├── .idea
├── .gitignore
├── vcs.xml
├── inspectionProfiles
│ └── profiles_settings.xml
├── modules.xml
├── misc.xml
└── fund_crawler.iml
├── Data
├── new.csv
├── crawler3.csv
├── fund_info.csv
├── fund_list.csv
├── company_list.csv
├── manager list.csv
├── instruments_ansi.csv
├── f10_ts
│ └── std and sharp ratio.csv
└── fail.csv
├── main.py
├── Data_Read.py
├── .gitignore
├── README.md
├── test.py
├── MyCrawyer.py
└── Data_solve.py
/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # Default ignored files
2 | /workspace.xml
--------------------------------------------------------------------------------
/Data/new.csv:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XDTD/fund_crawler/HEAD/Data/new.csv
--------------------------------------------------------------------------------
/Data/crawler3.csv:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XDTD/fund_crawler/HEAD/Data/crawler3.csv
--------------------------------------------------------------------------------
/Data/fund_info.csv:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XDTD/fund_crawler/HEAD/Data/fund_info.csv
--------------------------------------------------------------------------------
/Data/fund_list.csv:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XDTD/fund_crawler/HEAD/Data/fund_list.csv
--------------------------------------------------------------------------------
/Data/company_list.csv:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XDTD/fund_crawler/HEAD/Data/company_list.csv
--------------------------------------------------------------------------------
/Data/manager list.csv:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XDTD/fund_crawler/HEAD/Data/manager list.csv
--------------------------------------------------------------------------------
/Data/instruments_ansi.csv:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XDTD/fund_crawler/HEAD/Data/instruments_ansi.csv
--------------------------------------------------------------------------------
/Data/f10_ts/std and sharp ratio.csv:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XDTD/fund_crawler/HEAD/Data/f10_ts/std and sharp ratio.csv
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/inspectionProfiles/profiles_settings.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
--------------------------------------------------------------------------------
/.idea/fund_crawler.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | from Data_solve import *
2 | from Data_Read import *
3 | from MyCrawyer import *
4 |
5 | if __name__ == '__main__':
6 | # 获取公司列表
7 | url_company = 'http://fund.eastmoney.com/js/jjjz_gs.js?dt=1463791574015'
8 | get_company_list(url_company)
9 | # 获取基金列表
10 | url = 'http://fund.eastmoney.com/js/fundcode_search.js'
11 | get_fund_list(url)
12 | # 基金信息下载与处理
13 | get_pingzhong_data()
14 | # std 和夏普比率信息下载
15 | download_f10_ts_data()
16 | # 基金经理信息下载
17 | download_manager_info()
18 |
19 |
20 | # std 和夏普比率信息处理
21 | solve_f10_data()
22 | # 基金经理信息处理
23 | solve_manager_info()
24 | # pingzhong data 处理
25 | # solve_crawler3()
26 |
--------------------------------------------------------------------------------
/Data_Read.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import os
3 | from sqlalchemy import create_engine
4 |
5 |
6 | def listdir(path, list_name): # 传入存储的list
7 | for file in os.listdir(path):
8 | file_path = os.path.join(path , file)
9 | if os.path.isdir(file_path):
10 | listdir(file_path , list_name)
11 | else:
12 | list_name.append(file_path)
