├── .gitattributes
├── .gitignore
├── .idea
├── DataPreprocessing.iml
├── misc.xml
├── modules.xml
├── vcs.xml
└── workspace.xml
├── DataClass.py
├── DataCleaning
├── MissingDataHandle.py
├── OutlierHandle.py
└── __init__.py
├── DataReduction
└── RoughSetAttrSelecter.py
├── DataTransformation
├── NormalizeHandle.py
├── StandardizationHandle.py
└── __init__.py
├── LogHelper.py
├── README.md
├── README.pdf
├── pdf
└── 程序说明文档.pdf
├── picture
└── 流程图.png
└── sample
├── fz_micro.txt
└── weather.txt
/.gitattributes:
--------------------------------------------------------------------------------
1 | # Auto detect text files and perform LF normalization
2 | * text=auto
3 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | pip-wheel-metadata/
24 | share/python-wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | MANIFEST
29 |
30 | # PyInstaller
31 | # Usually these files are written by a python script from a template
32 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
33 | *.manifest
34 | *.spec
35 |
36 | # Installer logs
37 | pip-log.txt
38 | pip-delete-this-directory.txt
39 |
40 | # Unit test / coverage reports
41 | htmlcov/
42 | .tox/
43 | .nox/
44 | .coverage
45 | .coverage.*
46 | .cache
47 | nosetests.xml
48 | coverage.xml
49 | *.cover
50 | .hypothesis/
51 | .pytest_cache/
52 |
53 | # Translations
54 | *.mo
55 | *.pot
56 |
57 | # Django stuff:
58 | *.log
59 | local_settings.py
60 | db.sqlite3
61 |
62 | # Flask stuff:
63 | instance/
64 | .webassets-cache
65 |
66 | # Scrapy stuff:
67 | .scrapy
68 |
69 | # Sphinx documentation
70 | docs/_build/
71 |
72 | # PyBuilder
73 | target/
74 |
75 | # Jupyter Notebook
76 | .ipynb_checkpoints
77 |
78 | # IPython
79 | profile_default/
80 | ipython_config.py
81 |
82 | # pyenv
83 | .python-version
84 |
85 | # pipenv
86 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
87 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
88 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
89 | # install all needed dependencies.
90 | #Pipfile.lock
91 |
92 | # celery beat schedule file
93 | celerybeat-schedule
94 |
95 | # SageMath parsed files
96 | *.sage.py
97 |
98 | # Environments
99 | .env
100 | .venv
101 | env/
102 | venv/
103 | ENV/
104 | env.bak/
105 | venv.bak/
106 |
107 | # Spyder project settings
108 | .spyderproject
109 | .spyproject
110 |
111 | # Rope project settings
112 | .ropeproject
113 |
114 | # mkdocs documentation
115 | /site
116 |
117 | # mypy
118 | .mypy_cache/
119 | .dmypy.json
120 | dmypy.json
121 |
122 | # Pyre type checker
123 | .pyre/
124 | pdf/程序说明文档.pdf
125 | 程序说明文档.pdf
126 | README.pdf
127 | pdf/程序说明文档.pdf
128 | pdf/程序说明文档.pdf
129 |
--------------------------------------------------------------------------------
/.idea/DataPreprocessing.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
109 |
110 |
111 |
112 | len(data_class.data)
113 | append
114 | instence
115 |
116 |
117 |
118 |
119 |
120 |
121 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
368 |
374 |
375 |
376 |
377 |
378 |
379 |
380 |
381 |
382 | 1571901053804
383 |
384 |
385 | 1571901053804
386 |
387 |
388 |
389 |
390 |
391 |
392 |
393 |
394 |
395 |
396 |
397 |
398 |
399 |
400 |
401 |
402 |
403 |
404 |
405 |
406 |
407 |
408 |
409 |
410 |
411 |
412 |
413 |
414 |
415 |
416 |
417 |
418 |
419 |
420 |
421 |
422 |
423 |
424 |
425 |
426 | file://$PROJECT_DIR$/DataCleaning/MissingDataHandle.py
427 | 166
428 |
429 |
430 |
431 | file://$PROJECT_DIR$/DataCleaning/__init__.py
432 | 10
433 |
434 |
435 |
436 | file://$PROJECT_DIR$/DataTransformation/__init__.py
437 | 14
438 |
439 |
440 |
441 |
442 |
443 |
444 |
445 |
446 |
447 |
448 |
449 |
450 |
451 |
452 |
453 |
454 |
455 |
456 |
457 |
458 |
459 |
460 |
461 |
462 |
463 |
464 |
465 |
466 |
467 |
468 |
469 |
470 |
471 |
472 |
473 |
474 |
475 |
476 |
477 |
478 |
479 |
480 |
481 |
482 |
483 |
484 |
485 |
486 |
487 |
488 |
489 |
490 |
491 |
492 |
493 |
494 |
495 |
496 |
497 |
498 |
499 |
500 |
501 |
502 |
503 |
504 |
505 |
506 |
507 |
508 |
509 |
510 |
511 |
512 |
513 |
514 |
515 |
516 |
517 |
518 |
519 |
520 |
521 |
522 |
523 |
524 |
525 |
526 |
527 |
528 |
529 |
530 |
531 |
532 |
533 |
534 |
535 |
536 |
537 |
538 |
539 |
540 |
541 |
542 |
543 |
544 |
545 |
546 |
547 |
548 |
549 |
550 |
551 |
552 |
553 |
554 |
555 |
556 |
557 |
558 |
559 |
560 |
561 |
562 |
563 |
564 |
565 |
566 |
567 |
568 |
569 |
570 |
571 |
572 |
573 |
574 |
575 |
576 |
577 |
578 |
579 |
580 |
581 |
582 |
583 |
584 |
585 |
586 |
587 |
588 |
589 |
590 |
591 |
592 |
593 |
594 |
595 |
596 |
597 |
598 |
599 |
600 |
601 |
602 |
603 |
604 |
605 |
606 |
607 |
--------------------------------------------------------------------------------
/DataClass.py:
--------------------------------------------------------------------------------
1 | import LogHelper
2 |
3 |
4 | class DataClass:
5 | def __init__(self, type_list, init=None):
6 | if init:
7 | self.data = init
8 | else:
9 | self.data = []
10 | self.head = ''
11 | self.type_list = type_list
12 | self.normalize_max = {}
13 | self.normalize_min = {}
14 | self.standard_mean = {}
15 | self.standard_std = {}
16 |
17 | def read(self, path, has_head, split_tag='\t'):
18 | file = open(path)
19 | if has_head:
20 | self.head = file.readline()
21 | for line in file:
22 | items = line.strip('\n').split(split_tag)
23 | assert len(items) == self.attr_count
24 | self.data.append(items)
25 | return self.data
26 |
27 | def parse(self):
28 | """
29 | 按 type_list 中的数据类型进行格式转换
30 |
31 | type_list 长度必须等于数据的列数
32 | 与 type_list 中的数据类型不匹配的项填为空值
33 | :return:
34 | """
35 | if not self.data:
36 | raise ValueError()
37 | for i in range(len(self.data)):
38 | if len(self.data[i]) != len(self.type_list):
39 | raise ValueError(self.data[i])
40 | for j in range(len(self.type_list)):
41 | try:
42 | self.data[i][j] = self.type_list[j](self.data[i][j])
43 | except ValueError:
44 | # raise ValueError('DataClass.prase():cant convert row{:} {:}'.format(i + 1, self.data[i]))
45 | LogHelper.log('DataClass.prase():cant convert row{:} {:}', i + 1, self.data[i])
46 | self.data[i][j] = None
47 | return self.data
48 |
49 | def print(self):
50 | for line in self.data:
51 | print('|'.join(['{:.2f}'.format(line[i]) if i > 0 else line[i] for i in range(len(line))]))
52 |
53 | def copy(self):
54 | dc = DataClass(list(self.type_list), list(self.data))
55 | dc.head = self.head
56 | dc.type_list = self.type_list
57 | dc.normalize_max = self.normalize_max
58 | dc.normalize_min = self.normalize_min
59 | dc.standard_mean = self.standard_mean
60 | dc.standard_std = self.standard_std
61 |
62 | @property
63 | def len(self):
64 | return len(self.data)
65 |
66 | @property
67 | def attr_count(self):
68 | return len(self.type_list)
69 |
70 |
71 | if __name__ == "__main__":
72 | data = DataClass([str] + [float] * 12)
73 | data.read(r".\sample\fz_micro.txt", False)
74 | # data.parse()
75 |
--------------------------------------------------------------------------------
/DataCleaning/MissingDataHandle.py:
--------------------------------------------------------------------------------
1 | import DataClass as dc
2 | import numpy as np
3 |
4 | def delete_handle(data_class, handel_index):
5 | """
6 | 删除空值
7 |
8 | 要处理的属性不必是数值的
9 | :param data_class:
10 | :param handel_index: 要检查的列下标
11 | :return:
12 | """
13 | new_data = []
14 | for i in range(len(data_class.data)):
15 | need_delete = False
16 | for j in handel_index:
17 | if not data_class.data[i][j]:
18 | need_delete = True
19 | if not need_delete:
20 | new_data.append(data_class.data[i])
21 | data_class.data = new_data
22 | return data_class
23 |
