├── .gitignore
├── LICENSE.txt
├── README.md
├── README.rst
├── benchmarking
├── README.md
├── benchmarking.png
├── single_node_multiprocessing.py
└── single_node_serial_computing.py
├── minimalcluster
├── __init__.py
├── master_node.py
└── worker_node.py
├── setup.cfg
└── setup.py
/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
2 | dist/*
3 | build/*
4 | *.egg-info/*
5 |
--------------------------------------------------------------------------------
/LICENSE.txt:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) [2017] [Xiaodong DENG]
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # ***minimalcluster*** - A Minimal Cluster Computing Framework with Python
2 |
3 | 
 4 |
5 | "***minimal***" here means minimal dependency or platform requirements, as well as its nature of "minimum viable product". It's mainly for tackling straightforward "embarrassingly parallel" tasks using multiple commodity machines, also a good choice for *experimental and learning purposes*. The idea came from [Eli Bendersky's blog](https://eli.thegreenplace.net/2012/01/24/distributed-computing-in-python-with-multiprocessing).
6 |
7 | ***minimalcluster*** is built only using plain Python and its standard libraries (mainly `multiprocessing`). This brought a few advantages, including
8 |
9 | - no additional installation or configuration is needed
10 | - 100% cross-platform (you can even have Linux, MacOS, and Windows nodes within a single cluster).
11 |
12 | This package can be used with Python 2.7+ or 3.6+. But within a cluster, you can only choose a single version of Python, either 2 or 3.
13 |
14 | For more frameworks for parallel or cluster computing, you may also want to refer to [Parallel Processing and Multiprocessing in Python](https://wiki.python.org/moin/ParallelProcessing).
15 |
16 |
17 | #### Contents
18 |
19 | - [Benchmarking](#benchmarking)
20 |
21 | - [Usage & Examples](#usage--examples)
22 |
23 |
24 | ## Benchmarking
25 |
26 |
4 |
5 | "***minimal***" here means minimal dependency or platform requirements, as well as its nature of "minimum viable product". It's mainly for tackling straightforward "embarrassingly parallel" tasks using multiple commodity machines, also a good choice for *experimental and learning purposes*. The idea came from [Eli Bendersky's blog](https://eli.thegreenplace.net/2012/01/24/distributed-computing-in-python-with-multiprocessing).
6 |
7 | ***minimalcluster*** is built only using plain Python and its standard libraries (mainly `multiprocessing`). This brought a few advantages, including
8 |
9 | - no additional installation or configuration is needed
10 | - 100% cross-platform (you can even have Linux, MacOS, and Windows nodes within a single cluster).
11 |
12 | This package can be used with Python 2.7+ or 3.6+. But within a cluster, you can only choose a single version of Python, either 2 or 3.
13 |
14 | For more frameworks for parallel or cluster computing, you may also want to refer to [Parallel Processing and Multiprocessing in Python](https://wiki.python.org/moin/ParallelProcessing).
15 |
16 |
17 | #### Contents
18 |
19 | - [Benchmarking](#benchmarking)
20 |
21 | - [Usage & Examples](#usage--examples)
22 |
23 |
24 | ## Benchmarking
25 |
26 |
27 | 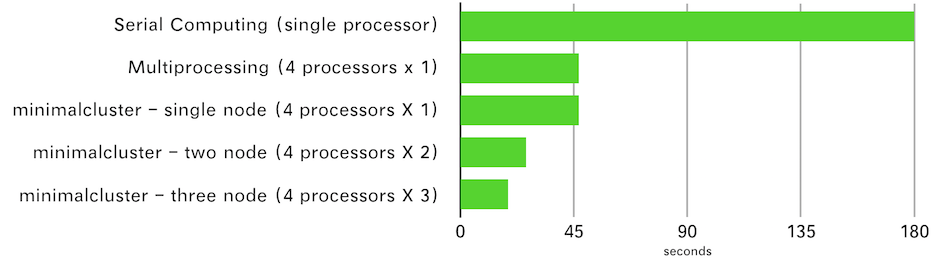 28 |
28 |
29 |
30 | ([Details](https://github.com/XD-DENG/minimalcluster-py/blob/master/benchmarking/README.md))
31 |
32 |
33 | ## Usage & Examples
34 |
35 | #### Step 1 - Install this package
36 |
37 | ```
38 | pip install minimalcluster
39 | ```
40 |
41 | #### Step 2 - Start master node
42 |
43 | Open your Python terminal on your machine which will be used as **Master Node**, and run
44 |
45 | ```python
46 | from minimalcluster import MasterNode
47 |
48 | your_host = '' # or use '0.0.0.0' if you have high enough privilege
49 | your_port=
50 | your_authkey = ''
51 |
52 | master = MasterNode(HOST = your_host, PORT = your_port, AUTHKEY = your_authkey)
53 | master.start_master_server()
54 | ```
55 |
56 | Please note the master node will join the cluster as worker node as well by default. If you prefer otherwise, you can have argument `if_join_as_worker` in `start_master_server()` to be `False`. In addition, you can also remove it from the cluster by invoking `master.stop_as_worker()` and join as worker node again by invoking `master.join_as_worker()`.
57 |
58 | #### Step 3 - Start worker nodes
59 |
60 | On all your **Worker Nodes**, run the command below in your Python terminal
61 |
62 | ```python
63 | from minimalcluster import WorkerNode
64 |
65 | your_host = ''
66 | your_port=
67 | your_authkey = ''
68 | N_processors_to_use =
69 |
70 | worker = WorkerNode(your_host, your_port, your_authkey, nprocs = N_processors_to_use)
71 |
72 | worker.join_cluster()
73 |
74 | ```
75 |
76 | Note: if your `nprocs` is bigger than the number of processors on your machine, it will be changed to be the number of processors.
