├── code
├── finetune
│ ├── core
│ │ ├── __init__.py
│ │ ├── datasets
│ │ │ ├── __init__.py
│ │ │ ├── Makefile
│ │ │ ├── utils.py
│ │ │ ├── megatron_dataset.py
│ │ │ ├── blended_megatron_dataset_config.py
│ │ │ ├── blended_dataset.py
│ │ │ ├── blended_megatron_dataset_builder.py
│ │ │ ├── gpt_dataset.py
│ │ │ ├── indexed_dataset.py
│ │ │ └── helpers.cpp
│ │ └── parse_mixture.py
│ ├── scripts
│ │ ├── count_tokens.sh
│ │ ├── preprocess_data.sh
│ │ └── run_finetune.sh
│ ├── tools
│ │ ├── count_mmap_token.py
│ │ └── codecmanipulator.py
│ ├── config
│ │ └── ds_config_zero2.json
│ └── requirements.txt
├── prompt_egs
│ ├── genre.txt
│ └── lyrics.txt
├── inference
│ ├── mm_tokenizer_v0.2_hf
│ │ └── tokenizer.model
│ ├── codecmanipulator.py
│ ├── mmtokenizer.py
│ └── infer.py
├── requirements.txt
├── evals
│ └── pitch_range
│ │ └── main.py
└── top_200_tags.json
├── example.mp3
├── fig
├── model.pdf
└── tokenpair.pdf
├── tokenpair.png
└── README.md
/code/finetune/core/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/code/finetune/core/datasets/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/example.mp3:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/WtxwNs/BACH/HEAD/example.mp3
--------------------------------------------------------------------------------
/fig/model.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/WtxwNs/BACH/HEAD/fig/model.pdf
--------------------------------------------------------------------------------
/tokenpair.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/WtxwNs/BACH/HEAD/tokenpair.png
--------------------------------------------------------------------------------
/fig/tokenpair.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/WtxwNs/BACH/HEAD/fig/tokenpair.pdf
--------------------------------------------------------------------------------
/code/prompt_egs/genre.txt:
--------------------------------------------------------------------------------
1 | inspiring female uplifting pop airy vocal electronic bright vocal vocal
--------------------------------------------------------------------------------
/code/inference/mm_tokenizer_v0.2_hf/tokenizer.model:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/WtxwNs/BACH/HEAD/code/inference/mm_tokenizer_v0.2_hf/tokenizer.model
--------------------------------------------------------------------------------
/code/requirements.txt:
--------------------------------------------------------------------------------
1 | torch
2 | omegaconf
3 | torchaudio
4 | einops
5 | numpy
6 | transformers
7 | sentencepiece
8 | tqdm
9 | tensorboard
10 | descript-audiotools>=0.7.2
11 | descript-audio-codec
12 | scipy
13 | accelerate>=0.26.0
14 |
--------------------------------------------------------------------------------
/code/finetune/core/datasets/Makefile:
--------------------------------------------------------------------------------
1 | CXXFLAGS += -O3 -Wall -shared -std=c++11 -fPIC -fdiagnostics-color
2 | CPPFLAGS += $(shell python3 -m pybind11 --includes)
3 | LIBNAME = helpers
4 | LIBEXT = $(shell python3-config --extension-suffix)
5 |
6 | default: $(LIBNAME)$(LIBEXT)
7 |
8 | %$(LIBEXT): %.cpp
9 | $(CXX) $(CXXFLAGS) $(CPPFLAGS) $< -o $@
10 |
--------------------------------------------------------------------------------
/code/finetune/scripts/count_tokens.sh:
--------------------------------------------------------------------------------
1 | echo "Please input parenet directory, will count all .bin files..."
2 | echo "Example: bash ./count_tokens.sh /workspace/dataset/music"
3 |
4 | PARENT_DIR=${1:-/workspace/dataset/music}
5 | LOG_DIR=./count_token_logs/
6 | mkdir -p $LOG_DIR
7 |
8 | # find all .bin files
9 | BINS=$(find $PARENT_DIR -name "*.bin" -type f)
10 |
11 | for bin in $BINS; do
12 | echo Checking mmap file: $bin
13 |
14 | mmap_path=$bin
15 |
16 | # mmap size in human readable format (e.g. 1.2G)
17 | mmap_size=$(du -h $mmap_path | awk '{print $1}')
18 | echo "Counting largest mmap file: $mmap_path, size: $mmap_size"
19 |
20 | # remove PARENT_DIR, replace / with _
21 | subdir=$(echo $mmap_path | sed "s|$PARENT_DIR/||g" | sed 's/\//_/g')
22 |
23 | cmd="nohup python tools/count_mmap_token.py --mmap_path $mmap_path > $LOG_DIR/count.$subdir.log 2>&1 &"
24 | echo $cmd
25 |
26 | eval $cmd
27 |
28 |
29 | echo "Finished!"
30 | done
31 |
32 |
33 |
--------------------------------------------------------------------------------
/code/finetune/tools/count_mmap_token.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__),
4 | os.path.pardir)))
5 | from core.datasets.indexed_dataset import MMapIndexedDataset
6 | import argparse
7 | from tqdm import tqdm
8 |
9 |
10 | def get_args():
11 | parser = argparse.ArgumentParser()
12 | parser.add_argument("--mmap_path", type=str, required=True, help="Path to the .bin mmap file")
13 | return parser.parse_args()
14 |
15 |
16 | args = get_args()
17 |
18 | slice_path = args.mmap_path
19 | if slice_path.endswith(".bin"):
20 | slice_path = slice_path[:-4]
21 |
22 | dataset = MMapIndexedDataset(slice_path)
23 |
24 |
25 | def count_ids(dataset):
26 | count = 0
27 | for doc_ids in tqdm(dataset):
28 | count += doc_ids.shape[0]
29 | return count
30 |
31 | print("Counting tokens in ", args.mmap_path)
32 | total_cnt = count_ids(dataset)
33 | print("Total number of tokens: ", total_cnt)
34 |
--------------------------------------------------------------------------------
/code/prompt_egs/lyrics.txt:
--------------------------------------------------------------------------------
1 | [verse]
2 | Staring at the sunset, colors paint the sky
3 | Thoughts of you keep swirling, can't deny
4 | I know I let you down, I made mistakes
5 | But I'm here to mend the heart I didn't break
6 |
7 | [chorus]
8 | Every road you take, I'll be one step behind
9 | Every dream you chase, I'm reaching for the light
10 | You can't fight this feeling now
11 | I won't back down
12 | You know you can't deny it now
13 | I won't back down
14 |
15 | [verse]
16 | They might say I'm foolish, chasing after you
17 | But they don't feel this love the way we do
18 | My heart beats only for you, can't you see?
19 | I won't let you slip away from me
20 |
21 | [chorus]
22 | Every road you take, I'll be one step behind
23 | Every dream you chase, I'm reaching for the light
24 | You can't fight this feeling now
25 | I won't back down
26 | You know you can't deny it now
27 | I won't back down
28 |
29 | [bridge]
30 | No, I won't back down, won't turn around
31 | Until you're back where you belong
32 | I'll cross the oceans wide, stand by your side
33 | Together we are strong
34 |
35 | [outro]
36 | Every road you take, I'll be one step behind
37 | Every dream you chase, love's the tie that binds
38 | You can't fight this feeling now
39 | I won't back down
--------------------------------------------------------------------------------
/code/finetune/config/ds_config_zero2.json:
--------------------------------------------------------------------------------
1 | {
2 | "fp16": {
3 | "enabled": "auto",
4 | "loss_scale": 0,
5 | "loss_scale_window": 1000,
6 | "initial_scale_power": 64,
7 | "hysteresis": 2,
8 | "min_loss_scale": 1
9 | },
10 | "bf16": {
11 | "enabled": "auto"
12 | },
13 | "optimizer": {
14 | "type": "AdamW",
15 | "params": {
16 | "lr": "auto",
17 | "betas": "auto",
18 | "eps": "auto",
19 | "weight_decay": "auto"
20 | }
21 | },
22 |
23 | "scheduler": {
24 | "type": "WarmupCosineLR",
25 | "params": {
26 | "total_num_steps": "auto",
27 | "warmup_min_ratio": 0.03,
28 | "warmup_num_steps": "auto",
29 | "cos_min_ratio": 0.1
30 | }
31 | },
32 |
33 | "zero_optimization": {
34 | "stage": 2,
35 | "offload_optimizer": {
36 | "device": "none",
37 | "pin_memory": true
38 | },
39 | "offload_param": {
40 | "device": "none",
41 | "pin_memory": true
42 | },
43 | "overlap_comm": false,
44 | "contiguous_gradients": true,
45 | "sub_group_size": 1e9,
46 | "reduce_bucket_size": "auto"
47 | },
48 |
49 | "gradient_accumulation_steps": "auto",
50 | "gradient_clipping": 1.0,
51 | "steps_per_print": 100,
52 | "train_batch_size": "auto",
53 | "train_micro_batch_size_per_gpu": "auto",
54 | "wall_clock_breakdown": false
55 | }
56 |
--------------------------------------------------------------------------------
/code/finetune/requirements.txt:
--------------------------------------------------------------------------------
1 | accelerate==1.6.0
2 | annotated-types==0.7.0
3 | blobfile==3.0.0
4 | certifi==2025.4.26
5 | charset-normalizer==3.4.2
6 | click==8.2.0
7 | deepspeed==0.16.7
8 | docker-pycreds==0.4.0
9 | einops==0.8.1
10 | filelock==3.13.1
11 | fsspec==2024.6.1
12 | gitdb==4.0.12
13 | GitPython==3.1.44
14 | hjson==3.1.0
15 | huggingface-hub==0.31.2
16 | idna==3.10
17 | Jinja2==3.1.4
18 | lxml==5.4.0
19 | MarkupSafe==2.1.5
20 | mpmath==1.3.0
21 | msgpack==1.1.0
22 | networkx==3.3
23 | ninja==1.11.1.4
24 | nltk==3.9.1
25 | numpy==2.1.2
26 | nvidia-cublas-cu12==12.1.3.1
27 | nvidia-cuda-cupti-cu12==12.1.105
28 | nvidia-cuda-nvrtc-cu12==12.1.105
29 | nvidia-cuda-runtime-cu12==12.1.105
30 | nvidia-cudnn-cu12==9.1.0.70
31 | nvidia-cufft-cu12==11.0.2.54
32 | nvidia-curand-cu12==10.3.2.106
33 | nvidia-cusolver-cu12==11.4.5.107
34 | nvidia-cusparse-cu12==12.1.0.106
35 | nvidia-ml-py==12.575.51
36 | nvidia-nccl-cu12==2.20.5
37 | nvidia-nvjitlink-cu12==12.1.105
38 | nvidia-nvtx-cu12==12.1.105
39 | packaging==25.0
40 | peft==0.15.2
41 | pillow==11.0.0
42 | platformdirs==4.3.8
43 | protobuf==6.30.2
44 | psutil==7.0.0
45 | py-cpuinfo==9.0.0
46 | pybind11==2.13.6
47 | pycryptodomex==3.22.0
48 | pydantic==2.11.4
49 | pydantic_core==2.33.2
50 | PyYAML==6.0.2
51 | regex==2024.11.6
52 | requests==2.32.3
53 | safetensors==0.5.3
54 | scipy==1.15.3
55 | sentencepiece==0.2.0
56 | sentry-sdk==2.28.0
57 | setproctitle==1.3.6
58 | six==1.17.0
59 | smmap==5.0.2
60 | sympy==1.13.3
61 | tiktoken==0.9.0
62 | tokenizers==0.21.1
63 | torch==2.4.0
64 | torchaudio==2.4.0
65 | torchvision==0.19.0
66 | tqdm==4.67.1
67 | transformers==4.50.0
68 | triton==3.0.0
69 | typing-inspection==0.4.0
70 | typing_extensions==4.12.2
71 | urllib3==2.4.0
72 | wandb==0.19.11
73 |
--------------------------------------------------------------------------------
/code/finetune/core/datasets/utils.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
2 |
3 | import logging
4 | from enum import Enum
5 | from typing import List
6 |
7 | import numpy
8 | import torch
9 |
10 | logger = logging.getLogger(__name__)
11 |
12 |
13 | class Split(Enum):
14 | train = 0
15 | valid = 1
16 | test = 2
17 |
18 |
19 | def compile_helpers():
20 | """Compile C++ helper functions at runtime. Make sure this is invoked on a single process.
21 | """
22 | import os
23 | import subprocess
24 |
25 | command = ["make", "-C", os.path.abspath(os.path.dirname(__file__))]
26 | if subprocess.run(command).returncode != 0:
27 | import sys
28 |
29 | log_single_rank(logger, logging.ERROR, "Failed to compile the C++ dataset helper functions")
30 | sys.exit(1)
31 |
32 |
33 | def log_single_rank(logger: logging.Logger, *args, rank=0, **kwargs):
34 | """If torch distributed is initialized, log only on rank
35 |
36 | Args:
37 | logger (logging.Logger): The logger to write the logs
38 |
39 | rank (int, optional): The rank to write on. Defaults to 0.
40 | """
41 | if torch.distributed.is_initialized():
42 | if torch.distributed.get_rank() == rank:
43 | logger.log(*args, **kwargs)
44 | else:
45 | logger.log(*args, **kwargs)
46 |
47 |
48 | def normalize(weights: List[float]) -> List[float]:
49 | """Do non-exponentiated normalization
50 |
51 | Args:
52 | weights (List[float]): The weights
53 |
54 | Returns:
55 | List[float]: The normalized weights
56 | """
57 | w = numpy.array(weights, dtype=numpy.float64)
58 | w_sum = numpy.sum(w)
59 | w = (w / w_sum).tolist()
60 | return w
61 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | 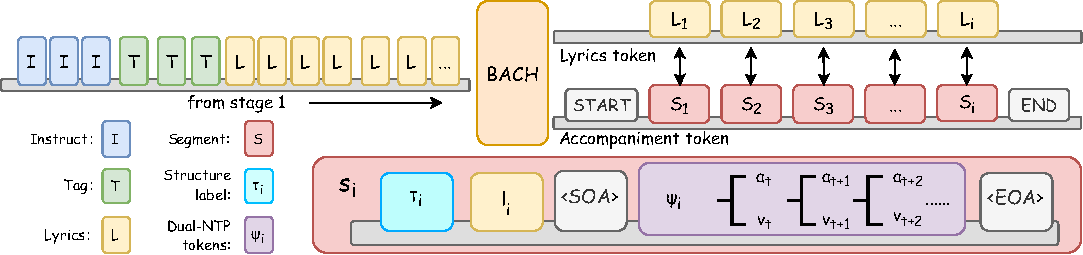 3 |
3 |
4 | Watch how BACH turns raw tokens into structured music—step by step.
5 |
6 |
7 | # BACH: Bar-level AI Composing Helper
8 |
9 |
10 |
11 |  12 |
13 |
14 |
12 |
13 |
14 |  15 |
16 |
15 |
16 |  17 |
17 |  18 |
18 |
19 |
20 | > *"Via Score to Performance: Efficient Human-Controllable Long Song Generation with Bar-Level Symbolic Notation"*
21 | > ICASSP 2026 Submission – **Pending Review**
22 |
23 | ---
24 |
25 | ## 🎼 One-sentence Summary
26 | BACH is the first **human-editable**, **bar-level** symbolic song generator:
27 | LLM writes lyrics → Transformer emits ABC score → off-the-shelf renderers give **minutes-long, Suno-level** music.
28 | **1 B params**, **minute-level** inference, **SOTA open-source**.
29 |
30 | ---
31 |
32 | ## 📦 What is inside this repo (preview release)
33 | | Path | Description |
34 | |------|-------------|
35 | | `README.md` | This file |
36 | | `code/` | inference code |
37 | | `example.mp3` | an example song |
38 | | `fig/` | Architecture figure |
39 |
40 | ---
41 |
42 | ## 🏗️ Model Architecture (one glance)
43 |
44 | User prompt
45 | Qwen3 — lyrics & style tags
46 | BACH-1B Decoder-Only Transformer
47 | ABC score (Dual-NTP + Chain-of-Score)
48 | ABC → MIDI → FluidSynth + VOCALOID
49 | Stereo mix
50 |
51 |
52 | | Component | Key idea |
53 | |-----------|----------|
54 | | **Dual-NTP** | Predict `{vocal_patch, accomp_patch}` jointly every step |
55 | | **Chain-of-Score** | Section tags `[START:Chorus] ... [END:Chorus]` for long coherence |
56 | | **Bar-stream patch** | 16-char non-overlapping patches per bar |
57 |
58 | ---
59 |
60 | ## 🧪 Quick start (CPU friendly)
61 | ```bash
62 | # 1. Clone
63 | git clone https://github.com/your-github/BACH.git
64 | cd BACH
65 |
66 | # 2. Install
67 | pip install -r requirements.txt # transformers>=4.41 mido abcpy fluidsynth
68 |
69 | # 3. Generate ABC
70 | python bach/generate.py \
71 | --prompt "A rainy-day lo-fi hip-hop song about missing the last train" \
72 | --out_abc demo/rainy_lofi.abc
73 |
74 | # 4. Render audio
75 | ```
76 |
77 | ## 🎧 Listen now
78 | example.mp3 is ready for you, it's a whole song. You can compare it with Suno🙂
79 |
80 | ## Full release upon related paper acceptance
81 | - Complete training set (ABC + lyrics + structure labels)
82 | - BACH-1B weights (Transformers format)
83 | - Training scripts (multiphase + multitask + ICL)
84 | - Complete Code
85 |
86 | ## 📎 Citation
87 | Paper is released on Arxiv,
88 | ```bibtex
89 | @misc{wang2025scoreperformanceefficienthumancontrollable,
90 | title={Via Score to Performance: Efficient Human-Controllable Long Song Generation with Bar-Level Symbolic Notation},
91 | author={Tongxi Wang and Yang Yu and Qing Wang and Junlang Qian},
92 | year={2025},
93 | eprint={2508.01394},
94 | archivePrefix={arXiv},
95 | primaryClass={cs.SD},
96 | url={https://arxiv.org/abs/2508.01394},
97 | }
98 |
--------------------------------------------------------------------------------
/code/evals/pitch_range/main.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import librosa
3 | import time
4 | import argparse
5 | import torch
6 | from extract_pitch_values_from_audio.src import RMVPE
7 | import os
8 | from pathlib import Path
9 | from tqdm import tqdm
10 |
11 | def process_audio(rmvpe, audio_path, output_path, device, hop_length, threshold):
12 | """Process an audio file in 10-second chunks and save the results."""
13 | # Load the audio file
14 | audio, sr = librosa.load(str(audio_path), sr=None)
15 | chunk_size = 10 * sr
16 | # pad to make the audio length to be multiple of hop_length
17 | audio = np.pad(audio, (0, chunk_size - len(audio) % chunk_size), mode='constant')
18 |
19 | # Calculate chunk size in samples (10 seconds * sample rate)
20 | total_chunks = int(np.round(len(audio) / chunk_size))
21 |
22 | # Initialize arrays to store results
23 | all_f0 = []
24 | total_infer_time = 0
25 |
26 | # Process each chunk
27 | for i in tqdm(range(total_chunks)):
28 | start_idx = i * chunk_size
29 | end_idx = min((i + 1) * chunk_size, len(audio))
30 | chunk = audio[start_idx:end_idx]
31 |
32 | # Process the chunk
33 | t = time.time()
34 | f0_chunk = rmvpe.infer_from_audio(chunk, sr, device=device, thred=threshold, use_viterbi=True)
35 | chunk_infer_time = time.time() - t
36 | total_infer_time += chunk_infer_time
37 |
38 | # Append results
39 | all_f0.extend(f0_chunk)
40 |
41 | # Create output directory if it doesn't exist
42 | output_path.parent.mkdir(parents=True, exist_ok=True)
43 |
44 | # remove all 0 in the f0
45 | all_f0 = np.array(all_f0)
46 | all_f0 = all_f0[all_f0 != 0]
47 |
48 | # convert all_f0 to a list
49 | all_f0 = all_f0.tolist()
50 |
51 | # Save the results
52 | with open(output_path, 'w') as f:
53 | for f0 in all_f0:
54 | f.write(f'{f0:.2f}\n')
55 |
56 | return total_infer_time, len(audio) / sr # Return total inference time and audio duration
57 |
58 | def main():
59 | input_dir = Path("/root/yue_pitch_evals/yue_vs_others_sep")
60 | output_dir = Path("/root/yue_pitch_evals/yue_vs_others_sep_pitch")
61 | device = "cuda"
62 |
63 | print(f'Using device: {device}')
64 | print('Loading model...')
65 | rmvpe = RMVPE("model.pt", hop_length=160)
66 |
67 | # Find all WAV files in input directory and subdirectories
68 | wav_files = list(input_dir.rglob('*.Vocals.mp3'))
69 | print(f'Found {len(wav_files)} WAV files to process')
70 |
71 | total_time = 0
72 | total_audio_duration = 0
73 |
74 | # Process each WAV file
75 | for wav_path in tqdm(wav_files, desc="Processing files"):
76 | # Calculate relative path to maintain directory structure
77 | rel_path = wav_path.relative_to(input_dir)
78 | # Create output path with .txt extension
79 | output_path = output_dir / str(rel_path).replace('.Vocals.mp3', '.txt')
80 |
81 | try:
82 | infer_time, audio_duration = process_audio(
83 | rmvpe, wav_path, output_path, device,
84 | 160, 0.03
85 | )
86 | total_time += infer_time
87 | total_audio_duration += audio_duration
88 |
89 | tqdm.write(f'Processed {wav_path.name}')
90 | tqdm.write(f'Time: {infer_time:.2f}s, RTF: {infer_time/audio_duration:.2f}')
91 |
92 | except Exception as e:
93 | tqdm.write(f'Error processing {wav_path}: {str(e)}')
94 | continue
95 |
96 | print('\nProcessing complete!')
97 | print(f'Total processing time: {total_time:.2f}s')
98 | print(f'Average RTF: {total_time/total_audio_duration:.2f}')
99 |
100 | if __name__ == '__main__':
101 | main()
--------------------------------------------------------------------------------
/code/finetune/scripts/preprocess_data.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | DATA_SETTING=$1
4 | MODE_TYPE=$2
5 | TOKENIZER_MODEL=$3
6 | AUDIO_PROMPT_MODES=($4)
7 | if [ -z "$4" ]; then
8 | AUDIO_PROMPT_MODES=('dual' 'inst' 'vocal' 'mixture')
9 | fi
10 |
11 | if [ -z "$DATA_SETTING" ] || [ -z "$MODE_TYPE" ]; then
12 | echo "Usage: $0 "
13 | echo " : e.g., dummy"
14 | echo " : cot or icl_cot"
15 | exit 1
16 | fi
17 |
18 | # Common settings based on DATA_SETTING
19 | if [ "$DATA_SETTING" == "dummy" ]; then
20 | DATA_ROOT=example
21 | NAME_PREFIX=dummy.msa.xcodec_16k
22 | CODEC_TYPE=xcodec
23 | INSTRUCTION="Generate music from the given lyrics segment by segment."
24 | ORDER=textfirst
25 | DROPOUT=0.0
26 | KEEP_SEQUENTIAL_SAMPLES=true
27 | QUANTIZER_BEGIN_IDX=0
28 | NUM_QUANTIZERS=1
29 | else
30 | echo "Invalid setting: $DATA_SETTING"
31 | exit 1
32 | fi
33 |
34 | JSONL_NAME=jsonl/$NAME_PREFIX.jsonl
35 |
36 | # Mode-specific settings and execution
37 | if [ "$MODE_TYPE" == "cot" ]; then
38 | echo "Running in 'cot' mode..."
39 | NAME_SUFFIX=stage_1_token_level_interleave_cot_xcodec
40 | MMAP_NAME=mmap/${NAME_PREFIX}_${NAME_SUFFIX}_$ORDER
41 |
42 | rm -f $DATA_ROOT/jsonl/${NAME_PREFIX}_*.jsonl # Use -f to avoid error if files don't exist
43 | mkdir -p $DATA_ROOT/$MMAP_NAME
44 |
45 | args="python core/preprocess_data_conditional_xcodec_segment.py \
46 | --input $DATA_ROOT/$JSONL_NAME \
47 | --output-prefix $DATA_ROOT/$MMAP_NAME \
48 | --tokenizer-model $TOKENIZER_MODEL \
49 | --tokenizer-type MMSentencePieceTokenizer \
50 | --codec-type $CODEC_TYPE \
51 | --workers 8 \
52 | --partitions 1 \
53 | --instruction \"$INSTRUCTION\" \
54 | --instruction-dropout-rate $DROPOUT \
55 | --order $ORDER \
56 | --append-eod \
57 | --quantizer-begin $QUANTIZER_BEGIN_IDX \
58 | --n-quantizer $NUM_QUANTIZERS \
59 | --use-token-level-interleave \
60 | --keep-sequential-samples \
61 | --cot
62 | "
63 |
64 | echo "$args"
65 | sleep 5
66 | eval $args
67 |
68 | rm -f $DATA_ROOT/jsonl/${NAME_PREFIX}_*.jsonl # Use -f
69 | rm -f $DATA_ROOT/${MMAP_NAME}_*_text_document.bin # Use -f
70 | rm -f $DATA_ROOT/${MMAP_NAME}_*_text_document.idx # Use -f
71 |
72 | elif [ "$MODE_TYPE" == "icl_cot" ]; then
73 | echo "Running in 'icl_cot' mode..."
74 | NAME_SUFFIX=stage_1_token_level_interleave_long_prompt_msa
75 | MMAP_NAME=mmap/${NAME_PREFIX}_${NAME_SUFFIX}_$ORDER # Define MMAP_NAME base for this mode
76 | PROMPT_LEN=30
77 |
78 | rm -f $DATA_ROOT/jsonl/${NAME_PREFIX}_*.jsonl # Use -f
79 | mkdir -p $DATA_ROOT/$MMAP_NAME # Ensure base MMAP dir exists
80 |
81 |
82 | for mode in "${AUDIO_PROMPT_MODES[@]}"; do
83 | echo "Processing mode: $mode"
84 | MODE_MMAP_NAME=${MMAP_NAME}_${mode} # Mode specific path
85 | mkdir -p $DATA_ROOT/$MODE_MMAP_NAME # Ensure mode-specific dir exists
86 |
87 | args="python core/preprocess_data_conditional_xcodec_segment.py \
88 | --input $DATA_ROOT/$JSONL_NAME \
89 | --output-prefix $DATA_ROOT/$MODE_MMAP_NAME \
90 | --tokenizer-model $TOKENIZER_MODEL \
91 | --tokenizer-type MMSentencePieceTokenizer \
92 | --codec-type $CODEC_TYPE \
93 | --workers 8 \
94 | --partitions 1 \
95 | --instruction \"$INSTRUCTION\" \
96 | --instruction-dropout-rate $DROPOUT \
97 | --order $ORDER \
98 | --append-eod \
99 | --quantizer-begin $QUANTIZER_BEGIN_IDX \
100 | --n-quantizer $NUM_QUANTIZERS \
101 | --cot \
102 | --use-token-level-interleave \
103 | --use-audio-icl \
104 | --audio-prompt-mode $mode \
105 | --audio-prompt-len $PROMPT_LEN \
106 | --keep-sequential-samples
107 | "
108 |
109 | echo "$args"
110 | sleep 5
111 | eval $args
112 |
113 | # Clean up mode-specific files
114 | rm -f $DATA_ROOT/jsonl/${NAME_PREFIX}_*.jsonl # Use -f
115 | rm -f $DATA_ROOT/${MODE_MMAP_NAME}_*_text_document.bin # Use -f
116 | rm -f $DATA_ROOT/${MODE_MMAP_NAME}_*_text_document.idx # Use -f
117 | done
118 |
119 | else
120 | echo "Invalid mode_type: $MODE_TYPE. Use 'cot' or 'icl_cot'."
121 | exit 1
122 | fi
123 |
124 | echo "Preprocessing finished for setting '$DATA_SETTING' and mode_type '$MODE_TYPE'."
