├── .gitignore
├── .gitignore~
├── .idea
└── vcs.xml
├── CMakeLists.txt
├── Makefile
├── Makefile.config
├── Makefile.config.example
├── README.md
├── README_en.md
├── a.out
├── build
├── caffe.cloc
├── cmake
├── ConfigGen.cmake
├── Cuda.cmake
├── Dependencies.cmake
├── External
│ ├── gflags.cmake
│ └── glog.cmake
├── Misc.cmake
├── Modules
│ ├── FindAtlas.cmake
│ ├── FindGFlags.cmake
│ ├── FindGlog.cmake
│ ├── FindLAPACK.cmake
│ ├── FindLMDB.cmake
│ ├── FindLevelDB.cmake
│ ├── FindMKL.cmake
│ ├── FindMatlabMex.cmake
│ ├── FindNumPy.cmake
│ ├── FindOpenBLAS.cmake
│ ├── FindSnappy.cmake
│ └── FindvecLib.cmake
├── ProtoBuf.cmake
├── Summary.cmake
├── Targets.cmake
├── Templates
│ ├── CaffeConfig.cmake.in
│ ├── CaffeConfigVersion.cmake.in
│ └── caffe_config.h.in
├── Utils.cmake
└── lint.cmake
├── examples
├── 00-classification.ipynb
├── 01-learning-lenet.ipynb
├── 02-fine-tuning.ipynb
├── CMakeLists.txt
├── brewing-logreg.ipynb
├── cifar10
│ ├── cifar10_full.prototxt
│ ├── cifar10_full_sigmoid_solver.prototxt
│ ├── cifar10_full_sigmoid_solver_bn.prototxt
│ ├── cifar10_full_sigmoid_train_test.prototxt
│ ├── cifar10_full_sigmoid_train_test_bn.prototxt
│ ├── cifar10_full_solver.prototxt
│ ├── cifar10_full_solver_lr1.prototxt
│ ├── cifar10_full_solver_lr2.prototxt
│ ├── cifar10_full_train_test.prototxt
│ ├── cifar10_quick.prototxt
│ ├── cifar10_quick_solver.prototxt
│ ├── cifar10_quick_solver_lr1.prototxt
│ ├── cifar10_quick_train_test.prototxt
│ ├── convert_cifar_data.cpp
│ ├── create_cifar10.sh
│ ├── readme.md
│ ├── train_full.sh
│ ├── train_full_sigmoid.sh
│ ├── train_full_sigmoid_bn.sh
│ └── train_quick.sh
├── cpp_classification
│ ├── classification.cpp
│ └── readme.md
├── detection.ipynb
├── feature_extraction
│ ├── imagenet_val.prototxt
│ └── readme.md
├── finetune_flickr_style
│ ├── assemble_data.py
│ ├── flickr_style.csv.gz
│ ├── readme.md
│ └── style_names.txt
├── finetune_pascal_detection
│ ├── pascal_finetune_solver.prototxt
│ └── pascal_finetune_trainval_test.prototxt
├── hdf5_classification
│ ├── nonlinear_auto_test.prototxt
│ ├── nonlinear_auto_train.prototxt
│ ├── nonlinear_train_val.prototxt
│ └── train_val.prototxt
├── imagenet
│ ├── create_imagenet.sh
│ ├── make_imagenet_mean.sh
│ ├── readme.md
│ ├── resume_training.sh
│ └── train_caffenet.sh
├── images
│ ├── cat gray.jpg
│ ├── cat.jpg
│ ├── cat_gray.jpg
│ └── fish-bike.jpg
├── mnist
│ ├── convert_mnist_data.cpp
│ ├── create_mnist.sh
│ ├── lenet.prototxt
│ ├── lenet_adadelta_solver.prototxt
│ ├── lenet_auto_solver.prototxt
│ ├── lenet_consolidated_solver.prototxt
│ ├── lenet_multistep_solver.prototxt
│ ├── lenet_solver.prototxt
│ ├── lenet_solver_adam.prototxt
│ ├── lenet_solver_rmsprop.prototxt
│ ├── lenet_train_test.prototxt
│ ├── mnist_autoencoder.prototxt
│ ├── mnist_autoencoder_solver.prototxt
│ ├── mnist_autoencoder_solver_adadelta.prototxt
│ ├── mnist_autoencoder_solver_adagrad.prototxt
│ ├── mnist_autoencoder_solver_nesterov.prototxt
│ ├── readme.md
│ ├── train_lenet.sh
│ ├── train_lenet_adam.sh
│ ├── train_lenet_consolidated.sh
│ ├── train_lenet_docker.sh
│ ├── train_lenet_rmsprop.sh
│ ├── train_mnist_autoencoder.sh
│ ├── train_mnist_autoencoder_adadelta.sh
│ ├── train_mnist_autoencoder_adagrad.sh
│ └── train_mnist_autoencoder_nesterov.sh
├── net_surgery.ipynb
├── net_surgery
│ ├── bvlc_caffenet_full_conv.prototxt
│ └── conv.prototxt
├── pascal-multilabel-with-datalayer.ipynb
├── pycaffe
│ ├── caffenet.py
│ ├── layers
│ │ ├── pascal_multilabel_datalayers.py
│ │ └── pyloss.py
│ ├── linreg.prototxt
│ └── tools.py
├── siamese
│ ├── convert_mnist_siamese_data.cpp
│ ├── create_mnist_siamese.sh
│ ├── mnist_siamese.ipynb
│ ├── mnist_siamese.prototxt
│ ├── mnist_siamese_solver.prototxt
│ ├── mnist_siamese_train_test.prototxt
│ ├── readme.md
│ └── train_mnist_siamese.sh
├── unreal_example
│ ├── CMakeLists.txt
│ ├── readme.md
│ └── src
│ │ ├── main.cpp
│ │ └── main.cpp~
└── web_demo
│ ├── app.py
│ ├── exifutil.py
│ ├── readme.md
│ ├── requirements.txt
│ └── templates
│ └── index.html
├── generatepb.sh
├── include
└── caffe
│ ├── blob.hpp
│ ├── caffe.hpp
│ ├── common.hpp
│ ├── data_transformer.hpp
│ ├── filler.hpp
│ ├── internal_thread.hpp
│ ├── layer.hpp
│ ├── layer_factory.hpp
│ ├── layers
│ ├── absval_layer.hpp
│ ├── accuracy_layer.hpp
│ ├── argmax_layer.hpp
│ ├── base_conv_layer.hpp
│ ├── base_data_layer.hpp
│ ├── batch_norm_layer.hpp
│ ├── batch_reindex_layer.hpp
│ ├── bias_layer.hpp
│ ├── bnll_layer.hpp
│ ├── box_annotator_ohem_layer.hpp
│ ├── concat_layer.hpp
│ ├── contrastive_loss_layer.hpp
│ ├── conv_layer.hpp
│ ├── crop_layer.hpp
│ ├── cudnn_conv_layer.hpp
│ ├── cudnn_lcn_layer.hpp
│ ├── cudnn_lrn_layer.hpp
│ ├── cudnn_pooling_layer.hpp
│ ├── cudnn_relu_layer.hpp
│ ├── cudnn_sigmoid_layer.hpp
│ ├── cudnn_softmax_layer.hpp
│ ├── cudnn_tanh_layer.hpp
│ ├── data_layer.hpp
│ ├── deconv_layer.hpp
│ ├── dense_image_data_layer.hpp.bk
│ ├── dropout_layer.hpp
│ ├── dummy_data_layer.hpp
│ ├── eltwise_layer.hpp
│ ├── elu_layer.hpp
│ ├── embed_layer.hpp
│ ├── euclidean_loss_layer.hpp
│ ├── exp_layer.hpp
│ ├── filter_layer.hpp
│ ├── flatten_layer.hpp
│ ├── hdf5_data_layer.hpp
│ ├── hdf5_output_layer.hpp
│ ├── hinge_loss_layer.hpp
│ ├── im2col_layer.hpp
│ ├── image_data_layer.hpp
│ ├── infogain_loss_layer.hpp
│ ├── inner_product_blob_layer.hpp
│ ├── inner_product_layer.hpp
│ ├── input_layer.hpp
│ ├── log_layer.hpp
│ ├── loss_layer.hpp
│ ├── lrn_layer.hpp
│ ├── lstm_layer.hpp
│ ├── memory_data_layer.hpp
│ ├── multinomial_logistic_loss_layer.hpp
│ ├── mvn_layer.hpp
│ ├── neuron_layer.hpp
│ ├── parameter_layer.hpp
│ ├── pooling_layer.hpp
│ ├── power_layer.hpp
│ ├── prelu_layer.hpp
│ ├── proposal_layer.bk
│ ├── psroi_pooling_layer.hpp
│ ├── python_layer.hpp
│ ├── recurrent_layer.hpp
│ ├── reduction_layer.hpp
│ ├── relu_layer.hpp
│ ├── reshape_layer.hpp
│ ├── rnn_layer.hpp
│ ├── roi_pooling_layer.hpp
│ ├── scale_layer.hpp
│ ├── sigmoid_cross_entropy_loss_layer.hpp
│ ├── sigmoid_layer.hpp
│ ├── silence_layer.hpp
│ ├── slice_layer.hpp
│ ├── smooth_l1_loss_layer.hpp
│ ├── smooth_l1_loss_ohem_layer.hpp
│ ├── softmax_layer.hpp
│ ├── softmax_loss_layer.hpp
│ ├── softmax_loss_ohem_layer.hpp
│ ├── split_layer.hpp
│ ├── spp_layer.hpp
│ ├── tanh_layer.hpp
│ ├── threshold_layer.hpp
│ ├── tile_layer.hpp
│ └── window_data_layer.hpp
│ ├── net.hpp
│ ├── parallel.hpp
│ ├── proto
│ └── caffe.pb.h
│ ├── sgd_solvers.hpp
│ ├── solver.hpp
│ ├── solver_factory.hpp
│ ├── syncedmem.hpp
│ ├── test
│ ├── test_caffe_main.hpp
│ └── test_gradient_check_util.hpp
│ └── util
│ ├── benchmark.hpp
│ ├── blocking_queue.hpp
│ ├── cudnn.hpp
│ ├── db.hpp
│ ├── db_leveldb.hpp
│ ├── db_lmdb.hpp
│ ├── device_alternate.hpp
│ ├── format.hpp
│ ├── gpu_util.cuh
│ ├── hdf5.hpp
│ ├── im2col.hpp
│ ├── insert_splits.hpp
│ ├── io.hpp
│ ├── math_functions.hpp
│ ├── mkl_alternate.hpp
│ ├── nccl.hpp
│ ├── rng.hpp
│ ├── signal_handler.h
│ └── upgrade_proto.hpp
├── install_depencies.sh
├── matlab
├── +caffe
│ ├── +test
│ │ ├── test_io.m
│ │ ├── test_net.m
│ │ └── test_solver.m
│ ├── Blob.m
│ ├── Layer.m
│ ├── Net.m
│ ├── Solver.m
│ ├── get_net.m
│ ├── get_solver.m
│ ├── imagenet
│ │ └── ilsvrc_2012_mean.mat
│ ├── io.m
│ ├── private
│ │ ├── CHECK.m
│ │ ├── CHECK_FILE_EXIST.m
│ │ ├── caffe_.cpp
│ │ └── is_valid_handle.m
│ ├── reset_all.m
│ ├── run_tests.m
│ ├── set_device.m
│ ├── set_mode_cpu.m
│ ├── set_mode_gpu.m
│ └── version.m
├── CMakeLists.txt
├── demo
│ └── classification_demo.m
└── hdf5creation
│ ├── .gitignore
│ ├── demo.m
│ └── store2hdf5.m
├── python
├── .gitignore
├── .gitignore~
├── CMakeLists.txt
├── caffe
│ ├── __init__.py
│ ├── __init__.pyc
│ ├── _caffe.cpp
│ ├── classifier.py
│ ├── classifier.pyc
│ ├── coord_map.py
│ ├── detector.py
│ ├── detector.pyc
│ ├── draw.py
│ ├── imagenet
│ │ └── ilsvrc_2012_mean.npy
│ ├── io.py
│ ├── io.pyc
│ ├── net_spec.py
│ ├── net_spec.pyc
│ ├── pycaffe.py
│ ├── pycaffe.pyc
│ └── test
│ │ ├── test_coord_map.py
│ │ ├── test_io.py
│ │ ├── test_layer_type_list.py
│ │ ├── test_net.py
│ │ ├── test_net_spec.py
│ │ ├── test_python_layer.py
│ │ ├── test_python_layer_with_param_str.py
│ │ └── test_solver.py
├── classify.py
├── detect.py
├── draw_net.py
├── net_pics
│ └── lenet.png
├── requirements.txt
└── train.py
├── scripts
├── build_docs.sh
├── copy_notebook.py
├── cpp_lint.py
├── deploy_docs.sh
├── download_model_binary.py
├── download_model_from_gist.sh
├── gather_examples.sh
├── split_caffe_proto.py
├── travis
│ ├── build.sh
│ ├── configure-cmake.sh
│ ├── configure-make.sh
│ ├── configure.sh
│ ├── defaults.sh
│ ├── install-deps.sh
│ ├── install-python-deps.sh
│ ├── setup-venv.sh
│ └── test.sh
└── upload_model_to_gist.sh
├── src
├── caffe
│ ├── CMakeLists.txt
│ ├── blob.cpp
│ ├── common.cpp
│ ├── data_transformer.cpp
│ ├── internal_thread.cpp
│ ├── layer.cpp
│ ├── layer_factory.cpp
│ ├── layers
│ │ ├── absval_layer.cpp
│ │ ├── absval_layer.cu
│ │ ├── accuracy_layer.cpp
│ │ ├── argmax_layer.cpp
│ │ ├── base_conv_layer.cpp
│ │ ├── base_data_layer.cpp
│ │ ├── base_data_layer.cu
│ │ ├── batch_norm_layer.cpp
│ │ ├── batch_norm_layer.cu
│ │ ├── batch_reindex_layer.cpp
│ │ ├── batch_reindex_layer.cu
│ │ ├── bias_layer.cpp
│ │ ├── bias_layer.cu
│ │ ├── bnll_layer.cpp
│ │ ├── bnll_layer.cu
│ │ ├── box_annotator_ohem_layer.cpp
│ │ ├── box_annotator_ohem_layer.cu
│ │ ├── concat_layer.cpp
│ │ ├── concat_layer.cu