24 |
25 | def fixed_value_padding_handle(data_class, handel_index, padding_value):
26 | """
27 | 固定值填充
28 |
29 | 要处理的属性不必是数值的,只填充空值
30 | :param data_class:
31 | :param handel_index: 要检查的列下标
32 | :return:
33 | """
34 | for i in range(len(data_class.data)):
35 | for j in handel_index:
36 | if not data_class.data[i][j]:
37 | data_class.data[i][j] = padding_value
38 | return data_class
39 |
40 |
41 | def mode_interpolation_handle(data_class, handel_index):
42 | """
43 | 众数填充
44 |
45 | 要处理的属性必须是整值的,非整值的数值类型计算众数可能会产生错误
46 | :param data_class:
47 | :param handel_index:
48 | :return:
49 | """
50 | return __interpolation_handle(data_class, handel_index, 'mode')
51 |
52 |
53 | def mean_interpolation_handle(data_class, handel_index):
54 | """
55 | 均数填充
56 |
57 | 要处理的属性必须是数值的,不是数值元素按空值处理
58 | :param data_class:
59 | :param handel_index:
60 | :return:
61 | """
62 | return __interpolation_handle(data_class, handel_index, 'mean')
63 |
64 |
65 | def median_interpolation_handle(data_class, handel_index):
66 | """
67 | 中数填充
68 |
69 | 要处理的属性必须是数值的,不是数值元素按空值处理
70 | :param data_class:
71 | :param handel_index:
72 | :return:
73 | """
74 | return __interpolation_handle(data_class, handel_index, 'median')
75 |
76 |
77 | def __interpolation_handle(data_class, handel_index, type):
78 | data = data_class.data
79 | need_alert = [[] for _ in range(len(data_class.type_list))] # 记录需要差值的位置
80 | data_list = [[] for _ in range(len(data_class.type_list))] # 记录去除空值后的列表
81 |
82 | for i in range(len(data)):
83 | for j in handel_index:
84 | if not data[i][j]:
85 | need_alert[j].append(i)
86 | else:
87 | try:
88 | data_list[j].append(float(data[i][j]))
89 | except ValueError:
90 | need_alert[j].append(i)
91 |
92 | for j in handel_index:
93 | if len(data_list[j]) == len(data):
94 | continue # 没有空值
95 |
96 | if type == 'mode': # 众数
97 | counts = np.bincount(data_list[j])
98 | interpol = np.argmax(counts)
99 | elif type == 'mean': # 均数
100 | interpol = np.mean(data_list[j])
101 | elif type == 'median': # 中位数
102 | interpol = np.median(data_list[j])
103 | else:
104 | raise NameError(type)
105 | for i in need_alert[j]:
106 | data[i][j] = interpol
107 | return data_class
108 |
109 |
110 | def mid_interpolation_handle(data_class, handel_index):
111 | """
112 | 插值法填充
113 |
114 | 需要 data.prase()
115 | :param data_class:
116 | :param handel_index:
117 | :return:
118 | """
119 | data = data_class.data
120 | need_alert = [[] for _ in range(len(data_class.type_list))] # 记录需要差值的位置
121 | data_list = [[] for _ in range(len(data_class.type_list))] # 记录去除空值后的列表
122 |
123 | for i in range(len(data)):
124 | for j in handel_index:
125 | if not data[i][j]:
126 | need_alert[j].append(i)
127 | else:
128 | try:
129 | data_list[j].append(float(data[i][j]))
130 | except ValueError:
131 | need_alert[j].append(i)
132 |
133 | for j in handel_index:
134 | if len(data_list[j]) == len(data):
135 | continue # 没有空值
136 |
137 | index = 0
138 | while index < len(need_alert[j]):
139 | count = 1 # 连续的空值
140 | while index + count < len(need_alert[j]) and need_alert[j][index + count] == need_alert[j][index] + count:
141 | count += 1
142 | before = after = 0
143 | i = need_alert[j][index]
144 | if i > 0:
145 | before = data[i - 1][j]
146 | if i + count - 1 < len(data) - 1:
147 | after = data[i + count - 1 + 1][j]
148 | if i == 0:
149 | before = after
150 | if i + count - 1 == len(data) - 1:
151 | after = before
152 |
153 | d = (after - before) / (count + 1)
154 | for c in range(count):
155 | data[i + c][j] = before + d * (c + 1)
156 |
157 | index = index + count
158 | return data_class
159 |
160 |
161 | if __name__ == "__main__":
162 | data = dc.DataClass([str] + [float] * 12)
163 | data.read(r"E:\_Python\DataPreprocessing\sample\fz_micro.txt", False)
164 | # delete_handle(data,[i for i in range(1, 13)])
165 | data.parse()
166 | mid_interpolation_handle(data, [i for i in range(1, 13)])
167 | print(data.data)
168 |
--------------------------------------------------------------------------------
/DataCleaning/OutlierHandle.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | def z_score_detection(data_class, handel_index, z_thr=3.0):
5 | """
6 | Z-score 异常值检测
7 |
8 | -数据无空值
9 | -数据经过 parse 方法格式转换
10 | :param data_class:
11 | :param handel_index:
12 | :param z_thr:
13 | :return:
14 | """
15 | outlier = [[] for _ in range(len(data_class.type_list))] # 记录离异值的位置(按列)
16 | for j in handel_index:
17 | col = []
18 | for i in range(len(data_class.data)):
19 | col.append(data_class.data[i][j])
20 | mean = np.mean(col, axis=0)
21 | std = np.std(col, axis=0)
22 | col = (col - mean) / std
23 | for i in range(len(data_class.data)):
24 | if col[i] > z_thr or col[i] < -z_thr:
25 | outlier[j].append(i)
26 | return outlier
27 |
28 |
29 | def outlier_none_handle(data_class, handel_index, detection="z_score", *args):
30 | """
31 | 离异值取空
32 | :param data_class:
33 | :param handel_index:
34 | :param detection:
35 | :param args:
36 | :return:
37 | """
38 | if detection == "z_score":
39 | outlier = z_score_detection(data_class, handel_index, args[0])
40 | else:
41 | raise NameError(detection)
42 |
43 | for j in range(len(data_class.type_list)):
44 | for i in outlier[j]:
45 | data_class.data[i][j] = None
46 | return data_class
47 |
--------------------------------------------------------------------------------
/DataCleaning/__init__.py:
--------------------------------------------------------------------------------
1 | import DataClass as dc
2 | import DataCleaning.MissingDataHandle as mdh
3 | import DataCleaning.OutlierHandle as oh
4 |
5 | if __name__ == "__main__":
6 | data = dc.DataClass([str] + [float] * 12)
7 | data.read(r"E:\_Python\DataPreprocessing\sample\fz_micro.txt", False)
8 | data.parse()
9 | mdh.mid_interpolation_handle(data, [i for i in range(1, 13)])
10 | oh.outlier_none_handle(data, [i for i in range(1, 13)], "z_score", 3.0)
11 | print(data.data)
--------------------------------------------------------------------------------
/DataReduction/RoughSetAttrSelecter.py:
--------------------------------------------------------------------------------
1 | """
2 | 基于粗糙集理论的属性选择.
3 |
4 | 数据必须满足:
5 | 1.离散
6 | 2.前n-1条属性是条件属性,第n条属性是决策属性
7 | """
8 |
9 | import numpy as np
10 | import DataClass
11 | import sys
12 |
13 |
14 | def get_attr_values_dicts(data_class):
15 | """
16 | 获取数据集中所有属性的取值及个数
17 | :param data_class:
18 | :return: [{'value1':count1,'value2':count2},{},...,{}]
19 | """
20 | dicts = [{} for _ in range(data_class.attr_count)]
21 | for i in range(data_class.len):
22 | for j in range(data_class.attr_count):
23 | if data_class.data[i][j] not in dicts[j]:
24 | dicts[j][data_class.data[i][j]] = 1
25 | else:
26 | dicts[j][data_class.data[i][j]] += 1
27 |
28 |
29 | def get_core(data_class):
30 | """
31 | 返回集合的 CORE 属性集.
32 | using Discernibility Matrix
33 | :param data_class:
34 | :return: 属性所在的下标标量.
35 | """
36 | core_attrs = set()
37 | for i in range(data_class.len):
38 | for j in range(i + 1, data_class.len):
39 | if data_class.data[i][data_class.attr_count - 1] != data_class.data[j][data_class.attr_count - 1]:
40 | dis_count = 0
41 | dis_attr = 0
42 | for attr in range(data_class.attr_count - 1):
43 | if data_class.data[i][attr] != data_class.data[j][attr]:
44 | dis_count += 1
45 | dis_attr = attr
46 | if dis_count == 1:
47 | core_attrs.add(dis_attr)
48 | return core_attrs
49 |
50 |
51 | def check_distinct(data_class, handel_index, considered_instance):
52 | """
53 | 检查在 handel_index 作为属性集下,是否存在不可区分集.
54 | :param data_class:
55 | :param handel_index:
56 | :return: true 表示没有不可区分集. False 表示存在不可区分集.
