。
280 | if (store[op].changed) {
281 | let instances = store[op].state;
282 | let tbody = $('tbody');
283 | tbody.empty();
284 | for (let i = 0; i < instances.length; i++) {
285 | let instance = getInstance(instances[i]);
286 | renderToTable(instance, tbody);
287 | }
288 | store[op].changed = false; // 记得将 changed 信号改回去哦。
289 | }
290 | break;
291 | case 'detail':
292 | if (store[op].changed) {// 当 detail 状态改变时,就更新 代码输入框,代码片段名输入框,结果输出框的状态
293 | let instance = store[op].state;
294 | $('#code-input').val(instance.code);
295 | $('#code-name-input').val(instance.name);
296 | $('#code-output').val('');// 记得请空上次运行代码的结果哦。
297 | flexSize('#code-input');// 同样的,没有出发 'input' 动作,就要手动改变值
298 | renderSpecificCodeOptions(instance.pk);// 渲染代码选项
299 | store[op].changed = false;// 把 changed 信号改回去
300 | }
301 | break;
302 | case 'output':
303 | if (store[op].changed) { //当 output 状态改变时,就改变输出框的的状态。
304 | let output = store[op].state;
305 | $('#code-output').val(output);
306 | flexSize('#code-output');// 记得手动调用这个函数。
307 | store[op].changed = false // changed 改回去
308 | }
309 | break;
310 | }
311 | }
312 | }
313 | //将UI主逻辑添加到时间队列中
314 |
315 | getList();// 初始化的时候我们应该手动的调用一次,好让列表能在页面上展示出来。
316 | renderGeneralCodeOptions();// 手动调用一次,好让代码选项渲染出来
317 | setInterval("watcher()", 500);// 将 watcher 设置为 500 毫秒,也就是 0.5 秒就执行一次,
318 | // 这样就实现了 UI 在不断的监听状态的变化。
319 |
320 |
321 |
--------------------------------------------------------------------------------
/Chapter-three/Django REST 系列教程(三)(中).md:
--------------------------------------------------------------------------------
1 | #Django RESTful 系列教程(三)(中)
2 | ---
3 | 在上一节中我们了解了 DRF ,现在我们要开始学习 Vue 了,这一前端神器。同样的,这不是官方文档复读机,我们会讲一些官方文档没有讲的东西,如果你对本节中所涉及到的东西想有更深的了解, [vue 官方文档](https://cn.vuejs.org/)是个好去处。一个好消息是,Vue 与 Django 的原理有着相通之处,大家应该可以很轻松的掌握,只是有一些小的知识点细节需要明确。同时 js 和 py 都支持面向对象编程,所以大家在看教程时,着重联系面向对象的编程思维,如果 js 代码不理解,那就想想同样的 python 代码是怎么写的。
4 |
5 | 本章会涵盖以下知识点:
6 |
7 | 1. Vue 原理。
8 | 2. 认识组件。
9 | 3. Vue 特色语法。
10 |
11 | >Vue 的中文文档已经非常优秀,作为国人开发的框架,对国人是非常友好的,并且官方文档的入门教程是真的不错,强烈建议大家去看看。
12 |
13 | ##Vue 原理
14 | 对于 Vue ,很多人应该听说过 [MVVM ](https://en.wikipedia.org/wiki/Model_View_ViewModel)模型,但是同 MTV 一样,很少有人能清楚的解释这到底是怎么回事。
15 |
16 | 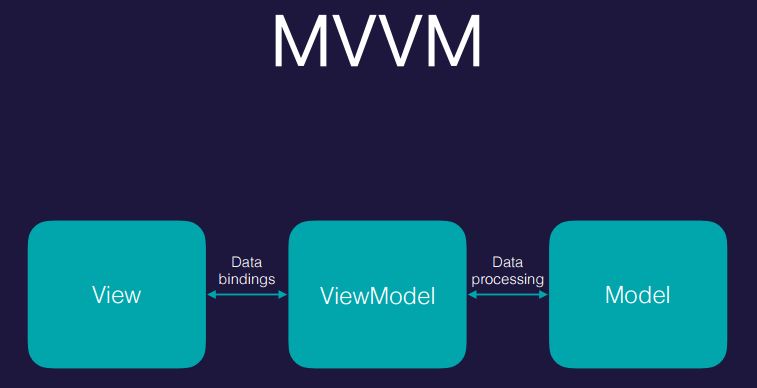
17 |
18 | 图片来源:https://academy.realm.io/cn/posts/mobilization-lukasz-mroz-mvvm-coordinators-rxswift/
19 |
20 | View: 展示数据的部分,也就是我们可以在页面上看到的 UI 。 View 使用 ViewModel 来做出对应的状态改变。同时,View 不会也不能进行改变数据的操作,它是通过 ViewModel 来修改数据的。也就是说,这里的 View 就真的只是个 View ,就像是被渲染之后的模板一样,就是一个 html 文件,什么数据操作都不能做。
21 |
22 | ViewModel: 数据的业务逻辑部分。所有的业务逻辑都在这里。不仅包含数据的处理逻辑,还包括 View 的逻辑都在这里了,所以叫做 ViewModel 。比如我们之前写的 `code-options` 的部分,不同的数据对应不同的 View 状态。这和 Djanogo 的模板很相似,我们在模板中编写了 html 相应的逻辑,最后由模板引擎渲染成固定的 html 文档。大家可以把这部分理解为前端的模板引擎,不仅包含视图逻辑,还包含对后端的数据处理。
23 |
24 | Model: 储存数据的地方。也就是我们的 Store 了,它负责向后端 API 发起请求,储存收到的数据。
25 |
26 | 我们来看看这样一个 MVVM 流程是怎样走完的:
27 |
28 | 1. 用户看到了一个按钮(View),点击了它(View 发出信号,ViewModel 捕捉信号)。
29 | 2. ViewModel 收到信号,根据 View 逻辑,此时应该从 Store 中获取数据,数据在处理之后,数据传到 View 中。
30 | 3. Store 收到请求,发现现在不需要重新请求数据,就直接把数据给了发起请求的 ViewModel 。
31 |
32 | 所以,总结一下,MVVM 的唯一不同之处就是把视图逻辑和数据逻辑放在了一起,称为“ViewModel”,View 的逻辑也被看成了是数据的一部分。剩下的部分和 Django 其实差不多。
33 |
34 | ##认识组件
35 | 在开始之前,我们需要做一些准备工作。建立如下文件结构:
36 |
37 | ```
38 | vue_learn/
39 | vue.js
40 | index.js
41 | bootstrap.js
42 | jquery.js
43 | bootstrap.css
44 | index.html
45 | ```
46 |
47 | vue.js: vue 的源文件,可以直接从[这里](https://vuejs.org/js/vue.js)复制粘贴,也可以直接从我的 github 仓库中拉取。
48 | index.js: 空文件,我们将会在这里学习 vue 。
49 | bootstrap.js: bootstrap 的 js 文件。可以从上一章的项目中复制。
50 | bootstrap.css: bootstrap 的 css 文件。可以从上一章的项目中复制。
51 | jquery.js: bootstrap.js 的依赖,必须使用。可以从上一章的项目中复制。
52 | 在 index.html 中写入下列代码:
53 |
54 | ```html
55 |
56 |
57 |
58 | Vue-learn
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 | ```
70 |
71 | 准备工作做完了。编辑器中打开你的 index.js 和 index.html,同时用浏览器打开 index.html ,以便我们随时查看编写的效果。这里需要你调整好自己的窗口规划,最好能够使用多任务桌面,如果你使用的 win7 ,`Dexport` 是个支持这项功能的好软件,支持快捷键切换桌面,特别方便,并且还是免费的。
72 |
73 | ###组件
74 |
75 | ####组件是什么?
