就是数据库中的记录,一个PO的数据结构对应着表的结构,表中的一条记录就是一个PO对象。
14 |
15 | 再来看看什么是DO。比如现在需要实现登录功能,那就只需要检查用户输入的 name 和 password 和数据库是否一致就可以了。 这种情况下,就用一个 User 对象来表示这个领域模型就可以了。我一般用 Domain Object ,也就是 DO 表示,对应下来就是 UserDO ( 统一用 Do 也可以)
16 |
17 |
18 |
19 | 再假设现在有一个展示用户信息的业务,假想给一个客服(不期望把用户密码给他看到的那种情况)
20 |
21 | 一般来说有两种做法:
22 |
23 | 第一种,你可以在序列化为 json 字符串的时候,隐藏 password 的序列化来实现;
24 |
25 | 第二种,你可以新建一个 VO ( View Object )对象,就叫 UserVO ,然后这里面就只有 id 和 name 两个属性即可;
26 |
27 |
28 |
29 | 再假设,现在的场景不是直接展示到页面上,而是被一个业务系统调用,这个系统需要依赖登录的服务。 然后需要提供 sdk 给这个业务系统集成,那么这个时候就可以声明一个 DTO 对象,里面也只有 id 和 name 属性即可。
30 |
31 | 当然实际业务肯定不可能说只有 id ,name ,password 这么简单,这里只是举个例子方便理解。
--------------------------------------------------------------------------------
/docs/zsxq/question/familiarize-new-project-qucikly.md:
--------------------------------------------------------------------------------
1 | # 如何快速熟悉一个新项目
2 |
3 | 很多人刚进入一家新公司后,最头疼的就是如何快速了解公司的业务和项目架构。
4 |
5 | 一方面是文档很少或者没有文档, 只能自己硬着头皮摸索;另一方面大家都很忙,很少有人会帮你梳理业务逻辑。如果你碰到一个特别热心的老员工,随时在你身边答疑解惑,那你的运气实在是太好了, 现实是大家都很忙,没人给你讲解。
6 |
7 | 领导只给你几天时间熟悉,接着就要深入项目做开发了,怎么办呢?
8 |
9 | 接下来分享我总结的一些经验。
10 |
11 | ## 从页面到数据库
12 |
13 | 对某个具体项目的了解,一定要建立在对整体了解的基础上。首先可以给项目画出一条线,并标明每一个节点的信息,就像这样:页面访问路径--前端项目--后台服务--数据库地址(也可以通过流程图的形式)。
14 |
15 | 这个整理的过程,主要是让自己梳理清楚前端项目分别调用了哪些后台服务,通过后台服务和数据库的名称,我们能大致了解到这条业务线提供了什么功能,从前端项目和页面路径,我们能了解到我们需要给用户展示什么。
16 |
17 | 这个阶段不需要花费太多时间,重点就是仅仅是了解这条业务线的整体内容。
18 |
19 | ## 整理数据库表
20 |
21 | 上面都是整理项目的大体框架,还没有涉及到具体的项目细节。
22 |
23 | 一般业务项目无非就是对数据库的增删改查操作而已,或者从使用者的角度看,一个项目就是输入一些参数得到一些返回结果。
24 |
25 | 接下来要做的就是整理**数据库表**了。
26 |
27 | 这里首先要选择一个核心项目去看,众多项目中一定有一个是核心项目,先从核心项目开始看起。
28 |
29 | 如果数据库的表比较少,直接一个个看就行了。但如果数据库表特别多,那就需要先筛选出哪些是核心的表了。
30 |
31 | 如何判断哪些是核心表呢?最快的方式就是找老员工问一下,一般核心表不会很多。有些表可以先忽略不看,比如copy结(备份),rel结尾的(中间关联表),statistics结尾的(数据统计表),log结尾(日志表),config结尾(配置表),等等。
32 |
33 | 到此,你就对整体的数据库结构有所了解了。根据表名也能对表的大致内容有所了解,接下来就是针对具体的表,看里面具体的字段和前人给出的备注,**这个过程就没有技巧了,要耐心,要慢慢熬**。
34 |
35 | ## 深入代码层
36 |
37 | 当你对数据库表有了大体的了解后,你基本上对这个系统能提供什么服务了解到差不多了。接下来就是深入代码层理解业务逻辑了。
38 |
39 | 一般业务相关的项目代码分三个部分:
40 |
41 | 1. 通过前端交互(Controller层)对数据库进行增删改查操作
42 | 2. 通过定时任务对数据库进行增删改查操作
43 | 3. 调用或通知其他服务做一些事情
44 |
45 | 这三种类型的代码研究清楚后,对于一个业务型的项目来说,已经基本足够了。
46 |
47 | 另外,在研究具体业务代码的同时,要不断地跳出来回顾整条业务线的框架,修正之前由于不了解具体业务而出现的理解偏差。
48 |
49 | ## 从小需求开始,尝试编码
50 |
51 | 通过做需求,带着具体问题去看,踩的坑多了,解的bug多了,自然而然就会更熟悉这个项目了。
52 |
53 |
54 |
55 |
--------------------------------------------------------------------------------
/docs/zsxq/question/frontend-or-backend.md:
--------------------------------------------------------------------------------
1 | 昨天在大彬的[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)中,有小伙伴提了一个关于方向选择的问题,可能挺多人有这样的困惑,跟大家分享一下。
2 |
3 | **圈友提问**:
4 |
5 | 先介绍一下个人背景:
6 |
7 | 学历: **中流 985 硕**,偏门工科方向。
8 |
9 | 基础: 大一学过 C 语言后一直都有零碎地写一写代码,但是系统性地计算机学习不是很多。接触时间长一点点的应该是 C++,但学的不够系统。 从大一 C 语言课入手,后续写过 C++/Python,Python拿来给实验室写过小工具(类似上位机)。
10 |
11 | **转行**的想法也很简单,因为自己是一个偏冷门一点的工科方向,跟 EE 沾点边,但是根本喝不上芯片大热门的一口汤。去年师兄找工作 offer 基本上动态清零了,大一点的企业投完了就是石沉大海,小一点的公司才会给面试机会,否则只能去各种小研究所。师姐们更惨,一个拿了国奖的师姐投了一圈一个 offer 没有。
12 |
13 | 现在给自己定的目标是二线中小厂。我的问题是:**转码的话,选择前端还是后端更合适**?
14 |
15 |
16 | -----
17 |
18 | **大彬的回答**:
19 |
20 | 我说一下我对前端和后端的理解:
21 |
22 | 前端开发是创建Web页面或APP等前端界面呈现给用户的过程。除了传统的 Web 前端开发之外,目前 Android 开发、iOS 开发以及第三方开发(各大平台的小程序等)都逐渐并入到了前端开发团队。而且随着 Nodejs 的应用,目前前端开发后端化也是一个比较明显的趋势(大前端)。
23 | 对于非科班同学,前端的**入门难度**比后端低一些,对计算机基础(数据结构&算法)的要求没有那么高。能够通过系统的学习,在**较短的时间**内掌握基本技能。当然,说前端比后端入门难度低,并不是说前端的知识比后端少,相反,前端的领域知识可能比后端还多,**技术更新**也更快。
24 | 我的建议就是:如果你对审美和交互本身就感兴趣,想做出那种让别人看到的东西,比较追求用户体验的话,那么推荐你选择前端。
25 | 另外,从**就业**的角度来说,前端开发相比后端开发,应该会更好找工作一些。
26 |
27 | 后端开发,比较关注业务和技术融合一起的技术整合能力,比较要从业务处理生命周期来设计接口,选择合适的中间件,合理运用各种技术来应对性能,并发,数据各方面的问题。相对前端更多是**业务的技术理解和解决方案能力**。
28 | 后端开发对于程序员**计算机基础**有一定的要求,包括操作系统、算法设计、数据结构、数据库等,这些基础性的内容决定了后端程序员的开发能力和上升空间。所以,如果想在技术领域走得更远,可以重点考虑一下后端开发岗位。后端更加接近**业务**,对业务的理解更为深刻,相比前端来说,**晋升空间**更大一些。
29 |
30 | ----
31 |
32 | 最后,给大家送福利啦,限时发放10张[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)60元的优惠券,先到先得!目前[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)已经有**300**多位成员了,想加入的小伙伴不要错过这一波优惠活动,**扫描下方二维码**领取优惠券即可加入。
33 |
34 | 
--------------------------------------------------------------------------------
/docs/zsxq/question/how-to-learn.md:
--------------------------------------------------------------------------------
1 | **读者提问**
2 |
3 | 彬哥好,请问下平时学技术应该通过什么去学呢?看书还是看视频?网上那些培训课怎么样,值不值得买呢?
4 |
5 | **大彬回答**
6 |
7 | 你好!我觉得对大部分人来说,看视频学习的方式比看书学习的效果更好些,比较易于理解和学习。我建议是以视频为主、书籍为辅的方式进行学习。在看视频过程中有不懂的,可以看下相关的书籍。
8 |
9 | 对于视频资源,要选择一个比较完整的视频,可以到B站找几个播放量比较高的视频,对比下评论区和视频章节,选择一个比较适合自己的进行学习。
10 |
11 | (Java方向的学习路线可以参考星球的这个帖子:https://t.zsxq.com/0ehuyAx9m)
12 |
13 | 第三个问题,网上那些培训课怎么样,值不值得买呢?
14 |
15 | 基础课程的话,到B站找资源就行,免费资源太多了,没必要花钱买课。如果想进一步深入学习的话,可以看看极客时间的一些课程,相对其他培训机构的课程质量会高一些。另外在学习圈置顶帖(https://articles.zsxq.com/id_5x8zu2718ih5.html)有整理一些付费课程,可以看看是否满足你的需求,当然如果经济能力允许的话,还是建议支持下正版~
--------------------------------------------------------------------------------
/docs/zsxq/question/java-or-bigdata.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 24届校招,Java开发和大数据开发怎么选
4 | category: 分享
5 | tag:
6 | - 星球
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 职业规划,岗位选择,Java还是大数据
11 | - - meta
12 | - name: description
13 | content: 星球问题摘录
14 | ---
15 |
16 | ## 24届校招,Java开发和大数据开发怎么选
17 |
18 | 最近在大彬的[学习圈](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247492252&idx=1&sn=8fc12e97763e3b994b0dd0e717a4b674&chksm=ce9b1fdaf9ec96cca6c03cb6e7b61156d3226dbb587f81cea27b71be6671b81b537c9b7e9b2d#rd)中,有小伙伴提了一个关于方向选择的问题:**24届校招,Java开发和大数据开发怎么选**?
19 |
20 | **原问题如下**:
21 |
22 | 想请教一下大彬,对于**java开发和大数据开发**的明年秋招情况的预测。java岗位多卷度也高,每家公司基本都有相关的职位,大数据开发的话培训班比岗位多,只有大公司和数据公司会有这类岗位。24年秋招的话**选择哪个方向**会比较合适呢?
23 |
24 | ---
25 |
26 | **大彬的回答**:
27 |
28 | 建议选大数据吧。就这几年校招来看,大数据岗位拿offer的**难度**相比Java还是比较小一些的。而且距离24年秋招还有一年多时间,转大数据完全来得及,而且有了Java基础,再来学大数据,应该会比较快入门。
29 |
30 | 再说下大数据和后端的**差异**。大数据门槛比Java高,除了熟悉数据库的操作之外,还要学习大数据整个生态,需要会分布式、数仓、数据分析统计等知识。因为大数据的学习门槛比 Java 高,所以市场上培训大数据的相比Java会少一些,**竞争也相对小**,没有Java那么卷。
31 |
32 | 另外,大数据**薪资**总体会比Java开发高一些(同一家公司同一级别,普通开发岗比大数据开发薪资会少一点),这也是大数据方向的一个优势。
33 |
34 | 不过呢,小点的公司,可能没有大数据的需求,毕竟业务量不大(小公司通常也不建议去,坑多)。
35 |
36 | 综上所述,还是建议你选择**大数据**方向。
37 |
38 |
39 |
40 | ---
41 |
42 | 最后,推荐大家加入我的[学习圈](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247492252&idx=1&sn=8fc12e97763e3b994b0dd0e717a4b674&chksm=ce9b1fdaf9ec96cca6c03cb6e7b61156d3226dbb587f81cea27b71be6671b81b537c9b7e9b2d&scene=21#wechat_redirect),目前已经有140多位小伙伴加入了,文末有50元的**优惠券**,**扫描文末二维码**领取优惠券加入。
43 |
44 | 学习圈提供以下这些**服务**:
45 |
46 | 1、学习圈内部**知识图谱**,汇总了**优质资源、面试高频问题、大厂面经、踩坑分享**,让你少走一些弯路
47 |
48 | 2、四个**优质专栏**、Java**面试手册完整版**(包含场景设计、系统设计、分布式、微服务等),持续更新
49 |
50 | 3、**一对一答疑**,我会尽自己最大努力为你答疑解惑
51 |
52 | 4、**免费的简历修改、面试指导服务**,绝对赚回门票
53 |
54 | 5、各个阶段的优质**学习资源**(新手小白到架构师),超值
55 |
56 | 6、打卡学习,**大学自习室的氛围**,一起蜕变成长
57 |
58 |
59 |
60 | **加入方式**:**扫描二维码**领取优惠券加入(**即将恢复原价**)~
61 |
62 | 
63 |
--------------------------------------------------------------------------------
/docs/zsxq/question/personality-test.md:
--------------------------------------------------------------------------------
1 | ## 想进大厂的年轻人,有多少败在了性格测试?
2 |
3 | 在互联网公司招聘技术岗位人才时,除了技术能力的考察,越来越多的公司开始注重应聘者的个人**性格测试**。这一趋势源自于互联网公司对员工全面发展和协同工作的需求,只有具有不同特点和性格的人才一起协作,才能产生更多的创新点和独特的想法。
4 |
5 | 互联网公司所进行的技术岗位性格测试大都是基于心理学理论和经验,以分析应聘者的人格、态度、价值观等方面的特点,评估其是否适合公司的团队文化和价值观,并为公司提供精准的人才匹配。
6 |
7 | 最近[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)有小伙伴提出了关于性格测试的疑问:
8 |
9 | **提问原文**:
10 |
11 | 大彬哥,问下性格测评,给了三个选项都是好的品质(比如具有领导力,能够洞察事物本质,做事情很有计划条理),选一个**最符合**的,一个**最不符合**的,这种题要怎么选啊,不明白目的是想选拔什么样的人才呢?
12 |
13 | 还有一种题,如果自己手头有比较繁重的任务,领导因为项目赶工期又派来了新任务,这种情况选择提前说明情况延期保证工作质量,还是选择接受任务努力把两个项目都干好呢?
14 |
15 | **听说性格测评真的会挂人**,所以比较慌。
16 |
17 | ---
18 |
19 | **大彬的回答**:
20 |
21 | 1. 首先性格没有**好坏之分**,内向外向也并不完全是考察的重点,不同的公司会有不同的标准。
22 | 2. 关于性格测试怎么做的问题,其实没有一个确定的方法,我觉得最关键的是根据自己**真实情况**来作答。在性格测试中,对于同一个维度的考察会出现内容不同、位置不相连的多道题目,如果在测试结果中出现了很多矛盾的回答,系统可能会判定测试者是在**作弊**。比如华为、滴滴的性格测试题就是这样的。
23 | 3. 你说的那两道题也没有对错之分,按照你自身情况作答即可,**保持前后回答一致**。
24 | 4. 另外也不建议**刻意去迎合**应聘公司的文化价值观,伪装往往可能会适得其反,很容易前后回答不一致导致测试不通过。
25 | 5. 如果涉及一些**原则性**的问题,比如是否一遇到困难就退缩,团队协作能力怎么样,这种还是要往正面的方向回答,没有公司会招一个团队协作能力差、遇到困难就退缩的员工。
26 |
27 | 当然,性格测试不仅是企业了解应聘者的方式,也是应聘者**了解自己**的方式。通过性格测试可以帮助应聘者全面认识自己的优点和缺陷,发现自己的潜力和不足,进而定位自己的特长和优势。所以应聘者在完成性格测试之后,可以进行**自我分析**,了解自己,精准面向优势和弱点,为自己的职业规划建立更好的基础。
28 |
29 | 更多信息可以查看原文(在**星球精华帖**):https://t.zsxq.com/0eJD15817
30 |
31 | 
32 |
33 | ---
34 |
35 | [星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)置顶帖汇总了所有球友的**提问**,内容包括**职业规划、技术问题、面试问题、岗位选择、学习路线**等等,现在很多现在困扰你的问题,在这里都能找到**答案**。
36 |
37 | 
38 |
39 | 
40 |
41 | 加入的同学一定要看看[星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)的置顶内容,相信对你会有帮助的!
42 |
43 | > 点击【阅读原文】直达星球!
--------------------------------------------------------------------------------
/docs/zsxq/question/qa-or-java.md:
--------------------------------------------------------------------------------
1 | 大彬老师您好
2 |
3 | 我是参加今年24届秋招的研二学生,本科就读于某211信息安全专业,硕士就读于中国科学院大学 网络空间安全专业,最近开始了秋招,但是在职业规划上十分迷茫,想听听您的建议。
4 |
5 | 我得求职期望是,在北京找一个高薪的岗位,工作几年后回家乡,找一个国企躺平。
6 |
7 | 目前我已经排除了算法岗,虽然已经发表了两篇论文,但是研究方向小众,不足以支撑我找到一个算法岗的工作。所以我在以下几个岗位中有所纠结:
8 |
9 | 1. java开发岗:为了准备开发岗,我跟着教程自己做了一个项目,整体的感受是工程能力很薄弱,并且只有一个学习项目,没有真正的工程项目。
10 | 2. 安全岗位:虽然我本硕都是安全专业,但是研究方向都比较小众,目前互联网需要的安全人才都是攻防方向的,我的竞争力不够。
11 | 3. 测试开发岗:这是我比较有把握的一个求职方向,因为之前有过一段在字节的测开实习经历,加上一直准备java开发,很多八股都是通用的。但是我比较担心测开岗位会不会不太好跳槽到国企,对未来比较担忧。
12 |
13 | 所以我目前采取的策略是:大厂投测开、中小厂投开发、国企/银行投安全
14 |
15 | 这令我十分地疲惫。很羞愧,已经7月份了,我竟让自己陷入了如此被动的局面,加上这两年互联网寒冬,我对秋招很担心。实际上我从很早之前就在准备找工作了,科研之余每天刷题、学java基础、学框架、写项目,但是时至今日我还是不够,始终比不上那些硕士阶段一直在参加工程的同学。
16 |
17 | 以上是我的基本情况
18 | - 想听听老师对我的现状有没有什么建议
19 | - 您是否了解测试开发岗位的发展前景,它的薪资和开发是差不多的嘛?
20 | - 测开有没有可能从互联网顺利转国企
21 | - 现阶段我是继续补充java基础卷java岗,还是把重点放在测开上呢?
22 |
23 | 原谅我现在处于焦虑状态因此问题比较多,图片是我的简历方便老师了解我的基本情况,期待老师回复🍓
24 | 谢谢老师~
25 |
26 | 1、建议投测开,你这个简历在测开岗里面算是比较好的,相反在Java开发岗中算是比较一般的,没有很大的竞争力。有了字节的测开实习,在测开岗里面应该领先一大波人了。
27 | 2、测开发展前景个人觉得也是不错的,随着互联网行业的发展,用户对产品的质量要求也越来越高,软件的性能测试、需求测试等方面的需求目前看是只增不减的。薪资方面,同职级测开跟开发基本持平。
28 | 3、测开有没有可能从互联网顺利转国企?完全可以,没问题
29 | 4、把重点放在测开,不建议同时准备两个岗位,可能顾此失彼
--------------------------------------------------------------------------------
/docs/zsxq/question/tech/service-expansion.md:
--------------------------------------------------------------------------------
1 | ## 怎么做到增加机器能线性增加性能的?
2 |
3 | 线性扩容有两种情况,一种是“无状态”服务,比如常见的 web 后端;另一种是“有状态服务”,比如 MySQL 数据库。
4 |
5 | 对于无状态服务,只要解决了服务发现功能,在服务启动之后能够把请求量引到新服务上,就可以做到线性扩容。常见的服务发现有 DNS 调度(通过域名解析到不同机器)、负载均衡调度(通过反向代理服务转发到不同机器)或者动态服务发现(比如 dubbo ),等等。
6 |
7 | 对于有状态服务,除了要解决服务发现问题之外,还要解决状态(数据)迁移问题,迁移又分两步:先是数据拆分,常见的用哈希把数据打散。然后是迁移,常见的办法有快照和日志两类迁移方式。也有一些数据库直接实现了开发无感知的状态迁移功能,比如 hbase。
--------------------------------------------------------------------------------
/docs/zsxq/question/三年测开转后端.md:
--------------------------------------------------------------------------------
1 | 大彬,您好!
2 |
3 | 首先介绍下基本情况:211本科,信息工程专业。
4 |
5 | 本人毕业快三年,第一年做了一些功能测试之类的活,后来,岗位调动去做低代码平台的开发,拖拉拽的那种,主要是写SQL,所以自学了MySQL,所以数据库这块看看面试题应该差不了太多。
6 |
7 | 从22年开始转Java后端,边工作边学习,看的都是B站黑马程序员的课程,目前已经学完了Javase,Javaweb,Spring,SSM,Springboot,Git,Maven等,也算比较系统的学了一遍。
8 |
9 | Javase课程基本是跟着用手敲了一遍,后面的视频就只认真看了一遍来赶进度。
10 |
11 | 大学里课程选修了linux操作系统,算法与数据结构,计算机网络,不过也快忘得差不多了,除了记得一些linux常用命令,因为驻场有用到。
12 |
13 | 目前主要是在学redis和mq等中间件,八股文也在准备,但是算法没有刷过题。
14 |
15 | 公司客户主要是一些金融机构,因为积累了差不多两年的业务经验,所以本人也初步打算继续往金融科技这块发展(不一定,哪钱多去哪)。
16 |
17 | 后面打算跳槽甲方,但是目前除了相关技术学了一轮,还没有做过后端开发的项目。
18 |
19 | 请问:
20 |
21 | 1、现在这个状态找测开怎么样,有什么需要重点准备的吗。虽然本人更想做开发。
22 |
23 | 2、现在提离职,估计要过一阵放我走。现在边工作边找,但是工作完没有太多时间学习,并且没有java项目开发的经历,应该只能投测开,长远看,本人更想做后端开发,还得准备刷下算法,背背八股。
24 |
25 | 因为我现在到手也就1w出头,所以如果三月底离职了还没找到理想的开发或测开工作,我是想直接找个比如黑马的瑞吉外卖项目,把已学的融汇贯通,认真做个把月冲击后端咋样?
26 |
27 | 3、继续骑驴找马,直到找到才提离职。但是这样准备项目的时间不太够,做完一个项目估计起码四五月份,还不说背其它的八股和算法。
28 |
29 | 目前继续做这份工作我也没有太多成长,温水煮青蛙。
30 |
31 | 4、如何面试包装下涨薪最快呢,想尽可能的提升下月base,目标是2w+,但是又好像有不超过30%的限制?问上家月薪的时候可以虚报吗,或者怎么说?
32 |
33 | 5、金融行业不少公司比较看重学历,请问咱做技术的,是否有必要花一年时间读个海外硕投资自己呢?
34 |
35 |
36 |
37 | ------
38 |
39 | 大彬的回答:
40 |
41 | 1、 遵从你的内心。如果确实想做开发,先按照开发的方向去努力吧,尽量投开发。后面又去做测开,可能你会有不甘心。当然3年经验转方向,可能会
42 |
43 | 2、已经提离职的话,工作上的内容 就推就推,马上就要走人了,身上就别挂那么多活了,特别是那种紧急上线,什么三月份之前上线,就是趁你走之前 赶紧开发完的那种, 都推一推,多给自己争取点自学的时间。
44 |
45 | 自己做一个项目是可以的,好好冲后端。
46 |
47 | 3、建议是尽量一边工作一边准备,如果时间确实挤不开,可以提离职,也是背水一战了。
48 |
49 | 4、入职的时候 上家公司的月薪 是要 银行流水截图发个hr的,不过有的人 是把 银行流水给p图了,改的薪资。
50 |
51 | 这么干只能说 有风险(可能被hr发现,终止offer),但确实不少人这么干的,然后也顺利入职了。
52 |
53 | 要不要这么搞 还需要你自己权衡一下。
54 |
55 | 你是 测试 转开发,double还是有难度。如果你面试表现足够好的话,要个double 也是有希望的,这个薪资 基本要去 北上深 这样的城市了。
56 |
57 | 5、自己攒够钱去 读个 香港 一年制 是可以的,提升一下自己,重新校招,学校认可度在大陆整体也还行,入学门槛相对足够低了。
58 |
59 | 不过花费不少,可能要50w起步, 这不是小数目,估计可以在老家买套不错的房子了。
60 |
61 | 不过如果你已经跳槽到一家不错的企业的话,我倾向于好好赚钱就好,毕竟 海外一年制学费不低,还要耽误 一年多的赚钱时间,后面能不能把这个钱赚回来,不太确定。
--------------------------------------------------------------------------------
/docs/zsxq/question/二本学历,想出国读研.md:
--------------------------------------------------------------------------------
1 | 大家好,我是大彬~
2 |
3 | 今天跟大家分享[知识星球](https://mp.weixin.qq.com/s/yzy-40-xeEOY34qrdIXJ4Q)小伙伴关于【**出国读研**】的提问。
4 |
5 | > 往期星球[提问](https://mp.weixin.qq.com/s/yzy-40-xeEOY34qrdIXJ4Q)整理:
6 | >
7 | > [非科班,如何补基础?](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247495380&idx=1&sn=b0555daa04aed83ea848d4b0b188dc18&chksm=ce9b1392f9ec9a84244572822a67c98fc7ac9d9f12124f779d7f98acf889f53c3db9f86c26b0#rd)
8 | >
9 | > [读博还是找工作?](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247495184&idx=1&sn=f22989dda1d725583f516d07682fc9bf&chksm=ce9b1356f9ec9a4061b70f38f6b76a5af4f079f93bed8269ee744f27f2f3cac6f7ecf98325a0&token=1194034453&lang=zh_CN#rd)
10 | >
11 | > [性格测试真的很重要](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247494301&idx=1&sn=89c095a1feb8f29a0e87c4b7835280fc&chksm=ce9b17dbf9ec9ecde1720b74e83b4c862a31d60139662592ba8967cf291f4244e9b9bf9738e9&token=1194034453&lang=zh_CN#rd)
12 | >
13 | > [想找一份实习工作,需要准备什么](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247495304&idx=1&sn=54163de5ee4da27373048dea6f41344a&chksm=ce9b13cef9ec9ad8b28635cfd2d22c723ae0731babbadb9456a35464a747d19fc6e20bebe448#rd)
14 |
15 | **球友提问**:
16 |
17 | 彬哥,有个问题咨询你
18 |
19 | 基本情况: 25岁,**二本非科班**程序员,在上海,最近想**出国读研**
20 |
21 | 本科读的工商管理,还挂过科,辅修了计算机,现在工资税前 17k 吧,感觉到瓶颈期了,想出去见见世面,回来有个应届生的 buff ,**冲冲大厂**。
22 |
23 | 不知道这个决定是否可靠?有没有建议?
24 |
25 | ---
26 |
27 | **大彬的回答**:
28 |
29 | 你好。按照目前互联网的行情,我**不建议**你这样做。
30 |
31 | 除非你出国是为了**留在国外**,国外文凭拿到国内**认可度**不见得比国内的高,或者你能够得上那种国内都认识的,不然 HR 最多参考一下 QS 排名,不然不认识的可能就被当成野鸡大学了。
32 |
33 | 还有一种为了拿**上海户口**,海归有优惠政策,可以去读个水硕回来就业落户
34 |
35 | 留学回来冲大厂最好就不要想了,**只有留学背景是不够的**,就现在应届生很多很多,如果你**本科学历和专业技能**都不够硬,现在再投校招岗位弄不好连简历筛选都过不去,连面试的机会都没有,而且出国读研是没法随时回来实习的,一些企业要求学生**实习**,如果你无法提前到岗位进行实习,可能直接被淘汰。对留学生而言在这方面没有任何优势。
36 |
37 | 唯一优势就是你留学后提升了你的**英语水平**,回来可以冲一些外企,英语好特别是口语好是有一定优势。
38 |
39 | 结论:如果出国留学是为了回国发展,你需要了解国内对于外国文凭的**认可度**问题,同时还要注重本科学历和专业技能的提高。出国留学的经历可以帮助你提升英语水平,学习不同的文化和思维方式,但并不一定就能为你在就业市场上带来直接的**竞争力**的。
40 |
41 |
--------------------------------------------------------------------------------
/docs/zsxq/question/怎样准备才能找到一份实习工作?.md:
--------------------------------------------------------------------------------
1 | 大家好,我是大彬~
2 |
3 | 今天跟大家分享[知识星球](https://mp.weixin.qq.com/s/yzy-40-xeEOY34qrdIXJ4Q)小伙伴关于【如何找实习工作】的提问。
4 |
5 |
6 |
7 | **球友提问**:
8 |
9 | 目前状况:学校是**双非一本**,目前阶段是大三上开始,9月份中旬提问。 然后希望能在十月,十一月份的时候**找一份寒假时期实习或者日常实习**,希望能够为简历添加一份实习经历,也为了熟悉面试流程,为明年秋招做好准备。
10 |
11 | 提问目的:大彬哥你好,麻烦大彬哥帮我看看,我目前的**个人总结**,麻烦你针对性的给出目前我和实习的差距,因为时间就这一两个月,想知道具体准备哪些部分才能找到一份实习。问题很多,麻烦大彬哥了!
12 |
13 | 然后这里看图片。
14 |
15 | 
16 |
17 | 最后提问
18 |
19 | 1. 麻烦大彬哥根据以上,针对性的给出我目前和寒假日常实习的**差距**,目标是通过面试,因为时间就这一两个月,想知道具体**重点准备**哪些部分才能找到一份实习。
20 | 2. 如果有机会还是希望能去大厂实习,是否差距是太大了?
21 | 3. 因为没有突出优势,基础部分没有系统学习如计网,操作系统,**只背面试题**够用吗。
22 | 4. 项目部分还要学习spring boot和redis和spring cloud 这些是必要的吗,学完这些做项目会不会太慢了。如果和大厂太遥远,目标放在小厂的话哪些知识点是重点,哪些是可以先放放的。
23 |
24 | ---
25 |
26 | **大彬的回答**:
27 |
28 | 学弟你好。
29 |
30 | 1. 按照你目前的情况,想要一份实习工作,之前需要补充学习这些内容:Redis,SpringBoot,微服务,消息队列,Nginx,至少一个项目。如果时间比较紧的话,建议刚开始学**先掌握基本的api用法**,等到后面有时间再去深入学习、看源码。
31 | 2. 关于项目,很多同学刚开始时,总想自己从零开始敲代码,或者以从零开始搭建一个项目为学习目标。其实刚开始学的时候,会遇到很多坑,比如一个分号一个单词拼错都可能会导致卡进展,从而影响到学习效率和学习积极性。正确的做法是,先运行跑通现有代码,运行时通过结果理解关键性语法和技能点,然后再尝试修改人家的代码看结果,这样就能达到边学边进步的效果。
32 | 3. 做什么项目呢?可以参考星球**置顶帖**分享的一些优质项目(https://t.zsxq.com/12mxN9kMJ)
33 |
34 | 2. 想进大厂的话,力扣算法之前刷300道左右,**计算机基础要扎实**,计算机网络、操作系统这些单靠背面试题是不够的,需要花时间去看看书,系统学习一下。
35 |
36 | 3. SpringBoot、Redis、Springcloud这些有必要学吗?如第一点所说的,肯定要学的,这些都是Java开发必备的知识了,其实学习简单使用还是挺快的,原理那些可以后面有时间在捡起来
37 |
38 | 4. **建议你先冲一下中小厂**,后面还有暑期实习和秋招,进大厂还是有机会的。优先把上面提到的那些知识点先学了,找个项目做做,然后准备下面试题和力扣(中小厂力扣前200就够了)
39 | 5. 一定别只学技术,也要去“背“面试题。建议把[**星球**](https://mp.weixin.qq.com/s/yzy-40-xeEOY34qrdIXJ4Q)的**面试手册**(在**星球置顶帖**:**https://t.zsxq.com/12mxN9kMJ**)过一遍,基本包括绝大部分常考面试题了。实习岗位不可能因为你技术到位自己跑过来,而是要你通过面试证明你的能力才能争取到,所以掌握面试技巧也很重要。面试前先找小公司练练手,亲历面试,并在面试中进一步学习面试技巧、查漏补缺。
--------------------------------------------------------------------------------
/docs/zsxq/question/读博还是找工作.md:
--------------------------------------------------------------------------------
1 | 前段时间[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)有小伙伴提出了关于读博还是找工作的疑问,跟大家分享一下:
2 |
3 | **学弟提问**:
4 |
5 | 大彬老师好,我是参加今年24届秋招的**研二**学生,本科是川大数学专业,硕士在xxx研究所读研,计算机应用技术专业。在所里主要是研究无人机的路径规划和强化学习。
6 |
7 | 所里因为不给出去实习,所以我也**没有实习项目**,所里给的福利也就是最后可以留所在央企研究所工作,但是我不太想留,所以想出去找工作。自己有2篇无人机相关的论文,但是以后也不想去做无人机相关。只想做纯计算机相关的工作。后面就想转java,可以说除了高中的竞赛基础,完全没有别的基础,java就跟着机构的视频在学。但是感觉学的太慢了,从4月才开始算0基础学,秋招感觉是完全赶不上了,学了2个月去看看面经发现基本都答不上。所以很迷茫到底是继续java开发往后学下去,反正最后有个保底。还是不去找工作了,凭着2篇论文去找个博士读,博士毕业再出去找企业。希望能给个建议,谢谢!
8 |
9 | ---
10 |
11 | **大彬的回答**:
12 |
13 | 你好,你现在研二了,过了两年的研究生生活,如果你适应这种探索性研究生活、**对科研有热情、有想法**想要去**探索**一些问题,而且没有太大生活压力,家里不需要你的经济支持,那建议你去申请读博。读完博士你的选择会更多更多。
14 |
15 | 如果你是处于**懵懂**状态,感觉硕士毕业找不到好工作就去读博,也没有科研热情,就这样盲目进行的话,这样只是**浪费时间**走一些弯路,之后也可能会后悔,建议你还是直接去找工作。因为读博也是有很大的挑战性的,需要克服焦虑和长时间的孤独,可能比你想象中的要困难一些。
16 |
17 | 另外如果想要找Java开发方向岗位的话,目前你的进度确实稍微慢了一些,秋招马上就要开始了,建议你抓重点去学,参考[星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)置顶帖的最新Java学习路线,加快学习节奏。
18 |
19 |
20 |
21 |
22 |
23 |
--------------------------------------------------------------------------------
/docs/zsxq/share/oom.md:
--------------------------------------------------------------------------------
1 | 记录一次内存泄露排查的过程。
2 |
3 | 最近经常告警有空指针异常报出,于是找到运维查日志定位到具体是哪一行代码抛出的空指针异常,发现是在解析cookie的一个方法内,调用`HttpServletRequest.getServerName()`获取不到抛出的NPE,这个获取服务名获取不到,平时都没有出现过的问题,最近也没有发版,那初步怀疑应该前端或者传输过程有问题导致获取不到参数。
4 |
5 | 后续找了运维查了ng的日志,确实存在状态码为**499**的错误码,查了一下这个是**客户端主动关闭请求或者客户端网络断掉时**报的错误码,那也就是前端断开了请求。
6 |
7 | 继续排查为啥前端会中断请求的原因,问了前端同学说是超时时间设置了10秒,又看了日志,确实是有处理时间超过10秒的,那问题大概定位到了。
8 |
9 | 接下来就是分析处理时长为什么会那么长,看了报错的时候请求量并没有很大,后续让运维查了机器有几台cpu用量处于30%左右,明显高于另外几台3%,而且499错误的集中在cpu用量高的几台,怀疑是否是内存问题导致,让运维跑了`jstat -gcutil`看了一下,确实存在full GC问题,又跑了`jmap -dump`下了dump文件,定位到是ip限流的方法,有一个清除Map的方法在多线程并发情况下没有生效,导致内存泄露。
10 |
11 | 知道问题后反推感觉就一切的疑问有了结果,ng报499是前置超时,超时是服务频繁full gc导致stw,无法处理请求导致耗时增加,ng探活接口在机器stw期间无法响应产生了error.log,而有几台机器cpu不高是因为之前重启过所以释放掉了内存没有触发full gc。
12 |
13 | 后续处理是改进了ip限流的方法,测试环境复现问题和改动限流方法,通过guaua的LoadingCache监听器的方式过期自动处理,这次问题嵌套问题比较多,由于上报量低,ng侧报了499没有纳入监控范围,而且机器由于重启没有快速发现问题,后续改进是代码侧能复用规范代码最好复用,不要重复造轮子。
--------------------------------------------------------------------------------
/docs/zsxq/share/由“ YYYY-MM-dd ”引发的bug.md:
--------------------------------------------------------------------------------
1 | # 由“ YYYY-MM-dd ”引发的bug
2 |
3 | 跟大家分享网上看到的一篇文章。
4 |
5 | ## 前言
6 |
7 | 在使用一些 App 的时候,竟然被我发现了一个应该是由于前端粗心而导致的 bug,在 2019.12.30 出发,结果 App 上显示的是 2020.12.30(吓得我以为我的订单下错了,此处是不是该把程序员拉去祭天了)。
8 |
9 | 鉴于可能会有程序员因此而被拉去祭天,而我以前学 Java 的时候就有留意过这个问题,所以我还是把这个问题拿出来说一下,希望能尽量避免这方面的粗心大意(毕竟这种问题也很难测出来)。
10 |
11 | ## 正文
12 |
13 | ```java
14 | public class DateTest {
15 | public static void main(String[] args) {
16 | Calendar calendar = Calendar.getInstance();
17 | calendar.set(2019, Calendar.AUGUST, 31);
18 | Date strDate = calendar.getTime();
19 | DateFormat formatUpperCase = new SimpleDateFormat("yyyy-MM-dd");
20 | System.out.println("2019-08-31 to yyyy-MM-dd: " + formatUpperCase.format(strDate));
21 | formatUpperCase = new SimpleDateFormat("YYYY-MM-dd");
22 | System.out.println("2019-08-31 to YYYY/MM/dd: " + formatUpperCase.format(strDate));
23 | }
24 | }
25 | ```
26 |
27 | 我们来看下运行结果:
28 |
29 | ```
30 | 2019-08-31 to yyyy-MM-dd: 2019-08-31
31 | 2019-08-31 to YYYY/MM/dd: 2019-08-31
32 | ```
33 |
34 | 如果我们日期改成 12.31:
35 |
36 | ```
37 | 2019-12-31 to yyyy-MM-dd: 2019-12-31
38 | 2019-12-31 to YYYY-MM-dd: 2020-12-31
39 | ```
40 |
41 | 问题就出现了是吧,虽然是一个小小的细节,但是用户看了也会一脸懵,但是我们作为开发者,不能懵啊,赶紧文档查起来:
42 |
43 | 
44 |
45 | y:year-of-era;正正经经的年,即元旦过后;
46 |
47 | Y:week-based-year;只要本周跨年,那么这周就算入下一年;就比如说今年(2019-2020) 12.31 这一周是跨年的一周,而 12.31 是周二,那使用 YYYY 的话会显示 2020,使用 yyyy 则会从 1.1 才开始算是 2020。
48 |
49 | 这虽然是个很小的知识点,但是也有很多人栽到坑里,在此记录一下~
--------------------------------------------------------------------------------
/docs/zsxq/springboot-inner-material.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tyson0314/Java-learning/9690a43241c7d21a77faa0928a27499d46d47c6d/docs/zsxq/springboot-inner-material.md
--------------------------------------------------------------------------------
/docs/zsxq/这可能是最全民的面试题库了.md:
--------------------------------------------------------------------------------
1 | 大家好,我是大彬。
2 |
3 | 最近是面试高峰期,有挺多读者来咨询我有没有一些**大厂的面试题目**,想在面试前重点复习一下,“抱佛腿”~
4 |
5 | 
6 |
7 | 
8 |
9 | 刚好我这几天有空,整理了近**300**家公司的面试题目,按照**社招、校招、实习**分类。
10 |
11 | 
12 |
13 | **社招面经**部分截图:
14 |
15 | 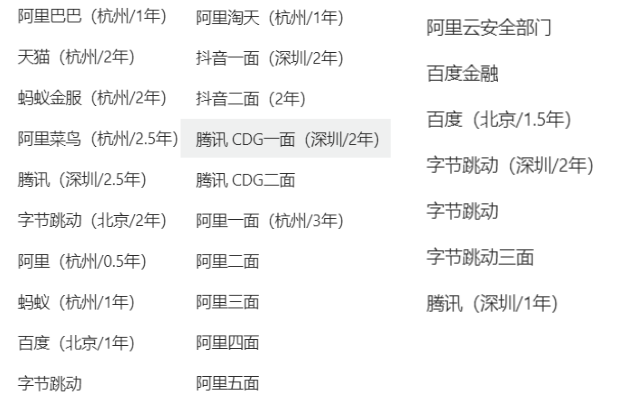
16 |
17 | 
18 |
19 | 
20 |
21 | 
22 |
23 | 
24 |
25 | **校招、实习面经**部分截图:
26 |
27 | 
28 |
29 | 
30 |
31 | 面试题目**获取方式**:添加我微信 dabinjava 或者 i_am_dabin,**备注**【**面试题目**】。PS:有偿,白嫖勿扰(花了挺多时间整理的,希望可以理解)
32 |
33 | 
34 |
35 |
--------------------------------------------------------------------------------
/docs/zsxq/面试真题共享群.md:
--------------------------------------------------------------------------------
1 | 为方便大家交流,大彬新建了**面试真题共享群,**群里可以讨论面试问题、发布内推信息,群成员可以共享各大公司的面试真题,同时可以**永久**查看大彬整理的**面试真题VIP**手册(目前整理了超过**300**家公司的面试题目)。
2 |
3 | 群友**评价**:
4 |
5 | 
6 |
7 | 
8 |
9 | 
10 |
11 | 面试真题分享群截图:
12 |
13 | 
14 |
15 | 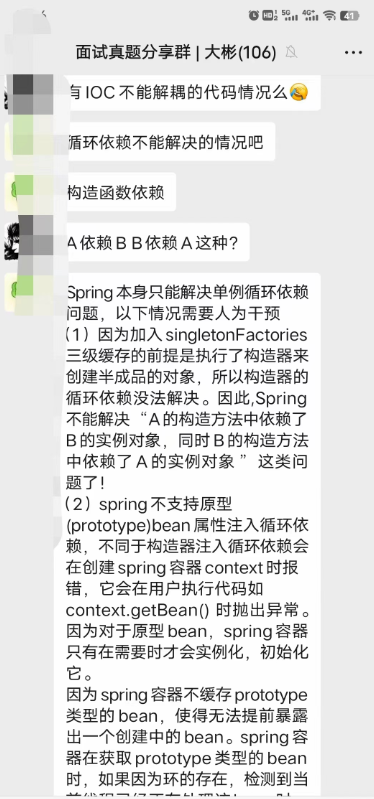
16 |
17 | 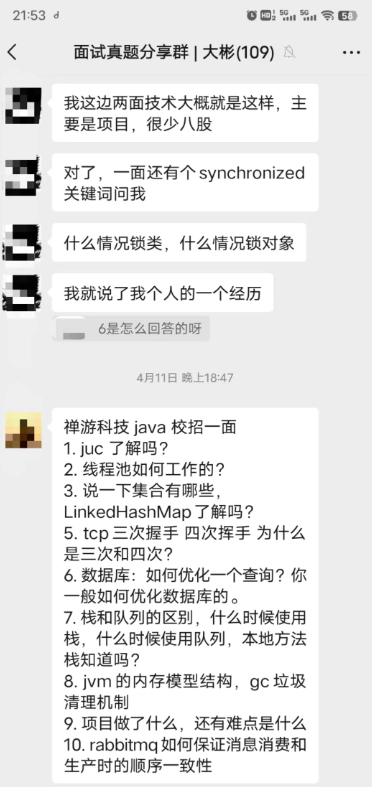
18 |
19 | 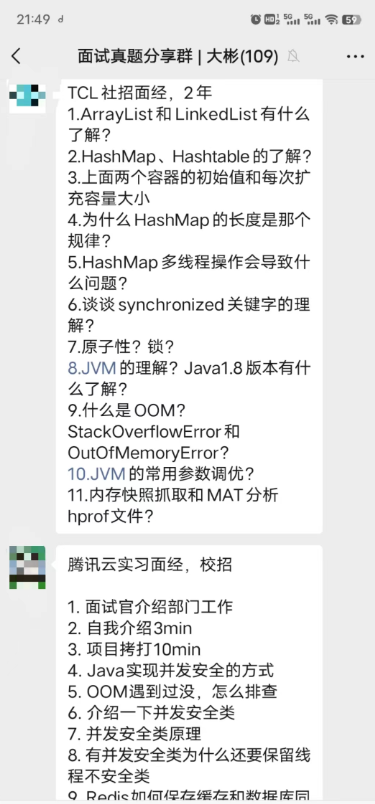
20 |
21 | 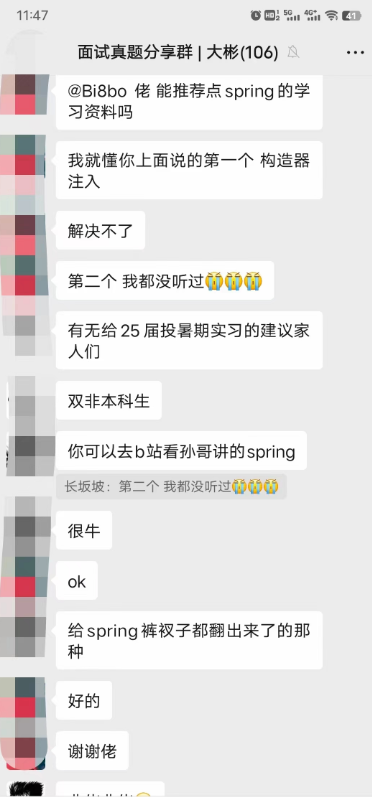
22 |
23 | 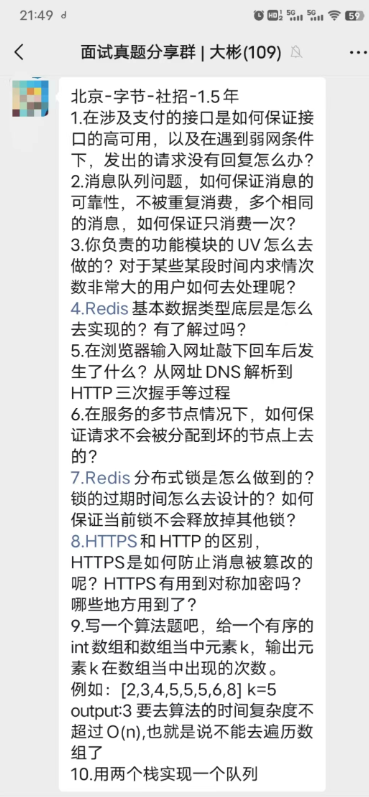
24 |
25 | 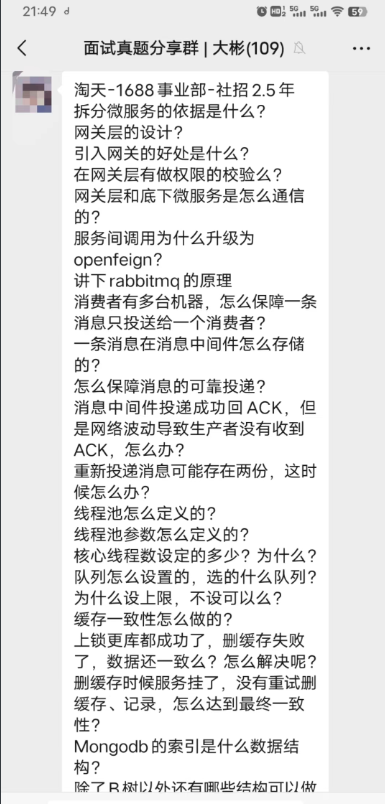
26 |
27 | 
28 |
29 |
30 |
31 | **面试真题VIP**手册截图:
32 |
33 | 
34 |
35 | **社招面经**部分截图:
36 |
37 | 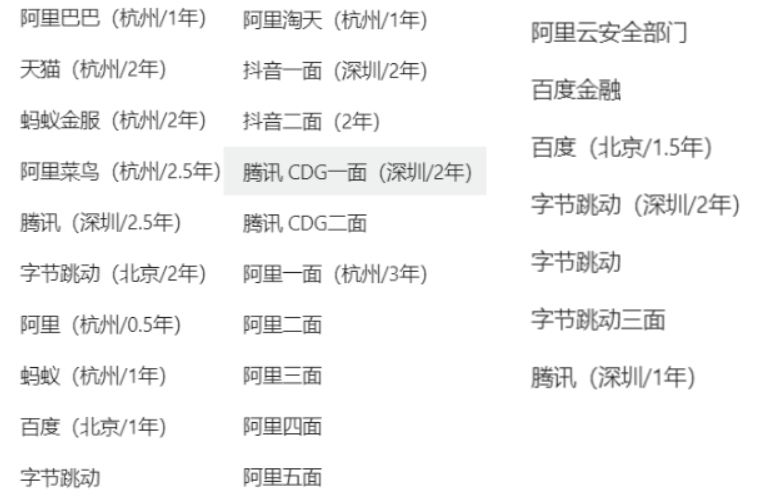
38 |
39 | 
40 |
41 | 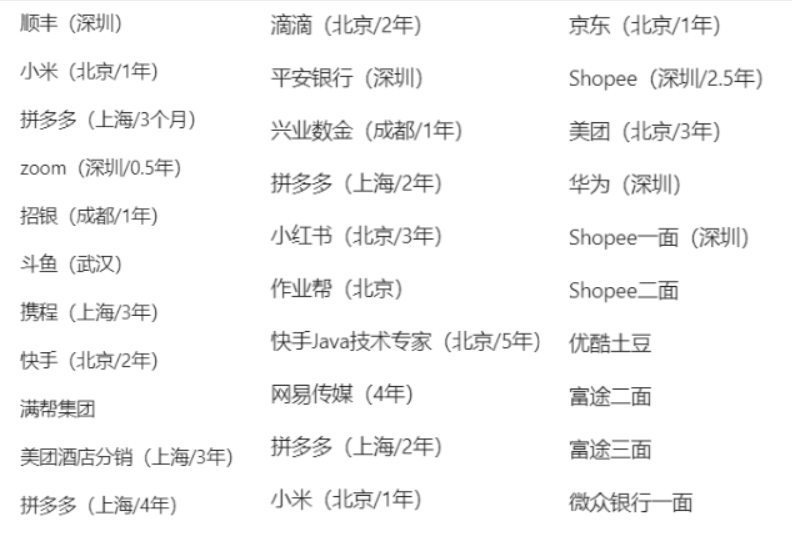
42 |
43 | 
44 |
45 | 
46 |
47 | **校招、实习面经**部分截图:
48 |
49 | 
50 |
51 | 
52 |
53 |
54 |
55 | 面试共享群**进群方式**:添加我微信 dabinjava 或者 i_am_dabin,**备注**【**面试真题**】。
56 |
57 | PS:**有偿**,白嫖勿扰(花了挺多时间整理的,希望可以理解)
58 |
59 | 
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "vuepress-theme-hope-template",
3 | "version": "2.0.0",
4 | "description": "A project of vuepress-theme-hope",
5 | "license": "MIT",
6 | "scripts": {
7 | "docs:build": "vuepress build docs",
8 | "docs:clean-dev": "vuepress dev docs --clean-cache",
9 | "docs:dev": "vuepress dev docs"
10 | },
11 | "devDependencies": {
12 | "@vuepress/client": "^2.0.0-beta.49",
13 | "@vuepress/plugin-docsearch": "^2.0.0-beta.49",
14 | "@vuepress/plugin-google-analytics": "^1.9.7",
15 | "@vuepress/plugin-nprogress": "^2.0.0-beta.49",
16 | "@vuepress/plugin-search": "^2.0.0-beta.49",
17 | "vue": "^3.2.36",
18 | "vuepress": "^2.0.0-beta.49",
19 | "vuepress-plugin-autometa": "^0.1.13",
20 | "vuepress-plugin-baidu-autopush": "^1.0.1",
21 | "vuepress-plugin-copyright2": "^2.0.0-beta.87",
22 | "vuepress-plugin-photo-swipe": "^2.0.0-beta.87",
23 | "vuepress-plugin-reading-time2": "^2.0.0-beta.87",
24 | "vuepress-plugin-sitemap2": "^2.0.0-beta.87",
25 | "vuepress-theme-hope": "^2.0.0-beta.87"
26 | }
27 | }
28 |
--------------------------------------------------------------------------------
25 |
26 | 感兴趣的小伙伴可以扫描下方的二维码**加我微信**,**备注加群**,我拉你进群,一起学习成长!