57 | """
58 | loop_instance = list(considered_instance)
59 | return_considered_instance = list(considered_instance)
60 | classify_num = 0
61 | is_reduct = True
62 | for i in range(data_class.len):
63 | if not loop_instance[i]:
64 | continue
65 | distinct_set = [i]
66 | is_distinct_set = True
67 | for j in range(i + 1, data_class.len):
68 | if not loop_instance[j]:
69 | continue
70 | decision_same = data_class.data[i][data_class.attr_count - 1] == data_class.data[j][
71 | data_class.attr_count - 1] # 决策属性是否相同
72 | condition_same = True # 选择的条件属性是否都相同
73 | for attr in handel_index:
74 | if data_class.data[i][attr] != data_class.data[j][attr]:
75 | condition_same = False
76 | break
77 | if condition_same:
78 | loop_instance[j] = False # 如果 i 和 j 条件属性相同,则 j 不用再进行计算
79 | if decision_same:
80 | distinct_set.append(j)
81 | else:
82 | is_distinct_set = False
83 | break
84 |
85 | if is_distinct_set:
86 | classify_num += 1
87 | for item in distinct_set:
88 | return_considered_instance[item] = False
89 | else:
90 | is_reduct = False
91 |
92 | if is_reduct:
93 | return True, classify_num, []
94 | else:
95 | return False, classify_num, return_considered_instance
96 |
97 |
98 | def attribute_select(data_class):
99 | """
100 | 在没有不可区分子集(reduct)的情况下,返回产生区分集个数最少的属性集
101 | 当产生的区分集个数相同时,选用取值种类数更少的属性
102 | :param data_class:
103 | :return:
104 | """
105 | considered_instance = np.array([True] * data_class.len, np.bool)
106 | selected_attr = get_core(data_class)
107 | attr_values_dicts = get_attr_values_dicts(data_class)
108 | is_reduction, classify_num, considered_instance = check_distinct(data_class, selected_attr, considered_instance)
109 | if is_reduction:
110 | return selected_attr, classify_num
111 |
112 | while True:
113 | if len(selected_attr) == data_class.attr_count - 1:
114 | raise ValueError('Cant reduce the attributes')
115 |
116 | min_classify_num_reduct = sys.maxsize
117 | min_classify_num_no_reduct = sys.maxsize
118 | considered_instance_no_reduct = []
119 | select_attr_step = -1
120 | has_reduct = False
121 | for attr in range(data_class.attr_count - 1):
122 | if attr in selected_attr:
123 | continue
124 | is_reduct, classify_num, _con = check_distinct(data_class, selected_attr + [attr], considered_instance)
125 | if is_reduct:
126 | has_reduct = True
127 | if classify_num < min_classify_num_reduct:
128 | min_classify_num_reduct = classify_num
129 | select_attr_step = attr
130 | elif classify_num == min_classify_num_reduct and len(attr_values_dicts[attr]) < len(
131 | attr_values_dicts[select_attr_step]):
132 | min_classify_num_reduct = classify_num
133 | select_attr_step = attr
134 | else:
135 | if has_reduct:
136 | continue
137 | else:
138 | if classify_num < min_classify_num_no_reduct:
139 | min_classify_num_no_reduct = classify_num
140 | select_attr_step = attr
141 | considered_instance_no_reduct = _con
142 | elif classify_num == min_classify_num_no_reduct and len(attr_values_dicts[attr]) < len(
143 | attr_values_dicts[select_attr_step]):
144 | min_classify_num_no_reduct = classify_num
145 | select_attr_step = attr
146 | considered_instance_no_reduct = _con
147 |
148 | if has_reduct:
149 | return selected_attr + [select_attr_step], min_classify_num_reduct
150 | else:
151 | selected_attr = selected_attr + [select_attr_step]
152 | considered_instance = considered_instance_no_reduct
153 |
154 |
155 | if __name__ == '__main__':
156 | # [Case1]
157 | # data = [['1', '0', '2', '1', '1'],
158 | # ['1', '0', '2', '0', '1'],
159 | # ['1', '2', '0', '0', '2'],
160 | # ['1', '2', '2', '1', '0'],
161 | # ['2', '1', '0', '0', '2'],
162 | # ['2', '1', '1', '0', '2'],
163 | # ['2', '1', '2', '1', '1']]
164 |
165 | # core = get_core(dc)
166 | # assert core == [1] # CORE(cd)=1 (the second attr)
167 | #
168 | # considered_instance = np.array([True] * dc.len, np.bool)
169 | # is_reduct, classify_num, considered_instance = check_distinct(dc, core, considered_instance)
170 | # assert (is_reduct, classify_num, considered_instance) == (False, 1, [False] * 2 + [True] * 5)
171 |
172 | # selected_attr, max_classify_num = attribute_select(dc)
173 | # assert selected_attr == {1, 3}
174 |
175 | # [Case2]
176 | dc = DataClass.DataClass([str] * 5)
177 | dc.read(r'..\sample\weather.txt', True)
178 | selected_attr, max_classify_num = attribute_select(dc)
179 | assert selected_attr == {0, 1, 3}
180 |
--------------------------------------------------------------------------------
/DataTransformation/NormalizeHandle.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | def min_max_normalize(data_class, handel_index):
5 | """
6 | 离差标准化
7 |
8 | -数据无空值
9 | -数据经过 parse 方法格式转换
10 | :param data_class:
11 | :param handel_index:
12 | :return:
13 | """
14 | max_list = {}
15 | min_list = {}
16 | for j in handel_index:
17 | col = []
18 | for i in range(len(data_class.data)):
19 | col.append(data_class.data[i][j])
20 | max_list[j] = max(col)
21 | min_list[j] = min(col)
22 | for i in range(len(data_class.data)):
23 | for j in handel_index:
24 | data_class.data[i][j] = (data_class.data[i][j] - min_list[j]) / (max_list[j] - min_list[j])
25 |
26 | data_class.normalize_max = max_list
27 | data_class.normalize_min = min_list
28 | return data_class
29 |
30 |
31 | def anti_min_max_normalize(data_class, handel_index):
32 | for i in range(len(data_class.data)):
33 | for j in handel_index:
34 | data_class.data[i][j] = (data_class.data[i][j] * (
35 | data_class.normalize_max[j] - data_class.normalize_min[j])) + data_class.normalize_min[j]
36 | return data_class
37 |
--------------------------------------------------------------------------------
/DataTransformation/StandardizationHandle.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | def standardization(data_class, handel_index):
5 | """
6 | 标准化
7 |
8 | -数据无空值
9 | -数据经过 parse 方法格式转换
10 | :param data_class:
11 | :param handel_index:
12 | :return:
13 | """
14 | mean_list = {}
15 | std_list = {}
16 | for j in handel_index:
17 | col = []
18 | for i in range(len(data_class.data)):
19 | col.append(data_class.data[i][j])
20 | mean_list[j] = np.mean(col, axis=0)
21 | std_list[j] = np.std(col, axis=0)
22 | col = (col - mean_list[j]) / std_list[j]
23 | for i in range(len(data_class.data)):
24 | data_class.data[i][j] = col[i]
25 |
26 | data_class.standard_mean = mean_list
27 | data_class.standard_std = std_list
28 | return data_class
29 |
30 |
31 | def anti_standardization(data_class, handel_index):
32 | """
33 | 反标准化
34 | :param data_class:
35 | :param handel_index:
36 | :return:
37 | """
38 | if not data_class.standard_mean:
39 | raise ValueError("standard_mean(std) is Null")
40 | for j in handel_index:
41 | if j not in data_class.standard_mean:
42 | raise ValueError(j + " is not in standard_mean(std):" + data_class.standard_mean)
43 |
44 | for i in range(len(data_class.data)):
45 | for j in handel_index:
46 | data_class.data[i][j] = (data_class.data[i][j] * data_class.standard_std[j]) + data_class.standard_mean[j]
47 | return data_class
48 |
--------------------------------------------------------------------------------
/DataTransformation/__init__.py:
--------------------------------------------------------------------------------
1 | import DataClass as dc
2 | import DataCleaning.MissingDataHandle as mdh
3 | import DataTransformation.NormalizeHandle as nh
4 | import DataTransformation.StandardizationHandle as sdh
5 |
6 | if __name__ == "__main__":
7 | data = dc.DataClass([str] + [float] * 12)
8 | data.read(r"E:\_Python\DataPreprocessing\sample\fz_micro.txt", False)
9 | data.parse()
10 | mdh.mid_interpolation_handle(data, [i for i in range(1, 13)])