77 |
78 | After the operations on the worker nodes, you can go back to your **Master node** and check the list of connected **Worker nodes**.
79 |
80 | ```python
81 | master.list_workers()
82 | ```
83 |
84 |
85 | #### Step 4 - Prepare environment to share with worker nodes
86 |
87 | We need to specify the task function (as well as its potential dependencies) and the arguments to share with worker nodes, including
88 |
89 | - **Environment**: The `environment` is simply the codes that's going to run on worker nodes. There are two ways to set up environment. The first one is to prepare a separate `.py` file as environment file and declare all the functions you need inside, then use `master.load_envir('')` to load the environment. Another way is for simple cases. You can use `master.load_envir('', from_file = False)` to load the environment, for example `master.load_envir("f = lambda x: x * 2", from_file = False)`.
90 |
91 | - **Task Function**: We need to register the task function using `master.register_target_function('')`, like `master.register_target_function("f")`. Please note the task function itself must be declared in the environment file or statement.
92 |
93 | - **Arguments**: The argument must be a list. It will be passed to the task function. Usage: `master.load_args(args)`. **Note the elements in list `args` must be unique.**
94 |
95 |
96 | #### Step 5 - Submit jobs
97 |
98 | Now your cluster is ready. you can try the examples below in your Python terminal on your **Master node**.
99 |
100 | ##### Example 1 - Estimate value of Pi
101 |
102 | ```python
103 | envir_statement = '''
104 | from random import random
105 | example_pi_estimate_throw = lambda x: 1 if (random() * 2 - 1)**2 + (random() * 2 - 1)**2 < 1 else 0
106 | '''
107 | master.load_envir(envir_statement, from_file = False)
108 | master.register_target_function("example_pi_estimate_throw")
109 |
110 | N = int(1e6)
111 | master.load_args(range(N))
112 |
113 | result = master.execute()
114 |
115 | print("Pi is roughly %f" % (4.0 * sum([x2 for x1, x2 in result.items()]) / N))
116 | ```
117 |
118 | ##### Example 2 - Factorization
119 |
120 | ```python
121 | envir_statement = '''
122 | # A naive factorization method. Take integer 'n', return list of factors.
123 | # Ref: https://eli.thegreenplace.net/2012/01/24/distributed-computing-in-python-with-multiprocessing
124 | def example_factorize_naive(n):
125 | if n < 2:
126 | return []
127 | factors = []
128 | p = 2
129 | while True:
130 | if n == 1:
131 | return factors
132 | r = n % p
133 | if r == 0:
134 | factors.append(p)
135 | n = n / p
136 | elif p * p >= n:
137 | factors.append(n)
138 | return factors
139 | elif p > 2:
140 | p += 2
141 | else:
142 | p += 1
143 | assert False, "unreachable"
144 | '''
145 |
146 | #Create N large numbers to factorize.
147 | def make_nums(N):
148 | nums = [999999999999]
149 | for i in range(N):
150 | nums.append(nums[-1] + 2)
151 | return nums
152 |
153 | master.load_args(make_nums(5000))
154 | master.load_envir(envir_statement, from_file = False)
155 | master.register_target_function("example_factorize_naive")
156 |
157 | result = master.execute()
158 |
159 | for x in result.items()[:10]: # if running on Python 3, use `list(result.items())` rather than `result.items()`
160 | print(x)
161 | ```
162 |
163 | ##### Example 3 - Feed multiple arguments to target function
164 |
165 | It's possible that you need to feed multiple arguments to target function. A small trick will be needed here: you need to wrap your arguments into a tuple, then pass the tuple to the target function as a "single" argument. Within your argument function, you can "unzip" this tuple and obtain your arguments.
166 |
167 | ```python
168 | envir_statement = '''
169 | f = lambda x:x[0]+x[1]
170 | '''
171 | master.load_envir(envir_statement, from_file = False)
172 | master.register_target_function("f")
173 |
174 | master.load_args([(1,2), (3,4), (5, 6), (7, 8)])
175 |
176 | result = master.execute()
177 |
178 | print(result)
179 | ```
180 |
181 | #### Step 6 - Shutdown the cluster
182 |
183 | You can shutdown the cluster by running
184 |
185 | ```python
186 | master.shutdown()
187 | ```
188 |
189 |
--------------------------------------------------------------------------------
/README.rst:
--------------------------------------------------------------------------------
1 | ====================================================================
2 | *minimalcluster* - A Minimal Cluster Computing Framework with Python
3 | ====================================================================
4 |
5 | "**minimal**" here means minimal dependency or platform requirements, as well as its nature of "minimum viable product". It's mainly for tackling straightforward "embarrassingly parallel" tasks using multiple commodity machines, also a good choice for experimental and learning purposes. The idea came from `Eli Bendersky's blog `_
6 | .
7 |
8 | **minimalcluster** is built only using plain Python and its standard libraries (mainly *multiprocessing*). This brings a few advantages, including
9 |
10 | - no additional installation or configuration is needed
11 |
12 | - 100% cross-platform (you can even have Linux, MacOS, and Windows nodes within a single cluster).
13 |
14 | This package can be used with Python 2.7+ or 3.6+. But within a cluster, you can only choose a single version of Python, either 2 or 3.
15 |
16 | For more frameworks for parallel or cluster computing, you may also want to refer to `Parallel Processing and Multiprocessing in Python `_
17 | .