76 | 正如我们在第一章中编写 html 一样,先把页面的框架搭好,再往每个部分里填 UI ,这些 UI 便被称为组件了。我们的 code-list 是一个组件,code-options 按钮组也是组件,我们在需要的时候渲染它们。就像是搭积木一样,组件是积木,网页就是我们用不同的积木搭建起来的堡垒。
77 |
78 | 把眼光放的再开一点看,我们的框架结构本身,也是个组件。只是这些组件没有形状,只有结构,等待其它组件被填充进去。在页面中,一切皆可为组件,相信大家在了解 REST 一切及资源之后理解这个应该不难。
79 |
80 | 所以,在我们之前写的前端代码中,那些包含模板字符串的函数就是我们组件了,我们可以随时调用他们来搭建页面。
81 |
82 | ####组件是实例。
83 | 因为我们使用的是 Vue ,所以应该使用 Vue 来构建我们组件。我们在 python 知道类和实例的概念,在这里我们说的实例也就是 Vue 类的实例。所以,象这样写我们就有了一个 Vue 实例:
84 |
85 | ```javascript
86 | let vueInstance = new Vue({...}) //{...} 为选项对象
87 | ```
88 |
89 | 既然是实例,那么 Vue 类有的属性和方法,Vue 实例也就是组件也应该有这些方法。同时,他们的参数,也就是选项对象也应该相同。然而事实是,有少数几个选项只在运行 `new` 时有效。至于为什么这样做,在下面会提到,
90 |
91 | 刚才我们也提到,组件之间可以相互组合,共同构成一个“大组件”,也就是我们的网页。那怎么把 Vue 和页面中的 html 相联系起来呢?
92 |
93 | 如果我们想要使用一个组件,我们需要告诉 Vue 我们需要把这个组件放在哪里。有几种方式可以选择,我们一个一个来看看。
94 |
95 | 第一种,**只**使用 `el` 选项。仅仅在 `new` 时有效。
96 |
97 | `index.html`
98 | ```html
99 |
100 | {{ message }}
101 |
102 | ```
103 | `index.js`
104 | ```javascript
105 | let cp = new Vue({
106 | el: '#app',
107 | data:function(){
108 | return {
109 | message:'Hello Vue!'
110 | }
111 | }
112 | })
113 | ```
114 | 保存他们并刷新你的浏览器,你会看到在 html 中本来的 `{{ message }}`部分被替换为了 `Hello Vue!` 。
115 |
116 | 我们使用 `el` 选项,告诉 Vue 我们要把匹配 `#app` 的 html 元素作为组件。把一个元素作为组件,也就是相当于告诉 Vue 我们的组件要放在这里了。
117 |
118 | 看到 `{{ }}` 我相信大家一定都非常熟悉了,这不就是模板的语法吗?那选项中的 `data` 参数是做什么用的呢?正如它的名字一样,这是给组件提供数据的地方。为什么使用的是函数来返回数据而不是直接把 `data` 定义为一个对象呢?保持你的好奇心。这个问题我们之后再来解答,现在你可以简单的就像理解我们在前端管理 API 时所做的那样,为了方便变动数据。
119 |
120 | 第二种方式,使用 `template` **和** `el` 选项。
121 |
122 | `index.html`
123 | ```html
124 |
125 | {{ message }}
126 |
127 |
128 | ```
129 | `index.js`
130 | ```javascript
131 | let cp2 = new Vue({
132 | el:'#app2',
133 | template:`
134 | {{ message }}
`,
135 | data:function(){
136 | return {
137 | message: 'Hello Component 2!'
138 | }
139 | }
140 | })
141 | ```
142 | 保存他们并刷新你的浏览器,你会看到在 html 中,本来的 `` ,被替换为了 `Hello Component 2!
` 。
143 |
144 | 我们可以把本来的组件写在 `template` 选项中,使用 `el` 选项告诉 Vue 我们会在哪里放这个组件,Vue 会用 `template` 的内容**替换**被匹配到的元素。替换,也是一种告诉 Vue 我们要把组件放到哪儿的方法。需要注意的是,`template` 只能有一个外层标签,因为有多个的话 Vue 就不知道该把哪个元素替换到目标标签上去。
145 |
146 | 第三种,使用 `$mount` **和** `template`。
147 |
148 | `index.html`
149 | ```html
150 |
151 |
152 | ```
153 | `index.js`
154 | ```javascript
155 | let cp3 = new Vue({
156 | template: `{{ message }}
`,
157 | data: function(){
158 | return {
159 | message:'Hello Component 3!'
160 | }
161 | }
162 | })
163 | cp3.$mount('#app3')
164 | ```
165 | 保存他们并刷新你的浏览器,你会看到在 html 中,本来的 `` ,被替换为了 `Hello Component 3!
` 。
166 |
167 | 当没有使用 `el` 指定要把一个组件放在哪里时,这个组件处于“**未挂载**”状态。我们可以在创建一个组件之后,使用其 `.$mount` 方法,将它“**挂载**”到一个元素上,这个元素会被 `template` **替换** 掉。
168 |
169 | ####组合组件
170 | 正如我们刚才所说,组件是可以被“组合”的。按照刚才的写法,我们应该怎样将组件们结合起来呢?也就是说,我们怎样做才能让组件知道有其它的组件存在呢?
171 |
172 | `index.html`
173 | ```html
174 |
175 | ```
176 |
177 | `index.js`
178 | ```javascript
179 | let cp4 = {
180 | template:'{{ message }}
',
181 | data:function(){
182 | return {
183 | message: 'Hello Component 4!'
184 | }
185 | }
186 | }
187 | let cp5 = new Vue({
188 | el:'#app5',
189 | template:`
190 |
191 |
192 | {{ msg }}
193 |
`,
194 | components:{
195 | 'cp-4':cp4
196 | },
197 | data:function(){
198 | return {
199 | msg:"I'm Component 5!"
