├── .idea
├── NLP-Algorithm-Interview.iml
├── modules.xml
├── vcs.xml
└── workspace.xml
├── NLP面试集锦-20100109.md
├── NLP面试集锦-20200104.md
├── NLP面试集锦-20200106.md
├── NLP面试集锦-20200108.md
├── README.md
├── references
├── word2vec中的数学.pdf
├── 关于百度ERNIE及将知识图谱引入Bert - 知乎.pdf
└── 放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN_RNN_TF)比较 - 知乎.pdf
└── 剑指offer-python版
├── 1-二维数组中的查找.md
├── 10-数值的整数次方.md
├── 11-调整数组顺序使奇数位于偶数后面.md
├── 12-链表中倒数第k个节点的输出.md
├── 13-反转链表.md
├── 14-合并两个排序的链表.md
├── 15-树的子结构.md
├── 2-替换空格.md
├── 3-从尾到头打印链表.md
├── 4-重建二叉树.md
├── 5-用两个栈来实现队列.md
├── 6-旋转数组的最小数字.md
├── 7-斐波那契数列求第n项.md
├── 8-青蛙跳.md
├── 9-变态跳台阶.md
├── 扩展题-中文分词算法.md
└── 扩展题-检测字符串中的括号是否有效.md
/.idea/NLP-Algorithm-Interview.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 | true
19 | DEFINITION_ORDER
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 | ^{2} "C=\sum_{i=1}^{n}(y_{i}-y_{i}^{-})^{2}") 42 |
43 | 这里的损失函数为什么要用平方差形式?
44 |
45 | 使用平方形式的时候,使用的是“最小二乘”的思想,这里的“二乘”指的是用平方来度量观测点与估计点的距离(远近),“最小”指的是参数值要保证各个观测点与估计点的距离的平方和达到最小。
46 |
47 | (2)SVM损失函数
48 |
49 |
42 |
43 | 这里的损失函数为什么要用平方差形式?
44 |
45 | 使用平方形式的时候,使用的是“最小二乘”的思想,这里的“二乘”指的是用平方来度量观测点与估计点的距离(远近),“最小”指的是参数值要保证各个观测点与估计点的距离的平方和达到最小。
46 |
47 | (2)SVM损失函数
48 |
49 |  "L_{i}=\sum_{j\neq y_{i}}max(0,S_{j}-S_{y_{i}}+\Delta )") 50 |
51 | 其中,S_{yi}表示真实类别得分,S_{j}表示其他类别的得分。delta表示为边界值,L_{i}表示第i个输出的损失值。
52 |
53 | (3)交叉熵损失函数
54 |
55 |
50 |
51 | 其中,S_{yi}表示真实类别得分,S_{j}表示其他类别的得分。delta表示为边界值,L_{i}表示第i个输出的损失值。
52 |
53 | (3)交叉熵损失函数
54 |
55 | log(1-\hat{y})] "L=-[ylog\hat{y}+(1-y)log(1-\hat{y})]") 56 |
57 |
58 |
59 | **26.GRU**
60 |
61 | GRU即Gated Recurrent Unit。之前说到为了克服RNN的梯度消失和无法很好地处理远距离依赖提出了LSTM,而GRU是LSTM的一个变体,它保持了LSTM效果的同时又使结构更加简单。
62 |
63 | GRU模型只有两个门:更新门和重置门,更新门用于控制前一时刻的状态信息有多少比例可以输入到下一状态中,更新门的权值越大说明前一时刻的状态信息带入越多;而重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略的越多。
64 |
65 | GRU将LSTM中的输入门和遗忘门合并成一个单一的更新门。
66 |
67 | GRU与LSTM的区别:
68 |
69 | (1)memory的控制:LSTM用输出门控制,然后传递给下一单元;而GRU直接将其传递给下一个单元,不做任何控制。
70 |
71 | (2)上一时刻的信息:LSTM计算新的记忆时不对上一时刻的信息做任何控制,通过使用遗忘门独立实现;而GRU计算新的记忆时利用重置门对上一时刻的信息进行控制。
72 |
73 | **27.Memory Network**
74 |
75 | 如RNN等网络的记忆存储太小,不能精确地记住过去的事实。由此提出了Memory Network。
76 |
77 | 一个Memory Network由一个记忆数组m和四个组件(输入I,泛化G、输出O、回答R)组成。
78 |
79 | 四个组件的作用:
80 |
81 | I(输入特征映射): 将输入转换为记忆网络内部特征的表示。给定输入x,可以是字符、单词、句子等不同的粒度,通过I(x)得到记忆网络内部的特征。
82 |
83 | G :(更新记忆) - 使用新的输入更新记忆数组m。
84 |
85 | O:(输出) - 在记忆数组m更新完以后,就可以将输入和记忆单元联系起来,根据输入选择与之相关的记忆单元。
86 |
87 | R:(输出回答) - 得到了输入编码向量I(x),记忆数组m和需要的支持事实,就可以根据问题来得到需要的答案了。文中给出了一个简单的R()函数,将输入和选择的记忆单元与此表中的每个单词进行评分Sr,然后选择得分最大的单词作为回答。
88 |
89 |
90 |
91 |
--------------------------------------------------------------------------------
/NLP面试集锦-20200104.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | **2020-01-04**
4 |
5 | **1.文本表示模型及其优缺点**
6 |
7 | 可分为传统模型和词嵌入模型。
8 |
9 | 传统模型包括词袋模型、TF-IDF、n-gram、LDA,其中词袋模型主要是依据字典来计算每个样本中的词语对应的频率/有无出现特征;而TF-IDF主要是用来衡量某个单词对于语义区别的重要性;n-gram主要是通过滑动窗口的形式将连续的单词作为对应特征;LDA是通过分解“文档-单词”矩阵来得到“文档-主题”和“主题-单词”两个概率分布,主要目的是计算每篇文档的主题分布。这一类传统模型实现较为简单,效率高,但所获得的的特征不包含语义信息,且易造成维度灾难。
10 |
11 | 词嵌入模型属于深度学习的范畴,旨在将每个单词映射成一个低维的稠密向量,包括word2vec、Glove、fasttext等算法,其中最常用的是word2vec,其次是fasttext。在语义获取上更有优势。
12 |
13 | **2.word2vec是如何工作的?它和LDA有什么区别和联系呢?**
14 |
15 | 关于word2vec的工作原理可参考[大话NLP领域的传统词向量预训练]([https://vincent131499.github.io/2020/01/03/%E5%A4%A7%E8%AF%9DNLP%E9%A2%86%E5%9F%9F%E7%9A%84%E4%BC%A0%E7%BB%9F%E8%AF%8D%E5%90%91%E9%87%8F%E9%A2%84%E8%AE%AD%E7%BB%83/](https://vincent131499.github.io/2020/01/03/大话NLP领域的传统词向量预训练/))。
16 |
17 | 而针对word2vec与LDA的区别与联系:
18 |
19 | LDA是通过分解“文档-单词”矩阵来得到“文档-主题”和“主题-单词”两个概率分布,主要目的是计算每篇文档的主题分布;而word2vec是通过浅层的三层网络来进行参数矩阵的训练,最终得到每个单词对应的词向量。
20 |
21 | 在计算一个语料库中各个单词之间的相似度可以使用word2vec来计算,而要计算一个语料库中各个文档之间的相似度,那还是LDA比较合适,通过文章主题会得到更好的相似度衡量。
22 |
23 | **3.处理文本数据时,RNN比CNN有什么特点?**
24 |
25 | 传统文本处理以TF-IDF和词袋模型作为特征,会使得模型丢失重要的语序特征。为了捕捉这个语序特征,提出了使用CNN和RNN来处理文本信息。
26 |
27 | CNN一般会接受定长的向量作为输入,然后通过滑动窗口加池化的方法来捕捉重要的局部特征,但对于单词间的长距离依赖特征难以学习。而RNN对于处理文本这样的序列信息有着天然的优势,因为它是将上一时刻的输出特征作为下一时刻的输入来进行传递处理,对于单词间的长距离依赖特征能够很好地捕捉。
28 |
29 | **4.RNN为什么会出现梯度消失或梯度爆炸?有哪些解决方案?**
30 |
31 | 定义:度神经网络训练的时候,采用的是反向传播方式,该方式使用链式求导,计算每层梯度的时候会涉及一些连乘 作,因此如果网络过深。那么如果连乘的因子大部分小于1,最后乘积的结果可能趋于0,也就是梯度消失,后面的网络层的参数不发生变化.那么如果连乘的因子大部分大于1,最后乘积可能趋于无穷,这就是梯度爆炸。
32 |
33 | 梯度消失或者梯度爆炸是由RNN中的sigmoid函数引起的,当网络层数较多时,随着预测误差沿神经网络每一层反向传播,当最初初始化的网络权值w小于1时,前面的层比后面的层梯度变化更小,梯度呈指数减小,故变化更慢,从而引起梯度消失;反之当w比较大时,前面的网络层比后面的网络层梯度变化更快,梯度呈指数增长,则会引起梯度爆炸。
34 |
35 | 解决方案:(1)ReLU替代sigmoid函数;(2)BN(Batch Normalization);(3)LSTM的结构设计也可以改善RNN中的梯度消失问题;(4)Resnet(残差网络)
36 |
37 | Note:在RNN采用Relu作为激活函数时,应将权重矩阵w初始化为单位矩阵。
38 |
39 | **5.LSTM是如何实现长短期记忆功能的?**
40 |
41 | [LSTM模型细节结构讲解](https://blog.csdn.net/dream_catcher_10/article/details/48522339)
42 |
43 | LSTM单元主要是由输入门、遗忘门和输出门三个结构组成;其中输入门用于控制当前时刻有哪些重要信息可以输入到记忆单元;遗忘门用于控制前一步的记忆单元有哪些无用信息会被遗忘掉;而输出门则是决定当前的记忆单元有哪些重要信息可以输出。
44 |
45 | 在一个训练好的网络中,当输入序列没有重要信息时,LSTM遗忘门的值接近于1,输入门接近于0,此时过去的记忆会被保存,从而实现了长期记忆;当输入的序列中存在重要信息时,LSTM会将其存在记忆中,此时输入门的值接近于1;当输入的序列中存在重要信息且该信息意味着之前的记忆不再重要的时候,输入门接近于1,,遗忘门接近于0,这样旧的记忆被遗忘,新的记忆被保存。经过这样的设计,整个网络更容易学习到序列之间的长期依赖。
46 |
47 | 6.LSTM中各模块分别使用什么激活函数,可以使用别的激活函数吗?