27 |
28 | 
29 |
--------------------------------------------------------------------------------
/docs/advance/concurrent/README.md:
--------------------------------------------------------------------------------
1 | ## 高并发专题(更新中)
2 |
3 | - [限流算法](./1-current-limiting.md)
4 | - [负载均衡](./2-load-balance.md)
5 |
--------------------------------------------------------------------------------
/docs/advance/design-pattern/1-principle.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 设计模式的六大原则
4 | category: 设计模式
5 | tag:
6 | - 设计模式
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 设计模式的六大原则,设计模式,设计模式面试题
11 | - - meta
12 | - name: description
13 | content: 设计模式常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 设计模式的六大原则
17 |
18 | - 开闭原则:对扩展开放,对修改关闭,多使用抽象类和接口。
19 | - 里氏替换原则:基类可以被子类替换,使用抽象类继承,不使用具体类继承。
20 | - 依赖倒转原则:要依赖于抽象,不要依赖于具体,针对接口编程,不针对实现编程。
21 | - 接口隔离原则:使用多个隔离的接口,比使用单个接口好,建立最小的接口。
22 | - 迪米特法则:一个软件实体应当尽可能少地与其他实体发生相互作用,通过中间类建立联系。
23 | - 合成复用原则:尽量使用合成/聚合,而不是使用继承。
24 |
25 |
--------------------------------------------------------------------------------
/docs/advance/design-pattern/7-iterator.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 设计模式之迭代器模式
4 | category: 设计模式
5 | tag:
6 | - 设计模式
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 迭代器模式,设计模式,迭代器
11 | - - meta
12 | - name: description
13 | content: 设计模式常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 迭代器模式
17 |
18 | 提供一种方法顺序访问一个聚合对象中的各个元素, 而又不暴露其内部的表示。
19 |
20 | 把在元素之间游走的责任交给迭代器,而不是聚合对象。
21 |
22 | **应用实例:**JAVA 中的 iterator。
23 |
24 | **优点:** 1、它支持以不同的方式遍历一个聚合对象。 2、迭代器简化了聚合类。 3、在同一个聚合上可以有多个遍历。 4、在迭代器模式中,增加新的聚合类和迭代器类都很方便,无须修改原有代码。
25 |
26 | **缺点:**由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
27 |
28 | **使用场景:** 1、访问一个聚合对象的内容而无须暴露它的内部表示。 2、需要为聚合对象提供多种遍历方式。 3、为遍历不同的聚合结构提供一个统一的接口。
29 |
30 | **迭代器模式在JDK中的应用**
31 |
32 | ArrayList的遍历:
33 |
34 | ```java
35 | Iterator iter = null;
36 |
37 | System.out.println("ArrayList:");
38 | iter = arrayList.iterator();
39 | while (iter.hasNext()) {
40 | System.out.print(iter.next() + "\t");
41 | }
42 | ```
43 |
44 |
45 |
46 |
--------------------------------------------------------------------------------
/docs/advance/design-pattern/9-adapter.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 设计模式之适配器模式
4 | category: 设计模式
5 | tag:
6 | - 设计模式
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 适配器模式,设计模式,适配器
11 | - - meta
12 | - name: description
13 | content: 设计模式常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 适配器模式
17 | 适配器模式将现成的对象通过适配变成我们需要的接口。 适配器让原本接口不兼容的类可以合作。
18 |
19 | 适配器模式有类的适配器模式和对象的适配器模式两种不同的形式。
20 |
21 | 对象适配器模式通过组合对象进行适配。
22 |
23 | 
24 |
25 | 类适配器通过继承来完成适配。
26 |
27 | 
28 |
29 | 适配器模式的**优点**:
30 |
31 | 1. 更好的复用性。系统需要使用现有的类,而此类的接口不符合系统的需要。那么通过适配器模式就可以让这些功能得到更好的复用。
32 | 2. 更好的扩展性。在实现适配器功能的时候,可以调用自己开发的功能,从而自然地扩展系统的功能。
33 |
34 |
--------------------------------------------------------------------------------
/docs/advance/design-pattern/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 设计模式
3 | icon: design
4 | date: 2022-08-07
5 | category: 设计模式
6 | star: true
7 | ---
8 |
9 | ::: tip 这是一则或许对你有帮助的信息
10 |
11 | - **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
12 | - **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
13 |
14 | :::
15 |
16 | **本专栏是大彬学习设计模式基础知识的学习笔记,如有错误,可以在评论区指出**~
17 |
18 | ## 设计模式详解
19 |
20 | - [设计模式的六大原则](./1-principle.md)
21 | - [单例模式](./2-singleton.md)
22 | - [工厂模式](./3-factory.md)
23 | - [模板模式](./4-template.md)
24 | - [策略模式](./5-strategy.md)
25 | - [责任链模式](./6-chain.md)
26 | - [迭代器模式](./7-iterator.md)
27 | - [装饰模式](./8-decorator.md)
28 | - [适配器模式](./9-adapter.md)
29 | - [观察者模式](./10-observer.md)
30 | - [代理模式](./11-proxy.md)
31 | - [建造者模式](./12-builder.md)
32 |
--------------------------------------------------------------------------------
/docs/advance/distributed/5-distibuted-arch.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 分布式架构
4 | category: 分布式
5 | tag:
6 | - 分布式架构
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 分布式架构,限流,熔断
11 | - - meta
12 | - name: description
13 | content: 分布式常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 分布式架构,微服务、限流、熔断....
17 |
18 | [分布式架构,微服务、限流、熔断....](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247490543&idx=1&sn=ee34bee96511d5e548381e0576f8b484&chksm=ce98e6a9f9ef6fbf7db9c2b6d2fed26853a3bc13a50c3228ab57bea55afe0772008cdb1f957b&token=1594696656&lang=zh_CN#rd)
19 |
--------------------------------------------------------------------------------
/docs/advance/distributed/README.md:
--------------------------------------------------------------------------------
1 | ## 目录
2 |
3 | - [全局唯一ID生成方案](./1-global-unique-id.md)
4 | - [分布式锁](./2-distributed-lock.md)
5 | - [RPC](./3-rpc.md)
6 | - [微服务](./4-micro-service.md)
7 | - [分布式架构,微服务、限流、熔断....](./6-distibuted-arch.md)
8 | - [分布式事务](./7-distributed-transaction.md)
9 |
--------------------------------------------------------------------------------
/docs/advance/excellent-article/11-8-architect-pattern.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 8种架构模式
4 | category: 优质文章
5 | tag:
6 | - 架构
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 架构模式
11 | - - meta
12 | - name: description
13 | content: 优质文章汇总
14 | ---
15 |
16 | # 8种架构模式
17 |
18 | [8种架构模式](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247490779&idx=2&sn=eff9e8cf9b15c29630514a137f102701&chksm=ce98e19df9ef688bd9c7b775658c704a51b7961347a7aabf70e6c555cb57560aa5e8b1e497a1&token=1170645384&lang=zh_CN#rd)
19 |
--------------------------------------------------------------------------------
/docs/advance/excellent-article/29-idempotent-design.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 接口的幂等性如何设计?
4 | category: 优质文章
5 | tag:
6 | - Spring Boot
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 接口幂等,幂等性
11 | - - meta
12 | - name: description
13 | content: 努力打造最优质的Java学习网站
14 | ---
15 |
16 | ## 接口的幂等性如何设计?
17 |
18 | 分布式系统中的某个接口,该如何保证幂等性?
19 |
20 | 假如有个服务提供一个付款接口供外部调用,这个服务部署在了 5 台机器上。然后用户在前端上操作的时候,不小心发起了两次支付请求,然后这俩请求分散在了这个服务部署的不同的机器上,结果一个订单扣款扣两次。
21 |
22 | 这就是典型的接口幂等性问题。
23 |
24 | 所谓幂等性,就是说一个接口,多次发起同一个请求,你这个接口得保证结果是准确的,比如不能多扣款、不能多插入一条数据、不能将统计值多加了 1。这就是幂等性。
25 |
26 | 其实保证幂等性主要是三点:
27 |
28 | 对于每个请求必须有一个唯一的标识,举个例子:订单支付请求,肯定得包含订单 id,一个订单 id 最多支付一次。每次处理完请求之后,必须有一个记录标识这个请求处理过了。常见的方案是在数据库中记录一个状态,比如支付之前记录一条这个订单的支付流水。
29 |
30 | 每次接收请求需要进行判断,判断之前是否处理过。如果订单已经支付了,就已经有了一条支付流水,那么如果重复发送这个请求,则此时先插入支付流水,orderId 已经存在了,唯一键约束生效,报错插入不进去的。然后你就不用再扣款了。
31 |
32 | 实际运作过程中,你要结合自己的业务来,比如说利用 Redis,用 orderId 作为唯一键。只有成功插入这个支付流水,才可以执行实际的支付扣款。
33 |
34 | 要求是支付一个订单,必须插入一条支付流水,order_id 建一个唯一键 unique key 。你在支付一个订单之前,先插入一条支付流水,order_id 就已经进去了。你就可以写一个标识到 Redis 里面去, set order_id payed ,下一次重复请求过来了,先查 Redis 的 order_id 对应的 value,如果是 payed 就说明已经支付过了,就别重复支付了。
35 |
--------------------------------------------------------------------------------
/docs/advance/excellent-article/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## 优质文章汇总
3 |
4 | - [Redis如何实现库存扣减操作和防止被超卖?](./1-redis-stock-minus.md)
5 | - [@Transactional事务注解详解](./2-spring-transaction.md)
6 | - [SpringBoot自动装配原理](./3-springboot-auto-assembly.md)
7 | - [干掉“重复代码”的技巧有哪些](./4-remove-duplicate-code.md)
8 | - [一次简单的 *JVM* 调优,拿去写到简历里](./5-jvm-optimize.md)
9 | - [Spring为何需要三级缓存解决循环依赖,而不是二级缓存?](./6-spring-three-cache.md)
10 | - [8种最坑SQL语法](./7-sql-optimize.md)
11 | - [面试官:如何保证接口幂等性?一口气说了12种方法!](./8-interface-idempotent.md)
12 | - [美团面试:熟悉哪些JVM调优参数?](./9-jvm-optimize-param.md)
13 | - [大文件上传时如何做到秒传?](./10-file-upload.md)
14 | - [8种架构模式](./11-8-architect-pattern.md)
15 | - [MySQL最大建议行数 2000w,靠谱吗?](./12-mysql-table-max-rows.md)
16 | - [order by是怎么工作的?](./13-order-by-work.md)
17 | - [架构的演进](./14-architect-forward.md)
18 | - [有了HTTP,为啥还要用RPC](./15-http-vs-rpc.md)
19 | - [什么是JWT](./16-what-is-jwt.md)
20 | - [限流的几种方案](./17-limit-scheme.md)
21 | - [为什么说数据库连接很消耗资源](./18-db-connect-resource.md)
22 | - [Java19新特性](./19-java19.md)
23 | - [几种常见的架构模式](./20-architect-pattern.md)
24 | - [新一代分布式任务调度框架](./22-distributed-scheduled-task.md)
25 | - [Arthas 常用命令](./23-arthas-intro.md)
--------------------------------------------------------------------------------
/docs/advance/system-design/19-high-concurrent-system-design.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何设计一个高并发系统?
4 | category: 场景设计
5 | tag:
6 | - 场景设计
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 场景设计面试题,高并发系统,高并发系统设计,场景设计
11 | - - meta
12 | - name: description
13 | content: 场景设计常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 如何设计一个高并发系统?
17 |
18 | ## 总览
19 |
20 | 在高并发的情景下进行系统设计,
21 |
22 | 可以分为以下 6 点:
23 |
24 | - 系统拆分
25 | - 熔断
26 | - 降级
27 | - 缓存
28 | - MQ
29 | - 分库分表
30 | - 读写分离
31 | - ElasticSearch
32 |
33 | 
34 |
35 | ### 系统拆分
36 |
37 | 将一个系统拆分为多个子系统,用 RPC 来搞。然后每个系统连一个数据库,这样本来就一个库,现在多个数据库,分担系统压力。
38 |
39 | ### 缓存
40 |
41 | 大部分的高并发场景,都是读多写少,那你完全可以在数据库和缓存里都写一份,然后读的时候大量走缓存就可以了。毕竟 Redis 轻轻松松单机几万的并发。所以你可以考虑你的项目里,那些承载主要请求的读场景,怎么用缓存来抗高并发。
42 |
43 | ### MQ
44 |
45 | 可能你还是会出现高并发写的场景,比如说一个业务操作里要频繁搞数据库几十次,增删改增删改。那高并发绝对搞挂你的系统,你要是用 Redis 来承载写那肯定不行,人家是缓存,数据随时就被 LRU 了,数据格式还很简单,没有事务支持。所以该用 MySQL 还得用 MySQL 啊。那你咋办?用 MQ 吧,大量的写请求灌入 MQ 里,后边系统消费后慢慢写,控制在 MySQL 承载范围之内。所以你可以考虑你的项目里,那些承载复杂写业务逻辑的场景里,如何用 MQ 来异步写,提升并发性。
46 |
47 | ### 分库分表
48 |
49 | 分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就将一个数据库拆分为多个库,多个库来扛更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高 SQL 执行的性能。
50 |
51 | ### 读写分离
52 |
53 | 读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。
54 |
55 | ### ElasticSearch
56 |
57 | ES 是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来扛更高的并发。那么一些比较简单的查询、统计类的操作,可以考虑用 ES 来承载,还有一些全文搜索类的操作,也可以考虑用 ES 来承载。
58 |
59 |
60 |
61 |
62 |
63 | > 参考链接:https://hadyang.com/interview/docs/architecture/concurrent/design/
64 |
--------------------------------------------------------------------------------
/docs/advance/system-design/3-file-send.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何把一个文件较快的发送到100w个服务器?
4 | category: 场景设计
5 | tag:
6 | - 场景设计
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 场景设计面试题,文件发送,场景设计
11 | - - meta
12 | - name: description
13 | content: 场景设计常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | ## 如何把一个文件较快的发送到100w个服务器?
17 |
18 | 可以采用p2p网络形式,比如树状形式,单个节点既可以从其他节点接收服务又可以向其他节点提供服务。
19 |
20 | 不过,树状结构会有什么问题呢?
21 |
22 | 第一,如果树上的某一个节点坏掉了,那么从这个节点往下的所有服务器全部接收不到文件。
23 |
24 | 第二,如果树中的某条路径,因为网络因素等原因,传递速度比较慢,导致传递时间比较长,这样会使传递效率退化。
25 |
26 | 改进的方案如下:
27 |
28 | 可以使用**连通图**。100W台服务器相当于有100W个节点的连通图。我们可以在图里生成多颗不同的生成树,在进行数据下发时,同时按照多颗不同的树去传递数据。这样就可以避免某个中间节点宕机,影响到后续的节点。同时这种传递方法实际上是一种依据时间的广度优先遍历,可以避免某条路径过长造成的效率低下。
29 |
--------------------------------------------------------------------------------
/docs/advance/system-design/4-oversold.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 超卖问题
4 | category: 场景设计
5 | tag:
6 | - 场景设计
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 场景设计面试题,超卖问题,场景设计
11 | - - meta
12 | - name: description
13 | content: 场景设计常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 超卖问题
17 |
18 | 先到数据库查询库存,在减库存。不是原子操作,会有超卖问题。
19 |
20 | 通过加排他锁解决该问题。
21 |
22 | - 开始事务。
23 | - 查询库存,并显式的设置排他锁:SELECT * FROM table_name WHERE … FOR UPDATE
24 | - 生成订单。
25 | - 去库存,update会隐式的设置排他锁:UPDATE products SET count=count-1 WHERE id=1
26 | - commit,释放锁。
27 |
28 | 也可以通过乐观锁实现。使用版本号实现乐观锁。
29 |
30 | 假设此时version = 100, num = 1; 100个线程进入到了这里,同时他们select出来版本号都是version = 100。
31 |
32 | 然后直接update的时候,只有其中一个先update了,同时更新了版本号。
33 |
34 | 那么其他99个在更新的时候,会发觉version并不等于上次select的version,就说明version被其他线程修改过了,则放弃此次update,重试直到成功。
35 |
36 | ```mysql
37 | select version from goods WHERE id= 1001
38 | update goods set num = num - 1, version = version + 1 WHERE id= 1001 AND num > 0 AND version = @version(上面查到的version);
39 | ```
40 |
--------------------------------------------------------------------------------
/docs/advance/system-design/README.md:
--------------------------------------------------------------------------------
1 | **系统设计高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到Java面试手册**完整版**。
2 |
3 | 
4 |
5 | 另外星球提供**专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
6 |
7 | 
8 |
9 | 
10 |
11 | 
12 |
13 | 如果你正在打算准备跳槽、面试,星球还提供**简历指导、修改服务**,大彬已经帮**120**+个小伙伴修改了简历,相对还是比较有经验的。
14 |
15 | 
16 |
17 | 
18 |
19 | 星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
20 |
21 | 
22 |
23 | 
24 |
25 | 
26 |
27 | 怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
28 |
29 | **扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
30 |
31 | 随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
32 |
33 | 
--------------------------------------------------------------------------------
/docs/campus-recruit/README.md:
--------------------------------------------------------------------------------
1 | 分享校招公司招聘信息,写简历技巧、面试技巧。
2 |
3 | 愿所有正在参与秋招的小伙伴能够找到一份满意的好工作!
--------------------------------------------------------------------------------
/docs/campus-recruit/biggest-difficulty.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 你在项目里遇到的最大困难是什么,如何解决的?
4 | category: 分享
5 | tag:
6 | - 面试题
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 项目里遇到的最大困难是什么
11 | - - meta
12 | - name: description
13 | content: 你在项目里遇到的最大困难是什么,如何解决的?
14 | ---
15 |
16 | ## 你在项目里遇到的最大困难是什么,如何解决的?
17 |
18 | 这是一道面试高频题,但是很多人都没能回答好,或者说没有准备好怎么去回答。
19 |
20 | 今天跟大家分享我是如何去回答这个问题的。
21 |
22 | 很多人可能觉得,自己每天都是干着CRUD的工作,难一点,再加个缓存,没有什么困难的地方。就算当时真的觉得有困难,做完了也就不觉得困难了。
23 |
24 | 其实,大部分人都是这样的状态,没有谁天天能遇到一些框架上的疑难杂症、超乎意外的生产问题,这种疑难问题很少,出现了可能也轮不到你处理。不过如果遇到这种问题的话,不管你是不是主要处理人,我建议你能主动参与进去,去分析问题产生的问题,应该怎么去处理,事后做好**复盘总结**。做好这些之后,面试就有的吹水了。
25 |
26 | 再者,平时开发过程多多少少也是会遇到一些问题,可以把遇到的这些问题记录下来,多去思考、网上搜索,或者跟别人请教,无论是怎样解决,解决以后,需要对问题进行**复盘总结**。比如下面就是我工作中遇到的OOM问题复盘总结,建议大家也养成记录的习惯。
27 |
28 | 
29 |
30 | 另外,关于“你在项目里遇到的最大困难是什么,如何解决的?”这个问题,可以使用 star 法则去回答:
31 |
32 | - Situation(背景信息):事情是在什么情况下发生,比如在生产环境遇到xxx问题
33 | - Target(目标任务):你的目标任务是什么,比如保证线上服务稳定、分析问题产生原因等
34 | - Action(采取的行动):针对这样的情况分析,你采用了什么行动方式,比如先重启保证服务正常,之后再进行分析等
35 | - Result(取得的成果):结果怎样,在这样的情况下你学习到了什么
36 |
37 |
38 |
39 | 最后总结一下,最重要是平时要多复盘总结,积累面试素材。不管是多小的问题,只要你认真对待,总能学到一些知识。大部分面试官也不会期待你有处理过多大的问题,毕竟大部分人都是普通人。只要能从你的回答中看出你的思考,解决问题的方式,那么面试官的问这个问题的目的也就达到了。
40 |
--------------------------------------------------------------------------------
/docs/campus-recruit/career-plan.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 程序员职业规划分享
4 | category: 分享
5 | tag:
6 | - 面试题
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 职业规划
11 | - - meta
12 | - name: description
13 | content: 面试高频题,职业规划
14 | ---
15 |
16 | 分享一下我的看法。
17 |
18 | 程序员的职业未来分为三个阶段,每个阶段都会遇到一个区分门槛。
19 |
20 | ## 第一阶段:前三年
21 |
22 | 工作前三年是程序员的第一道门槛,这三年会逐渐淘汰一批不适合写代码的人。
23 |
24 | 在这个阶段,我们走出校园,迈入社会,成为一名程序员,开始把书本上的知识应用到的真正的企业级开发。我们学会了如何团队协作、如何使用项目管理工具、项目版本如何控制、写的代码如何测试、如何在线上运行等等。
25 |
26 | 前三年,积累了一定的开发经验,也对代码有了一定深入的认识,是一个比较纯粹的码农阶段。
27 |
28 |
29 |
30 | ## 第二阶段:第五年
31 |
32 | 第五年是程序员的第二个门槛,这一年程序员的工作已经基本定型。
33 |
34 | 有些人在这五年里,除了完成工作,闲余时间就不会研究别的东西,这些人永远就是个码农。等到年纪大了便会被年轻人给替代。
35 |
36 | 有些人在这五年里,除了写代码,还热衷于研究各种技术实现细节、看了很多好书、写一些博客分享技术,这些人在五年后必然具备在技术上独当一面的能力并且清楚自己未来的发展方向,从一个码农逐步走向系统分析师或是架构师,成为项目组中不可或缺的人物。
37 |
38 |
39 |
40 | ## 第三阶段:第十年
41 |
42 | 第十年是程序的第三个门槛,转行或是继续做一名程序员就在这个节点上。
43 |
44 | 如果在前几年就抱定不转行的思路并且为之努力的话,那么在十年的这个节点上,有些人必然成长为一名对行业有着深入认识、对技术有着深入认识、能从零开始对一个产品进行分析的程序员,这样的人在公司基本担任的都是CTO、技术专家、首席架构师等最关键的职位。在这个阶段,还需要有趋势预判的能力,能够提前看到市场在未来几年的红利和缺口,提前进行布局,学习将来会稀缺的技术,积极主动去探索。
45 |
46 |
47 |
48 | > 参考:https://segmentfault.com/a/1190000040241465
49 |
--------------------------------------------------------------------------------
/docs/campus-recruit/hr-ask-offers.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: HR问目前拿到哪几个offer了,怎么回答好?
4 | category: 分享
5 | tag:
6 | - 面试题
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 面试题
11 | - - meta
12 | - name: description
13 | content: HR问目前拿到哪几个offer了,怎么回答好?
14 | ---
15 |
16 | ## HR问目前拿到哪几个offer了,怎么回答好?
17 |
18 | 这是比较常见的面试问题。
19 |
20 | HR提问的目的是要把握候选人的求职进展情况。
21 |
22 | 如果你手里已经有Offer了,公司综合评估你是比较适合的候选人,就会争取尽快和你进行薪酬谈判,尽快发Offer,推进的速度可以很快。
23 |
24 | HR也会根据你拿到的Offer的情况,评估你在市场上对标的位置一一有助于HR评估你接公司Offer,并且顺利入职的可能性。假如你拿到的offer是30w左右,而HR根据你前边面试情况定级,最高只能给到20w,那么这种情况大概率你会选择30w年薪的offer,HR可能就不会给你发offer了,而是考虑其他有可能入职的应聘者。
25 |
26 | 那么你该如何回答这个问题呢。
27 |
28 | ### 没有Offer
29 |
30 | 如果你目前还没有offer,可以说“目前没有,有两家公司在谈,还没发书面Offer。”
31 |
32 | 或者说:“还没有,我刚刚开始看机会。”
33 |
34 | 如果你真的是面试很多家,但是都没有什么成果。这个千万不要让对方知道,不然对方通过该信息得出的结论就是:这个人可能水平不是很高,没啥竞争力。可能HR面试你就被挂了。
35 |
36 | 不管面了多少家,只要没有Offer,都可以说刚刚开始面试。
37 |
38 | ### 手头有Offer,还在择优选择中
39 |
40 | 如果你手里有Offer,可以坦诚说大体信息。我们的目的是拿到所有Offer, 所以,一定要表达,我更倾向你公司Offer。
41 |
42 | 比如我目前手里有两个Offer, 但是我更倾向加入咱们公司,因为咱们公司发展前景更好之类的话,让HR相信你是想加入他们公司的。
43 |
44 | 如果对方没有问你什么公司,Offer多少。你就不要继续讲具体的内容。
45 |
46 | 可能HR会追问“是哪家公司? 给你Offer多少?”
47 |
48 | 这个时候,我建议不要诱露公司具体的名字。可以说某行业,比如“我有两个Offer,一个是金融行业独角兽,一个是互联网公司的”。这样含糊回答即可。
49 |
50 | 另外,不要说有太多Offer,即便你真的有很多,就说2-3个。站在HR的角度,候选人手里那么多Offer,还没确定去哪家,在市场上不断面试,大概率是来练手的。这种情况在HR面试估计就被pass了。
51 |
52 |
53 |
54 | 总之,回答要往对自己有利的方向进行,还有就是要自信。
55 |
56 |
57 |
58 | > 参考链接:https://www.zhihu.com/question/23751641
59 |
--------------------------------------------------------------------------------
/docs/campus-recruit/interview-question-career-plan.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 面试时问你的职业规划,该怎么回答?
4 | category: 分享
5 | tag:
6 | - 面试题
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 面试题,职业规划
11 | - - meta
12 | - name: description
13 | content: 面试时问你的职业规划,该怎么回答?
14 | ---
15 |
16 | ## 面试时问你的职业规划,该怎么回答?
17 |
18 | 建议紧扣工作和学习两个维度回答
19 |
20 | **第一点**: 介绍自己认真思考过这个问题,自己的规划是基于目前的实际情况来设计的,不是凭空想的。加分!加分! 加分!
21 |
22 | **第二点**:工作方面,突出自己打算通过积极完成工作任务,积累各方面的经验,让自己成为这个领域的专业人士,也希望有机会能够带领团队,成为优秀的管理者,为单位做出更大贡献,获得双赢。加分!加分! 加分!
23 |
24 | **第三点**: 在学习方面,打算在专业领域做进一步学习和研究,将实践经验与专业知识只相结合,为自己的职业成长做好铺垫,打好基础。加分!加分!加分!
25 |
26 | 根据以上的关键点,参考回复:
27 |
28 | **参考回复1**:
29 |
30 | 首先,自己认真思考过这个问题,自己的规划是基于目前的实际情况来设计的,不是凭空想的,自已毕竟刚毕业或者工作时间不长,经验还欠缺
31 |
32 | 其次,在工作方面,我打算通过积极完成工作任务,积累各方面的经验,让自己成为这个领域的专业人士,也希望有机会能够带领团队,成为优秀的管理者,为单位做出更大贡献
33 |
34 | 第三,在学习方面,打算在专业领域做进一步学习和研究,将实践经验与专业知识相结合,为自己的职业成长做好铺垫,打好基础。谢谢!
35 |
36 | **参考回复2**:
37 |
38 | 未来一年:我希望通过自己的学习和实践,加深对行业和岗位的理解,能够独立完成一些小项目,推动业务的发展。对此,我会针对性的看一些相关的书籍,与公司和行业的前辈多沟通交流,多调研用户加深业务的熟悉程度,并有机会成为业务本身的用户。
39 |
40 | 未来三年:可以同时独立负责几个项目,在完成任务本身的基础上主动做优化和迭代,总结形成自己的方法论和工作方式。对此,我会多整理复盘学习成果,延伸学习产品、技术等专业知识。
41 |
42 | 未来五年:可以带自己的team或者实习生,将所学所得与他们进行沟通交流,从团队协作和业务两方面共同提升团队效益;同时有机会跟业内的大牛老师交流学习共事。对此,我会学习一些心理学、管理学等相关知识,拓宽对团队管理方面的学习,并拓展在业务本身和上下游各联动产业的学习。
43 |
44 | > Tips: 回答这个问题强调你稳定性,踏实工作的态度,重点在工作技能方面的提升与内在积累,不要描述外在的东西,比如职位,薪资。
45 |
46 |
47 |
48 | 参考链接:https://www.zhihu.com/question/20054953
49 |
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/11-lixiang-car.md:
--------------------------------------------------------------------------------
1 | ## 理想汽车面经
2 |
3 | 一面:
4 |
5 | 1. 谈谈你常用的集合
6 | 2. arrarylist与linkedlist区别
7 | 3. hashmap扩容机制
8 | 4. 为什么用红黑树?
9 | 5. 线程安全吗? 怎么不安全?
10 | 6. 具体场景如何优化
11 | 7. concurrentHashMap实现原理
12 | 8. CAS自旋ABA问题
13 | 9. 乐观锁悲观锁的实现
14 | 10. Svnchronized与lock的区别
15 | 11. ReentrantLocklock中可公平锁是如何实现的
16 | 12. 如何理解Java对象头与Monitor
17 | 13. 说一下你知道的线程池
18 | 14. 线程池的七个参数
19 | 15. 核心线程数五个,最大线程数十个,现在有八个线程,如何分配?
20 | 16. 它的队列是做什么的?
21 | 17. 说一下拒绝策略说一下ivm组成吧
22 | 18. 哪些是公有的,哪些是私有的
23 | 19. 类加载过程双亲委派原理
24 | 20. 如何实现自定义类加载器
25 | 21. 对象创建的主要流程
26 | 22. 常用的垃圾回收器
27 | 23. 简单说一下垃圾回收算法
28 | 24. 你常用的索引(B树、哈希)
29 | 25. 在各种树里面为什么选择B+树 (AVL、红黑树、二叉树)
30 | 26. 索引失效的情况
31 | 27. 最左匹配原则
32 | 28. 谈谈mvcc
33 | 29. 内连接怎么实现
34 | 30. 事务的特性隔离级别
35 | 31. 什么是幻读
36 | 32. MVISAM与InnoDB区别
37 | 33. 引擎是如何实现事务四个特性的
38 |
39 | 二面:
40 | 1. 随着学习,项目中哪些点有更好的实现方式了吗
41 | 2. 实习项目说了消息中间件问了几种消息中间件的区别
42 | 3. sprngboot的常用注解以及含义
43 | 4. 你对spring的iocaop的理解
44 | 5. #几和$的区别说一下
45 | 6. mvbatis的一级缓存与二级缓存
46 | 7. Java四种引用
47 | 8. string与stringbuilder与stringbuffer说一下
48 | 9. 实现链表冒泡排序的思路
49 | 10. 了解的设计模式说一下
50 | 11. 单例模式懒汉饿汉的应用场景
51 | 12. 还有一道算法题(时间太久忘了)
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/2-tencent.md:
--------------------------------------------------------------------------------
1 | # 腾讯
2 |
3 | ## 一面
4 | 1. mysql索引结构?
5 | 2. redis持久化策略?
6 | 3. zookeeper节点类型说一下;
7 | 4. zookeeper选举机制?
8 | 5. zookeeper主节点故障,如何重新选举?
9 | 6. syn机制?
10 | 7. 线程池的核心参数;
11 | 8. threadlocal的实现,原理,业务用来做什么?
12 | 9. spring DI的原理;
13 | 10. 四次挥手;
14 | 11. gc root选择;
15 | 12. 标记清除算法的过程,标记清楚算法如何给对象分配内存空间?
16 | 13. cms算法的缺点;
17 | ## 二面
18 | 1. CorruntHashmap理解
19 | 2. ThreadLocal原理
20 | 3. hashmap;
21 | 4. Java数据类型,同步机制;
22 | 5. 讲讲贪心算法;
23 | 6. 如果线上用户出现502错误你怎么排查?
24 | 7. 并发量很大,服务器宕机。你会怎么做?
25 | ## 三面
26 | 1. syn和lock的区别,哪个更好?怎么选择?
27 | 2. hashmap源码,为什么8个节点变成红黑树又为什么到了6个节点才恢复为链表?
28 | 3. 缓存穿透,怎么解决?
29 | 4. 负载均衡算法,实现;
30 | 5. 轮询和随机的缺点;
31 | 6. 分布式服务治理;
32 | 7. dns迭代和递归的区别;
33 | 8. 算法题:最长回文串
34 | 9. 为什么连接的时候是三次握手,关闭的时候却是四次握手?
35 | ## 四面
36 | 1. 自我介绍
37 | 2. 简单说说计算机网络
38 | 3. 简单描述一下从浏览器输入一个地址到服务端整个交互过程
39 | 4. 说说数据结构
40 | 5. 操作系统用过吗
41 | 6. 用过 linux 的哪些命令
42 | 7. 查看一个进程监听了哪些端口
43 | 8. 详细介绍项目(简历上的域名访问不了)
44 | 9. 讲解之前工作经历中做的东西
45 | 10.做一道算法题(判断二叉树是否对称)
46 | 10. java 如何从源代码转换成机器码执行的
47 | 11. java 的击穿
48 | 12. 网络的七层结构
49 | 13. tcp\udp 详解 区别
50 | 14. https 协议的交互过程
51 | 15. linux 基础命令
52 | 16. linux 开机过程
53 | 17. 了解现在市面上主流的 cpu 架构
54 | 18. fpga 概念了解吗
55 | 19. 市面上的图数据库
56 | 20. rdf 讲解
57 | 21. 图数据库底层存储
58 | 22. b 树,b+树的概念和区别
59 | 23. 红黑树平衡二叉树优缺点和应用场景
60 | 24. 有没有了解 docker 等云技术
61 |
62 |
63 |
64 | **最后给大家分享一份精心整理的大厂高频面试题PDF,需要的小伙伴可以自行下载:**
65 |
66 | [大厂面试手册](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247485445&idx=1&sn=1c6e224b9bb3da457f5ee03894493dbc&chksm=ce98f543f9ef7c55325e3bf336607a370935a6c78dbb68cf86e59f5d68f4c51d175365a189f8#rd)
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/7-shopee.md:
--------------------------------------------------------------------------------
1 | # shopee
2 |
3 | ## 面经1
4 |
5 | 消息队列如何保证可靠性
6 | 消息队列如何保证消息幂等性
7 | 消息队列的优缺点
8 | 为什么用b+树
9 | 聚集索引和主键区别,其他引擎怎么做的
10 | 平时数据库编码
11 | explain参数
12 | http报文参数有哪些吗?
13 | 做题,链表奇偶有序输出
14 |
15 | ## 面经2
16 |
17 | 1. 自我介绍
18 | 2. 有哪些排序算法?
19 | 3. 介绍下快排/堆排/归并排序。
20 | 4. 数据库中的索引应该如何设计?
21 | 5. 有哪些索引失效的情况?
22 | 6. 你们用到的HTTP接口用到了什么提交方式?
23 | 7. GET/POST的区别?
24 | 8. 除了GET/POST还有哪些?
25 | 9. 面向对象的基本原则?再详细说下依赖倒转。
26 | 10. 介绍下策略模式和观察者模式?
27 | 11. 如何保证用户请求的等幂性?等幂性指的是用户可能连点提交三次支付请求,返回同样的结果(支付成功),但实际后台只执行一次,保持一致性。
28 | 12. 介绍下TCP四次挥手?
29 | 13. 第四次挥手后客户端是立刻就关闭了吗?是什么状态?
30 | 14. 两个大文件,分别每行都存一个url,查找两个文件中重复的url。
31 | 15. 一个大文件中,每一行有一个整数,怎么找第100大的数?
32 | 16. 一个大文件中,每一行有一个整数,怎么找中位数?
33 | 17. redis的基本数据结构?
34 | 18. zset是怎么实现的?有哪些命令?
35 | 19. 算法题 力扣221. 最大正方形
36 |
37 | ## 面经3
38 |
39 | 自我介绍、项目介绍,问了数据量
40 |
41 | 了解微服务吗?(有没有自己在做项目时进行调研,了解企业目前常用的工具、方法)
42 |
43 | 了解springcloud吗?
44 |
45 | 一台机器无法满足运载需求,怎么办呢?答:多搞几台机器,问:多台机器如何协同工作?
46 |
47 | 开始瞎答:mapreduce
48 |
49 | 解释一下mapreduce
50 |
51 | 如果有一个很大的文件,TB级别,文件里是乱序的数字,如何排序?mapreduce如何实现?
52 |
53 | 排序过程中的归并排序,请描述一下其过程?时间复杂度
54 |
55 | 进程、线程区别,问使用Java时,里面多线程的概念和os里的线程进程的区别是什么?真正使用时,Java里的线程和进程是如何调度?
56 |
57 | 多线程的同步互斥的方法?答了信号量,问具体怎么实现,答pv操作,给了具体的场景,问变量如何初始化(等同于口述代码)
58 |
59 | 有哪些索引?(mysql为例)
60 |
61 | b树、b+树是什么样的树结构,查询复杂度?是平衡二叉树吗?
62 |
63 | 使用过redis吗?具体做什么?
