 3 |
4 | > Large models have recently played a dominant role in natural language processing and multimodal vision-language learning. However, their effectiveness in text-related visual tasks remains relatively unexplored. In this paper, we conducted a comprehensive evaluation of Large Multimodal Models, such as GPT4V and Gemini, in various text-related visual tasks including Text Recognition, Scene Text-Centric Visual Question Answering (VQA), Document-Oriented VQA, Key Information Extraction (KIE), and Handwritten Mathematical Expression Recognition (HMER). To facilitate the assessment of Optical Character Recognition (OCR) capabilities in Large Multimodal Models, we propose OCRBench, a comprehensive evaluation benchmark. Our study encompasses 29 datasets, making it the most comprehensive OCR evaluation benchmark available. Furthermore, our study reveals both the strengths and weaknesses of these models, particularly in handling multilingual text, handwritten text, non-semantic text, and mathematical expression recognition. Most importantly, the baseline results showcased in this study could provide a foundational framework for the conception and assessment of innovative strategies targeted at enhancing zero-shot multimodal techniques.
5 |
6 | **[Project Page [This Page]](https://github.com/Yuliang-Liu/MultimodalOCR)** | **[Paper](https://arxiv.org/abs/2305.07895)** |**[OCRBench Leaderboard](https://huggingface.co/spaces/echo840/ocrbench-leaderboard)**|**[Opencompass Leaderboard](https://rank.opencompass.org.cn/leaderboard-multimodal)**|
7 |
8 |
9 | # Data
10 | To reduce false positives, we filter out questions that have answers containing fewer than 4 symbols from all datasets.
11 | | Data | Link | Description |
12 | | --- | --- | --- |
13 | | Full Test Json | [Full Test](./OCRBench/FullTest.json) | This file contains the test data used in Table 1 and Table 2 from [Paper](https://arxiv.org/abs/2305.07895). |
14 | | OCRBench Json | [OCRBench](./OCRBench/OCRBench.json) | This file contains the test data in OCRBench used in Table3 from [Paper](https://arxiv.org/abs/2305.07895). |
15 | | All Test Images |[All Images](https://drive.google.com/file/d/1U5AtLoJ7FrJe9yfcbssfeLmlKb7dTosc/view?usp=drive_link) | This file contains all the testing images used in [Paper](https://arxiv.org/abs/2305.07895), including OCRBench Images.|
16 | | OCRBench Images | [OCRBench Images](https://drive.google.com/file/d/1a3VRJx3V3SdOmPr7499Ky0Ug8AwqGUHO/view?usp=drive_link) | This file only contains the images used in OCRBench. |
17 | | Test Results | [Test Results](https://drive.google.com/drive/folders/15XlHCuNTavI1Ihqm4G7u3J34BHpkaqyE?usp=drive_link) | This file file contains the result files for the test models. |
18 |
19 |
20 | # OCRBench
21 |
22 | OCRBench is a comprehensive evaluation benchmark designed to assess the OCR capabilities of Large Multimodal Models. It comprises five components: Text Recognition, SceneText-Centric VQA, Document-Oriented VQA, Key Information Extraction, and Handwritten Mathematical Expression Recognition. The benchmark includes 1000 question-answer pairs, and all the answers undergo manual verification and correction to ensure a more precise evaluation.
23 |
24 | You can find the results of Large Multimodal Models in **[OCRBench Leaderboard](https://huggingface.co/spaces/echo840/ocrbench-leaderboard)**, if you would like to include your model in the OCRBench leaderboard, please follow the evaluation instructions provided below and feel free to contact us via email at zhangli123@hust.edu.cn. We will update the leaderboard in time.
25 |
26 |
3 |
4 | > Large models have recently played a dominant role in natural language processing and multimodal vision-language learning. However, their effectiveness in text-related visual tasks remains relatively unexplored. In this paper, we conducted a comprehensive evaluation of Large Multimodal Models, such as GPT4V and Gemini, in various text-related visual tasks including Text Recognition, Scene Text-Centric Visual Question Answering (VQA), Document-Oriented VQA, Key Information Extraction (KIE), and Handwritten Mathematical Expression Recognition (HMER). To facilitate the assessment of Optical Character Recognition (OCR) capabilities in Large Multimodal Models, we propose OCRBench, a comprehensive evaluation benchmark. Our study encompasses 29 datasets, making it the most comprehensive OCR evaluation benchmark available. Furthermore, our study reveals both the strengths and weaknesses of these models, particularly in handling multilingual text, handwritten text, non-semantic text, and mathematical expression recognition. Most importantly, the baseline results showcased in this study could provide a foundational framework for the conception and assessment of innovative strategies targeted at enhancing zero-shot multimodal techniques.
5 |
6 | **[Project Page [This Page]](https://github.com/Yuliang-Liu/MultimodalOCR)** | **[Paper](https://arxiv.org/abs/2305.07895)** |**[OCRBench Leaderboard](https://huggingface.co/spaces/echo840/ocrbench-leaderboard)**|**[Opencompass Leaderboard](https://rank.opencompass.org.cn/leaderboard-multimodal)**|
7 |
8 |
9 | # Data
10 | To reduce false positives, we filter out questions that have answers containing fewer than 4 symbols from all datasets.
11 | | Data | Link | Description |
12 | | --- | --- | --- |
13 | | Full Test Json | [Full Test](./OCRBench/FullTest.json) | This file contains the test data used in Table 1 and Table 2 from [Paper](https://arxiv.org/abs/2305.07895). |
14 | | OCRBench Json | [OCRBench](./OCRBench/OCRBench.json) | This file contains the test data in OCRBench used in Table3 from [Paper](https://arxiv.org/abs/2305.07895). |
15 | | All Test Images |[All Images](https://drive.google.com/file/d/1U5AtLoJ7FrJe9yfcbssfeLmlKb7dTosc/view?usp=drive_link) | This file contains all the testing images used in [Paper](https://arxiv.org/abs/2305.07895), including OCRBench Images.|
16 | | OCRBench Images | [OCRBench Images](https://drive.google.com/file/d/1a3VRJx3V3SdOmPr7499Ky0Ug8AwqGUHO/view?usp=drive_link) | This file only contains the images used in OCRBench. |
17 | | Test Results | [Test Results](https://drive.google.com/drive/folders/15XlHCuNTavI1Ihqm4G7u3J34BHpkaqyE?usp=drive_link) | This file file contains the result files for the test models. |
18 |
19 |
20 | # OCRBench
21 |
22 | OCRBench is a comprehensive evaluation benchmark designed to assess the OCR capabilities of Large Multimodal Models. It comprises five components: Text Recognition, SceneText-Centric VQA, Document-Oriented VQA, Key Information Extraction, and Handwritten Mathematical Expression Recognition. The benchmark includes 1000 question-answer pairs, and all the answers undergo manual verification and correction to ensure a more precise evaluation.
23 |
24 | You can find the results of Large Multimodal Models in **[OCRBench Leaderboard](https://huggingface.co/spaces/echo840/ocrbench-leaderboard)**, if you would like to include your model in the OCRBench leaderboard, please follow the evaluation instructions provided below and feel free to contact us via email at zhangli123@hust.edu.cn. We will update the leaderboard in time.
25 |
26 |  27 |
28 | # Evaluation
29 | The test code for evaluating models in the paper can be found in [scripts](./scripts). Before conducting the evaluation, you need to configure the model weights and environment based on the official code link provided in the scripts. If you want to evaluate other models, please edit the "TODO" things in [example](./example.py).
30 |
31 | You can also use [VLMEvalKit](https://github.com/open-compass/VLMEvalKit) and [lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval) for evaluation.