13 | # print(list_name) # 虽然打印出来,但是最后的打印才是return的最后结果
14 | return list_name
15 |
16 |
17 | # 获取一个路径下第一层,相同后缀的文件名列表
18 | # 获取所有标注文件
19 | def get_filenames(rootDir):
20 | L=[]
21 | list = os.listdir(rootDir) # 列出文件夹下所有的目录与文件
22 | for i in range(0,len(list)):
23 | if os.path.splitext(list[i])[1] == '.csv':
24 | path = os.path.join(rootDir,list[i])
25 | L.append(path)
26 | return L
27 | # 其中os.path.splitext()函数将路径拆分为文件名+扩展名
28 |
29 |
30 | def data_read(rootDir):
31 | # engine = create_engine('mysql+pymysql://root:13787441982qq,,@localhost:3306/DeecampData?charset=utf8')
32 | list_name = [] # 需要在外层定义,才能获取当前路径所有文件名,试想在内层定义会如何
33 | list_name = listdir(rootDir, list_name) # 返回当前路径下所有文件路径列表
34 | data_list = []
35 | for i in range(0, len(list_name)):
36 | if os.path.splitext(list_name[i])[1] == '.json':
37 | with open(list_name[i],'r',encoding='utf-8') as f:
38 | data = f.read()
39 | data_list.append(data)
40 | # df = data.astype(object).where(pd.notnull(data) , None)
41 | # tableName = os.path.splitext(list_name[i])[0].split('\\').pop()
42 | # df.to_sql(tableName, engine,if_exists='replace',index=False)
43 | return data_list,list_name
44 |
45 |
46 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | *.egg-info/
24 | .installed.cfg
25 | *.egg
26 | MANIFEST
27 |
28 | # PyInstaller
29 | # Usually these files are written by a python script from a template
30 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
31 | *.manifest
32 | *.spec
33 |
34 | # Installer logs
35 | pip-log.txt
36 | pip-delete-this-directory.txt
37 |
38 | # Unit test / coverage reports
39 | htmlcov/
40 | .tox/
41 | .coverage
42 | .coverage.*
43 | .cache
44 | nosetests.xml
45 | coverage.xml
46 | *.cover
47 | .hypothesis/
48 | .pytest_cache/
49 |
50 | # Translations
51 | *.mo
52 | *.pot
53 |
54 | # Django stuff:
55 | *.log
56 | local_settings.py
57 | db.sqlite3
58 |
59 | # Flask stuff:
60 | instance/
61 | .webassets-cache
62 |
63 | # Scrapy stuff:
64 | .scrapy
65 |
66 | # Sphinx documentation
67 | docs/_build/
68 |
69 | # PyBuilder
70 | target/
71 |
72 | # Jupyter Notebook
73 | .ipynb_checkpoints
74 |
75 | # pyenv
76 | .python-version
77 |
78 | # celery beat schedule file
79 | celerybeat-schedule
80 |
81 | # SageMath parsed files
82 | *.sage.py
83 |
84 | # Environments
85 | .env
86 | .venv
87 | env/
88 | venv/
89 | ENV/
90 | env.bak/
91 | venv.bak/
92 |
93 | # Spyder project settings
94 | .spyderproject
95 | .spyproject
96 |
97 | # Rope project settings
98 | .ropeproject
99 |
100 | # mkdocs documentation
101 | /site
102 |
103 | # mypy
104 | .mypy_cache/
105 | *.json
106 | *.csv
107 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # fund_crawler
2 | 基金爬虫,爬取天天基金的基金信息、基金经理信息、公司列表
3 |
4 | ## 环境依赖
5 |
6 | python3.8,三方库未进行版本的测试,应该默认即可。
7 |
8 | ```
9 | pip install pandas
10 | pip install sqlalchemy
11 | pip install requests
12 | ```
13 |
14 |
15 |
16 | ## 主要URL
17 |
18 | **首先天天基金robots.txt内容如下**
19 |
20 | ```vbnet
21 | User-agent: *
22 | Disallow: /*spm=*
23 | Disallow: /*aladin
24 | ```
25 |
26 | 表示不限制爬虫方式,不能爬取根目录下包含字符串'spm='的文件和根目录下'aladin'结尾的文件
27 |
28 |
29 |
30 | 1. 公司列表:包含公司名和公司代码
31 | - 示例图
32 | 
33 | - URL:[fund.eastmoney.com/js/jjjz_gs.js](http://fund.eastmoney.com/js/jjjz_gs.js)
34 |
35 | 2. 基金列表:包含基金名和基金代码
36 | - 示例图
37 | 
38 | - URL:http://fund.eastmoney.com/js/fundcode_search.js
39 |
40 | 3. 基金信息1:包含基金的基本信息
41 | - 示例图:
42 | - URL:http://fund.eastmoney.com/pingzhongdata/'+code+'.js‘ 其中,code为6位整数,如000001的URL位=为http://fund.eastmoney.com/pingzhongdata/000001.js
43 |
44 | 4. 基金信息2:包含基金风险指标近几年的风险指标-标准差和夏普比率
