├── models
├── __init__.py
├── model_store.py
├── resnet.py
├── resnet_dilation.py
└── fpn_global_local_fmreg_ensemble.py
├── utils
├── __init__.py
├── metrics.py
├── lr_scheduler.py
├── loss.py
└── lovasz_losses.py
├── dataset
├── __init__.py
└── deep_globe.py
├── docs
└── images
│ ├── glnet.png
│ ├── examples.jpg
│ ├── gl_branch.png
│ └── deep_globe_acc_mem_ext.jpg
├── requirements.txt
├── train_deep_globe_global.sh
├── train_deep_globe_global2local.sh
├── train_deep_globe_local2global.sh
├── eval_deep_globe.sh
├── LICENSE
├── .gitignore
├── test.txt
├── option.py
├── crossvali.txt
├── README.md
├── train.txt
├── train_deep_globe.py
└── helper.py
/models/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/dataset/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/docs/images/glnet.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/VITA-Group/GLNet/HEAD/docs/images/glnet.png
--------------------------------------------------------------------------------
/docs/images/examples.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/VITA-Group/GLNet/HEAD/docs/images/examples.jpg
--------------------------------------------------------------------------------
/docs/images/gl_branch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/VITA-Group/GLNet/HEAD/docs/images/gl_branch.png
--------------------------------------------------------------------------------
/docs/images/deep_globe_acc_mem_ext.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/VITA-Group/GLNet/HEAD/docs/images/deep_globe_acc_mem_ext.jpg
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy
2 | torch==0.4.1
3 | torchvision==0.3.0
4 | tqdm
5 | tensorboardX
6 | Pillow
7 | opencv-python==3.4.4
8 |
--------------------------------------------------------------------------------
/train_deep_globe_global.sh:
--------------------------------------------------------------------------------
1 | export CUDA_VISIBLE_DEVICES=0
2 | python train_deep_globe.py \
3 | --n_class 7 \
4 | --data_path "/ssd1/chenwy/deep_globe/data/" \
5 | --model_path "/home/chenwy/deep_globe/saved_models/" \
6 | --log_path "/home/chenwy/deep_globe/runs/" \
7 | --task_name "fpn_deepglobe_global" \
8 | --mode 1 \
9 | --batch_size 6 \
10 | --sub_batch_size 6 \
11 | --size_g 508 \
12 | --size_p 508 \
--------------------------------------------------------------------------------
/train_deep_globe_global2local.sh:
--------------------------------------------------------------------------------
1 | export CUDA_VISIBLE_DEVICES=0
2 | python train_deep_globe.py \
3 | --n_class 7 \
4 | --data_path "/ssd1/chenwy/deep_globe/data/" \
5 | --model_path "/home/chenwy/deep_globe/saved_models/" \
6 | --log_path "/home/chenwy/deep_globe/runs/" \
7 | --task_name "fpn_deepglobe_global2local" \
8 | --mode 2 \
9 | --batch_size 6 \
10 | --sub_batch_size 6 \
11 | --size_g 508 \
12 | --size_p 508 \
13 | --path_g "fpn_deepglobe_global.pth" \
--------------------------------------------------------------------------------
/train_deep_globe_local2global.sh:
--------------------------------------------------------------------------------
1 | export CUDA_VISIBLE_DEVICES=0
2 | python train_deep_globe.py \
3 | --n_class 7 \
4 | --data_path "/ssd1/chenwy/deep_globe/data/" \
5 | --model_path "/home/chenwy/deep_globe/saved_models/" \
6 | --log_path "/home/chenwy/deep_globe/runs/" \
7 | --task_name "fpn_deepglobe_local2global" \
8 | --mode 3 \
9 | --batch_size 6 \
10 | --sub_batch_size 6 \
11 | --size_g 508 \
12 | --size_p 508 \
13 | --path_g "fpn_deepglobe_global.pth" \
14 | --path_g2l "fpn_deepglobe_global2local.pth" \
--------------------------------------------------------------------------------
/eval_deep_globe.sh:
--------------------------------------------------------------------------------
1 | export CUDA_VISIBLE_DEVICES=0
2 | python train_deep_globe.py \
3 | --n_class 7 \
4 | --data_path "/ssd1/chenwy/deep_globe/data/" \
5 | --model_path "/home/chenwy/deep_globe/saved_models/" \
6 | --log_path "/home/chenwy/deep_globe/runs/" \
7 | --task_name "eval" \
8 | --mode 3 \
9 | --batch_size 6 \
10 | --sub_batch_size 6 \
11 | --size_g 508 \
12 | --size_p 508 \
13 | --path_g "fpn_deepglobe_global.pth" \
14 | --path_g2l "fpn_deepglobe_global2local.pth" \
15 | --path_l2g "fpn_deepglobe_local2global.pth" \
16 | --evaluation
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2019 Wuyang
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # vim swp files
2 | *.swp
3 | # caffe/pytorch model files
4 | *.pth
5 |
6 | # Mkdocs
7 | # /docs/
8 | /mkdocs/docs/temp
9 |
10 | .DS_Store
11 | .idea
12 | .vscode
13 | .pytest_cache
14 | /experiments
15 |
16 | # resource temp folder
17 | tests/resources/temp/*
18 | !tests/resources/temp/.gitkeep
19 |
20 | # Byte-compiled / optimized / DLL files
21 | __pycache__/
22 | *.py[cod]
23 | *$py.class
24 |
25 | # C extensions
26 | *.so
27 |
28 | # Distribution / packaging
29 | .Python
30 | build/
31 | develop-eggs/
32 | dist/
33 | downloads/
34 | eggs/
35 | .eggs/
36 | lib/
37 | lib64/
38 | parts/
39 | sdist/
40 | var/
41 | wheels/
42 | *.egg-info/
43 | .installed.cfg
44 | *.egg
45 | MANIFEST
46 |
47 | # PyInstaller
48 | # Usually these files are written by a python script from a template
49 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
50 | *.manifest
51 | *.spec
52 |
53 | # Installer logs
54 | pip-log.txt
55 | pip-delete-this-directory.txt
56 |
57 | # Unit test / coverage reports
58 | htmlcov/
59 | .tox/
60 | .coverage
61 | .coverage.*
62 | .cache
63 | nosetests.xml
64 | coverage.xml
65 | *.cover
66 | .hypothesis/
67 | .pytest_cache/
68 |
69 | # Translations
70 | *.mo
71 | *.pot
72 |
73 | # Django stuff:
74 | *.log
75 | .static_storage/
76 | .media/
77 | local_settings.py
78 | local_settings.py
79 | db.sqlite3
80 |
81 | # Flask stuff:
82 | instance/
83 | .webassets-cache
84 |
85 | # Scrapy stuff:
86 | .scrapy
87 |
88 | # Sphinx documentation
89 | docs/_build/
90 |
91 | # PyBuilder
92 | target/
93 |
94 | # Jupyter Notebook
95 | .ipynb_checkpoints
96 |
97 | # pyenv
98 | .python-version
99 |
100 | # celery beat schedule file
101 | celerybeat-schedule
102 |
103 | # SageMath parsed files
104 | *.sage.py
105 |
106 | # Environments
107 | .env
108 | .venv
109 | env/
110 | venv/
111 | ENV/
112 | env.bak/
113 | venv.bak/
114 |
115 | # Spyder project settings
116 | .spyderproject
117 | .spyproject
118 |
119 | # Rope project settings
120 | .ropeproject
121 |
122 | # mkdocs documentation
123 | /site
124 |
125 | # mypy
126 | .mypy_cache/
127 |
--------------------------------------------------------------------------------
/utils/metrics.py:
--------------------------------------------------------------------------------
1 | # Adapted from score written by wkentaro
2 | # https://github.com/wkentaro/pytorch-fcn/blob/master/torchfcn/utils.py
3 |
4 | import numpy as np
5 |
6 | class ConfusionMatrix(object):
7 |
8 | def __init__(self, n_classes):
9 | self.n_classes = n_classes
10 | # axis = 0: target
11 | # axis = 1: prediction
12 | self.confusion_matrix = np.zeros((n_classes, n_classes))
13 | # self.iou = []
14 | # self.iou_threshold = []
15 |
16 | def _fast_hist(self, label_true, label_pred, n_class):
17 | mask = (label_true >= 0) & (label_true < n_class)
18 | hist = np.bincount(n_class * label_true[mask].astype(int) + label_pred[mask], minlength=n_class**2).reshape(n_class, n_class)
19 | return hist
20 |
21 | def update(self, label_trues, label_preds):
22 | for lt, lp in zip(label_trues, label_preds):
23 | tmp = self._fast_hist(lt.flatten(), lp.flatten(), self.n_classes)
24 |
25 | # iu = np.diag(tmp) / (tmp.sum(axis=1) + tmp.sum(axis=0) - np.diag(tmp))
26 | # self.iou.append(iu[1])
27 | # if iu[1] >= 0.65: self.iou_threshold.append(iu[1])
28 | # else: self.iou_threshold.append(0)
29 |
30 | self.confusion_matrix += tmp
31 |
32 | def get_scores(self):
33 | """Returns accuracy score evaluation result.
34 | - overall accuracy
35 | - mean accuracy
36 | - mean IU
37 | - fwavacc
38 | """
39 | hist = self.confusion_matrix
40 | # accuracy is recall/sensitivity for each class, predicted TP / all real positives
41 | # axis in sum: perform summation along
42 | acc = np.nan_to_num(np.diag(hist) / hist.sum(axis=1))
43 | acc_mean = np.mean(np.nan_to_num(acc))
44 |
45 | intersect = np.diag(hist)
46 | union = hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist)
47 | iou = intersect / union
48 | mean_iou = np.mean(np.nan_to_num(iou))
49 |
50 | freq = hist.sum(axis=1) / hist.sum() # freq of each target
51 | # fwavacc = (freq[freq > 0] * iou[freq > 0]).sum()
52 | freq_iou = (freq * iou).sum()
53 |
54 | return {'accuracy': acc,
55 | 'accuracy_mean': acc_mean,
56 | 'freqw_iou': freq_iou,
57 | 'iou': iou,
58 | 'iou_mean': mean_iou,
59 | # 'IoU_threshold': np.mean(np.nan_to_num(self.iou_threshold)),
60 | }
61 |
62 | def reset(self):
63 | self.confusion_matrix = np.zeros((self.n_classes, self.n_classes))
64 | # self.iou = []
65 | # self.iou_threshold = []
--------------------------------------------------------------------------------
/test.txt:
--------------------------------------------------------------------------------
1 | 10452_sat.jpg
2 | 114473_sat.jpg
3 | 120245_sat.jpg
4 | 127660_sat.jpg
5 | 137499_sat.jpg
6 | 143364_sat.jpg
7 | 143794_sat.jpg
8 | 147545_sat.jpg
9 | 148260_sat.jpg
10 | 148381_sat.jpg
11 | 161109_sat.jpg
12 | 170535_sat.jpg
13 | 181447_sat.jpg
14 | 185522_sat.jpg
15 | 186739_sat.jpg
16 | 195769_sat.jpg
17 | 209787_sat.jpg
18 | 211316_sat.jpg
19 | 219555_sat.jpg
20 | 225393_sat.jpg
21 | 225945_sat.jpg
22 | 226788_sat.jpg
23 | 242583_sat.jpg
24 | 245846_sat.jpg
25 | 255876_sat.jpg
26 | 271245_sat.jpg
27 | 271941_sat.jpg
28 | 273002_sat.jpg
29 | 277049_sat.jpg
30 | 277900_sat.jpg
31 | 28689_sat.jpg
32 | 28935_sat.jpg
33 | 294978_sat.jpg
34 | 307626_sat.jpg
35 | 309818_sat.jpg
36 | 321711_sat.jpg
37 | 326173_sat.jpg
38 | 326238_sat.jpg
39 | 330838_sat.jpg
40 | 332354_sat.jpg
41 | 338111_sat.jpg
42 | 340798_sat.jpg
43 | 343215_sat.jpg
44 | 349442_sat.jpg
45 | 351228_sat.jpg
46 | 387018_sat.jpg
47 | 393043_sat.jpg
48 | 396979_sat.jpg
49 | 397137_sat.jpg
50 | 402209_sat.jpg
51 | 407467_sat.jpg
52 | 412210_sat.jpg
53 | 420078_sat.jpg
54 | 427037_sat.jpg
55 | 428841_sat.jpg
56 | 432089_sat.jpg
57 | 437963_sat.jpg
58 | 449319_sat.jpg
59 | 454655_sat.jpg
60 | 457070_sat.jpg
61 | 457265_sat.jpg
62 | 471187_sat.jpg
63 | 498049_sat.jpg
64 | 501284_sat.jpg
65 | 503968_sat.jpg
66 | 504704_sat.jpg
67 | 505217_sat.jpg
68 | 508676_sat.jpg
69 | 509290_sat.jpg
70 | 513585_sat.jpg
71 | 513968_sat.jpg
72 | 525105_sat.jpg
73 | 533948_sat.jpg
74 | 533952_sat.jpg
75 | 543806_sat.jpg
76 | 547080_sat.jpg
77 | 556452_sat.jpg
78 | 557439_sat.jpg
79 | 560353_sat.jpg
80 | 572237_sat.jpg
81 | 574789_sat.jpg
82 | 576417_sat.jpg
83 | 584663_sat.jpg
84 | 589940_sat.jpg
85 | 591815_sat.jpg
86 | 599743_sat.jpg
87 | 603617_sat.jpg
88 | 606_sat.jpg
89 | 615420_sat.jpg
90 | 620018_sat.jpg
91 | 624916_sat.jpg
92 | 627583_sat.jpg
93 | 635841_sat.jpg
94 | 639004_sat.jpg
95 | 649042_sat.jpg
96 | 652183_sat.jpg
97 | 659953_sat.jpg
98 | 660933_sat.jpg
99 | 661864_sat.jpg
100 | 671164_sat.jpg
101 | 68078_sat.jpg
102 | 684377_sat.jpg
103 | 691384_sat.jpg
104 | 708588_sat.jpg
105 | 71125_sat.jpg
106 | 713813_sat.jpg
107 | 732669_sat.jpg
108 | 751939_sat.jpg
109 | 755453_sat.jpg
110 | 757745_sat.jpg
111 | 771393_sat.jpg
112 | 772452_sat.jpg
113 | 777185_sat.jpg
114 | 7791_sat.jpg
115 | 78298_sat.jpg
116 | 78430_sat.jpg
117 | 7892_sat.jpg
118 | 79049_sat.jpg
119 | 799523_sat.jpg
120 | 810749_sat.jpg
121 | 819442_sat.jpg
122 | 828684_sat.jpg
123 | 829962_sat.jpg
124 | 835147_sat.jpg
125 | 842556_sat.jpg
126 | 850510_sat.jpg
127 | 857201_sat.jpg
128 | 858771_sat.jpg
129 | 875327_sat.jpg
130 | 882451_sat.jpg
131 | 898741_sat.jpg
132 | 925382_sat.jpg
133 | 937922_sat.jpg
134 | 950926_sat.jpg
135 | 956410_sat.jpg
136 | 956928_sat.jpg
137 | 965276_sat.jpg
138 | 982744_sat.jpg
139 | 987381_sat.jpg
140 | 992507_sat.jpg
141 | 994520_sat.jpg
142 | 998002_sat.jpg
143 |
--------------------------------------------------------------------------------
/utils/lr_scheduler.py:
--------------------------------------------------------------------------------
1 | ##+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
2 | ## Created by: Hang Zhang
3 | ## ECE Department, Rutgers University
4 | ## Email: zhang.hang@rutgers.edu
5 | ## Copyright (c) 2017
6 | ##
7 | ## This source code is licensed under the MIT-style license found in the
8 | ## LICENSE file in the root directory of this source tree
9 | ##+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
10 |
11 | import math
12 |
13 | class LR_Scheduler(object):
14 | """Learning Rate Scheduler
15 |
16 | Step mode: ``lr = baselr * 0.1 ^ {floor(epoch-1 / lr_step)}``
17 |
18 | Cosine mode: ``lr = baselr * 0.5 * (1 + cos(iter/maxiter))``
19 |
20 | Poly mode: ``lr = baselr * (1 - iter/maxiter) ^ 0.9``
21 |
22 | Args:
23 | args: :attr:`args.lr_scheduler` lr scheduler mode (`cos`, `poly`),
24 | :attr:`args.lr` base learning rate, :attr:`args.epochs` number of epochs,
25 | :attr:`args.lr_step`
26 |
27 | iters_per_epoch: number of iterations per epoch
28 | """
29 | def __init__(self, mode, base_lr, num_epochs, iters_per_epoch=0,
30 | lr_step=0, warmup_epochs=0):
31 | self.mode = mode
32 | print('Using {} LR Scheduler!'.format(self.mode))
33 | self.lr = base_lr
34 | if mode == 'step':
35 | assert lr_step
36 | self.lr_step = lr_step
37 | self.iters_per_epoch = iters_per_epoch
38 | self.N = num_epochs * iters_per_epoch
39 | self.epoch = -1
40 | self.warmup_iters = warmup_epochs * iters_per_epoch
41 |
42 | def __call__(self, optimizer, i, epoch, best_pred):
43 | T = epoch * self.iters_per_epoch + i
44 | if self.mode == 'cos':
45 | lr = 0.5 * self.lr * (1 + math.cos(1.0 * T / self.N * math.pi))
46 | elif self.mode == 'poly':
47 | lr = self.lr * pow((1 - 1.0 * T / self.N), 0.9)
48 | elif self.mode == 'step':
49 | lr = self.lr * (0.1 ** (epoch // self.lr_step))
50 | else:
51 | raise NotImplemented
52 | # warm up lr schedule
53 | if self.warmup_iters > 0 and T < self.warmup_iters:
54 | lr = lr * 1.0 * T / self.warmup_iters
55 | if epoch > self.epoch:
56 | print('\n=>Epoches %i, learning rate = %.7f, \
57 | previous best = %.4f' % (epoch, lr, best_pred))
58 | self.epoch = epoch
59 | assert lr >= 0
60 | self._adjust_learning_rate(optimizer, lr)
61 |
62 | def _adjust_learning_rate(self, optimizer, lr):
63 | if len(optimizer.param_groups) == 1:
64 | optimizer.param_groups[0]['lr'] = lr
65 | else:
66 | # enlarge the lr at the head
67 | for i in range(len(optimizer.param_groups)):
68 | if optimizer.param_groups[i]['lr'] > 0: optimizer.param_groups[i]['lr'] = lr
69 | # optimizer.param_groups[0]['lr'] = lr
70 | # for i in range(1, len(optimizer.param_groups)):
71 | # optimizer.param_groups[i]['lr'] = lr * 10
72 |
--------------------------------------------------------------------------------
/option.py:
--------------------------------------------------------------------------------
1 | ###########################################################################
2 | # Created by: CASIA IVA
3 | # Email: jliu@nlpr.ia.ac.cn
4 | # Copyright (c) 2018
5 | ###########################################################################
6 |
7 | import os
8 | import argparse
9 | import torch
10 |
11 | # path_g = os.path.join(model_path, "cityscapes_global.800_4.5.2019.lr5e5.pth")
12 | # # path_g = os.path.join(model_path, "fpn_global.804_nonorm_3.17.2019.lr2e5" + ".pth")
13 | # path_g2l = os.path.join(model_path, "fpn_global2local.508_deep.cat.1x_fmreg_ensemble.p3.0.15l2_3.19.2019.lr2e5.pth")
14 | # path_l2g = os.path.join(model_path, "fpn_local2global.508_deep.cat.1x_fmreg_ensemble.p3_3.19.2019.lr2e5.pth")
15 | class Options():
16 | def __init__(self):
17 | parser = argparse.ArgumentParser(description='PyTorch Segmentation')
18 | # model and dataset
19 | parser.add_argument('--n_class', type=int, default=7, help='segmentation classes')
20 | parser.add_argument('--data_path', type=str, help='path to dataset where images store')
21 | parser.add_argument('--model_path', type=str, help='path to store trained model files, no need to include task specific name')
22 | parser.add_argument('--log_path', type=str, help='path to store tensorboard log files, no need to include task specific name')
23 | parser.add_argument('--task_name', type=str, help='task name for naming saved model files and log files')
24 | parser.add_argument('--mode', type=int, default=1, choices=[1, 2, 3], help='mode for training procedure. 1: train global branch only. 2: train local branch with fixed global branch. 3: train global branch with fixed local branch')
25 | parser.add_argument('--evaluation', action='store_true', default=False, help='evaluation only')
26 | parser.add_argument('--batch_size', type=int, default=6, help='batch size for origin global image (without downsampling)')
27 | parser.add_argument('--sub_batch_size', type=int, default=6, help='batch size for using local image patches')
28 | parser.add_argument('--size_g', type=int, default=508, help='size (in pixel) for downsampled global image')
29 | parser.add_argument('--size_p', type=int, default=508, help='size (in pixel) for cropped local image')
30 | parser.add_argument('--path_g', type=str, default="", help='name for global model path')
31 | parser.add_argument('--path_g2l', type=str, default="", help='name for local from global model path')
32 | parser.add_argument('--path_l2g', type=str, default="", help='name for global from local model path')
33 | parser.add_argument('--lamb_fmreg', type=float, default=0.15, help='loss weight feature map regularization')
34 |
35 | # the parser
36 | self.parser = parser
37 |
38 | def parse(self):
39 | args = self.parser.parse_args()
40 | # default settings for epochs and lr
41 | if args.mode == 1 or args.mode == 3:
42 | args.num_epochs = 120
43 | args.lr = 5e-5
44 | else:
45 | args.num_epochs = 50
46 | args.lr = 2e-5
47 | return args
48 |
--------------------------------------------------------------------------------
/utils/loss.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 | import torch
4 |
5 |
6 | class CrossEntropyLoss2d(nn.Module):
7 | def __init__(self, weight=None, size_average=True, ignore_index=-100):
8 | super(CrossEntropyLoss2d, self).__init__()
9 | self.nll_loss = nn.NLLLoss(weight, size_average, ignore_index)
10 |
11 | def forward(self, inputs, targets):
12 | return self.nll_loss(F.log_softmax(inputs, dim=1), targets)
13 |
14 |
15 | def one_hot(index, classes):
16 | # index is not flattened (pypass ignore) ############
17 | # size = index.size()[:1] + (classes,) + index.size()[1:]
18 | # view = index.size()[:1] + (1,) + index.size()[1:]
19 | #####################################################
20 | # index is flatten (during ignore) ##################
21 | size = index.size()[:1] + (classes,)
22 | view = index.size()[:1] + (1,)
23 | #####################################################
24 |
25 | # mask = torch.Tensor(size).fill_(0).to(device)
26 | mask = torch.Tensor(size).fill_(0).cuda()
27 | index = index.view(view)
28 | ones = 1.