32 |
33 | Example evaluation scripts:
34 | ```python
35 |
36 | python ./scripts/monkey.py --image_folder ./OCRBench_Images --OCRBench_file ./OCRBench/OCRBench.json --save_name Monkey_OCRBench --num_workers GPU_Nums # Test on OCRBench
37 | python ./scripts/monkey.py --image_folder ./OCRBench_Images --OCRBench_file ./OCRBench/FullTest.json --save_name Monkey_FullTest --num_workers GPU_Nums # Full Test
38 |
39 | ```
40 |
41 | # Citation
42 | If you wish to refer to the baseline results published here, please use the following BibTeX entries:
43 | ```BibTeX
44 | @article{Liu_2024,
45 | title={OCRBench: on the hidden mystery of OCR in large multimodal models},
46 | volume={67},
47 | ISSN={1869-1919},
48 | url={http://dx.doi.org/10.1007/s11432-024-4235-6},
49 | DOI={10.1007/s11432-024-4235-6},
50 | number={12},
51 | journal={Science China Information Sciences},
52 | publisher={Springer Science and Business Media LLC},
53 | author={Liu, Yuliang and Li, Zhang and Huang, Mingxin and Yang, Biao and Yu, Wenwen and Li, Chunyuan and Yin, Xu-Cheng and Liu, Cheng-Lin and Jin, Lianwen and Bai, Xiang},
54 | year={2024},
55 | month=dec }
56 | ```
57 |
58 |
59 |
60 |
--------------------------------------------------------------------------------
/OCRBench/example.py:
--------------------------------------------------------------------------------
1 | import json
2 | from argparse import ArgumentParser
3 | import torch
4 | import os
5 | import json
6 | from tqdm import tqdm
7 | from PIL import Image
8 | import math
9 | import multiprocessing
10 | from multiprocessing import Pool, Queue, Manager
11 |
12 | # TODO model packages import
13 | # from transformers import AutoModelForCausalLM, AutoTokenizer
14 |
15 | def split_list(lst, n):
16 | length = len(lst)
17 | avg = length // n # 每份的大小
18 | result = [] # 存储分割后的子列表
19 | for i in range(n - 1):
20 | result.append(lst[i*avg:(i+1)*avg])
21 | result.append(lst[(n-1)*avg:])
22 | return result
23 |
24 | def save_json(json_list,save_path):
25 | with open(save_path, 'w') as file:
26 | json.dump(json_list, file,indent=4)
27 |
28 | def _get_args():
29 | parser = ArgumentParser()
30 | parser.add_argument("--image_folder", type=str, default="./OCRBench_Images")
31 | parser.add_argument("--output_folder", type=str, default="./results")
32 | parser.add_argument("--OCRBench_file", type=str, default="./OCRBench/OCRBench.json")
33 | parser.add_argument("--model_path", type=str, default="")#TODO Set the address of your model's weights
34 | parser.add_argument("--save_name", type=str, default="") #TODO Set the name of the JSON file you save in the output_folder.
35 | parser.add_argument("--num_workers", type=int, default=8)
36 | args = parser.parse_args()
37 | return args
38 |
39 | OCRBench_score = {"Regular Text Recognition":0,"Irregular Text Recognition":0,"Artistic Text Recognition":0,"Handwriting Recognition":0,
40 | "Digit String Recognition":0,"Non-Semantic Text Recognition":0,"Scene Text-centric VQA":0,"Doc-oriented VQA":0,"Doc-oriented VQA":0,
41 | "Key Information Extraction":0,"Handwritten Mathematical Expression Recognition":0}
42 | AllDataset_score = {"IIIT5K":0,"svt":0,"IC13_857":0,"IC15_1811":0,"svtp":0,"ct80":0,"cocotext":0,"ctw":0,"totaltext":0,"HOST":0,"WOST":0,"WordArt":0,"IAM":0,"ReCTS":0,"ORAND":0,"NonSemanticText":0,"SemanticText":0,
43 | "STVQA":0,"textVQA":0,"ocrVQA":0,"ESTVQA":0,"ESTVQA_cn":0,"docVQA":0,"infographicVQA":0,"ChartQA":0,"ChartQA_Human":0,"FUNSD":0,"SROIE":0,"POIE":0,"HME100k":0}
44 | num_all = {"IIIT5K":0,"svt":0,"IC13_857":0,"IC15_1811":0,"svtp":0,"ct80":0,"cocotext":0,"ctw":0,"totaltext":0,"HOST":0,"WOST":0,"WordArt":0,"IAM":0,"ReCTS":0,"ORAND":0,"NonSemanticText":0,"SemanticText":0,
45 | "STVQA":0,"textVQA":0,"ocrVQA":0,"ESTVQA":0,"ESTVQA_cn":0,"docVQA":0,"infographicVQA":0,"ChartQA":0,"ChartQA_Human":0,"FUNSD":0,"SROIE":0,"POIE":0,"HME100k":0}
46 |
47 | def eval_worker(args, data, eval_id, output_queue):
48 | print(f"Process {eval_id} start.")
49 | checkpoint = args.model_path
50 |
51 | # TODO model init
52 |
53 | # model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map='cuda', trust_remote_code=True).eval()
54 | # tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
55 | # tokenizer.padding_side = 'left'
56 | # tokenizer.pad_token_id = tokenizer.eod_id
57 |
58 | for i in tqdm(range(len(data))):
59 | img_path = os.path.join(args.image_folder, data[i]['image_path'])
60 | qs = data[i]['question']
61 |
62 | # TODO Generation process
63 | # query = f'
27 |
28 | # Evaluation
29 | The test code for evaluating models in the paper can be found in [scripts](./scripts). Before conducting the evaluation, you need to configure the model weights and environment based on the official code link provided in the scripts. If you want to evaluate other models, please edit the "TODO" things in [example](./example.py).
30 |
31 | You can also use [VLMEvalKit](https://github.com/open-compass/VLMEvalKit) and [lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval) for evaluation.
32 |
33 | Example evaluation scripts:
34 | ```python
35 |
36 | python ./scripts/monkey.py --image_folder ./OCRBench_Images --OCRBench_file ./OCRBench/OCRBench.json --save_name Monkey_OCRBench --num_workers GPU_Nums # Test on OCRBench
37 | python ./scripts/monkey.py --image_folder ./OCRBench_Images --OCRBench_file ./OCRBench/FullTest.json --save_name Monkey_FullTest --num_workers GPU_Nums # Full Test
38 |
39 | ```
40 |
41 | # Citation
42 | If you wish to refer to the baseline results published here, please use the following BibTeX entries:
43 | ```BibTeX
44 | @article{Liu_2024,
45 | title={OCRBench: on the hidden mystery of OCR in large multimodal models},
46 | volume={67},
47 | ISSN={1869-1919},
48 | url={http://dx.doi.org/10.1007/s11432-024-4235-6},
49 | DOI={10.1007/s11432-024-4235-6},
50 | number={12},
51 | journal={Science China Information Sciences},
52 | publisher={Springer Science and Business Media LLC},
53 | author={Liu, Yuliang and Li, Zhang and Huang, Mingxin and Yang, Biao and Yu, Wenwen and Li, Chunyuan and Yin, Xu-Cheng and Liu, Cheng-Lin and Jin, Lianwen and Bai, Xiang},
54 | year={2024},
55 | month=dec }
56 | ```
57 |
58 |
59 |
60 |
--------------------------------------------------------------------------------
/OCRBench/example.py:
--------------------------------------------------------------------------------
1 | import json
2 | from argparse import ArgumentParser
3 | import torch
4 | import os
5 | import json
6 | from tqdm import tqdm
7 | from PIL import Image
8 | import math
9 | import multiprocessing
10 | from multiprocessing import Pool, Queue, Manager
11 |
12 | # TODO model packages import
13 | # from transformers import AutoModelForCausalLM, AutoTokenizer
14 |
15 | def split_list(lst, n):
16 | length = len(lst)
17 | avg = length // n # 每份的大小
18 | result = [] # 存储分割后的子列表
19 | for i in range(n - 1):
20 | result.append(lst[i*avg:(i+1)*avg])
21 | result.append(lst[(n-1)*avg:])
22 | return result
23 |
24 | def save_json(json_list,save_path):
25 | with open(save_path, 'w') as file:
26 | json.dump(json_list, file,indent=4)
27 |
28 | def _get_args():
29 | parser = ArgumentParser()
30 | parser.add_argument("--image_folder", type=str, default="./OCRBench_Images")
31 | parser.add_argument("--output_folder", type=str, default="./results")
32 | parser.add_argument("--OCRBench_file", type=str, default="./OCRBench/OCRBench.json")
33 | parser.add_argument("--model_path", type=str, default="")#TODO Set the address of your model's weights
34 | parser.add_argument("--save_name", type=str, default="") #TODO Set the name of the JSON file you save in the output_folder.
35 | parser.add_argument("--num_workers", type=int, default=8)
36 | args = parser.parse_args()
37 | return args
38 |
39 | OCRBench_score = {"Regular Text Recognition":0,"Irregular Text Recognition":0,"Artistic Text Recognition":0,"Handwriting Recognition":0,
40 | "Digit String Recognition":0,"Non-Semantic Text Recognition":0,"Scene Text-centric VQA":0,"Doc-oriented VQA":0,"Doc-oriented VQA":0,
41 | "Key Information Extraction":0,"Handwritten Mathematical Expression Recognition":0}
42 | AllDataset_score = {"IIIT5K":0,"svt":0,"IC13_857":0,"IC15_1811":0,"svtp":0,"ct80":0,"cocotext":0,"ctw":0,"totaltext":0,"HOST":0,"WOST":0,"WordArt":0,"IAM":0,"ReCTS":0,"ORAND":0,"NonSemanticText":0,"SemanticText":0,
43 | "STVQA":0,"textVQA":0,"ocrVQA":0,"ESTVQA":0,"ESTVQA_cn":0,"docVQA":0,"infographicVQA":0,"ChartQA":0,"ChartQA_Human":0,"FUNSD":0,"SROIE":0,"POIE":0,"HME100k":0}
44 | num_all = {"IIIT5K":0,"svt":0,"IC13_857":0,"IC15_1811":0,"svtp":0,"ct80":0,"cocotext":0,"ctw":0,"totaltext":0,"HOST":0,"WOST":0,"WordArt":0,"IAM":0,"ReCTS":0,"ORAND":0,"NonSemanticText":0,"SemanticText":0,
45 | "STVQA":0,"textVQA":0,"ocrVQA":0,"ESTVQA":0,"ESTVQA_cn":0,"docVQA":0,"infographicVQA":0,"ChartQA":0,"ChartQA_Human":0,"FUNSD":0,"SROIE":0,"POIE":0,"HME100k":0}
46 |
47 | def eval_worker(args, data, eval_id, output_queue):
48 | print(f"Process {eval_id} start.")