│ │ ├── contrastive_loss_layer.cpp
│ │ ├── contrastive_loss_layer.cu
│ │ ├── conv_layer.cpp
│ │ ├── conv_layer.cu
│ │ ├── crop_layer.cpp
│ │ ├── crop_layer.cu
│ │ ├── cudnn_conv_layer.cpp
│ │ ├── cudnn_conv_layer.cu
│ │ ├── cudnn_lcn_layer.cpp
│ │ ├── cudnn_lcn_layer.cu
│ │ ├── cudnn_lrn_layer.cpp
│ │ ├── cudnn_lrn_layer.cu
│ │ ├── cudnn_pooling_layer.cpp
│ │ ├── cudnn_pooling_layer.cu
│ │ ├── cudnn_relu_layer.cpp
│ │ ├── cudnn_relu_layer.cu
│ │ ├── cudnn_sigmoid_layer.cpp
│ │ ├── cudnn_sigmoid_layer.cu
│ │ ├── cudnn_softmax_layer.cpp
│ │ ├── cudnn_softmax_layer.cu
│ │ ├── cudnn_tanh_layer.cpp
│ │ ├── cudnn_tanh_layer.cu
│ │ ├── data_layer.cpp
│ │ ├── deconv_layer.cpp
│ │ ├── deconv_layer.cu
│ │ ├── dense_image_data_layer.cpp.bk
│ │ ├── dropout_layer.cpp
│ │ ├── dropout_layer.cu
│ │ ├── dummy_data_layer.cpp
│ │ ├── eltwise_layer.cpp
│ │ ├── eltwise_layer.cu
│ │ ├── elu_layer.cpp
│ │ ├── elu_layer.cu
│ │ ├── embed_layer.cpp
│ │ ├── embed_layer.cu
│ │ ├── euclidean_loss_layer.cpp
│ │ ├── euclidean_loss_layer.cu
│ │ ├── exp_layer.cpp
│ │ ├── exp_layer.cu
│ │ ├── filter_layer.cpp
│ │ ├── filter_layer.cu
│ │ ├── flatten_layer.cpp
│ │ ├── hdf5_data_layer.cpp
│ │ ├── hdf5_data_layer.cu
│ │ ├── hdf5_output_layer.cpp
│ │ ├── hdf5_output_layer.cu
│ │ ├── hinge_loss_layer.cpp
│ │ ├── im2col_layer.cpp
│ │ ├── im2col_layer.cu
│ │ ├── image_data_layer.cpp
│ │ ├── infogain_loss_layer.cpp
│ │ ├── inner_product_blob_layer.cpp
│ │ ├── inner_product_blob_layer.cu
│ │ ├── inner_product_layer.cpp
│ │ ├── inner_product_layer.cu
│ │ ├── input_layer.cpp
│ │ ├── log_layer.cpp
│ │ ├── log_layer.cu
│ │ ├── loss_layer.cpp
│ │ ├── lrn_layer.cpp
│ │ ├── lrn_layer.cu
│ │ ├── lstm_layer.cpp
│ │ ├── lstm_unit_layer.cpp
│ │ ├── lstm_unit_layer.cu
│ │ ├── memory_data_layer.cpp
│ │ ├── multinomial_logistic_loss_layer.cpp
│ │ ├── mvn_layer.cpp
│ │ ├── mvn_layer.cu
│ │ ├── neuron_layer.cpp
│ │ ├── parameter_layer.cpp
│ │ ├── pooling_layer.cpp
│ │ ├── pooling_layer.cu
│ │ ├── power_layer.cpp
│ │ ├── power_layer.cu
│ │ ├── prelu_layer.cpp
│ │ ├── prelu_layer.cu
│ │ ├── proposal_layer.cpp.bk
│ │ ├── proposal_layer.cu.bk
│ │ ├── psroi_pooling_layer.cpp
│ │ ├── psroi_pooling_layer.cu
│ │ ├── recurrent_layer.cpp
│ │ ├── recurrent_layer.cu
│ │ ├── reduction_layer.cpp
│ │ ├── reduction_layer.cu
│ │ ├── relu_layer.cpp
│ │ ├── relu_layer.cu
│ │ ├── reshape_layer.cpp
│ │ ├── rnn_layer.cpp
│ │ ├── roi_pooling_layer.cpp
│ │ ├── roi_pooling_layer.cu
│ │ ├── scale_layer.cpp
│ │ ├── scale_layer.cu
│ │ ├── sigmoid_cross_entropy_loss_layer.cpp
│ │ ├── sigmoid_cross_entropy_loss_layer.cu
│ │ ├── sigmoid_layer.cpp
│ │ ├── sigmoid_layer.cu
│ │ ├── silence_layer.cpp
│ │ ├── silence_layer.cu
│ │ ├── slice_layer.cpp
│ │ ├── slice_layer.cu
│ │ ├── smooth_L1_loss_ohem_layer.cpp
│ │ ├── smooth_L1_loss_ohem_layer.cu
│ │ ├── smooth_l1_loss_layer.cpp
│ │ ├── smooth_l1_loss_layer.cu
│ │ ├── softmax_layer.cpp
│ │ ├── softmax_layer.cu
│ │ ├── softmax_loss_layer.cpp
│ │ ├── softmax_loss_layer.cu
│ │ ├── softmax_loss_ohem_layer.cpp
│ │ ├── softmax_loss_ohem_layer.cu
│ │ ├── split_layer.cpp
│ │ ├── split_layer.cu
│ │ ├── spp_layer.cpp
│ │ ├── tanh_layer.cpp
│ │ ├── tanh_layer.cu
│ │ ├── threshold_layer.cpp
│ │ ├── threshold_layer.cu
│ │ ├── tile_layer.cpp
│ │ ├── tile_layer.cu
│ │ └── window_data_layer.cpp
│ ├── net.cpp
│ ├── parallel.cpp
│ ├── proto
│ │ ├── caffe.pb.cc
│ │ ├── caffe.pb.h
│ │ └── caffe.proto
│ ├── solver.cpp
│ ├── solvers
│ │ ├── adadelta_solver.cpp
│ │ ├── adadelta_solver.cu
│ │ ├── adagrad_solver.cpp
│ │ ├── adagrad_solver.cu
│ │ ├── adam_solver.cpp
│ │ ├── adam_solver.cu
│ │ ├── nesterov_solver.cpp
│ │ ├── nesterov_solver.cu
│ │ ├── rmsprop_solver.cpp
│ │ ├── rmsprop_solver.cu
│ │ ├── sgd_solver.cpp
│ │ └── sgd_solver.cu
│ ├── syncedmem.cpp
│ ├── test
│ │ ├── CMakeLists.txt
│ │ ├── test_accuracy_layer.cpp
│ │ ├── test_argmax_layer.cpp
│ │ ├── test_batch_norm_layer.cpp
│ │ ├── test_batch_reindex_layer.cpp
│ │ ├── test_benchmark.cpp
│ │ ├── test_bias_layer.cpp
│ │ ├── test_blob.cpp
│ │ ├── test_caffe_main.cpp
│ │ ├── test_common.cpp
│ │ ├── test_concat_layer.cpp
│ │ ├── test_contrastive_loss_layer.cpp
│ │ ├── test_convolution_layer.cpp
│ │ ├── test_crop_layer.cpp
│ │ ├── test_data
│ │ │ ├── generate_sample_data.py
│ │ │ ├── sample_data.h5
│ │ │ ├── sample_data_2_gzip.h5
│ │ │ ├── sample_data_list.txt
│ │ │ ├── solver_data.h5
│ │ │ └── solver_data_list.txt
│ │ ├── test_data_layer.cpp
│ │ ├── test_data_transformer.cpp
│ │ ├── test_db.cpp
│ │ ├── test_deconvolution_layer.cpp
│ │ ├── test_dummy_data_layer.cpp
│ │ ├── test_eltwise_layer.cpp
│ │ ├── test_embed_layer.cpp
│ │ ├── test_euclidean_loss_layer.cpp
│ │ ├── test_filler.cpp
│ │ ├── test_filter_layer.cpp
│ │ ├── test_flatten_layer.cpp
│ │ ├── test_gradient_based_solver.cpp
│ │ ├── test_hdf5_output_layer.cpp
│ │ ├── test_hdf5data_layer.cpp
│ │ ├── test_hinge_loss_layer.cpp
│ │ ├── test_im2col_kernel.cu
│ │ ├── test_im2col_layer.cpp
│ │ ├── test_image_data_layer.cpp
│ │ ├── test_infogain_loss_layer.cpp
│ │ ├── test_inner_product_layer.cpp
│ │ ├── test_internal_thread.cpp
│ │ ├── test_io.cpp
│ │ ├── test_layer_factory.cpp
│ │ ├── test_lrn_layer.cpp
│ │ ├── test_lstm_layer.cpp
│ │ ├── test_math_functions.cpp
│ │ ├── test_maxpool_dropout_layers.cpp
│ │ ├── test_memory_data_layer.cpp
│ │ ├── test_multinomial_logistic_loss_layer.cpp
│ │ ├── test_mvn_layer.cpp
│ │ ├── test_net.cpp
│ │ ├── test_neuron_layer.cpp
│ │ ├── test_platform.cpp
│ │ ├── test_pooling_layer.cpp
│ │ ├── test_power_layer.cpp
│ │ ├── test_protobuf.cpp
│ │ ├── test_random_number_generator.cpp
│ │ ├── test_reduction_layer.cpp
│ │ ├── test_reshape_layer.cpp
│ │ ├── test_rnn_layer.cpp
│ │ ├── test_scale_layer.cpp
│ │ ├── test_sigmoid_cross_entropy_loss_layer.cpp
│ │ ├── test_slice_layer.cpp
│ │ ├── test_softmax_layer.cpp
│ │ ├── test_softmax_with_loss_layer.cpp
│ │ ├── test_solver.cpp
│ │ ├── test_solver_factory.cpp
│ │ ├── test_split_layer.cpp
│ │ ├── test_spp_layer.cpp
│ │ ├── test_stochastic_pooling.cpp
│ │ ├── test_syncedmem.cpp
│ │ ├── test_tanh_layer.cpp
│ │ ├── test_threshold_layer.cpp
│ │ ├── test_tile_layer.cpp
│ │ ├── test_upgrade_proto.cpp
│ │ └── test_util_blas.cpp
│ └── util
│ │ ├── benchmark.cpp
│ │ ├── blocking_queue.cpp
│ │ ├── cudnn.cpp
│ │ ├── db.cpp
│ │ ├── db_leveldb.cpp
│ │ ├── db_lmdb.cpp
│ │ ├── hdf5.cpp
│ │ ├── im2col.cpp
│ │ ├── im2col.cu
│ │ ├── insert_splits.cpp
│ │ ├── io.cpp
│ │ ├── math_functions.cpp
│ │ ├── math_functions.cu
│ │ ├── signal_handler.cpp
│ │ └── upgrade_proto.cpp
└── gtest
│ ├── CMakeLists.txt
│ ├── gtest-all.cpp
│ ├── gtest.h
│ └── gtest_main.cc
└── tools
├── CMakeLists.txt
├── caffe.cpp
├── caffe_pb2.py
├── compute_image_mean.cpp
├── convert_imageset.cpp
├── device_query.cpp
├── extra
├── extract_seconds.py
├── launch_resize_and_crop_images.sh
├── parse_log.py
├── parse_log.sh
├── plot_log.gnuplot.example
├── plot_training_log.py.example
├── resize_and_crop_images.py
└── summarize.py
├── extract_features.cpp
├── finetune_net.cpp
├── net_speed_benchmark.cpp
├── test_net.cpp
├── train_net.cpp
├── upgrade_net_proto_binary.cpp
├── upgrade_net_proto_text.cpp
└── upgrade_solver_proto_text.cpp
/.gitignore:
--------------------------------------------------------------------------------
1 | ./build
2 | cmake-build-debug/
3 | .idea/
4 | .build_release/
5 |
--------------------------------------------------------------------------------
/.gitignore~:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/UnrealVision/unreal_caffe/45243b6a2100739cd9110ffbeded55c5723894b3/.gitignore~
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/README_en.md:
--------------------------------------------------------------------------------
1 | # Unreal Caffe
2 |
3 | 
4 |
5 |
6 |
7 | This is a self-contained caffe version. I gathered many useful layers in here, and you can using this directly to run many tasks such as *Faster-RCNN*, *RFCN*, *FCN* etc. Briefly, I do those adjustment based on the official caffe:
8 |
9 | - cudnn 7 support, add to cudnn7;
10 | - `roi_pooling_layer` needed in Fast-RCNN series task;
11 | - `smooth_l1_loss_ohem_layer` needed in RFCN task;
12 | - `deformalable_conv_layer` which is the most advanced conv (still under test.);
13 |
14 |
15 |
16 | ### Installation
17 |
18 | In **unreal_caffe**, you are not need to bare the official full of errors. just:
19 |
20 | ```shell
21 | git clone https://github.com/UnrealVision/unreal_caffe.git
22 | cd unreal_caffe
23 | make -j32
24 | ```
25 |
26 | You should got this:
27 |
28 | 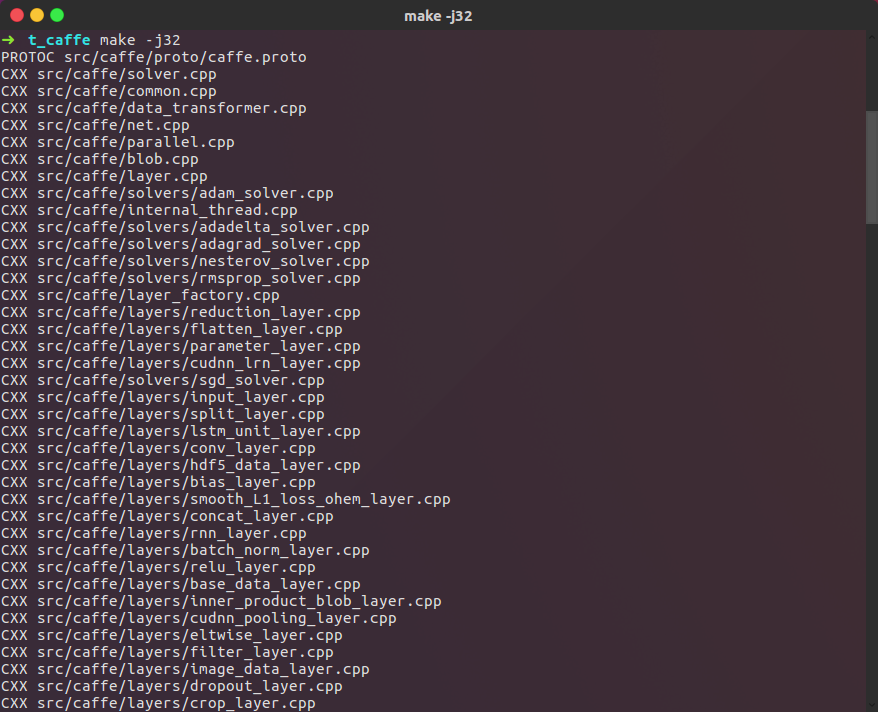
29 |
30 | And after build complete, you will got this:
31 |
32 | 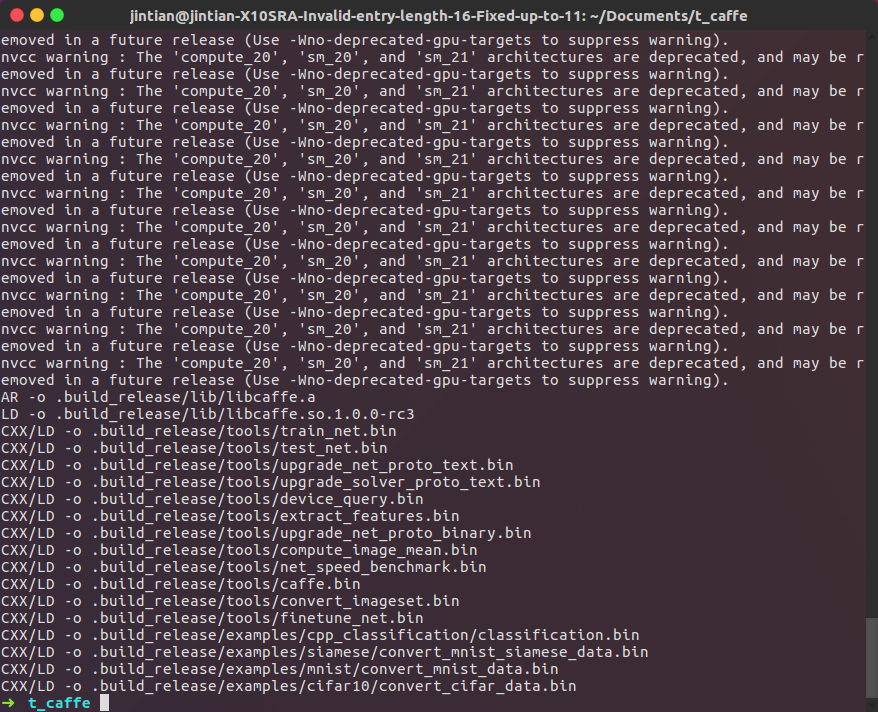
33 |
34 | Then directly:
35 |
36 | ```
37 | makepycaffe
38 | ```
39 |
40 | One last thing:
41 |
42 | Add `/path/to/unreal_caffe/python` to your `~/.bashrc` or `~/.zshrc` file. You will using caffe through python. **unreal_caffe default using Python2.7, you can open python3 support but not open them at same time!**
43 |
44 |
45 |
46 | ### Tasks
47 |
48 | I will later on post some demo to should how to using this caffe version do many tasks!
49 |
50 |
51 |
52 | # Copyright
53 |
54 | This code original written by BLVC and Yangqing Jia. I just do some modification beyond that. And I do help many others maintain this version with me, add more features into unreal_caffe.