48 |
49 | LSTM中的输入门、遗忘门和输出门的激活函数都是sigmoid,在生成候选记忆时,使用双曲正切函数Tanh作为激活函数。
50 |
51 | why-细节:
52 |
53 | 这两个函数都是饱和的,在输入达到一定值的情况下,输出不会发生明显变化。如果是非饱和的激活函数,比如Relu,那么就难以实现门控的效果。
54 |
55 | Sigmoid函数的输出在0~1之间,符合门控的物理意义。且当输入较小或较大时,其输出会非常接近0或1,从而保证该门开或关。
56 |
57 | 在生成候选记忆时,使用Tanh函数,因为其输出在-1~1之间,这与大多数场景下特征分布是0中心的吻合。此外,Tanh在输入为0的附近比Sigmoid有更大梯度,通常使模型收敛更快。
58 |
59 | 可以使用别的激活函数吗?---激活函数的选取并不是一成不变的,在原始LSTM中,使用的是sigmoid函数的变种;但是实际上在门控机制中,大多都使用了sigmoid。
60 |
61 |
62 |
63 |
64 |
65 |
--------------------------------------------------------------------------------
/NLP面试集锦-20200106.md:
--------------------------------------------------------------------------------
1 | **2020-01-06**
2 |
3 | **7.Seq2Seq模型的概念?优点?缺点?**
4 |
5 | Seq2Seq,全称为Sequence to Sequence模型,级序列到序列的模型,主要是将一个输入的序列信息,通过编码和解码生成一个新的输出序列,通常用于机器翻译、语音识别、自动对话等任务。
6 |
7 | 优点:seq2seq可以处理变长序列。在seq2seq出现之前,深度神经网络的输入和输出都是表示为固定长度的向量,如果长度稍有变化,会使用补零等操作。
8 |
9 | 缺点:计算效率低。
10 |
11 | **8.Seq2Seq模型在解码时,有哪些常用方法?**
12 |
13 | (1)贪心法
14 |
15 | 选定一个度量标准后,每次都在当前状态下选择一个最佳结果,直到结束。
16 |
17 | (2)集束搜索/beam search
18 |
19 | 当前状态下保存beam size个较佳选择,解码时每一步根据当前选择进行拓展和排序,接着选择前beam size个进行保存,循环迭代,直到结束。
20 |
21 | (3)加入注意力机制
22 |
23 | (4)加入记忆网络
24 |
25 | **9.Seq2Seq模型加入注意力机制是为了解决什么问题?为什么会选用双向循环神经网络?**
26 |
27 | 以机器翻译为例,随着序列长度的增加,模型在编码时将输入序列的全部信息压缩到一个向量表示中,序列越长,句子越前面的词的信息丢失就越严重,因为解码时丢失了当前词与对应源语言词的上下文信息和位置信息。Seq2Seq引入注意力机制就是为了解决这个问题,使得模型在解码时,可以让每一个输出词都依赖于前一个隐状态以及输入序列中对应的隐状态。
28 |
29 | 至于为什么要选用双向循环神经网络?其实在上面已经提到了,生成输出词时需要依赖输入序列中对应的隐状态,而是用双向RNN可以捕捉对应输入词的上下文特征,从而得到更好的注意力权重。这也说明了上下文语境向量在语言模型中的重要性。
30 |
31 | **10.命名实体识别算法有哪些?优缺点?**
32 |
33 | 命名实体识别,也被称为NER,就是从非结构化的输入文本中抽取出指定类型的实体。
34 |
35 | 最初是使用基于词典+规则的方法,后面引入深度学习,目前大多数都采用深度学习。最先使用RNN进行预测每个token的标签,然而这种模式不能直接利用上文已经预测的标签,只能通过隐状态传递上文信息,进而导致预测出来的标签可能无效。针对这种缺点,在神经网络的输出层加入CRF层(重点是利用标签转移概率)。典型模型有BiLSTM-CRF.
36 |
37 | **11.如何对中文分词问题利用隐马尔可夫模型(HMM)进行建模和训练**
38 |
39 | HMM常用来解决序列标注问题,可将分词问题转换成序列标注问题来进行建模。首先针对语料中句子的每个字进行BEMS标注(B代表一个词开头,E代表词尾的最后一个字,M代表词中间的字,S表示一个单字词),则隐状态的取值空间为(B,E,M,S),同时设定状态转移概率(M和M后面只能是M或者E),而每个字就是模型中的观测状态。然后使用维特比算法针对初始状态概率分布、状态转移概率矩阵、发射概率矩阵以及观测值计算,预测一个最有可能的状态序列。然后根据这个状态序列进行文本划分。
40 |
41 | **那么最大熵隐马尔可夫模型为什么会出现标注偏置问题,如何解决呢?**
42 |
43 | 最大熵隐马尔可夫模型由于局部归一化的影响,隐状态会倾向于转移到后续状态可能更少的状态上,以提高整体的后验概率。
44 |
45 | 解决方式:使用条件随机场CRF针对全局范围进行归一化,从而解决了局部归一化带来的标注偏置问题。
46 |
47 | **12.常见的概率图模型中,哪些是生成式模型,哪些是判别式模型?**
48 |
49 | Note:假设可观测的变量集合为X,需要预测的变量集合为Y,其他的变量集合为Z;生成式模型是对联合概率分布P(X,Y,Z)进行建模,在给定观测集合X的条件下,通过计算边缘分布来求得对变量集合Y的推断。而判别式模型是直接对条件概率分布P(Y,Z|X)进行建模,然后消掉无关变量Z就可以得到对变量Y的预测。
50 |
51 | 生成式模型:朴素贝叶斯、贝叶斯网络、LDA、HMM
52 |
53 | 判别式模型:CRF、最大熵HMM
54 |
55 | **13.使用TensorFlow或者pytorch简单写一个RNN**
56 |
57 | ===熟悉下常用构建网络代码的大致架构和流程===
58 |
59 | **14.爬虫相关**
60 |
61 | 了解并在网上实现过开源项目
62 |
63 | **15.基于语义匹配的实体链接算法**
64 |
65 | 基于实体链接的实体消歧方法,是指将实体指称项链接到知识库中特定的实体,也称为实体链接。实体链接阶段分为候选实体生成和候选实体消歧两步。
66 |
67 | (1)候选实体生成
68 |
69 | 基于实体词典+同义词词库的方法、检索排序法
70 |
71 | (2)候选实体消歧
72 |
73 | 简单/常用baseline:
74 |
75 | 检索的方法(将指称实体与邻近的关键词在知识库中查询)
76 |
77 | 基于向量空间模型的方法(余弦相似度,不能反映语义)
78 |
79 | 深度语义:
80 |
81 | 基于排序模型的方法(查询与文档的相似度、欧式距离、编辑距离、主题相似度、实体流行度等特征)
82 |
83 | 主题一致性方法(指称的实体与候选实体属于同一个主题)
84 |
85 | 神经网络方法(捕获待消歧实体上下文和候选实体描述不同粒度的语义,最新研究也结合了实体的属性特征)
86 |
87 |
88 |
89 |
90 |
91 |
--------------------------------------------------------------------------------
/NLP面试集锦-20200108.md:
--------------------------------------------------------------------------------
1 | **2020-01-08**
2 |
3 | **16.决策树的概念?有哪些常用的启发函数?如何对决策树进行剪枝?**
4 |
5 | 概念:决策树是一种自上而下,对样本数据进行树形分类的过程。节点分为内部节点和叶子节点。每个内部节点代表一个特征,叶节点代表类别。从顶部节点开始,所有样本聚在一起,经过根节点和不同内部子节点的划分,所有样本都被归到某一个类别(叶节点)。
6 |
7 | 启发式函数:ID3、C4.5、CART
8 |
9 | ID3:最大信息增益,选择能够带来最大的信息增益的那个特征;
10 |
11 | C4.5:最大信息增益比。
12 |
13 | CART:最大基尼系数。基尼指数反映了从数据集中随机抽取两个样本,其类别不一致的概率。CART每次选取使基尼系数最小的特征。
14 |
15 | 剪枝方法:决策树容易过拟合,需要剪枝。分为预剪枝和后剪枝。
16 |
17 | 预剪枝:在对树中节点扩展之前,先计算当前划分能否带来模型泛化能力的提升,若不能,则不再继续生长子树。
18 |
19 | 后剪枝:先生成一个完整的决策树,然后自底向上计算是否剪枝(将子树切除,用叶节点代替)。通过能够提升验证集准确率来计算。
20 |
21 | **17.介绍一下GBDT**
22 |
23 | 梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是Boosting算法中非常流行的一个。
24 |
25 | Gradient Boosting的流程:在每一轮迭代中,首先计算出当前模型在所有样本上的负梯度,然后以该值为目标训练出一个新的弱分类器进行拟合并计算出该弱分类器的权重。最终实现对模型的更新。
26 |
27 | 而采用决策树作为弱分类器的Gradient Boosting算法成为GBDT。GBDT中使用的决策树通常为CART。
28 |
29 | **18.Xgboost与GBDT的区别和联系?**
30 |
31 | (1)GBDT是机器学习算法,Xgboost是该算法的工程实现;
32 |
33 | (2)在使用CART作为基分类器的时候,XGBoost显式地加入了**正则项**来控制模型复杂度,有利于防止过拟合;
34 |
35 | (3)数据采样:传统的GBDT在每轮迭代时使用全部数据,XGBoost支持对数据进行采样;
36 |
37 | (4)缺失值处理:传统的GBDT没有设计对缺失值的处理,XGBoost能自动学出缺失值处理策略
38 |
39 | **19.深度学习中常见的优化器?**
40 |
41 | (1)SGD
42 |
43 | 目前SGD一般都是指mini-batch gradient descent,这是神经网络中大多使用的优化方法。
44 |
45 | SGD就是每一次迭代计算mini-batch的梯度,然后对参数更新。
46 |
47 | 这里说一下局部最优点和鞍点。
48 |
49 | 两者相似:在这个点的导数为0;
50 |
51 | 区别:是否在各个维度都是最低点。只要某个一阶导数为0的点在某个维度上是最高点而不是最低点,那它就是鞍点。
52 |
53 | (2)Momentum/动量更新
54 |
55 | 积累之前的动量来替代真正的梯度。通过在相关方向加速SGD,抑制震荡,加快收敛。
56 |
57 | (3)Adagrad
58 |
59 | 对学习率进行约束,通过以往的梯度自适应更新学习率,不同的参数具有不同的学习率。十分适合处理稀疏数据(对常出现的特征进行小幅度更新,不常出现的特征进行大幅度更新)。
60 |
61 | (4)RMSprop
62 |
63 | 可以算作Adadelta的一种特例,适合处理非平稳目标,结合RNN使用效果最好。
64 |
65 | (5)Adam
66 |
67 | 本质上是带有动量的RMSprop,利用梯度的一阶矩阵和二阶矩阵估计动态调整每个参数的学习率。结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点。
68 |
69 | **20.如何防止过拟合以及为什么可以?**
70 |
71 | (1)数据增强
72 |
73 | 数据集扩增
74 |
75 | (2)early stopping
76 |
77 | 一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。
78 |
79 | (3)正则化限制
80 |
81 | 这种方法一般是在目标函数或代价函数后面加上一个正则项,一般有L1正则、L2正则等。
82 |
83 | L1正则为什么可以防止过拟合?
84 |
85 | 添加L1正则项可以让那些原先处于0附近的参数往0移动,使得部分参数为0,进而降低模型的复杂度(模型的复杂度由参数决定),从而防止过拟合,提高模型的泛化能力。
86 |
87 | L2正则为什么可以防止过拟合?
88 |
89 | L2正则项可以加速参数变小,而更小的参数意味着模型的复杂度更低。
90 |
91 | L1和L2正则的区别?
92 |
93 | 区别1:L1是在loss函数后加上参数的1范数(|w|),即对应参数向量的绝对值之和,而L2是在loss函数后加上参数的2范数(sigma(w^2)),即对应参数向量的平方和的平方根;
94 |
95 | 区别2:L1会产生稀疏的特征,L2会产生更多的接近0的特征。L1在特征选择时候非常有用,L2只是一种规则化,提升模型的泛化能力。
96 |
97 | 区别3:L1正则先验服从拉普拉斯分布,L2正则先验服从高斯分布。
98 |
99 | L1在0出不可导,怎么处理?
100 |
101 | 可以使用Proximal Algorithms或者ADMM来解决。
102 |
103 | (4)Dropout
104 |
105 | 通过随机删除隐藏层的神经元个数来防止过拟合。
106 |
107 | 为什么可以防止过拟合?