49 | checkpoint = args.model_path
50 |
51 | # TODO model init
52 |
53 | # model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map='cuda', trust_remote_code=True).eval()
54 | # tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
55 | # tokenizer.padding_side = 'left'
56 | # tokenizer.pad_token_id = tokenizer.eod_id
57 |
58 | for i in tqdm(range(len(data))):
59 | img_path = os.path.join(args.image_folder, data[i]['image_path'])
60 | qs = data[i]['question']
61 |
62 | # TODO Generation process
63 | # query = f'
8 |  9 |
9 |
10 |
11 | # Data
12 | You can download OCRBench v2 from [Google Drive](https://drive.google.com/file/d/1Hk1TMu--7nr5vJ7iaNwMQZ_Iw9W_KI3C/view?usp=sharing)
13 | After downloading and extracting the dataset, the directory structure is as follows:
14 | ```
15 | OCRBench_v2/
16 | ├── EN_part/
17 | ├── CN_part/
18 | ├── OCRBench_v2.json
19 | ```
20 | # Evaluation
21 |
22 | ## Environment
23 | All Python dependencies required for the evaluation process are specified in the **requirements.txt**.
24 | To set up the environment, simply run the following commands in the project directory:
25 | ```python
26 | conda create -n ocrbench_v2 python==3.10 -y
27 | conda activate ocrbench_v2
28 | pip install -r requirements.txt
29 | ```
30 |
31 | ## Inference
32 | To evaluate the model's performance on OCRBench v2, please save the model's inference results in the JSON file within the `predict` field.
33 |
34 | Example structure of the JSON file:
35 |
36 | ```json
37 | {
38 | [
39 | "dataset_name": "xx",
40 | "type": "xx",
41 | "id": 0,
42 | "image_path": "xx",
43 | "question": "xx",
44 | "answers": [
45 | "xx"
46 | ],
47 | "predict": "xx"
48 | ]
49 | ...
50 | }
51 | ```
52 |
53 | ## Evaluation Scripts
54 | After obtaining the inference results from the model, you can use the following scripts to calculate the final score for OCRBench v2. For example, `./pred_folder/internvl2_5_26b.json` contains sample inference results generated by InternVL2.5-26B using [VLMEvalKit](https://github.com/open-compass/VLMEvalKit). To compute the score for each sample, you can use the script `./eval_scripts/eval.py`. The results will be saved in the `./res_folder`.
55 |
56 | ```python
57 | python ./eval_scripts/eval.py --input_path ./pred_folder/internvl2_5_26b.json --output_path ./res_folder/internvl2_5_26b.json
58 | ```
59 |
60 | Once the scores for all samples have been calculated, you can use the script `./eval_scripts/get_score.py` to compute the overall metrics for OCRBench v2.
61 |
62 | ```python
63 | python ./eval_scripts/get_score.py --json_file ./res_folder/internvl2_5_26b.json
64 | ```
65 |
66 | # Leaderboard
67 |
68 | ## Performance of LMMs on English subsets
69 |
70 |
71 | 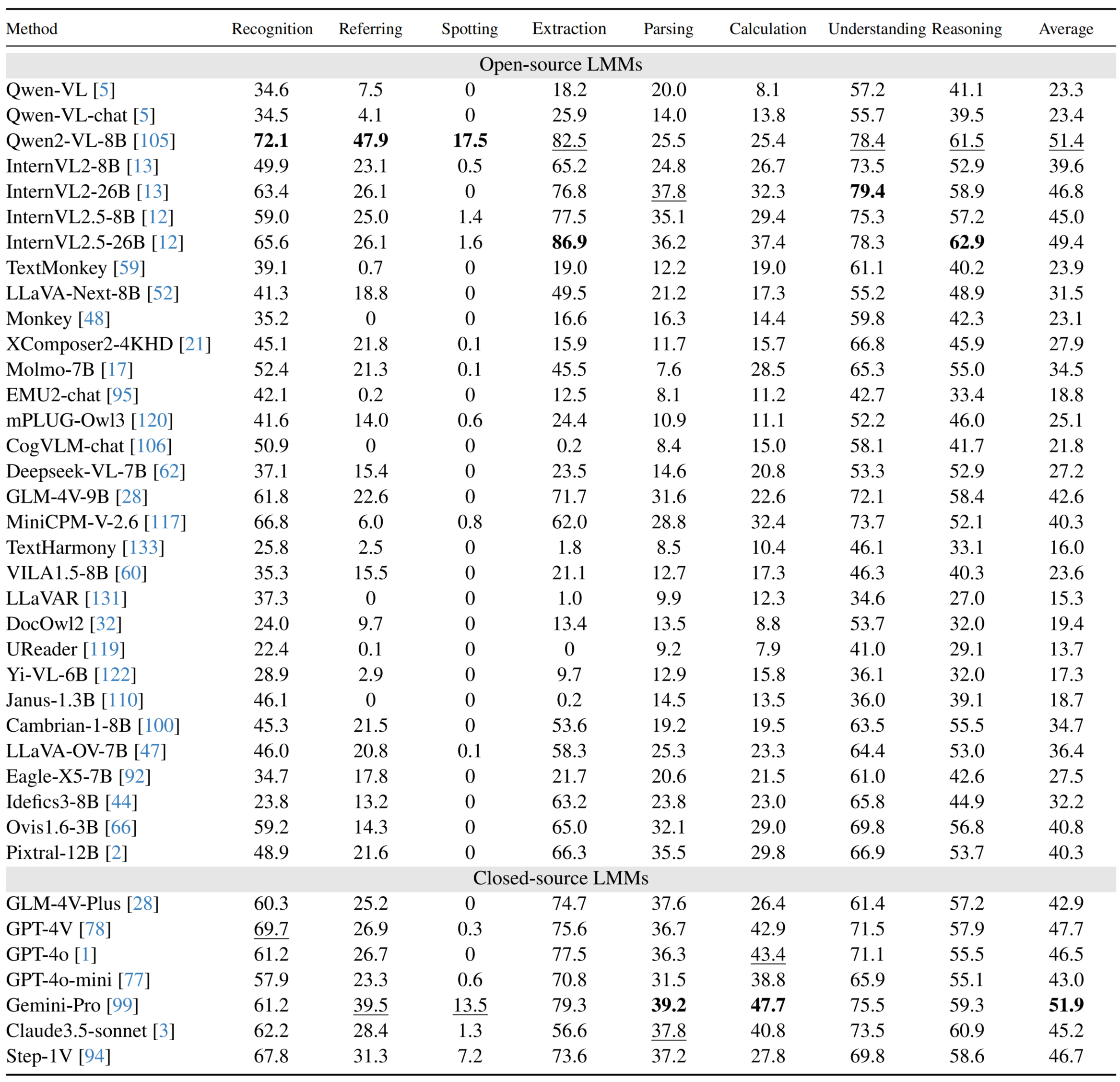 72 |
72 |
73 | 74 | ## Performance of LMMs on Chinese subsets 75 | 76 |
77 | 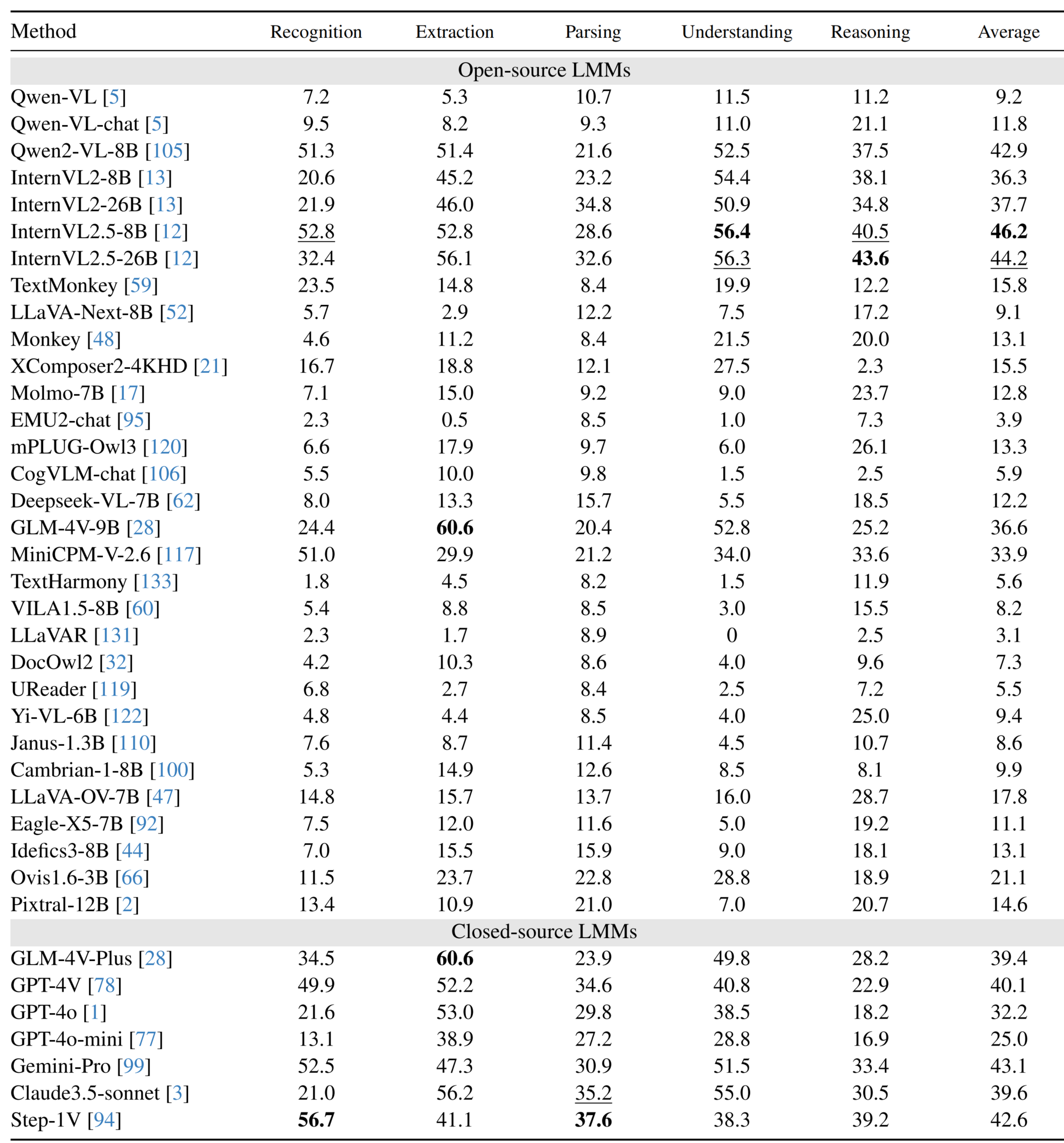 78 |
78 |
79 | 80 | # Copyright Statement 81 | The data are collected from public datasets and community user contributions. This dataset is for research purposes only and not for commercial use. If you have any copyright concerns, please contact ling_fu@hust.edu.cn. 82 | 83 | # Citation 84 | ```BibTeX 85 | @misc{fu2024ocrbenchv2improvedbenchmark, 86 | title={OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning}, 87 | author={Ling Fu and Biao Yang and Zhebin Kuang and Jiajun Song and Yuzhe Li and Linghao Zhu and Qidi Luo and Xinyu Wang and Hao Lu and Mingxin Huang and Zhang Li and Guozhi Tang and Bin Shan and Chunhui Lin and Qi Liu and Binghong Wu and Hao Feng and Hao Liu and Can Huang and Jingqun Tang and Wei Chen and Lianwen Jin and Yuliang Liu and Xiang Bai}, 88 | year={2024}, 89 | eprint={2501.00321}, 90 | archivePrefix={arXiv}, 91 | primaryClass={cs.CV}, 92 | url={https://arxiv.org/abs/2501.00321}, 93 | } 94 | ``` 95 | -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/IoUscore_metric.py: -------------------------------------------------------------------------------- 1 | import os 2 | import re 3 | import ast 4 | import ipdb 5 | from vqa_metric import vqa_evaluation 6 | 7 | 8 | def calculate_iou(box1, box2): 9 | 10 | try: 11 | box1 = [int(coordinate) for coordinate in box1] 12 | box2 = [int(coordinate) for coordinate in box2] 13 | except: 14 | return 0 15 | 16 | x1_inter = max(box1[0], box2[0]) 17 | y1_inter = max(box1[1], box2[1]) 18 | x2_inter = min(box1[2], box2[2]) 19 | y2_inter = min(box1[3], box2[3]) 20 | 21 | inter_area = max(0, x2_inter - x1_inter) * max(0, y2_inter - y1_inter) 22 | 23 | box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1]) 24 | box2_area = (box2[2] - box2[0]) * (box2[3] - box2[1]) 25 | 26 | union_area = box1_area + box2_area - inter_area 27 | 28 | iou = inter_area / union_area if union_area != 0 else 0 29 | 30 | return iou 31 | 32 | 33 | def vqa_with_position_evaluation(predict, img_metas): 34 | 35 | score_content, score_bbox = .0, .0 36 | if "answer" in predict.keys(): 37 | score_content = vqa_evaluation(predict["answer"], img_metas["answers"]) 38 | if "bbox" in predict.keys(): 39 | gt_bbox = img_metas["bbox"] 40 | try: 41 | predict_bbox_list = ast.literal_eval(predict["bbox"]) 42 | score_bbox = calculate_iou(predict_bbox_list, gt_bbox) 43 | except: 44 | score_bbox = 0 45 | return 0.5 * score_content + 0.5 * score_bbox 46 | 47 | 48 | def extract_coordinates(text): 49 | # Regex pattern to match coordinates in either (x1, y1, x2, y2) or [x1, y1, x2, y2] format 50 | 51 | pattern = r'[\(\[]\s*(\d+)\s*,\s*(\d+)\s*,\s*(\d+)\s*,\s*(\d+)\s*[\)\]]' 52 | 53 | matches = list(re.finditer(pattern, text)) 54 | coords_list = [] 55 | coords_set = set() 56 | for match in matches: 57 | 58 | x1, y1, x2, y2 = map(int, match.groups()) 59 | 60 | if all(0 <= n <= 1000 for n in [x1, y1, x2, y2]): 61 | coords = (x1, y1, x2, y2) 62 | 63 | if coords in coords_set: 64 | coords_list = [c for c in coords_list if c != coords] 65 | 66 | coords_list.append(coords) 67 | coords_set.add(coords) 68 | if coords_list: 69 | last_coords = coords_list[-1] 70 | return list(last_coords) 71 | else: 72 | return None 73 | 74 | 75 | if __name__ == "__main__": 76 | 77 | print("Example for Text Grounding task.") 78 | box1 = [50, 50, 150, 150] 79 | box2 = [60, 60, 140, 140] 80 | iou_score = calculate_iou(box1, box2) 81 | print(f"IoU score: {iou_score}") 82 | 83 | print("Example for VQA with position task.") 84 | pred = {"content": "The content is Hello Buddies", "bbox": box1} 85 | gt = {"content": "Hello Buddies", "bbox": box2} 86 | 87 | vqa_score = vqa_evaluation(pred["content"], gt["content"]) 88 | iou_score = calculate_iou(pred["bbox"], gt["bbox"]) 89 | 90 | print(f"VQA score: {vqa_score}") 91 | print(f"IoU score: {iou_score}") 92 | -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/__pycache__/IoUscore_metric.cpython-310.