29 |
30 | return mask.scatter_(1, index, ones)
31 |
32 |
33 | class FocalLoss(nn.Module):
34 |
35 | def __init__(self, gamma=0, eps=1e-7, size_average=True, one_hot=True, ignore=None):
36 | super(FocalLoss, self).__init__()
37 | self.gamma = gamma
38 | self.eps = eps
39 | self.size_average = size_average
40 | self.one_hot = one_hot
41 | self.ignore = ignore
42 |
43 | def forward(self, input, target):
44 | '''
45 | only support ignore at 0
46 | '''
47 | B, C, H, W = input.size()
48 | input = input.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, C
49 | target = target.view(-1)
50 | if self.ignore is not None:
51 | valid = (target != self.ignore)
52 | input = input[valid]
53 | target = target[valid]
54 |
55 | if self.one_hot: target = one_hot(target, input.size(1))
56 | probs = F.softmax(input, dim=1)
57 | probs = (probs * target).sum(1)
58 | probs = probs.clamp(self.eps, 1. - self.eps)
59 |
60 | log_p = probs.log()
61 | # print('probs size= {}'.format(probs.size()))
62 | # print(probs)
63 |
64 | batch_loss = -(torch.pow((1 - probs), self.gamma)) * log_p
65 | # print('-----bacth_loss------')
66 | # print(batch_loss)
67 |
68 | if self.size_average:
69 | loss = batch_loss.mean()
70 | else:
71 | loss = batch_loss.sum()
72 | return loss
73 |
74 |
75 | class SoftCrossEntropyLoss2d(nn.Module):
76 | def __init__(self):
77 | super(SoftCrossEntropyLoss2d, self).__init__()
78 |
79 | def forward(self, inputs, targets):
80 | loss = 0
81 | inputs = -F.log_softmax(inputs, dim=1)
82 | for index in range(inputs.size()[0]):
83 | loss += F.conv2d(inputs[range(index, index+1)], targets[range(index, index+1)])/(targets.size()[2] *
84 | targets.size()[3])
85 | return loss
86 |
--------------------------------------------------------------------------------
/models/model_store.py:
--------------------------------------------------------------------------------
1 | """Model store which provides pretrained models."""
2 | from __future__ import print_function
3 | __all__ = ['get_model_file', 'purge']
4 | import os
5 | import zipfile
6 |
7 | from .utils import download, check_sha1
8 |
9 | _model_sha1 = {name: checksum for checksum, name in [
10 | ('ebb6acbbd1d1c90b7f446ae59d30bf70c74febc1', 'resnet50'),
11 | ('2a57e44de9c853fa015b172309a1ee7e2d0e4e2a', 'resnet101'),
12 | ('0d43d698c66aceaa2bc0309f55efdd7ff4b143af', 'resnet152'),
13 | ('2e22611a7f3992ebdee6726af169991bc26d7363', 'deepten_minc'),
14 | ('662e979de25a389f11c65e9f1df7e06c2c356381', 'fcn_resnet50_ade'),
15 | ('eeed8e582f0fdccdba8579e7490570adc6d85c7c', 'fcn_resnet50_pcontext'),
16 | ('54f70c772505064e30efd1ddd3a14e1759faa363', 'psp_resnet50_ade'),
17 | ('075195c5237b778c718fd73ceddfa1376c18dfd0', 'deeplab_resnet50_ade'),
18 | ('5ee47ee28b480cc781a195d13b5806d5bbc616bf', 'encnet_resnet101_coco'),
19 | ('4de91d5922d4d3264f678b663f874da72e82db00', 'encnet_resnet50_pcontext'),
20 | ('9f27ea13d514d7010e59988341bcbd4140fcc33d', 'encnet_resnet101_pcontext'),
21 | ('07ac287cd77e53ea583f37454e17d30ce1509a4a', 'encnet_resnet50_ade'),
22 | ('3f54fa3b67bac7619cd9b3673f5c8227cf8f4718', 'encnet_resnet101_ade'),
23 | ]}
24 |
25 | encoding_repo_url = 'https://hangzh.s3.amazonaws.com/'
26 | _url_format = '{repo_url}encoding/models/{file_name}.zip'
27 |
28 | def short_hash(name):
29 | if name not in _model_sha1:
30 | raise ValueError('Pretrained model for {name} is not available.'.format(name=name))
31 | return _model_sha1[name][:8]
32 |
33 | def get_model_file(name, root=os.path.join('~', '.encoding', 'models')):
34 | r"""Return location for the pretrained on local file system.
35 |
36 | This function will download from online model zoo when model cannot be found or has mismatch.
37 | The root directory will be created if it doesn't exist.
38 |
39 | Parameters
40 | ----------
41 | name : str
42 | Name of the model.
43 | root : str, default '~/.encoding/models'
44 | Location for keeping the model parameters.
45 |
46 | Returns
47 | -------
48 | file_path
49 | Path to the requested pretrained model file.
50 | """
51 | file_name = '{name}-{short_hash}'.format(name=name, short_hash=short_hash(name))
52 | root = os.path.expanduser(root)
53 | file_path = os.path.join(root, file_name+'.pth')
54 | sha1_hash = _model_sha1[name]
55 | if os.path.exists(file_path):
56 | if check_sha1(file_path, sha1_hash):
57 | return file_path
58 | else:
59 | print('Mismatch in the content of model file {} detected.' +
60 | ' Downloading again.'.format(file_path))
61 | else:
62 | print('Model file {} is not found. Downloading.'.format(file_path))
63 |
64 | if not os.path.exists(root):
65 | os.makedirs(root)
66 |
67 | zip_file_path = os.path.join(root, file_name+'.zip')
68 | repo_url = os.environ.get('ENCODING_REPO', encoding_repo_url)
69 | if repo_url[-1] != '/':
70 | repo_url = repo_url + '/'
71 | download(_url_format.format(repo_url=repo_url, file_name=file_name),
72 | path=zip_file_path,
73 | overwrite=True)
74 | with zipfile.ZipFile(zip_file_path) as zf:
75 | zf.extractall(root)
76 | os.remove(zip_file_path)
77 |
78 | if check_sha1(file_path, sha1_hash):
79 | return file_path
80 | else:
81 | raise ValueError('Downloaded file has different hash. Please try again.')
82 |
83 | def purge(root=os.path.join('~', '.encoding', 'models')):
84 | r"""Purge all pretrained model files in local file store.
85 |
86 | Parameters
87 | ----------
88 | root : str, default '~/.encoding/models'
89 | Location for keeping the model parameters.
90 | """
91 | root = os.path.expanduser(root)
92 | files = os.listdir(root)
93 | for f in files:
94 | if f.endswith(".pth"):
95 | os.remove(os.path.join(root, f))
96 |
97 | def pretrained_model_list():
98 | return list(_model_sha1.keys())
99 |
--------------------------------------------------------------------------------
/crossvali.txt:
--------------------------------------------------------------------------------
1 | 102122_sat.jpg
2 | 114577_sat.jpg
3 | 115444_sat.jpg
4 | 119012_sat.jpg
5 | 123172_sat.jpg
6 | 124529_sat.jpg
7 | 125510_sat.jpg
8 | 126796_sat.jpg
9 | 127976_sat.jpg
10 | 129297_sat.jpg
11 | 129298_sat.jpg
12 | 133209_sat.jpg
13 | 136252_sat.jpg
14 | 139581_sat.jpg
15 | 143353_sat.jpg
16 | 147716_sat.jpg
17 | 154626_sat.jpg
18 | 155165_sat.jpg
19 | 162310_sat.jpg
20 | 16453_sat.jpg
21 | 166293_sat.jpg
22 | 166805_sat.jpg
23 | 168514_sat.jpg
24 | 176225_sat.jpg
25 | 180902_sat.jpg
26 | 192918_sat.jpg
27 | 194156_sat.jpg
28 | 19627_sat.jpg
29 | 200561_sat.jpg
30 | 200589_sat.jpg
31 | 210436_sat.jpg
32 | 211739_sat.jpg
33 | 219670_sat.jpg
34 | 229383_sat.jpg
35 | 233615_sat.jpg
36 | 234269_sat.jpg
37 | 246378_sat.jpg
38 | 247179_sat.jpg
39 | 255889_sat.jpg
40 | 262885_sat.jpg
41 | 264436_sat.jpg
42 | 268881_sat.jpg
43 | 273274_sat.jpg
44 | 2774_sat.jpg
45 | 280861_sat.jpg
46 | 283326_sat.jpg
47 | 286339_sat.jpg
48 | 300745_sat.jpg
49 | 312676_sat.jpg
50 | 315848_sat.jpg
51 | 323581_sat.jpg
52 | 324170_sat.jpg
53 | 329017_sat.jpg
54 | 331421_sat.jpg
55 | 334677_sat.jpg
56 | 334811_sat.jpg
57 | 338661_sat.jpg
58 | 34567_sat.jpg
59 | 350033_sat.jpg
60 | 350328_sat.jpg
61 | 351271_sat.jpg
62 | 354033_sat.jpg
63 | 358314_sat.jpg
64 | 358464_sat.jpg
65 | 362191_sat.jpg
66 | 373103_sat.jpg
67 | 375563_sat.jpg
68 | 394500_sat.jpg
69 | 406425_sat.jpg
70 | 416794_sat.jpg
71 | 418261_sat.jpg
72 | 419820_sat.jpg
73 | 424590_sat.jpg
74 | 427774_sat.jpg
75 | 428597_sat.jpg
76 | 430587_sat.jpg
77 | 434210_sat.jpg
78 | 43814_sat.jpg
79 | 438721_sat.jpg
80 | 44070_sat.jpg
81 | 442338_sat.jpg
82 | 443271_sat.jpg
83 | 455374_sat.jpg
84 | 461001_sat.jpg
85 | 461755_sat.jpg
86 | 462612_sat.jpg
87 | 467855_sat.jpg
88 | 471930_sat.jpg
89 | 472774_sat.jpg
90 | 479682_sat.jpg
91 | 491491_sat.jpg
92 | 495406_sat.jpg
93 | 499325_sat.jpg
94 | 499600_sat.jpg
95 | 501804_sat.jpg
96 | 512669_sat.jpg
97 | 514385_sat.jpg
98 | 514414_sat.jpg
99 | 51911_sat.jpg
100 | 536496_sat.jpg
101 | 537221_sat.jpg
102 | 538243_sat.jpg
103 | 538922_sat.jpg
104 | 544078_sat.jpg
105 | 544537_sat.jpg
106 | 550312_sat.jpg
107 | 552001_sat.jpg
108 | 557175_sat.jpg
109 | 559477_sat.jpg
110 | 563092_sat.jpg
111 | 565914_sat.jpg
112 | 570992_sat.jpg
113 | 571520_sat.jpg
114 | 577164_sat.jpg
115 | 584712_sat.jpg
116 | 584865_sat.jpg
117 | 586222_sat.jpg
118 | 586806_sat.jpg
119 | 600230_sat.jpg
120 | 605707_sat.jpg
121 | 614561_sat.jpg
122 | 619800_sat.jpg
123 | 62078_sat.jpg
124 | 621459_sat.jpg
125 | 626323_sat.jpg
126 | 628479_sat.jpg
127 | 638168_sat.jpg
128 | 638937_sat.jpg
129 | 641771_sat.jpg
130 | 646596_sat.jpg
131 | 650253_sat.jpg
132 | 651537_sat.jpg
133 | 652733_sat.jpg
134 | 654770_sat.jpg
135 | 660069_sat.jpg
136 | 669156_sat.jpg
137 | 673927_sat.jpg
138 | 679507_sat.jpg
139 | 686781_sat.jpg
140 | 688544_sat.jpg
141 | 692982_sat.jpg
142 | 702918_sat.jpg
143 | 703413_sat.jpg
144 | 705728_sat.jpg
145 | 706996_sat.jpg
146 | 707319_sat.jpg
147 | 708527_sat.jpg
148 | 725646_sat.jpg
149 | 726265_sat.jpg
150 | 728521_sat.jpg
151 | 730889_sat.jpg
152 | 733758_sat.jpg
153 | 741105_sat.jpg
154 | 748225_sat.jpg
155 | 749375_sat.jpg
156 | 762470_sat.jpg
157 | 762937_sat.jpg
158 | 767012_sat.jpg
159 | 772130_sat.jpg
160 | 775304_sat.jpg
161 | 77669_sat.jpg
162 | 784518_sat.jpg
163 | 794214_sat.jpg
164 | 81039_sat.jpg
165 | 818254_sat.jpg
166 | 820347_sat.jpg
167 | 831146_sat.jpg
168 | 834900_sat.jpg
169 | 838873_sat.jpg
170 | 839012_sat.jpg
171 | 839641_sat.jpg
172 | 841286_sat.jpg
173 | 841404_sat.jpg
174 | 861353_sat.jpg
175 | 864488_sat.jpg
176 | 867349_sat.jpg
177 | 867983_sat.jpg
178 | 875409_sat.jpg
179 | 876248_sat.jpg
180 | 891153_sat.jpg
181 | 893651_sat.jpg
182 | 897901_sat.jpg
183 | 900985_sat.jpg
184 | 904606_sat.jpg
185 | 908837_sat.jpg
186 | 912087_sat.jpg
187 | 912620_sat.jpg
188 | 918105_sat.jpg
189 | 919602_sat.jpg
190 | 925425_sat.jpg
191 | 930491_sat.jpg
192 | 934795_sat.jpg
193 | 935193_sat.jpg
194 | 935318_sat.jpg
195 | 941237_sat.jpg
196 | 942986_sat.jpg
197 | 949559_sat.jpg
198 | 958243_sat.jpg
199 | 958443_sat.jpg
200 | 961919_sat.jpg
201 | 96841_sat.jpg
202 | 970925_sat.jpg
203 | 97337_sat.jpg
204 | 978039_sat.jpg
205 | 981253_sat.jpg
206 | 986342_sat.jpg
207 | 997521_sat.jpg
208 |
--------------------------------------------------------------------------------
/models/resnet.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.utils.model_zoo as model_zoo
3 |
4 |
5 | __all__ = ['ResNet', 'resnet50', 'resnet101']
6 |
7 |
8 | model_urls = {
9 | 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
10 | 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
11 | 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
12 | 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
13 | 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
14 | }
15 |
16 |
17 | class Bottleneck(nn.Module):
18 | expansion = 4
19 |
20 | def __init__(self, inplanes, planes, stride=1, downsample=None):
21 | super(Bottleneck, self).__init__()
22 | self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
23 | self.bn1 = nn.BatchNorm2d(planes)
24 | self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
25 | padding=1, bias=False)
26 | self.bn2 = nn.BatchNorm2d(planes)
27 | self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
28 | self.bn3 = nn.BatchNorm2d(planes * self.expansion)
29 | self.relu = nn.ReLU(inplace=True)
30 | self.downsample = downsample
31 | self.stride = stride
32 |
33 | def forward(self, x):
34 | residual = x
35 |
36 | out = self.conv1(x)
37 | out = self.bn1(out)
38 | out = self.relu(out)
39 |
40 | out = self.conv2(out)
41 | out = self.bn2(out)
42 | out = self.relu(out)
43 |
44 | out = self.conv3(out)
45 | out = self.bn3(out)
46 |
47 | if self.downsample is not None:
48 | residual = self.downsample(x)
49 |
50 | out += residual
51 | out = self.relu(out)
52 |
53 | return out
54 |
55 |
56 | class ResNet(nn.Module):
57 |
58 | def __init__(self, block, layers):
59 | self.inplanes = 64
60 | super(ResNet, self).__init__()
61 | self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
62 | bias=False)
63 | self.bn1 = nn.BatchNorm2d(64)
64 | self.relu = nn.ReLU(inplace=True)
65 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
66 | self.layer1 = self._make_layer(block, 64, layers[0])
67 | self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
68 | self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
69 | self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
70 |
71 | for m in self.modules():
72 | if isinstance(m, nn.Conv2d):
73 | nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
74 | elif isinstance(m, nn.BatchNorm2d):
75 | nn.init.constant_(m.weight, 1)
76 | nn.init.constant_(m.bias, 0)
77 |
78 | def _make_layer(self, block, planes, blocks, stride=1):
79 | downsample = None
80 | if stride != 1 or self.inplanes != planes * block.expansion:
81 | downsample = nn.Sequential(
82 | nn.Conv2d(self.inplanes, planes * block.expansion,
83 | kernel_size=1, stride=stride, bias=False),
84 | nn.BatchNorm2d(planes * block.expansion),
85 | )
86 |
87 | layers = []
88 | layers.append(block(self.inplanes, planes, stride, downsample))
89 | self.inplanes = planes * block.expansion
90 | for i in range(1, blocks):
91 | layers.append(block(self.inplanes, planes))
92 |
93 | return nn.Sequential(*layers)
94 |
95 | def forward(self, x):
96 | x = self.conv1(x)
97 | x = self.bn1(x)
98 | x = self.relu(x)
99 | x = self.maxpool(x)
100 |
101 | c2 = self.layer1(x)
102 | c3 = self.layer2(c2)
103 | c4 = self.layer3(c3)
104 | c5 = self.layer4(c4)
105 |
106 | return c2, c3, c4, c5
107 |
108 |
109 | def resnet50(pretrained=False, **kwargs):
110 | """Constructs a ResNet-50 model.
111 | Args:
112 | pretrained (bool): If True, returns a model pre-trained on ImageNet
113 | """
114 | model = ResNet(Bottleneck, [3, 4, 6, 3])
115 | if pretrained:
116 | model.load_state_dict(model_zoo.load_url(model_urls['resnet50']), strict=False)
117 | return model
118 |
119 |
120 | def resnet101(pretrained=False, **kwargs):
121 | """Constructs a ResNet-101 model.
122 | Args:
123 | pretrained (bool): If True, returns a model pre-trained on ImageNet
124 | """
125 | model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
126 | if pretrained:
127 | model.load_state_dict(model_zoo.load_url(model_urls['resnet101']), strict=False)
128 | return model
129 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # GLNet for Memory-Efficient Segmentation of Ultra-High Resolution Images
2 |
3 | [](https://lgtm.com/projects/g/chenwydj/ultra_high_resolution_segmentation/context:python) [](https://opensource.org/licenses/MIT)
4 |
5 | Collaborative Global-Local Networks for Memory-Efficient Segmentation of Ultra-High Resolution Images
6 |
7 | Wuyang Chen*, Ziyu Jiang*, Zhangyang Wang, Kexin Cui, and Xiaoning Qian
8 |
9 | In CVPR 2019 (Oral). [[Youtube](https://www.youtube.com/watch?v=am1GiItQI88)]
10 |
11 | ## Overview
12 |
13 | Segmentation of ultra-high resolution images is increasingly demanded in a wide range of applications (e.g. urban planning), yet poses significant challenges for algorithm efficiency, in particular considering the (GPU) memory limits.
14 |
15 | We propose collaborative **Global-Local Networks (GLNet)** to effectively preserve both global and local information in a highly memory-efficient manner.
16 |
17 | * **Memory-efficient**: **training w. only one 1080Ti** and **inference w. less than 2GB GPU memory**, for ultra-high resolution images of up to 30M pixels.
18 |
19 | * **High-quality**: GLNet outperforms existing segmentation models on ultra-high resolution images.
20 |
21 |
22 | 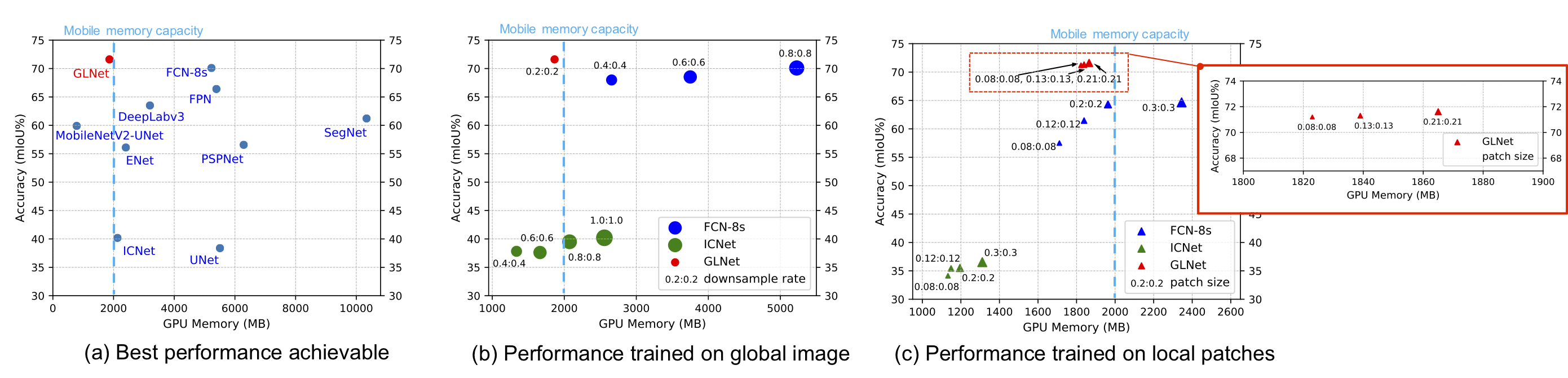 23 | Inference memory v.s. mIoU on the DeepGlobe dataset.