18 |
19 |
20 | ******************
21 | Benchmarking
22 | ******************
23 |
24 | .. image:: https://raw.githubusercontent.com/XD-DENG/minimalcluster-py/master/benchmarking/benchmarking.png
25 |
26 |
27 | `Details `_
28 |
29 | ******************
30 | Usage & Examples
31 | ******************
32 |
33 | Step 1 - Install this package
34 | =============================
35 |
36 | .. code-block:: bash
37 |
38 | pip install minimalcluster
39 |
40 | Step 2 - Start master node
41 | =============================
42 | Open your Python terminal on your machine which will be used as **Master Node**, and run
43 |
44 | .. code:: python
45 |
46 | from minimalcluster import MasterNode
47 |
48 | your_host = ''
49 | # or use '0.0.0.0' if you have high enough privilege
50 | your_port=
51 | your_authkey = ''
52 |
53 | master = MasterNode(HOST = your_host, PORT = your_port, AUTHKEY = your_authkey)
54 | master.start_master_server()
55 |
56 |
57 | Please note the master node will join the cluster as worker node as well by default. If you prefer otherwise, you can have argument *if_join_as_worker* in *start_master_server()* to be *False*. In addition, you can also remove it from the cluster by invoking *master.stop_as_worker()* and join as worker node again by invoking *master.join_as_worker()*.
58 |
59 |
60 | Step 3 - Start worker nodes
61 | =============================
62 |
63 | On all your **Worker Nodes**, run the command below in your Python terminal
64 |
65 | .. code:: python
66 |
67 | from minimalcluster import WorkerNode
68 |
69 | your_host = ''
70 | your_port=
71 | your_authkey = ''
72 | N_processors_to_use =
73 |
74 | worker = WorkerNode(your_host, your_port, your_authkey, nprocs = N_processors_to_use)
75 |
76 | worker.join_cluster()
77 |
78 | Note: if your nprocs is bigger than the number of processors on your machine, it will be changed to be the number of processors.
79 |
80 | After the operations on the worker nodes, you can go back to your Master node and check the list of connected Worker nodes.
81 |
82 | .. code:: python
83 |
84 | master.list_workers()
85 |
86 |
87 | Step 4 - Prepare environment to share with worker nodes
88 | =======================================================
89 |
90 | We need to specify the task function (as well as its potential dependencies) and the arguments to share with worker nodes, including
91 |
92 | **Environment**: The environment is simply the codes that's going to run on worker nodes. There are two ways to set up environment. The first one is to prepare a separate .py file as environment file and declare all the functions you need inside, then use *master.load_envir('')* to load the environment. Another way is for simple cases. You can use *master.load_envir('', from_file = False)* to load the environment, for example *master.load_envir("f = lambda x: x * 2", from_file = False)*.
93 |
94 | **Task Function**: We need to register the task function using *master.register_target_function('')*, like *master.register_target_function("f")*. Please note the task function itself must be declared in the environment file or statement.
95 |
96 | **Arguments**: The argument must be a list. It will be passed to the task function. Usage: *master.load_args(args)*. **Note the elements in list args must be unique.**
97 |
98 | Step 5 - Submit jobs
99 | ====================
100 |
101 | Now your cluster is ready. you can try the examples below in your Python terminal on your Master node.
102 |
103 | Example 1 - Estimate value of Pi
104 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
105 |
106 | .. code:: python
107 |
108 | envir_statement = '''
109 | from random import random
110 | example_pi_estimate_throw = lambda x: 1 if (random() * 2 - 1)**2 + (random() * 2 - 1)**2 < 1 else 0
111 | '''
112 | master.load_envir(envir_statement, from_file = False)
113 | master.register_target_function("example_pi_estimate_throw")
114 |
115 | N = int(1e6)
116 | master.load_args(range(N))
117 |
118 | result = master.execute()
119 |
120 | print("Pi is roughly %f" % (4.0 * sum([x2 for x1, x2 in result.items()]) / N))
121 |
122 |
123 | Example 2 - Factorization
124 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
125 |
126 | .. code:: python
127 |
128 | envir_statement = '''
129 | # A naive factorization method. Take integer 'n', return list of factors.
130 | # Ref: https://eli.thegreenplace.net/2012/01/24/distributed-computing-in-python-with-multiprocessing
131 | def example_factorize_naive(n):
132 | if n < 2:
133 | return []
134 | factors = []
135 | p = 2
136 | while True:
137 | if n == 1:
138 | return factors
139 | r = n % p
140 | if r == 0:
141 | factors.append(p)
142 | n = n / p
143 | elif p * p >= n:
144 | factors.append(n)
145 | return factors
146 | elif p > 2:
147 | p += 2
148 | else:
149 | p += 1
150 | assert False, "unreachable"
151 | '''
152 |
153 | #Create N large numbers to factorize.
154 | def make_nums(N):
155 | nums = [999999999999]
156 | for i in range(N):
157 | nums.append(nums[-1] + 2)
158 | return nums
159 |
160 | master.load_args(make_nums(5000))
161 | master.load_envir(envir_statement, from_file = False)
162 | master.register_target_function("example_factorize_naive")
163 |
164 | result = master.execute()
165 |
166 | for x in result.items()[:10]: # if running on Python 3, use `list(result.items())` rather than `result.items()`
167 | print(x)
168 |
169 | Example 3 - Feed multiple arguments to target function
170 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
171 |
172 | It's possible that you need to feed multiple arguments to target function. A small trick will be needed here: you need to wrap your arguments into a tuple, then pass the tuple to the target function as a "single" argument. Within your argument function, you can "unzip" this tuple and obtain your arguments.
173 |
174 | .. code:: python
175 |
176 | envir_statement = '''
177 | f = lambda x:x[0]+x[1]
178 | '''
179 | master.load_envir(envir_statement, from_file = False)
180 | master.register_target_function("f")
181 |
182 | master.load_args([(1,2), (3,4), (5, 6), (7, 8)])
183 |
184 | result = master.execute()
185 |
186 | print(result)
187 |
188 | Step 6 - Shutdown the cluster
189 | ==============================
190 |
191 | You can shutdown the cluster by running
192 |
193 | .. code:: python
194 |
195 | master.shutdown()
196 |
197 |
198 |
199 |
--------------------------------------------------------------------------------
/benchmarking/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## Sample Problem to Tackle
3 |
4 | We try to factorize some given big integers, using a naive factorization method.