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/__pycache__/IoUscore_metric.cpython-310.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/__pycache__/TEDS_metric.cpython-310.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/__pycache__/TEDS_metric.cpython-310.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/__pycache__/page_ocr_metric.cpython-310.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/__pycache__/page_ocr_metric.cpython-310.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/__pycache__/parallel.cpython-310.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/__pycache__/parallel.cpython-310.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/__pycache__/spotting_metric.cpython-310.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/__pycache__/spotting_metric.cpython-310.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/__pycache__/vqa_metric.cpython-310.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/__pycache__/vqa_metric.cpython-310.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/get_score.py: -------------------------------------------------------------------------------- 1 | import os 2 | import json 3 | import ipdb 4 | import argparse 5 | 6 | 7 | def calculate_average(scores_dict): 8 | averages = {key: sum(values) / len(values) for key, values in scores_dict.items() if len(values) > 0} 9 | return averages 10 | 11 | 12 | def main(): 13 | # Set up argument parser 14 | parser = argparse.ArgumentParser(description="Process a JSON file to calculate scores.") 15 | parser.add_argument("--json_file", type=str, required=True, help="Path to the JSON file containing inference data.") 16 | args = parser.parse_args() 17 | 18 | # Load data from JSON file 19 | inference_file = args.json_file 20 | if not os.path.exists(inference_file): 21 | print(f"Error: File '{inference_file}' does not exist.") 22 | return 23 | 24 | with open(inference_file, "r") as f: 25 | data_list = json.load(f) 26 | 27 | en_text_recognition_list, en_text_detection_list, en_text_spotting_list, en_relationship_extraction_list = [], [], [], [] 28 | en_element_parsing_list, en_mathematical_calculation_list, en_visual_text_understanding_list = [], [], [] 29 | en_knowledge_reasoning_list = [] 30 | 31 | cn_text_recognition_list, cn_relationship_extraction_list = [], [] 32 | cn_element_parsing_list, cn_visual_text_understanding_list = [], [] 33 | cn_knowledge_reasoning_list = [] 34 | 35 | res_list = [] 36 | for item in data_list: 37 | if "ignore" in item.keys(): 38 | assert item["ignore"] == "True" 39 | 40 | elif item["type"] == "text recognition en" or item["type"] == "fine-grained text recognition en" or item["type"] == "full-page OCR en": 41 | en_text_recognition_list.append(item["score"]) 42 | 43 | elif item["type"] == "text grounding en" or item["type"] == "VQA with position en": 44 | en_text_detection_list.append(item["score"]) 45 | 46 | elif item["type"] == "text spotting en": 47 | en_text_spotting_list.append(item["score"]) 48 | 49 | elif item["type"] == "key information extraction en" or item["type"] == "key information mapping en": 50 | en_relationship_extraction_list.append(item["score"]) 51 | 52 | elif item["type"] == "document parsing en" or item["type"] == "chart parsing en" \ 53 | or item["type"] == "table parsing en" or item["type"] == "formula recognition en": 54 | en_element_parsing_list.append(item["score"]) 55 | 56 | elif item["type"] == "math QA en" or item["type"] == "text counting en": 57 | en_mathematical_calculation_list.append(item["score"]) 58 | 59 | elif item["type"] == "document classification en" \ 60 | or item["type"] == "cognition VQA en" or item["type"] == "diagram QA en": 61 | en_visual_text_understanding_list.append(item["score"]) 62 | 63 | elif item["type"] == "reasoning VQA en" or item["type"] == "science QA en" \ 64 | or item["type"] == "APP agent en" or item["type"] == "ASCII art classification en": 65 | en_knowledge_reasoning_list.append(item["score"]) 66 | 67 | elif item["type"] == "full-page OCR cn": 68 | cn_text_recognition_list.append(item["score"]) 69 | 70 | elif item["type"] == "key information extraction cn" or item["type"] == "handwritten answer extraction cn": 71 | cn_relationship_extraction_list.append(item["score"]) 72 | 73 | elif item["type"] == "document parsing cn" or item["type"] == "table parsing cn" or item["type"] == "formula recognition cn": 74 | cn_element_parsing_list.append(item["score"]) 75 | 76 | elif item["type"] == "cognition VQA cn": 77 | cn_visual_text_understanding_list.append(item["score"]) 78 | 79 | elif item["type"] == "reasoning VQA cn" or item["type"] == "text translation cn": 80 | cn_knowledge_reasoning_list.append(item["score"]) 81 | 82 | else: 83 | raise ValueError("Unknown task type!") 84 | 85 | en_scores = { 86 | "text_recognition": en_text_recognition_list, 87 | "text_detection": en_text_detection_list, 88 | "text_spotting": en_text_spotting_list, 89 | "relationship_extraction": en_relationship_extraction_list, 90 | "element_parsing": en_element_parsing_list, 91 | "mathematical_calculation": en_mathematical_calculation_list, 92 | "visual_text_understanding": en_visual_text_understanding_list, 93 | "knowledge_reasoning": en_knowledge_reasoning_list 94 | } 95 | 96 | cn_scores = { 97 | "text_recognition": cn_text_recognition_list, 98 | "relationship_extraction": cn_relationship_extraction_list, 99 | "element_parsing": cn_element_parsing_list, 100 | "visual_text_understanding": cn_visual_text_understanding_list, 101 | "knowledge_reasoning": cn_knowledge_reasoning_list 102 | } 103 | 104 | en_averages = calculate_average(en_scores) 105 | cn_averages = calculate_average(cn_scores) 106 | 107 | print("English Scores:") 108 | for key, score in en_averages.items(): 109 | print(f"{key}: {score:.3f} (Count: {len(en_scores[key])})") 110 | 111 | print("\nChinese Scores:") 112 | for key, score in cn_averages.items(): 113 | print(f"{key}: {score:.3f} (Count: {len(cn_scores[key])})") 114 | 115 | score_en_overall = sum(en_averages.values()) / len(en_averages) 116 | score_cn_overall = sum(cn_averages.values()) / len(cn_averages) 117 | 118 | print("\nOverall Scores:") 119 | print(f"English Overall Score: {score_en_overall:.3f}") 120 | print(f"Chinese Overall Score: {score_cn_overall:.3f}") 121 | 122 | print("End of Code!") 123 | 124 | if __name__ == "__main__": 125 | main() 126 | -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/page_ocr_metric.py: -------------------------------------------------------------------------------- 1 | import json 2 | import argparse 3 | import nltk 4 | from nltk.metrics import precision, recall, f_measure 5 | import numpy