24 |
25 | GLNet (red dots) integrates both global and local information in a compact way, contributing to a well-balanced trade-off between accuracy and memory usage.
26 |
23 | Inference memory v.s. mIoU on the DeepGlobe dataset.
24 |
25 | GLNet (red dots) integrates both global and local information in a compact way, contributing to a well-balanced trade-off between accuracy and memory usage.
26 |
27 |
28 |
29 | 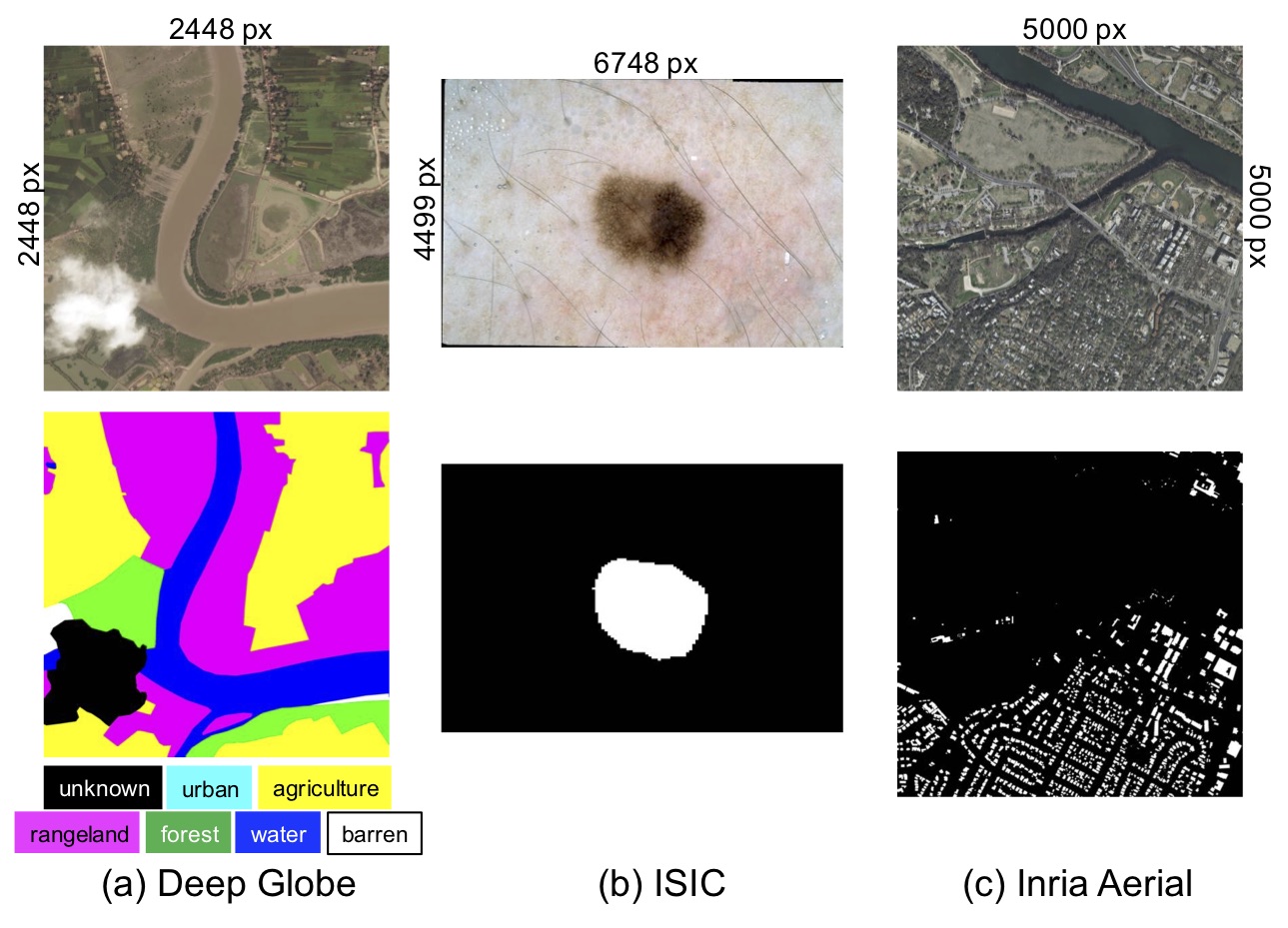 30 | Ultra-high resolution Datasets: DeepGlobe, ISIC, Inria Aerial
31 |
30 | Ultra-high resolution Datasets: DeepGlobe, ISIC, Inria Aerial
31 |
32 |
33 | ## Methods
34 |
35 |
36 | 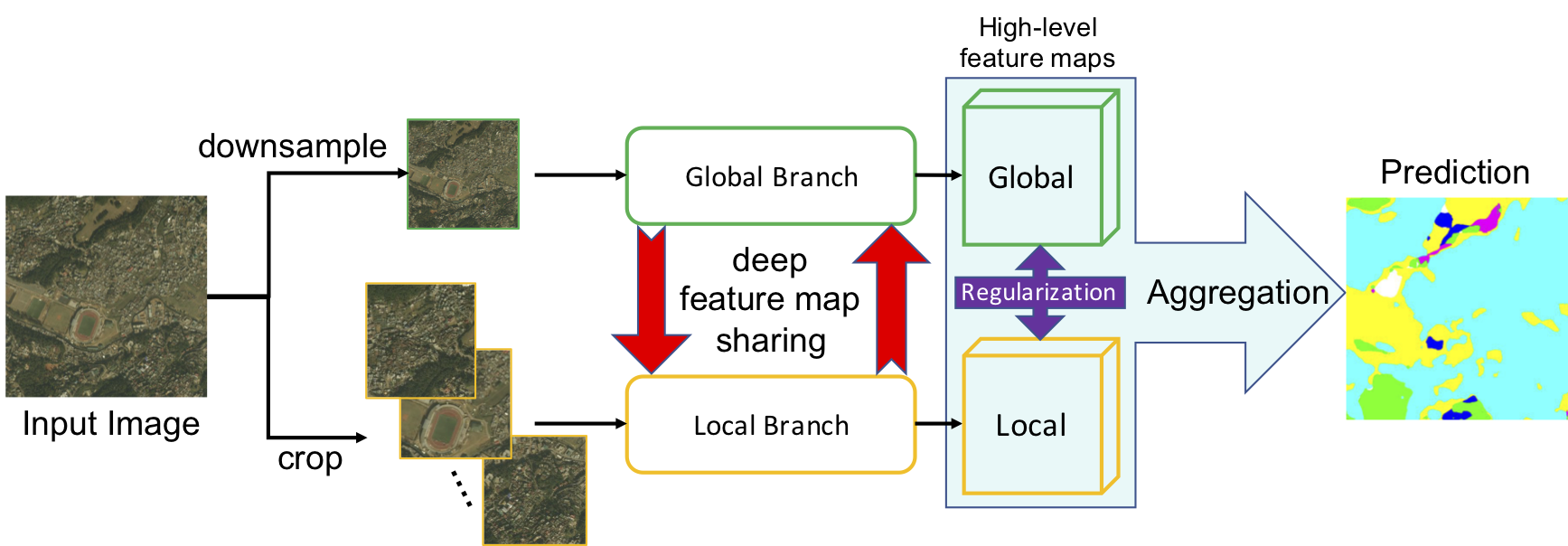 37 | GLNet: the global and local branch takes downsampled and cropped images, respectively. Deep feature map sharing and feature map regularization enforce our global-local collaboration. The final segmentation is generated by aggregating high-level feature maps from two branches.
38 |
37 | GLNet: the global and local branch takes downsampled and cropped images, respectively. Deep feature map sharing and feature map regularization enforce our global-local collaboration. The final segmentation is generated by aggregating high-level feature maps from two branches.
38 |
39 |
40 |
41 | 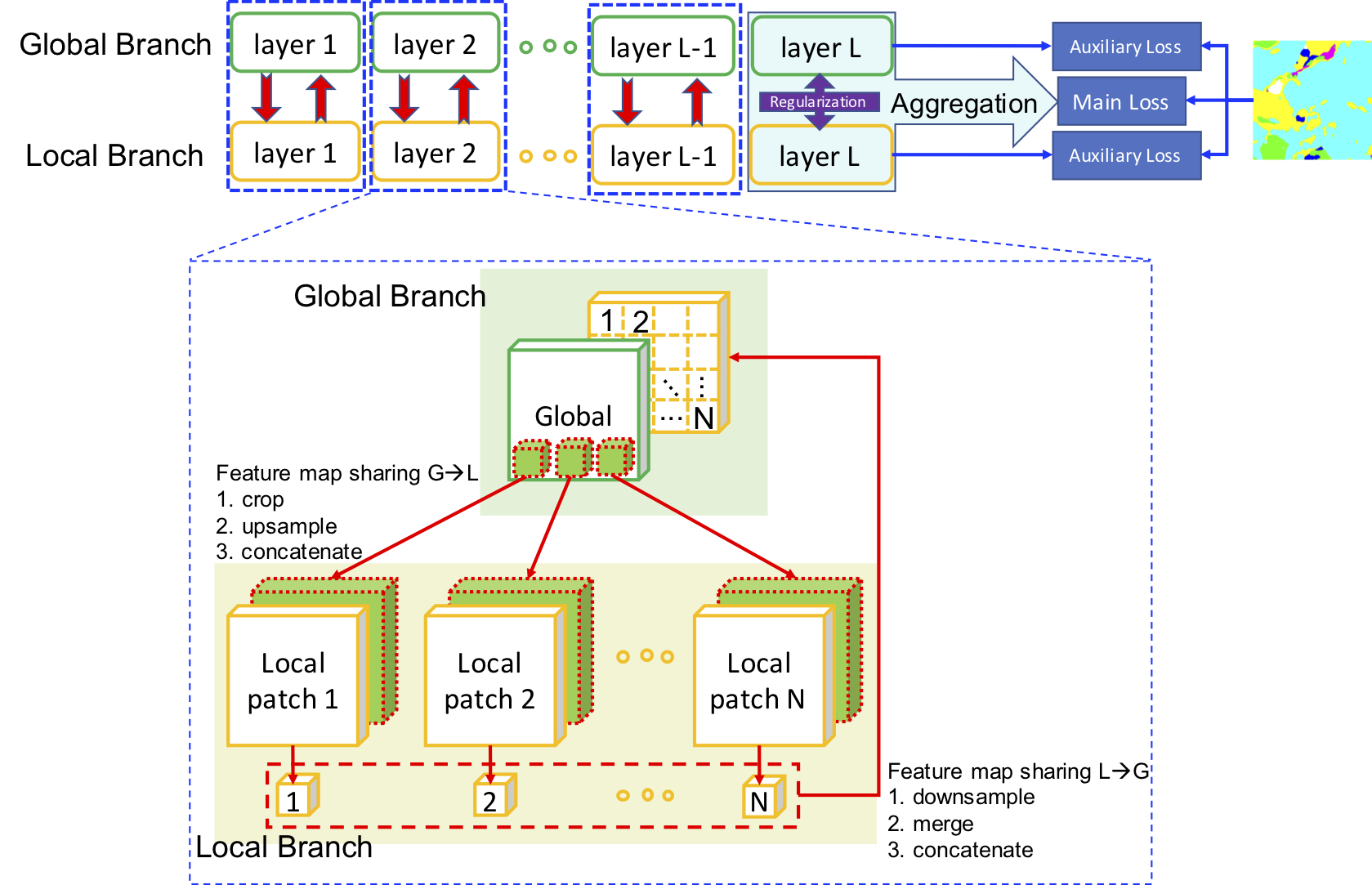 42 | Deep feature map sharing: at each layer, feature maps with global context and ones with local fine structures are bidirectionally brought together, contributing to a complete patch-based deep global-local collaboration.
43 |
42 | Deep feature map sharing: at each layer, feature maps with global context and ones with local fine structures are bidirectionally brought together, contributing to a complete patch-based deep global-local collaboration.
43 |
44 |
45 | ## Training
46 | Current this code base works for Python version >= 3.5.
47 |
48 | Please install the dependencies: `pip install -r requirements.txt`
49 |
50 | First, you could register and download the Deep Globe "Land Cover Classification" dataset here:
51 | https://competitions.codalab.org/competitions/18468
52 |
53 | Then please sequentially finish the following steps:
54 | 1. `./train_deep_globe_global.sh`
55 | 2. `./train_deep_globe_global2local.sh`
56 | 3. `./train_deep_globe_local2global.sh`
57 |
58 | The above jobs complete the following tasks:
59 | * create folder "saved_models" and "runs" to store the model checkpoints and logging files (you could configure the bash scrips to use your own paths).
60 | * step 1 and 2 prepare the trained models for step 2 and 3, respectively. You could use your own names to save the model checkpoints, but this requires to update values of the flag `path_g` and `path_g2l`.
61 |
62 | ## Evaluation
63 | 1. Please download the pre-trained models for the Deep Globe dataset and put them into folder "saved_models":
64 | * [fpn_deepglobe_global.pth](https://drive.google.com/file/d/1xUJoNEzj5LeclH9tHXZ2VsEI9LpC77kQ/view?usp=sharing)
65 | * [fpn_deepglobe_global2local.pth](https://drive.google.com/file/d/1_lCzi2KIygcrRcvBJ31G3cBwAMibn_AS/view?usp=sharing)
66 | * [fpn_deepglobe_local2global.pth](https://drive.google.com/file/d/198EcAO7VN8Ujn4N4FBg3sRgb8R_UKhYv/view?usp=sharing)
67 | 2. Download (see above "Training" section) and prepare the Deep Globe dataset according to the train.txt and crossvali.txt: put the image and label files into folder "train" and folder "crossvali"
68 | 3. Run script `./eval_deep_globe.sh`
69 |
70 | ## Citation
71 | If you use this code for your research, please cite our paper.
72 | ```
73 | @inproceedings{chen2019GLNET,
74 | title={Collaborative Global-Local Networks for Memory-Efficient Segmentation of Ultra-High Resolution Images},
75 | author={Chen, Wuyang and Jiang, Ziyu and Wang, Zhangyang and Cui, Kexin and Qian, Xiaoning},
76 | booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
77 | year={2019}
78 | }
79 | ```
80 |
81 | ## Acknowledgement
82 | We thank Prof. Andrew Jiang and Junru Wu for helping experiments.
83 |
84 |
86 |
--------------------------------------------------------------------------------
/dataset/deep_globe.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch.utils.data as data
3 | import numpy as np
4 | from PIL import Image, ImageFile
5 | import random
6 | from torchvision.transforms import ToTensor
7 | from torchvision import transforms
8 | import cv2
9 |
10 | ImageFile.LOAD_TRUNCATED_IMAGES = True
11 |
12 |
13 | def is_image_file(filename):
14 | return any(filename.endswith(extension) for extension in [".png", ".jpg", ".jpeg"])
15 |
16 |
17 | def find_label_map_name(img_filenames, labelExtension=".png"):
18 | img_filenames = img_filenames.replace('_sat.jpg', '_mask')
19 | return img_filenames + labelExtension
20 |
21 |
22 | def RGB_mapping_to_class(label):
23 | l, w = label.shape[0], label.shape[1]
24 | classmap = np.zeros(shape=(l, w))
25 | indices = np.where(np.all(label == (0, 255, 255), axis=-1))
26 | classmap[indices[0].tolist(), indices[1].tolist()] = 1
27 | indices = np.where(np.all(label == (255, 255, 0), axis=-1))
28 | classmap[indices[0].tolist(), indices[1].tolist()] = 2
29 | indices = np.where(np.all(label == (255, 0, 255), axis=-1))
30 | classmap[indices[0].tolist(), indices[1].tolist()] = 3
31 | indices = np.where(np.all(label == (0, 255, 0), axis=-1))
32 | classmap[indices[0].tolist(), indices[1].tolist()] = 4
33 | indices = np.where(np.all(label == (0, 0, 255), axis=-1))
34 | classmap[indices[0].tolist(), indices[1].tolist()] = 5
35 | indices = np.where(np.all(label == (255, 255, 255), axis=-1))
36 | classmap[indices[0].tolist(), indices[1].tolist()] = 6
37 | indices = np.where(np.all(label == (0, 0, 0), axis=-1))
38 | classmap[indices[0].tolist(), indices[1].tolist()] = 0
39 | # plt.imshow(colmap)
40 | # plt.show()
41 | return classmap
42 |
43 |
44 | def classToRGB(label):
45 | l, w = label.shape[0], label.shape[1]
46 | colmap = np.zeros(shape=(l, w, 3)).astype(np.float32)
47 | indices = np.where(label == 1)
48 | colmap[indices[0].tolist(), indices[1].tolist(), :] = [0, 255, 255]
49 | indices = np.where(label == 2)
50 | colmap[indices[0].tolist(), indices[1].tolist(), :] = [255, 255, 0]
51 | indices = np.where(label == 3)
52 | colmap[indices[0].tolist(), indices[1].tolist(), :] = [255, 0, 255]
53 | indices = np.where(label == 4)
54 | colmap[indices[0].tolist(), indices[1].tolist(), :] = [0, 255, 0]
55 | indices = np.where(label == 5)
56 | colmap[indices[0].tolist(), indices[1].tolist(), :] = [0, 0, 255]
57 | indices = np.where(label == 6)
58 | colmap[indices[0].tolist(), indices[1].tolist(), :] = [255, 255, 255]
59 | indices = np.where(label == 0)
60 | colmap[indices[0].tolist(), indices[1].tolist(), :] = [0, 0, 0]
61 | transform = ToTensor();
62 | # plt.imshow(colmap)
63 | # plt.show()
64 | return transform(colmap)
65 |
66 |
67 | def class_to_target(inputs, numClass):
68 | batchSize, l, w = inputs.shape[0], inputs.shape[1], inputs.shape[2]
69 | target = np.zeros(shape=(batchSize, l, w, numClass), dtype=np.float32)
70 | for index in range(7):
71 | indices = np.where(inputs == index)
72 | temp = np.zeros(shape=7, dtype=np.float32)
73 | temp[index] = 1
74 | target[indices[0].tolist(), indices[1].tolist(), indices[2].tolist(), :] = temp
75 | return target.transpose(0, 3, 1, 2)
76 |
77 |
78 | def label_bluring(inputs):
79 | batchSize, numClass, height, width = inputs.shape
80 | outputs = np.ones((batchSize, numClass, height, width), dtype=np.float)
81 | for batchCnt in range(batchSize):
82 | for index in range(numClass):
83 | outputs[batchCnt, index, ...] = cv2.GaussianBlur(inputs[batchCnt, index, ...].astype(np.float), (7, 7), 0)
84 | return outputs
85 |
86 |
87 | class DeepGlobe(data.Dataset):
88 | """input and label image dataset"""
89 |
90 | def __init__(self, root, ids, label=False, transform=False):
91 | super(DeepGlobe, self).__init__()
92 | """
93 | Args:
94 |
95 | fileDir(string): directory with all the input images.
96 | transform(callable, optional): Optional transform to be applied on a sample
97 | """
98 | self.root = root
99 | self.label = label
100 | self.transform = transform
101 | self.ids = ids
102 | self.classdict = {1: "urban", 2: "agriculture", 3: "rangeland", 4: "forest", 5: "water", 6: "barren", 0: "unknown"}
103 |
104 | self.color_jitter = transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.04)
105 | self.resizer = transforms.Resize((2448, 2448))
106 |
107 | def __getitem__(self, index):
108 | sample = {}
109 | sample['id'] = self.ids[index][:-8]
110 | image = Image.open(os.path.join(self.root, "Sat/" + self.ids[index])) # w, h
111 | sample['image'] = image
112 | # sample['image'] = transforms.functional.adjust_contrast(image, 1.4)
113 | if self.label:
114 | # label = scipy.io.loadmat(join(self.root, 'Notification/' + self.ids[index].replace('_sat.jpg', '_mask.mat')))["label"]
115 | # label = Image.fromarray(label)
116 | label = Image.open(os.path.join(self.root, 'Label/' + self.ids[index].replace('_sat.jpg', '_mask.png')))
117 | sample['label'] = label
118 | if self.transform and self.label:
119 | image, label = self._transform(image, label)
120 | sample['image'] = image
121 | sample['label'] = label
122 | # return {'image': image.astype(np.float32), 'label': label.astype(np.int64)}
123 | return sample
124 |
125 | def _transform(self, image, label):
126 | # if np.random.random() > 0.5:
127 | # image = self.color_jitter(image)
128 |
129 | # if np.random.random() > 0.5:
130 | # image = transforms.functional.vflip(image)
131 | # label = transforms.functional.vflip(label)
132 |
133 | if np.random.random() > 0.5:
134 | image = transforms.functional.hflip(image)
135 | label = transforms.functional.hflip(label)
136 |
137 | if np.random.random() > 0.5:
138 | degree = random.choice([90, 180, 270])
139 | image = transforms.functional.rotate(image, degree)
140 | label = transforms.functional.rotate(label, degree)
141 |
142 | # if np.random.random() > 0.5:
143 | # degree = 60 * np.random.random() - 30
144 | # image = transforms.functional.rotate(image, degree)
145 | # label = transforms.functional.rotate(label, degree)
146 |
147 | # if np.random.random() > 0.5:
148 | # ratio = np.random.random()
149 | # h = int(2448 * (ratio + 2) / 3.)
150 | # w = int(2448 * (ratio + 2) / 3.)
