├── .gitignore
├── LICENSE
├── README.md
├── VERSION
├── cog.yaml
├── datasets
└── README.md
├── experiments
└── pretrained_models
│ └── README.md
├── figures
├── Comparison.png
├── Performance_comparison.png
└── Visual_Results.png
├── hat
├── __init__.py
├── archs
│ ├── __init__.py
│ ├── discriminator_arch.py
│ ├── hat_arch.py
│ └── srvgg_arch.py
├── data
│ ├── __init__.py
│ ├── imagenet_paired_dataset.py
│ ├── meta_info
│ │ └── meta_info_DF2Ksub_GT.txt
│ └── realesrgan_dataset.py
├── models
│ ├── __init__.py
│ ├── hat_model.py
│ ├── realhatgan_model.py
│ └── realhatmse_model.py
├── test.py
└── train.py
├── options
├── test
│ ├── HAT-L_SRx2_ImageNet-pretrain.yml
│ ├── HAT-L_SRx3_ImageNet-pretrain.yml
│ ├── HAT-L_SRx4_ImageNet-pretrain.yml
│ ├── HAT-S_SRx2.yml
│ ├── HAT-S_SRx3.yml
│ ├── HAT-S_SRx4.yml
│ ├── HAT_GAN_Real_SRx4.yml
│ ├── HAT_SRx2.yml
│ ├── HAT_SRx2_ImageNet-pretrain.yml
│ ├── HAT_SRx3.yml
│ ├── HAT_SRx3_ImageNet-pretrain.yml
│ ├── HAT_SRx4.yml
│ ├── HAT_SRx4_ImageNet-LR.yml
│ ├── HAT_SRx4_ImageNet-pretrain.yml
│ └── HAT_tile_example.yml
└── train
│ ├── train_HAT-L_SRx2_ImageNet_from_scratch.yml
│ ├── train_HAT-L_SRx2_finetune_from_ImageNet_pretrain.yml
│ ├── train_HAT-L_SRx3_ImageNet_from_scratch.yml
│ ├── train_HAT-L_SRx3_finetune_from_ImageNet_pretrain.yml
│ ├── train_HAT-L_SRx4_ImageNet_from_scratch.yml
│ ├── train_HAT-L_SRx4_finetune_from_ImageNet_pretrain.yml
│ ├── train_HAT-S_SRx2_from_scratch.yml
│ ├── train_HAT-S_SRx3_from_scratch.yml
│ ├── train_HAT-S_SRx4_finetune_from_SRx2.yml
│ ├── train_HAT_SRx2_ImageNet_from_scratch.yml
│ ├── train_HAT_SRx2_finetune_from_ImageNet_pretrain.yml
│ ├── train_HAT_SRx2_from_scratch.yml
│ ├── train_HAT_SRx3_ImageNet_from_scratch.yml
│ ├── train_HAT_SRx3_finetune_from_ImageNet_pretrain.yml
│ ├── train_HAT_SRx3_from_scratch.yml
│ ├── train_HAT_SRx4_ImageNet_from_scratch.yml
│ ├── train_HAT_SRx4_finetune_from_ImageNet_pretrain.yml
│ ├── train_HAT_SRx4_finetune_from_SRx2.yml
│ ├── train_Real_HAT_GAN_SRx4_finetune_from_mse_model.yml
│ └── train_Real_HAT_SRx4_mse_model.yml
├── predict.py
├── requirements.txt
├── results
└── README.md
├── setup.cfg
└── setup.py
/.gitignore:
--------------------------------------------------------------------------------
1 | datasets/*
2 | experiments/*
3 | results/*
4 | tb_logger/*
5 | wandb/*
6 | tmp/*
7 | modify_model.py
8 | hat/version.py
9 |
10 | *.DS_Store
11 |
12 | # Byte-compiled / optimized / DLL files
13 | __pycache__/
14 | *.py[cod]
15 | *$py.class
16 |
17 | # C extensions
18 | *.so
19 |
20 | # Distribution / packaging
21 | .Python
22 | build/
23 | develop-eggs/
24 | dist/
25 | downloads/
26 | eggs/
27 | .eggs/
28 | lib/
29 | lib64/
30 | parts/
31 | sdist/
32 | var/
33 | wheels/
34 | pip-wheel-metadata/
35 | share/python-wheels/
36 | *.egg-info/
37 | .installed.cfg
38 | *.egg
39 | MANIFEST
40 |
41 | # PyInstaller
42 | # Usually these files are written by a python script from a template
43 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
44 | *.manifest
45 | *.spec
46 |
47 | # Installer logs
48 | pip-log.txt
49 | pip-delete-this-directory.txt
50 |
51 | # Unit test / coverage reports
52 | htmlcov/
53 | .tox/
54 | .nox/
55 | .coverage
56 | .coverage.*
57 | .cache
58 | nosetests.xml
59 | coverage.xml
60 | *.cover
61 | *.py,cover
62 | .hypothesis/
63 | .pytest_cache/
64 |
65 | # Translations
66 | *.mo
67 | *.pot
68 |
69 | # Django stuff:
70 | *.log
71 | local_settings.py
72 | db.sqlite3
73 | db.sqlite3-journal
74 |
75 | # Flask stuff:
76 | instance/
77 | .webassets-cache
78 |
79 | # Scrapy stuff:
80 | .scrapy
81 |
82 | # Sphinx documentation
83 | docs/_build/
84 |
85 | # PyBuilder
86 | target/
87 |
88 | # Jupyter Notebook
89 | .ipynb_checkpoints
90 |
91 | # IPython
92 | profile_default/
93 | ipython_config.py
94 |
95 | # pyenv
96 | .python-version
97 |
98 | # pipenv
99 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
100 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
101 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
102 | # install all needed dependencies.
103 | #Pipfile.lock
104 |
105 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
106 | __pypackages__/
107 |
108 | # Celery stuff
109 | celerybeat-schedule
110 | celerybeat.pid
111 |
112 | # SageMath parsed files
113 | *.sage.py
114 |
115 | # Environments
116 | .env
117 | .venv
118 | env/
119 | venv/
120 | ENV/
121 | env.bak/
122 | venv.bak/
123 |
124 | # Spyder project settings
125 | .spyderproject
126 | .spyproject
127 |
128 | # Rope project settings
129 | .ropeproject
130 |
131 | # mkdocs documentation
132 | /site
133 |
134 | # mypy
135 | .mypy_cache/
136 | .dmypy.json
137 | dmypy.json
138 |
139 | # Pyre type checker
140 | .pyre/
141 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright 2023 Xiangyu Chen
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [](https://paperswithcode.com/sota/image-super-resolution-on-set5-4x-upscaling?p=activating-more-pixels-in-image-super)
2 | [](https://paperswithcode.com/sota/image-super-resolution-on-urban100-4x?p=activating-more-pixels-in-image-super)
3 | [](https://paperswithcode.com/sota/image-super-resolution-on-set14-4x-upscaling?p=activating-more-pixels-in-image-super)
4 | [](https://paperswithcode.com/sota/image-super-resolution-on-manga109-4x?p=activating-more-pixels-in-image-super)
5 |
6 | # HAT [](https://replicate.com/cjwbw/hat)
7 |
8 | ### Activating More Pixels in Image Super-Resolution Transformer [[Paper Link]](https://arxiv.org/abs/2205.04437)
9 | [Xiangyu Chen](https://chxy95.github.io/), [Xintao Wang](https://xinntao.github.io/), [Jiantao Zhou](https://www.fst.um.edu.mo/personal/jtzhou/), [Yu Qiao](https://scholar.google.com.hk/citations?user=gFtI-8QAAAAJ) and [Chao Dong](https://scholar.google.com.hk/citations?user=OSDCB0UAAAAJ&hl=zh-CN)
10 |
11 | ### HAT: Hybrid Attention Transformer for Image Restoration [[Paper Link]](https://arxiv.org/abs/2309.05239)
12 | [Xiangyu Chen](https://chxy95.github.io/), [Xintao Wang](https://xinntao.github.io/), [Wenlong Zhang](https://wenlongzhang0517.github.io/), [Xiangtao Kong](https://xiangtaokong.github.io/), [Jiantao Zhou](https://www.fst.um.edu.mo/personal/jtzhou/), [Yu Qiao](https://scholar.google.com.hk/citations?user=gFtI-8QAAAAJ) and [Chao Dong](https://scholar.google.com.hk/citations?user=OSDCB0UAAAAJ&hl=zh-CN)
13 |
14 | ## Updates
15 | - ✅ 2022-05-09: Release the first version of the paper at Arxiv.
16 | - ✅ 2022-05-20: Release the codes, models and results of HAT.
17 | - ✅ 2022-08-29: Add a Replicate demo for SRx4.
18 | - ✅ 2022-09-25: Add the tile mode for inference with limited GPU memory.
19 | - ✅ 2022-11-24: Upload a GAN-based HAT model for **Real-World SR** (Real_HAT_GAN_SRx4.pth).
20 | - ✅ 2023-03-19: Update paper to CVPR version. Small HAT models are added.
21 | - ✅ 2023-04-05: Upload the HAT-S codes, models and results.
22 | - ✅ 2023-08-01: Upload another GAN model for sharper results (Real_HAT_GAN_SRx4_sharper.pth).
23 | - ✅ 2023-08-01: Upload the training configs for the **Real-World GAN-based model**.
24 | - ✅ 2023-09-11: Release the extended version of the paper at [Arxiv](https://arxiv.org/abs/2309.05239).
25 | - **(To do)** Add the tile mode for Replicate demo.
26 | - **(To do)** Update the Replicate demo for Real-World SR.
27 | - **(To do)** Add HAT models for Multiple Image Restoration tasks.
28 |
29 | ## Overview
30 | 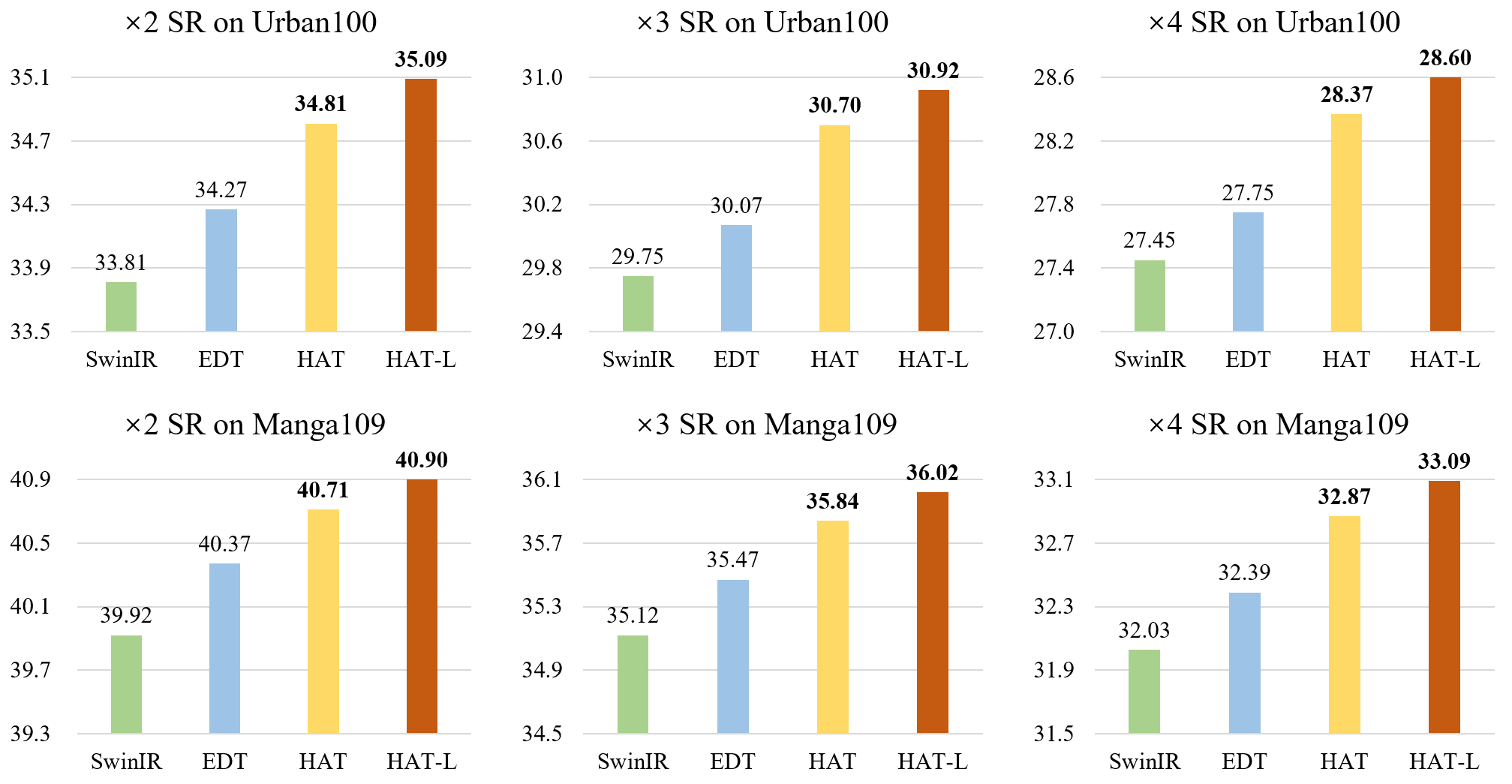 31 |
32 | **Benchmark results on SRx4 without ImageNet pretraining. Mulit-Adds are calculated for a 64x64 input.**
33 | | Model | Params(M) | Multi-Adds(G) | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
34 | |-------|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|
35 | | [SwinIR](https://github.com/JingyunLiang/SwinIR) | 11.9 | 53.6 | 32.92 | 29.09 | 27.92 | 27.45 | 32.03 |
36 | | HAT-S | 9.6 | 54.9 | 32.92 | 29.15 | 27.97 | 27.87 | 32.35 |
37 | | HAT | 20.8 | 102.4 | 33.04 | 29.23 | 28.00 | 27.97 | 32.48 |
38 |
39 | ## Real-World SR Results
40 | **Note that:**
41 | - The default settings in the training configs (almost the same as Real-ESRGAN) are for training **Real_HAT_GAN_SRx4_sharper**.
42 | - **Real_HAT_GAN_SRx4** is trained using similar settings without USM the ground truth.
43 | - **Real_HAT_GAN_SRx4** would have better fidelity.
44 | - **Real_HAT_GAN_SRx4_sharper** would have better perceptual quality.
45 |
46 | **Results produced by** Real_HAT_GAN_SRx4_sharper.pth.
47 |
48 |
31 |
32 | **Benchmark results on SRx4 without ImageNet pretraining. Mulit-Adds are calculated for a 64x64 input.**
33 | | Model | Params(M) | Multi-Adds(G) | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
34 | |-------|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|
35 | | [SwinIR](https://github.com/JingyunLiang/SwinIR) | 11.9 | 53.6 | 32.92 | 29.09 | 27.92 | 27.45 | 32.03 |
36 | | HAT-S | 9.6 | 54.9 | 32.92 | 29.15 | 27.97 | 27.87 | 32.35 |
37 | | HAT | 20.8 | 102.4 | 33.04 | 29.23 | 28.00 | 27.97 | 32.48 |
38 |
39 | ## Real-World SR Results
40 | **Note that:**
41 | - The default settings in the training configs (almost the same as Real-ESRGAN) are for training **Real_HAT_GAN_SRx4_sharper**.
42 | - **Real_HAT_GAN_SRx4** is trained using similar settings without USM the ground truth.
43 | - **Real_HAT_GAN_SRx4** would have better fidelity.
44 | - **Real_HAT_GAN_SRx4_sharper** would have better perceptual quality.
45 |
46 | **Results produced by** Real_HAT_GAN_SRx4_sharper.pth.
47 |
48 |  49 |
50 | **Comparison with the state-of-the-art Real-SR methods.**
51 |
52 |
49 |
50 | **Comparison with the state-of-the-art Real-SR methods.**
51 |
52 |  53 |
54 | ## Citations
55 | #### BibTeX
56 |
57 | @InProceedings{chen2023activating,
58 | author = {Chen, Xiangyu and Wang, Xintao and Zhou, Jiantao and Qiao, Yu and Dong, Chao},
59 | title = {Activating More Pixels in Image Super-Resolution Transformer},
60 | booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
61 | month = {June},
62 | year = {2023},
63 | pages = {22367-22377}
64 | }
65 |
66 | @article{chen2023hat,
67 | title={HAT: Hybrid Attention Transformer for Image Restoration},
68 | author={Chen, Xiangyu and Wang, Xintao and Zhang, Wenlong and Kong, Xiangtao and Qiao, Yu and Zhou, Jiantao and Dong, Chao},
69 | journal={arXiv preprint arXiv:2309.05239},
70 | year={2023}
71 | }
72 |
73 | ## Environment
74 | - [PyTorch >= 1.7](https://pytorch.org/) **(Recommend **NOT** using torch 1.8!!! It would cause abnormal performance.)**
75 | - [BasicSR == 1.3.4.9](https://github.com/XPixelGroup/BasicSR/blob/master/INSTALL.md)
76 | ### Installation
77 | Install Pytorch first.
78 | Then,
79 | ```
80 | pip install -r requirements.txt
81 | python setup.py develop
82 | ```
83 |
84 | ## How To Test
85 |
86 | Without implementing the codes, [chaiNNer](https://github.com/chaiNNer-org/chaiNNer) is a nice tool to run our models.
87 |
88 | Otherwise,
89 | - Refer to `./options/test` for the configuration file of the model to be tested, and prepare the testing data and pretrained model.
90 | - The pretrained models are available at
91 | [Google Drive](https://drive.google.com/drive/folders/1HpmReFfoUqUbnAOQ7rvOeNU3uf_m69w0?usp=sharing) or [Baidu Netdisk](https://pan.baidu.com/s/1u2r4Lc2_EEeQqra2-w85Xg) (access code: qyrl).
92 | - Then run the following codes (taking `HAT_SRx4_ImageNet-pretrain.pth` as an example):
93 | ```
94 | python hat/test.py -opt options/test/HAT_SRx4_ImageNet-pretrain.yml
95 | ```
96 | The testing results will be saved in the `./results` folder.
97 |
98 | - Refer to `./options/test/HAT_SRx4_ImageNet-LR.yml` for **inference** without the ground truth image.
99 |
100 | **Note that the tile mode is also provided for limited GPU memory when testing. You can modify the specific settings of the tile mode in your custom testing option by referring to `./options/test/HAT_tile_example.yml`.**
101 |
102 | ## How To Train
103 | - Refer to `./options/train` for the configuration file of the model to train.
104 | - Preparation of training data can refer to [this page](https://github.com/XPixelGroup/BasicSR/blob/master/docs/DatasetPreparation.md). ImageNet dataset can be downloaded at the [official website](https://image-net.org/challenges/LSVRC/2012/2012-downloads.php).
105 | - The training command is like
106 | ```
107 | CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 hat/train.py -opt options/train/train_HAT_SRx2_from_scratch.yml --launcher pytorch
108 | ```
109 | - Note that the default batch size per gpu is 4, which will cost about 20G memory for each GPU.
110 |
111 | The training logs and weights will be saved in the `./experiments` folder.
112 |
113 | ## Results
114 | The inference results on benchmark datasets are available at
115 | [Google Drive](https://drive.google.com/drive/folders/1t2RdesqRVN7L6vCptneNRcpwZAo-Ub3L?usp=sharing) or [Baidu Netdisk](https://pan.baidu.com/s/1CQtLpty-KyZuqcSznHT_Zw) (access code: 63p5).
116 |
117 |
118 | ## Contact
119 | If you have any question, please email chxy95@gmail.com or join in the [Wechat group of BasicSR](https://github.com/XPixelGroup/BasicSR#-contact) to discuss with the authors.
120 |
--------------------------------------------------------------------------------
/VERSION:
--------------------------------------------------------------------------------
1 | 0.1.0
--------------------------------------------------------------------------------
/cog.yaml:
--------------------------------------------------------------------------------
1 | build:
2 | cuda: "10.2"
3 | gpu: true
4 | python_version: "3.8"
5 | system_packages:
6 | - "libgl1-mesa-glx"
7 | - "libglib2.0-0"
8 | python_packages:
9 | - "numpy==1.21.5"
10 | - "ipython==7.21.0"
11 | - "opencv-python==4.5.4.58"
12 | - "torch==1.9.1"
13 | - "torchvision==0.10.1"
14 | - "einops==0.4.1"
15 |
16 | run:
17 | - pip install basicsr==1.3.4.9
18 |
19 | predict: "predict.py:Predictor"
20 |
--------------------------------------------------------------------------------
/datasets/README.md:
--------------------------------------------------------------------------------
1 | Recommend to put datasets or the soft links of datasets in this folder.
--------------------------------------------------------------------------------
/experiments/pretrained_models/README.md:
--------------------------------------------------------------------------------
1 | Put downloaded pre-trained models here.
--------------------------------------------------------------------------------
/figures/Comparison.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XPixelGroup/HAT/1638a9a822581657811867bf670717f8371fc3e5/figures/Comparison.png
--------------------------------------------------------------------------------
/figures/Performance_comparison.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XPixelGroup/HAT/1638a9a822581657811867bf670717f8371fc3e5/figures/Performance_comparison.png
--------------------------------------------------------------------------------
/figures/Visual_Results.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XPixelGroup/HAT/1638a9a822581657811867bf670717f8371fc3e5/figures/Visual_Results.png
--------------------------------------------------------------------------------
/hat/__init__.py:
--------------------------------------------------------------------------------
1 | # flake8: noqa
2 | from .archs import *
3 | from .data import *
4 | from .models import *
5 |
6 | # from .version import __gitsha__, __version__
7 |
--------------------------------------------------------------------------------
/hat/archs/__init__.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | from os import path as osp
3 |
4 | from basicsr.utils import scandir
5 |
6 | # automatically scan and import arch modules for registry
7 | # scan all the files that end with '_arch.py' under the archs folder
8 | arch_folder = osp.dirname(osp.abspath(__file__))
9 | arch_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(arch_folder) if v.endswith('_arch.py')]
10 | # import all the arch modules
11 | _arch_modules = [importlib.import_module(f'hat.archs.{file_name}') for file_name in arch_filenames]
12 |
--------------------------------------------------------------------------------
/hat/archs/discriminator_arch.py:
--------------------------------------------------------------------------------
1 | from basicsr.utils.registry import ARCH_REGISTRY
2 | from torch import nn as nn
3 | from torch.nn import functional as F
4 | from torch.nn.utils import spectral_norm
5 |
6 |
7 | @ARCH_REGISTRY.register()
8 | class UNetDiscriminatorSN(nn.Module):
9 | """Defines a U-Net discriminator with spectral normalization (SN)
10 |
11 | It is used in Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data.
12 |
13 | Arg:
14 | num_in_ch (int): Channel number of inputs. Default: 3.
15 | num_feat (int): Channel number of base intermediate features. Default: 64.
16 | skip_connection (bool): Whether to use skip connections between U-Net. Default: True.
17 | """
18 |
19 | def __init__(self, num_in_ch, num_feat=64, skip_connection=True):
20 | super(UNetDiscriminatorSN, self).__init__()
21 | self.skip_connection = skip_connection
22 | norm = spectral_norm
23 | # the first convolution
24 | self.conv0 = nn.Conv2d(num_in_ch, num_feat, kernel_size=3, stride=1, padding=1)
25 | # downsample
26 | self.conv1 = norm(nn.Conv2d(num_feat, num_feat * 2, 4, 2, 1, bias=False))
27 | self.conv2 = norm(nn.Conv2d(num_feat * 2, num_feat * 4, 4, 2, 1, bias=False))
28 | self.conv3 = norm(nn.Conv2d(num_feat * 4, num_feat * 8, 4, 2, 1, bias=False))
29 | # upsample
30 | self.conv4 = norm(nn.Conv2d(num_feat * 8, num_feat * 4, 3, 1, 1, bias=False))
31 | self.conv5 = norm(nn.Conv2d(num_feat * 4, num_feat * 2, 3, 1, 1, bias=False))
32 | self.conv6 = norm(nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1, bias=False))
33 | # extra convolutions
34 | self.conv7 = norm(nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=False))
35 | self.conv8 = norm(nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=False))
36 | self.conv9 = nn.Conv2d(num_feat, 1, 3, 1, 1)
37 |
38 | def forward(self, x):
39 | # downsample
40 | x0 = F.leaky_relu(self.conv0(x), negative_slope=0.2, inplace=True)
41 | x1 = F.leaky_relu(self.conv1(x0), negative_slope=0.2, inplace=True)
42 | x2 = F.leaky_relu(self.conv2(x1), negative_slope=0.2, inplace=True)
43 | x3 = F.leaky_relu(self.conv3(x2), negative_slope=0.2, inplace=True)
44 |
45 | # upsample
46 | x3 = F.interpolate(x3, scale_factor=2, mode='bilinear', align_corners=False)
47 | x4 = F.leaky_relu(self.conv4(x3), negative_slope=0.2, inplace=True)
48 |
49 | if self.skip_connection:
50 | x4 = x4 + x2
51 | x4 = F.interpolate(x4, scale_factor=2, mode='bilinear', align_corners=False)
52 | x5 = F.leaky_relu(self.conv5(x4), negative_slope=0.2, inplace=True)
53 |
54 | if self.skip_connection:
55 | x5 = x5 + x1
56 | x5 = F.interpolate(x5, scale_factor=2, mode='bilinear', align_corners=False)
57 | x6 = F.leaky_relu(self.conv6(x5), negative_slope=0.2, inplace=True)
58 |
59 | if self.skip_connection:
60 | x6 = x6 + x0
61 |
62 | # extra convolutions
63 | out = F.leaky_relu(self.conv7(x6), negative_slope=0.2, inplace=True)
64 | out = F.leaky_relu(self.conv8(out), negative_slope=0.2, inplace=True)
65 | out = self.conv9(out)
66 |
67 | return out
--------------------------------------------------------------------------------
/hat/archs/srvgg_arch.py:
--------------------------------------------------------------------------------
1 | from basicsr.utils.registry import ARCH_REGISTRY
2 | from torch import nn as nn
3 | from torch.nn import functional as F
4 |
5 |
6 | @ARCH_REGISTRY.register()
7 | class SRVGGNetCompact(nn.Module):
8 | """A compact VGG-style network structure for super-resolution.
9 |
10 | It is a compact network structure, which performs upsampling in the last layer and no convolution is
11 | conducted on the HR feature space.
12 |
13 | Args:
14 | num_in_ch (int): Channel number of inputs. Default: 3.
15 | num_out_ch (int): Channel number of outputs. Default: 3.
16 | num_feat (int): Channel number of intermediate features. Default: 64.
17 | num_conv (int): Number of convolution layers in the body network. Default: 16.
18 | upscale (int): Upsampling factor. Default: 4.
19 | act_type (str): Activation type, options: 'relu', 'prelu', 'leakyrelu'. Default: prelu.
20 | """
21 |
22 | def __init__(self, num_in_ch=3, num_out_ch=3, num_feat=64, num_conv=16, upscale=4, act_type='prelu'):
23 | super(SRVGGNetCompact, self).__init__()
24 | self.num_in_ch = num_in_ch
25 | self.num_out_ch = num_out_ch
26 | self.num_feat = num_feat
27 | self.num_conv = num_conv
28 | self.upscale = upscale
29 | self.act_type = act_type
30 |
31 | self.body = nn.ModuleList()
32 | # the first conv
33 | self.body.append(nn.Conv2d(num_in_ch, num_feat, 3, 1, 1))
34 | # the first activation
35 | if act_type == 'relu':
36 | activation = nn.ReLU(inplace=True)
37 | elif act_type == 'prelu':
38 | activation = nn.PReLU(num_parameters=num_feat)
39 | elif act_type == 'leakyrelu':
40 | activation = nn.LeakyReLU(negative_slope=0.1, inplace=True)
41 | self.body.append(activation)
42 |
43 | # the body structure
44 | for _ in range(num_conv):
45 | self.body.append(nn.Conv2d(num_feat, num_feat, 3, 1, 1))
46 | # activation
47 | if act_type == 'relu':
48 | activation = nn.ReLU(inplace=True)
49 | elif act_type == 'prelu':
50 | activation = nn.PReLU(num_parameters=num_feat)
51 | elif act_type == 'leakyrelu':
52 | activation = nn.LeakyReLU(negative_slope=0.1, inplace=True)
53 | self.body.append(activation)
54 |
55 | # the last conv
56 | self.body.append(nn.Conv2d(num_feat, num_out_ch * upscale * upscale, 3, 1, 1))
57 | # upsample
58 | self.upsampler = nn.PixelShuffle(upscale)
59 |
60 | def forward(self, x):
61 | out = x
62 | for i in range(0, len(self.body)):
63 | out = self.body[i](out)
64 |
65 | out = self.upsampler(out)
66 | # add the nearest upsampled image, so that the network learns the residual
67 | base = F.interpolate(x, scale_factor=self.upscale, mode='nearest')
68 | out += base
69 | return out
--------------------------------------------------------------------------------
/hat/data/__init__.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | from os import path as osp
3 |
4 | from basicsr.utils import scandir
5 |
6 | # automatically scan and import dataset modules for registry
7 | # scan all the files that end with '_dataset.py' under the data folder
8 | data_folder = osp.dirname(osp.abspath(__file__))
9 | dataset_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(data_folder) if v.endswith('_dataset.py')]
10 | # import all the dataset modules
11 | _dataset_modules = [importlib.import_module(f'hat.data.{file_name}') for file_name in dataset_filenames]
12 |
--------------------------------------------------------------------------------
/hat/data/imagenet_paired_dataset.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import numpy as np
3 | import os.path as osp
4 | from torch.utils import data as data
5 | from torchvision.transforms.functional import normalize
6 |
7 | from basicsr.data.data_util import paths_from_lmdb, scandir
8 | from basicsr.data.transforms import augment, paired_random_crop
9 | from basicsr.utils import FileClient, imfrombytes, img2tensor
10 | from basicsr.utils.matlab_functions import imresize, rgb2ycbcr
11 | from basicsr.utils.registry import DATASET_REGISTRY
12 |
13 |
14 | @DATASET_REGISTRY.register()
15 | class ImageNetPairedDataset(data.Dataset):
16 |
17 | def __init__(self, opt):
18 | super(ImageNetPairedDataset, self).__init__()
19 | self.opt = opt
20 | # file client (io backend)
21 | self.file_client = None
22 | self.io_backend_opt = opt['io_backend']
23 | self.mean = opt['mean'] if 'mean' in opt else None
24 | self.std = opt['std'] if 'std' in opt else None
25 | self.gt_folder = opt['dataroot_gt']
26 |
27 | if self.io_backend_opt['type'] == 'lmdb':
28 | self.io_backend_opt['db_paths'] = [self.gt_folder]
29 | self.io_backend_opt['client_keys'] = ['gt']
30 | self.paths = paths_from_lmdb(self.gt_folder)
31 | elif 'meta_info_file' in self.opt:
32 | with open(self.opt['meta_info_file'], 'r') as fin:
33 | self.paths = [osp.join(self.gt_folder, line.split(' ')[0]) for line in fin]
34 | else:
35 | self.paths = sorted(list(scandir(self.gt_folder, full_path=True)))
36 |
37 | def __getitem__(self, index):
38 | if self.file_client is None:
39 | self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
40 |
41 | scale = self.opt['scale']
42 |
43 | # Load gt and lq images. Dimension order: HWC; channel order: BGR;
44 | # image range: [0, 1], float32.