as np 6 | import jieba 7 | import re 8 | from nltk.translate import meteor_score 9 | 10 | 11 | def contain_chinese_string(text): 12 | chinese_pattern = re.compile(r'[\u4e00-\u9fa5]') 13 | return bool(chinese_pattern.search(text)) 14 | 15 | def cal_per_metrics(pred, gt): 16 | metrics = {} 17 | 18 | if contain_chinese_string(gt) or contain_chinese_string(pred): 19 | reference = jieba.lcut(gt) 20 | hypothesis = jieba.lcut(pred) 21 | else: 22 | reference = gt.split() 23 | hypothesis = pred.split() 24 | 25 | metrics["bleu"] = nltk.translate.bleu([reference], hypothesis) 26 | metrics["meteor"] = meteor_score.meteor_score([reference], hypothesis) 27 | 28 | reference = set(reference) 29 | hypothesis = set(hypothesis) 30 | metrics["f_measure"] = f_measure(reference, hypothesis) 31 | 32 | metrics["precision"] = precision(reference, hypothesis) 33 | metrics["recall"] = recall(reference, hypothesis) 34 | metrics["edit_dist"] = nltk.edit_distance(pred, gt) / max(len(pred), len(gt)) 35 | return metrics 36 | 37 | 38 | if __name__ == "__main__": 39 | 40 | # Examples for region text recognition and read all text tasks 41 | predict_text = "metrics['edit_dist'] = nltk.edit_distance(pred, gt) / max(len(pred), len(gt))" 42 | true_text = "metrics = nltk.edit_distance(pred, gt) / max(len(pred), len(gt))" 43 | 44 | scores = cal_per_metrics(predict_text, true_text) 45 | 46 | predict_text = "metrics['edit_dist'] len(gt))" 47 | true_text = "metrics = nltk.edit_distance(pred, gt) / max(len(pred), len(gt))" 48 | 49 | scores = cal_per_metrics(predict_text, true_text) 50 | print(scores) 51 | -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/parallel.py: -------------------------------------------------------------------------------- 1 | from tqdm import tqdm 2 | from concurrent.futures import ProcessPoolExecutor, as_completed 3 | 4 | def parallel_process(array, function, n_jobs=16, use_kwargs=False, front_num=0): 5 | """ 6 | A parallel version of the map function with a progress bar. 7 | 8 | Args: 9 | array (array-like): An array to iterate over. 10 | function (function): A python function to apply to the elements of array 11 | n_jobs (int, default=16): The number of cores to use 12 | use_kwargs (boolean, default=False): Whether to consider the elements of array as dictionaries of 13 | keyword arguments to function 14 | front_num (int, default=3): The number of iterations to run serially before kicking off the parallel job. 15 | Useful for catching bugs 16 | Returns: 17 | [function(array[0]), function(array[1]), ...] 18 | """ 19 | # We run the first few iterations serially to catch bugs 20 | if front_num > 0: 21 | front = [function(**a) if use_kwargs else function(a) for a in array[:front_num]] 22 | else: 23 | front = [] 24 | # If we set n_jobs to 1, just run a list comprehension. This is useful for benchmarking and debugging. 25 | if n_jobs == 1: 26 | return front + [function(**a) if use_kwargs else function(a) for a in tqdm(array[front_num:])] 27 | # Assemble the workers 28 | with ProcessPoolExecutor(max_workers=n_jobs) as pool: 29 | # Pass the elements of array into function 30 | if use_kwargs: 31 | futures = [pool.submit(function, **a) for a in array[front_num:]] 32 | else: 33 | futures = [pool.submit(function, a) for a in array[front_num:]] 34 | kwargs = { 35 | 'total': len(futures), 36 | 'unit': 'it', 37 | 'unit_scale': True, 38 | 'leave': True 39 | } 40 | # Print out the progress as tasks complete 41 | for f in tqdm(as_completed(futures), **kwargs): 42 | pass 43 | out = [] 44 | # Get the results from the futures. 45 | for i, future in tqdm(enumerate(futures)): 46 | try: 47 | out.append(future.result()) 48 | except Exception as e: 49 | out.append(e) 50 | return front + out -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/__init__.py: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/__init__.py -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/__pycache__/__init__.cpython-310.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/__pycache__/__init__.cpython-310.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/__pycache__/__init__.cpython-39.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/__pycache__/__init__.cpython-39.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/__pycache__/rrc_evaluation_funcs_1_1.cpython-310.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/__pycache__/rrc_evaluation_funcs_1_1.cpython-310.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/__pycache__/rrc_evaluation_funcs_1_1.cpython-39.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/__pycache__/rrc_evaluation_funcs_1_1.cpython-39.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/__pycache__/script.cpython-310.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/__pycache__/script.cpython-310.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/__pycache__/script.cpython-39.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/__pycache__/script.cpython-39.pyc -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/gt.zip: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/gt.zip -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/gt/gt_img_0.txt: -------------------------------------------------------------------------------- 1 | 442,380,507,380,507,399,442,399,CHEROKEE 2 | 506,380,547,380,547,397,506,397,STREET 3 | 481,399,536,399,536,417,481,417,BIKES 4 | 443,425,469,425,469,438,443,438,### 5 | 471,425,505,425,505,438,471,438,### 6 | 513,425,543,425,543,439,513,439,### -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/readme.txt: -------------------------------------------------------------------------------- 1 | INSTRUCTIONS FOR THE STANDALONE SCRIPTS 2 | Requirements: 3 | - Python version 3. 4 | - Each Task requires different Python modules. When running the script, if some module is not installed you will see a notification and installation instructions. 5 | 6 | Procedure: 7 | Download the ZIP file for the requested script and unzip it to a directory. 8 | 9 | Open a terminal in the directory and run the command: 10 | python script.py –g=gt.zip –s=submit.zip 11 | 12 | If you have already installed all the required modules, then you will see the method’s results or an error message if the submitted file is not correct. 13 | 14 | If a module is not present, you should install them with PIP: pip install 'module' 15 | 16 | In case of Polygon module, use: 'pip install Polygon3' 17 | 18 | parameters: 19 | -g: Path of the Ground Truth file. In most cases, the Ground Truth will be included in the same Zip file named 'gt.zip', gt.txt' or 'gt.json'. If not, you will be able to get it on the Downloads page of the Task. 20 | -s: Path of your method's results file. 21 | 22 | Optional parameters: 23 | -o: Path to a directory where to copy the file ‘results.zip’ that contains per-sample results. 