--------------------------------------------------------------------------------
/code/finetune/core/datasets/megatron_dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
2 |
3 | import hashlib
4 | import json
5 | from abc import ABC, abstractmethod, abstractstaticmethod
6 | from collections import OrderedDict
7 | from typing import Dict, List
8 |
9 | import numpy
10 | import torch
11 |
12 | from core.datasets.blended_megatron_dataset_config import BlendedMegatronDatasetConfig
13 | from core.datasets.indexed_dataset import MMapIndexedDataset
14 | from core.datasets.utils import Split
15 |
16 |
17 | class MegatronDataset(ABC, torch.utils.data.Dataset):
18 | """The wrapper class from which dataset classes should inherit e.g. GPTDataset
19 |
20 | Args:
21 | indexed_dataset (MMapIndexedDataset): The MMapIndexedDataset around which to build the
22 | MegatronDataset
23 |
24 | indexed_indices (numpy.ndarray): The set of the documents indices to expose
25 |
26 | num_samples (int): The number of samples to draw from the indexed dataset
27 |
28 | index_split (Split): The indexed_indices Split
29 |
30 | config (BlendedMegatronDatasetConfig): The container for all config sourced parameters
31 | """
32 |
33 | def __init__(
34 | self,
35 | indexed_dataset: MMapIndexedDataset,
36 | indexed_indices: numpy.ndarray,
37 | num_samples: int,
38 | index_split: Split,
39 | config: BlendedMegatronDatasetConfig,
40 | ) -> None:
41 | assert indexed_indices.size > 0
42 | assert num_samples > 0
43 | assert self.is_multimodal() == indexed_dataset.multimodal
44 | assert self.is_split_by_sequence() != self.is_split_by_document()
45 |
46 | self.indexed_dataset = indexed_dataset
47 | self.indexed_indices = indexed_indices
48 | self.num_samples = num_samples
49 | self.index_split = index_split
50 | self.config = config
51 |
52 | self.unique_identifiers = OrderedDict()
53 | self.unique_identifiers["class"] = type(self).__name__
54 | self.unique_identifiers["path_prefix"] = self.indexed_dataset.path_prefix
55 | self.unique_identifiers["num_samples"] = self.num_samples
56 | self.unique_identifiers["index_split"] = self.index_split.name
57 | for attr in self._key_config_attributes():
58 | self.unique_identifiers[attr] = getattr(self.config, attr)
59 | self.unique_identifiers["add_bos"] = getattr(self.config, "add_bos", False)
60 |
61 | self.unique_description = json.dumps(self.unique_identifiers, indent=4)
62 | self.unique_description_hash = hashlib.md5(
63 | self.unique_description.encode("utf-8")
64 | ).hexdigest()
65 |
66 | self._finalize()
67 |
68 | @abstractmethod
69 | def _finalize(self) -> None:
70 | """Build the dataset and assert any subclass-specific conditions
71 | """
72 | pass
73 |
74 | @abstractmethod
75 | def __len__(self) -> int:
76 | """Return the length of the dataset
77 |
78 | Returns:
79 | int: See abstract implementation
80 | """
81 | pass
82 |
83 | @abstractmethod
84 | def __getitem__(self, idx: int) -> Dict[str, numpy.ndarray]:
85 | """Return from the dataset
86 |
87 | Args:
88 | idx (int): The index into the dataset
89 |
90 | Returns:
91 | Dict[str, numpy.ndarray]: See abstract implementation
92 | """
93 | pass
94 |
95 | @abstractstaticmethod
96 | def is_multimodal() -> bool:
97 | """Return True if the inheritor class and its internal MMapIndexedDataset are multimodal
98 |
99 | Returns:
100 | bool: See abstract implementation
101 | """
102 | pass
103 |
104 | @abstractstaticmethod
105 | def is_split_by_sequence() -> bool:
106 | """Return whether the dataset is split by sequence
107 |
108 | For example, the GPT train/valid/test split is document agnostic
109 |
110 | Returns:
111 | bool: See abstract implementation
112 | """
113 | pass
114 |
115 | @classmethod
116 | def is_split_by_document(cls) -> bool:
117 | """Return whether the dataset is split by document
118 |
119 | For example, the BERT train/valid/test split is document aware
120 |
121 | Returns:
122 | bool: The negation of cls.is_split_by_sequence
123 | """
124 | return not cls.is_split_by_sequence()
125 |
126 | @staticmethod
127 | def _key_config_attributes() -> List[str]:
128 | """Return all config attributes which contribute to uniquely identifying the dataset.
129 |
130 | These attributes will be used to build a uniquely identifying string and MD5 hash which
131 | will be used to cache/load the dataset from run to run.
132 |
133 | Returns:
134 | List[str]: The key config attributes
135 | """
136 | return ["split", "random_seed", "sequence_length"]
--------------------------------------------------------------------------------
/code/finetune/core/parse_mixture.py:
--------------------------------------------------------------------------------
1 |
2 | """
3 | # you can run the following command to make DB2TOKCNT readable
4 | autopep8 --in-place --aggressive --aggressive finetune/scripts/parse_mixture.py
5 |
6 | This script is used to parse the mixture of the pretraining data
7 | input: path to the yaml file
8 | output: a megatron style data mixture string
9 | """
10 |
11 | import os
12 | import sys
13 | import argparse
14 | import yaml
15 | import re
16 |
17 |
18 | EXAMPLE_LOG_STRING = """Zarr-based strategies will not be registered because of missing packages
19 | Counting tokens in ./mmap/example.bin
20 |
21 | 0%| | 0/597667 [00:00= 1:
117 | mixture_str += repeat_str(
118 | f"1 {mmap_path_without_ext} ", int(repeat_times))
119 | else:
120 | # weight is less than 1
121 | mixture_str += f"{repeat_times} {mmap_path_without_ext} "
122 | tokcnt = DB2TOKCNT[mmap_path]
123 | if isinstance(tokcnt, str):
124 | assert tokcnt.endswith("B"), f"invalid tokcnt: {tokcnt}"
125 | tokcnt = float(tokcnt.replace("B", "")) * 10**9
126 | total_tokcnt += tokcnt * repeat_times
127 | else:
128 | assert isinstance(tokcnt, int), f"invalid tokcnt: {tokcnt}"
129 | total_tokcnt += tokcnt * repeat_times
130 |
131 | # total iter count
132 | total_iter = total_tokcnt / (cfg["GLOBAL_BATCH_SIZE"] * cfg["SEQ_LEN"])
133 |
134 | # into string x.xxxB
135 | total_tokcnt /= 1e9
136 | total_tokcnt = f"{total_tokcnt:.3f}B"
137 |
138 | return mixture_str, total_tokcnt, total_iter
139 |
140 |
141 | def parse_mixture_from_cfg(cfg):
142 | keys = list(cfg.keys())
143 | # find keys ends with _ROUND
144 | rounds = [k for k in keys if k.endswith("_ROUND")]
145 |
146 | def repeat_str(s, n):
147 | return "".join([s for _ in range(n)])
148 |
149 | total_tokcnt = 0
150 | mixture_str = ""
151 | for r in rounds:
152 | repeat_times = float(r.replace("_ROUND", ""))
153 | mmap_paths = sorted(set(cfg[r]))
154 | for mmap_path in mmap_paths:
155 | mmap_path_without_ext = os.path.splitext(mmap_path)[0]
156 | tokcnt = DB2TOKCNT[mmap_path]
157 | if isinstance(tokcnt, str):
158 | assert tokcnt.endswith("B"), f"invalid tokcnt: {tokcnt}"
159 | tokcnt = float(tokcnt.replace("B", "")) * 10**9
160 | total_tokcnt += tokcnt * repeat_times
161 | else:
162 | assert isinstance(tokcnt, int), f"invalid tokcnt: {tokcnt}"
163 | total_tokcnt += tokcnt * repeat_times
164 |
165 | mixture_str += f"{int(tokcnt * repeat_times)} {mmap_path_without_ext} "
166 |
167 | # total iter count
168 | total_iter = total_tokcnt / (cfg["GLOBAL_BATCH_SIZE"] * cfg["SEQ_LEN"])
169 |
170 | # into string x.xxxB
171 | total_tokcnt /= 1e9
172 | total_tokcnt = f"{total_tokcnt:.3f}B"
173 |
174 | return mixture_str, total_tokcnt, total_iter
175 |
176 |
177 | if __name__ == "__main__":
178 |
179 | args = parse_args()
180 |
181 | cfg = load_yaml(args.cfg)
182 | print(f"[INFO] Loaded cfg from {args.cfg}")
183 |
184 | TOKEN_COUNT_LOG_DIR = cfg["TOKEN_COUNT_LOG_DIR"]
185 | print(f"[INFO] TOKEN_COUNT_LOG_DIR: {TOKEN_COUNT_LOG_DIR}")
186 |
187 | get_tokcnts_from_logs(TOKEN_COUNT_LOG_DIR,
188 | by_billions=args.by_billions)
189 | print(f"[INFO] DB2TOKCNT reloaded from the logs in {TOKEN_COUNT_LOG_DIR}\n")
190 |
191 | mixture_str, total_tokcnt, total_iter = parse_mixture_from_cfg(cfg)
192 | print(f"[CRITICAL] DATA_PATH **(copy to the training script)**:\n{mixture_str}\n")
193 | print(f"[CRITICAL] TRAIN_ITERS **(copy to the training script)**:\n{total_iter}\n")
194 | print(f"[INFO] Total token count: {total_tokcnt}")
195 |
--------------------------------------------------------------------------------
/code/finetune/core/datasets/blended_megatron_dataset_config.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2023, NVIDIA CORPORATION. All rights reserved.
2 |
3 | import functools
4 | import logging
5 | import re
6 | from dataclasses import dataclass, field
7 | from typing import Callable, List, Optional, Tuple
8 |
9 | import torch
10 |
11 | from core.datasets.utils import Split, log_single_rank, normalize
12 | # from parallel_state import get_virtual_pipeline_model_parallel_rank
13 |
14 | logger = logging.getLogger(__name__)
15 |
16 |
17 | @dataclass
18 | class BlendedMegatronDatasetConfig:
19 | """Configuration object for megatron-core blended and megatron datasets
20 |
21 | Attributes:
22 | is_built_on_rank (Callable): A callable which returns True if the dataset should be built
23 | on the current rank. It should be Megatron Core parallelism aware i.e. global rank, group
24 | rank, and virtual rank may inform its return value.
25 |
26 | random_seed (int): The seed for all RNG during dataset creation.
27 |
28 | sequence_length (int): The sequence length.
29 |
30 | blend (Optional[List[str]]): The blend string, consisting of either a single dataset or a
31 | flattened sequential sequence of weight-dataset pairs. For exampe, ["dataset-path1"] and
32 | ["50", "dataset-path1", "50", "dataset-path2"] are both valid. Not to be used with
33 | 'blend_per_split'. Defaults to None.
34 |
35 | blend_per_split (blend_per_split: Optional[List[Optional[List[str]]]]): A set of blend
36 | strings, as defined above, one for each split distribution. Not to be used with 'blend'.
37 | Defauls to None.
38 |
39 | split (Optional[str]): The split string, a comma separated weighting for the dataset splits
40 | when drawing samples from a single distribution. Not to be used with 'blend_per_split'.
41 | Defaults to None.
42 |
43 | split_vector: (Optional[List[float]]): The split string, parsed and normalized post-
44 | initialization. Not to be passed to the constructor.
45 |
46 | path_to_cache (str): Where all re-useable dataset indices are to be cached.
47 | """
48 |
49 | is_built_on_rank: Callable
50 |
51 | random_seed: int
52 |
53 | sequence_length: int
54 |
55 | blend: Optional[List[str]] = None
56 |
57 | blend_per_split: Optional[List[Optional[List[str]]]] = None
58 |
59 | split: Optional[str] = None
60 |
61 | split_vector: Optional[List[float]] = field(init=False, default=None)
62 |
63 | path_to_cache: str = None
64 |
65 | def __post_init__(self):
66 | """Python dataclass method that is used to modify attributes after initialization. See
67 | https://docs.python.org/3/library/dataclasses.html#post-init-processing for more details.
68 | """
69 | if torch.distributed.is_initialized():
70 | gb_rank = torch.distributed.get_rank()
71 | # vp_rank = get_virtual_pipeline_model_parallel_rank()
72 | vp_rank = 0
73 | if gb_rank == 0 and (vp_rank == 0 or vp_rank is None):
74 | assert (
75 | self.is_built_on_rank()
76 | ), "is_built_on_rank must return True when global rank = 0 and vp rank = 0"
77 |
78 | if self.blend_per_split is not None and any(self.blend_per_split):
79 | assert self.blend is None, "blend and blend_per_split are incompatible"
80 | assert len(self.blend_per_split) == len(
81 | Split
82 | ), f"blend_per_split must contain {len(Split)} blends"
83 | if self.split is not None:
84 | self.split = None
85 | log_single_rank(logger, logging.WARNING, f"Let split = {self.split}")
86 | else:
87 | assert self.blend is not None, "one of either blend or blend_per_split must be provided"
88 | assert self.split is not None, "both blend and split must be provided"
89 | self.split_vector = _parse_and_normalize_split(self.split)
90 | self.split_matrix = convert_split_vector_to_split_matrix(self.split_vector)
91 | log_single_rank(logger, logging.INFO, f"Let split_vector = {self.split_vector}")
92 |
93 |
94 | @dataclass
95 | class GPTDatasetConfig(BlendedMegatronDatasetConfig):
96 | """Configuration object for megatron-core blended and megatron GPT datasets
97 |
98 | Attributes:
99 | return_document_ids (bool): Whether to return the document ids when querying the dataset.
100 | """
101 |
102 | return_document_ids: bool = False
103 |
104 | add_bos: bool = False
105 |
106 | enable_shuffle: bool = False
107 |
108 |
109 | def _parse_and_normalize_split(split: str) -> List[float]:
110 | """Parse the dataset split ratios from a string
111 |
112 | Args:
113 | split (str): The train valid test split string e.g. "99,1,0"
114 |
115 | Returns:
116 | List[float]: The trian valid test split ratios e.g. [99.0, 1.0, 0.0]
117 | """
118 | split = list(map(float, re.findall(r"[.0-9]+", split)))
119 | split = split + [0.0 for _ in range(len(Split) - len(split))]
120 |
121 | assert len(split) == len(Split)
122 | assert all(map(lambda _: _ >= 0.0, split))
123 |
124 | split = normalize(split)
125 |
126 | return split
127 |
128 |
129 | def convert_split_vector_to_split_matrix(
130 | vector_a: List[float], vector_b: Optional[List[float]] = None
131 | ) -> List[Optional[Tuple[float, float]]]:
132 | """Build the split matrix from one or optionally two contributing split vectors.
133 |
134 | Ex. a standard conversion:
135 |
136 | [0.99, 0.01, 0.0] -> [(0, 0.99), (0.99, 1.0), None]
137 |
138 | Ex. a conversion for Retro when Retro pretraining uses a [0.99, 0.01, 0.0] split and Retro
139 | preprocessing used a [0.98, 0.02, 0.0] split:
140 |
141 | [0.99, 0.01, 0.0], [0.98, 0.02, 0.0] -> [(0, 0.98), (0.99, 1.0), None]
142 |
143 | Args:
144 | vector_a (List[float]): The primary split vector
145 |
146 | vector_b (Optional[List[float]]): An optional secondary split vector which constrains the
147 | primary split vector. Defaults to None.
148 |
149 | Returns:
150 | List[Tuple[float, float]]: The split matrix consisting of book-ends of each split in order
151 | """
152 | if vector_b is None:
153 | vector_b = vector_a
154 |
155 | # [.900, .090, .010] -> [0.00, .900, .990, 100]
156 | expansion_a = functools.reduce(lambda a, b: a + [a[len(a) - 1] + b], [[0], *vector_a])
157 | expansion_b = functools.reduce(lambda a, b: a + [a[len(a) - 1] + b], [[0], *vector_b])
158 |
159 | # [0.00, .900, .990, 100.0] -> [(0.00, .900), (.900, .990), (.990, 100)]
160 | bookends_a = list(zip(expansion_a[:-1], expansion_a[1:]))
161 | bookends_b = list(zip(expansion_b[:-1], expansion_b[1:]))
162 |
163 | # gather per-split overlap or None
164 | matrix = []
165 | for bookend_a, bookend_b in zip(bookends_a, bookends_b):
166 | if min(bookend_a[1], bookend_b[1]) <= max(bookend_a[0], bookend_b[0]):
167 | overlap = None
168 | else:
169 | overlap = (max(bookend_a[0], bookend_b[0]), min(bookend_a[1], bookend_b[1]))
170 | matrix.append(overlap)
171 |
172 | return matrix
173 |
--------------------------------------------------------------------------------
/code/finetune/scripts/run_finetune.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # ==============================
4 | # YuE Fine-tuning Script
5 | # ==============================
6 |
7 | # Help information
8 | print_help() {
9 | echo "========================================================"
10 | echo "YuE Fine-tuning Script Help"
11 | echo "========================================================"
12 | echo "Before running this script, please update the following variables:"
13 | echo ""
14 | echo "1. Data paths:"
15 | echo " DATA_PATH - Replace with actual weights and data paths"
16 | echo " DATA_CACHE_PATH - Replace with actual cache directory"
17 | echo ""
18 | echo "2. Model configuration:"
19 | echo " TOKENIZER_MODEL_PATH - Replace with actual tokenizer path"
20 | echo " MODEL_CACHE_DIR - Replace with actual cache directory"
21 | echo " OUTPUT_DIR - Replace with actual output directory"
22 | echo ""
23 | echo "3. If using WandB:"
24 | echo " WANDB_API_KEY - Replace with your actual API key"
25 | echo ""
26 | echo "Example usage:"
27 | echo " DATA_PATH=\"data1-weight /path/to/data1 data2-weight /path/to/data2\""
28 | echo " DATA_CACHE_PATH=\"/path/to/cache\""
29 | echo " TOKENIZER_MODEL_PATH=\"/path/to/tokenizer\""
30 | echo " MODEL_CACHE_DIR=\"/path/to/model/cache\""
31 | echo " OUTPUT_DIR=\"/path/to/output\""
32 | echo " WANDB_API_KEY=\"your-actual-wandb-key\""
33 | echo "========================================================"
34 | exit 1
35 | }
36 |
37 | # Check if help is requested
38 | if [[ "$1" == "--help" || "$1" == "-h" ]]; then
39 | print_help
40 | fi
41 |
42 | # Check for placeholder values
43 | check_placeholders() {
44 | local has_placeholders=false
45 |
46 | if [[ "$DATA_PATH" == *""* ]]; then
52 | echo "Error: Please set actual data cache path in DATA_CACHE_PATH variable."
53 | has_placeholders=true
54 | fi
55 |
56 | if [[ "$TOKENIZER_MODEL_PATH" == *""* ]]; then
57 | echo "Error: Please set actual tokenizer model path in TOKENIZER_MODEL_PATH variable."
58 | has_placeholders=true
59 | fi
60 |
61 | if [[ "$MODEL_CACHE_DIR" == *""* ]]; then
62 | echo "Error: Please set actual model cache directory in MODEL_CACHE_DIR variable."
63 | has_placeholders=true
64 | fi
65 |
66 | if [[ "$OUTPUT_DIR" == *""* ]]; then
67 | echo "Error: Please set actual output directory in OUTPUT_DIR variable."
68 | has_placeholders=true
69 | fi
70 |
71 | if [[ "$USE_WANDB" == "true" && "$WANDB_API_KEY" == *""* ]]; then
72 | echo "Error: Please set actual WandB API key in WANDB_API_KEY variable or disable WandB."
73 | has_placeholders=true
74 | fi
75 |
76 | if [[ "$has_placeholders" == "true" ]]; then
77 | echo ""
78 | echo "Please update the script with your actual paths and values."
79 | echo "Run './scripts/run_finetune.sh --help' for more information."
80 | exit 1
81 | fi
82 | }
83 |
84 | # Exit on error
85 | set -e
86 |
87 | # Check if we're in the finetune directory
88 | CURRENT_DIR=$(basename "$PWD")
89 | if [ "$CURRENT_DIR" != "finetune" ]; then
90 | echo "Error: This script must be run from the finetune/ directory"
91 | echo "Current directory: $PWD"
92 | echo "Please change to the finetune directory and try again"
93 | exit 1
94 | fi
95 |
96 | # ==============================
97 | # Configuration Parameters
98 | # ==============================
99 |
100 | # Hardware configuration
101 | NUM_GPUS=8
102 | MASTER_PORT=9999
103 | # Uncomment and modify if you need specific GPUs
104 | # export CUDA_VISIBLE_DEVICES=4,5,6,7
105 |
106 | # Training hyperparameters
107 | PER_DEVICE_TRAIN_BATCH_SIZE=1
108 | PER_DEVICE_EVAL_BATCH_SIZE=1
109 | GLOBAL_BATCH_SIZE=$((NUM_GPUS*PER_DEVICE_TRAIN_BATCH_SIZE))
110 | USE_BF16=true
111 | SEQ_LENGTH=8192
112 | TRAIN_ITERS=150
113 | NUM_TRAIN_EPOCHS=10
114 |
115 | # Data paths (replace with your actual paths)
116 | DATA_PATH=""
117 | DATA_CACHE_PATH=""
118 |
119 | # Set comma-separated list of proportions for training, validation, and test split
120 | DATA_SPLIT="900,50,50"
121 |
122 | # Model configuration
123 | TOKENIZER_MODEL_PATH=""
124 | MODEL_NAME="m-a-p/YuE-s1-7B-anneal-en-cot"
125 | MODEL_CACHE_DIR=""
126 | OUTPUT_DIR=""
127 | DEEPSPEED_CONFIG=config/ds_config_zero2.json
128 |
129 | # LoRA configuration
130 | LORA_R=64
131 | LORA_ALPHA=32
132 | LORA_DROPOUT=0.1
133 | LORA_TARGET_MODULES="q_proj k_proj v_proj o_proj"
134 | # Logging configuration
135 | LOGGING_STEPS=5
136 | SAVE_STEPS=5
137 | USE_WANDB=true
138 | WANDB_API_KEY=""
139 | RUN_NAME="YuE-ft-lora"
140 |
141 | # ==============================
142 | # Environment Setup
143 | # ==============================
144 |
145 | # Check for placeholder values
146 | check_placeholders
147 |
148 | # Export environment variables
149 | export WANDB_API_KEY=$WANDB_API_KEY
150 | export PYTHONPATH=$PWD:$PYTHONPATH
151 |
152 | # Print configuration
153 | echo "==============================================="
154 | echo "YuE Fine-tuning Configuration:"
155 | echo "==============================================="
156 | echo "Number of GPUs: $NUM_GPUS"
157 | echo "Global batch size: $GLOBAL_BATCH_SIZE"
158 | echo "Model: $MODEL_NAME"
159 | echo "Output directory: $OUTPUT_DIR"
160 | echo "Training epochs: $NUM_TRAIN_EPOCHS"
161 | echo "==============================================="
162 |
163 | # ==============================
164 | # Build and Execute Command
165 | # ==============================
166 |
167 | # Base command
168 | CMD="torchrun --nproc_per_node=$NUM_GPUS --master_port=$MASTER_PORT scripts/train_lora.py \
169 | --seq-length $SEQ_LENGTH \
170 | --data-path $DATA_PATH \
171 | --data-cache-path $DATA_CACHE_PATH \
172 | --split $DATA_SPLIT \
173 | --tokenizer-model $TOKENIZER_MODEL_PATH \
174 | --global-batch-size $GLOBAL_BATCH_SIZE \
175 | --per-device-train-batch-size $PER_DEVICE_TRAIN_BATCH_SIZE \
176 | --per-device-eval-batch-size $PER_DEVICE_EVAL_BATCH_SIZE \
177 | --train-iters $TRAIN_ITERS \
178 | --num-train-epochs $NUM_TRAIN_EPOCHS \
179 | --logging-steps $LOGGING_STEPS \
180 | --save-steps $SAVE_STEPS \
181 | --deepspeed $DEEPSPEED_CONFIG"
182 |
183 | # Add conditional arguments
184 | if [ "$USE_WANDB" = true ]; then
185 | CMD="$CMD --report-to wandb --run-name \"$RUN_NAME\""
186 | elif [ "$USE_WANDB" = false ]; then
187 | CMD="$CMD --report-to none"
188 | fi
189 |
190 | CMD="$CMD \
191 | --model-name-or-path \"$MODEL_NAME\" \
192 | --cache-dir $MODEL_CACHE_DIR \
193 | --output-dir $OUTPUT_DIR \
194 | --lora-r $LORA_R \
195 | --lora-alpha $LORA_ALPHA \
196 | --lora-dropout $LORA_DROPOUT \
197 | --lora-target-modules $LORA_TARGET_MODULES"
198 |
199 | if [ "$USE_BF16" = true ]; then
200 | CMD="$CMD --bf16"
201 | fi
202 |
203 | # Execute the command
204 | echo "Running command: $CMD"
205 | echo "==============================================="
206 | eval $CMD
207 |
208 | # Check exit status
209 | if [ $? -eq 0 ]; then
210 | echo "==============================================="
211 | echo "Fine-tuning completed successfully!"
212 | echo "Output saved to: $OUTPUT_DIR"
213 | echo "==============================================="
214 | else
215 | echo "==============================================="
216 | echo "Error: Fine-tuning failed with exit code $?"
217 | echo "==============================================="
218 | exit 1
219 | fi
--------------------------------------------------------------------------------
/code/finetune/core/datasets/blended_dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
2 |
3 | import hashlib
4 | import json
5 | import logging
6 | import os
7 | import time
8 | from collections import OrderedDict
9 | from typing import Dict, List, Tuple, Union
10 |
11 | import numpy
12 | import torch
13 |
14 | from core.datasets.blended_megatron_dataset_config import BlendedMegatronDatasetConfig
15 | from core.datasets.megatron_dataset import MegatronDataset
16 | from core.datasets.utils import log_single_rank, normalize
17 |
18 | logger = logging.getLogger(__name__)
19 |
20 | _VERBOSE = False
21 |
22 |
23 | class BlendedDataset(torch.utils.data.Dataset):
24 | """Conjugating class for a set of MegatronDataset instances
25 |
26 | Args:
27 | datasets (List[MegatronDataset]): The MegatronDataset instances to blend
28 |
29 | weights (List[float]): The weights which determines the dataset blend ratios
30 |
31 | size (int): The number of samples to draw from the blend
32 |
33 | config (BlendedMegatronDatasetConfig): The config object which informs dataset creation
34 |
35 | Raises:
36 | RuntimeError: When the dataset has fewer or more samples than 'size' post-initialization
37 | """
38 |
39 | def __init__(
40 | self,
41 | datasets: List[MegatronDataset],
42 | weights: List[float],
43 | size: int,
44 | config: BlendedMegatronDatasetConfig,
45 | ) -> None:
46 | assert len(datasets) < 32767
47 | assert len(datasets) == len(weights)
48 | assert numpy.isclose(sum(weights), 1.0)
49 | assert all(map(lambda _: type(_) == type(datasets[0]), datasets))
50 |
51 | # Alert user to unnecessary blending
52 | if len(datasets) == 1:
53 | log_single_rank(
54 | logger, logging.WARNING, f"Building a BlendedDataset for a single MegatronDataset"
55 | )
56 |
57 | # Redundant normalization for bitwise identical comparison with Megatron-LM
58 | weights = normalize(weights)
59 |
60 | self.datasets = datasets
61 | self.weights = weights
62 | self.size = size
63 | self.config = config
64 |
65 | unique_identifiers = OrderedDict()
66 | unique_identifiers["class"] = type(self).__name__
67 | unique_identifiers["datasets"] = [dataset.unique_identifiers for dataset in self.datasets]
68 | unique_identifiers["weights"] = self.weights
69 | unique_identifiers["size"] = self.size
70 |
71 | self.unique_description = json.dumps(unique_identifiers, indent=4)
72 | self.unique_description_hash = hashlib.md5(
73 | self.unique_description.encode("utf-8")
74 | ).hexdigest()
75 |
76 | self.dataset_index, self.dataset_sample_index = self._build_indices()
77 |
78 | # Check size
79 | _ = self[self.size - 1]
80 | try:
81 | _ = self[self.size]
82 | raise RuntimeError(f"{type(self).__name__} size is improperly bounded")
83 | except IndexError:
84 | log_single_rank(logger, logging.INFO, f"> {type(self).__name__} length: {len(self)}")
85 |
86 | def __len__(self) -> int:
87 | return self.size
88 |
89 | def __getitem__(self, idx: int) -> Dict[str, Union[int, numpy.ndarray]]:
90 | dataset_id = self.dataset_index[idx]
91 | dataset_sample_id = self.dataset_sample_index[idx]
92 | return {
93 | "dataset_id": dataset_id,
94 | **self.datasets[dataset_id][dataset_sample_id],
95 | }
96 |
97 | def _build_indices(self) -> Tuple[numpy.ndarray, numpy.ndarray]:
98 | """Build and optionally cache the dataset index and the dataset sample index
99 |
100 | The dataset index is a 1-D mapping which determines the dataset to query. The dataset
101 | sample index is a 1-D mapping which determines the sample to request from the queried
102 | dataset.