11 | # nh.min_max_normalize(data, [i for i in range(1, 13)])
12 | # nh.anti_min_max_normalize(data, [i for i in range(1, 13)])
13 | # for line in data.data:
14 | # print('|'.join(['{:.2f}'.format(line[i]) if i > 0 else line[i] for i in range(len(line))]))
15 |
16 | sdh.standardization(data, [i for i in range(1, 13)])
17 | for line in data.data:
18 | print('|'.join(['{:.2f}'.format(line[i]) if i > 0 else line[i] for i in range(len(line))]))
19 |
--------------------------------------------------------------------------------
/LogHelper.py:
--------------------------------------------------------------------------------
1 |
2 | def log(message, *args):
3 | print(message.format(*args))
4 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # DataPreprocessing
2 | ## **数据预处理工具集**
3 | 此项目为 [大气环境数据挖掘实验室](https://wddzht.github.io/APDA.github.io/) 成员在大气污染物监测数据挖掘项目中常用的数据预处理方法整理,更多的是为数据处理分析的流程和方法做列举,仅供学习. 代码持续更新中,不足之处欢迎批评指正. [git here](https://github.com/Wddzht/DataPreprocessing)
4 |
5 | ## 目录结构:
6 | 1. **数据清洗** /DataCleaning
7 | 1. 空值处理 MissingDataHandle.py
8 | 1. 删除 delete_handle(data_class, handel_index)
9 | 2. 中位数插补 median_interpolation_handle(data_class, handel_index)
10 | 3. 众数插补 mode_interpolation_handle(data_class, handel_index)
11 | 4. 均值插补 mean_interpolation_handle(data_class, handel_index)
12 | 5. 固定值插补 fixed_value_padding_handle(data_class, handel_index, padding_value)
13 | 6. 间值法插补 mid_interpolation_handle(data_class, handel_index)
14 | 7. 线性回归法
15 | 8. 拉格朗日法
16 | 2. 异常值 OutlierHandle.py
17 | 1. Z-Score法 z_score_detection(data_class, handel_index, z_thr=3.0)
18 | 2. 滑动平均法
19 | 2. **数据集成** /Discretization
20 | 1. 合并
21 | 2. 去重
22 | 3. **数据变换** /DataTransformation
23 | 1. 函数变换
24 | 2. 归一化 NormalizeHandle.py
25 | 1. 离差标准化 min_max_normalize(data_class, handel_index)
26 | 2. 反离差标准化 anti_min_max_normalize(data_class, handel_index)
27 | 3. 标准化 StandardizationHandle.py
28 | 1. 标准化 standardization(data_class, handel_index)
29 | 2. 反标准化 anti_standardization(data_class, handel_index)
30 | 4. **数据规约** /DataReduction
31 | 1. 属性选择 RoughSetAttrSelecter
32 | 1. 基于粗糙集理论的属性选择 attribute_select(data_class)
33 | 5. **数据离散** /DataIntegration
34 | 1. 分箱
35 | 1. 等值分箱
36 | 2. 等频分箱
37 | 3. 基于Gini指数分箱
38 | 4. 基于熵增分箱
39 | 2. one-hot编码
40 | 6. **数据集结构** DataClass.py
41 | 1. 数据读取 read(self, path, has_head, split_tag='\t')
42 | 2. 数据格式转换 parse(self)
43 | 3. 打印 print(self)
44 | 7. **稀疏数据处理**
45 | 8. **日志记录** LogHelper.py
46 |
47 | ---
48 |
49 | ## 数据处理流程
50 |
51 | 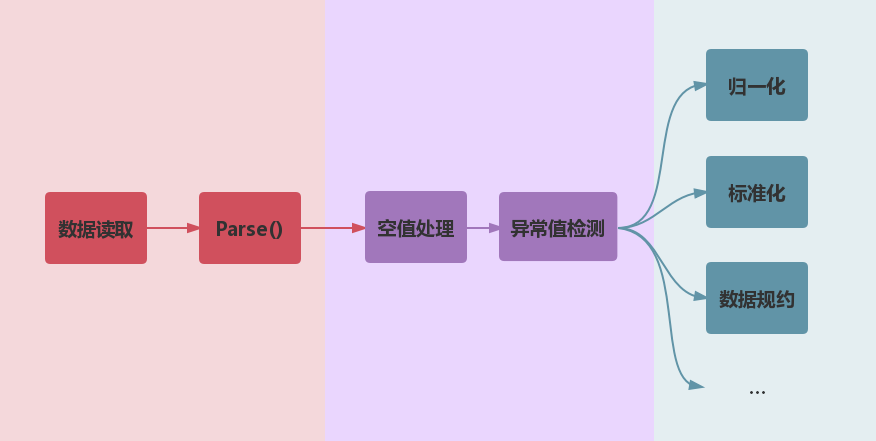
52 |
53 | ---
54 |
55 | ## 一、数据表结构DataClass
56 | ### 1.1 属性:
57 | 1. 二维的数据表`data = [[]]`
58 | 2. 表头`head`
59 | 3. 每一列的数据类型`type_list`
60 | 4. 归一化时的最大值列表(用于反归一化)`normalize_max`
61 | 5. 归一化时的最小值列表(用于反归一化)`normalize_min`
62 | 6. 标准化时的均值(用于反标准化)`standard_mean`
63 | 7. 标准化时的标准差(用于反标准化)`standard_std`
64 | ### 1.2 方法:
65 | + 数据读取 `read(self, path, has_head, split_tag='\t'):`
66 | - path:文件路径
67 | - has_head:是否有表头
68 | - split_tag:切分字符
69 | + 数据格式转换 `parse(self)`
70 |
71 | 在调用数据转换方法`parse(self)`时,格式错误的数据将被替换为空值.
72 |
73 | ```python {.line-numbers}
74 | data = DataClass([str] + [float] * 12) # 数据格式声明
75 | data.read(r".\sample\fz_micro.txt", True) # 数据读取
76 | data.parse() # 数据转换
77 | ```
78 | **数据样例 .\sample\fz_micro.txt (部分)**
79 |
80 | RECEIVETIME|CO|NO2|SO2|O3|PM25|PM10|TEMP|HUM|PM05N|PM1N|PM25N|PM10N
81 | :----|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:
82 | 2017/1/9 18:00||634.38|619.43|733.52|57.33|57.76|15.19|65.14|4026.38|1944.57|401.29|24.81
83 | 2017/1/9 19:00|431.47|962.93|570.17|824.27|51.8|52.17|14|67.8|3646.73|1758.57|357.47|22.6
84 | 2017/1/9 20:00|423|756.33|556.43|854.57|48.57|48.73|14|68.3|3513|1687.4|339.77|20.7
85 | 2017/1/9 21:00|419.93|1008.57|499.47|908.13|46|46.47|13.8|68.33|3345.13|1600.43|326.17|20.87
86 | 2017/1/9 22:00||1019.47|476.07|927.67|46.27|46.77|13.03|68.83|3401.73|1633.37|328.7|18.83
87 | 2017/1/9 23:00||904.8|475.37|947.03|53.47|53.8|13|68.63|3838.1|1856.47|379.37|22.07
88 | 2017/1/10 0:00|412.9|1052.7|467.23|955.4|60.5|60.87|**A5**|68.3|4242.37|2075.77|428.53|25.93
89 | 2017/1/10 1:00|412.93|876.2|503.9|930.7|66.8|67.17|13|68.07|4635.37|
90 |
91 |
92 | ---
93 | ## 二、数据清洗 /DataCleaning
94 | ### 2.1 空值处理 MissingDataHandle.py
95 | #### 2.1.1 空值删除 delete_handle(data_class, handel_index)
96 | 1. `data_class`类型为DataClass的数据
97 | 2. `handel_index`要处理的列的下标
98 | ```python {.line-numbers}
99 | import DataClass as dc
100 |
101 | data = dc.DataClass([str] + [float] * 12)
102 | data.read(r".\sample\fz_micro.txt", False)
103 | delete_handle(data,[i for i in range(1, 13)])
104 | data.parse()
105 | ```
106 | 处理后的 .data (空值删除并不会检查数据类型是否合法,如**A5**并不会被删除)
107 |
108 | RECEIVETIME|CO|NO2|SO2|O3|PM25|PM10|TEMP|HUM|PM05N|PM1N|PM25N|PM10N
109 | :----|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:
110 | 2017/1/9 19:00|431.47|962.93|570.17|824.27|51.8|52.17|14|67.8|3646.73|1758.57|357.47|22.6
111 | 2017/1/9 20:00|423|756.33|556.43|854.57|48.57|48.73|14|68.3|3513|1687.4|339.77|20.7
112 | 2017/1/9 21:00|419.93|1008.57|499.47|908.13|46|46.47|13.8|68.33|3345.13|1600.43|326.17|20.87
113 | 2017/1/10 0:00|412.9|1052.7|467.23|955.4|60.5|60.87|**A5**|68.3|4242.37|2075.77|428.53|25.93
114 |
115 | #### 2.1.2 均数填充 mean_interpolation_handle(data_class, handel_index)
116 | 要处理的属性必须是数值的,**不是数值元素按空值处理**
117 |
118 | 处理后的 .data
119 |
120 | RECEIVETIME|CO|NO2|SO2|O3|PM25|PM10|TEMP|HUM|PM05N|PM1N|PM25N|PM10N
121 | :----|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:
122 | 2017/1/9 18:00|**411.02**|634.38|619.43|733.52|57.33|57.76|15.19|65.14|4026.38|1944.57|401.29|24.81
123 | 2017/1/9 19:00|431.47|962.93|570.17|824.27|51.8|52.17|14|67.8|3646.73|1758.57|357.47|22.6
124 | 2017/1/9 20:00|423|756.33|556.43|854.57|48.57|48.73|14|68.3|3513|1687.4|339.77|20.7
125 | 2017/1/9 21:00|419.93|1008.57|499.47|908.13|46|46.47|13.8|68.33|3345.13|1600.43|326.17|20.87
126 | 2017/1/9 22:00|**411.02**|1019.47|476.07|927.67|46.27|46.77|13.03|68.83|3401.73|1633.37|328.7|18.83
127 | 2017/1/9 23:00|**411.02**|904.8|475.37|947.03|53.47|53.8|13|68.63|3838.1|1856.47|379.37|22.07
128 | 2017/1/10 0:00|412.9|1052.7|467.23|955.4|60.5|60.87|**13.28**|68.3|4242.37|2075.77|428.53|25.93
129 | 2017/1/10 1:00|412.93|876.2|503.9|930.7|66.8|67.17|13|68.07|4635.37|**2279.67**|**469.8**|**28.93**
130 |
131 | #### 2.1.3 插值法填充 mid_interpolation_handle(data_class, handel_index)
132 | 要处理的属性必须是数值的,**不是数值元素按空值处理**.
133 | 1. 若空值处于首位,则插值取空值的下一个最近的非空的元素.
134 | 2. 若空值位于末尾,则插值取空值的上一个最近的非空的元素.
135 | 3. 若一个或多个连续的空值位于前后两个非空元素之间,则差值取前后非空元素的等差间值.
136 |
137 | 处理后的 .data
138 |
139 | RECEIVETIME|CO|NO2|SO2|O3|PM25|PM10|TEMP|HUM|PM05N|PM1N|PM25N|PM10N
140 | :----|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:
141 | 2017/1/9 18:00|**431.47**|634.38|619.43|733.52|57.33|57.76|15.19|65.14|4026.38|1944.57|401.29|24.81
142 | 2017/1/9 19:00|431.47|962.93|570.17|824.27|51.8|52.17|14|67.8|3646.73|1758.57|357.47|22.6
143 | 2017/1/9 20:00|423|756.33|556.43|854.57|48.57|48.73|14|68.3|3513|1687.4|339.77|20.7
144 | 2017/1/9 21:00|419.93|1008.57|499.47|908.13|46|46.47|13.8|68.33|3345.13|1600.43|326.17|20.87
145 | 2017/1/9 22:00|**417.58**|1019.47|476.07|927.67|46.27|46.77|13.03|68.83|3401.73|1633.37|328.7|18.83
146 | 2017/1/9 23:00|**415.24**|904.8|475.37|947.03|53.47|53.8|13|68.63|3838.1|1856.47|379.37|22.07
147 | 2017/1/10 0:00|412.9|1052.7|467.23|955.4|60.5|60.87|**13**|68.3|4242.37|2075.77|428.53|25.93
148 | 2017/1/10 1:00|412.93|876.2|503.9|930.7|66.8|67.17|13|68.07|4635.37|**2360.77**|**489.71**|**29.58**
149 |
150 | #### 2.1.4+ 中数填充 众数填充 固定值填充 等
151 | 调用方法与插值法填充类似.