5 |
6 | ```python
7 | def example_factorize_naive(n):
8 | if n < 2:
9 | return []
10 | factors = []
11 | p = 2
12 | while True:
13 | if n == 1:
14 | return factors
15 | r = n % p
16 | if r == 0:
17 | factors.append(p)
18 | n = n / p
19 | elif p * p >= n:
20 | factors.append(n)
21 | return factors
22 | elif p > 2:
23 | p += 2
24 | else:
25 | p += 1
26 | assert False, "unreachable"
27 | ```
28 |
29 | The big integers are generated using the codes below
30 |
31 | ```python
32 | def make_nums(N):
33 | nums = [999999999999]
34 | for i in range(N):
35 | nums.append(nums[-1] + 2)
36 | return nums
37 |
38 | N = 20000
39 | big_ints = make_nums(N)
40 | ```
41 |
42 |
43 | ## Different Methods and Results
44 |
45 | Serial computing using single processor (`single_node_serial_computing.py`): ~180 seconds
46 |
47 | Parallel computing using multiple processors on a single machine (`single_node_multiprocessing.py`): ~47 seconds
48 |
49 | minimalcluster - single node (4 processors X 1): ~47 seconds
50 |
51 | minimalcluster - two node (4 processors X 2): ~26 seconds
52 |
53 | minimalcluster - three node (4 processors X 3): ~19 seconds
54 |
55 |
56 |
57 | ## Specs
58 |
59 | The benchmarking was done on three virtual machines on DigitalOcean.
60 |
61 | ### Network
62 |
63 | Using the normal network connection among virtual machines. The ping time is about 0.35 to 0.40 ms.
64 |
65 | ### CPU Info
66 |
67 | ```
68 | Architecture: x86_64
69 | CPU(s): 4
70 | Vendor ID: GenuineIntel
71 | CPU family: 6
72 | Model: 85
73 | Model name: Intel(R) Xeon(R) Platinum 8168 CPU @ 2.70GHz
74 | CPU MHz: 2693.658
75 | ```
76 |
77 | ### Software
78 |
79 | - Python 2.7.5
80 | - minimalcluster 0.1.0.dev5
--------------------------------------------------------------------------------
/benchmarking/benchmarking.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XD-DENG/minimalcluster-py/4c57908d93a5d5f8a3b0e72fa6275c49871183d6/benchmarking/benchmarking.png
--------------------------------------------------------------------------------
/benchmarking/single_node_multiprocessing.py:
--------------------------------------------------------------------------------
1 | import time
2 | from multiprocessing import Pool
3 |
4 | # A naive factorization method. Take integer 'n', return list of factors.
5 | # Ref: https://eli.thegreenplace.net/2012/01/24/distributed-computing-in-python-with-multiprocessing
6 | def example_factorize_naive(n):
7 | if n < 2:
8 | return []
9 | factors = []
10 | p = 2
11 | while True:
12 | if n == 1:
13 | return factors
14 | r = n % p
15 | if r == 0:
16 | factors.append(p)
17 | n = n / p
18 | elif p * p >= n:
19 | factors.append(n)
20 | return factors
21 | elif p > 2:
22 | p += 2
23 | else:
24 | p += 1
25 | assert False, "unreachable"
26 |
27 |
28 | def make_nums(N):
29 | nums = [999999999999]
30 | for i in range(N):
31 | nums.append(nums[-1] + 2)
32 | return nums
33 |
34 | N = 20000
35 | big_ints = make_nums(N)
36 |
37 | t_start = time.time()
38 | p = Pool(4)
39 | result = p.map(example_factorize_naive, big_ints)
40 | t_end = time.time()
41 |
42 | print("[Single-Node Parallel Computing (4 Cores)] Lapse: {} seconds".format(t_end - t_start))
--------------------------------------------------------------------------------
/benchmarking/single_node_serial_computing.py:
--------------------------------------------------------------------------------
1 | import time
2 |
3 | # A naive factorization method. Take integer 'n', return list of factors.
4 | # Ref: https://eli.thegreenplace.net/2012/01/24/distributed-computing-in-python-with-multiprocessing
5 | def example_factorize_naive(n):
6 | if n < 2:
7 | return []
8 | factors = []
9 | p = 2
10 | while True:
11 | if n == 1:
12 | return factors
13 | r = n % p
14 | if r == 0:
15 | factors.append(p)
16 | n = n / p
17 | elif p * p >= n:
18 | factors.append(n)
19 | return factors
20 | elif p > 2:
21 | p += 2
22 | else:
23 | p += 1
24 | assert False, "unreachable"
25 |
26 |
27 | def make_nums(N):
28 | nums = [999999999999]
29 | for i in range(N):
30 | nums.append(nums[-1] + 2)
31 | return nums
32 |
33 | N = 20000
34 | big_ints = make_nums(N)
35 |
36 | t_start = time.time()
37 | result = map(example_factorize_naive, big_ints)
38 | t_end = time.time()
39 |
40 | print("[Single-Node Serial Computing (Single Core)] Lapse: {} seconds".format(t_end - t_start))
--------------------------------------------------------------------------------
/minimalcluster/__init__.py:
--------------------------------------------------------------------------------
1 |
2 | __all__ = ['MasterNode', "WorkerNode"]
3 |
4 |
5 | import sys
6 | if sys.version_info.major == 3:
7 | from .master_node import MasterNode
8 | from .worker_node import WorkerNode
9 | else:
10 | from master_node import MasterNode
11 | from worker_node import WorkerNode
12 |
--------------------------------------------------------------------------------
/minimalcluster/master_node.py:
--------------------------------------------------------------------------------
1 | from multiprocessing.managers import SyncManager, DictProxy
2 | from multiprocessing import Process, cpu_count
3 | import os, signal, sys, time, datetime, random, string, inspect
4 | from functools import partial
5 | from types import FunctionType
6 | from socket import getfqdn
7 | if sys.version_info.major == 3:
8 | from queue import Queue as _Queue
9 | else:
10 | from Queue import Queue as _Queue
11 |
12 |
13 |
14 | __all__ = ['MasterNode']
15 |
16 |
17 |
18 | # Make Queue.Queue pickleable
19 | # Ref: https://stackoverflow.com/questions/25631266/cant-pickle-class-main-jobqueuemanager
20 | class Queue(_Queue):
21 | """ A picklable queue. """
22 | def __getstate__(self):
23 | # Only pickle the state we care about
24 | return (self.maxsize, self.queue, self.unfinished_tasks)
25 |
26 | def __setstate__(self, state):
27 | # Re-initialize the object, then overwrite the default state with
28 | # our pickled state.