--------------------------------------------------------------------------------
/a.out:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/UnrealVision/unreal_caffe/45243b6a2100739cd9110ffbeded55c5723894b3/a.out
--------------------------------------------------------------------------------
/build:
--------------------------------------------------------------------------------
1 | .build_release
--------------------------------------------------------------------------------
/caffe.cloc:
--------------------------------------------------------------------------------
1 | Bourne Shell
2 | filter remove_matches ^\s*#
3 | filter remove_inline #.*$
4 | extension sh
5 | script_exe sh
6 | C
7 | filter remove_matches ^\s*//
8 | filter call_regexp_common C
9 | filter remove_inline //.*$
10 | extension c
11 | extension ec
12 | extension pgc
13 | C++
14 | filter remove_matches ^\s*//
15 | filter remove_inline //.*$
16 | filter call_regexp_common C
17 | extension C
18 | extension cc
19 | extension cpp
20 | extension cxx
21 | extension pcc
22 | C/C++ Header
23 | filter remove_matches ^\s*//
24 | filter call_regexp_common C
25 | filter remove_inline //.*$
26 | extension H
27 | extension h
28 | extension hh
29 | extension hpp
30 | CUDA
31 | filter remove_matches ^\s*//
32 | filter remove_inline //.*$
33 | filter call_regexp_common C
34 | extension cu
35 | Python
36 | filter remove_matches ^\s*#
37 | filter docstring_to_C
38 | filter call_regexp_common C
39 | filter remove_inline #.*$
40 | extension py
41 | make
42 | filter remove_matches ^\s*#
43 | filter remove_inline #.*$
44 | extension Gnumakefile
45 | extension Makefile
46 | extension am
47 | extension gnumakefile
48 | extension makefile
49 | filename Gnumakefile
50 | filename Makefile
51 | filename gnumakefile
52 | filename makefile
53 | script_exe make
54 |
--------------------------------------------------------------------------------
/cmake/Modules/FindGFlags.cmake:
--------------------------------------------------------------------------------
1 | # - Try to find GFLAGS
2 | #
3 | # The following variables are optionally searched for defaults
4 | # GFLAGS_ROOT_DIR: Base directory where all GFLAGS components are found
5 | #
6 | # The following are set after configuration is done:
7 | # GFLAGS_FOUND
8 | # GFLAGS_INCLUDE_DIRS
9 | # GFLAGS_LIBRARIES
10 | # GFLAGS_LIBRARYRARY_DIRS
11 |
12 | include(FindPackageHandleStandardArgs)
13 |
14 | set(GFLAGS_ROOT_DIR "" CACHE PATH "Folder contains Gflags")
15 |
16 | # We are testing only a couple of files in the include directories
17 | if(WIN32)
18 | find_path(GFLAGS_INCLUDE_DIR gflags/gflags.h
19 | PATHS ${GFLAGS_ROOT_DIR}/src/windows)
20 | else()
21 | find_path(GFLAGS_INCLUDE_DIR gflags/gflags.h
22 | PATHS ${GFLAGS_ROOT_DIR})
23 | endif()
24 |
25 | if(MSVC)
26 | find_library(GFLAGS_LIBRARY_RELEASE
27 | NAMES libgflags
28 | PATHS ${GFLAGS_ROOT_DIR}
29 | PATH_SUFFIXES Release)
30 |
31 | find_library(GFLAGS_LIBRARY_DEBUG
32 | NAMES libgflags-debug
33 | PATHS ${GFLAGS_ROOT_DIR}
34 | PATH_SUFFIXES Debug)
35 |
36 | set(GFLAGS_LIBRARY optimized ${GFLAGS_LIBRARY_RELEASE} debug ${GFLAGS_LIBRARY_DEBUG})
37 | else()
38 | find_library(GFLAGS_LIBRARY gflags)
39 | endif()
40 |
41 | find_package_handle_standard_args(GFlags DEFAULT_MSG GFLAGS_INCLUDE_DIR GFLAGS_LIBRARY)
42 |
43 |
44 | if(GFLAGS_FOUND)
45 | set(GFLAGS_INCLUDE_DIRS ${GFLAGS_INCLUDE_DIR})
46 | set(GFLAGS_LIBRARIES ${GFLAGS_LIBRARY})
47 | message(STATUS "Found gflags (include: ${GFLAGS_INCLUDE_DIR}, library: ${GFLAGS_LIBRARY})")
48 | mark_as_advanced(GFLAGS_LIBRARY_DEBUG GFLAGS_LIBRARY_RELEASE
49 | GFLAGS_LIBRARY GFLAGS_INCLUDE_DIR GFLAGS_ROOT_DIR)
50 | endif()
51 |
--------------------------------------------------------------------------------
/cmake/Modules/FindGlog.cmake:
--------------------------------------------------------------------------------
1 | # - Try to find Glog
2 | #
3 | # The following variables are optionally searched for defaults
4 | # GLOG_ROOT_DIR: Base directory where all GLOG components are found
5 | #
6 | # The following are set after configuration is done:
7 | # GLOG_FOUND
8 | # GLOG_INCLUDE_DIRS
9 | # GLOG_LIBRARIES
10 | # GLOG_LIBRARYRARY_DIRS
11 |
12 | include(FindPackageHandleStandardArgs)
13 |
14 | set(GLOG_ROOT_DIR "" CACHE PATH "Folder contains Google glog")
15 |
16 | if(WIN32)
17 | find_path(GLOG_INCLUDE_DIR glog/logging.h
18 | PATHS ${GLOG_ROOT_DIR}/src/windows)
19 | else()
20 | find_path(GLOG_INCLUDE_DIR glog/logging.h
21 | PATHS ${GLOG_ROOT_DIR})
22 | endif()
23 |
24 | if(MSVC)
25 | find_library(GLOG_LIBRARY_RELEASE libglog_static
26 | PATHS ${GLOG_ROOT_DIR}
27 | PATH_SUFFIXES Release)
28 |
29 | find_library(GLOG_LIBRARY_DEBUG libglog_static
30 | PATHS ${GLOG_ROOT_DIR}
31 | PATH_SUFFIXES Debug)
32 |
33 | set(GLOG_LIBRARY optimized ${GLOG_LIBRARY_RELEASE} debug ${GLOG_LIBRARY_DEBUG})
34 | else()
35 | find_library(GLOG_LIBRARY glog
36 | PATHS ${GLOG_ROOT_DIR}
37 | PATH_SUFFIXES lib lib64)
38 | endif()
39 |
40 | find_package_handle_standard_args(Glog DEFAULT_MSG GLOG_INCLUDE_DIR GLOG_LIBRARY)
41 |
42 | if(GLOG_FOUND)
43 | set(GLOG_INCLUDE_DIRS ${GLOG_INCLUDE_DIR})
44 | set(GLOG_LIBRARIES ${GLOG_LIBRARY})
45 | message(STATUS "Found glog (include: ${GLOG_INCLUDE_DIR}, library: ${GLOG_LIBRARY})")
46 | mark_as_advanced(GLOG_ROOT_DIR GLOG_LIBRARY_RELEASE GLOG_LIBRARY_DEBUG
47 | GLOG_LIBRARY GLOG_INCLUDE_DIR)
48 | endif()
49 |
--------------------------------------------------------------------------------
/cmake/Modules/FindLMDB.cmake:
--------------------------------------------------------------------------------
1 | # Try to find the LMBD libraries and headers
2 | # LMDB_FOUND - system has LMDB lib
3 | # LMDB_INCLUDE_DIR - the LMDB include directory
4 | # LMDB_LIBRARIES - Libraries needed to use LMDB
5 |
6 | # FindCWD based on FindGMP by:
7 | # Copyright (c) 2006, Laurent Montel,
8 | #
9 | # Redistribution and use is allowed according to the terms of the BSD license.
10 |
11 | # Adapted from FindCWD by:
12 | # Copyright 2013 Conrad Steenberg
13 | # Aug 31, 2013
14 |
15 | find_path(LMDB_INCLUDE_DIR NAMES lmdb.h PATHS "$ENV{LMDB_DIR}/include")
16 | find_library(LMDB_LIBRARIES NAMES lmdb PATHS "$ENV{LMDB_DIR}/lib" )
17 |
18 | include(FindPackageHandleStandardArgs)
19 | find_package_handle_standard_args(LMDB DEFAULT_MSG LMDB_INCLUDE_DIR LMDB_LIBRARIES)
20 |
21 | if(LMDB_FOUND)
22 | message(STATUS "Found lmdb (include: ${LMDB_INCLUDE_DIR}, library: ${LMDB_LIBRARIES})")
23 | mark_as_advanced(LMDB_INCLUDE_DIR LMDB_LIBRARIES)
24 |
25 | caffe_parse_header(${LMDB_INCLUDE_DIR}/lmdb.h
26 | LMDB_VERSION_LINES MDB_VERSION_MAJOR MDB_VERSION_MINOR MDB_VERSION_PATCH)
27 | set(LMDB_VERSION "${MDB_VERSION_MAJOR}.${MDB_VERSION_MINOR}.${MDB_VERSION_PATCH}")
28 | endif()
29 |
--------------------------------------------------------------------------------
/cmake/Modules/FindSnappy.cmake:
--------------------------------------------------------------------------------
1 | # Find the Snappy libraries
2 | #
3 | # The following variables are optionally searched for defaults
4 | # Snappy_ROOT_DIR: Base directory where all Snappy components are found
5 | #
6 | # The following are set after configuration is done:
7 | # SNAPPY_FOUND
8 | # Snappy_INCLUDE_DIR
9 | # Snappy_LIBRARIES
10 |
11 | find_path(Snappy_INCLUDE_DIR NAMES snappy.h
12 | PATHS ${SNAPPY_ROOT_DIR} ${SNAPPY_ROOT_DIR}/include)
13 |
14 | find_library(Snappy_LIBRARIES NAMES snappy
15 | PATHS ${SNAPPY_ROOT_DIR} ${SNAPPY_ROOT_DIR}/lib)
16 |
17 | include(FindPackageHandleStandardArgs)
18 | find_package_handle_standard_args(Snappy DEFAULT_MSG Snappy_INCLUDE_DIR Snappy_LIBRARIES)
19 |
20 | if(SNAPPY_FOUND)
21 | message(STATUS "Found Snappy (include: ${Snappy_INCLUDE_DIR}, library: ${Snappy_LIBRARIES})")
22 | mark_as_advanced(Snappy_INCLUDE_DIR Snappy_LIBRARIES)
23 |
24 | caffe_parse_header(${Snappy_INCLUDE_DIR}/snappy-stubs-public.h
25 | SNAPPY_VERION_LINES SNAPPY_MAJOR SNAPPY_MINOR SNAPPY_PATCHLEVEL)
26 | set(Snappy_VERSION "${SNAPPY_MAJOR}.${SNAPPY_MINOR}.${SNAPPY_PATCHLEVEL}")
27 | endif()
28 |
29 |
--------------------------------------------------------------------------------
/cmake/Modules/FindvecLib.cmake:
--------------------------------------------------------------------------------
1 | # Find the vecLib libraries as part of Accelerate.framework or as standalon framework
2 | #
3 | # The following are set after configuration is done:
4 | # VECLIB_FOUND
5 | # vecLib_INCLUDE_DIR
6 | # vecLib_LINKER_LIBS
7 |
8 |
9 | if(NOT APPLE)
10 | return()
11 | endif()
12 |
13 | set(__veclib_include_suffix "Frameworks/vecLib.framework/Versions/Current/Headers")
14 |
15 | find_path(vecLib_INCLUDE_DIR vecLib.h
16 | DOC "vecLib include directory"
17 | PATHS /System/Library/Frameworks/Accelerate.framework/Versions/Current/${__veclib_include_suffix}
18 | /System/Library/${__veclib_include_suffix}
19 | /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.9.sdk/System/Library/Frameworks/Accelerate.framework/Versions/Current/Frameworks/vecLib.framework/Headers/
20 | NO_DEFAULT_PATH)
21 |
22 | include(FindPackageHandleStandardArgs)
23 | find_package_handle_standard_args(vecLib DEFAULT_MSG vecLib_INCLUDE_DIR)
24 |
25 | if(VECLIB_FOUND)
26 | if(vecLib_INCLUDE_DIR MATCHES "^/System/Library/Frameworks/vecLib.framework.*")
27 | set(vecLib_LINKER_LIBS -lcblas "-framework vecLib")
28 | message(STATUS "Found standalone vecLib.framework")
29 | else()
30 | set(vecLib_LINKER_LIBS -lcblas "-framework Accelerate")
31 | message(STATUS "Found vecLib as part of Accelerate.framework")
32 | endif()
33 |
34 | mark_as_advanced(vecLib_INCLUDE_DIR)
35 | endif()
36 |
--------------------------------------------------------------------------------
/cmake/Templates/CaffeConfigVersion.cmake.in:
--------------------------------------------------------------------------------
1 | set(PACKAGE_VERSION "@Caffe_VERSION@")
2 |
3 | # Check whether the requested PACKAGE_FIND_VERSION is compatible
4 | if("${PACKAGE_VERSION}" VERSION_LESS "${PACKAGE_FIND_VERSION}")
5 | set(PACKAGE_VERSION_COMPATIBLE FALSE)
6 | else()
7 | set(PACKAGE_VERSION_COMPATIBLE TRUE)
8 | if ("${PACKAGE_VERSION}" VERSION_EQUAL "${PACKAGE_FIND_VERSION}")
9 | set(PACKAGE_VERSION_EXACT TRUE)
10 | endif()
11 | endif()
12 |
--------------------------------------------------------------------------------
/cmake/Templates/caffe_config.h.in:
--------------------------------------------------------------------------------
1 | /* Sources directory */
2 | #define SOURCE_FOLDER "${PROJECT_SOURCE_DIR}"
3 |
4 | /* Binaries directory */
5 | #define BINARY_FOLDER "${PROJECT_BINARY_DIR}"
6 |
7 | /* NVIDA Cuda */
8 | #cmakedefine HAVE_CUDA
9 |
10 | /* NVIDA cuDNN */
11 | #cmakedefine HAVE_CUDNN
12 | #cmakedefine USE_CUDNN
13 |
14 | /* NVIDA cuDNN */
15 | #cmakedefine CPU_ONLY
16 |
17 | /* Test device */
18 | #define CUDA_TEST_DEVICE ${CUDA_TEST_DEVICE}
19 |
20 | /* Temporary (TODO: remove) */
21 | #if 1
22 | #define CMAKE_SOURCE_DIR SOURCE_FOLDER "/src/"
23 | #define EXAMPLES_SOURCE_DIR BINARY_FOLDER "/examples/"
24 | #define CMAKE_EXT ".gen.cmake"
25 | #else
26 | #define CMAKE_SOURCE_DIR "src/"
27 | #define EXAMPLES_SOURCE_DIR "examples/"
28 | #define CMAKE_EXT ""
29 | #endif
30 |
31 | /* Matlab */
32 | #cmakedefine HAVE_MATLAB
33 |
34 | /* IO libraries */
35 | #cmakedefine USE_OPENCV
36 | #cmakedefine USE_LEVELDB
37 | #cmakedefine USE_LMDB
38 | #cmakedefine ALLOW_LMDB_NOLOCK
39 |
--------------------------------------------------------------------------------
/cmake/lint.cmake:
--------------------------------------------------------------------------------
1 |
2 | set(CMAKE_SOURCE_DIR ..)
3 | set(LINT_COMMAND ${CMAKE_SOURCE_DIR}/scripts/cpp_lint.py)
4 | set(SRC_FILE_EXTENSIONS h hpp hu c cpp cu cc)
5 | set(EXCLUDE_FILE_EXTENSTIONS pb.h pb.cc)
6 | set(LINT_DIRS include src/caffe examples tools python matlab)
7 |
8 | cmake_policy(SET CMP0009 NEW) # suppress cmake warning
9 |
10 | # find all files of interest
11 | foreach(ext ${SRC_FILE_EXTENSIONS})
12 | foreach(dir ${LINT_DIRS})
13 | file(GLOB_RECURSE FOUND_FILES ${CMAKE_SOURCE_DIR}/${dir}/*.${ext})
14 | set(LINT_SOURCES ${LINT_SOURCES} ${FOUND_FILES})
15 | endforeach()
16 | endforeach()
17 |
18 | # find all files that should be excluded
19 | foreach(ext ${EXCLUDE_FILE_EXTENSTIONS})
20 | file(GLOB_RECURSE FOUND_FILES ${CMAKE_SOURCE_DIR}/*.${ext})
21 | set(EXCLUDED_FILES ${EXCLUDED_FILES} ${FOUND_FILES})
22 | endforeach()
23 |
24 | # exclude generated pb files
25 | list(REMOVE_ITEM LINT_SOURCES ${EXCLUDED_FILES})
26 |
27 | execute_process(
28 | COMMAND ${LINT_COMMAND} ${LINT_SOURCES}
29 | ERROR_VARIABLE LINT_OUTPUT
30 | ERROR_STRIP_TRAILING_WHITESPACE
31 | )
32 |
33 | string(REPLACE "\n" ";" LINT_OUTPUT ${LINT_OUTPUT})
34 |
35 | list(GET LINT_OUTPUT -1 LINT_RESULT)
36 | list(REMOVE_AT LINT_OUTPUT -1)
37 | string(REPLACE " " ";" LINT_RESULT ${LINT_RESULT})
38 | list(GET LINT_RESULT -1 NUM_ERRORS)
39 | if(NUM_ERRORS GREATER 0)
40 | foreach(msg ${LINT_OUTPUT})
41 | string(FIND ${msg} "Done" result)
42 | if(result LESS 0)
43 | message(STATUS ${msg})
44 | endif()
45 | endforeach()
46 | message(FATAL_ERROR "Lint found ${NUM_ERRORS} errors!")
47 | else()
48 | message(STATUS "Lint did not find any errors!")