103 |
104 | Returns:
105 | Tuple[numpy.ndarray, numpy.ndarray]: The dataset index and the dataset sample index
106 | """
107 | path_to_cache = self.config.path_to_cache
108 |
109 | if path_to_cache:
110 | get_path_to = lambda suffix: os.path.join(
111 | path_to_cache, f"{self.unique_description_hash}-{type(self).__name__}-{suffix}"
112 | )
113 | path_to_description = get_path_to("description.txt")
114 | path_to_dataset_index = get_path_to("dataset_index.npy")
115 | path_to_dataset_sample_index = get_path_to("dataset_sample_index.npy")
116 | cache_hit = all(
117 | map(
118 | os.path.isfile,
119 | [path_to_description, path_to_dataset_index, path_to_dataset_sample_index],
120 | )
121 | )
122 | else:
123 | cache_hit = False
124 |
125 | if not path_to_cache or (not cache_hit and torch.distributed.get_rank() == 0):
126 | log_single_rank(
127 | logger, logging.INFO, f"Build and save the {type(self).__name__} indices",
128 | )
129 |
130 | # Build the dataset and dataset sample indexes
131 | log_single_rank(
132 | logger, logging.INFO, f"\tBuild and save the dataset and dataset sample indexes"
133 | )
134 | t_beg = time.time()
135 | from core.datasets import helpers
136 |
137 | dataset_index = numpy.zeros(self.size, dtype=numpy.int16)
138 | dataset_sample_index = numpy.zeros(self.size, dtype=numpy.int64)
139 | helpers.build_blending_indices(
140 | dataset_index,
141 | dataset_sample_index,
142 | self.weights,
143 | len(self.datasets),
144 | self.size,
145 | _VERBOSE,
146 | )
147 |
148 | if path_to_cache:
149 | os.makedirs(path_to_cache, exist_ok=True)
150 | # Write the description
151 | with open(path_to_description, "wt") as writer:
152 | writer.write(self.unique_description)
153 | # Save the indexes
154 | numpy.save(path_to_dataset_index, dataset_index, allow_pickle=True)
155 | numpy.save(path_to_dataset_sample_index, dataset_sample_index, allow_pickle=True)
156 | else:
157 | log_single_rank(
158 | logger,
159 | logging.WARNING,
160 | "Unable to save the indexes because path_to_cache is None",
161 | )
162 |
163 | t_end = time.time()
164 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
165 |
166 | return dataset_index, dataset_sample_index
167 |
168 | log_single_rank(logger, logging.INFO, f"Load the {type(self).__name__} indices")
169 |
170 | log_single_rank(
171 | logger, logging.INFO, f"\tLoad the dataset index from {path_to_dataset_index}"
172 | )
173 | t_beg = time.time()
174 | dataset_index = numpy.load(path_to_dataset_index, allow_pickle=True, mmap_mode='r')
175 | t_end = time.time()
176 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
177 |
178 | log_single_rank(
179 | logger,
180 | logging.INFO,
181 | f"\tLoad the dataset sample index from {path_to_dataset_sample_index}",
182 | )
183 | t_beg = time.time()
184 | dataset_sample_index = numpy.load(
185 | path_to_dataset_sample_index, allow_pickle=True, mmap_mode='r'
186 | )
187 | t_end = time.time()
188 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
189 |
190 | return dataset_index, dataset_sample_index
191 |
--------------------------------------------------------------------------------
/code/finetune/tools/codecmanipulator.py:
--------------------------------------------------------------------------------
1 | import json
2 | import numpy as np
3 | import einops
4 |
5 |
6 | class CodecManipulator(object):
7 | r"""
8 | **mm tokenizer v0.1**
9 | see codeclm/hf/mm_tokenizer_v0.1_hf/id2vocab.json
10 |
11 | text tokens:
12 | llama tokenizer 0~31999
13 |
14 | special tokens: "32000": "", "32001": "", "32002": "", "32003": "", "32004": "", "32005": "", "32006": "", "32007": "", "32008": "", "32009": "", "32010": "", "32011": "", "32012": "", "32013": "", "32014": "", "32015": "", "32016": "", "32017": "", "32018": "", "32019": "", "32020": "", "32021": ""
15 |
16 | mm tokens:
17 | dac_16k: 4 codebook, 1024 vocab, 32022 - 36117
18 | dac_44k: 9 codebook, 1024 vocab, 36118 - 45333
19 | xcodec: 12 codebook, 1024 vocab, 45334 - 57621
20 | semantic mert: 1024, 57622 - 58645
21 | semantic hubert: 512, 58646 - 59157
22 | visual: 64000, not included in v0.1
23 | semanticodec 100tps 16384: semantic=16384, 59158 - 75541, acoustic=8192, 75542 - 83733
24 | """
25 | def __init__(self, codec_type, quantizer_begin=None, n_quantizer=None, teacher_forcing=False, data_feature="codec"):
26 | self.codec_type = codec_type
27 | self.mm_v0_2_cfg = {
28 | "dac16k": {"codebook_size": 1024, "num_codebooks": 4, "global_offset": 32022, "sep": [""], "fps": 50},
29 | "dac44k": {"codebook_size": 1024, "num_codebooks": 9, "global_offset": 36118, "sep": [""]},
30 | "xcodec": {"codebook_size": 1024, "num_codebooks": 12, "global_offset": 45334, "sep": [""], "fps": 50},
31 | "mert": {"codebook_size": 1024, "global_offset": 57622, "sep": [""]},
32 | "hubert": {"codebook_size": 512, "global_offset": 58646, "sep": [""]},
33 | "semantic/s": {"codebook_size": 16384, "num_codebooks": 1, "global_offset": 59158, "sep": ["", ""]},
34 | "semantic/a": {"codebook_size": 8192, "num_codebooks": 1, "global_offset": 75542, "sep": ["", ""]},
35 | "semanticodec": {"codebook_size": [16384, 8192], "num_codebooks": 2, "global_offset": 59158, "sep": [""], "fps": 50},
36 | "special_tokens": {
37 | '': 32000, '': 32001, '': 32002, '': 32003, '': 32004, '': 32005, '': 32006, '': 32007, '': 32008, '': 32009, '': 32010, '': 32011, '': 32012, '': 32013, '': 32014, '': 32015, '': 32016, '': 32017, '': 32018, '': 32019, '': 32020, '': 32021
38 | },
39 | "metadata": {
40 | "len": 83734,
41 | "text_range": [0, 31999],
42 | "special_range": [32000, 32021],
43 | "mm_range": [32022, 83733]
44 | },
45 | "codec_range": {
46 | "dac16k": [32022, 36117],
47 | "dac44k": [36118, 45333],
48 | "xcodec": [45334, 57621],
49 | # "hifi16k": [53526, 57621],
50 | "mert": [57622, 58645],
51 | "hubert": [58646, 59157],
52 | "semantic/s": [59158, 75541],
53 | "semantic/a": [75542, 83733],
54 | "semanticodec": [59158, 83733]
55 | }
56 | }
57 | self.sep = self.mm_v0_2_cfg[self.codec_type]["sep"]
58 | self.sep_ids = [self.mm_v0_2_cfg["special_tokens"][s] for s in self.sep]
59 | self.codebook_size = self.mm_v0_2_cfg[self.codec_type]["codebook_size"]
60 | self.num_codebooks = self.mm_v0_2_cfg[self.codec_type]["num_codebooks"]
61 | self.global_offset = self.mm_v0_2_cfg[self.codec_type]["global_offset"]
62 | self.fps = self.mm_v0_2_cfg[self.codec_type]["fps"] if "fps" in self.mm_v0_2_cfg[self.codec_type] else None
63 |
64 | self.quantizer_begin = quantizer_begin if quantizer_begin is not None else 0
65 | self.n_quantizer = n_quantizer if n_quantizer is not None else self.num_codebooks
66 | self.teacher_forcing = teacher_forcing
67 | self.data_feature = data_feature
68 |
69 |
70 | def offset_tok_ids(self, x, global_offset=0, codebook_size=2048, num_codebooks=4):
71 | """
72 | x: (K, T)
73 | """
74 | if isinstance(codebook_size, int):
75 | assert x.max() < codebook_size, f"max(x)={x.max()}, codebook_size={codebook_size}"
76 | elif isinstance(codebook_size, list):
77 | for i, cs in enumerate(codebook_size):
78 | assert x[i].max() < cs, f"max(x)={x[i].max()}, codebook_size={cs}, layer_id={i}"
79 | else:
80 | raise ValueError(f"codebook_size={codebook_size}")
81 | assert x.min() >= 0, f"min(x)={x.min()}"
82 | assert x.shape[0] == num_codebooks or x.shape[0] == self.n_quantizer, \
83 | f"x.shape[0]={x.shape[0]}, num_codebooks={num_codebooks}, n_quantizer={self.n_quantizer}"
84 |
85 | _x = x.copy()
86 | _x = _x.astype(np.uint32)
87 | cum_offset = 0
88 | quantizer_begin = self.quantizer_begin
89 | quantizer_end = quantizer_begin+self.n_quantizer
90 | for k in range(self.quantizer_begin, quantizer_end): # k: quantizer_begin to quantizer_end - 1
91 | if isinstance(codebook_size, int):
92 | _x[k] += global_offset + k * codebook_size
93 | elif isinstance(codebook_size, list):
94 | _x[k] += global_offset + cum_offset
95 | cum_offset += codebook_size[k]
96 | else:
97 | raise ValueError(f"codebook_size={codebook_size}")
98 | return _x[quantizer_begin:quantizer_end]
99 |
100 | def unoffset_tok_ids(self, x, global_offset=0, codebook_size=2048, num_codebooks=4):
101 | """
102 | x: (K, T)
103 | """
104 | if isinstance(codebook_size, int):
105 | assert x.max() < global_offset + codebook_size * num_codebooks, f"max(x)={x.max()}, codebook_size={codebook_size}"
106 | elif isinstance(codebook_size, list):
107 | assert x.max() < global_offset + sum(codebook_size), f"max(x)={x.max()}, codebook_size={codebook_size}"
108 | assert x.min() >= global_offset, f"min(x)={x.min()}, global_offset={global_offset}"
109 | assert x.shape[0] == num_codebooks or x.shape[0] == self.n_quantizer, \
110 | f"x.shape[0]={x.shape[0]}, num_codebooks={num_codebooks}, n_quantizer={self.n_quantizer}"
111 |
112 | _x = x.copy()
113 | _x = _x.astype(np.uint32)
114 | cum_offset = 0
115 | quantizer_begin = self.quantizer_begin
116 | quantizer_end = quantizer_begin+self.n_quantizer
117 | for k in range(quantizer_begin, quantizer_end):
118 | if isinstance(codebook_size, int):
119 | _x[k-quantizer_begin] -= global_offset + k * codebook_size
120 | elif isinstance(codebook_size, list):
121 | _x[k-quantizer_begin] -= global_offset + cum_offset
122 | cum_offset += codebook_size[k]
123 | else:
124 | raise ValueError(f"codebook_size={codebook_size}")
125 | return _x
126 |
127 | def flatten(self, x):
128 | if len(x.shape) > 2:
129 | x = x.squeeze()
130 | assert x.shape[0] == self.num_codebooks or x.shape[0] == self.n_quantizer, \
131 | f"x.shape[0]={x.shape[0]}, num_codebooks={self.num_codebooks}, n_quantizer={self.n_quantizer}"
132 | return einops.rearrange(x, 'K T -> (T K)')
133 |
134 | def unflatten(self, x, n_quantizer=None):
135 | if x.ndim > 1 and x.shape[0] == 1:
136 | x = x.squeeze(0)
137 | assert len(x.shape) == 1
138 | assert x.shape[0] % self.num_codebooks == 0 or x.shape[0] % self.n_quantizer == 0, \
139 | f"x.shape[0]={x.shape[0]}, num_codebooks={self.num_codebooks}, n_quantizer={self.n_quantizer}"
140 | if n_quantizer!=self.num_codebooks:
141 | return einops.rearrange(x, '(T K) -> K T', K=n_quantizer)
142 | return einops.rearrange(x, '(T K) -> K T', K=self.num_codebooks)
143 |
144 | # def check_codec_type_from_path(self, path):
145 | # if self.codec_type == "hifi16k":
146 | # assert "academicodec_hifi_16k_320d_large_uni" in path
147 |
148 | def get_codec_type_from_range(self, ids):
149 | ids_range = [ids.min(), ids.max()]
150 | codec_range = self.mm_v0_2_cfg["codec_range"]
151 | for codec_type, r in codec_range.items():
152 | if ids_range[0] >= r[0] and ids_range[1] <= r[1]:
153 | return codec_type
154 | raise ValueError(f"ids_range={ids_range}, codec_range={codec_range}")
155 |
156 | def npy2ids(self, npy):
157 | if isinstance(npy, str):
158 | data = np.load(npy)
159 | elif isinstance(npy, np.ndarray):
160 | data = npy
161 | else:
162 | raise ValueError(f"not supported type: {type(npy)}")
163 |
164 | assert len(data.shape)==2, f'data shape: {data.shape} is not (n_codebook, seq_len)'
165 | data = self.offset_tok_ids(
166 | data,
167 | global_offset=self.global_offset,
168 | codebook_size=self.codebook_size,
169 | num_codebooks=self.num_codebooks,
170 | )
171 | data = self.flatten(data)
172 | codec_range = self.get_codec_type_from_range(data)
173 | assert codec_range == self.codec_type, f"get_codec_type_from_range(data)={codec_range}, self.codec_type={self.codec_type}"
174 | data = data.tolist()
175 | return data
176 |
177 | def ids2npy(self, token_ids):
178 | # make sure token_ids starts with codebook 0
179 | if isinstance(self.codebook_size, int):
180 | codebook_0_range = (self.global_offset + self.quantizer_begin*self.codebook_size, self.global_offset + (self.quantizer_begin+1)*self.codebook_size)
181 | elif isinstance(self.codebook_size, list):
182 | codebook_0_range = (self.global_offset, self.global_offset + self.codebook_size[0])
183 | assert token_ids[0] >= codebook_0_range[0] \
184 | and token_ids[0] < codebook_0_range[1], f"token_ids[0]={token_ids[self.quantizer_begin]}, codebook_0_range={codebook_0_range}"
185 | data = np.array(token_ids)
186 | data = self.unflatten(data, n_quantizer=self.n_quantizer)
187 | data = self.unoffset_tok_ids(
188 | data,
189 | global_offset=self.global_offset,
190 | codebook_size=self.codebook_size,
191 | num_codebooks=self.num_codebooks,
192 | )
193 | return data
194 |
195 | def npy_to_json_str(self, npy_path):
196 | data = self.npy2ids(npy_path)
197 | return json.dumps({"text": data, "src": npy_path, "codec": self.codec_type})
198 |
199 | def sep(self):
200 | return ''.join(self.sep)
201 |
202 | def sep_ids(self):
203 | return self.sep_ids
204 |
--------------------------------------------------------------------------------
/code/inference/codecmanipulator.py:
--------------------------------------------------------------------------------
1 | import json
2 | import numpy as np
3 | import einops
4 |
5 |
6 | class CodecManipulator(object):
7 | r"""
8 | **mm tokenizer v0.1**
9 | see codeclm/hf/mm_tokenizer_v0.1_hf/id2vocab.json
10 |
11 | text tokens:
12 | llama tokenizer 0~31999
13 |
14 | special tokens: "32000": "", "32001": "", "32002": "", "32003": "", "32004": "", "32005": "", "32006": "", "32007": "", "32008": "", "32009": "", "32010": "", "32011": "", "32012": "", "32013": "", "32014": "", "32015": "", "32016": "", "32017": "", "32018": "", "32019": "", "32020": "", "32021": ""
15 |
16 | mm tokens:
17 | dac_16k: 4 codebook, 1024 vocab, 32022 - 36117
18 | dac_44k: 9 codebook, 1024 vocab, 36118 - 45333
19 | xcodec: 12 codebook, 1024 vocab, 45334 - 57621
20 | semantic mert: 1024, 57622 - 58645
21 | semantic hubert: 512, 58646 - 59157
22 | visual: 64000, not included in v0.1
23 | semanticodec 100tps 16384: semantic=16384, 59158 - 75541, acoustic=8192, 75542 - 83733
24 | """
25 | def __init__(self, codec_type, quantizer_begin=None, n_quantizer=None, teacher_forcing=False, data_feature="codec"):
26 | self.codec_type = codec_type
27 | self.mm_v0_2_cfg = {
28 | "dac16k": {"codebook_size": 1024, "num_codebooks": 4, "global_offset": 32022, "sep": [""], "fps": 50},
29 | "dac44k": {"codebook_size": 1024, "num_codebooks": 9, "global_offset": 36118, "sep": [""]},
30 | "xcodec": {"codebook_size": 1024, "num_codebooks": 12, "global_offset": 45334, "sep": [""], "fps": 50},
31 | "mert": {"codebook_size": 1024, "global_offset": 57622, "sep": [""]},
32 | "hubert": {"codebook_size": 512, "global_offset": 58646, "sep": [""]},
33 | "semantic/s": {"codebook_size": 16384, "num_codebooks": 1, "global_offset": 59158, "sep": ["", ""]},
34 | "semantic/a": {"codebook_size": 8192, "num_codebooks": 1, "global_offset": 75542, "sep": ["", ""]},
35 | "semanticodec": {"codebook_size": [16384, 8192], "num_codebooks": 2, "global_offset": 59158, "sep": [""], "fps": 50},
36 | "special_tokens": {
37 | '': 32000, '': 32001, '': 32002, '': 32003, '': 32004, '': 32005, '': 32006, '': 32007, '': 32008, '': 32009, '': 32010, '': 32011, '': 32012, '': 32013, '': 32014, '': 32015, '': 32016, '': 32017, '': 32018, '': 32019, '': 32020, '': 32021
38 | },
39 | "metadata": {
40 | "len": 83734,
41 | "text_range": [0, 31999],
42 | "special_range": [32000, 32021],
43 | "mm_range": [32022, 83733]
44 | },
45 | "codec_range": {
46 | "dac16k": [32022, 36117],
47 | "dac44k": [36118, 45333],
48 | "xcodec": [45334, 57621],
49 | # "hifi16k": [53526, 57621],
50 | "mert": [57622, 58645],
51 | "hubert": [58646, 59157],
52 | "semantic/s": [59158, 75541],
53 | "semantic/a": [75542, 83733],
54 | "semanticodec": [59158, 83733]
55 | }
56 | }
57 | self.sep = self.mm_v0_2_cfg[self.codec_type]["sep"]
58 | self.sep_ids = [self.mm_v0_2_cfg["special_tokens"][s] for s in self.sep]
59 | self.codebook_size = self.mm_v0_2_cfg[self.codec_type]["codebook_size"]
60 | self.num_codebooks = self.mm_v0_2_cfg[self.codec_type]["num_codebooks"]
61 | self.global_offset = self.mm_v0_2_cfg[self.codec_type]["global_offset"]
62 | self.fps = self.mm_v0_2_cfg[self.codec_type]["fps"] if "fps" in self.mm_v0_2_cfg[self.codec_type] else None
63 |
64 | self.quantizer_begin = quantizer_begin if quantizer_begin is not None else 0
65 | self.n_quantizer = n_quantizer if n_quantizer is not None else self.num_codebooks
66 | self.teacher_forcing = teacher_forcing
67 | self.data_feature = data_feature
68 |
69 |
70 | def offset_tok_ids(self, x, global_offset=0, codebook_size=2048, num_codebooks=4):
71 | """
72 | x: (K, T)
73 | """
74 | if isinstance(codebook_size, int):
75 | assert x.max() < codebook_size, f"max(x)={x.max()}, codebook_size={codebook_size}"
76 | elif isinstance(codebook_size, list):
77 | for i, cs in enumerate(codebook_size):
78 | assert x[i].max() < cs, f"max(x)={x[i].max()}, codebook_size={cs}, layer_id={i}"
79 | else:
80 | raise ValueError(f"codebook_size={codebook_size}")
81 | assert x.min() >= 0, f"min(x)={x.min()}"
82 | assert x.shape[0] == num_codebooks or x.shape[0] == self.n_quantizer, \
83 | f"x.shape[0]={x.shape[0]}, num_codebooks={num_codebooks}, n_quantizer={self.n_quantizer}"
84 |
85 | _x = x.copy()
86 | _x = _x.astype(np.uint32)
87 | cum_offset = 0
88 | quantizer_begin = self.quantizer_begin
89 | quantizer_end = quantizer_begin+self.n_quantizer
90 | for k in range(self.quantizer_begin, quantizer_end): # k: quantizer_begin to quantizer_end - 1
91 | if isinstance(codebook_size, int):
92 | _x[k] += global_offset + k * codebook_size
93 | elif isinstance(codebook_size, list):
94 | _x[k] += global_offset + cum_offset
95 | cum_offset += codebook_size[k]
96 | else:
97 | raise ValueError(f"codebook_size={codebook_size}")
98 | return _x[quantizer_begin:quantizer_end]
99 |
100 | def unoffset_tok_ids(self, x, global_offset=0, codebook_size=2048, num_codebooks=4):
101 | """
102 | x: (K, T)
103 | """
104 | if isinstance(codebook_size, int):
105 | assert x.max() < global_offset + codebook_size * num_codebooks, f"max(x)={x.max()}, codebook_size={codebook_size}"
106 | elif isinstance(codebook_size, list):
107 | assert x.max() < global_offset + sum(codebook_size), f"max(x)={x.max()}, codebook_size={codebook_size}"
108 | assert x.min() >= global_offset, f"min(x)={x.min()}, global_offset={global_offset}"
109 | assert x.shape[0] == num_codebooks or x.shape[0] == self.n_quantizer, \
110 | f"x.shape[0]={x.shape[0]}, num_codebooks={num_codebooks}, n_quantizer={self.n_quantizer}"
111 |
112 | _x = x.copy()
113 | _x = _x.astype(np.uint32)
114 | cum_offset = 0
115 | quantizer_begin = self.quantizer_begin
116 | quantizer_end = quantizer_begin+self.n_quantizer
117 | for k in range(quantizer_begin, quantizer_end):
118 | if isinstance(codebook_size, int):
119 | _x[k-quantizer_begin] -= global_offset + k * codebook_size
120 | elif isinstance(codebook_size, list):
121 | _x[k-quantizer_begin] -= global_offset + cum_offset
122 | cum_offset += codebook_size[k]
123 | else:
124 | raise ValueError(f"codebook_size={codebook_size}")
125 | return _x
126 |
127 | def flatten(self, x):
128 | if len(x.shape) > 2:
129 | x = x.squeeze()
130 | assert x.shape[0] == self.num_codebooks or x.shape[0] == self.n_quantizer, \
131 | f"x.shape[0]={x.shape[0]}, num_codebooks={self.num_codebooks}, n_quantizer={self.n_quantizer}"
132 | return einops.rearrange(x, 'K T -> (T K)')
133 |
134 | def unflatten(self, x, n_quantizer=None):
135 | if x.ndim > 1 and x.shape[0] == 1:
136 | x = x.squeeze(0)
137 | assert len(x.shape) == 1
138 | assert x.shape[0] % self.num_codebooks == 0 or x.shape[0] % self.n_quantizer == 0, \
139 | f"x.shape[0]={x.shape[0]}, num_codebooks={self.num_codebooks}, n_quantizer={self.n_quantizer}"
140 | if n_quantizer!=self.num_codebooks:
141 | return einops.rearrange(x, '(T K) -> K T', K=n_quantizer)
142 | return einops.rearrange(x, '(T K) -> K T', K=self.num_codebooks)
143 |
144 | # def check_codec_type_from_path(self, path):
145 | # if self.codec_type == "hifi16k":
146 | # assert "academicodec_hifi_16k_320d_large_uni" in path
147 |
148 | def get_codec_type_from_range(self, ids):
149 | ids_range = [ids.min(), ids.max()]
150 | codec_range = self.mm_v0_2_cfg["codec_range"]
151 | for codec_type, r in codec_range.items():
152 | if ids_range[0] >= r[0] and ids_range[1] <= r[1]:
153 | return codec_type
154 | raise ValueError(f"ids_range={ids_range}, codec_range={codec_range}")
155 |
156 | def npy2ids(self, npy):
157 | if isinstance(npy, str):
158 | data = np.load(npy)
159 | elif isinstance(npy, np.ndarray):
160 | data = npy
161 | else:
162 | raise ValueError(f"not supported type: {type(npy)}")
163 | # data = data.squeeze()
164 |
165 | assert len(data.shape)==2, f'data shape: {data.shape} is not (n_codebook, seq_len)'
166 | data = self.offset_tok_ids(
167 | data,
168 | global_offset=self.global_offset,
169 | codebook_size=self.codebook_size,
170 | num_codebooks=self.num_codebooks,
171 | )
172 | data = self.flatten(data)
173 | codec_range = self.get_codec_type_from_range(data)
174 | assert codec_range == self.codec_type, f"get_codec_type_from_range(data)={codec_range}, self.codec_type={self.codec_type}"
175 | data = data.tolist()
176 | return data
177 |
178 | def ids2npy(self, token_ids):
179 | # make sure token_ids starts with codebook 0
180 | if isinstance(self.codebook_size, int):
181 | codebook_0_range = (self.global_offset + self.quantizer_begin*self.codebook_size, self.global_offset + (self.quantizer_begin+1)*self.codebook_size)
182 | elif isinstance(self.codebook_size, list):
183 | codebook_0_range = (self.global_offset, self.global_offset + self.codebook_size[0])
184 | assert token_ids[0] >= codebook_0_range[0] \
185 | and token_ids[0] < codebook_0_range[1], f"token_ids[0]={token_ids[self.quantizer_begin]}, codebook_0_range={codebook_0_range}"
186 | data = np.array(token_ids)
187 | data = self.unflatten(data, n_quantizer=self.n_quantizer)
188 | data = self.unoffset_tok_ids(
189 | data,
190 | global_offset=self.global_offset,
191 | codebook_size=self.codebook_size,
192 | num_codebooks=self.num_codebooks,
193 | )
194 | return data
195 |
196 | def npy_to_json_str(self, npy_path):
197 | data = self.npy2ids(npy_path)
198 | return json.dumps({"text": data, "src": npy_path, "codec": self.codec_type})
199 |
200 | def sep(self):
201 | return ''.join(self.sep)
202 |
203 | def sep_ids(self):
204 | return self.sep_ids
205 |
--------------------------------------------------------------------------------
/code/inference/mmtokenizer.py:
--------------------------------------------------------------------------------
1 | from abc import ABC
2 | from abc import abstractmethod
3 |
4 |
5 | class AbstractTokenizer(ABC):
6 | """Abstract class for tokenizer."""
7 |
8 | def __init__(self, name):
9 | self.name = name
10 | super().__init__()
11 |
12 | @property
13 | @abstractmethod
14 | def vocab_size(self):
15 | pass
16 |
17 | @property
18 | @abstractmethod
19 | def vocab(self):
20 | """Dictionary from vocab text token to id token."""