29 | Queue.__init__(self)
30 | self.maxsize = state[0]
31 | self.queue = state[1]
32 | self.unfinished_tasks = state[2]
33 |
34 | # prepare for using functools.partial()
35 | def get_fun(fun):
36 | return fun
37 |
38 |
39 |
40 | class JobQueueManager(SyncManager):
41 | pass
42 |
43 |
44 | def clear_queue(q):
45 | while not q.empty():
46 | q.get()
47 |
48 |
49 | def start_worker_in_background(HOST, PORT, AUTHKEY, nprocs, quiet):
50 | from minimalcluster import WorkerNode
51 | worker = WorkerNode(HOST, PORT, AUTHKEY, nprocs, quiet)
52 | worker.join_cluster()
53 |
54 |
55 | class MasterNode():
56 |
57 | def __init__(self, HOST = '127.0.0.1', PORT = 8888, AUTHKEY = None, chunksize = 50):
58 | '''
59 | Method to initiate a master node object.
60 |
61 | HOST: the hostname or IP address to use
62 | PORT: the port to use
63 | AUTHKEY: The process's authentication key (a string or byte string).
64 | If None is given, a random string will be given
65 | chunksize: The numbers are split into chunks. Each chunk is pushed into the job queue.
66 | Here the size of each chunk if specified.
67 | '''
68 |
69 | # Check & process AUTHKEY
70 | # to [1] ensure compatilibity between Py 2 and 3; [2] to allow both string and byte string for AUTHKEY input.
71 | assert type(AUTHKEY) in [str, bytes] or AUTHKEY is None, "AUTKEY must be either one among string, byte string, and None (a random AUTHKEY will be generated if None is given)."
72 | if AUTHKEY != None and type(AUTHKEY) == str:
73 | AUTHKEY = AUTHKEY.encode()
74 |
75 | self.HOST = HOST
76 | self.PORT = PORT
77 | self.AUTHKEY = AUTHKEY if AUTHKEY != None else ''.join(random.choice(string.ascii_uppercase) for _ in range(6)).encode()
78 | self.chunksize = chunksize
79 | self.server_status = 'off'
80 | self.as_worker = False
81 | self.target_fun = None
82 | self.master_fqdn = getfqdn()
83 | self.pid_as_worker_on_master = None
84 |
85 |
86 | def join_as_worker(self):
87 | '''
88 | This method helps start the master node as a worker node as well
89 | '''
90 | if self.as_worker:
91 | print("[WARNING] This node has already joined the cluster as a worker node.")
92 | else:
93 | self.process_as_worker = Process(target = start_worker_in_background, args=(self.HOST, self.PORT, self.AUTHKEY, cpu_count(), True, ))
94 | self.process_as_worker.start()
95 |
96 | # waiting for the master node joining the cluster as a worker
97 | while self.master_fqdn not in [w[0] for w in self.list_workers()]:
98 | pass
99 |
100 | self.pid_as_worker_on_master = [w for w in self.list_workers() if w[0] == self.master_fqdn][0][2]
101 | self.as_worker = True
102 | print("[INFO] Current node has joined the cluster as a Worker Node (using {} processors; Process ID: {}).".format(cpu_count(), self.process_as_worker.pid))
103 |
104 | def start_master_server(self, if_join_as_worker = True):
105 | """
106 | Method to create a manager as the master node.
107 |
108 | Arguments:
109 | if_join_as_worker: Boolen.
110 | If True, the master node will also join the cluster as worker node. It will automatically run in background.
111 | If False, users need to explicitly configure if they want the master node to work as worker node too.
112 | The default value is True.
113 | """
114 | self.job_q = Queue()
115 | self.result_q = Queue()
116 | self.error_q = Queue()
117 | self.get_envir = Queue()
118 | self.target_function = Queue()
119 | self.raw_queue_of_worker_list = Queue()
120 | self.raw_dict_of_job_history = dict() # a queue to store the history of job assignment
121 |
122 | # Return synchronized proxies for the actual Queue objects.
123 | # Note that for "callable=", we don't use `lambda` which is commonly used in multiprocessing examples.
124 | # Instead, we use `partial()` to wrapper one more time.
125 | # This is to avoid "pickle.PicklingError" on Windows platform. This helps the codes run on both Windows and Linux/Mac OS.
