
105 |
3 | 一般Java在内存分配时会涉及到以下区域:
4 |5 |
6 |7 | 寄存器(Registers):速度最快的存储场所,因为寄存器位于处理器内部,我们在程序中无法控制
8 |9 | 栈(Stack):存放基本类型的数据和对象的引用,但对象本身不存放在栈中,而是存放在堆中
10 |11 | 堆(Heap):堆内存用来存放由new创建的对象和数组。在堆中分配的内存,由Java虚拟机的自动垃圾回收器(GC)来管理。
12 |13 | 静态域(static field): 静态存储区域就是指在固定的位置存放应用程序运行时一直存在的数据,Java在内存中专门划分了一个静态存储区域来管理一些特殊的数据变量如静态的数据变量
14 |15 | 常量池(constant pool):虚拟机必须为每个被装载的类型维护一个常量池。常量池就是该类型所用到常量的一个有序集和,包括直接常量(string,integer和floating point常量)和对其他类型,字段和方法的符号引用。
16 |17 | 非RAM存储:硬盘等永久存储空间
18 |19 |
20 |
堆栈特点对比:
22 |由于篇幅原因,下面只简单的介绍一下堆栈的一些特性。
23 |
栈:当定义一个变量时,Java就在栈中为这个变量分配内存空间,当该变量退出该作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
25 |
堆:当堆中的new产生数组和对象超出其作用域后,它们不会被释放,只有在没有引用变量指向它们的时候才变成垃圾,不能再被使用。即使这样,所占内存也不会立即释放,而是等待被垃圾回收器收走。这也是Java比较占内存的原因。
27 |
28 |
栈:存取速度比堆要快,仅次于寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。
30 |堆:堆是一个运行时数据区,可以动态地分配内存大小,因此存取速度较慢。也正因为这个特点,堆的生存期不必事先告诉编译器,而且Java的垃圾收集器会自动收走这些不再使用的数据。
31 |
32 |
栈:栈中的数据可以共享, 它是由编译器完成的,有利于节省空间。
34 |例如:需要定义两个变量int a = 3;int 35 | b = 3;
36 |编译器先处理int 37 | a = 3;首先它会在栈中创建一个变量为a的引用,然后查找栈中是否有3这个值,如果没找到,就将3存放进来,然后将a指向3。接着处理int b = 3;在创建完b的引用变量后,因为在栈中已经有3这个值,便将b直接指向3。这样,就出现了a与b同时均指向3的情况。这时,如果再让a=4;那么编译器会重新搜索栈中是否有4值,如果没有,则将4存放进来,并让a指向4;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
38 |堆:例如上面栈中a的修改并不会影响到b, 而在堆中一个对象引用变量修改了这个对象的内部状态,会影响到另一个对象引用变量。
39 |
40 |
内存耗用名词解析:
42 |VSS - Virtual Set Size 虚拟耗用内存(包含共享库占用的内存)
43 |RSS - Resident Set Size 实际使用物理内存(包含共享库占用的内存)
44 |PSS - Proportional Set Size 实际使用的物理内存(比例分配共享库占用的内存)
45 |USS - Unique Set Size 进程独自占用的物理内存(不包含共享库占用的内存)
46 |一般来说内存占用大小有如下规律:VSS >= RSS >= PSS >= USS
47 |
49 |
51 |
OOM:
52 |
53 |
内存泄露可以引发很多的问题:
55 |1.程序卡顿,响应速度慢(内存占用高时JVM虚拟机会频繁触发GC)
56 |2.莫名消失(当你的程序所占内存越大,它在后台的时候就越可能被干掉。反之内存占用越小,在后台存在的时间就越长)
57 |3.直接崩溃(OutOfMemoryError)
58 |
59 |
60 |
ANDROID内存面临的问题:
62 | 63 |1.有限的堆内存,原始只有16M
64 |2.内存大小消耗等根据设备,操作系统等级,屏幕尺寸的不同而不同
65 |3.程序不能直接控制
66 |4.支持后台多任务处理(multitasking)
67 |5.运行在虚拟机之上
68 | 69 |
70 |
72 |
5R:
73 |本文主要通过如下的5R方法来对ANDROID内存进行优化:
74 |1.Reckon(计算)
75 |首先需要知道你的app所消耗内存的情况,知己知彼才能百战不殆
76 |2.Reduce(减少)
77 |消耗更少的资源
78 |79 |
3.Reuse(重用)
80 |当第一次使用完以后,尽量给其他的使用
81 | 82 |5.Recycle(回收)
83 |返回资源
84 |4.Review(检查)
85 |
回顾检查你的程序,看看设计或代码有什么不合理的地方。
87 |88 |
89 |
Reckon (计算):
91 |了解自己应用的内存使用情况是很有必要的。如果当内存使用过高的话就需要对其进行优化,因为更少的使用内存可以减少ANDROID系统终止我们的进程的几率,也可以提高多任务执行效率和体验效果。
92 |下面从系统内存(system ram)和堆内存(heap)两个方面介绍一些查看和计算内存使用情况的方法:
93 |
94 |
System Ram(系统内存):
96 |
观察和计算系统内存使用情况,可以使用Android提供给我们的两个工具procstats,meminfo。他们一个侧重于后台的内存使用,另一个是运行时的内存使用。
98 | 99 |
118 |
Heap(堆内存):
120 |在程序中可以使用如下的方法去查询内存使用情况
121 |
122 |
ActivityManager#getMemoryClass()
124 |查询可用堆内存的限制
125 |3.0(HoneyComb)以上的版本可以通过largeHeap=“true”来申请更多的堆内存(不过这算作“作弊”)
126 |
127 |
android.os.Debug#getMemoryInfo(Debug.MemoryInfo memoryInfo)
138 |得到的MemoryInfo中可以查看如下Field的属性:
139 | 140 |166 |
android.os.Debug#getNativeHeapSize()
183 |返回的是当前进程navtive堆本身总的内存大小
184 |android.os.Debug#getNativeHeapAllocatedSize()
185 |返回的是当前进程navtive堆中已使用的内存大小
186 |android.os.Debug#getNativeHeapFreeSize()
187 |
返回的是当前进程navtive堆中已经剩余的内存大小
189 |
190 |
Memory Analysis Tool(MAT):
193 |通常内存泄露分析被认为是一件很有难度的工作,一般由团队中的资深人士进行。不过,今天我们要介绍的 MAT(Eclipse Memory Analyzer)被认为是一个“傻瓜式“的堆转储文件分析工具,你只需要轻轻点击一下鼠标就可以生成一个专业的分析报告。
194 |如下图:
195 |
197 |
关于详细的MAT使用我推荐下面这篇文章:使用 Eclipse Memory Analyzer 进行堆转储文件分析
199 |
200 |
202 |
写在最后:
204 |我准备将文章分为上、中、下三部分。现在已经全部完成:
205 |内存简介,Recoken(计算)请看:ANDROID内存优化(大汇总——上)
206 |Reduce(减少),Reuse(重用) 请看:ANDROID内存优化(大汇总——中)
207 |Recycle(回收), Review(检查) 请看:ANDROID内存优化(大汇总——全)
208 |
209 |
写这篇文章的目的就是想弄一个大汇总,将零散的内存知识点总结一下,如果有错误、不足或建议都希望告诉我。
211 |
213 |
参考文章:
215 |AnDevCon开发者大会演讲PPT:Putting Your App on a Memory Diet
216 |深入Java核心 Java内存分配原理精讲(http://developer.51cto.com/art/201009/225071.htm)
217 | 218 |Android内存性能优化(内部资料总结)(http://www.2cto.com/kf/201405/303276.html)
221 |
222 |
作为一名程序员,如果说沉迷一门编程语言算作一种乐趣的话,那么与此同时反过来去黑一门编程语言就是这种乐趣的升华。今天我们就来黑一把C语言,好好展示一下这门经典语言令人抓狂的一面。
2 |我们知道,全局变量是C语言语法和语义中一个很重要的知识点,首先它的存在意义需要从三个不同角度去理解:对于程序员来说,它是一个记录内容的变量(variable);对于编译/链接器来说,它是一个需要解析的符号(symbol);对于计算机来说,它可能是具有地址的一块内存(memory)。其次是语法/语义:从作用域上看,带static关键字的全局变量范围只能限定在文件里,否则会外联到整个模块和项目中;从生存期来看,它是静态的,贯穿整个程序或模块运行期间(注意,正是跨单元访问和持续生存周期这两个特点使得全局变量往往成为一段受攻击代码的突破口,了解这一点十分重要);从空间分配上看,定义且初始化的全局变量在编译时在数据段(.data)分配空间,定义但未初始化的全局变量暂存(tentative definition)在.bss段,编译时自动清零,而仅仅是声明的全局变量只能算个符号,寄存在编译器的符号表内,不会分配空间,直到链接或者运行时再重定向到相应的地址上。
3 |我们将向您展现一下,非static限定全局变量在编译/链接以及程序运行时会发生哪些有趣的事情,顺便可以对C编译器/链接器的解析原理管中窥豹。以下示例对ANSI C和GNU C标准都有效,笔者的编译环境是Ubuntu下的GCC-4.4.3。
4 |5 |
/* t.h */
7 | #ifndef _H_
8 | #define _H_
9 | int a;
10 | #endif
11 |
12 | /* foo.c */
13 | #include <stdio.h>
14 | #include "t.h"
15 |
16 | struct {
17 | char a;
18 | int b;
19 | } b = { 2, 4 };
20 |
21 | int main();
22 |
23 | void foo()
24 | {
25 | printf("foo:\t(&a)=0x%08x\n\t(&b)=0x%08x\n
26 | \tsizeof(b)=%d\n\tb.a=%d\n\tb.b=%d\n\tmain:0x%08x\n",
27 | &a, &b, sizeof b, b.a, b.b, main);
28 | }
29 |
30 | /* main.c */
31 | #include <stdio.h>
32 | #include "t.h"
33 |
34 | int b;
35 | int c;
36 |
37 | int main()
38 | {
39 | foo();
40 | printf("main:\t(&a)=0x%08x\n\t(&b)=0x%08x\n
41 | \t(&c)=0x%08x\n\tsize(b)=%d\n\tb=%d\n\tc=%d\n",
42 | &a, &b, &c, sizeof b, b, c);
43 | return 0;
44 | }
45 |
46 | Makefile如下:
47 |48 | test: main.o foo.o 49 | gcc -o test main.o foo.o 50 | 51 | main.o: main.c 52 | foo.o: foo.c 53 | 54 | clean: 55 | rm *.o test 56 |57 |
运行情况:
58 |59 | foo: (&a)=0x0804a024 60 | (&b)=0x0804a014 61 | sizeof(b)=8 62 | b.a=2 63 | b.b=4 64 | main:0x080483e4 65 | main: (&a)=0x0804a024 66 | (&b)=0x0804a014 67 | (&c)=0x0804a028 68 | size(b)=4 69 | b=2 70 | c=0 71 |72 |
这个项目里我们定义了四个全局变量,t.h头文件定义了一个整型a,main.c里定义了两个整型b和c并且未初始化,foo.c里定义了一个初始化了的结构体,还定义了一个main的函数指针变量。由于C语言每个源文件单独编译,所以t.h分别包含了两次,所以int a就被定义了两次。两个源文件里变量b和函数指针变量main被重复定义了,实际上可以看做代码段的地址。但编译器并未报错,只给出一条警告:
73 |/usr/bin/ld: Warning: size of symbol 'b' changed from 4 in main.o to 8 in foo.o74 |
运行程序发现,main.c打印中b大小是4个字节,而foo.c是8个字节,因为sizeof关键字是编译时决议,而源文件中对b类型定义不一样。但令人惊奇的是无论是在main.c还是foo.c中,a和b都是相同的地址,也就是说,a和b被定义了两次,b还是不同类型,但内存映像中只有一份拷贝。我们还看到,main.c中b的值居然就是foo.c中结构体第一个成员变量b.a的值,这证实了前面的推断——即便存在多次定义,内存中只有一份初始化的拷贝。另外在这里c是置身事外的一个独立变量。
75 |为何会这样呢?这涉及到C编译器对多重定义的全局符号的解析和链接。在编译阶段,编译器将全局符号信息隐含地编码在可重定位目标文件的符号表里。这里有个“强符号(strong)”和“弱符号(weak)”的概念——前者指的是定义并且初始化了的变量,比如foo.c里的结构体b,后者指的是未定义或者定义但未初始化的变量,比如main.c里的整型b和c,还有两个源文件都包含头文件里的a。当符号被多重定义时,GNU链接器(ld)使用以下规则决议:
76 |像上面这个例子中,全局变量a和b存在重复定义。如果我们将main.c中的b初始化赋值,那么就存在两个强符号而违反了规则一,编译器报错。如果满足规则二,则仅仅提出警告,实际运行时决议的是foo.c中的强符号。而变量a都是弱符号,所以只选择一个(按照目标文件链接时的顺序)。
86 |事实上,这种规则是C语言里的一个大坑,编译器对这种全局变量多重定义的“纵容”很可能会无端修改某个变量,导致程序不确定行为。如果你还没有意识到事态严重性,我再举个例子。
87 |/* foo.c */
89 | #include <stdio.h>;
90 |
91 | struct {
92 | int a;
93 | int b;
94 | } b = { 2, 4 };
95 |
96 | int main();
97 |
98 | void foo()
99 | {
100 | printf("foo:\t(&b)=0x%08x\n\tsizeof(b)=%d\n
101 | \tb.a=%d\n\tb.b=%d\n\tmain:0x%08x\n",
102 | &b, sizeof b, b.a, b.b, main);
103 | }
104 |
105 | /* main.c */
106 | #include <stdio.h>
107 |
108 | int b;
109 | int c;
110 |
111 | int main()
112 | {
113 | if (0 == fork()) {
114 | sleep(1);
115 | b = 1;
116 | printf("child:\tsleep(1)\n\t(&b):0x%08x\n
117 | \t(&c)=0x%08x\n\tsizeof(b)=%d\n\tset b=%d\n\tc=%d\n",
118 | &b, &c, sizeof b, b, c);
119 | foo();
120 | } else {
121 | foo();
122 | printf("parent:\t(&b)=0x%08x\n\t(&c)=0x%08x\n
123 | \tsizeof(b)=%d\n\tb=%d\n\tc=%d\n\twait child...\n",
124 | &b, &c, sizeof b, b, c);
125 | wait(-1);
126 | printf("parent:\tchild over\n\t(&b)=0x%08x\n
127 | \t(&c)=0x%08x\n\tsizeof(b)=%d\n\tb=%d\n\tc=%d\n",
128 | &b, &c, sizeof b, b, c);
129 | }
130 | return 0;
131 | }
132 | 运行情况如下:
133 |134 | foo: (&b)=0x0804a020 135 | sizeof(b)=8 136 | b.a=2 137 | b.b=4 138 | main:0x080484c8 139 | parent: (&b)=0x0804a020 140 | (&c)=0x0804a034 141 | sizeof(b)=4 142 | b=2 143 | c=0 144 | wait child... 145 | child: sleep(1) 146 | (&b):0x0804a020 147 | (&c)=0x0804a034 148 | sizeof(b)=4 149 | set b=1 150 | c=0 151 | foo: (&b)=0x0804a020 152 | sizeof(b)=8 153 | b.a=1 154 | b.b=4 155 | main:0x080484c8 156 | parent: child over 157 | (&b)=0x0804a020 158 | (&c)=0x0804a034 159 | sizeof(b)=4 160 | b=2 161 | c=0 162 |163 |
(说明一点,运行情况是直接输出到stdout的打印,笔者曾经将./test输出重定向到log中,结果发现打印的执行序列不一致,所以采用默认输出。)
164 |这是一个多进程环境,首先我们看到无论父进程还是子进程,main.c还是foo.c,全局变量b和c的地址仍然是一致的(当然只是个逻辑地址),而且对b的大小不同模块仍然有不同的决议。这里值得注意的是,我们在子进程中对变量b进行赋值动作,从此子进程本身包括foo()调用中,整型b以及结构体成员b.a的值都是1,而父进程中整型b和结构体成员b.a的值仍是2,但它们显示的逻辑地址仍是一致的。
165 |个人认为可以这样解释,fork创建新进程时,子进程获得了父进程上下文“镜像”(自然包括全局变量),虚拟地址相同但属于不同的进程空间,而且此时真正映射的物理地址中只有一份拷贝,所以b的值是相同的(都是2)。随后子进程对b改写,触发了操作系统的写时拷贝(copy on write)机制,这时物理内存中才产生真正的两份拷贝,分别映射到不同进程空间的虚拟地址上,但虚拟地址的值本身仍然不变,这对于应用程序来说是透明的,具有隐瞒性。
166 |还有一点值得注意,这个示例编译时没有出现第一个示例的警告,即对变量b的sizeof决议,笔者也不知道为什么,或许是GCC的一个bug?
167 |这个例子代码同上一个一致,只不过我们将foo.c做成一个静态链接库libfoo.a进行链接,这里只给出Makefile的改动。
169 |170 | test: main.o foo.o 171 | ar rcs libfoo.a foo.o 172 | gcc -static -o test main.o libfoo.a 173 | 174 | main.o: main.c 175 | foo.o: foo.c 176 | 177 | clean: 178 | rm -f *.o test 179 |180 |
运行情况如下:
181 |182 | foo: (&b)=0x080ca008 183 | sizeof(b)=8 184 | b.a=2 185 | b.b=4 186 | main:0x08048250 187 | parent: (&b)=0x080ca008 188 | (&c)=0x080cc084 189 | sizeof(b)=4 190 | b=2 191 | c=0 192 | wait child... 193 | child: sleep(1) 194 | (&b):0x080ca008 195 | (&c)=0x080cc084 196 | sizeof(b)=4 197 | set b=1 198 | c=0 199 | foo: (&b)=0x080ca008 200 | sizeof(b)=8 201 | b.a=1 202 | b.b=4 203 | main:0x08048250 204 | parent: child over 205 | (&b)=0x080ca008 206 | (&c)=0x080cc084 207 | sizeof(b)=4 208 | b=2 209 | c=0 210 |211 |
从这个例子看不出有啥差别,只不过使用静态链接后,全局变量加载的地址有所改变,b和c的地址之间似乎相隔更远了些。不过这次编译器倒是给出了变量b的sizeof决议警告。
212 |到此为止,有些人可能会对上面的例子嗤之以鼻,觉得这不过是列举了C语言的某些特性而已,算不上黑。有些人认为既然如此,对于一切全局变量要么用static限死,要么定义同时初始化,杜绝弱符号,以便在编译时报错检测出来。只要小心地使用,C语言还是很完美的嘛~对于抱这样想法的人,我只想说,请你在夜深人静的时候竖起耳朵仔细聆听,你很可能听到Dennis Richie在九泉之下邪恶的笑声——不,与其说是嘲笑,不如说是诅咒……
213 |/* foo.c */
215 | #include <stdio.h>
216 |
217 | const struct {
218 | int a;
219 | int b;
220 | } b = { 3, 3 };
221 |
222 | int main();
223 |
224 | void foo()
225 | {
226 | b.a = 4;
227 | b.b = 4;
228 | printf("foo:\t(&b)=0x%08x\n\tsizeof(b)=%d\n
229 | \tb.a=%d\n\tb.b=%d\n\tmain:0x%08x\n",
230 | &b, sizeof b, b.a, b.b, main);
231 | }
232 |
233 | /* t1.c */
234 | #include <stdio.h>
235 |
236 | int b = 1;
237 | int c = 1;
238 |
239 | int main()
240 | {
241 | int count = 5;
242 | while (count-- > 0) {
243 | t2();
244 | foo();
245 | printf("t1:\t(&b)=0x%08x\n\t(&c)=0x%08x\n
246 | \tsizeof(b)=%d\n\tb=%d\n\tc=%d\n",
247 | &b, &c, sizeof b, b, c);
248 | sleep(1);
249 | }
250 | return 0;
251 | }
252 |
253 | /* t2.c */
254 | #include <stdio.h>
255 |
256 | int b;
257 | int c;
258 |
259 | int t2()
260 | {
261 | printf("t2:\t(&b)=0x%08x\n\t(&c)=0x%08x\n
262 | \tsizeof(b)=%d\n\tb=%d\n\tc=%d\n",
263 | &b, &c, sizeof b, b, c);
264 | return 0;
265 | }
266 | Makefile脚本:
267 |export LD_LIBRARY_PATH:=. 268 | 269 | all: test 270 | ./test 271 | 272 | test: t1.o t2.o 273 | gcc -shared -fPIC -o libfoo.so foo.c 274 | gcc -o test t1.o t2.o -L. -lfoo 275 | 276 | t1.o: t1.c 277 | t2.o: t2.c 278 | 279 | .PHONY:clean 280 | clean: 281 | rm -f *.o *.so test* 282 |283 |
执行结果:
284 |285 | ./test 286 | t2: (&b)=0x0804a01c 287 | (&c)=0x0804a020 288 | sizeof(b)=4 289 | b=1 290 | c=1 291 | foo: (&b)=0x0804a01c 292 | sizeof(b)=8 293 | b.a=4 294 | b.b=4 295 | main:0x08048564 296 | t1: (&b)=0x0804a01c 297 | (&c)=0x0804a020 298 | sizeof(b)=4 299 | b=4 300 | c=4 301 | t2: (&b)=0x0804a01c 302 | (&c)=0x0804a020 303 | sizeof(b)=4 304 | b=4 305 | c=4 306 | foo: (&b)=0x0804a01c 307 | sizeof(b)=8 308 | b.a=4 309 | b.b=4 310 | main:0x08048564 311 | t1: (&b)=0x0804a01c 312 | (&c)=0x0804a020 313 | sizeof(b)=4 314 | b=4 315 | c=4 316 | ...317 |
其实前面几个例子只是开胃小菜而已,真正的大坑终于出现了!而且这次编译器既没报错也没警告,但我们确实眼睁睁地看到作为main()中强符号的b被改写了,而且一旁的c也“躺枪”了。眼尖的读者发现,这次foo.c是作为动态链接库运行时加载的,当t1第一次调用t2时,libfoo.so还未加载,一旦调用了foo函数,b立马中弹,而且c的地址居然还相邻着b,这使得c一同中弹了。不过笔者有些无法解释这种行为的原因,有种说法是强符号的全局变量在数据段中是连续分布的(相应地弱符号暂存在.bss段或者符号表里),或许可以上报GNU的编译器开发小组。
318 |另外笔者尝试过将t1.c中的b和c定义前面加上const限定词,编译器仍然默认通过,但程序在main()中第一次调用foo()时触发了Segment fault异常导致奔溃,在foo.c里使用指针改写它也一样。推断这是GCC对const常量所在地址启用了类似操作系统写保护机制,但我无法确定早期版本的GCC是否会让这个const常量被改写而程序不会奔溃。
319 |至于volatile关键词之于全局变量,自测似乎没有影响。
320 |怎么样?看了最后一个例子是否有点“不明觉厉”呢?C语言在你心目中是否还是当初那个“纯洁”、“干净”、“行为一致”的姑娘呢?也许趁着你不注意的时候她会偷偷给你戴顶绿帽,这一切都是通过全局变量,特别在动态链接的环境下,就算全部定义成强符号仍然无法为编译器所察觉。而一些IT界“恐怖分子”也经常将恶意代码包装成全局变量注入到root权限下存在漏洞的操作序列中,就像著名的栈溢出攻击那样。某一天当你傻傻地看着一个程序出现未定义的行为却无法定位原因的时候,请不要忘记Richie大爷那来自九泉之下最深沉的“问候”~
321 |或许有些人会偷换概念,把这一切归咎于编译器和链接器身上,认为这同语言无关,但我要提醒你,正是编译/链接器的行为支撑了整个语言的语法和语义。你可以反过来思考一下为何C的胞弟C++推出“命名空间(namespace)”的概念,或者你可以使用其它高级语言,对于重定义的全局变量是否能通过编译这一关。
322 |所以请时刻谨记,C是一门很恐怖的语言!
323 |P.S.题外话写在最后。我无意挑起语言之争,只是就事论事地去“黑(hack)”一门语言而已,而且要黑就要黑得有理有力有层次,还要带点娱乐精神。其实黑一门语言并非什么尖端复杂的技术,个人觉得起码要做到两点:
324 |(全文完) -------------------------------------------------------------------------------- /src/c1.md: -------------------------------------------------------------------------------- 1 | # C进阶指南(1) # 2 |
C语言可用于系统编程、嵌入式系统中,同时也是其他应用程序可能的实现工具之一。 当你对计算机编程怀有强烈兴趣的时候,却对C语言不感冒,这种可能性不大。想全方位地理解C语言是一件极具挑战性的事。
3 |Peter Fačka 在2014年1月份写下了这篇长文,内容包括:类型提升、内存分配,数组转指针、显式内联、打桩(interpositioning)和矢量变换。原文挺长,伯乐在线分三篇发出,这是第一篇。
4 |5 |
多数C程序员以为,整型间的基本操作都是安全的。事实上,整型间基本操作也容易出现问题,例如下面的代码:
7 |int main(int argc, char** argv) {
8 | long i = -1;
9 |
10 | if (i < sizeof(i)) {
11 | printf("OK\n");
12 | }
13 | else {
14 | printf("error\n");
15 | }
16 |
17 | return 0;
18 | }
19 | 上述代码中,变量 i 被转换为无符号整型。这样一来,它的值不再是-1,而是 size_t 的最大值。变量i的类型之所以被转换,是因为 sizeof 操作符的返回类型是无符号的。具体参见C99/C11标准之常用算术转换一章:
20 |“If the operand that has unsigned integer type has rank greater or equal to the rank of the type of the other operand, then the operand with signed integer type is converted to the type of the operand with unsigned integer type.”