152 |
153 |
154 |
155 | ### 2.2 离异值(异常值)处理 OutlierHandle.py
156 | #### 2.2.1 Z-Score异常值检测 z_score_detection(data_class, handel_index, z_thr=3.0)
157 | 1. `data_class`类型为DataClass的数据.
158 | 2. `handel_index`要处理的列的下标.
159 | 3. `z_thr`识别阈值. 一般取 2.5, 3.0, 3.5
160 | 4. `:return`每一列离异值的下标.
161 |
162 | 条件:-1. 数据无空值. -2. 数据经过 parse() 方法格式转换.调用方法如下
163 | ```python {.line-numbers}
164 | import DataClass as dc
165 | import DataCleaning.MissingDataHandle as mdh
166 | import DataCleaning.OutlierHandle as oh
167 |
168 | data = dc.DataClass([str] + [float] * 12)
169 | data.read(r".\sample\fz_micro.txt", False)
170 | data.parse()
171 | mdh.mid_interpolation_handle(data, [i for i in range(1, 13)]) # 插值法填充
172 | oh.outlier_none_handle(data, [i for i in range(1, 13)], "z_score", 3.0) # 通过`z_score`方法识别异常,并置为空值
173 | data.print()
174 | ```
175 |
176 |
177 | ---
178 | ## 三、数据变换 /DataTransformation
179 | ### 3.1 归一化 NormalizeHandle.py
180 | #### 3.1.1 离差归一化 min_max_normalize(data_class, handel_index)
181 | ```python {.line-numbers}
182 | import DataClass as dc
183 | import DataCleaning.MissingDataHandle as mdh
184 | import DataTransformation.NormalizeHandle as nh
185 |
186 | data = dc.DataClass([str] + [float] * 12)
187 | data.read(r".\sample\fz_micro.txt", False)
188 | data.parse()
189 | mdh.mid_interpolation_handle(data, [i for i in range(1, 13)]) # 插值法填充
190 | nh.min_max_normalize(data, [i for i in range(1, 13)]) # 离差归一化
191 | data.print()
192 | ```
193 |
194 | 条件:-1. 数据无空值. -2. 数据经过 parse() 方法格式转换处理. 处理后的 .data
195 |
196 | RECEIVETIME|CO|NO2|SO2|O3|PM25|PM10|TEMP|HUM|PM05N|PM1N|PM25N|PM10N
197 | :----|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:
198 | 2017/1/9 18:00|0.87|0.27|0.83|0.31|0.48|0.48|0.55|0.52|0.54|0.51|0.45|0.36
199 | 2017/1/9 19:00|0.87|0.51|0.76|0.44|0.43|0.43|0.43|0.57|0.49|0.46|0.4|0.33
200 | 2017/1/9 20:00|0.71|0.36|0.74|0.48|0.4|0.4|0.43|0.58|0.47|0.44|0.37|0.3
201 | 2017/1/9 21:00|0.66|0.55|0.66|0.56|0.38|0.38|0.41|0.58|0.44|0.41|0.36|0.3
202 | 2017/1/9 22:00|0.61|0.56|0.63|0.59|0.38|0.38|0.34|0.59|0.45|0.42|0.36|0.27
203 | 2017/1/9 23:00|0.57|0.47|0.63|0.61|0.45|0.44|0.33|0.59|0.52|0.48|0.42|0.32
204 | 2017/1/10 0:00|0.52|0.58|0.61|0.63|0.51|0.5|0.33|0.58|0.58|0.54|0.48|0.38
205 | 2017/1/10 1:00|0.53|0.45|0.67|0.59|0.56|0.56|0.33|0.58|0.63|0.62|0.55|0.44
206 |
207 | #### 3.1.2 反离差归一化 min_max_normalize(data_class, handel_index)
208 | 运行示例
209 | ```python {.line-numbers}
210 | import DataClass as dc
211 | import DataCleaning.MissingDataHandle as mdh
212 | import DataTransformation.NormalizeHandle as nh
213 |
214 | data = dc.DataClass([str] + [float] * 12)
215 | data.read(r".\sample\fz_micro.txt", False)
216 | data.parse()
217 | mdh.mid_interpolation_handle(data, [i for i in range(1, 13)]) # 插值法填充
218 | nh.min_max_normalize(data, [i for i in range(1, 13)]) # 离差归一化
219 | nh.anti_min_max_normalize(data, [i for i in range(1, 13)]) # 反离差归一化
220 | data.print()
221 | ```
222 |
223 | 运行结果
224 |
225 | RECEIVETIME|CO|NO2|SO2|O3|PM25|PM10|TEMP|HUM|PM05N|PM1N|PM25N|PM10N
226 | :----|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:
227 | 2017/1/9 18:00|431.47|634.38|619.43|733.52|57.33|57.76|15.19|65.14|4026.38|1944.57|401.29|24.81
228 | 2017/1/9 19:00|431.47|962.93|570.17|824.27|51.80|52.17|14.00|67.80|3646.73|1758.57|357.47|22.60
229 | 2017/1/9 20:00|423.00|756.33|556.43|854.57|48.57|48.73|14.00|68.30|3513.00|1687.40|339.77|20.70
230 | 2017/1/9 21:00|419.93|1008.57|499.47|908.13|46.00|46.47|13.80|68.33|3345.13|1600.43|326.17|20.87
231 | 2017/1/9 22:00|417.59|1019.47|476.07|927.67|46.27|46.77|13.03|68.83|3401.73|1633.37|328.70|18.83
232 | 2017/1/9 23:00|415.24|904.80|475.37|947.03|53.47|53.80|13.00|68.63|3838.10|1856.47|379.37|22.07
233 | 2017/1/10 0:00|412.90|1052.70|467.23|955.40|60.50|60.87|13.00|68.30|4242.37|2075.77|428.53|25.93
234 | 2017/1/10 1:00|412.93|876.20|503.90|930.70|66.80|67.17|13.00|68.07|4635.37|2360.77|489.71|29.58
235 |
236 | ### 3.2 标准化 StandardizationHandle.py
237 | #### 3.2.1 标准化 standardization(data_class, handel_index)
238 |
239 | ```python {.line-numbers}
240 | import DataClass as dc
241 | import DataTransformation.StandardizationHandle as sdh
242 |
243 | data = dc.DataClass([str] + [float] * 12)
244 | data.read(r"E:\_Python\DataPreprocessing\sample\fz_micro.txt", False)
245 | data.parse()
246 | mdh.mid_interpolation_handle(data, [i for i in range(1, 13)]) # 插值法填充
247 | sdh.standardization(data, [i for i in range(1, 13)]) # 标准化
248 | data.print()
249 | ```
250 | 条件:-1.数据无空值 -2.数据经过 parse() 方法格式转换.
251 | 执行结果
252 |
253 | RECEIVETIME|CO|NO2|SO2|O3|PM25|PM10|TEMP|HUM|PM05N|PM1N|PM25N|PM10N
254 | :----|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:
255 | 2017/1/9 18:00|1.47|-0.29|0.80|-0.81|0.05|0.04|1.04|-0.44|0.08|0.06|0.02|-0.14
256 | 2017/1/9 19:00|1.47|0.89|0.50|-0.21|-0.16|-0.17|0.39|-0.20|-0.16|-0.16|-0.22|-0.30
257 | 2017/1/9 20:00|0.86|0.15|0.42|-0.01|-0.29|-0.30|0.39|-0.16|-0.25|-0.25|-0.31|-0.44
258 | 2017/1/9 21:00|0.63|1.06|0.07|0.35|-0.39|-0.39|0.28|-0.15|-0.35|-0.35|-0.38|-0.42
259 | 2017/1/9 22:00|0.46|1.10|-0.08|0.48|-0.38|-0.38|-0.14|-0.11|-0.32|-0.31|-0.37|-0.57
260 | 2017/1/9 23:00|0.29|0.68|-0.08|0.60|-0.10|-0.11|-0.15|-0.13|-0.04|-0.05|-0.10|-0.34
261 | 2017/1/10 0:00|0.12|1.22|-0.13|0.66|0.17|0.16|-0.15|-0.16|0.22|0.21|0.16|-0.06
262 | 2017/1/10 1:00|0.12|0.58|0.09|0.50|0.41|0.40|-0.15|-0.18|0.46|0.55|0.49|0.21
263 |
264 |
265 | #### 3.2.2 反标准化 anti_standardization(data_class, handel_index)
266 |
267 | 运行示例
268 |
269 | ```python {.line-numbers}
270 | import DataClass as dc
271 | import DataTransformation.StandardizationHandle as sdh
272 |
273 | data = dc.DataClass([str] + [float] * 12)
274 | data.read(r"E:\_Python\DataPreprocessing\sample\fz_micro.txt", False)
275 | data.parse()
276 | mdh.mid_interpolation_handle(data, [i for i in range(1, 13)]) # 插值法填充
277 | sdh.standardization(data, [i for i in range(1, 13)]) # 标准化
278 | sdh.anti_standardization(data, [i for i in range(1, 13)]) # 反标准化
279 | data.print()
280 | ```
281 |
282 | ---
283 | ## 四、数据规约 /DataReduction
284 | ### 4.1 属性选择 RoughSetAttrSelecter.py
285 | #### 4.1.1 基于粗糙集理论的属性选择 attribute_select(data_class)
286 |
287 | Workflow:
288 | 1. 计算数据的CORE属性集:`core = get_core(dc)`,
289 | 2. 以CORE中的属性作为初始的属性选择,检查在选定的属性集下,是否存在不可区分集(即计算选定属性集在所有决策属性的下近似) ``check_distinct(dc, core, considered_instence)``
290 | $$Initial\:SelectedAttrs=\{CORE\}$$
291 | $$POS_{\{SelectedAttrs\}}(D)=U_{CX}$$
292 | 3. 若存在不可区分集,进行下一步迭代.若不存在不可区分集,则CORE就是Reduct.