126 | # Ref: https://stackoverflow.com/questions/25631266/cant-pickle-class-main-jobqueuemanager
127 |
128 | JobQueueManager.register('get_job_q', callable=partial(get_fun, self.job_q))
129 | JobQueueManager.register('get_result_q', callable=partial(get_fun, self.result_q))
130 | JobQueueManager.register('get_error_q', callable=partial(get_fun, self.error_q))
131 | JobQueueManager.register('get_envir', callable = partial(get_fun, self.get_envir))
132 | JobQueueManager.register('target_function', callable = partial(get_fun, self.target_function))
133 | JobQueueManager.register('queue_of_worker_list', callable = partial(get_fun, self.raw_queue_of_worker_list))
134 | JobQueueManager.register('dict_of_job_history', callable = partial(get_fun, self.raw_dict_of_job_history), proxytype=DictProxy)
135 |
136 | self.manager = JobQueueManager(address=(self.HOST, self.PORT), authkey=self.AUTHKEY)
137 | self.manager.start()
138 | self.server_status = 'on'
139 | print('[{}] Master Node started at {}:{} with authkey `{}`.'.format(str(datetime.datetime.now()), self.HOST, self.PORT, self.AUTHKEY.decode()))
140 |
141 | self.shared_job_q = self.manager.get_job_q()
142 | self.shared_result_q = self.manager.get_result_q()
143 | self.shared_error_q = self.manager.get_error_q()
144 | self.share_envir = self.manager.get_envir()
145 | self.share_target_fun = self.manager.target_function()
146 | self.queue_of_worker_list = self.manager.queue_of_worker_list()
147 | self.dict_of_job_history = self.manager.dict_of_job_history()
148 |
149 | if if_join_as_worker:
150 | self.join_as_worker()
151 |
152 | def stop_as_worker(self):
153 | '''
154 | Given the master node can also join the cluster as a worker, we also need to have a method to stop it as a worker node (which may be necessary in some cases).
155 | This method serves this purpose.
156 |
157 | Given the worker node will start a separate process for heartbeat purpose.
158 | We need to shutdown the heartbeat process separately.
159 | '''
160 | try:
161 | os.kill(self.pid_as_worker_on_master, signal.SIGTERM)
162 | self.pid_as_worker_on_master = None
163 | self.process_as_worker.terminate()
164 | except AttributeError:
165 | print("[WARNING] The master node has not started as a worker yet.")
166 | finally:
167 | self.as_worker = False
168 | print("[INFO] The master node has stopped working as a worker node.")
169 |
170 | def list_workers(self):
171 | '''
172 | Return a list of connected worker nodes.
173 | Each element of this list is:
174 | (hostname of worker node,
175 | # of available cores,
176 | pid of heartbeat process on the worker node,
177 | if the worker node is working on any work load currently (1:Yes, 0:No))
178 | '''
179 |
180 | # STEP-1: an element will be PUT into the queue "self.queue_of_worker_list"
181 | # STEP-2: worker nodes will watch on this queue and attach their information into this queue too
182 | # STEP-3: this function will collect the elements from the queue and return the list of workers node who responded
183 |
184 | self.queue_of_worker_list.put(".") # trigger worker nodes to contact master node to show their "heartbeat"
185 | time.sleep(0.3) # Allow some time for collecting "heartbeat"
186 |
187 | worker_list = []
188 | while not self.queue_of_worker_list.empty():
189 | worker_list.append(self.queue_of_worker_list.get())
190 |
191 | return list(set([w for w in worker_list if w != "."]))
192 |
193 |
194 | def load_envir(self, source, from_file = True):
195 | if from_file:
196 | with open(source, 'r') as f:
197 | self.envir_statements = "".join(f.readlines())
198 | else:
199 | self.envir_statements = source
200 |
201 | def register_target_function(self, fun_name):
202 | self.target_fun = fun_name
203 |
204 | def load_args(self, args):
205 | '''
206 | args should be a list
207 | '''
208 | self.args_to_share_to_workers = args
209 |
210 |
211 | def __check_target_function(self):
212 |
213 | try:
214 | exec(self.envir_statements)
215 | except:
216 | print("[ERROR] The environment statements given can't be executed.")
217 | raise
218 |
219 | if self.target_fun in locals() and isinstance(locals()[self.target_fun], FunctionType):
220 | return True
221 | else:
222 | return False
223 |
224 |
225 | def execute(self):
226 |
227 | # Ensure the error queue is empty
228 | clear_queue(self.shared_error_q)
229 |
230 | if self.target_fun == None:
231 | print("[ERROR] Target function is not registered yet.")
232 | elif not self.__check_target_function():
233 | print("[ERROR] The target function registered (`{}`) can't be built with the given environment statements.".format(self.target_fun))
234 | elif len(self.args_to_share_to_workers) != len(set(self.args_to_share_to_workers)):
235 | print("[ERROR]The arguments to share with worker nodes are not unique. Please check the data you passed to MasterNode.load_args().")
236 | elif len(self.list_workers()) == 0:
237 | print("[ERROR] No worker node is available. Can't proceed to execute")
238 | else:
239 | print("[{}] Assigning jobs to worker nodes.".format(str(datetime.datetime.now())))
240 |
241 |
242 | self.share_envir.put(self.envir_statements)
243 |
244 | self.share_target_fun.put(self.target_fun)
245 |
246 | # The numbers are split into chunks. Each chunk is pushed into the job queue
247 | for i in range(0, len(self.args_to_share_to_workers), self.chunksize):
248 | self.shared_job_q.put((i, self.args_to_share_to_workers[i:(i + self.chunksize)]))
249 |
250 | # Wait until all results are ready in shared_result_q
251 | numresults = 0
252 | resultdict = {}
253 | list_job_id_done = []
254 | while numresults < len(self.args_to_share_to_workers):
255 |
256 | if len(self.list_workers()) == 0:
257 | print("[{}][Warning] No valid worker node at this moment. You can wait for workers to join, or CTRL+C to cancle.".format(str(datetime.datetime.now())))
258 | continue
259 |
260 | if self.shared_job_q.empty() and sum([w[3] for w in self.list_workers()]) == 0:
261 | '''
262 | After all jobs are assigned and all worker nodes have finished their works,
263 | check if the nodes who have un-finished jobs are sitll alive.