45 | - 示例图
46 | 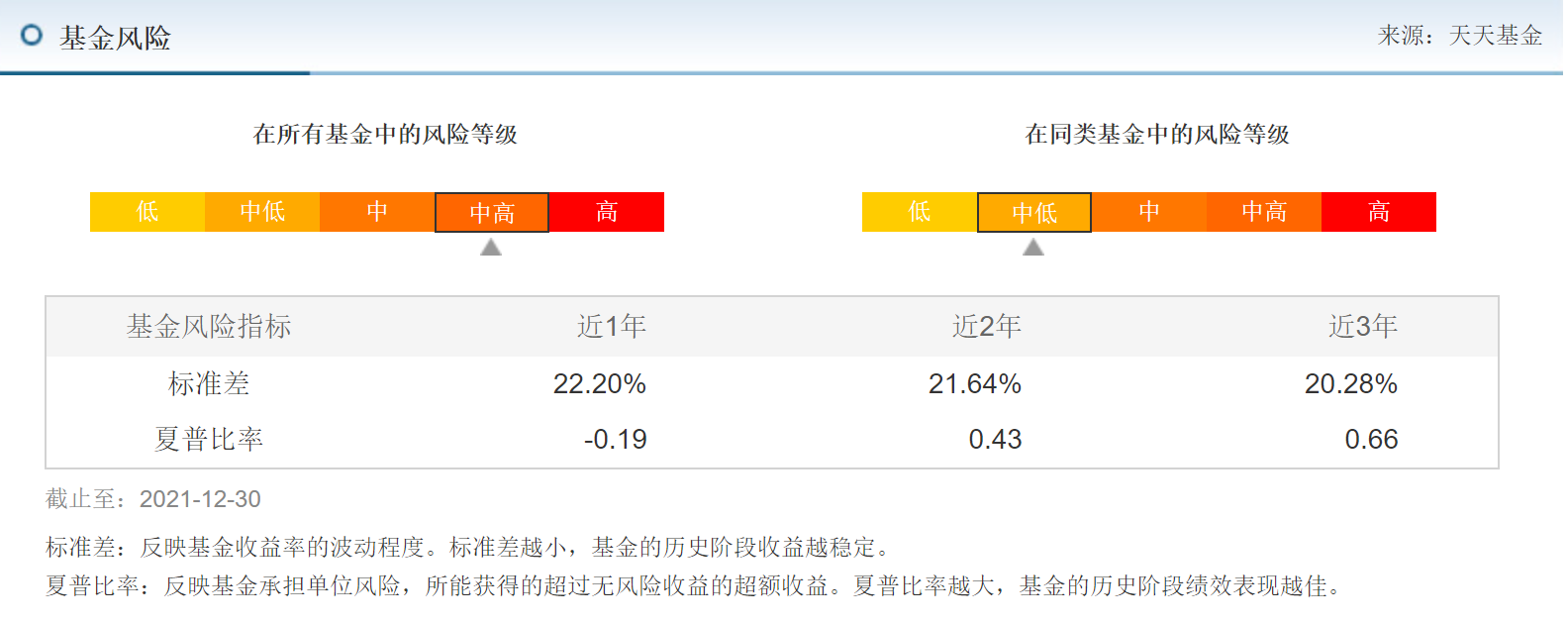
47 | - URL规律:http://fundf10.eastmoney.com/tsdata_'+code+'.html',同上
48 | - 注:天天基金这里进行过更新,老代码中的URL不适用了,现在已经更新
49 |
50 | 5. 基金经理信息:http://fundf10.eastmoney.com/jjjl_'+code+'.html',同上
51 |
52 |
53 |
54 |
55 |
56 | ## 使用方法
57 |
58 | 进入main.py执行即可
59 |
60 | - 注:除了solve开头的函数依赖于之前函数的下载文件,其他函数之间相互独立无先后顺序可以分别执行
61 |
62 |
63 | - 数据量太大只上传部分关键数据
64 | - 爬取部分基金信息会提示Failed to get response to url! 大部分情况应该是网站上没有这个基金信息的网页,可以在fail.csv查看失败的基金代码,如果代码有问题欢迎反馈
65 |
66 |
67 |
68 |
69 |
70 | ## Todo
71 |
72 | 经issue中用户anshe80的提示,adjusted_net_value.csv表格和/Data/fundInfo/目录都没有生成的方法,后续有时间会修复这个问题,现在可以通过手动创建文件/目录避免。模块之间比较独立, 这个问题不影响其他模块使用。
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | from pypfopt.efficient_frontier import EfficientFrontier
2 | import pypfopt.expected_returns as expected_returns
3 | import pypfopt.risk_models as risk_models
4 | import pandas as pd
5 | import os
6 | import argparse
7 |
8 |
9 | if __name__ == '__main__':
10 |
11 | parser = argparse.ArgumentParser()
12 | parser.add_argument("-p","--path", action='store',type=str,default='E:\\CODE/python/Deecamp/Proj/Data/funds/nav/')
13 | parser.add_argument("-s","--subdirs",action='store',type=str,default="00")
14 | parser.add_argument("-v","--volatility",action='store',type=float,default=-1)
15 | parser.add_argument("-r","--risk_free_rate",action='store',type=float,default=0.02)
16 | args=parser.parse_args()
17 |
18 | nav_path = args.path
19 | # 'E:\\CODE/python/Deecamp/Proj/Data/funds/nav/'
20 | #"C:/Users/qin_t/Desktop/PortfolioOptimization/funds/funds/nav"
21 | dateparser = lambda x: pd.datetime.strptime(x, "%Y-%m-%d")
22 | data_list = []
23 |
24 | for subdir in (os.listdir(nav_path) if args.subdirs=="all" else args.subdirs.split(',')):
25 | print(subdir)
26 | if not os.path.isdir(nav_path + "/" + subdir):
27 | continue
28 | for filename in os.listdir(nav_path + "/" + subdir):
29 | filepath = nav_path + "/" + subdir + "/" + filename
30 | tdata = pd.read_csv(str(filepath),
31 | parse_dates=['datetime'],
32 | index_col='datetime',
33 | date_parser=dateparser # 按时间对齐
34 | )
35 | if 'unit_net_value' in tdata.columns: # 非日结
36 | data_list.append(
37 | tdata[['unit_net_value']]
38 | .rename(columns={'unit_net_value': filename[0:6]}, index=str).astype('float'))
39 | else: # 日结
40 | data_list.append(
41 | (tdata[['weekly_yield']]+1)
42 | .rename(columns={'weekly_yield': filename[0:6]}, index=str).astype('float'))
43 |
44 | data = pd.concat(data_list, axis=1)
45 |
46 | print(data.head())
47 |
48 |
49 | # efficient frontier
50 | mu=expected_returns.ema_historical_return(data)
51 | S=risk_models.CovarianceShrinkage(data).ledoit_wolf()
52 | ef=EfficientFrontier(mu,S)
53 |
54 | if args.volatility<0:
55 | print(ef.max_sharpe(args.risk_free_rate))
56 | else:
57 | print(ef.efficient_risk(args.volatility,args.risk_free_rate))
58 |
59 | ef.portfolio_performance(True)
60 |
--------------------------------------------------------------------------------
/Data/fail.csv:
--------------------------------------------------------------------------------
1 | ,0
2 | 0,000145
3 | 1,000146
4 | 2,000315
5 | 3,000340
6 | 4,000348
7 | 5,000349
8 | 6,000382
9 | 7,000383
10 | 8,000384
11 | 9,000399
12 | 10,000453
13 | 11,000454
14 | 12,000455
15 | 13,000498
16 | 14,000499
17 | 15,000558
18 | 16,000611
19 | 17,000643
20 | 18,000670
21 | 19,000671
22 | 20,000702
23 | 21,000703
24 | 22,000732
25 | 23,000733
26 | 24,000806
27 | 25,000807
28 | 26,000820
29 | 27,000821
30 | 28,001465