151 | # i = int(np.floor(np.random.random() * (2448 - h)))
152 | # j = int(np.floor(np.random.random() * (2448 - w)))
153 | # image = self.resizer(transforms.functional.crop(image, i, j, h, w))
154 | # label = self.resizer(transforms.functional.crop(label, i, j, h, w))
155 |
156 | return image, label
157 |
158 |
159 | def __len__(self):
160 | return len(self.ids)
--------------------------------------------------------------------------------
/utils/lovasz_losses.py:
--------------------------------------------------------------------------------
1 | # https://github.com/bermanmaxim/LovaszSoftmax/blob/master/pytorch/lovasz_losses.py
2 | """
3 | Lovasz-Softmax and Jaccard hinge loss in PyTorch
4 | Maxim Berman 2018 ESAT-PSI KU Leuven (MIT License)
5 | """
6 |
7 | from __future__ import print_function, division
8 |
9 | import torch
10 | from torch.autograd import Variable
11 | import torch.nn.functional as F
12 | import numpy as np
13 | try:
14 | from itertools import ifilterfalse
15 | except ImportError: # py3k
16 | from itertools import filterfalse
17 |
18 |
19 | def lovasz_grad(gt_sorted):
20 | """
21 | Computes gradient of the Lovasz extension w.r.t sorted errors
22 | See Alg. 1 in paper
23 | """
24 | p = len(gt_sorted)
25 | gts = gt_sorted.sum()
26 | intersection = gts - gt_sorted.float().cumsum(0)
27 | union = gts + (1 - gt_sorted).float().cumsum(0)
28 | jaccard = 1. - intersection / union
29 | if p > 1: # cover 1-pixel case
30 | jaccard[1:p] = jaccard[1:p] - jaccard[0:-1]
31 | return jaccard
32 |
33 |
34 | def iou_binary(preds, labels, EMPTY=1., ignore=None, per_image=True):
35 | """
36 | IoU for foreground class
37 | binary: 1 foreground, 0 background
38 | """
39 | if not per_image:
40 | preds, labels = (preds,), (labels,)
41 | ious = []
42 | for pred, label in zip(preds, labels):
43 | intersection = ((label == 1) & (pred == 1)).sum()
44 | union = ((label == 1) | ((pred == 1) & (label != ignore))).sum()
45 | if not union:
46 | iou = EMPTY
47 | else:
48 | iou = float(intersection) / union
49 | ious.append(iou)
50 | iou = mean(ious) # mean accross images if per_image
51 | return 100 * iou
52 |
53 |
54 | def iou(preds, labels, C, EMPTY=1., ignore=None, per_image=False):
55 | """
56 | Array of IoU for each (non ignored) class
57 | """
58 | if not per_image:
59 | preds, labels = (preds,), (labels,)
60 | ious = []
61 | for pred, label in zip(preds, labels):
62 | iou = []
63 | for i in range(C):
64 | if i != ignore: # The ignored label is sometimes among predicted classes (ENet - CityScapes)
65 | intersection = ((label == i) & (pred == i)).sum()
66 | union = ((label == i) | ((pred == i) & (label != ignore))).sum()
67 | if not union:
68 | iou.append(EMPTY)
69 | else:
70 | iou.append(float(intersection) / union)
71 | ious.append(iou)
72 | ious = map(mean, zip(*ious)) # mean accross images if per_image
73 | return 100 * np.array(ious)
74 |
75 |
76 | # --------------------------- BINARY LOSSES ---------------------------
77 |
78 |
79 | def lovasz_hinge(logits, labels, per_image=True, ignore=None):
80 | """
81 | Binary Lovasz hinge loss
82 | logits: [B, H, W] Variable, logits at each pixel (between -\infty and +\infty)
83 | labels: [B, H, W] Tensor, binary ground truth masks (0 or 1)
84 | per_image: compute the loss per image instead of per batch
85 | ignore: void class id
86 | """
87 | if per_image:
88 | loss = mean(lovasz_hinge_flat(*flatten_binary_scores(log.unsqueeze(0), lab.unsqueeze(0), ignore))
89 | for log, lab in zip(logits, labels))
90 | else:
91 | loss = lovasz_hinge_flat(*flatten_binary_scores(logits, labels, ignore))
92 | return loss
93 |
94 |
95 | def lovasz_hinge_flat(logits, labels):
96 | """
97 | Binary Lovasz hinge loss
98 | logits: [P] Variable, logits at each prediction (between -\infty and +\infty)
99 | labels: [P] Tensor, binary ground truth labels (0 or 1)
100 | ignore: label to ignore
101 | """
102 | if len(labels) == 0:
103 | # only void pixels, the gradients should be 0
104 | return logits.sum() * 0.
105 | signs = 2. * labels.float() - 1.
106 | errors = (1. - logits * Variable(signs))
107 | errors_sorted, perm = torch.sort(errors, dim=0, descending=True)
108 | perm = perm.data
109 | gt_sorted = labels[perm]
110 | grad = lovasz_grad(gt_sorted)
111 | loss = torch.dot(F.relu(errors_sorted), Variable(grad))
112 | return loss
113 |
114 |
115 | def flatten_binary_scores(scores, labels, ignore=None):
116 | """
117 | Flattens predictions in the batch (binary case)
118 | Remove labels equal to 'ignore'
119 | """
120 | scores = scores.view(-1)
121 | labels = labels.view(-1)
122 | if ignore is None:
123 | return scores, labels
124 | valid = (labels != ignore)
125 | vscores = scores[valid]
126 | vlabels = labels[valid]
127 | return vscores, vlabels
128 |
129 |
130 | class StableBCELoss(torch.nn.modules.Module):
131 | def __init__(self):
132 | super(StableBCELoss, self).__init__()
133 | def forward(self, input, target):
134 | neg_abs = - input.abs()
135 | loss = input.clamp(min=0) - input * target + (1 + neg_abs.exp()).log()
136 | return loss.mean()
137 |
138 |
139 | def binary_xloss(logits, labels, ignore=None):
140 | """
141 | Binary Cross entropy loss
142 | logits: [B, H, W] Variable, logits at each pixel (between -\infty and +\infty)
143 | labels: [B, H, W] Tensor, binary ground truth masks (0 or 1)
144 | ignore: void class id
145 | """
146 | logits, labels = flatten_binary_scores(logits, labels, ignore)
147 | loss = StableBCELoss()(logits, Variable(labels.float()))
148 | return loss
149 |
150 |
151 | # --------------------------- MULTICLASS LOSSES ---------------------------
152 |
153 |
154 | def lovasz_softmax(probas, labels, only_present=False, per_image=False, ignore=None):
155 | """
156 | Multi-class Lovasz-Softmax loss
157 | probas: [B, C, H, W] Variable, class probabilities at each prediction (between 0 and 1)
158 | labels: [B, H, W] Tensor, ground truth labels (between 0 and C - 1)
159 | only_present: average only on classes present in ground truth
160 | per_image: compute the loss per image instead of per batch
161 | ignore: void class labels
162 | """
163 | if per_image:
164 | loss = mean(lovasz_softmax_flat(*flatten_probas(prob.unsqueeze(0), lab.unsqueeze(0), ignore), only_present=only_present)
165 | for prob, lab in zip(probas, labels))
166 | else:
167 | loss = lovasz_softmax_flat(*flatten_probas(probas, labels, ignore), only_present=only_present)
168 | return loss
169 |
170 |
171 | def lovasz_softmax_flat(probas, labels, only_present=False):
172 | """
173 | Multi-class Lovasz-Softmax loss
174 | probas: [P, C] Variable, class probabilities at each prediction (between 0 and 1)
175 | labels: [P] Tensor, ground truth labels (between 0 and C - 1)
176 | only_present: average only on classes present in ground truth
177 | """
178 | C = probas.size(1)
179 | losses = []
180 | for c in range(C):
181 | fg = (labels == c).float() # foreground for class c
182 | if only_present and fg.sum() == 0:
183 | continue
184 | errors = (Variable(fg) - probas[:, c]).abs()
185 | errors_sorted, perm = torch.sort(errors, 0, descending=True)
186 | perm = perm.data
187 | fg_sorted = fg[perm]
188 | losses.append(torch.dot(errors_sorted, Variable(lovasz_grad(fg_sorted))))
189 | return mean(losses)
190 |
191 |
192 | def flatten_probas(probas, labels, ignore=None):
193 | """
194 | Flattens predictions in the batch
195 | """
196 | B, C, H, W = probas.size()
197 | probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, C
198 | labels = labels.view(-1)
199 | if ignore is None:
200 | return probas, labels
201 | valid = (labels != ignore)
202 | vprobas = probas[valid.nonzero().squeeze()]
203 | vlabels = labels[valid]
204 | # vlabels = labels[valid] - 1
205 | return vprobas, vlabels
206 |
207 | def xloss(logits, labels, ignore=None):
208 | """
209 | Cross entropy loss
210 | """
211 | return F.cross_entropy(logits, Variable(labels), ignore_index=255)
212 |
213 |
214 | # --------------------------- HELPER FUNCTIONS ---------------------------
215 |
216 | def mean(l, ignore_nan=False, empty=0):
217 | """
218 | nanmean compatible with generators.
219 | """
220 | l = iter(l)
221 | if ignore_nan:
222 | l = ifilterfalse(np.isnan, l)
223 | try:
224 | n = 1
225 | acc = next(l)
226 | except StopIteration:
227 | if empty == 'raise':
228 | raise ValueError('Empty mean')
229 | return empty
230 | for n, v in enumerate(l, 2):
231 | acc += v
232 | if n == 1:
233 | return acc
234 | return acc / n
235 |
--------------------------------------------------------------------------------
/train.txt:
--------------------------------------------------------------------------------
1 | 100694_sat.jpg
2 | 10233_sat.jpg
3 | 103665_sat.jpg
4 | 103730_sat.jpg
5 | 104113_sat.jpg
6 | 10901_sat.jpg
7 | 111335_sat.jpg
8 | 114433_sat.jpg
9 | 119079_sat.jpg
10 | 119_sat.jpg
11 | 120625_sat.jpg
12 | 122104_sat.jpg
13 | 122178_sat.jpg
14 | 125795_sat.jpg
15 | 131720_sat.jpg
16 | 133254_sat.jpg
17 | 13415_sat.jpg
18 | 134465_sat.jpg
19 | 137806_sat.jpg
20 | 139482_sat.jpg
21 | 140299_sat.jpg
22 | 141685_sat.jpg
23 | 142766_sat.jpg
24 | 149624_sat.jpg
25 | 152569_sat.jpg
26 | 154124_sat.jpg
27 | 15573_sat.jpg
28 | 156574_sat.jpg
29 | 156951_sat.jpg
30 | 157839_sat.jpg
31 | 158163_sat.jpg
32 | 159177_sat.jpg
33 | 159280_sat.jpg
34 | 159322_sat.jpg
35 | 160037_sat.jpg
36 | 161838_sat.jpg
37 | 164029_sat.jpg
38 | 172307_sat.jpg
39 | 172854_sat.jpg
40 | 174980_sat.jpg
41 | 176112_sat.jpg
42 | 176506_sat.jpg
43 | 182027_sat.jpg
44 | 182422_sat.jpg
45 | 185562_sat.jpg
46 | 192576_sat.jpg
47 | 192602_sat.jpg
48 | 20187_sat.jpg
49 | 202277_sat.jpg
50 | 204494_sat.jpg
51 | 204562_sat.jpg
52 | 207663_sat.jpg
53 | 207743_sat.jpg
54 | 208495_sat.jpg
55 | 208695_sat.jpg
56 | 21023_sat.jpg
57 | 210473_sat.jpg
58 | 210669_sat.jpg
59 | 215525_sat.jpg
60 | 217085_sat.jpg
61 | 21717_sat.jpg
62 | 218329_sat.jpg
63 | 221278_sat.jpg
64 | 232373_sat.jpg
65 | 2334_sat.jpg
66 | 235869_sat.jpg
67 | 238322_sat.jpg
68 | 239955_sat.jpg
69 | 244423_sat.jpg
70 | 24813_sat.jpg
71 | 252743_sat.jpg
72 | 253691_sat.jpg
73 | 254565_sat.jpg
74 | 255711_sat.jpg
75 | 256189_sat.jpg
76 | 257695_sat.jpg
77 | 26261_sat.jpg
78 | 263576_sat.jpg
79 | 266_sat.jpg
80 | 267065_sat.jpg
81 | 267163_sat.jpg
82 | 269601_sat.jpg
83 | 271609_sat.jpg
84 | 27460_sat.jpg
85 | 276761_sat.jpg
86 | 276912_sat.jpg
87 | 277644_sat.jpg
88 | 277994_sat.jpg
89 | 280703_sat.jpg
90 | 282120_sat.jpg
91 | 28559_sat.jpg
92 | 291214_sat.jpg
93 | 291781_sat.jpg
94 | 293776_sat.jpg
95 | 29419_sat.jpg
96 | 294697_sat.jpg
97 | 296279_sat.jpg
98 | 296368_sat.jpg
99 | 298396_sat.jpg
100 | 298817_sat.jpg
101 | 299287_sat.jpg
102 | 300626_sat.jpg
103 | 300967_sat.jpg
104 | 303327_sat.jpg
105 | 306486_sat.jpg
106 | 308959_sat.jpg
107 | 310419_sat.jpg
108 | 311386_sat.jpg
109 | 315352_sat.jpg
110 | 316446_sat.jpg
111 | 318338_sat.jpg
112 | 321724_sat.jpg
113 | 322400_sat.jpg
114 | 325354_sat.jpg
115 | 331533_sat.jpg
116 | 331994_sat.jpg
117 | 33262_sat.jpg
118 | 333661_sat.jpg
119 | 335737_sat.jpg
120 | 33573_sat.jpg
121 | 337272_sat.jpg
122 | 338798_sat.jpg
123 | 340898_sat.jpg
124 | 343016_sat.jpg
125 | 34330_sat.jpg
126 | 343425_sat.jpg
127 | 34359_sat.jpg
128 | 345134_sat.jpg
129 | 345494_sat.jpg
130 | 347676_sat.jpg
131 | 347725_sat.jpg
132 | 3484_sat.jpg
133 | 351727_sat.jpg
134 | 352808_sat.jpg
135 | 358591_sat.jpg
136 | 361129_sat.jpg
137 | 36183_sat.jpg
138 | 362274_sat.jpg
139 | 365555_sat.jpg
140 | 373186_sat.jpg
141 | 37586_sat.jpg
142 | 376441_sat.jpg
143 | 37755_sat.jpg
144 | 382428_sat.jpg
145 | 383392_sat.jpg
146 | 383637_sat.jpg
147 | 384477_sat.jpg
148 | 387554_sat.jpg
149 | 388811_sat.jpg
150 | 392711_sat.jpg
151 | 397351_sat.jpg
152 | 397864_sat.jpg
153 | 400179_sat.jpg
154 | 40168_sat.jpg
155 | 402002_sat.jpg
156 | 40350_sat.jpg
157 | 403978_sat.jpg
158 | 405378_sat.jpg
159 | 405744_sat.jpg
160 | 411741_sat.jpg
161 | 413779_sat.jpg
162 | 416381_sat.jpg
163 | 416463_sat.jpg
164 | 417313_sat.jpg
165 | 41944_sat.jpg
166 | 420066_sat.jpg
167 | 423117_sat.jpg
168 | 428327_sat.jpg
169 | 434243_sat.jpg
170 | 435277_sat.jpg
171 | 439854_sat.jpg
172 | 442329_sat.jpg
173 | 444902_sat.jpg
174 | 45357_sat.jpg
175 | 45676_sat.jpg
176 | 457982_sat.jpg
177 | 458687_sat.jpg
178 | 458776_sat.jpg
179 | 463855_sat.jpg
180 | 467076_sat.jpg
181 | 468103_sat.jpg
182 | 470446_sat.jpg
183 | 470798_sat.jpg
184 | 476582_sat.jpg
185 | 476991_sat.jpg
186 | 482365_sat.jpg
187 | 483506_sat.jpg
188 | 485061_sat.jpg
189 | 491356_sat.jpg
190 | 491696_sat.jpg
191 | 492365_sat.jpg
192 | 495876_sat.jpg
193 | 496948_sat.jpg
194 | 499161_sat.jpg
195 | 499266_sat.jpg
196 | 499418_sat.jpg
197 | 499511_sat.jpg
198 | 501053_sat.jpg
199 | 507241_sat.jpg
200 | 508571_sat.jpg
201 | 511850_sat.jpg
202 | 515521_sat.jpg
203 | 516056_sat.jpg
204 | 516317_sat.jpg
205 | 518833_sat.jpg
206 | 520614_sat.jpg
207 | 524056_sat.jpg
208 | 524518_sat.jpg
209 | 528163_sat.jpg
210 | 530040_sat.jpg
211 | 534154_sat.jpg
212 | 53987_sat.jpg
213 | 541060_sat.jpg
214 | 541353_sat.jpg
215 | 544464_sat.jpg
216 | 547201_sat.jpg
217 | 547785_sat.jpg
218 | 548423_sat.jpg
219 | 548686_sat.jpg
220 | 549870_sat.jpg
221 | 549959_sat.jpg
222 | 552206_sat.jpg
223 | 552396_sat.jpg
224 | 55374_sat.jpg
225 | 556572_sat.jpg
226 | 557309_sat.jpg
227 | 561117_sat.jpg
228 | 568270_sat.jpg
229 | 56924_sat.jpg
230 | 570332_sat.jpg
231 | 575902_sat.jpg
232 | 584941_sat.jpg
233 | 585043_sat.jpg
234 | 586670_sat.jpg
235 | 587968_sat.jpg
236 | 588542_sat.jpg
237 | 58864_sat.jpg
238 | 58910_sat.jpg
239 | 596837_sat.jpg
240 | 599842_sat.jpg
241 | 599975_sat.jpg
242 | 601966_sat.jpg
243 | 602453_sat.jpg
244 | 604647_sat.jpg
245 | 604833_sat.jpg
246 | 605037_sat.jpg
247 | 605764_sat.jpg
248 | 606014_sat.jpg
249 | 606370_sat.jpg
250 | 607622_sat.jpg
251 | 608673_sat.jpg
252 | 609234_sat.jpg
253 | 611015_sat.jpg
254 | 612214_sat.jpg
255 | 61245_sat.jpg
256 | 613687_sat.jpg
257 | 616234_sat.jpg
258 | 616860_sat.jpg
259 | 617844_sat.jpg
260 | 618372_sat.jpg
261 | 621206_sat.jpg
262 | 621633_sat.jpg
263 | 622733_sat.jpg
264 | 623857_sat.jpg
265 | 625296_sat.jpg
266 | 626208_sat.jpg
267 | 627806_sat.jpg
268 | 629198_sat.jpg
269 | 632489_sat.jpg
270 | 634421_sat.jpg
271 | 634717_sat.jpg
272 | 635157_sat.jpg
273 | 636849_sat.jpg
274 | 638158_sat.jpg
275 | 639149_sat.jpg
276 | 639314_sat.jpg
277 | 6399_sat.jpg
278 | 642909_sat.jpg
279 | 644103_sat.jpg
280 | 644150_sat.jpg
281 | 645001_sat.jpg
282 | 649260_sat.jpg
283 | 650751_sat.jpg
284 | 651312_sat.jpg
285 | 65170_sat.jpg
286 | 651774_sat.jpg
287 | 652883_sat.jpg
288 | 655313_sat.jpg
289 | 66344_sat.jpg
290 | 664140_sat.jpg
291 | 664396_sat.jpg
292 | 665914_sat.jpg
293 | 668465_sat.jpg
294 | 669010_sat.jpg
295 | 669779_sat.jpg
296 | 672041_sat.jpg
297 | 672823_sat.jpg
298 | 675424_sat.jpg
299 | 675849_sat.jpg
300 | 676758_sat.jpg
301 | 678520_sat.jpg
302 | 679036_sat.jpg
303 | 682046_sat.jpg
304 | 682688_sat.jpg
305 | 682949_sat.jpg
306 | 692004_sat.jpg
307 | 695475_sat.jpg
308 | 696257_sat.jpg
309 | 69628_sat.jpg
310 | 698065_sat.jpg
311 | 698628_sat.jpg
312 | 699650_sat.jpg
313 | 711893_sat.jpg
314 | 714414_sat.jpg
315 | 715633_sat.jpg
316 | 715846_sat.jpg
317 | 71619_sat.jpg
318 | 717225_sat.jpg
319 | 723067_sat.jpg
320 | 723719_sat.jpg
321 | 727832_sat.jpg
322 | 72807_sat.jpg
323 | 730821_sat.jpg
324 | 736869_sat.jpg
325 | 736933_sat.jpg
326 | 739122_sat.jpg
327 | 739760_sat.jpg
328 | 740937_sat.jpg
329 | 747824_sat.jpg
330 | 749523_sat.jpg
331 | 753408_sat.jpg
332 | 759668_sat.jpg
333 | 759855_sat.jpg
334 | 761189_sat.jpg
335 | 762359_sat.jpg
336 | 763075_sat.jpg
337 | 763892_sat.jpg
338 | 765792_sat.jpg
339 | 76759_sat.jpg
340 | 768475_sat.jpg
341 | 772144_sat.jpg
342 | 772567_sat.jpg
343 | 77388_sat.jpg
344 | 774779_sat.jpg
345 | 778804_sat.jpg
346 | 782103_sat.jpg
347 | 784140_sat.jpg
348 | 786226_sat.jpg
349 | 7906_sat.jpg
350 | 798411_sat.jpg
351 | 801361_sat.jpg
352 | 802645_sat.jpg
353 | 80318_sat.jpg
354 | 803958_sat.jpg
355 | 805150_sat.jpg
356 | 806805_sat.jpg
357 | 807146_sat.jpg
358 | 80808_sat.jpg
359 | 808980_sat.jpg
360 | 81011_sat.jpg
361 | 810368_sat.jpg
362 | 811075_sat.jpg
363 | 820543_sat.jpg
364 | 825592_sat.jpg
365 | 825816_sat.jpg
366 | 827126_sat.jpg
367 | 830444_sat.jpg
368 | 834433_sat.jpg
369 | 838669_sat.jpg
370 | 841621_sat.jpg
371 | 845069_sat.jpg
372 | 847604_sat.jpg
373 | 848649_sat.jpg
374 | 848728_sat.jpg
375 | 848780_sat.jpg
376 | 849797_sat.jpg
377 | 853702_sat.jpg
378 | 855_sat.jpg
379 | 860326_sat.jpg
380 | 866782_sat.jpg
381 | 867017_sat.jpg
382 | 868003_sat.jpg
383 | 86805_sat.jpg
384 | 870705_sat.jpg
385 | 873132_sat.jpg
386 | 875328_sat.jpg
387 | 877160_sat.jpg
388 | 878990_sat.jpg
389 | 880610_sat.jpg
390 | 88571_sat.jpg
391 | 888263_sat.jpg
392 | 888343_sat.jpg
393 | 889145_sat.jpg
394 | 889920_sat.jpg
395 | 890145_sat.jpg
396 | 893261_sat.jpg
397 | 893904_sat.jpg
398 | 895509_sat.jpg
399 | 899693_sat.jpg
400 | 901715_sat.jpg
401 | 902350_sat.jpg
402 | 903649_sat.jpg
403 | 906113_sat.jpg
404 | 910525_sat.jpg
405 | 911457_sat.jpg
406 | 914008_sat.jpg
407 | 916141_sat.jpg
408 | 916336_sat.jpg
409 | 916518_sat.jpg
410 | 917081_sat.jpg
411 | 918446_sat.jpg
412 | 919051_sat.jpg
413 | 923223_sat.jpg
414 | 923618_sat.jpg
415 | 924236_sat.jpg
416 | 926392_sat.jpg
417 | 927126_sat.jpg
418 | 927644_sat.jpg
419 | 930028_sat.jpg
420 | 939614_sat.jpg
421 | 940229_sat.jpg
422 | 942307_sat.jpg
423 | 942594_sat.jpg
424 | 943463_sat.jpg
425 | 943943_sat.jpg
426 | 946386_sat.jpg
427 | 946408_sat.jpg
428 | 946475_sat.jpg
429 | 947994_sat.jpg
430 | 949235_sat.jpg
431 | 951120_sat.jpg
432 | 952430_sat.jpg
433 | 954552_sat.jpg
434 | 95613_sat.jpg
435 | 95683_sat.jpg
436 | 95863_sat.jpg
437 | 961407_sat.jpg
438 | 965977_sat.jpg
439 | 967818_sat.jpg
440 | 96870_sat.jpg
441 | 969934_sat.jpg
442 | 971880_sat.jpg
443 | 98150_sat.jpg
444 | 981852_sat.jpg
445 | 983603_sat.jpg
446 | 987079_sat.jpg
447 | 987427_sat.jpg
448 | 988517_sat.jpg
449 | 989499_sat.jpg
450 | 990573_sat.jpg
451 | 990617_sat.jpg
452 | 990619_sat.jpg
453 | 991758_sat.jpg
454 | 995492_sat.jpg
455 |
--------------------------------------------------------------------------------
/train_deep_globe.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | from __future__ import absolute_import, division, print_function
5 |
6 | import os
7 | import numpy as np
8 | import torch
9 | import torch.nn as nn
10 | from torchvision import transforms
11 | from tqdm import tqdm
12 | from dataset.deep_globe import DeepGlobe, classToRGB, is_image_file
13 | from utils.loss import CrossEntropyLoss2d, SoftCrossEntropyLoss2d, FocalLoss
14 | from utils.lovasz_losses import lovasz_softmax
15 | from utils.lr_scheduler import LR_Scheduler
16 | from tensorboardX import SummaryWriter
17 | from helper import create_model_load_weights, get_optimizer, Trainer, Evaluator, collate, collate_test
18 | from option import Options
19 |
20 | args = Options().parse()
21 | n_class = args.n_class
22 |
23 | # torch.cuda.synchronize()
24 | # torch.backends.cudnn.benchmark = True
25 | torch.backends.cudnn.deterministic = True
26 |
27 | data_path = args.data_path
28 | model_path = args.model_path
29 | if not os.path.isdir(model_path): os.mkdir(model_path)
30 | log_path = args.log_path
31 | if not os.path.isdir(log_path): os.mkdir(log_path)
32 | task_name = args.task_name
33 |
34 | print(task_name)
35 | ###################################
36 |
37 | mode = args.mode # 1: train global; 2: train local from global; 3: train global from local
38 | evaluation = args.evaluation
39 | test = evaluation and False
40 | print("mode:", mode, "evaluation:", evaluation, "test:", test)
41 |
42 | ###################################
43 | print("preparing datasets and dataloaders......")