45 | gt_path = self.paths[index]
46 | img_bytes = self.file_client.get(gt_path, 'gt')
47 | img_gt = imfrombytes(img_bytes, float32=True)
48 |
49 | # modcrop
50 | size_h, size_w, _ = img_gt.shape
51 | size_h = size_h - size_h % scale
52 | size_w = size_w - size_w % scale
53 | img_gt = img_gt[0:size_h, 0:size_w, :]
54 |
55 | # generate training pairs
56 | size_h = max(size_h, self.opt['gt_size'])
57 | size_w = max(size_w, self.opt['gt_size'])
58 | img_gt = cv2.resize(img_gt, (size_w, size_h))
59 | img_lq = imresize(img_gt, 1 / scale)
60 |
61 | img_gt = np.ascontiguousarray(img_gt, dtype=np.float32)
62 | img_lq = np.ascontiguousarray(img_lq, dtype=np.float32)
63 |
64 | # augmentation for training
65 | if self.opt['phase'] == 'train':
66 | gt_size = self.opt['gt_size']
67 | # random crop
68 | img_gt, img_lq = paired_random_crop(img_gt, img_lq, gt_size, scale, gt_path)
69 | # flip, rotation
70 | img_gt, img_lq = augment([img_gt, img_lq], self.opt['use_hflip'], self.opt['use_rot'])
71 |
72 | # color space transform
73 | if 'color' in self.opt and self.opt['color'] == 'y':
74 | img_gt = rgb2ycbcr(img_gt, y_only=True)[..., None]
75 | img_lq = rgb2ycbcr(img_lq, y_only=True)[..., None]
76 |
77 | # crop the unmatched GT images during validation or testing, especially for SR benchmark datasets
78 | # TODO: It is better to update the datasets, rather than force to crop
79 | if self.opt['phase'] != 'train':
80 | img_gt = img_gt[0:img_lq.shape[0] * scale, 0:img_lq.shape[1] * scale, :]
81 |
82 | # BGR to RGB, HWC to CHW, numpy to tensor
83 | img_gt, img_lq = img2tensor([img_gt, img_lq], bgr2rgb=True, float32=True)
84 | # normalize
85 | if self.mean is not None or self.std is not None:
86 | normalize(img_lq, self.mean, self.std, inplace=True)
87 | normalize(img_gt, self.mean, self.std, inplace=True)
88 |
89 | return {'lq': img_lq, 'gt': img_gt, 'gt_path': gt_path}
90 |
91 | def __len__(self):
92 | return len(self.paths)
93 |
--------------------------------------------------------------------------------
/hat/data/realesrgan_dataset.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import math
3 | import numpy as np
4 | import os
5 | import os.path as osp
6 | import random
7 | import time
8 | import torch
9 | from basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels
10 | from basicsr.data.transforms import augment
11 | from basicsr.utils import FileClient, get_root_logger, imfrombytes, img2tensor
12 | from basicsr.utils.registry import DATASET_REGISTRY
13 | from torch.utils import data as data
14 | from basicsr.data.data_util import scandir
15 |
16 | @DATASET_REGISTRY.register()
17 | class RealESRGANDataset(data.Dataset):
18 | """Dataset used for Real-ESRGAN model:
19 | Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data.
20 |
21 | It loads gt (Ground-Truth) images, and augments them.
22 | It also generates blur kernels and sinc kernels for generating low-quality images.
23 | Note that the low-quality images are processed in tensors on GPUS for faster processing.
24 |
25 | Args:
26 | opt (dict): Config for train datasets. It contains the following keys:
27 | dataroot_gt (str): Data root path for gt.
28 | meta_info (str): Path for meta information file.
29 | io_backend (dict): IO backend type and other kwarg.
30 | use_hflip (bool): Use horizontal flips.
31 | use_rot (bool): Use rotation (use vertical flip and transposing h and w for implementation).
32 | Please see more options in the codes.
33 | """
34 |
35 | def __init__(self, opt):
36 | super(RealESRGANDataset, self).__init__()
37 | self.opt = opt
38 | self.file_client = None
39 | self.io_backend_opt = opt['io_backend']
40 | self.gt_folder = opt['dataroot_gt']
41 |
42 | # file client (lmdb io backend)
43 | if self.io_backend_opt['type'] == 'lmdb':
44 | self.io_backend_opt['db_paths'] = [self.gt_folder]
45 | self.io_backend_opt['client_keys'] = ['gt']
46 | if not self.gt_folder.endswith('.lmdb'):
47 | raise ValueError(f"'dataroot_gt' should end with '.lmdb', but received {self.gt_folder}")
48 | with open(osp.join(self.gt_folder, 'meta_info.txt')) as fin:
49 | self.paths = [line.split('.')[0] for line in fin]
50 | elif 'meta_info' in self.opt and self.opt['meta_info'] is not None:
51 | # disk backend with meta_info
52 | # Each line in the meta_info describes the relative path to an image
53 | with open(self.opt['meta_info']) as fin:
54 | paths = [line.strip().split(' ')[0] for line in fin]
55 | self.paths = [os.path.join(self.gt_folder, v) for v in paths]
56 | else:
57 | self.paths = sorted(list(scandir(self.gt_folder, full_path=True)))
58 |
59 | # blur settings for the first degradation
60 | self.blur_kernel_size = opt['blur_kernel_size']
61 | self.kernel_list = opt['kernel_list']
62 | self.kernel_prob = opt['kernel_prob'] # a list for each kernel probability
63 | self.blur_sigma = opt['blur_sigma']
64 | self.betag_range = opt['betag_range'] # betag used in generalized Gaussian blur kernels
65 | self.betap_range = opt['betap_range'] # betap used in plateau blur kernels
66 | self.sinc_prob = opt['sinc_prob'] # the probability for sinc filters
67 |
68 | # blur settings for the second degradation
69 | self.blur_kernel_size2 = opt['blur_kernel_size2']
70 | self.kernel_list2 = opt['kernel_list2']
71 | self.kernel_prob2 = opt['kernel_prob2']
72 | self.blur_sigma2 = opt['blur_sigma2']
73 | self.betag_range2 = opt['betag_range2']
74 | self.betap_range2 = opt['betap_range2']
75 | self.sinc_prob2 = opt['sinc_prob2']
76 |
77 | # a final sinc filter
78 | self.final_sinc_prob = opt['final_sinc_prob']
79 |
80 | self.kernel_range = [2 * v + 1 for v in range(3, 11)] # kernel size ranges from 7 to 21
81 | # TODO: kernel range is now hard-coded, should be in the configure file
82 | self.pulse_tensor = torch.zeros(21, 21).float() # convolving with pulse tensor brings no blurry effect
83 | self.pulse_tensor[10, 10] = 1
84 |
85 | def __getitem__(self, index):
86 | if self.file_client is None:
87 | self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
88 |
89 | # -------------------------------- Load gt images -------------------------------- #
90 | # Shape: (h, w, c); channel order: BGR; image range: [0, 1], float32.
91 | gt_path = self.paths[index]
92 | # avoid errors caused by high latency in reading files
93 | retry = 3
94 | while retry > 0:
95 | try:
96 | img_bytes = self.file_client.get(gt_path, 'gt')
97 | except (IOError, OSError) as e:
98 | logger = get_root_logger()
99 | logger.warn(f'File client error: {e}, remaining retry times: {retry - 1}')
100 | # change another file to read
101 | index = random.randint(0, self.__len__())
102 | gt_path = self.paths[index]
103 | time.sleep(1) # sleep 1s for occasional server congestion
104 | else:
105 | break
106 | finally:
107 | retry -= 1
108 | img_gt = imfrombytes(img_bytes, float32=True)
109 |
110 | # -------------------- Do augmentation for training: flip, rotation -------------------- #
111 | img_gt = augment(img_gt, self.opt['use_hflip'], self.opt['use_rot'])
112 |
113 | # crop or pad to 400
114 | # TODO: 400 is hard-coded. You may change it accordingly
115 | h, w = img_gt.shape[0:2]
116 | crop_pad_size = 400
117 | # pad
118 | if h < crop_pad_size or w < crop_pad_size:
119 | pad_h = max(0, crop_pad_size - h)
120 | pad_w = max(0, crop_pad_size - w)
121 | img_gt = cv2.copyMakeBorder(img_gt, 0, pad_h, 0, pad_w, cv2.BORDER_REFLECT_101)
122 | # crop
123 | if img_gt.shape[0] > crop_pad_size or img_gt.shape[1] > crop_pad_size:
124 | h, w = img_gt.shape[0:2]
125 | # randomly choose top and left coordinates
126 | top = random.randint(0, h - crop_pad_size)
127 | left = random.randint(0, w - crop_pad_size)
128 | img_gt = img_gt[top:top + crop_pad_size, left:left + crop_pad_size, ...]
129 |
130 | # ------------------------ Generate kernels (used in the first degradation) ------------------------ #
131 | kernel_size = random.choice(self.kernel_range)
132 | if np.random.uniform() < self.opt['sinc_prob']:
133 | # this sinc filter setting is for kernels ranging from [7, 21]
134 | if kernel_size < 13:
135 | omega_c = np.random.uniform(np.pi / 3, np.pi)
136 | else:
137 | omega_c = np.random.uniform(np.pi / 5, np.pi)
138 | kernel = circular_lowpass_kernel(omega_c, kernel_size, pad_to=False)
139 | else:
140 | kernel = random_mixed_kernels(
141 | self.kernel_list,
142 | self.kernel_prob,
143 | kernel_size,
144 | self.blur_sigma,
145 | self.blur_sigma, [-math.pi, math.pi],
146 | self.betag_range,
147 | self.betap_range,
148 | noise_range=None)
149 | # pad kernel
150 | pad_size = (21 - kernel_size) // 2
151 | kernel = np.pad(kernel, ((pad_size, pad_size), (pad_size, pad_size)))
152 |
153 | # ------------------------ Generate kernels (used in the second degradation) ------------------------ #
154 | kernel_size = random.choice(self.kernel_range)
155 | if np.random.uniform() < self.opt['sinc_prob2']:
156 | if kernel_size < 13:
157 | omega_c = np.random.uniform(np.pi / 3, np.pi)
158 | else:
159 | omega_c = np.random.uniform(np.pi / 5, np.pi)
160 | kernel2 = circular_lowpass_kernel(omega_c, kernel_size, pad_to=False)
161 | else:
162 | kernel2 = random_mixed_kernels(
163 | self.kernel_list2,
164 | self.kernel_prob2,
165 | kernel_size,
166 | self.blur_sigma2,
167 | self.blur_sigma2, [-math.pi, math.pi],
168 | self.betag_range2,
169 | self.betap_range2,
170 | noise_range=None)
171 |
172 | # pad kernel
173 | pad_size = (21 - kernel_size) // 2
174 | kernel2 = np.pad(kernel2, ((pad_size, pad_size), (pad_size, pad_size)))
175 |
176 | # ------------------------------------- the final sinc kernel ------------------------------------- #
177 | if np.random.uniform() < self.opt['final_sinc_prob']:
178 | kernel_size = random.choice(self.kernel_range)
179 | omega_c = np.random.uniform(np.pi / 3, np.pi)
180 | sinc_kernel = circular_lowpass_kernel(omega_c, kernel_size, pad_to=21)
181 | sinc_kernel = torch.FloatTensor(sinc_kernel)
182 | else:
183 | sinc_kernel = self.pulse_tensor
184 |
185 | # BGR to RGB, HWC to CHW, numpy to tensor
186 | img_gt = img2tensor([img_gt], bgr2rgb=True, float32=True)[0]
187 | kernel = torch.FloatTensor(kernel)
188 | kernel2 = torch.FloatTensor(kernel2)
189 |
190 | return_d = {'gt': img_gt, 'kernel1': kernel, 'kernel2': kernel2, 'sinc_kernel': sinc_kernel, 'gt_path': gt_path}
191 | return return_d
192 |
193 | def __len__(self):
194 | return len(self.paths)
--------------------------------------------------------------------------------
/hat/models/__init__.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | from os import path as osp
3 |
4 | from basicsr.utils import scandir
5 |
6 | # automatically scan and import model modules for registry
7 | # scan all the files that end with '_model.py' under the model folder
8 | model_folder = osp.dirname(osp.abspath(__file__))
9 | model_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(model_folder) if v.endswith('_model.py')]
10 | # import all the model modules
11 | _model_modules = [importlib.import_module(f'hat.models.{file_name}') for file_name in model_filenames]
12 |
--------------------------------------------------------------------------------
/hat/models/hat_model.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.nn import functional as F
3 |
4 | from basicsr.utils.registry import MODEL_REGISTRY
5 | from basicsr.models.sr_model import SRModel
6 | from basicsr.metrics import calculate_metric
7 | from basicsr.utils import imwrite, tensor2img
8 |
9 | import math
10 | from tqdm import tqdm
11 | from os import path as osp
12 |
13 | @MODEL_REGISTRY.register()
14 | class HATModel(SRModel):
15 |
16 | def pre_process(self):
17 | # pad to multiplication of window_size
18 | window_size = self.opt['network_g']['window_size']
19 | self.scale = self.opt.get('scale', 1)
20 | self.mod_pad_h, self.mod_pad_w = 0, 0
21 | _, _, h, w = self.lq.size()
22 | if h % window_size != 0:
23 | self.mod_pad_h = window_size - h % window_size
24 | if w % window_size != 0:
25 | self.mod_pad_w = window_size - w % window_size
26 | self.img = F.pad(self.lq, (0, self.mod_pad_w, 0, self.mod_pad_h), 'reflect')
27 |
28 | def process(self):
29 | # model inference
30 | if hasattr(self, 'net_g_ema'):
31 | self.net_g_ema.eval()
32 | with torch.no_grad():
33 | self.output = self.net_g_ema(self.img)
34 | else:
35 | self.net_g.eval()
36 | with torch.no_grad():
37 | self.output = self.net_g(self.img)
38 | # self.net_g.train()
39 |
40 | def tile_process(self):
41 | """It will first crop input images to tiles, and then process each tile.
42 | Finally, all the processed tiles are merged into one images.
43 | Modified from: https://github.com/ata4/esrgan-launcher
44 | """
45 | batch, channel, height, width = self.img.shape
46 | output_height = height * self.scale
47 | output_width = width * self.scale
48 | output_shape = (batch, channel, output_height, output_width)
49 |
50 | # start with black image
51 | self.output = self.img.new_zeros(output_shape)
52 | tiles_x = math.ceil(width / self.opt['tile']['tile_size'])
53 | tiles_y = math.ceil(height / self.opt['tile']['tile_size'])
54 |
55 | # loop over all tiles
56 | for y in range(tiles_y):
57 | for x in range(tiles_x):
58 | # extract tile from input image
59 | ofs_x = x * self.opt['tile']['tile_size']
60 | ofs_y = y * self.opt['tile']['tile_size']
61 | # input tile area on total image
62 | input_start_x = ofs_x
63 | input_end_x = min(ofs_x + self.opt['tile']['tile_size'], width)
64 | input_start_y = ofs_y
65 | input_end_y = min(ofs_y + self.opt['tile']['tile_size'], height)
66 |
67 | # input tile area on total image with padding
68 | input_start_x_pad = max(input_start_x - self.opt['tile']['tile_pad'], 0)
69 | input_end_x_pad = min(input_end_x + self.opt['tile']['tile_pad'], width)
70 | input_start_y_pad = max(input_start_y - self.opt['tile']['tile_pad'], 0)
71 | input_end_y_pad = min(input_end_y + self.opt['tile']['tile_pad'], height)
72 |
73 | # input tile dimensions
74 | input_tile_width = input_end_x - input_start_x
75 | input_tile_height = input_end_y - input_start_y
76 | tile_idx = y * tiles_x + x + 1
77 | input_tile = self.img[:, :, input_start_y_pad:input_end_y_pad, input_start_x_pad:input_end_x_pad]
78 |
79 | # upscale tile
80 | try:
81 | if hasattr(self, 'net_g_ema'):
82 | self.net_g_ema.eval()
83 | with torch.no_grad():
84 | output_tile = self.net_g_ema(input_tile)
85 | else:
86 | self.net_g.eval()
87 | with torch.no_grad():
88 | output_tile = self.net_g(input_tile)
89 | except RuntimeError as error:
90 | print('Error', error)
91 | print(f'\tTile {tile_idx}/{tiles_x * tiles_y}')
92 |
93 | # output tile area on total image
94 | output_start_x = input_start_x * self.opt['scale']
95 | output_end_x = input_end_x * self.opt['scale']
96 | output_start_y = input_start_y * self.opt['scale']
97 | output_end_y = input_end_y * self.opt['scale']
98 |
99 | # output tile area without padding
100 | output_start_x_tile = (input_start_x - input_start_x_pad) * self.opt['scale']
101 | output_end_x_tile = output_start_x_tile + input_tile_width * self.opt['scale']
102 | output_start_y_tile = (input_start_y - input_start_y_pad) * self.opt['scale']
103 | output_end_y_tile = output_start_y_tile + input_tile_height * self.opt['scale']
104 |
105 | # put tile into output image
106 | self.output[:, :, output_start_y:output_end_y,
107 | output_start_x:output_end_x] = output_tile[:, :, output_start_y_tile:output_end_y_tile,
108 | output_start_x_tile:output_end_x_tile]
109 |
110 | def post_process(self):
111 | _, _, h, w = self.output.size()
112 | self.output = self.output[:, :, 0:h - self.mod_pad_h * self.scale, 0:w - self.mod_pad_w * self.scale]
113 |
114 | def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
115 | dataset_name = dataloader.dataset.opt['name']
116 | with_metrics = self.opt['val'].get('metrics') is not None
117 | use_pbar = self.opt['val'].get('pbar', False)
118 |
119 | if with_metrics:
120 | if not hasattr(self, 'metric_results'): # only execute in the first run
121 | self.metric_results = {metric: 0 for metric in self.opt['val']['metrics'].keys()}
122 | # initialize the best metric results for each dataset_name (supporting multiple validation datasets)
123 | self._initialize_best_metric_results(dataset_name)
124 | # zero self.metric_results
125 | if with_metrics:
126 | self.metric_results = {metric: 0 for metric in self.metric_results}
127 |
128 | metric_data = dict()
129 | if use_pbar:
130 | pbar = tqdm(total=len(dataloader), unit='image')
131 |
132 | for idx, val_data in enumerate(dataloader):
133 | img_name = osp.splitext(osp.basename(val_data['lq_path'][0]))[0]
134 | self.feed_data(val_data)
135 |
136 | self.pre_process()
137 | if 'tile' in self.opt:
138 | self.tile_process()
139 | else:
140 | self.process()
141 | self.post_process()
142 |
143 | visuals = self.get_current_visuals()
144 | sr_img = tensor2img([visuals['result']])
145 | metric_data['img'] = sr_img
146 | if 'gt' in visuals:
147 | gt_img = tensor2img([visuals['gt']])
148 | metric_data['img2'] = gt_img
149 | del self.gt
150 |
151 | # tentative for out of GPU memory
152 | del self.lq
153 | del self.output
154 | torch.cuda.empty_cache()
155 |
156 | if save_img:
157 | if self.opt['is_train']:
158 | save_img_path = osp.join(self.opt['path']['visualization'], img_name,
159 | f'{img_name}_{current_iter}.png')
160 | else:
161 | if self.opt['val']['suffix']:
162 | save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,
163 | f'{img_name}_{self.opt["val"]["suffix"]}.png')
164 | else:
165 | save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,
166 | f'{img_name}_{self.opt["name"]}.png')
167 | imwrite(sr_img, save_img_path)
168 |
169 | if with_metrics:
170 | # calculate metrics
171 | for name, opt_ in self.opt['val']['metrics'].items():
172 | self.metric_results[name] += calculate_metric(metric_data, opt_)
173 | if use_pbar:
174 | pbar.update(1)
175 | pbar.set_description(f'Test {img_name}')
176 | if use_pbar:
177 | pbar.close()
178 |
179 | if with_metrics:
180 | for metric in self.metric_results.keys():
181 | self.metric_results[metric] /= (idx + 1)
182 | # update the best metric result
183 | self._update_best_metric_result(dataset_name, metric, self.metric_results[metric], current_iter)
184 |
185 | self._log_validation_metric_values(current_iter, dataset_name, tb_logger)
186 |
--------------------------------------------------------------------------------
/hat/models/realhatgan_model.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import random
3 | import torch
4 | from basicsr.data.degradations import random_add_gaussian_noise_pt, random_add_poisson_noise_pt
5 | from basicsr.data.transforms import paired_random_crop
6 | from basicsr.models.srgan_model import SRGANModel
7 | from basicsr.utils import DiffJPEG, USMSharp
8 | from basicsr.utils.img_process_util import filter2D
9 | from basicsr.utils.registry import MODEL_REGISTRY
10 | from collections import OrderedDict
11 | from torch.nn import functional as F
12 |
13 |
14 | @MODEL_REGISTRY.register()
15 | class RealHATGANModel(SRGANModel):
16 | """GAN-based Real_HAT Model.
17 |
18 | It mainly performs:
19 | 1. randomly synthesize LQ images in GPU tensors
20 | 2. optimize the networks with GAN training.
21 | """
22 |
23 | def __init__(self, opt):
24 | super(RealHATGANModel, self).__init__(opt)
25 | self.jpeger = DiffJPEG(differentiable=False).cuda() # simulate JPEG compression artifacts
26 | self.usm_sharpener = USMSharp().cuda() # do usm sharpening
27 | self.queue_size = opt.get('queue_size', 180)
28 |
29 | @torch.no_grad()
30 | def _dequeue_and_enqueue(self):
31 | """It is the training pair pool for increasing the diversity in a batch.
32 |
33 | Batch processing limits the diversity of synthetic degradations in a batch. For example, samples in a
34 | batch could not have different resize scaling factors. Therefore, we employ this training pair pool
35 | to increase the degradation diversity in a batch.
36 | """
37 | # initialize
38 | b, c, h, w = self.lq.size()
39 | if not hasattr(self, 'queue_lr'):
40 | assert self.queue_size % b == 0, f'queue size {self.queue_size} should be divisible by batch size {b}'
41 | self.queue_lr = torch.zeros(self.queue_size, c, h, w).cuda()
42 | _, c, h, w = self.gt.size()
43 | self.queue_gt = torch.zeros(self.queue_size, c, h, w).cuda()
44 | self.queue_ptr = 0
45 | if self.queue_ptr == self.queue_size: # the pool is full
46 | # do dequeue and enqueue
47 | # shuffle
48 | idx = torch.randperm(self.queue_size)
49 | self.queue_lr = self.queue_lr[idx]
50 | self.queue_gt = self.queue_gt[idx]
51 | # get first b samples
52 | lq_dequeue = self.queue_lr[0:b, :, :, :].clone()
53 | gt_dequeue = self.queue_gt[0:b, :, :, :].clone()
54 | # update the queue
55 | self.queue_lr[0:b, :, :, :] = self.lq.clone()
56 | self.queue_gt[0:b, :, :, :] = self.gt.clone()
57 |
58 | self.lq = lq_dequeue
59 | self.gt = gt_dequeue
60 | else:
61 | # only do enqueue
62 | self.queue_lr[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.lq.clone()
63 | self.queue_gt[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.gt.clone()
64 | self.queue_ptr = self.queue_ptr + b
65 |
66 | @torch.no_grad()
67 | def feed_data(self, data):
68 | """Accept data from dataloader, and then add two-order degradations to obtain LQ images.
69 | """
70 | if self.is_train and self.opt.get('high_order_degradation', True):
71 | # training data synthesis
72 | self.gt = data['gt'].to(self.device)
73 | self.gt_usm = self.usm_sharpener(self.gt)
74 |
75 | self.kernel1 = data['kernel1'].to(self.device)
76 | self.kernel2 = data['kernel2'].to(self.device)
77 | self.sinc_kernel = data['sinc_kernel'].to(self.device)
78 |
79 | ori_h, ori_w = self.gt.size()[2:4]
80 |
81 | # ----------------------- The first degradation process ----------------------- #
82 | # blur
83 | out = filter2D(self.gt_usm, self.kernel1)
84 | # random resize
85 | updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob'])[0]
86 | if updown_type == 'up':
87 | scale = np.random.uniform(1, self.opt['resize_range'][1])
88 | elif updown_type == 'down':
89 | scale = np.random.uniform(self.opt['resize_range'][0], 1)
90 | else:
91 | scale = 1
92 | mode = random.choice(['area', 'bilinear', 'bicubic'])
93 | out = F.interpolate(out, scale_factor=scale, mode=mode)
94 | # add noise
95 | gray_noise_prob = self.opt['gray_noise_prob']
96 | if np.random.uniform() < self.opt['gaussian_noise_prob']:
97 | out = random_add_gaussian_noise_pt(
98 | out, sigma_range=self.opt['noise_range'], clip=True, rounds=False, gray_prob=gray_noise_prob)
99 | else:
100 | out = random_add_poisson_noise_pt(
101 | out,
102 | scale_range=self.opt['poisson_scale_range'],
103 | gray_prob=gray_noise_prob,
104 | clip=True,
105 | rounds=False)
106 | # JPEG compression
107 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range'])
108 | out = torch.clamp(out, 0, 1) # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
109 | out = self.jpeger(out, quality=jpeg_p)
110 |
111 | # ----------------------- The second degradation process ----------------------- #
112 | # blur
113 | if np.random.uniform() < self.opt['second_blur_prob']:
114 | out = filter2D(out, self.kernel2)
115 | # random resize
116 | updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob2'])[0]
117 | if updown_type == 'up':
118 | scale = np.random.uniform(1, self.opt['resize_range2'][1])
119 | elif updown_type == 'down':
120 | scale = np.random.uniform(self.opt['resize_range2'][0], 1)
121 | else:
122 | scale = 1
123 | mode = random.choice(['area', 'bilinear', 'bicubic'])
124 | out = F.interpolate(
125 | out, size=(int(ori_h / self.opt['scale'] * scale), int(ori_w / self.opt['scale'] * scale)), mode=mode)
126 | # add noise
127 | gray_noise_prob = self.opt['gray_noise_prob2']
128 | if np.random.uniform() < self.opt['gaussian_noise_prob2']:
129 | out = random_add_gaussian_noise_pt(
130 | out, sigma_range=self.opt['noise_range2'], clip=True, rounds=False, gray_prob=gray_noise_prob)
131 | else:
132 | out = random_add_poisson_noise_pt(
133 | out,
134 | scale_range=self.opt['poisson_scale_range2'],
135 | gray_prob=gray_noise_prob,
136 | clip=True,
137 | rounds=False)
138 |
139 | # JPEG compression + the final sinc filter
140 | # We also need to resize images to desired sizes. We group [resize back + sinc filter] together
141 | # as one operation.
142 | # We consider two orders:
143 | # 1. [resize back + sinc filter] + JPEG compression
144 | # 2. JPEG compression + [resize back + sinc filter]
145 | # Empirically, we find other combinations (sinc + JPEG + Resize) will introduce twisted lines.