293 | 4. 从剩下的属性中依次选取一个属性$a_i$加入:$$SelectedAttrs=\{CORE\}+\{a_i\}$$ 检查在选定的属性集下,是否存在不可区分集.
294 | 5. 若存在一个或多个个数相同的属性集,都不会产生不可区分集,则在这些属性中选取值种类数较少的属性加入并返回SelectedAttrs,并返回SelectedAttrs,程序运行结束.
295 | 6. 若对于所有的$\{CORE\}+\{a_i\}$属性集,都会产生不可区分集(没有 Reduct )),则选择区分集个数最少的属性进入下一轮迭代(第4步).
296 |
297 | **Case 1:**
298 | data: (其中a,b,c,d为条件属性, E为决策属性)
299 |
300 | U|a|b|c|d|**E**
301 | :----|-----:|-----:|-----:|-----:|-----:
302 | u1|1|0|2|1|1
303 | u2|1|0|2|0|1
304 | u3|1|2|0|0|2
305 | u4|1|2|2|1|0
306 | u5|2|1|0|0|2
307 | u6|2|1|1|0|2
308 | u7|2|1|2|1|1
309 |
310 | ```python {.line-numbers}
311 | # 方法测试
312 | dc = DataClass.DataClass([str] * 5, data)
313 | core = get_core(dc)
314 | assert core == [1] # CORE(cd)=1 (the second attr)
315 |
316 | considered_instence = np.array([True] * dc.len, np.bool)
317 | is_reduct, classify_num, considered_instence = check_distinct(dc, core, considered_instence)
318 | assert (is_reduct, classify_num, considered_instence) == (False, 1, [False] * 2 + [True] * 5)
319 |
320 | # 属性选择
321 | selected_attr, max_classify_num = attribute_select(dc)
322 | assert selected_attr == [1, 3] # 选择{b,d}作为约简后的属性集
323 | ```
324 | 方法说明:
325 | 其中`get_core(data)`方法通过构造 Discernibility Matrix 的方法选出CORE属性.
326 | `check_distinct`方法用来检查在选定的属性集下,是否存在**不可区分集**. 并返回**分类个数**和**数据集约简**
327 |
328 | 不可区分集:
329 | 存在两条或多条记录,它们的(已选择的)条件属性相同,但对应的决策属性不同,则这些记录构成了不可区分集,如:当选择{a,b}作为Reduct时,
330 | U|a|b|**E**
331 | :----|-----:|-----:|-----:
332 | u3|1|2|2
333 | u4|1|2|0
334 | u5|2|1|2
335 | u6|2|1|2
336 | u7|2|1|1
337 |
338 | a1b2→E2, a1b2→E0 ({u3,u4}构成不可区分集)
339 | a2b1→E2, a2b1→E1 (\{u5,u6,u7}构成不可区分集)
340 |
341 | **Case 2:**
342 | ```python {.line-numbers}
343 | # [case2]
344 | dc = DataClass.DataClass([str] * 5)
345 | dc.read(r'..\sample\weather.txt', True)
346 |
347 | selected_attr, max_classify_num = attribute_select(dc)
348 | assert selected_attr == {0, 1, 3} # 选择属性 {Outlook, Temperature, Windy}
349 | ```
350 |
351 | Weather数据集:
352 | U|Outlook|Temperature|Humidity|Windy|**Play**
353 | :----|-----:|-----:|-----:|-----:|-----:
354 | x1|sunny|hot|high|false|no
355 | x2|sunny|hot|high|true|no
356 | x3|overcast|hot|high|false|yes
357 | x4|rainy|mild|high|false|yes
358 | x5|rainy|cool|normal|false|no
359 | x6|overcast|cool|normal|true|yes
360 | x7|sunny|mild|high|false|no
361 | x8|sunny|cool|normal|false|yes
362 | x9|rainy|mild|normal|false|yes
363 | x10|sunny|mild|normal|true|yes
364 | x11|overcast|mild|high|true|yes
365 | x12|overcast|hot|normal|false|yes
366 | x13|rainy|mild|high|true|no
367 |
368 | 属性化简后的数据:
369 | U|Outlook|Temperature|Windy|**Play**
370 | :----|-----:|-----:|-----:|-----:
371 | x1|sunny|hot|false|no
372 | x2|sunny|hot|true|no
373 | x3|overcast|hot|false|yes
374 | x4|rainy|mild|false|yes
375 | x5|rainy|cool|false|no
376 | x6|overcast|cool|true|yes
377 | x7|sunny|mild|false|no
378 | x8|sunny|cool|false|yes
379 | x9|rainy|mild|false|yes
380 | x10|sunny|mild|true|yes
381 | x11|overcast|mild|true|yes
382 | x12|overcast|hot|false|yes
383 | x13|rainy|mild|true|no
384 | ---
385 |
--------------------------------------------------------------------------------
/README.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Wddzht/DataPreprocessing/12ced380503b3365629fdd73b589f37ce6292a24/README.pdf
--------------------------------------------------------------------------------
/pdf/程序说明文档.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Wddzht/DataPreprocessing/12ced380503b3365629fdd73b589f37ce6292a24/pdf/程序说明文档.pdf
--------------------------------------------------------------------------------
/picture/流程图.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Wddzht/DataPreprocessing/12ced380503b3365629fdd73b589f37ce6292a24/picture/流程图.png
--------------------------------------------------------------------------------
/sample/fz_micro.txt:
--------------------------------------------------------------------------------
1 | 2017/1/9 18:00 634.38 619.43 733.52 57.33 57.76 15.19 65.14 4026.38 1944.57 401.29 24.81
2 | 2017/1/9 19:00 431.47 962.93 570.17 824.27 51.8 52.17 14 67.8 3646.73 1758.57 357.47 22.6
3 | 2017/1/9 20:00 423 756.33 556.43 854.57 48.57 48.73 14 68.3 3513 1687.4 339.77 20.7
4 | 2017/1/9 21:00 419.93 1008.57 499.47 908.13 46 46.47 13.8 68.33 3345.13 1600.43 326.17 20.87
5 | 2017/1/9 22:00 1019.47 476.07 927.67 46.27 46.77 13.03 68.83 3401.73 1633.37 328.7 18.83
6 | 2017/1/9 23:00 904.8 475.37 947.03 53.47 53.8 13 68.63 3838.1 1856.47 379.37 22.07
7 | 2017/1/10 0:00 412.9 1052.7 467.23 955.4 60.5 60.87 A5 68.3 4242.37 2075.77 428.53 25.93
8 | 2017/1/10 1:00 412.93 876.2 503.9 930.7 66.8 67.17 13 68.07 4635.37
9 | 2017/1/10 2:00 413.37 888.23 512.8 910.6 77.87 78.47 13 68.2 5326.07 2645.77 550.9 33.23
10 | 2017/1/10 3:00 411.67 833.53 503.67 880.13 73.43 73.7 68.63 5144.67 2544.87 526.73 33.37
11 | 2017/1/10 4:00 410.13 863.67 553.37 874.3 75.07 13 68.13 5107.3 2534 526.6 31.33
12 | 2017/1/10 5:00 746.47 589.83 852.43 79.37 79.6 13 68.8 5439.7 2718.9 564.83 35.17
13 | 2017/1/10 6:00 409 724.13 567.4 855.4 74 74.27 13 68.93 5050.37 2517.5 522.5 31.9
14 | 2017/1/10 7:00 410.53 804.13 544.8 866 69.73 70.03 13 69.03 4818.6 2386.5 502.77 32.07
15 | 2017/1/10 8:00 413.5 696.6 596.9 865.9 58.8 59.1 13.27 67.93 4105.93 1996.47 413.13 26.3
16 | 2017/1/10 9:00 420.17 605.07 576 894.47 66.5 67.2 14.27 65.6 4606.3 2262.7 476.23 31.63
17 | 2017/1/10 10:00 421 690.3 556.67 903.87 62.83 63.6 15.23 63.27 4377.33 2111.4 430.03 26.77
18 | 2017/1/10 11:00 422.9 687.1 563.6 928.17 59.97 60.93 16.3 62.03 4230.13 2031.3 411.73 26.13
19 | 2017/1/10 12:00 428.2 773.43 489.33 1056.17 77 78.73 18.1 58.17 5243.8 2553 520.97 34
20 | 2017/1/10 13:00 430.07 802.9 482.9 1145.87 80.57 83.5 19.57 55.57 5481.17 2654.8 533.87 35.43
21 | 2017/1/10 14:00 433.63 780.43 495.2 1101.77 71.17 73.27 19.77 55.8 4950.07 2360.53 457.87 29.97
22 | 2017/1/10 15:00 425.93 719.37 518.33 1029.93 78.47 80.6 18.9 58.63 5341.57 2597.4 519.23 34.57
23 | 2017/1/10 16:00 422.93 815.07 472.13 1022.13 81.7 83.33 17.63 60.63 5481.5 2692.73 556 36.37
24 | 2017/1/10 17:00 419.1 763.03 512.07 993.5 90.57 92.63 16.7 62.7 6037.53 2999.13 623.63 43.83
25 | 2017/1/10 18:00 422.91 615.91 536.41 965.32 92.86 95.41 16.32 63.55 6025.41 3006.64 651.09 44.5