44 | batch_size = args.batch_size
45 | ids_train = [image_name for image_name in os.listdir(os.path.join(data_path, "train", "Sat")) if is_image_file(image_name)]
46 | ids_val = [image_name for image_name in os.listdir(os.path.join(data_path, "crossvali", "Sat")) if is_image_file(image_name)]
47 | ids_test = [image_name for image_name in os.listdir(os.path.join(data_path, "offical_crossvali", "Sat")) if is_image_file(image_name)]
48 |
49 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
50 | dataset_train = DeepGlobe(os.path.join(data_path, "train"), ids_train, label=True, transform=True)
51 | dataloader_train = torch.utils.data.DataLoader(dataset=dataset_train, batch_size=batch_size, num_workers=10, collate_fn=collate, shuffle=True, pin_memory=True)
52 | dataset_val = DeepGlobe(os.path.join(data_path, "crossvali"), ids_val, label=True)
53 | dataloader_val = torch.utils.data.DataLoader(dataset=dataset_val, batch_size=batch_size, num_workers=10, collate_fn=collate, shuffle=False, pin_memory=True)
54 | dataset_test = DeepGlobe(os.path.join(data_path, "offical_crossvali"), ids_test, label=False)
55 | dataloader_test = torch.utils.data.DataLoader(dataset=dataset_test, batch_size=batch_size, num_workers=10, collate_fn=collate_test, shuffle=False, pin_memory=True)
56 |
57 | ##### sizes are (w, h) ##############################
58 | # make sure margin / 32 is over 1.5 AND size_g is divisible by 4
59 | size_g = (args.size_g, args.size_g) # resized global image
60 | size_p = (args.size_p, args.size_p) # cropped local patch size
61 | sub_batch_size = args.sub_batch_size # batch size for train local patches
62 | ###################################
63 | print("creating models......")
64 |
65 | path_g = os.path.join(model_path, args.path_g)
66 | path_g2l = os.path.join(model_path, args.path_g2l)
67 | path_l2g = os.path.join(model_path, args.path_l2g)
68 | model, global_fixed = create_model_load_weights(n_class, mode, evaluation, path_g=path_g, path_g2l=path_g2l, path_l2g=path_l2g)
69 |
70 | ###################################
71 | num_epochs = args.num_epochs
72 | learning_rate = args.lr
73 | lamb_fmreg = args.lamb_fmreg
74 |
75 | optimizer = get_optimizer(model, mode, learning_rate=learning_rate)
76 |
77 | scheduler = LR_Scheduler('poly', learning_rate, num_epochs, len(dataloader_train))
78 | ##################################
79 |
80 | criterion1 = FocalLoss(gamma=3)
81 | criterion2 = nn.CrossEntropyLoss()
82 | criterion3 = lovasz_softmax
83 | criterion = lambda x,y: criterion1(x, y)
84 | # criterion = lambda x,y: 0.5*criterion1(x, y) + 0.5*criterion3(x, y)
85 | mse = nn.MSELoss()
86 |
87 | if not evaluation:
88 | writer = SummaryWriter(log_dir=log_path + task_name)
89 | f_log = open(log_path + task_name + ".log", 'w')
90 |
91 | trainer = Trainer(criterion, optimizer, n_class, size_g, size_p, sub_batch_size, mode, lamb_fmreg)
92 | evaluator = Evaluator(n_class, size_g, size_p, sub_batch_size, mode, test)
93 |
94 | best_pred = 0.0
95 | print("start training......")
96 | for epoch in range(num_epochs):
97 | trainer.set_train(model)
98 | optimizer.zero_grad()
99 | tbar = tqdm(dataloader_train); train_loss = 0
100 | for i_batch, sample_batched in enumerate(tbar):
101 | if evaluation: break
102 | scheduler(optimizer, i_batch, epoch, best_pred)
103 | loss = trainer.train(sample_batched, model, global_fixed)
104 | train_loss += loss.item()
105 | score_train, score_train_global, score_train_local = trainer.get_scores()
106 | if mode == 1: tbar.set_description('Train loss: %.3f; global mIoU: %.3f' % (train_loss / (i_batch + 1), np.mean(np.nan_to_num(score_train_global["iou"]))))
107 | else: tbar.set_description('Train loss: %.3f; agg mIoU: %.3f' % (train_loss / (i_batch + 1), np.mean(np.nan_to_num(score_train["iou"]))))
108 |
109 | score_train, score_train_global, score_train_local = trainer.get_scores()
110 | trainer.reset_metrics()
111 | # torch.cuda.empty_cache()
112 |
113 | if epoch % 1 == 0:
114 | with torch.no_grad():
115 | model.eval()
116 | print("evaluating...")
117 |
118 | if test: tbar = tqdm(dataloader_test)
119 | else: tbar = tqdm(dataloader_val)
120 |
121 | for i_batch, sample_batched in enumerate(tbar):
122 | predictions, predictions_global, predictions_local = evaluator.eval_test(sample_batched, model, global_fixed)
123 | score_val, score_val_global, score_val_local = evaluator.get_scores()
124 | # use [1:] since class0 is not considered in deep_globe metric
125 | if mode == 1: tbar.set_description('global mIoU: %.3f' % (np.mean(np.nan_to_num(score_val_global["iou"])[1:])))
126 | else: tbar.set_description('agg mIoU: %.3f' % (np.mean(np.nan_to_num(score_val["iou"])[1:])))
127 | images = sample_batched['image']
128 | if not test:
129 | labels = sample_batched['label'] # PIL images
130 |
131 | if test:
132 | if not os.path.isdir("./prediction/"): os.mkdir("./prediction/")
133 | for i in range(len(images)):
134 | if mode == 1:
135 | transforms.functional.to_pil_image(classToRGB(predictions_global[i]) * 255.).save("./prediction/" + sample_batched['id'][i] + "_mask.png")
136 | else:
137 | transforms.functional.to_pil_image(classToRGB(predictions[i]) * 255.).save("./prediction/" + sample_batched['id'][i] + "_mask.png")
138 |
139 | if not evaluation and not test:
140 | if i_batch * batch_size + len(images) > (epoch % len(dataloader_val)) and i_batch * batch_size <= (epoch % len(dataloader_val)):
141 | writer.add_image('image', transforms.ToTensor()(images[(epoch % len(dataloader_val)) - i_batch * batch_size]), epoch)
142 | if not test:
143 | writer.add_image('mask', classToRGB(np.array(labels[(epoch % len(dataloader_val)) - i_batch * batch_size])) * 255., epoch)
144 | if mode == 2 or mode == 3:
145 | writer.add_image('prediction', classToRGB(predictions[(epoch % len(dataloader_val)) - i_batch * batch_size]) * 255., epoch)
146 | writer.add_image('prediction_local', classToRGB(predictions_local[(epoch % len(dataloader_val)) - i_batch * batch_size]) * 255., epoch)
147 | writer.add_image('prediction_global', classToRGB(predictions_global[(epoch % len(dataloader_val)) - i_batch * batch_size]) * 255., epoch)
148 |
149 | # torch.cuda.empty_cache()
150 |
151 | # if not (test or evaluation): torch.save(model.state_dict(), "./saved_models/" + task_name + ".epoch" + str(epoch) + ".pth")
152 | if not (test or evaluation): torch.save(model.state_dict(), "./saved_models/" + task_name + ".pth")
153 |
154 | if test: break
155 | else:
156 | score_val, score_val_global, score_val_local = evaluator.get_scores()
157 | evaluator.reset_metrics()
158 | if mode == 1:
159 | if np.mean(np.nan_to_num(score_val_global["iou"][1:])) > best_pred: best_pred = np.mean(np.nan_to_num(score_val_global["iou"][1:]))
160 | else:
161 | if np.mean(np.nan_to_num(score_val["iou"][1:])) > best_pred: best_pred = np.mean(np.nan_to_num(score_val["iou"][1:]))
162 | log = ""
163 | log = log + 'epoch [{}/{}] IoU: train = {:.4f}, val = {:.4f}'.format(epoch+1, num_epochs, np.mean(np.nan_to_num(score_train["iou"][1:])), np.mean(np.nan_to_num(score_val["iou"][1:]))) + "\n"
164 | log = log + 'epoch [{}/{}] Local -- IoU: train = {:.4f}, val = {:.4f}'.format(epoch+1, num_epochs, np.mean(np.nan_to_num(score_train_local["iou"][1:])), np.mean(np.nan_to_num(score_val_local["iou"][1:]))) + "\n"
165 | log = log + 'epoch [{}/{}] Global -- IoU: train = {:.4f}, val = {:.4f}'.format(epoch+1, num_epochs, np.mean(np.nan_to_num(score_train_global["iou"][1:])), np.mean(np.nan_to_num(score_val_global["iou"][1:]))) + "\n"
166 | log = log + "train: " + str(score_train["iou"]) + "\n"
167 | log = log + "val:" + str(score_val["iou"]) + "\n"
168 | log = log + "Local train:" + str(score_train_local["iou"]) + "\n"
169 | log = log + "Local val:" + str(score_val_local["iou"]) + "\n"
170 | log = log + "Global train:" + str(score_train_global["iou"]) + "\n"
171 | log = log + "Global val:" + str(score_val_global["iou"]) + "\n"
172 | log += "================================\n"
173 | print(log)
174 | if evaluation: break
175 |
176 | f_log.write(log)
177 | f_log.flush()
178 | if mode == 1:
179 | writer.add_scalars('IoU', {'train iou': np.mean(np.nan_to_num(score_train_global["iou"][1:])), 'validation iou': np.mean(np.nan_to_num(score_val_global["iou"][1:]))}, epoch)
180 | else:
181 | writer.add_scalars('IoU', {'train iou': np.mean(np.nan_to_num(score_train["iou"][1:])), 'validation iou': np.mean(np.nan_to_num(score_val["iou"][1:]))}, epoch)
182 |
183 | if not evaluation: f_log.close()
--------------------------------------------------------------------------------
/models/resnet_dilation.py:
--------------------------------------------------------------------------------
1 | """Dilated ResNet"""
2 | # https://github.com/zhanghang1989/PyTorch-Encoding/blob/master/encoding/dilated/resnet.py
3 | # https://github.com/fyu/drn
4 | import math
5 | import torch
6 | import torch.utils.model_zoo as model_zoo
7 | import torch.nn as nn
8 | from .model_store import get_model_file
9 |
10 | __all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
11 | 'resnet152', 'BasicBlock', 'Bottleneck']
12 |
13 | model_urls = {
14 | 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
15 | 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
16 | 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
17 | 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
18 | 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
19 | }
20 |
21 |
22 | def conv3x3(in_planes, out_planes, stride=1):
23 | "3x3 convolution with padding"
24 | return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
25 | padding=1, bias=False)
26 |
27 |
28 | class BasicBlock(nn.Module):
29 | """ResNet BasicBlock
30 | """
31 | expansion = 1
32 | def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None, previous_dilation=1,
33 | norm_layer=None):
34 | super(BasicBlock, self).__init__()
35 | self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride,
36 | padding=dilation, dilation=dilation, bias=False)
37 | self.bn1 = norm_layer(planes)
38 | self.relu = nn.ReLU(inplace=True)
39 | self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1,
40 | padding=previous_dilation, dilation=previous_dilation, bias=False)
41 | self.bn2 = norm_layer(planes)
42 | self.downsample = downsample
43 | self.stride = stride
44 |
45 | def forward(self, x):
46 | residual = x
47 |
48 | out = self.conv1(x)
49 | out = self.bn1(out)
50 | out = self.relu(out)
51 |
52 | out = self.conv2(out)
53 | out = self.bn2(out)
54 |
55 | if self.downsample is not None:
56 | residual = self.downsample(x)
57 |
58 | out += residual
59 | out = self.relu(out)
60 |
61 | return out
62 |
63 |
64 | class Bottleneck(nn.Module):
65 | """ResNet Bottleneck
66 | """
67 | # pylint: disable=unused-argument
68 | expansion = 4
69 | def __init__(self, inplanes, planes, stride=1, dilation=1,
70 | downsample=None, previous_dilation=1, norm_layer=None):
71 | super(Bottleneck, self).__init__()
72 | self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
73 | self.bn1 = norm_layer(planes)
74 | self.conv2 = nn.Conv2d(
75 | planes, planes, kernel_size=3, stride=stride,
76 | padding=dilation, dilation=dilation, bias=False)
77 | self.bn2 = norm_layer(planes)
78 | self.conv3 = nn.Conv2d(
79 | planes, planes * 4, kernel_size=1, bias=False)
80 | self.bn3 = norm_layer(planes * 4)
81 | self.relu = nn.ReLU(inplace=True)
82 | self.downsample = downsample
83 | self.dilation = dilation
84 | self.stride = stride
85 |
86 | def _sum_each(self, x, y):
87 | assert(len(x) == len(y))
88 | z = []
89 | for i in range(len(x)):
90 | z.append(x[i]+y[i])
91 | return z
92 |
93 | def forward(self, x):
94 | residual = x
95 |
96 | out = self.conv1(x)
97 | out = self.bn1(out)
98 | out = self.relu(out)
99 |
100 | out = self.conv2(out)
101 | out = self.bn2(out)
102 | out = self.relu(out)
103 |
104 | out = self.conv3(out)
105 | out = self.bn3(out)
106 |
107 | if self.downsample is not None:
108 | residual = self.downsample(x)
109 |
110 | out += residual
111 | out = self.relu(out)
112 |
113 | return out
114 |
115 |
116 | class ResNet(nn.Module):
117 | """Dilated Pre-trained ResNet Model, which preduces the stride of 8 featuremaps at conv5.
118 |
119 | Parameters
120 | ----------
121 | block : Block
122 | Class for the residual block. Options are BasicBlockV1, BottleneckV1.
123 | layers : list of int
124 | Numbers of layers in each block
125 | classes : int, default 1000
126 | Number of classification classes.
127 | dilated : bool, default False
128 | Applying dilation strategy to pretrained ResNet yielding a stride-8 model,
129 | typically used in Semantic Segmentation.
130 | norm_layer : object
131 | Normalization layer used in backbone network (default: :class:`mxnet.gluon.nn.BatchNorm`;
132 | for Synchronized Cross-GPU BachNormalization).
133 |
134 | Reference:
135 |
136 | - He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
137 |
138 | - Yu, Fisher, and Vladlen Koltun. "Multi-scale context aggregation by dilated convolutions."
139 | """
140 | # pylint: disable=unused-variable
141 | def __init__(self, block, layers, num_classes=1000, dilated=True, norm_layer=nn.BatchNorm2d, multi_grid=True, multi_dilation=(1, 2, 3)):
142 | self.inplanes = 128 # 64
143 | super(ResNet, self).__init__()
144 | # self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
145 | self.conv1 = nn.Sequential(
146 | nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False),
147 | norm_layer(64),
148 | nn.ReLU(inplace=True),
149 | nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False),
150 | norm_layer(64),
151 | nn.ReLU(inplace=True),
152 | nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1, bias=False),
153 | )
154 | self.bn1 = norm_layer(self.inplanes)
155 | self.relu = nn.ReLU(inplace=True)
156 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
157 | self.layer1 = self._make_layer(block, 64, layers[0], norm_layer=norm_layer)
158 | self.layer2 = self._make_layer(block, 128, layers[1], stride=2, norm_layer=norm_layer)
159 | if dilated:
160 | if multi_grid:
161 | self.layer3 = self._make_layer(block,256,layers[2],stride=1,
162 | dilation=2, norm_layer=norm_layer)
163 | self.layer4 = self._make_layer(block,512,layers[3],stride=1,
164 | dilation=4, norm_layer=norm_layer,
165 | multi_grid=multi_grid, multi_dilation=multi_dilation)
166 | else:
167 | self.layer3 = self._make_layer(block, 256, layers[2], stride=1,
168 | dilation=2, norm_layer=norm_layer)
169 | self.layer4 = self._make_layer(block, 512, layers[3], stride=1,
170 | dilation=4, norm_layer=norm_layer)
171 | else:
172 | self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
173 | norm_layer=norm_layer)
174 | self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
175 | norm_layer=norm_layer)
176 | # self.avgpool = nn.AvgPool2d(7)
177 | # self.fc = nn.Linear(512 * block.expansion, num_classes)
178 |
179 | for m in self.modules():
180 | if isinstance(m, nn.Conv2d):
181 | n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
182 | m.weight.data.normal_(0, math.sqrt(2. / n))
183 | elif isinstance(m, norm_layer):
184 | m.weight.data.fill_(1)
185 | m.bias.data.zero_()
186 |
187 | def _make_layer(self, block, planes, blocks, stride=1, dilation=1, norm_layer=None, multi_grid=False, multi_dilation=None):
188 | downsample = None
189 | if stride != 1 or self.inplanes != planes * block.expansion:
190 | downsample = nn.Sequential(
191 | nn.Conv2d(self.inplanes, planes * block.expansion,
192 | kernel_size=1, stride=stride, bias=False),
193 | norm_layer(planes * block.expansion),
194 | )
195 |
196 | layers = []
197 | if multi_grid == False:
198 | if dilation == 1 or dilation == 2:
199 | layers.append(block(self.inplanes, planes, stride, dilation=1,
200 | downsample=downsample, previous_dilation=dilation, norm_layer=norm_layer))
201 | elif dilation == 4:
202 | layers.append(block(self.inplanes, planes, stride, dilation=2,
203 | downsample=downsample, previous_dilation=dilation, norm_layer=norm_layer))
204 | else:
205 | raise RuntimeError("=> unknown dilation size: {}".format(dilation))
206 | else:
207 | layers.append(block(self.inplanes, planes, stride, dilation=multi_dilation[0],
208 | downsample=downsample, previous_dilation=dilation, norm_layer=norm_layer))
209 | self.inplanes = planes * block.expansion
210 | if multi_grid:
211 | div = len(multi_dilation)
212 | for i in range(1,blocks):
213 | layers.append(block(self.inplanes, planes, dilation=multi_dilation[i%div], previous_dilation=dilation,
214 | norm_layer=norm_layer))
215 | else:
216 | for i in range(1, blocks):
217 | layers.append(block(self.inplanes, planes, dilation=dilation, previous_dilation=dilation,
218 | norm_layer=norm_layer))
219 |
220 | return nn.Sequential(*layers)
221 |
222 | def forward(self, x):
223 | x = self.conv1(x)
224 | x = self.bn1(x)
225 | x = self.relu(x)
226 | x = self.maxpool(x)
227 |
228 | c2 = self.layer1(x)
229 | c3 = self.layer2(c2)
230 | c4 = self.layer3(c3)
231 | c5 = self.layer4(c4)
232 | # x = self.avgpool(x)
233 | # x = x.view(x.size(0), -1)
234 | # x = self.fc(x)
235 | # return x
236 | return c2, c3, c4, c5
237 |
238 |
239 | def resnet18(pretrained=False, **kwargs):
240 | """Constructs a ResNet-18 model.