146 | if np.random.uniform() < 0.5:
147 | # resize back + the final sinc filter
148 | mode = random.choice(['area', 'bilinear', 'bicubic'])
149 | out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
150 | out = filter2D(out, self.sinc_kernel)
151 | # JPEG compression
152 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
153 | out = torch.clamp(out, 0, 1)
154 | out = self.jpeger(out, quality=jpeg_p)
155 | else:
156 | # JPEG compression
157 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
158 | out = torch.clamp(out, 0, 1)
159 | out = self.jpeger(out, quality=jpeg_p)
160 | # resize back + the final sinc filter
161 | mode = random.choice(['area', 'bilinear', 'bicubic'])
162 | out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
163 | out = filter2D(out, self.sinc_kernel)
164 |
165 | # clamp and round
166 | self.lq = torch.clamp((out * 255.0).round(), 0, 255) / 255.
167 |
168 | # random crop
169 | gt_size = self.opt['gt_size']
170 | (self.gt, self.gt_usm), self.lq = paired_random_crop([self.gt, self.gt_usm], self.lq, gt_size,
171 | self.opt['scale'])
172 |
173 | # training pair pool
174 | self._dequeue_and_enqueue()
175 | # sharpen self.gt again, as we have changed the self.gt with self._dequeue_and_enqueue
176 | self.gt_usm = self.usm_sharpener(self.gt)
177 | self.lq = self.lq.contiguous() # for the warning: grad and param do not obey the gradient layout contract
178 | else:
179 | # for paired training or validation
180 | self.lq = data['lq'].to(self.device)
181 | if 'gt' in data:
182 | self.gt = data['gt'].to(self.device)
183 | self.gt_usm = self.usm_sharpener(self.gt)
184 |
185 | def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
186 | # do not use the synthetic process during validation
187 | self.is_train = False
188 | super(RealHATGANModel, self).nondist_validation(dataloader, current_iter, tb_logger, save_img)
189 | self.is_train = True
190 |
191 | def optimize_parameters(self, current_iter):
192 | # usm sharpening
193 | l1_gt = self.gt_usm
194 | percep_gt = self.gt_usm
195 | gan_gt = self.gt_usm
196 | if self.opt['l1_gt_usm'] is False:
197 | l1_gt = self.gt
198 | if self.opt['percep_gt_usm'] is False:
199 | percep_gt = self.gt
200 | if self.opt['gan_gt_usm'] is False:
201 | gan_gt = self.gt
202 |
203 | # optimize net_g
204 | for p in self.net_d.parameters():
205 | p.requires_grad = False
206 |
207 | self.optimizer_g.zero_grad()
208 | self.output = self.net_g(self.lq)
209 |
210 | l_g_total = 0
211 | loss_dict = OrderedDict()
212 | if (current_iter % self.net_d_iters == 0 and current_iter > self.net_d_init_iters):
213 | # pixel loss
214 | if self.cri_pix:
215 | l_g_pix = self.cri_pix(self.output, l1_gt)
216 | l_g_total += l_g_pix
217 | loss_dict['l_g_pix'] = l_g_pix
218 | # perceptual loss
219 | if self.cri_perceptual:
220 | l_g_percep, l_g_style = self.cri_perceptual(self.output, percep_gt)
221 | if l_g_percep is not None:
222 | l_g_total += l_g_percep
223 | loss_dict['l_g_percep'] = l_g_percep
224 | if l_g_style is not None:
225 | l_g_total += l_g_style
226 | loss_dict['l_g_style'] = l_g_style
227 | # gan loss
228 | fake_g_pred = self.net_d(self.output)
229 | l_g_gan = self.cri_gan(fake_g_pred, True, is_disc=False)
230 | l_g_total += l_g_gan
231 | loss_dict['l_g_gan'] = l_g_gan
232 |
233 | l_g_total.backward()
234 | self.optimizer_g.step()
235 |
236 | # optimize net_d
237 | for p in self.net_d.parameters():
238 | p.requires_grad = True
239 |
240 | self.optimizer_d.zero_grad()
241 | # real
242 | real_d_pred = self.net_d(gan_gt)
243 | l_d_real = self.cri_gan(real_d_pred, True, is_disc=True)
244 | loss_dict['l_d_real'] = l_d_real
245 | loss_dict['out_d_real'] = torch.mean(real_d_pred.detach())
246 | l_d_real.backward()
247 | # fake
248 | fake_d_pred = self.net_d(self.output.detach().clone()) # clone for pt1.9
249 | l_d_fake = self.cri_gan(fake_d_pred, False, is_disc=True)
250 | loss_dict['l_d_fake'] = l_d_fake
251 | loss_dict['out_d_fake'] = torch.mean(fake_d_pred.detach())
252 | l_d_fake.backward()
253 | self.optimizer_d.step()
254 |
255 | if self.ema_decay > 0:
256 | self.model_ema(decay=self.ema_decay)
257 |
258 | self.log_dict = self.reduce_loss_dict(loss_dict)
259 |
260 | def test(self):
261 | # pad to multiplication of window_size
262 | window_size = self.opt['network_g']['window_size']
263 | scale = self.opt.get('scale', 1)
264 | mod_pad_h, mod_pad_w = 0, 0
265 | _, _, h, w = self.lq.size()
266 | if h % window_size != 0:
267 | mod_pad_h = window_size - h % window_size
268 | if w % window_size != 0:
269 | mod_pad_w = window_size - w % window_size
270 | img = F.pad(self.lq, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
271 | if hasattr(self, 'net_g_ema'):
272 | self.net_g_ema.eval()
273 | with torch.no_grad():
274 | self.output = self.net_g_ema(img)
275 | else:
276 | self.net_g.eval()
277 | with torch.no_grad():
278 | self.output = self.net_g(img)
279 | self.net_g.train()
280 |
281 | _, _, h, w = self.output.size()
282 | self.output = self.output[:, :, 0:h - mod_pad_h * scale, 0:w - mod_pad_w * scale]
--------------------------------------------------------------------------------
/hat/models/realhatmse_model.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import random
3 | import torch
4 | from basicsr.data.degradations import random_add_gaussian_noise_pt, random_add_poisson_noise_pt
5 | from basicsr.data.transforms import paired_random_crop
6 | from basicsr.models.sr_model import SRModel
7 | from basicsr.utils import DiffJPEG, USMSharp
8 | from basicsr.utils.img_process_util import filter2D
9 | from basicsr.utils.registry import MODEL_REGISTRY
10 | from torch.nn import functional as F
11 |
12 |
13 | @MODEL_REGISTRY.register()
14 | class RealHATMSEModel(SRModel):
15 | """MSE-based Real_HAT Model.
16 |
17 | It is trained without GAN losses.
18 | It mainly performs:
19 | 1. randomly synthesize LQ images in GPU tensors
20 | 2. optimize the networks with GAN training.
21 | """
22 |
23 | def __init__(self, opt):
24 | super(RealHATMSEModel, self).__init__(opt)
25 | self.jpeger = DiffJPEG(differentiable=False).cuda() # simulate JPEG compression artifacts
26 | self.usm_sharpener = USMSharp().cuda() # do usm sharpening
27 | self.queue_size = opt.get('queue_size', 180)
28 |
29 | @torch.no_grad()
30 | def _dequeue_and_enqueue(self):
31 | """It is the training pair pool for increasing the diversity in a batch.
32 |
33 | Batch processing limits the diversity of synthetic degradations in a batch. For example, samples in a
34 | batch could not have different resize scaling factors. Therefore, we employ this training pair pool
35 | to increase the degradation diversity in a batch.
36 | """
37 | # initialize
38 | b, c, h, w = self.lq.size()
39 | if not hasattr(self, 'queue_lr'):
40 | assert self.queue_size % b == 0, f'queue size {self.queue_size} should be divisible by batch size {b}'
41 | self.queue_lr = torch.zeros(self.queue_size, c, h, w).cuda()
42 | _, c, h, w = self.gt.size()
43 | self.queue_gt = torch.zeros(self.queue_size, c, h, w).cuda()
44 | self.queue_ptr = 0
45 | if self.queue_ptr == self.queue_size: # the pool is full
46 | # do dequeue and enqueue
47 | # shuffle
48 | idx = torch.randperm(self.queue_size)
49 | self.queue_lr = self.queue_lr[idx]
50 | self.queue_gt = self.queue_gt[idx]
51 | # get first b samples
52 | lq_dequeue = self.queue_lr[0:b, :, :, :].clone()
53 | gt_dequeue = self.queue_gt[0:b, :, :, :].clone()
54 | # update the queue
55 | self.queue_lr[0:b, :, :, :] = self.lq.clone()
56 | self.queue_gt[0:b, :, :, :] = self.gt.clone()
57 |
58 | self.lq = lq_dequeue
59 | self.gt = gt_dequeue
60 | else:
61 | # only do enqueue
62 | self.queue_lr[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.lq.clone()
63 | self.queue_gt[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.gt.clone()
64 | self.queue_ptr = self.queue_ptr + b
65 |
66 | @torch.no_grad()
67 | def feed_data(self, data):
68 | """Accept data from dataloader, and then add two-order degradations to obtain LQ images.
69 | """
70 | if self.is_train and self.opt.get('high_order_degradation', True):
71 | # training data synthesis
72 | self.gt = data['gt'].to(self.device)
73 | # USM sharpen the GT images
74 | if self.opt['gt_usm'] is True:
75 | self.gt = self.usm_sharpener(self.gt)
76 |
77 | self.kernel1 = data['kernel1'].to(self.device)
78 | self.kernel2 = data['kernel2'].to(self.device)
79 | self.sinc_kernel = data['sinc_kernel'].to(self.device)
80 |
81 | ori_h, ori_w = self.gt.size()[2:4]
82 |
83 | # ----------------------- The first degradation process ----------------------- #
84 | # blur
85 | out = filter2D(self.gt, self.kernel1)
86 | # random resize
87 | updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob'])[0]
88 | if updown_type == 'up':
89 | scale = np.random.uniform(1, self.opt['resize_range'][1])
90 | elif updown_type == 'down':
91 | scale = np.random.uniform(self.opt['resize_range'][0], 1)
92 | else:
93 | scale = 1
94 | mode = random.choice(['area', 'bilinear', 'bicubic'])
95 | out = F.interpolate(out, scale_factor=scale, mode=mode)
96 | # add noise
97 | gray_noise_prob = self.opt['gray_noise_prob']
98 | if np.random.uniform() < self.opt['gaussian_noise_prob']:
99 | out = random_add_gaussian_noise_pt(
100 | out, sigma_range=self.opt['noise_range'], clip=True, rounds=False, gray_prob=gray_noise_prob)
101 | else:
102 | out = random_add_poisson_noise_pt(
103 | out,
104 | scale_range=self.opt['poisson_scale_range'],
105 | gray_prob=gray_noise_prob,
106 | clip=True,
107 | rounds=False)
108 | # JPEG compression
109 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range'])
110 | out = torch.clamp(out, 0, 1) # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
111 | out = self.jpeger(out, quality=jpeg_p)
112 |
113 | # ----------------------- The second degradation process ----------------------- #
114 | # blur
115 | if np.random.uniform() < self.opt['second_blur_prob']:
116 | out = filter2D(out, self.kernel2)
117 | # random resize
118 | updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob2'])[0]
119 | if updown_type == 'up':
120 | scale = np.random.uniform(1, self.opt['resize_range2'][1])
121 | elif updown_type == 'down':
122 | scale = np.random.uniform(self.opt['resize_range2'][0], 1)
123 | else:
124 | scale = 1
125 | mode = random.choice(['area', 'bilinear', 'bicubic'])
126 | out = F.interpolate(
127 | out, size=(int(ori_h / self.opt['scale'] * scale), int(ori_w / self.opt['scale'] * scale)), mode=mode)
128 | # add noise
129 | gray_noise_prob = self.opt['gray_noise_prob2']
130 | if np.random.uniform() < self.opt['gaussian_noise_prob2']:
131 | out = random_add_gaussian_noise_pt(
132 | out, sigma_range=self.opt['noise_range2'], clip=True, rounds=False, gray_prob=gray_noise_prob)
133 | else:
134 | out = random_add_poisson_noise_pt(
135 | out,
136 | scale_range=self.opt['poisson_scale_range2'],
137 | gray_prob=gray_noise_prob,
138 | clip=True,
139 | rounds=False)
140 |
141 | # JPEG compression + the final sinc filter
142 | # We also need to resize images to desired sizes. We group [resize back + sinc filter] together
143 | # as one operation.
144 | # We consider two orders:
145 | # 1. [resize back + sinc filter] + JPEG compression
146 | # 2. JPEG compression + [resize back + sinc filter]
147 | # Empirically, we find other combinations (sinc + JPEG + Resize) will introduce twisted lines.
148 | if np.random.uniform() < 0.5:
149 | # resize back + the final sinc filter
150 | mode = random.choice(['area', 'bilinear', 'bicubic'])
151 | out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
152 | out = filter2D(out, self.sinc_kernel)
153 | # JPEG compression
154 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
155 | out = torch.clamp(out, 0, 1)
156 | out = self.jpeger(out, quality=jpeg_p)
157 | else:
158 | # JPEG compression
159 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
160 | out = torch.clamp(out, 0, 1)
161 | out = self.jpeger(out, quality=jpeg_p)
162 | # resize back + the final sinc filter
163 | mode = random.choice(['area', 'bilinear', 'bicubic'])
164 | out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
165 | out = filter2D(out, self.sinc_kernel)
166 |
167 | # clamp and round
168 | self.lq = torch.clamp((out * 255.0).round(), 0, 255) / 255.
169 |
170 | # random crop
171 | gt_size = self.opt['gt_size']
172 | self.gt, self.lq = paired_random_crop(self.gt, self.lq, gt_size, self.opt['scale'])
173 |
174 | # training pair pool
175 | self._dequeue_and_enqueue()
176 | self.lq = self.lq.contiguous() # for the warning: grad and param do not obey the gradient layout contract
177 | else:
178 | # for paired training or validation
179 | self.lq = data['lq'].to(self.device)
180 | if 'gt' in data:
181 | self.gt = data['gt'].to(self.device)
182 | self.gt_usm = self.usm_sharpener(self.gt)
183 |
184 | def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
185 | # do not use the synthetic process during validation
186 | self.is_train = False
187 | super(RealHATMSEModel, self).nondist_validation(dataloader, current_iter, tb_logger, save_img)
188 | self.is_train = True
189 |
190 | def test(self):
191 | # pad to multiplication of window_size
192 | window_size = self.opt['network_g']['window_size']
193 | scale = self.opt.get('scale', 1)
194 | mod_pad_h, mod_pad_w = 0, 0
195 | _, _, h, w = self.lq.size()
196 | if h % window_size != 0:
197 | mod_pad_h = window_size - h % window_size
198 | if w % window_size != 0:
199 | mod_pad_w = window_size - w % window_size
200 | img = F.pad(self.lq, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
201 | if hasattr(self, 'net_g_ema'):
202 | self.net_g_ema.eval()
203 | with torch.no_grad():
204 | self.output = self.net_g_ema(img)
205 | else:
206 | self.net_g.eval()
207 | with torch.no_grad():
208 | self.output = self.net_g(img)
209 | self.net_g.train()
210 |
211 | _, _, h, w = self.output.size()
212 | self.output = self.output[:, :, 0:h - mod_pad_h * scale, 0:w - mod_pad_w * scale]
--------------------------------------------------------------------------------
/hat/test.py:
--------------------------------------------------------------------------------
1 | # flake8: noqa
2 | import os.path as osp
3 |
4 | import hat.archs
5 | import hat.data
6 | import hat.models
7 | from basicsr.test import test_pipeline
8 |
9 | if __name__ == '__main__':
10 | root_path = osp.abspath(osp.join(__file__, osp.pardir, osp.pardir))
11 | test_pipeline(root_path)
12 |
--------------------------------------------------------------------------------
/hat/train.py:
--------------------------------------------------------------------------------
1 | # flake8: noqa
2 | import os.path as osp
3 |
4 | import hat.archs
5 | import hat.data
6 | import hat.models
7 | from basicsr.train import train_pipeline
8 |
9 | if __name__ == '__main__':
10 | root_path = osp.abspath(osp.join(__file__, osp.pardir, osp.pardir))
11 | train_pipeline(root_path)
12 |
--------------------------------------------------------------------------------
/options/test/HAT-L_SRx2_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT-L_SRx2_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 2
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod2
12 | dataroot_lq: ./datasets/Set5/LRbicx2
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod2
20 | # dataroot_lq: ./datasets/Set14/LRbicx2
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod2
28 | # dataroot_lq: ./datasets/urban100/LRbicx2
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod2
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx2
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod2
44 | # dataroot_lq: ./datasets/manga109/LRbicx2
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 2
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-L_SRx2_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 2
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 2
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT-L_SRx3_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT-L_SRx3_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 3
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod3
12 | dataroot_lq: ./datasets/Set5/LRbicx3
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod3
20 | # dataroot_lq: ./datasets/Set14/LRbicx3
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod3
28 | # dataroot_lq: ./datasets/urban100/LRbicx3
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod3
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx3
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod3
44 | # dataroot_lq: ./datasets/manga109/LRbicx3
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 3
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-L_SRx3_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 3
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 3
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT-L_SRx4_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT-L_SRx4_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod4
12 | dataroot_lq: ./datasets/Set5/LRbicx4
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod4
20 | # dataroot_lq: ./datasets/Set14/LRbicx4
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod4
28 | # dataroot_lq: ./datasets/urban100/LRbicx4
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod4
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx4
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod4
44 | # dataroot_lq: ./datasets/manga109/LRbicx4
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 4
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-L_SRx4_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 4
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 4
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT-S_SRx2.yml:
--------------------------------------------------------------------------------
1 | name: HAT-S_SRx2
2 | model_type: HATModel
3 | scale: 2
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod2
12 | dataroot_lq: ./datasets/Set5/LRbicx2
13 | io_backend:
14 | type: disk
15 |
16 | test_2: # the 2nd test dataset
17 | name: Set14
18 | type: PairedImageDataset
19 | dataroot_gt: ./datasets/Set14/GTmod2
20 | dataroot_lq: ./datasets/Set14/LRbicx2
21 | io_backend:
22 | type: disk
23 |
24 | test_3:
25 | name: Urban100
26 | type: PairedImageDataset
27 | dataroot_gt: ./datasets/urban100/GTmod2
28 | dataroot_lq: ./datasets/urban100/LRbicx2
29 | io_backend:
30 | type: disk
31 |
32 | test_4:
33 | name: BSDS100
34 | type: PairedImageDataset
35 | dataroot_gt: ./datasets/BSDS100/GTmod2
36 | dataroot_lq: ./datasets/BSDS100/LRbicx2
37 | io_backend:
38 | type: disk
39 |
40 | test_5:
41 | name: Manga109
42 | type: PairedImageDataset
43 | dataroot_gt: ./datasets/manga109/GTmod2
44 | dataroot_lq: ./datasets/manga109/LRbicx2
45 | io_backend:
46 | type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 2
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 24
56 | squeeze_factor: 24
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 144
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-S_SRx2.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 2
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 2
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT-S_SRx3.yml:
--------------------------------------------------------------------------------
1 | name: HAT-S_SRx3
2 | model_type: HATModel
3 | scale: 3
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod3
12 | dataroot_lq: ./datasets/Set5/LRbicx3
13 | io_backend:
14 | type: disk
15 |
16 | test_2: # the 2nd test dataset
17 | name: Set14
18 | type: PairedImageDataset
19 | dataroot_gt: ./datasets/Set14/GTmod3
20 | dataroot_lq: ./datasets/Set14/LRbicx3
21 | io_backend:
22 | type: disk
23 |
24 | test_3:
25 | name: Urban100
26 | type: PairedImageDataset
27 | dataroot_gt: ./datasets/urban100/GTmod3
28 | dataroot_lq: ./datasets/urban100/LRbicx3
29 | io_backend:
30 | type: disk
31 |
32 | test_4:
33 | name: BSDS100
34 | type: PairedImageDataset
35 | dataroot_gt: ./datasets/BSDS100/GTmod3
36 | dataroot_lq: ./datasets/BSDS100/LRbicx3
37 | io_backend:
38 | type: disk
39 |
40 | test_5:
41 | name: Manga109
42 | type: PairedImageDataset
43 | dataroot_gt: ./datasets/manga109/GTmod3
44 | dataroot_lq: ./datasets/manga109/LRbicx3
45 | io_backend:
46 | type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 3
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 24
56 | squeeze_factor: 24
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 144
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-S_SRx3.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 3
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 3
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT-S_SRx4.yml:
--------------------------------------------------------------------------------
1 | name: HAT-S_SRx4
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod4
12 | dataroot_lq: ./datasets/Set5/LRbicx4
13 | io_backend:
14 | type: disk
15 |
16 | test_2: # the 2nd test dataset
17 | name: Set14
18 | type: PairedImageDataset
19 | dataroot_gt: ./datasets/Set14/GTmod4
20 | dataroot_lq: ./datasets/Set14/LRbicx4
21 | io_backend:
22 | type: disk
23 |
24 | test_3:
25 | name: Urban100
26 | type: PairedImageDataset
27 | dataroot_gt: ./datasets/urban100/GTmod4
28 | dataroot_lq: ./datasets/urban100/LRbicx4
29 | io_backend:
30 | type: disk
31 |
32 | test_4:
33 | name: BSDS100
34 | type: PairedImageDataset
35 | dataroot_gt: ./datasets/BSDS100/GTmod4
36 | dataroot_lq: ./datasets/BSDS100/LRbicx4
37 | io_backend:
38 | type: disk
39 |
40 | test_5:
41 | name: Manga109
42 | type: PairedImageDataset
43 | dataroot_gt: ./datasets/manga109/GTmod4
44 | dataroot_lq: ./datasets/manga109/LRbicx4
45 | io_backend:
46 | type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 4
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 24
56 | squeeze_factor: 24
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 144
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-S_SRx4.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 4
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 4
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_GAN_Real_SRx4.yml:
--------------------------------------------------------------------------------
1 | name: HAT_GAN_Real_SRx4
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | tile: # use the tile mode for limited GPU memory when testing.
8 | tile_size: 512 # the higher, the more utilized GPU memory and the less performance change against the full image. must be an integer multiple of the window size.
9 | tile_pad: 32 # overlapping between adjacency patches.must be an integer multiple of the window size.
10 |
11 | datasets:
12 | test_1: # the 1st test dataset
13 | name: custom
14 | type: SingleImageDataset
15 | dataroot_lq: input_dir
16 | io_backend:
17 | type: disk
18 |
19 | # network structures
20 | network_g:
21 | type: HAT
22 | upscale: 4
23 | in_chans: 3
24 | img_size: 64
25 | window_size: 16
26 | compress_ratio: 3
27 | squeeze_factor: 30
28 | conv_scale: 0.01
29 | overlap_ratio: 0.5
30 | img_range: 1.
31 | depths: [6, 6, 6, 6, 6, 6]
32 | embed_dim: 180
33 | num_heads: [6, 6, 6, 6, 6, 6]
34 | mlp_ratio: 2
35 | upsampler: 'pixelshuffle'
36 | resi_connection: '1conv'
37 |
38 |
39 | # path
40 | path:
41 | pretrain_network_g: ./experiments/pretrained_models/Real_HAT_GAN_SRx4.pth
42 | strict_load_g: true
43 | param_key_g: 'params_ema'
44 |
45 | # validation settings
46 | val:
47 | save_img: true
48 | suffix: ~ # add suffix to saved images, if None, use exp name
--------------------------------------------------------------------------------
/options/test/HAT_SRx2.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx2
2 | model_type: HATModel
3 | scale: 2
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod2
12 | dataroot_lq: ./datasets/Set5/LRbicx2
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod2
20 | # dataroot_lq: ./datasets/Set14/LRbicx2
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod2
28 | # dataroot_lq: ./datasets/urban100/LRbicx2
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod2
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx2
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod2
44 | # dataroot_lq: ./datasets/manga109/LRbicx2
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 2
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx2.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 2
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 2
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx2_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx2_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 2
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod2
12 | dataroot_lq: ./datasets/Set5/LRbicx2
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod2
20 | # dataroot_lq: ./datasets/Set14/LRbicx2
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod2
28 | # dataroot_lq: ./datasets/urban100/LRbicx2
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod2
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx2
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod2
44 | # dataroot_lq: ./datasets/manga109/LRbicx2
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 2
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx2_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 2
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 2
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx3.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx3
2 | model_type: HATModel
3 | scale: 3
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod3
12 | dataroot_lq: ./datasets/Set5/LRbicx3
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod3
20 | # dataroot_lq: ./datasets/Set14/LRbicx3
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod3
28 | # dataroot_lq: ./datasets/urban100/LRbicx3
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod3
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx3
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod3
44 | # dataroot_lq: ./datasets/manga109/LRbicx3
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 3
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx3.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 3
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 3
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx3_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx3_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 3
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod3
12 | dataroot_lq: ./datasets/Set5/LRbicx3
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod3
20 | # dataroot_lq: ./datasets/Set14/LRbicx3
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod3
28 | # dataroot_lq: ./datasets/urban100/LRbicx3
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod3
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx3
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod3
44 | # dataroot_lq: ./datasets/manga109/LRbicx3
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 3
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx3_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 3
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 3
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx4.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx4
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod4
12 | dataroot_lq: ./datasets/Set5/LRbicx4
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod4
20 | # dataroot_lq: ./datasets/Set14/LRbicx4
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod4
28 | # dataroot_lq: ./datasets/urban100/LRbicx4
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod4
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx4
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod4
44 | # dataroot_lq: ./datasets/manga109/LRbicx4
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 4
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx4.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 4
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 4
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx4_ImageNet-LR.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx4_ImageNet-LR
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | tile:
8 | tile_size: 512 # max patch size for the tile mode
9 | tile_pad: 32
10 |
11 | datasets:
12 | test_1: # the 1st test dataset
13 | name: custom
14 | type: SingleImageDataset
15 | dataroot_lq: input_dir
16 | io_backend:
17 | type: disk
18 |
19 | # network structures
20 | network_g:
21 | type: HAT
22 | upscale: 4
23 | in_chans: 3
24 | img_size: 64
25 | window_size: 16
26 | compress_ratio: 3
27 | squeeze_factor: 30
28 | conv_scale: 0.01
29 | overlap_ratio: 0.5
30 | img_range: 1.
31 | depths: [6, 6, 6, 6, 6, 6]
32 | embed_dim: 180
33 | num_heads: [6, 6, 6, 6, 6, 6]
34 | mlp_ratio: 2
35 | upsampler: 'pixelshuffle'
36 | resi_connection: '1conv'
37 |
38 |
39 | # path
40 | path:
41 | pretrain_network_g: experiments/pretrained_models/HAT_SRx4_ImageNet-pretrain.pth
42 | strict_load_g: true
43 | param_key_g: 'params_ema'
44 |
45 | # validation settings
46 | val:
47 | save_img: true
48 | suffix: ~ # add suffix to saved images, if None, use exp name
49 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx4_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx4_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod4
12 | dataroot_lq: ./datasets/Set5/LRbicx4
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod4
20 | # dataroot_lq: ./datasets/Set14/LRbicx4
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod4
28 | # dataroot_lq: ./datasets/urban100/LRbicx4
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod4
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx4
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod4
44 | # dataroot_lq: ./datasets/manga109/LRbicx4
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 4
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx4_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 4
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 4
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_tile_example.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx4_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | tile: # use the tile mode for limited GPU memory when testing.
8 | tile_size: 256 # the higher, the more utilized GPU memory and the less performance change against the full image. must be an integer multiple of the window size.
9 | tile_pad: 32 # overlapping between adjacency patches.must be an integer multiple of the window size.
10 |
11 | datasets:
12 | test_1: # the 1st test dataset
13 | name: Set5
14 | type: PairedImageDataset
15 | dataroot_gt: ./datasets/Set5/GTmod4
16 | dataroot_lq: ./datasets/Set5/LRbicx4
17 | io_backend:
18 | type: disk
19 |
20 | # test_2: # the 2nd test dataset
21 | # name: Set14
22 | # type: PairedImageDataset
23 | # dataroot_gt: ./datasets/Set14/GTmod4
24 | # dataroot_lq: ./datasets/Set14/LRbicx4
25 | # io_backend:
26 | # type: disk
27 |
28 | test_3:
29 | name: Urban100
30 | type: PairedImageDataset
31 | dataroot_gt: ./datasets/urban100/GTmod4
32 | dataroot_lq: ./datasets/urban100/LRbicx4
33 | io_backend:
34 | type: disk
35 |
36 | # test_4:
37 | # name: BSDS100
38 | # type: PairedImageDataset
39 | # dataroot_gt: ./datasets/BSDS100/GTmod4
40 | # dataroot_lq: ./datasets/BSDS100/LRbicx4
41 | # io_backend:
42 | # type: disk
43 |
44 | # test_5:
45 | # name: Manga109
46 | # type: PairedImageDataset
47 | # dataroot_gt: ./datasets/manga109/GTmod4
48 | # dataroot_lq: ./datasets/manga109/LRbicx4
49 | # io_backend:
50 | # type: disk
51 |
52 | # network structures
53 | network_g:
54 | type: HAT
55 | upscale: 4
56 | in_chans: 3
57 | img_size: 64
58 | window_size: 16
59 | compress_ratio: 3
60 | squeeze_factor: 30
61 | conv_scale: 0.01
62 | overlap_ratio: 0.5
63 | img_range: 1.