21 |若无符号整型类型的操作数的转换优先级不低于另一操作数,则有符号数转为无符号数的类型。
22 |C标准中,size_t 被定义为不低于16位的无符号整型。通常 size_t 完全对应于 long。这样一来,int 和 size_t 的大小至少相等,可基于上述准则,强转为无符号整型。
23 |(译者注:本人印象深刻的相关问题是“if(-1U > 0L)”在32、64位机器上的判断结果分别是什么,为什么;除long long外,long 类型在涉及兼容性的产品代码中应被禁用)
24 |这个故事给了我们一个关于整型大小可移植性的观念。C标准并未定义short、int、long、long long 的确切大小及其无符号形式。标准仅限定了它们的最小长度。以x86_64架构为例,long 在Linux环境中是64比特,但在64位Windows系统中是32比特。为了使代码更具移植性,常见的方法是使用C99的 stdint.h 文件中定义的、指定长度的特殊类型,包括 uint16_t、int32_t 等。此文件定义了三种整型类型:
25 |但不幸的是,仅依靠 stdint.h 并不能根除类型转换的困扰。C标准中“整型提升规则”中写道:
31 |若int的表达范围足以覆盖所有的基础类型,此值将被转换为int;否则将转为unsigned int。这就叫做整型提升。整型提升过程中,所有其他的类型保持不变。
32 |下述代码在32位平台中将返回65536,在16位平台上返回0:
33 |uint32_t sum()
34 | {
35 | uint16_t a = 65535;
36 | uint16_t b = 1;
37 | return a+b;
38 | }
39 | 无论C语言实现中,是否把未修饰的char看做有符号的,整型提升都连同符号一起把值保留下来。
40 |如何实现char类型通常取决于硬件体系或操作系统,常由其平台的ABI(应用程序二进制接口)指定。如果你愿意自己尝试的话,char会被转为signed char,下述代码将打印出-128和-127,而不是128和129。x86架构中可用GCC的-funsigned-char参数切换到强制无符号提升。
41 |char c = 128;
42 | char d = 129;
43 | printf("%d,%d\n",c,d);
44 | 使用malloc分配指定字节大小的、未初始化的内存对象。若入参值为0,其行为取决于操作系统实现,或者说,这是C和POSIX标准均未定义的行为。
47 |若请求的空间大小为0,则结果视具体实现而定:返回值可以是空指针或特殊指针。
48 |malloc(0) 通常返回有效的特殊指针。或者返回的值可成为 free 函数的参数,且函数不会错误退出。例如 free 函数对NULL指针不做任何操作。
49 |因此,若空间大小参数是某个表达式的结果的话,要确保测试过整型溢出的情况。
50 |size_t computed_size;
51 |
52 | if (elem_size && num > SIZE_MAX / elem_size) {
53 | errno = ENOMEM;
54 | err(1, "overflow");
55 | }
56 |
57 | computed_size = elem_size*num;
58 | 一般说来,要分配一个元素大小相同的序列,可考虑使用 calloc 而非用表达式计算大小。同时 calloc 将把分配的内存初始化为0。像往常一样使用 free 释放分配的内存。
59 |realloc 将改变已分配内存对象的大小。此函数返回一个指针,指针可能指向新的内存起始位置,内存大小取决于入参中请求的空间大小,内容不变。若新的空间更大,额外的空间未被初始化。若 realloc 入参中,指向旧对象的指针为NULL,并且大小非0,此行为等价于 malloc。若新的大小为0,且提供的指针非空,此时 realloc 的行为依赖于操作系统。
60 |多数实现将尝试释放对象内存,返回NULL或与malloc(0)相同的返回值。例如在Windows中,此操作会释放内存并返回NULL。OpenBSD也会释放内存,但返回的指针指向的空间大小为0。
61 |realloc 失败时会返回NULL,也因此断开与旧的内存对象的关联。所以不但要检查空间大小参数是否存在整型溢出,还要正确处理 realloc 失败时的对象大小。
62 |#include <stdio.h>
63 | #include <stdint.h>
64 | #include <malloc.h>
65 | #include <errno.h>
66 |
67 | #define VECTOR_OK 0
68 | #define VECTOR_NULL_ERROR 1
69 | #define VECTOR_SIZE_ERROR 2
70 | #define VECTOR_ALLOC_ERROR 3
71 |
72 | struct vector {
73 | int *data;
74 | size_t size;
75 | };
76 |
77 | int create_vector(struct vector *vc, size_t num) {
78 |
79 | if (vc == NULL) {
80 | return VECTOR_NULL_ERROR;
81 | }
82 |
83 | vc->data = 0;
84 | vc->size = 0;
85 |
86 | /* check for integer and SIZE_MAX overflow */
87 | if (num == 0 || SIZE_MAX / num < sizeof(int)) {
88 | errno = ENOMEM;
89 | return VECTOR_SIZE_ERROR;
90 | }
91 |
92 | vc->data = calloc(num, sizeof(int));
93 |
94 | /* calloc faild */
95 | if (vc->data == NULL) {
96 | return VECTOR_ALLOC_ERROR;
97 | }
98 |
99 | vc->size = num * sizeof(int);
100 | return VECTOR_OK;
101 | }
102 |
103 | int grow_vector(struct vector *vc) {
104 |
105 | void *newptr = 0;
106 | size_t newsize;
107 |
108 | if (vc == NULL) {
109 | return VECTOR_NULL_ERROR;
110 | }
111 |
112 | /* check for integer and SIZE_MAX overflow */
113 | if (vc->size == 0 || SIZE_MAX / 2 < vc->size) {
114 | errno = ENOMEM;
115 | return VECTOR_SIZE_ERROR;
116 | }
117 |
118 | newsize = vc->size * 2;
119 |
120 | newptr = realloc(vc->data, newsize);
121 |
122 | /* realloc faild; vector stays intact size was not changed */
123 | if (newptr == NULL) {
124 | return VECTOR_ALLOC_ERROR;
125 | }
126 |
127 | /* upon success; update new address and size */
128 | vc->data = newptr;
129 | vc->size = newsize;
130 | return VECTOR_OK;
131 | }
132 | 一般避免动态内存分配问题的方法无非是尽可能把代码写得谨慎、有防御性。本文列举了一些常见问题和少量避免这些问题的方法。
134 |调用 free 可能导致此问题,此时入参指针可能为NULL(依照《C++ Primer Plus》,free(0)不会出现问题。译者注)、未使用 malloc 类函数分配的指针,或已经调用过 free / realloc(realloc参数中大小填0,可释放内存。译者注)的指针。考虑下列几点可让代码更健壮:
136 |char *ptr = NULL;
144 |
145 | /* ... */
146 |
147 | void nullfree(void **pptr) {
148 | void *ptr = *pptr;
149 | assert(ptr != NULL)
150 | free(ptr);
151 | *pptr = NULL;
152 | }
153 | 代码中的检查规则应只用于NULL或有效的指针。对于去除指针和分配的动态内存间联系的函数或代码块,可在开头检查空指针。
155 |(孔乙己式译者注:你能说出strcpy / strncpy / strlcpy的区别么,能的话这节就不必看)
157 |访问内存对象边界之外的地方并不一定导致程序崩溃。程序可能使用损坏了的数据继续运行,其行为可能很危险,也可能是故意而为之,利用此越界操作来改变程序的行为,以此获取其他受限的数据,甚至注入可执行代码。 老套地人工检查数组和动态分配内存的边界是避免此类问题的主要方法。内存对象边界的相关信息必须人工跟踪。数组的大小可由sizeof操作符指出,但数组被转换为指针后,函数调用sizeof仅返回指针大小(视机器位数而定,译者注),而非原来的数组大小。
158 |C11标准中边界检查接口Annex K定义了一些新的库函数集合,这些函数可用于替换标准库(如字符串和I/O操作)常见部分,它们更安全、更易于使用。例如[the slibc library][slibc]都是上述函数的开源实现,但接口不被广泛采用。基于BSD(或基于Mac OS X)的系统提供了strlcpy、strlcat 函数来完成更好的字符串操作。其他系统可通过libbsd库调用它们。
159 |许多操作系统提供了通过内存区域间接控制受保护内存的接口,以防止意外读/写操作,入Posxi mprotect。类似的间接访问的保护机制常用于所有的内存页。
160 |内存泄露,常由于程序中未释放不再使用的动态分配的内存导致。因此,真正理解所需要的分配的内存对象的范围大小是很有必要的。更重要的是,要明白何时调用 free。但当程序复杂度增加时,要确定 free 的调用时机将变得更加困难。早期设计决策时,规划内存很重要。
162 |以下是处理内存泄露的技能表:
163 |想让内存管理保持简单,一个方法是在启动时在堆中分配所有所需的内存。程序结束时,释放内存的重任就交给了操作系统。这种方法在许多场景中的效果令人满意,特别是当程序在一个批量操作中完成对输入的处理的情况。
165 |如果你需要有着变长大小的临时存储,并且其生命周期在变量内部时,可考虑VLA(Variable Length Array,变长数组)。但这有个限制:每个函数的空间不能超过数百字节。因为C99指出边长数组能自动存储,它们像其他自动变量一样受限于同一作用域。即便标准未明确规定,VLA的实现都是把内存数据放到栈中。VLA的最大长度为SIZE_MAX字节。考虑到目标平台的栈大小,我们必须更加谨慎小心,以保证程序不会面临栈溢出、下个内存段的数据损坏的尴尬局面。
167 |这个技术的想法是对某个内存对象的每次引用、去引用计数。赋值时,计数器会增加;去引用时,计数器减少。当引用计数变为0时,这意味着此内存对象不再被使用,可以释放。因为C不提供自动析构(事实上,GCC和Clang都支持cleanup语言扩展), 也不是重写赋值运算符,引用计数由调用retain/release的函数手动完成。更好的方式,是把它作为程序的可变部分,能通过这部分获取和释放一个内存对象的拥有权。但是,使用这种方法需要很多(编程)规范来防止忘记调用release(停止内存泄露)或不必要地调用释放函数(这将导致内存释放地过早)。若内存对象的生命期需要外部事件指出,或应用程序的数据结构隐含了某个内存对象的持有权的处理,无论何种情况,都容易导致问题。下述代码块含有简化了的内存管理引用计数。
169 |#include <stdlib.h>
170 | #include <stdint.h>
171 |
172 | #define MAX_REF_OBJ 100
173 | #define RC_ERROR -1
174 |
175 | struct mem_obj_t{
176 | void *ptr;
177 | uint16_t count;
178 | };
179 |
180 | static struct mem_obj_t references[MAX_REF_OBJ];
181 | static uint16_t reference_count = 0;
182 |
183 | /* create memory object and return handle */
184 | uint16_t create(size_t size){
185 |
186 | if (reference_count >= MAX_REF_OBJ)
187 | return RC_ERROR;
188 |
189 | if (size){
190 | void *ptr = calloc(1, size);
191 |
192 | if (ptr != NULL){
193 | references[reference_count].ptr = ptr;
194 | references[reference_count].count = 0;
195 | return reference_count++;
196 | }
197 | }
198 |
199 | return RC_ERROR;
200 | }
201 |
202 | /* get memory object and increment reference counter */
203 | void* retain(uint16_t handle){
204 |
205 | if(handle < reference_count && handle >= 0){
206 | references[handle].count++;
207 | return references[handle].ptr;
208 | } else {
209 | return NULL;
210 | }
211 | }
212 |
213 | /* decrement reference counter */
214 | void release(uint16_t handle){
215 | printf("release\n");
216 |
217 | if(handle < reference_count && handle >= 0){
218 | struct mem_obj_t *object = &references[handle];
219 |
220 | if (object->count <= 1){
221 | printf("released\n");
222 | free(object->ptr);
223 | reference_count--;
224 | } else {
225 | printf("decremented\n");
226 | object->count--;
227 | }
228 | }
229 | }
230 | 如果你关心编译器的兼容性,可用 cleanup 属性在C中模拟自动析构。
231 |void cleanup_release(void** pmem) {
232 | int i;
233 | for(i = 0; i < reference_count; i++) {
234 | if(references[i].ptr == *pmem)
235 | release(i);
236 | }
237 | }
238 |
239 | void usage() {
240 | int16_t ref = create(64);
241 |
242 | void *mem = retain(ref);
243 | __attribute__((cleanup(cleanup_release), mem));
244 |
245 | /* ... */
246 | }
247 | 上述方案的另一缺陷是提供对象地址让 cleanup_release 释放,而非引用计数值。这样一来,cleanup_release 必须在 references 数组中做开销大的查找操作。一种解决办法是,改变填充的接口为返回一个指向 struct mem_obj_t 的指针。另一种办法是使用下面的宏集合,这些宏能够创建保存引用计数值的变量并追加 clean 属性。
248 |/* helper macros */
249 | #define __COMB(X,Y) X##Y
250 | #define COMB(X,Y) __COMB(X,Y)
251 | #define __CLEANUP_RELEASE __attribute__((cleanup(cleanup_release)))
252 |
253 | #define retain_auto(REF) retain(REF); int16_t __CLEANUP_RELEASE COMB(__ref,__LINE__) = REF
254 |
255 | void cleanup_release(int16_t* phd) {
256 | release(*phd);
257 | }
258 |
259 | void usage() {
260 | int16_t ref = create(64);
261 |
262 | void *mem = retain_auto(ref);
263 | /* ... */
264 | }
265 | (译者注:##符号源自C99,用于连接两个变量的名称,一般用在宏里。如int a##b就会定义一个叫做ab的变量;__LINE__指代码行号,类似的还有__FUNCTION__或__func__和__FILE__,可用于打印调试信息;__attribute__符号来自gcc,主要用于指导编译器优化,也提供了一些如构造、析构、字节对齐等功能)
266 |若一个程序经过数阶段才能彻底执行,每阶段的开头都分配有内存池,需要分配内存时,就使用内存池的一部分。内存池的选择,要考虑分配的内存对象的生命周期,以及对象在程序中所属的阶段。每个阶段一旦结束,整个内存池就要立即释放。这种方法在记录型运行程序中特别有用,例如守护进程,它可能随着时间减少内存分段。下述代码是个内存池内存管理的仿真:
268 |#include <stdlib.h>
269 | #include <stdint.h>
270 |
271 | struct pool_t{
272 | void *ptr;
273 | size_t size;
274 | size_t used;
275 | };
276 |
277 | /* create memory pool*/
278 | struct pool_t* create_pool(size_t size) {
279 | struct pool_t* pool = calloc(1, sizeof(struct pool_t));
280 |
281 | if(pool == NULL)
282 | return NULL;
283 |
284 | if (size) {
285 | void *mem = calloc(1, size);
286 |
287 | if (mem != NULL) {
288 | pool->ptr = mem;
289 | pool->size = size;
290 | pool->used = 0;
291 | return pool;
292 | }
293 | }
294 | return NULL;
295 | }
296 |
297 | /* allocate memory from memory pool */
298 | void* pool_alloc(struct pool_t* pool, size_t size) {
299 |
300 | if(pool == NULL)
301 | return NULL;
302 |
303 | size_t avail_size = pool->size - pool->used;
304 |
305 | if (size && size <= avail_size){
306 | void *mem = pool->ptr + pool->used;
307 | pool->used += size;
308 | return mem;
309 | }
310 |
311 | return NULL;
312 | }
313 |
314 | /* release memory for whole pool */
315 | void delete_pool(struct pool_t* pool) {
316 | if (pool != NULL) {
317 | free(pool->ptr);
318 | free(pool);
319 | }
320 | }
321 | 内存池的实现涉及非常艰难的任务。可能一些现有的库能很好地满足你的需求:
322 |把数据存到正确的数据结构里,能解决很多内存管理问题。而数据结构的选择,大多取决于算法,这些算法访问数据、把数据保存到例如链表、哈希表或树中。按算法选择数据结构有额外的好处,例如能够遍历数据结构一次就能释放数据。因为标准库并未提供对数据结构的支持,这里列出几个支持数据结构的库:
329 |处理内存问题的另一种方式,就是利用自动垃圾收集器的优势,自此从自己清除内存中解放出来。于引用计数中内存不再需要时清除机制相反,垃圾收集器在发生指定事件是被调用,如内存分配错误,或分配后超过了确切的阀值。标记清除算法是实现垃圾收集器的一种方式。此算法先为每个引用到分配内存的对象遍历堆,标记这些仍然可用的内存对象,然后清除未标记的内存对象。
337 |可能C中最有名的类似垃圾收集器的实现是Boehm-Demers-Weiser conservative garbage collector 。使用垃圾收集器的瑕疵可能是性能问题,或向程序引入非确定性的延缓。另一问题是,这可能导致库函数使用 malloc,这些库函数申请的内存不受垃圾处理器监管,必须手动释放。
338 |虽然实时环境无法接受不可预料的卡顿,仍有许多环境从中获取的好处远超过不足。从性能的角度看,甚至有性能提升。一些项目使用含有Mono项目GNU Objective C运行环境或Irssi IRC客户端的Boehm垃圾收集器。
339 | ------------------------ 340 | 341 | - [C进阶指南(2)](https://github.com/LippiOuYang/practical-computer-skills/blob/master/src/c2.md) 342 | - [C进阶指南(3)](https://github.com/LippiOuYang/practical-computer-skills/blob/master/src/c3.md) -------------------------------------------------------------------------------- /src/c2.md: -------------------------------------------------------------------------------- 1 | - [C进阶指南(1)](https://github.com/LippiOuYang/practical-computer-skills/blob/master/src/c1.md) 2 | - [C进阶指南(3)](https://github.com/LippiOuYang/practical-computer-skills/blob/master/src/c3.md) 3 | 4 | ----------------------------- 5 |尽管在某些上下文中数组和指针可相互替换,但在编译器看来二者完全不同,并且在运行时所表达的含义也不同。
7 |当我们说对象或表达式有类型的时候,我们通常想的是定位器值的类型,也叫做左值。当左值有完全non-const类型时,此类型不是数组类型(因为数组本质是内存的一部分,是个只读常量,译者注),我们称此左值为可修改左值,并且此变量是个值,当表达式放到赋值运算符左边的时候,它被赋值。若表达式在赋值运算符的右边,此变量不必被修改,变量成为了修改左值的的内容。若表达式有数组类型,则此表达式的值是个指向数组第一个元素的指针。
8 |上文描述了大多数场景下数组如何转为指针。在两种情形下,数组的值类型不被转换:当用在一元运算符 &(取地址)或 sizeof 时。参见C99/C11标准 6.3.2.1小节:
9 |(Except when it is the operand of the sizeof operator or the unary & operator, or is a string literal used to initialize an array, an expression that has type “array of type” is converted to an expression with type “pointer to type” that points to the initial element of the array object and is not an lvalue.)
10 |除非它是sizeof或一元运算符&的操作数,再或者它是用于初始化数组的字符文本,否则有着“类型数组”类型的表达式被转换为“指向类型”类型的指针,此指针指向数组对象的首个元素且指针不是左值。
11 |由于数组没有可修改的左值,并且在绝大多数情况下,数组类型的表达式的值被转为指针,因此不可能用赋值运算符给数组变量赋值(即int a[10]; a = 1;是错的,译者注)。下面是一个小示例:
12 |short a[] = {1,2,3};
13 | short *pa;
14 | short (*px)[];
15 |
16 | void init(){
17 | pa = a;
18 | px = &a;
19 |
20 | printf("a:%p; pa:%p; px:%p\n", a, pa, px);
21 |
22 | printf("a[1]:%i; pa[1]:%i (*px)[1]:%i\n", a[1], pa[1], (*px)[1]);
23 | }
24 | (译者注:%i能识别输入的八进制和十六进制)
25 |a 是 int 型数组,pa 是指向 int 的指针,px 是个未完成的、指向数组的指针。a 赋值给 pa 前,它的值被转为一个指向数组开头的指针。右值表达式 &a 并非意味着指向 int,而是一个指针,指向 int 型数组因为当使用一元符号&时右值不被转换为指针。
26 |表达式 a[1] 中下标的使用等价于 *(a+1),且服从如同 pa[1] 的指针算术规则。但二者有一个重要区别。对于 a 是数组的情况,a 变量的实际内存地址用于获取指向第一个元素的指针。当对于 pa 是指针的情况,pa 的实际值并不用于定位。编译器必须注意到 a 和 pa见的类型区别,因此声明外部变量时,指明正确的类型很重要。
27 |int a[]; 28 | int *pa;29 |
但在另外的编译单元使用下述声明是不正确的,将毁坏代码:
30 |extern int *a; 31 | extern int pa[];32 |
某些类型数组变为指针的另一个场合在函数声明中。下述三个函数声明是等价的:
34 |void sum(int data[10]) {}
35 |
36 | void sum(int data[]) {}
37 |
38 | void sum(int *data) {}
39 | 编译器应报告函数 sum 重定义相关错误,因为在编译器看来上述三个例子中的参数都是 int 型的。.
40 |多维数组是有点棘手的话题。首先,虽然用了“多维”这个词,C并不完全支持多维数组。数组的数组可能是更准确的描述。
41 |typedef int[4] vector;
42 | vector m[2] = {{1,2,3,4}, {4,5,6,7}};
43 | int n[2][4] = {{1,2,3,4}, {4,5,6,7}};
44 | 变量 m 是长度为2的 vector 类型,vector 是长为4的 int 型数组。除了存储的内存位置不同外,数组 n 与 m 是相同的。从内存的角度讲,两个数组都如同括号内展示的内容那样,排布在连续的内存区域。访问到的和声明的完全一致。
45 |int *p = n[1]; 46 | int y = p[2];47 |
通过使用下标符号 n[1],我们获取到了每个元素大小为4字节的整型数组。因为我们要定位数组的第二个元素, 其位置在多维数组中是数组开始偏移四倍的整型大小。我们知道,在这个表达式中整型数组被转为指向 int 的指针,然后存为 p。然后 p[2] 将访问之前表达式产生的数组中的第三个元素。上面代码中的 y 等价于下面代码中的 z:
48 |int z = *(*(n+1)+2);49 |
也等价于我们初学C时写的表达式:
50 |int x = n[1][2];51 |
当把上文中的二维数组作为参数传输时,第一“维”数组会转为指针,指向再次阵列的数组的第一个元素。因此不需要指明第一维。剩余的维度需要明确指出其长度。否则下标将不能正确工作。当我们能够随心所欲地使用下述表格中的任一形式来定义函数接受数组时,我们总是被强制显式地定义最里面的(即维度最低的)数组的维度。
52 |void sum(int data[2][4]) {}
53 |
54 | void sum(int data[][4]) {}
55 |
56 | void sum(int (*data)[4]) {}
57 | 为绕过这一限制,可以转换数组为指针,然后计算所需元素的偏移。
58 |void list(int *arr, int max_i, int max_j){
59 | int i,j;
60 |
61 | for(i=0; i<max_i; i++){
62 |
63 | for(j=0; j<max_j; j++){
64 | int x = arr[max_i*i+j];
65 | printf("%i, ", x);
66 | }
67 |
68 | printf("\n");
69 | }
70 | }
71 | 另一种方法是main函数用以传输参数列表的方式。main函数接收二级指针而非二维数组。这种方法的缺陷是,必须建立不同的数据,或者转换为二级指针的形式。不过,好在它运行我们像以前一样使用下标符号,因为我们现在有了每个子数组的首地址。
72 |int main(int argc, char **argv){
73 | int arr1[4] = {1,2,3,4};
74 | int arr2[4] = {5,6,7,8};
75 |
76 | int *arr[] = {arr1, arr2};
77 |
78 | list(arr, 2, 4);
79 | }
80 |
81 | void list(int **arr, int max_i, int max_j){
82 | int i,j;
83 |
84 | for(i=0; i<max_i; i++){
85 |
86 | for(j=0; j<max_j; j++){
87 | int x = arr[i][j];
88 | printf("%i, ", x);
89 | }
90 |
91 | printf("\n");
92 | }
93 | }
94 | 用字符串类型的话,初始化部分变得相当简单,因为它允许直接初始化指向字符串的指针。
95 |const char *strings[] = {
96 | "one",
97 | "two",
98 | "three"
99 | };
100 | 但这有个陷阱,字符串实例被转换成指针,用 sizeof 操作符时会返回指针大小,而不是整个字符串文本所占空间。另一个重要区别是,若直接用指针修改字符串内容,则此行为是未定义的。
101 |假设你能使用变长数组,那就有了第三种传多维数组给函数的方法。使用前面定义的变量来指定最里面数组的维度,变量 arr 变为一个指针,指向未完成的int数组。
102 |void list(int max_i, int max_j, int arr[][max_j]){
103 | /* ... */
104 | int x = arr[1][3];
105 | }
106 | 此方法对更高维度的数组仍然有效,因为第一维总是被转换为指向数组的指针。类似的规则同样作用于函数指示器。若函数指示器不是 sizeof 或一元操作符 & 的参数,它的值是一个指向函数的指针。这就是我们传回调函数时不需要 & 操作符的原因。
107 |static void catch_int(int no) {
108 | /* ... */
109 | };
110 |
111 | int main(){
112 | signal(SIGINT, catch_int);
113 |
114 | /* ... */
115 | }
116 |
117 | 打桩是一种用定制的函数替换链接库函数且不需重新编译的技术。甚至可用此技术替换系统调用(更确切地说,库函数包装系统调用)。可能的应用是沙盒、调试或性能优化库。为演示过程,此处给出一个简单库,以记录GNU/Linux中 malloc 调用次数。
119 |/* _GNU_SOURCE is needed for RTLD_NEXT, GCC will not define it by default */
120 | #define _GNU_SOURCE
121 | #include <stdio.h>
122 | #include <stdlib.h>
123 | #include <dlfcn.h>
124 | #include <stdint.h>
125 | #include <inttypes.h>
126 |
127 | static uint32_t malloc_count = 0;
128 | static uint64_t total = 0;
129 |
130 | void summary(){
131 | fprintf(stderr, "malloc called: %u times\n", count);
132 | fprintf(stderr, "total allocated memory: %" PRIu64 " bytes\n", total);
133 | }
134 |
135 | void *malloc(size_t size){
136 | static void* (*real_malloc)(size_t) = NULL;
137 | void *ptr = 0;
138 |
139 | if(real_malloc == NULL){
140 | real_malloc = dlsym(RTLD_NEXT, "malloc");
141 | atexit(summary);
142 | }
143 |
144 | count++;
145 | total += size;
146 |
147 | return real_malloc(size);
148 | }
149 | 打桩要在链接libc.so之前加载此库,这样我们的 malloc 实现就会在二进制文件执行时被链接。可通过设置 LD_PRELOAD 环境变量为我们想让链接器优先链接的全路径。这也能确保其他动态链接库的调用最终使用我们的 malloc 实现。因为我们的目标只是记录调用次数,不是真正地实现内存分配,所以我们仍需要调用“真正”的 malloc 。通过传递 RTLD_NEXT 伪处理程序到 dlsym,我们获得了指向下一个已加载的链接库中 malloc 事件的指针。第一次 malloc 调用 libc 的 malloc,当程序终止时,会调用由 atexit 注册的获取和 summary 函数。看GNU/Linxu中打桩行为(真的184次调用!):
150 |$ gcc -shared -ldl -fPIC malloc_counter.c -o /tmp/libmcnt.so 151 | $ export LD_PRELOAD="/tmp/libstr.so" 152 | $ ps 153 | PID TTY TIME CMD 154 | 2758 pts/2 00:00:00 bash 155 | 4371 pts/2 00:00:00 ps 156 | malloc called: 184 times 157 | total allocated memory: 302599 bytes158 |
默认情况下,所有的非静态函数可被导出,所有可能仅定义有着与其他动态链接库函数甚至模板文件相同特征标的函数,就可能在无意中插入其它名称空间。为防止意外打桩、污染导出的函数名称空间,有效的做法是把每个函数声明为静态的,此函数在目标文件之外不能被使用。
160 |在共享库中,另一种控制导出的共享目标的方式是用编译器扩展。GCC 4.x和Clang都支持 visibility 属性和 -fvisibility 编译命令来对每个目标文件设置全局规则。其中 default 意味着不修改可见性,hidden 对可见性的影响与 static 限定符相同。此符号不会被放入动态符号表,其他共享目标或可执行文件看不到此符号。
161 |#if __GNUC__ >= 4 || __clang__
162 | #define EXPORT_SYMBOL __attribute__ ((visibility ("default")))
163 | #define LOCAL_SYMBOL __attribute__ ((visibility ("hidden")))
164 | #else
165 | #define EXPORT_SYMBOL
166 | #define LOCAL_SYMBOL
167 | #endif
168 | 全局可见性由编译器参数指定,可通过设置 visibility 属性被本地覆盖。实际上,全局策略设置为 hidden,则所有符号会被默认为本地的,只有修饰 __attribute__ ((visibility (“default”))) 才将被导出。
-------------------------------------------------------------------------------- /src/c3.md: -------------------------------------------------------------------------------- 1 | - [C进阶指南(1)](https://github.com/LippiOuYang/practical-computer-skills/blob/master/src/c1.md) 2 | - [C进阶指南(2)](https://github.com/LippiOuYang/practical-computer-skills/blob/master/src/c2.md) 3 | 4 | 5 | ---------- 6 | 7 |(想让)函数代码被直接集成到调用函数中,而非产生独立的函数目标和单个调用,可显式地使用 inline 限定符来指示编译器这么做。根据 section 6.7.4 of C standard inline 限定符仅建议编译器使得”调用要尽可能快”,并且“此建议是否有效由具体实现定义”
9 |要用内联函数优点的最简单方法是把函数定义为 static ,然后将定义放入头文件。
10 |/* middle.h */
11 | static inline int middle(int a, int b){
12 | return (b-a)/2;
13 | }
14 | 独立的函数对象仍然可能被导出,但在翻译单元的外部它是不可见的。这种头文件被包含在多个翻译单元中,编译器可能为每个单元发射函数的多份拷贝。因此,有可能两个变量指向相同的函数名,指针的值可能不相等。
15 |另一种方法是,既提供外部可连接的版本,也提供内联版本,两个版本功能相同,让编译器决定使用哪个。这实际上是内嵌限定符的定义:
16 |18 |If all of the file scope declarations for a function in a translation unit include the inline function specifier without extern, then the definition in that translation unit is an inline definition. An inline definition does not provide an external definition for the function, and does not forbid an external definition in another translation unit. An inline definition provides an alternative to an external definition, which a translator may use to implement any call to the function in the same translation unit. It is unspecified whether a call to the function uses the inline definition or the external definition.