26 | 2017/1/10 19:00 421.57 642.2 497.27 958.6 98.27 100 15.7 65.57 6376.83 3223.67 693.27 47.8
27 | 2017/1/10 20:00 417.5 710.3 511.97 946.87 98.73 100.53 15 67 6446.93 3271.37 707.47 48.97
28 | 2017/1/10 21:00 418.43 701.47 537 922.1 97.93 99.47 15 67.17 6333.3 3220.53 709.5 50.77
29 | 2017/1/10 22:00 418.93 576.23 569.17 886.63 104.17 106.9 15 68 6676.97 3407.13 756.03 55.93
30 | 2017/1/10 23:00 419.2 626.03 554.57 867.2 104.47 106.53 14.77 68.8 6704.4 3434.77 763.47 55.73
31 | 2017/1/11 0:00 417.57 746.33 535.47 870.63 100 101.63 14 69.1 6388.43 3276.3 729.87 52.93
32 | 2017/1/11 1:00 416.87 780.57 518.07 862.77 100.47 101.93 14 69.77 6441 3302.33 736.47 52.53
33 | 2017/1/11 2:00 415.1 612.4 540.77 856.47 101.77 103.07 14 70.13 6526.77 3362.8 746.8 51.73
34 | 2017/1/11 3:00 425.63 721.33 531.87 837.6 105.37 106.87 14 70.43 6558.03 3413.87 787.97 54.5
35 | 2017/1/11 4:00 433.17 608.23 582.7 792.3 117.1 118.97 14 70.8 7106.67 3727.97 876.4 65.87
36 | 2017/1/11 5:00 432.2 649.47 612.7 797.73 102.73 104.7 14 69 6536.13 3364.3 758.83 53.8
37 | 2017/1/11 6:00 430.2 727.33 540.77 850.23 84.7 86.13 14 67.03 5536.1 2795.47 616.37 43.97
38 | 2017/1/11 7:00 427.93 788.83 494.1 840.1 83.47 84.67 14 67.43 5451.1 2762.13 611.17 42.47
39 | 2017/1/11 8:00 422.77 775.57 480.07 859.63 79.2 80.17 14 67.3 5321.17 2669.8 580.8 41.33
40 | 2017/1/11 9:00 430.1 557.5 614 847.67 88.87 91.13 14.87 66.1 5739.83 2900.3 642.87 48.27
41 | 2017/1/11 10:00 438.2 533.73 603.27 841.1 99.6 101.43 15 66.9 6488.9 3289.4 719.27 53.07
42 | 2017/1/11 11:00 423.47 750.8 518.63 857.87 91.4 93.47 15 66.6 5911.53 2994.8 660.73 47.97
43 | 2017/1/11 12:00 415.4 725.1 509.53 861.7 90 91.03 15 66.97 5885.87 2976.7 651.2 46.53
44 | 2017/1/11 13:00 416.17 618.23 546.23 877.9 90.73 92.17 15 66.03 5872.7 2952.4 648.8 46.6
45 | 2017/1/11 14:00 422.57 736.87 504.27 873.13 88.73 90.3 15 66.2 5705.67 2903 638.2 45.03
46 | 2017/1/11 15:00 425.37 778.4 456.47 874.9 88.03 89.6 15 67.6 5630.93 2861.07 639.53 47.2
47 | 2017/1/11 16:00 428.83 796.13 441.13 888.53 84.8 86.07 14.8 69.4 5542.47 2794.27 623.13 45
48 | 2017/1/11 17:00 434 854.93 463.67 924.23 85.17 85.97 15 69.13 5690.4 2838.13 614.9 41.93
49 | 2017/1/11 18:00 428.97 761.9 486.7 853.77 79.9 80.97 14.03 70.23 5294.03 2650.27 577.87 40.9
50 | 2017/1/11 19:00 425 717.4 498.63 839.7 67.23 68.27 14.07 70.47 4534.3 2237.63 477.23 33.4
51 | 2017/1/11 20:00 423.4 679.73 516.4 840.43 61.63 62.57 14 71.4 4298.17 2082.07 439.43 30.43
52 | 2017/1/11 21:00 421.7 637.2 578.03 798.77 71.73 72.37 14 71.5 4917.13 2408.4 502.37 31.63
53 | 2017/1/11 22:00 417.23 510.23 605.23 767.47 71.43 72.07 14 71.9 4902.53 2408.73 508.63 32.9
54 | 2017/1/11 23:00 412.63 602.9 591.67 782.43 59.7 60.37 14 71.07 4188.07 2032.83 413.63 27.2
55 | 2017/1/12 0:00 409.87 510.97 614.8 767.57 53.47 53.7 14 71 3886.77 1845.97 373.97 23.37
56 | 2017/1/12 1:00 413.37 640.73 603.6 741.07 57.03 57.37 14 71.7 4043.73 1941.43 402.63 23.63
57 | 2017/1/12 2:00 414.23 521.2 589.23 742.67 48.57 49.13 14 72 3525.8 1674.1 338.03 20.97
58 | 2017/1/12 3:00 409.73 663.73 585.4 747.77 43.7 43.87 14 72.47 3160.4 1490.63 306.87 18.4
59 | 2017/1/12 4:00 414.37 522.7 610.5 729.67 45.27 45.67 14 74.67 3262.4 1560.93 317.23 20.37
60 | 2017/1/12 5:00 413.5 436.27 663.3 668.57 58.9 59.43 13.07 80.37 4127.4 2012.53 412.17 25.73
61 | 2017/1/12 6:00 409.67 427.87 669.13 681 50.83 51.23 13.7 80.17 3684.9 1746.8 355.47 20.77
62 | 2017/1/12 7:00 408.67 424.43 662.97 688.97 46.2 46.5 14 79.63 3398.37 1599.2 322.7 18.83
63 | 2017/1/12 8:00 416.47 431.43 636.53 704.33 50.4 50.63 14 80.67 3629.03 1716.2 355.97 22.73
64 | 2017/1/12 9:00 423.4 402.43 662.07 679.97 63.7 64.07 14 82.23 4509.9 2171.87 444.07 28.33
65 | 2017/1/12 10:00 421.3 444.63 648.93 732.03 52.1 52.53 14 79.7 3771.67 1761.73 353.73 22.87
66 | 2017/1/12 11:00 427.7 427.87 629.33 732.83 63.6 64.43 14.63 79.37 4485.13 2153.13 447.43 30.2
67 | 2017/1/12 12:00 427.43 429.6 629.1 735.6 73.1 74.03 14.63 79.73 5050.67 2449 511.23 35.77
68 | 2017/1/12 13:00 424.27 467.6 596.27 745.77 60.8 61.43 15 78.63 4310.97 2053.87 433.37 29.6
69 | 2017/1/12 14:00 415.87 416.03 637.03 733.9 33.07 33.2 14.93 79.73 2464.5 1115.6 222.7 13.07
70 | 2017/1/12 15:00 413.4 416.77 649.23 734.4 22.93 23.2 14.97 79.33 1898.17 827.1 153.1 8.13
71 | 2017/1/12 16:00 425 412.63 631.1 728.93 25.43 25.67 14.07 80.63 2033.1 893.07 172.4 11.53
72 | 2017/1/12 17:00 429.07 419.67 627.53 729.97 30.13 30.6 14 82.5 2344.9 1044.63 201.97 12.5
73 | 2017/1/12 18:00 427.67 419.33 619.67 738.63 25.33 25.8 14 83.53 2009.87 891.27 174.57 11.93
74 | 2017/1/12 19:00 434.97 421.53 618.07 720.63 24.17 24.8 14 85.87 1906.3 841.77 168.43 11.63
75 | 2017/1/12 20:00 436.1 442.5 587.03 758.37 56.5 56.8 14 87.33 4104.27 1940.5 394.63 24.23
76 | 2017/1/12 21:00 421.9 417.37 617.17 725.8 51.8 52.1 14 87.63 3855.5 1777.23 349.37 18.63
77 | 2017/1/12 22:00 412.2 433.73 606.63 722.5 32.67 32.9 13.87 87.93 2579.2 1166.1 222.17 11.87
78 | 2017/1/12 23:00 400 430.67 631.33 684.17 20.07 20.17 13 89.07 1725.63 733.37 134.3 7.37
79 | 2017/1/13 0:00 392.97 436.7 641.07 688.8 14.57 14.7 13 88.93 1320.1 540.7 97.17 5.13
80 | 2017/1/13 1:00 389.77 496.93 588.67 716.07 13.23 13.37 13 89.2 1247.9 513.2 91.2 4.37
81 | 2017/1/13 2:00 389 457.4 610.87 700.4 16.53 16.67 13 89.37 1427.17 613.03 112.63 5.27
82 | 2017/1/13 3:00 388.33 435.23 626.67 675.37 19.1 19.2 12.5 89.37 1613.53 697.27 128.27 5.37
83 | 2017/1/13 4:00 388.67 401.3 657.43 661.6 18.53 18.77 12.63 89.27 1618.17 691.47 125.67 6.37
84 | 2017/1/13 5:00 390.33 386.97 656.77 640.53 20.07 20.27 12.03 89.9 1700.1 739.27 138.93 8.4
85 | 2017/1/13 6:00 402 349.8 692.7 572.03 9.17 9.2 12.1 89.2 906.03 350.67 63.7 3.33
86 | 2017/1/13 7:00 416.8 282.7 733.03 520.9 2.1 2.17 12 88.87 356.3 102.6 18.1 1.37
87 | 2017/1/13 8:00 419.63 265.33 722.33 516.93 3.3 3.4 12 88.23 433.27 138.37 26.1 1.73
88 | 2017/1/13 9:00 425.53 279.27 714.77 514.97 3.7 3.7 12 87.53 466.9 154.67 29.43 1.53
89 | 2017/1/13 10:00 430.53 302.73 704.63 544.17 4.23 4.27 12.7 85.33 518.8 178.27 34.07 3.17
90 | 2017/1/13 11:00 424.97 356.2 665.83 600.9 10.13 10.17 13 83.37 969.87 382.03 70.63 4.4