64 | depths: [6, 6, 6, 6, 6, 6]
65 | embed_dim: 180
66 | num_heads: [6, 6, 6, 6, 6, 6]
67 | mlp_ratio: 2
68 | upsampler: 'pixelshuffle'
69 | resi_connection: '1conv'
70 |
71 |
72 | # path
73 | path:
74 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx4_ImageNet-pretrain.pth
75 | strict_load_g: true
76 | param_key_g: 'params_ema'
77 |
78 | # validation settings
79 | val:
80 | save_img: true
81 | suffix: ~ # add suffix to saved images, if None, use exp name
82 |
83 | metrics:
84 | psnr: # metric name, can be arbitrary
85 | type: calculate_psnr
86 | crop_border: 4
87 | test_y_channel: true
88 | ssim:
89 | type: calculate_ssim
90 | crop_border: 4
91 | test_y_channel: true
92 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx2_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx2_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 128
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod2
33 | dataroot_lq: ./datasets/Set5/LRbicx2
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod2
41 | dataroot_lq: ./datasets/Set14/LRbicx2
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod2
49 | # dataroot_lq: ./datasets/urban100/LRbicx2
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 2
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 2
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 2
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx2_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx2_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx2_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 128
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod2
34 | dataroot_lq: ./datasets/Set5/LRbicx2
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod2
42 | dataroot_lq: ./datasets/Set14/LRbicx2
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod2
50 | # dataroot_lq: ./datasets/urban100/LRbicx2
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 2
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT-L_SRx2_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 2
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 2
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx3_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx3_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 192
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod3
33 | dataroot_lq: ./datasets/Set5/LRbicx3
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod3
41 | dataroot_lq: ./datasets/Set14/LRbicx3
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod3
49 | # dataroot_lq: ./datasets/urban100/LRbicx3
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 3
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 3
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 3
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx3_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx3_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx3_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 192
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod3
34 | dataroot_lq: ./datasets/Set5/LRbicx3
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod3
42 | dataroot_lq: ./datasets/Set14/LRbicx3
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod3
50 | # dataroot_lq: ./datasets/urban100/LRbicx3
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 3
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT-L_SRx3_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 3
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 3
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx4_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx4_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 256
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod4
33 | dataroot_lq: ./datasets/Set5/LRbicx4
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod4
41 | dataroot_lq: ./datasets/Set14/LRbicx4
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod4
49 | # dataroot_lq: ./datasets/urban100/LRbicx4
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 4
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 4
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 4
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx4_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx4_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx4_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 256
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod4
34 | dataroot_lq: ./datasets/Set5/LRbicx4
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod4
42 | dataroot_lq: ./datasets/Set14/LRbicx4
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod4
50 | # dataroot_lq: ./datasets/urban100/LRbicx4
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 4
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT-L_SRx4_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 4
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 4
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT-S_SRx2_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-S_SRx2_from_scratch
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx2_sub
15 | meta_info_file: hct/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 128
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: datasets/Set5/GTmod2
34 | dataroot_lq: datasets/Set5/LRbicx2
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: datasets/Set14/GTmod2
42 | dataroot_lq: datasets/Set14/LRbicx2
43 | io_backend:
44 | type: disk
45 |
46 | val_3:
47 | name: Urban100
48 | type: PairedImageDataset
49 | dataroot_gt: datasets/urban100/GTmod2
50 | dataroot_lq: datasets/urban100/LRbicx2
51 | io_backend:
52 | type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 2
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 24
63 | squeeze_factor: 24
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 144
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ~
77 | strict_load_g: true
78 | resume_state: ~
79 |
80 | # training settings
81 | train:
82 | ema_decay: 0.999
83 | optim_g:
84 | type: Adam
85 | lr: !!float 2e-4
86 | weight_decay: 0
87 | betas: [0.9, 0.99]
88 |
89 | scheduler:
90 | type: MultiStepLR
91 | milestones: [250000, 400000, 450000, 475000]
92 | gamma: 0.5
93 |
94 | total_iter: 500000
95 | warmup_iter: -1 # no warm up
96 |
97 | # losses
98 | pixel_opt:
99 | type: L1Loss
100 | loss_weight: 1.0
101 | reduction: mean
102 |
103 | # validation settings
104 | val:
105 | val_freq: !!float 2e4
106 | save_img: false
107 | pbar: False
108 |
109 | metrics:
110 | psnr:
111 | type: calculate_psnr
112 | crop_border: 2
113 | test_y_channel: true
114 | better: higher # the higher, the better. Default: higher
115 | ssim:
116 | type: calculate_ssim
117 | crop_border: 2
118 | test_y_channel: true
119 | better: higher # the higher, the better. Default: higher
120 |
121 | # logging settings
122 | logger:
123 | print_freq: 100
124 | save_checkpoint_freq: !!float 2e4
125 | use_tb_logger: true
126 | wandb:
127 | project: ~
128 | resume_id: ~
129 |
130 | # dist training settings
131 | dist_params:
132 | backend: nccl
133 | port: 29500
134 |
--------------------------------------------------------------------------------
/options/train/train_HAT-S_SRx3_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-S_SRx3_from_scratch
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx3_sub
15 | meta_info_file: hct/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 192
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: datasets/Set5/GTmod3
34 | dataroot_lq: datasets/Set5/LRbicx3
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: datasets/Set14/GTmod3
42 | dataroot_lq: datasets/Set14/LRbicx3
43 | io_backend:
44 | type: disk
45 |
46 | val_3:
47 | name: Urban100
48 | type: PairedImageDataset
49 | dataroot_gt: datasets/urban100/GTmod3
50 | dataroot_lq: datasets/urban100/LRbicx3
51 | io_backend:
52 | type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 3
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 24
63 | squeeze_factor: 24
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 144
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ~
77 | strict_load_g: true
78 | resume_state: ~
79 |
80 | # training settings
81 | train:
82 | ema_decay: 0.999
83 | optim_g:
84 | type: Adam
85 | lr: !!float 2e-4
86 | weight_decay: 0
87 | betas: [0.9, 0.99]
88 |
89 | scheduler:
90 | type: MultiStepLR
91 | milestones: [250000, 400000, 450000, 475000]
92 | gamma: 0.5
93 |
94 | total_iter: 500000
95 | warmup_iter: -1 # no warm up
96 |
97 | # losses
98 | pixel_opt:
99 | type: L1Loss
100 | loss_weight: 1.0
101 | reduction: mean
102 |
103 | # validation settings
104 | val:
105 | val_freq: !!float 2e4
106 | save_img: false
107 | pbar: False
108 |
109 | metrics:
110 | psnr:
111 | type: calculate_psnr
112 | crop_border: 3
113 | test_y_channel: true
114 | better: higher # the higher, the better. Default: higher
115 | ssim:
116 | type: calculate_ssim
117 | crop_border: 3
118 | test_y_channel: true
119 | better: higher # the higher, the better. Default: higher
120 |
121 | # logging settings
122 | logger:
123 | print_freq: 100
124 | save_checkpoint_freq: !!float 2e4
125 | use_tb_logger: true
126 | wandb:
127 | project: ~
128 | resume_id: ~
129 |
130 | # dist training settings
131 | dist_params:
132 | backend: nccl
133 | port: 29500
134 |
--------------------------------------------------------------------------------
/options/train/train_HAT-S_SRx4_finetune_from_SRx2.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-S_SRx4_finetune_from_SRx2
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx4_sub
15 | meta_info_file: hct/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 256
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: datasets/Set5/GTmod4
34 | dataroot_lq: datasets/Set5/LRbicx4
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: datasets/Set14/GTmod4
42 | dataroot_lq: datasets/Set14/LRbicx4
43 | io_backend:
44 | type: disk
45 |
46 | val_3:
47 | name: Urban100
48 | type: PairedImageDataset
49 | dataroot_gt: datasets/urban100/GTmod4
50 | dataroot_lq: datasets/urban100/LRbicx4
51 | io_backend:
52 | type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 4
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 24
63 | squeeze_factor: 24
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 144
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/563_train_HAT-S_SRx2_scratch_DF2K_500k_B4G8/models/net_g_latest.pth
77 | strict_load_g: false
78 | resume_state: ~
79 |
80 | # training settings
81 | train:
82 | ema_decay: 0.999
83 | optim_g:
84 | type: Adam
85 | lr: !!float 1e-4
86 | weight_decay: 0
87 | betas: [0.9, 0.99]
88 |
89 | scheduler:
90 | type: MultiStepLR
91 | milestones: [125000, 200000, 225000, 240000]
92 | gamma: 0.5
93 |
94 | total_iter: 250000
95 | warmup_iter: -1 # no warm up
96 |
97 | # losses
98 | pixel_opt:
99 | type: L1Loss
100 | loss_weight: 1.0
101 | reduction: mean
102 |
103 | # validation settings
104 | val:
105 | val_freq: !!float 2e4
106 | save_img: false
107 | pbar: False
108 |
109 | metrics:
110 | psnr:
111 | type: calculate_psnr
112 | crop_border: 4
113 | test_y_channel: true
114 | better: higher # the higher, the better. Default: higher
115 | ssim:
116 | type: calculate_ssim
117 | crop_border: 4
118 | test_y_channel: true
119 | better: higher # the higher, the better. Default: higher
120 |
121 | # logging settings
122 | logger:
123 | print_freq: 100
124 | save_checkpoint_freq: !!float 2e4
125 | use_tb_logger: true
126 | wandb:
127 | project: ~
128 | resume_id: ~
129 |
130 | # dist training settings
131 | dist_params:
132 | backend: nccl
133 | port: 29500
134 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx2_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx2_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 128
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod2
33 | dataroot_lq: ./datasets/Set5/LRbicx2
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod2
41 | dataroot_lq: ./datasets/Set14/LRbicx2
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod2
49 | # dataroot_lq: ./datasets/urban100/LRbicx2
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 2
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 2
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 2
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx2_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx2_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx2_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 128
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod2
34 | dataroot_lq: ./datasets/Set5/LRbicx2
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod2
42 | dataroot_lq: ./datasets/Set14/LRbicx2
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod2
50 | # dataroot_lq: ./datasets/urban100/LRbicx2
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 2
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT_SRx2_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 2
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 2
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx2_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx2_from_scratch
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx2_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 128
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod2
34 | dataroot_lq: ./datasets/Set5/LRbicx2
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod2
42 | dataroot_lq: ./datasets/Set14/LRbicx2
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod2
50 | # dataroot_lq: ./datasets/urban100/LRbicx2
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 2
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ~
77 | strict_load_g: true
78 | resume_state: ~
79 |
80 | # training settings
81 | train:
82 | ema_decay: 0.999
83 | optim_g:
84 | type: Adam
85 | lr: !!float 2e-4
86 | weight_decay: 0
87 | betas: [0.9, 0.99]
88 |
89 | scheduler:
90 | type: MultiStepLR
91 | milestones: [250000, 400000, 450000, 475000]
92 | gamma: 0.5
93 |
94 | total_iter: 500000
95 | warmup_iter: -1 # no warm up
96 |
97 | # losses
98 | pixel_opt:
99 | type: L1Loss
100 | loss_weight: 1.0
101 | reduction: mean
102 |
103 | # validation settings
104 | val:
105 | val_freq: !!float 5e3
106 | save_img: false
107 | pbar: False
108 |
109 | metrics:
110 | psnr:
111 | type: calculate_psnr
112 | crop_border: 2
113 | test_y_channel: true
114 | better: higher # the higher, the better. Default: higher
115 | ssim:
116 | type: calculate_ssim
117 | crop_border: 2
118 | test_y_channel: true
119 | better: higher # the higher, the better. Default: higher
120 |
121 | # logging settings
122 | logger:
123 | print_freq: 100
124 | save_checkpoint_freq: !!float 5e3
125 | use_tb_logger: true
126 | wandb:
127 | project: ~
128 | resume_id: ~
129 |
130 | # dist training settings
131 | dist_params:
132 | backend: nccl
133 | port: 29500
134 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx3_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx3_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 192
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod3
33 | dataroot_lq: ./datasets/Set5/LRbicx3
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod3
41 | dataroot_lq: ./datasets/Set14/LRbicx3
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod3
49 | # dataroot_lq: ./datasets/urban100/LRbicx3
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 3
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 3
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 3
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx3_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx3_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx3_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 192
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod3
34 | dataroot_lq: ./datasets/Set5/LRbicx3
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod3
42 | dataroot_lq: ./datasets/Set14/LRbicx3
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod3
50 | # dataroot_lq: ./datasets/urban100/LRbicx3
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 3
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT_SRx3_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 3
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 3
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx3_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx3_from_scratch
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx3_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 192
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod3
34 | dataroot_lq: ./datasets/Set5/LRbicx3
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod3
42 | dataroot_lq: ./datasets/Set14/LRbicx3
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod3
50 | # dataroot_lq: ./datasets/urban100/LRbicx3
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 3
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ~
77 | strict_load_g: true
78 | resume_state: ~
79 |
80 | # training settings
81 | train:
82 | ema_decay: 0.999
83 | optim_g:
84 | type: Adam
85 | lr: !!float 2e-4
86 | weight_decay: 0
87 | betas: [0.9, 0.99]
88 |
89 | scheduler:
90 | type: MultiStepLR
91 | milestones: [250000, 400000, 450000, 475000]
92 | gamma: 0.5
93 |
94 | total_iter: 500000
95 | warmup_iter: -1 # no warm up
96 |
97 | # losses
98 | pixel_opt:
99 | type: L1Loss
100 | loss_weight: 1.0
101 | reduction: mean
102 |
103 | # validation settings
104 | val:
105 | val_freq: !!float 5e3
106 | save_img: false
107 | pbar: False
108 |
109 | metrics:
110 | psnr:
111 | type: calculate_psnr
112 | crop_border: 3
113 | test_y_channel: true
114 | better: higher # the higher, the better. Default: higher
115 | ssim:
116 | type: calculate_ssim
117 | crop_border: 3
118 | test_y_channel: true
119 | better: higher # the higher, the better. Default: higher
120 |
121 | # logging settings
122 | logger:
123 | print_freq: 100
124 | save_checkpoint_freq: !!float 5e3
125 | use_tb_logger: true
126 | wandb:
127 | project: ~
128 | resume_id: ~
129 |
130 | # dist training settings
131 | dist_params:
132 | backend: nccl
133 | port: 29500
134 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx4_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx4_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 256
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod4
33 | dataroot_lq: ./datasets/Set5/LRbicx4
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod4
41 | dataroot_lq: ./datasets/Set14/LRbicx4
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod4
49 | # dataroot_lq: ./datasets/urban100/LRbicx4
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 4
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 4
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 4
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx4_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx4_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx4_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 256
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod4
34 | dataroot_lq: ./datasets/Set5/LRbicx4
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod4
42 | dataroot_lq: ./datasets/Set14/LRbicx4
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod4
50 | # dataroot_lq: ./datasets/urban100/LRbicx4
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 4
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT_SRx4_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 4
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 4
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx4_finetune_from_SRx2.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx4_finetune_from_SRx2
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx4_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 256
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod4
34 | dataroot_lq: ./datasets/Set5/LRbicx4
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod4
42 | dataroot_lq: ./datasets/Set14/LRbicx4
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod4
50 | # dataroot_lq: ./datasets/urban100/LRbicx4
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 4
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT_SRx2_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-4
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 4
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 4
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_Real_HAT_GAN_SRx4_finetune_from_mse_model.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_Real_HAT_GAN_SRx4_finetune_from_mse_model
3 | model_type: RealHATGANModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # ----------------- options for synthesizing training data in RealESRGANModel ----------------- #
9 | # USM the ground-truth
10 | l1_gt_usm: True
11 | percep_gt_usm: True
12 | gan_gt_usm: False
13 |
14 | # the first degradation process
15 | resize_prob: [0.2, 0.7, 0.1] # up, down, keep
16 | resize_range: [0.15, 1.5]
17 | gaussian_noise_prob: 0.5
18 | noise_range: [1, 30]
19 | poisson_scale_range: [0.05, 3]
20 | gray_noise_prob: 0.4
21 | jpeg_range: [30, 95]
22 |
23 | # the second degradation process
24 | second_blur_prob: 0.8
25 | resize_prob2: [0.3, 0.4, 0.3] # up, down, keep
26 | resize_range2: [0.3, 1.2]
27 | gaussian_noise_prob2: 0.5
28 | noise_range2: [1, 25]
29 | poisson_scale_range2: [0.05, 2.5]
30 | gray_noise_prob2: 0.4
31 | jpeg_range2: [30, 95]
32 |
33 | gt_size: 256
34 | queue_size: 180
35 |
36 | # dataset and data loader settings
37 | datasets:
38 | train:
39 | name: DF2K+OST
40 | type: RealESRGANDataset
41 | dataroot_gt: datasets/DFO/DFO_sub # Refer to Real-ESRGAN for OST dataset. Only DF2K is OK.
42 | meta_info_file: hat/data/meta_info/meta_info_DFOsub_GT.txt
43 | io_backend:
44 | type: disk
45 |
46 | blur_kernel_size: 21
47 | kernel_list: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
48 | kernel_prob: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
49 | sinc_prob: 0.1
50 | blur_sigma: [0.2, 3]
51 | betag_range: [0.5, 4]
52 | betap_range: [1, 2]
53 |
54 | blur_kernel_size2: 21
55 | kernel_list2: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
56 | kernel_prob2: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
57 | sinc_prob2: 0.1
58 | blur_sigma2: [0.2, 1.5]
59 | betag_range2: [0.5, 4]
60 | betap_range2: [1, 2]
61 |
62 | final_sinc_prob: 0.8
63 |
64 | gt_size: 256
65 | use_hflip: True
66 | use_rot: False
67 |
68 | # data loader
69 | use_shuffle: true
70 | num_worker_per_gpu: 5
71 | batch_size_per_gpu: 4
72 | dataset_enlarge_ratio: 1
73 | prefetch_mode: ~
74 |
75 | # Uncomment these for validation
76 | # val:
77 | # name: validation
78 | # type: SingleImageDataset
79 | # dataroot_lq: datasets/RealSRSet+5images
80 | # io_backend:
81 | # type: disk
82 |
83 | # network structures
84 | network_g:
85 | type: HAT
86 | upscale: 4
87 | in_chans: 3
88 | img_size: 64
89 | window_size: 16
90 | compress_ratio: 3
91 | squeeze_factor: 30
92 | conv_scale: 0.01
93 | overlap_ratio: 0.5
94 | img_range: 1.
95 | depths: [6, 6, 6, 6, 6, 6]
96 | embed_dim: 180
97 | num_heads: [6, 6, 6, 6, 6, 6]
98 | mlp_ratio: 2
99 | upsampler: 'pixelshuffle'
100 | resi_connection: '1conv'
101 |
102 | network_d:
103 | type: UNetDiscriminatorSN
104 | num_in_ch: 3
105 | num_feat: 64
106 | skip_connection: True
107 |
108 | # path
109 | path:
110 | # use the pre-trained Real-ESRNet model
111 | pretrain_network_g: experiments/pretrained_models/Real_HAT_x4.pth # train the MSE-based model 'Real_HAT' first.
112 | param_key_g: params_ema
113 | strict_load_g: true
114 | resume_state: ~
115 |
116 | # training settings
117 | train:
118 | ema_decay: 0.999
119 | optim_g:
120 | type: Adam
121 | lr: !!float 1e-4
122 | weight_decay: 0
123 | betas: [0.9, 0.99]
124 | optim_d:
125 | type: Adam
126 | lr: !!float 1e-4
127 | weight_decay: 0
128 | betas: [0.9, 0.99]
129 |
130 | scheduler:
131 | type: MultiStepLR
132 | milestones: [400000]
133 | gamma: 0.5
134 |
135 | total_iter: 400000
136 | warmup_iter: -1 # no warm up
137 |
138 | # losses
139 | pixel_opt:
140 | type: L1Loss
141 | loss_weight: 1.0
142 | reduction: mean
143 | # perceptual loss (content and style losses)
144 | perceptual_opt:
145 | type: PerceptualLoss
146 | layer_weights:
147 | # before relu
148 | 'conv1_2': 0.1
149 | 'conv2_2': 0.1
150 | 'conv3_4': 1
151 | 'conv4_4': 1
152 | 'conv5_4': 1
153 | vgg_type: vgg19
154 | use_input_norm: true
155 | perceptual_weight: !!float 1.0
156 | style_weight: 0
157 | range_norm: false
158 | criterion: l1
159 | # gan loss
160 | gan_opt:
161 | type: GANLoss
162 | gan_type: vanilla
163 | real_label_val: 1.0
164 | fake_label_val: 0.0
165 | loss_weight: !!float 1e-1
166 |
167 | net_d_iters: 1
168 | net_d_init_iters: 0
169 |
170 | # Uncomment these for validation
171 | # validation settings
172 | # val:
173 | # val_freq: !!float 1e4
174 | # save_img: True
175 |
176 | # metrics:
177 | # psnr: # metric name
178 | # type: calculate_psnr
179 | # crop_border: 4
180 | # test_y_channel: false
181 |
182 | # logging settings
183 | logger:
184 | print_freq: 200
185 | save_checkpoint_freq: !!float 1e4
186 | use_tb_logger: true
187 | wandb:
188 | project: ~
189 | resume_id: ~
190 |
191 | # dist training settings
192 | dist_params:
193 | backend: nccl
194 | port: 29500
--------------------------------------------------------------------------------
/options/train/train_Real_HAT_SRx4_mse_model.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_Real_HAT_mse_model
3 | model_type: RealHATMSEModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # ----------------- options for synthesizing training data in RealESRNetModel ----------------- #
9 | gt_usm: True # USM the ground-truth
10 |
11 | # the first degradation process
12 | resize_prob: [0.2, 0.7, 0.1] # up, down, keep
13 | resize_range: [0.15, 1.5]
14 | gaussian_noise_prob: 0.5
15 | noise_range: [1, 30]
16 | poisson_scale_range: [0.05, 3]
17 | gray_noise_prob: 0.4
18 | jpeg_range: [30, 95]
19 |
20 | # the second degradation process
21 | second_blur_prob: 0.8
22 | resize_prob2: [0.3, 0.4, 0.3] # up, down, keep
23 | resize_range2: [0.3, 1.2]
24 | gaussian_noise_prob2: 0.5
25 | noise_range2: [1, 25]
26 | poisson_scale_range2: [0.05, 2.5]
27 | gray_noise_prob2: 0.4
28 | jpeg_range2: [30, 95]
29 |
30 | gt_size: 256
31 | queue_size: 180
32 |
33 | # dataset and data loader settings
34 | datasets:
35 | train:
36 | name: DF2K+OST
37 | type: RealESRGANDataset
38 | dataroot_gt: datasets/DFO/DFO_sub # Refer to Real-ESRGAN for OST dataset. Only DF2K is OK.
39 | meta_info_file: hat/data/meta_info/meta_info_DFOsub_GT.txt
40 | io_backend:
41 | type: disk
42 |
43 | blur_kernel_size: 21
44 | kernel_list: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
45 | kernel_prob: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
46 | sinc_prob: 0.1
47 | blur_sigma: [0.2, 3]
48 | betag_range: [0.5, 4]
49 | betap_range: [1, 2]
50 |
51 | blur_kernel_size2: 21
52 | kernel_list2: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
53 | kernel_prob2: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
54 | sinc_prob2: 0.1
55 | blur_sigma2: [0.2, 1.5]
56 | betag_range2: [0.5, 4]
57 | betap_range2: [1, 2]
58 |
59 | final_sinc_prob: 0.8
60 |
61 | gt_size: 256
62 | use_hflip: True
63 | use_rot: False
64 |
65 | # data loader
66 | use_shuffle: true
67 | num_worker_per_gpu: 5
68 | batch_size_per_gpu: 4
69 | dataset_enlarge_ratio: 1
70 | prefetch_mode: ~
71 |
72 | # Uncomment these for validation
73 | # val:
74 | # name: validation
75 | # type: SingleImageDataset
76 | # dataroot_lq: datasets/RealSRSet+5images
77 | # io_backend:
78 | # type: disk
79 |
80 | # network structures
81 | network_g:
82 | type: HAT
83 | upscale: 4
84 | in_chans: 3
85 | img_size: 64
86 | window_size: 16
87 | compress_ratio: 3
88 | squeeze_factor: 30
89 | conv_scale: 0.01
90 | overlap_ratio: 0.5
91 | img_range: 1.
92 | depths: [6, 6, 6, 6, 6, 6]
93 | embed_dim: 180
94 | num_heads: [6, 6, 6, 6, 6, 6]
95 | mlp_ratio: 2
96 | upsampler: 'pixelshuffle'
97 | resi_connection: '1conv'
98 |
99 | # path
100 | path:
101 | pretrain_network_g: ~
102 | param_key_g: params_ema
103 | strict_load_g: true
104 | resume_state: ~
105 |
106 | # training settings
107 | train:
108 | ema_decay: 0.999
109 | optim_g:
110 | type: Adam
111 | lr: !!float 1e-4
112 | weight_decay: 0
113 | betas: [0.9, 0.99]
114 | optim_d:
115 | type: Adam
116 | lr: !!float 1e-4
117 | weight_decay: 0
118 | betas: [0.9, 0.99]
119 |
120 | scheduler:
121 | type: MultiStepLR
122 | milestones: [1000000]
123 | gamma: 0.5
124 |
125 | total_iter: 1000000
126 | warmup_iter: -1 # no warm up
127 |
128 | # losses
129 | pixel_opt:
130 | type: L1Loss
131 | loss_weight: 1.0
132 | reduction: mean
133 |
134 | # Uncomment these for validation
135 | # validation settings
136 | # val:
137 | # val_freq: !!float 1e4
138 | # save_img: True
139 |
140 | # metrics:
141 | # psnr: # metric name
142 | # type: calculate_psnr
143 | # crop_border: 4
144 | # test_y_channel: false
145 |
146 | # logging settings
147 | logger:
148 | print_freq: 200
149 | save_checkpoint_freq: !!float 1e4
150 | use_tb_logger: true
151 | wandb:
152 | project: ~
153 | resume_id: ~
154 |
155 | # dist training settings
156 | dist_params:
157 | backend: nccl
158 | port: 29500
159 |
--------------------------------------------------------------------------------
/predict.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import tempfile
3 | import shutil
4 | import os
5 | from PIL import Image
6 | import subprocess
7 | from cog import BasePredictor, Input, Path
8 |
9 |
10 | class Predictor(BasePredictor):
11 | def predict(
12 | self,
13 | image: Path = Input(
14 | description="Input Image.",
15 | ),
16 | ) -> Path:
17 | input_dir = "input_dir"
18 | output_path = Path(tempfile.mkdtemp()) / "output.png"
19 |
20 | try:
21 | for d in [input_dir, "results"]:
22 | if os.path.exists(input_dir):
23 | shutil.rmtree(input_dir)
24 | os.makedirs(input_dir, exist_ok=False)
25 |
26 | input_path = os.path.join(input_dir, os.path.basename(image))
27 | shutil.copy(str(image), input_path)
28 | subprocess.call(
29 | [
30 | "python",
31 | "hat/test.py",
32 | "-opt",
33 | "options/test/HAT_SRx4_ImageNet-LR.yml",
34 | ]
35 | )
36 | res_dir = os.path.join(
37 | "results", "HAT_SRx4_ImageNet-LR", "visualization", "custom"
38 | )
39 | assert (
40 | len(os.listdir(res_dir)) == 1
41 | ), "Should contain only one result for Single prediction."
42 | res = Image.open(os.path.join(res_dir, os.listdir(res_dir)[0]))
43 | res.save(str(output_path))
44 |
45 | finally:
46 | pass
47 | shutil.rmtree(input_dir)
48 | shutil.rmtree("results")
49 |
50 | return output_path
51 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | einops
2 | torch>=1.7
3 | basicsr==1.3.4.9
4 |
--------------------------------------------------------------------------------
/results/README.md:
--------------------------------------------------------------------------------
1 | The testing results will be saved in this folder.
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [flake8]
2 | ignore =
3 | # line break before binary operator (W503)
4 | W503,
5 | # line break after binary operator (W504)
6 | W504,
7 | max-line-length=120
8 |
9 | [yapf]
10 | based_on_style = pep8
11 | column_limit = 120
12 | blank_line_before_nested_class_or_def = true
13 | split_before_expression_after_opening_paren = true
14 |
15 | [isort]
16 | line_length = 120
17 | multi_line_output = 0
18 | known_standard_library = pkg_resources,setuptools
19 | known_first_party = basicsr
20 | known_third_party = cv2,requests,torch,torchvision
21 | no_lines_before = STDLIB,LOCALFOLDER
22 | default_section = THIRDPARTY
23 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | from setuptools import find_packages, setup
4 |
5 | import os
6 | import subprocess
7 | import time
8 |
9 | version_file = 'hat/version.py'
10 |
11 |
12 | def readme():
13 | with open('README.md', encoding='utf-8') as f:
14 | content = f.read()
15 | return content
16 |
17 |
18 | def get_git_hash():
19 |
20 | def _minimal_ext_cmd(cmd):
21 | # construct minimal environment
22 | env = {}
23 | for k in ['SYSTEMROOT', 'PATH', 'HOME']:
24 | v = os.environ.get(k)
25 | if v is not None:
26 | env[k] = v
27 | # LANGUAGE is used on win32
28 | env['LANGUAGE'] = 'C'
29 | env['LANG'] = 'C'
30 | env['LC_ALL'] = 'C'
31 | out = subprocess.Popen(cmd, stdout=subprocess.PIPE, env=env).communicate()[0]
32 | return out
33 |
34 | try:
35 | out = _minimal_ext_cmd(['git', 'rev-parse', 'HEAD'])
36 | sha = out.strip().decode('ascii')
37 | except OSError:
38 | sha = 'unknown'
39 |
40 | return sha
41 |
42 |
43 | def get_hash():
44 | if os.path.exists('.git'):
45 | sha = get_git_hash()[:7]
46 | else:
47 | sha = 'unknown'
48 |
49 | return sha
50 |
51 |
52 | def write_version_py():
53 | content = """# GENERATED VERSION FILE
54 | # TIME: {}
55 | __version__ = '{}'
56 | __gitsha__ = '{}'
57 | version_info = ({})
58 | """
59 | sha = get_hash()
60 | with open('VERSION', 'r') as f:
61 | SHORT_VERSION = f.read().strip()
62 | VERSION_INFO = ', '.join([x if x.isdigit() else f'"{x}"' for x in SHORT_VERSION.split('.')])