264 | if not, re-collect these jobs and put them inot the job queue
265 | '''
266 | while not self.shared_result_q.empty():
267 | try:
268 | job_id_done, outdict = self.shared_result_q.get(False)
269 | resultdict.update(outdict)
270 | list_job_id_done.append(job_id_done)
271 | numresults += len(outdict)
272 | except:
273 | pass
274 |
275 | [self.dict_of_job_history.pop(k, None) for k in list_job_id_done]
276 |
277 | for job_id in [x for x,y in self.dict_of_job_history.items()]:
278 | print("Putting {} back to the job queue".format(job_id))
279 | self.shared_job_q.put((job_id, self.args_to_share_to_workers[job_id:(job_id + self.chunksize)]))
280 |
281 | if not self.shared_error_q.empty():
282 | print("[ERROR] Running error occured in remote worker node:")
283 | print(self.shared_error_q.get())
284 |
285 | clear_queue(self.shared_job_q)
286 | clear_queue(self.shared_result_q)
287 | clear_queue(self.share_envir)
288 | clear_queue(self.share_target_fun)
289 | clear_queue(self.shared_error_q)
290 | self.dict_of_job_history.clear()
291 |
292 | return None
293 |
294 | # job_id_done is the unique id of the jobs that have been done and returned to the master node.
295 | while not self.shared_result_q.empty():
296 | try:
297 | job_id_done, outdict = self.shared_result_q.get(False)
298 | resultdict.update(outdict)
299 | list_job_id_done.append(job_id_done)
300 | numresults += len(outdict)
301 | except:
302 | pass
303 |
304 |
305 | print("[{}] Aggregating on Master node...".format(str(datetime.datetime.now())))
306 |
307 | # After the execution is done, empty all the args & task function queues
308 | # to prepare for the next execution
309 | clear_queue(self.shared_job_q)
310 | clear_queue(self.shared_result_q)
311 | clear_queue(self.share_envir)
312 | clear_queue(self.share_target_fun)
313 | self.dict_of_job_history.clear()
314 |
315 | return resultdict
316 |
317 |
318 | def shutdown(self):
319 | if self.as_worker:
320 | self.stop_as_worker()
321 |
322 | if self.server_status == 'on':
323 | self.manager.shutdown()
324 | self.server_status = "off"
325 | print("[INFO] The master node is shut down.")
326 | else:
327 | print("[WARNING] The master node is not started yet or already shut down.")
328 |
--------------------------------------------------------------------------------
/minimalcluster/worker_node.py:
--------------------------------------------------------------------------------
1 | from multiprocessing.managers import SyncManager
2 | import multiprocessing
3 | import sys, os, time, datetime
4 | from socket import getfqdn
5 | if sys.version_info.major == 3:
6 | import queue as Queue
7 | else:
8 | import Queue
9 |
10 | __all__ = ['WorkerNode']
11 |
12 | def single_worker(envir, fun, job_q, result_q, error_q, history_d, hostname):
13 | """ A worker function to be launched in a separate process. Takes jobs from
14 | job_q - each job a list of numbers to factorize. When the job is done,
15 | the result (dict mapping number -> list of factors) is placed into
16 | result_q. Runs until job_q is empty.
17 | """
18 |
19 | # Reference:
20 | #https://stackoverflow.com/questions/4484872/why-doesnt-exec-work-in-a-function-with-a-subfunction
21 | exec(envir) in locals()
22 | globals().update(locals())
23 | while True:
24 | try:
25 | job_id, job_detail = job_q.get_nowait()
26 | # history_q.put({job_id: hostname})
27 | history_d[job_id] = hostname
28 | outdict = {n: globals()[fun](n) for n in job_detail}
29 | result_q.put((job_id, outdict))
30 | except Queue.Empty:
31 | return
32 | except:
33 | # send the Unexpected error to master node
34 | error_q.put("Worker Node '{}': ".format(hostname) + "; ".join([repr(e) for e in sys.exc_info()]))
35 | return
36 |
37 | def mp_apply(envir, fun, shared_job_q, shared_result_q, shared_error_q, shared_history_d, hostname, nprocs):
38 | """ Split the work with jobs in shared_job_q and results in
39 | shared_result_q into several processes. Launch each process with
40 | single_worker as the worker function, and wait until all are
41 | finished.
42 | """
43 |
44 | procs = []
45 | for i in range(nprocs):
46 | p = multiprocessing.Process(
47 | target=single_worker,
48 | args=(envir, fun, shared_job_q, shared_result_q, shared_error_q, shared_history_d, hostname))
49 | procs.append(p)
50 | p.start()
51 |
52 | for p in procs:
53 | p.join()
54 |
55 | # this function is put at top level rather than as a method of WorkerNode class
56 | # this is to bypass the error "AttributeError: type object 'ServerQueueManager' has no attribute 'from_address'""
57 | def heartbeat(queue_of_worker_list, worker_hostname, nprocs, status):
58 | '''
59 | heartbeat will keep an eye on whether the master node is checking the list of valid nodes
60 | if it detects the signal, it will share the information of current node with the master node.
61 | '''
62 | while True:
63 | if not queue_of_worker_list.empty():
64 | queue_of_worker_list.put((worker_hostname, nprocs, os.getpid(), status.value))
65 | time.sleep(0.01)
66 |
67 | class WorkerNode():
68 |
69 | def __init__(self, IP, PORT, AUTHKEY, nprocs, quiet = False):
70 | '''
71 | Method to initiate a master node object.
72 |
73 | IP: the hostname or IP address of the Master Node
74 | PORT: the port to use (decided by Master NOde)
75 | AUTHKEY: The process's authentication key (a string or byte string).