49 | endif()
50 |
51 |
--------------------------------------------------------------------------------
/examples/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | file(GLOB_RECURSE examples_srcs "${PROJECT_SOURCE_DIR}/examples/*.cpp")
2 |
3 | foreach(source_file ${examples_srcs})
4 | # get file name
5 | get_filename_component(name ${source_file} NAME_WE)
6 |
7 | # get folder name
8 | get_filename_component(path ${source_file} PATH)
9 | get_filename_component(folder ${path} NAME_WE)
10 |
11 | add_executable(${name} ${source_file})
12 | target_link_libraries(${name} ${Caffe_LINK})
13 | caffe_default_properties(${name})
14 |
15 | # set back RUNTIME_OUTPUT_DIRECTORY
16 | set_target_properties(${name} PROPERTIES
17 | RUNTIME_OUTPUT_DIRECTORY "${PROJECT_BINARY_DIR}/examples/${folder}")
18 |
19 | caffe_set_solution_folder(${name} examples)
20 |
21 | # install
22 | install(TARGETS ${name} DESTINATION bin)
23 |
24 | if(UNIX OR APPLE)
25 | # Funny command to make tutorials work
26 | # TODO: remove in future as soon as naming is standardized everywhere
27 | set(__outname ${PROJECT_BINARY_DIR}/examples/${folder}/${name}${Caffe_POSTFIX})
28 | add_custom_command(TARGET ${name} POST_BUILD
29 | COMMAND ln -sf "${__outname}" "${__outname}.bin")
30 | endif()
31 | endforeach()
32 |
--------------------------------------------------------------------------------
/examples/cifar10/cifar10_full_sigmoid_solver.prototxt:
--------------------------------------------------------------------------------
1 | # reduce learning rate after 120 epochs (60000 iters) by factor 0f 10
2 | # then another factor of 10 after 10 more epochs (5000 iters)
3 |
4 | # The train/test net protocol buffer definition
5 | net: "examples/cifar10/cifar10_full_sigmoid_train_test.prototxt"
6 | # test_iter specifies how many forward passes the test should carry out.
7 | # In the case of CIFAR10, we have test batch size 100 and 100 test iterations,
8 | # covering the full 10,000 testing images.
9 | test_iter: 10
10 | # Carry out testing every 1000 training iterations.
11 | test_interval: 1000
12 | # The base learning rate, momentum and the weight decay of the network.
13 | base_lr: 0.001
14 | momentum: 0.9
15 | #weight_decay: 0.004
16 | # The learning rate policy
17 | lr_policy: "step"
18 | gamma: 1
19 | stepsize: 5000
20 | # Display every 100 iterations
21 | display: 100
22 | # The maximum number of iterations
23 | max_iter: 60000
24 | # snapshot intermediate results
25 | snapshot: 10000
26 | snapshot_prefix: "examples/cifar10_full_sigmoid"
27 | # solver mode: CPU or GPU
28 | solver_mode: GPU
29 |
--------------------------------------------------------------------------------
/examples/cifar10/cifar10_full_sigmoid_solver_bn.prototxt:
--------------------------------------------------------------------------------
1 | # reduce learning rate after 120 epochs (60000 iters) by factor 0f 10
2 | # then another factor of 10 after 10 more epochs (5000 iters)
3 |
4 | # The train/test net protocol buffer definition
5 | net: "examples/cifar10/cifar10_full_sigmoid_train_test_bn.prototxt"
6 | # test_iter specifies how many forward passes the test should carry out.
7 | # In the case of CIFAR10, we have test batch size 100 and 100 test iterations,
8 | # covering the full 10,000 testing images.
9 | test_iter: 10
10 | # Carry out testing every 1000 training iterations.
11 | test_interval: 1000
12 | # The base learning rate, momentum and the weight decay of the network.
13 | base_lr: 0.001
14 | momentum: 0.9
15 | #weight_decay: 0.004
16 | # The learning rate policy
17 | lr_policy: "step"
18 | gamma: 1
19 | stepsize: 5000
20 | # Display every 100 iterations
21 | display: 100
22 | # The maximum number of iterations
23 | max_iter: 60000
24 | # snapshot intermediate results
25 | snapshot: 10000
26 | snapshot_prefix: "examples/cifar10_full_sigmoid_bn"
27 | # solver mode: CPU or GPU
28 | solver_mode: GPU
29 |
--------------------------------------------------------------------------------
/examples/cifar10/cifar10_full_solver.prototxt:
--------------------------------------------------------------------------------
1 | # reduce learning rate after 120 epochs (60000 iters) by factor 0f 10
2 | # then another factor of 10 after 10 more epochs (5000 iters)
3 |
4 | # The train/test net protocol buffer definition
5 | net: "examples/cifar10/cifar10_full_train_test.prototxt"
6 | # test_iter specifies how many forward passes the test should carry out.
7 | # In the case of CIFAR10, we have test batch size 100 and 100 test iterations,
8 | # covering the full 10,000 testing images.
9 | test_iter: 100
10 | # Carry out testing every 1000 training iterations.
11 | test_interval: 1000
12 | # The base learning rate, momentum and the weight decay of the network.
13 | base_lr: 0.001
14 | momentum: 0.9
15 | weight_decay: 0.004
16 | # The learning rate policy
17 | lr_policy: "fixed"
18 | # Display every 200 iterations
19 | display: 200
20 | # The maximum number of iterations
21 | max_iter: 60000
22 | # snapshot intermediate results
23 | snapshot: 10000
24 | snapshot_format: HDF5
25 | snapshot_prefix: "examples/cifar10/cifar10_full"
26 | # solver mode: CPU or GPU
27 | solver_mode: GPU
28 |
--------------------------------------------------------------------------------
/examples/cifar10/cifar10_full_solver_lr1.prototxt:
--------------------------------------------------------------------------------
1 | # reduce learning rate after 120 epochs (60000 iters) by factor 0f 10
2 | # then another factor of 10 after 10 more epochs (5000 iters)
3 |
4 | # The train/test net protocol buffer definition
5 | net: "examples/cifar10/cifar10_full_train_test.prototxt"
6 | # test_iter specifies how many forward passes the test should carry out.
7 | # In the case of CIFAR10, we have test batch size 100 and 100 test iterations,
8 | # covering the full 10,000 testing images.
9 | test_iter: 100
10 | # Carry out testing every 1000 training iterations.
11 | test_interval: 1000
12 | # The base learning rate, momentum and the weight decay of the network.
13 | base_lr: 0.0001
14 | momentum: 0.9
15 | weight_decay: 0.004
16 | # The learning rate policy
17 | lr_policy: "fixed"
18 | # Display every 200 iterations
19 | display: 200
20 | # The maximum number of iterations
21 | max_iter: 65000
22 | # snapshot intermediate results
23 | snapshot: 5000
24 | snapshot_format: HDF5
25 | snapshot_prefix: "examples/cifar10/cifar10_full"
26 | # solver mode: CPU or GPU
27 | solver_mode: GPU
28 |
--------------------------------------------------------------------------------
/examples/cifar10/cifar10_full_solver_lr2.prototxt:
--------------------------------------------------------------------------------
1 | # reduce learning rate after 120 epochs (60000 iters) by factor 0f 10
2 | # then another factor of 10 after 10 more epochs (5000 iters)
3 |
4 | # The train/test net protocol buffer definition
5 | net: "examples/cifar10/cifar10_full_train_test.prototxt"
6 | # test_iter specifies how many forward passes the test should carry out.
7 | # In the case of CIFAR10, we have test batch size 100 and 100 test iterations,
8 | # covering the full 10,000 testing images.
9 | test_iter: 100
10 | # Carry out testing every 1000 training iterations.
11 | test_interval: 1000
12 | # The base learning rate, momentum and the weight decay of the network.
13 | base_lr: 0.00001
14 | momentum: 0.9
15 | weight_decay: 0.004
16 | # The learning rate policy
17 | lr_policy: "fixed"
18 | # Display every 200 iterations
19 | display: 200
20 | # The maximum number of iterations
21 | max_iter: 70000
22 | # snapshot intermediate results
23 | snapshot: 5000
24 | snapshot_format: HDF5
25 | snapshot_prefix: "examples/cifar10/cifar10_full"
26 | # solver mode: CPU or GPU
27 | solver_mode: GPU
28 |
--------------------------------------------------------------------------------
/examples/cifar10/cifar10_quick_solver.prototxt:
--------------------------------------------------------------------------------
1 | # reduce the learning rate after 8 epochs (4000 iters) by a factor of 10
2 |
3 | # The train/test net protocol buffer definition
4 | net: "examples/cifar10/cifar10_quick_train_test.prototxt"
5 | # test_iter specifies how many forward passes the test should carry out.
6 | # In the case of MNIST, we have test batch size 100 and 100 test iterations,
7 | # covering the full 10,000 testing images.
8 | test_iter: 100
9 | # Carry out testing every 500 training iterations.
10 | test_interval: 500
11 | # The base learning rate, momentum and the weight decay of the network.
12 | base_lr: 0.001
13 | momentum: 0.9
14 | weight_decay: 0.004
15 | # The learning rate policy
16 | lr_policy: "fixed"
17 | # Display every 100 iterations
18 | display: 100
19 | # The maximum number of iterations
20 | max_iter: 4000
21 | # snapshot intermediate results
22 | snapshot: 4000
23 | snapshot_format: HDF5
24 | snapshot_prefix: "examples/cifar10/cifar10_quick"
25 | # solver mode: CPU or GPU
26 | solver_mode: GPU
27 |
--------------------------------------------------------------------------------
/examples/cifar10/cifar10_quick_solver_lr1.prototxt:
--------------------------------------------------------------------------------
1 | # reduce the learning rate after 8 epochs (4000 iters) by a factor of 10
2 |
3 | # The train/test net protocol buffer definition
4 | net: "examples/cifar10/cifar10_quick_train_test.prototxt"
5 | # test_iter specifies how many forward passes the test should carry out.
6 | # In the case of MNIST, we have test batch size 100 and 100 test iterations,
7 | # covering the full 10,000 testing images.
8 | test_iter: 100
9 | # Carry out testing every 500 training iterations.
10 | test_interval: 500
11 | # The base learning rate, momentum and the weight decay of the network.
12 | base_lr: 0.0001
13 | momentum: 0.9
14 | weight_decay: 0.004
15 | # The learning rate policy
16 | lr_policy: "fixed"
17 | # Display every 100 iterations
18 | display: 100
19 | # The maximum number of iterations
20 | max_iter: 5000
21 | # snapshot intermediate results
22 | snapshot: 5000
23 | snapshot_format: HDF5
24 | snapshot_prefix: "examples/cifar10/cifar10_quick"
25 | # solver mode: CPU or GPU
26 | solver_mode: GPU
27 |
--------------------------------------------------------------------------------
/examples/cifar10/create_cifar10.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | # This script converts the cifar data into leveldb format.
3 | set -e
4 |
5 | EXAMPLE=examples/cifar10
6 | DATA=data/cifar10
7 | DBTYPE=lmdb
8 |
9 | echo "Creating $DBTYPE..."
10 |
11 | rm -rf $EXAMPLE/cifar10_train_$DBTYPE $EXAMPLE/cifar10_test_$DBTYPE
12 |
13 | ./build/examples/cifar10/convert_cifar_data.bin $DATA $EXAMPLE $DBTYPE
14 |
15 | echo "Computing image mean..."
16 |
17 | ./build/tools/compute_image_mean -backend=$DBTYPE \
18 | $EXAMPLE/cifar10_train_$DBTYPE $EXAMPLE/mean.binaryproto
19 |
20 | echo "Done."
21 |
--------------------------------------------------------------------------------
/examples/cifar10/train_full.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | TOOLS=./build/tools
5 |
6 | $TOOLS/caffe train \
7 | --solver=examples/cifar10/cifar10_full_solver.prototxt $@
8 |
9 | # reduce learning rate by factor of 10
10 | $TOOLS/caffe train \
11 | --solver=examples/cifar10/cifar10_full_solver_lr1.prototxt \
12 | --snapshot=examples/cifar10/cifar10_full_iter_60000.solverstate.h5 $@
13 |
14 | # reduce learning rate by factor of 10
15 | $TOOLS/caffe train \
16 | --solver=examples/cifar10/cifar10_full_solver_lr2.prototxt \
17 | --snapshot=examples/cifar10/cifar10_full_iter_65000.solverstate.h5 $@
18 |
--------------------------------------------------------------------------------
/examples/cifar10/train_full_sigmoid.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | TOOLS=./build/tools
5 |
6 | $TOOLS/caffe train \
7 | --solver=examples/cifar10/cifar10_full_sigmoid_solver.prototxt $@
8 |
9 |
--------------------------------------------------------------------------------
/examples/cifar10/train_full_sigmoid_bn.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | TOOLS=./build/tools
5 |
6 | $TOOLS/caffe train \
7 | --solver=examples/cifar10/cifar10_full_sigmoid_solver_bn.prototxt $@
8 |
9 |
--------------------------------------------------------------------------------
/examples/cifar10/train_quick.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | TOOLS=./build/tools
5 |
6 | $TOOLS/caffe train \
7 | --solver=examples/cifar10/cifar10_quick_solver.prototxt $@
8 |
9 | # reduce learning rate by factor of 10 after 8 epochs
10 | $TOOLS/caffe train \
11 | --solver=examples/cifar10/cifar10_quick_solver_lr1.prototxt \
12 | --snapshot=examples/cifar10/cifar10_quick_iter_4000.solverstate.h5 $@
13 |
--------------------------------------------------------------------------------
/examples/finetune_flickr_style/flickr_style.csv.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/UnrealVision/unreal_caffe/45243b6a2100739cd9110ffbeded55c5723894b3/examples/finetune_flickr_style/flickr_style.csv.gz
--------------------------------------------------------------------------------
/examples/finetune_flickr_style/style_names.txt:
--------------------------------------------------------------------------------
1 | Detailed
2 | Pastel
3 | Melancholy
4 | Noir
5 | HDR
6 | Vintage
7 | Long Exposure
8 | Horror
9 | Sunny
10 | Bright
11 | Hazy
12 | Bokeh
13 | Serene
14 | Texture
15 | Ethereal
16 | Macro
17 | Depth of Field
18 | Geometric Composition
19 | Minimal
20 | Romantic
21 |
--------------------------------------------------------------------------------
/examples/finetune_pascal_detection/pascal_finetune_solver.prototxt:
--------------------------------------------------------------------------------
1 | net: "examples/finetune_pascal_detection/pascal_finetune_trainval_test.prototxt"
2 | test_iter: 100
3 | test_interval: 1000
4 | base_lr: 0.001
5 | lr_policy: "step"
6 | gamma: 0.1
7 | stepsize: 20000
8 | display: 20
9 | max_iter: 100000
10 | momentum: 0.9
11 | weight_decay: 0.0005
12 | snapshot: 10000
13 | snapshot_prefix: "examples/finetune_pascal_detection/pascal_det_finetune"
14 |
--------------------------------------------------------------------------------
/examples/hdf5_classification/nonlinear_auto_test.prototxt:
--------------------------------------------------------------------------------
1 | layer {
2 | name: "data"
3 | type: "HDF5Data"
4 | top: "data"
5 | top: "label"
6 | hdf5_data_param {
7 | source: "examples/hdf5_classification/data/test.txt"
8 | batch_size: 10
9 | }
10 | }
11 | layer {
12 | name: "ip1"
13 | type: "InnerProduct"
14 | bottom: "data"
15 | top: "ip1"
16 | inner_product_param {
17 | num_output: 40
18 | weight_filler {
19 | type: "xavier"
20 | }
21 | }
22 | }
23 | layer {
24 | name: "relu1"
25 | type: "ReLU"
26 | bottom: "ip1"
27 | top: "ip1"
28 | }
29 | layer {
30 | name: "ip2"
31 | type: "InnerProduct"
32 | bottom: "ip1"
33 | top: "ip2"
34 | inner_product_param {
35 | num_output: 2
36 | weight_filler {
37 | type: "xavier"
38 | }
39 | }
40 | }
41 | layer {
42 | name: "accuracy"
43 | type: "Accuracy"
44 | bottom: "ip2"
45 | bottom: "label"
46 | top: "accuracy"
47 | }
48 | layer {
49 | name: "loss"
50 | type: "SoftmaxWithLoss"
51 | bottom: "ip2"
52 | bottom: "label"
53 | top: "loss"
54 | }
55 |
--------------------------------------------------------------------------------
/examples/hdf5_classification/nonlinear_auto_train.prototxt:
--------------------------------------------------------------------------------
1 | layer {
2 | name: "data"
3 | type: "HDF5Data"
4 | top: "data"
5 | top: "label"
6 | hdf5_data_param {
7 | source: "examples/hdf5_classification/data/train.txt"
8 | batch_size: 10
9 | }
10 | }
11 | layer {
12 | name: "ip1"
13 | type: "InnerProduct"
14 | bottom: "data"
15 | top: "ip1"
16 | inner_product_param {
17 | num_output: 40
18 | weight_filler {
19 | type: "xavier"
20 | }
21 | }
22 | }
23 | layer {
24 | name: "relu1"
25 | type: "ReLU"
26 | bottom: "ip1"
27 | top: "ip1"
28 | }
29 | layer {
30 | name: "ip2"
31 | type: "InnerProduct"
32 | bottom: "ip1"
33 | top: "ip2"
34 | inner_product_param {
35 | num_output: 2
36 | weight_filler {
37 | type: "xavier"
38 | }
39 | }
40 | }
41 | layer {
42 | name: "accuracy"
43 | type: "Accuracy"
44 | bottom: "ip2"
45 | bottom: "label"
46 | top: "accuracy"
47 | }
48 | layer {
49 | name: "loss"
50 | type: "SoftmaxWithLoss"
51 | bottom: "ip2"
52 | bottom: "label"
53 | top: "loss"
54 | }
55 |
--------------------------------------------------------------------------------
/examples/hdf5_classification/nonlinear_train_val.prototxt:
--------------------------------------------------------------------------------
1 | name: "LogisticRegressionNet"
2 | layer {
3 | name: "data"
4 | type: "HDF5Data"
5 | top: "data"
6 | top: "label"
7 | include {
8 | phase: TRAIN
9 | }
10 | hdf5_data_param {
11 | source: "examples/hdf5_classification/data/train.txt"
12 | batch_size: 10
13 | }
14 | }
15 | layer {
16 | name: "data"
17 | type: "HDF5Data"
18 | top: "data"
19 | top: "label"
20 | include {
21 | phase: TEST
22 | }
23 | hdf5_data_param {
24 | source: "examples/hdf5_classification/data/test.txt"
25 | batch_size: 10
26 | }
27 | }
28 | layer {
29 | name: "fc1"
30 | type: "InnerProduct"
31 | bottom: "data"
32 | top: "fc1"
33 | param {
34 | lr_mult: 1
35 | decay_mult: 1
36 | }
37 | param {
38 | lr_mult: 2
39 | decay_mult: 0
40 | }
41 | inner_product_param {
42 | num_output: 40
43 | weight_filler {
44 | type: "xavier"
45 | }
46 | bias_filler {
47 | type: "constant"
48 | value: 0
49 | }
50 | }
51 | }
52 | layer {
53 | name: "relu1"
54 | type: "ReLU"
55 | bottom: "fc1"
56 | top: "fc1"
57 | }
58 | layer {
59 | name: "fc2"
60 | type: "InnerProduct"
61 | bottom: "fc1"
62 | top: "fc2"
63 | param {
64 | lr_mult: 1
65 | decay_mult: 1
66 | }
67 | param {
68 | lr_mult: 2
69 | decay_mult: 0
70 | }
71 | inner_product_param {
72 | num_output: 2
73 | weight_filler {
74 | type: "xavier"
75 | }
76 | bias_filler {
77 | type: "constant"
78 | value: 0
79 | }
80 | }
81 | }
82 | layer {
83 | name: "loss"
84 | type: "SoftmaxWithLoss"
85 | bottom: "fc2"
86 | bottom: "label"
87 | top: "loss"
88 | }
89 | layer {
90 | name: "accuracy"
91 | type: "Accuracy"
92 | bottom: "fc2"
93 | bottom: "label"
94 | top: "accuracy"
95 | include {
96 | phase: TEST
97 | }
98 | }
99 |
--------------------------------------------------------------------------------
/examples/hdf5_classification/train_val.prototxt:
--------------------------------------------------------------------------------
1 | name: "LogisticRegressionNet"
2 | layer {
3 | name: "data"
4 | type: "HDF5Data"
5 | top: "data"
6 | top: "label"
7 | include {
8 | phase: TRAIN
9 | }
10 | hdf5_data_param {
11 | source: "examples/hdf5_classification/data/train.txt"
12 | batch_size: 10
13 | }
14 | }
15 | layer {
16 | name: "data"
17 | type: "HDF5Data"
18 | top: "data"
19 | top: "label"
20 | include {
21 | phase: TEST
22 | }
23 | hdf5_data_param {
24 | source: "examples/hdf5_classification/data/test.txt"
25 | batch_size: 10
26 | }
27 | }
28 | layer {
29 | name: "fc1"
30 | type: "InnerProduct"
31 | bottom: "data"
32 | top: "fc1"
33 | param {
34 | lr_mult: 1
35 | decay_mult: 1
36 | }
37 | param {
38 | lr_mult: 2
39 | decay_mult: 0
40 | }
41 | inner_product_param {
42 | num_output: 2
43 | weight_filler {
44 | type: "xavier"
45 | }
46 | bias_filler {
47 | type: "constant"
48 | value: 0
49 | }
50 | }
51 | }
52 | layer {
53 | name: "loss"
54 | type: "SoftmaxWithLoss"
55 | bottom: "fc1"
56 | bottom: "label"
57 | top: "loss"
58 | }
59 | layer {
60 | name: "accuracy"
61 | type: "Accuracy"
62 | bottom: "fc1"
63 | bottom: "label"
64 | top: "accuracy"
65 | include {
66 | phase: TEST
67 | }
68 | }
69 |
--------------------------------------------------------------------------------
/examples/imagenet/create_imagenet.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | # Create the imagenet lmdb inputs
3 | # N.B. set the path to the imagenet train + val data dirs
4 | set -e
5 |
6 | EXAMPLE=examples/imagenet
7 | DATA=data/ilsvrc12
8 | TOOLS=build/tools
9 |
10 | TRAIN_DATA_ROOT=/path/to/imagenet/train/
11 | VAL_DATA_ROOT=/path/to/imagenet/val/
12 |
13 | # Set RESIZE=true to resize the images to 256x256. Leave as false if images have
14 | # already been resized using another tool.