63 |
64 | version_file_str = content.format(time.asctime(), SHORT_VERSION, sha, VERSION_INFO)
65 | with open(version_file, 'w') as f:
66 | f.write(version_file_str)
67 |
68 |
69 | def get_version():
70 | with open(version_file, 'r') as f:
71 | exec(compile(f.read(), version_file, 'exec'))
72 | return locals()['__version__']
73 |
74 |
75 | def get_requirements(filename='requirements.txt'):
76 | here = os.path.dirname(os.path.realpath(__file__))
77 | with open(os.path.join(here, filename), 'r') as f:
78 | requires = [line.replace('\n', '') for line in f.readlines()]
79 | return requires
80 |
81 |
82 | if __name__ == '__main__':
83 | write_version_py()
84 | setup(
85 | name='hat',
86 | version=get_version(),
87 | description='HAT',
88 | long_description=readme(),
89 | long_description_content_type='text/markdown',
90 | author='Xiangyu Chen',
91 | author_email='chxy95@gmail.com',
92 | keywords='computer vision, pytorch, basicsr, image restoration, super-resolution',
93 | url='https://github.com/chxy95/HAT',
94 | include_package_data=True,
95 | packages=find_packages(exclude=('options', 'datasets', 'experiments', 'results', 'tb_logger', 'wandb')),
96 | classifiers=[
97 | 'Development Status :: 4 - Beta',
98 | 'License :: OSI Approved :: Apache Software License',
99 | 'Operating System :: OS Independent',
100 | 'Programming Language :: Python :: 3',
101 | 'Programming Language :: Python :: 3.7',
102 | 'Programming Language :: Python :: 3.8',
103 | ],
104 | license='MIT License',
105 | setup_requires=['cython', 'numpy'],
106 | install_requires=get_requirements(),
107 | zip_safe=False)
108 |
--------------------------------------------------------------------------------
53 |
54 | ## Citations
55 | #### BibTeX
56 |
57 | @InProceedings{chen2023activating,
58 | author = {Chen, Xiangyu and Wang, Xintao and Zhou, Jiantao and Qiao, Yu and Dong, Chao},
59 | title = {Activating More Pixels in Image Super-Resolution Transformer},
60 | booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
61 | month = {June},
62 | year = {2023},
63 | pages = {22367-22377}
64 | }
65 |
66 | @article{chen2023hat,
67 | title={HAT: Hybrid Attention Transformer for Image Restoration},
68 | author={Chen, Xiangyu and Wang, Xintao and Zhang, Wenlong and Kong, Xiangtao and Qiao, Yu and Zhou, Jiantao and Dong, Chao},
69 | journal={arXiv preprint arXiv:2309.05239},
70 | year={2023}
71 | }
72 |
73 | ## Environment
74 | - [PyTorch >= 1.7](https://pytorch.org/) **(Recommend **NOT** using torch 1.8!!! It would cause abnormal performance.)**
75 | - [BasicSR == 1.3.4.9](https://github.com/XPixelGroup/BasicSR/blob/master/INSTALL.md)
76 | ### Installation
77 | Install Pytorch first.
78 | Then,
79 | ```
80 | pip install -r requirements.txt
81 | python setup.py develop
82 | ```
83 |
84 | ## How To Test
85 |
86 | Without implementing the codes, [chaiNNer](https://github.com/chaiNNer-org/chaiNNer) is a nice tool to run our models.
87 |
88 | Otherwise,
89 | - Refer to `./options/test` for the configuration file of the model to be tested, and prepare the testing data and pretrained model.
90 | - The pretrained models are available at
91 | [Google Drive](https://drive.google.com/drive/folders/1HpmReFfoUqUbnAOQ7rvOeNU3uf_m69w0?usp=sharing) or [Baidu Netdisk](https://pan.baidu.com/s/1u2r4Lc2_EEeQqra2-w85Xg) (access code: qyrl).
92 | - Then run the following codes (taking `HAT_SRx4_ImageNet-pretrain.pth` as an example):
93 | ```
94 | python hat/test.py -opt options/test/HAT_SRx4_ImageNet-pretrain.yml
95 | ```
96 | The testing results will be saved in the `./results` folder.
97 |
98 | - Refer to `./options/test/HAT_SRx4_ImageNet-LR.yml` for **inference** without the ground truth image.
99 |
100 | **Note that the tile mode is also provided for limited GPU memory when testing. You can modify the specific settings of the tile mode in your custom testing option by referring to `./options/test/HAT_tile_example.yml`.**
101 |
102 | ## How To Train
103 | - Refer to `./options/train` for the configuration file of the model to train.
104 | - Preparation of training data can refer to [this page](https://github.com/XPixelGroup/BasicSR/blob/master/docs/DatasetPreparation.md). ImageNet dataset can be downloaded at the [official website](https://image-net.org/challenges/LSVRC/2012/2012-downloads.php).
105 | - The training command is like
106 | ```
107 | CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 hat/train.py -opt options/train/train_HAT_SRx2_from_scratch.yml --launcher pytorch
108 | ```
109 | - Note that the default batch size per gpu is 4, which will cost about 20G memory for each GPU.
110 |
111 | The training logs and weights will be saved in the `./experiments` folder.
112 |
113 | ## Results
114 | The inference results on benchmark datasets are available at
115 | [Google Drive](https://drive.google.com/drive/folders/1t2RdesqRVN7L6vCptneNRcpwZAo-Ub3L?usp=sharing) or [Baidu Netdisk](https://pan.baidu.com/s/1CQtLpty-KyZuqcSznHT_Zw) (access code: 63p5).
116 |
117 |
118 | ## Contact
119 | If you have any question, please email chxy95@gmail.com or join in the [Wechat group of BasicSR](https://github.com/XPixelGroup/BasicSR#-contact) to discuss with the authors.
120 |
--------------------------------------------------------------------------------
/VERSION:
--------------------------------------------------------------------------------
1 | 0.1.0
--------------------------------------------------------------------------------
/cog.yaml:
--------------------------------------------------------------------------------
1 | build:
2 | cuda: "10.2"
3 | gpu: true
4 | python_version: "3.8"
5 | system_packages:
6 | - "libgl1-mesa-glx"
7 | - "libglib2.0-0"
8 | python_packages:
9 | - "numpy==1.21.5"
10 | - "ipython==7.21.0"
11 | - "opencv-python==4.5.4.58"
12 | - "torch==1.9.1"
13 | - "torchvision==0.10.1"
14 | - "einops==0.4.1"
15 |
16 | run:
17 | - pip install basicsr==1.3.4.9
18 |
19 | predict: "predict.py:Predictor"
20 |
--------------------------------------------------------------------------------
/datasets/README.md:
--------------------------------------------------------------------------------
1 | Recommend to put datasets or the soft links of datasets in this folder.
--------------------------------------------------------------------------------
/experiments/pretrained_models/README.md:
--------------------------------------------------------------------------------
1 | Put downloaded pre-trained models here.
--------------------------------------------------------------------------------
/figures/Comparison.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XPixelGroup/HAT/1638a9a822581657811867bf670717f8371fc3e5/figures/Comparison.png
--------------------------------------------------------------------------------
/figures/Performance_comparison.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XPixelGroup/HAT/1638a9a822581657811867bf670717f8371fc3e5/figures/Performance_comparison.png
--------------------------------------------------------------------------------
/figures/Visual_Results.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/XPixelGroup/HAT/1638a9a822581657811867bf670717f8371fc3e5/figures/Visual_Results.png
--------------------------------------------------------------------------------
/hat/__init__.py:
--------------------------------------------------------------------------------
1 | # flake8: noqa
2 | from .archs import *
3 | from .data import *
4 | from .models import *
5 |
6 | # from .version import __gitsha__, __version__
7 |
--------------------------------------------------------------------------------
/hat/archs/__init__.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | from os import path as osp
3 |
4 | from basicsr.utils import scandir
5 |
6 | # automatically scan and import arch modules for registry
7 | # scan all the files that end with '_arch.py' under the archs folder
8 | arch_folder = osp.dirname(osp.abspath(__file__))
9 | arch_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(arch_folder) if v.endswith('_arch.py')]
10 | # import all the arch modules
11 | _arch_modules = [importlib.import_module(f'hat.archs.{file_name}') for file_name in arch_filenames]
12 |
--------------------------------------------------------------------------------
/hat/archs/discriminator_arch.py:
--------------------------------------------------------------------------------
1 | from basicsr.utils.registry import ARCH_REGISTRY
2 | from torch import nn as nn
3 | from torch.nn import functional as F
4 | from torch.nn.utils import spectral_norm
5 |
6 |
7 | @ARCH_REGISTRY.register()
8 | class UNetDiscriminatorSN(nn.Module):
9 | """Defines a U-Net discriminator with spectral normalization (SN)
10 |
11 | It is used in Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data.
12 |
13 | Arg:
14 | num_in_ch (int): Channel number of inputs. Default: 3.
15 | num_feat (int): Channel number of base intermediate features. Default: 64.
16 | skip_connection (bool): Whether to use skip connections between U-Net. Default: True.
17 | """
18 |
19 | def __init__(self, num_in_ch, num_feat=64, skip_connection=True):
20 | super(UNetDiscriminatorSN, self).__init__()
21 | self.skip_connection = skip_connection
22 | norm = spectral_norm
23 | # the first convolution
24 | self.conv0 = nn.Conv2d(num_in_ch, num_feat, kernel_size=3, stride=1, padding=1)
25 | # downsample
26 | self.conv1 = norm(nn.Conv2d(num_feat, num_feat * 2, 4, 2, 1, bias=False))
27 | self.conv2 = norm(nn.Conv2d(num_feat * 2, num_feat * 4, 4, 2, 1, bias=False))
28 | self.conv3 = norm(nn.Conv2d(num_feat * 4, num_feat * 8, 4, 2, 1, bias=False))
29 | # upsample
30 | self.conv4 = norm(nn.Conv2d(num_feat * 8, num_feat * 4, 3, 1, 1, bias=False))
31 | self.conv5 = norm(nn.Conv2d(num_feat * 4, num_feat * 2, 3, 1, 1, bias=False))
32 | self.conv6 = norm(nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1, bias=False))
33 | # extra convolutions
34 | self.conv7 = norm(nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=False))
35 | self.conv8 = norm(nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=False))
36 | self.conv9 = nn.Conv2d(num_feat, 1, 3, 1, 1)
37 |
38 | def forward(self, x):
39 | # downsample
40 | x0 = F.leaky_relu(self.conv0(x), negative_slope=0.2, inplace=True)
41 | x1 = F.leaky_relu(self.conv1(x0), negative_slope=0.2, inplace=True)
42 | x2 = F.leaky_relu(self.conv2(x1), negative_slope=0.2, inplace=True)
43 | x3 = F.leaky_relu(self.conv3(x2), negative_slope=0.2, inplace=True)
44 |
45 | # upsample
46 | x3 = F.interpolate(x3, scale_factor=2, mode='bilinear', align_corners=False)
47 | x4 = F.leaky_relu(self.conv4(x3), negative_slope=0.2, inplace=True)
48 |
49 | if self.skip_connection:
50 | x4 = x4 + x2
51 | x4 = F.interpolate(x4, scale_factor=2, mode='bilinear', align_corners=False)
52 | x5 = F.leaky_relu(self.conv5(x4), negative_slope=0.2, inplace=True)
53 |
54 | if self.skip_connection:
55 | x5 = x5 + x1
56 | x5 = F.interpolate(x5, scale_factor=2, mode='bilinear', align_corners=False)
57 | x6 = F.leaky_relu(self.conv6(x5), negative_slope=0.2, inplace=True)
58 |
59 | if self.skip_connection:
60 | x6 = x6 + x0
61 |
62 | # extra convolutions
63 | out = F.leaky_relu(self.conv7(x6), negative_slope=0.2, inplace=True)
64 | out = F.leaky_relu(self.conv8(out), negative_slope=0.2, inplace=True)
65 | out = self.conv9(out)
66 |
67 | return out
--------------------------------------------------------------------------------
/hat/archs/srvgg_arch.py:
--------------------------------------------------------------------------------
1 | from basicsr.utils.registry import ARCH_REGISTRY
2 | from torch import nn as nn
3 | from torch.nn import functional as F
4 |
5 |
6 | @ARCH_REGISTRY.register()
7 | class SRVGGNetCompact(nn.Module):
8 | """A compact VGG-style network structure for super-resolution.
9 |
10 | It is a compact network structure, which performs upsampling in the last layer and no convolution is
11 | conducted on the HR feature space.
12 |
13 | Args:
14 | num_in_ch (int): Channel number of inputs. Default: 3.
15 | num_out_ch (int): Channel number of outputs. Default: 3.
16 | num_feat (int): Channel number of intermediate features. Default: 64.
17 | num_conv (int): Number of convolution layers in the body network. Default: 16.
18 | upscale (int): Upsampling factor. Default: 4.
19 | act_type (str): Activation type, options: 'relu', 'prelu', 'leakyrelu'. Default: prelu.
20 | """
21 |
22 | def __init__(self, num_in_ch=3, num_out_ch=3, num_feat=64, num_conv=16, upscale=4, act_type='prelu'):
23 | super(SRVGGNetCompact, self).__init__()
24 | self.num_in_ch = num_in_ch
25 | self.num_out_ch = num_out_ch
26 | self.num_feat = num_feat
27 | self.num_conv = num_conv
28 | self.upscale = upscale
29 | self.act_type = act_type
30 |
31 | self.body = nn.ModuleList()
32 | # the first conv
33 | self.body.append(nn.Conv2d(num_in_ch, num_feat, 3, 1, 1))
34 | # the first activation
35 | if act_type == 'relu':
36 | activation = nn.ReLU(inplace=True)
37 | elif act_type == 'prelu':
38 | activation = nn.PReLU(num_parameters=num_feat)
39 | elif act_type == 'leakyrelu':
40 | activation = nn.LeakyReLU(negative_slope=0.1, inplace=True)
41 | self.body.append(activation)
42 |
43 | # the body structure
44 | for _ in range(num_conv):
45 | self.body.append(nn.Conv2d(num_feat, num_feat, 3, 1, 1))
46 | # activation
47 | if act_type == 'relu':
48 | activation = nn.ReLU(inplace=True)
49 | elif act_type == 'prelu':
50 | activation = nn.PReLU(num_parameters=num_feat)
51 | elif act_type == 'leakyrelu':
52 | activation = nn.LeakyReLU(negative_slope=0.1, inplace=True)
53 | self.body.append(activation)
54 |
55 | # the last conv
56 | self.body.append(nn.Conv2d(num_feat, num_out_ch * upscale * upscale, 3, 1, 1))
57 | # upsample
58 | self.upsampler = nn.PixelShuffle(upscale)
59 |
60 | def forward(self, x):
61 | out = x
62 | for i in range(0, len(self.body)):
63 | out = self.body[i](out)
64 |
65 | out = self.upsampler(out)
66 | # add the nearest upsampled image, so that the network learns the residual
67 | base = F.interpolate(x, scale_factor=self.upscale, mode='nearest')
68 | out += base
69 | return out
--------------------------------------------------------------------------------
/hat/data/__init__.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | from os import path as osp
3 |
4 | from basicsr.utils import scandir
5 |
6 | # automatically scan and import dataset modules for registry
7 | # scan all the files that end with '_dataset.py' under the data folder
8 | data_folder = osp.dirname(osp.abspath(__file__))
9 | dataset_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(data_folder) if v.endswith('_dataset.py')]
10 | # import all the dataset modules
11 | _dataset_modules = [importlib.import_module(f'hat.data.{file_name}') for file_name in dataset_filenames]
12 |
--------------------------------------------------------------------------------
/hat/data/imagenet_paired_dataset.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import numpy as np
3 | import os.path as osp
4 | from torch.utils import data as data
5 | from torchvision.transforms.functional import normalize
6 |
7 | from basicsr.data.data_util import paths_from_lmdb, scandir
8 | from basicsr.data.transforms import augment, paired_random_crop
9 | from basicsr.utils import FileClient, imfrombytes, img2tensor
10 | from basicsr.utils.matlab_functions import imresize, rgb2ycbcr
11 | from basicsr.utils.registry import DATASET_REGISTRY
12 |
13 |
14 | @DATASET_REGISTRY.register()
15 | class ImageNetPairedDataset(data.Dataset):
16 |
17 | def __init__(self, opt):
18 | super(ImageNetPairedDataset, self).__init__()
19 | self.opt = opt
20 | # file client (io backend)
21 | self.file_client = None
22 | self.io_backend_opt = opt['io_backend']
23 | self.mean = opt['mean'] if 'mean' in opt else None
24 | self.std = opt['std'] if 'std' in opt else None
25 | self.gt_folder = opt['dataroot_gt']
26 |
27 | if self.io_backend_opt['type'] == 'lmdb':
28 | self.io_backend_opt['db_paths'] = [self.gt_folder]
29 | self.io_backend_opt['client_keys'] = ['gt']
30 | self.paths = paths_from_lmdb(self.gt_folder)
31 | elif 'meta_info_file' in self.opt:
32 | with open(self.opt['meta_info_file'], 'r') as fin:
33 | self.paths = [osp.join(self.gt_folder, line.split(' ')[0]) for line in fin]
34 | else:
35 | self.paths = sorted(list(scandir(self.gt_folder, full_path=True)))
36 |
37 | def __getitem__(self, index):
38 | if self.file_client is None:
39 | self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
40 |
41 | scale = self.opt['scale']
42 |
43 | # Load gt and lq images. Dimension order: HWC; channel order: BGR;
44 | # image range: [0, 1], float32.
45 | gt_path = self.paths[index]
46 | img_bytes = self.file_client.get(gt_path, 'gt')
47 | img_gt = imfrombytes(img_bytes, float32=True)
48 |
49 | # modcrop
50 | size_h, size_w, _ = img_gt.shape
51 | size_h = size_h - size_h % scale
52 | size_w = size_w - size_w % scale
53 | img_gt = img_gt[0:size_h, 0:size_w, :]
54 |
55 | # generate training pairs
56 | size_h = max(size_h, self.opt['gt_size'])
57 | size_w = max(size_w, self.opt['gt_size'])
58 | img_gt = cv2.resize(img_gt, (size_w, size_h))
59 | img_lq = imresize(img_gt, 1 / scale)
60 |
61 | img_gt = np.ascontiguousarray(img_gt, dtype=np.float32)
62 | img_lq = np.ascontiguousarray(img_lq, dtype=np.float32)
63 |
64 | # augmentation for training
65 | if self.opt['phase'] == 'train':
66 | gt_size = self.opt['gt_size']
67 | # random crop
68 | img_gt, img_lq = paired_random_crop(img_gt, img_lq, gt_size, scale, gt_path)
69 | # flip, rotation
70 | img_gt, img_lq = augment([img_gt, img_lq], self.opt['use_hflip'], self.opt['use_rot'])
71 |
72 | # color space transform
73 | if 'color' in self.opt and self.opt['color'] == 'y':
74 | img_gt = rgb2ycbcr(img_gt, y_only=True)[..., None]
75 | img_lq = rgb2ycbcr(img_lq, y_only=True)[..., None]
76 |
77 | # crop the unmatched GT images during validation or testing, especially for SR benchmark datasets
78 | # TODO: It is better to update the datasets, rather than force to crop
79 | if self.opt['phase'] != 'train':
80 | img_gt = img_gt[0:img_lq.shape[0] * scale, 0:img_lq.shape[1] * scale, :]
81 |
82 | # BGR to RGB, HWC to CHW, numpy to tensor
83 | img_gt, img_lq = img2tensor([img_gt, img_lq], bgr2rgb=True, float32=True)
84 | # normalize
85 | if self.mean is not None or self.std is not None:
86 | normalize(img_lq, self.mean, self.std, inplace=True)
87 | normalize(img_gt, self.mean, self.std, inplace=True)
88 |
89 | return {'lq': img_lq, 'gt': img_gt, 'gt_path': gt_path}
90 |
91 | def __len__(self):
92 | return len(self.paths)
93 |
--------------------------------------------------------------------------------
/hat/data/realesrgan_dataset.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import math
3 | import numpy as np
4 | import os
5 | import os.path as osp
6 | import random
7 | import time
8 | import torch
9 | from basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels
10 | from basicsr.data.transforms import augment
11 | from basicsr.utils import FileClient, get_root_logger, imfrombytes, img2tensor
12 | from basicsr.utils.registry import DATASET_REGISTRY
13 | from torch.utils import data as data
14 | from basicsr.data.data_util import scandir
15 |
16 | @DATASET_REGISTRY.register()
17 | class RealESRGANDataset(data.Dataset):
18 | """Dataset used for Real-ESRGAN model:
19 | Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data.
20 |
21 | It loads gt (Ground-Truth) images, and augments them.
22 | It also generates blur kernels and sinc kernels for generating low-quality images.
23 | Note that the low-quality images are processed in tensors on GPUS for faster processing.
24 |
25 | Args:
26 | opt (dict): Config for train datasets. It contains the following keys:
27 | dataroot_gt (str): Data root path for gt.
28 | meta_info (str): Path for meta information file.
29 | io_backend (dict): IO backend type and other kwarg.
30 | use_hflip (bool): Use horizontal flips.
31 | use_rot (bool): Use rotation (use vertical flip and transposing h and w for implementation).
32 | Please see more options in the codes.
33 | """
34 |
35 | def __init__(self, opt):
36 | super(RealESRGANDataset, self).__init__()
37 | self.opt = opt
38 | self.file_client = None
39 | self.io_backend_opt = opt['io_backend']
40 | self.gt_folder = opt['dataroot_gt']
41 |
42 | # file client (lmdb io backend)
43 | if self.io_backend_opt['type'] == 'lmdb':
44 | self.io_backend_opt['db_paths'] = [self.gt_folder]
45 | self.io_backend_opt['client_keys'] = ['gt']
46 | if not self.gt_folder.endswith('.lmdb'):
47 | raise ValueError(f"'dataroot_gt' should end with '.lmdb', but received {self.gt_folder}")
48 | with open(osp.join(self.gt_folder, 'meta_info.txt')) as fin:
49 | self.paths = [line.split('.')[0] for line in fin]
50 | elif 'meta_info' in self.opt and self.opt['meta_info'] is not None:
51 | # disk backend with meta_info
52 | # Each line in the meta_info describes the relative path to an image
53 | with open(self.opt['meta_info']) as fin:
54 | paths = [line.strip().split(' ')[0] for line in fin]
55 | self.paths = [os.path.join(self.gt_folder, v) for v in paths]
56 | else:
57 | self.paths = sorted(list(scandir(self.gt_folder, full_path=True)))
58 |
59 | # blur settings for the first degradation
60 | self.blur_kernel_size = opt['blur_kernel_size']
61 | self.kernel_list = opt['kernel_list']
62 | self.kernel_prob = opt['kernel_prob'] # a list for each kernel probability
63 | self.blur_sigma = opt['blur_sigma']
64 | self.betag_range = opt['betag_range'] # betag used in generalized Gaussian blur kernels
65 | self.betap_range = opt['betap_range'] # betap used in plateau blur kernels
66 | self.sinc_prob = opt['sinc_prob'] # the probability for sinc filters
67 |
68 | # blur settings for the second degradation
69 | self.blur_kernel_size2 = opt['blur_kernel_size2']
70 | self.kernel_list2 = opt['kernel_list2']
71 | self.kernel_prob2 = opt['kernel_prob2']
72 | self.blur_sigma2 = opt['blur_sigma2']
73 | self.betag_range2 = opt['betag_range2']
74 | self.betap_range2 = opt['betap_range2']
75 | self.sinc_prob2 = opt['sinc_prob2']
76 |
77 | # a final sinc filter
78 | self.final_sinc_prob = opt['final_sinc_prob']
79 |
80 | self.kernel_range = [2 * v + 1 for v in range(3, 11)] # kernel size ranges from 7 to 21
81 | # TODO: kernel range is now hard-coded, should be in the configure file
82 | self.pulse_tensor = torch.zeros(21, 21).float() # convolving with pulse tensor brings no blurry effect
83 | self.pulse_tensor[10, 10] = 1
84 |
85 | def __getitem__(self, index):
86 | if self.file_client is None:
87 | self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
88 |
89 | # -------------------------------- Load gt images -------------------------------- #
90 | # Shape: (h, w, c); channel order: BGR; image range: [0, 1], float32.
91 | gt_path = self.paths[index]
92 | # avoid errors caused by high latency in reading files
93 | retry = 3
94 | while retry > 0:
95 | try:
96 | img_bytes = self.file_client.get(gt_path, 'gt')
97 | except (IOError, OSError) as e:
98 | logger = get_root_logger()
99 | logger.warn(f'File client error: {e}, remaining retry times: {retry - 1}')
100 | # change another file to read
101 | index = random.randint(0, self.__len__())
102 | gt_path = self.paths[index]
103 | time.sleep(1) # sleep 1s for occasional server congestion
104 | else:
105 | break
106 | finally:
107 | retry -= 1
108 | img_gt = imfrombytes(img_bytes, float32=True)
109 |
110 | # -------------------- Do augmentation for training: flip, rotation -------------------- #
111 | img_gt = augment(img_gt, self.opt['use_hflip'], self.opt['use_rot'])
112 |
113 | # crop or pad to 400
114 | # TODO: 400 is hard-coded. You may change it accordingly
115 | h, w = img_gt.shape[0:2]
116 | crop_pad_size = 400
117 | # pad
118 | if h < crop_pad_size or w < crop_pad_size:
119 | pad_h = max(0, crop_pad_size - h)
120 | pad_w = max(0, crop_pad_size - w)
121 | img_gt = cv2.copyMakeBorder(img_gt, 0, pad_h, 0, pad_w, cv2.BORDER_REFLECT_101)
122 | # crop
123 | if img_gt.shape[0] > crop_pad_size or img_gt.shape[1] > crop_pad_size:
124 | h, w = img_gt.shape[0:2]
125 | # randomly choose top and left coordinates
126 | top = random.randint(0, h - crop_pad_size)
127 | left = random.randint(0, w - crop_pad_size)
128 | img_gt = img_gt[top:top + crop_pad_size, left:left + crop_pad_size, ...]