24 | -p: JSON string parameters to override the script default parameters. The parameters that can be overrided are inside the function 'default_evaluation_params' located at the begining of the evaluation Script. 25 | 26 | Example: python script.py –g=gt.zip –s=submit.zip –o=./ -p={\"IOU_CONSTRAINT\":0.8} -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/results.zip: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/results.zip -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/script_test_ch4_t4_e1-1577983164.zip: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/script_test_ch4_t4_e1-1577983164.zip -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/submit.zip: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Yuliang-Liu/MultimodalOCR/b5ecad3e3408dd924497d9329ff4b0b8295dfe15/OCRBench_v2/eval_scripts/spotting_eval/submit.zip -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_eval/submit/res_img_0.txt: -------------------------------------------------------------------------------- 1 | 0,0,1000,0,1000,1000,0,1000,CHEROKEE STREET BIKES -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/spotting_metric.py: -------------------------------------------------------------------------------- 1 | import re 2 | import os 3 | import ast 4 | import ipdb 5 | import shutil 6 | import zipfile 7 | import subprocess 8 | import spotting_eval.rrc_evaluation_funcs_1_1 as rrc_evaluation_funcs 9 | from spotting_eval.script import default_evaluation_params,validate_data,evaluate_method 10 | 11 | 12 | def extract_bounding_boxes_robust(predict_str): 13 | """ 14 | Extract coordinates and text content from the given prediction string, 15 | handling potential format issues. 16 | 17 | Args: 18 | predict_str (str): Model prediction output as a string. 19 | 20 | Returns: 21 | list: Extracted data in the format [[x1, y1, x2, y2, text_content], ...]. 22 | Returns None if no valid data is extracted. 23 | """ 24 | results = [] 25 | seen = set() 26 | 27 | # try parsing with ast.literal_eval 28 | try: 29 | data = ast.literal_eval(predict_str) 30 | except Exception: 31 | data = None 32 | 33 | if data is not None: 34 | if isinstance(data, (list, tuple)): 35 | for item in data: 36 | if isinstance(item, (list, tuple)) and len(item) >= 5: 37 | x1_str, y1_str, x2_str, y2_str = item[:4] 38 | text_content = item[4] 39 | 40 | x1_str = str(x1_str).strip() 41 | y1_str = str(y1_str).strip() 42 | x2_str = str(x2_str).strip() 43 | y2_str = str(y2_str).strip() 44 | text_content = str(text_content).replace("\n", "").strip().strip('"').strip("'") 45 | 46 | try: 47 | x1 = int(x1_str) 48 | y1 = int(y1_str) 49 | x2 = int(x2_str) 50 | y2 = int(y2_str) 51 | 52 | if not (0 <= x1 <= 1000 and 0 <= y1 <= 1000 and 0 <= x2 <= 1000 and 0 <= y2 <= 1000): 53 | continue 54 | 55 | key = (x1, y1, x2, y2, text_content) 56 | if key in seen: 57 | continue 58 | 59 | seen.add(key) 60 | results.append([x1, y1, x2, y2, text_content]) 61 | except ValueError: 62 | continue 63 | else: 64 | # try parsing with regular expression 65 | 66 | list_content = predict_str 67 | items = re.findall(r'[\[\(]\s*([^\[\]\(\)]*?)\s*[\]\)]', list_content) 68 | 69 | if not items: 70 | return None 71 | 72 | for item in items: 73 | parts = item.split(',', 4) 74 | if len(parts) < 5: 75 | continue 76 | 77 | x1_str, y1_str, x2_str, y2_str, text_content = parts 78 | 79 | x1_str = x1_str.strip() 80 | y1_str = y1_str.strip() 81 | x2_str = x2_str.strip() 82 | y2_str = y2_str.strip() 83 | text_content = text_content.replace("\n", "").strip().strip('"').strip("'") 84 | 85 | try: 86 | x1 = int(x1_str) 87 | y1 = int(y1_str) 88 | x2 = int(x2_str) 89 | y2 = int(y2_str) 90 | 91 | if not (0 <= x1 <= 1000 and 0 <= y1 <= 1000 and 0 <= x2 <= 1000 and 0 <= y2 <= 1000): 92 | continue 93 | 94 | key = (x1, y1, x2, y2, text_content) 95 | if key in seen: 96 | continue 97 | 98 | seen.add(key) 99 | results.append([x1, y1, x2, y2, text_content]) 100 | except ValueError: 101 | continue 102 | 103 | if not results: 104 | return None 105 | 106 | return results 107 | 108 | 109 | def zip_folder(source_folder, destination_zip): 110 | abs_source = os.path.abspath(source_folder) 111 | abs_destination = os.path.abspath(destination_zip) 112 | 113 | with zipfile.ZipFile(abs_destination, 'w', zipfile.ZIP_DEFLATED) as zf: 114 | for root, _, files in os.walk(abs_source): 115 | for file in files: 116 | abs_file_path = os.path.join(root, file) 117 | 118 | relative_path = os.path.relpath(abs_file_path, abs_source) 119 | zf.write(abs_file_path, relative_path) 120 | 121 | 122 | def spotting_evaluation(prediction_list, img_metas): 123 | score = 0 124 | 125 | submit_path = "./eval_scripts/spotting_eval/submit" 126 | gt_path = "./eval_scripts/spotting_eval/gt" 127 | submit_zip_path = "./eval_scripts/spotting_eval/submit.zip" 128 | gt_zip_path = "./eval_scripts/spotting_eval/gt.zip" 129 | for file_path in [submit_path, gt_path, submit_zip_path, gt_zip_path]: 130 | if "zip" in file_path: 131 | if os.path.exists(file_path): 132 | os.remove(file_path) 133 | else: 134 | if os.path.exists(file_path): 135 | shutil.rmtree(file_path) 136 | os.makedirs(file_path) 137 | 138 | res_submit_list = [] 139 | for item in prediction_list: 140 | if len(item) != 5: 141 | ipdb.set_trace() 142 | x1, y1, x2, y2, rec = item 143 | if x1 >= x2 or y1 >= y2: 144 | continue 145 | 146 | res_submit_list.append(",".join([str(x1),str(y1),str(x2),str(y1),str(x2),str(y2),str(x1),str(y2),rec])) 147 | 148 | res_gt_list = [] 149 | for bbox, rec in zip(img_metas["bbox"], img_metas["content"]): 150 | x_coords = bbox[0::2] 151 | y_coords = bbox[1::2] 152 | 153 | x1, y1 = min(x_coords), min(y_coords) 154 | x2, y2 = max(x_coords), max(y_coords) 155 | 156 | res_gt_list.append(",".join([str(x1),str(y1),str(x2),str(y1),str(x2),str(y2),str(x1),str(y2),rec])) 157 | 158 | if len(res_submit_list) == 0 or len(res_gt_list) == 0: 159 | return 0 160 | 161 | with open(os.path.join(submit_path,"res_img_0.txt"), "w") as f: 162 | for item in res_submit_list[:-1]: 163 | f.write(item + "\n") 164 | f.write(res_submit_list[-1]) 165 | 166 | with open(os.path.join(gt_path,"gt_img_0.txt"), "w") as f: 167 | for item in res_gt_list[:-1]: 168 | f.write(item + "\n") 169 | f.write(res_gt_list[-1]) 170 | 171 | zip_folder(submit_path, submit_zip_path) 172 | zip_folder(gt_path, gt_zip_path) 173 | 174 | command = { 175 | 'g': gt_zip_path, 176 | 's': submit_zip_path, 177 | 'o': './', 178 | 'p': '{"IOU_CONSTRAINT":0.5}' 179 | } 180 | 181 | # run rrc_evaluation_funcs 182 | result = rrc_evaluation_funcs.main_evaluation(command,default_evaluation_params,validate_data,evaluate_method) 