108 |
109 | 原因1:不同的网络训练时可能产生不能的过拟合,而dropout对丢失隐藏层神经单元的多个不同网络**取平均**,其中互为“反向”的拟合相互抵消就可以达到整体上过拟合减少;
110 |
111 | 原因2:减少神经元之间复杂的**共适应**关系。dropout导致两个神经元不一定每次都在同一个网络中出现,这样就可以使网络去学习更加鲁棒的特征,提升模型的泛化能力。
112 |
113 | (5)Batch Normalization
114 |
115 | BN实际使用时会将特征强制性的归到**均值为0**,**方差为1**的数学模型下。有两个功能:一个是加快训练和收敛,一个是防止过拟合。
116 |
117 | 为什么可以防止过拟合?
118 |
119 | BN的使用使得同一个样本的输出不仅仅取决于这个样本本身的特征,也取决于与这个样本属于同一个mini-batch的其他样本的特征,进而增强模型的泛化能力。
120 |
121 | 如何加快训练和收敛速度?
122 |
123 | BN将每层网络的数据都转换到均值为0,方差为1的状态下,一方面,数据的分布相同,训练比较容易收敛,另一方面,均值为0,方差为1的状态下,梯度计算时会产生较大的梯度值,可以加快参数的训练。更进一步,BN也可以很好的控制梯度消失和梯度爆炸现象。
124 |
125 | BN最大的优点就是允许网络使用较大的学习率进行训练,加快网络的训练速度。
126 |
127 |
128 |
129 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # NLP-Algorithm-Interview
2 | NLP算法领域的面试资料大全,包括笔试、面试题目
3 | # 面试记录
4 | 2020-3-4:
5 | 一面:问了一些项目的技术路线以及采用的各种模型
6 | 二面:项目模型细节讲解、深度学习基础知识考查、Transformer介绍、BERT介绍以及开放题目(对于AI的理解)。最后手写代码“[Python检测字符串中的括号是否有效](https://github.com/Vincent131499/NLP-Algorithm-Interview/tree/master/剑指offer-python版/扩展题-检测字符串中的括号是否有效.md)”。
7 |
8 |
9 |
--------------------------------------------------------------------------------
/references/word2vec中的数学.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Vincent131499/NLP-Algorithm-Interview/b47e5114496785ace7e0fa48e3a70a4144b9543a/references/word2vec中的数学.pdf
--------------------------------------------------------------------------------
/references/关于百度ERNIE及将知识图谱引入Bert - 知乎.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Vincent131499/NLP-Algorithm-Interview/b47e5114496785ace7e0fa48e3a70a4144b9543a/references/关于百度ERNIE及将知识图谱引入Bert - 知乎.pdf
--------------------------------------------------------------------------------
/references/放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN_RNN_TF)比较 - 知乎.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Vincent131499/NLP-Algorithm-Interview/b47e5114496785ace7e0fa48e3a70a4144b9543a/references/放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN_RNN_TF)比较 - 知乎.pdf
--------------------------------------------------------------------------------
/剑指offer-python版/1-二维数组中的查找.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
4 |
5 | 解题思路1:按照行遍历数组,判断这个整数是否在行中出现?
6 |
7 | ```Python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | # array 二维列表
11 | def Find(self, target, array):
12 | # write code here
13 | flag = False
14 | for i in range(len(array)):
15 | line = array[i]
16 | if target in line:
17 | flag = True
18 | return flag
19 | ```
20 |
21 |
22 |
23 | 解题思路2:从左下角元素开始查找,若大于该元素,向右查找(列数+1);若小于该元素,则向上查找(行数-1);若等于该元素,直接返回。
24 |
25 | ```Python
26 | # -*- coding:utf-8 -*-
27 | class Solution:
28 | # array 二维列表
29 | def Find(self, target, array):
30 | # write code here
31 | row_index = len(array) - 1
32 | col_index = len(array[0]) - 1
33 | i = row_index
34 | j = 0
35 | while i >= 0 and j <= col_index:
36 | if target > array[i][j]:
37 | j += 1
38 | elif target < array[i][j]:
39 | i -= 1
40 | else:
41 | return True
42 | return False
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/剑指offer-python版/10-数值的整数次方.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 给定一个double类型的浮点数base和int类型的整数exponent。求base的exponent次方。
4 |
5 | 保证base和exponent不同时为0
6 |
7 | 解题思路:
8 |
9 | 需要注意的地方:
10 | 当指数为负数的时候
11 | 当底数为零切指数为负数的情况
12 | 在判断底数base是不是等于0的时候,不能直接写base==0, 因为计算机内表示小数时有误差,只能判断他们的差的绝对值是不是在一个很小的范围内
13 |
14 | 当n为偶数, a^n = a^(n/2) * a^(n/2)
15 | 当n为奇数, a^n = a^((n-1)/2) * a^((n-1)/2)) * a
16 |
17 | ```python
18 | # -*- coding:utf-8 -*-
19 | class Solution:
20 | def Power(self, base, exponent):
21 | # write code here
22 | if exponent == 0:
23 | return 1
24 | if exponent == 1:
25 | return base
26 | if exponent == -1:
27 | return 1/base
28 | result = self.Power(base, exponent/2)
29 | result *= result
30 | if (exponent % 2) == 1:
31 | result *= base
32 | return result
33 | ```
34 |
35 |
--------------------------------------------------------------------------------
/剑指offer-python版/11-调整数组顺序使奇数位于偶数后面.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
4 |
5 | 解题思路1:直接利用python的trick即可解决
6 |
7 | ```python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | def reOrderArray(self, array):
11 | # write code here
12 | left = [x for x in array if x%2 != 0]
13 | right = [x for x in array if x%2 == 0]
14 | return left+right
15 | ```
16 |
17 |
--------------------------------------------------------------------------------
/剑指offer-python版/12-链表中倒数第k个节点的输出.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入一个链表,输出该链表中倒数第k个结点。
4 |
5 | 解题思路:
6 |
7 | 这道题的思路很好,
8 |
9 | 如果在只希望一次遍历的情况下, 寻找倒数第k个结点, 可以设置两个指针
10 |
11 | 第一个指针先往前走k-1步,然后从第k步开始第二个指针指向头结点
12 |
13 | 然后两个指针一起遍历
14 |
15 | 当第一个指针指向尾结点的时候,第二个指针正好指向倒数第k个节点
16 |
17 | ```python
18 | # -*- coding:utf-8 -*-
19 | # class ListNode:
20 | # def __init__(self, x):
21 | # self.val = x
22 | # self.next = None
23 |
24 | class Solution:
25 | def FindKthToTail(self, head, k):
26 | # write code here
27 | # head表示头结点,k表示第k个节点
28 | if head == None or k <= 0:
29 | return
30 | phead1 = head
31 | phead2 = None
32 | for i in range(k-1):
33 | if phead1.next != None:
34 | phead1 = phead1.next
35 | else:
36 | return None
37 | phead2 = head
38 | while phead1.next != None:
39 | phead1 = phead1.next
40 | phead2 = phead2.next
41 | return phead2
42 | ```
43 |
44 |
--------------------------------------------------------------------------------
/剑指offer-python版/13-反转链表.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入一个链表,反转链表后,输出新链表的表头。
4 |
5 | 解题思路:
6 |
7 | **递归思想**。
8 | 我们使其先走到链表的末尾,确保每次回溯时都返回最后一个节点的指针。同时从倒数第二个结点开始反序。
9 | `head.next.next = head;`是指使当前节点的下一个节点指向自己
10 | `head.next = null`断开与下一个节点的联系,完成真正的反序操作
11 |
12 | 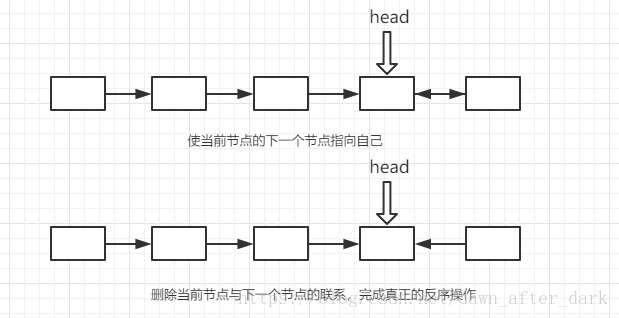
13 |
14 | ```python
15 | # -*- coding:utf-8 -*-
16 | # class ListNode:
17 | # def __init__(self, x):
18 | # self.val = x
19 | # self.next = None
20 | class Solution:
21 | # 返回ListNode
22 | def ReverseList(self, pHead):
23 | # write code here
24 | if not pHead or not pHead.next:
25 | return pHead
26 | else:
27 | target = self.ReverseList(pHead.next)
28 | pHead.next.next = pHead
29 | pHead.next = None
30 | return target
31 | ```
32 |
33 |
--------------------------------------------------------------------------------
/剑指offer-python版/14-合并两个排序的链表.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入两个**单调递增**的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足**单调不减**规则
4 |
5 | 解题思路:
6 |
7 | 要注意特殊输入,如果输入是空链表,不能崩溃。
8 |
9 | ```python
10 | # -*- coding:utf-8 -*-
11 | # class ListNode:
12 | # def __init__(self, x):
13 | # self.val = x
14 | # self.next = None
15 | class Solution:
16 | # 返回合并后列表
17 | def Merge(self, pHead1, pHead2):
18 | # write code here
19 | if pHead1==None:
20 | return pHead2
21 | elif pHead2==None:
22 | return pHead1
23 | pMergedHead = None
24 | if pHead1.val < pHead2.val:
25 | pMergedHead = pHead1
26 | pMergedHead.next = self.Merge(pHead1.next, pHead2)
27 | else:
28 | pMergedHead = pHead2
29 | pMergedHead.next = self.Merge(pHead1, pHead2.next)
30 | return pMergedHead
31 | ```
32 |
33 |
--------------------------------------------------------------------------------
/剑指offer-python版/15-树的子结构.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入两棵二叉树A,B,判断B是不是A的子结构。(ps:我们约定空树不是任意一个树的子结构)
4 |
5 | 解题思路:
6 |
7 | 多出需要判断指针是不是None,避免访问空指针而造成程序崩溃。
8 |
9 | ```python
10 | # -*- coding:utf-8 -*-
11 | # class TreeNode:
12 | # def __init__(self, x):
13 | # self.val = x
14 | # self.left = None
15 | # self.right = None
16 | class Solution:
17 | def HasSubtree(self, pRoot1, pRoot2):
18 | result = False
19 | if pRoot1 != None and pRoot2 != None:
20 | if pRoot1.val == pRoot2.val:
21 | result = self.DoesTree1haveTree2(pRoot1, pRoot2)
22 | if not result:
23 | result = self.HasSubtree(pRoot1.left, pRoot2)
24 | if not result:
25 | result = self.HasSubtree(pRoot1.right, pRoot2)
26 | return result
27 | # 用于递归判断树的每个节点是否相同
28 | # 需要注意的地方是: 前两个if语句不可以颠倒顺序
29 | # 如果颠倒顺序, 会先判断pRoot1是否为None, 其实这个时候pRoot2的结点已经遍历完成确定相等了, 但是返回了False, 判断错误
30 | def DoesTree1haveTree2(self, pRoot1, pRoot2):
31 | if pRoot2 == None:
32 | return True
33 | if pRoot1 == None:
34 | return False
35 | if pRoot1.val != pRoot2.val:
36 | return False
37 |
38 | return self.DoesTree1haveTree2(pRoot1.left, pRoot2.left) and self.DoesTree1haveTree2(pRoot1.right, pRoot2.right)
39 | ```
40 |
41 |
--------------------------------------------------------------------------------
/剑指offer-python版/2-替换空格.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 请实现一个函数,将一个字符串中的每个空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
4 |
5 | 解题思路1:使用replace语句生成一个新的str,原始的s还是带空格的str变量
6 |
7 | ```Python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | # s 源字符串
11 | def replaceSpace(self, s):
12 | # write code here
13 | if type(s) != str:
14 | return
15 | s_new = s.replace(' ', '%20')
16 | return s_new
17 | ```
18 |
19 |
20 |
21 | 解题思路2:使用append一次遍历即可替换,由于list的append是O(1)的时间复杂度,因此该算法复杂度为O(n)
22 |
23 | ```Python
24 | # -*- coding:utf-8 -*-
25 | class Solution:
26 | # s 源字符串
27 | def replaceSpace(self, s):
28 | # write code here
29 | s_new = []
30 | for term in s:
31 | if term == ' ':
32 | s_new.append('%')
33 | s_new.append('2')
34 | s_new.append('0')
35 | else:
36 | s_new.append(term)
37 | return ''.join(s_new)
38 | ```
39 |
40 |
--------------------------------------------------------------------------------
/剑指offer-python版/3-从尾到头打印链表.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入一个链表,按链表从尾到头的顺序返回一个ArrayList。
4 |
5 | 解题思路:将当前节点设置为头结点head,而后使用while循环判断head节点是否为空,若不为空,则将该节点的val值插入到列表的第1个位置,并将head设置为下一个节点,继续循环。
6 |
7 | ```Python
8 | # -*- coding:utf-8 -*-
9 | # class ListNode:
10 | # def __init__(self, x):
11 | # self.val = x
12 | # self.next = None
13 |
14 | class Solution:
15 | # 返回从尾部到头部的列表值序列,例如[1,2,3]
16 | def printListFromTailToHead(self, listNode):
17 | # write code here
18 | l = []
19 | head = listNode
20 | while head:
21 | l.insert(0, head.val)
22 | head = head.next
23 | return l
24 | ```
25 |
26 |
27 |
--------------------------------------------------------------------------------
/剑指offer-python版/4-重建二叉树.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
4 |
5 | 解题思路:利用二叉树前序遍历和中序遍历的特性。前序遍历的第一个值一定为根节点,对应于中序遍历中间的一个点(记根节点在中序序列中的index为i)。在中序遍历序列中,这个点左侧的均为根的左子树,这个点右侧的均为根的右子树。这时可以利用递归:分别取前序遍历[1:i+1]和中序遍历[:i]对应于左子树继续上一个过程,取前序遍历[i+1:]和中序遍历[i+1:]对应于右子树继续上一个过程,最终得以重建二叉树。
6 |
7 | ```Python
8 | # -*- coding:utf-8 -*-
9 | # class TreeNode:
10 | # def __init__(self, x):
11 | # self.val = x
12 | # self.left = None
13 | # self.right = None
14 | class Solution:
15 | # 返回构造的TreeNode根节点
16 | def reConstructBinaryTree(self, pre, tin):
17 | # write code here
18 | if len(pre) == 0:
19 | return
20 | if len(pre) == 1:
21 | return TreeNode(pre[0])
22 | index = tin.index(pre[0])
23 | root = TreeNode(pre[0])
24 | root.left = self.reConstructBinaryTree(pre[1:1+index], tin[:index])
25 | root.right = self.reConstructBinaryTree(pre[index+1:], tin[index+1:])
26 | return root
27 | ```
28 |
29 | ‘
30 |
--------------------------------------------------------------------------------
/剑指offer-python版/5-用两个栈来实现队列.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
4 |
5 | 解题思路:首先需要初始化两个栈stack1和stack2,队列的push操作只需要将元素append到stack1里面即可。对于队列的pop操作,首先需要判断stack1和stack2中元素的数量情况。两个都空直接返回,若stack1不空stack2空(因为在push时针对stack1操作),则需要将stack1的元素出栈放入到stack2中,然后stack2的元素出栈。
6 |
7 | ```Python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | def __init__(self):
11 | self.stack1 = []
12 | self.stack2 = []
13 | def push(self, node):
14 | # write code here
15 | self.stack1.append(node)
16 | def pop(self):
17 | # return xx
18 | if len(self.stack1) == 0 and len(self.stack2) == 0:
19 | return
20 | elif len(self.stack2) == 0:
21 | while len(self.stack1) > 0:
22 | self.stack2.append(self.stack1.pop())
23 | return self.stack2.pop()
24 | ```
25 |
26 |
27 |
--------------------------------------------------------------------------------
/剑指offer-python版/6-旋转数组的最小数字.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。
4 | 输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。
5 | 例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转,该数组的最小值为1。
6 | NOTE:给出的所有元素都大于0,若数组大小为0,请返回0。
7 |
8 | 解题思路1:蛮力破解,直接使用python提供的sorted函数进行排序,返回最小元素
9 |
10 | ```python
11 | # -*- coding:utf-8 -*-
12 | class Solution:
13 | def minNumberInRotateArray(self, rotateArray):
14 | # write code here
15 | if len(rotateArray) == 0:
16 | return 0
17 | else:
18 | sorted_list = sorted(rotateArray)
19 | return sorted_list[0]
20 | ```
21 |
22 | 解题思路2:二分查找的变形,注意到旋转数组的首元素肯定不小于旋转数组的尾元素,设置中间点。如果中间点大于首元素,说明最小数字在后面一半,如果中间点小于尾元素,说明最小数字在前一半。依次循环。同时,当一次循环中首元素小于尾元素,说明最小值就是首元素。但是当首元素等于尾元素等于中间值,只能在这个区域顺序查找。
23 |
24 | ```python
25 | # -*- coding:utf-8 -*-
26 | class Solution:
27 | def minNumberInRotateArray(self, rotateArray):
28 | # write code here
29 | if len(rotateArray) == 0:
30 | return 0
31 | left, right = 0, len(rotateArray)-1
32 | while rotateArray[left] >= rotateArray[right]:
33 | if (right - left) == 1:
34 | return rotateArray[right]
35 | mid = (left + right) / 2
36 | if rotateArray[left] <= rotateArray[mid]:
37 | left = mid
38 | if rotateArray[right] >= rotateArray[mid]:
39 | right = mid
40 | return rotateArray[0]
41 | ```
42 |
43 |
--------------------------------------------------------------------------------
/剑指offer-python版/7-斐波那契数列求第n项.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0)。
4 |
5 | n<=39
6 |
7 | 解题思路:如何不使用递归实现斐波那契数列,需要把前面两个数字存入在一个数组中。斐波那契数列的变形有很多,如青蛙跳台阶,一次跳一个或者两个;铺瓷砖问题。**变态青蛙跳**,每次至少跳一个,至多跳n个,一共有f(n)=2n-1种跳法。考察数学建模的能力。
8 |
9 | ```python
10 | # -*- coding:utf-8 -*-
11 | class Solution:
12 | def Fibonacci(self, n):
13 | # write code here
14 | if n > 39:
15 | return
16 | tempArray = [0, 1]
17 | if n >= 2:
18 | for i in range(2, n+1):
19 | tempArray[i%2] = tempArray[0] + tempArray[1]
20 | return tempArray[n%2]
21 | ```
22 |
23 |
--------------------------------------------------------------------------------
/剑指offer-python版/8-青蛙跳.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法(先后次序不同算不同的结果)。
4 |
5 | 解题思路:类似斐波那契数列的做法。
6 |
7 | ```python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | def jumpFloor(self, number):
11 | # write code here
12 | temp_list = [1,2]
13 | if number >= 3:
14 | for i in range(3, number+1):
15 | temp_list[(i+1)%2]=temp_list[0] + temp_list[1]
16 | return temp_list[(number+1)%2]
17 | ```
18 |
19 |
--------------------------------------------------------------------------------
/剑指offer-python版/9-变态跳台阶.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
4 |
5 | 解题思路:类似于2的n-1次方
6 |
7 | ```python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | def jumpFloorII(self, number):
11 | # write code here
12 | ans = 1
13 | if number >= 2:
14 | for i in range(number-1):
15 | ans = ans * 2
16 | return ans
17 | ```
18 |
19 |
--------------------------------------------------------------------------------
/剑指offer-python版/扩展题-中文分词算法.md:
--------------------------------------------------------------------------------
1 | **背景:**
2 |
3 | 偶然间回忆起了NLP中基础的分词算法,参考之前的[博客](https://blog.csdn.net/weixin_34613450/article/details/88915099)回顾一下其中的经典算法。
4 |
5 | 这里主要针对正向最大匹配和逆向最大匹配两个算法进行工程实现。
6 |
7 | # 正向最大匹配算法-Maximum Match Method,MM法
8 |
9 | 核心思想:
10 |
11 | 1.首先计算得到词典中的词语的最大长度max_len;
12 |
13 | 2.遍历用户输入的待分词句子,以max_len取该句子中的对应词语,若该词语存在于词典中则将其切分出来,继续下一个词语;若不存在则将max_len减1,直至全部匹配完成。若都不存在,则将单个字保存。
14 |
15 | ```python
16 | # -*- coding: utf-8 -*-
17 | """
18 | Description : 分词-最大正向匹配
19 | Author : MeteorMan
20 | date: 2020/1/14
21 |
22 | """
23 |
24 | dict = ['喜欢', '研究生', '生命', '起源', '研究']
25 |
26 | def max_match(text, dict):
27 | dict_len_list = [len(term) for term in dict]
28 | max_len = max(dict_len_list)
29 | n = 0
30 | seg_words = []
31 | while n < len(text):
32 | matched_flag = False
33 | for i in range(max_len, 0, -1):
34 | s = text[n:n+i]
35 | if s in dict:
36 | seg_words.append(s)
37 | matched_flag = True
38 | n += i
39 | break
40 | if not matched_flag:
41 | seg_words.append(text[n])
42 | n += 1
43 | return seg_words
44 |
45 | while True:
46 | text = input('test-case:') #'我喜欢研究生命的起源'
47 | print(max_match(text, dict)) #['我', '喜欢', '研究生', '命', '的', '起源']