200 | }
201 | }
202 | })
203 | ```
204 | 保存他们并刷新你的浏览器,你会看到我们的组件成功的被组合在了一起,可以查看一下浏览器,看看他们是否都在同一个`div`下。
205 |
206 | 组合组件的方法就是使用 `components` 选项,我们不需要传给 `components` Vue 实例,只需要传子组件的名字作为属性,它的选项作为值就好了。以上的过程,我们称为“**注册组件**”这样,组件就可以使用在 `components` 中的其它组件了。并且,只需要像使用普通的 html 一样就可以使用它了。
207 |
208 | 刚才说的是“**局部注册**”,也就是只是把组件和某个特定的组件组合起来。但是有时候,我们希望能够“**全局注册**”这个组件,也就是说,我们希望能够在所有的组件中使用它。 Vue 为我们提供了全局注册的方法。
209 |
210 | `index.html`
211 | ```html
212 |
213 |
214 |
215 | ```
216 | `index.js`
217 | ```javascript
218 | Vue.component('global-cp',{
219 | template:`{{ msg }}
`,
220 | data:function(){
221 | return {
222 | msg:"I'm global!"
223 | }
224 | }
225 | })
226 | let cp6 = new Vue({
227 | el:'#app6',
228 | template:`
229 | I'm app6!
230 |
231 |
`
232 | })
233 | let cp7 = new Vue({
234 | el:'#app7',
235 | template:`
236 |
237 | {{ msg }}
238 |
`,
239 | data:function(){
240 | return {
241 | msg:"I'm app7!"
242 | }
243 | }
244 | })
245 | ```
246 |
247 | 保存他们并刷新你的浏览器,你会看到我们的全局组件已经起作用了。我们使用的是 Vue 类的方法来添加全局组件。类的就是实例的,所以类有了某个组件,那么用这个类生成的实例也应该有这些组件。
248 |
249 | ####正确的使用组件
250 | 刚才我们说道,一个网页也可以是一个组件。也就是说,我们可以先创建一个空的组件,然后让这个组件来容纳其它的组件,这样我们就可以实现仅仅使用 Vue 就可以对网页进行全权的控制,从而实现许多酷炫的功能。SPA(Single Page Application,单页应用)就是一个很好的范例。整个应用只有一个网址,网页的所有变动都是组件的变动,同时,这也减轻了前端的压力,不用再去写那么多页面,只需要写变化的组件就行了。
251 |
252 | 所以,组件的一般写法是:
253 | 1. 先写一个空的组件作为组件入口。
254 | 2. 通过在这个空的组件中组合其它组件来达到组合成网页的目的
255 |
256 | 删除 `index.html` 中所有的 `div` 元素,删除 `index.js` 中的所有代码,编写代码如下:
257 |
258 | `index.html`
259 | ```html
260 |
261 | ```
262 | `index.js`
263 | ```javascript
264 | let navBar = {
265 | template:`
266 |
274 | `,
275 | data:function(){
276 | return {
277 | home:'http://example.com/',
278 | about:'http://example.com/about'
279 | }
280 | }
281 | }
282 |
283 | let mainContent = {
284 | template:`
285 | {{ content }}
286 | `,
287 | data:function(){
288 | return {
289 | content:'This is main content!'
290 | }
291 | }
292 | }
293 | let app = {
294 | template:`
295 |
296 |
297 |
298 |
299 |
300 |
301 |
302 |
Hello, {{ name }}. {{ greeting }}
',
447 | data: function(){
448 | return {
449 | name:'Ucag'
450 | }
451 | },
452 | computed:{
453 | greeting: {
454 | get: function(){
455 | return 'I am Vue. ' + 'Nice to meet you ' + this.name
456 | },
457 | set: function(value){
458 | console.log('You can not change greeting to ' + value)
459 | }
460 | }
461 | }
462 | })
463 | ```
464 | 保存并在浏览器中打开,打开你的浏览器控制台,输入下面的代码:
465 |
466 | ```
467 | >app.greeting = 'Good morning'
468 | <: You can not change greeting to Good morning
469 | ```
470 |
471 | `setter` 运行成攻了。
472 |
473 | #####methods
474 | 我们可以把我们需要在组件中使用的函数定义在这里,我们可以在 `{{ }}` 中调用它。修改我们的组件如下:
475 |
476 | ```javascript
477 | let app = new Vue({
478 | el:'#app',
479 | template:`
480 |
{{ say('hello') }} to {{ name }}
481 |
568 | -
569 |
Name: {{ person.name }}
570 | Age: {{ person.age }}
571 |
572 |
`,
573 | data:function(){
574 | return {
575 | personList:[
576 | {name:'Ucag',age:'18'},
577 | {name:'Ace',age:'20'},
578 | {name:'Lily',age:'22'}]
579 | }
580 | }
581 | })
582 | ```
583 | 保存并在浏览器中打开,你会看到浏览器渲染出了我们的列表。
584 |
585 | `v-for` 用于迭代某个标签,指令的基本语法是:
586 |
587 | ```
588 |
589 | ```
590 | `alias` 是当前迭代对象的别名。
591 |
592 | 当被迭代对象是 `Array` ,`string` ,`number` 时,可以使用以下两种语法迭代:
593 | ```
594 |
595 |
596 | ```
597 | 在第二种迭代方式中,`index` 是其索引,也就是从 0 开始。
598 |
599 | 当迭代对象是 `Object` 时,可以使用以下三种方式迭代:
600 | ```
601 |
602 |
603 |
604 | ```
605 | 第一种是直接迭代对象的**属性值**。第二种则包含了**属性值**和**属性**。第三种相对第二种多了一个索引值。
606 |
607 | `v-if` 用于判断某个标签,基本语法是:
608 | ```
609 |
610 | ```
611 | 如果条件成立则渲染这个 `tag` ,不成立则不渲染。同样的,它还有自己其它的配套语法。
612 | ```
613 | // 和 v-else 一起使用
614 |
615 | Now you see me
616 |
617 |
618 | Now you don't
619 |
620 |
621 | //和 v-else-if 一起使用
622 |
623 | A
624 |
625 |
626 | B
627 |
628 |
629 | C
630 |
631 |
632 | Not A/B/C
633 |
634 | ```
635 | 不过需要注意的是,`v-else` 或者 `v-else-if` 必须紧跟在 `v-if` 后使用,不然这些指令不会被识别。
636 |
637 | 当同时在一个标签中使用 `v-if` 与 `v-for` 时,总是会先执行 `v-for` ,再执行 `v-if`。也就是说,`v-for` 的优先级要高。
638 |
639 |
640 | ---
641 | 本节的 Vue 基础就讲完了。我们只是简单的入门了 Vue ,但是仅仅这些知识就已经够我们编写最基本的页面了。在下一节,我们将会运用前两节学到的知识,重构我们的 APP 。不过由于最近期末考试了,下一次更应该是在一月十号之后了。最后祝大家冬至快乐~
642 |
643 |
644 |
645 |
646 |
647 |
648 |
--------------------------------------------------------------------------------
/Chapter-four/Django RESTful 系列教程(四).md:
--------------------------------------------------------------------------------
1 | 前后端分离的好处就是可以使前端和后端的开发分离开来,如果使用 Django 的模板系统,我们需要在前端和后端的开发中不停的切换,前后端分离可以把前端项目和后端项目分离开来,各自建立项目单独开发。那么问题来了,前端怎么建项目?这就是本章需要解决的问题。
2 |
3 | 对于任何的工具,我的哲学是“工具为人服务,而不是人为工具服务”,希望大家不要为了学习某个工具而学习,任何工具的出现都是为了满足不同的需求。这是在学习前端工具链时需要牢记的一点,不然等学完了,学的东西就全部忘了。前端的世界浩瀚无比,小小的一章并不能很详尽的介绍它们,仅仅是作为一个入门的介绍,但是对于我们来说一定是够用的。
4 |
5 | ##JavaScript 的解释器 —— node 与 “模块化”
6 |
7 | js 和 python 同为脚本语言,他们都有自己的解释器。js 的解释器是 node 。
8 |
9 | 在 node 出现前 js 有没有自己的解释器呢?有的,那就是我们的浏览器中的 js 引擎,但是这个引擎的实现仅仅是针对浏览器环境的,这个引擎限制了 js 的很多功能,比如 js 在浏览器引擎下都不能进行文件的读写,当然这么做是为了用户的安全着想。如果我们想要用 js 实现 python 的许多功能呢?这时就需要 node 了。
10 |
11 | 先去[这里](http://nodejs.cn/download/)下载 node ,像安装 python 一样把 node 安装到你的电脑上,记得把安装路径添加到环境变量中。这些都是和安装 python 是一样的。
12 |
13 | python 运行 `.py` 脚本是 `python .py` 命令,node 也是同理, `node .js` 就可以运行一个 js 脚本了。
14 |
15 | 在上一章,我们在写 `index.js` 时需要考虑代码编写的顺序,这是一件烦人的事情。等到以后代码量大起来,谁知道哪个组件引用了哪个组件,还容易出现 undefined 错误。要是我们能单独把组件都写在一个地方,要用他们的时候再按照需求引入就好了。也就是,我们希望能够进行“模块化”开发。不用去考虑代码顺序,做到代码解耦。
16 |
17 | js 被创建的时候并没有考虑到模块化开发,因为当时的需求还是很简单的,随着需求变多,模块化开发成了必须。我们知道,我们可以在 python 中使用 import 来引入我们需要的包和库。 由于在 es6 之前还没有官方提供这个功能,于是 js 社区就自己实现了这项需求。这就是 `require` 和 `module.exports` 的故事,也就是 CommonJS 规范。
18 |
19 | 在 python 中,我们直接使用 `import` 就可以从一个包中直接导入我们需要的东西。但是 js 有些不同,js 需要被导入的包主动导出内部变量,然后其它的包才能导入他们。
20 |
21 | 在 CommonJS 规范中,每一个模块都默认含有一个全局**变量** `module` ,它有一个 `exports` 属性,我们可以通过这个属性来向外暴露内部的变量。`module.exports` 的默认值为一个空对象。外部可以通过全局的 `require` 函数来导入其它包内的 `module.exports` 变量。
22 |
23 | ```javascript
24 | // A.js
25 | function out(){
26 | console.log('model A.')
27 | }
28 |
29 | module.exports = out // 导出 out 函数
30 |
31 | // B.js
32 | const out = require('./A') // 从 A.js 引入 out
33 | out()
34 | ```
35 |
36 | 在终端里输入 `node B.js` ,你就会看到控制台打印出了 `model A.` 。
37 |
38 | 就这么简单。和 Python 的差别就是 js 需要你主动导出变量。这也是 node 引用模块的方法。
39 |
40 | 如果你不想写 `module.exports` ,还有另外一个全局变量 `exports` 供你使用,它是 `module.exports` 的**引用**,由于 `module.exports` 的默认值为一个空对象,所以它的默认值也是一个空对象。如:
41 |
42 | ```javascript
43 | // A.js
44 | exports.a = 'a';
45 | exports.b = function(){
46 | console.log('b')
47 | }
48 |
49 | // B.js
50 | const A = require('./A')
51 | console.log(A.a) // 'a'
52 | A.b() // 'b'
53 | ```
54 |
55 | 有时候我们的模块不止一个文件,而是有很多个文件。我们可以直接使用 `require` 来引入模块路径,`require` 会自动搜寻引入目录下的 `index.js` 文件,它会把这个文件作为整个模块的入口。如:
56 |
57 | ```
58 | // 模块 ucag
59 | ucag/
60 | index.js // module.exports = {
61 | name: require('./name').name,
62 | age: require('./age').age,
63 | job: require('./job').job
64 | }
65 |
66 | age.js // exports.age = 18
67 | name.js // exports.name = 'ucag'
68 | job.js // exports.job = 'student'
69 | ```
70 | 我们在一个文件里引入:
71 | ```javascript
72 | const ucag = require('./ucag')
73 | ucag.name // 'ucag'
74 | ucag.age // 18
75 | ucag.job // 'student'
76 | ```
77 |
78 |
79 | 在 es6 之后,js 有了自己引用模块的方法,它有了自己的 `import` 和 `export` **关键字**。对外导出用 `export` ,对内引入用 `import`。
80 |
81 | 对于导出,需要遵循以下语法:
82 | ```javascript
83 | export expression
84 | // 如:
85 | export var a = 1, b = 2; // 导出 a 和 b 两个变量
86 |
87 | export {var1, var2, ...} //var1 var2 为导要出的变量
88 |
89 | export { v1 as var1, v2 as var2} // 使用 as 来改变导出变量的名字
90 |
91 | ```
92 | 不过需要注意的是,当我们只想导出一个变量时,我们不能这么写:
93 |
94 | ```javascript
95 | let a = 1;
96 | export a; // 这是错误的写法
97 | export { a } // 这才是正确的写法
98 | ```
99 |
100 | 我们可以这样来引入:
101 |
102 | ```javascript
103 | import { var1 }from 'model' // 从 model 导出 var1 变量
104 | import {v1, v2 } from 'model' // 从 model 导出多个变量
105 | import { var1 as v1 }from 'model' // 从 model 导出 var1 变量并命名为 v1
106 | import * as NewVar from 'model' // 从 model 导入全部的变量
107 | ```
108 |
109 | 在使用 `import` 时,`import` 的变量名要和 `export` 的变量名完全相同,但是有时候我们我们并不知道一个文件导出的变量叫什么名字,只知道我们需要使用这个模块默认导出的东西,于是便出现了 `default` 关键字的使用。我们可以在 `export` 时使用这个关键字来做到“匿名”导出,在 `import` 时,随便取个变量名就可以了。
110 |
111 | ```javascript
112 | export default expression
113 | // 如:
114 | export default class {} // 导出一个类
115 | export default {} //导出一个对象
116 | export default function(){} //导出一个函数
117 |
118 | ```
119 |
120 | 我们可以这样来引入:
121 |
122 | ```javascript
123 | import NewVar from 'model' // NewVar 是我们为 export default 导出变量取的名字。
124 | ```
125 |
126 | 注意,默认导出和命名导出各自的导入是有区别的:
127 | ```javascript
128 | // 默认导出
129 | export default {
130 | name:'ucag'
131 | }
132 | // 默认导出对应导入
133 | import AnyVarName from 'model' // 没有花括号