64 |
65 | 手撕代码:LRU算法;正反序层序遍历二叉树
66 |
67 |
68 |
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/8-jingdong.md:
--------------------------------------------------------------------------------
1 | # 京东
2 |
3 | ## 一面
4 |
5 | - kafka在应用场景以及 项目 里的实现
6 | - bitmap底层
7 | - object里有哪些方法
8 | - hashmap相关
9 | - sychronized和reentrantlock相关问题以及锁升级
10 | - cas和volatile
11 | - 线程几种状态以及转化
12 | - jvm内存模型
13 | - mybatis相关问题
14 | - Redis数据结构,问了下跳表的底层
15 | - RDB和AOF
16 | - MySQL索引有哪些
17 | - b+树底层实现
18 | - 最左前缀原理
19 |
20 | ## 二面
21 |
22 | - 线程的状态
23 | - cms
24 | - 增量更新法
25 | - GcRoots是哪些
26 | - java基础
27 | - mysql索引
28 | - 项目具体实现
29 |
30 | ## 三面
31 |
32 | - 索引
33 | - 谈谈多线程
34 | - jvm如何调优
35 | - mq在项目中的用法
36 | - 遇到的多线程问题,如何解决
37 | - 最长无重复字串
38 | - 找到A^2+B^2 = C
39 |
40 | ## 四面
41 |
42 | - 数据库乐观锁、悲观锁
43 | - 为啥用Redis
44 | - sql语句执行顺序
45 | - SpringMVC优点,原理
46 | - aop优点,原理
47 | - ioc优点,原理
48 | - 面向对象概念
49 | - 封装
50 | - 项目中封装如何体现
51 | - 高内聚,低耦合啥意思,如何去设计
52 | - 设计一个电梯场景,实现面向对象,高内聚,低耦合的情况
53 | - 统计学校内共享单车数量,你有啥想法(开放题)
54 |
55 | **最后分享一个BAT大佬总结的高频面试题PDF,需要的小伙伴可以自行下载(复制链接到浏览器打开):**
56 |
57 | 链接:https://pan.baidu.com/s/16GnVoALA1r6BhumuUrXIRg
58 | 提取码:6666
59 |
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/9-huawei.md:
--------------------------------------------------------------------------------
1 | # 华为
2 |
3 | 最近越来越多公司校招进入面试流程了,为了帮助大家更好的应对面试,大彬整理了往年华为校招面试的题目,供大家参考~
4 |
5 | ## 面经1
6 |
7 | ### 技术一面
8 |
9 | 1. 自我介绍
10 | 2. 说下项目中的难点
11 | 3. volatile和synchronized的区别, 问的比较细
12 | 4. 大顶堆小顶堆怎么删除根节点
13 | 5. CSRF攻击是什么,怎么预防
14 | 6. 线程通信方式。
15 | 7. Volitate关键字。
16 | 8. Java 高效拷贝数组。
17 | 9. 算法题 跳跃游戏 leetcode 55。
18 |
19 |
20 | ### 技术二面
21 | 1. 上来就手撕代码 ,奇偶链表,leetcode原题,先说思路,然后打开ide共享屏幕撕代码
22 | 2. 手写单例模式,并说为什么这样写,会不会有什么问题,涉及到volatile原理
23 | 3. mysql常用的数据类型
24 | 4. Java集合框架的主类是什么,HashSet有没有继承Collection软件工程学过哪些课程
25 | 5. 软件工程学过哪些课程
26 | 6. 进程和线程的区别
27 | 7. 知道哪些排序算法,快排的时间复杂度是多少,是稳定的排序算法吗
28 | 8. 编程题/算法
29 | 题目大概:请输出两个字符串a和b相减的结果(a>b,a和b的字符串长度介于1~50之间)。
30 | 例:输入a:“99999”,b=“99998”
31 | 输出:“1”
32 |
33 |
34 | ## 面经2
35 | ### 华为一面
36 | 1. 项目、论文。
37 | 2. String能否被继承。
38 | 3. Java内存泄露和排查。
39 | 4. Hash方式和Hash冲突解决。
40 | 5. 静态代理和动态代理。
41 | 6. spring boot常用的注解有哪些
42 | 7. spring boot的配置文件
43 | 8. redis集群的几种方式详细说一下
44 | 9. redis缓存雪崩,缓存击穿,缓存穿透是什么,怎么解决
45 | 10. mysql索引相关,为什么用B+树
46 | 11. 手撕代码,链表求和,leetcode原题
47 |
48 | ### 华为二面
49 | - 是否用过Java、Python做系统的项目
50 | - 平时熟练使用哪种语言
51 | - HashMap、HashSet、HashTable、StringBuffer、StringBuilder哪些是线程安全,哪些是线程不安全
52 | - HashSet数据结构,跟HashMap有什么区别
53 | - char和varchar的区别
54 | - mysql建索引的原则,索引是不是越多越好,为什么
55 | - spring boot用到了哪些设计模式,从源码层面说说你熟悉的以及实现
56 | - jvm调优你用什么工具,具体怎么做的,怎么调优
57 |
--------------------------------------------------------------------------------
/docs/campus-recruit/interview/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## 大厂面经汇总
3 |
4 | - [字节跳动](./1-byte-and-dance.md)
5 | - [腾讯](./2-tencent.md)
6 | - [百度](./3-baidu.md)
7 | - [阿里](./4-ali.md)
8 | - [快手](./5-kuaishou.md)
9 | - [美团](./6-meituan.md)
10 | - [shopee](./7-shopee.md)
11 | - [京东](./8-jingdong.md)
12 | - [华为](./9-huawei.md)
13 | - [网易](./10-netease.md)
14 |
--------------------------------------------------------------------------------
/docs/campus-recruit/layoffs-solution.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | ---
4 |
5 | 今年确实是互联网寒冬啊!
6 |
7 | 从2022年5月中旬以来,包括腾讯、阿里巴巴、字节跳动、美团、拼多多、快手、百度、京东、网易等在内的十余家企业被爆出裁员消息。
8 |
9 | 也有一些校招毁约的公司,真的是。。。
10 |
11 | 对于2023届的同学,这里给几个建议:
12 |
13 | 1. **准备充足**,再去面试!今年行情不好,很多互联网中大厂都在缩招,hc比往年少,所以更要准备充分,争取多拿几个offer,才有主动选择的余地!
14 | 2. **多投简历**,不要有“非大厂不进”的心态。今年秋招会比往年难些,毕竟僧多粥少,建议海投简历,争取多一些面试机会。
15 | 3. 找师兄师姐**内推**。内推可以避免在简历关被筛掉,见过太多学历不好的同学,投了很多简历,最终面试的机会寥寥无几。多找一些内推渠道,包括你的师兄师姐、牛客网、一些求职交流裙等。
16 | 4. **选择好方向**,不要“三心二意”。有些同学没有规划好自己的职业发展,在秋招会投递多个方向,比如前段时间我的读者就投了嵌入式工程师、Java后台工程师、测试工程师,大彬不建议大家这么做。虽然投递多个岗位方向,可以多几个面试机会,但是相应的你得多准备几个岗位的知识复习,精力会分散。就Java后台的知识点,没有半个月一个月的时间,是复习不完的(大佬除外)。因此,建议大家秋招之前就定好方向,专注一个方向进行复习。
17 | 5. 多看看银行、研究所等**国企**的机会,相对稳定。近两年很多公司爆出校招毁约的劣迹,而国企一般不会轻易毁约,这算是一个优势。
18 | 6. **打好基础**。校招比较注重基础知识,包括操作系统、计算机网络、数据结构与算法等(针对开发岗位),小伙伴们一定要把基础巩固好,不要等到面试的时候,一问三不知,成了秋招的“炮灰”。
19 |
20 |
21 |
22 | 最后,互联网行业,**年年都是最难的一年**,大家放好心态,面试没过也不用气馁,面试通过与否跟很多因素相关(自身知识储备、竞争者的水平等等),面试完多复盘,相信大家最终都能找到自己满意的offer!
23 |
24 |
25 |
--------------------------------------------------------------------------------
/docs/campus-recruit/program-language/README.md:
--------------------------------------------------------------------------------
1 | # 编程语言(更新中)
2 |
3 | - [Java和Golang怎么选?](./java-or-golang.md)
4 | - [Java和C++怎么选?](./java-or-c++.md)
5 |
6 |
--------------------------------------------------------------------------------
/docs/campus-recruit/program-language/java-or-c++.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Java和C++怎么选?
4 | category: 分享
5 | tag:
6 | - 职业规划
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: java和c++,语言选择
11 | - - meta
12 | - name: description
13 | content: 努力打造最优质的Java学习网站
14 | ---
15 |
16 | # Java和C++怎么选?
17 |
18 | 很多读者私底下问过我这个问题:Java和c++应该选择哪个?哪个好就业、前景更好?
19 |
20 | 首先,Java和C++都是主流的编程语言,不存在哪个好哪个差的说法,学得好的话,都很有前途。
21 |
22 | 下面我从几个方面来比较Java和C++的差异。
23 |
24 | ## 学习难度
25 |
26 | 毫无疑问,C++相对于Java更难学。C++面向底层,而Java面向上层。C++要求对于计算机底层的知识更高,更难,学习C++更有利于理解计算机基础。
27 |
28 | ## 使用场景
29 |
30 | Java 是大型 web 应用后台的首选语言,像淘宝和京东这些大型电商系统的 web 服务器都选用Java技术栈。很多大数据相关的框架,都是用 Java 开发的,所以在大数据领域 Java 有着天然的优势。另外,移动端安卓APP开发语言也是Java。
31 |
32 | C++在人工智能、机器学习、计算机视觉与图像识别、自动驾驶等新兴技术领域运用更多,这些领域对性能、效率要求更高。
33 |
34 | ## 市场需求
35 |
36 | 从招聘网站的数据来看,Java开发需求是大于C++的,而且相比于C++,Java更好入门,比Java简单一些,很适合短期学习快速上手工作。如果你想从事后台开发方向,那么建议你选择Java,因为互联网公司在后台开发方向招的 Java 程序员会更多一些。C++ 主要是底层应用开发、语音、图形图像、音视频、游戏等方面用得多。
37 |
38 | ## 发展前景
39 |
40 | Java 和 C++是两门主流的热门开发语言,一直名列世界编程语言排行榜的前几位。在 TIOBE2022 年 5 月最新的世界编程语言排行榜中,C++和 Java 依然稳定在前几位。两者目前发展前景都很好,暂时不存在谁替代谁或者被其他编程语言替代的情况。
41 |
42 |
43 |
44 | 最后,每个人学习能力、职业规划、兴趣不一样,对于选择哪种编程语言,应该根据自身的具体情况,选择相应的编程语言,做出最优的选择。
45 |
46 |
--------------------------------------------------------------------------------
/docs/campus-recruit/share/2-no-offer.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 非科班,秋招还没offer,该怎么办
4 | category: 分享
5 | tag:
6 | - 校招
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 非科班转码,秋招没offer,23秋招,秋招
11 | - - meta
12 | - name: description
13 | content: 秋招经验分享
14 | ---
15 |
16 | # 非科班,秋招还没offer,该怎么办
17 |
18 | 前两天有个学弟微信私聊我,他是非科班的(985硕士,机械专业),因为秋招准备的比较晚,目前还没拿offer,感觉秋招已经没希望了,只能春招再战了。学弟很焦虑,作为一个985硕士,周围很多人都拿到offer了,只有他还在“苦苦挣扎”,问我有没有什么**学习建议**?
19 |
20 | 学弟目前**基本情况**如下:
21 |
22 | **已经学习的知识**:
23 |
24 | - 计算机基础:操作系统、数据结构 、计网、组成原理、数据库
25 | - Java 基础、集合、JVM、Java并发
26 | - 框架:Spring Boot、Mybatis、SpringMVC、Spring Cloud
27 | - LeetCode 刷了几百道题
28 | - 其他的像Redis、RabbitMQ、Kafka这些都学了
29 |
30 | 项目经验是烂大街的秒杀系统,没有什么亮点。
31 |
32 | 因为我也是非科班出身,比较了解转码人秋招的“**痛**”,周末花了时间整理了一下,给了几点**建议**:
33 |
34 | ## 校招是最好的机会
35 |
36 | 一定要明白**校招的重要性**,如果校招没拿到offer,那么只能走社招,而社招跟校招的难度不是一个级别的,看重的是你的项目经历,只会更难。无论是秋招,还是春招,对于应届毕业生来说,都是拿offer的最好机会,一定要抓住这个机会!秋招没把握住机会,那么春招更应该加足马力,争取拿到满意的offer。
37 |
38 | ## 实习经验很重要
39 |
40 | **特别对于非科班同学**。如果现在还没有实习经验,最好找一下实习。非科班选手,如果不是名校出身,学历不够突出,没有相关实习经验,可能简历都过不了。
41 |
42 | ## 项目经验同样很重要
43 |
44 | 现在大部分应届生简历上的项目都是秒杀商城、RPC、外卖系统等等,这些项目也不是说没亮点,只是亮点都差不多,给人的感觉就是抄网上现成的,不是从头到尾自己实现的。假如面试时让你介绍一下这个项目,**你觉得这个项目亮点在哪里?你自己实现的功能有哪些?有没有其他解决方案**?这些都是需要自己仔细去考虑的。
45 |
46 | 可以看看类似的开源项目,取长补短,**包装**自己的项目经验,当然,包装要适度,要经得住面试的“灵魂拷问”,否则得不偿失。
47 |
48 | ## 面向面试准备
49 |
50 | 多在网上搜索面经,看看心仪的公司面试是个什么难度,喜欢考察什么类型的问题,思考怎么去准备,有**针对性**的进行查漏补缺。
51 |
52 | ## 关于算法题
53 |
54 | 学弟刷了400道LeetCode题目了,如果不是“无效刷题”,其实已经完全够用了。挺多人刷题量非常大,但是到最后发现还是效果不好,一道题做完之后,隔了半个月再来看,依旧一头雾水,这样刷再多题也没用。**建议是每刷完一道题,将解题思路写下来**,方便后续复习查看,这样刷题的效率会更高。
55 |
56 | ## 抓住秋招的尾巴
57 |
58 | **秋招尚未结束,抓住秋招的尾巴**。11月-12月这个时间段,会有公司针对秋招时没有招满的岗位进行补录,要抓住这个机会。秋招补录的流程很快,一般只有整个流程几天内可以走完。
59 |
60 |
61 |
62 |
63 |
64 | 最后,如果秋招面试过程有疑问、offer抉择问题、简历问题等,可以扫码加大彬的微信交流~
65 |
66 | 
67 |
68 |
--------------------------------------------------------------------------------
/docs/campus-recruit/share/README.md:
--------------------------------------------------------------------------------
1 | # 校招分享(持续更新中)
2 |
3 | - [双非本,非科班的自我救赎之路](./1-23-backend.md)
4 | - [非科班,秋招还没offer,该怎么办](./2-no-offer.md)
5 |
6 |
--------------------------------------------------------------------------------
/docs/career-plan/java-or-bigdata.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 24届校招,Java开发和大数据开发怎么选
4 | category: 分享
5 | tag:
6 | - 星球
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 职业规划,岗位选择,Java还是大数据
11 | - - meta
12 | - name: description
13 | content: 星球问题摘录
14 | ---
15 |
16 | ## 24届校招,Java开发和大数据开发怎么选
17 |
18 | 最近在大彬的[学习圈](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247492252&idx=1&sn=8fc12e97763e3b994b0dd0e717a4b674&chksm=ce9b1fdaf9ec96cca6c03cb6e7b61156d3226dbb587f81cea27b71be6671b81b537c9b7e9b2d#rd)中,有小伙伴提了一个关于方向选择的问题:**24届校招,Java开发和大数据开发怎么选**?
19 |
20 | **原问题如下**:
21 |
22 | 想请教一下大彬,对于**java开发和大数据开发**的明年秋招情况的预测。java岗位多卷度也高,每家公司基本都有相关的职位,大数据开发的话培训班比岗位多,只有大公司和数据公司会有这类岗位。24年秋招的话**选择哪个方向**会比较合适呢?
23 |
24 | ---
25 |
26 | **大彬的回答**:
27 |
28 | 建议选大数据吧。就这几年校招来看,大数据岗位拿offer的**难度**相比Java还是比较小一些的。而且距离24年秋招还有一年多时间,转大数据完全来得及,而且有了Java基础,再来学大数据,应该会比较快入门。
29 |
30 | 再说下大数据和后端的**差异**。大数据门槛比Java高,除了熟悉数据库的操作之外,还要学习大数据整个生态,需要会分布式、数仓、数据分析统计等知识。因为大数据的学习门槛比 Java 高,所以市场上培训大数据的相比Java会少一些,**竞争也相对小**,没有Java那么卷。
31 |
32 | 另外,大数据**薪资**总体会比Java开发高一些(同一家公司同一级别,普通开发岗比大数据开发薪资会少一点),这也是大数据方向的一个优势。
33 |
34 | 不过呢,小点的公司,可能没有大数据的需求,毕竟业务量不大(小公司通常也不建议去,坑多)。
35 |
36 | 综上所述,还是建议你选择**大数据**方向。
37 |
38 |
39 |
40 | ---
41 |
42 | 最后,推荐大家加入我的[学习圈](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247492252&idx=1&sn=8fc12e97763e3b994b0dd0e717a4b674&chksm=ce9b1fdaf9ec96cca6c03cb6e7b61156d3226dbb587f81cea27b71be6671b81b537c9b7e9b2d&scene=21#wechat_redirect),目前已经有140多位小伙伴加入了,文末有50元的**优惠券**,**扫描文末二维码**领取优惠券加入。
43 |
44 | 学习圈提供以下这些**服务**:
45 |
46 | 1、学习圈内部**知识图谱**,汇总了**优质资源、面试高频问题、大厂面经、踩坑分享**,让你少走一些弯路
47 |
48 | 2、四个**优质专栏**、Java**面试手册完整版**(包含场景设计、系统设计、分布式、微服务等),持续更新
49 |
50 | 3、**一对一答疑**,我会尽自己最大努力为你答疑解惑
51 |
52 | 4、**免费的简历修改、面试指导服务**,绝对赚回门票
53 |
54 | 5、各个阶段的优质**学习资源**(新手小白到架构师),超值
55 |
56 | 6、打卡学习,**大学自习室的氛围**,一起蜕变成长
57 |
58 |
59 |
60 | **加入方式**:**扫描二维码**领取优惠券加入(**即将恢复原价**)~
61 |
62 | 
63 |
--------------------------------------------------------------------------------
/docs/computer-basic/network.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 计算机网络常见面试题
4 | category: 计算机基础
5 | tag:
6 | - 网络
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 计算机网络常见面试题
11 | - - meta
12 | - name: description
13 | content: 计算机网络常见面试题,努力打造最优质的Java学习网站
14 | ---
15 |
16 | **计算机网络重要知识点&高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到**Java面试手册完整版**。
17 |
18 | 
19 |
20 | 如果你正在打算准备跳槽、面试,星球还提供**简历指导、修改服务**,大彬已经帮**120**+个小伙伴修改了简历,相对还是比较有经验的。
21 |
22 | 
23 |
24 | 
25 |
26 | 另外星球也提供**专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
27 |
28 | 
29 |
30 | 
31 |
32 | 
33 |
34 | 星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
35 |
36 | 
37 |
38 | 
39 |
40 | 
41 |
42 | 怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
43 |
44 | **扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
45 |
46 | 随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
47 |
48 | 
49 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/10-view.md:
--------------------------------------------------------------------------------
1 | # 视图
2 |
3 | 视图为虚拟的表。视图提供了一种MySQL的SELECT语句层次的封装,可用来简化数据处理以及重新格式化基础数据或保护基础数据。
4 |
5 | ## 应用
6 |
7 | - 重用SQL语句。
8 | - 保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限。
9 | - 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
10 |
11 | ## 限制
12 |
13 | - 与表一样,视图必须唯一命名
14 | - 视图不能索引,也不能有关联的触发器或默认值。
15 | - 视图可以和表一起使用。例如,编写一条联结表和视图的SELECT语句。
16 | - ORDER BY可以用在视图中,但如果从该视图检索数据SELECT中也含有ORDER BY,那么该视图中的ORDER BY将被覆盖。
17 |
18 | ## 语法
19 |
20 | `CREATE VIEW`:创建视图
21 |
22 | `SHOW CREATE VIEW viewname`:查看创建视图的语句
23 |
24 | `DROP VIEW viewname`:删除视图
25 |
26 | `CREATE ORREPLACE VIEW`:更新视图,相当于先用`DROP`再用`CREATE`
27 |
28 | ## 简化复杂连接
29 |
30 | 创建一个视图,返回订购了任意产品的客户列表。
31 |
32 | ```mysql
33 | CREATE VIEW productcustomers AS
34 | SELECT cust_name, orders, orderitems
35 | FROM customers, orders, orderitems
36 | WHERE orderitems.order_num = orders.order_num
37 | AND customers.cust_id = orders.cust_id;
38 | ```
39 |
40 | 使用视图:
41 |
42 | ```mysql
43 | SELECT cust_name, cust_contact
44 | FROM productcustomers
45 | WHERE prod_id = 'nike';
46 | ```
47 |
48 | ## 更新视图
49 |
50 | 对视图增加或删除行,实际上是对其基表增加或删除行。视图主要用于数据检索。
--------------------------------------------------------------------------------
/docs/database/mysql-basic/12-cursor.md:
--------------------------------------------------------------------------------
1 | # 游标
2 |
3 | 存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。MySQL游标只能用于存储过程(和函数)。
4 |
5 | ## 创建游标
6 |
7 | DECLARE 命名游标。存储过程处理完成后,游标便消失(游标只存在于存储过程)。定义游标之后,便可以打开它。
8 |
9 | ```mysql
10 | CREATE PROCEDURE processorders()
11 | BEGIN
12 | DECLARE ordernumbers CURSOR
13 | FOR
14 | SELECT order_num FROM orders;
15 | END;
16 | ```
17 |
18 | ## 使用游标
19 |
20 | `OPEN ordernumbers` 打开游标。
21 | `CLOSE ordernumbers` CLOSE释放游标使用的所有内部内存和资源。
22 |
23 | ```mysql
24 | CREATE PROCEDURE processorders()
25 | BEGIN
26 |
27 | DECLARE done BOOLEAN DEFAULT 0;
28 | DECLARE o INT;
29 | DECLARE t DECIMAL(8, 2);
30 |
31 | DECLARE ordernumbers CURSOR
32 | FOR
33 | SELECT order_num FROM orders;
34 |
35 | DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done=1; #游标移到最后
36 |
37 | CREATE TABLE IF NOT EXISTS ordertotals
38 | (order_num INT, total DECIMAL(8,2));
39 | -- 打开游标
40 | OPEN ordernumbers;
41 |
42 | -- 循环
43 | REPEAT
44 | FETCH ordernumbers INTO o;
45 | CALL ordertotal(o, 1, t);
46 |
47 | -- 插入订单号和订单金额
48 | INSERT INTO ordertotals(order_num, total)
49 | VALUES(o, t);
50 |
51 | -- done为1结束循环
52 | UNTIL done END REPEAT;
53 |
54 | CLOSE ordernumbers;
55 | END;
56 | ```
57 |
58 | 存储过程还在运行中创建了一个新表,。这个表将保存存储过程生成的结果。FETCH取每个order_num,然后用CALL执行另一个存储过程,计算每个订单税后金额。最后,用INSERT保存每个订单的订单号和金额。
--------------------------------------------------------------------------------
/docs/database/mysql-basic/13-trigger.md:
--------------------------------------------------------------------------------
1 | # 触发器
2 |
3 | 触发器提供SQL语句自动执行的功能。DELETE/INSERT/UPDATE支持触发器,其他SQL语句不支持。
4 |
5 | ## 创建
6 |
7 | 创建触发器四要素:1.唯一的触发器名(MySQL5规定触发器名在表中唯一,数据库没要求);2.触发器关联的表;3.相应的SQL语句;4.何时执行(处理之前或者之后)。
8 |
9 | ```mysql
10 | CREATE TRIGGER newproduct AFTER INSERT ON products #插入之后执行
11 | FOR EACH ROW SELECT 'product added'; #对每个插入行执行
12 | ```
13 |
14 | 只有表支持触发器,视图不支持。单一触发器不能与多个事件或多个表关联,如果需要对INSERT和UPDATE操作执行触发器,则应该定义两个触发器。
15 |
16 | ## 删除
17 |
18 | `DROP TRIGGER newproduct`
19 |
20 | ## 使用
21 |
22 | INSERT 触发器可饮用名为 NEW 的虚拟表,访问被插入的行。NEW中的值也可以被更新(允许更改被插入的值)。
23 |
24 | ```mysql
25 | CREATE TRIGGER neworder AFTER INSERT ON order
26 | FOR EACH ROW SELECT NEW.order_num; #返回新的订单号
27 | ```
28 |
29 | DELETE 触发器可以引用名为 OLD 的虚拟表,访问被删除的行。OLD中的值全都是只读的,不能更新。
30 |
31 | ```mysql
32 | CREATE TRIGGER deleteorder BEFORE DELETE ON orders
33 | FOR EACH ROW
34 | BEGIN
35 | INSERT INTO archive_orders(order_num, cust_id)
36 | VALUES(OLD.order_num, OLD.cust_id);
37 | END;
38 | ```
39 |
40 | 订单删除之前保存订单信息到存档表。
41 |
42 | UPDATE 触发器可以引用名为 OLD 的虚拟表访问以前的值,引用一个名为NEW的虚拟表访问新更新的值。NEW 值可被更新,OLD 值是只读的。
43 |
44 | 下面的例子保证州名缩写总是大写。
45 |
46 | ```mysql
47 | CREATE TRIGGER updatevendor BEFORE UPDATE ON vendor
48 | FOR EACH ROW SET NEW.vend_state = Upper(NEW.vend_state);
49 | ```
50 |
51 |
52 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/14-transaction.md:
--------------------------------------------------------------------------------
1 | # 事务处理
2 |
3 | 事务处理可以用来维护数据库的完整性。它保证成批的MySQL操作要么完全执行,要么完全不执行。
4 |
5 | CREATE/DROP 操作不能回退,即便可以执行回退操作,回退不会有效果。
6 |
7 | 执行事务过程,一旦某个SQL失败,则之前执行成功的SQL会被自动撤销。
8 |
9 | ## 语法
10 |
11 | ```mysql
12 | START TRANSACTION;
13 | DELETE FROM orderitems WHERE order_num = 20010;
14 | DELETE FROM orders WHERE order_num = 20010;
15 | COMMIT;
16 | ```
17 |
18 | 当COMMIT或ROLLBACK语句执行后,事务会自动关闭。
19 |
20 | ## 保留点
21 |
22 | 为了支持回退部分事务处理,必须能在事务处理块中合适的位置放置占位符。这样,如果需要回退,可以回退到某个占位符。
23 |
24 | 保留点在事务处理完成后自动释放。
25 |
26 | ```mysql
27 | ...
28 | SAVEPOINT delete1;
29 | ...
30 | ROLLBACK TO delete1;
31 | ```
32 |
33 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/15-permission.md:
--------------------------------------------------------------------------------
1 | # 权限
2 |
3 | MySQL用户账号和信息存储在名为mysql的MySQL数据库中。
4 |
5 | 获取用户账号列表:
6 |
7 | ```mysql
8 | USE mysql;
9 | SELECT user FROM user;
10 | ```
11 |
12 | 创建用户账号:`CREATE USER tyson IDENTIFIED BY 'abc123'`
13 |
14 | 修改密码:`SET PASSWORD FOR tyson = Password('xxx');`,新密码需传递到Password()函数进行加密。
15 |
16 | 设置当前用户密码:`SET PASSWORD = Password('xxx');`
17 |
18 | 重命名账号:`RENAME USER tyson TO tom`
19 |
20 | 删除用户账号:`DROP USER tyson`
21 |
22 | 查看访问权限:`SHOW GRANTS FOR tyson`,返回`USAGE ON *.*`则表示没有权限。
23 |
24 | 授予访问权限:`GRANT SELECT ON mall.# TO tyson`,允许用户在mall数据库所有表使用SELECT。
25 |
26 | 撤销权限:`REVOKE SELECT, INSERT ON mall.* FROM tyson`,被撤销的访问权限必须存在,否则会出错。
27 |
28 | GRANT和REVOKE可在几个层次上控制访问权限:
29 |
30 | - 整个服务器,使用GRANT ALL和REVOKE ALL;
31 | - 整个数据库,使用ON database.*;
32 | - 特定的表,使用ON database.table;
33 | - 特定的列;
34 | - 特定的存储过程。
35 |
36 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/16-performace-optimization.md:
--------------------------------------------------------------------------------
1 | # 性能优化
2 |
3 | 使用EXPLAIN语句让MySQL解释它将如何执行一条SELECT语句。
4 |
5 | 如果一个简单的WHERE子句返回结果所花的时间太长,则可以断定其中使用的某些列就是需要索引的对象。
6 |
7 | 避免使用OR。通过使用多条SELECT语句和连接它们的UNION语句,会有极大的性能改进。
8 |
9 | LIKE很慢,最好是使用FULLTEXT而不是LIKE。
10 |
11 | 很多高性能的应用都会对关联查询进行分解,有如下的优势:
12 |
13 | 1 、让缓存效率更高。如果某张表很少变化,那么基于该表的查询就可以重复利用查询缓存结果。
14 | 2 、将查询分解后,执行单个查询可以减少锁的竞争。
15 | 3 、在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展。
16 | 4 、查询本身效率也可能会有所提升。例如 IN()代替关联查询,可能比随机的关联更高效。
17 | 5 、减少冗余记录得查询。
18 | 6 、更进一步,这样做相当于在应用中实现了哈希关联,而不是使用 MySQL 得嵌套循环关联。某些场景哈希关联得效率要高很多。
--------------------------------------------------------------------------------
/docs/database/mysql-basic/17-index.md:
--------------------------------------------------------------------------------
1 | # 索引
2 |
3 | ## 创建索引
4 |
5 | ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
6 |
7 | ```mysql
8 | ALTER TABLE table_name ADD INDEX index_name (column_list)
9 | ALTER TABLE table_name ADD UNIQUE (column_list)
10 | ALTER TABLE table_name ADD PRIMARY KEY (column_list)
11 | ```
12 |
13 | CREATE INDEX可对表增加普通索引或UNIQUE索引。
14 |
15 | ```mysql
16 | CREATE INDEX index_name ON table_name (column_list)
17 | CREATE UNIQUE INDEX index_name ON table_name (column_list)
18 | ```
19 |
20 | 在创建索引时,可以规定索引能否包含重复值。如果不包含,则索引应该创建为PRIMARY KEY或UNIQUE索引。
21 |
22 | ## 删除索引
23 |
24 | ```mysql
25 | DROP INDEX index_name ON talbe_name
26 | ALTER TABLE table_name DROP INDEX index_name
27 | ALTER TABLE table_name DROP PRIMARY KEY #只有一个主键,不需要指定索引名
28 | ```
29 |
30 | ## 查看索引
31 |
32 | ```mysql
33 | show index from tblname;
34 | show keys from tblname;
35 | ```
36 |
37 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/3-function.md:
--------------------------------------------------------------------------------
1 | # 函数
2 | ## 文本处理
3 |
4 | ```mysql
5 | SELECT vend_name, Upper(vend_name) AS vend_name_upcase
6 | FROM vendors
7 | ORDER BY vend_name;
8 | ```
9 |
10 | Soundex()函数,匹配所有同音字符串。
11 |
12 | ```mysql
13 | SELECT cust_name, cust_contact
14 | FROM customers
15 | WHERE Soundex(cust_contact) = Soundex('Y Lie');
16 | ```
17 |
18 | 返回数据:`Tyson Y lee`
19 |
20 | ## 日期处理函数
21 |
22 | 
23 | 查找2005年9月的所有订单:
24 |
25 | ```mysql
26 | SELECT cust_id, order_num
27 | FROM orders
28 | WHERE Date(order_date) BETWEEN '2005-09-01' AND '2005-09-30';
29 | ```
30 |
31 | 或者
32 |
33 | ```mysql
34 | SELECT cust_id, order_num
35 | FROM orders
36 | WHERE Year(order_date) = 2005 AND Month(order_date) = 9;
37 | ```
38 |
39 | ## 数值处理函数
40 |
41 | 
42 |
43 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/4-sum.md:
--------------------------------------------------------------------------------
1 | # 聚集函数
2 |
3 | Sum:求和
4 | Avg:求平均数
5 | Max:求最大值
6 | Min:求最小值
7 | Count:求记录
8 |
9 | ```mysql
10 | SELECT SUM(item_price*quanlity) AS total_price
11 | FROM orderitems
12 | WHERE order_num = 2005;
13 | ```
14 |
15 | 聚集不同值:
16 |
17 | ```mysql
18 | SELECT AVG(DISTINCT prod_price) AS avg_price #只考虑不同价格
19 | FROM products
20 | WHERE vend_id = 1003;
21 | ```
22 |
23 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/5-group.md:
--------------------------------------------------------------------------------
1 | # 分组
2 |
3 | 单独地使用group by没意义,它只能显示出每组记录的第一条记录。
4 |
5 | ```mysql
6 | SELECT * FROM orders
7 | GROUP BY cust_id;
8 | ```
9 |
10 | 
11 |
12 | 除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出。
13 |
14 | ```mysql
15 | SELECT vend_id, COUNT(*) AS num_prods #vend_id在GROUP BY子句给出
16 | FROM products
17 | GROUP BY vend_id;
18 | ```
19 |
20 | GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
21 |
22 | ## 过滤分组
23 |
24 | having 用来分组查询后指定一些条件来输出查询结果,having作用和where类似,但是having只能用在group by场合,并且必须位于group by之后order by之前。
25 |
26 | ```mysql
27 | SELECT cust_id, COUNT(*) AS orders
28 | FROM orders
29 | GROUP BY cust_id
30 | HAVING COUNT(*) >= 2;
31 | ```
32 |
33 | ## having和where区别
34 |
35 | ```mysql
36 | SELECT cust_id FROM orders GROUP BY cust_id HAVING COUNT(cust_id) >= 2;
37 | SELECT cust_id FROM orders GROUP BY cust_id WHERE COUNT(cust_id) >= 2; #Error Code : 1064
38 | ```
39 |
40 | 第一个sql语句可以执行,但是第二个会报错。
41 |
42 | - WHERE子句不起作用,因为过滤是基于分组聚集值而不是特定行值的。
43 |
44 | - 二者作用的对象不同,where子句作用于表和视图,having作用于组。
45 |
46 | - WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。
47 |
48 | ```mysql
49 | SELECT vend_id, COUNT(*) AS num_prods
50 | FROM products
51 | WHERE prod_price >= 10
52 | GROUP BY vend_id
53 | HAVING COUNT(*) >= 2;
54 | ```
55 |
56 | WHERE子句过滤所有prod_price至少为10的行。然后按vend_id分组数据,HAVING子句过滤计数为2或2以上的分组。
57 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/7-full-text-query.md:
--------------------------------------------------------------------------------
1 | # 全文搜索
2 | 为了进行全文本搜索,必须索引被搜索的列,而且要随着数据的改变不断地重新索引。在对表列进行适当设计后,MySQL会自动进行所有的索引和重新索引。
3 |
4 | 启动全文搜索(仅在MyISAM数据库引擎中支持全文本搜索):
5 |
6 | ```mysql
7 | CREATE TABLE productnotes
8 | (
9 | note_id int NOT NULL AUTO_INCREMENT,
10 | note_text text NULL,
11 | PRIMARY KEY(note_id),
12 | FULLTEXT(note_text)
13 | ) ENGINE=MyISAM;
14 | ```
15 |
16 | 在定义之后,MySQL自动维护该索引。在增加、更新或删除行时,索引随之自动更新。
17 |
18 | 不要在导入数据时使用FULLTEXT,。应该首先导入所有数据,然后再修改表,定义FULLTEXT,这样可以更快导入数据。
19 |
20 | 使用全文搜索:
21 |
22 | ```mysql
23 | SELECT note_text
24 | FROM productnotes
25 | WHERE Match(note_text) Against('shoe'); #Match指定搜索列,Against指定搜索词
26 | ```
27 |
28 | 返回结果:`nike shoes is good`,搜索不区分大小写。
29 |
30 | 全文搜索会对返回结果进行排序,具有高等级的行先返回:
31 |
32 | ```mysql
33 | SELECT note_text,
34 | Match(note_text) Against('shoes') AS rank #等级由MySQL根据行中词的数目、唯一词的数目、整个索引中词的总数以及包含该词的行的数目计算出来。
35 | FROM productnotes;
36 | ```
37 |
38 | 全文搜索数据是有索引的,速度快。
39 |
40 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/8-table-operate.md:
--------------------------------------------------------------------------------
1 | # 表操作
2 |
3 | ## 创建表
4 |
5 | ```mysql
6 | CREATE TABLE productnotes
7 | (
8 | note_id int NOT NULL AUTO_INCREMENT,
9 | note_text text NULL,
10 | quanlity int NOT NULL DEFAULT 1, # 默认值,只支持常量
11 | PRIMARY KEY(note_id),
12 | FULLTEXT(note_text)
13 | ) ENGINE=MyISAM;
14 | ```
15 |
16 | 主键中只能使用NOT NULL值的列。
17 |
18 | ## 更新表
19 |
20 | 数据库表的更改不能撤销,应先做好备份。
21 |
22 | 添加列:
23 |
24 | ```mysql
25 | ALTER TABLE vendors
26 | ADD vend_phone CHAR(20);
27 | ```
28 |
29 | 删除列:
30 |
31 | ```mysql
32 | ALTER TABLE vendors
33 | DROP COLUMN vend_phone;
34 | ```
35 |
36 | 更改列属性:
37 |
38 | ```mysql
39 | ALTER TABLE vendors
40 | MODIFY vend_phone CHAR(16);
41 | ```
42 |
43 | 复杂的表结构更改一般需要手动删除过程:
44 |
45 | - 用新的列布局创建一个新表;
46 |
47 | - 使用INSERT SELECT语句,从旧表复制数据到新表;
48 |
49 | - 检验包含所需数据的新表;
50 | - 重命名旧表(如果确定,可以删除它);
51 |
52 | - 用旧表原来的名字重命名新表;
53 |
54 | - 重新创建触发器、存储过程、索引和外键。
55 |
56 | ## 约束
57 |
58 | 添加主键约束:
59 |
60 | ```mysql
61 | ALTER TABLE vendors
62 | ADD CONSTRAINT pk_vendors PRIMARY KEY(vend_id);
63 | ```
64 |
65 | 删除主键约束:
66 |
67 | ```mysql
68 | ALTER TABLE vendors
69 | DROP PRIMARY KEY;
70 | ```
71 |
72 | 添加外键约束:
73 |
74 | ```mysql
75 | ALTER TABLE products
76 | ADD FOREIGN KEY(vendor_id) REFERENCES vendors(vendor_id);
77 | ```
78 |
79 | 删除外键约束:
80 |
81 | ```mysql
82 | ALTER TABLE products DROP FOREIGN KEY vendor_id;
83 | ```
84 |
85 | ## 删除表
86 |
87 | `DROP TABLE cumstomers`
88 |
89 | ## truncate、delete与drop区别
90 |
91 | **相同点:**
92 |
93 | 1. truncate和不带where子句的delete、以及drop都会删除表内的数据。
94 |
95 | 2. drop、truncate都是DDL语句(数据定义语言),执行后会自动提交。
96 |
97 | **不同点:**
98 |
99 | 1. truncate 和 delete 只删除数据不删除表的结构;drop 语句将删除表的结构被依赖的约束、触发器、索引;
100 |
101 | 2. 速度,一般来说: drop> truncate > delete。
102 |
103 | ## 重命名表
104 |
105 | `RENAME TABLE cusmtomers TO cust`
106 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/9-column-operate.md:
--------------------------------------------------------------------------------
1 | # 列操作
2 |
3 | ## 插入数据
4 |
5 | MySQL用单条INSERT语句处理多个插入比使用多条INSERT语句快。
6 |
7 | ```mysql
8 | INSERT INTO customers(cust_name, cust_city)
9 | VALUES('Tyson', 'GD'),
10 | ('sophia','GZ');
11 | ```
12 |
13 | INSERT操作可能很耗时(特别是有很多索引需要更新时),而且它可能降低等待处理的SELECT语句的性能。降低INSERT语句的优先级:`INSERT LOW_PRIORITY INTO`
14 |
15 | ## 更新数据
16 |
17 | 如果用UPDATE语句更新多行,并且在更新这些行中的一行或多行时出一个现错误,则整个UPDATE操作被取消。为了在发生错误时也继续进行更新,可使用IGNORE关键字:`UPDATE IGNORE customers...`
18 |
19 | ```mysql
20 | UPDATE customers
21 | SET cust_city = NULL
22 | WHERE cust_id = 1005;
23 | ```
24 |
25 | 返回值是受影响的记录数。
26 |
27 | ## 删除数据
28 |
29 | 如果想从表中删除所有行,不要使用DELETE。可使用TRUNCATE TABLE语句,它完成相同的工作,但速度更快(TRUNCATE实际是删除原来的表并重新创建一个表,而不是逐行删除表中的数据)。
30 |
31 | ```mysql
32 | DELETE FROM customers
33 | WHERE cust_id = 1006;
34 | ```
35 |
36 | 如果执行DELETE语句而不带WHERE子句,表的所有数据都将被删除。MySQL没有撤销操作,应该非常小心地使用UPDATE和DELETE。
37 |
38 | delete使用别名的时候,要在delete和from间加上删除表的别名。
39 |
40 | ```mysql
41 | DELETE a #加上删除表的别名
42 | FROM table1 a
43 | WHERE a.status = 0
44 | AND EXISTS
45 | (SELECT b.id FROM table2 b
46 | WHERE b.id = a.id);
47 | ```
48 |
49 |
--------------------------------------------------------------------------------
/docs/database/mysql-basic/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: MySQL基础
3 | icon: linux
4 | date: 2022-08-06
5 | category: MySQL
6 | star: true
7 | ---
8 |
9 | **本专栏是大彬学习MySQL基础知识的学习笔记,如有错误,可以在评论区指出**~
10 |
11 | 
12 |
13 | ## MySQL基础总结
14 |
15 | - [数据类型](./1-data-type.md)
16 | - [基本命令](./2-basic-command.md)
17 | - [函数](./3-function.md)
18 | - [聚集函数](./4-sum.md)
19 | - [分组](./5-group.md)
20 | - [连接](./6-join.md)
21 | - [全文搜索](./7-full-text-query.md)
22 | - [表操作](./8-table-operate.md)
23 | - [列操作](./9-column-operate.md)
24 | - [视图](./10-view.md)
25 | - [存储过程](./11-procedure.md)
26 | - [游标](./12-cursor.md)
27 | - [触发器](./13-trigger.md)
28 | - [事务处理](./14-transaction.md)
29 | - [权限](./15-permission.md)
30 | - [性能优化](./16-performace-optimization.md)
31 | - [索引](./17-index.md)
32 |
--------------------------------------------------------------------------------
/docs/database/一条 SQL 查询语句如何执行的.md:
--------------------------------------------------------------------------------
1 | 一条 SQL 查询语句如何执行的
2 |
3 | 在平常的开发中,可能很多人都是 CRUD,对 SQL 语句的语法很熟练,但是说起一条 SQL 语句在 MySQL 中是怎么执行的却浑然不知,今天大彬就由浅入深,带大家一点点剖析一条 SQL 语句在 MySQL 中是怎么执行的。
4 |
5 | 比如你执行下面这个 SQL 语句时,我们看到的只是输入一条语句,返回一个结果,却不知道 MySQL 内部的执行过程:
6 |
7 | ```mysql
8 | mysql> select * from T where ID=10;
9 | ```
10 |
11 | 在剖析这个语句怎么执行之前,我们先看一下 MySQL 的基本架构示意图,能更清楚的看到 SQL 语句在 MySQL 的各个功能模块中的执行过程。
12 |
13 | 
14 |
15 | 整体来说,MySQL 可以分为 Server 层和存储引擎两部分。
16 |
17 | Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
18 |
19 | ### 连接器
20 |
21 | 如果要操作 MySQL 数据库,我们必须使用 MySQL 客户端来连接 MySQL 服务器,这时候就是服务器中的连接器来负责根客户端建立连接、获取权限、维持和管理连接。
22 |
23 | 在和服务端完成 TCP 连接后,连接器就要认证身份,需要用到用户名和密码,确保用户有足够的权限执行该SQL语句。
24 |
25 | ### 查询缓存
26 |
27 | 建立完连接后,就可以执行查询语句了,来到第二步:查询缓存。
28 |
29 | MySQL 拿到第一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中,如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
30 |
31 | 如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
32 |
33 | ### 分析器
34 |
35 | 如果没有命中缓存,就要开始真正执行语句了,MySQL 首先会对 SQL 语句做解析。
36 |
37 | 分析器会先做 “词法分析”,MySQL 需要识别出 SQL 里面的字符串分别是什么,代表什么。
38 |
39 | 做完之后就要做“语法分析”,根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。若果语句不对,就会收到错误提醒。
40 |
41 | ### 优化器
42 |
43 | 经过了分析器,MySQL 就知道要做什么了,但是在开始执行之前,要先经过优化器的处理。
44 |
45 | 比如:优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
46 |
47 | MySQL 会帮我去使用他自己认为的最好的方式去优化这条 SQL 语句,并生成一条条的执行计划,比如你创建了多个索引,MySQL 会依据**成本最小原则**来选择使用对应的索引,这里的成本主要包括两个方面, IO 成本和 CPU 成本。
48 |
49 | ### 执行器
50 |
51 | 执行优化之后的执行计划,在开始执行之前,先判断一下用户对这个表有没有执行查询的权限,如果没有,就会返回没有权限的错误;如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
52 |
53 | ### 存储引擎
54 |
55 | 执行器将查询请求发送给存储引擎组件。
56 |
57 | 存储引擎组件负责具体的数据存储、检索和修改操作。
58 |
59 | 存储引擎根据执行器的请求,从磁盘或内存中读取或写入相关数据。
60 |
61 | ### 返回结果
62 |
63 | 存储引擎将查询结果返回给执行器。
64 |
65 | 执行器将结果返回给连接器。
66 |
67 | 最后,连接器将结果发送回客户端,完成整个执行过程。
--------------------------------------------------------------------------------
/docs/framework/Apollo配置中心.md:
--------------------------------------------------------------------------------
1 | Apollo从设计之初就立志于成为一个有治理能力的配置发布平台,目前提供了以下的特性
2 |
3 | - **统一管理不同环境、不同集群的配置**
4 |
5 | - - Apollo提供了一个统一界面集中式管理不同环境(Environment)、不同集群(Cluster)、不同命名空间(Namespace)的配置
6 | - 同一份代码部署在不同的集群,可以有不同的配置
7 | - 通过命名空间可以很方便地支持多个不同应用共享同一份配置,同时还允许应用对共享的配置进行覆盖
8 |
9 | - **热发布--配置修改实时生效** 用户在Apollo修改完配置并发布后,客户端能实时(1秒)接收到最新的配置,并通知到应用程序
10 |
11 | - **版本发布管理** 所有的配置发布都有版本概念,从而可以方便地支持配置的回滚
12 |
13 | - **灰度发布** 支持配置的灰度发布,比如点了发布后,只对部分应用实例生效,等观察一段时间没问题后再推给所有应用实例
14 |
15 | - **权限管理、发布审核、操作审计**
16 |
17 | - - 应用和配置的管理都有完善的权限管理机制,对配置的管理还分为了编辑和发布两个环节,从而减少人为的错误
18 | - 所有的操作都有审计日志,可以方便地追踪问题
19 |
20 | - **客户端配置信息监控** 可以在界面上方便地看到配置在被哪些实例使用
21 |
22 | - **提供Java和.Net原生客户端**
23 |
24 | - - 提供了Java和.Net的原生客户端,方便应用集成
25 | - 支持Spring Placeholder, Annotation和Spring Boot的ConfigurationProperties,方便应用使用(需要Spring 3.1.1+)
26 | - 同时提供了Http接口,非Java和.Net应用也可以方便地使用
27 |
28 | - 提供开放平台API
29 |
30 | - 部署简单
31 |
32 |
33 |
34 | **基础模型**
35 |
36 | - 用户在配置中心对配置进行修改并发布
37 | - 配置中心通知Apollo客户端有配置更新
38 | - Apollo客户端从配置中心拉取最新的配置、更新本地配置并通知到应用
39 |
40 |
41 |
42 |
43 |
44 | **配置中心如何做到实时更新并且通知到客户端的?**
--------------------------------------------------------------------------------
/docs/framework/netty/1-overview.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | ## netty 核心组件
4 |
5 | - Channel:传入和传出数据的载体,它可以连接或者断开连接。
6 |
7 | - 回调:操作完成后通知相关方。
8 | - Future:提供了另一种在操作完成时通知应用程序的方式。
9 | - 事件和 ChannelHandler
10 |
11 | ## NIO
12 |
13 | 当一个 socket 建立好之后,Thread 会把这个连接请求交给 Selector,Selector 会不断去遍历所有的 Socket,一旦有一个 Socket 建立完成,它就会通知 Thread,然后 Thread 处理完数据在返回给客户端,这个过程是不阻塞的。
14 |
15 |
16 |
17 |
--------------------------------------------------------------------------------
/docs/framework/netty/8-eventloop-thread-model.md:
--------------------------------------------------------------------------------
1 | # EventLoop 和线程模型
2 |
3 | ## EventLoop 接口
4 |
5 | EventLoop 构建在 java.util.concurrent 和 io.netty.channel 之上。EventLoop 继承了 ScheduledExecutorService。EventLoop 由一个永远不会改变的 Thread 驱动,同时任务可以直接提交给 EventLoop 实现。EventLoop 可能服务于多个 Channel。
6 |
7 | Netty4中所有的 io 操作和事件都由 EventLoop 的 Thread 处理。Netty3只保证入站事件在 EventLoop(io 线程)执行,所有出站事件都由调用线程处理,可能是 io 线程或者别的线程,因此需要在 ChannelHandler 中对出站事件进行同步。
8 |
9 | Netty 4 中所采用的线程模型,通过在同一个线程中处理某个给定的EventLoop 中所产生的所有事件,解决了这个问题。这提供了一个更加简单的执行体系架构,并且消除了在多个ChannelHandler 中进行同步的需要
10 |
11 | ## 任务调度
12 |
13 | 使用 EventLoop 调度任务:
14 |
15 | ```java
16 | Channel ch = ...