183 | score = result["method"]["hmean"] 184 | return score 185 | -------------------------------------------------------------------------------- /OCRBench_v2/eval_scripts/vqa_metric.py: -------------------------------------------------------------------------------- 1 | import re 2 | import os 3 | import json 4 | import ipdb 5 | import math 6 | import numpy as np 7 | 8 | 9 | def levenshtein_distance(s1, s2): 10 | if len(s1) > len(s2): 11 | s1, s2 = s2, s1 12 | 13 | distances = range(len(s1) + 1) 14 | for i2, c2 in enumerate(s2): 15 | distances_ = [i2+1] 16 | for i1, c1 in enumerate(s1): 17 | if c1 == c2: 18 | distances_.append(distances[i1]) 19 | else: 20 | distances_.append(1 + min((distances[i1], distances[i1 + 1], distances_[-1]))) 21 | distances = distances_ 22 | return distances[-1] 23 | 24 | 25 | def vqa_evaluation(predict, answers): 26 | score = 0 27 | if type(answers)==list: 28 | for j in range(len(answers)): 29 | if isinstance(answers[j], (int, float)): 30 | answers[j] = str(answers[j]) 31 | try: 32 | answer = answers[j].lower().strip().replace("\n"," ") 33 | except: 34 | ipdb.set_trace() 35 | if isinstance(predict, (int, float)): 36 | predict = str(predict) 37 | predict = predict.lower().strip().replace("\n"," ") 38 | if len(answer.split()) < 5: 39 | if answer in predict: 40 | score = 1 41 | else: 42 | dist = levenshtein_distance(predict, answer) 43 | length = max(len(predict), len(answer)) 44 | ANLS_value = 0.0 if length == 0 else float(dist) / float(length) 45 | ANLS_value = 1 - ANLS_value 46 | 47 | if ANLS_value >= 0.5 and ANLS_value > score: 48 | score = ANLS_value 49 | 50 | else: 51 | answers = answers.lower().strip().replace("\n"," ") 52 | predict = predict.lower().strip().replace("\n"," ") 53 | if len(answers.split()) < 5: 54 | if answers in predict: 55 | score = 1 56 | else: 57 | dist = levenshtein_distance(predict, answers) 58 | length = max(len(predict), len(answers)) 59 | ANLS_value = 0.0 if length == 0 else float(dist) / float(length) 60 | ANLS_value = 1 - ANLS_value 61 | 62 | if ANLS_value >= 0.5 and ANLS_value > score: 63 | score = ANLS_value 64 | 65 | return score 66 | 67 | 68 | def cn_vqa_evaluation(predict, answers): 69 | score = 0 70 | if type(answers)==list: 71 | for j in range(len(answers)): 72 | if isinstance(answers[j], (int, float)): 73 | answers[j] = str(answers[j]) 74 | try: 75 | answer = answers[j].lower().strip().replace("\n"," ").replace(" ", "") 76 | except: 77 | ipdb.set_trace() 78 | if isinstance(predict, (int, float)): 79 | predict = str(predict) 80 | predict = predict.lower().strip().replace("\n"," ").replace(" ", "") 81 | if len(answer.split(",")) < 4: 82 | if answer in predict: 83 | score = 1 84 | else: 85 | dist = levenshtein_distance(predict, answer) 86 | length = max(len(predict), len(answer)) 87 | ANLS_value = 0.0 if length == 0 else float(dist) / float(length) 88 | ANLS_value = 1 - ANLS_value 89 | 90 | if ANLS_value >= 0.5 and ANLS_value > score: 91 | score = ANLS_value 92 | 93 | else: 94 | answers = answers.lower().strip().replace("\n"," ").replace(" ", "") 95 | predict = predict.lower().strip().replace("\n"," ").replace(" ", "") 96 | if len(answer.split(",")) < 4: 97 | if answers in predict: 98 | score = 1 99 | else: 100 | dist = levenshtein_distance(predict, answers) 101 | length = max(len(predict), len(answers)) 102 | ANLS_value = 0.0 if length == 0 else float(dist) / float(length) 103 | ANLS_value = 1 - ANLS_value 104 | 105 | if ANLS_value >= 0.5 and ANLS_value > score: 106 | score = ANLS_value 107 | 108 | return score 109 | 110 | 111 | def vqa_evaluation_case_sensitive(predict, answers): 112 | score = 0 113 | if type(answers)==list: 114 | for j in range(len(answers)): 115 | if isinstance(answers[j], (int, float)): 116 | answers[j] = str(answers[j]) 117 | try: 118 | answer = answers[j].strip().replace("\n"," ") 119 | except: 120 | ipdb.set_trace() 121 | predict = predict.strip().replace("\n"," ") 122 | if len(answer.split()) < 5: 123 | if answer in predict: 124 | score = 1 125 | else: 126 | dist = levenshtein_distance(predict, answer) 127 | length = max(len(predict), len(answer)) 128 | ANLS_value = 0.0 if length == 0 else float(dist) / float(length) 129 | ANLS_value = 1 - ANLS_value 130 | 131 | if ANLS_value >= 0.5 and ANLS_value > score: 132 | score = ANLS_value 133 | 134 | else: 135 | answers = answers.strip().replace("\n"," ") 136 | predict = predict.strip().replace("\n"," ") 137 | if len(answers.split()) < 5: 138 | if answers in predict: 139 | score = 1 140 | else: 141 | dist = levenshtein_distance(predict, answers) 142 | length = max(len(predict), len(answers)) 143 | ANLS_value = 0.0 if length == 0 else float(dist) / float(length) 144 | ANLS_value = 1 - ANLS_value 145 | 146 | if ANLS_value >= 0.5 and ANLS_value > score: 147 | score = ANLS_value 148 | 149 | return score 150 | 151 | 152 | def extract_first_number(string): 153 | match = re.search(r'\d+', string) 154 | if match: 155 | return int(match.group()) 156 | return None 157 | 158 | 159 | def counting_evaluation(predict, answers, eval_method): 160 | score = 0 161 | 162 | if isinstance(predict, str): 163 | predict_processed = predict.lower().strip().replace("\n", " ") 164 | elif math.isnan(predict): 165 | return 0 166 | else: 167 | predict_processed = int(predict) 168 | if type(answers)==list: 169 | temp_score = 0 170 | for j in range(len(answers)): 171 | if isinstance(answers[j], (int, float)): 172 | answers[j] = str(answers[j]) 173 | answer = answers[j].lower().strip().replace("\n"," ") 174 | if eval_method == "exact match": 175 | if answer in predict: 176 | score = 1 177 | else: 178 | score = 0 179 | elif eval_method == "regression": 180 | predict_number = extract_first_number(predict_processed) 181 | if predict_number: 182 | 183 | answer = int(answer) 184 | 185 | if predict_number <= 0 or predict_number >= 2 * answer: 186 | score = 0 187 | else: 188 | iou = 1 - abs(predict_number - answer) / answer 189 | if iou > 0.5: 190 | score = iou 191 | else: 192 | score = 0 193 | else: 194 | score = 0 195 | if score > temp_score: 196 | temp_score = score 197 | score = temp_score 198 | 199 | else: 200 | answers = answers.lower().strip().replace("\n"," ") 201 | predict = predict.lower().strip().replace("\n"," ") 202 | if eval_method == "exact match": 203 | if answer in predict: 204 | score = 1 205 | else: 206 | score = 0 207 | elif eval_method == "regression": 208 | predict = extract_first_number(predict) 209 | if predict: 210 | answer = int(answer) 211 | if predict <= 0 or predict >= 2 * answer: 212 | score = 0 213 | else: 214 | iou = 1 - abs(predict - answer) / answer 215 | 216 | if iou > 0.5: 217 | score = iou 218 | else: 219 | score = 0 220 | else: 221 | score = 0 222 | return score 223 | 224 | 225 | def math_expression_evaluation(predict, answers): 226 | score = 0 227 | if type(answers)==list: 228 | for j in range(len(answers)): 229 | answer = answers[j].strip().replace("\n"," ").replace(" ","") 230 | predict = predict.strip().replace("\n"," ").replace(" ","") 231 | if answer in predict: 232 | score = 1 233 | else: 234 | answers = answers.strip().replace("\n"," ").replace(" ","") 235 | predict = predict.strip().replace("\n"," ").replace(" ","") 236 | if answers in predict: 237 | score = 1 238 | return score 239 | 240 | 241 | def remove_text_tags(latex_str): 242 | """ 243 | Removes LaTeX \text{...