31 | 29,001519
32 | 30,001525
33 | 31,020006
34 | 32,020008
35 | 33,020025
36 | 34,020030
37 | 35,040006
38 | 36,040042
39 | 37,040043
40 | 38,050129
41 | 39,070007
42 | 40,080016
43 | 41,080017
44 | 42,080018
45 | 43,080019
46 | 44,100007
47 | 45,100070
48 | 46,100071
49 | 47,101007
50 | 48,121007
51 | 49,121099
52 | 50,150001
53 | 51,150002
54 | 52,150003
55 | 53,150006
56 | 54,150007
57 | 55,150010
58 | 56,150011
59 | 57,150025
60 | 58,150026
61 | 59,150027
62 | 60,150038
63 | 61,150041
64 | 62,150043
65 | 63,150044
66 | 64,150045
67 | 65,150046
68 | 66,150061
69 | 67,150062
70 | 68,150063
71 | 69,150068
72 | 70,150069
73 | 71,150070
74 | 72,150071
75 | 73,150072
76 | 74,150078
77 | 75,150079
78 | 76,150080
79 | 77,150081
80 | 78,150082
81 | 79,150087
82 | 80,150098
83 | 81,150099
84 | 82,150110
85 | 83,150111
86 | 84,150114
87 | 85,150115
88 | 86,150116
89 | 87,150127
90 | 88,150132
91 | 89,150137
92 | 90,159917
93 | 91,160619
94 | 92,160641
95 | 93,160811
96 | 94,161016
97 | 95,161717
98 | 96,161909
99 | 97,162106
100 | 98,162109
101 | 99,162512
102 | 100,162602
103 | 101,163112
104 | 102,163303
105 | 103,163908
106 | 104,164207
107 | 105,164209
108 | 106,165518
109 | 107,165706
110 | 108,166013
111 | 109,166106
112 | 110,167502
113 | 111,184688
114 | 112,184689
115 | 113,184690
116 | 114,184691
117 | 115,184692
118 | 116,184693
119 | 117,184695
120 | 118,184696
121 | 119,184698
122 | 120,184699
123 | 121,184700
124 | 122,184701
125 | 123,184702
126 | 124,184703
127 | 125,184705
128 | 126,184706
129 | 127,184708
130 | 128,184709
131 | 129,184710
132 | 130,184711
133 | 131,184712
134 | 132,184713
135 | 133,184718
136 | 134,184719
137 | 135,184720
138 | 136,184738
139 | 137,202201
140 | 138,206016
141 | 139,206017
142 | 140,229001
143 | 141,240021
144 | 142,241002
145 | 143,253070
146 | 144,270024
147 | 145,360017
148 | 146,360018
149 | 147,360021
150 | 148,360022
151 | 149,471021
152 | 150,471028
153 | 151,472028
154 | 152,500001
155 | 153,500002
156 | 154,500003
157 | 155,500005
158 | 156,500006
159 | 157,500007
160 | 158,500008
161 | 159,500009
162 | 160,500010
163 | 161,500011
164 | 162,500013
165 | 163,500015
166 | 164,500016
167 | 165,500017
168 | 166,500018
169 | 167,500019
170 | 168,500021
171 | 169,500025
172 | 170,500028
173 | 171,500029
174 | 172,500035
175 | 173,500039
176 | 174,510700
177 | 175,519052
178 | 176,519053
179 | 177,519192
180 | 178,519528
181 | 179,519529
182 | 180,519886
183 | 181,519887
184 | 182,675021
185 | 183,675023
186 | 184,960040
187 | 185,960041
188 |
--------------------------------------------------------------------------------
/MyCrawyer.py:
--------------------------------------------------------------------------------
1 | import requests
2 | import pandas as pd
3 | import re
4 | import sys
5 | import math
6 |
7 |
8 | def progress_bar(portion, total):
9 | """
10 | total 总数据大小,portion 已经传送的数据大小
11 | :param portion: 已经接收的数据量
12 | :param total: 总数据量
13 | :return: 接收数据完成,返回True
14 | """
15 | part = total / 50 # 1%数据的大小
16 | count = math.ceil(portion / part)
17 | sys.stdout.write('\r')
18 | sys.stdout.write(('[%-50s]%.2f%%' % (('>' * count), portion / total * 100)))
19 | sys.stdout.flush()
20 |
21 | if portion >= total:
22 | sys.stdout.write('\n')
23 | return True
24 |
25 | def get_resonse(url):
26 | """
27 | :param url: 网页URL
28 | :return: 爬取的文本信息
29 | """
30 | try:
31 | r = requests.get(url)
32 | r.raise_for_status()
33 | r.encoding = 'utf-8'
34 | return r.text
35 | except:
36 | print('Failed to get response to url!')