129 |
130 | # ------------------------ Generate kernels (used in the first degradation) ------------------------ #
131 | kernel_size = random.choice(self.kernel_range)
132 | if np.random.uniform() < self.opt['sinc_prob']:
133 | # this sinc filter setting is for kernels ranging from [7, 21]
134 | if kernel_size < 13:
135 | omega_c = np.random.uniform(np.pi / 3, np.pi)
136 | else:
137 | omega_c = np.random.uniform(np.pi / 5, np.pi)
138 | kernel = circular_lowpass_kernel(omega_c, kernel_size, pad_to=False)
139 | else:
140 | kernel = random_mixed_kernels(
141 | self.kernel_list,
142 | self.kernel_prob,
143 | kernel_size,
144 | self.blur_sigma,
145 | self.blur_sigma, [-math.pi, math.pi],
146 | self.betag_range,
147 | self.betap_range,
148 | noise_range=None)
149 | # pad kernel
150 | pad_size = (21 - kernel_size) // 2
151 | kernel = np.pad(kernel, ((pad_size, pad_size), (pad_size, pad_size)))
152 |
153 | # ------------------------ Generate kernels (used in the second degradation) ------------------------ #
154 | kernel_size = random.choice(self.kernel_range)
155 | if np.random.uniform() < self.opt['sinc_prob2']:
156 | if kernel_size < 13:
157 | omega_c = np.random.uniform(np.pi / 3, np.pi)
158 | else:
159 | omega_c = np.random.uniform(np.pi / 5, np.pi)
160 | kernel2 = circular_lowpass_kernel(omega_c, kernel_size, pad_to=False)
161 | else:
162 | kernel2 = random_mixed_kernels(
163 | self.kernel_list2,
164 | self.kernel_prob2,
165 | kernel_size,
166 | self.blur_sigma2,
167 | self.blur_sigma2, [-math.pi, math.pi],
168 | self.betag_range2,
169 | self.betap_range2,
170 | noise_range=None)
171 |
172 | # pad kernel
173 | pad_size = (21 - kernel_size) // 2
174 | kernel2 = np.pad(kernel2, ((pad_size, pad_size), (pad_size, pad_size)))
175 |
176 | # ------------------------------------- the final sinc kernel ------------------------------------- #
177 | if np.random.uniform() < self.opt['final_sinc_prob']:
178 | kernel_size = random.choice(self.kernel_range)
179 | omega_c = np.random.uniform(np.pi / 3, np.pi)
180 | sinc_kernel = circular_lowpass_kernel(omega_c, kernel_size, pad_to=21)
181 | sinc_kernel = torch.FloatTensor(sinc_kernel)
182 | else:
183 | sinc_kernel = self.pulse_tensor
184 |
185 | # BGR to RGB, HWC to CHW, numpy to tensor
186 | img_gt = img2tensor([img_gt], bgr2rgb=True, float32=True)[0]
187 | kernel = torch.FloatTensor(kernel)
188 | kernel2 = torch.FloatTensor(kernel2)
189 |
190 | return_d = {'gt': img_gt, 'kernel1': kernel, 'kernel2': kernel2, 'sinc_kernel': sinc_kernel, 'gt_path': gt_path}
191 | return return_d
192 |
193 | def __len__(self):
194 | return len(self.paths)
--------------------------------------------------------------------------------
/hat/models/__init__.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | from os import path as osp
3 |
4 | from basicsr.utils import scandir
5 |
6 | # automatically scan and import model modules for registry
7 | # scan all the files that end with '_model.py' under the model folder
8 | model_folder = osp.dirname(osp.abspath(__file__))
9 | model_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(model_folder) if v.endswith('_model.py')]
10 | # import all the model modules
11 | _model_modules = [importlib.import_module(f'hat.models.{file_name}') for file_name in model_filenames]
12 |
--------------------------------------------------------------------------------
/hat/models/hat_model.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.nn import functional as F
3 |
4 | from basicsr.utils.registry import MODEL_REGISTRY
5 | from basicsr.models.sr_model import SRModel
6 | from basicsr.metrics import calculate_metric
7 | from basicsr.utils import imwrite, tensor2img
8 |
9 | import math
10 | from tqdm import tqdm
11 | from os import path as osp
12 |
13 | @MODEL_REGISTRY.register()
14 | class HATModel(SRModel):
15 |
16 | def pre_process(self):
17 | # pad to multiplication of window_size
18 | window_size = self.opt['network_g']['window_size']
19 | self.scale = self.opt.get('scale', 1)
20 | self.mod_pad_h, self.mod_pad_w = 0, 0
21 | _, _, h, w = self.lq.size()
22 | if h % window_size != 0:
23 | self.mod_pad_h = window_size - h % window_size
24 | if w % window_size != 0:
25 | self.mod_pad_w = window_size - w % window_size
26 | self.img = F.pad(self.lq, (0, self.mod_pad_w, 0, self.mod_pad_h), 'reflect')
27 |
28 | def process(self):
29 | # model inference
30 | if hasattr(self, 'net_g_ema'):
31 | self.net_g_ema.eval()
32 | with torch.no_grad():
33 | self.output = self.net_g_ema(self.img)
34 | else:
35 | self.net_g.eval()
36 | with torch.no_grad():
37 | self.output = self.net_g(self.img)
38 | # self.net_g.train()
39 |
40 | def tile_process(self):
41 | """It will first crop input images to tiles, and then process each tile.
42 | Finally, all the processed tiles are merged into one images.
43 | Modified from: https://github.com/ata4/esrgan-launcher
44 | """
45 | batch, channel, height, width = self.img.shape
46 | output_height = height * self.scale
47 | output_width = width * self.scale
48 | output_shape = (batch, channel, output_height, output_width)
49 |
50 | # start with black image
51 | self.output = self.img.new_zeros(output_shape)
52 | tiles_x = math.ceil(width / self.opt['tile']['tile_size'])
53 | tiles_y = math.ceil(height / self.opt['tile']['tile_size'])
54 |
55 | # loop over all tiles
56 | for y in range(tiles_y):
57 | for x in range(tiles_x):
58 | # extract tile from input image
59 | ofs_x = x * self.opt['tile']['tile_size']
60 | ofs_y = y * self.opt['tile']['tile_size']
61 | # input tile area on total image
62 | input_start_x = ofs_x
63 | input_end_x = min(ofs_x + self.opt['tile']['tile_size'], width)
64 | input_start_y = ofs_y
65 | input_end_y = min(ofs_y + self.opt['tile']['tile_size'], height)
66 |
67 | # input tile area on total image with padding
68 | input_start_x_pad = max(input_start_x - self.opt['tile']['tile_pad'], 0)
69 | input_end_x_pad = min(input_end_x + self.opt['tile']['tile_pad'], width)
70 | input_start_y_pad = max(input_start_y - self.opt['tile']['tile_pad'], 0)
71 | input_end_y_pad = min(input_end_y + self.opt['tile']['tile_pad'], height)
72 |
73 | # input tile dimensions
74 | input_tile_width = input_end_x - input_start_x
75 | input_tile_height = input_end_y - input_start_y
76 | tile_idx = y * tiles_x + x + 1
77 | input_tile = self.img[:, :, input_start_y_pad:input_end_y_pad, input_start_x_pad:input_end_x_pad]
78 |
79 | # upscale tile
80 | try:
81 | if hasattr(self, 'net_g_ema'):
82 | self.net_g_ema.eval()
83 | with torch.no_grad():
84 | output_tile = self.net_g_ema(input_tile)
85 | else:
86 | self.net_g.eval()
87 | with torch.no_grad():
88 | output_tile = self.net_g(input_tile)
89 | except RuntimeError as error:
90 | print('Error', error)
91 | print(f'\tTile {tile_idx}/{tiles_x * tiles_y}')
92 |
93 | # output tile area on total image
94 | output_start_x = input_start_x * self.opt['scale']
95 | output_end_x = input_end_x * self.opt['scale']
96 | output_start_y = input_start_y * self.opt['scale']
97 | output_end_y = input_end_y * self.opt['scale']
98 |
99 | # output tile area without padding
100 | output_start_x_tile = (input_start_x - input_start_x_pad) * self.opt['scale']
101 | output_end_x_tile = output_start_x_tile + input_tile_width * self.opt['scale']
102 | output_start_y_tile = (input_start_y - input_start_y_pad) * self.opt['scale']
103 | output_end_y_tile = output_start_y_tile + input_tile_height * self.opt['scale']
104 |
105 | # put tile into output image
106 | self.output[:, :, output_start_y:output_end_y,
107 | output_start_x:output_end_x] = output_tile[:, :, output_start_y_tile:output_end_y_tile,
108 | output_start_x_tile:output_end_x_tile]
109 |
110 | def post_process(self):
111 | _, _, h, w = self.output.size()
112 | self.output = self.output[:, :, 0:h - self.mod_pad_h * self.scale, 0:w - self.mod_pad_w * self.scale]
113 |
114 | def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
115 | dataset_name = dataloader.dataset.opt['name']
116 | with_metrics = self.opt['val'].get('metrics') is not None
117 | use_pbar = self.opt['val'].get('pbar', False)
118 |
119 | if with_metrics:
120 | if not hasattr(self, 'metric_results'): # only execute in the first run
121 | self.metric_results = {metric: 0 for metric in self.opt['val']['metrics'].keys()}
122 | # initialize the best metric results for each dataset_name (supporting multiple validation datasets)
123 | self._initialize_best_metric_results(dataset_name)
124 | # zero self.metric_results
125 | if with_metrics:
126 | self.metric_results = {metric: 0 for metric in self.metric_results}
127 |
128 | metric_data = dict()
129 | if use_pbar:
130 | pbar = tqdm(total=len(dataloader), unit='image')
131 |
132 | for idx, val_data in enumerate(dataloader):
133 | img_name = osp.splitext(osp.basename(val_data['lq_path'][0]))[0]
134 | self.feed_data(val_data)
135 |
136 | self.pre_process()
137 | if 'tile' in self.opt:
138 | self.tile_process()
139 | else:
140 | self.process()
141 | self.post_process()
142 |
143 | visuals = self.get_current_visuals()
144 | sr_img = tensor2img([visuals['result']])
145 | metric_data['img'] = sr_img
146 | if 'gt' in visuals:
147 | gt_img = tensor2img([visuals['gt']])
148 | metric_data['img2'] = gt_img
149 | del self.gt
150 |
151 | # tentative for out of GPU memory
152 | del self.lq
153 | del self.output
154 | torch.cuda.empty_cache()
155 |
156 | if save_img:
157 | if self.opt['is_train']:
158 | save_img_path = osp.join(self.opt['path']['visualization'], img_name,
159 | f'{img_name}_{current_iter}.png')
160 | else:
161 | if self.opt['val']['suffix']:
162 | save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,
163 | f'{img_name}_{self.opt["val"]["suffix"]}.png')
164 | else:
165 | save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,
166 | f'{img_name}_{self.opt["name"]}.png')
167 | imwrite(sr_img, save_img_path)
168 |
169 | if with_metrics:
170 | # calculate metrics
171 | for name, opt_ in self.opt['val']['metrics'].items():
172 | self.metric_results[name] += calculate_metric(metric_data, opt_)
173 | if use_pbar:
174 | pbar.update(1)
175 | pbar.set_description(f'Test {img_name}')
176 | if use_pbar:
177 | pbar.close()
178 |
179 | if with_metrics:
180 | for metric in self.metric_results.keys():
181 | self.metric_results[metric] /= (idx + 1)
182 | # update the best metric result
183 | self._update_best_metric_result(dataset_name, metric, self.metric_results[metric], current_iter)
184 |
185 | self._log_validation_metric_values(current_iter, dataset_name, tb_logger)
186 |
--------------------------------------------------------------------------------
/hat/models/realhatgan_model.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import random
3 | import torch
4 | from basicsr.data.degradations import random_add_gaussian_noise_pt, random_add_poisson_noise_pt
5 | from basicsr.data.transforms import paired_random_crop
6 | from basicsr.models.srgan_model import SRGANModel
7 | from basicsr.utils import DiffJPEG, USMSharp
8 | from basicsr.utils.img_process_util import filter2D
9 | from basicsr.utils.registry import MODEL_REGISTRY
10 | from collections import OrderedDict
11 | from torch.nn import functional as F
12 |
13 |
14 | @MODEL_REGISTRY.register()
15 | class RealHATGANModel(SRGANModel):
16 | """GAN-based Real_HAT Model.
17 |
18 | It mainly performs:
19 | 1. randomly synthesize LQ images in GPU tensors
20 | 2. optimize the networks with GAN training.
21 | """
22 |
23 | def __init__(self, opt):
24 | super(RealHATGANModel, self).__init__(opt)
25 | self.jpeger = DiffJPEG(differentiable=False).cuda() # simulate JPEG compression artifacts
26 | self.usm_sharpener = USMSharp().cuda() # do usm sharpening
27 | self.queue_size = opt.get('queue_size', 180)
28 |
29 | @torch.no_grad()
30 | def _dequeue_and_enqueue(self):
31 | """It is the training pair pool for increasing the diversity in a batch.
32 |
33 | Batch processing limits the diversity of synthetic degradations in a batch. For example, samples in a
34 | batch could not have different resize scaling factors. Therefore, we employ this training pair pool
35 | to increase the degradation diversity in a batch.
36 | """
37 | # initialize
38 | b, c, h, w = self.lq.size()
39 | if not hasattr(self, 'queue_lr'):
40 | assert self.queue_size % b == 0, f'queue size {self.queue_size} should be divisible by batch size {b}'
41 | self.queue_lr = torch.zeros(self.queue_size, c, h, w).cuda()
42 | _, c, h, w = self.gt.size()
43 | self.queue_gt = torch.zeros(self.queue_size, c, h, w).cuda()
44 | self.queue_ptr = 0
45 | if self.queue_ptr == self.queue_size: # the pool is full
46 | # do dequeue and enqueue
47 | # shuffle
48 | idx = torch.randperm(self.queue_size)
49 | self.queue_lr = self.queue_lr[idx]
50 | self.queue_gt = self.queue_gt[idx]
51 | # get first b samples
52 | lq_dequeue = self.queue_lr[0:b, :, :, :].clone()
53 | gt_dequeue = self.queue_gt[0:b, :, :, :].clone()
54 | # update the queue
55 | self.queue_lr[0:b, :, :, :] = self.lq.clone()
56 | self.queue_gt[0:b, :, :, :] = self.gt.clone()
57 |
58 | self.lq = lq_dequeue
59 | self.gt = gt_dequeue
60 | else:
61 | # only do enqueue
62 | self.queue_lr[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.lq.clone()
63 | self.queue_gt[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.gt.clone()
64 | self.queue_ptr = self.queue_ptr + b
65 |
66 | @torch.no_grad()
67 | def feed_data(self, data):
68 | """Accept data from dataloader, and then add two-order degradations to obtain LQ images.
69 | """
70 | if self.is_train and self.opt.get('high_order_degradation', True):
71 | # training data synthesis
72 | self.gt = data['gt'].to(self.device)
73 | self.gt_usm = self.usm_sharpener(self.gt)
74 |
75 | self.kernel1 = data['kernel1'].to(self.device)
76 | self.kernel2 = data['kernel2'].to(self.device)
77 | self.sinc_kernel = data['sinc_kernel'].to(self.device)
78 |
79 | ori_h, ori_w = self.gt.size()[2:4]
80 |
81 | # ----------------------- The first degradation process ----------------------- #
82 | # blur
83 | out = filter2D(self.gt_usm, self.kernel1)
84 | # random resize
85 | updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob'])[0]
86 | if updown_type == 'up':
87 | scale = np.random.uniform(1, self.opt['resize_range'][1])
88 | elif updown_type == 'down':
89 | scale = np.random.uniform(self.opt['resize_range'][0], 1)
90 | else:
91 | scale = 1
92 | mode = random.choice(['area', 'bilinear', 'bicubic'])
93 | out = F.interpolate(out, scale_factor=scale, mode=mode)
94 | # add noise
95 | gray_noise_prob = self.opt['gray_noise_prob']
96 | if np.random.uniform() < self.opt['gaussian_noise_prob']:
97 | out = random_add_gaussian_noise_pt(
98 | out, sigma_range=self.opt['noise_range'], clip=True, rounds=False, gray_prob=gray_noise_prob)
99 | else:
100 | out = random_add_poisson_noise_pt(
101 | out,
102 | scale_range=self.opt['poisson_scale_range'],
103 | gray_prob=gray_noise_prob,
104 | clip=True,
105 | rounds=False)
106 | # JPEG compression
107 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range'])
108 | out = torch.clamp(out, 0, 1) # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
109 | out = self.jpeger(out, quality=jpeg_p)
110 |
111 | # ----------------------- The second degradation process ----------------------- #
112 | # blur
113 | if np.random.uniform() < self.opt['second_blur_prob']:
114 | out = filter2D(out, self.kernel2)
115 | # random resize
116 | updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob2'])[0]
117 | if updown_type == 'up':
118 | scale = np.random.uniform(1, self.opt['resize_range2'][1])
119 | elif updown_type == 'down':
120 | scale = np.random.uniform(self.opt['resize_range2'][0], 1)
121 | else:
122 | scale = 1
123 | mode = random.choice(['area', 'bilinear', 'bicubic'])
124 | out = F.interpolate(
125 | out, size=(int(ori_h / self.opt['scale'] * scale), int(ori_w / self.opt['scale'] * scale)), mode=mode)
126 | # add noise
127 | gray_noise_prob = self.opt['gray_noise_prob2']
128 | if np.random.uniform() < self.opt['gaussian_noise_prob2']:
129 | out = random_add_gaussian_noise_pt(
130 | out, sigma_range=self.opt['noise_range2'], clip=True, rounds=False, gray_prob=gray_noise_prob)
131 | else:
132 | out = random_add_poisson_noise_pt(
133 | out,
134 | scale_range=self.opt['poisson_scale_range2'],
135 | gray_prob=gray_noise_prob,
136 | clip=True,
137 | rounds=False)
138 |
139 | # JPEG compression + the final sinc filter
140 | # We also need to resize images to desired sizes. We group [resize back + sinc filter] together
141 | # as one operation.
142 | # We consider two orders:
143 | # 1. [resize back + sinc filter] + JPEG compression
144 | # 2. JPEG compression + [resize back + sinc filter]
145 | # Empirically, we find other combinations (sinc + JPEG + Resize) will introduce twisted lines.
146 | if np.random.uniform() < 0.5:
147 | # resize back + the final sinc filter
148 | mode = random.choice(['area', 'bilinear', 'bicubic'])
149 | out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
150 | out = filter2D(out, self.sinc_kernel)
151 | # JPEG compression
152 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
153 | out = torch.clamp(out, 0, 1)
154 | out = self.jpeger(out, quality=jpeg_p)
155 | else:
156 | # JPEG compression
157 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
158 | out = torch.clamp(out, 0, 1)
159 | out = self.jpeger(out, quality=jpeg_p)
160 | # resize back + the final sinc filter
161 | mode = random.choice(['area', 'bilinear', 'bicubic'])
162 | out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
163 | out = filter2D(out, self.sinc_kernel)
164 |
165 | # clamp and round
166 | self.lq = torch.clamp((out * 255.0).round(), 0, 255) / 255.
167 |
168 | # random crop
169 | gt_size = self.opt['gt_size']
170 | (self.gt, self.gt_usm), self.lq = paired_random_crop([self.gt, self.gt_usm], self.lq, gt_size,
171 | self.opt['scale'])
172 |
173 | # training pair pool
174 | self._dequeue_and_enqueue()
175 | # sharpen self.gt again, as we have changed the self.gt with self._dequeue_and_enqueue
176 | self.gt_usm = self.usm_sharpener(self.gt)
177 | self.lq = self.lq.contiguous() # for the warning: grad and param do not obey the gradient layout contract
178 | else:
179 | # for paired training or validation
180 | self.lq = data['lq'].to(self.device)
181 | if 'gt' in data:
182 | self.gt = data['gt'].to(self.device)
183 | self.gt_usm = self.usm_sharpener(self.gt)
184 |
185 | def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
186 | # do not use the synthetic process during validation
187 | self.is_train = False
188 | super(RealHATGANModel, self).nondist_validation(dataloader, current_iter, tb_logger, save_img)
189 | self.is_train = True
190 |
191 | def optimize_parameters(self, current_iter):
192 | # usm sharpening
193 | l1_gt = self.gt_usm
194 | percep_gt = self.gt_usm
195 | gan_gt = self.gt_usm
196 | if self.opt['l1_gt_usm'] is False:
197 | l1_gt = self.gt
198 | if self.opt['percep_gt_usm'] is False:
199 | percep_gt = self.gt
200 | if self.opt['gan_gt_usm'] is False:
201 | gan_gt = self.gt
202 |
203 | # optimize net_g
204 | for p in self.net_d.parameters():
205 | p.requires_grad = False
206 |
207 | self.optimizer_g.zero_grad()
208 | self.output = self.net_g(self.lq)
209 |
210 | l_g_total = 0
211 | loss_dict = OrderedDict()
212 | if (current_iter % self.net_d_iters == 0 and current_iter > self.net_d_init_iters):
213 | # pixel loss
214 | if self.cri_pix:
215 | l_g_pix = self.cri_pix(self.output, l1_gt)
216 | l_g_total += l_g_pix
217 | loss_dict['l_g_pix'] = l_g_pix
218 | # perceptual loss
219 | if self.cri_perceptual:
220 | l_g_percep, l_g_style = self.cri_perceptual(self.output, percep_gt)
221 | if l_g_percep is not None:
222 | l_g_total += l_g_percep
223 | loss_dict['l_g_percep'] = l_g_percep
224 | if l_g_style is not None:
225 | l_g_total += l_g_style
226 | loss_dict['l_g_style'] = l_g_style
227 | # gan loss
228 | fake_g_pred = self.net_d(self.output)
229 | l_g_gan = self.cri_gan(fake_g_pred, True, is_disc=False)
230 | l_g_total += l_g_gan
231 | loss_dict['l_g_gan'] = l_g_gan
232 |
233 | l_g_total.backward()
234 | self.optimizer_g.step()
235 |
236 | # optimize net_d
237 | for p in self.net_d.parameters():
238 | p.requires_grad = True
239 |
240 | self.optimizer_d.zero_grad()
241 | # real
242 | real_d_pred = self.net_d(gan_gt)
243 | l_d_real = self.cri_gan(real_d_pred, True, is_disc=True)
244 | loss_dict['l_d_real'] = l_d_real
245 | loss_dict['out_d_real'] = torch.mean(real_d_pred.detach())
246 | l_d_real.backward()
247 | # fake
248 | fake_d_pred = self.net_d(self.output.detach().clone()) # clone for pt1.9
249 | l_d_fake = self.cri_gan(fake_d_pred, False, is_disc=True)
250 | loss_dict['l_d_fake'] = l_d_fake
251 | loss_dict['out_d_fake'] = torch.mean(fake_d_pred.detach())
252 | l_d_fake.backward()
253 | self.optimizer_d.step()
254 |
255 | if self.ema_decay > 0:
256 | self.model_ema(decay=self.ema_decay)
257 |
258 | self.log_dict = self.reduce_loss_dict(loss_dict)
259 |
260 | def test(self):
261 | # pad to multiplication of window_size
262 | window_size = self.opt['network_g']['window_size']
263 | scale = self.opt.get('scale', 1)
264 | mod_pad_h, mod_pad_w = 0, 0
265 | _, _, h, w = self.lq.size()
266 | if h % window_size != 0:
267 | mod_pad_h = window_size - h % window_size
268 | if w % window_size != 0:
269 | mod_pad_w = window_size - w % window_size
270 | img = F.pad(self.lq, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
271 | if hasattr(self, 'net_g_ema'):
272 | self.net_g_ema.eval()
273 | with torch.no_grad():
274 | self.output = self.net_g_ema(img)
275 | else:
276 | self.net_g.eval()
277 | with torch.no_grad():
278 | self.output = self.net_g(img)
279 | self.net_g.train()
280 |
281 | _, _, h, w = self.output.size()
282 | self.output = self.output[:, :, 0:h - mod_pad_h * scale, 0:w - mod_pad_w * scale]
--------------------------------------------------------------------------------
/hat/models/realhatmse_model.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import random
3 | import torch
4 | from basicsr.data.degradations import random_add_gaussian_noise_pt, random_add_poisson_noise_pt
5 | from basicsr.data.transforms import paired_random_crop
6 | from basicsr.models.sr_model import SRModel
7 | from basicsr.utils import DiffJPEG, USMSharp
8 | from basicsr.utils.img_process_util import filter2D
9 | from basicsr.utils.registry import MODEL_REGISTRY
10 | from torch.nn import functional as F
11 |
12 |
13 | @MODEL_REGISTRY.register()
14 | class RealHATMSEModel(SRModel):
15 | """MSE-based Real_HAT Model.
16 |
17 | It is trained without GAN losses.
18 | It mainly performs:
19 | 1. randomly synthesize LQ images in GPU tensors
20 | 2. optimize the networks with GAN training.
21 | """
22 |
23 | def __init__(self, opt):
24 | super(RealHATMSEModel, self).__init__(opt)
25 | self.jpeger = DiffJPEG(differentiable=False).cuda() # simulate JPEG compression artifacts
26 | self.usm_sharpener = USMSharp().cuda() # do usm sharpening
27 | self.queue_size = opt.get('queue_size', 180)
28 |
29 | @torch.no_grad()
30 | def _dequeue_and_enqueue(self):
31 | """It is the training pair pool for increasing the diversity in a batch.
32 |
33 | Batch processing limits the diversity of synthetic degradations in a batch. For example, samples in a
34 | batch could not have different resize scaling factors. Therefore, we employ this training pair pool
35 | to increase the degradation diversity in a batch.
36 | """
37 | # initialize
38 | b, c, h, w = self.lq.size()
39 | if not hasattr(self, 'queue_lr'):
40 | assert self.queue_size % b == 0, f'queue size {self.queue_size} should be divisible by batch size {b}'
41 | self.queue_lr = torch.zeros(self.queue_size, c, h, w).cuda()
42 | _, c, h, w = self.gt.size()
43 | self.queue_gt = torch.zeros(self.queue_size, c, h, w).cuda()
44 | self.queue_ptr = 0
45 | if self.queue_ptr == self.queue_size: # the pool is full
46 | # do dequeue and enqueue
47 | # shuffle
48 | idx = torch.randperm(self.queue_size)
49 | self.queue_lr = self.queue_lr[idx]
50 | self.queue_gt = self.queue_gt[idx]
51 | # get first b samples
52 | lq_dequeue = self.queue_lr[0:b, :, :, :].clone()
53 | gt_dequeue = self.queue_gt[0:b, :, :, :].clone()
54 | # update the queue
55 | self.queue_lr[0:b, :, :, :] = self.lq.clone()
56 | self.queue_gt[0:b, :, :, :] = self.gt.clone()
57 |
58 | self.lq = lq_dequeue
59 | self.gt = gt_dequeue
60 | else:
61 | # only do enqueue
62 | self.queue_lr[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.lq.clone()
63 | self.queue_gt[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.gt.clone()
64 | self.queue_ptr = self.queue_ptr + b
65 |
66 | @torch.no_grad()
67 | def feed_data(self, data):
68 | """Accept data from dataloader, and then add two-order degradations to obtain LQ images.
69 | """
70 | if self.is_train and self.opt.get('high_order_degradation', True):
71 | # training data synthesis
72 | self.gt = data['gt'].to(self.device)
73 | # USM sharpen the GT images
74 | if self.opt['gt_usm'] is True:
75 | self.gt = self.usm_sharpener(self.gt)
76 |
77 | self.kernel1 = data['kernel1'].to(self.device)
78 | self.kernel2 = data['kernel2'].to(self.device)
79 | self.sinc_kernel = data['sinc_kernel'].to(self.device)
80 |
81 | ori_h, ori_w = self.gt.size()[2:4]
82 |
83 | # ----------------------- The first degradation process ----------------------- #
84 | # blur
85 | out = filter2D(self.gt, self.kernel1)
86 | # random resize
87 | updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob'])[0]
88 | if updown_type == 'up':
89 | scale = np.random.uniform(1, self.opt['resize_range'][1])
90 | elif updown_type == 'down':
91 | scale = np.random.uniform(self.opt['resize_range'][0], 1)
92 | else:
93 | scale = 1
94 | mode = random.choice(['area', 'bilinear', 'bicubic'])
95 | out = F.interpolate(out, scale_factor=scale, mode=mode)
96 | # add noise
97 | gray_noise_prob = self.opt['gray_noise_prob']
98 | if np.random.uniform() < self.opt['gaussian_noise_prob']:
99 | out = random_add_gaussian_noise_pt(
100 | out, sigma_range=self.opt['noise_range'], clip=True, rounds=False, gray_prob=gray_noise_prob)
101 | else:
102 | out = random_add_poisson_noise_pt(
103 | out,
104 | scale_range=self.opt['poisson_scale_range'],
105 | gray_prob=gray_noise_prob,
106 | clip=True,
107 | rounds=False)
108 | # JPEG compression
109 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range'])
110 | out = torch.clamp(out, 0, 1) # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
111 | out = self.jpeger(out, quality=jpeg_p)
112 |
113 | # ----------------------- The second degradation process ----------------------- #
114 | # blur
115 | if np.random.uniform() < self.opt['second_blur_prob']:
116 | out = filter2D(out, self.kernel2)
117 | # random resize
118 | updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob2'])[0]
119 | if updown_type == 'up':
120 | scale = np.random.uniform(1, self.opt['resize_range2'][1])
121 | elif updown_type == 'down':
122 | scale = np.random.uniform(self.opt['resize_range2'][0], 1)
123 | else:
124 | scale = 1
125 | mode = random.choice(['area', 'bilinear', 'bicubic'])
126 | out = F.interpolate(
127 | out, size=(int(ori_h / self.opt['scale'] * scale), int(ori_w / self.opt['scale'] * scale)), mode=mode)
128 | # add noise
129 | gray_noise_prob = self.opt['gray_noise_prob2']
130 | if np.random.uniform() < self.opt['gaussian_noise_prob2']:
131 | out = random_add_gaussian_noise_pt(
132 | out, sigma_range=self.opt['noise_range2'], clip=True, rounds=False, gray_prob=gray_noise_prob)
133 | else:
134 | out = random_add_poisson_noise_pt(
135 | out,
136 | scale_range=self.opt['poisson_scale_range2'],
137 | gray_prob=gray_noise_prob,
138 | clip=True,
139 | rounds=False)
140 |
141 | # JPEG compression + the final sinc filter
142 | # We also need to resize images to desired sizes. We group [resize back + sinc filter] together
143 | # as one operation.
144 | # We consider two orders:
145 | # 1. [resize back + sinc filter] + JPEG compression
146 | # 2. JPEG compression + [resize back + sinc filter]
147 | # Empirically, we find other combinations (sinc + JPEG + Resize) will introduce twisted lines.
148 | if np.random.uniform() < 0.5:
149 | # resize back + the final sinc filter
150 | mode = random.choice(['area', 'bilinear', 'bicubic'])
151 | out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
152 | out = filter2D(out, self.sinc_kernel)
153 | # JPEG compression
154 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
155 | out = torch.clamp(out, 0, 1)
156 | out = self.jpeger(out, quality=jpeg_p)
157 | else:
158 | # JPEG compression
159 | jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
160 | out = torch.clamp(out, 0, 1)
161 | out = self.jpeger(out, quality=jpeg_p)
162 | # resize back + the final sinc filter
163 | mode = random.choice(['area', 'bilinear', 'bicubic'])
164 | out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
165 | out = filter2D(out, self.sinc_kernel)
166 |
167 | # clamp and round
168 | self.lq = torch.clamp((out * 255.0).round(), 0, 255) / 255.