134 | AnyVarName.name // 'ucag'
135 |
136 | //命名导出
137 | export var name='ucag'
138 | //命名导出对应导入
139 | import { name } from 'model' // 有花括号
140 | name // 'ucag'
141 |
142 | //两种导出方式同时使用
143 | export default {
144 | name:'ucag'
145 | }
146 | export var age=18;
147 |
148 | //两种导入
149 | import NameObj from 'model' //导入默认导出
150 | import { age } from 'model' //导入命名导出
151 |
152 | NameObj.name // 'ucag'
153 | age // 18
154 | ```
155 |
156 | 总结一下:
157 |
158 | 1. 目前我们学了两种模块化的方式。他们是 CommonJS 的模块化方式与 es6 的模块化方式。两种方式不要混用了哦。
159 | 2. CommonJS 规范:
160 | 1. 使用 `module.exports` 或 `exports` 来导出内部变量
161 | 2. 使用 `require` 导入变量。当被导入对象是路径时,`require` 会自动搜寻并引入目录下的 `index.js` 文件,会把这个文件作为整个文件的入口。
162 | 3. es6 规范:
163 | 1. 使用 `import` 与 `export` 来导出内部变量
164 | 2. 当导入命名导出变量时,使用基于 `import { varName } from 'model'` 的语法;当导入匿名或默认导入时,使用 `import varName from 'model'` 语法;
165 |
166 | 悲催的是,node 只支持 CommonJS 方式来进行模块化编写代码。
167 |
168 | ##前端的 pip —— npm
169 |
170 | 刚才我们讲了模块化,现在我们就可以用不同的模块做很多事情了。 我们可以使用 pip 来安装 python 的相关包,在 node 下,我们可以使用 npm 来安装我们需要的库。当然,安装包的工具不止有 npm 一种,还有许多其它的包管理工具供我们使用。现在的 python 已经在安装时默认安装了 pip ,node 在安装时已经默认安装了 npm ,所以我们就用这个现成的工具。
171 |
172 | 前端项目有个特点 —— 版本更替特别快。今天页面是一个样子,明天可能就换成另外的样子了,变化特别频繁,可能今天的依赖库是一个较低的版本,明天它就更新了。所以需要把依赖的库和项目放在一起,而不是全局安装到 node 环境中。每开发一个新项目就需要重新安装一次依赖库。而真正的 node 环境下可能是什么都没有的,就一个 npm 。
173 |
174 | 在一个前端项目中,总是会把依赖库放进一个文件夹里,然后从这个文件夹里导入需要的库和依赖,这个文件夹叫做 `node_modules` 。
175 |
176 | 在 pip 中,我们可以使用 `requirements.txt` 来记录我们的项目依赖。在 npm 下,我们使用 `package.json` 来记录依赖。当我们在 `package.json` 中写好需要的依赖后,在同一路径下运行 `npm install`, npm 会自动搜寻当前目录下的 `package.json` 并且自动安装其中的依赖到 `node_modules` 中,要是当前目录没有 `node_modules` 目录,npm 就会帮我们自己创建一个。当我们想要使用别人的项目时,直接把他们的 `package.json` 拷贝过来,再 `npm install` 就可以完成开发环境的搭建了。这样是不是特别的方便。
177 |
178 | 当你在运行完了 `npm install` 时,如果在以后的开发中想要再安装新的包,直接使用 `npm install ` 安装新的包就行了,npm 会自动帮你把新的包装到当前的 `node_modules` 下。
179 |
180 | 在我们发布一个 python 项目时,我们对于依赖的说明通常是自己写一个 `requirements.txt` ,让用户们自己去装依赖。 npm 为我们提供了更加炫酷的功能。在开发项目时,你直接在含有 `package.json` 的目录下运行 `npm install --save-dev` ,npm 会自动帮你把依赖写到 `package.json` 中。以后你就可以直接发布自己的项目,都不用在 `package.json` 中手写依赖。
181 |
182 | 通过上面的内容我们知道,我们只需要在一个文件夹中创建好 `package.json` ,就可以自动安装我们的包了。 我们还可以使用 npm 自动生成这个文件。在一个空目录下,运行 `npm init` ,npm 会问你一些有的没的问题,你可以随便回答,也可以一路回车什么都不答,目录下就会自动多一个 `package.json` 文件。比如我们在一个叫做 vue-test 的路径下运行这个命令,记得以**管理员**权限运行。
183 |
184 | ```
185 | λ npm init
186 | This utility will walk you through creating a package.json file.
187 | It only covers the most common items, and tries to guess sensible defaults.
188 |
189 | See `npm help json` for definitive documentation on these fields
190 | and exactly what they do.
191 |
192 | Use `npm install ` afterwards to install a package and
193 | save it as a dependency in the package.json file.
194 |
195 | Press ^C at any time to quit.
196 | package name: (vue-test)
197 | version: (1.0.0)
198 | description:
199 | entry point: (index.js)
200 | test command:
201 | git repository:
202 | keywords:
203 | author:
204 | license: (ISC)
205 | About to write to C:\Users\Administrator\Desktop\vue-test\package.json:
206 |
207 | {
208 | "name": "vue-test",
209 | "version": "1.0.0",
210 | "description": "",
211 | "main": "index.js",
212 | "scripts": {
213 | "test": "echo \"Error: no test specified\" && exit 1"
214 | },
215 | "author": "",
216 | "license": "ISC"
217 | }
218 |
219 |
220 | Is this ok? (yes)
221 |
222 | ```
223 |
224 | 如果你不想按回车,在运行 `npm init` 时加一个 `-y` 参数,`npm` 就会默认你使用它生成的答案。也就是运行 `npm init -y` 就行了。
225 | ```
226 | λ npm init -y
227 | Wrote to C:\Users\Administrator\Desktop\vue-test\package.json:
228 |
229 | {
230 | "name": "vue-test",
231 | "version": "1.0.0",
232 | "description": "",
233 | "main": "index.js",
234 | "scripts": {
235 | "test": "echo \"Error: no test specified\" && exit 1"
236 | },
237 | "keywords": [],
238 | "author": "",
239 | "license": "ISC"
240 | }
241 | ```
242 |
243 | 然后在以后的安装中,我们使用 `npm install --save-dev` ,就会自动把依赖库安装到 `node_modules` 中,把相关库依赖的版本信息写入到 `package.json` 中。
244 |
245 | 还是以刚才的 vue-test 为例,在创建完了 `package.json` 后,运行:
246 |
247 | ```
248 | λ npm install --save-dev jquery
249 | npm notice created a lockfile as package-lock.json. You should commit this file.
250 | npm WARN vue-test@1.0.0 No description
251 | npm WARN vue-test@1.0.0 No repository field.