17 | ScheduledFuture future = ch.eventLoop().schedule(
18 | new Runnable() {
19 | @Override
20 | public void run() {
21 | //逻辑
22 | }
23 | }, 60, TimeUnit.SECONDS);
24 | ```
25 |
26 | 周期性任务:
27 |
28 | ```java
29 | Channel ch = ...
30 | ScheduledFuture future = ch.eventLoop().scheduleAtFixedRate(
31 | new Runnable() {
32 | @Override
33 | public void run() {
34 | //逻辑
35 | }
36 | }, 60, 60, TimeUnit.SECONDES);
37 | ```
38 |
39 | ## 实现细节
40 |
41 | 
42 |
43 |
44 |
45 |
46 |
47 |
--------------------------------------------------------------------------------
/docs/framework/netty/9-guide.md:
--------------------------------------------------------------------------------
1 | # 引导
2 |
3 | 配置 netty 应用程序,使它运行起来。服务器使用一个父 Channel 接受来自客户端的连接,并创建子 Channel 以用于它们之间的通信。客户端只需要一个 Channel 完成所有的网络交互。
4 |
5 | 引导类是 cloneable 的,在引导类实例上调用 clone() 就可以创建多个具有类似配置或者完全相同配置的 Channel。
6 |
7 | ## 引导客户端
8 |
9 | BootStrap 类被用于客户端或者使用了无连接协议的应用程序中。
10 |
11 | ## 引导服务器
12 |
13 | 
14 |
15 | 在基类AbstractBootstrap有handler方法,目的是添加一个handler,监听Bootstrap的动作。
16 |
17 | 在服务端的ServerBootstrap中增加了一个方法childHandler,它的目的是添加handler,用来监听已经连接的客户端的Channel的动作和状态。
18 |
19 | **handler在初始化时就会执行,而childHandler会在客户端成功connect后才执行。**
20 |
21 | ## 在引导过程添加多个 ChannelHandler
22 |
23 | 在 handler 传入 ChannelInitializer 的实现类,重写 initChannel 方法,在这个方法中添加多个 ChannelHandler。
24 |
25 | ```java
26 | EventLoopGroup group = new NioEventLoopGroup();
27 | try {
28 | Bootstrap bootstrap = new Bootstrap();
29 | bootstrap.group(group)
30 | .channel(NioSocketChannel.class)//适用于nio传输的channel类型
31 | .remoteAddress(new InetSocketAddress(host, port))
32 | .handler(new ChannelInitializer() {
33 | @Override
34 | protected void initChannel(SocketChannel socketChannel) throws Exception {
35 | socketChannel.pipeline().addLast(
36 | new EchoClientHandler());
37 | }
38 | });
39 | ChannelFuture future = bootstrap.connect().sync();//连接到远程节点,阻塞等待
40 | future.channel().closeFuture().sync();//阻塞直到channel关闭
41 | } finally {
42 | group.shutdownGracefully().sync();//关闭线程池并释放所有的资源
43 | }
44 | ```
45 |
46 | ## 关闭
47 |
48 | 关闭 EventLoopGroup,它将处理任何挂起的事件和任务,随后释放所有活动的线程。
49 |
50 | ```java
51 | Future future = group.shutdownGracefully();//释放所有资源,关闭Channel
52 | // block until the group has shutdown
53 | future.syncUninterruptibly();
54 | ```
55 |
56 |
57 |
58 |
--------------------------------------------------------------------------------
/docs/framework/netty/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Netty基础
3 | icon: netty
4 | date: 2022-08-06
5 | category: netty
6 | star: true
7 | ---
8 |
9 | 
10 |
11 |
12 |
13 | ## Netty总结
14 |
15 | - [简介](./1-overview.md)
16 | - [简单的netty应用程序](./2-make-your-app.md)
17 | - [Netty的组件和设计](./3-component.md)
18 | - [传输](./4-transport.md)
19 | - [ChannelHandler](./6-channel-handler.md)
20 | - [ChannelPipeline接口](./7-channel-pipeline.md)
21 | - [EventLoop和线程模型](./8-eventloop-thread-model.md)
22 | - [引导](./9-guide.md)
23 | - [编解码器](./10-encoder-decoder.md)
24 | - [预置的ChannelHandler和编解码器](./11-preset-channel-handler.md)
25 |
--------------------------------------------------------------------------------
/docs/framework/springcloud/1-basic.md:
--------------------------------------------------------------------------------
1 | # 基础知识
2 |
3 | 微服务是将一个原本独立的系统拆分成多个小型服务,这些小型服务都在各自独立的进程中运行。
4 |
5 | [从单体应用到微服务](https://www.zhihu.com/question/65502802/answer/802678798)
6 |
7 | 单体系统的缺点:
8 |
9 | 1. 修改一个小功能,就需要将整个系统重新部署上线,影响其他功能的运行;
10 | 2. 功能模块互相依赖,强耦合,扩展困难。如果出现性能瓶颈,需要对整体应用进行升级,虽然影响性能的可能只是其中一个小模块;
11 |
12 | 单体系统的优点:
13 |
14 | 1. 容易部署,程序单一,不存在分布式集群的复杂部署环境;
15 | 2. 容易测试,没有复杂的服务调用关系。
16 |
17 | 微服务的优点:
18 |
19 | 1. 不同的服务可以使用不同的技术;
20 | 2. 隔离性。一个服务不可用不会导致其他服务不可用;
21 | 3. 可扩展性。某个服务出现性能瓶颈,只需对此服务进行升级即可;
22 | 4. 简化部署。服务的部署是独立的,哪个服务出现问题,只需对此服务进行修改重新部署;
23 |
24 | 微服务的缺点:
25 |
26 | 1. 网络调用频繁。性能相对函数调用较差。
27 | 2. 运维成本增加。系统由多个独立运行的微服务构成,需要设计一个良好的监控系统对各个微服务的运行状态进行监控。
28 |
29 | springcloud是一个基于Spring Boot实现的微服务架构开发工具。spring cloud包含多个子项目:
30 |
31 | - Spring Cloud Config:配置管理工具,支持使用Git存储配置内容, 可以使用它实现应用配置的外部化存储, 并支持客户端配置信息刷新、加密/解密配置内容等。
32 | - Spring Cloud Netflix:核心 组件,对多个Netflix OSS开源套件进行整合。
33 | - Eureka: 服务治理组件, 包含服务注册中心、服务注册与发现机制的实现。
34 | - Hystrix: 容错管理组件,实现断路器模式, 帮助服务依赖中出现的延迟和为故障提供强大的容错能力。
35 | - Ribbon: 客户端负载均衡的服务调用组件。
36 | - Feign: 基于Ribbon 和Hystrix 的声明式服务调用组件。
37 | - Zuul: 网关组件, 提供智能路由、访问过滤等功能。
38 | - Archaius: 外部化配置组件。
39 | - Spring Cloud Bus: 事件、消息总线, 用于传播集群中的状态变化或事件, 以触发后续的处理, 比如用来动态刷新配置等。
40 | - Spring Cloud Cluster: 针对ZooKeeper、Redis、Hazelcast、Consul 的选举算法和通用状态模式的实现。
41 | - Spring Cloud Consul: 服务发现与配置管理工具。
42 | - Spring Cloud ZooKeeper: 基于ZooKeeper 的服务发现与配置管理组件。
43 | - Spring Cloud Security:Spring Security组件封装,提供用户验证和权限验证,一般与Spring Security OAuth2 组一起使用,通过搭建授权服务,验证Token或者JWT这种形式对整个微服务系统进行安全验证
44 | - Spring Cloud Sleuth:分布式链路追踪组件,他分封装了Dapper、Zipkin、Kibana 的组件
45 | - Spring Cloud Stream:Spring Cloud框架的数据流操作包,可以封装RabbitMq,ActiveMq,Kafka,Redis等消息组件,利用Spring Cloud Stream可以实现消息的接收和发送
46 |
47 | spring-boot-starter-actuator:该模块能够自动为Spring Boot 构建的应用提供一系列用于监控的端点。
48 |
49 |
--------------------------------------------------------------------------------
/docs/framework/springcloud/10-bus.md:
--------------------------------------------------------------------------------
1 | # Spring Cloud Bus
2 |
3 | 我们通常会使用消息代理来构建一个主题,然后把微服务架构中的所有服务都连接到这个主题上去,当我们向该主题发送消息时,所有订阅该主题的服务都会收到消息并进行消费。使用 Spring Cloud Bus 可以方便地构建起这套机制,所以 Spring Cloud Bus 又被称为消息总线。Spring Cloud Bus 配合 Spring Cloud Config 使用可以实现配置的动态刷新。
4 |
5 |
6 |
7 |
--------------------------------------------------------------------------------
/docs/framework/springcloud/11-security.md:
--------------------------------------------------------------------------------
1 | # Spring Cloud Security
2 |
3 | Spring Cloud Security 为构建安全的SpringBoot应用提供了一系列解决方案,结合Oauth2可以实现单点登录、令牌中继、令牌交换等功能。
4 |
5 | OAuth 是一个验证授权(Authorization)的开放标准,所有人都有基于这个标准实现自己的OAuth。在OAuth之前,使用的是`HTTP Basic Authentication`(在浏览网页时候,浏览器会弹出一个登录验证的对话框),需要用户输入用户名和密码的形式进行验证, 这种形式是不安全的。OAuth的出现就是为了解决访问资源的安全性以及灵活性。OAuth使得第三方应用对资源的访问更加安全。
6 |
7 | 适用场景:[OAuth 2.0](https://www.ruanyifeng.com/blog/2014/05/oauth_2_0.html)
8 |
9 | 有一个"云冲印"的网站,可以将用户储存在Google的照片,冲印出来。用户为了使用该服务,必须让"云冲印"读取自己储存在Google上的照片。传统方法是,用户将自己的Google用户名和密码,告诉"云冲印",后者就可以读取用户的照片了。但是这种方法可能会导致用户密码泄露等问题。
10 |
11 | OAuth在"客户端"(云冲印)与"服务提供商"(谷歌)之间,设置了一个授权层(authorization layer)。"客户端"不能直接登录"服务提供商",只能登录授权层,以此将用户与客户端区分开来。"客户端"登录授权层所用的令牌(token),与用户的密码不同。用户可以在登录的时候,指定授权层令牌的权限范围和有效期。
12 |
13 | "客户端"登录授权层以后,"服务提供商"根据令牌的权限范围和有效期,向"客户端"开放用户储存的资料。
14 |
15 | 
16 |
17 | (A)用户打开客户端以后,客户端要求用户给予授权。
18 |
19 | (B)用户同意给予客户端授权。
20 |
21 | (C)客户端使用上一步获得的授权,向认证服务器申请令牌。
22 |
23 | (D)认证服务器对客户端进行认证以后,确认无误,同意发放令牌。
24 |
25 | (E)客户端使用令牌,向资源服务器申请获取资源。
26 |
27 | (F)资源服务器确认令牌无误,同意向客户端开放资源。
28 |
29 |
--------------------------------------------------------------------------------
/docs/framework/springcloud/2-springboot-springcloud-diff.md:
--------------------------------------------------------------------------------
1 | # 说说对SpringBoot 和SpringCloud的理解
2 |
3 | - SpringBoot专注于快速方便的开发单个个体微服务。
4 | - SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来,为各个微服务之间提供,配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等集成服务
5 | - SpringBoot可以离开SpringCloud独立使用开发项目,但是SpringCloud离不开SpringBoot,属于依赖的关系。
6 | - SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架。
7 |
8 | Spring Boot可以离开Spring Cloud独立使用开发项目,但是Spring Cloud离不开Spring Boot,属于依赖的关系。
9 |
10 |
--------------------------------------------------------------------------------
/docs/framework/springcloud/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: SpringCloud基础
3 | icon: cloud
4 | date: 2022-08-06
5 | category: springcloud
6 | star: true
7 | ---
8 |
9 |
10 | ## SpringCloud总结
11 |
12 | - [基础知识](./1-basic.md)
13 | - [说说对SpringBoot和SpringCloud的理解](./2-springboot-springcloud-diff.md)
14 | - [SpringCloudEureka](./3-eureka.md)
15 | - [SpringCloudRibbon](./4-ribbon.md)
16 | - [SpringCloudHystrix](./5-hystrix.md)
17 | - [SpringCloudFeign](./6-feign.md)
18 | - [SpringCloudZuul](./7-zuul.md)
19 | - [SpringCloudGateway](./8-gateway.md)
20 | - [SpringCloudConfig](./9-config.md)
21 | - [SpringCloudBus](./10-bus.md)
22 | - [SpringCloudSecurity](./11-security.md)
23 |
--------------------------------------------------------------------------------
/docs/framework/springmvc.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Spring MVC常见面试题总结
4 | category: 框架
5 | tag:
6 | - Spring MVC
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Spring MVC面试题,MVC模式,Spring MVC和Struts,Spring MVC工作原理,Spring MVC常用注解,Spring MVC异常处理,Spring MVC拦截器,REST
11 | - - meta
12 | - name: description
13 | content: 高质量的Spring MVC常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 |
17 |
18 | **Spring MVC高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到**Java面试手册完整版**。
19 |
20 | 
21 |
22 | 如果你正在打算准备跳槽、面试,星球还提供**简历指导、修改服务**,大彬已经帮**120**+个小伙伴修改了简历,相对还是比较有经验的。
23 |
24 | 
25 |
26 | 
27 |
28 | 另外星球也提供**专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
29 |
30 | 
31 |
32 | 
33 |
34 | 
35 |
36 | 星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
37 |
38 | 
39 |
40 | 
41 |
42 | 
43 |
44 | 怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
45 |
46 | **扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
47 |
48 | 随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
49 |
50 | 
--------------------------------------------------------------------------------
/docs/interview/concurrent/1-forbid-default-executor.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 为什么阿里禁止使用Java内置线程池?
4 | category: Java
5 | tag:
6 | - Java并发
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Java并发,多线程,线程池,为什么禁止使用Java内置线程池
11 | - - meta
12 | - name: description
13 | content: 高质量的Java并发常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | ## 为什么阿里禁止使用Java内置线程池?
17 |
18 | 首先要了解一下线程池 ThreadPoolExecutor 的参数及其作用。
19 |
20 | ThreadPoolExecutor有以下这些参数。
21 |
22 | 1. **corePoolSize** 指定了线程池里的线程数量,核心线程池大小
23 |
24 | 2. maximumPoolSize 指定了线程池里的最大线程数量
25 |
26 | 3. **keepAliveTime** 当线程池线程数量大于corePoolSize时候,多出来的空闲线程,多长时间会被销毁。
27 |
28 | 4. **TimeUnit**时间单位。
29 |
30 | 5. workQueue 任务队列,用于存放提交但是尚未被执行的任务。
31 |
32 | 6. **threadFactory** 线程工厂,用于创建线程,一般可以用默认的
33 |
34 | 7. **RejectedExecutionHandler** 拒绝策略,所谓拒绝策略,是指将任务添加到线程池中时,线程池拒绝该任务所采取的相应策略。
35 |
36 | 阿里规约之所以强制要求手动创建线程池,也是和这些参数有关。
37 |
38 | 阿里规约上指出,线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的**运行规则**,规避资源耗尽的风险。
39 |
40 | 虽然Executor提供的四个静态方法创建线程池,但是不建议去使用这些静态方法创建线程池,因为这些方法创建的线程池,如果使用不当,可能会有OOM的风险。
41 |
42 | 比如**newFixedThreadPool**和**newSingleThreadExecutor**的问题是堆积的请求处理队列可能会耗费非常大的内存,甚至**OOM**。
43 |
44 | **newCachedThreadPool**和**newScheduledThreadPool**的问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至**OOM**。
45 |
46 |
47 |
48 | --end--
49 |
50 | 最后分享一份大彬精心整理的**大厂面试手册**,包含**操作系统、计算机网络、Java基础、JVM、分布式**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
51 |
52 | 
53 |
54 | 
55 |
56 | **手册获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**手册**」就可以找到下载链接了(**无套路,无解压密码**)。
57 |
58 | 
59 |
--------------------------------------------------------------------------------
/docs/interview/java/1-create-object.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Java创建对象有几种方式?
4 | category: Java
5 | tag:
6 | - Java基础
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: java创建对象的方式
11 | - - meta
12 | - name: description
13 | content: 高质量的Java基础常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | ## Java创建对象有几种方式?
17 |
18 | Java创建对象有以下几种方式:
19 |
20 | - 1、用new语句创建对象。
21 | - 2、使用反射机制创建对象,用Class类或Constructor类的newInstance()方法。
22 | - 3、调用对象的clone()方法。需要实现Cloneable接口,重写object类的clone方法。当调用一个对象的clone方法,JVM就会创建一个新的对象,将前面对象的内容全部拷贝进去。
23 | - 4、运用反序列化手段。需要让类实现Serializable接口,通过ObjectInputStream的readObject()方法反序列化类。当我们序列化和反序列化一个对象,JVM会给我们创建一个单独的对象。
24 |
25 |
--------------------------------------------------------------------------------
/docs/interview/java/2-3rd-interface.md:
--------------------------------------------------------------------------------
1 | ## 对接第三方接口要考虑什么?
2 |
3 | 嗯,需要考虑以下几点:
4 |
5 | 1. 确认接口对接的网络协议,是https/http或者自定义的私有协议等。
6 | 2. 约定好数据传参、响应格式(如application/json),弱类型对接强类型语言时要特别注意
7 | 3. 接口安全方面,要确定身份校验方式,使用token、证书校验等
8 | 4. 确认是否需要接口调用失败后的重试机制,保证数据传输的最终一致性。
9 | 5. 日志记录要全面。接口出入参数,以及解析之后的参数值,都要用日志记录下来,方便定位问题(甩锅)。
10 |
11 |
12 |
13 | 参考:https://blog.csdn.net/gzt19881123/article/details/108791034
--------------------------------------------------------------------------------
/docs/interview/java/3-design-interface.md:
--------------------------------------------------------------------------------
1 | ## 设计接口要注意什么?
2 |
3 | 1. 接口参数校验。接口必须校验参数,比如入参是否允许为空,入参长度是否符合预期。
4 | 2. 设计接口时,充分考虑接口的可扩展性。思考接口是否可以复用,怎样保持接口的可扩展性。
5 | 3. 串行调用考虑改并行调用。比如设计一个商城首页接口,需要查商品信息、营销信息、用户信息等等。如果是串行一个一个查,那耗时就比较大了。这种场景是可以改为并行调用的,降低接口耗时。
6 | 4. 接口是否需要防重处理。涉及到数据库修改的,要考虑防重处理,可以使用数据库防重表,以唯一流水号作为唯一索引。
7 | 5. 日志打印全面,入参出参,接口耗时,记录好日志,方便甩锅。
8 | 6. 修改旧接口时,注意兼容性设计。
9 | 7. 异常处理得当。使用finally关闭流资源、使用log打印而不是e.printStackTrace()、不要吞异常等等
10 | 8. 是否需要考虑限流。限流为了保护系统,防止流量洪峰超过系统的承载能力。
11 |
12 |
--------------------------------------------------------------------------------
/docs/interview/java/4-interface-slow.md:
--------------------------------------------------------------------------------
1 | ## 线上接口很慢怎么办?
2 |
3 | 使用调用链跟踪,如zipkin,查看每一条路线的耗时情况,甚至包括此时 CPU 性能,然后再针对性能差的服务接口进行分析。
4 |
5 | 针对数据库性能优化问题,从设计上来说,设计表之前考虑好引擎,数据量,字段格式,索引等。
6 |
7 | 从 SQL 层面要利用好索引覆盖,尽量不回表,优化好 SQL。
8 |
9 | 从架构上来说,采用高可用的架构,如 MySQL 扩展的 MHA 架构
10 |
11 | 从业务代码层面来说,分析是不是代码问题,比如查询 SQL 过慢,返回超时,或者限流不合理等情况
12 |
13 | 如果数据量比较大的话,千万以及上亿级别,做好分表分库或者选用分布式数据库等
14 |
15 | 如果下游处理能力薄弱或者调用链路很深,考虑是否能够使用消息队列方式处理。
16 |
17 |
18 |
19 | > 参考:https://youle.zhipin.com/questions/d260cce58d0333c9tnVy2tW8GFQ~.html
--------------------------------------------------------------------------------
/docs/interview/java/5-comparable-vs-comparator.md:
--------------------------------------------------------------------------------
1 | ## Comparable和Comparator有什么区别?
2 |
3 | Comparable 和 Comparator 都是用来进行元素排序的。它们之间的区别如下:
4 |
5 | 1、字面含义不同。Comparable 是“比较”的意思,而 Comparator 是“比较器”的意思。
6 |
7 | 2、Comparable 是通过重写 compareTo 方法实现排序的,而 Comparator 是通过重写compare 方法实现排序的。
8 |
9 | 3、Comparable 必须由自定义类内部实现排序方法,而 Comparator 是外部定义并实现排序的。
10 |
11 |
12 |
13 | 总结一下:Comparable 可以看作是“对内”进行排序接口,而 Comparator 是“对外”进行排序的接口。
14 |
15 |
--------------------------------------------------------------------------------
/docs/interview/java/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## 目录
3 |
4 | - [Java创建对象有几种方式?](./1-create-object.md)
5 | - [对接第三方接口要考虑什么?](./2-3rd-interface.md)
6 | - [设计接口要注意什么?](./3-design-interface.md)
7 | - [线上接口很慢怎么办?](./4-interface-slow.md)
8 |
--------------------------------------------------------------------------------
/docs/interview/javaweb/1-interceptor-filter.md:
--------------------------------------------------------------------------------
1 | ## 过滤器和拦截器有什么区别?
2 |
3 | 1、**实现原理不同**。
4 |
5 | 过滤器和拦截器底层实现不同。过滤器是基于函数回调的,拦截器是基于Java的反射机制(动态代理)实现的。一般自定义的过滤器中都会实现一个doFilter()方法,这个方法有一个FilterChain参数,而实际上它是一个回调接口。
6 |
7 | 2、**使用范围不同**。
8 |
9 | 过滤器实现的是 javax.servlet.Filter 接口,而这个接口是在Servlet规范中定义的,也就是说过滤器Filter的使用要依赖于Tomcat等容器,导致它只能在web程序中使用。而拦截器是一个Spring组件,并由Spring容器管理,并不依赖Tomcat等容器,是可以单独使用的。拦截器不仅能应用在web程序中,也可以用于Application、Swing等程序中。
10 |
11 | 3、**使用的场景不同**。
12 |
13 | 因为拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:日志记录、权限判断等业务。而过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、响应数据压缩等功能。
14 |
15 | 4、**触发时机不同**。
16 |
17 | 过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。
18 |
19 | 拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。
20 |
21 | 5、**拦截的请求范围不同**。
22 |
23 | 请求的执行顺序是:请求进入容器 -> 进入过滤器 -> 进入 Servlet -> 进入拦截器 -> 执行控制器。可以看到过滤器和拦截器的执行时机也是不同的,过滤器会先执行,然后才会执行拦截器,最后才会进入真正的要调用的方法。
24 |
25 |
26 |
27 | > 参考链接:https://segmentfault.com/a/1190000022833940
--------------------------------------------------------------------------------
/docs/interview/mq/1-why-to-use-mq.md:
--------------------------------------------------------------------------------
1 | ## 为什么要使用消息队列?
2 |
3 | 主要有以下几点原因:
4 |
5 | 1、解**耦**。比如,用户下单后,订单系统需要通知库存系统,假如库存系统无法访问,则订单减库存将失败,从而导致订单操作失败。订单系统与库存系统耦合,这个时候如果使用消息队列,可以返回给用户成功,先把消息持久化,等库存系统恢复后,就可以正常消费减去库存了。
6 |
7 | 2、**异步**。将消息写入消息队列,非必要的业务逻辑以异步的方式运行,不影响主流程业务。
8 |
9 | 3、**削峰**。消费端慢慢的按照数据库能处理的并发量,从消息队列中慢慢拉取消息。在生产中,这个短暂的高峰期积压是允许的。比如秒杀活动,一般会因为流量过大,从而导致流量暴增,应用挂掉。这个时候加上消息队列,服务器接收到用户的请求后,首先写入消息队列,如果消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面。
10 |
11 | 总结一下,主要三点原因:**解耦、异步、削峰**。
12 |
13 | ## 那使用了消息队列会有什么缺点
14 |
15 | - **系统可用性降低**。引入消息队列之后,如果消息队列挂了,可能会影响到业务系统的可用性。
16 | - **系统复杂性增加**。加入了消息队列,要多考虑很多方面的问题,比如:一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。
17 |
18 |
19 |
20 |
21 |
22 | ---
23 |
24 |
25 |
26 | [整理了200本计算机经典书籍,含下载方式](https://github.com/Tyson0314/java-books)
27 |
28 | [Github疯传!谷歌师兄的LeetCode刷题笔记](https://topjavaer.cn/learning-resources/leetcode-note.html)
29 |
30 | [大彬花了一周收集的简历模板](https://mp.weixin.qq.com/s/JEG11UnWdO_Wi8-Qib89VQ)
31 |
32 | [学弟靠这本大厂面试手册,拿了字节跳动offer!](https://mp.weixin.qq.com/s/LVa4H5feXrjZL-DUtQQ0Yg)
--------------------------------------------------------------------------------
/docs/interview/network/1-input-url-return-page.md:
--------------------------------------------------------------------------------
1 | ## 说说浏览器中输入URL返回页面过程
2 |
3 | 1. **解析域名**,找到主机 IP。
4 | 2. 浏览器利用 IP 直接与网站主机通信,**三次握手**,建立 TCP 连接。浏览器会以一个随机端口向服务端的 web 程序 80 端口发起 TCP 的连接。
5 | 3. 建立 TCP 连接后,浏览器向主机发起一个HTTP请求。
6 | 4. 参数从客户端传递到服务器端。
7 | 5. 服务器端得到客户端参数之后,进行相应的业务处理,再将结果封装成 HTTP 包,返回给客户端。
8 | 6. 服务器端和客户端的交互完成,断开 TCP 连接(4 次挥手)。
9 | 7. 浏览器**解析响应内容,进行渲染**,呈现给用户。
10 |
11 | 
12 |
13 | ## DNS 域名解析的过程详细讲讲
14 |
15 | 在网络中定位是依靠 IP 进行身份定位的,所以 URL 访问的第一步便是先要得到服务器端的 IP 地址。而得到服务器的 IP 地址需要使用 DNS(Domain Name System,域名系统)域名解析,DNS 域名解析就是通过 URL 找到与之相对应的 IP 地址。
16 |
17 | DNS 域名解析的大致流程如下:
18 |
19 | 1. 先检**查浏览器中的 DNS 缓存**,如果浏览器中有对应的记录会直接使用,并完成解析;
20 | 2. 如果浏览器没有缓存,那就去**查询操作系统的缓存**,如果查询到记录就可以直接返回 IP 地址,完成解析;
21 | 3. 如果操作系统没有 DNS 缓存,就会去**查看本地 host 文件**,Windows 操作系统下,host 文件一般位于 "C:\Windows\System32\drivers\etc\hosts",如果 host 文件有记录则直接使用;
22 | 4. 如果本地 host 文件没有相应的记录,会**请求本地 DNS 服务器**,本地 DNS 服务器一般是由本地网络服务商如移动、联通等提供。通常情况下可通过 DHCP 自动分配,当然也可以自己手动配置。目前用的比较多的是谷歌提供的公用 DNS 是 8.8.8.8 和国内的公用 DNS 是 114.114.114.114。
23 | 5. 如果本地 DNS 服务器没有相应的记录,就会**去根域名服务器查询**了。为了能更高效完成全球所有域名的解析请求,根域名服务器本身并不会直接去解析域名,而是会把不同的解析请求分配给下面的其他服务器去完成。
24 |
25 | 
--------------------------------------------------------------------------------
/docs/java/java8/1-functional-program.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 函数式编程
4 | category: Java
5 | tag:
6 | - Java8
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 函数式编程
11 | - - meta
12 | - name: description
13 | content: 高质量的Java基础常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 函数式编程
17 |
18 | 面向对象编程:面向对象的语言,一切皆对象,如果想要调用一个函数,函数必须属于一个类或对象,然后在使用类或对象进行调用。面向对象编程可能需要多写很多重复的代码行。
19 |
20 | ```java
21 | Runnable runnable = new Runnable() {
22 | @Override
23 | public void run() {
24 | System.out.println("do something...");
25 | }
26 | };
27 |
28 | ```
29 |
30 | 函数式编程:在某些编程语言中,如js、c++,我们可以直接写一个函数,然后在需要的时候进行调用,即函数式编程。
31 |
32 |
--------------------------------------------------------------------------------
/docs/java/java8/2-lambda.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Lambda表达式
4 | category: Java
5 | tag:
6 | - Java8
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Lambda表达式
11 | - - meta
12 | - name: description
13 | content: 高质量的Java基础常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # Lambda 表达式
17 |
18 | 在Java8以前,使用`Collections`的sort方法对字符串排序的写法:
19 |
20 | ```java
21 | List names = Arrays.asList("dabin", "tyson", "sophia");
22 |
23 | Collections.sort(names, new Comparator() {
24 | @Override
25 | public int compare(String a, String b) {
26 | return b.compareTo(a);
27 | }
28 | });
29 | ```
30 |
31 | Java8 推荐使用lambda表达式,简化这种写法。
32 |
33 | ```java
34 | List names = Arrays.asList("dabin", "tyson", "sophia");
35 |
36 | Collections.sort(names, (String a, String b) -> b.compareTo(a)); //简化写法一
37 | names.sort((a, b) -> b.compareTo(a)); //简化写法二,省略入参类型,Java 编译器能够根据类型推断机制判断出参数类型
38 | ```
39 |
40 | 可以看到使用lambda表示式之后,代码变得很简短并且易于阅读。
41 |
42 |
--------------------------------------------------------------------------------
/docs/java/java8/3-functional-interface.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 函数式接口
4 | category: Java
5 | tag:
6 | - Java8
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 函数式接口
11 | - - meta
12 | - name: description
13 | content: 高质量的Java基础常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 函数式接口
17 |
18 | Functional Interface:函数式接口,只包含一个抽象方法的接口。只有函数式接口才能缩写成 Lambda 表达式。@FunctionalInterface 定义类为一个函数式接口,如果添加了第二个抽象方法,编译器会立刻抛出错误提示。
19 |
20 | ```java
21 | @FunctionalInterface
22 | interface Converter {
23 | T convert(F from);
24 | }
25 |
26 | public class FunctionalInterfaceTest {
27 | public static void main(String[] args) {
28 | Converter converter = (from) -> Integer.valueOf(from);
29 | Integer converted = converter.convert("666");
30 | System.out.println(converted);
31 | }
32 | /**
33 | * output
34 | * 666
35 | */
36 | }
37 | ```
38 |
39 |
40 |
41 |
--------------------------------------------------------------------------------
/docs/java/java8/6-parallel-stream.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Parallel-Streams
4 | category: Java
5 | tag:
6 | - Java8
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Parallel-Streams,并行流
11 | - - meta
12 | - name: description
13 | content: 高质量的Java基础常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # Parallel-Streams
17 |
18 | 并行流。`stream` 流是支持**顺序**和**并行**的。顺序流操作是单线程操作,串行化的流无法带来性能上的提升,通常我们会使用多线程来并行执行任务,处理速度更快。
19 |
20 | ```java
21 | /**
22 | * @description:
23 | * @author: 程序员大彬
24 | * @time: 2021-09-06 00:05
25 | */
26 | public class StreamTest7 {
27 | public static void main(String[] args) {
28 | int max = 100;
29 | List strs = new ArrayList<>(max);
30 | for (int i = 0; i < max; i++) {
31 | UUID uuid = UUID.randomUUID();
32 | strs.add(uuid.toString());
33 | }
34 |
35 | List sortedStrs = strs.stream().sorted().collect(Collectors.toList());
36 | System.out.println(sortedStrs);
37 | }
38 | /**
39 | * output
40 | * [029be6d0-e77e-4188-b511-f1571cdbf299, 02d97425-b696-483a-80c6-e2ef51c05d83, 0632f1e9-e749-4bce-8bac-1cf6c9e93afa, ...]
41 | */
42 | }
43 | ```
44 |
45 |
46 |
47 |
--------------------------------------------------------------------------------
/docs/java/java8/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## Java8总结
3 |
4 | - [函数式编程](./1-functional-program.md)
5 | - [Lambda表达式](./2-lambda.md)
6 | - [函数式接口](./3-functional-interface.md)
7 | - [内置的函数式接口](./4-inner-functional-interface.md)
8 | - [Stream](./5-stream.md)
9 | - [Parallel-Streams](./6-parallel-stream.md)
10 | - [Map集合](./7-map.md)
11 |
12 |
--------------------------------------------------------------------------------
/docs/java/jvm.md:
--------------------------------------------------------------------------------
1 | **JVM重要知识点&高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到Java面试手册**完整版**。
2 |
3 | 
4 |
5 | 除了Java面试手册完整版之外,星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
6 |
7 | 
8 |
9 | 
10 |
11 | 
12 |
13 | **专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
14 |
15 | 
16 |
17 | 
18 |
19 | 
20 |
21 | 如果你正在打算准备跳槽、面试,星球还提供**简历指导、修改服务**,大彬已经帮**120**+个小伙伴修改了简历,相对还是比较有经验的。
22 |
23 | 
24 |
25 | 
26 |
27 | 怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
28 |
29 | **扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
30 |
31 | 随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
32 |
33 | 
--------------------------------------------------------------------------------
/docs/learn/leetcode.md:
--------------------------------------------------------------------------------
1 | 在学习数据结构和算法,或者准备面试的小伙伴们,千万不要错过这份宝藏算法笔记!
2 |
3 | 
4 |
5 | 
6 |
7 | **手册获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**谷歌**」就可以找到下载链接了(**无套路,无解压密码**)。
8 |
9 | 
10 |
11 |
12 |
13 |
14 |
15 | ---
16 |
17 |
18 |
19 | > 最后给大家分享一个Github仓库,上面有大彬整理的**300多本经典的计算机书籍PDF**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~
20 |
21 | 
22 |
23 | 
24 |
25 | **Github地址**:https://github.com/Tyson0314/java-books
--------------------------------------------------------------------------------
/docs/learn/manual.md:
--------------------------------------------------------------------------------
1 | 大家好,我是大彬~
2 |
3 | 最近抽空将小破站的**面试题汇总成PDF手册**了,方便小伙伴打印出来看。手册内容基本跟网站上的一致,包含**Java基础、MySQL、SpringBoot、MyBatis、Redis、RabbitMQ、计算机网络、数据结构与算法、微服务、场景题**等内容。
4 |
5 | 这份面试手册非常**详细**,并且有相应的**配图讲解**:
6 |
7 | 
8 |
9 | 
10 |
11 | 
12 |
13 | 
14 |
15 | 
16 |
17 | **手册获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**手册**」就可以找到下载链接了(**无套路,无解压密码**)。
18 |
19 | 
20 |
21 | 祝大家学习愉快!
22 |
23 |
--------------------------------------------------------------------------------
/docs/learning-resources/chang-gou-mall.md:
--------------------------------------------------------------------------------
1 | 畅购商城项目是一个B2C的电商网站,采用了微服务架构,并且使用了前后端分离的方式进行开发。
2 |
3 | 整个微服务的开发是基于SpringBoot的,OAuth2.0是用来进行授权操作的,JWT用来封装用户的授权信息,Spring AMQP是消息队列协议。然后就是一套Spring Cloud的微服务框架。
4 |
5 | 持久化技术栈选用了MyBatis。数据库采用了MySQL,消息队列选用了RabbitMQ,还实现了MySQL读写分离。支付接口就选择了微信支付。
6 |
7 | 项目架构图如下:
8 |
9 | 
10 |
11 | 这个项目比较适合在校生学习,推荐给大家。
12 |
13 | **获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**畅购**」就可以找到下载链接了(**无套路,无解压密码**)。
14 |
15 | 
--------------------------------------------------------------------------------
/docs/learning-resources/leetcode-note.md:
--------------------------------------------------------------------------------
1 | 分享三份LeetCode刷题笔记,分别是**c/c++、Java、Go**版本的,每份笔记都挺详细,内容分别有**字符串、栈队列、树、排序、查找、BFS、DFS、贪心、动态规划**等等,每道题都包含解题思路、最佳解法、拓展题型等。
2 |
3 | 
4 |
5 | **c/c++版本**:
6 |
7 | 
8 |
9 | **Java版本**:
10 |
11 | 
12 |
13 | **Go版本**:
14 |
15 | 
16 |
17 | 正在学习数据结构和算法,或者准备面试的小伙伴们,千万不要错过这几份**宝藏笔记**!
18 |
19 | **手册获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**力扣**」就可以找到下载链接了(**无套路,无解压密码**)。
20 |
21 | 
22 |
23 | 祝大家学习愉快!
24 |
25 |
26 |
27 |
--------------------------------------------------------------------------------
/docs/learning-resources/mysql45-section.md:
--------------------------------------------------------------------------------
1 | MySQL 使用和面试中遇到的问题,很多人会通过搜索别人的经验来解决 ,零散不成体系。实际上只要理解了 MySQL 的底层工作原理,就能很快地直戳问题的本质。
2 |
3 | MySQL45讲专栏通过探讨 MySQL 实战中最常见的 **36 个** 痛点问题,串起各个零散的知识点,配合 **100+** 手绘详解图,由线到面带你构建 MySQL 系统的学习路径。
4 |
5 | 专栏共包括两大模块。
6 |
7 | **模块一,基础篇**。为你深入浅出地讲述 MySQL 核心知识,涵盖 MySQL 基础架构、日志系统、事务隔离、锁等内容。
8 |
9 | **模块二,实践篇**。将从一个个关键的数据库问题出发,分析数据库原理,并给出实践指导。每个问题,都不只是简单地给出答案,而是从为什么要这么想、到底该怎样做出发,让你能够知其所以然,都将能够解决你平时工作中的一个疑惑点。
10 |
11 | 建议大家都去听听这个专栏,干货满满!
12 |
13 | 
14 |
15 |
16 |
17 | **手册获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**1003**」就可以找到下载链接了(**无套路,无解压密码**)。
18 |
19 | 
--------------------------------------------------------------------------------
/docs/learning-resources/sgg-java-learn.md:
--------------------------------------------------------------------------------
1 | 尚硅谷的 java 教程,不用多说,在行业内是排前面的,java 相关的所有技术,尚硅谷基本上都有对应的视频教程,这里给大家分享尚硅谷 java 全套教程,200多G,**文末直接获取**。
2 |
3 | ## 全套视频共5部分
4 |
5 | 
6 |
7 | ## 基础必备
8 |
9 | 
10 |
11 | ## 微服务核心
12 |
13 | 
14 |
15 | ## 微服务生态
16 |
17 | 
18 |
19 | 
20 |
21 | ## 项目实战
22 |
23 | 
24 |
25 | ## 选学技术
26 |
27 | 
28 |
29 | 
30 |
31 | ## 获取方式
32 |
33 | 百度云链接: https://pan.baidu.com/s/1F5HJKF9o455_1_oqMhMOEw?pwd=dv9s 提取码: dv9s
--------------------------------------------------------------------------------
/docs/learning-resources/shang-chou.md:
--------------------------------------------------------------------------------
1 | 尚筹网项目是一个众筹项目,整个项目分为后台管理与前台会员两大部分。其整体框架图如下:
2 |
3 | 
4 |
5 | 1、后台管理系统为单一架构,由SSM框架进行实现,同时整合SpringSecurity来对用户权限进行控制。
6 |
7 | 2、前台会员系统 前台会员系统为分布式微服务架构,由SpringBoot+SpringCloud进行实现,同时为了上传项目图片整合了oss服务,以及为了支付整合了阿里的支付API。
8 |
9 | 
10 |
11 | **获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**尚筹网**」就可以找到下载链接了(**无套路,无解压密码**)。
12 |
13 | 
--------------------------------------------------------------------------------
/docs/learning-resources/springboot-guide.md:
--------------------------------------------------------------------------------
1 | # Alibaba官方上线!SpringBoot+SpringCloud全彩指南(终极版)
2 |
3 | **Alibaba**作为国内一线互联网大厂,其中**SpringCloudAlibaba**更是阿里微服务最具代表性的技术之一,很多人只知道SpringCloudAlibaba其实面向微服务技术基本上都有的下面就给大家**推荐一份**Alibaba官网最新版:Spring+SpringBoot+SpringCloud微服务全栈开发小册,带你全面掌握Spring全家桶的知识。
4 |
5 | 下面直接给大家展示**目录**:
6 |
7 | **SpringBoot**
8 |
9 | 
10 |
11 | 
12 |
13 | **SpringCloudAlibaba**
14 |
15 | 
16 |
17 | 
18 |
19 | **高清pdf版获取方式**:微信搜索「**程序员大彬**」或者扫描下面的二维码,关注后发送关键字「**1001**」就可以找到下载链接了(**无套路,无解压密码**)。
20 |
21 | 
--------------------------------------------------------------------------------
/docs/leetcode/hot120/1-two-sum.md:
--------------------------------------------------------------------------------
1 | # 1. 两数之和
2 |
3 | [1. 两数之和](https://leetcode.cn/problems/two-sum/)
4 |
5 | **题目描述**
6 |
7 | 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
8 |
9 | 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
10 |
11 | 你可以按任意顺序返回答案。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:nums = [2,7,11,15], target = 9
17 | 输出:[0,1]
18 | 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
19 | ```
20 |
21 | **解题思路**
22 |
23 | - 遍历数组 nums,i 为当前下标,每个值都判断map中是否存在 `nums[i]` 的 key 值。
24 |
25 | - 如果存在则找到了两个值,如果不存在则将当前的 `(target - nums[i],i)` 存入 map 中,继续遍历直到找到为止。
26 |
27 | **参考代码**:
28 |
29 | ```java
30 | class Solution {
31 | public int[] twoSum(int[] nums, int target) {
32 | int[] result = new int[2];
33 | Map map = new HashMap<>();
34 |
35 | for (int i = 0; i < nums.length; i++) {
36 | if (map.containsKey(nums[i])) {
37 | result[0] = map.get(nums[i]);
38 | result[1] = i;
39 | return result;
40 | }
41 | map.put(target - nums[i], i);
42 | }
43 |
44 | return result;
45 | }
46 | }
47 | ```
48 |
49 |
50 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/104-maximum-depth-of-binary-tree.md:
--------------------------------------------------------------------------------
1 | # 104. 二叉树的最大深度
2 |
3 | [题目链接](https://leetcode.cn/problems/maximum-depth-of-binary-tree/)
4 |
5 | **题目描述**
6 |
7 | 给定一个二叉树,找出其最大深度。
8 |
9 | 二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
10 |
11 | **说明:** 叶子节点是指没有子节点的节点。
12 |
13 | **示例**
14 |
15 | ```java
16 | 给定二叉树 [3,9,20,null,null,15,7],
17 | 3
18 | / \
19 | 9 20
20 | / \
21 | 15 7
22 | 返回它的最大深度 3 。
23 | ```
24 |
25 | **解题思路**
26 |
27 | 找出终止条件:当前节点为空
28 | 找出返回值:节点为空时说明高度为 0,所以返回 0;节点不为空时则分别求左右子树的高度的最大值,同时加1表示当前节点的高度,返回该数值
29 |
30 | **参考代码**:
31 |
32 | ```java
33 | /**
34 | * Definition for a binary tree node.