17 |在一个翻译单元中,若某个函数在所有的文件范围内都包含不带extern的内联函数限定符,则此翻译单元中此函数定义是内联定义。内联定义不为函数提供外部的定义,也不禁止其他翻译单元的外部定义。内联定义为外部定义提供一个可选项,在同一翻译单元内翻译器可用它实现对函数的任意调用。调用函数时,使用内联定义或外联定义是不确定的。
(译者注:即gcc中的 extern inline,优先使用内联版本,允许外部版本的存在)
19 |对于函数的两个版本,我们可以把下面的定义放在头文件中:
20 |/* middle.h */
21 | inline int middle(int a, int b){
22 | return (b-a)/2;
23 | }
24 | 然后在具体的源文件中,用extern限定符发射翻译单元中外部可链接的版本:
25 |#include "middle.h" 26 | extern int middle(int a, int b);27 |
GCC编译器的实现不同于上述译码方式。若函数由 inline 声明,GCC总是发射外部可链接的目标代码,并且程序中只存在一个这样的定义。若函数被声明为export inline的,GCC将永不为此函数发射外部可链接的目标代码。自GCC 4.3版本起,可使用-STD= c99的选项使能为内联定义使能C99规则。若C99的规则被启用,则定义GNUC_STDC_INLINE。之前描述的 static 使用方法不受GCC对内联函数解释的影响。如果你需要同时使用内联和外部可链接功能的函数,可考虑以下解决方案:
28 |/* global.h */ 29 | #ifndef INLINE 30 | # if __GNUC__ && !__GNUC_STDC_INLINE__ 31 | # define INLINE extern inline 32 | # else 33 | # define INLINE inline 34 | # endif 35 | #endif36 |
头文件中有函数定义:
37 |/* middle.h */
38 | #include "global.h"
39 | INLINE int middle(int a, int b) {
40 | return (b-a)/2;
41 | }
42 | 在某个具体实现的源文件中:
43 |#define INLINE 44 | #include "middle.h45 |
若要对函数强制执行内联,GCC和Clang编译器都可用 always_inline 属性达成此目的。下面的例子中,独立的函数对象从未被发射。
46 |/* cdefs.h */
47 | # define __always_inline inline __attribute__((always_inline))
48 |
49 | /* middle.h */
50 | #include <cdefs.h>
51 | static __always_inline int middle(int a, int b) {
52 | return (b-a)/2;
53 | }
54 | 一旦编译器内联失败,编译将因错误而终止。例如 Linux kernel 就使用这种方法。可在 cdefs.h 中上述代码中使用的 __always_inline 。
55 |56 |
许多微处理器(特别是x86架构的)提供单指令多数据(SIMD)指令集来使能矢量操作。例如下面的代码:
58 |#include <stdint.h>
59 | #include <string.h>
60 | #define SIZE 8
61 | int16_t a[SIZE], b[SIZE];
62 |
63 | void addtwo(){
64 | int16_t i = 0;
65 |
66 | while (i < SIZE) {
67 | a[i] = b[i] + 2;
68 | i++;
69 | }
70 | }
71 |
72 | int main(){
73 | addtwo();
74 | return a[0];
75 | }
76 | addtwo 中的循环迭代 8 次,每次往数组 b 上加 2,数组 b 每个元素是 16 位的有符号整型。函数 addtwo 将被编译成下面的汇编代码:
77 |$ gcc -O2 auto.c -S -o auto_no.asm78 |
addtwo: 79 | .LFB22: 80 | .cfi_startproc 81 | movl $0, %eax 82 | .L2: 83 | movzwl b(%rax), %edx 84 | addl $2, %edx 85 | movw %dx, a(%rax) 86 | addq $2, %rax 87 | cmpq $16, %rax 88 | jne .L2 89 | rep 90 | ret 91 | .cfi_endproc92 |
起初,0 写入到 eax 寄存器。标签 L2 标着循环的开始。b 的首个元素由 movzwl 指令被装入的32位寄存器 edx 前16位。 edx寄存器的其余部分填 0。然后 addl 指令往 edx 寄存器中 a 的第一个元素的值加 2 并将结果存在 dx 寄存器中。累加结果从 dx(edx 寄存器的低16位)复制到 a 的第一个元素。最后,显然存放了步长为 2 (占2个字节 – 16位)的数组的 rax 寄存器与数组的总大小(以字节为单位)进行比较。如果 rax 不等于16,执行跳到 L2 ,否则会继续执行,函数返回。
93 |SSE2 指令集提供了能够一次性给 8 个 16 位整型做加法的指令 paddw。实际上,最现代化的编译器都能够自动使用如 paddw 之类的矢量指令优化代码。Clang 默认启用自动向量化。 GCC的编译器中可用 -ftree-vectorize 或 -O3 开关启用它。这样一来,向量指令优化后的 addtwo 函数汇编代码将会大有不同:
94 |$ gcc -O2 -msse -msse2 -ftree-vectorize -ftree-vectorizer-verbose=5 auto.c -S -o auto.asm95 |
addtwo: 96 | .LFB22: 97 | .cfi_startproc 98 | movdqa .LC0(%rip), %xmm0 99 | paddw b(%rip), %xmm0 100 | movdqa %xmm0, a(%rip) 101 | ret 102 | .cfi_endproc 103 | 104 | ;... 105 | 106 | .LC0: 107 | .value 2 108 | .value 2 109 | .value 2 110 | .value 2 111 | .value 2 112 | .value 2 113 | .value 2 114 | .value 2115 |
最显着的区别在于循环处理消失了。首先,8 个 16 位值为 2 整数被标记为 LC0,由 movdqa 加载到 xmm0 寄存器。然后paddw 把 b 的每个 16 位的元素分别加到 xmm0 中的多个数值 2上。结果写回到 a,函数可以返回。指令 movqda 只能用在由16个字节对齐的内存对象上。这表明编译器能够对齐两个数组的内存地址以提高效率。
116 |数组的大小不必一定只是 8 个元素,但它必须以 16 字节对齐(需要的话,填充),因此也可以用 128 位向量。用内联函数也可能是一个好主意,特别是当数组作为参数传递的时候。因为数组被转换为指针,指针地址需要16字节对齐。如果函数是内联的,编译器也许能减少额外的对齐开销。
117 |#include <stdint.h>
118 |
119 | void __always_inline addtwo(int16_t* a, int16_t *b, int16_t size){
120 | int16_t i;
121 |
122 | for (i = 0; i < size; i++) {
123 | a[i] = b[i] + 2;
124 | }
125 | }
126 |
127 | int main(){
128 | const int16_t size = 1024;
129 | int16_t a[size], b[size];
130 |
131 | addtwo(a, b, size);
132 | return a[0];
133 | }
134 | 循环迭代 1024 次,每次把两个长度为 16 比特的有符号整型相加。使用矢量操作的话,上例中的循环总数可减少到 128。但这也可能自动完成,在GCC环境中,可用 vector_size 定义矢量数据类型,用这些数据和属性显式指导编译器使用矢量扩展操作。此处列举出 emmintrin.h 定义的采用 SSE 指令集的多种矢量数据类型。
135 |/* SSE2 */ 136 | typedef double __v2df __attribute__ ((__vector_size__ (16))); 137 | typedef long long __v2di __attribute__ ((__vector_size__ (16))); 138 | typedef int __v4si __attribute__ ((__vector_size__ (16))); 139 | typedef short __v8hi __attribute__ ((__vector_size__ (16))); 140 | typedef char __v16qi __attribute__ ((__vector_size__ (16)));141 |
这是用 __v8hi 类型优化之前的示例代码后的样子:
142 |#include <stdint.h>
143 | #include <string.h>
144 | #include <emmintrin.h>
145 |
146 | static void __always_inline _addtwo(__v8hi *a, __v8hi *b, const int16_t sz){
147 | __v8hi c = {2,2,2,2,2,2,2,2};
148 |
149 | int16_t i;
150 | for (i = 0; i < sz; i++) {
151 | a[i] = b[i] + c;
152 | }
153 | }
154 |
155 | static void __always_inline addtwo(int16_t *a, int16_t *b, const int16_t sz){
156 | _addtwo((__v8hi *) a, (__v8hi *) b, sz/8);
157 | }
158 |
159 | int main(){
160 | const int16_t size = 1024;
161 | int16_t a[size], b[size];
162 | /* ... */
163 |
164 | addtwo(a, b, size);
165 | return a[0];
166 | }
167 | 关键是把数据转到合适的类型(此例中为 __v8hi),然后由此调整其他的代码。优化的效果主要看操作类型和处理数据量的大小,可能不同情况的结果差异很大。下表是上例中 addtwo 函数被循环调用 1 亿次的执行时间:
168 || Compiler | 172 |Time | 173 |
|---|---|
| gcc 4.5.4 O2 | 178 |1m 5.3s | 179 |
| gcc 4.5.4 O2 auto vectorized | 182 |12.7s | 183 |
| gcc 4.5.4 O2 manual | 186 |8.9s | 187 |
| gcc 4.7.3 O2 auto vectorized | 190 |25.s | 191 |
| gcc 4.7.3 O2 manual | 194 |8.9s | 195 |
| clang 3.3 O3 auto vectorized | 198 |8.1s | 199 |
| clang 3.3 O3 manual | 202 |9.5s | 203 |
Clang 编译器自动矢量化得更快,可能是因为用以测试的外部循环被优化的更好。慢一点的 GCC 4.7.3在内存对齐(见下文)方面效率稍低。
207 |int32_t i;
208 | for(i=0; i < 100000000; i++){
209 | addtwo(a, b, size);
210 | }
211 | GCC 和 Clang 编译器也提供了内建函数,用来显式地调用汇编指令。
213 |确切的内建函数跟编译器联系很大。x86 平台下,GCC 和 Clang 编译器都提供了带有定义的头文件,通过 x86intrin.h 匹配 Intel 编译器的内建函数(即 GCC 和 Clang 用 Intel 提供的头文件,调用 Intel 的内建函数。译者注)。下表是含特殊指令集的头文件:
214 |使用内建函数后,前面的例子可以改为:
223 |#include <stdint.h>
224 | #include <string.h>
225 | #include <emmintrin.h>
226 |
227 | static void __always_inline addtwo(int16_t *a, int16_t *b, int16_t size){
228 |
229 | int16_t i;
230 | __m128i c = _mm_set1_epi16(2);
231 |
232 | for (i = 0; i < size; i+=8) {
233 | __m128i bb = _mm_loadu_si128(b+i); // movqdu b+i -> xmm0
234 | __m128i r = _mm_add_epi16(bb, c); // paddw c + xmm0 -> xmm0
235 | _mm_storeu_si128(a+i, r); // movqdu xmm0 -> a+i
236 | }
237 | }
238 |
239 | int main(){
240 | const int16_t size = 1024;
241 | int16_t a[size], b[size];
242 | /* ... */
243 |
244 | addtwo(a, b, size);
245 | return a[0];
246 | }
247 | 当编译器产生次优的代码,或因代码中的 if 条件矢量类型不可能表达需要的操作时时,可能需要这种编写代码的方法。
248 |注意到上个例子用了与 movqdu 而非 movqda (上面的例子里仅用 SIMD 产生的汇编指令使用的是 movqda。译者注)同义的 _mm_loadu_si128。这因为不确定 a 或 b 是否已按 16 字节对齐。使用的指令是期望内存对象对齐的,但使用的内存对象是未对齐的,这样肯定会导致运行错误或数据毁坏。为了让内存对象对齐,可在定义时用 aligned 属性指导编译器对齐内存对象。某些情况下,可考虑把关键数据按 64 字节对齐,因为 x86 L1 缓存也是这个大小,这样能提高缓存使用率。
250 |#include <stdint.h>
251 | #include <string.h>
252 | #include <emmintrin.h>
253 |
254 | static void __always_inline addtwo(int16_t *a, int16_t *b, int16_t size){
255 |
256 | int16_t i;
257 | __m128i c = _mm_set1_epi16(2) __attribute__((aligned(16)));
258 |
259 | for (i = 0; i < size; i+=8) {
260 | __m128i bb = _mm_load_si128(b+i); // movqda b+i -> xmm0
261 | __m128i r = _mm_add_epi16(bb, c); // paddw c + xmm0 -> xmm0
262 | _mm_store_si128(a+i, r); // movqda xmm0 -> a+i
263 | }
264 | }
265 |
266 | int main(){
267 | const int16_t size = 1024;
268 | int16_t a[size], b[size] __attribute__((aligned(16)));
269 | /* ... */
270 |
271 | addtwo(a, b, size);
272 | return a[0];
273 | }
274 | 考虑到程序运行速度,使用自动变量好过静态或全局变量,情况允许的话还应避免动态内存分配。当动态内存分配无法避免时,Posix 标准 和 Windows 分别提供了 posix_memalign 和 _aligned_malloc 函数返回对齐的内存。
275 |高效使用矢量扩展喊代码优化需要深入理解目标架构工作原理和能加速代码运行的汇编指令。这两个主题相关的信息源有 Agner`s CPU blog 和它的装订版 Optimization manuals。
276 |277 |
本文最后一节讨论 C 编程语言里一些有趣的地方:
279 |array[i] == i[array];280 |
因为下标操作符等价于*(array + i),因此 array 和 i 是可交换的,二者等价。
281 |$ gcc -dM -E - < /dev/null | grep -e linux -e unix 282 | #define unix 1 283 | #define linux 1284 |
默认情况下,GCC 把 linux 和 unix 都定义为 1,所以一旦把其中一个用作函数名,代码就会编不过。
285 |int x = 'FOO!'; 286 | short y = 'BO';287 |
没错,字符表达式可扩展到任意整型大小。
288 |x = i+++k; 289 | x = i++ +k;290 |
后缀自增符在加号之前被词法分析扫描到。
291 |(即示例中两句等价,不同于 x = i + (++k) 。译者注)
292 |x = i+++++k; //error 293 | x = i++ ++ +k; //error 294 | 295 | y = i++ + ++k; //ok296 |
词法分析查找可被处理的最长的非空格字符序列(C标准6.4节)。第一行将被解析成第二行的样子,它们俩都会产生关于缺少左值的错误,缺失的左值本应该被第二个自增符处理。
297 |【编者按】StackOverflow是一个IT技术问答网站,用户可以在网站上提交和回答问题。当下的StackOverflow已拥有400万个用户,4000万个回答,月PV5.6亿,世界排行第54。然而值得关注的是,支撑他们网站的全部服务器只有25台,并且都保持着非常低的资源使用率,这是一场高有效性、负载均衡、缓存、数据库、搜索及高效代码上的较量。近日,High 4 | Scalability创始人Todd Hoff根据Marco Cecconi的演讲视频“ 5 | The architecture of StackOverflow”以及Nick Craver的博文“ 6 | What it takes to run Stack Overflow”总结了StackOverflow的成功原因。
以下为译文 12 |
13 |
意料之中,也是意料之外,Stack Overflow仍然重度使用着微软的产品。他们认为既然微软的基础设施可以满足需求,又足够便宜,那么没有什么理由去做根本上的改变。而在需要的地方,他们同样使用了Linux。究其根本,一切都是为了性能。
14 |另一个值得关注的地方是,Stack Overflow仍然使用着纵向扩展策略,没有使用云。他们使用了384GB的内存和2TB的SSD来支撑SQL 15 | Servers,如果使用AWS的话,花费可想而知。没有使用云的另一个原因是Stack Overflow认为云会一定程度上的降低性能,同时也会给优化和排查系统问题增加难度。此外,他们的架构也并不需要横向扩展。峰值期间是横向扩展的杀手级应用场景,然而他们有着丰富的系统调整经验去应对。该公司仍然坚持着Jeff 16 | Atwood的名言——硬件永远比程序员便宜。
17 |Marco Ceccon曾提到,在谈及系统时,有一件事情必须首先弄明白——需要解决问题的类型。首先,从简单方面着手,StackExchange究竟是用来做什么的——首先是一些主题,然后围绕这些主题建立社区,最后就形成了这个令人敬佩的问答网站。
18 |其次则是规模相关。StackExchange在飞速增长,需要处理大量的数据传输,那么这些都是如何完成的,特别是只使用了25台服务器,下面一起追根揭底:
19 |21 |
51 |
64 |
74 |
87 |
99 |
109 |
128 |
133 |
153 |
161 |
173 |
181 |
189 |
194 |
202 |
207 |
223 |
229 |
234 |
242 |
257 |
263 |
274 |
282 |
289 |
1. 为什么使用MS产品的同时还使用Redis?什么好用用什么,不要做无必要的系统之争,比如C#在Windows机器上运行最好,我们使用IIS;Redis在*nix机器上可以得到充分发挥,我们使用*nix。
299 |2. Overkill即策略。平常的利用率并不能代表什么,当某些特定的事情发生时,比如备份、重建等完全可以将资源使用拉满。
300 |3. 坚固的SSD。所有数据库都建立在SSD之上,这样可以获得0延时。
301 |4. 了解你的读写负载。
302 |5. 高效的代码意味着更少的主机。只有新项目上线时才会因为特殊需求增加硬件,通常情况下是添加内存,但在此之外,高效的代码就意味着0硬件添加。所以经常只讨论两个问题:为存储增加新的SSD;为新项目增加硬件。
303 |6. 不要害怕定制化。SO在Tag上使用复杂查询,因此专门开发了所需的Tag Engine。
304 |7. 只做必须做的事情。之所以不需要测试是因为有一个活跃的社区支撑,比如,开发者不用担心出现“Square Wheel”效应,如果开发者可以制作一个更更轻量级的组件,那就替代吧。
305 |8. 注重硬件知识,比如IL。一些代码使用IL而不是C#。聚焦SQL查询计划。使用web server的内存转储究竟做了些什么。探索,比如为什么一个split会产生2GB的垃圾。
306 |9. 切勿官僚作风。总有一些新的工具是你需要的,比如,一个编辑器,新版本的Visual Studio,降低提升过程中的一切阻力。
307 |10. 垃圾回收驱动编程。SO在减少垃圾回收成本上做了很多努力,跳过类似TDD的实践,避免抽象层,使用静态方法。虽然极端,但是确实打造出非常高效的代码。
308 |11. 高效代码的价值远远超出你想象,它可以让硬件跑的更快,降低资源使用,切记让代码更容易被程序员理解。
-------------------------------------------------------------------------------- /src/jvm.md: -------------------------------------------------------------------------------- 1 |Java虚拟机(JVM)是Java应用的运行环境,从一般意义上来讲,JVM是通过规范来定义的一个虚拟的计算机,被设计用来解释执行从Java源码编译而来的字节码。更通俗地说,JVM是指对这个规范的具体实现。这种实现基于严格的指令集和全面的内存模型。另外,JVM也通常被形容为对软件运行时环境的实现。通常JVM实现主要指的是HotSpot。
3 |JVM规范保证任何的实现都能够以同样的方式解释执行字节码。其实现可以多样化,包括进程、独立的Java操作系统或者直接执行字节码的处理器芯片。我们了解最多的JVM是作为软件实现,运行在流行的操作系统平台上(包括Windows、OS X、Linux和Solaris等)。
4 |JVM的结构允许对一个Java应用进行更细微的控制。这些应用运行在沙箱(Sandbox)环境中。确保在没有恰当的许可时,无法访问到本地文件系统、处理器和网络连接。远程执行时,代码还需要进行证书认证。
5 |除了解释执行Java字节码,大多数的JVM实现还包含一个JIT(just-in-time 即时)编译器,用于为常用的方法生成机器码。机器码使用的是CPU的本地语言,相比字节码有着更快的运行速度。
6 |虽然理解JVM不是开发或运行Java程序的必要条件,但是如果多了解一些JVM知识,那么就有机会避免很多性能上的问题。理解了JVM,实际上这些问题会变得简单明了。
7 |JVM规范定义了一系列子系统以及它们的外部行为。JVM主要有以下子系统:
9 |Class Loader 类加载器。 用于读入Java源代码并将类加载到数据区。Execution Engine 执行引擎。 执行来自数据区的指令。数据区使用的是底层操作系统分配给JVM的内存。
14 |
JVM在下面几种不同的层面使用不同的类加载器:
17 |当一个类加载器收到一个加载类的请求,首先它会检查缓存,确认该类是否已经被加载,然后把请求代理给它的父类。如果父类没能成功的加载类,那么子类就会自己去尝试加载该类。子类可检查父类加载器的缓存,但父类不能看到子类所加载的类。之所类加载体系会这样设计,是认为一个子类不应该重复加载已经被父类加载过的类。
24 |执行引擎一个接一个地执行被加载到数据区的字节码。为了保证字节码指令对于机器来说是可读的,执行引擎使用下面两个方法:
26 |尽管即时编译比解释执行要占用更多的时间,但是对于需要使用成千上万次的方法,只需要处理一次。相比每次都解释执行,以本地代码的方式运行会节约很多执行时间。
31 |JVM规范中并不规定一定要使用即时编译。即时编译也不是用于提高JVM性能的唯一的手段。规范仅仅规定了每条字节码对应的本地代码,至于执行引擎如何实现这一对应过程的,完全由JVM的具体实现来决定。
32 |Java内存模型建立在自动内存管理的概念之上。当一个对象不再被一个应用所引用,垃圾回收器就会回收它,从而释放相应的内存。这一点和其他很多需要自行释放内存的语言有很大不同。
34 |JVM从底层操作系统中分配内存,并将它们分为以下几个区域:
35 |一个有效的管理内存方法是把对空间划分为不同代,这样垃圾回收器就不用扫描整个堆区。大多数的对象的生命周期都很段短暂,那些生命周期较长的对象往往直到应用退出才需要被清除。
41 |当一个Java应用创建了一个对象,这个对象是被存储到“初生池”(eden pool)。一旦初生池存储满了,就会在新生代触发一次minor gc(小范围的垃圾回收)。首先,垃圾回收器会标记出那些“死对象”(不再被应用所引用的对象),同时延长所有保留对象的生命周期(这个生命周期长度是用数字来描述,代表了期所经历过的垃圾回收的次数)。然后,垃圾回收器会回收这些死对象,并把剩余的活着的对象移动到“幸存池”(survivor pool),从而清空初生池。
当一个对象存活达到一定的周期后,它就会被移动到堆中的老生代:“终身代”(tenured pool)。最后,当终身代被填满时,就会触发一次full gc或major gc(完全的垃圾回收),以清理终身代。
(译者注:一般我们把初生池和幸存池所在的区域合并成为新生代,把终身代所在的区域成为老生代。对应的,在新生代上产生的gc称为minor gc,在老生代上产生的gc称为full gc。希望这样大家在其他地方看到对应的术语时能更好理解)
44 |当垃圾回收(gc)执行的时候,所有应用线程都要被停止,系统产生一次暂停。minor gc非常频繁,所以被优化的能够快速的回收死对象,是新生代的内存的主要的回收方式。major gc运行起来就相对慢得多,因为要扫描非常多的活着的对象。垃圾回收器本身也有多种实现,有些垃圾回收器在一定情况下能更快的执行major gc。
45 |堆的大小是动态的,只有堆需要扩张的时候才会从内存中分配。当堆被填满时,JVM会重新给堆分配更多的内存,直到达到堆大小的上限,这种重新分配同样会导致应用的短暂停止。
46 |JVM是运行在一个独立的进程中的,但它可以并发执行多个线程,每个线程都运行自己的方法,这是Java必备的一个部分。以即时消息客户端这样一个应用为例,它至少运行两个线程。一个线程用于等待用户输入,另一个检查服务端是否有新的消息传输。再以服务端应用为例,有时一个请求可能要涉及多个线程并发执行,所以需要多线程来处理请求。
48 |在JVM的进程中,所有的线程共享内存和其他可用的资源。每一个JVM进程在进入点(main方法)处都要启动一个主线程,其他线程都从主线程启动,成为执行过程中的一个独立部分。线程可以再不同的处理器上并行执行,同样也可以共享一个处理器,线程调度器负责处理多个线程共享一个处理器的情况。
49 |很多应用(特别是服务端应用)会处理很多任务,需要并行运行。这些任务中有些是非常重要的,需要实时执行的。而另外一些是后台任务,可以在CPU空闲时执行。任务是在不同的线程中运行的。举例子来说,服务端可能有一些低优先级的线程,它们会根据一些数据来计算统计信息。同时也会启动一些高优先级的进程用于处理传入的数据,响应对这些统计信息的请求。这里可能有很多的源数据,很多来自客户端的数据请求,每个请求都会使服务端短暂的停止后台计算的线程以响应这个请求。所以,你必须监控在运行的线程数目并且保证有足够的CPU时间来执行必要的计算。
50 |(译者注:这一段在原文中是在性能优化的章节,译者认为这可能是作者的不小心,似乎放在线程的章节更合适。)
51 |JVM的性能取决于其配置是否与应用的功能相匹配。尽管垃圾回收器和内存回收进程是自动管理内存的,但是你必须掌管它们的频率。通常来说,你的应用可使用的内存越多,那么这些会导致应用暂停的内存管理进程需要起作用的就越少。
53 |如果垃圾回收发生的频率比你想的要多很多,那么可以在启动JVM的时候为其配置更大的最大堆大小值。堆被填满的时间越久,就越能降低垃圾回收发生的频率。最大堆大小值可以在启动JVM的时候,用-Xmx参数来设定。默认的最大堆大小是被设置为可用的操作系统内存的四分之一,或者最小1GB。
如果问题出在经常重新分配内存,那么你可以把初始化堆大小设置为和最大堆大小一样。这就意味着JVM永远不需要为堆重新分配内存。但这样做就会失去动态堆大小适配的优化,堆的大小从一开始就被固定下来。配置初始化对大小是在启动JVM,用-Xms来设定。默认初始化堆大小会被设定为操作系统可用的物理内存的六十四分之一,或者设置一个最小值。这个值是根据不同的平台来确定的。
如果你清楚是哪种垃圾回收(minor gc或major gc)导致了性能问题,可以在不改变整个堆大小的情况下设定新生代和老生代的大小比例。对于需要产生大量临时对象的应用,需要增大新生代的比例(当然,后果是减小了老生代的大小)。对于长生命周期对象较多的应用,则需增大老生代的比例(自然需要减少新生代的大小)。以下几种方法可以用来设定新生代和老生代的大小:
56 |-XX:NewRatio参数来具体指定新生代和老生代的大小比例。比如,如果想让老生代的大小是新生代的五倍,则设置参数为-XX:NewRatio=5,默认这个参数设定为2(即老生代占用堆空间的三分之二,新生代占用三分之一)。-Xmn参数设定初始化和最大新生代大小,那么堆中的剩余大小即是老生代的大小。-XX:NewSize和-XX:MaxNewSize参数设定初始化和最大新生代大小,那么堆中的剩余大小即是老生代的大小。每一个线程都有一个栈,用于保存函数调用、返回地址等等,这些栈有着对应的内存分配。如果线程过多,就会导致OutOfMemory错误。即使你有足够的空间的堆来存放对象,你的应用也可能会因为创建一个新的线程而崩溃。这种情况下,需要考虑限制线程中的栈大小的最大值。线程栈大小可以在JVM启动的时候,通过-Xss参数来设置,默认这个值被设定为320KB至1024KB之间,这和平台相关。
当开发或运行一个Java应用的时候,对JVM的性能进行监控是很重要的。配置JVM不是一次配置就万事大吉的,特别是你要应对的是Java服务器应用的情况。你必须持续的检查堆内存和非堆内存的分配和使用情况,线程数的创建情况和内存中加载的类的数据情况等。这些都是核心参数。
64 |使用Anturis控制台,你可以为任何的硬件组件上运行的JVM配置监控(例如,在一台电脑上运行的一个Tomcat网页服务器)。
65 |JVM监控可以使用以下衡量标准:
66 |日志用来记录用户操作、系统运行状态等,是一个系统的重要组成部分。然而由于日志并非系统核心功能,通常情况下并不受团队的重视。在出现问题需要通过日志来定位时,才发现日志还存在很多问题。
3 | 日志记录的好坏直接关系到系统出现问题时定位的速度,同时可以通过对日志的观察和分析,提前发现系统可能的风险,避免线上事故的发生。
4 | 我们在开发和运维NOS(网易对象存储,Netease Object Storage)的过程中,对整个系统的日志进行了分析优化,积累出一些经验,归纳如下。
我们通常使用的日志库(如log4j等),将日志基本分为以下几类(从低到高):
8 | TRACE - The TRACE Level designates finer-grained informational events than the DEBUG
9 | DEBUG – The DEBUG Level designates fine-grained informational events that are most useful to debug an application.
10 | INFO - The INFO level designates informational messages that highlight the progress of the application at coarse-grained level.
11 | WARN - The WARN level designates potentially harmful situations.
12 | ERROR - The ERROR level designates error events that might still allow the application to continue running.
13 | FATAL - The FATAL level designates very severe error events that will presumably lead the application to abort.