252 |
253 | + jquery@3.2.1
254 | added 1 package in 5.114s
255 | ```
256 |
257 | 此时,我们发现又多了一个 `package-lock.json`文件, 先不管它。我们再打开 `package.json` 看看,你会发现它的内容变成了这样:
258 | ```
259 | λ cat package.json
260 | {
261 | "name": "vue-test",
262 | "version": "1.0.0",
263 | "description": "",
264 | "main": "index.js",
265 | "scripts": {
266 | "test": "echo \"Error: no test specified\" && exit 1"
267 | },
268 | "keywords": [],
269 | "author": "",
270 | "license": "ISC",
271 | "devDependencies": {
272 | "jquery": "^3.2.1"
273 | }
274 | }
275 | ```
276 |
277 | 依赖已经自动写入了 `package.json` 中。我们再删除 `node_modules` 文件夹和 `package-lock.json` ,只留下 `package.json` 。再运行 `npm install`。
278 | ```
279 | λ npm install
280 | npm notice created a lockfile as package-lock.json. You should commit this file.
281 | npm WARN vue-test@1.0.0 No description
282 | npm WARN vue-test@1.0.0 No repository field.
283 |
284 | added 1 package in 5.4s
285 | ```
286 | 我们发现 npm 已经为我们安装好了依赖。
287 |
288 | 当然,我们有时需要一些各个项目都会用到的工具。还是以 python 为例,我们会使用 `virtualenv` 来创建虚拟环境,在安装它时,我们直接全局安装到了系统中。npm 也可以全局安装我们的包。在任意路径下,使用 `npm install -g ` 就可以全局安装一个包了。我们在以后会用到一个工具叫做 `vue-cli` ,我们可以用它来快速的创建一个 vue 项目。为什么要用它呢,在前端项目中,有一些库是必须要用到的比如我们的 `webpack` ,比如开发 vue 需要用到的 `vue` 包,`vue-router`,`vuex` 等等,它会帮我们把这些自动写入 `package.json` 中,并且会为我们建立起最基本的项目结构。就像是我们使用 `django-admin` 来创建一个 Django 项目一样。这样的工具,在前端被称为**“脚手架”**。
289 |
290 | 任意路径下运行:
291 | ```
292 | npm install -g vue-cli
293 | ```
294 | vue 脚手架就被安装到了我们的 node 环境中。我们就可以在命令行中使用 `vue` 命令来创建新的项目了,不需要自己手动创建项目。大家可以试着运行 `vue --help` ,看看你是否安装成功了 `vue-cli`。
295 | ```
296 | λ vue --help
297 |
298 | Usage: vue [options]
299 |
300 |
301 | Options:
302 |
303 | -V, --version output the version number
304 | -h, --help output usage information
305 |
306 |
307 | Commands:
308 |
309 | init generate a new project from a template
310 | list list available official templates
311 | build prototype a new project
312 | help [cmd] display help for [cmd]
313 | ```
314 |
315 | npm 除了可以安装包之外,还可以使用 `npm run` 用来管理脚本命令。
316 | 还是以刚才安装 'jquery' 的包为例,打开 `package.json` ,把 `scripts` 字段改成这样:
317 | ```json
318 | "scripts": {
319 | "test": "echo \"Error: no test specified\" && exit 1",
320 | "vh": "vue --help"
321 | }
322 | ```
323 | 然后在 `package.json` 路径下运行 `npm run vh` ,你就会看到控制台输出了 vue 脚手架的帮助信息。
324 |
325 | 当我们运行 `npm run `时,npm 会搜寻同目录下的 `package.json` 中的 `scripts` 中对应的属性,然后把当前的 `node_modules` 加入环境变量中,执行其中命令,这样就不用我们每次都都手动输入长长的命令了。
326 |
327 | 还是总结一下:
328 |
329 | 1. npm 是 node 中的包管理工具。
330 | 2. `npm install`: 安装 `package.json` 中的依赖到 `node_modules` 中。
331 | 3. `npm install --save-dev`:把包安装到 `node_modules` 中,并把包依赖写入 `package.json` 中。
332 | 4. `npm install -g`:全局安装某个包。
333 | 5. `npm run `: 运行当前目录下 `package.json` 的 `scripts` 中的命令。
334 |
335 |
336 | ##前端工具链
337 | 前端开发会用到许许多多的工具,有的工具是为了更加方便的开发而生,有的工具是为了使代码更好的适应浏览器环境。每个工具的出现都是为了解决特定的问题。
338 | ###解决版本差异 —— babel
339 | 版本差异一直是个很让人头痛的问题。用 python2 写的代码,大概率会在 python3 上运行失败。 js 是运行在浏览器上的,很多的浏览器更新并没有能够很稳定的跟上 js 更新的步伐,有的浏览器只支持到 es5 ,或者只支持部分 es6 特性。为了能够向下兼容,大家想了办法 —— 把 es6 的代码转换为 es5 的代码就行了!开发的时候用 es6 ,最后再把代码转换成 es5 代码就行了!于是便出现了 babel 。
340 |
341 | 创建一个叫做 `babel-test` 的文件夹,在此路径下运行:
342 | ```
343 | npm init -y
344 | npm install --save-dev babel-cli
345 | ```
346 |
347 | 在使用 babel 前,我们需要通过配置文件告诉它转码规则是什么。babel 默认的配置文件名为 `.babelrc`。
348 | 在 `babel-test` 下创建 `.babelrc`,写入:
349 | ```json
350 | {
351 | "presets": [
352 | "es2015"
353 | ],
354 | "plugins": []
355 | }
356 | ```
357 | 转码规则是以附加规则包的形式出现的。所以在配置好了之后我们还需要安装规则包。
358 | ```
359 | npm install --save-dev babel-preset-es2015
360 | ```
361 | babel 是以命令行的形式使用的,最常用的几个命令如下:
362 | ```
363 | # 转码结果打印到控制台
364 | babel es6.js
365 |
366 | # 转码结果写入一个文件
367 | babel es6.js -o es5.js # 将 es6.js 的转码结果写入 es5.js 中
368 |
369 | # 转码整个目录到指定路径
370 | babel es6js -d es5js # 将 es6js 路径下的 js 文件转码到 es5js 路径下
371 | ```
372 | 但是由于我们的 babel 是安装在 babel-test 的 `node_modules` 中的,所以需要使用 `npm run` 来方便运行以上命令。
373 |
374 | 编辑 `package.json`:
375 | ```json
376 | "scripts": {
377 | "test": "echo \"Error: no test specified\" && exit 1",
378 | "build": "babel inputs -d outputs"
379 | }
380 | ```
381 |
382 | 在 babel-test 下创建一个新的目录 inputs ,在其中写入新的文件 a.js:
383 | ```javascript
384 | // es6 语法,模板字符串
385 | let name = 'ucag'
386 | let greeting = `hello my name is ${name}`
387 | ```
388 | 然后运行:
389 | ```
390 | npm run build
391 | ```
392 | 在转换完成之后,我们在 outputs 下找到 a.js,发现代码变成了这样:
393 | ```javascript
394 | 'use strict';
395 |
396 | var name = 'ucag';
397 | var greeting = 'hello my name is ' + name;
398 | ```
399 | es6 代码已经被转换为了 es5 代码。
400 |
401 | ###整合资源 —— webpack
402 | 在一个前端项目中,会有许许多多的文件。更重要的是,最后我们需要通过浏览器来运行他们。我们用 es6 写的代码,需要转换一次之后才能上线使用。如果我们用的是 TypeScript 写的 js ,那我们还需要先把 TypeScript 转换为原生 js ,再用 babel 转换为 es5 代码。如果我们使用的是模块化开发,但是浏览器又不支持,我们还需要把模块化的代码整合为浏览器可执行的代码。总之,为了方便开发与方便在浏览器上运行,我们需要用到许许多多的工具。
403 |
404 | webpack 最重要的功能就是可以把相互依赖的模块打包。我们在模块化开发之后,可能会产生许多的 js 文件,要是一个个手写把他们引入到 html 中是一件很麻烦的事情,所以我们此时就需要 webpack 来帮我们把分离的模块组织到一起,这样就会方便很多了