35 | * public class TreeNode {
36 | * int val;
37 | * TreeNode left;
38 | * TreeNode right;
39 | * TreeNode(int x) { val = x; }
40 | * }
41 | */
42 | class Solution {
43 | public int maxDepth(TreeNode root) {
44 | if (root == null) {
45 | return 0;
46 | }
47 | return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
48 | }
49 | }
50 | ```
51 |
52 |
53 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/11-container-with-most-water.md:
--------------------------------------------------------------------------------
1 | # 11. 盛最多水的容器
2 |
3 | [11. 盛最多水的容器](https://leetcode.cn/problems/container-with-most-water/)
4 |
5 | **题目描述**
6 |
7 | 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
8 |
9 | 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
10 |
11 | 返回容器可以储存的最大水量。
12 |
13 | 说明:你不能倾斜容器。
14 |
15 | 
16 |
17 | **示例**
18 |
19 | ```java
20 | 输入:[1,8,6,2,5,4,8,3,7]
21 | 输出:49
22 | 解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
23 |
24 | 输入:height = [1,1]
25 | 输出:1
26 | ```
27 |
28 | **解题思路**
29 |
30 | 左右指针,数字小的指针往数字大的指针移动,面积才有可能变大。注意左右指针数字相同的情况。
31 |
32 | ```java
33 | class Solution {
34 | public int maxArea(int[] height) {
35 | int maxArea = 0;
36 | int left = 0;
37 | int right = height.length - 1;
38 |
39 | while(left < right) {
40 | maxArea = Math.max(maxArea, Math.min(height[left], height[right]) * (right - left));
41 | if(height[left] > height[right]) {
42 | right--;
43 | } else {
44 | left++;
45 | }
46 | }
47 |
48 | return maxArea;
49 | }
50 | }
51 | ```
52 |
53 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/120-triangle.md:
--------------------------------------------------------------------------------
1 | # 120. 三角形最小路径和
2 |
3 | [题目链接](https://leetcode.cn/problems/triangle/)
4 |
5 | **题目描述**
6 |
7 | 给定一个三角形 triangle ,找出自顶向下的最小路径和。
8 |
9 | 每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。也就是说,如果正位于当前行的下标 i ,那么下一步可以移动到下一行的下标 i 或 i + 1 。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:triangle = [[2],[3,4],[6,5,7],[4,1,8,3]]
15 | 输出:11
16 | 解释:如下面简图所示:
17 | 2
18 | 3 4
19 | 6 5 7
20 | 4 1 8 3
21 | 自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
22 |
23 | 来源:力扣(LeetCode)
24 | 链接:https://leetcode.cn/problems/triangle
25 | 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
26 | ```
27 |
28 | **解题思路**
29 |
30 | 动态规划。
31 |
32 | ```java
33 | class Solution {
34 | public int minimumTotal(List> triangle) {
35 | int size = triangle.size();
36 | int[] minLen = new int[size + 1];//+1
37 | for (int i = size - 1; i >= 0 ; i--) {
38 | for (int j = 0; j <= i; j++) {
39 | minLen[j] = Math.min(minLen[j], minLen[j + 1]) + triangle.get(i).get(j);
40 | }
41 | }
42 |
43 | return minLen[0];
44 | }
45 | }
46 | ```
47 |
48 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/121-best-time-to-buy-and-sell-stock.md:
--------------------------------------------------------------------------------
1 | # 121. 买卖股票的最佳时机
2 |
3 | [原题链接](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/)
4 |
5 | ## 题目描述
6 |
7 | 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
8 |
9 | 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
10 |
11 | 返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
12 |
13 | **示例**:
14 |
15 | ```java
16 | 输入:[7,1,5,3,6,4]
17 | 输出:5
18 | 解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
19 | 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
20 | ```
21 |
22 | ## 解题思路
23 |
24 | 动态规划。前i天的最大收益 = max{前i-1天的最大收益,第i天的价格-前i-1天中的最小价格}
25 |
26 | ```java
27 | class Solution {
28 | public int maxProfit(int[] prices) {
29 | int minPrice = Integer.MAX_VALUE;
30 | int maxProfit = 0;
31 | for (int i = 0; i < prices.length; i++) {
32 | if (prices[i] < minPrice) {
33 | minPrice = prices[i];
34 | }
35 | maxProfit = Math.max(prices[i] - minPrice, maxProfit);
36 | }
37 | return maxProfit;
38 | }
39 | }
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/122-best-time-to-buy-and-sell-stock-ii.md:
--------------------------------------------------------------------------------
1 | # 122. 买卖股票的最佳时机 II
2 |
3 | [题目链接](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-ii/)
4 |
5 | **题目描述**:
6 |
7 | 给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
8 |
9 | 在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
10 |
11 | 返回 你能获得的 最大 利润 。
12 |
13 | **示例**:
14 |
15 | ```java
16 | 输入:prices = [1,2,3,4,5]
17 | 输出:4
18 | 解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
19 | 总利润为 4 。
20 | ```
21 |
22 | **解题思路**
23 |
24 | 可以尽可能地完成更多的交易,但不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
25 |
26 | ```java
27 | //输入: [7,1,5,3,6,4]
28 | //输出: 7
29 | class Solution {
30 | public int maxProfit(int[] prices) {
31 | int profit = 0;
32 | for (int i = 1; i < prices.length; i++) {
33 | int tmp = prices[i] - prices[i - 1];
34 | if (tmp > 0) {
35 | profit += tmp;
36 | }
37 | }
38 |
39 | return profit;
40 | }
41 | }
42 | ```
43 |
44 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/128-longest-consecutive-sequence.md:
--------------------------------------------------------------------------------
1 | # 128. 最长连续序列
2 |
3 | [128. 最长连续序列](https://leetcode.cn/problems/longest-consecutive-sequence/)
4 |
5 | **题目描述**:
6 |
7 | 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
8 |
9 | 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
10 |
11 | **示例**:
12 |
13 | ```java
14 | 输入:nums = [100,4,200,1,3,2]
15 | 输出:4
16 | 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
17 | ```
18 |
19 | **解题思路**
20 |
21 | 将数组存入set。遍历数组,对`num[i]`前后连续的数字进行计数,并将set中的这些数字移除,避免重复计算。
22 |
23 | 比如`[10, 9, 8, 7, 11, 14]`,存入set。遍历第一个元素10,set移除10,10前面有7-8-9,后面有11,连续序列长度为5,将set中的7-8-9-11移除,后续遍历到7-8-9-11,直接跳过。
24 |
25 | ```java
26 | class Solution {
27 | public int longestConsecutive(int[] nums) {
28 | Set set = new HashSet<>();
29 | for (int num : nums) {
30 | set.add(num);
31 | }
32 |
33 | int len = 0;
34 | int maxLen = 0;
35 | for (int num : nums) {
36 | len = 1;
37 | if (set.remove(num)) {
38 | int cur = num;
39 | while (set.remove(--cur)) {
40 | len++;
41 | }
42 | cur = num;
43 | while (set.remove(++cur)) {
44 | len++;
45 | }
46 | maxLen = maxLen > len ? maxLen : len;
47 | }
48 | }
49 |
50 | return maxLen;
51 | }
52 | }
53 | ```
54 |
55 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/134-gas-station.md:
--------------------------------------------------------------------------------
1 | # 134. 加油站
2 |
3 | [134. 加油站](https://leetcode.cn/problems/gas-station/)
4 |
5 | **题目描述**
6 |
7 | 在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
8 |
9 | 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
10 |
11 | 给定两个整数数组 gas 和 cost ,如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入: gas = [1,2,3,4,5], cost = [3,4,5,1,2]
17 | 输出: 3
18 | 解释:
19 | 从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
20 | 开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
21 | 开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
22 | 开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
23 | 开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
24 | 开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
25 | 因此,3 可为起始索引。
26 | ```
27 |
28 | **解题思路**:
29 |
30 | 1. 遍历一周,总获得的油量少于要花掉的油量必然没有结果;
31 | 2. 先苦后甜,记录遍历时所存的油量最少的站点,由于题目有解只有唯一解,所以从当前站点的下一个站点开始是唯一可能成功开完全程的。
32 |
33 | ```java
34 | class Solution {
35 | public int canCompleteCircuit(int[] gas, int[] cost) {
36 | int minIdx=0;
37 | int sum=Integer.MAX_VALUE;
38 | int num=0;
39 | for (int i = 0; i < gas.length; i++) {
40 | num+=gas[i]-cost[i];
41 | if(num 作者:cxywushixiong
29 | > 链接:https://leetcode.cn/problems/remove-nth-node-from-end-of-list/solution/dong-hua-tu-jie-leetcode-di-19-hao-wen-ti-shan-chu/
30 | > 来源:力扣(LeetCode)
31 |
32 | **代码实现**
33 |
34 | ```java
35 | class Solution {
36 | public ListNode removeNthFromEnd(ListNode head, int n) {
37 | ListNode dummy = new ListNode(-1);
38 | dummy.next = head;
39 | ListNode pre = dummy;
40 | ListNode slow = head;
41 | ListNode fast = head;
42 | for(int i=0;i rightSideView(TreeNode root) {
23 | List res = new ArrayList<>();
24 | if (root == null) {
25 | return res;
26 | }
27 |
28 | Queue queue = new ArrayDeque<>();
29 | queue.offer(root);
30 |
31 | while (!queue.isEmpty()) {
32 | int size = queue.size();
33 | while (size-- > 0) { //先取size的值,再自减
34 | TreeNode node = queue.poll();
35 | if (node.left != null) {
36 | queue.offer(node.left);
37 | }
38 | if (node.right != null) {
39 | queue.offer(node.right);
40 | }
41 | if (size == 0) { //最右边的节点
42 | res.add(node.val);
43 | }
44 | }
45 | }
46 |
47 | return res;
48 | }
49 | }
50 | ```
51 |
52 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/20-valid-parentheses.md:
--------------------------------------------------------------------------------
1 | # 20. 有效的括号
2 |
3 | [20. 有效的括号](https://leetcode.cn/problems/valid-parentheses/)
4 |
5 | **题目描述**
6 |
7 | 给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
8 |
9 | 有效字符串需满足:
10 |
11 | - 左括号必须用相同类型的右括号闭合。
12 | - 左括号必须以正确的顺序闭合。
13 | - 每个右括号都有一个对应的相同类型的左括号。
14 |
15 | **示例**
16 |
17 | ```java
18 | 输入:s = "()"
19 | 输出:true
20 |
21 | 输入:s = "()[]{}"
22 | 输出:true
23 | ```
24 |
25 | **解题思路**
26 |
27 | 使用栈实现。
28 |
29 | ```java
30 | class Solution {
31 | public boolean isValid(String s) {
32 | Stack stack = new Stack<>();
33 |
34 | for (int i = 0; i < s.length(); i++) {
35 | switch (s.charAt(i)) {
36 | case '(':
37 | stack.push(')');//存进相反符号
38 | break;
39 | case '[':
40 | stack.push(']');
41 | break;
42 | case '{':
43 | stack.push('}');
44 | break;
45 | default:
46 | if (stack.isEmpty() || s.charAt(i) != stack.pop()) {
47 | return false;
48 | }
49 | break;
50 | }
51 | }
52 | return stack.isEmpty();
53 | }
54 | }
55 | ```
56 |
57 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/200-number-of-islands.md:
--------------------------------------------------------------------------------
1 | # 200. 岛屿数量
2 |
3 | [题目链接](https://leetcode.cn/problems/number-of-islands/)
4 |
5 | **题目描述**
6 |
7 | 给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
8 |
9 | 岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
10 |
11 | 此外,你可以假设该网格的四条边均被水包围。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:grid = [
17 | ["1","1","1","1","0"],
18 | ["1","1","0","1","0"],
19 | ["1","1","0","0","0"],
20 | ["0","0","0","0","0"]
21 | ]
22 | 输出:1
23 | ```
24 |
25 | **解题思路**
26 |
27 | 深度优先遍历,使用isVisited数组记录元素是否被访问过。
28 |
29 | ```java
30 | class Solution {
31 | public int numIslands(char[][] grid) {
32 | if (grid == null || grid.length == 0 || grid[0].length == 0) {
33 | return 0;
34 | }
35 |
36 | boolean[][] isVisited = new boolean[grid.length][grid[0].length];
37 | int count = 0;
38 |
39 | for (int i = 0; i < grid.length; i++) {
40 | for (int j = 0; j < grid[0].length; j++) {
41 | if (grid[i][j] == '1' && !isVisited[i][j]) {
42 | dfs(grid, isVisited, i, j);
43 | count++;
44 | }
45 | }
46 | }
47 |
48 | return count;
49 | }
50 |
51 | private void dfs(char[][] grid, boolean[][] isVisited, int i, int j) {
52 | if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == '0') {
53 | return;
54 | }
55 | if (!isVisited[i][j]) {
56 | isVisited[i][j] = true;
57 | dfs(grid, isVisited, i + 1, j);
58 | dfs(grid, isVisited, i - 1, j);
59 | dfs(grid, isVisited, i, j + 1);
60 | dfs(grid, isVisited, i, j - 1);
61 | }
62 | }
63 | }
64 | ```
65 |
66 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/206-reverse-linked-list.md:
--------------------------------------------------------------------------------
1 | # 206. 反转链表
2 |
3 | [原题链接](https://leetcode.cn/problems/reverse-linked-list/)
4 |
5 | **题目描述**
6 |
7 | 给你单链表的头节点 `head` ,请你反转链表,并返回反转后的链表。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:head = [1,2,3,4,5]
13 | 输出:[5,4,3,2,1]
14 | ```
15 |
16 | **解题思路**:
17 |
18 | 1. 定义两个指针,第一个指针叫 pre,最初是指向 null 的。
19 | 2. 第二个指针 cur 指向 head,然后不断遍历 cur。
20 | 3. 每次迭代到 cur,都将 cur 的 next 指向 pre,然后 pre 和 cur 前进一位。
21 | 4. 都迭代完了(cur 变成 null 了),pre 就是最后一个节点了。
22 |
23 | ```java
24 | class Solution {
25 | public ListNode reverseList(ListNode head) {
26 | if (head == null) {
27 | return null;
28 | }
29 |
30 | ListNode pre = null;
31 | ListNode cur = head;
32 | ListNode tmp = null;
33 | while (cur != null) {
34 | tmp = cur.next;
35 | cur.next = pre;
36 | pre = cur;
37 | cur = tmp;
38 | }
39 |
40 | return pre;
41 | }
42 | }
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/21-merge-two-sorted-lists.md:
--------------------------------------------------------------------------------
1 | # 21. 合并两个有序链表
2 |
3 | [21. 合并两个有序链表](https://leetcode.cn/problems/merge-two-sorted-lists/)
4 |
5 | **题目描述**
6 |
7 | 将两个升序链表合并为一个新的 **升序** 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:l1 = [1,2,4], l2 = [1,3,4]
13 | 输出:[1,1,2,3,4,4]
14 | ```
15 |
16 | **参考代码**
17 |
18 | ```java
19 | class Solution {
20 | public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
21 | ListNode ans = new ListNode(0);
22 | ListNode tmp = ans;
23 |
24 | while (l1 != null && l2!= null) {
25 | if (l1.val > l2.val) {
26 | tmp.next = l2; //tmp.next = new ListNode(l2.val); 没必要这么做
27 | l2 = l2.next;
28 | } else {
29 | tmp.next = l1;
30 | l1 = l1.next;
31 | }
32 | tmp = tmp.next;
33 | }
34 |
35 | tmp.next = l1 == null ? l2 : l1;
36 |
37 | return ans.next;
38 | }
39 | }
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/234-palindrome-linked-list.md:
--------------------------------------------------------------------------------
1 | # 234. 回文链表
2 |
3 | [234. 回文链表](https://leetcode.cn/problems/palindrome-linked-list/)
4 |
5 | **题目描述**
6 |
7 | 给你一个单链表的头节点 `head` ,请你判断该链表是否为回文链表。如果是,返回 `true` ;否则,返回 `false` 。
8 |
9 | **示例**
10 |
11 | ```java
12 | 给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
13 | ```
14 |
15 | **解题思路**
16 |
17 | 快慢指针。
18 |
19 | 快指针走到末尾,慢指针刚好到中间。其中慢指针将前半部分反转。然后比较。
20 |
21 | **参考代码**:
22 |
23 | ```java
24 | public boolean isPalindrome(ListNode head) {
25 | if(head == null || head.next == null) {
26 | return true;
27 | }
28 | ListNode slow = head, fast = head;
29 | ListNode pre = head, prepre = null;
30 | while(fast != null && fast.next != null) {
31 | pre = slow;
32 | slow = slow.next;
33 | fast = fast.next.next;
34 | pre.next = prepre;
35 | prepre = pre;
36 | }
37 | if(fast != null) {
38 | slow = slow.next;
39 | }
40 | while(pre != null && slow != null) {
41 | if(pre.val != slow.val) {
42 | return false;
43 | }
44 | pre = pre.next;
45 | slow = slow.next;
46 | }
47 | return true;
48 | }
49 |
50 | 作者:nuan
51 | 链接:https://leetcode.cn/problems/palindrome-linked-list/solution/wo-de-kuai-man-zhi-zhen-du-cong-tou-kai-shi-gan-ju/
52 | 来源:力扣(LeetCode)
53 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
54 | ```
55 |
56 |
57 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/236-lowest-common-ancestor-of-a-binary-tree.md:
--------------------------------------------------------------------------------
1 | # 236. 二叉树的最近公共祖先
2 |
3 | [题目链接](https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-tree/)
4 |
5 | **题目描述**
6 |
7 | 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
8 |
9 | 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
15 | 输出:3
16 | 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
17 | ```
18 |
19 | **解题思路**
20 |
21 | [后序遍历](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/solution/236-er-cha-shu-de-zui-jin-gong-gong-zu-xian-hou-xu/)
22 |
23 | ```java
24 | class Solution {
25 | public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
26 | if (root == null || root == p || root == q) {
27 | return root;
28 | }
29 |
30 | TreeNode left = lowestCommonAncestor(root.left, p, q);
31 | TreeNode right = lowestCommonAncestor(root.right, p, q);
32 |
33 | if (left != null && right != null) {
34 | return root;
35 | } else {
36 | return left == null ? right : left;
37 | }
38 | }
39 | }
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/24-swap-nodes-in-pairs.md:
--------------------------------------------------------------------------------
1 | # 24. 两两交换链表中的节点
2 |
3 | [两两交换链表中的节点](https://leetcode.cn/problems/swap-nodes-in-pairs/)
4 |
5 | **题目描述**
6 |
7 | 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
8 |
9 | 
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:head = [1,2,3,4]
15 | 输出:[2,1,4,3]
16 | ```
17 |
18 | **解题思路**
19 |
20 | 使用递归实现。
21 |
22 | ```java
23 | class Solution {
24 | public ListNode swapPairs(ListNode head) {
25 | if (head == null) {
26 | return head;
27 | }
28 | ListNode left = head;
29 | ListNode right = head.next;
30 |
31 | if (right == null) {
32 | right = left;
33 | } else {
34 | left.next = swapPairs(right.next);
35 | right.next = left;
36 | }
37 |
38 | return right;
39 | }
40 | }
41 | ```
42 |
43 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/26-remove-duplicates-from-sorted-array.md:
--------------------------------------------------------------------------------
1 | # 26. 删除有序数组中的重复项
2 |
3 | [题目链接](https://leetcode.cn/problems/remove-duplicates-from-sorted-array/)
4 |
5 | **题目描述**
6 |
7 | 给你一个 **升序排列** 的数组 `nums` ,请你**[ 原地](http://baike.baidu.com/item/原地算法)** 删除重复出现的元素,使每个元素 **只出现一次** ,返回删除后数组的新长度。元素的 **相对顺序** 应该保持 **一致** 。
8 |
9 | 由于在某些语言中不能改变数组的长度,所以必须将结果放在数组nums的第一部分。更规范地说,如果在删除重复项之后有 `k` 个元素,那么 `nums` 的前 `k` 个元素应该保存最终结果。
10 |
11 | 将最终结果插入 `nums` 的前 `k` 个位置后返回 `k` 。
12 |
13 | 不要使用额外的空间,你必须在 **[原地 ](https://baike.baidu.com/item/原地算法)修改输入数组** 并在使用 O(1) 额外空间的条件下完成。
14 |
15 | **示例**:
16 |
17 | ```java
18 | 输入:nums = [1,1,2]
19 | 输出:2, nums = [1,2,_]
20 | 解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
21 | ```
22 |
23 | **参考代码**
24 |
25 | ```java
26 | class Solution {
27 | public int removeDuplicates(int[] nums) {
28 | if (nums == null || nums.length == 0) {
29 | return 0;
30 | }
31 | int left = 0;
32 | int right = 1;
33 | int count = 1;
34 |
35 | while (right < nums.length) {
36 | if (nums[right] == nums[left]) {
37 | if (count < 2) {
38 | nums[++left] = nums[right++];
39 | } else {
40 | right++;
41 | }
42 | count++;
43 | } else {
44 | count = 1;
45 | nums[++left] = nums[right++];
46 | }
47 | }
48 | return left + 1;
49 | }
50 | }
51 | ```
52 |
53 |
54 |
55 |
56 |
57 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/27-remove-element.md:
--------------------------------------------------------------------------------
1 | # 27. 移除元素
2 |
3 | [移除元素](https://leetcode.cn/problems/remove-element/)
4 |
5 | **题目描述**
6 |
7 | 给你一个数组 `nums` 和一个值 `val`,你需要 **[原地](https://baike.baidu.com/item/原地算法)** 移除所有数值等于 `val` 的元素,并返回移除后数组的新长度。
8 |
9 | 不要使用额外的数组空间,你必须仅使用 `O(1)` 额外空间并 **[原地 ](https://baike.baidu.com/item/原地算法)修改输入数组**。
10 |
11 | 元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:nums = [3,2,2,3], val = 3
17 | 输出:2, nums = [2,2]
18 | 解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
19 | ```
20 |
21 | **解题思路**
22 |
23 | 
24 |
25 | > 作者:画手大鹏
26 | > 链接:https://leetcode.cn/problems/remove-element/solutions/10388/hua-jie-suan-fa-27-yi-chu-yuan-su-by-guanpengchn/
27 | > 来源:力扣(LeetCode)
28 | > 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
29 |
30 | ```java
31 | class Solution {
32 | public int removeElement(int[] nums, int val) {
33 | int ans = 0;
34 | for(int num: nums) {
35 | if(num != val) {
36 | nums[ans] = num;
37 | ans++;
38 | }
39 | }
40 | return ans;
41 | }
42 | }
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/28-mirror-binary-tree.md:
--------------------------------------------------------------------------------
1 | # 28. 对称的二叉树
2 |
3 | [28. 对称的二叉树](https://leetcode.cn/problems/dui-cheng-de-er-cha-shu-lcof/)
4 |
5 | **题目描述**
6 |
7 | 请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
8 |
9 | 例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:root = [1,2,2,3,4,4,3]
15 | 输出:true
16 | ```
17 |
18 | **解题思路**
19 |
20 | 从顶至底递归,判断每对节点是否对称,从而判断树是否为对称二叉树。
21 |
22 | ```java
23 | class Solution {
24 | public boolean isSymmetric(TreeNode root) {
25 | if (root == null) {
26 | return true;
27 | }
28 | return isMirror(root.left, root.right);
29 | }
30 |
31 | public boolean isMirror(TreeNode node1, TreeNode node2) {
32 | if (node1 == null && node2 == null) {
33 | return true;
34 | }
35 |
36 | if (node1 == null || node2 == null || node1.val != node2.val) {
37 | return false;
38 | }
39 |
40 | return isMirror(node1.left, node2.right) && isMirror(node1.right, node2.left);
41 | }
42 | }
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/29-divide-two-integers.md:
--------------------------------------------------------------------------------
1 | # 29. 两数相除
2 |
3 | [29. 两数相除](https://leetcode.cn/problems/divide-two-integers/)
4 |
5 | **题目描述**
6 |
7 | 给定两个整数,被除数 `dividend` 和除数 `divisor`。将两数相除,要求不使用乘法、除法和 mod 运算符。
8 |
9 | 返回被除数 `dividend` 除以除数 `divisor` 得到的商。
10 |
11 | 整数除法的结果应当截去(`truncate`)其小数部分,例如:`truncate(8.345) = 8` 以及 `truncate(-2.7335) = -2`
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入: dividend = 10, divisor = 3
17 | 输出: 3
18 | 解释: 10/3 = truncate(3.33333..) = truncate(3) = 3
19 | ```
20 |
21 | **解题思路**
22 |
23 | Integer.MIN_VALUE 转为正数会溢出,故将 dividend 和 divisor 都转化为负数。**两个负数相加溢出会大于0**。
24 |
25 | ```java
26 | class Solution {
27 | //dividend / divisor
28 | public int divide(int dividend, int divisor) {
29 | if (dividend == Integer.MIN_VALUE && divisor == -1) {
30 | return Integer.MAX_VALUE;
31 | }
32 | if (divisor == 1) { //不加上会超时
33 | return dividend;
34 | }
35 | int sign = 1;
36 | if ((dividend < 0 && divisor > 0) || (dividend > 0 && divisor < 0)) {
37 | sign = -1;
38 | }
39 | int a = dividend > 0 ? -dividend : dividend;
40 | int b = divisor > 0 ? -divisor : divisor;
41 | if (a > b) {
42 | return 0;
43 | }
44 | int ans = divideHelper(a, b);
45 |
46 | return sign > 0 ? ans : -ans;
47 | }
48 |
49 | private int divideHelper(int a, int b) {
50 | if (a > b) {
51 | return 0;
52 | }
53 |
54 | int count = 1;
55 | int tmp = b;
56 | while (tmp + tmp >= a && tmp + tmp < 0) { //两个负数相加溢出会大于0
57 | tmp += tmp;
58 | count += count;
59 | }
60 |
61 | return count + divideHelper(a - tmp, b);
62 | }
63 | }
64 | ```
65 |
66 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/3-longest-substring-without-repeating-characters.md:
--------------------------------------------------------------------------------
1 | # 3 . 无重复字符的最长子串
2 |
3 | [题目链接](https://leetcode.cn/problems/longest-substring-without-repeating-characters/)
4 |
5 | **题目描述**
6 |
7 | 给定一个字符串 `s` ,请你找出其中不含有重复字符的 **最长子串** 的长度。
8 |
9 | **示例**
10 |
11 | ```
12 | 输入: s = "abcabcbb"
13 | 输出: 3
14 | 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
15 | ```
16 |
17 | **解题思路**
18 |
19 | 这道题主要用到思路是:滑动窗口
20 |
21 | **什么是滑动窗口**?
22 |
23 | 其实就是一个队列,比如例题中的 abcabcbb,进入这个队列(窗口)为 abc 满足题目要求,当再进入 a,队列变成了 abca,这时候不满足要求。所以,我们要移动这个队列!
24 |
25 | **如何移动**?
26 |
27 | 我们只要把队列的左边的元素移出就行了,直到满足题目要求!
28 |
29 | 一直维持这样的队列,找出队列出现最长的长度时候,求出解!
30 |
31 | 时间复杂度:O(n)
32 |
33 | **代码实现**
34 |
35 | ```java
36 | class Solution {
37 | public int lengthOfLongestSubstring(String s) {
38 | if (s.length()==0) return 0;
39 | HashMap map = new HashMap();
40 | int max = 0;
41 | int left = 0;
42 | for(int i = 0; i < s.length(); i ++){
43 | if(map.containsKey(s.charAt(i))){
44 | left = Math.max(left,map.get(s.charAt(i)) + 1);
45 | }
46 | map.put(s.charAt(i),i);
47 | max = Math.max(max,i-left+1);
48 | }
49 | return max;
50 |
51 | }
52 | }
53 | ```
54 |
55 |
56 |
57 | > 作者:powcai
58 | > 链接:https://leetcode.cn/problems/longest-substring-without-repeating-characters/solution/hua-dong-chuang-kou-by-powcai/
59 | > 来源:力扣(LeetCode)
--------------------------------------------------------------------------------
/docs/leetcode/hot120/31-next-permutation.md:
--------------------------------------------------------------------------------
1 | # 31. 下一个排列
2 |
3 | [31. 下一个排列](https://leetcode.cn/problems/next-permutation/)
4 |
5 | **题目描述**
6 |
7 | 整数数组的一个 **排列** 就是将其所有成员以序列或线性顺序排列。
8 |
9 | - 例如,`arr = [1,2,3]` ,以下这些都可以视作 `arr` 的排列:`[1,2,3]`、`[1,3,2]`、`[3,1,2]`、`[2,3,1]` 。
10 |
11 | 整数数组的 **下一个排列** 是指其整数的下一个字典序更大的排列。更正式地,如果数组的所有排列根据其字典顺序从小到大排列在一个容器中,那么数组的 **下一个排列** 就是在这个有序容器中排在它后面的那个排列。如果不存在下一个更大的排列,那么这个数组必须重排为字典序最小的排列(即,其元素按升序排列)。
12 |
13 | - 例如,`arr = [1,2,3]` 的下一个排列是 `[1,3,2]` 。
14 | - 类似地,`arr = [2,3,1]` 的下一个排列是 `[3,1,2]` 。
15 | - 而 `arr = [3,2,1]` 的下一个排列是 `[1,2,3]` ,因为 `[3,2,1]` 不存在一个字典序更大的排列。
16 |
17 | 给你一个整数数组 `nums` ,找出 `nums` 的下一个排列。
18 |
19 | 必须**[ 原地 ](https://baike.baidu.com/item/原地算法)**修改,只允许使用额外常数空间。
20 |
21 | **示例**
22 |
23 | ```java
24 | 输入:nums = [1,2,3]
25 | 输出:[1,3,2]
26 | ```
27 |
28 | **参考代码**
29 |
30 | ```java
31 | class Solution {
32 | public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
33 | ListNode ans = new ListNode(0);
34 | ListNode tmp = ans;
35 |
36 | while (l1 != null && l2!= null) {
37 | if (l1.val > l2.val) {
38 | tmp.next = l2; //tmp.next = new ListNode(l2.val); 没必要这么做
39 | l2 = l2.next;
40 | } else {
41 | tmp.next = l1;
42 | l1 = l1.next;
43 | }
44 | tmp = tmp.next;
45 | }
46 |
47 | tmp.next = l1 == null ? l2 : l1;
48 |
49 | return ans.next;
50 | }
51 | }
52 | ```
53 |
54 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/34-find-first-and-last-position-of-element-in-sorted-array.md:
--------------------------------------------------------------------------------
1 | # 34. 在排序数组中查找元素的第一个和最后一个位置
2 |
3 | [34. 在排序数组中查找元素的第一个和最后一个位置](https://leetcode.cn/problems/find-first-and-last-position-of-element-in-sorted-array/)
4 |
5 | **题目描述**
6 |
7 | 给你一个按照非递减顺序排列的整数数组 `nums`,和一个目标值 `target`。请你找出给定目标值在数组中的开始位置和结束位置。
8 |
9 | 如果数组中不存在目标值 `target`,返回 `[-1, -1]`。
10 |
11 | 你必须设计并实现时间复杂度为 `O(log n)` 的算法解决此问题。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:nums = [5,7,7,8,8,10], target = 8
17 | 输出:[3,4]
18 | ```
19 |
20 | **参考代码**
21 |
22 | ```java
23 | //输入: nums = [5,7,7,8,8,10], target = 8
24 | //输出: [3,4]
25 |
26 | class Solution {
27 | public int[] searchRange(int[] nums, int target) {
28 | if (nums == null || nums.length == 0) {
29 | return new int[]{-1, -1};
30 | }
31 | int left = searchRangeHelper(nums, target);
32 | int right = searchRangeHelper(nums, target + 1);//复用代码
33 |
34 | if (left == nums.length || nums[left] != target) {//left==nums.length数组元素比target小
35 | return new int[]{-1, -1};
36 | }
37 | return new int[]{left, right - 1};
38 | }
39 |
40 | private int searchRangeHelper(int[] nums, int target) {
41 | int left = 0;
42 | int right = nums.length;//特殊情况[1] 1
43 | while (left < right) {
44 | int mid = (left + right) >> 1;
45 | if (nums[mid] < target) {
46 | left = mid + 1;
47 | } else {
48 | right = mid;
49 | }
50 | }
51 |
52 | return left;
53 | }
54 | }
55 | ```
56 |
57 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/40-combination-sum-ii.md:
--------------------------------------------------------------------------------
1 | # 40. 组合总和 II
2 |
3 | [40. 组合总和 II](https://leetcode.cn/problems/combination-sum-ii/)
4 |
5 | **题目描述**
6 |
7 | 给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
8 |
9 | candidates 中的每个数字在每个组合中只能使用 一次 。
10 |
11 | 注意:解集不能包含重复的组合。
12 |
13 | **示例**:
14 |
15 | ```
16 | 输入: candidates = [2,5,2,1,2], target = 5,
17 | 输出:
18 | [
19 | [1,2,2],
20 | [5]
21 | ]
22 | ```
23 |
24 | **解题思路**
25 |
26 | 数组元素可能重复。使用回溯算法。
27 |
28 | 剪枝:
29 |
30 | 
31 |
32 | 去重复组合:
33 |
34 | 
35 |
36 | ```java
37 | class Solution {
38 | private List> ans = new ArrayList<>();
39 | public List> combinationSum2(int[] candidates, int target) {
40 | if (candidates == null || candidates.length == 0) {
41 | return ans;
42 | }
43 | Arrays.sort(candidates);//排序方便回溯剪枝
44 | Deque path = new ArrayDeque<>();//作为栈来使用,效率高于Stack;也可以作为队列来使用,效率高于LinkedList;线程不安全
45 | combinationSum2Helper(candidates, target, 0, path);
46 | return ans;
47 | }
48 |
49 | public void combinationSum2Helper(int[] arr, int target, int start, Deque path) {
50 | if (target == 0) {
51 | ans.add(new ArrayList(path));
52 | }
53 |
54 | for (int i = start; i < arr.length; i++) {
55 | if (target < arr[i]) {//剪枝
56 | return;
57 | }
58 | if (i > start && arr[i] == arr[i - 1]) {//在一个层级,会产生重复
59 | continue;
60 | }
61 | path.addLast(arr[i]);
62 | combinationSum2Helper(arr, target - arr[i], i + 1, path);
63 | path.removeLast();
64 | }
65 | }
66 | }
67 | ```
68 |
69 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/415-add-strings.md:
--------------------------------------------------------------------------------
1 | # 415. 字符串相加
2 |
3 | [415. 字符串相加](https://leetcode.cn/problems/add-strings/)
4 |
5 | **题目描述**
6 |
7 | 给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。
8 |
9 | 你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直接将输入的字符串转换为整数形式。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:num1 = "11", num2 = "123"
15 | 输出:"134"
16 | ```
17 |
18 | **解题思路**
19 |
20 | 
21 |
22 | **参考代码**:
23 |
24 | ```java
25 | class Solution {
26 | public String addStrings(String num1, String num2) {
27 | StringBuilder res = new StringBuilder("");
28 | int i = num1.length() - 1, j = num2.length() - 1, carry = 0;
29 | while(i >= 0 || j >= 0){
30 | int n1 = i >= 0 ? num1.charAt(i) - '0' : 0;
31 | int n2 = j >= 0 ? num2.charAt(j) - '0' : 0;
32 | int tmp = n1 + n2 + carry;
33 | carry = tmp / 10;
34 | res.append(tmp % 10);
35 | i--; j--;
36 | }
37 | if(carry == 1) res.append(1);
38 | return res.reverse().toString();
39 | }
40 | }
41 |
42 | 作者:jyd
43 | 链接:https://leetcode.cn/problems/add-strings/solution/add-strings-shuang-zhi-zhen-fa-by-jyd/
44 | 来源:力扣(LeetCode)
45 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
46 | ```
47 |
48 |
49 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/43-multiply-strings.md:
--------------------------------------------------------------------------------
1 | # 43. 字符串相乘
2 |
3 | [43. 字符串相乘](https://leetcode.cn/problems/multiply-strings/)
4 |
5 | **题目描述**
6 |
7 | 给定两个以字符串形式表示的非负整数 `num1` 和 `num2`,返回 `num1` 和 `num2` 的乘积,它们的乘积也表示为字符串形式。
8 |
9 | **注意:**不能使用任何内置的 BigInteger 库或直接将输入转换为整数。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入: num1 = "2", num2 = "3"
15 | 输出: "6"
16 | ```
17 |
18 | **解题思路**
19 |
20 | 参考自:https://leetcode-cn.com/problems/multiply-strings/solution/you-hua-ban-shu-shi-da-bai-994-by-breezean/
21 |
22 | 
23 |
24 | ```java
25 | class Solution {
26 | public String multiply(String num1, String num2) {
27 | if (num1.equals("0") || num2.equals("0")) { //乘0
28 | return "0";
29 | }
30 | int[] arr = new int[num1.length() + num2.length()];
31 | for (int i = num1.length() - 1; i >= 0; i--) {
32 | int m = num1.charAt(i) - '0';
33 | for (int j = num2.length() - 1; j >= 0; j--) {
34 | int n = num2.charAt(j) - '0';
35 | int sum = arr[i + j + 1] + m * n;
36 | arr[i + j + 1] = sum % 10;
37 | arr[i + j] += sum / 10; //+=,不能忘了原先的数
38 | }
39 | }
40 |
41 | StringBuilder ans = new StringBuilder("");
42 | if (arr[0] != 0) {
43 | ans.append(arr[0]);
44 | }
45 | for (int i = 1; i < arr.length; i++) {
46 | ans.append(arr[i]);
47 | }
48 |
49 | return ans.toString();
50 | }
51 | }
52 | ```
53 |
54 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/46-permutations.md:
--------------------------------------------------------------------------------
1 | # 46. 全排列
2 |
3 | [题目链接](https://leetcode.cn/problems/permutations/)
4 |
5 | **题目描述**
6 |
7 | 给定一个不含重复数字的数组 `nums` ,返回其 *所有可能的全排列* 。你可以 **按任意顺序** 返回答案。
8 |
9 | 示例:
10 |
11 | ```
12 | 输入:nums = [1,2,3]
13 | 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
14 | ```
15 |
16 | **解题思路**
17 |
18 | 使用回溯。注意与组合总和的区别(数字有无顺序)。
19 |
20 | ```java
21 | class Solution {
22 | private List> ans = new ArrayList<>();
23 | public List> permute(int[] nums) {
24 | boolean[] flag = new boolean[nums.length];
25 | ArrayDeque path = new ArrayDeque<>();
26 | permuteHelper(nums, flag, path);
27 |
28 | return ans;
29 | }
30 |
31 | private void permuteHelper(int[] nums, boolean[] flag, ArrayDeque path) {
32 | if (path.size() == nums.length) {
33 | ans.add(new ArrayList<>(path));
34 | return;
35 | }
36 | for (int i = 0; i < nums.length; i++) {
37 | if (flag[i]) {
38 | continue;//继续循环
39 | }
40 | path.addLast(nums[i]);
41 | flag[i] = true;
42 | permuteHelper(nums, flag, path);
43 | path.removeLast();
44 | flag[i] = false;
45 | }
46 | }
47 | }
48 | ```
49 |
50 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/47-permutations-ii.md:
--------------------------------------------------------------------------------
1 | # 47. 全排列 II
2 |
3 | [题目链接](https://leetcode.cn/problems/permutations-ii/)
4 |
5 | **题目描述**
6 |
7 | 给定一个可包含重复数字的序列,返回所有不重复的全排列。注意与组合总和的区别。
8 |
9 | 示例:
10 |
11 | ```java
12 | 输入:nums = [1,2,3]
13 | 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
14 | ```
15 |
16 | **解题思路**
17 |
18 | 1、排序;
19 |
20 | 2、同一层级相同元素剪枝。
21 |
22 | > 参考自:https://leetcode-cn.com/problems/permutations-ii/solution/hui-su-suan-fa-python-dai-ma-java-dai-ma-by-liwe-2/
23 |
24 | 
25 |
26 | ```java
27 | class Solution {
28 | private List> ans = new ArrayList<>();
29 | public List> permuteUnique(int[] nums) {
30 | if (nums == null || nums.length == 0) {
31 | return ans;
32 | }
33 | ArrayDeque path = new ArrayDeque<>();
34 | boolean[] used = new boolean[nums.length];
35 | Arrays.sort(nums);//切记
36 | dps(nums, used, path);
37 |
38 | return ans;
39 | }
40 |
41 | private void dps(int[] nums, boolean[] used, ArrayDeque path) {
42 | if (path.size() == nums.length) {
43 | ans.add(new ArrayList<>(path));
44 | return;
45 | }
46 | for (int i = 0; i < nums.length; i++) {
47 | if (used[i]) {
48 | continue;
49 | }
50 | if ((i > 0 && nums[i] == nums[i - 1]) && !used[i - 1]) {//同一层相同的元素,剪枝