241 |
242 | Args:
243 | pretrained (bool): If True, returns a model pre-trained on ImageNet
244 | """
245 | model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
246 | if pretrained:
247 | model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
248 | return model
249 |
250 |
251 | def resnet34(pretrained=False, **kwargs):
252 | """Constructs a ResNet-34 model.
253 |
254 | Args:
255 | pretrained (bool): If True, returns a model pre-trained on ImageNet
256 | """
257 | model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
258 | if pretrained:
259 | model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
260 | return model
261 |
262 |
263 | def resnet50(pretrained=False, root='./pretrain_models', **kwargs):
264 | """Constructs a ResNet-50 model.
265 |
266 | Args:
267 | pretrained (bool): If True, returns a model pre-trained on ImageNet
268 | """
269 | model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
270 | if pretrained:
271 | # from ..models.model_store import get_model_file
272 | model.load_state_dict(torch.load(
273 | get_model_file('resnet50', root=root)), strict=False)
274 | return model
275 |
276 |
277 | def resnet101(pretrained=False, root='./pretrain_models', **kwargs):
278 | """Constructs a ResNet-101 model.
279 |
280 | Args:
281 | pretrained (bool): If True, returns a model pre-trained on ImageNet
282 | """
283 | model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
284 | #Remove the following lines of comments
285 | #if u want to train from a pretrained model
286 | if pretrained:
287 | # from ..models.model_store import get_model_file
288 | model.load_state_dict(torch.load(
289 | get_model_file('resnet101', root=root)), strict=False)
290 | return model
291 |
292 |
293 | def resnet152(pretrained=False, root='~/.encoding/models', **kwargs):
294 | """Constructs a ResNet-152 model.
295 |
296 | Args:
297 | pretrained (bool): If True, returns a model pre-trained on ImageNet
298 | """
299 | model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
300 | if pretrained:
301 | # model.load_state_dict(model_zoo.load_url(model_urls['resnet152']))
302 | model.load_state_dict(torch.load(
303 | './pretrain_models/resnet152-b121ed2d.pth'), strict=False)
304 | return model
305 |
--------------------------------------------------------------------------------
/models/fpn_global_local_fmreg_ensemble.py:
--------------------------------------------------------------------------------
1 | from .resnet import resnet50
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | import torch
5 | import numpy as np
6 |
7 |
8 | class fpn_module_global(nn.Module):
9 | def __init__(self, numClass):
10 | super(fpn_module_global, self).__init__()
11 | self._up_kwargs = {'mode': 'bilinear'}
12 | # Top layer
13 | self.toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
14 | # Lateral layers
15 | self.latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
16 | self.latlayer2 = nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0)
17 | self.latlayer3 = nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0)
18 | # Smooth layers
19 | self.smooth1_1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
20 | self.smooth2_1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
21 | self.smooth3_1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
22 | self.smooth4_1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
23 | self.smooth1_2 = nn.Conv2d(256, 128, kernel_size=3, stride=1, padding=1)
24 | self.smooth2_2 = nn.Conv2d(256, 128, kernel_size=3, stride=1, padding=1)
25 | self.smooth3_2 = nn.Conv2d(256, 128, kernel_size=3, stride=1, padding=1)
26 | self.smooth4_2 = nn.Conv2d(256, 128, kernel_size=3, stride=1, padding=1)
27 | # Classify layers
28 | self.classify = nn.Conv2d(128*4, numClass, kernel_size=3, stride=1, padding=1)
29 |
30 | # Local2Global: double #channels ####################################
31 | # Top layer
32 | self.toplayer_ext = nn.Conv2d(2048*2, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
33 | # Lateral layers
34 | self.latlayer1_ext = nn.Conv2d(1024*2, 256, kernel_size=1, stride=1, padding=0)
35 | self.latlayer2_ext = nn.Conv2d(512*2, 256, kernel_size=1, stride=1, padding=0)
36 | self.latlayer3_ext = nn.Conv2d(256*2, 256, kernel_size=1, stride=1, padding=0)
37 | # Smooth layers
38 | self.smooth1_1_ext = nn.Conv2d(256*2, 256, kernel_size=3, stride=1, padding=1)
39 | self.smooth2_1_ext = nn.Conv2d(256*2, 256, kernel_size=3, stride=1, padding=1)
40 | self.smooth3_1_ext = nn.Conv2d(256*2, 256, kernel_size=3, stride=1, padding=1)
41 | self.smooth4_1_ext = nn.Conv2d(256*2, 256, kernel_size=3, stride=1, padding=1)
42 | self.smooth1_2_ext = nn.Conv2d(256*2, 128, kernel_size=3, stride=1, padding=1)
43 | self.smooth2_2_ext = nn.Conv2d(256*2, 128, kernel_size=3, stride=1, padding=1)
44 | self.smooth3_2_ext = nn.Conv2d(256*2, 128, kernel_size=3, stride=1, padding=1)
45 | self.smooth4_2_ext = nn.Conv2d(256*2, 128, kernel_size=3, stride=1, padding=1)
46 | self.smooth = nn.Conv2d(128*4*2, 128*4, kernel_size=3, stride=1, padding=1)
47 |
48 | def _concatenate(self, p5, p4, p3, p2):
49 | _, _, H, W = p2.size()
50 | p5 = F.interpolate(p5, size=(H, W), **self._up_kwargs)
51 | p4 = F.interpolate(p4, size=(H, W), **self._up_kwargs)
52 | p3 = F.interpolate(p3, size=(H, W), **self._up_kwargs)
53 | return torch.cat([p5, p4, p3, p2], dim=1)
54 |
55 | def _upsample_add(self, x, y):
56 | '''Upsample and add two feature maps.
57 | Args:
58 | x: (Variable) top feature map to be upsampled.
59 | y: (Variable) lateral feature map.
60 | Returns:
61 | (Variable) added feature map.
62 | Note in PyTorch, when input size is odd, the upsampled feature map
63 | with `F.interpolate(..., scale_factor=2, mode='nearest')`
64 | maybe not equal to the lateral feature map size.
65 | e.g.
66 | original input size: [N,_,15,15] ->
67 | conv2d feature map size: [N,_,8,8] ->
68 | upsampled feature map size: [N,_,16,16]
69 | So we choose bilinear upsample which supports arbitrary output sizes.
70 | '''
71 | _, _, H, W = y.size()
72 | return F.interpolate(x, size=(H, W), **self._up_kwargs) + y
73 |
74 | def forward(self, c2, c3, c4, c5, c2_ext=None, c3_ext=None, c4_ext=None, c5_ext=None, ps0_ext=None, ps1_ext=None, ps2_ext=None):
75 |
76 | # Top-down
77 | if c5_ext is None:
78 | p5 = self.toplayer(c5)
79 | p4 = self._upsample_add(p5, self.latlayer1(c4))
80 | p3 = self._upsample_add(p4, self.latlayer2(c3))
81 | p2 = self._upsample_add(p3, self.latlayer3(c2))
82 | else:
83 | p5 = self.toplayer_ext(torch.cat((c5, c5_ext), dim=1))
84 | p4 = self._upsample_add(p5, self.latlayer1_ext(torch.cat((c4, c4_ext), dim=1)))
85 | p3 = self._upsample_add(p4, self.latlayer2_ext(torch.cat((c3, c3_ext), dim=1)))
86 | p2 = self._upsample_add(p3, self.latlayer3_ext(torch.cat((c2, c2_ext), dim=1)))
87 | ps0 = [p5, p4, p3, p2]
88 |
89 | # Smooth
90 | if ps0_ext is None:
91 | p5 = self.smooth1_1(p5)
92 | p4 = self.smooth2_1(p4)
93 | p3 = self.smooth3_1(p3)
94 | p2 = self.smooth4_1(p2)
95 | else:
96 | p5 = self.smooth1_1_ext(torch.cat((p5, ps0_ext[0]), dim=1))
97 | p4 = self.smooth2_1_ext(torch.cat((p4, ps0_ext[1]), dim=1))
98 | p3 = self.smooth3_1_ext(torch.cat((p3, ps0_ext[2]), dim=1))
99 | p2 = self.smooth4_1_ext(torch.cat((p2, ps0_ext[3]), dim=1))
100 | ps1 = [p5, p4, p3, p2]
101 |
102 | if ps1_ext is None:
103 | p5 = self.smooth1_2(p5)
104 | p4 = self.smooth2_2(p4)
105 | p3 = self.smooth3_2(p3)
106 | p2 = self.smooth4_2(p2)
107 | else:
108 | p5 = self.smooth1_2_ext(torch.cat((p5, ps1_ext[0]), dim=1))
109 | p4 = self.smooth2_2_ext(torch.cat((p4, ps1_ext[1]), dim=1))
110 | p3 = self.smooth3_2_ext(torch.cat((p3, ps1_ext[2]), dim=1))
111 | p2 = self.smooth4_2_ext(torch.cat((p2, ps1_ext[3]), dim=1))
112 | ps2 = [p5, p4, p3, p2]
113 |
114 | # Classify
115 | if ps2_ext is None:
116 | ps3 = self._concatenate(p5, p4, p3, p2)
117 | output = self.classify(ps3)
118 | else:
119 | p = self._concatenate(
120 | torch.cat((p5, ps2_ext[0]), dim=1),
121 | torch.cat((p4, ps2_ext[1]), dim=1),
122 | torch.cat((p3, ps2_ext[2]), dim=1),
123 | torch.cat((p2, ps2_ext[3]), dim=1)
124 | )
125 | ps3 = self.smooth(p)
126 | output = self.classify(ps3)
127 |
128 | return output, ps0, ps1, ps2, ps3
129 |
130 |
131 | class fpn_module_local(nn.Module):
132 | def __init__(self, numClass):
133 | super(fpn_module_local, self).__init__()
134 | self._up_kwargs = {'mode': 'bilinear'}
135 | # Top layer
136 | fold = 2
137 | self.toplayer = nn.Conv2d(2048 * fold, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
138 | # Lateral layers [C]
139 | self.latlayer1 = nn.Conv2d(1024 * fold, 256, kernel_size=1, stride=1, padding=0)
140 | self.latlayer2 = nn.Conv2d(512 * fold, 256, kernel_size=1, stride=1, padding=0)
141 | self.latlayer3 = nn.Conv2d(256 * fold, 256, kernel_size=1, stride=1, padding=0)
142 | # Smooth layers
143 | # ps0
144 | self.smooth1_1 = nn.Conv2d(256 * fold, 256, kernel_size=3, stride=1, padding=1)
145 | self.smooth2_1 = nn.Conv2d(256 * fold, 256, kernel_size=3, stride=1, padding=1)
146 | self.smooth3_1 = nn.Conv2d(256 * fold, 256, kernel_size=3, stride=1, padding=1)
147 | self.smooth4_1 = nn.Conv2d(256 * fold, 256, kernel_size=3, stride=1, padding=1)
148 | # ps1
149 | self.smooth1_2 = nn.Conv2d(256 * fold, 128, kernel_size=3, stride=1, padding=1)
150 | self.smooth2_2 = nn.Conv2d(256 * fold, 128, kernel_size=3, stride=1, padding=1)
151 | self.smooth3_2 = nn.Conv2d(256 * fold, 128, kernel_size=3, stride=1, padding=1)
152 | self.smooth4_2 = nn.Conv2d(256 * fold, 128, kernel_size=3, stride=1, padding=1)
153 | # ps2 is concatenation
154 | # Classify layers
155 | self.smooth = nn.Conv2d(128*4*fold, 128*4, kernel_size=3, stride=1, padding=1)
156 | self.classify = nn.Conv2d(128*4, numClass, kernel_size=3, stride=1, padding=1)
157 |
158 | def _concatenate(self, p5, p4, p3, p2):
159 | _, _, H, W = p2.size()
160 | p5 = F.interpolate(p5, size=(H, W), **self._up_kwargs)
161 | p4 = F.interpolate(p4, size=(H, W), **self._up_kwargs)
162 | p3 = F.interpolate(p3, size=(H, W), **self._up_kwargs)
163 | return torch.cat([p5, p4, p3, p2], dim=1)
164 |
165 | def _upsample_add(self, x, y):
166 | '''Upsample and add two feature maps.
167 | Args:
168 | x: (Variable) top feature map to be upsampled.
169 | y: (Variable) lateral feature map.
170 | Returns:
171 | (Variable) added feature map.
172 | Note in PyTorch, when input size is odd, the upsampled feature map
173 | with `F.interpolate(..., scale_factor=2, mode='nearest')`
174 | maybe not equal to the lateral feature map size.
175 | e.g.
176 | original input size: [N,_,15,15] ->
177 | conv2d feature map size: [N,_,8,8] ->
178 | upsampled feature map size: [N,_,16,16]
179 | So we choose bilinear upsample which supports arbitrary output sizes.
180 | '''
181 | _, _, H, W = y.size()
182 | return F.interpolate(x, size=(H, W), **self._up_kwargs) + y
183 |
184 | def forward(self, c2, c3, c4, c5, c2_ext, c3_ext, c4_ext, c5_ext, ps0_ext, ps1_ext, ps2_ext):
185 |
186 | # Top-down
187 | p5 = self.toplayer(torch.cat([c5] + [F.interpolate(c5_ext[0], size=c5.size()[2:], **self._up_kwargs)], dim=1))
188 | p4 = self._upsample_add(p5, self.latlayer1(torch.cat([c4] + [F.interpolate(c4_ext[0], size=c4.size()[2:], **self._up_kwargs)], dim=1)))
189 | p3 = self._upsample_add(p4, self.latlayer2(torch.cat([c3] + [F.interpolate(c3_ext[0], size=c3.size()[2:], **self._up_kwargs)], dim=1)))
190 | p2 = self._upsample_add(p3, self.latlayer3(torch.cat([c2] + [F.interpolate(c2_ext[0], size=c2.size()[2:], **self._up_kwargs)], dim=1)))
191 | ps0 = [p5, p4, p3, p2]
192 |
193 | # Smooth
194 | p5 = self.smooth1_1(torch.cat([p5] + [F.interpolate(ps0_ext[0][0], size=p5.size()[2:], **self._up_kwargs)], dim=1))
195 | p4 = self.smooth2_1(torch.cat([p4] + [F.interpolate(ps0_ext[1][0], size=p4.size()[2:], **self._up_kwargs)], dim=1))
196 | p3 = self.smooth3_1(torch.cat([p3] + [F.interpolate(ps0_ext[2][0], size=p3.size()[2:], **self._up_kwargs)], dim=1))
197 | p2 = self.smooth4_1(torch.cat([p2] + [F.interpolate(ps0_ext[3][0], size=p2.size()[2:], **self._up_kwargs)], dim=1))
198 | ps1 = [p5, p4, p3, p2]
199 |
200 | p5 = self.smooth1_2(torch.cat([p5] + [F.interpolate(ps1_ext[0][0], size=p5.size()[2:], **self._up_kwargs)], dim=1))
201 | p4 = self.smooth2_2(torch.cat([p4] + [F.interpolate(ps1_ext[1][0], size=p4.size()[2:], **self._up_kwargs)], dim=1))
202 | p3 = self.smooth3_2(torch.cat([p3] + [F.interpolate(ps1_ext[2][0], size=p3.size()[2:], **self._up_kwargs)], dim=1))
203 | p2 = self.smooth4_2(torch.cat([p2] + [F.interpolate(ps1_ext[3][0], size=p2.size()[2:], **self._up_kwargs)], dim=1))
204 | ps2 = [p5, p4, p3, p2]
205 |
206 | # Classify
207 | # use ps2_ext
208 | ps3 = self._concatenate(
209 | torch.cat([p5] + [F.interpolate(ps2_ext[0][0], size=p5.size()[2:], **self._up_kwargs)], dim=1),
210 | torch.cat([p4] + [F.interpolate(ps2_ext[1][0], size=p4.size()[2:], **self._up_kwargs)], dim=1),
211 | torch.cat([p3] + [F.interpolate(ps2_ext[2][0], size=p3.size()[2:], **self._up_kwargs)], dim=1),
212 | torch.cat([p2] + [F.interpolate(ps2_ext[3][0], size=p2.size()[2:], **self._up_kwargs)], dim=1)
213 | )
214 | ps3 = self.smooth(ps3)
215 | output = self.classify(ps3)
216 |
217 | return output, ps0, ps1, ps2, ps3
218 |
219 |
220 | class fpn(nn.Module):
221 | def __init__(self, numClass):
222 | super(fpn, self).__init__()
223 | self._up_kwargs = {'mode': 'bilinear'}
224 | # Res net
225 | self.resnet_global = resnet50(True)
226 | self.resnet_local = resnet50(True)
227 |
228 | # fpn module
229 | self.fpn_global = fpn_module_global(numClass)
230 | self.fpn_local = fpn_module_local(numClass)
231 |
232 | self.c2_g = None; self.c3_g = None; self.c4_g = None; self.c5_g = None; self.output_g = None
233 | self.ps0_g = None; self.ps1_g = None; self.ps2_g = None; self.ps3_g = None
234 |
235 | self.c2_l = []; self.c3_l = []; self.c4_l = []; self.c5_l = [];
236 | self.ps00_l = []; self.ps01_l = []; self.ps02_l = []; self.ps03_l = [];
237 | self.ps10_l = []; self.ps11_l = []; self.ps12_l = []; self.ps13_l = [];
238 | self.ps20_l = []; self.ps21_l = []; self.ps22_l = []; self.ps23_l = [];
239 | self.ps0_l = None; self.ps1_l = None; self.ps2_l = None
240 | self.ps3_l = []#; self.output_l = []
241 |
242 | self.c2_b = None; self.c3_b = None; self.c4_b = None; self.c5_b = None;
243 | self.ps00_b = None; self.ps01_b = None; self.ps02_b = None; self.ps03_b = None;
244 | self.ps10_b = None; self.ps11_b = None; self.ps12_b = None; self.ps13_b = None;
245 | self.ps20_b = None; self.ps21_b = None; self.ps22_b = None; self.ps23_b = None;
246 | self.ps3_b = []#; self.output_b = []
247 |
248 | self.patch_n = 0
249 |
250 | self.mse = nn.MSELoss()
251 |
252 | self.ensemble_conv = nn.Conv2d(128*4 * 2, numClass, kernel_size=3, stride=1, padding=1)
253 | nn.init.normal_(self.ensemble_conv.weight, mean=0, std=0.01)
254 |
255 | # init fpn
256 | for m in self.fpn_global.children():
257 | if hasattr(m, 'weight'): nn.init.normal_(m.weight, mean=0, std=0.01)
258 | if hasattr(m, 'bias'): nn.init.constant_(m.bias, 0)
259 | for m in self.fpn_local.children():
260 | if hasattr(m, 'weight'): nn.init.normal_(m.weight, mean=0, std=0.01)
261 | if hasattr(m, 'bias'): nn.init.constant_(m.bias, 0)
262 |
263 | def clear_cache(self):
264 | self.c2_g = None; self.c3_g = None; self.c4_g = None; self.c5_g = None; self.output_g = None
265 | self.ps0_g = None; self.ps1_g = None; self.ps2_g = None; self.ps3_g = None
266 |
267 | self.c2_l = []; self.c3_l = []; self.c4_l = []; self.c5_l = [];
268 | self.ps00_l = []; self.ps01_l = []; self.ps02_l = []; self.ps03_l = [];
269 | self.ps10_l = []; self.ps11_l = []; self.ps12_l = []; self.ps13_l = [];
270 | self.ps20_l = []; self.ps21_l = []; self.ps22_l = []; self.ps23_l = [];
271 | self.ps0_l = None; self.ps1_l = None; self.ps2_l = None
272 | self.ps3_l = []; self.output_l = []
273 |
274 | self.c2_b = None; self.c3_b = None; self.c4_b = None; self.c5_b = None;
275 | self.ps00_b = None; self.ps01_b = None; self.ps02_b = None; self.ps03_b = None;
276 | self.ps10_b = None; self.ps11_b = None; self.ps12_b = None; self.ps13_b = None;
277 | self.ps20_b = None; self.ps21_b = None; self.ps22_b = None; self.ps23_b = None;
278 | self.ps3_b = []; self.output_b = []
279 |
280 | self.patch_n = 0
281 |
282 |
283 | def _sample_grid(self, fm, bbox, sampleSize):
284 | """
285 | :param fm: tensor(b,c,h,w) the global feature map
286 | :param bbox: list [b* nparray(x1, y1, x2, y2)] the (x1,y1) is the left_top of bbox, (x2, y2) is the right_bottom of bbox
287 | there are in range [0, 1]. x is corresponding to width dimension and y is corresponding to height dimension
288 | :param sampleSize: (oH, oW) the point to sample in height dimension and width dimension
289 | :return: tensor(b, c, oH, oW) sampled tensor
290 | """
291 | b, c, h, w = fm.shape
292 | b_bbox = len(bbox)
293 | bbox = [x*2 - 1 for x in bbox] # range transform
294 | if b != b_bbox and b == 1:
295 | fm = torch.cat([fm,]*b_bbox, dim=0)
296 | grid = np.zeros((b_bbox,) + sampleSize + (2,), dtype=np.float32)
297 | gridMap = np.array([[(cnt_w/(sampleSize[1]-1), cnt_h/(sampleSize[0]-1)) for cnt_w in range(sampleSize[1])] for cnt_h in range(sampleSize[0])])
298 | for cnt_b in range(b_bbox):
299 | grid[cnt_b, :, :, 0] = bbox[cnt_b][0] + (bbox[cnt_b][2] - bbox[cnt_b][0])*gridMap[:, :, 0]
300 | grid[cnt_b, :, :, 1] = bbox[cnt_b][1] + (bbox[cnt_b][3] - bbox[cnt_b][1])*gridMap[:, :, 1]
301 | grid = torch.from_numpy(grid).cuda()
302 | return F.grid_sample(fm, grid)
303 |
304 | def _crop_global(self, f_global, top_lefts, ratio):
305 | '''
306 | top_lefts: [(top, left)] * b
307 | '''
308 | _, c, H, W = f_global.size()
309 | b = len(top_lefts)
310 | h, w = int(np.round(H * ratio[0])), int(np.round(W * ratio[1]))
311 |
312 | # bbox = [ np.array([left, top, left + ratio, top + ratio]) for (top, left) in top_lefts ]
313 | # crop = self._sample_grid(f_global, bbox, (H, W))
314 |
315 | crop = []
316 | for i in range(b):
317 | top, left = int(np.round(top_lefts[i][0] * H)), int(np.round(top_lefts[i][1] * W))
318 | # # global's sub-region & upsample