21 | pass
22 |
23 | @property
24 | @abstractmethod
25 | def inv_vocab(self):
26 | """Dictionary from vocab id token to text token."""
27 | pass
28 |
29 | @abstractmethod
30 | def tokenize(self, text):
31 | pass
32 |
33 | def detokenize(self, token_ids):
34 | raise NotImplementedError('detokenizer is not implemented for {} '
35 | 'tokenizer'.format(self.name))
36 |
37 | @property
38 | def cls(self):
39 | raise NotImplementedError('CLS is not provided for {} '
40 | 'tokenizer'.format(self.name))
41 |
42 | @property
43 | def sep(self):
44 | raise NotImplementedError('SEP is not provided for {} '
45 | 'tokenizer'.format(self.name))
46 |
47 | @property
48 | def pad(self):
49 | raise NotImplementedError('PAD is not provided for {} '
50 | 'tokenizer'.format(self.name))
51 |
52 | @property
53 | def eod(self):
54 | raise NotImplementedError('EOD is not provided for {} '
55 | 'tokenizer'.format(self.name))
56 |
57 | @property
58 | def mask(self):
59 | raise NotImplementedError('MASK is not provided for {} '
60 | 'tokenizer'.format(self.name))
61 |
62 |
63 | class _SentencePieceTokenizer(AbstractTokenizer):
64 | """SentencePieceTokenizer-Megatron wrapper"""
65 |
66 | def __init__(self, model_file, vocab_extra_ids=0):
67 | name = 'SentencePieceTokenizer'
68 | super().__init__(name)
69 |
70 | import sentencepiece
71 | self.tokenizer = sentencepiece.SentencePieceProcessor(model_file=model_file)
72 | self._initalize(vocab_extra_ids)
73 |
74 | def _populate_vocab(self):
75 | self._vocab = {}
76 | self._inv_vocab = {}
77 |
78 | for i in range(len(self.tokenizer)):
79 | t = self.tokenizer.id_to_piece(i)
80 | self._inv_vocab[i] = t
81 | self._vocab[t] = i
82 |
83 | def _initalize(self, vocab_extra_ids):
84 | self._populate_vocab()
85 | self._special_tokens = {}
86 | self._inv_special_tokens = {}
87 |
88 | self._t5_tokens = []
89 |
90 | def _add_special_token(t):
91 | if t not in self._vocab:
92 | next_id = len(self._vocab)
93 | self._vocab[t] = next_id
94 | self._inv_vocab[next_id] = t
95 | self._special_tokens[t] = self._vocab[t]
96 | self._inv_special_tokens[self._vocab[t]] = t
97 |
98 | _add_special_token('')
99 | self._cls_id = self._vocab['']
100 | _add_special_token('')
101 | self._sep_id = self._vocab['']
102 | _add_special_token('')
103 | self._eod_id = self._vocab['']
104 | _add_special_token('')
105 | self._mask_id = self._vocab['']
106 |
107 | pad_id = self.tokenizer.pad_id()
108 | try:
109 | pad_token = self.tokenizer.id_to_piece(pad_id)
110 | except IndexError:
111 | pad_token = ''
112 | _add_special_token(pad_token)
113 | self._pad_id = self._vocab[pad_token]
114 |
115 | bos_id = self.tokenizer.bos_id()
116 | try:
117 | bos_token = self.tokenizer.id_to_piece(bos_id)
118 | except IndexError:
119 | bos_token = ''
120 | _add_special_token(bos_token)
121 | self._bos_id = self._vocab[bos_token]
122 |
123 | eos_id = self.tokenizer.eos_id()
124 | try:
125 | eos_token = self.tokenizer.id_to_piece(eos_id)
126 | except IndexError:
127 | eos_token = ''
128 | _add_special_token(eos_token)
129 | self._eos_id = self._vocab[eos_token]
130 |
131 | for i in range(vocab_extra_ids):
132 | t = "".format(i)
133 | _add_special_token(t)
134 | self._t5_tokens += [t]
135 |
136 | @property
137 | def vocab_size(self):
138 | return len(self._vocab)
139 |
140 | @property
141 | def vocab(self):
142 | return self._vocab
143 |
144 | @property
145 | def inv_vocab(self):
146 | return self._inv_vocab
147 |
148 | @property
149 | def decoder(self):
150 | return self._inv_vocab
151 |
152 | @property
153 | def encoder(self):
154 | return self._vocab
155 |
156 | # From:
157 | # https://github.com/NVIDIA/NeMo/blob/c8fa217e811d60d11d014827c7f3845ff6c99ae7/nemo/collections/common/tokenizers/sentencepiece_tokenizer.py#L89
158 | def tokenize(self, text):
159 | ids = []
160 | idx = 0
161 |
162 | while 1:
163 | indices = {}
164 | for token in self._special_tokens:
165 | try:
166 | indices[token] = text[idx:].index(token)
167 | except ValueError:
168 | continue
169 | if len(indices) == 0:
170 | break
171 |
172 | next_token = min(indices, key=indices.get)
173 | next_idx = idx + indices[next_token]
174 |
175 | ids.extend(self.tokenizer.encode_as_ids(text[idx:next_idx]))
176 | ids.append(self._special_tokens[next_token])
177 | idx = next_idx + len(next_token)
178 |
179 | ids.extend(self.tokenizer.encode_as_ids(text[idx:]))
180 | return ids
181 |
182 | # From:
183 | # https://github.com/NVIDIA/NeMo/blob/c8fa217e811d60d11d014827c7f3845ff6c99ae7/nemo/collections/common/tokenizers/sentencepiece_tokenizer.py#L125
184 | def detokenize(self, ids):
185 | text = ""
186 | last_i = 0
187 |
188 | for i, id in enumerate(ids):
189 | if id in self._inv_special_tokens:
190 | text += self.tokenizer.decode_ids(ids[last_i:i]) + " "
191 | text += self._inv_special_tokens[id] + " "
192 | last_i = i + 1
193 |
194 | text += self.tokenizer.decode_ids(ids[last_i:])
195 | return text
196 |
197 | @property
198 | def cls(self):
199 | return self._cls_id
200 |
201 | @property
202 | def sep(self):
203 | return self._sep_id
204 |
205 | @property
206 | def pad(self):
207 | return self._pad_id
208 |
209 | @property
210 | def bos_token_id(self):
211 | return self._bos_id
212 |
213 | @property
214 | def bos(self):
215 | return self._bos_id
216 |
217 | @property
218 | def eod(self):
219 | return self._eod_id
220 |
221 | @property
222 | def eos_token_id(self):
223 | return self._eos_id
224 |
225 | @property
226 | def eos(self):
227 | return self._eos_id
228 |
229 | @property
230 | def mask(self):
231 | return self._mask_id
232 |
233 | @property
234 | def additional_special_tokens_ids(self):
235 | return [self.vocab[k] for k in self._t5_tokens]
236 |
237 | class _MMSentencePieceTokenizer(_SentencePieceTokenizer):
238 | """SentencePieceTokenizer-Megatron wrapper"""
239 |
240 | def __init__(self, model_file, vocab_extra_ids=0):
241 | super().__init__(model_file, vocab_extra_ids)
242 |
243 |
244 | def _initalize(self, vocab_extra_ids):
245 | self._populate_vocab()
246 | self._special_tokens = {}
247 | self._inv_special_tokens = {}
248 |
249 | self._t5_tokens = []
250 |
251 | def _add_special_token(t):
252 | if t not in self._vocab:
253 | next_id = len(self._vocab)
254 | self._vocab[t] = next_id
255 | self._inv_vocab[next_id] = t
256 | self._special_tokens[t] = self._vocab[t]
257 | self._inv_special_tokens[self._vocab[t]] = t
258 |
259 | _add_special_token('')
260 | self._cls_id = self._vocab['']
261 | _add_special_token('')
262 | self._sep_id = self._vocab['']
263 | _add_special_token('')
264 | self._eod_id = self._vocab['']
265 | _add_special_token('')
266 | self._mask_id = self._vocab['']
267 |
268 | _add_special_token('')
269 | self._soa_id = self._vocab['']
270 | _add_special_token('')
271 | self._eoa_id = self._vocab['']
272 | _add_special_token('')
273 | self._sov_id = self._vocab['']
274 | _add_special_token('')
275 | self._eov_id = self._vocab['']
276 | _add_special_token('')
277 | self._soi_id = self._vocab['']
278 | _add_special_token('')
279 | self._eoi_id = self._vocab['']
280 | _add_special_token('')
281 | self._s_local_id = self._vocab['']
282 | _add_special_token('')
283 | self._e_local_id = self._vocab['']
284 | _add_special_token('')
285 | self._s_global_id = self._vocab['']
286 | _add_special_token('')
287 | self._e_global_id = self._vocab['']
288 | _add_special_token('')
289 | self._stage_1_id = self._vocab['']
290 | _add_special_token('')
291 | self._stage_2_id = self._vocab['']
292 | pad_id = self.tokenizer.pad_id()
293 | try:
294 | pad_token = self.tokenizer.id_to_piece(pad_id)
295 | except IndexError:
296 | pad_token = ''
297 | _add_special_token(pad_token)
298 | self._pad_id = self._vocab[pad_token]
299 |
300 | bos_id = self.tokenizer.bos_id()
301 | try:
302 | bos_token = self.tokenizer.id_to_piece(bos_id)
303 | except IndexError:
304 | bos_token = ''
305 | _add_special_token(bos_token)
306 | self._bos_id = self._vocab[bos_token]
307 |
308 | eos_id = self.tokenizer.eos_id()
309 | try:
310 | eos_token = self.tokenizer.id_to_piece(eos_id)
311 | except IndexError:
312 | eos_token = ''
313 | _add_special_token(eos_token)
314 | self._eos_id = self._vocab[eos_token]
315 |
316 | for i in range(vocab_extra_ids):
317 | t = "".format(i)
318 | _add_special_token(t)
319 | self._t5_tokens += [t]
320 |
321 | @property
322 | def soa(self):
323 | return self._soa_id
324 |
325 | @property
326 | def eoa(self):
327 | return self._eoa_id
328 |
329 | @property
330 | def sov(self):
331 | return self._sov_id
332 |
333 | @property
334 | def eov(self):
335 | return self._eov_id
336 |
337 | @property
338 | def soi(self):
339 | return self._soi_id
340 |
341 | @property
342 | def eoi(self):
343 | return self._eoi_id
344 |
345 | @property
346 | def s_local(self):
347 | return self._s_local_id
348 |
349 | @property
350 | def e_local(self):
351 | return self._e_local_id
352 |
353 | @property
354 | def s_global(self):
355 | return self._s_global_id
356 |
357 | @property
358 | def e_global(self):
359 | return self._e_global_id
360 |
361 | @property
362 | def stage_1(self):
363 | return self._stage_1_id
364 |
365 | @property
366 | def stage_2(self):
367 | return self._stage_2_id
368 |
--------------------------------------------------------------------------------
/code/finetune/core/datasets/blended_megatron_dataset_builder.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
2 |
3 | import logging
4 | import math
5 | from typing import Any, Callable, List, Optional, Tuple, Type, Union
6 |
7 | import numpy
8 | import torch
9 |
10 | from core.datasets.blended_dataset import BlendedDataset
11 | from core.datasets.blended_megatron_dataset_config import BlendedMegatronDatasetConfig
12 | from core.datasets.indexed_dataset import MMapIndexedDataset
13 | from core.datasets.megatron_dataset import MegatronDataset
14 | from core.datasets.utils import Split, normalize
15 |
16 | logger = logging.getLogger(__name__)
17 |
18 | DistributedDataset = Union[
19 | BlendedDataset, MegatronDataset, MMapIndexedDataset, torch.utils.data.Dataset
20 | ]
21 |
22 |
23 | class BlendedMegatronDatasetBuilder(object):
24 | """Builder class for the BlendedDataset and MegatronDataset classes
25 |
26 | Args:
27 | cls (Type[MegatronDataset]): The class to instantiate, must inherit from MegatronDataset
28 |
29 | sizes (List[int]): The minimum number of total samples to draw from each split, varies
30 | with blend
31 |
32 | config (BlendedMegatronDatasetConfig): The config object which informs dataset creation
33 | """
34 |
35 | def __init__(
36 | self, cls: Type[MegatronDataset], sizes: List[int], config: BlendedMegatronDatasetConfig,
37 | ):
38 | self.cls = cls
39 | self.sizes = sizes
40 | self.config = config
41 |
42 | def build(self) -> List[Optional[Union[BlendedDataset, MegatronDataset]]]:
43 | """Build all dataset splits according to the provided blend(s)
44 |
45 | This method is distributed-aware and must be called on all ranks.
46 |
47 | The dataset splits returned can vary according to the config. Supply config.blend and
48 | config.split to build BlendedDataset and/or MegatronDataset splits from the same
49 | distribution. Supply config.blend_per_split to build BlendedDataset and/or MegatronDataset
50 | splits from separate distributions.
51 |
52 | Returns:
53 | List[Optional[Union[BlendedDataset, MegatronDataset]]]: A list of either
54 | MegatronDataset or BlendedDataset (or None) per split
55 | """
56 | return self._build_blended_dataset_splits()
57 |
58 | def _build_blended_dataset_splits(
59 | self,
60 | ) -> List[Optional[Union[BlendedDataset, MegatronDataset]]]:
61 | """Build all dataset splits according to the provided blend(s)
62 |
63 | See the BlendedMegatronDatasetBuilder.build alias for more information.
64 |
65 | Returns:
66 | List[Optional[Union[BlendedDataset, MegatronDataset]]]: A list of either
67 | MegatronDataset or BlendedDataset (or None) per split
68 | """
69 |
70 | if self.config.blend:
71 | blend = self.config.blend
72 | split = self.config.split_matrix
73 |
74 | # Blend consists of a single prefix
75 | if len(blend) == 1:
76 | return self._build_megatron_dataset_splits(blend[0], split, self.sizes)
77 |
78 | # Blend consists of multiple weights and prefixes
79 | (
80 | prefix_per_dataset,
81 | weight_per_dataset,
82 | sizes_per_dataset,
83 | ) = _get_prefixes_weights_and_sizes_for_blend(blend, self.sizes)
84 |
85 | megatron_datasets = [[] for _ in range(len(Split))]
86 |
87 | for i in range(len(prefix_per_dataset)):
88 | megatron_datasets_split = self._build_megatron_dataset_splits(
89 | prefix_per_dataset[i], split, sizes_per_dataset[i]
90 | )
91 | for j in range(len(megatron_datasets_split)):
92 | megatron_datasets[j].append(megatron_datasets_split[j])
93 |
94 | # Sum over all contributing datasets, per split
95 | size_per_split = list(map(sum, zip(*sizes_per_dataset)))
96 |
97 | blended_datasets = []
98 |
99 | for i in range(len(megatron_datasets)):
100 | is_none = map(lambda _: _ is None, megatron_datasets[i])
101 |
102 | if split[i] is None:
103 | assert all(is_none)
104 | blended_datasets.append(None)
105 | else:
106 | assert all(is_none) or not any(is_none)
107 | blended_datasets.append(
108 | self.build_generic_dataset(
109 | BlendedDataset,
110 | self.config.is_built_on_rank,
111 | megatron_datasets[i],
112 | weight_per_dataset,
113 | size_per_split[i],
114 | self.config,
115 | )
116 | )
117 |
118 | return blended_datasets
119 |
120 | else:
121 | blended_datasets = []
122 | for i in range(len(Split)):
123 | blend = self.config.blend_per_split[i]
124 |
125 | # Blend is not provided
126 | if not blend:
127 | blended_datasets.append(None)
128 | continue
129 |
130 | split_spoof = [None] * len(Split)
131 | split_spoof[i] = (0.0, 1.0)
132 | sizes_spoof = [0] * len(Split)
133 | sizes_spoof[i] = self.sizes[i]
134 |
135 | # Blend consists of a sigle prefix
136 | if len(blend) == 1:
137 | blended_datasets.append(
138 | self._build_megatron_dataset_splits(blend[0], split_spoof, sizes_spoof)[i]
139 | )
140 |
141 | # Blend consists of multiple weights and prefixes
142 | else:
143 | (
144 | prefix_per_dataset,
145 | weight_per_dataset,
146 | sizes_per_dataset,
147 | ) = _get_prefixes_weights_and_sizes_for_blend(blend, sizes_spoof)
148 |
149 | megatron_datasets = []
150 | for j in range(len(prefix_per_dataset)):
151 | megatron_datasets.append(
152 | self._build_megatron_dataset_splits(
153 | prefix_per_dataset[j], split_spoof, sizes_per_dataset[j],
154 | )[i]
155 | )
156 |
157 | size_per_split = list(map(sum, zip(*sizes_per_dataset)))
158 |
159 | blended_datasets.append(
160 | self.build_generic_dataset(
161 | BlendedDataset,
162 | self.config.is_built_on_rank,
163 | megatron_datasets,
164 | weight_per_dataset,
165 | size_per_split[i],
166 | self.config,
167 | )
168 | )
169 |
170 | return blended_datasets
171 |
172 | def _build_megatron_dataset_splits(
173 | self, path_prefix: str, split: List[float], sizes: List[int],
174 | ) -> List[Optional[MegatronDataset]]:
175 | """Build each MegatronDataset split from a single MMapIndexedDataset
176 |
177 | Args:
178 | path_prefix (str): The MMapIndexedDataset .bin and .idx file prefix
179 |
180 | split (List[Tuple[float, float]]): The dataset split matrix
181 |
182 | sizes (List[int]): The number of total samples to draw from each split
183 |
184 | Returns:
185 | List[Optional[MegatronDataset]]: The MegatronDatset (or None) per split
186 | """
187 | indexed_dataset = self.build_generic_dataset(
188 | MMapIndexedDataset, self.config.is_built_on_rank, path_prefix, self.cls.is_multimodal(),
189 | )
190 |
191 | if indexed_dataset is not None:
192 | if self.cls.is_split_by_sequence():
193 | num_elements = indexed_dataset.sequence_lengths.shape[0]
194 | else:
195 | num_elements = indexed_dataset.document_indices.shape[0] - 1
196 |
197 | split_indices = []
198 | for i, _ in enumerate(Split):
199 | if split[i] is not None:
200 | beg = int(round(split[i][0] * float(num_elements)))
201 | end = int(round(split[i][1] * float(num_elements)))
202 | split_indices.append(
203 | numpy.arange(start=beg, stop=end, step=1, dtype=numpy.int32)
204 | )
205 | else:
206 | split_indices.append(None)
207 | else:
208 | split_indices = [None for _ in Split]
209 |
210 | megatron_datasets = []
211 | for i, _split in enumerate(Split):
212 | if split[i] is None:
213 | megatron_datasets.append(None)
214 | else:
215 | megatron_datasets.append(
216 | self.build_generic_dataset(
217 | self.cls,
218 | self.config.is_built_on_rank,
219 | indexed_dataset,
220 | split_indices[i],
221 | sizes[i],
222 | _split,
223 | self.config,
224 | )
225 | )
226 |
227 | return megatron_datasets
228 |
229 | @staticmethod
230 | def build_generic_dataset(
231 | cls: Type[DistributedDataset], is_built_on_rank: Callable, *args: Any
232 | ) -> Optional[DistributedDataset]:
233 | """Build the DistributedDataset
234 |
235 | Return None if and only if the underlying MegatronDataset class is not built on the current
236 | rank and torch.distributed is initialized.
237 |
238 | Args:
239 | cls (Type[DistributedDataset]): The DistributedDataset class to be built
240 |
241 | args (Tuple[Any]): The positional arguments used to build the provided
242 | DistributedDataset class
243 |
244 | Raises:
245 | Exception: When the dataset constructor raises an OSError
246 |
247 | Returns:
248 | Optional[DistributedDataset]: The DistributedDataset instantion or None
249 | """
250 | if torch.distributed.is_initialized():
251 | rank = torch.distributed.get_rank()
252 |
253 | dataset = None
254 |
255 | # First, build on rank 0
256 | if rank == 0 and is_built_on_rank():
257 | try:
258 | dataset = cls(*args)
259 | except OSError as err:
260 | log = (
261 | f"Failed to write dataset materials to the data cache directory. "
262 | + f"Please supply a directory to which you have write access via "
263 | + f"the path_to_cache attribute in BlendedMegatronDatasetConfig and "
264 | + f"retry. Refer to the preserved traceback above for more information."
265 | )
266 | raise Exception(log) from err
267 |
268 | torch.distributed.barrier()
269 |
270 | # After, build on other ranks
271 | if rank != 0 and is_built_on_rank():
272 | dataset = cls(*args)
273 |
274 | return dataset
275 |
276 | return cls(*args)
277 |
278 |
279 | def _get_prefixes_weights_and_sizes_for_blend(
280 | blend: List[str], target_num_samples_per_split: List[int]
281 | ) -> Tuple[List[str], List[float], List[List[int]]]:
282 | """Determine the contribution of the MegatronDataset splits to the BlendedDataset splits
283 |
284 | Args:
285 | blend (List[str]): e.g. ["30", "path/to/dataset_1_prefix", "70",
286 | "path/to/dataset_2_prefix"]
287 |
288 | target_num_samples_per_split (List[int]): The number of samples to target for each
289 | BlendedDataset split
290 |
291 | Returns:
292 | Tuple[List[str], List[float], List[List[int]]]: The prefix strings e.g.
293 | ["path/to/dataset_1_prefix", "path/to/dataset_2_prefix"], the normalized weights e.g.