169 |
170 | # random crop
171 | gt_size = self.opt['gt_size']
172 | self.gt, self.lq = paired_random_crop(self.gt, self.lq, gt_size, self.opt['scale'])
173 |
174 | # training pair pool
175 | self._dequeue_and_enqueue()
176 | self.lq = self.lq.contiguous() # for the warning: grad and param do not obey the gradient layout contract
177 | else:
178 | # for paired training or validation
179 | self.lq = data['lq'].to(self.device)
180 | if 'gt' in data:
181 | self.gt = data['gt'].to(self.device)
182 | self.gt_usm = self.usm_sharpener(self.gt)
183 |
184 | def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
185 | # do not use the synthetic process during validation
186 | self.is_train = False
187 | super(RealHATMSEModel, self).nondist_validation(dataloader, current_iter, tb_logger, save_img)
188 | self.is_train = True
189 |
190 | def test(self):
191 | # pad to multiplication of window_size
192 | window_size = self.opt['network_g']['window_size']
193 | scale = self.opt.get('scale', 1)
194 | mod_pad_h, mod_pad_w = 0, 0
195 | _, _, h, w = self.lq.size()
196 | if h % window_size != 0:
197 | mod_pad_h = window_size - h % window_size
198 | if w % window_size != 0:
199 | mod_pad_w = window_size - w % window_size
200 | img = F.pad(self.lq, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
201 | if hasattr(self, 'net_g_ema'):
202 | self.net_g_ema.eval()
203 | with torch.no_grad():
204 | self.output = self.net_g_ema(img)
205 | else:
206 | self.net_g.eval()
207 | with torch.no_grad():
208 | self.output = self.net_g(img)
209 | self.net_g.train()
210 |
211 | _, _, h, w = self.output.size()
212 | self.output = self.output[:, :, 0:h - mod_pad_h * scale, 0:w - mod_pad_w * scale]
--------------------------------------------------------------------------------
/hat/test.py:
--------------------------------------------------------------------------------
1 | # flake8: noqa
2 | import os.path as osp
3 |
4 | import hat.archs
5 | import hat.data
6 | import hat.models
7 | from basicsr.test import test_pipeline
8 |
9 | if __name__ == '__main__':
10 | root_path = osp.abspath(osp.join(__file__, osp.pardir, osp.pardir))
11 | test_pipeline(root_path)
12 |
--------------------------------------------------------------------------------
/hat/train.py:
--------------------------------------------------------------------------------
1 | # flake8: noqa
2 | import os.path as osp
3 |
4 | import hat.archs
5 | import hat.data
6 | import hat.models
7 | from basicsr.train import train_pipeline
8 |
9 | if __name__ == '__main__':
10 | root_path = osp.abspath(osp.join(__file__, osp.pardir, osp.pardir))
11 | train_pipeline(root_path)
12 |
--------------------------------------------------------------------------------
/options/test/HAT-L_SRx2_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT-L_SRx2_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 2
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod2
12 | dataroot_lq: ./datasets/Set5/LRbicx2
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod2
20 | # dataroot_lq: ./datasets/Set14/LRbicx2
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod2
28 | # dataroot_lq: ./datasets/urban100/LRbicx2
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod2
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx2
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod2
44 | # dataroot_lq: ./datasets/manga109/LRbicx2
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 2
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-L_SRx2_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 2
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 2
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT-L_SRx3_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT-L_SRx3_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 3
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod3
12 | dataroot_lq: ./datasets/Set5/LRbicx3
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod3
20 | # dataroot_lq: ./datasets/Set14/LRbicx3
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod3
28 | # dataroot_lq: ./datasets/urban100/LRbicx3
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod3
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx3
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod3
44 | # dataroot_lq: ./datasets/manga109/LRbicx3
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 3
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-L_SRx3_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 3
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 3
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT-L_SRx4_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT-L_SRx4_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod4
12 | dataroot_lq: ./datasets/Set5/LRbicx4
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod4
20 | # dataroot_lq: ./datasets/Set14/LRbicx4
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod4
28 | # dataroot_lq: ./datasets/urban100/LRbicx4
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod4
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx4
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod4
44 | # dataroot_lq: ./datasets/manga109/LRbicx4
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 4
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-L_SRx4_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 4
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 4
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT-S_SRx2.yml:
--------------------------------------------------------------------------------
1 | name: HAT-S_SRx2
2 | model_type: HATModel
3 | scale: 2
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod2
12 | dataroot_lq: ./datasets/Set5/LRbicx2
13 | io_backend:
14 | type: disk
15 |
16 | test_2: # the 2nd test dataset
17 | name: Set14
18 | type: PairedImageDataset
19 | dataroot_gt: ./datasets/Set14/GTmod2
20 | dataroot_lq: ./datasets/Set14/LRbicx2
21 | io_backend:
22 | type: disk
23 |
24 | test_3:
25 | name: Urban100
26 | type: PairedImageDataset
27 | dataroot_gt: ./datasets/urban100/GTmod2
28 | dataroot_lq: ./datasets/urban100/LRbicx2
29 | io_backend:
30 | type: disk
31 |
32 | test_4:
33 | name: BSDS100
34 | type: PairedImageDataset
35 | dataroot_gt: ./datasets/BSDS100/GTmod2
36 | dataroot_lq: ./datasets/BSDS100/LRbicx2
37 | io_backend:
38 | type: disk
39 |
40 | test_5:
41 | name: Manga109
42 | type: PairedImageDataset
43 | dataroot_gt: ./datasets/manga109/GTmod2
44 | dataroot_lq: ./datasets/manga109/LRbicx2
45 | io_backend:
46 | type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 2
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 24
56 | squeeze_factor: 24
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 144
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-S_SRx2.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 2
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 2
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT-S_SRx3.yml:
--------------------------------------------------------------------------------
1 | name: HAT-S_SRx3
2 | model_type: HATModel
3 | scale: 3
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod3
12 | dataroot_lq: ./datasets/Set5/LRbicx3
13 | io_backend:
14 | type: disk
15 |
16 | test_2: # the 2nd test dataset
17 | name: Set14
18 | type: PairedImageDataset
19 | dataroot_gt: ./datasets/Set14/GTmod3
20 | dataroot_lq: ./datasets/Set14/LRbicx3
21 | io_backend:
22 | type: disk
23 |
24 | test_3:
25 | name: Urban100
26 | type: PairedImageDataset
27 | dataroot_gt: ./datasets/urban100/GTmod3
28 | dataroot_lq: ./datasets/urban100/LRbicx3
29 | io_backend:
30 | type: disk
31 |
32 | test_4:
33 | name: BSDS100
34 | type: PairedImageDataset
35 | dataroot_gt: ./datasets/BSDS100/GTmod3
36 | dataroot_lq: ./datasets/BSDS100/LRbicx3
37 | io_backend:
38 | type: disk
39 |
40 | test_5:
41 | name: Manga109
42 | type: PairedImageDataset
43 | dataroot_gt: ./datasets/manga109/GTmod3
44 | dataroot_lq: ./datasets/manga109/LRbicx3
45 | io_backend:
46 | type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 3
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 24
56 | squeeze_factor: 24
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 144
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-S_SRx3.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 3
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 3
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT-S_SRx4.yml:
--------------------------------------------------------------------------------
1 | name: HAT-S_SRx4
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod4
12 | dataroot_lq: ./datasets/Set5/LRbicx4
13 | io_backend:
14 | type: disk
15 |
16 | test_2: # the 2nd test dataset
17 | name: Set14
18 | type: PairedImageDataset
19 | dataroot_gt: ./datasets/Set14/GTmod4
20 | dataroot_lq: ./datasets/Set14/LRbicx4
21 | io_backend:
22 | type: disk
23 |
24 | test_3:
25 | name: Urban100
26 | type: PairedImageDataset
27 | dataroot_gt: ./datasets/urban100/GTmod4
28 | dataroot_lq: ./datasets/urban100/LRbicx4
29 | io_backend:
30 | type: disk
31 |
32 | test_4:
33 | name: BSDS100
34 | type: PairedImageDataset
35 | dataroot_gt: ./datasets/BSDS100/GTmod4
36 | dataroot_lq: ./datasets/BSDS100/LRbicx4
37 | io_backend:
38 | type: disk
39 |
40 | test_5:
41 | name: Manga109
42 | type: PairedImageDataset
43 | dataroot_gt: ./datasets/manga109/GTmod4
44 | dataroot_lq: ./datasets/manga109/LRbicx4
45 | io_backend:
46 | type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 4
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 24
56 | squeeze_factor: 24
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 144
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT-S_SRx4.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 4
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 4
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_GAN_Real_SRx4.yml:
--------------------------------------------------------------------------------
1 | name: HAT_GAN_Real_SRx4
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | tile: # use the tile mode for limited GPU memory when testing.
8 | tile_size: 512 # the higher, the more utilized GPU memory and the less performance change against the full image. must be an integer multiple of the window size.
9 | tile_pad: 32 # overlapping between adjacency patches.must be an integer multiple of the window size.
10 |
11 | datasets:
12 | test_1: # the 1st test dataset
13 | name: custom
14 | type: SingleImageDataset
15 | dataroot_lq: input_dir
16 | io_backend:
17 | type: disk
18 |
19 | # network structures
20 | network_g:
21 | type: HAT
22 | upscale: 4
23 | in_chans: 3
24 | img_size: 64
25 | window_size: 16
26 | compress_ratio: 3
27 | squeeze_factor: 30
28 | conv_scale: 0.01
29 | overlap_ratio: 0.5
30 | img_range: 1.
31 | depths: [6, 6, 6, 6, 6, 6]
32 | embed_dim: 180
33 | num_heads: [6, 6, 6, 6, 6, 6]
34 | mlp_ratio: 2
35 | upsampler: 'pixelshuffle'
36 | resi_connection: '1conv'
37 |
38 |
39 | # path
40 | path:
41 | pretrain_network_g: ./experiments/pretrained_models/Real_HAT_GAN_SRx4.pth
42 | strict_load_g: true
43 | param_key_g: 'params_ema'
44 |
45 | # validation settings
46 | val:
47 | save_img: true
48 | suffix: ~ # add suffix to saved images, if None, use exp name
--------------------------------------------------------------------------------
/options/test/HAT_SRx2.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx2
2 | model_type: HATModel
3 | scale: 2
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod2
12 | dataroot_lq: ./datasets/Set5/LRbicx2
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod2
20 | # dataroot_lq: ./datasets/Set14/LRbicx2
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod2
28 | # dataroot_lq: ./datasets/urban100/LRbicx2
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod2
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx2
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod2
44 | # dataroot_lq: ./datasets/manga109/LRbicx2
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 2
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx2.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 2
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 2
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx2_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx2_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 2
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod2
12 | dataroot_lq: ./datasets/Set5/LRbicx2
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod2
20 | # dataroot_lq: ./datasets/Set14/LRbicx2
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod2
28 | # dataroot_lq: ./datasets/urban100/LRbicx2
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod2
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx2
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod2
44 | # dataroot_lq: ./datasets/manga109/LRbicx2
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 2
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx2_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 2
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 2
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx3.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx3
2 | model_type: HATModel
3 | scale: 3
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod3
12 | dataroot_lq: ./datasets/Set5/LRbicx3
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod3
20 | # dataroot_lq: ./datasets/Set14/LRbicx3
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod3
28 | # dataroot_lq: ./datasets/urban100/LRbicx3
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod3
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx3
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod3
44 | # dataroot_lq: ./datasets/manga109/LRbicx3
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 3
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx3.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 3
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 3
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx3_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx3_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 3
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod3
12 | dataroot_lq: ./datasets/Set5/LRbicx3
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod3
20 | # dataroot_lq: ./datasets/Set14/LRbicx3
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod3
28 | # dataroot_lq: ./datasets/urban100/LRbicx3
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod3
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx3
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod3
44 | # dataroot_lq: ./datasets/manga109/LRbicx3
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 3
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx3_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 3
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 3
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx4.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx4
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod4
12 | dataroot_lq: ./datasets/Set5/LRbicx4
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod4
20 | # dataroot_lq: ./datasets/Set14/LRbicx4
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod4
28 | # dataroot_lq: ./datasets/urban100/LRbicx4
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod4
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx4
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod4
44 | # dataroot_lq: ./datasets/manga109/LRbicx4
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 4
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx4.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 4
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 4
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx4_ImageNet-LR.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx4_ImageNet-LR
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | tile:
8 | tile_size: 512 # max patch size for the tile mode
9 | tile_pad: 32
10 |
11 | datasets:
12 | test_1: # the 1st test dataset
13 | name: custom
14 | type: SingleImageDataset
15 | dataroot_lq: input_dir
16 | io_backend:
17 | type: disk
18 |
19 | # network structures
20 | network_g:
21 | type: HAT
22 | upscale: 4
23 | in_chans: 3
24 | img_size: 64
25 | window_size: 16
26 | compress_ratio: 3
27 | squeeze_factor: 30
28 | conv_scale: 0.01
29 | overlap_ratio: 0.5
30 | img_range: 1.
31 | depths: [6, 6, 6, 6, 6, 6]
32 | embed_dim: 180
33 | num_heads: [6, 6, 6, 6, 6, 6]
34 | mlp_ratio: 2
35 | upsampler: 'pixelshuffle'
36 | resi_connection: '1conv'
37 |
38 |
39 | # path
40 | path:
41 | pretrain_network_g: experiments/pretrained_models/HAT_SRx4_ImageNet-pretrain.pth
42 | strict_load_g: true
43 | param_key_g: 'params_ema'
44 |
45 | # validation settings
46 | val:
47 | save_img: true
48 | suffix: ~ # add suffix to saved images, if None, use exp name
49 |
--------------------------------------------------------------------------------
/options/test/HAT_SRx4_ImageNet-pretrain.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx4_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | datasets:
8 | test_1: # the 1st test dataset
9 | name: Set5
10 | type: PairedImageDataset
11 | dataroot_gt: ./datasets/Set5/GTmod4
12 | dataroot_lq: ./datasets/Set5/LRbicx4
13 | io_backend:
14 | type: disk
15 |
16 | # test_2: # the 2nd test dataset
17 | # name: Set14
18 | # type: PairedImageDataset
19 | # dataroot_gt: ./datasets/Set14/GTmod4
20 | # dataroot_lq: ./datasets/Set14/LRbicx4
21 | # io_backend:
22 | # type: disk
23 |
24 | # test_3:
25 | # name: Urban100
26 | # type: PairedImageDataset
27 | # dataroot_gt: ./datasets/urban100/GTmod4
28 | # dataroot_lq: ./datasets/urban100/LRbicx4
29 | # io_backend:
30 | # type: disk
31 |
32 | # test_4:
33 | # name: BSDS100
34 | # type: PairedImageDataset
35 | # dataroot_gt: ./datasets/BSDS100/GTmod4
36 | # dataroot_lq: ./datasets/BSDS100/LRbicx4
37 | # io_backend:
38 | # type: disk
39 |
40 | # test_5:
41 | # name: Manga109
42 | # type: PairedImageDataset
43 | # dataroot_gt: ./datasets/manga109/GTmod4
44 | # dataroot_lq: ./datasets/manga109/LRbicx4
45 | # io_backend:
46 | # type: disk
47 |
48 | # network structures
49 | network_g:
50 | type: HAT
51 | upscale: 4
52 | in_chans: 3
53 | img_size: 64
54 | window_size: 16
55 | compress_ratio: 3
56 | squeeze_factor: 30
57 | conv_scale: 0.01
58 | overlap_ratio: 0.5
59 | img_range: 1.
60 | depths: [6, 6, 6, 6, 6, 6]
61 | embed_dim: 180
62 | num_heads: [6, 6, 6, 6, 6, 6]
63 | mlp_ratio: 2
64 | upsampler: 'pixelshuffle'
65 | resi_connection: '1conv'
66 |
67 |
68 | # path
69 | path:
70 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx4_ImageNet-pretrain.pth
71 | strict_load_g: true
72 | param_key_g: 'params_ema'
73 |
74 | # validation settings
75 | val:
76 | save_img: true
77 | suffix: ~ # add suffix to saved images, if None, use exp name
78 |
79 | metrics:
80 | psnr: # metric name, can be arbitrary
81 | type: calculate_psnr
82 | crop_border: 4
83 | test_y_channel: true
84 | ssim:
85 | type: calculate_ssim
86 | crop_border: 4
87 | test_y_channel: true
88 |
--------------------------------------------------------------------------------
/options/test/HAT_tile_example.yml:
--------------------------------------------------------------------------------
1 | name: HAT_SRx4_ImageNet-pretrain
2 | model_type: HATModel
3 | scale: 4
4 | num_gpu: 1 # set num_gpu: 0 for cpu mode
5 | manual_seed: 0
6 |
7 | tile: # use the tile mode for limited GPU memory when testing.
8 | tile_size: 256 # the higher, the more utilized GPU memory and the less performance change against the full image. must be an integer multiple of the window size.
9 | tile_pad: 32 # overlapping between adjacency patches.must be an integer multiple of the window size.
10 |
11 | datasets:
12 | test_1: # the 1st test dataset
13 | name: Set5
14 | type: PairedImageDataset
15 | dataroot_gt: ./datasets/Set5/GTmod4
16 | dataroot_lq: ./datasets/Set5/LRbicx4
17 | io_backend:
18 | type: disk
19 |
20 | # test_2: # the 2nd test dataset
21 | # name: Set14
22 | # type: PairedImageDataset
23 | # dataroot_gt: ./datasets/Set14/GTmod4
24 | # dataroot_lq: ./datasets/Set14/LRbicx4
25 | # io_backend:
26 | # type: disk
27 |
28 | test_3:
29 | name: Urban100
30 | type: PairedImageDataset
31 | dataroot_gt: ./datasets/urban100/GTmod4
32 | dataroot_lq: ./datasets/urban100/LRbicx4
33 | io_backend:
34 | type: disk
35 |
36 | # test_4:
37 | # name: BSDS100
38 | # type: PairedImageDataset
39 | # dataroot_gt: ./datasets/BSDS100/GTmod4
40 | # dataroot_lq: ./datasets/BSDS100/LRbicx4
41 | # io_backend:
42 | # type: disk
43 |
44 | # test_5:
45 | # name: Manga109
46 | # type: PairedImageDataset
47 | # dataroot_gt: ./datasets/manga109/GTmod4
48 | # dataroot_lq: ./datasets/manga109/LRbicx4
49 | # io_backend:
50 | # type: disk
51 |
52 | # network structures
53 | network_g:
54 | type: HAT
55 | upscale: 4
56 | in_chans: 3
57 | img_size: 64
58 | window_size: 16
59 | compress_ratio: 3
60 | squeeze_factor: 30
61 | conv_scale: 0.01
62 | overlap_ratio: 0.5
63 | img_range: 1.
64 | depths: [6, 6, 6, 6, 6, 6]
65 | embed_dim: 180
66 | num_heads: [6, 6, 6, 6, 6, 6]
67 | mlp_ratio: 2
68 | upsampler: 'pixelshuffle'
69 | resi_connection: '1conv'
70 |
71 |
72 | # path
73 | path:
74 | pretrain_network_g: ./experiments/pretrained_models/HAT_SRx4_ImageNet-pretrain.pth
75 | strict_load_g: true
76 | param_key_g: 'params_ema'
77 |
78 | # validation settings
79 | val:
80 | save_img: true
81 | suffix: ~ # add suffix to saved images, if None, use exp name
82 |
83 | metrics:
84 | psnr: # metric name, can be arbitrary
85 | type: calculate_psnr
86 | crop_border: 4
87 | test_y_channel: true
88 | ssim:
89 | type: calculate_ssim
90 | crop_border: 4
91 | test_y_channel: true
92 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx2_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx2_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 128
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod2
33 | dataroot_lq: ./datasets/Set5/LRbicx2
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod2
41 | dataroot_lq: ./datasets/Set14/LRbicx2
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod2
49 | # dataroot_lq: ./datasets/urban100/LRbicx2
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 2
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 2
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 2
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx2_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx2_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx2_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 128
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod2
34 | dataroot_lq: ./datasets/Set5/LRbicx2
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod2
42 | dataroot_lq: ./datasets/Set14/LRbicx2
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod2
50 | # dataroot_lq: ./datasets/urban100/LRbicx2
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 2
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT-L_SRx2_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 2
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 2
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx3_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx3_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 192
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod3
33 | dataroot_lq: ./datasets/Set5/LRbicx3
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod3
41 | dataroot_lq: ./datasets/Set14/LRbicx3
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod3
49 | # dataroot_lq: ./datasets/urban100/LRbicx3
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 3
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 3
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 3
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx3_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx3_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx3_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 192
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod3
34 | dataroot_lq: ./datasets/Set5/LRbicx3
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod3
42 | dataroot_lq: ./datasets/Set14/LRbicx3
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod3
50 | # dataroot_lq: ./datasets/urban100/LRbicx3
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 3
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT-L_SRx3_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 3
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 3
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx4_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx4_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 256
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod4
33 | dataroot_lq: ./datasets/Set5/LRbicx4
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod4
41 | dataroot_lq: ./datasets/Set14/LRbicx4
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod4
49 | # dataroot_lq: ./datasets/urban100/LRbicx4
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 4
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 4
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 4
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT-L_SRx4_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-L_SRx4_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx4_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 256
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod4
34 | dataroot_lq: ./datasets/Set5/LRbicx4
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod4
42 | dataroot_lq: ./datasets/Set14/LRbicx4
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod4
50 | # dataroot_lq: ./datasets/urban100/LRbicx4
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 4
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT-L_SRx4_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 4
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 4
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT-S_SRx2_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-S_SRx2_from_scratch
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx2_sub
15 | meta_info_file: hct/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 128
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: datasets/Set5/GTmod2
34 | dataroot_lq: datasets/Set5/LRbicx2
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: datasets/Set14/GTmod2
42 | dataroot_lq: datasets/Set14/LRbicx2
43 | io_backend:
44 | type: disk
45 |
46 | val_3:
47 | name: Urban100
48 | type: PairedImageDataset
49 | dataroot_gt: datasets/urban100/GTmod2
50 | dataroot_lq: datasets/urban100/LRbicx2
51 | io_backend:
52 | type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 2
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 24
63 | squeeze_factor: 24
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 144
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ~
77 | strict_load_g: true
78 | resume_state: ~
79 |
80 | # training settings
81 | train:
82 | ema_decay: 0.999
83 | optim_g:
84 | type: Adam
85 | lr: !!float 2e-4
86 | weight_decay: 0
87 | betas: [0.9, 0.99]
88 |
89 | scheduler:
90 | type: MultiStepLR
91 | milestones: [250000, 400000, 450000, 475000]
92 | gamma: 0.5
93 |
94 | total_iter: 500000
95 | warmup_iter: -1 # no warm up
96 |
97 | # losses
98 | pixel_opt:
99 | type: L1Loss
100 | loss_weight: 1.0
101 | reduction: mean
102 |
103 | # validation settings
104 | val:
105 | val_freq: !!float 2e4
106 | save_img: false
107 | pbar: False
108 |
109 | metrics:
110 | psnr:
111 | type: calculate_psnr
112 | crop_border: 2
113 | test_y_channel: true
114 | better: higher # the higher, the better. Default: higher
115 | ssim:
116 | type: calculate_ssim
117 | crop_border: 2
118 | test_y_channel: true
119 | better: higher # the higher, the better. Default: higher
120 |
121 | # logging settings
122 | logger:
123 | print_freq: 100
124 | save_checkpoint_freq: !!float 2e4
125 | use_tb_logger: true
126 | wandb:
127 | project: ~
128 | resume_id: ~
129 |
130 | # dist training settings
131 | dist_params:
132 | backend: nccl
133 | port: 29500
134 |
--------------------------------------------------------------------------------
/options/train/train_HAT-S_SRx3_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-S_SRx3_from_scratch
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx3_sub
15 | meta_info_file: hct/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 192
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: datasets/Set5/GTmod3
34 | dataroot_lq: datasets/Set5/LRbicx3
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: datasets/Set14/GTmod3
42 | dataroot_lq: datasets/Set14/LRbicx3
43 | io_backend:
44 | type: disk
45 |
46 | val_3:
47 | name: Urban100
48 | type: PairedImageDataset
49 | dataroot_gt: datasets/urban100/GTmod3
50 | dataroot_lq: datasets/urban100/LRbicx3
51 | io_backend:
52 | type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 3
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 24
63 | squeeze_factor: 24
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 144
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ~
77 | strict_load_g: true
78 | resume_state: ~
79 |
80 | # training settings
81 | train:
82 | ema_decay: 0.999
83 | optim_g:
84 | type: Adam
85 | lr: !!float 2e-4
86 | weight_decay: 0
87 | betas: [0.9, 0.99]
88 |
89 | scheduler:
90 | type: MultiStepLR
91 | milestones: [250000, 400000, 450000, 475000]
92 | gamma: 0.5
93 |
94 | total_iter: 500000
95 | warmup_iter: -1 # no warm up
96 |
97 | # losses
98 | pixel_opt:
99 | type: L1Loss
100 | loss_weight: 1.0
101 | reduction: mean
102 |
103 | # validation settings
104 | val:
105 | val_freq: !!float 2e4
106 | save_img: false
107 | pbar: False
108 |
109 | metrics:
110 | psnr:
111 | type: calculate_psnr
112 | crop_border: 3
113 | test_y_channel: true
114 | better: higher # the higher, the better. Default: higher
115 | ssim:
116 | type: calculate_ssim
117 | crop_border: 3
118 | test_y_channel: true
119 | better: higher # the higher, the better. Default: higher
120 |
121 | # logging settings
122 | logger:
123 | print_freq: 100
124 | save_checkpoint_freq: !!float 2e4
125 | use_tb_logger: true
126 | wandb:
127 | project: ~
128 | resume_id: ~
129 |
130 | # dist training settings
131 | dist_params:
132 | backend: nccl
133 | port: 29500
134 |
--------------------------------------------------------------------------------
/options/train/train_HAT-S_SRx4_finetune_from_SRx2.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT-S_SRx4_finetune_from_SRx2
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx4_sub
15 | meta_info_file: hct/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 256
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: datasets/Set5/GTmod4
34 | dataroot_lq: datasets/Set5/LRbicx4
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: datasets/Set14/GTmod4
42 | dataroot_lq: datasets/Set14/LRbicx4
43 | io_backend:
44 | type: disk
45 |
46 | val_3:
47 | name: Urban100
48 | type: PairedImageDataset
49 | dataroot_gt: datasets/urban100/GTmod4
50 | dataroot_lq: datasets/urban100/LRbicx4
51 | io_backend:
52 | type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 4
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 24
63 | squeeze_factor: 24
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 144
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/563_train_HAT-S_SRx2_scratch_DF2K_500k_B4G8/models/net_g_latest.pth
77 | strict_load_g: false
78 | resume_state: ~
79 |
80 | # training settings
81 | train:
82 | ema_decay: 0.999
83 | optim_g:
84 | type: Adam
85 | lr: !!float 1e-4
86 | weight_decay: 0
87 | betas: [0.9, 0.99]
88 |
89 | scheduler:
90 | type: MultiStepLR
91 | milestones: [125000, 200000, 225000, 240000]
92 | gamma: 0.5
93 |
94 | total_iter: 250000
95 | warmup_iter: -1 # no warm up
96 |
97 | # losses
98 | pixel_opt:
99 | type: L1Loss
100 | loss_weight: 1.0
101 | reduction: mean
102 |
103 | # validation settings
104 | val:
105 | val_freq: !!float 2e4
106 | save_img: false
107 | pbar: False
108 |
109 | metrics:
110 | psnr:
111 | type: calculate_psnr
112 | crop_border: 4
113 | test_y_channel: true
114 | better: higher # the higher, the better. Default: higher
115 | ssim:
116 | type: calculate_ssim
117 | crop_border: 4
118 | test_y_channel: true
119 | better: higher # the higher, the better. Default: higher
120 |
121 | # logging settings
122 | logger:
123 | print_freq: 100
124 | save_checkpoint_freq: !!float 2e4
125 | use_tb_logger: true
126 | wandb:
127 | project: ~
128 | resume_id: ~
129 |
130 | # dist training settings
131 | dist_params:
132 | backend: nccl
133 | port: 29500
134 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx2_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx2_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 128
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod2
33 | dataroot_lq: ./datasets/Set5/LRbicx2
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod2
41 | dataroot_lq: ./datasets/Set14/LRbicx2
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod2
49 | # dataroot_lq: ./datasets/urban100/LRbicx2
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 2
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 2
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 2
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx2_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx2_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx2_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 128
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod2
34 | dataroot_lq: ./datasets/Set5/LRbicx2
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod2
42 | dataroot_lq: ./datasets/Set14/LRbicx2
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod2
50 | # dataroot_lq: ./datasets/urban100/LRbicx2
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 2
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT_SRx2_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 2
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 2
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx2_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx2_from_scratch
3 | model_type: HATModel
4 | scale: 2
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx2_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 128
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod2
34 | dataroot_lq: ./datasets/Set5/LRbicx2
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod2
42 | dataroot_lq: ./datasets/Set14/LRbicx2
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod2
50 | # dataroot_lq: ./datasets/urban100/LRbicx2
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 2
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ~
77 | strict_load_g: true
78 | resume_state: ~
79 |
80 | # training settings
81 | train:
82 | ema_decay: 0.999
83 | optim_g:
84 | type: Adam
85 | lr: !!float 2e-4
86 | weight_decay: 0
87 | betas: [0.9, 0.99]
88 |
89 | scheduler:
90 | type: MultiStepLR
91 | milestones: [250000, 400000, 450000, 475000]
92 | gamma: 0.5
93 |
94 | total_iter: 500000
95 | warmup_iter: -1 # no warm up
96 |
97 | # losses
98 | pixel_opt:
99 | type: L1Loss
100 | loss_weight: 1.0
101 | reduction: mean
102 |
103 | # validation settings
104 | val:
105 | val_freq: !!float 5e3
106 | save_img: false
107 | pbar: False
108 |
109 | metrics:
110 | psnr:
111 | type: calculate_psnr
112 | crop_border: 2
113 | test_y_channel: true
114 | better: higher # the higher, the better. Default: higher
115 | ssim:
116 | type: calculate_ssim
117 | crop_border: 2
118 | test_y_channel: true
119 | better: higher # the higher, the better. Default: higher
120 |
121 | # logging settings
122 | logger:
123 | print_freq: 100
124 | save_checkpoint_freq: !!float 5e3
125 | use_tb_logger: true
126 | wandb:
127 | project: ~
128 | resume_id: ~
129 |
130 | # dist training settings
131 | dist_params:
132 | backend: nccl
133 | port: 29500
134 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx3_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx3_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 192
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod3
33 | dataroot_lq: ./datasets/Set5/LRbicx3
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod3
41 | dataroot_lq: ./datasets/Set14/LRbicx3
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod3
49 | # dataroot_lq: ./datasets/urban100/LRbicx3
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 3
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 3
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 3
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx3_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx3_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx3_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 192
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod3
34 | dataroot_lq: ./datasets/Set5/LRbicx3
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod3
42 | dataroot_lq: ./datasets/Set14/LRbicx3
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod3
50 | # dataroot_lq: ./datasets/urban100/LRbicx3
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 3
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT_SRx3_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 3
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 3
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx3_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx3_from_scratch
3 | model_type: HATModel
4 | scale: 3
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx3_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 192
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod3
34 | dataroot_lq: ./datasets/Set5/LRbicx3
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod3
42 | dataroot_lq: ./datasets/Set14/LRbicx3
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod3
50 | # dataroot_lq: ./datasets/urban100/LRbicx3
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 3
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ~
77 | strict_load_g: true
78 | resume_state: ~
79 |
80 | # training settings
81 | train:
82 | ema_decay: 0.999
83 | optim_g:
84 | type: Adam
85 | lr: !!float 2e-4
86 | weight_decay: 0
87 | betas: [0.9, 0.99]
88 |
89 | scheduler:
90 | type: MultiStepLR
91 | milestones: [250000, 400000, 450000, 475000]
92 | gamma: 0.5
93 |
94 | total_iter: 500000
95 | warmup_iter: -1 # no warm up
96 |
97 | # losses
98 | pixel_opt:
99 | type: L1Loss
100 | loss_weight: 1.0
101 | reduction: mean
102 |
103 | # validation settings
104 | val:
105 | val_freq: !!float 5e3
106 | save_img: false
107 | pbar: False
108 |
109 | metrics:
110 | psnr:
111 | type: calculate_psnr
112 | crop_border: 3
113 | test_y_channel: true
114 | better: higher # the higher, the better. Default: higher
115 | ssim:
116 | type: calculate_ssim
117 | crop_border: 3
118 | test_y_channel: true
119 | better: higher # the higher, the better. Default: higher
120 |
121 | # logging settings
122 | logger:
123 | print_freq: 100
124 | save_checkpoint_freq: !!float 5e3
125 | use_tb_logger: true
126 | wandb:
127 | project: ~
128 | resume_id: ~
129 |
130 | # dist training settings
131 | dist_params:
132 | backend: nccl
133 | port: 29500
134 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx4_ImageNet_from_scratch.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx4_ImageNet_from_scratch
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: ImageNet
12 | type: ImageNetPairedDataset
13 | dataroot_gt: datasets/ImageNet/GT
14 | meta_info_file: hat/data/meta_info/meta_info_ImageNet_GT.txt
15 | io_backend:
16 | type: disk
17 |
18 | gt_size: 256
19 | use_hflip: true
20 | use_rot: true
21 |
22 | # data loader
23 | use_shuffle: true
24 | num_worker_per_gpu: 6
25 | batch_size_per_gpu: 4
26 | dataset_enlarge_ratio: 1
27 | prefetch_mode: ~
28 |
29 | val_1:
30 | name: Set5
31 | type: PairedImageDataset
32 | dataroot_gt: ./datasets/Set5/GTmod4
33 | dataroot_lq: ./datasets/Set5/LRbicx4
34 | io_backend:
35 | type: disk
36 |
37 | val_2:
38 | name: Set14
39 | type: PairedImageDataset
40 | dataroot_gt: ./datasets/Set14/GTmod4
41 | dataroot_lq: ./datasets/Set14/LRbicx4
42 | io_backend:
43 | type: disk
44 |
45 | # val_3:
46 | # name: Urban100
47 | # type: PairedImageDataset
48 | # dataroot_gt: ./datasets/urban100/GTmod4
49 | # dataroot_lq: ./datasets/urban100/LRbicx4
50 | # io_backend:
51 | # type: disk
52 |
53 |
54 | # network structures
55 | network_g:
56 | type: HAT
57 | upscale: 4
58 | in_chans: 3
59 | img_size: 64
60 | window_size: 16
61 | compress_ratio: 3
62 | squeeze_factor: 30
63 | conv_scale: 0.01
64 | overlap_ratio: 0.5
65 | img_range: 1.