319 | # f_global_patch = F.interpolate(f_global[0:1, :, top:top+h, left:left+w], size=(h, w), mode='bilinear')
320 | f_global_patch = f_global[0:1, :, top:top+h, left:left+w]
321 | crop.append(f_global_patch[0])
322 | crop = torch.stack(crop, dim=0) # stack into mini-batch
323 | return [crop] # return as a list for easy to torch.cat
324 |
325 | def _merge_local(self, f_local, merge, f_global, top_lefts, oped, ratio, template):
326 | '''
327 | merge feature maps from local patches, and finally to a whole image's feature map (on cuda)
328 | f_local: a sub_batch_size of patch's feature map
329 | oped: [start, end)
330 | '''
331 | b, _, _, _ = f_local.size()
332 | _, c, H, W = f_global.size() # match global feature size
333 | if merge is None:
334 | merge = torch.zeros((1, c, H, W)).cuda()
335 | h, w = int(np.round(H * ratio[0])), int(np.round(W * ratio[1]))
336 | for i in range(b):
337 | index = oped[0] + i
338 | top, left = int(np.round(H * top_lefts[index][0])), int(np.round(W * top_lefts[index][1]))
339 | merge[:, :, top:top+h, left:left+w] += F.interpolate(f_local[i:i+1], size=(h, w), **self._up_kwargs)
340 | if oped[1] >= len(top_lefts):
341 | template = F.interpolate(template, size=(H, W), **self._up_kwargs)
342 | template = template.expand_as(merge)
343 | # template = Variable(template).cuda()
344 | merge /= template
345 | return merge
346 |
347 | def ensemble(self, f_local, f_global):
348 | return self.ensemble_conv(torch.cat((f_local, f_global), dim=1))
349 |
350 | def collect_local_fm(self, image_global, patches, ratio, top_lefts, oped, batch_size, global_model=None, template=None, n_patch_all=None):
351 | '''
352 | patches: 1 patch
353 | top_lefts: all top-left
354 | oped: [start, end)
355 | '''
356 | with torch.no_grad():
357 | if self.patch_n == 0:
358 | self.c2_g, self.c3_g, self.c4_g, self.c5_g = global_model.module.resnet_global.forward(image_global)
359 | self.output_g, self.ps0_g, self.ps1_g, self.ps2_g, self.ps3_g = global_model.module.fpn_global.forward(self.c2_g, self.c3_g, self.c4_g, self.c5_g)
360 | # self.output_g = F.interpolate(self.output_g, image_global.size()[2:], mode='nearest')
361 | self.patch_n += patches.size()[0]
362 | self.patch_n %= n_patch_all
363 |
364 | self.resnet_local.eval()
365 | self.fpn_local.eval()
366 | c2, c3, c4, c5 = self.resnet_local.forward(patches)
367 | # global's 1x patch cat
368 | output, ps0, ps1, ps2, ps3 = self.fpn_local.forward(
369 | c2, c3, c4, c5,
370 | self._crop_global(self.c2_g, top_lefts[oped[0]:oped[1]], ratio),
371 | c3_ext=self._crop_global(self.c3_g, top_lefts[oped[0]:oped[1]], ratio),
372 | c4_ext=self._crop_global(self.c4_g, top_lefts[oped[0]:oped[1]], ratio),
373 | c5_ext=self._crop_global(self.c5_g, top_lefts[oped[0]:oped[1]], ratio),
374 | ps0_ext=[ self._crop_global(f, top_lefts[oped[0]:oped[1]], ratio) for f in self.ps0_g ],
375 | ps1_ext=[ self._crop_global(f, top_lefts[oped[0]:oped[1]], ratio) for f in self.ps1_g ],
376 | ps2_ext=[ self._crop_global(f, top_lefts[oped[0]:oped[1]], ratio) for f in self.ps2_g ]
377 | )
378 | # output = F.interpolate(output, patches.size()[2:], mode='nearest')
379 |
380 | self.c2_b = self._merge_local(c2, self.c2_b, self.c2_g, top_lefts, oped, ratio, template)
381 | self.c3_b = self._merge_local(c3, self.c3_b, self.c3_g, top_lefts, oped, ratio, template)
382 | self.c4_b = self._merge_local(c4, self.c4_b, self.c4_g, top_lefts, oped, ratio, template)
383 | self.c5_b = self._merge_local(c5, self.c5_b, self.c5_g, top_lefts, oped, ratio, template)
384 |
385 | self.ps00_b = self._merge_local(ps0[0], self.ps00_b, self.ps0_g[0], top_lefts, oped, ratio, template)
386 | self.ps01_b = self._merge_local(ps0[1], self.ps01_b, self.ps0_g[1], top_lefts, oped, ratio, template)
387 | self.ps02_b = self._merge_local(ps0[2], self.ps02_b, self.ps0_g[2], top_lefts, oped, ratio, template)
388 | self.ps03_b = self._merge_local(ps0[3], self.ps03_b, self.ps0_g[3], top_lefts, oped, ratio, template)
389 | self.ps10_b = self._merge_local(ps1[0], self.ps10_b, self.ps1_g[0], top_lefts, oped, ratio, template)
390 | self.ps11_b = self._merge_local(ps1[1], self.ps11_b, self.ps1_g[1], top_lefts, oped, ratio, template)
391 | self.ps12_b = self._merge_local(ps1[2], self.ps12_b, self.ps1_g[2], top_lefts, oped, ratio, template)
392 | self.ps13_b = self._merge_local(ps1[3], self.ps13_b, self.ps1_g[3], top_lefts, oped, ratio, template)
393 | self.ps20_b = self._merge_local(ps2[0], self.ps20_b, self.ps2_g[0], top_lefts, oped, ratio, template)
394 | self.ps21_b = self._merge_local(ps2[1], self.ps21_b, self.ps2_g[1], top_lefts, oped, ratio, template)
395 | self.ps22_b = self._merge_local(ps2[2], self.ps22_b, self.ps2_g[2], top_lefts, oped, ratio, template)
396 | self.ps23_b = self._merge_local(ps2[3], self.ps23_b, self.ps2_g[3], top_lefts, oped, ratio, template)
397 |
398 | self.ps3_b.append(ps3.cpu())
399 | # self.output_b.append(output.cpu()) # each output is 1, 7, h, w
400 |
401 | if self.patch_n == 0:
402 | # merged all patches into an image
403 | self.c2_l.append(self.c2_b); self.c3_l.append(self.c3_b); self.c4_l.append(self.c4_b); self.c5_l.append(self.c5_b);
404 | self.ps00_l.append(self.ps00_b); self.ps01_l.append(self.ps01_b); self.ps02_l.append(self.ps02_b); self.ps03_l.append(self.ps03_b)
405 | self.ps10_l.append(self.ps10_b); self.ps11_l.append(self.ps11_b); self.ps12_l.append(self.ps12_b); self.ps13_l.append(self.ps13_b)
406 | self.ps20_l.append(self.ps20_b); self.ps21_l.append(self.ps21_b); self.ps22_l.append(self.ps22_b); self.ps23_l.append(self.ps23_b)
407 |
408 | # collected all ps3 and output of patches as a (b) tensor, append into list
409 | self.ps3_l.append(torch.cat(self.ps3_b, dim=0)); # a list of tensors
410 | # self.output_l.append(torch.cat(self.output_b, dim=0)) # a list of 36, 7, h, w tensors
411 |
412 | self.c2_b = None; self.c3_b = None; self.c4_b = None; self.c5_b = None;
413 | self.ps00_b = None; self.ps01_b = None; self.ps02_b = None; self.ps03_b = None;
414 | self.ps10_b = None; self.ps11_b = None; self.ps12_b = None; self.ps13_b = None;
415 | self.ps20_b = None; self.ps21_b = None; self.ps22_b = None; self.ps23_b = None;
416 | self.ps3_b = []# ; self.output_b = []
417 | if len(self.c2_l) == batch_size:
418 | self.c2_l = torch.cat(self.c2_l, dim=0)# .cuda()
419 | self.c3_l = torch.cat(self.c3_l, dim=0)# .cuda()
420 | self.c4_l = torch.cat(self.c4_l, dim=0)# .cuda()
421 | self.c5_l = torch.cat(self.c5_l, dim=0)# .cuda()
422 | self.ps00_l = torch.cat(self.ps00_l, dim=0)# .cuda()
423 | self.ps01_l = torch.cat(self.ps01_l, dim=0)# .cuda()
424 | self.ps02_l = torch.cat(self.ps02_l, dim=0)# .cuda()
425 | self.ps03_l = torch.cat(self.ps03_l, dim=0)# .cuda()
426 | self.ps10_l = torch.cat(self.ps10_l, dim=0)# .cuda()
427 | self.ps11_l = torch.cat(self.ps11_l, dim=0)# .cuda()
428 | self.ps12_l = torch.cat(self.ps12_l, dim=0)# .cuda()
429 | self.ps13_l = torch.cat(self.ps13_l, dim=0)# .cuda()
430 | self.ps20_l = torch.cat(self.ps20_l, dim=0)# .cuda()
431 | self.ps21_l = torch.cat(self.ps21_l, dim=0)# .cuda()
432 | self.ps22_l = torch.cat(self.ps22_l, dim=0)# .cuda()
433 | self.ps23_l = torch.cat(self.ps23_l, dim=0)# .cuda()
434 | self.ps0_l = [self.ps00_l, self.ps01_l, self.ps02_l, self.ps03_l]
435 | self.ps1_l = [self.ps10_l, self.ps11_l, self.ps12_l, self.ps13_l]
436 | self.ps2_l = [self.ps20_l, self.ps21_l, self.ps22_l, self.ps23_l]
437 | # self.ps3_l = torch.cat(self.ps3_l, dim=0)# .cuda()
438 | return self.ps3_l, output# self.output_l
439 |
440 |
441 | def forward(self, image_global, patches, top_lefts, ratio, mode=1, global_model=None, n_patch=None):
442 | if mode == 1:
443 | # train global model
444 | c2_g, c3_g, c4_g, c5_g = self.resnet_global.forward(image_global)
445 | output_g, ps0_g, ps1_g, ps2_g, ps3_g = self.fpn_global.forward(c2_g, c3_g, c4_g, c5_g)
446 | # imsize = image_global.size()[2:]
447 | # output_g = F.interpolate(output_g, imsize, mode='nearest')
448 | return output_g, None
449 | elif mode == 2:
450 | # train global2local model
451 | with torch.no_grad():
452 | if self.patch_n == 0:
453 | # calculate global images only if patches belong to a new set of global images (when self.patch_n % n_patch == 0)
454 | self.c2_g, self.c3_g, self.c4_g, self.c5_g = self.resnet_global.forward(image_global)
455 | self.output_g, self.ps0_g, self.ps1_g, self.ps2_g, self.ps3_g = self.fpn_global.forward(self.c2_g, self.c3_g, self.c4_g, self.c5_g)
456 | # imsize_glb = image_global.size()[2:]
457 | # self.output_g = F.interpolate(self.output_g, imsize_glb, mode='nearest')
458 | self.patch_n += patches.size()[0]
459 | self.patch_n %= n_patch
460 |
461 | # train local model #######################################
462 | c2_l, c3_l, c4_l, c5_l = self.resnet_local.forward(patches)
463 | # global's 1x patch cat
464 | output_l, ps0_l, ps1_l, ps2_l, ps3_l = self.fpn_local.forward(c2_l, c3_l, c4_l, c5_l,
465 | self._crop_global(self.c2_g, top_lefts, ratio),
466 | self._crop_global(self.c3_g, top_lefts, ratio),
467 | self._crop_global(self.c4_g, top_lefts, ratio),
468 | self._crop_global(self.c5_g, top_lefts, ratio),
469 | [ self._crop_global(f, top_lefts, ratio) for f in self.ps0_g ],
470 | [ self._crop_global(f, top_lefts, ratio) for f in self.ps1_g ],
471 | [ self._crop_global(f, top_lefts, ratio) for f in self.ps2_g ]
472 | )
473 | # imsize = patches.size()[2:]
474 | # output_l = F.interpolate(output_l, imsize, mode='nearest')
475 | ps3_g2l = self._crop_global(self.ps3_g, top_lefts, ratio)[0] # only calculate loss on 1x
476 | ps3_g2l = F.interpolate(ps3_g2l, size=ps3_l.size()[2:], **self._up_kwargs)
477 |
478 | output = self.ensemble(ps3_l, ps3_g2l)
479 | # output = F.interpolate(output, imsize, mode='nearest')
480 | return output, self.output_g, output_l, self.mse(ps3_l, ps3_g2l)
481 | else:
482 | # train local2global model
483 | c2_g, c3_g, c4_g, c5_g = self.resnet_global.forward(image_global)
484 | # local patch cat into global
485 | output_g, ps0_g, ps1_g, ps2_g, ps3_g = self.fpn_global.forward(c2_g, c3_g, c4_g, c5_g, c2_ext=self.c2_l, c3_ext=self.c3_l, c4_ext=self.c4_l, c5_ext=self.c5_l, ps0_ext=self.ps0_l, ps1_ext=self.ps1_l, ps2_ext=self.ps2_l)
486 | # imsize = image_global.size()[2:]
487 | # output_g = F.interpolate(output_g, imsize, mode='nearest')
488 | self.clear_cache()
489 | return output_g, ps3_g
--------------------------------------------------------------------------------
/helper.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | from __future__ import absolute_import, division, print_function
5 |
6 | import cv2
7 | import numpy as np
8 | import torch
9 | import torch.nn as nn
10 | import torch.nn.functional as F
11 | from torch.autograd import Variable
12 | from torchvision import transforms
13 | from models.fpn_global_local_fmreg_ensemble import fpn
14 | from utils.metrics import ConfusionMatrix
15 | from PIL import Image
16 |
17 | # torch.cuda.synchronize()
18 | # torch.backends.cudnn.benchmark = True
19 | torch.backends.cudnn.deterministic = True
20 |
21 | transformer = transforms.Compose([
22 | transforms.ToTensor(),
23 | ])
24 |
25 | def resize(images, shape, label=False):
26 | '''
27 | resize PIL images
28 | shape: (w, h)
29 | '''
30 | resized = list(images)
31 | for i in range(len(images)):
32 | if label:
33 | resized[i] = images[i].resize(shape, Image.NEAREST)
34 | else:
35 | resized[i] = images[i].resize(shape, Image.BILINEAR)
36 | return resized
37 |
38 | def _mask_transform(mask):
39 | target = np.array(mask).astype('int32')
40 | target[target == 255] = -1
41 | # target -= 1 # in DeepGlobe: make class 0 (should be ignored) as -1 (to be ignored in cross_entropy)
42 | return target
43 |
44 | def masks_transform(masks, numpy=False):
45 | '''
46 | masks: list of PIL images
47 | '''
48 | targets = []
49 | for m in masks:
50 | targets.append(_mask_transform(m))
51 | targets = np.array(targets)
52 | if numpy:
53 | return targets
54 | else:
55 | return torch.from_numpy(targets).long().cuda()
56 |
57 | def images_transform(images):
58 | '''
59 | images: list of PIL images
60 | '''
61 | inputs = []
62 | for img in images:
63 | inputs.append(transformer(img))
64 | inputs = torch.stack(inputs, dim=0).cuda()
65 | return inputs
66 |
67 | def get_patch_info(shape, p_size):
68 | '''
69 | shape: origin image size, (x, y)
70 | p_size: patch size (square)
71 | return: n_x, n_y, step_x, step_y
72 | '''
73 | x = shape[0]
74 | y = shape[1]
75 | n = m = 1
76 | while x > n * p_size:
77 | n += 1
78 | while p_size - 1.0 * (x - p_size) / (n - 1) < 50:
79 | n += 1
80 | while y > m * p_size:
81 | m += 1
82 | while p_size - 1.0 * (y - p_size) / (m - 1) < 50:
83 | m += 1
84 | return n, m, (x - p_size) * 1.0 / (n - 1), (y - p_size) * 1.0 / (m - 1)
85 |
86 | def global2patch(images, p_size):
87 | '''
88 | image/label => patches
89 | p_size: patch size
90 | return: list of PIL patch images; coordinates: images->patches; ratios: (h, w)
91 | '''
92 | patches = []; coordinates = []; templates = []; sizes = []; ratios = [(0, 0)] * len(images); patch_ones = np.ones(p_size)
93 | for i in range(len(images)):
94 | w, h = images[i].size
95 | size = (h, w)
96 | sizes.append(size)
97 | ratios[i] = (float(p_size[0]) / size[0], float(p_size[1]) / size[1])
98 | template = np.zeros(size)
99 | n_x, n_y, step_x, step_y = get_patch_info(size, p_size[0])
100 | patches.append([images[i]] * (n_x * n_y))
101 | coordinates.append([(0, 0)] * (n_x * n_y))
102 | for x in range(n_x):
103 | if x < n_x - 1: top = int(np.round(x * step_x))
104 | else: top = size[0] - p_size[0]
105 | for y in range(n_y):
106 | if y < n_y - 1: left = int(np.round(y * step_y))
107 | else: left = size[1] - p_size[1]
108 | template[top:top+p_size[0], left:left+p_size[1]] += patch_ones
109 | coordinates[i][x * n_y + y] = (1.0 * top / size[0], 1.0 * left / size[1])
110 | patches[i][x * n_y + y] = transforms.functional.crop(images[i], top, left, p_size[0], p_size[1])
111 | templates.append(Variable(torch.Tensor(template).expand(1, 1, -1, -1)).cuda())
112 | return patches, coordinates, templates, sizes, ratios
113 |
114 | def patch2global(patches, n_class, sizes, coordinates, p_size):
115 | '''
116 | predicted patches (after classify layer) => predictions
117 | return: list of np.array
118 | '''
119 | predictions = [ np.zeros((n_class, size[0], size[1])) for size in sizes ]
120 | for i in range(len(sizes)):
121 | for j in range(len(coordinates[i])):
122 | top, left = coordinates[i][j]
123 | top = int(np.round(top * sizes[i][0])); left = int(np.round(left * sizes[i][1]))
124 | predictions[i][:, top: top + p_size[0], left: left + p_size[1]] += patches[i][j]
125 | return predictions
126 |
127 | def template_patch2global(size_g, size_p, n, step):
128 | template = np.zeros(size_g)
129 | coordinates = [(0, 0)] * n ** 2
130 | patch = np.ones(size_p)
131 | step = (size_g[0] - size_p[0]) // (n - 1)
132 | x = y = 0
133 | i = 0
134 | while x + size_p[0] <= size_g[0]:
135 | while y + size_p[1] <= size_g[1]:
136 | template[x:x+size_p[0], y:y+size_p[1]] += patch
137 | coordinates[i] = (1.0 * x / size_g[0], 1.0 * y / size_g[1])
138 | i += 1
139 | y += step
140 | x += step
141 | y = 0
142 | return Variable(torch.Tensor(template).expand(1, 1, -1, -1)).cuda(), coordinates
143 |
144 | def one_hot_gaussian_blur(index, classes):
145 | '''
146 | index: numpy array b, h, w
147 | classes: int
148 | '''
149 | mask = np.transpose((np.arange(classes) == index[..., None]).astype(float), (0, 3, 1, 2))
150 | b, c, _, _ = mask.shape
151 | for i in range(b):
152 | for j in range(c):
153 | mask[i][j] = cv2.GaussianBlur(mask[i][j], (0, 0), 8)
154 |
155 | return mask
156 |
157 | def collate(batch):
158 | image = [ b['image'] for b in batch ] # w, h
159 | label = [ b['label'] for b in batch ]
160 | id = [ b['id'] for b in batch ]
161 | return {'image': image, 'label': label, 'id': id}
162 |
163 | def collate_test(batch):
164 | image = [ b['image'] for b in batch ] # w, h
165 | id = [ b['id'] for b in batch ]
166 | return {'image': image, 'id': id}
167 |
168 |
169 | def create_model_load_weights(n_class, mode=1, evaluation=False, path_g=None, path_g2l=None, path_l2g=None):
170 | model = fpn(n_class)
171 | model = nn.DataParallel(model)
172 | model = model.cuda()
173 |
174 | if (mode == 2 and not evaluation) or (mode == 1 and evaluation):
175 | # load fixed basic global branch
176 | partial = torch.load(path_g)
177 | state = model.state_dict()
178 | # 1. filter out unnecessary keys
179 | pretrained_dict = {k: v for k, v in partial.items() if k in state and "local" not in k}
180 | # 2. overwrite entries in the existing state dict
181 | state.update(pretrained_dict)
182 | # 3. load the new state dict
183 | model.load_state_dict(state)
184 |
185 | if (mode == 3 and not evaluation) or (mode == 2 and evaluation):
186 | partial = torch.load(path_g2l)
187 | state = model.state_dict()
188 | # 1. filter out unnecessary keys
189 | pretrained_dict = {k: v for k, v in partial.items() if k in state}# and "global" not in k}
190 | # 2. overwrite entries in the existing state dict
191 | state.update(pretrained_dict)
192 | # 3. load the new state dict
193 | model.load_state_dict(state)
194 |
195 | global_fixed = None
196 | if mode == 3:
197 | # load fixed basic global branch
198 | global_fixed = fpn(n_class)
199 | global_fixed = nn.DataParallel(global_fixed)
200 | global_fixed = global_fixed.cuda()
201 | partial = torch.load(path_g)
202 | state = global_fixed.state_dict()
203 | # 1. filter out unnecessary keys
204 | pretrained_dict = {k: v for k, v in partial.items() if k in state and "local" not in k}
205 | # 2. overwrite entries in the existing state dict
206 | state.update(pretrained_dict)
207 | # 3. load the new state dict
208 | global_fixed.load_state_dict(state)
209 | global_fixed.eval()
210 |
211 | if mode == 3 and evaluation:
212 | partial = torch.load(path_l2g)
213 | state = model.state_dict()
214 | # 1. filter out unnecessary keys
215 | pretrained_dict = {k: v for k, v in partial.items() if k in state}# and "global" not in k}
216 | # 2. overwrite entries in the existing state dict
217 | state.update(pretrained_dict)
218 | # 3. load the new state dict