294 | [0.3, 0.7], and the number of samples to request per MegatronDataset per split
295 | """
296 | weights, prefixes = zip(
297 | *[(float(blend[i]), blend[i + 1].strip()) for i in range(0, len(blend), 2)]
298 | )
299 |
300 | weights = normalize(weights)
301 |
302 | # Use 0.5% target margin to ensure we satiate the network
303 | sizes_per_dataset = [
304 | [
305 | int(math.ceil(target_num_samples * weight * 1.005))
306 | for target_num_samples in target_num_samples_per_split
307 | ]
308 | for weight in weights
309 | ]
310 |
311 | return prefixes, weights, sizes_per_dataset
312 |
--------------------------------------------------------------------------------
/code/top_200_tags.json:
--------------------------------------------------------------------------------
1 | {
2 | "genre": [
3 | "Pop",
4 | "rock",
5 | "pop",
6 | "electronic",
7 | "Classical",
8 | "R&B",
9 | "Electronic",
10 | "Rock",
11 | "Folk",
12 | "rap",
13 | "classical",
14 | "soundtrack",
15 | "country",
16 | "indie-rock",
17 | "punk",
18 | "hiphop",
19 | "folk",
20 | "jazz",
21 | "Country",
22 | "hip-hop",
23 | "Hip-hop",
24 | "experimental",
25 | "Hip Hop",
26 | "Funk",
27 | "blues",
28 | "ambient",
29 | "Rap",
30 | "Jazz",
31 | "Ambient",
32 | "New Age",
33 | "Blues",
34 | "experimental pop",
35 | "classic rock",
36 | "indie rock",
37 | "alternative rock",
38 | "Reggae",
39 | "Electro pop",
40 | "K-pop",
41 | "Dance",
42 | "Soundtrack",
43 | "Hip hop",
44 | "80s",
45 | "Dancehall",
46 | "Disco",
47 | "House",
48 | "Death Metal",
49 | "Thrash Metal",
50 | "international",
51 | "progressive rock",
52 | "hard rock",
53 | "instrumental",
54 | "Lounge",
55 | "house",
56 | "Latin",
57 | "hardcore",
58 | "Metalcore",
59 | "Soul",
60 | "grunge",
61 | "Easy listening",
62 | "easylistening",
63 | "Indian",
64 | "ethno",
65 | "Hard rock",
66 | "hip hop",
67 | "Indie Pop",
68 | "Electro",
69 | "industrial",
70 | "grindcore",
71 | "post-rock",
72 | "Soul-R&B",
73 | "Reggaeton",
74 | "World",
75 | "latin pop",
76 | "Classic Rock",
77 | "Latin pop",
78 | "Deathcore",
79 | "soul",
80 | "improvisation",
81 | "Chinese",
82 | "techno",
83 | "Salsa",
84 | "indie pop",
85 | "Hardcore",
86 | "拉丁",
87 | "Black metal",
88 | " Americana",
89 | "dance",
90 | "rock nacional",
91 | "tejano",
92 | "indie",
93 | "ambient electronic",
94 | "world",
95 | "Death metal",
96 | "Trap",
97 | "avant-garde",
98 | "Chillout",
99 | "Americana",
100 | "new wave",
101 | "rnb",
102 | "pop rock",
103 | "post-hardcore",
104 | "singer-songwriter",
105 | "pop punk",
106 | "Power metal",
107 | "indie folk",
108 | "opera",
109 | "Metal",
110 | "African",
111 | "instrumental rock",
112 | "Gospel",
113 | "downtempo",
114 | "New Wave",
115 | "Electro-pop",
116 | "rockabilly",
117 | "MPB",
118 | "goth rock",
119 | "soul-R&B",
120 | "Black Metal",
121 | "Dubstep",
122 | "Eurovision",
123 | "Bossa Nova",
124 | "bossanova",
125 | "民谣",
126 | "big band",
127 | "Synthpop",
128 | "死亡金属",
129 | "中国传统音乐",
130 | "glam rock",
131 | "国际音乐",
132 | "latin",
133 | "operatic",
134 | "Melodic Death Metal",
135 | "lounge",
136 | " Regional Mexican",
137 | "instrumental pop",
138 | "emo",
139 | "旋律死亡金属",
140 | "Pop Rock",
141 | "popfolk",
142 | " Latin",
143 | "poprock",
144 | "eurovision",
145 | "Ska",
146 | "Techno",
147 | "disco",
148 | "基督教音乐",
149 | "Indie rock",
150 | "Goregrind",
151 | "8-bit",
152 | "Pop rock",
153 | "screamo",
154 | "Dance pop",
155 | "Guitar",
156 | "chillout",
157 | "beats",
158 | "Big band",
159 | "mpb",
160 | "Bluegrass",
161 | "流行",
162 | "Thrash metal",
163 | "easy listening",
164 | "Samba",
165 | "Heavy metal",
166 | "Symphonic metal",
167 | "Chanson",
168 | "Oriental",
169 | "synthpop",
170 | "Girl group",
171 | "Epic",
172 | "Celtic",
173 | "Screamo",
174 | "Espanol",
175 | "Middle Eastern",
176 | "electro",
177 | " Soul-R&B",
178 | " Classic Rock",
179 | "Heavy Metal",
180 | "dubstep",
181 | "民乐",
182 | "country rock",
183 | "funk",
184 | "ska",
185 | "Indie Rock",
186 | "Choral",
187 | "J-rock",
188 | "shoegaze",
189 | "Rockabilly",
190 | "grime",
191 | "Italian pop",
192 | "摇滚",
193 | " latin",
194 | "Bolero",
195 | " orchestral",
196 | "experimental hip-hop",
197 | "eurodance",
198 | "noise rock",
199 | "electro pop",
200 | "noise",
201 | "Crossover Country",
202 | "Glitch"
203 | ],
204 | "instrument": [
205 | "Piano",
206 | "drums",
207 | "guitar",
208 | "electric guitar",
209 | "Guitar",
210 | "synthesizer",
211 | "Synthesizer",
212 | "Keyboard",
213 | "piano",
214 | "Drums",
215 | "Violin",
216 | "bass",
217 | "acoustic guitar",
218 | "Bass",
219 | "violin",
220 | "voice",
221 | "vocal",
222 | "acousticguitar",
223 | "Electric guitar",
224 | "Acoustic guitar",
225 | "electricguitar",
226 | "Voice",
227 | "keyboard",
228 | "saxophone",
229 | "beat",
230 | "Drum machine",
231 | "Cello",
232 | "harmonica",
233 | "fiddle",
234 | "Percussion",
235 | "beatboxing",
236 | "Vocal",
237 | "鼓",
238 | "Saxophone",
239 | "keys",
240 | "harp",
241 | "Keyboards",
242 | "keyboards",
243 | " harmonica",
244 | "singing",
245 | "吉他",
246 | "贝斯",
247 | "钢琴",
248 | "beats",
249 | "flute",
250 | "bass guitar",
251 | "drum",
252 | "brass",
253 | "Flute",
254 | "Fiddle",
255 | "charango",
256 | "Sitar",
257 | "strings",
258 | "trumpet",
259 | "Brass",
260 | "Vocals",
261 | "Trumpet",
262 | "string",
263 | "Singing",
264 | " banjo",
265 | "drum machine",
266 | "cello",
267 | "Acoustic Guitar",
268 | "glockenspiel",
269 | "computer",
270 | "电吉他",
271 | "合成器",
272 | "键盘",
273 | "mallets",
274 | "原声吉他",
275 | "Drum",
276 | "Bass guitar",
277 | "Dholak",
278 | "congas",
279 | "Electric Guitar",
280 | "二胡",
281 | "鼓机",
282 | "synth",
283 | "Strings",
284 | "小提琴",
285 | "Trombone",
286 | "percussion",
287 | "弦乐",
288 | "electricpiano",
289 | "风琴",
290 | "oboe",
291 | "horns",
292 | "Erhu",
293 | " synthesizer",
294 | "acoustic drums",
295 | " pedal steel guitar",
296 | " Voice",
297 | "Tambourine",
298 | "singer-songwriter",
299 | "Oud",
300 | "Qanun",
301 | "electronic",
302 | " pedal steel",
303 | "rapping",
304 | "Funky bass",
305 | "guitars",
306 | "木吉他",
307 | "Alto saxophone",
308 | "Ukulele",
309 | "扬琴",
310 | "oud",
311 | "sitar",
312 | "打击乐器",
313 | "Synth",
314 | "organ",
315 | "Kanun",
316 | "人声",
317 | "古筝",
318 | " accordion",
319 | "bandura",
320 | "banjo",
321 | "长笛",
322 | "pandeira",
323 | "turntables",
324 | "Alto Saxophone",
325 | " slideguitar",
326 | " electricguitar",
327 | "rap",
328 | "harpsichord",
329 | "萨克斯管",
330 | "maracas",
331 | "口琴",
332 | "Guitars",
333 | "Dobro guitar",
334 | "vocals",
335 | "choir",
336 | "Ableton",
337 | "Horns",
338 | "AcousticGuitar",
339 | "笛子",
340 | "synth drums",
341 | "Glockenspiel",
342 | "Harp",
343 | "zither",
344 | "Dobro",
345 | "Musical instrument",
346 | "electric piano",
347 | "竖琴",
348 | "Horn",
349 | "手风琴",
350 | "None",
351 | "Choir",
352 | "铜管乐器",
353 | "String",
354 | "vocal samples",
355 | "trombone",
356 | "班卓琴",
357 | "hu lu si",
358 | "Pandeira",
359 | "采样器",
360 | " Banjo",
361 | "Synth bass",
362 | "synth bass",
363 | "mallet",
364 | " tabla",
365 | "dulcimer",
366 | "声乐",
367 | "Cavaquinho",
368 | "大提琴",
369 | "toms",
370 | "ney",
371 | " trumpet",
372 | " voice",
373 | "低音",
374 | "Zither",
375 | "shakuhachi",
376 | "主唱",
377 | " electric guitar",
378 | "tambourine",
379 | "Turntables",
380 | "lyrics",
381 | " concertina",
382 | " piano",
383 | " steel guitar",
384 | "Bongos",
385 | "Koto",
386 | "808 bass",
387 | "Marimba",
388 | " drums",
389 | "Dance",
390 | "萨克斯风",
391 | "木琴",
392 | " bass",
393 | "ukulele",
394 | "Steel pan",
395 | "女声",
396 | "键盘乐器",
397 | "whistle",
398 | "soprano saxophone",
399 | "Nylon string guitar",
400 | "synth_lead",
401 | "电脑",
402 | "Shakuhachi",
403 | "oboes",
404 | "Rap"
405 | ],
406 | "mood": [
407 | "Uplifting",
408 | "emotional",
409 | "uplifting",
410 | "happy",
411 | "Inspiring",
412 | "romantic",
413 | "sad",
414 | "Love",
415 | "melancholic",
416 | "dark",
417 | "Upbeat",
418 | "Energetic",
419 | "Romantic",
420 | "Melancholic",
421 | "Nostalgic",
422 | "Calm",
423 | "Hopeful",
424 | "melodic",
425 | "relaxing",
426 | "Romance",
427 | "Emotional",
428 | "Dreamy",
429 | "energetic",
430 | "rebellious",
431 | "Dance",
432 | "inspiring",
433 | " introspective",
434 | "Confident",
435 | "aggressive",
436 | "Positive",
437 | "calm",
438 | "cool",
439 | "Happy",
440 | "hopeful",
441 | "beautiful",
442 | "advertising",
443 | "angry",
444 | "Sad",
445 | "relaxed",
446 | "Celebratory",
447 | "Angry",
448 | "Bold",
449 | "Introspective",
450 | "Optimistic",
451 | "sentimental",
452 | "optimistic",
453 | "Tough",
454 | "motivational",
455 | "Heartfelt",
456 | "Funky",
457 | "communication",
458 | "Danceable",
459 | "vivacious",
460 | "love",
461 | "commercial",
462 | "Vivacious",
463 | "heavy",
464 | "ballad",
465 | "thoughtful",
466 | "fast-paced",
467 | "Futuristic",
468 | "Joyful",
469 | "emotion",
470 | "Soulful",
471 | "attitude",
472 | "positive",
473 | "epic",
474 | "Festive",
475 | "Melodic",
476 | "Dancy",
477 | "Aggressive",
478 | "soft",
479 | "Calming",
480 | "exciting",
481 | "dreamy",
482 | "Epic",
483 | "nostalgic",
484 | "powerful",
485 | "adventure",
486 | "passionate",
487 | "Determined",
488 | "沟通",
489 | "Sensual",
490 | "Playful",
491 | "street",
492 | "heartfelt",
493 | "Rebellious",
494 | "intense",
495 | "Sentimental",
496 | "inspirational",
497 | "travel",
498 | "Adventurous",
499 | "atmospheric",
500 | "summer",
501 | "easygoing",
502 | "Cheerful",
503 | "Cool",
504 | "Dark",
505 | "rock",
506 | "Inspiration",
507 | "Chill",
508 | "Intense",
509 | "confident",
510 | "empowering",
511 | "Violent",
512 | "Intimate",
513 | "longing",
514 | " meditative",
515 | "Attitude",
516 | "romance",
517 | "experimental",
518 | "at sea",
519 | "放松",
520 | "chill",
521 | "Exciting",
522 | "Soothing",
523 | "Empowering",
524 | "暴力",
525 | "Brawny",
526 | "cheerful",
527 | "Motivational",
528 | "Vibraphone",
529 | "tough",
530 | "determined",
531 | "hardcore",
532 | "Reflective",
533 | "funny",
534 | "Peaceful",
535 | "loud",
536 | "Pensive",
537 | "向上",
538 | "playful",
539 | "Furious",
540 | "时尚",
541 | "希望",
542 | "rough",
543 | "Intimacy",
544 | "dance",
545 | "Vibrant",
546 | "Relaxed",
547 | "soundscape",
548 | "Brutal",
549 | "thought-provoking",
550 | "success",
551 | "sleepy",
552 | "Elegant",
553 | "children",
554 | "intimate",
555 | "残酷",
556 | "怀旧",
557 | "improvisational",
558 | "浪漫",
559 | "Ambient",
560 | "Affectionate",
561 | "Gory",
562 | "Dramatic",
563 | "enthusiastic",
564 | "感性",
565 | "ambient",
566 | "Gentle",
567 | "愤怒",
568 | "快乐",
569 | "黑暗",
570 | "brawny",
571 | "Seductive",
572 | "Dancing",
573 | "introspective",
574 | "instrumental",
575 | "Satisfied",
576 | "hard",
577 | "史诗",
578 | " documentary",
579 | " dreamy",
580 | "Lively",
581 | "child",
582 | "sassy",
583 | "dissonant",
584 | "Emotive",
585 | "electronic",
586 | "抒情",
587 | "meditative",
588 | "Gloomy",
589 | "groovy",
590 | " film",
591 | "adventure, emotion",
592 | "ambitious",
593 | "Spiritual",
594 | "christmas",
595 | "reminiscent",
596 | "saloon",
597 | "vintage",
598 | "梦幻",
599 | "爱",
600 | "fast_decay",
601 | "Comedy",
602 | "Asian",
603 | "侵略性",
604 | "Admirative",
605 | " communication",
606 | "忧郁"
607 | ],
608 | "gender": [
609 | "male",
610 | "female",
611 | "singing",
612 | "soprano",
613 | "child",
614 | "human",
615 | "human female voice",
616 | "unspecified",
617 | "screamo",
618 | "mezzo-soprano",
619 | "human voice",
620 | "not specified",
621 | "tenor",
622 | "rapping",
623 | "singing voice",
624 | "squeaky",
625 | "童声",
626 | "children"
627 | ],
628 | "timbre": [
629 | "bright vocal",
630 | "full vocal",
631 | "airy vocal",
632 | "clear vocal",
633 | "mellow vocal",
634 | "dark vocal",
635 | "rich vocal",
636 | "reverb vocal",
637 | "light vocal",
638 | "crisp vocal",
639 | "broad vocal",
640 | "powerful vocal",
641 | "piercing vocal",
642 | "high-pitched vocal",
643 | "bass vocal",
644 | "deep vocal",
645 | "not applicable vocal",
646 | "baritone vocal",
647 | "not specified vocal",
648 | "vibrant vocal",
649 | "boomy vocal",
650 | "varied vocal",
651 | "bouncy vocal",
652 | "range vocal",
653 | "harsh vocal",
654 | " airy vocal",
655 | "round vocal",
656 | "uplifting vocal",
657 | "soft vocal",
658 | "husky vocal",
659 | "tenor vocal",
660 | "pontificate vocal",
661 | "aggressive vocal",
662 | "neat vocal",
663 | "high vocal",
664 | "exuberant vocal",
665 | "open vocal",
666 | "full bodied vocal",
667 | "strong vocal",
668 | "grainy vocal",
669 | "vocal fry vocal",
670 | "gravelly vocal",
671 | "low vocal",
672 | "long_release vocal",
673 | "polished vocal",
674 | "velvet vocal",
675 | "placid vocal",
676 | "plastic vocal",
677 | "sharp vocal",
678 | "robust vocal",
679 | "muffled vocal",
680 | "distortion vocal",
681 | "crunchy vocal",
682 | "resonant vocal",
683 | "pure vocal",
684 | "年轻 vocal",
685 | "preenched vocal",
686 | "gruff vocal",
687 | "raspy vocal",
688 | "passionate vocal",
689 | "nonlinear_env vocal",
690 | "high pitched vocal",
691 | "athletic vocal",
692 | "reedy vocal",
693 | "shimmering vocal",
694 | "charismatic vocal",
695 | "gliding vocal",
696 | "raw vocal",
697 | "plucky vocal",
698 | "loud vocal",
699 | "youthful vocal",
700 | "thin vocal",
701 | "soulful vocal",
702 | "smooth vocal",
703 | "flat vocal",
704 | "tempo-synced vocal",
705 | "opulent vocal",
706 | "variable vocal",
707 | "happy vocal",
708 | "prettily vocal",
709 | "percussive vocal",
710 | "singing voice vocal",
711 | "barrel vocal",
712 | "breezy vocal",
713 | "vocal vocal",
714 | "honeyed vocal",
715 | "vivacious vocal",
716 | "full-bodied vocal",
717 | "persuasive vocal",
718 | "tender vocal",
719 | "potent vocal",
720 | "preppy vocal",
721 | " raspy vocal",
722 | "narrow vocal",
723 | "fruity vocal",
724 | "whiny vocal",
725 | "hollow vocal",
726 | "singing vocal",
727 | "rapping vocal",
728 | "flexible vocal",
729 | " alto vocal",
730 | "sweet vocal",
731 | "agitated vocal",
732 | "shaky vocal",
733 | "dainty vocal",
734 | "明亮 vocal",
735 | "soprano vocal",
736 | "vocal range vocal",
737 | "rough vocal",
738 | "有力 vocal",
739 | "成熟 vocal",
740 | "sultry vocal",
741 | "barren vocal",
742 | "bulky vocal",
743 | "prevalent vocal",
744 | "bellowing vocal",
745 | "dusty vocal",
746 | "elevated vocal",
747 | "wide vocal",
748 | "rumbly vocal",
749 | "shrill vocal",
750 | "prettily produced vocal",
751 | "projected vocal",
752 | "low pitched vocal",
753 | "bold vocal",
754 | "grassy vocal",
755 | "plush vocal",
756 | "glorious vocal",
757 | "elevated pitch vocal",
758 | "whispery vocal",
759 | "long vocal",
760 | "nasal vocal",
761 | "preened vocal",
762 | "squeaky vocal",
763 | "hellosing vocal",
764 | "commanding vocal",
765 | "textural vocal",
766 | "noble vocal",
767 | "frustrated vocal",
768 | "warm vocal",
769 | "punchy vocal",
770 | "pretty vocal",
771 | "changeable vocal",
772 | "mushy vocal",
773 | "vocalist vocal",
774 | "gritty vocal",
775 | "barking vocal",
776 | "human vocal",
777 | "bass heavy vocal",
778 | "dulcet vocal",
779 | " smooth vocal",
780 | "young vocal",
781 | "rhythmic vocal",
782 | "vocals vocal",
783 | "helmet vocal",
784 | "screamy vocal",
785 | "hoarse vocal",
786 | "rebellious vocal",
787 | "soothing vocal",
788 | "童声 vocal",
789 | "bitter vocal",
790 | "为了让声乐更加生动,使用了混响效果。 vocal",
791 | "barrel-shaped vocal",
792 | "reed vocal",
793 | "强有力 vocal",
794 | "低沉 vocal",
795 | "whimsical vocal",
796 | "exaggerated vocal",
797 | "温暖 vocal",
798 | "low-pitched vocal",
799 | "emotional vocal",
800 | "graceful vocal",
801 | "breakable vocal",
802 | "screechy vocal",
803 | "muddy vocal",
804 | "breathy vocal",
805 | "柔和 vocal",
806 | "weathered vocal",
807 | "roaring vocal",
808 | "青春 vocal",
809 | "pensive vocal",
810 | "textured vocal",
811 | "清脆 vocal",
812 | "melodic vocal",
813 | "helmeted vocal",
814 | " velvety vocal",
815 | "充满活力 vocal",
816 | "圆润 vocal",
817 | "preteen vocal",
818 | "rhythm vocal",
819 | "treble vocal",
820 | "shouty vocal",
821 | " husky vocal",
822 | "medium vocal",
823 | "blue vocal",
824 | "screeching vocal",
825 | "multiphonic vocal",
826 | "quaint vocal",
827 | "rhytmic vocal",
828 | "轻盈 vocal"
829 | ]
830 | }
--------------------------------------------------------------------------------
/code/finetune/core/datasets/gpt_dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
2 |
3 | import logging
4 | import os
5 | import time
6 | from dataclasses import dataclass
7 | from typing import Dict, Tuple, Union
8 |
9 | import numpy
10 | import torch
11 |
12 | # from megatron import get_tokenizer
13 | from core.datasets.blended_megatron_dataset_config import BlendedMegatronDatasetConfig
14 | from core.datasets.indexed_dataset import MMapIndexedDataset
15 | from core.datasets.megatron_dataset import MegatronDataset
16 | from core.datasets.utils import Split, log_single_rank
17 |
18 | logger = logging.getLogger(__name__)
19 |
20 |
21 | @dataclass
22 | class GPTDatasetConfig(BlendedMegatronDatasetConfig):
23 | """Configuration object for Megatron Core GPT datasets
24 |
25 | Attributes:
26 | return_document_ids (bool): Whether to return the document ids when querying the dataset.
27 |
28 | reset_position_ids (bool): Option to reset the position IDs in the dataset at an interval
29 |
30 | reset_attention_mask (bool): Option to reset the attention mask from the dataset
31 |
32 | eod_mask_loss (bool): Option to enable the EOD mask loss
33 |
34 | eod_id (int): Has the identity of the end of document
35 |
36 | """
37 |
38 | return_document_ids: bool = False
39 | reset_position_ids: bool = False
40 | reset_attention_mask: bool = False
41 | eod_mask_loss: bool = False
42 | eod_id: int = 0
43 | add_bos: bool = False
44 | enable_shuffle: bool = False
45 |
46 |
47 | class GPTDataset(MegatronDataset):
48 | """The base GPT dataset
49 |
50 | Args:
51 | indexed_dataset (MMapIndexedDataset): The MMapIndexedDataset around which to build the
52 | MegatronDataset
53 |
54 | indexed_indices (numpy.ndarray): The set of the documents indices to expose
55 |
56 | num_samples (int): The number of samples to draw from the indexed dataset
57 |
58 | index_split (Split): The indexed_indices Split
59 |
60 | config (GPTDatasetConfig): The GPT-specific container for all config sourced parameters
61 | """
62 |
63 | def __init__(
64 | self,
65 | indexed_dataset: MMapIndexedDataset,
66 | indexed_indices: numpy.ndarray,
67 | num_samples: int,
68 | index_split: Split,
69 | config: GPTDatasetConfig,
70 | ) -> None:
71 | super().__init__(indexed_dataset, indexed_indices, num_samples, index_split, config)
72 | # tokenizer = get_tokenizer()
73 | # self.bos_id = tokenizer.bos
74 | # self.eod_id = tokenizer.eod
75 |
76 | def _finalize(self) -> None:
77 | """Abstract method implementation
78 |
79 | Load or build/cache the document, sample, and shuffle indices
80 | """
81 | assert isinstance(self.config, GPTDatasetConfig)
82 |
83 | (
84 | self.document_index,
85 | self.sample_index,
86 | self.shuffle_index,
87 | ) = self._build_document_sample_shuffle_indices()
88 |
89 | def __len__(self) -> int:
90 | """Abstract method implementation
91 |
92 | Returns:
93 | int: The length of the dataset
94 | """
95 | return self.sample_index.shape[0] - 1
96 |
97 | def __getitem__(self, idx: int) -> Dict[str, torch.Tensor]:
98 | """Abstract method implementation
99 |
100 | Args:
101 | idx (int): The index into the dataset
102 |
103 | Returns:
104 | Dict[str, torch.Tensor]: The text ids wrapped in a dictionary
105 | """
106 | text, _ = self._query_document_sample_shuffle_indices(idx)
107 |
108 | text = torch.from_numpy(text)
109 |
110 | tokens_ = text.long()
111 | labels = tokens_[1:].contiguous()
112 | tokens = tokens_[:-1].contiguous()
113 |
114 | attention_mask, loss_mask, position_ids = _get_ltor_masks_and_position_ids(
115 | tokens,
116 | self.config.eod_id,
117 | self.config.reset_position_ids,
118 | self.config.reset_attention_mask,
119 | self.config.eod_mask_loss,
120 | )
121 |
122 | return {
123 | "input_ids": tokens,
124 | "labels": labels,
125 | "attention_mask": attention_mask,
126 | "loss_mask": loss_mask,
127 | "position_ids": position_ids,
128 | }
129 |
130 | @staticmethod
131 | def is_multimodal() -> bool:
132 | """Abstract method implementation
133 |
134 | Returns:
135 | bool: False
136 | """
137 | return False
138 |
139 | @staticmethod
140 | def is_split_by_sequence() -> bool:
141 | """Abstract method implementation
142 |
143 | Returns:
144 | bool: True
145 | """
146 | return True
147 |
148 | def _query_document_sample_shuffle_indices(
149 | self, idx: int
150 | ) -> Tuple[numpy.ndarray, numpy.ndarray]:
151 | """Get the text (token ids) and document ids for a given index
152 |
153 | Args:
154 | idx (int): The index into the dataset
155 |
156 | Returns:
157 | Tuple[numpy.ndarray, numpy.ndarray]: The text ids and document ids
158 | """
159 | # Do the shuffle mapping
160 | idx = self.shuffle_index[idx]
161 |
162 | # Get the beginning and end documents and offsets
163 | doc_index_beg, doc_index_beg_offset = self.sample_index[idx]
164 | doc_index_end, doc_index_end_offset = self.sample_index[idx + 1]
165 |
166 | document_ids = []
167 | sample_parts = []
168 |
169 | # Sample spans a single document
170 | if doc_index_beg == doc_index_end:
171 | # Add the document id
172 | document_ids.append(self.document_index[doc_index_beg])
173 |
174 | # Add the entire sample
175 | sample_parts.append(
176 | self.indexed_dataset.get(
177 | self.document_index[doc_index_beg],
178 | offset=doc_index_beg_offset,
179 | length=doc_index_end_offset - doc_index_beg_offset + 1,
180 | )
181 | )
182 |
183 | # Sample spans multiple documents
184 | else:
185 | for i in range(doc_index_beg, doc_index_end + 1):
186 | # Add the document id
187 | document_ids.append(self.document_index[i])
188 |
189 | # Add the sample part
190 | offset = 0 if i > doc_index_beg else doc_index_beg_offset
191 | length = None if i < doc_index_end else doc_index_end_offset + 1
192 | sample_parts.append(
193 | self.indexed_dataset.get(self.document_index[i], offset=offset, length=length)
194 | )
195 |
196 | if getattr(self.config, "add_bos"):
197 | sample = sample_parts[0]
198 | add_token = self.bos_id if sample[0] != self.bos_id else self.eod_id
199 | sample_parts.insert(0, numpy.array([add_token], dtype=sample.dtype))
200 |
201 | return (
202 | numpy.array(numpy.concatenate(sample_parts), dtype=numpy.int64),
203 | numpy.array(document_ids, dtype=numpy.int64),
204 | )
205 |
206 | def _build_document_sample_shuffle_indices(
207 | self,
208 | ) -> Tuple[numpy.ndarray, numpy.ndarray, numpy.ndarray]:
209 | """Build the document index, the sample index, and the shuffle index
210 |
211 | The document index:
212 | -- 1-D
213 | -- An ordered array of document ids
214 |
215 | The sample index:
216 | -- 2-D
217 | -- The document indices and offsets which mark the start of every sample
218 |
219 | The shuffle index:
220 | -- 1-D
221 | -- A random permutation of index range of the sample index
222 |
223 | Returns:
224 | Tuple[numpy.ndarray, numpy.ndarray]: The document index, the sample index, and the
225 | shuffle index
226 |
227 | TODO: Explain the 80% threshold
228 | """
229 | path_to_cache = self.config.path_to_cache
230 | if path_to_cache is None:
231 | path_to_cache = os.path.join(
232 | self.indexed_dataset.path_prefix, "cache", f"{type(self).__name__}_indices"
233 | )
234 |
235 | get_path_to = lambda suffix: os.path.join(
236 | path_to_cache, f"{self.unique_description_hash}-{type(self).__name__}-{suffix}"
237 | )
238 | path_to_description = get_path_to("description.txt")
239 | path_to_document_index = get_path_to("document_index.npy")
240 | path_to_sample_index = get_path_to("sample_index.npy")
241 | path_to_shuffle_index = get_path_to("shuffle_index.npy")
242 | cache_hit = all(
243 | map(
244 | os.path.isfile,
245 | [
246 | path_to_description,
247 | path_to_document_index,
248 | path_to_sample_index,
249 | path_to_shuffle_index,
250 | ],
251 | )
252 | )
253 |
254 | num_tokens_per_epoch = self._get_num_tokens_per_epoch()
255 | num_epochs = self._get_num_epochs(num_tokens_per_epoch)
256 |
257 | if not cache_hit and torch.distributed.get_rank() == 0:
258 | log_single_rank(
259 | logger,
260 | logging.INFO,
261 | f"Build and save the {type(self).__name__} {self.index_split.name} indices",
262 | )
263 |
264 | sequence_length = self.config.sequence_length
265 |
266 | if num_epochs == 1:
267 | separate_final_epoch = False
268 | else:
269 | # Get the number of samples for the last epoch
270 | num_samples_sans_final_epoch = (
271 | (num_epochs - 1) * num_tokens_per_epoch - 1
272 | ) // sequence_length
273 | num_samples_from_final_epoch = self.num_samples - num_samples_sans_final_epoch
274 | num_samples_per_epoch = (num_tokens_per_epoch - 1) // sequence_length
275 |
276 | # num_samples_from_final_epoch should be non-negative
277 | assert num_samples_from_final_epoch >= 0
278 |
279 | # num_samples_from_final_epoch should not exceed max value
280 | assert num_samples_from_final_epoch <= num_samples_per_epoch + 1
281 |
282 | # Separate the final epoch if it falls below the threshold
283 | threshold = 0.80
284 | separate_final_epoch = num_samples_from_final_epoch < int(
285 | threshold * num_samples_per_epoch
286 | )
287 |
288 | log_single_rank(
289 | logger,
290 | logging.DEBUG,
291 | f"> num_samples_from_final_epoch: {num_samples_from_final_epoch}",
292 | )
293 | log_single_rank(logger, logging.DEBUG, f"> threshold: {threshold}")
294 | log_single_rank(
295 | logger, logging.DEBUG, f"> num_samples_per_epoch: {num_samples_per_epoch}"
296 | )
297 |
298 | log_single_rank(
299 | logger, logging.DEBUG, f"> separate_final_epoch: {separate_final_epoch}"
300 | )
301 |
302 | numpy_random_state = numpy.random.RandomState(self.config.random_seed)
303 |
304 | os.makedirs(path_to_cache, exist_ok=True)
305 |
306 | # Write the description
307 | with open(path_to_description, "wt") as writer:
308 | writer.write(self.unique_description)
309 |
310 | # Build the document index
311 | log_single_rank(
312 | logger,
313 | logging.INFO,
314 | f"\tBuild and save the document index to {os.path.basename(path_to_document_index)}",
315 | )
316 | t_beg = time.time()
317 | document_index = _build_document_index(
318 | self.indexed_indices, num_epochs, numpy_random_state, separate_final_epoch, self.config.enable_shuffle
319 | )
320 | numpy.save(path_to_document_index, document_index, allow_pickle=True)
321 | t_end = time.time()
322 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
323 |
324 | # Build the sample index
325 | log_single_rank(
326 | logger,
327 | logging.INFO,
328 | f"\tBuild and save the sample index to {os.path.basename(path_to_sample_index)}",
329 | )
330 | t_beg = time.time()
331 | from core.datasets import helpers
332 |
333 | assert document_index.dtype == numpy.int32
334 | assert self.indexed_dataset.sequence_lengths.dtype == numpy.int32
335 | sample_index = helpers.build_sample_idx(
336 | self.indexed_dataset.sequence_lengths,
337 | document_index,
338 | sequence_length,
339 | num_epochs,
340 | num_tokens_per_epoch,
341 | )
342 | numpy.save(path_to_sample_index, sample_index, allow_pickle=True)
343 | t_end = time.time()
344 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
345 |
346 | # Build the shuffle index
347 | log_single_rank(
348 | logger,
349 | logging.INFO,
350 | f"\tBuild and save the shuffle index to {os.path.basename(path_to_shuffle_index)}",
351 | )
352 | t_beg = time.time()
353 | if separate_final_epoch:
354 | shuffle_index = _build_shuffle_index(
355 | num_samples_sans_final_epoch, sample_index.shape[0] - 1, numpy_random_state, True
356 | )
357 | else:
358 | shuffle_index = _build_shuffle_index(
359 | sample_index.shape[0] - 1, sample_index.shape[0] - 1, numpy_random_state, True
360 | )
361 | numpy.save(path_to_shuffle_index, shuffle_index, allow_pickle=True)
362 | t_end = time.time()
363 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
364 |
365 | log_single_rank(
366 | logger, logging.INFO, f"> total number of samples: {sample_index.shape[0] - 1}"
367 | )
368 | log_single_rank(logger, logging.INFO, f"> total number of epochs: {num_epochs}")
369 |
370 | return document_index, sample_index, shuffle_index
371 |
372 | log_single_rank(
373 | logger, logging.INFO, f"Load the {type(self).__name__} {self.index_split.name} indices"
374 | )
375 |
376 | log_single_rank(
377 | logger,
378 | logging.INFO,
379 | f"\tLoad the document index from {os.path.basename(path_to_document_index)}",
380 | )
381 | t_beg = time.time()
382 | document_index = numpy.load(path_to_document_index, allow_pickle=True, mmap_mode='r')
383 | t_end = time.time()
384 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
385 |
386 | log_single_rank(
387 | logger,
388 | logging.INFO,
389 | f"\tLoad the sample index from {os.path.basename(path_to_sample_index)}",
390 | )
391 | t_beg = time.time()
392 | sample_index = numpy.load(path_to_sample_index, allow_pickle=True, mmap_mode='r')
393 | t_end = time.time()
394 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
395 |
396 | log_single_rank(
397 | logger,
398 | logging.INFO,
399 | f"\tLoad the shuffle index from {os.path.basename(path_to_shuffle_index)}",
400 | )
401 | t_beg = time.time()
402 | shuffle_index = numpy.load(path_to_shuffle_index, allow_pickle=True, mmap_mode='r')
403 | t_end = time.time()
404 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
405 |
406 | log_single_rank(
407 | logger, logging.INFO, f"> total number of samples: {sample_index.shape[0] - 1}"
408 | )
409 | log_single_rank(logger, logging.INFO, f"> total number of epochs: {num_epochs}")
410 |
411 | return document_index, sample_index, shuffle_index
412 |
413 | def _get_num_tokens_per_epoch(self) -> int:
414 | """Calculate the number of tokens in a single epoch
415 |
416 | Returns:
417 | int: The number of tokens in a single epoch
418 | """
419 | return int(numpy.sum(self.indexed_dataset.sequence_lengths[self.indexed_indices]))
420 |
421 | def _get_num_epochs(self, num_tokens_per_epoch: int) -> int:
422 | """Calculate the number of epochs
423 |
424 | Args:
425 | num_tokens_per_epoch (int): The number of tokens in a single epoch
426 |
427 | Returns:
428 | int: The number of epochs
429 | """
430 | num_epochs = 0
431 | num_tokens = 0
432 | num_tokens_requested = (self.num_samples * self.config.sequence_length) + 1
433 | while True:
434 | num_epochs += 1
435 | num_tokens += num_tokens_per_epoch
436 | if num_tokens >= num_tokens_requested:
437 | return num_epochs
438 |
439 |
440 | def _build_document_index(
441 | documents: numpy.ndarray,
442 | num_epochs: int,
443 | numpy_random_state: numpy.random.RandomState,
444 | separate_final_epoch: bool,
445 | enable_shuffle: bool = False,
446 | ) -> numpy.ndarray:
447 | """Build an array with length = num epochs * num documents
448 |
449 | Args:
450 | documents (numpy.ndarray): the subset of exposed document indices
451 |
452 | num_epochs (int): The number of epochs
453 |
454 | numpy_random_state (numpy.random.RandomState): The NumPy random state
455 |
456 | separate_final_epoch (bool): Whether to exclude the last epoch from the global shuffle
457 |
458 | enable_shuffle (bool): Whether to enable the shuffle. Default is False to ensure the reproducibility
459 |
460 | Returns:
461 | numpy.ndarray: The document index
462 |
463 | TODO: Explain separate_final_epoch
464 | """
465 | if not separate_final_epoch or num_epochs == 1:
466 | document_index = numpy.mgrid[0:num_epochs, 0 : len(documents)][1]
467 | document_index[:] = documents
468 | document_index = document_index.reshape(-1)
469 | document_index = document_index.astype(numpy.int32)
470 | if enable_shuffle:
471 | print("INFO: document_index shuffle is enabled...")