405 | 创建一个新的路径 webpack-test ,在此路径下运行:
406 | ```
407 | npm init -y
408 | npm install --save-dev webpack
409 | ```
410 |
411 | 使用前先配置,在配置之前我们需要知道一些最基本的概念。
412 |
413 | 1. 入口 entry:不管一个项目有多复杂,它总是有一个入口的。这个入口就被称为 entry 。这就像是我们的模块有个 `index.js` 一样。
414 | 2. 出口 output:webpack 根据入口文件将被依赖的文件按照一定的规则打包在一起,最终需要一个输出打包文件的地方,这就是 output 。
415 |
416 | 这就是最基本的概念了,我们会在以后的教程中学习到更多有关 webpack 配置的知识,不过由于我们目前的需求还很简单,还用不到其它的一些功能,就算是现在讲了也难以体会其中的作用,所以我们目前不着急,慢慢来。
417 |
418 | webpack 有多种加载配置的方法,一种是写一个独立的配置文件,一种是在命令行内编写配置,还有许多其它更灵活编写配置的方法,我们以后再说。当我们在 webpack-test 下不带任何参数运行 `webpack` 命令时,`webpack` 会自动去寻找名为 `webpack.config.js` 的文件,这就是它默认的配置文件名了。
419 |
420 | 在 webpack-test 下创建一个新的文件 `webpack.config.js`:
421 | ```javascript
422 | module.exports = {
423 | entry:'./main.js', // 入口文件为当前路径下的 main.js 为文件
424 | output:{
425 | path:__dirname, // __dirname 是 node 中的全局变量,代表当前路径。
426 | filename:'index.js' // 打包之后的文件名
427 | }
428 | }
429 | ```
430 |
431 |
432 | 编辑 `package.json` :
433 | ```json
434 | "scripts"{
435 | 'pkg':'webpack' // 编辑快捷命令
436 | }
437 | ```
438 |
439 | 以第三章的 index.js 为例,当时我们把所有的代码都写到了一个文件中,现在我们可以把他们分开写了,最后再打包起来。
440 |
441 | 创建几个新文件分别为 `components.js` `api.js` `store.js` `main.js` `vue.js` `jquery.js`
442 |
443 | `vue.js`: vue 源文件
444 | `jquery`: jquery 源文件
445 |
446 | `api.js`:
447 | ```javascript
448 | let api = {
449 | v1: {
450 | run: function () {
451 | return '/api/v1/run/'
452 | },
453 | code: {
454 | list: function () {
455 | return '/api/v1/code/'
456 | },
457 | create: function (run = false) {
458 | let base = '/api/v1/code/';
459 | return run ? base + '?run' : base
460 | },
461 | detail: function (id, run = false) {
462 | let base = `/api/v1/code/${id}/`;
463 | return run ? base + '?run' : base
464 | },
465 | remove: function (id) {
466 | return api.v1.code.detail(id, false)
467 | },
468 | update: function (id, run = false) {
469 | return api.v1.code.detail(id, run)
470 | }
471 | }
472 | }
473 | }
474 |
475 | module.exports = api // 导出 API
476 | ```
477 |
478 | `store.js`
479 | ```javascript
480 | const $ = require('./jquery') // 引入 jquery
481 |
482 | let store = {
483 | state: {
484 | list: [],
485 | code: '',
486 | name: '',
487 | id: '',
488 | output: ''
489 | },
490 | actions: {
491 | run: function (code) { //运行代码
492 | $.post({
493 | url: api.v1.run(),
494 | data: {code: code},
495 | dataType: 'json',
496 | success: function (data) {
497 | store.state.output = data.output
498 | }
499 | })
500 | },
501 | runDetail: function (id) { //运行特定的代码
502 | $.getJSON({
503 | url: api.v1.run() + `?id=${id}`,
504 | success: function (data) {
505 | store.state.output = data.output
506 | }
507 | })
508 | },
509 | freshList: function () { //获得代码列表
510 | $.getJSON({
511 | url: api.v1.code.list(),
512 | success: function (data) {
513 | store.state.list = data
514 | }
515 | })
516 | },
517 | getDetail: function (id) {//获得特定的代码实例
518 | $.getJSON({
519 | url: api.v1.code.detail(id),
520 | success: function (data) {
521 | store.state.id = data.id;
522 | store.state.name = data.name;
523 | store.state.code = data.code;
524 | store.state.output = '';
525 | }
526 | })
527 | },
528 | create: function (run = false) { //创建新代码
529 | $.post({
530 | url: api.v1.code.create(run),
531 | data: {
532 | name: store.state.name,
533 | code: store.state.code
534 | },
535 | dataType: 'json',
536 | success: function (data) {
537 | if (run) {
538 | store.state.output = data.output
539 | }
540 | store.actions.freshList()
541 | }
542 | })
543 | },
544 | update: function (id, run = false) { //更新代码
545 | $.ajax({
546 | url: api.v1.code.update(id, run),
547 | type: 'PUT',
548 | data: {
549 | code: store.state.code,
550 | name: store.state.name
551 | },
552 | dataType: 'json',
553 | success: function (data) {
554 | if (run) {
555 | store.state.output = data.output
556 | }
557 | store.actions.freshList()
558 | }
559 | })
560 | },
561 | remove: function (id) { //删除代码
562 | $.ajax({
563 | url: api.v1.code.remove(id),
564 | type: 'DELETE',
565 | dataType: 'json',
566 | success: function (data) {
567 | store.actions.freshList()
568 | }
569 | })
570 | }
571 | }
572 | }
573 |
574 | store.actions.freshList() // Store的初始化工作,先获取代码列表
575 |
576 | module.exports = store // 导出 store
577 | ```
578 |
579 | `components.js`
580 | ```javascript
581 | const store = require('./store')
582 | let list = { //代码列表组件
583 | template: `
584 |
585 |
586 |
587 | | 文件名 |
588 | 选项 |
589 |
590 |
591 |
592 |
593 | | {{ item.name }} |
594 |
595 |
596 |
597 |
598 | |
599 |
600 |
601 |
602 | `,
603 | data() {
604 | return {
605 | state: store.state
606 | }
607 | },
608 | methods: {
609 | getDetail(id) {
610 | store.actions.getDetail(id)
611 | },
612 | run(id) {
613 | store.actions.runDetail(id)
614 | },
615 | remove(id) {
616 | store.actions.remove(id)
617 | }
618 | }
619 | }