尽管log4j官方文档对各个日志级别进行了简单定义。然而在实践中,究竟哪些操作需要记入日志,哪种错误应该记为WARN级别,而哪种错误又为ERROR级别,还需要进行进一步讨论。
15 |关于该问题,在StackOverflow上有一个讨论贴进行过讨论。
16 |此处对贴子中的一些观点,加上我们在平时运维过程中遇到的相关问题进行归纳:
17 |Rule 1:整个团队(包括运维人员)需要对日志级别有明确的规定,什么日志记入什么级别的日志,什么级别的错误出现要如何处理等
28 |由于DEBUG(或TRACE)级别的日志对于定位问题至关重要,因此该种日志记录是否完备且不冗余、格式是否规范等也需要花费大量精力来优化。此处有以下几个比较好的实践:
30 |Rule 2:需要定期对日志内容进行优化更新,目的就是通过日志快速准确的定位问题
37 |日志从功能来说,可分为诊断日志、统计日志、审计日志。
39 |诊断日志, 典型的有:
40 |统计日志:
51 |审计日志:
56 |将不同需求的日志记入到不同的日志文件中,可以方便相关问题(管理平台操作审计,用户操作计费等)的处理。针对每一种需求,需要对日志的格式,日志记录的内容等进行特别的记录。
60 |Rule 3:要明确不同日志的用途,对日志内容进行分类
61 |在很多应用中,用户都需要通过Fuse方式来挂载使用NOS。
63 |POSIX标准中文件系统接口不允许文件 /a 与目录 /a/ 同时存在,而NOS作为对象存储系统,/a 和 /a/ 是不同的对象,是能够同时存在的,一般地,NOS 中我们会规定 /a/ 是目录,/a 是文件,目录对象大小为0。
64 |POSIX标准对文件的getattr操作,无论是 /a 还是 /a/,对应的请求都是 /a。为了避免遗漏,需分别向 NOS 请求 HeadObject(“/a“)和 HeadObject(“/a/“)。如果命中/a,说明 /a 是一个文件,不用再请求 getattr(“/a/“)。
65 |因此当用户访问 */a/b/c.txt* 时,实际上向NOS发送了以下请求:
66 | # HeadObject(“/a”)
67 | # HeadObject(“/a/”)
68 | # HeadObject(“/a/b”)
69 | # HeadObject(“/a/b/”)
70 | # HeadObject(“/a/b/c.txt”)
对于上面的请求,实际上HeadObject(“/a”)和HeadObject(“/a/b”)都会返回NoSuchKey错误,而Fuse正是该错误来判断该文件不存在,而可能是个目录的。
72 |然而对于NOS来说,这将导致产生大量无意义的NoSuchKey日志(整个日志文件的80%都是该错误日志)。这些日志对于开发人员进行日志观察,运维人员定位问题,日志监控等都造成了困难。
73 |Rule 4: 绝不要打印没有用的日志,防止无用日志淹没重要信息
74 |解决办法:Fuse请求时,在Http头部加入 User-Agent 字段,当NOS发现请求是 Fuse发过来的且为HeadObject操作且为NoSuchKey错误时,则不打印错误日志。
75 |问题描述:
77 |NOS提供分块上传的接口,用户可以通过以下的调用序列,来实现一次分块上传的流程:
78 |之前在某个产品上线初期,由于其开发人员对NOS的熟悉程度不够等原因。出现过如下问题:客户端常常会收到NoSuchUpload的错误。该错误出现的原因是,用户在未调用InitMultiUpload之前,或者在调用了CompleteMultiUpload(AbortMultiUpload)之后再次调用UploadPart。
87 |然而当我们查日志,希望可以看到该UploadPart请求对哪个UploadID进行操作,该UploadID又对应哪些操作时,却发现我们的日志中没有记录UploadPart请求对应的UploadID。
88 |类似的问题还有很多,很多针对特定请求的日志缺失,导致很多问题无法定位。
89 |因此,需要进一步对日志中需要记录哪些内容进行规定,此处推荐的需要在日志中记录的内容有:
90 |而不推荐记录日志的内容有:
100 |Rule 5:日志信息要准确全面,能做到仅凭日志就可以定位问题
106 |解决办法:整理所有的请求处理流程,针对每一个操作(去重,分块上传……)打印特定的日志。
107 |测试代码(单元测试,接口测试……)的日志同样重要。特别是,当一个测试失败时,可以通过日志很快确定是测试代码有问题,还是系统出现了故障,如果做不到这一点,那就需要优化测试的日志了。
109 |测试日志应该包含以下内容:
110 |Rule 6:要以同样严格的要求对待测试程序的日志
119 |在线上出现问题的时候,需要尽快发现问题并解决,而同时,需要借此机会好好思考一下当前系统的日志是否合理。需要考虑以下问题:
121 |通过系统出现的问题来优化日志,应该是一项长期的实践,不断地从日志发现系统的问题,不断地从系统异常发现日志的问题。
126 |Rule 7:日志的优化是一件持续不断需要投入精力的事,需要不断从错误中学习
127 |如今NOS有8台机器,共40个tomcat对外提供服务。通常用户在请求出错的时候,我们都希望用户告诉我们请求的RequestID,以此我们可以确定请求是在哪台机器上进行处理的。
130 |NOS通过以下信息生成一个请求的RequestID:
131 |因此我们可以通过一个简单的程序从RequestID中得到该请求的处理时间和处理请求的服务器地址,更方便的去查看日志:
137 | ./decode.sh 4b2c009a0a7800000142789f42b8ca96
138 | Thu Nov 21 11:06:12 CST 2013
139 | 10.120.202.150
140 | 4b2c009a
141 | Rule 8:在RequestID中尽量编码更多的信息
142 |在NOS性能测试中,之前存在的一个问题是,由于在打印错误堆栈的地方,并没有打印请求的RequestID,因此当一个请求出现错误时,很难(日志量太大)将该请求的错误堆栈和具体的请求关联起来。
144 |另一个问题是,NOS后端有视频服务器集群和图片处理服务器集群。因此我们可能会有以下需求:当用户视频截图失败时,用户会告诉我们请求的RequestID,由于NOS并没有将该RequestID转发到后端的图片处理服务器,因此无法利用该信息去查看视频处理服务器上的日志,而需要通过用户请求的URL进行查找。同时,由于我们无法知道该请求是在哪个具体的视频处理的worker上进行,进一步导致查找日志的困难。
145 |还有一个潜在的问题是:如果NOS将所有的日志收集起来(tomcat,图片处理集群,视频处理集群……),我们无法做到通过requestID来查找一个请求的处理流程。
146 |Rule 9:将一个请求的整个处理流程和唯一的requestID关联起来
147 |问题描述:
149 |NOS的DEBUG日志非常详细的记录了请求处理相关信息,然而由于DEBUG日志量太大,因此通常线上只开INFO级别日志。然而INFO级别的日志却有可能导致部分问题无法定位。NOS线上一个请求可能随机地分发到4台机器进行处理,因此如果某一种错误在一段时间内多次出现,它也会在4台服务器上都出现。
150 |因此我们推荐的做法是,选择一台机器开启DEBUG级别的日志,方便定位问题。其实该做法背后的目的是,在线上任何问题的时候,都可以通过日志最快的找到问题的根源。
151 |Rule 10:让一台机器开启DEBUG日志
152 |随着NOS开始服务越来越多的产品,NOS每次版本升级之后,通过对日志的观察来确定服务是否正常变得至关重要。同时在上线新功能时,来发人员需要通过观察一些特定的日志,来确定新功能是否工作正常。
154 |举例来说:
155 |NOS在实现了桶表缓存的功能之后,首先上线一台服务器,并对该功能是否工作正常进行观察。通过将桶缓存的所有操作(如插入,查找,过期删除等)以及桶缓存的状态(如缓存桶数量)都记录在DEBUG级别的日志中。将新上线的机器的日志级别调为DEBUG,并对桶缓存的相关操作是否正确,缓存桶数量等信息进行观察,确认一切正常之后再上线其他机器。
156 |Rule 11:新上线服务器后一定要对日志进行观察,特别地,开发人员可以通过观察日志来确认新功能是否工作正常
157 |NOS在接收到一个请求的时候,会记录请求的接收时间(T1),在请求处理完成待发送的时候,会记录请求发送时间(T2),通常一个请求的日志都记为INFO级别,然而当出现请求处理时间(T2-T1)超过一定时间(如10s)时,会将该日志提升为WARN级别。通过该方法,可以预先发现系统可能存在的一些问题。
159 |同样的慢操作日志还可以用来记录系统一些外部依赖的处理时间,如NOS依赖外部认证服务器来进行认证。我们会记录每个请求的认证时间,如果认证时间超过某个值,也需要将该事件的日志级别进行提升,这样我们可以尽早发现认证服务器是不是需要扩容等问题。
160 |慢日志的时间阀值应该是可以动态调整的,这样在进行系统优化时,可以将该报警时间阀值逐渐调小,不断地对系统进行优化。
161 |Rule 12:通过日志级别的提升来发现潜在问题
162 |错误日志报警:
164 |NOS通过[运维平台|https://m.hz.netease.com/]设置了日志监控报警,周期性的(1分钟,5分钟)对服务器新产生的日志进行监控,如果发现错误数超过某个阀值,则进行报警。这类报警通常不一定是我们服务本身的问题,也有可能是用户使用NOS不当造成的。
165 |此处需要注意的问题是,日志报警相当于grep操作,如果日志量过大,或者匹配规则过多,可能对线上的服务产生影响。因此在设置好日志报警后,需要周期性的关注每次日志扫描的时间,评估日志监控是否对服务产生影响。
166 |Rule 13:对日志进行监控报警,比客户先发现系统问题
167 |关键字报警:
168 |NOS为每个用户分配了一定量的存储配额,当用户容量超限时,会限制用户的上传操作。通过在日志中记录关键字,如“Quota Warning”等,可以及时提醒用户进行扩容,避免用户服务中断。
169 |类似的关键字报警还有很多:如对InternalError的数量进行监控,对缓存的桶数量进行监控等等。
170 |Rule 14:通过日志中的关键字来确定系统的运行状态
171 |日志格式一定要统一,不能任由开发人员的喜好来。举例来说,对于NOS视频截图超时的ERROR日志,有以下几种方式打印:
173 |第一种:
174 | logger.error(“Gearman timeout exception for request ” + getRequestID() + ” value: ” + value, e);
第二种:
176 | logger.error(“RequestID: ” + getRequestID() + “, Error Message: Gearman timeout exception: ” + e);
第三种:
178 | logger.error(getErrorMessage(getRequestID(), getErrorMessage(), e));
第一种方式打印日志即是开发人员按照自己的喜好来的,这种方法带来的问题是:
180 |而第三种方式,通过一个函数来规范日志格式,所有开发人员便可以通过该接口实现统一的日志。
186 |Rule 15:日志格式要统一规范
187 |在性能测试中遇到的另一个问题是,当并发量很大时,可能会有一些请求处理失败(如0.5%),为了对这些错误进行分析,需要去查这些错误请求的日志。而由于这种情况下并发量很大,使得对错误日志的分析变得困难。
189 |这种情况下可以将所有的错误日志同时输出到一个单独的文件之中。
190 |Rule 16:将错误日志输出到一个单独的文件中进行分析
191 |日志文件不宜过大,过大的日志文件对于日志监控,问题定位等都会带来不便。因此需要进行日志文件的切分,日志文件的切分可以通过log4j等日志工具来配置,日志文件应该按天来分割,还是按照小时来分割,应该根据日志量来决定,原则就是方便开发或运维人员能快速查找日志。
193 |为了防止日志文件将整个磁盘空间占满,需要定期对日志文件进行删除。例如,在收到磁盘报警时,可以将两个月以前的日志文件删除。此处比较好的实践是:
194 |log4j关于日志切分的相关配置,可以参考这篇文章。
199 |Rule 17:要把日志的大小,如何切分,如何删除等作为规范建立起来
200 |此处对以上总结的所有经验进行汇总:
202 |[1] ”Optimal Logging” Anthony Vallone from Google http://googletesting.blogspot.jp/2013/06/optimal-logging.html
-------------------------------------------------------------------------------- /src/malloc.md: -------------------------------------------------------------------------------- 1 |任何一个用过或学过C的人对malloc都不会陌生。大家都知道malloc可以分配一段连续的内存空间,并且在不再使用时可以通过free释放掉。但是,许多程序员对malloc背后的事情并不熟悉,许多人甚至把malloc当做操作系统所提供的系统调用或C的关键字。实际上,malloc只是C的标准库中提供的一个普通函数,而且实现malloc的基本思想并不复杂,任何一个对C和操作系统有些许了解的程序员都可以很容易理解。
2 |这篇文章通过实现一个简单的malloc来描述malloc背后的机制。当然与现有C的标准库实现(例如glibc)相比,我们实现的malloc并不是特别高效,但是这个实现比目前真实的malloc实现要简单很多,因此易于理解。重要的是,这个实现和真实实现在基本原理上是一致的。
3 |这篇文章将首先介绍一些所需的基本知识,如操作系统对进程的内存管理以及相关的系统调用,然后逐步实现一个简单的malloc。为了简单起见,这篇文章将只考虑x86_64体系结构,操作系统为Linux。
4 | 5 | 6 |在实现malloc之前,先要相对正式地对malloc做一个定义。
47 |根据标准C库函数的定义,malloc具有如下原型:
48 |void* malloc(size_t size); 49 |50 |
这个函数要实现的功能是在系统中分配一段连续的可用的内存,具体有如下要求:
51 |对于malloc更多的说明可以在命令行中键入以下命令查看:
59 |man malloc 60 |61 |
在实现malloc之前,需要先解释一些Linux系统内存相关的知识。
63 |为了简单,现代操作系统在处理内存地址时,普遍采用虚拟内存地址技术。即在汇编程序(或机器语言)层面,当涉及内存地址时,都是使用虚拟内存地址。采用这种技术时,每个进程仿佛自己独享一片$2^N$字节的内存,其中$N$是机器位数。例如在64位CPU和64位操作系统下,每个进程的虚拟地址空间为$2^{64}$Byte。
66 |这种虚拟地址空间的作用主要是简化程序的编写及方便操作系统对进程间内存的隔离管理,真实中的进程不太可能(也用不到)如此大的内存空间,实际能用到的内存取决于物理内存大小。
67 |由于在机器语言层面都是采用虚拟地址,当实际的机器码程序涉及到内存操作时,需要根据当前进程运行的实际上下文将虚拟地址转换为物理内存地址,才能实现对真实内存数据的操作。这个转换一般由一个叫MMU(Memory Management Unit)的硬件完成。
68 |在现代操作系统中,不论是虚拟内存还是物理内存,都不是以字节为单位进行管理的,而是以页(Page)为单位。一个内存页是一段固定大小的连续内存地址的总称,具体到Linux中,典型的内存页大小为4096Byte(4K)。
70 |所以内存地址可以分为页号和页内偏移量。下面以64位机器,4G物理内存,4K页大小为例,虚拟内存地址和物理内存地址的组成如下:
71 |
上面是虚拟内存地址,下面是物理内存地址。由于页大小都是4K,所以页内偏移都是用低12位表示,而剩下的高地址表示页号。
73 |MMU映射单位并不是字节,而是页,这个映射通过查一个常驻内存的数据结构页表来实现。现在计算机具体的内存地址映射比较复杂,为了加快速度会引入一系列缓存和优化,例如TLB等机制。下面给出一个经过简化的内存地址翻译示意图,虽然经过了简化,但是基本原理与现代计算机真实的情况的一致的。
74 |
我们知道一般将内存看做磁盘的的缓存,有时MMU在工作时,会发现页表表明某个内存页不在物理内存中,此时会触发一个缺页异常(Page Fault),此时系统会到磁盘中相应的地方将磁盘页载入到内存中,然后重新执行由于缺页而失败的机器指令。关于这部分,因为可以看做对malloc实现是透明的,所以不再详细讲述,有兴趣的可以参考《深入理解计算机系统》相关章节。
77 |最后附上一张在维基百科找到的更加符合真实地址翻译的流程供大家参考,这张图加入了TLB和缺页异常的流程(图片来源页)。
78 |
明白了虚拟内存和物理内存的关系及相关的映射机制,下面看一下具体在一个进程内是如何排布内存的。
82 |以Linux 64位系统为例。理论上,64bit内存地址可用空间为0x0000000000000000 ~ 0xFFFFFFFFFFFFFFFF,这是个相当庞大的空间,Linux实际上只用了其中一小部分(256T)。
83 |根据Linux内核相关文档描述,Linux64位操作系统仅使用低47位,高17位做扩展(只能是全0或全1)。所以,实际用到的地址为空间为0x0000000000000000 ~ 0x00007FFFFFFFFFFF和0xFFFF800000000000 ~ 0xFFFFFFFFFFFFFFFF,其中前面为用户空间(User Space),后者为内核空间(Kernel Space)。图示如下:
84 |
对用户来说,主要关注的空间是User Space。将User Space放大后,可以看到里面主要分为如下几段:
86 |下面我们主要关注Heap区域的操作。对整个Linux内存排布有兴趣的同学可以参考其它资料。
95 |一般来说,malloc所申请的内存主要从Heap区域分配(本文不考虑通过mmap申请大块内存的情况)。
97 |由上文知道,进程所面对的虚拟内存地址空间,只有按页映射到物理内存地址,才能真正使用。受物理存储容量限制,整个堆虚拟内存空间不可能全部映射到实际的物理内存。Linux对堆的管理示意如下:
98 |
Linux维护一个break指针,这个指针指向堆空间的某个地址。从堆起始地址到break之间的地址空间为映射好的,可以供进程访问;而从break往上,是未映射的地址空间,如果访问这段空间则程序会报错。
100 |由上文知道,要增加一个进程实际的可用堆大小,就需要将break指针向高地址移动。Linux通过brk和sbrk系统调用操作break指针。两个系统调用的原型如下:
102 |int brk(void *addr); 103 | void *sbrk(intptr_t increment); 104 |105 |
brk将break指针直接设置为某个地址,而sbrk将break从当前位置移动increment所指定的增量。brk在执行成功时返回0,否则返回-1并设置errno为ENOMEM;sbrk成功时返回break移动之前所指向的地址,否则返回(void *)-1。
106 |一个小技巧是,如果将increment设置为0,则可以获得当前break的地址。
107 |另外需要注意的是,由于Linux是按页进行内存映射的,所以如果break被设置为没有按页大小对齐,则系统实际上会在最后映射一个完整的页,从而实际已映射的内存空间比break指向的地方要大一些。但是使用break之后的地址是很危险的(尽管也许break之后确实有一小块可用内存地址)。
108 |系统对每一个进程所分配的资源不是无限的,包括可映射的内存空间,因此每个进程有一个rlimit表示当前进程可用的资源上限。这个限制可以通过getrlimit系统调用得到,下面代码获取当前进程虚拟内存空间的rlimit:
110 |int main() {
111 | struct rlimit *limit = (struct rlimit *)malloc(sizeof(struct rlimit));
112 | getrlimit(RLIMIT_AS, limit);
113 | printf("soft limit: %ld, hard limit: %ld\n", limit->rlim_cur, limit->rlim_max);
114 | }
115 |
116 | 其中rlimit是一个结构体:
117 |struct rlimit {
118 | rlim_t rlim_cur; /* Soft limit */
119 | rlim_t rlim_max; /* Hard limit (ceiling for rlim_cur) */
120 | };
121 |
122 | 每种资源有软限制和硬限制,并且可以通过setrlimit对rlimit进行有条件设置。其中硬限制作为软限制的上限,非特权进程只能设置软限制,且不能超过硬限制。
123 |在正式开始讨论malloc的实现前,我们可以利用上述知识实现一个简单但几乎没法用于真实的玩具malloc,权当对上面知识的复习:
126 |/* 一个玩具malloc */
127 | #include <sys/types.h>
128 | #include <unistd.h>
129 | void *malloc(size_t size)
130 | {
131 | void *p;
132 | p = sbrk(0);
133 | if (sbrk(size) == (void *)-1)
134 | return NULL;
135 | return p;
136 | }
137 |
138 | 这个malloc每次都在当前break的基础上增加size所指定的字节数,并将之前break的地址返回。这个malloc由于对所分配的内存缺乏记录,不便于内存释放,所以无法用于真实场景。
139 |下面严肃点讨论malloc的实现方案。
141 |首先我们要确定所采用的数据结构。一个简单可行方案是将堆内存空间以块(Block)的形式组织起来,每个块由meta区和数据区组成,meta区记录数据块的元信息(数据区大小、空闲标志位、指针等等),数据区是真实分配的内存区域,并且数据区的第一个字节地址即为malloc返回的地址。
143 |可以用如下结构体定义一个block:
144 |typedef struct s_block *t_block;
145 | struct s_block {
146 | size_t size; /* 数据区大小 */
147 | t_block next; /* 指向下个块的指针 */
148 | int free; /* 是否是空闲块 */
149 | int padding; /* 填充4字节,保证meta块长度为8的倍数 */
150 | char data[1] /* 这是一个虚拟字段,表示数据块的第一个字节,长度不应计入meta */
151 | };
152 |
153 | 由于我们只考虑64位机器,为了方便,我们在结构体最后填充一个int,使得结构体本身的长度为8的倍数,以便内存对齐。示意图如下:
154 |
现在考虑如何在block链中查找合适的block。一般来说有两种查找算法:
157 |两种方法各有千秋,best fit具有较高的内存使用率(payload较高),而first fit具有更好的运行效率。这里我们采用first fit算法。
162 |/* First fit */
163 | t_block find_block(t_block *last, size_t size) {
164 | t_block b = first_block;
165 | while(b && !(b->free && b->size >= size)) {
166 | *last = b;
167 | b = b->next;
168 | }
169 | return b;
170 | }
171 |
172 | find_block从frist_block开始,查找第一个符合要求的block并返回block起始地址,如果找不到这返回NULL。这里在遍历时会更新一个叫last的指针,这个指针始终指向当前遍历的block。这是为了如果找不到合适的block而开辟新block使用的,具体会在接下来的一节用到。
173 |如果现有block都不能满足size的要求,则需要在链表最后开辟一个新的block。这里关键是如何只使用sbrk创建一个struct:
175 |#define BLOCK_SIZE 24 /* 由于存在虚拟的data字段,sizeof不能正确计算meta长度,这里手工设置 */
176 |
177 | t_block extend_heap(t_block last, size_t s) {
178 | t_block b;
179 | b = sbrk(0);
180 | if(sbrk(BLOCK_SIZE + s) == (void *)-1)
181 | return NULL;
182 | b->size = s;
183 | b->next = NULL;
184 | if(last)
185 | last->next = b;
186 | b->free = 0;
187 | return b;
188 | }
189 |
190 | First fit有一个比较致命的缺点,就是可能会让很小的size占据很大的一块block,此时,为了提高payload,应该在剩余数据区足够大的情况下,将其分裂为一个新的block,示意如下:
192 |
实现代码:
194 |void split_block(t_block b, size_t s) {
195 | t_block new;
196 | new = b->data + s;
197 | new->size = b->size - s - BLOCK_SIZE ;
198 | new->next = b->next;
199 | new->free = 1;
200 | b->size = s;
201 | b->next = new;
202 | }
203 |
204 | 有了上面的代码,我们可以利用它们整合成一个简单但初步可用的malloc。注意首先我们要定义个block链表的头first_block,初始化为NULL;另外,我们需要剩余空间至少有BLOCK_SIZE + 8才执行分裂操作。
206 |由于我们希望malloc分配的数据区是按8字节对齐,所以在size不为8的倍数时,我们需要将size调整为大于size的最小的8的倍数:
207 |size_t align8(size_t s) {
208 | if(s & 0x7 == 0)
209 | return s;
210 | return ((s >> 3) + 1) << 3;
211 | }
212 |
213 | #define BLOCK_SIZE 24
214 | void *first_block=NULL;
215 |
216 | /* other functions... */
217 |
218 | void *malloc(size_t size) {
219 | t_block b, last;
220 | size_t s;
221 | /* 对齐地址 */
222 | s = align8(size);
223 | if(first_block) {
224 | /* 查找合适的block */
225 | last = first_block;
226 | b = find_block(&last, s);
227 | if(b) {
228 | /* 如果可以,则分裂 */
229 | if ((b->size - s) >= ( BLOCK_SIZE + 8))
230 | split_block(b, s);
231 | b->free = 0;
232 | } else {
233 | /* 没有合适的block,开辟一个新的 */
234 | b = extend_heap(last, s);
235 | if(!b)
236 | return NULL;
237 | }
238 | } else {
239 | b = extend_heap(NULL, s);
240 | if(!b)
241 | return NULL;
242 | first_block = b;
243 | }
244 | return b->data;
245 | }
246 |
247 | 有了malloc,实现calloc只要两步:
249 |由于我们的数据区是按8字节对齐的,所以为了提高效率,我们可以每8字节一组置0,而不是一个一个字节设置。我们可以通过新建一个size_t指针,将内存区域强制看做size_t类型来实现。
254 |void *calloc(size_t number, size_t size) {
255 | size_t *new;
256 | size_t s8, i;
257 | new = malloc(number * size);
258 | if(new) {
259 | s8 = align8(number * size) >> 3;
260 | for(i = 0; i < s8; i++)
261 | new[i] = 0;
262 | }
263 | return new;
264 | }
265 |
266 | free的实现并不像看上去那么简单,这里我们要解决两个关键问题:
268 |首先我们要保证传入free的地址是有效的,这个有效包括两方面:
273 |第一个问题比较好解决,只要进行地址比较就可以了,关键是第二个问题。这里有两种解决方案:一是在结构体内埋一个magic number字段,free之前通过相对偏移检查特定位置的值是否为我们设置的magic number,另一种方法是在结构体内增加一个magic pointer,这个指针指向数据区的第一个字节(也就是在合法时free时传入的地址),我们在free前检查magic pointer是否指向参数所指地址。这里我们采用第二种方案:
278 |首先我们在结构体中增加magic pointer(同时要修改BLOCK_SIZE):
279 |typedef struct s_block *t_block;
280 | struct s_block {
281 | size_t size; /* 数据区大小 */
282 | t_block next; /* 指向下个块的指针 */
283 | int free; /* 是否是空闲块 */
284 | int padding; /* 填充4字节,保证meta块长度为8的倍数 */
285 | void *ptr; /* Magic pointer,指向data */
286 | char data[1] /* 这是一个虚拟字段,表示数据块的第一个字节,长度不应计入meta */
287 | };
288 |
289 | 然后我们定义检查地址合法性的函数:
290 |t_block get_block(void *p) {
291 | char *tmp;
292 | tmp = p;
293 | return (p = tmp -= BLOCK_SIZE);
294 | }
295 |
296 | int valid_addr(void *p) {
297 | if(first_block) {
298 | if(p > first_block && p < sbrk(0)) {
299 | return p == (get_block(p))->ptr;
300 | }
301 | }
302 | return 0;
303 | }
304 |
305 | 当多次malloc和free后,整个内存池可能会产生很多碎片block,这些block很小,经常无法使用,甚至出现许多碎片连在一起,虽然总体能满足某此malloc要求,但是由于分割成了多个小block而无法fit,这就是碎片问题。
306 |一个简单的解决方式时当free某个block时,如果发现它相邻的block也是free的,则将block和相邻block合并。为了满足这个实现,需要将s_block改为双向链表。修改后的block结构如下:
307 |typedef struct s_block *t_block;
308 | struct s_block {
309 | size_t size; /* 数据区大小 */
310 | t_block prev; /* 指向上个块的指针 */
311 | t_block next; /* 指向下个块的指针 */
312 | int free; /* 是否是空闲块 */
313 | int padding; /* 填充4字节,保证meta块长度为8的倍数 */
314 | void *ptr; /* Magic pointer,指向data */
315 | char data[1] /* 这是一个虚拟字段,表示数据块的第一个字节,长度不应计入meta */
316 | };
317 |
318 | 合并方法如下:
319 |t_block fusion(t_block b) {
320 | if (b->next && b->next->free) {
321 | b->size += BLOCK_SIZE + b->next->size;
322 | b->next = b->next->next;
323 | if(b->next)
324 | b->next->prev = b;
325 | }
326 | return b;
327 | }
328 |
329 | 有了上述方法,free的实现思路就比较清晰了:首先检查参数地址的合法性,如果不合法则不做任何事;否则,将此block的free标为1,并且在可以的情况下与后面的block进行合并。如果当前是最后一个block,则回退break指针释放进程内存,如果当前block是最后一个block,则回退break指针并设置first_block为NULL。实现如下:
330 |void free(void *p) {
331 | t_block b;
332 | if(valid_addr(p)) {
333 | b = get_block(p);
334 | b->free = 1;
335 | if(b->prev && b->prev->free)
336 | b = fusion(b->prev);
337 | if(b->next)
338 | fusion(b);
339 | else {
340 | if(b->prev)
341 | b->prev->prev = NULL;
342 | else
343 | first_block = NULL;
344 | brk(b);
345 | }
346 | }
347 | }
348 |
349 | 为了实现realloc,我们首先要实现一个内存复制方法。如同calloc一样,为了效率,我们以8字节为单位进行复制:
351 |void copy_block(t_block src, t_block dst) {
352 | size_t *sdata, *ddata;
353 | size_t i;
354 | sdata = src->ptr;
355 | ddata = dst->ptr;
356 | for(i = 0; (i * 8) < src->size && (i * 8) < dst->size; i++)
357 | ddata[i] = sdata[i];
358 | }
359 |
360 | 然后我们开始实现realloc。一个简单(但是低效)的方法是malloc一段内存,然后将数据复制过去。但是我们可以做的更高效,具体可以考虑以下几个方面:
361 |下面是realloc的实现:
367 |void *realloc(void *p, size_t size) {
368 | size_t s;
369 | t_block b, new;
370 | void *newp;
371 | if (!p)
372 | /* 根据标准库文档,当p传入NULL时,相当于调用malloc */
373 | return malloc(size);
374 | if(valid_addr(p)) {
375 | s = align8(size);
376 | b = get_block(p);
377 | if(b->size >= s) {
378 | if(b->size - s >= (BLOCK_SIZE + 8))
379 | split_block(b,s);
380 | } else {
381 | /* 看是否可进行合并 */
382 | if(b->next && b->next->free
383 | && (b->size + BLOCK_SIZE + b->next->size) >= s) {
384 | fusion(b);
385 | if(b->size - s >= (BLOCK_SIZE + 8))
386 | split_block(b, s);
387 | } else {
388 | /* 新malloc */
389 | newp = malloc (s);
390 | if (!newp)
391 | return NULL;
392 | new = get_block(newp);
393 | copy_block(b, new);
394 | free(p);
395 | return(newp);
396 | }
397 | }
398 | return (p);
399 | }
400 | return NULL;
401 | }
402 |
403 | 以上是一个较为简陋,但是初步可用的malloc实现。还有很多遗留的可能优化点,例如:
405 |还有很多可能的优化,这里不一一赘述。下面附上一些参考文献,有兴趣的同学可以更深入研究。
412 |早期计算机比现在更为简单。系统的各种组件例如CPU,内存,大容量存储器和网口,由于被共同开发因而有非常均衡的表现。例如,内存和网口并不比CPU在提供数据的时候更(特别的)快。
3 |曾今计算机稳定的基本结构悄然改变,硬件开发人员开始致力于优化单个子系统。于是电脑一些组件的性能大大的落后因而成为了瓶颈。由于开销的原因,大容量存储器和内存子系统相对于其他组件来说改善得更为缓慢。
4 |大容量存储的性能问题往往靠软件来改善: 操作系统将常用(且最有可能被用)的数据放在主存中,因为后者的速度要快上几个数量级。或者将缓存加入存储设备中,这样就可以在不修改操作系统的前提下提升性能。{然而,为了在使用缓存时保证数据的完整性,仍然要作出一些修改。}这些内容不在本文的谈论范围之内,就不作赘述了。
5 |而解决内存的瓶颈更为困难,它与大容量存储不同,几乎每种方案都需要对硬件作出修改。目前,这些变更主要有以下这些方式:
6 |本文主要关心的是CPU缓存和内存控制器的设计。在讨论这些主题的过程中,我们还会研究DMA。不过,我们首先会从当今商用硬件的设计谈起。这有助于我们理解目前在使用内存子系统时可能遇到的问题和限制。我们还会详细介绍RAM的分类,说明为什么会存在这么多不同类型的内存。
13 |本文不会包括所有内容,也不会包括最终性质的内容。我们的讨论范围仅止于商用硬件,而且只限于其中的一小部分。另外,本文中的许多论题,我们只会点到为止,以达到本文目标为标准。对于这些论题,大家可以阅读其它文档,获得更详细的说明。
14 |当本文提到操作系统特定的细节和解决方案时,针对的都是Linux。无论何时都不会包含别的操作系统的任何信息,作者无意讨论其他操作系统的情况。如果读者认为他/她不得不使用别的操作系统,那么必须去要求供应商提供其操作系统类似于本文的文档。
15 |在开始之前最后的一点说明,本文包含大量出现的术语“经常”和别的类似的限定词。这里讨论的技术在现实中存在于很多不同的实现,所以本文只阐述使用得最广泛最主流的版本。在阐述中很少有地方能用到绝对的限定词。
16 |这个文档主要视为软件开发者而写的。本文不会涉及太多硬件细节,所以喜欢硬件的读者也许不会觉得有用。但是在我们讨论一些有用的细节之前,我们先要描述足够多的背景。
18 |在这个基础上,本文的第二部分将描述RAM(随机寄存器)。懂得这个部分的内容很好,但是此部分的内容并不是懂得其后内容必须部分。我们会在之后引用不少之前的部分,所以心急的读者可以跳过任何章节来读他们认为有用的部分。
19 |第三部分会谈到不少关于CPU缓存行为模式的内容。我们会列出一些图标,这样你们不至于觉得太枯燥。第三部分对于理解整个文章非常重要。第四部分将简短的描述虚拟内存是怎么被实现的。这也是你们需要理解全文其他部分的背景知识之一。
20 |第五部分会提到许多关于Non Uniform Memory Access (NUMA)系统。
21 |第六部分是本文的中心部分。在这个部分里面,我们将回顾其他许多部分中的信息,并且我们将给阅读本文的程序员许多在各种情况下的编程建议。如果你真的很心急,那么你可以直接阅读第六部分,并且我们建议你在必要的时候回到之前的章节回顾一下必要的背景知识。
22 |本文的第七部分将介绍一些能够帮助程序员更好的完成任务的工具。即便在彻底理解了某一项技术的情况下,距离彻底理解在非测试环境下的程序还是很遥远的。我们需要借助一些工具。
23 |第八部分,我们将展望一些在未来我们可能认为好用的科技。
24 |1.2 反馈问题
25 |作者会不定期更新本文档。这些更新既包括伴随技术进步而来的更新也包含更改错误。非常欢迎有志于反馈问题的读者发送电子邮件。
26 |1.3 致谢
27 |我首先需要感谢Johnray Fuller尤其是Jonathan Corbet,感谢他们将作者的英语转化成为更为规范的形式。Markus Armbruster提供大量本文中对于问题和缩写有价值的建议。
28 |1.4 关于本文
29 |本文题目对David Goldberg的经典文献《What Every Computer Scientist Should Know About Floating-Point Arithmetic》[goldberg]表示致敬。Goldberg的论文虽然不普及,但是对于任何有志于严格编程的人都会是一个先决条件。
30 |鉴于目前专业硬件正在逐渐淡出,理解商用硬件的现状变得十分重要。现如今,人们更多的采用水平扩展,也就是说,用大量小型、互联的商用计算机代替巨大、超快(但超贵)的系统。原因在于,快速而廉价的网络硬件已经崛起。那些大型的专用系统仍然有一席之地,但已被商用硬件后来居上。2007年,Red Hat认为,未来构成数据中心的“积木”将会是拥有最多4个插槽的计算机,每个插槽插入一个四核CPU,这些CPU都是超线程的。{超线程使单个处理器核心能同时处理两个以上的任务,只需加入一点点额外硬件}。也就是说,这些数据中心中的标准系统拥有最多64个虚拟处理器。当然可以支持更大的系统,但人们认为4插槽、4核CPU是最佳配置,绝大多数的优化都针对这样的配置。
32 |在不同商用计算机之间,也存在着巨大的差异。不过,我们关注在主要的差异上,可以涵盖到超过90%以上的硬件。需要注意的是,这些技术上的细节往往日新月异,变化极快,因此大家在阅读的时候也需要注意本文的写作时间。
33 |这么多年来,个人计算机和小型服务器被标准化到了一个芯片组上,它由两部分组成: 北桥和南桥,见图2.1。
34 |35 |38 |36 |
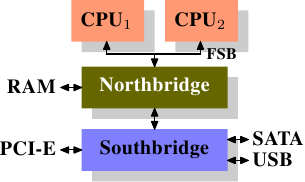
图2.1 北桥和南桥组成的结构
37 |
CPU通过一条通用总线(前端总线,FSB)连接到北桥。北桥主要包括内存控制器和其它一些组件,内存控制器决定了RAM芯片的类型。不同的类型,包括DRAM、Rambus和SDRAM等等,要求不同的内存控制器。
39 |为了连通其它系统设备,北桥需要与南桥通信。南桥又叫I/O桥,通过多条不同总线与设备们通信。目前,比较重要的总线有PCI、PCI Express、SATA和USB总线,除此以外,南桥还支持PATA、IEEE 1394、串行口和并行口等。比较老的系统上有连接北桥的AGP槽。那是由于南北桥间缺乏高速连接而采取的措施。现在的PCI-E都是直接连到南桥的。
40 |这种结构有一些需要注意的地方:
41 |第二个瓶颈来自北桥与RAM间的总线。总线的具体情况与内存的类型有关。在早期的系统上,只有一条总线,因此不能实现并行访问。近期的RAM需要两条独立总线(或者说通道,DDR2就是这么叫的,见图2.8),可以实现带宽加倍。北桥将内存访问交错地分配到两个通道上。更新的内存技术(如FB-DRAM)甚至加入了更多的通道。
49 |由于带宽有限,我们需要以一种使延迟最小化的方式来对内存访问进行调度。我们将会看到,处理器的速度比内存要快得多,需要等待内存。如果有多个超线程核心或CPU同时访问内存,等待时间则会更长。对于DMA也是同样。
50 |除了并发以外,访问模式也会极大地影响内存子系统、特别是多通道内存子系统的性能。关于访问模式,可参见2.2节。
51 |在一些比较昂贵的系统上,北桥自己不含内存控制器,而是连接到外部的多个内存控制器上(在下例中,共有4个)。
52 |53 |56 | 这种架构的好处在于,多条内存总线的存在,使得总带宽也随之增加了。而且也可以支持更多的内存。通过同时访问不同内存区,还可以降低延时。对于像图2.2中这种多处理器直连北桥的设计来说,尤其有效。而这种架构的局限在于北桥的内部带宽,非常巨大(来自Intel)。{出于完整性的考虑,还需要补充一下,这样的内存控制器布局还可以用于其它用途,比如说「内存RAID」,它可以与热插拔技术一起使用。} 57 |54 |

图2.2 拥有外部控制器的北桥
55 |
使用外部内存控制器并不是唯一的办法,另一个最近比较流行的方法是将控制器集成到CPU内部,将内存直连到每个CPU。这种架构的走红归功于基于AMD Opteron处理器的SMP系统。图2.3展示了这种架构。Intel则会从Nehalem处理器开始支持通用系统接口(CSI),基本上也是类似的思路——集成内存控制器,为每个处理器提供本地内存。
58 |59 |62 |60 |

图2.3 集成的内存控制器
61 |
通过采用这样的架构,系统里有几个处理器,就可以有几个内存库(memory bank)。比如,在4 CPU的计算机上,不需要一个拥有巨大带宽的复杂北桥,就可以实现4倍的内存带宽。另外,将内存控制器集成到CPU内部还有其它一些优点,这里就不赘述了。
63 |同样也有缺点。首先,系统仍然要让所有内存能被所有处理器所访问,导致内存不再是统一的资源(NUMA即得名于此)。处理器能以正常的速度访问本地内存(连接到该处理器的内存)。但它访问其它处理器的内存时,却需要使用处理器之间的互联通道。比如说,CPU 1如果要访问CPU 2的内存,则需要使用它们之间的互联通道。如果它需要访问CPU 4的内存,那么需要跨越两条互联通道。
64 |使用互联通道是有代价的。在讨论访问远端内存的代价时,我们用「NUMA因子」这个词。在图2.3中,每个CPU有两个层级: 相邻的CPU,以及两个互联通道外的CPU。在更加复杂的系统中,层级也更多。甚至有些机器有不止一种连接,比如说IBM的x445和SGI的Altix系列。CPU被归入节点,节点内的内存访问时间是一致的,或者只有很小的NUMA因子。而在节点之间的连接代价很大,而且有巨大的NUMA因子。
65 |目前,已经有商用的NUMA计算机,而且它们在未来应该会扮演更加重要的角色。人们预计,从2008年底开始,每台SMP机器都会使用NUMA。每个在NUMA上运行的程序都应该认识到NUMA的代价。在第5节中,我们将讨论更多的架构,以及Linux内核为这些程序提供的一些技术。
66 |除了本节中所介绍的技术之外,还有其它一些影响RAM性能的因素。它们无法被软件所左右,所以没有放在这里。如果大家有兴趣,可以在第2.1节中看一下。介绍这些技术,仅仅是因为它们能让我们绘制的RAM技术全图更为完整,或者是可能在大家购买计算机时能够提供一些帮助。
67 |以下的两节主要介绍一些入门级的硬件知识,同时讨论内存控制器与DRAM芯片间的访问协议。这些知识解释了内存访问的原理,程序员可能会得到一些启发。不过,这部分并不是必读的,心急的读者可以直接跳到第2.2.5节。
68 |这些年来,出现了许多不同类型的RAM,各有差异,有些甚至有非常巨大的不同。那些很古老的类型已经乏人问津,我们就不仔细研究了。我们主要专注于几类现代RAM,剖开它们的表面,研究一下内核和应用开发人员们可以看到的一些细节。
70 |第一个有趣的细节是,为什么在同一台机器中有不同的RAM?或者说得更详细一点,为什么既有静态RAM(SRAM {SRAM还可以表示「同步内存」。}),又有动态RAM(DRAM)。功能相同,前者更快。那么,为什么不全部使用SRAM?答案是,代价。无论在生产还是在使用上,SRAM都比DRAM要贵得多。生产和使用,这两个代价因子都很重要,后者则是越来越重要。为了理解这一点,我们分别看一下SRAM和DRAM一个位的存储的实现过程。
71 |在本节的余下部分,我们将讨论RAM实现的底层细节。我们将尽量控制细节的层面,比如,在「逻辑的层面」讨论信号,而不是硬件设计师那种层面,因为那毫无必要。
72 |74 |77 |75 |
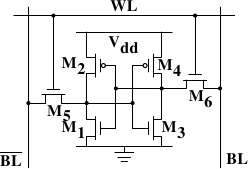
图2.6 6-T静态RAM
76 |
图2.4展示了6晶体管SRAM的一个单元。核心是4个晶体管M1-M4,它们组成两个交叉耦合的反相器。它们有两个稳定的状态,分别代表0和1。只要保持Vdd有电,状态就是稳定的。
78 |当需要访问单元的状态时,升起字访问线WL。BL和BL上就可以读取状态。如果需要覆盖状态,先将BL和BL设置为期望的值,然后升起WL。由于外部的驱动强于内部的4个晶体管,所以旧状态会被覆盖。
79 |更多详情,可以参考[sramwiki]。为了下文的讨论,需要注意以下问题:
80 |一个单元需要6个晶体管。也有采用4个晶体管的SRAM,但有缺陷。
81 |维持状态需要恒定的电源。
82 |升起WL后立即可以读取状态。信号与其它晶体管控制的信号一样,是直角的(快速在两个状态间变化)。
83 |状态稳定,不需要刷新循环。
84 |SRAM也有其它形式,不那么费电,但比较慢。由于我们需要的是快速RAM,因此不在关注范围内。这些较慢的SRAM的主要优点在于接口简单,比动态RAM更容易使用。
85 |动态RAM比静态RAM要简单得多。图2.5展示了一种普通DRAM的结构。它只含有一个晶体管和一个电容器。显然,这种复杂性上的巨大差异意味着功能上的迥异。
87 |88 |91 |89 |
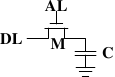
图2.5 1-T动态RAM
90 |
动态RAM的状态是保持在电容器C中。晶体管M用来控制访问。如果要读取状态,升起访问线AL,这时,可能会有电流流到数据线DL上,也可能没有,取决于电容器是否有电。如果要写入状态,先设置DL,然后升起AL一段时间,直到电容器充电或放电完毕。
92 |动态RAM的设计有几个复杂的地方。由于读取状态时需要对电容器放电,所以这一过程不能无限重复,不得不在某个点上对它重新充电。
93 |更糟糕的是,为了容纳大量单元(现在一般在单个芯片上容纳10的9次方以上的RAM单元),电容器的容量必须很小(0.000000000000001法拉以下)。这样,完整充电后大约持有几万个电子。即使电容器的电阻很大(若干兆欧姆),仍然只需很短的时间就会耗光电荷,称为「泄漏」。
94 |这种泄露就是现在的大部分DRAM芯片每隔64ms就必须进行一次刷新的原因。在刷新期间,对于该芯片的访问是不可能的,这甚至会造成半数任务的延宕。(相关内容请察看【highperfdram】一章)
95 |这个问题的另一个后果就是无法直接读取芯片单元中的信息,而必须通过信号放大器将0和1两种信号间的电势差增大。
96 |最后一个问题在于电容器的冲放电是需要时间的,这就导致了信号放大器读取的信号并不是典型的矩形信号。所以当放大器输出信号的时候就需要一个小小的延宕,相关公式如下
97 |98 |100 |99 |
这就意味着需要一些时间(时间长短取决于电容C和电阻R)来对电容进行冲放电。另一个负面作用是,信号放大器的输出电流不能立即就作为信号载体使用。图2.6显示了冲放电的曲线,x轴表示的是单位时间下的R*C
101 | 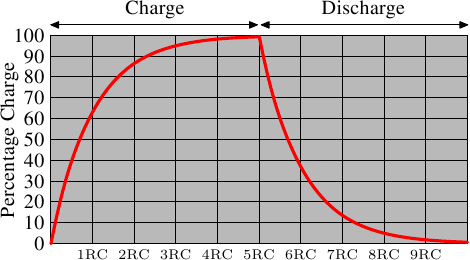
与静态RAM可以即刻读取数据不同的是,当要读取动态RAM的时候,必须花一点时间来等待电容的冲放电完全。这一点点的时间最终限制了DRAM的速度。
103 |当然了,这种读取方式也是有好处的。最大的好处在于缩小了规模。一个动态RAM的尺寸是小于静态RAM的。这种规模的减小不单单建立在动态RAM的简单结构之上,也是由于减少了静态RAM的各个单元独立的供电部分。以上也同时导致了动态RAM模具的简单化。
104 |综上所述,由于不可思议的成本差异,除了一些特殊的硬件(包括路由器什么的)之外,我们的硬件大多是使用DRAM的。这一点深深的影响了咱们这些程序员,后文将会对此进行讨论。在此之前,我们还是先了解下DRAM的更多细节。
105 |2.1.3 DRAM 访问
106 |一个程序选择了一个内存位置使用到了一个虚拟地址。处理器转换这个到物理地址最后将内存控制选择RAM芯片匹配了那个地址。在RAM芯片去选择单个内存单元,部分的物理地址以许多地址行的形式被传递。
107 |它单独地去处理来自于内存控制器的内存位置将完全不切实际:4G的RAM将需要 232 地址行。地址传递DRAM芯片的这种方式首先必须被路由器解析。一个路由器的N多地址行将有2N 输出行。这些输出行能被使用到选择内存单元。使用这个直接方法对于小容量芯片不再是个大问题
108 |但如果许多的单元生成这种方法不在适合。一个1G的芯片容量(我反感那些SI前缀,对于我一个giga-bit将总是230 而不是109字节)将需要30地址行和230 选项行。一个路由器的大小及许多的输入行以指数方式递增当速度不被牺牲时。一个30地址行路由器需要一大堆芯片的真实身份另外路由器也就复杂起来了。更重要的是,传递30脉冲在地址行同步要比仅仅传递15脉冲困难的多。较少列能精确布局相同长度或恰当的时机(现代DRAM类型像DDR3能自动调整时序但这个限制能让他什么都能忍受)
109 | 
图2.7展示了一个很高级别的一个DRAM芯片,DRAM被组织在行和列里。他们能在一行中对奇但DRAM芯片需要一个大的路由器。通过阵列方法设计能被一个路由器和一个半的multiplexer获得{多路复用器(multiplexer)和路由器是一样的,这的multiplexer需要以路由器身份工作当写数据时候。那么从现在开始我们开始讨论其区别.}这在所有方面会是一个大的存储。例如地址linesa0和a1通过行地址选择路由器来选择整个行的芯片的地址列,当读的时候,所有的芯片目录能使其纵列选择路由器可用,依据地址linesa2和a3一个纵列的目录用于数据DRAM芯片的接口类型。这发生了许多次在许多DRAM芯片产生一个总记录数的字节匹配给一个宽范围的数据总线。
111 |对于写操作,内存单元的数据新值被放到了数据总线,当使用RAS和CAS方式选中内存单元时,数据是存放在内存单元内的。这是一个相当直观的设计,在现实中——很显然——会复杂得多,对于读,需要规范从发出信号到数据在数据总线上变得可读的时延。电容不会像前面章节里面描述的那样立刻自动放电,从内存单元发出的信号是如此这微弱以至于它需要被放大。对于写,必须规范从数据RAS和CAS操作完成后到数据成功的被写入内存单元的时延(当然,电容不会立刻自动充电和放电)。这些时间常量对于DRAM芯片的性能是至关重要的,我们将在下章讨论它。
112 |另一个关于伸缩性的问题是,用30根地址线连接到每一个RAM芯片是行不通的。芯片的针脚是非常珍贵的资源,以至数据必须能并行传输就并行传输(比如:64位为一组)。内存控制器必须有能力解析每一个RAM模块(RAM芯片集合)。如果因为性能的原因要求并发行访问多个RAM模块并且每个RAM模块需要自己独占的30或多个地址线,那么对于8个RAM模块,仅仅是解析地址,内存控制器就需要240+之多的针脚。
113 | 在很长一段时间里,地址线被复用以解决DRAM芯片的这些次要的可扩展性问题。这意味着地址被转换成两部分。第一部分由地址位a0和a1选择行(如图2.7)。这个选择保持有效直到撤销。然后是第二部分,地址位a2和a3选择列。关键差别在于:只需要两根外部地址线。需要一些很少的线指明RAS和CAS信号有效,但是把地址线的数目减半所付出的代价更小。可是地址复用也带来自身的一些问题。我们将在2.2章中提到。 114 |2.1.4 总结
115 |如果这章节的内容有些难以应付,不用担心。纵观这章节的重点,有:
116 |在上文介绍DRAM的时候,我们已经看到DRAM芯片为了节约资源,对地址进行了复用。而且,访问DRAM单元是需要一些时间的,因为电容器的放电并不是瞬时的。此外,我们还看到,DRAM需要不停地刷新。在这一节里,我们将把这些因素拼合起来,看看它们是如何决定DRAM的访问过程。
125 |我们将主要关注在当前的科技上,不会再去讨论异步DRAM以及它的各种变体。如果对它感兴趣,可以去参考[highperfdram]及[arstechtwo]。我们也不会讨论Rambus DRAM(RDRAM),虽然它并不过时,但在系统内存领域应用不广。我们将主要介绍同步DRAM(SDRAM)及其后继者双倍速DRAM(DDR)。
126 |同步DRAM,顾名思义,是参照一个时间源工作的。由内存控制器提供一个时钟,时钟的频率决定了前端总线(FSB)的速度。FSB是内存控制器提供给DRAM芯片的接口。在我写作本文的时候,FSB已经达到800MHz、1066MHz,甚至1333MHz,并且下一代的1600MHz也已经宣布。但这并不表示时钟频率有这么高。实际上,目前的总线都是双倍或四倍传输的,每个周期传输2次或4次数据。报的越高,卖的越好,所以这些厂商们喜欢把四倍传输的200MHz总线宣传为“有效的”800MHz总线。
127 |以今天的SDRAM为例,每次数据传输包含64位,即8字节。所以FSB的传输速率应该是有效总线频率乘于8字节(对于4倍传输200MHz总线而言,传输速率为6.4GB/s)。听起来很高,但要知道这只是峰值速率,实际上无法达到的最高速率。我们将会看到,与RAM模块交流的协议有大量时间是处于非工作状态,不进行数据传输。我们必须对这些非工作时间有所了解,并尽量缩短它们,才能获得最佳的性能。
128 |130 |133 |131 |
图2.8: SDRAM读访问的时序 132 |
图2.8展示了某个DRAM模块一些连接器上的活动,可分为三个阶段,图上以不同颜色表示。按惯例,时间为从左向右流逝。这里忽略了许多细节,我们只关注时钟频率、RAS与CAS信号、地址总线和数据总线。首先,内存控制器将行地址放在地址总线上,并降低RAS信号,读周期开始。所有信号都在时钟(CLK)的上升沿读取,因此,只要信号在读取的时间点上保持稳定,就算不是标准的方波也没有关系。设置行地址会促使RAM芯片锁住指定的行。
134 |CAS信号在tRCD(RAS到CAS时延)个时钟周期后发出。内存控制器将列地址放在地址总线上,降低CAS线。这里我们可以看到,地址的两个组成部分是怎么通过同一条总线传输的。
135 |至此,寻址结束,是时候传输数据了。但RAM芯片任然需要一些准备时间,这个时间称为CAS时延(CL)。在图2.8中CL为2。这个值可大可小,它取决于内存控制器、主板和DRAM模块的质量。CL还可能是半周期。假设CL为2.5,那么数据将在蓝色区域内的第一个下降沿准备就绪。
136 |既然数据的传输需要这么多的准备工作,仅仅传输一个字显然是太浪费了。因此,DRAM模块允许内存控制指定本次传输多少数据。可以是2、4或8个字。这样,就可以一次填满高速缓存的整条线,而不需要额外的RAS/CAS序列。另外,内存控制器还可以在不重置行选择的前提下发送新的CAS信号。这样,读取或写入连续的地址就可以变得非常快,因为不需要发送RAS信号,也不需要把行置为非激活状态(见下文)。是否要将行保持为“打开”状态是内存控制器判断的事情。让它一直保持打开的话,对真正的应用会有不好的影响(参见[highperfdram])。CAS信号的发送仅与RAM模块的命令速率(Command Rate)有关(常常记为Tx,其中x为1或2,高性能的DRAM模块一般为1,表示在每个周期都可以接收新命令)。
137 |在上图中,SDRAM的每个周期输出一个字的数据。这是第一代的SDRAM。而DDR可以在一个周期中输出两个字。这种做法可以减少传输时间,但无法降低时延。DDR2尽管看上去不同,但在本质上也是相同的做法。对于DDR2,不需要再深入介绍了,我们只需要知道DDR2更快、更便宜、更可靠、更节能(参见[ddrtwo])就足够了。
138 |图2.8并不完整,它只画出了访问DRAM的完整循环的一部分。在发送RAS信号之前,必须先把当前锁住的行置为非激活状态,并对新行进行预充电。在这里,我们主要讨论由于显式发送指令而触发以上行为的情况。协议本身作了一些改进,在某些情况下是可以省略这个步骤的,但预充电带来的时延还是会影响整个操作。
140 |141 |144 |142 |
图2.9: SDRAM的预充电与激活 143 |
图2.9显示的是两次CAS信号的时序图。第一次的数据在CL周期后准备就绪。图中的例子里,是在SDRAM上,用两个周期传输了两个字的数据。如果换成DDR的话,则可以传输4个字。
145 |即使是在一个命令速率为1的DRAM模块上,也无法立即发出预充电命令,而要等数据传输完成。在上图中,即为两个周期。刚好与CL相同,但只是巧合而已。预充电信号并没有专用线,某些实现是用同时降低写使能(WE)线和RAS线的方式来触发。这一组合方式本身没有特殊的意义(参见[micronddr])。
146 |发出预充电信命令后,还需等待tRP(行预充电时间)个周期之后才能使行被选中。在图2.9中,这个时间(紫色部分)大部分与内存传输的时间(淡蓝色部分)重合。不错。但tRP大于传输时间,因此下一个RAS信号只能等待一个周期。
147 |如果我们补充完整上图中的时间线,最后会发现下一次数据传输发生在前一次的5个周期之后。这意味着,数据总线的7个周期中只有2个周期才是真正在用的。再用它乘于FSB速度,结果就是,800MHz总线的理论速率6.4GB/s降到了1.8GB/s。真是太糟了。第6节将介绍一些技术,可以帮助我们提高总线有效速率。程序员们也需要尽自己的努力。
148 |SDRAM还有一些定时值,我们并没有谈到。在图2.9中,预充电命令仅受制于数据传输时间。除此之外,SDRAM模块在RAS信号之后,需要经过一段时间,才能进行预充电(记为tRAS)。它的值很大,一般达到tRP的2到3倍。如果在某个RAS信号之后,只有一个CAS信号,而且数据只传输很少几个周期,那么就有问题了。假设在图2.9中,第一个CAS信号是直接跟在一个RAS信号后免的,而tRAS为8个周期。那么预充电命令还需要被推迟一个周期,因为tRCD、CL和tRP加起来才7个周期。
149 |DDR模块往往用w-z-y-z-T来表示。例如,2-3-2-8-T1,意思是:
150 |151 | w 2 CAS时延(CL) 152 |160 |
x 3 RAS-to-CAS时延(t 153 | RCD) 154 |
y 2 RAS预充电时间(t 155 | RP) 156 |
z 8 激活到预充电时间(t 157 | RAS) 158 |
T T1 命令速率 159 |
当然,除以上的参数外,还有许多其它参数影响命令的发送与处理。但以上5个参数已经足以确定模块的性能。
161 |在解读计算机性能参数时,这些信息可能会派上用场。而在购买计算机时,这些信息就更有用了,因为它们与FSB/SDRAM速度一起,都是决定计算机速度的关键因素。
162 |喜欢冒险的读者们还可以利用它们来调优系统。有些计算机的BIOS可以让你修改这些参数。SDRAM模块有一些可编程寄存器,可供设置参数。BIOS一般会挑选最佳值。如果RAM模块的质量足够好,我们可以在保持系统稳定的前提下将减小以上某个时延参数。互联网上有大量超频网站提供了相关的文档。不过,这是有风险的,需要大家自己承担,可别怪我没有事先提醒哟。
163 |谈到DRAM的访问时,重充电是常常被忽略的一个主题。在2.1.2中曾经介绍,DRAM必须保持刷新。……行在充电时是无法访问的。[highperfdram]的研究发现,“令人吃惊,DRAM刷新对性能有着巨大的影响”。
165 |根据JEDEC规范,DRAM单元必须保持每64ms刷新一次。对于8192行的DRAM,这意味着内存控制器平均每7.8125µs就需要发出一个刷新命令(在实际情况下,由于刷新命令可以纳入队列,因此这个时间间隔可以更大一些)。刷新命令的调度由内存控制器负责。DRAM模块会记录上一次刷新行的地址,然后在下次刷新请求时自动对这个地址进行递增。
166 |对于刷新及发出刷新命令的时间点,程序员无法施加影响。但我们在解读性能参数时有必要知道,它也是DRAM生命周期的一个部分。如果系统需要读取某个重要的字,而刚好它所在的行正在刷新,那么处理器将会被延迟很长一段时间。刷新的具体耗时取决于DRAM模块本身。
167 |我们有必要花一些时间来了解一下目前流行的内存,以及那些即将流行的内存。首先从SDR(单倍速)SDRAM开始,因为它们是DDR(双倍速)SDRAM的基础。SDR非常简单,内存单元和数据传输率是相等的。
169 |170 |173 |171 |
图2.10: SDR SDRAM的操作 172 |
在图2.10中,DRAM单元阵列能以等同于内存总线的速率输出内容。假设DRAM单元阵列工作在100MHz上,那么总线的数据传输率可以达到100Mb/s。所有组件的频率f保持相同。由于提高频率会导致耗电量增加,所以提高吞吐量需要付出很高的的代价。如果是很大规模的内存阵列,代价会非常巨大。{功率 = 动态电容 x 电压2 x 频率}。而且,提高频率还需要在保持系统稳定的情况下提高电压,这更是一个问题。因此,就有了DDR SDRAM(现在叫DDR1),它可以在不提高频率的前提下提高吞吐量。
174 |175 |178 |176 |
图2.11 DDR1 SDRAM的操作 177 |
我们从图2.11上可以看出DDR1与SDR的不同之处,也可以从DDR1的名字里猜到那么几分,DDR1的每个周期可以传输两倍的数据,它的上升沿和下降沿都传输数据。有时又被称为“双泵(double-pumped)”总线。为了在不提升频率的前提下实现双倍传输,DDR引入了一个缓冲区。缓冲区的每条数据线都持有两位。它要求内存单元阵列的数据总线包含两条线。实现的方式很简单,用同一个列地址同时访问两个DRAM单元。对单元阵列的修改也很小。
179 |SDR DRAM是以频率来命名的(例如,对应于100MHz的称为PC100)。为了让DDR1听上去更好听,营销人员们不得不想了一种新的命名方案。这种新方案中含有DDR模块可支持的传输速率(DDR拥有64位总线):
180 |181 | 100MHz x 64位 x 2 = 1600MB/s 182 |183 |
于是,100MHz频率的DDR模块就被称为PC1600。由于1600 > 100,营销方面的需求得到了满足,听起来非常棒,但实际上仅仅只是提升了两倍而已。{我接受两倍这个事实,但不喜欢类似的数字膨胀戏法。}
184 |185 |189 |186 |
187 | 图2.12: DDR2 SDRAM的操作 188 |
为了更进一步,DDR2有了更多的创新。在图2.12中,最明显的变化是,总线的频率加倍了。频率的加倍意味着带宽的加倍。如果对单元阵列的频率加倍,显然是不经济的,因此DDR2要求I/O缓冲区在每个时钟周期读取4位。也就是说,DDR2的变化仅在于使I/O缓冲区运行在更高的速度上。这是可行的,而且耗电也不会显著增加。DDR2的命名与DDR1相仿,只是将因子2替换成4(四泵总线)。图2.13显示了目前常用的一些模块的名称。
190 |191 |240 |192 | 193 |
237 |194 | 200 |阵列频率 195 |总线频率 196 |数据率 197 |名称(速率) 198 |名称 199 |
(FSB)201 | 207 |133MHz 202 |266MHz 203 |4,256MB/s 204 |PC2-4200 205 |DDR2-533 206 |208 | 214 |166MHz 209 |333MHz 210 |5,312MB/s 211 |PC2-5300 212 |DDR2-667 213 |215 | 221 |200MHz 216 |400MHz 217 |6,400MB/s 218 |PC2-6400 219 |DDR2-800 220 |222 | 228 |250MHz 223 |500MHz 224 |8,000MB/s 225 |PC2-8000 226 |DDR2-1000 227 |229 | 235 | 236 |266MHz 230 |533MHz 231 |8,512MB/s 232 |PC2-8500 233 |DDR2-1066 234 |
238 | 图2.13: DDR2模块名 239 |
在命名方面还有一个拧巴的地方。FSB速度是用有效频率来标记的,即把上升、下降沿均传输数据的因素考虑进去,因此数字被撑大了。所以,拥有266MHz总线的133MHz模块有着533MHz的FSB“频率”。
241 |DDR3要求更多的改变(这里指真正的DDR3,而不是图形卡中假冒的GDDR3)。电压从1.8V下降到1.5V。由于耗电是与电压的平方成正比,因此可以节约30%的电力。加上管芯(die)的缩小和电气方面的其它进展,DDR3可以在保持相同频率的情况下,降低一半的电力消耗。或者,在保持相同耗电的情况下,达到更高的频率。又或者,在保持相同热量排放的情况下,实现容量的翻番。
242 |DDR3模块的单元阵列将运行在内部总线的四分之一速度上,DDR3的I/O缓冲区从DDR2的4位提升到8位。见图2.14。
243 |244 |248 |245 |
246 | 图2.14: DDR3 SDRAM的操作 247 |