} tags while keeping their content. 244 | 245 | :param latex_str: A string containing LaTeX expressions 246 | :return: The processed string with \text{...} tags removed 247 | """ 248 | 249 | pattern = r'\\text\{([^{}]*)\}' 250 | 251 | processed_str = re.sub(pattern, r'\1', latex_str) 252 | 253 | return processed_str 254 | 255 | 256 | def cn_math_expression_evaluation(predict, answers): 257 | score = 0 258 | 259 | assert len(answers) == 1 260 | answers = [remove_text_tags(answers[0])] 261 | predict = remove_text_tags(predict) 262 | 263 | if type(answers)==list: 264 | for j in range(len(answers)): 265 | answer = answers[j].strip().replace("\n"," ").replace(" ","") 266 | predict = predict.strip().replace("\n"," ").replace(" ","") 267 | if answer in predict: 268 | score = 1 269 | else: 270 | answers = answers.strip().replace("\n"," ").replace(" ","") 271 | predict = predict.strip().replace("\n"," ").replace(" ","") 272 | if answers in predict: 273 | score = 1 274 | return score 275 | 276 | 277 | if __name__ == "__main__": 278 | test_predict = "apple pie and banana" 279 | test_answers = ["apple", "banana pie", "apple pie and orange"] 280 | 281 | vqa_score = vqa_evaluation(test_predict, test_answers) 282 | print(f"VQA evaluation score for predict '{test_predict}' and answers {test_answers}: {vqa_score}") 283 | -------------------------------------------------------------------------------- /OCRBench_v2/requirements.txt: -------------------------------------------------------------------------------- 1 | numpy 2 | distance 3 | apted 4 | lxml 5 | zss 6 | Levenshtein 7 | editdistance 8 | nltk 9 | jieba 10 | Polygon3 11 | tqdm 12 | ipdb -------------------------------------------------------------------------------- /README.md: -------------------------------------------------------------------------------- 1 | # OCRBench & OCRBench v2 2 | 3 | **This is the repository of the [OCRBench](./OCRBench/README.md) & [OCRBench v2](./OCRBench_v2/README.md).** 4 | 5 | **OCRBench** is a comprehensive evaluation benchmark designed to assess the OCR capabilities of Large Multimodal Models. It comprises five components: Text Recognition, SceneText-Centric VQA, Document-Oriented VQA, Key Information Extraction, and Handwritten Mathematical Expression Recognition. The benchmark includes 1000 question-answer pairs, and all the answers undergo manual verification and correction to ensure a more precise evaluation. More details can be found in [OCRBench README](./OCRBench/README.md). 6 | 7 |
8 |  9 |
9 |
14 |
15 |
16 | 17 | # News 18 | * ```2024.12.31``` 🚀 [OCRBench v2](./OCRBench_v2/README.md) is released. 19 | * ```2024.12.11``` 🚀 OCRBench has been accepted by [Science China Information Sciences](https://link.springer.com/article/10.1007/s11432-024-4235-6). 20 | * ```2024.5.19 ``` 🚀 We realese [DTVQA](https://github.com/ShuoZhang2003/DT-VQA), to explore the Capabilities of Large Multimodal Models on Dense Text. 21 | * ```2024.5.01 ``` 🚀 Thanks to [SWHL](https://github.com/Yuliang-Liu/MultimodalOCR/issues/29) for releasing [ChineseOCRBench](https://huggingface.co/datasets/SWHL/ChineseOCRBench). 22 | * ```2024.3.26 ``` 🚀 OCRBench is now supported in [lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval). 23 | * ```2024.3.12 ``` 🚀 We plan to construct OCRBench v2 to include more ocr tasks and data. Any contribution will be appreciated. 24 | * ```2024.2.25 ``` 🚀 OCRBench is now supported in [VLMEvalKit](https://github.com/open-compass/VLMEvalKit). 25 | 26 | 27 | # Other Related Multilingual Datasets 28 | | Data | Link | Description | 29 | | --- | --- | --- | 30 | | EST-VQA Dataset (CVPR 2020, English and Chinese) | [Link](https://github.com/xinke-wang/EST-VQA) | On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering. | 31 | | Swahili Dataset (ICDAR 2024) | [Link](https://arxiv.org/abs/2405.11437) | The First Swahili Language Scene Text Detection and Recognition Dataset. | 32 | | Urdu Dataset (ICDAR 2024) | [Link](https://arxiv.org/abs/2405.12533) | Dataset and Benchmark for Urdu Natural Scenes Text Detection, Recognition and Visual Question Answering. | 33 | | MTVQA (9 languages) | [Link](https://arxiv.org/abs/2405.11985) | MTVQA: Benchmarking Multilingual Text-Centric Visual Question Answering. | 34 | | EVOBC (Oracle Bone Script Evolution Dataset) | [Link](https://arxiv.org/abs/2401.12467) | We systematically collected ancient characters from authoritative texts and websites spanning six historical stages. | 35 | | HUST-OBC (Oracle Bone Script Character Dataset) | [Link](https://arxiv.org/abs/2401.15365) | For deciphering oracle bone script characters. | 36 | 37 | # Citation 38 | If you wish to refer to the baseline results published here, please use the following BibTeX entries: 39 | ```BibTeX 40 | @article{Liu_2024, 41 | title={OCRBench: on the hidden mystery of OCR in large multimodal models}, 42 | volume={67}, 43 | ISSN={1869-1919}, 44 | url={http://dx.doi.org/10.1007/s11432-024-4235-6}, 45 | DOI={10.1007/s11432-024-4235-6}, 46 | number={12}, 47 | journal={Science China Information Sciences}, 48 | publisher={Springer Science and Business Media LLC}, 49 | author={Liu, Yuliang and Li, Zhang and Huang, Mingxin and Yang, Biao and Yu, Wenwen and Li, Chunyuan and Yin, Xu-Cheng and Liu, Cheng-Lin and Jin, Lianwen and Bai, Xiang}, 50 | year={2024}, 51 | month=dec } 52 | 53 | @misc{fu2024ocrbenchv2improvedbenchmark, 54 | title={OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning}, 55 | author={Ling Fu and Biao Yang and Zhebin Kuang and Jiajun Song and Yuzhe Li and Linghao Zhu and Qidi Luo and Xinyu Wang and Hao Lu and Mingxin Huang and Zhang Li and Guozhi Tang and Bin Shan and Chunhui Lin and Qi Liu and Binghong Wu and Hao Feng and Hao Liu and Can Huang and Jingqun Tang and Wei Chen and Lianwen Jin and Yuliang Liu and Xiang Bai}, 56 | year={2024}, 57 | eprint={2501.00321}, 58 | archivePrefix={arXiv}, 59 | primaryClass={cs.CV}, 60 | url={https://arxiv.org/abs/2501.00321}, 61 | } 62 | ``` 63 | 64 | 65 | 66 | --------------------------------------------------------------------------------