15 | RESIZE=false
16 | if $RESIZE; then
17 | RESIZE_HEIGHT=256
18 | RESIZE_WIDTH=256
19 | else
20 | RESIZE_HEIGHT=0
21 | RESIZE_WIDTH=0
22 | fi
23 |
24 | if [ ! -d "$TRAIN_DATA_ROOT" ]; then
25 | echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
26 | echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
27 | "where the ImageNet training data is stored."
28 | exit 1
29 | fi
30 |
31 | if [ ! -d "$VAL_DATA_ROOT" ]; then
32 | echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
33 | echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
34 | "where the ImageNet validation data is stored."
35 | exit 1
36 | fi
37 |
38 | echo "Creating train lmdb..."
39 |
40 | GLOG_logtostderr=1 $TOOLS/convert_imageset \
41 | --resize_height=$RESIZE_HEIGHT \
42 | --resize_width=$RESIZE_WIDTH \
43 | --shuffle \
44 | $TRAIN_DATA_ROOT \
45 | $DATA/train.txt \
46 | $EXAMPLE/ilsvrc12_train_lmdb
47 |
48 | echo "Creating val lmdb..."
49 |
50 | GLOG_logtostderr=1 $TOOLS/convert_imageset \
51 | --resize_height=$RESIZE_HEIGHT \
52 | --resize_width=$RESIZE_WIDTH \
53 | --shuffle \
54 | $VAL_DATA_ROOT \
55 | $DATA/val.txt \
56 | $EXAMPLE/ilsvrc12_val_lmdb
57 |
58 | echo "Done."
59 |
--------------------------------------------------------------------------------
/examples/imagenet/make_imagenet_mean.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | # Compute the mean image from the imagenet training lmdb
3 | # N.B. this is available in data/ilsvrc12
4 |
5 | EXAMPLE=examples/imagenet
6 | DATA=data/ilsvrc12
7 | TOOLS=build/tools
8 |
9 | $TOOLS/compute_image_mean $EXAMPLE/ilsvrc12_train_lmdb \
10 | $DATA/imagenet_mean.binaryproto
11 |
12 | echo "Done."
13 |
--------------------------------------------------------------------------------
/examples/imagenet/resume_training.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | ./build/tools/caffe train \
5 | --solver=models/bvlc_reference_caffenet/solver.prototxt \
6 | --snapshot=models/bvlc_reference_caffenet/caffenet_train_10000.solverstate.h5 \
7 | $@
8 |
--------------------------------------------------------------------------------
/examples/imagenet/train_caffenet.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | ./build/tools/caffe train \
5 | --solver=models/bvlc_reference_caffenet/solver.prototxt $@
6 |
--------------------------------------------------------------------------------
/examples/images/cat gray.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/UnrealVision/unreal_caffe/45243b6a2100739cd9110ffbeded55c5723894b3/examples/images/cat gray.jpg
--------------------------------------------------------------------------------
/examples/images/cat.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/UnrealVision/unreal_caffe/45243b6a2100739cd9110ffbeded55c5723894b3/examples/images/cat.jpg
--------------------------------------------------------------------------------
/examples/images/cat_gray.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/UnrealVision/unreal_caffe/45243b6a2100739cd9110ffbeded55c5723894b3/examples/images/cat_gray.jpg
--------------------------------------------------------------------------------
/examples/images/fish-bike.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/UnrealVision/unreal_caffe/45243b6a2100739cd9110ffbeded55c5723894b3/examples/images/fish-bike.jpg
--------------------------------------------------------------------------------
/examples/mnist/create_mnist.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | # This script converts the mnist data into lmdb/leveldb format,
3 | # depending on the value assigned to $BACKEND.
4 | set -e
5 |
6 | EXAMPLE=examples/mnist
7 | DATA=data/mnist
8 | BUILD=build/examples/mnist
9 |
10 | BACKEND="lmdb"
11 |
12 | echo "Creating ${BACKEND}..."
13 |
14 | rm -rf $EXAMPLE/mnist_train_${BACKEND}
15 | rm -rf $EXAMPLE/mnist_test_${BACKEND}
16 |
17 | $BUILD/convert_mnist_data.bin $DATA/train-images-idx3-ubyte \
18 | $DATA/train-labels-idx1-ubyte $EXAMPLE/mnist_train_${BACKEND} --backend=${BACKEND}
19 | $BUILD/convert_mnist_data.bin $DATA/t10k-images-idx3-ubyte \
20 | $DATA/t10k-labels-idx1-ubyte $EXAMPLE/mnist_test_${BACKEND} --backend=${BACKEND}
21 |
22 | echo "Done."
23 |
--------------------------------------------------------------------------------
/examples/mnist/lenet_adadelta_solver.prototxt:
--------------------------------------------------------------------------------
1 | # The train/test net protocol buffer definition
2 | net: "examples/mnist/lenet_train_test.prototxt"
3 | # test_iter specifies how many forward passes the test should carry out.
4 | # In the case of MNIST, we have test batch size 100 and 100 test iterations,
5 | # covering the full 10,000 testing images.
6 | test_iter: 100
7 | # Carry out testing every 500 training iterations.
8 | test_interval: 500
9 | # The base learning rate, momentum and the weight decay of the network.
10 | base_lr: 1.0
11 | lr_policy: "fixed"
12 | momentum: 0.95
13 | weight_decay: 0.0005
14 | # Display every 100 iterations
15 | display: 100
16 | # The maximum number of iterations
17 | max_iter: 10000
18 | # snapshot intermediate results
19 | snapshot: 5000
20 | snapshot_prefix: "examples/mnist/lenet_adadelta"
21 | # solver mode: CPU or GPU
22 | solver_mode: GPU
23 | type: "AdaDelta"
24 | delta: 1e-6
25 |
--------------------------------------------------------------------------------
/examples/mnist/lenet_auto_solver.prototxt:
--------------------------------------------------------------------------------
1 | # The train/test net protocol buffer definition
2 | train_net: "mnist/lenet_auto_train.prototxt"
3 | test_net: "mnist/lenet_auto_test.prototxt"
4 | # test_iter specifies how many forward passes the test should carry out.
5 | # In the case of MNIST, we have test batch size 100 and 100 test iterations,
6 | # covering the full 10,000 testing images.
7 | test_iter: 100
8 | # Carry out testing every 500 training iterations.
9 | test_interval: 500
10 | # The base learning rate, momentum and the weight decay of the network.
11 | base_lr: 0.01
12 | momentum: 0.9
13 | weight_decay: 0.0005
14 | # The learning rate policy
15 | lr_policy: "inv"
16 | gamma: 0.0001
17 | power: 0.75
18 | # Display every 100 iterations
19 | display: 100
20 | # The maximum number of iterations
21 | max_iter: 10000
22 | # snapshot intermediate results
23 | snapshot: 5000
24 | snapshot_prefix: "mnist/lenet"
25 |
--------------------------------------------------------------------------------
/examples/mnist/lenet_multistep_solver.prototxt:
--------------------------------------------------------------------------------
1 | # The train/test net protocol buffer definition
2 | net: "examples/mnist/lenet_train_test.prototxt"
3 | # test_iter specifies how many forward passes the test should carry out.
4 | # In the case of MNIST, we have test batch size 100 and 100 test iterations,
5 | # covering the full 10,000 testing images.
6 | test_iter: 100
7 | # Carry out testing every 500 training iterations.
8 | test_interval: 500
9 | # The base learning rate, momentum and the weight decay of the network.
10 | base_lr: 0.01
11 | momentum: 0.9
12 | weight_decay: 0.0005
13 | # The learning rate policy
14 | lr_policy: "multistep"
15 | gamma: 0.9
16 | stepvalue: 5000
17 | stepvalue: 7000
18 | stepvalue: 8000
19 | stepvalue: 9000
20 | stepvalue: 9500
21 | # Display every 100 iterations
22 | display: 100
23 | # The maximum number of iterations
24 | max_iter: 10000
25 | # snapshot intermediate results
26 | snapshot: 5000
27 | snapshot_prefix: "examples/mnist/lenet_multistep"
28 | # solver mode: CPU or GPU
29 | solver_mode: GPU
30 |
--------------------------------------------------------------------------------
/examples/mnist/lenet_solver.prototxt:
--------------------------------------------------------------------------------
1 | # The train/test net protocol buffer definition
2 | net: "examples/mnist/lenet_train_test.prototxt"
3 | # test_iter specifies how many forward passes the test should carry out.
4 | # In the case of MNIST, we have test batch size 100 and 100 test iterations,
5 | # covering the full 10,000 testing images.
6 | test_iter: 100
7 | # Carry out testing every 500 training iterations.
8 | test_interval: 500
9 | # The base learning rate, momentum and the weight decay of the network.
10 | base_lr: 0.01
11 | momentum: 0.9
12 | weight_decay: 0.0005
13 | # The learning rate policy
14 | lr_policy: "inv"
15 | gamma: 0.0001
16 | power: 0.75
17 | # Display every 100 iterations
18 | display: 100
19 | # The maximum number of iterations
20 | max_iter: 10000
21 | # snapshot intermediate results
22 | snapshot: 5000
23 | snapshot_prefix: "examples/mnist/lenet"
24 | # solver mode: CPU or GPU
25 | solver_mode: GPU
26 |
--------------------------------------------------------------------------------
/examples/mnist/lenet_solver_adam.prototxt:
--------------------------------------------------------------------------------
1 | # The train/test net protocol buffer definition
2 | # this follows "ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION"
3 | net: "examples/mnist/lenet_train_test.prototxt"
4 | # test_iter specifies how many forward passes the test should carry out.
5 | # In the case of MNIST, we have test batch size 100 and 100 test iterations,
6 | # covering the full 10,000 testing images.
7 | test_iter: 100
8 | # Carry out testing every 500 training iterations.
9 | test_interval: 500
10 | # All parameters are from the cited paper above
11 | base_lr: 0.001
12 | momentum: 0.9
13 | momentum2: 0.999
14 | # since Adam dynamically changes the learning rate, we set the base learning
15 | # rate to a fixed value
16 | lr_policy: "fixed"
17 | # Display every 100 iterations
18 | display: 100
19 | # The maximum number of iterations
20 | max_iter: 10000
21 | # snapshot intermediate results
22 | snapshot: 5000
23 | snapshot_prefix: "examples/mnist/lenet"
24 | # solver mode: CPU or GPU
25 | type: "Adam"
26 | solver_mode: GPU
27 |
--------------------------------------------------------------------------------
/examples/mnist/lenet_solver_rmsprop.prototxt:
--------------------------------------------------------------------------------
1 | # The train/test net protocol buffer definition
2 | net: "examples/mnist/lenet_train_test.prototxt"
3 | # test_iter specifies how many forward passes the test should carry out.
4 | # In the case of MNIST, we have test batch size 100 and 100 test iterations,
5 | # covering the full 10,000 testing images.
6 | test_iter: 100
7 | # Carry out testing every 500 training iterations.
8 | test_interval: 500
9 | # The base learning rate, momentum and the weight decay of the network.