66 | depths: [6, 6, 6, 6, 6, 6]
67 | embed_dim: 180
68 | num_heads: [6, 6, 6, 6, 6, 6]
69 | mlp_ratio: 2
70 | upsampler: 'pixelshuffle'
71 | resi_connection: '1conv'
72 |
73 | # path
74 | path:
75 | pretrain_network_g: ~
76 | strict_load_g: true
77 | resume_state: ~
78 |
79 | # training settings
80 | train:
81 | ema_decay: 0.999
82 | optim_g:
83 | type: Adam
84 | lr: !!float 2e-4
85 | weight_decay: 0
86 | betas: [0.9, 0.99]
87 |
88 | scheduler:
89 | type: MultiStepLR
90 | milestones: [300000, 500000, 650000, 700000, 750000]
91 | gamma: 0.5
92 |
93 | total_iter: 800000
94 | warmup_iter: -1 # no warm up
95 |
96 | # losses
97 | pixel_opt:
98 | type: L1Loss
99 | loss_weight: 1.0
100 | reduction: mean
101 |
102 | # validation settings
103 | val:
104 | val_freq: !!float 1e4
105 | save_img: false
106 | pbar: False
107 |
108 | metrics:
109 | psnr:
110 | type: calculate_psnr
111 | crop_border: 4
112 | test_y_channel: true
113 | better: higher # the higher, the better. Default: higher
114 | ssim:
115 | type: calculate_ssim
116 | crop_border: 4
117 | test_y_channel: true
118 | better: higher # the higher, the better. Default: higher
119 |
120 | # logging settings
121 | logger:
122 | print_freq: 100
123 | save_checkpoint_freq: !!float 1e4
124 | use_tb_logger: true
125 | wandb:
126 | project: ~
127 | resume_id: ~
128 |
129 | # dist training settings
130 | dist_params:
131 | backend: nccl
132 | port: 29500
133 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx4_finetune_from_ImageNet_pretrain.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx4_finetune_from_ImageNet_pretrain
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx4_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 256
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod4
34 | dataroot_lq: ./datasets/Set5/LRbicx4
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod4
42 | dataroot_lq: ./datasets/Set14/LRbicx4
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod4
50 | # dataroot_lq: ./datasets/urban100/LRbicx4
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 4
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT_SRx4_ImageNet_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-5
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 4
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 4
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_HAT_SRx4_finetune_from_SRx2.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_HAT_SRx4_finetune_from_SRx2
3 | model_type: HATModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # dataset and data loader settings
9 | datasets:
10 | train:
11 | name: DF2K
12 | type: PairedImageDataset
13 | dataroot_gt: datasets/DF2K/DF2K_HR_sub
14 | dataroot_lq: datasets/DF2K/DF2K_bicx4_sub
15 | meta_info_file: hat/data/meta_info/meta_info_DF2Ksub_GT.txt
16 | io_backend:
17 | type: disk
18 |
19 | gt_size: 256
20 | use_hflip: true
21 | use_rot: true
22 |
23 | # data loader
24 | use_shuffle: true
25 | num_worker_per_gpu: 6
26 | batch_size_per_gpu: 4
27 | dataset_enlarge_ratio: 1
28 | prefetch_mode: ~
29 |
30 | val_1:
31 | name: Set5
32 | type: PairedImageDataset
33 | dataroot_gt: ./datasets/Set5/GTmod4
34 | dataroot_lq: ./datasets/Set5/LRbicx4
35 | io_backend:
36 | type: disk
37 |
38 | val_2:
39 | name: Set14
40 | type: PairedImageDataset
41 | dataroot_gt: ./datasets/Set14/GTmod4
42 | dataroot_lq: ./datasets/Set14/LRbicx4
43 | io_backend:
44 | type: disk
45 |
46 | # val_3:
47 | # name: Urban100
48 | # type: PairedImageDataset
49 | # dataroot_gt: ./datasets/urban100/GTmod4
50 | # dataroot_lq: ./datasets/urban100/LRbicx4
51 | # io_backend:
52 | # type: disk
53 |
54 |
55 | # network structures
56 | network_g:
57 | type: HAT
58 | upscale: 4
59 | in_chans: 3
60 | img_size: 64
61 | window_size: 16
62 | compress_ratio: 3
63 | squeeze_factor: 30
64 | conv_scale: 0.01
65 | overlap_ratio: 0.5
66 | img_range: 1.
67 | depths: [6, 6, 6, 6, 6, 6]
68 | embed_dim: 180
69 | num_heads: [6, 6, 6, 6, 6, 6]
70 | mlp_ratio: 2
71 | upsampler: 'pixelshuffle'
72 | resi_connection: '1conv'
73 |
74 | # path
75 | path:
76 | pretrain_network_g: ./experiments/train_HAT_SRx2_from_scratch/models/net_g_latest.pth
77 | param_key_g: 'params_ema'
78 | strict_load_g: true
79 | resume_state: ~
80 |
81 | # training settings
82 | train:
83 | ema_decay: 0.999
84 | optim_g:
85 | type: Adam
86 | lr: !!float 1e-4
87 | weight_decay: 0
88 | betas: [0.9, 0.99]
89 |
90 | scheduler:
91 | type: MultiStepLR
92 | milestones: [125000, 200000, 225000, 240000]
93 | gamma: 0.5
94 |
95 | total_iter: 250000
96 | warmup_iter: -1 # no warm up
97 |
98 | # losses
99 | pixel_opt:
100 | type: L1Loss
101 | loss_weight: 1.0
102 | reduction: mean
103 |
104 | # validation settings
105 | val:
106 | val_freq: !!float 5e3
107 | save_img: false
108 | pbar: False
109 |
110 | metrics:
111 | psnr:
112 | type: calculate_psnr
113 | crop_border: 4
114 | test_y_channel: true
115 | better: higher # the higher, the better. Default: higher
116 | ssim:
117 | type: calculate_ssim
118 | crop_border: 4
119 | test_y_channel: true
120 | better: higher # the higher, the better. Default: higher
121 |
122 | # logging settings
123 | logger:
124 | print_freq: 100
125 | save_checkpoint_freq: !!float 5e3
126 | use_tb_logger: true
127 | wandb:
128 | project: ~
129 | resume_id: ~
130 |
131 | # dist training settings
132 | dist_params:
133 | backend: nccl
134 | port: 29500
135 |
--------------------------------------------------------------------------------
/options/train/train_Real_HAT_GAN_SRx4_finetune_from_mse_model.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_Real_HAT_GAN_SRx4_finetune_from_mse_model
3 | model_type: RealHATGANModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # ----------------- options for synthesizing training data in RealESRGANModel ----------------- #
9 | # USM the ground-truth
10 | l1_gt_usm: True
11 | percep_gt_usm: True
12 | gan_gt_usm: False
13 |
14 | # the first degradation process
15 | resize_prob: [0.2, 0.7, 0.1] # up, down, keep
16 | resize_range: [0.15, 1.5]
17 | gaussian_noise_prob: 0.5
18 | noise_range: [1, 30]
19 | poisson_scale_range: [0.05, 3]
20 | gray_noise_prob: 0.4
21 | jpeg_range: [30, 95]
22 |
23 | # the second degradation process
24 | second_blur_prob: 0.8
25 | resize_prob2: [0.3, 0.4, 0.3] # up, down, keep
26 | resize_range2: [0.3, 1.2]
27 | gaussian_noise_prob2: 0.5
28 | noise_range2: [1, 25]
29 | poisson_scale_range2: [0.05, 2.5]
30 | gray_noise_prob2: 0.4
31 | jpeg_range2: [30, 95]
32 |
33 | gt_size: 256
34 | queue_size: 180
35 |
36 | # dataset and data loader settings
37 | datasets:
38 | train:
39 | name: DF2K+OST
40 | type: RealESRGANDataset
41 | dataroot_gt: datasets/DFO/DFO_sub # Refer to Real-ESRGAN for OST dataset. Only DF2K is OK.
42 | meta_info_file: hat/data/meta_info/meta_info_DFOsub_GT.txt
43 | io_backend:
44 | type: disk
45 |
46 | blur_kernel_size: 21
47 | kernel_list: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
48 | kernel_prob: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
49 | sinc_prob: 0.1
50 | blur_sigma: [0.2, 3]
51 | betag_range: [0.5, 4]
52 | betap_range: [1, 2]
53 |
54 | blur_kernel_size2: 21
55 | kernel_list2: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
56 | kernel_prob2: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
57 | sinc_prob2: 0.1
58 | blur_sigma2: [0.2, 1.5]
59 | betag_range2: [0.5, 4]
60 | betap_range2: [1, 2]
61 |
62 | final_sinc_prob: 0.8
63 |
64 | gt_size: 256
65 | use_hflip: True
66 | use_rot: False
67 |
68 | # data loader
69 | use_shuffle: true
70 | num_worker_per_gpu: 5
71 | batch_size_per_gpu: 4
72 | dataset_enlarge_ratio: 1
73 | prefetch_mode: ~
74 |
75 | # Uncomment these for validation
76 | # val:
77 | # name: validation
78 | # type: SingleImageDataset
79 | # dataroot_lq: datasets/RealSRSet+5images
80 | # io_backend:
81 | # type: disk
82 |
83 | # network structures
84 | network_g:
85 | type: HAT
86 | upscale: 4
87 | in_chans: 3
88 | img_size: 64
89 | window_size: 16
90 | compress_ratio: 3
91 | squeeze_factor: 30
92 | conv_scale: 0.01
93 | overlap_ratio: 0.5
94 | img_range: 1.
95 | depths: [6, 6, 6, 6, 6, 6]
96 | embed_dim: 180
97 | num_heads: [6, 6, 6, 6, 6, 6]
98 | mlp_ratio: 2
99 | upsampler: 'pixelshuffle'
100 | resi_connection: '1conv'
101 |
102 | network_d:
103 | type: UNetDiscriminatorSN
104 | num_in_ch: 3
105 | num_feat: 64
106 | skip_connection: True
107 |
108 | # path
109 | path:
110 | # use the pre-trained Real-ESRNet model
111 | pretrain_network_g: experiments/pretrained_models/Real_HAT_x4.pth # train the MSE-based model 'Real_HAT' first.
112 | param_key_g: params_ema
113 | strict_load_g: true
114 | resume_state: ~
115 |
116 | # training settings
117 | train:
118 | ema_decay: 0.999
119 | optim_g:
120 | type: Adam
121 | lr: !!float 1e-4
122 | weight_decay: 0
123 | betas: [0.9, 0.99]
124 | optim_d:
125 | type: Adam
126 | lr: !!float 1e-4
127 | weight_decay: 0
128 | betas: [0.9, 0.99]
129 |
130 | scheduler:
131 | type: MultiStepLR
132 | milestones: [400000]
133 | gamma: 0.5
134 |
135 | total_iter: 400000
136 | warmup_iter: -1 # no warm up
137 |
138 | # losses
139 | pixel_opt:
140 | type: L1Loss
141 | loss_weight: 1.0
142 | reduction: mean
143 | # perceptual loss (content and style losses)
144 | perceptual_opt:
145 | type: PerceptualLoss
146 | layer_weights:
147 | # before relu
148 | 'conv1_2': 0.1
149 | 'conv2_2': 0.1
150 | 'conv3_4': 1
151 | 'conv4_4': 1
152 | 'conv5_4': 1
153 | vgg_type: vgg19
154 | use_input_norm: true
155 | perceptual_weight: !!float 1.0
156 | style_weight: 0
157 | range_norm: false
158 | criterion: l1
159 | # gan loss
160 | gan_opt:
161 | type: GANLoss
162 | gan_type: vanilla
163 | real_label_val: 1.0
164 | fake_label_val: 0.0
165 | loss_weight: !!float 1e-1
166 |
167 | net_d_iters: 1
168 | net_d_init_iters: 0
169 |
170 | # Uncomment these for validation
171 | # validation settings
172 | # val:
173 | # val_freq: !!float 1e4
174 | # save_img: True
175 |
176 | # metrics:
177 | # psnr: # metric name
178 | # type: calculate_psnr
179 | # crop_border: 4
180 | # test_y_channel: false
181 |
182 | # logging settings
183 | logger:
184 | print_freq: 200
185 | save_checkpoint_freq: !!float 1e4
186 | use_tb_logger: true
187 | wandb:
188 | project: ~
189 | resume_id: ~
190 |
191 | # dist training settings
192 | dist_params:
193 | backend: nccl
194 | port: 29500
--------------------------------------------------------------------------------
/options/train/train_Real_HAT_SRx4_mse_model.yml:
--------------------------------------------------------------------------------
1 | # general settings
2 | name: train_Real_HAT_mse_model
3 | model_type: RealHATMSEModel
4 | scale: 4
5 | num_gpu: auto
6 | manual_seed: 0
7 |
8 | # ----------------- options for synthesizing training data in RealESRNetModel ----------------- #
9 | gt_usm: True # USM the ground-truth
10 |
11 | # the first degradation process
12 | resize_prob: [0.2, 0.7, 0.1] # up, down, keep
13 | resize_range: [0.15, 1.5]
14 | gaussian_noise_prob: 0.5
15 | noise_range: [1, 30]
16 | poisson_scale_range: [0.05, 3]
17 | gray_noise_prob: 0.4
18 | jpeg_range: [30, 95]
19 |
20 | # the second degradation process
21 | second_blur_prob: 0.8
22 | resize_prob2: [0.3, 0.4, 0.3] # up, down, keep
23 | resize_range2: [0.3, 1.2]
24 | gaussian_noise_prob2: 0.5
25 | noise_range2: [1, 25]
26 | poisson_scale_range2: [0.05, 2.5]
27 | gray_noise_prob2: 0.4
28 | jpeg_range2: [30, 95]
29 |
30 | gt_size: 256
31 | queue_size: 180
32 |
33 | # dataset and data loader settings
34 | datasets:
35 | train:
36 | name: DF2K+OST
37 | type: RealESRGANDataset
38 | dataroot_gt: datasets/DFO/DFO_sub # Refer to Real-ESRGAN for OST dataset. Only DF2K is OK.
39 | meta_info_file: hat/data/meta_info/meta_info_DFOsub_GT.txt
40 | io_backend:
41 | type: disk
42 |
43 | blur_kernel_size: 21
44 | kernel_list: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
45 | kernel_prob: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
46 | sinc_prob: 0.1
47 | blur_sigma: [0.2, 3]
48 | betag_range: [0.5, 4]
49 | betap_range: [1, 2]
50 |
51 | blur_kernel_size2: 21
52 | kernel_list2: ['iso', 'aniso', 'generalized_iso', 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
53 | kernel_prob2: [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
54 | sinc_prob2: 0.1
55 | blur_sigma2: [0.2, 1.5]
56 | betag_range2: [0.5, 4]
57 | betap_range2: [1, 2]
58 |
59 | final_sinc_prob: 0.8
60 |
61 | gt_size: 256
62 | use_hflip: True
63 | use_rot: False
64 |
65 | # data loader
66 | use_shuffle: true
67 | num_worker_per_gpu: 5
68 | batch_size_per_gpu: 4
69 | dataset_enlarge_ratio: 1
70 | prefetch_mode: ~
71 |
72 | # Uncomment these for validation
73 | # val:
74 | # name: validation
75 | # type: SingleImageDataset
76 | # dataroot_lq: datasets/RealSRSet+5images
77 | # io_backend:
78 | # type: disk
79 |
80 | # network structures
81 | network_g:
82 | type: HAT
83 | upscale: 4
84 | in_chans: 3
85 | img_size: 64
86 | window_size: 16
87 | compress_ratio: 3
88 | squeeze_factor: 30
89 | conv_scale: 0.01
90 | overlap_ratio: 0.5
91 | img_range: 1.
92 | depths: [6, 6, 6, 6, 6, 6]
93 | embed_dim: 180
94 | num_heads: [6, 6, 6, 6, 6, 6]
95 | mlp_ratio: 2
96 | upsampler: 'pixelshuffle'
97 | resi_connection: '1conv'
98 |
99 | # path
100 | path:
101 | pretrain_network_g: ~
102 | param_key_g: params_ema
103 | strict_load_g: true
104 | resume_state: ~
105 |
106 | # training settings
107 | train:
108 | ema_decay: 0.999
109 | optim_g:
110 | type: Adam
111 | lr: !!float 1e-4
112 | weight_decay: 0
113 | betas: [0.9, 0.99]
114 | optim_d:
115 | type: Adam
116 | lr: !!float 1e-4
117 | weight_decay: 0
118 | betas: [0.9, 0.99]
119 |
120 | scheduler:
121 | type: MultiStepLR
122 | milestones: [1000000]
123 | gamma: 0.5
124 |
125 | total_iter: 1000000
126 | warmup_iter: -1 # no warm up
127 |
128 | # losses
129 | pixel_opt:
130 | type: L1Loss
131 | loss_weight: 1.0
132 | reduction: mean
133 |
134 | # Uncomment these for validation
135 | # validation settings
136 | # val:
137 | # val_freq: !!float 1e4
138 | # save_img: True
139 |
140 | # metrics:
141 | # psnr: # metric name
142 | # type: calculate_psnr
143 | # crop_border: 4
144 | # test_y_channel: false
145 |
146 | # logging settings
147 | logger:
148 | print_freq: 200
149 | save_checkpoint_freq: !!float 1e4
150 | use_tb_logger: true
151 | wandb:
152 | project: ~
153 | resume_id: ~
154 |
155 | # dist training settings
156 | dist_params:
157 | backend: nccl
158 | port: 29500
159 |
--------------------------------------------------------------------------------
/predict.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import tempfile
3 | import shutil
4 | import os
5 | from PIL import Image
6 | import subprocess
7 | from cog import BasePredictor, Input, Path
8 |
9 |
10 | class Predictor(BasePredictor):
11 | def predict(
12 | self,
13 | image: Path = Input(
14 | description="Input Image.",
15 | ),
16 | ) -> Path:
17 | input_dir = "input_dir"
18 | output_path = Path(tempfile.mkdtemp()) / "output.png"
19 |
20 | try:
21 | for d in [input_dir, "results"]:
22 | if os.path.exists(input_dir):
23 | shutil.rmtree(input_dir)
24 | os.makedirs(input_dir, exist_ok=False)
25 |
26 | input_path = os.path.join(input_dir, os.path.basename(image))
27 | shutil.copy(str(image), input_path)
28 | subprocess.call(
29 | [
30 | "python",
31 | "hat/test.py",
32 | "-opt",
33 | "options/test/HAT_SRx4_ImageNet-LR.yml",
34 | ]
35 | )
36 | res_dir = os.path.join(
37 | "results", "HAT_SRx4_ImageNet-LR", "visualization", "custom"
38 | )
39 | assert (
40 | len(os.listdir(res_dir)) == 1
41 | ), "Should contain only one result for Single prediction."
42 | res = Image.open(os.path.join(res_dir, os.listdir(res_dir)[0]))
43 | res.save(str(output_path))
44 |
45 | finally:
46 | pass
47 | shutil.rmtree(input_dir)
48 | shutil.rmtree("results")
49 |
50 | return output_path
51 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | einops
2 | torch>=1.7
3 | basicsr==1.3.4.9
4 |
--------------------------------------------------------------------------------
/results/README.md:
--------------------------------------------------------------------------------
1 | The testing results will be saved in this folder.
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [flake8]
2 | ignore =
3 | # line break before binary operator (W503)
4 | W503,
5 | # line break after binary operator (W504)
6 | W504,
7 | max-line-length=120
8 |
9 | [yapf]
10 | based_on_style = pep8
11 | column_limit = 120
12 | blank_line_before_nested_class_or_def = true
13 | split_before_expression_after_opening_paren = true
14 |
15 | [isort]
16 | line_length = 120
17 | multi_line_output = 0
18 | known_standard_library = pkg_resources,setuptools
19 | known_first_party = basicsr
20 | known_third_party = cv2,requests,torch,torchvision
21 | no_lines_before = STDLIB,LOCALFOLDER
22 | default_section = THIRDPARTY
23 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | from setuptools import find_packages, setup
4 |
5 | import os
6 | import subprocess
7 | import time
8 |
9 | version_file = 'hat/version.py'
10 |
11 |
12 | def readme():
13 | with open('README.md', encoding='utf-8') as f:
14 | content = f.read()
15 | return content
16 |
17 |
18 | def get_git_hash():
19 |
20 | def _minimal_ext_cmd(cmd):
21 | # construct minimal environment
22 | env = {}
23 | for k in ['SYSTEMROOT', 'PATH', 'HOME']:
24 | v = os.environ.get(k)
25 | if v is not None:
26 | env[k] = v
27 | # LANGUAGE is used on win32
28 | env['LANGUAGE'] = 'C'
29 | env['LANG'] = 'C'
30 | env['LC_ALL'] = 'C'
31 | out = subprocess.Popen(cmd, stdout=subprocess.PIPE, env=env).communicate()[0]
32 | return out
33 |
34 | try:
35 | out = _minimal_ext_cmd(['git', 'rev-parse', 'HEAD'])
36 | sha = out.strip().decode('ascii')
37 | except OSError:
38 | sha = 'unknown'
39 |
40 | return sha
41 |
42 |
43 | def get_hash():
44 | if os.path.exists('.git'):
45 | sha = get_git_hash()[:7]
46 | else:
47 | sha = 'unknown'
48 |
49 | return sha
50 |
51 |
52 | def write_version_py():
53 | content = """# GENERATED VERSION FILE
54 | # TIME: {}
55 | __version__ = '{}'
56 | __gitsha__ = '{}'
57 | version_info = ({})
58 | """
59 | sha = get_hash()
60 | with open('VERSION', 'r') as f:
61 | SHORT_VERSION = f.read().strip()
62 | VERSION_INFO = ', '.join([x if x.isdigit() else f'"{x}"' for x in SHORT_VERSION.split('.')])
63 |
64 | version_file_str = content.format(time.asctime(), SHORT_VERSION, sha, VERSION_INFO)
65 | with open(version_file, 'w') as f:
66 | f.write(version_file_str)
67 |
68 |
69 | def get_version():
70 | with open(version_file, 'r') as f:
71 | exec(compile(f.read(), version_file, 'exec'))
72 | return locals()['__version__']
73 |
74 |
75 | def get_requirements(filename='requirements.txt'):
76 | here = os.path.dirname(os.path.realpath(__file__))
77 | with open(os.path.join(here, filename), 'r') as f:
78 | requires = [line.replace('\n', '') for line in f.readlines()]
79 | return requires
80 |
81 |
82 | if __name__ == '__main__':
83 | write_version_py()
84 | setup(
85 | name='hat',
86 | version=get_version(),
87 | description='HAT',
88 | long_description=readme(),
89 | long_description_content_type='text/markdown',
90 | author='Xiangyu Chen',
91 | author_email='chxy95@gmail.com',
92 | keywords='computer vision, pytorch, basicsr, image restoration, super-resolution',
93 | url='https://github.com/chxy95/HAT',
94 | include_package_data=True,
95 | packages=find_packages(exclude=('options', 'datasets', 'experiments', 'results', 'tb_logger', 'wandb')),
96 | classifiers=[
97 | 'Development Status :: 4 - Beta',
98 | 'License :: OSI Approved :: Apache Software License',
99 | 'Operating System :: OS Independent',
100 | 'Programming Language :: Python :: 3',
101 | 'Programming Language :: Python :: 3.7',
102 | 'Programming Language :: Python :: 3.8',
103 | ],
104 | license='MIT License',
105 | setup_requires=['cython', 'numpy'],
106 | install_requires=get_requirements(),
107 | zip_safe=False)
108 |
--------------------------------------------------------------------------------