48 |
49 | ```
50 |
51 | # 逆向最大匹配算法-Reverse Maximum Match Method,RMM法
52 |
53 | 核心思想:
54 |
55 | 逆向最大匹配(Reverse Maximum Match Method,RMM法)的基本原理与MM法相同,不同的是分词切分的方向与MM法相反。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的i个字符(i为词典中最长词数)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。
56 |
57 | ```python
58 | # -*- coding: utf-8 -*-
59 | """
60 | Description : 分词算法-逆向最大匹配
61 | Author : MeteorMan
62 | date: 2020/1/14
63 |
64 | """
65 |
66 | dict = ['喜欢', '研究生', '生命', '起源']
67 |
68 | def rmm(text, dict):
69 | dict_len_list = [len(term) for term in dict]
70 | max_len = max(dict_len_list)
71 | tail = len(text)
72 | seg_words = []
73 | while tail > 0:
74 | matched_flag = False
75 | head = max(tail-max_len, 0) #避免输入句长小于词典中词语的最大长度
76 | for i in range(head, tail-1):
77 | s = text[i:tail]
78 | if s in dict:
79 | seg_words.append(s)
80 | matched_flag = True
81 | tail = i
82 | break
83 | if not matched_flag:
84 | seg_words.append(text[tail-1])
85 | tail -= 1
86 | return seg_words
87 |
88 | while True:
89 | text = input('test-case:') #'我喜欢研究生命的起源'
90 | print(rmm(text, dict)) #['我', '喜欢', '研究生', '命', '的', '起源']
91 |
92 | ```
93 |
94 |
95 |
96 |
--------------------------------------------------------------------------------
/剑指offer-python版/扩展题-检测字符串中的括号是否有效.md:
--------------------------------------------------------------------------------
1 | # Python检测字符串中的括号是否有效
2 | ```Bash
3 | ()\[]\{} 返回True
4 | ([{}]) 返回True
5 | ([)] 返回false
6 | (){}[] 返回True
7 | ((]) 返回false
8 |
9 | ```
10 | 利用栈来解决问题:
11 | ```Python
12 | def check_brace(str_raw):
13 | # 如果传入为空,直接返回True
14 | if str_raw == "":
15 | return True
16 |
17 | # 定义一个空列表,模拟栈。
18 | stack = []
19 |
20 | while str_raw != "":
21 | # 获取本次循环的字符串的第一个字符
22 | thisChar = str_raw[0]
23 | # ^_^去掉第一个元素
24 | str_raw = str_raw[1:]
25 | # 如果本次循环的第一个字符是左括号,将其压栈
26 | if thisChar == "(" or thisChar == "{" or thisChar == "[":
27 | stack.append(thisChar)
28 | # 如果本次循环的第一个字符是右括号,检测栈是否为空,栈长为空表示栈内没有可以匹配的左括号,返回false
29 | # 如果栈长不为空,且栈内最后一个元素是相匹配的左括号,此次匹配成功,将其弹出,进入下一轮循环。
30 | elif thisChar == ")" or thisChar == "}" or thisChar == "]":
31 | # 提高效率
32 | len_stack = len(stack)
33 | if len_stack == 0:
34 | return False
35 | else:
36 | if thisChar == ")" and stack[len_stack - 1] == "(":
37 | stack.pop(len_stack - 1)
38 | elif thisChar == "]" and stack[len_stack - 1] == "[":
39 | stack.pop(len_stack - 1)
40 | elif thisChar == "}" and stack[len_stack - 1] == "{":
41 | stack.pop(len_stack - 1)
42 | else:
43 | return False
44 | # 循环结束,如果栈为空,则表示全部匹配完成
45 | if stack == []:
46 | return True
47 | else:
48 | return False
49 |
50 |
51 | print(check_brace('(){}[]'))
52 |
53 | ```
54 |
--------------------------------------------------------------------------------
56 |
57 |
58 |
59 | **26.GRU**
60 |
61 | GRU即Gated Recurrent Unit。之前说到为了克服RNN的梯度消失和无法很好地处理远距离依赖提出了LSTM,而GRU是LSTM的一个变体,它保持了LSTM效果的同时又使结构更加简单。
62 |
63 | GRU模型只有两个门:更新门和重置门,更新门用于控制前一时刻的状态信息有多少比例可以输入到下一状态中,更新门的权值越大说明前一时刻的状态信息带入越多;而重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略的越多。
64 |
65 | GRU将LSTM中的输入门和遗忘门合并成一个单一的更新门。
66 |
67 | GRU与LSTM的区别:
68 |
69 | (1)memory的控制:LSTM用输出门控制,然后传递给下一单元;而GRU直接将其传递给下一个单元,不做任何控制。
70 |
71 | (2)上一时刻的信息:LSTM计算新的记忆时不对上一时刻的信息做任何控制,通过使用遗忘门独立实现;而GRU计算新的记忆时利用重置门对上一时刻的信息进行控制。
72 |
73 | **27.Memory Network**
74 |
75 | 如RNN等网络的记忆存储太小,不能精确地记住过去的事实。由此提出了Memory Network。
76 |
77 | 一个Memory Network由一个记忆数组m和四个组件(输入I,泛化G、输出O、回答R)组成。
78 |
79 | 四个组件的作用:
80 |
81 | I(输入特征映射): 将输入转换为记忆网络内部特征的表示。给定输入x,可以是字符、单词、句子等不同的粒度,通过I(x)得到记忆网络内部的特征。
82 |
83 | G :(更新记忆) - 使用新的输入更新记忆数组m。
84 |
85 | O:(输出) - 在记忆数组m更新完以后,就可以将输入和记忆单元联系起来,根据输入选择与之相关的记忆单元。
86 |
87 | R:(输出回答) - 得到了输入编码向量I(x),记忆数组m和需要的支持事实,就可以根据问题来得到需要的答案了。文中给出了一个简单的R()函数,将输入和选择的记忆单元与此表中的每个单词进行评分Sr,然后选择得分最大的单词作为回答。
88 |
89 |
90 |
91 |
--------------------------------------------------------------------------------
/NLP面试集锦-20200104.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | **2020-01-04**
4 |
5 | **1.文本表示模型及其优缺点**
6 |
7 | 可分为传统模型和词嵌入模型。
8 |
9 | 传统模型包括词袋模型、TF-IDF、n-gram、LDA,其中词袋模型主要是依据字典来计算每个样本中的词语对应的频率/有无出现特征;而TF-IDF主要是用来衡量某个单词对于语义区别的重要性;n-gram主要是通过滑动窗口的形式将连续的单词作为对应特征;LDA是通过分解“文档-单词”矩阵来得到“文档-主题”和“主题-单词”两个概率分布,主要目的是计算每篇文档的主题分布。这一类传统模型实现较为简单,效率高,但所获得的的特征不包含语义信息,且易造成维度灾难。
10 |
11 | 词嵌入模型属于深度学习的范畴,旨在将每个单词映射成一个低维的稠密向量,包括word2vec、Glove、fasttext等算法,其中最常用的是word2vec,其次是fasttext。在语义获取上更有优势。
12 |
13 | **2.word2vec是如何工作的?它和LDA有什么区别和联系呢?**
14 |
15 | 关于word2vec的工作原理可参考[大话NLP领域的传统词向量预训练]([https://vincent131499.github.io/2020/01/03/%E5%A4%A7%E8%AF%9DNLP%E9%A2%86%E5%9F%9F%E7%9A%84%E4%BC%A0%E7%BB%9F%E8%AF%8D%E5%90%91%E9%87%8F%E9%A2%84%E8%AE%AD%E7%BB%83/](https://vincent131499.github.io/2020/01/03/大话NLP领域的传统词向量预训练/))。
16 |
17 | 而针对word2vec与LDA的区别与联系:
18 |
19 | LDA是通过分解“文档-单词”矩阵来得到“文档-主题”和“主题-单词”两个概率分布,主要目的是计算每篇文档的主题分布;而word2vec是通过浅层的三层网络来进行参数矩阵的训练,最终得到每个单词对应的词向量。
20 |
21 | 在计算一个语料库中各个单词之间的相似度可以使用word2vec来计算,而要计算一个语料库中各个文档之间的相似度,那还是LDA比较合适,通过文章主题会得到更好的相似度衡量。
22 |
23 | **3.处理文本数据时,RNN比CNN有什么特点?**
24 |
25 | 传统文本处理以TF-IDF和词袋模型作为特征,会使得模型丢失重要的语序特征。为了捕捉这个语序特征,提出了使用CNN和RNN来处理文本信息。
26 |
27 | CNN一般会接受定长的向量作为输入,然后通过滑动窗口加池化的方法来捕捉重要的局部特征,但对于单词间的长距离依赖特征难以学习。而RNN对于处理文本这样的序列信息有着天然的优势,因为它是将上一时刻的输出特征作为下一时刻的输入来进行传递处理,对于单词间的长距离依赖特征能够很好地捕捉。
28 |
29 | **4.RNN为什么会出现梯度消失或梯度爆炸?有哪些解决方案?**
30 |
31 | 定义:度神经网络训练的时候,采用的是反向传播方式,该方式使用链式求导,计算每层梯度的时候会涉及一些连乘 作,因此如果网络过深。那么如果连乘的因子大部分小于1,最后乘积的结果可能趋于0,也就是梯度消失,后面的网络层的参数不发生变化.那么如果连乘的因子大部分大于1,最后乘积可能趋于无穷,这就是梯度爆炸。
32 |
33 | 梯度消失或者梯度爆炸是由RNN中的sigmoid函数引起的,当网络层数较多时,随着预测误差沿神经网络每一层反向传播,当最初初始化的网络权值w小于1时,前面的层比后面的层梯度变化更小,梯度呈指数减小,故变化更慢,从而引起梯度消失;反之当w比较大时,前面的网络层比后面的网络层梯度变化更快,梯度呈指数增长,则会引起梯度爆炸。
34 |
35 | 解决方案:(1)ReLU替代sigmoid函数;(2)BN(Batch Normalization);(3)LSTM的结构设计也可以改善RNN中的梯度消失问题;(4)Resnet(残差网络)
36 |
37 | Note:在RNN采用Relu作为激活函数时,应将权重矩阵w初始化为单位矩阵。
38 |
39 | **5.LSTM是如何实现长短期记忆功能的?**
40 |
41 | [LSTM模型细节结构讲解](https://blog.csdn.net/dream_catcher_10/article/details/48522339)
42 |
43 | LSTM单元主要是由输入门、遗忘门和输出门三个结构组成;其中输入门用于控制当前时刻有哪些重要信息可以输入到记忆单元;遗忘门用于控制前一步的记忆单元有哪些无用信息会被遗忘掉;而输出门则是决定当前的记忆单元有哪些重要信息可以输出。
44 |
45 | 在一个训练好的网络中,当输入序列没有重要信息时,LSTM遗忘门的值接近于1,输入门接近于0,此时过去的记忆会被保存,从而实现了长期记忆;当输入的序列中存在重要信息时,LSTM会将其存在记忆中,此时输入门的值接近于1;当输入的序列中存在重要信息且该信息意味着之前的记忆不再重要的时候,输入门接近于1,,遗忘门接近于0,这样旧的记忆被遗忘,新的记忆被保存。经过这样的设计,整个网络更容易学习到序列之间的长期依赖。
46 |
47 | 6.LSTM中各模块分别使用什么激活函数,可以使用别的激活函数吗?
48 |
49 | LSTM中的输入门、遗忘门和输出门的激活函数都是sigmoid,在生成候选记忆时,使用双曲正切函数Tanh作为激活函数。
50 |
51 | why-细节:
52 |
53 | 这两个函数都是饱和的,在输入达到一定值的情况下,输出不会发生明显变化。如果是非饱和的激活函数,比如Relu,那么就难以实现门控的效果。
54 |
55 | Sigmoid函数的输出在0~1之间,符合门控的物理意义。且当输入较小或较大时,其输出会非常接近0或1,从而保证该门开或关。
56 |
57 | 在生成候选记忆时,使用Tanh函数,因为其输出在-1~1之间,这与大多数场景下特征分布是0中心的吻合。此外,Tanh在输入为0的附近比Sigmoid有更大梯度,通常使模型收敛更快。
58 |
59 | 可以使用别的激活函数吗?---激活函数的选取并不是一成不变的,在原始LSTM中,使用的是sigmoid函数的变种;但是实际上在门控机制中,大多都使用了sigmoid。
60 |
61 |
62 |
63 |
64 |
65 |
--------------------------------------------------------------------------------
/NLP面试集锦-20200106.md:
--------------------------------------------------------------------------------
1 | **2020-01-06**
2 |
3 | **7.Seq2Seq模型的概念?优点?缺点?**
4 |
5 | Seq2Seq,全称为Sequence to Sequence模型,级序列到序列的模型,主要是将一个输入的序列信息,通过编码和解码生成一个新的输出序列,通常用于机器翻译、语音识别、自动对话等任务。
6 |
7 | 优点:seq2seq可以处理变长序列。在seq2seq出现之前,深度神经网络的输入和输出都是表示为固定长度的向量,如果长度稍有变化,会使用补零等操作。
8 |
9 | 缺点:计算效率低。
10 |
11 | **8.Seq2Seq模型在解码时,有哪些常用方法?**
12 |
13 | (1)贪心法
14 |
15 | 选定一个度量标准后,每次都在当前状态下选择一个最佳结果,直到结束。
16 |
17 | (2)集束搜索/beam search
18 |
19 | 当前状态下保存beam size个较佳选择,解码时每一步根据当前选择进行拓展和排序,接着选择前beam size个进行保存,循环迭代,直到结束。
20 |
21 | (3)加入注意力机制
22 |
23 | (4)加入记忆网络
24 |
25 | **9.Seq2Seq模型加入注意力机制是为了解决什么问题?为什么会选用双向循环神经网络?**
26 |
27 | 以机器翻译为例,随着序列长度的增加,模型在编码时将输入序列的全部信息压缩到一个向量表示中,序列越长,句子越前面的词的信息丢失就越严重,因为解码时丢失了当前词与对应源语言词的上下文信息和位置信息。Seq2Seq引入注意力机制就是为了解决这个问题,使得模型在解码时,可以让每一个输出词都依赖于前一个隐状态以及输入序列中对应的隐状态。
28 |
29 | 至于为什么要选用双向循环神经网络?其实在上面已经提到了,生成输出词时需要依赖输入序列中对应的隐状态,而是用双向RNN可以捕捉对应输入词的上下文特征,从而得到更好的注意力权重。这也说明了上下文语境向量在语言模型中的重要性。
30 |
31 | **10.命名实体识别算法有哪些?优缺点?**
32 |
33 | 命名实体识别,也被称为NER,就是从非结构化的输入文本中抽取出指定类型的实体。
34 |
35 | 最初是使用基于词典+规则的方法,后面引入深度学习,目前大多数都采用深度学习。最先使用RNN进行预测每个token的标签,然而这种模式不能直接利用上文已经预测的标签,只能通过隐状态传递上文信息,进而导致预测出来的标签可能无效。针对这种缺点,在神经网络的输出层加入CRF层(重点是利用标签转移概率)。典型模型有BiLSTM-CRF.