620 | let options = {//代码选项组件
621 | template: `
622 |
625 |
626 |
627 |
628 |
629 |
630 | `,
631 | data() {
632 | return {
633 | state: store.state
634 | }
635 | },
636 | methods: {
637 | run(code) {
638 | store.actions.run(code)
639 | },
640 | update(id, run = false) {
641 | if (typeof id == 'string') {
642 | store.actions.create(run)
643 | } else {
644 | store.actions.update(id, run)
645 | }
646 | },
647 | newOptions() {
648 | this.state.name = '';
649 | this.state.code = '';
650 | this.state.id = '';
651 | this.state.output = '';
652 | }
653 | }
654 | }
655 | let output = { //代码输出组件
656 | template: `
657 |
659 | `,
660 | data() {
661 | return {
662 | state: store.state
663 | }
664 | },
665 | updated() {
666 | let ele = $(this.$el);
667 | ele.css({
668 | 'height': 'auto',
669 | 'overflow-y': 'hidden'
670 | }).height(ele.prop('scrollHeight'))
671 | }
672 | }
673 | let input = { //代码输入组件
674 | template: `
675 |
689 | `,
690 | data() {
691 | return {
692 | state: store.state
693 | }
694 | },
695 | methods: {
696 | flexSize(selector) {
697 | let ele = $(selector);
698 | ele.css({
699 | 'height': 'auto',
700 | 'overflow-y': 'hidden'
701 | }).height(ele.prop('scrollHeight'))
702 | },
703 | inputHandler(e) {
704 | this.state.code = e.target.value;
705 | this.flexSize(e.target)
706 | }
707 | }
708 | }
709 |
710 | module.exports = {
711 | list, input, output, options
712 | } // 导出组件
713 | ```
714 |
715 | `main.js`
716 | ```javascript
717 | const cmp = require('./components') //引入组件
718 | const list = cmp.list
719 | const options = cmp.options
720 | const input = cmp.input
721 | const output = cmp.output
722 | const Vue = require('./vue')
723 |
724 | let app = { //整体页面布局
725 | template: `
726 |
727 |
728 | 在线 Python 解释器
729 |
730 |
731 |
732 |
733 |
734 |
735 |
736 |
737 |
738 |
请在下方输入代码:
739 |
740 |
741 |
742 |
743 |
输出
744 |
745 |
746 |
747 |
748 |
749 |
750 |
703 |
704 | 在线 Python 解释器
705 |
706 |
707 |
708 |
709 |
710 |
711 |
712 |
713 |
714 |
请在下方输入代码:
715 |
716 |
717 |
718 |
719 |
输出
720 |
721 |
722 |
723 |
724 |
725 |
726 |
745 |
746 |
747 | | 文件名 |
748 | 选项 |
749 |
750 |
751 |
752 |
753 | | {{ item.name }} |
754 |
755 |
756 |
757 |
758 | |
759 |
760 |
761 |
762 | `,
763 | data() {
764 | return {
765 | state: store.state
766 | }
767 | },
768 | methods: {
769 | getDetail(id) {
770 | store.actions.getDetail(id)
771 | },
772 | run(id) {
773 | store.actions.runDetail(id)
774 | },
775 | remove(id) {
776 | store.actions.remove(id)
777 | }
778 | }
779 | }
780 | ```
781 |
782 | options 组件:
783 |
784 | `index.js`
785 | ```javascript
786 | let options = {//代码选项组件
787 | template: `
788 |
791 |
792 |
793 |
794 |
795 |
796 | `,
797 | data() {
798 | return {
799 | state: store.state
800 | }
801 | },
802 | methods: {
803 | run(code) {
804 | store.actions.run(code)
805 | },
806 | update(id, run = false) {
807 | if (typeof id == 'string') {
808 | store.actions.create(run)
809 | } else {
810 | store.actions.update(id, run)
811 | }
812 | },
813 | newOptions() {
814 | this.state.name = '';
815 | this.state.code = '';
816 | this.state.id = '';
817 | this.state.output = '';
818 | }
819 | }
820 | }
821 | ```
822 |
823 | input 组件:
824 |
825 | `index.js`
826 | ```javascript
827 | let input = { //代码输入组件
828 | template: `
829 |
843 | `,
844 | data() {
845 | return {
846 | state: store.state
847 | }
848 | },
849 | methods: {
850 | flexSize(selector) {
851 | let ele = $(selector);
852 | ele.css({
853 | 'height': 'auto',
854 | 'overflow-y': 'hidden'
855 | }).height(ele.prop('scrollHeight'))
856 | },
857 | inputHandler(e) {
858 | this.state.code = e.target.value;
859 | this.flexSize(e.target)
860 | }
861 | }
862 | }
863 | ```
864 |
865 | 我们把之前的 `flexSize`直接复制粘贴过来了。这样做的好处是,和组件有关的东西都在组件内,而不需要去到处找。
866 |
867 | output 组件:
868 |
869 | `index.js`
870 | ```javascript
871 | let output = { //代码输出组件
872 | template: `
873 |
875 | `,
876 | data() {
877 | return {
878 | state: store.state
879 | }
880 | },
881 | updated() {
882 | let ele = $(this.$el);
883 | ele.css({
884 | 'height': 'auto',
885 | 'overflow-y': 'hidden'
886 | }).height(ele.prop('scrollHeight'))
887 | }
888 | }
889 | ```
890 |
891 | 在这里我们选择了完全不同的动态大小方案。在 input 组件中,我们选择的是使用 input 事件来触发调整大小的函数。而在这里,我们选择在 output 组件**更新**完毕之后之后再触发这个函数。
892 |
893 | `.$el` 是这个组件最外层的 html 标签。在这里就是我们的 `textarea` 标签了。
894 |
895 | 如果我们需要组件在更新完毕之后做什么事情,就在选项对象里定义 `updated` 属性,组件会在更新完毕后调用它。这属于组件的生命周期的一部分。
896 |
897 | 生命周期有点类似 Django 的信号系统。比如有的同学可能知道 `post_save` ,我们可以用它来让一个模型保存完毕之后做些事情。而组件则有许多这样的东西。
898 | Vue 给我们提供了组件在不同阶段的接口。
899 |
900 | 关于生命周期更详细的细节,我们会在后面的章节里讨论。
901 |
902 | 到这里我们就完成了这次重构。赶紧试试效果吧。
903 |
904 | ---
905 | 本章我们初次接触了 DRF 和 Vue ,并且重构了一下试了试效果。DRF 则节约了我们不少接口开发的时间。vue 使我们的开发更加有调理,页面不再是一团乱麻。在下一章,我们将学习前端工具链。要一路从 node 学到 webpack 。
906 |
907 |
908 |
909 |
910 |
911 |
--------------------------------------------------------------------------------