51 | continue;//继续循环,不是return退出循环
52 | }
53 | path.addLast(nums[i]);
54 | used[i] = true;
55 | dps(nums, used, path);
56 | path.removeLast();
57 | used[i] = false;
58 | }
59 | }
60 | }
61 | ```
62 |
63 |
64 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/48-rotate-image.md:
--------------------------------------------------------------------------------
1 | # 48. 旋转图像
2 |
3 | [48. 旋转图像](https://leetcode.cn/problems/rotate-image/)
4 |
5 | **题目描述**
6 |
7 | 给定一个 *n* × *n* 的二维矩阵 `matrix` 表示一个图像。请你将图像顺时针旋转 90 度。
8 |
9 | 你必须在**[ 原地](https://baike.baidu.com/item/原地算法)** 旋转图像,这意味着你需要直接修改输入的二维矩阵。**请不要** 使用另一个矩阵来旋转图像。
10 |
11 | **示例**
12 |
13 | 
14 |
15 | ```java
16 | 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
17 | 输出:[[7,4,1],[8,5,2],[9,6,3]]
18 | ```
19 |
20 | **解题思路**
21 |
22 | 先转置,然后翻转每一行。
23 |
24 | ```java
25 | class Solution {
26 | public void rotate(int[][] matrix) {
27 | if (matrix == null || matrix.length <= 1) {
28 | return;
29 | }
30 | //转置
31 | for (int i = 0; i < matrix.length; i++) {
32 | for (int j = i + 1; j < matrix.length; j++) {
33 | int tmp = matrix[i][j];
34 | matrix[i][j] = matrix[j][i];
35 | matrix[j][i] = tmp;
36 | }
37 | }
38 | //翻转每一行
39 | for (int i = 0; i < matrix.length; i++) {
40 | for (int j = 0; j < matrix.length / 2; j++) {
41 | int tmp = matrix[i][j];
42 | matrix[i][j] = matrix[i][matrix.length - j - 1];
43 | matrix[i][matrix.length - j - 1] = tmp;
44 | }
45 | }
46 | }
47 | }
48 | ```
49 |
50 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/49-group-anagrams.md:
--------------------------------------------------------------------------------
1 | # 49. 字母异位词分组
2 |
3 | [49. 字母异位词分组](https://leetcode.cn/problems/group-anagrams/description/)
4 |
5 | **题目描述**
6 |
7 | 给你一个字符串数组,请你将 **字母异位词** 组合在一起。可以按任意顺序返回结果列表。
8 |
9 | **字母异位词** 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
15 | 输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
16 | ```
17 |
18 | **解题思路**
19 |
20 | 由于互为字母异位词的两个字符串包含的字母相同,因此对两个字符串分别进行排序之后得到的字符串一定是相同的,故可以将排序之后的字符串作为哈希表的键。
21 |
22 | ```java
23 | class Solution {
24 | public List> groupAnagrams(String[] strs) {
25 | if (strs == null || strs.length == 0) {
26 | return new ArrayList();
27 | }
28 |
29 | Map ans = new HashMap<>();
30 | for (String s : strs) {
31 | char[] arr = s.toCharArray();
32 | Arrays.sort(arr);
33 | String key = String.valueOf(arr);
34 | if (!ans.containsKey(key)) {
35 | ans.put(key, new ArrayList());
36 | }
37 | ans.get(key).add(s);
38 | }
39 |
40 | return new ArrayList(ans.values());//没有<>
41 | }
42 | }
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/50-powx-n.md:
--------------------------------------------------------------------------------
1 | # 50. Pow(x, n)
2 |
3 | [50. Pow(x, n)](https://leetcode.cn/problems/powx-n/)
4 |
5 | **题目描述**
6 |
7 | 实现 pow(x, n) ,即计算 `x` 的整数 `n` 次幂函数(即,`x^n` )。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:x = 2.00000, n = 10
13 | 输出:1024.00000
14 | ```
15 |
16 | **解题思路**
17 |
18 | 快速幂算法。
19 |
20 | ```java
21 | class Solution {
22 | public double myPow(double x, int n) {
23 | if (n == 0) {
24 | return 1.0;
25 | }
26 | if (n == -1) {//负数边界
27 | return 1 / x;
28 | }
29 | double res = myPow(x, n / 2);
30 | double ans = 0;
31 | if (n % 2 == 0) {
32 | ans = res * res;
33 | } else {
34 | ans = n > 0 ? res * res * x : res * res / x;
35 | }
36 |
37 | return ans;
38 | }
39 | }
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/53-maximum-subarray.md:
--------------------------------------------------------------------------------
1 | # 53. 最大子数组和
2 |
3 | [原题链接](https://leetcode.cn/problems/maximum-subarray/)
4 |
5 | ## 题目描述
6 |
7 | 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
8 |
9 | 子数组 是数组中的一个连续部分。
10 |
11 | ```java
12 | 示例 1:
13 |
14 | 输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
15 | 输出:6
16 | 解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
17 | ```
18 |
19 | ## 解题
20 |
21 | ```java
22 | class Solution {
23 | public int maxSubArray(int[] nums) {
24 | int res = nums[0];
25 | int sum = 0;
26 | for (int num : nums) {
27 | if (sum > 0)
28 | sum += num;
29 | else
30 | sum = num;
31 | res = Math.max(res, sum);
32 | }
33 | return res;
34 | }
35 | }
36 | ```
37 |
38 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/543-diameter-of-binary-tree.md:
--------------------------------------------------------------------------------
1 | # 543. 二叉树的直径
2 |
3 | [题目链接](https://leetcode.cn/problems/diameter-of-binary-tree/)
4 |
5 | **题目描述**
6 |
7 | 给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
8 |
9 | **示例**
10 |
11 | ```java
12 | 1
13 | / \
14 | 2 3
15 | / \
16 | 4 5
17 |
18 | 返回 3, 它的长度是路径 [4,2,1,3] 或者 [5,2,1,3]。
19 | ```
20 |
21 | **解题思路**
22 |
23 | **深度优先搜索**
24 |
25 | ```java
26 | class Solution {
27 | private int max = 0;
28 |
29 | public int diameterOfBinaryTree(TreeNode root) {
30 | depth(root);
31 | return max;
32 | }
33 |
34 | private int depth(TreeNode node) {
35 | if (node == null) {
36 | return 0;
37 | }
38 |
39 | int left = depth(node.left);
40 | int right = depth(node.right);
41 |
42 | max = Math.max(max, left + right);
43 | return Math.max(left, right) + 1;
44 | }
45 | }
46 | ```
47 |
48 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/55-jump-game.md:
--------------------------------------------------------------------------------
1 | # 55. 跳跃游戏
2 |
3 | [题目链接](https://leetcode.cn/problems/jump-game/)
4 |
5 | **题目描述**
6 |
7 | 给定一个非负整数数组 `nums` ,你最初位于数组的 **第一个下标** 。
8 |
9 | 数组中的每个元素代表你在该位置可以跳跃的最大长度。
10 |
11 | 判断你是否能够到达最后一个下标。
12 |
13 | **示例**:
14 |
15 | ```java
16 | 输入:nums = [2,3,1,1,4]
17 | 输出:true
18 | 解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
19 | ```
20 |
21 | **解题思路**:
22 |
23 | 1. 如果某一个作为 起跳点 的格子可以跳跃的距离是 3,那么表示后面 3 个格子都可以作为 起跳点
24 | 2. 可以对每一个能作为 起跳点 的格子都尝试跳一次,把 能跳到最远的距离 不断更新
25 | 3. 如果可以一直跳到最后,就成功了
26 |
27 | ```java
28 | class Solution {
29 | public boolean canJump(int[] nums) {
30 | if (nums == null || nums.length == 0) {
31 | return true;
32 | }
33 |
34 | int maxIndex = nums[0];
35 | for (int i = 1; i < nums.length; i++) {
36 | if (maxIndex >= i) {
37 | maxIndex = Math.max(maxIndex, i + nums[i]);
38 | } else {
39 | return false;
40 | }
41 | }
42 |
43 | return true;
44 | }
45 | }
46 | ```
47 |
48 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/56-merge-intervals.md:
--------------------------------------------------------------------------------
1 | # 56. 合并区间
2 |
3 | [56. 合并区间](https://leetcode.cn/problems/merge-intervals/)
4 |
5 | **题目描述**
6 |
7 | 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
13 | 输出:[[1,6],[8,10],[15,18]]
14 | 解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
15 | ```
16 |
17 | **解题思路**
18 |
19 | 先对区间左边界排序 `Array.sort(arr, (i1, i2) -> i1[0] - i2[0])`,然后新建数组进行合并。
20 |
21 | ```java
22 | class Solution {
23 | public int[][] merge(int[][] intervals) {
24 | if (intervals == null || intervals.length == 0) {
25 | throw new IllegalArgumentException("array is null or array is empty");
26 | }
27 |
28 | Arrays.sort(intervals, (a, b) -> a[0] - b[0]); //lambda表达式写法,返回值是int
29 |
30 | int index = 0;
31 | for (int i = 1; i < intervals.length; i++) {
32 | if (intervals[index][1] < intervals[i][0]) {
33 | intervals[++index] = intervals[i]; //++index,先自增,再取值
34 | } else {
35 | intervals[index][1] = Math.max(intervals[i][1], intervals[index][1]);
36 | }
37 | }
38 |
39 | return Arrays.copyOf(intervals, index + 1); //第二个参数是数组长度
40 | }
41 | }
42 | ```
43 |
44 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/59-spiral-matrix-ii.md:
--------------------------------------------------------------------------------
1 | # 59. 螺旋矩阵II
2 |
3 | [题目链接](https://leetcode.cn/problems/spiral-matrix-ii/)
4 |
5 | **题目描述**
6 |
7 | 给你一个正整数 `n` ,生成一个包含 `1` 到 `n2` 所有元素,且元素按顺时针顺序螺旋排列的 `n x n` 正方形矩阵 `matrix` 。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:n = 3
13 | 输出:[[1,2,3],[8,9,4],[7,6,5]]
14 | ```
15 |
16 | **解题思路**
17 |
18 | tips:定义上下左右边界。
19 |
20 | ```java
21 | class Solution {
22 | public int[][] generateMatrix(int n) {
23 | int left = 0;
24 | int right = n - 1;
25 | int top = 0;
26 | int bottom = n - 1;
27 |
28 | int[][] ans = new int[n][n];
29 | int num = 1;
30 | while (true) {
31 | for (int i = left; i <= right; i++) {
32 | ans[top][i] = num++;//注意下标顺序
33 | }
34 | if (++top > bottom) {
35 | break;
36 | }
37 | for (int j = top; j <= bottom; j++) {
38 | ans[j][right] = num++;
39 | }
40 | if (--right < left) {
41 | break;
42 | }
43 | for (int m = right; m >= left; m--) {
44 | ans[bottom][m] = num++;
45 | }
46 | if (--bottom < top) {
47 | break;
48 | }
49 | for (int k = bottom; k >= top; k--) {
50 | ans[k][left] = num++;
51 | }
52 | if (++left > right) {
53 | break;
54 | }
55 | }
56 | return ans;
57 | }
58 | }
59 | ```
60 |
61 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/7-reverse-integer.md:
--------------------------------------------------------------------------------
1 | # 7. 整数反转
2 |
3 | [题目链接](https://leetcode.cn/problems/reverse-integer/)
4 |
5 | **题目描述**
6 |
7 | 给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。
8 |
9 | 如果反转后整数超过 32 位的有符号整数的范围 [−231, 231 − 1] ,就返回 0。
10 |
11 | 假设环境不允许存储 64 位整数(有符号或无符号)。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:x = 123
17 | 输出:321
18 |
19 | 输入:x = 120
20 | 输出:21
21 | ```
22 |
23 | **解题思路**
24 |
25 | - 本题如果不考虑溢出问题,是非常简单的。解决溢出问题有两个思路,第一个思路是通过字符串转换加`try catch`的方式来解决,第二个思路就是通过数学计算来解决。
26 | - 由于字符串转换的效率较低且使用较多库函数,所以解题方案不考虑该方法,而是通过数学计算来解决。
27 | - 通过循环将数字`x`的每一位拆开,在计算新值时每一步都判断是否溢出。
28 | - 溢出条件有两个,一个是大于整数最大值`MAX_VALUE`,另一个是小于整数最小值`MIN_VALUE`,设当前计算结果为`ans`,下一位为`pop`。
29 | - 从`ans * 10 + pop > MAX_VALUE`这个溢出条件来看
30 | - 当出现 `ans > MAX_VALUE / 10` 且 `还有pop需要添加` 时,则一定溢出
31 | - 当出现 `ans == MAX_VALUE / 10` 且 `pop > 7` 时,则一定溢出,`7`是`2^31 - 1`的个位数
32 | - 从`ans * 10 + pop < MIN_VALUE`这个溢出条件来看
33 | - 当出现 `ans < MIN_VALUE / 10` 且 `还有pop需要添加` 时,则一定溢出
34 | - 当出现 `ans == MIN_VALUE / 10` 且 `pop < -8` 时,则一定溢出,`8`是`-2^31`的个位数
35 |
36 | > 作者:guanpengchn
37 | > 链接:https://leetcode.cn/problems/reverse-integer/solution/hua-jie-suan-fa-7-zheng-shu-fan-zhuan-by-guanpengc/
38 | > 来源:力扣(LeetCode)
39 | > 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
40 |
41 | ```java
42 | class Solution {
43 | public int reverse(int x) {
44 | int ans = 0;
45 | while (x != 0) {
46 | int pop = x % 10;
47 | if (ans > Integer.MAX_VALUE / 10 || (ans == Integer.MAX_VALUE / 10 && pop > 7))
48 | return 0;
49 | if (ans < Integer.MIN_VALUE / 10 || (ans == Integer.MIN_VALUE / 10 && pop < -8))
50 | return 0;
51 | ans = ans * 10 + pop;
52 | x /= 10;
53 | }
54 | return ans;
55 | }
56 | }
57 | ```
58 |
59 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/71-simplify-path.md:
--------------------------------------------------------------------------------
1 | # 71. 简化路径
2 |
3 | [题目链接](https://leetcode.cn/problems/simplify-path/)
4 |
5 | **题目描述**
6 |
7 | 给你一个字符串 `path` ,表示指向某一文件或目录的 Unix 风格 **绝对路径** (以 `'/'` 开头),请你将其转化为更加简洁的规范路径。
8 |
9 | 在 Unix 风格的文件系统中,一个点(`.`)表示当前目录本身;此外,两个点 (`..`) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,`'//'`)都被视为单个斜杠 `'/'` 。 对于此问题,任何其他格式的点(例如,`'...'`)均被视为文件/目录名称。
10 |
11 | 请注意,返回的 **规范路径** 必须遵循下述格式:
12 |
13 | - 始终以斜杠 `'/'` 开头。
14 | - 两个目录名之间必须只有一个斜杠 `'/'` 。
15 | - 最后一个目录名(如果存在)**不能** 以 `'/'` 结尾。
16 | - 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含 `'.'` 或 `'..'`)。
17 |
18 | 返回简化后得到的 **规范路径** 。
19 |
20 | **示例**:
21 |
22 | ```java
23 | 输入:path = "/home/"
24 | 输出:"/home"
25 | 解释:注意,最后一个目录名后面没有斜杠。
26 |
27 | 输入:path = "/../"
28 | 输出:"/"
29 | 解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。
30 | ```
31 |
32 | **解题思路**
33 |
34 | 使用栈实现。
35 |
36 | ```java
37 | //输入:"/a/./b/../../c/"
38 | //输出:"/c"
39 | class Solution {
40 | public String simplifyPath(String path) {
41 | Stack stack = new Stack<>();
42 | String[] strs = path.split("/");
43 |
44 | for (String s : strs) {
45 | if ("..".equals(s)) {
46 | if (!stack.isEmpty()) {
47 | stack.pop();
48 | }
49 | continue;//只要是"..",就执行下一个循环,不能放入栈
50 | }
51 | if (!"".equals(s) && !".".equals(s)) {
52 | stack.push(s);
53 | }
54 | }
55 |
56 | if (stack.isEmpty()) {
57 | return "/";
58 | }
59 |
60 | StringBuilder sb = new StringBuilder();
61 | int size = stack.size();
62 | for (int i = 0; i < size; i++) {
63 | sb.append("/").append(stack.get(i));//tips
64 | }
65 | return sb.toString();
66 | }
67 | }
68 | ```
69 |
70 |
71 |
72 |
73 |
74 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/74-search-a-2d-matrix.md:
--------------------------------------------------------------------------------
1 | # 74. 搜索二维矩阵
2 |
3 | [题目链接](https://leetcode.cn/problems/search-a-2d-matrix/)
4 |
5 | **题目描述**
6 |
7 | 编写一个高效的算法来判断 `m x n` 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
8 |
9 | - 每行中的整数从左到右按升序排列。
10 | - 每行的第一个整数大于前一行的最后一个整数。
11 |
12 | **示例**:
13 |
14 | 
15 |
16 | ```java
17 | 输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
18 | 输出:true
19 | ```
20 |
21 | **参考代码**
22 |
23 | ```java
24 | class Solution {
25 | public boolean searchMatrix(int[][] matrix, int target) {
26 | if (null == matrix || matrix.length == 0 || matrix[0].length == 0) {
27 | return false;
28 | }
29 | int rows = matrix.length;
30 | int cols = matrix[0].length;
31 | int left = 0;
32 | int right = rows * cols - 1;
33 |
34 | while (left <= right) {
35 | int mid = (left + right) >> 1; //!
36 | int val = matrix[mid / cols][mid % cols]; //cols!不是rows
37 | if (target == val) {
38 | return true;
39 | } else if (target > val) {
40 | left = mid + 1;
41 | } else {
42 | right = mid - 1;
43 | }
44 | }
45 |
46 | return false;
47 | }
48 | }
49 | ```
50 |
51 |
52 |
53 |
54 |
55 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/75-sort-colors.md:
--------------------------------------------------------------------------------
1 | # 75. 颜色分类
2 |
3 | [题目链接](https://leetcode.cn/problems/sort-colors/)
4 |
5 | **题目描述**
6 |
7 | 给定一个包含红色、白色和蓝色、共 `n` 个元素的数组 `nums` ,**[原地](https://baike.baidu.com/item/原地算法)**对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
8 |
9 | 我们使用整数 `0`、 `1` 和 `2` 分别表示红色、白色和蓝色。
10 |
11 | > 必须在不使用库的sort函数的情况下解决这个问题。
12 |
13 | **示例**:
14 |
15 | ```java
16 | 输入:nums = [2,0,2,1,1,0]
17 | 输出:[0,0,1,1,2,2]
18 | ```
19 |
20 | **解题思路**
21 |
22 | 三指针。
23 |
24 | ```java
25 | class Solution {
26 | public void sortColors(int[] nums) {
27 | if (nums == null || nums.length == 0) {
28 | return;
29 | }
30 | int p1 = 0, cur = 0, p2 = nums.length - 1;
31 | while (cur <= p2) { //边界,nums全为1的情况
32 | if (nums[cur] == 0) {
33 | int tmp = nums[p1];
34 | nums[p1++] = 0;
35 | nums[cur++] = tmp; //cur++
36 | } else if (nums[cur] == 2) {
37 | int tmp = nums[p2];
38 | nums[p2--] = 2;
39 | nums[cur] = tmp; //nums[cur]可能为2,不自增
40 | } else {
41 | cur++;
42 | }
43 | }
44 | }
45 | }
46 | ```
47 |
48 |
49 |
50 |
51 |
52 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/77-combinations.md:
--------------------------------------------------------------------------------
1 | # 77. 组合
2 |
3 | [题目链接](https://leetcode.cn/problems/combinations/)
4 |
5 | **题目描述**
6 |
7 | 给定两个整数 `n` 和 `k`,返回范围 `[1, n]` 中所有可能的 `k` 个数的组合。
8 |
9 | 你可以按 **任何顺序** 返回答案。
10 |
11 | **示例**:
12 |
13 | ```java
14 | 输入:n = 4, k = 2
15 | 输出:
16 | [
17 | [2,4],
18 | [3,4],
19 | [2,3],
20 | [1,2],
21 | [1,3],
22 | [1,4],
23 | ]
24 |
25 | 输入:n = 1, k = 1
26 | 输出:[[1]]
27 | ```
28 |
29 | **解题思路**
30 |
31 | 回溯。剪枝优化。
32 |
33 | 
34 |
35 | ```java
36 | class Solution {
37 | public List> combine(int n, int k) {
38 | List> res = new ArrayList<>();
39 | if (n <= 0 || k <= 0 || n < k) {
40 | return res;
41 | }
42 | Stack stack = new Stack<>();
43 | combineHelper(res, stack, 1, n, k);
44 | return res;
45 | }
46 |
47 | public void combineHelper(List> res, Stack stack, int index,int n, int k) {
48 | if (stack.size() == k) {
49 | res.add(new ArrayList<>(stack));
50 | return;
51 | }
52 | // i 的极限值满足: n - i + 1 = (k - pre.size())。
53 | // 【关键】n - i + 1 是闭区间 [i,n] 的长度。
54 | // k - pre.size() 是剩下还要寻找的数的个数。
55 | for (int i = index; i <= n - (k - stack.size()) + 1; i++) {
56 | stack.push(i);
57 | combineHelper(res, stack, i + 1, n, k);
58 | stack.pop();
59 | }
60 | }
61 | }
62 | ```
63 |
64 |
65 |
66 |
67 |
68 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/83-remove-duplicates-from-sorted-list.md:
--------------------------------------------------------------------------------
1 | # 83. 删除排序链表中的重复元素
2 |
3 | [83. 删除排序链表中的重复元素](https://leetcode.cn/problems/remove-duplicates-from-sorted-list/)
4 |
5 | **题目描述**
6 |
7 | 给定一个已排序的链表的头 `head` , *删除所有重复的元素,使每个元素只出现一次* 。返回 *已排序的链表* 。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:head = [1,1,2]
13 | 输出:[1,2]
14 | ```
15 |
16 | **解题思路**
17 |
18 | 使用快慢指针。
19 |
20 | ```java
21 | class Solution {
22 | public int removeDuplicates(int[] nums) {
23 | if (nums == null || nums.length <= 0) {
24 | return 0;
25 | }
26 |
27 | int slow = 0;
28 | for (int fast = 1; fast < nums.length; fast++) {
29 | if (nums[slow] != nums[fast]) {
30 | slow++;
31 | nums[slow] = nums[fast];
32 | }
33 | }
34 |
35 | return slow + 1;
36 | }
37 | }
38 | ```
39 |
40 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/9-palindrome-number.md:
--------------------------------------------------------------------------------
1 | # 9. 回文数
2 |
3 | [9. 回文数](https://leetcode.cn/problems/palindrome-number/)
4 |
5 | **题目描述**
6 |
7 | 给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。
8 |
9 | 回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
10 |
11 | 例如,121 是回文,而 123 不是。
12 |
13 | **示例**
14 |
15 | ```java
16 | 输入:x = 121
17 | 输出:true
18 |
19 | 输入:x = -121
20 | 输出:false
21 | 解释:从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
22 | ```
23 |
24 | **解题思路**
25 |
26 | 将数字后半段反转,跟数字前半段相比即可。
27 |
28 | ```java
29 | class Solution {
30 | public boolean isPalindrome(int x) {
31 | //排除负数和整十的数
32 | if (x < 0 || (x % 10 == 0 && x != 0)) {
33 | return false;
34 | }
35 |
36 | int reverseNum = 0;
37 | //反转x的后半段数字,再做比较即可
38 | while(x > reverseNum) {
39 | reverseNum = reverseNum * 10 + x % 10;
40 | x /= 10;
41 | }
42 |
43 | //x为奇数位时,转换后reverseNum会比x多一位
44 | //如x为1234321,转换后reverseNum为1234,x为123
45 | return x == reverseNum || x == reverseNum / 10;
46 | }
47 | }
48 | ```
49 |
50 |
51 |
52 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/92-reverse-linked-list-ii.md:
--------------------------------------------------------------------------------
1 | # 92. 反转链表 II
2 |
3 | [原题链接](https://leetcode.cn/problems/reverse-linked-list-ii/)
4 |
5 | **题目描述**
6 |
7 | 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
8 |
9 | **示例**
10 |
11 | ```java
12 | 输入:head = [1,2,3,4,5], left = 2, right = 4
13 | 输出:[1,4,3,2,5]
14 | ```
15 |
16 | **解题思路**
17 |
18 | 双指针+头插法。
19 |
20 | ```java
21 | class Solution {
22 | public ListNode reverseBetween(ListNode head, int m, int n) {
23 | ListNode dummy = new ListNode(0);
24 | dummy.next = head;
25 | ListNode pre = dummy;
26 | for (int i = 1; i < m; i++) {
27 | pre = pre.next;
28 | }
29 | head = pre.next;
30 | for (int i = m; i < n; i++) {
31 | ListNode cur = head.next;
32 | head.next = cur.next;
33 | cur.next = pre.next;
34 | pre.next = cur;
35 | }
36 |
37 | return dummy.next;
38 | }
39 | }
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/958-check-completeness-of-a-binary-tree.md:
--------------------------------------------------------------------------------
1 | # 28. 对称的二叉树
2 |
3 | [28. 对称的二叉树](https://leetcode.cn/problems/dui-cheng-de-er-cha-shu-lcof/)
4 |
5 | **题目描述**
6 |
7 | 给定一个二叉树的 root ,确定它是否是一个 完全二叉树 。
8 |
9 | 在一个 完全二叉树 中,除了最后一个关卡外,所有关卡都是完全被填满的,并且最后一个关卡中的所有节点都是尽可能靠左的。它可以包含 1 到 2^h 节点之间的最后一级 h 。
10 |
11 | **示例**
12 |
13 | ```java
14 | 输入:root = [1,2,3,4,5,6]
15 | 输出:true
16 | 解释:最后一层前的每一层都是满的(即,结点值为 {1} 和 {2,3} 的两层),且最后一层中的所有结点({4,5,6})都尽可能地向左。
17 | ```
18 |
19 | **解题思路**
20 |
21 | 层序遍历,当且仅当存在两个相邻节点:前一个为null,后一个不为null时,则不是完全二叉树。
22 |
23 | ```
24 | 1
25 | / \
26 | 2 3
27 | / \ \
28 | 4 5 6
29 | 层序遍历序列为:[1, 2, 3, 4, 5, null, 6],其中 null 出现在了6前面,所以不是完全二叉树
30 | ```
31 |
32 | 代码实现:
33 |
34 | ```java
35 | class Solution {
36 | public boolean isCompleteTree(TreeNode root) {
37 | LinkedList list = new LinkedList<>();
38 | TreeNode pre = root;
39 | TreeNode cur = root;
40 | list.addLast(root);
41 |
42 | while (!list.isEmpty()) {
43 | cur = list.removeFirst();
44 | if (cur != null) {
45 | if (pre == null) {
46 | return false;
47 | }
48 | list.addLast(cur.left);
49 | list.addLast(cur.right);
50 | }
51 | pre = cur;
52 | }
53 | return true;
54 | }
55 | }
56 | ```
57 |
58 |
--------------------------------------------------------------------------------
/docs/leetcode/hot120/98-validate-binary-search-tree.md:
--------------------------------------------------------------------------------
1 | # 98. 验证二叉搜索树
2 |
3 | [题目链接](https://leetcode.cn/problems/validate-binary-search-tree/)
4 |
5 | **题目描述**
6 |
7 | 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
8 |
9 | 有效 二叉搜索树定义如下:
10 |
11 | - 节点的左子树只包含 小于 当前节点的数。
12 | - 节点的右子树只包含 大于 当前节点的数。
13 | - 所有左子树和右子树自身必须也是二叉搜索树。
14 |
15 | **示例**
16 |
17 | ```java
18 | 输入:root = [2,1,3]
19 | 输出:true
20 |
21 | 输入:root = [5,1,4,null,null,3,6]
22 | 输出:false
23 | 解释:根节点的值是 5 ,但是右子节点的值是 4 。
24 | ```
25 |
26 | **解题思路**
27 |
28 | 中序遍历时,判断当前节点是否大于中序遍历的前一个节点,如果大于,说明满足 BST,继续遍历;否则直接返回 false。
29 |
30 | > 作者:sweetiee
31 | > 链接:https://leetcode.cn/problems/validate-binary-search-tree/solution/zhong-xu-bian-li-qing-song-na-xia-bi-xu-miao-dong-/
32 | > 来源:力扣(LeetCode)
33 | > 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
34 |
35 | ```java
36 | class Solution {
37 | long pre = Long.MIN_VALUE;
38 | public boolean isValidBST(TreeNode root) {
39 | if (root == null) {
40 | return true;
41 | }
42 | // 访问左子树
43 | if (!isValidBST(root.left)) {
44 | return false;
45 | }
46 | // 访问当前节点:如果当前节点小于等于中序遍历的前一个节点,说明不满足BST,返回 false;否则继续遍历。
47 | if (root.val <= pre) {
48 | return false;
49 | }
50 | pre = root.val;
51 | // 访问右子树
52 | return isValidBST(root.right);
53 | }
54 | }
55 | ```
56 |
57 |
--------------------------------------------------------------------------------
/docs/mass-data/3-find-same-url.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 查找两个大文件共同的URL
4 | category: 海量数据
5 | tag:
6 | - 海量数据
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 海量数据面试题,大文件共同的URL,海量数据
11 | - - meta
12 | - name: description
13 | content: 海量数据常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 查找两个大文件共同的URL
17 |
18 | ## 题目
19 |
20 | 给定 a、b 两个文件,各存放 50 亿个 URL,每个 URL 各占 64B,找出 a、b 两个文件共同的 URL。内存限制是 4G。
21 |
22 | ## 分析
23 |
24 | 每个 URL 占 64B,那么 50 亿个 URL占用的空间大小约为 320GB。
25 |
26 | 5,000,000,000 * 64B ≈ 320GB
27 |
28 | 由于内存大小只有 4G,因此,不可能一次性把所有 URL 加载到内存中处理。
29 |
30 | 可以采用分治策略,也就是把一个文件中的 URL 按照某个特征划分为多个小文件,使得每个小文件大小不超过 4G,这样就可以把这个小文件读到内存中进行处理了。
31 |
32 | 首先遍历文件a,对遍历到的 URL 进行哈希取余 `hash(URL) % 1000`,根据计算结果把遍历到的 URL 存储到 a0, a1,a2, ..., a999,这样每个大小约为 300MB。使用同样的方法遍历文件 b,把文件 b 中的 URL 分别存储到文件 b0, b1, b2, ..., b999 中。这样处理过后,所有可能相同的 URL 都在对应的小文件中,即 a0 对应 b0, ..., a999 对应 b999,不对应的小文件不可能有相同的 URL。那么接下来,我们只需要求出这 1000 对小文件中相同的 URL 就好了。
33 |
34 | 接着遍历 ai( `i∈[0,999]`),把 URL 存储到一个 HashSet 集合中。然后遍历 bi 中每个 URL,看在 HashSet 集合中是否存在,若存在,说明这就是共同的 URL,可以把这个 URL 保存到一个单独的文件中。
35 |
36 | ## 总结
37 |
38 | 最后总结一下:
39 |
40 | 1. 分而治之,进行哈希取余;
41 | 2. 对每个子文件进行 HashSet 统计。
42 |
--------------------------------------------------------------------------------
/docs/mass-data/4-find-mid-num.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何在100亿数据中找到中位数?
4 | category: 海量数据
5 | tag:
6 | - 海量数据
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 海量数据面试题,100亿数据找中位数,海量数据
11 | - - meta
12 | - name: description
13 | content: 海量数据常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 如何在100亿数据中找到中位数?
17 |
18 | ## 题目描述
19 |
20 | 给定100亿个无符号的乱序的整数序列,如何求出这100亿个数的中位数(中位数指的是排序后最中间那个数),内存只有**512M**。
21 |
22 | ## 分析
23 |
24 | 中位数问题可以看做一个统计问题,而不是排序问题,无符号整数大小为4B,则能表示的数的范围为为0 ~ 2^32 - 1(40亿),如果没有限制内存大小,则可以用一个2^32(4GB)大小的数组(也叫做桶)来保存100亿个数中每个无符号数出现的次数。遍历这100亿个数,当元素值等于桶元素索引时,桶元素的值加1。当统计完100亿个数以后,则从索引为0的值开始累加桶的元素值,当累加值等于50亿时,这个值对应的索引为中位数。时间复杂度为O(n)。
25 |
26 | 因为题目要求内存限制512M,所以上述解法不合适。
27 |
28 | 下面分享另一种解法(**分治法**的思想)
29 |
30 | 如果100亿个数字保存在一个大文件中,可以依次读一部分文件到内存(不超过内存限制),将每个数字用二进制表示,比较二进制的最高位(第32位,符号位,0是正,1是负)。
31 |
32 | 如果数字的最高位为0,则将这个数字写入 file_0文件中;如果最高位为 1,则将该数字写入file_1文件中。 从而将100亿个数字分成了两个文件。
33 |
34 | 假设 file_0文件中有 60亿 个数字,file_1文件中有 40亿 个数字。那么中位数就在 file_0 文件中,并且是 file_0 文件中所有数字排序之后的第 10亿 个数字。因为file_1中的数都是负数,file_0中的数都是正数,也即这里一共只有40亿个负数,那么排序之后的第50亿个数一定位于file_0中。
35 |
36 | 现在,我们只需要处理 file_0 文件了,不需要再考虑file_1文件。对于 file_0 文件,同样采取上面的措施处理:将file_0文件依次读一部分到内存(不超过内存限制),将每个数字用二进制表示,比较二进制的 次高位(第31位),如果数字的次高位为0,写入file_0_0文件中;如果次高位为1,写入file_0_1文件 中。
37 |
38 | 现假设 file_0_0文件中有30亿个数字,file_0_1中也有30亿个数字,则中位数就是:file_0_0文件中的数字从小到大排序之后的第10亿个数字。
39 |
40 | 抛弃file_0_1文件,继续对 file_0_0文件 根据 次次高位(第30位) 划分,假设此次划分的两个文件为:file_0_0_0中有5亿个数字,file_0_0_1中有25亿个数字,那么中位数就是 file_0_0_1文件中的所有数字排序之后的 第 5亿 个数。
41 |
42 | 按照上述思路,直到划分的文件可直接加载进内存时,就可以直接对数字进行快速排序,找出中位数了。
43 |
44 |
45 |
46 | > 参考链接:https://blog.csdn.net/qq_41306849/article/details/119828746
47 |
--------------------------------------------------------------------------------
/docs/mass-data/5-find-hot-string.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何查询最热门的查询串?
4 | category: 海量数据
5 | tag:
6 | - 海量数据
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 海量数据面试题,查询最热门的查询串,海量数据
11 | - - meta
12 | - name: description
13 | content: 海量数据常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 如何查询最热门的查询串?
17 |
18 | ## 题目描述
19 |
20 | 搜索引擎会通过日志文件把用户每次检索使用的所有查询串都记录下来,每个查询床的长度不超过 255 字节。
21 |
22 | 假设目前有 1000w 个记录(这些查询串的重复度比较高,虽然总数是 1000w,但如果除去重复后,则不超过 300w 个)。请统计最热门的 10 个查询串,要求使用的内存不能超过 1G。(一个查询串的重复度越高,说明查询它的用户越多,也就越热门。)
23 |
24 | ## 解答思路
25 |
26 | 每个查询串最长为 255B,1000w 个串需要占用 约 2.55G 内存,因此,我们无法将所有字符串全部读入到内存中处理。
27 |
28 | ### 方法一:分治法
29 |
30 | 分治法依然是一个非常实用的方法。
31 |
32 | 划分为多个小文件,保证单个小文件中的字符串能被直接加载到内存中处理,然后求出每个文件中出现次数最多的 10 个字符串;最后通过一个小顶堆统计出所有文件中出现最多的 10 个字符串。
33 |
34 | 方法可行,但不是最好,下面介绍其他方法。
35 |
36 | ### 方法二:HashMap 法
37 |
38 | 虽然字符串总数比较多,但去重后不超过 300w,因此,可以考虑把所有字符串及出现次数保存在一个 HashMap 中,所占用的空间为 300w*(255+4)≈777M(其中,4表示整数占用的4个字节)。由此可见,1G 的内存空间完全够用。
39 |
40 | **思路如下**:
41 |
42 | 首先,遍历字符串,若不在 map 中,直接存入 map,value 记为 1;若在 map 中,则把对应的 value 加 1,这一步时间复杂度 `O(N)`。
43 |
44 | 接着遍历 map,构建一个 10 个元素的小顶堆,若遍历到的字符串的出现次数大于堆顶字符串的出现次数,则进行替换,并将堆调整为小顶堆。
45 |
46 | 遍历结束后,堆中 10 个字符串就是出现次数最多的字符串。这一步时间复杂度 `O(Nlog10)`。
47 |
48 | ### 方法三:前缀树法
49 |
50 | 方法二使用了 HashMap 来统计次数,当这些字符串有大量相同前缀时,可以考虑使用前缀树来统计字符串出现的次数,树的结点保存字符串出现次数,0 表示没有出现。
51 |
52 | **思路如下**:
53 |
54 | 在遍历字符串时,在前缀树中查找,如果找到,则把结点中保存的字符串次数加 1,否则为这个字符串构建新结点,构建完成后把叶子结点中字符串的出现次数置为 1。
55 |
56 | 最后依然使用小顶堆来对字符串的出现次数进行排序。
57 |
58 | ## 方法总结
59 |
60 | 前缀树经常被用来统计字符串的出现次数。它的另外一个大的用途是字符串查找,判断是否有重复的字符串等。
61 |
62 |
63 |
64 | > 作者:yanglbme
65 | > 链接:https://juejin.cn/post/6844904003998842887
66 |
--------------------------------------------------------------------------------
/docs/mass-data/7-query-frequency-sort.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何按照 query 的频度排序?
4 | category: 海量数据
5 | tag:
6 | - 海量数据
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 海量数据面试题,海量数据
11 | - - meta
12 | - name: description
13 | content: 海量数据常见面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | ## 如何按照 query 的频度排序?
17 |
18 | ### 题目描述
19 |
20 | 有 10 个文件,每个文件大小为 1G,每个文件的每一行存放的都是用户的 query,每个文件的 query 都可能重复。要求按照 query 的频度排序。
21 |
22 | ### 解答思路
23 |
24 | 如果 query 的重复度比较大,可以考虑一次性把所有 query 读入内存中处理;如果 query 的重复率不高,那么可用内存不足以容纳所有的 query,这时候就需要采用分治法或其他的方法来解决。
25 |
26 | #### 方法一:HashMap 法
27 |
28 | 如果 query 重复率高,说明不同 query 总数比较小,可以考虑把所有的 query 都加载到内存中的 HashMap 中。接着就可以按照 query 出现的次数进行排序。
29 |
30 | #### 方法二:分治法
31 |
32 | 分治法需要根据数据量大小以及可用内存的大小来确定问题划分的规模。对于这道题,可以顺序遍历 10 个文件中的 query,通过 Hash 函数 `hash(query) % 10` 把这些 query 划分到 10 个小文件中。之后对每个小文件使用 HashMap 统计 query 出现次数,根据次数排序并写入到零外一个单独文件中。
33 |
34 | 接着对所有文件按照 query 的次数进行排序,这里可以使用归并排序(由于无法把所有 query 都读入内存,因此需要使用外排序)。
35 |
36 | ### 方法总结
37 |
38 | - 内存若够,直接读入进行排序;
39 | - 内存不够,先划分为小文件,小文件排好序后,整理使用外排序进行归并。
40 |
41 |
42 |
43 | > 作者:yanglbme
44 | > 链接:https://juejin.cn/post/6844904003998842887
45 |
--------------------------------------------------------------------------------
/docs/mass-data/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## 海量数据面试题(更新中)
3 |
4 | - [如何查询最热门的查询串?](./5-find-hot-string.md)
5 | - [统计不同号码的个数](./1-count-phone-num.md)
6 | - [出现频率最高的100个词](./2-find-hign-frequency-word.md)
7 | - [查找两个大文件共同的URL](./3-find-same-url.md)
8 | - [如何在100亿数据中找到中位数?](./4-find-mid-num)
9 | - [如何查询最热门的查询串?](./5-find-hot-string)
10 | - [如何找出排名前 500 的数?](./6-top-500-num)
11 | - [如何按照 query 的频度排序?](./7-query-frequency-sort)
12 | - [大数据中 TopK 问题的常用套路](./8-topk-template)
13 |
--------------------------------------------------------------------------------
/docs/message-queue/mq/consume-by-order.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 如何保证消息的顺序性?
4 | category: 消息队列
5 | tag:
6 | - 消息队列
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 消息队列面试题,如何保证消息消费的顺序性
11 | - - meta
12 | - name: description
13 | content: 高质量的消息队列常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | ## 如何保证消息的顺序性?
17 |
18 | 假设有这样一个场景,使用 MySQL `binlog` 将数据从一个 MySQL 库原封不动地同步到另一个 MySQL 库里面去。
19 |
20 | 你在 MySQL 里增删改一条数据,对应出来了增删改 3 条 `binlog` 日志,接着这三条 `binlog` 发送到 MQ 里面,再消费出来依次执行,这时需要保证按照顺序去执行,不然本来是:增加、修改、删除;调换了顺序变成执行成删除、修改、增加,这就有问题了。
21 |
22 | 本来这个数据同步过来,应该最后这个数据被删除了;结果搞错了这个顺序,最后这个数据保留下来了,数据同步就出错了。
23 |
24 | 先看看顺序会错乱的俩场景:
25 |
26 | - **RabbitMQ**:一个 queue,多个 consumer。比如,生产者向 RabbitMQ 里发送了三条数据,顺序依次是 data1/data2/data3,压入的是 RabbitMQ 的一个内存队列。有三个消费者分别从 MQ 中消费这三条数据中的一条,结果消费者 2 先执行完操作,把 data2 存入数据库,然后是 data1/data3。这明显就乱了。
27 |
28 | 
29 |
30 | - **Kafka**:比如说我们建了一个 topic,有三个 partition。生产者在写的时候,其实可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
31 | - 消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还是 ok 的,没有错乱。接着,我们在消费者里可能会搞**多个线程来并发处理消息**。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。
32 |
33 | 
34 |
35 | ### 解决方案
36 |
37 | #### RabbitMQ
38 |
39 | 拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点,这样也会造成吞吐量下降,可以在消费者内部采用多线程的方式取消费。
40 |
41 | 
42 |
43 | 或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
44 |
45 | 注意,这里消费者不直接消费消息,而是将消息根据关键值(比如:订单 id)进行哈希,哈希值相同的消息保存到相同的内存队列里。也就是说,需要保证顺序的消息存到了相同的内存队列,然后由一个唯一的 worker 去处理。
46 |
47 | #### Kafka
48 |
49 | - 一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
50 | - 写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
51 |
52 | 
53 |
--------------------------------------------------------------------------------
/docs/note/README.md:
--------------------------------------------------------------------------------
1 | - [一小时彻底吃透Redis](https://topjavaer.cn/note/redis-note.html)
2 | - [21个写SQL的好习惯](https://topjavaer.cn/note/write-sql.html)
3 | - [Docker详解与部署微服务实战](https://topjavaer.cn/note/docker-note.html)
4 | - [计算机专业的同学都看看这几点建议](https://topjavaer.cn/note/computor-advice.html)
5 | - [建议计算机专业同学都看看这门课](https://topjavaer.cn/note/computor-advice.html)
6 |
7 |
--------------------------------------------------------------------------------
/docs/note/computer-blogger.md:
--------------------------------------------------------------------------------
1 | ## 湖科大教书匠——计算机网络
2 |
3 | “宝藏老师”、“干货满满”、“羡慕湖科大”...这些都是网友对这门网课的评价,可见网课质量之高!
4 |
5 | 湖南科技大学《计算机网络》微课堂是该校高军老师精心制作的视频课程,用简单的语言描述复杂的问题,用生动的动画演示抽象概念,更加便于学生理解和记忆。推荐初学者去看看,一定不会亏!
6 |
7 | 
8 |
9 |
10 |
11 | ## 鱼C-小甲鱼——带你学C带你飞
12 |
13 | 小甲鱼的课程是很多转码人的第一门编程课,非常不错,对于自学的初学者来说挺友好。小甲鱼会从学生的角度思考问题,会针对一些初学者的疑惑进行解答,比很多大学老师教学水平强太多!
14 |
15 | 另外,小甲鱼的零基础入门学习python系列课程也很不错,推荐~
16 |
17 | 
18 |
19 | ## 跟李沐学AI——机器学习
20 |
21 | bilibili 2021新人奖UP主、亚马逊资深首席科学家,李沐老师的机器学习课程,可以说是机器学习入门课程的天花板,非常适合新手入门,没有很复杂的推导过程和数学知识,偏向于运用的角度。
22 |
23 | 
24 |
25 | ## 莫烦Python——Python
26 |
27 | 莫烦python的Python基础课程非常适合刚入门, 或者是以前使用过其语言的朋友,每一段视频都不会很长,节节相连,对于迅速掌握基础的使用方法很有帮助。
28 |
29 | 
30 |
31 |
32 |
33 | ## 懒猫老师——用动画讲编程
34 |
35 | 每个视频都用心制作,形象生动,用动画讲编程,在快乐中学习编程,太赞了。
36 |
37 | 
38 |
39 | ## 尚硅谷——Java教程
40 |
41 | 虽然是培训机构,但是尚硅谷也在某站上传了很多编程入门的视频,质量相对还是不错的,Java入门教程的播放量达到千万了,很多人都是看尚硅谷的视频学Java的哈哈(尚硅谷打qian!)。
42 |
43 | 
44 |
45 |
--------------------------------------------------------------------------------
/docs/note/computer-course.md:
--------------------------------------------------------------------------------
1 | ## GitHub
2 |
3 | 
4 |
5 | GitHub是一个面向开源及私有软件项目的托管平台,因为只支持Git作为唯一的版本库格式进行托管,故名GitHub。
6 |
7 | 作为开源代码库以及版本控制系统,Github拥有超过900万开发者用户。随着越来越多的应用程序转移到了云上,Github已经成为了管理软件开发以及发现已有代码的首选方法。
8 |
9 | 在GitHub,用户甚至可以十分轻易地找到海量的开源代码。
10 |
11 |
12 |
13 | ## LeetCode
14 |
15 | 
16 |
17 | 力扣,强推!力扣虐我千百遍,我待力扣如初恋!
18 |
19 | LeetCode是一个集合了大量算法面试题和AI面试题的网站,它为全世界的码农提供了练习自我技能的良好平台。
20 |
21 | 除了在题库中直接找题目之外,还可以根据该网站提供的阶梯训练进行练习。阶梯训练板块收纳了中美等不同公司的面试真题并以关卡的形式呈现给挑战者
22 |
23 | ## GeeksforGeeks
24 |
25 | 
26 |
27 | GeeksforGeeks是一个主要专注于计算机科学的网站。它有大量的算法,解决方案和编程问题。该网站也有很多面试中经常问到的问题。由于该网站更多地涉及计算机科学,因此你可以找到很多编程问题在大多数著名语言下的解决方案。
28 |
29 | ## StackOverflow
30 |
31 | 
32 |
33 | 程序员最痛苦的事莫过于深陷于BUG的泥潭,而stack overflow作为全球最大的技术问答网站,可以说每个搞过技术的人是必上的网站。开发过程中遇到什么 bug,上去搜一下,只要搜索的方式对,百分之 99 的问题都能搜到答案。
34 |
35 | 在 Stackoverflow 你也可以看到很多经典的问题,我们也可以从这些问题中学习如何去提问,如何和答题者沟通。
36 |
37 | ## Codebeautify
38 |
39 | 
40 |
41 | 由于我们是程序员,所以美不是我们所关心的。很多时候,我们的代码很难被其他人阅读。Codebeautify可以使你的代码易于阅读。该网站有大多数可以美化的语言。另外,如果你想让你的代码不能被某人读取,你也可以这样做。
42 |
43 |
44 |
45 | ## 菜鸟教程
46 |
47 | 菜鸟教程提供了编程的基础技术教程, 介绍了HTML、CSS、Javascript、Python,Java,Ruby,C,PHP , MySQL等各种编程语言的基础知识,对于计算机小白和初学者非常有用!