37 | return ''
38 |
39 |
40 | def get_company_list(url):
41 | """
42 | :param url: 公司信息的URL
43 | :return: 将结果存储在当前目录Data/company_list.csv中
44 | """
45 | response = get_resonse(url)
46 | code_list = []
47 | name_list = []
48 | tmp = re.findall(r"(\".*?\")", response)
49 | for i in range(0,len(tmp)):
50 | if i%2 == 0:
51 | code_list.append(tmp[i])
52 | else:
53 | name_list.append(tmp[i])
54 |
55 | data = {}
56 | data['code']=code_list
57 | data['name']=name_list
58 | df = pd.DataFrame(data)
59 | df.to_csv('Data/company_list.csv', encoding='ANSI')
60 |
61 |
62 | def get_fund_list(url):
63 | """
64 | :param url: 基金概况信息的URL
65 | :return: 将基金统计信息存入当前目录Data/fund_list.csv中,返回基金代码号列表
66 | """
67 | data = {}
68 | response = get_resonse(url)
69 | code_list = []
70 | abbreviation_list = []
71 | name_list = []
72 | type_list = []
73 | name_en_list = []
74 | tmp = re.findall(r"(\".*?\")" , response)
75 | for i in range(0,len(tmp)):
76 | if i%5==0:
77 | code_list.append(eval(tmp[i]))
78 | elif i%5==1:
79 | abbreviation_list.append(eval(tmp[i]))
80 | elif i%5==2:
81 | name_list.append(eval(tmp[i]))
82 | elif i%5==3:
83 | type_list.append(eval(tmp[i]))
84 | else:
85 | name_en_list.append(eval(tmp[i]))
86 | data['code']=code_list
87 | data['abbreviation']=abbreviation_list
88 | data['name']=name_list
89 | data['type']=type_list
90 | data['name_en']=name_en_list
91 | df = pd.DataFrame(data)
92 | df.to_csv('Data/fund_list.csv',encoding='ANSI')
93 | return code_list
94 |
95 |
96 | def get_fund_info(code):
97 | failed_list = []
98 | data_list = {}
99 | url = 'http://fund.eastmoney.com/pingzhongdata/'+code+'.js'
100 | response = get_resonse(url)
101 | # 爬取失败等待再次爬取
102 | if response is '':
103 | return ''
104 | else:
105 | strs = re.findall(r'var(.*?);',response)
106 | for i in range(0,len(strs)):
107 | tmp = strs[i].split('=')
108 | var_name = tmp[0].strip()
109 | data_list[var_name] = [tmp[1]]
110 | return data_list
111 |
112 |
113 |
114 |
115 | def get_pingzhong_data():
116 | data = pd.read_csv('Data\instruments_ansi.csv',encoding='ANSI')
117 | code_list = data['code']
118 | data = {'fS_name':[],
119 | 'fS_code':[],
120 | 'fund_sourceRate':[]
121 | ,'fund_Rate':[]
122 | ,'fund_minsg':[]
123 | ,'stockCodes':[]
124 | ,'zqCodes':[]
125 | ,'syl_1n':[]
126 | ,'syl_6y':[]
127 | ,'syl_3y':[]
128 | ,'syl_1y':[]
129 | ,'Data_holderStructure':[]
130 | ,'Data_assetAllocation':[]
131 | ,'Data_currentFundManager':[]
132 | ,'Data_buySedemption':[]}
133 | failed_list = []
134 | for i in range(0,len(code_list)):
135 | code = '%06d' % code_list[i]
136 | # progress = i/len(code_list)*100
137 | # print('爬取'+code+'中,进度','%.2f'%progress+'%')
138 | progress_bar(i , len(code_list))
139 | fund_info = get_fund_info(code)
140 | if fund_info is '':
141 | failed_list.append(code)
142 | else:
143 | for key in data.keys():
144 | if key in fund_info.keys():
145 | if 'Data' not in key and key != 'zqCodes':
146 | data[key].append(eval(fund_info[key][0]))
147 | else:
148 | data[key].append(fund_info[key][0])
149 | else:
150 | data[key].append('')
151 | df = pd.DataFrame(data)
152 | df.to_csv('Data/crawler3.csv',encoding='ANSI')
153 | df_fail = pd.DataFrame(failed_list)
154 | df_fail.to_csv('Data/fail.csv',encoding='ANSI')
155 |
156 |
157 | def download_f10_ts_data():
158 | data = pd.read_csv('Data\instruments_ansi.csv',encoding='ANSI')
159 | code_list = data['code']
160 | for i in range(0,len(code_list)):
161 | progress_bar(i,len(code_list))
162 | name = '%06d' % code_list[i]
163 | url = 'http://fundf10.eastmoney.com/tsdata_'+name+'.html'
164 | file_name = 'Data/f10_ts/'+name+'.json'
165 | response = get_resonse(url)
166 | with open(file_name,'w',encoding='utf-8') as f:
167 | print(response,file =f)
168 |
169 |
170 | def download_manager_info():
171 | data = pd.read_csv('Data/instruments_ansi.csv',encoding='ANSI')
172 | code_list = data['code']
173 | for i in range(0,len(code_list)):
174 | progress_bar(i,len(code_list))