76 | It can't be None for Worker Nodes.
77 | nprocs: Integer. The number of processors on the Worker Node to be available to the Master Node.
78 | It should be less or equal to the number of processors on the Worker Node. If higher than that, the # of available processors will be used instead.
79 | '''
80 |
81 | assert type(AUTHKEY) in [str, bytes], "AUTHKEY must be either string or byte string."
82 | assert type(nprocs) == int, "'nprocs' must be an integer."
83 |
84 | self.IP = IP
85 | self.PORT = PORT
86 | self.AUTHKEY = AUTHKEY.encode() if type(AUTHKEY) == str else AUTHKEY
87 | N_local_cores = multiprocessing.cpu_count()
88 | if nprocs > N_local_cores:
89 | print("[WARNING] nprocs specified is more than the # of cores of this node. Using the # of cores ({}) instead.".format(N_local_cores))
90 | self.nprocs = N_local_cores
91 | elif nprocs < 1:
92 | print("[WARNING] nprocs specified is not valid. Using the # of cores ({}) instead.".format(N_local_cores))
93 | self.nprocs = N_local_cores
94 | else:
95 | self.nprocs = nprocs
96 | self.connected = False
97 | self.worker_hostname = getfqdn()
98 | self.quiet = quiet
99 | self.working_status = multiprocessing.Value("i", 0) # if the node is working on any work loads
100 |
101 | def connect(self):
102 | """
103 | Connect to Master Node after the Worker Node is initialized.
104 | """
105 | class ServerQueueManager(SyncManager):
106 | pass
107 |
108 | ServerQueueManager.register('get_job_q')
109 | ServerQueueManager.register('get_result_q')
110 | ServerQueueManager.register('get_error_q')
111 | ServerQueueManager.register('get_envir')
112 | ServerQueueManager.register('target_function')
113 | ServerQueueManager.register('queue_of_worker_list')
114 | ServerQueueManager.register('dict_of_job_history')
115 |
116 | self.manager = ServerQueueManager(address=(self.IP, self.PORT), authkey=self.AUTHKEY)
117 |
118 | try:
119 | if not self.quiet:
120 | print('[{}] Building connection to {}:{}'.format(str(datetime.datetime.now()), self.IP, self.PORT))
121 | self.manager.connect()
122 | if not self.quiet:
123 | print('[{}] Client connected to {}:{}'.format(str(datetime.datetime.now()), self.IP, self.PORT))
124 | self.connected = True
125 | self.job_q = self.manager.get_job_q()
126 | self.result_q = self.manager.get_result_q()
127 | self.error_q = self.manager.get_error_q()
128 | self.envir_to_use = self.manager.get_envir()
129 | self.target_func = self.manager.target_function()
130 | self.queue_of_worker_list = self.manager.queue_of_worker_list()
131 | self.dict_of_job_history = self.manager.dict_of_job_history()
132 | except:
133 | print("[ERROR] No connection could be made. Please check the network or your configuration.")
134 |
135 | def join_cluster(self):
136 | """
137 | This method will connect the worker node with the master node, and start to listen to the master node for any job assignment.
138 | """
139 |
140 | self.connect()
141 |
142 | if self.connected:
143 |
144 | # start the `heartbeat` process so that the master node can always know if this node is still connected.
145 | self.heartbeat_process = multiprocessing.Process(target = heartbeat, args = (self.queue_of_worker_list, self.worker_hostname, self.nprocs, self.working_status,))
146 | self.heartbeat_process.start()
147 |
148 | if not self.quiet:
149 | print('[{}] Listening to Master node {}:{}'.format(str(datetime.datetime.now()), self.IP, self.PORT))
150 |
151 | while True:
152 |
153 | try:
154 | if_job_q_empty = self.job_q.empty()
155 | except EOFError:
156 | print("[{}] Lost connection with Master node.".format(str(datetime.datetime.now())))
157 | sys.exit(1)
158 |
159 | if not if_job_q_empty and self.error_q.empty():
160 |
161 | print("[{}] Started working on some tasks.".format(str(datetime.datetime.now())))
162 |
163 |
164 | # load environment setup
165 | try:
166 | envir = self.envir_to_use.get(timeout = 3)
167 | self.envir_to_use.put(envir)
168 | except:
169 | sys.exit("[ERROR] Failed to get the environment statement from Master node.")
170 |
171 | # load task function
172 | try:
173 | target_func = self.target_func.get(timeout = 3)
174 | self.target_func.put(target_func)
175 | except:
176 | sys.exit("[ERROR] Failed to get the task function from Master node.")
177 |
178 | self.working_status.value = 1
179 | mp_apply(envir, target_func, self.job_q, self.result_q, self.error_q, self.dict_of_job_history, self.worker_hostname, self.nprocs)
180 | print("[{}] Tasks finished.".format(str(datetime.datetime.now())))
181 | self.working_status.value = 0
182 |
183 | time.sleep(0.1) # avoid too frequent communication which is unnecessary
184 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [bdist_wheel]
2 | universal=1
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup
2 | from os import path
3 |
4 | here = path.abspath(path.dirname(__file__))
5 |
6 | # Get the long description from the README file
7 | with open(path.join(here, 'README.rst')) as f:
8 | long_description = f.read()
9 |
10 |
11 | setup(
12 | name="minimalcluster",
13 | version="0.1.0.dev14",
14 | description='A minimal cluster computing framework',
15 | long_description=long_description,
16 | url='https://github.com/XD-DENG/minimalcluster-py',
17 | author='Xiaodong DENG',
18 | author_email='xd.deng.r@gmail.com',
19 | license='MIT',
20 | keywords='parallel cluster multiprocessing',
21 | packages=["minimalcluster"]
22 | )
23 |
--------------------------------------------------------------------------------