48 |
49 | 
50 |
51 |
52 |
53 | ## 中国大学MOOC
54 |
55 | 
56 |
57 | 中国大学MOOC(慕课) 是国内优质的中文MOOC学习平台,由网易有道与高教社携手推出的中国大学生MOOC承载了一万多门开放课、1400多门国家级精品课,与803所高校开展合作,已经成为最大的中文慕课平台。课程相对比较优质,推荐。
58 |
59 |
60 |
61 | ## 牛客网
62 |
63 | 
64 |
65 | 牛客网是一个集笔面试系统、题库、课程教育、社群交流、招聘内推于一体的招聘类网站。牛客网题库中包含几万道题目,题库涵盖六类行业题目,包含:IT技术类、硬件类、产品运营类、金融财会类、市场营销类、管理类、职能类。而且牛客网每年都会组织往年求职者分享面试经验,以供后来者学习、参考、交流。
--------------------------------------------------------------------------------
/docs/note/computor-advice.md:
--------------------------------------------------------------------------------
1 | 计算机专业的同学都看看这几点建议!
2 |
3 | 
4 |
5 | 
6 |
7 | 
8 |
9 | 
--------------------------------------------------------------------------------
/docs/note/crash-course-computer-science.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | 
4 |
5 | 
--------------------------------------------------------------------------------
/docs/note/docker-note.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | 
4 |
5 | 
6 |
7 | 
8 |
9 | 
10 |
11 | 
12 |
13 | 
14 |
15 | 
--------------------------------------------------------------------------------
/docs/note/freshman-planning.md:
--------------------------------------------------------------------------------
1 | 自学计算机的大彬来分享下几点宝贵经验。
2 |
3 | 1、看下**计算机科学速成课**,一门很全面的计算机原理入门课程,短短10分钟可以把大学老师十几节课讲的东西讲清楚!整个系列一共41个视频,B站上有中文字幕版。
4 |
5 | 每个视频都是一个特定的主题,例如软件工程、人工智能、操作系统等,主题之间都是紧密相连的,比国内很多大学计算机课程强太多!
6 |
7 | 这门课程通过生动形象的讲解方式,向普通人介绍了计算机科学相关的基础知识,包括**计算机的发展史、二进制、指令和程序、数据结构与算法、人工智能、计算机视觉、自然语言处理**等等。
8 |
9 | 每节课程短小精悍,只有短短十几分钟,适合平时碎片化时间观看。
10 |
11 | 
12 |
13 | 2、**学会使用google搜索**。很多同学遇到问题,不会利用好搜索引擎,而是在一些交流群咨询,往往“事倍功半”,问了半天也没得到想要的答案。建议题主学习下搜索的技巧,多用谷歌搜索,少用百度搜索,谷歌搜出来答案更准确,而不是通篇复制粘贴的“垃圾”。
14 |
15 | 
16 |
17 | 3、**多逛技术社区**。平时多逛逛全球最大的同xing交友社区Github、StackoverFlow等技术社区,关注最新的技术动态,尽量参与到开源项目建设,如果能给优秀的开源项目奉献自己的代码,那是非常nice的,对于以后找工作面试也有非常大的帮助。
18 |
19 | 
20 |
21 | 4、**多动手写代码**,切忌眼高手低!如果你确信自己对大多数的基础知识和概念足够熟悉,并且能够以某种方式将它们联系起来,那么你就可以进行下一步了,你可以开始尝试编写一些有趣的 Java 程序。刚开始动手编写程序时,请可能会困难重重。但是一旦挺过去,接下来即使这些问题再次出现,你也能轻松解决。
22 |
23 | 5、**阅读经典书籍**,比如《深入理解计算机系统》、《数据库系统概念》、《代码整洁之道》等等,这些都是非常优秀的书籍,每次阅读都会有新的收获。PS:不要看那种3天学会Java之类的垃圾书,内容很浅没深度!
24 |
25 | 6、学好英语,干计算机这行,要想走在前列,就必须学好英语。因为计算机很多术语都是英文,中文翻译的话经常翻译的非常生涩。而且很多前沿的东西都是国外的,国内教材资料需要等待一段时间才能跟上,因此良好的英语能力能让你快人一步获取一手资料。
26 |
27 | 7、**每天刷一道算法题**,养成刷题的习惯。很多互联网公司都会考察手写算法题,如果平时没有练习,那么笔试或面试的时候大概率会脑袋空白,game over。建议从大二开始,每天抽空到leetcode上刷刷题。
28 |
29 | 8、**参与计算机竞赛**。比如ACM国际大学生程序设计竞赛、GPLT团队程序设计天梯赛、蓝桥杯、中国大学生计算机设计大赛等,或者企业主办的比赛,如华为软件杯精英挑战赛、百度之星程序设计大赛等,参加这些比赛对找工作和保研都有加分,并且对你的代码能力、团队合作能力和逻辑思维能力也有很大的提升。
30 |
31 | 9、**绩点要刷高一点**,绩点高对你保研、考研或者找工作都有很大的帮助。尽量提高绩点,还有就是不能挂科!挂科对你以后发展影响挺大,切记!
32 |
33 | 10、**打牢计算机基础**
34 |
35 | 要特别重视计算机基础,无论以后是找工作还是考研,基础很重要。
36 |
37 | 计算机专业课程里边,**计算机基础课程无非以下几个:**
38 |
39 | 1. **计算机组成原理**
40 | 2. **操作系统**
41 | 3. **编译原理**
42 | 4. **计算机网络**
43 | 5. **数据结构与算法**
44 | 6. **数据库基础**
45 |
46 | 11、**培养写文档的能力**。写文档是计算机专业学生的必备技能。有空可以学习下markdown语法,比word好用太多了。markdown编辑器推荐Typora(最近收费了)、语雀。
--------------------------------------------------------------------------------
/docs/note/redis-note.md:
--------------------------------------------------------------------------------
1 | ::: tip 这是一则或许对你有帮助的信息
2 |
3 | - **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
4 | - **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
5 |
6 | :::
7 |
8 | ## 一小时彻底吃透Redis
9 |
10 | 
11 |
12 | 
13 |
14 | 
15 |
16 |
17 |
18 | 
19 |
20 | 
21 |
22 | 
23 |
24 | 
25 |
26 | 
27 |
28 | 
--------------------------------------------------------------------------------
/docs/other/leave-a-message.md:
--------------------------------------------------------------------------------
1 | # 留言区
2 |
3 | 大家有什么建议,或者觉得某个知识点理解有误的,欢迎到评论区留言~
4 |
5 |
--------------------------------------------------------------------------------
/docs/practice/service-performance-optimization.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 线上接口很慢怎么办?
4 | category: 实践经验
5 | tag:
6 | - 实践经验
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 线上接口很慢怎么处理
11 | - - meta
12 | - name: description
13 | content: 编程实践经验分享
14 | ---
15 |
16 | ## 线上接口很慢怎么办?
17 |
18 | 首先需要明确一个问题,是只有**一个接口**变慢,还是**多个接口**变慢。
19 |
20 | 如果系统中有多个服务的接口都变慢,那可能是**系统共用的资源不足**导致的。比如数据库连接数太多、数据库有大量慢查询、共同依赖的下游服务性能问题等。
21 |
22 | 可以查看系统中调用量突然增多的服务,它的调用量是否导致数据库的并发达到了瓶颈,是不是共同调用的下游服务出现了性能问题,数据库中是不是有大量这个服务引起的慢查询等。
23 |
24 | 可以有以下针对性优化:
25 |
26 | - 如果数据库并发达到瓶颈,可以考虑用**读写分离、分库分表、加读缓存**等方式来解决
27 | - 如果下游接口出现性能问题,需要通知下游服务做优化,同时要加**降级开关**
28 | - 如果数据库中有大量慢查询,需要**优化sql**或**加索引**等
29 |
30 | 如果是只有一个服务的接口变慢,那就要针对这个服务做分析,查看它的cpu占用率和gc频率是不是异常,做针对性的优化。
31 |
32 | 1. 比如在循环里获取远程数据,可以改成只调用一次,**批量获取数据**
33 | 2. 比如在链路中多次调用同一个远程接口获取相同数据,可以第一次调用之后就把数据**缓存**起来,后续直接从缓存中获取
34 | 3. 比如如果多个比较耗时的操作是串行执行的,但它们又没有依赖关系,就可以把串行改成**并行**,可以用countDownLatch
35 | 4. 还有如果实在无法再缩短请求处理耗时的话,也可以考虑从产品逻辑上进行优化,比如把原来的同步请求改为**异步**的,前端再去轮询请求处理结果
36 | 5. 比如为了得到一个复杂的model,需要调多个接口获取信息,但当前接口只需要其中部分比较简单的数据,那么需要根据实际情况,**重新写**一个简单model的获取方法
37 |
38 |
39 |
40 | > 参考链接:https://juejin.cn/post/7064140627578978334
41 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/1-introduce.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Redis简介
4 | category: 缓存
5 | tag:
6 | - Redis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Redis简介,redis优缺点,io多路复用,Memcached和Redis的区别,redis应用场景
11 | - - meta
12 | - name: description
13 | content: Redis常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 简介
17 |
18 | Redis是一个高性能的key-value数据库。Redis对数据的操作都是原子性的。
19 |
20 | ## 优缺点
21 |
22 | 优点:
23 |
24 | 1. 基于内存操作,内存读写速度快。
25 | 2. Redis是单线程的,避免线程切换开销及多线程的竞争问题。单线程是指在处理网络请求(一个或多个redis客户端连接)的时候只有一个线程来处理,redis运行时不止有一个线程,数据持久化或者向slave同步aof时会另起线程。
26 | 3. 支持多种数据类型,包括String、Hash、List、Set、ZSet等
27 | 4. 支持持久化。Redis支持RDB和AOF两种持久化机制,持久化功能有效地避免数据丢失问题。
28 | 5. redis 采用IO多路复用技术。多路指的是多个socket连接,复用指的是复用一个线程。redis使用单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。
29 |
30 | 缺点:对join或其他结构化查询的支持就比较差。
31 |
32 | ## io多路复用
33 |
34 | 将用户socket对应的文件描述符(file description)注册进epoll,然后epoll帮你监听哪些socket上有消息到达。当某个socket可读或者可写的时候,它可以给你一个通知。只有当系统通知哪个描述符可读了,才去执行read操作,可以保证每次read都能读到有效数据。这样,多个描述符的I/O操作都能在一个线程内并发交替地顺序完成,这就叫I/O多路复用,这里的复用指的是复用同一个线程。
35 |
36 | ## 应用场景
37 |
38 | 1. 缓存热点数据,缓解数据库的压力。
39 | 2. 利用Redis中原子性的自增操作,可以用使用实现计算器的功能,比如统计用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力。
40 | 3. 简单消息队列,不要求高可靠的情况下,可以使用Redis自身的发布/订阅模式或者List来实现一个队列,实现异步操作。
41 | 4. 好友关系,利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好友、共同爱好之类的功能。
42 | 5. 限速器,比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力。
43 |
44 | ## Memcached和Redis的区别
45 |
46 | 1. Redis只使用单核,而Memcached可以使用多核。
47 | 2. MemCached数据结构单一,仅用来缓存数据,而Redis支持更加丰富的数据类型,也可以在服务器端直接对数据进行丰富的操作,这样可以减少网络IO次数和数据体积。
48 | 3. MemCached不支持数据持久化,断电或重启后数据消失。Redis支持数据持久化和数据恢复,允许单点故障。
49 |
50 |
51 |
52 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/11-deletion-policy.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Redis删除策略
4 | category: 缓存
5 | tag:
6 | - Redis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Redis删除策略
11 | - - meta
12 | - name: description
13 | content: Redis常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 删除策略
17 |
18 | 1. 被动删除。在访问key时,如果发现key已经过期,那么会将key删除。
19 | 2. 主动删除。定时清理key,每次清理会依次遍历所有DB,从db随机取出20个key,如果过期就删除,如果其中有5个key过期,那么就继续对这个db进行清理,否则开始清理下一个db。
20 |
21 | 3. 内存不够时清理。Redis有最大内存的限制,通过maxmemory参数可以设置最大内存,当使用的内存超过了设置的最大内存,就要进行内存释放, 在进行内存释放的时候,会按照配置的淘汰策略清理内存,淘汰策略一般有6种,Redis4.0版本后又增加了2种,主要由分为三类:
22 |
23 | - 第一类 不处理 noeviction。发现内存不够时,不删除key,执行写入命令时直接返回错误信息。(默认的配置)
24 |
25 | - 第二类 从所有结果集中的key中挑选,进行淘汰
26 |
27 | - allkeys-random 就是从所有的key中随机挑选key,进行淘汰
28 | - allkeys-lru 就是从所有的key中挑选最近最少使用的数据淘汰
29 | - allkeys-lfu 就是从所有的key中挑选使用频率最低的key,进行淘汰。(这是Redis 4.0版本后新增的策略)
30 |
31 | - 第三类 从设置了过期时间的key中挑选,进行淘汰
32 |
33 | 这种就是从设置了expires过期时间的结果集中选出一部分key淘汰,挑选的算法有:
34 |
35 | - volatile-random 从设置了过期时间的结果集中随机挑选key删除。
36 | - volatile-lru 从设置了过期时间的结果集中挑选最近最少使用的数据淘汰
37 | - volatile-ttl 从设置了过期时间的结果集中挑选可存活时间最短的key开始删除(也就是从哪些快要过期的key中先删除)
38 | - volatile-lfu 从过期时间的结果集中选择使用频率最低的key开始删除(这是Redis 4.0版本后新增的策略)
39 |
40 |
41 |
42 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/5-sort.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Redis排序
4 | category: 缓存
5 | tag:
6 | - Redis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Redis排序
11 | - - meta
12 | - name: description
13 | content: Redis常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 排序
17 |
18 | ```
19 | LPUSH myList 4 8 2 3 6
20 | SORT myList DESC
21 | ```
22 |
23 | ```
24 | LPUSH letters f l d n c
25 | SORT letters ALPHA
26 | ```
27 |
28 | **BY参数**
29 |
30 | ```
31 | LPUSH list1 1 2 3
32 | SET score:1 50
33 | SET score:2 100
34 | SET score:3 10
35 | SORT list1 BY score:* DESC
36 | ```
37 |
38 | **GET参数**
39 |
40 | GET参数命令作用是使SORT命令的返回结果是GET参数指定的键值。
41 |
42 | `SORT tag:Java:posts BY post:*->time DESC GET post:*->title GET post:*->time GET #`
43 |
44 | GET #返回文章ID。
45 |
46 | **STORE参数**
47 |
48 | `SORT tag:Java:posts BY post:*->time DESC GET post:*->title STORE resultCache`
49 |
50 | `EXPIRE resultCache 10 //STORE结合EXPIRE可以缓存排序结果`
51 |
52 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/6-transaction.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Redis事务
4 | category: 缓存
5 | tag:
6 | - Redis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Redis事务
11 | - - meta
12 | - name: description
13 | content: Redis常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 事务
17 |
18 | 事务的原理是将一个事务范围内的若干命令发送给Redis,然后再让Redis依次执行这些命令。
19 |
20 | 事务的生命周期:
21 |
22 | 1. 使用MULTI开启一个事务
23 | 2. 在开启事务的时候,每次操作的命令将会被插入到一个队列中,同时这个命令并不会被真的执行
24 |
25 | 3. EXEC命令进行提交事务
26 |
27 | 
28 |
29 | DISCARD:放弃事务,即该事务内的所有命令都将取消
30 |
31 | 一个事务范围内某个命令出错不会影响其他命令的执行,不保证原子性:
32 |
33 | ```
34 | 127.0.0.1:6379> multi
35 | OK
36 | 127.0.0.1:6379> set a 1
37 | QUEUED
38 | 127.0.0.1:6379> set b 1 2
39 | QUEUED
40 | 127.0.0.1:6379> set c 3
41 | QUEUED
42 | 127.0.0.1:6379> exec
43 | 1) OK
44 | 2) (error) ERR syntax error
45 | 3) OK
46 | ```
47 |
48 | 事务里的命令执行时会读取最新的值:
49 |
50 | 
51 |
52 | ## WATCH命令
53 |
54 | WATCH命令可以监控一个或多个键,一旦其中有一个键被修改,之后的事务就不会执行(类似于乐观锁)。执行EXEC命令之后,就会自动取消监控。
55 |
56 | ```
57 | 127.0.0.1:6379> watch name
58 | OK
59 | 127.0.0.1:6379> set name 1
60 | OK
61 | 127.0.0.1:6379> multi
62 | OK
63 | 127.0.0.1:6379> set name 2
64 | QUEUED
65 | 127.0.0.1:6379> set gender 1
66 | QUEUED
67 | 127.0.0.1:6379> exec
68 | (nil)
69 | 127.0.0.1:6379> get gender
70 | (nil)
71 | ```
72 |
73 | UNWATCH:取消WATCH命令对多有key的监控,所有监控锁将会被取消。
74 |
75 |
76 |
77 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/7-message-queue.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: Redis实现消息队列
4 | category: 缓存
5 | tag:
6 | - Redis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: Redis实现消息队列
11 | - - meta
12 | - name: description
13 | content: Redis常见知识点和面试题总结,让天下没有难背的八股文!
14 | ---
15 |
16 | # 消息队列
17 |
18 | 使用一个列表,让生产者将任务使用LPUSH命令放进列表,消费者不断用RPOP从列表取出任务。
19 |
20 | BRPOP和RPOP命令相似,唯一的区别就是当列表没有元素时BRPOP命令会一直阻塞连接,直到有新元素加入。
21 | `BRPOP queue 0 //0表示不限制等待时间`
22 |
23 | ## 优先级队列
24 |
25 | `BLPOP queue:1 queue:2 queue:3 0`
26 | 如果多个键都有元素,则按照从左到右的顺序取元素
27 |
28 | ## 发布/订阅模式
29 |
30 | ```
31 | PUBLISH channel1 hi
32 | SUBSCRIBE channel1
33 | UNSUBSCRIBE channel1 //退订通过SUBSCRIBE命令订阅的频道。
34 | ```
35 |
36 | `PSUBSCRIBE channel?*` 按照规则订阅
37 | `PUNSUBSCRIBE channel?*` 退订通过PSUBSCRIBE命令按照某种规则订阅的频道。其中订阅规则要进行严格的字符串匹配,`PUNSUBSCRIBE *`无法退订`channel?*`规则。
38 |
39 | 缺点:在消费者下线的情况下,生产的消息会丢失。
40 |
41 | ## 延时队列
42 |
43 | 使用sortedset,拿时间戳作为score,消息内容作为key,调用zadd来生产消息,消费者用`zrangebyscore`指令获取N秒之前的数据轮询进行处理。
44 |
45 |
46 |
47 |
--------------------------------------------------------------------------------
/docs/redis/redis-basic/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis基础
3 | icon: redis
4 | date: 2022-08-06
5 | category: redis
6 | star: true
7 | ---
8 |
9 | **本专栏是大彬学习MySQL基础知识的学习笔记,如有错误,可以在评论区指出**~
10 |
11 | 
12 |
13 | ## Redis总结
14 |
15 | - [简介](./1-introduce.md)
16 | - [数据类型](./2-data-type.md)
17 | - [数据结构](./3-data-structure.md)
18 | - [底层实现](./4-implement.md)
19 | - [排序](./5-sort.md)
20 | - [事务](./6-transaction.md)
21 | - [消息队列](./7-message-queue.md)
22 | - [持久化](./8-persistence.md)
23 | - [集群](./9-cluster.md)
24 | - [LUA脚本](./10-lua.md)
25 | - [删除策略](./11-deletion-policy.md)
26 | - [其他](./12-others.md)
27 |
--------------------------------------------------------------------------------
/docs/snippets/ads.md:
--------------------------------------------------------------------------------
1 | ::: tip 这是一则或许对你有帮助的信息
2 |
3 | - **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
4 | - **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
5 |
6 | :::
--------------------------------------------------------------------------------
/docs/source/mybatis/1-overview.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: MyBatis源码分析
4 | category: 源码分析
5 | tag:
6 | - MyBatis
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: MyBatis面试题,MyBatis源码分析,MyBatis整体架构,MyBatis源码,Hibernate,Executor,MyBatis分页,MyBatis插件运行原理,MyBatis延迟加载,MyBatis预编译,一级缓存和二级缓存
11 | - - meta
12 | - name: description
13 | content: 高质量的MyBatis源码分析总结
14 | ---
15 |
16 | `MyBatis` 是一款旨在帮助开发人员屏蔽底层重复性原生 `JDBC` 代码的持久化框架,其支持通过映射文件配置或注解将 `ResultSet` 映射为 `Java` 对象。相对于其它 `ORM` 框架,`MyBatis` 更为轻量级,支持定制化 `SQL` 和动态 `SQL`,方便优化查询性能,同时包含了良好的缓存机制。
17 |
18 | ## MyBatis 整体架构
19 |
20 | 
21 |
22 | ### 基础支持层
23 |
24 | - 反射模块:提供封装的反射 `API`,方便上层调用。
25 | - 类型转换:为简化配置文件提供了别名机制,并且实现了 `Java` 类型和 `JDBC` 类型的互转。
26 | - 日志模块:能够集成多种第三方日志框架。
27 | - 资源加载模块:对类加载器进行封装,提供加载类文件和其它资源文件的功能。
28 | - 数据源模块:提供数据源实现并能够集成第三方数据源模块。
29 | - 事务管理:可以和 `Spring` 集成开发,对事务进行管理。
30 | - 缓存模块:提供一级缓存和二级缓存,将部分请求拦截在缓存层。
31 | - `Binding` 模块:在调用 `SqlSession` 相应方法执行数据库操作时,需要指定映射文件中的 `SQL` 节点,`MyBatis` 通过 `Binding` 模块将自定义 `Mapper` 接口与映射文件关联,避免拼写等错误导致在运行时才发现相应异常。
32 |
33 | ### 核心处理层
34 |
35 | - 配置解析:`MyBatis` 初始化时会加载配置文件、映射文件和 `Mapper` 接口的注解信息,解析后会以对象的形式保存到 `Configuration` 对象中。
36 | - `SQL` 解析与 `scripting` 模块:`MyBatis` 支持通过配置实现动态 `SQL`,即根据不同入参生成 `SQL`。
37 | - `SQL` 执行与结果解析:`Executor` 负责维护缓存和事务管理,并将数据库相关操作委托给 `StatementHandler`,`ParmeterHadler` 负责完成 `SQL` 语句的实参绑定并通过 `Statement` 对象执行 `SQL`,通过 `ResultSet` 返回结果,交由 `ResultSetHandler` 处理。
38 |
39 | - 插件:支持开发者通过插件接口对 `MyBatis` 进行扩展。
40 |
41 | ### 接口层
42 |
43 | `SqlSession` 接口定义了暴露给应用程序调用的 `API`,接口层在收到请求时会调用核心处理层的相应模块完成具体的数据库操作。
--------------------------------------------------------------------------------
/docs/system-design/README.md:
--------------------------------------------------------------------------------
1 | **系统设计高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到Java面试手册**完整版**。
2 |
3 | 
4 |
5 | 除了Java面试手册完整版之外,星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
6 |
7 | 
8 |
9 | 
10 |
11 | 
12 |
13 | **专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
14 |
15 | 
16 |
17 | 
18 |
19 | 另外星球还提供**简历指导、修改服务**,大彬已经帮**90**+个小伙伴修改了简历,相对还是比较有经验的。
20 |
21 | 
22 |
23 | 
24 |
25 | [知识星球](https://topjavaer.cn/zsxq/introduce.html)**加入方式**:
26 |
27 | 
--------------------------------------------------------------------------------
/docs/tools/docker/1-introduce.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | Docker是一个开源的应用容器引擎,通过容器可以隔离应用程序的运行时环境(程序运行时依赖的各种库和配置),比虚拟机更轻量(虚拟机在操作系统层面进行隔离)。docker的另一个优点就是build once, run everywhere,只编译一次,就可以在各个平台(windows、linux等)运行。
4 |
5 | ## 基本概念
6 |
7 | docker的基本概念:
8 |
9 | 1. 镜像(image),类似于虚拟机中的镜像,可以理解为可执行程序。
10 |
11 | 2. 容器(container),类似于一个轻量级的沙盒,可以将其看作一个极简的Linux系统环境。Docker引擎利用容器来运行、隔离各个应用。容器是镜像创建的应用实例,可以创建、启动、停止、删除容器,各个容器之间是是相互隔离的,互不影响。
12 |
13 | 3. 镜像仓库(repository),是Docker用来集中存放镜像文件的地方。注意与注册服务器(Registry)的区别:注册服务器是存放仓库的地方,一般会有多个仓库;而仓库是存放镜像的地方,一般每个仓库存放一类镜像,每个镜像利用tag进行区分,比如Ubuntu仓库存放有多个版本(12.04、14.04等)的Ubuntu镜像。
14 | 4. dockerfile,image的编译配置文件,docker就是"编译器"。
15 |
16 | docker的基本命令:
17 |
18 | 1、docker build:我们只需要在dockerfile中指定需要哪些程序、依赖什么样的配置,之后把dockerfile交给“编译器”docker进行“编译”,生成的可执行程序就是image。
19 |
20 | 2、docker run:运行image,运行起来后就是docker container。
21 |
22 | 3、docker pull:到Docker Hub(docker registry)下载别人写好的image。
23 |
24 | 
25 |
26 | > 图片来源:知乎小灰
27 |
28 |
--------------------------------------------------------------------------------
/docs/tools/docker/6-other.md:
--------------------------------------------------------------------------------
1 | # 其他
2 |
3 | ## 给nginx增加端口映射
4 |
5 | nginx一开始只映射了80端口,后面载部署项目的时候,需要用到其他端口,不想重新部署容器,所以通过修改配置文件的方式给容器添加其他端口。
6 |
7 | 1、执行命令`docker inspect nginx`,找到容器id
8 |
9 | 2、停止容器`docker stop nginx`,不然修改了配置会自动还原
10 |
11 | 3、修改hostconfig.json
12 |
13 | ```java
14 | cd /var/lib/docker/containers/135254e3429d1e75aa68569137c753b789416256f2ced52b4c5a85ec3849db87 # container id
15 | vim hostconfig.json
16 | ```
17 |
18 | 添加端口:
19 |
20 | ```java
21 | "PortBindings": {
22 | "80/tcp": [
23 | {
24 | "HostIp": "",
25 | "HostPort": "80"
26 | }
27 | ],
28 | "8080/tcp": [
29 | {
30 | "HostIp": "",
31 | "HostPort": "8080"
32 | }
33 | ]
34 | },
35 | ```
36 |
37 | 4、修改同目录下 config.v2.json
38 |
39 | ```java
40 | "ExposedPorts": {
41 | "80/tcp": {},
42 | "8080/tcp": {},
43 | "8189/tcp": {}
44 | },
45 | ```
46 |
47 | 5、重启容器
48 |
49 | ```java
50 | systemctl restart docker.service # 重启docker服务
51 | docker start nginx
52 | ```
53 |
54 |
--------------------------------------------------------------------------------
/docs/tools/docker/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Docker基础
3 | icon: docker
4 | date: 2022-08-06
5 | category: docker
6 | star: true
7 | ---
8 |
9 | 
10 | ## Docker总结
11 |
12 | - [简介](./1-introduce.md)
13 | - [docker镜像常用命令](./2-image-command.md)
14 | - [docker容器常用命令](./3-container-command.md)
15 | - [docker-compose](./4-docker-compose.md)
16 | - [maven插件构建docker镜像](./5-maven-build.md)
17 | - [其他](./6-other.md)
18 |
--------------------------------------------------------------------------------
/docs/tools/git/1-introduce.md:
--------------------------------------------------------------------------------
1 | # Git 简介
2 |
3 | Git 是一个开源的分布式版本控制系统,可以有效、快速的进行项目版本管理。Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
4 |
5 | ## Git工作流程
6 |
7 | Git工作流程如下:
8 |
9 | - 从远程仓库中克隆资源作为本地仓库;
10 | - 在本地仓库中进行代码修改;
11 | - 在提交本地仓库前先将代码提交到暂存区;
12 | - 提交修改,提交到本地仓库。本地仓库中保存修改的所有历史版本;
13 | - 在需要和团队成员共享代码时,可以将修改的代码push到远程仓库。
14 |
15 | Git 的工作流程图如下:
16 |
17 | 
18 |
19 | > 图片来源:https://blog.csdn.net/ThinkWon/article/details/94346816
20 |
21 | ## 存储原理
22 |
23 | Git 在保存项目状态时,它主要对全部文件制作一个快照并保存这个快照的索引,如果文件没有被修改,Git 不会重新存储这个文件,而是只保留一个链接指向之前存储的文件。
24 |
25 | ## Git 快照
26 |
27 | 快照就是将旧文件所占的空间保留下来,并且保存一个引用,而新文件中会继续使用与旧文件内容相同部分的磁盘空间,不同部分则写入新的磁盘空间。
28 |
29 | ## 三种状态
30 |
31 | Git 的三种状态:已修改(modified)、已暂存(staged)和已提交(committed)。已修改表示修改了文件,但还没保存到数据库。已暂存表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。已提交表示数据已经安全的保存到本地数据库。
32 |
33 | 基本的 Git 工作流程:在工作目录修改文件;暂存文件,将文件快照放到暂存区域;提交更新到本地库。暂存区保存了下次将要提交的文件列表信息,一般在 Git 仓库目录中。
34 |
35 | 
36 |
37 | > 图片来源:`https://img2018.cnblogs.com/blog/1252910/201907/1252910-20190726163829113-2056815874.png`
38 |
39 | 
40 |
41 | ## 配置
42 |
43 | 设置用户名和邮箱地址:
44 |
45 | ```bash
46 | git config --global user.name "dabin"
47 | git config --global user.email xxx@xxx.com
48 | ```
49 |
50 | 如果使用了 --global 选项,那么该命令只需要运行一次,因为之后无论你在该系统上做任何事情,Git 都会使用那些信息。 当你想针对特定项目使用不同的用户名称与邮件地址时,可以在那个项目目录下运行没有 --global 选项的命令来配置。
51 |
52 | 查看配置信息:
53 |
54 | ```bash
55 | git config --list
56 | ```
57 |
58 | 查看某一项配置:
59 |
60 | ```bash
61 | git config user.name
62 | ```
63 |
64 | ## 获取帮助
65 |
66 | 获取 config 命令的手册:
67 |
68 | ```bash
69 | git help config
70 | ```
71 |
72 |
--------------------------------------------------------------------------------
/docs/tools/git/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Git基础
3 | icon: git
4 | date: 2022-08-06
5 | category: git
6 | star: true
7 | ---
8 |
9 | 
10 |
11 | ## Git总结
12 |
13 | - [Git简介](./1-introduce.md)
14 | - [Git基础](./2-basic.md)
15 | - [远程仓库](./3-remote-repo.md)
16 | - [标签](./4-label.md)
17 | - [git分支](./5-branch.md)
18 |
--------------------------------------------------------------------------------
/docs/tools/linux/3-search.md:
--------------------------------------------------------------------------------
1 | # 检索相关
2 |
3 | ## grep
4 |
5 | ```
6 | #反向匹配, 查找不包含xxx的内容
7 | grep -v xxx
8 |
9 | #排除所有空行
10 | grep -v '^/pre>
11 |
12 | #返回结果 2,则说明第二行是空行
13 | grep -n “^$” 111.txt
14 |
15 | #查询以abc开头的行
16 | grep -n “^abc” 111.txt
17 |
18 | #同时列出该词语出现在文章的第几行
19 | grep 'xxx' -n xxx.log
20 |
21 | #计算一下该字串出现的次数
22 | grep 'xxx' -c xxx.log
23 |
24 | #比对的时候,不计较大小写的不同
25 | grep 'xxx' -i xxx.log
26 | ```
27 |
28 | ## awk
29 |
30 | ```
31 | #以':' 为分隔符,如果第五域有user则输出该行
32 | awk -F ':' '{if ($5 ~ /user/) print $0}' /etc/passwd
33 |
34 | #统计单个文件中某个字符(串)(中文无效)出现的次数
35 | awk -v RS='character' 'END {print --NR}' xxx.txt
36 | ```
37 |
38 | ## find检索命令
39 |
40 | ```
41 | #在目录下找后缀是.mysql的文件
42 | find /home/eagleye -name '*.mysql' -print
43 |
44 | #会从 /usr 目录开始往下找,找最近3天之内存取过的文件。
45 | find /usr -atime 3 –print
46 |
47 | #会从 /usr 目录开始往下找,找最近5天之内修改过的文件。
48 | find /usr -ctime 5 –print
49 |
50 | #会从 /doc 目录开始往下找,找jacky 的、文件名开头是 j的文件。
51 | find /doc -user jacky -name 'j*' –print
52 |
53 | #会从 /doc 目录开始往下找,找寻文件名是 ja 开头或者 ma开头的文件。
54 | find /doc \( -name 'ja*' -o- -name 'ma*' \) –print
55 |
56 | #会从 /doc 目录开始往下找,找到凡是文件名结尾为 bak的文件,把它删除掉。-exec 选项是执行的意思,rm 是删除命令,{ } 表示文件名,“\;”是规定的命令结尾。
57 | find /doc -name '*bak' -exec rm {} \;
58 | ```
59 |
60 |
--------------------------------------------------------------------------------
/docs/tools/linux/README.md:
--------------------------------------------------------------------------------
1 | 虽然平时大部分工作都是和Java相关的开发, 但是每天都会接触Linux系统, 尤其是使用了Mac之后, 每天都是工作在黑色背景的命令行环境中. 自己记忆力不好, 很多有用的Linux命令不能很好的记忆, 现在逐渐总结一下, 以便后续查看。
2 |
3 | > 来源:siye1982.github.io/2016/02/25/linux-list
4 |
5 |
6 | ## Linux基础命令
7 |
8 | - [基本操作](./1-basic.md)
9 | - [磁盘,文件,目录相关操作](./2-disk-file.md)
10 | - [检索相关](./3-search.md)
11 | - [网络相关](./4-net.md)
12 | - [监控linux性能命令](./5-monitor.md)
13 |
--------------------------------------------------------------------------------
/docs/tools/maven/1-introduce.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | Maven 是强大的构建工具,能够帮我们自动化构建过程--清理、编译、测试、打包和部署。比如测试,我们无需告诉 maven 如何去测试,只需遵循 maven 的约定编写好测试用例,当我们运行构建的时候,这些测试就会自动运行。
4 |
5 | Maven 不仅是构建工具,还是一个依赖管理工具和项目信息管理工具。它提供了中央仓库,能帮助我们自动下载构件。
6 |
7 | ## 配置
8 |
9 | 配置用户范围 settings.xml。M2_HOME/conf/settings.xml 是全局范围的,而~/.m2/settings.xml 是用户范围的。配置成用户范围便于 Maven 升级。若直接修改 conf 目录下的 settings.xml,每次 Maven 升级时,都需要直接 settings.xml 文件。
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/docs/tools/maven/3-dependency.md:
--------------------------------------------------------------------------------
1 | # 依赖
2 |
3 | ```xml
4 |
5 | junit
6 | junit
7 | 4.7
8 | test
9 |
10 | ```
11 |
12 | - scope:依赖的范围
13 |
14 | - type:依赖的类型,jar 或者 war
15 |
16 | - exclusions:用来排除传递性依赖
17 |
18 | ## 依赖范围 scope
19 |
20 | maven 在编译、测试和运行项目时会使用不同的 classpath(编译classpath、测试 classpath、运行 classpath)。依赖范围就是用来控制依赖和这三种 classpath 的关系。maven 中有以下几种依赖范围:
21 |
22 | - compile:默认值,使用该依赖范围的 maven 依赖,在编译、测试和运行时都需要使用该依赖
23 | - test:只对测试 classpath 有效,在编译主代码和运行项目时无法使用此类依赖。如 JUnit 只在编译测试代码和运行测试的时候才需要此类依赖
24 | - provided:已提供依赖范围。对于编译和测试 classpath 有效,但在运行时无效。如 servlet-api,编译和测试时需要该依赖,但在运行项目时,由于容器已经提供此依赖,故不需要 maven重复引入
25 | - runtime:运行时依赖范围。对于测试和运行 classpath 有效,但在编译主代码时无效。如 JDBC 驱动实现,项目主代码的编译只需要 JDK 提供的 JDBC接口,只有在测试和运行时才需要实现 JDBC 接口的具体实现
26 | - system:系统依赖范围
27 | - import:导入依赖范围 [import 导入依赖管理](#import-导入依赖管理)
28 |
29 |
30 | ## 传递性依赖
31 |
32 | 假如项目 account 有一个 compile 范围的 spring-core 依赖,而 spring-core 有一个 compile 范围的 common-logging 依赖,那么 common-logging 就会成为 account 的 compile 范围依赖,common-logging 是 account 的一个传递性依赖。maven 会直接解析各个直接依赖的 POM,将那些必要的间接依赖,以传递性依赖的形式引入到项目中。
33 |
34 | spring-core 是 account 的第一直接依赖,common-logging 是 spring-core 的第二直接依赖,common-logging 是 account 的传递性依赖。第一直接依赖的范围和第二直接依赖的范围共同决定了传递性依赖的范围。下表左边是第一直接依赖的范围,上面一行是第二直接依赖的范围,中间部分是传递依赖的范围
35 |
36 | 
37 |
38 | ## 排除依赖
39 |
40 | 传递性依赖可能会带来一些问题,像引入一些类库的 SNAPSHOT 版本,会影响到当前项目的稳定性。此时可以通过 exclusions 元素声明排除传递性依赖,exclusions 元素可以包含一个或多个 exclusion 元素,因此可以排除多个传递性依赖。声明 exclusion 时只需要 groupId 和 artifactId,而不需要 version 元素。
41 |
42 | 
43 |
44 | ## 优化依赖
45 |
46 | 查看当前项目的依赖:`mvn dependency:list`
47 |
48 | 查看依赖树:`mvn dependency:tree`
49 |
50 | 分析依赖:`mvn dependency:analyze`
51 |
52 |
53 |
54 |
--------------------------------------------------------------------------------
/docs/tools/maven/5-lifecycle.md:
--------------------------------------------------------------------------------
1 | # 生命周期
2 |
3 | 项目构建过程包括:清理项目- 编译-测试-打包-部署
4 |
5 | ## 三套生命周期
6 |
7 | clean 生命周期:pre-clean、clean 和 post-clean;
8 |
9 | default 生命周期;
10 |
11 | site 生命周期:pre-site、site、post-site 和 site-deploy
12 |
13 | ## 命令行与生命周期
14 |
15 | `mvn clean`:调用 clean 生命周期的 clean 阶段,实际上执行的是 clean 的 pre-clean 和 clean 阶段;
16 |
17 | `mvn test`:调用 default 生命周期的 test 阶段;
18 |
19 | `mvn clean install`:调用 clean 生命周期的 clean 阶段和 default 生命周期的 install 阶段;
20 |
21 | `mvn clean deploy site-deploy`:调用 clean 生命周期的 clean 阶段、default 生命周期的 deploy 阶段,以及 site 生命周期的 site-deploy 阶段。
22 |
23 |
24 |
25 |
--------------------------------------------------------------------------------
/docs/tools/maven/6-plugin.md:
--------------------------------------------------------------------------------
1 | # 插件
2 |
3 | maven 的生命周期和插件相互绑定,用以完成具体的构建任务。
4 |
5 | ## 内置绑定
6 |
7 | 
8 |
9 | 
10 |
11 | ## 自定义绑定
12 |
13 | 内置绑定无法完成一些任务,如创建项目的源码 jar 包,此时需要用户自行配置。maven-source-plugin 可以完成这个任务,它的 jar-no-fork 目标能够将项目的主代码打包成 jar 文件,可以将其绑定到 default 生命周期的 verify 阶段,在执行完测试和安装构件之前创建源码 jar 包。
14 |
15 | ```xml
16 |
17 |
18 |
19 | org.apache.maven.plugins
20 | maven-source-plugin
21 | 2.1.1
22 |
23 |
24 | attach-sources
25 | verify
26 |
27 | jar-no-fork
28 |
29 |
30 |
31 |
32 |
33 |
34 | ```
35 |
36 | ## 命令行插件配置
37 |
38 | maven-surefire-plugin 提供了一个 maven.test.skip 参数,当其值为 true 时,就会跳过执行测试。
39 |
40 | `mvn install -Dmaven.test.skip=true` -D 是 Java 自带的。
41 |
42 | ## 插件全局配置
43 |
44 | 有些参数值从项目创建到发布都不会改变,可以在 pom 中一次性配置,避免重新在命令行输入。如配置 maven-compiler-plugin ,生成与 JVM1.5 兼容的字节码文件。
45 |
46 | ```xml
47 |
48 |
49 |
50 | org.apache.maven.plugins
51 | maven-compiler-plugin
52 | 2.1
53 |
54 | 1.5
55 | 1.5
56 |
57 |
58 |
59 |
60 | ```
61 |
62 |
63 |
64 |
--------------------------------------------------------------------------------
/docs/tools/maven/7-aggregator.md:
--------------------------------------------------------------------------------
1 | # 聚合
2 |
3 | 项目有多个模块时,使用一个聚合体将这些模块聚合起来,通过聚合体就可以一次构建全部模块。
4 |
5 | 
6 |
7 | accout-aggregator 的版本号要跟各个模块版本号相同,packaging 的值必须为 pom。module 标签的值是模块根目录名字(为了方便,模块根目录名字常与 artifactId 同名)。这样聚合模块和其他模块的目录结构是父子关系。如果使用平行目录结构,聚合模块的 pom 文件需要做相应的修改。
8 |
9 | ```xml
10 |
11 | ../account-register
12 | ../account-persist
13 |
14 | ```
15 |
16 |
17 |
18 |
--------------------------------------------------------------------------------
/docs/tools/maven/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Maven基础
3 | icon: build
4 | date: 2022-08-08
5 | category: maven
6 | star: true
7 | ---
8 |
9 | 
10 |
11 | ## Maven总结
12 |
13 | - [简介](./1-introduce.md)
14 | - [入门](./2-basic.md)
15 | - [依赖](./3-dependency.md)
16 | - [仓库](./4-repo.md)
17 | - [生命周期](./5-lifecycle.md)
18 | - [插件](./6-plugin.md)
19 | - [聚合](./7-aggregator.md)
20 | - [继承](./8-inherit.md)
21 |
--------------------------------------------------------------------------------
/docs/zookeeper/zk-usage.md:
--------------------------------------------------------------------------------
1 | ## Zookeeper有哪些使用场景?
2 |
3 | zookeeper 的使用场景有:
4 |
5 | - 分布式协调
6 | - 分布式锁
7 | - 元数据/配置信息管理
8 | - HA 高可用性
9 |
10 | ### 分布式协调
11 |
12 | 这个其实是 zookeeper 很经典的一个用法,简单来说,比如 A 系统发送个请求到 mq,然后 B 系统消息消费之后处理了。那 A 系统如何知道 B 系统的处理结果?用 zookeeper 就可以实现分布式系统之间的协调工作。A 系统发送请求之后可以在 zookeeper 上**对某个节点的值注册个监听器**,一旦 B 系统处理完了就修改 zookeeper 那个节点的值,A 系统立马就可以收到通知。
13 |
14 | 
15 |
16 | ### 分布式锁
17 |
18 | 比如对某一个数据连续发出两个修改操作,两台机器同时收到了请求,但是只能一台机器先执行完另外一个机器再执行。那么此时就可以使用 zookeeper 分布式锁,一个机器接收到了请求之后先获取 zookeeper 上的一把分布式锁,就是可以去创建一个 znode,接着执行操作;然后另外一个机器也**尝试去创建**那个 znode,结果发现自己创建不了,因为被别人创建了,那只能等着,等第一个机器执行完了自己再执行。
19 |
20 | 
21 |
22 | ### 元数据/配置信息管理
23 |
24 | zookeeper 可以用作很多系统的配置信息的管理,比如 kafka、storm 等等很多分布式系统都会选用 zookeeper 来做一些元数据、配置信息的管理。
25 |
26 | 
27 |
28 | ### HA 高可用性
29 |
30 | 这个应该是很常见的,比如 hadoop、hdfs、yarn 等很多大数据系统,都选择基于 zookeeper 来开发 HA 高可用机制,就是一个**重要进程一般会做主备**两个,主进程挂了立马通过 zookeeper 感知到切换到备用进程。
31 |
32 | 
33 |
34 |
35 |
36 | **参考资料**
37 |
38 | https://zhuanlan.zhihu.com/p/59669985
39 |
40 | https://doocs.github.io/
--------------------------------------------------------------------------------
/docs/zsxq/inner-material.md:
--------------------------------------------------------------------------------
1 | **JVM重要知识点&高频面试题**是我的**[知识星球](https://topjavaer.cn/zsxq/introduce.html)内部专属资料**,已经整理到Java面试手册完整版。除了Java面试手册完整版之外,星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
2 |
3 | 
4 |
5 | 
6 |
7 | 
8 |
9 | 
10 |
11 | 另外星球还提供**简历指导、修改服务**,大彬已经帮**90**+个小伙伴修改了简历,相对还是比较有经验的。
12 |
13 | 
14 |
15 | 
16 |
17 | **专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会优先解答球友的问题。
18 |
19 | 
20 |
21 | 
22 |
23 | [知识星球](https://topjavaer.cn/zsxq/introduce.html)**加入方式**:
24 |
25 | 
--------------------------------------------------------------------------------
/docs/zsxq/question/VO, BO, PO, DO, DTO.md:
--------------------------------------------------------------------------------
1 | 最近[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)有小伙伴提出了关于性格测试的疑问:
2 |
3 | **球友提问**:
4 |
5 | 大彬大佬,请教一个概念和具体应用上的问题, VO, BO, PO, DO, DTO 这些概念和具体应用是怎样的?