一开始,DDR3可能会有较高的CAS时延,因为DDR2的技术相比之下更为成熟。由于这个原因,DDR3可能只会用于DDR2无法达到的高频率下,而且带宽比时延更重要的场景。此前,已经有讨论指出,1.3V的DDR3可以达到与DDR2相同的CAS时延。无论如何,更高速度带来的价值都会超过时延增加带来的影响。
249 |DDR3可能会有一个问题,即在1600Mb/s或更高速率下,每个通道的模块数可能会限制为1。在早期版本中,这一要求是针对所有频率的。我们希望这个要求可以提高一些,否则系统容量将会受到严重的限制。
250 |图2.15显示了我们预计中各DDR3模块的名称。JEDEC目前同意了前四种。由于Intel的45nm处理器是1600Mb/s的FSB,1866Mb/s可以用于超频市场。随着DDR3的发展,可能会有更多类型加入。
251 |252 |300 |253 | 254 |
298 | 图2.15: DDR3模块名 299 |255 | 261 |阵列频率 256 |总线频率 257 |数据速率 258 |名称(速率) 259 |名称 260 |
(FSB)262 | 268 |100MHz 263 |400MHz 264 |6,400MB/s 265 |PC3-6400 266 |DDR3-800 267 |269 | 275 |133MHz 270 |533MHz 271 |8,512MB/s 272 |PC3-8500 273 |DDR3-1066 274 |276 | 282 |166MHz 277 |667MHz 278 |10,667MB/s 279 |PC3-10667 280 |DDR3-1333 281 |283 | 289 |200MHz 284 |800MHz 285 |12,800MB/s 286 |PC3-12800 287 |DDR3-1600 288 |290 | 296 | 297 |233MHz 291 |933MHz 292 |14,933MB/s 293 |PC3-14900 294 |DDR3-1866 295 |
所有的DDR内存都有一个问题:不断增加的频率使得建立并行数据总线变得十分困难。一个DDR2模块有240根引脚。所有到地址和数据引脚的连线必须被布置得差不多一样长。更大的问题是,如果多于一个DDR模块通过菊花链连接在同一个总线上,每个模块所接收到的信号随着模块的增加会变得越来越扭曲。DDR2规范允许每条总线(又称通道)连接最多两个模块,DDR3在高频率下只允许每个通道连接一个模块。每条总线多达240根引脚使得单个北桥无法以合理的方式驱动两个通道。替代方案是增加外部内存控制器(如图2.2),但这会提高成本。
301 |这意味着商品主板所搭载的DDR2或DDR3模块数将被限制在最多四条,这严重限制了系统的最大内存容量。即使是老旧的32位IA-32处理器也可以使用64GB内存。即使是家庭对内存的需求也在不断增长,所以,某些事必须开始做了。
302 |一种解法是,在处理器中加入内存控制器,我们在第2节中曾经介绍过。AMD的Opteron系列和Intel的CSI技术就是采用这种方法。只要我们能把处理器要求的内存连接到处理器上,这种解法就是有效的。如果不能,按照这种思路就会引入NUMA架构,当然同时也会引入它的缺点。而在有些情况下,我们需要其它解法。
303 |Intel针对大型服务器方面的解法(至少在未来几年),是被称为全缓冲DRAM(FB-DRAM)的技术。FB-DRAM采用与DDR2相同的器件,因此造价低廉。不同之处在于它们与内存控制器的连接方式。FB-DRAM没有用并行总线,而用了串行总线(Rambus DRAM had this back when, too, 而SATA是PATA的继任者,就像PCI Express是PCI/AGP的继承人一样)。串行总线可以达到更高的频率,串行化的负面影响,甚至可以增加带宽。使用串行总线后
304 |FB-DRAM只有69个脚。通过菊花链方式连接多个FB-DRAM也很简单。FB-DRAM规范允许每个通道连接最多8个模块。
310 |在对比下双通道北桥的连接性,采用FB-DRAM后,北桥可以驱动6个通道,而且脚数更少——6x69对比2x240。每个通道的布线也更为简单,有助于降低主板的成本。
311 |全双工的并行总线过于昂贵。而换成串行线后,这不再是一个问题,因此串行总线按全双工来设计的,这也意味着,在某些情况下,仅靠这一特性,总线的理论带宽已经翻了一倍。还不止于此。由于FB-DRAM控制器可同时连接6个通道,因此可以利用它来增加某些小内存系统的带宽。对于一个双通道、4模块的DDR2系统,我们可以用一个普通FB-DRAM控制器,用4通道来实现相同的容量。串行总线的实际带宽取决于在FB-DRAM模块中所使用的DDR2(或DDR3)芯片的类型。
312 |我们可以像这样总结这些优势:
313 |314 | DDR2 FB-DRAM 315 |316 |
317 |如果在单个通道上使用多个DIMM,会有一些问题。信号在每个DIMM上都会有延迟(尽管很小),也就是说,延迟是递增的。不过,如果在相同频率和相同容量上进行比较,FB-DRAM总是能快过DDR2及DDR3,因为FB-DRAM只需要在每个通道上使用一个DIMM即可。而如果说到大型内存系统,那么DDR更是没有商用组件的解决方案。 352 |318 | 319 |
351 |320 | 324 |321 |
DDR2 322 |FB-DRAM 323 |325 | 329 |脚 326 |240 327 |69 328 |330 | 334 |通道 331 |2 332 |6 333 |335 | 339 |每通道DIMM数 336 |2 337 |8 338 |340 | 344 |最大内存 341 |16GB 342 |192GB 343 |345 | 349 | 350 |吞吐量 346 |~10GB/s 347 |~40GB/s 348 |
通过本节,大家应该了解到访问DRAM的过程并不是一个快速的过程。至少与处理器的速度相比,或与处理器访问寄存器及缓存的速度相比,DRAM的访问不算快。大家还需要记住CPU和内存的频率是不同的。Intel Core 2处理器运行在2.933GHz,而1.066GHz FSB有11:1的时钟比率(注: 1.066GHz的总线为四泵总线)。那么,内存总线上延迟一个周期意味着处理器延迟11个周期。绝大多数机器使用的DRAM更慢,因此延迟更大。在后续的章节中,我们需要讨论延迟这个问题时,请把以上的数字记在心里。
354 |前文中读命令的时序图表明,DRAM模块可以支持高速数据传输。每个完整行可以被毫无延迟地传输。数据总线可以100%被占。对DDR而言,意味着每个周期传输2个64位字。对于DDR2-800模块和双通道而言,意味着12.8GB/s的速率。
355 |但是,除非是特殊设计,DRAM的访问并不总是串行的。访问不连续的内存区意味着需要预充电和RAS信号。于是,各种速度开始慢下来,DRAM模块急需帮助。预充电的时间越短,数据传输所受的惩罚越小。
356 |硬件和软件的预取(参见第6.3节)可以在时序中制造更多的重叠区,降低延迟。预取还可以转移内存操作的时间,从而减少争用。我们常常遇到的问题是,在这一轮中生成的数据需要被存储,而下一轮的数据需要被读出来。通过转移读取的时间,读和写就不需要同时发出了。
357 |除了CPU外,系统中还有其它一些组件也可以访问主存。高性能网卡或大规模存储控制器是无法承受通过CPU来传输数据的,它们一般直接对内存进行读写(直接内存访问,DMA)。在图2.1中可以看到,它们可以通过南桥和北桥直接访问内存。另外,其它总线,比如USB等也需要FSB带宽,即使它们并不使用DMA,但南桥仍要通过FSB连接到北桥。
359 |DMA当然有很大的优点,但也意味着FSB带宽会有更多的竞争。在有大量DMA流量的情况下,CPU在访问内存时必然会有更大的延迟。我们可以用一些硬件来解决这个问题。例如,通过图2.3中的架构,我们可以挑选不受DMA影响的节点,让它们的内存为我们的计算服务。还可以在每个节点上连接一个南桥,将FSB的负荷均匀地分担到每个节点上。除此以外,还有许多其它方法。我们将在第6节中介绍一些技术和编程接口,它们能够帮助我们通过软件的方式改善这个问题。
360 |最后,还需要提一下某些廉价系统,它们的图形系统没有专用的显存,而是采用主存的一部分作为显存。由于对显存的访问非常频繁(例如,对于1024x768、16bpp、60Hz的显示设置来说,需要95MB/s的数据速率),而主存并不像显卡上的显存,并没有两个端口,因此这种配置会对系统性能、尤其是时延造成一定的影响。如果大家对系统性能要求比较高,最好不要采用这种配置。这种系统带来的问题超过了本身的价值。人们在购买它们时已经做好了性能不佳的心理准备。
361 |继续阅读:
362 |导读:Kristóf Kovács 是一位软件架构师和咨询顾问,他最近发布了一片对比各种类型NoSQL数据库的文章。
2 |虽然SQL数据库是非常有用的工具,但经历了15年的一支独秀之后垄断即将被打破。这只是时间问题:被迫使用关系数据库,但最终发现不能适应需求的情况不胜枚举。
3 |但是NoSQL数据库之间的不同,远超过两 SQL数据库之间的差别。这意味着软件架构师更应该在项目开始时就选择好一个适合的 NoSQL数据库。针对这种情况,这里对 Cassandra、Mongodb、CouchDB、Redis、 Riak、Membase、Neo4j 和 HBase 进行了比较:
4 |(编注1:NoSQL:是一项全新的数据库革命性运动,NoSQL的拥护者们提倡运用非关系型的数据存储。现今的计算机体系结构在数据存储方面要求具 备庞大的水平扩 展性,而NoSQL致力于改变这一现状。目前Google的 BigTable 和Amazon 的Dynamo使用的就是NoSQL型数据库。 参见NoSQL词条。)
5 |6 |
1. CouchDB
7 |30 |
最佳应用场景:适用于数据变化较少,执行预定义查询,进行数据统计的应用程序。适用于需要提供数据版本支持的应用程序。
31 |例如: CRM、CMS系统。 master-master复制对于多站点部署是非常有用的。
32 |(编注2:master-master复制:是一种数据库同步方法,允许数据在一组计算机之间共享数据,并且可以通过小组中任意成员在组内进行数据更新。)
33 |34 |
2. Redis
35 |54 |
最佳应用场景:适用于数据变化快且数据库大小可遇见(适合内存容量)的应用程序。
55 |例如:股票价格、数据分析、实时数据搜集、实时通讯。
56 |(编注3:Master-slave复制:如果同一时刻只有一台服务器处理所有的复制请求,这被称为 Master-slave复制,通常应用在需要提供高可用性的服务器集群。)
57 |58 |
3. MongoDB
59 |77 |
最佳应用场景:适用于需要动态查询支持;需要使用索引而不是 map/reduce功能;需要对大数据库有性能要求;需要使用 CouchDB但因为数据改变太频繁而占满内存的应用程序。
78 |例如:你本打算采用 MySQL或 PostgreSQL,但因为它们本身自带的预定义栏让你望而却步。
79 |80 |
4. Riak
81 |97 |
最佳应用场景:适用于想使用类似 Cassandra(类似Dynamo)数据库但无法处理 bloat及复杂性的情况。适用于你打算做多站点复制,但又需要对单个站点的扩展性,可用性及出错处理有要求的情况。
98 |例如:销售数据搜集,工厂控制系统;对宕机时间有严格要求;可以作为易于更新的 web服务器使用。
99 |5. Membase
100 |115 |
最佳应用场景:适用于需要低延迟数据访问,高并发支持以及高可用性的应用程序
116 |例如:低延迟数据访问比如以广告为目标的应用,高并发的 web 应用比如网络游戏(例如 Zynga)
117 |118 |
6. Neo4j
119 |136 |
最佳应用场景:适用于图形一类数据。这是 Neo4j与其他nosql数据库的最显著区别
137 |例如:社会关系,公共交通网络,地图及网络拓谱
138 |139 |
7. Cassandra
140 |153 |
最佳应用场景:当使用写操作多过读操作(记录日志)如果每个系统组建都必须用 Java编写(没有人因为选用 Apache的软件被解雇)
154 |例如:银行业,金融业(虽然对于金融交易不是必须的,但这些产业对数据库的要求会比它们更大)写比读更快,所以一个自然的特性就是实时数据分析
155 |156 |
8. HBase
157 |(配合 ghshephard使用)
158 |176 |
最佳应用场景:适用于偏好BigTable:)并且需要对大数据进行随机、实时访问的场合。
177 |例如: Facebook消息数据库(更多通用的用例即将出现)
178 |编注4:Thrift 是一种接口定义语言,为多种其他语言提供定义和创建服务,由Facebook开发并开源。
179 |当然,所有的系统都不只具有上面列出的这些特性。这里我仅仅根据自己的观点列出一些我认为的重要特性。与此同时,技术进步是飞速的,所以上述的内容肯定需要不断更新。我会尽我所能地更新这个列表。
180 |-------------------------------------------------------------------------------- /src/picture-server.md: -------------------------------------------------------------------------------- 1 |
现在几乎任何一个网站、Web App以及移动APP等应用都需要有图片展示的功能,对于图片功能从下至上都是很重要的。必须要具有前瞻性的规划好图片服务器,图片的上传和下载速度至关重要,当然这并不是说一上来就搞很NB的架构,至少具备一定扩展性和稳定性。虽然各种架构设计都有,在这里我只是谈谈我的一些个人想法。
2 |3 |
4 |
对于图片服务器来说IO无疑是消耗资源最为严重的,对于web应用来说需要将图片服务器做一定的分离,否则很可能因为图片服务器的IO负载导致应用崩溃。因此尤其对于大型网站和应用来说,非常有必要将图片服务器和应用服务器分离,构建独立的图片服务器集群,构建独立的图片服务器其主要优势:
5 |1)分担Web服务器的I/O负载-将耗费资源的图片服务分离出来,提高服务器的性能和稳定性。
6 |2)能够专门对图片服务器进行优化-为图片服务设置有针对性的缓存方案,减少带宽网络成本,提高访问速度。
7 |3)提高网站的可扩展性-通过增加图片服务器,提高图片服务吞吐能力。
8 |9 |
从传统互联网的web1.0,历经web2.0时代以及发展到现在的web3.0,随着图片存储规模的增加,图片服务器的架构也在逐渐发生变化,以下主要论述三个阶段的图片服务器架构演进。
10 |11 |
初始阶段
12 |
在介绍初始阶段的早期的小型图片服务器架构之前,首先让我们了解一下NFS技术,NFS是Network File System的缩写,即网络文件系统。NFS是由Sun开发并发展起来的一项用于在不同机器,不同操作系统之间通过网络互相分享各自的文件。NFS server也可以看作是一个FILE SERVER,用于在UNIX类系统之间共享文件,可以轻松的挂载(mount)到一个目录上,操作起来就像本地文件一样的方便。
14 |15 |
如果不想在每台图片服务器同步所有图片,那么NFS是最简单的文件共享方式。NFS是个分布式的客户机/服务器文件系统,NFS的实质在于用户间计算机的共享,用户可以联结到共享计算机并象访问本地硬盘一样访问共享计算机上的文件。具体实现思路是:
16 |17 |
1)所有前端web服务器都通过nfs挂载3台图片服务器export出来的目录,以接收web服务器写入的图片。然后[图片1]服务器挂载另外两台图片服务器的export目录到本地给apache对外提供访问。
18 | 2) 用户上传图片
19 | 用户通过Internet访问页面提交上传请求post到web服务器,web服务器处理完图片后由web服务器拷贝到对应的mount本地目录。
20 | 3)用户访问图片
21 | 用户访问图片时,通过[图片1]这台图片服务器来读取相应mount目录里边的图片。
23 |
以上架构存在的问题:
24 |1)性能:现有结构过度依赖nfs,当图片服务器的nfs服务器有问题时,可能影响到前端web服务器。NFS的问题主要是锁的问题. 很容易造成死锁, 只有硬件重启才能解决。尤其当图片达到一定的量级后,nfs会有严重的性能问题。
25 | 2)高可用:对外提供下载的图片服务器只有一台,容易出现单点故障。
26 | 3) 扩展性:图片服务器之间的依赖过多,而且横向扩展余地不够。
27 | 4) 存储:web服务器上传热点不可控,造成现有图片服务器空间占用不均衡。
28 | 5) 安全性:nfs方式对于拥有web服务器的密码的人来说,可以随意修改nfs里边的内容,安全级别不高。
30 |
当然图片服务器的图片同步可以不采用NFS,也可以采用ftp或rsync,采用ftp这样的话每个图片服务器就都保存一份图片的副本,也起到了备份的作用。但是缺点是将图片ftp到服务器比较耗时,如果使用异步方式去同步图片的话又会有延时,不过一般的小图片文件也还好了。使用rsync同步,当数据文件达到一定的量级后,每次rsync扫描会耗时很久也会带来一定的延时性。
31 |32 |
33 |
发展阶段
34 |35 |

37 |
当网站达到一定的规模后,对图片服务器的性能和稳定性有一定的要求后,上述NFS图片服务架构面临着挑战,严重的依赖NFS,而且系统存在单点机器容易出现故障,需要对整体架构进行升级。于是出现了上图图片服务器架构,出现了分布式的图片存储。
38 |39 |
其实现的具体思路如下:
40 |1)用户上传图片到web服务器后,web服务器处理完图片,然后再由前端web服务器把图片post到到[图片1]、[图片2]…[图片N]其中的一个,图片服务器接收到post过来的图片,然后把图片写入到本地磁盘并返回对应成功状态码。前端web服务器根据返回状态码决定对应操作,如果成功的话,处理生成各尺寸的缩略图、打水印,把图片服务器对应的ID和对应图片路径写入DB数据库。
41 | 2) 上传控制
42 | 我们需要调节上传时,只需要修改web服务器post到的目的图片服务器的ID,就可以控制上传到哪台图片存储服务器,对应的图片存储服务器只需要安装nginx同时提供一个python或者php服务接收并保存图片,如果不想不想开启python或者php服务,也可以编写一个nginx扩展模块。
3) 用户访问流程
44 | 用户访问页面的时候,根据请求图片的URL到对应图片服务器去访问图片。
如: http://imgN.xxx.com/image1.jpg
46 |47 |
此阶段的图片服务器架构,增加了负载均衡和分布式图片存储,能够在一定程度上解决并发访问量高和存储量大的问题。负载均衡在有一定财力的情况下可以考虑F5硬负载,当然也可以考虑使用开源的LVS软负载(同时还可开启缓存功能)。此时将极大提升访问的并发量,可以根据情况随时调配服务器。当然此时也存在一定的瑕疵,那就是可能在多台Squid上存在同一张图片,因为访问图片时可能第一次分到squid1,在LVS过期后第二次访问到squid2或者别的,当然相对并发问题的解决,此种少量的冗余完全在我们的允许范围之内。在该系统架构中二级缓存可以使用squid也可以考虑使用varnish或者traffic server,对于cache的开源软件选型要考率以下几点
48 |49 |
1)性能:varnish本身的技术上优势要高于squid,它采用了“Visual Page Cache”技术,在内存的利用上,Varnish比Squid具有优势,它避免了Squid频繁在内存、磁盘中交换文件,性能要比Squid高。varnish是不能cache到本地硬盘上的。还有强大的通过Varnish管理端口,可以使用正则表达式快速、批量地清除部分缓存。nginx是用第三方模块ncache做的缓冲,其性能基本达到varnish,但在架构中nginx一般作为反向(静态文件现在用nginx的很多,并发能支持到2万+)。在静态架构中,如果前端直接面对的是cdn活着前端了4层负载的话,完全用nginx的cache就够了。
50 |51 |
2)避免文件系统式的缓存,在文件数据量非常大的情况下,文件系统的性能很差,像squid,nginx的proxy_store,proxy_cache之类的方式缓存,当缓存的量级上来后,性能将不能满足要求。开源的traffic server直接用裸盘缓存,是一个不错的选择,国内大规模应用并公布出来的主要是淘宝,并不是因为它做的差,而是开源时间晚。Traffic Server 在 Yahoo 内部使用了超过 4 年,主要用于 CDN 服务,CDN 用于分发特定的HTTP 内容,通常是静态的内容如图片、JavaScript、CSS。当然使用leveldb之类的做缓存,我估计也能达到很好的效果。
52 |53 |
3)稳定性:squid作为老牌劲旅缓存,其稳定性更可靠一些,从我身边一些使用者反馈来看varnish偶尔会出现crash的情况。Traffic Server在雅虎目前使用期间也没有出现已知的数据损坏情况,其稳定性相对也比较可靠,对于未来我其实更期待Traffic Server在国内能够拥有更多的用户。
54 |以上图片服务架构设计消除了早期的NFS依赖以及单点问题,时能够均衡图片服务器的空间,提高了图片服务器的安全性等问题,但是又带来一个问题是图片服务器的横向扩展冗余问题。只想在普通的硬盘上存储,首先还是要考虑一下物理硬盘的实际处理能力。是 7200 转的还是 15000 转的,实际表现差别就很大。至于文件系统选择xfs、ext3、ext4还是reiserFs,需要做一些性能方面的测试,从官方的一些测试数据来看,reiserFs更适合存储一些小图片文件。创建文件系统的时候 Inode 问题也要加以考虑,选择合适大小的 inode size ,因为Linux 为每个文件分配一个称为索引节点的号码inode,可以将inode简单理解成一个指针,它永远指向本文件的具体存储位置。一个文件系统允许的inode节点数是有限的,如果文件数量太多,即使每个文件都是0字节的空文件,系统最终也会因为节点空间耗尽而不能再创建文件,因此需要在空间和速度上做取舍,构造合理的文件目录索引。
55 |56 |
57 |
云存储阶段
58 |
60 |
2011年李彦宏在百度联盟峰会上就提到过互联网的读图时代已经到来,图片服务早已成为一个互联网应用中占比很大的部分,对图片的处理能力也相应地变成企业和开发者的一项基本技能,图片的下载和上传速度显得更加重要,要想处理好图片,需要面对的三个主要问题是:大流量、高并发、海量存储。
61 |62 |
阿里云存储服务(OpenStorageService,简称OSS),是阿里云对外提供的海量,安全,低成本,高可靠的云存储服务。用户可以通过简单的 REST接口,在任何时间、任何地点上传和下载数据,也可以使用WEB页面对数据进行管理。同时,OSS提供Java、Python、PHP SDK,简化用户的编程。基于OSS,用户可以搭建出各种多媒体分享网站、网盘、个人企业数据备份等基于大规模数据的服务。在以下图片云存储主要以阿里云的云存储OSS为切入点介绍,上图为OSS云存储的简单架构示意图。
63 |64 |
真正意义上的“云存储”,不是存储而是提供云服务,使用云存储服务的主要优势有以下几点:
65 |1)用户无需了解存储设备的类型、接口、存储介质等。
66 |2)无需关心数据的存储路径。
67 |3)无需对存储设备进行管理、维护。
68 |4)无需考虑数据备份和容灾
69 |5)简单接入云存储,尽情享受存储服务。
70 | 71 | 72 | 73 |74 |
75 |

1)KV Engine
78 |OSS中的Object源信息和数据文件都是存放在KV Engine上。在6.15的版本,V Engine将使用0.8.6版本,并使用为OSS提供的OSSFileClient。
79 |80 |
2)Quota
81 |此模块记录了Bucket和用户的对应关系,和以分钟为单位的Bucket资源使用情况。Quota还将提供HTTP接口供Boss系统查询。
82 |83 |
3)安全模块
84 |安全模块主要记录User对应的ID和Key,并提供OSS访问的用户验证功能。
85 | 86 | 87 |88 |
90 |
1 )Access Key ID & Access Key Secret (API密钥)
91 | 用户注册OSS时,系统会给用户分配一对Access Key ID & Access Key Secret,称为ID对,用于标识用户,为访问OSS做签名验证。
93 |
2) Service
94 | OSS提供给用户的虚拟存储空间,在这个虚拟空间中,每个用户可拥有一个到多个Bucket。
96 |
3) Bucket
97 | Bucket是OSS上的命名空间;Bucket名在整个OSS中具有全局唯一性,且不能修改;存储在OSS上的每个Object必须都包含在某个Bucket中。一个应用,例如图片分享网站,可以对应一个或多个Bucket。一个用户最多可创建10个Bucket,但每个Bucket中存放的Object的数量和大小总和没有限制,用户不需要考虑数据的可扩展性。
4) Object
99 | 在OSS中,用户的每个文件都是一个Object,每个文件需小于5TB。Object包含key、data和user meta。其中,key是Object的名字;data是Object的数据;user meta是用户对该object的描述。
100 | 其使用方式非常简单,如下为java sdk:
OSSClient ossClient = new OSSClient(accessKeyId,accessKeySecret);
102 |PutObjectResult result = ossClient.putObject(bucketname, bucketKey, inStream, new ObjectMetadata());
103 |执行以上代码即可将图片流上传至OSS服务器上。
104 |图片的访问方式也非常简单其url为:http://bucketname.oss.aliyuncs.com/bucketKey
105 |106 |
107 |
分布式文件系统
108 |用分布式存储有几个好处,分布式能自动提供冗余,不需要我们去备份,担心数据安全,在文件数量特别大的情况下,备份是一件很痛苦的事情,rsync扫一次可能是就是好几个小时,还有一点就是分布式存储动态扩容方便。当然在国内的其他一些文件系统里,TFS(http://code.taobao.org/p/tfs/src/)和FASTDFS也有一些用户,但是TFS的优势更是针对一些小文件存储,主要是淘宝在用。另外FASTDFS在并发高于300写入的情况下出现性能问题,稳定性不够友好。OSS存储使用的是阿里云基于飞天5k平台自主研发的高可用,高可靠的分布式文件系统盘古。分布式文件系统盘古和Google的GFS类似,盘古的架构是Master-Slave主从架构,Master负责元数据管理,Sliave叫做Chunk Server,负责读写请求。其中Master是基于Paxos的多Master架构,一个Master死了之后,另外一个Master可以很快接过去,基本能够做到故障恢复在一分钟以内 。文件是按照分片存放,每个会分三个副本,放在不同的机架上,最后提供端到端的数据校验。
109 |110 |
111 |
HAPROXY负载均衡
112 |基于haproxy的自动hash架构 ,这是一种新的缓存架构,由nginx作为最前端,代理到缓存机器。 nginx后面是缓存组,由nginx经过url hash后将请求分到缓存机器。
113 | 这个架构方便纯squid缓存升级,可以在squid的机器上加装nginx。 nginx有缓存的功能,可以将一些访问量特大的链接直接缓存在nginx上,就不用经过多一次代理的请求,能够保证图片服务器的高可用、高性能。比如favicon.ico和网站的logo。 负载均衡负责OSS所有的请求的负载均衡,后台的http服务器故障会自动切换,从而保证了OSS的服务不间断。
115 |
116 |
CDN
117 |阿里云CDN服务是一个遍布全国的分布式缓存系统,能够将网站文件(如图片或JavaScript代码文件)缓存到全国多个城市机房中的服务器上,当一个用户访问你的网站时,会就近到靠近TA的城市的服务器上获取数据,这样最终用户访问你的服务速度会非常快。
118 |阿里云CDN服务在全国部署超过100个节点,能提供给用户优良的网络加速效果。当网站业务突然爆发增长时,无需手忙脚乱地扩容网络带宽,使用CDN服务即可轻松应对。和OSS服务一样,使用CDN,需要先在aliyun.com网站上开通CDN服务。开通后,需要在网站上的管理中心创建你的distribution(即分发频道),每个distribution由两个必须的部分组成:distribution ID和源站地址。
119 |使用阿里云OSS和CDN可以非常方便的针对每个bucket进行内容加速,因为每个bucket对应一个独立的二级域名,针对每个文件进行CDN删除,简单、经济地解决服务的存储和网络问题,毕竟大多数网站或应用的存储和网络带宽多半是被图片或视频消耗掉的。
120 |从整个业界来看,最近这样的面向个人用户的云存储如国外的DropBox和Box.net非常受欢迎,国内的云存储目前比较不错的主要有七牛云存储和又拍云存储。
121 |122 |
123 |
上传下载分而治之
124 |图片服务器的图片下载比例远远高于上传比例,业务逻辑的处理也区别明显,上传服器对图片重命名,记录入库信息,下载服务器对图片添加水印、修改尺寸之类的动态处理。从高可用的角度,我们能容忍部分图片下载失败,但绝不能有图片上传失败,因为上传失败,意味着数据的丢失。上传与下载分开,能保证不会因下载的压力影响图片的上传,而且还有一点,下载入口和上传入口的负载均衡策略也有所不同。上传需要经过Quota Server记录用户和图片的关系等逻辑处理,下载的逻辑处理如果绕过了前端缓存处理,穿透后端业务逻辑处理,需要从OSS获取图片路径信息。近期阿里云会推出基于CDN就近上传的功能,自动选择离用户最近的CDN节点,使得数据的上传下载速度均得到最优化。相较传统IDC,访问速度提升数倍。
125 |126 |
127 |
图片防盗链处理
128 |如果服务不允许防盗链,那么访问量会引起带宽、服务器压力等问题。比较通用的解决方案是在nginx或者squid反向代理软件上添加refer ACL判断,OSS也提供了基于refer的防盗链技术。当然OSS也提供了更为高级的URL签名防盗链,其其实现思路如下:
129 |130 |
首先,确认自己的bucket权限是private,即这个bucket的所有请求必须在签名认证通过后才被认为是合法的。然后根据操作类型、要访问的bucket、要访问的object以及超时时间,动态地生成一个经过签名的URL。通过这个签名URL,你授权的用户就可以在该签名URL过期时间前执行相应的操作。
131 |132 |
签名的Python代码如下:
133 |h=hmac.new(“OtxrzxIsfpFjA7SwPzILwy8Bw21TLhquhboDYROV”, “GET\n\n\n1141889120\n/oss-example/oss-api.jpg”,sha);
134 |urllib.quote_plus (base64.encodestring(h.digest()).strip());
135 |136 |
其中method可以是PUT、GET、HEAD、DELETE中的任意一种;最后一个参数“timeout”是超时的时间,单位是秒。一个通过上面Python方法,计算得到的签名URL为:
137 |http://oss-example.oss-cn-hangzhou.aliyuncs.com/oss-api.jpg?OSSAccessKeyId=44CF9590006BF252F707&Expires=1141889120&Signature=vjbyPxybdZaNmGa%2ByT272YEAiv4%3D
138 |139 |
通过这种动态计算签名URL的方法,可以有效地保护放在OSS上的数据,防止被其他人盗链。
140 |141 |
142 |
图片编辑处理API
143 |对于在线图片的编辑处理,GraphicsMagick(GraphicsMagick(http://www.graphicsmagick.org/))对于从事互联网的技术人员应该不会陌生。GraphicsMagick是从 ImageMagick 5.5.2 分支出来的,但是现在他变得更稳定和优秀,GM更小更容易安装、GM更有效率、GM的手册非常丰富GraphicsMagick的命令与ImageMagick基本是一样的。
144 |145 |
GraphicsMagick 提供了包括裁、缩放、合成、打水印、图像转换、填充等非常丰富的接口API,其中的开发包SDK也非常丰富,包括了JAVA(im4java)、C、C++、Perl、PHP、Tcl、Ruby等的调用,支持超过88中图像格式,包括重要的DPX、GIF、JPEG、JPEG-2000、PNG、PDF、PNM和TIFF,GraphicsMagick可以再绝大多数的平台上使用,Linux、Mac、Windows都没有问题。但是独立开发这些图片处理服务,对服务器的IO要求相对要高一些,而且目前这些开源的图片处理编辑库,相对来说还不是很稳定,笔者在使用GraphicsMagick 的时候就遇到了tomcat 进程crash情况,需要手动重启tomcat服务。
146 |147 |
阿里云目前已经对外开放图片处理API,包括了大多数常用处理解决方案:缩略图、打水印、文字水印、样式、管道等。开发者可以非常方便的使用如上图片处理方案,希望越来越多的开发者能够基于OSS开放出更多优秀的产品。
-------------------------------------------------------------------------------- /src/sql.md: -------------------------------------------------------------------------------- 1 |很多程序员视 SQL 为洪水猛兽。SQL 是一种为数不多的声明性语言,它的运行方式完全不同于我们所熟知的命令行语言、面向对象的程序语言、甚至是函数语言(尽管有些人认为 SQL 语言也是一种函数式语言)。
2 |我们每天都在写 SQL 并且应用在开源软件 jOOQ 中。于是我想把 SQL 之美介绍给那些仍然对它头疼不已的朋友,所以本文是为了以下读者而特地编写的:
3 |1、 在工作中会用到 SQL 但是对它并不完全了解的人。
4 |2、 能够熟练使用 SQL 但是并不了解其语法逻辑的人。
5 |3、 想要教别人 SQL 的人。
6 |
本文着重介绍 SELECT 句式,其他的 DML (Data Manipulation Language 数据操纵语言命令)将会在别的文章中进行介绍。
8 |首先要把这个概念记在脑中:“声明”。 SQL 语言是为计算机声明了一个你想从原始数据中获得什么样的结果的一个范例,而不是告诉计算机如何能够得到结果。这是不是很棒?