175 | name = '%06d' % code_list[i]
176 | url = 'http://fundf10.eastmoney.com/jjjl_'+name+'.html'
177 | file_name = 'Data/managerInfo/'+name+'.json'
178 | response = get_resonse(url)
179 | with open(file_name,'w',encoding='utf-8') as f:
180 | print(response,file =f)
181 |
182 |
183 | def download_risk_info():
184 | data = pd.read_csv('Data/instruments_ansi.csv',encoding='ANSI')
185 | code_list = data['code']
186 | for i in range(0,len(code_list)):
187 | progress_bar(i,len(code_list))
188 | name = '%06d' % code_list[i]
189 | url = 'http://fund.eastmoney.com/'+name+'.html'
190 | file_name = 'Data/risk/'+name+'.json'
191 | response = get_resonse(url)
192 | with open(file_name,'w',encoding='utf-8') as f:
193 | print(response,file =f)
194 |
195 |
196 | if __name__ == '__main__':
197 | # download_manager_info()
198 | # solve_f10_data()
199 | # solve_fund_info()
200 | download_risk_info()
201 |
--------------------------------------------------------------------------------
/Data_solve.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | from datetime import datetime
3 | from Data_Read import *
4 | import re
5 | import math
6 | import sys
7 |
8 |
9 | def progress_bar(portion, total):
10 | """
11 | total 总数据大小,portion 已经传送的数据大小
12 | :param portion: 已经接收的数据量
13 | :param total: 总数据量
14 | :return: 接收数据完成,返回True
15 | """
16 | part = total / 50 # 1%数据的大小
17 | count = math.ceil(portion / part)
18 | sys.stdout.write('\r')
19 | sys.stdout.write(('[%-50s]%.2f%%' % (('>' * count), portion / total * 100)))
20 | sys.stdout.flush()
21 |
22 | if portion >= total:
23 | sys.stdout.write('\n')
24 | return True
25 |
26 |
27 | def data_select():
28 | benchmark_time = datetime.strptime('2015-05-04','%Y-%m-%d')
29 | listed_to_delisted = [] # 上市持续时间
30 | establishment_to_stop = [] # 建立持续时间
31 | TabuList = [] # 筛选出局的股票代码
32 | data = pd.read_csv('E:\\CODE\Python\Deecamp\Proj\Data\instruments_ansi.csv',encoding='ANSI')
33 | for i in range(0,len(data['establishment_date'])):
34 | d1 = datetime.strptime(data['establishment_date'][i], '%Y-%m-%d')
35 | d3 = datetime.strptime(data['listed_date'][i], '%Y-%m-%d')
36 | if data['stop_date'][i] == '0000-00-00':
37 | establishment_to_stop.append(0)
38 | listed_to_delisted.append(0)
39 | else:
40 | d2 = datetime.strptime(data['stop_date'][i], '%Y-%m-%d')
41 | d4 = datetime.strptime(data['de_listed_date'][i], '%Y-%m-%d')
42 | delta1 = d2 - d1
43 | delta2 = d4 - d3
44 | establishment_to_stop.append(delta1.days)
45 | listed_to_delisted.append(delta2.days)
46 | # 与基准时间比较
47 | if (d2 - benchmark_time).days < 0:
48 | TabuList.append(data['code'][i])
49 |
50 | data['listed_to_delisted'] = listed_to_delisted
51 | data['establishment_to_stop'] = establishment_to_stop
52 | data.to_csv('Data/new.csv',encoding='ANSI')
53 |
54 |
55 | def solve_fund_info():
56 | rootDir = 'E:\\CODE/python/Deecamp/Proj/Data/fundInfo/'
57 | org_data_list = data_read(rootDir)
58 | data_list = {}
59 | data_list = {'fS_name':[],
60 | 'fS_code':[],
61 | 'fund_sourceRate':[]
62 | ,'fund_Rate':[]
63 | ,'fund_minsg':[]
64 | ,'syl_1n':[]
65 | ,'syl_6y':[]
66 | ,'syl_3y':[]
67 | ,'syl_1y':[]
68 | ,'Data_holderStructure':[]
69 | ,'Data_assetAllocation':[]
70 | ,'Data_currentFundManager':[]
71 | ,'Data_buySedemption':[]}
72 | for i in range(0,len(org_data_list)):
73 | strs = re.findall(r'var(.*?);',org_data_list[i])
74 | fund_info = {}
75 | for j in range(0,len(strs)):
76 | tmp = strs[j].split('=')
77 | var_name = tmp[0].strip()
78 | fund_info[var_name] = [tmp[1]]
79 | for key in data_list.keys():
80 | if key in fund_info.keys() :
81 | if key is 'Data_assetAllocation' and 'Data_assetAllocationCurrency' in fund_info.keys():
82 | data_list[key].append(fund_info['Data_assetAllocationCurrency'])
83 | data_list['Data_buySedemption'].append(fund_info[key])
84 | elif 'Data' not in key and key != 'zqCodes':
85 | data_list[key].append(eval(fund_info[key][0]))
86 | else:
87 | data_list[key].append(fund_info[key][0])
88 | # elif len(data_list[key])<=i:
89 | # data_list[key].append('')
90 | df = pd.DataFrame(data_list)
91 | df.to_csv('Data/crawler3.csv',encoding='ANSI')
92 |
93 |
94 |
95 | def solve_f10_data():
96 | rootDir = 'Data/f10_ts/'
97 | org_data_list = data_read(rootDir)
98 | data_list = {}
99 | data_list['基金号'] = []
100 | data_list['近1年std']=[]
101 | data_list['近2年std']=[]
102 | data_list['近3年std']=[]
103 | data_list['近1年夏普率'] = []
104 | data_list['近2年夏普率'] = []
105 | data_list['近3年夏普率'] = []
106 |
107 | for i in range(0,len(org_data_list)):
108 | a = re.findall(r'| (.*?) | ',org_data_list[i])
109 | if len(a)>0:
110 | data_list['近1年std'].append(a[0])
111 | data_list['近2年std'].append(a[1])
112 | data_list['近3年std'].append(a[2])
113 | data_list['近1年夏普率'].append(a[3])
114 | data_list['近2年夏普率'].append(a[4])
115 | data_list['近3年夏普率'].append(a[5])
116 | a = re.findall(r'tsdata_(.*?).htm',org_data_list[i])
117 | code = '%06d' %int(a[0])
118 | data_list['基金号'].append(code)
119 | df = pd.DataFrame(data_list,index=data_list['基金号'])
120 | df.to_csv('Data/f10_ts/std and sharp ratio.csv',encoding='ANSI')
121 |
122 |
123 |
124 | def solve_crawler3():
125 | df = pd.read_csv('Data/crawler3.csv', encoding='ANSI')
126 | data_list = {}
127 | # 经理信息
128 | data_list['基金经理'] = []
129 | data_list['经理工作时间'] = []
130 | data_list['经理管理基金size'] = []
131 | # 占净比
132 | data_list['股票占净比'] = []
133 | data_list['债券占净比'] = []
134 | data_list['现金占净比'] = []
135 | data_list['净资产'] = []
136 | data_list['categories1']=[]
137 | # 买卖信息
138 | data_list['期间申购'] = []
139 | data_list['期间赎回'] = []
140 | data_list['总份额']=[]
141 | data_list['categories2']=[]
142 | # 比例信息
143 | data_list['机构持有比例']=[]
144 | data_list['个人持有比例']=[]
145 | data_list['内部持有比例']=[]
146 | data_list['categories3']=[]
147 | # 占净比信息
148 | tmp = df['Data_assetAllocation']
149 | for i in range(0,len(tmp)):
150 | strs = re.findall(r'\"data\":(.*?),\"',tmp[i])
151 | t = re.findall(r'\"categories\":(.*?)}',tmp[i])
152 | if len(strs)==4:
153 | data_list['股票占净比'].append(strs[0])
154 | data_list['债券占净比'].append(strs[1])
155 | data_list['现金占净比'].append(strs[2])
156 | data_list['净资产'].append(strs[3])
157 | else:
158 | strs = re.findall(r'\"data\":(.*?)\}',tmp[i])
159 | data_list['股票占净比'].append(strs[0])
160 | data_list['债券占净比'].append(strs[1])
161 | data_list['现金占净比'].append(strs[2])
162 | data_list['净资产'].append('')
163 | t = t[0].split(',"series":')
164 | if len(t)>0:
165 | data_list['categories1'].append(t[0])
166 | else:
167 | data_list['categories1'].append('')
168 | del df['Data_assetAllocation']
169 |
170 | # 买卖信息
171 | tmp = df['Data_buySedemption']
172 | for i in range(0,len(tmp)):
173 | strs = re.findall(r'\"data\":(.*?)}',tmp[0])
174 | t = re.findall(r'\"categories\":(.*?)}',tmp[i])
175 | if len(strs)>0:
176 | data_list['期间申购'].append(strs[0])
177 | data_list['期间赎回'].append(strs[1])
178 | data_list['总份额'].append(strs[2])
179 | else:
180 | data_list['期间申购'].append('')
181 | data_list['期间赎回'].append('')
182 | data_list['总份额'].append('')
183 | if len(t)>0:
184 | data_list['categories2'].append(t[0])
185 | else:
186 | data_list['categories2'].append('')
187 | del df['Data_buySedemption']
188 |
189 | # 经理信息
190 | tmp = df['Data_currentFundManager']
191 | for i in range(0,len(tmp)):
192 | name = re.findall(r'\"name\":(.*?),',tmp[i])
193 | workTime = re.findall(r'\"workTime\":(.*?),',tmp[i])
194 | fundSize = re.findall(r'\"fundSize\":(.*?),',tmp[i])
195 | if len(workTime)>0:
196 | data_list['经理工作时间'].append(eval(workTime[0]))
197 | else:
198 | data_list['经理工作时间'].append('')
199 | if len(name) > 0:
200 | data_list['基金经理'].append(name[0])
201 | else:
202 | data_list['基金经理'].append('')
203 | if len(fundSize) > 0:
204 | data_list['经理管理基金size'].append(eval(fundSize[0]))
205 | else:
206 | data_list['经理管理基金size'].append('')
207 | del df['Data_currentFundManager']
208 |
209 | # 比例信息
210 | tmp = df['Data_holderStructure']
211 | for i in range(0,len(tmp)):
212 | strs = re.findall(r'\"data\":(.*?)\}',tmp[i])