10 | base_lr: 0.01
11 | momentum: 0.0
12 | weight_decay: 0.0005
13 | # The learning rate policy
14 | lr_policy: "inv"
15 | gamma: 0.0001
16 | power: 0.75
17 | # Display every 100 iterations
18 | display: 100
19 | # The maximum number of iterations
20 | max_iter: 10000
21 | # snapshot intermediate results
22 | snapshot: 5000
23 | snapshot_prefix: "examples/mnist/lenet_rmsprop"
24 | # solver mode: CPU or GPU
25 | solver_mode: GPU
26 | type: "RMSProp"
27 | rms_decay: 0.98
28 |
--------------------------------------------------------------------------------
/examples/mnist/mnist_autoencoder_solver.prototxt:
--------------------------------------------------------------------------------
1 | net: "examples/mnist/mnist_autoencoder.prototxt"
2 | test_state: { stage: 'test-on-train' }
3 | test_iter: 500
4 | test_state: { stage: 'test-on-test' }
5 | test_iter: 100
6 | test_interval: 500
7 | test_compute_loss: true
8 | base_lr: 0.01
9 | lr_policy: "step"
10 | gamma: 0.1
11 | stepsize: 10000
12 | display: 100
13 | max_iter: 65000
14 | weight_decay: 0.0005
15 | snapshot: 10000
16 | snapshot_prefix: "examples/mnist/mnist_autoencoder"
17 | momentum: 0.9
18 | # solver mode: CPU or GPU
19 | solver_mode: GPU
20 |
--------------------------------------------------------------------------------
/examples/mnist/mnist_autoencoder_solver_adadelta.prototxt:
--------------------------------------------------------------------------------
1 | net: "examples/mnist/mnist_autoencoder.prototxt"
2 | test_state: { stage: 'test-on-train' }
3 | test_iter: 500
4 | test_state: { stage: 'test-on-test' }
5 | test_iter: 100
6 | test_interval: 500
7 | test_compute_loss: true
8 | base_lr: 1.0
9 | lr_policy: "fixed"
10 | momentum: 0.95
11 | delta: 1e-8
12 | display: 100
13 | max_iter: 65000
14 | weight_decay: 0.0005
15 | snapshot: 10000
16 | snapshot_prefix: "examples/mnist/mnist_autoencoder_adadelta_train"
17 | # solver mode: CPU or GPU
18 | solver_mode: GPU
19 | type: "AdaDelta"
20 |
--------------------------------------------------------------------------------
/examples/mnist/mnist_autoencoder_solver_adagrad.prototxt:
--------------------------------------------------------------------------------
1 | net: "examples/mnist/mnist_autoencoder.prototxt"
2 | test_state: { stage: 'test-on-train' }
3 | test_iter: 500
4 | test_state: { stage: 'test-on-test' }
5 | test_iter: 100
6 | test_interval: 500
7 | test_compute_loss: true
8 | base_lr: 0.01
9 | lr_policy: "fixed"
10 | display: 100
11 | max_iter: 65000
12 | weight_decay: 0.0005
13 | snapshot: 10000
14 | snapshot_prefix: "examples/mnist/mnist_autoencoder_adagrad_train"
15 | # solver mode: CPU or GPU
16 | solver_mode: GPU
17 | type: "AdaGrad"
18 |
--------------------------------------------------------------------------------
/examples/mnist/mnist_autoencoder_solver_nesterov.prototxt:
--------------------------------------------------------------------------------
1 | net: "examples/mnist/mnist_autoencoder.prototxt"
2 | test_state: { stage: 'test-on-train' }
3 | test_iter: 500
4 | test_state: { stage: 'test-on-test' }
5 | test_iter: 100
6 | test_interval: 500
7 | test_compute_loss: true
8 | base_lr: 0.01
9 | lr_policy: "step"
10 | gamma: 0.1
11 | stepsize: 10000
12 | display: 100
13 | max_iter: 65000
14 | weight_decay: 0.0005
15 | snapshot: 10000
16 | snapshot_prefix: "examples/mnist/mnist_autoencoder_nesterov_train"
17 | momentum: 0.95
18 | # solver mode: CPU or GPU
19 | solver_mode: GPU
20 | type: "Nesterov"
21 |
--------------------------------------------------------------------------------
/examples/mnist/train_lenet.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | ./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt $@
5 |
--------------------------------------------------------------------------------
/examples/mnist/train_lenet_adam.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | ./build/tools/caffe train --solver=examples/mnist/lenet_solver_adam.prototxt $@
5 |
--------------------------------------------------------------------------------
/examples/mnist/train_lenet_consolidated.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | ./build/tools/caffe train \
5 | --solver=examples/mnist/lenet_consolidated_solver.prototxt $@
6 |
--------------------------------------------------------------------------------
/examples/mnist/train_lenet_rmsprop.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | ./build/tools/caffe train \
5 | --solver=examples/mnist/lenet_solver_rmsprop.prototxt $@
6 |
--------------------------------------------------------------------------------
/examples/mnist/train_mnist_autoencoder.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | ./build/tools/caffe train \
5 | --solver=examples/mnist/mnist_autoencoder_solver.prototxt $@
6 |
--------------------------------------------------------------------------------
/examples/mnist/train_mnist_autoencoder_adadelta.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -e
3 |
4 | ./build/tools/caffe train \
5 | --solver=examples/mnist/mnist_autoencoder_solver_adadelta.prototxt $@
6 |
--------------------------------------------------------------------------------
/examples/mnist/train_mnist_autoencoder_adagrad.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -e
3 |
4 | ./build/tools/caffe train \
5 | --solver=examples/mnist/mnist_autoencoder_solver_adagrad.prototxt $@
6 |
--------------------------------------------------------------------------------
/examples/mnist/train_mnist_autoencoder_nesterov.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -e
3 |
4 | ./build/tools/caffe train \
5 | --solver=examples/mnist/mnist_autoencoder_solver_nesterov.prototxt $@
6 |
--------------------------------------------------------------------------------
/examples/net_surgery/conv.prototxt:
--------------------------------------------------------------------------------
1 | # Simple single-layer network to showcase editing model parameters.
2 | name: "convolution"
3 | layer {
4 | name: "data"
5 | type: "Input"
6 | top: "data"
7 | input_param { shape: { dim: 1 dim: 1 dim: 100 dim: 100 } }
8 | }
9 | layer {
10 | name: "conv"
11 | type: "Convolution"
12 | bottom: "data"
13 | top: "conv"
14 | convolution_param {
15 | num_output: 3
16 | kernel_size: 5
17 | stride: 1
18 | weight_filler {
19 | type: "gaussian"
20 | std: 0.01
21 | }
22 | bias_filler {
23 | type: "constant"
24 | value: 0
25 | }
26 | }
27 | }
28 |
--------------------------------------------------------------------------------
/examples/pycaffe/layers/pyloss.py:
--------------------------------------------------------------------------------
1 | import caffe
2 | import numpy as np
3 |
4 |
5 | class EuclideanLossLayer(caffe.Layer):
6 | """
7 | Compute the Euclidean Loss in the same manner as the C++ EuclideanLossLayer
8 | to demonstrate the class interface for developing layers in Python.
9 | """
10 |
11 | def setup(self, bottom, top):
12 | # check input pair
13 | if len(bottom) != 2:
14 | raise Exception("Need two inputs to compute distance.")
15 |
16 | def reshape(self, bottom, top):
17 | # check input dimensions match
18 | if bottom[0].count != bottom[1].count:
19 | raise Exception("Inputs must have the same dimension.")
20 | # difference is shape of inputs
21 | self.diff = np.zeros_like(bottom[0].data, dtype=np.float32)
22 | # loss output is scalar
23 | top[0].reshape(1)
24 |
25 | def forward(self, bottom, top):
26 | self.diff[...] = bottom[0].data - bottom[1].data
27 | top[0].data[...] = np.sum(self.diff**2) / bottom[0].num / 2.
28 |
29 | def backward(self, top, propagate_down, bottom):
30 | for i in range(2):
31 | if not propagate_down[i]:
32 | continue
33 | if i == 0:
34 | sign = 1
35 | else:
36 | sign = -1
37 | bottom[i].diff[...] = sign * self.diff / bottom[i].num
38 |
--------------------------------------------------------------------------------
/examples/pycaffe/linreg.prototxt:
--------------------------------------------------------------------------------
1 | name: 'LinearRegressionExample'
2 | # define a simple network for linear regression on dummy data
3 | # that computes the loss by a PythonLayer.
4 | layer {
5 | type: 'DummyData'
6 | name: 'x'
7 | top: 'x'
8 | dummy_data_param {
9 | shape: { dim: 10 dim: 3 dim: 2 }
10 | data_filler: { type: 'gaussian' }
11 | }
12 | }
13 | layer {
14 | type: 'DummyData'
15 | name: 'y'
16 | top: 'y'
17 | dummy_data_param {
18 | shape: { dim: 10 dim: 3 dim: 2 }
19 | data_filler: { type: 'gaussian' }
20 | }
21 | }
22 | # include InnerProduct layers for parameters
23 | # so the net will need backward
24 | layer {
25 | type: 'InnerProduct'
26 | name: 'ipx'
27 | top: 'ipx'
28 | bottom: 'x'
29 | inner_product_param {
30 | num_output: 10
31 | weight_filler { type: 'xavier' }
32 | }
33 | }
34 | layer {
35 | type: 'InnerProduct'
36 | name: 'ipy'
37 | top: 'ipy'
38 | bottom: 'y'
39 | inner_product_param {
40 | num_output: 10
41 | weight_filler { type: 'xavier' }
42 | }
43 | }
44 | layer {
45 | type: 'Python'
46 | name: 'loss'
47 | top: 'loss'
48 | bottom: 'ipx'
49 | bottom: 'ipy'
50 | python_param {
51 | # the module name -- usually the filename -- that needs to be in $PYTHONPATH
52 | module: 'pyloss'
53 | # the layer name -- the class name in the module
54 | layer: 'EuclideanLossLayer'
55 | }
56 | # set loss weight so Caffe knows this is a loss layer.
57 | # since PythonLayer inherits directly from Layer, this isn't automatically
58 | # known to Caffe
59 | loss_weight: 1
60 | }
61 |
--------------------------------------------------------------------------------
/examples/siamese/create_mnist_siamese.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | # This script converts the mnist data into leveldb format.
3 | set -e
4 |
5 | EXAMPLES=./build/examples/siamese
6 | DATA=./data/mnist
7 |
8 | echo "Creating leveldb..."
9 |
10 | rm -rf ./examples/siamese/mnist_siamese_train_leveldb
11 | rm -rf ./examples/siamese/mnist_siamese_test_leveldb
12 |
13 | $EXAMPLES/convert_mnist_siamese_data.bin \
14 | $DATA/train-images-idx3-ubyte \
15 | $DATA/train-labels-idx1-ubyte \
16 | ./examples/siamese/mnist_siamese_train_leveldb
17 | $EXAMPLES/convert_mnist_siamese_data.bin \
18 | $DATA/t10k-images-idx3-ubyte \
19 | $DATA/t10k-labels-idx1-ubyte \
20 | ./examples/siamese/mnist_siamese_test_leveldb
21 |
22 | echo "Done."
23 |
--------------------------------------------------------------------------------
/examples/siamese/mnist_siamese_solver.prototxt:
--------------------------------------------------------------------------------
1 | # The train/test net protocol buffer definition
2 | net: "examples/siamese/mnist_siamese_train_test.prototxt"
3 | # test_iter specifies how many forward passes the test should carry out.
4 | # In the case of MNIST, we have test batch size 100 and 100 test iterations,
5 | # covering the full 10,000 testing images.
6 | test_iter: 100
7 | # Carry out testing every 500 training iterations.
8 | test_interval: 500
9 | # The base learning rate, momentum and the weight decay of the network.
10 | base_lr: 0.01
11 | momentum: 0.9
12 | weight_decay: 0.0000
13 | # The learning rate policy
14 | lr_policy: "inv"
15 | gamma: 0.0001
16 | power: 0.75
17 | # Display every 100 iterations
18 | display: 100
19 | # The maximum number of iterations
20 | max_iter: 50000
21 | # snapshot intermediate results
22 | snapshot: 5000
23 | snapshot_prefix: "examples/siamese/mnist_siamese"
24 | # solver mode: CPU or GPU
25 | solver_mode: GPU
26 |
--------------------------------------------------------------------------------
/examples/siamese/train_mnist_siamese.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 | set -e
3 |
4 | TOOLS=./build/tools
5 |
6 | $TOOLS/caffe train --solver=examples/siamese/mnist_siamese_solver.prototxt $@
7 |
--------------------------------------------------------------------------------
/examples/unreal_example/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | cmake_minimum_required(VERSION 3.8)
2 | project(unreal)
3 | set(CMAKE_CXX_STANDARD 11)
4 |
5 |
6 | file(GLOB_RECURSE SOURCES src/*.cpp lib/*.cpp )
7 | file(GLOB_RECURSE HEADERS include/*.h lib/*.h)
8 |
9 | find_package(OpenCV 3.0)
10 | if (NOT OpenCV_FOUND)
11 | message(FATAL_ERROR "OpenCV > 3.0 not found.")
12 | endif ()
13 |
14 |
15 | # ------------------ find Caffe and include directories ------------------------
16 | set(Caffe_INCLUDE_DIRS "../../build/install/include")
17 | set(Caffe_LIBRARIES "../../build/install/lib/libcaffe.so")
18 | find_package(Caffe REQUIRED)
19 | include_directories(${Caffe_INCLUDE_DIRS})
20 | if (Caffe_FOUND)
21 | message(STATUS "[caffe] we just found caffe.")
22 | message(STATUS ${Caffe_INCLUDE_DIRS})
23 | endif ()
24 | # ------------------ we must mannully specific directories of caffe -----------------
25 |
26 |
27 | # ----------------- find CUDA to compatible caffe build with CUDA ------------
28 | find_package(CUDA REQUIRED)
29 | if (CUDA_FOUND)
30 | message(STATUS "[cuda] we found CUDA.")
31 | message(STATUS ${CUDA_INCLUDE_DIRS})
32 | endif ()
33 | include_directories(${CUDA_INCLUDE_DIRS})
34 |
35 |
36 | set(EXECUTABLE_OUTPUT_PATH ${PROJECT_BINARY_DIR}/bin)
37 | set(LIBRARY_OUTPUT_PATH ${PROJECT_BINARY_DIR}/lib)
38 |
39 | set(BUILD_SHARED_LIBS OFF)
40 |
41 | set(SOURCE_FILES src/main.cpp)
42 |
43 | add_executable(show_layers ${SOURCE_FILES} ${SOURCES} ${HEADERS})
44 | target_link_libraries(show_layers ${OpenCV_LIBS} ${Caffe_LIBRARIES} ${CUDA_LIBS})
45 |
--------------------------------------------------------------------------------
/examples/unreal_example/readme.md:
--------------------------------------------------------------------------------
1 | # unreal example
2 | This dir contains some unread examples. You can using **Clion** open this project, it will load caffe defination automatically.
3 |
--------------------------------------------------------------------------------
/examples/unreal_example/src/main.cpp:
--------------------------------------------------------------------------------
1 | #include
2 |
3 | using namespace std;
4 |
5 | int main() {
6 |
7 | cout << "hello, unreal.\n";
8 | return 0;
9 |
10 | }
11 |
--------------------------------------------------------------------------------
/examples/unreal_example/src/main.cpp~:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/UnrealVision/unreal_caffe/45243b6a2100739cd9110ffbeded55c5723894b3/examples/unreal_example/src/main.cpp~
--------------------------------------------------------------------------------
/examples/web_demo/exifutil.py:
--------------------------------------------------------------------------------
1 | """
2 | This script handles the skimage exif problem.
3 | """
4 |
5 | from PIL import Image
6 | import numpy as np
7 |
8 | ORIENTATIONS = { # used in apply_orientation
9 | 2: (Image.FLIP_LEFT_RIGHT,),
10 | 3: (Image.ROTATE_180,),
11 | 4: (Image.FLIP_TOP_BOTTOM,),
12 | 5: (Image.FLIP_LEFT_RIGHT, Image.ROTATE_90),
13 | 6: (Image.ROTATE_270,),
14 | 7: (Image.FLIP_LEFT_RIGHT, Image.ROTATE_270),
15 | 8: (Image.ROTATE_90,)
16 | }
17 |
18 |
19 | def open_oriented_im(im_path):
20 | im = Image.open(im_path)
21 | if hasattr(im, '_getexif'):
22 | exif = im._getexif()
23 | if exif is not None and 274 in exif:
24 | orientation = exif[274]
25 | im = apply_orientation(im, orientation)
26 | img = np.asarray(im).astype(np.float32) / 255.
27 | if img.ndim == 2:
28 | img = img[:, :, np.newaxis]
29 | img = np.tile(img, (1, 1, 3))
30 | elif img.shape[2] == 4:
31 | img = img[:, :, :3]
32 | return img
33 |
34 |
35 | def apply_orientation(im, orientation):
36 | if orientation in ORIENTATIONS:
37 | for method in ORIENTATIONS[orientation]:
38 | im = im.transpose(method)
39 | return im
40 |
--------------------------------------------------------------------------------
/examples/web_demo/requirements.txt:
--------------------------------------------------------------------------------
1 | werkzeug
2 | flask
3 | tornado
4 | numpy
5 | pandas
6 | pillow
7 | pyyaml
8 |
--------------------------------------------------------------------------------
/generatepb.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | protoc -I="./src/caffe/proto" --cpp_out="./src/caffe/proto" --python_out="./tools" "./src/caffe/proto/caffe.proto"
4 |
--------------------------------------------------------------------------------
/include/caffe/caffe.hpp:
--------------------------------------------------------------------------------
1 | // caffe.hpp is the header file that you need to include in your code. It wraps
2 | // all the internal caffe header files into one for simpler inclusion.