6 |
7 | ---
8 |
9 | **大彬的回答**:
10 |
11 | 你好,这个问题要结合实际业务来讲更好理解。
12 |
13 | 比如现在有一个用户登录的业务。 有一张表user存用户数据,这个表里面有 id ,name ,password。首先说说PO,PO比较好理解,就是数据库中的记录,一个PO的数据结构对应着表的结构,表中的一条记录就是一个PO对象。
14 |
15 | 再来看看什么是DO。比如现在需要实现登录功能,那就只需要检查用户输入的 name 和 password 和数据库是否一致就可以了。 这种情况下,就用一个 User 对象来表示这个领域模型就可以了。我一般用 Domain Object ,也就是 DO 表示,对应下来就是 UserDO ( 统一用 Do 也可以)
16 |
17 |
18 |
19 | 再假设现在有一个展示用户信息的业务,假想给一个客服(不期望把用户密码给他看到的那种情况)
20 |
21 | 一般来说有两种做法:
22 |
23 | 第一种,你可以在序列化为 json 字符串的时候,隐藏 password 的序列化来实现;
24 |
25 | 第二种,你可以新建一个 VO ( View Object )对象,就叫 UserVO ,然后这里面就只有 id 和 name 两个属性即可;
26 |
27 |
28 |
29 | 再假设,现在的场景不是直接展示到页面上,而是被一个业务系统调用,这个系统需要依赖登录的服务。 然后需要提供 sdk 给这个业务系统集成,那么这个时候就可以声明一个 DTO 对象,里面也只有 id 和 name 属性即可。
30 |
31 | 当然实际业务肯定不可能说只有 id ,name ,password 这么简单,这里只是举个例子方便理解。
--------------------------------------------------------------------------------
/docs/zsxq/question/familiarize-new-project-qucikly.md:
--------------------------------------------------------------------------------
1 | # 如何快速熟悉一个新项目
2 |
3 | 很多人刚进入一家新公司后,最头疼的就是如何快速了解公司的业务和项目架构。
4 |
5 | 一方面是文档很少或者没有文档, 只能自己硬着头皮摸索;另一方面大家都很忙,很少有人会帮你梳理业务逻辑。如果你碰到一个特别热心的老员工,随时在你身边答疑解惑,那你的运气实在是太好了, 现实是大家都很忙,没人给你讲解。
6 |
7 | 领导只给你几天时间熟悉,接着就要深入项目做开发了,怎么办呢?
8 |
9 | 接下来分享我总结的一些经验。
10 |
11 | ## 从页面到数据库
12 |
13 | 对某个具体项目的了解,一定要建立在对整体了解的基础上。首先可以给项目画出一条线,并标明每一个节点的信息,就像这样:页面访问路径--前端项目--后台服务--数据库地址(也可以通过流程图的形式)。
14 |
15 | 这个整理的过程,主要是让自己梳理清楚前端项目分别调用了哪些后台服务,通过后台服务和数据库的名称,我们能大致了解到这条业务线提供了什么功能,从前端项目和页面路径,我们能了解到我们需要给用户展示什么。
16 |
17 | 这个阶段不需要花费太多时间,重点就是仅仅是了解这条业务线的整体内容。
18 |
19 | ## 整理数据库表
20 |
21 | 上面都是整理项目的大体框架,还没有涉及到具体的项目细节。
22 |
23 | 一般业务项目无非就是对数据库的增删改查操作而已,或者从使用者的角度看,一个项目就是输入一些参数得到一些返回结果。
24 |
25 | 接下来要做的就是整理**数据库表**了。
26 |
27 | 这里首先要选择一个核心项目去看,众多项目中一定有一个是核心项目,先从核心项目开始看起。
28 |
29 | 如果数据库的表比较少,直接一个个看就行了。但如果数据库表特别多,那就需要先筛选出哪些是核心的表了。
30 |
31 | 如何判断哪些是核心表呢?最快的方式就是找老员工问一下,一般核心表不会很多。有些表可以先忽略不看,比如copy结(备份),rel结尾的(中间关联表),statistics结尾的(数据统计表),log结尾(日志表),config结尾(配置表),等等。
32 |
33 | 到此,你就对整体的数据库结构有所了解了。根据表名也能对表的大致内容有所了解,接下来就是针对具体的表,看里面具体的字段和前人给出的备注,**这个过程就没有技巧了,要耐心,要慢慢熬**。
34 |
35 | ## 深入代码层
36 |
37 | 当你对数据库表有了大体的了解后,你基本上对这个系统能提供什么服务了解到差不多了。接下来就是深入代码层理解业务逻辑了。
38 |
39 | 一般业务相关的项目代码分三个部分:
40 |
41 | 1. 通过前端交互(Controller层)对数据库进行增删改查操作
42 | 2. 通过定时任务对数据库进行增删改查操作
43 | 3. 调用或通知其他服务做一些事情
44 |
45 | 这三种类型的代码研究清楚后,对于一个业务型的项目来说,已经基本足够了。
46 |
47 | 另外,在研究具体业务代码的同时,要不断地跳出来回顾整条业务线的框架,修正之前由于不了解具体业务而出现的理解偏差。
48 |
49 | ## 从小需求开始,尝试编码
50 |
51 | 通过做需求,带着具体问题去看,踩的坑多了,解的bug多了,自然而然就会更熟悉这个项目了。
52 |
53 |
54 |
55 |
--------------------------------------------------------------------------------
/docs/zsxq/question/frontend-or-backend.md:
--------------------------------------------------------------------------------
1 | 昨天在大彬的[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)中,有小伙伴提了一个关于方向选择的问题,可能挺多人有这样的困惑,跟大家分享一下。
2 |
3 | **圈友提问**:
4 |
5 | 先介绍一下个人背景:
6 |
7 | 学历: **中流 985 硕**,偏门工科方向。
8 |
9 | 基础: 大一学过 C 语言后一直都有零碎地写一写代码,但是系统性地计算机学习不是很多。接触时间长一点点的应该是 C++,但学的不够系统。 从大一 C 语言课入手,后续写过 C++/Python,Python拿来给实验室写过小工具(类似上位机)。
10 |
11 | **转行**的想法也很简单,因为自己是一个偏冷门一点的工科方向,跟 EE 沾点边,但是根本喝不上芯片大热门的一口汤。去年师兄找工作 offer 基本上动态清零了,大一点的企业投完了就是石沉大海,小一点的公司才会给面试机会,否则只能去各种小研究所。师姐们更惨,一个拿了国奖的师姐投了一圈一个 offer 没有。
12 |
13 | 现在给自己定的目标是二线中小厂。我的问题是:**转码的话,选择前端还是后端更合适**?
14 |
15 |
16 | -----
17 |
18 | **大彬的回答**:
19 |
20 | 我说一下我对前端和后端的理解:
21 |
22 | 前端开发是创建Web页面或APP等前端界面呈现给用户的过程。除了传统的 Web 前端开发之外,目前 Android 开发、iOS 开发以及第三方开发(各大平台的小程序等)都逐渐并入到了前端开发团队。而且随着 Nodejs 的应用,目前前端开发后端化也是一个比较明显的趋势(大前端)。
23 | 对于非科班同学,前端的**入门难度**比后端低一些,对计算机基础(数据结构&算法)的要求没有那么高。能够通过系统的学习,在**较短的时间**内掌握基本技能。当然,说前端比后端入门难度低,并不是说前端的知识比后端少,相反,前端的领域知识可能比后端还多,**技术更新**也更快。
24 | 我的建议就是:如果你对审美和交互本身就感兴趣,想做出那种让别人看到的东西,比较追求用户体验的话,那么推荐你选择前端。
25 | 另外,从**就业**的角度来说,前端开发相比后端开发,应该会更好找工作一些。
26 |
27 | 后端开发,比较关注业务和技术融合一起的技术整合能力,比较要从业务处理生命周期来设计接口,选择合适的中间件,合理运用各种技术来应对性能,并发,数据各方面的问题。相对前端更多是**业务的技术理解和解决方案能力**。
28 | 后端开发对于程序员**计算机基础**有一定的要求,包括操作系统、算法设计、数据结构、数据库等,这些基础性的内容决定了后端程序员的开发能力和上升空间。所以,如果想在技术领域走得更远,可以重点考虑一下后端开发岗位。后端更加接近**业务**,对业务的理解更为深刻,相比前端来说,**晋升空间**更大一些。
29 |
30 | ----
31 |
32 | 最后,给大家送福利啦,限时发放10张[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)60元的优惠券,先到先得!目前[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)已经有**300**多位成员了,想加入的小伙伴不要错过这一波优惠活动,**扫描下方二维码**领取优惠券即可加入。
33 |
34 | 
--------------------------------------------------------------------------------
/docs/zsxq/question/how-to-learn.md:
--------------------------------------------------------------------------------
1 | **读者提问**
2 |
3 | 彬哥好,请问下平时学技术应该通过什么去学呢?看书还是看视频?网上那些培训课怎么样,值不值得买呢?
4 |
5 | **大彬回答**
6 |
7 | 你好!我觉得对大部分人来说,看视频学习的方式比看书学习的效果更好些,比较易于理解和学习。我建议是以视频为主、书籍为辅的方式进行学习。在看视频过程中有不懂的,可以看下相关的书籍。
8 |
9 | 对于视频资源,要选择一个比较完整的视频,可以到B站找几个播放量比较高的视频,对比下评论区和视频章节,选择一个比较适合自己的进行学习。
10 |
11 | (Java方向的学习路线可以参考星球的这个帖子:https://t.zsxq.com/0ehuyAx9m)
12 |
13 | 第三个问题,网上那些培训课怎么样,值不值得买呢?
14 |
15 | 基础课程的话,到B站找资源就行,免费资源太多了,没必要花钱买课。如果想进一步深入学习的话,可以看看极客时间的一些课程,相对其他培训机构的课程质量会高一些。另外在学习圈置顶帖(https://articles.zsxq.com/id_5x8zu2718ih5.html)有整理一些付费课程,可以看看是否满足你的需求,当然如果经济能力允许的话,还是建议支持下正版~
--------------------------------------------------------------------------------
/docs/zsxq/question/java-or-bigdata.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | title: 24届校招,Java开发和大数据开发怎么选
4 | category: 分享
5 | tag:
6 | - 星球
7 | head:
8 | - - meta
9 | - name: keywords
10 | content: 职业规划,岗位选择,Java还是大数据
11 | - - meta
12 | - name: description
13 | content: 星球问题摘录
14 | ---
15 |
16 | ## 24届校招,Java开发和大数据开发怎么选
17 |
18 | 最近在大彬的[学习圈](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247492252&idx=1&sn=8fc12e97763e3b994b0dd0e717a4b674&chksm=ce9b1fdaf9ec96cca6c03cb6e7b61156d3226dbb587f81cea27b71be6671b81b537c9b7e9b2d#rd)中,有小伙伴提了一个关于方向选择的问题:**24届校招,Java开发和大数据开发怎么选**?
19 |
20 | **原问题如下**:
21 |
22 | 想请教一下大彬,对于**java开发和大数据开发**的明年秋招情况的预测。java岗位多卷度也高,每家公司基本都有相关的职位,大数据开发的话培训班比岗位多,只有大公司和数据公司会有这类岗位。24年秋招的话**选择哪个方向**会比较合适呢?
23 |
24 | ---
25 |
26 | **大彬的回答**:
27 |
28 | 建议选大数据吧。就这几年校招来看,大数据岗位拿offer的**难度**相比Java还是比较小一些的。而且距离24年秋招还有一年多时间,转大数据完全来得及,而且有了Java基础,再来学大数据,应该会比较快入门。
29 |
30 | 再说下大数据和后端的**差异**。大数据门槛比Java高,除了熟悉数据库的操作之外,还要学习大数据整个生态,需要会分布式、数仓、数据分析统计等知识。因为大数据的学习门槛比 Java 高,所以市场上培训大数据的相比Java会少一些,**竞争也相对小**,没有Java那么卷。
31 |
32 | 另外,大数据**薪资**总体会比Java开发高一些(同一家公司同一级别,普通开发岗比大数据开发薪资会少一点),这也是大数据方向的一个优势。
33 |
34 | 不过呢,小点的公司,可能没有大数据的需求,毕竟业务量不大(小公司通常也不建议去,坑多)。
35 |
36 | 综上所述,还是建议你选择**大数据**方向。
37 |
38 |
39 |
40 | ---
41 |
42 | 最后,推荐大家加入我的[学习圈](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247492252&idx=1&sn=8fc12e97763e3b994b0dd0e717a4b674&chksm=ce9b1fdaf9ec96cca6c03cb6e7b61156d3226dbb587f81cea27b71be6671b81b537c9b7e9b2d&scene=21#wechat_redirect),目前已经有140多位小伙伴加入了,文末有50元的**优惠券**,**扫描文末二维码**领取优惠券加入。
43 |
44 | 学习圈提供以下这些**服务**:
45 |
46 | 1、学习圈内部**知识图谱**,汇总了**优质资源、面试高频问题、大厂面经、踩坑分享**,让你少走一些弯路
47 |
48 | 2、四个**优质专栏**、Java**面试手册完整版**(包含场景设计、系统设计、分布式、微服务等),持续更新
49 |
50 | 3、**一对一答疑**,我会尽自己最大努力为你答疑解惑
51 |
52 | 4、**免费的简历修改、面试指导服务**,绝对赚回门票
53 |
54 | 5、各个阶段的优质**学习资源**(新手小白到架构师),超值
55 |
56 | 6、打卡学习,**大学自习室的氛围**,一起蜕变成长
57 |
58 |
59 |
60 | **加入方式**:**扫描二维码**领取优惠券加入(**即将恢复原价**)~
61 |
62 | 
63 |
--------------------------------------------------------------------------------
/docs/zsxq/question/personality-test.md:
--------------------------------------------------------------------------------
1 | ## 想进大厂的年轻人,有多少败在了性格测试?
2 |
3 | 在互联网公司招聘技术岗位人才时,除了技术能力的考察,越来越多的公司开始注重应聘者的个人**性格测试**。这一趋势源自于互联网公司对员工全面发展和协同工作的需求,只有具有不同特点和性格的人才一起协作,才能产生更多的创新点和独特的想法。
4 |
5 | 互联网公司所进行的技术岗位性格测试大都是基于心理学理论和经验,以分析应聘者的人格、态度、价值观等方面的特点,评估其是否适合公司的团队文化和价值观,并为公司提供精准的人才匹配。
6 |
7 | 最近[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)有小伙伴提出了关于性格测试的疑问:
8 |
9 | **提问原文**:
10 |
11 | 大彬哥,问下性格测评,给了三个选项都是好的品质(比如具有领导力,能够洞察事物本质,做事情很有计划条理),选一个**最符合**的,一个**最不符合**的,这种题要怎么选啊,不明白目的是想选拔什么样的人才呢?
12 |
13 | 还有一种题,如果自己手头有比较繁重的任务,领导因为项目赶工期又派来了新任务,这种情况选择提前说明情况延期保证工作质量,还是选择接受任务努力把两个项目都干好呢?
14 |
15 | **听说性格测评真的会挂人**,所以比较慌。
16 |
17 | ---
18 |
19 | **大彬的回答**:
20 |
21 | 1. 首先性格没有**好坏之分**,内向外向也并不完全是考察的重点,不同的公司会有不同的标准。
22 | 2. 关于性格测试怎么做的问题,其实没有一个确定的方法,我觉得最关键的是根据自己**真实情况**来作答。在性格测试中,对于同一个维度的考察会出现内容不同、位置不相连的多道题目,如果在测试结果中出现了很多矛盾的回答,系统可能会判定测试者是在**作弊**。比如华为、滴滴的性格测试题就是这样的。
23 | 3. 你说的那两道题也没有对错之分,按照你自身情况作答即可,**保持前后回答一致**。
24 | 4. 另外也不建议**刻意去迎合**应聘公司的文化价值观,伪装往往可能会适得其反,很容易前后回答不一致导致测试不通过。
25 | 5. 如果涉及一些**原则性**的问题,比如是否一遇到困难就退缩,团队协作能力怎么样,这种还是要往正面的方向回答,没有公司会招一个团队协作能力差、遇到困难就退缩的员工。
26 |
27 | 当然,性格测试不仅是企业了解应聘者的方式,也是应聘者**了解自己**的方式。通过性格测试可以帮助应聘者全面认识自己的优点和缺陷,发现自己的潜力和不足,进而定位自己的特长和优势。所以应聘者在完成性格测试之后,可以进行**自我分析**,了解自己,精准面向优势和弱点,为自己的职业规划建立更好的基础。
28 |
29 | 更多信息可以查看原文(在**星球精华帖**):https://t.zsxq.com/0eJD15817
30 |
31 | 
32 |
33 | ---
34 |
35 | [星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)置顶帖汇总了所有球友的**提问**,内容包括**职业规划、技术问题、面试问题、岗位选择、学习路线**等等,现在很多现在困扰你的问题,在这里都能找到**答案**。
36 |
37 | 
38 |
39 | 
40 |
41 | 加入的同学一定要看看[星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)的置顶内容,相信对你会有帮助的!
42 |
43 | > 点击【阅读原文】直达星球!
--------------------------------------------------------------------------------
/docs/zsxq/question/qa-or-java.md:
--------------------------------------------------------------------------------
1 | 大彬老师您好
2 |
3 | 我是参加今年24届秋招的研二学生,本科就读于某211信息安全专业,硕士就读于中国科学院大学 网络空间安全专业,最近开始了秋招,但是在职业规划上十分迷茫,想听听您的建议。
4 |
5 | 我得求职期望是,在北京找一个高薪的岗位,工作几年后回家乡,找一个国企躺平。
6 |
7 | 目前我已经排除了算法岗,虽然已经发表了两篇论文,但是研究方向小众,不足以支撑我找到一个算法岗的工作。所以我在以下几个岗位中有所纠结:
8 |
9 | 1. java开发岗:为了准备开发岗,我跟着教程自己做了一个项目,整体的感受是工程能力很薄弱,并且只有一个学习项目,没有真正的工程项目。
10 | 2. 安全岗位:虽然我本硕都是安全专业,但是研究方向都比较小众,目前互联网需要的安全人才都是攻防方向的,我的竞争力不够。
11 | 3. 测试开发岗:这是我比较有把握的一个求职方向,因为之前有过一段在字节的测开实习经历,加上一直准备java开发,很多八股都是通用的。但是我比较担心测开岗位会不会不太好跳槽到国企,对未来比较担忧。
12 |
13 | 所以我目前采取的策略是:大厂投测开、中小厂投开发、国企/银行投安全
14 |
15 | 这令我十分地疲惫。很羞愧,已经7月份了,我竟让自己陷入了如此被动的局面,加上这两年互联网寒冬,我对秋招很担心。实际上我从很早之前就在准备找工作了,科研之余每天刷题、学java基础、学框架、写项目,但是时至今日我还是不够,始终比不上那些硕士阶段一直在参加工程的同学。
16 |
17 | 以上是我的基本情况
18 | - 想听听老师对我的现状有没有什么建议
19 | - 您是否了解测试开发岗位的发展前景,它的薪资和开发是差不多的嘛?
20 | - 测开有没有可能从互联网顺利转国企
21 | - 现阶段我是继续补充java基础卷java岗,还是把重点放在测开上呢?
22 |
23 | 原谅我现在处于焦虑状态因此问题比较多,图片是我的简历方便老师了解我的基本情况,期待老师回复🍓
24 | 谢谢老师~
25 |
26 | 1、建议投测开,你这个简历在测开岗里面算是比较好的,相反在Java开发岗中算是比较一般的,没有很大的竞争力。有了字节的测开实习,在测开岗里面应该领先一大波人了。
27 | 2、测开发展前景个人觉得也是不错的,随着互联网行业的发展,用户对产品的质量要求也越来越高,软件的性能测试、需求测试等方面的需求目前看是只增不减的。薪资方面,同职级测开跟开发基本持平。
28 | 3、测开有没有可能从互联网顺利转国企?完全可以,没问题
29 | 4、把重点放在测开,不建议同时准备两个岗位,可能顾此失彼
--------------------------------------------------------------------------------
/docs/zsxq/question/tech/service-expansion.md:
--------------------------------------------------------------------------------
1 | ## 怎么做到增加机器能线性增加性能的?
2 |
3 | 线性扩容有两种情况,一种是“无状态”服务,比如常见的 web 后端;另一种是“有状态服务”,比如 MySQL 数据库。
4 |
5 | 对于无状态服务,只要解决了服务发现功能,在服务启动之后能够把请求量引到新服务上,就可以做到线性扩容。常见的服务发现有 DNS 调度(通过域名解析到不同机器)、负载均衡调度(通过反向代理服务转发到不同机器)或者动态服务发现(比如 dubbo ),等等。
6 |
7 | 对于有状态服务,除了要解决服务发现问题之外,还要解决状态(数据)迁移问题,迁移又分两步:先是数据拆分,常见的用哈希把数据打散。然后是迁移,常见的办法有快照和日志两类迁移方式。也有一些数据库直接实现了开发无感知的状态迁移功能,比如 hbase。
--------------------------------------------------------------------------------
/docs/zsxq/question/三年测开转后端.md:
--------------------------------------------------------------------------------
1 | 大彬,您好!
2 |
3 | 首先介绍下基本情况:211本科,信息工程专业。
4 |
5 | 本人毕业快三年,第一年做了一些功能测试之类的活,后来,岗位调动去做低代码平台的开发,拖拉拽的那种,主要是写SQL,所以自学了MySQL,所以数据库这块看看面试题应该差不了太多。
6 |
7 | 从22年开始转Java后端,边工作边学习,看的都是B站黑马程序员的课程,目前已经学完了Javase,Javaweb,Spring,SSM,Springboot,Git,Maven等,也算比较系统的学了一遍。
8 |
9 | Javase课程基本是跟着用手敲了一遍,后面的视频就只认真看了一遍来赶进度。
10 |
11 | 大学里课程选修了linux操作系统,算法与数据结构,计算机网络,不过也快忘得差不多了,除了记得一些linux常用命令,因为驻场有用到。
12 |
13 | 目前主要是在学redis和mq等中间件,八股文也在准备,但是算法没有刷过题。
14 |
15 | 公司客户主要是一些金融机构,因为积累了差不多两年的业务经验,所以本人也初步打算继续往金融科技这块发展(不一定,哪钱多去哪)。
16 |
17 | 后面打算跳槽甲方,但是目前除了相关技术学了一轮,还没有做过后端开发的项目。
18 |
19 | 请问:
20 |
21 | 1、现在这个状态找测开怎么样,有什么需要重点准备的吗。虽然本人更想做开发。
22 |
23 | 2、现在提离职,估计要过一阵放我走。现在边工作边找,但是工作完没有太多时间学习,并且没有java项目开发的经历,应该只能投测开,长远看,本人更想做后端开发,还得准备刷下算法,背背八股。
24 |
25 | 因为我现在到手也就1w出头,所以如果三月底离职了还没找到理想的开发或测开工作,我是想直接找个比如黑马的瑞吉外卖项目,把已学的融汇贯通,认真做个把月冲击后端咋样?
26 |
27 | 3、继续骑驴找马,直到找到才提离职。但是这样准备项目的时间不太够,做完一个项目估计起码四五月份,还不说背其它的八股和算法。
28 |
29 | 目前继续做这份工作我也没有太多成长,温水煮青蛙。
30 |
31 | 4、如何面试包装下涨薪最快呢,想尽可能的提升下月base,目标是2w+,但是又好像有不超过30%的限制?问上家月薪的时候可以虚报吗,或者怎么说?
32 |
33 | 5、金融行业不少公司比较看重学历,请问咱做技术的,是否有必要花一年时间读个海外硕投资自己呢?
34 |
35 |
36 |
37 | ------
38 |
39 | 大彬的回答:
40 |
41 | 1、 遵从你的内心。如果确实想做开发,先按照开发的方向去努力吧,尽量投开发。后面又去做测开,可能你会有不甘心。当然3年经验转方向,可能会
42 |
43 | 2、已经提离职的话,工作上的内容 就推就推,马上就要走人了,身上就别挂那么多活了,特别是那种紧急上线,什么三月份之前上线,就是趁你走之前 赶紧开发完的那种, 都推一推,多给自己争取点自学的时间。
44 |
45 | 自己做一个项目是可以的,好好冲后端。
46 |
47 | 3、建议是尽量一边工作一边准备,如果时间确实挤不开,可以提离职,也是背水一战了。
48 |
49 | 4、入职的时候 上家公司的月薪 是要 银行流水截图发个hr的,不过有的人 是把 银行流水给p图了,改的薪资。
50 |
51 | 这么干只能说 有风险(可能被hr发现,终止offer),但确实不少人这么干的,然后也顺利入职了。
52 |
53 | 要不要这么搞 还需要你自己权衡一下。
54 |
55 | 你是 测试 转开发,double还是有难度。如果你面试表现足够好的话,要个double 也是有希望的,这个薪资 基本要去 北上深 这样的城市了。
56 |
57 | 5、自己攒够钱去 读个 香港 一年制 是可以的,提升一下自己,重新校招,学校认可度在大陆整体也还行,入学门槛相对足够低了。
58 |
59 | 不过花费不少,可能要50w起步, 这不是小数目,估计可以在老家买套不错的房子了。
60 |
61 | 不过如果你已经跳槽到一家不错的企业的话,我倾向于好好赚钱就好,毕竟 海外一年制学费不低,还要耽误 一年多的赚钱时间,后面能不能把这个钱赚回来,不太确定。
--------------------------------------------------------------------------------
/docs/zsxq/question/二本学历,想出国读研.md:
--------------------------------------------------------------------------------
1 | 大家好,我是大彬~
2 |
3 | 今天跟大家分享[知识星球](https://mp.weixin.qq.com/s/yzy-40-xeEOY34qrdIXJ4Q)小伙伴关于【**出国读研**】的提问。
4 |
5 | > 往期星球[提问](https://mp.weixin.qq.com/s/yzy-40-xeEOY34qrdIXJ4Q)整理:
6 | >
7 | > [非科班,如何补基础?](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247495380&idx=1&sn=b0555daa04aed83ea848d4b0b188dc18&chksm=ce9b1392f9ec9a84244572822a67c98fc7ac9d9f12124f779d7f98acf889f53c3db9f86c26b0#rd)
8 | >
9 | > [读博还是找工作?](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247495184&idx=1&sn=f22989dda1d725583f516d07682fc9bf&chksm=ce9b1356f9ec9a4061b70f38f6b76a5af4f079f93bed8269ee744f27f2f3cac6f7ecf98325a0&token=1194034453&lang=zh_CN#rd)
10 | >
11 | > [性格测试真的很重要](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247494301&idx=1&sn=89c095a1feb8f29a0e87c4b7835280fc&chksm=ce9b17dbf9ec9ecde1720b74e83b4c862a31d60139662592ba8967cf291f4244e9b9bf9738e9&token=1194034453&lang=zh_CN#rd)
12 | >
13 | > [想找一份实习工作,需要准备什么](https://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247495304&idx=1&sn=54163de5ee4da27373048dea6f41344a&chksm=ce9b13cef9ec9ad8b28635cfd2d22c723ae0731babbadb9456a35464a747d19fc6e20bebe448#rd)
14 |
15 | **球友提问**:
16 |
17 | 彬哥,有个问题咨询你
18 |
19 | 基本情况: 25岁,**二本非科班**程序员,在上海,最近想**出国读研**
20 |
21 | 本科读的工商管理,还挂过科,辅修了计算机,现在工资税前 17k 吧,感觉到瓶颈期了,想出去见见世面,回来有个应届生的 buff ,**冲冲大厂**。
22 |
23 | 不知道这个决定是否可靠?有没有建议?
24 |
25 | ---
26 |
27 | **大彬的回答**:
28 |
29 | 你好。按照目前互联网的行情,我**不建议**你这样做。
30 |
31 | 除非你出国是为了**留在国外**,国外文凭拿到国内**认可度**不见得比国内的高,或者你能够得上那种国内都认识的,不然 HR 最多参考一下 QS 排名,不然不认识的可能就被当成野鸡大学了。
32 |
33 | 还有一种为了拿**上海户口**,海归有优惠政策,可以去读个水硕回来就业落户
34 |
35 | 留学回来冲大厂最好就不要想了,**只有留学背景是不够的**,就现在应届生很多很多,如果你**本科学历和专业技能**都不够硬,现在再投校招岗位弄不好连简历筛选都过不去,连面试的机会都没有,而且出国读研是没法随时回来实习的,一些企业要求学生**实习**,如果你无法提前到岗位进行实习,可能直接被淘汰。对留学生而言在这方面没有任何优势。
36 |
37 | 唯一优势就是你留学后提升了你的**英语水平**,回来可以冲一些外企,英语好特别是口语好是有一定优势。
38 |
39 | 结论:如果出国留学是为了回国发展,你需要了解国内对于外国文凭的**认可度**问题,同时还要注重本科学历和专业技能的提高。出国留学的经历可以帮助你提升英语水平,学习不同的文化和思维方式,但并不一定就能为你在就业市场上带来直接的**竞争力**的。
40 |
41 |
--------------------------------------------------------------------------------
/docs/zsxq/question/怎样准备才能找到一份实习工作?.md:
--------------------------------------------------------------------------------
1 | 大家好,我是大彬~
2 |
3 | 今天跟大家分享[知识星球](https://mp.weixin.qq.com/s/yzy-40-xeEOY34qrdIXJ4Q)小伙伴关于【如何找实习工作】的提问。
4 |
5 |
6 |
7 | **球友提问**:
8 |
9 | 目前状况:学校是**双非一本**,目前阶段是大三上开始,9月份中旬提问。 然后希望能在十月,十一月份的时候**找一份寒假时期实习或者日常实习**,希望能够为简历添加一份实习经历,也为了熟悉面试流程,为明年秋招做好准备。
10 |
11 | 提问目的:大彬哥你好,麻烦大彬哥帮我看看,我目前的**个人总结**,麻烦你针对性的给出目前我和实习的差距,因为时间就这一两个月,想知道具体准备哪些部分才能找到一份实习。问题很多,麻烦大彬哥了!
12 |
13 | 然后这里看图片。
14 |
15 | 
16 |
17 | 最后提问
18 |
19 | 1. 麻烦大彬哥根据以上,针对性的给出我目前和寒假日常实习的**差距**,目标是通过面试,因为时间就这一两个月,想知道具体**重点准备**哪些部分才能找到一份实习。
20 | 2. 如果有机会还是希望能去大厂实习,是否差距是太大了?
21 | 3. 因为没有突出优势,基础部分没有系统学习如计网,操作系统,**只背面试题**够用吗。
22 | 4. 项目部分还要学习spring boot和redis和spring cloud 这些是必要的吗,学完这些做项目会不会太慢了。如果和大厂太遥远,目标放在小厂的话哪些知识点是重点,哪些是可以先放放的。
23 |
24 | ---
25 |
26 | **大彬的回答**:
27 |
28 | 学弟你好。
29 |
30 | 1. 按照你目前的情况,想要一份实习工作,之前需要补充学习这些内容:Redis,SpringBoot,微服务,消息队列,Nginx,至少一个项目。如果时间比较紧的话,建议刚开始学**先掌握基本的api用法**,等到后面有时间再去深入学习、看源码。
31 | 2. 关于项目,很多同学刚开始时,总想自己从零开始敲代码,或者以从零开始搭建一个项目为学习目标。其实刚开始学的时候,会遇到很多坑,比如一个分号一个单词拼错都可能会导致卡进展,从而影响到学习效率和学习积极性。正确的做法是,先运行跑通现有代码,运行时通过结果理解关键性语法和技能点,然后再尝试修改人家的代码看结果,这样就能达到边学边进步的效果。
32 | 3. 做什么项目呢?可以参考星球**置顶帖**分享的一些优质项目(https://t.zsxq.com/12mxN9kMJ)
33 |
34 | 2. 想进大厂的话,力扣算法之前刷300道左右,**计算机基础要扎实**,计算机网络、操作系统这些单靠背面试题是不够的,需要花时间去看看书,系统学习一下。
35 |
36 | 3. SpringBoot、Redis、Springcloud这些有必要学吗?如第一点所说的,肯定要学的,这些都是Java开发必备的知识了,其实学习简单使用还是挺快的,原理那些可以后面有时间在捡起来
37 |
38 | 4. **建议你先冲一下中小厂**,后面还有暑期实习和秋招,进大厂还是有机会的。优先把上面提到的那些知识点先学了,找个项目做做,然后准备下面试题和力扣(中小厂力扣前200就够了)
39 | 5. 一定别只学技术,也要去“背“面试题。建议把[**星球**](https://mp.weixin.qq.com/s/yzy-40-xeEOY34qrdIXJ4Q)的**面试手册**(在**星球置顶帖**:**https://t.zsxq.com/12mxN9kMJ**)过一遍,基本包括绝大部分常考面试题了。实习岗位不可能因为你技术到位自己跑过来,而是要你通过面试证明你的能力才能争取到,所以掌握面试技巧也很重要。面试前先找小公司练练手,亲历面试,并在面试中进一步学习面试技巧、查漏补缺。
--------------------------------------------------------------------------------
/docs/zsxq/question/读博还是找工作.md:
--------------------------------------------------------------------------------
1 | 前段时间[知识星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)有小伙伴提出了关于读博还是找工作的疑问,跟大家分享一下:
2 |
3 | **学弟提问**:
4 |
5 | 大彬老师好,我是参加今年24届秋招的**研二**学生,本科是川大数学专业,硕士在xxx研究所读研,计算机应用技术专业。在所里主要是研究无人机的路径规划和强化学习。
6 |
7 | 所里因为不给出去实习,所以我也**没有实习项目**,所里给的福利也就是最后可以留所在央企研究所工作,但是我不太想留,所以想出去找工作。自己有2篇无人机相关的论文,但是以后也不想去做无人机相关。只想做纯计算机相关的工作。后面就想转java,可以说除了高中的竞赛基础,完全没有别的基础,java就跟着机构的视频在学。但是感觉学的太慢了,从4月才开始算0基础学,秋招感觉是完全赶不上了,学了2个月去看看面经发现基本都答不上。所以很迷茫到底是继续java开发往后学下去,反正最后有个保底。还是不去找工作了,凭着2篇论文去找个博士读,博士毕业再出去找企业。希望能给个建议,谢谢!
8 |
9 | ---
10 |
11 | **大彬的回答**:
12 |
13 | 你好,你现在研二了,过了两年的研究生生活,如果你适应这种探索性研究生活、**对科研有热情、有想法**想要去**探索**一些问题,而且没有太大生活压力,家里不需要你的经济支持,那建议你去申请读博。读完博士你的选择会更多更多。
14 |
15 | 如果你是处于**懵懂**状态,感觉硕士毕业找不到好工作就去读博,也没有科研热情,就这样盲目进行的话,这样只是**浪费时间**走一些弯路,之后也可能会后悔,建议你还是直接去找工作。因为读博也是有很大的挑战性的,需要克服焦虑和长时间的孤独,可能比你想象中的要困难一些。
16 |
17 | 另外如果想要找Java开发方向岗位的话,目前你的进度确实稍微慢了一些,秋招马上就要开始了,建议你抓重点去学,参考[星球](https://mp.weixin.qq.com/s/6eAOmYiNhEjIvhhXoXm9QQ)置顶帖的最新Java学习路线,加快学习节奏。
18 |
19 |
20 |
21 |
22 |
23 |
--------------------------------------------------------------------------------
/docs/zsxq/share/oom.md:
--------------------------------------------------------------------------------
1 | 记录一次内存泄露排查的过程。
2 |
3 | 最近经常告警有空指针异常报出,于是找到运维查日志定位到具体是哪一行代码抛出的空指针异常,发现是在解析cookie的一个方法内,调用`HttpServletRequest.getServerName()`获取不到抛出的NPE,这个获取服务名获取不到,平时都没有出现过的问题,最近也没有发版,那初步怀疑应该前端或者传输过程有问题导致获取不到参数。
4 |
5 | 后续找了运维查了ng的日志,确实存在状态码为**499**的错误码,查了一下这个是**客户端主动关闭请求或者客户端网络断掉时**报的错误码,那也就是前端断开了请求。
6 |
7 | 继续排查为啥前端会中断请求的原因,问了前端同学说是超时时间设置了10秒,又看了日志,确实是有处理时间超过10秒的,那问题大概定位到了。
8 |
9 | 接下来就是分析处理时长为什么会那么长,看了报错的时候请求量并没有很大,后续让运维查了机器有几台cpu用量处于30%左右,明显高于另外几台3%,而且499错误的集中在cpu用量高的几台,怀疑是否是内存问题导致,让运维跑了`jstat -gcutil`看了一下,确实存在full GC问题,又跑了`jmap -dump`下了dump文件,定位到是ip限流的方法,有一个清除Map的方法在多线程并发情况下没有生效,导致内存泄露。
10 |
11 | 知道问题后反推感觉就一切的疑问有了结果,ng报499是前置超时,超时是服务频繁full gc导致stw,无法处理请求导致耗时增加,ng探活接口在机器stw期间无法响应产生了error.log,而有几台机器cpu不高是因为之前重启过所以释放掉了内存没有触发full gc。
12 |
13 | 后续处理是改进了ip限流的方法,测试环境复现问题和改动限流方法,通过guaua的LoadingCache监听器的方式过期自动处理,这次问题嵌套问题比较多,由于上报量低,ng侧报了499没有纳入监控范围,而且机器由于重启没有快速发现问题,后续改进是代码侧能复用规范代码最好复用,不要重复造轮子。
--------------------------------------------------------------------------------
/docs/zsxq/share/由“ YYYY-MM-dd ”引发的bug.md:
--------------------------------------------------------------------------------
1 | # 由“ YYYY-MM-dd ”引发的bug
2 |
3 | 跟大家分享网上看到的一篇文章。
4 |
5 | ## 前言
6 |
7 | 在使用一些 App 的时候,竟然被我发现了一个应该是由于前端粗心而导致的 bug,在 2019.12.30 出发,结果 App 上显示的是 2020.12.30(吓得我以为我的订单下错了,此处是不是该把程序员拉去祭天了)。
8 |
9 | 鉴于可能会有程序员因此而被拉去祭天,而我以前学 Java 的时候就有留意过这个问题,所以我还是把这个问题拿出来说一下,希望能尽量避免这方面的粗心大意(毕竟这种问题也很难测出来)。
10 |
11 | ## 正文
12 |
13 | ```java
14 | public class DateTest {
15 | public static void main(String[] args) {
16 | Calendar calendar = Calendar.getInstance();
17 | calendar.set(2019, Calendar.AUGUST, 31);
18 | Date strDate = calendar.getTime();
19 | DateFormat formatUpperCase = new SimpleDateFormat("yyyy-MM-dd");
20 | System.out.println("2019-08-31 to yyyy-MM-dd: " + formatUpperCase.format(strDate));
21 | formatUpperCase = new SimpleDateFormat("YYYY-MM-dd");
22 | System.out.println("2019-08-31 to YYYY/MM/dd: " + formatUpperCase.format(strDate));
23 | }
24 | }
25 | ```
26 |
27 | 我们来看下运行结果:
28 |
29 | ```
30 | 2019-08-31 to yyyy-MM-dd: 2019-08-31
31 | 2019-08-31 to YYYY/MM/dd: 2019-08-31
32 | ```
33 |
34 | 如果我们日期改成 12.31:
35 |
36 | ```
37 | 2019-12-31 to yyyy-MM-dd: 2019-12-31
38 | 2019-12-31 to YYYY-MM-dd: 2020-12-31
39 | ```
40 |
41 | 问题就出现了是吧,虽然是一个小小的细节,但是用户看了也会一脸懵,但是我们作为开发者,不能懵啊,赶紧文档查起来:
42 |
43 | 
44 |
45 | y:year-of-era;正正经经的年,即元旦过后;
46 |
47 | Y:week-based-year;只要本周跨年,那么这周就算入下一年;就比如说今年(2019-2020) 12.31 这一周是跨年的一周,而 12.31 是周二,那使用 YYYY 的话会显示 2020,使用 yyyy 则会从 1.1 才开始算是 2020。
48 |
49 | 这虽然是个很小的知识点,但是也有很多人栽到坑里,在此记录一下~
--------------------------------------------------------------------------------
/docs/zsxq/springboot-inner-material.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Tyson0314/Java-learning/9690a43241c7d21a77faa0928a27499d46d47c6d/docs/zsxq/springboot-inner-material.md
--------------------------------------------------------------------------------
/docs/zsxq/这可能是最全民的面试题库了.md:
--------------------------------------------------------------------------------
1 | 大家好,我是大彬。
2 |
3 | 最近是面试高峰期,有挺多读者来咨询我有没有一些**大厂的面试题目**,想在面试前重点复习一下,“抱佛腿”~
4 |
5 | 
6 |
7 | 
8 |
9 | 刚好我这几天有空,整理了近**300**家公司的面试题目,按照**社招、校招、实习**分类。
10 |
11 | 
12 |
13 | **社招面经**部分截图:
14 |
15 | 
16 |
17 | 
18 |
19 | 
20 |
21 | 
22 |
23 | 
24 |
25 | **校招、实习面经**部分截图:
26 |
27 | 
28 |
29 | 
30 |
31 | 面试题目**获取方式**:添加我微信 dabinjava 或者 i_am_dabin,**备注**【**面试题目**】。PS:有偿,白嫖勿扰(花了挺多时间整理的,希望可以理解)
32 |
33 | 
34 |
35 |
--------------------------------------------------------------------------------
/docs/zsxq/面试真题共享群.md:
--------------------------------------------------------------------------------
1 | 为方便大家交流,大彬新建了**面试真题共享群,**群里可以讨论面试问题、发布内推信息,群成员可以共享各大公司的面试真题,同时可以**永久**查看大彬整理的**面试真题VIP**手册(目前整理了超过**300**家公司的面试题目)。
2 |
3 | 群友**评价**:
4 |
5 | 
6 |
7 | 
8 |
9 | 
10 |
11 | 面试真题分享群截图:
12 |
13 | 
14 |
15 | 
16 |
17 | 
18 |
19 | 
20 |
21 | 
22 |
23 | 
24 |
25 | 
26 |
27 | 
28 |
29 |
30 |
31 | **面试真题VIP**手册截图:
32 |
33 | 
34 |
35 | **社招面经**部分截图:
36 |
37 | 
38 |
39 | 
40 |
41 | 
42 |
43 | 
44 |
45 | 
46 |
47 | **校招、实习面经**部分截图:
48 |
49 | 
50 |
51 | 
52 |
53 |
54 |
55 | 面试共享群**进群方式**:添加我微信 dabinjava 或者 i_am_dabin,**备注**【**面试真题**】。
56 |
57 | PS:**有偿**,白嫖勿扰(花了挺多时间整理的,希望可以理解)
58 |
59 | 
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "vuepress-theme-hope-template",
3 | "version": "2.0.0",
4 | "description": "A project of vuepress-theme-hope",
5 | "license": "MIT",
6 | "scripts": {
7 | "docs:build": "vuepress build docs",
8 | "docs:clean-dev": "vuepress dev docs --clean-cache",
9 | "docs:dev": "vuepress dev docs"
10 | },
11 | "devDependencies": {
12 | "@vuepress/client": "^2.0.0-beta.49",
13 | "@vuepress/plugin-docsearch": "^2.0.0-beta.49",
14 | "@vuepress/plugin-google-analytics": "^1.9.7",
15 | "@vuepress/plugin-nprogress": "^2.0.0-beta.49",
16 | "@vuepress/plugin-search": "^2.0.0-beta.49",
17 | "vue": "^3.2.36",
18 | "vuepress": "^2.0.0-beta.49",
19 | "vuepress-plugin-autometa": "^0.1.13",
20 | "vuepress-plugin-baidu-autopush": "^1.0.1",
21 | "vuepress-plugin-copyright2": "^2.0.0-beta.87",
22 | "vuepress-plugin-photo-swipe": "^2.0.0-beta.87",
23 | "vuepress-plugin-reading-time2": "^2.0.0-beta.87",
24 | "vuepress-plugin-sitemap2": "^2.0.0-beta.87",
25 | "vuepress-theme-hope": "^2.0.0-beta.87"
26 | }
27 | }
28 |
--------------------------------------------------------------------------------