213 | t = re.findall(r'\"categories\":(.*?)}',tmp[i])
214 | if len(strs)>0:
215 | data_list['机构持有比例'].append(strs[0])
216 | data_list['个人持有比例'].append(strs[1])
217 | data_list['内部持有比例'].append(strs[2])
218 | else:
219 | data_list['机构持有比例'].append('')
220 | data_list['个人持有比例'].append('')
221 | data_list['内部持有比例'].append('')
222 | if len(t)>0:
223 | data_list['categories3'].append(t[0])
224 | else:
225 | data_list['categories3'].append('')
226 | del df['Data_holderStructure']
227 | df2 = pd.DataFrame(data_list)
228 | df = pd.concat([df,df2],axis=1)
229 | df.to_csv('Data/data.csv',encoding = 'ANSI')
230 |
231 |
232 | def solve_manager_info():
233 | rootDir = 'Data/managerInfo/'
234 | org_data_list = data_read(rootDir)
235 | name_list = []
236 | manager_info_list={'name':[],'code':[]}
237 | for i in range(0, len(org_data_list)):
238 | data_list = {'姓名':[], '上任日期':[],'经理代号':[],'简介':[], '基金名称':[],'基金代码':[],'基金类型':[],'起始时间':[],'截止时间':[],'任职天数':[],'任职回报':[],'同类平均':[],'同类排名':[]}
239 | # 姓名
240 | a = re.findall(r'姓名(.*?)', org_data_list[i])
241 | for ii in range(0,len(a)):
242 | b = a[ii]
243 | name = re.findall(r'\">(.*?)', b)[0]
244 | if name not in name_list:
245 | name_list.append(name)
246 | duty_date = re.findall(r'上任日期:(.*?)
', b)[0]
247 | brief_intro = re.findall(r'(.*?)
', b)[0].split('
')[-1]
248 | manager_code = re.findall(r'"http://fund.eastmoney.com/manager/(.*?).html',b)[0]
249 | data_list['姓名'].append(name)
250 | data_list['上任日期'].append(duty_date)
251 | data_list['经理代号'].append(manager_code)
252 | data_list['简介'].append(brief_intro)
253 | fund_info_list = re.findall(r'html\"(.*?)', b)[1:]
254 |
255 | # manager list
256 | manager_info_list['name'].append(name)
257 | manager_info_list['code'].append(manager_code)
258 |
259 | for iii in range(0, len(fund_info_list)):
260 | fund_list = re.findall(r'>(.*?)' or r'>(.*?)',fund_info_list[iii])
261 | fund_list[0] = fund_list[0].split('<')[0]
262 | fund_list[1] = re.findall(r'>(.*?)<', fund_list[1])[0]
263 | data_list['基金名称'].append(fund_list[1])
264 | data_list['基金代码'].append(fund_list[0])
265 | data_list['基金类型'].append(fund_list[2])
266 | data_list['起始时间'].append(fund_list[3])
267 | data_list['截止时间'].append(fund_list[4])
268 | data_list['任职天数'].append(fund_list[5])
269 | data_list['任职回报'].append(fund_list[6])
270 | data_list['同类平均'] .append(fund_list[7])
271 | data_list['同类排名'] .append(fund_list[8])
272 | if iii>0:
273 | data_list['姓名'].append('')
274 | data_list['上任日期'].append('')
275 | data_list['经理代号'].append('')
276 | data_list['简介'].append('')
277 | dir = 'Data/managerSlv/'+name+'.csv'
278 | df = pd.DataFrame(data_list)
279 | order = ['姓名','上任日期','经理代号','简介','基金名称','基金代码','基金类型','起始时间','截止时间','任职天数','任职回报','同类平均','同类排名']
280 | df = df[order]
281 | df.to_csv(dir,encoding='ANSI')
282 | df_manager_info_list = pd.DataFrame(manager_info_list)
283 | df_manager_info_list.to_csv('Data/manager.csv',encoding='ANSI')
284 |
285 |
286 | def solve_risk_data():
287 | rootDir = 'Data/risk/'
288 | org_data_list ,list_name = data_read(rootDir)
289 | data_list = {}
290 | data_list['基金号'] = []
291 | data_list['风险类别'] = []
292 | data = pd.read_csv('Data/adjusted_net_value.csv')
293 | idx = data.columns.values
294 | for i in range(0,len(org_data_list)):
295 | progress_bar(i,len(org_data_list))
296 | a = re.findall(r'基金类型(.*?)基金规模',org_data_list[i])
297 | code = re.findall('risk/(.*?)\.',list_name[i])[0]
298 | code = '%06d' % int(code)
299 | if code in idx:
300 | if len(a)>0:
301 | b = re.findall(r' \| (.*?)
',a[0])
302 | if len(b)>0:
303 | data_list['风险类别'].append(b[0])
304 | else:
305 | data_list['风险类别'].append('')
306 | else:
307 | data_list['风险类别'].append('')
308 |
309 | data_list['基金号'].append(code)
310 | df = pd.DataFrame(data_list)
311 | df.to_csv('Data/risk.csv',encoding='ANSI')
312 |
313 |
314 | if __name__ == '__main__':
315 | solve_risk_data()
316 |
--------------------------------------------------------------------------------
|