472 | numpy_random_state.shuffle(document_index)
473 | else:
474 | print("INFO: document_index shuffle is disabled...")
475 | return document_index
476 |
477 | doc_idx_first = _build_document_index(documents, num_epochs - 1, numpy_random_state, False, enable_shuffle)
478 | doc_idx_last = _build_document_index(documents, 1, numpy_random_state, False, enable_shuffle)
479 | return numpy.concatenate((doc_idx_first, doc_idx_last))
480 |
481 |
482 | def _build_shuffle_index(
483 | num_samples: int, total_size: int, numpy_random_state: numpy.random.RandomState,
484 | enable_shuffle: bool = False,
485 | ) -> numpy.ndarray:
486 | """Build the range [0, size) and shuffle
487 |
488 | Args:
489 | num_samples (int): The size of the first shuffle range [0, num_samples)
490 |
491 | total_size (int): The size of the entire index. If larger than 'num_samples', it defines
492 |
493 | the second shuffle range [num_samples, total_size)
494 |
495 | numpy_random_state (numpy.random.RandomState): The NumPy random state
496 |
497 | Returns:
498 | numpy.ndarray: The shuffle index
499 |
500 | TODO: Explain [0, num_samples) [num_samples, total_size) split
501 | """
502 | dtype_ = numpy.uint32
503 | if total_size >= (numpy.iinfo(numpy.uint32).max - 1):
504 | dtype_ = numpy.int64
505 |
506 | shuffle_idx_first = numpy.arange(start=0, stop=num_samples, step=1, dtype=dtype_)
507 | if enable_shuffle:
508 | print("INFO: shuffle_index shuffle is enabled...")
509 | numpy_random_state.shuffle(shuffle_idx_first)
510 | else:
511 | print("INFO: shuffle_index shuffle is disabled...")
512 | if num_samples == total_size:
513 | return shuffle_idx_first
514 |
515 | shuffle_idx_last = numpy.arange(start=num_samples, stop=total_size, step=1, dtype=dtype_)
516 | if enable_shuffle:
517 | print("INFO: shuffle_index shuffle is enabled...")
518 | numpy_random_state.shuffle(shuffle_idx_last)
519 | else:
520 | print("INFO: shuffle_index shuffle is disabled...")
521 |
522 | return numpy.concatenate((shuffle_idx_first, shuffle_idx_last))
523 |
524 |
525 | def _get_ltor_masks_and_position_ids(
526 | data: torch.Tensor,
527 | eod_token: int,
528 | reset_position_ids: bool,
529 | reset_attention_mask: bool,
530 | eod_mask_loss: bool,
531 | ):
532 | """Build masks and position id for left to right model.
533 |
534 | Args:
535 | data (torch.Tensor): The data tenor that holds the tokens from the dataset
536 |
537 | eod_token (int): ID of the token to that is considered the EOD
538 |
539 | reset_position_ids (bool): Switch to reset the document position ID's
540 |
541 | reset_attention_mask (bool): Switch to reset the attention mask
542 |
543 | eod_mask_loss (bool): Switch to enable the EOD mask loss
544 |
545 | Returns:
546 | torch.Tensor : Attention mask needed to be used for Attention
547 |
548 | torch.Tensor : The mask used for loss value during training
549 |
550 | torch.Tensor : The position ID's of the token
551 |
552 | """
553 |
554 | # Extract batch size and sequence length.
555 | seq_length = data.numel()
556 |
557 | attention_mask = torch.tril(torch.ones((seq_length, seq_length), device=data.device)).unsqueeze(
558 | 0
559 | )
560 |
561 | # Loss mask.
562 | loss_mask = torch.ones(seq_length, dtype=torch.float, device=data.device)
563 | if eod_mask_loss:
564 | loss_mask[data == eod_token] = 0.0
565 |
566 | # Position ids.
567 | position_ids = torch.arange(seq_length, dtype=torch.long, device=data.device)
568 | # We need to clone as the ids will be modifed based on batch index.
569 | if reset_position_ids:
570 | position_ids = position_ids.clone()
571 |
572 | if reset_position_ids or reset_attention_mask:
573 |
574 | # Find indecies where EOD token is.
575 | eod_index = position_ids[data[b] == eod_token]
576 | # Detach indecies from positions if going to modify positions.
577 | if reset_position_ids:
578 | eod_index = eod_index.clone()
579 |
580 | # Loop through EOD indecies:
581 | prev_index = 0
582 | for j in range(eod_index.numel()):
583 | i = eod_index[j]
584 | # Mask attention loss.
585 | if reset_attention_mask:
586 | attention_mask[0, (i + 1) :, : (i + 1)] = 0
587 | # Reset positions.
588 | if reset_position_ids:
589 | position_ids[(i + 1) :] -= i + 1 - prev_index
590 | prev_index = i + 1
591 |
592 | # Convert attention mask to binary:
593 | attention_mask = attention_mask < 0.5
594 | attention_mask = attention_mask.float()
595 |
596 | return attention_mask, loss_mask, position_ids
--------------------------------------------------------------------------------
/code/finetune/core/datasets/indexed_dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | #
3 | # This source code is licensed under the MIT license found in the
4 | # LICENSE file in the root directory of this source tree.
5 |
6 | # Essentially re-written in entirety
7 |
8 | import logging
9 | import os
10 | import shutil
11 | import struct
12 | import time
13 | from enum import Enum
14 | from functools import lru_cache
15 | from itertools import accumulate
16 | from types import TracebackType
17 | from typing import List, Optional, Tuple, Type, Union
18 |
19 | import numpy
20 | import torch
21 |
22 | from core.datasets.utils import log_single_rank
23 |
24 | logger = logging.getLogger(__name__)
25 |
26 | _INDEX_HEADER = b"MMIDIDX\x00\x00"
27 |
28 |
29 | class DType(Enum):
30 | """The NumPy data type Enum for writing/reading the MMapIndexedDataset indices
31 | """
32 |
33 | uint8 = 1
34 | int8 = 2
35 | int16 = 3
36 | int32 = 4
37 | int64 = 5
38 | float64 = 6
39 | float32 = 7
40 | uint16 = 8
41 |
42 | @classmethod
43 | def code_from_dtype(cls, value: Type[numpy.number]) -> int:
44 | """Get the code from the dtype
45 |
46 | Args:
47 | value (Type[numpy.number]): The dtype
48 |
49 | Returns:
50 | int: The code
51 | """
52 | return cls[value.__name__].value
53 |
54 | @classmethod
55 | def dtype_from_code(cls, value: int) -> Type[numpy.number]:
56 | """Get the dtype from the code
57 |
58 | Args:
59 | value (int): The code
60 |
61 | Returns:
62 | Type[numpy.number]: The dtype
63 | """
64 | return getattr(numpy, cls(value).name)
65 |
66 | @staticmethod
67 | def size(key: Union[int, Type[numpy.number]]) -> int:
68 | """Get the size of the dtype/code in bytes
69 |
70 | Args:
71 | key (Union[int, Type[numpy.number]]): The dtype or code
72 |
73 | Raises:
74 | ValueError: If the key is neither dtype nor integer code
75 |
76 | Returns:
77 | int: The size of the dtype/code in in bytes
78 | """
79 | if isinstance(key, int):
80 | return DType.dtype_from_code(key)().itemsize
81 | elif numpy.number in key.__mro__:
82 | return key().itemsize
83 | else:
84 | raise ValueError
85 |
86 | @staticmethod
87 | def optimal_dtype(cardinality: Optional[int]) -> Type[numpy.number]:
88 | """Get the dtype to use for an index of a certain cardinality
89 |
90 | Args:
91 | cardinality (Optional[int]): The number of elements to be indexed
92 |
93 | Returns:
94 | Type[numpy.number]: The dtype to use for the index
95 | """
96 | if cardinality is not None and cardinality < 65500:
97 | return numpy.uint16
98 | else:
99 | return numpy.int32
100 |
101 |
102 | class _IndexWriter(object):
103 | """Object class to write the index (.idx) file
104 |
105 | Args:
106 | idx_path (str): The path to the index file
107 |
108 | dtype (Type[numpy.number]): The dtype of the index file
109 | """
110 |
111 | def __init__(self, idx_path: str, dtype: Type[numpy.number]) -> None:
112 | self.idx_path = idx_path
113 | self.dtype = dtype
114 |
115 | def __enter__(self) -> "_IndexWriter":
116 | """Enter the context introduced by the 'with' keyword
117 |
118 | Returns:
119 | _IndexWriter: The instance
120 | """
121 | self.idx_writer = open(self.idx_path, "wb")
122 | # fixed, vestigial practice
123 | self.idx_writer.write(_INDEX_HEADER)
124 | # fixed, vestigial practice
125 | self.idx_writer.write(struct.pack(" Optional[bool]:
136 | """Exit the context introduced by the 'with' keyword
137 |
138 | Args:
139 | exc_type (Optional[Type[BaseException]]): Exception type
140 |
141 | exc_val (Optional[BaseException]): Exception value
142 |
143 | exc_tb (Optional[TracebackType]): Exception traceback object
144 |
145 | Returns:
146 | Optional[bool]: Whether to silence the exception
147 | """
148 | self.idx_writer.close()
149 |
150 | def write(
151 | self,
152 | sequence_lengths: List[int],
153 | sequence_modes: Optional[List[int]],
154 | document_indices: List[int],
155 | ) -> None:
156 | """Write the index (.idx) file
157 |
158 | Args:
159 | sequence_lengths (List[int]): The length of each sequence
160 |
161 | sequence_modes (Optional[List[int]]): The mode of each sequences
162 |
163 | document_indices (List[int]): The seqyebce indices demarcating the end of each document
164 | """
165 | sequence_pointers = self._sequence_pointers(sequence_lengths)
166 |
167 | # the number of sequences in the dataset
168 | sequence_count = len(sequence_lengths)
169 | self.idx_writer.write(struct.pack(" List[int]:
196 | """Build the sequence pointers per the sequence lengths and dtype size
197 |
198 | Args:
199 | sequence_lengths (List[int]): The length of each sequence
200 |
201 | Returns:
202 | List[int]: The pointer to the beginning of each sequence
203 | """
204 | itemsize = DType.size(self.dtype)
205 | curr_ptr = 0
206 | list_ptr = []
207 | for length in sequence_lengths:
208 | list_ptr.append(curr_ptr)
209 | curr_ptr += length * itemsize
210 | return list_ptr
211 |
212 |
213 | class _IndexReader(object):
214 | """Object class to read the index (.idx) file
215 |
216 | Args:
217 | idx_path (str): The path to the index file
218 |
219 | multimodal (bool): Whether the dataset is multimodal
220 | """
221 |
222 | def __init__(self, idx_path: str, multimodal: bool) -> None:
223 |
224 | log_single_rank(logger, logging.INFO, f"Load the {type(self).__name__} from {idx_path}")
225 |
226 | with open(idx_path, "rb") as stream:
227 | header = stream.read(9)
228 | assert header == _INDEX_HEADER, f"bad header, cannot read: {idx_path}"
229 |
230 | version = struct.unpack(" time elapsed: {t_end - t_beg:4f} seconds")
252 |
253 | log_single_rank(logger, logging.INFO, f"\tExtract the sequence pointers")
254 | t_beg = time.time()
255 | self.sequence_pointers = numpy.frombuffer(
256 | self.bin_buffer,
257 | dtype=numpy.int64,
258 | count=self.sequence_count,
259 | offset=offset + self.sequence_lengths.nbytes,
260 | )
261 | t_end = time.time()
262 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
263 |
264 | log_single_rank(logger, logging.INFO, f"\tExtract the document indices")
265 | t_beg = time.time()
266 | self.document_indices = numpy.frombuffer(
267 | self.bin_buffer,
268 | dtype=numpy.int64,
269 | count=self.document_count,
270 | offset=offset + self.sequence_lengths.nbytes + self.sequence_pointers.nbytes,
271 | )
272 | t_end = time.time()
273 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
274 |
275 | self.sequence_modes = None
276 | if multimodal:
277 | log_single_rank(logger, logging.INFO, f"\tExtract the sequence modes")
278 | t_beg = time.time()
279 | self.sequence_modes = numpy.frombuffer(
280 | self.bin_buffer,
281 | dtype=numpy.int8,
282 | count=self.sequence_count,
283 | offset=offset
284 | + self.sequence_lengths.nbytes
285 | + self.sequence_pointers.nbytes
286 | + self.document_indices.nbytes,
287 | )
288 | t_end = time.time()
289 | log_single_rank(logger, logging.DEBUG, f"\t> time elapsed: {t_end - t_beg:4f} seconds")
290 |
291 | assert self.sequence_lengths.shape[0] == len(self)
292 | assert self.sequence_lengths.shape[0] == self.sequence_count
293 | assert self.sequence_lengths.shape[0] == self.document_indices[-1]
294 |
295 | log_single_rank(logger, logging.INFO, f"> total number of sequences: {len(self)}")
296 | log_single_rank(
297 | logger,
298 | logging.INFO,
299 | f"> total number of documents: {self.document_indices.shape[0] - 1}",
300 | )
301 |
302 | def __del__(self) -> None:
303 | """Clean up the object
304 | """
305 | self.bin_buffer_mmap._mmap.close()
306 | del self.bin_buffer_mmap
307 |
308 | def __len__(self) -> int:
309 | """Return the length of the dataset
310 |
311 | Returns:
312 | int: The length of the dataset
313 | """
314 | return self.sequence_count
315 |
316 | @lru_cache(maxsize=8)
317 | def __getitem__(self, idx: int) -> Tuple[numpy.int32, numpy.int64, Optional[numpy.int8]]:
318 | """Return the pointer, length, and mode at the index
319 |
320 | Args:
321 | idx (int): The index into the dataset
322 |
323 | Returns:
324 | Tuple[numpy.int32, numpy.int64, Optional[numpy.int8]]: The pointer, length and mode at
325 | the index
326 | """
327 | return (
328 | self.sequence_pointers[idx],
329 | self.sequence_lengths[idx],
330 | self.sequence_modes[idx] if self.sequence_modes is not None else None,
331 | )
332 |
333 |
334 | class MMapIndexedDataset(torch.utils.data.Dataset):
335 | """The low-level interface dataset class
336 |
337 | Args:
338 | path_prefix (str): The index (.idx) and data (.bin) prefix
339 |
340 | multimodal (bool, optional): Whether the dataset is multimodal. Defaults to False.
341 | """
342 |
343 | def __init__(self, path_prefix: str, multimodal: bool = False) -> None:
344 | super().__init__()
345 | self.path_prefix = None
346 | self.multimodal = None
347 |
348 | self.index = None
349 | self.bin_buffer = None
350 | self.bin_buffer_mmap = None
351 |
352 | self.initialize(path_prefix, multimodal)
353 |
354 | def initialize(self, path_prefix: str, multimodal: bool) -> None:
355 | """Initialize the dataset
356 |
357 | This method is called by MMapIndexedDataset.__init__ during object creation and by
358 | MMapIndexedDataset.__setstate__ during un-puckling
359 |
360 | Args:
361 | path_prefix (str): The index (.idx) and data (.bin) prefix
362 |
363 | multimodal (bool): Whether the dataset is multimodal
364 | """
365 | self.path_prefix = path_prefix
366 | self.multimodal = multimodal
367 | self.index = _IndexReader(get_idx_path(self.path_prefix), self.multimodal)
368 | self.bin_buffer_mmap = numpy.memmap(get_bin_path(self.path_prefix), mode="r", order="C")
369 | self.bin_buffer = memoryview(self.bin_buffer_mmap)
370 |
371 | def __getstate__(self) -> Tuple[str, bool]:
372 | """Get the state during pickling
373 |
374 | Returns:
375 | Tuple[str, bool]: The state tuple
376 | """
377 | return self.path_prefix, self.multimodal
378 |
379 | def __setstate__(self, state: Tuple[str, bool]) -> None:
380 | """Set the state during un-pickling
381 |
382 | Args:
383 | state (Tuple[str, bool]): The state tuple
384 | """
385 | path_prefix, multimodal = state
386 | self.initialize(path_prefix, multimodal)
387 |
388 | def __del__(self) -> None:
389 | """Clean up the object
390 | """
391 | if self.bin_buffer_mmap is not None:
392 | self.bin_buffer_mmap._mmap.close()
393 | del self.bin_buffer_mmap
394 | del self.index
395 |
396 | def __len__(self) -> int:
397 | """Return the length of the dataset i.e. the number of sequences in the index
398 |
399 | Returns:
400 | int: The length of the dataset
401 | """
402 | return len(self.index)
403 |
404 | def __getitem__(
405 | self, idx: Union[int, numpy.integer, slice]
406 | ) -> Union[numpy.ndarray, Tuple[numpy.ndarray, numpy.ndarray]]:
407 | """Return from the dataset
408 |
409 | Args:
410 | idx (Union[int, numpy.integer, slice]): The index or index slice into the dataset
411 |
412 | Raises:
413 | ValueError: When the index slice is non-contiguous
414 |
415 | TypeError: When the index is of an unexpected type
416 |
417 | Returns:
418 | Union[numpy.ndarray, Tuple[numpy.ndarray, numpy.ndarray]]: The sequence tokens and
419 | modes at the index or index slice
420 | """
421 | if isinstance(idx, (int, numpy.integer)):
422 | sequence_pointer, sequence_length, sequence_mode = self.index[idx]
423 | sequence = numpy.frombuffer(
424 | self.bin_buffer,
425 | dtype=self.index.dtype,
426 | count=sequence_length,
427 | offset=sequence_pointer,
428 | )
429 | return (sequence, sequence_mode) if sequence_mode is not None else sequence
430 | elif isinstance(idx, slice):
431 | start, stop, step = idx.indices(len(self))
432 | if step != 1:
433 | raise ValueError("Slices into indexed_dataset must be contiguous")
434 | sequence_lengths = self.index.sequence_lengths[idx]
435 | sequence_modes = self.index.sequence_modes[idx] if self.multimodal else None
436 | sequence_offsets = list(accumulate(sequence_lengths))
437 | sequences = numpy.split(
438 | numpy.frombuffer(
439 | self.bin_buffer,
440 | dtype=self.index.dtype,
441 | count=sum(sequence_lengths),
442 | offset=self.index.sequence_pointers[start],
443 | ),
444 | sequence_offsets[:-1],
445 | )
446 | return (sequences, sequence_modes) if sequence_modes is not None else sequences
447 | else:
448 | raise TypeError("Unexpected type received for idx: {}".format(type(idx)))
449 |
450 | def get(self, idx: int, offset: int = 0, length: Optional[int] = None) -> numpy.ndarray:
451 | """Retrieve a single item from the dataset with the option to only
452 | return a portion of the item.
453 |
454 | get(idx) is the same as [idx] but get() does not support slicing.
455 | """
456 | sequence_pointer, sequence_length, sequence_mode = self.index[idx]
457 | if length is None:
458 | length = sequence_length - offset
459 | sequence_pointer += offset * DType.size(self.index.dtype)
460 | sequence = numpy.frombuffer(
461 | self.bin_buffer, dtype=self.index.dtype, count=length, offset=sequence_pointer
462 | )
463 | return (sequence, sequence_mode) if sequence_mode is not None else sequence
464 |
465 | @property
466 | def sequence_lengths(self) -> numpy.ndarray:
467 | """Get the sequence lengths
468 |
469 | Returns:
470 | numpy.ndarray: The sequence lengths
471 | """
472 | return self.index.sequence_lengths
473 |
474 | @property
475 | def document_indices(self) -> numpy.ndarray:
476 | """Get the document indices
477 |
478 | Returns:
479 | numpy.ndarray: The document indices
480 | """
481 | return self.index.document_indices
482 |
483 | def get_document_indices(self) -> numpy.ndarray:
484 | """Get the document indices
485 |
486 | This method is slated for deprecation.
487 |
488 | Returns:
489 | numpy.ndarray: The document indices
490 | """
491 | return self.index.document_indices
492 |
493 | def set_document_indices(self, document_indices: numpy.ndarray) -> None:
494 | """Set the document indices
495 |
496 | This method is slated for deprecation.
497 |
498 | Args:
499 | document_indices (numpy.ndarray): The document indices
500 | """
501 | self.index.document_indices = document_indices
502 |
503 | @property
504 | def sequence_modes(self) -> numpy.ndarray:
505 | """Get the sequence modes
506 |
507 | Returns:
508 | numpy.ndarray: The sequence modes
509 | """
510 | return self.index.sequence_modes
511 |
512 | @staticmethod
513 | def exists(path_prefix: str) -> bool:
514 | """Return whether the MMapIndexedDataset exists on disk at the prefix
515 |
516 | Args:
517 | path_prefix (str): The prefix to the index (.idx) and data (.bin) files
518 |
519 | Returns:
520 | bool: Whether the MMapIndexedDataset exists on disk at the prefix
521 | """
522 | return os.path.exists(get_idx_path(path_prefix)) and os.path.exists(
523 | get_bin_path(path_prefix)
524 | )
525 |
526 |
527 | class MMapIndexedDatasetBuilder(object):
528 | """Builder class for the MMapIndexedDataset class
529 |
530 | Args:
531 | bin_path (str): The path to the data (.bin) file
532 |
533 | dtype (Type[numpy.number], optional): The dtype of the index file. Defaults to numpy.int32.
534 |
535 | multimodal (bool, optional): Whether the dataset is multimodal. Defaults to False.
536 | """
537 |
538 | def __init__(
539 | self, bin_path: str, dtype: Type[numpy.number] = numpy.int32, multimodal: bool = False
540 | ) -> None:
541 | self.data_file = open(bin_path, "wb")
542 | self.dtype = dtype
543 | self.multimodal = multimodal
544 |
545 | self.sequence_lengths = []
546 | self.document_indices = [0]
547 | self.sequence_modes = [] if self.multimodal else None
548 |
549 | def add_item(self, tensor: torch.Tensor, mode: int = 0) -> None:
550 | """Add a single item to the dataset
551 |
552 | Args:
553 | tensor (torch.Tensor): The item to add to the data file
554 |
555 | mode (int, optional): The mode for the item. Defaults to 0.
556 | """
557 | np_array = numpy.array(tensor.numpy(), dtype=self.dtype)
558 | self.data_file.write(np_array.tobytes(order="C"))
559 | self.sequence_lengths.append(np_array.size)
560 | if self.multimodal:
561 | self.sequence_modes.append(mode)
562 |
563 | def add_document(
564 | self, tensor: torch.Tensor, lengths: List[int], modes: Optional[List[int]] = None
565 | ) -> None:
566 | """Add an entire document to the dataset
567 |
568 | Args:
569 | tensor (torch.Tensor): The document to add
570 | lengths (List[int]): The lengths of each item in the document
571 | modes (Optional[List[int]], optional): The modes for each item in the document.
572 | Defaults to None.