91 | 2017/1/13 12:00 428.27 299.07 691.8 548.6 13.47 13.7 13 85.73 1188.5 487.47 90.07 5.2
92 | 2017/1/13 13:00 419.13 394.9 607.03 618.77 17.4 17.6 12.43 87.2 1478.4 633.37 121.17 7.87
93 | 2017/1/13 14:00 408.87 422.9 609.1 670.37 15.27 15.4 12 86.13 1364.2 572.37 107.67 6.17
94 | 2017/1/13 15:00 409.43 661.93 487.13 761.8 20.4 20.47 12 82.33 1744.17 750.57 138.27 7.3
95 | 2017/1/13 16:00 408.07 616.57 486.57 781.83 25.27 25.37 12 80.63 2096.27 921.97 171.53 8.63
96 | 2017/1/13 17:00 406.17 635.3 488.07 767.87 31.87 31.9 12 79.37 2512.23 1130.5 215.13 12.2
97 | 2017/1/13 18:00 408.17 668.83 467.9 769.83 35.6 35.83 12 77.57 2704.43 1247.23 247.5 16.17
98 | 2017/1/13 19:00 411.8 627.93 506.07 781.8 38.73 38.93 12 75.47 2918.53 1358.8 273.3 17.57
99 | 2017/1/13 20:00 413.27 462.57 566.83 728.8 39.77 40 12 75.57 2976.23 1390.6 279.8 17.37
100 | 2017/1/13 21:00 409.2 628.53 505.6 811.03 28.9 29.3 12 67.4 2208.73 1015.23 205.07 15.03
101 | 2017/1/13 22:00 402.5 583.9 508.17 802.03 26.27 26.67 12 63.73 2068.7 933.73 190.3 12.7
102 | 2017/1/13 23:00 400.03 503.67 541.17 789.83 29.37 29.97 12 63.67 2264.23 1034.37 208.4 14.73
103 | 2017/1/14 0:00 396.77 667.83 490.77 776.77 34.33 34.53 11.9 67.63 2582.3 1202.07 238.93 14.8
104 | 2017/1/14 1:00 396.87 503.7 553.93 725.13 40.27 40.53 11 73.1 2984.1 1395.4 275.3 17.33
105 | 2017/1/14 2:00 398.1 480.83 568.97 718.27 42.17 42.37 11 75.17 3177.57 1490.67 290.9 17.33
106 | 2017/1/14 3:00 396.1 497.3 563.43 739.5 47.3 47.37 11 76.73 3525.87 1671.73 329.53 20.97
107 | 2017/1/14 4:00 395.37 569.17 536.33 788.37 55.27 55.5 10.9 76.3 3983.7 1900.4 387.6 23.7
108 | 2017/1/14 5:00 393.4 645.6 486.77 844.23 67.87 68.23 10 76.67 4878.8 2372.57 481.63 31.33
109 | 2017/1/14 6:00 396.23 662.83 455.7 866.8 83.53 83.73 10 77.63 5816.97 2854.1 580.63 34.03
110 | 2017/1/14 7:00 401.03 727.5 434.97 910.4 84.73 84.93 10.17 75.37 5856.67 2871.17 594.33 36.2
111 | 2017/1/14 8:00 398.67 808.3 401.23 892.33 87.13 87.2 10.2 75.33 6035.6 2964.07 611.7 38.57
112 | 2017/1/14 9:00 399.8 800.3 428.83 905.57 77.57 77.83 11 70.5 5484.37 2681.77 545.73 34.67
113 | 2017/1/14 10:00 400.77 662.37 473.87 876.03 70.63 70.7 11 69.53 4997.8 2419.2 497.53 30.87
114 | 2017/1/14 11:00 395.67 1093.8 311 976.8 56.8 57.07 11.93 61.97 4042.87 1934.87 402.8 27.87
115 | 2017/1/14 12:00 395.67 1175.6 207.73 1031.37 48.07 48.67 12.57 54.3 3347 1605.13 342.73 25.83
116 | 2017/1/14 13:00 397.2 1145.73 152.27 1081.63 48.83 49.57 13.73 49.67 3434.43 1645.13 352.07 25.1
117 | 2017/1/14 14:00 397.77 1479.93 86.13 1133.27 48.73 49.7 14.27 45.7 3394.43 1632.9 352.27 25.97
118 | 2017/1/14 15:00 397.7 1520.53 83.37 1172.2 45.73 46.43 15.13 40.37 3241.9 1528.8 324.6 23.77
119 | 2017/1/14 16:00 393.83 1333.23 60.4 1185.67 45.3 46.27 15 38.03 3181.87 1532.13 327.03 23.5
120 | 2017/1/14 17:00 393.73 1624.03 53.93 1174.43 46.6 47.33 13.9 40.9 3284.03 1579 335.9 25.57
121 | 2017/1/14 18:00 395.47 1247.53 81.87 1168.4 55.8 56.47 13 45.5 3862.27 1891.87 407.73 30.17
122 | 2017/1/14 19:00 397.9 1383.6 55.93 1177.17 71.27 71.67 12.03 52.2 4751.67 2335.13 509.37 37.43
123 | 2017/1/14 20:00 395.6 1473.9 45.17 1218.27 68.53 68.9 12 52.4 4670.97 2295.73 494.53 33.9
124 | 2017/1/14 21:00 395.57 1363.27 45.3 1201.97 63.87 64.4 11.93 55.27 4451 2173.57 460.13 33.9
125 | 2017/1/14 22:00 393.2 1253.77 83 1156.77 58.93 59.27 11.33 58.33 4102.17 1999.57 431.7 28.8
126 | 2017/1/14 23:00 390 1287.7 75.5 1145.3 53.63 54.13 11 59.07 3785.43 1835.47 388.07 28.6
127 | 2017/1/15 0:00 386.67 1249.97 131.23 1119.97 43.47 44.27 11 58.6 3088.27 1485.9 320.27 23.93
128 | 2017/1/15 1:00 385 1155.03 164.93 1075.3 34.77 35.33 11 58.9 2507.93 1188.03 260.87 18.5
129 | 2017/1/15 2:00 385.33 1081.97 212.1 1056.77 38.57 38.8 11 60.27 2754.43 1320 283.93 20.87
130 | 2017/1/15 3:00 385.2 928.17 234.4 991.67 39.2 39.37 10.2 65.67 2786.87 1335.13 288.57 21.2
131 | 2017/1/15 4:00 385.37 793.67 353.73 935.47 39.17 39.57 9.63 70 2769.63 1334.97 288 20.63
132 | 2017/1/15 5:00 392.03 706.2 450.7 886.93 43.5 43.77 9.93 70.8 3071.5 1485.27 321.17 23.8
133 | 2017/1/15 6:00 390.6 713.07 419.73 923.37 47.67 48.1 10 68.83 3359.33 1630.53 345.63 24.73
134 | 2017/1/15 7:00 389.73 740.33 425.43 923.5 52.9 53.3 10 68 3730.63 1822.27 387.1 26.27
135 | 2017/1/15 8:00 391.53 697.23 441.83 928.27 60.93 61.37 10 66.87 4285.17 2098.77 440.83 29.13
136 | 2017/1/15 9:00 395.33 805.9 363.93 959.4 68 68.4 10.3 65.87 4680.3 2318.33 496.3 36.1
137 | 2017/1/15 10:00 395.6 787.93 390.2 964.1 71.07 71.37 11 64.2 4903.87 2430.43 514.17 36.97
138 | 2017/1/15 11:00 397.67 943.33 307.93 986.93 65.3 65.97 11.93 60.07 4525.6 2216.5 462.87 31
139 | 2017/1/15 12:00 402.3 1063.67 231.07 980.03 53.57 53.9 12.23 58.8 3727.37 1814.33 380.63 26.47
140 | 2017/1/15 13:00 411.3 924.2 316.4 982.33 52.1 52.5 13 57 3701.67 1775.5 367.93 24.63
141 | 2017/1/15 14:00 411.43 1043.53 309.9 974.93 49.1 49.6 13 56.97 3564.67 1707.13 351.3 23.13
142 | 2017/1/15 15:00 413.4 968 296.67 967.6 49.87 50.33 13 57.27 3521.87 1693.07 354.1 23.77
143 | 2017/1/15 16:00 407.13 968.1 341.03 970.3 41.73 42.27 13 55.9 3037.57 1432.93 295.67 21.33
144 | 2017/1/15 17:00 401.3 955.07 343.3 959.93 30.37 30.57 13 55.47 2302.57 1050.43 213.83 14.83
145 | 2017/1/15 18:00 406.27 775.07 403.53 928 33.33 33.87 12.1 56.77 2517.43 1170.1 241.3 18.67
146 | 2017/1/15 19:00 400.2 839.77 370.63 900.93 34.7 35.07 12 58.77 2602.77 1210.7 243.7 16.8
147 | 2017/1/15 20:00 401.9 778.13 384.5 870.77 40.43 40.8 12 61.17 2930.07 1388.67 285.93 19.97
148 |
--------------------------------------------------------------------------------
/sample/weather.txt:
--------------------------------------------------------------------------------
1 | Outlook Temperature Humidity Windy Play
2 | sunny hot high false no
3 | sunny hot high true no
4 | overcast hot high false yes
5 | rainy mild high false yes
6 | rainy cool normal false no
7 | overcast cool normal true yes
8 | sunny mild high false no
9 | sunny cool normal false yes
10 | rainy mild normal false yes
11 | sunny mild normal true yes
12 | overcast mild high true yes
13 | overcast hot normal false yes
14 | rainy mild high true no
--------------------------------------------------------------------------------