36 |
37 | **11.如何对中文分词问题利用隐马尔可夫模型(HMM)进行建模和训练**
38 |
39 | HMM常用来解决序列标注问题,可将分词问题转换成序列标注问题来进行建模。首先针对语料中句子的每个字进行BEMS标注(B代表一个词开头,E代表词尾的最后一个字,M代表词中间的字,S表示一个单字词),则隐状态的取值空间为(B,E,M,S),同时设定状态转移概率(M和M后面只能是M或者E),而每个字就是模型中的观测状态。然后使用维特比算法针对初始状态概率分布、状态转移概率矩阵、发射概率矩阵以及观测值计算,预测一个最有可能的状态序列。然后根据这个状态序列进行文本划分。
40 |
41 | **那么最大熵隐马尔可夫模型为什么会出现标注偏置问题,如何解决呢?**
42 |
43 | 最大熵隐马尔可夫模型由于局部归一化的影响,隐状态会倾向于转移到后续状态可能更少的状态上,以提高整体的后验概率。
44 |
45 | 解决方式:使用条件随机场CRF针对全局范围进行归一化,从而解决了局部归一化带来的标注偏置问题。
46 |
47 | **12.常见的概率图模型中,哪些是生成式模型,哪些是判别式模型?**
48 |
49 | Note:假设可观测的变量集合为X,需要预测的变量集合为Y,其他的变量集合为Z;生成式模型是对联合概率分布P(X,Y,Z)进行建模,在给定观测集合X的条件下,通过计算边缘分布来求得对变量集合Y的推断。而判别式模型是直接对条件概率分布P(Y,Z|X)进行建模,然后消掉无关变量Z就可以得到对变量Y的预测。
50 |
51 | 生成式模型:朴素贝叶斯、贝叶斯网络、LDA、HMM
52 |
53 | 判别式模型:CRF、最大熵HMM
54 |
55 | **13.使用TensorFlow或者pytorch简单写一个RNN**
56 |
57 | ===熟悉下常用构建网络代码的大致架构和流程===
58 |
59 | **14.爬虫相关**
60 |
61 | 了解并在网上实现过开源项目
62 |
63 | **15.基于语义匹配的实体链接算法**
64 |
65 | 基于实体链接的实体消歧方法,是指将实体指称项链接到知识库中特定的实体,也称为实体链接。实体链接阶段分为候选实体生成和候选实体消歧两步。
66 |
67 | (1)候选实体生成
68 |
69 | 基于实体词典+同义词词库的方法、检索排序法
70 |
71 | (2)候选实体消歧
72 |
73 | 简单/常用baseline:
74 |
75 | 检索的方法(将指称实体与邻近的关键词在知识库中查询)
76 |
77 | 基于向量空间模型的方法(余弦相似度,不能反映语义)
78 |
79 | 深度语义:
80 |
81 | 基于排序模型的方法(查询与文档的相似度、欧式距离、编辑距离、主题相似度、实体流行度等特征)
82 |
83 | 主题一致性方法(指称的实体与候选实体属于同一个主题)
84 |
85 | 神经网络方法(捕获待消歧实体上下文和候选实体描述不同粒度的语义,最新研究也结合了实体的属性特征)
86 |
87 |
88 |
89 |
90 |
91 |
--------------------------------------------------------------------------------
/NLP面试集锦-20200108.md:
--------------------------------------------------------------------------------
1 | **2020-01-08**
2 |
3 | **16.决策树的概念?有哪些常用的启发函数?如何对决策树进行剪枝?**
4 |
5 | 概念:决策树是一种自上而下,对样本数据进行树形分类的过程。节点分为内部节点和叶子节点。每个内部节点代表一个特征,叶节点代表类别。从顶部节点开始,所有样本聚在一起,经过根节点和不同内部子节点的划分,所有样本都被归到某一个类别(叶节点)。
6 |
7 | 启发式函数:ID3、C4.5、CART
8 |
9 | ID3:最大信息增益,选择能够带来最大的信息增益的那个特征;
10 |
11 | C4.5:最大信息增益比。
12 |
13 | CART:最大基尼系数。基尼指数反映了从数据集中随机抽取两个样本,其类别不一致的概率。CART每次选取使基尼系数最小的特征。
14 |
15 | 剪枝方法:决策树容易过拟合,需要剪枝。分为预剪枝和后剪枝。
16 |
17 | 预剪枝:在对树中节点扩展之前,先计算当前划分能否带来模型泛化能力的提升,若不能,则不再继续生长子树。
18 |
19 | 后剪枝:先生成一个完整的决策树,然后自底向上计算是否剪枝(将子树切除,用叶节点代替)。通过能够提升验证集准确率来计算。
20 |
21 | **17.介绍一下GBDT**
22 |
23 | 梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是Boosting算法中非常流行的一个。
24 |
25 | Gradient Boosting的流程:在每一轮迭代中,首先计算出当前模型在所有样本上的负梯度,然后以该值为目标训练出一个新的弱分类器进行拟合并计算出该弱分类器的权重。最终实现对模型的更新。
26 |
27 | 而采用决策树作为弱分类器的Gradient Boosting算法成为GBDT。GBDT中使用的决策树通常为CART。
28 |
29 | **18.Xgboost与GBDT的区别和联系?**
30 |
31 | (1)GBDT是机器学习算法,Xgboost是该算法的工程实现;
32 |
33 | (2)在使用CART作为基分类器的时候,XGBoost显式地加入了**正则项**来控制模型复杂度,有利于防止过拟合;
34 |
35 | (3)数据采样:传统的GBDT在每轮迭代时使用全部数据,XGBoost支持对数据进行采样;
36 |
37 | (4)缺失值处理:传统的GBDT没有设计对缺失值的处理,XGBoost能自动学出缺失值处理策略
38 |
39 | **19.深度学习中常见的优化器?**
40 |
41 | (1)SGD
42 |
43 | 目前SGD一般都是指mini-batch gradient descent,这是神经网络中大多使用的优化方法。
44 |
45 | SGD就是每一次迭代计算mini-batch的梯度,然后对参数更新。
46 |
47 | 这里说一下局部最优点和鞍点。
48 |
49 | 两者相似:在这个点的导数为0;
50 |
51 | 区别:是否在各个维度都是最低点。只要某个一阶导数为0的点在某个维度上是最高点而不是最低点,那它就是鞍点。
52 |
53 | (2)Momentum/动量更新
54 |
55 | 积累之前的动量来替代真正的梯度。通过在相关方向加速SGD,抑制震荡,加快收敛。
56 |
57 | (3)Adagrad
58 |
59 | 对学习率进行约束,通过以往的梯度自适应更新学习率,不同的参数具有不同的学习率。十分适合处理稀疏数据(对常出现的特征进行小幅度更新,不常出现的特征进行大幅度更新)。
60 |
61 | (4)RMSprop
62 |
63 | 可以算作Adadelta的一种特例,适合处理非平稳目标,结合RNN使用效果最好。
64 |
65 | (5)Adam
66 |
67 | 本质上是带有动量的RMSprop,利用梯度的一阶矩阵和二阶矩阵估计动态调整每个参数的学习率。结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点。
68 |
69 | **20.如何防止过拟合以及为什么可以?**
70 |
71 | (1)数据增强
72 |
73 | 数据集扩增
74 |
75 | (2)early stopping
76 |
77 | 一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。
78 |
79 | (3)正则化限制
80 |
81 | 这种方法一般是在目标函数或代价函数后面加上一个正则项,一般有L1正则、L2正则等。
82 |
83 | L1正则为什么可以防止过拟合?
84 |
85 | 添加L1正则项可以让那些原先处于0附近的参数往0移动,使得部分参数为0,进而降低模型的复杂度(模型的复杂度由参数决定),从而防止过拟合,提高模型的泛化能力。
86 |
87 | L2正则为什么可以防止过拟合?
88 |
89 | L2正则项可以加速参数变小,而更小的参数意味着模型的复杂度更低。
90 |
91 | L1和L2正则的区别?
92 |
93 | 区别1:L1是在loss函数后加上参数的1范数(|w|),即对应参数向量的绝对值之和,而L2是在loss函数后加上参数的2范数(sigma(w^2)),即对应参数向量的平方和的平方根;
94 |
95 | 区别2:L1会产生稀疏的特征,L2会产生更多的接近0的特征。L1在特征选择时候非常有用,L2只是一种规则化,提升模型的泛化能力。
96 |
97 | 区别3:L1正则先验服从拉普拉斯分布,L2正则先验服从高斯分布。
98 |
99 | L1在0出不可导,怎么处理?
100 |
101 | 可以使用Proximal Algorithms或者ADMM来解决。
102 |
103 | (4)Dropout
104 |
105 | 通过随机删除隐藏层的神经元个数来防止过拟合。
106 |
107 | 为什么可以防止过拟合?
108 |
109 | 原因1:不同的网络训练时可能产生不能的过拟合,而dropout对丢失隐藏层神经单元的多个不同网络**取平均**,其中互为“反向”的拟合相互抵消就可以达到整体上过拟合减少;
110 |
111 | 原因2:减少神经元之间复杂的**共适应**关系。dropout导致两个神经元不一定每次都在同一个网络中出现,这样就可以使网络去学习更加鲁棒的特征,提升模型的泛化能力。
112 |
113 | (5)Batch Normalization
114 |
115 | BN实际使用时会将特征强制性的归到**均值为0**,**方差为1**的数学模型下。有两个功能:一个是加快训练和收敛,一个是防止过拟合。
116 |
117 | 为什么可以防止过拟合?
118 |
119 | BN的使用使得同一个样本的输出不仅仅取决于这个样本本身的特征,也取决于与这个样本属于同一个mini-batch的其他样本的特征,进而增强模型的泛化能力。
120 |
121 | 如何加快训练和收敛速度?