573 | """
574 | np_array = numpy.array(tensor, dtype=self.dtype)
575 | self.data_file.write(np_array.tobytes(order="C"))
576 | self.sequence_lengths.extend(lengths)
577 | self.document_indices.append(len(self.sequence_lengths))
578 | if self.multimodal:
579 | self.sequence_modes.extend(modes if modes is not None else [0] * lengths)
580 |
581 | def end_document(self) -> None:
582 | """Finalize the document, for use with MMapIndexedDatasetBuilder.add_item
583 | """
584 | self.document_indices.append(len(self.sequence_lengths))
585 |
586 | def add_index(self, path_prefix: str) -> None:
587 | """Add an entire MMapIndexedDataset to the dataset
588 |
589 | Args:
590 | path_prefix (str): The index (.idx) and data (.bin) prefix
591 | """
592 | # Concatenate index
593 | index = _IndexReader(get_idx_path(path_prefix), multimodal=self.multimodal)
594 | assert index.dtype == self.dtype
595 |
596 | offset = len(self.sequence_lengths)
597 | self.sequence_lengths.extend(index.sequence_lengths)
598 | self.document_indices.extend((offset + index.document_indices)[1:])
599 |
600 | if self.multimodal:
601 | self.sequence_modes.extend(index.sequence_modes)
602 |
603 | # Concatenate data
604 | with open(get_bin_path(path_prefix), "rb") as f:
605 | shutil.copyfileobj(f, self.data_file)
606 |
607 | def finalize(self, idx_path: str) -> None:
608 | """Clean up and write the index (.idx) file
609 |
610 | Args:
611 | idx_path (str): The path to the index file
612 | """
613 | self.data_file.close()
614 | with _IndexWriter(idx_path, self.dtype) as writer:
615 | writer.write(self.sequence_lengths, self.sequence_modes, self.document_indices)
616 |
617 |
618 | def get_idx_path(path_prefix: str) -> str:
619 | """Get the path to the index file from the prefix
620 |
621 | Args:
622 | path_prefix (str): The prefix
623 |
624 | Returns:
625 | str: The path to the index file
626 | """
627 | return path_prefix + ".idx"
628 |
629 |
630 | def get_bin_path(path_prefix: str) -> str:
631 | """Get the path to the data file from the prefix
632 |
633 | Args:
634 | path_prefix (str): The prefix
635 |
636 | Returns:
637 | str: The path to the data file
638 | """
639 | return path_prefix + ".bin"
640 |
--------------------------------------------------------------------------------
/code/inference/infer.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | sys.path.append(os.path.join(os.path.dirname(os.path.abspath(__file__)), 'xcodec_mini_infer'))
4 | sys.path.append(os.path.join(os.path.dirname(os.path.abspath(__file__)), 'xcodec_mini_infer', 'descriptaudiocodec'))
5 | import re
6 | import random
7 | import uuid
8 | import copy
9 | from tqdm import tqdm
10 | from collections import Counter
11 | import argparse
12 | import numpy as np
13 | import torch
14 | import torchaudio
15 | from torchaudio.transforms import Resample
16 | import soundfile as sf
17 | from einops import rearrange
18 | from transformers import AutoTokenizer, AutoModelForCausalLM, LogitsProcessor, LogitsProcessorList
19 | from omegaconf import OmegaConf
20 | from codecmanipulator import CodecManipulator
21 | from mmtokenizer import _MMSentencePieceTokenizer
22 | from models.soundstream_hubert_new import SoundStream
23 | from vocoder import build_codec_model, process_audio
24 | from post_process_audio import replace_low_freq_with_energy_matched
25 |
26 |
27 | parser = argparse.ArgumentParser()
28 | # Model Configuration:
29 | parser.add_argument("--stage1_model", type=str, default="m-a-p/YuE-s1-7B-anneal-en-cot", help="The model checkpoint path or identifier for the Stage 1 model.")
30 | parser.add_argument("--stage2_model", type=str, default="m-a-p/YuE-s2-1B-general", help="The model checkpoint path or identifier for the Stage 2 model.")
31 | parser.add_argument("--max_new_tokens", type=int, default=3000, help="The maximum number of new tokens to generate in one pass during text generation.")
32 | parser.add_argument("--repetition_penalty", type=float, default=1.1, help="repetition_penalty ranges from 1.0 to 2.0 (or higher in some cases). It controls the diversity and coherence of the audio tokens generated. The higher the value, the greater the discouragement of repetition. Setting value to 1.0 means no penalty.")
33 | parser.add_argument("--run_n_segments", type=int, default=2, help="The number of segments to process during the generation.")
34 | parser.add_argument("--stage2_batch_size", type=int, default=4, help="The batch size used in Stage 2 inference.")
35 | # Prompt
36 | parser.add_argument("--genre_txt", type=str, required=True, help="The file path to a text file containing genre tags that describe the musical style or characteristics (e.g., instrumental, genre, mood, vocal timbre, vocal gender). This is used as part of the generation prompt.")
37 | parser.add_argument("--lyrics_txt", type=str, required=True, help="The file path to a text file containing the lyrics for the music generation. These lyrics will be processed and split into structured segments to guide the generation process.")
38 | parser.add_argument("--use_audio_prompt", action="store_true", help="If set, the model will use an audio file as a prompt during generation. The audio file should be specified using --audio_prompt_path.")
39 | parser.add_argument("--audio_prompt_path", type=str, default="", help="The file path to an audio file to use as a reference prompt when --use_audio_prompt is enabled.")
40 | parser.add_argument("--prompt_start_time", type=float, default=0.0, help="The start time in seconds to extract the audio prompt from the given audio file.")
41 | parser.add_argument("--prompt_end_time", type=float, default=30.0, help="The end time in seconds to extract the audio prompt from the given audio file.")
42 | parser.add_argument("--use_dual_tracks_prompt", action="store_true", help="If set, the model will use dual tracks as a prompt during generation. The vocal and instrumental files should be specified using --vocal_track_prompt_path and --instrumental_track_prompt_path.")
43 | parser.add_argument("--vocal_track_prompt_path", type=str, default="", help="The file path to a vocal track file to use as a reference prompt when --use_dual_tracks_prompt is enabled.")
44 | parser.add_argument("--instrumental_track_prompt_path", type=str, default="", help="The file path to an instrumental track file to use as a reference prompt when --use_dual_tracks_prompt is enabled.")
45 | # Output
46 | parser.add_argument("--output_dir", type=str, default="./output", help="The directory where generated outputs will be saved.")
47 | parser.add_argument("--keep_intermediate", action="store_true", help="If set, intermediate outputs will be saved during processing.")
48 | parser.add_argument("--disable_offload_model", action="store_true", help="If set, the model will not be offloaded from the GPU to CPU after Stage 1 inference.")
49 | parser.add_argument("--cuda_idx", type=int, default=0)
50 | parser.add_argument("--seed", type=int, default=42, help="An integer value to reproduce generation.")
51 | # Config for xcodec and upsampler
52 | parser.add_argument('--basic_model_config', default='./xcodec_mini_infer/final_ckpt/config.yaml', help='YAML files for xcodec configurations.')
53 | parser.add_argument('--resume_path', default='./xcodec_mini_infer/final_ckpt/ckpt_00360000.pth', help='Path to the xcodec checkpoint.')
54 | parser.add_argument('--config_path', type=str, default='./xcodec_mini_infer/decoders/config.yaml', help='Path to Vocos config file.')
55 | parser.add_argument('--vocal_decoder_path', type=str, default='./xcodec_mini_infer/decoders/decoder_131000.pth', help='Path to Vocos decoder weights.')
56 | parser.add_argument('--inst_decoder_path', type=str, default='./xcodec_mini_infer/decoders/decoder_151000.pth', help='Path to Vocos decoder weights.')
57 | parser.add_argument('-r', '--rescale', action='store_true', help='Rescale output to avoid clipping.')
58 |
59 |
60 | args = parser.parse_args()
61 | if args.use_audio_prompt and not args.audio_prompt_path:
62 | raise FileNotFoundError("Please offer audio prompt filepath using '--audio_prompt_path', when you enable 'use_audio_prompt'!")
63 | if args.use_dual_tracks_prompt and not args.vocal_track_prompt_path and not args.instrumental_track_prompt_path:
64 | raise FileNotFoundError("Please offer dual tracks prompt filepath using '--vocal_track_prompt_path' and '--inst_decoder_path', when you enable '--use_dual_tracks_prompt'!")
65 | stage1_model = args.stage1_model
66 | stage2_model = args.stage2_model
67 | cuda_idx = args.cuda_idx
68 | max_new_tokens = args.max_new_tokens
69 | stage1_output_dir = os.path.join(args.output_dir, f"stage1")
70 | stage2_output_dir = stage1_output_dir.replace('stage1', 'stage2')
71 | os.makedirs(stage1_output_dir, exist_ok=True)
72 | os.makedirs(stage2_output_dir, exist_ok=True)
73 | def seed_everything(seed=42):
74 | random.seed(seed)
75 | np.random.seed(seed)
76 | torch.manual_seed(seed)
77 | torch.cuda.manual_seed_all(seed)
78 | torch.backends.cudnn.deterministic = True
79 | torch.backends.cudnn.benchmark = False
80 | seed_everything(args.seed)
81 | # load tokenizer and model
82 | device = torch.device(f"cuda:{cuda_idx}" if torch.cuda.is_available() else "cpu")
83 | mmtokenizer = _MMSentencePieceTokenizer("./mm_tokenizer_v0.2_hf/tokenizer.model")
84 | model = AutoModelForCausalLM.from_pretrained(
85 | stage1_model,
86 | torch_dtype=torch.bfloat16,
87 | attn_implementation="flash_attention_2", # To enable flashattn, you have to install flash-attn
88 | # device_map="auto",
89 | )
90 | # to device, if gpu is available
91 | model.to(device)
92 | model.eval()
93 |
94 | if torch.__version__ >= "2.0.0":
95 | model = torch.compile(model)
96 |
97 | codectool = CodecManipulator("xcodec", 0, 1)
98 | codectool_stage2 = CodecManipulator("xcodec", 0, 8)
99 | model_config = OmegaConf.load(args.basic_model_config)
100 | codec_model = eval(model_config.generator.name)(**model_config.generator.config).to(device)
101 | parameter_dict = torch.load(args.resume_path, map_location='cpu', weights_only=False)
102 | codec_model.load_state_dict(parameter_dict['codec_model'])
103 | codec_model.to(device)
104 | codec_model.eval()
105 |
106 | class BlockTokenRangeProcessor(LogitsProcessor):
107 | def __init__(self, start_id, end_id):
108 | self.blocked_token_ids = list(range(start_id, end_id))
109 |
110 | def __call__(self, input_ids, scores):
111 | scores[:, self.blocked_token_ids] = -float("inf")
112 | return scores
113 |
114 | def load_audio_mono(filepath, sampling_rate=16000):
115 | audio, sr = torchaudio.load(filepath)
116 | # Convert to mono
117 | audio = torch.mean(audio, dim=0, keepdim=True)
118 | # Resample if needed
119 | if sr != sampling_rate:
120 | resampler = Resample(orig_freq=sr, new_freq=sampling_rate)
121 | audio = resampler(audio)
122 | return audio
123 |
124 | def encode_audio(codec_model, audio_prompt, device, target_bw=0.5):
125 | if len(audio_prompt.shape) < 3:
126 | audio_prompt.unsqueeze_(0)
127 | with torch.no_grad():
128 | raw_codes = codec_model.encode(audio_prompt.to(device), target_bw=target_bw)
129 | raw_codes = raw_codes.transpose(0, 1)
130 | raw_codes = raw_codes.cpu().numpy().astype(np.int16)
131 | return raw_codes
132 |
133 | def split_lyrics(lyrics):
134 | pattern = r"\[(\w+)\](.*?)(?=\[|\Z)"
135 | segments = re.findall(pattern, lyrics, re.DOTALL)
136 | structured_lyrics = [f"[{seg[0]}]\n{seg[1].strip()}\n\n" for seg in segments]
137 | return structured_lyrics
138 |
139 | # Call the function and print the result
140 | stage1_output_set = []
141 | # Tips:
142 | # genre tags support instrumental,genre,mood,vocal timbr and vocal gender
143 | # all kinds of tags are needed
144 | with open(args.genre_txt) as f:
145 | genres = f.read().strip()
146 | with open(args.lyrics_txt) as f:
147 | lyrics = split_lyrics(f.read())
148 | # intruction
149 | full_lyrics = "\n".join(lyrics)
150 | prompt_texts = [f"Generate music from the given lyrics segment by segment.\n[Genre] {genres}\n{full_lyrics}"]
151 | prompt_texts += lyrics
152 |
153 |
154 | random_id = uuid.uuid4()
155 | output_seq = None
156 | # Here is suggested decoding config
157 | top_p = 0.93
158 | temperature = 1.0
159 | repetition_penalty = args.repetition_penalty
160 | # special tokens
161 | start_of_segment = mmtokenizer.tokenize('[start_of_segment]')
162 | end_of_segment = mmtokenizer.tokenize('[end_of_segment]')
163 | # Format text prompt
164 | run_n_segments = min(args.run_n_segments+1, len(lyrics))
165 | for i, p in enumerate(tqdm(prompt_texts[:run_n_segments], desc="Stage1 inference...")):
166 | section_text = p.replace('[start_of_segment]', '').replace('[end_of_segment]', '')
167 | guidance_scale = 1.5 if i <=1 else 1.2
168 | if i==0:
169 | continue
170 | if i==1:
171 | if args.use_dual_tracks_prompt or args.use_audio_prompt:
172 | if args.use_dual_tracks_prompt:
173 | vocals_ids = load_audio_mono(args.vocal_track_prompt_path)
174 | instrumental_ids = load_audio_mono(args.instrumental_track_prompt_path)
175 | vocals_ids = encode_audio(codec_model, vocals_ids, device, target_bw=0.5)
176 | instrumental_ids = encode_audio(codec_model, instrumental_ids, device, target_bw=0.5)
177 | vocals_ids = codectool.npy2ids(vocals_ids[0])
178 | instrumental_ids = codectool.npy2ids(instrumental_ids[0])
179 | ids_segment_interleaved = rearrange([np.array(vocals_ids), np.array(instrumental_ids)], 'b n -> (n b)')
180 | audio_prompt_codec = ids_segment_interleaved[int(args.prompt_start_time*50*2): int(args.prompt_end_time*50*2)]
181 | audio_prompt_codec = audio_prompt_codec.tolist()
182 | elif args.use_audio_prompt:
183 | audio_prompt = load_audio_mono(args.audio_prompt_path)
184 | raw_codes = encode_audio(codec_model, audio_prompt, device, target_bw=0.5)
185 | # Format audio prompt
186 | code_ids = codectool.npy2ids(raw_codes[0])
187 | audio_prompt_codec = code_ids[int(args.prompt_start_time *50): int(args.prompt_end_time *50)] # 50 is tps of xcodec
188 | audio_prompt_codec_ids = [mmtokenizer.soa] + codectool.sep_ids + audio_prompt_codec + [mmtokenizer.eoa]
189 | sentence_ids = mmtokenizer.tokenize("[start_of_reference]") + audio_prompt_codec_ids + mmtokenizer.tokenize("[end_of_reference]")
190 | head_id = mmtokenizer.tokenize(prompt_texts[0]) + sentence_ids
191 | else:
192 | head_id = mmtokenizer.tokenize(prompt_texts[0])
193 | prompt_ids = head_id + start_of_segment + mmtokenizer.tokenize(section_text) + [mmtokenizer.soa] + codectool.sep_ids
194 | else:
195 | prompt_ids = end_of_segment + start_of_segment + mmtokenizer.tokenize(section_text) + [mmtokenizer.soa] + codectool.sep_ids
196 |
197 | prompt_ids = torch.as_tensor(prompt_ids).unsqueeze(0).to(device)
198 | input_ids = torch.cat([raw_output, prompt_ids], dim=1) if i > 1 else prompt_ids
199 | # Use window slicing in case output sequence exceeds the context of model
200 | max_context = 16384-max_new_tokens-1
201 | if input_ids.shape[-1] > max_context:
202 | print(f'Section {i}: output length {input_ids.shape[-1]} exceeding context length {max_context}, now using the last {max_context} tokens.')
203 | input_ids = input_ids[:, -(max_context):]
204 | with torch.no_grad():
205 | output_seq = model.generate(
206 | input_ids=input_ids,
207 | max_new_tokens=max_new_tokens,
208 | min_new_tokens=100,
209 | do_sample=True,
210 | top_p=top_p,
211 | temperature=temperature,
212 | repetition_penalty=repetition_penalty,
213 | eos_token_id=mmtokenizer.eoa,
214 | pad_token_id=mmtokenizer.eoa,
215 | logits_processor=LogitsProcessorList([BlockTokenRangeProcessor(0, 32002), BlockTokenRangeProcessor(32016, 32016)]),
216 | guidance_scale=guidance_scale,
217 | )
218 | if output_seq[0][-1].item() != mmtokenizer.eoa:
219 | tensor_eoa = torch.as_tensor([[mmtokenizer.eoa]]).to(model.device)
220 | output_seq = torch.cat((output_seq, tensor_eoa), dim=1)
221 | if i > 1:
222 | raw_output = torch.cat([raw_output, prompt_ids, output_seq[:, input_ids.shape[-1]:]], dim=1)
223 | else:
224 | raw_output = output_seq
225 |
226 | # save raw output and check sanity
227 | ids = raw_output[0].cpu().numpy()
228 | soa_idx = np.where(ids == mmtokenizer.soa)[0].tolist()
229 | eoa_idx = np.where(ids == mmtokenizer.eoa)[0].tolist()
230 | if len(soa_idx)!=len(eoa_idx):
231 | raise ValueError(f'invalid pairs of soa and eoa, Num of soa: {len(soa_idx)}, Num of eoa: {len(eoa_idx)}')
232 |
233 | vocals = []
234 | instrumentals = []
235 | range_begin = 1 if args.use_audio_prompt or args.use_dual_tracks_prompt else 0
236 | for i in range(range_begin, len(soa_idx)):
237 | codec_ids = ids[soa_idx[i]+1:eoa_idx[i]]
238 | if codec_ids[0] == 32016:
239 | codec_ids = codec_ids[1:]
240 | codec_ids = codec_ids[:2 * (codec_ids.shape[0] // 2)]
241 | vocals_ids = codectool.ids2npy(rearrange(codec_ids,"(n b) -> b n", b=2)[0])
242 | vocals.append(vocals_ids)
243 | instrumentals_ids = codectool.ids2npy(rearrange(codec_ids,"(n b) -> b n", b=2)[1])
244 | instrumentals.append(instrumentals_ids)
245 | vocals = np.concatenate(vocals, axis=1)
246 | instrumentals = np.concatenate(instrumentals, axis=1)
247 | vocal_save_path = os.path.join(stage1_output_dir, f"{genres.replace(' ', '-')}_tp{top_p}_T{temperature}_rp{repetition_penalty}_maxtk{max_new_tokens}_{random_id}_vtrack".replace('.', '@')+'.npy')
248 | inst_save_path = os.path.join(stage1_output_dir, f"{genres.replace(' ', '-')}_tp{top_p}_T{temperature}_rp{repetition_penalty}_maxtk{max_new_tokens}_{random_id}_itrack".replace('.', '@')+'.npy')
249 | np.save(vocal_save_path, vocals)
250 | np.save(inst_save_path, instrumentals)
251 | stage1_output_set.append(vocal_save_path)
252 | stage1_output_set.append(inst_save_path)
253 |
254 |
255 | # offload model
256 | if not args.disable_offload_model:
257 | model.cpu()
258 | del model
259 | torch.cuda.empty_cache()
260 |
261 | print("Stage 2 inference...")
262 | model_stage2 = AutoModelForCausalLM.from_pretrained(
263 | stage2_model,
264 | torch_dtype=torch.bfloat16,
265 | attn_implementation="flash_attention_2",
266 | # device_map="auto",
267 | )
268 | model_stage2.to(device)
269 | model_stage2.eval()
270 |
271 | if torch.__version__ >= "2.0.0":
272 | model_stage2 = torch.compile(model_stage2)
273 |
274 | def stage2_generate(model, prompt, batch_size=16):
275 | codec_ids = codectool.unflatten(prompt, n_quantizer=1)
276 | codec_ids = codectool.offset_tok_ids(
277 | codec_ids,
278 | global_offset=codectool.global_offset,
279 | codebook_size=codectool.codebook_size,
280 | num_codebooks=codectool.num_codebooks,
281 | ).astype(np.int32)
282 |
283 | # Prepare prompt_ids based on batch size or single input
284 | if batch_size > 1:
285 | codec_list = []
286 | for i in range(batch_size):
287 | idx_begin = i * 300
288 | idx_end = (i + 1) * 300
289 | codec_list.append(codec_ids[:, idx_begin:idx_end])
290 |
291 | codec_ids = np.concatenate(codec_list, axis=0)
292 | prompt_ids = np.concatenate(
293 | [
294 | np.tile([mmtokenizer.soa, mmtokenizer.stage_1], (batch_size, 1)),
295 | codec_ids,
296 | np.tile([mmtokenizer.stage_2], (batch_size, 1)),
297 | ],
298 | axis=1
299 | )
300 | else:
301 | prompt_ids = np.concatenate([
302 | np.array([mmtokenizer.soa, mmtokenizer.stage_1]),
303 | codec_ids.flatten(), # Flatten the 2D array to 1D
304 | np.array([mmtokenizer.stage_2])
305 | ]).astype(np.int32)
306 | prompt_ids = prompt_ids[np.newaxis, ...]
307 |
308 | codec_ids = torch.as_tensor(codec_ids).to(device)
309 | prompt_ids = torch.as_tensor(prompt_ids).to(device)
310 | len_prompt = prompt_ids.shape[-1]
311 |
312 | block_list = LogitsProcessorList([BlockTokenRangeProcessor(0, 46358), BlockTokenRangeProcessor(53526, mmtokenizer.vocab_size)])
313 |
314 | # Teacher forcing generate loop
315 | for frames_idx in range(codec_ids.shape[1]):
316 | cb0 = codec_ids[:, frames_idx:frames_idx+1]
317 | prompt_ids = torch.cat([prompt_ids, cb0], dim=1)
318 | input_ids = prompt_ids
319 |
320 | with torch.no_grad():
321 | stage2_output = model.generate(input_ids=input_ids,
322 | min_new_tokens=7,
323 | max_new_tokens=7,
324 | eos_token_id=mmtokenizer.eoa,
325 | pad_token_id=mmtokenizer.eoa,
326 | logits_processor=block_list,
327 | )
328 |
329 | assert stage2_output.shape[1] - prompt_ids.shape[1] == 7, f"output new tokens={stage2_output.shape[1]-prompt_ids.shape[1]}"
330 | prompt_ids = stage2_output
331 |
332 | # Return output based on batch size
333 | if batch_size > 1:
334 | output = prompt_ids.cpu().numpy()[:, len_prompt:]
335 | output_list = [output[i] for i in range(batch_size)]
336 | output = np.concatenate(output_list, axis=0)
337 | else:
338 | output = prompt_ids[0].cpu().numpy()[len_prompt:]
339 |
340 | return output
341 |
342 | def stage2_inference(model, stage1_output_set, stage2_output_dir, batch_size=4):
343 | stage2_result = []
344 | for i in tqdm(range(len(stage1_output_set))):
345 | output_filename = os.path.join(stage2_output_dir, os.path.basename(stage1_output_set[i]))
346 |
347 | if os.path.exists(output_filename):
348 | print(f'{output_filename} stage2 has done.')
349 | continue
350 |
351 | # Load the prompt
352 | prompt = np.load(stage1_output_set[i]).astype(np.int32)
353 |
354 | # Only accept 6s segments
355 | output_duration = prompt.shape[-1] // 50 // 6 * 6
356 | num_batch = output_duration // 6
357 |
358 | if num_batch <= batch_size:
359 | # If num_batch is less than or equal to batch_size, we can infer the entire prompt at once
360 | output = stage2_generate(model, prompt[:, :output_duration*50], batch_size=num_batch)
361 | else:
362 | # If num_batch is greater than batch_size, process in chunks of batch_size
363 | segments = []
364 | num_segments = (num_batch // batch_size) + (1 if num_batch % batch_size != 0 else 0)
365 |
366 | for seg in range(num_segments):
367 | start_idx = seg * batch_size * 300
368 | # Ensure the end_idx does not exceed the available length
369 | end_idx = min((seg + 1) * batch_size * 300, output_duration*50) # Adjust the last segment
370 | current_batch_size = batch_size if seg != num_segments-1 or num_batch % batch_size == 0 else num_batch % batch_size
371 | segment = stage2_generate(
372 | model,
373 | prompt[:, start_idx:end_idx],
374 | batch_size=current_batch_size
375 | )
376 | segments.append(segment)
377 |
378 | # Concatenate all the segments
379 | output = np.concatenate(segments, axis=0)
380 |
381 | # Process the ending part of the prompt
382 | if output_duration*50 != prompt.shape[-1]:
383 | ending = stage2_generate(model, prompt[:, output_duration*50:], batch_size=1)
384 | output = np.concatenate([output, ending], axis=0)
385 | output = codectool_stage2.ids2npy(output)
386 |
387 | # Fix invalid codes (a dirty solution, which may harm the quality of audio)
388 | # We are trying to find better one
389 | fixed_output = copy.deepcopy(output)
390 | for i, line in enumerate(output):
391 | for j, element in enumerate(line):
392 | if element < 0 or element > 1023:
393 | counter = Counter(line)
394 | most_frequant = sorted(counter.items(), key=lambda x: x[1], reverse=True)[0][0]
395 | fixed_output[i, j] = most_frequant
396 | # save output
397 | np.save(output_filename, fixed_output)
398 | stage2_result.append(output_filename)
399 | return stage2_result
400 |
401 | stage2_result = stage2_inference(model_stage2, stage1_output_set, stage2_output_dir, batch_size=args.stage2_batch_size)
402 | print(stage2_result)
403 | print('Stage 2 DONE.\n')
404 | # convert audio tokens to audio
405 | def save_audio(wav: torch.Tensor, path, sample_rate: int, rescale: bool = False):
406 | folder_path = os.path.dirname(path)
407 | if not os.path.exists(folder_path):
408 | os.makedirs(folder_path)
409 | limit = 0.99
410 | max_val = wav.abs().max()
411 | wav = wav * min(limit / max_val, 1) if rescale else wav.clamp(-limit, limit)
412 | torchaudio.save(str(path), wav, sample_rate=sample_rate, encoding='PCM_S', bits_per_sample=16)
413 | # reconstruct tracks
414 | recons_output_dir = os.path.join(args.output_dir, "recons")
415 | recons_mix_dir = os.path.join(recons_output_dir, 'mix')
416 | os.makedirs(recons_mix_dir, exist_ok=True)
417 | tracks = []
418 | for npy in stage2_result:
419 | codec_result = np.load(npy)
420 | decodec_rlt=[]
421 | with torch.no_grad():
422 | decoded_waveform = codec_model.decode(torch.as_tensor(codec_result.astype(np.int16), dtype=torch.long).unsqueeze(0).permute(1, 0, 2).to(device))
423 | decoded_waveform = decoded_waveform.cpu().squeeze(0)
424 | decodec_rlt.append(torch.as_tensor(decoded_waveform))
425 | decodec_rlt = torch.cat(decodec_rlt, dim=-1)
426 | save_path = os.path.join(recons_output_dir, os.path.splitext(os.path.basename(npy))[0] + ".mp3")
427 | tracks.append(save_path)
428 | save_audio(decodec_rlt, save_path, 16000)
429 | # mix tracks
430 | for inst_path in tracks:
431 | try:
432 | if (inst_path.endswith('.wav') or inst_path.endswith('.mp3')) \
433 | and '_itrack' in inst_path:
434 | # find pair
435 | vocal_path = inst_path.replace('_itrack', '_vtrack')
436 | if not os.path.exists(vocal_path):
437 | continue
438 | # mix
439 | recons_mix = os.path.join(recons_mix_dir, os.path.basename(inst_path).replace('_itrack', '_mixed'))
440 | vocal_stem, sr = sf.read(inst_path)
441 | instrumental_stem, _ = sf.read(vocal_path)
442 | mix_stem = (vocal_stem + instrumental_stem) / 1
443 | sf.write(recons_mix, mix_stem, sr)
444 | except Exception as e:
445 | print(e)
446 |
447 | # vocoder to upsample audios
448 | vocal_decoder, inst_decoder = build_codec_model(args.config_path, args.vocal_decoder_path, args.inst_decoder_path)
449 | vocoder_output_dir = os.path.join(args.output_dir, 'vocoder')
450 | vocoder_stems_dir = os.path.join(vocoder_output_dir, 'stems')
451 | vocoder_mix_dir = os.path.join(vocoder_output_dir, 'mix')
452 | os.makedirs(vocoder_mix_dir, exist_ok=True)
453 | os.makedirs(vocoder_stems_dir, exist_ok=True)
454 | for npy in stage2_result:
455 | if '_itrack' in npy:
456 | # Process instrumental
457 | instrumental_output = process_audio(
458 | npy,
459 | os.path.join(vocoder_stems_dir, 'itrack.mp3'),
460 | args.rescale,
461 | args,
462 | inst_decoder,
463 | codec_model
464 | )
465 | else:
466 | # Process vocal
467 | vocal_output = process_audio(
468 | npy,
469 | os.path.join(vocoder_stems_dir, 'vtrack.mp3'),
470 | args.rescale,
471 | args,
472 | vocal_decoder,
473 | codec_model
474 | )
475 | # mix tracks
476 | try:
477 | mix_output = instrumental_output + vocal_output
478 | vocoder_mix = os.path.join(vocoder_mix_dir, os.path.basename(recons_mix))
479 | save_audio(mix_output, vocoder_mix, 44100, args.rescale)
480 | print(f"Created mix: {vocoder_mix}")
481 | except RuntimeError as e:
482 | print(e)
483 | print(f"mix {vocoder_mix} failed! inst: {instrumental_output.shape}, vocal: {vocal_output.shape}")
484 |
485 | # Post process
486 | replace_low_freq_with_energy_matched(
487 | a_file=recons_mix, # 16kHz
488 | b_file=vocoder_mix, # 48kHz
489 | c_file=os.path.join(args.output_dir, os.path.basename(recons_mix)),
490 | cutoff_freq=5500.0
491 | )
492 |
--------------------------------------------------------------------------------
/code/finetune/core/datasets/helpers.cpp:
--------------------------------------------------------------------------------
1 | /* Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved. */
2 |
3 | /* Helper methods for fast index mapping builds */
4 |
5 | #include
6 | #include
7 | #include
8 | #include
9 | #include
10 | #include
11 | #include
12 | #include
13 |
14 | namespace py = pybind11;
15 | using namespace std;
16 |
17 | const int32_t LONG_SENTENCE_LEN = 512;
18 |
19 | void build_blending_indices(py::array_t &dataset_index,
20 | py::array_t &dataset_sample_index,
21 | const py::array_t &weights,
22 | const int32_t num_datasets,
23 | const int64_t size, const bool verbose)
24 | {
25 | /* Given multiple datasets and a weighting array, build samples
26 | such that it follows those wieghts.*/
27 |
28 | if (verbose)
29 | {
30 | std::cout << "> building indices for blended datasets ..." << std::endl;
31 | }
32 |
33 | // Get the pointer access without the checks.