219 | model.load_state_dict(state)
220 |
221 | if mode == 1 or mode == 3:
222 | model.module.resnet_local.eval()
223 | model.module.fpn_local.eval()
224 | else:
225 | model.module.resnet_global.eval()
226 | model.module.fpn_global.eval()
227 |
228 | return model, global_fixed
229 |
230 |
231 | def get_optimizer(model, mode=1, learning_rate=2e-5):
232 | if mode == 1 or mode == 3:
233 | # train global
234 | optimizer = torch.optim.Adam([
235 | {'params': model.module.resnet_global.parameters(), 'lr': learning_rate},
236 | {'params': model.module.resnet_local.parameters(), 'lr': 0},
237 | {'params': model.module.fpn_global.parameters(), 'lr': learning_rate},
238 | {'params': model.module.fpn_local.parameters(), 'lr': 0},
239 | {'params': model.module.ensemble_conv.parameters(), 'lr': learning_rate},
240 | ], weight_decay=5e-4)
241 | else:
242 | # train local
243 | optimizer = torch.optim.Adam([
244 | {'params': model.module.resnet_global.parameters(), 'lr': 0},
245 | {'params': model.module.resnet_local.parameters(), 'lr': learning_rate},
246 | {'params': model.module.fpn_global.parameters(), 'lr': 0},
247 | {'params': model.module.fpn_local.parameters(), 'lr': learning_rate},
248 | {'params': model.module.ensemble_conv.parameters(), 'lr': learning_rate},
249 | ], weight_decay=5e-4)
250 | return optimizer
251 |
252 |
253 | class Trainer(object):
254 | def __init__(self, criterion, optimizer, n_class, size_g, size_p, sub_batch_size=6, mode=1, lamb_fmreg=0.15):
255 | self.criterion = criterion
256 | self.optimizer = optimizer
257 | self.metrics_global = ConfusionMatrix(n_class)
258 | self.metrics_local = ConfusionMatrix(n_class)
259 | self.metrics = ConfusionMatrix(n_class)
260 | self.n_class = n_class
261 | self.size_g = size_g
262 | self.size_p = size_p
263 | self.sub_batch_size = sub_batch_size
264 | self.mode = mode
265 | self.lamb_fmreg = lamb_fmreg
266 |
267 | def set_train(self, model):
268 | model.module.ensemble_conv.train()
269 | if self.mode == 1 or self.mode == 3:
270 | model.module.resnet_global.train()
271 | model.module.fpn_global.train()
272 | else:
273 | model.module.resnet_local.train()
274 | model.module.fpn_local.train()
275 |
276 | def get_scores(self):
277 | score_train = self.metrics.get_scores()
278 | score_train_local = self.metrics_local.get_scores()
279 | score_train_global = self.metrics_global.get_scores()
280 | return score_train, score_train_global, score_train_local
281 |
282 | def reset_metrics(self):
283 | self.metrics.reset()
284 | self.metrics_local.reset()
285 | self.metrics_global.reset()
286 |
287 | def train(self, sample, model, global_fixed):
288 | images, labels = sample['image'], sample['label'] # PIL images
289 | labels_npy = masks_transform(labels, numpy=True) # label of origin size in numpy
290 |
291 | images_glb = resize(images, self.size_g) # list of resized PIL images
292 | images_glb = images_transform(images_glb)
293 | labels_glb = resize(labels, (self.size_g[0] // 4, self.size_g[1] // 4), label=True) # FPN down 1/4, for loss
294 | labels_glb = masks_transform(labels_glb)
295 |
296 | if self.mode == 2 or self.mode == 3:
297 | patches, coordinates, templates, sizes, ratios = global2patch(images, self.size_p)
298 | label_patches, _, _, _, _ = global2patch(labels, self.size_p)
299 | predicted_patches = [ np.zeros((len(coordinates[i]), self.n_class, self.size_p[0], self.size_p[1])) for i in range(len(images)) ]
300 | predicted_ensembles = [ np.zeros((len(coordinates[i]), self.n_class, self.size_p[0], self.size_p[1])) for i in range(len(images)) ]
301 | outputs_global = [ None for i in range(len(images)) ]
302 |
303 | if self.mode == 1:
304 | # training with only (resized) global image #########################################
305 | outputs_global, _ = model.forward(images_glb, None, None, None)
306 | loss = self.criterion(outputs_global, labels_glb)
307 | loss.backward()
308 | self.optimizer.step()
309 | self.optimizer.zero_grad()
310 | ##############################################
311 |
312 | if self.mode == 2:
313 | # training with patches ###########################################
314 | for i in range(len(images)):
315 | j = 0
316 | while j < len(coordinates[i]):
317 | patches_var = images_transform(patches[i][j : j+self.sub_batch_size]) # b, c, h, w
318 | label_patches_var = masks_transform(resize(label_patches[i][j : j+self.sub_batch_size], (self.size_p[0] // 4, self.size_p[1] // 4), label=True)) # down 1/4 for loss
319 |
320 | output_ensembles, output_global, output_patches, fmreg_l2 = model.forward(images_glb[i:i+1], patches_var, coordinates[i][j : j+self.sub_batch_size], ratios[i], mode=self.mode, n_patch=len(coordinates[i]))
321 | loss = self.criterion(output_patches, label_patches_var) + self.criterion(output_ensembles, label_patches_var) + self.lamb_fmreg * fmreg_l2
322 | loss.backward()
323 |
324 | # patch predictions
325 | predicted_patches[i][j:j+output_patches.size()[0]] = F.interpolate(output_patches, size=self.size_p, mode='nearest').data.cpu().numpy()
326 | predicted_ensembles[i][j:j+output_ensembles.size()[0]] = F.interpolate(output_ensembles, size=self.size_p, mode='nearest').data.cpu().numpy()
327 | j += self.sub_batch_size
328 | outputs_global[i] = output_global
329 | outputs_global = torch.cat(outputs_global, dim=0)
330 |
331 | self.optimizer.step()
332 | self.optimizer.zero_grad()
333 | #####################################################################################
334 |
335 | if self.mode == 3:
336 | # train global with help from patches ##################################################
337 | # go through local patches to collect feature maps
338 | # collect predictions from patches
339 | for i in range(len(images)):
340 | j = 0
341 | while j < len(coordinates[i]):
342 | patches_var = images_transform(patches[i][j : j+self.sub_batch_size]) # b, c, h, w
343 | fm_patches, output_patches = model.module.collect_local_fm(images_glb[i:i+1], patches_var, ratios[i], coordinates[i], [j, j+self.sub_batch_size], len(images), global_model=global_fixed, template=templates[i], n_patch_all=len(coordinates[i]))
344 | predicted_patches[i][j:j+output_patches.size()[0]] = F.interpolate(output_patches, size=self.size_p, mode='nearest').data.cpu().numpy()
345 | j += self.sub_batch_size
346 | # train on global image
347 | outputs_global, fm_global = model.forward(images_glb, None, None, None, mode=self.mode)
348 | loss = self.criterion(outputs_global, labels_glb)
349 | loss.backward(retain_graph=True)
350 | # fmreg loss
351 | # generate ensembles & calc loss
352 | for i in range(len(images)):
353 | j = 0
354 | while j < len(coordinates[i]):
355 | label_patches_var = masks_transform(resize(label_patches[i][j : j+self.sub_batch_size], (self.size_p[0] // 4, self.size_p[1] // 4), label=True))
356 | fl = fm_patches[i][j : j+self.sub_batch_size].cuda()
357 | fg = model.module._crop_global(fm_global[i:i+1], coordinates[i][j:j+self.sub_batch_size], ratios[i])[0]
358 | fg = F.interpolate(fg, size=fl.size()[2:], mode='bilinear')
359 | output_ensembles = model.module.ensemble(fl, fg)
360 | loss = self.criterion(output_ensembles, label_patches_var)# + 0.15 * mse(fl, fg)
361 | if i == len(images) - 1 and j + self.sub_batch_size >= len(coordinates[i]):
362 | loss.backward()
363 | else:
364 | loss.backward(retain_graph=True)
365 |
366 | # ensemble predictions
367 | predicted_ensembles[i][j:j+output_ensembles.size()[0]] = F.interpolate(output_ensembles, size=self.size_p, mode='nearest').data.cpu().numpy()
368 | j += self.sub_batch_size
369 | self.optimizer.step()
370 | self.optimizer.zero_grad()
371 |
372 | # global predictions ###########################
373 | outputs_global = outputs_global.cpu()
374 | predictions_global = [F.interpolate(outputs_global[i:i+1], images[i].size[::-1], mode='nearest').argmax(1).detach().numpy() for i in range(len(images))]
375 | self.metrics_global.update(labels_npy, predictions_global)
376 |
377 | if self.mode == 2 or self.mode == 3:
378 | # patch predictions ###########################
379 | scores_local = np.array(patch2global(predicted_patches, self.n_class, sizes, coordinates, self.size_p)) # merge softmax scores from patches (overlaps)
380 | predictions_local = scores_local.argmax(1) # b, h, w
381 | self.metrics_local.update(labels_npy, predictions_local)
382 | ###################################################
383 | # combined/ensemble predictions ###########################
384 | scores = np.array(patch2global(predicted_ensembles, self.n_class, sizes, coordinates, self.size_p)) # merge softmax scores from patches (overlaps)
385 | predictions = scores.argmax(1) # b, h, w
386 | self.metrics.update(labels_npy, predictions)
387 | return loss
388 |
389 |
390 | class Evaluator(object):
391 | def __init__(self, n_class, size_g, size_p, sub_batch_size=6, mode=1, test=False):
392 | self.metrics_global = ConfusionMatrix(n_class)
393 | self.metrics_local = ConfusionMatrix(n_class)
394 | self.metrics = ConfusionMatrix(n_class)
395 | self.n_class = n_class
396 | self.size_g = size_g
397 | self.size_p = size_p
398 | self.sub_batch_size = sub_batch_size
399 | self.mode = mode
400 | self.test = test
401 |
402 | if test:
403 | self.flip_range = [False, True]
404 | self.rotate_range = [0, 1, 2, 3]
405 | else:
406 | self.flip_range = [False]
407 | self.rotate_range = [0]
408 |
409 | def get_scores(self):
410 | score_train = self.metrics.get_scores()
411 | score_train_local = self.metrics_local.get_scores()
412 | score_train_global = self.metrics_global.get_scores()
413 | return score_train, score_train_global, score_train_local
414 |
415 | def reset_metrics(self):
416 | self.metrics.reset()
417 | self.metrics_local.reset()
418 | self.metrics_global.reset()
419 |
420 | def eval_test(self, sample, model, global_fixed):
421 | with torch.no_grad():
422 | images = sample['image']
423 | if not self.test:
424 | labels = sample['label'] # PIL images
425 | labels_npy = masks_transform(labels, numpy=True)
426 |
427 | images_global = resize(images, self.size_g)
428 | outputs_global = np.zeros((len(images), self.n_class, self.size_g[0] // 4, self.size_g[1] // 4))
429 | if self.mode == 2 or self.mode == 3:
430 | images_local = [ image.copy() for image in images ]
431 | scores_local = [ np.zeros((1, self.n_class, images[i].size[1], images[i].size[0])) for i in range(len(images)) ]
432 | scores = [ np.zeros((1, self.n_class, images[i].size[1], images[i].size[0])) for i in range(len(images)) ]
433 |
434 | for flip in self.flip_range:
435 | if flip:
436 | # we already rotated images for 270'
437 | for b in range(len(images)):
438 | images_global[b] = transforms.functional.rotate(images_global[b], 90) # rotate back!
439 | images_global[b] = transforms.functional.hflip(images_global[b])
440 | if self.mode == 2 or self.mode == 3:
441 | images_local[b] = transforms.functional.rotate(images_local[b], 90) # rotate back!
442 | images_local[b] = transforms.functional.hflip(images_local[b])
443 | for angle in self.rotate_range:
444 | if angle > 0:
445 | for b in range(len(images)):
446 | images_global[b] = transforms.functional.rotate(images_global[b], 90)
447 | if self.mode == 2 or self.mode == 3:
448 | images_local[b] = transforms.functional.rotate(images_local[b], 90)
449 |
450 | # prepare global images onto cuda
451 | images_glb = images_transform(images_global) # b, c, h, w
452 |
453 | if self.mode == 2 or self.mode == 3:
454 | patches, coordinates, templates, sizes, ratios = global2patch(images, self.size_p)
455 | predicted_patches = [ np.zeros((len(coordinates[i]), self.n_class, self.size_p[0], self.size_p[1])) for i in range(len(images)) ]
456 | predicted_ensembles = [ np.zeros((len(coordinates[i]), self.n_class, self.size_p[0], self.size_p[1])) for i in range(len(images)) ]
457 |
458 | if self.mode == 1:
459 | # eval with only resized global image ##########################
460 | if flip:
461 | outputs_global += np.flip(np.rot90(model.forward(images_glb, None, None, None)[0].data.cpu().numpy(), k=angle, axes=(3, 2)), axis=3)
462 | else:
463 | outputs_global += np.rot90(model.forward(images_glb, None, None, None)[0].data.cpu().numpy(), k=angle, axes=(3, 2))
464 | ################################################################
465 |
466 | if self.mode == 2:
467 | # eval with patches ###########################################
468 | for i in range(len(images)):
469 | j = 0
470 | while j < len(coordinates[i]):
471 | patches_var = images_transform(patches[i][j : j+self.sub_batch_size]) # b, c, h, w
472 | output_ensembles, output_global, output_patches, _ = model.forward(images_glb[i:i+1], patches_var, coordinates[i][j : j+self.sub_batch_size], ratios[i], mode=self.mode, n_patch=len(coordinates[i]))
473 |
474 | # patch predictions
475 | predicted_patches[i][j:j+output_patches.size()[0]] += F.interpolate(output_patches, size=self.size_p, mode='nearest').data.cpu().numpy()
476 | predicted_ensembles[i][j:j+output_ensembles.size()[0]] += F.interpolate(output_ensembles, size=self.size_p, mode='nearest').data.cpu().numpy()
477 | j += patches_var.size()[0]
478 | if flip:
479 | outputs_global[i] += np.flip(np.rot90(output_global[0].data.cpu().numpy(), k=angle, axes=(2, 1)), axis=2)
480 | scores_local[i] += np.flip(np.rot90(np.array(patch2global(predicted_patches[i:i+1], self.n_class, sizes[i:i+1], coordinates[i:i+1], self.size_p)), k=angle, axes=(3, 2)), axis=3) # merge softmax scores from patches (overlaps)
481 | scores[i] += np.flip(np.rot90(np.array(patch2global(predicted_ensembles[i:i+1], self.n_class, sizes[i:i+1], coordinates[i:i+1], self.size_p)), k=angle, axes=(3, 2)), axis=3) # merge softmax scores from patches (overlaps)
482 | else:
483 | outputs_global[i] += np.rot90(output_global[0].data.cpu().numpy(), k=angle, axes=(2, 1))
484 | scores_local[i] += np.rot90(np.array(patch2global(predicted_patches[i:i+1], self.n_class, sizes[i:i+1], coordinates[i:i+1], self.size_p)), k=angle, axes=(3, 2)) # merge softmax scores from patches (overlaps)
485 | scores[i] += np.rot90(np.array(patch2global(predicted_ensembles[i:i+1], self.n_class, sizes[i:i+1], coordinates[i:i+1], self.size_p)), k=angle, axes=(3, 2)) # merge softmax scores from patches (overlaps)
486 | ###############################################################
487 |
488 | if self.mode == 3:
489 | # eval global with help from patches ##################################################
490 | # go through local patches to collect feature maps
491 | # collect predictions from patches
492 | for i in range(len(images)):
493 | j = 0
494 | while j < len(coordinates[i]):
495 | patches_var = images_transform(patches[i][j : j+self.sub_batch_size]) # b, c, h, w
496 | fm_patches, output_patches = model.module.collect_local_fm(images_glb[i:i+1], patches_var, ratios[i], coordinates[i], [j, j+self.sub_batch_size], len(images), global_model=global_fixed, template=templates[i], n_patch_all=len(coordinates[i]))
497 | predicted_patches[i][j:j+output_patches.size()[0]] += F.interpolate(output_patches, size=self.size_p, mode='nearest').data.cpu().numpy()
498 | j += self.sub_batch_size
499 | # go through global image
500 | tmp, fm_global = model.forward(images_glb, None, None, None, mode=self.mode)
501 | if flip:
502 | outputs_global += np.flip(np.rot90(tmp.data.cpu().numpy(), k=angle, axes=(3, 2)), axis=3)
503 | else:
504 | outputs_global += np.rot90(tmp.data.cpu().numpy(), k=angle, axes=(3, 2))
505 | # generate ensembles
506 | for i in range(len(images)):
507 | j = 0
508 | while j < len(coordinates[i]):
509 | fl = fm_patches[i][j : j+self.sub_batch_size].cuda()
510 | fg = model.module._crop_global(fm_global[i:i+1], coordinates[i][j:j+self.sub_batch_size], ratios[i])[0]
511 | fg = F.interpolate(fg, size=fl.size()[2:], mode='bilinear')
512 | output_ensembles = model.module.ensemble(fl, fg) # include cordinates
513 |
514 | # ensemble predictions
515 | predicted_ensembles[i][j:j+output_ensembles.size()[0]] += F.interpolate(output_ensembles, size=self.size_p, mode='nearest').data.cpu().numpy()
516 | j += self.sub_batch_size
517 | if flip:
518 | scores_local[i] += np.flip(np.rot90(np.array(patch2global(predicted_patches[i:i+1], self.n_class, sizes[i:i+1], coordinates[i:i+1], self.size_p)), k=angle, axes=(3, 2)), axis=3)[0] # merge softmax scores from patches (overlaps)
519 | scores[i] += np.flip(np.rot90(np.array(patch2global(predicted_ensembles[i:i+1], self.n_class, sizes[i:i+1], coordinates[i:i+1], self.size_p)), k=angle, axes=(3, 2)), axis=3)[0] # merge softmax scores from patches (overlaps)
520 | else:
521 | scores_local[i] += np.rot90(np.array(patch2global(predicted_patches[i:i+1], self.n_class, sizes[i:i+1], coordinates[i:i+1], self.size_p)), k=angle, axes=(3, 2)) # merge softmax scores from patches (overlaps)
522 | scores[i] += np.rot90(np.array(patch2global(predicted_ensembles[i:i+1], self.n_class, sizes[i:i+1], coordinates[i:i+1], self.size_p)), k=angle, axes=(3, 2)) # merge softmax scores from patches (overlaps)
523 | ###################################################
524 |
525 | # global predictions ###########################
526 | outputs_global = torch.Tensor(outputs_global)
527 | predictions_global = [F.interpolate(outputs_global[i:i+1], images[i].size[::-1], mode='nearest').argmax(1).detach().numpy()[0] for i in range(len(images))]
528 | if not self.test:
529 | self.metrics_global.update(labels_npy, predictions_global)
530 |
531 | if self.mode == 2 or self.mode == 3:
532 | # patch predictions ###########################
533 | predictions_local = [ score.argmax(1)[0] for score in scores_local ]
534 | if not self.test:
535 | self.metrics_local.update(labels_npy, predictions_local)
536 | ###################################################
537 | # combined/ensemble predictions ###########################
538 | predictions = [ score.argmax(1)[0] for score in scores ]
539 | if not self.test:
540 | self.metrics.update(labels_npy, predictions)
541 | return predictions, predictions_global, predictions_local
542 | else:
543 | return None, predictions_global, None
544 |
--------------------------------------------------------------------------------