122 |
123 | BN将每层网络的数据都转换到均值为0,方差为1的状态下,一方面,数据的分布相同,训练比较容易收敛,另一方面,均值为0,方差为1的状态下,梯度计算时会产生较大的梯度值,可以加快参数的训练。更进一步,BN也可以很好的控制梯度消失和梯度爆炸现象。
124 |
125 | BN最大的优点就是允许网络使用较大的学习率进行训练,加快网络的训练速度。
126 |
127 |
128 |
129 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # NLP-Algorithm-Interview
2 | NLP算法领域的面试资料大全,包括笔试、面试题目
3 | # 面试记录
4 | 2020-3-4:
5 | 一面:问了一些项目的技术路线以及采用的各种模型
6 | 二面:项目模型细节讲解、深度学习基础知识考查、Transformer介绍、BERT介绍以及开放题目(对于AI的理解)。最后手写代码“[Python检测字符串中的括号是否有效](https://github.com/Vincent131499/NLP-Algorithm-Interview/tree/master/剑指offer-python版/扩展题-检测字符串中的括号是否有效.md)”。
7 |
8 |
9 |
--------------------------------------------------------------------------------
/references/word2vec中的数学.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Vincent131499/NLP-Algorithm-Interview/b47e5114496785ace7e0fa48e3a70a4144b9543a/references/word2vec中的数学.pdf
--------------------------------------------------------------------------------
/references/关于百度ERNIE及将知识图谱引入Bert - 知乎.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Vincent131499/NLP-Algorithm-Interview/b47e5114496785ace7e0fa48e3a70a4144b9543a/references/关于百度ERNIE及将知识图谱引入Bert - 知乎.pdf
--------------------------------------------------------------------------------
/references/放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN_RNN_TF)比较 - 知乎.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Vincent131499/NLP-Algorithm-Interview/b47e5114496785ace7e0fa48e3a70a4144b9543a/references/放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN_RNN_TF)比较 - 知乎.pdf
--------------------------------------------------------------------------------
/剑指offer-python版/1-二维数组中的查找.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
4 |
5 | 解题思路1:按照行遍历数组,判断这个整数是否在行中出现?
6 |
7 | ```Python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | # array 二维列表
11 | def Find(self, target, array):
12 | # write code here
13 | flag = False
14 | for i in range(len(array)):
15 | line = array[i]
16 | if target in line:
17 | flag = True
18 | return flag
19 | ```
20 |
21 |
22 |
23 | 解题思路2:从左下角元素开始查找,若大于该元素,向右查找(列数+1);若小于该元素,则向上查找(行数-1);若等于该元素,直接返回。
24 |
25 | ```Python
26 | # -*- coding:utf-8 -*-
27 | class Solution:
28 | # array 二维列表
29 | def Find(self, target, array):
30 | # write code here
31 | row_index = len(array) - 1
32 | col_index = len(array[0]) - 1
33 | i = row_index
34 | j = 0
35 | while i >= 0 and j <= col_index:
36 | if target > array[i][j]:
37 | j += 1
38 | elif target < array[i][j]:
39 | i -= 1
40 | else:
41 | return True
42 | return False
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/剑指offer-python版/10-数值的整数次方.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 给定一个double类型的浮点数base和int类型的整数exponent。求base的exponent次方。
4 |
5 | 保证base和exponent不同时为0
6 |
7 | 解题思路:
8 |
9 | 需要注意的地方:
10 | 当指数为负数的时候
11 | 当底数为零切指数为负数的情况
12 | 在判断底数base是不是等于0的时候,不能直接写base==0, 因为计算机内表示小数时有误差,只能判断他们的差的绝对值是不是在一个很小的范围内
13 |
14 | 当n为偶数, a^n = a^(n/2) * a^(n/2)
15 | 当n为奇数, a^n = a^((n-1)/2) * a^((n-1)/2)) * a
16 |
17 | ```python
18 | # -*- coding:utf-8 -*-
19 | class Solution:
20 | def Power(self, base, exponent):
21 | # write code here
22 | if exponent == 0:
23 | return 1
24 | if exponent == 1:
25 | return base
26 | if exponent == -1:
27 | return 1/base
28 | result = self.Power(base, exponent/2)
29 | result *= result
30 | if (exponent % 2) == 1:
31 | result *= base
32 | return result
33 | ```
34 |
35 |
--------------------------------------------------------------------------------
/剑指offer-python版/11-调整数组顺序使奇数位于偶数后面.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
4 |
5 | 解题思路1:直接利用python的trick即可解决
6 |
7 | ```python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | def reOrderArray(self, array):
11 | # write code here
12 | left = [x for x in array if x%2 != 0]
13 | right = [x for x in array if x%2 == 0]
14 | return left+right
15 | ```
16 |
17 |
--------------------------------------------------------------------------------
/剑指offer-python版/12-链表中倒数第k个节点的输出.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入一个链表,输出该链表中倒数第k个结点。
4 |
5 | 解题思路:
6 |
7 | 这道题的思路很好,
8 |
9 | 如果在只希望一次遍历的情况下, 寻找倒数第k个结点, 可以设置两个指针
10 |
11 | 第一个指针先往前走k-1步,然后从第k步开始第二个指针指向头结点
12 |
13 | 然后两个指针一起遍历
14 |
15 | 当第一个指针指向尾结点的时候,第二个指针正好指向倒数第k个节点
16 |
17 | ```python
18 | # -*- coding:utf-8 -*-
19 | # class ListNode:
20 | # def __init__(self, x):
21 | # self.val = x
22 | # self.next = None
23 |
24 | class Solution:
25 | def FindKthToTail(self, head, k):
26 | # write code here
27 | # head表示头结点,k表示第k个节点
28 | if head == None or k <= 0:
29 | return
30 | phead1 = head
31 | phead2 = None
32 | for i in range(k-1):
33 | if phead1.next != None:
34 | phead1 = phead1.next
35 | else:
36 | return None
37 | phead2 = head
38 | while phead1.next != None:
39 | phead1 = phead1.next
40 | phead2 = phead2.next
41 | return phead2
42 | ```
43 |
44 |
--------------------------------------------------------------------------------
/剑指offer-python版/13-反转链表.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入一个链表,反转链表后,输出新链表的表头。
4 |
5 | 解题思路:
6 |
7 | **递归思想**。
8 | 我们使其先走到链表的末尾,确保每次回溯时都返回最后一个节点的指针。同时从倒数第二个结点开始反序。
9 | `head.next.next = head;`是指使当前节点的下一个节点指向自己
10 | `head.next = null`断开与下一个节点的联系,完成真正的反序操作
11 |
12 | 
13 |
14 | ```python
15 | # -*- coding:utf-8 -*-
16 | # class ListNode:
17 | # def __init__(self, x):
18 | # self.val = x
19 | # self.next = None
20 | class Solution:
21 | # 返回ListNode
22 | def ReverseList(self, pHead):
23 | # write code here
24 | if not pHead or not pHead.next:
25 | return pHead
26 | else:
27 | target = self.ReverseList(pHead.next)
28 | pHead.next.next = pHead
29 | pHead.next = None
30 | return target
31 | ```
32 |
33 |
--------------------------------------------------------------------------------
/剑指offer-python版/14-合并两个排序的链表.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入两个**单调递增**的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足**单调不减**规则
4 |
5 | 解题思路:
6 |
7 | 要注意特殊输入,如果输入是空链表,不能崩溃。
8 |
9 | ```python
10 | # -*- coding:utf-8 -*-
11 | # class ListNode:
12 | # def __init__(self, x):
13 | # self.val = x
14 | # self.next = None
15 | class Solution:
16 | # 返回合并后列表
17 | def Merge(self, pHead1, pHead2):
18 | # write code here
19 | if pHead1==None:
20 | return pHead2
21 | elif pHead2==None:
22 | return pHead1
23 | pMergedHead = None
24 | if pHead1.val < pHead2.val:
25 | pMergedHead = pHead1
26 | pMergedHead.next = self.Merge(pHead1.next, pHead2)
27 | else:
28 | pMergedHead = pHead2
29 | pMergedHead.next = self.Merge(pHead1, pHead2.next)
30 | return pMergedHead
31 | ```
32 |
33 |
--------------------------------------------------------------------------------
/剑指offer-python版/15-树的子结构.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入两棵二叉树A,B,判断B是不是A的子结构。(ps:我们约定空树不是任意一个树的子结构)
4 |
5 | 解题思路:
6 |
7 | 多出需要判断指针是不是None,避免访问空指针而造成程序崩溃。
8 |
9 | ```python
10 | # -*- coding:utf-8 -*-
11 | # class TreeNode:
12 | # def __init__(self, x):
13 | # self.val = x
14 | # self.left = None
15 | # self.right = None
16 | class Solution:
17 | def HasSubtree(self, pRoot1, pRoot2):
18 | result = False
19 | if pRoot1 != None and pRoot2 != None:
20 | if pRoot1.val == pRoot2.val:
21 | result = self.DoesTree1haveTree2(pRoot1, pRoot2)
22 | if not result:
23 | result = self.HasSubtree(pRoot1.left, pRoot2)
24 | if not result:
25 | result = self.HasSubtree(pRoot1.right, pRoot2)
26 | return result
27 | # 用于递归判断树的每个节点是否相同
28 | # 需要注意的地方是: 前两个if语句不可以颠倒顺序
29 | # 如果颠倒顺序, 会先判断pRoot1是否为None, 其实这个时候pRoot2的结点已经遍历完成确定相等了, 但是返回了False, 判断错误
30 | def DoesTree1haveTree2(self, pRoot1, pRoot2):
31 | if pRoot2 == None:
32 | return True
33 | if pRoot1 == None:
34 | return False
35 | if pRoot1.val != pRoot2.val:
36 | return False
37 |
38 | return self.DoesTree1haveTree2(pRoot1.left, pRoot2.left) and self.DoesTree1haveTree2(pRoot1.right, pRoot2.right)
39 | ```
40 |
41 |
--------------------------------------------------------------------------------
/剑指offer-python版/2-替换空格.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 请实现一个函数,将一个字符串中的每个空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
4 |
5 | 解题思路1:使用replace语句生成一个新的str,原始的s还是带空格的str变量
6 |
7 | ```Python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | # s 源字符串
11 | def replaceSpace(self, s):
12 | # write code here
13 | if type(s) != str:
14 | return
15 | s_new = s.replace(' ', '%20')
16 | return s_new
17 | ```
18 |
19 |
20 |
21 | 解题思路2:使用append一次遍历即可替换,由于list的append是O(1)的时间复杂度,因此该算法复杂度为O(n)
22 |
23 | ```Python
24 | # -*- coding:utf-8 -*-
25 | class Solution:
26 | # s 源字符串
27 | def replaceSpace(self, s):
28 | # write code here
29 | s_new = []
30 | for term in s:
31 | if term == ' ':
32 | s_new.append('%')
33 | s_new.append('2')
34 | s_new.append('0')
35 | else:
36 | s_new.append(term)
37 | return ''.join(s_new)
38 | ```
39 |
40 |
--------------------------------------------------------------------------------
/剑指offer-python版/3-从尾到头打印链表.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入一个链表,按链表从尾到头的顺序返回一个ArrayList。
4 |
5 | 解题思路:将当前节点设置为头结点head,而后使用while循环判断head节点是否为空,若不为空,则将该节点的val值插入到列表的第1个位置,并将head设置为下一个节点,继续循环。
6 |
7 | ```Python
8 | # -*- coding:utf-8 -*-
9 | # class ListNode:
10 | # def __init__(self, x):
11 | # self.val = x
12 | # self.next = None
13 |
14 | class Solution:
15 | # 返回从尾部到头部的列表值序列,例如[1,2,3]
16 | def printListFromTailToHead(self, listNode):
17 | # write code here
18 | l = []
19 | head = listNode
20 | while head:
21 | l.insert(0, head.val)
22 | head = head.next
23 | return l
24 | ```
25 |
26 |
27 |
--------------------------------------------------------------------------------
/剑指offer-python版/4-重建二叉树.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
4 |
5 | 解题思路:利用二叉树前序遍历和中序遍历的特性。前序遍历的第一个值一定为根节点,对应于中序遍历中间的一个点(记根节点在中序序列中的index为i)。在中序遍历序列中,这个点左侧的均为根的左子树,这个点右侧的均为根的右子树。这时可以利用递归:分别取前序遍历[1:i+1]和中序遍历[:i]对应于左子树继续上一个过程,取前序遍历[i+1:]和中序遍历[i+1:]对应于右子树继续上一个过程,最终得以重建二叉树。
6 |
7 | ```Python
8 | # -*- coding:utf-8 -*-
9 | # class TreeNode:
10 | # def __init__(self, x):
11 | # self.val = x
12 | # self.left = None
13 | # self.right = None
14 | class Solution:
15 | # 返回构造的TreeNode根节点
16 | def reConstructBinaryTree(self, pre, tin):
17 | # write code here
18 | if len(pre) == 0:
19 | return
20 | if len(pre) == 1:
21 | return TreeNode(pre[0])
22 | index = tin.index(pre[0])
23 | root = TreeNode(pre[0])
24 | root.left = self.reConstructBinaryTree(pre[1:1+index], tin[:index])
25 | root.right = self.reConstructBinaryTree(pre[index+1:], tin[index+1:])
26 | return root
27 | ```
28 |
29 | ‘
30 |
--------------------------------------------------------------------------------
/剑指offer-python版/5-用两个栈来实现队列.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
4 |
5 | 解题思路:首先需要初始化两个栈stack1和stack2,队列的push操作只需要将元素append到stack1里面即可。对于队列的pop操作,首先需要判断stack1和stack2中元素的数量情况。两个都空直接返回,若stack1不空stack2空(因为在push时针对stack1操作),则需要将stack1的元素出栈放入到stack2中,然后stack2的元素出栈。
6 |
7 | ```Python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | def __init__(self):
11 | self.stack1 = []
12 | self.stack2 = []
13 | def push(self, node):
14 | # write code here
15 | self.stack1.append(node)
16 | def pop(self):
17 | # return xx
18 | if len(self.stack1) == 0 and len(self.stack2) == 0:
19 | return
20 | elif len(self.stack2) == 0:
21 | while len(self.stack1) > 0:
22 | self.stack2.append(self.stack1.pop())
23 | return self.stack2.pop()
24 | ```
25 |
26 |
27 |
--------------------------------------------------------------------------------
/剑指offer-python版/6-旋转数组的最小数字.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。
4 | 输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。
5 | 例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转,该数组的最小值为1。
6 | NOTE:给出的所有元素都大于0,若数组大小为0,请返回0。
7 |
8 | 解题思路1:蛮力破解,直接使用python提供的sorted函数进行排序,返回最小元素
9 |
10 | ```python
11 | # -*- coding:utf-8 -*-
12 | class Solution:
13 | def minNumberInRotateArray(self, rotateArray):
14 | # write code here
15 | if len(rotateArray) == 0:
16 | return 0
17 | else:
18 | sorted_list = sorted(rotateArray)
19 | return sorted_list[0]
20 | ```
21 |
22 | 解题思路2:二分查找的变形,注意到旋转数组的首元素肯定不小于旋转数组的尾元素,设置中间点。如果中间点大于首元素,说明最小数字在后面一半,如果中间点小于尾元素,说明最小数字在前一半。依次循环。同时,当一次循环中首元素小于尾元素,说明最小值就是首元素。但是当首元素等于尾元素等于中间值,只能在这个区域顺序查找。
23 |
24 | ```python
25 | # -*- coding:utf-8 -*-
26 | class Solution:
27 | def minNumberInRotateArray(self, rotateArray):
28 | # write code here
29 | if len(rotateArray) == 0:
30 | return 0
31 | left, right = 0, len(rotateArray)-1
32 | while rotateArray[left] >= rotateArray[right]:
33 | if (right - left) == 1:
34 | return rotateArray[right]
35 | mid = (left + right) / 2
36 | if rotateArray[left] <= rotateArray[mid]:
37 | left = mid
38 | if rotateArray[right] >= rotateArray[mid]:
39 | right = mid
40 | return rotateArray[0]
41 | ```
42 |
43 |
--------------------------------------------------------------------------------
/剑指offer-python版/7-斐波那契数列求第n项.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0)。
4 |
5 | n<=39
6 |
7 | 解题思路:如何不使用递归实现斐波那契数列,需要把前面两个数字存入在一个数组中。斐波那契数列的变形有很多,如青蛙跳台阶,一次跳一个或者两个;铺瓷砖问题。**变态青蛙跳**,每次至少跳一个,至多跳n个,一共有f(n)=2n-1种跳法。考察数学建模的能力。
8 |
9 | ```python
10 | # -*- coding:utf-8 -*-
11 | class Solution:
12 | def Fibonacci(self, n):
13 | # write code here
14 | if n > 39:
15 | return
16 | tempArray = [0, 1]
17 | if n >= 2:
18 | for i in range(2, n+1):
19 | tempArray[i%2] = tempArray[0] + tempArray[1]
20 | return tempArray[n%2]
21 | ```
22 |
23 |
--------------------------------------------------------------------------------
/剑指offer-python版/8-青蛙跳.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法(先后次序不同算不同的结果)。
4 |
5 | 解题思路:类似斐波那契数列的做法。
6 |
7 | ```python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | def jumpFloor(self, number):
11 | # write code here
12 | temp_list = [1,2]
13 | if number >= 3:
14 | for i in range(3, number+1):
15 | temp_list[(i+1)%2]=temp_list[0] + temp_list[1]
16 | return temp_list[(number+1)%2]
17 | ```
18 |
19 |
--------------------------------------------------------------------------------
/剑指offer-python版/9-变态跳台阶.md:
--------------------------------------------------------------------------------
1 | 题目描述:
2 |
3 | 一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
4 |
5 | 解题思路:类似于2的n-1次方
6 |
7 | ```python
8 | # -*- coding:utf-8 -*-
9 | class Solution:
10 | def jumpFloorII(self, number):
11 | # write code here
12 | ans = 1
13 | if number >= 2:
14 | for i in range(number-1):
15 | ans = ans * 2
16 | return ans
17 | ```
18 |
19 |
--------------------------------------------------------------------------------
/剑指offer-python版/扩展题-中文分词算法.md:
--------------------------------------------------------------------------------
1 | **背景:**
2 |
3 | 偶然间回忆起了NLP中基础的分词算法,参考之前的[博客](https://blog.csdn.net/weixin_34613450/article/details/88915099)回顾一下其中的经典算法。
4 |
5 | 这里主要针对正向最大匹配和逆向最大匹配两个算法进行工程实现。
6 |
7 | # 正向最大匹配算法-Maximum Match Method,MM法
8 |
9 | 核心思想:
10 |
11 | 1.首先计算得到词典中的词语的最大长度max_len;
12 |
13 | 2.遍历用户输入的待分词句子,以max_len取该句子中的对应词语,若该词语存在于词典中则将其切分出来,继续下一个词语;若不存在则将max_len减1,直至全部匹配完成。若都不存在,则将单个字保存。
14 |
15 | ```python
16 | # -*- coding: utf-8 -*-
17 | """
18 | Description : 分词-最大正向匹配
19 | Author : MeteorMan
20 | date: 2020/1/14
21 |
22 | """
23 |
24 | dict = ['喜欢', '研究生', '生命', '起源', '研究']
25 |
26 | def max_match(text, dict):
27 | dict_len_list = [len(term) for term in dict]
28 | max_len = max(dict_len_list)
29 | n = 0
30 | seg_words = []
31 | while n < len(text):
32 | matched_flag = False
33 | for i in range(max_len, 0, -1):
34 | s = text[n:n+i]
35 | if s in dict:
36 | seg_words.append(s)
37 | matched_flag = True
38 | n += i
39 | break
40 | if not matched_flag:
41 | seg_words.append(text[n])
42 | n += 1
43 | return seg_words
44 |
45 | while True:
46 | text = input('test-case:') #'我喜欢研究生命的起源'
47 | print(max_match(text, dict)) #['我', '喜欢', '研究生', '命', '的', '起源']
48 |
49 | ```
50 |
51 | # 逆向最大匹配算法-Reverse Maximum Match Method,RMM法
52 |
53 | 核心思想:
54 |
55 | 逆向最大匹配(Reverse Maximum Match Method,RMM法)的基本原理与MM法相同,不同的是分词切分的方向与MM法相反。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的i个字符(i为词典中最长词数)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。
56 |
57 | ```python
58 | # -*- coding: utf-8 -*-
59 | """
60 | Description : 分词算法-逆向最大匹配
61 | Author : MeteorMan
62 | date: 2020/1/14
63 |
64 | """
65 |
66 | dict = ['喜欢', '研究生', '生命', '起源']
67 |
68 | def rmm(text, dict):
69 | dict_len_list = [len(term) for term in dict]
70 | max_len = max(dict_len_list)
71 | tail = len(text)
72 | seg_words = []
73 | while tail > 0:
74 | matched_flag = False
75 | head = max(tail-max_len, 0) #避免输入句长小于词典中词语的最大长度
76 | for i in range(head, tail-1):
77 | s = text[i:tail]
78 | if s in dict:
79 | seg_words.append(s)
80 | matched_flag = True
81 | tail = i
82 | break
83 | if not matched_flag:
84 | seg_words.append(text[tail-1])
85 | tail -= 1
86 | return seg_words
87 |
88 | while True:
89 | text = input('test-case:') #'我喜欢研究生命的起源'
90 | print(rmm(text, dict)) #['我', '喜欢', '研究生', '命', '的', '起源']
91 |
92 | ```
93 |
94 |
95 |
96 |
--------------------------------------------------------------------------------
/剑指offer-python版/扩展题-检测字符串中的括号是否有效.md:
--------------------------------------------------------------------------------
1 | # Python检测字符串中的括号是否有效
2 | ```Bash
3 | ()\[]\{} 返回True
4 | ([{}]) 返回True
5 | ([)] 返回false
6 | (){}[] 返回True
7 | ((]) 返回false
8 |
9 | ```
10 | 利用栈来解决问题:
11 | ```Python
12 | def check_brace(str_raw):
13 | # 如果传入为空,直接返回True
14 | if str_raw == "":
15 | return True
16 |
17 | # 定义一个空列表,模拟栈。
18 | stack = []
19 |
20 | while str_raw != "":
21 | # 获取本次循环的字符串的第一个字符
22 | thisChar = str_raw[0]
23 | # ^_^去掉第一个元素
24 | str_raw = str_raw[1:]
25 | # 如果本次循环的第一个字符是左括号,将其压栈
26 | if thisChar == "(" or thisChar == "{" or thisChar == "[":
27 | stack.append(thisChar)
28 | # 如果本次循环的第一个字符是右括号,检测栈是否为空,栈长为空表示栈内没有可以匹配的左括号,返回false
29 | # 如果栈长不为空,且栈内最后一个元素是相匹配的左括号,此次匹配成功,将其弹出,进入下一轮循环。
30 | elif thisChar == ")" or thisChar == "}" or thisChar == "]":
31 | # 提高效率
32 | len_stack = len(stack)
33 | if len_stack == 0:
34 | return False
35 | else:
36 | if thisChar == ")" and stack[len_stack - 1] == "(":
37 | stack.pop(len_stack - 1)
38 | elif thisChar == "]" and stack[len_stack - 1] == "[":
39 | stack.pop(len_stack - 1)
40 | elif thisChar == "}" and stack[len_stack - 1] == "{":
41 | stack.pop(len_stack - 1)
42 | else:
43 | return False
44 | # 循环结束,如果栈为空,则表示全部匹配完成
45 | if stack == []:
46 | return True
47 | else:
48 | return False
49 |
50 |
51 | print(check_brace('(){}[]'))
52 |
53 | ```
54 |
--------------------------------------------------------------------------------