11 |(译者注:简单地说,SQL 语言声明的是结果集的属性,计算机会根据 SQL 所声明的内容来从数据库中挑选出符合声明的数据,而不是像传统编程思维去指示计算机如何操作。)
12 |SELECT first_name, last_name FROM employees WHERE salary > 10000013 |
上面的例子很容易理解,我们不关心这些雇员记录从哪里来,我们所需要的只是那些高薪者的数据(译者注: salary>100000 )。
14 |我们从哪儿学习到这些?
15 |如果 SQL 语言这么简单,那么是什么让人们“闻 SQL 色变”?主要的原因是:我们潜意识中的是按照命令式编程的思维方式思考问题的。就好像这样:“电脑,先执行这一步,再执行那一步,但是在那之前先检查一下是否满足条件 A 和条件 B ”。例如,用变量传参、使用循环语句、迭代、调用函数等等,都是这种命令式编程的思维惯式。
16 |SQL 语句有一个让大部分人都感到困惑的特性,就是:SQL 语句的执行顺序跟其语句的语法顺序并不一致。SQL 语句的语法顺序是:
18 |为了方便理解,上面并没有把所有的 SQL 语法结构都列出来,但是已经足以说明 SQL 语句的语法顺序和其执行顺序完全不一样,就以上述语句为例,其执行顺序为:
28 |关于 SQL 语句的执行顺序,有三个值得我们注意的地方:
39 |1、 FROM 才是 SQL 语句执行的第一步,并非 SELECT 。数据库在执行 SQL 语句的第一步是将数据从硬盘加载到数据缓冲区中,以便对这些数据进行操作。(译者注:原文为“The first thing that happens is loading data from the disk into memory, in order to operate on such data.”,但是并非如此,以 Oracle 等常用数据库为例,数据是从硬盘中抽取到数据缓冲区中进行操作。)
40 |2、 SELECT 是在大部分语句执行了之后才执行的,严格的说是在 FROM 和 GROUP BY 之后执行的。理解这一点是非常重要的,这就是你不能在 WHERE 中使用在 SELECT 中设定别名的字段作为判断条件的原因。
41 |SELECT A.x + A.y AS z 42 | FROM A 43 | WHERE z = 10 -- z 在此处不可用,因为SELECT是最后执行的语句!44 |
如果你想重用别名z,你有两个选择。要么就重新写一遍 z 所代表的表达式:
45 |SELECT A.x + A.y AS z 46 | FROM A 47 | WHERE (A.x + A.y) = 1048 |
…或者求助于衍生表、通用数据表达式或者视图,以避免别名重用。请看下文中的例子。
49 |3、 无论在语法上还是在执行顺序上, UNION 总是排在在 ORDER BY 之前。很多人认为每个 UNION 段都能使用 ORDER BY 排序,但是根据 SQL 语言标准和各个数据库 SQL 的执行差异来看,这并不是真的。尽管某些数据库允许 SQL 语句对子查询(subqueries)或者派生表(derived tables)进行排序,但是这并不说明这个排序在 UNION 操作过后仍保持排序后的顺序。
50 |注意:并非所有的数据库对 SQL 语句使用相同的解析方式。如 MySQL、PostgreSQL和 SQLite 中就不会按照上面第二点中所说的方式执行。
51 |我们学到了什么?
52 |既然并不是所有的数据库都按照上述方式执行 SQL 预计,那我们的收获是什么?我们的收获是永远要记得: SQL 语句的语法顺序和其执行顺序并不一致,这样我们就能避免一般性的错误。如果你能记住 SQL 语句语法顺序和执行顺序的差异,你就能很容易的理解一些很常见的 SQL 问题。
53 |当然,如果一种语言被设计成语法顺序直接反应其语句的执行顺序,那么这种语言对程序员是十分友好的,这种编程语言层面的设计理念已经被微软应用到了 LINQ 语言中。
54 |由于 SQL 语句语法顺序和执行顺序的不同,很多同学会认为SELECT 中的字段信息是 SQL 语句的核心。其实真正的核心在于对表的引用。
56 |根据 SQL 标准,FROM 语句被定义为:
57 |<from clause> ::= FROM <table reference> [ { <comma> <table reference> }... ]
58 | FROM 语句的“输出”是一张联合表,来自于所有引用的表在某一维度上的联合。我们们慢慢来分析:
59 |FROM a, b60 |
上面这句 FROM 语句的输出是一张联合表,联合了表 a 和表 b 。如果 a 表有三个字段, b 表有 5 个字段,那么这个“输出表”就有 8 ( =5+3)个字段。
61 |这个联合表里的数据是 a*b,即 a 和 b 的笛卡尔积。换句话说,也就是 a 表中的每一条数据都要跟 b 表中的每一条数据配对。如果 a 表有3 条数据, b 表有 5 条数据,那么联合表就会有 15 ( =5*3)条数据。
62 |FROM 输出的结果被 WHERE 语句筛选后要经过 GROUP BY 语句处理,从而形成新的输出结果。我们后面还会再讨论这方面问题。
63 |如果我们从集合论(关系代数)的角度来看,一张数据库的表就是一组数据元的关系,而每个 SQL 语句会改变一种或数种关系,从而产生出新的数据元的关系(即产生新的表)。
64 |我们学到了什么?
65 |思考问题的时候从表的角度来思考问题提,这样很容易理解数据如何在 SQL 语句的“流水线”上进行了什么样的变动。
66 |灵活引用表能使 SQL 语句变得更强大。一个简单的例子就是 JOIN 的使用。严格的说 JOIN 语句并非是 SELECT 中的一部分,而是一种特殊的表引用语句。 SQL 语言标准中表的连接定义如下:
68 |<table reference> ::= 69 | <table name> 70 | | <derived table> 71 | | <joined table>72 |
就拿之前的例子来说:
73 |FROM a, b74 |
a 可能输如下表的连接:
75 |a1 JOIN a2 ON a1.id = a2.id76 |
将它放到之前的例子中就变成了:
77 |FROM a1 JOIN a2 ON a1.id = a2.id, b78 |
尽管将一个连接表用逗号跟另一张表联合在一起并不是常用作法,但是你的确可以这么做。结果就是,最终输出的表就有了 a1+a2+b 个字段了。
79 |(译者注:原文这里用词为 degree ,译为维度。如果把一张表视图化,我们可以想象每一张表都是由横纵两个维度组成的,横向维度即我们所说的字段或者列,英文为columns;纵向维度即代表了每条数据,英文为 record ,根据上下文,作者这里所指的应该是字段数。)
80 |在 SQL 语句中派生表的应用甚至比表连接更加强大,下面我们就要讲到表连接。
81 |我们学到了什么?
82 |思考问题时,要从表引用的角度出发,这样就很容易理解数据是怎样被 SQL 语句处理的,并且能够帮助你理解那些复杂的表引用是做什么的。
83 |更重要的是,要理解 JOIN 是构建连接表的关键词,并不是 SELECT 语句的一部分。有一些数据库允许在 INSERT 、 UPDATE 、 DELETE 中使用 JOIN 。
84 |我们先看看刚刚这句话:
86 |FROM a, b87 |
高级 SQL 程序员也许学会给你忠告:尽量不要使用逗号来代替 JOIN 进行表的连接,这样会提高你的 SQL 语句的可读性,并且可以避免一些错误。
88 |利用逗号来简化 SQL 语句有时候会造成思维上的混乱,想一下下面的语句:
89 |FROM a, b, c, d, e, f, g, h 90 | WHERE a.a1 = b.bx 91 | AND a.a2 = c.c1 92 | AND d.d1 = b.bc 93 | -- etc...94 |
我们不难看出使用 JOIN 语句的好处在于:
95 |我们学到了什么?
102 |记着要尽量使用 JOIN 进行表的连接,永远不要在 FROM 后面使用逗号连接表。
103 |SQL 语句中,表连接的方式从根本上分为五种:
105 |EQUI JOIN
113 |这是一种最普通的 JOIN 操作,它包含两种连接方式:
114 |用例子最容易说明其中区别:
119 |-- This table reference contains authors and their books.
120 | -- There is one record for each book and its author.
121 | -- authors without books are NOT included
122 | author JOIN book ON author.id = book.author_id
123 |
124 | -- This table reference contains authors and their books
125 | -- There is one record for each book and its author.
126 | -- ... OR there is an "empty" record for authors without books
127 | -- ("empty" meaning that all book columns are NULL)
128 | author LEFT OUTER JOIN book ON author.id = book.author_id
129 | SEMI JOIN
130 |这种连接关系在 SQL 中有两种表现方式:使用 IN,或者使用 EXISTS。“ SEMI ”在拉丁文中是“半”的意思。这种连接方式是只连接目标表的一部分。这是什么意思呢?再想一下上面关于作者和书名的连接。我们想象一下这样的情况:我们不需要作者 / 书名这样的组合,只是需要那些在书名表中的书的作者信息。那我们就能这么写:
131 |-- Using IN 132 | FROM author 133 | WHERE author.id IN (SELECT book.author_id FROM book) 134 | 135 | -- Using EXISTS 136 | FROM author 137 | WHERE EXISTS (SELECT 1 FROM book WHERE book.author_id = author.id)138 |
尽管没有严格的规定说明你何时应该使用 IN ,何时应该使用 EXISTS ,但是这些事情你还是应该知道的:
139 |因为使用 INNER JOIN 也能得到书名表中书所对应的作者信息,所以很多初学者机会认为可以通过 DISTINCT 进行去重,然后将 SEMI JOIN 语句写成这样:
149 |-- Find only those authors who also have books 150 | SELECT DISTINCT first_name, last_name 151 | FROM author 152 | JOIN book ON author.id = book.author_id153 |
这是一种很糟糕的写法,原因如下:
154 |更多的关于滥用 DISTINCT 的危害可以参考这篇博文
161 |(http://blog.jooq.org/2013/07/30/10-common-mistakes-java-developers-make-when-writing-sql/)。
162 |ANTI JOIN
163 |这种连接的关系跟 SEMI JOIN 刚好相反。在 IN 或者 EXISTS 前加一个 NOT 关键字就能使用这种连接。举个例子来说,我们列出书名表里没有书的作者:
164 |-- Using IN 165 | FROM author 166 | WHERE author.id NOT IN (SELECT book.author_id FROM book) 167 | 168 | -- Using EXISTS 169 | FROM author 170 | WHERE NOT EXISTS (SELECT 1 FROM book WHERE book.author_id = author.id)171 |
关于性能、可读性、表达性等特性也完全可以参考 SEMI JOIN。
172 |这篇博文介绍了在使用 NOT IN 时遇到 NULL 应该怎么办,因为有一点背离本篇主题,就不详细介绍,有兴趣的同学可以读一下
173 |(http://blog.jooq.org/2012/01/27/sql-incompatibilities-not-in-and-null-values/)。
174 |CROSS JOIN
175 |这个连接过程就是两个连接的表的乘积:即将第一张表的每一条数据分别对应第二张表的每条数据。我们之前见过,这就是逗号在 FROM 语句中的用法。在实际的应用中,很少有地方能用到 CROSS JOIN,但是一旦用上了,你就可以用这样的 SQL语句表达:
176 |-- Combine every author with every book 177 | author CROSS JOIN book178 |
DIVISION
179 |DIVISION 的确是一个怪胎。简而言之,如果 JOIN 是一个乘法运算,那么 DIVISION 就是 JOIN 的逆过程。DIVISION 的关系很难用 SQL 表达出来,介于这是一个新手指南,解释 DIVISION 已经超出了我们的目的。但是有兴趣的同学还是可以来看看这三篇文章
180 |(http://blog.jooq.org/2012/03/30/advanced-sql-relational-division-in-jooq/)
181 |(http://en.wikipedia.org/wiki/Relational_algebra#Division)
182 |(https://www.simple-talk.com/sql/t-sql-programming/divided-we-stand-the-sql-of-relational-division/)。
183 |我们学到了什么?
185 |学到了很多!让我们在脑海中再回想一下。 SQL 是对表的引用, JOIN 则是一种引用表的复杂方式。但是 SQL 语言的表达方式和实际我们所需要的逻辑关系之间是有区别的,并非所有的逻辑关系都能找到对应的 JOIN 操作,所以这就要我们在平时多积累和学习关系逻辑,这样你就能在以后编写 SQL 语句中选择适当的 JOIN 操作了。
186 |在这之前,我们学习到过 SQL 是一种声明性的语言,并且 SQL 语句中不能包含变量。但是你能写出类似于变量的语句,这些就叫做派生表:
188 |说白了,所谓的派生表就是在括号之中的子查询:
189 |-- A derived table 190 | FROM (SELECT * FROM author)191 |
需要注意的是有些时候我们可以给派生表定义一个相关名(即我们所说的别名)。
192 |-- A derived table with an alias 193 | FROM (SELECT * FROM author) a194 |
派生表可以有效的避免由于 SQL 逻辑而产生的问题。举例来说:如果你想重用一个用 SELECT 和 WHERE 语句查询出的结果,这样写就可以(以 Oracle 为例):
195 |-- Get authors' first and last names, and their age in days 196 | SELECT first_name, last_name, age 197 | FROM ( 198 | SELECT first_name, last_name, current_date - date_of_birth age 199 | FROM author 200 | ) 201 | -- If the age is greater than 10000 days 202 | WHERE age > 10000203 |
需要我们注意的是:在有些数据库,以及 SQL : 1990 标准中,派生表被归为下一级——通用表语句( common table experssion)。这就允许你在一个 SELECT 语句中对派生表多次重用。上面的例子就(几乎)等价于下面的语句:
204 |WITH a AS ( 205 | SELECT first_name, last_name, current_date - date_of_birth age 206 | FROM author 207 | ) 208 | SELECT * 209 | FROM a 210 | WHERE age > 10000211 |
当然了,你也可以给“ a ”创建一个单独的视图,这样你就可以在更广泛的范围内重用这个派生表了。更多信息可以阅读下面的文章(http://en.wikipedia.org/wiki/View_%28SQL%29)。
212 |我们学到了什么?
213 |我们反复强调,大体上来说 SQL 语句就是对表的引用,而并非对字段的引用。要好好利用这一点,不要害怕使用派生表或者其他更复杂的语句。
214 |让我们再回想一下之前的 FROM 语句:
216 |FROM a, b217 |
现在,我们将 GROUP BY 应用到上面的语句中:
218 |GROUP BY A.x, A.y, B.z219 |
上面语句的结果就是产生出了一个包含三个字段的新的表的引用。我们来仔细理解一下这句话:当你应用 GROUP BY 的时候, SELECT 后没有使用聚合函数的列,都要出现在 GROUP BY 后面。(译者注:原文大意为“当你是用 GROUP BY 的时候,你能够对其进行下一级逻辑操作的列会减少,包括在 SELECT 中的列”)。
220 |SELECT A.x, A.y, SUM(A.z) 224 | FROM A 225 | GROUP BY A.x, A.y226 |
我们学到了什么?
230 |GROUP BY,再次强调一次,是在表的引用上进行了操作,将其转换为一种新的引用方式。
231 |我个人比较喜欢“映射”这个词,尤其是把它用在关系代数上。(译者注:原文用词为 projection ,该词有两层含义,第一种含义是预测、规划、设计,第二种意思是投射、映射,经过反复推敲,我觉得这里用映射能够更直观的表达出 SELECT 的作用)。一旦你建立起来了表的引用,经过修改、变形,你能够一步一步的将其映射到另一个模型中。 SELECT 语句就像一个“投影仪”,我们可以将其理解成一个将源表中的数据按照一定的逻辑转换成目标表数据的函数。
233 |通过 SELECT语句,你能对每一个字段进行操作,通过复杂的表达式生成所需要的数据。
234 |SELECT 语句有很多特殊的规则,至少你应该熟悉以下几条:
235 |一些更复杂的规则多到足够写出另一篇文章了。比如:为何你不能在一个没有 GROUP BY 的 SELECT 语句中同时使用普通函数和聚合函数?(上面的第 4 条)
244 |原因如下:
245 |糊涂了?是的,我也是。我们再回过头来看点浅显的东西吧。
250 |我们学到了什么?
251 |SELECT 语句可能是 SQL 语句中最难的部分了,尽管他看上去很简单。其他语句的作用其实就是对表的不同形式的引用。而 SELECT 语句则把这些引用整合在了一起,通过逻辑规则将源表映射到目标表,而且这个过程是可逆的,我们可以清楚的知道目标表的数据是怎么来的。
252 |想要学习好 SQL 语言,就要在使用 SELECT 语句之前弄懂其他的语句,虽然 SELECT 是语法结构中的第一个关键词,但它应该是我们最后一个掌握的。
253 |在学习完复杂的 SELECT 豫剧之后,我们再来看点简单的东西:
255 |集合运算( set operation):
262 |集合运算主要操作在于集合上,事实上指的就是对表的一种操作。从概念上来说,他们很好理解:
263 |排序运算( ordering operation):
279 |排序运算跟逻辑关系无关。这是一个 SQL 特有的功能。排序运算不仅在 SQL 语句的最后,而且在 SQL 语句运行的过程中也是最后执行的。使用 ORDER BY 和 OFFSET…FETCH 是保证数据能够按照顺序排列的最有效的方式。其他所有的排序方式都有一定随机性,尽管它们得到的排序结果是可重现的。
280 |OFFSET…SET是一个没有统一确定语法的语句,不同的数据库有不同的表达方式,如 MySQL 和 PostgreSQL 的 LIMIT…OFFSET、SQL Server 和 Sybase 的 TOP…START AT 等。具体关于 OFFSET..FETCH 的不同语法可以参考这篇文章
281 |(http://www.jooq.org/doc/3.1/manual/sql-building/sql-statements/select-statement/limit-clause/)。
282 |让我们在工作中尽情的使用 SQL!
283 |正如其他语言一样,想要学好 SQL 语言就要大量的练习。上面的 10 个简单的步骤能够帮助你对你每天所写的 SQL 语句有更好的理解。另一方面来讲,从平时常见的错误中也能积累到很多经验。下面的两篇文章就是介绍一些 JAVA 和其他开发者所犯的一些常见的 SQL 错误:
284 |为了获取文中提到的一个命令的更多信息,先试下“man <命令名称>”,在一些情况下,为了让这条命令可以正常执行,你必须安装相应的包,可以用aptitude 或者 yum。如果失败了,求助Google。
2 |find . -name \*.py | xargs grep some_function
22 | cat hosts | xargs -l{} ssh root@{} hostname
23 | #在当前目录下做一些事情 33 | (cd /一些/另外的/目录;执行别的操作) 34 | #继续在原来的目录下执行35 |
if var==foo.pdf, then echo ${var%.pdf}.txt #会打印"foo.txt"。
38 | TCPKeepAlive=yes 48 | ServerAliveInterval=15 49 | ServerAliveCountMax=6 50 | StrictHostKeyChecking=no 51 | Compression=yes 52 | ForwardAgent=yes53 |
cat a b | sort | uniq > c # c is a union b 63 | cat a b | sort | uniq -d > c # c is a intersect b 64 | cat a b b | sort | uniq -u > c # c is set difference a - b65 |
perl -pi.bak -e 's/old-string/new-string/g' my-files-*.txt73 |
uconv -f utf-8 -t utf-8 -x '::Any-Lower; ::Any-NFD; [:Nonspacing Mark:] >; ::Any-NFC; ' < input.txt > output.txt84 |
Vim的学习曲线相当的大,所以,如果你一开始看到的是一大堆VIM的命令分类,你一定会对这个编辑器失去兴趣的。下面的文章翻译自《Learn Vim Progressively》,我觉得这是给新手最好的VIM的升级教程了,没有列举所有的命令,只是列举了那些最有用的命令。非常不错。
2 |
——————————正文开始——————————
4 |你想以最快的速度学习人类史上最好的文本编辑器VIM吗?你先得懂得如何在VIM幸存下来,然后一点一点地学习各种戏法。
5 |Vim the Six Billion Dollar editor
6 |Better, Stronger, Faster.
7 |学习 vim 并且其会成为你最后一个使用的文本编辑器。没有比这个更好的文本编辑器了,非常地难学,但是却不可思议地好用。
8 |我建议下面这四个步骤:
9 |1. 存活
10 |2. 感觉良好
11 |3. 觉得更好,更强,更快
12 |4.使用VIM的超能力
13 |当你走完这篇文章,你会成为一个vim的 superstar。
14 |在开始学习以前,我需要给你一些警告:
15 |● 学习vim在开始时是痛苦的。
16 |● 需要时间
17 |● 需要不断地练习,就像你学习一个乐器一样。
18 |● 不要期望你能在3天内把vim练得比别的编辑器更有效率。
19 |● 事实上,你需要2周时间的苦练,而不是3天。
20 |21 |
第一级 – 存活
22 |1. 安装 vim
23 |2. 启动 vim
24 |3. 什么也别干!请先阅读
25 |当你安装好一个编辑器后,你一定会想在其中输入点什么东西,然后看看这个编辑器是什么样子。但vim不是这样的,请按照下面的命令操作:
26 |● 启 动Vim后,vim在 Normal 模式下。
27 |● 让我们进入 Insert 模式,请按下键 i 。(陈皓注:你会看到vim左下角有一个–insert–字样,表示,你可以以插入的方式输入了)
28 |● 此时,你可以输入文本了,就像你用“记事本”一样。
29 |● 如果你想返回 Normal 模式,请按 ESC 键。
现在,你知道如何在 Insert 和 Normal 模式下切换了。下面是一些命令,可以让你在 Normal 模式下幸存下来:
31 |● i → Insert 模式,按 ESC 回到 Normal 模式.
● x → 删当前光标所在的一个字符。
● :wq → 存盘 + 退出 (:w 存盘, :q 退出) (陈皓注::w 后可以跟文件名)
● dd → 删除当前行,并把删除的行存到剪贴板里
● p → 粘贴剪贴板
推荐:
37 |● hjkl (强例推荐使用其移动光标,但不必需) →你也可以使用光标键 (←↓↑→). 注: j 就像下箭头。
● :help <command> → 显示相关命令的帮助。你也可以就输入 :help 而不跟命令。(陈皓注:退出帮助需要输入:q)
你能在vim幸存下来只需要上述的那5个命令,你就可以编辑文本了,你一定要把这些命令练成一种下意识的状态。于是你就可以开始进阶到第二级了。
40 |当是,在你进入第二级时,需要再说一下 Normal 模式。在一般的编辑器下,当你需要copy一段文字的时候,你需要使用 Ctrl 键,比如:Ctrl-C。也就是说,Ctrl键就好像功能键一样,当你按下了功能键Ctrl后,C就不在是C了,而且就是一个命令或是一个快键键了,在VIM的Normal模式下,所有的键就是功能键了。这个你需要知道。
标记:
42 |● 下面的文字中,如果是 Ctrl-λ我会写成 <C-λ>.
● 以 : 开始的命令你需要输入 <enter>回车,例如 — 如果我写成 :q 也就是说你要输入 :q<enter>.