3 |
4 | #ifndef CAFFE_CAFFE_HPP_
5 | #define CAFFE_CAFFE_HPP_
6 |
7 | #include "caffe/blob.hpp"
8 | #include "caffe/common.hpp"
9 | #include "caffe/filler.hpp"
10 | #include "caffe/layer.hpp"
11 | #include "caffe/layer_factory.hpp"
12 | #include "caffe/net.hpp"
13 | #include "caffe/parallel.hpp"
14 | #include "caffe/proto/caffe.pb.h"
15 | #include "caffe/solver.hpp"
16 | #include "caffe/solver_factory.hpp"
17 | #include "caffe/util/benchmark.hpp"
18 | #include "caffe/util/io.hpp"
19 | #include "caffe/util/upgrade_proto.hpp"
20 |
21 | #endif // CAFFE_CAFFE_HPP_
22 |
--------------------------------------------------------------------------------
/include/caffe/internal_thread.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_INTERNAL_THREAD_HPP_
2 | #define CAFFE_INTERNAL_THREAD_HPP_
3 |
4 | #include "caffe/common.hpp"
5 |
6 | /**
7 | Forward declare boost::thread instead of including boost/thread.hpp
8 | to avoid a boost/NVCC issues (#1009, #1010) on OSX.
9 | */
10 | namespace boost { class thread; }
11 |
12 | namespace caffe {
13 |
14 | /**
15 | * Virtual class encapsulate boost::thread for use in base class
16 | * The child class will acquire the ability to run a single thread,
17 | * by reimplementing the virtual function InternalThreadEntry.
18 | */
19 | class InternalThread {
20 | public:
21 | InternalThread() : thread_() {}
22 | virtual ~InternalThread();
23 |
24 | /**
25 | * Caffe's thread local state will be initialized using the current
26 | * thread values, e.g. device id, solver index etc. The random seed
27 | * is initialized using caffe_rng_rand.
28 | */
29 | void StartInternalThread();
30 |
31 | /** Will not return until the internal thread has exited. */
32 | void StopInternalThread();
33 |
34 | bool is_started() const;
35 |
36 | protected:
37 | /* Implement this method in your subclass
38 | with the code you want your thread to run. */
39 | virtual void InternalThreadEntry() {}
40 |
41 | /* Should be tested when running loops to exit when requested. */
42 | bool must_stop();
43 |
44 | private:
45 | void entry(int device, Caffe::Brew mode, int rand_seed,
46 | int solver_count, int solver_rank, bool multiprocess);
47 |
48 | shared_ptr thread_;
49 | };
50 |
51 | } // namespace caffe
52 |
53 | #endif // CAFFE_INTERNAL_THREAD_HPP_
54 |
--------------------------------------------------------------------------------
/include/caffe/layers/cudnn_lcn_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_CUDNN_LCN_LAYER_HPP_
2 | #define CAFFE_CUDNN_LCN_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | #include "caffe/layers/lrn_layer.hpp"
11 | #include "caffe/layers/power_layer.hpp"
12 |
13 | namespace caffe {
14 |
15 | #ifdef USE_CUDNN
16 | template
17 | class CuDNNLCNLayer : public LRNLayer {
18 | public:
19 | explicit CuDNNLCNLayer(const LayerParameter& param)
20 | : LRNLayer(param), handles_setup_(false), tempDataSize(0),
21 | tempData1(NULL), tempData2(NULL) {}
22 | virtual void LayerSetUp(const vector*>& bottom,
23 | const vector*>& top);
24 | virtual void Reshape(const vector*>& bottom,
25 | const vector*>& top);
26 | virtual ~CuDNNLCNLayer();
27 |
28 | protected:
29 | virtual void Forward_gpu(const vector*>& bottom,
30 | const vector*>& top);
31 | virtual void Backward_gpu(const vector*>& top,
32 | const vector& propagate_down, const vector*>& bottom);
33 |
34 | bool handles_setup_;
35 | cudnnHandle_t handle_;
36 | cudnnLRNDescriptor_t norm_desc_;
37 | cudnnTensorDescriptor_t bottom_desc_, top_desc_;
38 |
39 | int size_, pre_pad_;
40 | Dtype alpha_, beta_, k_;
41 |
42 | size_t tempDataSize;
43 | void *tempData1, *tempData2;
44 | };
45 | #endif
46 |
47 | } // namespace caffe
48 |
49 | #endif // CAFFE_CUDNN_LCN_LAYER_HPP_
50 |
--------------------------------------------------------------------------------
/include/caffe/layers/cudnn_lrn_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_CUDNN_LRN_LAYER_HPP_
2 | #define CAFFE_CUDNN_LRN_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | #include "caffe/layers/lrn_layer.hpp"
11 |
12 | namespace caffe {
13 |
14 | #ifdef USE_CUDNN
15 | template
16 | class CuDNNLRNLayer : public LRNLayer {
17 | public:
18 | explicit CuDNNLRNLayer(const LayerParameter& param)
19 | : LRNLayer(param), handles_setup_(false) {}
20 | virtual void LayerSetUp(const vector*>& bottom,
21 | const vector*>& top);
22 | virtual void Reshape(const vector*>& bottom,
23 | const vector*>& top);
24 | virtual ~CuDNNLRNLayer();
25 |
26 | protected:
27 | virtual void Forward_gpu(const vector*>& bottom,
28 | const vector*>& top);
29 | virtual void Backward_gpu(const vector*>& top,
30 | const vector& propagate_down, const vector*>& bottom);
31 |
32 | bool handles_setup_;
33 | cudnnHandle_t handle_;
34 | cudnnLRNDescriptor_t norm_desc_;
35 | cudnnTensorDescriptor_t bottom_desc_, top_desc_;
36 |
37 | int size_;
38 | Dtype alpha_, beta_, k_;
39 | };
40 | #endif
41 |
42 | } // namespace caffe
43 |
44 | #endif // CAFFE_CUDNN_LRN_LAYER_HPP_
45 |
--------------------------------------------------------------------------------
/include/caffe/layers/cudnn_pooling_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_CUDNN_POOLING_LAYER_HPP_
2 | #define CAFFE_CUDNN_POOLING_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | #include "caffe/layers/pooling_layer.hpp"
11 |
12 | namespace caffe {
13 |
14 | #ifdef USE_CUDNN
15 | /*
16 | * @brief cuDNN implementation of PoolingLayer.
17 | * Fallback to PoolingLayer for CPU mode.
18 | */
19 | template
20 | class CuDNNPoolingLayer : public PoolingLayer {
21 | public:
22 | explicit CuDNNPoolingLayer(const LayerParameter& param)
23 | : PoolingLayer(param), handles_setup_(false) {}
24 | virtual void LayerSetUp(const vector*>& bottom,
25 | const vector*>& top);
26 | virtual void Reshape(const vector*>& bottom,
27 | const vector*>& top);
28 | virtual ~CuDNNPoolingLayer();
29 | // Currently, cuDNN does not support the extra top blob.
30 | virtual inline int MinTopBlobs() const { return -1; }
31 | virtual inline int ExactNumTopBlobs() const { return 1; }
32 |
33 | protected:
34 | virtual void Forward_gpu(const vector*>& bottom,
35 | const vector*>& top);
36 | virtual void Backward_gpu(const vector*>& top,
37 | const vector& propagate_down, const vector*>& bottom);
38 |
39 | bool handles_setup_;
40 | cudnnHandle_t handle_;
41 | cudnnTensorDescriptor_t bottom_desc_, top_desc_;
42 | cudnnPoolingDescriptor_t pooling_desc_;
43 | cudnnPoolingMode_t mode_;
44 | };
45 | #endif
46 |
47 | } // namespace caffe
48 |
49 | #endif // CAFFE_CUDNN_POOLING_LAYER_HPP_
50 |
--------------------------------------------------------------------------------
/include/caffe/layers/cudnn_relu_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_CUDNN_RELU_LAYER_HPP_
2 | #define CAFFE_CUDNN_RELU_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | #include "caffe/layers/neuron_layer.hpp"
11 | #include "caffe/layers/relu_layer.hpp"
12 |
13 | namespace caffe {
14 |
15 | #ifdef USE_CUDNN
16 | /**
17 | * @brief CuDNN acceleration of ReLULayer.
18 | */
19 | template
20 | class CuDNNReLULayer : public ReLULayer {
21 | public:
22 | explicit CuDNNReLULayer(const LayerParameter& param)
23 | : ReLULayer(param), handles_setup_(false) {}
24 | virtual void LayerSetUp(const vector*>& bottom,
25 | const vector*>& top);
26 | virtual void Reshape(const vector*>& bottom,
27 | const vector*>& top);
28 | virtual ~CuDNNReLULayer();
29 |
30 | protected:
31 | virtual void Forward_gpu(const vector*>& bottom,
32 | const vector*>& top);
33 | virtual void Backward_gpu(const vector*>& top,
34 | const vector& propagate_down, const vector*>& bottom);
35 |
36 | bool handles_setup_;
37 | cudnnHandle_t handle_;
38 | cudnnTensorDescriptor_t bottom_desc_;
39 | cudnnTensorDescriptor_t top_desc_;
40 | cudnnActivationDescriptor_t activ_desc_;
41 | };
42 | #endif
43 |
44 | } // namespace caffe
45 |
46 | #endif // CAFFE_CUDNN_RELU_LAYER_HPP_
47 |
--------------------------------------------------------------------------------
/include/caffe/layers/cudnn_sigmoid_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_CUDNN_SIGMOID_LAYER_HPP_
2 | #define CAFFE_CUDNN_SIGMOID_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | #include "caffe/layers/neuron_layer.hpp"
11 | #include "caffe/layers/sigmoid_layer.hpp"
12 |
13 | namespace caffe {
14 |
15 | #ifdef USE_CUDNN
16 | /**
17 | * @brief CuDNN acceleration of SigmoidLayer.
18 | */
19 | template
20 | class CuDNNSigmoidLayer : public SigmoidLayer {
21 | public:
22 | explicit CuDNNSigmoidLayer(const LayerParameter& param)
23 | : SigmoidLayer(param), handles_setup_(false) {}
24 | virtual void LayerSetUp(const vector*>& bottom,
25 | const vector*>& top);
26 | virtual void Reshape(const vector*>& bottom,
27 | const vector*>& top);
28 | virtual ~CuDNNSigmoidLayer();
29 |
30 | protected:
31 | virtual void Forward_gpu(const vector*>& bottom,
32 | const vector*>& top);
33 | virtual void Backward_gpu(const vector*>& top,
34 | const vector& propagate_down, const vector*>& bottom);
35 |
36 | bool handles_setup_;
37 | cudnnHandle_t handle_;
38 | cudnnTensorDescriptor_t bottom_desc_;
39 | cudnnTensorDescriptor_t top_desc_;
40 | cudnnActivationDescriptor_t activ_desc_;
41 | };
42 | #endif
43 |
44 | } // namespace caffe
45 |
46 | #endif // CAFFE_CUDNN_SIGMOID_LAYER_HPP_
47 |
--------------------------------------------------------------------------------
/include/caffe/layers/cudnn_softmax_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_CUDNN_SOFTMAX_LAYER_HPP_
2 | #define CAFFE_CUDNN_SOFTMAX_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | #include "caffe/layers/softmax_layer.hpp"
11 |
12 | namespace caffe {
13 |
14 | #ifdef USE_CUDNN
15 | /**
16 | * @brief cuDNN implementation of SoftmaxLayer.
17 | * Fallback to SoftmaxLayer for CPU mode.
18 | */
19 | template
20 | class CuDNNSoftmaxLayer : public SoftmaxLayer {
21 | public:
22 | explicit CuDNNSoftmaxLayer(const LayerParameter& param)
23 | : SoftmaxLayer(param), handles_setup_(false) {}
24 | virtual void LayerSetUp(const vector*>& bottom,
25 | const vector*>& top);
26 | virtual void Reshape(const vector*>& bottom,
27 | const vector*>& top);
28 | virtual ~CuDNNSoftmaxLayer();
29 |
30 | protected:
31 | virtual void Forward_gpu(const vector*>& bottom,
32 | const vector*>& top);
33 | virtual void Backward_gpu(const vector*>& top,
34 | const vector& propagate_down, const vector*>& bottom);
35 |
36 | bool handles_setup_;
37 | cudnnHandle_t handle_;
38 | cudnnTensorDescriptor_t bottom_desc_;
39 | cudnnTensorDescriptor_t top_desc_;
40 | };
41 | #endif
42 |
43 | } // namespace caffe
44 |
45 | #endif // CAFFE_CUDNN_SOFTMAX_LAYER_HPP_
46 |
--------------------------------------------------------------------------------
/include/caffe/layers/cudnn_tanh_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_CUDNN_TANH_LAYER_HPP_
2 | #define CAFFE_CUDNN_TANH_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | #include "caffe/layers/neuron_layer.hpp"
11 | #include "caffe/layers/tanh_layer.hpp"
12 |
13 | namespace caffe {
14 |
15 | #ifdef USE_CUDNN
16 | /**
17 | * @brief CuDNN acceleration of TanHLayer.
18 | */
19 | template
20 | class CuDNNTanHLayer : public TanHLayer {
21 | public:
22 | explicit CuDNNTanHLayer(const LayerParameter& param)
23 | : TanHLayer(param), handles_setup_(false) {}
24 | virtual void LayerSetUp(const vector*>& bottom,
25 | const vector*>& top);
26 | virtual void Reshape(const vector*>& bottom,
27 | const vector*>& top);
28 | virtual ~CuDNNTanHLayer();
29 |
30 | protected:
31 | virtual void Forward_gpu(const vector*>& bottom,
32 | const vector*>& top);
33 | virtual void Backward_gpu(const vector*>& top,
34 | const vector& propagate_down, const vector*>& bottom);
35 |
36 | bool handles_setup_;
37 | cudnnHandle_t handle_;
38 | cudnnTensorDescriptor_t bottom_desc_;
39 | cudnnTensorDescriptor_t top_desc_;
40 | cudnnActivationDescriptor_t activ_desc_;
41 | };
42 | #endif
43 |
44 | } // namespace caffe
45 |
46 | #endif // CAFFE_CUDNN_TANH_LAYER_HPP_
47 |
--------------------------------------------------------------------------------
/include/caffe/layers/data_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_DATA_LAYER_HPP_
2 | #define CAFFE_DATA_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/data_transformer.hpp"
8 | #include "caffe/internal_thread.hpp"
9 | #include "caffe/layer.hpp"
10 | #include "caffe/layers/base_data_layer.hpp"
11 | #include "caffe/proto/caffe.pb.h"
12 | #include "caffe/util/db.hpp"
13 |
14 | namespace caffe {
15 |
16 | template
17 | class DataLayer : public BasePrefetchingDataLayer {
18 | public:
19 | explicit DataLayer(const LayerParameter& param);
20 | virtual ~DataLayer();
21 | virtual void DataLayerSetUp(const vector*>& bottom,
22 | const vector*>& top);
23 | // DataLayer uses DataReader instead for sharing for parallelism
24 | virtual inline bool ShareInParallel() const { return false; }
25 | virtual inline const char* type() const { return "Data"; }
26 | virtual inline int ExactNumBottomBlobs() const { return 0; }
27 | virtual inline int MinTopBlobs() const { return 1; }
28 | virtual inline int MaxTopBlobs() const { return 2; }
29 |
30 | protected:
31 | void Next();
32 | bool Skip();
33 | virtual void load_batch(Batch* batch);
34 |
35 | shared_ptr db_;
36 | shared_ptr cursor_;
37 | uint64_t offset_;
38 | };
39 |
40 | } // namespace caffe
41 |
42 | #endif // CAFFE_DATA_LAYER_HPP_
43 |
--------------------------------------------------------------------------------
/include/caffe/layers/dense_image_data_layer.hpp.bk:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_DENSE_IMAGE_DATA_LAYER_HPP_
2 | #define CAFFE_DENSE_IMAGE_DATA_LAYER_HPP_
3 |
4 | #include
5 | #include
6 | #include
7 |
8 | #include "boost/scoped_ptr.hpp"
9 | #include "hdf5.h"
10 |
11 | #include "caffe/blob.hpp"
12 | #include "caffe/layer.hpp"
13 | #include "caffe/proto/caffe.pb.h"
14 | #include "caffe/common.hpp"
15 | #include "caffe/filler.hpp"
16 | #include "caffe/syncedmem.hpp"
17 | #include "caffe/internal_thread.hpp"
18 | #include "caffe/util/math_functions.hpp"
19 | #include "caffe/util/benchmark.hpp"
20 | #include "caffe/util/io.hpp"
21 | #include "caffe/util/rng.hpp"
22 | #include "caffe/data_transformer.hpp"
23 |
24 |
25 | namespace caffe {
26 |
27 |
28 | template
29 | class DenseImageDataLayer : public BasePrefetchingDataLayer {
30 | public:
31 | explicit DenseImageDataLayer(const LayerParameter& param)
32 | : BasePrefetchingDataLayer(param) {}
33 | virtual ~DenseImageDataLayer();
34 | virtual void DataLayerSetUp(const vector*>& bottom,
35 | const vector*>& top);
36 |
37 | virtual inline const char* type() const { return "DenseImageData"; }
38 | virtual inline int ExactNumBottomBlobs() const { return 0; }
39 | virtual inline int ExactNumTopBlobs() const { return 2; }
40 |
41 | protected:
42 | shared_ptr prefetch_rng_;
43 | virtual void ShuffleImages();
44 | virtual void InternalThreadEntry();
45 |
46 | vector > lines_;
47 | int lines_id_;
48 | Blob transformed_label_;
49 |
50 |
51 | };
52 |
53 |
54 | } // namespace caffe
55 |
56 | #endif
57 |
--------------------------------------------------------------------------------
/include/caffe/layers/dummy_data_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_DUMMY_DATA_LAYER_HPP_
2 | #define CAFFE_DUMMY_DATA_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/filler.hpp"
8 | #include "caffe/layer.hpp"
9 | #include "caffe/proto/caffe.pb.h"
10 |
11 | namespace caffe {
12 |
13 | /**
14 | * @brief Provides data to the Net generated by a Filler.