34 | auto dataset_index_ptr = dataset_index.mutable_unchecked<1>();
35 | auto dataset_sample_index_ptr = dataset_sample_index.mutable_unchecked<1>();
36 | auto weights_ptr = weights.unchecked<1>();
37 |
38 | // Initialize buffer for number of samples used for each dataset.
39 | int64_t current_samples[num_datasets];
40 | for (int64_t i = 0; i < num_datasets; ++i)
41 | {
42 | current_samples[i] = 0;
43 | }
44 |
45 | // For each sample:
46 | for (int64_t sample_idx = 0; sample_idx < size; ++sample_idx)
47 | {
48 |
49 | // Determine where the max error in sampling is happening.
50 | auto sample_idx_double = std::max(static_cast(sample_idx), 1.0);
51 | int64_t max_error_index = 0;
52 | double max_error = weights_ptr[0] * sample_idx_double -
53 | static_cast(current_samples[0]);
54 | for (int64_t dataset_idx = 1; dataset_idx < num_datasets; ++dataset_idx)
55 | {
56 | double error = weights_ptr[dataset_idx] * sample_idx_double -
57 | static_cast(current_samples[dataset_idx]);
58 | if (error > max_error)
59 | {
60 | max_error = error;
61 | max_error_index = dataset_idx;
62 | }
63 | }
64 |
65 | // Populate the indices.
66 | dataset_index_ptr[sample_idx] = static_cast(max_error_index);
67 | dataset_sample_index_ptr[sample_idx] = current_samples[max_error_index];
68 |
69 | // Update the total samples.
70 | current_samples[max_error_index] += 1;
71 | }
72 |
73 | // print info
74 | if (verbose)
75 | {
76 | std::cout << " > sample ratios:" << std::endl;
77 | for (int64_t dataset_idx = 0; dataset_idx < num_datasets; ++dataset_idx)
78 | {
79 | auto ratio = static_cast(current_samples[dataset_idx]) /
80 | static_cast(size);
81 | std::cout << " dataset " << dataset_idx << ", input: " << weights_ptr[dataset_idx] << ", achieved: " << ratio << std::endl;
82 | }
83 | }
84 | }
85 |
86 | py::array build_sample_idx(const py::array_t &sizes_,
87 | const py::array_t &doc_idx_,
88 | const int32_t seq_length,
89 | const int32_t num_epochs,
90 | const int64_t tokens_per_epoch)
91 | {
92 | /* Sample index (sample_idx) is used for gpt2 like dataset for which
93 | the documents are flattened and the samples are built based on this
94 | 1-D flatten array. It is a 2D array with sizes [number-of-samples + 1, 2]
95 | where [..., 0] contains the index into `doc_idx` and [..., 1] is the
96 | starting offset in that document.*/
97 |
98 | // Consistency checks.
99 | assert(seq_length > 1);
100 | assert(num_epochs > 0);
101 | assert(tokens_per_epoch > 1);
102 |
103 | // Remove bound checks.
104 | auto sizes = sizes_.unchecked<1>();
105 | auto doc_idx = doc_idx_.unchecked<1>();
106 |
107 | // Mapping and it's length (1D).
108 | int64_t num_samples = (num_epochs * tokens_per_epoch - 1) / seq_length;
109 | int32_t *sample_idx = new int32_t[2 * (num_samples + 1)];
110 |
111 | // Index into sample_idx.
112 | int64_t sample_index = 0;
113 | // Index into doc_idx.
114 | int64_t doc_idx_index = 0;
115 | // Begining offset for each document.
116 | int32_t doc_offset = 0;
117 | // Start with first document and no offset.
118 | sample_idx[2 * sample_index] = doc_idx_index;
119 | sample_idx[2 * sample_index + 1] = doc_offset;
120 | ++sample_index;
121 |
122 | while (sample_index <= num_samples)
123 | {
124 | // Start with a fresh sequence.
125 | int32_t remaining_seq_length = seq_length + 1;
126 | while (remaining_seq_length != 0)
127 | {
128 | // Get the document length.
129 | auto doc_id = doc_idx[doc_idx_index];
130 | auto doc_length = sizes[doc_id] - doc_offset;
131 | // And add it to the current sequence.
132 | remaining_seq_length -= doc_length;
133 | // If we have more than a full sequence, adjust offset and set
134 | // remaining length to zero so we return from the while loop.
135 | // Note that -1 here is for the same reason we have -1 in
136 | // `_num_epochs` calculations.
137 | if (remaining_seq_length <= 0)
138 | {
139 | doc_offset += (remaining_seq_length + doc_length - 1);
140 | remaining_seq_length = 0;
141 | }
142 | else
143 | {
144 | // Otherwise, start from the begining of the next document.
145 | ++doc_idx_index;
146 | doc_offset = 0;
147 | }
148 | }
149 | // Record the sequence.
150 | sample_idx[2 * sample_index] = doc_idx_index;
151 | sample_idx[2 * sample_index + 1] = doc_offset;
152 | ++sample_index;
153 | }
154 |
155 | // Method to deallocate memory.
156 | py::capsule free_when_done(sample_idx, [](void *mem_)
157 | {
158 | int32_t *mem = reinterpret_cast(mem_);
159 | delete[] mem; });
160 |
161 | // Return the numpy array.
162 | const auto byte_size = sizeof(int32_t);
163 | return py::array(std::vector{num_samples + 1, 2}, // shape
164 | {2 * byte_size, byte_size}, // C-style contiguous strides
165 | sample_idx, // the data pointer
166 | free_when_done); // numpy array references
167 | }
168 |
169 | inline int32_t get_target_sample_len(const int32_t short_seq_ratio,
170 | const int32_t max_length,
171 | std::mt19937 &rand32_gen)
172 | {
173 | /* Training sample length. */
174 | if (short_seq_ratio == 0)
175 | {
176 | return max_length;
177 | }
178 | const auto random_number = rand32_gen();
179 | if ((random_number % short_seq_ratio) == 0)
180 | {
181 | return 2 + random_number % (max_length - 1);
182 | }
183 | return max_length;
184 | }
185 |
186 | template
187 | py::array build_mapping_impl(const py::array_t &docs_,
188 | const py::array_t &sizes_,
189 | const int32_t num_epochs,
190 | const uint64_t max_num_samples,
191 | const int32_t max_seq_length,
192 | const double short_seq_prob,
193 | const int32_t seed,
194 | const bool verbose,
195 | const int32_t min_num_sent)
196 | {
197 | /* Build a mapping of (start-index, end-index, sequence-length) where
198 | start and end index are the indices of the sentences in the sample
199 | and sequence-length is the target sequence length.
200 | */
201 |
202 | // Consistency checks.
203 | assert(num_epochs > 0);
204 | assert(max_seq_length > 1);
205 | assert(short_seq_prob >= 0.0);
206 | assert(short_seq_prob <= 1.0);
207 | assert(seed > 0);
208 |
209 | // Remove bound checks.
210 | auto docs = docs_.unchecked<1>();
211 | auto sizes = sizes_.unchecked<1>();
212 |
213 | // For efficiency, convert probability to ratio. Note: rand() generates int.
214 | int32_t short_seq_ratio = 0;
215 | if (short_seq_prob > 0)
216 | {
217 | short_seq_ratio = static_cast(round(1.0 / short_seq_prob));
218 | }
219 |
220 | if (verbose)
221 | {
222 | const auto sent_start_index = docs[0];
223 | const auto sent_end_index = docs[docs_.shape(0) - 1];
224 | const auto num_sentences = sent_end_index - sent_start_index;
225 | cout << " using:" << endl
226 | << std::flush;
227 | cout << " number of documents: " << docs_.shape(0) - 1 << endl
228 | << std::flush;
229 | cout << " sentences range: [" << sent_start_index << ", " << sent_end_index << ")" << endl
230 | << std::flush;
231 | cout << " total number of sentences: " << num_sentences << endl
232 | << std::flush;
233 | cout << " number of epochs: " << num_epochs << endl
234 | << std::flush;
235 | cout << " maximum number of samples: " << max_num_samples << endl
236 | << std::flush;
237 | cout << " maximum sequence length: " << max_seq_length << endl
238 | << std::flush;
239 | cout << " short sequence probability: " << short_seq_prob << endl
240 | << std::flush;
241 | cout << " short sequence ration (1/prob): " << short_seq_ratio << endl
242 | << std::flush;
243 | cout << " seed: " << seed << endl
244 | << std::flush;
245 | }
246 |
247 | // Mapping and it's length (1D).
248 | int64_t num_samples = -1;
249 | DocIdx *maps = NULL;
250 |
251 | // Perform two iterations, in the first iteration get the size
252 | // and allocate memory and in the second iteration populate the map.
253 | bool second = false;
254 | for (int32_t iteration = 0; iteration < 2; ++iteration)
255 | {
256 |
257 | // Set the seed so both iterations produce the same results.
258 | std::mt19937 rand32_gen(seed);
259 |
260 | // Set the flag on second iteration.
261 | second = (iteration == 1);
262 |
263 | // Counters:
264 | uint64_t empty_docs = 0;
265 | uint64_t one_sent_docs = 0;
266 | uint64_t long_sent_docs = 0;
267 |
268 | // Current map index.
269 | uint64_t map_index = 0;
270 |
271 | // For each epoch:
272 | for (int32_t epoch = 0; epoch < num_epochs; ++epoch)
273 | {
274 | if (map_index >= max_num_samples)
275 | {
276 | if (verbose && (!second))
277 | {
278 | cout << " reached " << max_num_samples << " samples after "
279 | << epoch << " epochs ..." << endl
280 | << std::flush;
281 | }
282 | break;
283 | }
284 | // For each document:
285 | for (int32_t doc = 0; doc < (docs.shape(0) - 1); ++doc)
286 | {
287 |
288 | // Document sentences are in [sent_index_first, sent_index_last)
289 | const auto sent_index_first = docs[doc];
290 | const auto sent_index_last = docs[doc + 1];
291 |
292 | // At the begining of the document previous index is the
293 | // start index.
294 | auto prev_start_index = sent_index_first;
295 |
296 | // Remaining documents.
297 | auto num_remain_sent = sent_index_last - sent_index_first;
298 |
299 | // Some bookkeeping
300 | if ((epoch == 0) && (!second))
301 | {
302 | if (num_remain_sent == 0)
303 | {
304 | ++empty_docs;
305 | }
306 | if (num_remain_sent == 1)
307 | {
308 | ++one_sent_docs;
309 | }
310 | }
311 |
312 | // Detect documents with long sentences.
313 | bool contains_long_sentence = false;
314 | if (num_remain_sent > 1)
315 | {
316 | for (auto sent_index = sent_index_first;
317 | sent_index < sent_index_last; ++sent_index)
318 | {
319 | if (sizes[sent_index] > LONG_SENTENCE_LEN)
320 | {
321 | if ((epoch == 0) && (!second))
322 | {
323 | ++long_sent_docs;
324 | }
325 | contains_long_sentence = true;
326 | break;
327 | }
328 | }
329 | }
330 |
331 | // If we have more than two sentences.
332 | if ((num_remain_sent >= min_num_sent) && (!contains_long_sentence))
333 | {
334 |
335 | // Set values.
336 | auto seq_len = int32_t{0};
337 | auto num_sent = int32_t{0};
338 | auto target_seq_len = get_target_sample_len(short_seq_ratio,
339 | max_seq_length,
340 | rand32_gen);
341 |
342 | // Loop through sentences.
343 | for (auto sent_index = sent_index_first;
344 | sent_index < sent_index_last; ++sent_index)
345 | {
346 |
347 | // Add the size and number of sentences.
348 | seq_len += sizes[sent_index];
349 | ++num_sent;
350 | --num_remain_sent;
351 |
352 | // If we have reached the target length.
353 | // and if not only one sentence is left in the document.
354 | // and if we have at least two sentneces.
355 | // and if we have reached end of the document.
356 | if (((seq_len >= target_seq_len) &&
357 | (num_remain_sent > 1) &&
358 | (num_sent >= min_num_sent)) ||
359 | (num_remain_sent == 0))
360 | {
361 |
362 | // Check for overflow.
363 | if ((3 * map_index + 2) >
364 | std::numeric_limits::max())
365 | {
366 | cout << "number of samples exceeded maximum "
367 | << "allowed by type int64: "
368 | << std::numeric_limits::max()
369 | << endl;
370 | throw std::overflow_error("Number of samples");
371 | }
372 |
373 | // Populate the map.
374 | if (second)
375 | {
376 | const auto map_index_0 = 3 * map_index;
377 | maps[map_index_0] = static_cast(prev_start_index);
378 | maps[map_index_0 + 1] = static_cast(sent_index + 1);
379 | maps[map_index_0 + 2] = static_cast(target_seq_len);
380 | }
381 |
382 | // Update indices / counters.
383 | ++map_index;
384 | prev_start_index = sent_index + 1;
385 | target_seq_len = get_target_sample_len(short_seq_ratio,
386 | max_seq_length,
387 | rand32_gen);
388 | seq_len = 0;
389 | num_sent = 0;
390 | }
391 |
392 | } // for (auto sent_index=sent_index_first; ...
393 | } // if (num_remain_sent > 1) {
394 | } // for (int doc=0; doc < num_docs; ++doc) {
395 | } // for (int epoch=0; epoch < num_epochs; ++epoch) {
396 |
397 | if (!second)
398 | {
399 | if (verbose)
400 | {
401 | cout << " number of empty documents: " << empty_docs << endl
402 | << std::flush;
403 | cout << " number of documents with one sentence: " << one_sent_docs << endl
404 | << std::flush;
405 | cout << " number of documents with long sentences: " << long_sent_docs << endl
406 | << std::flush;
407 | cout << " will create mapping for " << map_index << " samples" << endl
408 | << std::flush;
409 | }
410 | assert(maps == NULL);
411 | assert(num_samples < 0);
412 | maps = new DocIdx[3 * map_index];
413 | num_samples = static_cast(map_index);
414 | }
415 |
416 | } // for (int iteration=0; iteration < 2; ++iteration) {
417 |
418 | // Shuffle.
419 | // We need a 64 bit random number generator as we might have more
420 | // than 2 billion samples.
421 | std::mt19937_64 rand64_gen(seed + 1);
422 | for (auto i = (num_samples - 1); i > 0; --i)
423 | {
424 | const auto j = static_cast(rand64_gen() % (i + 1));
425 | const auto i0 = 3 * i;
426 | const auto j0 = 3 * j;
427 | // Swap values.
428 | swap(maps[i0], maps[j0]);
429 | swap(maps[i0 + 1], maps[j0 + 1]);
430 | swap(maps[i0 + 2], maps[j0 + 2]);
431 | }
432 |
433 | // Method to deallocate memory.
434 | py::capsule free_when_done(maps, [](void *mem_)
435 | {
436 | DocIdx *mem = reinterpret_cast(mem_);
437 | delete[] mem; });
438 |
439 | // Return the numpy array.
440 | const auto byte_size = sizeof(DocIdx);
441 | return py::array(std::vector{num_samples, 3}, // shape
442 | {3 * byte_size, byte_size}, // C-style contiguous strides
443 | maps, // the data pointer
444 | free_when_done); // numpy array references
445 | }
446 |
447 | py::array build_mapping(const py::array_t &docs_,
448 | const py::array_t &sizes_,
449 | const int num_epochs,
450 | const uint64_t max_num_samples,
451 | const int max_seq_length,
452 | const double short_seq_prob,
453 | const int seed,
454 | const bool verbose,
455 | const int32_t min_num_sent)
456 | {
457 |
458 | if (sizes_.size() > std::numeric_limits::max())
459 | {
460 | if (verbose)
461 | {
462 | cout << " using uint64 for data mapping..." << endl
463 | << std::flush;
464 | }
465 | return build_mapping_impl(docs_, sizes_, num_epochs,
466 | max_num_samples, max_seq_length,
467 | short_seq_prob, seed, verbose,
468 | min_num_sent);
469 | }
470 | else
471 | {
472 | if (verbose)
473 | {
474 | cout << " using uint32 for data mapping..." << endl
475 | << std::flush;
476 | }
477 | return build_mapping_impl(docs_, sizes_, num_epochs,
478 | max_num_samples, max_seq_length,
479 | short_seq_prob, seed, verbose,
480 | min_num_sent);
481 | }
482 | }
483 |
484 | template
485 | py::array build_blocks_mapping_impl(const py::array_t &docs_,
486 | const py::array_t &sizes_,
487 | const py::array_t &titles_sizes_,
488 | const int32_t num_epochs,
489 | const uint64_t max_num_samples,
490 | const int32_t max_seq_length,
491 | const int32_t seed,
492 | const bool verbose,
493 | const bool use_one_sent_blocks)
494 | {
495 | /* Build a mapping of (start-index, end-index, sequence-length) where
496 | start and end index are the indices of the sentences in the sample
497 | and sequence-length is the target sequence length.
498 | */
499 |
500 | // Consistency checks.
501 | assert(num_epochs > 0);
502 | assert(max_seq_length > 1);
503 | assert(seed > 0);
504 |
505 | // Remove bound checks.
506 | auto docs = docs_.unchecked<1>();
507 | auto sizes = sizes_.unchecked<1>();
508 | auto titles_sizes = titles_sizes_.unchecked<1>();
509 |
510 | if (verbose)
511 | {
512 | const auto sent_start_index = docs[0];
513 | const auto sent_end_index = docs[docs_.shape(0) - 1];
514 | const auto num_sentences = sent_end_index - sent_start_index;
515 | cout << " using:" << endl
516 | << std::flush;
517 | cout << " number of documents: " << docs_.shape(0) - 1 << endl
518 | << std::flush;
519 | cout << " sentences range: [" << sent_start_index << ", " << sent_end_index << ")" << endl
520 | << std::flush;
521 | cout << " total number of sentences: " << num_sentences << endl
522 | << std::flush;
523 | cout << " number of epochs: " << num_epochs << endl
524 | << std::flush;
525 | cout << " maximum number of samples: " << max_num_samples << endl
526 | << std::flush;
527 | cout << " maximum sequence length: " << max_seq_length << endl
528 | << std::flush;
529 | cout << " seed: " << seed << endl
530 | << std::flush;
531 | }
532 |
533 | // Mapping and its length (1D).
534 | int64_t num_samples = -1;
535 | DocIdx *maps = NULL;
536 |
537 | // Acceptable number of sentences per block.
538 | int min_num_sent = 2;
539 | if (use_one_sent_blocks)
540 | {
541 | min_num_sent = 1;
542 | }
543 |
544 | // Perform two iterations, in the first iteration get the size
545 | // and allocate memory and in the second iteration populate the map.
546 | bool second = false;
547 | for (int32_t iteration = 0; iteration < 2; ++iteration)
548 | {
549 |
550 | // Set the flag on second iteration.
551 | second = (iteration == 1);
552 |
553 | // Current map index.
554 | uint64_t map_index = 0;
555 |
556 | uint64_t empty_docs = 0;
557 | uint64_t one_sent_docs = 0;
558 | uint64_t long_sent_docs = 0;
559 | // For each epoch:
560 | for (int32_t epoch = 0; epoch < num_epochs; ++epoch)
561 | {
562 | // assign every block a unique id
563 | int32_t block_id = 0;
564 |
565 | if (map_index >= max_num_samples)
566 | {
567 | if (verbose && (!second))
568 | {
569 | cout << " reached " << max_num_samples << " samples after "
570 | << epoch << " epochs ..." << endl
571 | << std::flush;
572 | }
573 | break;
574 | }
575 | // For each document:
576 | for (int32_t doc = 0; doc < (docs.shape(0) - 1); ++doc)
577 | {
578 |
579 | // Document sentences are in [sent_index_first, sent_index_last)
580 | const auto sent_index_first = docs[doc];
581 | const auto sent_index_last = docs[doc + 1];
582 | const auto target_seq_len = max_seq_length - titles_sizes[doc];
583 |
584 | // At the begining of the document previous index is the
585 | // start index.
586 | auto prev_start_index = sent_index_first;
587 |
588 | // Remaining documents.
589 | auto num_remain_sent = sent_index_last - sent_index_first;
590 |
591 | // Some bookkeeping
592 | if ((epoch == 0) && (!second))
593 | {
594 | if (num_remain_sent == 0)
595 | {
596 | ++empty_docs;
597 | }
598 | if (num_remain_sent == 1)
599 | {
600 | ++one_sent_docs;
601 | }
602 | }
603 | // Detect documents with long sentences.
604 | bool contains_long_sentence = false;
605 | if (num_remain_sent >= min_num_sent)
606 | {
607 | for (auto sent_index = sent_index_first;
608 | sent_index < sent_index_last; ++sent_index)
609 | {
610 | if (sizes[sent_index] > LONG_SENTENCE_LEN)
611 | {
612 | if ((epoch == 0) && (!second))
613 | {
614 | ++long_sent_docs;
615 | }
616 | contains_long_sentence = true;
617 | break;
618 | }
619 | }
620 | }
621 | // If we have enough sentences and no long sentences.
622 | if ((num_remain_sent >= min_num_sent) && (!contains_long_sentence))
623 | {
624 |
625 | // Set values.
626 | auto seq_len = int32_t{0};
627 | auto num_sent = int32_t{0};
628 |
629 | // Loop through sentences.
630 | for (auto sent_index = sent_index_first;
631 | sent_index < sent_index_last; ++sent_index)
632 | {
633 |
634 | // Add the size and number of sentences.
635 | seq_len += sizes[sent_index];
636 | ++num_sent;
637 | --num_remain_sent;
638 |
639 | // If we have reached the target length.
640 | // and there are an acceptable number of sentences left
641 | // and if we have at least the minimum number of sentences.
642 | // or if we have reached end of the document.
643 | if (((seq_len >= target_seq_len) &&
644 | (num_remain_sent >= min_num_sent) &&
645 | (num_sent >= min_num_sent)) ||
646 | (num_remain_sent == 0))
647 | {
648 |
649 | // Populate the map.
650 | if (second)
651 | {
652 | const auto map_index_0 = 4 * map_index;
653 | // Each sample has 4 items: the starting sentence index, ending sentence index,
654 | // the index of the document from which the block comes (used for fetching titles)
655 | // and the unique id of the block (used for creating block indexes)
656 |
657 | maps[map_index_0] = static_cast(prev_start_index);
658 | maps[map_index_0 + 1] = static_cast(sent_index + 1);
659 | maps[map_index_0 + 2] = static_cast(doc);
660 | maps[map_index_0 + 3] = static_cast(block_id);
661 | }
662 |
663 | // Update indices / counters.
664 | ++map_index;
665 | ++block_id;
666 | prev_start_index = sent_index + 1;
667 | seq_len = 0;
668 | num_sent = 0;
669 | }
670 | } // for (auto sent_index=sent_index_first; ...
671 | } // if (num_remain_sent > 1) {
672 | } // for (int doc=0; doc < num_docs; ++doc) {
673 | } // for (int epoch=0; epoch < num_epochs; ++epoch) {
674 |
675 | if (!second)
676 | {
677 | if (verbose)
678 | {
679 | cout << " number of empty documents: " << empty_docs << endl
680 | << std::flush;
681 | cout << " number of documents with one sentence: " << one_sent_docs << endl
682 | << std::flush;
683 | cout << " number of documents with long sentences: " << long_sent_docs << endl
684 | << std::flush;
685 | cout << " will create mapping for " << map_index << " samples" << endl
686 | << std::flush;
687 | }
688 | assert(maps == NULL);
689 | assert(num_samples < 0);
690 | maps = new DocIdx[4 * map_index];
691 | num_samples = static_cast(map_index);
692 | }
693 |
694 | } // for (int iteration=0; iteration < 2; ++iteration) {
695 |
696 | // Shuffle.
697 | // We need a 64 bit random number generator as we might have more
698 | // than 2 billion samples.
699 | std::mt19937_64 rand64_gen(seed + 1);
700 | for (auto i = (num_samples - 1); i > 0; --i)
701 | {
702 | const auto j = static_cast(rand64_gen() % (i + 1));
703 | const auto i0 = 4 * i;
704 | const auto j0 = 4 * j;
705 | // Swap values.
706 | swap(maps[i0], maps[j0]);
707 | swap(maps[i0 + 1], maps[j0 + 1]);
708 | swap(maps[i0 + 2], maps[j0 + 2]);
709 | swap(maps[i0 + 3], maps[j0 + 3]);
710 | }
711 |
712 | // Method to deallocate memory.
713 | py::capsule free_when_done(maps, [](void *mem_)
714 | {
715 | DocIdx *mem = reinterpret_cast(mem_);
716 | delete[] mem; });
717 |
718 | // Return the numpy array.
719 | const auto byte_size = sizeof(DocIdx);
720 | return py::array(std::vector{num_samples, 4}, // shape
721 | {4 * byte_size, byte_size}, // C-style contiguous strides
722 | maps, // the data pointer
723 | free_when_done); // numpy array references
724 | }
725 |
726 | py::array build_blocks_mapping(const py::array_t &docs_,
727 | const py::array_t &sizes_,
728 | const py::array_t &titles_sizes_,
729 | const int num_epochs,
730 | const uint64_t max_num_samples,
731 | const int max_seq_length,
732 | const int seed,
733 | const bool verbose,
734 | const bool use_one_sent_blocks)
735 | {
736 |
737 | if (sizes_.size() > std::numeric_limits::max())
738 | {
739 | if (verbose)
740 | {
741 | cout << " using uint64 for data mapping..." << endl
742 | << std::flush;
743 | }
744 | return build_blocks_mapping_impl(docs_, sizes_, titles_sizes_,
745 | num_epochs, max_num_samples, max_seq_length, seed, verbose, use_one_sent_blocks);
746 | }
747 | else
748 | {
749 | if (verbose)
750 | {
751 | cout << " using uint32 for data mapping..." << endl
752 | << std::flush;
753 | }
754 | return build_blocks_mapping_impl(docs_, sizes_, titles_sizes_,
755 | num_epochs, max_num_samples, max_seq_length, seed, verbose, use_one_sent_blocks);
756 | }
757 | }
758 |
759 | PYBIND11_MODULE(helpers, m)
760 | {
761 | m.def("build_mapping", &build_mapping);
762 | m.def("build_blocks_mapping", &build_blocks_mapping);
763 | m.def("build_sample_idx", &build_sample_idx);
764 | m.def("build_blending_indices", &build_blending_indices);
765 | }
766 |
--------------------------------------------------------------------------------