第二级 – 感觉良好
46 |上面的那些命令只能让你存活下来,现在是时候学习一些更多的命令了,下面是我的建议:(陈皓注:所有的命令都需要在Normal模式下使用,如果你不知道现在在什么样的模式,你就狂按几次ESC键)
47 |1. 各种插入模式
48 |● a → 在光标后插入
● o → 在当前行后插入一个新行
● O → 在当前行前插入一个新行
● cw → 替换从光标所在位置后到一个单词结尾的字符
2. 简单的移动光标
53 |● 0 → 数字零,到行头
● ^ → 到本行第一个不是blank字符的位置(所谓blank字符就是空格,tab,换行,回车等)
● $ → 到本行行尾
● g_ → 到本行最后一个不是blank字符的位置。
● /pattern → 搜索 pattern 的字符串(陈皓注:如果搜索出多个匹配,可按n键到下一个)
3. 拷贝/粘贴 (陈皓注:p/P都可以,p是表示在当前位置之后,P表示在当前位置之前)
59 |● P → 粘贴
● yy → 拷贝当前行当行于 ddP
4. Undo/Redo
● u → undo
● <C-r> → redo
5. 打开/保存/退出/改变文件(Buffer)
65 |● :e <path/to/file> → 打开一个文件
● :w → 存盘
● :saveas <path/to/file> → 另存为 <path/to/file>
● :x, ZZ 或 :wq → 保存并退出 (:x 表示仅在需要时保存,ZZ不需要输入冒号并回车)
● :q! → 退出不保存 :qa! 强行退出所有的正在编辑的文件,就算别的文件有更改。
● :bn 和 :bp → 你可以同时打开很多文件,使用这两个命令来切换下一个或上一个文件。(陈皓注:我喜欢使用:n到下一个文件)
花点时间熟悉一下上面的命令,一旦你掌握他们了,你就几乎可以干其它编辑器都能干的事了。但是到现在为止,你还是觉得使用vim还是有点笨拙,不过没关系,你可以进阶到第三级了。
72 | 73 |第三级 – 更好,更强,更快
74 |先恭喜你!你干的很不错。我们可以开始一些更为有趣的事了。在第三级,我们只谈那些和vi可以兼容的命令。
75 |更好
76 |下面,让我们看一下vim是怎么重复自己的:
77 |1. . → (小数点) 可以重复上一次的命令
2. N<command> → 重复某个命令N次
79 |下面是一个示例,找开一个文件你可以试试下面的命令:
80 |● 2dd → 删除2行
● 3p → 粘贴文本3次
● 100idesu [ESC] → 会写下 “desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu “
● . → 重复上一个命令—— 100 “desu “.
● 3. → 重复 3 次 “desu” (注意:不是 300,你看,VIM多聪明啊).
更强
86 |你要让你的光标移动更有效率,你一定要了解下面的这些命令,千万别跳过。
87 |1. NG → 到第 N 行 (陈皓注:注意命令中的G是大写的,另我一般使用 : N 到第N行,如 :137 到第137行)
2. gg → 到第一行。(陈皓注:相当于1G,或 :1)
3. G → 到最后一行。
4. 按单词移动:
91 |● w → 到下一个单词的开头。
● e → 到下一个单词的结尾。
> 如果你认为单词是由默认方式,那么就用小写的e和w。默认上来说,一个单词由字母,数字和下划线组成(陈皓注:程序变量)
94 |> 如果你认为单词是由blank字符分隔符,那么你需要使用大写的E和W。(陈皓注:程序语句)
95 |
下面,让我来说说最强的光标移动:
97 |● % : 匹配括号移动,包括 (, {, [. (陈皓注:你需要把光标先移到括号上)
● * 和 #: 匹配光标当前所在的单词,移动光标到下一个(或上一个)匹配单词(*是下一个,#是上一个)
相信我,上面这三个命令对程序员来说是相当强大的。
100 |更快
101 |你一定要记住光标的移动,因为很多命令都可以和这些移动光标的命令连动。很多命令都可以如下来干:
102 |<start position><command><end position>
例如 0y$ 命令意味着:
● 0 → 先到行头
● y → 从这里开始拷贝
● $ → 拷贝到本行最后一个字符
你可可以输入 ye,从当前位置拷贝到本单词的最后一个字符。
你也可以输入 y2/foo 来拷贝2个 “foo” 之间的字符串。
还有很多时间并不一定你就一定要按y才会拷贝,下面的命令也会被拷贝:
110 |● d (删除 )
● v (可视化的选择)
● gU (变大写)
● gu (变小写)
● 等等
115 |第四级 – Vim 超能力
118 |你只需要掌握前面的命令,你就可以很舒服的使用VIM了。但是,现在,我们向你介绍的是VIM杀手级的功能。下面这些功能是我只用vim的原因。
119 |在当前行上移动光标: 0 ^ $ f F t T , ;
● 0 → 到行头
● ^ → 到本行的第一个非blank字符
● $ → 到行尾
● g_ → 到本行最后一个不是blank字符的位置。
● fa → 到下一个为a的字符处,你也可以fs到下一个为s的字符。
● t, → 到逗号前的第一个字符。逗号可以变成其它字符。
● 3fa → 在当前行查找第三个出现的a。
● F 和 T → 和 f 和 t 一样,只不过是相反方向。

还有一个很有用的命令是 dt" → 删除所有的内容,直到遇到双引号—— "。
区域选择 <action>a<object> 或 <action>i<object>
在visual 模式下,这些命令很强大,其命令格式为
132 |<action>a<object> 和 <action>i<object>
● action可以是任何的命令,如 d (删除), y (拷贝), v (可以视模式选择)。
● object 可能是: w 一个单词, W 一个以空格为分隔的单词, s 一个句字, p 一个段落。也可以是一个特别的字符:"、 '、 )、 }、 ]。
假设你有一个字符串 (map (+) ("foo")).而光标键在第一个 o 的位置。
● vi" → 会选择 foo.
● va" → 会选择 "foo".
● vi) → 会选择 "foo".
● va) → 会选择("foo").
● v2i) → 会选择 map (+) ("foo")
● v2a) → 会选择 (map (+) ("foo"))

块操作: <C-v>
块操作,典型的操作: 0 <C-v> <C-d> I-- [ESC]
● ^ → 到行头
● <C-v> → 开始块操作
● <C-d> → 向下移动 (你也可以使用hjkl来移动光标,或是使用%,或是别的)
● I-- [ESC] → I是插入,插入“--”,按ESC键来为每一行生效。

在Windows下的vim,你需要使用 <C-q> 而不是 <C-v> ,<C-v> 是拷贝剪贴板。
自动提示: <C-n> 和 <C-p>
在 Insert 模式下,你可以输入一个词的开头,然后按 <C-p>或是<C-n>,自动补齐功能就出现了……

宏录制: qa 操作序列 q, @a, @@
● qa 把你的操作记录在寄存器 a。
● 于是 @a 会replay被录制的宏。
● @@ 是一个快捷键用来replay最新录制的宏。
示例
159 |在一个只有一行且这一行只有“1”的文本中,键入如下命令:
160 |● qaYp<C-a>q→
● qa 开始录制
● Yp 复制行.
● <C-a> 增加1.
● q 停止录制.
● @a → 在1下面写下 2
● @@ → 在2 正面写下3
● 现在做 100@@ 会创建新的100行,并把数据增加到 103.

可视化选择: v,V,<C-v>
前面,我们看到了 <C-v>的示例 (在Windows下应该是<C-q>),我们可以使用 v 和 V。一但被选好了,你可以做下面的事:
● J → 把所有的行连接起来(变成一行)
● < 或 > → 左右缩进
● = → 自动给缩进 (陈皓注:这个功能相当强大,我太喜欢了)

在所有被选择的行后加上点东西:
176 |● <C-v>
177 |● 选中相关的行 (可使用 j 或 <C-d> 或是 /pattern 或是 % 等……)
● $ 到行最后
● A, 输入字符串,按 ESC。

:split 和 vsplit.下面是主要的命令,你可以使用VIM的帮助 :help split. 你可以参考本站以前的一篇文章VIM分屏。
● :split → 创建分屏 (:vsplit创建垂直分屏)
● <C-w><dir> : dir就是方向,可以是 hjkl 或是 ←↓↑→ 中的一个,其用来切换分屏。
● <C-w>_ (或 <C-w>|) : 最大化尺寸 (<C-w>| 垂直分屏)
● <C-w>+ (或 <C-w>-) : 增加尺寸

结束语
190 |● 上面是作者最常用的90%的命令。
191 |● 我建议你每天都学1到2个新的命令。
192 |● 在两到三周后,你会感到vim的强大的。
193 |● 有时候,学习VIM就像是在死背一些东西。
194 |● 幸运的是,vim有很多很不错的工具和优秀的文档。
195 |● 运行vimtutor直到你熟悉了那些基本命令。
196 |● 其在线帮助文档中你应该要仔细阅读的是 :help usr_02.txt.
● 你会学习到诸如 !, 目录,寄存器,插件等很多其它的功能。
学习vim就像学弹钢琴一样,一旦学会,受益无穷。
199 |——————————正文结束——————————
200 |对于vi/vim只是点评一点:这是一个你不需要使用鼠标,不需使用小键盘,只需要使用大键盘就可以完成很多复杂功能文本编辑的编辑器。不然,Visual Studio也不就会有vim的插件了。
-------------------------------------------------------------------------------- /src/virtual-memory.md: -------------------------------------------------------------------------------- 1 |处理器的虚拟内存子系统为每个进程实现了虚拟地址空间。这让每个进程认为它在系统中是独立的。虚拟内存的优点列表别的地方描述的非常详细,所以这里就不重复了。本节集中在虚拟内存的实际的实现细节,和相关的成本。
2 |虚拟地址空间是由CPU的内存管理单元(MMU)实现的。OS必须填充页表数据结构,但大多数CPU自己做了剩下的工作。这事实上是一个相当复杂的机制;最好的理解它的方法是引入数据结构来描述虚拟地址空间。
3 |由MMU进行地址翻译的输入地址是虚拟地址。通常对它的值很少有限制 — 假设还有一点的话。 虚拟地址在32位系统中是32位的数值,在64位系统中是64位的数值。在一些系统,例如x86和x86-64,使用的地址实际上包含了另一个层次的间接寻址:这些结构使用分段,这些分段只是简单的给每个逻辑地址加上位移。我们可以忽略这一部分的地址产生,它不重要,不是程序员非常关心的内存处理性能方面的东西。{x86的分段限制是与性能相关的,但那是另一回事了}
4 |有趣的地方在于由虚拟地址到物理地址的转换。MMU可以在逐页的基础上重新映射地址。就像地址缓存排列的时候,虚拟地址被分割为不同的部分。这些部分被用来做多个表的索引,而这些表是被用来创建最终物理地址用的。最简单的模型是只有一级表。
6 |7 |10 |8 |
Figure 4.1: 1-Level Address Translation
9 |
图 4.1 显示了虚拟地址的不同部分是如何使用的。高字节部分是用来选择一个页目录的条目;那个目录中的每个地址可以被OS分别设置。页目录条目决定了物理内存页的地址;页面中可以有不止一个条目指向同样的物理地址。完整的内存物理地址是由页目录获得的页地址和虚拟地址低字节部分合并起来决定的。页目录条目还包含一些附加的页面信息,如访问权限。
11 |页目录的数据结构存储在内存中。OS必须分配连续的物理内存,并将这个地址范围的基地址存入一个特殊的寄存器。然后虚拟地址的适当的位被用来作为页目录的索引,这个页目录事实上是目录条目的列表。
12 |作为一个具体的例子,这是 x86机器4MB分页设计。虚拟地址的位移部分是22位大小,足以定位一个4M页内的每一个字节。虚拟地址中剩下的10位指定页目录中1024个条目的一个。每个条目包括一个10位的4M页内的基地址,它与位移结合起来形成了一个完整的32位地址。
13 |4MB的页不是规范,它们会浪费很多内存,因为OS需要执行的许多操作需要内存页的队列。对于4kB的页(32位机器的规范,甚至通常是64位机器的规范),虚拟地址的位移部分只有12位大小。这留下了20位作为页目录的指针。具有220个条目的表是不实际的。即使每个条目只要4比特,这个表也要4MB大小。由于每个进程可能具有其唯一的页目录,因为这些页目录许多系统中物理内存被绑定起来。
15 |解决办法是用多级页表。然后这些就能表示一个稀疏的大的页目录,目录中一些实际不用的区域不需要分配内存。因此这种表示更紧凑,使它可能为内存中的很多进程使用页表而并不太影响性能。.
16 |今天最复杂的页表结构由四级构成。图4.2显示了这样一个实现的原理图。
17 |18 |21 |19 |
Figure 4.2: 4-Level Address Translation
20 |
在这个例子中,虚拟地址被至少分为五个部分。其中四个部分是不同的目录的索引。被引用的第4级目录使用CPU中一个特殊目的的寄存器。第4级到第2级目录的内容是对次低一级目录的引用。如果一个目录条目标识为空,显然就是不需要指向任何低一级的目录。这样页表树就能稀疏和紧凑。正如图4.1,第1级目录的条目是一部分物理地址,加上像访问权限的辅助数据。
22 | 为了决定相对于虚拟地址的物理地址,处理器先决定最高级目录的地址。这个地址一般保存在一个寄存器。然后CPU取出虚拟地址中相对于这个目录的索引部分,并用那个索引选择合适的条目。这个条目是下一级目录的地址,它由虚拟地址的下一部分索引。处理器继续直到它到达第1级目录,那里那个目录条目的值就是物理地址的高字节部分。物理地址在加上虚拟地址中的页面位移之后就完整了。这个过程称为页面树遍历。一些处理器(像x86和x86-64)在硬件中执行这个操作,其他的需要OS的协助。 23 |系统中运行的每个进程可能需要自己的页表树。有部分共享树的可能,但是这相当例外。因此如果页表树需要的内存尽可能小的话将对性能与可扩展性有利。理想的情况是将使用的内存紧靠着放在虚拟地址空间;但实际使用的物理地址不影响。一个小程序可能只需要第2,3,4级的一个目录和少许第1级目录就能应付过去。在一个采用4kB页面和每个目录512条目的x86-64机器上,这允许用4级目录对2MB定位(每一级一个)。1GB连续的内存可以被第2到第4级的一个目录和第1级的512个目录定位。
24 |但是,假设所有内存可以被连续分配是太简单了。由于复杂的原因,大多数情况下,一个进程的栈与堆的区域是被分配在地址空间中非常相反的两端。这样使得任一个区域可以根据需要尽可能的增长。这意味着最有可能需要两个第2级目录和相应的更多的低一级的目录。
25 |但即使这也不常常匹配现在的实际。由于安全的原因,一个可运行的(代码,数据,堆,栈,动态共享对象,aka共享库)不同的部分被映射到随机的地址[未选中的]。随机化延伸到不同部分的相对位置;那意味着一个进程使用的不同的内存范围,遍布于虚拟地址空间。通过对随机的地址位数采用一些限定,范围可以被限制,但在大多数情况下,这当然不会让一个进程只用一到两个第2和第3级目录运行。
26 |如果性能真的远比安全重要,随机化可以被关闭。OS然后通常是在虚拟内存中至少连续的装载所有的动态共享对象(DSO)。
27 |页表的所有数据结构都保存在主存中;在那里OS建造和更新这些表。当一个进程创建或者一个页表变化,CPU将被通知。页表被用来解决每个虚拟地址到物理地址的转换,用上面描述的页表遍历方式。更多有关于此:至少每一级有一个目录被用于处理虚拟地址的过程。这需要至多四次内存访问(对一个运行中的进程的单次访问来说),这很慢。有可能像普通数据一样处理这些目录表条目,并将他们缓存在L1d,L2等等,但这仍然非常慢。
29 |
所以,替代于只是缓存目录表条目,物理页地址的完整的计算结果被缓存了。因为同样的原因,代码和数据缓存也工作起来,这样的地址计算结果的缓存是高效的。由于虚拟地址的页面位移部分在物理页地址的计算中不起任何作用,只有虚拟地址的剩余部分被用作缓存的标签。根据页面大小这意味着成百上千的指令或数据对象共享同一个标签,因此也共享同一个物理地址前缀。
33 |保存计算数值的缓存叫做旁路转换缓存(TLB)。因为它必须非常的快,通常这是一个小的缓存。现代CPU像其它缓存一样,提供了多级TLB缓存;越高级的缓存越大越慢。小号的L1级TLB通常被用来做全相联映像缓存,采用LRU回收策略。最近这种缓存大小变大了,而且在处理器中变得集相联。其结果之一就是,当一个新的条目必须被添加的时候,可能不是最久的条目被回收于替换了。
34 |正如上面提到的,用来访问TLB的标签是虚拟地址的一个部分。如果标签在缓存中有匹配,最终的物理地址将被计算出来,通过将来自虚拟地址的页面位移地址加到缓存值的方式。这是一个非常快的过程;也必须这样,因为每条使用绝对地址的指令都需要物理地址,还有在一些情况下,因为使用物理地址作为关键字的L2查找。如果TLB查询未命中,处理器就必须执行一次页表遍历;这可能代价非常大。
35 |通过软件或硬件预取代码或数据,会在地址位于另一页面时,暗中预取TLB的条目。硬件预取不可能允许这样,因为硬件会初始化非法的页面表遍历。因此程序员不能依赖硬件预取机制来预取TLB条目。它必须使用预取指令明确的完成。就像数据和指令缓存,TLB可以表现为多个等级。正如数据缓存,TLB通常表现为两种形式:指令TLB(ITLB)和数据TLB(DTLB)。高级的TLB像L2TLB通常是统一的,就像其他的缓存情形一样。
36 |4.3.1 使用TLB的注意事项
37 |TLB是以处理器为核心的全局资源。所有运行于处理器的线程与进程使用同一个TLB。由于虚拟到物理地址的转换依赖于安装的是哪一种页表树,如果页表变化了,CPU不能盲目的重复使用缓存的条目。每个进程有一个不同的页表树(不算在同一个进程中的线程),内核与内存管理器VMM(管理程序)也一样,如果存在的话。也有可能一个进程的地址空间布局发生变化。有两种解决这个问题的办法:
38 |第一种情况,只要执行一个上下文切换TLB就被刷新。因为大多数OS中,从一个线程/进程到另一个的切换需要执行一些核心代码,TLB刷新被限制进入或离开核心地址空间。在虚拟化的系统中,当内核必须调用内存管理器VMM和返回的时候,这也会发生。如果内核和/或内存管理器没有使用虚拟地址,或者当进程或内核调用系统/内存管理器时,能重复使用同一个虚拟地址,TLB必须被刷新。当离开内核或内存管理器时,处理器继续执行一个不同的进程或内核。
43 | 刷新TLB高效但昂贵。例如,当执行一个系统调用,触及的内核代码可能仅限于几千条指令,或许少许新页面(或一个大的页面,像某些结构的Linux的就是这样)。这个工作将替换触及页面的所有TLB条目。对Intel带128ITLB和256DTLB条目的Core2架构,完全的刷新意味着多于100和200条目(分别的)将被不必要的刷新。当系统调用返回同一个进程,所有那些被刷新的TLB条目可能被再次用到,但它们没有了。内核或内存管理器常用的代码也一样。每条进入内核的条目上,TLB必须擦去再装,即使内核与内存管理器的页表通常不会改变。因此理论上说,TLB条目可以被保持一个很长时间。这也解释了为什么现在处理器中的TLB缓存都不大:程序很有可能不会执行时间长到装满所有这些条目。 44 |当然事实逃脱不了CPU的结构。对缓存刷新优化的一个可能的方法是单独的使TLB条目失效。例如,如果内核代码与数据落于一个特定的地址范围,只有落入这个地址范围的页面必须被清除出TLB。这只需要比较标签,因此不是很昂贵。在部分地址空间改变的场合,例如对去除内存页的一次调用,这个方法也是有用的,
45 |更好的解决方法是为TLB访问扩展标签。如果除了虚拟地址的一部分之外,一个唯一的对应每个页表树的标识(如一个进程的地址空间)被添加,TLB将根本不需要完全刷新。内核,内存管理程序,和独立的进程都可以有唯一的标识。这种场景唯一的问题在于,TLB标签可以获得的位数异常有限,但是地址空间的位数却不是。这意味着一些标识的再利用是有必要的。这种情况发生时TLB必须部分刷新(如果可能的话)。所有带有再利用标识的条目必须被刷新,但是希望这是一个非常小的集合。
46 |当多个进程运行在系统中时,这种扩展的TLB标签具有一般优势。如果每个可运行进程对内存的使用(因此TLB条目的使用)做限制,进程最近使用的TLB条目,当其再次列入计划时,有很大机会仍然在TLB。但还有两个额外的优势:
47 |4.3.2 影响TLB性能
53 |有一些因素会影响TLB性能。第一个是页面的大小。显然页面越大,装进去的指令或数据对象就越多。所以较大的页面大小减少了所需的地址转换总次数,即需要更少的TLB缓存条目。大多数架构允许使用多个不同的页面尺寸;一些尺寸可以并存使用。例如,x86/x86-64处理器有一个普通的4kB的页面尺寸,但它们也可以分别用4MB和2MB页面。IA-64 和 PowerPC允许如64kB的尺寸作为基本的页面尺寸。
54 |然而,大页面尺寸的使用也随之带来了一些问题。用作大页面的内存范围必须是在物理内存中连续的。如果物理内存管理的单元大小升至虚拟内存页面的大小,浪费的内存数量将会增长。各种内存操作(如加载可执行文件)需要页面边界对齐。这意味着平均每次映射浪费了物理内存中页面大小的一半。这种浪费很容易累加;因此它给物理内存分配的合理单元大小划定了一个上限。
55 |在x86-64结构中增加单元大小到2MB来适应大页面当然是不实际的。这是一个太大的尺寸。但这转而意味着每个大页面必须由许多小一些的页面组成。这些小页面必须在物理内存中连续。以4kB单元页面大小分配2MB连续的物理内存具有挑战性。它需要找到有512个连续页面的空闲区域。在系统运行一段时间并且物理内存开始碎片化以后,这可能极为困难(或者不可能)
56 |因此在Linux中有必要在系统启动的时候,用特别的Huge TLBfs文件系统,预分配这些大页面。一个固定数目的物理页面被保留,以单独用作大的虚拟页面。这使可能不会经常用到的资源捆绑留下来。它也是一个有限的池;增大它一般意味着要重启系统。尽管如此,大页面是进入某些局面的方法,在这些局面中性能具有保险性,资源丰富,而且麻烦的安装不会成为大的妨碍。数据库服务器就是一个例子。
57 |增大最小的虚拟页面大小(正如选择大页面的相反面)也有它的问题。内存映射操作(例如加载应用)必须确认这些页面大小。不可能有更小的映射。对大多数架构来说,一个可执行程序的各个部分位置有一个固定的关系。如果页面大小增加到超过了可执行程序或DSO(Dynamic Shared Object)创建时考虑的大小,加载操作将无法执行。脑海里记得这个限制很重要。图4.3显示了一个ELF二进制的对齐需求是如何决定的。它编码在ELF程序头部。
58 |$ eu-readelf -l /bin/ls 59 | Program Headers: 60 | Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align 61 | ... 62 | LOAD 0x000000 0x0000000000400000 0x0000000000400000 0x0132ac 0x0132ac R E 0x200000 63 | LOAD 0x0132b0 0x00000000006132b0 0x00000000006132b0 0x001a71 0x001a71 RW 0x200000 64 | ... 65 |66 |
Figure 4.3: ELF 程序头表明了对齐需求
67 |在这个例子中,一个x86-64二进制,它的值为0x200000 = 2,097,152 = 2MB,符合处理器支持的最大页面尺寸。
68 |使用较大内存尺寸有第二个影响:页表树的级数减少了。由于虚拟地址相对于页面位移的部分增加了,需要用来在页目录中使用的位,就没有剩下许多了。这意味着当一个TLB未命中时,需要做的工作数量减少了。
69 |超出使用大页面大小,它有可能减少移动数据时需要同时使用的TLB条目数目,减少到数页。这与一些上面我们谈论的缓存使用的优化机制类似。只有现在对齐需求是巨大的。考虑到TLB条目数目如此小,这可能是一个重要的优化。
70 |OS映像的虚拟化将变得越来越流行;这意味着另一个层次的内存处理被加入了想象。进程(基本的隔间)或者OS容器的虚拟化,因为只涉及一个OS而没有落入此分类。类似Xen或KVM的技术使OS映像能够独立运行 — 有或者没有处理器的协助。这些情形下,有一个单独的软件直接控制物理内存的访问。
72 |73 |76 |74 |
图 4.4: Xen 虚拟化模型
75 |
对Xen来说(见图4.4),Xen VMM(Xen内存管理程序)就是那个软件。但是,VMM没有自己实现许多硬件的控制,不像其他早先的系统(包括Xen VMM的第一个版本)的VMM,内存以外的硬件和处理器由享有特权的Dom0域控制。现在,这基本上与没有特权的DomU内核一样,就内存处理方面而言,它们没有什么不同。这里重要的是,VMM自己分发物理内存给Dom0和DomU内核,然后就像他们是直接运行在一个处理器上一样,实现通常的内存处理
77 | 为了实现完成虚拟化所需的各个域之间的分隔,Dom0和DomU内核中的内存处理不具有无限制的物理内存访问权限。VMM不是通过分发独立的物理页并让客户OS处理地址的方式来分发内存;这不能提供对错误或欺诈客户域的防范。替代的,VMM为每一个客户域创建它自己的页表树,并且用这些数据结构分发内存。好处是对页表树管理信息的访问能得到控制。如果代码没有合适的特权,它不能做任何事。 78 | 在虚拟化的Xen支持中,这种访问控制已被开发,不管使用的是参数的或硬件的(又名全)虚拟化。客户域以意图上与参数的和硬件的虚拟化极为相似的方法,给每个进程创建它们的页表树。每当客户OS修改了VMM调用的页表,VMM就会用客户域中更新的信息去更新自己的影子页表。这些是实际由硬件使用的页表。显然这个过程非常昂贵:每次对页表树的修改都需要VMM的一次调用。而没有虚拟化时内存映射的改变也不便宜,它们现在变得甚至更昂贵。 79 | 考虑到从客户OS的变化到VMM以及返回,其本身已经相当昂贵,额外的代价可能真的很大。这就是为什么处理器开始具有避免创建影子页表的额外功能。这样很好不仅是因为速度的问题,而且它减少了VMM消耗的内存。Intel有扩展页表(EPTs),AMD称之为嵌套页表(NPTs)。基本上两种技术都具有客户OS的页表,来产生虚拟的物理地址。然后通过每个域一个EPT/NPT树的方式,这些地址会被进一步转换为真实的物理地址。这使得可以用几乎非虚拟化情境的速度进行内存处理,因为大多数用来内存处理的VMM条目被移走了。它也减少了VMM使用的内存,因为现在一个域(相对于进程)只有一个页表树需要维护。 80 | 额外的地址转换步骤的结果也存储于TLB。那意味着TLB不存储虚拟物理地址,而替代以完整的查询结果。已经解释过AMD的帕西菲卡扩展为了避免TLB刷新而给每个条目引入ASID。ASID的位数在最初版本的处理器扩展中是一位;这正好足够区分VMM和客户OS。Intel有服务同一个目的的虚拟处理器ID(VPIDs),它们只有更多位。但对每个客户域VPID是固定的,因此它不能标记单独的进程,也不能避免TLB在那个级别刷新。 81 |对虚拟OS,每个地址空间的修改需要的工作量是一个问题。但是还有另一个内在的基于VMM虚拟化的问题:没有什么办法处理两层的内存。但内存处理很难(特别是考虑到像NUMA一样的复杂性,见第5部分)。Xen方法使用一个单独的VMM,这使最佳的(或最好的)处理变得困难,因为所有内存管理实现的复杂性,包括像发现内存范围之类“琐碎的”事情,必须被复制于VMM。OS有完全成熟的与最佳的实现;人们确实想避免复制它们。
82 |83 |86 | 这就是为什么对VMM/Dom0模型的分析是这么有吸引力的一个选择。图4.5显示了KVM的Linux内核扩展如何尝试解决这个问题的。并没有直接运行在硬件之上且管理所有客户的单独的VMM,替代的,一个普通的Linux内核接管了这个功能。这意味着Linux内核中完整且复杂的内存管理功能,被用来管理系统的内存。客户域运行于普通的用户级进程,创建者称其为“客户模式”。虚拟化的功能,参数的或全虚拟化的,被另一个用户级进程KVM VMM控制。这也就是另一个进程用特别的内核实现的KVM设备,去恰巧控制一个客户域。 87 |84 |
图 4.5: KVM 虚拟化模型
85 |
这个模型相较Xen独立的VMM模型好处在于,即使客户OS使用时,仍然有两个内存处理程序在工作,只需要在Linux内核里有一个实现。不需要像Xen VMM那样从另一段代码复制同样的功能。这带来更少的工作,更少的bug,或许还有更少的两个内存处理程序接触产生的摩擦,因为一个Linux客户的内存处理程序与运行于裸硬件之上的Linux内核的外部内存处理程序,做出了相同的假设。
88 |总的来说,程序员必须清醒认识到,采用虚拟化时,内存操作的代价比没有虚拟化要高很多。任何减少这个工作的优化,将在虚拟化环境付出更多。随着时间的过去,处理器的设计者将通过像EPT和NPT技术越来越减少这个差距,但它永远都不会完全消失。
89 | 90 | --------------------------------------------------------------------------------