15 | *
16 | * TODO(dox): thorough documentation for Forward and proto params.
17 | */
18 | template
19 | class DummyDataLayer : public Layer {
20 | public:
21 | explicit DummyDataLayer(const LayerParameter& param)
22 | : Layer(param) {}
23 | virtual void LayerSetUp(const vector*>& bottom,
24 | const vector*>& top);
25 | // Data layers should be shared by multiple solvers in parallel
26 | virtual inline bool ShareInParallel() const { return true; }
27 | // Data layers have no bottoms, so reshaping is trivial.
28 | virtual void Reshape(const vector*>& bottom,
29 | const vector*>& top) {}
30 |
31 | virtual inline const char* type() const { return "DummyData"; }
32 | virtual inline int ExactNumBottomBlobs() const { return 0; }
33 | virtual inline int MinTopBlobs() const { return 1; }
34 |
35 | protected:
36 | virtual void Forward_cpu(const vector*>& bottom,
37 | const vector*>& top);
38 | virtual void Backward_cpu(const vector*>& top,
39 | const vector& propagate_down, const vector*>& bottom) {}
40 | virtual void Backward_gpu(const vector*>& top,
41 | const vector& propagate_down, const vector*>& bottom) {}
42 |
43 | vector > > fillers_;
44 | vector refill_;
45 | };
46 |
47 | } // namespace caffe
48 |
49 | #endif // CAFFE_DUMMY_DATA_LAYER_HPP_
50 |
--------------------------------------------------------------------------------
/include/caffe/layers/eltwise_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_ELTWISE_LAYER_HPP_
2 | #define CAFFE_ELTWISE_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | namespace caffe {
11 |
12 | /**
13 | * @brief Compute elementwise operations, such as product and sum,
14 | * along multiple input Blobs.
15 | *
16 | * TODO(dox): thorough documentation for Forward, Backward, and proto params.
17 | */
18 | template
19 | class EltwiseLayer : public Layer {
20 | public:
21 | explicit EltwiseLayer(const LayerParameter& param)
22 | : Layer(param) {}
23 | virtual void LayerSetUp(const vector*>& bottom,
24 | const vector*>& top);
25 | virtual void Reshape(const vector*>& bottom,
26 | const vector*>& top);
27 |
28 | virtual inline const char* type() const { return "Eltwise"; }
29 | virtual inline int MinBottomBlobs() const { return 2; }
30 | virtual inline int ExactNumTopBlobs() const { return 1; }
31 |
32 | protected:
33 | virtual void Forward_cpu(const vector*>& bottom,
34 | const vector*>& top);
35 | virtual void Forward_gpu(const vector*>& bottom,
36 | const vector*>& top);
37 | virtual void Backward_cpu(const vector*>& top,
38 | const vector& propagate_down, const vector*>& bottom);
39 | virtual void Backward_gpu(const vector*>& top,
40 | const vector& propagate_down, const vector*>& bottom);
41 |
42 | EltwiseParameter_EltwiseOp op_;
43 | vector coeffs_;
44 | Blob max_idx_;
45 |
46 | bool stable_prod_grad_;
47 | };
48 |
49 | } // namespace caffe
50 |
51 | #endif // CAFFE_ELTWISE_LAYER_HPP_
52 |
--------------------------------------------------------------------------------
/include/caffe/layers/image_data_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_IMAGE_DATA_LAYER_HPP_
2 | #define CAFFE_IMAGE_DATA_LAYER_HPP_
3 |
4 | #include
5 | #include
6 | #include
7 |
8 | #include "caffe/blob.hpp"
9 | #include "caffe/data_transformer.hpp"
10 | #include "caffe/internal_thread.hpp"
11 | #include "caffe/layer.hpp"
12 | #include "caffe/layers/base_data_layer.hpp"
13 | #include "caffe/proto/caffe.pb.h"
14 |
15 | namespace caffe {
16 |
17 | /**
18 | * @brief Provides data to the Net from image files.
19 | *
20 | * TODO(dox): thorough documentation for Forward and proto params.
21 | */
22 | template
23 | class ImageDataLayer : public BasePrefetchingDataLayer {
24 | public:
25 | explicit ImageDataLayer(const LayerParameter& param)
26 | : BasePrefetchingDataLayer(param) {}
27 | virtual ~ImageDataLayer();
28 | virtual void DataLayerSetUp(const vector*>& bottom,
29 | const vector*>& top);
30 |
31 | virtual inline const char* type() const { return "ImageData"; }
32 | virtual inline int ExactNumBottomBlobs() const { return 0; }
33 | virtual inline int ExactNumTopBlobs() const { return 2; }
34 |
35 | protected:
36 | shared_ptr prefetch_rng_;
37 | virtual void ShuffleImages();
38 | virtual void load_batch(Batch* batch);
39 |
40 | vector > lines_;
41 | int lines_id_;
42 | };
43 |
44 |
45 | } // namespace caffe
46 |
47 | #endif // CAFFE_IMAGE_DATA_LAYER_HPP_
48 |
--------------------------------------------------------------------------------
/include/caffe/layers/input_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_INPUT_LAYER_HPP_
2 | #define CAFFE_INPUT_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | namespace caffe {
11 |
12 | /**
13 | * @brief Provides data to the Net by assigning tops directly.
14 | *
15 | * This data layer is a container that merely holds the data assigned to it;
16 | * forward, backward, and reshape are all no-ops.
17 | */
18 | template
19 | class InputLayer : public Layer {
20 | public:
21 | explicit InputLayer(const LayerParameter& param)
22 | : Layer(param) {}
23 | virtual void LayerSetUp(const vector*>& bottom,
24 | const vector*>& top);
25 | // Data layers should be shared by multiple solvers in parallel
26 | virtual inline bool ShareInParallel() const { return true; }
27 | // Data layers have no bottoms, so reshaping is trivial.
28 | virtual void Reshape(const vector*>& bottom,
29 | const vector*>& top) {}
30 |
31 | virtual inline const char* type() const { return "Input"; }
32 | virtual inline int ExactNumBottomBlobs() const { return 0; }
33 | virtual inline int MinTopBlobs() const { return 1; }
34 |
35 | protected:
36 | virtual void Forward_cpu(const vector*>& bottom,
37 | const vector*>& top) {}
38 | virtual void Backward_cpu(const vector*>& top,
39 | const vector& propagate_down, const vector*>& bottom) {}
40 | };
41 |
42 | } // namespace caffe
43 |
44 | #endif // CAFFE_INPUT_LAYER_HPP_
45 |
--------------------------------------------------------------------------------
/include/caffe/layers/mvn_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_MVN_LAYER_HPP_
2 | #define CAFFE_MVN_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | namespace caffe {
11 |
12 | /**
13 | * @brief Normalizes the input to have 0-mean and/or unit (1) variance.
14 | *
15 | * TODO(dox): thorough documentation for Forward, Backward, and proto params.
16 | */
17 | template
18 | class MVNLayer : public Layer {
19 | public:
20 | explicit MVNLayer(const LayerParameter& param)
21 | : Layer(param) {}
22 | virtual void Reshape(const vector*>& bottom,
23 | const vector*>& top);
24 |
25 | virtual inline const char* type() const { return "MVN"; }
26 | virtual inline int ExactNumBottomBlobs() const { return 1; }
27 | virtual inline int ExactNumTopBlobs() const { return 1; }
28 |
29 | protected:
30 | virtual void Forward_cpu(const vector*>& bottom,
31 | const vector*>& top);
32 | virtual void Forward_gpu(const vector*>& bottom,
33 | const vector*>& top);
34 | virtual void Backward_cpu(const vector*>& top,
35 | const vector& propagate_down, const vector*>& bottom);
36 | virtual void Backward_gpu(const vector*>& top,
37 | const vector& propagate_down, const vector*>& bottom);
38 |
39 | Blob mean_, variance_, temp_;
40 |
41 | /// sum_multiplier is used to carry out sum using BLAS
42 | Blob sum_multiplier_;
43 | Dtype eps_;
44 | };
45 |
46 | } // namespace caffe
47 |
48 | #endif // CAFFE_MVN_LAYER_HPP_
49 |
--------------------------------------------------------------------------------
/include/caffe/layers/neuron_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_NEURON_LAYER_HPP_
2 | #define CAFFE_NEURON_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | namespace caffe {
11 |
12 | /**
13 | * @brief An interface for layers that take one blob as input (@f$ x @f$)
14 | * and produce one equally-sized blob as output (@f$ y @f$), where
15 | * each element of the output depends only on the corresponding input
16 | * element.
17 | */
18 | template
19 | class NeuronLayer : public Layer {
20 | public:
21 | explicit NeuronLayer(const LayerParameter& param)
22 | : Layer(param) {}
23 | virtual void Reshape(const vector*>& bottom,
24 | const vector*>& top);
25 |
26 | virtual inline int ExactNumBottomBlobs() const { return 1; }
27 | virtual inline int ExactNumTopBlobs() const { return 1; }
28 | };
29 |
30 | } // namespace caffe
31 |
32 | #endif // CAFFE_NEURON_LAYER_HPP_
33 |
--------------------------------------------------------------------------------
/include/caffe/layers/parameter_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_PARAMETER_LAYER_HPP_
2 | #define CAFFE_PARAMETER_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/layer.hpp"
7 |
8 | namespace caffe {
9 |
10 | template
11 | class ParameterLayer : public Layer {
12 | public:
13 | explicit ParameterLayer(const LayerParameter& param)
14 | : Layer(param) {}
15 | virtual void LayerSetUp(const vector*>& bottom,
16 | const vector*>& top) {
17 | if (this->blobs_.size() > 0) {
18 | LOG(INFO) << "Skipping parameter initialization";
19 | } else {
20 | this->blobs_.resize(1);
21 | this->blobs_[0].reset(new Blob());
22 | this->blobs_[0]->Reshape(this->layer_param_.parameter_param().shape());
23 | }
24 | top[0]->Reshape(this->layer_param_.parameter_param().shape());
25 | }
26 | virtual void Reshape(const vector*>& bottom,
27 | const vector*>& top) { }
28 | virtual inline const char* type() const { return "Parameter"; }
29 | virtual inline int ExactNumBottomBlobs() const { return 0; }
30 | virtual inline int ExactNumTopBlobs() const { return 1; }
31 |
32 | protected:
33 | virtual void Forward_cpu(const vector*>& bottom,
34 | const vector*>& top) {
35 | top[0]->ShareData(*(this->blobs_[0]));
36 | top[0]->ShareDiff(*(this->blobs_[0]));
37 | }
38 | virtual void Backward_cpu(const vector*>& top,
39 | const vector& propagate_down, const vector*>& bottom)
40 | { }
41 | };
42 |
43 | } // namespace caffe
44 |
45 | #endif
46 |
--------------------------------------------------------------------------------
/include/caffe/layers/proposal_layer.bk:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_PROPOSAL_LAYERS_HPP_
2 | #define CAFFE_PROPOSAL_LAYERS_HPP_
3 |
4 | #include
5 |
6 | #include "../layer.hpp"
7 |
8 | namespace caffe {
9 |
10 | class ProposalLayer : public Layer {
11 | public:
12 | explicit ProposalLayer(const LayerParameter& param)
13 | : Layer(param) {}
14 | virtual void LayerSetUp(const vector& bottom,
15 | const vector& top);
16 | virtual void Reshape(const vector& bottom,
17 | const vector& top) {
18 | //LOG(FATAL) << "Reshaping happens during the call to forward.";
19 | }
20 | virtual void ClearInternalBuffer() {
21 | proposals_.Release();
22 | nms_mask_.Release();
23 | }
24 |
25 | virtual const char* type() const { return "ProposalLayer"; }
26 |
27 | protected:
28 | virtual void Forward_cpu(const vector& bottom,
29 | const vector& top);
30 | virtual void Forward_gpu(const vector& bottom,
31 | const vector& top);
32 |
33 | int base_size_;
34 | int feat_stride_;
35 | int pre_nms_topn_;
36 | int post_nms_topn_;
37 | real_t nms_thresh_;
38 | int min_size_;
39 | Blob anchors_;
40 | Blob proposals_;
41 | BlobInt roi_indices_;
42 | BlobInt nms_mask_;
43 | };
44 |
45 | } // namespace caffe
46 |
47 | #endif // CAFFE_PROPOSAL_LAYERS_HPP_
48 |
--------------------------------------------------------------------------------
/include/caffe/layers/rnn_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_RNN_LAYER_HPP_
2 | #define CAFFE_RNN_LAYER_HPP_
3 |
4 | #include
5 | #include
6 | #include
7 |
8 | #include "caffe/blob.hpp"
9 | #include "caffe/common.hpp"
10 | #include "caffe/layer.hpp"
11 | #include "caffe/layers/recurrent_layer.hpp"
12 | #include "caffe/net.hpp"
13 | #include "caffe/proto/caffe.pb.h"
14 |
15 | namespace caffe {
16 |
17 | template class RecurrentLayer;
18 |
19 | /**
20 | * @brief Processes time-varying inputs using a simple recurrent neural network
21 | * (RNN). Implemented as a network unrolling the RNN computation in time.
22 | *
23 | * Given time-varying inputs @f$ x_t @f$, computes hidden state @f$
24 | * h_t := \tanh[ W_{hh} h_{t_1} + W_{xh} x_t + b_h ]
25 | * @f$, and outputs @f$
26 | * o_t := \tanh[ W_{ho} h_t + b_o ]
27 | * @f$.
28 | */
29 | template
30 | class RNNLayer : public RecurrentLayer {
31 | public:
32 | explicit RNNLayer(const LayerParameter& param)
33 | : RecurrentLayer(param) {}
34 |
35 | virtual inline const char* type() const { return "RNN"; }
36 |
37 | protected:
38 | virtual void FillUnrolledNet(NetParameter* net_param) const;
39 | virtual void RecurrentInputBlobNames(vector* names) const;
40 | virtual void RecurrentOutputBlobNames(vector* names) const;
41 | virtual void RecurrentInputShapes(vector* shapes) const;
42 | virtual void OutputBlobNames(vector* names) const;
43 | };
44 |
45 | } // namespace caffe
46 |
47 | #endif // CAFFE_RNN_LAYER_HPP_
48 |
--------------------------------------------------------------------------------
/include/caffe/layers/silence_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_SILENCE_LAYER_HPP_
2 | #define CAFFE_SILENCE_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | namespace caffe {
11 |
12 | /**
13 | * @brief Ignores bottom blobs while producing no top blobs. (This is useful
14 | * to suppress outputs during testing.)
15 | */
16 | template
17 | class SilenceLayer : public Layer {
18 | public:
19 | explicit SilenceLayer(const LayerParameter& param)
20 | : Layer(param) {}
21 | virtual void Reshape(const vector*>& bottom,
22 | const vector*>& top) {}
23 |
24 | virtual inline const char* type() const { return "Silence"; }
25 | virtual inline int MinBottomBlobs() const { return 1; }
26 | virtual inline int ExactNumTopBlobs() const { return 0; }
27 |
28 | protected:
29 | virtual void Forward_cpu(const vector*>& bottom,
30 | const vector*>& top) {}
31 | // We can't define Forward_gpu here, since STUB_GPU will provide
32 | // its own definition for CPU_ONLY mode.
33 | virtual void Forward_gpu(const vector*>& bottom,
34 | const vector*>& top);
35 | virtual void Backward_cpu(const vector*>& top,
36 | const vector& propagate_down, const vector*>& bottom);
37 | virtual void Backward_gpu(const vector*>& top,
38 | const vector& propagate_down, const vector*>& bottom);
39 | };
40 |
41 | } // namespace caffe
42 |
43 | #endif // CAFFE_SILENCE_LAYER_HPP_
44 |
--------------------------------------------------------------------------------
/include/caffe/layers/slice_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_SLICE_LAYER_HPP_
2 | #define CAFFE_SLICE_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | namespace caffe {
11 |
12 | /**
13 | * @brief Takes a Blob and slices it along either the num or channel dimension,
14 | * outputting multiple sliced Blob results.
15 | *
16 | * TODO(dox): thorough documentation for Forward, Backward, and proto params.
17 | */
18 | template
19 | class SliceLayer : public Layer {
20 | public:
21 | explicit SliceLayer(const LayerParameter& param)
22 | : Layer